[HUDI-2285][HUDI-2476] Metadata table synchronous design. Rebased and Squashed from pull/3426 #3590
Conversation
|
Descriptive pr titles with jira numbers please? Even for WIP. |
648e36e to
8c32253
Compare
b4d93b0 to
38bf430
Compare
38bf430 to
7793fbd
Compare
|
@vinothchandar : wrt multi-writer and compaction, here is what is happening in this patch. (have covered this in the description of the patch, but anyways). All writes to metadata table happens within the datatable lock. So, implicitly there are no multi-writers (including compaction, cleaning for metadata table) to metadata table. There will always be only one writer. For regular writes to data table, we do conflict resolution, where as for compaction and clustering (data table), we don't do any conflict resolution. Remember taking a lock while committing compaction and clustering in data table is being added in this patch. So, please pay attention if there is something I am missing. All we ensure is to commit by taking a lock. So, in summary, we have a constraint only single writer model to metadata table. May be we need to revisit this when we integrate record level index. But for now, this is our current state of things. |
hudi-client/hudi-spark-client/src/main/java/org/apache/hudi/client/SparkRDDWriteClient.java
Outdated
Show resolved
Hide resolved
7793fbd to
9c0123c
Compare
13b8006 to
ef75097
Compare
0f68d42 to
2f30991
Compare
 vinothchandar
left a comment
vinothchandar
left a comment
There was a problem hiding this comment.
Initial set of comments.
hudi-cli/src/test/java/org/apache/hudi/cli/commands/TestArchivedCommitsCommand.java
Show resolved
Hide resolved
...lient/hudi-client-common/src/main/java/org/apache/hudi/client/AbstractHoodieWriteClient.java
Outdated
Show resolved
Hide resolved
...lient/hudi-client-common/src/main/java/org/apache/hudi/client/AbstractHoodieWriteClient.java
Outdated
Show resolved
Hide resolved
...di-client-common/src/main/java/org/apache/hudi/metadata/HoodieBackedTableMetadataWriter.java
Outdated
Show resolved
Hide resolved
...ent/hudi-flink-client/src/main/java/org/apache/hudi/table/upgrade/FlinkUpgradeDowngrade.java
Show resolved
Hide resolved
| Configuration hadoopConf) { | ||
| return HoodieSparkTable.create(config, context); | ||
| Configuration hadoopConf, | ||
| boolean refreshTimeline) { |
hudi-client/hudi-spark-client/src/main/java/org/apache/hudi/client/SparkRDDWriteClient.java
Outdated
Show resolved
Hide resolved
hudi-client/hudi-spark-client/src/main/java/org/apache/hudi/client/SparkRDDWriteClient.java
Outdated
Show resolved
Hide resolved
hudi-client/hudi-spark-client/src/main/java/org/apache/hudi/client/SparkRDDWriteClient.java
Outdated
Show resolved
Hide resolved
2f30991 to
c83d176
Compare
vinothchandar
left a comment
There was a problem hiding this comment.
Will resume again from base table metadata
...lient/hudi-client-common/src/main/java/org/apache/hudi/client/AbstractHoodieWriteClient.java
Outdated
Show resolved
Hide resolved
...di-client-common/src/main/java/org/apache/hudi/metadata/HoodieBackedTableMetadataWriter.java
Outdated
Show resolved
Hide resolved
...di-client-common/src/main/java/org/apache/hudi/metadata/HoodieBackedTableMetadataWriter.java
Outdated
Show resolved
Hide resolved
...di-client-common/src/main/java/org/apache/hudi/metadata/HoodieBackedTableMetadataWriter.java
Outdated
Show resolved
Hide resolved
There was a problem hiding this comment.
I feel it may not be easy to relax this. we can discuss this async as we close out this patch.
here are the two dependencies, of which 1 could be relaxed.
- during rollback, we check if commit that is being rollback is already synced or not. if it is < last compacted time, we assume it's already synced. We can get away with this if need be. We can always assume, if the commit being rollbacked is not part of active timeline of metadata, its not synced and go ahead with it. Only difference we might have here is, there could be some additional files which are added to delete list which are not original synced to metadata table at all.
