The main purpose of this project is to reproduce a classical model in game theory : the prisonner dilemma (I used as a model the work of Harrald and Fogel 1996). This work provides an implementation of the iterated prisonner dilemma with a evolutionnary approach for strategies selection.
We archieved to obtain exactly the same results as Harrald and Fogel (1996). The simulation works as intended, and shows that the defect behavior (and strategy) is clearly dominant.
A simulation log is available in csv in the results folder. A summary plot is available here.
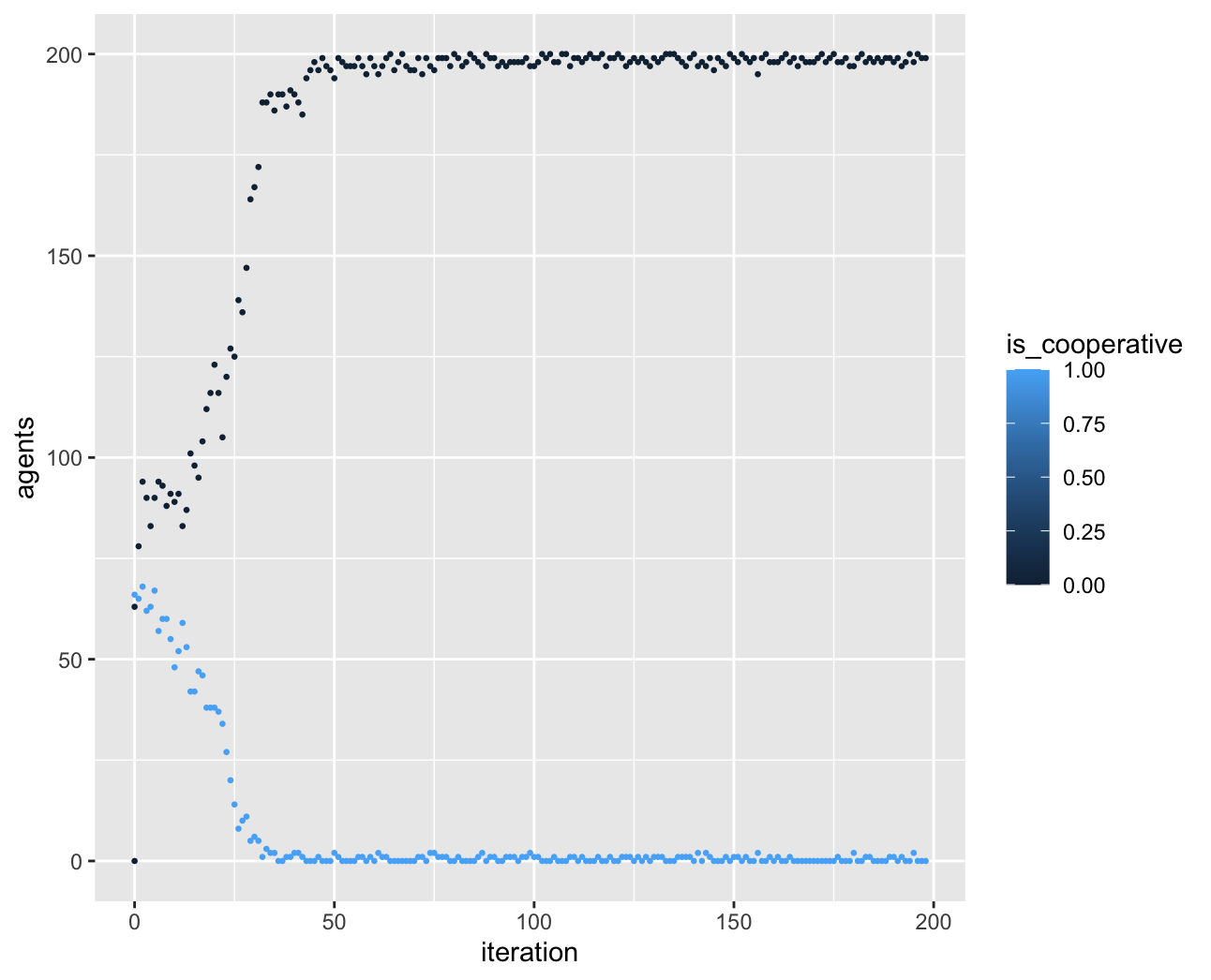
Each agents has a memory of 6 units : his 3 past actions, and the 3 past actions of his coplayer. The agent is, in fact, a neural network with two hidden layers that can choose either to cooperate (1) or to defect (0). The payoff matrix is defiened in constants.hpp.
NeuralNetworks are based on the AKML framework (which I created for this type of academic purposes).