This repo cantains the training code used during Visual Similarity research at Fynd. One can easily reproduce our state of the art models MILDNet and Ranknet and 2 other research works from the past. 25 configs are present which constitutes configurations of most critical experiments by us.
For more details, refer to the Colab Notebook (execute training on Free GPUs or TPUs provided by Google in just 2 clicks) or head to our research papers on Arxiv:
- MILDNet: A Lightweight Single Scaled Deep Ranking Architecture
- Retrieving Similar E-Commerce Images Using Deep Learning
We have also open-sourced 8 of our top experiment results with weights here. To analyze and compare all the results (training) head to this Colab notebook. To get an idea on using any of our open-sourced models models to find n similar items (inferencing) from your entire dataset head to this Colab notebook.
Visual Recommendation is a crucial feature for any ecommerce platform. It gives the platform power of instantly suggesting similar looking products to what a user is browsing, thus capturing his/her immediate intent which could result in higher customer engagment (CTR) and hence the conversion.
The task of identifying similar products is not trivial as the details concerned here (pattern, structure etc.) are complexely grained in the product image pixels and these product comes in various variety even within the same class. CNNs have showed great understanding and results in this task.
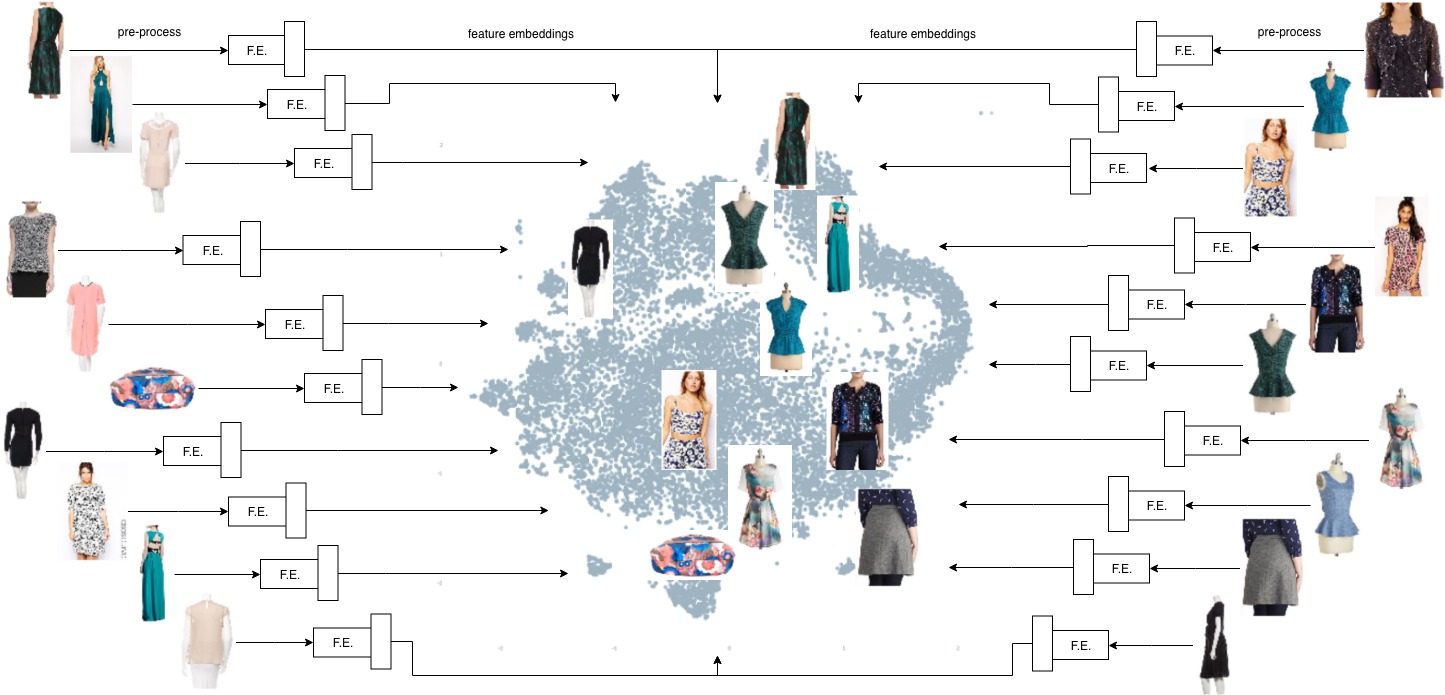
The base of such a system is a CNN extracting key features from product images and returning a vector respresenting those features. When these embeddings for all the products are mapped on an n-dimensional space, it places similar products closer to non-similar items. The nearest neighbours are then the top most visual similar items. Below diagram gives a brief overview:
- execute.py: Execute this to run training locally or on Google Cloud ML Engine.
- MILDNet_on_Colab.ipynb: Google Colaboratory notebook describes the task and contains training, exploration and inference code.
- requirements-local-cpu.txt/requirements-local-gpu.txt: Requirement files only need to execute when running locally.
- settings.cfg: Global configs to setup: -- MILDNET_JOB_DIR (mandatory): Requires directory path to store training outputs. Either pass path of local directory or Google cloud storage (gs://.....) -- MILDNET_REGION (optional): Only needed when running on ML Engine (e.g. us-east1) -- MILDNET_DATA_PATH (mandatory): Path where training data is stored. Change only when using custom data. -- HYPERDASH_KEY: Hyperdash is a nice tool to log system out or to track training metrics. One can easily monitor all the jobs running using their Android app or webpage.
- job_configs: Contains 25 configs defines the basic job configs like the training model architecture, loss function, optimizer, number of epoch, learning rate etc.
- trainer: Contains all script needed for training.
- training_configs: Training related environment config, only needed when running on ML Engine. Defines the cluster type, gpu type etc.
We carried out various experiments to study the performace of 4 research works (including ours). 8 of those variants can be readily tested here by this notebook:
- Multiscale-Alexnet: Multiscale model with base convnet as Alexnet and 2 shallow networks. We couldn’t find a good implementation of Alexnet on Tensorflow, so we used Theano to train this network.
- Visnet: Visnet Multiscale model with base convnet as VGG16 and 2 shallow networks. Without LRN2D layer from Caffe.
- Visnet-LRN2D: Visnet Multiscale model with base convnet as VGG16 and 2 shallow networks. Contains LRN2D layer from Caffe.
- RankNet: Multiscale model with base convnet as VGG19 and 2 shallow networks. Hinge Loss is used here.
- MILDNet: Single VGG16 architecture with 4 skip connections
- MILDNet-Contrastive: Single VGG16 architecture with 4 skip connections, uses contrastive loss.
- MILDNet-512-No-Dropout: MILDNet: Single VGG16 architecture with 4 skip connections. Dropouts are not used after feature concatenation.
- MILDNet-MobileNet: MILDNet: Single MobileNet architecture with 4 skip connections.
Based on this experiments, below is the list of all the configs available to try out:
- Default Models:
- alexnet.cnf
- ranknet.cnf
- vanila_vgg16.cnf
- visnet.cnf
- mildnet.cnf
- visnet-lrn2d.cnf
- Mildnet Ablation Study
- mildnet_skip_3.cnf
- mildnet_skip_2.cnf
- mildnet_skip_4.cnf
- mildnet_skip_1.cnf
- Mildnet Low Features
- mildnet_512_512.cnf
- mildnet_1024_512.cnf
- mildnet_512_no_dropout.cnf
- Mildnet Other Losses
- mildnet_hinge_new.cnf
- mildnet_angular_2.cnf
- mildnet_contrastive.cnf
- mildnet_lossless.cnf
- mildnet_angular_1.cnf
- Mildnet Other Variants
- mildnet_without_skip_big.cnf
- mildnet_vgg19.cnf
- mildnet_vgg16_big.cnf
- mildnet_without_skip.cnf
- mildnet_mobilenet.cnf
- mildnet_all_trainable.cnf
- mildnet_cropped.cnf
Note that mildnet_contrastive.cnf and the Default Models configs are the models compared in the research paper.
-
execute.py: Single point entry for running training job on local or Google Cloud ML Engine. Asks user whether to run the training locally or on ML Engine. The user then need to select a config from a list of configs. Finally, the script executes gcloud.local.run.keras.sh if user selects to run locally or gcloud.remote.run.keras.sh if user selects to run on Google Cloud ML Engine. Make sure to setup settings.cfg if running on ML Engine.
-
MILDNet_on_Colab.ipynb: Google Colaboratory notebook, gives a brief introduction of the task. Also one can execute training in just 2 clicks: -- 1. Open notebook on google colab. -- 2. From menu select Runtime -> Run all
Make sure to have gsutil installed and the user to be logged in:
curl https://sdk.cloud.google.com | bash
exec -l $SHELL
gcloud init
Install requirements:
- Running training on CPU:
pip install -r requirements-local-cpu.txt - Running training on GPU:
pip install -r requirements-local-gpu.txt
Set below configs in settings.cfg:
- MILDNET_JOB_DIR=gs://....
- MILDNET_REGION=us-east1
- MILDNET_DATA_PATH=gs://fynd-open-source/research/MILDNet/
- HYPERDASH_KEY=your_hyperdash_key
-
Config for the job to be trained need to be added in job_config folder
-
Run
python execute.py
-
Stream logs on terminal using:
gcloud ml-engine jobs stream-logs {{job_name}} -
Check tensorboard of ongoing training using:
tensorboard --logdir=gs://fynd-open-source/research/MILDNet/top_jobs/{{job_name}} --port=8080 -
Hyperdash: Either use Hyperdash Website or Android App/iOS App to monitor logs.
Please read CONTRIBUTING.md and CONDUCT.md for details on our code of conduct, and the process for submitting pull requests to us.
Please see HISTORY.md. For the versions available, see the tags on this repository.
- Anirudha Vishvakarma - Initial work ([email protected])
This project is licensed under the Apache License - see the LICENSE.txt file for details
- All aspiring research works cited in our research paper
- Google Colaboratory to provide free GPUs/TPUs, helped us lot with experimentations and reporting.
- Annoy: Easy to use and fast Approximate Nearest Neighbour library.
- convnets-keras: Github repo contains Alexnet implementation on Keras, helped us to evaluate Alexnet base models as presented in this research work.
- image-similarity-deep-ranking: Github repo helped us to use triplet data in keras.
- Hyperdash: Free monitoring tool for ML tasks.