Planetary impact simulation super slow with large dead time #22
Comments
|
Hi, Glad to see that you are interested in our code and that you already have results. This is a known limitation of the code in its current form. Specifically, the particles ejected from the system are still trying to search for neighbours and by doing so also slow down the other neighbour search. A change to the algorithm for neighbour finding has been in the works for a while but it's a non-trivial modification of some of the core algorithms. Things that may help now:
|
|
Dear Matthieu, Thank you so much for your advice, I'll try to reduce the h_max. Are you suggesting the unreasonable large h_max set is the reason that caused the mpi version code to be frozen somehow? Sometimes, at some point, the code just goes to a "freezing" status which gives me no error and won't stop either. And it happened basically at the same number of steps. The same IC and yml file will work well if I use fewer CPUs or only one node. I first thought it has something to do with domain decomposition, as for now, ParMETIS is not available, only "grid" strategy can be used. I'm not sure if it's the poor domain decomposition method that freezes the code. Could you please give me some suggestions on this issue? Thank you very much! |
|
Could you expand on what you see happening in these MPI runs? Note that parmetis will be unlikely to help significantly here. |
|
normally it takes around 1min to generate a snapshot then at some point it suddenly begins takes 10mins and then 30mins 1hours and one night, and I hit the time limit. I guess it's becoming super slow at some point and getting worse with growing steps. |
|
Hi Jingyao, Likewise it's great to hear that you're using the code, and it looks like maybe WoMa/SEAGen too? Are you working with Zoe Leinhardt perhaps? I've never met her but have had some email contact with others in the Bristol group, it's great that some other planetary impact work is happening in the UK! And thank you for raising this issue, we're actively continuing to develop swift so it's helpful to have more than just our small planetary group within Durham testing the code in different situations. Matthieu knows much more about the inner workings and performance of the code than me, but from my experience I'd guess there's a chance this is not related to h_max. I felt the large-h_max slowdown we've seen made sense because it kicked in soon after the initial impact -- right when particles start flying away from the initial planets and begin having to search very far away for neighbours if not corralled by h_max. So the fact that this is happening at much later times surprises me. But I suppose there's no harm in testing it. I have less intuition for 10^5 particles, but perhaps 10% or even 5% of the planet radius would be a place to start? If that is the problem then I hope we aren't too far away from merging in the fix, and the "good" news is that SPH probably shouldn't be trusted when the density is low enough that neighbours are so far away, so if that change affects the science results then that could be a hint that the original resolution is too low regardless. We very rarely run planetary simulations over MPI (mostly since cosma nodes at Durham have many cores so a single node is much more efficient in our case), so in that context I'd also not be surprised if there are other sources of slowdown (my guess might also be the decomposition like you, though I'm not an expert on that part of the code) that we haven't encountered ourselves. We have also not done many speed tests with as few as 10^5 particles. I hope and suspect that swift will outperform gadget with higher resolution simulations. I hope some of that long reply might help you or Matthieu! I'm currently in a US time zone getting started at a new post so may not be able to respond immediately, but I'll keep checking in when I can. Best, Jacob |
|
Dear Jacob, Thank you very much for your kind reply! Yes, I'm Zoe's student and I'm using WOMA and SWIFT. Thanks to the brilliant code, my life could get easier. Sorry for the late reply, it takes me some time to test with h_max on our HPC. It turns out, scaling down the h_max does fix the problem, the code finally goes well. Really appreciate the advice from you and Matthiew. As you suggested, I'm using too many CPUs while having a very low resolution which will give each cell very few particles and may cause the slow down problem. Again, many thanks for your patience and time! |
|
That's great news. Glad you got it to work as intended. Parameters are not always easy to figure out. :) |
|
Great news, and you're very welcome, it's great that other people are starting to make use of the codes -- and to help us find and resolve issues like this one! Hopefully we'll soon be able to finish testing and merge the fixes that stop larger h_max's from slowing the code in the first place. I can at least say from our tests that using a smaller value doesn't affect the major (resolution-appropriate) outcomes of simulations, as you'd intuitively hope. The issue would be trying to inspect something like the detailed thermodynamic states of low-density debris. I can't always promise immediate responses, but do stay in touch and let us know if anything comes up, including requests for future features in either code -- and keep an eye out for ones that appear from time to time anyway :) And of course especially being in the UK (or at least the rest of the Durham group besides me now!) we could always meet up to chat or collaborate, besides this occasional tech support haha. At any rate I'll hope to maybe meet you and Zoe et al at a conference some time. |
|
Dear all,
|



|
I don't know precisely what is going on here. My initial guess is that by allowing a very large h_max, you effectively let h be as large as the code allows, which is 1/3 of the box size. Could you share your parameter file? As a side note, Gadget does not have an h_max, but when the particle density becomes very low, the calculation is wrong anyway (or rather leads to a breakdown of the method). So by setting an h_max you actually set a hard limit rather than possibly fooling yourself in thinking you have the resolution to get infinitely small densities. |
|
The parameter file and initial condition file are loaded here, please have a look. You are absolutely right about the h_max, I didn't realize this problem until you mentioned it last time. Without h_max limit, Gadget indeed can have ridiculous smoothing length and that should be avoided. Based on my current impact simulation where I use around 8% of the largest planet radius in the simulation as the value of h_max, after 20h simulation time, around 10%~12% particles will hit this h_max limit whereas all other particles have a reasonable smoothing length distribution. I think a comparison test between this small h_max and a reasonably large h_max simulation would help me to identify whether the density error introduced by these 10% particles will affect the final result greatly. |
|
From the logs of the run, can you check whether the code performed a regriding? |
|
Sorry for the late reply, the previous simulation didn't have verbose output, so I run it again. Below is the log for 1 step around the time when gaps begin to appear and it shows there is space regriding. |
|
Ok, so that's what I was worried about. It did indeed regrid all the way down to the minimum possible 2x2x2 top-level grid. That's a rather unusual scenario and I am not sure we are ready for it. There are two things I do not know whether
You could try setting h_max to This may be slower but that's all I can suggest for now before we have time to have a deeper look at the gravity solver behaviour when regriding. You can also make the box size larger such that |
|
Thank you very much for the advice, I will give it a try.
Thank you very much for the help. |
|
Rebuild == normal tree construction. Happens all the time and is safe. Regrid == much more severe change. This is a procedure where we change the size of the base grid used. The tree is built on top of this base grid. This never happens in normal simulations. The base grid cells have to be smaller than 2 * max(h). So if you let h grow unlimited, at some point the code will have to create a new base grid. Scaling the number of cells with the number of CPUs makes no sense. I'd make it 16x16x16 and only make it larger if the gravity solver gets very slow. h_max is in internal units. i.e. whatever unit system you set in the parameter file. cell_min is not a parameter. |
|
Really appreciate your help, it's much clear now! Thank you again for your time and patience. |
|
Dear Matthieu and Jacob,
Thank you very much for your time and help. Happy Christmas! |
|
Can you tell me what the Also, 30 levels deep seems implausible if you only have so few particles. The part of the code where you get the error is only for diagnostics. But it's a very bad sign if you need that many levels in the tree. |
|
Hi, Matthieu, I use It could be WOMA somehow randomly placed too many particles at the same position since the warning didn't always show. Do you think I should change the |
|
No, I would not change the max depth. It is a sign that something is not good with the ICs. I would have a look at them to make sure everything is is sensible. |
|
Thank you very much for the quick reply. Do you have any idea why the simulation time would vary with boxsize? |
|
Not yet. Likely the neighbour finding being silly in some configurations. All these setups are very far from the normal way we operate. |
|
No worries, these are just some extreme tests, we basically won't use this large |
|
I'll have a more detailed look in the new year. |
|
Regarding #22 (comment), could you try your test once more but using the code branch |
|
Hi Matthieu, thank you for the fixed version of the code. I have tried the new branch code with equal to boxsize |
|
Could you verify whether the latest version of the code in master fixes the issue? |
|
Sorry for the late reply, HPC is very busy these days. The issue is fixed using the new master branch. Gaps around x=0 and y=0 disappear and the simulation result of large hmax is similar to that of the smaller ones. The simulation time is still very large for the large hmax one. |
|
Great. Thanks for confirming. At least the bug is out. We'll keep working on the speed. |
@MatthieuSchaller do you suggest to use just ./swift instead of mpirun for a 64 core and 128 threads machine (single node). Thank you in advance for the answer |
|
Yes, most definitely. Don't use the mpi version unless you actually need to use more than one node. |
|
I take the opportunity to aks one more question: I compiled with: ./configure --enable-compiler-warnings --with-tbbmalloc --with-parmetis=/home/francesco-radica/Documenti/parmetis-4.0.3 --with-hydro=planetary --with-equation-of-state=planetary I'm running my simulation with the command: ../../../swift -s -G -t 128 earth_impact.yml 2>&1 | tee output.log and in my system i have: swift_parameters: -s -G My cpu has in total 64 cores and 128 threads. The point is that according to the task manager it's not working at 100% (while m1 Pro worked every time at 100%). This doesn't happen with mpirun (other programs), where i can clearly see that is insanely faster.
It's like fluctuating (and I also think that, in proportion, is not as fast as it should be compared to my laptop (M1Pro)). It's surely faster, but compared with the "old CPU" it should be somekind of 10x faster at least. |

|
Hi Maybe try running without hyperthreading, i.e. using a single thread per core. IIRC in most situations our code is memory bound, so hyperthreading shouldn't do it any favours in terms of speed. On the contrary, I'd expect a performance penalty. When you say "insanely faster", do you mean in terms of how fast the simulation advances, or in terms of how much CPU usage your system reports? |
|
thank you for the answer. When I say Insanely faster i mean "how fast the simulation advance". idk, should I try a slower number (10-20-30?), should i just compile with planetary planetary eos and without using tbb and parametis? I also have enough RAM to handle the whole thing. The point is that i'm a little bit confused because with COSMA super computer which uses thousands of cores you can handle thousands of simulations with 10kk particles each, so I should expect that using more threads and cores means just more speed. I wait for suggestions and explanations, thank you in advance! Francesco |
Have you made sure you were running on 64 cores?
No, not lower. One thread per core is optimal.
tbbmalloc should be an improvement. Metis and parmetis are only used when running with MPI, so in your case, it shouldn't matter.
Neglecting MPI effects, that should indeed be the case. Unless we have some strange bottleneck that I'm not aware of. One more thing that comes to mind that might help is to run with pinned threads. You can activate that with the |
|
i'm doing a try witht he command: ../../../swift -s -G -t 64 -v 2 simulation.yml 2>&1 | tee output.log and: input:
output:
swift_parameters: -s -G This is the task manager:
and it says that i'm running with 12% of CPU more or less It's also creating 1 snap every minute, like the 128 threads run (maybe because the collision didn't started? i don't know...) I'm running on a ThreadRipper 7980X and i have 200 Gb of RAM. tomorrow i'll do a run with --pin adn 128 threads, i promise |

|
How many particles do you have? |
I'm running with the command: The speed seems the same, not matter if i use 64 or 128 threads...
I have 1.5 millions particles. ALso, the simulation is very fast when they are joined, it start to slow down immediatly after the collision to become then faster when the system is settled. units: |
|
Ok, that's not many particles for this number of cores. At some point you won't have enough particles / core to make good use of the extra resources. When it slows down around the collision is it because the time-step size drops? |
Do you mean that if i use a larger number of particle the speed won't collapse? Here there are info about the timestep. Do you need other? |
|
no, I mainly mean that for a fixed number of particles, there is always a point beyond which using more cores won't help. From this file, it looks like it's taking ~2s per step consistently so not bad I'd think. I would use the Intel compiler btw. That will speed things up. |
|
Thank you for the suggestion. I installed intel compilers and compiles succesfully:
After make, i have this error: I did Thank you for the suggesions and help. Do you think that in general intel's compilers make every simulator that uses OpenMPI faster in general or it's just a swiftsim case? |
Dear SWIFT team,
I'm having a serious slow downing issue when trying to use swift_mpi running planetary impact simulation on our HPC. The issue can only happen if I use a specific number of nodes and CPUs (basically all happened when I tried to use 2 or 4 full nodes). I've listed some situations below that I've tested:
the timestep plot of the HPC-2 10^6 particles simulation is like this:
After some steps, the dead time becomes extremely large basically taking 98% CPU time of each step.
Here is my configure and running recipe:
submit script like this:
parameters file and initial condition:
parameters yml file
Initial condition
ParMETIS lib is currently unavailable on both HPC, so I can't use that. Also, HPC 2 doesn't have parallel hdf5 lib, but the same issue happened on HPC 1 which has parallel hdf5 loaded.
Here below is the log file from 10^6 particles simulation on HPC2:
10^6 output log file
rank_cpu_balance.log
rank_memory_balance.log
task_level_0000_0.txt
timesteps_96.txt
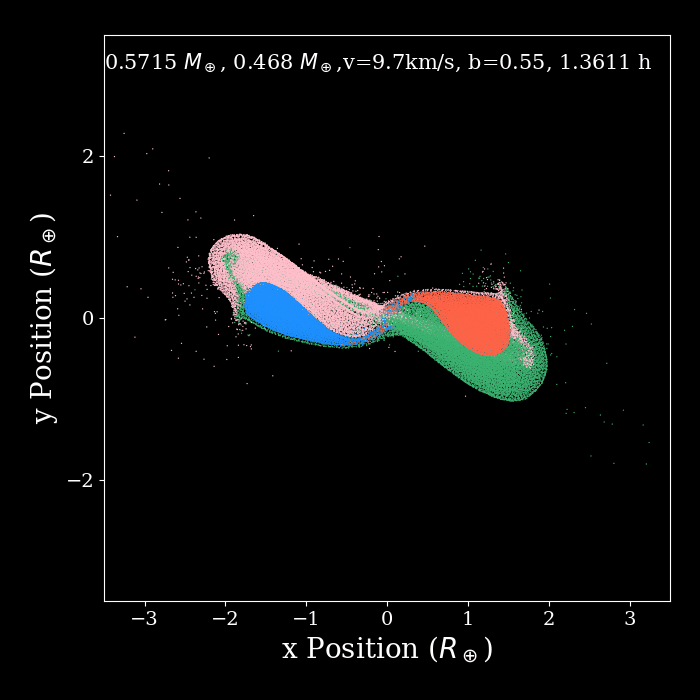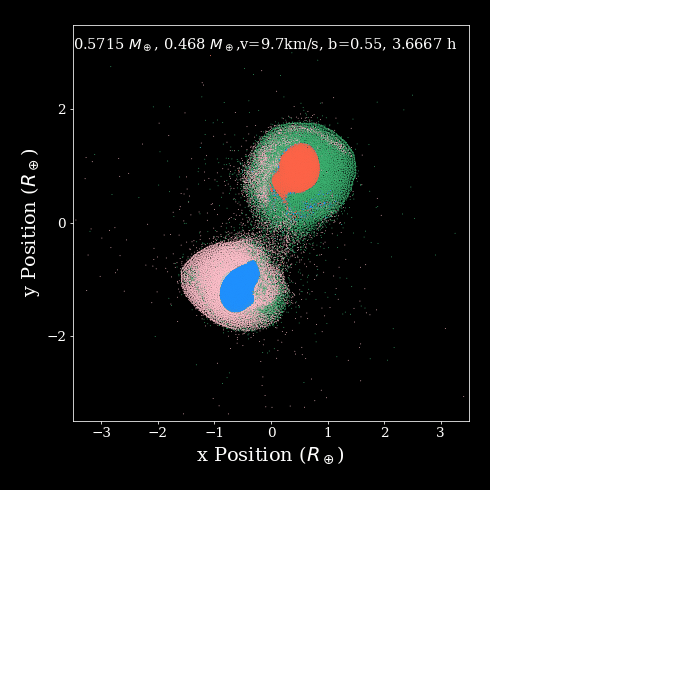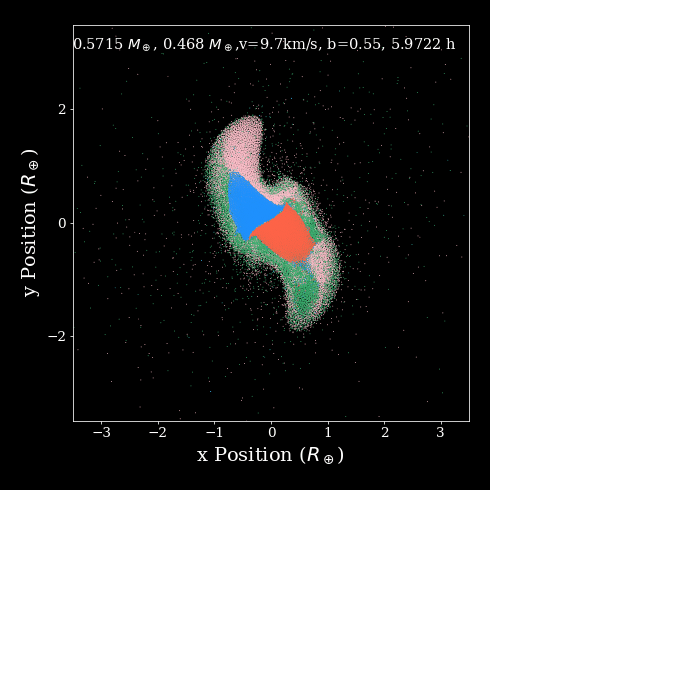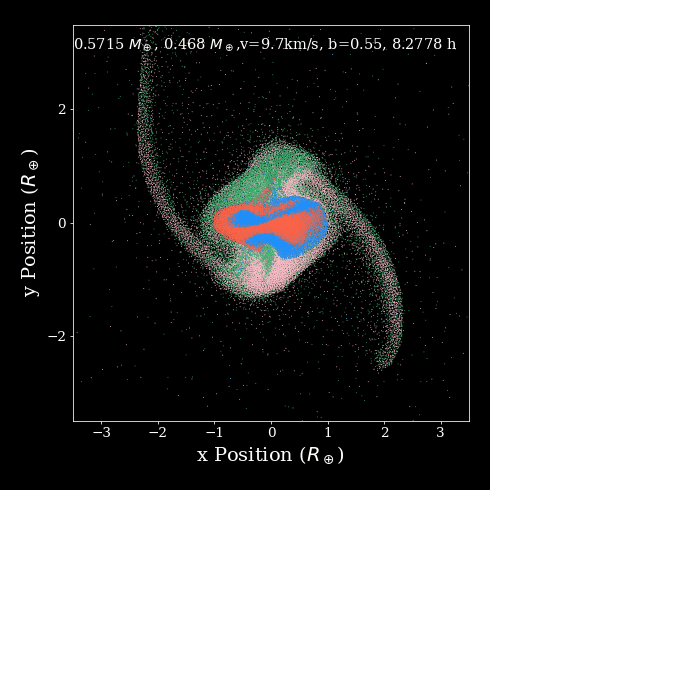
I'm doing some not very series benchmark tests with swift and Gadget when running planetary simulations. The below plot shows some results, which suggest SWIFT is always running a little bit slower than Gadget2 during the period of 1.5~8h (simulation time). The gif shows the period where this sluggish situation happened. Looks like SWIFT gets slower when the position of particles changed dramatically. After this period two planets just merged into a single one and behave not as drastically as in the first stage. I was expecting SWIFT to be always faster during the simulation, do you have any suggestions on how I could improve the performance of the code.
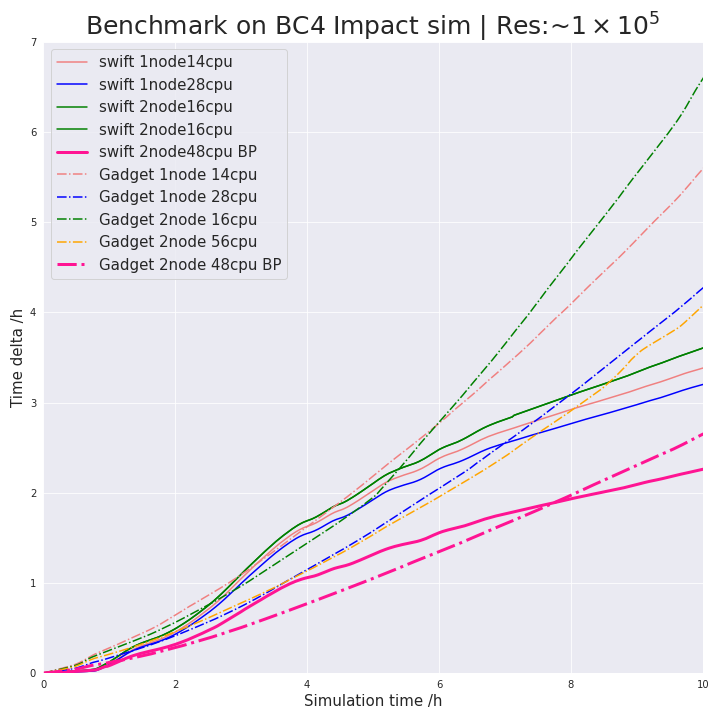
The text was updated successfully, but these errors were encountered: