Fix comment in RFC46 #6745
Fix comment in RFC46 #6745
Conversation
|
@alexeykudinkin Could you please review it? Really thanks! Geng Xiaoyu and me have fix comments in RFC46. I found |
|
@wzx140 can you please validate that |
| if (combinedValue != oldValue) { | ||
| hoodieRecord.setData(combinedValue); | ||
| records.put(key, hoodieRecord); | ||
| records.put(key, hoodieRecord.newInstance(combinedValue)); |
There was a problem hiding this comment.
@wzx140 why do we still need to do newInstance why can't we use HoodieRecord returned by the merger?
There was a problem hiding this comment.
We can see the old logic. It make a new record that use combinedValue and other parts from hoodieRecord.
HoodieRecord<? extends HoodieRecordPayload> oldRecord = records.get(key);
HoodieRecordPayload oldValue = oldRecord.getData();
HoodieRecordPayload combinedValue = hoodieRecord.getData().preCombine(oldValue);
// If combinedValue is oldValue, no need rePut oldRecord
if (combinedValue != oldValue) {
HoodieOperation operation = hoodieRecord.getOperation();
records.put(key, new HoodieAvroRecord<>(new HoodieKey(key, hoodieRecord.getPartitionPath()), combinedValue, operation));
}There was a problem hiding this comment.
But that doesn't make sense, right? Previously preCombine would return HoodieRecordPayload we're now returning HoodieRecord then call getData and immediately write it back into HoodieRecord.
Let's simplify it
| * @param structType {@link StructType} instance. | ||
| * @return Column value if a single column, or concatenated String values by comma. | ||
| */ | ||
| public static Object getRecordColumnValues(InternalRow row, |
There was a problem hiding this comment.
Let's not forget to change the interface to return Object[]
| * that needs to be serialized. | ||
| */ | ||
| class SparkStructTypeSerializer(schemas: Map[Long, StructType]) extends KSerializer[HoodieSparkRecord] { | ||
| class HoodieSparkRecordSerializer() extends KSerializer[HoodieSparkRecord] { |
...-client/hudi-spark-client/src/main/java/org/apache/hudi/commmon/model/HoodieSparkRecord.java
Show resolved
Hide resolved
| val record = datum.newInstance().asInstanceOf[HoodieSparkRecord] | ||
| record.setStructType(null) | ||
| val stream = new ObjectOutputStream(output) | ||
| val byteStream = new ByteArrayOutputStream() |
There was a problem hiding this comment.
Sorry, i skimmed t/h this initially but overlooked how we're doing the serialization here:
- We should only serialize the
UnsafeRowthat HoodieSparkRecord holds (see my comment above);UnsafeRowimplements KryoSerializable so we can use these methods to properly write it out into the stream; we should not be relying on Java's object serialization framework for that
| /** | ||
| * Space-efficient, comparable, immutable lists, copied from calcite core. | ||
| */ | ||
| public class FlatLists { |
There was a problem hiding this comment.
Shall we call this ComparableLists? "Flat" reference is confusing
There was a problem hiding this comment.
It is copied from calcite core. And ComparableLists already exists in FlatLists.java.
Yes. I check it in UT with printing some message in HoodieSparkRecordSerializer. |
|
@hudi-bot run azure |
|
@alexeykudinkin Please review the update when you have time. |
...-client/hudi-spark-client/src/main/java/org/apache/hudi/commmon/model/HoodieSparkRecord.java
Show resolved
Hide resolved
| if (combinedValue != oldValue) { | ||
| hoodieRecord.setData(combinedValue); | ||
| records.put(key, hoodieRecord); | ||
| records.put(key, hoodieRecord.newInstance(combinedValue)); |
There was a problem hiding this comment.
But that doesn't make sense, right? Previously preCombine would return HoodieRecordPayload we're now returning HoodieRecord then call getData and immediately write it back into HoodieRecord.
Let's simplify it
| public HoodieSparkParquetStreamWriter(FSDataOutputStream outputStream, | ||
| HoodieRowParquetConfig parquetConfig) throws IOException { | ||
| this.writeSupport = parquetConfig.getWriteSupport(); | ||
| this.writeSupport.enableLegacyFormat(); |
There was a problem hiding this comment.
Why are we doing that?
There was a problem hiding this comment.
Because in avro2parquetLog AvroWriteSupport#"parquet.avro.write-old-list-structure" default value is true and currently we use its default value. In order to be compatible, We should also let sparkRecord2parquetLog write with legency format
There was a problem hiding this comment.
Sorry, not sure what avro2parquetLog is
There was a problem hiding this comment.
If we use HoodieAvroRecord to write parquetLog, it will write with AvroWriteSupport#"parquet.avro.write-old-list-structure"=true. In order to be compatible, We should also use HoodieSparkRecord write parquetLog with legency format. So that we can use HoodieAvroRecord to read the parquet log which written by HoodieSparkRecord.
// Standard mode:
//
// <list-repetition> group <name> (LIST) {
// repeated group list {
// ^~~~ repeatedGroupName
// <element-repetition> <element-type> element;
// ^~~~~~~ elementFieldName
// }
// }
// Legacy mode, with non-nullable elements:
//
// <list-repetition> group <name> (LIST) {
// repeated <element-type> array;
// ^~~~~ repeatedFieldName
// }
| List<Object> result = new ArrayList<>(); | ||
| for (String col : columns) { | ||
| NestedFieldPath posList = HoodieInternalRowUtils.getCachedPosList(structType, col); | ||
| result.add(Option.ofNullable(HoodieUnsafeRowUtils.getNestedInternalRowValue(row, posList)).orElse("").toString()); |
There was a problem hiding this comment.
@wzx140 We should not be converting values to strings
| } | ||
|
|
||
| /** | ||
| * For UT. |
There was a problem hiding this comment.
There's common annotation used for this: @VisibleForTesting
| hoodieRecord | ||
| }).toJavaRDD() | ||
| case HoodieRecord.HoodieRecordType.SPARK => | ||
| log.info("Use spark record") |
There was a problem hiding this comment.
Let's generalize this to log whatever record-type is used. Let's also downgrade to debug
| HoodieInternalRowUtils.addCompressedSchema(structType) | ||
| val structTypeWithMetaField = HoodieInternalRowUtils.getCachedSchema(schemaWithMetaField) | ||
| val structTypeBC = sparkContext.broadcast(structType) | ||
| HoodieInternalRowUtils.broadcastCompressedSchema(List(structType, structTypeWithMetaField), sparkContext) |
There was a problem hiding this comment.
Why do we need this?
There was a problem hiding this comment.
The broadcast ensures that every executor has the same fingerprint->schema cache. We can't make every executor initialize fingerprint->schema locally.
For example, if we initialize fingerprint->schema in sparksqlwriter df, it is possible that the number of dataframe partitions is less than the number of executors.
HoodieInternalRowUtils.addCompressedSchema(structType)
df.queryExecution.toRdd.map(row => {
val internalRow = row.copy()
val (processedRow, writeSchema) = getSparkProcessedRecord(partitionCols, internalRow, dropPartitionColumns, structTypeBC.value)
val recordKey = sparkKeyGenerator.getRecordKey(internalRow, structTypeBC.value)
val partitionPath = sparkKeyGenerator.getPartitionPath(internalRow, structTypeBC.value)
val key = new HoodieKey(recordKey.toString, partitionPath.toString)
// See this We can't guarantee that this is executed in all executors
HoodieInternalRowUtils.addCompressedSchema(structType)
new HoodieSparkRecord(key, processedRow, writeSchema)
}).toJavaRDD().asInstanceOf[JavaRDD[HoodieRecord[_]]]As shown in the figure below, executor3 do not has the fingerPrint cache and can not deserialize the fingerPrint to schema.
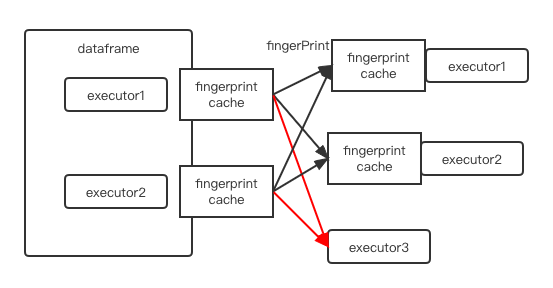
There was a problem hiding this comment.
Sorry, i misread your original intent with this change. Unfortunately, this is not going to work: for Broadcast to work exactly the same object has to be passed in (w/in captured Closure) from Driver to Executor (Broadcasts are identified by unique bid). In the current setup you're just overwriting static variables w/in HoodieInternalRowUtils creating new Broadcasts which aren't propagated to Executors (the reason it works in tests is b/c we run phony Spark cluster where both Driver and Executor share memory, ie they access the same loaded HoodieInternalRowUtils and this problem is not apparent)
There was a problem hiding this comment.
We need a simpler solution here:
-
We should remove the schema from
HoodieSparkRecords. At this point we ultimately are familiar with all the limitations of the approach which Spark uses to reduce overhead of serializing the schema along w/ every record -- it requires us to provide all the schemas upfront to be distributed to all Executors (viaSparkConfwhich is read-only afterSparkContextis created). -
We will have to pass record's schema externally: we can approach it the same way it's currently done for
ExpressionPayloadin this PR
There was a problem hiding this comment.
I don't agree with that Broadcast does not work. I have tested this on yarn and it worked. The process of broadcast: the driver will put the blockcast variable into the blockmanager. And executors will be obtained locally according to the block id, and if it is not available locally, it will be pulled from the remote driver.
If the Broadcast works, we do not need to pass record's schema externally right? Passing record's schema externally requires user of HoodieRecord to pass the right schema.
| HoodieWriteConfig.MERGER_IMPLS.defaultValue()), | ||
| mergerStrategy = optParams.getOrElse(HoodieWriteConfig.MERGER_STRATEGY.key(), | ||
| metaClient.getTableConfig.getMergerStrategy) | ||
| mergerImpls = mergerImpls, |
There was a problem hiding this comment.
Leaving comments here for generateRecordMerger as well:
- Let's do config parsing here, passing in
Seq[String]instead ofString - Let's rename
generateRecordMergertocreateRecordMerger
| maxCompactionMemoryInBytes, config, internalSchema) | ||
| } | ||
|
|
||
| log.info(s"Use ${logScanner.getRecordType}") |
There was a problem hiding this comment.
Please downgrade to debug
| .getParent | ||
| } | ||
|
|
||
| private def registerStructTypeSerializerIfNeed(schemas: List[StructType]): Unit = { |
There was a problem hiding this comment.
Why do we need this method?
Schema registration should be adhoc -- whenever someone is requesting to serialize HoodieSparkRecord we'd cache the schema, replacing w/ the fingerprint
5365302 to
f2823f9
Compare
|
@hudi-bot run azure |
|
@alexeykudinkin I have implement without the Broadcast and schema inside HoodieSparkRecord and pass record's schema externally. Please review the update when you have time. |
|
@hudi-bot run azure |
|
CI fail with testReadFilterExistAfterBulkInsertPrepped. And it will fix after rebasing on master with commit HUDI-4923. |
| @Override | ||
| public void write(HoodieRecord oldRecord) { | ||
| String key = oldRecord.getRecordKey(keyGeneratorOpt); | ||
| Schema schema = useWriterSchemaForCompaction ? tableSchemaWithMetaFields : tableSchema; |
| * of the single record, both orders of operations applications have to yield the same result) | ||
| */ | ||
| Option<HoodieRecord> merge(HoodieRecord older, HoodieRecord newer, Schema schema, Properties props) throws IOException; | ||
| Pair<Option<HoodieRecord>, Schema> merge(HoodieRecord older, Schema oldSchema, HoodieRecord newer, Schema newSchema, Properties props) throws IOException; |
There was a problem hiding this comment.
I think we should invert this to be Option<Pair<HoodieRecord, Schema>>
| // If it is an IGNORE_RECORD, just copy the old record, and do not update the new record. | ||
| copyOldRecord = true; | ||
| } else if (writeUpdateRecord(hoodieRecord, oldRecord, combinedRecord)) { | ||
| } else if (writeUpdateRecord(hoodieRecord, oldRecord, combinedRecord, combineRecordSchema)) { |
There was a problem hiding this comment.
nit: hoodieRecord > newRecord
| } | ||
|
|
||
| protected boolean writeUpdateRecord(HoodieRecord<T> hoodieRecord, HoodieRecord oldRecord, Option<HoodieRecord> combineRecordOp) throws IOException { | ||
| protected boolean writeUpdateRecord(HoodieRecord<T> hoodieRecord, HoodieRecord<T> oldRecord, Option<HoodieRecord> combineRecordOp, Schema writerSchema) throws IOException { |
There was a problem hiding this comment.
@wzx140 this API is rather confusing: why do we need to pass all 3 records at the same time?
There was a problem hiding this comment.
Disregard. This is how it's right now, left note to self to revisit this.
...ient/hudi-client-common/src/main/java/org/apache/hudi/io/HoodieMergeHandleWithChangeLog.java
Outdated
Show resolved
Hide resolved
hudi-client/hudi-spark-client/src/main/java/org/apache/hudi/util/HoodieSparkRecordUtils.java
Outdated
Show resolved
Hide resolved
hudi-client/hudi-spark-client/src/main/java/org/apache/hudi/util/HoodieSparkRecordUtils.java
Outdated
Show resolved
Hide resolved
hudi-client/hudi-spark-client/src/main/scala/org/apache/hudi/HoodieInternalRowUtils.scala
Show resolved
Hide resolved
hudi-client/hudi-spark-client/src/main/scala/org/apache/hudi/HoodieInternalRowUtils.scala
Outdated
Show resolved
Hide resolved
hudi-common/src/main/java/org/apache/hudi/common/model/HoodieAvroRecordMerger.java
Show resolved
Hide resolved
| protected boolean writeUpdateRecord(HoodieRecord<T> hoodieRecord, HoodieRecord<T> oldRecord, Option<HoodieRecord> combineRecordOp, Schema writerSchema) | ||
| throws IOException { | ||
| final boolean result = super.writeUpdateRecord(hoodieRecord, oldRecord, combineRecordOp); | ||
| Option<HoodieRecord> savedCombineRecordOp = combineRecordOp.map(HoodieRecord::newInstance); |
There was a problem hiding this comment.
I see what you're working around now.
