Core: Support _deleted metadata column in vectorized read #4888
Conversation
| required(101, "data", Types.StringType.get()), | ||
| MetadataColumns.ROW_POSITION, | ||
| MetadataColumns.IS_DELETED | ||
| MetadataColumns.ROW_POSITION |
There was a problem hiding this comment.
We need this change since the class VectorizedReaderBuilder is shared by all spark versions. The change in line 94 of VectorizedReaderBuilder changes the type of the reader as the following code shows. Then, the read throws exception in the method IcebergArrowColumnVector.forHolder() of the old Spark version. This change should be fine due to the old Spark doesn't really support _deleted metadata column.
reorderedFields.add(new VectorizedArrowReader.DeletedVectorReader());
| numRowsUndeleted = applyEqDelete(newColumnarBatch); | ||
| } | ||
|
|
||
| if (hasColumnIsDeleted) { |
There was a problem hiding this comment.
This is a nit but, i think this makes more sense read a hasIsDeletedColumn
| return new ConstantVectorHolder(numRows, constantValue); | ||
| } | ||
|
|
||
| public static <T> VectorHolder isDeletedHolder(int numRows) { |
There was a problem hiding this comment.
This is another kinda on the fence for me, while the return type isn't boolean, this does seem like a boolean method. Maybe it should just be deletedHolder ? Just skip the "is" since it's a bit confusing in this context?
There was a problem hiding this comment.
I think the class name is fine, just this method seems a little confusing to me, but maybe it's just me :)
There was a problem hiding this comment.
We may keep it as is to keep the naming consistent since we don't change the class name.
arrow/src/main/java/org/apache/iceberg/arrow/vectorized/VectorizedArrowReader.java
Outdated
Show resolved
Hide resolved
...k/v3.2/spark/src/main/java/org/apache/iceberg/spark/data/vectorized/ColumnarBatchReader.java
Outdated
Show resolved
Hide resolved
...k/v3.2/spark/src/main/java/org/apache/iceberg/spark/data/vectorized/ColumnarBatchReader.java
Outdated
Show resolved
Hide resolved
...k/v3.2/spark/src/main/java/org/apache/iceberg/spark/data/vectorized/ColumnarBatchReader.java
Outdated
Show resolved
Hide resolved
| } | ||
|
|
||
| @Override | ||
| public byte getByte(int rowId) { |
There was a problem hiding this comment.
Not sure if we did this in the others, but IMHO all the accessors should throw UnsupportedOperationException except for getBoolean
There was a problem hiding this comment.
Make sense. We did in class RowPositionColumnVector.
| private ColumnarBatch columnarBatch; | ||
| private final int numRowsToRead; | ||
| private int[] rowIdMapping; // the rowId mapping to skip deleted rows for all column vectors inside a batch | ||
| private boolean[] isDeleted; // the array to indicate if a row is deleted or not |
There was a problem hiding this comment.
For my confusion below can we indicate here for these two arrays to describe when these two can be null?
...2/spark/src/test/java/org/apache/iceberg/spark/data/TestSparkParquetReadMetadataColumns.java
Show resolved
Hide resolved
|
|
||
| @Test | ||
| public void testPosDeletesWithDeletedColumn() throws IOException { | ||
| Assume.assumeFalse(vectorized); |
 RussellSpitzer
left a comment
RussellSpitzer
left a comment
There was a problem hiding this comment.
I think this is pretty close, I just have a few questions about how we propagate around null rowIdMapping and isDeletedColumns and a few naming nits.
|
Thanks @RussellSpitzer for the review. Refactor class |
|
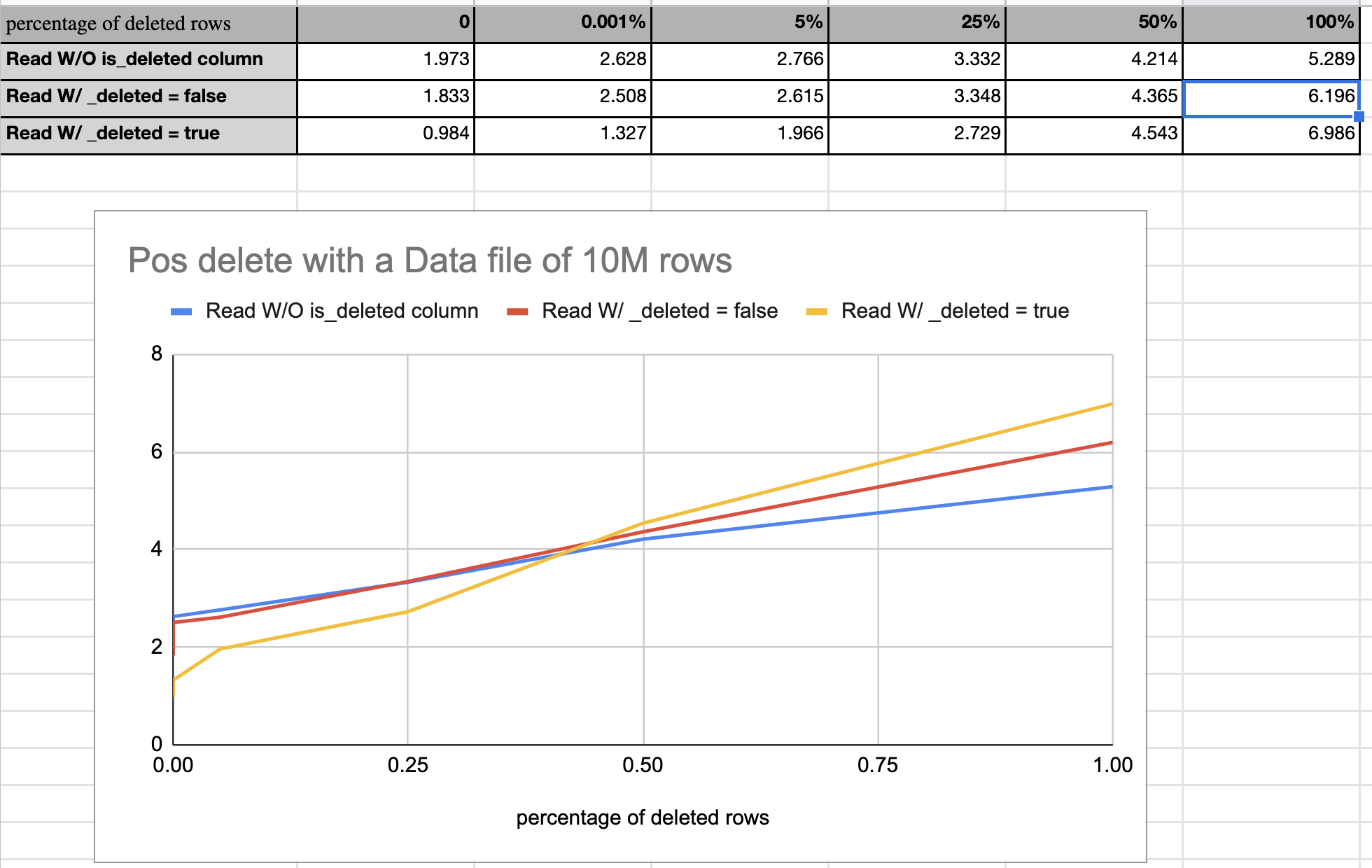
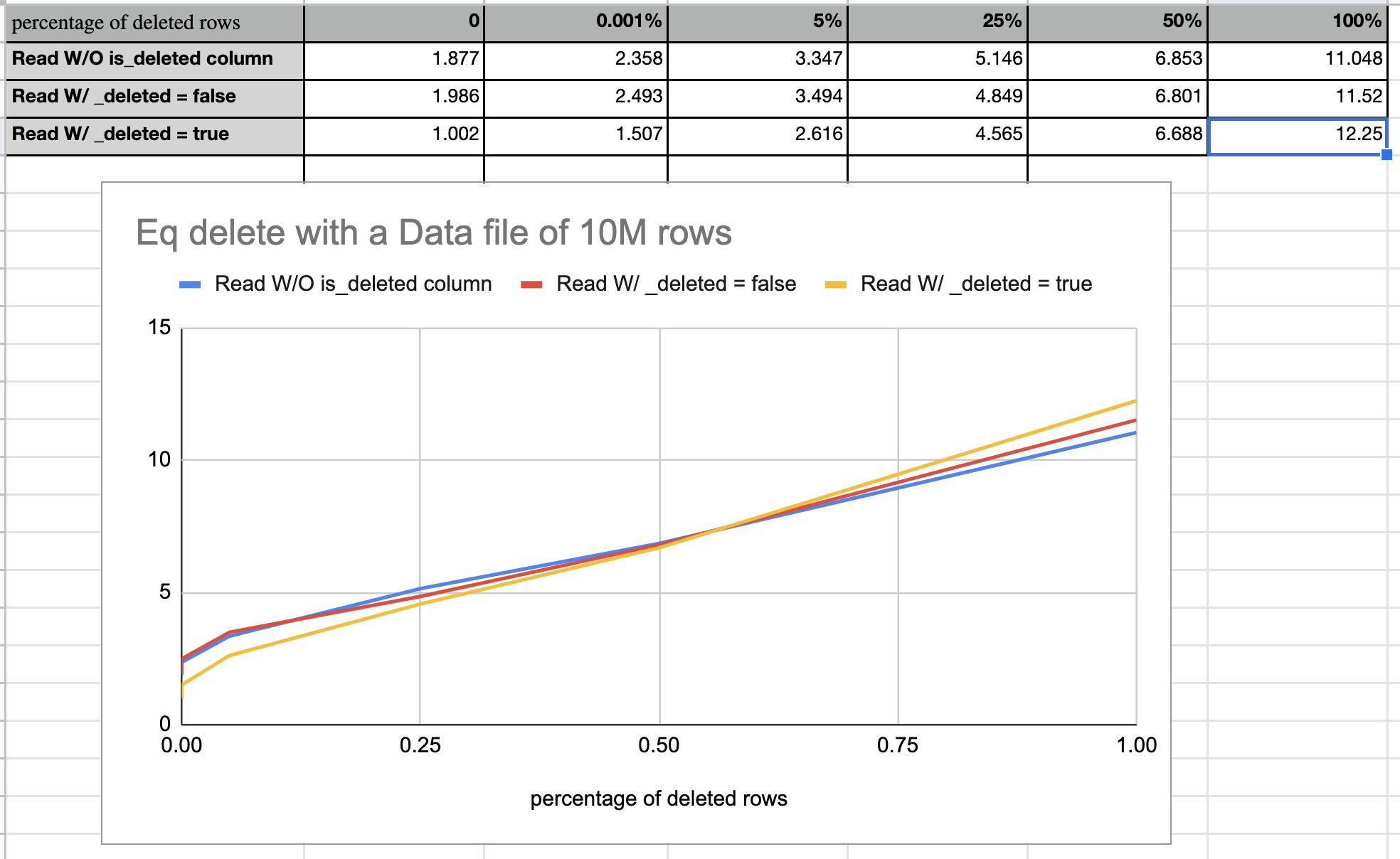
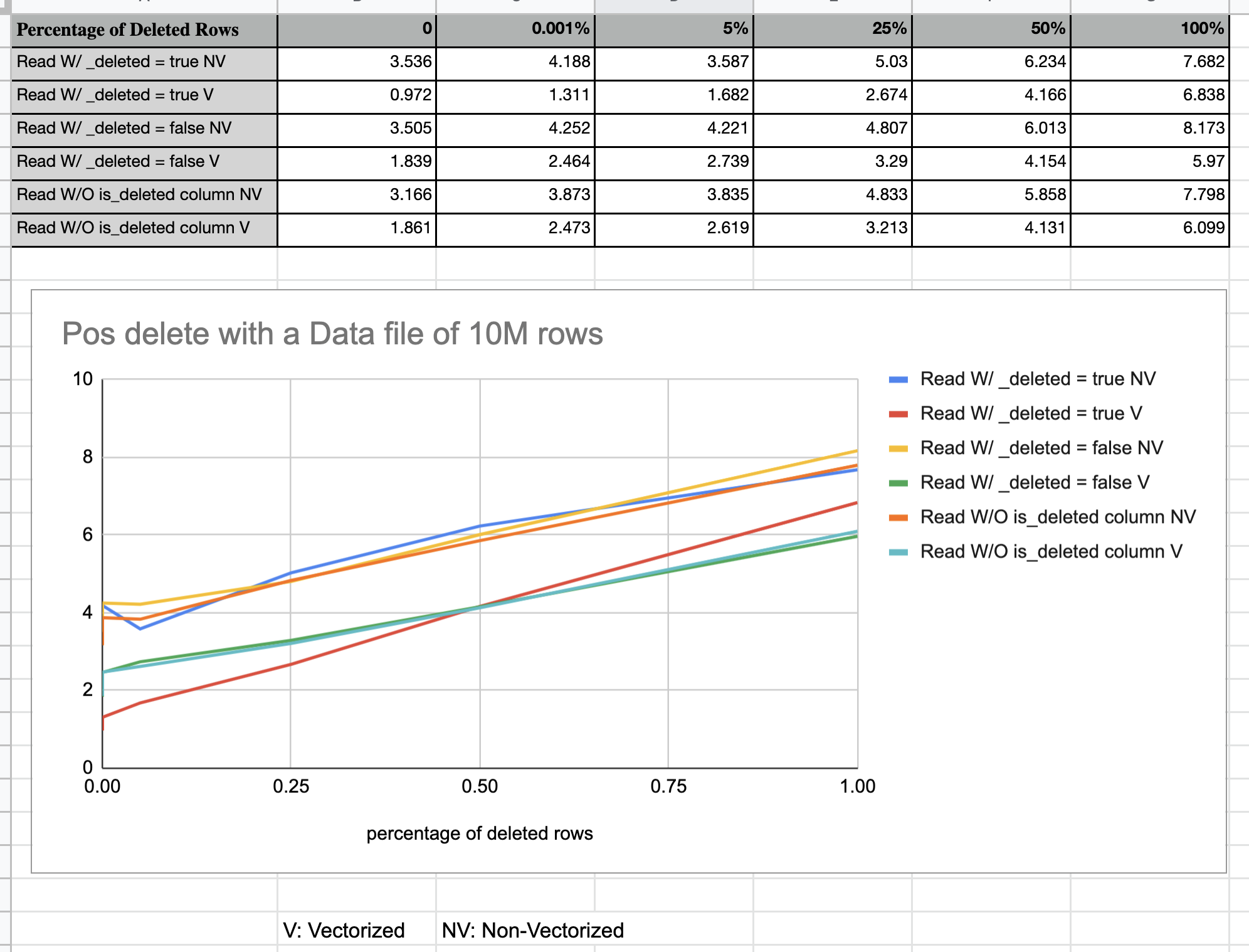
Hi @aokolnychyi and @RussellSpitzer, vectorized read is enabled by default several months ago. But the benchmark still assumes it false by default. I have set it false explicitly, and run the benchmark again. Now we can see the big performance gain between vectorized and non-vectorized read, as the following diagram shows. |
RussellSpitzer
left a comment
There was a problem hiding this comment.
I'm good to go on this, @aokolnychyi are you ready as well?
|
Sorry for the delay. Let me see. |
arrow/src/main/java/org/apache/iceberg/arrow/vectorized/VectorHolder.java
Outdated
Show resolved
Hide resolved
arrow/src/main/java/org/apache/iceberg/arrow/vectorized/VectorizedArrowReader.java
Show resolved
Hide resolved
...4/spark/src/test/java/org/apache/iceberg/spark/data/TestSparkParquetReadMetadataColumns.java
Show resolved
Hide resolved
| public void readIceberg(Blackhole blackhole) { | ||
| Map<String, String> tableProperties = Maps.newHashMap(); | ||
| tableProperties.put(SPLIT_OPEN_FILE_COST, Integer.toString(128 * 1024 * 1024)); | ||
| tableProperties.put(TableProperties.PARQUET_VECTORIZATION_ENABLED, "false"); |
There was a problem hiding this comment.
nit: Let's add a static import like we have for SPLIT_OPEN_FILE_COST for consistency
There was a problem hiding this comment.
Applies to all places in this class.
| import org.apache.iceberg.types.Types; | ||
| import org.apache.spark.sql.vectorized.ColumnVector; | ||
|
|
||
| public class ColumnVectorBuilder { |
There was a problem hiding this comment.
Do this class and its constructors/methods have to be public?
There was a problem hiding this comment.
It's not necessary. Let me change it to package-level.
| if (hasIsDeletedColumn && rowIdMapping != null) { | ||
| // reset the row id mapping array, so that it doesn't filter out the deleted rows | ||
| for (int i = 0; i < numRowsToRead; i++) { | ||
| rowIdMapping[i] = i; |
There was a problem hiding this comment.
Question: do we have to populate the row ID mapping initially if we know we have _deleted metadata column?
There was a problem hiding this comment.
That's a good question. In short, I'm using row ID mapping to improve eq deletes perf when we have both pos deletes and eq deletes. I think it is worth to do that since applying eq deletes is expensive, it has to go row by row. Here is an example, after the pos deletes, we will only need to iterate 6 rows instead of 8 rows for applying eq delete.
* Filter out the equality deleted rows. Here is an example,
* [0,1,2,3,4,5,6,7] -- Original status of the row id mapping array
* [F,F,F,F,F,F,F,F] -- Original status of the isDeleted array
* Position delete 2, 6
* [0,1,3,4,5,7,-,-] -- After applying position deletes [Set Num records to 6]
* [F,F,T,F,F,F,T,F] -- After applying position deletes
* Equality delete 1 <= x <= 3
* [0,4,5,7,-,-,-,-] -- After applying equality deletes [Set Num records to 4]
* [F,T,T,T,F,F,T,F] -- After applying equality deletes
| arrowColumnVectors[i] = hasDeletes() ? | ||
| ColumnVectorWithFilter.forHolder(vectorHolders[i], rowIdMapping, numRows) : | ||
| IcebergArrowColumnVector.forHolder(vectorHolders[i], numRowsInVector); | ||
| arrowColumnVectors[i] = new ColumnVectorBuilder(vectorHolders[i], numRowsInVector) |
There was a problem hiding this comment.
Do we have to construct a column vector builder for every column? What about having a constructor accepting the row ID mapping and is deleted array and making build(VectorHolder holder, int numRows)? That way you can init the builder outside of the for loop and call build inside the loop for a particular vectorHolder.
ColumnVectorBuilder columnVectorBuilder = new ColumnVectorBuilder(rowIdMapping, isDeleted);
for (int i = 0; i < readers.length; i += 1) {
...
arrowColumnVectors[i] = columnVectorBuilder.build(vectorHolders[i], numRowsInVector);
}
There was a problem hiding this comment.
Nice suggestion. Made the change.
| return new DeletedMetaColumnVector(Types.BooleanType.get(), isDeleted); | ||
| } else if (holder instanceof ConstantVectorHolder) { | ||
| return new ConstantColumnVector(Types.IntegerType.get(), numRows, | ||
| ((ConstantVectorHolder) holder).getConstant()); |
There was a problem hiding this comment.
nit: ConstantVectorHolder -> ConstantVectorHolder<?>.
| return new DeletedMetaColumnVector(Types.BooleanType.get(), isDeleted); | ||
| } else if (holder instanceof ConstantVectorHolder) { | ||
| return new ConstantColumnVector(Types.IntegerType.get(), numRows, | ||
| ((ConstantVectorHolder) holder).getConstant()); |
There was a problem hiding this comment.
nit: I think this should fit on a single line
There was a problem hiding this comment.
it cannot with the <?>
| import org.apache.spark.sql.vectorized.ColumnarMap; | ||
| import org.apache.spark.unsafe.types.UTF8String; | ||
|
|
||
| public class DeletedMetaColumnVector extends ColumnVector { |
There was a problem hiding this comment.
The naming in new classes is a bit inconsistent. Can we align that?
IsDeletedVectorHolder
DeletedMetaColumnVector
DeletedVectorReader
There was a problem hiding this comment.
Made the following changes
IsDeletedVectorHolder -> DeletedVectorHolder
DeletedMetaColumnVector -> DeletedColumnVector
DeletedVectorReader
|
This seems correct to me. I had only a few questions/comments. |
3487b88 to
411bdda
Compare
411bdda to
a81ebc6
Compare
|
Hi @aokolnychyi, this is ready for review. I have to apply the same changes to Spark 3.3, otherwise unit test won't pass. |
 aokolnychyi
left a comment
aokolnychyi
left a comment
There was a problem hiding this comment.
LGTM. I had only one nit (same in 3.2 and 3.3).
| private boolean[] isDeleted; | ||
| private int[] rowIdMapping; | ||
|
|
||
| public ColumnVectorBuilder withDeletedRows(int[] rowIdMappingArray, boolean[] isDeletedArray) { |
There was a problem hiding this comment.
nit: I feel we better make this a constructor and pass these arrays only once during the construction.
There was a problem hiding this comment.
I am trying to make the builder more generic so that it can also be used for creation of vectors without deletes.
There was a problem hiding this comment.
Okay, I see now. Then it is fine.
| ColumnVector[] readDataToColumnVectors() { | ||
| ColumnVector[] arrowColumnVectors = new ColumnVector[readers.length]; | ||
|
|
||
| ColumnVectorBuilder columnVectorBuilder = new ColumnVectorBuilder(); |
There was a problem hiding this comment.
nit: This is probably where you can pass rowIdMapping and isDeleted as those two don't change.
| if (hasIsDeletedColumn && rowIdMapping != null) { | ||
| // reset the row id mapping array, so that it doesn't filter out the deleted rows | ||
| for (int i = 0; i < numRowsToRead; i++) { | ||
| rowIdMapping[i] = i; |
| private boolean[] isDeleted; | ||
| private int[] rowIdMapping; | ||
|
|
||
| public ColumnVectorBuilder withDeletedRows(int[] rowIdMappingArray, boolean[] isDeletedArray) { |
|
Thanks, @flyrain! Great to have this done. Thanks for reviewing, @RussellSpitzer! |
|
Thanks for the review, @aokolnychyi @RussellSpitzer. Per discussion with @aokolnychyi, I will file a followup to throw an exception when |
|
@aokolnychyi, checked the module Spark2.4/3.0/3.1. Metadata column It reports the following errors. We don't need to change anything in that sense. And the change I did in class |
The vectorized version of #4683.
cc @aokolnychyi @szehon-ho @RussellSpitzer @chenjunjiedada @stevenzwu @Reo-LEI @hameizi @singhpk234 @rajarshisarkar @kbendick @rdblue
Benchmarks for pos delete and eq delete