pillar是基于redis的分布式主从任务分配通用框架, 主要解决分布式服务之间: 任务分配, 心跳机制, 宕机处理, 异步执行的通用框架, 支持高可用, 高可靠。
由于pillar是基于redis, 故服务与服务之间无需知道对方的ip端口, 只需通过redis队列进行任务发放和消费即可, 开发人员只需着重于业务开发, 无需考虑主从节点宕机后的处理, 也无需考虑分布式锁等问题。
此框架目标是希望所有想实现master/slave任务分配架构的项目无需再造轮子, 只需要基于pillar之上开发即可。
现在大数据组需要自研任务调度服务, 此服务的设计是master/slave架构, master负责接收后端请求的任务&访问mysql数据库&业务元数据更改等操作, 而slave节点只负责执行任务即可, slave节点可以支持的任务:spark-etl/flink-etl/hive-sql查询等。
架构图如下:master/slave分别部署在不同的物理机, master支持多活
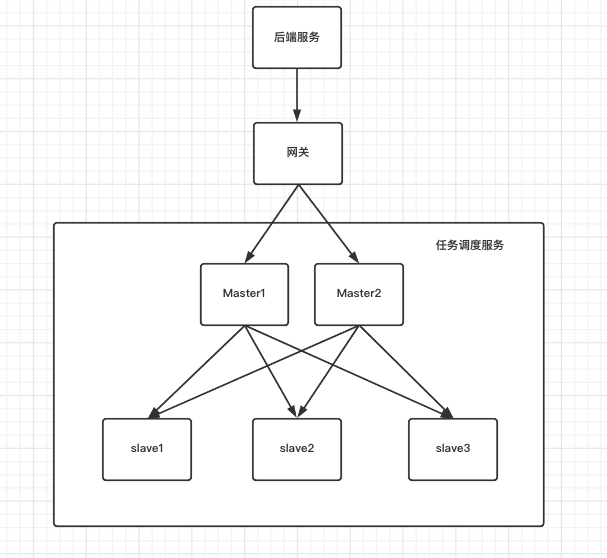
基于上图的设计, 设计人员需要着眼解决以下几个问题:
1、执行节点可执行的任务数量应该是有限的, 例如slave节点可执行10个任务数,当此节点第11个任务到来时如何处理
2、如果master/slave节点宕机, 则正在执行的任务如何处理
3、master/slave之间如果使用http进行通信, 当slave执行一个spark任务要运行很久, 就需要解决长连接的问题
4、如何设置任务优先级
而使用pillar可以很好的解决以上问题, 后面将会详细讲解pillar的架构设计;
在大数据领域有很多自研的项目, 经常会遇见一种场景: 就是在服务内部将业务数据存储至redis队列中,再由自己进行消费处理;
如下图:
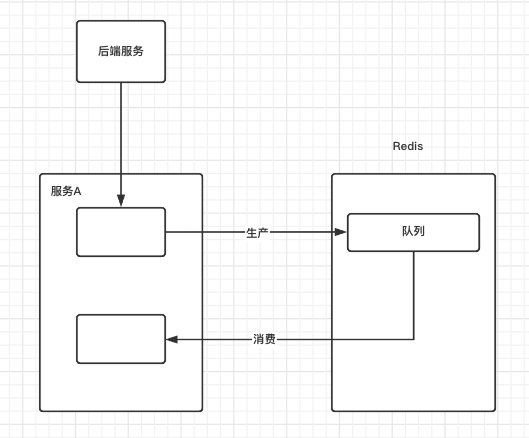
此模式下开发设计人员需要着眼解决以下几个问题:
1、当此服务宕机后, 则正在执行的任务如何处理
2、当此服务是分布式的, 部署多个此服务, 此时消费同一队列, 多个服务可能抢占同一个任务并执行, 需要考虑使用分布式锁
pillar同样可以解决以上问题, 后面将会详细讲解pillar的架构设计;
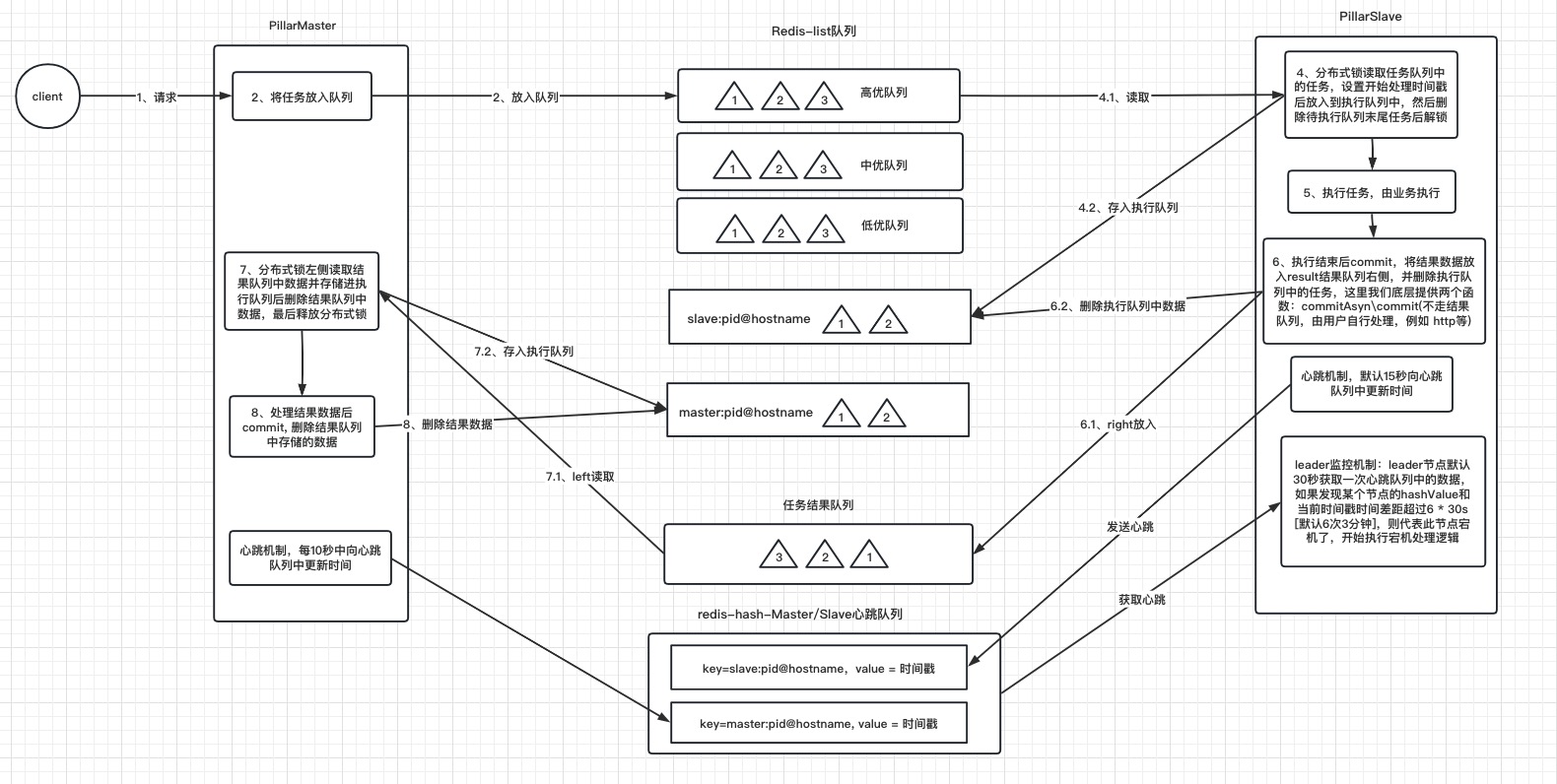
上图为了方便理解只画了单master/slave,实际开发中master/slave可以分布式部署多台;
对于pillar而言, 所有任务都可以用字符串进行表达,开发人员可以根据任务自行设计字符串格式, 例如json
任务队列用于slave获取任务;
目前的任务队列支持三种: 高优、中优、低优,开发人员可以根据业务类型进行优先级分配,slave节点会从高到低获取任务
redis的任务队列为sortSet,故天然支持任务优先级,开发人员可以通过参数设置或更改任务的顺序
注意:由于redis有序队列是不允许重复的成员!故建议在业务层面上给任务字符串上增加唯一id, 否则相同任务字符串会被覆盖,导致下游slave只会执行一次任务
结果队列为redis-list结构并且只有一个结果队列,用来存放salve执行任务后的任务结果, 供master获取。
执行队列用来存放master/slave正在执行的任务,结构为redis-hash
hashKey结构为: master/slave:pid@hostname
hashValue结构为: 任务字符串^pillar^任务字符串
此设计的目的是通过pid@hostname来区分各个节点, 考虑到使用pillar的服务不见得是微服务, 可能不存在port,故此处使用pid来表示唯一进程
