[HUDI-1527] automatically infer the data directory, users only need to specify the table directory #2475
Conversation
Codecov Report
@@ Coverage Diff @@
## master #2475 +/- ##
============================================
+ Coverage 51.14% 51.17% +0.03%
- Complexity 3215 3219 +4
============================================
Files 438 438
Lines 20041 20055 +14
Branches 2064 2067 +3
============================================
+ Hits 10250 10264 +14
Misses 8946 8946
Partials 845 845
Flags with carried forward coverage won't be shown. Click here to find out more.
|

|
This is a great and important feature to make Hudi easier for no heavy users. |
|
@zhedoubushishi @umehrot2 could you please take a first pass |
 vinothchandar
left a comment
vinothchandar
left a comment
There was a problem hiding this comment.
Thanks for this! Seems very useful.
One thing I wanted to understand was - whether an user can still do basePath/2020/*/* and have only the parquet files for 2020 read out for e.g?
There was a problem hiding this comment.
this short circuits the recursive stack, once we get one partition path I guess
There was a problem hiding this comment.
So, I am wondering if we can use the HoodieTableMetadata abstraction to read a partition path, instead of listing alone. We are trying to avoid any introduction of single point listings. There is a method to get all partition paths already FSUtils.getAllPartitionPaths(), lets just use that for now? I am thinking that it will be little bit of an overkill to list all partition paths, without metadata table
There was a problem hiding this comment.
Yea I agree it would be better to use HoodieTableMetadata to avoid fs.listStatus. But what about the tables w/o metadata feature enable? Will it take super long time if it's a table with many partitions?
Also hoodie_partition_metadata saves a parameter called partitionDepth, could we take advantage of this?
There was a problem hiding this comment.
Thank you for your review, this method of obtaining partitions is very fast. As long as one partition path is obtained, it will return directly. FSUtils.getAllPartitionPaths will obtain all partition paths, which is very time-consuming.
There was a problem hiding this comment.
@teeyog we could even add a new overload/methods for this under HoodieTableMetadata interface, but really good to keep all of this under the interface. With the metadata table, its actually okay to call getAllPartitionPaths(), its pretty fast.
Of course it can, but it is specified by the parameter |
|
@teeyog if you could call FSUtils.getAllPartitionPaths() or add a new method |
@teeyog can you please expand on this. is this related to this PR or a general comment? |
I want to clarify this a bit. do you mean if I do the following, I see that we reset the |
|
other than these two I am good with this |
If the hive metadata tabproperties contains The resolveRelation in the second step will go directly to the DefaultSource of hudi, so reading the hive table is automatically converted to reading the hudi table |
I understand what you mean. The situation you said is really not supported, because the data path will be automatically inferred to cover the path configured by the user, but you only check the requirements of 2020 and 2021, you can use dadaframe when Filter again, or do I need to judge whether the path specified by the user contains *, if it does, the data path is not automatically inferred, what do you think? |
It has been modified to obtain the partition path by |
There was a problem hiding this comment.
@teeyog Sorry it's not still clear to me. I supplied a globbed path 2015/*/*/* and even that overrides path -> tablePath/*/*/*/*
Won't this incur reading all partitions in the tablePath as opposed only 2015's?
