The goal of this project is to fine tune LLAMA for Indian Languages as it is originally trained on 90% English Language and 10% Mathematical equations
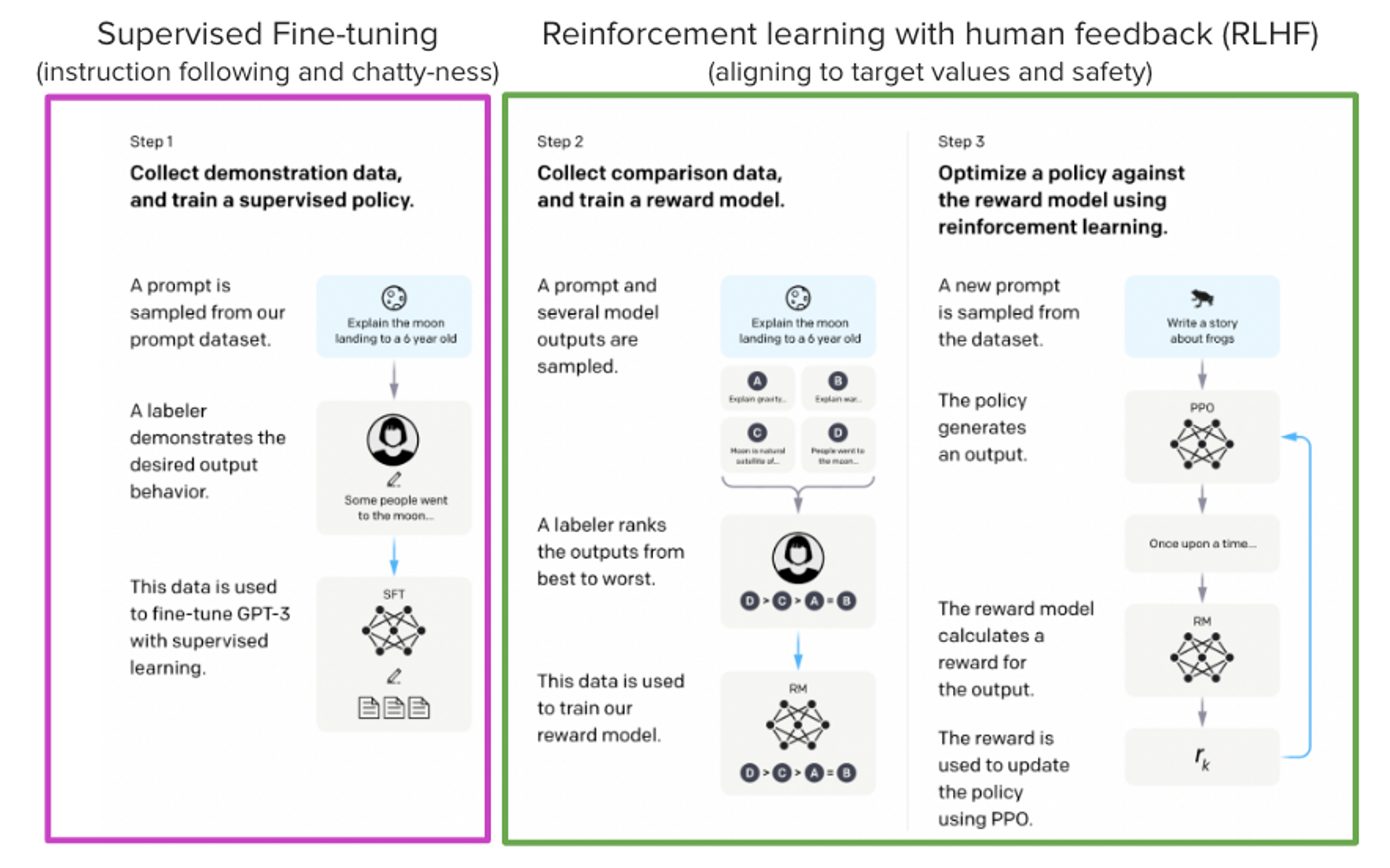
Models such as ChatGPT, GPT-4, and Claude are powerful language models that have been fine-tuned using a method called Reinforcement Learning from Human Feedback (RLHF) to be better aligned with how we expect them to behave and would like to use them.
The steps involveed :
- Supervised Fine-tuning (SFT)
- Reward / preference modeling (RM)
- Reinforcement Learning from Human Feedback (RLHF)
- 85 different languages, 1620 language pairs
- 134M parallel sentences, out of which 34M are aligned with English
- this table shows the amount of mined parallel sentences for most of the language pairs
- the mined bitext are stored on AWS and can de downloaded with the following command:
wget https://dl.fbaipublicfiles.com/laser/WikiMatrix/v1/WikiMatrix.en-fr.tsv.gzReplace "en-fr" with the ISO codes of the desired language pair. The language pair must be in alphabetical order, e.g. "de-en" and not "en-de". The list of available bitexts and their sizes are given in the file list_of_bitexts.txt. Please do not loop over all files since AWs implements some limitations to avoid abuse.
Use this command if you want to download all 1620 language pairs in one tar file (but this is 65GB!):
wget https://dl.fbaipublicfiles.com/laser/WikiMatrix/WikiMatrix.v1.1620_language_pairs.tar[1] Holger Schwenk, Vishrav Chaudhary, Shuo Sun, Hongyu Gong and Paco Guzman, WikiMatrix: Mining 135M Parallel Sentences in 1620 Language Pairs from Wikipedia arXiv, July 11 2019.
[2] Hugo Touvron and Thibaut Lavril and Gautier Izacard and Xavier Martinet and Marie-Anne Lachaux and Timothée Lacroix and Baptiste Rozière and Naman Goyal and Eric Hambro and Faisal Azhar and Aurelien Rodriguez and Armand Joulin and Edouard Grave and Guillaume Lample, LLaMA: Open and Efficient Foundation Language Models arXiv, Feb 27, 2023
[3] Edward Beeching and Younes Belkada and Kashif Rasul and Lewis Tunstall and Leandro von Werra and Nazneen Rajani and Nathan Lambert, [*StackLLaMA: A hands-on guide to train LLaMA with RLHF