-
Notifications
You must be signed in to change notification settings - Fork 124
Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
Add deployment examples to docs (#584)
- Loading branch information
1 parent
0269835
commit 546484b
Showing
2 changed files
with
272 additions
and
1 deletion.
There are no files selected for viewing
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,271 @@ | ||
| --- | ||
| title: Deployment Examples | ||
| description: 'See the capabilities of remote execution and cache' | ||
| --- | ||
|
|
||
| # AWS Terraform Deployment | ||
|
|
||
| This directory contains a reference/starting point on creating a full AWS | ||
| Terraform deployment of Native Link's cache and remote execution system. | ||
|
|
||
| ## Prerequisites - Setup Hosted Zone / Base Domain | ||
| You are required to first setup a Route53 Hosted Zone in AWS. This is because | ||
| we will generate SSL certificates and need a domain to register them under. | ||
|
|
||
| 1. Login to AWS and go to | ||
| [Route53](https://console.aws.amazon.com/route53/v2/hostedzones) | ||
| 2. Click `Create hosted zone` | ||
| 3. Enter a domain (or subdomain) that you plan on using as the name and ensure | ||
| it's a `Public hosted zone` | ||
| 4. Click into the hosted zone you just created and expand `Hosted zone details` | ||
| and copy the `Name servers` | ||
| 5. In the DNS server that your domain is currently hosted under (it may be | ||
| another Route53 hosted zone) create a new `NS` record with the same | ||
| domain/subdomain that you used in Step 3. The value should be the | ||
| `Name servers` from Step 4 | ||
|
|
||
| It may take a few mins to propagate | ||
|
|
||
| ## Terraform Setup | ||
| 1. [Install Terraform](https://www.terraform.io/downloads) | ||
| 2. Open terminal and run `terraform init` in this directory | ||
| 3. Run `terraform apply -var | ||
| base_domain=INSERT_DOMAIN_NAME_YOU_SETUP_IN_PREREQUISITES_HERE` | ||
|
|
||
| It will take some time to apply, when it is finished everything should be | ||
| running. The endpoints are: | ||
|
|
||
| ```txt | ||
| CAS: grpcs://cas.INSERT_DOMAIN_NAME_YOU_SETUP_IN_PREREQUISITES_HERE | ||
| Scheduler: grpcs://scheduler.INSERT_DOMAIN_NAME_YOU_SETUP_IN_PREREQUISITES_HERE | ||
| ``` | ||
|
|
||
| As a reference you should be able to compile this project using Bazel with | ||
| something like: | ||
|
|
||
| ```sh | ||
| bazel test //... \ | ||
| --remote_cache=grpcs://cas.INSERT_DOMAIN_NAME_YOU_SETUP_IN_PREREQUISITES_HERE \ | ||
| --remote_executor=grpcs://scheduler.INSERT_DOMAIN_NAME_YOU_SETUP_IN_PREREQUISITES_HERE \ | ||
| --remote_instance_name=main | ||
| ``` | ||
|
|
||
| ## Server configuration | ||
| 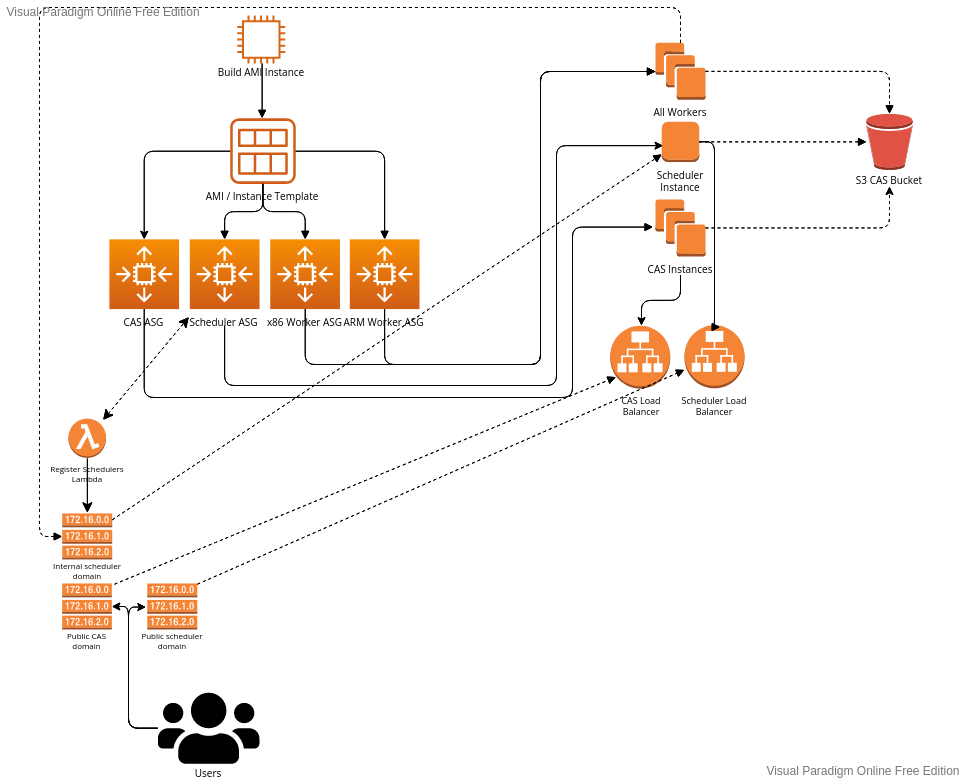 | ||
|
|
||
| ## Instances | ||
| All instances use the same configuration for the AMI. There are technically two | ||
| AMI's but only because by default this solution will spawn workers for x86 | ||
| servers and ARM servers, so two AMIs are required. | ||
|
|
||
| ### CAS | ||
| The CAS is only used as a public interface to the S3 data. All the services | ||
| will talk to S3 directly, so they don't need to talk to the CAS instance. | ||
|
|
||
| #### More optimal configuration | ||
| You can reduce cost and increase reliability by moving the CAS onto the same | ||
| machine that invokes the remote execution protocol (like Bazel). Then point | ||
| the configuration to `localhost` and it will translate the S3 calls into the | ||
| Bazel Remote Execution Protocol API. | ||
|
|
||
| ### Scheduler | ||
| The scheduler is currently the only single point of failure in the system. | ||
| We currently only support one scheduler at a time. | ||
| The workers will lookup the scheduler in a Route53 DNS record set by a | ||
| lambda function that is configured to execute every time an instance | ||
| change happens on the auto-scaling group the scheduler is under. | ||
| We don't use a load balancer here mostly for cost reaons and the | ||
| fact that there's no real gain from using one, since we don't want/need | ||
| to encrypt our data since we are using it all inside the VPC. | ||
|
|
||
| ### Workers | ||
| Worker instances in this confugration (but can be changed) will only spawn 1 or | ||
| 2 CPU machines all with NVMe drives. This is also for cost reasons, since NVMe | ||
| drives are much faster and often cheaper than EBS volumes. | ||
| When the instance spawns it will lookup the available properties of the node | ||
| and notify the scheduler. For example, if the instance has 2 cores it will | ||
| let the scheduler know it has two cores. | ||
|
|
||
| ## Security | ||
| The security permissions of each instance group is very strict. | ||
| The major vulnerabilities are that the instances by default are all public ip | ||
| instances and we allow incoming traffic on all instances to port 22 (SSH) for | ||
| debugging reaons. | ||
|
|
||
| The risk of a user using this configuration in production is quite high and | ||
| for this reason we don't allow the two S3 buckets (access logs for ELBs and | ||
| S3 CAS bucket) to be deleted if they have content. | ||
| If you prefer to use `terraform destroy`, you need to manually purge these | ||
| buckets or change the Terraform files to force destroy them. | ||
| Taking the safer route seemed like the best route, even if it means the | ||
| default developer life is slightly more difficult. | ||
|
|
||
| ## Future work / TODOs | ||
| * Currently we never delete S3 files. Depending on the configuration this needs | ||
| to be done carefully. Likely the best approach is with a service that runs | ||
| constantly. | ||
| * Auto scaling up the instances is not confugred. An endpoint needs to be made | ||
| so that a parsable (like json) feed can be read out of the scheduler through a | ||
| lambda and publish the results to `CloudWatch`; then a scaling rule should be | ||
| made for that ASG. | ||
|
|
||
| ## Useful tips | ||
| You can add `-var terminate_ami_builder=false` to the `terraform apply` command | ||
| and it makes it easier to modify/apply/test your changes to these `.tf` files. | ||
| This command will cause the AMI builder instances to not be terminated, which | ||
| costs more money, but makes it so that Terraform will not create a new AMI | ||
| each time you call the command. | ||
|
|
||
|
|
||
| # GCP Terraform Deployment | ||
|
|
||
| This directory contains a reference/starting point on creating a full GCP | ||
| [Terraform](https://www.terraform.io/downloads) deployment of Native Link's | ||
| cache and remote execution system. | ||
|
|
||
| ## Prerequisites | ||
|
|
||
| 1. Google Compute Cloud project with billing enabled. | ||
| 2. A domain where name servers can be pointed to Google DNS Cloud. | ||
|
|
||
| ## Terraform Setup | ||
|
|
||
| Setup is done in two configurations, a **global** configuration and **dev** | ||
| configuration. The dev configuration depends on the global configuration. | ||
| Global configuration is a one-time setup which requires an out-of-bound step | ||
| of updating registrar managed name servers. This step is required for | ||
| certificate manager authorization to generate certificate chain. | ||
|
|
||
| ### Global Setup | ||
|
|
||
| Setup basic configurations for DNS, certificates, Compute API and Terraform | ||
| state storage bucket. The global setup should be a one-time process, once | ||
| properly configured it does not need to be redone. | ||
|
|
||
| It is important to note that after these configurations are applied the | ||
| managed name servers for the DNS zone need to be configured. If the certificate | ||
| management fails to generate the entire process might need to be redone. | ||
|
|
||
| After this is applied grab the name servers from the Terraform state and enter | ||
| the four name servers into the owning domains registrar configuration page. | ||
|
|
||
| Confirm certificates are generated by checking the | ||
| [Certificate Manager](https://cloud.google.com/certificate-manager/docs/overview) | ||
| page in [Google Cloud Console](https://console.cloud.google.com) that the | ||
| status is Active before moving onto running the dev plan. | ||
|
|
||
| ```sh | ||
| PROJECT_ID=example-sandbox | ||
| DNS_ZONE=example-sandbox.example.com | ||
|
|
||
| cd deployment-examples/terraform/experimental_GCP/deployments/global | ||
| terraform init | ||
| terraform apply -var gcp_project_id=$PROJECT_ID -var gcp_dns_zone=$DNS_ZONE | ||
| # Print google name servers, ex: ns-cloud-XX.googledomains.com. | ||
| terraform state show module.native_link.data.google_dns_managed_zone.dns_zone | ||
| ``` | ||
|
|
||
| ### Development Setup | ||
|
|
||
| Setup and deploy the `native-link` servers and dependencies. The general | ||
| configuration is laid out similar to | ||
| [Native Link AWS Terraform Diagram](https://user-images.githubusercontent.com/1831202/176286845-ff683266-3f23-489c-b58a-3eda49e484be.png) | ||
| from | ||
| [AWS deployment example](https://github.com/TraceMachina/native-link/blob/main/deployment-examples/terraform/experimental_AWS/README.md). | ||
| Deployment has additional flags in `variables.tf` for controlling machine | ||
| type, prefixing resource name space for multiple deployments and other | ||
| template parameters. | ||
|
|
||
| ```sh | ||
| PROJECT_ID=example-sandbox | ||
| cd deployment-examples/terraform/experimental_GCP/deployments/dev | ||
| terraform init | ||
| terraform apply -var gcp_project_id=$PROJECT_ID | ||
| ``` | ||
|
|
||
| A complete and successful deployment should be able to run remote execution | ||
| commands from Bazel (or other supported build systems). | ||
|
|
||
| ## Example Test | ||
|
|
||
| Simple way to test as a client is by | ||
| [creating](https://cloud.google.com/sdk/gcloud/reference/compute/instances/create) | ||
| a "workstation" instance on Google Cloud Platform, install Bazel, clone | ||
| `native-link` and run tests using the deployed remote cache and | ||
| remote executor. | ||
|
|
||
| ```sh | ||
| # Example of using gcloud generated cli command bootstrap instance. | ||
| # Using google cloud console is easy to generate this command. | ||
| # Use ubuntu-2204 x86_64 as the base image as it is compatible | ||
| # with remote execution environment setup by the Terraform scripts. | ||
| NAME=dev-workstation-001 | ||
| PROJECT_ID=example-sandbox | ||
| REGION=us-central1 # defaulted value in variables.tf | ||
| ZONE=us-central1-a # defaulted value in variables.tf | ||
| [email protected] | ||
| OS_IMAGE=projects/ubuntu-os-cloud/global/images/ubuntu-2204-jammy-v20231201 | ||
| DISK=projects/example-sandbox/zones/$ZONE/diskTypes/pd-standard | ||
|
|
||
| gcloud compute instances create $NAME \ | ||
| --project=$PROJECT_ID \ | ||
| --zone=$ZONE \ | ||
| --machine-type=e2-standard-8 \ | ||
| --network-interface=network-tier=PREMIUM,stack-type=IPV4_ONLY,subnet=default \ | ||
| --maintenance-policy=MIGRATE \ | ||
| --provisioning-model=STANDARD \ | ||
| --service-account=$SERVICE_ACCOUNT \ | ||
| --scopes=https://www.googleapis.com/auth/devstorage.read_only,https://www.googleapis.com/auth/logging.write,https://www.googleapis.com/auth/monitoring.write,https://www.googleapis.com/auth/servicecontrol,https://www.googleapis.com/auth/service.management.readonly,https://www.googleapis.com/auth/trace.append \ | ||
| --create-disk=auto-delete=yes,boot=yes,device-name=instance-1,image=${OS_IMAGE},mode=rw,size=30,type=$DISK \ | ||
| --no-shielded-secure-boot \ | ||
| --shielded-vtpm \ | ||
| --shielded-integrity-monitoring \ | ||
| --labels=goog-ec-src=vm_add-gcloud \ | ||
| --reservation-affinity=any | ||
| ``` | ||
|
|
||
| [SSH](https://cloud.google.com/sdk/gcloud/reference/compute/ssh) into the | ||
| workstation instance, install deps and clone `native-link` | ||
| (which has Bazel compatible remote execution setup). On first run it could | ||
| take the a few minutes for the DNS records and load balancers to pick up | ||
| the new resources (usually under ten minutes). | ||
|
|
||
| ```sh | ||
| # On local machine | ||
| NAME=dev-workstation-001 | ||
| PROJECT_ID=example-sandbox | ||
| ZONE=us-central1-a | ||
| gcloud compute ssh --zone $ZONE $NAME --project $PROJECT_ID | ||
|
|
||
| # On gcp workstation | ||
| git clone https://github.com/TraceMachina/native-link.git | ||
| sudo apt install -y npm | ||
| sudo npm install -g @bazel/bazelisk | ||
| cd native-link | ||
|
|
||
| DNS_ZONE=example-sandbox.example.com | ||
| CAS="cas.${DNS_ZONE}" | ||
| EXECUTOR="scheduler.${DNS_ZONE}" | ||
|
|
||
| bazel test //... --experimental_remote_execution_keepalive \ | ||
| --remote_instance_name=main \ | ||
| --remote_cache=$CAS \ | ||
| --remote_executor=$EXECUTOR \ | ||
| --remote_default_exec_properties=cpu_count=1 \ | ||
| --remote_timeout=3600 \ | ||
| --remote_download_minimal \ | ||
| --verbose_failures | ||
| ``` | ||
|
|
||
| ### Developing/Testing | ||
|
|
||
| [Visual Studio Code](https://code.visualstudio.com/) could be used to actively | ||
| work on native-link code cloned by using | ||
| [Visual Studio Remote Development](https://code.visualstudio.com/docs/remote/remote-overview). | ||
| The setup will allow for Visual Studio running on a local machine connected to | ||
| a remote workstation, mapping along the file system and access to terminal. | ||
| Using this setup can allow for working on native-link or testing different | ||
| workloads without having to match environment expectations. Install the | ||
| [Visual Studio Remote Development Extension Pack](https://marketplace.visualstudio.com/items?itemName=ms-vscode-remote.vscode-remote-extensionpack), | ||
| connect using ssh to work station instance and map `native-link` folder | ||
| (or any other cloned project). |
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters