[HUDI-3221] Support querying a table as of a savepoint #4720
Conversation
21448f9 to
bd1cd8e
Compare
|
@xushiyan , there is anything that I can help from my side to help you on this PR? |
15931c0 to
c9b323f
Compare
4774500 to
7d05809
Compare
hey @fedsp thank you for offering help. Feel free to build this branch against spark 3.2 (using maven profile spark3) and test with your datasets. Feel free to post any results or feedback. That'd be of great help! |
|
@xushiyan great! I will do this by today. I'm planning to use it on aws glue which unfortunately only offers spark 3.1 today. I know that Hudi documentation says explicitly that the supported version of spark is 3.2, but there is any chance that it will work on 3.1? |
hi @fedsp Here is a multi version PR, you can test it. #4885 |
9efcab8 to
53e7897
Compare
|
@YannByron can you help reviewing this too? thanks |
As discussed with @XuQianJin-Stars, I prefer to make a separate pr based on the separate spark env with https://issues.apache.org/jira/browse/SPARK-37219. And we can merge this to hudi master once Spark3.3 releases. |
 xushiyan
left a comment
xushiyan
left a comment
There was a problem hiding this comment.
it'll be helpful to keep notes in hudi-spark-datasource README.md and make it clear which files are copied over from spark with modifications, and ready to be removed after using spark 3.3.
hudi-client/hudi-spark-client/src/main/scala/org/apache/hudi/SparkAdapterSupport.scala
Outdated
Show resolved
Hide resolved
hudi-client/hudi-spark-client/src/main/scala/org/apache/hudi/SparkAdapterSupport.scala
Outdated
Show resolved
Hide resolved
...datasource/hudi-spark/src/main/scala/org/apache/spark/sql/hudi/analysis/HoodieAnalysis.scala
Outdated
Show resolved
Hide resolved
...datasource/hudi-spark/src/main/scala/org/apache/spark/sql/hudi/analysis/HoodieAnalysis.scala
Outdated
Show resolved
Hide resolved
...rk-datasource/hudi-spark/src/test/scala/org/apache/spark/sql/hudi/TestTimeTravelParser.scala
Outdated
Show resolved
Hide resolved
...rk-datasource/hudi-spark/src/test/scala/org/apache/spark/sql/hudi/TestTimeTravelParser.scala
Outdated
Show resolved
Hide resolved
...rk-datasource/hudi-spark/src/test/scala/org/apache/spark/sql/hudi/TestTimeTravelParser.scala
Outdated
Show resolved
Hide resolved
...ark-datasource/hudi-spark/src/test/scala/org/apache/spark/sql/hudi/TestTimeTravelTable.scala
Outdated
Show resolved
Hide resolved
...ark-datasource/hudi-spark/src/test/scala/org/apache/spark/sql/hudi/TestTimeTravelTable.scala
Show resolved
Hide resolved
53e7897 to
e543483
Compare
...atasource/hudi-spark3-common/src/main/scala/org/apache/spark/sql/adapter/Spark3Adapter.scala
Outdated
Show resolved
Hide resolved
| <version>${spark3.version}</version> | ||
| <version>${spark3.2.version}</version> |
There was a problem hiding this comment.
can you clarify why this change? what if user needs to build the project with spark 3.1.x profile?
There was a problem hiding this comment.
can you clarify why this change? what if user needs to build the project with spark 3.1.x profile?
spark 3.1.x profile use <hudi.spark.module>hudi-spark3.1.x</hudi.spark.module> with spark3.1.x version.
spark 3 profile use <hudi.spark.module>hudi-spark3</hudi.spark.module> with spark 3.2.0(and above) versions.
There was a problem hiding this comment.
we should prefer to simple set of properties to maintain: both spark3.version and hudi.spark.module change based on different spark profile. When spark3.version switch to 3.1.2, module will be hudi-spark3.1.x and effectively ignores hudi-spark3 here. So I don't think we need to introduce more properties here.
