{kind=link}
{kind=link}
{kind=link}
{kind=link}
多任务学习是继深度学习能够解决单个分类或回归问题之后的一个重要研究方向,它提出的主要背景是,算法工程师总能希望进行一次训练,可以将多个相关的任务目标或不那么相关的目标进行统一的学习,想法很容易理解,这样Multi Task Learing既可以找到同一个对象的多个任务(诸如一个人的身高、体重、年龄、收入等多个目标的预测)相关联系,以便于更好得获得高层语义理解(如任务画像的多个标签),同时还可以并行学习,节约大量的时间。MTL正是在这样的背景之下提出,但是想法遭遇了现实问题的抵抗,容易想到的是,每个任务的loss function评价体系不一样怎么处理、在训练过程中,每个Task的权重怎么进行有效学习,复杂的任务如何避免遭受一些简单学习任务的影响(换句话说,复杂任务的loss死活下降不下去,而简单任务的准确度accuracy却已接近于、假使你也已经训练出来了,那么如何评价这个MTL模型的好坏也是一个要研究的问题。
幸好,前人已经做了大量的基础研究工作。针对MTL,我们能够找到大体三种学习方法:
- (1)基于特征分享的多任务学习方法;
- (2)基于模型参数分享的多任务学习方法;
- (3)基于深度学习的多任务学习方法。
对于前两种方法,大多是SVM等机器学习的方法,不再赘述,详情可参考中科大博士的一篇论文进行查找。本文基于深度学习的多任务学习方法,讲2种方法,一种是手动调参(loss_weight),任务学习个数不受限制,第二种方法则是重构loss_function,将同方差Uncertainty(可以理解为求使多个任务loss的乘积最小值的一组loss_weight参数求解),对于回归和分类2个任务学习的代码也展示在这里。
在自然语言处理中,有一个常见的问题就是对客户的评价进行分析。 这些用户评论中,包含了大量的有用信息,例如情感分析,或者相关事实描述。 例如:
“味道不错的面馆,性价比也相当之高,分量很足~女生吃小份,胃口小的,可能吃不完呢。环境在面馆来说算是好的,至少看上去堂子很亮,也比较干净,一般苍蝇馆子还是比不上这个卫生状况的。中午饭点的时候,人很多,人行道上也是要坐满的,隔壁的冒菜馆子,据说是一家,有时候也会开放出来坐吃面的人。“
- 首先情感是正向的,除此之外我们还能够进行知道这个的几个事实描述:1. 性价比比较高; 2. 装修比较好; 3. 分量足。
- 这些信息是非常重要宝贵的,不论是对于公司进行商业分析或者要建立一个搜索引擎排序,这些信息都是重要的参考因素。 那么在这个时候,我们就需要进行文本的情感分类了
这个问题我们希望的是,输入一句话,输出是这句话对于以下6大类,20小类进行打标,对于每个小类而言,都会有<正面情感, 中性情感, 负面情感, 情感倾向未提及 > 这4个类别。
> 位置: location
>>>> 交通是否便利(traffic convenience)
>>>> 距离商圈远近(distance from business district)
>>>> 是否容易寻找(easy to find)
> 服务(service)
>>>> 排队等候时间(wait time)
>>>> 服务人员态度(waiter’s attitude)
>>>> 是否容易停车(parking convenience)
>>>> 点菜/上菜速度(serving speed)
> 价格(price)
>>>> 价格水平(price level)
>>>> 性价比(cost-effective)
>>>> 折扣力度(discount)
> 环境(environment)
>>>> 装修情况(decoration)
>>>> 嘈杂情况(noise)
>>>> 就餐空间(space)
>>>> 卫生情况(cleaness)
> 菜品(dish)
>>>> 分量(portion)
>>>> 口感(taste)
>>>> 外观(look)
>>>> 推荐程度(recommendation)
> 其他(others)
>>>> 本次消费感受(overall experience)
>>>> 再次消费的意愿(willing to consume again)
而为了方便训练数据的标标注,训练数据中,<** 正面情感, 中性情感, 负面情感, 情感倾向未提及 > ** 分别对应与 (1, 0, -1, -2).
例如说,“味道不错的面馆,性价比也相当之高,分量很足~女生吃小份,胃口小的,可能吃不完呢。环境在面馆来说算是好的,至少看上去堂子很亮,也比较干净,一般苍蝇馆子还是比不上这个卫生状况的。中午饭点的时候,人很多,人行道上也是要坐满的,隔壁的冒菜馆子,据说是一家,有时候也会开放出来坐吃面的人。
____
这句话对应的结果就是:
交通是否便利(traffic convenience) -2
距离商圈远近(distance from business district) -2
是否容易寻找(easy to find) -2
排队等候时间(wait time) -2
服务人员态度(waiter’s attitude) -2
是否容易停车(parking convenience) -2
点菜/上菜速度(serving speed) -2
价格水平(price level) -2
性价比(cost-effective) 1
折扣力度(discount) -2
装修情况(decoration) 1
嘈杂情况(noise) -2
就餐空间(space) -2
卫生情况(cleaness) 1
分量(portion) 1
口感(taste) 1
外观(look) -2
推荐程度(recommendation) -2
次消费感受(overall experience) 1
再次消费的意愿(willing to consume again) -2
乍眼一看,该项目的6个基本问题和20个小类很容易给人迷惑的印象,再加上该问题在业界的名称叫做
文本细粒度分类,更容易让习惯了二分类单任务的人产生怀疑。但细细品读,可以发现其实是20个任务的4分类问题。而且20个任务在文本语义上是有联系的,要不也不会称之为细粒度或者6个大类。因此,在前提判断上,我们认为是可以利用深度学习算法进行训练的。
关于机器学习or深度学习,建模过程是一个比较考虑经验的事情。但总有一些方法可寻,最简单的方法肯定是根据以往的模型经验去做,但有3个方面确实是需要重点来规划的。
首先应当将该问题划入一个基本问题中去,视觉类先考虑基本的CNN结构,可以把基本的CNN结构获得的结果当做是后续模型改造的基准。之后,在准确率较小的基础上应该迅速考虑神经元单元数目、网络层数等基本套路,并且在加单元或者加层的过程中,应该考虑训练集和验证集的ACC是否产生了过拟合 过拟合很好判断,如果在验证集上,经过一定的循环之后,验证集的ACC开始下降,但训练集的ACC却很高,这个时候就是过拟合发生的时候,从这一点讲,过拟合也是一件好事。
<1> 网络结构
网络结构最基础的就是全连接网络,本文不必使用全连接网络,可以用简单的RNNCEll进行训练看下准确度。把这个准确度看做基准(而不必按照自然概率1/20去判别)。本文使用了tensorflow的RNN Cell之后,准确度为0.35,之后,我们考虑到该项目主要是长句子(后面讲关于停用词的微调),针对于长句子的语义理解,使用LSTM可以很好的解决信息丢失问题。之后我们沿用了加入双向LSTM的层进行加工。此时得到的效果比较好,epochs=5之后,验证集的准确度已经达到0.6.
<2> 损失函数 loss_function
再次回到开头写的问题,为什么会引入Loss Function的问题?这是因为单项任务的loss(MSE、CrossEntropy等)并不能决定多任务的loss,有的Loss在训练过程中下降的很快,但总体任务却不能以单个任务的loss作为评价指标,否则训练出来的结果将会很糟。针对任务数目比较小的多任务,可以采用同方差不确定度的方法去重塑loss function,将$$loss = L_i*w_i$$中的$w_i$也当做一层进行训练,但这个也有一定的问题,因为该loss function需要手动推导,我们且看下图:

这个新创建的联合loss,是手动推导的,并且其中要去凑
<3> 其他微调
超参数的微调操作也很重要,调整参数涉及的方面较多(句子长度、停用词、神经元数目、网络层数、网络的单双向等)。这些参数在调节上没有十分特殊的方法可寻,只有一个目标,就是提高ACC,又不至于过拟合。
请看本文在调整是否去掉停用词的验证结果(结果发现,停用词去掉之后,epoch=1,并没有增加ACC)
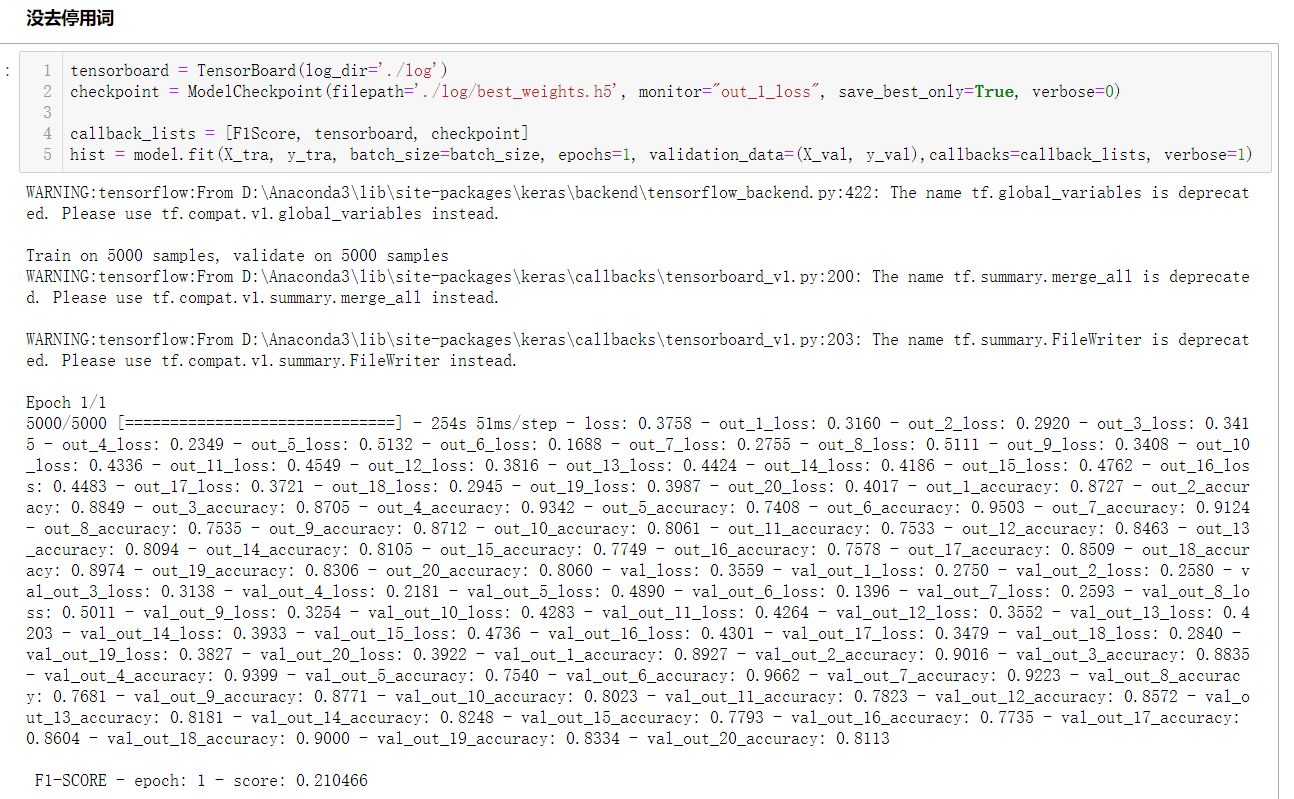
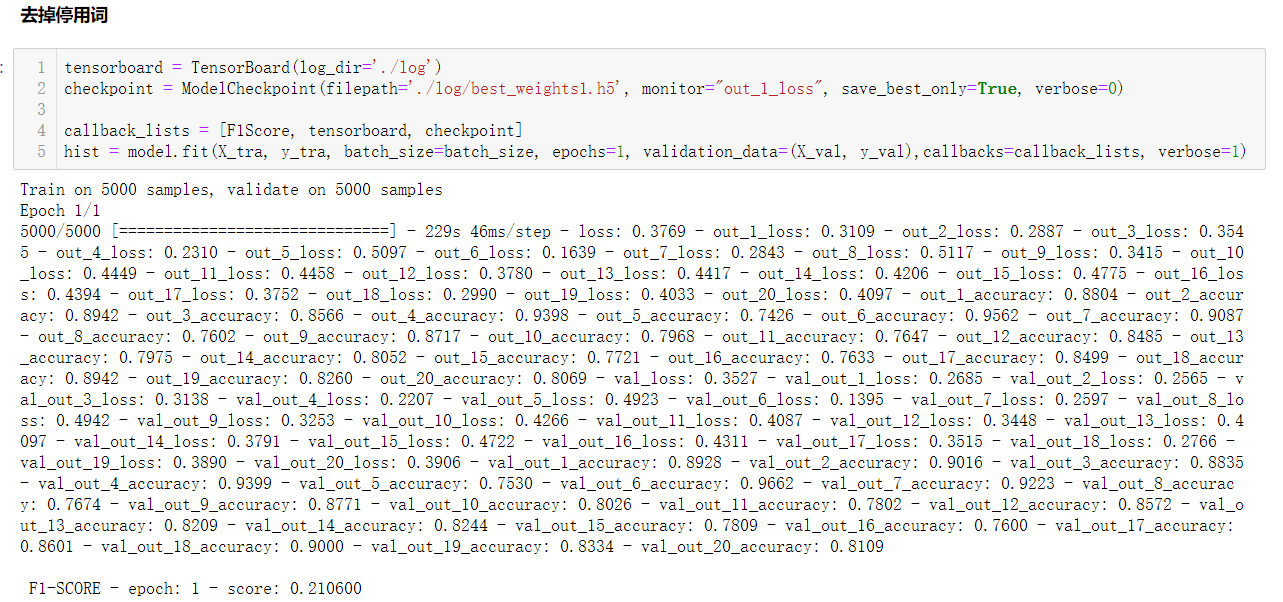
贴一张最后的网络结构
Model: "model_1"
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_1 (InputLayer) (None, 300) 0
__________________________________________________________________________________________________
embedding_1 (Embedding) (None, 300, 300) 60000000 input_1[0][0]
__________________________________________________________________________________________________
spatial_dropout1d_1 (SpatialDro (None, 300, 300) 0 embedding_1[0][0]
