Deepfillv1 reproduction based on PaddlePaddle framework.
This project reproduces Generative Image Inpainting with Contextual Attention based on the paddlepaddle framework and participates in the Baidu paper reproduction competition. The AIStudio link is provided as follow:
-
Generative Image Inpainting with Contextual Attention是UIUC的Jiahui Yu在Thomas S. Huang的指导下,联合Adobe Research完成的一项工作,发表于CVPR 2018。
-
作者在Iizuka等人提出的Globally and locally consistent image completion工作的基础上进行改进(Improved Generative Inpainting Network),并提出Contextual Attention,以利用传统方法中要求图像之中的patch之间存在相似性的思路,弥补卷积神经网络不能有效的从图像较远的区域提取信息的不足。
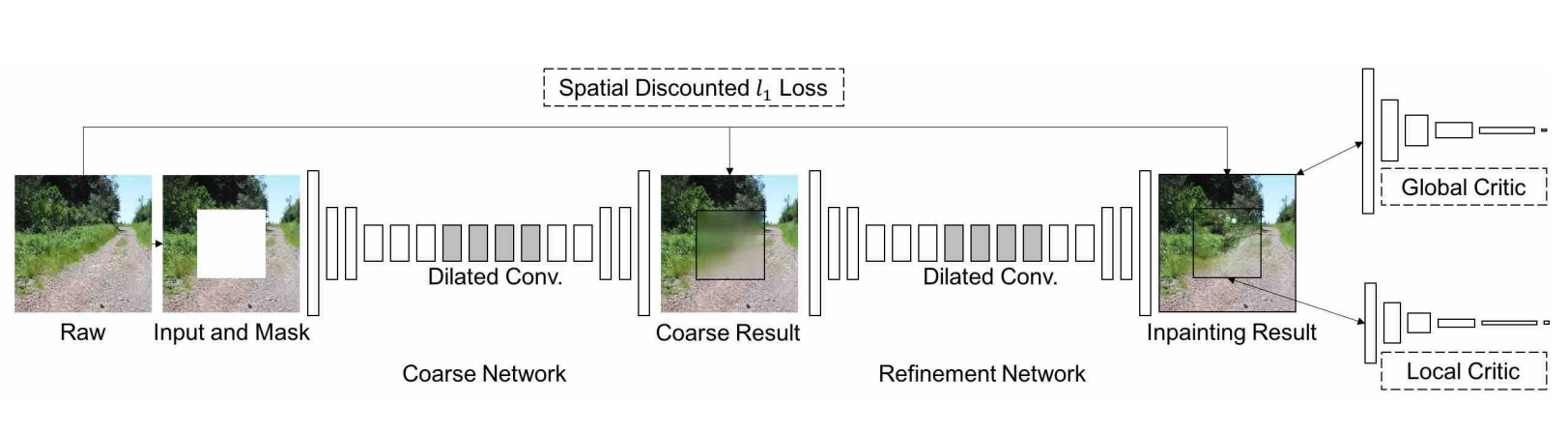
- 生成器:包括两个阶段。第一个阶段是一个粗糙网络(Coarse Network),利用空间衰减重构损失训练。第二个阶段是一个细化网络(Refinement Network),利用重构损失和WGAN损失训练。
- 判别器:包括两个部分。第一个部分负责局部判别(Local Critic),第二个部分负责全局判别(Global Critic),都是基于 WGAN-GP损失(带梯度惩罚的WGAN损失)。

- 思路为从已知图像中借鉴特征信息,以此生成缺失的patch。首先在背景区域提取3x3的patch,并作为卷积核。为了匹配前景(待修复区域)的patch,使用标准化内积(即余弦相似度)来测量,然后用softmax来为每个背景中的patch计算权值,最后选取出一个最好的patch,并反卷积出前景区域。对于反卷积过程中的重叠区域取平均值。
- 通俗一点讲,假设有待修补区域x,通过卷积的方法,从整个图中匹配几个像x的区域a,b,c,d,然后从上述区域中利用softmax找出最像x的区域,最终通过反卷积的方式,来生成x区域的图像。
- WGAN损失:
其中$P_r$是真实的分布,$P_g$是生成数据的分布,这损失在GAN损失的基础上去掉了log。
- 梯度惩罚项:
只对位于空洞区域的像素点进行梯度惩罚,利用一个mask实现:
- 重构损失:
- 空间衰减重构损失:改变重构损失的mask权重,每一点的权值为$\gamma^{l}$,$\gamma = 0.99$,$l$ 表示该点到已知的像素点最近的距离。
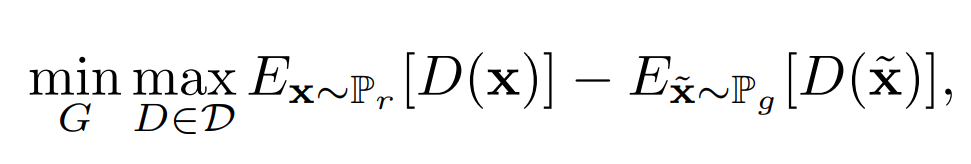
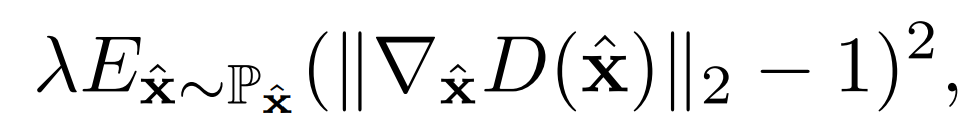
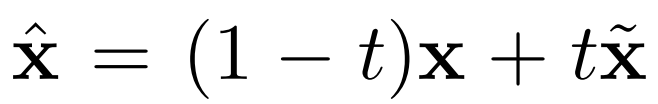
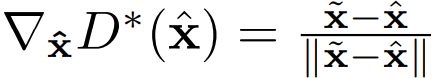
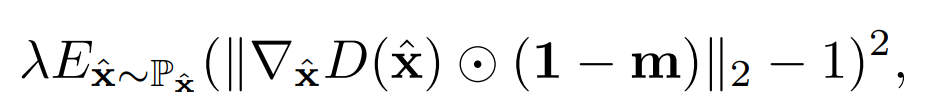
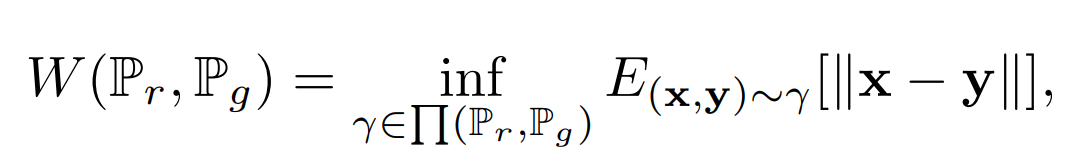
优化器为Adam,学习率为0.0001,batch-size为48,单卡1080Ti训练,在Place2数据集上进心训练,输入图片size为256256,patch大小为128128。
- 定性对比
从左往右为原图,输入图片,baseline输出,model输出。
- 定量对比


python train.py
the models and optimizer will be saved in checkpoints you can see the past training log in train.txt
python test.py
you can change the total test number in test.py and change the test model in tester.py you can see the test log in test.txt
you may find our pre-trained model here:
link:https://pan.baidu.com/s/16uKEXhe71AxLeOnakQ32Rg
key:x4tr
References