做了229. Majority Element II,要求查出数组中出现次数超过其长度 1/3 的所有元素。
首先想到的思路是计算每个元素出现的次数,然后返回出现次数超过 n/3 的元素,实现代码如下:
public class Solution{
Set<Integer> integers = new HashSet<>();
public List<Integer> majorityElement(int[] nums) {
HashMap<Integer, Integer> map = new HashMap<>();
int length = nums.length;
for (int i = 0; i < length; i ++) {
int times = map.getOrDefault(nums[i], 0) + 1;
if (times > length/3 ) {
integers.add(nums[i]);
}
map.put(nums[i], times);
}
List<Integer> result = new ArrayList<>();
result.addAll(integers);
return result;
}
}虽然可以实现题目的要求,但是效率较低,中间有频繁的 Map 和 Set 的读写,最后还要新建一个 List 返回,虽然时间复杂度为 O(N),但隐藏系数其实是比较大的,另外也违背了原题要求的 O(1) 的空间复杂度。
改进方案是看的已有提交中效率较高的一个的实现,思路是: 我们要找的是出现次数超过 n/3 的元素,那么最多不会超过 2 个。因此我们可以先超出出现次数最多的两个元素,然后在计算这两个元素出现的次数,如果超过 n/3 则加入结果列表中。虽然需要遍历两次数组,但中间只涉及数据的比较,省去了之前方案中频繁的集合读写操作,效率提升很大, 从原来的 10ms 提升到了 2ms。实现代码如下:
public List<Integer> majorityElement(int[] nums) {
int num1 = 0;
int num2 = 0;
int count1 = 0;
int count2 = 0;
for (int num :
nums) {
if (num == num1){
count1 ++;
}else if (num == num2) {
count2 ++;
}else if (count1 == 0) {
num1 = num;
count1 ++;
}else if (count2 == 0) {
num2 = num;
count2 ++;
}else {
count1 --;
count2 --;
}
}
count1 = 0;
count2 = 0;
for (int num :
nums) {
if (num == num1) {
count1 ++;
}else if (num == num2) {
count2 ++;
}
}
int length = nums.length / 3;
List<Integer> result = new ArrayList<>();
if (count1 > length) {
result.add(num1);
}
if (count2 > length) {
result.add(num2);
}