- archival of dataset if dependent on compaction in metadata table. This might need more thoughts.
hudi-client/hudi-spark-client/src/main/java/org/apache/hudi/table/HoodieSparkTable.java
Outdated
Show resolved
Hide resolved
hudi-client/hudi-spark-client/src/main/java/org/apache/hudi/table/HoodieSparkTable.java
Outdated
Show resolved
Hide resolved
hudi-client/hudi-spark-client/src/main/java/org/apache/hudi/table/HoodieSparkTable.java
Outdated
Show resolved
Hide resolved
hudi-client/hudi-spark-client/src/main/java/org/apache/hudi/table/HoodieSparkTable.java
Outdated
Show resolved
Hide resolved
hudi-common/src/main/java/org/apache/hudi/common/table/log/HoodieLogFormat.java
Outdated
Show resolved
Hide resolved
vinothchandar
left a comment
There was a problem hiding this comment.
@nsivabalan I have gone over most of this PR. looks good. On the HoodieBackedTableMetadata lets see if we can unit test lot more.
There was a problem hiding this comment.
are we tracking a Jira to re-enable this
hudi-common/src/main/java/org/apache/hudi/metadata/HoodieBackedTableMetadata.java
Outdated
Show resolved
Hide resolved
hudi-common/src/main/java/org/apache/hudi/metadata/HoodieBackedTableMetadata.java
Outdated
Show resolved
Hide resolved
There was a problem hiding this comment.
please audit this and ensure the reuse of readers across different calls to getRecordKeyByKey() works from the timeline server path. Otherwise, performance will suffer from repeated open and close-es
There was a problem hiding this comment.
This method is too long. lets break them down nicely
There was a problem hiding this comment.
I might need some help in auditing the callers of getRecordKeyByKey. I see lot of callers to fetchAllPartitionPaths. Don't have good clarity on how to weed out required ones from rest. I will sync up with you sometime on this comment.
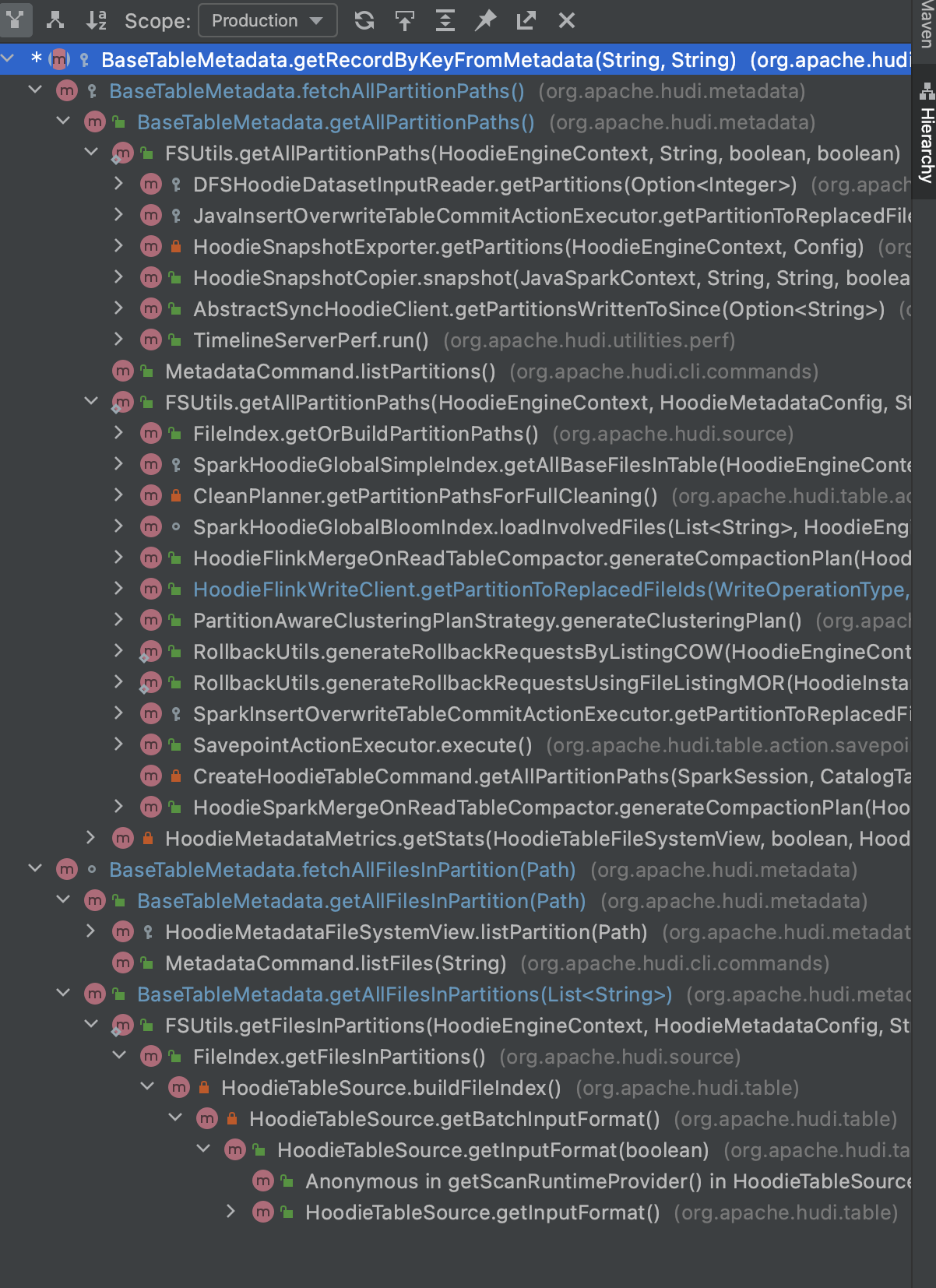
There was a problem hiding this comment.
lets please unit test this file thoroughly.
92634fb to
3b5fbfa
Compare
|
@hudi-bot azure run |
87d2ec0 to
c09f5e3
Compare
vinothchandar
left a comment
There was a problem hiding this comment.
@nsivabalan have we unit tested HoodieBackedTableMetadata or BaseTableMetadata here?
There was a problem hiding this comment.
It'spretty hard to reason about these locking issues while insidethe method. Can we please move Comments to the caller
There was a problem hiding this comment.
Don't we already create a table instance from the caller? Can we not reuse it. Are you saying you need to see even the in-flight instants in this commit
There was a problem hiding this comment.
this was already there. infact I tried to re-use existing table instance and tests started to fail. and then I noticed this comments and reverted it back.
There was a problem hiding this comment.
I feel adding this comment at the caller does not fit in well. This is what it looks like.
try {
// Precommit is meant for resolving conflicts if any and to update metadata table if enabled.
// Create a Hoodie table within preCommit after starting the transaction which encapsulated the commits and files visible
// (instead of using an existing instance of Hoodie table). It is important to create this after the lock to ensure latest
// commits show up in the timeline without need for reload.
preCommit(instantTime, metadata);
commit(table, commitActionType, instantTime, metadata, stats);
postCommit(table, metadata, instantTime, extraMetadata);
...
I feel having this within preCommit just belongs to the place where it is needed or used.
Let me know what do you think.
...lient/hudi-client-common/src/main/java/org/apache/hudi/client/AbstractHoodieWriteClient.java
Outdated
Show resolved
Hide resolved
...di-client-common/src/main/java/org/apache/hudi/metadata/HoodieBackedTableMetadataWriter.java
Outdated
Show resolved
Hide resolved
...di-client-common/src/main/java/org/apache/hudi/metadata/HoodieBackedTableMetadataWriter.java
Outdated
Show resolved
Hide resolved
...n/src/test/java/org/apache/hudi/client/transaction/FileSystemBasedLockProviderTestClass.java
Outdated
Show resolved
Hide resolved
...park-client/src/main/java/org/apache/hudi/metadata/SparkHoodieBackedTableMetadataWriter.java
Outdated
Show resolved
Hide resolved
hudi-client/hudi-spark-client/src/main/java/org/apache/hudi/table/HoodieSparkTable.java
Outdated
Show resolved
Hide resolved
…of commits in data timelime. - Added support to do synchronous updates to metadata table. A write will first get commited to metadata table followed by data table. - Reader will ignore any commits found only in metadata table while serving files via metadata table. - Removed option for runtime validation of metadata table against file listing. Validation does not work in several cases especially with multi-writer. So its best to remove it. - Fixed compactions on the Metadata Table. We cannot perform compaction if there are previous inflight operations on the dataset. This is because a compacted metadata base file at time Tx should represent all the actions on the dataset till time Tx. - Added support for buckets in metadata table partitions. 1. There will be fixed number of buckets for each Metadata Table partition. 2. Buckets are implemented using filenames of format bucket-ABCD where ABCD is the bucket number. This allows easy identification of the files and their order while still keeping the names unique. 3. Buckets are pre-allocated during the time of bootstrap. 4. Currently only "files" partition has 1 bucket. But this building block is required for record-level-index and other indices and so implemented here. - Do not archive instants on the dataset if they are newer than latest compaction on metadata table. LogBlocks written to the log file of Metadata Table need to be validated - they are used only if they correspond to a completed action on the dataset. - Handle Metadata Table upgrade/downgrade by deleting the table and re-bootstrapping. The two versions differ in schema and its complicated to check whether the table is in sync. So its simpler to re-bootstrap as its only the file listing which needs to be re-bootstrapped. - Multi-writers in data table is also supported with metadata table. Since each operation on metadata table writes to the same files (file-listing partition has a single FileSlice), we can only allow single-writer access to the metadata table. To ensure this, any commit that happens in data table is guarded within the data table lock. Prior to this patch, table services like compaction and clustering was not taking any locks while committing to data table. But with this patch, added the lock. - Enabling metadata table by default.
c09f5e3 to
b432e1d
Compare
b432e1d to
0d70dba
Compare
|
@hudi-bot azure run |
I started writing unit tests and later realized that all of our existing validation is happening using apis in BaseTableMetadata (getAllPartitionPaths and getAllFilesInPartition). Also there are tests to test reader wrt valid instants separately. So, I just enhanced existing tests and added extra validation that fileSystemMetadata is not used during these validations(or in other words only metadata table is used strictly during these validations). |
|
@hudi-bot azure run |
 prashantwason
left a comment
prashantwason
left a comment
There was a problem hiding this comment.
Great job on this PR @nsivabalan. Left a few minor comments but looks great.
| * Update metadata table if available. Any update to metadata table happens within data table lock. | ||
| * @param cleanMetadata intance of {@link HoodieCleanMetadata} to be applied to metadata. | ||
| */ | ||
| private void writeMetadata(HoodieCleanMetadata cleanMetadata) { |
There was a problem hiding this comment.
Can we move the txnManager to the base class to save on code duplication and having to write two levels of these functions?
writeMetadata
writeCleanMetadata
| // and it is for the same reason we enabled withAllowMultiWriteOnSameInstant for metadata table. | ||
| HoodieInstant alreadyCompletedInstant = metadataMetaClient.getActiveTimeline().filterCompletedInstants().filter(entry -> entry.getTimestamp().equals(instantTime)).lastInstant().get(); | ||
| HoodieActiveTimeline.deleteInstantFile(metadataMetaClient.getFs(), metadataMetaClient.getMetaPath(), alreadyCompletedInstant); | ||
| metadataMetaClient.reloadActiveTimeline(); |
There was a problem hiding this comment.
This reload is extra as the next line 123 also reloads.
| // Load to memory | ||
| HoodieWriteConfig config = getConfig(); | ||
| HoodieWriteConfig config = getConfigBuilder(100, false, false) | ||
| .withMetadataConfig(HoodieMetadataConfig.newBuilder().enable(false).build()).build(); |
There was a problem hiding this comment.
this is used so often that it may be good to introduce a helper function here:
withDisabledMetadata()
| lastSyncedInstantTime.get())); | ||
| } else { | ||
| LOG.info("Not archiving as there is no instants yet on the metadata table"); | ||
| Option<String> latestCompactionTime = tableMetadata.getLatestCompactionTime(); |
There was a problem hiding this comment.
@nsivabalan
Adding a clarifying comment on this PR to debug an issue regarding archival of tables.
https://issues.apache.org/jira/browse/HUDI-2735
What should be done for enabling the archiving for MOR table ? I think after this change getLatestCompactionTime is only filtering .commits and for an MOR table this would always be empty and is causing archival to be disabled.
