做了 21. Merge Two Sorted Lists,合并两个有序链表,并且合并完成后链表也是有序的。
基本思路就是遍历两个链表,优先遍历较小的值,实现代码如下:
class Solution {
public ListNode mergeTwoLists(ListNode l1, ListNode l2) {
if (l1 == null && l2 == null) {
return null;
}
if (l1 == null) {
return l2;
}
if (l2 == null) {
return l1;
}
ListNode node = null;
if (l2.val < l1.val) {
node = new ListNode(l2.val);
l2 = l2.next;
}else {
node = new ListNode(l1.val);
l1 = l1.next;
}
ListNode tail = node;
while (l1 != null && l2 != null) {
if (l1.val >= l2.val) {
tail.next = new ListNode(l2.val);
tail = tail.next;
l2 = l2.next;
}else {
tail.next = new ListNode(l1.val);
tail = tail.next;
l1 = l1.next;
}
}
if (l1 == null) {
tail.next = l2;
}else {
tail.next = l1;
}
return node;
}
}最终耗时取决于较短的链表长度,时间复杂度为 O(N)。
另外还做了 24. Swap Nodes in Pairs,交换链表中相邻节点的值,就是每两个节点为一组进行值的交换,实现原理比较简单,就是每两个节点进行一次遍历, 遍历的时候记录下当前节点对的尾节点和下一个要交换的节点对的头节点,然后迭代交换即可。思路简单,但是实现起来很容易出错,主要是节点指针之间的交换比较容易出错,这个时候一定要画图,将一组节点交换过程中指针的指向变化花出来,实现代码如下,一次成功,时间复杂度为 O(N),实际运行 2ms,better than 99%。
class Solution {
public ListNode swapPairs(ListNode head) {
if (head == null || head.next == null) {
return head;
}
ListNode preNode = head;
ListNode next = head.next;
ListNode nextHead = next.next;
preNode.next = nextHead;
next.next = preNode;
ListNode result = next;
while (nextHead != null && nextHead.next != null) {
ListNode tmpNode = nextHead.next;
preNode.next = tmpNode;
nextHead.next = tmpNode.next;
tmpNode.next = nextHead;
preNode = nextHead;
nextHead = nextHead.next;
}
return result;
}
}继续阅读 Nignx 微服务系列文章,本次是第四篇 Service Discovery in a Microservices Architecture,讲的是微服务架构中的服务发现。