hashValue通过内置字符^pillar^进行拼凑
master/slave节点启动时便会不断向心跳队列发送心跳,结构为redis-hash
hashKey结构为: master/slave:pid@hostname
hashValue结构为: 时间戳
细心的小伙伴可以发现心跳队列中的hashKey和任务执行队列中的hashKey保持一致,这样做的目的是当leader发现节点宕机后可以直接根据hashKey找到对应任务执行队列中的值, 从而获取到此节点未完成的任务。
master并不负责slave节点的宕机处理[节点健康监控由leader负责],master主要负责任务的发放到任务队列,并且获取结果队列中的数据;
master心跳发送:
master节点在启动时会生成自身的hashKey: master:pid@hostname 注册到心跳队列中,并每隔[默认30s]发送一次时间戳
master任务发送:
多个master节点发送至任务队列时无需考虑使用分布式锁
master结果获取:
master获取任务时内置分布式锁, 故开发人员无需考虑一个结果数据被多次消费的问题
master节点会先读取结果队列最左侧的数据, 然后将此数据存储至执行队列中,最后删除结果队列中的数据后返回给上层开发人员。
master结果提交:
master处理完结果数据后, 上层开发人员需要调用一次commit接口,参数为结果数据,master会通过结果数据将执行队列中的任务数据删除,至此一套结果数据消费流程结束。
slave节点主要负责任务数据的获取和结果数据放入
slave的消费速度由外界开发人员决定, slave对外开放consume接口,此接口调用一次便会消费一次,若不调用则永不消费,故开发人员可以在外部设置线程池和并发数来调用slave的consume接口, 自行控制消费速度。
slave心跳:
slave节点在启动时会生成自身的hashKey: slave:pid@hostname 注册到心跳队列中,并每隔[默认30s]发送一次时间戳
slave消费:
slave消费时内置分布式锁, 故开发人员无需考虑一个结果数据被多次消费的问题
slave会从高到低获取任务队列中的数据
slave会先读取队列中权重最高的任务后放入到执行队列中,最后删除任务队列中的数据后,将数据返回给上层开发人员
slave结果提交:
slave在执行完任务后发送结果数据时, 上层开发人员需要调用一次commit接口,参数为结果数据和任务数据,slave会先将结果数据存储至结果队列的最右侧,然后通过任务数据去删除执行队列中的数据,至此一套任务数据消费流程结束。
PillarMaster / PillarSlave 都会定时发送心跳[默认30s]到心跳队列中, 由Leader进行监听节点存活情况。
Leader节点是通过抢占redis-key实现, 先抢占到key的为leader节点,其他节点会循环抢占,如果leader宕机,则其他节点晋升为leader。
leader节点可以是master节点,也可以是slave节点,leader节点同样要具备master/slave节点的功能,只不过增加了额外的工作量,即监听心跳队列和节点宕机后的逻辑处理。
leader监控机制:
leader节点默认30秒获取一次心跳队列中的数据,如果发现某个节点的hashValue和当前时间戳时间差距超过6 * 30s [默认6次],则代表此节点宕机了,开始执行宕机处理逻辑
leader执行宕机处理逻辑:
先到执行队列中,将相同hashKey存储的hashValue任务列表获取到,然后根据hashKey判断宕机的节点是slave还是master节点;
若是slave节点, 则将所有未完成的任务放入到高优队列最右侧
若是master节点,则将所有未完成的任务放入到结果任务队列的最左侧
以上操作完成后删除执行队列中的hashKey,并且删除心跳队列里的hashKey。
1、执行节点可执行的任务数量应该是有限的, 例如slave节点可执行10个任务数,当此节点第11个任务到来时如何处理
2、如果master/slave节点宕机, 则正在执行的任务如何处理
3、master/slave之间如果使用http进行通信, 当slave执行一个spark任务要运行很久, 就需要解决长连接的问题
4、如何设置任务优先级
答:
1、pillar内部使用高/中/低 三种队列进行存储任务数据, 故当pillarSlave忙碌时,用户只需不调用slave的consume接口,由其他slave消费即可
2、当master/slave节点宕机时,leader监控机制就会发现节点宕机,随后进行宕机处理逻辑, 此处看处理逻辑
3、pillar通过redis队列发放任务,天然异步处理。
4、pillar内部使用高/中/低 三种队列进行存储任务数据,并且队列使用sortSet,天然支持权重设置
1、当此服务宕机后, 则正在执行的任务如何处理
2、当此服务是分布式的, 部署多个此服务, 此时消费同一队列, 多个服务可能抢占同一个任务并执行, 需要考虑使用分布式锁
答:
1、此服务分布式部署时, pillar-leader会进行节点健康监控。
2、pillar-cosume消费内置分布式锁,不会有同一任务执行两次的问题。
pillar是基于redis的分布式主从任务分配通用框架, 故项目中需要大量操作redis, 而pillar使用redisson-common公共包作为reids的操作模块,关于redisson-common项目可以看我的另一个项目: https://github.com/gaolight/bigdata-common/tree/master/redisson-common
由于pillar项目依赖redis, 故宿主机上应有redis服务, 这里建议使用docker进行安装:
docker run -itd --name redis-test -p 6379:6379 redis通过git下载源码并install到本地仓库
# 先打包redisson-common项目到maven仓库
mkdir gitPillar
cd gitPillar
git clone https://github.com/gaolight/bigdata-common.git
cd bigdata-common
mvn -U clean install -DskipTests
# 再打包pillar项目到maven仓库
cd ../
git clone https://github.com/gaolight/pillar.git
cd pillar
mvn -U clean install -DskipTests项目使用pillar时可以根据服务的角色进行分别依赖
<!-- 用户开发master服务时可以依赖pillar-master的pom -->
<dependencies>
<dependency>
<groupId>org.pillar</groupId>
<artifactId>pillar-master</artifactId>
<version>1.0</version>
</dependency>
</dependencies>
<!-- 用户开发slave服务时可以依赖pillar-slave的pom -->
<dependencies>
<dependency>
<groupId>org.pillar</groupId>
<artifactId>pillar-slave</artifactId>
<version>1.0</version>
</dependency>
</dependencies>
<!-- 用户也可以依赖pillar-clients的pom,此模块可以同时支持pillar-master/pillar-slave -->
<dependencies>
<dependency>
<groupId>org.pillar</groupId>
<artifactId>pillar-clients</artifactId>
<version>1.0</version>
</dependency>
</dependencies>由于用户环境的redis可能有多种模式[local/集群/哨兵等], 故pillar对外开放了redissonClient的创建,交给用户灵活实现,
pillar项目中依赖了redisson-3.17.0,故用户无需再做依赖,直接创建redissonClient即可,
这里简单举例如何创建redissonClient:
1、java - 创建:
public void init() {
// 配置序列化, 建议主动声明默认序列化为JsonJacksonCodec, 方便查看
Config config = new Config().setCodec(new JsonJacksonCodec());
// 使用单机Redis服务
config.useSingleServer().setAddress("redis://127.0.0.1:6379");
// 创建Redisson客户端
RedissonClient redisson = Redisson.create(config);
this.redissonUtils = RedissonUtils.getInstance(Optional.ofNullable(redisson));
}
2、yml创建[参考TestRedisson测试类]:
public void init() throws IOException {
final URL resource = TestRedisson.class.getClassLoader().getResource("redisson.yml");
final RedissonClient redissonClient = Redisson.create(Config.fromYAML(resource));
this.redissonUtils = RedissonUtils.getInstance(Optional.ofNullable(redissonClient));
}
3、spring框架集成:
@Configuration
public class TestConfiguration {
@Bean
RedissonClient redissonClient() {
Config config = new Config();
config.useSingleServer().setAddress("redis://127.0.0.1:6379");
return Redisson.create(config);
}
}redisson支持多种方式创建, 更多方式参考官网: https://github.com/redisson/redisson/wiki/%E7%9B%AE%E5%BD%95 yml配置参考官网: https://github.com/redisson/redisson/wiki/2.-%E9%85%8D%E7%BD%AE%E6%96%B9%E6%B3%95#221-%E9%80%9A%E8%BF%87yaml%E6%A0%BC%E5%BC%8F%E9%85%8D%E7%BD%AE
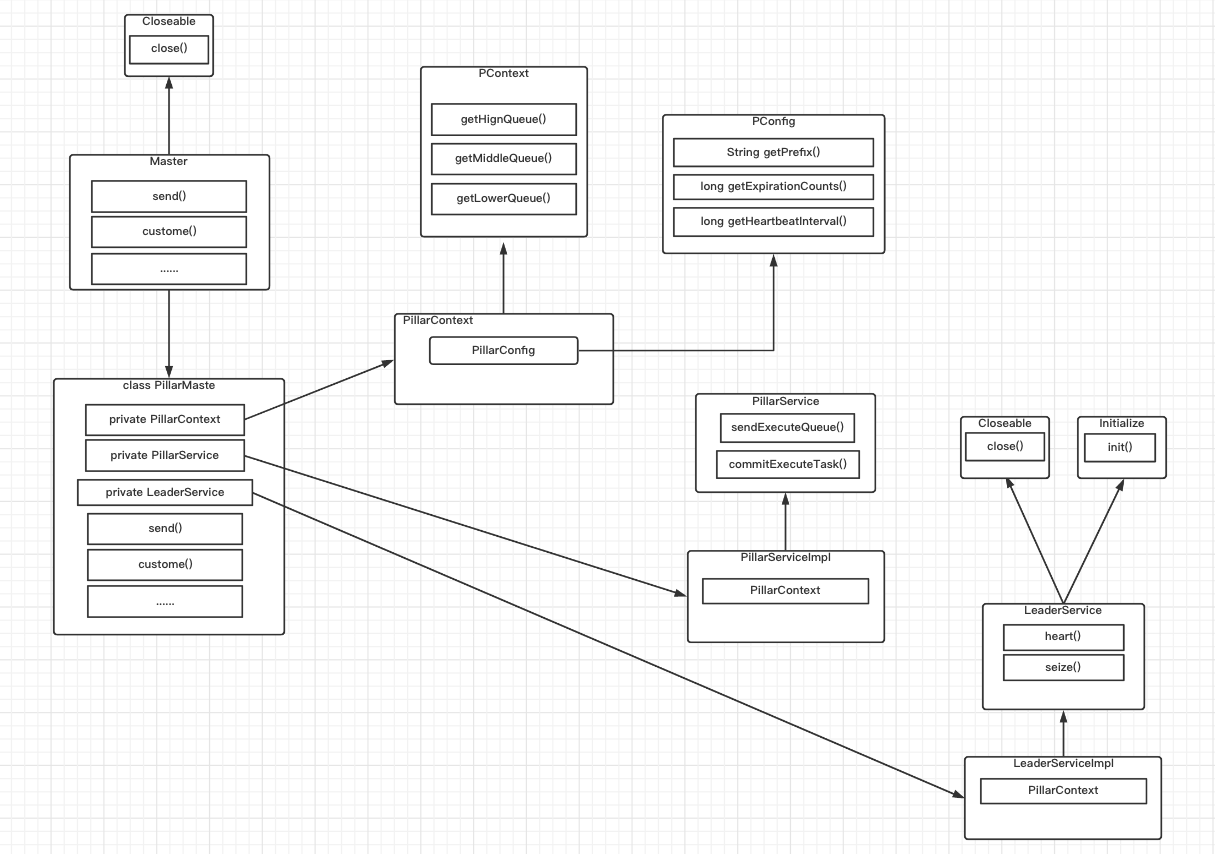
public class Pillar {
public void createMaster() {
PConfig pConfig = pillarConfig(redissonClient());
PMaster<String> pillarMaster = new PillarMaster(pConfig); // 目前泛型只支持String类型, 后期1.0版本会兼容所有基本类型和类类型
}
public void createSlave() {
PConfig pConfig = pillarConfig(redissonClient());
PSlave<String> pillarSlave = new PillarSlave(pConfig);
}
private RedissonClient redissonClient() {
Config config = new Config();
config.setCodec(new JsonJacksonCodec()) // 序列化
.useSingleServer() // local模式
.setAddress("redis://127.0.0.1:6379"); // ip端口
return Redisson.create(config);
}
private PConfig pillarConfig(RedissonClient redissonClient) {
return org.pillar.core.config.PillarConfig.builder()
.prefix("pillar") // redis前缀
.redissonClient(redissonClient) // redissonClient
.expirationCount(5) // 心跳到期次数
.heartbeatInterval(1000 * 30) // 心跳间隔
.build();
}
}更多关于pillarMaster/pillarSlave的使用可以参考单元测试类:
@Configuration
public class TestConfiguration {
// 构建redissonClient
@Bean
RedissonClient redissonClient() {
Config config = new Config();
config.setCodec(new JsonJacksonCodec()) // 序列化
.useSingleServer() // local模式
.setAddress("redis://127.0.0.1:6379"); // ip端口
return Redisson.create(config);
}
// 构建pillarConfig
@Bean
PConfig pillarConfig(RedissonClient redissonClient) {
return PillarConfig.builder()
.prefix("pillar")
.redissonClient(redissonClient)
.expirationCount(5)
.heartbeatInterval(1000 * 30)
.build();
}
// 构建PillarMaster
@Bean
PMaster<String> pillarMaster(PConfig pillarConfig) {
return new PillarMaster(pillarConfig);
}
// 构建pillarSlave
@Bean
PSlave<String> pillarSlave(PConfig pillarConfig) {
return new PillarSlave(pillarConfig);
}
}1、PillarConfig中的prefix参数极为重要, 此参数代表pillar项目中所有内置redis-key的前缀, 故master和slave要的prefix要保持一致,否则会造成队列不一致从而导致消费不到或注册不到心跳;
若想在一个服务中使用多组不同的master/slave,则可以创建多个不同prefix参数的pillarConfig,然后创建master/slave。
注意:pillar默认是运行在分布式服务上的,若运行在单个服务器上则无法保证可靠性,因leader只有一个,单服务宕机后则无法监控;
此外由于pillar的心跳机制是根据pid@hostname为key的,故如果单服务器上的启动多个pillarSlave则心跳机制会失效,因其key完全一致,此问题会在pillar2.0版本解决。
2、pillarMaster/pillarSlave 的consume消费接口调用一次便会消费一次,若不调用则永不消费,故开发人员可以在外部设置线程池和并发数来调用slave的consume接口, 自行控制消费速度。
3、pillarMaster/pillarSlave 消费一次数据处理完毕后记得调用commit接口, 此时pillar会将内置的执行队列中的数据删除, 若不提交pillar会认为此任务一直在执行。
4、pillar的高/中/低三种任务队列都是redis的有序队列[sortSet],而有序队列中相同的数据会覆盖!故建议在业务层面上给任务字符串上增加唯一id, 否则相同任务字符串会被覆盖,从而导致下游slave只会执行一次任务。
5、pillar当前版本只支持String任务类型, 如: PMaster = new PillarMaster() 泛型只支持String; 后期1.0版本将会支持Java所有基本类型和类类型;
6、若调用pillarMaster/pillarSlave的close接口,则pillarMaster/pillarSlave 将不会再向redis注册心跳,但此时若是调用consume接口,还是可以正常消费数据,故此接口常用于java进程kill时设置关闭钩子时调用。
mvn clean validate -Dforce.refresh.release=truemvn clean compile -Dcheckstyle.skip=truemvn -U clean install -DskipTestsmvn versions:set -DnewVersion=2.0| 模块 | 类型 | 端口 | 用途 |
|---|---|---|---|
| pillar-core | jar | 无 | 公共包,仅包含通用类定义和工具类,尽量不引入第三方包 |
| pillar-service | jar | 无 | 核心服务模块 |
| pillar-master | jar | 无 | master核心模块 |
| pillar-slave | jar | 无 | slave核心模块 |
| pillar-clients | jar | 无 | 对外统一依赖包模块, 自身无代码 |
pillar每个模块下都有对应的单元测试, 代码更改后建议执行单元测试进行验证
pillar-clients模块单元测试模拟了双master、双slave 共四个节点, 可供整体测试。