
An end-to-end tutorial where we'll fine-tune an LLM to perform batch inference and online serving at scale. While entity recognition is the main task, we can easily extend these end-to-end workflows to any use case.
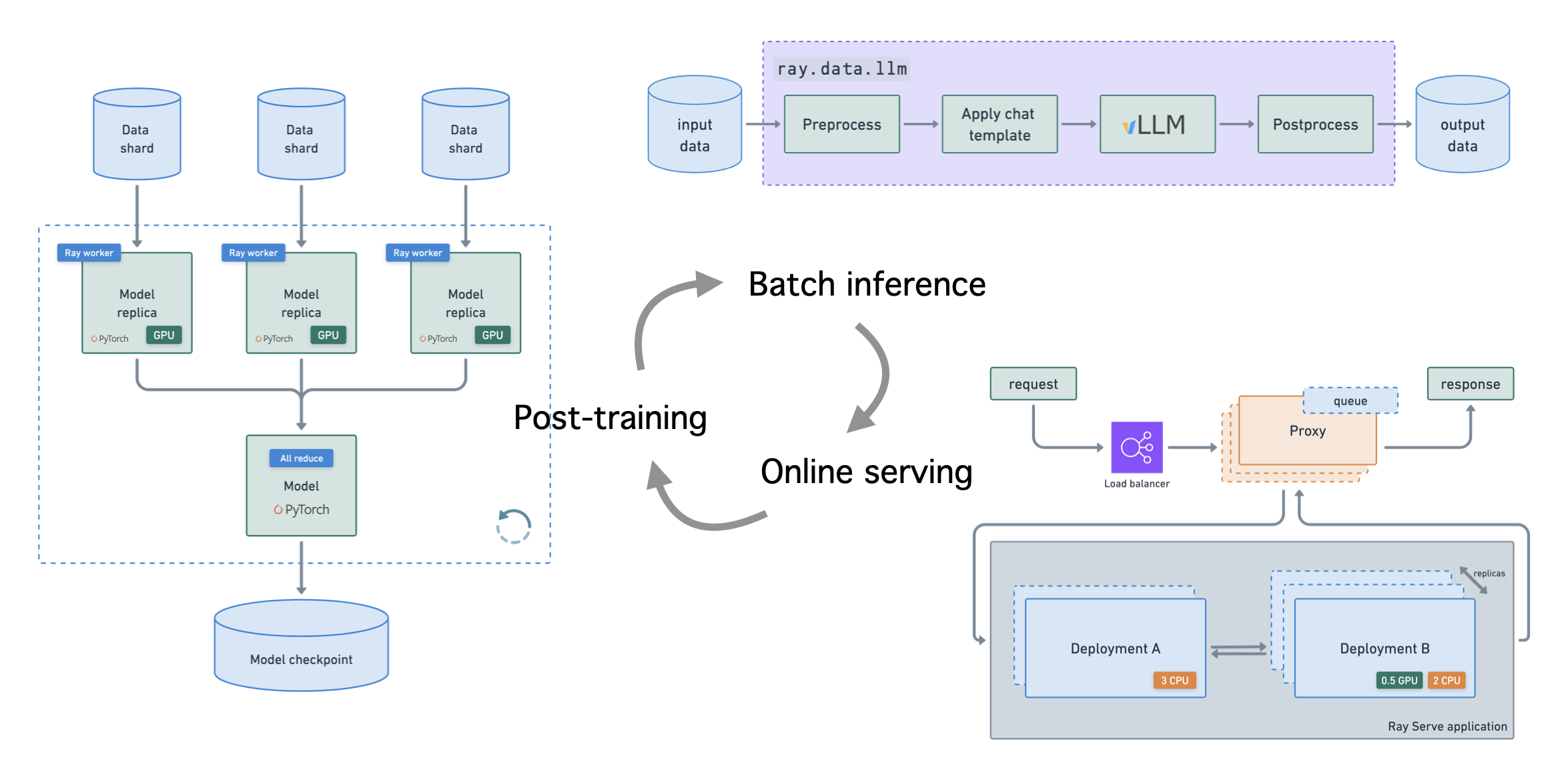
Note: the intent of this tutorial is to show how Ray can be use to implement end-to-end LLM workflows that can extend to any use case.
This Anyscale Workspace will automatically provision and autoscale the compute our workloads will need. If you're not on Anyscale, then you will need to provision 4xA10G:48CPU-192GB for this tutorial.
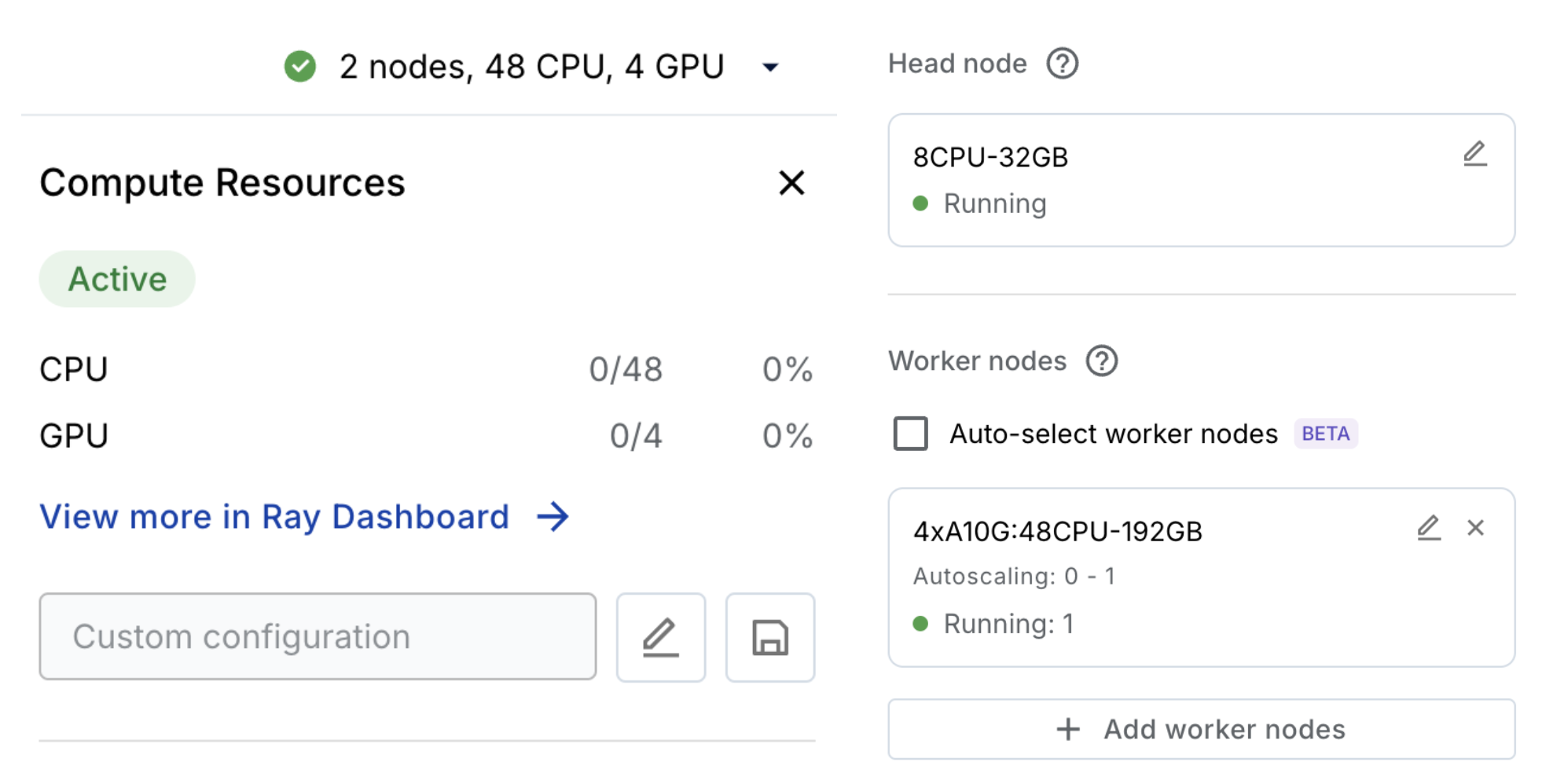
Let's start by downloading the dependencies required for this tutorial. You'll notice in our containerfile we have a base image FROM anyscale/ray:2.44.1-py312-cu125 followed by a list of pip packages. If you're not on any Anyscale, you can pull this docker image yourself and install the dependencies.
%%bash
# Install dependencies
pip install -q \
"ray[serve,llm]>=2.44.0" \
"vllm>=0.7.2" \
"xgrammar==0.1.11" \
"pynvml==12.0.0" \
"hf_transfer==0.1.9" \
"tensorboard" \
"llamafactory @ git+https://github.com/hiyouga/LLaMA-Factory.git#egg=llamafactory"import json
import requests
import textwrap
from IPython.display import Code, Image, displayWe'll start by downloading our data from cloud storage to local shared storage.
%%bash
rm -rf /mnt/cluster_storage/viggo # clean up
aws s3 cp s3://viggo-ds/train.jsonl /mnt/cluster_storage/viggo/
aws s3 cp s3://viggo-ds/val.jsonl /mnt/cluster_storage/viggo/
aws s3 cp s3://viggo-ds/test.jsonl /mnt/cluster_storage/viggo/
aws s3 cp s3://viggo-ds/dataset_info.json /mnt/cluster_storage/viggo/%%bash
head -n 1 /mnt/cluster_storage/viggo/train.jsonl | python3 -m json.tool{
"instruction": "Given a target sentence construct the underlying meaning representation of the input sentence as a single function with attributes and attribute values. This function should describe the target string accurately and the function must be one of the following ['inform', 'request', 'give_opinion', 'confirm', 'verify_attribute', 'suggest', 'request_explanation', 'recommend', 'request_attribute']. The attributes must be one of the following: ['name', 'exp_release_date', 'release_year', 'developer', 'esrb', 'rating', 'genres', 'player_perspective', 'has_multiplayer', 'platforms', 'available_on_steam', 'has_linux_release', 'has_mac_release', 'specifier']",
"input": "Blizzard North is mostly an okay developer, but they released Diablo II for the Mac and so that pushes the game from okay to good in my view.",
"output": "give_opinion(name[Diablo II], developer[Blizzard North], rating[good], has_mac_release[yes])"
}with open("/mnt/cluster_storage/viggo/train.jsonl", "r") as fp:
first_line = fp.readline()
item = json.loads(first_line)
system_content = item["instruction"]
print(textwrap.fill(system_content, width=80))Given a target sentence construct the underlying meaning representation of the input sentence as a single function with attributes and attribute values. This function should describe the target string accurately and the function must be one of the following ['inform', 'request', 'give_opinion', 'confirm', 'verify_attribute', 'suggest', 'request_explanation', 'recommend', 'request_attribute']. The attributes must be one of the following: ['name', 'exp_release_date', 'release_year', 'developer', 'esrb', 'rating', 'genres', 'player_perspective', 'has_multiplayer', 'platforms', 'available_on_steam', 'has_linux_release', 'has_mac_release', 'specifier']
We also have an info file that identifies the datasets and format --- alpaca and sharegpt (great for multimodal tasks) formats are supported --- to use for post training.
display(Code(filename="/mnt/cluster_storage/viggo/dataset_info.json", language="json")){
"viggo-train": {
"file_name": "/mnt/cluster_storage/viggo/train.jsonl",
"formatting": "alpaca",
"columns": {
"prompt": "instruction",
"query": "input",
"response": "output"
}
},
"viggo-val": {
"file_name": "/mnt/cluster_storage/viggo/val.jsonl",
"formatting": "alpaca",
"columns": {
"prompt": "instruction",
"query": "input",
"response": "output"
}
}
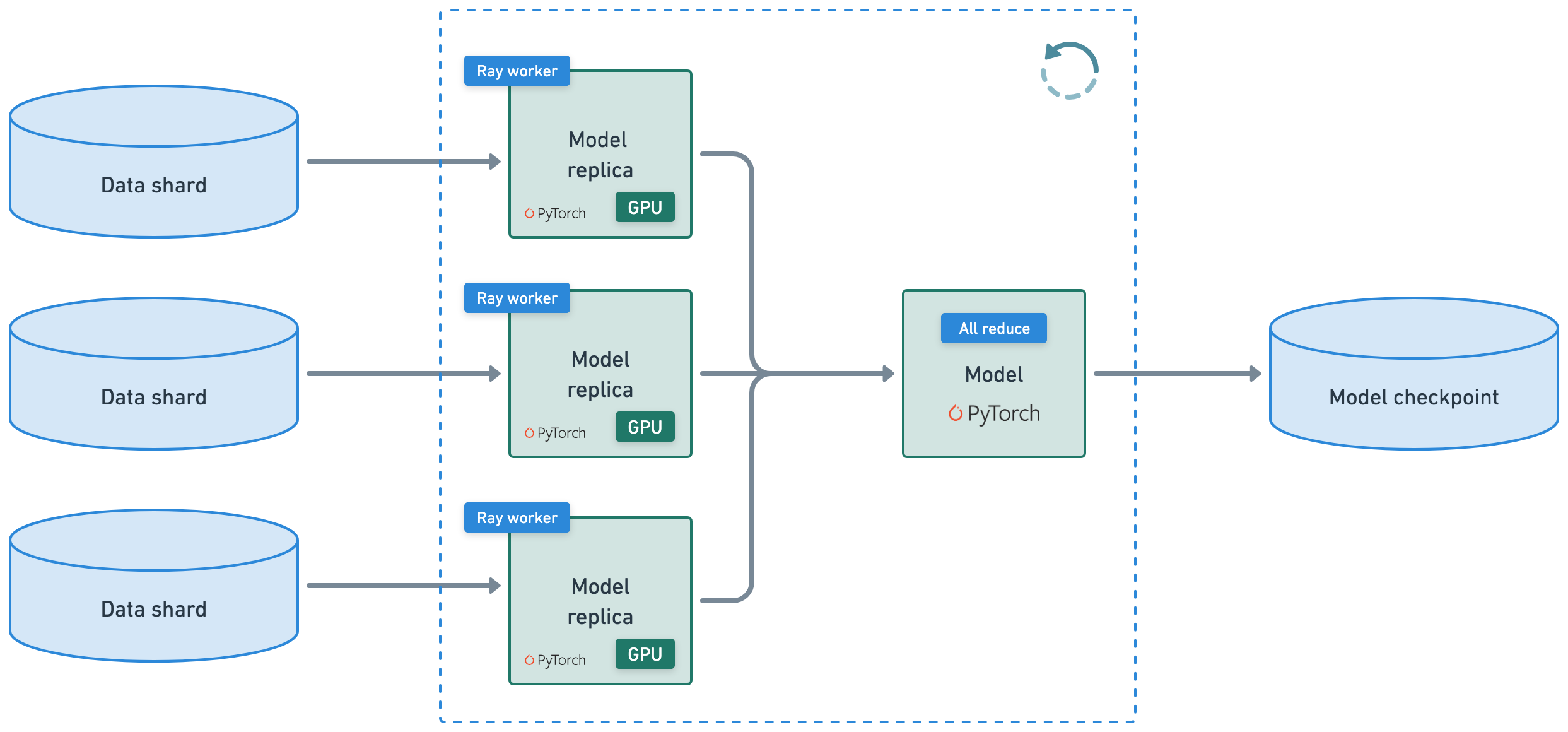
}We'll use Ray Train + LLaMA-Factory to peform multinode training. The parameters for our training workload -- post-training method, dataset location, train/val details, etc. --- can be found in the llama3_lora_sft_ray.yaml config file. Check out recipes for even more post-training methods (sft, pretraining, ppo, dpo, kto, etc.) here.
Note: We also support using other tools like axolotl or even Ray Train + HF Accelreate + FSDP/Deepspeed directly for complete control of your post-training workloads.
import os
from pathlib import Path
import yamldisplay(Code(filename="lora_sft_ray.yaml", language="yaml"))### model
model_name_or_path: Qwen/Qwen2.5-7B-Instruct
trust_remote_code: true
### method
stage: sft
do_train: true
finetuning_type: lora
lora_rank: 8
lora_target: all
### dataset
dataset: viggo-train
dataset_dir: /mnt/cluster_storage/viggo # shared storage workers have access to
template: qwen
cutoff_len: 2048
max_samples: 1000
overwrite_cache: true
preprocessing_num_workers: 16
dataloader_num_workers: 4
### output
output_dir: /mnt/cluster_storage/viggo/outputs # should be somewhere workers have access to (ex. s3, nfs)
logging_steps: 10
save_steps: 500
plot_loss: true
overwrite_output_dir: true
save_only_model: false
### ray
ray_run_name: lora_sft_ray
ray_storage_path: /mnt/cluster_storage/viggo/saves # should be somewhere workers have access to (ex. s3, nfs)
ray_num_workers: 4
resources_per_worker:
GPU: 1
anyscale/accelerator_shape:4xA10G: 1 # Use this to specify a specific node shape,
# accelerator_type:A10G: 1 # Or use this to simply specify a GPU type.
# see https://docs.ray.io/en/master/ray-core/accelerator-types.html#accelerator-types for a full list of accelerator types
placement_strategy: PACK
### train
per_device_train_batch_size: 1
gradient_accumulation_steps: 8
learning_rate: 1.0e-4
num_train_epochs: 5.0
lr_scheduler_type: cosine
warmup_ratio: 0.1
bf16: true
ddp_timeout: 180000000
resume_from_checkpoint: null
### eval
eval_dataset: viggo-val # uses same dataset_dir as training data
# val_size: 0.1 # only if using part of training data for validation
per_device_eval_batch_size: 1
eval_strategy: steps
eval_steps: 500model_id = "ft-model" # call it whatever you want
model_source = yaml.safe_load(open("lora_sft_ray.yaml"))["model_name_or_path"] # HF model ID, S3 mirror config, or GCS mirror config
print (model_source)Qwen/Qwen2.5-7B-Instruct
%%bash
# Run multinode distributed fine-tuning workload
USE_RAY=1 llamafactory-cli train lora_sft_ray.yamlTraining started with configuration:
╭──────────────────────────────────────────────────────────────────────────────────────────────────────╮
│ Training config │
├──────────────────────────────────────────────────────────────────────────────────────────────────────┤
│ train_loop_config/args/bf16 True │
│ train_loop_config/args/cutoff_len 2048 │
│ train_loop_config/args/dataloader_num_workers 4 │
│ train_loop_config/args/dataset viggo-train │
│ train_loop_config/args/dataset_dir ...ter_storage/viggo │
│ train_loop_config/args/ddp_timeout 180000000 │
│ train_loop_config/args/do_train True │
│ train_loop_config/args/eval_dataset viggo-val │
│ train_loop_config/args/eval_steps 500 │
│ train_loop_config/args/eval_strategy steps │
│ train_loop_config/args/finetuning_type lora │
│ train_loop_config/args/gradient_accumulation_steps 8 │
│ train_loop_config/args/learning_rate 0.0001 │
│ train_loop_config/args/logging_steps 10 │
│ train_loop_config/args/lora_rank 8 │
│ train_loop_config/args/lora_target all │
│ train_loop_config/args/lr_scheduler_type cosine │
│ train_loop_config/args/max_samples 1000 │
│ train_loop_config/args/model_name_or_path ...en2.5-7B-Instruct │
│ train_loop_config/args/num_train_epochs 5.0 │
│ train_loop_config/args/output_dir ...age/viggo/outputs │
│ train_loop_config/args/overwrite_cache True │
│ train_loop_config/args/overwrite_output_dir True │
│ train_loop_config/args/per_device_eval_batch_size 1 │
│ train_loop_config/args/per_device_train_batch_size 1 │
│ train_loop_config/args/placement_strategy PACK │
│ train_loop_config/args/plot_loss True │
│ train_loop_config/args/preprocessing_num_workers 16 │
│ train_loop_config/args/ray_num_workers 4 │
│ train_loop_config/args/ray_run_name lora_sft_ray │
│ train_loop_config/args/ray_storage_path ...orage/viggo/saves │
│ train_loop_config/args/resources_per_worker/GPU 1 │
│ train_loop_config/args/resources_per_worker/anyscale/accelerator_shape:4xA10G 1 │
│ train_loop_config/args/resume_from_checkpoint │
│ train_loop_config/args/save_only_model False │
│ train_loop_config/args/save_steps 500 │
│ train_loop_config/args/stage sft │
│ train_loop_config/args/template qwen │
│ train_loop_config/args/trust_remote_code True │
│ train_loop_config/args/warmup_ratio 0.1 │
│ train_loop_config/callbacks ... 0x7e1262910e10>] │
╰──────────────────────────────────────────────────────────────────────────────────────────────────────╯
100%|██████████| 155/155 [07:12<00:00, 2.85s/it][INFO|trainer.py:3942] 2025-04-11 14:57:59,207 >> Saving model checkpoint to /mnt/cluster_storage/viggo/outputs/checkpoint-155
Training finished iteration 1 at 2025-04-11 14:58:02. Total running time: 10min 24s
╭─────────────────────────────────────────╮
│ Training result │
├─────────────────────────────────────────┤
│ checkpoint_dir_name checkpoint_000000 │
│ time_this_iter_s 521.83827 │
│ time_total_s 521.83827 │
│ training_iteration 1 │
│ epoch 4.704 │
│ grad_norm 0.14288 │
│ learning_rate 0. │
│ loss 0.0065 │
│ step 150 │
╰─────────────────────────────────────────╯
Training saved a checkpoint for iteration 1 at: (local)/mnt/cluster_storage/viggo/saves/lora_sft_ray/TorchTrainer_95d16_00000_0_2025-04-11_14-47-37/checkpoint_000000
Using Ray Train here has several advantages:
- automatically handles multi-node, multi-GPU setup with no manual SSH setup or hostfile configs.
- define per-worker franctional resource requirements (e.g., 2 CPUs and 0.5 GPU per worker)
- run on heterogeneous machines and scale flexibly (e.g., CPU for preprocessing and GPU for training)
- built-in fault tolerance via retry of failed workers (and continue from last checkpoint).
- supports Data Parallel, Model Parallel, Parameter Server, and even custom strategies.
- Ray Compiled graphs allow us to even define different parallelism for jointly optimizing multipe models (Megatron, Deepspeed, etc. only allow for one global setting).
RayTurbo Train offers even more improvement to the price-performance ratio, performance monitoring and more:
- elastic training to scale to a dynamic number of workers, continue training on fewer resources (even on spot instances).
- purpose-built dashboard designed to streamline the debugging of Ray Train workloads
- Monitoring: View the status of training runs and train workers.
- Metrics: See insights on training throughput, training system operation time.
- Profiling: Investigate bottlenecks, hangs, or errors from individual training worker processes.
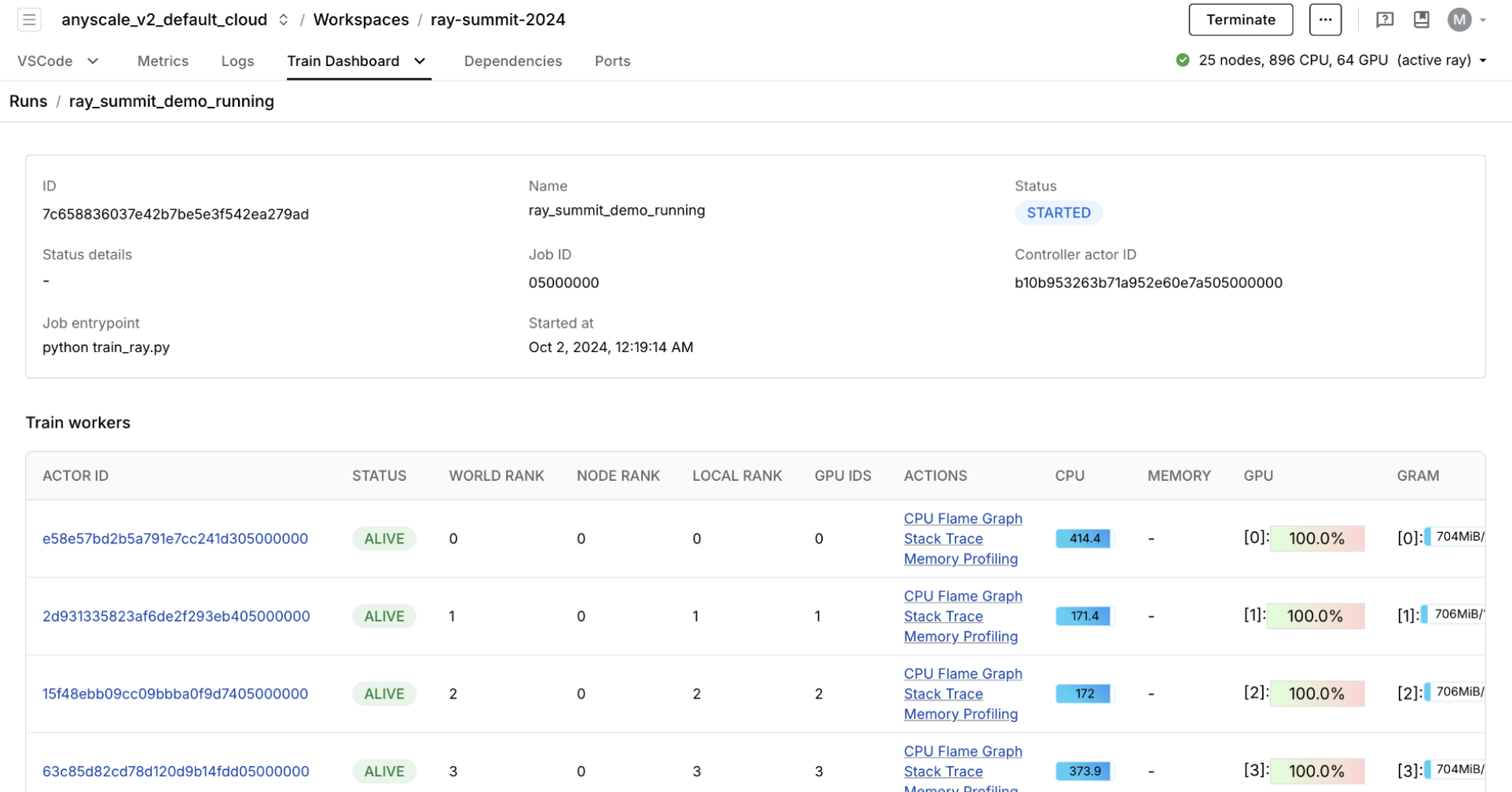
OSS Ray offers an extensive observability suite that offers logs and an observability dashboard that we can use to monitor and debug. The dashboard includes a lot of different components such as:
- memory, utilization, etc. of the tasks running in our cluster
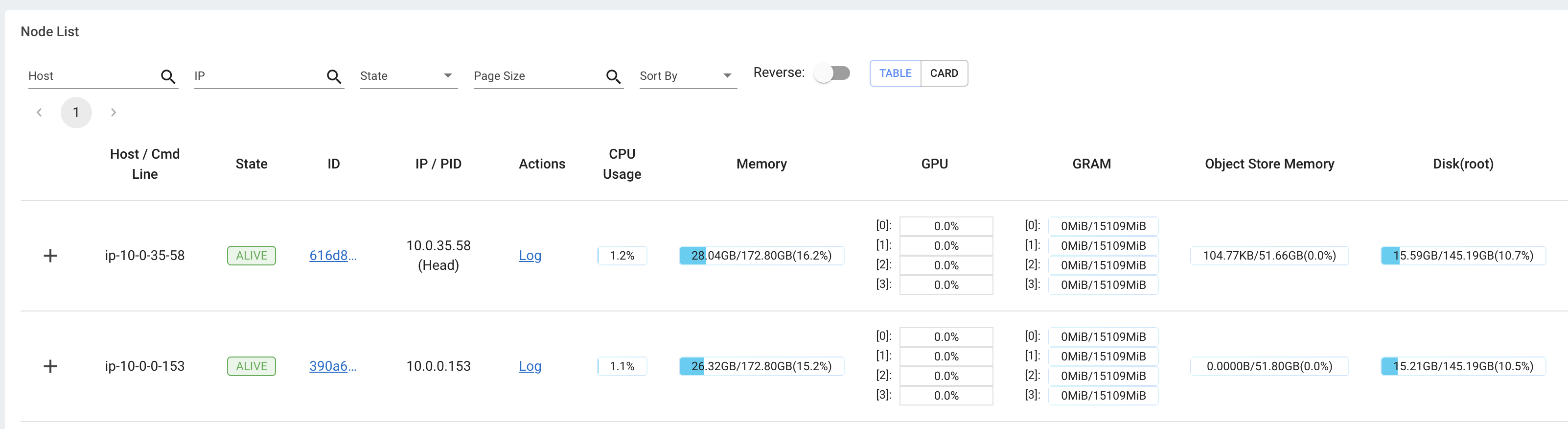
- views to see all our running tasks, utilization across instance types, autoscaling, etc.

While OSS Ray comes with an extensive obervability suite, Anyscale takes it many steps further to make it even easier and faster to monitor and debug your workloads.
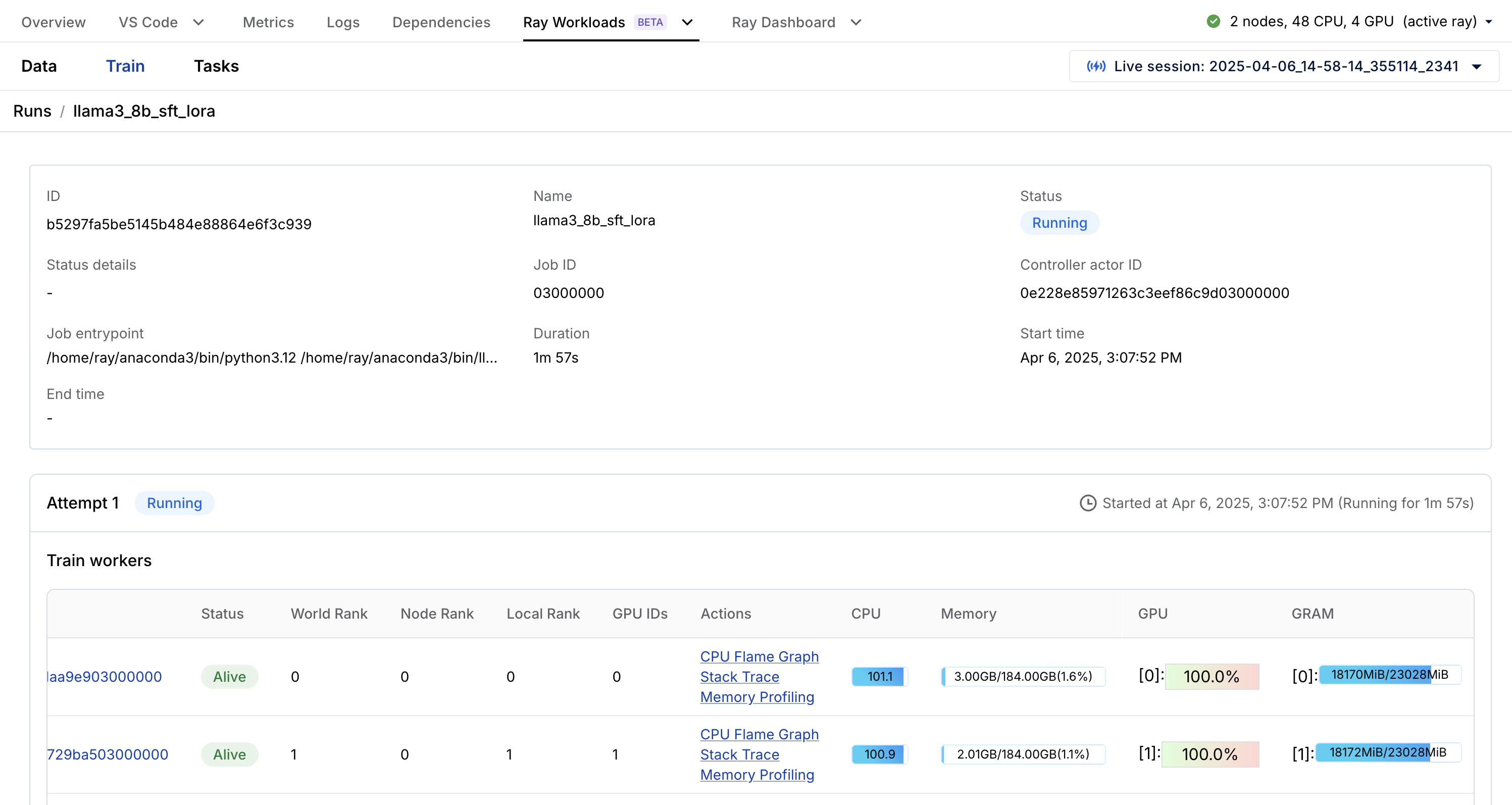
- unified log viewer to see logs from all our driver and worker processes
- Ray workload specific dashboard (Data, Train, etc.) that can breakdown the tasks. For example, our training workload above can be observed live through the Train specific Ray Workloads dashboard:
We can always store to our data inside any storage buckets but Anyscale offers a default storage bucket to make things even easier. We also have plenty of other storage options as well (shared at the cluster, user and cloud levels).
%%bash
# Anyscale default storage bucket
echo $ANYSCALE_ARTIFACT_STORAGEs3://anyscale-test-data-cld-i2w99rzq8b6lbjkke9y94vi5/org_7c1Kalm9WcX2bNIjW53GUT/cld_kvedZWag2qA8i5BjxUevf5i7/artifact_storage
%%bash
# Save fine-tuning artifacts to cloud storage
aws s3 rm $ANYSCALE_ARTIFACT_STORAGE/viggo --recursive --quiet
aws s3 cp /mnt/cluster_storage/viggo/outputs $ANYSCALE_ARTIFACT_STORAGE/viggo/outputs --recursive --quiet
aws s3 cp $2 /mnt/cluster_storage/viggo/saves $ANYSCALE_ARTIFACT_STORAGE/viggo/saves --recursive --quietdisplay(Code(filename="/mnt/cluster_storage/viggo/outputs/all_results.json", language="json")){
"epoch": 4.864,
"eval_viggo-val_loss": 0.13618840277194977,
"eval_viggo-val_runtime": 20.2797,
"eval_viggo-val_samples_per_second": 35.208,
"eval_viggo-val_steps_per_second": 8.827,
"total_flos": 4.843098686147789e+16,
"train_loss": 0.2079355036479331,
"train_runtime": 437.2951,
"train_samples_per_second": 11.434,
"train_steps_per_second": 0.354
}display(Image(filename="/mnt/cluster_storage/viggo/outputs/training_loss.png"))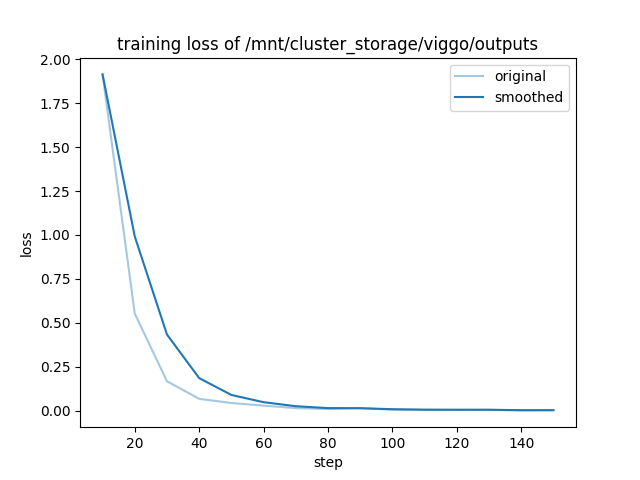
%%bash
ls /mnt/cluster_storage/viggo/saves/lora_sft_rayTorchTrainer_95d16_00000_0_2025-04-11_14-47-37
TorchTrainer_f9e4e_00000_0_2025-04-11_12-41-34
basic-variant-state-2025-04-11_12-41-34.json
basic-variant-state-2025-04-11_14-47-37.json
experiment_state-2025-04-11_12-41-34.json
experiment_state-2025-04-11_14-47-37.json
trainer.pkl
tuner.pkl
# LoRA paths
save_dir = Path("/mnt/cluster_storage/viggo/saves/lora_sft_ray")
trainer_dirs = [d for d in save_dir.iterdir() if d.name.startswith("TorchTrainer_") and d.is_dir()]
latest_trainer = max(trainer_dirs, key=lambda d: d.stat().st_mtime, default=None)
lora_path = f"{latest_trainer}/checkpoint_000000/checkpoint"
s3_lora_path = os.path.join(os.getenv("ANYSCALE_ARTIFACT_STORAGE"), lora_path.split("/mnt/cluster_storage/")[-1])
dynamic_lora_path, lora_id = s3_lora_path.rsplit("/", 1)%%bash -s "$lora_path"
ls $1README.md
adapter_config.json
adapter_model.safetensors
added_tokens.json
merges.txt
optimizer.pt
rng_state_0.pth
rng_state_1.pth
rng_state_2.pth
rng_state_3.pth
scheduler.pt
special_tokens_map.json
tokenizer.json
tokenizer_config.json
trainer_state.json
training_args.bin
vocab.json
The ray.data.llm module integrates with key large language model (LLM) inference engines and deployed models to enable LLM batch inference. These llm modules use Ray Data under the hood, which makes it extremely easy to distribute our workloads but also ensures that they happen:
- efficiently: minimize CPU/GPU idletime with hetergenous resource scheduling.
- at scale: streaming execution to petabyte-scale datasets (especially when working with LLMs)
- reliably by checkpointing processes, especially when running workloads on spot instanes (with on-demand fallback).
- flexiblibly: connect to data from any source, apply your transformations and save to any format/location for your next workload.
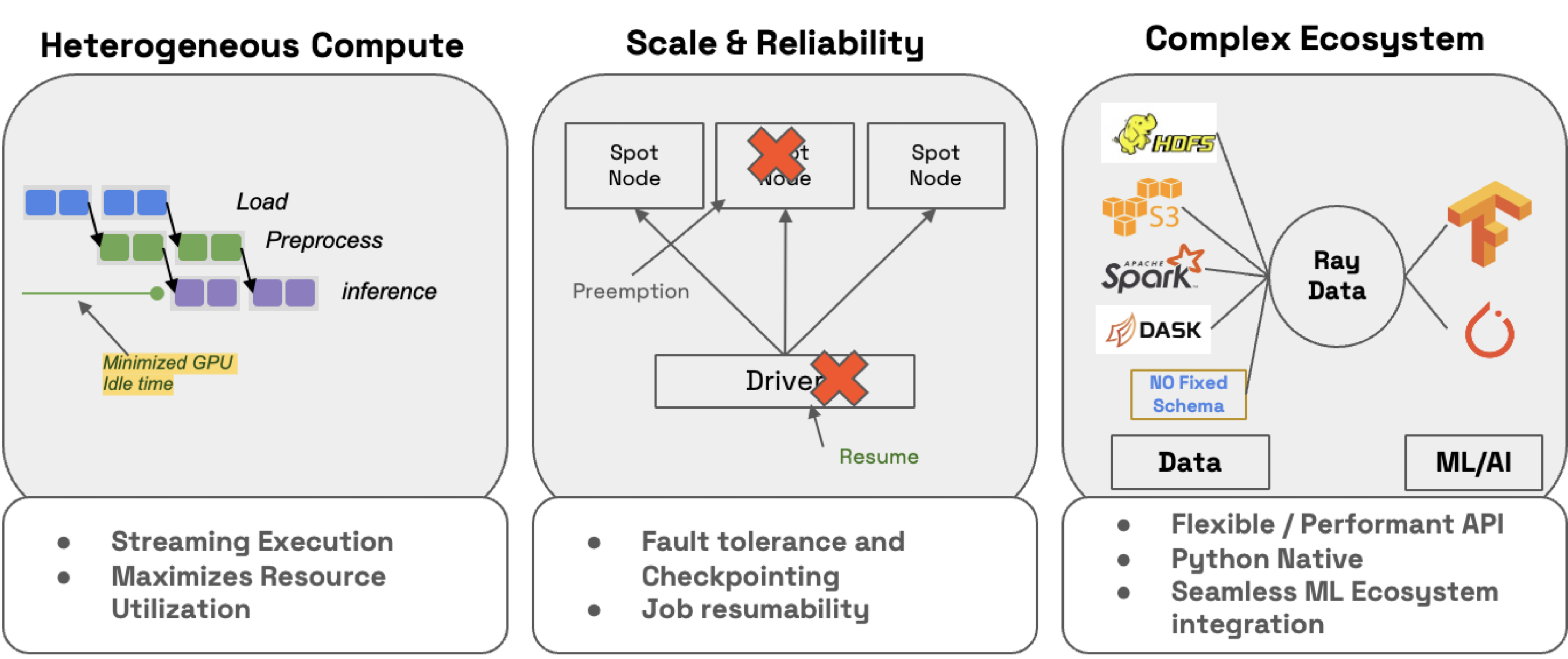
RayTurbo Data has even more functionality on top of Ray Data:
- accelerated metadata fetching to improve reading first time from large datasets
- optimized autoscaling where Jobs can kick off before waiting for the entire cluster to start
- high reliabilty where entire fails jobs (head node, cluster, uncaptured exceptions, etc.) can resume from checkpoints (OSS Ray can only recover from worker node failures)
Let's start by defining the vLLM engine processor config where we can select the model we want to use and the engine behavior. The model can come from HuggingFace (HF) Hub or a local model path /path/to/your/model (GPTQ, GGUF, or LoRA model formats supported).

import os
import ray
from ray.data.llm import vLLMEngineProcessorConfig, build_llm_processor
import numpy as npconfig = vLLMEngineProcessorConfig(
model_source=model_source,
# runtime_env={"env_vars": {"HF_TOKEN": os.environ.get("HF_TOKEN")}},
engine_kwargs={
"enable_lora": True,
"max_lora_rank": 8,
"max_loras": 1,
"pipeline_parallel_size": 1,
"tensor_parallel_size": 1,
"enable_prefix_caching": True,
"enable_chunked_prefill": True,
"max_num_batched_tokens": 4096,
"max_model_len": 4096, # or increase KV cache size
# complete list: https://docs.vllm.ai/en/stable/serving/engine_args.html
},
concurrency=1,
batch_size=16,
accelerator_type="A10G",
)Next, we'll pass our config to an llm processor where we can define the preprocessing and postprocessing steps around inference. With our base model defined in the processor config, we can define the lora adapter layers as part of the preprocessing step of the llm processor itself.
processor = build_llm_processor(
config,
preprocess=lambda row: dict(
model=lora_path, # REMOVE this line if doing inference with just the base model
messages=[
{"role": "system", "content": system_content},
{"role": "user", "content": row["input"]}
],
sampling_params={
"temperature": 0.3,
"max_tokens": 250,
# complete list: https://docs.vllm.ai/en/stable/api/inference_params.html
},
),
postprocess=lambda row: {
**row, # all contents
"generated_output": row["generated_text"],
# add additional outputs
},
)# Evaluation on test dataset
ds = ray.data.read_json("/mnt/cluster_storage/viggo/test.jsonl") # complete list: https://docs.ray.io/en/latest/data/api/input_output.html
ds = processor(ds)
results = ds.take_all()
results[0]{
"batch_uuid": "d7a6b5341cbf4986bb7506ff277cc9cf",
"embeddings": null,
"generated_text": "request(esrb)",
"generated_tokens": [2035, 50236, 10681, 8, 151645],
"input": "Do you have a favorite ESRB content rating?",
"instruction": "Given a target sentence construct the underlying meaning representation of the input sentence as a single function with attributes and attribute values. This function should describe the target string accurately and the function must be one of the following ['inform', 'request', 'give_opinion', 'confirm', 'verify_attribute', 'suggest', 'request_explanation', 'recommend', 'request_attribute']. The attributes must be one of the following: ['name', 'exp_release_date', 'release_year', 'developer', 'esrb', 'rating', 'genres', 'player_perspective', 'has_multiplayer', 'platforms', 'available_on_steam', 'has_linux_release', 'has_mac_release', 'specifier']",
"messages": [
{
"content": "Given a target sentence construct the underlying meaning representation of the input sentence as a single function with attributes and attribute values. This function should describe the target string accurately and the function must be one of the following ['inform', 'request', 'give_opinion', 'confirm', 'verify_attribute', 'suggest', 'request_explanation', 'recommend', 'request_attribute']. The attributes must be one of the following: ['name', 'exp_release_date', 'release_year', 'developer', 'esrb', 'rating', 'genres', 'player_perspective', 'has_multiplayer', 'platforms', 'available_on_steam', 'has_linux_release', 'has_mac_release', 'specifier']",
"role": "system"
},
{
"content": "Do you have a favorite ESRB content rating?",
"role": "user"
}
],
"metrics": {
"arrival_time": 1744408857.148983,
"finished_time": 1744408863.09091,
"first_scheduled_time": 1744408859.130259,
"first_token_time": 1744408862.7087252,
"last_token_time": 1744408863.089174,
"model_execute_time": null,
"model_forward_time": null,
"scheduler_time": 0.04162892400017881,
"time_in_queue": 1.981276035308838
},
"model": "/mnt/cluster_storage/viggo/saves/lora_sft_ray/TorchTrainer_95d16_00000_0_2025-04-11_14-47-37/checkpoint_000000/checkpoint",
"num_generated_tokens": 5,
"num_input_tokens": 164,
"output": "request_attribute(esrb[])",
"params": "SamplingParams(n=1, presence_penalty=0.0, frequency_penalty=0.0, repetition_penalty=1.0, temperature=0.3, top_p=1.0, top_k=-1, min_p=0.0, seed=None, stop=[], stop_token_ids=[], bad_words=[], include_stop_str_in_output=False, ignore_eos=False, max_tokens=250, min_tokens=0, logprobs=None, prompt_logprobs=None, skip_special_tokens=True, spaces_between_special_tokens=True, truncate_prompt_tokens=None, guided_decoding=None)",
"prompt": "<|im_start|>system\nGiven a target sentence construct the underlying meaning representation of the input sentence as a single function with attributes and attribute values. This function should describe the target string accurately and the function must be one of the following ['inform', 'request', 'give_opinion', 'confirm', 'verify_attribute', 'suggest', 'request_explanation', 'recommend', 'request_attribute']. The attributes must be one of the following: ['name', 'exp_release_date', 'release_year', 'developer', 'esrb', 'rating', 'genres', 'player_perspective', 'has_multiplayer', 'platforms', 'available_on_steam', 'has_linux_release', 'has_mac_release', 'specifier']<|im_end|>\n<|im_start|>user\nDo you have a favorite ESRB content rating?<|im_end|>\n<|im_start|>assistant\n",
"prompt_token_ids": [151644, "...", 198],
"request_id": 94,
"time_taken_llm": 6.028705836999961,
"generated_output": "request(esrb)"
}# Exact match (strict!)
matches = 0
for item in results:
if item["output"] == item["generated_output"]:
matches += 1
matches / float(len(results))0.6879039704524469
Note: the objective of fine-tuning here is not to create the most performant model (increase num_train_epochs if you want to though) but to show it can be leveraged for downstream workloads (batch inference and online serving) at scale.
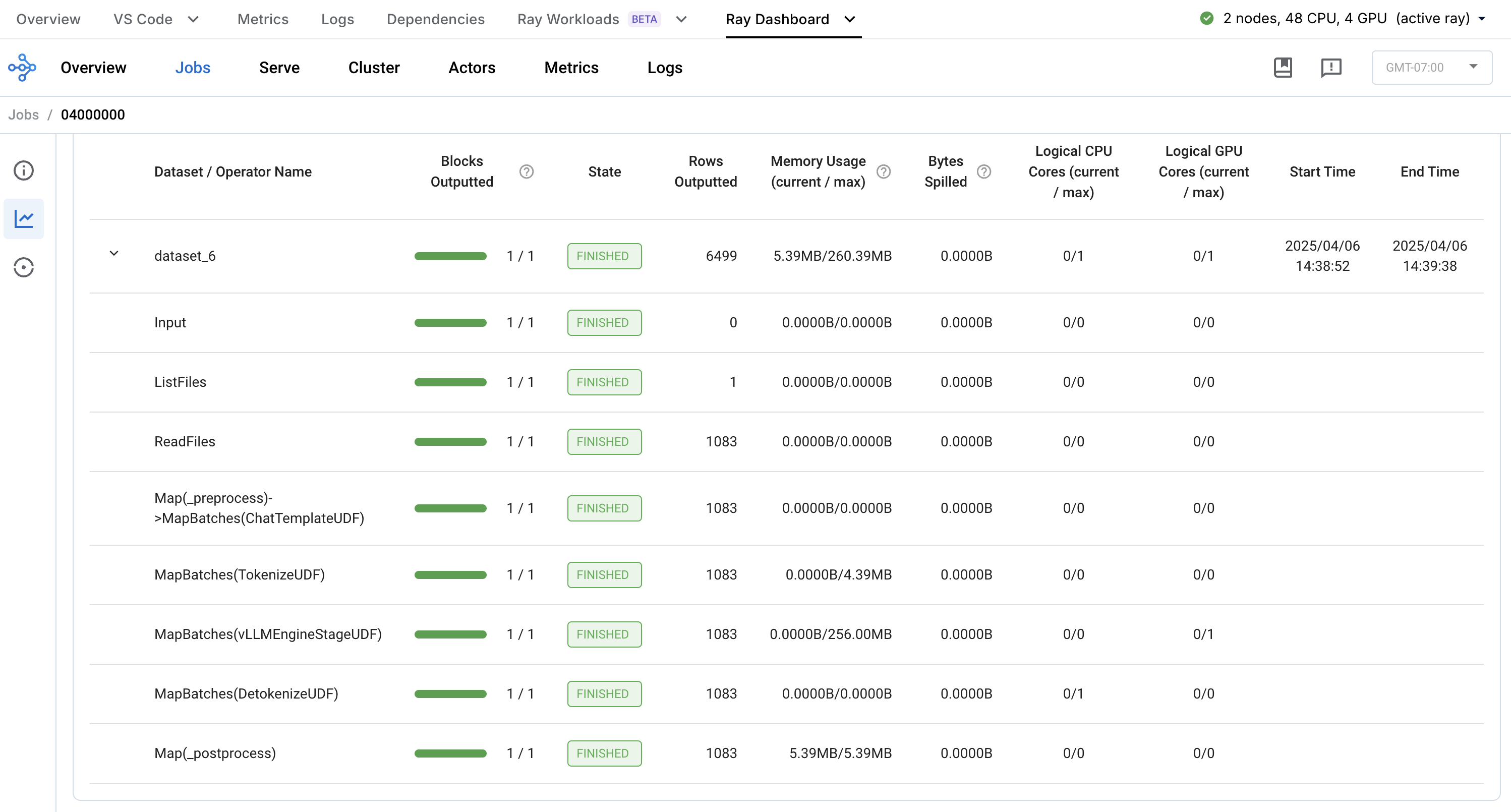
We can observe the individual steps in our our batch inference workload through the Anyscale Ray Data dashboard:
💡 For more advanced guides on topics like optimized model loading, multi-lora, openai-compatible endpoints, etc. check out more examples and the API reference.
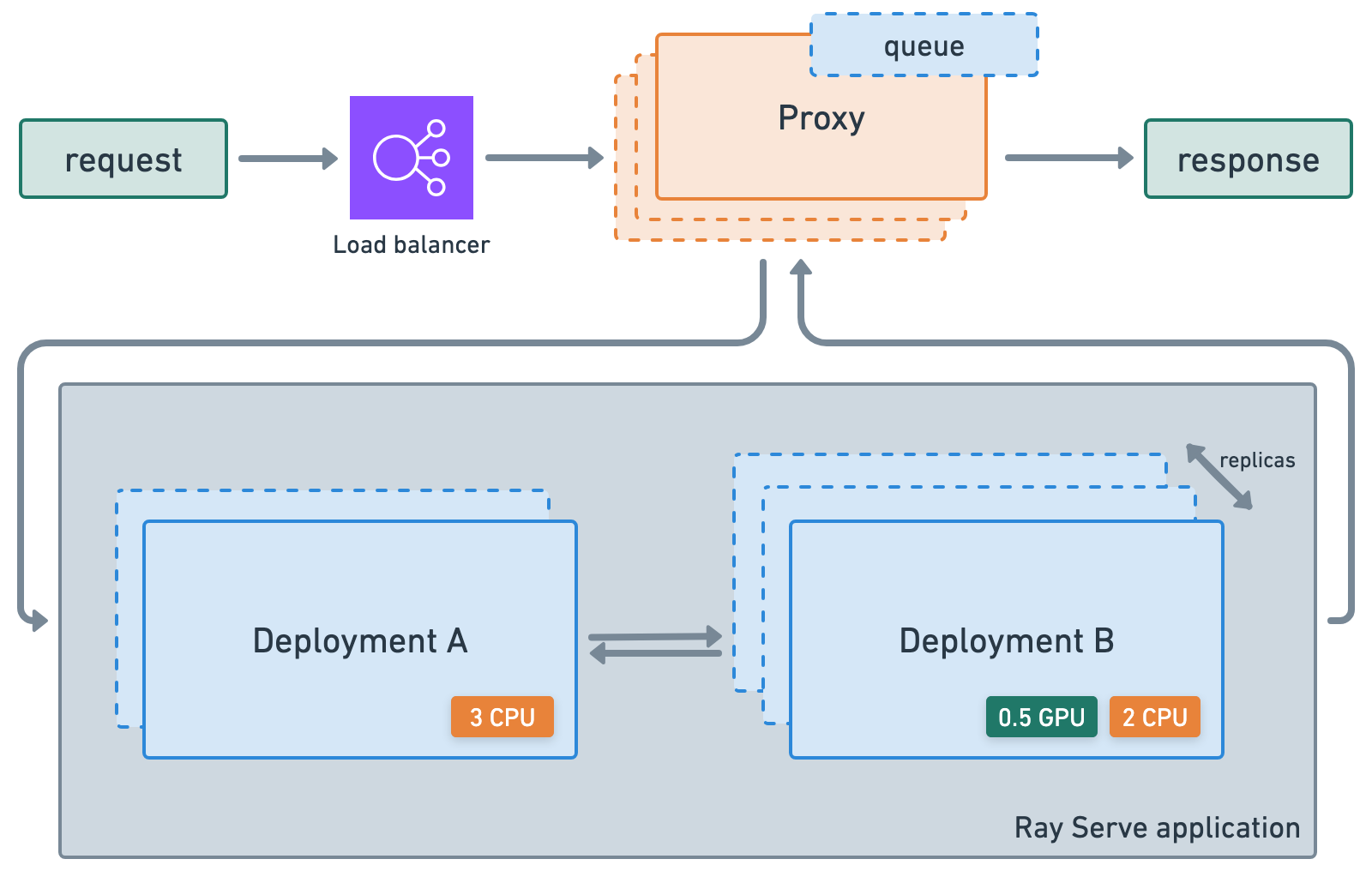
ray.serve.llm APIs allow users to deploy multiple LLM models together with a familiar Ray Serve API, while providing compatibility with the OpenAI API.

Ray Serve LLM is designed with the following features:
- Automatic scaling and load balancing
- Unified multi-node multi-model deployment
- OpenAI compatibility
- Multi-LoRA support with shared base models
- Deep integration with inference engines (vLLM to start)
- Composable multi-model LLM pipelines
RayTurbo Serve on Anyscale has even more functionality on top of Ray Serve:
- fast autoscaling and model loading to get our services up and running even faster (5x improvements even for LLMs)
- 54% higher QPS and up-to 3x streaming tokens per second for high traffic serving use-cases
- replica compaction into fewer nodes where possible to reduce resource fragmentation and improve hardware utilization
- zero-downtime incremental rollouts so your service is never interrupted
- different environments for each service in a multi-serve application
- multi availability-zone aware scheduling of Ray Serve replicas to provide higher redundancy to availability zone failures
import os
from openai import OpenAI # to use openai api format
from ray import serve
from ray.serve.llm import LLMConfig, build_openai_appLet's define an LLM config where we can define where our model comes from, it's autoscaling behavior, what hardware to use and engine arguments.
# Define config
llm_config = LLMConfig(
model_loading_config={
"model_id": model_id,
"model_source": model_source
},
lora_config={ # REMOVE this section if you are only using a base model
"dynamic_lora_loading_path": dynamic_lora_path,
"max_num_adapters_per_replica": 16, # we only have 1
},
# runtime_env={"env_vars": {"HF_TOKEN": os.environ.get("HF_TOKEN")}},
deployment_config={
"autoscaling_config": {
"min_replicas": 1,
"max_replicas": 2,
# complete list: https://docs.ray.io/en/latest/serve/autoscaling-guide.html#serve-autoscaling
}
},
accelerator_type="A10G",
engine_kwargs={
"max_model_len": 4096, # or increase KV cache size
"tensor_parallel_size": 1,
"enable_lora": True,
# complete list: https://docs.vllm.ai/en/stable/serving/engine_args.html
},
)Now we'll deploy our llm config as an application. And since this is all built on top of Ray Serve, we can have advanvced service logic around composing models together, deploying multiple applications, model multiplexing, observability, etc.
# Deploy
app = build_openai_app({"llm_configs": [llm_config]})
serve.run(app)DeploymentHandle(deployment='LLMRouter')
# Initialize client
client = OpenAI(base_url="http://localhost:8000/v1", api_key="fake-key")
response = client.chat.completions.create(
model=f"{model_id}:{lora_id}",
messages=[
{"role": "system", "content": "Given a target sentence construct the underlying meaning representation of the input sentence as a single function with attributes and attribute values. This function should describe the target string accurately and the function must be one of the following ['inform', 'request', 'give_opinion', 'confirm', 'verify_attribute', 'suggest', 'request_explanation', 'recommend', 'request_attribute']. The attributes must be one of the following: ['name', 'exp_release_date', 'release_year', 'developer', 'esrb', 'rating', 'genres', 'player_perspective', 'has_multiplayer', 'platforms', 'available_on_steam', 'has_linux_release', 'has_mac_release', 'specifier']"},
{"role": "user", "content": "Blizzard North is mostly an okay developer, but they released Diablo II for the Mac and so that pushes the game from okay to good in my view."},
],
stream=True
)
for chunk in response:
if chunk.choices[0].delta.content is not None:
print(chunk.choices[0].delta.content, end="", flush=True)Avg prompt throughput: 20.3 tokens/s, Avg generation throughput: 0.1 tokens/s, Running: 1 reqs, Swapped: 0 reqs, Pending: 0 reqs, GPU KV cache usage: 0.3%, CPU KV cache usage: 0.0%.
_opinion(name[Diablo II], developer[Blizzard North], rating[good], has_mac_release[yes])
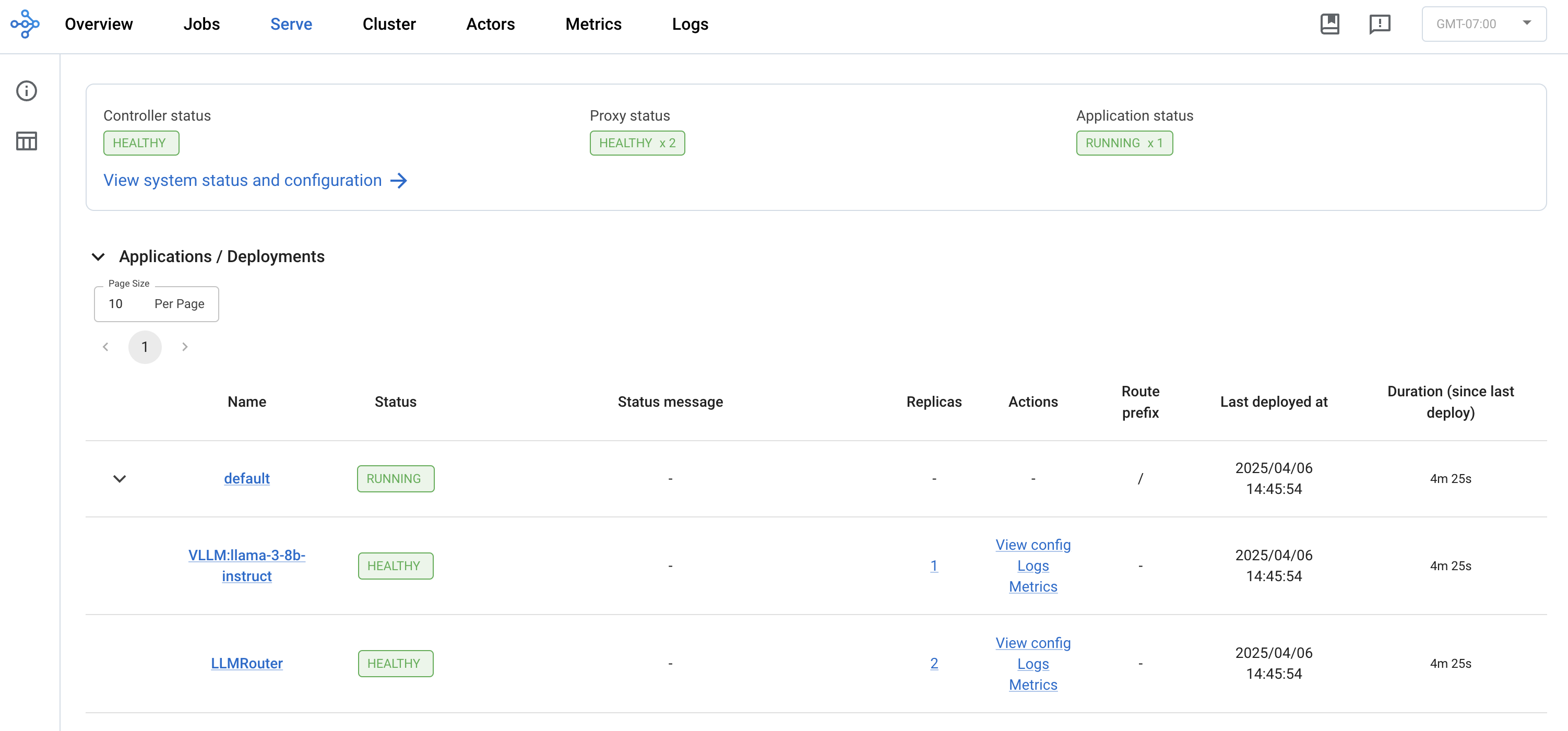
And of course, we can observe our running service (deployments and metrics like QPS, latency, etc.) through the Ray Dashboard's Serve view:
💡 For more advanced guides on topics like structured outputs (ex. json), vision LMs, multi-lora on shared base models, using other inference engines (ex. sglang), etc. fast model loading, etc. check out more examples and the API reference.
Seamlessly integrate with your existing CI/CD pipelines by leveraging the Anyscale CLI or SDK to run reliable batch jobs and deploy highly available services. Given we've been developing in an environment that's almost identical to production (multinode cluster), this should drastically speed up our dev → prod velocity.
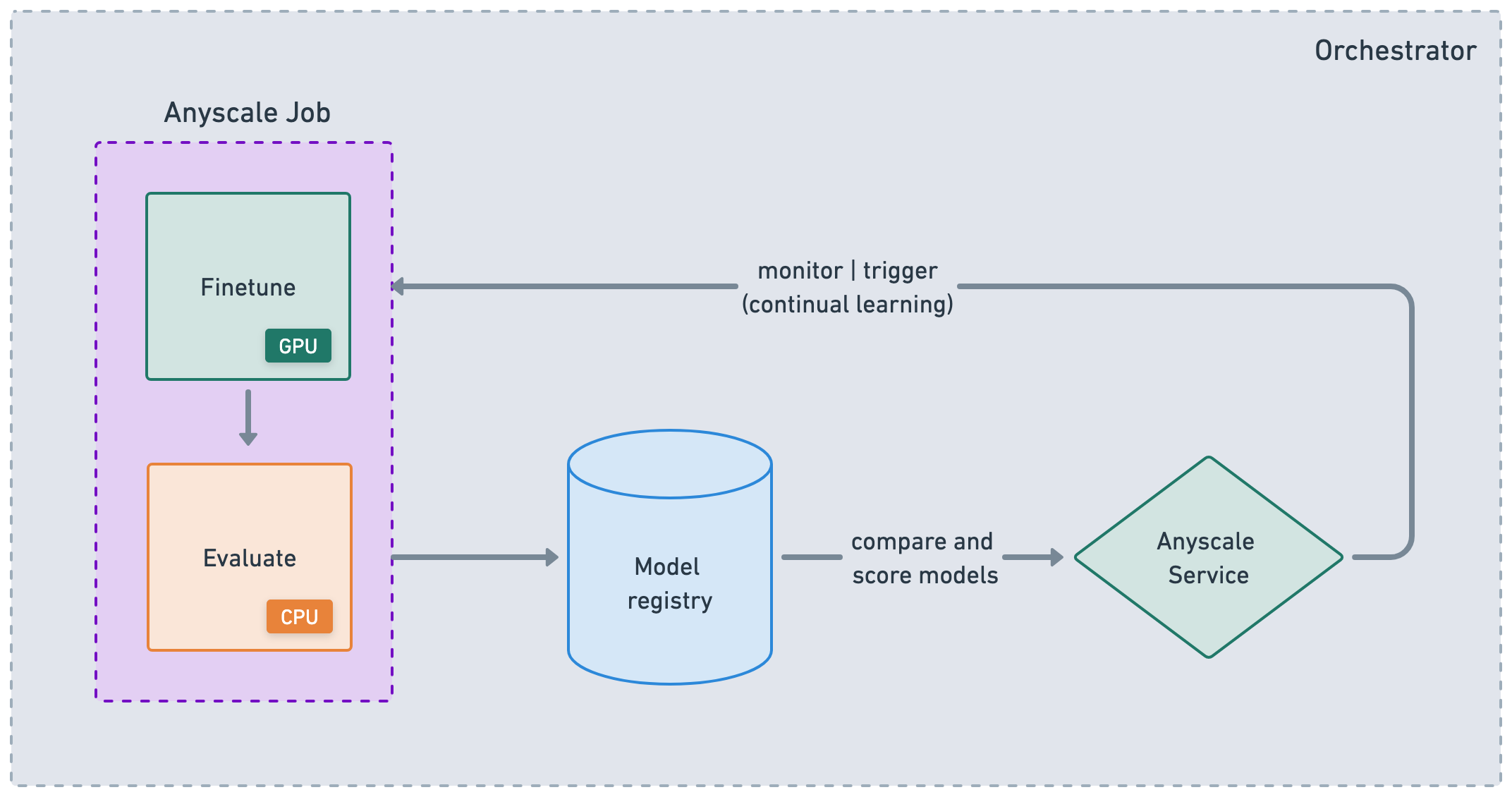
Anyscale Jobs (API ref) allows us to execute discrete workloads in production such as batch inference, embeddings generation, or model fine-tuning.
- define and manage our Jobs in many different ways (CLI, Python SDK)
- set up queues and schedules
- set up all the observability, alerting, etc. around our Jobs
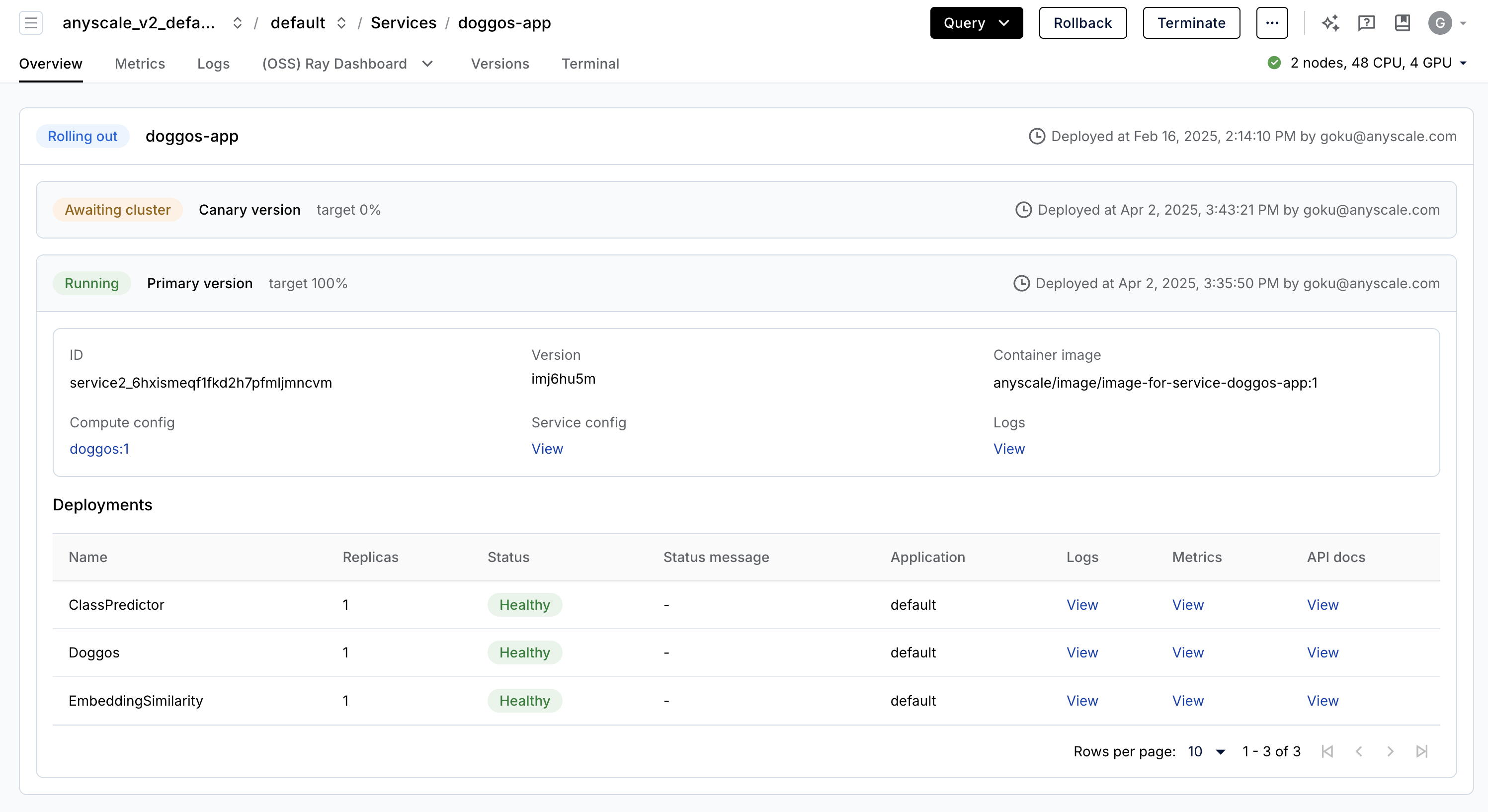
Anyscale Services (API ref) offers an extremely fault tolerant, scalable and optimized way to serve our Ray Serve applications.
- we can rollout and update our services with canary deployment (zero-downtime upgrades)
- monitor our Services through a dedicated Service page, unified log viewer, tracing, set up alerts, etc.
- scale a service (
num_replicas=auto) and utilize replica compaction to consolidate nodes that are fractionally utilized - head node fault tolerance (OSS Ray recovers from failed workers and replicas but not head node crashes)
- serving muliple applications in a single Service
%%bash
# clean up
rm -rf /mnt/cluster_storage/viggo # clean up
aws s3 rm $ANYSCALE_ARTIFACT_STORAGE/viggo --recursive --quiet