Website: https://www2.informatik.uni-hamburg.de/wtm/omgchallenges/omg_emotion.html
Quick Start: Data Download
python prepare_data.py --split-file omg_TrainVideos.csv --target-dir train
python prepare_data.py --split-file omg_TestVideos_WithLabels.csv --target-dir test
Organization
Pablo Barros, University of Hamburg, Germany
Egor Lakomkin, University of Hamburg, Germany
Henrique Siqueira, Hamburg University, Germany
Alexander Sutherland, Hamburg University, Germany
Stefan Wermter, Hamburg University, Germany
Final Results and Leaderboards
https://www2.informatik.uni-hamburg.de/wtm/omgchallenges/omg_emotion.html
OMG Emotion Dataset
Our One-Minute-Gradual Emotion Dataset (OMG-Emotion Dataset) is composed of 420 relatively long emotion videos with an average length of 1 minute, collected from a variety of Youtube channels. The videos were selected automatically based on specific search terms related to the term monologue. Using monologue videos allowed for different emotional behaviors to be presented in one context that changed gradually over time.. Videos were separated into clips based on utterances, and each utterance was annotated by at least five independent subjects using the Amazon Mechanical Turk tool. To maintain the contextual information for each video, each annotator watched the clips of a video in sequence and had to annotate each video using an arousal/valence scale.
Each annotator was also given the full contextual information of the video up to that point when annotating the dataset. That means that each annotator could take into consideration not only the vision and audio information but also the context of each video, i.e. what was spoken in the current and previous utterances through the context clips provided by the annotation tool. In this manner, each annotation is based on multimodal information, different from most recent datasets on emotion recognition. This gives our corpus an advantage when used in cross-modal research, especially when analyzing the audio, vision, and language modalities.

Annotations and Labels
We used the Amazon Mechanical Turk platform to create utterance-level annotation for each video, exemplified in the Figure below. We assure that for each video have a total of 5 different annotations. To make sure that the contextual information was taken into consideration, the annotator watched the whole video in a sequence and was asked, after each utterance, to annotate the arousal and valence of what was displayed. We provide a gold standard for the annotations. This results in trustworthy labels that are truly representative of the subjective annotations from each of the annotators, providing an objective metric for evaluation. That means that for each utterance we have one value of arousal and valence. We then calculate the Concordance Correlation Coefficient (CCC) for each video, which represents the correlation between the annotations and varies from -1 (total disagreement) to 1 (total agreement).
We release the dataset with the gold standar for arousal and valence as well the invidivual annotations for each reviewer, which can help the development of different models. We will calculate the final CCC against the goldstandard for each video. We also distribute the transcripts of what was spoken in each of the videos, as the contextual information is important to determine gradual emotional change through the utterances. The participants are encouraged to use crossmodal information in their models, as the videos were labeled by humans without distinction of any modality. We also will let available to the participant teams a set of scripts which will help them to pre-process the dataset and evaluate their model during in the training phase.
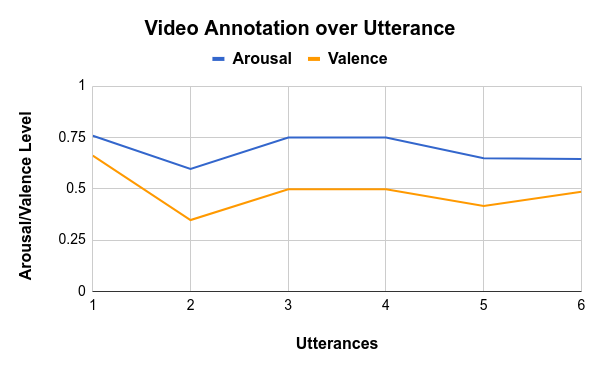
Dataset Structure
The dataset is separated into the following files:
- omg_TrainVideos.csv
- omg_ValidationVideos.csv
- DetailedAnnotations
- omg_TrainTranscripts.csv
- omg_TestTranscripts.csv
Each of the data CSV files contain the following information:
link: The link to access the youtube video start: the timestamp where the video starts end: the timestamp where the video ends video: the video-id, used to associate the video with the annotations utterance: the utterance name, used to associate the video with the annotations arousal: the calculated goldstandard of the arousal valence: the calculated goldstandard of the valence emotionMaxVote: the resulting categorical emotion from voting over all annotations
the transcripts csvs contain the following information:
link: The link to access the youtube video video: the video-id, used to associate the video with the annotations utterance: the utterance name, used to associate the video with the annotations transcript: The transcript of the audio from each videoHow to participate
We compute the arousal/valence value of a model with the goldstandard of the test set. The categorical emotion will not be used for evaluating the model, but could be usefull when designing or training your model. The categorical emotion is encoded as follows:
- 0 - Anger
- 1 - Disgust
- 2 - Fear
- 3 - Happy
- 4 - Neutral
- 5 - Sad
- 6 - Surprise
The DetailedAnnotations folder contains all the annotations for each utterance. Each annotation was made when taking into consideration the video as part of a sequence, so it could be useful to use this additional information when designing your models.
The Transcripts folder contains all the transcripts for each of the utterance in the dataset.
Baselines
To serve a baseline for this challenge, we used three different modesl: one for each modality.
The vision baseline was made with an updated version of the Face channel [1] pre-trained on the FER+ dataset and fine-tuned with 10 randomly selected faces of each training utterance.
We have two audio baselines, the first one was made with an updated version of the Audio channel [1] pre-trained on the RAVDESS.
The second one was made by using the opensmile library to extract auditory features and a Suport Vector Machine (SVM) to classify them.
The baseline text classifier is trained on the OMG training data and uses the word2vec Google News corpus vectors as pretrained word embeddings. The model feeds the transcribed sentences as sequences of word embeddings into a 1D CNN with 128 filters and a kernel size of 3.
The CNN is followed by a global max pooling layer and a fully connected layer with 500 units, ending finally in a single neuron with a sigmoidal activation function that predicts the valence and arousal levels of the input utterance. The CNN and fully connected layer use a ReLU activation and a dropout factor of 0.2 is applied after the word embedding and fully connected layer.
We calculate the Congruence Correlation Coeficient (CCC) and Mean-Squared Error (MSE) for both arousal and valence of the validation set only.
| Modality | CCC Arousal | CCC Valence | MSE Arousal | MSE Valence |
|---|---|---|---|---|
| Vision - Face Channel [1] | 0.12 | 0.23 | 0.053 | 0.12 |
| Audio - Audio Channel [1] | 0.08 | 0.10 | 0.048 | 0.12 |
| Audio - OpenSmile Features | 0.15 | 0.21 | 0.045 | 0.10 |
| Text | 0.05 | 0.20 | 0.062 | 0.123 |
[1] Barros, P., & Wermter, S. (2016). Developing crossmodal expression recognition based on a deep neural model. Adaptive behavior, 24(5), 373-396.
Scripts
We provide the following scripts:
- prepare_data.py: a script used to read, download, cut and organize the dataset.
- calculateEvaluationCCC.py: a script used to calculate the Correlation Concordance Coeficient (CCC) of the output of a model and the validation set. The file with the model's output must be a CSV file containng the following information:
video,utterance,arousal,valence
74de88564,utterance_1.mp4,0.05738688939330001,0.115515408794,
74de88564,utterance_2.mp4,0.05738688939330001,0.119515408794,
74de88564,utterance_3.mp4,0.05738688939330001,0.2122515408794,
74de88564,utterance_4.mp4,0.05738688939330001,0.314515408794,
74de88564,utterance_5.mp4,0.05738688939330001,0.10294515408794,
74de88564,utterance_6.mp4,0.05738688939330001,0.1224515408794,
74de88564,utterance_7.mp4,0.05738688939330001,0.654515408794,
...
It is important to note that the order of the videos and utterances present in this file must be the same as the order of the videos and utterances on the omg_ValidationVideos.csv.
OMG-Emotion Recognition Challenge 2018
Important dates:
- Publishing of training and validation data with annotations: March 14, 2018.
- Publishing of the test data, and opening of the online submission: April 27, 2018.
- Closing of the submission portal (Code and Results): April 30, 2018.
- Closing of the submission portal (Paper): May 04, 2018.
- Announcement of the winner through the submission portal: May 07, 2018.
To participate, please send us an email to [email protected] with the title "OMG-Emotion Recognition Team Registration". This e-mail must contain the following information:
- Team Name
- Team Members
- Affiliation
Each team can have a maximum of 5 participants. You will receive from us the access to the dataset and all the important information about how to train and evaluate your models. For the final submission, each team will have to send us a .csv file containing the final arousal/valence values for each of the utterances on the test dataset. We also request a link to a GitHub repository where your solution must be stored, and a link to an ArXiv paper with 2-4 pages describing your model and results. The best papers will be invited to submit their detailed research to a journal yet to be specified. Also, the best participating teams will hold an oral presentation about their solution during the WCCI/IJCNN 2018 conference.
Final Results: https://www2.informatik.uni-hamburg.de/wtm/omgchallenges/omg_emotion2018_results2018.html
License
This corpus is distributed under the Creative Commons CC BY-NC-SA 3.0 DE license. If you use this corpus, you have to agree with the following itens:
- To cite our reference in any of your papers that make any use of the database.
- The references are provided at the end of this page.
- To use the corpus for research purpose only.
- To not provide the corpus to any second parties.
- To delete the dataset as soon as you finish using it.
Access do the dataset
If you are having problems downloading the videos of the dataset, please send an e-mail to: [email protected]
References
P. Barros, N. Churamani, E. Lakomkin, H. Siqueira, A. Sutherland and S. Wermter, "The OMG-Emotion Behavior Dataset", 2018 International Joint Conference on Neural Networks (IJCNN), Rio de Janeiro, Brazil, 2018, pp. 1408--1414.
DOI: 10.1109/IJCNN.2018.8489099
@inproceedings{Barros2018OMG,
author={Barros, Pablo and Churamani, Nikhil and Lakomkin, Egor and Sequeira, Henrique and Sutherland, Alexander and Wermter, Stefan},
booktitle={2018 International Joint Conference on Neural Networks (IJCNN)},
title={{The OMG-Emotion Behavior Dataset}},
year={2018},
moth={July},
organization={IEEE},
pages={1408--1414},
location={Rio de Janeiro, Brazil},
doi={10.1109/IJCNN.2018.8489099}
}
More information
- You can access a detailed information about an early version of the dataset here: https://arxiv.org/abs/1803.05434
- You can also find usefull information here: https://www2.informatik.uni-hamburg.de/wtm/OMG-EmotionChallenge/
For more informations: [email protected]