Kubernetes Pod Operator support running with multiple containers #23450
Conversation
|
Congratulations on your first Pull Request and welcome to the Apache Airflow community! If you have any issues or are unsure about any anything please check our Contribution Guide (https://github.com/apache/airflow/blob/main/CONTRIBUTING.rst)
|
|
I'm wondering if instead we should just check the We also need to be mindful of how this will play with delete_worker_pods being false. K8s sidecars can get so messy. |
|
My first approach was to check the |
|
Hi @jedcunningham. Following your suggestion to watch the In addition, I think that we can just check if the container is not running, because that implies that the container is in a terminated state. According to the documentation, there are three different states, and if the container is in a running state it can only move to the terminated state. |
|
Hey @jedcunningham - not sure if you are available :) .but if you do, I am preparing release of providers now and I think this one might be a good one to be included. |
|
Seems we have some realated failures - it will have to wait for the next round of providers. |
| while True: | ||
| remote_pod = self.read_pod(pod) | ||
| if remote_pod.status.phase in PodPhase.terminal_states: | ||
| if not self.container_is_running(pod=remote_pod, container_name=base_container): |
There was a problem hiding this comment.
this changes the meaning of this method from "await pod completion" to "await container completion"
There was a problem hiding this comment.
Probably worth having a separate method for doing it based on container, if we go that way, so we dont introduce a breaking change here.
| time.sleep(1) | ||
|
|
||
| def await_pod_completion(self, pod: V1Pod) -> V1Pod: | ||
| def await_pod_completion(self, pod: V1Pod, base_container: str) -> V1Pod: |
There was a problem hiding this comment.
if i were gonna add this param, i would not call it 'base_container'. this method doesn't know that the caller is providing the "base" container, so better to just be generic with container_name or something. BUT i am not sure we should change this method anyway, since the purpose is to wait for pod termination.
|
i'm not seeing the |
|
I still have concerns with how this will interact with delete_worker_pods being false, seems like a good way to get orphaned still-running pods in your cluster. |
|
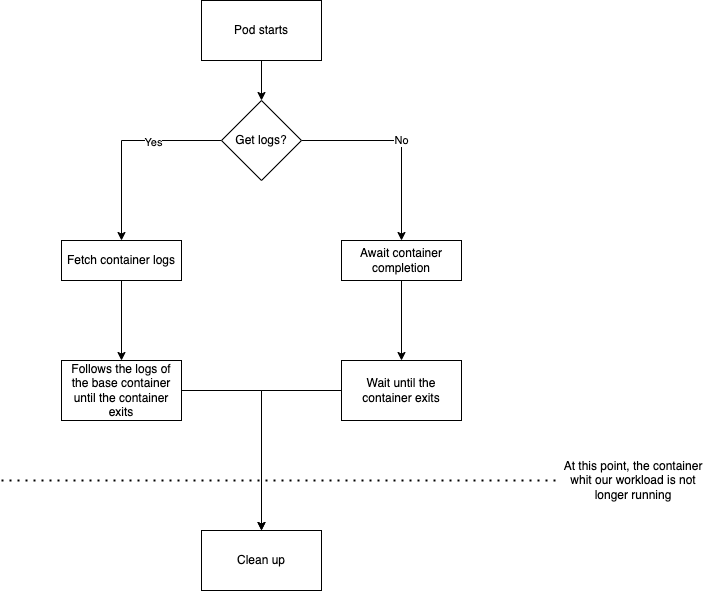
Hi @dstandish and @jedcunningham. Thank you for your review, and sorry for the delay, it's been a busy week. Going back to this PR, I have made a diagram to clarify it because I think that we can delete this function method call https://github.com/apache/airflow/blob/main/airflow/providers/cncf/kubernetes/operators/kubernetes_pod.py#L418. That point can only be reached when the base container has finished, so we don't need to wait until the pod has finished. This will continue working with single containers, and it will fix the behavior when running with sidecars.
Regarding the Let me know what do you think about this :) |
|
I have found other behavior that it isn't working as expected with multiple containers. During the |
|
@dgdelahera re usage of remote pod there's a related PR in flight #22092 also, when we patch the pod, which is sometimes done in |
|
@dstandish My PR doesn't modify that workflow. https://github.com/apache/airflow/pull/23450/files#diff-947f9f98b4aedccee6dd81558568c350c738f5da050aad1224d8b48ec43677cdR418 There we are still reading the latest pod state before calling the |
So, when there is an xcom sidecar, it is terminated when we call Separately it seems either your description needs updating or the PR because it's talking about adding an "await all containers" option but not seeing that in the PR. It might be helpful, in evaluating your approach, to have an example too, demonstrating how your change would help with multiple containers / sidecars. |
|
@dstandish Oh, I didn't take into account the xcom sidecar. I will think it again, and I will also update the description. Thank you so much for the feedback |
|
@dstandish @jedcunningham I have updated the description and also added a check to the xcom container. If you are agree with this approach, I will add the unit tests for the new methods. Thanks 😄 |
|
Hi @jedcunningham @dstandish, would you mind taking a new review? Thanks |
I think it would be good to make the tests pass first. |
|
This pull request has been automatically marked as stale because it has not had recent activity. It will be closed in 5 days if no further activity occurs. Thank you for your contributions. |
Motivation of the PR
This PR allows Kubernetes Pod Operator to run with sidecars containers.
When running the Kubernetes Pod Operator, the task waits until the pod is in a Terminate state. In the case that we are running the Pod Operator with multiple containers, the Pod will not be in a Terminate state until all the containers are in a Terminate state. This is a problem when running the main container among sidecars containers, because in many case this containers doesn't receive the signal to exit. An example would be an envoy container that handles the pod network.
Example of a Pod with one container in a terminated state. Note that the Pod status is
Running.The other part that won't work is the cleanup. At the moment, the task will be marked as failed if the pod is not in the
SUCCEEDEDphase. When running with sidecars, if the sidecars hasn't stop running, the pod won't be in that state.Changes
As we can see in the follow diagram of the run workflow, we don't need to wait until the pod have finished, so I have removed that part. Our base container (the one that is executing the workload) will always be finished when we reach that point. If we are running with a xcom container, now we will wait for that container.
For the cleanup, now we check if the base container is completed or not. In the case that the container is not in that state, it means that the task has failed.
The changes have been tested more than a week in an AWS EKS.