CMIP7 Historical Forcings are part of the DECK #222
Comments
|
Hi @johndunne13, just to make sure we're all on the same page. You're saying that there is only one DECK. So, unlike other MIPs, which could have a fast track phase and a later phase, for the DECK simulations there is only one phase. Key implication: the DECK forcings that are being released now are the only DECK forcings that will be released throughout the entirety of CMIP7 (at least under the title of the DECK). If yes, that's good to understand. Can you please also confirm that this does not need to go through a CMIP panel meeting, I should just update the docs now. |
|
Yes, my understanding is that the proposal CMIP presented and ratified by
WCRP at the Hamburg meeting last year is for a single mandatory DECK
(including the historical) across CMIP's 7th phase. ccing Eleanor and
Helene to correct me if I have mischaracterized anything, but this would
not require any new CMIP Panel discussion.
…On Fri, Mar 14, 2025 at 12:17 PM znichollscr ***@***.***> wrote:
Hi @johndunne13 <https://github.com/johndunne13>, just to make sure we're
all on the same page. You're saying that there is only one DECK. So, unlike
other MIPs, which could have a fast track phase and a later phase, for the
DECK simulations there is only one. Key implication: the DECK forcings that
are being released now are the only DECK forcings that will be released
throughout the entirety of CMIP7 (at least under the title of the DECK).
If yes, that's good to understand. Can you please also confirm that this
does not need to go through a CMIP panel meeting, I should just update the
docs now.
—
Reply to this email directly, view it on GitHub
<#222 (comment)>,
or unsubscribe
<https://github.com/notifications/unsubscribe-auth/AGUJAMRXAYXAZOPXBL3JYIL2UL6I5AVCNFSM6AAAAABZA7NQC2VHI2DSMVQWIX3LMV43OSLTON2WKQ3PNVWWK3TUHMZDOMRVGE2TSMBSG4>
.
You are receiving this because you were mentioned.Message ID:
***@***.***>
[image: znichollscr]*znichollscr* left a comment
(PCMDI/input4MIPs_CVs#222)
<#222 (comment)>
Hi @johndunne13 <https://github.com/johndunne13>, just to make sure we're
all on the same page. You're saying that there is only one DECK. So, unlike
other MIPs, which could have a fast track phase and a later phase, for the
DECK simulations there is only one. Key implication: the DECK forcings that
are being released now are the only DECK forcings that will be released
throughout the entirety of CMIP7 (at least under the title of the DECK).
If yes, that's good to understand. Can you please also confirm that this
does not need to go through a CMIP panel meeting, I should just update the
docs now.
—
Reply to this email directly, view it on GitHub
<#222 (comment)>,
or unsubscribe
<https://github.com/notifications/unsubscribe-auth/AGUJAMRXAYXAZOPXBL3JYIL2UL6I5AVCNFSM6AAAAABZA7NQC2VHI2DSMVQWIX3LMV43OSLTON2WKQ3PNVWWK3TUHMZDOMRVGE2TSMBSG4>
.
You are receiving this because you were mentioned.Message ID:
***@***.***>
|
|
OFFICIAL
I agree – only one DECK.
…---
Prof. Helene Hewitt OBE (she/her)
Met Office Science Fellow: Ocean, Cryosphere and Climate
Co-chair of Coupled Model Intercomparison Project (CMIP) Panel
Met Office FitzRoy Road Exeter Devon EX1 3PB United Kingdom
Tel: +44 (0)1392 884956
Email: ***@***.******@***.***> Website: www.metoffice.gov.uk<http://www.metoffice.gov.uk/>
Visiting Professor at University of Southampton
Adjunct Fellow at National Oceanography Centre
Professeure Invitee Benevolee University of Geneva
OFFICIAL
From: John Dunne - NOAA Federal ***@***.***>
Sent: 14 March 2025 16:27
To: PCMDI/input4MIPs_CVs ***@***.***>
Cc: PCMDI/input4MIPs_CVs ***@***.***>; Mention ***@***.***>; Eleanor O'Rourke ***@***.***>; Helene Hewitt ***@***.***>
Subject: Re: [PCMDI/input4MIPs_CVs] CMIP7 Historical Forcings are part of the DECK (Issue #222)
Yes, my understanding is that the proposal CMIP presented and ratified by WCRP at the Hamburg meeting last year is for a single mandatory DECK (including the historical) across CMIP's 7th phase. ccing Eleanor and Helene to correct me if I have mischaracterized anything, but this would not require any new CMIP Panel discussion.
On Fri, Mar 14, 2025 at 12:17 PM znichollscr ***@***.******@***.***>> wrote:
Hi @johndunne13<https://github.com/johndunne13>, just to make sure we're all on the same page. You're saying that there is only one DECK. So, unlike other MIPs, which could have a fast track phase and a later phase, for the DECK simulations there is only one. Key implication: the DECK forcings that are being released now are the only DECK forcings that will be released throughout the entirety of CMIP7 (at least under the title of the DECK).
If yes, that's good to understand. Can you please also confirm that this does not need to go through a CMIP panel meeting, I should just update the docs now.
—
Reply to this email directly, view it on GitHub<#222 (comment)>, or unsubscribe<https://github.com/notifications/unsubscribe-auth/AGUJAMRXAYXAZOPXBL3JYIL2UL6I5AVCNFSM6AAAAABZA7NQC2VHI2DSMVQWIX3LMV43OSLTON2WKQ3PNVWWK3TUHMZDOMRVGE2TSMBSG4>.
You are receiving this because you were mentioned.Message ID: ***@***.******@***.***>>
[znichollscr]znichollscr left a comment (PCMDI/input4MIPs_CVs#222)<#222 (comment)>
Hi @johndunne13<https://github.com/johndunne13>, just to make sure we're all on the same page. You're saying that there is only one DECK. So, unlike other MIPs, which could have a fast track phase and a later phase, for the DECK simulations there is only one. Key implication: the DECK forcings that are being released now are the only DECK forcings that will be released throughout the entirety of CMIP7 (at least under the title of the DECK).
If yes, that's good to understand. Can you please also confirm that this does not need to go through a CMIP panel meeting, I should just update the docs now.
—
Reply to this email directly, view it on GitHub<#222 (comment)>, or unsubscribe<https://github.com/notifications/unsubscribe-auth/AGUJAMRXAYXAZOPXBL3JYIL2UL6I5AVCNFSM6AAAAABZA7NQC2VHI2DSMVQWIX3LMV43OSLTON2WKQ3PNVWWK3TUHMZDOMRVGE2TSMBSG4>.
You are receiving this because you were mentioned.Message ID: ***@***.******@***.***>>
|
|
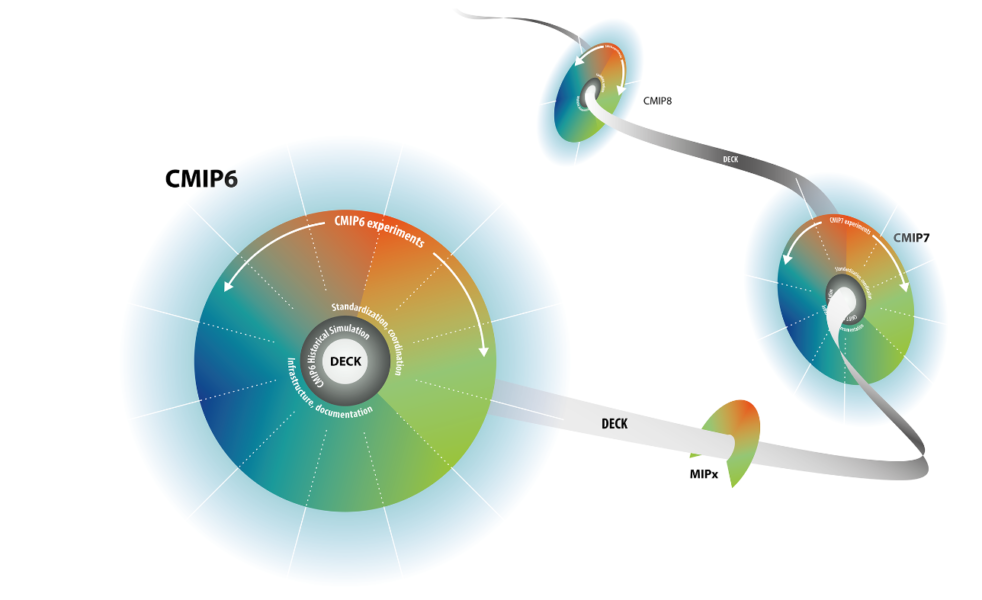
Just flagging that even for CMIP6, the DECK was identified "continuous" - such as the graphic below. We need to be a little careful about conflating "entry card" (CMIP6 terminology) which relates to what a modelling group needs to do to contribute to CMIP7, and what forcing data is used to generate the simulations - with all likelihood being that there will be updates to forcing data over the lifetime of CMIP7, which will likely start with first data available in 2025, and if precedents are a guide, extend well past 2030.. |
|
A key point to note, is that in CMIP6 any simulations that met the CMIP6 data specifications were allowed to publish their data into the CMIP6 ESGF project. We have no technical way to validate what forcing data was used for a piControl, historical (or their esm* variants), and consequently we will get what we get in the CMIP7 archive - this is an "ensemble of opportunity" after all! Most, but not all modeling groups used the CMIP6 provided forcings (e.g. Lurton et al., 2020), but some groups did not (e.g. Danabasoglu et al., 2020 note the VolcanEESM volcanic forcing was used, not the Luo et al data provided in input4MIPs). Both these sims are published side-by-side in CMIP6, and it is likely the same will happen in CMIP7 |
My understanding is that the communications made to date are saying the opposite of this. We are freezing the forcings for the historical. There will be no updates as part of the DECK (i.e. if you want to do updates, do them in a MIP). @durack1 are you arguing for us to put back in the distinction between CMIP7/fast track/whatever comes now? If no, I'm a bit confused about the point being made, I thought we had clarity about the next steps (drop fast track) but now I'm not sure. |
|
Ok, so surely we put those updates under a mip_era of "CMIP7Plus" to make clear that we do not expect modelling centres to re-run?
To clarify, if they're "historical-ext" simulations then they're not DECK simulations anyway, right? |
For the forcing data and input4MIPs ESGF project, this makes sense to me. I'm not sure it makes sense to others. For example, would Steve be happy for his "provisional" data to be marked CMIP7Plus? As a single vote, I'd be more than happy for my PCMDI-AMIP-2-x-y data to be marked CMIP7Plus if that makes comms cleaner. I would note that however we identify these forcings, they are likely to be used in simulations published to the CMIP7 ESGF project, so I am just noting that nuance. |
If we put this under CMIP7, it'll be super confusing (are we saying that this should be used for the DECK or not?). Maybe the other way through it would be to put it under mip_era="CMIP7" but target_mip="SomeNewMIPOnProvisionalData". Either way, it wouldn't be under mip_era="CMIP7" and target_mip="CMIP" so we can differentiate. |
|
I've done a suggested update of the docs in #223. A preview of how they would look with this update is here (only this page is relevant, fast track is not mentioned anywhere else): https://input4mips-controlled-vocabularies-cvs--223.org.readthedocs.build/en/223/dataset-overviews/ |
|
@vnaik60 can you chime in on the forcing data labelling "CMIP7" small set specifically to get DECK sims started now, and "CMIP7Plus" organically growing set? From a modelling group perspective, does that make our comms, along with the aspiration to collate and develop "sustained" forcings that temporally extend, and potentially completely overhaul in the coming years (during the CMIP7 project window) clear? |
|
Isn't provisional only extending the timeseries? |
The point of the "provisional" identity (note this is my placeholder naming, not sure what Steve will do) was to capture data that will likely change. As this will change, it should not be used for "production" CMIP7 simulations. So 1850-2021 CEDS data is "CEDS-CMIP-2025-02-01" for example, whereas the 2022-2023 CEDS data which will be made available soonafter or at the same time, is not identified the same way (some provisional marker - say "CEDS-CMIP-2025-02-01-provisional"). In 2026 this "provisional" data will be revised likely markedly to extend the "CEDS-CMIP-2025-02-01" data from the 1850-2021 to the 1850-2023 period, ensuring the 2021-12 and 2022-01 timestep is smooth. This new data will have an identity of "CEDS-CMIP-2026-02-01" (or similar).
The point of this thread and all this recent chatter over the last days is to come up with very explicit guidance. "Fast Track" is a vague term. What we are trying to do here is match forcing data to experiments, and specifically the experimental protocol. If we change the data, we change the protocol, we change the simulations that result. So for the DECK experiments (1pctCO2, abrupt-4xCO2, amip, piControl, esm-piControl, historical, esm-hist, piClim-control, piClim-anthro, piClim-4xCO2), with the historical that covers the 1850-2021 period, what forcing (identified by source_id's) are we recommending? Once we recommend these, the protocol is set, and anything not using these forcings is not a CMIP7:CMIP:historical simulation (although I have noted, the CMIP6 precedent was looser than what we are discussing now - #222 (comment)) |
My two cents: this either goes in CMIP7Plus or it goes in a different target_mip (ExtensionMIP for example).
I agree with this. I'd actually go further. If we're trying to match forcings to experiments, that's a job for the experiment definitions. The experiment definition should say: for this experiment, use these source IDs for your forcing data. We as forcings providers don't provide the recommendation, the experiment protocol provides the recommendation (which then allows for DAMIP, AerChemMIP etc. to use the forcings data without us having to predict such uses in advance, which is impossible).
I think it's good we're moving away from this, we can improve our communication I feel. |
I agree with everything immediately above in #222 (comment), and extend one step further. We will need to keep a running table of the data that are required to meet the CMIP7:CMIP:piControl/historical (and esm-* variants), as these are likely to evolve from what we receive first, which is exactly what these doc pages that we're discussing are targeted at. For context, it's useful to consider the CMIP6 experience, which straddled almost a year of find, fix issues and restart - see below (this is all captured in gory detail in the CMIP6 Forcing Datasets Summary google doc)
If it wasn't obvious, I was recommending that we follow a similar 7.0.0, 7.0.1, 7.1.0, 7.1.1, 7.2.0 or hopefully a considerably more simple versioning experience for CMIP7. First number = mip_era, second = DECK collection version (a DECK-required dataset changes), third = a marker that changes if ANYTHING changes (MIP data publication), docs, data, anything. Once we have the forcing data clearly and uniquely identified, it's then over to modelling groups to start to use them, and once sims are complete, to document their forcing use alongside the simulations that are being published. A question, do we want this info (considering we have unique source_id's) to be embedded in netcdf file metadata? The best template we have to document forcing data use is Lurton et al., 2020, but that was the anomaly in the CMIP6 model doc suite, rather than the rule across modelling groups. We also had groups that used the r W i X p Y f @znichollscr I hope this syncs with what you're thinking, and @vnaik60 I hope this meets your expectations too - following our CMIP6 experience.. @znichollscr I’d also note this dovetails the documenting the “CMIP experimental protocol” discussion from months back, which could be folded into the CV TT remit.. noting ES-Doc attempted to do this in CMIP6, but never synced with the forcing info, as this was more loosely identified than now - we have a source_id managed repo here |
Do you have any sense of whose remit this is? Is it a data request thing, a forcings thing, is their an experiment protocol task team? (maybe the last comment answers this, "roll into the CVs task team" and make it a CVs and experiment definition task team)
I very much hope we are not doing this for a year...
I think the suggestion is fine. However, I don't think it actually solves the problem. People want to know a) what data they should use for what experiment and b) if they need to restart. The labelling suggested is too broad for this (it can't distinguish between 'restart historical' vs. 'restart piControl' for example). I think we can get what we want, but it needs something that links experiments and source IDs (i.e. an answer to the first question posed above).
I would say that it's already over to modelling groups to be using forcing data, we already have the data identified (yes, we are missing the experiment connection piece but we will get that and modelling groups shouldn't wait in the meantime).
Ideally, yes. In practice, I think we should assume that this won't happen and build a system that allows us to update this information after the files have been published (so we're not republishing TBs of data just to add missing forcing IDs). |
|
Summarizing what we agree on and discussing open questions (as I lost track of things in the thread) :
Once we have a stable dataset (no bugs found, no further discussions etc) and time is ticking to get the models started, then we will use what is available here https://input4mips-cvs.readthedocs.io/en/latest/database-views/input4MIPs_source-id_CMIP7.html. If game-changing updates come in later, those who can restart their simulations, will do and those who cannot, will not (at least this is what happened in CMIP6). And since all the datasets are versioned, modelers will have a way of keeping track of what forcings they have used. Now the question is how can the modelers share the information on which versions of forcings have been used. I personally did not find the convention r W i X p Y f Z helpful (remember having conversations with Balaji on this). fZ was a label for all forcings so when a forcing changed, Z changed but there was no way to tell which forcing Z was referring to. On,
To clarify, are you thinking about embedding the metadata for all the forcings in the netcdf file that was generated from a simualtion that used those forcings? If so, I dont think this is a great idea as this would increase the size of the metadata (and the file). As of now, there are a max of 10 forcings data that are used by the current generation of models (in various combinations, e.g., prescribed ozone versus emission-driven ozone), and having their source_id and some additional information included in the metadata of each file is an overkill, in my humble opinion. Instead, I agree with this
If a journal paper is not feasible, modeling centers could be given the option to put together a technical document summarizing the source_ids for the forcing dataset used in the simualtions they have uploaded on ESGF. Something like this https://data.giss.nasa.gov/modelE/cmip6/ but with specific forcings dataset versions. As much as, we would like information on forcings datasets being used for specific model simulations to be automated, I don't think there is a viable way to do this other than a manually filled document or spreadsheet (at least that's what we did at GFDL, though on hindsight Thibaut's way was better). %%
For forcings, this numbering may get complicated. Our CMIP7 forcing collection already did not follow this numbering. Data providers have their on versioning system and it is probably convenient that way. The important thing is that we should have information on which version of each forcing dataset is used in a particular model experiment, consistent with Zeb's thinking - "People want to know a) what data they should use for what experiment and b) if they need to restart." @@ In CMIP6, it was probably added later per Eyring et al 2016 "To distinguish between the portion of the historical period when all models will use the same forcing data sets (i.e. 1850–2014) from the extended period where different data sets might be used, the experiment for 1850–2014 will be labelled historical (esm-hist in the case of the emission-driven run) and the period from 2015 through near-present will likely be labelled historical-ext (esm-hist-ext). " |
|
Thanks @vnaik60, helpful. My quick replies
A good question. I don't think anyone has an answer for this and I don't think it is urgent yet so I would suggest leaving this to one side for now.
I'd agree with this (although, to be honest, I think a journal paper is never feasible, they're way too slow to write and publish so I would go for a much more lightweight solution as compulsory, with a journal paper being optional).
I agree and don't think the forcing collection version number will provide the information we want. My takeaway: "People want to know a) what data they should use for what experiment and b) if they need to restart" is still the thing we need to do next. |
Dataset source ID(s)
Dataset source ID(s):
Describe the issue
This githip page site https://input4mips-cvs.readthedocs.io/en/latest/dataset-overviews/ currently incorrectly refers to the historical forcings as part of "CMIP7 AR7 Fast Track". As discussed in the CMIP7 description paper, the CMIP Panel highlights the importance of the Historical simulation for CMIP7 by including it in the mandatory DECK set of experiments rather than any optional set of experiments. The github page should be corrected to reflect this distinction and avoid confusion. Thanks! John
Expected data
Screenshots
Additional context
The text was updated successfully, but these errors were encountered: