本周做了 61. Rotate List,难度 Mdeium,要求从链表的右侧开始翻转指定的步长。
示例如下:
Input: 1->2->3->4->5->NULL, k = 2
Output: 4->5->1->2->3->NULL
Explanation:
rotate 1 steps to the right: 5->1->2->3->4->NULL
rotate 2 steps to the right: 4->5->1->2->3->NULL
从右侧开始反转,原来的尾节点变为头结点,操作起来很麻烦,最直接的一种思路是先把链表进行一次反转,然后就可以从头进行反转了,完事了在反转回来,也就是说要经历两次链表的全反转和 K 次的部分反转。代码如下:
public class Solution {
public ListNode rotateRight(ListNode head, int k) {
if (head == null || head.next == null) {
return head;
}
head = reverseList(head);
ListNode tail = head;
while (tail.next != null) {
tail = tail.next;
}
while (k != 0) {
tail.next = head;
tail = head;
head = head.next;
tail.next = null;
k --;
}
return reverseList(head);
}
private ListNode reverseList(ListNode node) {
ListNode next = null;
ListNode preNode = null;
while (node.next != null) {
next = node.next;
node.next = preNode;
preNode = node;
node = next;
}
node.next = preNode;
return node;
}
}不出所料,效率令人发指的低,虽然理论上时间复杂度为 O(N),但实际操作非常耗时,提交的结果也表明了了这一点: 耗时 2000 多 ms,beats 5%。
思路是对的,始终要把从右反转变为从左反转的操作,但实现方式不对。换个思路,如果链表长度为 N,那么从头开始旋转 K 次等同于从 右边旋转 N - K 次,从例子中也可以看出,将 5、4 一次置于头部等同于将 1、2、3 依次置于尾部。
Input: 1->2->3->4->5->NULL, k = 2
Output: 4->5->1->2->3->NULL
Explanation:
rotate 1 steps to the right: 5->1->2->3->4->NULL
rotate
那么实际任务就变成了计算需要从左边旋转几步,即 求 N - K,那就很简单了,只需要简单的遍历一次链表求出链表长度即可。虽然也是遍历,但是没有方法一中遍历反转链表时复杂的指针变换,因此速度是非常快的。实现代码如下:
public class Solution {
public ListNode rotateRight(ListNode head, int k) {
if (head == null || head.next == null) {
return head;
}
ListNode tail = head;
int len = 1;
while (tail.next != null) {
len ++;
tail = tail.next;
}
int newK = 0;
if (k > len) {
newK = Math.abs(len - k % len);
}else {
newK = Math.abs(len - k);
}
while (newK != 0) {
tail.next = head;
tail = head;
head = head.next;
tail.next = null;
newK --;
}
return head;
}
}有一个地方需要注意下,就是 K 的值可能是大于链表实际长度的,因此在求 N -K 时要进行一次取模运行,因为 如果 N = K 的话等于无需反转。修改后的代码理论上时间复杂度为 O(N),实际执行时间 5ms, beats 100%。
继续阅读 Nginx 微服务系列文章: Choosing a Microservices Deployment Strategy。本篇主要讲述了在微服务架构模式下的服务部署策略。
单体应用
- 一台多台机器部署,每台机器部署一个实例
- 部署方便,环境配置比较方便,一次配置完成后,后续只需更新代码、重启服务即可
微服务架构
- 实例较多,可能有成百上千个微服务实例需要部署
- 不同服务可能使用了不同的语言和框架,因此对资源的要求、监控、扩展性要求都有所不同, 从而提高了部署的复杂性
- 需要根据服务的特点选择合适的机器,比如存储服务要选高存储量、高 IO 的机器,而对于业务服务需要选择高 CPU 配置的机器,而对于 ES 搜索引擎则又需要高内存的机制。
以上提到的微服务的部署特点极大提高了微服务应用部署的复杂性,下面看下几种常用的微服务部署方式:
顾名思义,就是在一台机器或者虚拟机上部署多个服务实例,如图所示:

优点
- 充分的利用了机器资源,节约成本
- 部署方便,可以通过复制代码的形式快速部署
- 重启方便,可以在不影响其他服务的前提下随意启动服务
缺点
- 服务间的隔离性较差,除非一台机器上的多个服务都是不同的服务,这样就会导致机器无法根据某个微服务的性质选择最合适的配置
- 服务之间可能会抢占资源
- 因为不同服务可能使用不同的语言和框架,因此运维团队必须了解其实现方式,从而选择合适的部署方式,提高了运维成本
鉴于上面一台机器部署多台服务的问题,我们可以采用一台机器部署一台服务的形式,该形式有两种实现方式
采用虚拟机的方式,将服务打包为镜像,每个服务部署到一台单独的虚拟机上,如图所示:
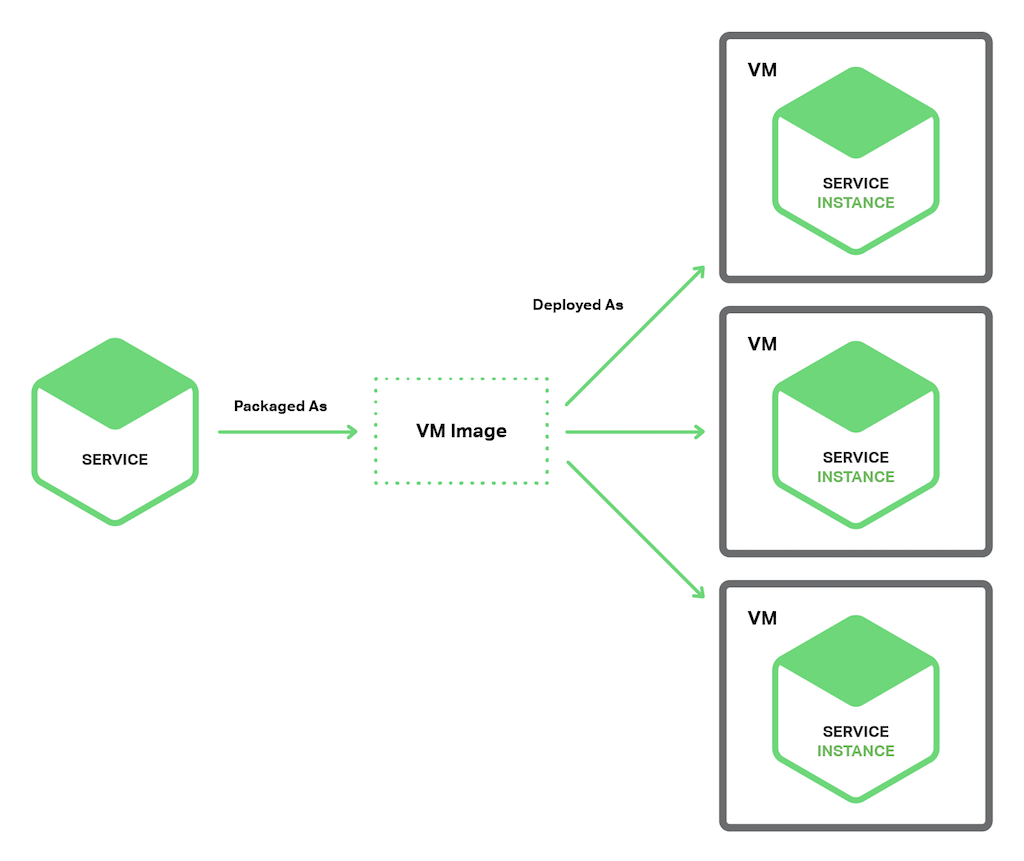
Netflix 公司主要就是采用了这种方式进行部署,
优点
- 服务实现了完全隔离,服务的资源使用不受其他服务影响
- 可以利用成熟的云架构组件实现功能,比如 AWS 提供了负载均衡和自动扩展等功能
- 因为是将服务打包为镜像,其屏蔽了内部的实现方式,因此运维团队只需要简单的操作镜像就可以了,无需再了解其实现的语言和框架
缺点
- 资源利用不够充分,甚至可能因为自动伸缩不够有效造成资源浪费
- 部署较慢,VM 的打包需要时间无法做到快速的部署
- 需要分出精力去管理 VM
容器是当下最火的虚拟化技术了,其有独立的命令空间和文件系统,可以通过配置限制其内存和 CPU 资源的占用,甚至是 IO 的速率也可以进行限制,最常用的容易有 Docker 、Solaris Zones 等通过容器部署实例如图:
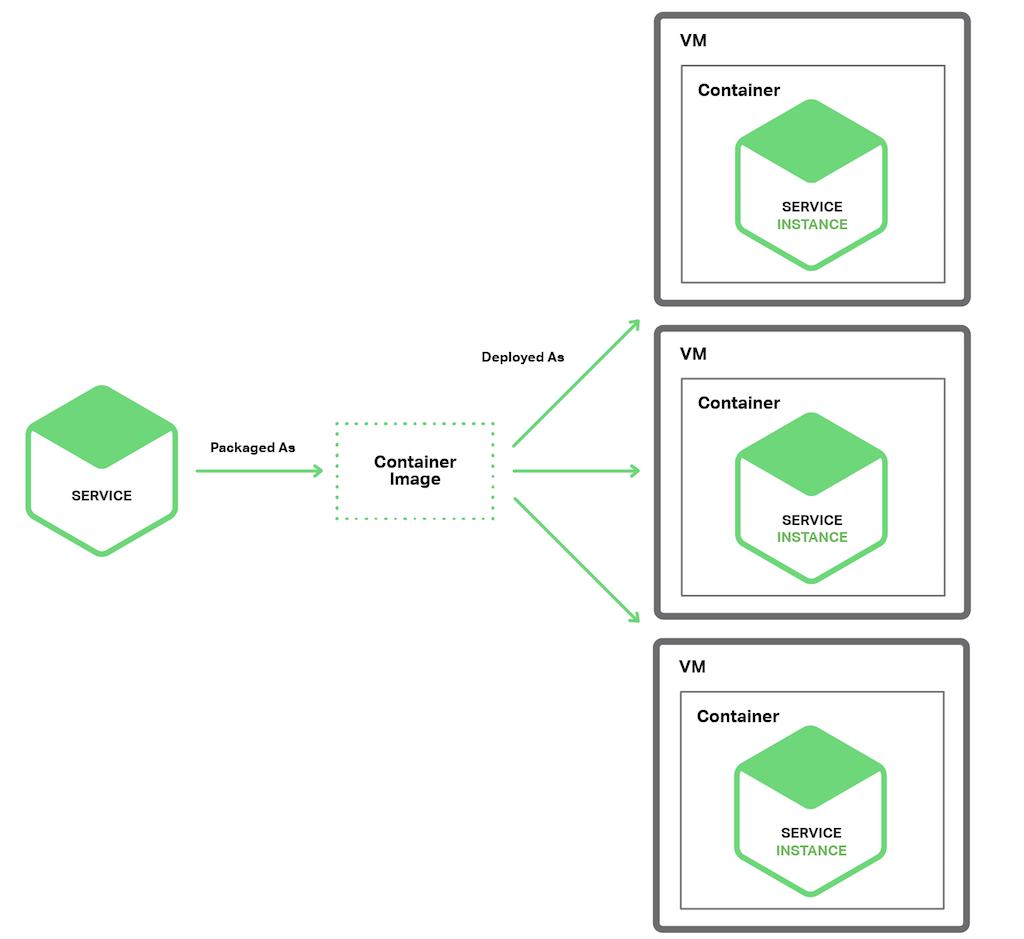
利用容器部署时,我们可以将服务所依赖的环境打包到容器镜像中,同时可以采用 K8S 这样的工具对容器进行管理。
优点
- 和 VM 模式一样,实现了服务之间的隔离
- 和 VM 相比容器镜像的构建速度更快,其使用起来更加的轻量级。
- 容器可以实现资源使用上的限制,避免了在同一台物理机上的某些应用过度抢占资源的情况
缺点
- 和 VM 相比容器技术依然不够成熟,另外因为需要和其他容器共享内核,因此安全性上也稍逊一筹
- 除非你采用云厂商提供的容器服务,否则你需要自己去进行容器相关的运维
- 容器一般来说也是部署在 VM 上的,因为也会出现资源冗余过多的情况
以 AWS Lambda 为代表的无服务模式的服务部署也已经有所发展了,其要求我们将服务进行压缩后上传到 AWS Lambda 中,AWS Lambda 根据当前实际请求自动部署所需要的服务数量以及相关的资源配置,然后可以通过如下几种方式调用服务:
- 直接发送请求
- 事件驱动,订阅时事件进行处理
- 通过 AWS 网关接收客户端请求进行处理
- 类似于 cron 的定时任务
优点
- 基于服务都由云厂商做好了,自己只需要关注应用开发即可
- 按需收费,费用是基于服务的调用数来计算的,因此可以节约成本
但是无服务部署也有一定的局限性:
- 服务必须是无状态的
- 服务必须足够小,执行时不允许耗时过长,否则很容易超时
- 必须采用云生成 serverless 服务支持的语言进行编写
简单来说微服务的部署有如下几种方式:
- 机器部署
- 容器部署
- 无服务函数部署
随着容器技术的发展,容器部署应该会应用的越来越多,是时候深入学习一下容器相关的技术啦。
分享几个有趣的 Linux 命令彩蛋吧,不太实用,但是挺有意思的。
输入该命令,会打印出下面图案,翻译成人话我理解是是 “你今天喵喵喵了吗?”
# root @ 81b413418fb5 in / [14:10:36]
$ apt-get moo
(__)
(oo)
/------\/
/ | ||
* /\---/\
~~ ~~
..."Have you mooed today?"...
输入 vim 命令打开 Vim 后输入如下命令:
:help 42
然后会出现如下文本:
What is the meaning of life, the universe and everything? *42*
Douglas Adams, the only person who knew what this question really was about is
now dead, unfortunately. So now you might wonder what the meaning of death
is...
==============================================================================
Next chapter: |usr_43.txt| Using filetypes
Copyright: see |manual-copyright| vim:tw=78:ts=8:ft=help:norl:
通过 telnet 执行如下命令:
telnet towel.blinkenlights.nl
你就可以在终端中观看星球大战啦。 给个示例图片:

话说大家是怎么做 ARTS 的呢?记得之前大家也讨论过 ARTS 跟不上的问题,说下自己做 ARTS 的过程吧,自己算是最早加入 ARTS 的同学,全部完成的自己也坚持了 34 期了,还有几期只完成了部分,所以觉得还是有用的,分享下欢迎交流学习。
虽然耗子叔要求每周整一道算法题,但实际的刷题数量肯定是超过的。前期做 ARTS 的时候每次都是现做现卖,现在会有所变化,ARTS 中优先列那些有技巧的题目,其次是自己做出来的 Medium 难度及以上的题目。比如上一期做的找链表的中间节点,虽然不难,但方式是双指针,一定比较典型的解题思路,因此写到 ARTS 上。本期做的 Medium 链表相关的题目,也是将自己两步的优化过程写出来,这样使自己印象更加深刻,而对于那些分分钟能做出来的 Easy 题目,就没必要写到 ARTS 了。
算法这一块自己还比较薄弱,因此做的题目还是非常少的,如果有时间后面打算按照 《数据结构与算法之美》的目录,每周选一个知识点,比如链表、平衡查找树、红黑树、散列表+哈希算法、动态规划等,每周一个,先看文章和相关书籍资料,然后这一周全刷与之相关的题目,就算没有熟练掌握,入个门应该是可以的。
最开始写 Review 的时候也是都等到写的时候才看,这样其实在写之前找一篇文章就很费时间了。现在改为了只要有时间、有文章就看,并且尽量保证文章是系列性质的,比如最近看的耗子叔推荐的 Nginx 微服务系列文章,共 7 篇,这就是 7 期 ARTS 的 Review 啊。这样提前选好了文章,就可以有时间就看了,比如微服务系列文章,虽然前期 ARTS 只做了 3、4 期,但是我的所有文章已经看完了,对于后面的 ARTS 我只需要在完成另外三部分就好了,无形中提高了后续工作的效率。
另外说一句其实没必要花时间找文章了,都在耗子叔的练级攻略里面的 = =
对于 Tips 优先列自己最近工作中使用到的一些技巧,比如第一期分享的 git pull -i 的相关使用,Django Debug 脚本的操作,其次是学习到一些技巧,比如用 Go 写爬虫时字节码的转换,最后就是搜索了,结合最近学习的知识点,然后搜索相关的 tips 文章或者相关方法论的文章,看完后在分享出来,约等于一次变相的 Review 吧,只不过更偏实战型。比如上一期 33 期 ARTS 的 Tips 分享的 WireShark 相关的,是在看了极客专栏 《Linux 性能优化实战》之后搜索出的文章,对自己学习还是起了很好的正向作用的。
Share 是最痛苦的一部分了,耗子叔说每周分享一个关于技术的想法,实际在操作中其实很大一部分并没有侧重技术。因为觉得自己确实没有那么多的输出,主要还是没有积累吧。开始写 ARTS 后才觉得积累的重要性,肚子里没东西就是写不出好东西来啊,翻来覆去几句话就没余粮了。Share 其实是对自己平时积累的一个体现,整天不学习没积累 Share 肯定是质量不高的。不过自己在 Share 做的最基本的一点一定是坚持原创的,无论好坏一定是自己想到的,也算是对自己的一个鞭策,虽然现在写的确实一般般,但希望自己坚持积累、不断输出,努力提高自己的输出质量。
以上就是自己写 ARTS 时一些做法,总体而言最大的变化就是化整为零,各个击破,这样虽然开始的时候会降低自己 ARTS 的速度,但随着积累的增加,各个部分一个个的完成,后期 ARTS 的速度是会提高很多。