Face Swapping Inference
First make sure you have all the latest version models in fsgan/weights directory. Fill out this form, place download_fsgan_models.py in the root directory of the fsgan repository, and run:
python download_fsgan_models.pyThe swap inference script can be called using the following template:
python swap.py SOURCE -t TARGET -o OUTPUT [FLAGS]For best quality follow this example:
# From FSGAN's root directory
python fsgan/inference/swap.py docs/examples/shinzo_abe.mp4 -t docs/examples/conan_obrien.mp4 -o . --finetune --finetune_save --seg_remove_mouth
finetune: enable an initial finetuning stage of the reenactment generator
finetune_save: save the finetuning weights to the cache directory
seg_remove_mouth: remove the inner part of the mouth from the segmentation mask
For best performance follow this example:
# From FSGAN's root directory
python fsgan/inference/swap.py docs/examples/shinzo_abe.mp4 -t docs/examples/conan obrien.mp4 -o . --seg_remove_mouth
Output cropped video:
# From FSGAN's root directory
python swap.py docs/examples/shinzo_abe.mp4 -t docs/examples/conan_obrien.mp4 -o . --output_crop -f -fs -srm
Output cropped video with together with the queried source frames from the appearance map and the target frame:
# From FSGAN's root directory
python fsgan/inference/swap.py docs/examples/shinzo_abe.mp4 -t docs/examples/conan_obrien.mp4 -o . --verbose 1 -f -fs -srm
First three columns are the queried source frames, the 4th column is the result, and the last column is the target frame.
Output all available information including intermediate stages (useful for debugging):
# From FSGAN's root directory
python fsgan/inference/swap.py docs/examples/shinzo_abe.mp4 -t docs/examples/conan_obrien.mp4 -o . --verbose 2 -f -fs -srm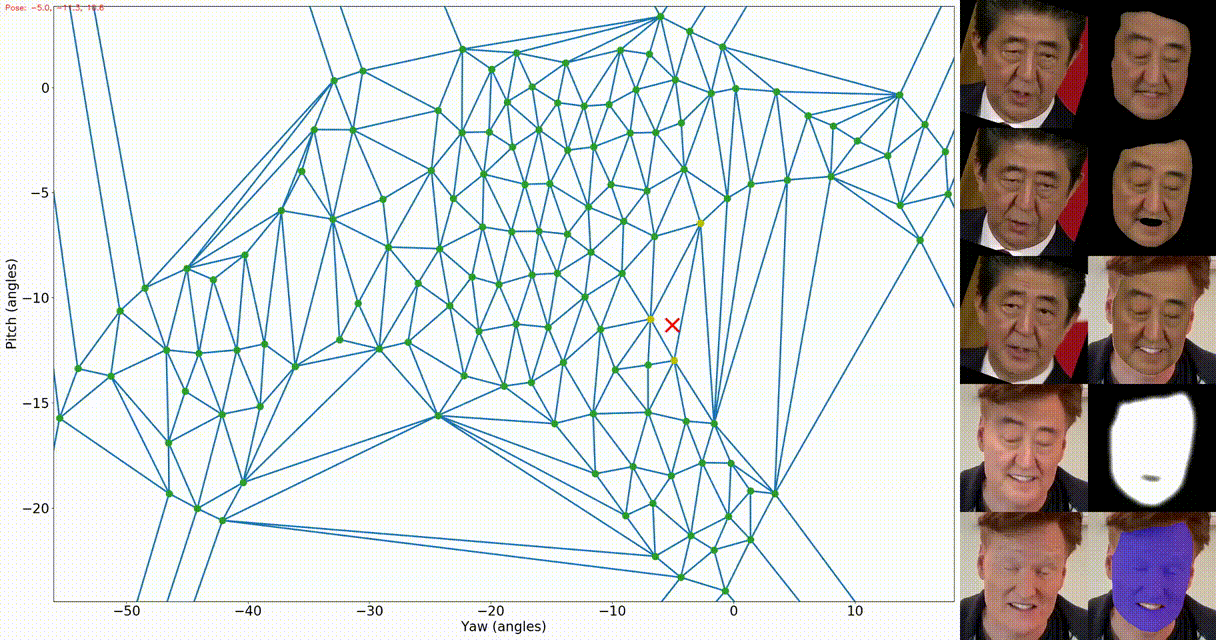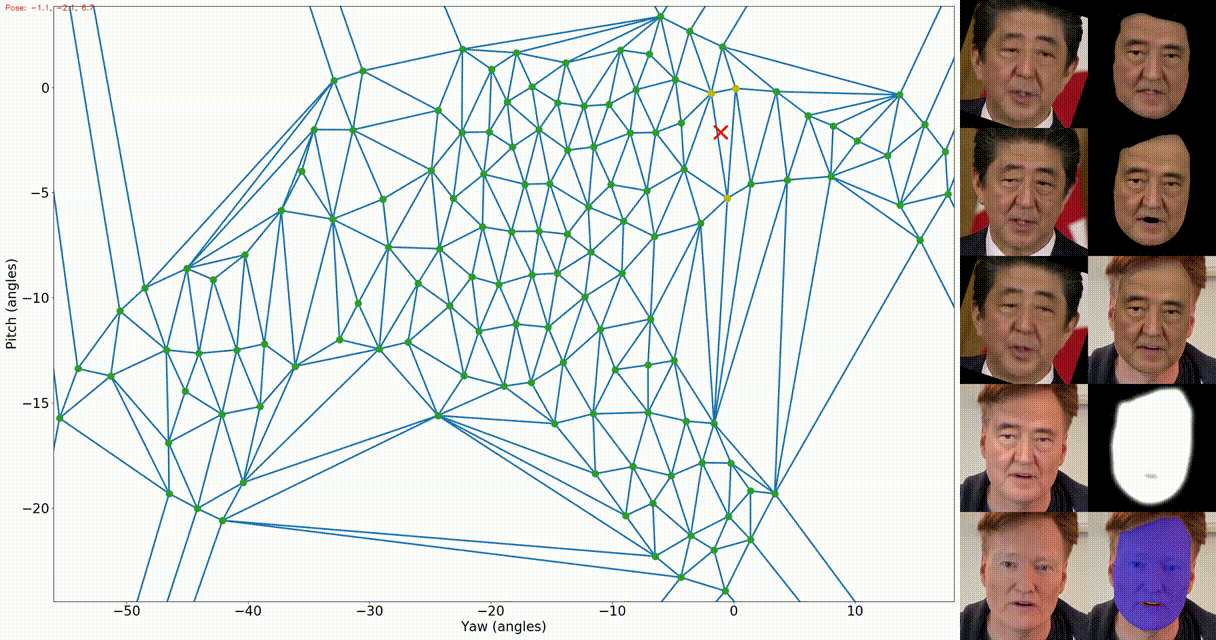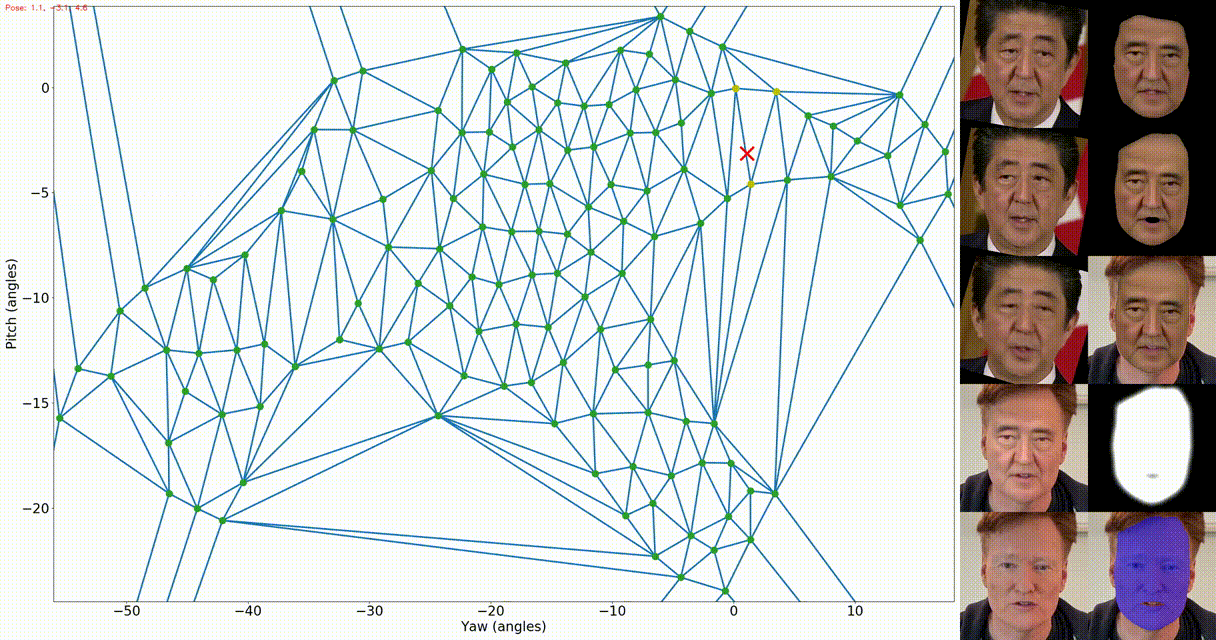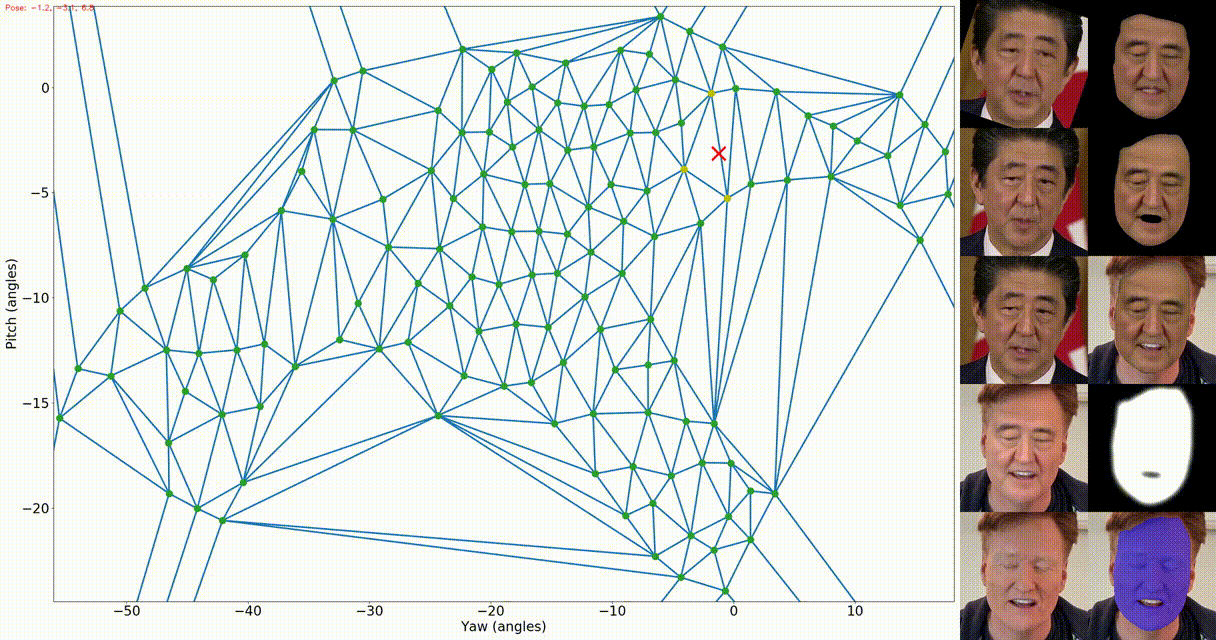 Left: the appearance map. The green dots represent the source views (after filtering close views),
the blue lines represent the the Delaunay triangulation, the yellow dots represent the current queried views,
and the red X represent the current target pose. Right: The first column is the same as the above output. The
second column includes: reenactment result after barycentric coordinates interpolation, completion result,
the completed face transferred onto the target image, soft mask used for combining the blending result with the
target frame, and finally the target segmentation.
Left: the appearance map. The green dots represent the source views (after filtering close views),
the blue lines represent the the Delaunay triangulation, the yellow dots represent the current queried views,
and the red X represent the current target pose. Right: The first column is the same as the above output. The
second column includes: reenactment result after barycentric coordinates interpolation, completion result,
the completed face transferred onto the target image, soft mask used for combining the blending result with the
target frame, and finally the target segmentation.