[HUDI-6085] Eliminate cleaning tasks for flink mor table if online async compaciton is disabled #8394
Conversation
| return Pipelines.compact(conf, pipeline); | ||
| } else if (OptionsResolver.isMorTable(conf)) { | ||
| return Pipelines.dummySink(pipeline); | ||
| } else { |
There was a problem hiding this comment.
So what component is responsible for data cleaning then?
There was a problem hiding this comment.
Offline compaction do clean,Consistent with clustering.
// Append mode
if (OptionsResolver.isAppendMode(conf)) {
DataStream<Object> pipeline = Pipelines.append(conf, rowType, dataStream, context.isBounded());
if (OptionsResolver.needsAsyncClustering(conf)) {
return Pipelines.cluster(conf, rowType, pipeline);
} else {
return Pipelines.dummySink(pipeline);// If async-clustering=true, no clean operator.
}
}
There was a problem hiding this comment.
The cleaning can take effect finally right? Because the table would get compacted for sometime anyway.
There was a problem hiding this comment.
Offline clustering/compaction will do clean by default , add --clean-async-enabled config will close it.
There was a problem hiding this comment.
Current online async-clean and offline clean use the same configuration :clean.async.enabled. Add a new configuration clean.offline.enable,making the configuration description clearer.
There was a problem hiding this comment.
The spark offline compaction Job does not take care of cleaning, could you make it clrear how user can handle the cleaning when they use the flink streaming ingestion and spark offline compaction.
There was a problem hiding this comment.
Adjust the cleaning operation in SparkRDDWriteClient#cluster/compact, when ASYNC_CLEAN is true will do asynchronous clean in prewrite, otherwise will do synchronous clean in autoCleanOnCommit().
There was a problem hiding this comment.
We need to think through the e2e use case for flink streaming ingestion and spark offline compaction, we should add cleaning for spark compaction and clustering first which is a block change of this patch.
There was a problem hiding this comment.
We will not schedule cleaning task if async cleaning is disabled:
, so should be fine?There was a problem hiding this comment.
If CLEAN_ASYNC_ENABLED = true,a schedule will still be executed. I think cluster and compact should be consistent here(If the cow table async cluster is closed, there will be no clean operator). And now both Spark and Flink will clean up when executing offline jobs, unless forcibly closed. What do you think?
47cb215 to
67fc8b9
Compare
67fc8b9 to
36fc037
Compare
...k-datasource/hudi-flink/src/main/java/org/apache/hudi/sink/compact/HoodieFlinkCompactor.java
Outdated
Show resolved
Hide resolved
hudi-flink-datasource/hudi-flink/src/main/java/org/apache/hudi/configuration/FlinkOptions.java
Outdated
Show resolved
Hide resolved
...ource/hudi-flink/src/main/java/org/apache/hudi/sink/clustering/HoodieFlinkClusteringJob.java
Outdated
Show resolved
Hide resolved
36fc037 to
79ec658
Compare
| return tableServiceClient.cluster(clusteringInstant, shouldComplete); | ||
| HoodieWriteMetadata<JavaRDD<WriteStatus>> clusteringMetadata = tableServiceClient.cluster(clusteringInstant, shouldComplete); | ||
| autoCleanOnCommit(); | ||
| return clusteringMetadata; |
There was a problem hiding this comment.
Do not introduce unrelated changes in one patch, if we want to add cleaning procedure for Spark compaction and cleaning, fire another PR and let's discuss with it.
There was a problem hiding this comment.
Removed Spark related modifications and migrated to a new PR. #8505
9edae81 to
79ec658
Compare
|
@zhuanshenbsj1 @danny0405 is this PR still relevant? |
|
cc @zhuanshenbsj1 I think we can cloase it, because we already have #8505 . |
Change Logs
MOR table in upsert scenario, not need to clean when online async compaction is turned off.
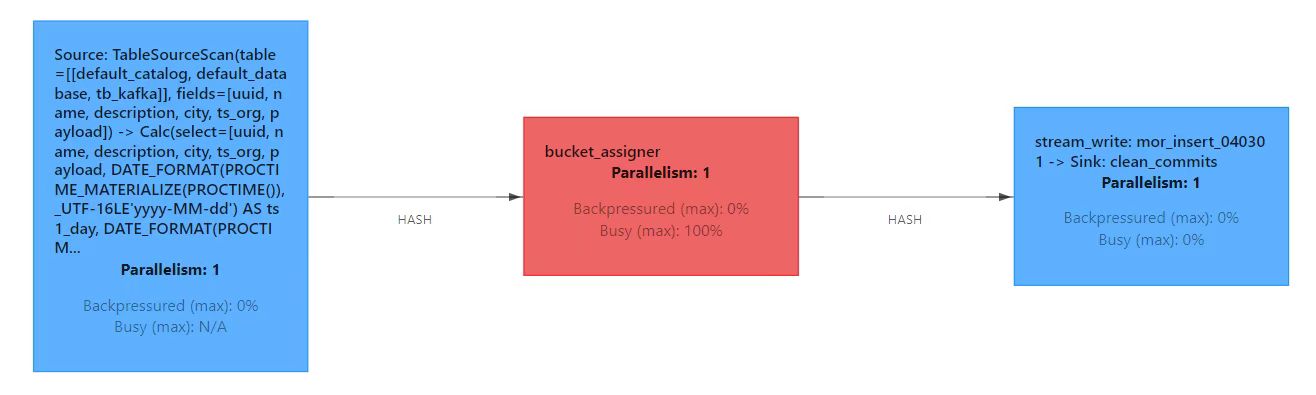
In scenarios with a large number of files and partitions, turning off clean will improve performance

Impact
Describe any public API or user-facing feature change or any performance impact.
Risk level (write none, low medium or high below)
If medium or high, explain what verification was done to mitigate the risks.
Documentation Update
Describe any necessary documentation update if there is any new feature, config, or user-facing change
ticket number here and follow the instruction to make
changes to the website.
Contributor's checklist