GH-33737: [C++] simplify exec plan tracing #33738
Conversation
|
Example Plan Trace:
Note: I can already see something I find rather interesting in the above trace. The final pipeline calls |
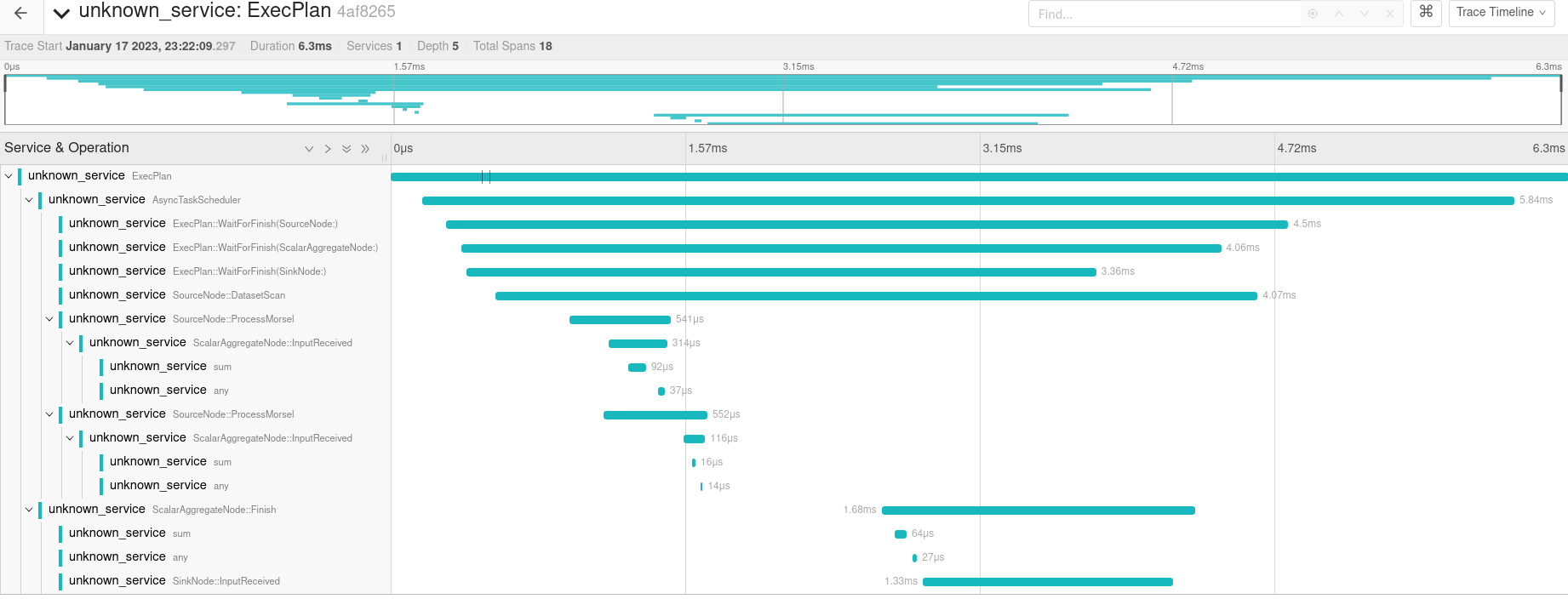
|
CC @mbrobbel please review if you have a chance |
|
Looks like I still have a CI issue. Converting to draft while I work that out. |
 joosthooz
left a comment
joosthooz
left a comment
There was a problem hiding this comment.
Thanks a lot for this, I still have to try this branch for myself but I left some questions!
| span, span_, "InputReceived", | ||
| {{"node.label", label()}, {"batch.length", batch.length}}); | ||
|
|
||
| auto scope = TraceInputReceived(batch); |
There was a problem hiding this comment.
If the sink applies backpressure (e.g. the datasetwriter), it does not result in an event being created on the span as is the case for the normal SinkNode here https://github.com/apache/arrow/pull/33738/files#diff-967cff6ef1964402635ac0769dece741ca0ed58bcefb8d669ecfe3ed8371998eR175
Is there a way to do this? For example, we could compare the value of backpressure_counter_ before and after calling Consume(), but then we wouldn't be able to know if backpressure was applied or released.
There was a problem hiding this comment.
The backpressure is applied in the dataset writer (it has it's own queue). However, we can add tracing events in the dataset writer. I'm kind of interested now to see what a dataset writer trace looks like. I will add something.
There was a problem hiding this comment.
Yes, I think that makes a lot of sense especially because the dataset writer submits tasks to the IO executor that can run in parallel. All that would otherwise be lost behind a single ConsumingSinkNode span
| } | ||
|
|
||
| void InputReceived(ExecNode* input, ExecBatch batch) override { | ||
| EVENT(span_, "InputReceived", {{"batch.length", batch.length}}); |
There was a problem hiding this comment.
Does this need a TraceInputReceived or NoteInputReceived?
There was a problem hiding this comment.
It gets it from MapNode. This will be more obvious in #15253 because subclasses will no longer implement InputReceived (they will use MapNode::InputReceived and instead just implement ProcessBatch)
| } | ||
|
|
||
| void InputReceived(ExecNode* input, ExecBatch batch) override { | ||
| EVENT(span_, "InputReceived", {{"batch.length", batch.length}}); |
There was a problem hiding this comment.
Does this need a TraceInputReceived?
| } | ||
|
|
||
| void InputReceived(compute::ExecNode* input, compute::ExecBatch batch) override { | ||
| EVENT(span_, "InputReceived", {{"batch.length", batch.length}}); |
There was a problem hiding this comment.
Does this need a TraceInputReceived?
cpp/src/arrow/dataset/file_base.cc
Outdated
| MapNode::Finish(std::move(finish_st)); | ||
| return; | ||
| } | ||
| auto scope = TraceFinish(); |
There was a problem hiding this comment.
Why do we do a TraceFinish here and not inside DatasetWriter::Finish? That's the only thing inside this trace and it seems weird to only trace it if it is inside a TeeNode (e.g. it is missing here https://github.com/apache/arrow/pull/33738/files#diff-2caf4e9bd3f139e05e55dca80725d8a9c436f5ccf65c76a37cebfa6ee9b36a6aL418)
|
In the figure, why does |
The code looks roughly like:
All of the node-specific spans and events should have the node label as an attribute. I don't think it's displayed here. The node label defaults (I think) to NodeType:NodeCounter but I'll check
There are two kinds of sinks. The SinkNode has an external queue. All it does is push batches into the queue. So no, it should not be doing any work. The ConsumingSinkNode assumes the batch is consumed as part of the plan (e.g. dataset write) and has no output but it does do work. |
|
Here's a trace from a dataset write. There are still things that could be cleaned up here. Pretty much all of the
|
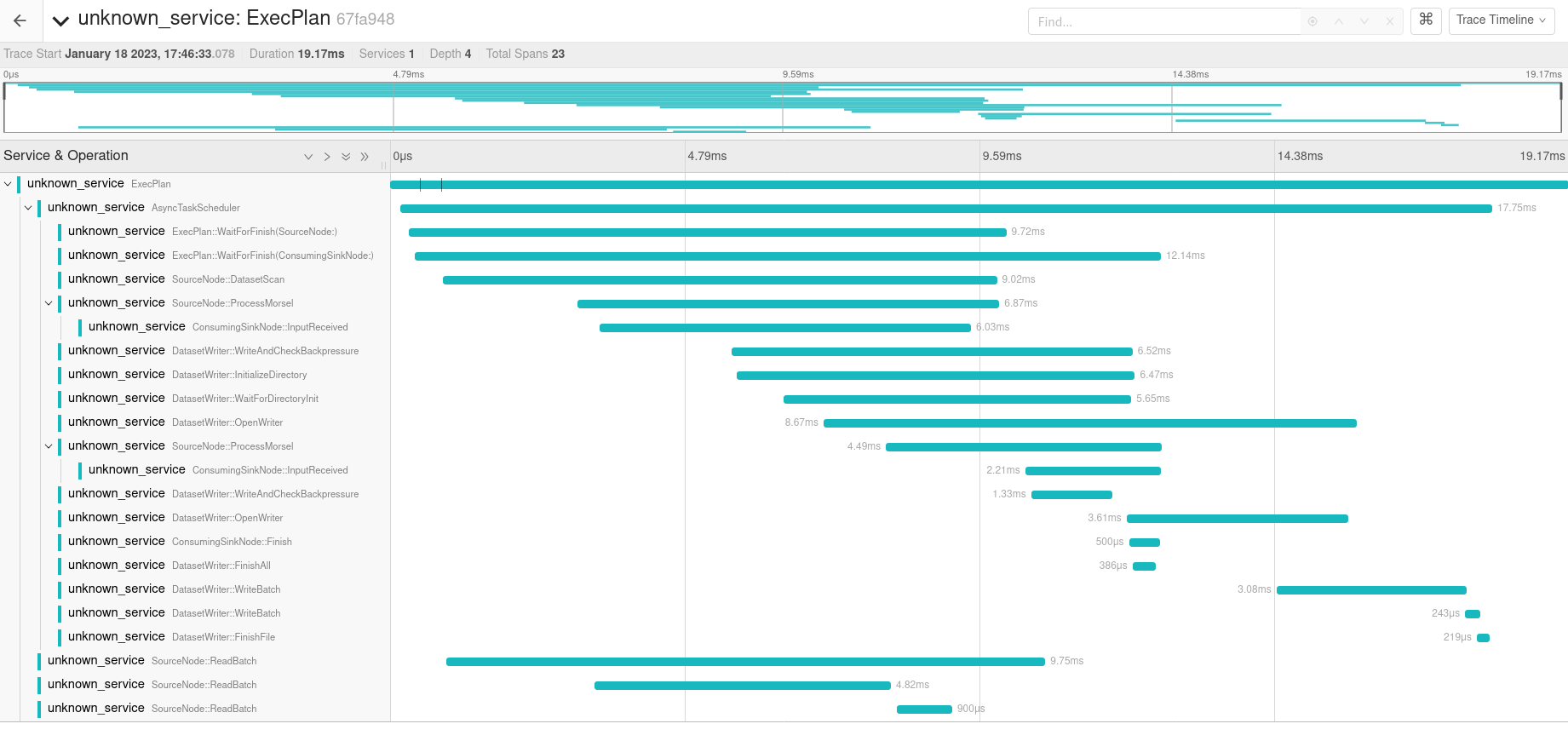
|
Nice, I think the WriteAndCheckBackpressure span is important because that's where the backpressure is checked and also it performs some work combining staged batches (in |
…t for more clarity
|
@joosthooz I slightly changed things so the current task will be used as parent and not the scheduler. This makes it more clear that WriteAndCheckBackpressure is actually creating some of those following spans. However, at this point, I think we are veering from my original goal which was "remove the dependence on the exec node finished future so I can get away with it but don't break OT worse than it already was". I think I'd like to merge this in as it is. Would you be interested in investigating better ways of handling spans in a future PR?
I think I/O of any kind is generally interesting enough to always justify a span. |
|
Hi, I gave this branch a spin (this code reads in a partitioned csv dataset and writes it to a partitioned parquet dataset), and it seems that the nesting has become inconsistent: |
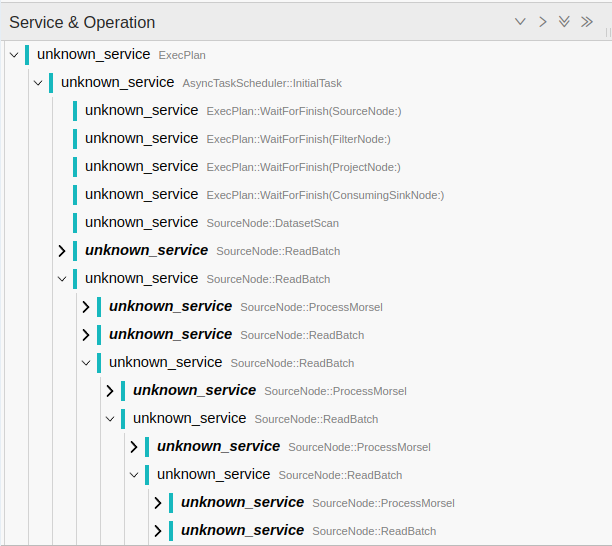
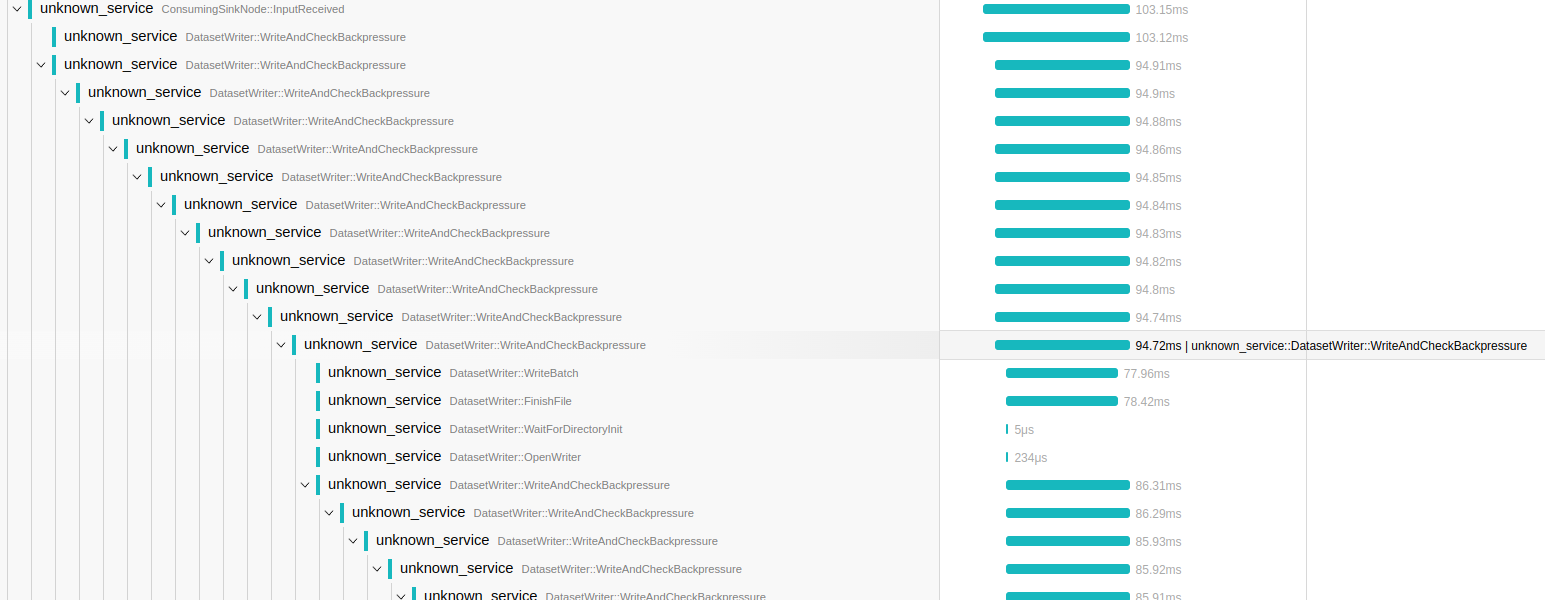
Yes. The recursion is probably somewhat accurate but I agree it makes it harder to read. Having them as siblings makes sense too. I will revert back to this understanding.
Yes, I believe so. A more generic term than
But today it ends up being (because the last part of each node is to call the downstream node):
Yet another case where the conceptual/logical understanding is different than the physical understanding. Although, perhaps there is some merit for the physical understanding as it mirrors reality more closely. Perhaps it depends on the goal of the reader. If someone is trying to improve the threading and execution of the plan itself they might want the physical model. If someone is trying to focus on the performance of a single node they might want the logical model. I'll leave that for a follow-up PR.
