本项目是本博主大二的人工智能导论课程的课程设计。
博主读的是机械类专业,代码中如有错误不当之处敬请提出。
若参考使用本项目,请仔细阅读本文和代码。
博主博客:www.anleo.top
欢迎关注:哔哩哔哩
本设计主要研究针对微博等短博文互动情景下的基于支持向量机(SVM)机器学习算法和词频-逆文档频率(TF-IDF)自然语言处理(NLP)算法的中文文本分类和情感分析系统。
本设计收集了清华大学自然语言处理实验室推出的中文文本分类工具包(THUCTC)中的语料数据集(THUCNews)通过结巴(jieba)中文分词工具对 指定文本分词并去除停用词(Stop Words)。然后通过卡方检验的方法过滤并顺序 选得一定词语作为特征词。通过 TF-IDF 算法逐一对每一文本每一特征词检验并 组成特征向量,送入台湾大学开发的 libSVM 工具包形成模型文件。通过测试数 据集预测检验准确率,结果符合预期与基本使用场景。
本设计还设计了交互界面,通过输入某一文本,经过分词处理、特征分析、TFIDF 数值化,送入指定模型预测分析,在窗口输出预测分类。
本项目选择清华大学自然语言处理 实验室推出的中文文本分类工具包(THUCTC)中的语料数据集(THUCNews)1,选取其中包含 的 12 类作为本次项目的分类参考和训练数据集,分别为“财经”“房产”“股票” “家居”“教育”“科技”“社会”“时尚”“时政”“体育”“游戏”“娱乐”。考虑 到机器的性能,每类选取 5000 + 200 篇文章作为训练集和测试集。
流程图如下所示。
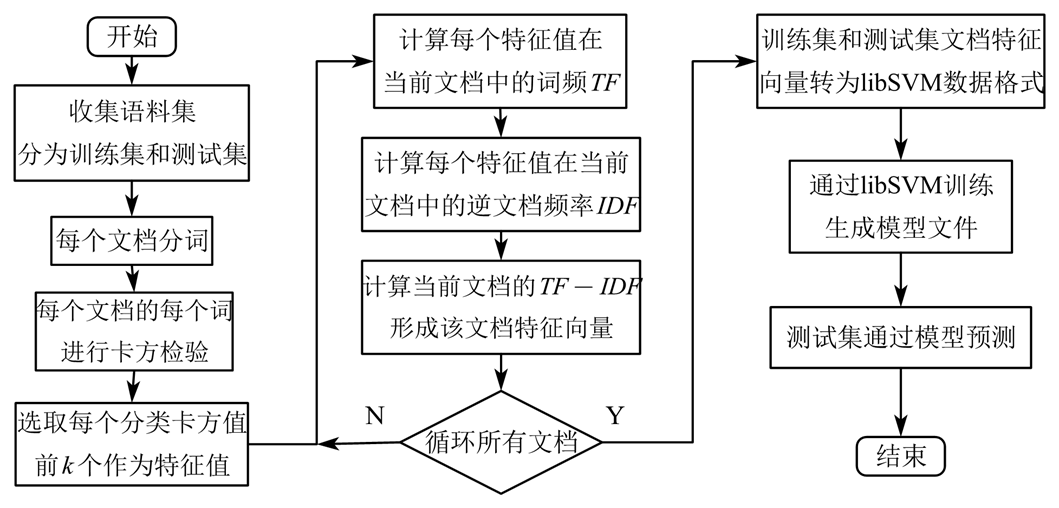
本项目通过“cutWords.py”,引用“jieba”工具库将每类 5200 篇文档 分词并且去除“ChineseStopWords.txt”中包含的停用词,另存在分词文件夹。
通过“featureSelection.py”,逐一计算得到每类中每个词的卡方值2,由大至小排序选取前 k 个作为该分类 的特征词。所有特征词不按顺序地、不重复地存入 “classFeature.txt”。
通过“featureWeight.py”,将计算的TF--IDF3作为特征值,构成特征向量。将词频存入“classDfFeature.txt”,将特征向量转为 libSVM 4数据格式存入“classTrainData.svm”。
通过 Windows 版 libSVM 中的 svm-scale 程序将“classTrainData.svm” 的特征值缩放至 [0~1]之间,并输出每个特征词特征值数据围 导出为 “classParam.svm”。调用 Python 版 libSVM 库将“classTrainData.svm”数据训练转为训练模型 “classTrain.model”。
本项目选取微博评论语料集5,分为褒义和贬义类。
流程图如下所示。
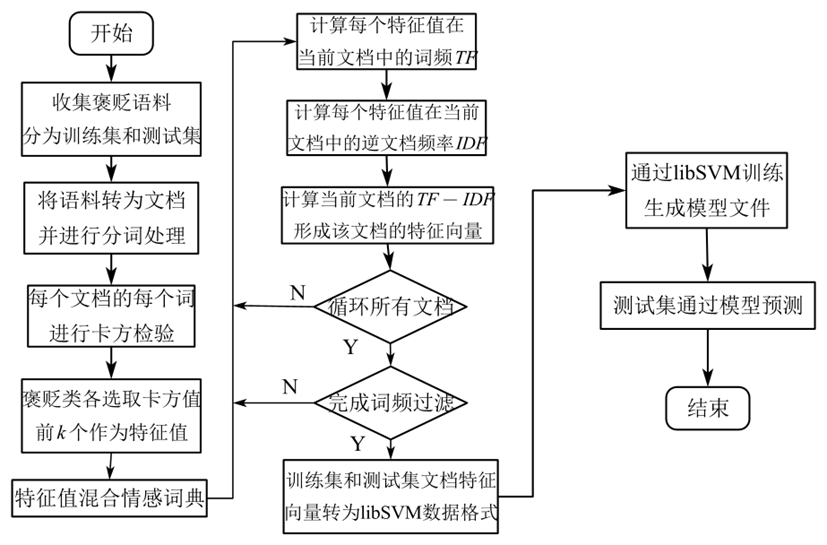
卡方检验选取特征值过程与文本分类系统相同。
由于考虑到自然语言中表达情感的词语与方式庞大且众多,而当前语料集每 条语料情感密度不大,分词后的词语稀疏,无法保证对当前情感有较好的映射,上述按卡方选取出来的特征词汇具有明显的局限性。所以本项目引入成熟的中文褒贬情感词典作为特征词汇的扩充集合。本项目选取台湾大学和台湾地区“中央研究院”团队总结的情感词典(NTUSD)6中的简体中文词典作为扩展词典。
通过“featureComb.txt”,将情感词典的两类 词汇与上述得到的特征词汇不规律地、不重复地整合为一个新的特征词汇文档。
TF--IDF特征值及libSVM模型训练与文本分类系统相同。
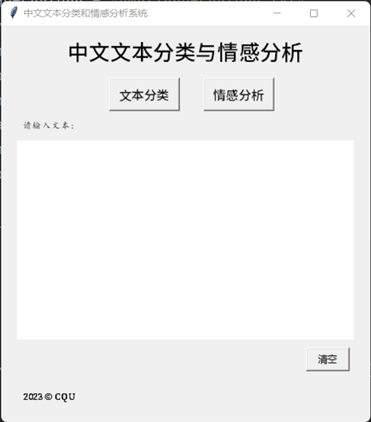
模型训练之后,通过“main.py”的交互界面可以对指定输入文字进行文本分类或情感分析。如下图所示。
Footnotes
-
请自行下载THUCNews,详见http://thuctc.thunlp.org/ 。 ↩
-
卡方值及其计算自行查阅资料。 ↩
-
自行查阅TF--IDF算法计算原理。 ↩
-
自行下载libSVM资料,详见https://www.csie.ntu.edu.tw/~cjlin/libsvm/。 ↩
-
请自行检索下载相关语料。 ↩
-
该情感词典需要在其网站联系获取,请自行考虑。 ↩