return result;
}题目本身不难,但是还是需要提高解题时思路的开阔性,第一时间想当然的想到计算每个元素的出现次数,而忽略了 n/3 这个条件带来的隐藏条件,导致没有找到更好的方案。日常工作中也会遇到很多时间因为思维不够开阔从而没有想到更好的方案的情况,还是要多实践、多涉猎、多交流才行啊。
本次 Review Nginx 微服务系列文章第三篇 Building Microservices: Inter-Process Communication in a Microservices Architecture。
本篇主要讲解了微服务之间的通信机制,不同于单体引用中语言级别的方法、函数调用,微服务拆分后其通信方式全部变为了远程调用,如下图所示:
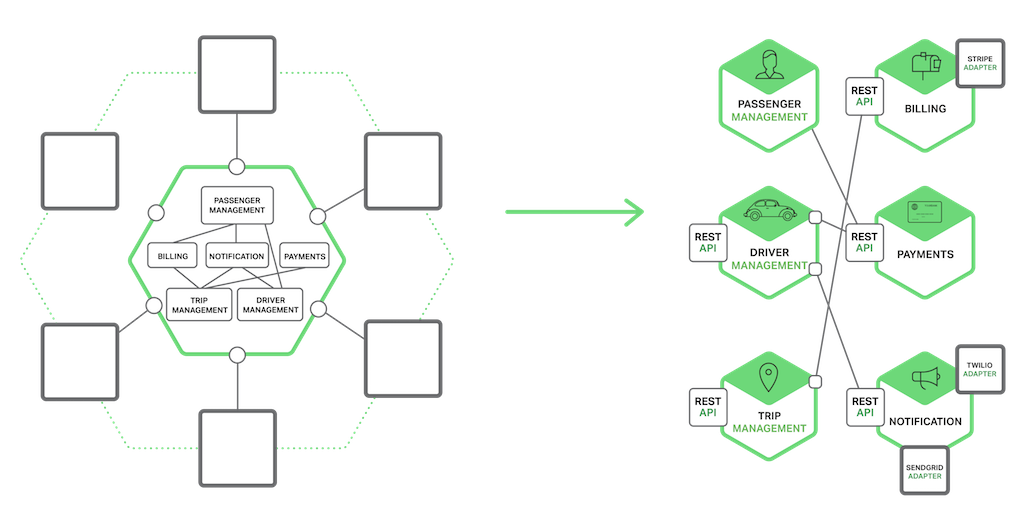
文章中提到,客户端到服务端之间的通信方式可以从两个维度进行划分:
节点关系
- One-to-One: 客户端请求发送给固定的服务器
- One-to-Many: 一个请求可能被多台服务器接收
是否异步
- 同步: 客户端要求服务端实时返回响应,在等待过程中可能会加锁
- 异步: 无需实时响应,等待过程中不加锁
基于以上分类,可以引出如下几种通信方式:
One-to-One
- 请求响应
- 消息机制: 单边发送,服务端无需返回
- 请求/异步响应
One-to-Many
- Pub/Sub 机制
- Pub/异步响应
一般来说,微服务之间的通信是上述其中 1 种或者多种通讯方式的组合,如图所示:

可以看到 passenger 服务使用 消息机制向 trip 服务发送消息,trip 接收消息后通过 实时请求的方式获取乘客信息,然后通过 pub 机制向 dispatcher 发布消息,其他微服务之间的也有采用消息、PUB/SUB 的通讯方式。
以上是关于通讯方式的一个简介。
API 定义
API 是服务之间交互的协议,无论使用何种通讯方式,我们都需要定义客户端和服务端都能够承认的、规范的 API,关于 API 的实现可以参考这篇文章:How To Design Great APIs With API-First Design 。在着手进行实际开发之前,定义好比较完备的 API 是一件非常值得做的事情,制定 API 的过程也是深入对业务和项目进行思考的过程,当 API 定义完成后,接下来就是实现的事情了。
不过不同的 IPC 通信方式也会对 API 的定义产生影响,比如如果是 HTTP 请求通信,那么 API 中必须定义请求 URL、request 参数和 response 内容;如果是消息机制,则可能需要定义好消息通道和消息类型。
API 的修改迭代
需求是不断变化的,因此已经定义好的 API 也有可能发生变化。对于单体应用,修改已有的 API 是一件相对比较容易的事情,但对于微服务就会显得比较麻烦,因为某个服务的 API 可能被多个其他服务使用,一旦 API 升级,就可能导致其他服务不可用,而我们又可能无法保证其他的所有服务都能够及时的升级适配,这样一来就可能出现因为 API 重构导致服务不可用的问题。
对于该问题的处理取决于修改的粒度,有些比较简单的修改可以不影响其他服务的调用,比如在 request 或者 response 中添加参数,只要保证未传的参数有默认值,这些客户端即使不作处理也不会对 API 的使用有任何影响。但如果改动较大,比如修改了整个 response 响应结构或者添加了一些必传参数,那么此时就要求客户端进行修改,但是此时依然要对旧版本进行兼容,一般来说此时有两种做法:
- URL 中加入版本号,这样就可以区分不同的 API 版本,从而兼容旧版本的客户端调用。自己在工作中也经常用到这种方式,一般来说我们加入公司时并不都是从 0 开发,都是接手别人的工作内容,此时如果需要修改一个接口而又不知道会有哪些影响面时,添加一个新的并加入版本号标识是一个比较可取的做法。
- 为不同版本的 API 布置不同的服务器实例,然后基于网关进行调度,将不同版本的 API 调用路由到指定的服务器。
错误处理
在网关中也提到过,在分布式系统中,故障发生的概率是很高的,在微服务架构中,如果某个服务发生故障,而请求它的客户端又没有做错误处理的话,可能会出现多米诺骨牌效应,使得一个服务搞垮整个服务集群。因此我们必须要做错误处理,下面是 Netfix 公司提出的针对错误处理的一些策略:
- 请求超时: 所有请求必须设置超时时间。
- 限流操作: 对各个服务监控,当某个服务的请求次数超过某一阈值时,则应对其限流,对于超过的请求不走逻辑,直接返回
- 熔断机制: 追踪各个服务的请求情况,如果错误的请求超过某一阈值,表示该服务不可用,此时采用熔断器进行熔断,告知客户端服务不可用,当然客户端后续应该再次访问,如果成功表示服务可用,此时要关闭熔断器。
- 提供失败时的返回: 如果请求失败,可以考虑返回缓存或者某些默认值。
文章还是推荐了 Netflix Hystrix ,这是 Netfix 开发的 Java 平台上一个非常强大的网关,提供了上面提到的众多功能,有兴趣的同学可以尝试学习下,另外关于服务限领、熔断等在耗子叔专栏分布式系统设计系列文章里面也有提到,可以继续深入的钻研学习、
实现异步通信一般都是通过消息传递的机制实现,客户端向一个或者多个服务端发送消息,消息的传递可以是直接点对点的传递,也可以通过 channel 进行传递,这样客户端不需要等待请求的返回,减低了服务间的依赖,同时也能提高性能。
消息传递机制
- point-to-point: 客户端发送一个消息,只有一个 consumer 读取消息并处理,从而可以实现点到点的信息传递
- Pub/Sub: 通过消息订阅机制,一个客户端生成的消息可以被多个 consumer 接收并处理,从而实现 one-to-many 的通信。
异步通信的消息传递示例如图:
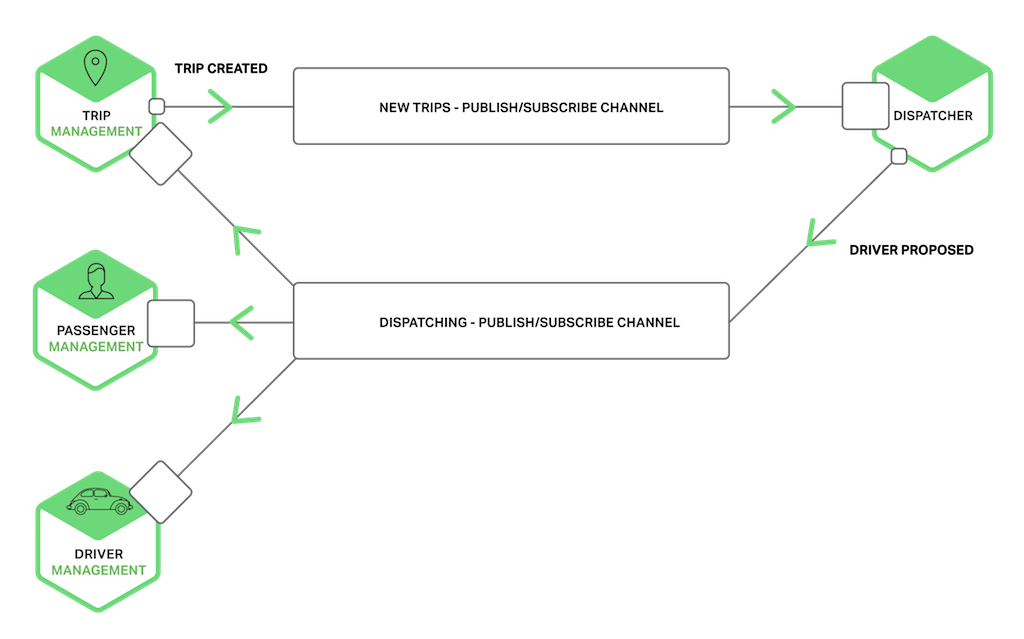
对于消息机制具体的实现就是消息队列了,比如 RabbitMQ/Apache Kafka/Apache ActiveMQ 等非常流行的消息队列。
使用消息机制的优势
- 实现了客户端与服务端的解耦,同时客户端也不需要在关心服务发现的问题,只管发送消息即可
- 消息缓存,可以根据服务端的处理能力进行消息的发送,当服务端负载过大时可以暂时将消息缓存,实现了削峰的功能
- 一种显式的进程通信,避免了 RPC 机制带来的不确定性
使用消息机制的缺点
- 增加了系统复杂度,消息队列作为一个对可用性、性能有较高要求的组件,需要人力进行维护和优化
- 对于基于请求响应进行通信的服务,增加了处理的复杂度,每个请求必须要要有一个唯一的请求标识以及响应标识,服务端在响应时需要将响应标识加到 response 的内容中,客户端基于该标识来进行正确的对应,如果是直接的 HTTP 通信则不会有该问题
对于同步的请求响应,客户端要求服务端必须立即返回响应内容,有两种流行的协议来实现:
- REST
- Apache Thrift
REST 协议是现在最流行的 API 设计规范了,关于 REST 的使用可以参考阮一峰老师的几篇文章:RESTful API 最佳实践、理解 RESTful 架构、RESTful API 设计指南。
Thrift 是一个跨平台的、可以定义客户端与服务端远程通信机制的框架,因为自己对这个也不熟所以这里不作深入探讨了,以后有机会拿出专门时间来进行学习。
对于消息可以有两种格式:
- Text 文本类型
- Binary 二进制类型
文本类型有两种常见格式:
- JSON
- XML
对于文本类型的消息,其最大的优势是其可读性和自描述的,可以直观的反映其数据结构和含义,缺点是很容易变得臃肿,尤其是 XML,整个文件结构会显得有点啰嗦,另外一个就是对于文本类型的编码解码会消耗较多的资源。
对于二进制格式的消息也有很多可以选择:
- binary Thrift: 使用 Thrift 协议时的二进制序列化数据格式
- protocol buffers: 一种与语言无关,平台无关,可扩展的序列化结构化数据的方法,用于通信协议,数据存储 等功能
- Apache Avro: 一种数据序列化系统
因为没用过 Thrift 和二进制类型的消息通信,因此对上面的内容也不是很熟悉,这里先混个脸熟,等以后用到的时候在做深入的研究吧。
文章对微服务间的消息通信做了一个比较浅显的讲解,主要有两种通信机制: 同步请求和异步通信。异步通信采用消息机制,同步通信使用 HTTP 请求,我们需要考虑服务之间的交互方式、API 的定义和改进以及错误处理来确定通信方式和数据的传输格式,关于数据格式既可以采用文本类型的 XML 或者 JSON,也可以是二进制类型,这些都需要根据实际情况进行深入的调研和思考后进行决定。
最近用 Python 操作 Redis 时遇到个小坑,在存储字符串时,Redis 是会进行编码的,而读取值的时候不会进行解码,因为对于字符串类型的值,在存储时会转成字节串存,而读出来的值依然是字节串,如果不进行手动转码会遇到问题,示例如下:
# 创建一个字符串
In [33]: s = u"123"
In [34]: type(s)
Out[34]: unicode
# 存储
In [35]: cache.client.set(s, s)
Out[35]: True
# 取出来的值是字节串,和原来相比多了两个双引号
# 如果是 web 接口请求,直接返回的话客户端展示的文本是 "123" 而不是 123
In [36]: value = cache.client.get(s)
In [37]: value
Out[37]: '"123"'
In [38]: type(value)
Out[38]: str
# 手动进行一次解码
In [39]: value = cache.client.decode(value)
In [40]: value
Out[40]: u'123'
In [41]: type(value)
Out[41]: unicode
最近阅读学习量较少,没有让自己满意的 share,分享点之前存货吧。之前学习 Scrapy 框架写爬虫记得笔记,希望对需要的同学有帮助。