Great. Mentally, when I think of the dataset writer, I think there are two parts. The first part should be the trailing part of the fragment/pipeline that feeds the writer. In this first part we partition the batch, select the appropriate file queues, and deposit the batches into the queues. There is then a separate dedicated thread task to write each batch to the writer. |
|
I'm going to merge this as-is to unblock the error handling cleanup. We can fine tune in future PRs. |
|
I was about to start reviewing it, sorry for the delay 😅 In any case, Joost already took a look here fortunately. |
No problem. I might be moving a little fast but I think the tracing stuff is still pretty experimental at the moment. One thing I forgot to note is that I have upgraded OT from 1.4 to 1.8. I found that 1.4 could not connect directly to a connector for some reason. 1.8 seems to work out of the box. Also, I noticed that 1.8 now has a jaeger exporter which could potentially avoid the need to have a collector at all. I tried to enable it but quickly ran into trouble with the bundled build which seems to be pretty custom. |
|
The upgrade sounds fine. I think OT itself is also moving fast so that might explain the incompatibility. As mentioned in the original OT PRs, there's a tension between whether Arrow counts as a library or an application to OT. Really we shouldn't be setting up any exporters at all, letting the application control it all, but that is inconvenient/impossible for Python users at the moment... |
|
Benchmark runs are scheduled for baseline = b9d1162 and contender = 589b5b2. 589b5b2 is a master commit associated with this PR. Results will be available as each benchmark for each run completes. |
This PR does two things. First, it requires that all "tasks" (for the AsyncTaskScheduler, not the executor) have a name. Second, it simplifies and cleans up the way that exec nodes report their tracing using a
TracedNodehelper class.