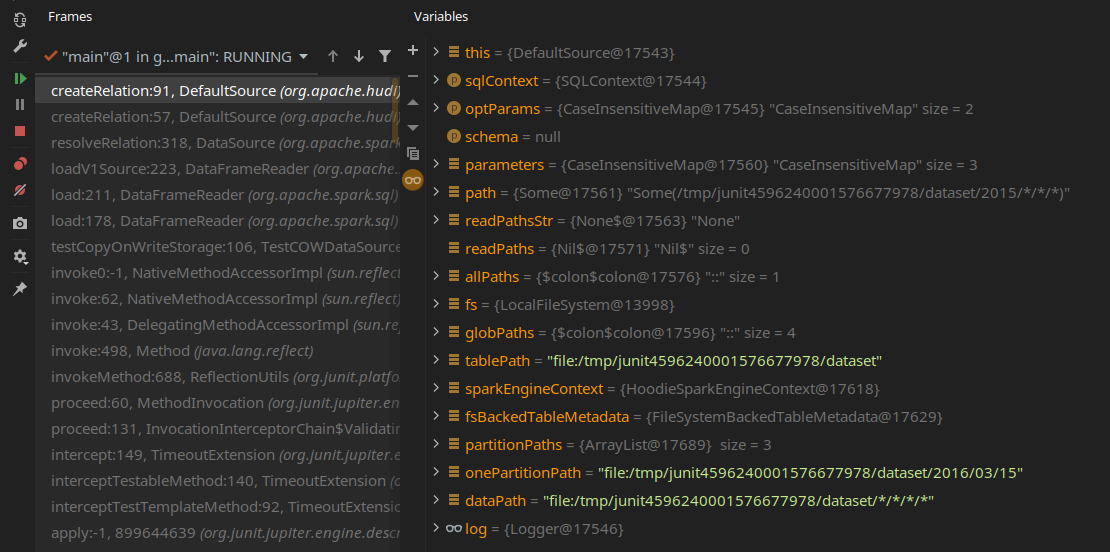
There was a problem hiding this comment.
The path specified by the user will be overwritten by the automatically inferred data directory, and your needs cannot be met
There was a problem hiding this comment.
I will try to see if I can automatically infer this but also meet your needs
There was a problem hiding this comment.
@vinothchandar Now it supports your needs. If the path specified by the user is a table path, it will be automatically inferred, otherwise it will not be inferred.
…o specify the table directory
…o specify the table directory [adapt no partition]
…o specify the table directory [adapt no partition]
…o specify the table directory [adapt no partition]
…o specify the table directory [adapt no partition]
| val sparkEngineContext = new HoodieSparkEngineContext(sqlContext.sparkContext) | ||
| val fsBackedTableMetadata = | ||
| new FileSystemBackedTableMetadata(sparkEngineContext, new SerializableConfiguration(fs.getConf), tablePath, false) | ||
| val partitionPaths = fsBackedTableMetadata.getAllPartitionPaths |
There was a problem hiding this comment.
@teeyog hello, now infer the partition for getallpartition paths from metadata table.
The partition mode is set as hoodie.datasource.write.partitionpath.field when write the hudi table. Can we persist the hoodie.datasource.write.partitionpath.field to metatable? Then read just get the properties , not get all the partition path? cc @vinothchandar
There was a problem hiding this comment.
@lw309637554 Thank you for your review, the previous path to get the hudi table can also be obtained through configuration instead of inference
|
Closing in favor of #3353 |
Tips
What is the purpose of the pull request
To read the hudi table, you need to specify the path, but the path is not only the tablePath corresponding to the table, but needs to be determined by the partition directory structure. Different keyGenerators correspond to different partition directory structures. The first-level partition directory uses path=
.../table/*/*, the secondary partition directory path=.../table/*/*/*,so it is troublesome to let the user specify the data path, the user only needs to specify the tablePath:.../tableAt the same time, after reading the hudi table by configuring path=
.../table, it is more convenient to use sparksql to query the hudi table. You only need to add tabproperties to the hive table metadata:spark.sql.sources.provider= hudi, you can automatically convert the hive table to the hudi table.Brief change log
(for example:)
Verify this pull request
(Please pick either of the following options)
This pull request is a trivial rework / code cleanup without any test coverage.
(or)
This pull request is already covered by existing tests, such as (please describe tests).
(or)
This change added tests and can be verified as follows:
(example:)
Committer checklist
Has a corresponding JIRA in PR title & commit
Commit message is descriptive of the change
CI is green
Necessary doc changes done or have another open PR
For large changes, please consider breaking it into sub-tasks under an umbrella JIRA.