...ark-datasource/hudi-spark3/src/main/scala/org/apache/spark/sql/adapter/Spark3_2Adapter.scala
Outdated
Show resolved
Hide resolved
|
|
||
| import org.apache.spark.sql.catalyst.expressions.{Attribute, Expression} | ||
|
|
||
| case class TimeTravelRelation( |
There was a problem hiding this comment.
this looks identical to the one in hudi-spark. can we deduplicate?
pom.xml
Outdated
| <spark3.1.version>3.1.2</spark3.1.version> | ||
| <spark3.2.version>3.2.1</spark3.2.version> |
There was a problem hiding this comment.
not sure why we need these new properties. spark3.version is always the default and point to the latest supported spark 3. and we shall build the project with spark3.1.x if we want spark3.version point to 3.1. can you clarify
This PR is ready for testing with |
908fec5 to
62a9c1d
Compare
|
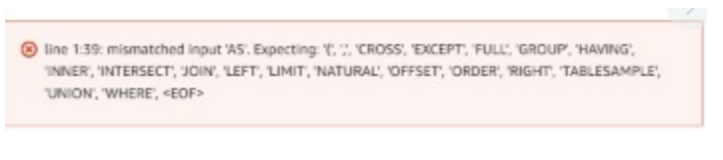
Hi @xushiyan! Sorry for the long response, I had some trouble building the .jar (not used to do it) Anyways, I'm receiving a error from a straight sql statement running from AwsAthena (no problem creating the table on aws glue using spark 3 tho) This is the error: And this is the query that I used on athena: and this is the DDL of the table creation (I created the table by hand, not on the spark write operation): Did I did something wrong? |
|
hi @fedsp Your spark version is 3.2.x? |
|
No, @XuQianJin-Stars , unfortunatelly it is 3.1, since I am limited to the aws glue environment. But I used your branch #4885 |
|
Also please note that this error is not from a spark environment, but from AwsAthena, which uses prestodb as a engine. There is any additional setup? |
prestodb also needs to support this syntax. |
|
@fedsp let me clarify that the time travel query here is supported in Spark SQL with Spark 3.2+ but not yet in other query engine like presto. So you won't be able to run this in Athena. Are you able to verify the branch by running spark sql against your datasets? |
|
Thank you for the clarification @xushiyan! |
|
|
||
| LogicalRelation(dataSource.resolveRelation(checkFilesExist = false), table) | ||
| } else { | ||
| plan |
There was a problem hiding this comment.
if not a Hoodie table, it should return the origin object: l.
| * @since 1.3.0 | ||
| */ | ||
| @Stable | ||
| class AnalysisException protected[sql]( |
There was a problem hiding this comment.
why we need to define this instead of using AnalysisException inside of Spark.
| /** | ||
| * The adapter for spark3.2. | ||
| */ | ||
| class Spark3_2Adapter extends SparkAdapter { |
There was a problem hiding this comment.
can you let Spark3_2Adapter extend Spark3Adapter, and only overwrite isRelationTimeTravel and getRelationTimeTravel.
|
Now, from a spark context (glue context), I tried the following pyspark command:
and it gave me the following error: |
59e0270 to
b989ca6
Compare
|
@hudi-bot run azure |
3cc3b11 to
82a8886
Compare
|
@fedsp it's a spark bundle or version mismatch problem where the syntax is not recognized. Maybe previous version from the branch has some misconfig but now it's resolved. I verified the feature in spark 3.2.1 |
Tips
What is the purpose of the pull request
Support querying a table as of a savepoint
link: HUDI-3221
Support Spark Version:
Brief change log
HoodieSpark3_2ExtendedSqlAstBuilderhave comments in the code fork fromorg.apache.spark.sql.catalyst.parser.AstBuilder, AdditionalwithTimeTravelmethod.SqlBase.g4have comments in the code forked from spark parser, Add SparkSQL SyntaxTIMESTAMP AS OFandVERSION AS OF.TestTimeTravelParser,TestTimeTravelTableVerify this pull request
(Please pick either of the following options)
This pull request is a trivial rework / code cleanup without any test coverage.
(or)
This pull request is already covered by existing tests, such as (please describe tests).
(or)
This change added tests and can be verified as follows:
(example:)
Committer checklist
Has a corresponding JIRA in PR title & commit
Commit message is descriptive of the change
CI is green
Necessary doc changes done or have another open PR
For large changes, please consider breaking it into sub-tasks under an umbrella JIRA.