[HUDI-4790][RFC-68] a more effective HoodieMergeHandler for COW table with parquet #6612
Conversation
同步 hudi master
|
can you please fill in PR description and template. |
|
Overall an interesting idea, let put the details in the document. |
|
@nsivabalan @danny0405 Thanks for review. I updated comment. |
|
Hi loukey-lj, excited to hear a fantastic idea. |
|
@loukey-lj : can you respond to @guanziyue 's comment above. I will review this patch by this week. |
Yes, this optimization is applicable to other frameworks. For hudi, its advantage is that it can get rowgroups and store them in the index while updating the index. For schema evolution, we currently only support adding fields. Different rowgroups in the Parquet file can have different schmeas, but this is unknown to the query side. If schema changes are not considered, I can submit a small demo |
Thanks for your reply. Agree that this idea can improve performance a lot theoretically. It worries me that current parquet implementation or interface cannot fully support this idea. Looking forward to this RFC! |
|
I don't know if I can fully support schema evolution. I hope to improve this function with the help of the community. I will write a small demo as soon as possible |
|
From this class, maybe you can have a general understanding of the parquet partial update implementation |
Wow! This code shows your idea clearly. Thanks for your clarification. I found parquet internal API is used in this code. I believe the schema evolution problem I mentioned can be resolved by this way. Looking forward to this RFC! |
 nsivabalan
left a comment
nsivabalan
left a comment
There was a problem hiding this comment.
I definitely see a good benefit for partial update use-cases. Have left 2 minor comments. please loop me in once you have the impl.
|
|
||
| * In current version of Hudi, a complex De/serialization and De/compression happens every time upserting long tail data on COW, which causes giant CPU/IO cost. | ||
|
|
||
| * The purpose of current RFC aims to decrease costs of De/serialization and De/compression in upserting. Try to think about the reality, if we know which row groups need to be updated and even more the columns need to be updated in these row groups, we can skip much data's de/serialization and de/compression. That brings giant improvement. |
There was a problem hiding this comment.
So, this could be effective only incase of partial updates? In other words, for most commonly used payloads like OverwriteWithLatestAvroPayload, DefaultHoodieRecordPayload etc, this might cause unnecessary overhead right?
There was a problem hiding this comment.
It has nothing to do with what payload is used. It is important to know which columns need to be updated and which columns do not need to be updated. If we know which columns need to be updated, even if OverwriteWithLatestAvroPayload is used, it can be partially updated. The copy of rowGroup is applicable to all Payloads. My current scenario is based on merge into. The updated columns come from the syntax parsing of SQL, and then are set in conf
There was a problem hiding this comment.
I get it. my point was. in case of OverwriteWithLatestAvroPayload, new record is going to contain every column. and unless we read the old record from disk and deser, we never know which column is being updated. Infact, we have an optimization here, where in we don't even deser old record from storage incase of OverwriteWithLatestAvroPayload, bcoz we are going to overide entire record anyways.
There was a problem hiding this comment.
yeah, SQL merge into uses ExpressionPayload and hence I def see a real benefit. but other payloads, its very much impl dependent as I have explained above.
|
|
||
| 2. Using HoodieRecordPayload#getInsertValue to deserialize the upserting data, then invoking HoodieRecordPayload#getInsertValue to combine the updating rows. | ||
|
|
||
| 3. Converting combined data into column structure, just like `[{"name":"zs","age":10},{"name":"ls","age":20}] ==> {"name":["sz","ls"],"age":[10,20]}` |
There was a problem hiding this comment.
I would assume w/ impl, we will decide whether to take this path depending on the payload impl used. we don't want to incur additional overhead for the ones which may not be effective (for eg OverwriteWithLatestAvroPayload, DefaultHoodieRecordPayload)
|
@loukey-lj still interested in driving this? Its a great idea. |
Of course, hopefully the community will merge this RFC first |
|
|
||
| ## Abstract | ||
|
|
||
| To provide a more effective HoodieMergeHandler for COW table with parquet. Hudi rewrite whole parquet file every COW, that costs a lot in De/serialization and De/compression. To decrease this cost, a 'surgery' is introduced, which rebuilds a new parquet from an old one, just copying unchanged rowGroups and overwriting changed rowGroups when updating parquet files. |
There was a problem hiding this comment.
