一般来说,产品做出的原型多多少少会带有“个人”倾向,UI设计的交互也会人所不同,而当公司生存下来了后,数据沉淀达到一定量了后,这种迭代就决不能拍脑袋了,因为人是具有偏见的,如果带有“偏见”的产品上线后,其反响是不能预估的,我们不能将公司的生存放在“可能”这种说法上。
小步快跑,通过迭代来优化产品,但如果每个迭代都颠覆了之前的设计,那就是原地踏步,每一次迭代都要知道这个迭代哪里出了问题,然后再针对问题做优化,而不是频繁的改版,持续优化,这个就必须建立在比较良好的数据监控与数据分析上,人有偏见但是数据不会,。
所以大公司的核心产品,每一个决策,每一个迭代都需要分析各种数据,建立完善的AB Testing与小流量机制,待收到了充分的信息证明这次迭代是有效的后再做真正的全量更新。
数据中往往会有我们需要的答案,比如前段时间,我们发现我们的订单转化率比较低,那么我们盯着转换率本身是没有意义的,我们可以考虑影响几个数据的其他指标:
① 页面PV,一般来说增大PV能有效增加转化率
② 按钮点击的前提,比如需要登录后才能下单,和匿名下单的转化率对比
③ 优惠券使用情况(据说,中国没有5元买不到的用户)
④ ......
我们不同的渠道,很有可能产生这不同的场景,不同的场景下获得的数据,便能知道哪种是我们真实需要的,如此一来研发才能真正帮助公司做出正确的判断,为后续迭代提供参考。
系列文章:
【数据可视化之数据定义】如何设计一个前端监控系统 描述如何获取各种指标数据,如何归类,首篇博客补足
【数据可视化之持久化】如何设计一个前端监控系统 描述如何做存储(涉及大数据部分由其他同事整理)
【数据可视化之图表呈现(dashboard)】如何设计一个前端监控系统 描述如何将数据变为有效的展示
代码地址:https://github.com/yexiaochai/medlog
如果文中有误的地方请您指出。
统计属于海量数据的范畴,产品分析做的越细,所产生的数据量越大,比如我要做一个用户点击热点的话,就需要收集用户所有的点击数据,这个可能是pv的数十倍;另一方面,海量统计应该是脱离业务本身的,用户可定制化打点需求,以满足不同业务的变化。
了解了基本概念,我们便可以确定我们到底需要什么数据,这个拍脑袋想不出来,就可以先进行基础穷举:
① pv&uv
② 页面点击(pv&uv)
③ 页面来源(web处理这个有些困难),定义页面从哪里来,在海量数据的情况下也可以不记录
④ 页面停留时间(web不一定准确)
⑤ 前端错误日志(这个比较庞大,后面详述)
⑥ 首屏载入速度
⑦ 用户环境收集(一般来说这个是附带的)
⑧ 跨域资源监测(监测所有非白名单脚本,发现脚本注入行为,附件特性)
而因为现在一套H5代码会用于不同的平台入口,所以这些数据又会额外具有“渠道信息”的标志。
再我们有了以上数据的情况下,我们能很轻易的得出某个渠道的转化率:
因为不同渠道表现也许会有所不同,有可能微信渠道的入口在首页,他的转化率计算一般会经过这么一个过程:
首页pv -> 列表页pv -> 订单填写页pv -> 下单按钮点击pv -> server最终成单数
而搜索引擎入口,可能直接就到了订单填写页,所以转化率计算公式又变成了:
订单填写页pv -> 下单按钮点击pv -> server最终成单数
这里结合首屏载入速度与页面停留时间,辅以用户点击轨迹,就能从某些程度上,追踪分析一个用户的行为了。
曾今有一次我们发现我们订单转化率下降了50%,于是老板让我们马上给出原因,我们当时怀疑过BUG,怀疑过运营商接口有问题,但是我们所有的推论都没有很好的佐证,于是各种查询数据库,最后与整个打点的pv数据,我们便得出了一个结论:
因为,多数用户的优惠券过期了,所以转化率急剧下降!!!
为了证明这个猜想,我们由将某一个渠道的优惠券加上,第二天转化率就回归了,我们这里能判断出转化率下降的原因和我们平时完善的打点是息息相关的。
另一方面,当代码迭代到一定量的时候,code review也就只能解决很小一部分问题了,前端预警和前端错误日志产生的蛛丝马迹才会将一些隐藏的很深的BUG揪出来,所有的这一切都需要从数据采集开始。
我原来也遇到一个BUG,潜伏期很长,而且只有在特定的场景才会触发,这种BUG一般来说测试是无力的,当时我发现2个版本的日志有些奇怪的错误,再一步步抽丝剥茧,终于定位到了那个错误,当我们代码量大了后,合理的错误埋点+前端监控才能让系统变得更健康。
这里引用一张错误监控图(http://rapheal.sinaapp.com/2014/11/06/javascript-error-monitor/):

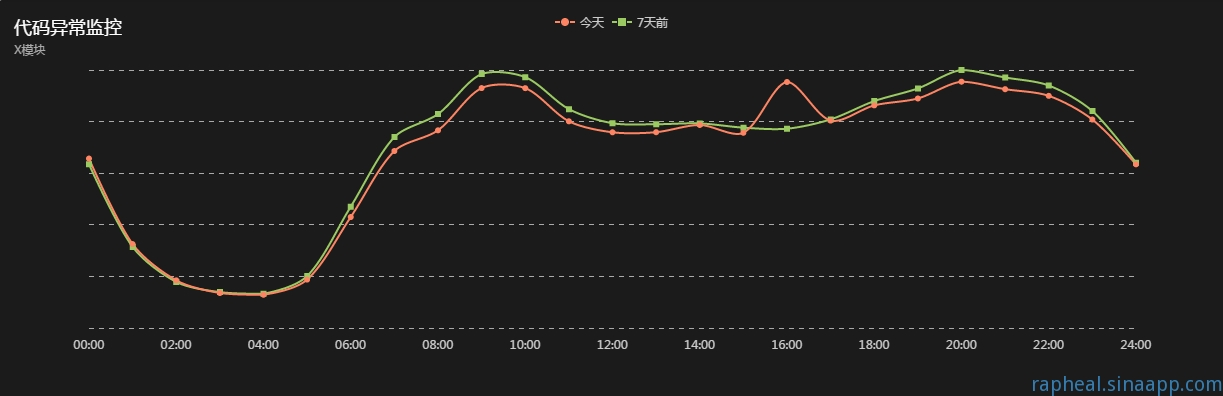
这里将上一周的错误数与本周做对比,如果没有大的迭代,稍微有异常就会产生报警,一般来说用户才是最好的测试,上线后没有报警就没有BUG。
PS:原来我们每次大版本发布,60%的几率要回滚......
前端错误捕捉,一般使用onerror,这个偶尔会被try cache影响:
1 window.onerror = function (msg, url, line, col, error) { 2 //...... 3 }
当时生产上的错误日志因为是压缩过的,真实抓到的错误信息十分难看:
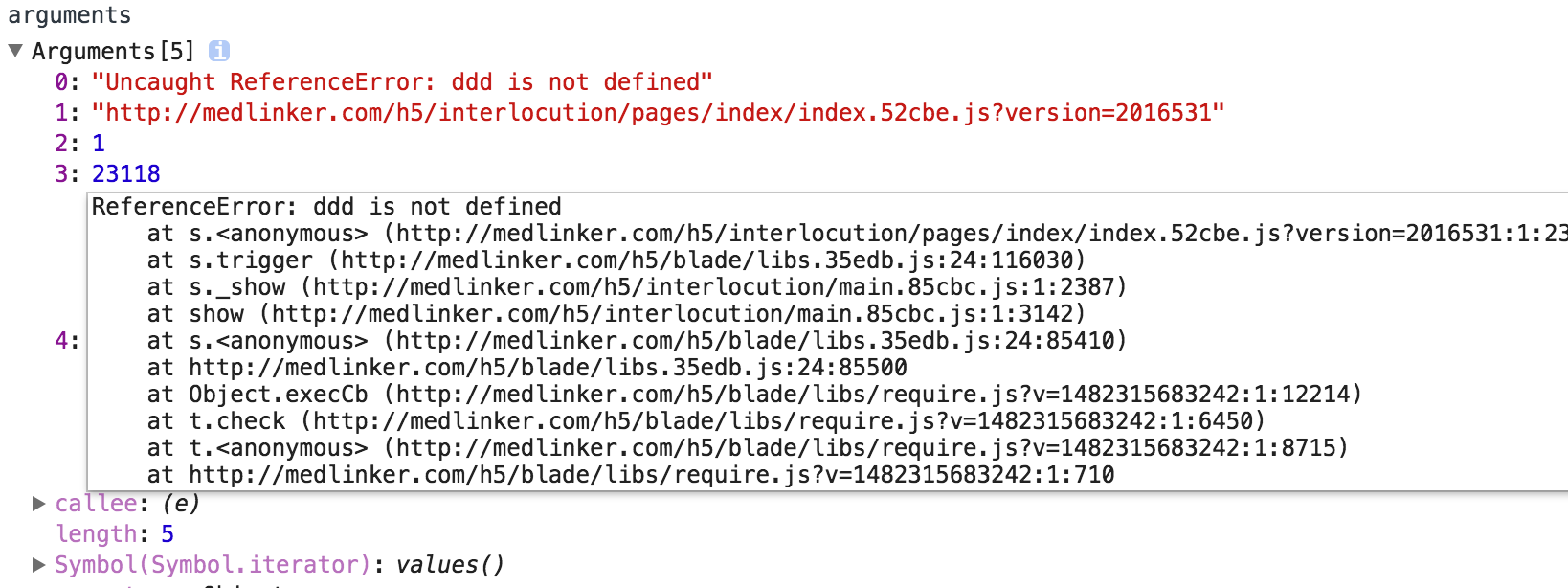
错误信息全部是第一行,报错的地方也是做过混淆的,如果不是页面划分的过开,这个错误会让人一头雾水,要想深入了解错误信息,这里便可以了解下source map了
简单来说,sourcemap是一个信息文件,里面存储着位置信息,也就是说,在js代码压缩混淆合并后的每个代码位置,对应的源码行列都是有标志的,有了这个source map,我们就能直接将源码对应的错误上报回去,大大降低我们的错误定位成本。
这里不同的业务使用的不同的构建工具,这里以grunt为例,grunt打包一般来说是使用的require,这里需要为其配置加入一段代码即可:
1 "generateSourceMaps": true, 2 "preserveLicenseComments": false, 3 "optimize": "uglify2",
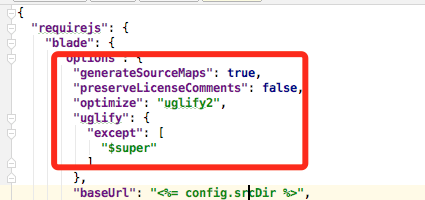
上面那个有一些问题,他将我的关键字过滤了,最后采用的这个:

然后就会生成你要的sourcemap了

可以看到压缩文件中,包含了map引用:

于是我们线上代码就会变成这个样子:
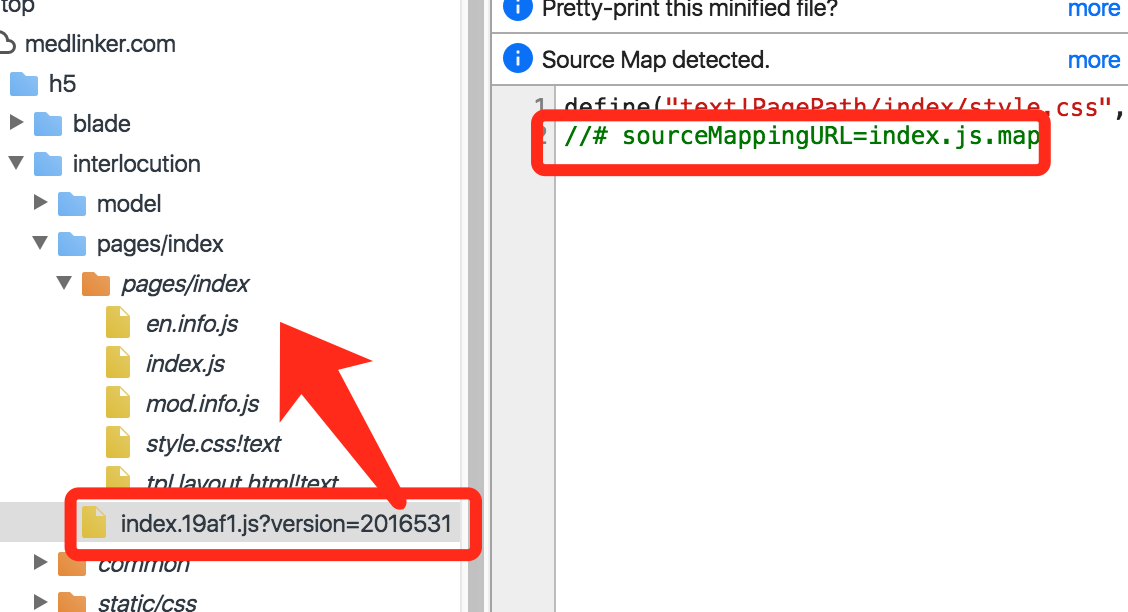
这个时候,我们故意写个错误的话,这里查看报错:

虽然看到的是源码,但是上报的数据似乎没有什么意义,这个时候可以借助一些第三方工具对日志做二次解析:
Sentry(GitHub - getsentry/sentry: Sentry is cross-platform crash reporting built with love)
并且,显然我们并不希望我们的源代码被人看到,所以我们将sourcemap文件存到线下,在线下将日志反应为我们看得懂的源码,这里简单看看这个文件定义:
1 - version:Source map的版本,目前为3。 2 - file:转换后的文件名。 3 - sourceRoot:转换前的文件所在的目录。如果与转换前的文件在同一目录,该项为空。 4 - sources:转换前的文件。该项是一个数组,表示可能存在多个文件合并。 5 - names:转换前的所有变量名和属性名。 6 - mappings:记录位置信息的字符串。
sourcemap的机制什么的,就不是我关注的重点,想了解的可以看阮老师的博客,我现在的需求是:
获取了列号和行,如何可以在线下映射成我们要的真实行号
比如我们拿到了上述的行号与列号为{1,13310},那么我们这里真实映射的是,合并文件中的某一行:
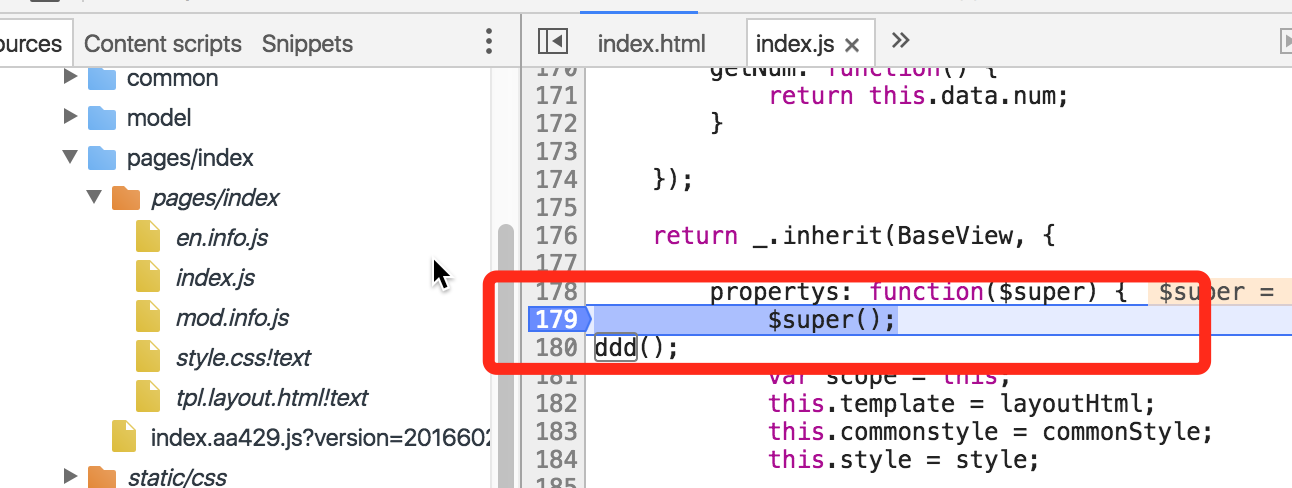
要完成这一切,我们需要一套“错误还原”的后台系统,这个直接坐到js监控其中一环就好,比如我们可以简单这样做:

这个被一国外网站实现了(一般来说要钱的......),所以是可以实现的,我们便去追寻他的实现即可。
后续在github找了一个库,完成了类似的功能,这里使用nodejs:
1 var mapData = require('./index.json'); 2 // console.log(sourceMap); 3 var sourceMap = require('source-map'); 4 var consumer = new sourceMap.SourceMapConsumer(mapData); 5 var numInfo = consumer.originalPositionFor({ line: 1, column: 13330 }) 6 console.log(numInfo)
输出==>
1 { source: 'pages/index/index.js', 2 line: 182, 3 column: 0, 4 name: 'layoutHtml' }
于是,我们已经找到了自己要的东西了。最初,在快速调研的时候,我们不要知道https://github.com/mozilla/source-map是干什么的,但是如果我们决定使用的话,就需要去仔细研究一番了。
总而言之,线上错误日志搜集的行号信息,在线下平台便能很好的翻译了,这里方案有了,我接下来马上想法落地,落地情况在存储篇反馈
错误日志这里,因为比较重要,也与普通的打点不一样,占的篇幅有点长,我们这里先继续往下说,等日志简单落地后再详述。
本来,我们数据采集可以使用百度或者友盟,但是总有那么一些东西得不到满足,而且也没有数据对外输出的API,而公司如果稳步上升的话,做这块是迟早的事情,所以宜早不宜迟吧,而我这里主要还是先关注的移动体系,所以不太会关注兼容性,这个可以少考虑一些东西,真的遇到一些情况如跨域什么的,我们后面再说吧。
关于存储一块有很多需要考虑,比如如何计算首屏加载时间,webapp和传统网易的异同,hybrid的差异,uv的计算方法等都需要考虑,但是我们今天变只将采集代码实现即可,剩下的下篇再处理。
简单来讲,日志采集,其实就是一个get请求,你就算想用ajax发出去也是没有问题的,为了加入额外信息可能我们会做一个收口:
1 ajax(url, { 2 s: '' 3 b: '' 4 c: '' 5 });
但是这个不是主流的做法,一般来说,我们打点信息使用的图片的方式发出,而因为重复的请求会被浏览器忽略,我们甚至会加入uniqueId做标志:
1 var log = function () { 2 var img = new Image(); 3 img.src = 'http://domain.com/bi/event?'+ uniqueId; 4 };
基本的采集实现就这么简单,但是后续逐步完善的功能,会增加复杂度,于是我建立了一个git仓库存储代码,后续大数据一块的代码也将放到这里:
https://github.com/yexiaochai/medlog
闭门造车的意义不大,翻看前辈的一些采集代码比如alog,会发现他打点的一块是这样做的:
1 /** 2 * 上报数据 3 * 4 * @param {string} url 目标链接 5 * @param {Object} data 上报数据 6 */ 7 function report(url, data) { 8 if (!url || !data) { 9 return; 10 } 11 // @see http://jsperf.com/new-image-vs-createelement-img 12 var image = doc.createElement('img'); 13 var items = []; 14 for (var key in data) { 15 if (data[key]) { 16 items.push(key + '=' + encodeURIComponent(data[key])); 17 } 18 } 19 var name = 'img_' + (+new Date()); 20 entry[name] = image; 21 image.onload = image.onerror = function () { 22 entry[name] = 23 image = 24 image.onload = 25 image.onerror = null; 26 delete entry[name]; 27 }; 28 image.src = url + (url.indexOf('?') < 0 ? '?' : '&') + items.join('&'); 29 }
其中有一块差异是绑定了onload等事件,应该是想释放资源吧?
这里的代码,想与公司业务管理起来,比如根据业务线或者项目生成某个规则的id,上报代码比较简单,但是每次都要带哪些信息,还没很好的思路,先在这里立一个flag吧,接下来时间里全力补足吧,毕竟这块东西很多。
前端数据有很多需要处理的地方,而数据的核心分为数据采集打点,数据持久化,数据使用,数据分析。
打点又会区分H5打点与native打点,native由于权限本身,能做的事情更多,但是底层数据收集基本能做到统一。
采集的代码是其中一部分,但采集的各项数据获取是另一个更重要的部分,会包含数据设计,各种细节处理,我们下篇文章接着研究,有兴趣的同学可关注。
代码地址:https://github.com/yexiaochai/medlog