[HUDI-2144]Bug-Fix:Offline clustering(HoodieClusteringJob) will cause insert action losing data #3240
Conversation
Codecov Report
@@ Coverage Diff @@
## master #3240 +/- ##
============================================
+ Coverage 47.61% 47.67% +0.06%
- Complexity 5487 5517 +30
============================================
Files 924 929 +5
Lines 41206 41303 +97
Branches 4133 4144 +11
============================================
+ Hits 19619 19691 +72
- Misses 19844 19864 +20
- Partials 1743 1748 +5
Flags with carried forward coverage won't be shown. Click here to find out more.
Continue to review full report at Codecov.
|

|
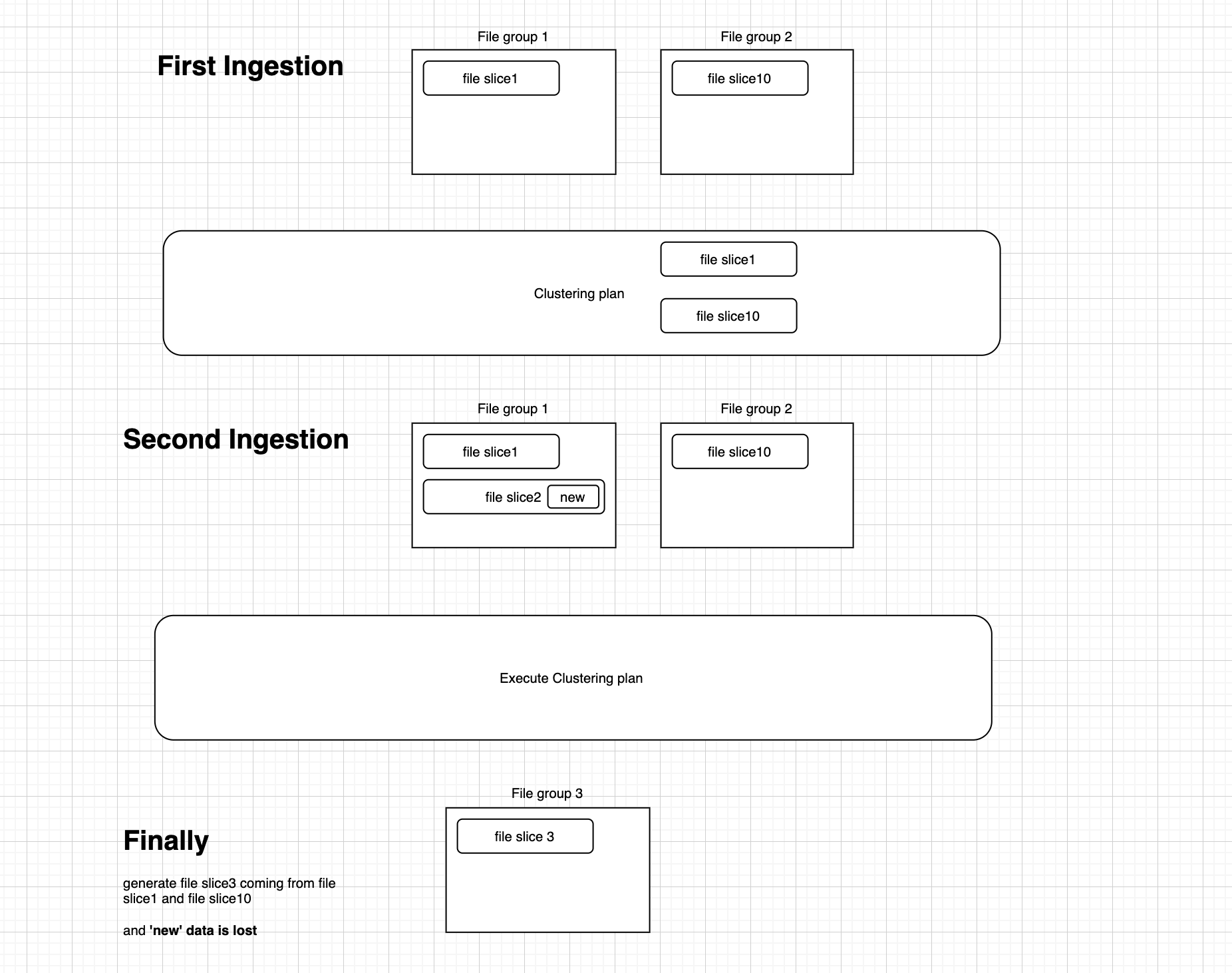
when clustering plan contains the small files, the new insert should not get into small files, so the new insert get into file slice2 is strange. |
|
Hi @leesf Thanks for your review. Yes, what I means is that this limitation is not good enough because others job like HoodieClusteringJob also can generate cluster plan and the insert job mentioned above can't be aware of it and can't use |
|
@satishkotha @codope Can one of you please help review? |
| */ | ||
| private List<SmallFile> filterSmallFilesInClustering(final Set<String> pendingClusteringFileGroupsId, final List<SmallFile> smallFiles) { | ||
| if (this.config.isClusteringEnabled()) { | ||
| if (this.config.isClusteringEnabled() || !pendingClusteringFileGroupsId.isEmpty()) { |
There was a problem hiding this comment.
If the clustering is not enabled, can the pendingClusteringFileGroupsId set be non-empty? Would be great if we can add a test to replicate the scenario.
There was a problem hiding this comment.
Hi @codope Thanks for your view.
As I mentioned above. If the clustering is not enabled during insert but there is an offline clustering plan job is running for this table, the pendingClusteringFileGroupsId set could be non-empty too.
I just add a UT named testUpsertPartitionerWithSmallFileHandlingAndClusteringPlan to prove it. I set withClusteringConfig(HoodieClusteringConfig.newBuilder().withInlineClustering(false).withAsyncClustering(false).build()) during ingestion and create a clustering plan manually out of this ingestion scope.
As you you can see, If the condition is this.config.isClusteringEnabled() only, there will be two small slices can be inserted including file slice 1 in pending clustering plan.
If the condition is !pendingClusteringFileGroupsId.isEmpty(), there will be only one small slice can be used and file slice 1 is filtered.
| * @return smallFiles not in clustering | ||
| */ | ||
| private List<SmallFile> filterSmallFilesInClustering(final Set<String> pendingClusteringFileGroupsId, final List<SmallFile> smallFiles) { | ||
| if (this.config.isClusteringEnabled()) { |
There was a problem hiding this comment.
Good find. We can probably remove config.isClusteringEnabled() check below and only rely on pendingClusteringFileGroupsId?
cc: @lw309637554 any reason to base this on config originally in #2275?
There was a problem hiding this comment.
Hi @satishkotha Thanks for your view. Only rely on pendingClusteringFileGroupsId is much better :) changed.
There was a problem hiding this comment.
@satishkotha @zhangyue19921010
At first we have two config for clustering. If set ASYNC_CLUSTERING_ENABLE_OPT_KEY will be ok.
public boolean isAsyncClusteringEnabled() {
return Boolean.parseBoolean(props.getProperty(HoodieClusteringConfig.ASYNC_CLUSTERING_ENABLE_OPT_KEY));
}
public boolean isClusteringEnabled() {
// TODO: future support async clustering
return inlineClusteringEnabled() || isAsyncClusteringEnabled();
}
There was a problem hiding this comment.
@satishkotha @zhangyue19921010
Use "if (!pendingClusteringFileGroupsId.isEmpty())" will improve ease of use.
Another need to modify. But if this will bring performance loss? @satishkotha
" private JavaRDD<HoodieRecord> clusteringHandleUpdate(JavaRDD<HoodieRecord> inputRecordsRDD) {
if (config.isClusteringEnabled()) {"
|
@vinothchandar @satishkotha It looks good to me and I've verified the patch. Can you guys take a pass and land it? |
change the insret overwrte return type [HUDI-1860] Test wrapper for insert_overwrite and insert_overwrite_table [HUDI-2084] Resend the uncommitted write metadata when start up (apache#3168) Co-authored-by: 喻兆靖 <[email protected]> [HUDI-2081] Move schema util tests out from TestHiveSyncTool (apache#3166) [HUDI-2094] Supports hive style partitioning for flink writer (apache#3178) [HUDI-2097] Fix Flink unable to read commit metadata error (apache#3180) [HUDI-2085] Support specify compaction paralleism and compaction target io for flink batch compaction (apache#3169) [HUDI-2092] Fix NPE caused by FlinkStreamerConfig#writePartitionUrlEncode null value (apache#3176) [HUDI-2006] Adding more yaml templates to test suite (apache#3073) [HUDI-2103] Add rebalance before index bootstrap (apache#3185) Co-authored-by: 喻兆靖 <[email protected]> [HUDI-1944] Support Hudi to read from committed offset (apache#3175) * [HUDI-1944] Support Hudi to read from committed offset * [HUDI-1944] Adding group option to KafkaResetOffsetStrategies * [HUDI-1944] Update Exception msg [HUDI-2052] Support load logFile in BootstrapFunction (apache#3134) Co-authored-by: 喻兆靖 <[email protected]> [HUDI-89] Add configOption & refactor all configs based on that (apache#2833) Co-authored-by: Wenning Ding <[email protected]> [MINOR] Update .asf.yaml to codify notification settings, turn on jira comments, gh discussions (apache#3164) - Turn on comment for jira, so we can track PR activity better - Create a notification settings that match https://gitbox.apache.org/schemes.cgi?hudi - Try and turn on "discussions" on Github, to experiment [MINOR] Fix broken build due to FlinkOptions (apache#3198) [HUDI-2088] Missing Partition Fields And PreCombineField In Hoodie Properties For Table Written By Flink (apache#3171) [MINOR] Add Documentation to KEYGENERATOR_TYPE_PROP (apache#3196) [HUDI-2105] Compaction Failed For MergeInto MOR Table (apache#3190) [HUDI-2051] Enable Hive Sync When Spark Enable Hive Meta For Spark Sql (apache#3126) [HUDI-2112] Support reading pure logs file group for flink batch reader after compaction (apache#3202) [HUDI-2114] Spark Query MOR Table Written By Flink Return Incorrect Timestamp Value (apache#3208) [HUDI-2121] Add operator uid for flink stateful operators (apache#3212) [HUDI-2123] Exception When Merge With Null-Value Field (apache#3214) [HUDI-2124] A Grafana dashboard for HUDI. (apache#3216) [HUDI-2057] CTAS Generate An External Table When Create Managed Table (apache#3146) [HUDI-1930] Bootstrap support configure KeyGenerator by type (apache#3170) * [HUDI-1930] Bootstrap support configure KeyGenerator by type [HUDI-2116] Support batch synchronization of partition datas to hive metastore to avoid oom problem (apache#3209) [HUDI-2126] The coordinator send events to write function when there are no data for the checkpoint (apache#3219) [HUDI-2127] Initialize the maxMemorySizeInBytes in log scanner (apache#3220) [HUDI-2058]support incremental query for insert_overwrite_table/insert_overwrite operation on cow table (apache#3139) [HUDI-2129] StreamerUtil.medianInstantTime should return a valid date time string (apache#3221) [HUDI-2131] Exception Throw Out When MergeInto With Decimal Type Field (apache#3224) [HUDI-2122] Improvement in packaging insert into smallfiles (apache#3213) [HUDI-2132] Make coordinator events as POJO for efficient serialization (apache#3223) [HUDI-2106] Fix flink batch compaction bug while user don't set compaction tasks (apache#3192) [HUDI-2133] Support hive1 metadata sync for flink writer (apache#3225) [HUDI-2089]fix the bug that metatable cannot support non_partition table (apache#3182) [HUDI-2028] Implement RockDbBasedMap as an alternate to DiskBasedMap in ExternalSpillableMap (apache#3194) Co-authored-by: Rajesh Mahindra <[email protected]> [HUDI-2135] Add compaction schedule option for flink (apache#3226) [HUDI-2055] Added deltastreamer metric for time of lastSync (apache#3129) [HUDI-2046] Loaded too many classes like sun/reflect/GeneratedSerializationConstructorAccessor in JVM metaspace (apache#3121) Loaded too many classes when use kryo of spark to hudi Co-authored-by: weiwei.duan <[email protected]> [HUDI-1996] Adding functionality to allow the providing of basic auth creds for confluent cloud schema registry (apache#3097) * adding support for basic auth with confluent cloud schema registry [HUDI-2093] Fix empty avro schema path caused by duplicate parameters (apache#3177) * [HUDI-2093] Fix empty avro schema path caused by duplicate parameters * rename shcmea option key * fix doc * rename var name [HUDI-2113] Fix integration testing failure caused by sql results out of order (apache#3204) [HUDI-2016] Fixed bootstrap of Metadata Table when some actions are in progress. (apache#3083) Metadata Table cannot be bootstrapped when any action is in progress. This is detected by the presence of inflight or requested instants. The bootstrapping is initiated in preWrite and postWrite of each commit. So bootstrapping will be retried again until it succeeds. Also added metrics for when the bootstrapping fails or a table is re-bootstrapped. This will help detect tables which are not getting bootstrapped. [HUDI-2140] Fixed the unit test TestHoodieBackedMetadata.testOnlyValidPartitionsAdded. (apache#3234) [HUDI-2115] FileSlices in the filegroup is not descending by timestamp (apache#3206) [HUDI-1104] Adding support for UserDefinedPartitioners and SortModes to BulkInsert with Rows (apache#3149) [HUDI-2069] Refactored String constants (apache#3172) [HUDI-1105] Adding dedup support for Bulk Insert w/ Rows (apache#2206) [HUDI-2134]Add generics to avoif forced conversion in BaseSparkCommitActionExecutor#partition (apache#3232) [HUDI-2009] Fixing extra commit metadata in row writer path (apache#3075) [HUDI-2099]hive lock which state is WATING should be released, otherwise this hive lock will be locked forever (apache#3186) [MINOR] Fix build broken from apache#3186 (apache#3245) [HUDI-2136] Fix conflict when flink-sql-connector-hive and hudi-flink-bundle are both in flink lib (apache#3227) [HUDI-2087] Support Append only in Flink stream (apache#3174) Co-authored-by: 喻兆靖 <[email protected]> UnitTest for deltaSync Removing cosmetic changes and reuse function for insert_overwrite_table unit test intial unit test for the insert_overwrite and insert_over_write_table Adding failed test code for insert_overwrite Revert "[HUDI-2087] Support Append only in Flink stream (apache#3174)" (apache#3251) This reverts commit 3715267. [HUDI-2147] Remove unused class AvroConvertor in hudi-flink (apache#3243) [MINOR] Fix some wrong assert reasons (apache#3248) [HUDI-2087] Support Append only in Flink stream (apache#3252) Co-authored-by: 喻兆靖 <[email protected]> [HUDI-2143] Tweak the default compaction target IO to 500GB when flink async compaction is off (apache#3238) [HUDI-2142] Support setting bucket assign parallelism for flink write task (apache#3239) [HUDI-1483] Support async clustering for deltastreamer and Spark streaming (apache#3142) - Integrate async clustering service with HoodieDeltaStreamer and HoodieStreamingSink - Added methods in HoodieAsyncService to reuse code [HUDI-2107] Support Read Log Only MOR Table For Spark (apache#3193) [HUDI-2144]Bug-Fix:Offline clustering(HoodieClusteringJob) will cause insert action losing data (apache#3240) * fixed * add testUpsertPartitionerWithSmallFileHandlingAndClusteringPlan ut * fix CheckStyle Co-authored-by: yuezhang <[email protected]> [MINOR] Fix EXTERNAL_RECORD_AND_SCHEMA_TRANSFORMATION config (apache#3250) [HUDI-2168] Fix for AccessControlException for anonymous user (apache#3264) [HUDI-2045] Support Read Hoodie As DataSource Table For Flink And DeltaStreamer test with insert-overwrite and insert-overwrite-table removing hardcoded action to pass the unit test [HUDI-1969] Support reading logs for MOR Hive rt table (apache#3033) [HUDI-2171] Add parallelism conf for bootstrap operator using delta-commit for insert_overwrite
… insert action losing data (apache#3240) * fixed * add testUpsertPartitionerWithSmallFileHandlingAndClusteringPlan ut * fix CheckStyle Co-authored-by: yuezhang <[email protected]>
… insert action losing data (apache#3240) * fixed * add testUpsertPartitionerWithSmallFileHandlingAndClusteringPlan ut * fix CheckStyle Co-authored-by: yuezhang <[email protected]>
What is the purpose of the pull request
Please read https://issues.apache.org/jira/projects/HUDI/issues/HUDI-2144 for details
Brief change log
Modify UpsertPartitioner.java
Verify this pull request
(Please pick either of the following options)
This pull request is a trivial rework / code cleanup without any test coverage.
(or)
This pull request is already covered by existing tests, such as (please describe tests).
(or)
This change added tests and can be verified as follows:
(example:)
Committer checklist
Has a corresponding JIRA in PR title & commit
Commit message is descriptive of the change
CI is green
Necessary doc changes done or have another open PR
For large changes, please consider breaking it into sub-tasks under an umbrella JIRA.