PARQUET-2160: Close ZstdInputStream to free off-heap memory in time. #982
Conversation
| } | ||
| InputStream is = codec.createInputStream(bytes.toInputStream(), decompressor); | ||
| decompressed = BytesInput.from(is, uncompressedSize); | ||
| if (codec instanceof ZstandardCodec) { |
There was a problem hiding this comment.
This looks a little weird, but considering doing so will load the decompressor stream into heap in advance, and only zstd has this problem currently, so I made this modification only for zstd stream.
There was a problem hiding this comment.
Maybe we can consider closing the decompressed stream after it has been read:
https://github.com/apache/parquet-mr/blob/0819356a9dafd2ca07c5eab68e2bffeddc3bd3d9/parquet-common/src/main/java/org/apache/parquet/bytes/BytesInput.java#L283-L288
But I'm not sure if there is a situation where the decompressed stream is read more than once.
There was a problem hiding this comment.
The change looks OK to me, we probably should add some comments explaining why ZSTD deserves the special treatment here.
The change on BytesInput looks more intrusive since it is used not only for decompression but other places like compression. For instance, BytesInput.copy calls toByteArray underneath, and after the call the original object should still be valid.
There was a problem hiding this comment.
Added comment.
 sunchao
left a comment
sunchao
left a comment
There was a problem hiding this comment.
cc @shangxinli @ggershinsky too
| } | ||
| InputStream is = codec.createInputStream(bytes.toInputStream(), decompressor); | ||
| decompressed = BytesInput.from(is, uncompressedSize); | ||
| if (codec instanceof ZstandardCodec) { |
There was a problem hiding this comment.
The change looks OK to me, we probably should add some comments explaining why ZSTD deserves the special treatment here.
The change on BytesInput looks more intrusive since it is used not only for decompression but other places like compression. For instance, BytesInput.copy calls toByteArray underneath, and after the call the original object should still be valid.
| // This change will load the decompressor stream into heap a little earlier, since the problem it solves | ||
| // only happens in the ZSTD codec, so this modification is only made for ZSTD streams. | ||
| if (codec instanceof ZstandardCodec) { | ||
| decompressed = BytesInput.copy(BytesInput.from(is, uncompressedSize)); |
There was a problem hiding this comment.
I understand we had the discussion in the Jira that ByteInput.copy() just loads into a heap in advance but not add extra overall. Can we have a benchmark on the heap/GC(Heap size, GC time etc). I just want to make sure we fix one problem while introducing another problem.
Other than that, the ZSTD is treated especially might be OK since we had pretty decent coments.
There was a problem hiding this comment.
Can we have a benchmark on the heap/GC(Heap size, GC time etc).
Sure, will do a benchmark.
There was a problem hiding this comment.
Hi @shangxinli , very sorry about the big delay, I was a little busy last week. The benchmark result and detailed data has been posted in the PR describe block, also cc @sunchao.
There was a problem hiding this comment.
Thanks for working on it!
|
LGTM |
sunchao
left a comment
There was a problem hiding this comment.
LGTM too, thanks @zhongyujiang !
|
wondering why this PR has not been merged we have face this problem and are looking for a solution (spark 3.2.2+zstd-parquet) |
|
@gszadovszky @ggershinsky @shangxinli Folks, do we have an approximate timeline for the next patch release that will be including this patch? This is a severe problem that does affect our ability to use Parquet w/ Zstd and i'm aware of at least of handful of similar occasions and issues occurring to others. Corresponding issue in Spark: https://issues.apache.org/jira/browse/SPARK-41952 |
|
@alexeykudinkin We might release a new patch in the next 2 or 3 months. Can you elaborate why "this is a severe problem that does affect our ability to use Parquet w/ Zstd"? I understand it is an issue but we have been running Parquet w/ Zstd for 2+ years in production. |
|
Totally @shangxinli We have running Spark clusters in production ingesting from 100s of Apache Hudi tables (using Parquet and Zstd) and writing into other ones. We switched from gzip to zstd slightly over a month ago and we started to have OOM issues almost immediately. It took us a bit of triaging to zero in on zstd, but now we're confident that it's not mis-calibration of our configs but slow-bleeding leak of the native memory. The crux of the problem is very particular type of the job -- one that reads a lot of Zstd compressed Parquet (therefore triggering the affected path). Other jobs not reading Parquet are not affected. |
|
Thanks @alexeykudinkin for the explanation. |
|
same problem with @alexeykudinkin currently we replace paruqet jar with patched one in our image, waiting for release |
|
same, we have certain jobs that can't function without a patched jar. Seems to get worse with the more columns you read. Our worst offender (table with thousands of columns), can easily hit 90+ GiB of resident memory on a 25 GiB heap executor in an hour or so (running on Yarn without memory limit enforcement) |
|
I also encountered this memory issue when migrating data from parquet/snappy to parquet/zstd, Spark executors always occupy unreasonable off-heap memory and have a high risk of being killed by NM, this patch can solve this problem. It's a critical issue in my case, wish the upstream publish a patched version so that we don't need to maintain the internal version. |
…und for PARQUET-2160 ### What changes were proposed in this pull request? SPARK-41952 was raised for a while, but unfortunately, the Parquet community does not publish the patched version yet, as a workaround, we can fix the issue on the Spark side first. We encountered this memory issue when migrating data from parquet/snappy to parquet/zstd, Spark executors always occupy unreasonable off-heap memory and have a high risk of being killed by NM. See more discussions at apache/parquet-java#982 and apache/iceberg#5681 ### Why are the changes needed? The issue is fixed in the parquet community [PARQUET-2160](https://issues.apache.org/jira/browse/PARQUET-2160), but the patched version is not available yet. ### Does this PR introduce _any_ user-facing change? Yes, it's bug fix. ### How was this patch tested? The existing UT should cover the correctness check, I also verified this patch by scanning a large parquet/zstd table. ``` spark-shell --executor-cores 4 --executor-memory 6g --conf spark.executor.memoryOverhead=2g ``` ``` spark.sql("select sum(hash(*)) from parquet_zstd_table ").show(false) ``` - before this patch All executors get killed by NM quickly. ``` ERROR YarnScheduler: Lost executor 1 on hadoop-xxxx.****.org: Container killed by YARN for exceeding physical memory limits. 8.2 GB of 8 GB physical memory used. Consider boosting spark.executor.memoryOverhead. ``` <img width="1872" alt="image" src="https://user-images.githubusercontent.com/26535726/220031678-e9060244-5586-4f0c-8fe7-55bb4e20a580.png"> - after this patch Query runs well, no executor gets killed. <img width="1881" alt="image" src="https://user-images.githubusercontent.com/26535726/220031917-4fe38c07-b38f-49c6-a982-2091a6c2a8ed.png"> Closes #40091 from pan3793/SPARK-41952. Authored-by: Cheng Pan <[email protected]> Signed-off-by: Chao Sun <[email protected]>
{kind=link}
{kind=link}
…und for PARQUET-2160 ### What changes were proposed in this pull request? SPARK-41952 was raised for a while, but unfortunately, the Parquet community does not publish the patched version yet, as a workaround, we can fix the issue on the Spark side first. We encountered this memory issue when migrating data from parquet/snappy to parquet/zstd, Spark executors always occupy unreasonable off-heap memory and have a high risk of being killed by NM. See more discussions at apache/parquet-java#982 and apache/iceberg#5681 ### Why are the changes needed? The issue is fixed in the parquet community [PARQUET-2160](https://issues.apache.org/jira/browse/PARQUET-2160), but the patched version is not available yet. ### Does this PR introduce _any_ user-facing change? Yes, it's bug fix. ### How was this patch tested? The existing UT should cover the correctness check, I also verified this patch by scanning a large parquet/zstd table. ``` spark-shell --executor-cores 4 --executor-memory 6g --conf spark.executor.memoryOverhead=2g ``` ``` spark.sql("select sum(hash(*)) from parquet_zstd_table ").show(false) ``` - before this patch All executors get killed by NM quickly. ``` ERROR YarnScheduler: Lost executor 1 on hadoop-xxxx.****.org: Container killed by YARN for exceeding physical memory limits. 8.2 GB of 8 GB physical memory used. Consider boosting spark.executor.memoryOverhead. ``` <img width="1872" alt="image" src="https://user-images.githubusercontent.com/26535726/220031678-e9060244-5586-4f0c-8fe7-55bb4e20a580.png"> - after this patch Query runs well, no executor gets killed. <img width="1881" alt="image" src="https://user-images.githubusercontent.com/26535726/220031917-4fe38c07-b38f-49c6-a982-2091a6c2a8ed.png"> Closes #40091 from pan3793/SPARK-41952. Authored-by: Cheng Pan <[email protected]> Signed-off-by: Chao Sun <[email protected]>
…und for PARQUET-2160 ### What changes were proposed in this pull request? SPARK-41952 was raised for a while, but unfortunately, the Parquet community does not publish the patched version yet, as a workaround, we can fix the issue on the Spark side first. We encountered this memory issue when migrating data from parquet/snappy to parquet/zstd, Spark executors always occupy unreasonable off-heap memory and have a high risk of being killed by NM. See more discussions at apache/parquet-java#982 and apache/iceberg#5681 ### Why are the changes needed? The issue is fixed in the parquet community [PARQUET-2160](https://issues.apache.org/jira/browse/PARQUET-2160), but the patched version is not available yet. ### Does this PR introduce _any_ user-facing change? Yes, it's bug fix. ### How was this patch tested? The existing UT should cover the correctness check, I also verified this patch by scanning a large parquet/zstd table. ``` spark-shell --executor-cores 4 --executor-memory 6g --conf spark.executor.memoryOverhead=2g ``` ``` spark.sql("select sum(hash(*)) from parquet_zstd_table ").show(false) ``` - before this patch All executors get killed by NM quickly. ``` ERROR YarnScheduler: Lost executor 1 on hadoop-xxxx.****.org: Container killed by YARN for exceeding physical memory limits. 8.2 GB of 8 GB physical memory used. Consider boosting spark.executor.memoryOverhead. ``` <img width="1872" alt="image" src="https://user-images.githubusercontent.com/26535726/220031678-e9060244-5586-4f0c-8fe7-55bb4e20a580.png"> - after this patch Query runs well, no executor gets killed. <img width="1881" alt="image" src="https://user-images.githubusercontent.com/26535726/220031917-4fe38c07-b38f-49c6-a982-2091a6c2a8ed.png"> Closes #40091 from pan3793/SPARK-41952. Authored-by: Cheng Pan <[email protected]> Signed-off-by: Chao Sun <[email protected]>
…und for PARQUET-2160 ### What changes were proposed in this pull request? SPARK-41952 was raised for a while, but unfortunately, the Parquet community does not publish the patched version yet, as a workaround, we can fix the issue on the Spark side first. We encountered this memory issue when migrating data from parquet/snappy to parquet/zstd, Spark executors always occupy unreasonable off-heap memory and have a high risk of being killed by NM. See more discussions at apache/parquet-java#982 and apache/iceberg#5681 ### Why are the changes needed? The issue is fixed in the parquet community [PARQUET-2160](https://issues.apache.org/jira/browse/PARQUET-2160), but the patched version is not available yet. ### Does this PR introduce _any_ user-facing change? Yes, it's bug fix. ### How was this patch tested? The existing UT should cover the correctness check, I also verified this patch by scanning a large parquet/zstd table. ``` spark-shell --executor-cores 4 --executor-memory 6g --conf spark.executor.memoryOverhead=2g ``` ``` spark.sql("select sum(hash(*)) from parquet_zstd_table ").show(false) ``` - before this patch All executors get killed by NM quickly. ``` ERROR YarnScheduler: Lost executor 1 on hadoop-xxxx.****.org: Container killed by YARN for exceeding physical memory limits. 8.2 GB of 8 GB physical memory used. Consider boosting spark.executor.memoryOverhead. ``` <img width="1872" alt="image" src="https://user-images.githubusercontent.com/26535726/220031678-e9060244-5586-4f0c-8fe7-55bb4e20a580.png"> - after this patch Query runs well, no executor gets killed. <img width="1881" alt="image" src="https://user-images.githubusercontent.com/26535726/220031917-4fe38c07-b38f-49c6-a982-2091a6c2a8ed.png"> Closes #40091 from pan3793/SPARK-41952. Authored-by: Cheng Pan <[email protected]> Signed-off-by: Chao Sun <[email protected]>
…und for PARQUET-2160 ### What changes were proposed in this pull request? SPARK-41952 was raised for a while, but unfortunately, the Parquet community does not publish the patched version yet, as a workaround, we can fix the issue on the Spark side first. We encountered this memory issue when migrating data from parquet/snappy to parquet/zstd, Spark executors always occupy unreasonable off-heap memory and have a high risk of being killed by NM. See more discussions at apache/parquet-java#982 and apache/iceberg#5681 ### Why are the changes needed? The issue is fixed in the parquet community [PARQUET-2160](https://issues.apache.org/jira/browse/PARQUET-2160), but the patched version is not available yet. ### Does this PR introduce _any_ user-facing change? Yes, it's bug fix. ### How was this patch tested? The existing UT should cover the correctness check, I also verified this patch by scanning a large parquet/zstd table. ``` spark-shell --executor-cores 4 --executor-memory 6g --conf spark.executor.memoryOverhead=2g ``` ``` spark.sql("select sum(hash(*)) from parquet_zstd_table ").show(false) ``` - before this patch All executors get killed by NM quickly. ``` ERROR YarnScheduler: Lost executor 1 on hadoop-xxxx.****.org: Container killed by YARN for exceeding physical memory limits. 8.2 GB of 8 GB physical memory used. Consider boosting spark.executor.memoryOverhead. ``` <img width="1872" alt="image" src="https://user-images.githubusercontent.com/26535726/220031678-e9060244-5586-4f0c-8fe7-55bb4e20a580.png"> - after this patch Query runs well, no executor gets killed. <img width="1881" alt="image" src="https://user-images.githubusercontent.com/26535726/220031917-4fe38c07-b38f-49c6-a982-2091a6c2a8ed.png"> Closes apache#40091 from pan3793/SPARK-41952. Authored-by: Cheng Pan <[email protected]> Signed-off-by: Chao Sun <[email protected]>
…und for PARQUET-2160 ### What changes were proposed in this pull request? SPARK-41952 was raised for a while, but unfortunately, the Parquet community does not publish the patched version yet, as a workaround, we can fix the issue on the Spark side first. We encountered this memory issue when migrating data from parquet/snappy to parquet/zstd, Spark executors always occupy unreasonable off-heap memory and have a high risk of being killed by NM. See more discussions at apache/parquet-java#982 and apache/iceberg#5681 ### Why are the changes needed? The issue is fixed in the parquet community [PARQUET-2160](https://issues.apache.org/jira/browse/PARQUET-2160), but the patched version is not available yet. ### Does this PR introduce _any_ user-facing change? Yes, it's bug fix. ### How was this patch tested? The existing UT should cover the correctness check, I also verified this patch by scanning a large parquet/zstd table. ``` spark-shell --executor-cores 4 --executor-memory 6g --conf spark.executor.memoryOverhead=2g ``` ``` spark.sql("select sum(hash(*)) from parquet_zstd_table ").show(false) ``` - before this patch All executors get killed by NM quickly. ``` ERROR YarnScheduler: Lost executor 1 on hadoop-xxxx.****.org: Container killed by YARN for exceeding physical memory limits. 8.2 GB of 8 GB physical memory used. Consider boosting spark.executor.memoryOverhead. ``` <img width="1872" alt="image" src="https://user-images.githubusercontent.com/26535726/220031678-e9060244-5586-4f0c-8fe7-55bb4e20a580.png"> - after this patch Query runs well, no executor gets killed. <img width="1881" alt="image" src="https://user-images.githubusercontent.com/26535726/220031917-4fe38c07-b38f-49c6-a982-2091a6c2a8ed.png"> Closes apache#40091 from pan3793/SPARK-41952. Authored-by: Cheng Pan <[email protected]> Signed-off-by: Chao Sun <[email protected]>
|
@zhongyujiang |
|
@wangzzu I guess it's because ZSTD allocates and uses off-heap memory very frequently, and before this PR the release of those native resources is subject to Java's GC, so I tried to relieve off-heap memory pressure by releasing them in time. |
Make sure you have checked all steps below.
Jira
Tests
Commits
Documentation
Benchmark
Benchmark:
The benchmark data consists of 500 string columns * 1_000_000 rows(10.85GB under ZSTD compression), and the benchmark is simply reading all the data out and pass them to the black hole.
JMH Configuration:
3 rounds of warmup iterations
5 rounds of measurenemt iterations
Notes:
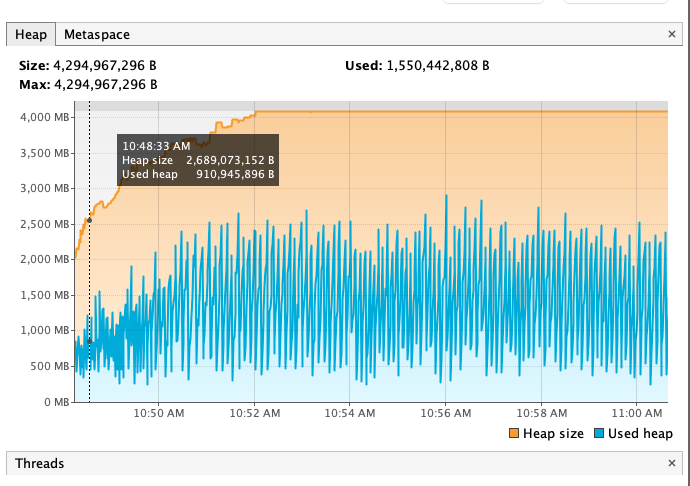
According to the benchmark results below, closing stream does not bring additional heap overload, but improves GC instead. From the comparison of the first two results of below table, we can see that closing stream improves the read performance and reduces the GC load.
I also measured the impact of heap size (GC) on read performance. After reducing heap memory to 3GB, GC Events increased, but the read performance is not decreased; However, after increasing heap memory to 5GB, GC Events decreased by about 30% , but the GC time has increased by about 2 times, and the read performance has also been significantly reduced, which may verify the previous guess in Jira: Untimely GC may exacerbate the off-heap memory fragmentation issue. (Of course, this may require more in-depth testing to corroborate)
Out of curiosity, I also tested the effect of closing stream on Snappy and Gzip, the benchmark results show that in such simple read scenario closing stream also has some positive effect on both Snappy and Gzip.
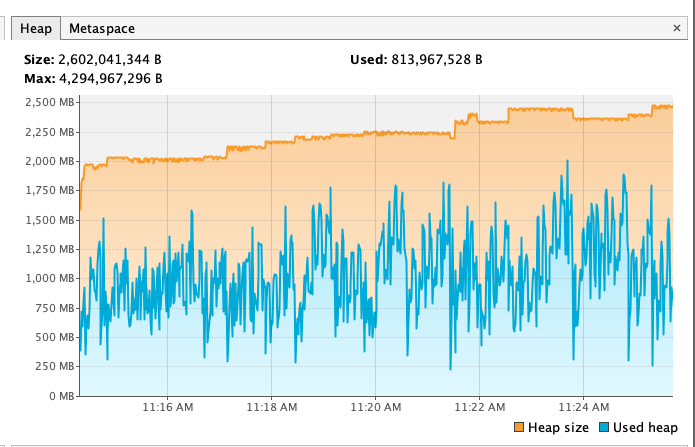
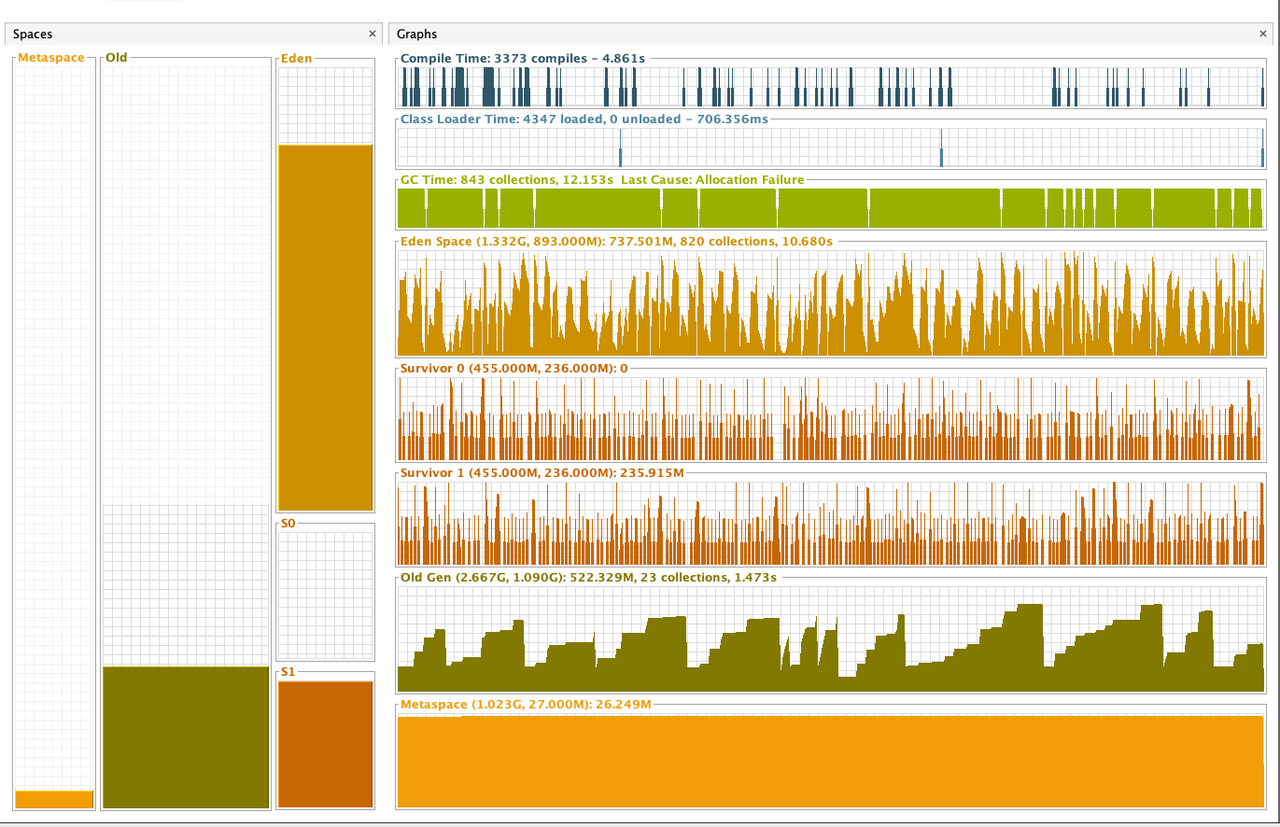
For more details, please refer to the following pictures:
ZSTD + Not close + 4GB
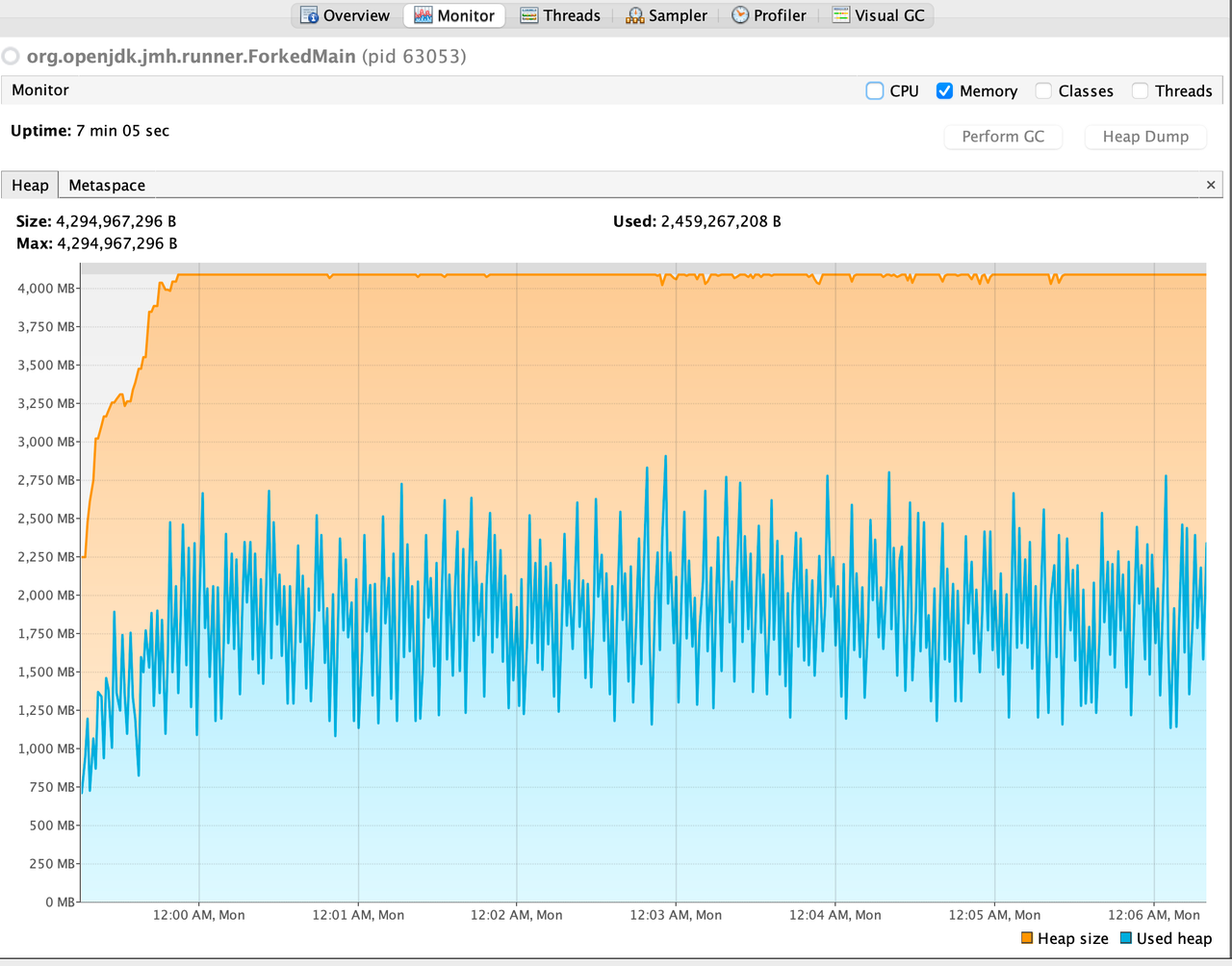
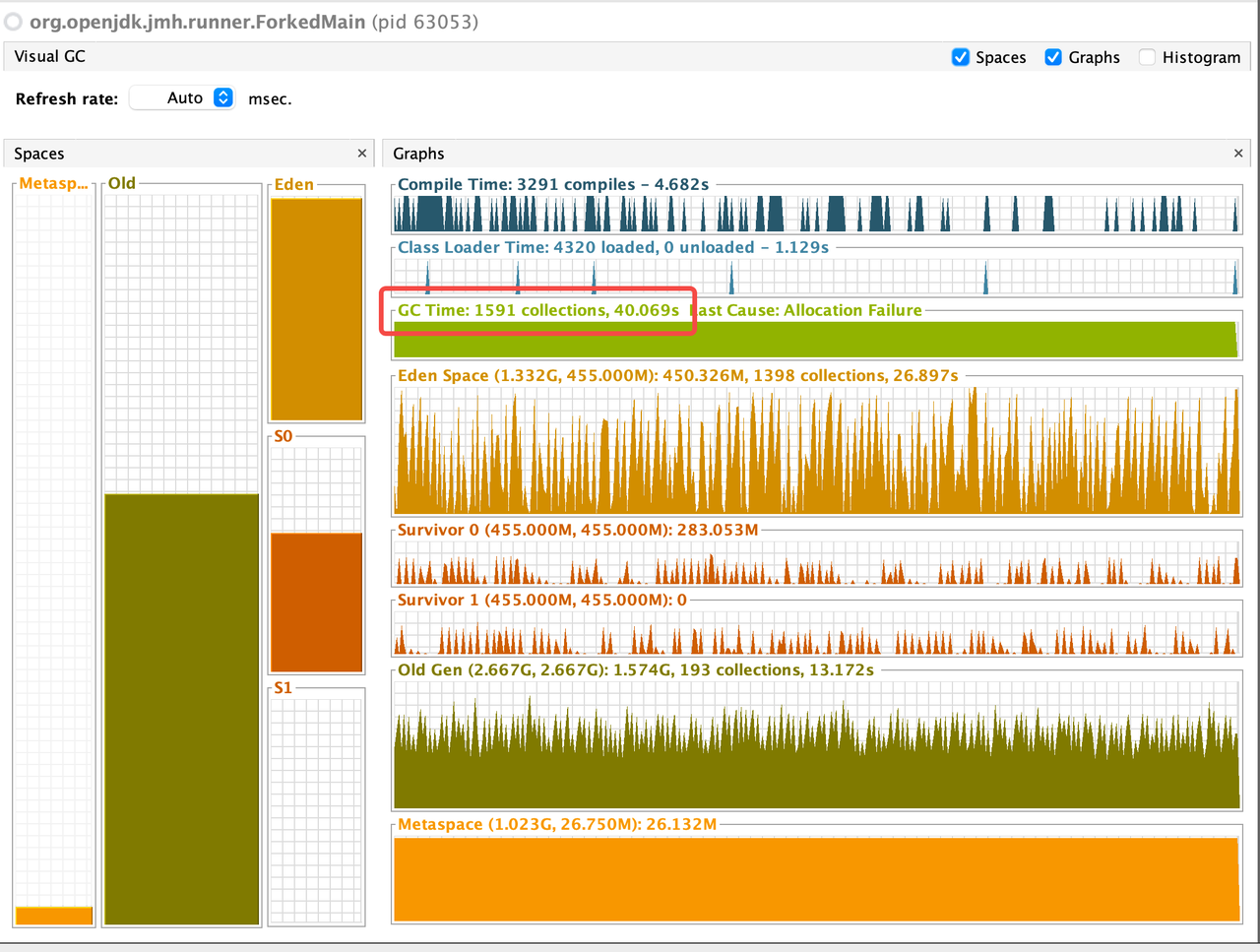
ZSTD + Close + 4GB
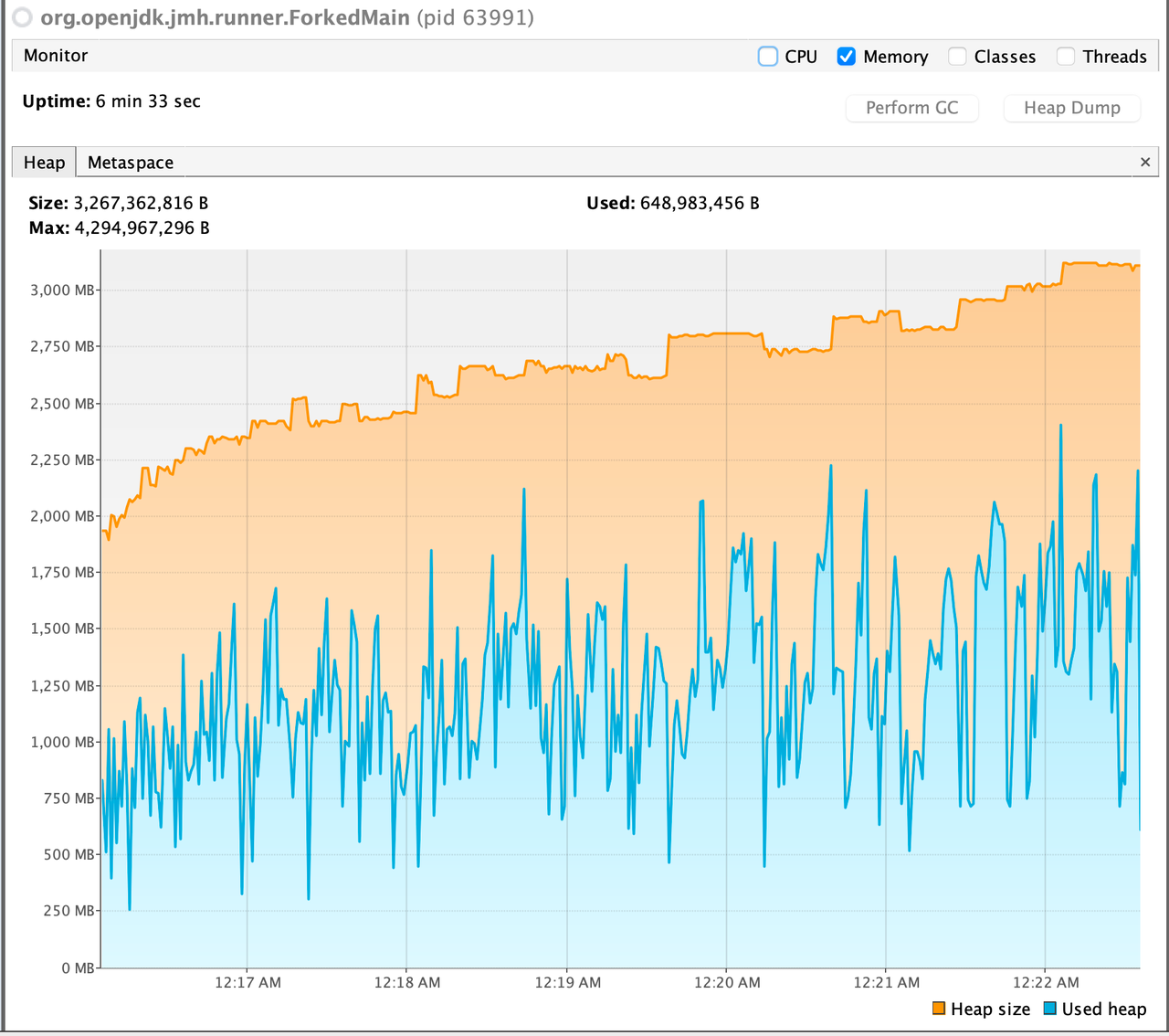
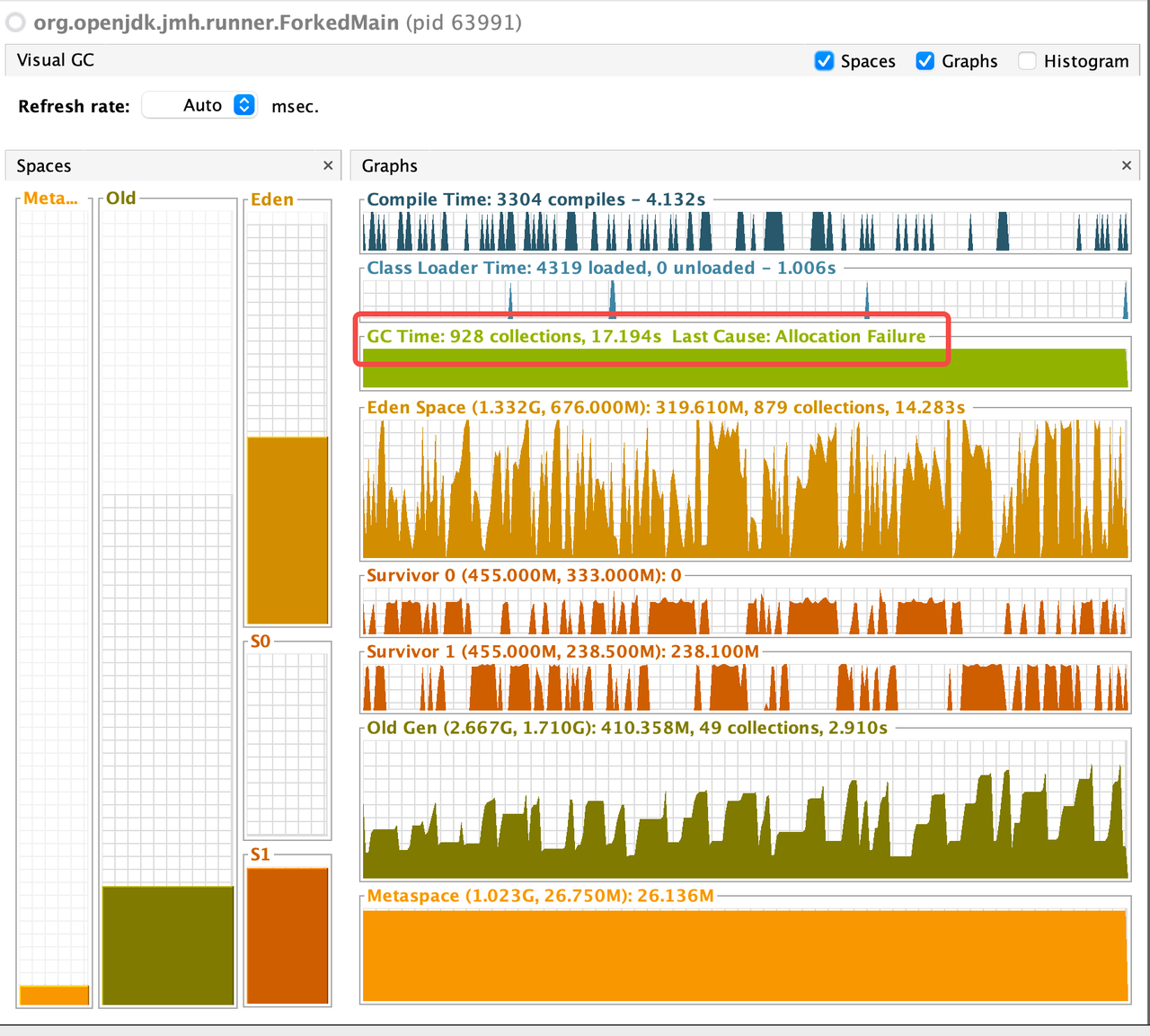
ZSTD + Not close + 3GB
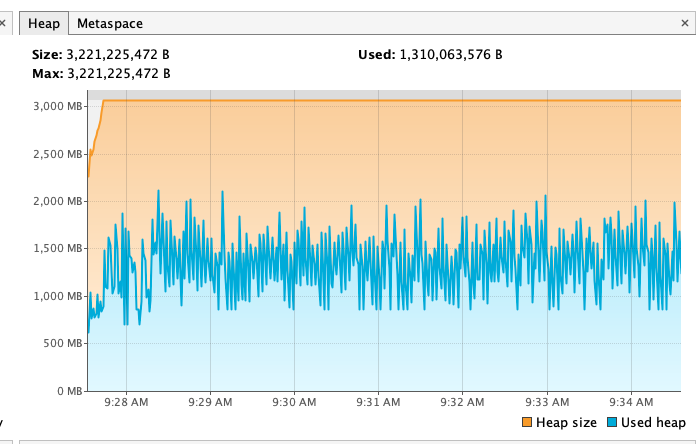
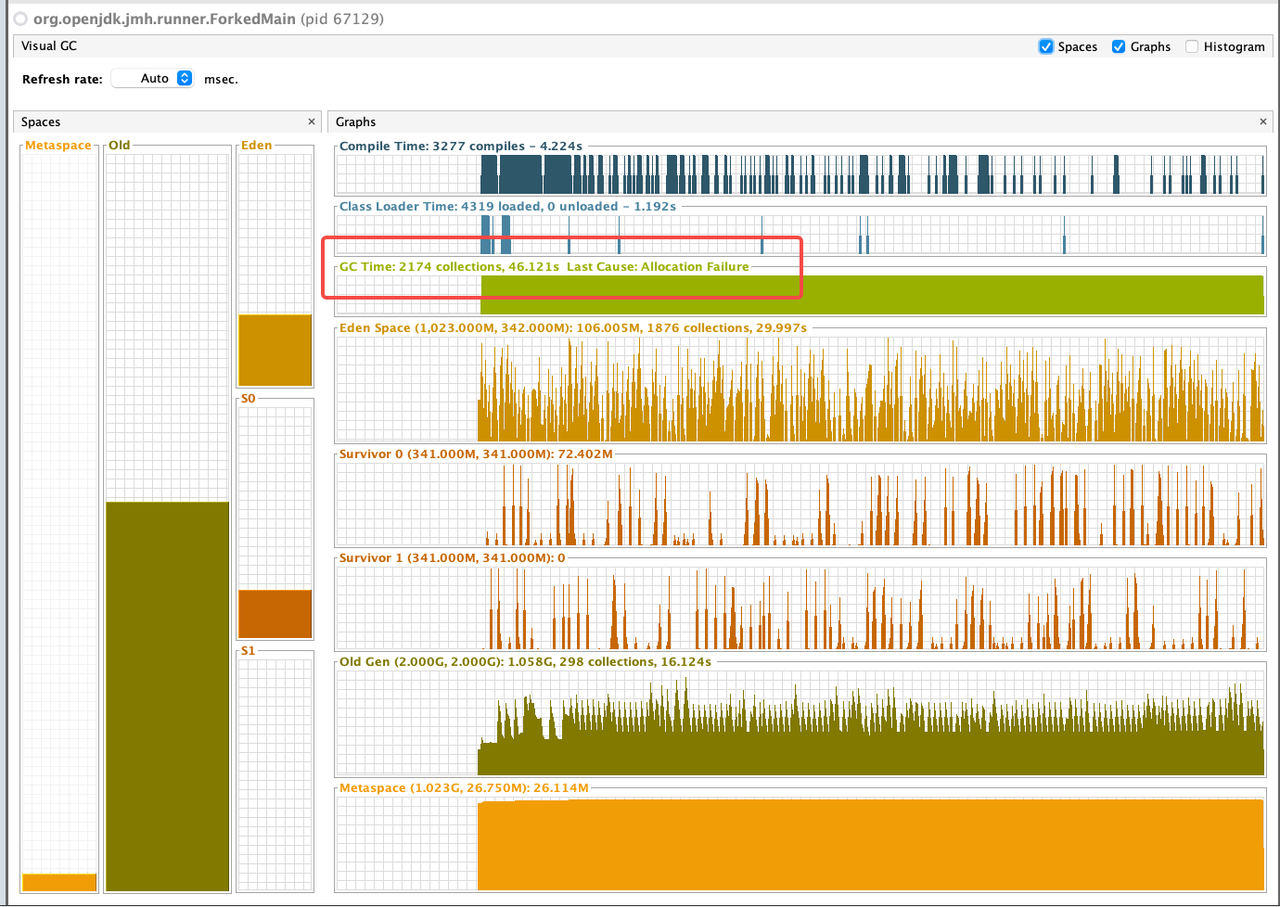
ZSTD + Not close + 5GB
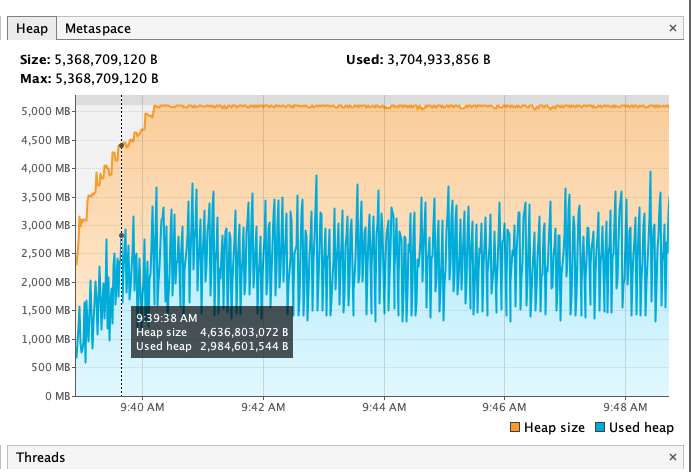

Snappy + Not close + 4GB
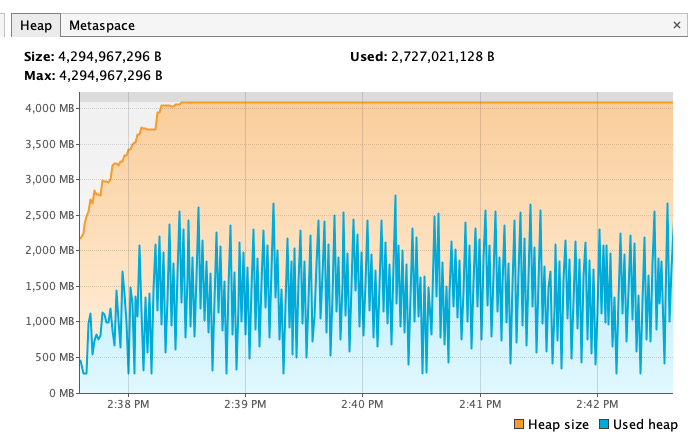
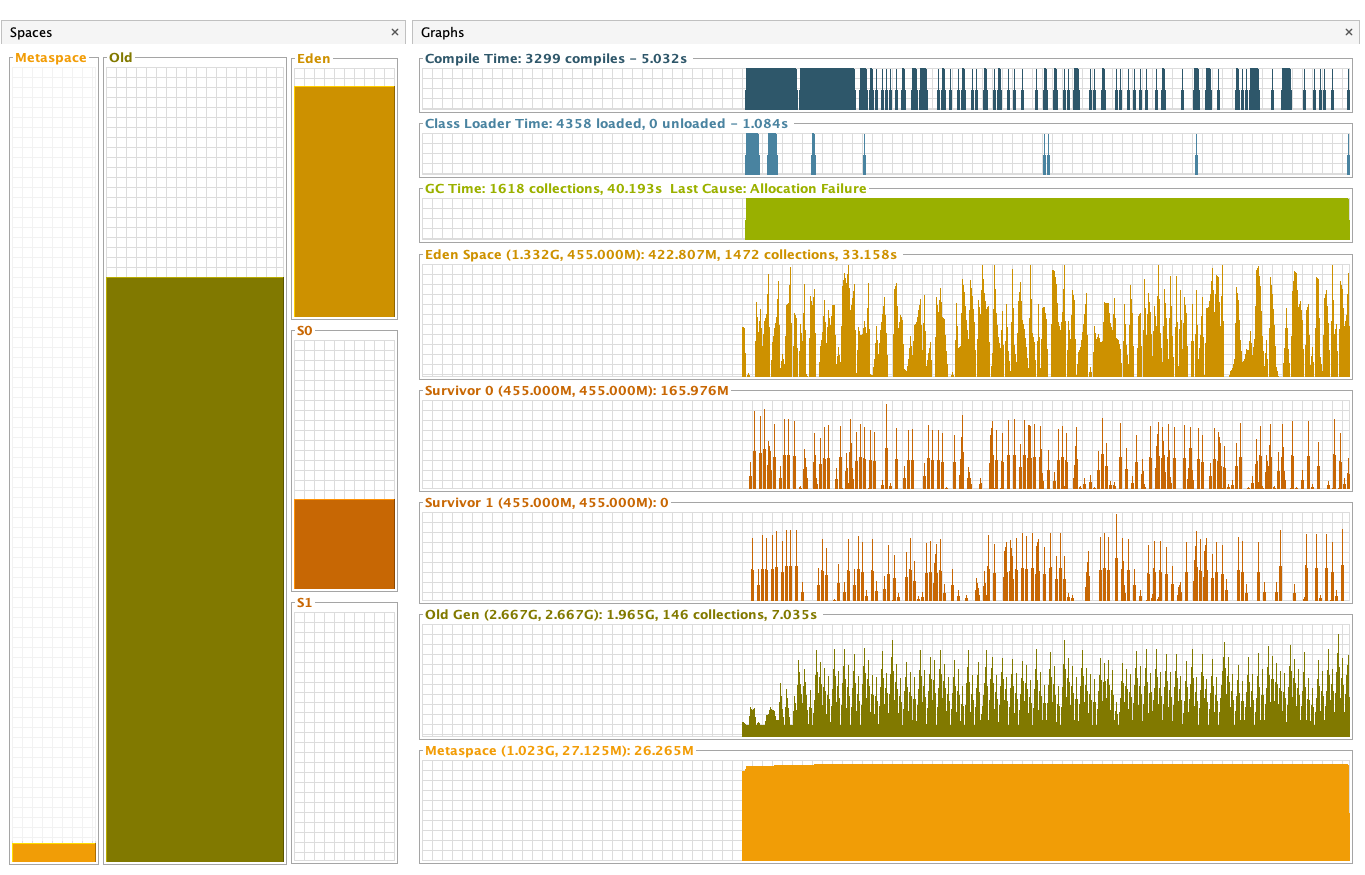
Snappy + Close + 4GB
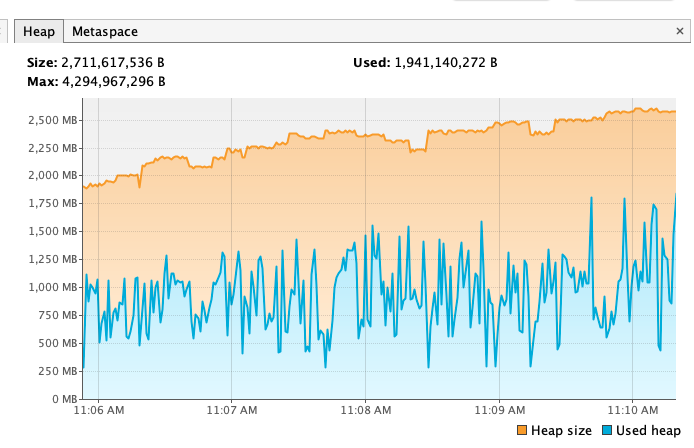
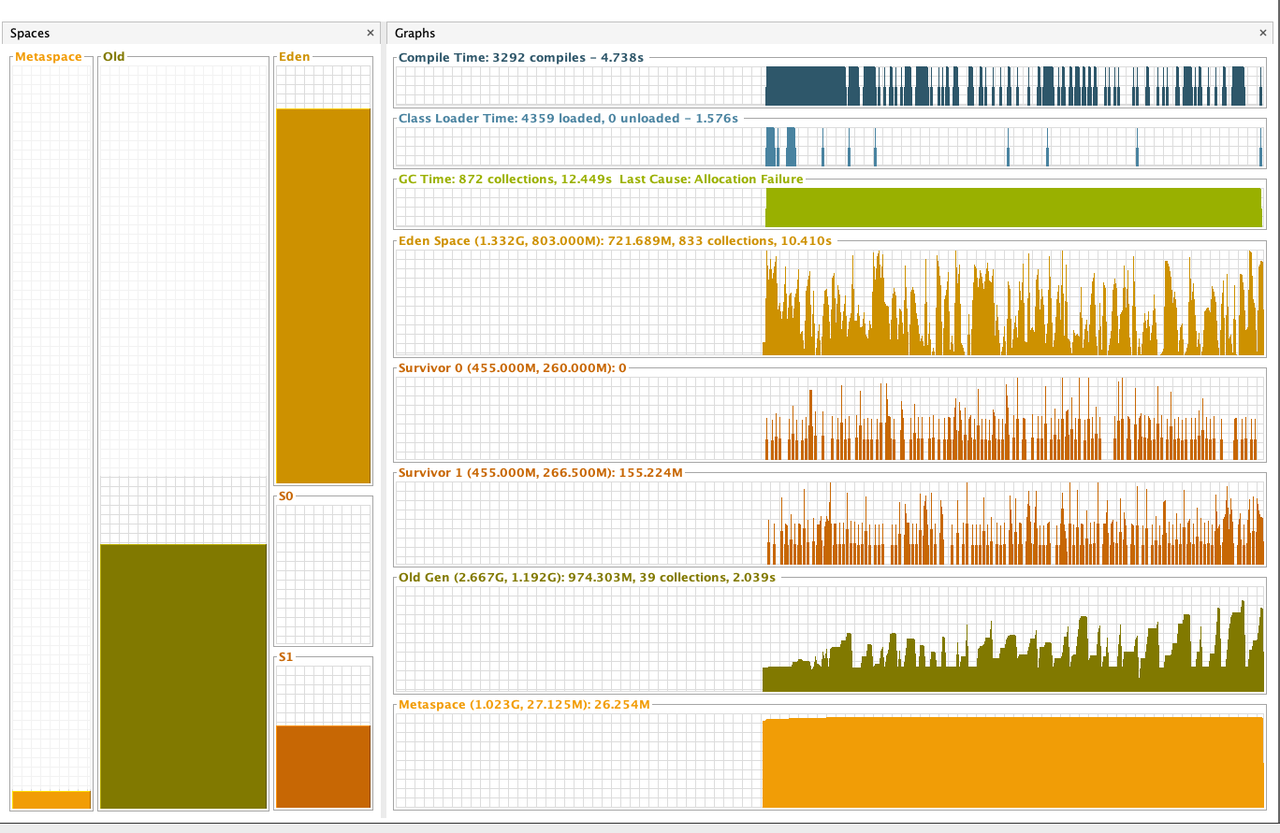
Gzip + Not Close + 4GB
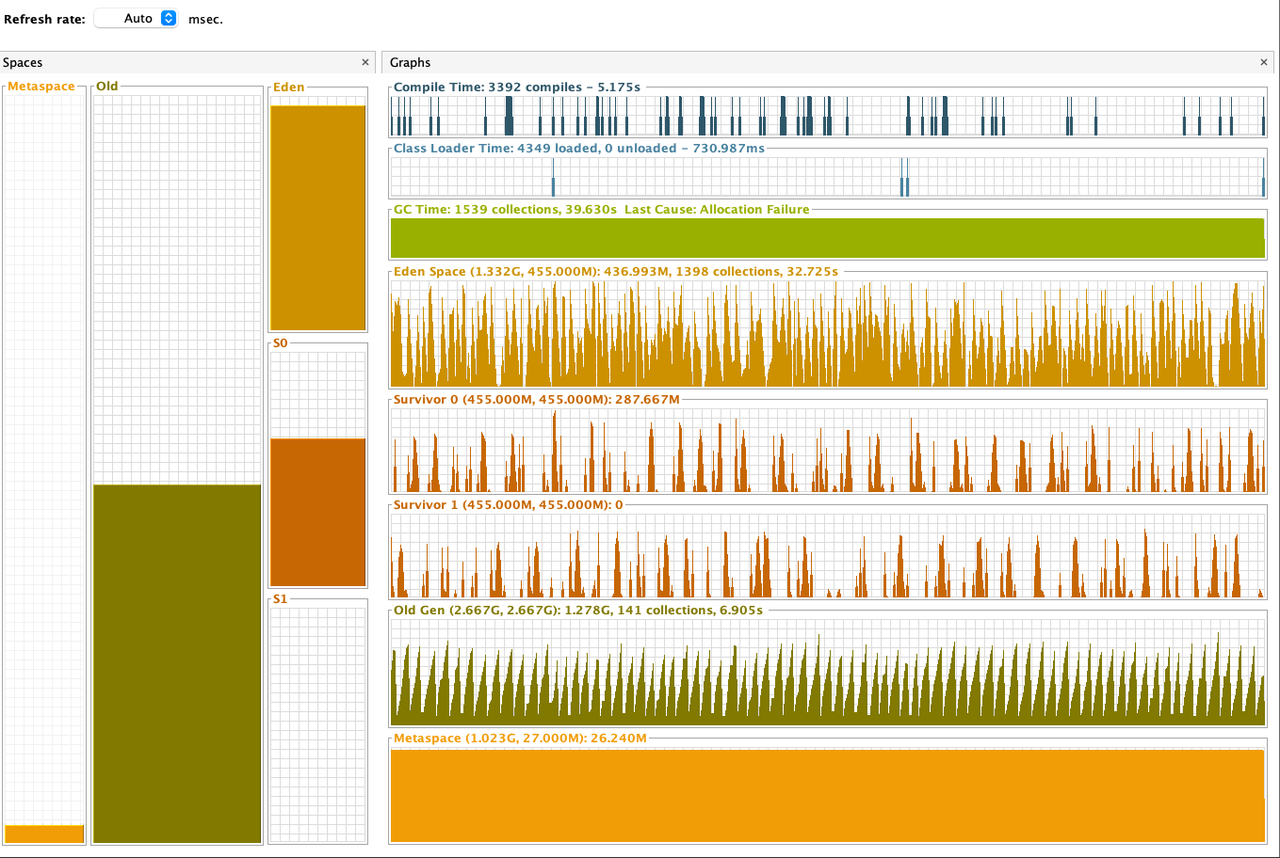
Gzip + Close + 4GB