OP/ED misidentification issue #172
Comments
#172 numbered following lettered numbered (1a, 1b, 2) would be off need all files following same numbering convention but works now: "Owarimonogatari (2017)" s00e102 "ANIDB_RX-1" "" "Owarimonogatari (2017) - OP1b [Dmon] [BD, 720p, AAC] [C7E110E0].mkv" "Owarimonogatari (2017)" s00e103 "ANIDB_RX-1" "" "Owarimonogatari (2017) - OP2 [Dmon] [BD, 720p, AAC] [63B59143].mkv" "Owarimonogatari (2017)" s00e104 "ANIDB_RX-1" "" "Owarimonogatari (2017) - OP3 [Dmon] [BD, 720p, AAC] [C0D815AE].mkv"
|
Please update (major scanner update done then this fix). Please report any difference |
|
Using Owarimonogatari (2017) as my test case again, I first tried refreshing the metadata for the series, and unmatching/rematching it, both of which gave the same result as above (Even after unmatching, OP1b and OP2 were still shown in Plex as versions of the same episode, with no option to split). So I created a new library containing only the series, which resulted in a different issue: ASS identified OP1b, OP2 and OP3 as episodes 106, 107 and 108, respectively. As you can see below, the series only has four OPs on AniDB, total: I'm not sure what variable from AniDB you are using to match OP/EDs, but I'm guessing you're likely doing something similar to what my AniAdd renaming script does (except in reverse), that is, cycling through an array of the XMLs episode elements to match the episode number prefixes OP and ED (and their variations) to AniDB's internal episode type 3 (internal prefix C), then using the episode.title variable to match OP1/ED1 to "Opening" or "Opening 1"/"Ending" or "Ending 1" respectively, and OP/ED(n)[a-z] to "Opening (n)[a-z]"/"Ending (n)[a-z]" for the rest? At least, that is the only way I can think of, given the limited information in AniDB's series XML files, to match them based on OP/ED number, since the internal categorization/numbering scheme doesn't distinguish between OPs and EDs at all (Off-topic, but it would be awesome if ASS could eventually identify OP/ED and "Other" files by AniDB's internal numbering, i.e. C1, C2, O1, O2, etc as well). I don't really know what scheme you use to assign them an episode number in Plex, though (aside from the category offsets), that is, which episode becomes 101, 102, etc, since AniDB's C category (type 3) numbering frequently does not reflect the OP/ED numbering order - for Owarimonogatari (2017), for example, OP1b, OP2 and OP3 are C3, C2 and C4, respectively, and, in the latest version of ASS, were assigned to 106, 107 and 108. If you are assigning the episode numbers by alphabetical order of the episode.title variable (in this case, OP1a, OP1b, OP2, OP3), which seems to be case, could the current situation simply be an offset issue? I.e. instead of OP1a -> 101, OP1b -> 102, etc, it is assigning them stating at 105, hence OP1b being 106, OP2 107 and OP3 108, but still associating the metadata with the correct numbering? It seems like an odd offset miss (4), but it would match the results. Anyway, I suppose that is enough guesswork for now, hope it is in some way helpful, and, as always, thanks for all the hard work :-) I may try and take a look at the code myself, but my Python experience is essentially limited to looking at HAMA and the Shoko Metadata Agent, so I'm very much a beginner. |


|
Lines 804-814 responsible for that. From scanner logs Before they were not shifted if 1b, etc... were present before 2, 3, ... Please update and report and if not solved paste series specific scanner logs located in Plex Media Server\Plug-in Support\Data\com.plexapp.agents.hama\DataItems_Logs |
|
Crashes. Error in Python: Running scanner:
Traceback (most recent call last):
File "/share/CACHEDEV1_DATA/.qpkg/PlexMediaServer/Library/Plex Media Server/Scanners/Series/Absolute Series Scanner.py", line 810, in Scan
offset += sum( AniDB_op[ANIDB_RX.index(rx)].values() )
KeyError: (2,) |
Edit:Just noticed from your post that your test run came up with the same results as below, i.e. 102 and 103 being set to the wrong file (or wrong entry on AniDB), likely because, like with many AniDB series, the OP entries aren't in order. /Edit Edit 2:The project page only just now updated to reflect the merged Pull request for me, will try the updated version. /Edit Not solved yet, sadly, and seems to have generated other issues (Creating a new library, only half the series show up in Plex, and previously correctly IDed series misidentified). Results this time, creating new Library with same series as example as previously (And leaving aside the other series, which were included as samples for the AniDB Series Poster Priority/Ranking Issue with HAMA), are as such: Essentially, the episode number in Plex now matches AniDB's internal C episode number and name, but is still being associated with the wrong file. So, ...given a big Pull Request was added while I was writing this and testing things for this and the issue with HAMA, I'm not sure if any of this is still relevant or helpful, however. I've attached the logs for the series - some of the data may be from the previous test-version of ASS, as, while I created a new Library each time, it was always named 'test1', so the logs were written to the same folder. I've also uploaded the logs for the entire 'test1' Library (15 series) to a Google Drive folder here, in part for the other issue, but they might prove helpful here as well, at least in giving a hint as to what went wrong with the series identification. Owarimonogatari (2017) [Dmon] [BD, 720p].agent-search.log |


|
Ok, this is post-commit 306101e58727e3b542a96876fa506b0b55615cc1, using the new version of ASS: Deleted/recreated Library, but same OP/ED issue remains, as well as the issue of half the series in the Library's folder not showing up in Plex, and one series being misidentified as its own sequel, which it had not been, using earlier revisions, although I personally started seeing similar series identification issues (mostly, series with a year and movies with 'Gekijouban' in their name no longer seeming to have the year/movie portion count as part of the name for ID weight purposes, i.e. "Shingeki no Kyojin" and Shingeki no Kyojin (2017)", a synonym, being weighted equally in this case) after commit 2ca520f1ae8241c0251e082d85911654489975ce, so that part may be nothing new. I've uploaded the new logs for the Library, as well as the HAMA log, to a Google Drive folder here, and am attaching the logs specific to the series I have been using for testing to this post as well. All the best! Owarimonogatari (2017) [Dmon] [BD, 720p].filelist.log |
|
Just FYI, I rolled back to an older version of ASS (Commit be48f45), and all the missing series in my test library were detected - of course, the OP/EDs were back where we started, but it seems like something in the first of those two big recent merges caused the series detection issue (or something right before it, as I've updated ASS fairly regularly, and the first time it happened to me was after switching to that version). Don't know if that is helpful information or not, but I'm a firm believer in there being no such thing as too much information. And now, to bed :-) |
|
@purposelycryptic That should do it. It took quite a while to spot as most times when the scanner crashes, it doesn't tell you where... Looks better now and no longer crashes. Please test and report |
|
It is detecting all the series in the library again, but, somehow is still not matching Owarimonogatari (2017) OP1b & OP2 correctly :-/ The log makes it look correct (ignoring the line "Forced ID in series folder: 'youtube' with id 'Dmon'", no clue as to where YouTube came from): But then in Plex, it's the same as before (The absence of episode thumbs in this screenshot is due to using a new dummy library on a different drive, rather than using symlinks as I had in previous tests): I think the issue may actually be with HAMA, or rather how ASS and HAMA interact; ASS assigns the episode number and name, but according to your ReadMe, the name is then overwritten by HAMA - at least that was my hunch, so I checked out the HAMA log, and found this: Despite being for the file "Owarimonogatari (2017) - OP1b [Dmon] [BD, 720p, AAC] [C7E110E0].mkv", this line shows HAMA associating s0e102 with "Opening 2": So, that would explain why changing things in ASS hasn't had the expected effect - there appears to be a disconnect between HAMA and ASS. Which side is responsible for the resulting issue, I'm not sure, since HAMA depends on ASS for the episode number, but HAMA discards the episode name and assigns it metadata, and I'm not sure how HAMA associates the Specials episode numbers with actual metadata, given those episode numbers are unique to ASS/HAMA (reverse-translating them to AniDB episode numbers? In which case, changes to how ASS numbers them would require changes to HAMA as well...) But that seems to solve part of the mystery, at least - still getting the same series-level mismatches, seems to be due to precise name matches being given the same matching score as ones with a year/period/apostrophe at the end, which then appear above them on the list (see images below for examples from sample library), but that is a separate issue. |



#175 #172 (comment) source name is optional for youtube playlist and channels as already super long youtube id can be in subfolder (series folder inside grouping folder)
|
I fixed the obvious, the specials numbering in ASS, which now look grand' BUT relies on files present so if missing 1a, 1b, 1c, OP2 is 102... |
|
