BRJS Intro
The BRJS model is a hierarchical object model similar to what you find in a browser, where brjs is the root node of the model. Some examples of model accessor code are:
brjs.app('my-app').defaultAspect()brjs.app('my-app').bladeset('fx').blade('tile').workbench()
Although the asset containers (e.g. aspect & blade)) within the model are discovered by core BRJS code, the assets within these containers are discovered by plug-ins, and are accessed via AssetContainer.assets() (e.g. brjs.app('my-app').defaultAspect().assets()).
Each part of the object-model contains methods for accessing the resources that that object logically contains (e.g. blade-sets contain blades, and blades contain workbenches, and workbenches contain tests, etc).
Because we use an object model that can be queried at will, rather than an imperative style of coding where we can order operations so that expensive operations are performed only once, memoization must be used to make the performance acceptable. This is done by having accessor methods make use of a memoization primitive (MemoizedValue) to ensure that work is only re-performed when there have been changes to relevant parts of the disk.
Consider the following code for example:
private File dir; // initialized somehow
private MemoizedValue<Workbench> memoizedWorkbench = new MemoizedValue(dir);
public Workbench workbench() {
return memoizedWorkbench.value(() -> {
return new Workbench(this, new File(dir, "workbench"));
});
}Here, the Java 8 lambda contains the code that will perform the actual work, but this won't be re-run until a file change is detected within dir. This is very cheap to do because the file watching happens in a background thread, and MemoizedValue.value need only check a boolean value to determine whether it can return the memoized value, or whether it should rebuild a new one.
In practice, you won't see as much memoization code as you might naturally expect to since we have NodeItem and NodeList classes that wrap MemoizedValue, and which are used for single-object and object-list accessor methods respectively. NodeItem and NodeList also prevent objects being re-created too, which wouldn't be the case if the simpler MemoizedValue primitive was used. Unfortunately, these classes obfuscate what's actually happening for little benefit, and if they hadn't pre-dated the creation of MemoizedValue probably wouldn't exist.
The model is instantiated fresh each time the brjs command is run. This is done by the CommandRunner class, and must be done before the CommandPlugin instances (which provide the various sub-commands) can be interacted with, since these command plug-ins are given a reference to the model at initialization, within setBRJS().
Additionally, model instantiation is also sometimes initiated by BRJSDevServlet, since it's possible to use the BRJS servlet (the workhorse behind brjs serve) in a Java App server of your choice, allowing the development environment to be more representative of the production environment.
Because the BRJS model isn't thread-safe, but Java Servlets are required to be thread-safe, model initialization and model acquisition are performed using ThreadSafeStaticBRJSAccessor, using its initializeModel() and acquireModel() methods.
Some parts of the model are discovered using plug-ins rather than by the core BRJS code. To understand this better, consider this diagram which shows some of the parts of the model that are discovered by the core code:
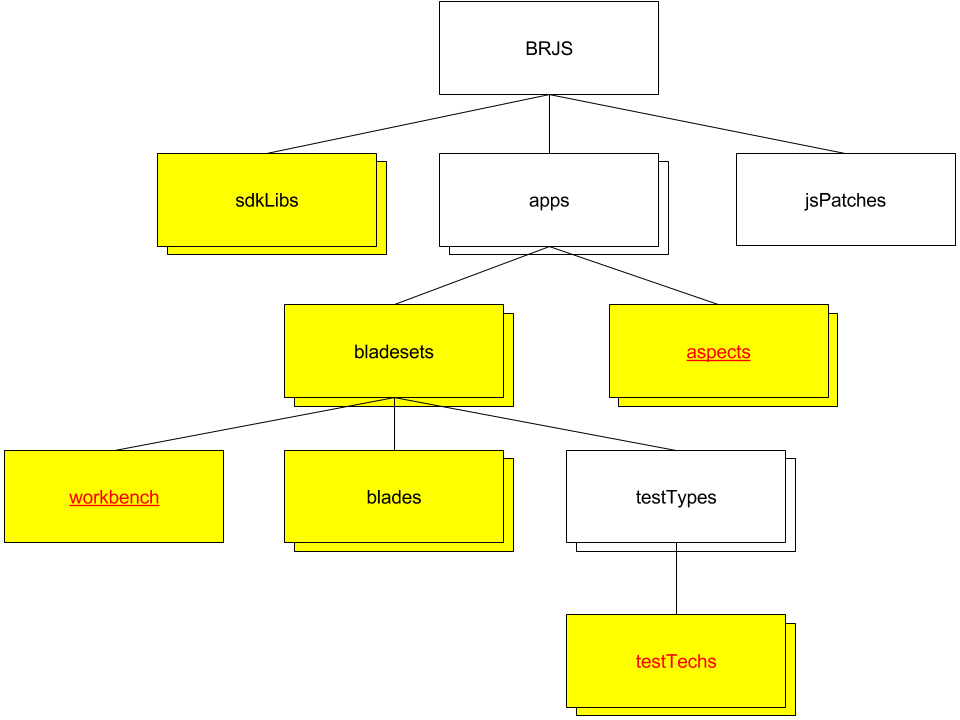
Some things to note here:
- Each box in this diagram is a node in the object model, and as such implements
Node. - The yellow nodes are able to contain JavaScript and non-JavaScript assets, and so implement
AssetContainer. - Nodes with red text are able to have bundles generated for them, and implement
BundlableNode. - Nodes with underlined red text have index pages that can be served to the browser, and implement
BrowsableNode.
The JavaScript and non-JavaScript assets within each asset-container can be accessed using the AssetContainer.assets() method, but the asset-containers use the registered AssetPlugin instances to actually find these assets.
The AssetPlugin interface has a single discoverFurtherAssets() method that gives each asset plug-in the chance to discover leaf-node assets within a directory (using the AssetRegistry.registerAsset() call-back), or completely new directories to discover assets within (using the AssetRegistry.discoverFurtherAssets() call-back). The various asset plug-ins work in tandem to find the assets and further asset directories within an asset container, and the discovery process recurses as new directories are found — that is, invoking AssetRegistry.discoverFurtherAssets() causes AssetPlugin.discoverFurtherAssets() to be invoked on each asset plug-in.
At present, asset plug-ins that discover leaf nodes are distinct from asset plug-ins that discover directory structures, but this isn't required.
The plug-in discovered assets form an asset-graph due to the fact that assets are allowed to depend on other assets, where these dependencies are expressed as a list of require-paths. The asset-graph is comprised of objects implementing the following three interfaces:
SourceModule -> LinkedAsset -> Asset
Some notes about these interfaces:
-
Assetis the most basic asset interface that the other two intefaces extend. -
LinkeedAssets are assets that can depend on other assets (viaLinkedAsset.getDependentAssets()). -
SourceModules are JavaScript assets that can express their asset dependencies in a more nuanced way (viagetPreExportDefineTimeDependentAssets(),getPostExportDefineTimeDependentAssets()&getUseTimeDependentAssets()).
Because the original BladeRunner had some complex rules about how JavaScript modules implicitly depend on any resources within the same directory and any parent directories, or the asset-container resources directory, and since thirdparty global libraries and NPM libraries have different rules again, the plug-ins take advantage of the modelling power of the asset-graph to express these rules. This is done through the creation of logical assets (e.g. directory assets that can be made to depend on all assets within a directory) and/or implicit dependencies, that can be forced onto each asset discovered within a particular directory.
For instance, the BRJSConformantAssetPlugin creates a DirectoryAsset for the src directory and all sub-directories, where each directory is made to depend on the discovered assets within that directory and the parent directory, or the resources directory if we're at the root of the src directory. By then insisting that any discovered assets have an implicit dependency on these AssetDirectory instances, the BRJS asset loading behaviour can be expressed using the asset-graph alone.
Bundling is performed using ContentPlugin instances, but before any bundling can take place, a bundle-set must be generated. A bundle-set is merely an ordered collection of assets taken from the asset-containers that are in scope for a particular bundlable-node (via AssetContainer.scopeAssetContainers()). For example, if we are creating a bundle-set for a blade's workbench then we wouldn't consider assets within any of the other blade asset-containers that are available.
The bundle-set contains only the assets that are reachable from a bundlable node's seed assets (via BundlableNode.seedAssets()), and where the assets are ordered most-significant first, so that, for example, i18n tokens defined at the aspect level override i18n tokens defined at the library level.
What a bundlable node's seed assets actually are will depend on the bundlable node. For a test it will be the source-modules contained within the test directory, whereas for an aspect it will be index.html or index.jsp — whichever there happens to be.
Finally, the bundle-set is created using BundlableNode.getBundleSet(), which in turn uses BundleSetCreator.createBundleSet() to do the work.
Bundling is performed using the following method on the ContentPlugin class:
ResponseContent handleRequest(String contentPath, BundleSet bundleSet, ...);It is the job of the content plug-in to return a bundle suitable for the requested contentPath and using the provided bundle-set, where plug-ins are free to determine the set of paths they want to support. For example, the CommonJS content plug-in accepts a path of common-js/bundle.js to access the complete bundle, or common-js/module/<module>.js to access the various source modules individually.
Because all content plug-ins are required to use a ContentPathParserBuilder for content-path parsing, you can see a declarative description of the paths a particular content plug-in supports, for example:
ContentPathParserBuilder contentPathParserBuilder = new ContentPathParserBuilder();
contentPathParserBuilder
.accepts("common-js/bundle.js").as(BUNDLE_REQUEST)
.and("common-js/module/<module>.js").as(SINGLE_MODULE_REQUEST)
.where("module").hasForm(ContentPathParserBuilder.PATH_TOKEN);
Bundles are made use of by a number of the brjs commands including brjs serve, brjs test & brjs build-app.
The BRJS server receives URL requests of the form:
http://<server>:<port>/<server-path>/v/<version>/<content-plugin-id>/<content-plugin-path>
By parsing these URLs, the server is able to determine which content plug-in a request is being directed at, and proxy it through. In the context of the BRJS server then, content plug-ins perform the same role that servlets perform for a Java server. However, there are some differences:
- Content-plugins determine the path at which they appear at (via
ContentPlugin.getRequestPrefix()) rather than allowing this to be configured by the administrator. - Content-plugins must be deterministic, always providing the same output given the same input path and files on disk.
- Content-plugins must be finite, only accepting a finite set of input paths.
The final two differences are needed because BRJS apps can be deployed as a set of flat files to a simple web server, using the brjs build-app command.
The BRJS server is implemented as a Java servlet and servlet filter that handles all of the requests running through the Java App server they are used on. The server takes care of setting things like the Content-Type and Cache-Control headers, but leaves all content provision to the content plug-ins.
In addition to generating bundles of the files within bundle-sets its given, content plug-ins are also required to list the complete set of valid content paths they can accept for a given bundle-set (using getValidContentPaths()) so that BRJS apps can be exported to a set of flat files.
Additionally, the getValidContentPaths() method is also key to allowing content plug-in composition. Content-types like text/javascript and text/css can end up with multiple content plug-ins of the same type, yet it's useful (e.g. for minification and sourcemaps reasons) to wrap the output of all of these plug-ins into a single composite bundle.
Tag handler plug-ins allow logical tags (e.g. <@css.bundle theme="dark"@>) to be used to make the browser load content from the server. When the server sees a logical tag like this, it has the appropriate tag-handler plug-in provide replacement content for that tag, for example:
<link rel="stylesheet" href="v/dev/css/common/bundle.css"/>
<link rel="stylesheet" title="standard" href="v/dev/css/dark/bundle.css"/>They are handy because they allow us to hide implementation details like the particular URLs that need to be used from the end-developer, and allow the developer to focus only on their unique requirements, like the theme they want to use. Most plug-ins that implements ContentPlugin will also implement TagHandlerPlugin, simplifying how requests to the content plug-in are added to the developer's index page.
Although asset plug-ins are typically responsible for discovering all assets, developers occasionally need to refer to logical assets using a require-paths that an asset plug-in might not be able to predict ahead of time.
When this is the case, a RequirePlugin can be used. These allow developers to use require-paths of the form <require-plugin-name>!<require-plugin-path>. When a require-path like this is seen by BRJS then it directs the request to the relevant plug-in using RequirePlugin.getAsset().
A plug-in is a Jar file containing a number of classes, with one or more of those classes implementing one of the Plugin interfaces, for example:
CommandPluginAssetPluginContentPluginTagHandlerPluginRequirePluginMiniferPluginModelObserverPlugin
The various plug-in classes provided by a plug-in must be separately registered by adding their fully qualified package names to the relevant BRJS service manifest — there is one manifest per plug-in class type, for example META-INF/services/org.bladerunnerjs.api.plugin.CommandPlugin.
The ordering of these lists may or may not be significant, depending on the plug-in class. Although having separate lists gives us more control over order, in retrospect this was probably a mistake since it makes it harder to just drop a plug-in into a system.
Plug-ins present an initialization dilemma because they depend on the model, yet are a part of that model. To overcome the circular dependency issues this naturally creates, each plug-in interface has its methods classified as follows:
-
Identifier methods: Can be invoked prior to the plug-in being initialized with the model (via
Plugin.setBRJS()). - General methods: May depend on the model depending on the implementation of the plug-in.
This separation is helpful because it allows us to initialize plug-ins on an as needed basis, avoiding the dependency resolution dead-locks we otherwise see. This works by having a virtual plug-in wrapper for each plug-in interface (e.g. VirtualProxyCommandPlugin) that proxies all of the methods through to the real plug-in, but which avoids initializing the plug-in with the model until a general method is invoked.
Unlike CommonJs files, which have require() methods that indicate the exact locations at which require-paths may be found, namespaced scripts, HTML templates, XML configuration files & HTML index pages are able to contain require-paths (or dotted notation class references) at any point within the file. Scanning files like this using conventional approaches is way too slow, so something more exotic is needed.
We use a type of Trie called a Suffix Tree to allow us to do this. The Trie<T> class we use for this purpose is a generic container similar in nature to a map of type Map<T>, in that you can add keys to it (using void add(String key, T value)), and then efficiently ask whether those keys are present (via boolean containsKey(String key)).
The difference to a map though is that the trie is able to find all of the keys within a string simultaneously, at no additional cost, and this is done using the List<T> getMatches(Reader reader) method.
Population of the trie is done by adding all assets (using AssetContainer.assets()) for all in-scope asset-containers (using AssetContainer.scopeAssetContainers()). Once this is done it allows a LinkedAsset to implement getDependentAssets() by simply returning the result of Trie.getMatches().
Although memoization is necessary for performance, it can lead to subtle bugs that aren't spotted by our unit tests. To reduce the chance that this can happen we co-opt Java's SecurityManager to act as a cache-invalidation checker, by having it throw an error if a read file lies outside all the declared directories of all of the MemoizedValue.value() invocations currently within the call-stack.
This approach has worked well, though we still occasionally see caching bugs despite this mechanism. On the other hand, when the SecurityManager does catch cache invalidation bugs, it's quite tricky to determine which of the MemoizedValue.value() invocations within the call-stack are responsible (though this could probably be improved by printing it's unique object identifier).