__________________________________________________________________________________________________
bidirectional_1 (Bidirectional) (None, 300, 160) 243840 spatial_dropout1d_1[0][0]
__________________________________________________________________________________________________
global_average_pooling1d_1 (Glo (None, 160) 0 bidirectional_1[0][0]
__________________________________________________________________________________________________
global_max_pooling1d_1 (GlobalM (None, 160) 0 bidirectional_1[0][0]
__________________________________________________________________________________________________
concatenate_1 (Concatenate) (None, 320) 0 global_average_pooling1d_1[0][0]
global_max_pooling1d_1[0][0]
__________________________________________________________________________________________________
out_1 (Dense) (None, 4) 1284 concatenate_1[0][0]
__________________________________________________________________________________________________
out_2 (Dense) (None, 4) 1284 concatenate_1[0][0]
__________________________________________________________________________________________________
out_3 (Dense) (None, 4) 1284 concatenate_1[0][0]
__________________________________________________________________________________________________
out_4 (Dense) (None, 4) 1284 concatenate_1[0][0]
__________________________________________________________________________________________________
out_5 (Dense) (None, 4) 1284 concatenate_1[0][0]
__________________________________________________________________________________________________
out_6 (Dense) (None, 4) 1284 concatenate_1[0][0]
__________________________________________________________________________________________________
out_7 (Dense) (None, 4) 1284 concatenate_1[0][0]
__________________________________________________________________________________________________
out_8 (Dense) (None, 4) 1284 concatenate_1[0][0]
__________________________________________________________________________________________________
out_9 (Dense) (None, 4) 1284 concatenate_1[0][0]
__________________________________________________________________________________________________
out_10 (Dense) (None, 4) 1284 concatenate_1[0][0]
__________________________________________________________________________________________________
out_11 (Dense) (None, 4) 1284 concatenate_1[0][0]
__________________________________________________________________________________________________
out_12 (Dense) (None, 4) 1284 concatenate_1[0][0]
__________________________________________________________________________________________________
out_13 (Dense) (None, 4) 1284 concatenate_1[0][0]
__________________________________________________________________________________________________
out_14 (Dense) (None, 4) 1284 concatenate_1[0][0]
__________________________________________________________________________________________________
out_15 (Dense) (None, 4) 1284 concatenate_1[0][0]
__________________________________________________________________________________________________
out_16 (Dense) (None, 4) 1284 concatenate_1[0][0]
__________________________________________________________________________________________________
out_17 (Dense) (None, 4) 1284 concatenate_1[0][0]
__________________________________________________________________________________________________
out_18 (Dense) (None, 4) 1284 concatenate_1[0][0]
__________________________________________________________________________________________________
out_19 (Dense) (None, 4) 1284 concatenate_1[0][0]
__________________________________________________________________________________________________
out_20 (Dense) (None, 4) 1284 concatenate_1[0][0]
==================================================================================================
Total params: 60,269,520
Trainable params: 60,269,520
Non-trainable params: 0
## 获取分词后的句子
X_train = gram(X_train)
X_valid = gram(X_valid)
# 建立字典
tokenizer = text.Tokenizer(num_words=max_feature)
tokenizer.fit_on_texts(X_train + X_valid)
# 建立索引
X_train = tokenizer.texts_to_sequences(X_train)
X_valid = tokenizer.texts_to_sequences(X_valid)
# 截断和补充
x_train = sequence.pad_sequences(X_train, maxlen=maxlen) # 一句话长为300单词
x_valid = sequence.pad_sequences(X_valid, maxlen=maxlen)
def get_coefs(word, *arr): return word, np.asarray(arr, dtype='float32') # asarray不会copy新的副本
# 建立预训练的词向量矩阵
embeddings_index = dict(get_coefs(*o.rstrip().rsplit(' ')) for o in open(EMBEDDING_FILE, encoding='utf-8'))
word_index = tokenizer.word_index
nb_words = min(max_feature, len(word_index))
embedding_matrix = np.zeros((nb_words, embed_size)) # 构建新的词向量矩阵
for word, i in word_index.items():
if i >= max_feature: continue
embedding_vector = embeddings_index.get(word)
if embedding_vector is not None: embedding_matrix[i] = embedding_vector
### F1Score的评价指标
class F1ScoreEvaluation(Callback):
def __init__(self, validation_data=(), interval=1):
super(Callback, self).__init__()
self.interval = interval
self.X_val, self.Y_val = validation_data # valid data与train格式一致
def on_epoch_end(self, epoch, logs={}):
if epoch % self.interval == 0:
Y_pred = self.model.predict(self.X_val, verbose=0)
score = []
for i in range(20):
y_pred = np.argmax(Y_pred[i], axis=1)
y_val = np.argmax(self.Y_val[i], axis=1)
score.append(f1_score(y_val, y_pred, average='macro'))
F_score = np.average(score)
print("\n F1-SCORE - epoch: %d - score: %.6f \n" % (epoch + 1, F_score))
def output_layer():
# 20个输出层的定义
avg_loss, avg_loss_weight = defaultdict(list), defaultdict(list)
for i in range(1, 21):
avg_loss['out_' + str(i)] = 'binary_crossentropy'
avg_loss_weight['out_' + str(i)] = float(1 / 20) # 平均分布
return avg_loss, avg_loss_weight
# 定义输出层
avg_loss, avg_loss_weight = output_layer()
# 定义主模型
def get_model():
inp = Input(shape=(maxlen, ))
x = Embedding(max_feature, embed_size, weights=[embedding_matrix])(inp)
x = SpatialDropout1D(0.2)(x)
x = Bidirectional(LSTM(80, return_sequences=True))(x)
avg_pool = GlobalAveragePooling1D()(x)
max_pool = GlobalMaxPooling1D()(x)
conc = concatenate([avg_pool, max_pool]) # 按照axis=-1(行)串联起来输出张量
# 平行结构
name = locals()
out = list()
for i in range(1, 21):
name['out_' + str(i)] = Dense(4, activation='sigmoid', name='out_' + str(i))(conc)
out.append(name['out_' + str(i)])
model = Model(inputs=inp, outputs=out)
model.compile(loss=avg_loss,
loss_weights=avg_loss_weight,
optimizer='adam',
metrics=['accuracy'])
return model
def data_label():
#
Y_tra = list()
for i, j in train_label.items():
Y_tra.append(j)
#
Y_val = list()
for i, j in valid_label.items():
Y_val.append(j)
return Y_tra, Y_val
F1Score = F1ScoreEvaluation(validation_data=(X_val, Y_val), interval=1)
model = get_model()
tensorboard = TensorBoard(log_dir='./log/best_weights.h5')
checkpoint = ModelCheckpoint(filepath='./log/best_weights.h5', monitor="out_1_loss", save_best_only=True, verbose=0)
callback_lists = [F1Score, tensorboard, checkpoint]
hist = model.fit(X_tra, Y_tra, batch_size=batch_size, epochs=1, validation_data=(X_val, Y_val),callbacks=callback_lists, verbose=1)有必要一提的是,评价模型好坏指标的建立。我们知道评价一个连续值的回归问题只能使用MSE的指标,但多分类的评价指标是有多个,ACC、Recall、F1Score、F2Score、AUC...,很明显使用ACC、Recall表示多分类容易导致信息遗漏,类间差别也容易被隐藏,F_Score和AUC应该对于本项目都可以,我们使用sklearn提供的f1_score进行再加工。