I'm actually seriously impressed ASS has done such a good job so far in almost every case without referencing a series' AniDB XML - it's essentially like working blind with a 99% success rate. But, given a the majority of releases don't contain a full set of OP/EDs (or, rather, the OP/ED list on AniDB tries to cover every variation from every format the series was released in, so different media-type groups simply don't have them to release), using the XML is probably the only way to achieve full accuracy. I don't suppose it's as simple as using the same AniDB XML storage folder for both ASS and HAMA, so that, for either one, if a sufficiently recent version is present locally, it can use that vs. downloading a fresh copy... Or rather, even if it is, the larger part is then integrating the use of the XML data into ASS. Knowing that definitely explains a lot about the code and how it is structured, though - I spent a couple hours yesterday reading over it (HAMA/ASS have been my first major exposure to Python outside of minor script editing), and somehow completely missed the fact that the XML is never fetched/referenced. Up until a few months ago, I had been using Emby/Mediabrowser for almost a decade, and Emby Server uses it's own scanner, with plugins only able to serve as agents, so I never got a real look at the scanner side; for what it's worth, HAMA was essentially the reason I switched to Plex, despite preferring Emby over Plex in almost every other respect. |
|
AniDB XML example: http://api.anidb.net:9001/httpapi?request=anime&client=hama&clientver=1&protover=1&aid=13033
Solutions:
Still researching how to solve efficiently
Detective Conan currently has 41 openings and 49 endings. Edit: I cannot achieve 100% with no anidbid forced and numerous OP/ED with lettered versions with normal methods as i cannot determine if ep 1b is ep 2 or 3 in plex without, especially since they are not in sequence in the xml ... I could take the biggest steps (a-h=8?) and spread every episode away by this step but op1a = 1 and op2 = 9 in this case i could make openings 1-50 and 1b 51, 2b 52, 1c 101, etc... as a variant... both ideas would work needing no xml building the list, the second option looks more natural though but bad numbering for second versions and after of the op/ed... It could load the xml and no need for episode ranges anymore... i need to load the xml it seems but you have to force the anidb id when opening/Endings are wrong... OR i leave as is and adjust in hama... |
#172 using estimated OP/ED numbering unless anidb id present, and it will take the ep number from title since entered out of order
|
@purposelycryptic re-did the op/ed part. Issue was, if op1a and op1b not present, op2 is ep 2 (+100/150)... Please test and report, but this is for the scanner part only. New house with mortgage starting any day so time is scarce. |
|
@ZeroQI, doesn't this new dl of anidb info |
|
@EndOfLine369 it only download if the anidb id is present and there are openings and wait 6s afterwards. |
|
ah, just rechecked. found the |
|
Did a test. And corrected the check to pull when 'anidb_xml' is None and NOT when it 'is not None': FROM:
if source.startswith('anidb') and id and not anidb_xml and rx in ANIDB_RX[1:3]: #2nd and 3rd rx
TO:
if source.startswith('anidb') and id and anidb_xml is None and rx in ANIDB_RX[1:3]: #2nd and 3rd rx |
|
What is afterwards that test populate anidb-xml so it is downloaded only once in the file loop if needed |
|
Looks like there are still issues in the test I have of openings. |
|
Look like it is in manual mode and doesn't use the mappings |
Looks like an issue in setting 'cumulative_offset' as should = 3 for ep2 openings |
|
Think I have narrowed it down to this piece in issue. if anidb_xml is not None:
if ANIDB_RX.index(rx) in AniDB_op: AniDB_op [ ANIDB_RX.index(rx) ] [ ep ] = offset # {101: 0 for op1a / 152: for ed2b} and the distance between a and the version we have hereep, offset = str( int( ep[:-1] ) ), offset + sum( AniDB_op.values() ) # "if xxx isdigit() else 1" implied since OP1a for example... # get the offset (100, 150, 200, 300, 400) + the sum of all the mini offset caused by letter version (1b, 2b, 3c = 4 mini offset)
else: AniDB_op [ ANIDB_RX.index(rx) ] = { ep: offset }
Log.info("AniDB_op: {}".format(AniDB_op))LOG: |
|
@EndOfLine369
i then add the offset for all prior episodes (1a=0, ab=1, 1c=2...) then the offset for that episode then the epis I believe you are better than me at python, but your pull request changed dramatically the behaviour: " - - Good: "not anidb_xml" replaced with "anidb_xml is None"
|
|
|
I see you undid the typo. Fixed crashes from that code as noted above. |
|
@EndOfLine369 "fixes" from the end of the top (summary) line combined with the issue number at the beginning of the description, which is unintuitive behavior at best. Closing an issue referenced by number with "fixes", "closes", "resolves" etc. before it is documented GitHub behavior, but it probably shouldn't happen in this special case. I'd say it's worth writing to GitHub support. |
|
Thanks @dgw for the explanation on the unexpected issue closure |
|
Glad to help! I wrote GitHub support about it, not that I expect anything to change. |
|
FYI, @ZeroQI, cumulative_offset = sum( [ AniDB_op [ ANIDB_RX.index(rx) ][x] for x in Dict(AniDB_op, ANIDB_RX.index(rx), default={0:0}) if x<ep ] )
KeyError: (0,)Due to |
'KeyError: (0,)' crashes on 'cumulative_offset' calculation line #172
|
Updated code to confirm 'AniDB_op's contents on the 'cumulative_offset=' line. seems to have fixed the issue. |
|
@purposelycryptic latest version is stable for you ? |
|
@purposelycryptic latest version is stable for you ? |
First of all, thank you for all your hard work on HAMA/ASS.
This is a rather odd issue I've only recently noticed, after finally figuring out how to get AniAdd to properly rename OP/EDs with ASS-compatible numbering:
For some reason, ASS will misidentify certain OP/ED files, usually identifying them as the OP/ED above or below the correct one in AniDB's internal ordering (i.e. episode C3 will be IDed as episode C2 or C4 instead).
My Files are all organized/named according to the following scheme:
Where Ep_Num is the AniDB Episode Number (Specials using the SP prefix, OPs and EDs the OP and ED prefix, respectively, and an [a-z] suffix when necessary, Trailer/Previews the T prefix, and non-systematic Other files the O prefix), with multi-part episodes having a ' - partX' suffix, and conjoined episodes having a '-XX' suffix, where X/XX is the respective part/episode number.
As an example, here is the file/folder layout for Owarimonogatari (2017):
And this is what the Specials look like in Plex:
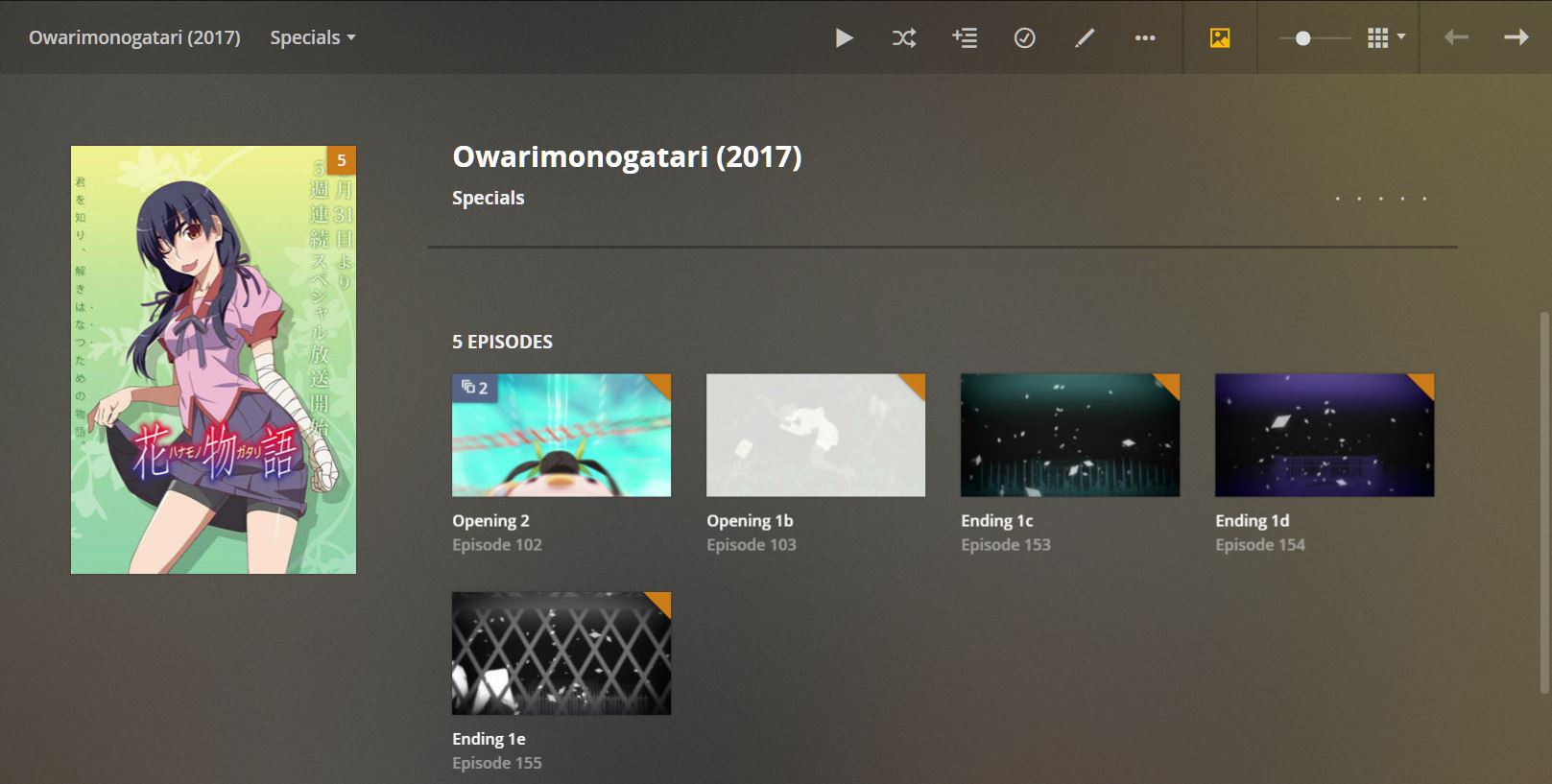
Here the EDs were correctly IDed, but as for the OPs, they were instead matched like this:
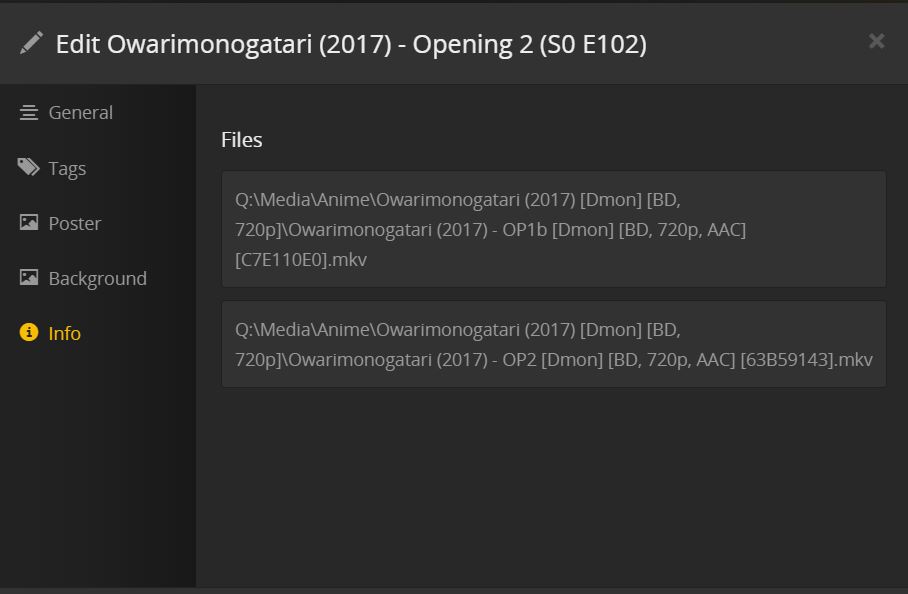
I'm not entirely sure what factor could be causing the issue, as it seems to be somewhat random - in some series, all OP/EDs are correctly matched, in some only OPs or EDs, and in some a few of both. There is obviously some common factor at work, but it eludes me.
Up until recently, all my OP/EDs were numbered according to AniDB's internal scheme (C1, C2, etc), simply because that is what AniAdd uses, and thus weren't identifiable by ASS and instead labeled as 5XX-numbered episodes. But after much script-wrangling, I finally managed to get it to name them with ASS-compatible numbering, or so I thought. If the issue is on my end, I apologize for taking up your time, and would appreciate any advice you could give to correct it.
Thanks!
The text was updated successfully, but these errors were encountered: