[Format] Expand BYTE_STREAM_SPLIT to support FIXED_LEN_BYTE_ARRAY, INT32 and INT64 #296
Comments
|
Gang Wu / @wgtmac: BTW, I have two questions:
|
|
Gabor Szadovszky / @gszadovszky: I agree with @wgtmac: If we support FIXED_LEN_BYTE_ARRAY(DECIMAL) why wouldn't we do so for the INT32 and INT64 representations. |
I think that's a reasonable choice for writers to do, but I'm not sure the spec should mandate it.
Those two types can use DELTA_BINARY_PACKED, which should generally give very good results. |
IMHO the only downside with enabling it always is compatibility with older readers. Otherwise, I would say the choice is a no-brainer. |
|
Antoine Pitrou / @pitrou: |
|
Micah Kornfield / @emkornfield: |
|
Antoine Pitrou / @pitrou: |
|
Antoine Pitrou / @pitrou: @wesm @rdblue You both opined on the original BYTE_STREAM_SPLIT vote, would you like to give your opinion on whether to extend the encoding's applicability as proposed as the thread I linked above? |
|
Antoine Pitrou / @pitrou: |
|
Antoine Pitrou / @pitrou: |
In PARQUET-1622 we added the BYTE_STREAM_SPLIT encoding which, while simple to implement, allows to significantly improve compression efficiency on FLOAT and DOUBLE columns.
In PARQUET-758 we added the FLOAT16 logical type which annotates a 2-byte-wide FIXED_LEN_BYTE_ARRAY column to denote that it contains 16-bit IEEE binary floating-point (colloquially called "half float").
This issue proposes to widen the types supported by the BYTE_STREAM_SPLIT encoding. By allowing the BYTE_STREAM_SPLIT encoding on any FIXED_LEN_BYTE_ARRAY column, we can automatically improve compression efficiency on various column types including:
half-float data
fixed-width decimal data
Also, by allowing the BYTE_STREAM_SPLIT encoding on any INT32 or INT64 column, we can improve compression efficiency on further column types such as timestamps.
I've run compression measurements on various pieces of sample data which I detail below.
Float16 data
I've downloaded the sample datasets from
https://userweb.cs.txstate.edu/~burtscher/research/datasets/FPsingle/ , uncompressed them and converted them to half-float using NumPy. Two files had to be discarded because of overflow when converting to half-float.
I've then run three different compression algorithms (lz4, zstd, snappy), optionally preceded by a BYTE_STREAM_SPLIT encoding with 2 streams (corresponding to the byte width of the FLBA columns. Here are the results:
Explanation:
the columns "lz4", "snappy", "zstd" show the compression ratio achieved with the respective compressors (i.e. uncompressed size divided by compressed size)
the columns "bss_lz4", "bss_snappy", "bss_zstd" are similar, but with a BYTE_STREAM_SPLIT encoding applied first
the columns "bss_ratio_lz4", "bss_ratio_snappy", "bss_ratio_zstd" show the additional compression ratio achieved by prepending the BYTE_STREAM_SPLIT encoding step (i.e. PLAIN-encoded compressed size divided by BYTE_STREAM_SPLIT-encoded compressed size).
(reference) Float32 data
For reference, here are the measurements for the original single-precision floating-point data.
Comments
The additional efficiency of the BYTE_STREAM_SPLIT encoding step is very significant on most files (except
obs_temp.spwhich generally doesn't compress at all), with additional gains usually around 30%.The BYTE_STREAM_SPLIT encoding is, perhaps surprisingly, on average as beneficial on Float16 data as it is on Float32 data.
Decimal data from OpenStreetMap changesets
I've downloaded one of the recent OSM changesets file
changesets-231030.orc, and loaded the four decimal columns from the first stripe of that file. Those columns look like:{code}
pyarrow.RecordBatch
min_lat: decimal128(9, 7)
max_lat: decimal128(9, 7)
min_lon: decimal128(10, 7)
max_lon: decimal128(10, 7)
min_lat: [51.5288506,51.0025063,51.5326805,51.5248871,51.5266800,51.5261841,51.5264130,51.5238914,59.9463692,59.9513092,...,50.8238277,52.1707376,44.2701598,53.1589748,43.5988333,37.7867167,45.5448822,null,50.7998334,50.5653478]
max_lat: [51.5288620,51.0047760,51.5333176,51.5289383,51.5291901,51.5300598,51.5264130,51.5238914,59.9525642,59.9561501,...,50.8480772,52.1714300,44.3790161,53.1616817,43.6001496,37.7867913,45.5532716,null,51.0188961,50.5691352]
min_lon: [-0.1465242,-1.0052705,-0.1566335,-0.1485492,-0.1418076,-0.1550623,-0.1539768,-0.1432930,10.7782278,10.7719727,...,10.6863813,13.2218676,19.8840738,8.9128186,1.4030591,-122.4212761,18.6789571,null,-4.2085209,8.6851671]
max_lon: [-0.1464925,-0.9943439,-0.1541054,-0.1413791,-0.1411505,-0.1453212,-0.1539768,-0.1432930,10.7898550,10.7994537,...,10.7393494,13.2298706,20.2262343,8.9183611,1.4159345,-122.4212503,18.6961594,null,-4.0496079,8.6879264]
------------------------
+-----+---------+--------+------------+------+----------+---------------+------------------+-----------------+| name | uncompressed | lz4 | bss_lz4 | snappy | bss_snappy | zstd | bss_zstd | bss_ratio_lz4 | bss_ratio_snappy | bss_ratio_zstd |




==============================================================================================================================================
|
|-|-|-|-|-|-|-|-|-|-|-|-|
| min_lat | 4996652.00 | 1.00 | 1.01 | 1.00 | 1.03 | 1.05 | 1.12 | 1.01 | 1.03 | 1.07 |
------------------------
+-----+---------+--------+------------+------+----------+---------------+------------------+-----------------+|
| max_lat | 4996652.00 | 1.00 | 1.01 | 1.00 | 1.03 | 1.05 | 1.13 | 1.01 | 1.03 | 1.07 |
------------------------
+-----+---------+--------+------------+------+----------+---------------+------------------+-----------------+|
| min_lon | 6245825.00 | 1.00 | 1.14 | 1.00 | 1.16 | 1.15 | 1.31 | 1.14 | 1.16 | 1.14 |
------------------------
+-----+---------+--------+------------+------+----------+---------------+------------------+-----------------+|
| max_lon | 6245825.00 | 1.00 | 1.14 | 1.00 | 1.16 | 1.15 | 1.31 | 1.14 | 1.16 | 1.14 |
------------------------
+-----+---------+--------+------------+------+----------+---------------+------------------+-----------------+Java<br> <br> <br>!bss_osm_changesets.png! <br> <br>h3. Comments <br> <br>On this dataset, compression efficiency is generally quite poor and BYTE_STREAM_SPLIT encoding brings almost no additional efficiency to the table. It can be assumed that OSM changeset entries have geographical coordinates all over the place (literally!) and therefore do not offer many opportunities for compression. <br> <br>h2. Decimal data from an OpenStreetMap region <br> <br>I've chosen a small region of the world (Belgium) whose geographical coordinates presumably allow for better compression by being much more clustered. The file {{belgium-latest.osm.pbf}} was converted to ORC for easier handling, resulting in a 745 MB ORC file. <br> <br>I've then loaded the decimal columns from the first stripe in that file: <br>pyarrow.RecordBatch
lat: decimal128(9, 7)
lon: decimal128(10, 7)
----
lat: [50.4443865,50.4469017,50.4487890,50.4499558,50.4523446,50.4536530,50.4571053,50.4601436,50.4631197,50.4678563,...,51.1055899,51.1106197,51.1049620,51.1047010,51.1104755,51.0997955,51.1058101,51.1010664,51.1014336,51.1055106]
lon: [3.6857362,3.6965046,3.7074481,3.7173626,3.8126033,3.9033178,3.9193678,3.9253319,3.9292409,3.9332670,...,4.6663214,4.6699997,4.6720536,4.6655159,4.6666372,4.6680394,4.6747172,4.6684242,4.6713693,4.6644899]
Java<br> <br> <br>Here are the compression measurements for these columns. As in the previous dataset, the number of BYTE_STREAM_SPLIT streams is the respective byte width of each FLBA column (i.e., 4 for latitudes and 5 for longitudes). <br>-----------------------
+-----+---------+--------+------------+------+----------+---------------+------------------+-----------------+|
| name | uncompressed | lz4 | bss_lz4 | snappy | bss_snappy | zstd | bss_zstd | bss_ratio_lz4 | bss_ratio_snappy | bss_ratio_zstd |
=============================================================================================================================================
|
| lat | 12103680.00 | 1.00 | 1.63 | 1.00 | 1.63 | 1.18 | 1.73 | 1.63 | 1.63 | 1.47 |
-----------------------
+-----+---------+--------+------------+------+----------+---------------+------------------+-----------------+|
| lon | 15129600.00 | 1.00 | 1.93 | 1.00 | 1.90 | 1.27 | 2.06 | 1.93 | 1.90 | 1.62 |
-----------------------
+-----+---------+--------+------------+------+----------+---------------+------------------+-----------------+{code}
### Comments
This dataset shows that a BYTE_STREAM_SPLIT encoding before compression achieves a very significant additional efficiency compared to compression alone.
## Integer data from two OpenStreetMap data files
I also tried to evaluate the efficiency of BYTE_STREAM_SPLIT on integer columns (INT32 or INT64). Here, however, another efficient encoding is already available (DELTA_BINARY_PACKED). So the evaluation focussed on comparing BYTE_STREAM_SPLIT + compression against DELTA_BINARY_PACKED alone.
The comparison was done on the two same OpenStreetMap files as above, using only the first stripe. Here are the measurement results in table format:
*Caution*: the DELTA_BINARY_PACKED length measurement did not use a real encoder implementation, but a length estimation function written in pure Python. The estimation function should be accurate according to quick tests.
### Comments
The results are very heterogeneous, depending on the kind of data those integer columns represent.
Some columns achieve very good compression ratios, far above 10x, with all methods; for these columns, it does not make sense to compare the compression ratios, since the column sizes will be very small in all cases; performance and interoperability should be the only concerns.
On other columns, the compression ratios are more moderate and BYTE_STREAM_SPLIT + compression seems to be preferable to DELTA_BINARY_PACKED.
## Integer data from a PyPI archive file
I downloaded one of the "index" Parquet files from https://github.com/pypi-data/data/releases and read the first row group.
The measurement results are as follows:
### Comments
On this data, BYTE_STREAM_SPLIT + compression is clearly better than DELTA_BINARY_PACKED. The timestamp column ("uploaded_on") in particular shows very strong benefits.
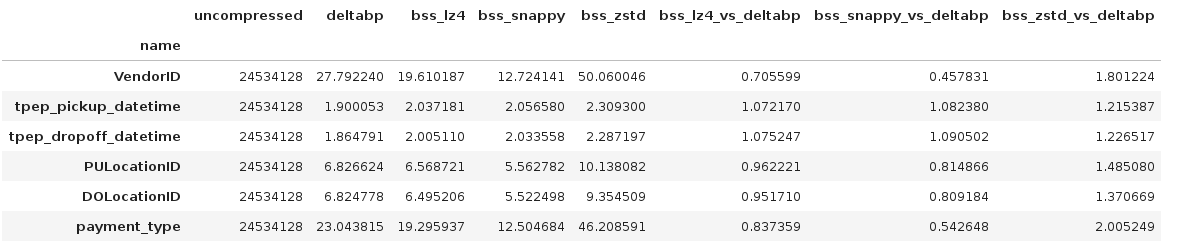
## Integer data from a NYC "yellow" taxi file
I downloaded one of the "yellow" taxi trip records from https://www.nyc.gov/site/tlc/about/tlc-trip-record-data.page and read the first row group. The measurement results are as follows:
### Comments
These results are a bit of a mixed bag. Only BYTE_STREAM_SPLIT + zstd is consistenly superior to DELTA_BINARY_PACKED. However, if one focusses on the timestamp columns, then all three general-purpose compressors provide a benefit.
## Discussion
When reading these results, it is important to remind that the exact compression ratios do not necessarily matter, as long as the efficiency is high enough. A compressor that achieves 100x compression on a column is not necessarily worse than one that achieves 300x compression on the same column: both are "good enough" on this particular data. On the contrary, when compression ratios are moderate (lower than 10x), they should certainly be compared.
### Efficiency
#### Efficiency on FIXED_LEN_BYTE_ARRAY data
These examples show that extending the BYTE_STREAM_SPLIT encoding to FIXED_LEN_BYTE_ARRAY columns (even regardless of their logical types) can yield very significant compression efficiency improvements on two specific types of FIXED_LEN_BYTE_ARRAY data: FLOAT16 data and DECIMAL data.
#### Efficiency on INT32 / INT64 data
Extending the BYTE_STREAM_SPLIT encoding to INT32 and INT64 columns can bring significant benefits over DELTA_BINARY_PACKED. However, whether and by how much depends on the kind of data that is encoded as integers. Timestamps seem to always benefit from BYTE_STREAM_SPLIT encoding. Pairing BYTE_STREAM_SPLIT with zstd also generally achieves higher efficiency than DELTA_BINARY_PACKED.
Whether to choose BYTE_STREAM_SPLIT + compression over DELTA_BINARY_PACKED will in practice have to be informed by several factors, such as performance expectations and interoperability. Sophisticated writers might also implement some form of sampling to find out the best encoding + compression combination for a given column.
*Note*: all tested data above is actually INT64. However, given the mechanics of BYTE_STREAM_SPLIT and DELTA_BINARY_PACKED, we can assume that similar results would have been obtained for INT32 data.
### Performance
Since BYTE_STREAM_SPLIT only brings benefits in combination with compression, the overall encoding + compression cost should be considered.
#### Performance on FIXED_LEN_BYTE_ARRAY data
The choice is between BYTE_STREAM_SPLIT + compression vs. compression alone. Even a non-SIMD optimized version of BYTE_STREAM_SPLIT, such as in Parquet C++, can achieve multiple GB/s; there is little reason to pay the cost of compression but refuse to pay the much smaller cost of the BYTE_STREAM_SPLIT encoding step.
#### Performance on INT32 / INT64 data
The choice is between BYTE_STREAM_SPLIT + compression vs. DELTA_BINARY_PACKED alone. DELTA_BINARY_PACKED has a significant performance edge. The current Parquet C++ implementation of DELTA_BINARY_PACKED encodes between 600 MB/s and 2 GB/s, and decodes between 3 and 6 GB/s. This is faster than any of the general-purpose compression schemes available in Parquet, even lz4.
### Implementation complexity
BYTE_STREAM_SPLIT, even byte width-agnostic, is almost trivial to implement. A simple implementation can yield good performance with a minimum of work.
For example, the non-SIMD-optimized BYTE_STREAM_SPLIT encoding and decoding routines in Parquet C++ amount to a mere total of ~200 lines of code, despite explicitly-unrolled loops:
https://github.com/apache/arrow/blob/4e58f7ca0016c2b2d8a859a0c5965df3b15523e0/cpp/src/arrow/util/byte_stream_split_internal.h#L593-L702
|
Reporter: Antoine Pitrou / @pitrou
Assignee: Antoine Pitrou / @pitrou
Related issues:
Original Issue Attachments:
PRs and other links:
Note: This issue was originally created as PARQUET-2414. Please see the migration documentation for further details.
The text was updated successfully, but these errors were encountered: