In this project we are predicticting the customer churn rate - the percentage of customers who either cancel or don't renew their subscription. It is an important measure that can help businesses to retain their clients.
- Data source - This Kaggle dataset tracks a telco company's customer churn based on a variety of possible factors.
- Target value is churn - it indicates whether or not the customer left within the last month
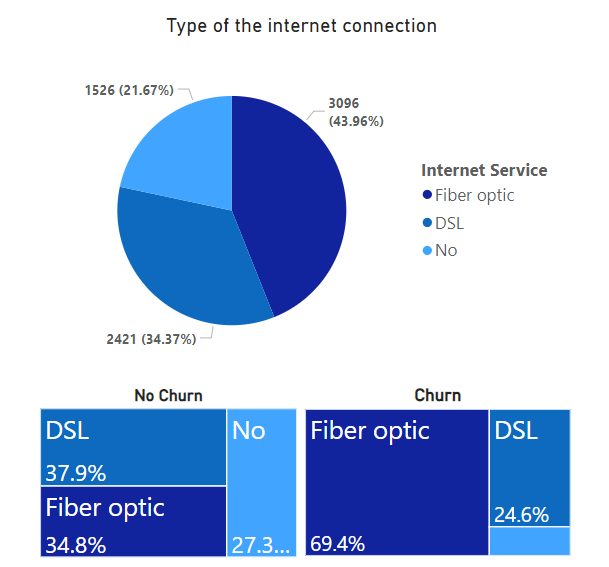
- Features include: customerID, gender, SeniorCitizen, Partner, Dependents, tenure, PhoneService, MultipleLines, InternetService, OnlineSecurity, OnlineBackup, DeviceProtection, TechSupport, StreamingTV, StreamingMovies, Contract, PaperlessBilling, PaymentMethod, MonthlyCharges, TotalCharges
- Exploring and pre-processing the data (Pandas,Numpy)
- Visualising (Matplotlib, Seaborn, Plotly)
- Comparing performance of various ML models (Sklearn)
- Fine tuning the best performing models (Sklearn)
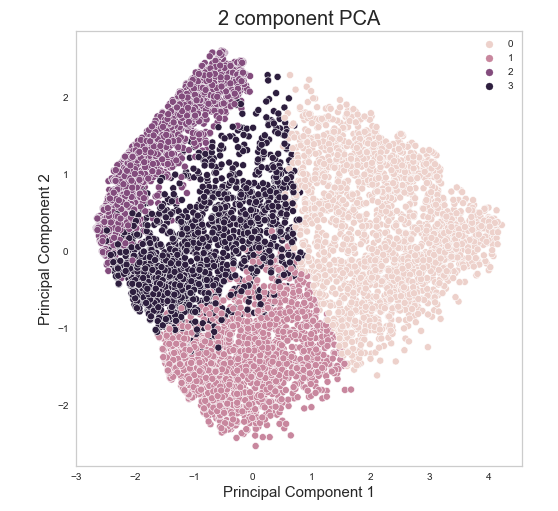
- Looking for clusters in the data (Sklearn)
- Interpreting the results (Sklearn)
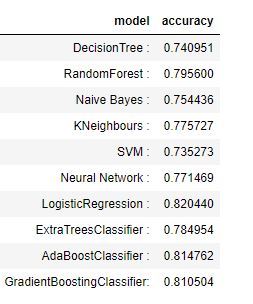
Overview of the models we tested:
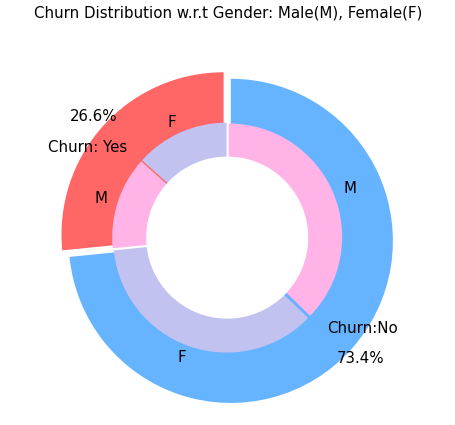
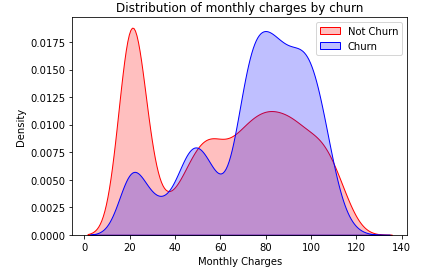
In this unsupervised way of machine learning, we take away the target column (churn? yes/no) from the database and use Kmeans clustering to let the algorithm decide for itself which customers share certain patterns.
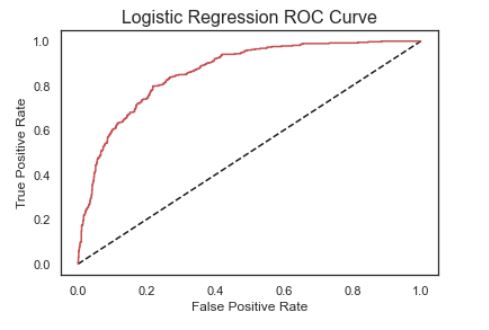
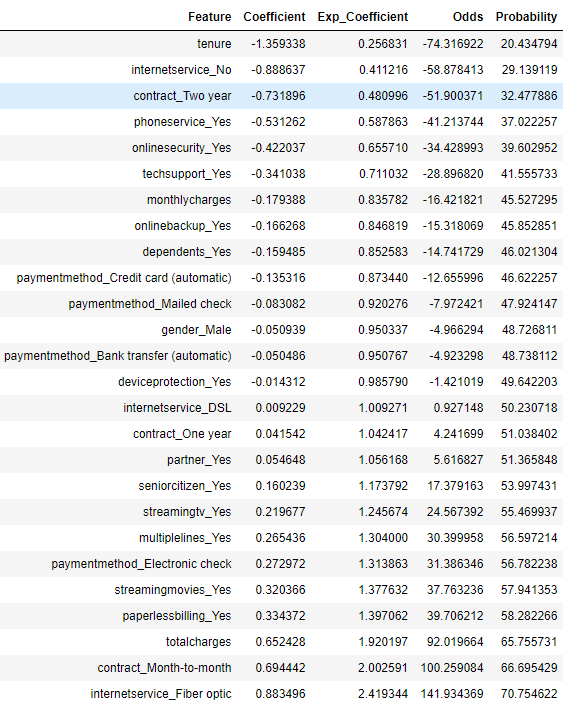
Here we have an overview of how certain featues impact the chance of churning.