🚀 REST API: AGI can Create, Start and Stop multiple Autonomous Agents (Monitoring coming soon)🚀 #765
Conversation
|
Hang tight on this one, I am making sure the decorator to stop the threads is added to al the major IO methods. I know this is going to be a long road to merge this one. Once it's ready to be merged I will create more commits, currently, it's all into one. |
| .idea | ||
| ai_settings.yaml | ||
| app/.DS_Store | ||
| .DS_Store |
There was a problem hiding this comment.
Good that you added .DS_Store to gitignore, I still see lots of .DS_Store files already committed, please remove them.
| if not thread.is_alive(): | ||
| return JSONResponse(content={"message": "The thread is already terminated"}, status_code=500) | ||
|
|
||
| threads_to_terminate = read_file("threads_to_terminate.json") |
There was a problem hiding this comment.
reading and json.loading the threads_to_terminate.json could be in a function, it's also used in the def termination_check
requirements.txt
Outdated
| uvicorn[standard]==0.21.0 | ||
| pydantic[dotenv]==1.10.6 | ||
| yarl==1.8.2 | ||
| ujson==5.7.0 |
There was a problem hiding this comment.
Can you re-use orjson, or does it really have to be ujson?
scripts/chat.py
Outdated
| @@ -63,10 +64,9 @@ def chat_with_ai( | |||
| """ | |||
| model = cfg.fast_llm_model # TODO: Change model from hardcode to argument | |||
| # Reserve 1000 tokens for the response | |||
|
|
|||
| if cfg.debug: | |||
| if os.environ.get("DEBUG"): | |||
There was a problem hiding this comment.
I think it's better to keep using cfg.debug and then move the env var to the Config.debug code. Or call cfg.set_debug_mode(os.environ.get("DEBUG")) even though those setter/getters are not pythonic.
|
Looks intriguing, does it work with gpt3.5 at all? |
Vicuna is really impressive... I don't have it running locally yet, no time yet. Would love to see/make a Vicuna integration for AutoGPT. |
|
@Wladastic don't think tokens cost because I am telling you: in a few months you're going to have a bunch of things free, or at least very cheap, for the same quality of GPT3.5 and that will run locally (Vicuna is already great for chat and questions/answers, not so much to code, I have found). When that time comes, you don't want to have to run multiple processes to run multiple agents, you want multiple threads (threads are lighter) like my implementation. I only develop with GPT 3.5 right now, because GPT4 will be too expansive to run CI/CD on. @dhensen yes, the only problem with Vicuna is it's 20Gb. If we have a github pipeline with it, we will have to create an instance in a cloud provider and call it from there, so it might be more expensive in the long run, because on github action it's going to be too much I think. But we might try. Honestly, GPT3.5 is great and extremely cheap. I think it's a good middle-ground for now. |
|
damn it, there is still an issue in my PR because the project is working at the scripts level. |
|
@Torantulino is the scope too large to sensibly merge? |
|
@nponeccop what do you want me to do ? create just one endpoint to create the agent and then nobody can do anything with it ? and if people start an agent they have to be able to stop it. The whole skeleton of the web server has to be pushed all at once, we can't afford to just put a little app.py in scripts folder and then "improve it later". If you add a web server improperly built it's going to cost a lot, like the main.py in this project that easily cost probably 100 hours of dev time wasted, if you add up all the contributors. |
|
Make it a compound PR where the parts are more or less independent and can be easily reviewed. I don't want you to do anything, it's @Torantulino who decides. I'm sorry if I sounded like the official opinion of the repo. I'm not. |
|
👍 👎 💯 🔢 🥇 🍇 😁 😀 🤣 😂 🚀 🎸 😧 🥺 🙏 😟 🧇 👋 🤚 🤨 🤙 👈 👇 👉 ☝️ 👆 🤛 👊 ✊ 🤜 🤳 💪 🍄 🎹 👶 🚼 |
|
@merwanehamadi Have you tried vicuna? |
|
@merwanehamadi There are conflicts. But frankly you should only resolve them when you get a @Torantulino confirmation of merge. |
9dd0eab to
7a9977f
Compare
|
Changes:
@Torantulino I created a new branch with just the web server and the create endpoint, very little change and gives us a solid structure for the backend API. |

|
FYI @Torantulino amongst these 56 files, a lot of them are tests. |
7a9977f to
4ff986f
Compare
|
It's not about tests, it's about implementing multiple features at once. A single feature is fine, we don't count lines. But your PR is clearly splittable into small improvements that can be applied before you add the REST API. |
|
OK I see, so here is my suggestion. I am making these code changes right now:
How about I create a PR that just does this:
|
f7b4a68 to
141e550
Compare
141e550 to
972c8cc
Compare
Signed-off-by: Merwane Hamadi <[email protected]>
|
rebase is still ongoing. I prefer to rebase often, it's easier.
@Torantulino if I create a PR to do the items above, will you consider it ? |
|
@nponeccop @Torantulino please prioritize these very small changes in the following PRs:
|
|
I have added the smallest change possible in this PR:
|
|
This pull request has conflicts with the base branch, please resolve those so we can evaluate the pull request. |
2 similar comments
|
This pull request has conflicts with the base branch, please resolve those so we can evaluate the pull request. |
|
This pull request has conflicts with the base branch, please resolve those so we can evaluate the pull request. |
|
This is a mass message from the AutoGPT core team. For more details (and for infor on joining our Discord), please refer to: |
|
the interesting thing here is that this sort of interface would make scaling rather straightforward - you could even hook up multiple Auto-GPT instances together, running on different computers in the same network/LAN or possibly by coming up with a clustered network where people could volunteer their Auto-GPT instances to work towards a common goal (think SETI/protein folding etc) - so this sort of feature could become the foundation for crowd computing, and the scale would be massive if each Auto-GPT has access to the same network and different LLMs - the interesting thing being that a distributed setup would add network latencies to the pool of resources to be tracked (#3466 ) Related: https://github.com/Significant-Gravitas/Auto-GPT/discussions/2497 |
|
The REST API would actually be good to have, as it would make it much easier to add a simple UI/web UI on top of the whole thing, without having to dissect all the underlying code. |

|
a rest api is coming in the rearch |
* Small docstring change for clarity * Added tentative changes to docs * Update website/docs/Use-Cases/Task-Oriented-AutoML.md Co-authored-by: Chi Wang <[email protected]> * Update flaml/model.py Co-authored-by: Chi Wang <[email protected]> * Updated model.py to reflect `n_jobs = None` suggestion * Updated tutorial to reflect `n_jobs=None` suggestion * Update model.py Improved string Co-authored-by: Chi Wang <[email protected]> Co-authored-by: Qingyun Wu <[email protected]>
Background
The goal is to build an AGI. This AGI might be one single Auto-GPT that loops against itself, but I doubt it because the LLM is super slow. We can't expect to have something that has high computing power with only one autonomous agent. And we can't have one agent per computing machine, that's stupid, because most of the time the running process will just hang and do nothing, waiting for Open AI to give back an answer. Waste of resources. Running multiple agents in different tabs is not ideal either because processes are heavier than threads.
On the current PR I was able to spawn 20 concurrent workers simultaneously without any problem.
So I think that in order to build an AGI, we need to build an entity able to:
Which programmatic language is the AGI going to use to do that? A proper, well-defined REST API is the way to go, we can only do so much with a CLI.
This AGI will talk to its workers through rest api calls, which are nothing more than JSON sent over the network.
At the beginning we will be playing the AGI, so we will use these endpoints to communicate with our agents, through a web browser UI.
Changes
Now let's come back to reality, I had to work with what the repo provides, so I made the smallest changes possible to achieve these goals. The first thing I want to say, is that my changes won't affect the users in any way. All the existing features are preserved and unchanged.
Additions to the repo that are all necessary to achieve this User Story (I insist they're all necessary to be merged together):
CHANGES to the repo:
Documentation
Look at the tests, they document clearly the following requests and responses as well as the output of the worker:
2 integration tests at the moment:
Test Plan
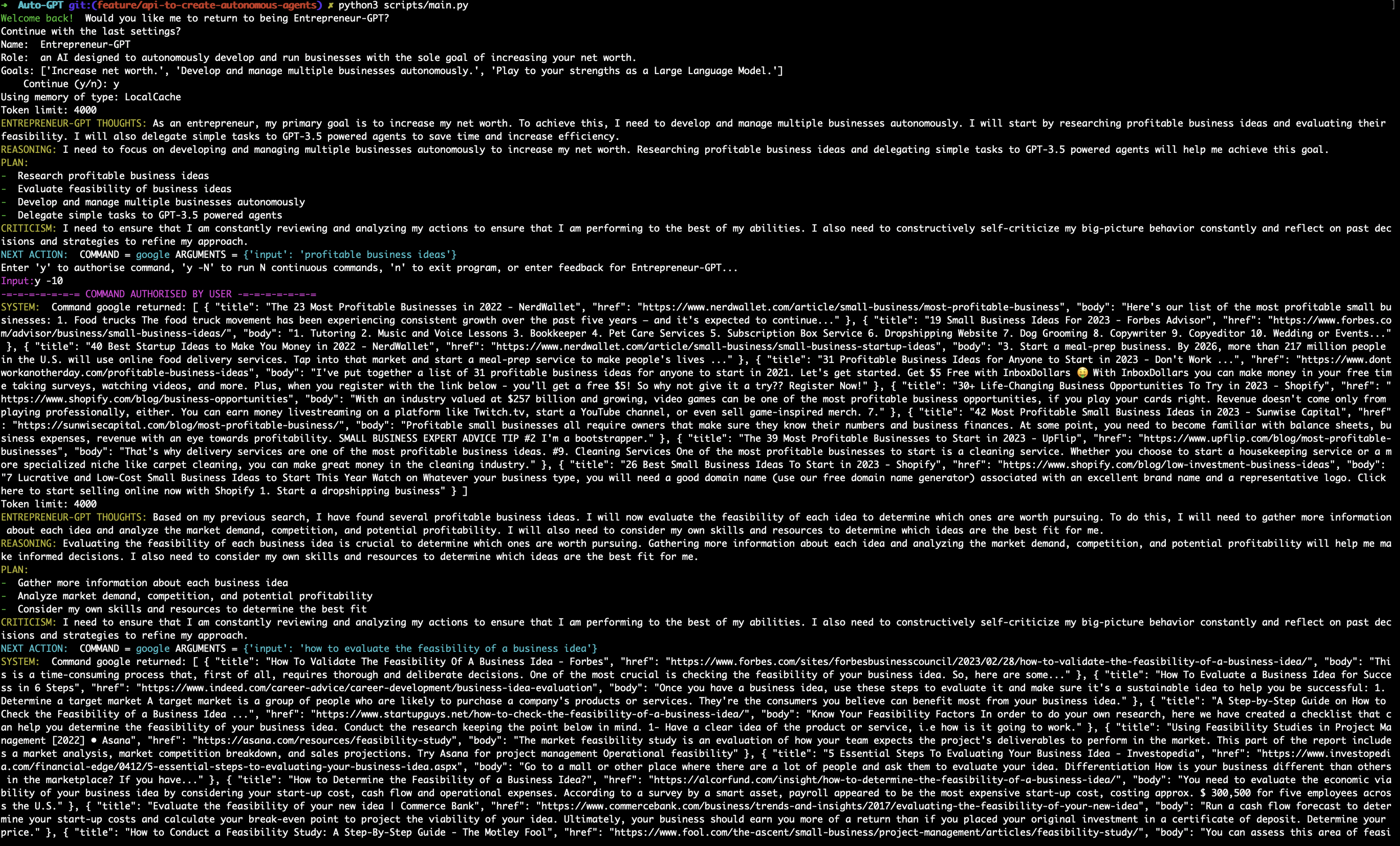
The CLI has to keep working !!! So I tested it thoroughly Here is one run example.

PR Quality Checklist