change delete logic #3834
change delete logic #3834
Conversation
|
I'm assuming that the equality delete column in your example is the ID. Is that correct? If so, then there is still some value in writing the delete because you get the previous columns written into the file. That allows reconstructing a CDC stream with the delete. |
@rdblue But when we reconstructing a CDC stream with the delete we can't guarantee the order of delete data and append data. So we just can guarantee eventual Consistency. This PR can also guarantee eventual Consistency. |
| PathOffset previous = insertedRowMap.get(key); | ||
|
|
||
| eqDeleteWriter.write(row); | ||
| if (previous != null){ |
There was a problem hiding this comment.
Style: there should be a space between ) and {.
| // TODO attach the previous row if has a positional-delete row schema in appender factory. | ||
| posDeleteWriter.delete(previous.path, previous.rowOffset, null); | ||
| } | ||
| insertedRowMap.put(copiedKey, pathOffset); |
There was a problem hiding this comment.
Why is this changing as well? I think that the logic here was intended to implement upsert just in case there are duplicate inserts without a delete. @openinx, can you take a look at this?
There was a problem hiding this comment.
@rdblue yes,as you said that the logic here was intended to implement upsert just in case there are duplicate inserts without a delete. This logic can be retain, just i think duplicate inserts should be avoid by upstream semantic but not writer. If need i will rollback this change.
There was a problem hiding this comment.
@rdblue After test i think this is necessary, and i think old logic is error. Because old logic only write pos-delete in write function what should happen in delete function. And below test case is also puzzle:
write.upsert.enable #2863 to execute delete semantic but not write sementic(this is error sementic) when there is duplicate inserts.So we just need record the postion of key in insertedRowMap when execute
write function then write pos-delete file when execute delete function.
There was a problem hiding this comment.
Let's remove this change.
The logic here is to opportunistically catch duplicates when there are only inserts. This is not intended to replace the real upsert logic, which requires calling delete as you noted. Instead, it is here because we're updating the insertedRowMap and may get a previous insert location. When that happens, the right thing to do is to delete the duplicate row.
I also just realized that the changes below are incorrect. Instead of calling internalPosDelete(key), this checks the insertedRowMap itself using get. The logic in internalPosDeleteusedremove` so that the entry was removed before the insert occurred and we have a second opportunistic check.
To fix this, you should instead update internalPosDelete to return true if a row was deleted and false otherwise. Then you can update your previous != null check like this:
public void delete(T row) throws IOException {
if (!internalPosDelete(structProjection.wrap(asStructLike(row)))) {
eqDeleteWriter.write(row);
}
}| PathOffset previous = insertedRowMap.get(structLikeKey); | ||
|
|
||
| eqDeleteWriter.write(key); | ||
| if (previous != null){ |
There was a problem hiding this comment.
Style is incorrect here as well.
|
@rdblue code style fix in new commit. |
|
@rdblue Is there any more question of this PR? |
|
@hameizi, I'm mainly just waiting for a reply to the comment above. I wanted more information about that change. Thanks! |
0a48c7f to
aa179de
Compare
| OutputFileFactory fileFactory, FileIO io, long targetFileSize) { | ||
| protected BaseTaskWriter( | ||
| PartitionSpec spec, FileFormat format, FileAppenderFactory<T> appenderFactory, | ||
| OutputFileFactory fileFactory, FileIO io, long targetFileSize) { |
There was a problem hiding this comment.
These lines don't need to change. Can you revert this?
aa179de to
8ad553d
Compare
|
@rdblue fix all. Can you help take a look? |
| Sets.newHashSet(result.deleteFiles()[0].content(), result.deleteFiles()[1].content())); | ||
| Assert.assertEquals(1, result.deleteFiles().length); | ||
| Assert.assertEquals(Sets.newHashSet(FileContent.POSITION_DELETES), | ||
| Sets.newHashSet(result.deleteFiles()[0].content())); |
There was a problem hiding this comment.
Unnecessary whitespace change, and this is not the correct indentation.
|
Thanks, @hameizi! I merged this since there was only a style problem left. |
|
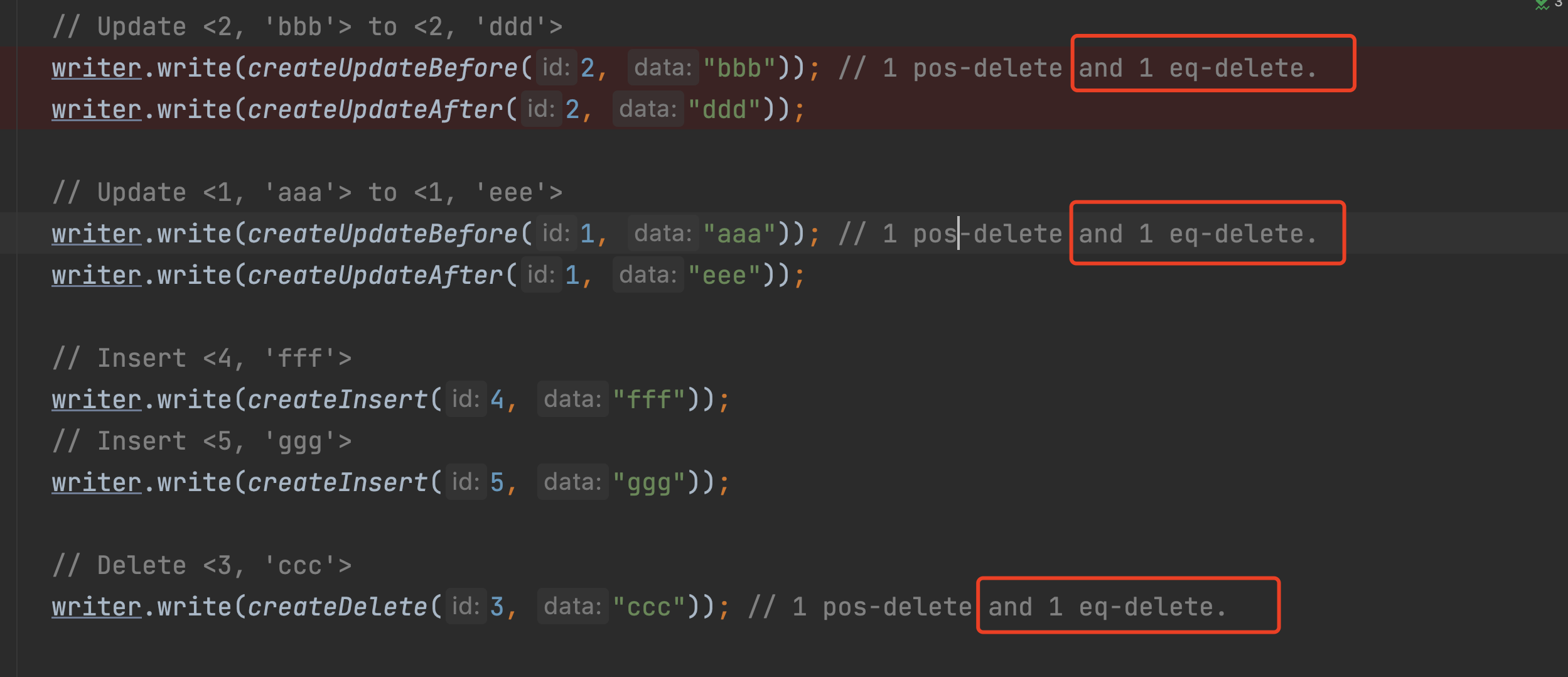
The comment in TestDeltaTaskWriter.testCdcEvents should also be updated since it may confuse the user.
|
Reference:(cherry picked from commit 2247e77)
Previous delete logic is write all delete data in eq-delete file although there is same key in pos-delete file. This PR change this logic to just write the delete data what is not exist in pos-delete file in eq-delete file. And the old logic will send several delete but one insert of one primary key in one snapshot when we want reperform the data by streaming read, in some scene will cause error (like aggregete count).
the following is difference between old delete logic and the new.
table schema:
old logic:
tx1:
tx2:
result:
eq-delete file has (1,'aa'),(1,'bb')
pos-delete file has (1,filepath)
new logic:
tx1:
tx2:
result:
eq-delete file has (1,'aa')
pos-delete file has (1,filepath)
Actually the data (1,'bb') is unnecessary in eq-delete file, because when we call function applyPosdelete that (1,'bb') will be delete from result so there is not data match (1,'bb') when we call applyEqdelete. In streaming read scene the old logic will send two delete (1,'aa'),(1,'bb') of key 1 but one insert (1,'cc') to down opeator, but new logic just send one delete and one insert.