') - return INDEX_HTML_TEMPLATE.format(items="\n".join(href_tags), comment=comment) - - -def generate_package_index( - wheel_files: list[WheelFileInfo], - wheel_base_dir: Path, - index_base_dir: Path, - comment: str = "", -) -> tuple[str, str]: - """Generate package index HTML and metadata JSON linking to wheel files.""" - href_tags = [] - metadata = [] - for file in sorted(wheel_files, key=lambda x: x.filename): - relative_path = wheel_base_dir.relative_to(index_base_dir, walk_up=True) / file.filename - # handle '+' in URL; avoid double-encoding '/' and '%2B' (AWS S3 behavior) - file_path_quoted = quote(relative_path.as_posix(), safe=":%/") - href_tags.append(f' {file.filename}
') - file_meta = asdict(file) - file_meta["path"] = file_path_quoted - metadata.append(file_meta) - index_str = INDEX_HTML_TEMPLATE.format(items="\n".join(href_tags), comment=comment) - metadata_str = json.dumps(metadata, indent=2) - return index_str, metadata_str - - -def generate_index( - whl_files: list[str], - wheel_base_dir: Path, - index_base_dir: Path, - comment: str = "", -): - """ - Generate PEP 503 index for all wheel files. - - Output structure: - index_base_dir/ - index.html # project list linking to vllm-omni/ - vllm-omni/ - index.html # package index linking to wheel files - metadata.json # machine-readable metadata - """ - parsed_files = [parse_from_filename(f) for f in whl_files] - - if not parsed_files: - print("No wheel files found, skipping index generation.") - return - - comment_str = f" ({comment})" if comment else "" - comment_tmpl = f"Generated on {datetime.now().isoformat()}{comment_str}" - - # Group by normalized package name - packages: dict[str, list[WheelFileInfo]] = {} - for file in parsed_files: - name = normalize_package_name(file.package_name) - packages.setdefault(name, []).append(file) - - print(f"Found packages: {list(packages.keys())}") - - # Generate per-package index - for package, files in packages.items(): - package_dir = index_base_dir / package - package_dir.mkdir(parents=True, exist_ok=True) - index_str, metadata_str = generate_package_index(files, wheel_base_dir, package_dir, comment) - with open(package_dir / "index.html", "w") as f: - f.write(index_str) - with open(package_dir / "metadata.json", "w") as f: - f.write(metadata_str) - - # Generate top-level project list - project_list_str = generate_project_list(sorted(packages.keys()), comment_tmpl) - with open(index_base_dir / "index.html", "w") as f: - f.write(project_list_str) - - -if __name__ == "__main__": - parser = argparse.ArgumentParser(description="Generate PEP 503 wheel index from S3 object listing.") - parser.add_argument("--version", type=str, required=True, help="Version string (e.g., commit hash)") - parser.add_argument("--current-objects", type=str, required=True, help="Path to JSON from S3 list-objects-v2") - parser.add_argument("--output-dir", type=str, required=True, help="Directory to write index files") - parser.add_argument("--wheel-dir", type=str, default=None, help="Wheel directory (defaults to --version)") - parser.add_argument("--comment", type=str, default="", help="Comment for generated HTML") - - args = parser.parse_args() - - version = args.version - if "\\" in version or "/" in version: - raise ValueError("Version string must not contain slashes or backslashes.") - - output_dir = Path(args.output_dir) - output_dir.mkdir(parents=True, exist_ok=True) - - with open(args.current_objects) as f: - current_objects: dict[str, list[dict[str, Any]]] = json.load(f) - - wheel_files = [ - item["Key"].split("/")[-1] for item in current_objects.get("Contents", []) if item["Key"].endswith(".whl") - ] - - print(f"Found {len(wheel_files)} wheel files for version {version}: {wheel_files}") - - # For release versions, filter to only matching non-dev wheels - PY_VERSION_RE = re.compile(r"^\d+\.\d+\.\d+([a-zA-Z0-9.+-]*)?$") - if PY_VERSION_RE.match(version): - wheel_files = [f for f in wheel_files if version in f and "dev" not in f] - print(f"Non-nightly version detected, wheel files used: {wheel_files}") - else: - print("Nightly version detected, keeping all wheel files.") - - wheel_dir = (args.wheel_dir or version).strip().rstrip("/") - wheel_base_dir = Path(output_dir).parent / wheel_dir - index_base_dir = Path(output_dir) - - generate_index( - whl_files=wheel_files, - wheel_base_dir=wheel_base_dir, - index_base_dir=index_base_dir, - comment=args.comment.strip(), - ) - print(f"Successfully generated index in {output_dir}") diff --git a/.buildkite/scripts/hardware_ci/run-amd-test.sh b/.buildkite/scripts/hardware_ci/run-amd-test.sh deleted file mode 100755 index 96c139c8f7b..00000000000 --- a/.buildkite/scripts/hardware_ci/run-amd-test.sh +++ /dev/null @@ -1,154 +0,0 @@ -#!/bin/bash -# vllm-omni customized version -# Based on: vllm/.buildkite/scripts/hardware_ci/run-amd-test.sh -# Last synced: 2025-12-15 -# Modifications: docker image name for vllm-omni - -# This script runs test inside the corresponding ROCm docker container. -set -o pipefail - -# Export Python path -export PYTHONPATH=".." - -# Print ROCm version -echo "--- ROCm info" -rocminfo - -# cleanup older docker images -cleanup_docker() { - # Get Docker's root directory - docker_root=$(docker info -f '{{.DockerRootDir}}') - if [ -z "$docker_root" ]; then - echo "Failed to determine Docker root directory." - exit 1 - fi - echo "Docker root directory: $docker_root" - # Check disk usage of the filesystem where Docker's root directory is located - disk_usage=$(df "$docker_root" | tail -1 | awk '{print $5}' | sed 's/%//') - # Define the threshold - threshold=70 - if [ "$disk_usage" -gt "$threshold" ]; then - echo "Disk usage is above $threshold%. Cleaning up Docker images and volumes..." - # Remove dangling images (those that are not tagged and not used by any container) - docker image prune -f - # Remove unused volumes / force the system prune for old images as well. - docker volume prune -f && docker system prune --force --filter "until=72h" --all - echo "Docker images and volumes cleanup completed." - else - echo "Disk usage is below $threshold%. No cleanup needed." - fi -} - -# Call the cleanup docker function -cleanup_docker - -echo "--- Pulling container" -## Temporary change to use AMD Docker Hub to store the vllm-omni image -# to bypass the rate limit issue with ECR Public Gallery. -# Images are now stored in a separate repository for vllm-omni, instead of vllm-ci. -# TODO: @tjtanaa point back to ECR Public Gallery -# once the amd agents are configured to use ECR Public Gallery. -# image_name="public.ecr.aws/q9t5s3a7/vllm-ci-test-repo:${BUILDKITE_COMMIT}-rocm-omni" -image_name="rocm/vllm-omni:${BUILDKITE_COMMIT}" -container_name="rocm_${BUILDKITE_COMMIT}_$(tr -dc A-Za-z0-9 < /dev/urandom | head -c 10; echo)" - -# TODO: @tjtanaa uncomment this once the amd agents are configured to use ECR Public Gallery. -# # Install AWS CLI to authenticate to ECR Public Gallery to get higher rate limit for pulling images -# sudo apt-get update && sudo apt-get install -y awscli -## Use safe docker login helper to prevent race conditions -# source "$(dirname "${BASH_SOURCE[0]}")/../docker_login_ecr_public.sh" -# safe_docker_login_ecr_public - -## Pull the container from AMD Docker Hub - -docker pull "${image_name}" - -remove_docker_container() { - docker rm -f "${container_name}" || docker image rm -f "${image_name}" || true -} -trap remove_docker_container EXIT - -echo "--- Running container" - -HF_CACHE="$(realpath ~)/huggingface" -mkdir -p "${HF_CACHE}" -HF_MOUNT="/root/.cache/huggingface" - -if [[ -n "${TEST_COMMAND:-}" ]]; then - commands="$TEST_COMMAND" -else - commands="$@" -fi -echo "Commands:$commands" - -PARALLEL_JOB_COUNT=8 -MYPYTHONPATH=".." - -# Test that we're launching on the machine that has -# proper access to GPUs -render_gid=$(getent group render | cut -d: -f3) -if [[ -z "$render_gid" ]]; then - echo "Error: 'render' group not found. This is required for GPU access." >&2 - exit 1 -fi - -# check if the command contains shard flag, we will run all shards in parallel because the host have 8 GPUs. -# TODO: @tjtanaa reenable to run VLLM_ROCM_USE_AITER=1 when AITER is shipped with prebuilt kernels. -if [[ $commands == *"--shard-id="* ]]; then - # assign job count as the number of shards used - commands=$(echo "$commands" | sed -E "s/--num-shards[[:blank:]]*=[[:blank:]]*[0-9]*/--num-shards=${PARALLEL_JOB_COUNT} /g" | sed 's/ \\ / /g') - for GPU in $(seq 0 $(($PARALLEL_JOB_COUNT-1))); do - # assign shard-id for each shard - commands_gpu=$(echo "$commands" | sed -E "s/--shard-id[[:blank:]]*=[[:blank:]]*[0-9]*/--shard-id=${GPU} /g" | sed 's/ \\ / /g') - echo "Shard ${GPU} commands:$commands_gpu" - echo "Render devices: $BUILDKITE_AGENT_META_DATA_RENDER_DEVICES" - docker run \ - --device /dev/kfd $BUILDKITE_AGENT_META_DATA_RENDER_DEVICES \ - --network=host \ - --shm-size=16gb \ - --group-add "$render_gid" \ - --rm \ - -e MIOPEN_DEBUG_CONV_DIRECT=0 \ - -e MIOPEN_DEBUG_CONV_GEMM=0 \ - -e VLLM_ROCM_USE_AITER=0 \ - -e HIP_VISIBLE_DEVICES="${GPU}" \ - -e HF_TOKEN \ - -v "${HF_CACHE}:${HF_MOUNT}" \ - -e "HF_HOME=${HF_MOUNT}" \ - -e "PYTHONPATH=${MYPYTHONPATH}" \ - --name "${container_name}_${GPU}" \ - "${image_name}" \ - /bin/bash -c "${commands_gpu}" \ - |& while read -r line; do echo ">>Shard $GPU: $line"; done & - PIDS+=($!) - done - #wait for all processes to finish and collect exit codes - for pid in "${PIDS[@]}"; do - wait "${pid}" - STATUS+=($?) - done - for st in "${STATUS[@]}"; do - if [[ ${st} -ne 0 ]]; then - echo "One of the processes failed with $st" - exit "${st}" - fi - done -else - echo "Render devices: $BUILDKITE_AGENT_META_DATA_RENDER_DEVICES" - docker run \ - --device /dev/kfd $BUILDKITE_AGENT_META_DATA_RENDER_DEVICES \ - --network=host \ - --shm-size=16gb \ - --group-add "$render_gid" \ - --rm \ - -e MIOPEN_DEBUG_CONV_DIRECT=0 \ - -e MIOPEN_DEBUG_CONV_GEMM=0 \ - -e VLLM_ROCM_USE_AITER=0 \ - -e HF_TOKEN \ - -v "${HF_CACHE}:${HF_MOUNT}" \ - -e "HF_HOME=${HF_MOUNT}" \ - -e "PYTHONPATH=${MYPYTHONPATH}" \ - --name "${container_name}" \ - "${image_name}" \ - /bin/bash -c "${commands}" -fi diff --git a/.buildkite/scripts/hardware_ci/run-xpu-test.sh b/.buildkite/scripts/hardware_ci/run-xpu-test.sh deleted file mode 100755 index e1d464ef0bc..00000000000 --- a/.buildkite/scripts/hardware_ci/run-xpu-test.sh +++ /dev/null @@ -1,56 +0,0 @@ -#!/bin/bash - -# This script build the XPU docker image and run the offline inference inside the container. -set -ex - -omni_source_dir=$(git rev-parse --show-toplevel) - -base_image_name="xpu/vllm-omni-ci-base:${VLLM_VERSION:?VLLM_VERSION must be set}" -image_name="xpu/vllm-omni-ci:${BUILDKITE_COMMIT:?BUILDKITE_COMMIT must be set}" -container_name="xpu_${BUILDKITE_COMMIT}_$( - tr -dc A-Za-z0-9 =6.0 pytest-cov modelscope - -COPY . . - -# Install vllm-omni -WORKDIR /workspace -ARG VLLM_OMNI_REPO=https://github.com/vllm-project/vllm-omni.git -ARG VLLM_OMNI_TAG=main -ARG BUILDKITE_PULL_REQUEST -ARG BUILDKITE_PULL_REQUEST_REPO -RUN git config --global url."https://gh-proxy.test.osinfra.cn/https://github.com/".insteadOf "https://github.com/" && \ - if [ "\$BUILDKITE_PULL_REQUEST" != "false" ] && [ -n "\$BUILDKITE_PULL_REQUEST" ]; then \ - echo "Cloning and checking out PR #\$BUILDKITE_PULL_REQUEST..." && \ - git clone \$VLLM_OMNI_REPO /workspace/vllm-omni && \ - cd /workspace/vllm-omni && \ - git fetch origin pull/\$BUILDKITE_PULL_REQUEST/head:pr-\$BUILDKITE_PULL_REQUEST && \ - git checkout pr-\$BUILDKITE_PULL_REQUEST; \ - else \ - echo "Not a PR build, using main branch" && \ - git clone --depth 1 \$VLLM_OMNI_REPO /workspace/vllm-omni; \ - fi - -RUN --mount=type=cache,target=/root/.cache/pip \ - export PIP_EXTRA_INDEX_URL=https://mirrors.huaweicloud.com/ascend/repos/pypi && \ - source /usr/local/Ascend/ascend-toolkit/set_env.sh && \ - source /usr/local/Ascend/nnal/atb/set_env.sh && \ - export LD_LIBRARY_PATH=\$LD_LIBRARY_PATH:/usr/local/Ascend/ascend-toolkit/latest/`uname -i`-linux/devlib && \ - python3 -m pip install -v -e /workspace/vllm-omni/ - -ENV VLLM_WORKER_MULTIPROC_METHOD=spawn - -WORKDIR /workspace/vllm-omni -CMD ["/bin/bash"] - -EOF - -# Setup cleanup -remove_docker_container() { - docker rm -f "${container_name}" || true; - docker image rm -f "${image_name}" || true; - docker system prune -f || true; -} -trap remove_docker_container EXIT - -# Generate corresponding --device args based on BUILDKITE_AGENT_NAME -# Ascend NPU BUILDKITE_AGENT_NAME format is {hostname}-{agent_idx}-{npu_card_num}cards, and agent_idx starts from 1. -# e.g. atlas-a2-001-1-2cards means this is the 1-th agent on atlas-a2-001 host, and it has 2 NPU cards. -# returns --device /dev/davinci0 --device /dev/davinci1 -parse_and_gen_devices() { - local input="$1" - local index cards_num - if [[ "$input" =~ ([0-9]+)-([0-9]+)cards$ ]]; then - index="${BASH_REMATCH[1]}" - cards_num="${BASH_REMATCH[2]}" - else - echo "parse error" >&2 - return 1 - fi - - local devices="" - local i=0 - while (( i < cards_num )); do - local dev_idx=$(((index - 1)*cards_num + i )) - devices="$devices --device /dev/davinci${dev_idx}" - ((i++)) - done - - # trim leading space - devices="${devices#"${devices%%[![:space:]]*}"}" - # Output devices: assigned to the caller variable - printf '%s' "$devices" -} - -devices=$(parse_and_gen_devices "${BUILDKITE_AGENT_NAME}") || exit 1 - -# Run the image and execute the Out-Of-Tree (OOT) platform interface test case on Ascend NPU hardware. -# This test checks whether the OOT platform interface is functioning properly in conjunction with -# the hardware plugin vllm-ascend. -hf_model_cache_dir=/mnt/hf_cache${agent_idx} -ms_model_cache_dir=/mnt/modelscope${agent_idx} -mkdir -p ${hf_model_cache_dir} -mkdir -p ${ms_model_cache_dir} -docker run \ - --init \ - ${devices} \ - --device /dev/davinci_manager \ - --device /dev/devmm_svm \ - --device /dev/hisi_hdc \ - -v /usr/local/dcmi:/usr/local/dcmi \ - -v /usr/local/bin/npu-smi:/usr/local/bin/npu-smi \ - -v /usr/local/Ascend/driver/lib64/:/usr/local/Ascend/driver/lib64/ \ - -v /usr/local/Ascend/driver/version.info:/usr/local/Ascend/driver/version.info \ - -v /etc/ascend_install.info:/etc/ascend_install.info \ - -v ${hf_model_cache_dir}:/root/.cache/huggingface \ - -v ${ms_model_cache_dir}:/root/.cache/modelscope \ - --network host \ - --entrypoint="" \ - --name "${container_name}" \ - "${image_name}" \ - bash -c ' - set -e - VLLM_USE_MODELSCOPE=True pytest -s -v tests/e2e/offline_inference/test_qwen2_5_omni_expansion.py -' diff --git a/.buildkite/scripts/upload-nightly-wheels.sh b/.buildkite/scripts/upload-nightly-wheels.sh deleted file mode 100755 index d50da1deda1..00000000000 --- a/.buildkite/scripts/upload-nightly-wheels.sh +++ /dev/null @@ -1,33 +0,0 @@ -#!/usr/bin/env bash - -set -ex - -# Upload a single wheel to S3 under the omni/ prefix. -# Index generation is handled separately by generate-and-upload-nightly-index.sh. - -BUCKET="vllm-wheels" -SUBPATH="omni/$BUILDKITE_COMMIT" -S3_COMMIT_PREFIX="s3://$BUCKET/$SUBPATH/" - -# ========= collect & upload the wheel ========== - -# python3 -m build outputs to dist/ by default -wheel_files=(dist/*.whl) - -# Check that exactly one wheel is found -if [[ ${#wheel_files[@]} -ne 1 ]]; then - echo "Error: Expected exactly one wheel file in dist/, but found ${#wheel_files[@]}" - exit 1 -fi -wheel="${wheel_files[0]}" - -echo "Uploading wheel: $wheel" - -# Extract the version from the wheel -version=$(unzip -p "$wheel" '**/METADATA' | grep '^Version: ' | cut -d' ' -f2) -echo "Version in wheel: $version" - -# Upload wheel to S3 -aws s3 cp "$wheel" "$S3_COMMIT_PREFIX" - -echo "Wheel uploaded to $S3_COMMIT_PREFIX. Index generation is handled by a separate step." diff --git a/.buildkite/scripts/upload_pipeline_with_skip_ci.sh b/.buildkite/scripts/upload_pipeline_with_skip_ci.sh deleted file mode 100644 index 6259d39b290..00000000000 --- a/.buildkite/scripts/upload_pipeline_with_skip_ci.sh +++ /dev/null @@ -1,137 +0,0 @@ -#!/usr/bin/env bash -# Evaluate docs-only skip-ci and upload continuation steps from the same `.buildkite/pipeline.yml` -# (YAML document after the first `---`). Buildkite `if` is evaluated at upload time. -set -euo pipefail - -ROOT="$(cd "$(dirname "${BASH_SOURCE[0]}")/../.." && pwd)" -PIPELINE_YML="${ROOT}/.buildkite/pipeline.yml" - -# Prints a single digit to stdout: 1 = skip image CI, 0 = run. Logs go to stderr. -is_docs_only_change() { - local file_path - local has_any=0 - - while IFS= read -r file_path; do - [[ -z "${file_path}" ]] && continue - has_any=1 - - if [[ "${file_path}" == docs/* ]]; then - continue - fi - if [[ "${file_path}" == *.md ]]; then - continue - fi - if [[ "${file_path}" == "mkdocs.yaml" ]]; then - continue - fi - return 1 - done - - [[ "${has_any}" -eq 1 ]] -} - -resolve_skip_ci() { - local is_pr_build=0 - local files - local base_branch base_ref - - if [[ "${BUILDKITE_PULL_REQUEST:-false}" != "false" && -n "${BUILDKITE_PULL_REQUEST:-}" ]]; then - is_pr_build=1 - fi - - if [[ "${is_pr_build}" -eq 1 ]]; then - base_branch="${BUILDKITE_PULL_REQUEST_BASE_BRANCH:-main}" - if ! git rev-parse --verify "origin/${base_branch}" >/dev/null 2>&1; then - echo "resolve_skip_ci: origin/${base_branch} not found locally; trying fetch" >&2 - git fetch --depth=200 origin "${base_branch}" >/dev/null 2>&1 || true - fi - - base_ref="" - if git rev-parse --verify "origin/${base_branch}" >/dev/null 2>&1; then - base_ref="origin/${base_branch}" - elif git rev-parse --verify "${base_branch}" >/dev/null 2>&1; then - base_ref="${base_branch}" - else - echo "resolve_skip_ci: cannot resolve PR base ${base_branch}; skip-ci=0" >&2 - echo -n 0 - return 0 - fi - - if ! files="$(git diff --name-only "${base_ref}...${BUILDKITE_COMMIT}" 2>/dev/null)"; then - echo "resolve_skip_ci: failed to compute PR changed files; skip-ci=0" >&2 - echo -n 0 - return 0 - fi - elif [[ "${BUILDKITE_BRANCH:-}" == "main" ]]; then - if ! git rev-parse --verify "${BUILDKITE_COMMIT}^" >/dev/null 2>&1; then - echo "resolve_skip_ci: commit has no parent on main; skip-ci=0" >&2 - echo -n 0 - return 0 - fi - if ! files="$(git diff --name-only "${BUILDKITE_COMMIT}^..${BUILDKITE_COMMIT}" 2>/dev/null)"; then - echo "resolve_skip_ci: failed to compute main changed files; skip-ci=0" >&2 - echo -n 0 - return 0 - fi - else - echo "resolve_skip_ci: not PR/main build; skip-ci=0" >&2 - echo -n 0 - return 0 - fi - - if is_docs_only_change <<< "${files}"; then - echo "resolve_skip_ci: docs-only change detected; skip-ci=1" >&2 - echo -n 1 - return 0 - fi - - echo "resolve_skip_ci: non-doc changes detected; skip-ci=0" >&2 - echo -n 0 -} - -SKIP_CI="$(resolve_skip_ci)" - -if [[ ! -f "${PIPELINE_YML}" ]]; then - echo "upload_pipeline_with_skip_ci: missing ${PIPELINE_YML}" >&2 - exit 1 -fi - -export ROOT SKIP_CI PIPELINE_YML -python3 <<'PY' | buildkite-agent pipeline upload -import os -import pathlib - -path = pathlib.Path(os.environ["PIPELINE_YML"]) -text = path.read_text(encoding="utf-8") -sep = "\n---\n" -if sep not in text: - raise SystemExit( - "upload_pipeline_with_skip_ci: .buildkite/pipeline.yml must contain a '\\n---\\n' separator " - "(document 1 = bootstrap, document 2 = uploaded steps)" - ) -_, continuation = text.split(sep, 1) - -skip = os.environ.get("SKIP_CI") == "1" -# When docs-only skip-ci: skip default CI image, but still build for L4 nightly (PR label nightly-test or -# main NIGHTLY=1), otherwise upload-nightly (depends_on image-build) would be skipped too. -nightly_only = ( - '(build.pull_request.labels includes "nightly-test") ' - '|| (build.branch == "main" && build.env("NIGHTLY") == "1")' -) -# Placeholder in pipeline.yml is `if: __IMAGE_BUILD_IF__` (valid YAML); replace value only. -if skip: - rep = f"'{nightly_only}'" - ready_rep = "'false'" - merge_rep = "'false'" -else: - rep = "'true'" - ready_rep = "'build.branch != \"main\" && build.pull_request.labels includes \"ready\"'" - merge_rep = "'(build.branch == \"main\" && build.env(\"NIGHTLY\") != \"1\") || (build.branch != \"main\" && build.pull_request.labels includes \"merge-test\")'" -rendered = ( - continuation - .replace("__IMAGE_BUILD_IF__", rep) - .replace("__UPLOAD_READY_IF__", ready_rep) - .replace("__UPLOAD_MERGE_IF__", merge_rep) -) -print(rendered, end="") -PY diff --git a/.buildkite/test-amd-merge.yml b/.buildkite/test-amd-merge.yml deleted file mode 100644 index aabff610d57..00000000000 --- a/.buildkite/test-amd-merge.yml +++ /dev/null @@ -1,223 +0,0 @@ -steps: - -- label: "Simple Unit Test" - agent_pool: mi325_1 - depends_on: amd-build - mirror_hardwares: [amdproduction] - grade: Blocking - commands: - - export VLLM_ROCM_USE_AITER=0 - # ignore test_teacache_extractors.py because it use rocm gemm kernel from vLLM - # that is not supported on CPU - - "timeout 20m pytest -v -s -m 'core_model and cpu' --ignore=tests/diffusion/cache/test_teacache_extractors.py --cov=vllm_omni --cov-branch --cov-report=term-missing --cov-report=html --cov-report=xml" - -- label: "Diffusion Model Test" - agent_pool: mi325_2 - depends_on: amd-build - mirror_hardwares: [amdproduction] - grade: Blocking - commands: - - export GPU_ARCHS=gfx942 - - timeout 20m pytest -s -v tests/e2e/offline_inference/test_t2i_model.py -m "advanced_model and diffusion" --run-level "advanced_model" - -- label: "Diffusion Images API LoRA E2E" - agent_pool: mi325_1 - depends_on: amd-build - mirror_hardwares: [amdproduction] - grade: Blocking - commands: - - timeout 20m pytest -s -v tests/e2e/online_serving/test_images_generations_lora.py - -- label: "Diffusion Model CPU offloading Test" - agent_pool: mi325_1 - depends_on: amd-build - mirror_hardwares: [amdproduction] - grade: Blocking - commands: - - export VLLM_LOGGING_LEVEL=DEBUG - - export VLLM_WORKER_MULTIPROC_METHOD=spawn - - | - timeout 20m bash -c ' - set +e - pytest -s -v tests/e2e/offline_inference/test_diffusion_cpu_offload.py - EXIT1=\$? - pytest -s -v tests/e2e/offline_inference/test_diffusion_layerwise_offload.py - EXIT2=\$? - exit \$((EXIT1 | EXIT2)) - ' - -## ISSUE depends on `diffusers` package: https://github.com/huggingface/diffusers/issues/13274 -# - label: "Audio Generation Model Test" -# agent_pool: mi325_1 -# depends_on: amd-build -# mirror_hardwares: [amdproduction] -# grade: Blocking -# commands: -# - export GPU_ARCHS=gfx942 -# - export VLLM_LOGGING_LEVEL=DEBUG -# - export VLLM_WORKER_MULTIPROC_METHOD=spawn -# - timeout 20m pytest -s -v tests/e2e/offline_inference/test_stable_audio_expansion.py -m "advanced_model and diffusion and L4" --run-level advanced_model - -- label: "Diffusion Cache Backend Test" - agent_pool: mi325_1 - depends_on: amd-build - mirror_hardwares: [amdproduction] - grade: Blocking - commands: - - export VLLM_LOGGING_LEVEL=DEBUG - - export VLLM_WORKER_MULTIPROC_METHOD=spawn - - timeout 15m pytest -s -v -m "core_model and cache and diffusion and not distributed_cuda and L4" - -- label: "Diffusion Sequence Parallelism Test (Need 4 GPUs)" - agent_pool: mi325_4 - depends_on: amd-build - mirror_hardwares: [amdproduction] - grade: Blocking - commands: - - export VLLM_LOGGING_LEVEL=DEBUG - - export VLLM_WORKER_MULTIPROC_METHOD=spawn - - timeout 20m pytest -s -v tests/e2e/offline_inference/test_sequence_parallel.py - - timeout 20m pytest -s -v tests/diffusion/distributed/test_ulysses_uaa_perf.py - -# merge-only tests -- label: "Diffusion Tensor Parallelism Test" - agent_pool: mi325_2 - depends_on: amd-build - mirror_hardwares: [amdproduction] - grade: Blocking - commands: - - pytest -s -v tests/e2e/offline_inference/test_zimage_parallelism.py - -- label: "Diffusion GPU Worker Test" - agent_pool: mi325_2 - depends_on: amd-build - mirror_hardwares: [amdproduction] - grade: Blocking - commands: - - timeout 20m pytest -s -v tests/diffusion/test_diffusion_worker.py - -- label: "Engine Test" - agent_pool: mi325_1 - depends_on: amd-build - mirror_hardwares: [amdproduction] - grade: Blocking - commands: - - export VLLM_WORKER_MULTIPROC_METHOD=spawn - - timeout 20m pytest -s -v tests/engine/test_async_omni_engine_abort.py - -- label: "Omni Model Test Qwen2-5-Omni" - agent_pool: mi325_2 - depends_on: amd-build - mirror_hardwares: [amdproduction] - grade: Blocking - commands: - - export VLLM_LOGGING_LEVEL=DEBUG - - export VLLM_WORKER_MULTIPROC_METHOD=spawn - - timeout 20m pytest -s -v tests/e2e/offline_inference/test_qwen2_5_omni_expansion.py - - timeout 20m pytest -s -v tests/e2e/online_serving/test_qwen2_5_omni_expansion.py -m "advanced_model" --run-level "core_model" - -- label: "Omni Model Test Qwen3-Omni" - agent_pool: mi325_2 - depends_on: amd-build - mirror_hardwares: [amdproduction] - grade: Blocking - commands: - - export VLLM_LOGGING_LEVEL=DEBUG - - export VLLM_WORKER_MULTIPROC_METHOD=spawn - - export VLLM_TEST_CLEAN_GPU_MEMORY=1 - - timeout 30m pytest -s -v tests/e2e/offline_inference/test_qwen3_omni.py tests/e2e/online_serving/test_qwen3_omni.py tests/e2e/online_serving/test_mimo_audio.py -m "advanced_model" --run-level "advanced_model" - -- label: "Qwen3-TTS CustomVoice E2E Test" - agent_pool: mi325_1 - depends_on: amd-build - mirror_hardwares: [amdproduction] - grade: Blocking - commands: - - | - timeout 20m bash -c ' - export VLLM_LOGGING_LEVEL=DEBUG - export VLLM_WORKER_MULTIPROC_METHOD=spawn - export VLLM_ALLOW_LONG_MAX_MODEL_LEN="1" - pytest -s -v tests/e2e/online_serving/test_qwen3_tts_customvoice.py tests/e2e/offline_inference/test_qwen3_tts_customvoice.py -m "advanced_model" --run-level "advanced_model" - ' - -- label: "Qwen3-TTS Base E2E Test" - agent_pool: mi325_1 - depends_on: amd-build - mirror_hardwares: [amdproduction] - grade: Blocking - commands: - - | - timeout 30m bash -c ' - export VLLM_LOGGING_LEVEL=DEBUG - export VLLM_WORKER_MULTIPROC_METHOD=spawn - export VLLM_ALLOW_LONG_MAX_MODEL_LEN="1" - pytest -s -v tests/e2e/online_serving/test_qwen3_tts_base.py tests/e2e/offline_inference/test_qwen3_tts_base.py -m "advanced_model" --run-level "advanced_model" - ' - -- label: "Diffusion Image Edit Test" - agent_pool: mi325_1 - depends_on: amd-build - mirror_hardwares: [amdproduction] - grade: Blocking - commands: - - export GPU_ARCHS=gfx942 - - export VLLM_LOGGING_LEVEL=DEBUG - - export VLLM_WORKER_MULTIPROC_METHOD=spawn - - timeout 20m pytest -s -v tests/e2e/online_serving/test_image_gen_edit.py - -# TODO: Bagel test on ROCm is very unstable. @tjtanaa -# Need to debug before reneable numerical changes across large PRs -# # split Bagel Model Test with H100 (Real Weights) into three tests -# - label: "Bagel Text2Img Model Test (1/3)" -# agent_pool: mi325_1 -# depends_on: amd-build -# mirror_hardwares: [amdproduction] -# grade: Blocking -# commands: -# - export GPU_ARCHS=gfx942 -# - export VLLM_TEST_CLEAN_GPU_MEMORY=1 -# - export VLLM_LOGGING_LEVEL=DEBUG -# - export VLLM_WORKER_MULTIPROC_METHOD=spawn -# - export VLLM_ROCM_USE_AITER_RMSNORM=0 -# - timeout 30m pytest -s -v tests/e2e/offline_inference/test_bagel_text2img.py -m "advanced_model" --run-level "advanced_model" -k "shared_memory" -k "rocm" - -# - label: "Bagel Img2Img Model Test (2/3)" -# agent_pool: mi325_1 -# depends_on: amd-build -# mirror_hardwares: [amdproduction] -# grade: Blocking -# commands: -# - export GPU_ARCHS=gfx942 -# - export VLLM_TEST_CLEAN_GPU_MEMORY=1 -# - export VLLM_LOGGING_LEVEL=DEBUG -# - export VLLM_WORKER_MULTIPROC_METHOD=spawn -# - export VLLM_ROCM_USE_AITER_RMSNORM=0 -# - timeout 30m pytest -s -v tests/e2e/offline_inference/test_bagel_img2img.py -m "advanced_model" --run-level "advanced_model" -k "rocm" - -# - label: "Bagel Online Serving Test (3/3)" -# agent_pool: mi325_1 -# depends_on: amd-build -# mirror_hardwares: [amdproduction] -# grade: Blocking -# commands: -# - export GPU_ARCHS=gfx942 -# - export VLLM_TEST_CLEAN_GPU_MEMORY=1 -# - export VLLM_IMAGE_FETCH_TIMEOUT=60 -# - export VLLM_LOGGING_LEVEL=DEBUG -# - export VLLM_WORKER_MULTIPROC_METHOD=spawn -# - export VLLM_ROCM_USE_AITER_RMSNORM=0 -# - timeout 40m pytest -s -v tests/e2e/online_serving/test_bagel_online.py -m "advanced_model" --run-level "advanced_model" -k "rocm" - -- label: "Voxtral-TTS E2E Test" - agent_pool: mi325_1 - depends_on: amd-build - mirror_hardwares: [amdproduction] - grade: Blocking - commands: - - | - timeout 20m bash -c ' - export VLLM_LOGGING_LEVEL=DEBUG - export VLLM_WORKER_MULTIPROC_METHOD=spawn - pytest -s -v tests/e2e/online_serving/test_voxtral_tts.py tests/e2e/offline_inference/test_voxtral_tts.py -m "advanced_model" --run-level "advanced_model" - ' diff --git a/.buildkite/test-amd-ready.yaml b/.buildkite/test-amd-ready.yaml deleted file mode 100644 index 597733cbb86..00000000000 --- a/.buildkite/test-amd-ready.yaml +++ /dev/null @@ -1,229 +0,0 @@ -steps: - -- label: "Simple Unit Test" - agent_pool: mi325_1 - depends_on: amd-build - mirror_hardwares: [amdproduction] - grade: Blocking - commands: - - export VLLM_ROCM_USE_AITER=0 - # ignore test_teacache_extractors.py because it use rocm gemm kernel from vLLM - # that is not supported on CPU - - "timeout 20m pytest -vvvv -s -m 'core_model and cpu' --ignore=tests/diffusion/cache/test_teacache_extractors.py --cov=vllm_omni --cov-branch --cov-report=term-missing --cov-report=html --cov-report=xml" - -- label: "Voxtral TTS CUDA Unit Test" - agent_pool: mi325_1 - depends_on: amd-build - mirror_hardwares: [amdproduction] - grade: Blocking - commands: - - timeout 10m pytest -s -v tests/model_executor/models/voxtral_tts/test_cuda_graph_acoustic_transformer.py - -- label: "Diffusion Model Test" - agent_pool: mi325_1 - depends_on: amd-build - mirror_hardwares: [amdproduction] - grade: Blocking - commands: - - timeout 30m pytest -s -v tests/e2e/offline_inference/test_t2i_model.py -m "core_model and diffusion" --run-level "core_model" - -- label: "Diffusion Batching Test" - agent_pool: mi325_1 - depends_on: amd-build - mirror_hardwares: [amdproduction] - grade: Blocking - commands: - - timeout 20m pytest -s -v tests/e2e/offline_inference/test_qwen_image_diffusion_batching.py -m "core_model and diffusion" --run-level "core_model" - -- label: "Custom Pipeline Test" - agent_pool: mi325_1 - depends_on: amd-build - mirror_hardwares: [amdproduction] - grade: Blocking - commands: - - timeout 20m pytest -s -v tests/e2e/offline_inference/custom_pipeline/ -m "core_model" - -- label: "Diffusion Model CPU offloading Test" - agent_pool: mi325_1 - depends_on: amd-build - mirror_hardwares: [amdproduction] - grade: Blocking - commands: - - export VLLM_LOGGING_LEVEL=DEBUG - - export VLLM_WORKER_MULTIPROC_METHOD=spawn - - | - timeout 20m bash -c ' - set +e - pytest -s -v tests/e2e/offline_inference/test_diffusion_cpu_offload.py - EXIT1=\$? - pytest -s -v tests/e2e/offline_inference/test_diffusion_layerwise_offload.py - EXIT2=\$? - exit \$((EXIT1 | EXIT2)) - ' - -## ISSUE depends on `diffusers` package: https://github.com/huggingface/diffusers/issues/13274 -# - label: "Audio Generation Model Test" -# agent_pool: mi325_1 -# depends_on: amd-build -# mirror_hardwares: [amdproduction] -# grade: Blocking -# commands: -# - export GPU_ARCHS=gfx942 -# - export VLLM_LOGGING_LEVEL=DEBUG -# - export VLLM_WORKER_MULTIPROC_METHOD=spawn -# - timeout 20m pytest -s -v tests/e2e/offline_inference/test_stable_audio_expansion.py -m "advanced_model and diffusion and L4" --run-level advanced_model - -- label: "Diffusion Cache Backend Test" - agent_pool: mi325_1 - depends_on: amd-build - mirror_hardwares: [amdproduction] - grade: Blocking - commands: - - export GPU_ARCHS=gfx942 - - export VLLM_LOGGING_LEVEL=DEBUG - - export VLLM_WORKER_MULTIPROC_METHOD=spawn - - timeout 15m pytest -s -v -m "core_model and cache and diffusion and not distributed_cuda and L4" - -- label: "Diffusion Sequence Parallelism Test" - agent_pool: mi325_2 - depends_on: amd-build - mirror_hardwares: [amdproduction] - grade: Blocking - commands: - - export VLLM_LOGGING_LEVEL=DEBUG - - export VLLM_WORKER_MULTIPROC_METHOD=spawn - - timeout 20m pytest -s -v tests/e2e/offline_inference/test_sequence_parallel.py -m core_model - -- label: "Diffusion GPU Worker Test" - agent_pool: mi325_2 - depends_on: amd-build - mirror_hardwares: [amdproduction] - grade: Blocking - commands: - - timeout 20m pytest -s -v tests/diffusion/test_diffusion_worker.py - -- label: "Engine Test" - agent_pool: mi325_1 - depends_on: amd-build - mirror_hardwares: [amdproduction] - grade: Blocking - commands: - - export VLLM_WORKER_MULTIPROC_METHOD=spawn - - | - timeout 15m bash -c ' - pytest -s -v tests/engine/test_async_omni_engine_abort.py - ' - -# - label: "Omni Model Test Qwen3-Omni" -# agent_pool: mi325_2 -# depends_on: amd-build -# mirror_hardwares: [amdproduction] -# grade: Blocking -# commands: -# - export VLLM_LOGGING_LEVEL=DEBUG -# - export VLLM_WORKER_MULTIPROC_METHOD=spawn -# - export VLLM_TEST_CLEAN_GPU_MEMORY=1 -# - timeout 10m pytest -s -v tests/e2e/offline_inference/test_qwen3_omni.py -# - timeout 20m pytest -s -v tests/e2e/online_serving/test_qwen3_omni.py -m "core_model" --run-level "core_model" - -- label: "MiMo-Audio E2E Test with H100" - agent_pool: mi325_1 - depends_on: amd-build - mirror_hardwares: [amdproduction] - grade: Blocking - commands: - - | - timeout 30m bash -c ' - export VLLM_LOGGING_LEVEL=DEBUG - export VLLM_WORKER_MULTIPROC_METHOD=spawn - pytest -s -v tests/e2e/online_serving/test_mimo_audio.py -m "core_model" --run-level "core_model" - ' - -- label: "Qwen3-TTS E2E Test" - agent_pool: mi325_1 - depends_on: amd-build - mirror_hardwares: [amdproduction] - grade: Blocking - commands: - - export VLLM_LOGGING_LEVEL=DEBUG - - export VLLM_WORKER_MULTIPROC_METHOD=spawn - - export VLLM_ALLOW_LONG_MAX_MODEL_LEN="1" - - timeout 30m pytest -s -v tests/e2e/online_serving/test_qwen3_tts_customvoice.py -m "core_model" --run-level "core_model" - -- label: "Voxtral-TTS E2E Test" - agent_pool: mi325_1 - depends_on: amd-build - mirror_hardwares: [amdproduction] - grade: Blocking - commands: - - | - timeout 20m bash -c ' - export VLLM_LOGGING_LEVEL=DEBUG - export VLLM_WORKER_MULTIPROC_METHOD=spawn - pytest -s -v tests/e2e/online_serving/test_voxtral_tts.py -m "advanced_model" --run-level "advanced_model" - pytest -s -v tests/e2e/offline_inference/test_voxtral_tts.py -m "advanced_model" --run-level "advanced_model" - ' - -- label: "Diffusion Image Edit Test" - agent_pool: mi325_1 - depends_on: amd-build - mirror_hardwares: [amdproduction] - grade: Blocking - commands: - - export GPU_ARCHS=gfx942 - - export VLLM_LOGGING_LEVEL=DEBUG - - export VLLM_WORKER_MULTIPROC_METHOD=spawn - - timeout 20m pytest -s -v tests/e2e/online_serving/test_image_gen_edit.py - -# TODO: Bagel test on ROCm is very unstable. @tjtanaa -# Need to debug before reneable numerical changes across large PRs -# - label: "Bagel Text2Img Model Test" -# agent_pool: mi325_1 -# depends_on: amd-build -# mirror_hardwares: [amdproduction] -# grade: Blocking -# commands: -# - export GPU_ARCHS=gfx942 -# - export VLLM_TEST_CLEAN_GPU_MEMORY=1 -# - export VLLM_LOGGING_LEVEL=DEBUG -# - export VLLM_WORKER_MULTIPROC_METHOD=spawn -# - export VLLM_ROCM_USE_AITER_RMSNORM=0 -# - timeout 30m pytest -s -v tests/e2e/offline_inference/test_bagel_text2img.py -m "core_model" --run-level "core_model" -k "rocm" - -# - label: "Bagel Img2Img Model Test" -# agent_pool: mi325_1 -# depends_on: amd-build -# mirror_hardwares: [amdproduction] -# grade: Blocking -# commands: -# - export GPU_ARCHS=gfx942 -# - export VLLM_TEST_CLEAN_GPU_MEMORY=1 -# - export VLLM_LOGGING_LEVEL=DEBUG -# - export VLLM_WORKER_MULTIPROC_METHOD=spawn -# - export VLLM_ROCM_USE_AITER_RMSNORM=0 -# - timeout 30m pytest -s -v tests/e2e/offline_inference/test_bagel_img2img.py -m "core_model" --run-level "core_model" -k "rocm" - -# - label: "Bagel Online Serving Test" -# agent_pool: mi325_1 -# depends_on: amd-build -# mirror_hardwares: [amdproduction] -# grade: Blocking -# commands: -# - export GPU_ARCHS=gfx942 -# - export VLLM_TEST_CLEAN_GPU_MEMORY=1 -# - export VLLM_IMAGE_FETCH_TIMEOUT=60 -# - export VLLM_LOGGING_LEVEL=DEBUG -# - export VLLM_WORKER_MULTIPROC_METHOD=spawn -# - export VLLM_ROCM_USE_AITER_RMSNORM=0 -# - timeout 40m pytest -s -v tests/e2e/online_serving/test_bagel_online.py -m "core_model" --run-level "core_model" -k "rocm" - -- label: "CosyVoice3-TTS E2E Test" - agent_pool: mi325_1 - depends_on: amd-build - mirror_hardwares: [amdproduction] - grade: Blocking - commands: - - | - timeout 20m bash -c ' - pytest -s -v tests/e2e/online_serving/test_cosyvoice3_tts.py -m "core_model" --run-level "core_model" - ' diff --git a/.buildkite/test-amd.yaml b/.buildkite/test-amd.yaml deleted file mode 100644 index 8942b640744..00000000000 --- a/.buildkite/test-amd.yaml +++ /dev/null @@ -1,133 +0,0 @@ -steps: - -- label: "Diffusion Model Test" - timeout_in_minutes: 30 - agent_pool: mi325_2 - depends_on: amd-build - mirror_hardwares: [amdproduction] - grade: Blocking - commands: - - export GPU_ARCHS=gfx942 - - pytest -s -v tests/e2e/offline_inference/test_t2i_model.py - -- label: "Diffusion Images API LoRA E2E" - timeout_in_minutes: 30 - agent_pool: mi325_1 - depends_on: amd-build - mirror_hardwares: [amdproduction] - grade: Blocking - commands: - - export GPU_ARCHS=gfx942 - - export VLLM_LOGGING_LEVEL=DEBUG - - export VLLM_WORKER_MULTIPROC_METHOD=spawn - - pytest -s -v tests/e2e/online_serving/test_images_generations_lora.py - -- label: "Diffusion Model CPU offloading Test" - timeout_in_minutes: 20 - agent_pool: mi325_1 - depends_on: amd-build - mirror_hardwares: [amdproduction] - grade: Blocking - commands: - - export GPU_ARCHS=gfx942 - - export VLLM_LOGGING_LEVEL=DEBUG - - export VLLM_WORKER_MULTIPROC_METHOD=spawn - - pytest -s -v tests/e2e/offline_inference/test_diffusion_cpu_offload.py - - pytest -s -v tests/e2e/offline_inference/test_diffusion_layerwise_offload.py - -- label: "Diffusion Cache Backend Test" - timeout_in_minutes: 15 - agent_pool: mi325_1 - depends_on: amd-build - mirror_hardwares: [amdproduction] - grade: Blocking - commands: - - export GPU_ARCHS=gfx942 - - export VLLM_LOGGING_LEVEL=DEBUG - - export VLLM_WORKER_MULTIPROC_METHOD=spawn - - pytest -s -v -m 'core_model and cache and diffusion and not distributed_rocm and MI325' - -- label: "Diffusion Sequence Parallelism Test" - timeout_in_minutes: 20 - agent_pool: mi325_2 - depends_on: amd-build - mirror_hardwares: [amdproduction] - grade: Blocking - commands: - - export GPU_ARCHS=gfx942 - - export VLLM_LOGGING_LEVEL=DEBUG - - export VLLM_WORKER_MULTIPROC_METHOD=spawn - - pytest -s -v tests/e2e/offline_inference/test_sequence_parallel.py -m core_model - -- label: "Diffusion Tensor Parallelism Test" - timeout_in_minutes: 20 - agent_pool: mi325_2 - depends_on: amd-build - commands: - - export GPU_ARCHS=gfx942 - - export VLLM_LOGGING_LEVEL=DEBUG - - export VLLM_WORKER_MULTIPROC_METHOD=spawn - - pytest -s -v tests/e2e/offline_inference/test_zimage_parallelism.py - -- label: "Diffusion GPU Worker Test" - timeout_in_minutes: 20 - agent_pool: mi325_2 - depends_on: amd-build - mirror_hardwares: [amdproduction] - grade: Blocking - commands: - - pytest -s -v tests/diffusion/test_diffusion_worker.py - -- label: "Omni Model Test Qwen2-5-Omni" - timeout_in_minutes: 15 - agent_pool: mi325_2 - depends_on: amd-build - mirror_hardwares: [amdproduction] - grade: Blocking - commands: - - export GPU_ARCHS=gfx942 - - export VLLM_LOGGING_LEVEL=DEBUG - - export VLLM_WORKER_MULTIPROC_METHOD=spawn - - pytest -s -v tests/e2e/offline_inference/test_qwen2_5_omni_expansion.py - - pytest -s -v tests/engine/test_async_omni_engine_abort.py - -- label: "Omni Model Test Qwen3-Omni" - timeout_in_minutes: 15 - agent_pool: mi325_2 - depends_on: amd-build - mirror_hardwares: [amdproduction] - grade: Blocking - commands: - - export VLLM_LOGGING_LEVEL=DEBUG - - export VLLM_WORKER_MULTIPROC_METHOD=spawn - - export VLLM_TEST_CLEAN_GPU_MEMORY="1" - - export VLLM_ROCM_USE_AITER=0 - - pytest -s -v tests/e2e/offline_inference/test_qwen3_omni.py - - pytest -s -v tests/e2e/online_serving/test_qwen3_omni.py - - -- label: "Diffusion Image Edit Test" - timeout_in_minutes: 15 - agent_pool: mi325_1 - depends_on: amd-build - mirror_hardwares: [amdproduction] - grade: Blocking - commands: - - export GPU_ARCHS=gfx942 - - export VLLM_LOGGING_LEVEL=DEBUG - - export VLLM_WORKER_MULTIPROC_METHOD=spawn - - pytest -s -v tests/e2e/online_serving/test_image_gen_edit.py - - -- label: "Omni Sleep Mode Test" - timeout_in_minutes: 40 - agent_pool: mi325_2 - depends_on: amd-build - mirror_hardwares: [amdproduction] - grade: Blocking - commands: - - export GPU_ARCHS=gfx942 - - export VLLM_LOGGING_LEVEL=DEBUG - - export VLLM_WORKER_MULTIPROC_METHOD=spawn - - export VLLM_TEST_CLEAN_GPU_MEMORY="1" - - pytest -s -v tests/e2e/offline_inference/test_omni_sleep_mode.py -m "advanced_model and omni and MI325" --run-level "advanced_model" diff --git a/.buildkite/test-merge.yml b/.buildkite/test-merge.yml deleted file mode 100644 index f5afa7e8510..00000000000 --- a/.buildkite/test-merge.yml +++ /dev/null @@ -1,487 +0,0 @@ -env: - VLLM_WORKER_MULTIPROC_METHOD: spawn - HF_HUB_DOWNLOAD_TIMEOUT: 300 - HF_HUB_ETAG_TIMEOUT: 60 - -steps: - - label: "Simple Unit Test" - depends_on: upload-merge-pipeline - commands: - - "pytest -v -s -m 'core_model and cpu' --cov=vllm_omni --cov-branch --cov-report=term-missing --cov-report=html --cov-report=xml" - agents: - queue: "gpu_1_queue" - plugins: - - docker#v5.2.0: - image: public.ecr.aws/q9t5s3a7/vllm-ci-test-repo:$BUILDKITE_COMMIT - always-pull: true - propagate-environment: true - environment: - - "HF_HOME=/fsx/hf_cache" - - "HF_TOKEN" - volumes: - - "/fsx/hf_cache:/fsx/hf_cache" - - - label: "Diffusion Model Test" - timeout_in_minutes: 30 - depends_on: upload-merge-pipeline - commands: - - pytest -s -v tests/e2e/offline_inference/test_t2i_model.py -m "advanced_model and diffusion" --run-level "advanced_model" - agents: - queue: "gpu_1_queue" # g6.4xlarge instance on AWS, has 1 L4 GPU - plugins: - - docker#v5.2.0: - image: public.ecr.aws/q9t5s3a7/vllm-ci-test-repo:$BUILDKITE_COMMIT - always-pull: true - propagate-environment: true - environment: - - "HF_HOME=/fsx/hf_cache" - - "HF_TOKEN" - volumes: - - "/fsx/hf_cache:/fsx/hf_cache" - - - label: "Diffusion Images API LoRA E2E" - timeout_in_minutes: 30 - depends_on: upload-merge-pipeline - commands: - - pytest -s -v tests/e2e/online_serving/test_images_generations_lora.py - agents: - queue: "gpu_1_queue" # g6.4xlarge instance on AWS, has 1 L4 GPU - plugins: - - docker#v5.2.0: - image: public.ecr.aws/q9t5s3a7/vllm-ci-test-repo:$BUILDKITE_COMMIT - always-pull: true - propagate-environment: true - environment: - - "HF_HOME=/fsx/hf_cache" - - "HF_TOKEN" - volumes: - - "/fsx/hf_cache:/fsx/hf_cache" - - - label: "Diffusion Model CPU offloading Test" - timeout_in_minutes: 20 - depends_on: upload-merge-pipeline - commands: - # Single pytest session for one combined summary at end of log. - - pytest -s -v tests/e2e/offline_inference/test_diffusion_cpu_offload.py tests/e2e/offline_inference/test_diffusion_layerwise_offload.py - agents: - queue: "gpu_1_queue" # g6.4xlarge instance on AWS, has 1 L4 GPU - plugins: - - docker#v5.2.0: - image: public.ecr.aws/q9t5s3a7/vllm-ci-test-repo:$BUILDKITE_COMMIT - always-pull: true - propagate-environment: true - environment: - - "HF_HOME=/fsx/hf_cache" - - "HF_TOKEN" - volumes: - - "/fsx/hf_cache:/fsx/hf_cache" - - - label: "Diffusion Cache Backend Test" - timeout_in_minutes: 15 - depends_on: upload-merge-pipeline - commands: - - pytest -s -v -m 'core_model and cache and diffusion and not distributed_cuda and L4' - agents: - queue: "gpu_1_queue" # g6.4xlarge instance on AWS, has 1 L4 GPU - plugins: - - docker#v5.2.0: - image: public.ecr.aws/q9t5s3a7/vllm-ci-test-repo:$BUILDKITE_COMMIT - always-pull: true - propagate-environment: true - environment: - - "HF_HOME=/fsx/hf_cache" - - "HF_TOKEN" - volumes: - - "/fsx/hf_cache:/fsx/hf_cache" - - - label: "Diffusion Sequence Parallelism Test" - timeout_in_minutes: 25 - depends_on: upload-merge-pipeline - commands: - - pytest -s -v tests/e2e/offline_inference/test_sequence_parallel.py tests/diffusion/distributed/test_ulysses_uaa_perf.py - agents: - queue: "gpu_4_queue" # g6.12xlarge instance on AWS, has 4 L4 GPU - plugins: - - docker#v5.2.0: - image: public.ecr.aws/q9t5s3a7/vllm-ci-test-repo:$BUILDKITE_COMMIT - always-pull: true - propagate-environment: true - shm-size: "8gb" - environment: - - "HF_HOME=/fsx/hf_cache" - - "HF_TOKEN" - volumes: - - "/fsx/hf_cache:/fsx/hf_cache" - - - label: "Diffusion Tensor Parallelism Test" - timeout_in_minutes: 20 - depends_on: upload-merge-pipeline - commands: - - pytest -s -v tests/e2e/offline_inference/test_zimage_parallelism.py - agents: - queue: "gpu_4_queue" # g6.12xlarge instance on AWS, has 4 L4 GPU - plugins: - - docker#v5.2.0: - image: public.ecr.aws/q9t5s3a7/vllm-ci-test-repo:$BUILDKITE_COMMIT - always-pull: true - propagate-environment: true - shm-size: "8gb" - environment: - - "HF_HOME=/fsx/hf_cache" - - "HF_TOKEN" - volumes: - - "/fsx/hf_cache:/fsx/hf_cache" - - - label: "Diffusion GPU Worker Test" - timeout_in_minutes: 20 - depends_on: upload-merge-pipeline - commands: - - pytest -s -v tests/diffusion/test_diffusion_worker.py - agents: - queue: "gpu_4_queue" # g6.12xlarge instance on AWS, has 4 L4 GPU - plugins: - - docker#v5.2.0: - image: public.ecr.aws/q9t5s3a7/vllm-ci-test-repo:$BUILDKITE_COMMIT - always-pull: true - propagate-environment: true - shm-size: "8gb" - environment: - - "HF_HOME=/fsx/hf_cache" - - "HF_TOKEN" - volumes: - - "/fsx/hf_cache:/fsx/hf_cache" - - - label: "Engine Test" - depends_on: upload-merge-pipeline - commands: - - | - timeout 15m bash -c ' - pytest -s -v tests/engine/test_async_omni_engine_abort.py - ' - agents: - queue: "gpu_1_queue" # g6.12xlarge instance on AWS, has 4 L4 GPU - plugins: - - docker#v5.2.0: - image: public.ecr.aws/q9t5s3a7/vllm-ci-test-repo:$BUILDKITE_COMMIT - always-pull: true - propagate-environment: true - shm-size: "8gb" - environment: - - "HF_HOME=/fsx/hf_cache" - - "HF_TOKEN" - volumes: - - "/fsx/hf_cache:/fsx/hf_cache" - - - label: "Qwen3-TTS CustomVoice E2E Test" - depends_on: upload-merge-pipeline - commands: - - | - timeout 20m bash -c ' - export VLLM_LOGGING_LEVEL=DEBUG - export VLLM_ALLOW_LONG_MAX_MODEL_LEN="1" - pytest -s -v tests/e2e/online_serving/test_qwen3_tts_customvoice.py tests/e2e/offline_inference/test_qwen3_tts_customvoice.py -m "advanced_model" --run-level "advanced_model" - ' - agents: - queue: "gpu_1_queue" - plugins: - - docker#v5.2.0: - image: public.ecr.aws/q9t5s3a7/vllm-ci-test-repo:$BUILDKITE_COMMIT - always-pull: true - propagate-environment: true - shm-size: "8gb" - environment: - - "HF_HOME=/fsx/hf_cache" - volumes: - - "/fsx/hf_cache:/fsx/hf_cache" - - - label: "Qwen3-TTS Base E2E Test" - depends_on: upload-merge-pipeline - commands: - - | - timeout 20m bash -c ' - export VLLM_LOGGING_LEVEL=DEBUG - export VLLM_ALLOW_LONG_MAX_MODEL_LEN="1" - pytest -s -v tests/e2e/online_serving/test_qwen3_tts_base.py tests/e2e/offline_inference/test_qwen3_tts_base.py -m "advanced_model" --run-level "advanced_model" - ' - agents: - queue: "gpu_1_queue" - plugins: - - docker#v5.2.0: - image: public.ecr.aws/q9t5s3a7/vllm-ci-test-repo:$BUILDKITE_COMMIT - always-pull: true - propagate-environment: true - shm-size: "8gb" - environment: - - "HF_HOME=/fsx/hf_cache" - volumes: - - "/fsx/hf_cache:/fsx/hf_cache" - - # - label: "MOSS-TTS-Nano E2E Test" - # depends_on: upload-merge-pipeline - # commands: - # - | - # timeout 20m bash -c ' - # export VLLM_LOGGING_LEVEL=DEBUG - # export VLLM_ALLOW_LONG_MAX_MODEL_LEN="1" - # pytest -s -v tests/e2e/online_serving/test_moss_tts_nano.py tests/e2e/offline_inference/test_moss_tts_nano.py -m "advanced_model" --run-level "advanced_model" - # ' - # agents: - # queue: "gpu_1_queue" - # plugins: - # - docker#v5.2.0: - # image: public.ecr.aws/q9t5s3a7/vllm-ci-test-repo:$BUILDKITE_COMMIT - # always-pull: true - # propagate-environment: true - # shm-size: "8gb" - # environment: - # - "HF_HOME=/fsx/hf_cache" - # volumes: - # - "/fsx/hf_cache:/fsx/hf_cache" - - - label: "Omni Model Test with H100" - timeout_in_minutes: 30 - depends_on: upload-merge-pipeline - commands: - - export VLLM_TEST_CLEAN_GPU_MEMORY="1" - - pytest -s -v tests/e2e/offline_inference/test_qwen3_omni.py tests/e2e/online_serving/test_qwen3_omni.py tests/e2e/online_serving/test_mimo_audio.py -m "advanced_model" --run-level "advanced_model" - agents: - queue: "mithril-h100-pool" - plugins: - - kubernetes: - podSpec: - containers: - - image: 936637512419.dkr.ecr.us-west-2.amazonaws.com/vllm-ci-pull-through-cache/q9t5s3a7/vllm-ci-test-repo:$BUILDKITE_COMMIT - resources: - limits: - nvidia.com/gpu: 2 - volumeMounts: - - name: devshm - mountPath: /dev/shm - - name: hf-cache - mountPath: /root/.cache/huggingface - env: - - name: HF_HOME - value: /root/.cache/huggingface - - name: HF_TOKEN - valueFrom: - secretKeyRef: - name: hf-token-secret - key: token - nodeSelector: - node.kubernetes.io/instance-type: gpu-h100-sxm - volumes: - - name: devshm - emptyDir: - medium: Memory - - name: hf-cache - hostPath: - path: /mnt/hf-cache - type: DirectoryOrCreate - - - label: "Audio Streaming Input Test with H100" - timeout_in_minutes: 30 - depends_on: upload-merge-pipeline - commands: - - export VLLM_TEST_CLEAN_GPU_MEMORY="1" - - pytest -s -v tests/entrypoints/openai_api/test_qwen3_omni_realtime_websocket.py -m "advanced_model" --run-level "advanced_model" - agents: - queue: "mithril-h100-pool" - plugins: - - kubernetes: - podSpec: - containers: - - image: 936637512419.dkr.ecr.us-west-2.amazonaws.com/vllm-ci-pull-through-cache/q9t5s3a7/vllm-ci-test-repo:$BUILDKITE_COMMIT - resources: - limits: - nvidia.com/gpu: 2 - volumeMounts: - - name: devshm - mountPath: /dev/shm - - name: hf-cache - mountPath: /root/.cache/huggingface - env: - - name: HF_HOME - value: /root/.cache/huggingface - - name: HF_TOKEN - valueFrom: - secretKeyRef: - name: hf-token-secret - key: token - nodeSelector: - node.kubernetes.io/instance-type: gpu-h100-sxm - volumes: - - name: devshm - emptyDir: - medium: Memory - - name: hf-cache - hostPath: - path: /mnt/hf-cache - type: DirectoryOrCreate - - - label: "Diffusion Image Edit Test with H100 (1 GPU)" - timeout_in_minutes: 20 - depends_on: upload-merge-pipeline - commands: - - pytest -s -v tests/e2e/online_serving/test_image_gen_edit.py - agents: - queue: "mithril-h100-pool" - plugins: - - kubernetes: - podSpec: - containers: - - image: 936637512419.dkr.ecr.us-west-2.amazonaws.com/vllm-ci-pull-through-cache/q9t5s3a7/vllm-ci-test-repo:$BUILDKITE_COMMIT - resources: - limits: - nvidia.com/gpu: 1 - volumeMounts: - - name: devshm - mountPath: /dev/shm - - name: hf-cache - mountPath: /root/.cache/huggingface - env: - - name: HF_HOME - value: /root/.cache/huggingface - - name: HF_TOKEN - valueFrom: - secretKeyRef: - name: hf-token-secret - key: token - nodeSelector: - node.kubernetes.io/instance-type: gpu-h100-sxm - volumes: - - name: devshm - emptyDir: - medium: Memory - - name: hf-cache - hostPath: - path: /mnt/hf-cache - type: DirectoryOrCreate - - - label: "Bagel Model Test with H100 (Real Weights)" - timeout_in_minutes: 60 - depends_on: upload-merge-pipeline - commands: - - | - timeout 55m bash -c ' - set -e - export VLLM_TEST_CLEAN_GPU_MEMORY=1 - export VLLM_IMAGE_FETCH_TIMEOUT=60 - pytest -s -v tests/e2e/offline_inference/test_bagel_text2img.py -m "advanced_model" --run-level "advanced_model" - pytest -s -v tests/e2e/offline_inference/test_bagel_img2img.py tests/e2e/online_serving/test_bagel_online.py -m "advanced_model" --run-level "advanced_model" - ' - agents: - queue: "mithril-h100-pool" - plugins: - - kubernetes: - podSpec: - containers: - - image: 936637512419.dkr.ecr.us-west-2.amazonaws.com/vllm-ci-pull-through-cache/q9t5s3a7/vllm-ci-test-repo:$BUILDKITE_COMMIT - resources: - limits: - nvidia.com/gpu: 1 - volumeMounts: - - name: devshm - mountPath: /dev/shm - - name: hf-cache - mountPath: /root/.cache/huggingface - env: - - name: HF_HOME - value: /root/.cache/huggingface - - name: HF_TOKEN - valueFrom: - secretKeyRef: - name: hf-token-secret - key: token - nodeSelector: - node.kubernetes.io/instance-type: gpu-h100-sxm - volumes: - - name: devshm - emptyDir: - medium: Memory - - name: hf-cache - hostPath: - path: /mnt/hf-cache - type: DirectoryOrCreate - - - label: "Omni Sleep Mode Test with H100" - timeout_in_minutes: 30 - depends_on: upload-merge-pipeline - commands: - - export VLLM_TEST_CLEAN_GPU_MEMORY="1" - - pytest -s -v tests/e2e/offline_inference/test_omni_sleep_mode.py -m "advanced_model and H100 and omni" --run-level "advanced_model" - agents: - queue: "mithril-h100-pool" - plugins: - - kubernetes: - podSpec: - containers: - - image: 936637512419.dkr.ecr.us-west-2.amazonaws.com/vllm-ci-pull-through-cache/q9t5s3a7/vllm-ci-test-repo:$BUILDKITE_COMMIT - resources: - limits: - nvidia.com/gpu: 2 - volumeMounts: - - name: devshm - mountPath: /dev/shm - - name: hf-cache - mountPath: /root/.cache/huggingface - env: - - name: HF_HOME - value: /root/.cache/huggingface - - name: HF_TOKEN - valueFrom: - secretKeyRef: - name: hf-token-secret - key: token - nodeSelector: - node.kubernetes.io/instance-type: gpu-h100-sxm - volumes: - - name: devshm - emptyDir: - medium: Memory - - name: hf-cache - hostPath: - path: /mnt/hf-cache - type: DirectoryOrCreate - - - label: "Voxtral-TTS E2E Test" - timeout_in_minutes: 20 - depends_on: upload-merge-pipeline - commands: - - | - timeout 20m bash -c ' - export VLLM_LOGGING_LEVEL=DEBUG - pytest -s -v tests/e2e/online_serving/test_voxtral_tts.py tests/e2e/offline_inference/test_voxtral_tts.py -m "advanced_model" --run-level "advanced_model" - ' - agents: - queue: "mithril-h100-pool" - plugins: - - kubernetes: - podSpec: - containers: - - image: 936637512419.dkr.ecr.us-west-2.amazonaws.com/vllm-ci-pull-through-cache/q9t5s3a7/vllm-ci-test-repo:$BUILDKITE_COMMIT - resources: - limits: - nvidia.com/gpu: 1 - volumeMounts: - - name: devshm - mountPath: /dev/shm - - name: hf-cache - mountPath: /root/.cache/huggingface - env: - - name: HF_HOME - value: /root/.cache/huggingface - - name: HF_TOKEN - valueFrom: - secretKeyRef: - name: hf-token-secret - key: token - nodeSelector: - node.kubernetes.io/instance-type: gpu-h100-sxm - volumes: - - name: devshm - emptyDir: - medium: Memory - - name: hf-cache - hostPath: - path: /mnt/hf-cache - type: DirectoryOrCreate diff --git a/.buildkite/test-nightly.yml b/.buildkite/test-nightly.yml deleted file mode 100644 index 6f206422a4b..00000000000 --- a/.buildkite/test-nightly.yml +++ /dev/null @@ -1,807 +0,0 @@ -env: - VLLM_WORKER_MULTIPROC_METHOD: spawn - HF_HUB_DOWNLOAD_TIMEOUT: 300 - HF_HUB_ETAG_TIMEOUT: 60 - -steps: - # Group: collapses under one heading in the Buildkite UI; child steps still run in parallel. - - group: ":card_index_dividers: Omni Model Test" - key: nightly-omni-test-group - depends_on: upload-nightly-pipeline - if: build.env("NIGHTLY") == "1" || build.pull_request.labels includes "nightly-test" || build.pull_request.labels includes "omni-test" - steps: - - label: ":full_moon: Omni · Function Test with H100" - timeout_in_minutes: 90 - commands: - - pytest -s -v tests/e2e/ -m "full_model and H100 and omni" --run-level "full_model" --ignore=tests/e2e/accuracy - agents: - queue: "mithril-h100-pool" - plugins: - - kubernetes: - podSpec: - containers: - - image: 936637512419.dkr.ecr.us-west-2.amazonaws.com/vllm-ci-pull-through-cache/q9t5s3a7/vllm-ci-test-repo:$BUILDKITE_COMMIT - resources: - limits: - nvidia.com/gpu: 2 - volumeMounts: - - name: devshm - mountPath: /dev/shm - - name: hf-cache - mountPath: /root/.cache/huggingface - env: - - name: HF_HOME - value: /root/.cache/huggingface - - name: HF_TOKEN - valueFrom: - secretKeyRef: - name: hf-token-secret - key: token - nodeSelector: - node.kubernetes.io/instance-type: gpu-h100-sxm - volumes: - - name: devshm - emptyDir: - medium: Memory - - name: hf-cache - hostPath: - path: /mnt/hf-cache - type: DirectoryOrCreate - - - label: ":full_moon: Omni · Function Test with L4" - timeout_in_minutes: 90 - commands: - - export VLLM_ALLOW_LONG_MAX_MODEL_LEN="1" - - pytest -s -v tests/e2e/*/test_qwen2_5_omni_expansion.py --run-level "core_model" - agents: - queue: "gpu_4_queue" # g6.12xlarge instance on AWS, has 4 L4 GPU - plugins: - - docker#v5.2.0: - image: public.ecr.aws/q9t5s3a7/vllm-ci-test-repo:$BUILDKITE_COMMIT - always-pull: true - propagate-environment: true - shm-size: "8gb" - environment: - - "HF_HOME=/fsx/hf_cache" - - "HF_TOKEN" - volumes: - - "/fsx/hf_cache:/fsx/hf_cache" - - - label: ":full_moon: Omni · Doc Test with L4" - timeout_in_minutes: 90 - commands: - - export VLLM_ALLOW_LONG_MAX_MODEL_LEN="1" - - pytest -s -v tests/examples/ -m "full_model and omni and L4" --run-level "full_model" - agents: - queue: "gpu_4_queue" # g6.12xlarge instance on AWS, has 4 L4 GPU - plugins: - - docker#v5.2.0: - image: public.ecr.aws/q9t5s3a7/vllm-ci-test-repo:$BUILDKITE_COMMIT - always-pull: true - propagate-environment: true - shm-size: "8gb" - environment: - - "HF_HOME=/fsx/hf_cache" - - "HF_TOKEN" - volumes: - - "/fsx/hf_cache:/fsx/hf_cache" - - - label: ":full_moon: Omni · Doc Test with H100" - timeout_in_minutes: 90 - commands: - - pytest -s -v tests/examples/ -m "full_model and omni and H100" --run-level "full_model" - agents: - queue: "mithril-h100-pool" - plugins: - - kubernetes: - podSpec: - containers: - - image: 936637512419.dkr.ecr.us-west-2.amazonaws.com/vllm-ci-pull-through-cache/q9t5s3a7/vllm-ci-test-repo:$BUILDKITE_COMMIT - resources: - limits: - nvidia.com/gpu: 2 - volumeMounts: - - name: devshm - mountPath: /dev/shm - - name: hf-cache - mountPath: /root/.cache/huggingface - env: - - name: HF_HOME - value: /root/.cache/huggingface - - name: HF_TOKEN - valueFrom: - secretKeyRef: - name: hf-token-secret - key: token - nodeSelector: - node.kubernetes.io/instance-type: gpu-h100-sxm - volumes: - - name: devshm - emptyDir: - medium: Memory - - name: hf-cache - hostPath: - path: /mnt/hf-cache - type: DirectoryOrCreate - - - label: ":full_moon: Omni · Accuracy Test" - timeout_in_minutes: 180 - commands: - - export SEED_TTS_WER_EVAL=1 - - export SEED_TTS_EVAL_DEVICE=cuda:1 - - | - set +e - pytest -s -v tests/e2e/accuracy/qwen3_omni/test_qwen3_omni.py -m "full_model" --run-level full_model - EXIT=$$? - buildkite-agent artifact upload "tests/e2e/accuracy/qwen3_omni/results/qwen_omni_acc/*.json" - exit $$EXIT - agents: - queue: "mithril-h100-pool" - plugins: - - kubernetes: - podSpec: - containers: - - image: 936637512419.dkr.ecr.us-west-2.amazonaws.com/vllm-ci-pull-through-cache/q9t5s3a7/vllm-ci-test-repo:$BUILDKITE_COMMIT - resources: - limits: - nvidia.com/gpu: 2 - volumeMounts: - - name: devshm - mountPath: /dev/shm - - name: hf-cache - mountPath: /root/.cache/huggingface - env: - - name: HF_HOME - value: /root/.cache/huggingface - - name: HF_TOKEN - valueFrom: - secretKeyRef: - name: hf-token-secret - key: token - nodeSelector: - node.kubernetes.io/instance-type: gpu-h100-sxm - volumes: - - name: devshm - emptyDir: - medium: Memory - - name: hf-cache - hostPath: - path: /mnt/hf-cache - type: DirectoryOrCreate - - - label: ":full_moon: Omni · Perf Test" - key: nightly-omni-performance - timeout_in_minutes: 180 - commands: - - export BENCHMARK_DIR=tests/dfx/perf/results - - | - set +e - pytest -s -v tests/dfx/perf/scripts/run_benchmark.py --test-config-file tests/dfx/perf/tests/test_qwen_omni.json - EXIT=$$? - buildkite-agent artifact upload "tests/dfx/perf/results/*.json" - exit $$EXIT - agents: - queue: "mithril-h100-pool" - plugins: - - kubernetes: - podSpec: - containers: - - image: 936637512419.dkr.ecr.us-west-2.amazonaws.com/vllm-ci-pull-through-cache/q9t5s3a7/vllm-ci-test-repo:$BUILDKITE_COMMIT - resources: - limits: - nvidia.com/gpu: 2 - volumeMounts: - - name: devshm - mountPath: /dev/shm - - name: hf-cache - mountPath: /root/.cache/huggingface - env: - - name: HF_HOME - value: /root/.cache/huggingface - - name: HF_TOKEN - valueFrom: - secretKeyRef: - name: hf-token-secret - key: token - nodeSelector: - node.kubernetes.io/instance-type: gpu-h100-sxm - volumes: - - name: devshm - emptyDir: - medium: Memory - - name: hf-cache - hostPath: - path: /mnt/hf-cache - type: DirectoryOrCreate - - - - group: ":card_index_dividers: TTS Model Test" - key: nightly-tts-test-group - depends_on: upload-nightly-pipeline - if: build.env("NIGHTLY") == "1" || build.pull_request.labels includes "nightly-test" || build.pull_request.labels includes "tts-test" - steps: - - label: ":full_moon: TTS · Function Test" - timeout_in_minutes: 90 - commands: - - export VLLM_ALLOW_LONG_MAX_MODEL_LEN="1" - - pytest -s -v tests/e2e/ -m "full_model and L4 and omni" -k "not test_qwen2_5" --run-level "full_model" --ignore=tests/e2e/accuracy - agents: - queue: "gpu_1_queue" # g6.12xlarge instance on AWS, has 4 L4 GPU - plugins: - - docker#v5.2.0: - image: public.ecr.aws/q9t5s3a7/vllm-ci-test-repo:$BUILDKITE_COMMIT - always-pull: true - propagate-environment: true - shm-size: "8gb" - environment: - - "HF_HOME=/fsx/hf_cache" - - "HF_TOKEN" - volumes: - - "/fsx/hf_cache:/fsx/hf_cache" - - - label: ":full_moon: TTS · Perf Test" - key: nightly-tts-performance - timeout_in_minutes: 180 - commands: - - export BENCHMARK_DIR=tests/dfx/perf/results - - export VLLM_ALLOW_LONG_MAX_MODEL_LEN="1" - - | - set +e - pytest -s -v tests/dfx/perf/scripts/run_benchmark.py --test-config-file tests/dfx/perf/tests/test_tts.json - EXIT=$$? - buildkite-agent artifact upload "tests/dfx/perf/results/*.json" - exit $$EXIT - agents: - queue: "mithril-h100-pool" - plugins: - - kubernetes: - podSpec: - containers: - - image: 936637512419.dkr.ecr.us-west-2.amazonaws.com/vllm-ci-pull-through-cache/q9t5s3a7/vllm-ci-test-repo:$BUILDKITE_COMMIT - resources: - limits: - nvidia.com/gpu: 1 - volumeMounts: - - name: devshm - mountPath: /dev/shm - - name: hf-cache - mountPath: /root/.cache/huggingface - env: - - name: HF_HOME - value: /root/.cache/huggingface - - name: HF_TOKEN - valueFrom: - secretKeyRef: - name: hf-token-secret - key: token - nodeSelector: - node.kubernetes.io/instance-type: gpu-h100-sxm - volumes: - - name: devshm - emptyDir: - medium: Memory - - name: hf-cache - hostPath: - path: /mnt/hf-cache - type: DirectoryOrCreate - - # Diffusion X2I suite: x2i / x2a / x2t and related non-video paths; x2v is only in "Diffusion X2V Model Test" below. - - group: ":card_index_dividers: Diffusion X2I(&A&T) Model Test" - key: nightly-diffusion-x2iat-group - depends_on: upload-nightly-pipeline - if: >- - build.env("NIGHTLY") == "1" || - build.pull_request.labels includes "nightly-test" || - build.pull_request.labels includes "diffusion-x2iat-test" - steps: - - label: ":full_moon: Diffusion X2I(&A&T) · Function Test with H100" - timeout_in_minutes: 120 - commands: - - pytest -sv tests/e2e/ -k "not test_wan and not test_bagel_expansion and not hunyuan" -m "full_model and diffusion and H100" --run-level "full_model" --ignore=tests/e2e/accuracy - agents: - queue: "mithril-h100-pool" - plugins: - - kubernetes: - podSpec: - containers: - - image: 936637512419.dkr.ecr.us-west-2.amazonaws.com/vllm-ci-pull-through-cache/q9t5s3a7/vllm-ci-test-repo:$BUILDKITE_COMMIT - resources: - limits: - nvidia.com/gpu: 2 - volumeMounts: - - name: devshm - mountPath: /dev/shm - - name: hf-cache - mountPath: /root/.cache/huggingface - env: - - name: HF_HOME - value: /root/.cache/huggingface - - name: HF_TOKEN - valueFrom: - secretKeyRef: - name: hf-token-secret - key: token - nodeSelector: - node.kubernetes.io/instance-type: gpu-h100-sxm - volumes: - - name: devshm - emptyDir: - medium: Memory - - name: hf-cache - hostPath: - path: /mnt/hf-cache - type: DirectoryOrCreate - - - label: ":full_moon: Diffusion X2I(&A&T) · Bagel Function Test with H100" - timeout_in_minutes: 120 - commands: - - pytest -sv tests/e2e/online_serving/test_bagel_expansion.py -m "full_model and diffusion and H100" --run-level "full_model" - agents: - queue: "mithril-h100-pool" - plugins: - - kubernetes: - podSpec: - containers: - - image: 936637512419.dkr.ecr.us-west-2.amazonaws.com/vllm-ci-pull-through-cache/q9t5s3a7/vllm-ci-test-repo:$BUILDKITE_COMMIT - resources: - limits: - nvidia.com/gpu: 3 - volumeMounts: - - name: devshm - mountPath: /dev/shm - - name: hf-cache - mountPath: /root/.cache/huggingface - env: - - name: HF_HOME - value: /root/.cache/huggingface - - name: HF_TOKEN - valueFrom: - secretKeyRef: - name: hf-token-secret - key: token - nodeSelector: - node.kubernetes.io/instance-type: gpu-h100-sxm - volumes: - - name: devshm - emptyDir: - medium: Memory - - name: hf-cache - hostPath: - path: /mnt/hf-cache - type: DirectoryOrCreate - - - label: ":full_moon: Diffusion X2I(&A&T) · Function Test with L4" - timeout_in_minutes: 60 - commands: - - pytest -sv tests/e2e/ -k "not test_wan and not test_bagel_expansion and not hunyuan" -m "full_model and diffusion and L4" --run-level "full_model" --ignore=tests/e2e/accuracy - agents: - queue: "gpu_4_queue" # g6.12xlarge instance on AWS, has 4 L4 GPU - plugins: - - docker#v5.2.0: - image: public.ecr.aws/q9t5s3a7/vllm-ci-test-repo:$BUILDKITE_COMMIT - always-pull: true - propagate-environment: true - shm-size: "8gb" - environment: - - "HF_HOME=/fsx/hf_cache" - - "HF_TOKEN" - volumes: - - "/fsx/hf_cache:/fsx/hf_cache" - - - label: ":full_moon: Diffusion X2I(&A&T) · Doc Test" - timeout_in_minutes: 60 - commands: - - export VLLM_TEST_CLEAN_GPU_MEMORY="1" - - pytest -s -v tests/examples/*/test_text_to_image.py -m "full_model and example and H100" --run-level "full_model" - agents: - queue: "mithril-h100-pool" - plugins: - - kubernetes: - podSpec: - containers: - - image: 936637512419.dkr.ecr.us-west-2.amazonaws.com/vllm-ci-pull-through-cache/q9t5s3a7/vllm-ci-test-repo:$BUILDKITE_COMMIT - resources: - limits: - nvidia.com/gpu: 2 - volumeMounts: - - name: devshm - mountPath: /dev/shm - - name: hf-cache - mountPath: /root/.cache/huggingface - env: - - name: HF_HOME - value: /root/.cache/huggingface - - name: HF_TOKEN - valueFrom: - secretKeyRef: - name: hf-token-secret - key: token - nodeSelector: - node.kubernetes.io/instance-type: gpu-h100-sxm - volumes: - - name: devshm - emptyDir: - medium: Memory - - name: hf-cache - hostPath: - path: /mnt/hf-cache - type: DirectoryOrCreate - - - label: ":full_moon: Diffusion X2I(&A&T) · GEBench Accuracy Test" - timeout_in_minutes: 60 - commands: - - pytest -s -v tests/e2e/accuracy/test_gebench_h100_smoke.py --run-level full_model --gebench-model Qwen/Qwen-Image-2512 --accuracy-judge-model QuantTrio/Qwen3-VL-30B-A3B-Instruct-AWQ --accuracy-gpu 0 --gebench-port 8093 --accuracy-workers 1 - - buildkite-agent artifact upload "tests/e2e/accuracy/artifacts/gebench_qwen-image-2512/summary*.json" - agents: - queue: "mithril-h100-pool" - plugins: - - kubernetes: - podSpec: - containers: - - image: 936637512419.dkr.ecr.us-west-2.amazonaws.com/vllm-ci-pull-through-cache/q9t5s3a7/vllm-ci-test-repo:$BUILDKITE_COMMIT - resources: - limits: - nvidia.com/gpu: 1 - volumeMounts: - - name: devshm - mountPath: /dev/shm - - name: hf-cache - mountPath: /root/.cache/huggingface - env: - - name: HF_HOME - value: /root/.cache/huggingface - - name: HF_TOKEN - valueFrom: - secretKeyRef: - name: hf-token-secret - key: token - nodeSelector: - node.kubernetes.io/instance-type: gpu-h100-sxm - volumes: - - name: devshm - emptyDir: - medium: Memory - - name: hf-cache - hostPath: - path: /mnt/hf-cache - type: DirectoryOrCreate - - - label: ":full_moon: Diffusion X2I(&A&T) · GEdit-Bench Accuracy Test" - timeout_in_minutes: 60 - commands: - - pytest -s -v tests/e2e/accuracy/test_gedit_bench_h100_smoke.py --run-level full_model --gedit-model Qwen/Qwen-Image-Edit --accuracy-judge-model QuantTrio/Qwen3-VL-30B-A3B-Instruct-AWQ --accuracy-gpu 0 --gedit-port 8093 --gedit-samples-per-group 20 --accuracy-workers 1 - - buildkite-agent artifact upload "tests/e2e/accuracy/artifacts/gedit_scores_qwen-image-edit/qwen-image-edit_all_all_vie_score_*.csv" - - buildkite-agent artifact upload "tests/e2e/accuracy/artifacts/gedit_scores_qwen-image-edit/qwen-image-edit_all_all_summary_*.json" - agents: - queue: "mithril-h100-pool" - plugins: - - kubernetes: - podSpec: - containers: - - image: 936637512419.dkr.ecr.us-west-2.amazonaws.com/vllm-ci-pull-through-cache/q9t5s3a7/vllm-ci-test-repo:$BUILDKITE_COMMIT - resources: - limits: - nvidia.com/gpu: 1 - volumeMounts: - - name: devshm - mountPath: /dev/shm - - name: hf-cache - mountPath: /root/.cache/huggingface - env: - - name: HF_HOME - value: /root/.cache/huggingface - - name: VLLM_HTTP_TIMEOUT_KEEP_ALIVE - value: "120" - - name: HF_TOKEN - valueFrom: - secretKeyRef: - name: hf-token-secret - key: token - nodeSelector: - node.kubernetes.io/instance-type: gpu-h100-sxm - volumes: - - name: devshm - emptyDir: - medium: Memory - - name: hf-cache - hostPath: - path: /mnt/hf-cache - type: DirectoryOrCreate - - - label: ":full_moon: Diffusion X2I(&A&T) · Accuracy Test" - timeout_in_minutes: 180 - commands: - - pytest -s -v tests/e2e/accuracy/test_qwen_image*.py --run-level full_model - agents: - queue: "mithril-h100-pool" - plugins: - - kubernetes: - podSpec: - containers: - - image: 936637512419.dkr.ecr.us-west-2.amazonaws.com/vllm-ci-pull-through-cache/q9t5s3a7/vllm-ci-test-repo:$BUILDKITE_COMMIT - resources: - limits: - nvidia.com/gpu: 1 - volumeMounts: - - name: devshm - mountPath: /dev/shm - - name: hf-cache - mountPath: /root/.cache/huggingface - env: - - name: HF_HOME - value: /root/.cache/huggingface - - name: VLLM_HTTP_TIMEOUT_KEEP_ALIVE - value: "120" - - name: HF_TOKEN - valueFrom: - secretKeyRef: - name: hf-token-secret - key: token - nodeSelector: - node.kubernetes.io/instance-type: gpu-h100-sxm - volumes: - - name: devshm - emptyDir: - medium: Memory - - name: hf-cache - hostPath: - path: /mnt/hf-cache - type: DirectoryOrCreate - - - label: ":full_moon: Diffusion X2I(&A&T) · Perf Test" - key: nightly-diffusion-x2iat-performance - timeout_in_minutes: 180 - commands: - - export DIFFUSION_BENCHMARK_DIR=tests/dfx/perf/results - - export DIFFUSION_ATTENTION_BACKEND=FLASH_ATTN - - export CACHE_DIT_VERSION=1.3.0 - # [HACK]: run upload in the same command block as pytest. - # Because `exit` aborts the entire commands list. - - | - set +e - pytest -s -v tests/dfx/perf/scripts/run_diffusion_benchmark.py --test-config-file tests/dfx/perf/tests/test_qwen_image_vllm_omni.json - EXIT1=$$? - pytest -s -v tests/dfx/perf/scripts/run_diffusion_benchmark.py --test-config-file tests/dfx/perf/tests/test_qwen_image_edit_vllm_omni.json - EXIT2=$$? - pytest -s -v tests/dfx/perf/scripts/run_diffusion_benchmark.py --test-config-file tests/dfx/perf/tests/test_qwen_image_edit_2509_vllm_omni.json - EXIT3=$$? - pytest -s -v tests/dfx/perf/scripts/run_diffusion_benchmark.py --test-config-file tests/dfx/perf/tests/test_qwen_image_layered_vllm_omni.json - EXIT4=$$? - buildkite-agent artifact upload "tests/dfx/perf/results/diffusion_result_*.json" - buildkite-agent artifact upload "tests/dfx/perf/results/logs/*.log" - exit $$((EXIT1 | EXIT2 | EXIT3 | EXIT4)) - agents: - queue: "mithril-h100-pool" - plugins: - - kubernetes: - podSpec: - containers: - - image: 936637512419.dkr.ecr.us-west-2.amazonaws.com/vllm-ci-pull-through-cache/q9t5s3a7/vllm-ci-test-repo:$BUILDKITE_COMMIT - resources: - limits: - nvidia.com/gpu: 4 - volumeMounts: - - name: devshm - mountPath: /dev/shm - - name: hf-cache - mountPath: /root/.cache/huggingface - env: - - name: HF_HOME - value: /root/.cache/huggingface - - name: HF_TOKEN - valueFrom: - secretKeyRef: - name: hf-token-secret - key: token - nodeSelector: - node.kubernetes.io/instance-type: gpu-h100-sxm - volumes: - - name: devshm - emptyDir: - medium: Memory - - name: hf-cache - hostPath: - path: /mnt/hf-cache - type: DirectoryOrCreate - - # Diffusion x2v only (Wan, HunyuanVideo, …). x2i/x2a/x2t live in the X2I group above, not here. - - group: ":card_index_dividers: Diffusion X2V Model Test" - key: nightly-diffusion-x2v-group - depends_on: upload-nightly-pipeline - if: >- - build.env("NIGHTLY") == "1" || - build.pull_request.labels includes "nightly-test" || - build.pull_request.labels includes "diffusion-x2v-test" - steps: - - label: ":full_moon: Diffusion X2V · Function Test" - timeout_in_minutes: 90 - commands: - - pytest -s -v tests/e2e/online_serving/test_wan22_expansion.py tests/e2e/online_serving/test_wan_2_1_vace_expansion.py tests/e2e/online_serving/test_hunyuan_video_15_expansion.py --run-level "full_model" - agents: - queue: "mithril-h100-pool" - plugins: - - kubernetes: - podSpec: - containers: - - image: 936637512419.dkr.ecr.us-west-2.amazonaws.com/vllm-ci-pull-through-cache/q9t5s3a7/vllm-ci-test-repo:$BUILDKITE_COMMIT - resources: - limits: - nvidia.com/gpu: 2 - volumeMounts: - - name: devshm - mountPath: /dev/shm - - name: hf-cache - mountPath: /root/.cache/huggingface - env: - - name: HF_HOME - value: /root/.cache/huggingface - - name: HF_TOKEN - valueFrom: - secretKeyRef: - name: hf-token-secret - key: token - nodeSelector: - node.kubernetes.io/instance-type: gpu-h100-sxm - volumes: - - name: devshm - emptyDir: - medium: Memory - - name: hf-cache - hostPath: - path: /mnt/hf-cache - type: DirectoryOrCreate - - - label: ":full_moon: Diffusion X2V · Accuracy Test" - timeout_in_minutes: 180 - commands: - - pytest -s -v tests/e2e/accuracy/wan22_i2v/test_wan22_i2v_video_similarity.py -m full_model --run-level full_model - - pytest -s -v tests/e2e/accuracy/test_ltx2_3_video_similarity.py -m advanced_model --run-level advanced_model - agents: - queue: "mithril-h100-pool" - plugins: - - kubernetes: - podSpec: - containers: - - image: 936637512419.dkr.ecr.us-west-2.amazonaws.com/vllm-ci-pull-through-cache/q9t5s3a7/vllm-ci-test-repo:$BUILDKITE_COMMIT - resources: - limits: - nvidia.com/gpu: 2 - volumeMounts: - - name: devshm - mountPath: /dev/shm - - name: hf-cache - mountPath: /root/.cache/huggingface - env: - - name: HF_HOME - value: /root/.cache/huggingface - - name: HF_TOKEN - valueFrom: - secretKeyRef: - name: hf-token-secret - key: token - nodeSelector: - node.kubernetes.io/instance-type: gpu-h100-sxm - volumes: - - name: devshm - emptyDir: - medium: Memory - - name: hf-cache - hostPath: - path: /mnt/hf-cache - type: DirectoryOrCreate - - - label: ":full_moon: Diffusion X2V · Perf Test" - key: nightly-diffusion-x2v-performance - timeout_in_minutes: 180 - commands: - - export DIFFUSION_BENCHMARK_DIR=tests/dfx/perf/results - - export DIFFUSION_ATTENTION_BACKEND=FLASH_ATTN - - | - set +e - pytest -s -v tests/dfx/perf/scripts/run_diffusion_benchmark.py --test-config-file tests/dfx/perf/tests/test_wan22_i2v_vllm_omni.json - EXIT1=$$? - buildkite-agent artifact upload "tests/dfx/perf/results/diffusion_result_*.json" - buildkite-agent artifact upload "tests/dfx/perf/results/logs/*.log" - exit $$EXIT1 - agents: - queue: "mithril-h100-pool" - plugins: - - kubernetes: - podSpec: - containers: - - image: 936637512419.dkr.ecr.us-west-2.amazonaws.com/vllm-ci-pull-through-cache/q9t5s3a7/vllm-ci-test-repo:$BUILDKITE_COMMIT - resources: - limits: - nvidia.com/gpu: 2 - volumeMounts: - - name: devshm - mountPath: /dev/shm - - name: hf-cache - mountPath: /root/.cache/huggingface - env: - - name: HF_HOME - value: /root/.cache/huggingface - - name: HF_TOKEN - valueFrom: - secretKeyRef: - name: hf-token-secret - key: token - nodeSelector: - node.kubernetes.io/instance-type: gpu-h100-sxm - volumes: - - name: devshm - emptyDir: - medium: Memory - - name: hf-cache - hostPath: - path: /mnt/hf-cache - type: DirectoryOrCreate - - - label: ":bar_chart: Testcase Statistics" - key: nightly-testcase-statistics - timeout_in_minutes: 120 - depends_on: upload-nightly-pipeline - if: build.env("NIGHTLY") == "1" || build.pull_request.labels includes "nightly-test" - commands: - - python tools/nightly/buildkite_testcase_statistics.py -o tests/dfx/perf/results/buildkite_testcase_statistics.html - - buildkite-agent artifact upload "tests/dfx/perf/results/*.html" - agents: - queue: "mithril-h100-pool" - plugins: - - kubernetes: - podSpec: - containers: - - image: 936637512419.dkr.ecr.us-west-2.amazonaws.com/vllm-ci-pull-through-cache/q9t5s3a7/vllm-ci-test-repo:$BUILDKITE_COMMIT - resources: - limits: - nvidia.com/gpu: 2 - volumeMounts: - - name: devshm - mountPath: /dev/shm - - name: hf-cache - mountPath: /root/.cache/huggingface - env: - - name: HF_HOME - value: /root/.cache/huggingface - - name: HF_TOKEN - valueFrom: - secretKeyRef: - name: hf-token-secret - key: token - nodeSelector: - node.kubernetes.io/instance-type: gpu-h100-sxm - volumes: - - name: devshm - emptyDir: - medium: Memory - - name: hf-cache - hostPath: - path: /mnt/hf-cache - type: DirectoryOrCreate - - # No need to run this step for PRs with label nightly-test - - label: ":email: Nightly Collection & Email" - key: nightly-perf-distribution - depends_on: - - nightly-omni-performance - - nightly-tts-performance - - nightly-diffusion-x2iat-performance - - nightly-diffusion-x2v-performance - - nightly-testcase-statistics - if: build.env("NIGHTLY") == "1" - commands: - - pip install openpyxl - - export DEFAULT_INPUT_DIR=tests/dfx/perf/results - - export DEFAULT_OUTPUT_DIR=tests/dfx/perf/results - - buildkite-agent artifact download "tests/dfx/perf/results/*.json" . --step nightly-tts-performance - - buildkite-agent artifact download "tests/dfx/perf/results/*.json" . --step nightly-omni-performance - - buildkite-agent artifact download "tests/dfx/perf/results/*.json" . --step nightly-diffusion-x2iat-performance - - buildkite-agent artifact download "tests/dfx/perf/results/*.json" . --step nightly-diffusion-x2v-performance - - buildkite-agent artifact download "tests/dfx/perf/results/*.html" . --step nightly-testcase-statistics - - python tools/nightly/generate_nightly_perf_excel.py - - python tools/nightly/generate_nightly_perf_html.py - - python tools/nightly/send_nightly_email.py --report-file "tests/dfx/perf/results/*.xlsx, tests/dfx/perf/results/*.html" - - buildkite-agent artifact upload "tests/dfx/perf/results/*.xlsx" - - buildkite-agent artifact upload "tests/dfx/perf/results/*.html" - agents: - queue: "cpu_queue_premerge" diff --git a/.buildkite/test-ready.yml b/.buildkite/test-ready.yml deleted file mode 100644 index 080f18885ef..00000000000 --- a/.buildkite/test-ready.yml +++ /dev/null @@ -1,621 +0,0 @@ -env: - VLLM_WORKER_MULTIPROC_METHOD: spawn - HF_HUB_DOWNLOAD_TIMEOUT: 300 - HF_HUB_ETAG_TIMEOUT: 60 - -steps: - - label: "Simple Unit Test" - depends_on: upload-ready-pipeline - commands: - - "timeout 20m pytest -v -s -m 'core_model and cpu' --cov=vllm_omni --cov-branch --cov-report=term-missing --cov-report=html --cov-report=xml" - agents: - queue: "gpu_1_queue" - plugins: - - docker#v5.2.0: - image: public.ecr.aws/q9t5s3a7/vllm-ci-test-repo:$BUILDKITE_COMMIT - always-pull: true - propagate-environment: true - environment: - - "HF_HOME=/fsx/hf_cache" - - "HF_TOKEN" - volumes: - - "/fsx/hf_cache:/fsx/hf_cache" - - - label: "CUDA Unit Test with single card" - depends_on: upload-ready-pipeline - commands: - - timeout 10m pytest -v -s -m 'core_model and cuda and L4 and not distributed_cuda' --ignore=tests/e2e --ignore=tests/engine/test_async_omni_engine_abort.py --cov=vllm_omni --cov-branch --cov-report=term-missing --cov-report=html --cov-report=xml - agents: - queue: "gpu_1_queue" - plugins: - - docker#v5.2.0: - image: public.ecr.aws/q9t5s3a7/vllm-ci-test-repo:$BUILDKITE_COMMIT - always-pull: true - propagate-environment: true - environment: - - "HF_HOME=/fsx/hf_cache" - volumes: - - "/fsx/hf_cache:/fsx/hf_cache" - - - label: "CUDA Unit Test with multi cards" - depends_on: upload-ready-pipeline - commands: - - timeout 10m pytest -v -s -m 'core_model and cuda and L4 and distributed_cuda' --ignore=tests/e2e --cov=vllm_omni --cov-branch --cov-report=term-missing --cov-report=html --cov-report=xml - agents: - queue: "gpu_4_queue" - plugins: - - docker#v5.2.0: - image: public.ecr.aws/q9t5s3a7/vllm-ci-test-repo:$BUILDKITE_COMMIT - always-pull: true - propagate-environment: true - environment: - - "HF_HOME=/fsx/hf_cache" - volumes: - - "/fsx/hf_cache:/fsx/hf_cache" - - - label: "Diffusion Model Test" - depends_on: upload-ready-pipeline - commands: - - timeout 30m pytest -s -v tests/e2e/offline_inference/test_t2i_model.py -m "core_model and diffusion" --run-level "core_model" - agents: - queue: "gpu_1_queue" - plugins: - - docker#v5.2.0: - image: public.ecr.aws/q9t5s3a7/vllm-ci-test-repo:$BUILDKITE_COMMIT - always-pull: true - propagate-environment: true - environment: - - "HF_HOME=/fsx/hf_cache" - - "HF_TOKEN" - volumes: - - "/fsx/hf_cache:/fsx/hf_cache" - - - label: "Diffusion Batching Test" - depends_on: upload-ready-pipeline - commands: - - timeout 20m pytest -s -v tests/e2e/offline_inference/test_qwen_image_diffusion_batching.py -m "core_model and diffusion" --run-level "core_model" - agents: - queue: "gpu_1_queue" # g6.4xlarge instance on AWS, has 1 L4 GPU - plugins: - - docker#v5.2.0: - image: public.ecr.aws/q9t5s3a7/vllm-ci-test-repo:$BUILDKITE_COMMIT - always-pull: true - propagate-environment: true - environment: - - "HF_HOME=/fsx/hf_cache" - - "HF_TOKEN" - volumes: - - "/fsx/hf_cache:/fsx/hf_cache" - - - label: "Custom Pipeline Test" - depends_on: upload-ready-pipeline - commands: - - timeout 20m pytest -s -v tests/e2e/offline_inference/custom_pipeline/ -m "core_model" - agents: - queue: "gpu_1_queue" - plugins: - - docker#v5.2.0: - image: public.ecr.aws/q9t5s3a7/vllm-ci-test-repo:$BUILDKITE_COMMIT - always-pull: true - propagate-environment: true - environment: - - "HF_HOME=/fsx/hf_cache" - volumes: - - "/fsx/hf_cache:/fsx/hf_cache" - - - label: "Diffusion Model CPU offloading Test" - depends_on: upload-ready-pipeline - commands: - - timeout 10m pytest -s -v tests/e2e/offline_inference/test_diffusion_cpu_offload.py - agents: - queue: "gpu_1_queue" # g6.4xlarge instance on AWS, has 1 L4 GPU - plugins: - - docker#v5.2.0: - image: public.ecr.aws/q9t5s3a7/vllm-ci-test-repo:$BUILDKITE_COMMIT - always-pull: true - propagate-environment: true - environment: - - "HF_HOME=/fsx/hf_cache" - - "HF_TOKEN" - volumes: - - "/fsx/hf_cache:/fsx/hf_cache" - - - label: "Diffusion Cache Backend Test" - depends_on: upload-ready-pipeline - commands: - - timeout 15m pytest -s -v -m 'core_model and cache and diffusion and not distributed_cuda and L4' - agents: - queue: "gpu_1_queue" # g6.4xlarge instance on AWS, has 1 L4 GPU - plugins: - - docker#v5.2.0: - image: public.ecr.aws/q9t5s3a7/vllm-ci-test-repo:$BUILDKITE_COMMIT - always-pull: true - propagate-environment: true - environment: - - "HF_HOME=/fsx/hf_cache" - - "HF_TOKEN" - volumes: - - "/fsx/hf_cache:/fsx/hf_cache" - - - label: "Diffusion Sequence Parallelism Test" - depends_on: upload-ready-pipeline - commands: - - timeout 20m pytest -s -v tests/e2e/offline_inference/test_sequence_parallel.py -m core_model - agents: - queue: "gpu_4_queue" # g6.12xlarge instance on AWS, has 4 L4 GPU - plugins: - - docker#v5.2.0: - image: public.ecr.aws/q9t5s3a7/vllm-ci-test-repo:$BUILDKITE_COMMIT - always-pull: true - propagate-environment: true - shm-size: "8gb" - environment: - - "HF_HOME=/fsx/hf_cache" - - "HF_TOKEN" - volumes: - - "/fsx/hf_cache:/fsx/hf_cache" - - - - label: "Engine Test" - depends_on: upload-ready-pipeline - commands: - - | - timeout 15m bash -c ' - pytest -s -v tests/engine/test_async_omni_engine_abort.py - ' - agents: - queue: "gpu_1_queue" # g6.12xlarge instance on AWS, has 4 L4 GPU - plugins: - - docker#v5.2.0: - image: public.ecr.aws/q9t5s3a7/vllm-ci-test-repo:$BUILDKITE_COMMIT - always-pull: true - propagate-environment: true - shm-size: "8gb" - environment: - - "HF_HOME=/fsx/hf_cache" - - "HF_TOKEN" - volumes: - - "/fsx/hf_cache:/fsx/hf_cache" - - - label: "Omni Model Test with H100" - depends_on: upload-ready-pipeline - commands: - - | - timeout 20m bash -c ' - pytest -s -v tests/e2e/online_serving/test_qwen3_omni.py -m "core_model" --run-level "core_model" - ' - agents: - queue: "mithril-h100-pool" - plugins: - - kubernetes: - podSpec: - containers: - - image: 936637512419.dkr.ecr.us-west-2.amazonaws.com/vllm-ci-pull-through-cache/q9t5s3a7/vllm-ci-test-repo:$BUILDKITE_COMMIT - resources: - limits: - nvidia.com/gpu: 2 - volumeMounts: - - name: devshm - mountPath: /dev/shm - - name: hf-cache - mountPath: /root/.cache/huggingface - env: - - name: HF_HOME - value: /root/.cache/huggingface - nodeSelector: - node.kubernetes.io/instance-type: gpu-h100-sxm - volumes: - - name: devshm - emptyDir: - medium: Memory - - name: hf-cache - hostPath: - path: /mnt/hf-cache - type: DirectoryOrCreate - - - label: "MiMo-Audio E2E Test with H100" - depends_on: upload-ready-pipeline - commands: - - | - timeout 30m bash -c ' - export VLLM_LOGGING_LEVEL=DEBUG - pytest -s -v tests/e2e/online_serving/test_mimo_audio.py -m "core_model" --run-level "core_model" - ' - agents: - queue: "mithril-h100-pool" - plugins: - - kubernetes: - podSpec: - containers: - - image: 936637512419.dkr.ecr.us-west-2.amazonaws.com/vllm-ci-pull-through-cache/q9t5s3a7/vllm-ci-test-repo:$BUILDKITE_COMMIT - resources: - limits: - nvidia.com/gpu: 1 - volumeMounts: - - name: devshm - mountPath: /dev/shm - - name: hf-cache - mountPath: /root/.cache/huggingface - env: - - name: HF_HOME - value: /root/.cache/huggingface - - name: HF_TOKEN - valueFrom: - secretKeyRef: - name: hf-token-secret - key: token - nodeSelector: - node.kubernetes.io/instance-type: gpu-h100-sxm - volumes: - - name: devshm - emptyDir: - medium: Memory - - name: hf-cache - hostPath: - path: /mnt/hf-cache - type: DirectoryOrCreate - - - label: "Qwen3-TTS E2E Test" - depends_on: upload-ready-pipeline - commands: - - | - timeout 20m bash -c ' - export VLLM_LOGGING_LEVEL=DEBUG - export VLLM_ALLOW_LONG_MAX_MODEL_LEN="1" - pytest -s -v tests/e2e/online_serving/test_qwen3_tts_customvoice.py -m "core_model" --run-level "core_model" - ' - agents: - queue: "gpu_1_queue" - plugins: - - docker#v5.2.0: - image: public.ecr.aws/q9t5s3a7/vllm-ci-test-repo:$BUILDKITE_COMMIT - always-pull: true - propagate-environment: true - shm-size: "8gb" - environment: - - "HF_HOME=/fsx/hf_cache" - - "HF_TOKEN" - volumes: - - "/fsx/hf_cache:/fsx/hf_cache" - - - label: "VoxCPM E2E Test" - timeout_in_minutes: 20 - depends_on: upload-ready-pipeline - commands: - - | - timeout 20m bash -c ' - pip install voxcpm - export VLLM_LOGGING_LEVEL=DEBUG - export VLLM_WORKER_MULTIPROC_METHOD=spawn - pytest -s -v tests/e2e/offline_inference/test_voxcpm.py -m "core_model" --run-level "core_model" - ' - agents: - queue: "gpu_1_queue" - plugins: - - docker#v5.2.0: - image: public.ecr.aws/q9t5s3a7/vllm-ci-test-repo:$BUILDKITE_COMMIT - always-pull: true - propagate-environment: true - shm-size: "8gb" - environment: - - "HF_HOME=/fsx/hf_cache" - - "HF_TOKEN" - volumes: - - "/fsx/hf_cache:/fsx/hf_cache" - - - label: "VoxCPM2 Native AR E2E Test" - timeout_in_minutes: 20 - depends_on: upload-ready-pipeline - commands: - - | - timeout 20m bash -c ' - pip install voxcpm - export VLLM_LOGGING_LEVEL=DEBUG - export VLLM_WORKER_MULTIPROC_METHOD=spawn - pytest -s -v tests/e2e/offline_inference/test_voxcpm2.py -m "core_model" --run-level "core_model" - ' - agents: - queue: "gpu_1_queue" - plugins: - - docker#v5.2.0: - image: public.ecr.aws/q9t5s3a7/vllm-ci-test-repo:$BUILDKITE_COMMIT - always-pull: true - propagate-environment: true - shm-size: "8gb" - environment: - - "HF_HOME=/fsx/hf_cache" - - "HF_TOKEN" - volumes: - - "/fsx/hf_cache:/fsx/hf_cache" - - - label: "OmniVoice E2E Test" - timeout_in_minutes: 20 - depends_on: upload-ready-pipeline - commands: - - | - timeout 20m bash -c ' - export VLLM_LOGGING_LEVEL=DEBUG - pytest -s -v tests/e2e/online_serving/test_omnivoice.py -m "core_model" --run-level "core_model" - ' - agents: - queue: "gpu_1_queue" - plugins: - - docker#v5.2.0: - image: public.ecr.aws/q9t5s3a7/vllm-ci-test-repo:$BUILDKITE_COMMIT - always-pull: true - propagate-environment: true - shm-size: "8gb" - environment: - - "HF_HOME=/fsx/hf_cache" - volumes: - - "/fsx/hf_cache:/fsx/hf_cache" - - - label: "Qwen3-TTS Base E2E Test (ModelRunner V2)" - depends_on: upload-ready-pipeline - soft_fail: - - exit_status: 1 - commands: - - | - timeout 20m bash -c ' - export VLLM_LOGGING_LEVEL=DEBUG - export VLLM_WORKER_MULTIPROC_METHOD=spawn - export VLLM_ALLOW_LONG_MAX_MODEL_LEN="1" - export VLLM_OMNI_USE_V2_RUNNER="1" - pytest -s -v tests/e2e/online_serving/test_qwen3_tts_base.py -m "core_model" --run-level "core_model" - ' - agents: - queue: "gpu_1_queue" - plugins: - - docker#v5.2.0: - image: public.ecr.aws/q9t5s3a7/vllm-ci-test-repo:$BUILDKITE_COMMIT - always-pull: true - propagate-environment: true - shm-size: "8gb" - environment: - - "HF_HOME=/fsx/hf_cache" - - "HF_TOKEN" - volumes: - - "/fsx/hf_cache:/fsx/hf_cache" - - - label: "Voxtral-TTS E2E Test" - timeout_in_minutes: 20 - depends_on: upload-ready-pipeline - commands: - - | - timeout 20m bash -c ' - export VLLM_LOGGING_LEVEL=DEBUG - pytest -s -v tests/e2e/online_serving/test_voxtral_tts.py -m "core_model" --run-level "core_model" - ' - agents: - queue: "mithril-h100-pool" - plugins: - - kubernetes: - podSpec: - containers: - - image: 936637512419.dkr.ecr.us-west-2.amazonaws.com/vllm-ci-pull-through-cache/q9t5s3a7/vllm-ci-test-repo:$BUILDKITE_COMMIT - resources: - limits: - nvidia.com/gpu: 1 - volumeMounts: - - name: devshm - mountPath: /dev/shm - - name: hf-cache - mountPath: /root/.cache/huggingface - env: - - name: HF_HOME - value: /root/.cache/huggingface - nodeSelector: - node.kubernetes.io/instance-type: gpu-h100-sxm - volumes: - - name: devshm - emptyDir: - medium: Memory - - name: hf-cache - hostPath: - path: /mnt/hf-cache - type: DirectoryOrCreate - - # - label: "Diffusion Image Edit Test with H100 (1 GPU)" - # depends_on: upload-ready-pipeline - # commands: - # - | - # timeout 20m bash -c ' - # pytest -s -v tests/e2e/online_serving/test_image_gen_edit.py - # ' - # agents: - # queue: "mithril-h100-pool" - # plugins: - # - kubernetes: - # podSpec: - # containers: - # - image: 936637512419.dkr.ecr.us-west-2.amazonaws.com/vllm-ci-pull-through-cache/q9t5s3a7/vllm-ci-test-repo:$BUILDKITE_COMMIT - # resources: - # limits: - # nvidia.com/gpu: 1 - # volumeMounts: - # - name: devshm - # mountPath: /dev/shm - # - name: hf-cache - # mountPath: /root/.cache/huggingface - # env: - # - name: HF_HOME - # value: /root/.cache/huggingface - # nodeSelector: - # node.kubernetes.io/instance-type: gpu-h100-sxm - # volumes: - # - name: devshm - # emptyDir: - # medium: Memory - # - name: hf-cache - # hostPath: - # path: /mnt/hf-cache - # type: DirectoryOrCreate - - - label: "Bagel Text2Img Model Test with H100" - depends_on: upload-ready-pipeline - commands: - - | - timeout 30m bash -c ' - export VLLM_TEST_CLEAN_GPU_MEMORY=1 - pytest -s -v tests/e2e/offline_inference/test_bagel_text2img.py -m "core_model" --run-level "core_model" - ' - agents: - queue: "mithril-h100-pool" - plugins: - - kubernetes: - podSpec: - containers: - - image: 936637512419.dkr.ecr.us-west-2.amazonaws.com/vllm-ci-pull-through-cache/q9t5s3a7/vllm-ci-test-repo:$BUILDKITE_COMMIT - resources: - limits: - nvidia.com/gpu: 1 - volumeMounts: - - name: devshm - mountPath: /dev/shm - - name: hf-cache - mountPath: /root/.cache/huggingface - env: - - name: HF_HOME - value: /root/.cache/huggingface - - name: HF_TOKEN - valueFrom: - secretKeyRef: - name: hf-token-secret - key: token - nodeSelector: - node.kubernetes.io/instance-type: gpu-h100-sxm - volumes: - - name: devshm - emptyDir: - medium: Memory - - name: hf-cache - hostPath: - path: /mnt/hf-cache - type: DirectoryOrCreate - - - label: "Bagel Img2Img Model Test with H100" - depends_on: upload-ready-pipeline - commands: - - | - timeout 30m bash -c ' - export VLLM_TEST_CLEAN_GPU_MEMORY=1 - pytest -s -v tests/e2e/offline_inference/test_bagel_img2img.py -m "core_model" --run-level "core_model" - ' - agents: - queue: "mithril-h100-pool" - plugins: - - kubernetes: - podSpec: - containers: - - image: 936637512419.dkr.ecr.us-west-2.amazonaws.com/vllm-ci-pull-through-cache/q9t5s3a7/vllm-ci-test-repo:$BUILDKITE_COMMIT - resources: - limits: - nvidia.com/gpu: 1 - volumeMounts: - - name: devshm - mountPath: /dev/shm - - name: hf-cache - mountPath: /root/.cache/huggingface - env: - - name: HF_HOME - value: /root/.cache/huggingface - - name: HF_TOKEN - valueFrom: - secretKeyRef: - name: hf-token-secret - key: token - nodeSelector: - node.kubernetes.io/instance-type: gpu-h100-sxm - volumes: - - name: devshm - emptyDir: - medium: Memory - - name: hf-cache - hostPath: - path: /mnt/hf-cache - type: DirectoryOrCreate - - - label: "Bagel Online Serving Test with H100" - depends_on: upload-ready-pipeline - commands: - - | - timeout 40m bash -c ' - export VLLM_TEST_CLEAN_GPU_MEMORY=1 - export VLLM_IMAGE_FETCH_TIMEOUT=60 - pytest -s -v tests/e2e/online_serving/test_bagel_online.py -m "core_model" --run-level "core_model" - ' - agents: - queue: "mithril-h100-pool" - plugins: - - kubernetes: - podSpec: - containers: - - image: 936637512419.dkr.ecr.us-west-2.amazonaws.com/vllm-ci-pull-through-cache/q9t5s3a7/vllm-ci-test-repo:$BUILDKITE_COMMIT - resources: - limits: - nvidia.com/gpu: 1 - volumeMounts: - - name: devshm - mountPath: /dev/shm - - name: hf-cache - mountPath: /root/.cache/huggingface - env: - - name: HF_HOME - value: /root/.cache/huggingface - - name: HF_TOKEN - valueFrom: - secretKeyRef: - name: hf-token-secret - key: token - nodeSelector: - node.kubernetes.io/instance-type: gpu-h100-sxm - volumes: - - name: devshm - emptyDir: - medium: Memory - - name: hf-cache - hostPath: - path: /mnt/hf-cache - type: DirectoryOrCreate - - - label: "CosyVoice3-TTS E2E Test" - timeout_in_minutes: 20 - depends_on: upload-ready-pipeline - commands: - - | - timeout 20m bash -c ' - pytest -s -v tests/e2e/online_serving/test_cosyvoice3_tts.py -m "core_model" --run-level "core_model" - ' - agents: - queue: "mithril-h100-pool" - plugins: - - kubernetes: - podSpec: - containers: - - image: 936637512419.dkr.ecr.us-west-2.amazonaws.com/vllm-ci-pull-through-cache/q9t5s3a7/vllm-ci-test-repo:$BUILDKITE_COMMIT - resources: - limits: - nvidia.com/gpu: 1 - volumeMounts: - - name: devshm - mountPath: /dev/shm - - name: hf-cache - mountPath: /root/.cache/huggingface - env: - - name: HF_HOME - value: /root/.cache/huggingface - - name: HF_TOKEN - valueFrom: - secretKeyRef: - name: hf-token-secret - key: token - nodeSelector: - node.kubernetes.io/instance-type: gpu-h100-sxm - volumes: - - name: devshm - emptyDir: - medium: Memory - - name: hf-cache - hostPath: - path: /mnt/hf-cache - type: DirectoryOrCreate diff --git a/.buildkite/test-template-amd-omni.j2 b/.buildkite/test-template-amd-omni.j2 deleted file mode 100644 index 78f47d1aec0..00000000000 --- a/.buildkite/test-template-amd-omni.j2 +++ /dev/null @@ -1,62 +0,0 @@ -{# vllm-omni customized version - Based on: https://github.com/vllm-project/ci-infra/blob/main/buildkite/test-template-amd.j2 - Last synced: 2025-12-15 - Modifications: Removed unused CUDA/NVIDIA logic, keeping only AMD tests -#} -{% set docker_image_amd = "rocm/vllm-omni:$BUILDKITE_COMMIT" %} -{% set default_working_dir = "/app/vllm-omni" %} - - - group: "AMD Tests" - depends_on: ~ - steps: - - label: "AMD: :docker: build image" - depends_on: ~ - soft_fail: false - commands: - - "docker build -f docker/Dockerfile.rocm -t {{ docker_image_amd }} --target test --build-arg ARG_PYTORCH_ROCM_ARCH=gfx942 --progress plain ." - - "docker push {{ docker_image_amd }}" - key: "amd-build" - env: - DOCKER_BUILDKIT: "1" - retry: - automatic: - - exit_status: -1 # Agent was lost - limit: 2 - - exit_status: -10 # Agent was lost - limit: 2 - - exit_status: 128 # Git connectivity issues - limit: 2 - - exit_status: 1 # Machine occasionally fail - limit: 1 - agents: - queue: amd-cpu - - {% for step in steps %} - {% if step.mirror_hardwares and mirror_hw in step.mirror_hardwares %} - - label: "{{ step.agent_pool }}: {{ step.label }}" - depends_on: amd-build - agents: - {% if step.agent_pool %} - queue: amd_{{ step.agent_pool }} - {% else %} - queue: amd_mi325_1 - {% endif %} -{% set cmd_body = (step.command or (step.commands | join("\n"))) | trim %} -{% set indented_cmd = cmd_body | replace("\n", "\n ") %} - command: bash .buildkite/scripts/hardware_ci/run-amd-test.sh - env: - DOCKER_BUILDKIT: "1" - TEST_COMMAND: |- - (command rocm-smi || true) && cd {{ (step.working_dir or default_working_dir) | safe }} -{% if "mi250" in step.agent_pool %} - python3 -m pip uninstall -y amd-aiter -{% endif %} - {{ indented_cmd | safe }} - priority: 100 - {% if step.grade and step.grade == "Blocking" %} - soft_fail: false - {% else %} - soft_fail: true - {% endif%} - {% endif %} - {% endfor %} diff --git a/.buildkite/test-weekly.yml b/.buildkite/test-weekly.yml deleted file mode 100644 index dba64899605..00000000000 --- a/.buildkite/test-weekly.yml +++ /dev/null @@ -1,85 +0,0 @@ -env: - VLLM_WORKER_MULTIPROC_METHOD: spawn - HF_HUB_DOWNLOAD_TIMEOUT: 300 - HF_HUB_ETAG_TIMEOUT: 60 - -steps: - - label: "Reliability Test - qwen3-omni" - timeout_in_minutes: 180 - depends_on: upload-weekly-pipeline - if: build.env("WEEKLY") == "1" || build.pull_request.labels includes "weekly-test" - commands: - - pytest -s -v tests/dfx/reliability/test_reliability_qwen3_omni.py -m "slow" - agents: - queue: "mithril-h100-pool" - plugins: - - kubernetes: - podSpec: - containers: - - image: 936637512419.dkr.ecr.us-west-2.amazonaws.com/vllm-ci-pull-through-cache/q9t5s3a7/vllm-ci-test-repo:$BUILDKITE_COMMIT - resources: - limits: - nvidia.com/gpu: 2 - volumeMounts: - - name: devshm - mountPath: /dev/shm - - name: hf-cache - mountPath: /root/.cache/huggingface - env: - - name: HF_HOME - value: /root/.cache/huggingface - - name: HF_TOKEN - valueFrom: - secretKeyRef: - name: hf-token-secret - key: token - nodeSelector: - node.kubernetes.io/instance-type: gpu-h100-sxm - volumes: - - name: devshm - emptyDir: - medium: Memory - - name: hf-cache - hostPath: - path: /mnt/hf-cache - type: DirectoryOrCreate - - - label: "Reliability Test - wan22" - timeout_in_minutes: 180 - depends_on: upload-weekly-pipeline - if: build.env("WEEKLY") == "1" || build.pull_request.labels includes "weekly-test" - commands: - - pytest -s -v tests/dfx/reliability/test_reliability_wan22.py -m "slow" - agents: - queue: "mithril-h100-pool" - plugins: - - kubernetes: - podSpec: - containers: - - image: 936637512419.dkr.ecr.us-west-2.amazonaws.com/vllm-ci-pull-through-cache/q9t5s3a7/vllm-ci-test-repo:$BUILDKITE_COMMIT - resources: - limits: - nvidia.com/gpu: 2 - volumeMounts: - - name: devshm - mountPath: /dev/shm - - name: hf-cache - mountPath: /root/.cache/huggingface - env: - - name: HF_HOME - value: /root/.cache/huggingface - - name: HF_TOKEN - valueFrom: - secretKeyRef: - name: hf-token-secret - key: token - nodeSelector: - node.kubernetes.io/instance-type: gpu-h100-sxm - volumes: - - name: devshm - emptyDir: - medium: Memory - - name: hf-cache - hostPath: - path: /mnt/hf-cache - type: DirectoryOrCreate diff --git a/.claude/skills/add-diffusion-model/SKILL.md b/.claude/skills/add-diffusion-model/SKILL.md deleted file mode 100644 index 212e8b02ced..00000000000 --- a/.claude/skills/add-diffusion-model/SKILL.md +++ /dev/null @@ -1,575 +0,0 @@ ---- -name: add-diffusion-model -description: Add a new diffusion model (text-to-image, text-to-video, image-to-video, text-to-audio, image editing) to vLLM-Omni, including Cache-DiT acceleration and parallelism support (TP, SP/USP, CFG-Parallel, HSDP). Use when integrating a new diffusion model, porting a diffusers pipeline or a custom model repo to vllm-omni, creating a new DiT transformer adapter, adding diffusion model support, or enabling multi-GPU parallelism and cache acceleration for an existing model. ---- - -# Adding a Diffusion Model to vLLM-Omni - -## Overview - -This skill guides you through adding a new diffusion model to vLLM-Omni. The model may come from HuggingFace Diffusers (structured pipeline) or from a private/custom repo. The workflow differs significantly depending on the source. - -## Prerequisites - -Before starting, determine: - -1. **Model category**: Text-to-Image, Text-to-Video, Image-to-Video, Image Editing, Text-to-Audio, or Omni -2. **Reference source**: Diffusers pipeline, custom repo, or a combination -3. **Model HuggingFace ID** or local checkpoint path -4. **Architecture**: Scheduler, text encoder, VAE, transformer/backbone - -## Step 0: Classify the Migration Path - -Check the model's HF repo for `model_index.json`. This determines your path: - -| Scenario | How to identify | Migration path | -|----------|----------------|----------------| -| **Already supported** | `_class_name` in `model_index.json` matches a key in `_DIFFUSION_MODELS` in `registry.py` | Skip to Step 5 (test) and Step 7 (docs) | -| **Diffusers-based** | Has standard `model_index.json` with `_diffusers_version`, subfolders for `transformer/`, `vae/`, etc. | Follow **Path A** below | -| **Custom/private repo** | No diffusers `model_index.json`, weights in non-standard format, custom model code in a separate git repo | Follow **Path B** below | -| **Hybrid** | Has some diffusers components (VAE) but custom transformer/fusion | Mix of Path A and Path B | - -## Path A: Diffusers-Based Model - -For models with a standard diffusers layout. See [references/transformer-adaptation.md](references/transformer-adaptation.md) for detailed code patterns. - -### A1. Analyze `model_index.json` - -Identify components: `transformer`, `scheduler`, `vae`, `text_encoder`, `tokenizer`. - -### A2. Create model directory - -``` -vllm_omni/diffusion/models/your_model_name/ -├── __init__.py -├── pipeline_your_model.py -└── your_model_transformer.py -``` - -### A3. Adapt transformer - -1. Copy from diffusers source. Remove mixins (`ModelMixin`, `ConfigMixin`, `AttentionModuleMixin`). -2. Replace attention with `vllm_omni.diffusion.attention.layer.Attention` (QKV shape: `[B, seq, heads, head_dim]`). -3. Add `od_config: OmniDiffusionConfig | None = None` to `__init__`. -4. Add `load_weights()` method mapping diffusers weight names to vllm-omni names. -5. Add class attributes: `_repeated_blocks`, `_layerwise_offload_blocks_attr`. - -### A4. Adapt pipeline - -Inherit from `nn.Module`. The key contract: - -```python -class YourPipeline(nn.Module): - def __init__(self, *, od_config: OmniDiffusionConfig, prefix: str = ""): - # Load VAE, text encoder, tokenizer via from_pretrained() - # Instantiate transformer (weights loaded later via weights_sources) - self.weights_sources = [ - DiffusersPipelineLoader.ComponentSource( - model_or_path=od_config.model, subfolder="transformer", - prefix="transformer.", fall_back_to_pt=True)] - - def forward(self, req: OmniDiffusionRequest) -> DiffusionOutput: - # Encode prompt → prepare latents → denoise loop → VAE decode - return DiffusionOutput(output=output) - - def load_weights(self, weights): - return AutoWeightsLoader(self).load_weights(weights) -``` - -Add post/pre-process functions in the same pipeline file. Register them in `registry.py`. - -### A5. Register, test, docs → continue at Step 4 below. - ---- - -## Path B: Custom/Private Repo Model - -For models without a diffusers pipeline — weights in custom format, model code in a private repo. Real examples: DreamID-Omni, BAGEL, HunyuanImage3. - -### B1. Understand the reference repo - -Study the original model's code to identify: -- **Model architecture files** (transformers, fusion modules, embeddings) -- **Weight format** (safetensors, `.pth`, custom checkpoint structure) -- **Weight loading helpers** (custom init functions, checkpoint loaders) -- **Pre/post-processing** (image/audio transforms, tokenization, VAE encode/decode) -- **External dependencies** (packages not on PyPI) -- **Config format** (JSON config files, hardcoded dicts) - -### B2. Decide what lives WHERE - -This is the key design decision for custom models. Follow these placement rules: - -| Code type | Where to place | Example | -|-----------|---------------|---------| -| **Pipeline orchestration** (init, forward, denoise loop) | `vllm_omni/diffusion/models/
-
-
-Changes synced from GPU:
--
-
-```
-
-### Files to Stage
-- [ ] `vllm_omni/platforms/npu/worker/npu_model_runner.py`
-- [ ] `vllm_omni/platforms/npu/worker/npu_ar_model_runner.py`
-- [ ] `vllm_omni/platforms/npu/worker/npu_generation_model_runner.py`
-- [ ] Any other modified files
-
----
-
-## Troubleshooting
-
-### Import Errors
-- Check if vllm-ascend module paths have changed
-- Verify PYTHONPATH includes both vllm-ascend and vllm-omni
-
-### Type Errors
-- Check method signatures match between GPU and NPU
-- Verify NamedTuple fields match expected structure
-
-### Runtime Errors
-- Enable debug logging: `export VLLM_LOGGING_LEVEL=DEBUG`
-- Check graph capture issues: try `--enforce-eager`
-- Check attention issues: verify AscendAttentionState usage
-
-### Performance Regression
-- Compare with previous version on same model
-- Check if graph capture is working: look for ACLGraph logs
-- Verify SP/EP configurations are correct
diff --git a/.gitattributes b/.gitattributes
deleted file mode 100644
index 9f1b343de6d..00000000000
--- a/.gitattributes
+++ /dev/null
@@ -1,45 +0,0 @@
-# Set default behavior to automatically normalize line endings
-* text=auto
-
-# Explicitly declare text files you want to always be normalized and converted
-# to native line endings on checkout
-*.py text eol=lf
-*.yaml text eol=lf
-*.yml text eol=lf
-*.md text eol=lf
-*.txt text eol=lf
-*.json text eol=lf
-*.toml text eol=lf
-*.sh text eol=lf
-*.bat text eol=crlf
-*.cmd text eol=crlf
-
-# Declare files that will always have CRLF line endings on checkout
-*.bat text eol=crlf
-*.cmd text eol=crlf
-
-# Denote all files that are truly binary and should not be modified
-*.png binary
-*.jpg binary
-*.jpeg binary
-*.gif binary
-*.ico binary
-*.mov binary
-*.mp4 binary
-*.mp3 binary
-*.wav binary
-*.flv binary
-*.fla binary
-*.swf binary
-*.gz binary
-*.zip binary
-*.7z binary
-*.ttf binary
-*.eot binary
-*.woff binary
-*.woff2 binary
-*.pyc binary
-*.pdf binary
-*.ai binary
-*.psd binary
-*.xcf binary
diff --git a/.github/CODEOWNERS b/.github/CODEOWNERS
deleted file mode 100644
index 23731948120..00000000000
--- a/.github/CODEOWNERS
+++ /dev/null
@@ -1,17 +0,0 @@
-# CODEOWNERS is used to automatically assign PR reviewers
-# Format: path pattern @username or @team
-# More info: https://docs.github.com/en/repositories/managing-your-repositorys-settings-and-features/customizing-your-repository/about-code-owners
-
-# Default owners (fallback reviewers for all files)
-# later, we can add more reviewers here
-* @hsliuustc0106
-
-# Assign reviewers by directory
-/.github/ @owner1
-/tests/ @owner1
-/docs/ @owner1
-
-# Example: reviewers for specific directories
-# /examples/offline_inference/ @offline-inference-team
-# /vllm_omni/core/ @core-team
-# /vllm_omni/model_executor/ @model-team
diff --git a/.github/ISSUE_TEMPLATE/100-documentation.yml b/.github/ISSUE_TEMPLATE/100-documentation.yml
deleted file mode 100644
index 230c6259efb..00000000000
--- a/.github/ISSUE_TEMPLATE/100-documentation.yml
+++ /dev/null
@@ -1,29 +0,0 @@
-name: 📚 Documentation
-description: Report an issue related to documentation
-title: "[Doc]: "
-labels: ["documentation"]
-
-body:
-- type: textarea
- attributes:
- label: 📚 The doc issue
- description: >
- A clear and concise description of what content in the documentation is an issue.
- validations:
- required: true
-- type: textarea
- attributes:
- label: Suggest a potential alternative/fix
- description: >
- Tell us how we could improve the documentation in this regard.
-- type: markdown
- attributes:
- value: >
- Thanks for contributing 🎉!
-- type: checkboxes
- id: askllm
- attributes:
- label: Before submitting a new issue...
- options:
- - label: Make sure you already searched for relevant issues, and asked the chatbot living at the bottom right corner of the [documentation page](https://vllm-omni.readthedocs.io), which can answer lots of frequently asked questions.
- required: true
diff --git a/.github/ISSUE_TEMPLATE/200-installation.yml b/.github/ISSUE_TEMPLATE/200-installation.yml
deleted file mode 100644
index 83112901815..00000000000
--- a/.github/ISSUE_TEMPLATE/200-installation.yml
+++ /dev/null
@@ -1,47 +0,0 @@
-name: 🛠️ Installation
-description: Report an issue here when you hit errors during installation.
-title: "[Installation]: "
-labels: ["installation"]
-
-body:
-- type: markdown
- attributes:
- value: >
- #### Before submitting an issue, please make sure the issue hasn't been already addressed by searching through [the existing and past issues](https://github.com/vllm-project/vllm-omni/issues?q=is%3Aissue+sort%3Acreated-desc+).
-- type: textarea
- attributes:
- label: Your current environment
- description: |
- Please run the following and paste the output below.
- ```sh
- wget https://raw.githubusercontent.com/vllm-project/vllm-omni/main/vllm_omni/collect_env.py
- # For security purposes, please feel free to check the contents of collect_env.py before running it.
- python collect_env.py
- ```
- It is suggested to download and execute the latest script, as vllm-omni might frequently update the diagnosis information needed for accurately and quickly responding to issues.
- value: |
- ```text
- The output of `python collect_env.py`
- ```
- validations:
- required: true
-- type: textarea
- attributes:
- label: How you are installing vllm-omni
- description: |
- Paste the full command you are trying to execute.
- value: |
- ```sh
- pip install -vvv vllm-omni
- ```
-- type: markdown
- attributes:
- value: >
- Thanks for contributing 🎉!
-- type: checkboxes
- id: askllm
- attributes:
- label: Before submitting a new issue...
- options:
- - label: Make sure you already searched for relevant issues, and asked the chatbot living at the bottom right corner of the [documentation page](https://vllm-omni.readthedocs.io), which can answer lots of frequently asked questions.
- required: true
diff --git a/.github/ISSUE_TEMPLATE/400-bug-report.yml b/.github/ISSUE_TEMPLATE/400-bug-report.yml
deleted file mode 100644
index c3799b19400..00000000000
--- a/.github/ISSUE_TEMPLATE/400-bug-report.yml
+++ /dev/null
@@ -1,129 +0,0 @@
-name: 🐛 Bug report
-description: Raise an issue here if you find a bug.
-title: "[Bug]: "
-labels: ["bug"]
-
-body:
-- type: markdown
- attributes:
- value: >
- #### Before submitting an issue, please make sure the issue hasn't been already addressed by searching through [the existing and past issues](https://github.com/vllm-project/vllm-omni/issues?q=is%3Aissue+sort%3Acreated-desc+).
-- type: markdown
- attributes:
- value: |
- ⚠️ **SECURITY WARNING:** Please review any text you paste to ensure it does not contain sensitive information such as:
- - API tokens or keys (e.g., Hugging Face tokens, OpenAI API keys)
- - Passwords or authentication credentials
- - Private URLs or endpoints
- - Personal or confidential data
-
- Consider redacting or replacing sensitive values with placeholders like `
- The output of
-
- ```text
- Your output of `python collect_env.py` here
- ```
-
-
- validations:
- required: true
-
-- type: textarea
- attributes:
- label: Your code version
- description: |
- Please provide a description of which commit id or version the code is.
-
- value: |
- The output of python collect_env.py
-
- ```text
- Your output of `python collect_env.py` here
- ```
-
-
-
- The commit id or version of vllm
- - ```text - - ``` -
-
- validations:
- required: true
-
-- type: textarea
- attributes:
- label: 🐛 Describe the bug
- description: |
- Please provide a clear and concise description of what the bug is.
-
- If relevant, add a minimal example so that we can reproduce the error by running the code. It is very important for the snippet to be as succinct (minimal) as possible, so please take time to trim down any irrelevant code to help us debug efficiently. We are going to copy-paste your code and we expect to get the same result as you did: avoid any external data, and include the relevant imports, etc. For example:
-
- ```python
- from vllm_omni.entrypoints.omni import Omni
- from vllm_omni.inputs.data import OmniDiffusionSamplingParams
- from vllm import SamplingParams
-
- omni = Omni(
- model="Qwen/Qwen-Image",
- stage_configs_path="/path/to/stage_configs.yaml",
- )
-
- prompts = [{"prompt": "A scenic watercolor painting of a lighthouse at sunset"}]
- sampling_params_list = [
- SamplingParams(max_tokens=1),
- OmniDiffusionSamplingParams(num_outputs_per_prompt=1),
- ]
- outputs = omni.generate(prompts=prompts, sampling_params_list=sampling_params_list)
- ```
-
- If the code is too long (hopefully, it isn't), feel free to put it in a public gist and link it in the issue: https://gist.github.com.
-
- Please also paste or describe the results you observe instead of the expected results. If you observe an error, please paste the error message including the **full** traceback of the exception. It may be relevant to wrap error messages in ```` ```triple quotes blocks``` ````.
-
- Please set the environment variable `export VLLM_OMNI_LOGGING_LEVEL=DEBUG` to turn on more logging to help debugging potential issues.
-
- If you experienced crashes or hangs, it would be helpful to run vllm-omni with `export VLLM_OMNI_TRACE_FUNCTION=1` . All the function calls in vllm-omni will be recorded. Inspect these log files, and tell which function crashes or hangs.
- placeholder: |
- A clear and concise description of what the bug is.
-
- ```python
- # Sample code to reproduce the problem
- ```
-
- ```
- The error message you got, with the full traceback and the error logs with [dump_input.py:##] if present.
- ```
- validations:
- required: true
-- type: markdown
- attributes:
- value: |
- ⚠️ Please separate bugs of `transformers` implementation or usage from bugs of `vllm-omni`. If you think anything is wrong with the model's output:
-
- - Try the counterpart of `transformers` first. If the error appears, please go to [their issues](https://github.com/huggingface/transformers/issues?q=is%3Aissue+is%3Aopen+sort%3Aupdated-desc).
-
- - If the error only appears in vllm-omni, please provide the detailed script of how you run `transformers` and `vllm-omni`, also highlight the difference and what you expect.
-
- Thanks for reporting 🙏!
-- type: checkboxes
- id: askllm
- attributes:
- label: Before submitting a new issue...
- options:
- - label: Make sure you already searched for relevant issues, and asked the chatbot living at the bottom right corner of the [documentation page](https://vllm-omni.readthedocs.io), which can answer lots of frequently asked questions.
- required: true
diff --git a/.github/ISSUE_TEMPLATE/500-feature-request.yml b/.github/ISSUE_TEMPLATE/500-feature-request.yml
deleted file mode 100644
index 98dec8276a6..00000000000
--- a/.github/ISSUE_TEMPLATE/500-feature-request.yml
+++ /dev/null
@@ -1,38 +0,0 @@
-name: 🚀 Feature request
-description: Submit a proposal/request for a new vllm-omni feature
-title: "[Feature]: "
-labels: ["feature request"]
-
-body:
-- type: markdown
- attributes:
- value: >
- #### Before submitting an issue, please make sure the issue hasn't been already addressed by searching through [the existing and past issues](https://github.com/vllm-project/vllm-omni/issues?q=is%3Aissue+sort%3Acreated-desc+).
-- type: textarea
- attributes:
- label: 🚀 The feature, motivation and pitch
- description: >
- A clear and concise description of the feature proposal. Please outline the motivation for the proposal. Is your feature request related to a specific problem? e.g., *"I'm working on X and would like Y to be possible"*. If this is related to another GitHub issue, please link here too.
- validations:
- required: true
-- type: textarea
- attributes:
- label: Alternatives
- description: >
- A description of any alternative solutions or features you've considered, if any.
-- type: textarea
- attributes:
- label: Additional context
- description: >
- Add any other context or screenshots about the feature request.
-- type: markdown
- attributes:
- value: >
- Thanks for contributing 🎉!
-- type: checkboxes
- id: askllm
- attributes:
- label: Before submitting a new issue...
- options:
- - label: Make sure you already searched for relevant issues, and asked the chatbot living at the bottom right corner of the [documentation page](https://vllm-omni.readthedocs.io), which can answer lots of frequently asked questions.
- required: true
diff --git a/.github/ISSUE_TEMPLATE/600-new-model.yml b/.github/ISSUE_TEMPLATE/600-new-model.yml
deleted file mode 100644
index cf621ba1dc7..00000000000
--- a/.github/ISSUE_TEMPLATE/600-new-model.yml
+++ /dev/null
@@ -1,45 +0,0 @@
-name: 🤗 Support request for a new model
-description: Submit a proposal/request for a new model support
-title: "[New Model]: "
-labels: ["new model"]
-
-body:
-- type: markdown
- attributes:
- value: >
- #### Before submitting an issue, please make sure the issue hasn't been already addressed by searching through [the existing and past issues](https://github.com/vllm-project/vllm-omni/issues?q=is%3Aissue+sort%3Acreated-desc+).
-
- #### We also highly recommend you read the contributing guidelines first to understand how to add a new model.
-- type: textarea
- attributes:
- label: The model to consider.
- description: >
- A huggingface url, pointing to the model, e.g. https://huggingface.co/openai-community/gpt2 .
- validations:
- required: true
-- type: textarea
- attributes:
- label: The closest model vllm-omni already supports.
- description: >
- Here is the list of models already supported by vllm-omni. Which model is the most similar to the model you want to add support for?
-- type: textarea
- attributes:
- label: What's your difficulty of supporting the model you want?
- description: >
- For example, any new operators or new architecture? Is it a multimodal model? Does it require special preprocessing?
-- type: textarea
- attributes:
- label: Use case and motivation
- description: >
- What is the primary use case for this model? Why is it important to support in vllm-omni?
-- type: markdown
- attributes:
- value: >
- Thanks for contributing 🎉!
-- type: checkboxes
- id: askllm
- attributes:
- label: Before submitting a new issue...
- options:
- - label: Make sure you already searched for relevant issues, and asked the chatbot living at the bottom right corner of the [documentation page](https://vllm-omni.readthedocs.io), which can answer lots of frequently asked questions.
- required: true
diff --git a/.github/ISSUE_TEMPLATE/700-performance-discussion.yml b/.github/ISSUE_TEMPLATE/700-performance-discussion.yml
deleted file mode 100644
index 7a4f374b867..00000000000
--- a/.github/ISSUE_TEMPLATE/700-performance-discussion.yml
+++ /dev/null
@@ -1,59 +0,0 @@
-name: ⚡ Discussion on the performance of vllm-omni
-description: Submit a proposal/discussion about the performance of vllm-omni
-title: "[Performance]: "
-labels: ["performance"]
-
-body:
-- type: markdown
- attributes:
- value: >
- #### Before submitting an issue, please make sure the issue hasn't been already addressed by searching through [the existing and past issues](https://github.com/vllm-project/vllm-omni/issues?q=is%3Aissue+sort%3Acreated-desc+).
-- type: textarea
- attributes:
- label: Proposal to improve performance
- description: >
- How do you plan to improve vllm-omni's performance?
- validations:
- required: false
-- type: textarea
- attributes:
- label: Report of performance regression
- description: >
- Please provide detailed description of performance comparison to confirm the regression. You may want to run the benchmark script at https://github.com/vllm-project/vllm-omni/tree/main/tests/benchmarks .
- validations:
- required: false
-- type: textarea
- attributes:
- label: Misc discussion on performance
- description: >
- Anything about the performance.
- validations:
- required: false
-- type: textarea
- attributes:
- label: Your current environment (if you think it is necessary)
- description: |
- Please run the following and paste the output below.
- ```sh
- wget https://raw.githubusercontent.com/vllm-project/vllm-omni/main/vllm_omni/collect_env.py
- # For security purposes, please feel free to check the contents of collect_env.py before running it.
- python collect_env.py
- ```
- It is suggested to download and execute the latest script, as vllm-omni might frequently update the diagnosis information needed for accurately and quickly responding to issues.
- value: |
- ```text
- The output of `python collect_env.py`
- ```
- validations:
- required: false
-- type: markdown
- attributes:
- value: >
- Thanks for contributing 🎉!
-- type: checkboxes
- id: askllm
- attributes:
- label: Before submitting a new issue...
- options:
- - label: Make sure you already searched for relevant issues, and asked the chatbot living at the bottom right corner of the [documentation page](https://vllm-omni.readthedocs.io), which can answer lots of frequently asked questions.
- required: true
diff --git a/.github/ISSUE_TEMPLATE/750-RFC.yml b/.github/ISSUE_TEMPLATE/750-RFC.yml
deleted file mode 100644
index eb0ba401712..00000000000
--- a/.github/ISSUE_TEMPLATE/750-RFC.yml
+++ /dev/null
@@ -1,54 +0,0 @@
-name: 💬 Request for comments (RFC).
-description: Ask for feedback on major architectural changes or design choices.
-title: "[RFC]: "
-labels: ["RFC"]
-
-body:
-- type: markdown
- attributes:
- value: >
- #### Please take a look at previous [RFCs](https://github.com/vllm-project/vllm-omni/issues?q=in%3Atitle%20RFC%20sort%3Aupdated-desc) for reference.
-- type: textarea
- attributes:
- label: Motivation.
- description: >
- The motivation of the RFC.
- validations:
- required: true
-- type: textarea
- attributes:
- label: Proposed Change.
- description: >
- The proposed change of the RFC.
- value: |
- Please provide the detailed design document of the RFC using the [template](https://docs.google.com/document/d/1jcgR3cDaUQH3VczD4ZcKaJAoYWHjCmnYzHkCNyz-9fk/edit?usp=sharing).
- validations:
- required: true
-- type: textarea
- attributes:
- label: Feedback Period.
- description: >
- The feedback period of the RFC. Usually at least one week.
- validations:
- required: false
-- type: textarea
- attributes:
- label: CC List.
- description: >
- The list of people you want to CC.
- validations:
- required: false
-- type: textarea
- attributes:
- label: Any Other Things.
- description: >
- Any other things you would like to mention.
- validations:
- required: false
-- type: checkboxes
- id: askllm
- attributes:
- label: Before submitting a new issue...
- options:
- - label: Make sure you already searched for relevant issues, and asked the chatbot living at the bottom right corner of the [documentation page](https://vllm-omni.readthedocs.io), which can answer lots of frequently asked questions.
- required: true
diff --git a/.github/ISSUE_TEMPLATE/config.yml b/.github/ISSUE_TEMPLATE/config.yml
deleted file mode 100644
index 0890ac09b0a..00000000000
--- a/.github/ISSUE_TEMPLATE/config.yml
+++ /dev/null
@@ -1,5 +0,0 @@
-blank_issues_enabled: false
-contact_links:
- - name: Questions
- url: https://slack.vllm.ai
- about: Ask questions and discuss with other vLLM-Omni community members in our #sig-omni slack channel.
diff --git a/.github/PULL_REQUEST_TEMPLATE.md b/.github/PULL_REQUEST_TEMPLATE.md
deleted file mode 100644
index 1b4762794d4..00000000000
--- a/.github/PULL_REQUEST_TEMPLATE.md
+++ /dev/null
@@ -1,21 +0,0 @@
-
-PLEASE FILL IN THE PR DESCRIPTION HERE ENSURING ALL CHECKLIST ITEMS (AT THE BOTTOM) HAVE BEEN CONSIDERED.
-
-## Purpose
-
-## Test Plan
-
-## Test Result
-
----
-The commit id or version of vllm-omni
- - ```text - - ``` -
-
-
-**BEFORE SUBMITTING, PLEASE READ Essential Elements of an Effective PR Description Checklist
- -- [ ] The purpose of the PR, such as "Fix some issue (link existing issues this PR will resolve)". -- [ ] The test plan. Please provide the test scripts & test commands. Please state the reasons if your codes don't require additional test scripts. For test file guidelines, please check the [test style doc](https://docs.vllm.ai/projects/vllm-omni/en/latest/contributing/ci/tests_style/) -- [ ] The test results. Please paste the results comparison before and after, or the e2e results. -- [ ] (Optional) The necessary documentation update, such as updating `supported_models.md` and `examples` for a new model. **Please run `mkdocs serve` to sync the documentation editions to `./docs`.** -- [ ] (Optional) Release notes update. If your change is user-facing, please update the release notes draft. -
- > Is
- >
- >
-
-- name: comment-dco-failure
- description: Comment on PR when DCO check fails
- conditions:
- - status-failure=dco
- - -closed
- - -draft
- actions:
- comment:
- message: |
- Hi @{{author}}, the DCO check has failed. Please click on DCO in the Checks section for instructions on how to resolve this.
-
-- name: label-ci-build
- description: Automatically apply ci/build label
- conditions:
- - label != stale
- - or:
- - files~=^\.github/
- - files~=\.buildkite/
- - files~=^cmake/
- - files=CMakeLists.txt
- - files~=^docker/Dockerfile
- - files~=^requirements.*\.txt
- - files=setup.py
- actions:
- label:
- add:
- - ci/build
-
-- name: label-frontend
- description: Automatically apply frontend label
- conditions:
- - label != stale
- - files~=^vllm_omni/entrypoints/
- actions:
- label:
- add:
- - frontend
-
-- name: label-diffusion
- description: Automatically apply diffusion label
- conditions:
- - label != stale
- - files~=^vllm_omni/diffusion/
- actions:
- label:
- add:
- - diffusion
-
-- name: label-new-model
- description: Automatically apply new-model label
- conditions:
- - label != stale
- - or:
- - files=vllm_omni/model_executor/models/registry.py
- - files=vllm_omni/diffusion/registry.py
- actions:
- label:
- add:
- - new-model
-
-- name: label-npu
- description: Automatically apply npu label
- conditions:
- - label != stale
- - or:
- - files~=^vllm_omni/platforms/npu/
- - title~=(?i)NPU
- - title~=(?i)Ascend
- actions:
- label:
- add:
- - npu
- assign:
- users:
- - "gcanlin"
-
-- name: label-rocm
- description: Automatically apply rocm label
- conditions:
- - label != stale
- - or:
- - files~=^vllm_omni/platforms/rocm/
- - title~=(?i)AMD
- - title~=(?i)ROCm
- actions:
- label:
- add:
- - rocm
- assign:
- users:
- - "tjtanaa"
-
-- name: label-xpu
- description: Automatically apply xpu label
- conditions:
- - label != stale
- - or:
- - files~=^vllm_omni/platforms/xpu/
- - title~=(?i)Intel
- - title~=(?i)XPU
- actions:
- label:
- add:
- - xpu
- assign:
- users:
- - "yma11"
-
-- name: label-modelrunner
- description: Automatically apply modelrunner label
- conditions:
- - label != stale
- - or:
- - files~=^vllm_omni/worker/
- - title~=(?i)ModelRunner
- - title~=(?i)worker
- actions:
- label:
- add:
- - ModelRunner
- assign:
- users:
- - "gcanlin" # To check whether need to sync to NPU
-
-- name: auto-rebase if approved, ready, and 30 commits behind main
- conditions:
- - base = main
- - label=ready
- - "#approved-reviews-by >= 1"
- - "#commits-behind >= 30"
- - -closed
- - -draft
- - -conflict
- actions:
- rebase: {}
-
-- name: ping author on conflicts and add 'needs-rebase' label
- conditions:
- - label != stale
- - conflict
- - -closed
- actions:
- label:
- add:
- - needs-rebase
- comment:
- message: |
- This pull request has merge conflicts that must be resolved before it can be
- merged. Please rebase the PR, @{{author}}.
-
- https://docs.github.com/en/pull-requests/collaborating-with-pull-requests/working-with-forks/syncing-a-fork
-
-- name: remove 'needs-rebase' label when conflict is resolved
- conditions:
- - -conflict
- - -closed
- actions:
- label:
- remove:
- - needs-rebase
-
-- name: label-bug
- description: Automatically apply bug label
- conditions:
- - label != stale
- - or:
- - title~=(?i)\bbug\b
- - title~=(?i)\bbugfix\b
- actions:
- label:
- add:
- - bug
diff --git a/.github/scripts/detect_changed_tests.sh b/.github/scripts/detect_changed_tests.sh
deleted file mode 100755
index a3e7518e240..00000000000
--- a/.github/scripts/detect_changed_tests.sh
+++ /dev/null
@@ -1,89 +0,0 @@
-#!/bin/bash
-# Script to detect changed files and find corresponding test files
-# Usage: ./detect_changed_tests.sh [base_sha] [head_sha] [event_type]
-#
-# Outputs to GITHUB_OUTPUT:
-# test_files: Space-separated list of test files to run
-# has_tests: 'true' if test files found, 'false' otherwise
-
-set -e
-
-BASE_SHA="${1:-}"
-HEAD_SHA="${2:-}"
-EVENT_TYPE="${3:-push}"
-
-# Determine base and head SHA based on event type
-if [ "$EVENT_TYPE" = "pull_request" ]; then
- BASE_SHA="${BASE_SHA:-$GITHUB_BASE_REF}"
- HEAD_SHA="${HEAD_SHA:-$GITHUB_SHA}"
-elif [ -z "$BASE_SHA" ] || [ -z "$HEAD_SHA" ]; then
- # For push events, use git to find the previous commit
- BASE_SHA="${BASE_SHA:-$(git rev-parse HEAD~1 2>/dev/null || echo HEAD)}"
- HEAD_SHA="${HEAD_SHA:-HEAD}"
-fi
-
-echo "Event type: $EVENT_TYPE"
-echo "Base SHA: $BASE_SHA"
-echo "Head SHA: $HEAD_SHA"
-
-# Get changed Python files
-CHANGED_FILES=$(git diff --name-only --diff-filter=ACMRT "$BASE_SHA" "$HEAD_SHA" | grep -E '\.(py)$' || true)
-
-if [ -z "$CHANGED_FILES" ]; then
- echo "No Python files changed"
- echo "test_files=" >> "$GITHUB_OUTPUT"
- echo "has_tests=false" >> "$GITHUB_OUTPUT"
- exit 0
-fi
-
-echo "Changed Python files:"
-echo "$CHANGED_FILES"
-
-# Extract related test files
-TEST_FILES=""
-for file in $CHANGED_FILES; do
- # If changed file is a test file, add it directly
- if [[ "$file" == tests/* ]]; then
- TEST_FILES="$TEST_FILES $file"
- # If changed file is source code, find corresponding test file
- elif [[ "$file" == vllm_omni/* ]]; then
- # Convert vllm_omni/path/to/module.py to possible test file paths
- REL_PATH=$(echo "$file" | sed 's|^vllm_omni/||' | sed 's|\.py$||')
- MODULE_NAME=$(basename "$REL_PATH")
- DIR_PATH=$(dirname "$REL_PATH")
-
- # Try multiple possible test file naming patterns
- POSSIBLE_TESTS=(
- "tests/test_${REL_PATH//\//_}.py"
- "tests/${REL_PATH//\//_}_test.py"
- )
-
- # If multi-level directory, also try directory structure
- if [ "$DIR_PATH" != "." ]; then
- POSSIBLE_TESTS+=(
- "tests/${DIR_PATH}/test_${MODULE_NAME}.py"
- "tests/${DIR_PATH}/${MODULE_NAME}_test.py"
- )
- fi
-
- for test_file in "${POSSIBLE_TESTS[@]}"; do
- if [ -f "$test_file" ]; then
- TEST_FILES="$TEST_FILES $test_file"
- break
- fi
- done
- fi
-done
-
-# Deduplicate and format
-TEST_FILES=$(echo "$TEST_FILES" | tr ' ' '\n' | grep -v '^$' | sort -u | tr '\n' ' ' | sed 's/^ *//;s/ *$//')
-
-if [ -z "$TEST_FILES" ]; then
- echo "No related test files found, will run all tests"
- echo "test_files=" >> "$GITHUB_OUTPUT"
- echo "has_tests=false" >> "$GITHUB_OUTPUT"
-else
- echo "Found test files: $TEST_FILES"
- echo "test_files=$TEST_FILES" >> "$GITHUB_OUTPUT"
- echo "has_tests=true" >> "$GITHUB_OUTPUT"
-fi
diff --git a/.github/workflows/build_wheel.yml b/.github/workflows/build_wheel.yml
deleted file mode 100644
index f8087c5e902..00000000000
--- a/.github/workflows/build_wheel.yml
+++ /dev/null
@@ -1,63 +0,0 @@
-name: Build Wheel
-
-on:
- push:
- branches:
- - main
- paths-ignore:
- - 'docs/**'
- - 'examples/**'
- - 'apps/**'
- - '.github/**'
- - '.buildkite/**'
- - '**.md'
- - '*.yml'
- - '.gitignore'
- - '.gitattributes'
- - 'LICENSE'
- pull_request:
- branches:
- - main
- paths-ignore:
- - 'docs/**'
- - 'examples/**'
- - 'apps/**'
- - '.github/**'
- - '.buildkite/**'
- - '*.yml'
- - '**.md'
- - '.gitignore'
- - '.gitattributes'
- - 'LICENSE'
- workflow_dispatch:
-
-jobs:
- build:
- runs-on: ubuntu-latest
- strategy:
- matrix:
- python-version: ["3.11", "3.12"]
-
- steps:
- - uses: actions/checkout@v6
-
- - name: Set up Python ${{ matrix.python-version }}
- uses: actions/setup-python@v6
- with:
- python-version: ${{ matrix.python-version }}
-
- - name: Install uv
- run: |
- pip install uv
-
- - name: Build Wheel
- env:
- UV_SYSTEM_PYTHON: 1
- run: |
- bash scripts/build_wheel.sh --python python
-
- - name: Upload Wheel Artifact
- uses: actions/upload-artifact@v7
- with:
- name: vllm-omni-wheel-py${{ matrix.python-version }}
- path: dist/*.whl
diff --git a/.github/workflows/pre-commit.yml b/.github/workflows/pre-commit.yml
deleted file mode 100644
index 964fb5abcc9..00000000000
--- a/.github/workflows/pre-commit.yml
+++ /dev/null
@@ -1,26 +0,0 @@
-name: pre-commit
-
-on:
- pull_request:
- branches: [main]
- push:
- branches: [main]
- workflow_dispatch: # for manual trigger
-
-concurrency:
- group: ${{ github.workflow }}-${{ github.ref }}
- cancel-in-progress: ${{ github.event_name == 'pull_request' }}
-
-permissions:
- contents: read
-
-jobs:
- pre-commit:
- runs-on: ubuntu-latest
- steps:
- - uses: actions/checkout@v6
- - uses: actions/setup-python@v6
- with:
- python-version: "3.12"
- cache: 'pip'
- - uses: pre-commit/action@v3.0.1
diff --git a/.gitignore b/.gitignore
deleted file mode 100644
index bf5e28510a0..00000000000
--- a/.gitignore
+++ /dev/null
@@ -1,271 +0,0 @@
-# Byte-compiled / optimized / DLL files
-__pycache__/
-*.py[cod]
-*$py.class
-
-# C extensions
-*.so
-
-# Distribution / packaging
-.Python
-build/
-develop-eggs/
-dist/
-downloads/
-eggs/
-.eggs/
-lib/
-lib64/
-parts/
-sdist/
-var/
-wheels/
-vllm/
-share/python-wheels/
-*.egg-info/
-.installed.cfg
-*.egg
-MANIFEST
-
-# PyInstaller
-# Usually these files are written by a python script from a template
-# before PyInstaller builds the exe, so as to inject date/other infos into it.
-*.manifest
-*.spec
-
-# Installer logs
-pip-log.txt
-pip-delete-this-directory.txt
-
-# Unit test / coverage reports
-htmlcov/
-.tox/
-.nox/
-.coverage
-.coverage.*
-.cache
-nosetests.xml
-coverage.xml
-*.cover
-*.py,cover
-.hypothesis/
-.pytest_cache/
-cover/
-
-# Translations
-*.mo
-*.pot
-
-# Django stuff:
-*.log
-local_settings.py
-db.sqlite3
-db.sqlite3-journal
-
-# Flask stuff:
-instance/
-.webassets-cache
-
-# Scrapy stuff:
-.scrapy
-
-# Sphinx documentation
-docs/_build/
-
-# PyBuilder
-.pybuilder/
-target/
-
-# Jupyter Notebook
-.ipynb_checkpoints
-
-# IPython
-profile_default/
-ipython_config.py
-
-# uv
-uv.lock
-
-# pyenv
-# For a library or package, you might want to ignore these files since the code is
-# intended to run in multiple environments; otherwise, check them in:
-# .python-version
-
-# pipenv
-# According to pypa/pipenv#598, it is recommended to include Pipfile.lock in version control.
-# However, in case of collaboration, if having platform-specific dependencies or dependencies
-# having no cross-platform support, pipenv may install dependencies that don't work, or not
-# install all needed dependencies.
-#Pipfile.lock
-
-# poetry
-# Similar to Pipfile.lock, it is generally recommended to include poetry.lock in version control.
-# This is especially recommended for binary packages to ensure reproducibility, and is more
-# commonly ignored for libraries.
-# https://python-poetry.org/docs/basic-usage/#commit-your-poetrylock-file-to-version-control
-#poetry.lock
-
-# pdm
-# Similar to Pipfile.lock, it is generally recommended to include pdm.lock in version control.
-#pdm.lock
-# pdm stores project-wide configurations in .pdm.toml, but it is recommended to not include it
-# in version control.
-# https://pdm.fming.dev/#use-with-ide
-.pdm.toml
-
-# PEP 582; used by e.g. github.com/David-OConnor/pyflow and github.com/pdm-project/pdm
-__pypackages__/
-
-# Celery stuff
-celerybeat-schedule
-celerybeat.pid
-
-# SageMath parsed files
-*.sage.py
-
-# Environments
-.env
-.venv
-env/
-venv/
-ENV/
-env.bak/
-venv.bak/
-
-# Spyder project settings
-.spyderproject
-.spyproject
-
-# Rope project settings
-.ropeproject
-
-# mkdocs documentation
-/site
-
-# mypy
-.mypy_cache/
-.dmypy.json
-dmypy.json
-
-# Pyre type checker
-.pyre/
-
-# pytype static type analyzer
-.pytype/
-
-# Cython debug symbols
-cython_debug/
-
-# Claude
-CLAUDE.md
-/.claude/*
-!.claude/skills/
-!.claude/skills/readme.md
-!.claude/skills/add-diffusion-model/
-!.claude/skills/add-diffusion-model/SKILL.md
-!.claude/skills/add-diffusion-model/references/
-!.claude/skills/add-diffusion-model/references/*.md
-!.claude/skills/add-tts-model/
-!.claude/skills/add-tts-model/SKILL.md
-!.claude/skills/review-pr/
-!.claude/skills/review-pr/SKILL.md
-!.claude/skills/review-pr/references/
-!.claude/skills/review-pr/references/*.md
-
-# Codex
-AGENTS.md
-.codex
-.codex/
-
-# cursor
-.cursor/
-
-# scripts
-/scripts/
-
-# PyCharm
-# JetBrains specific template is maintained in a separate JetBrains.gitignore that can
-# be added to the global gitignore or merged into this project gitignore. For a PyCharm
-# project, it is recommended to include the following files:
-# .idea/
-# *.iml
-# *.ipr
-# *.iws
-# .idea/
-
-# vLLM-Omni specific
-# Model files and checkpoints
-checkpoints/
-*.bin
-*.safetensors
-*.pt
-*.pth
-
-# Cache directories
-cache/
-!vllm_omni/diffusion/cache/
-!tests/diffusion/cache/
-.cache/
-diffusion_cache/
-kv_cache/
-
-# Logs
-logs/
-*.log
-
-# Temporary files
-tmp/
-temp/
-.tmp/
-
-# IDE files
-.vscode/
-.idea/
-*.swp
-*.swo
-*~
-
-# OS files
-.DS_Store
-.DS_Store?
-._*
-.Spotlight-V100
-.Trashes
-ehthumbs.db
-Thumbs.db
-
-# Data files
-data/
-datasets/
-*.csv
-*.json
-!apps/ComfyUI-vLLM-Omni/example_workflows/*.json
-*.jsonl
-*.parquet
-
-# Output files
-outputs/
-results/
-generated/
-output_*/
-
-# Configuration overrides
-configs/local.yaml
-configs/production.yaml
-configs/development.yaml
-
-# Docker
-.dockerignore
-Dockerfile.dev
-discussion
-tmp_test
-
-# Auto-generated version file (created by setuptools_scm during build)
-vllm_omni/_version.py
-# output files
-*.wav
-# Vendored test reference audio (small, intentionally checked in)
-!tests/assets/**/*.wav
-.worktrees/
-# CI overlay yamls materialized from tests/utils.py:_CI_OVERLAYS at test time
-tests/.ci_generated/
diff --git a/.pre-commit-config.yaml b/.pre-commit-config.yaml
deleted file mode 100644
index 6db093e0ee2..00000000000
--- a/.pre-commit-config.yaml
+++ /dev/null
@@ -1,71 +0,0 @@
-default_install_hook_types:
- - pre-commit
- - commit-msg
-repos:
- - repo: https://github.com/pre-commit/pre-commit-hooks
- rev: v6.0.0
- hooks:
- # list of supported hooks: https://pre-commit.com/hooks.html
- - id: check-yaml
- args: ["--unsafe"]
- exclude: "examples/online_serving/chart-helm/templates/"
- - id: debug-statements
- - id: end-of-file-fixer
- - id: mixed-line-ending
- args: ["--fix=lf"]
- - id: trailing-whitespace
- args: ["--markdown-linebreak-ext=md"]
-
- - repo: https://github.com/astral-sh/ruff-pre-commit
- rev: v0.14.10
- hooks:
- - id: ruff-check
- args: [--output-format, github, --fix]
- - id: ruff-format
-
- - repo: https://github.com/crate-ci/typos
- rev: typos-dict-v0.13.13
- hooks:
- - id: typos
- # only for staged files
-
- - repo: https://github.com/rhysd/actionlint
- # v1.7.8+ sets `go 1.24.0` in go.mod, which older Go toolchains (and most
- # current CI images) cannot parse. Pin to v1.7.7 until actionlint fixes the
- # go.mod directive.
- rev: v1.7.7
- hooks:
- - id: actionlint
- files: ^\.github/workflows/.*\.ya?ml$
-
-
- - repo: local
- hooks:
- - id: signoff-commit
- name: Sign-off Commit
- entry: bash
- args:
- - -c
- - |
- if ! grep -q "^Signed-off-by: $(git config user.name) <$(git config user.email)>" "$(git rev-parse --git-path COMMIT_EDITMSG)"; then
- printf "\nSigned-off-by: $(git config user.name) <$(git config user.email)>\n" >> "$(git rev-parse --git-path COMMIT_EDITMSG)"
- fi
- language: system
- verbose: true
- stages: [commit-msg]
-
- # Keep `suggestion` last
- - id: suggestion
- name: Suggestion
- entry: bash -c 'echo "To bypass all the pre-commit hooks, add --no-verify to git commit. To skip a specific hook, prefix the commit command with SKIP=Is mypy or markdownlint failing?
- > - >
mypy and markdownlint are run differently in CI. If the failure is related to either of these checks, please use the following commands to run them locally:
- >
- > ```bash
- > # For mypy (substitute "3.10" with the failing version if needed)
- > pre-commit run --hook-stage manual mypy-3.10
- > # For markdownlint
- > pre-commit run --hook-stage manual markdownlint
- > ```
- >
- ![]() -
-
-Easy, fast, and cheap omni-modality model serving for everyone -
- --| Documentation | User Forum | Developer Slack | WeChat | Paper | Slides | -
- - ---- - -*Latest News* 🔥 -- [2026/03] We released [0.18.0](https://github.com/vllm-project/vllm-omni/releases/tag/v0.18.0) - strengthens the core runtime through a large entrypoint refactor and scheduler/runtime cleanups, expands unified quantization and diffusion execution, broadens multimodal model coverage, and improves production readiness across audio, omni, image, video, RL, and multi-platform deployments. -- [2026/03] Check out our first public [project deepdive](https://youtu.be/sgwNfsNnR9I) at the vLLM Hong Kong Meetup! -- [2026/03] **[vllm-omni-skills](https://github.com/hsliuustc0106/vllm-omni-skills)** is a community-driven collection of AI assistant skills that help developers work with vLLM-Omni more effectively. These skills can be used with popular agentic AI coding assistants like **Cursor IDE**, **Claude**, **Codex**, and more. -- [2026/02] We released [0.16.0](https://github.com/vllm-project/vllm-omni/releases/tag/v0.16.0) - A major alignment + capability release that rebases onto **upstream vLLM v0.16.0** and significantly expands performance, distributed execution, and production readiness across **Qwen3-Omni / Qwen3-TTS**, **Bagel**, **MiMo-Audio**, **GLM-Image** and the **Diffusion (DiT) image/video stack**—while also improving platform coverage (CUDA / ROCm / NPU / XPU), CI quality, and documentation. -- [2026/02] We released [0.14.0](https://github.com/vllm-project/vllm-omni/releases/tag/v0.14.0) - This is the first **stable release** of vLLM-Omni that expands Omni’s diffusion / image-video generation and audio / TTS stack, improves distributed execution and memory efficiency, and broadens platform/backend coverage (GPU/ROCm/NPU/XPU). It also brings meaningful upgrades to serving APIs, profiling & benchmarking, and overall stability. Please check our latest [paper](https://arxiv.org/abs/2602.02204) for architecture design and performance results. -- [2026/01] We released [0.12.0rc1](https://github.com/vllm-project/vllm-omni/releases/tag/v0.12.0rc1) - a major RC milestone focused on maturing the diffusion stack, strengthening OpenAI-compatible serving, expanding omni-model coverage, and improving stability across platforms (GPU/NPU/ROCm). -- [2025/11] vLLM community officially released [vllm-project/vllm-omni](https://github.com/vllm-project/vllm-omni) in order to support omni-modality models serving. - ---- - -## About - -[vLLM](https://github.com/vllm-project/vllm) was originally designed to support large language models for text-based autoregressive generation tasks. vLLM-Omni is a framework that extends its support for omni-modality model inference and serving: - -- **Omni-modality**: Text, image, video, and audio data processing -- **Non-autoregressive Architectures**: extend the AR support of vLLM to Diffusion Transformers (DiT) and other parallel generation models -- **Heterogeneous outputs**: from traditional text generation to multimodal outputs - -{kind=link}
- 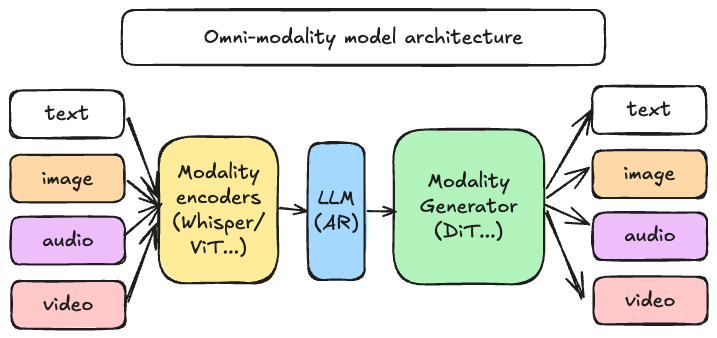 -
-
- 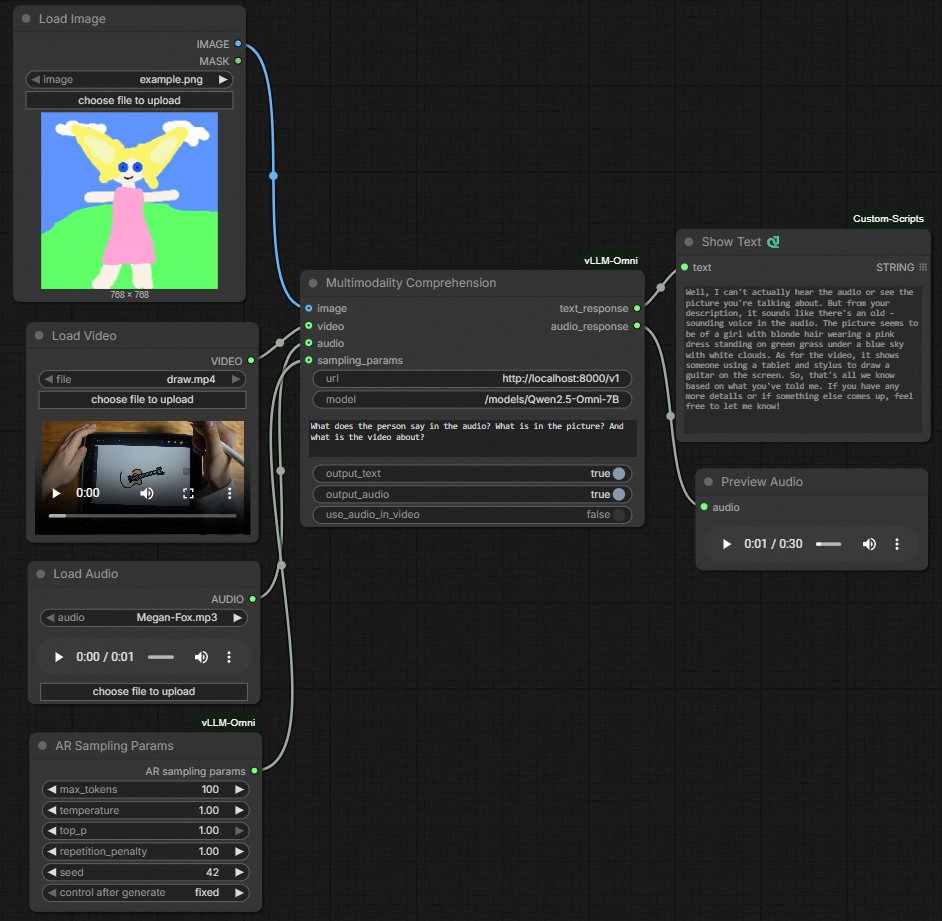 -
-
- 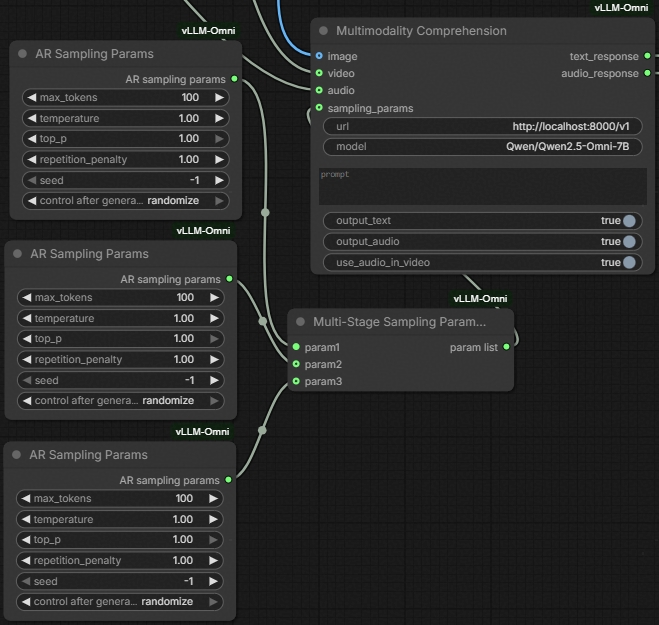 -
-
- 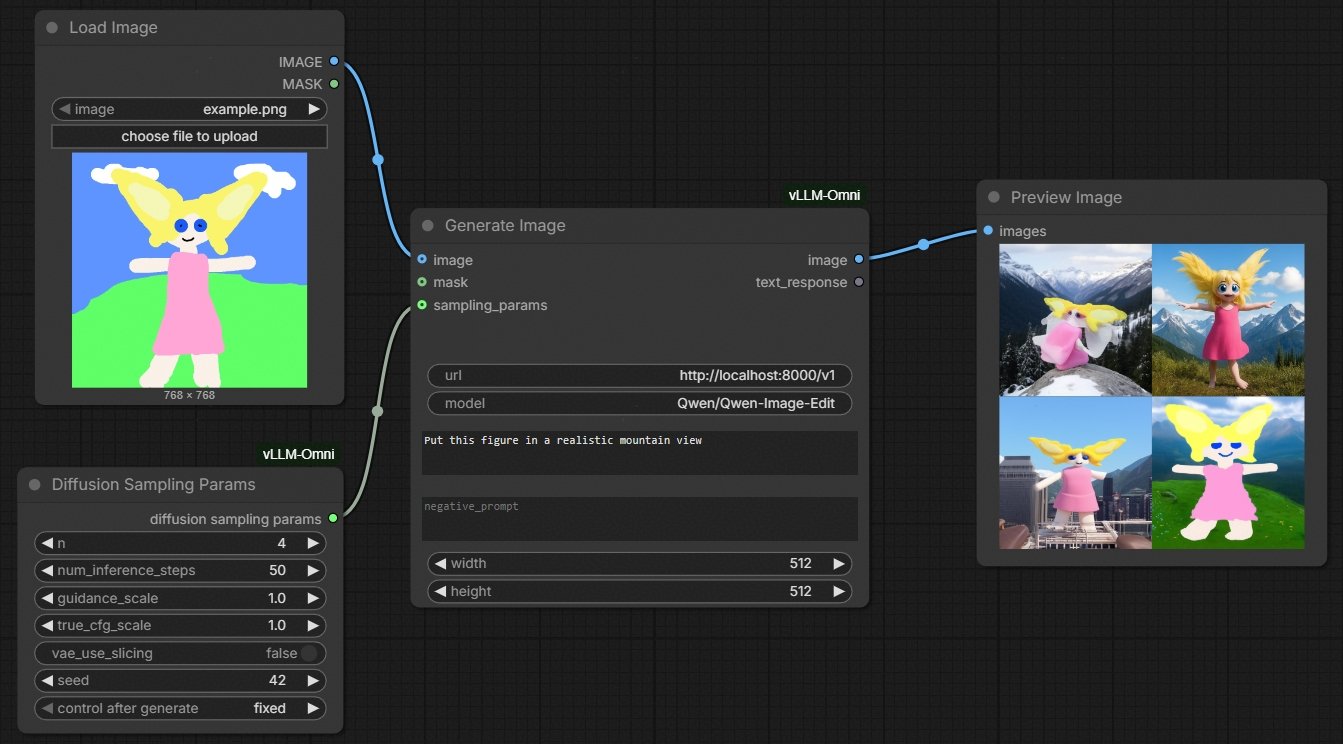 -
-
- 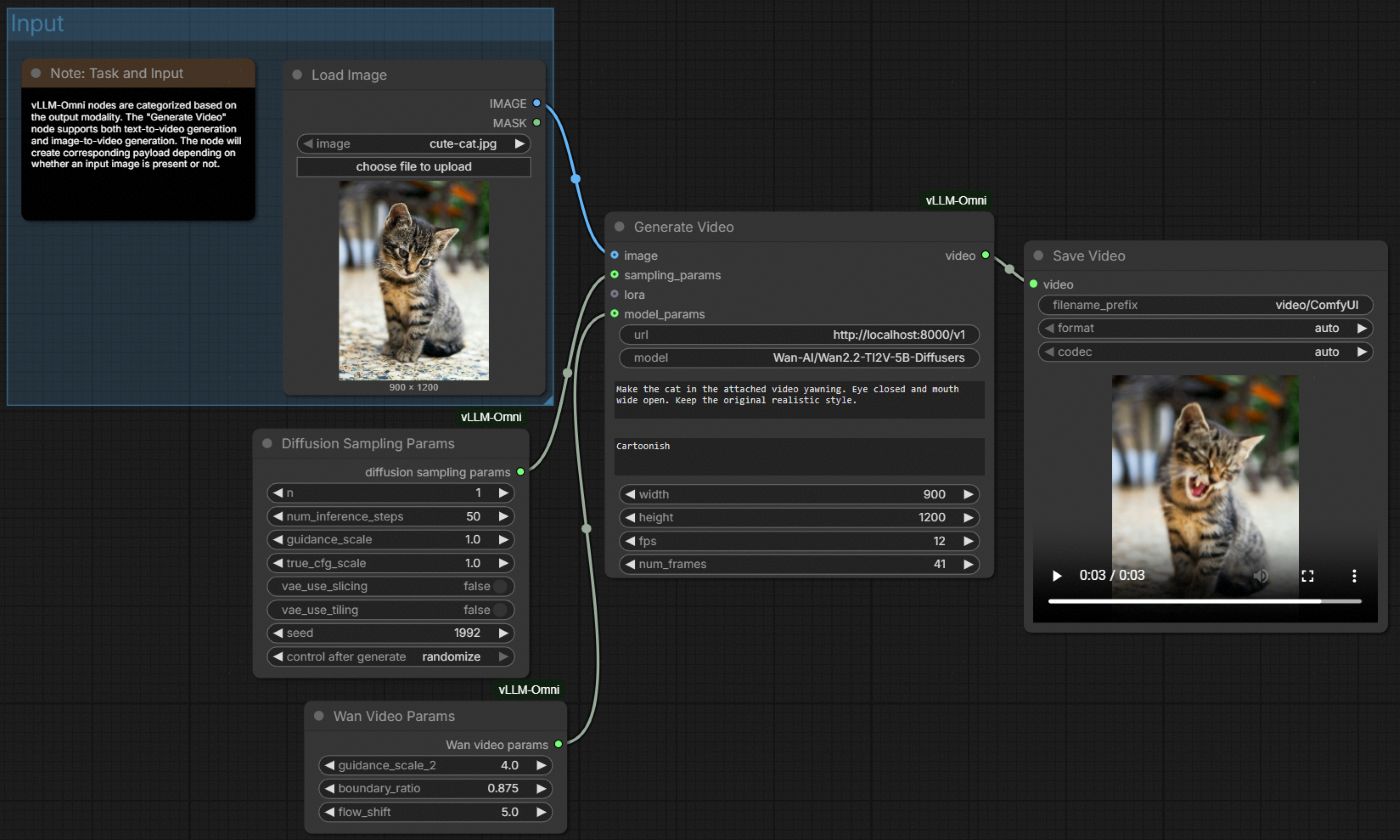 -
-
- 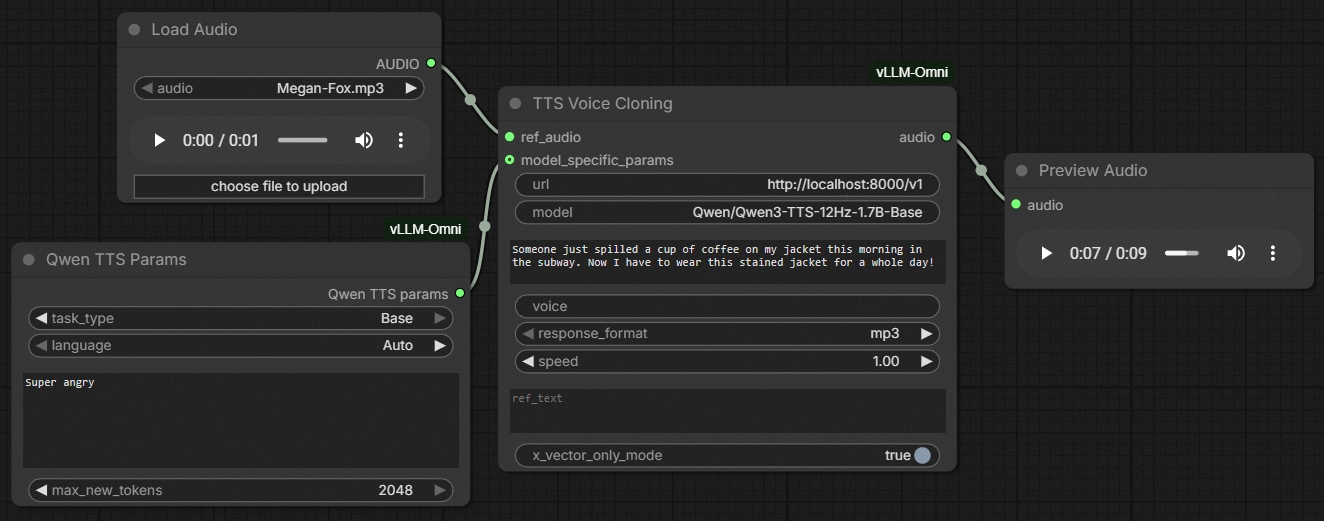 -
-
- 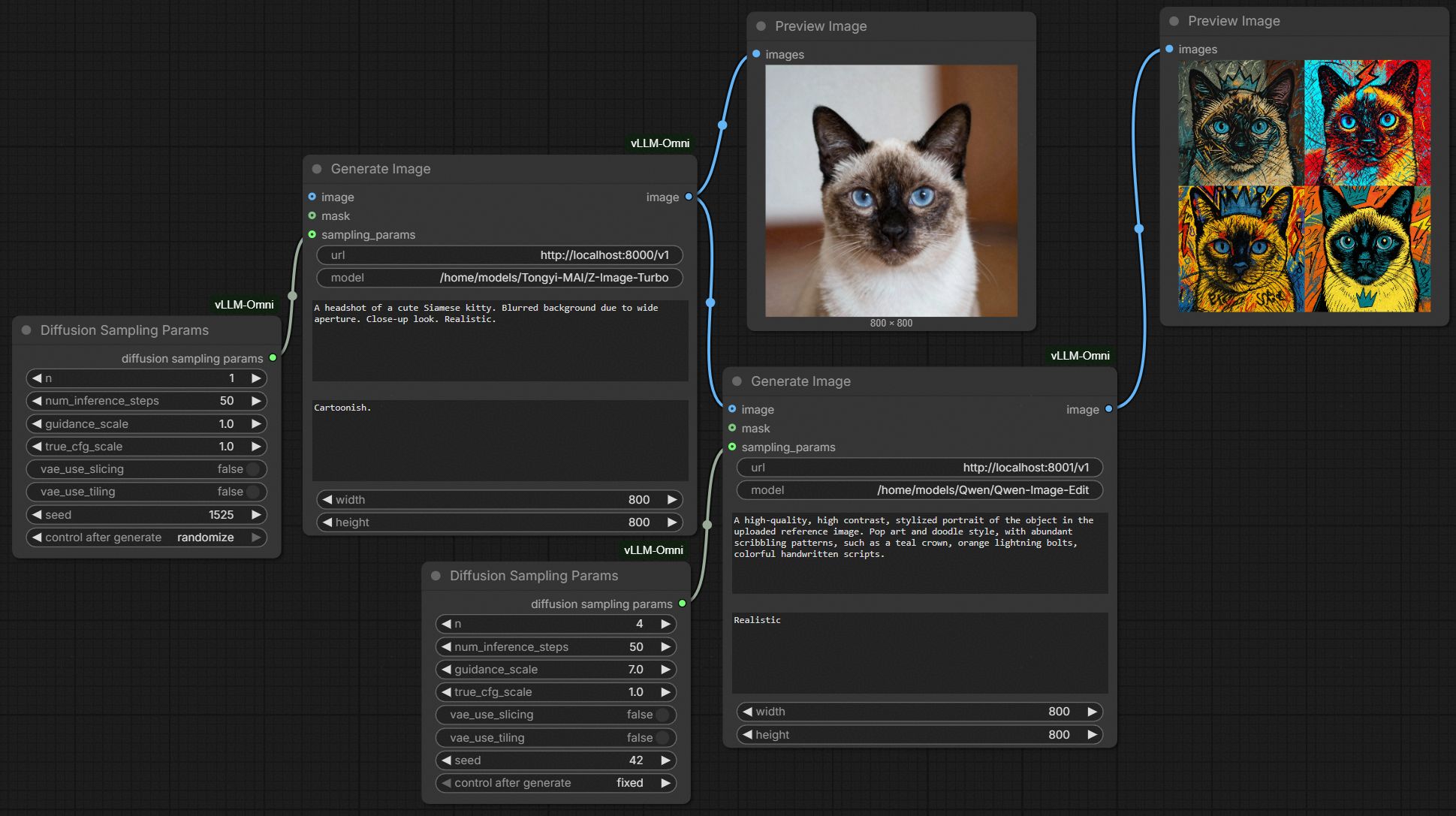 -
-
- ![]() -
-
-Easy, fast, and cheap omni-modality model serving for everyone -
- - - - -## About - -[vLLM](https://github.com/vllm-project/vllm) was originally designed to support large language models for text-based autoregressive generation tasks. vLLM-Omni is a framework that extends its support for omni-modality model inference and serving: - -- **Omni-modality**: Text, image, video, and audio data processing -- **Non-autoregressive Architectures**: extend the AR support of vLLM to Diffusion Transformers (DiT) and other parallel generation models -- **Heterogeneous outputs**: from traditional text generation to multimodal outputs - -
-  -
-
-
-
-### Multi-Modal Benchmark
-
-Show more
- -First start serving your model: - -```bash -vllm serve Qwen/Qwen2.5-Omni-7B --omni -``` - -Then run the benchmarking for sharegpt: - -```bash -# download dataset -# wget https://huggingface.co/datasets/anon8231489123/ShareGPT_Vicuna_unfiltered/resolve/main/ShareGPT_V3_unfiltered_cleaned_split.json -vllm bench serve \ - --omni \ - --port 43845 \ - --model /home/models/Qwen/Qwen3-Omni-30B-A3B-Instruct \ - --endpoint /v1/chat/completions \ - --backend openai-chat-omni \ - --num-prompts 2 \ - --dataset-name sharegpt \ - --dataset-path ShareGPT_V3_unfiltered_cleaned_split.json \ - --percentile-metrics ttft,tpot,itl,e2el -``` -If successful, you will see the following output: -```text -============ Serving Benchmark Result ============ -Successful requests: 2 -Failed requests: 0 -Benchmark duration (s): 81.63 -Request throughput (req/s): 0.02 -Peak concurrent requests: 2.00 -----------------End-to-end Latency---------------- -Mean E2EL (ms): 56966.13 -Median E2EL (ms): 56966.13 -P99 E2EL (ms): 81016.80 -================== Text Result =================== -Total input tokens: 36 -Total generated tokens: 5926 -Output token throughput (tok/s): 72.60 -Peak output token throughput (tok/s): 103.00 -Peak concurrent requests: 2.00 -Total Token throughput (tok/s): 73.04 ----------------Time to First Token---------------- -Mean TTFT (ms): 124.76 -Median TTFT (ms): 124.76 -P99 TTFT (ms): 156.10 ------Time per Output Token (excl. 1st token)------ -Mean TPOT (ms): 481.30 -Median TPOT (ms): 481.30 -P99 TPOT (ms): 947.55 ----------------Inter-token Latency---------------- -Mean ITL (ms): 25.11 -Median ITL (ms): 0.33 -P99 ITL (ms): 25.17 -================== Audio Result ================== -Total audio duration generated(s): 3.95 -Total audio frames generated: 94890 -Audio throughput(audio duration/s): 0.05 -================================================== -``` - -Or run the benchmarking for random: - -```bash -vllm bench serve \ - --omni \ - --port 43845 \ - --endpoint /v1/chat/completions \ - --backend openai-chat-omni \ - --model /home/models/Qwen/Qwen3-Omni-30B-A3B-Instruct \ - --dataset-name random \ - --num-prompts 2 \ - --random-prefix-len 5 \ - --random-input-len 10 \ - --random-output-len 100 \ - --percentile-metrics ttft,tpot,itl,e2el,audio_ttfp,audio_rtf \ - --ignore-eos -``` - -If successful, you will see the following output: - -```text -============ Serving Benchmark Result ============ -Successful requests: 2 -Failed requests: 0 -Benchmark duration (s): 3.89 -Request throughput (req/s): 0.51 -Peak concurrent requests: 2.00 -----------------End-to-end Latency---------------- -Mean E2EL (ms): 3824.76 -Median E2EL (ms): 3824.76 -P99 E2EL (ms): 3888.54 -================== Text Result =================== -Total input tokens: 30 -Total generated tokens: 10101 -Output token throughput (tok/s): 2595.57 -Peak output token throughput (tok/s): 111.00 -Peak concurrent requests: 2.00 -Total Token throughput (tok/s): 2603.28 ----------------Time to First Token---------------- -Mean TTFT (ms): 117.15 -Median TTFT (ms): 117.15 -P99 TTFT (ms): 142.69 ------Time per Output Token (excl. 1st token)------ -Mean TPOT (ms): 0.73 -Median TPOT (ms): 0.73 -P99 TPOT (ms): 0.74 ----------------Inter-token Latency---------------- -Mean ITL (ms): 16.47 -Median ITL (ms): 16.19 -P99 ITL (ms): 52.55 -================== Audio Result ================== -Total audio duration generated(s): 15.79 -Total audio frames generated: 379050 -Audio throughput(audio duration/s): 4.06 ----------------Time to First Packet--------------- -Mean AUDIO_TTFP (ms): 3701.37 -Median AUDIO_TTFP (ms): 3701.37 -P99 AUDIO_TTFP (ms): 3762.25 ------------------Real Time Factor----------------- -Mean AUDIO_RTF: 0.47 -Median AUDIO_RTF: 0.47 -P99 AUDIO_RTF: 0.48 -================================================== -``` -Notes: -We use audio generation time / audio duration to calculate RTF. - -
-
diff --git a/docs/cli/serve.md b/docs/cli/serve.md
deleted file mode 100644
index 9d1747e0be2..00000000000
--- a/docs/cli/serve.md
+++ /dev/null
@@ -1,65 +0,0 @@
-# vllm-omni serve
-
-## Stage-based CLI quickstart
-
-The stage-based CLI is designed for deployments that require launching each pipeline stage in an isolated process
-(e.g., across separate operating system processes, distinct GPUs, or distributed hosts).
-
-- For **migrated models** that utilize the bundled deployment YAML configurations located in
- `vllm_omni/deploy/`, the `--deploy-config` flag is only required to override the default configuration. By default, executing `vllm serve MODEL --omni ...`
- automatically loads the bundled deployment configuration.
-- For **legacy models** utilizing configuration files located in
- `vllm_omni/model_executor/stage_configs/`, the `--stage-configs-path` parameter remains mandatory.
-
-Example: Initializing Stage 0 (Orchestrator and API Server):
-The commands below show a common device mapping where Stage 0 uses GPU 0 and
-worker stages use GPU 1 via `CUDA_VISIBLE_DEVICES`.
-
-```bash
-CUDA_VISIBLE_DEVICES=0 vllm serve Qwen/Qwen3-Omni-30B-A3B-Instruct --omni \
- --port 8091 \
- --stage-id 0 \
- --omni-master-address 127.0.0.1 \
- --omni-master-port 26000
-```
-
-Example: Initializing a Headless Worker Stage (Stage 1):
-
-```bash
-CUDA_VISIBLE_DEVICES=1 vllm serve Qwen/Qwen3-Omni-30B-A3B-Instruct --omni \
- --stage-id 1 \
- --headless \
- --omni-master-address 127.0.0.1 \
- --omni-master-port 26000
-```
-
-When utilizing a custom deployment YAML based on the new schema, append `--deploy-config /path/to/override.yaml` to each command execution. Conversely, for legacy models, substitute this parameter with `--stage-configs-path /path/to/stage_configs.yaml`.
-
-In the standard execution paradigm, the `--stage-overrides` argument is utilized to apply stage-specific configurations from a single CLI command.
-However, under the **stage-based CLI** paradigm, where each process strictly encapsulates a single stage, it is recommended to specify tuning parameters directly via discrete command-line flags for the respective stage, rather than constructing a composite `--stage-overrides` JSON string.
-
-For example, as an alternative to the following composite configuration:
-
-```bash
-vllm serve Qwen/Qwen3-Omni-30B-A3B-Instruct --omni --port 8091 \
- --stage-overrides '{"1": {"gpu_memory_utilization": 0.5}}'
-```
-
-the stage-based CLI permits the direct initialization of Stage 1 with explicit parameters:
-
-```bash
-CUDA_VISIBLE_DEVICES=1 vllm serve Qwen/Qwen3-Omni-30B-A3B-Instruct --omni \
- --stage-id 1 \
- --headless \
- --gpu-memory-utilization 0.5 \
- --omni-master-address 127.0.0.1 \
- --omni-master-port 26000
-```
-
-## JSON CLI Arguments
-
---8<-- "docs/cli/json_tip.inc.md"
-
-## Arguments
-
---8<-- "docs/generated/argparse_omni/omni_serve.inc.md"
diff --git a/docs/community/contact_us.md b/docs/community/contact_us.md
deleted file mode 100644
index 09c7815a038..00000000000
--- a/docs/community/contact_us.md
+++ /dev/null
@@ -1,5 +0,0 @@
-# Contact Us
-
-- For technical questions and feature requests, please use GitHub [Issues](https://github.com/vllm-project/vllm-omni/issues)
-- For coordinating contributions and development and discussing with other users and developers, please join `sig-omni` channel in our [Slack](https://slack.vllm.ai/) or use the [vLLM Forum](https://discuss.vllm.ai/)
-- For security disclosures, please use GitHub's [Security Advisories](https://github.com/vllm-project/vllm-omni/security/advisories) feature
diff --git a/docs/community/governance.md b/docs/community/governance.md
deleted file mode 100644
index 6af578e2d8f..00000000000
--- a/docs/community/governance.md
+++ /dev/null
@@ -1,54 +0,0 @@
-# Governance
-
-vLLM-Omni's governance is inspired by the [vLLM governance process](https://docs.vllm.ai/en/latest/governance/process/). We share the same commitment to open source community and meritocratic norms.
-
-## Values
-
-vLLM-Omni aims to be the fastest and easiest-to-use omni-modality inference and serving engine. Our values are aligned with [vLLM's values](https://docs.vllm.ai/en/latest/governance/process/#values):
-
-### Design Values
-
-1. **Top performance**: System performance is our top priority. We monitor overheads, optimize kernels, and publish benchmarks. We never leave performance on the table.
-2. **Ease of use**: vLLM-Omni must be simple to install, configure, and operate. We provide clear documentation, fast startup, clean logs, helpful error messages, and monitoring guides. Many users fork our code or study it deeply, so we keep it readable and modular.
-3. **Wide coverage**: vLLM-Omni supports frontier models and high-performance accelerators. We make it easy to add new models and hardware. vLLM-Omni + PyTorch form a simple interface that avoids complexity.
-4. **Production ready**: vLLM-Omni runs 24/7 in production. It must be easy to operate and monitor for health issues.
-5. **Extensibility**: vLLM-Omni serves as fundamental omni-modality infrastructure. Our codebase cannot cover every use case, so we design for easy forking and customization.
-
-### Collaboration Values
-
-1. **Tightly Knit and Fast-Moving**: Our maintainer team is aligned on vision, philosophy, and roadmap. We work closely to unblock each other and move quickly.
-2. **Individual Merit**: No one buys their way into governance. Committer status belongs to individuals, not companies. We reward contribution, maintenance, and project stewardship.
-
-## Project Maintainers
-
-### Lead Maintainers
-
-Lead maintainers are responsible for the overall direction and strategy of the project:
-
-- [@Gaohan123](https://github.com/Gaohan123)
-- [@hsliuustc0106](https://github.com/hsliuustc0106)
-- [@ywang96](https://github.com/ywang96)
-
-### Active Committers
-
-Committers have write access and merge rights. They typically have deep expertise in specific areas of this project and shepherd the community contributions:
-
-- [@david6666666](https://github.com/david6666666): Quantization and Community Relationship
-- [@gcanlin](https://github.com/gcanlin): Hardware plugin and NPU integration
-- [@Isotr0py](https://github.com/Isotr0py): Diffusion and Quantization
-- [@linyueqian](https://github.com/linyueqian): TTS and Omni Support
-- [@lishunyang12](https://github.com/lishunyang12): Quantization and Configuration
-- [@princepride](https://github.com/princepride): Diffusion and Omni Support
-- [@SamitHuang](https://github.com/SamitHuang): RL and Diffusion
-- [@tzhouam](https://github.com/tzhouam): Engine and New Model Support
-- [@wtomin](https://github.com/wtomin): Diffusion and Parallelism
-- [@ZeldaHuang](https://github.com/ZeldaHuang): Omni Support
-- [@ZJY0516](https://github.com/ZJY0516): Diffusion and CustomOp
-
-## Meetings
-
-Committers hold **bi-weekly meetings** to discuss future directions and collaborations of the project.
-
-## Committer Nomination Process
-
-Every month, any active committer can nominate new committer(s) to the project. Up to **two new committers** will be admitted per month based on the quality and impact of their contributions.
diff --git a/docs/community/meetups.md b/docs/community/meetups.md
deleted file mode 100644
index 3374fe711cf..00000000000
--- a/docs/community/meetups.md
+++ /dev/null
@@ -1 +0,0 @@
-# Meetups
diff --git a/docs/community/volunteers.md b/docs/community/volunteers.md
deleted file mode 100644
index 2c25485ea90..00000000000
--- a/docs/community/volunteers.md
+++ /dev/null
@@ -1,12 +0,0 @@
-# Volunteers for Bugfix and CI
-
-We encourage you to check current docs and [issues](https://github.com/vllm-project/vllm-omni/issues) to find possible solutions for your questions. If non of these can solve it, please propose an issue to describe your questions about bug or CI problems for developing.
-
-If you have urgent need for locating and solving bugfix or CI problems, please find community volunteers below.
-
-| Dec 4-Dec 12 | Dec 15-Dec 19 | Dec 22-Dec 26 | Dec 29- Jan 2, 2026| Jan 5-Jan 9 | Jan 12-Jan 16 |
-|----------|----------|----------|----------|----------|----------|
-| Conw729 | yinpeiqi | tzhouam | SamitHuang | gcanlin | natureofnature |
-| david6666666 | R2-Y | hsliuustc0106 | Gaohan123 | ZJY0516 | qibaoyuan |
-
-We kindly welcome more contributors to fix bugs and contribute new features!
diff --git a/docs/configuration/README.md b/docs/configuration/README.md
deleted file mode 100644
index 390176e9cea..00000000000
--- a/docs/configuration/README.md
+++ /dev/null
@@ -1,23 +0,0 @@
-# Configuration Options
-
-This section lists the most common options for running vLLM-Omni.
-
-For options within a vLLM Engine. Please refer to [vLLM Configuration](https://docs.vllm.ai/en/v0.16.0/configuration/index.html)
-
-Currently, the main options are maintained by stage configs for each model.
-
-For a specific example, see the [Qwen2.5-Omni deploy config](gh-file:vllm_omni/deploy/qwen2_5_omni.yaml). The matching frozen pipeline topology lives at [vllm_omni/model_executor/models/qwen2_5_omni/pipeline.py](gh-file:vllm_omni/model_executor/models/qwen2_5_omni/pipeline.py).
-
-For introduction, please check [Introduction for stage config](./stage_configs.md)
-
-## Memory Configuration
-
-- **[GPU Memory Calculation and Configuration](./gpu_memory_utilization.md)** - Guide on how to calculate memory requirements and set up `gpu_memory_utilization` for optimal performance
-
-## Multi-Stage Recipes
-
-- **[Prefill-Decode Disaggregation](./pd_disaggregation.md)** - How to derive a PD-aware Qwen3-Omni stage config from the default config without introducing another bundled YAML
-
-## Optimization Features
-
-- **[Diffusion Features Overview](../user_guide/diffusion_features.md)** - Complete overview of all diffusion model features and supported models
diff --git a/docs/configuration/gpu_memory_utilization.md b/docs/configuration/gpu_memory_utilization.md
deleted file mode 100644
index 74106603532..00000000000
--- a/docs/configuration/gpu_memory_utilization.md
+++ /dev/null
@@ -1,207 +0,0 @@
-# GPU Memory Calculation and Configuration
-
-This guide explains how to calculate GPU memory requirements and properly configure `gpu_memory_utilization` for vLLM-Omni stages.
-
-## Overview
-
-`gpu_memory_utilization` is a critical parameter that controls how much GPU memory each stage can use. It's specified as a fraction between 0.0 and 1.0, where:
-- `0.8` means 80% of the GPU's total memory
-- `1.0` means 100% of the GPU's total memory (not recommended, leaves no buffer)
-
-## How Memory is Calculated
-
-### Memory Allocation Formula
-
-For each stage, vLLM-Omni calculates the requested memory as:
-
-```
-requested_memory = total_gpu_memory × gpu_memory_utilization
-```
-
-The system checks that:
-```
-free_memory ≥ requested_memory
-```
-
-If this condition is not met, the stage will fail to initialize with an error message showing the memory requirements.
-
-### Memory Components
-
-The total memory used by a stage includes:
-
-1. **Model Weights**: The size of the model parameters loaded on the GPU
-2. **KV Cache**: Memory for storing key-value cache during generation
-3. **Activation Memory**: Temporary memory for intermediate computations
-4. **System Overhead**: Memory used by CUDA, PyTorch, and other system components
-5. **Non-Torch Memory**: Memory allocated outside of PyTorch (e.g., CUDA graphs)
-
-### Example Calculation
-
-For a GPU with 80GB total memory:
-- `gpu_memory_utilization: 0.8` → 64GB available for the stage
-- `gpu_memory_utilization: 0.6` → 48GB available for the stage
-- `gpu_memory_utilization: 0.15` → 12GB available for the stage
-
-## Setting Up `gpu_memory_utilization`
-
-### Step 1: Determine GPU Memory
-
-First, check your GPU's total memory:
-
-```bash
-# Using nvidia-smi
-nvidia-smi --query-gpu=memory.total --format=csv
-
-# Or using Python
-python -c "import torch; print(f'{torch.cuda.get_device_properties(0).total_memory / 1e9:.1f} GB')"
-```
-
-### Step 2: Estimate Model Memory Requirements
-
-#### For Autoregressive (AR) Stages
-
-AR stages typically need more memory due to:
-- Large model weights
-- KV cache for attention
-- Activation buffers
-
-#### For Diffusion/Generation Stages
-
-Diffusion stages (like code2wav) typically need less memory:
-- Smaller model components
-- Different memory access patterns
-
-**Typical values:**
-- `0.1 - 0.3` for most diffusion stages
-
-### Step 3: Consider Multi-Stage Scenarios
-
-When multiple stages share the same GPU, you must ensure the sum of their `gpu_memory_utilization` values doesn't exceed 1.0.
-
-**Example: Two stages on GPU 0**
-```yaml
-stage_args:
- - stage_id: 0
- runtime:
- devices: "0"
- engine_args:
- gpu_memory_utilization: 0.6 # Uses 60% of GPU 0
-
- - stage_id: 1
- runtime:
- devices: "0"
- engine_args:
- gpu_memory_utilization: 0.3 # Uses 30% of GPU 0
- # Total: 90% of GPU 0 (safe, leaves 10% buffer)
-```
-
-**Important:** If stages run on different GPUs, each can use up to 1.0 independently.
-
-### Step 4: Account for Tensor Parallelism
-
-When using `tensor_parallel_size > 1`, the model is split across multiple GPUs, so each GPU needs less memory.
-
-**Example: 2-way tensor parallelism**
-```yaml
-stage_args:
- - stage_id: 0
- runtime:
- devices: "0,1" # Uses both GPUs
- engine_args:
- tensor_parallel_size: 2
- gpu_memory_utilization: 0.6 # 60% per GPU
- # Model is split, so each GPU uses ~30% of model memory
-```
-
-## Examples
-
-### Qwen3-Omni-MoE on 2x H100-80GB
-
-```yaml
-stage_args:
- - stage_id: 0 # Thinker stage with TP=2
- runtime:
- devices: "0,1"
- engine_args:
- tensor_parallel_size: 2
- gpu_memory_utilization: 0.6 # 48GB per GPU
-
- - stage_id: 1 # Talker stage
- runtime:
- devices: "1"
- engine_args:
- gpu_memory_utilization: 0.3 # 24GB on GPU 1
-
- - stage_id: 2 # Code2Wav stage
- runtime:
- devices: "0"
- engine_args:
- gpu_memory_utilization: 0.1 # 8GB on GPU 0
-```
-**Note:** In this configuration, stages 0 and 2 share GPU 0, but they run at different times in the pipeline, so their memory usage doesn't overlap.
-
-## Troubleshooting
-
-### Error: "Free memory is less than desired GPU memory utilization"
-
-This means the GPU doesn't have enough free memory when the stage starts.
-
-**Solutions:**
-1. Free up memory by closing other processes
-2. Reduce `gpu_memory_utilization` for this stage
-3. Use a GPU with more memory
-4. Move the stage to a different GPU
-
-### Error: OOM during inference
-
-The stage initialized but ran out of memory during processing.
-
-**Solutions:**
-1. Reduce `max_num_batched_tokens`
-2. Reduce `max_num_seqs` in engine_args
-3. Lower `gpu_memory_utilization` slightly
-4. Enable quantization if supported
-
-### Memory Not Fully Utilized
-
-If you see low memory usage, you can:
-1. Increase `gpu_memory_utilization` to allow larger KV cache
-2. Increase `max_num_batched_tokens` for better batching
-3. Check if other stages are limiting throughput
-
-## Useful formula for Memory Calculation
-
-### KV Cache Memory
-
-The KV cache size depends on:
-- Number of sequences in batch
-- Sequence length (prompt + generation)
-- Model hidden size
-- Number of attention heads
-- Number of layers
-
-approximate Formula:
-```
-kv_cache_memory ≈ batch_size × seq_len × hidden_size × num_layers × 2 × dtype_size
-```
-2 for k & v
-
-### Model Weight Memory
-
-```
-model_memory ≈ num_parameters × dtype_size
-```
-
-For example:
-- 7B parameters in FP16: ~14GB
-- 7B parameters in FP32: ~28GB
-- 7B parameters in INT8: ~7GB
-
-### Activation Memory
-
-Activation memory is typically smaller but varies with:
-- Batch size
-- Sequence length
-- Model architecture
-
-It's usually 10-30% of model weight memory during inference.
diff --git a/docs/configuration/pd_disaggregation.md b/docs/configuration/pd_disaggregation.md
deleted file mode 100644
index 9196bdb0240..00000000000
--- a/docs/configuration/pd_disaggregation.md
+++ /dev/null
@@ -1,171 +0,0 @@
-# Prefill-Decode (PD) Disaggregation
-
-PD disaggregation splits the Qwen3-Omni thinker into separate prefill and decode
-stages so prompt processing and token generation can run on different workers.
-
-This is documented as a stage-config recipe instead of a bundled YAML because the
-deployment-specific values usually change per environment:
-
-- GPU placement
-- `tensor_parallel_size`
-- connector backend and connector ports
-- connector IPs or bootstrap addresses
-
-Start from the [default Qwen3-Omni stage config](gh-file:vllm_omni/deploy/qwen3_omni_moe.yaml)
-and copy it to your own file, for example `qwen3_omni_pd.yaml`. Then apply the
-changes below.
-
-## Requirements
-
-- 3+ GPUs for a basic layout: prefill, decode, and talker+code2wav
-- A KV connector supported by vLLM, such as `MooncakeConnector`
-- Matching `tensor_parallel_size` on the prefill and decode thinker stages
-
-## 1. Split the thinker into prefill and decode stages
-
-Replace the original thinker stage with two stages:
-
-```yaml
-stage_args:
- - stage_id: 0
- stage_type: llm
- is_prefill_only: true
- runtime:
- devices: "0"
- engine_args:
- max_num_seqs: 16
- model_stage: thinker
- model_arch: Qwen3OmniMoeForConditionalGeneration
- worker_type: ar
- scheduler_cls: vllm_omni.core.sched.omni_ar_scheduler.OmniARScheduler
- gpu_memory_utilization: 0.9
- enforce_eager: true
- trust_remote_code: true
- engine_output_type: latent
- distributed_executor_backend: "mp"
- enable_prefix_caching: false
- max_num_batched_tokens: 32768
- hf_config_name: thinker_config
- tensor_parallel_size: 1
- kv_transfer_config:
- kv_connector: "MooncakeConnector"
- kv_role: "kv_producer"
- kv_rank: 0
- kv_parallel_size: 2
- kv_connector_extra_config:
- mooncake_bootstrap_port: 25201
- final_output: false
- is_comprehension: true
- default_sampling_params:
- temperature: 0.4
- top_p: 0.9
- top_k: 1
- max_tokens: 2048
- seed: 42
- detokenize: True
- repetition_penalty: 1.05
-
- - stage_id: 1
- stage_type: llm
- is_decode_only: true
- runtime:
- devices: "1"
- engine_args:
- max_num_seqs: 64
- model_stage: thinker
- model_arch: Qwen3OmniMoeForConditionalGeneration
- worker_type: ar
- scheduler_cls: vllm_omni.core.sched.omni_ar_scheduler.OmniARScheduler
- gpu_memory_utilization: 0.9
- enforce_eager: true
- trust_remote_code: true
- engine_output_type: latent
- distributed_executor_backend: "mp"
- enable_prefix_caching: false
- max_num_batched_tokens: 32768
- hf_config_name: thinker_config
- tensor_parallel_size: 1
- kv_transfer_config:
- kv_connector: "MooncakeConnector"
- kv_role: "kv_consumer"
- kv_rank: 1
- kv_parallel_size: 2
- kv_connector_extra_config:
- mooncake_bootstrap_port: 25202
- engine_input_source: [0]
- final_output: true
- final_output_type: text
- is_comprehension: true
- default_sampling_params:
- temperature: 0.4
- top_p: 0.9
- top_k: 1
- max_tokens: 2048
- seed: 42
- detokenize: True
- repetition_penalty: 1.05
-```
-
-Notes:
-
-- `is_prefill_only: true` marks the thinker stage that only saves KV.
-- `is_decode_only: true` marks the thinker stage that resumes from remote KV.
-- `kv_transfer_config` is required on both stages.
-- The orchestrator forces the prefill stage to run with `max_tokens=1`, so the
- prefill side only processes the prompt and exports KV.
-
-## 2. Shift the downstream stages by one index
-
-After inserting the extra thinker stage, renumber the remaining stages:
-
-```yaml
- - stage_id: 2
- runtime:
- devices: "2"
- engine_input_source: [1]
- custom_process_input_func: vllm_omni.model_executor.stage_input_processors.qwen3_omni.thinker2talker
-
- - stage_id: 3
- runtime:
- devices: "2"
- engine_args:
- max_num_seqs: 1
- engine_input_source: [2]
- custom_process_input_func: vllm_omni.model_executor.stage_input_processors.qwen3_omni.talker2code2wav
-```
-
-Compared with the default Qwen3-Omni config:
-
-- the talker becomes stage `2` instead of stage `1`
-- the code2wav stage becomes stage `3` instead of stage `2`
-- the talker now reads from decode stage `1`
-
-## 3. Add runtime edges for the four-stage pipeline
-
-```yaml
-runtime:
- enabled: true
- edges:
- - from: 0
- to: 1
- - from: 1
- to: 2
- - from: 2
- to: 3
-```
-
-## 4. Launch with your custom config
-
-```bash
-vllm serve Qwen/Qwen3-Omni-30B-A3B-Instruct --omni --port 8091 \
- --stage-configs-path /path/to/qwen3_omni_pd.yaml
-```
-
-## Operational Notes
-
-- `MooncakeConnector` does not support heterogeneous TP sizes across the PD
- pair. Keep prefill and decode at the same `tensor_parallel_size`.
-- If the thinker requires TP=2, both thinker stages must use TP=2 and be given
- separate GPU sets, for example `"0,1"` for prefill and `"2,3"` for decode.
-- Choose connector ports and addresses that match your deployment. The values
- shown above are examples only.
diff --git a/docs/configuration/stage_configs.md b/docs/configuration/stage_configs.md
deleted file mode 100644
index 3a17f1c4013..00000000000
--- a/docs/configuration/stage_configs.md
+++ /dev/null
@@ -1,509 +0,0 @@
-# Stage configs for vLLM-Omni
-
-In vLLM-Omni, the target model is separated into multiple stages, which are processed by different LLMEngines, DiffusionEngines or other types of engines. Depending on different types of stages, such as Autoregressive (AR) stage or Diffusion transformer (DiT) stage, each can choose corresponding schedulers, model workers to load with the Engines in a plug-in fashion.
-
-!!! note
- Default deploy config YAMLs (for example, `vllm_omni/deploy/qwen2_5_omni.yaml`, `vllm_omni/deploy/qwen3_omni_moe.yaml`, and `vllm_omni/deploy/qwen3_tts.yaml`) are bundled and loaded automatically when neither `--stage-configs-path` nor `--deploy-config` is provided — the model registry resolves the right pipeline + deploy YAML by `model_type`. The bundled defaults have been verified on 1xH100 for Qwen2.5-Omni and 2xH100 for Qwen3-Omni. Models that have not yet migrated to the new schema continue to use the legacy `vllm_omni/model_executor/stage_configs/Show more
- -Benchmark the performance of multi-modal requests in vLLM-Omni. - -Generate synthetic image、video、audio inputs alongside random text prompts to stress-test vision models without external datasets. - -Notes: - -- Works only with online benchmark via the OpenAI backend (`--backend openai-chat-omni`) and endpoint `/v1/chat/completions`. - -Start the server (example): - -```bash -vllm serve Qwen/Qwen2.5-Omni-7B --omni -``` - -It is recommended to use the flag `--ignore-eos` to simulate real responses. You can set the size of the output via the arg `random-output-len`. - -Then run the benchmarking script: -```bash -vllm bench serve \ - --omni \ - --dataset-name random-mm \ - --port 40849 \ - --model /home/models/Qwen/Qwen3-Omni-30B-A3B-Instruct \ - --endpoint /v1/chat/completions \ - --backend openai-chat-omni \ - --request-rate 1 \ - --num-prompts 1 \ - --random-input-len 10 \ - --random-range-ratio 0.0 \ - --random-mm-base-items-per-request 2 \ - --random-mm-num-mm-items-range-ratio 0 \ - --random-mm-limit-mm-per-prompt '{"image":1,"video":1, "audio": 1}' \ - --random-mm-bucket-config '{"(32, 32, 1)": 0.5, "(0, 1, 1)": 0.1, "(32, 32, 2)":0.4}' \ - --ignore-eos \ - --percentile-metrics ttft,tpot,itl \ - --random-output-len 2 \ - --extra_body '{"modalities": ["text"]}' -``` - -If successful, you will see the following output: - -```text -============ Serving Benchmark Result ============ -Successful requests: 1 -Failed requests: 0 -Request rate configured (RPS): 1.00 -Benchmark duration (s): 1.21 -Request throughput (req/s): 0.83 -Peak concurrent requests: 1.00 -================== Text Result =================== -Total input tokens: 10 -Total generated tokens: 3 -Output token throughput (tok/s): 2.49 -Peak output token throughput (tok/s): 3.00 -Peak concurrent requests: 1.00 -Total Token throughput (tok/s): 10.77 ----------------Time to First Token---------------- -Mean TTFT (ms): 179.74 -Median TTFT (ms): 179.74 -P99 TTFT (ms): 179.74 ------Time per Output Token (excl. 1st token)------ -Mean TPOT (ms): 12.76 -Median TPOT (ms): 12.76 -P99 TPOT (ms): 12.76 ----------------Inter-token Latency---------------- -Mean ITL (ms): 12.76 -Median ITL (ms): 12.76 -P99 ITL (ms): 25.24 -================== Audio Result ================== -Total audio duration generated(s): 0.00 -Total audio frames generated: 0 -Audio throughput(audio duration/s): 0.00 -================================================== -``` - -Behavioral notes: - -- If the requested base item count cannot be satisfied under the provided per-prompt limits, the tool raises an error rather than silently clamping. - -How sampling works: - -- Determine per-request item count k by sampling uniformly from the integer range defined by `--random-mm-base-items-per-request` and `--random-mm-num-mm-items-range-ratio`, then clamp k to at most the sum of per-modality limits. -- For each of the k items, sample a bucket (H, W, T) according to the normalized probabilities in `--random-mm-bucket-config`, while tracking how many items of each modality have been added. -- If a modality (e.g., image) reaches its limit from `--random-mm-limit-mm-per-prompt`, all buckets of that modality are excluded and the remaining bucket probabilities are renormalized before continuing. -This should be seen as an edge case, and if this behavior can be avoided by setting `--random-mm-limit-mm-per-prompt` to a large number. Note that this might result in errors due to engine config `--limit-mm-per-prompt`. -- The resulting request contains synthetic image data in `multi_modal_data` (OpenAI Chat format). When `random-mm` is used with the OpenAI Chat backend, prompts remain text and MM content is attached via `multi_modal_data`. -| Level | -Scope & Focus | -Time Cost | -Test Dir | -Doc | -Frequency | -Hardware | -
|---|---|---|---|---|---|---|
| Common | -Contribution Guideline & PR checklist | -/ | -/ | -.github/PULL_REQUEST_TEMPLATE.md Test Style (PR Checklist) | -/ | -/ | -
| CI Failure Description | -/ | -/ | -CI Failures | -/ | -/ | -|
| L1 (Unit & Logic) |
- Unit tests for components like entrypoints, models | -<15min | -/tests/{component_name}/test_xxx | -
- Chapter 1 - Section 1 L1&L2: Purpose, Test Content, Directory Location, Example - |
- PR with ready label (also can run locally) | -CPU | -
| L2 (E2E across models & GPU-required UT) |
- Online & Offline (basic deployment scenarios): dummy, normal inference function (output format, stream), some instance startup UT |
-
- /tests/e2e/online_serving/test_{model_name}.py - /tests/e2e/offline_inference/test_{model_name}.py - |
-
- Chapter 1 - L1&L2: Purpose, Test Content, Directory Location, Example - |
- PR with ready label | -GPU | -|
| L3 (Important Perf & Integration & Accuracy) |
- Online & Offline (multiple deployment scenarios): real model, normal inference function, normal accuracy |
- <30min | -
- /tests/e2e/online_serving/test_{model_name}.py - /tests/e2e/offline_inference/test_{model_name}.py - |
-
- Chapter 2 - L3: Purpose, Test Content, Directory Location, Example - |
- PR Merged (Also run L1&L2 Tests) | -GPU | -
| L4 (Perf & Integration & Accuracy) |
- Online & Offline: full functional scenarios + performance test + doc test | -<3 hour | -
- Full Function: - /tests/e2e/online_serving/test_{model_name}_expansion.py - /tests/e2e/offline_inference/test_{model_name}_expansion.py - Performance: - /tests/dfx/perf/tests/test_qwen_omni.json (Omni), test_tts.json (TTS), - and /tests/dfx/perf/tests/test_{diffusion_model}_vllm_omni.json (Diffusion) - Doc Test: - tests/example/online_serving/test_{model_name}.py - tests/example/offline_inference/test_{model_name}.py - |
-
- Chapter 3 - L4: Purpose, Test Content, Directory Location, Example - |
- Nightly | -GPU | -
| L5 (Stability & Reliability) |
- Online & Offline: long-term stability test + reliability test | -Depends on reality | -
- Stability: - /tests/dfx/stability/tests/test_qwen3_omni.json - /tests/dfx/stability/tests/test_wan22.json - Reliability: - tests/dfx/reliability/test_reliability_{model_key}.py - (e.g. test_reliability_qwen3_omni.py, test_reliability_wan22.py)
- |
-
- Chapter 4 - L5: Purpose, Test Content, Directory Location, Example - |
- Weekly / Days before Release | -GPU | -
-
-
-
-## Common Specifications
-
-Before entering specific testing levels, the project establishes two common specifications aimed at standardizing the development process and quickly locating issues.
-
-1. ***PR Checklist ([Tests Style](../ci/tests_style.md))***: This template defines the self-check items that must be completed before submitting a code review (Pull Request). It ensures that each code change meets basic requirements such as code style, dependency updates, and documentation synchronization before entering the automated testing pipeline, serving as the first manual line of defense for quality assurance.
-2. ***CI Failure Explanation ([CI Failures](../ci/failures.md))***: This document archives and explains common failure patterns in the Continuous Integration (CI) pipeline, error log interpretation, and preliminary troubleshooting steps. It helps developers and testers quickly diagnose the causes of automated test failures, improving problem-solving efficiency.
-
-## Chapter 1: L1 & L2 Level Testing - Unit Testing and Basic End-to-End Verification
-
-### 1.1 Testing Purpose
-
-L1 and L2 level testing form the foundation of the quality assurance system. L1 level testing focuses on verifying the internal logic correctness of code units (e.g., functions, classes), ensuring each independent component behaves as designed.
-
-L2 level testing builds upon L1 by introducing GPU resources and verifying that the end-to-end (E2E) process of the model in basic deployment scenarios is smooth. For example, it uses dummy models to confirm that core interfaces like the inference pipeline, output format, and streaming response work properly. The common goal of these two levels is to provide developers with rapid feedback, discovering and fixing issues early in the development cycle.
-
-
-
-### 1.2 Testing Content and Scope
-
-- ***L1 (Unit & Logic Testing)***:
-- - ***Scope***: Tests internal functions and methods of core components such as `entrypoints`, `models`.
- - ***Focus***: Branch coverage, exception handling, algorithm logic correctness. Does not involve external dependencies or the complete service stack.
- - ***Time Cost***: Execution time is controlled within ***15 minutes*** to ensure fast feedback.
-- ***L2 (Basic End-to-End Testing)***:
-- - ***Scope***: Covers two basic deployment scenarios: `online` (serving) and `offline` (inference).
- - ***Focus***: Uses `dummy` models or lightweight real models to verify that the entire chain from request input to result output works normally, including output data structure, streaming (stream) support, etc. Also includes some unit tests that require launching independent service instances.
- - ***Characteristic***: Requires ***GPU*** resources to perform model computations.
-
-### 1.3 Test Directory and Execution Files
-
-A clear directory structure is key to managing test cases efficiently.
-
-- ***L1 Test Directory***: `/tests/{component_name}/test_xxx.py`
-- - Here, `{component_name}` corresponds to modules in the source code, such as `distributed`, `entrypoints`, etc., and `test_xxx.py` is the specific test file.
-- ***L2 Test Directory***:
-- - Online Serving: `/tests/e2e/online_serving/test_{model_name}.py`
- - Offline Inference: `/tests/e2e/offline_inference/test_{model_name}.py`
-
-### 1.4 Execution Method and Example
-
-- ***Trigger Timing***: **`PR with ready label`**. That is, when a developer adds a "ready for review" or similar label to a PR on platforms like GitHub, L1 and L2 tests are automatically triggered.
-- ***Execution Environment***: L1 uses ***CPU*** environment; L2 requires ***GPU*** environment.
-- ***Script Example***:
-
-The folder structure for tests file based on the 5 levels design
-Legend: `✅` = test exists, `⬜` = suggested to add. -``` -vllm_omni/ tests/ -├── config/ → ├── config/ -│ ├── model.py │ └── test_model.py ⬜ -│ └── lora.py │ └── test_lora.py ⬜ -│ -├── core/ → ├── core/ -│ └── sched/ │ └── sched/ -│ ├── omni_ar_scheduler.py │ ├── test_omni_ar_scheduler.py ⬜ -│ ├── omni_generation_scheduler.py │ ├── test_omni_generation_scheduler.py ⬜ -│ └── output.py │ └── test_output.py ✅ currently in entrypoints/test_omni_new_request_data.py (tests output.OmniNewRequestData) -│ -├── diffusion/ → ├── diffusion/ -│ ├── diffusion_engine.py │ ├── test_diffusion_engine.py ⬜ -│ ├── attention/ │ ├── attention/ -│ │ ├── layer.py │ │ ├── test_attention_sp.py ✅ -│ │ └── backends/ │ │ └── test_flash_attn.py ✅ -│ ├── distributed/ │ ├── distributed/ -│ │ └── ... │ │ ├── test_comm.py ✅ -│ │ │ │ ├── test_cfg_parallel.py ✅ -│ │ │ │ └── test_sp_plan_hooks.py ✅ -│ ├── lora/ │ ├── lora/ -│ │ └── ... │ │ ├── test_base_linear.py ✅ -│ │ │ │ └── test_lora_manager.py ✅ -│ ├── models/ │ ├── models/ -│ │ ├── qwen_image/ │ │ ├── qwen_image/ (e2e coverage) -│ │ ├── z_image/ │ │ └── z_image/ -│ │ └── ... │ │ └── test_zimage_tp_constraints.py ✅ -│ └── worker/ │ └── worker/ -│ ├── diffusion_worker.py │ └── test_diffusion_worker.py ✅ file at diffusion/test_diffusion_worker.py -│ └── diffusion_model_runner.py │ -│ -├── distributed/ → ├── distributed/ -│ └── omni_connectors/ │ └── omni_connectors/ -│ ├── adapter.py │ ├── test_adapter_and_flow.py ✅ -│ ├── kv_transfer_manager.py │ ├── test_basic_connectors.py ✅ -│ ├── connectors/ │ ├── test_kv_flow.py ✅ -│ └── utils/ │ └── test_omni_connector_configs.py ✅ -│ -├── engine/ → ├── engine/ -│ ├── input_processor.py │ ├── test_input_processor.py ⬜ (no processor.py in source) -│ ├── output_processor.py │ └── test_output_processor.py ⬜ -│ └── arg_utils.py │ └── test_arg_utils.py ⬜ -│ -├── entrypoints/ → ├── entrypoints/ -│ ├── stage_utils.py │ ├── test_stage_utils.py ✅ -│ ├── cli/ │ ├── cli/ (benchmarks/test_serve_cli.py covers CLI serve) -│ │ └── ... │ │ └── test_*.py ⬜ -│ └── openai/ │ └── openai_api/ # maps to entrypoints/openai/ -│ ├── api_server.py │ ├── test_api_server.py ⬜ (e2e indirect coverage) -│ ├── serving_chat.py │ ├── test_serving_chat_sampling_params.py ✅ -│ ├── serving_speech.py │ ├── test_serving_speech.py ✅ -│ └── image_api_utils.py │ └── test_image_server.py ✅ -│ -├── inputs/ → ├── inputs/ -│ ├── data.py │ ├── test_data.py ⬜ -│ ├── parse.py │ ├── test_parse.py ⬜ -│ └── preprocess.py │ └── test_preprocess.py ✅ currently in entrypoints/test_omni_input_preprocessor.py -│ -├── model_executor/ → ├── model_executor/ -│ ├── layers/ │ ├── layers/ -│ │ └── mrope.py │ │ └── test_mrope.py ⬜ -│ ├── model_loader/ │ ├── model_loader/ -│ │ └── weight_utils.py │ │ └── test_weight_utils.py ⬜ -│ ├── models/ │ ├── models/ -│ │ ├── qwen2_5_omni/ │ │ ├── qwen2_5_omni/ -│ │ │ ├── qwen2_5_omni_thinker.py │ │ │ ├── test_audio_length.py ✅ -│ │ │ ├── qwen2_5_omni_talker.py │ │ │ ├── test_qwen2_5_omni_thinker.py ⬜ -│ │ │ └── qwen2_5_omni_token2wav.py │ │ │ ├── test_qwen2_5_omni_talker.py ⬜ -│ │ └── qwen3_omni/ │ │ │ └── test_qwen2_5_omni_token2wav.py ⬜ -│ │ └── ... │ │ └── qwen3_omni/ -│ ├── stage_configs/ │ │ └── test_*.py ⬜ -│ │ └── *.yaml │ └── stage_configs/ (used by e2e, test_*.py can be added) ⬜ -│ └── stage_input_processors/ │ └── stage_input_processors/ -│ └── ... │ └── test_*.py ⬜ -│ -├── sample/ → ├── sample/ -│ └── __init__.py │ └── test_*.py ⬜ -│ -├── utils/ → ├── utils/ -│ └── __init__.py │ └── test_*.py ⬜ (no platform_utils.py currently) -│ -├── worker/ → ├── worker/ -│ ├── gpu_ar_model_runner.py │ ├── test_gpu_ar_model_runner.py ⬜ -│ ├── gpu_ar_worker.py │ ├── test_gpu_ar_worker.py ⬜ -│ ├── gpu_generation_model_runner.py │ ├── test_gpu_generation_model_runner.py ✅ -│ ├── gpu_generation_worker.py │ ├── test_gpu_generation_worker.py ⬜ -│ ├── gpu_model_runner.py │ ├── test_omni_gpu_model_runner.py ✅ -│ └── mixins.py │ └── (npu under platforms/npu/worker/) # not worker/npu/ -│ -├── platforms/ → (no tests/platforms/, e2e and stage_configs provide indirect coverage) -│ ├── cuda/ -│ ├── npu/worker/ # NPU worker here, not vllm_omni/worker/npu/ -│ ├── rocm/ -│ └── xpu/worker/ -│ -├── outputs.py → test_outputs.py ✅ (at tests root) -├── (logger, patch, request, version) → (no corresponding unit test) -│ -└── e2e (tests side only) → ├── e2e/ - ├── online_serving/ ✅ non-empty - │ ├── test_qwen2_5_omni.py - │ ├── test_async_omni.py - │ ├── test_qwen3_omni.py - │ ├── test_qwen3_omni_expansion.py - │ ├── test_mimo_audio.py - │ ├── test_image_gen_edit.py - │ └── test_images_generations_lora.py - └── offline_inference/ ✅ - ├── test_qwen2_5_omni.py - ├── test_qwen3_omni.py - ├── test_bagel_text2img.py - ├── test_t2i_model.py - ├── test_t2v_model.py - ├── test_ovis_image.py - ├── test_zimage_tensor_parallel.py - ├── test_cache_dit.py - ├── test_teacache.py - ├── test_stable_audio_expansion.py - ├── test_diffusion_cpu_offload.py - ├── test_diffusion_layerwise_offload.py - ├── test_diffusion_lora.py - ├── test_sequence_parallel.py - └── stage_configs/ (legacy schema, still - ├── bagel_*.yaml present for unmigrated - └── npu/, rocm/, etc. models) - -# Migrated models (qwen3_omni_moe, qwen2_5_omni, qwen3_tts) live under -# vllm_omni/deploy/ instead — see docs/configuration/stage_configs.md. -``` - - -
-
-
-L1 Test Examples
- -Examples from `tests/model_executor/models/qwen2_5_omni/test_audio_length.py` -```python -# SPDX-License-Identifier: Apache-2.0 -# SPDX-FileCopyrightText: Copyright contributors to the vLLM project - -import pytest - -pytestmark = [pytest.mark.core_model, pytest.mark.cpu] - -def test_resolve_max_mel_frames_default(): - from vllm_omni.model_executor.models.qwen2_5_omni.audio_length import resolve_max_mel_frames - - assert resolve_max_mel_frames(None, default=30000) == 30000 - assert resolve_max_mel_frames(None, default=6000) == 6000 - - -def test_resolve_max_mel_frames_explicit(): - from vllm_omni.model_executor.models.qwen2_5_omni.audio_length import resolve_max_mel_frames - - # Explicit argument always wins over default - assert resolve_max_mel_frames(123, default=30000) == 123 - assert resolve_max_mel_frames(6000, default=30000) == 6000 - assert resolve_max_mel_frames(0, default=30000) == 0 - - -@pytest.mark.parametrize("repeats", [2, 4]) -@pytest.mark.parametrize("code_len", [0, 1, 32768]) -@pytest.mark.parametrize("max_mel_frames", [None, -1, 0, 1, 6000, 30000]) -def test_cap_and_align_mel_length_no_mismatch(repeats, code_len, max_mel_frames): - """Guard that any max_mel_frames yields a mel length aligned to repeats, and - consistent with the truncated code length (prevents concat mismatch). - """ - from vllm_omni.model_executor.models.qwen2_5_omni.audio_length import cap_and_align_mel_length - - target_code_len, target_mel_len = cap_and_align_mel_length( - code_len=code_len, - repeats=repeats, - max_mel_frames=max_mel_frames, - ) - - assert isinstance(target_code_len, int) - assert isinstance(target_mel_len, int) - - if code_len == 0: - assert target_code_len == 0 - assert target_mel_len == 0 - return - - assert target_code_len >= 1 - assert target_mel_len >= repeats - assert target_mel_len % repeats == 0 - assert target_mel_len == target_code_len * repeats - assert target_code_len <= code_len - - if max_mel_frames is not None and int(max_mel_frames) > 0 and int(max_mel_frames) >= repeats: - assert target_mel_len <= int(max_mel_frames) -``` -
-
-
-- - ***Run Command***:
-
- `pytest -s -v /tests/e2e/online_serving/test_{model_name}.py`
- `pytest -s -v -m 'core_model and cpu' --run-level=core_model`
-
-## Chapter 2: L3 Level Testing - Core Integration, Performance, and Accuracy Verification
-
-### 2.1 Testing Purpose
-
-L3 level testing executes after code is merged into the main branch. Its core purpose is to verify the integration effect, key performance indicators, and output accuracy of ***real models*** in ***multiple deployment scenarios***
-
-. It acts as the "quality gatekeeper" for the main branch, ensuring that no merge breaks the core capabilities of the model service. Testing needs to provide clear conclusions within a relatively short time (<30min), balancing test depth with feedback speed.
-
-
-
-### 2.2 Testing Content and Scope
-
-- ***Deployment Scenarios***: Covers richer `online` and `offline` deployment configurations, which may include different hardware configurations, batch sizes, concurrency levels, etc.
-- ***Core Verification***:
-- 1. ***Inference Functionality***: Ensures real models can perform forward computation normally and return results.
- 2. ***Accuracy Compliance***: Verifies that the model's evaluation metrics (e.g., accuracy) meet the expected baseline, preventing code changes from introducing accuracy issues.
- 3. ***Important Performance***: Verifies whether performance (e.g., P99 latency, throughput) in core scenarios meets preset thresholds.
-
-### 2.3 Test Directory and Execution Files
-
-- ***Functional Testing***:
-- - Online Serving: `/tests/e2e/online_serving/test_{model_name}_expansion.py`
- - Offline Inference: `/tests/e2e/offline_inference/test_{model_name}_expansion.py`
- - (Note: `_expansion.py` likely means it contains more comprehensive scenario cases compared to L2 tests).
-
-### 2.4 Execution Method and Example
-
-- ***Trigger Timing***: **`PR Merged`**. Automatically triggered after code review is approved and merged into the main branch.
-- ***Execution Environment***: ***GPU*** servers.
-- ***Script Example***:
-
-???+ example "Test Examples"
-
- **2.4.1 Mark Declaration Section**
-
- ```python
- @pytest.mark.advanced_model
- @pytest.mark.core_model
- @pytest.mark.parametrize("omni_server", test_params, indirect=True)
- ```
-
- **Explanation**:
-
- @pytest.mark.advanced_model: Marks the test as L3 merge level, indicating deep validation with real models. @pytest.mark.full_model: Marks L4 nightly-only suites (e.g. `test_*_expansion.py`, doc examples).
-
- @pytest.mark.core_model: Marks the test as L1 or L2 level, indicating that this test case validates the basic functionality of the core model. It uses mock weights and only checks if the relevant interface functions correctly.
-
- @pytest.mark.parametrize: A parameterization decorator that allows abstracting test data into parameters, enabling reuse of the same test logic across different data configurations. indirect=True indicates that parameters will be passed to the fixture for processing.
-
- **Notes**: If you believe the test case only needs to execute basic run logic at the PR-level CI, you can mark it only with @pytest.mark.core_model. If you believe it only needs to execute deep validation at merge (L3), use @pytest.mark.advanced_model. For L4 nightly-only expansion and doc-example tests, use @pytest.mark.full_model with `--run-level full_model`. If the test case needs both basic run and deep validation, mark with @pytest.mark.core_model and the appropriate L3/L4 marker (`advanced_model` and/or `full_model`).
-
- **2.4.2 Test Function Definition and Documentation**
-
- ```python
- def test_mix_to_text_audio_001(omni_server, openai_client) -> None:
- """
- Test multi-modal input processing and text/audio output generation via OpenAI API.
- Deploy Setting: default yaml
- Input Modal: text + audio + video + image
- Output Modal: text + audio
- Input Setting: stream=True
- Datasets: single request
- """
- ```
-
- **Explanation**:
-
- **Function Naming Convention**: Uses the test_ prefix, describes the test scenario mix_to_text_audio, and the number 001 indicates the first test case for this scenario.
-
- **Parameter Explanation**:
-
- omni_server: Omni server instance obtained via fixture, containing model information and configuration.
-
- openai_client: Unified OpenAI client processing instance, encapsulating request sending and response validation logic.
-
- Docstring: Describes the test purpose, deployment settings, input/output modalities, streaming settings, and dataset type in detail, providing clear context for test maintenance.
-
- **2.4.3 Multimodal Data Preparation**
-
- ```python
- video_data_url = f"data:video/mp4;base64,{generate_synthetic_video(224, 224, 300)['base64']}"
- image_data_url = f"data:image/jpeg;base64,{generate_synthetic_image(224, 224)['base64']}"
- audio_data_url = f"data:audio/wav;base64,{generate_synthetic_audio(5, 1)['base64']}"
- ```
-
- **Explanation**:
-
- **Data Generation Functions**: Use the generate_synthetic_* series of functions to generate synthetic test data, avoiding reliance on external resources and ensuring test reproducibility and stability.
-
- **Parameter Explanation**:
-
- Video: width, height, duration_frames
-
- Image: width, height
-
- Audio: duration_seconds, channels
-
- **2.4.4 Request Configuration and Keyword Validation**
-
- ```python
- request_config = {
- "model": omni_server.model,
- "messages": messages,
- "stream": True,
- "key_words": {
- "audio": ["water", "cricket"],
- "video": ["sphere", "globe", "circle", "round"],
- "image": ["square", "quadrate"],
- "text": ["beijing"]
- },
- }
- ```
-
- **Explanation**:
-
- **Model Specification**: Uses omni_server.model to ensure the test aligns with the model configured on the server.
-
- **Keyword Validation Mechanism**: This is an innovative design of the template to address the specific needs of multimodal testing:
-
- Audio Keywords: Validate whether the generated text's description of audio content contains expected elements (e.g., "water" for water sounds, "cricket" for cricket sounds). If you provide multiple keywords, the validation is considered successful if at least one keyword is present.
-
- **Video Keywords**: Validate whether the generated text's description of video content contains expected elements. If you provide multiple keywords, the validation is considered successful if at least one keyword is present.
-
- Image Keywords: Validate whether the generated text's description of image content contains expected elements. If you provide multiple keywords, the validation is considered successful if at least one keyword is present.
-
- Text Keywords: Validate whether the generated text contains expected elements. If you provide multiple keywords, the validation is considered successful if at least one keyword is present.
-
- **2.4.5 Request Execution**
-
- ```python
- openai_client.send_omni_request(request_config, request_num=1) # for omni-understanding models
- # or
- openai_client.send_diffusion_request(request_config, request_num=1) # for diffusion models
- ```
-
- **Explanation**:
-
- **Unified Client**: Uses the OpenAIClientHandler instance to send requests. This client encapsulates error handling, retry mechanisms, and response validation logic.
-
- **Single Request**: The comment clearly states this is a single-request completion test. For concurrent testing, it can be extended to multiple requests using request_num = n.
-
- **Implicit Validation**: The `send_omni_request` and `send_diffusion_request` methods internally includes validation logic dynamically selected based on the --run-level parameter: core_model performs basic validation, while advanced_model and full_model perform deep validation.
-
-- ***Run Command (L3 merge)***: `pytest -s -v /tests/e2e/online_serving/test_{model_name}.py -m advanced_model --run-level=advanced_model`
-
-- ***Run Command (L4 nightly expansion)***: `pytest -s -v /tests/e2e/online_serving/test_{model_name}_expansion.py -m full_model --run-level=full_model`
-
-## Chapter 3: L4 Level Testing - Full Functionality, Performance, and Documentation Testing
-
-### 3.1 Testing Purpose
-
-L4 level testing is a comprehensive quality audit before a version release. It expands upon L3, executing ***full*** functional scenarios, conducting systematic ***performance stress tests***, and simultaneously verifying the correctness of accompanying ***example documentation***. Its purpose is to perform deep validation of the system during off-peak nighttime hours, providing quality trend reports for daytime development and data support for release decisions.
-
-
-
-### 3.2 Testing Content and Scope
-
-- ***Full Functionality Testing***: Executes all test cases defined in `test_{model_name}_expansion.py`, covering all implemented features, positive flows, boundary conditions, and exception handling.
-- ***Performance Testing***: Uses `tests/dfx/perf/tests/test_qwen_omni.json`, `tests/dfx/perf/tests/test_tts.json`, and diffusion configs in the form `tests/dfx/perf/tests/test_*_vllm_omni.json` (passed to `run_benchmark.py` via `--test-config-file`) to drive performance testing tools for stress, load, and endurance tests, collecting metrics like throughput, response time, and resource utilization.
-- ***Documentation Testing***: Verifies whether the example code provided to users is runnable and its results match the description.
-
-### 3.3 Test Directory and Execution Files
-
-- ***Functional Testing***: Same directories as L3.
-- ***Performance Test Configuration***: `tests/dfx/perf/tests/test_qwen_omni.json`, `tests/dfx/perf/tests/test_tts.json`, and diffusion configs `tests/dfx/perf/tests/test_*_vllm_omni.json` (e.g. `test_qwen_image_vllm_omni.json`)
-- ***Documentation Example Tests***:
-- - `tests/example/online_serving/test_{model_name}.py`
- - `tests/example/offline_inference/test_{model_name}.py`
-
-### 3.4 Execution Method and Example
-
-- ***Trigger Timing***: **`Nightly`**, automatically executed every night.
-- ***Execution Environment***: ***GPU*** server clusters to meet the resource demands of performance testing.
-- ***Script Example***:
-
-??? example "Test Examples: Documentation Example Tests"
-
- --8<-- "docs/contributing/ci/test_examples/l4_doc_example_tests.inc.md"
-
-??? example "Test Examples: Performance Tests"
-
- --8<-- "docs/contributing/ci/test_examples/l4_performance_tests.inc.md"
-
-??? example "Test Examples: Functionality Tests"
-
- --8<-- "docs/contributing/ci/test_examples/l4_functionality_tests.inc.md"
-
-- ***Run Command***: (Specific commands would depend on the performance testing tool and configuration defined in `nightly.json`).
-
-## Chapter 4: L5 Level Testing - Stability and Reliability Testing
-
-### 4.1 Testing Purpose
-
-L5 level testing focuses on the performance of model services under ***long-running*** and ***abnormal fault*** scenarios. It aims to uncover deep-seated issues that only manifest under sustained pressure or extreme conditions, such as memory leaks, resource contention, gradual performance degradation, and lack of fault tolerance mechanisms. This is the final, yet crucial, line of defense for ensuring service high availability and production environment robustness.
-
-
-
-### 4.2 Testing Content and Scope
-
-- ***Long-term Stability (Stability) Testing***: Uses JSON under `tests/dfx/stability/tests/` (for example `test_qwen3_omni.json` and `test_wan22.json`) to run the service under moderate load for an extended period (e.g., over 12 hours), monitoring whether metrics like memory/VRAM usage, response time, and throughput degrade over time, and whether the service process remains stable.
-- ***Reliability Testing***: Uses pytest suites under `tests/dfx/reliability/` to inject controlled faults against a **live** `vllm_omni serve` instance (same **`omni_server` / `omni_server_function`** fixture style as E2E). Current suites emphasize **GPU memory pressure** (CUDA sidecar “memory hog”), **worker / runtime process kill** (`SIGKILL` on `VLLM::Worker` for Qwen3-Omni or `multiprocessing.spawn` for Wan2.2 video workers), **large multimodal chat** or **`/v1/videos`** jobs under OOM, **`/health` → 503** and **fast-fail / non-hanging concurrent** requests after kill, and **OpenAI-style 5xx error contracts** (e.g. text vs text+audio under OOM). **Post-fault recovery** checks exist where enabled (some cases may be `skip` while issues are tracked). See the Reliability `L2 Test Examples
-You can refer to Test Examples in Chapter 2 to see example test cases that incorporate both L2 and L3 testing logic. -` block in Section 4.4 for file-level responsibilities and CI markers (`slow`, `hardware_test`, POSIX-only kill).
-
-### 4.3 Test Directory and Execution Files
-
-- ***Stability Test Configuration***: `tests/dfx/stability/tests/test_qwen3_omni.json`, `tests/dfx/stability/tests/test_wan22.json` (one JSON per model / runner family)
-- ***Reliability Test Suite*** (`tests/dfx/reliability/`):
- - `test_reliability_qwen3_omni.py` — Qwen3-Omni chat / multimodal reliability (GPU OOM, process kill, recovery, error contract under `--async-chunk` vs default).
- - `test_reliability_wan22.py` — Wan2.2 T2V video API reliability (`/v1/videos` under OOM and process kill, recovery).
- - `helpers.py` — Shared primitives used by current suites: raw HTTP probes for `/v1/chat/completions` and `/health`, OpenAI-style error parsing, GPU OOM sidecar (`inject_gpu_oom` / `stop_gpu_oom_hogs`), and `pgrep`-based process-kill injector construction (`make_process_kill_fault_injector`).
- - `conftest.py` — `fault_injector` and `omni_server_after_fault` / `omni_server_after_fault_function` fixtures to run a callable **after** the server is ready.
- - `README.md` — Short local run commands for this directory.
-
-### 4.4 Execution Method and Example
-
-- ***Trigger Timing***: **`Weekly`** (weekly) or **`Days before Release`** (several days before a major release). Due to long execution times, the frequency is lower.
-- ***Execution Environment***: ***GPU*** servers, requiring a stable and exclusive testing environment.
-- ***Script Example***:
-.py` alongside a matching JSON config)
- - ***Reliability***: `pytest -s -v tests/dfx/reliability/test_reliability_qwen3_omni.py -m slow` and/or `pytest -s -v tests/dfx/reliability/test_reliability_wan22.py -m slow` (add `test_reliability_.py` for new models)
-
-## Summary
-
-This multi-level testing system achieves continuous, progressive validation of model service quality by tightly integrating testing activities with the development workflow (commit, review, merge, release). From rapid unit testing to comprehensive end-to-end testing, and further to in-depth performance, stability, and reliability verification, each level has clear objectives, collectively building a robust quality protection net. By following this system, teams can deliver high-quality, highly reliable model services more efficiently.
diff --git a/docs/contributing/ci/failures.md b/docs/contributing/ci/failures.md
deleted file mode 100644
index 68e468be1df..00000000000
--- a/docs/contributing/ci/failures.md
+++ /dev/null
@@ -1,106 +0,0 @@
-# CI Failures
-
-## Overview of CI Checks
-
-When you open a PR against vLLM-Omni, several CI checks run automatically:
-
-| Check | Platform | What it does |
-| ----- | -------- | ------------ |
-| **pre-commit** | GitHub Actions | Runs linting (Ruff), formatting, spell-checking (typos), and YAML validation. |
-| **Build Wheel** | GitHub Actions | Builds Python wheels for Python 3.11 and 3.12 on Ubuntu. Skipped for docs-only or Markdown-only changes (controlled by `paths-ignore` in the workflow). |
-| **DCO** | GitHub | Verifies every commit has a `Signed-off-by` line. |
-| **docs/readthedocs.org:vllm-omni** | Read the Docs | Builds the MkDocs documentation site. |
-| **buildkite/vllm-omni** | Buildkite | Runs GPU-based tests on NVIDIA CUDA hardware (L4, H100). |
-| **buildkite/vllm-omni-amd** | Buildkite | Runs GPU-based tests on AMD ROCm hardware (MI325). |
-| **buildkite/vllm-omni-intel** | Buildkite | Runs GPU-based tests on Intel XPU hardware (Intel Arc BMG). |
-
-## Step 1: Identify the Failing Check
-
-Click the **Details** link next to the failing check on your PR to open the build log. The most common failures fall into these categories:
-
-### pre-commit failures
-
-These are typically formatting or linting issues introduced by your PR. Fix them locally:
-
-```bash
-uv pip install pre-commit
-pre-commit run --all-files
-```
-
-Then commit the fixes and push.
-
-### DCO failures
-
-Every commit must include a `Signed-off-by` line. If you forgot, amend your commits:
-
-```bash
-git commit --amend -s
-git push --force-with-lease
-```
-
-For multiple commits, use an interactive rebase to add the sign-off to each one.
-
-### Read the Docs failures
-
-The documentation build uses MkDocs with `fail_on_warning: true`, so even a minor warning (not just errors) will cause the build to fail. To reproduce locally:
-
-```bash
-uv pip install -e ".[docs]"
-mkdocs build --strict
-```
-
-Common causes include broken cross-references, invalid admonition syntax, or missing files referenced by `--8<--` includes.
-
-### Buildkite failures
-
-Buildkite runs GPU tests in Docker containers. These are the most complex checks and can fail for reasons unrelated to your PR (infrastructure issues, flaky tests, etc.). See the sections below for how to investigate.
-
-## Step 2: Check if the Failure Is a Known Issue
-
-Before spending time debugging, check whether the failure already exists on the `main` branch:
-
-1. **Look at the Buildkite build log** — the test name and error message are usually enough to identify the issue.
-2. **Check recent CI runs on `main`** — if the same test is failing there, the failure is not caused by your PR.
-3. **Search existing issues** — look for open issues in the [vllm-omni issue tracker](https://github.com/vllm-project/vllm-omni/issues) with the test name or error message.
-
-If the failure is already tracked, leave a comment on your PR noting that the failure is pre-existing and link the issue.
-
-## Step 3: Investigate the Failure
-
-If the failure appears to be new, investigate whether your changes caused it.
-
-### Reading Buildkite Logs
-
-1. Click **Details** next to the Buildkite check on your PR.
-2. Find the failing step in the pipeline (e.g., "Diffusion Model Test", "Simple Unit Test").
-3. Expand the step to see the full test output with the traceback.
-
-### Running Tests Locally
-
-For instructions on running tests locally (including specific test files, functions, and markers), see the [Running Tests](https://docs.vllm.ai/projects/vllm-omni/en/latest/contributing/ci/test_guide/#running-tests) section in the Test Guide.
-
-## Step 4: Raise an Issue or Fix It
-
-### If the failure is pre-existing (not caused by your PR)
-
-1. **Raise a new issue** if one doesn't already exist, using the title format:
- `[CI Failure]: [job-name] - [test-path]`
-2. Include the error message, relevant log excerpts, and the commit hash where the failure occurs (e.g., "Still failing on main as of commit `abc1234`").
-3. Leave a comment on your PR linking to the issue and noting that the failure is unrelated to your changes.
-
-### If the failure is caused by your PR
-
-1. Fix the issue in your branch and push the update.
-2. If the fix is non-trivial, consider adding a test to prevent regression.
-
-## Common Failure Patterns
-
-| Symptom | Likely Cause | Fix |
-| ------- | ------------ | --- |
-| `ruff` or formatting errors | Code style violation | Run `pre-commit run --all-files` |
-| `Signed-off-by` missing | DCO check | Amend commits with `git commit --amend -s` |
-| MkDocs build warning | Broken docs reference | Run `mkdocs build --strict` locally |
-| `OOM` or `CUDA out of memory` | Test exceeds GPU memory | Check if your changes increased memory usage; use `--vae_use_slicing` / `--vae_use_tiling` for diffusion tests |
-| Import errors | Missing or changed dependency | Check `pyproject.toml` and make sure dependencies are correct |
-| Timeout (step exceeded N minutes) | Test is too slow or hangs | Profile the test; check for infinite loops or deadlocks |
-| `Agent lost` in Buildkite | Infrastructure issue (not your fault) | Re-trigger the build; comment on your PR |
diff --git a/docs/contributing/ci/test_examples/l4_doc_example_tests.inc.md b/docs/contributing/ci/test_examples/l4_doc_example_tests.inc.md
deleted file mode 100644
index 13dd032e275..00000000000
--- a/docs/contributing/ci/test_examples/l4_doc_example_tests.inc.md
+++ /dev/null
@@ -1,49 +0,0 @@
-**Preferred Test Strategy**
-
-Use one of the following patterns depending on page type:
-
-- **Dynamic code-block extraction (preferred for offline docs)**
- - Extract Python/Bash code blocks from markdown AST analyzer, then execute them directly in tests.
- - Benefit: test logic stays automatically aligned with docs.
- - Basic idea: Use `ReadmeSnippet.extract_readme_snippets` to extract a list of code blocks as a global variable in file,
- use this list as `pytest.mark.parametrize` parameters, and pass each snippet item to `example_runner.run` inside the parametrized test.
- Additionally pass an `output_subfolder` argument for the 2nd-level output folder explained in **Output Directory Structure** below.
- If any extra environment variable is need for a test (e.g., the example script reads it), `example_runner.run` also accepts a 3rd `env` parameter.
- - See [tests/examples/offline_inference/test_text_to_image.py](https://github.com/vllm-project/vllm-omni/blob/main/tests/examples/offline_inference/test_text_to_image.py) for reference implementation.
-
-- **Explicit copied scripts (used by online docs for now until further update)**
- - For online serving pages, it is acceptable to copy code from docs into dedicated test functions, because only client-side, request-sending scripts are tested.
- - Benefit: dynamic extraction is overly complex: need to tell server-launch and client-request scripts.
- - Requirement: copied test code must be kept in sync with doc updates.
-
-**Test Case Naming Convention**
-
-- Dynamic code extraction (auto-generated internally):
- - `test_{single_function_name_matching_file_name}[h2_heading_00X]`
- - Example: `test_text_to_image[basic_usage_001]`
-- Explicit copied scripts:
- - `test_{h2_heading_00X}[{dummy_param_id_for_omni_server}]`
- - Example: `test_api_calls_001[omni_server0]`
-
-**Runtime Configuration**
-
-In the example code tests, do **not** reduce `num_inference_steps` just to speed up the tests unless there is a strong CI reliability reason to do otherwise.
-
-**Skipping Rules**
-
-You may skip examples falling in the following categories using `pytest.mark.skip` or `pytest.skip`:
-
-- Gradio UI scripts
-- Scenarios that significantly overlap with existing tests and add little new coverage.
-
-**Output Directory Structure**
-
-Use a three-layer output structure to store output artifacts:
-
-1. Root output directory
- - Auto-detected from `OUTPUT_DIR` env var or auto-generated under `/tmp`.
-2. Doc-page directory
- - Define and use a clear page-level folder name in each `test_*.py` yourself (abbreviations are acceptable, e.g., `example_offline_t2i`).
-3. Test-case directory
- - Must match the case identifier (e.g., `basic_usage_001`).