Let's leave a TODO and create a ticket to follow-up
- Remove record deflation: instead of deflation, we should just make sure we avoid keeping refs to the Record instant itself (so that it'd be collected)
- Remove these unnecessary
newInstanceinvocations
.../hudi-client-common/src/main/java/org/apache/hudi/table/action/commit/HoodieWriteHelper.java
Outdated
Show resolved
Hide resolved
...ient/hudi-client-common/src/main/java/org/apache/hudi/io/HoodieMergeHandleWithChangeLog.java
Outdated
Show resolved
Hide resolved
...i-flink-client/src/main/java/org/apache/hudi/io/FlinkMergeAndReplaceHandleWithChangeLog.java
Outdated
Show resolved
Hide resolved
| public HoodieRecord rewriteRecord(Schema recordSchema, Properties props, Schema targetSchema) throws IOException { | ||
| StructType structType = HoodieInternalRowUtils.getCachedSchema(recordSchema); | ||
| StructType targetStructType = HoodieInternalRowUtils.getCachedSchema(targetSchema); | ||
| UTF8String[] metaFields = extractMetaField(targetStructType); |
There was a problem hiding this comment.
Right, but you're extracting this meta-fields from the current record, and so if it doesn't currently have it there's nothing to extract.
My point is we can't apply new schema to the record, until we rewrite the record into new schema -- we should use recordSchema to check whether it has the meta-fields
...-client/hudi-spark-client/src/main/java/org/apache/hudi/commmon/model/HoodieSparkRecord.java
Outdated
Show resolved
Hide resolved
| } | ||
| }.withConf(conf).build(); | ||
| ParquetReaderIterator<InternalRow> parquetReaderIterator = new ParquetReaderIterator<>(reader, InternalRow::copy); | ||
| ParquetReaderIterator<InternalRow> parquetReaderIterator = new ParquetReaderIterator<>(reader, |
There was a problem hiding this comment.
@wzx140 let me elaborate on the context of my question:
I'm aware that Spark is using mutable buffers for reading the data, but we shouldn't need to copy it right away, we should only have to copy where absolutely necessary. Meaning that by default, if we'd just be iterating over the records from one file and writing it into another one we wouldn't need to make any copies, right? We can easily reuse the same buffer, and while we continue to read and write 1 record at a time (while iterating over provided Iterator).
val iter = parquet.read(file)
while (iter.hasNext) {
writeToFile(iter.next)
}
We only really need to make a copy whenever we retain a reference to the Row, for ex, if we do reduceByKey (as below, or if we'd hold it in a Map, etc)
val iter = parquet.read(file)
iter.reduceByKey((r1, r2) => {
// NOTE: In this case we're holding refs to 2 rows simultaneously, hence we'd need to make a copy before that
// since otherwise both r1 and r2 will be pointing to the same buffer
})
So, we basically need:
- Avoid blanket copying here
- Find the place where we hold the refs to the row (as described above, this is the reason the test is failing) and allow copying in the least possible scope
Does it make sense?
hudi-client/hudi-spark-client/src/main/scala/org/apache/hudi/HoodieInternalRowUtils.scala
Show resolved
Hide resolved
| @Override | ||
| public Option<HoodieAvroIndexedRecord> toIndexedRecord(Schema schema, Properties props) throws IOException { | ||
| Option<IndexedRecord> avroData = getData().getInsertValue(schema, props); | ||
| public Option<HoodieAvroIndexedRecord> toIndexedRecord(Schema recordSchema, Properties props) throws IOException { |
There was a problem hiding this comment.
Sorry, my 2d statement was confusing, let me elaborate on my comment:
- This API converts from one
HoodieRecordto anotherHoodieRecord - There's no reason why we'd be returning an Option (from external perspective, it looks really strange that we actually return an Option, though we simply do a lateral conversion)
- Ideally we should be returning an
Optionwhen this object is dereferenced (getDatais called), but this would affect the API
Let's keep it as it is for now, we can change it later when we'll be getting rid of HoodieAvroRecord
| .map(String::trim).distinct().collect(Collectors.toList()); | ||
| } | ||
|
|
||
| public static Properties setDeDuping(Properties props) { |
There was a problem hiding this comment.
Let's move this util to HoodieAvroRecordMerger (since it's only useful with it)
|
|
||
| return ((HoodieAvroRecord) newer).getData().combineAndGetUpdateValue(previousRecordAvroPayload.get().getData(), schema, props) | ||
| return ((HoodieAvroRecord) newer).getData().combineAndGetUpdateValue(previousAvroData.get(), schema, props) | ||
| .map(combinedAvroPayload -> new HoodieAvroIndexedRecord((IndexedRecord) combinedAvroPayload)); |
There was a problem hiding this comment.
@wzx140 we should actually produce HoodieAvroRecord here instead:
- Merged records will be subsequently reshuffled a few times, and shuffling
IndexedRecordwill kill performance - Instead we should use
HoodieAvroRecordholding some dummyRecordPayloadjust holds Avro bytes for us (and throws if anyone will try to use it for merging)
Does it make sense?
There was a problem hiding this comment.
I don't think so. In HoodieAvroRecordMerger, we do combineAndGetUpdateValue before writing and shuffling is done before combineAndGetUpdateValue. We do preCombine with record which hold avro byte and then shuffle the result. So there is no performce loss. This is also the original logic.
There was a problem hiding this comment.
You're right, i double-checked and we do indeed not shuffle the HoodieAvroIndexedRecord
| protected boolean writeUpdateRecord(HoodieRecord<T> newRecord, HoodieRecord<T> oldRecord, Option<HoodieRecord> combineRecordOpt, Schema writerSchema) | ||
| throws IOException { | ||
| final boolean result = super.writeUpdateRecord(hoodieRecord, oldRecord, combineRecordOp); | ||
| // TODO Remove these unnecessary newInstance invocations |
There was a problem hiding this comment.
@wzx140 please create a ticket under RFC-46 epic, and link it here like TODO(HUDI-xxx)
| I records, HoodieIndex<?, ?> index, int parallelism, String schema, Properties props, HoodieRecordMerger merge); | ||
| public I deduplicateRecords( | ||
| I records, HoodieIndex<?, ?> index, int parallelism, String schema, Properties props, HoodieRecordMerger merger) { | ||
| return innerDeduplicateRecords(records, index, parallelism, schema, HoodieAvroRecordMerger.withDeDuping(props), merger); |
There was a problem hiding this comment.
It's better to actually do the other way around:
- Keep inherited method named
deduplicateRecords - Create new private method
deduplicateRecordsInternalmodifying props and invoke it in this class
There was a problem hiding this comment.
Well, deduplicateRecords also used in StreamWriteFunction in Flink. So we should modify props in deduplicateRecords.
| public HoodieRecord rewriteRecord(Schema recordSchema, Properties props, Schema targetSchema) throws IOException { | ||
| StructType structType = HoodieInternalRowUtils.getCachedSchema(recordSchema); | ||
| StructType targetStructType = HoodieInternalRowUtils.getCachedSchema(targetSchema); | ||
| UTF8String[] metaFields = extractMetaField(targetStructType); |
There was a problem hiding this comment.
@wzx140 you extract meta-fields from the current records using targetStructType which is a new schema.
Let's consider the case when current record doesn't have meta-fields (it doesn't have it in the schema), this code would fail unpredictably in that case since we're using field ordinals from targetStructType (targetStructType != structType)
| } | ||
| }.withConf(conf).build(); | ||
| ParquetReaderIterator<InternalRow> parquetReaderIterator = new ParquetReaderIterator<>(reader, InternalRow::copy); | ||
| ParquetReaderIterator<InternalRow> parquetReaderIterator = new ParquetReaderIterator<>(reader, |
There was a problem hiding this comment.
@wzx140 that's exactly what i'm referring to -- let's move such copying to the least possible scope to make sure we're only making copies where we absolutely have (and nowhere else)
|
|
||
| return ((HoodieAvroRecord) newer).getData().combineAndGetUpdateValue(previousRecordAvroPayload.get().getData(), schema, props) | ||
| return ((HoodieAvroRecord) newer).getData().combineAndGetUpdateValue(previousAvroData.get(), schema, props) | ||
| .map(combinedAvroPayload -> new HoodieAvroIndexedRecord((IndexedRecord) combinedAvroPayload)); |
There was a problem hiding this comment.
You're right, i double-checked and we do indeed not shuffle the HoodieAvroIndexedRecord
| // For directly use InternalRow | ||
| private Function<T, T> mapper; | ||
| // Whether next is consumed | ||
| private boolean consumed; |
There was a problem hiding this comment.
Why are we changing this one?
There was a problem hiding this comment.
ParquetReaderIterator#next will return the current row and get the next row. We should get rid of it if we do not want to copy row in ParquetReaderIterator.
T retVal = this.next;
// This is what I want to remove if we not copy the retVal.
this.next = read();
return retVal;| } | ||
| } | ||
| T retVal = this.next; | ||
| this.next = read(); |
There was a problem hiding this comment.
This is wrong, we should not be doing read() in next, instead it should be like following:
def hasNext() {
if (next == null) {
next = read()
}
return next != null
}
def next() {
if (next == null) throw
val ret = next
next = null
return next
}
|
@hudi-bot run azure |
* Tidying up * Tidying up more * Cleaning up duplication * Tidying up * Revisited legacy operating mode configuration * Tidying up * Cleaned up `projectUnsafe` API * Fixing compilation * Cleaning up `HoodieSparkRecord` ctors; Revisited mandatory unsafe-projection * Fixing compilation * Cleaned up `ParquetReader` initialization * Revisited `HoodieSparkRecord` to accept either `UnsafeRow` or `HoodieInternalRow`, and avoid unnecessary copying after unsafe-projection * Cleaning up redundant exception spec * Make sure `updateMetadataFields` properly wraps `InternalRow` into `HoodieInternalRow` if necessary; Cleaned up `MetadataValues` * Fixed meta-fields extraction and `HoodieInternalRow` composition w/in `HoodieSparkRecord` * De-duplicate `HoodieSparkRecord` ctors; Make sure either only `UnsafeRow` or `HoodieInternalRow` are permitted inside `HoodieSparkRecord` * Removed unnecessary copying * Cleaned up projection for `HoodieSparkRecord` (dropping partition columns); Removed unnecessary copying * Fixing compilation * Fixing compilation (for Flink) * Cleaned up File Raders' interfaces: - Extracted `HoodieSeekingFileReader` interface (for key-ranged reads) - Pushed down concrete implementation methods into `HoodieAvroFileReaderBase` from the interfaces * Cleaned up File Readers impls (inline with then new interfaces) * Rebsaed `HoodieBackedTableMetadata` onto new `HoodieSeekingFileReader` * Tidying up * Missing licenses * Re-instate custom override for `HoodieAvroParquetReader`; Tidying up * Fixed missing cloning w/in `HoodieLazyInsertIterable` * Fixed missing cloning in deduplication flow * Allow `HoodieSparkRecord` to hold `ColumnarBatchRow` * Missing licenses * Fixing compilation * Missing changes * Fixed Spark 2.x validation whether the row was read as a batch
[minor] add more test for rfc46 (apache#7003) ## Change Logs - Add HoodieSparkValidateDuplicateKeyRecordMerger behaving the same as ValidateDuplicateKeyPayload. We should use it with config "hoodie.sql.insert.mode=strict". - Fix nest field exist in HoodieCatalystExpressionUtils - Fix rewrite in HoodieInternalRowUtiles to support type promoted as avro - Fallback to avro when use "merge into" sql - Fix some schema handling issue - Support delta streamer - Convert parquet schema to spark schema and then avro schema(in org.apache.hudi.io.storage.HoodieSparkParquetReader#getSchema). Some types in avro are not compatible with parquet. For ex, decimal as int32/int64 in parquet will convert to int/long in avro. Because avro do not has decimal as int/long . We will lose the logic type info if we directly convert it to avro schema. - Support schema evolution in parquet block [Minor] fix multi deser avro payload (apache#7021) In HoodieAvroRecord, we will call isDelete, shouldIgnore before we write it to the file. Each method will deserialize HoodiePayload. So we add deserialization method in HoodieRecord and call this method once before calling isDelete or shouldIgnore. Co-authored-by: wangzixuan.wzxuan <[email protected]> Co-authored-by: Alexey Kudinkin <[email protected]> Co-authored-by: Alexey Kudinkin <[email protected]> [MINOR] Properly registering target classes w/ Kryo (apache#7026) * Added `HoodieKryoRegistrar` registering necessary Hudi's classes w/ Kryo to make their serialization more efficient (by serializing just the class id, in-liue the fully qualified class-name) * Redirected Kryo registration to `HoodieKryoRegistrar` * Registered additional classes likely to be serialized by Kryo * Updated tests * Fixed serialization of Avro's `Utf8` to serialize just the bytes * Added tests * Added custom `AvroUtf8Serializer`; Tidying up * Extracted `HoodieCommonKryoRegistrar` to leverage in `SerializationUtils` * `HoodieKryoRegistrar` > `HoodieSparkKryoRegistrar`; Rebased `HoodieSparkKryoRegistrar` onto `HoodieCommonKryoRegistrar` * `lint` * Fixing compilation for Spark 2.x * Disabling flaky test [MINOR] Make sure all `HoodieRecord`s are appropriately serializable by Kryo (apache#6977) * Make sure `HoodieRecord`, `HoodieKey`, `HoodieRecordLocation` are all `KryoSerializable` * Revisited `HoodieRecord` serialization hooks to make sure they a) could not be overridden, b) provide for hooks to properly serialize record's payload; Implemented serialization hooks for `HoodieAvroIndexedRecord`; Implemented serialization hooks for `HoodieEmptyRecord`; * Revisited `HoodieRecord` serialization hooks to make sure they a) could not be overridden, b) provide for hooks to properly serialize record's payload; Implemented serialization hooks for `HoodieAvroIndexedRecord`; Implemented serialization hooks for `HoodieEmptyRecord`; Implemented serialization hooks for `HoodieAvroRecord`; * Revisited `HoodieSparkRecord` to transiently hold on to the schema