对于传统的单体服务,客户端一般会有一个配置文件来记录服务的地址,每当发请求时直接访问即可,但是在微服务架构中,服务众多并且是可自动伸缩的,这意味的服务的 IP 地址可能会经常发生变化,此时通过 IP 地址进行访问就会很容易出错,如下图所示:
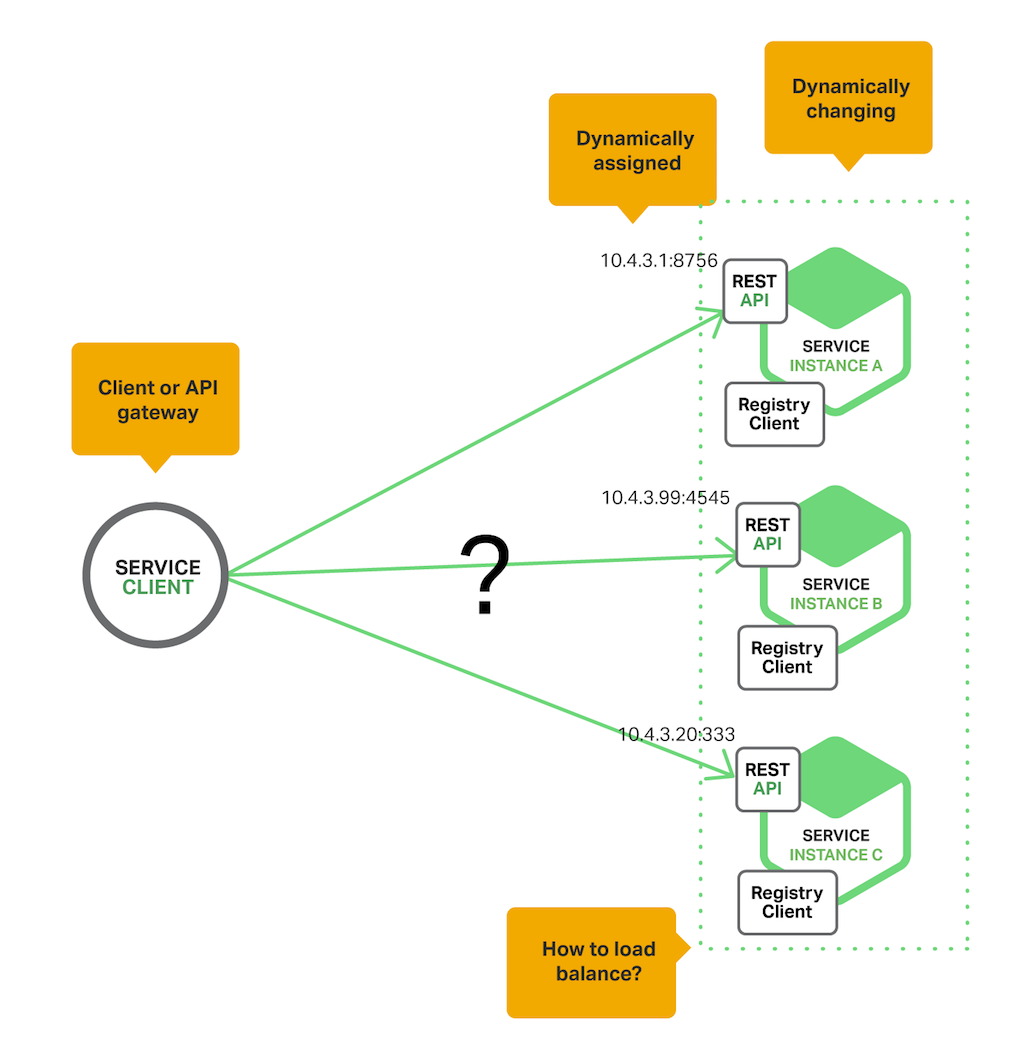
因此为了保证服务访问的正确性,我们需要服务发现机制,服务发现有两种实现方式:
首先我们需要一个服务注册中心,即一个存储所有可用服务实例信息的数据库,当客户端需要向某个服务发送请求时,首先向注册中心发起请求,获取到可用的实例的网络地址,然后通过负载均衡算法选择其中一个然后向对应的服务发起请求,过程如图所示:
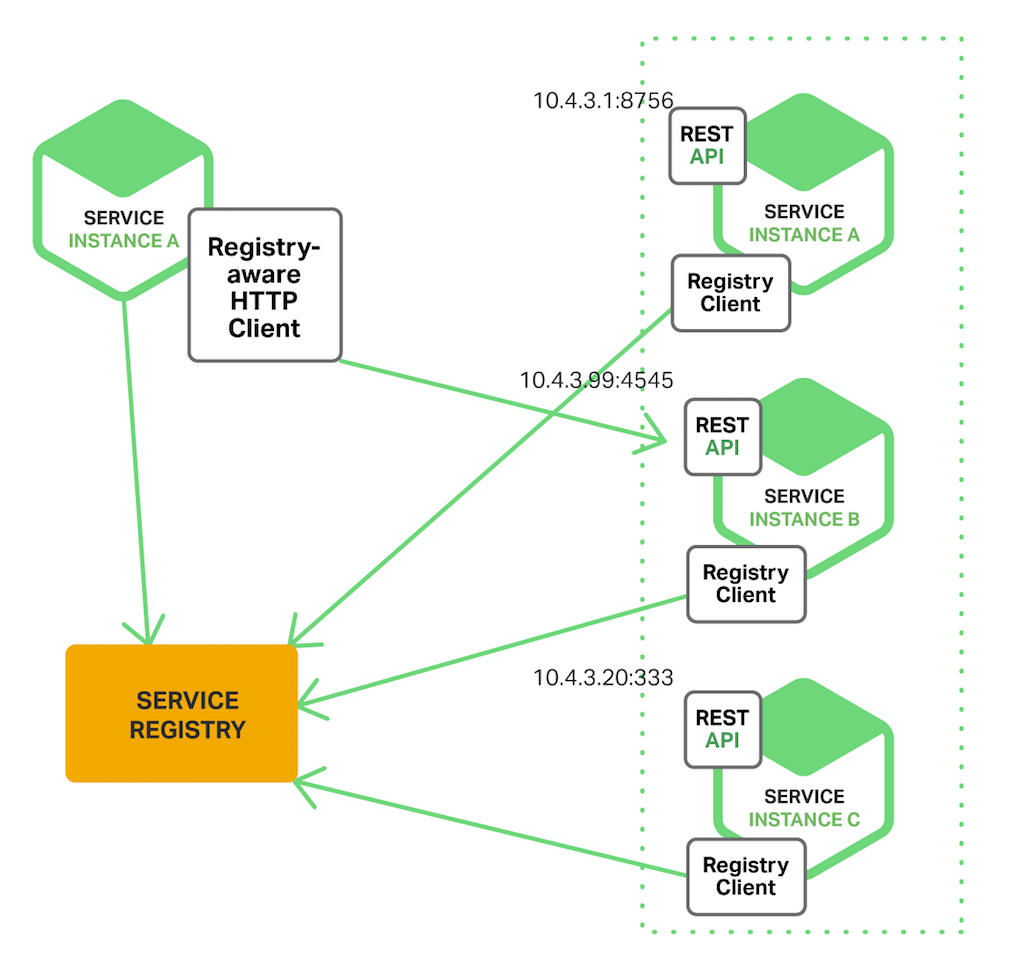
文章中推荐了 Netflix 提供的 Netflix Eureka 和 Netflix Ribbon 两个开源组件,前者是一个服务注册中心,后者是一个实现 IPC 通信的框架,并内置了负载均衡算法,有兴趣的同学可以深入研究学习下。
关于客户端发现有如下好处:
- 比较简单明了,除了注册中心需要单独处理外,不需要再做更多的操作
- 客户端可以自行选择负载均衡算法,比如哈希一致算法,来决定服务请求的路由
任何一种技术都是有利有弊的,客户端服务发现也会有如下弊端:
- 客户端与服务中心有耦合
- 因为访问某个服务的客户端可能有很多种,并且实现语言可能也会有所不同,因此我们可能需要为每种语言、框架实现服务发现逻辑,增加的工作量并且降低了代码的可维护性。
采用服务端发现,客户端不关心具体访问哪个实例,只管向负载均衡节点(或者网关)发送请求即可,load balancer 查询注册中心然后确定向哪个服务实例发送请求,架构图如下:
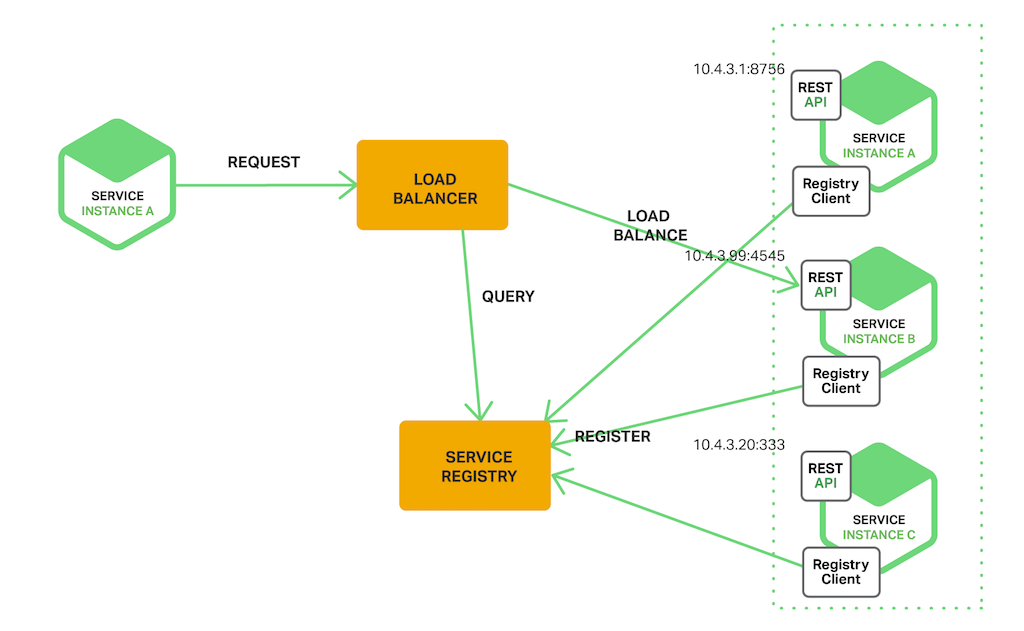
文章列举了 AWS ELB 的例子,ELB 通常用来面向外网做负载均衡,当然在内网中也可以使用,使用 ELB 作为负载均衡,任何服务可以通过域名直接访问 ELB,ELB 也作为注册中心存储了所有的服务实例,然后 ELB 选择合适的 EC2 实例或者 ECS 服务进行请求的转发,从而完成服务端的服务发现。当然,文章还是推荐了 Nginx 自家的 Nginx Plus 和 Nginx。
对于像 K8S 或者 Marathon 的部署环境,一般来说在集群的节点中会自带一个 proxy,这个 proxy 就可以作为负载均衡器使用,客户端通过 IP 向 proxy 发送请求,然后 proxy 负载向请求的转发。
服务端发现有如下优势:
- 实现了客户端与服务发现的解耦,客户端只需要直接向负载均衡器发送请求即可,不需要关心其他的事情,也节省了需要为多种语言编写服务发现逻辑的工作
当然服务端发现也有其缺点:
- 负载均衡器是一个需要高可用、高性能的组件,需要耗费人力为维护管理。
上面提到了服务发现需要查询注册中心,服务注册中心是微服务中一个非常重要的组件,其本质是一个数据库,存储了所有服务的实例地址以及相关信息。注册中心必须保证高可用和数据的有效性,一般来说注册中心由一组服务器组成,其通过复制的方式保持数据的一致性。
文章推荐了 Netflix Eureka ,该组件可以用来做注册中心,其提供了基于 REST 协议的 API,我们可能通过 POST、DELETE、PUT、GET 的 http 请求进行服务信息的增删改查。其采用集群的方式保证服务的可用性,除此之外还可以用如下组件实现注册中心:
注册中心的实现一般来说有两种机制:
服务的注册和接触注册由服务本身负责,进一步,如果可以的服务还需要发送心跳请求防止注册过期,架构如图所示:
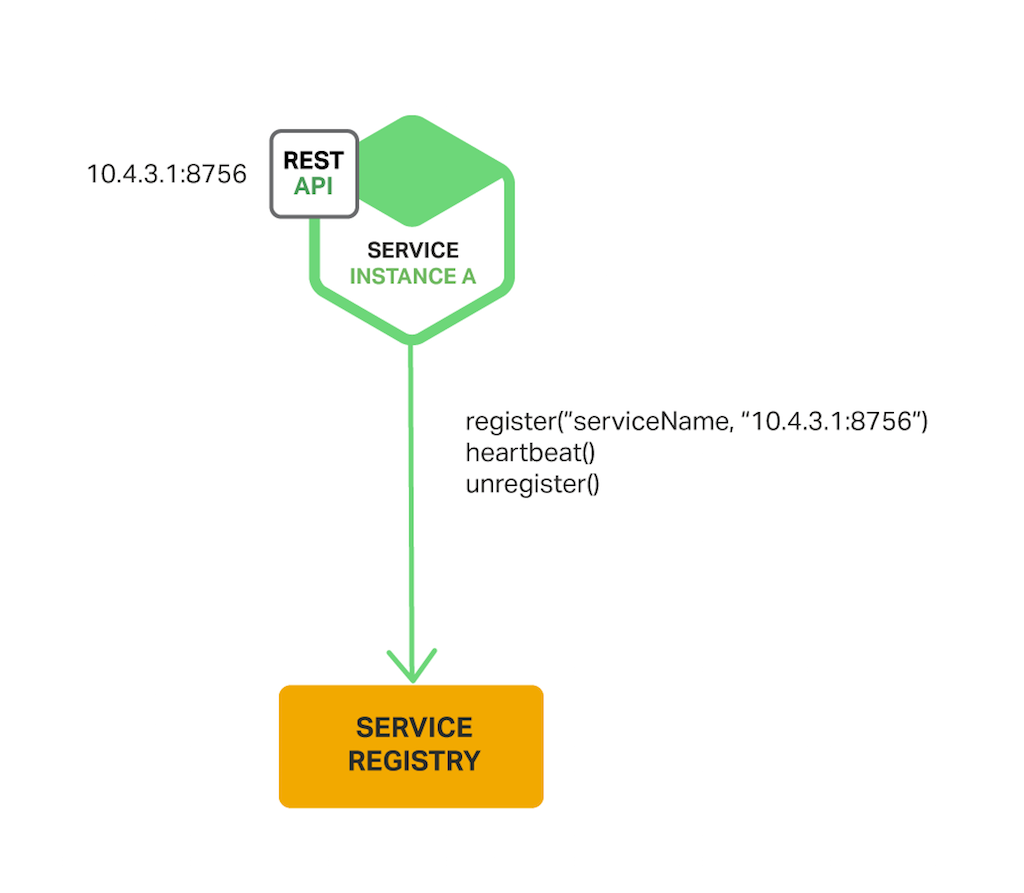
优点
- 不需要维护额外的组件
缺点
- 每个服务都要实现,如果服务之间实现的语言不通,那么就需要为多种语言编写相应的注册服务
第三方注册服务通过轮询或者订阅时间的形式来跟踪服务实例的状态,当发现有新的服务或者服务不可用后就向注册中心发请求进行服务的注册或者解注册,架构如下:
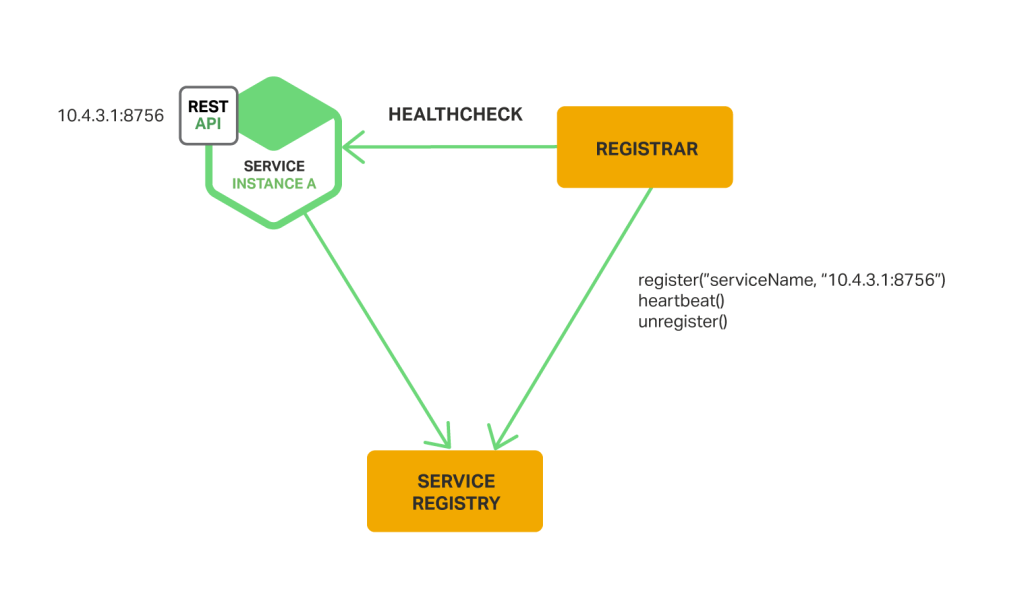
优点
- 服务与服务注册解耦,不需要再为每种语言实现单独的注册服务
缺点
- 服务注册服务是另一个需要维护的高可用组件
简单介绍了服务发现的两种方式和服务注册的两种方式,总的来说讲的比较浅显,只是简单介绍了大概的实现方式,没有进行更深一步的探索,如果想要深入学习还是得下功夫去学习别的资料和实战。极客时间上有好几门微服务相关的课程,看了几节讲的非常不错,有兴趣的同学可以学习交流。
读了一篇 Linux 使用技巧相关的文章: 20 Linux Command Tips and Tricks That Will Save You A Lot of Time,分享下其中几个 Linux 命令行的使用技巧吧。
当我们需要输入命令或者选择文件时,可以通过 Tab 键进行自动提示与完成,比如我要拷贝一个文件,输入 my 后直接按 tab 就可以显示所有匹配到的文件:

比较传统的命令是:
cd ~
但其实直接输入 cd 就可以了.
cd
传统方式是
ls -l
快速方式:
ll
使用 ; 隔开
同时执行多个命令
command_1; command_2; command_3
使用 && 隔开
同时执行多个命令,但是只有在前一个命令执行成功后才会执行后面的。
command_1 && command_2
可以通过先按 crtl + r 然后在输入匹配模式的形式查找使用过的命令, 如下图所示,我先按 crtl + r 然后输入 abc 后其提示的命令:

crtl + A : 移动到命令头
crtl + E : 移动到命令尾部

可以通过如下命令实时监控日志:
tail -f path_to_Log
另外还可以通过 grep 进行过滤监控:
tail -f path_to_log | grep search_term
一般我们都是解压缩后在查看文件的,但是我们可以通过如下命令不需要解压缩即可查看:
- zcat
- zgrep
- zless、zmore
- zdiff
分享下读《黑客与画家》第六章《如何创造财富》时的一些简记:
何为工作
工作是做出人们需要的东西、创造财富的一种途径,而上班是你和其他人日复一日的走近某栋建筑里面,去做你平时没兴趣做的事情。既然是为了创造财富,做出人们需要的东西,无论是否在某家公司内就显得不那么重要了。你可以自己创业,也可以在某家公司与他人一起,创造出别人需要的有价值的东西。从这个角度来看,工作或者上班,就变成了一件非常值得追求的事情,我们要非常努力的去工作,做出有价值的东西。如果一个成年人能将他的工作视为一件有意义的事情,那将是一件非常幸福的事情。所以,希望我们每天都是去工作,而不是上班。
财富与金钱
财富是我们所拥有的一切东西,我们拥有的亲情、友情、爱情、健康,我们的阅历、知识、喜怒哀乐都是财富,而金钱是财务最直观的一种表现方式以及达成物质交换的媒介。金钱是流动的财富,我们赚的金钱,然后用金钱去换取我们需要的东西。所以金钱其实是我们获取的想要的财富的一种工具,而不是最终的目的。
可测量性
对于我们工作产生的价值,可测量性是一个非常重要的标准。对于像销售这种按销售额发报酬的,其可测量性相对较高。而对于在大公司中人,其个人的可测量性非常低,取而代之的是团队的可测量性,也就是说其工作的价值被团队给平均了,这样对那些工作效率非常之高的人其实是不公平的,因而作者建议这些人去更小的团队工作,这样可以使得自己的贡献能够比较真实的测量出来。