Two questions:
a) is there a way to copy over unchanged columns as well within each row group? or do this at the page level?
b) IIUC I think this helps in cases where the parquet file has multiple row groups and only few of them are changed? would you expect to see any performance improvements with the default 120 MB file size, with 120MB block size? i.e with just one row group in the parquet file
There was a problem hiding this comment.
a) If the column is not updated, then the page does not need to be decompressed, and if the data in the page is updated, the page needs to be deserialized and read out one by one
b)Our rowgroup size is 30M, if the parquet file has only one rowgroup, it will not benefit from rowgroup skipping
|
@loukey-lj I updated the RFC number for you. |
|
Is this RFC only valid for SQL update scenarios, because it can parse out which columns have been updated from SQL statement. But in other scenarios, such as the "mysql -> debezium -> kafka -> hudi" scenario, we have no way of knowing which columns are updated unless additional calculations are spent, so it can't be applied immediately, right? |
This applies not only to partial field update scenarios, but also to entire row updates |
|
Hi @loukey-lj thanks for putting up the RFC and the great ideas on improving the write performance in Hudi! I'll merge this RFC now. |
|
@loukey-lj @yihua hi, any progress on this improvement? very look forword to this. |
Change Logs
In the cow scenario, updating just one piece of data in the file would require rewriting the entire file, which is very inefficient. In reality, many update datasets are long-tail datasets, so it is necessary to improve the efficiency of cow update. This pr is a solution for how to speed up cow update. This requires expanding the index structure. www.sf-tech.com.cn combined record_level_index with this solution in the production environment last year and achieved a good performance improvement.
How partial update works
a. Add one more member variable(Integer rowGroupId) into the class HoodieRecordLocation.
b. Number of rowgroup of a Parquet starts from 0 which continously increases util BlockSize reaches
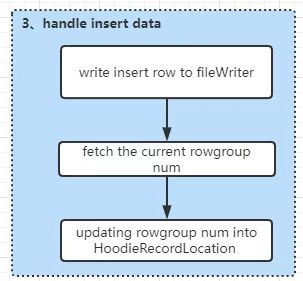
hoodie.parquet.block.size. Since every record in parquet belongs to a rowgroup, we can simply use parquet API to locate rowgroup num of new record which needs to be written into corresponding parquet file, and then record rowgroup num into hoodieRecordLocation of each hoodieRecord. HoodieRecordLocations will be collected into WriteStatus which will be updated to the index on batch.c. At phase of tagging index, rowgroup num will be queried out, so that they can be used to accelerate updating files.
Concrete flow of upserting is as below:
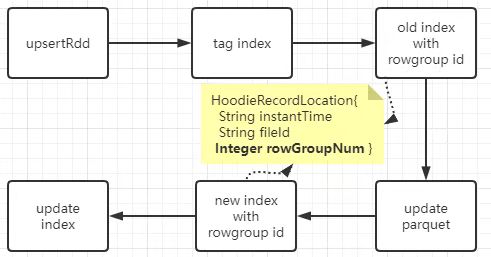
steps of writing a parquet file on cow
(upserting) data preparing
At phase of tag indexing, find out
HoodieRecord.currentLocation.rowGroupNumof updating records, if rowgroup num is empty, record does implicitly not exists, which means current operation is a INSERT, otherwise DELETE or UPDATE. At next, rowgroup nums are used to make grouping by of the updating records so as to collect all rowgroups which should be updated.rowgroup updating
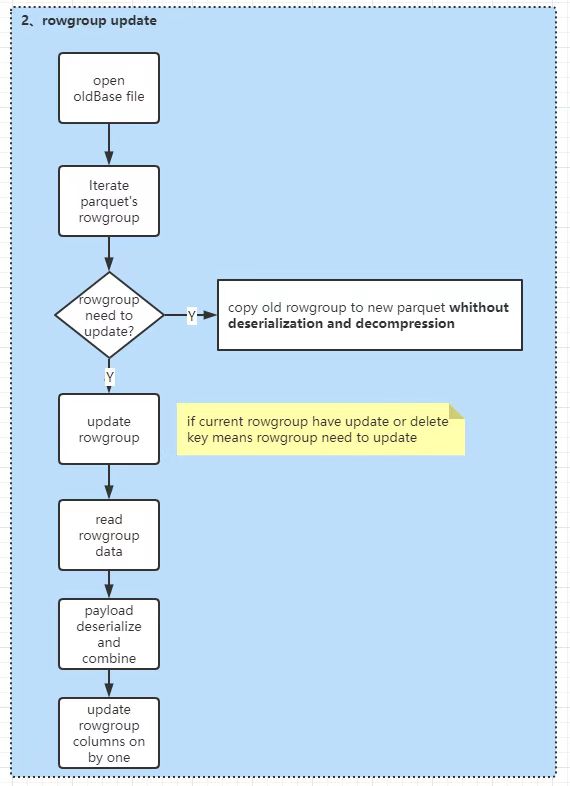
The process of updating rowgroup is divided into 5 steps.
Deserializing and decompressing the columns which need to be combined and assembled into a List<Pari<rowKey,Pari<offset,record>> structure, where offset represents record's row number in rowgroup(every rowgroup's row number starts with zero).
Using HoodieRecordPayload#getInsertValue to deserialize the upserting data, then invoking HoodieRecordPayload#getInsertValue to combine the updating rows.
Converting combined data into column structure, just like
[{"name":"zs","age":10},{"name":"ls","age":20}] ==> {"name":["sz","ls"],"age":[10,20]}Iterating rowgroups' columns. if column needn't be updated then writing column by datapage without decompression and deserialization.
If column needs to be updated then write columns one by one.
insert handling
Impact
NA
Risk level
NA
Documentation Update
RFC
Contributor's checklist