so that it could project row * Implemented serialization hooks for `HoodieSparkRecord` * Added `TestHoodieSparkRecord` * Added tests for Avro-based records * Added test for `HoodieEmptyRecord` * Fixed sealing/unsealing for `HoodieRecord` in `HoodieBackedTableMetadataWriter` * Properly handle deflated records * Fixing `Row`s encoding * Fixed `HoodieRecord` to be properly sealed/unsealed * Fixed serialization of the `HoodieRecordGlobalLocation` [MINOR] Additional fixes for apache#6745 (apache#6947) * Tidying up * Tidying up more * Cleaning up duplication * Tidying up * Revisited legacy operating mode configuration * Tidying up * Cleaned up `projectUnsafe` API * Fixing compilation * Cleaning up `HoodieSparkRecord` ctors; Revisited mandatory unsafe-projection * Fixing compilation * Cleaned up `ParquetReader` initialization * Revisited `HoodieSparkRecord` to accept either `UnsafeRow` or `HoodieInternalRow`, and avoid unnecessary copying after unsafe-projection * Cleaning up redundant exception spec * Make sure `updateMetadataFields` properly wraps `InternalRow` into `HoodieInternalRow` if necessary; Cleaned up `MetadataValues` * Fixed meta-fields extraction and `HoodieInternalRow` composition w/in `HoodieSparkRecord` * De-duplicate `HoodieSparkRecord` ctors; Make sure either only `UnsafeRow` or `HoodieInternalRow` are permitted inside `HoodieSparkRecord` * Removed unnecessary copying * Cleaned up projection for `HoodieSparkRecord` (dropping partition columns); Removed unnecessary copying * Fixing compilation * Fixing compilation (for Flink) * Cleaned up File Raders' interfaces: - Extracted `HoodieSeekingFileReader` interface (for key-ranged reads) - Pushed down concrete implementation methods into `HoodieAvroFileReaderBase` from the interfaces * Cleaned up File Readers impls (inline with then new interfaces) * Rebsaed `HoodieBackedTableMetadata` onto new `HoodieSeekingFileReader` * Tidying up * Missing licenses * Re-instate custom override for `HoodieAvroParquetReader`; Tidying up * Fixed missing cloning w/in `HoodieLazyInsertIterable` * Fixed missing cloning in deduplication flow * Allow `HoodieSparkRecord` to hold `ColumnarBatchRow` * Missing licenses * Fixing compilation * Missing changes * Fixed Spark 2.x validation whether the row was read as a batch Fix comment in RFC46 (apache#6745) * rename * add MetadataValues in updateMetadataValues * remove singleton in fileFactory * add truncateRecordKey * remove hoodieRecord#setData * rename HoodieAvroRecord * fix code style * fix HoodieSparkRecordSerializer * fix benchmark * fix SparkRecordUtils * instantiate HoodieWriteConfig on the fly * add test * fix HoodieSparkRecordSerializer. Replace Java's object serialization with kryo * add broadcast * fix comment * remove unnecessary broadcast * add unsafe check in spark record * fix getRecordColumnValues * remove spark.sql.parquet.writeLegacyFormat * fix unsafe projection * fix * pass external schema * update doc * rename back to HoodieAvroRecord * fix * remove comparable wrapper * fix comment * fix comment * fix comment * fix comment * simplify row copy * fix ParquetReaderIterator Co-authored-by: Shawy Geng <[email protected]> Co-authored-by: wangzixuan.wzxuan <[email protected]> [RFC-46][HUDI-4414] Update the RFC-46 doc to fix comments feedback (apache#6132) * Update the RFC-46 doc to fix comments feedback * fix Co-authored-by: wangzixuan.wzxuan <[email protected]> [HUDI-4301] [HUDI-3384][HUDI-3385] Spark specific file reader/writer.(apache#5629) * [HUDI-4301] [HUDI-3384][HUDI-3385] Spark specific file reader/writer. * add schema finger print * add benchmark * a new way to config the merger * fix Co-authored-by: wangzixuan.wzxuan <[email protected]> Co-authored-by: gengxiaoyu <[email protected]> [HUDI-3350][HUDI-3351] Support HoodieMerge API and Spark engine-specific HoodieRecord (apache#5627) Co-authored-by: wangzixuan.wzxuan <[email protected]> [HUDI-4344] fix usage of HoodieDataBlock#getRecordIterator (apache#6005) Co-authored-by: wangzixuan.wzxuan <[email protected]> [HUDI-4292][RFC-46] Update doc to align with the Record Merge API changes (apache#5927) [MINOR] Fix type casting in TestHoodieHFileReaderWriter [HUDI-3378][HUDI-3379][HUDI-3381] Migrate usage of HoodieRecordPayload and raw Avro payload to HoodieRecord (apache#5522) Co-authored-by: Alexey Kudinkin <[email protected]> Co-authored-by: wangzixuan.wzxuan <[email protected]>
[minor] add more test for rfc46 (apache#7003) ## Change Logs - Add HoodieSparkValidateDuplicateKeyRecordMerger behaving the same as ValidateDuplicateKeyPayload. We should use it with config "hoodie.sql.insert.mode=strict". - Fix nest field exist in HoodieCatalystExpressionUtils - Fix rewrite in HoodieInternalRowUtiles to support type promoted as avro - Fallback to avro when use "merge into" sql - Fix some schema handling issue - Support delta streamer - Convert parquet schema to spark schema and then avro schema(in org.apache.hudi.io.storage.HoodieSparkParquetReader#getSchema). Some types in avro are not compatible with parquet. For ex, decimal as int32/int64 in parquet will convert to int/long in avro. Because avro do not has decimal as int/long . We will lose the logic type info if we directly convert it to avro schema. - Support schema evolution in parquet block [Minor] fix multi deser avro payload (apache#7021) In HoodieAvroRecord, we will call isDelete, shouldIgnore before we write it to the file. Each method will deserialize HoodiePayload. So we add deserialization method in HoodieRecord and call this method once before calling isDelete or shouldIgnore. Co-authored-by: wangzixuan.wzxuan <[email protected]> Co-authored-by: Alexey Kudinkin <[email protected]> Co-authored-by: Alexey Kudinkin <[email protected]> [MINOR] Properly registering target classes w/ Kryo (apache#7026) * Added `HoodieKryoRegistrar` registering necessary Hudi's classes w/ Kryo to make their serialization more efficient (by serializing just the class id, in-liue the fully qualified class-name) * Redirected Kryo registration to `HoodieKryoRegistrar` * Registered additional classes likely to be serialized by Kryo * Updated tests * Fixed serialization of Avro's `Utf8` to serialize just the bytes * Added tests * Added custom `AvroUtf8Serializer`; Tidying up * Extracted `HoodieCommonKryoRegistrar` to leverage in `SerializationUtils` * `HoodieKryoRegistrar` > `HoodieSparkKryoRegistrar`; Rebased `HoodieSparkKryoRegistrar` onto `HoodieCommonKryoRegistrar` * `lint` * Fixing compilation for Spark 2.x * Disabling flaky test [MINOR] Make sure all `HoodieRecord`s are appropriately serializable by Kryo (apache#6977) * Make sure `HoodieRecord`, `HoodieKey`, `HoodieRecordLocation` are all `KryoSerializable` * Revisited `HoodieRecord` serialization hooks to make sure they a) could not be overridden, b) provide for hooks to properly serialize record's payload; Implemented serialization hooks for `HoodieAvroIndexedRecord`; Implemented serialization hooks for `HoodieEmptyRecord`; * Revisited `HoodieRecord` serialization hooks to make sure they a) could not be overridden, b) provide for hooks to properly serialize record's payload; Implemented serialization hooks for `HoodieAvroIndexedRecord`; Implemented serialization hooks for `HoodieEmptyRecord`; Implemented serialization hooks for `HoodieAvroRecord`; * Revisited `HoodieSparkRecord` to transiently hold on to the schema so that it could project row * Implemented serialization hooks for `HoodieSparkRecord` * Added `TestHoodieSparkRecord` * Added tests for Avro-based records * Added test for `HoodieEmptyRecord` * Fixed sealing/unsealing for `HoodieRecord` in `HoodieBackedTableMetadataWriter` * Properly handle deflated records * Fixing `Row`s encoding * Fixed `HoodieRecord` to be properly sealed/unsealed * Fixed serialization of the `HoodieRecordGlobalLocation` [MINOR] Additional fixes for apache#6745 (apache#6947) * Tidying up * Tidying up more * Cleaning up duplication * Tidying up * Revisited legacy operating mode configuration * Tidying up * Cleaned up `projectUnsafe` API * Fixing compilation * Cleaning up `HoodieSparkRecord` ctors; Revisited mandatory unsafe-projection * Fixing compilation * Cleaned up `ParquetReader` initialization * Revisited `HoodieSparkRecord` to accept either `UnsafeRow` or `HoodieInternalRow`, and avoid unnecessary copying after unsafe-projection * Cleaning up redundant exception spec * Make sure `updateMetadataFields` properly wraps `InternalRow` into `HoodieInternalRow` if necessary; Cleaned up `MetadataValues` * Fixed meta-fields extraction and `HoodieInternalRow` composition w/in `HoodieSparkRecord` * De-duplicate `HoodieSparkRecord` ctors; Make sure either only `UnsafeRow` or `HoodieInternalRow` are permitted inside `HoodieSparkRecord` * Removed unnecessary copying * Cleaned up projection for `HoodieSparkRecord` (dropping partition columns); Removed unnecessary copying * Fixing compilation * Fixing compilation (for Flink) * Cleaned up File Raders' interfaces: - Extracted `HoodieSeekingFileReader` interface (for key-ranged reads) - Pushed down concrete implementation methods into `HoodieAvroFileReaderBase` from the interfaces * Cleaned up File Readers impls (inline with then new interfaces) * Rebsaed `HoodieBackedTableMetadata` onto new `HoodieSeekingFileReader` * Tidying up * Missing licenses * Re-instate custom override for `HoodieAvroParquetReader`; Tidying up * Fixed missing cloning w/in `HoodieLazyInsertIterable` * Fixed missing cloning in deduplication flow * Allow `HoodieSparkRecord` to hold `ColumnarBatchRow` * Missing licenses * Fixing compilation * Missing changes * Fixed Spark 2.x validation whether the row was read as a batch Fix comment in RFC46 (apache#6745) * rename * add MetadataValues in updateMetadataValues * remove singleton in fileFactory * add truncateRecordKey * remove hoodieRecord#setData * rename HoodieAvroRecord * fix code style * fix HoodieSparkRecordSerializer * fix benchmark * fix SparkRecordUtils * instantiate HoodieWriteConfig on the fly * add test * fix HoodieSparkRecordSerializer. Replace Java's object serialization with kryo * add broadcast * fix comment * remove unnecessary broadcast * add unsafe check in spark record * fix getRecordColumnValues * remove spark.sql.parquet.writeLegacyFormat * fix unsafe projection * fix * pass external schema * update doc * rename back to HoodieAvroRecord * fix * remove comparable wrapper * fix comment * fix comment * fix comment * fix comment * simplify row copy * fix ParquetReaderIterator Co-authored-by: Shawy Geng <[email protected]> Co-authored-by: wangzixuan.wzxuan <[email protected]> [RFC-46][HUDI-4414] Update the RFC-46 doc to fix comments feedback (apache#6132) * Update the RFC-46 doc to fix comments feedback * fix Co-authored-by: wangzixuan.wzxuan <[email protected]> [HUDI-4301] [HUDI-3384][HUDI-3385] Spark specific file reader/writer.(apache#5629) * [HUDI-4301] [HUDI-3384][HUDI-3385] Spark specific file reader/writer. * add schema finger print * add benchmark * a new way to config the merger * fix Co-authored-by: wangzixuan.wzxuan <[email protected]> Co-authored-by: gengxiaoyu <[email protected]> [HUDI-3350][HUDI-3351] Support HoodieMerge API and Spark engine-specific HoodieRecord (apache#5627) Co-authored-by: wangzixuan.wzxuan <[email protected]> [HUDI-4344] fix usage of HoodieDataBlock#getRecordIterator (apache#6005) Co-authored-by: wangzixuan.wzxuan <[email protected]> [HUDI-4292][RFC-46] Update doc to align with the Record Merge API changes (apache#5927) [MINOR] Fix type casting in TestHoodieHFileReaderWriter [HUDI-3378][HUDI-3379][HUDI-3381] Migrate usage of HoodieRecordPayload and raw Avro payload to HoodieRecord (apache#5522) Co-authored-by: Alexey Kudinkin <[email protected]> Co-authored-by: wangzixuan.wzxuan <[email protected]>
[minor] add more test for rfc46 (apache#7003) ## Change Logs - Add HoodieSparkValidateDuplicateKeyRecordMerger behaving the same as ValidateDuplicateKeyPayload. We should use it with config "hoodie.sql.insert.mode=strict". - Fix nest field exist in HoodieCatalystExpressionUtils - Fix rewrite in HoodieInternalRowUtiles to support type promoted as avro - Fallback to avro when use "merge into" sql - Fix some schema handling issue - Support delta streamer - Convert parquet schema to spark schema and then avro schema(in org.apache.hudi.io.storage.HoodieSparkParquetReader#getSchema). Some types in avro are not compatible with parquet. For ex, decimal as int32/int64 in parquet will convert to int/long in avro. Because avro do not has decimal as int/long . We will lose the logic type info if we directly convert it to avro schema. - Support schema evolution in parquet block [Minor] fix multi deser avro payload (apache#7021) In HoodieAvroRecord, we will call isDelete, shouldIgnore before we write it to the file. Each method will deserialize HoodiePayload. So we add deserialization method in HoodieRecord and call this method once before calling isDelete or shouldIgnore. Co-authored-by: wangzixuan.wzxuan <[email protected]> Co-authored-by: Alexey Kudinkin <[email protected]> Co-authored-by: Alexey Kudinkin <[email protected]> [MINOR] Properly registering target classes w/ Kryo (apache#7026) * Added `HoodieKryoRegistrar` registering necessary Hudi's classes w/ Kryo to make their serialization more efficient (by serializing just the class id, in-liue the fully qualified class-name) * Redirected Kryo registration to `HoodieKryoRegistrar` * Registered additional classes likely to be serialized by Kryo * Updated tests * Fixed serialization of Avro's `Utf8` to serialize just the bytes * Added tests * Added custom `AvroUtf8Serializer`; Tidying up * Extracted `HoodieCommonKryoRegistrar` to leverage in `SerializationUtils` * `HoodieKryoRegistrar` > `HoodieSparkKryoRegistrar`; Rebased `HoodieSparkKryoRegistrar` onto `HoodieCommonKryoRegistrar` * `lint` * Fixing compilation for Spark 2.x * Disabling flaky test [MINOR] Make sure all `HoodieRecord`s are appropriately serializable by Kryo (apache#6977) * Make sure `HoodieRecord`, `HoodieKey`, `HoodieRecordLocation` are all `KryoSerializable` * Revisited `HoodieRecord` serialization hooks to make sure they a) could not be overridden, b) provide for hooks to properly serialize record's payload; Implemented serialization hooks for `HoodieAvroIndexedRecord`; Implemented serialization hooks for `HoodieEmptyRecord`; * Revisited `HoodieRecord` serialization hooks to make sure they a) could not be overridden, b) provide for hooks to properly serialize record's payload; Implemented serialization hooks for `HoodieAvroIndexedRecord`; Implemented serialization hooks for `HoodieEmptyRecord`; Implemented serialization hooks for `HoodieAvroRecord`; * Revisited `HoodieSparkRecord` to transiently hold on to the schema so that it could project row * Implemented serialization hooks for `HoodieSparkRecord` * Added `TestHoodieSparkRecord` * Added tests for Avro-based records * Added test for `HoodieEmptyRecord` * Fixed sealing/unsealing for `HoodieRecord` in `HoodieBackedTableMetadataWriter` * Properly handle deflated records * Fixing `Row`s encoding * Fixed `HoodieRecord` to be properly sealed/unsealed * Fixed serialization of the `HoodieRecordGlobalLocation` [MINOR] Additional fixes for apache#6745 (apache#6947) * Tidying up * Tidying up more * Cleaning up duplication * Tidying up * Revisited legacy operating mode configuration * Tidying up * Cleaned up `projectUnsafe` API * Fixing compilation * Cleaning up `HoodieSparkRecord` ctors; Revisited mandatory unsafe-projection * Fixing compilation * Cleaned up `ParquetReader` initialization * Revisited `HoodieSparkRecord` to accept either `UnsafeRow` or `HoodieInternalRow`, and avoid unnecessary copying after unsafe-projection * Cleaning up redundant exception spec * Make sure `updateMetadataFields` properly wraps `InternalRow` into `HoodieInternalRow` if necessary; Cleaned up `MetadataValues` * Fixed meta-fields extraction and `HoodieInternalRow` composition w/in `HoodieSparkRecord` * De-duplicate `HoodieSparkRecord` ctors; Make sure either only `UnsafeRow` or `HoodieInternalRow` are permitted inside `HoodieSparkRecord` * Removed unnecessary copying * Cleaned up projection for `HoodieSparkRecord` (dropping partition columns); Removed unnecessary copying * Fixing compilation * Fixing compilation (for Flink) * Cleaned up File Raders' interfaces: - Extracted `HoodieSeekingFileReader` interface (for key-ranged reads) - Pushed down concrete implementation methods into `HoodieAvroFileReaderBase` from the interfaces * Cleaned up File Readers impls (inline with then new interfaces) * Rebsaed `HoodieBackedTableMetadata` onto new `HoodieSeekingFileReader` * Tidying up * Missing licenses * Re-instate custom override for `HoodieAvroParquetReader`; Tidying up * Fixed missing cloning w/in `HoodieLazyInsertIterable` * Fixed missing cloning in deduplication flow * Allow `HoodieSparkRecord` to hold `ColumnarBatchRow` * Missing licenses * Fixing compilation * Missing changes * Fixed Spark 2.x validation whether the row was read as a batch Fix comment in RFC46 (apache#6745) * rename * add MetadataValues in updateMetadataValues * remove singleton in fileFactory * add truncateRecordKey * remove hoodieRecord#setData * rename HoodieAvroRecord * fix code style * fix HoodieSparkRecordSerializer * fix benchmark * fix SparkRecordUtils * instantiate HoodieWriteConfig on the fly * add test * fix HoodieSparkRecordSerializer. Replace Java's object serialization with kryo * add broadcast * fix comment * remove unnecessary broadcast * add unsafe check in spark record * fix getRecordColumnValues * remove spark.sql.parquet.writeLegacyFormat * fix unsafe projection * fix * pass external schema * update doc * rename back to HoodieAvroRecord * fix * remove comparable wrapper * fix comment * fix comment * fix comment * fix comment * simplify row copy * fix ParquetReaderIterator Co-authored-by: Shawy Geng <[email protected]> Co-authored-by: wangzixuan.wzxuan <[email protected]> [RFC-46][HUDI-4414] Update the RFC-46 doc to fix comments feedback (apache#6132) * Update the RFC-46 doc to fix comments feedback * fix Co-authored-by: wangzixuan.wzxuan <[email protected]> [HUDI-4301] [HUDI-3384][HUDI-3385] Spark specific file reader/writer.(apache#5629) * [HUDI-4301] [HUDI-3384][HUDI-3385] Spark specific file reader/writer. * add schema finger print * add benchmark * a new way to config the merger * fix Co-authored-by: wangzixuan.wzxuan <[email protected]> Co-authored-by: gengxiaoyu <[email protected]> [HUDI-3350][HUDI-3351] Support HoodieMerge API and Spark engine-specific HoodieRecord (apache#5627) Co-authored-by: wangzixuan.wzxuan <[email protected]> [HUDI-4344] fix usage of HoodieDataBlock#getRecordIterator (apache#6005) Co-authored-by: wangzixuan.wzxuan <[email protected]> [HUDI-4292][RFC-46] Update doc to align with the Record Merge API changes (apache#5927) [MINOR] Fix type casting in TestHoodieHFileReaderWriter [HUDI-3378][HUDI-3379][HUDI-3381] Migrate usage of HoodieRecordPayload and raw Avro payload to HoodieRecord (apache#5522) Co-authored-by: Alexey Kudinkin <[email protected]> Co-authored-by: wangzixuan.wzxuan <[email protected]>
[minor] add more test for rfc46 (apache#7003) ## Change Logs - Add HoodieSparkValidateDuplicateKeyRecordMerger behaving the same as ValidateDuplicateKeyPayload. We should use it with config "hoodie.sql.insert.mode=strict". - Fix nest field exist in HoodieCatalystExpressionUtils - Fix rewrite in HoodieInternalRowUtiles to support type promoted as avro - Fallback to avro when use "merge into" sql - Fix some schema handling issue - Support delta streamer - Convert parquet schema to spark schema and then avro schema(in org.apache.hudi.io.storage.HoodieSparkParquetReader#getSchema). Some types in avro are not compatible with parquet. For ex, decimal as int32/int64 in parquet will convert to int/long in avro. Because avro do not has decimal as int/long . We will lose the logic type info if we directly convert it to avro schema. - Support schema evolution in parquet block [Minor] fix multi deser avro payload (apache#7021) In HoodieAvroRecord, we will call isDelete, shouldIgnore before we write it to the file. Each method will deserialize HoodiePayload. So we add deserialization method in HoodieRecord and call this method once before calling isDelete or shouldIgnore. Co-authored-by: wangzixuan.wzxuan <[email protected]> Co-authored-by: Alexey Kudinkin <[email protected]> Co-authored-by: Alexey Kudinkin <[email protected]> [MINOR] Properly registering target classes w/ Kryo (apache#7026) * Added `HoodieKryoRegistrar` registering necessary Hudi's classes w/ Kryo to make their serialization more efficient (by serializing just the class id, in-liue the fully qualified class-name) * Redirected Kryo registration to `HoodieKryoRegistrar` * Registered additional classes likely to be serialized by Kryo * Updated tests * Fixed serialization of Avro's `Utf8` to serialize just the bytes * Added tests * Added custom `AvroUtf8Serializer`; Tidying up * Extracted `HoodieCommonKryoRegistrar` to leverage in `SerializationUtils` * `HoodieKryoRegistrar` > `HoodieSparkKryoRegistrar`; Rebased `HoodieSparkKryoRegistrar` onto `HoodieCommonKryoRegistrar` * `lint` * Fixing compilation for Spark 2.x * Disabling flaky test [MINOR] Make sure all `HoodieRecord`s are appropriately serializable by Kryo (apache#6977) * Make sure `HoodieRecord`, `HoodieKey`, `HoodieRecordLocation` are all `KryoSerializable` * Revisited `HoodieRecord` serialization hooks to make sure they a) could not be overridden, b) provide for hooks to properly serialize record's payload; Implemented serialization hooks for `HoodieAvroIndexedRecord`; Implemented serialization hooks for `HoodieEmptyRecord`; * Revisited `HoodieRecord` serialization hooks to make sure they a) could not be overridden, b) provide for hooks to properly serialize record's payload; Implemented serialization hooks for `HoodieAvroIndexedRecord`; Implemented serialization hooks for `HoodieEmptyRecord`; Implemented serialization hooks for `HoodieAvroRecord`; * Revisited `HoodieSparkRecord` to transiently hold on to the schema so that it could project row * Implemented serialization hooks for `HoodieSparkRecord` * Added `TestHoodieSparkRecord` * Added tests for Avro-based records * Added test for `HoodieEmptyRecord` * Fixed sealing/unsealing for `HoodieRecord` in `HoodieBackedTableMetadataWriter` * Properly handle deflated records * Fixing `Row`s encoding * Fixed `HoodieRecord` to be properly sealed/unsealed * Fixed serialization of the `HoodieRecordGlobalLocation` [MINOR] Additional fixes for apache#6745 (apache#6947) * Tidying up * Tidying up more * Cleaning up duplication * Tidying up * Revisited legacy operating mode configuration * Tidying up * Cleaned up `projectUnsafe` API * Fixing compilation * Cleaning up `HoodieSparkRecord` ctors; Revisited mandatory unsafe-projection * Fixing compilation * Cleaned up `ParquetReader` initialization * Revisited `HoodieSparkRecord` to accept either `UnsafeRow` or `HoodieInternalRow`, and avoid unnecessary copying after unsafe-projection * Cleaning up redundant exception spec * Make sure `updateMetadataFields` properly wraps `InternalRow` into `HoodieInternalRow` if necessary; Cleaned up `MetadataValues` * Fixed meta-fields extraction and `HoodieInternalRow` composition w/in `HoodieSparkRecord` * De-duplicate `HoodieSparkRecord` ctors; Make sure either only `UnsafeRow` or `HoodieInternalRow` are permitted inside `HoodieSparkRecord` * Removed unnecessary copying * Cleaned up projection for `HoodieSparkRecord` (dropping partition columns); Removed unnecessary copying * Fixing compilation * Fixing compilation (for Flink) * Cleaned up File Raders' interfaces: - Extracted `HoodieSeekingFileReader` interface (for key-ranged reads) - Pushed down concrete implementation methods into `HoodieAvroFileReaderBase` from the interfaces * Cleaned up File Readers impls (inline with then new interfaces) * Rebsaed `HoodieBackedTableMetadata` onto new `HoodieSeekingFileReader` * Tidying up * Missing licenses * Re-instate custom override for `HoodieAvroParquetReader`; Tidying up * Fixed missing cloning w/in `HoodieLazyInsertIterable` * Fixed missing cloning in deduplication flow * Allow `HoodieSparkRecord` to hold `ColumnarBatchRow` * Missing licenses * Fixing compilation * Missing changes * Fixed Spark 2.x validation whether the row was read as a batch Fix comment in RFC46 (apache#6745) * rename * add MetadataValues in updateMetadataValues * remove singleton in fileFactory * add truncateRecordKey * remove hoodieRecord#setData * rename HoodieAvroRecord * fix code style * fix HoodieSparkRecordSerializer * fix benchmark * fix SparkRecordUtils * instantiate HoodieWriteConfig on the fly * add test * fix HoodieSparkRecordSerializer. Replace Java's object serialization with kryo * add broadcast * fix comment * remove unnecessary broadcast * add unsafe check in spark record * fix getRecordColumnValues * remove spark.sql.parquet.writeLegacyFormat * fix unsafe projection * fix * pass external schema * update doc * rename back to HoodieAvroRecord * fix * remove comparable wrapper * fix comment * fix comment * fix comment * fix comment * simplify row copy * fix ParquetReaderIterator Co-authored-by: Shawy Geng <[email protected]> Co-authored-by: wangzixuan.wzxuan <[email protected]> [RFC-46][HUDI-4414] Update the RFC-46 doc to fix comments feedback (apache#6132) * Update the RFC-46 doc to fix comments feedback * fix Co-authored-by: wangzixuan.wzxuan <[email protected]> [HUDI-4301] [HUDI-3384][HUDI-3385] Spark specific file reader/writer.(apache#5629) * [HUDI-4301] [HUDI-3384][HUDI-3385] Spark specific file reader/writer. * add schema finger print * add benchmark * a new way to config the merger * fix Co-authored-by: wangzixuan.wzxuan <[email protected]> Co-authored-by: gengxiaoyu <[email protected]> [HUDI-3350][HUDI-3351] Support HoodieMerge API and Spark engine-specific HoodieRecord (apache#5627) Co-authored-by: wangzixuan.wzxuan <[email protected]> [HUDI-4344] fix usage of HoodieDataBlock#getRecordIterator (apache#6005) Co-authored-by: wangzixuan.wzxuan <[email protected]> [HUDI-4292][RFC-46] Update doc to align with the Record Merge API changes (apache#5927) [MINOR] Fix type casting in TestHoodieHFileReaderWriter [HUDI-3378][HUDI-3379][HUDI-3381] Migrate usage of HoodieRecordPayload and raw Avro payload to HoodieRecord (apache#5522) Co-authored-by: Alexey Kudinkin <[email protected]> Co-authored-by: wangzixuan.wzxuan <[email protected]>
[minor] add more test for rfc46 (apache#7003) ## Change Logs - Add HoodieSparkValidateDuplicateKeyRecordMerger behaving the same as ValidateDuplicateKeyPayload. We should use it with config "hoodie.sql.insert.mode=strict". - Fix nest field exist in HoodieCatalystExpressionUtils - Fix rewrite in HoodieInternalRowUtiles to support type promoted as avro - Fallback to avro when use "merge into" sql - Fix some schema handling issue - Support delta streamer - Convert parquet schema to spark schema and then avro schema(in org.apache.hudi.io.storage.HoodieSparkParquetReader#getSchema). Some types in avro are not compatible with parquet. For ex, decimal as int32/int64 in parquet will convert to int/long in avro. Because avro do not has decimal as int/long . We will lose the logic type info if we directly convert it to avro schema. - Support schema evolution in parquet block [Minor] fix multi deser avro payload (apache#7021) In HoodieAvroRecord, we will call isDelete, shouldIgnore before we write it to the file. Each method will deserialize HoodiePayload. So we add deserialization method in HoodieRecord and call this method once before calling isDelete or shouldIgnore. Co-authored-by: wangzixuan.wzxuan <[email protected]> Co-authored-by: Alexey Kudinkin <[email protected]> Co-authored-by: Alexey Kudinkin <[email protected]> [MINOR] Properly registering target classes w/ Kryo (apache#7026) * Added `HoodieKryoRegistrar` registering necessary Hudi's classes w/ Kryo to make their serialization more efficient (by serializing just the class id, in-liue the fully qualified class-name) * Redirected Kryo registration to `HoodieKryoRegistrar` * Registered additional classes likely to be serialized by Kryo * Updated tests * Fixed serialization of Avro's `Utf8` to serialize just the bytes * Added tests * Added custom `AvroUtf8Serializer`; Tidying up * Extracted `HoodieCommonKryoRegistrar` to leverage in `SerializationUtils` * `HoodieKryoRegistrar` > `HoodieSparkKryoRegistrar`; Rebased `HoodieSparkKryoRegistrar` onto `HoodieCommonKryoRegistrar` * `lint` * Fixing compilation for Spark 2.x * Disabling flaky test [MINOR] Make sure all `HoodieRecord`s are appropriately serializable by Kryo (apache#6977) * Make sure `HoodieRecord`, `HoodieKey`, `HoodieRecordLocation` are all `KryoSerializable` * Revisited `HoodieRecord` serialization hooks to make sure they a) could not be overridden, b) provide for hooks to properly serialize record's payload; Implemented serialization hooks for `HoodieAvroIndexedRecord`; Implemented serialization hooks for `HoodieEmptyRecord`; * Revisited `HoodieRecord` serialization hooks to make sure they a) could not be overridden, b) provide for hooks to properly serialize record's payload; Implemented serialization hooks for `HoodieAvroIndexedRecord`; Implemented serialization hooks for `HoodieEmptyRecord`; Implemented serialization hooks for `HoodieAvroRecord`; * Revisited `HoodieSparkRecord` to transiently hold on to the schema so that it could project row * Implemented serialization hooks for `HoodieSparkRecord` * Added `TestHoodieSparkRecord` * Added tests for Avro-based records * Added test for `HoodieEmptyRecord` * Fixed sealing/unsealing for `HoodieRecord` in `HoodieBackedTableMetadataWriter` * Properly handle deflated records * Fixing `Row`s encoding * Fixed `HoodieRecord` to be properly sealed/unsealed * Fixed serialization of the `HoodieRecordGlobalLocation` [MINOR] Additional fixes for apache#6745 (apache#6947) * Tidying up * Tidying up more * Cleaning up duplication * Tidying up * Revisited legacy operating mode configuration * Tidying up * Cleaned up `projectUnsafe` API * Fixing compilation * Cleaning up `HoodieSparkRecord` ctors; Revisited mandatory unsafe-projection * Fixing compilation * Cleaned up `ParquetReader` initialization * Revisited `HoodieSparkRecord` to accept either `UnsafeRow` or `HoodieInternalRow`, and avoid unnecessary copying after unsafe-projection * Cleaning up redundant exception spec * Make sure `updateMetadataFields` properly wraps `InternalRow` into `HoodieInternalRow` if necessary; Cleaned up `MetadataValues` * Fixed meta-fields extraction and `HoodieInternalRow` composition w/in `HoodieSparkRecord` * De-duplicate `HoodieSparkRecord` ctors; Make sure either only `UnsafeRow` or `HoodieInternalRow` are permitted inside `HoodieSparkRecord` * Removed unnecessary copying * Cleaned up projection for `HoodieSparkRecord` (dropping partition columns); Removed unnecessary copying * Fixing compilation * Fixing compilation (for Flink) * Cleaned up File Raders' interfaces: - Extracted `HoodieSeekingFileReader` interface (for key-ranged reads) - Pushed down concrete implementation methods into `HoodieAvroFileReaderBase` from the interfaces * Cleaned up File Readers impls (inline with then new interfaces) * Rebsaed `HoodieBackedTableMetadata` onto new `HoodieSeekingFileReader` * Tidying up * Missing licenses * Re-instate custom override for `HoodieAvroParquetReader`; Tidying up * Fixed missing cloning w/in `HoodieLazyInsertIterable` * Fixed missing cloning in deduplication flow * Allow `HoodieSparkRecord` to hold `ColumnarBatchRow` * Missing licenses * Fixing compilation * Missing changes * Fixed Spark 2.x validation whether the row was read as a batch Fix comment in RFC46 (apache#6745) * rename * add MetadataValues in updateMetadataValues * remove singleton in fileFactory * add truncateRecordKey * remove hoodieRecord#setData * rename HoodieAvroRecord * fix code style * fix HoodieSparkRecordSerializer * fix benchmark * fix SparkRecordUtils * instantiate HoodieWriteConfig on the fly * add test * fix HoodieSparkRecordSerializer. Replace Java's object serialization with kryo * add broadcast * fix comment * remove unnecessary broadcast * add unsafe check in spark record * fix getRecordColumnValues * remove spark.sql.parquet.writeLegacyFormat * fix unsafe projection * fix * pass external schema * update doc * rename back to HoodieAvroRecord * fix * remove comparable wrapper * fix comment * fix comment * fix comment * fix comment * simplify row copy * fix ParquetReaderIterator Co-authored-by: Shawy Geng <[email protected]> Co-authored-by: wangzixuan.wzxuan <[email protected]> [RFC-46][HUDI-4414] Update the RFC-46 doc to fix comments feedback (apache#6132) * Update the RFC-46 doc to fix comments feedback * fix Co-authored-by: wangzixuan.wzxuan <[email protected]> [HUDI-4301] [HUDI-3384][HUDI-3385] Spark specific file reader/writer.(apache#5629) * [HUDI-4301] [HUDI-3384][HUDI-3385] Spark specific file reader/writer. * add schema finger print * add benchmark * a new way to config the merger * fix Co-authored-by: wangzixuan.wzxuan <[email protected]> Co-authored-by: gengxiaoyu <[email protected]> [HUDI-3350][HUDI-3351] Support HoodieMerge API and Spark engine-specific HoodieRecord (apache#5627) Co-authored-by: wangzixuan.wzxuan <[email protected]> [HUDI-4344] fix usage of HoodieDataBlock#getRecordIterator (apache#6005) Co-authored-by: wangzixuan.wzxuan <[email protected]> [HUDI-4292][RFC-46] Update doc to align with the Record Merge API changes (apache#5927) [MINOR] Fix type casting in TestHoodieHFileReaderWriter [HUDI-3378][HUDI-3379][HUDI-3381] Migrate usage of HoodieRecordPayload and raw Avro payload to HoodieRecord (apache#5522) Co-authored-by: Alexey Kudinkin <[email protected]> Co-authored-by: wangzixuan.wzxuan <[email protected]>
[minor] add more test for rfc46 (apache#7003) ## Change Logs - Add HoodieSparkValidateDuplicateKeyRecordMerger behaving the same as ValidateDuplicateKeyPayload. We should use it with config "hoodie.sql.insert.mode=strict". - Fix nest field exist in HoodieCatalystExpressionUtils - Fix rewrite in HoodieInternalRowUtiles to support type promoted as avro - Fallback to avro when use "merge into" sql - Fix some schema handling issue - Support delta streamer - Convert parquet schema to spark schema and then avro schema(in org.apache.hudi.io.storage.HoodieSparkParquetReader#getSchema). Some types in avro are not compatible with parquet. For ex, decimal as int32/int64 in parquet will convert to int/long in avro. Because avro do not has decimal as int/long . We will lose the logic type info if we directly convert it to avro schema. - Support schema evolution in parquet block [Minor] fix multi deser avro payload (apache#7021) In HoodieAvroRecord, we will call isDelete, shouldIgnore before we write it to the file. Each method will deserialize HoodiePayload. So we add deserialization method in HoodieRecord and call this method once before calling isDelete or shouldIgnore. Co-authored-by: wangzixuan.wzxuan <[email protected]> Co-authored-by: Alexey Kudinkin <[email protected]> Co-authored-by: Alexey Kudinkin <[email protected]> [MINOR] Properly registering target classes w/ Kryo (apache#7026) * Added `HoodieKryoRegistrar` registering necessary Hudi's classes w/ Kryo to make their serialization more efficient (by serializing just the class id, in-liue the fully qualified class-name) * Redirected Kryo registration to `HoodieKryoRegistrar` * Registered additional classes likely to be serialized by Kryo * Updated tests * Fixed serialization of Avro's `Utf8` to serialize just the bytes * Added tests * Added custom `AvroUtf8Serializer`; Tidying up * Extracted `HoodieCommonKryoRegistrar` to leverage in `SerializationUtils` * `HoodieKryoRegistrar` > `HoodieSparkKryoRegistrar`; Rebased `HoodieSparkKryoRegistrar` onto `HoodieCommonKryoRegistrar` * `lint` * Fixing compilation for Spark 2.x * Disabling flaky test [MINOR] Make sure all `HoodieRecord`s are appropriately serializable by Kryo (apache#6977) * Make sure `HoodieRecord`, `HoodieKey`, `HoodieRecordLocation` are all `KryoSerializable` * Revisited `HoodieRecord` serialization hooks to make sure they a) could not be overridden, b) provide for hooks to properly serialize record's payload; Implemented serialization hooks for `HoodieAvroIndexedRecord`; Implemented serialization hooks for `HoodieEmptyRecord`; * Revisited `HoodieRecord` serialization hooks to make sure they a) could not be overridden, b) provide for hooks to properly serialize record's payload; Implemented serialization hooks for `HoodieAvroIndexedRecord`; Implemented serialization hooks for `HoodieEmptyRecord`; Implemented serialization hooks for `HoodieAvroRecord`; * Revisited `HoodieSparkRecord` to transiently hold on to the schema so that it could project row * Implemented serialization hooks for `HoodieSparkRecord` * Added `TestHoodieSparkRecord` * Added tests for Avro-based records * Added test for `HoodieEmptyRecord` * Fixed sealing/unsealing for `HoodieRecord` in `HoodieBackedTableMetadataWriter` * Properly handle deflated records * Fixing `Row`s encoding * Fixed `HoodieRecord` to be properly sealed/unsealed * Fixed serialization of the `HoodieRecordGlobalLocation` [MINOR] Additional fixes for apache#6745 (apache#6947) * Tidying up * Tidying up more * Cleaning up duplication * Tidying up * Revisited legacy operating mode configuration * Tidying up * Cleaned up `projectUnsafe` API * Fixing compilation * Cleaning up `HoodieSparkRecord` ctors; Revisited mandatory unsafe-projection * Fixing compilation * Cleaned up `ParquetReader` initialization * Revisited `HoodieSparkRecord` to accept either `UnsafeRow` or `HoodieInternalRow`, and avoid unnecessary copying after unsafe-projection * Cleaning up redundant exception spec * Make sure `updateMetadataFields` properly wraps `InternalRow` into `HoodieInternalRow` if necessary; Cleaned up `MetadataValues` * Fixed meta-fields extraction and `HoodieInternalRow` composition w/in `HoodieSparkRecord` * De-duplicate `HoodieSparkRecord` ctors; Make sure either only `UnsafeRow` or `HoodieInternalRow` are permitted inside `HoodieSparkRecord` * Removed unnecessary copying * Cleaned up projection for `HoodieSparkRecord` (dropping partition columns); Removed unnecessary copying * Fixing compilation * Fixing compilation (for Flink) * Cleaned up File Raders' interfaces: - Extracted `HoodieSeekingFileReader` interface (for key-ranged reads) - Pushed down concrete implementation methods into `HoodieAvroFileReaderBase` from the interfaces * Cleaned up File Readers impls (inline with then new interfaces) * Rebsaed `HoodieBackedTableMetadata` onto new `HoodieSeekingFileReader` * Tidying up * Missing licenses * Re-instate custom override for `HoodieAvroParquetReader`; Tidying up * Fixed missing cloning w/in `HoodieLazyInsertIterable` * Fixed missing cloning in deduplication flow * Allow `HoodieSparkRecord` to hold `ColumnarBatchRow` * Missing licenses * Fixing compilation * Missing changes * Fixed Spark 2.x validation whether the row was read as a batch Fix comment in RFC46 (apache#6745) * rename * add MetadataValues in updateMetadataValues * remove singleton in fileFactory * add truncateRecordKey * remove hoodieRecord#setData * rename HoodieAvroRecord * fix code style * fix HoodieSparkRecordSerializer * fix benchmark * fix SparkRecordUtils * instantiate HoodieWriteConfig on the fly * add test * fix HoodieSparkRecordSerializer. Replace Java's object serialization with kryo * add broadcast * fix comment * remove unnecessary broadcast * add unsafe check in spark record * fix getRecordColumnValues * remove spark.sql.parquet.writeLegacyFormat * fix unsafe projection * fix * pass external schema * update doc * rename back to HoodieAvroRecord * fix * remove comparable wrapper * fix comment * fix comment * fix comment * fix comment * simplify row copy * fix ParquetReaderIterator Co-authored-by: Shawy Geng <[email protected]> Co-authored-by: wangzixuan.wzxuan <[email protected]> [RFC-46][HUDI-4414] Update the RFC-46 doc to fix comments feedback (apache#6132) * Update the RFC-46 doc to fix comments feedback * fix Co-authored-by: wangzixuan.wzxuan <[email protected]> [HUDI-4301] [HUDI-3384][HUDI-3385] Spark specific file reader/writer.(apache#5629) * [HUDI-4301] [HUDI-3384][HUDI-3385] Spark specific file reader/writer. * add schema finger print * add benchmark * a new way to config the merger * fix Co-authored-by: wangzixuan.wzxuan <[email protected]> Co-authored-by: gengxiaoyu <[email protected]> [HUDI-3350][HUDI-3351] Support HoodieMerge API and Spark engine-specific HoodieRecord (apache#5627) Co-authored-by: wangzixuan.wzxuan <[email protected]> [HUDI-4344] fix usage of HoodieDataBlock#getRecordIterator (apache#6005) Co-authored-by: wangzixuan.wzxuan <[email protected]> [HUDI-4292][RFC-46] Update doc to align with the Record Merge API changes (apache#5927) [MINOR] Fix type casting in TestHoodieHFileReaderWriter [HUDI-3378][HUDI-3379][HUDI-3381] Migrate usage of HoodieRecordPayload and raw Avro payload to HoodieRecord (apache#5522) Co-authored-by: Alexey Kudinkin <[email protected]> Co-authored-by: wangzixuan.wzxuan <[email protected]>
[minor] add more test for rfc46 (apache#7003) - Add HoodieSparkValidateDuplicateKeyRecordMerger behaving the same as ValidateDuplicateKeyPayload. We should use it with config "hoodie.sql.insert.mode=strict". - Fix nest field exist in HoodieCatalystExpressionUtils - Fix rewrite in HoodieInternalRowUtiles to support type promoted as avro - Fallback to avro when use "merge into" sql - Fix some schema handling issue - Support delta streamer - Convert parquet schema to spark schema and then avro schema(in org.apache.hudi.io.storage.HoodieSparkParquetReader#getSchema). Some types in avro are not compatible with parquet. For ex, decimal as int32/int64 in parquet will convert to int/long in avro. Because avro do not has decimal as int/long . We will lose the logic type info if we directly convert it to avro schema. - Support schema evolution in parquet block [Minor] fix multi deser avro payload (apache#7021) In HoodieAvroRecord, we will call isDelete, shouldIgnore before we write it to the file. Each method will deserialize HoodiePayload. So we add deserialization method in HoodieRecord and call this method once before calling isDelete or shouldIgnore. Co-authored-by: wangzixuan.wzxuan <[email protected]> Co-authored-by: Alexey Kudinkin <[email protected]> Co-authored-by: Alexey Kudinkin <[email protected]> [MINOR] Properly registering target classes w/ Kryo (apache#7026) * Added `HoodieKryoRegistrar` registering necessary Hudi's classes w/ Kryo to make their serialization more efficient (by serializing just the class id, in-liue the fully qualified class-name) * Redirected Kryo registration to `HoodieKryoRegistrar` * Registered additional classes likely to be serialized by Kryo * Updated tests * Fixed serialization of Avro's `Utf8` to serialize just the bytes * Added tests * Added custom `AvroUtf8Serializer`; Tidying up * Extracted `HoodieCommonKryoRegistrar` to leverage in `SerializationUtils` * `HoodieKryoRegistrar` > `HoodieSparkKryoRegistrar`; Rebased `HoodieSparkKryoRegistrar` onto `HoodieCommonKryoRegistrar` * `lint` * Fixing compilation for Spark 2.x * Disabling flaky test [MINOR] Make sure all `HoodieRecord`s are appropriately serializable by Kryo (apache#6977) * Make sure `HoodieRecord`, `HoodieKey`, `HoodieRecordLocation` are all `KryoSerializable` * Revisited `HoodieRecord` serialization hooks to make sure they a) could not be overridden, b) provide for hooks to properly serialize record's payload; Implemented serialization hooks for `HoodieAvroIndexedRecord`; Implemented serialization hooks for `HoodieEmptyRecord`; * Revisited `HoodieRecord` serialization hooks to make sure they a) could not be overridden, b) provide for hooks to properly serialize record's payload; Implemented serialization hooks for `HoodieAvroIndexedRecord`; Implemented serialization hooks for `HoodieEmptyRecord`; Implemented serialization hooks for `HoodieAvroRecord`; * Revisited `HoodieSparkRecord` to transiently hold on to the schema so that it could project row * Implemented serialization hooks for `HoodieSparkRecord` * Added `TestHoodieSparkRecord` * Added tests for Avro-based records * Added test for `HoodieEmptyRecord` * Fixed sealing/unsealing for `HoodieRecord` in `HoodieBackedTableMetadataWriter` * Properly handle deflated records * Fixing `Row`s encoding * Fixed `HoodieRecord` to be properly sealed/unsealed * Fixed serialization of the `HoodieRecordGlobalLocation` [MINOR] Additional fixes for apache#6745 (apache#6947) * Tidying up * Tidying up more * Cleaning up duplication * Tidying up * Revisited legacy operating mode configuration * Tidying up * Cleaned up `projectUnsafe` API * Fixing compilation * Cleaning up `HoodieSparkRecord` ctors; Revisited mandatory unsafe-projection * Fixing compilation * Cleaned up `ParquetReader` initialization * Revisited `HoodieSparkRecord` to accept either `UnsafeRow` or `HoodieInternalRow`, and avoid unnecessary copying after unsafe-projection * Cleaning up redundant exception spec * Make sure `updateMetadataFields` properly wraps `InternalRow` into `HoodieInternalRow` if necessary; Cleaned up `MetadataValues` * Fixed meta-fields extraction and `HoodieInternalRow` composition w/in `HoodieSparkRecord` * De-duplicate `HoodieSparkRecord` ctors; Make sure either only `UnsafeRow` or `HoodieInternalRow` are permitted inside `HoodieSparkRecord` * Removed unnecessary copying * Cleaned up projection for `HoodieSparkRecord` (dropping partition columns); Removed unnecessary copying * Fixing compilation * Fixing compilation (for Flink) * Cleaned up File Raders' interfaces: - Extracted `HoodieSeekingFileReader` interface (for key-ranged reads) - Pushed down concrete implementation methods into `HoodieAvroFileReaderBase` from the interfaces * Cleaned up File Readers impls (inline with then new interfaces) * Rebsaed `HoodieBackedTableMetadata` onto new `HoodieSeekingFileReader` * Tidying up * Missing licenses * Re-instate custom override for `HoodieAvroParquetReader`; Tidying up * Fixed missing cloning w/in `HoodieLazyInsertIterable` * Fixed missing cloning in deduplication flow * Allow `HoodieSparkRecord` to hold `ColumnarBatchRow` * Missing licenses * Fixing compilation * Missing changes * Fixed Spark 2.x validation whether the row was read as a batch Fix comment in RFC46 (apache#6745) * rename * add MetadataValues in updateMetadataValues * remove singleton in fileFactory * add truncateRecordKey * remove hoodieRecord#setData * rename HoodieAvroRecord * fix code style * fix HoodieSparkRecordSerializer * fix benchmark * fix SparkRecordUtils * instantiate HoodieWriteConfig on the fly * add test * fix HoodieSparkRecordSerializer. Replace Java's object serialization with kryo * add broadcast * fix comment * remove unnecessary broadcast * add unsafe check in spark record * fix getRecordColumnValues * remove spark.sql.parquet.writeLegacyFormat * fix unsafe projection * fix * pass external schema * update doc * rename back to HoodieAvroRecord * fix * remove comparable wrapper * fix comment * fix comment * fix comment * fix comment * simplify row copy * fix ParquetReaderIterator Co-authored-by: Shawy Geng <[email protected]> Co-authored-by: wangzixuan.wzxuan <[email protected]> [RFC-46][HUDI-4414] Update the RFC-46 doc to fix comments feedback (apache#6132) * Update the RFC-46 doc to fix comments feedback * fix Co-authored-by: wangzixuan.wzxuan <[email protected]> [HUDI-4301] [HUDI-3384][HUDI-3385] Spark specific file reader/writer.(apache#5629) * [HUDI-4301] [HUDI-3384][HUDI-3385] Spark specific file reader/writer. * add schema finger print * add benchmark * a new way to config the merger * fix Co-authored-by: wangzixuan.wzxuan <[email protected]> Co-authored-by: gengxiaoyu <[email protected]> [HUDI-3350][HUDI-3351] Support HoodieMerge API and Spark engine-specific HoodieRecord (apache#5627) Co-authored-by: wangzixuan.wzxuan <[email protected]> [HUDI-4344] fix usage of HoodieDataBlock#getRecordIterator (apache#6005) Co-authored-by: wangzixuan.wzxuan <[email protected]> [HUDI-4292][RFC-46] Update doc to align with the Record Merge API changes (apache#5927) [MINOR] Fix type casting in TestHoodieHFileReaderWriter [HUDI-3378][HUDI-3379][HUDI-3381] Migrate usage of HoodieRecordPayload and raw Avro payload to HoodieRecord (apache#5522) Co-authored-by: Alexey Kudinkin <[email protected]> Co-authored-by: wangzixuan.wzxuan <[email protected]>
[minor] add more test for rfc46 (apache#7003) ## Change Logs - Add HoodieSparkValidateDuplicateKeyRecordMerger behaving the same as ValidateDuplicateKeyPayload. We should use it with config "hoodie.sql.insert.mode=strict". - Fix nest field exist in HoodieCatalystExpressionUtils - Fix rewrite in HoodieInternalRowUtiles to support type promoted as avro - Fallback to avro when use "merge into" sql - Fix some schema handling issue - Support delta streamer - Convert parquet schema to spark schema and then avro schema(in org.apache.hudi.io.storage.HoodieSparkParquetReader#getSchema). Some types in avro are not compatible with parquet. For ex, decimal as int32/int64 in parquet will convert to int/long in avro. Because avro do not has decimal as int/long . We will lose the logic type info if we directly convert it to avro schema. - Support schema evolution in parquet block [Minor] fix multi deser avro payload (apache#7021) In HoodieAvroRecord, we will call isDelete, shouldIgnore before we write it to the file. Each method will deserialize HoodiePayload. So we add deserialization method in HoodieRecord and call this method once before calling isDelete or shouldIgnore. Co-authored-by: wangzixuan.wzxuan <[email protected]> Co-authored-by: Alexey Kudinkin <[email protected]> Co-authored-by: Alexey Kudinkin <[email protected]> [MINOR] Properly registering target classes w/ Kryo (apache#7026) * Added `HoodieKryoRegistrar` registering necessary Hudi's classes w/ Kryo to make their serialization more efficient (by serializing just the class id, in-liue the fully qualified class-name) * Redirected Kryo registration to `HoodieKryoRegistrar` * Registered additional classes likely to be serialized by Kryo * Updated tests * Fixed serialization of Avro's `Utf8` to serialize just the bytes * Added tests * Added custom `AvroUtf8Serializer`; Tidying up * Extracted `HoodieCommonKryoRegistrar` to leverage in `SerializationUtils` * `HoodieKryoRegistrar` > `HoodieSparkKryoRegistrar`; Rebased `HoodieSparkKryoRegistrar` onto `HoodieCommonKryoRegistrar` * `lint` * Fixing compilation for Spark 2.x * Disabling flaky test [MINOR] Make sure all `HoodieRecord`s are appropriately serializable by Kryo (apache#6977) * Make sure `HoodieRecord`, `HoodieKey`, `HoodieRecordLocation` are all `KryoSerializable` * Revisited `HoodieRecord` serialization hooks to make sure they a) could not be overridden, b) provide for hooks to properly serialize record's payload; Implemented serialization hooks for `HoodieAvroIndexedRecord`; Implemented serialization hooks for `HoodieEmptyRecord`; * Revisited `HoodieRecord` serialization hooks to make sure they a) could not be overridden, b) provide for hooks to properly serialize record's payload; Implemented serialization hooks for `HoodieAvroIndexedRecord`; Implemented serialization hooks for `HoodieEmptyRecord`; Implemented serialization hooks for `HoodieAvroRecord`; * Revisited `HoodieSparkRecord` to transiently hold on to the schema so that it could project row * Implemented serialization hooks for `HoodieSparkRecord` * Added `TestHoodieSparkRecord` * Added tests for Avro-based records * Added test for `HoodieEmptyRecord` * Fixed sealing/unsealing for `HoodieRecord` in `HoodieBackedTableMetadataWriter` * Properly handle deflated records * Fixing `Row`s encoding * Fixed `HoodieRecord` to be properly sealed/unsealed * Fixed serialization of the `HoodieRecordGlobalLocation` [MINOR] Additional fixes for apache#6745 (apache#6947) * Tidying up * Tidying up more * Cleaning up duplication * Tidying up * Revisited legacy operating mode configuration * Tidying up * Cleaned up `projectUnsafe` API * Fixing compilation * Cleaning up `HoodieSparkRecord` ctors; Revisited mandatory unsafe-projection * Fixing compilation * Cleaned up `ParquetReader` initialization * Revisited `HoodieSparkRecord` to accept either `UnsafeRow` or `HoodieInternalRow`, and avoid unnecessary copying after unsafe-projection * Cleaning up redundant exception spec * Make sure `updateMetadataFields` properly wraps `InternalRow` into `HoodieInternalRow` if necessary; Cleaned up `MetadataValues` * Fixed meta-fields extraction and `HoodieInternalRow` composition w/in `HoodieSparkRecord` * De-duplicate `HoodieSparkRecord` ctors; Make sure either only `UnsafeRow` or `HoodieInternalRow` are permitted inside `HoodieSparkRecord` * Removed unnecessary copying * Cleaned up projection for `HoodieSparkRecord` (dropping partition columns); Removed unnecessary copying * Fixing compilation * Fixing compilation (for Flink) * Cleaned up File Raders' interfaces: - Extracted `HoodieSeekingFileReader` interface (for key-ranged reads) - Pushed down concrete implementation methods into `HoodieAvroFileReaderBase` from the interfaces * Cleaned up File Readers impls (inline with then new interfaces) * Rebsaed `HoodieBackedTableMetadata` onto new `HoodieSeekingFileReader` * Tidying up * Missing licenses * Re-instate custom override for `HoodieAvroParquetReader`; Tidying up * Fixed missing cloning w/in `HoodieLazyInsertIterable` * Fixed missing cloning in deduplication flow * Allow `HoodieSparkRecord` to hold `ColumnarBatchRow` * Missing licenses * Fixing compilation * Missing changes * Fixed Spark 2.x validation whether the row was read as a batch Fix comment in RFC46 (apache#6745) * rename * add MetadataValues in updateMetadataValues * remove singleton in fileFactory * add truncateRecordKey * remove hoodieRecord#setData * rename HoodieAvroRecord * fix code style * fix HoodieSparkRecordSerializer * fix benchmark * fix SparkRecordUtils * instantiate HoodieWriteConfig on the fly * add test * fix HoodieSparkRecordSerializer. Replace Java's object serialization with kryo * add broadcast * fix comment * remove unnecessary broadcast * add unsafe check in spark record * fix getRecordColumnValues * remove spark.sql.parquet.writeLegacyFormat * fix unsafe projection * fix * pass external schema * update doc * rename back to HoodieAvroRecord * fix * remove comparable wrapper * fix comment * fix comment * fix comment * fix comment * simplify row copy * fix ParquetReaderIterator Co-authored-by: Shawy Geng <[email protected]> Co-authored-by: wangzixuan.wzxuan <[email protected]> [RFC-46][HUDI-4414] Update the RFC-46 doc to fix comments feedback (apache#6132) * Update the RFC-46 doc to fix comments feedback * fix Co-authored-by: wangzixuan.wzxuan <[email protected]> [HUDI-4301] [HUDI-3384][HUDI-3385] Spark specific file reader/writer.(apache#5629) * [HUDI-4301] [HUDI-3384][HUDI-3385] Spark specific file reader/writer. * add schema finger print * add benchmark * a new way to config the merger * fix Co-authored-by: wangzixuan.wzxuan <[email protected]> Co-authored-by: gengxiaoyu <[email protected]> [HUDI-3350][HUDI-3351] Support HoodieMerge API and Spark engine-specific HoodieRecord (apache#5627) Co-authored-by: wangzixuan.wzxuan <[email protected]> [HUDI-4344] fix usage of HoodieDataBlock#getRecordIterator (apache#6005) Co-authored-by: wangzixuan.wzxuan <[email protected]> [HUDI-4292][RFC-46] Update doc to align with the Record Merge API changes (apache#5927) [MINOR] Fix type casting in TestHoodieHFileReaderWriter [HUDI-3378][HUDI-3379][HUDI-3381] Migrate usage of HoodieRecordPayload and raw Avro payload to HoodieRecord (apache#5522) Co-authored-by: Alexey Kudinkin <[email protected]> Co-authored-by: wangzixuan.wzxuan <[email protected]>
[minor] add more test for rfc46 (apache#7003) - Add HoodieSparkValidateDuplicateKeyRecordMerger behaving the same as ValidateDuplicateKeyPayload. We should use it with config "hoodie.sql.insert.mode=strict". - Fix nest field exist in HoodieCatalystExpressionUtils - Fix rewrite in HoodieInternalRowUtiles to support type promoted as avro - Fallback to avro when use "merge into" sql - Fix some schema handling issue - Support delta streamer - Convert parquet schema to spark schema and then avro schema(in org.apache.hudi.io.storage.HoodieSparkParquetReader#getSchema). Some types in avro are not compatible with parquet. For ex, decimal as int32/int64 in parquet will convert to int/long in avro. Because avro do not has decimal as int/long . We will lose the logic type info if we directly convert it to avro schema. - Support schema evolution in parquet block [Minor] fix multi deser avro payload (apache#7021) In HoodieAvroRecord, we will call isDelete, shouldIgnore before we write it to the file. Each method will deserialize HoodiePayload. So we add deserialization method in HoodieRecord and call this method once before calling isDelete or shouldIgnore. Co-authored-by: wangzixuan.wzxuan <[email protected]> Co-authored-by: Alexey Kudinkin <[email protected]> Co-authored-by: Alexey Kudinkin <[email protected]> [MINOR] Properly registering target classes w/ Kryo (apache#7026) * Added `HoodieKryoRegistrar` registering necessary Hudi's classes w/ Kryo to make their serialization more efficient (by serializing just the class id, in-liue the fully qualified class-name) * Redirected Kryo registration to `HoodieKryoRegistrar` * Registered additional classes likely to be serialized by Kryo * Updated tests * Fixed serialization of Avro's `Utf8` to serialize just the bytes * Added tests * Added custom `AvroUtf8Serializer`; Tidying up * Extracted `HoodieCommonKryoRegistrar` to leverage in `SerializationUtils` * `HoodieKryoRegistrar` > `HoodieSparkKryoRegistrar`; Rebased `HoodieSparkKryoRegistrar` onto `HoodieCommonKryoRegistrar` * `lint` * Fixing compilation for Spark 2.x * Disabling flaky test [MINOR] Make sure all `HoodieRecord`s are appropriately serializable by Kryo (apache#6977) * Make sure `HoodieRecord`, `HoodieKey`, `HoodieRecordLocation` are all `KryoSerializable` * Revisited `HoodieRecord` serialization hooks to make sure they a) could not be overridden, b) provide for hooks to properly serialize record's payload; Implemented serialization hooks for `HoodieAvroIndexedRecord`; Implemented serialization hooks for `HoodieEmptyRecord`; * Revisited `HoodieRecord` serialization hooks to make sure they a) could not be overridden, b) provide for hooks to properly serialize record's payload; Implemented serialization hooks for `HoodieAvroIndexedRecord`; Implemented serialization hooks for `HoodieEmptyRecord`; Implemented serialization hooks for `HoodieAvroRecord`; * Revisited `HoodieSparkRecord` to transiently hold on to the schema so that it could project row * Implemented serialization hooks for `HoodieSparkRecord` * Added `TestHoodieSparkRecord` * Added tests for Avro-based records * Added test for `HoodieEmptyRecord` * Fixed sealing/unsealing for `HoodieRecord` in `HoodieBackedTableMetadataWriter` * Properly handle deflated records * Fixing `Row`s encoding * Fixed `HoodieRecord` to be properly sealed/unsealed * Fixed serialization of the `HoodieRecordGlobalLocation` [MINOR] Additional fixes for apache#6745 (apache#6947) * Tidying up * Tidying up more * Cleaning up duplication * Tidying up * Revisited legacy operating mode configuration * Tidying up * Cleaned up `projectUnsafe` API * Fixing compilation * Cleaning up `HoodieSparkRecord` ctors; Revisited mandatory unsafe-projection * Fixing compilation * Cleaned up `ParquetReader` initialization * Revisited `HoodieSparkRecord` to accept either `UnsafeRow` or `HoodieInternalRow`, and avoid unnecessary copying after unsafe-projection * Cleaning up redundant exception spec * Make sure `updateMetadataFields` properly wraps `InternalRow` into `HoodieInternalRow` if necessary; Cleaned up `MetadataValues` * Fixed meta-fields extraction and `HoodieInternalRow` composition w/in `HoodieSparkRecord` * De-duplicate `HoodieSparkRecord` ctors; Make sure either only `UnsafeRow` or `HoodieInternalRow` are permitted inside `HoodieSparkRecord` * Removed unnecessary copying * Cleaned up projection for `HoodieSparkRecord` (dropping partition columns); Removed unnecessary copying * Fixing compilation * Fixing compilation (for Flink) * Cleaned up File Raders' interfaces: - Extracted `HoodieSeekingFileReader` interface (for key-ranged reads) - Pushed down concrete implementation methods into `HoodieAvroFileReaderBase` from the interfaces * Cleaned up File Readers impls (inline with then new interfaces) * Rebsaed `HoodieBackedTableMetadata` onto new `HoodieSeekingFileReader` * Tidying up * Missing licenses * Re-instate custom override for `HoodieAvroParquetReader`; Tidying up * Fixed missing cloning w/in `HoodieLazyInsertIterable` * Fixed missing cloning in deduplication flow * Allow `HoodieSparkRecord` to hold `ColumnarBatchRow` * Missing licenses * Fixing compilation * Missing changes * Fixed Spark 2.x validation whether the row was read as a batch Fix comment in RFC46 (apache#6745) * rename * add MetadataValues in updateMetadataValues * remove singleton in fileFactory * add truncateRecordKey * remove hoodieRecord#setData * rename HoodieAvroRecord * fix code style * fix HoodieSparkRecordSerializer * fix benchmark * fix SparkRecordUtils * instantiate HoodieWriteConfig on the fly * add test * fix HoodieSparkRecordSerializer. Replace Java's object serialization with kryo * add broadcast * fix comment * remove unnecessary broadcast * add unsafe check in spark record * fix getRecordColumnValues * remove spark.sql.parquet.writeLegacyFormat * fix unsafe projection * fix * pass external schema * update doc * rename back to HoodieAvroRecord * fix * remove comparable wrapper * fix comment * fix comment * fix comment * fix comment * simplify row copy * fix ParquetReaderIterator Co-authored-by: Shawy Geng <[email protected]> Co-authored-by: wangzixuan.wzxuan <[email protected]> [RFC-46][HUDI-4414] Update the RFC-46 doc to fix comments feedback (apache#6132) * Update the RFC-46 doc to fix comments feedback * fix Co-authored-by: wangzixuan.wzxuan <[email protected]> [HUDI-4301] [HUDI-3384][HUDI-3385] Spark specific file reader/writer.(apache#5629) * [HUDI-4301] [HUDI-3384][HUDI-3385] Spark specific file reader/writer. * add schema finger print * add benchmark * a new way to config the merger * fix Co-authored-by: wangzixuan.wzxuan <[email protected]> Co-authored-by: gengxiaoyu <[email protected]> [HUDI-3350][HUDI-3351] Support HoodieMerge API and Spark engine-specific HoodieRecord (apache#5627) Co-authored-by: wangzixuan.wzxuan <[email protected]> [HUDI-4344] fix usage of HoodieDataBlock#getRecordIterator (apache#6005) Co-authored-by: wangzixuan.wzxuan <[email protected]> [HUDI-4292][RFC-46] Update doc to align with the Record Merge API changes (apache#5927) [MINOR] Fix type casting in TestHoodieHFileReaderWriter [HUDI-3378][HUDI-3379][HUDI-3381] Migrate usage of HoodieRecordPayload and raw Avro payload to HoodieRecord (apache#5522) Co-authored-by: Alexey Kudinkin <[email protected]> Co-authored-by: wangzixuan.wzxuan <[email protected]>
[minor] add more test for rfc46 (apache#7003) - Add HoodieSparkValidateDuplicateKeyRecordMerger behaving the same as ValidateDuplicateKeyPayload. We should use it with config "hoodie.sql.insert.mode=strict". - Fix nest field exist in HoodieCatalystExpressionUtils - Fix rewrite in HoodieInternalRowUtiles to support type promoted as avro - Fallback to avro when use "merge into" sql - Fix some schema handling issue - Support delta streamer - Convert parquet schema to spark schema and then avro schema(in org.apache.hudi.io.storage.HoodieSparkParquetReader#getSchema). Some types in avro are not compatible with parquet. For ex, decimal as int32/int64 in parquet will convert to int/long in avro. Because avro do not has decimal as int/long . We will lose the logic type info if we directly convert it to avro schema. - Support schema evolution in parquet block [Minor] fix multi deser avro payload (apache#7021) In HoodieAvroRecord, we will call isDelete, shouldIgnore before we write it to the file. Each method will deserialize HoodiePayload. So we add deserialization method in HoodieRecord and call this method once before calling isDelete or shouldIgnore. Co-authored-by: wangzixuan.wzxuan <[email protected]> Co-authored-by: Alexey Kudinkin <[email protected]> Co-authored-by: Alexey Kudinkin <[email protected]> [MINOR] Properly registering target classes w/ Kryo (apache#7026) * Added `HoodieKryoRegistrar` registering necessary Hudi's classes w/ Kryo to make their serialization more efficient (by serializing just the class id, in-liue the fully qualified class-name) * Redirected Kryo registration to `HoodieKryoRegistrar` * Registered additional classes likely to be serialized by Kryo * Updated tests * Fixed serialization of Avro's `Utf8` to serialize just the bytes * Added tests * Added custom `AvroUtf8Serializer`; Tidying up * Extracted `HoodieCommonKryoRegistrar` to leverage in `SerializationUtils` * `HoodieKryoRegistrar` > `HoodieSparkKryoRegistrar`; Rebased `HoodieSparkKryoRegistrar` onto `HoodieCommonKryoRegistrar` * `lint` * Fixing compilation for Spark 2.x * Disabling flaky test [MINOR] Make sure all `HoodieRecord`s are appropriately serializable by Kryo (apache#6977) * Make sure `HoodieRecord`, `HoodieKey`, `HoodieRecordLocation` are all `KryoSerializable` * Revisited `HoodieRecord` serialization hooks to make sure they a) could not be overridden, b) provide for hooks to properly serialize record's payload; Implemented serialization hooks for `HoodieAvroIndexedRecord`; Implemented serialization hooks for `HoodieEmptyRecord`; * Revisited `HoodieRecord` serialization hooks to make sure they a) could not be overridden, b) provide for hooks to properly serialize record's payload; Implemented serialization hooks for `HoodieAvroIndexedRecord`; Implemented serialization hooks for `HoodieEmptyRecord`; Implemented serialization hooks for `HoodieAvroRecord`; * Revisited `HoodieSparkRecord` to transiently hold on to the schema so that it could project row * Implemented serialization hooks for `HoodieSparkRecord` * Added `TestHoodieSparkRecord` * Added tests for Avro-based records * Added test for `HoodieEmptyRecord` * Fixed sealing/unsealing for `HoodieRecord` in `HoodieBackedTableMetadataWriter` * Properly handle deflated records * Fixing `Row`s encoding * Fixed `HoodieRecord` to be properly sealed/unsealed * Fixed serialization of the `HoodieRecordGlobalLocation` [MINOR] Additional fixes for apache#6745 (apache#6947) * Tidying up * Tidying up more * Cleaning up duplication * Tidying up * Revisited legacy operating mode configuration * Tidying up * Cleaned up `projectUnsafe` API * Fixing compilation * Cleaning up `HoodieSparkRecord` ctors; Revisited mandatory unsafe-projection * Fixing compilation * Cleaned up `ParquetReader` initialization * Revisited `HoodieSparkRecord` to accept either `UnsafeRow` or `HoodieInternalRow`, and avoid unnecessary copying after unsafe-projection * Cleaning up redundant exception spec * Make sure `updateMetadataFields` properly wraps `InternalRow` into `HoodieInternalRow` if necessary; Cleaned up `MetadataValues` * Fixed meta-fields extraction and `HoodieInternalRow` composition w/in `HoodieSparkRecord` * De-duplicate `HoodieSparkRecord` ctors; Make sure either only `UnsafeRow` or `HoodieInternalRow` are permitted inside `HoodieSparkRecord` * Removed unnecessary copying * Cleaned up projection for `HoodieSparkRecord` (dropping partition columns); Removed unnecessary copying * Fixing compilation * Fixing compilation (for Flink) * Cleaned up File Raders' interfaces: - Extracted `HoodieSeekingFileReader` interface (for key-ranged reads) - Pushed down concrete implementation methods into `HoodieAvroFileReaderBase` from the interfaces * Cleaned up File Readers impls (inline with then new interfaces) * Rebsaed `HoodieBackedTableMetadata` onto new `HoodieSeekingFileReader` * Tidying up * Missing licenses * Re-instate custom override for `HoodieAvroParquetReader`; Tidying up * Fixed missing cloning w/in `HoodieLazyInsertIterable` * Fixed missing cloning in deduplication flow * Allow `HoodieSparkRecord` to hold `ColumnarBatchRow` * Missing licenses * Fixing compilation * Missing changes * Fixed Spark 2.x validation whether the row was read as a batch Fix comment in RFC46 (apache#6745) * rename * add MetadataValues in updateMetadataValues * remove singleton in fileFactory * add truncateRecordKey * remove hoodieRecord#setData * rename HoodieAvroRecord * fix code style * fix HoodieSparkRecordSerializer * fix benchmark * fix SparkRecordUtils * instantiate HoodieWriteConfig on the fly * add test * fix HoodieSparkRecordSerializer. Replace Java's object serialization with kryo * add broadcast * fix comment * remove unnecessary broadcast * add unsafe check in spark record * fix getRecordColumnValues * remove spark.sql.parquet.writeLegacyFormat * fix unsafe projection * fix * pass external schema * update doc * rename back to HoodieAvroRecord * fix * remove comparable wrapper * fix comment * fix comment * fix comment * fix comment * simplify row copy * fix ParquetReaderIterator Co-authored-by: Shawy Geng <[email protected]> Co-authored-by: wangzixuan.wzxuan <[email protected]> [RFC-46][HUDI-4414] Update the RFC-46 doc to fix comments feedback (apache#6132) * Update the RFC-46 doc to fix comments feedback * fix Co-authored-by: wangzixuan.wzxuan <[email protected]> [HUDI-4301] [HUDI-3384][HUDI-3385] Spark specific file reader/writer.(apache#5629) * [HUDI-4301] [HUDI-3384][HUDI-3385] Spark specific file reader/writer. * add schema finger print * add benchmark * a new way to config the merger * fix Co-authored-by: wangzixuan.wzxuan <[email protected]> Co-authored-by: gengxiaoyu <[email protected]> [HUDI-3350][HUDI-3351] Support HoodieMerge API and Spark engine-specific HoodieRecord (apache#5627) Co-authored-by: wangzixuan.wzxuan <[email protected]> [HUDI-4344] fix usage of HoodieDataBlock#getRecordIterator (apache#6005) Co-authored-by: wangzixuan.wzxuan <[email protected]> [HUDI-4292][RFC-46] Update doc to align with the Record Merge API changes (apache#5927) [MINOR] Fix type casting in TestHoodieHFileReaderWriter [HUDI-3378][HUDI-3379][HUDI-3381] Migrate usage of HoodieRecordPayload and raw Avro payload to HoodieRecord (apache#5522) Co-authored-by: Alexey Kudinkin <[email protected]> Co-authored-by: wangzixuan.wzxuan <[email protected]>
[minor] add more test for rfc46 (apache#7003) ## Change Logs - Add HoodieSparkValidateDuplicateKeyRecordMerger behaving the same as ValidateDuplicateKeyPayload. We should use it with config "hoodie.sql.insert.mode=strict". - Fix nest field exist in HoodieCatalystExpressionUtils - Fix rewrite in HoodieInternalRowUtiles to support type promoted as avro - Fallback to avro when use "merge into" sql - Fix some schema handling issue - Support delta streamer - Convert parquet schema to spark schema and then avro schema(in org.apache.hudi.io.storage.HoodieSparkParquetReader#getSchema). Some types in avro are not compatible with parquet. For ex, decimal as int32/int64 in parquet will convert to int/long in avro. Because avro do not has decimal as int/long . We will lose the logic type info if we directly convert it to avro schema. - Support schema evolution in parquet block [Minor] fix multi deser avro payload (apache#7021) In HoodieAvroRecord, we will call isDelete, shouldIgnore before we write it to the file. Each method will deserialize HoodiePayload. So we add deserialization method in HoodieRecord and call this method once before calling isDelete or shouldIgnore. Co-authored-by: wangzixuan.wzxuan <[email protected]> Co-authored-by: Alexey Kudinkin <[email protected]> Co-authored-by: Alexey Kudinkin <[email protected]> [MINOR] Properly registering target classes w/ Kryo (apache#7026) * Added `HoodieKryoRegistrar` registering necessary Hudi's classes w/ Kryo to make their serialization more efficient (by serializing just the class id, in-liue the fully qualified class-name) * Redirected Kryo registration to `HoodieKryoRegistrar` * Registered additional classes likely to be serialized by Kryo * Updated tests * Fixed serialization of Avro's `Utf8` to serialize just the bytes * Added tests * Added custom `AvroUtf8Serializer`; Tidying up * Extracted `HoodieCommonKryoRegistrar` to leverage in `SerializationUtils` * `HoodieKryoRegistrar` > `HoodieSparkKryoRegistrar`; Rebased `HoodieSparkKryoRegistrar` onto `HoodieCommonKryoRegistrar` * `lint` * Fixing compilation for Spark 2.x * Disabling flaky test [MINOR] Make sure all `HoodieRecord`s are appropriately serializable by Kryo (apache#6977) * Make sure `HoodieRecord`, `HoodieKey`, `HoodieRecordLocation` are all `KryoSerializable` * Revisited `HoodieRecord` serialization hooks to make sure they a) could not be overridden, b) provide for hooks to properly serialize record's payload; Implemented serialization hooks for `HoodieAvroIndexedRecord`; Implemented serialization hooks for `HoodieEmptyRecord`; * Revisited `HoodieRecord` serialization hooks to make sure they a) could not be overridden, b) provide for hooks to properly serialize record's payload; Implemented serialization hooks for `HoodieAvroIndexedRecord`; Implemented serialization hooks for `HoodieEmptyRecord`; Implemented serialization hooks for `HoodieAvroRecord`; * Revisited `HoodieSparkRecord` to transiently hold on to the schema so that it could project row * Implemented serialization hooks for `HoodieSparkRecord` * Added `TestHoodieSparkRecord` * Added tests for Avro-based records * Added test for `HoodieEmptyRecord` * Fixed sealing/unsealing for `HoodieRecord` in `HoodieBackedTableMetadataWriter` * Properly handle deflated records * Fixing `Row`s encoding * Fixed `HoodieRecord` to be properly sealed/unsealed * Fixed serialization of the `HoodieRecordGlobalLocation` [MINOR] Additional fixes for apache#6745 (apache#6947) * Tidying up * Tidying up more * Cleaning up duplication * Tidying up * Revisited legacy operating mode configuration * Tidying up * Cleaned up `projectUnsafe` API * Fixing compilation * Cleaning up `HoodieSparkRecord` ctors; Revisited mandatory unsafe-projection * Fixing compilation * Cleaned up `ParquetReader` initialization * Revisited `HoodieSparkRecord` to accept either `UnsafeRow` or `HoodieInternalRow`, and avoid unnecessary copying after unsafe-projection * Cleaning up redundant exception spec * Make sure `updateMetadataFields` properly wraps `InternalRow` into `HoodieInternalRow` if necessary; Cleaned up `MetadataValues` * Fixed meta-fields extraction and `HoodieInternalRow` composition w/in `HoodieSparkRecord` * De-duplicate `HoodieSparkRecord` ctors; Make sure either only `UnsafeRow` or `HoodieInternalRow` are permitted inside `HoodieSparkRecord` * Removed unnecessary copying * Cleaned up projection for `HoodieSparkRecord` (dropping partition columns); Removed unnecessary copying * Fixing compilation * Fixing compilation (for Flink) * Cleaned up File Raders' interfaces: - Extracted `HoodieSeekingFileReader` interface (for key-ranged reads) - Pushed down concrete implementation methods into `HoodieAvroFileReaderBase` from the interfaces * Cleaned up File Readers impls (inline with then new interfaces) * Rebsaed `HoodieBackedTableMetadata` onto new `HoodieSeekingFileReader` * Tidying up * Missing licenses * Re-instate custom override for `HoodieAvroParquetReader`; Tidying up * Fixed missing cloning w/in `HoodieLazyInsertIterable` * Fixed missing cloning in deduplication flow * Allow `HoodieSparkRecord` to hold `ColumnarBatchRow` * Missing licenses * Fixing compilation * Missing changes * Fixed Spark 2.x validation whether the row was read as a batch Fix comment in RFC46 (apache#6745) * rename * add MetadataValues in updateMetadataValues * remove singleton in fileFactory * add truncateRecordKey * remove hoodieRecord#setData * rename HoodieAvroRecord * fix code style * fix HoodieSparkRecordSerializer * fix benchmark * fix SparkRecordUtils * instantiate HoodieWriteConfig on the fly * add test * fix HoodieSparkRecordSerializer. Replace Java's object serialization with kryo * add broadcast * fix comment * remove unnecessary broadcast * add unsafe check in spark record * fix getRecordColumnValues * remove spark.sql.parquet.writeLegacyFormat * fix unsafe projection * fix * pass external schema * update doc * rename back to HoodieAvroRecord * fix * remove comparable wrapper * fix comment * fix comment * fix comment * fix comment * simplify row copy * fix ParquetReaderIterator Co-authored-by: Shawy Geng <[email protected]> Co-authored-by: wangzixuan.wzxuan <[email protected]> [RFC-46][HUDI-4414] Update the RFC-46 doc to fix comments feedback (apache#6132) * Update the RFC-46 doc to fix comments feedback * fix Co-authored-by: wangzixuan.wzxuan <[email protected]> [HUDI-4301] [HUDI-3384][HUDI-3385] Spark specific file reader/writer.(apache#5629) * [HUDI-4301] [HUDI-3384][HUDI-3385] Spark specific file reader/writer. * add schema finger print * add benchmark * a new way to config the merger * fix Co-authored-by: wangzixuan.wzxuan <[email protected]> Co-authored-by: gengxiaoyu <[email protected]> [HUDI-3350][HUDI-3351] Support HoodieMerge API and Spark engine-specific HoodieRecord (apache#5627) Co-authored-by: wangzixuan.wzxuan <[email protected]> [HUDI-4344] fix usage of HoodieDataBlock#getRecordIterator (apache#6005) Co-authored-by: wangzixuan.wzxuan <[email protected]> [HUDI-4292][RFC-46] Update doc to align with the Record Merge API changes (apache#5927) [MINOR] Fix type casting in TestHoodieHFileReaderWriter [HUDI-3378][HUDI-3379][HUDI-3381] Migrate usage of HoodieRecordPayload and raw Avro payload to HoodieRecord (apache#5522) Co-authored-by: Alexey Kudinkin <[email protected]> Co-authored-by: wangzixuan.wzxuan <[email protected]>
## Change Logs - Add HoodieSparkValidateDuplicateKeyRecordMerger behaving the same as ValidateDuplicateKeyPayload. We should use it with config "hoodie.sql.insert.mode=strict". - Fix nest field exist in HoodieCatalystExpressionUtils - Fix rewrite in HoodieInternalRowUtiles to support type promoted as avro - Fallback to avro when use "merge into" sql - Fix some schema handling issue - Support delta streamer - Convert parquet schema to spark schema and then avro schema(in org.apache.hudi.io.storage.HoodieSparkParquetReader#getSchema). Some types in avro are not compatible with parquet. For ex, decimal as int32/int64 in parquet will convert to int/long in avro. Because avro do not has decimal as int/long . We will lose the logic type info if we directly convert it to avro schema. - Support schema evolution in parquet block [Minor] fix multi deser avro payload (#7021) In HoodieAvroRecord, we will call isDelete, shouldIgnore before we write it to the file. Each method will deserialize HoodiePayload. So we add deserialization method in HoodieRecord and call this method once before calling isDelete or shouldIgnore. Co-authored-by: wangzixuan.wzxuan <[email protected]> Co-authored-by: Alexey Kudinkin <[email protected]> Co-authored-by: Alexey Kudinkin <[email protected]> [MINOR] Properly registering target classes w/ Kryo (#7026) * Added `HoodieKryoRegistrar` registering necessary Hudi's classes w/ Kryo to make their serialization more efficient (by serializing just the class id, in-liue the fully qualified class-name) [MINOR] Make sure all `HoodieRecord`s are appropriately serializable by Kryo (#6977) * Make sure `HoodieRecord`, `HoodieKey`, `HoodieRecordLocation` are all `KryoSerializable` * Revisited `HoodieRecord` serialization hooks to make sure they a) could not be overridden, b) provide for hooks to properly serialize record's payload; Implemented serialization hooks for `HoodieAvroIndexedRecord`; Implemented serialization hooks for `HoodieEmptyRecord`; Implemented serialization hooks for `HoodieAvroRecord`; * Revisited `HoodieSparkRecord` to transiently hold on to the schema so that it could project row [MINOR] Additional fixes for #6745 (#6947) Co-authored-by: Shawy Geng <[email protected]> Co-authored-by: wangzixuan.wzxuan <[email protected]> [RFC-46][HUDI-4414] Update the RFC-46 doc to fix comments feedback (#6132) Co-authored-by: wangzixuan.wzxuan <[email protected]> [HUDI-4301] [HUDI-3384][HUDI-3385] Spark specific file reader/writer.(#5629) Co-authored-by: wangzixuan.wzxuan <[email protected]> Co-authored-by: gengxiaoyu <[email protected]> [HUDI-3350][HUDI-3351] Support HoodieMerge API and Spark engine-specific HoodieRecord (#5627) Co-authored-by: wangzixuan.wzxuan <[email protected]> [HUDI-4344] fix usage of HoodieDataBlock#getRecordIterator (#6005) Co-authored-by: wangzixuan.wzxuan <[email protected]> [HUDI-4292][RFC-46] Update doc to align with the Record Merge API changes (#5927) [MINOR] Fix type casting in TestHoodieHFileReaderWriter [HUDI-3378][HUDI-3379][HUDI-3381] Migrate usage of HoodieRecordPayload and raw Avro payload to HoodieRecord (#5522) Co-authored-by: Alexey Kudinkin <[email protected]> Co-authored-by: wangzixuan.wzxuan <[email protected]> Co-authored-by: gengxiaoyu <[email protected]>
## Change Logs - Add HoodieSparkValidateDuplicateKeyRecordMerger behaving the same as ValidateDuplicateKeyPayload. We should use it with config "hoodie.sql.insert.mode=strict". - Fix nest field exist in HoodieCatalystExpressionUtils - Fix rewrite in HoodieInternalRowUtiles to support type promoted as avro - Fallback to avro when use "merge into" sql - Fix some schema handling issue - Support delta streamer - Convert parquet schema to spark schema and then avro schema(in org.apache.hudi.io.storage.HoodieSparkParquetReader#getSchema). Some types in avro are not compatible with parquet. For ex, decimal as int32/int64 in parquet will convert to int/long in avro. Because avro do not has decimal as int/long . We will lose the logic type info if we directly convert it to avro schema. - Support schema evolution in parquet block [Minor] fix multi deser avro payload (apache#7021) In HoodieAvroRecord, we will call isDelete, shouldIgnore before we write it to the file. Each method will deserialize HoodiePayload. So we add deserialization method in HoodieRecord and call this method once before calling isDelete or shouldIgnore. Co-authored-by: wangzixuan.wzxuan <[email protected]> Co-authored-by: Alexey Kudinkin <[email protected]> Co-authored-by: Alexey Kudinkin <[email protected]> [MINOR] Properly registering target classes w/ Kryo (apache#7026) * Added `HoodieKryoRegistrar` registering necessary Hudi's classes w/ Kryo to make their serialization more efficient (by serializing just the class id, in-liue the fully qualified class-name) [MINOR] Make sure all `HoodieRecord`s are appropriately serializable by Kryo (apache#6977) * Make sure `HoodieRecord`, `HoodieKey`, `HoodieRecordLocation` are all `KryoSerializable` * Revisited `HoodieRecord` serialization hooks to make sure they a) could not be overridden, b) provide for hooks to properly serialize record's payload; Implemented serialization hooks for `HoodieAvroIndexedRecord`; Implemented serialization hooks for `HoodieEmptyRecord`; Implemented serialization hooks for `HoodieAvroRecord`; * Revisited `HoodieSparkRecord` to transiently hold on to the schema so that it could project row [MINOR] Additional fixes for apache#6745 (apache#6947) Co-authored-by: Shawy Geng <[email protected]> Co-authored-by: wangzixuan.wzxuan <[email protected]> [RFC-46][HUDI-4414] Update the RFC-46 doc to fix comments feedback (apache#6132) Co-authored-by: wangzixuan.wzxuan <[email protected]> [HUDI-4301] [HUDI-3384][HUDI-3385] Spark specific file reader/writer.(apache#5629) Co-authored-by: wangzixuan.wzxuan <[email protected]> Co-authored-by: gengxiaoyu <[email protected]> [HUDI-3350][HUDI-3351] Support HoodieMerge API and Spark engine-specific HoodieRecord (apache#5627) Co-authored-by: wangzixuan.wzxuan <[email protected]> [HUDI-4344] fix usage of HoodieDataBlock#getRecordIterator (apache#6005) Co-authored-by: wangzixuan.wzxuan <[email protected]> [HUDI-4292][RFC-46] Update doc to align with the Record Merge API changes (apache#5927) [MINOR] Fix type casting in TestHoodieHFileReaderWriter [HUDI-3378][HUDI-3379][HUDI-3381] Migrate usage of HoodieRecordPayload and raw Avro payload to HoodieRecord (apache#5522) Co-authored-by: Alexey Kudinkin <[email protected]> Co-authored-by: wangzixuan.wzxuan <[email protected]> Co-authored-by: gengxiaoyu <[email protected]>
Change Logs
Fix comments in rfc46. You can check all commits.
Impact
Describe any public API or user-facing feature change or any performance impact.
Risk level: none | low | medium | high
Choose one. If medium or high, explain what verification was done to mitigate the risks.
Contributor's checklist