ConnectionStateListener change #15991
Conversation
sdk/cosmos/azure-cosmos/src/main/java/com/azure/cosmos/DirectConnectionConfig.java
Outdated
Show resolved
Hide resolved
sdk/cosmos/azure-cosmos/src/main/java/com/azure/cosmos/implementation/RequestTimeline.java
Show resolved
Hide resolved
...main/java/com/azure/cosmos/implementation/directconnectivity/rntbd/RntbdConnectionEvent.java
Outdated
Show resolved
Hide resolved
|
/azp run java - cosmos - tests |
|
Azure Pipelines successfully started running 1 pipeline(s). |
There was a problem hiding this comment.
RntbdConnectionStateListener::partitionAddressCache is a local cache and can be stale. as a result of that RntbdConnectionStateListener may remove addresses of unrelated pkranges causing unnecessary address refresh.
Consider this scenario:
- PKR1, PKR2, PKR3 are hosted on the same physical node.
- request1 with PKR1, request2 with PKR2, and request3 with PKR3 are sent and as a result
RntbdConnectionStateListener:partitionAddressCacheis populated with PKR1, PKR2, and PKR3. - due to partition movement PKR1 moves out of the physical node, but PKR2 and PKR3 stay on the node.
- now the node hosting PKR2 and PKR3 shuts down.
- RntbdConnectionStateListener thinks PKR1 is still on this physical node, and hence will remove addresses of PKR1, PKR2, and PKR3. But PKR1 addresses shouldn't have been removed!!.
- this will result in unnecessary address refresh for PKR1.
sdk/cosmos/azure-cosmos/src/main/java/com/azure/cosmos/DirectConnectionConfig.java
Outdated
Show resolved
Hide resolved
sdk/cosmos/azure-cosmos/src/main/java/com/azure/cosmos/DirectConnectionConfig.java
Outdated
Show resolved
Hide resolved
...cosmos/src/main/java/com/azure/cosmos/implementation/directconnectivity/AddressResolver.java
Show resolved
Hide resolved
...s/src/main/java/com/azure/cosmos/implementation/directconnectivity/RntbdTransportClient.java
Show resolved
Hide resolved
...s/src/main/java/com/azure/cosmos/implementation/directconnectivity/RntbdTransportClient.java
Show resolved
Hide resolved
...in/java/com/azure/cosmos/implementation/directconnectivity/rntbd/RntbdClientChannelPool.java
Outdated
Show resolved
Hide resolved
...a/com/azure/cosmos/implementation/directconnectivity/rntbd/RntbdConnectionStateListener.java
Outdated
Show resolved
Hide resolved
...mos/src/main/java/com/azure/cosmos/implementation/directconnectivity/rntbd/RntbdRequest.java
Outdated
Show resolved
Hide resolved
.../main/java/com/azure/cosmos/implementation/directconnectivity/rntbd/RntbdRequestManager.java
Outdated
Show resolved
Hide resolved
...a/com/azure/cosmos/implementation/directconnectivity/rntbd/RntbdConnectionStateListener.java
Show resolved
Hide resolved
There was a problem hiding this comment.
LGTM. (please make sure we run CTL)
@xinlian12 very great work.
Please track the following as an improvement outside of the scope of this PR:
RntbdConnectionStateListener::partitionAddressCache is a local cache and can be stale. as a result of that RntbdConnectionStateListener may remove addresses of unrelated pkranges causing unnecessary address refresh.
Consider this scenario:
- PKR1, PKR2, PKR3 are hosted on the same physical node.
- request1 with PKR1, request2 with PKR2, and request3 with PKR3 are sent and as a result
RntbdConnectionStateListener:partitionAddressCacheis populated with PKR1, PKR2, and PKR3. - due to partition movement PKR1 moves out of the physical node, but PKR2 and PKR3 stay on the node.
- now the node hosting PKR2 and PKR3 shuts down.
- RntbdConnectionStateListener thinks PKR1 is still on this physical node, and hence will remove addresses of PKR1, PKR2, and PKR3. But PKR1 addresses shouldn't have been removed!!.
- this will result in unnecessary address refresh for PKR1.
...a/com/azure/cosmos/implementation/directconnectivity/rntbd/RntbdConnectionStateListener.java
Show resolved
Hide resolved
 moderakh
left a comment
moderakh
left a comment
There was a problem hiding this comment.
The PR looks good code-wise.
There are a few improvement which Annie is tracking outside of the scope of this PR.
for This PR however we are waiting for
- CTL result
- perf testing (there was some discussion that on dotNet side enabling this feature resulted in perf impact) we need to measure if that's the case in Java as well or not.
sdk/cosmos/azure-cosmos/src/main/java/com/azure/cosmos/DirectConnectionConfig.java
Show resolved
Hide resolved
sdk/cosmos/azure-cosmos/src/main/java/com/azure/cosmos/DirectConnectionConfig.java
Show resolved
Hide resolved
|
/azp run java - cosmos - tests |
|
Azure Pipelines successfully started running 1 pipeline(s). |
|
Test Result: 1. Adobe Tests (default config): 2. Benchmark Runner-ReadLatency: P95: P99: P999: Throughput: 3. CTL Run:
Test results from 4 core CPU: Benchmark test results: |

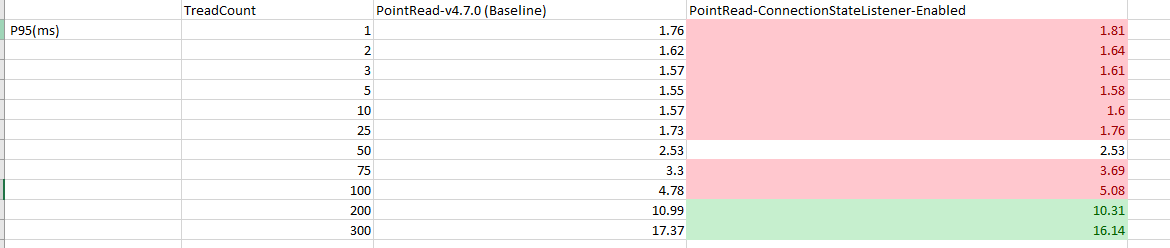

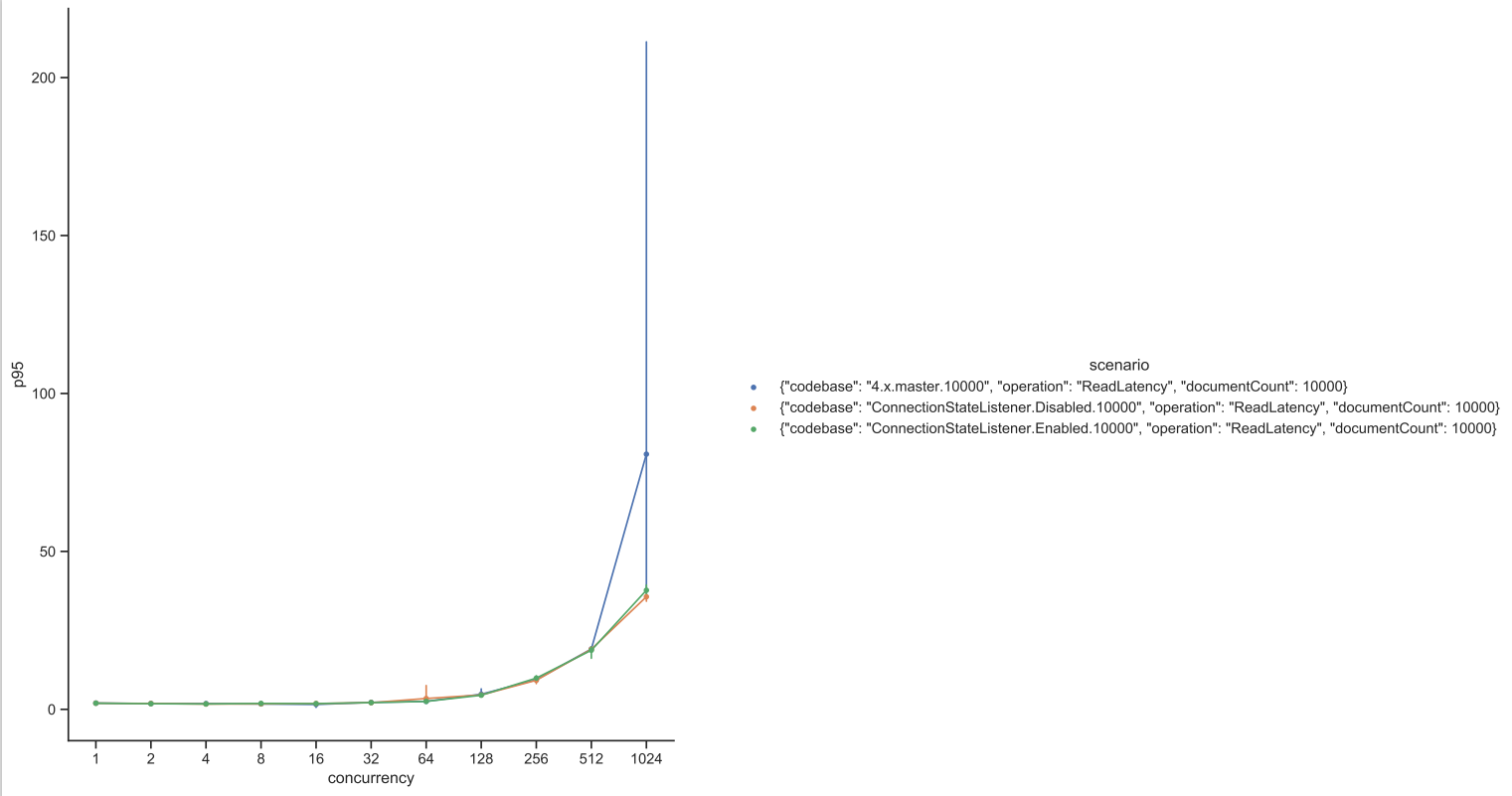
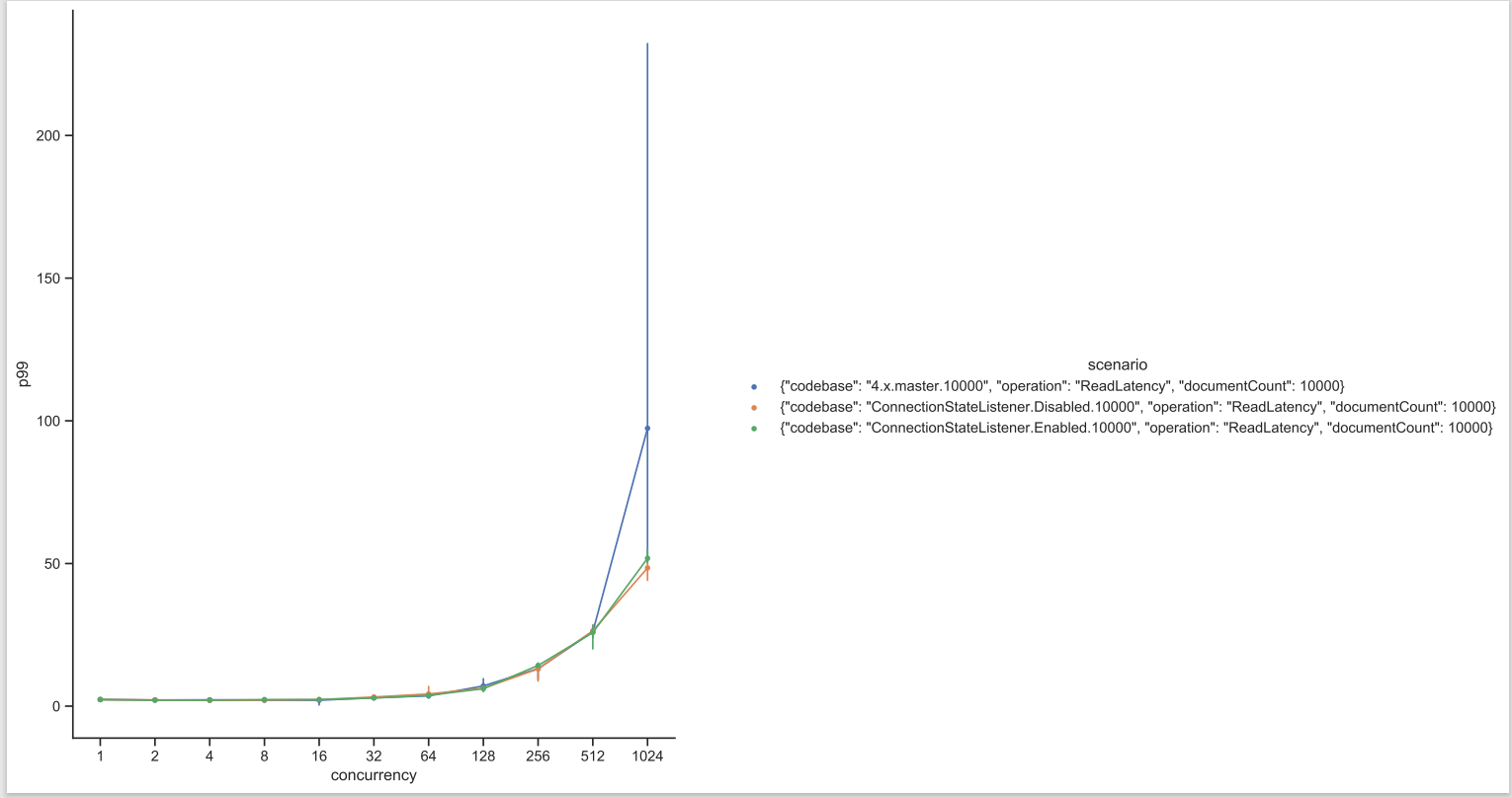
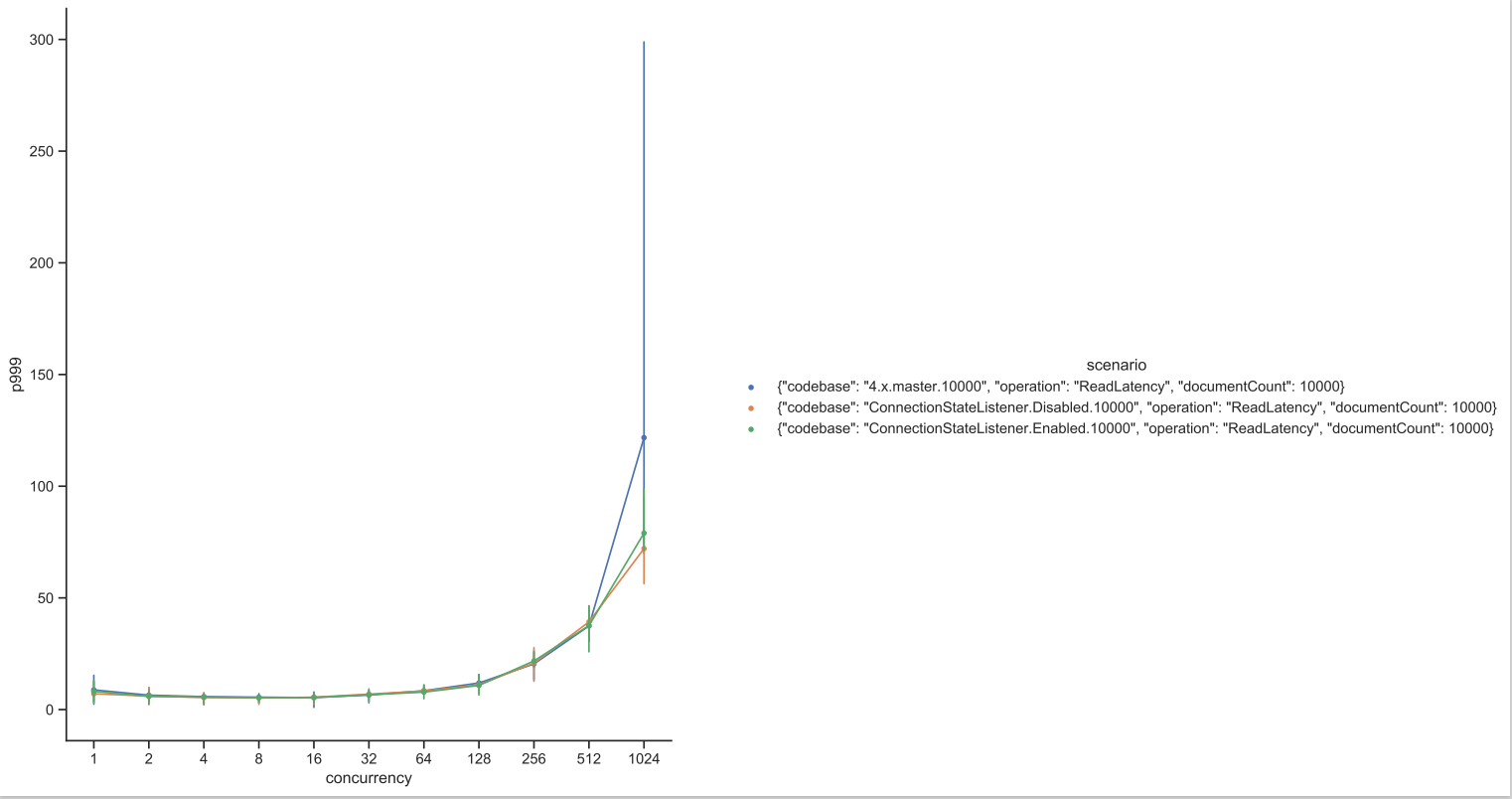
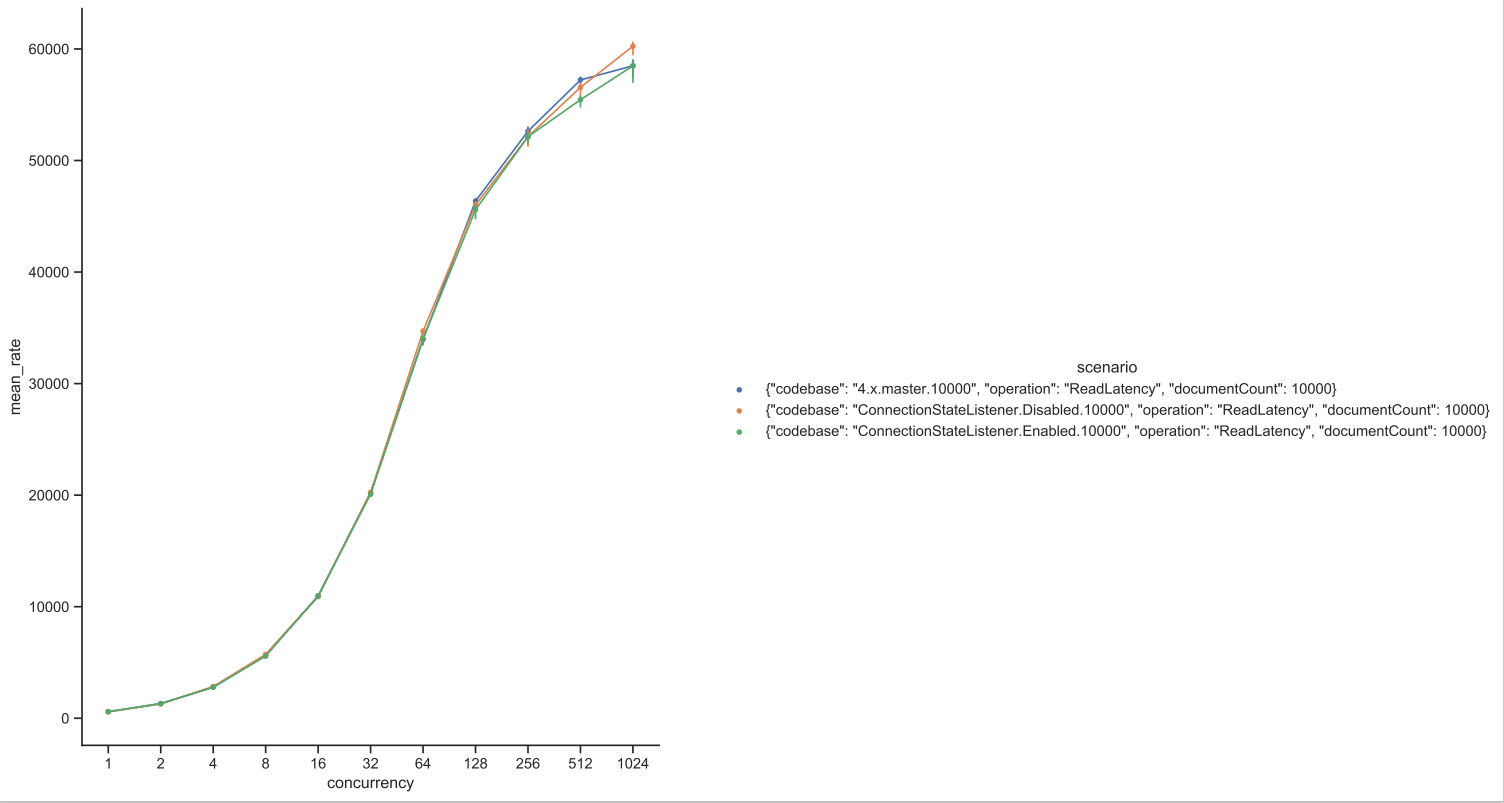






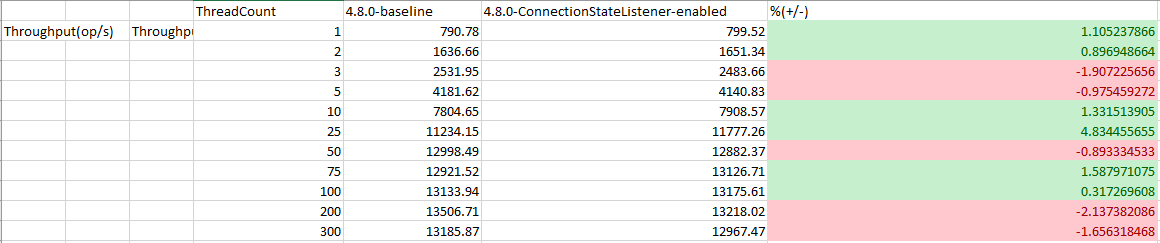
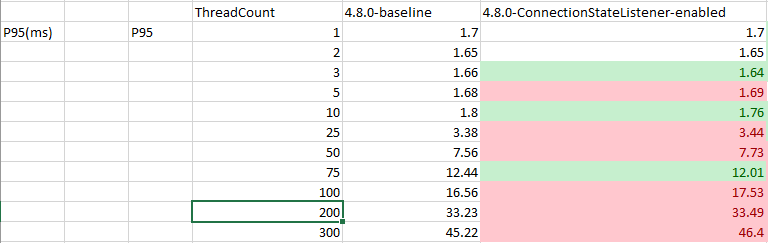
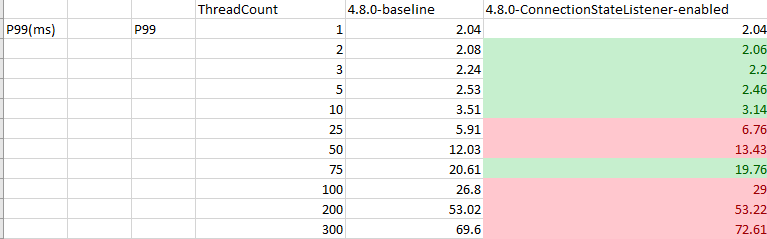
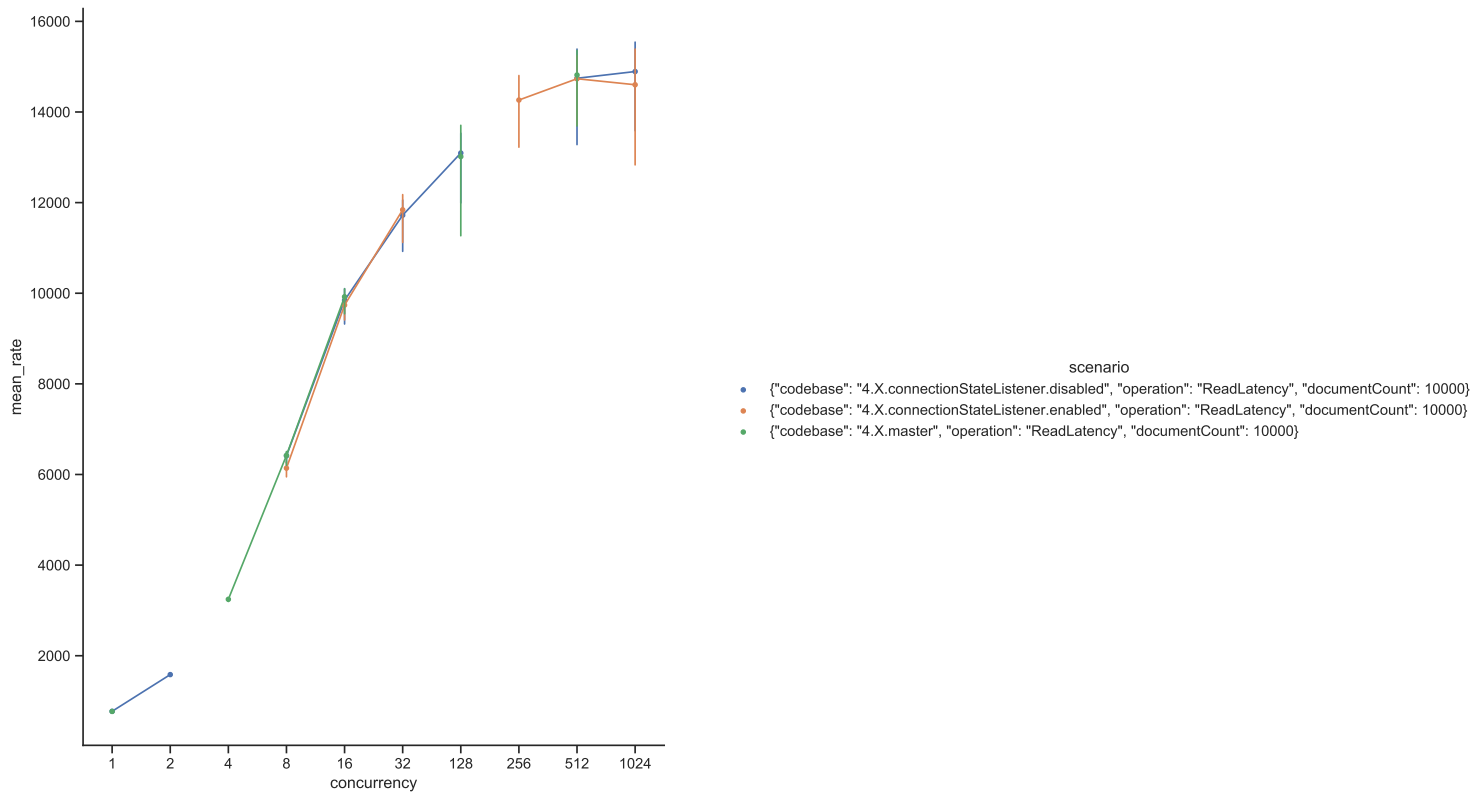
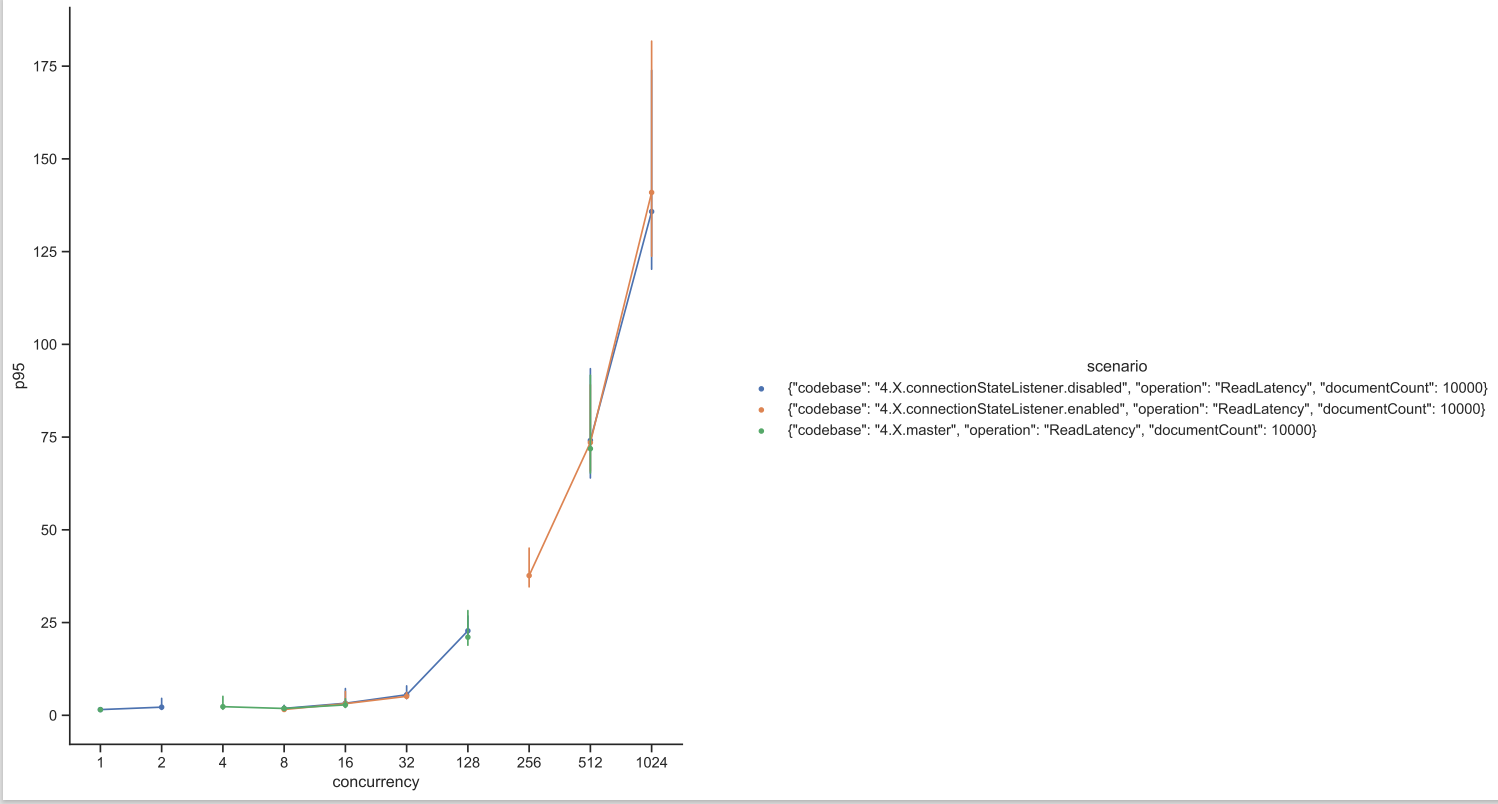
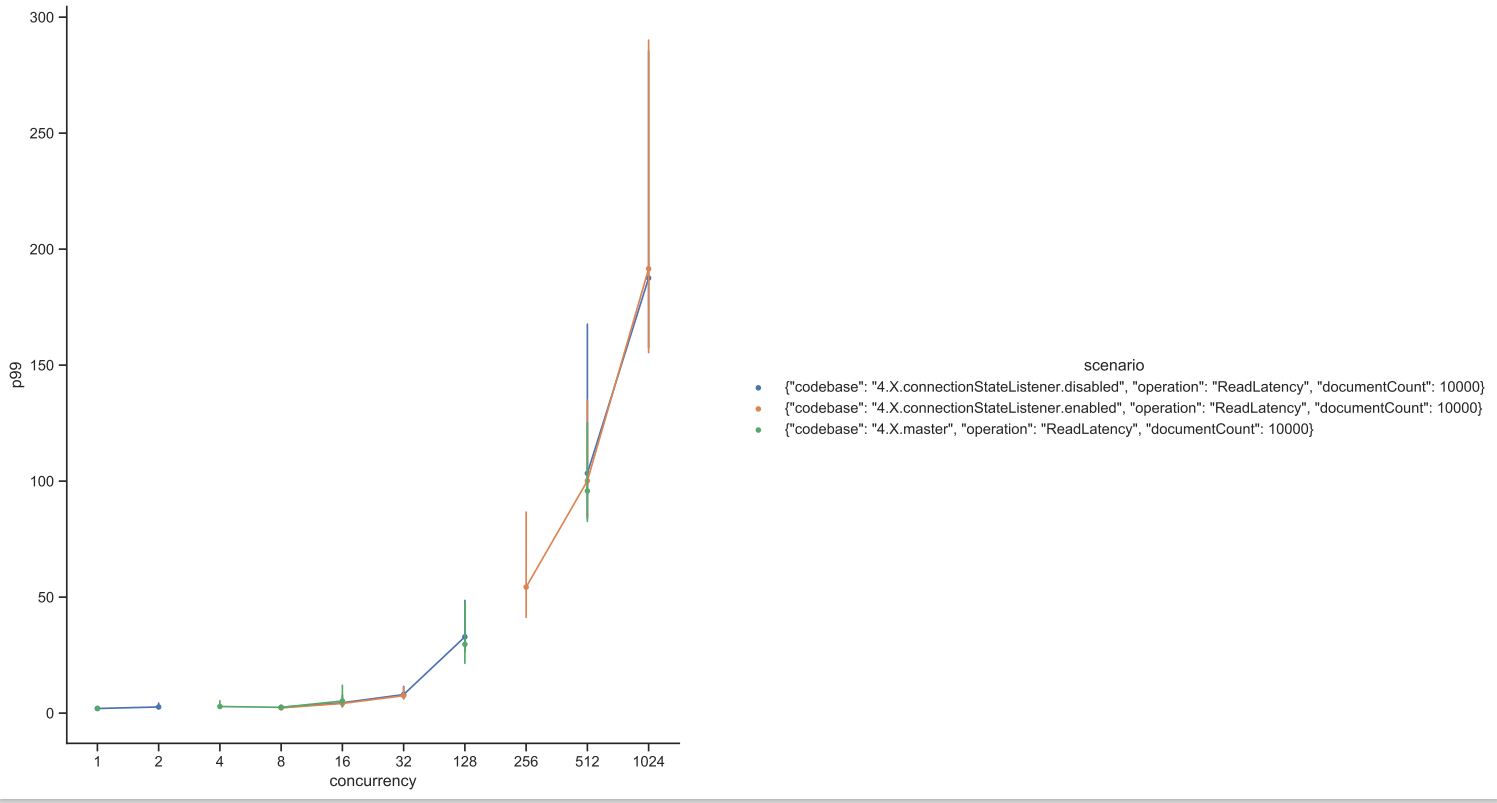
This PR is mostly a duplicate of ConnectionStateListener change incuded in PR #14697 with few differences.
Implementation:
Each
RntbdServiceEndpointhas aRntbdConnectionStateListenerto keep tracking the partitionKeyRangeIdentity sets. New partitionKeyRangeIdentity will be added whenRntbdServiceEndpoint.request()called.When detecting a server is going down, we will remove all the effected
PartitionKeyRangeIdentityfrom gateway address cache. Currently, only ClosedChannelException will triggeronConnectionEventsince this is more sure as a signal the server is going down.Workflow:
Three major workflows could be triggered.
Server starts a graceful connection closure. (FIN)
Normal netty close channle flow will be triggered. (closeFuture, inactive, unregister).
RntbdRequestManagerwill complete all pending requests for the channel withClosedChannelException.Server ungracefully close a connection (RST).
This will trigger netty exceptionCaught() flow. 'RntbdRequestManager.exceptionCaught()` will be called, and complete all pending requests for the channel with IOException. Channel will be closed.
When the server down, client trying to start a new connection:
Eventually get ConnectTimeOutException
Test:
Test33:
Did TCP packets capture for package upgrade and manually retart VM. Based on the tcp traces, the first and third workflow will be triggered.
Test Results from benchmark run:
Pending
Test Results from CTL run:
Pending