There was a problem hiding this comment.
@vinishjail97 This is required for proper functioning of the metadata table. Until a compaction occurs on the metadata table, any instants on the dataset cannot be archived.
Every action on the dataset (COMMIT, CLEAN, ROLLBACK, etc) will write to the metadata table and create a deltacommit on the metadata table. Currently, after every 10 actions on the dataset the metadata table is compacted. You can lower this but will cause greater IO to compact the metadata table again and again.
There was a problem hiding this comment.
This is required for proper functioning of the metadata table.
What logic of metadata table relies on this restriction ? Can you please explain a little more ? Shouldn't the metadata table compaction just relies on its on log data blocks which are already committed metadata ?
There was a problem hiding this comment.
In the synchronous metadata table design (0.10+), the following is the order of how an action completes in HUDI when metadata table is enabled (assuming a commit).
t1.commit.requested
t1.commit.inflight
finalizeWrite()
<NOTE: the t1.commit on the dataset has not yet completed as we have not created t1.commit yet>
t1.commit is created.
So the deltacommit to the metadata table is completed before the commit completes. Remember, these are two different HUDI tables.
There is an error condition - when we crash / fail before the very last step - t1.deltacommit is created on dataset but t1.commit is not created. In this case, t1.deltacommit is NOT VALID on the metadata table. We ignore t1.deltacommit while reading from metadata table. This validation requires us to check each tX.deltacommmit against corresponding instants on the dataset timeline. So if the dataset timeline is archived independent of metadata table compaction then this logic will not work.
This is further complicated in the presence of multiple writers - each of them in parallel writing to the dataset (e.g. t2.commit.inflight, t3.commit.inflight, etc) and writing to the metadata table when complete. So metadata table could have t3.deltacommit but no t2.deltacommit which could have failed or not completed yet.
There was a problem hiding this comment.
This validation requires us to check each tX.deltacommmit against corresponding instants on the dataset timeline
This is true but i did not see any reason why the delta commits on the timeline can not archive, somehow, the decision on whether a delta commit is committed successfully should not rely on whether it is archived, in other words, the archiving of delta commits should be transparent to the view callers.
There was a problem hiding this comment.
You are right. But attempting to read a deltacommit from a commit archive will introduce a long delay. So currently only the active timeline is used leading to this restriction.
… Squashed from pull/3426 (apache#3590) * [HUDI-2285] Adding Synchronous updates to metadata before completion of commits in data timelime. - This patch adds synchronous updates to metadata table. In other words, every write is first committed to metadata table followed by data table. While reading metadata table, we ignore any delta commits that are present only in metadata table and not in data table timeline. - Compaction of metadata table is fenced by the condition that we trigger compaction only when there are no inflight requests in datatable. This ensures that all base files in metadata table is always in sync with data table(w/o any holes) and only there could be some extra invalid commits among delta log files in metadata table. - Due to this, archival of data table also fences itself up until compacted instant in metadata table. All writes to metadata table happens within the datatable lock. So, metadata table works in one writer mode only. This might be tough to loosen since all writers write to same FILES partition and so, will result in a conflict anyways. - As part of this, have added acquiring locks in data table for those operations which were not before while committing (rollback, clean, compaction, cluster). To note, we were not doing any conflict resolution. All we are doing here is to commit by taking a lock. So that all writes to metadata table is always a single writer. - Also added building block to add buckets for partitions, which will be leveraged by other indexes like record level index, etc. For now, FILES partition has only one bucket. In general, any number of buckets per partition is allowed and each partition has a fixed fileId prefix with incremental suffix for each bucket within each partition. Have fixed [HUDI-2476]. This fix is about retrying a failed compaction if it succeeded in metadata for first time, but failed w/ data table. - Enabling metadata table by default. - Adding more tests for metadata table Co-authored-by: Prashant Wason <[email protected]>
What is the purpose of the pull request
Verify this pull request
Committer checklist
Has a corresponding JIRA in PR title & commit
Commit message is descriptive of the change
CI is green
Necessary doc changes done or have another open PR
For large changes, please consider breaking it into sub-tasks under an umbrella JIRA.