做了 105. Construct Binary Tree from Preorder and Inorder Traversal 和 106. Construct Binary Tree from Inorder and Postorder Traversal 两道题目。
首先是 105 题,基于前序遍历数据和中序遍历数组构建出二叉树。通过前序遍历可以很容易知道其第一个元素就是根节点,重点在于如果拿到根节点后在找到左右子节点。要解出这道题目重点在于理解前序、中序遍历的数组的特点:
- 前序遍历数组中,第一个节点是根节点,接下来是左子树的节点,然后是右子树的节点。
- 中序遍历数组中,根节点两侧是左右子树节点。
如图:

那么我们先拿到前序遍历的第一个元素(即为根节点),然后找到其在中序遍历数组中的位置,那么左右两侧即为左右子树节点。知道左右子树后,就可以知道前序数组中右子节点的位置了。拿到两个左右子树之后,又可以按照相同方式来进行递归操作,直到所有的节点都被遍历到。逻辑总结如下:
- 根据前序遍历数组找到当前子树根节点。
- 找到根节点在中序遍历中的位置,那么该位置左侧即为左子树,右侧即为右子树。
- 继续递归左右子树。
实现代码如下:
public class Solution {
private int[] preOrder;
private int[] inOrder;
private int len;
public TreeNode buildTree(int[] preorder, int[] inorder) {
this.preOrder = preorder;
this.inOrder = inorder;
this.len = inorder.length;
TreeNode root = this.findRoot(0, 0, inorder.length - 1);
return root;
}
// preStart 代表的就是前序数组中的根节点索引
public TreeNode findRoot(int preStart, int inStart, int inEnd) {
if (preStart > this.len - 1 || inStart > inEnd) {
return null;
}
TreeNode root = new TreeNode(preOrder[preStart]);
int index = 0;
for (int i = inStart; i <= inEnd; i ++) {
if (inOrder[i] == root.val) {
index = i;
break;
}
}
// 最重要的逻辑:计算前序遍历中的根节点索引和中序遍历左右子树的起止索引
root.left = this.findRoot(preStart+1, inStart, index -1);
root.right = this.findRoot(preStart + index - inStart + 1, index + 1, inEnd);
return root;
}
}搞明白了通过前序和中序数组来构建二叉树的话,第 106 题通过后序和中序数组构建二叉树也就很简单的了,不同的是根节点变为了最后一个,这里不再赘述,实现代码如下:
class Solution {
private int[] inOrder;
private int[] postOrder;
private int len;
public TreeNode buildTree(int[] inorder, int[] postorder) {
this.inOrder = inorder;
this.postOrder = postOrder;
this.len = inorder.length;
return findRoot(len-1, 0, len-1);
}
public TreeNode findRoot(int postEnd, int inStart, int inEnd) {
if (postEnd < 0 || inStart > inEnd) {
return null;
}
TreeNode root = new TreeNode(this.postOrder[postEnd]);
int inIndex = 0;
for (int i = inStart; i <= inEnd; i ++) {
if (this.inOrder[i] == root.val) {
inIndex = i;
}
}
root.left = findRoot(postEnd - inEnd + inIndex - 1, inStart, inIndex-1);
root.right = findRoot(postEnd - 1, inIndex + 1, inEnd);
return root;
}
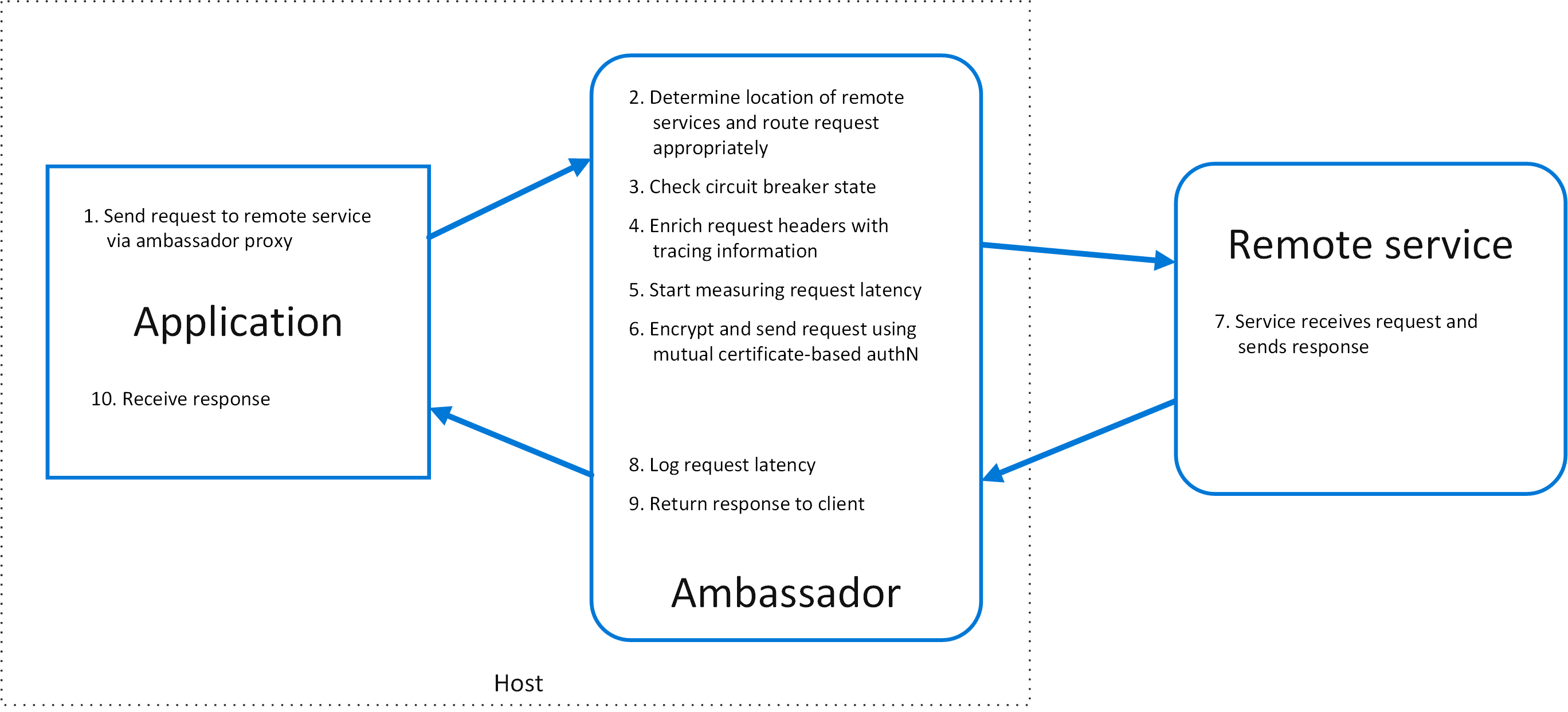
}读微软云设计模式系列之:Ambassador pattern(外交官模式)。通过创建一个 Ambassador 辅助服务来代表我们的应用与外界客户端进行请求交互,可以将 Ambassador 辅助服务看做是和应用部署在同一台主机上的代理。
基于云的应用的弹力设计需要有熔断、路由、计量、监控以及对于网络相关配置的升级等功能。这些功能在遗留系统或者某些库中可能较难实现,因为这些代码可能已经不再维护或者修改成本很大。另外对于网络调用可能也需要连接、校验、授权等相关的配置,如果有多个不同语言或者框架实现的应用需要互相访问,那么我们需要针对每一个应用做单独的配置,这样会带来极大的运维成本。
通过创建一个外部进程来充当应用和外部服务之间的代理,将进程与我们的应用部署在同一个主机上,并提供路由、弹性设计、安全等功能,并且避免任何与主机相关的访问限制。另外该进程还可以监控请求延迟、资源占用相关的指标,因为进程与应用是在同一主机上,因此可以直观的展示应用的资源占用情况。设计如图:

代理服务中的功能是可以随时修改的,并且不会影响到我们正式服务的使用,我们也可以有专门的团队来维护 Ambassador 服务。Ambassador 服务可以设计成边车模式,也就是说该服务的生命周期和正式服务是一致的。另外如果 Ambassador 服务为同一个主机上的多个应用提供代理,可以将该服务设置为一个守护进程运行。如果应用是集装箱化的(也就是通过容器等实现的),那么 Ambassador 服务也应该采用类似的实现,并与正式服务之间建立联系。
- 添加代理会造成一定的请求延迟,因此在使用时需要和采用 sdk、库的形式或者直接调用等方式相比较,选择更加合适的方案。
- 考虑 Ambassador 服务中的特性是否合理,比如可以通过 Ambassador 服务进行请求重试,但是需要保证重试的幂等性。
- 可以考虑实现一种机制,将客户端的上下文发送给 Ambassador 服务,比如请求的 Header,客户端设置的重试次数等。
- 仔细思考打包和部署策略。
- 认真斟酌是采用 一对多还是一对一的方式提供 Ambassador 服务。
比较合适的使用场景
- 需要为多种语言和框架提供一个通用的客户端访问时。
- 需要将多个客户端之间的交叉请求问题整合到基础架构之中或者需要由专门的团队开发运维时需要构建 Ambassador 服务
- 对于某些旧的或者难以修改的应用提供类似功能时,此时一般只能创建 Ambassador 服务来实现。
不合适的场景
- 对于请求延迟特别敏感的服务不适合,因为 Ambassador 服务会引入延迟,可能引发问题。
- 当客户端团队只有一种开发语言时,此时采用包的形式分发给客户端是更好的选择。
- 当连接功能与客户端需要深入集成时,此时不太适合采用 Ambassador 服务。
下面是文章中一个简单的图例:
以上是文件的简单翻译。个人感觉外交官模式和边车模式比较类似,但是从文中的内容来看,外交官模式更加侧重于请求代理,另外边车模式的生命周期与对应的应用的一致的。对于一对多形式的外交官模式,又和网关模式非常相似,这几个模式的核心思想主要还是尽量将业务无关的服务剥离出来吧。下面是网络上的一幅示意图:

可以看到边车、外交官模式都是针对于某个微服务做业务无关的一些操作。
最近看了 codedump 的博客,感觉主题特别的简洁,因此自己也倒腾了下把原来基于 Hexo 的博客换成了 Hugo 的 Even 主题的风格。下面是操作的步骤:
- 安装 Hugo
brew install hugo
- 创建博客站点
hugo new site blog
- Event 主题安装
主题的网址是 hugo-theme-even,首先需要通过 yarn 来安装依赖
brew install yarn
Yarn 安装后就可以安装主题了,进入刚才新建的博客站点目录 blog 将主题 clone 下来:
cd blog
git clone https://github.com/olOwOlo/hugo-theme-even themes/even
cd ./themes/even/
# install dependencies
yarn install
# build
yarn build
完成后修改 blog 下的 config.toml 文件,将主题改为 even:
theme = "even"
完成后执行命令 hugo server 就可以在本地预览效果了。
关于 Even 主题需要注意两点:
- 默认的创建新博客的命令是
hugo new posts/my-first-post.md,但是even主题是 post 而不是 posts,即命令为hugo new post/my-first-post.md - 命令中的文件名必须带上
.md后缀。
本地环境搭建好就可以正常使用了,但是为了将博客分享出去与他人交流学习,还需要将博客部署到线上才行。最常用的方式就是部署到 GitHub 了。下面操作步骤:
创建 GitHub 仓库
按文档提示的,首先要创建两个项目:
- blog:项目仓库
- zouyingjie.github.io:博客部署仓库
本地构建仓库
创建完成后 将项目仓库 clone 下来,并且将之前创建本地的博客站点 (我本地的叫 blog)的文件复制到该仓库下。此时在该仓库下执行 hugo server 就可以启动博客本地访问了。
拷贝完成后如果仓库目录下有 public 则务必删除,然后执行下面命令:
// USERNAME 就是你的 Github 名和刚才新建的博客部署仓库名,我的都是 zouyingjie
git submodule add -b master [email protected]:<USERNAME>/<USERNAME>.github.io.git public.
执行该命令完成后,在项目仓库下就有了 public 目录,然后执行 hugo 命令就会将我们最新的改动存入 public 目录中等待部署了。
创建部署脚本,执行部署
上面步骤操作完成后就可以创建部署脚本,每次执行脚本即可完成博客的部署了,脚本内容如下:
#!/bin/bash
echo -e "\033[0;32mDeploying updates to GitHub...\033[0m"
# Build the project.
hugo # if using a theme, replace with `hugo -t <YOURTHEME>`
# Go To Public folder
cd public
# Add changes to git.
git add .
# Commit changes.
msg="rebuilding site `date`"
if [ $# -eq 1 ]
then msg="$1"
fi
git commit -m "$msg"
# Push source and build repos.
git push origin master
# Come Back up to the Project Root
cd ..
保存后执行下面命令就可以部署成功了
 。
。
现在访问 .github.io 就可以访问你的博客了,比如我的博客地址是 https://zouyingjie.github.io ,可以正常访问了,后面就是将之前写的博客和 ARTS 迁移上来啦。
最近在读《麦肯锡精英高效阅读法》,分享下里面提到的一些方法:
一来大多数情况下我们并不会回头去看我们做的那些笔记,二是这样做会打断我们集中精力阅读的状态,而这种集中注意力、中止、在集中注意力的过程很让人疲惫懈怠。书中更推荐的一种方式是 划线,这种方式不仅便于我们后续回顾书中的重要内容,还节省时间,对于大量阅读电子书的人来说也非常的便于搜索,一举三得。
书中建议阅读一本书时,以每小时内读完几万字为目标,逐步提升,即使读不懂在读完之前也不要重读。一旦想着重读那么在阅读时就可能放松懈怠,因此最好的方式就是绝不重读,这样可以强迫我们在阅读第一遍时就得努力理解书中讲的内容,有种破釜沉舟的意味在里面。
立即写博客可以加深我们对书中内容的理解,并且可以获得交流与反馈,而这些又会加深我们的理解,改进我们的阅读习惯、方法和思考方式,形成正向循环。书中提到的写博客方法概要如下:
- 没必要花费太多时间
- 准备模板,将书中印象最深的内容写进标题,然后列出与之相关的 4 ~ 5 个小标题,接下来针对每个标题做总结,相当于变写作题为填空题,这样可以大幅降低写作难度曲线,提高积极性。
- 不要在意措辞,想到什么些什么。
万维钢老师在他的《精英日课》专栏中也提到过读一本书的方法:强力研读,就是将书至少读两遍。 重读可以使我们加深对书中内容的印象,并提高知识的转化程度,并且可能遇到之前所没有的收获,所谓“读书百遍其义自见”就是这个道理。