- - Auto-generated for dynamic extracted tests.
diff --git a/docs/contributing/ci/test_examples/l4_functionality_tests.inc.md b/docs/contributing/ci/test_examples/l4_functionality_tests.inc.md
deleted file mode 100644
index 688933f135d..00000000000
--- a/docs/contributing/ci/test_examples/l4_functionality_tests.inc.md
+++ /dev/null
@@ -1,46 +0,0 @@
-**Scope**
-
-For diffusion models, the L4 functionality test covers all or common *diffusion features* that are supported by this model, including several [parallelism acceleration methods](https://docs.vllm.ai/projects/vllm-omni/en/latest/user_guide/diffusion/parallelism_acceleration/), [CPU offloading](https://docs.vllm.ai/projects/vllm-omni/en/latest/user_guide/diffusion/cpu_offload_diffusion/), [TeaCache](https://docs.vllm.ai/projects/vllm-omni/en/latest/user_guide/diffusion/teacache/) and [Cache-DiT](https://docs.vllm.ai/projects/vllm-omni/en/latest/user_guide/diffusion/cache_dit_acceleration/) cache backends, [quantization methods](https://docs.vllm.ai/projects/vllm-omni/en/latest/user_guide/quantization/overview/).
-
-**Test Case Design**
-
-For a *high priority* model (currently listed in [issue #1832](https://github.com/vllm-project/vllm-omni/issues/1832)), we use several test cases, each with multiple features turned on, so that each supported feature is tested in at least one test case. This is to relieve the GPU workload on the CI machine. The suggested test case combination is as follows:
-
-- If the model can fit into 4 L4 GPU (with quantization and tensor parallel always on) (20GB RAM each)
- - (1 GPU) TeaCache + Layerwise CPU offloading + GGUF
- - (4 GPUs) CacheDiT + Ulysses=2 + TP=2 + VAE=2 + FP8
- - (4 GPUs) CacheDiT + Ring=2 + HSDP=2 + VAE=2 + GGUF
- - (4 GPUs) TeaCache + CFG=2 + TP=2 + VAE=2 + FP8
-- Otherwise, consider 2 H100 GPU environment (80GB RAM each) with the following tests
- - (1 GPU) TeaCache + Layerwise CPU offloading + GGUF
- - (2 GPUs) CacheDiT + Ulysses=2 + FP8
- - (2 GPUs) CacheDiT + Ring=2 + GGUF
- - (2 GPUs) TeaCache + CFG=2 + FP8
- - (2 GPUs) CacheDiT + TP=2 + VAE=2 + FP8
- - (2 GPUs) CacheDiT + HSDP=2 + VAE=2 + GGUF
-- If 2 H100 GPU cannot handle the model either (e.g., HunyuanImage 3.0)
- - Still design tests and feature combinations that can best fit real-world scenario.
- - Do not include it in CI (or exclude it from the CI's filtering criteria). Instead, relevant PR authors are suggested to run these tests locally.
-- Fallback plan
- - If the model does not support layerwise CPU offloading, replace the corresponding test case with module-wise offloading
- - If the model only supports specific or no caching feature, use this option or remove this option in all test cases.
- - If the model only supports specific or no quantization feature, use this option or remove this option in all test cases.
- - If the model does not support certain other features, remove this option from that test case. If, consequently, the coverage of this modified test case completely overlaps with others, remove this test case.
-
-For a *normal priority* model, further reduce the number of test cases.
-
-- Only write one or two test cases for the most common feature combinations.
-- The author can explore themselves to see which feature combination balances output quality and performance. Alternatively, the author can refer to any example code in the PR that adds the model, or the example code in the PR that adds a feature (if the code involves this model of interest).
-
-Currently all the features are available in online serving mode. Hence, only need to add `tests/e2e/online_serving/test_{model}_expansion.py`.
-
-**Code Style**
-
-- Validation: test that the multimodal output files of your model have the correct shapes. `OpenAIClientHandler.send_diffusion_request` should have taken care of this.
-- Test marks: always add `full_model` and `diffusion` for L4 nightly `test_*_expansion.py` cases. Add GPU-related marks if needed. Ref: [Markers for Tests](https://docs.vllm.ai/projects/vllm-omni/en/latest/contributing/ci/tests_markers/).
-- To maximize code reuse, you may refer to
- - `tests/conftest.py` for `omni_server` (running server in subprocess) and `openai_client` fixtures (sending requests and validating output), `generate_synthetic_image` and `assert_XXX_valid` helper.
- - `tests/helpers/mark.py` for `@hardware_test(...)` and `hardware_marks`.
- - [Parametrizing tests (pytest doc)](https://docs.pytest.org/en/stable/example/parametrize.html) to reuse test function implementation for different cases.
-- Doc: add a concise docstring for each test function.
-- Reference L4 test implementation: [tests/e2e/online_serving/test_qwen_image_edit_expansion.py](https://github.com/vllm-project/vllm-omni/blob/main/tests/e2e/online_serving/test_qwen_image_edit_expansion.py).
diff --git a/docs/contributing/ci/test_examples/l4_performance_tests.inc.md b/docs/contributing/ci/test_examples/l4_performance_tests.inc.md
deleted file mode 100644
index f1f3073dc52..00000000000
--- a/docs/contributing/ci/test_examples/l4_performance_tests.inc.md
+++ /dev/null
@@ -1,89 +0,0 @@
-When you want to add L4-level ***performance test*** cases, you can refer to the following format for case addition in `tests/dfx/perf/tests/test_qwen_omni.json`, `tests/dfx/perf/tests/test_tts.json`, or diffusion configs such as `tests/dfx/perf/tests/test_*_vllm_omni.json` (selected via `pytest ... run_benchmark.py --test-config-file `):
-
-```JSON
-{
- "test_name": "test_qwen3_omni",
- "server_params": {
- "model": "Qwen/Qwen3-Omni-30B-A3B-Instruct",
- "stage_config_name": "qwen3_omni.yaml"
- },
- "benchmark_params": [
- {
- "dataset_name": "random",
- "num_prompts": [10, 20],
- "max_concurrency": [1, 4],
- "random_input_len": 2500,
- "random_output_len": 900,
- "ignore_eos": true,
- "percentile-metrics": "ttft,tpot,itl,e2el,audio_rtf,audio_ttfp,audio_duration",
- "baseline": {
- "mean_ttft_ms": [500, 800],
- "mean_audio_ttfp_ms": [2000, 3500],
- "mean_audio_rtf": [0.25, 0.35]
- }
- }
- ]
-}
-```
-
-**Parameter Explanation**
-
-*Overview*
-
-| Field | Required | Description |
-| ---------------- | -------- | --------------------------------------------------------------- |
-| test_name | Yes | Unique identifier for the test case |
-| server_params | Yes | Server-side configuration parameters |
-| benchmark_params | Yes | Benchmark running parameters (supports multiple configurations) |
-
-**`server_params` Configuration**
-
-*Basic Parameters*
-
-| Parameter | Required | Example | Description |
-| ----------------- | -------- | ---------------------------------- | ----------------------------- |
-| model | Yes | "Qwen/Qwen3-Omni-30B-A3B-Instruct" | Model name or path |
-| stage_config_name | Yes | "qwen3_omni.yaml" | Stage configuration file name |
-
-*Dynamic Configuration (update/delete)*
-
-Supports incremental modifications based on the basic configuration:
-
-| Operation | Description |
-| --------- | ------------------------------------ |
-| update | Update or add configuration items |
-| delete | Delete specified configuration items |
-
-**Example**:
-
-```
-"update": {
- "async_chunk": true, // Enable asynchronous chunk processing
- "stage_args": {
- "0": {
- "engine_args.custom_process_next_stage_input_func": "vllm_omni.model_executor.stage_input_processors.qwen3_omni.thinker2talker_async_chunk"
- }
- }
-},
-"delete": {
- "stage_args": {
- "2": ["custom_process_input_func"] // Delete this configuration for stage 2
- }
-}
-```
-
-**`benchmark_params` Configuration**
-
-You can add any benchmark running parameters you need here. For all optional parameters, refer to the [benchmark documentation](https://github.com/vllm-project/vllm-omni/blob/main/docs/cli/bench/serve.md). General modifications are as follows:
-
-1. Change the --xxx-xx-xx running parameters to xxx_xx_xx format and fill them as keys in the JSON file.
-2. For boolean variables in the running parameters, modify them to forms such as ignore_eos: true/false and fill them into the JSON file.
-3. Optionally add a `baseline` object (see **Baseline thresholds** below). If you omit `baseline` or leave it empty, the performance test still runs but does not assert metric thresholds from this field.
-4. The qps and concurrency modes are recommended to be mutually exclusive. For detailed explanations, see the table below:
-
-| Parameter | Type | Required | Example/Values | Description |
-| --------------- | ----------- | -------- | --------------- | -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
-| num_prompts | int / array | Yes | 10,[10, 20, 30] | Number of requests. Supports single values or arrays. If a single value is used, it will be automatically expanded to match the number of qps or max_concurrency, e.g., [10,10,10]. If an array is used, its length must match the number of qps or max_concurrency. |
-| request_rate | float / array | No | 0.5, [0.5, 1, inf] | Queries per second. Supports single values or arrays. If a single value is used, it will be automatically expanded to match the number of num_prompts, e.g., [1,1,1]. If an array is used, its length must match the number of num_prompts. |
-| max_concurrency | int / array | No | 1, [1, 2, 3] | Maximum concurrent in-flight requests. Same array / expansion rules as `request_rate` (mutually exclusive with QPS mode). |
-| baseline | object | No | see above | Optional per-metric thresholds; keys must match benchmark output fields. Scalar, list (per sweep step), or object (keyed by concurrency or QPS string).
diff --git a/docs/contributing/ci/test_guide.md b/docs/contributing/ci/test_guide.md
deleted file mode 100644
index 018c47b053f..00000000000
--- a/docs/contributing/ci/test_guide.md
+++ /dev/null
@@ -1,106 +0,0 @@
-# Test Guide
-## Setting Up the Test Environment
-### Creating a Container
-vLLM-Omni provides an official Docker image for deployment. These images are built upon vLLM Docker images and are available on [Docker Hub](https://hub.docker.com/r/vllm/vllm-omni/tags). The version of vLLM-Omni indicates which vLLM release it is based on.
-For a local test environment, you can follow the steps below to create a container:
-## Installing Dependencies
-### vLLM & vLLM-Omni
-vLLM-Omni is built based on vLLM. You can follow [install guide](../../getting_started/installation/README.md) to build your local environment.
-
-### Test Case Dependencies
-When running test cases, you may need to install the following dependencies:
-
-```bash
-uv pip install ".[dev]"
-apt-get install -y ffmpeg
-```
-
-## Running Tests
-Our test scripts use the pytest framework. First, please use `git clone https://github.com/vllm-project/vllm-omni.git` to download the vllm-omni source code. Then, in the root directory of vllm-omni, you can run the following commands in your local test environment to execute the corresponding test cases.
-
-=== "L1 level"
-
- ```bash
- cd tests
- pytest -s -v -m "core_model and cpu"
- ```
- The latest test command is available in the "Simple Unit Test" step of this [pipeline](https://github.com/vllm-project/vllm-omni/blob/main/.buildkite/test-ready.yml).
-
-=== "L2 level"
-
- ```bash
- cd tests
- pytest -s -v -m "core_model and not cpu" --run-level=core_model
- ```
- If you only want to run a specific test case, you can use:
- ```bash
- pytest -s -v test_xxxx.py --run-level=core_model
- ```
- If you only want to run specific test cases on a particular platform, you can use:
- ```bash
- pytest -s -v -m "core_model and distributed_cuda and L4" --run-level=core_model
- ```
- The latest test commands for various test suites can be found in the [pipeline](https://github.com/vllm-project/vllm-omni/blob/main/.buildkite/test-ready.yml).
-
-=== "L3 level"
-
- ```bash
- pytest -s -v -m "advanced_model" --run-level=advanced_model
- ```
- If you only want to run a specific test case, you can use:
- ```bash
- pytest -s -v test_xxxx.py --run-level=advanced_model
- ```
- If you only want to run specific test cases on a particular platform, you can use:
- ```bash
- pytest -s -v -m "advanced_model and distributed_cuda and L4" --run-level=advanced_model
- ```
- The latest L3 test commands for various test suites can be found in the [pipeline](https://github.com/vllm-project/vllm-omni/blob/main/.buildkite/test-merge.yml).
-
-
-=== "L4 level"
-
- ```bash
- cd tests
- pytest -s -v -m "full_model" --run-level=full_model
- ```
- If you only want to run a specific test case, you can use:
- ```bash
- pytest -s -v test_xxxx.py --run-level=full_model
- ```
- If you only want to run specific test cases on a particular platform, you can use:
- ```bash
- pytest -s -v -m "full_model and distributed_cuda and L4" --run-level=full_model
- ```
- Note: To run performance tests (defaults to ``test_qwen_omni.json``; use ``--test-config-file tests/dfx/perf/tests/test_tts.json`` for TTS):
- ```bash
- pytest -s -v tests/dfx/perf/scripts/run_benchmark.py
- ```
- The latest L4 (nightly) test commands use the `full_model` marker and `--run-level full_model` (see [test-nightly.yml](https://github.com/vllm-project/vllm-omni/blob/main/.buildkite/test-nightly.yml) and [test-nightly-diffusion.yml](https://github.com/vllm-project/vllm-omni/blob/main/.buildkite/test-nightly-diffusion.yml)). Example:
-
- ```bash
- cd tests
- pytest -s -v -m "full_model and omni and H100" --run-level=full_model
- ```
-
-=== "L5 level"
-
- L5 includes stability and reliability testing. Typical commands:
-
- ```bash
- cd tests
-
- # Stability: Qwen3-Omni
- pytest -s -v dfx/stability/scripts/test_stability_qwen3_omni.py
-
- # Stability: Wan2.2 (v1/videos diffusion benchmark loop)
- pytest -s -v dfx/stability/scripts/test_stability_wan22.py
-
- ```
-
- The latest L5 commands for CI can be found in the [pipeline](https://github.com/vllm-project/vllm-omni/blob/main/.buildkite/test-ready.yml).
-
-You can find more information about markers in the documentation: [marker doc](./tests_markers.md)
-
-## Adding New Test Cases
-Please refer to the [L5 Layering Specification document](./CI_5levels.md).
diff --git a/docs/contributing/ci/tests_markers.md b/docs/contributing/ci/tests_markers.md
deleted file mode 100644
index 6130541a617..00000000000
--- a/docs/contributing/ci/tests_markers.md
+++ /dev/null
@@ -1,179 +0,0 @@
-# Markers for Tests
-
-By adding markers before test functions, tests can later be executed uniformly by simply declaring the corresponding marker type.
-
-## Current Markers
-Defined in `pyproject.toml`:
-
-| Marker | Description |
-| ------------------ | --------------------------------------------------------- |
-| `core_model` | L1&L2 tests (run in each PR) |
-| `advanced_model` | L3 tests (run on each merge to main) |
-| `full_model` | L4 tests (run nightly) |
-| `diffusion` | Diffusion model tests |
-| `omni` | Omni model tests |
-| `cache` | Cache backend tests |
-| `parallel` | Parallelism/distributed tests |
-| `cpu` | Tests that run on CPU |
-| `gpu` | Tests that run on GPU * |
-| `cuda` | Tests that run on CUDA * |
-| `rocm` | Tests that run on AMD/ROCm * |
-| `xpu` | Tests that run on Intel XPU * |
-| `npu` | Tests that run on NPU/Ascend * |
-| `H100` | Tests that require H100 GPU * |
-| `L4` | Tests that require L4 GPU * |
-| `MI325` | Tests that require MI325 GPU (AMD/ROCm) * |
-| `A2` | Tests that require A2 NPU * |
-| `A3` | Tests that require A3 NPU * |
-| `distributed_cuda` | Tests that require multi cards on CUDA platform * |
-| `distributed_rocm` | Tests that require multi cards on ROCm platform * |
-| `distributed_npu` | Tests that require multi cards on NPU platform * |
-| `skipif_cuda` | Skip if the num of CUDA cards is less than the required * |
-| `skipif_rocm` | Skip if the num of ROCm cards is less than the required * |
-| `skipif_npu` | Skip if the num of NPU cards is less than the required * |
-| `slow` | Slow tests (may skip in quick CI) |
-| `benchmark` | Benchmark tests |
-
-\* Means those markers are auto-added by `@hardware_test` (parametrization decorator) or `hardware_marks` (only returning the list of marks for flexibility).
-
-### Example usage for markers
-
-```python
-from tests.helpers.mark import hardware_test
-
-@pytest.mark.core_model
-@pytest.mark.omni
-@hardware_test(
- res={"cuda": "L4", "rocm": "MI325", "npu": "A2"},
- num_cards=2,
-)
-@pytest.mark.parametrize("omni_server", test_params, indirect=True)
-def test_video_to_audio()
- ...
-```
-
-### Decorator: `@hardware_test`
-
-This decorator is intended to make hardware-aware, cross-platform test authoring easier and more robust for CI/CD environments. The `hardware_test` decorator in `vllm-omni/tests/helpers/mark.py` performs the following actions:
-
-1. **Applies platform and resource markers**
- Adds the appropriate pytest markers for each specified hardware platform (e.g., `cuda`, `rocm`, `xpu`, `npu`) and resource type (e.g., `L4`, `H100`, `MI325`, `B60`, `A2`, `A3`).
- ```
- @pytest.mark.cuda
- @pytest.mark.L4
- ```
-2. **Handles multi-card (distributed) scenarios**
- For tests requiring multiple cards, it automatically adds distributed markers such as `distributed_cuda`, `distributed_rocm`, or `distributed_npu`.
- ```
- @pytest.mark.distributed_cuda(num_cards=num_cards)
- ```
-3. **Supports flexible card requirements**
- Accepts `num_cards` as either a single integer for all platforms or as a dictionary with per-platform values. If not specified, defaults to 1 card per platform.
-
-4. **Integrates resource validation**
- On CUDA, adds a skip marker (`skipif_cuda`) if the system does not have the required number of devices.
- Support for `skipif_rocm` and `skipif_npu` will be implemented later.
-
-
-5. **Works with pytest filtering**
- Allows tests to be filtered and selected at runtime using standard pytest marker expressions (e.g., `-m "distributed_cuda and L4"`).
-
-#### Example usage for decorator
-- Single call for multiple platforms:
- ```python
- @hardware_test(
- res={"cuda": "L4", "rocm": "MI325", "xpu": "B60", "npu": "A2"},
- num_cards={"cuda": 2, "rocm": 2, "xpu": 2, "npu": 2},
- )
- ```
- or
- ```python
- @hardware_test(
- res={"cuda": "L4", "rocm": "MI325", "xpu": "B60", "npu": "A2"},
- num_cards=2,
- )
- ```
-- `res` must be a dict; supported resources: CUDA (L4/H100), ROCm (MI325), NPU (A2/A3)
-- `num_cards` can be int (all platforms) or dict (per platform); defaults to 1 when missing
-- Distributed markers (`distributed_cuda`, `distributed_rocm`, `distributed_npu`) are auto-added for multi-card cases
-- Filtering examples:
- - CUDA only: `pytest -m "distributed_cuda and L4"`
- - ROCm only: `pytest -m "distributed_rocm and MI325"`
- - NPU only: `pytest -m "distributed_npu"`
-
-### Function: `hardware_marks`
-
-`hardware_marks` returns a list of pytest mark objects with the same signature as `@hardware_test`. Use it when you need more flexibility, such as attaching hardware marks to individual `pytest.param` entries rather than an entire test function.
-
-```python
-from tests.helpers.mark import hardware_marks
-
-MULTI_CARD_MARKS = hardware_marks(
- res={"cuda": "H100", "rocm": "MI325", "npu": "A2"}, num_cards=2
-)
-
-@pytest.mark.parametrize("omni_server", [
- pytest.param(OmniServerParams(...), id="case_001", marks=MULTI_CARD_MARKS),
-], indirect=True)
-def test_feature(omni_server):
- ...
-```
-
-## Add Support for a New Platform
-
-If you want to add support for a new platform (e.g., "tpu" for a new accelerator), follow these steps:
-
-1. **Extend the marker list in your pytest config** so that platform/resource markers are defined:
- ```toml
- # In pyproject.toml or pytest.ini
- [tool.pytest.ini_options]
- markers = [
- # ... existing markers ...
- "tpu: Tests that require TPU device",
- "TPU_V3: Tests that require TPU v3 hardware",
- "distributed_tpu: Tests that require multiple TPU devices",
- ]
- ```
-2. **Implement a marker construction function for your platform** in `vllm-omni/tests/helpers/mark.py`:
- ```python
- # In vllm-omni/tests/helpers/mark.py
-
- def tpu_marks(*, res: str, num_cards: int):
- test_platform = pytest.mark.tpu
- if res == "TPU_V3":
- test_resource = pytest.mark.TPU_V3
- else:
- raise ValueError(
- f"Invalid TPU resource type: {res}. Supported: TPU_V3")
-
- if num_cards == 1:
- return [test_platform, test_resource]
- else:
- test_distributed = pytest.mark.distributed_tpu(num_cards=num_cards)
- # Optionally: add skipif_tpu when implemented
- return [test_platform, test_resource, test_distributed]
- ```
-3. **Update `hardware_marks` to recognize your new platform**:
- In the relevant place (see the `hardware_marks` implementation), add:
- ```python
- if platform == "tpu":
- marks = tpu_marks(res=resource, num_cards=cards)
- ```
- (`hardware_test` calls `hardware_marks` internally, so both will pick up the change.)
-4. **(Recommended) Add a test using your new markers**:
- ```python
- @hardware_test(
- res={"tpu": "TPU_V3"},
- num_cards=2,
- )
- def test_my_tpu_feature():
- ...
- ```
-
-**Summary**:
-- Add pytest markers for your new platform/resources
-- Implement a marker function (`xxx_marks`)
-- Plug into `hardware_marks`
-- You're done: tests using `@hardware_test` or `hardware_marks` with your platform now automatically get the correct markers, distribution, and isolation!
-
-See code in `vllm-omni/tests/helpers/mark.py` for existing examples (`cuda_marks`, `rocm_marks`, `npu_marks`).
diff --git a/docs/contributing/ci/tests_style.md b/docs/contributing/ci/tests_style.md
deleted file mode 100644
index 3a8cb0f127c..00000000000
--- a/docs/contributing/ci/tests_style.md
+++ /dev/null
@@ -1,467 +0,0 @@
-# Test File Structure and Style Guide
-
-To ensure project maintainability and sustainable development, we encourage contributors to submit test code (unit tests, system tests, or end-to-end tests) alongside their code changes. This document outlines the guidelines for organizing and naming test files.
-
-## Checklist before submitting your test files
-
-1. The file is saved in an appropriate place and the file name is clear.
-2. The coding style follows the requirements outlined below.
-3. All test functions have appropriate pytest markers.
-4. For tests that need run in CI, please ensure it labeled as ``@pytest.mark.core_model` the test is configured under the `./buildkite/` folder.
-
-
-## Test Types
-
-For more details about our [Five Levels Tests design](../ci/CI_5levels.md).
-
-### Unit Tests and System Tests
-For unit tests and system tests, we strongly recommend placing test files in the same directory structure as the source code being tested, using the naming convention `test_*.py`.
-
-### End-to-End (E2E) Tests for Models
-End-to-end tests verify the complete functionality of a system or component. For our project, the E2E tests for different omni models are organized into two subdirectories:
-
-- **`tests/e2e/offline_inference/`**: Tests for offline inference modes (e.g., Qwen3Omni offline inference)
-
-- **`tests/e2e/online_serving/`**: Tests for online serving scenarios (e.g., API server tests)
-
-## Test Directory Structure
-
-The ideal directory structure mirrors the source code organization. Legend: `✅` = test exists, `⬜` = suggested to add.
-
-```
-vllm_omni/ tests/
-├── config/ → ├── config/
-│ ├── model.py │ └── test_model.py ⬜
-│ └── lora.py │ └── test_lora.py ⬜
-│
-├── core/ → ├── core/
-│ └── sched/ │ └── sched/
-│ ├── omni_ar_scheduler.py │ ├── test_omni_ar_scheduler.py ⬜
-│ ├── omni_generation_scheduler.py │ ├── test_omni_generation_scheduler.py ⬜
-│ └── output.py │ └── test_output.py ✅ currently in entrypoints/test_omni_new_request_data.py (tests output.OmniNewRequestData)
-│
-├── diffusion/ → ├── diffusion/
-│ ├── diffusion_engine.py │ ├── test_diffusion_engine.py ⬜
-│ ├── attention/ │ ├── attention/
-│ │ ├── layer.py │ │ ├── test_attention_sp.py ✅
-│ │ └── backends/ │ │ └── test_flash_attn.py ✅
-│ ├── distributed/ │ ├── distributed/
-│ │ └── ... │ │ ├── test_comm.py ✅
-│ │ │ │ ├── test_cfg_parallel.py ✅
-│ │ │ │ └── test_sp_plan_hooks.py ✅
-│ ├── lora/ │ ├── lora/
-│ │ └── ... │ │ ├── test_base_linear.py ✅
-│ │ │ │ └── test_lora_manager.py ✅
-│ ├── models/ │ ├── models/
-│ │ ├── qwen_image/ │ │ ├── qwen_image/ (e2e coverage)
-│ │ ├── z_image/ │ │ └── z_image/
-│ │ └── ... │ │ └── test_zimage_tp_constraints.py ✅
-│ └── worker/ │ └── worker/
-│ ├── diffusion_worker.py │ └── test_diffusion_worker.py ✅ file at diffusion/test_diffusion_worker.py
-│ └── diffusion_model_runner.py │
-│
-├── distributed/ → ├── distributed/
-│ └── omni_connectors/ │ └── omni_connectors/
-│ ├── adapter.py │ ├── test_adapter_and_flow.py ✅
-│ ├── kv_transfer_manager.py │ ├── test_basic_connectors.py ✅
-│ ├── connectors/ │ ├── test_kv_flow.py ✅
-│ └── utils/ │ └── test_omni_connector_configs.py ✅
-│
-├── engine/ → ├── engine/
-│ ├── input_processor.py │ ├── test_input_processor.py ⬜ (no processor.py in source)
-│ ├── output_processor.py │ └── test_output_processor.py ⬜
-│ └── arg_utils.py │ └── test_arg_utils.py ⬜
-│
-├── entrypoints/ → ├── entrypoints/
-│ ├── stage_utils.py │ ├── test_stage_utils.py ✅
-│ ├── cli/ │ ├── cli/ (benchmarks/test_serve_cli.py covers CLI serve)
-│ │ └── ... │ │ └── test_*.py ⬜
-│ └── openai/ │ └── openai_api/ # maps to entrypoints/openai/
-│ ├── api_server.py │ ├── test_api_server.py ⬜ (e2e indirect coverage)
-│ ├── serving_chat.py │ ├── test_serving_chat_sampling_params.py ✅
-│ ├── serving_speech.py │ ├── test_serving_speech.py ✅
-│ └── image_api_utils.py │ └── test_image_server.py ✅
-│
-├── inputs/ → ├── inputs/
-│ ├── data.py │ ├── test_data.py ⬜
-│ ├── parse.py │ ├── test_parse.py ⬜
-│ └── preprocess.py │ └── test_preprocess.py ✅ currently in entrypoints/test_omni_input_preprocessor.py
-│
-├── model_executor/ → ├── model_executor/
-│ ├── layers/ │ ├── layers/
-│ │ └── mrope.py │ │ └── test_mrope.py ⬜
-│ ├── model_loader/ │ ├── model_loader/
-│ │ └── weight_utils.py │ │ └── test_weight_utils.py ⬜
-│ ├── models/ │ ├── models/
-│ │ ├── qwen2_5_omni/ │ │ ├── qwen2_5_omni/
-│ │ │ ├── qwen2_5_omni_thinker.py │ │ │ ├── test_audio_length.py ✅
-│ │ │ ├── qwen2_5_omni_talker.py │ │ │ ├── test_qwen2_5_omni_thinker.py ⬜
-│ │ │ └── qwen2_5_omni_token2wav.py │ │ │ ├── test_qwen2_5_omni_talker.py ⬜
-│ │ └── qwen3_omni/ │ │ │ └── test_qwen2_5_omni_token2wav.py ⬜
-│ │ └── ... │ │ └── qwen3_omni/
-│ ├── stage_configs/ │ │ └── test_*.py ⬜
-│ │ └── *.yaml │ └── stage_configs/ (used by e2e, test_*.py can be added) ⬜
-│ └── stage_input_processors/ │ └── stage_input_processors/
-│ └── ... │ └── test_*.py ⬜
-│
-├── sample/ → ├── sample/
-│ └── __init__.py │ └── test_*.py ⬜
-│
-├── utils/ → ├── utils/
-│ └── __init__.py │ └── test_*.py ⬜ (no platform_utils.py currently)
-│
-├── worker/ → ├── worker/
-│ ├── gpu_ar_model_runner.py │ ├── test_gpu_ar_model_runner.py ⬜
-│ ├── gpu_ar_worker.py │ ├── test_gpu_ar_worker.py ⬜
-│ ├── gpu_generation_model_runner.py │ ├── test_gpu_generation_model_runner.py ✅
-│ ├── gpu_generation_worker.py │ ├── test_gpu_generation_worker.py ⬜
-│ ├── gpu_model_runner.py │ ├── test_omni_gpu_model_runner.py ✅
-│ └── mixins.py │ └── (npu under platforms/npu/worker/) # not worker/npu/
-│
-├── platforms/ → (no tests/platforms/, e2e and stage_configs provide indirect coverage)
-│ ├── cuda/
-│ ├── npu/worker/ # NPU worker here, not vllm_omni/worker/npu/
-│ ├── rocm/
-│ └── xpu/worker/
-│
-├── outputs.py → test_outputs.py ✅ (at tests root)
-├── (logger, patch, request, version) → (no corresponding unit test)
-│
-└── e2e (tests side only) → ├── e2e/
- ├── online_serving/ ✅ non-empty
- │ ├── test_qwen2_5_omni.py
- │ ├── test_async_omni.py
- │ ├── test_qwen3_omni.py
- │ ├── test_qwen3_omni_expansion.py
- │ ├── test_mimo_audio.py
- │ ├── test_image_gen_edit.py
- │ └── test_images_generations_lora.py
- └── offline_inference/ ✅
- ├── test_qwen2_5_omni.py
- ├── test_qwen3_omni.py
- ├── test_bagel_text2img.py
- ├── test_t2i_model.py
- ├── test_t2v_model.py
- ├── test_ovis_image.py
- ├── test_zimage_tensor_parallel.py
- ├── test_cache_dit.py
- ├── test_teacache.py
- ├── test_stable_audio_expansion.py
- ├── test_diffusion_cpu_offload.py
- ├── test_diffusion_layerwise_offload.py
- ├── test_diffusion_lora.py
- ├── test_sequence_parallel.py
- ├── test_qwen_image_edit_expansion.py
- └── stage_configs/ (legacy schema, still present
- ├── bagel_*.yaml for unmigrated models)
- └── npu/, rocm/, etc.
-
-# Migrated models (qwen3_omni_moe, qwen2_5_omni, qwen3_tts) live under
-# vllm_omni/deploy/ instead — see docs/configuration/stage_configs.md.
-examples/ tests
-│ └── examples
-├── online_serving/ → ├── online_serving/
-│ └── {doc_page_title}/README.md │ └── test_{doc_page_title}.py ⬜
-└── offline_inference/ → └── offline_inference/
- └── {doc_page_title}/README.md └── test_{doc_page_title}.py ⬜
-```
-
-
-
-### Naming Conventions
-
-- **Unit Tests**: Use `test_.py` format. Example: `stage_utils.py` → `test_stage_utils.py`
-
-- **E2E Tests**: Place in `tests/e2e/offline_inference/` or `tests/e2e/online_serving/` with descriptive names. Example: `tests/e2e/offline_inference/test_qwen3_omni.py`, `tests/e2e/offline_inference/test_diffusion_model.py`
-
-- **Expansion Tests**
-
-### Best Practices
-
-1. **Mirror Source Structure**: Test directories should mirror the source code structure
-2. **Test Type Indicators**: Use comments to indicate test types (UT for unit tests, E2E for end-to-end tests)
-3. **Shared Resources**: Place shared test configurations (e.g., CI configs) in appropriate subdirectories
-4. **Consistent Naming**: Follow the `test_*.py` naming convention consistently across all test files
-
-
-## Test codes requirements
-
-### Coding style
-
-1. **File header**: Add SPDX license header to all test files
-2. **Imports**: Pls don't use manual `sys.path` modifications, use standard imports instead.
-3. **Test type differentiation**:
-
- - Unit tests: Maintain mock style
- - E2E tests for models: Consider using OmniRunner uniformly, avoid decorators
-
-4. **Documentation**: Add docstrings to all test functions
-5. **Environment variables**: Set uniformly in `conftest.py` or at the top of files
-6. **Type annotations**: Add type annotations to all test function parameters
-7. **Pytest Markers**: Add necessary markers like `@pytest.mark.core_model` and use `@hardware_test` to declare hardware requirements (check detailed in [Markers for Tests](../ci/tests_markers.md)).
-
-### Template
-#### E2E - Online serving
-
-E2E Online tests for Qwen3-Omni model with mix input and audio+text output. Based on `tests/e2e/online_serving/test_qwen3_omni.py`.
-
-```python
-"""
-E2E Online tests for Qwen3-Omni model with mix input and audio+text output.
-"""
-
-import os
-
-os.environ["VLLM_WORKER_MULTIPROC_METHOD"] = "spawn"
-os.environ["VLLM_TEST_CLEAN_GPU_MEMORY"] = "0"
-
-import threading
-from pathlib import Path
-
-import openai
-import pytest
-
-from tests.helpers.media import (
- convert_audio_bytes_to_text,
- cosine_similarity_text,
- generate_synthetic_video,
-)
-from tests.helpers.runtime import OmniServer, dummy_messages_from_mix_data
-from tests.helpers.stage_config import get_deploy_config_path, modify_stage_config
-from vllm_omni.platforms import current_omni_platform
-
-# Edit: model name and stage config path
-models = ["Qwen/Qwen3-Omni-30B-A3B-Instruct"]
-
-#If you use the default configuration file, you can directly use the following address.
-def get_default_config():
- return get_deploy_config_path("ci/qwen3_omni_moe.yaml")
-
-#If you need to modify the configuration file, you can use modify_stage_config.
-def get_chunk_config():
- path = modify_stage_config(
- get_default_config(),
- updates={
- "async_chunk": True,
- "stage_args": {
- 0: {
- "engine_args.custom_process_next_stage_input_func": "vllm_omni.model_executor.stage_input_processors.qwen3_omni.thinker2talker_async_chunk"
- },
- 1: {
- "engine_args.custom_process_next_stage_input_func": "vllm_omni.model_executor.stage_input_processors.qwen3_omni.talker2code2wav_async_chunk"
- },
- },
- },
- deletes={"stage_args": {2: ["custom_process_input_func"]}},
- )
- return path
-
-stage_configs = [get_default_config(), CHUNK_CONFIG_PATH]
-
-test_params = [(model, stage_config) for model in models for stage_config in stage_configs]
-
-
-#Please use this method to launch the online instance.
-_omni_server_lock = threading.Lock()
-
-@pytest.fixture(scope="module")
-def omni_server(request):
- """Start vLLM-Omni server as a subprocess. Use module scope for multi-stage init (10-20+ min)."""
- with _omni_server_lock:
- model, stage_config_path = request.param
- with OmniServer(
- model,
- ["--stage-configs-path", stage_config_path, "--stage-init-timeout", "120"],
- ) as server:
- yield server
-
-
-@pytest.fixture
-def client(omni_server):
- """OpenAI client for the running vLLM-Omni server."""
- return openai.OpenAI(
- base_url=f"http://{omni_server.host}:{omni_server.port}/v1",
- api_key="EMPTY",
- )
-
-#Please use function definitions above the test function to define the prompts and other parameters you need.
-def get_system_prompt():
- return {
- "role": "system",
- "content": [
- {
- "type": "text",
- "text": (
- "You are Qwen, a virtual human developed by the Qwen Team, "
- "Alibaba Group, capable of perceiving auditory and visual inputs, "
- "as well as generating text and speech."
- ),
- }
- ],
- }
-
-...
-
-#Please define test case tags according to the instructions in the marker documentation.
-@pytest.mark.core_model
-@pytest.mark.omni
-@pytest.mark.parametrize("omni_server", test_params, indirect=True)
-def test_mix_to_text_audio_001(client: openai.OpenAI, omni_server, request) -> None:
- # PLEASE FOLLOW THESE TEMPLATE INSTRUCTIONS:
- # ============================================================================
- # TEMPLATE USAGE GUIDE:
- # 1. Copy this entire function as a starting point for multi-modal tests
- # 2. Update the test name to reflect your specific test scenario
- # 3. Modify input/output modalities as needed (see OPTIONS section below)
- # 4. Adjust assertions based on your expected outcomes
- # 5. Add custom validation logic for your specific use case
- # ============================================================================
-
- #Please list the relevant test points.
- """
- Test multi-modal input processing and text/audio output generation via OpenAI API.
- Deploy Setting: default yaml
- Input Modal: text + audio + video + image
- Output Modal: text + audio
- Input Setting: stream=True
- Datasets: single request
- """
- # SECTION 1: TEST SETUP AND INITIALIZATION
- # =========================================
- # INSTRUCTIONS: Initialize test variables and prepare test environment
- # MODIFY: Add any additional test setup required for your scenario
- e2e_list = list()
- # SECTION 2: TEST DATA GENERATION
- # ================================
- # INSTRUCTIONS: Generate or load test data for each input modality
- # MODIFY: Replace synthetic generators with your actual data sources
- # VIDEO DATA - Generate synthetic video for testing
- # FORMAT: data:video/mp4;base64,{base64_encoded_video}
- # PARAMETERS: width, height, duration_frames
- video_data_url = f"data:video/mp4;base64,{generate_synthetic_video(224, 224, 300)['base64']}"
- # IMAGE DATA - Generate synthetic image for testing
- # FORMAT: data:image/jpeg;base64,{base64_encoded_image}
- # PARAMETERS: width, height
- image_data_url = f"data:image/jpeg;base64,{generate_synthetic_image(224, 224)['base64']}"
- # AUDIO DATA - Generate synthetic audio for testing
- # FORMAT: data:audio/wav;base64,{base64_encoded_audio}
- # PARAMETERS: duration_seconds, channels
- audio_data_url = f"data:audio/wav;base64,{generate_synthetic_audio(5, 1)['base64']}"
-
- # SECTION 3: MESSAGE CONSTRUCTION
- # ================================
- # INSTRUCTIONS: Assemble the complete message payload for API request
- # MODIFY: Add/remove modalities or change prompt structure as needed
-
- # USAGE: Construct a message containing all input modalities
- # IMPORTANT: Ensure the message structure matches OpenAI API expectations
- # CUSTOMIZATION POINTS:
- # - system_prompt: Controls the assistant's behavior
- # - content_text: The user's text prompt/question
- # - *_data_url: URLs for media content (video/image/audio)
- messages = dummy_messages_from_mix_data(
- system_prompt=get_system_prompt(),
- video_data_url=video_data_url,
- image_data_url=image_data_url,
- audio_data_url=audio_data_url,
- content_text=get_prompt("mix"),
- )
-
- # SECTION 4: API REQUEST EXECUTION
- # =================================
- # INSTRUCTIONS: Make the API call and measure performance
- # MODIFY: Add timeout, retry logic, or additional parameters
- start_time = time.perf_counter()
- chat_completion = client.chat.completions.create(model=omni_server.model, messages=messages, stream=True)
-
- #Call using your preferred method and obtain the final audio and text outputs.
- ...
-
- # SECTION 5: OUTPUT VALIDATION
- # =============================
- # INSTRUCTIONS: Verify that outputs meet expected criteria
- # MODIFY: Adjust validation logic for your specific requirements
-
- # ASSERTION 1: E2E Validation
- # PURPOSE: Verify that the E2E latency is less than the baseline.
- current_e2e = time.perf_counter() - start_time
- print(f"the request e2e is: {current_e2e}")
- e2e_list.append(current_e2e)
-
- print(f"the avg e2e is: {sum(e2e_list) / len(e2e_list)}")
-
-
-
- # ASSERTION 2: Text Output Validation
- # PURPOSE: Verify that text output was generated with keyword content
- assert text_content is not None and len(text_content) >= 2, "No text output is generated"
- assert any(
- keyword in text_content.lower() for keyword in ["square", "quadrate", "sphere", "globe", "circle", "round"]
- ), "The output does not contain any of the keywords."
-
-
- # ASSERTION 3: Cross-Modal Consistency
- # PURPOSE: Verify text and audio outputs convey the same information
- # CUSTOMIZATION: Adjust similarity threshold (0.9) based on accuracy requirements
- assert audio_data is not None, "No audio output is generated"
- audio_content = convert_audio_bytes_to_text(audio_data)
- print(f"text content is: {text_content}")
- print(f"audio content is: {audio_content}")
- similarity = cosine_similarity_text(audio_content.lower(), text_content.lower())
- print(f"similarity is: {similarity}")
- assert similarity > 0.9, "The audio content is not same as the text"
-```
-
-
-#### E2E - Offline inference
-```python
-# SPDX-License-Identifier: Apache-2.0
-# SPDX-FileCopyrightText: Copyright contributors to the vLLM project
-"""
-Offline E2E smoke test for an omni model (video → audio).
-"""
-
-import os
-from pathlib import Path
-
-import pytest
-from vllm.assets.video import VideoAsset
-
-from tests.helpers.mark import hardware_test
-from ..multi_stages.conftest import OmniRunner
-
-# Optional: set process start method for workers
-os.environ["VLLM_WORKER_MULTIPROC_METHOD"] = "spawn"
-
-models = ["{your model name}"] #Edit here to load your model
-stage_configs = [str(Path(__file__).parent / "stage_configs" / {your model yaml})] #Edit here to load your model yaml
-
-# Create parameter combinations for model and stage config
-test_params = [(model, stage_config) for model in models for stage_config in stage_configs]
-
-# function name: test_{input_modality}_to_{output_modality}
-# modality candidate: text, image, audio, video, mixed_modalities
-@pytest.mark.core_model
-@pytest.mark.omni
-@hardware_test(
- res={"cuda": "L4", "rocm": "MI325", "npu": "A2"},
- num_cards=2,
-)
-@pytest.mark.parametrize("test_config", test_params)
-def test_video_to_audio(omni_runner: type[OmniRunner], model: str) -> None:
- """Offline inference: video input, audio output."""
- model, stage_config_path = test_config
- with omni_runner(model, seed=42, stage_configs_path=stage_config_path) as runner:
- # Prepare inputs
- video = VideoAsset(name="sample", num_frames=4).np_ndarrays
-
- outputs = runner.generate_multimodal(
- prompts="Describe this video briefly.",
- videos=video,
- )
-
- # Minimal assertions: got outputs and at least one audio result
- assert outputs
- has_audio = any(o.final_output_type == "audio" for o in outputs)
- assert has_audio
-```
diff --git a/docs/contributing/metrics.md b/docs/contributing/metrics.md
deleted file mode 100644
index 92dcd92ccac..00000000000
--- a/docs/contributing/metrics.md
+++ /dev/null
@@ -1,173 +0,0 @@
-
-# Metrics
-
-You can use these metrics in production to monitor the health and performance of the vLLM-omni system. Typical scenarios include:
-
-- **Performance Monitoring**: Track throughput (e.g., `e2e_avg_tokens_per_s`), latency (e.g., `e2e_total_ms`), and resource utilization to verify that the system meets expected standards.
-
-- **Debugging and Troubleshooting**: Use detailed per-request metrics to diagnose issues, such as high transfer times or unexpected token counts.
-
-## How to Enable and View Metrics
-
-### Start the Service with Metrics Logging
-
-```bash
-vllm serve /workspace/models/Qwen3-Omni-30B-A3B-Instruct --omni --port 8014 --log-stats
-```
-
-### Send a Request
-
-```bash
-python openai_chat_completion_client_for_multimodal_generation.py --query-type use_image
-```
-
-### What You Will See
-
-With `--log-stats` enabled, the server will output detailed metrics logs after each request. Example output:
-
-
-#### Overall Summary
-
-| Field | Value |
-|-----------------------------|--------------|
-| e2e_requests | 1 |
-| e2e_wall_time_ms | 41,299.190 |
-| e2e_total_tokens | 5,202 |
-| e2e_avg_time_per_request_ms | 41,299.190 |
-| e2e_avg_tokens_per_s | 125.959 |
-| e2e_stage_0_wall_time_ms | 10,192.289 |
-| e2e_stage_1_wall_time_ms | 30,541.409 |
-| e2e_stage_2_wall_time_ms | 207.496 |
-
-#### RequestE2EStats
-
-| Field | Value |
-|-------------------------|------------|
-| e2e_total_ms | 41,299.133 |
-| e2e_total_tokens | 5,202 |
-| transfers_total_time_ms | 245.895 |
-| transfers_total_kbytes | 138,089.939|
-
-#### StageRequestStats
-
-| Field | 0 | 1 | 2 |
-|------------------------|--------|--------|--------|
-| audio_generated_frames | 0 | 0 | 525,525|
-| batch_id | 38 | 274 | 0 |
-| batch_size | 1 | 1 | 1 |
-| num_tokens_in | 4,860 | 4,826 | 4,384 |
-| num_tokens_out | 67 | 275 | 0 |
-| postprocess_time_ms | 256.158| 0.491 | 0.000 |
-| stage_gen_time_ms | 9,910.007|30,379.198|160.745|
-
-#### TransferEdgeStats
-
-| Field | 0->1 | 1->2 |
-|---------------------|-------------|------------|
-| size_kbytes | 109,277.349 | 28,812.591 |
-| tx_time_ms | 78.701 | 18.790 |
-| rx_decode_time_ms | 111.865 | 31.706 |
-| in_flight_time_ms | 2.015 | 2.819 |
-
-
-These logs include:
-
-- **Overall summary**: total requests, wall time, average tokens/sec, etc.
-
-- **E2E table**: per-request latency and token counts.
-
-- **Stage table**: per-stage batch and timing details.
-
-- **Transfer table**: data transfer and timing for each edge.
-
-You can use these logs to monitor system health, debug performance, and analyze request-level metrics as described above.
-
-
-## Metrics Scope: Offline vs Online Inference
-
-For **offline inference** (batch mode), the summary includes both system-level metrics (aggregated across all requests) and per-request metrics. In this case, `e2e_requests` can be greater than 1, reflecting multiple completed requests in a batch.
-
-For **online inference** (serving mode), the summary is always per-request. `e2e_requests` is always 1, and only request-level metrics are reported for each completion.
-
----
-
-## Parameter Details
-
-### Summary Metrics
-
-| Field | Meaning |
-|---------------------------|----------------------------------------------------------------------------------------------|
-| `e2e_requests` | Number of completed requests. |
-| `e2e_wall_time_ms` | Wall-clock time span from run start to last completion, in ms. |
-| `e2e_total_tokens` | Total tokens counted across all completed requests (stage0 input + all stage outputs). |
-| `e2e_avg_time_per_request_ms` | Average wall time per request: `e2e_wall_time_ms / e2e_requests`. |
-| `e2e_avg_tokens_per_s` | Average token throughput over wall time: `e2e_total_tokens * 1000 / e2e_wall_time_ms`. |
-| `e2e_stage_{i}_wall_time_ms` | Wall-clock time span for stage i, in ms. Each stage's wall time is reported as a separate field, e.g., `e2e_stage_0_wall_time_ms`, `e2e_stage_1_wall_time_ms`, etc. |
-
----
-
-### E2E Table (per request)
-
-| Field | Meaning |
-|---------------------------|-----------------------------------------------------------------------|
-| `e2e_total_ms` | End-to-end latency in ms. |
-| `e2e_total_tokens` | Total tokens for the request (stage0 input + all stage outputs). |
-| `transfers_total_time_ms` | Sum of transfer edge `total_time_ms` for this request. |
-| `transfers_total_kbytes` | Sum of transfer kbytes for this request. |
-
-
----
-
-### Stage Table (per stage event / request)
-
-| Field | Meaning |
-|---------------------------|-------------------------------------------------------------------------------------------------|
-| `batch_id` | Batch index. |
-| `batch_size` | Batch size. |
-| `num_tokens_in` | Input tokens to the stage. |
-| `num_tokens_out` | Output tokens from the stage. |
-| `stage_gen_time_ms` | Stage compute time in ms, excluding postprocessing time (reported separately as `postprocess_time_ms`). |
-| `image_num` | Number of images generated (for diffusion/image stages). |
-| `resolution` | Image resolution (for diffusion/image stages). |
-| `postprocess_time_ms` | Diffusion/image: post-processing time in ms. |
-
----
-
-### Transfer Table (per edge / request)
-
-| Field | Meaning |
-|----------------------|---------------------------------------------------------------------------|
-| `size_kbytes` | Total kbytes transferred. |
-| `tx_time_ms` | Sender transfer time in ms. |
-| `rx_decode_time_ms` | Receiver decode time in ms. |
-| `in_flight_time_ms` | In-flight time in ms. |
-
-
-### Expectation of the Numbers (Verification)
-
-**Formulas:**
-
-- `e2e_total_tokens = Stage0's num_tokens_in + sum(all stages' num_tokens_out)`
-
-- `transfers_total_time_ms = sum(tx_time_ms + rx_decode_time_ms + in_flight_time_ms)` for every edge
-
-**Using the example above:**
-
-**e2e_total_tokens**
-
-- Stage0's `num_tokens_in`: **4,860**
-- Stage0's `num_tokens_out`: **67**
-- Stage1's `num_tokens_out`: **275**
-- Stage2's `num_tokens_out`: **0**
-
-so `e2e_total_tokens = 4,860 + 67 + 275 + 0 = 5,202`, which matches the table value `e2e_total_tokens`.
-
-**transfers_total_time_ms**
-
-For each edge:
-
-- 0->1: tx_time_ms (**78.701**) + rx_decode_time_ms (**111.865**) + in_flight_time_ms (**2.015**) = **192.581**
-
-- 1->2: tx_time_ms (**18.790**) + rx_decode_time_ms (**31.706**) + in_flight_time_ms (**2.819**) = **53.315**
-
-192.581 + 53.315 = **245.896** = transfers_total_time_ms, which matches the calculation (difference is due to rounding)
diff --git a/docs/contributing/model/README.md b/docs/contributing/model/README.md
deleted file mode 100644
index b3e951c8bfe..00000000000
--- a/docs/contributing/model/README.md
+++ /dev/null
@@ -1,15 +0,0 @@
-# Adding a New Model
-
-This section provides comprehensive guidance on how to add a new model to vLLM-Omni.
-
-## Documentation
-
-- **[Adding an Omni-Modality Model](adding_omni_model.md)**: Complete step-by-step guide using Qwen3-Omni as an example.
-
-- **[Adding a Diffusion Model](adding_diffusion_model.md)**: Complete step-by-step guide using Qwen/Qwen-Image-Edit as an example.
-
-
-
-## Quick Start
-
-For a quick reference, see the [Adding a New Multi-Stage Model Guide](adding_omni_model.md) and [Adding a New Diffusion Model Guide](adding_diffusion_model.md).
diff --git a/docs/contributing/model/adding_diffusion_model.md b/docs/contributing/model/adding_diffusion_model.md
deleted file mode 100644
index 6d5782a6e3c..00000000000
--- a/docs/contributing/model/adding_diffusion_model.md
+++ /dev/null
@@ -1,1071 +0,0 @@
-# Adding a Diffusion Model
-
-This guide walks you through adding a new diffusion model to vLLM-Omni. We use **Qwen-Image** as the primary example, with references to other models (LongCat, Flux, Wan2.2) to illustrate different patterns.
-
-
----
-
-## Table of Contents
-
-1. [Overview](#overview)
-2. [Directory Structure](#directory-structure)
-3. [Basic Implementation](#basic-implementation)
-4. [Advanced Features](#advanced-features)
-5. [Troubleshooting](#troubleshooting)
-6. [Pull Request Checklist](#pull-request-checklist)
-7. [Reference Implementations](#reference-implementations)
-8. [Summary](#summary)
-
----
-
-## Overview
-
-vLLM-Omni's diffusion inference follows this architecture:
-
-.py`)
-
-The `omni_server` fixture in `tests/conftest.py` is **module-scoped**. Each distinct
-`OmniServerParams` id in the same test file forces the fixture to tear the server
-down and spawn a new one mid-module. A few rules that save real CI debugging time:
-
-- **Prefer a single `OmniServerParams` set per file.** If you need to exercise two
- deploy variants (e.g. `model.yaml` and `model_async_chunk.yaml`), either use one
- variant and exercise streaming via request args, or split into two test files so
- each file does exactly one server lifecycle. Mid-module teardown/restart is the
- fragile path and surfaces startup races first.
-- **Never depend on server-side fetching of external URLs** for reference audio or
- other fixture data. CI runners (and China-hosted dev boxes) routinely fail on
- SSL/DNS for public URLs. Inline the payload as a `data:audio/wav;base64,...`
- ref_audio value — the serving layer accepts both forms.
-- **Don't roll your own readiness probe.** The harness already waits for HTTP 200
- on `/health` before releasing the server to the test. If your model needs extra
- warmup signals, expose them through `/health` rather than adding `time.sleep(...)`
- inside the test. (Bare TCP `connect_ex` probes were insufficient; see
- `tests/conftest.py` `OmniServer.wait_for_ready`.)
-- **Use `core_model` marker + H100 hardware_test** to match the `test-ready.yml`
- pipeline so your test is picked up by the `ready` label, not only nightly.
-
-## Online Serving Integration
-
-To expose your model through the `/v1/audio/speech` OpenAI-compatible endpoint, add
-**all five** of the following integration points to
-`vllm_omni/entrypoints/openai/serving_speech.py` in a **single commit**. Adding them
-piecemeal causes partial-integration failures that are hard to debug.
-
-### 1. Stage constant
-
-Near the top of the file, alongside the other `_*_TTS_MODEL_STAGES` constants:
-
-```python
-_YOUR_MODEL_TTS_MODEL_STAGES = {"your_model_stage_key"}
-```
-
-### 2. Union into `_TTS_MODEL_STAGES`
-
-Add to the `_TTS_MODEL_STAGES` set union:
-
-```python
-_TTS_MODEL_STAGES: set[str] = (
- ...
- | _YOUR_MODEL_TTS_MODEL_STAGES
-)
-```
-
-### 3. Model type detection
-
-In `_detect_tts_model_type()`, add before the final `return None`:
-
-```python
-if model_stage in _YOUR_MODEL_TTS_MODEL_STAGES:
- return "your_model"
-```
-
-### 4. Request validation dispatch
-
-In `_validate_tts_request()`, add before the fallback `return`:
-
-```python
-if self._tts_model_type == "your_model":
- return self._validate_your_model_request(request)
-```
-
-### 5. Validation and parameter-builder methods
-
-Add two new methods:
-
-```python
-def _validate_your_model_request(
- self, request: OpenAICreateSpeechRequest
-) -> str | None:
- """Validate YourModel request. Returns an error string or None."""
- if not request.input or not request.input.strip():
- return "Input text cannot be empty"
- return None
-
-def _build_your_model_params(
- self, request: OpenAICreateSpeechRequest
-) -> dict[str, Any]:
- """Build additional_information dict for YourModel."""
- params: dict[str, Any] = {"text": [request.input]}
- if request.voice is not None:
- params["voice"] = [request.voice]
- # Add any other model-specific fields here
- return params
-```
-
-Then wire `_build_your_model_params` into the request-dispatch block in
-`_create_tts_request()` (search for the equivalent `_build_*_params` call for an
-existing model to find the right location). If the model supports voice cloning
-(`ref_audio` → `prompt_audio_path`, `ref_text` → `prompt_text`), add those mappings
-here too — follow any existing `_build__params` in `serving_speech.py` (e.g.
-`_build_moss_tts_params` for the voice-cloning variant) for the pattern.
-
-> **Two dispatch patterns coexist:** Fish Speech uses a `self._is_fish_speech` boolean
-> checked *before* `elif self._is_tts`. All newer models use the `_tts_model_type`
-> string pattern shown above. For new models, always use the string pattern — do not
-> add new `_is_*` boolean flags.
-
-> **Note on unused variables:** Only extract parameters in `_build_your_model_params`
-> that you actually pass to the model's generate / `inference_stream` call. Extracting
-> a variable without forwarding it will trigger a `ruff F841` pre-commit failure.
-
-### Merge conflicts
-
-`serving_speech.py` is modified by every new model PR and is the most common source of
-rebase conflicts. When rebasing onto `main` and a conflict appears here, the resolution
-is always to **keep both** the upstream model's additions and your own — never discard
-either side. After resolving:
-
-```bash
-git add vllm_omni/entrypoints/openai/serving_speech.py
-git rebase --continue
-```
-
-## Single-Stage Models
-
-Some TTS models (e.g. MOSS-TTS-Nano) do not use a two-stage pipeline. Instead the
-entire AR LM and audio decoder run inside a single AR worker, streaming audio chunks
-directly from the model's own generator.
-
-### Directory structure
-
-```
-vllm_omni/model_executor/models/your_model_name/
- __init__.py
- modeling_your_model_name.py # unified class: load_weights + forward + streaming
-
-vllm_omni/model_executor/stage_configs/your_model_name.yaml
-```
-
-No stage input processor is needed.
-
-### Stage config
-
-Use a single stage with `worker_type: ar`. The `is_comprehension: true` field and the
-top-level `async_chunk: false` are required — omitting them causes silent
-misclassification in the serving layer. Set `max_num_seqs` to at least 4 for
-concurrent production use.
-
-```yaml
-# stage_configs/your_model_name.yaml
-async_chunk: false
-
-stage_args:
- - stage_id: 0
- stage_type: llm
- is_comprehension: true # required for serving_speech.py dispatch
- runtime:
- devices: "0"
- engine_args:
- model_stage: your_model_stage_key
- model_arch: YourModelForCausalLM
- worker_type: ar
- scheduler_cls: vllm_omni.core.sched.omni_ar_scheduler.OmniARScheduler
- engine_output_type: audio
- max_num_seqs: 4 # min 4 for concurrent requests; default 1 causes gaps
- final_output: true
- final_output_type: audio
-```
-
-### Generator-based streaming pattern
-
-This is the MOSS-TTS-Nano pattern, distinct from VoxCPM2's vLLM-native AR pattern
-(see `plan/voxcpm2_native_ar_design.md` for that variant). Load model weights in
-`load_weights()` (not `__init__`) so vLLM finishes distributed initialisation before
-any CUDA allocations. Stream via a per-request generator stored in an instance dict:
-
-```python
-class YourModelForCausalLM(nn.Module):
-
- def __init__(self, *, vllm_config: VllmConfig, prefix: str = ""):
- super().__init__()
- self._lm: nn.Module | None = None # populated in load_weights()
- self._stream_gens: dict[str, Any] = {} # request_key → generator
-
- def load_weights(self, weights):
- # Load self._lm here, after vLLM distributed init
- ...
-
- def forward(
- self,
- input_ids,
- positions,
- intermediate_tensors=None,
- inputs_embeds=None,
- runtime_additional_information: list[dict] | None = None, # one dict per request
- **kwargs,
- ) -> OmniOutput:
- infos = runtime_additional_information or [{}]
- # Return empty output during dummy/profiling calls
- if not runtime_additional_information or all(i.get("_is_dummy") for i in infos):
- self._ar_emit_stop_token = True
- return OmniOutput(...)
-
- outputs, last_flags = [], []
- for info in infos:
- request_key = str(info.get("_omni_req_id", "0")) # set by vLLM, not user code
- if request_key not in self._stream_gens:
- self._stream_gens[request_key] = self._create_stream_gen(info)
- try:
- chunk, is_last = next(self._stream_gens[request_key])
- except StopIteration:
- chunk, is_last = torch.zeros(0), True
- if is_last:
- del self._stream_gens[request_key]
- outputs.append(chunk)
- last_flags.append(is_last)
-
- self._ar_emit_stop_token = all(last_flags)
- return OmniOutput(multimodal_outputs={"model_outputs": outputs, "is_last": last_flags})
-
- def _create_stream_gen(self, info: dict):
- """Yield (waveform_tensor, is_last) from the model's inference_stream().
-
- Handle both incremental ("audio" events) and batch ("result" event) models:
- some upstream implementations emit one "result" event with the full waveform
- instead of incremental "audio" events. Both paths must be covered.
- """
- for event in self._lm.inference_stream(...):
- if event["type"] == "audio":
- yield event["waveform"], False
- elif event["type"] == "result":
- # Fallback for models that don't emit incremental audio events
- yield event.get("waveform", torch.zeros(0)), True
- return
- yield torch.zeros(0), True
-
- def compute_logits(self, hidden_states, sampling_metadata):
- # Emit EOS only when the last chunk has been yielded so the AR
- # scheduler ends the request at the right time.
- ...
-```
-
-For an in-tree reference, look for any single-stage AR model under
-`vllm_omni/model_executor/models/` (for example
-`moss_tts_nano/modeling_moss_tts_nano.py` once its integration has landed).
-
-## Pre-commit and DCO
-
-All contributions must pass the pre-commit checks and the Developer Certificate of
-Origin (DCO) sign-off before merging.
-
-### Running pre-commit
-
-Install the hooks once with `pre-commit install`. Then run before committing:
-
-```bash
-pre-commit run --files \
- vllm_omni/model_executor/models/your_model_name/*.py \
- vllm_omni/entrypoints/openai/serving_speech.py \
- vllm_omni/model_executor/models/registry.py \
- tests/e2e/offline_inference/test_your_model_name.py \
- tests/e2e/online_serving/test_your_model_name.py
-```
-
-When pre-commit **modifies files**, it exits with a non-zero code but the reformatting
-is correct. Stage the modified files and commit again — do not revert the changes.
-
-Common failures and fixes:
-
-| Check | Cause | Fix |
-|-------|-------|-----|
-| `ruff F841` | Local variable assigned but never used | Remove the extraction or forward it to the model call |
-| `ruff E402` | Module-level import not at top of file | Move import to the top-level import block |
-| `ruff format` | Line length, spacing, or quote style | Accept the auto-fix, stage, and re-commit |
-
-### DCO sign-off
-
-Every commit must carry a `Signed-off-by` trailer. Use the `-s` flag when committing:
-
-```bash
-git commit -s -m "feat(your-model): add YourModel TTS support"
-```
-
-Or configure git to add it automatically:
-
-```bash
-git config format.signOff true
-```
-
-To fix a missing sign-off on the most recent commit:
-
-```bash
-git commit --amend -s --no-edit
-git push origin your-branch --force-with-lease
-```
-
-> The DCO check verifies that the commit author email matches the `Signed-off-by` email.
-> Make sure `git config user.email` is set to the address associated with your GitHub
-> account before committing.
-
-## Adding a Model Recipe
-
-After implementing and testing your model, add a model recipe to the
-[vllm-project/recipes](https://github.com/vllm-project/recipes) repository so users can
-get started quickly. See [Adding an Omni-Modality Model](./adding_omni_model.md#adding-a-model-recipe)
-for the expected format.
-
-## Summary
-
-Adding a TTS model to vLLM-Omni involves:
-
-1. **Create model directory** with AR stage, decoder stage, and unified class (two-stage)
- or a single unified class with generator-based streaming (single-stage)
-2. **AR stage** - use vLLM's native decoder layers with fused QKV; do not wrap HF directly
-3. **Decoder stage** - thin wrapper around your audio decoder; implement `chunked_decode_streaming()`
-4. **Unified class** - dispatches on `model_stage`; same structure as `Qwen3TTSModelForGeneration`
-5. **Register** all stage classes in `registry.py`
-6. **YAML configs** - provide both batch and `async_chunk` variants (two-stage), or a single-stage AR config
-7. **Stage input processor** - buffer Stage 0 outputs and forward in chunks of 25 (two-stage only)
-8. **Online serving** - add all 5 integration points to `serving_speech.py` in one commit
-9. **Tests** - cover single request, batching, and streaming
-10. **Pre-commit + DCO** - run `pre-commit` before pushing; sign every commit with `git commit -s`
-11. **Model recipe** - add to [vllm-project/recipes](https://github.com/vllm-project/recipes)
-12. **Invariants** - re-check I1–I5 (streaming contract, consumer hygiene, hot-loop discipline, validation pyramid, per-request state) at the end of every phase
-
-### Qwen3-TTS Reference Files
-
-| File | Purpose |
-|------|---------|
-| `models/qwen3_tts/qwen3_tts.py` | Unified model class |
-| `models/qwen3_tts/qwen3_tts_code_predictor_vllm.py` | AR stage with vLLM fused ops |
-| `models/qwen3_tts/qwen3_tts_code2wav.py` | Decoder stage with `chunked_decode_streaming()` |
-| `models/qwen3_tts/pipeline.py` | Frozen pipeline topology (registered at import time) |
-| `deploy/qwen3_tts.yaml` | Deploy config (user-editable, async_chunk + SharedMemoryConnector) |
-| `stage_input_processors/qwen3_tts.py` | Stage transition processors |
-
-For more information, see:
-
-- [Architecture Overview](../../design/architecture_overview.md)
-- [Async Chunk Design](../../design/feature/async_chunk.md)
-- [Stage Configuration Guide](../../configuration/stage_configs.md)
diff --git a/docs/contributing/profiling.md b/docs/contributing/profiling.md
deleted file mode 100644
index e1dbc8234b0..00000000000
--- a/docs/contributing/profiling.md
+++ /dev/null
@@ -1,286 +0,0 @@
-# Profiling Diffusion Models
-
-> **Warning:** Profiling is for development and debugging only. It adds significant overhead and should not be enabled in production.
-
-Diffusion profiling supports two backends through `profiler_config`:
-
-- `torch`: detailed CPU/CUDA traces, operator tables, and optional memory snapshots
-- `cuda`: low-overhead CUDA range control for NVIDIA Nsight Systems (`nsys`)
-
-## 1. Configure `profiler_config`
-
-Use `profiler_config` to enable profiling for a diffusion model. For diffusion usage, pass it directly to `Omni(...)` or `vllm serve`.
-
-Minimal torch-profiler config:
-
-```yaml
-profiler_config:
- profiler: torch
- torch_profiler_dir: ./perf
-```
-
-Supported fields:
-
-| Field | Description |
-|---|---|
-| `profiler` | Profiler backend. Supported values: `torch`, `cuda`. Use `torch` for `trace.json`, Excel operator tables, and optional memory snapshots. Use `cuda` for Nsight Systems only. |
-| `torch_profiler_dir` | Output directory for torch-profiler artifacts. Required when `profiler: torch`. |
-| `torch_profiler_use_gzip` | Compress `trace_rank*.json` into `trace_rank*.json.gz`. |
-| `torch_profiler_record_shapes` | Record input shapes and add a `by_shape` sheet to `ops_rank*.xlsx`. |
-| `torch_profiler_with_stack` | Record call stacks, add a `by_stack` sheet to `ops_rank*.xlsx`, and export `stacks_cpu_rank*.txt` and `stacks_cuda_rank*.txt`. |
-| `torch_profiler_with_memory` | Enable memory profiling and attempt to dump `memory_snapshot_rank*.pickle`. The pickle is only generated when the current backend supports memory history and snapshot APIs. |
-| `torch_profiler_with_flops` | Enable FLOPs collection in `torch.profiler`. This does not add a separate output file. |
-| `torch_profiler_dump_cuda_time_total` | Export an additional text summary `profiler_out_.txt` sorted by `self_cuda_time_total`. |
-| `delay_iterations` | Number of worker iterations to skip before profiling starts. |
-| `max_iterations` | Maximum number of worker iterations to capture before auto-stop. |
-| `wait_iterations` | Torch-profiler wait iterations before warmup. |
-| `warmup_iterations` | Torch-profiler warmup iterations. |
-| `active_iterations` | Torch-profiler active iterations. |
-
-### Minimal configurations by output
-
-Only collect trace output:
-
-```python
-profiler_config = {
- "profiler": "torch",
- "torch_profiler_dir": "./perf",
-}
-```
-
-Outputs:
-
-- `trace_rank*.json`
-- `ops_rank*.xlsx` with a `summary` sheet
-
-Collect compressed trace output:
-
-```python
-profiler_config = {
- "profiler": "torch",
- "torch_profiler_dir": "./perf",
- "torch_profiler_use_gzip": True,
-}
-```
-
-Outputs:
-
-- `trace_rank*.json.gz`
-- `ops_rank*.xlsx` with a `summary` sheet
-
-Collect trace and full operator tables:
-
-```python
-profiler_config = {
- "profiler": "torch",
- "torch_profiler_dir": "./perf",
- "torch_profiler_record_shapes": True,
- "torch_profiler_with_stack": True,
-}
-```
-
-Outputs:
-
-- `trace_rank*.json`
-- `ops_rank*.xlsx` with `summary`, `by_shape`, and `by_stack`
-- `stacks_cpu_rank*.txt`
-- `stacks_cuda_rank*.txt`
-
-Collect trace, operator tables, and memory snapshots:
-
-```python
-profiler_config = {
- "profiler": "torch",
- "torch_profiler_dir": "./perf",
- "torch_profiler_record_shapes": True,
- "torch_profiler_with_stack": True,
- "torch_profiler_with_memory": True,
-}
-```
-
-Outputs:
-
-- `trace_rank*.json`
-- `ops_rank*.xlsx` with `summary`, `by_shape`, and `by_stack`
-- `stacks_cpu_rank*.txt`
-- `stacks_cuda_rank*.txt`
-- `memory_snapshot_rank*.pickle` when supported by the current backend
-
-### Full torch-profiler configuration
-
-If you want to enable the commonly used torch-profiler options together:
-
-```python
-profiler_config = {
- "profiler": "torch",
- "torch_profiler_dir": "./perf",
- "torch_profiler_use_gzip": False,
- "torch_profiler_record_shapes": True,
- "torch_profiler_with_stack": True,
- "torch_profiler_with_memory": True,
- "torch_profiler_with_flops": False,
- "torch_profiler_dump_cuda_time_total": False,
- "delay_iterations": 0,
- "max_iterations": 0,
- "wait_iterations": 0,
- "warmup_iterations": 0,
- "active_iterations": 0,
-}
-```
-
-## 2. Profiling Diffusion with PyTorch Profiler
-
-Single-stage diffusion models use `start_profile()` / `stop_profile()` controls. The profiler only writes artifacts after profiling has been started and then stopped.
-
-```python
-from vllm_omni import Omni
-
-omni = Omni(
- model="Wan-AI/Wan2.2-I2V-A14B-Diffusers",
- profiler_config={
- "profiler": "torch",
- "torch_profiler_dir": "./perf",
- },
-)
-
-omni.start_profile()
-...
-omni.stop_profile()
-```
-
-For diffusion offline example scripts under `examples/offline_inference/`, pass `--profiler-config` as a JSON object. The script enables profiling when this argument is set and wraps generation with `start_profile()` / `stop_profile()`.
-
-Example:
-
-```bash
-python examples/offline_inference/image_to_video/image_to_video.py \
- --model Wan-AI/Wan2.2-I2V-A14B-Diffusers \
- --image input.jpg \
- --prompt "A cat playing with yarn" \
- --profiler-config '{
- "profiler": "torch",
- "torch_profiler_dir": "./perf",
- "torch_profiler_record_shapes": true,
- "torch_profiler_with_stack": true
- }'
-```
-
-Examples:
-
-1. [Image edit example](https://github.com/vllm-project/vllm-omni/blob/main/examples/offline_inference/image_to_image/image_edit.py)
-2. [Image to video example](https://github.com/vllm-project/vllm-omni/tree/main/examples/offline_inference/image_to_video)
-
-## 3. Profiling Diffusion with Nsight Systems (`nsys`)
-
-For Nsight Systems, use `profiler: cuda` and wrap the process with `nsys profile`.
-
-```bash
-nsys profile \
- --trace-fork-before-exec=true \
- --cuda-graph-trace=node \
- --capture-range=cudaProfilerApi \
- --capture-range-end=repeat \
- -o diffusion_trace \
- python image_to_video.py ...
-```
-
-The Python process being profiled must create the diffusion engine with:
-
-```python
-profiler_config = {"profiler": "cuda"}
-```
-
-Then call `start_profile()` before the requests you want to capture and `stop_profile()` after them. The diffusion worker processes open and close the CUDA capture range themselves, so `nsys` sees the actual GPU work instead of only the parent process.
-
-## 4. Profiling Online Serving
-
-When `profiler_config.profiler` is set for a diffusion model, the server exposes:
-
-- `POST /start_profile`
-- `POST /stop_profile`
-
-### Start the server
-
-Single-stage diffusion serving with torch profiler:
-
-```bash
-vllm serve Wan-AI/Wan2.2-I2V-A14B-Diffusers \
- --omni \
- --port 8091 \
- --profiler-config '{
- "profiler": "torch",
- "torch_profiler_dir": "/tmp/vllm_profile_wan22_i2v",
- "torch_profiler_with_stack": true,
- "torch_profiler_with_flops": false,
- "torch_profiler_use_gzip": true,
- "torch_profiler_dump_cuda_time_total": false,
- "torch_profiler_record_shapes": true,
- "torch_profiler_with_memory": true,
- "delay_iterations": 0,
- "max_iterations": 0,
- "wait_iterations": 0,
- "warmup_iterations": 0,
- "active_iterations": 0
- }'
-```
-
-Single-stage diffusion serving with Nsight Systems:
-
-```bash
-nsys profile \
- --trace-fork-before-exec=true \
- --cuda-graph-trace=node \
- --capture-range=cudaProfilerApi \
- --capture-range-end=repeat \
- -o serving_trace \
- vllm serve Wan-AI/Wan2.2-I2V-A14B-Diffusers \
- --omni \
- --port 8091 \
- --profiler-config '{"profiler": "cuda"}'
-```
-
-### Control capture
-
-Example profiling flow for an online Qwen-Image request:
-
-```bash
-# Start profiling.
-curl -X POST http://localhost:8091/start_profile
-
-# Send a Qwen-Image generation request while profiling is active.
-curl http://localhost:8091/v1/images/generations \
- -H "Content-Type: application/json" \
- -d '{
- "model": "Qwen/Qwen-Image",
- "prompt": "A red vintage bicycle parked beside a quiet canal at sunset"
- }'
-
-# Stop profiling and flush profiler artifacts.
-curl -X POST http://localhost:8091/stop_profile
-```
-
-## 5. Diffusion Pipeline Profiler
-
-For lightweight per-stage pipeline timing such as `vae.decode` or `diffuse`, see [Diffusion Pipeline Profiler](model/adding_diffusion_model.md#diffusion-pipeline-profiler-performance-profiling). That utility logs stage durations only and does not generate torch-profiler artifacts such as `trace.json`, Excel tables, or memory snapshots.
-
-## 6. Analyze Results
-
-Torch-profiler output:
-
-- Chrome/Perfetto trace: `trace_rank*.json` or `trace_rank*.json.gz`
-- Excel workbook: `ops_rank*.xlsx` with `summary`, and optional `by_shape` / `by_stack` sheets
-- Stack exports: `stacks_cpu_rank*.txt` and `stacks_cuda_rank*.txt` when stack capture is enabled
-- Memory snapshot: `memory_snapshot_rank*.pickle` when memory capture is enabled and supported by the backend
-- Optional CUDA-time text summary: `profiler_out_.txt` when `torch_profiler_dump_cuda_time_total` is enabled
-
-CUDA profiler / Nsight Systems output:
-
-- `.nsys-rep` report files written by `nsys -o ...`
-
-Recommended viewers:
-
-- [Perfetto](https://ui.perfetto.dev/) for torch traces
-- `nsys stats .nsys-rep` for CLI summaries
-- Nsight Systems GUI for CUDA kernel timelines
-
-For upstream background on the underlying vLLM profiling infrastructure, see the [vLLM profiling guide](https://docs.vllm.ai/en/stable/contributing/profiling/).
diff --git a/docs/design/architecture_overview.md b/docs/design/architecture_overview.md
deleted file mode 100644
index 1c38ba67183..00000000000
--- a/docs/design/architecture_overview.md
+++ /dev/null
@@ -1,202 +0,0 @@
-# Architecture Overview
-
-This document outlines the architectural design for vLLM-Omni.
-
-
-
-
- 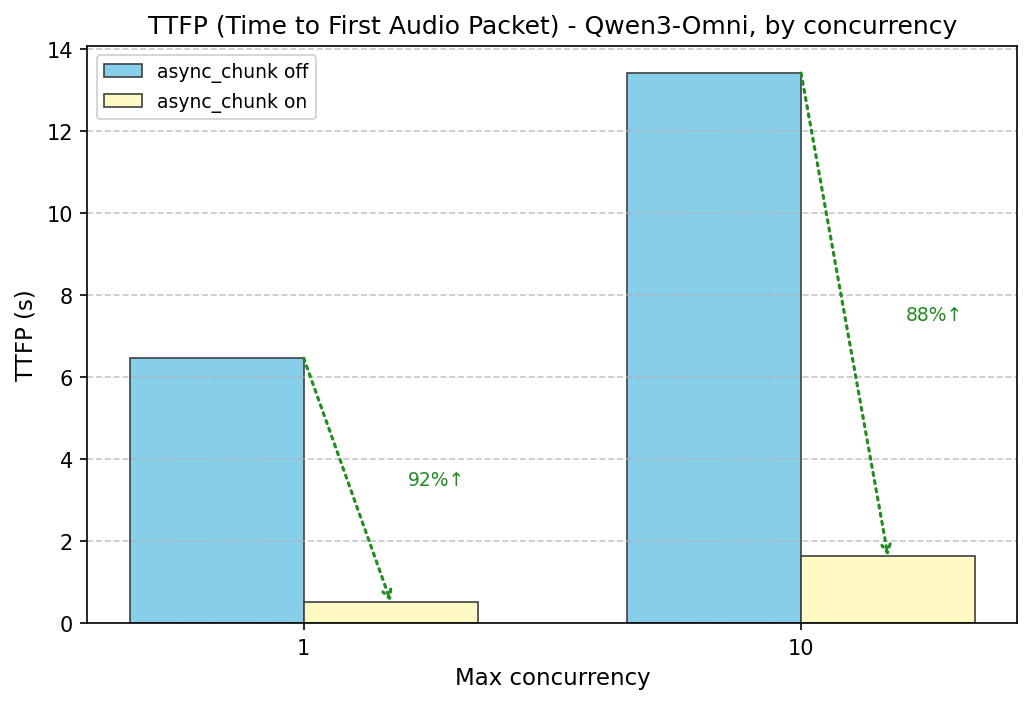 -
-
-
-
-:8080/metadata"
- master: ":50051"
- segment: 512000000
- localbuf: 64000000
- proto: "tcp"
-```
-
-Wire stages to the connector:
-
-```yaml
-stage_args:
- - stage_id: 0
- output_connectors:
- to_stage_1: connector_of_mooncake
-
- - stage_id: 1
- input_connectors:
- from_stage_0: connector_of_mooncake
-```
-
-Parameters:
-
-- host: local worker IP registered in the metadata server.
-- metadata_server: metadata server URL for discovery and setup.
-- master: Mooncake Master address.
-- segment: global memory segment size in bytes.
-- localbuf: local buffer size in bytes.
-- proto: transport protocol ("tcp" or "rdma").
-
-For more details, refer to the
-[Mooncake repository](https://github.com/kvcache-ai/Mooncake).
-
----
-
-## Design
-
-### 1. Overview
-
-`MooncakeStoreConnector` is the storage-oriented remote connector in `vllm_omni/distributed/omni_connectors`. It is built on top of Mooncake distributed store APIs and provides a uniform `put()` / `get()` abstraction for transferring stage payloads across nodes.
-
-Compared with `SharedMemoryConnector`, this connector is intended for multi-node deployments. Compared with `MooncakeTransferEngineConnector`, it is simpler and more object-oriented: data is written into a distributed store and fetched back by key, rather than transferred through an explicit remote-memory write protocol.
-
-Its primary role is to provide a general-purpose remote connector for stage payloads when:
-
-- the pipeline spans multiple hosts
-- a shared-memory connector is not possible
-- a simpler remote backend is preferred over the RDMA-oriented transfer engine
-
-### 2. Relationship with the OmniConnector System
-
-`MooncakeStoreConnector` implements `OmniConnectorBase`, so it integrates with the same connector lifecycle as the other backends:
-
-- `OmniConnectorFactory` instantiates it from `ConnectorSpec`
-- `load_omni_transfer_config()` maps edge config to the connector spec
-- All callers (batch forwarding, chunk transfer, KV transfer, etc.) interact with it through the same `put()` / `get()` contract
-
-This means the rest of the pipeline does not need store-specific logic. It only relies on the generic connector contract.
-
-### 3. Design Goals
-
-The connector is designed around the following goals:
-
-- **Cross-node object transfer** using a single key-based abstraction
-- **Minimal connector-specific control plane**, since the store itself is the shared medium
-- **Compatibility with arbitrary Python payloads** through the Omni serializer
-- **Operational simplicity** compared with the transfer-engine-based remote connector
-
-The connector is intentionally not optimized for zero-copy tensor movement or direct remote-memory access.
-
-### 4. Core Design
-
-#### 4.1 Object-Oriented Transfer Model
-
-`MooncakeStoreConnector` treats the transport backend as a distributed object store:
-
-1. Serialize the Python object into bytes.
-2. Generate a unique connector key.
-3. Store the bytes in Mooncake.
-4. Fetch the bytes from Mooncake on the receiver side.
-5. Deserialize the bytes back into the original object.
-
-This design makes the connector conceptually close to a distributed key-value transport.
-
-#### 4.2 Key Construction
-
-The connector uses `OmniConnectorBase._make_key()` to derive the internal store key:
-
-```text
-{request_key}@{from_stage}_{to_stage}
-```
-
-This adds stage routing information to the logical request key and avoids collisions between different pipeline edges.
-
-#### 4.3 No Extra Metadata Path
-
-Unlike `SharedMemoryConnector` and `MooncakeTransferEngineConnector`, this connector returns:
-
-```python
-metadata = None
-```
-
-from `put()`.
-
-This is a meaningful design difference:
-
-- the store itself is the shared rendezvous point
-- consumers only need the same key
-- no transport handle, address, or side-channel metadata needs to be propagated
-
-As a result, the control plane is simpler for this connector than for the SHM and RDMA variants.
-
-### 5. Initialization
-
-#### 5.1 Required Mooncake Components
-
-The connector requires the Mooncake Python bindings to expose:
-
-- `MooncakeDistributedStore`
-- `ReplicateConfig`
-
-If these symbols are unavailable, construction fails immediately with `ImportError`. This keeps startup failures explicit and avoids silent fallback behavior.
-
-#### 5.2 Store Setup
-
-During `_init_store()`, the connector:
-
-1. creates `MooncakeDistributedStore()`
-2. calls `store.setup(...)`
-3. validates the return code
-4. creates a `ReplicateConfig`
-5. enables `with_soft_pin = True`
-
-The setup step is completed during connector construction, not lazily at first use.
-
-### 6. Put / Get Flow
-
-#### 6.1 Producer Flow: `put()`
-
-The producer-side flow is:
-
-1. Validate that the store has been initialized.
-2. Serialize the payload into bytes.
-3. Build the internal key with stage routing information.
-4. Call `store.put(key, serialized_data, self.pin)`.
-5. Update metrics and return success.
-
-The returned tuple is:
-
-```python
-(True, len(serialized_data), None)
-```
-
-#### 6.2 Consumer Flow: `get()`
-
-The consumer-side flow is:
-
-1. Validate that the store has been initialized.
-2. Build the same internal key.
-3. Poll `store.get(key)` for up to 20 retries.
-4. Sleep 50 ms between retries.
-5. If data is found, deserialize it and return `(data, payload_size)`.
-6. If all retries are exhausted, record a timeout and return `None`.
-
-This design gives the connector a bounded waiting model rather than an indefinite blocking get.
-
-### 7. Integration with Stage Communication
-
-All callers use the connector through the same `put()` / `get()` contract:
-
-- the sender calls `put()` to serialize and store the payload
-- the receiver calls `get()` to retrieve and deserialize it
-- no connector-specific metadata is required, since the store key is the rendezvous point
-
-Because `put()` returns `metadata=None`, the connector is naturally compatible with callers that do not forward metadata (e.g. polling-based flows). The trade-off is that all payloads incur full serialization and deserialization costs, which makes the connector functional but not the highest-performance option for large payloads such as KV cache blocks.
-
-### 8. Data Flow in the Pipeline
-
-The end-to-end transfer model is:
-
-```mermaid
-sequenceDiagram
- participant SenderStage
- participant MooncakeStoreConnector
- participant MooncakeStore
- participant ReceiverStage
-
- SenderStage->>MooncakeStoreConnector: put(from_stage, to_stage, put_key, data)
- MooncakeStoreConnector->>MooncakeStoreConnector: serialize object
- MooncakeStoreConnector->>MooncakeStore: put(internal_key, bytes)
- MooncakeStoreConnector-->>SenderStage: (success, size, None)
-
- ReceiverStage->>MooncakeStoreConnector: get(from_stage, to_stage, get_key)
- MooncakeStoreConnector->>MooncakeStore: get(internal_key)
- MooncakeStoreConnector->>MooncakeStoreConnector: deserialize bytes
- MooncakeStoreConnector-->>ReceiverStage: (data, size)
-```
-
-This is a store-mediated remote transfer model rather than a direct peer-to-peer transport model.
-
-### 9. Strengths and Trade-offs
-
-#### Strengths
-
-- Simple conceptual model: store by key, fetch by key.
-- No connector-specific metadata handoff is required.
-- Works naturally for remote multi-node stage transfer.
-- Easy to integrate into the existing connector abstraction.
-
-#### Trade-offs
-
-- Full serialization and deserialization are always required.
-- Large payloads are more expensive than in direct-memory transports.
-- Runtime behavior depends on external Mooncake services being available.
-- Cleanup semantics are weaker than request-scoped local buffer management.
-
-### 10. Important Implementation Characteristics
-
-#### 10.1 Cleanup Is a No-op
-
-`cleanup()` only logs a debug message and does not actively delete remote data. The current design assumes Mooncake-side lifecycle management rather than explicit per-request removal.
-
-This keeps the connector implementation simple but means request-level reclamation is not modeled inside the connector itself.
-
-#### 10.2 Close Releases the Store Handle
-
-Unlike `SharedMemoryConnector`, where `close()` is a no-op, `MooncakeStoreConnector.close()` performs a meaningful shutdown:
-
-1. Calls `self.store.close()` to release the Mooncake store handle.
-2. Sets `self.store = None` to prevent further operations.
-
-This ensures the connector releases its connection to the external Mooncake service on shutdown. Errors during close are logged but do not propagate.
-
-#### 10.3 Health Output Uses a Shared Schema
-
-`health()` reports:
-
-- `host`
-- `metadata_server`
-- `master`
-- metrics
-
-and also includes placeholder fields such as `protocol`, `pool_device`, and `pool_size` to keep a more uniform shape across connector health outputs. This reflects a system-level consistency choice rather than a store-specific design need.
-
-#### 10.4 Get Is Retry-Based, Not Event-Driven
-
-The receiver side polls the store with a short retry loop. This is simple and robust, but it means the connector is latency-sensitive to:
-
-- store visibility delay
-- network jitter
-- payload size
-
-If the payload is not visible within the retry window, the connector reports a timeout.
-
-### 11. Summary
-
-`MooncakeStoreConnector` is the remote, store-based connector in the OmniConnector stack. Its design is straightforward:
-
-- serialize the payload
-- store it in Mooncake under a stage-qualified key
-- fetch it by the same key on the receiver side
-- deserialize it back into the original object
-
-This connector fills an important gap in the system:
-
-1. It enables cross-node transfer without requiring shared memory.
-2. It keeps the stage communication model uniform.
-3. It provides a simpler operational alternative to the transfer-engine-based remote connector.
-
-Its simplicity is also its main trade-off: it favors a clean object-transfer model over the fast-path and peer-to-peer optimizations implemented by `MooncakeTransferEngineConnector`.
diff --git a/docs/design/feature/omni_connectors/mooncake_transfer_engine_connector.md b/docs/design/feature/omni_connectors/mooncake_transfer_engine_connector.md
deleted file mode 100644
index 306a0620b4b..00000000000
--- a/docs/design/feature/omni_connectors/mooncake_transfer_engine_connector.md
+++ /dev/null
@@ -1,793 +0,0 @@
-# MooncakeTransferEngineConnector
-
-## When to Use
-
-Best for high-performance multi-node data transfer between stages using Mooncake
-Transfer Engine. Supports both RDMA and TCP protocols with a managed memory pool,
-zero-copy deserialization, and optional GPUDirect RDMA. Applicable to any
-inter-stage data (KV caches, request payloads, etc.), not limited to KV cache transfer.
-
-Compared to `MooncakeStoreConnector` (TCP key-value store), this connector
-provides **~60x faster** data transfer via RDMA direct memory access.
-
-## Installation
-
-```bash
-pip install mooncake-transfer-engine
-```
-
-Ensure RDMA drivers are installed on all nodes (e.g., Mellanox OFED for
-InfiniBand/RoCE NICs).
-
-## Configuration
-
-Define the connector in runtime:
-
-```yaml
-runtime:
- connectors:
- rdma_connector:
- name: MooncakeTransferEngineConnector
- extra:
- host: "auto" # Auto-detect local RDMA IP
- zmq_port: 50051 # ZMQ base port (see "Port Offset Scheme" below)
- protocol: "rdma" # "rdma" or "tcp"
- device_name: "" # RDMA device (e.g., "mlx5_0"), empty for auto-detect
- memory_pool_size: 4294967296 # 4 GB (CPU); use 2147483648 (2 GB) for GPU
- memory_pool_device: "cpu" # "cpu" for pinned memory (recommended), "cuda" for GPUDirect RDMA
-```
-
-Wire stages to the connector:
-
-```yaml
-stage_args:
- - stage_id: 0
- output_connectors:
- to_stage_1: rdma_connector
-
- - stage_id: 1
- input_connectors:
- from_stage_0: rdma_connector
-```
-
-## Parameters
-
-### Required
-
-| Parameter | Description |
-|---|---|
-| `role` | **Internal, do not set manually.** Auto-injected by the orchestration layer (`"sender"` for `output_connectors`, `"receiver"` for `input_connectors`). Defaults to `"sender"` if omitted. |
-| `host` | Local IP address for RDMA. `"auto"` detects from network interfaces. |
-| `protocol` | Transport protocol: `"rdma"` (InfiniBand/RoCE) or `"tcp"`. |
-
-### Memory Pool
-
-| Parameter | Default | Description |
-|---|---|---|
-| `memory_pool_size` | 4 GB (CPU) / 2 GB (GPU) | Total size of the RDMA-registered memory pool in bytes. Recommended 4 GB for CPU pinned memory; 2 GB for GPU VRAM to conserve device memory. |
-| `memory_pool_device` | `"cpu"` | `"cpu"`: pinned host memory (recommended, works on all topologies). `"cuda"`: GPU VRAM for GPUDirect RDMA (requires NIC-GPU direct PCIe connectivity, PIX topology). |
-
-### Networking
-
-| Parameter | Default | Description |
-|---|---|---|
-| `zmq_port` | 50051 | ZMQ **base** port. The orchestration layer computes the actual port as `base + purpose_offset + stage_offset` (see table below). Users only set this base value. |
-| `sender_host` | `None` | **Internal.** Receiver-side only — dynamically resolved via `update_sender_info()`. Not needed in YAML. |
-| `sender_zmq_port` | `None` | **Internal.** Receiver-side only — defaults to the sender's adjusted port. Not needed in YAML. |
-| `device_name` | `""` | RDMA device name (e.g., `"mlx5_0"`). Empty for auto-detect. Can also be set via `RDMA_DEVICE_NAME` env var. |
-
-#### ZMQ Port Offset Scheme
-
-To avoid port conflicts when multiple edges, purposes, DP replicas, or TP ranks share the same node, the actual ZMQ port is computed as:
-
-```
-side_channel_port = zmq_port + purpose_offset + stage_offset + dp_index * tp_size
-sender_listen = side_channel_port + tp_rank
-receiver_connect = remote_side_channel_port + tp_rank
-```
-
-| Component | Value | Description |
-|---|---|---|
-| `zmq_port` | 50051 (default) | Base port from YAML config |
-| `purpose_offset` | `request_forwarding` = 0, `kv_transfer` = 100 | Separates control-plane vs KV-cache connections |
-| `stage_offset` | `int(from_stage)` (0, 1, 2...) | Separates edges from different source stages |
-| `dp_index * tp_size` | e.g., DP1 × TP2 = 2 | Each DP replica reserves a port range of size `tp_size` (following vLLM convention: `VLLM_MOONCAKE_BOOTSTRAP_PORT + dp_index * tp_size`) |
-| `tp_rank` | 0, 1, 2... | Each TP rank within a DP replica uses its own port |
-| orchestrator | +200 | Extra offset when caller is the orchestrator (avoids collision with stage workers on the same node) |
-
-**Example** (base=50051, stage 0→1, DP=2, TP=2, kv_transfer):
-
-| Caller | DP | TP rank | Port |
-|---|---|---|---|
-| Stage worker | DP0 | rank 0 | `50051 + 100 + 0 + 0×2 + 0 = 50151` |
-| Stage worker | DP0 | rank 1 | `50051 + 100 + 0 + 0×2 + 1 = 50152` |
-| Stage worker | DP1 | rank 0 | `50051 + 100 + 0 + 1×2 + 0 = 50153` |
-| Stage worker | DP1 | rank 1 | `50051 + 100 + 0 + 1×2 + 1 = 50154` |
-| Orchestrator | — | — | `50051 + 200 + 0 = 50251` |
-
-## Memory Pool Modes
-
-| Mode | Config | Recommended Pool Size | Data Flow | Best For |
-|---|---|---|---|---|
-| CPU Pinned | `memory_pool_device: "cpu"` | 4 GB | GPU → CPU pool → RDMA → CPU pool → GPU | Most hardware topologies (recommended) |
-| GPUDirect | `memory_pool_device: "cuda"` | 2 GB | GPU → GPU pool → RDMA (NIC reads GPU BAR1) → GPU pool | NIC-GPU direct PCIe (PIX topology) |
-
-> **Note**: GPUDirect RDMA requires the NIC and GPU to share a direct PCIe
-> switch (PIX topology). On systems where they are connected via PXB or NODE,
-> CPU pinned memory is faster due to GPU BAR1 bandwidth limitations.
-
-## Environment Variables
-
-| Variable | Description |
-|---|---|
-| `RDMA_DEVICE_NAME` | Override RDMA device name (e.g., `mlx5_0`). |
-| `MC_IB_PCI_RELAXED_ORDERING` | Set to `1` to enable PCIe relaxed ordering for GPUDirect. |
-
-## Docker / Container Setup
-
-RDMA requires host-level device access:
-
-```bash
-docker run -it \
- --cap-add=SYS_PTRACE \
- --cap-add=IPC_LOCK \
- --security-opt seccomp=unconfined \
- --network=host \
- --device=/dev/infiniband \
- -v /sys/class/infiniband:/sys/class/infiniband:ro \
- your-image:tag
-```
-
-## Performance
-
-Benchmark results on H800 GPUs with mlx5_0 RDMA NIC (~186 MB KV cache):
-
-| Metric | MooncakeStoreConnector | MooncakeTransferEngineConnector (CPU) |
-|---|---|---|
-| KV transfer wall time | ~810 ms | **~14 ms** |
-| RDMA throughput | N/A (TCP) | ~22 GB/s |
-| Speedup | 1x | **58x** |
-
-## Troubleshooting
-
-### Quick Diagnostics
-
-```bash
-# 1. Check RDMA devices and link status
-ibdev2netdev
-# Expected: "mlx5_X port 1 ==> (Up)"
-# RoCE devices map to Ethernet interfaces (e.g., enp75s0f0)
-# IB devices map to ib0, ib1, etc.
-
-# 2. Check InfiniBand device details
-ibstat
-
-# 3. Verify /dev/infiniband is accessible (required in containers)
-ls /dev/infiniband/
-
-# 4. Check Mooncake installation
-python -c "from mooncake.engine import TransferEngine; print('OK')"
-
-# 5. Check environment variables
-echo "RDMA_DEVICE_NAME=${RDMA_DEVICE_NAME:-}"
-echo "MC_IB_PCI_RELAXED_ORDERING=${MC_IB_PCI_RELAXED_ORDERING:-}"
-```
-
-### Common Issues
-
-| Symptom | Cause | Fix |
-|---|---|---|
-| `Failed to modify QP to RTR` | Cross-NIC QP handshake failure (multi-NIC DGX) | Set `device_name` to a single RoCE NIC (e.g., `mlx5_2`) or set `RDMA_DEVICE_NAME` env var |
-| `transport retry counter exceeded` | RDMA path between incompatible NICs | Same as above — restrict to one NIC |
-| `zmq.error.Again: Resource temporarily unavailable` | ZMQ recv timeout (transfer took too long) | Check NIC selection; increase data may need longer timeout |
-| `Mooncake Engine initialization failed` | Missing RDMA drivers or `/dev/infiniband` | Install Mellanox OFED; in Docker add `--device=/dev/infiniband` |
-| `MemoryError` in allocator | Memory pool too small for payload | Increase `memory_pool_size` |
-| GPU transfer slower than CPU | GPU BAR1 bandwidth limitation (PXB/NODE topology) | Use `memory_pool_device: "cpu"` instead of `"cuda"` |
-
-### Multi-NIC Environments (DGX)
-
-On DGX machines with 12+ RDMA NICs, only RoCE NICs (with a bound network
-interface) reliably support loopback. IB-only NICs may fail cross-NIC QP
-handshakes. To identify RoCE NICs:
-
-```bash
-ibdev2netdev | grep -v "ib[0-9]"
-# RoCE devices show Ethernet interface names like enp75s0f0
-```
-
-Then configure the connector:
-```yaml
-device_name: "mlx5_2" # or set RDMA_DEVICE_NAME=mlx5_2
-```
-
-See the RDMA Test README in tests/distributed/omni_connectors/README.md
-for test-specific setup instructions.
-
-For more details on the underlying engine, refer to the
-[Mooncake repository](https://github.com/kvcache-ai/Mooncake).
-
----
-
-## Design
-
-### 1. Overview
-
-`MooncakeTransferEngineConnector` is the high-performance remote connector in `vllm_omni/distributed/omni_connectors`. It is built on top of Mooncake `TransferEngine` and combines:
-
-- a **direct data plane** for remote memory writes
-- a **ZMQ side channel** for metadata lookup, handshake, and completion signaling
-- a **managed local memory pool** for both send and receive buffers
-
-Unlike `MooncakeStoreConnector`, which treats the backend as a distributed store, `MooncakeTransferEngineConnector` is designed as a peer-to-peer transport. Its goal is to move large stage payloads efficiently while still fitting the common `put()` / `get()` API defined by `OmniConnectorBase`.
-
-It is the most performance-oriented connector in the current OmniConnector family and is intended for large remote payloads such as:
-
-- KV cache transfer
-- stage hidden-state payloads
-- streaming chunk payloads
-- other binary-heavy inter-stage artifacts
-
-### 2. Relationship with the OmniConnector System
-
-`MooncakeTransferEngineConnector` implements the same connector contract as the other backends:
-
-- `put(from_stage, to_stage, put_key, data)`
-- `get(from_stage, to_stage, get_key, metadata=None)`
-- `cleanup(request_id, ...)`
-- `health()`
-- `close()`
-
-It is integrated into the system through the standard connector plumbing:
-
-- `OmniConnectorFactory` constructs the connector from `ConnectorSpec`
-- `load_omni_transfer_config()` resolves the edge-level connector configuration
-- `get_connectors_config_for_stage()` and `resolve_omni_kv_config_for_stage()` inject the connector role
-- All callers (batch forwarding, chunk transfer, KV transfer, etc.) interact with it through the same `put()` / `get()` contract
-
-The key system-level distinction is that this connector is **role-aware**:
-
-- sender instances expose data and listen for pull requests
-- receiver instances allocate buffers and actively pull data from the sender
-
-### 3. Design Goals
-
-The connector is designed around four primary goals:
-
-1. **High-throughput remote transfer**
- Avoid store-mediated round trips and write directly into the receiver memory region.
-
-2. **Fast path for raw payloads**
- Support `torch.Tensor`, `bytes`, and `ManagedBuffer` without forcing all traffic through full object serialization.
-
-3. **Unified connector abstraction**
- Preserve the same `put()` / `get()` interface used by the rest of the OmniConnector stack.
-
-4. **Safe lifecycle management**
- Manage allocation, reuse, cleanup, and failure recovery for a registered memory pool.
-
-### 4. Architecture Overview
-
-At a high level, the connector is composed of four main subsystems:
-
-```mermaid
-classDiagram
- class OmniConnectorBase {
- <>
- +put(from_stage, to_stage, put_key, data)
- +get(from_stage, to_stage, get_key, metadata)
- +cleanup(request_id)
- +health()
- +close()
- }
-
- class MooncakeTransferEngineConnector {
- +supports_raw_data: bool
- -engine: TransferEngine
- -allocator: BufferAllocator
- -pool: torch.Tensor
- -zmq_ctx: zmq.Context
- -_local_buffers: dict
- -_sender_executor: ThreadPoolExecutor
- -_listener_thread: threading.Thread
- +put(...)
- +get(...)
- +update_sender_info(sender_host, sender_zmq_port)
- +get_connection_info()
- +cleanup(request_id, from_stage, to_stage)
- +close()
- }
-
- class BufferAllocator {
- -total_size: int
- -alignment: int
- -free_blocks: list
- +alloc(size) int
- +free(offset, size)
- }
-
- class ManagedBuffer {
- -allocator: BufferAllocator
- -offset: int
- -size: int
- -pool_tensor: torch.Tensor
- +tensor
- +as_tensor(dtype, shape) torch.Tensor
- +to_bytes() bytes
- +release()
- }
-
- class TransferEngine {
- +initialize(host, handshake, protocol, device_name)
- +register_memory(base_ptr, size)
- +batch_transfer_sync_write(remote_session, src_addrs, dst_addrs, lengths)
- +unregister_memory(base_ptr)
- +get_rpc_port() int
- }
-
- class QueryRequest {
- +request_id: str
- }
-
- class QueryResponse {
- +request_id: str
- +data_size: int
- +is_fast_path: bool
- }
-
- class MooncakeAgentMetadata {
- +remote_hostname: str
- +remote_port: int
- +request_id: str
- +dst_addrs: list[int]
- +lengths: list[int]
- }
-
- OmniConnectorBase <|-- MooncakeTransferEngineConnector
- MooncakeTransferEngineConnector *-- BufferAllocator
- MooncakeTransferEngineConnector *-- TransferEngine
- ManagedBuffer --> BufferAllocator : releases to
- ManagedBuffer --> "1" torch.Tensor : views
- MooncakeTransferEngineConnector ..> ManagedBuffer : returns / retains
- MooncakeTransferEngineConnector ..> QueryRequest : decodes
- MooncakeTransferEngineConnector ..> QueryResponse : encodes
- MooncakeTransferEngineConnector ..> MooncakeAgentMetadata : exchanges
-```
-
-#### 4.1 Transfer Engine
-
-Mooncake `TransferEngine` is responsible for the actual data-plane transfer. It registers local memory and performs synchronous remote writes through:
-
-```python
-batch_transfer_sync_write(...)
