HDDS-3160. Disable index and filter block cache for RocksDB. #665
Conversation
|
Thanks @elek for the patch. Given the block cache size (256MB) and the per SST index/filter cost ~5.5MB, It would handle up to about 50 SST files before thrashing happen. I agree that the mix the index/filter with block data could impact the performance of the block cache. This is one catch moving it out of block cache with this change. We will lost the control over the max memory usage of those index/filters. We should consider adding profiles for larger block cache size (e.g., change the current 256MB to 8GB or higher for OM DB with 100M+ keys or above) for the scenario when taming rocks db memory usage is required, or adding support for portioned index filters. I'm +1 on this change with one minor ask: If would be great if you could attach some RocksDB block cache metrics on block cache hit/miss ratio before and after this change, on index/filter/data, respectively. |
|
Hi @elek , thanks for the patch. I tried it locally and got 50% performance gain. I tested two approach,
So I'm wondering if we can make these two configurable. User can choose the approach according to their hardware resource and key size. For example, 1GB is enough for 100 millions keys. When we want to host 1000 million keys, we may want to configure a higher block cache size. |
|
Thanks @ChenSammi to test it.
Currently there are two options to adjust RocksDB settings. Profile (SSD, DISK) based defaults ( This patch modifies the defaults. I tested the second option, unfortunately the JNI binding of Rocksdb is bad: It doesn't return any error if the config file couldn't been loaded or contains error. Agree: We can improve it with adding a different method to set custom RocksDB parameters. |
|
Thanks @xiaoyuyao the review.
I would be happy to repeat the isolated OM test with and without this patch, but I am not sure If I get good metrics from RocksDB. With moving index/filter out from the cache I think the cache hit / miss will be zero for index / filter all the time. Do you have any more details what are interested about? |
|
I mean do we see better BLOCK_CACHE_DATA_HIT after moving out of the index/filter. More detail of the block cache statistics can be found here: https://github.com/facebook/rocksdb/wiki/Block-Cache#statistics |
@xiaoyuyao Good questions, I checked it and saved the screenshot to have it in this PR (FTR). And the answer is yes:
|
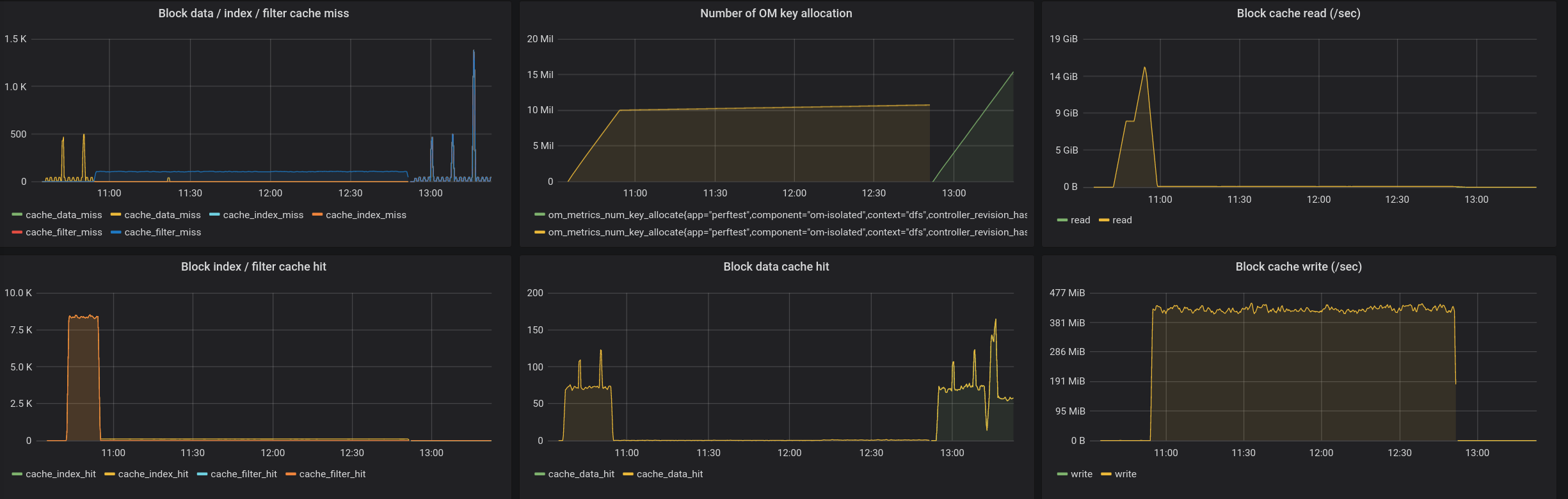
|
Thanks @elek for the additional info. That helps. I'm just curious on the bottom-right, why rocks DB suddenly had a sustained block cache write (300+MB/s) around 11:00. That explains why key creation stalled because the block cache got refreshed every seconds with a block cache size of 256MB during that period of time. Given this does not happen during the key creation earlier. This seems very likely from a RocksDB compaction, which updates the filters/indices of the SSTs. |
Yes, this is after a compaction:
I think after the compaction both the size of index/filter and block numbers are increased and the fixed amount of cache is not enough. |
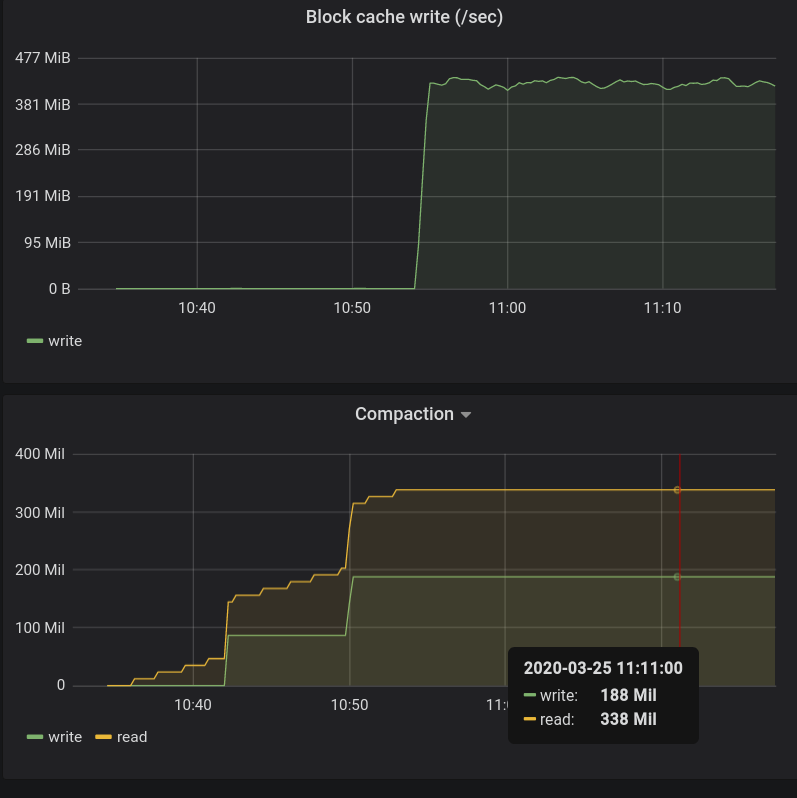
|
Base branch is changed. Please don't merge it from github ui, only manually. |
|
Note even we don't put the filter/index into the block cache after this change, they will still be put into off-heap memory by rocksdb. It is good to track the OM JVM heap usage w/wo this change during compaction to fully understand the impact of this change. |
Yes, this fact should be added to a "performance guide" ideally. Thanks the review @xiaoyuyao, @arp7 and @ChenSammi . I am merging this change. |
What changes were proposed in this pull request?
During preformance tests It was noticed that the OM performance is dropped after 10-20 million of keys. (screenshot is attached to the JIRA)
By default
cache_index_and_filter_blocksis enabled for all of our RocksDB instances (seeDBProfile.java) which is not the best option. (For example see this thread: facebook/rocksdb#3961)With turning on this cache the indexes and bloom filters are cached inside the block cache which makes slower the cache when we have significant amount of data.
Without turning it on (based on my understanding) all the indexes will remain open without any cache. With our current settings we have only a few number of sst files (even with million of keys) therefore it seems to be safe to turn this option off.
With turning this option of I was able to write >200M keys with high throughput (10 k key allocation / sec + 10 k key close / sec)
What is the link to the Apache JIRA
https://issues.apache.org/jira/browse/HDDS-3160
How was this patch tested?
With the help of #656 I started long-running OM load tests. (See the details there). Without the patch after 10-20M of keys the performance is dropped from 10 k key allocation / sec to a few hundreds (see the screenshot of the JIRA).
With the patch It was possible to maintain the 10k / sec rate during the firstm 200M key allocation (still running...)