{Core} Reducing the risk of logging file fd leaking #12971
Conversation
|
add to S168 |
5e8e9e5 to
a9b935b
Compare
|
Handlers are added by which is called when azure-cli/src/azure-cli-core/azure/cli/core/commands/__init__.py Lines 503 to 504 in 34f9033 I think we can use the same mechanism to call Currently, the only place where which is never called during in a |
There was a problem hiding this comment.
self.command_metadata_logger.removeHandler(handler) [](start = 14, length = 53)
remove elements in the array loop may cause unexpected result
There was a problem hiding this comment.
it's a copy from slice [:], won't have side affect.
There was a problem hiding this comment.
Will this get cleaned up if the az process returns an error? I seem to remember the call to end_cmd_metadata_logging being skipped if an exception was raised when I was testing as it was only called on a successful path rather than from a finally block.
There was a problem hiding this comment.
@elpollouk If you were using az, that would go with code in __main__.py
azure-cli/src/azure-cli/azure/cli/__main__.py
Lines 48 to 73 in 1bab798
whenever an exception is raised, the final exception on top of exception stack would be SystemExit because there is a hook:
azure-cli/src/azure-cli-core/azure/cli/core/parser.py
Lines 148 to 157 in 4770a43
With this PR merged, I guess there won't be a leaking problem. But after that, it should be a leaking as you said.
That's my understanding, if anything missing/wrong, could you please give a detailed report?
|
@jiasli What event name do you suggest? And that where do we raise the end logger event? |
|
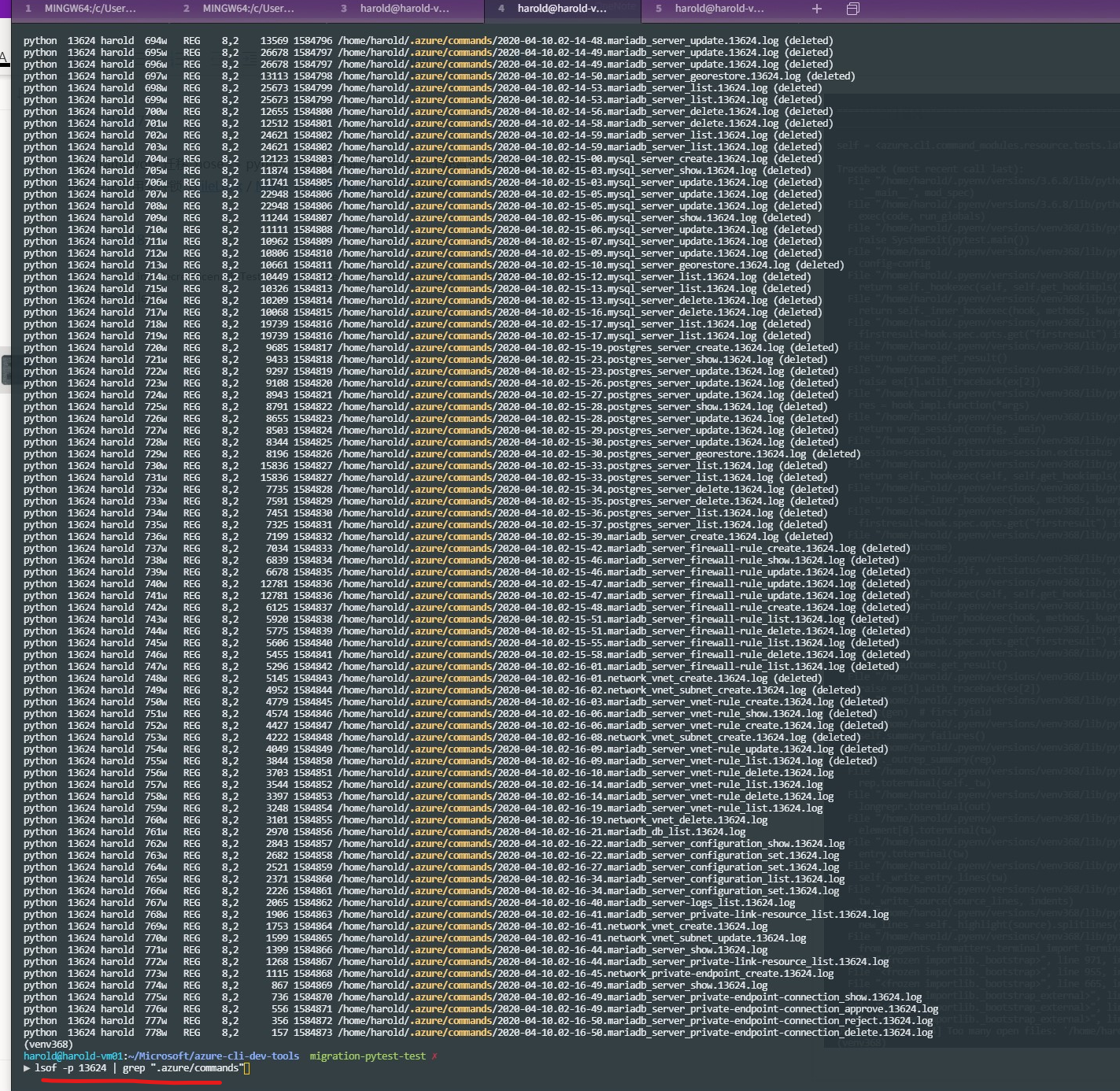
I see that the same log handler(delete) appears repeatedly in the second picture. Could we design the log handler object which handle the same type of business as a singleton? This can also avoid repeated creation after multiple calls and reduce the fd. |
Good suggestion. Can singletion affect the logging order? If CLI were used concurrenly, will it affect anything? I am concered about it. |
8be4bc6 to
4addfb7
Compare
|
The idea comes from the fact that when I used a logging framework in Java before, I always create a LogFactory to generates singleton logger objects for different businesses:
However, I don't have a deep understanding for Python's log, just a guess based on my previous experience in Java, maybe you can use it as a reference |
52450f5 to
61ab0a3
Compare
61ab0a3 to
2d99cb5
Compare
Got it. azure-cli/src/azure-cli-core/azure/cli/core/azlogging.py Lines 99 to 111 in ec56c66 If we are going to implement the singleton on logger level, I think it's unncessary for now. Because it's more meaningful under the cocurrent scenaro. And if we decide to make it singleton, the feedback it's involved to change because it needs logs. |
|
Closed due to mistaken merged. |
Description
As I discovered in #12949, CLI would crash after long time running due to running out of available fd because it didn't close the fd properly.
Running tests with pytest, testing is terminated after the number of avaliable fd is consumed.
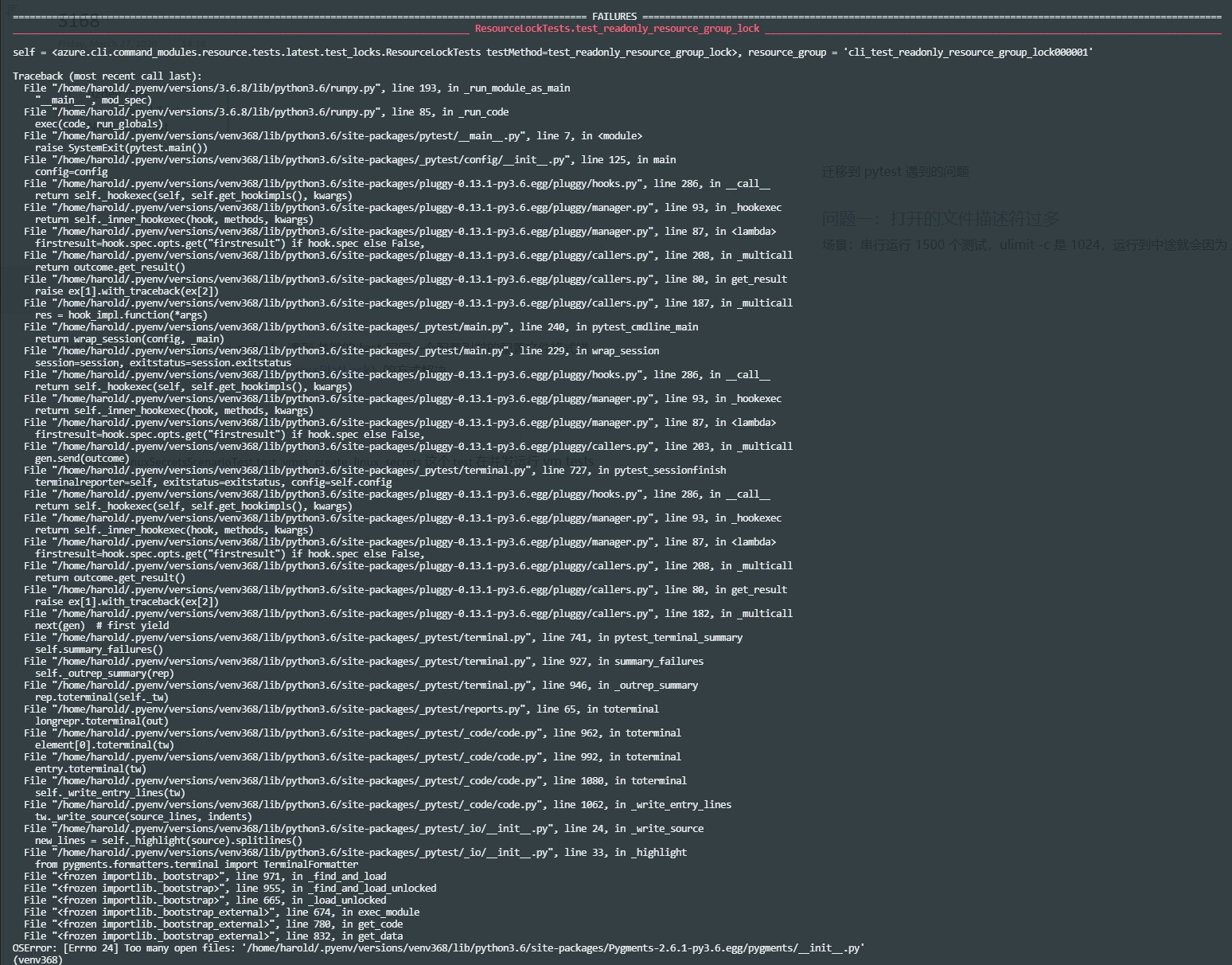
I add a hook
doCleanupsof unittest.Testcase to mandatorily clean those unclosed fd hold by CLI's logger.This could reduce the risk of fd leaking but still need developer to manually call
end_cmd_metadata_logging()of AzLogging, like:azure-cli/src/azure-cli/azure/cli/__main__.py
Lines 49 to 50 in 806e431
Why I say reducing
ScenarioTest/LiveScenarioTestbutunittest.TestCase, so, they couldn't benifit from this fix.In both scenarios, we will still have chance to see
(deleted)files that are unclosed and leakingTesting Guide
test_network_commands.py,lsof -p {TestProcessID} | grep "azure",(deleted)like the image above. That's the leaking fds.pytest -x -v --capture=noand with tons of tests, process will crash.lsof -p {TestProcessID}, but they will disappear very soon.History Notes
This checklist is used to make sure that common guidelines for a pull request are followed.
The PR title and description has followed the guideline in Submitting Pull Requests.
I adhere to the Command Guidelines.