-```
-
-#### 4.2 Managed Memory Pool
-
-Each connector instance owns a large pre-registered memory pool:
-
-- CPU pinned memory when `memory_pool_device == "cpu"`
-- GPU memory when `memory_pool_device == "cuda"`
-
-This avoids repeated memory registration and allows each transfer to allocate subranges from one long-lived pool.
-
-#### 4.3 Buffer Manager
-
-Two helper classes control local memory ownership:
-
-- `BufferAllocator`
- Manages aligned subrange allocation and free-list merging.
-
-- `ManagedBuffer`
- Represents one live slice of the pool and exposes:
- - `.tensor`
- - `.as_tensor(dtype, shape)`
- - `.to_bytes()`
- - `.release()`
-
-#### 4.4 ZMQ Side Channel
-
-ZMQ is used for transport coordination, not for the data payload itself. It handles:
-
-- metadata query from receiver to sender
-- pull request submission
-- completion or error signaling
-- internal notification from worker threads back to the listener thread
-
-This split makes the control plane lightweight while keeping the bulk payload on the transfer engine data plane.
-
-### 5. Role Model
-
-#### 5.1 Sender Role
-
-A sender connector:
-
-- accepts `put()` calls
-- stores live transfer-ready buffers in `_local_buffers`
-- starts a ZMQ listener thread
-- responds to metadata queries and pull requests from receivers
-
-#### 5.2 Receiver Role
-
-A receiver connector:
-
-- does not bind the sender-side ZMQ listener
-- accepts `get()` calls
-- allocates receive buffers from its own pool
-- requests metadata or transfer service from the sender
-
-The role is not inferred dynamically. It is injected by the stage configuration layer:
-
-- incoming edge for a stage -> `role="receiver"`
-- outgoing edge for a stage -> `role="sender"`
-
-This is important because incorrect role assignment would break initialization semantics.
-
-#### 5.3 Host Auto-Detection
-
-The `host` configuration field supports the special value `"auto"`. When set, the connector auto-detects the local IP address that would be used for external communication (via a UDP socket probe to `8.8.8.8`). If that fails, it falls back to hostname resolution, and ultimately to `127.0.0.1`.
-
-This is useful in environments where the operator does not want to hard-code IP addresses in the connector config.
-
-#### 5.4 RDMA Device Filtering
-
-The `device_name` configuration field allows the operator to specify which RDMA NICs to use (comma-separated, e.g. `"mlx5_0,mlx5_1"`). If not set in config, the connector also checks the `RDMA_DEVICE_NAME` environment variable.
-
-This is important in environments with mixed InfiniBand/RoCE NICs, where not all devices are suitable for the transfer engine.
-
-### 6. Local Memory Management
-
-#### 6.1 Memory Pool Registration
-
-During initialization, the connector:
-
-1. allocates a large pool tensor
-2. records its base pointer
-3. registers that memory with Mooncake
-4. creates a `BufferAllocator` for subrange management
-
-This means every later transfer only allocates offsets inside the pre-registered pool rather than registering memory per request.
-
-#### 6.2 BufferAllocator
-
-`BufferAllocator` maintains a sorted free list of `(offset, size)` blocks and enforces alignment. Its responsibilities include:
-
-- aligned allocation
-- freeing previously allocated blocks
-- adjacent block merging
-- double-free detection
-- overlap detection to catch corruption
-
-This is a critical piece of the connector because both sender and receiver depend on long-lived pool reuse.
-
-#### 6.3 ManagedBuffer
-
-`ManagedBuffer` is the main fast-path data wrapper. It can:
-
-- expose the pool slice as a zero-copy 1D `uint8` tensor
-- reinterpret that slice as a typed tensor
-- copy out the contents as Python `bytes`
-- release the slice back to the allocator
-
-The connector uses `ManagedBuffer` in two different ways:
-
-- as a send-side holder to keep the pool slice alive
-- as a receive-side return type when `is_fast_path=True`
-
-### 7. Put Flow
-
-#### 7.1 High-Level Behavior
-
-`put()` is only valid in sender mode. Its job is to expose a payload for later remote pull by the receiver.
-
-The high-level flow is:
-
-1. validate connector state and role
-2. convert the input into a pool-backed transferable representation
-3. store the transfer metadata in `_local_buffers`
-4. return lightweight metadata describing how the receiver can fetch the data
-
-#### 7.2 Payload Type Handling
-
-`put()` supports three payload classes:
-
-**A. `ManagedBuffer`**
-
-If the buffer belongs to the same pool, the connector can use it directly without copying. This is the most efficient path.
-
-If the buffer comes from a different pool, the connector falls back to a copy path.
-
-**B. `torch.Tensor` or `bytes`**
-
-These payloads are copied into the local pool and marked as fast-path data:
-
-- no Omni object serialization is required
-- receiver can get a `ManagedBuffer` back
-
-**C. Generic Python object**
-
-Any other payload is serialized via `OmniSerializer.serialize(...)` and then copied into the pool.
-
-In this case:
-
-- `is_fast_path=False`
-- the receiver will deserialize back into a Python object
-
-#### 7.3 Sender Metadata
-
-The sender returns:
-
-```python
-{
- "source_host": self.host,
- "source_port": self.zmq_port,
- "data_size": size,
- "is_fast_path": is_fast_path,
-}
-```
-
-This metadata is intentionally lightweight. It tells the receiver:
-
-- where the sender-side control plane lives
-- how large the remote transfer will be
-- whether the payload should be returned as a `ManagedBuffer` or a deserialized object
-
-#### 7.4 Sender Buffer Table
-
-The sender stores each live payload in `_local_buffers` under the stage-qualified key. Each entry contains:
-
-- source addresses
-- lengths
-- the holder object
-- ownership information (`should_release`)
-- `is_fast_path`
-- creation time
-
-This table is the sender-side truth source for both metadata queries and pull requests.
-
-### 8. Get Flow
-
-#### 8.1 High-Level Behavior
-
-`get()` runs on the receiver side and performs four steps:
-
-1. resolve metadata
-2. allocate a destination buffer in the local pool
-3. request the sender to write into that destination buffer
-4. return either a `ManagedBuffer` or a deserialized object
-
-#### 8.2 Metadata Resolution Paths
-
-The `metadata` parameter in `get()` is optional. The connector supports two resolution modes depending on whether the caller supplies it.
-
-**With metadata**
-
-When the caller passes metadata, the connector uses it directly. The metadata carries:
-
-- `source_host` / `source_port` — sender ZMQ endpoint
-- `data_size` — payload byte count
-- `is_fast_path` — whether the receiver gets a `ManagedBuffer` or a deserialized object
-
-This mode is suitable when the control plane already forwards the sender's `put()` output to the receiver.
-
-**Without metadata**
-
-When `get(metadata=None)` is called, the connector queries the sender over ZMQ to discover the same fields (`data_size`, `is_fast_path`). The caller must first call:
-
-```python
-update_sender_info(sender_host, sender_zmq_port)
-```
-
-so that the connector knows where to send the query.
-
-This mode is suitable for polling-based flows (e.g. KV transfer, async chunk transfer) where the receiver does not have metadata from the control plane.
-
-#### 8.3 Destination Allocation
-
-Once metadata is resolved, the receiver:
-
-1. allocates a subrange from its own local pool
-2. wraps it in a `ManagedBuffer`
-3. builds a `MooncakeAgentMetadata` request containing:
- - receiver hostname
- - receiver RPC port
- - request ID
- - destination addresses
- - transfer lengths
-
-This tells the sender exactly where to write the incoming data.
-
-#### 8.4 Transfer Completion
-
-The receiver then sends the pull request over ZMQ and waits for:
-
-- `TRANS_DONE`
-- or `TRANS_ERROR`
-
-If the transfer succeeds:
-
-- for `is_fast_path=True`, the receiver returns `(ManagedBuffer, size)`
-- for `is_fast_path=False`, the receiver copies to bytes, deserializes, releases the buffer, and returns `(object, size)`
-
-### 9. Sender-Side Listener Design
-
-#### 9.1 Listener Thread
-
-In sender mode, the connector starts `_zmq_listener_loop()` after initialization. The listener:
-
-- binds `tcp://{host}:{zmq_port}`
-- receives incoming requests
-- uses a poller for socket events and internal notifications
-- periodically reclaims stale buffers
-
-If the bind fails, initialization fails immediately. The code does not silently downgrade the connector role.
-
-#### 9.2 Worker Thread Pool
-
-The listener hands work to `_sender_executor` so that the listener thread does not block on transfer work.
-
-There are two request types:
-
-- metadata query -> `_handle_query_request(...)`
-- transfer request -> `_handle_pull_request(...)`
-
-#### 9.3 Query Handling
-
-For metadata queries, the sender looks up the request ID in `_local_buffers` and returns:
-
-- data size
-- fast-path flag
-
-This supports consumers that only know the sender endpoint but not the original sender metadata.
-
-#### 9.4 Pull Handling
-
-For a transfer request, the sender:
-
-1. locates the source addresses in `_local_buffers`
-2. constructs the remote session identifier
-3. calls `batch_transfer_sync_write(...)`
-4. replies `TRANS_DONE` or `TRANS_ERROR`
-
-On success, the sender immediately calls `cleanup(meta.request_id)` and frees the producer-side buffer if it owns it.
-
-This choice is important: it makes the connector effectively a **single-consumer transfer model** for each successful put/get pair.
-
-### 10. Fast Path Semantics
-
-This connector explicitly advertises:
-
-```python
-supports_raw_data = True
-```
-
-That means it can move raw payloads without forcing everything through the Omni object serializer.
-
-#### Fast Path
-
-For `torch.Tensor`, `bytes`, or pool-local `ManagedBuffer`:
-
-- sender returns `is_fast_path=True`
-- receiver returns a `ManagedBuffer`
-- caller is responsible for calling `release()`
-
-This avoids an unnecessary copy on the receiver side.
-
-#### Serialized Object Path
-
-For arbitrary Python objects:
-
-- sender serializes the payload
-- receiver converts the receive buffer to bytes
-- receiver deserializes the object
-- receive buffer is released internally
-
-This preserves a uniform object-oriented API while still allowing optimized raw-data transport when possible.
-
-### 11. Failure Handling and Cleanup
-
-#### 11.1 Timeouts and Socket Recovery
-
-The receiver caches ZMQ REQ sockets per thread, but invalidates them after failures. This avoids reusing sockets that may be stuck in a bad state after timeout or receive errors.
-
-Timeout is scaled based on payload size:
-
-- a base timeout
-- plus additional time for large payloads
-
-This is intended to reduce false timeouts for large remote writes.
-
-#### 11.2 Stale Buffer Reclamation
-
-The sender periodically reclaims old entries from `_local_buffers` using a TTL policy. This protects the memory pool from permanent leaks if a receiver crashes or never consumes a prepared payload.
-
-This is a practical recovery mechanism, although the code notes that TTL cleanup can still race with very long-running in-flight transfers.
-
-#### 11.3 Connector Shutdown
-
-`close()` is a full resource teardown routine. It:
-
-- stops the listener thread
-- shuts down the worker executor
-- releases all pending buffers
-- closes cached sockets
-- unregisters memory from the engine when supported
-- terminates the ZMQ context
-- drops the pool reference
-
-This makes `MooncakeTransferEngineConnector` the most lifecycle-aware connector in the current connector family.
-
-### 12. Current Implementation Constraints
-
-The current code documents several important topology constraints.
-
-#### 12.1 One Sender to One Receiver per Successful Transfer
-
-After a successful transfer, the sender-side buffer is cleaned up immediately. This means the same prepared payload is not retained for multiple independent receivers.
-
-#### 12.2 One Receiver to One Active Sender Endpoint
-
-The receiver only stores one `(sender_host, sender_zmq_port)` pair through `update_sender_info(...)`. So the metadata-query mode is currently single-sender at a time.
-
-#### 12.3 Explicit Buffer Ownership Matters
-
-When the connector allocates a pool slice internally, it is responsible for releasing it. When a caller passes an externally owned `ManagedBuffer`, the connector keeps it alive for transfer but does not assume ownership of its eventual release.
-
-These constraints are consistent with the current implementation and should be treated as design assumptions rather than incidental behavior.
-
-### 13. Data Flow in the Pipeline
-
-The end-to-end sender/receiver interaction is:
-
-```mermaid
-sequenceDiagram
- participant SenderStage
- participant SenderConnector
- participant ReceiverConnector
- participant ReceiverStage
-
- SenderStage->>SenderConnector: put(from_stage, to_stage, put_key, data)
- SenderConnector->>SenderConnector: place payload in local memory pool
- SenderConnector-->>SenderStage: metadata(source_host, source_port, data_size, is_fast_path)
-
- ReceiverStage->>ReceiverConnector: get(..., metadata)
- ReceiverConnector->>ReceiverConnector: allocate destination buffer
- ReceiverConnector->>SenderConnector: ZMQ pull request with dst addr
- SenderConnector->>ReceiverConnector: TransferEngine remote write
- SenderConnector-->>ReceiverConnector: TRANS_DONE
- ReceiverConnector-->>ReceiverStage: ManagedBuffer or deserialized object
-```
-
-For metadata-less polling, the flow simply adds a metadata query step before the pull request.
-
-### 14. Strengths and Trade-offs
-
-#### Strengths
-
-- Best remote-transfer design in the current connector stack for large payloads.
-- Supports raw-data fast path.
-- Keeps stage communication under the same connector abstraction.
-- Includes real lifecycle and memory-pool management.
-- Works for both stage payload transfer and KV transfer scenarios.
-
-#### Trade-offs
-
-- More complex than the store-based connector.
-- Correctness depends on role injection and endpoint coordination.
-- Caller must release fast-path receive buffers.
-- Current implementation is optimized for single-consumer transfer semantics.
-
-### 15. Summary
-
-`MooncakeTransferEngineConnector` is the high-performance peer-to-peer transport in the OmniConnector system. Its design combines:
-
-- a registered memory pool
-- a safe subrange allocator
-- a ZMQ control plane
-- a Mooncake transfer-engine data plane
-
-This allows the connector to support both:
-
-1. a **fast path** for raw tensors and bytes
-2. a **generic object path** for arbitrary Python payloads
-
-Within vLLM-Omni, it is the connector that most directly targets performance-sensitive remote transfer, especially for large payloads and KV cache movement. Its additional complexity is deliberate: it is the connector that turns the generic OmniConnector abstraction into a transport capable of efficient remote memory movement rather than simple object storage.
diff --git a/docs/design/feature/omni_connectors/shared_memory_connector.md b/docs/design/feature/omni_connectors/shared_memory_connector.md
deleted file mode 100644
index 5b35014f233..00000000000
--- a/docs/design/feature/omni_connectors/shared_memory_connector.md
+++ /dev/null
@@ -1,259 +0,0 @@
-# SharedMemoryConnector
-
-## When to Use
-
-Best for single-node deployments where stages run on the same host. It is
-auto-configured when no explicit connector is specified for an edge.
-
-## How It Works
-
-All payloads are serialized and stored in shared memory (`/dev/shm`); the SHM
-segment name is returned in metadata. The configuration exposes a
-`shm_threshold_bytes` field for a future inline-vs-SHM split, but the current
-implementation always uses shared memory regardless of payload size.
-
-## Configuration
-
-```yaml
-runtime:
- connectors:
- connector_of_shared_memory:
- name: SharedMemoryConnector
- extra:
- shm_threshold_bytes: 65536
-```
-
-## Notes
-
-- Auto-mode uses SharedMemoryConnector if no connector is declared for an edge.
-
----
-
-## Design
-
-### 1. Overview
-
-`SharedMemoryConnector` is the default same-node connector in `vllm_omni/distributed/omni_connectors`. It is designed for stage-to-stage transfer when producer and consumer processes run on the same host and can share `/dev/shm`.
-
-The connector provides a unified `put()` / `get()` API for arbitrary Python objects while keeping the control plane lightweight:
-
-- The payload is serialized by the connector.
-- The serialized bytes are placed in shared memory.
-- The queue/control plane only carries a small metadata handle.
-
-This makes `SharedMemoryConnector` the simplest connector in the OmniConnector family and the default fallback when an edge does not explicitly configure another backend.
-
-### 2. Relationship with the OmniConnector System
-
-`SharedMemoryConnector` implements `OmniConnectorBase`, so it follows the same lifecycle and API contract as the other connectors:
-
-- `put(from_stage, to_stage, put_key, data)`
-- `get(from_stage, to_stage, get_key, metadata=None)`
-- `cleanup(request_id)`
-- `health()`
-- `close()`
-
-Within the larger system:
-
-- `load_omni_transfer_config()` automatically fills missing edges with `SharedMemoryConnector`.
-- Callers interact with the connector exclusively through the `put()` / `get()` / `cleanup()` contract — the connector does not require caller-specific logic.
-
-Compared with the remote Mooncake-based connectors, `SharedMemoryConnector` is intentionally minimal and local-only.
-
-### 3. Design Goals
-
-The connector is built around the following goals:
-
-- **Low-friction local transfer** for single-node multi-process pipelines.
-- **Unified object semantics** for arbitrary Python payloads.
-- **Small control-plane overhead** by passing only metadata through queues.
-- **Zero external dependencies** beyond Python shared memory and the existing stage utilities.
-
-It is not intended to provide cross-node transfer, RDMA, or raw tensor zero-copy semantics across processes.
-
-### 4. Core Design
-
-#### 4.1 Serialization Model
-
-`SharedMemoryConnector` always starts from a Python object and serializes it through the shared Omni serializer:
-
-```python
-payload = self.serialize_obj(data)
-```
-
-This keeps the connector behavior consistent with the rest of the connector stack:
-
-- producer code does not need connector-specific serialization logic
-- consumer code always receives the original object after deserialization
-- the connector can reuse the same serializer used by other backends
-
-#### 4.2 Shared Memory as the Data Plane
-
-The actual data plane is a shared-memory segment created by:
-
-- `shm_write_bytes(...)`
-- `shm_read_bytes(...)`
-
-The connector stores a small metadata object such as:
-
-```python
-{
- "shm": {"name": ..., "size": ...},
- "size": ...
-}
-```
-
-This metadata is passed over the control plane and allows the downstream stage to locate the shared-memory segment.
-
-#### 4.3 Locking Model
-
-To avoid races between the producer and consumer, the connector uses a lock file per request:
-
-```text
-/dev/shm/shm_{put_key}_lockfile.lock
-```
-
-Locking is done with `fcntl.flock`:
-
-- producer uses `LOCK_EX`
-- consumer uses `LOCK_EX`
-
-Both sides acquire an exclusive lock. This ensures that the shared-memory segment is not read while it is still being written and makes the handoff safer in a multi-process environment.
-
-### 5. Put / Get Flow
-
-#### 5.1 Producer Flow: `put()`
-
-The producer-side flow is:
-
-1. Serialize the input object to bytes.
-2. Compute the payload size.
-3. Acquire the per-request lock file.
-4. Write the bytes into shared memory.
-5. Return lightweight metadata to the caller.
-
-The returned tuple is:
-
-```python
-(success, serialized_size, metadata)
-```
-
-where `metadata` contains the shared-memory handle needed by the consumer.
-
-#### 5.2 Consumer Flow: `get(metadata=...)`
-
-The primary consumer path is metadata-driven:
-
-1. Extract the shared-memory handle from `metadata`.
-2. Acquire the exclusive lock.
-3. Read the raw bytes from shared memory.
-4. Deserialize the bytes back into the original Python object.
-5. Remove the lock file if it still exists.
-
-This is the path used by the current stage-to-stage connector flow.
-
-#### 5.3 Compatibility Flow: `get(metadata=None)`
-
-The connector also keeps a compatibility path for callers that only know the key:
-
-1. Attempt to open the shared-memory segment by name via `SharedMemory(name=get_key)`.
-2. If the segment exists and has non-zero size, acquire the exclusive lock and read the bytes.
-3. Deserialize the bytes and return the object.
-
-If the segment does not exist or any exception occurs, the call returns `None` immediately. There is no retry loop in this path -- it is a single-attempt open.
-
-This path is mainly for older code paths and is not the preferred mode for the current connector pipeline.
-
-### 6. Key Implementation Characteristics
-
-#### 6.1 Threshold Exists, but the Current Code Always Uses SHM
-
-The class keeps a `shm_threshold_bytes` field and still exposes metrics for inline writes. However, the current implementation uses:
-
-```python
-if True:
- ...
-```
-
-inside `put()`, which means the current code path always writes to shared memory.
-
-So the design still suggests a future split between:
-
-- small payloads inline
-- large payloads in shared memory
-
-but the current behavior is effectively:
-
-- all payloads go through shared memory
-
-This should be documented because it affects real runtime behavior.
-
-#### 6.2 Cleanup Is Currently Passive
-
-`cleanup()` is currently a no-op. The intended assumption is:
-
-- the consumer reads the segment
-- the underlying shared-memory helpers unlink it
-
-If the consumer never executes `get()`, the shared-memory segment may remain allocated. This means the connector relies on the normal success path for resource reclamation.
-
-#### 6.3 Close Is Currently Minimal
-
-`close()` is also a no-op. There is no connector-owned background thread, socket, or memory pool to tear down, so the lifecycle is simple. The trade-off is that `close()` does not scan or recover leaked shared-memory resources.
-
-### 7. Data Flow in the Pipeline
-
-The typical flow with `SharedMemoryConnector` is:
-
-```mermaid
-sequenceDiagram
- participant SenderStage
- participant SharedMemoryConnector
- participant QueueOrControlPlane
- participant ReceiverStage
-
- SenderStage->>SharedMemoryConnector: put(from_stage, to_stage, put_key, data)
- SharedMemoryConnector->>SharedMemoryConnector: serialize object
- SharedMemoryConnector->>SharedMemoryConnector: write bytes to /dev/shm
- SharedMemoryConnector-->>SenderStage: metadata {shm, size}
- SenderStage->>QueueOrControlPlane: forward connector metadata
- QueueOrControlPlane->>ReceiverStage: task + connector metadata
- ReceiverStage->>SharedMemoryConnector: get(from_stage, to_stage, get_key, metadata)
- SharedMemoryConnector->>SharedMemoryConnector: read bytes from /dev/shm
- SharedMemoryConnector->>SharedMemoryConnector: deserialize object
- SharedMemoryConnector-->>ReceiverStage: (data, size)
-```
-
-This is a classic split-control-plane / data-plane design, but constrained to a single host.
-
-### 8. Strengths and Trade-offs
-
-#### Strengths
-
-- Very simple deployment model.
-- No external service dependency.
-- Fits naturally into the existing queue-driven orchestration flow.
-- Good default for local multi-process pipelines.
-
-#### Trade-offs
-
-- Same-node only.
-- Full object serialization and deserialization are still required.
-- Resource cleanup depends on the normal consumer path.
-- Shared memory capacity is limited by host configuration.
-
-### 9. Summary
-
-`SharedMemoryConnector` is the baseline local transport for the OmniConnector system. Its design is intentionally straightforward:
-
-- serialize object
-- place bytes in shared memory
-- pass metadata through the control plane
-- deserialize on the receiving side
-
-It plays two important roles in vLLM-Omni:
-
-1. It is the simplest production-ready connector for same-node stage pipelines.
-2. It serves as the automatic fallback connector when no explicit edge transport is configured.
-
-Although the current implementation is deliberately minimal, it provides the foundation for reliable local connector semantics and keeps the stage communication model uniform across the system.
diff --git a/docs/design/feature/omni_connectors/yuanrong_connector.md b/docs/design/feature/omni_connectors/yuanrong_connector.md
deleted file mode 100644
index 12127ba3e64..00000000000
--- a/docs/design/feature/omni_connectors/yuanrong_connector.md
+++ /dev/null
@@ -1,358 +0,0 @@
-# YuanrongConnector
-
-## When to Use
-
-Best for multi-node distributed inference using Yuanrong Datasystem.
-
-## Mechanism
-
-Uses Yuanrong Datasystem's distributed KV store (`datasystem.kv_client`).
-
-- Data Plane: TCP or RDMA for high-bandwidth transfer.
-- Control Plane: Yuanrong Datasystem workers and etcd.
-- Keying: deterministic keys based on `put_key` (often composed as `request_id:fromStage_toStage`).
-
-## Installation
-
-```bash
-pip install openyuanrong-datasystem
-```
-
-## Start etcd
-
-```bash
-# Download and install etcd (v3.5.12 or higher)
-ETCD_VERSION="v3.5.12"
-ETCD_ARCH="linux-arm64"
-wget https://github.com/etcd-io/etcd/releases/download/${ETCD_VERSION}/etcd-${ETCD_VERSION}-${ETCD_ARCH}.tar.gz
-tar -xvf etcd-${ETCD_VERSION}-${ETCD_ARCH}.tar.gz
-cd etcd-${ETCD_VERSION}-${ETCD_ARCH}
-sudo cp etcd etcdctl /usr/local/bin/
-
-# Start etcd
-etcd \
- --name etcd-single \
- --data-dir /tmp/etcd-data \
- --listen-client-urls http://0.0.0.0:2379 \
- --advertise-client-urls http://0.0.0.0:2379 \
- --listen-peer-urls http://0.0.0.0:2380 \
- --initial-advertise-peer-urls http://0.0.0.0:2380 \
- --initial-cluster etcd-single=http://0.0.0.0:2380 &
-
-# Verify etcd is running
-etcdctl --endpoints "127.0.0.1:2379" put key "value"
-etcdctl --endpoints "127.0.0.1:2379" get key
-```
-
-For production environments, refer to the
-[official etcd clustering documentation](https://etcd.io/docs/current/op-guide/clustering/).
-
-## Start Datasystem Worker
-
-```bash
-# Replace ${ETCD_IP} with etcd node IP, ${WORKER_IP} with local node IP
-dscli start -w \
- --worker_address "${WORKER_IP}:31501" \
- --etcd_address "${ETCD_IP}:2379" \
- --shared_memory_size_mb 20480
-```
-
-To stop the worker:
-
-```bash
-dscli stop --worker_address "${WORKER_IP}:31501"
-```
-
-## Configuration
-
-Define the connector in runtime:
-
-```yaml
-runtime:
- connectors:
- connector_of_yuanrong:
- name: YuanrongConnector
- extra:
- host: "127.0.0.1"
- port: 31501
- get_sub_timeout_ms: 1000
-```
-
-Wire stages to the connector:
-
-```yaml
-stage_args:
- - stage_id: 0
- output_connectors:
- to_stage_1: connector_of_yuanrong
-
- - stage_id: 1
- input_connectors:
- from_stage_0: connector_of_yuanrong
-```
-
-Parameters:
-
-- host: datasystem worker host.
-- port: datasystem worker port (default: `35001` if omitted; the example above uses `31501` to match the worker startup command).
-- get_sub_timeout_ms: get timeout in milliseconds (0 for no timeout).
-
-For more details, refer to the
-[Yuanrong Datasystem repository](https://atomgit.com/openeuler/yuanrong-datasystem).
-
----
-
-## Design
-
-### 1. Overview
-
-`YuanrongConnector` is the Datasystem-based remote connector in `vllm_omni/distributed/omni_connectors`. It uses Yuanrong Datasystem's distributed key-value client as the transport backend and exposes the same `put()` / `get()` interface as the other OmniConnectors.
-
-Like `MooncakeStoreConnector`, it is a store-oriented remote connector rather than a direct peer-to-peer transport. Its role is to let stage payloads move across nodes through a deterministic key-based storage abstraction while keeping the rest of the pipeline on the common connector API.
-
-It is intended for deployments that already use Yuanrong Datasystem and want a remote connector that integrates with the existing OmniConnector configuration and orchestration model.
-
-### 2. Relationship with the OmniConnector System
-
-`YuanrongConnector` implements `OmniConnectorBase`, so it participates in the same connector lifecycle as the other backends:
-
-- `OmniConnectorFactory` constructs it from a `ConnectorSpec`
-- stage edge configuration is resolved by `load_omni_transfer_config()`
-- All callers (batch forwarding, chunk transfer, KV transfer, etc.) interact with it through the same `put()` / `get()` contract
-
-This means the connector is not exposed directly to stage logic. Stages only interact with the generic connector contract, and the backend choice remains a configuration concern.
-
-### 3. Design Goals
-
-The connector is built around the following goals:
-
-1. **Cross-node payload transfer through Datasystem**
- Reuse Yuanrong Datasystem as the remote exchange medium for stage data.
-
-2. **Uniform object transfer semantics**
- Allow arbitrary Python objects to be transmitted through the shared Omni serializer.
-
-3. **Minimal connector-specific control plane**
- Use deterministic keys so that consumers can retrieve data without an extra transport metadata handoff.
-
-4. **Operational reuse of existing infrastructure**
- Fit into environments that already deploy Yuanrong Datasystem workers and etcd.
-
-The connector is not designed for direct remote-memory writes or tensor-specific fast-path transfer.
-
-### 4. Core Design
-
-#### 4.1 Store-Oriented Transfer Model
-
-`YuanrongConnector` treats the transport backend as a distributed object store:
-
-1. serialize the Python payload
-2. build a deterministic connector key
-3. write the serialized bytes into Datasystem
-4. read the bytes back on the receiver side
-5. deserialize them into the original object
-
-This is the same broad architectural class as `MooncakeStoreConnector`, but implemented on top of Yuanrong Datasystem APIs instead of Mooncake store APIs.
-
-#### 4.2 Deterministic Keying
-
-Unlike the default `_make_key()` in `OmniConnectorBase`, `YuanrongConnector` defines its own key format:
-
-```text
-{request_id}:{from_stage}_{to_stage}
-```
-
-This has two design implications:
-
-- the request identifier remains the primary lookup handle
-- stage routing information is embedded in the key so that the same logical request ID can safely appear on different edges
-
-The explicit override also makes the key format easier to align with Datasystem-side debugging and operational inspection.
-
-#### 4.3 No Extra Metadata Hand-off
-
-`put()` returns:
-
-```python
-(success, serialized_size, None)
-```
-
-and does not generate connector-specific metadata.
-
-This design works because the receiver can reconstruct the exact same key from:
-
-- `get_key`
-- `from_stage`
-- `to_stage`
-
-As a result, the connector does not require a separate side-channel metadata handoff.
-
-### 5. Initialization
-
-#### 5.1 Datasystem Client Dependency
-
-The connector requires the Datasystem Python bindings to expose:
-
-- `KVClient`
-- `SetParam`
-- `WriteMode`
-
-If any of these symbols are unavailable, connector construction fails immediately with `ImportError`. This keeps configuration errors explicit and avoids a partially initialized runtime.
-
-#### 5.2 Client Setup
-
-During `_init_client()`, the connector:
-
-1. reads `host` and `port`
-2. creates `KVClient(host, port)`
-3. calls `client.init()`
-
-At construction time it also creates a `SetParam` and fixes:
-
-```python
-self.set_param.write_mode = WriteMode.NONE_L2_CACHE_EVICT
-```
-
-This means the connector has a stable write policy for all writes and does not currently expose write-mode selection as a higher-level connector option.
-
-### 6. Put / Get Flow
-
-#### 6.1 Producer Flow: `put()`
-
-The producer-side flow is:
-
-1. verify that the Datasystem client has been initialized
-2. serialize the input object with the shared Omni serializer
-3. build the Datasystem key using the connector-specific `_make_key()`
-4. call `client.set(key, serialized_data, self.set_param.write_mode)`
-5. update metrics and return success
-
-The returned metadata is always `None`, because the Datasystem key itself is the lookup contract between producer and consumer.
-
-#### 6.2 Consumer Flow: `get()`
-
-The consumer-side flow is:
-
-1. verify that the Datasystem client has been initialized
-2. rebuild the same key with `from_stage`, `to_stage`, and `get_key`
-3. call:
-
-```python
-client.get([key], False, self.get_sub_timeout_ms)
-```
-
-4. take the first returned element if present
-5. deserialize it and return `(data, payload_size)`
-
-If the returned list is empty or contains no data for the key, `get()` returns `None`.
-
-### 7. Timeout and Retrieval Semantics
-
-The connector uses `get_sub_timeout_ms` as its read timeout. Unlike `MooncakeStoreConnector`, which performs an explicit retry loop in Python, `YuanrongConnector` delegates waiting behavior more directly to the Datasystem client call.
-
-This leads to a slightly different retrieval model:
-
-- `MooncakeStoreConnector`: retry-oriented polling in connector code
-- `YuanrongConnector`: single client call with backend-managed timeout behavior
-
-From the connector API perspective the result is the same, but operationally the waiting behavior is more dependent on Datasystem client semantics.
-
-### 8. Integration with Stage Communication
-
-All callers use the connector through the same `put()` / `get()` contract:
-
-- the sender calls `put()` to serialize and store the payload
-- the receiver calls `get()` to retrieve and deserialize it
-- no connector-specific metadata is required, since the Datasystem key is the rendezvous point
-
-Because `put()` returns `metadata=None`, the connector is naturally compatible with callers that do not forward metadata (e.g. polling-based flows). The trade-off is that all payloads incur full serialization and deserialization costs, and there is no raw tensor fast path, which makes the connector functional but not optimized for the largest payloads.
-
-### 9. Data Flow in the Pipeline
-
-The end-to-end transfer model is:
-
-```mermaid
-sequenceDiagram
- participant SenderStage
- participant YuanrongConnector
- participant Datasystem
- participant ReceiverStage
-
- SenderStage->>YuanrongConnector: put(from_stage, to_stage, put_key, data)
- YuanrongConnector->>YuanrongConnector: serialize object
- YuanrongConnector->>Datasystem: set(key, bytes)
- YuanrongConnector-->>SenderStage: (success, size, None)
-
- ReceiverStage->>YuanrongConnector: get(from_stage, to_stage, get_key)
- YuanrongConnector->>Datasystem: get([key], timeout)
- YuanrongConnector->>YuanrongConnector: deserialize bytes
- YuanrongConnector-->>ReceiverStage: (data, size)
-```
-
-This is a store-mediated remote connector design with deterministic key lookup and no explicit side-channel metadata exchange.
-
-### 10. Strengths and Trade-offs
-
-#### Strengths
-
-- Reuses existing Yuanrong Datasystem infrastructure.
-- Keeps the connector contract simple and uniform.
-- Requires no connector-specific metadata handoff.
-- Suitable for remote stage transfer in Datasystem-based deployments.
-
-#### Trade-offs
-
-- Always pays full serialization and deserialization cost.
-- Does not support raw bytes / tensor fast-path semantics.
-- Depends on external Datasystem worker availability.
-- Retrieval and timeout behavior are partly delegated to the backend client.
-
-### 11. Important Implementation Characteristics
-
-#### 11.1 Cleanup Is a No-op
-
-`cleanup()` only logs a debug message and does not explicitly remove data from Datasystem. The current design assumes backend-side lifecycle or garbage collection rather than request-scoped delete semantics inside the connector.
-
-This mirrors the same design trade-off seen in other store-based connectors: simplicity over explicit per-request data reclamation.
-
-#### 11.2 Close Only Releases the Local Client Handle
-
-`close()` does not perform a remote shutdown. It simply clears the local `client` reference and marks the connector as closed from the process perspective:
-
-```python
-self.client = None
-```
-
-This is appropriate for a client-based store connector, but it also means that backend resource lifecycle remains outside the connector's control.
-
-#### 11.3 Error and Timeout Metrics Are Coarse-Grained
-
-The connector tracks:
-
-- `puts`
-- `gets`
-- `bytes_transferred`
-- `errors`
-- `timeouts`
-
-In the current code, failed `put()` increments `errors`, while `get()` exceptions increment `timeouts`. This is operationally useful, but it does not distinguish between:
-
-- backend timeout
-- not-found result
-- transport failure
-- deserialization failure
-
-So the metrics should be read as high-level health indicators, not detailed root-cause diagnostics.
-
-### 12. Summary
-
-`YuanrongConnector` is the Datasystem-backed remote connector in the OmniConnector family. Its design is straightforward:
-
-- serialize payloads
-- store them under a deterministic stage-qualified key
-- retrieve them by the same key
-- deserialize them on the receiving side
-
-Within vLLM-Omni, it provides a clean integration point for Yuanrong Datasystem-based deployments while preserving the same connector abstraction used by the rest of the pipeline.
-
-Its design priorities are simplicity, infrastructure reuse, and API consistency rather than direct-memory transport optimization.
diff --git a/docs/design/feature/prefix_caching.md b/docs/design/feature/prefix_caching.md
deleted file mode 100644
index ebad8b69106..00000000000
--- a/docs/design/feature/prefix_caching.md
+++ /dev/null
@@ -1,164 +0,0 @@
-# Automatic Prefix Caching in Omni Models
-
-
----
-
-## Table of Contents
-
-- [Overview](#overview)
-- [High-Level Approach](#high-level-approach)
-- [Example](#example)
-- [What About Multimodal Inputs?](#what-about-multimodal-inputs)
-
----
-
-### Overview
-
-Prefix caching in the context of kv-cache management is a useful optimization for avoiding redundant computations. The main idea is that we store portions of the kv-cache from processed requests, so that we can reuse them if incoming requests have the same prefix as previous requests.
-
-vLLM manages the kv-cache as blocks, which represent a span of tokens of a fixed length. Blocks are hashable by the content that they contain, which typically means the tokens within the span, but also could be influenced by other factors, e.g., LoRA and multimodal data.
-
-vLLM implements automatic prefix caching for managing its kv-cache, which is best understood by reading the design document [here](https://docs.vllm.ai/en/latest/design/prefix_caching/). vLLM-Omni builds on top of the prefix caching mechanism in a noninvasive way to allow caching between stages in Omni pipelines. This typically means for a given stage we aim to support caching for the following:
-
-- The last hidden states produced by the stage
-- Model / stage specific multimodal data
-
-!!! note "Note 1"
- This document describes vLLM-Omni's mechanism for caching tensor outputs that are meant to be passed between stages, when requests have common prefixes, similar to the way in which vLLM has prefix caching for the kv-cache. This works in conjunction with vLLM's multimodal encoder caching, but is distinct. See the final section for a concrete example for how they tie together in practice.
-
-### High-Level Approach
-!!! note "Note 2"
- Prior to reading this section, it's recommended to take a look at the design documents in vLLM for [Automatic Prefix Caching](https://docs.vllm.ai/en/latest/features/automatic_prefix_caching/), which will make some of the concepts more clear.
-
-The main focus of vLLM-Omni's approach to prefix caching stage outputs is to build on vLLM's prefix caching in the least invasive way possible while minimizing impact for cache misses, and consuming a minimal amount of GPU memory. To understand the implementation, there are a few important things to note:
-
-- Between stages, device tensors are generally moved to CPU; this is important since we're just caching the outputs of stages, so it is okay to keep the entire cache on the CPU.
-
-- For a tensor to be considered cacheable, the first dimension (currently) needs to be the same as the token count, as it allows us to reuse block/slot mappings for our externally maintained tensor caches. This allows us to dynamically discover the tensors to be marked as cacheable outputs in each Omni model without having to explicitly specify cacheable output field names in every model.
-
-With this in mind, consider the set of blocks in a 2D layout, where the row represents the index of blocks being considered, and the columns represent the slots corresponding to tokens within each block. Since we know the `num_blocks` and `block_size` from our kv cache config, if we want to cache a tensor with feature size `D`, we can preallocate a CPU tensor of size `(num_blocks, block_size, D)`, and use the same block index and slot mapping to retrieve the corresponding feature vector.
-
-
-### Example
-!!! note "Note 3"
- Prefix caching in vLLM-Omni currently is only supported on AutoRegressive stages with one kv-cache group. It can be enabled/disabled per-stage via the `enable_prefix_caching` parameter in the model's stage config.
-
-The way in which vLLM-Omni ties into vLLM's prefix caching is best understood by example. Say that we have the following:
-
-- `num_blocks=8`
-- `block_size=4`
-- `hidden_size=2`
-- A stage specific multimodal output tensor named `mm_feature` with feature dimension `16`
-
-The prefix cache flow is then outlined below.
-
-1. When the model is initialized, we can determine the `hidden_size` from the `ModelConfig`, and allocate a cache of size `(num_blocks, block_size, hidden_size)`.
-
-2. Say we process the request `The quick brown fox was tired and slept beneath the shady tree`, which is 12 tokens and evenly divides into 3 blocks as shown below.
-
-```
- [ The quick brown fox ] [ was tired and slept ] [beneath the shady tree ]
-Block 1: |<--- block tokens ---->|
-Block 2: |<------- prefix ------>| |<--- block tokens --->|
-Block 3: |<------------------ prefix -------------------->| |<--- block tokens ---->|
-```
-
-When the request processes, we inspect the multimodal outputs and identify the `mm_feature` tensor, which will be of shape `(seq_len, feature_dim)`, i.e., `(12, 16)` in this example. We note that the first axis is dependent on the `seq_len` and add a new cache_tensor of shape `(num_blocks, block_size, feature_dim)` to our multimodal cache for tensors.
-
-
-3. If we lay out the cache as a 2D tensor of shape (`num_blocks`, `block_size`), we'll have something like the following:
-
-```
-0: [ The quick brown fox ]
-1: [ was tired and slept ]
-2: [beneath the shady tree ]
-3: [EMPTY]
-...
-7: [EMPTY]
-```
-
-Or, if we flatten it down to 1D,
-```
-0: The
-1: quick
-2: brown
-3: fox
-...
-11: tree
-12: [EMPTY]
-...
-```
-
-which we can think of as row indices into the hidden states tensor if we view it as the 2D shape `(num_blocks x block_size, feature_dim)`. That is, the analogous flattened (from 3D -> 2D) mapping of the cache for hidden states becomes the following.
-```
-0:
-1:
-2:
-3:
-...
-11:
-12: [EMPTY]
-...
-```
-
-Similarly, for the multimodal outputs cache, the flattened coordinates are the same, but the `mm_feature` maps to vectors of length `16` instead of the hidden size of `2`. Note that in practice, we may have multiple multimodal output tensors per forward pass, which may have different names and different feature dimensions.
-
-
-4. Now, say that we receive a new request `The quick brown fox jumped over the dog`.
-
-```
- [ The quick brown fox ] [ jumped over the dog ]
-Block 1: |<--- block tokens ---->|
-Block 2: |<------- prefix ------>| |<--- block tokens --->|
-```
-
-Here, we will have a cache hit for `Block 1` which will be detected by vLLM based on the hash of the first block when it's handling the prefix caching on the kv-cache. As a result, when we get the output from the scheduler, we will see that `num_computed_tokens=4` (corresponding to the cached first block), and we only need to process the remaining 4 new tokens in the new prefill.
-
-Since we have the block indices / slot mappings from the kv cache manager, we can simply mirror the mappings and leverage the same indices for the cached hidden states and multimodal outputs. This allows us to look up the correct tensors from our externally maintained 3D caches.
-
-```
-0: [ The quick brown fox ] < already in the cache
-1: [ was tired and slept ]
-2: [beneath the shady tree ]
-3: [ jumped over the dog ] < added on the second request
-4: [EMPTY]
-...
-7: [EMPTY]
-...
-```
-
-Finally, to pass the full hidden states and multimodal outputs to the next stage, we simply concatenate the cached contents with the corresponding new tensors computed from the current forward call.
-
-
-### What About Multimodal Inputs?
-It's also useful to consider the case about how Omni prefix caching is handled when we have multimodal inputs that don't cleanly end on block boundaries, as well as how this works with multimodal encoder caching in vLLM. For example:
-
-```
- [ Im0 Im1 Im2 Im3 ] [ Im4 Im5 foo ]
-Block 1: |<--- block tokens ---->|
-Block 2: |<------- prefix ------>| |<--- block tokens --->|
-```
-
-In this case, only `Block 1` will have outputs stored in the prefix tensor cache, because vLLM does not store partial blocks. This may appear to be a problem at first glance, because the multimodal input is fragmented across a new block that wasn't cached.
-
-In reality, this isn't a big problem for correctness, because vLLM also maintains an encoder cache for multimodal inputs. In other words, after the first pass, we'll have the following:
-
-- The Block 1 hash, which is used for prefix caching
-- The hash describing the image data starting at position 0 and with length 6
-- In vLLM's encoder cache, a mapping from the image hash above to the encoder output
-
-
-To understand what happens, say we get the following input as a second request:
-```
- [ Im0 Im1 Im2 Im3 ] [ Im4 Im5 bar baz ]
-Block 1: |<--- block tokens ---->|
-Block 2: |<------- prefix ------>| |<--- block tokens --->|
-```
-
-First, the scheduler will check for a prefix cache hit, which we will see on `Block 1`. As a result, we will have 4 tokens marked as precomputed, and only see the remaining 4 tokens in the following prefill.
-
-Because we have multimodal data in a scheduled span that isn't fully precomputed, we still need to call the visual encoder. However, since we have the image hash and encoder cache, we will retrieve the encoder outputs for `Im4` and `Im5` as we create the multimodal embeddings.
-
-When we pass our multimodal tensors to the language model component in the same stage, we'll then expect the same outputs, because the prefix caching behaviors in vLLM-Omni / vLLM match, so the LLM will use vLLM's KV cache manager's prefix caching to correctly handle the attention information for `Block 1` while calculating the outputs for `Block 2`, giving us the correct results for processing `Block 2` with the context of `Block 1`.
-
-Finally, we look up the output hidden states/multimodal tensors corresponding to the prefix cache hit `Block 1` and concatenate it with the forward pass result to get the final result, which is expected to be identical to the full hidden states when prefix caching is disabled.
diff --git a/docs/design/feature/ray_based_execution.md b/docs/design/feature/ray_based_execution.md
deleted file mode 100644
index ae10d661fd6..00000000000
--- a/docs/design/feature/ray_based_execution.md
+++ /dev/null
@@ -1,59 +0,0 @@
-# Distributed utils
-
-This directory (vllm_omni/distributed/ray_utils) contains utilities for distributed execution in vllm-omni, supporting both **Ray** and **Multiprocessing** backends.
-## 1. Installation
-```bash
-pip install "ray[default]"
-```
-## 2. Ray Utils
-
-The `ray_utils` module provides helper functions for managing Ray clusters and actors, which is essential for:
-* **Multi-node deployment**: Running pipeline stages across different physical machines.
-* **Resource management**: Efficient GPU/CPU allocation.
-
-### 2.1 Basic Usage
-
-To use the Ray backend, specify `worker_backend="ray"` when initializing the engine.
-
-**Command Line Example:**
-```bash
-vllm serve Qwen/Qwen2.5-Omni-7B \
- --omni \
- --port 8091 \
- --worker-backend ray \
- --ray-address auto
-```
-
-### 2.2 Cluster Setup
-
-**Step 1: Start Head Node**
-Run this on your primary machine:
-```bash
-ray start --head --port=6399
-```
-
-**Step 2: Connect Worker Nodes**
-Run this on each worker machine:
-```bash
-ray start --address=:6399
-```
-
-> **Tip**: For a complete cluster setup script, refer to the vLLM example:
-> [run_cluster.sh](https://github.com/vllm-project/vllm/blob/main/examples/online_serving/run_cluster.sh)
-
-### 2.3 Distributed Connector Support
-
-When running on Ray, the system automatically adapts its communication strategy:
-
-* **Cross-Node**: Recommended to use `MooncakeTransferEngineConnector` (RDMA, fastest) or `MooncakeStoreConnector` (TCP fallback).
-* **Same-Node**: Can still use `SharedMemoryConnector` for efficiency, or Ray's native object store (plasma).
-* **SHM threshold default differs**: when `worker_backend="ray"`, the SharedMemoryConnector default threshold is set to `sys.maxsize`, which forces payloads to go inline (no SHM). Override `shm_threshold_bytes` in the connector config if you want SHM for Ray runs.
-
-### 2.4 Internal Helpers
-
-* **`initialize_ray_cluster`**: Connects to an existing Ray cluster or starts a local one.
-
-## 3. Troubleshooting
-
-* **Connection Issues**: Ensure the Ray head node is accessible and ports (default 6399 in this example) are open.
-* **Version Mismatch**: Ensure all nodes run the same version of Ray and Python.
diff --git a/docs/design/feature/sequence_parallel.md b/docs/design/feature/sequence_parallel.md
deleted file mode 100644
index d0328bcf611..00000000000
--- a/docs/design/feature/sequence_parallel.md
+++ /dev/null
@@ -1,531 +0,0 @@
-# Sequence Parallel
-
-This section describes how to add Sequence Parallel (SP) to a diffusion transformer model. We use the Qwen-Image transformer and Wan2.2 transformer as reference implementations.
-
----
-
-## Table of Contents
-
-- [Overview](#overview)
-- [UAA Mode (Experimental)](#uaa-mode-experimental)
-- [Approach 1: Non-Intrusive `_sp_plan` (Recommended)](#approach-1-non-intrusive-_sp_plan-recommended)
-- [Approach 2: Intrusive Modification (For Complex Cases)](#approach-2-intrusive-modification-for-complex-cases)
-- [Testing](#testing)
-- [Troubleshooting](#troubleshooting)
-- [Reference Implementations](#reference-implementations)
-- [Summary](#summary)
-
----
-
-## Overview
-
-
-### What is Sequence Parallel?
-
-**Terminology Note:** Our "Sequence Parallelism" (SP) corresponds to "Context Parallelism" (CP) in the [diffusers library](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/_modeling_parallel.py). We use "Sequence Parallelism" to align with vLLM-Omni's terminology.
-
-Diffusion transformers process long sequences of image patches or video frames. For high-resolution generation, these sequences can become very large. Enabling SP allows each GPU to process only a portion of the sequence, with attention mechanisms (Ulysses/Ring) handling cross-GPU communication transparently.
-
-### Architecture
-
-The major APIs for Sequence Parallel:
-
-```python
-from vllm_omni.diffusion.distributed.sp_plan import (
- SequenceParallelInput, # For sharding (splitting) tensors
- SequenceParallelOutput, # For gathering tensors
-)
-from vllm_omni.diffusion.distributed.sp_sharding import sp_shard, sp_gather
-```
-
-| Method/Class | Purpose | Behavior |
-|--------------|---------|----------|
-| `SequenceParallelInput` | Declare input sharding in `_sp_plan` | Auto-shards tensors at module input |
-| `SequenceParallelOutput` | Declare output gathering in `_sp_plan` | Auto-gathers tensors at module output |
-| `sp_shard()` | Manual tensor sharding | Splits tensor across SP workers |
-| `sp_gather()` | Manual tensor gathering | Gathers sharded tensors from all workers |
-
----
-
-## UAA Mode (Experimental)
-
-`ulysses_mode="advanced_uaa"` enables the experimental UAA ("Ulysses Anything Attention") feature, which lets Ulysses attention handle arbitrary sequence lengths and arbitrary attention head counts. The same idea is also supported by [Cache-DiT](https://cache-dit.readthedocs.io/en/latest/user_guide/CONTEXT_PARALLEL/#uaa-ulysses-anything-attention).
-
-Use it when plain Ulysses-SP would otherwise fail because:
-
-- the local sequence shards are not evenly divisible after split hooks, or
-- the attention head count is not divisible by `ulysses_degree`.
-
-### Design Summary
-
-1. **Strict mode stays unchanged.**
- `ulysses_mode="strict"` keeps the original fast path and still requires divisible sequence/head shapes.
-
-2. **UAA uses variable all-to-all split sizes for sequence shards.**
- Before the Ulysses Q/K/V exchange, each rank all-gathers its local sequence length and uses those lengths as `all_to_all_single(..., output_split_sizes=seq_lens)`. This lets Ulysses gather the full sequence even when each rank started with a different local shard length.
-
-3. **UAA pads heads only inside the Ulysses exchange.**
- If `head_cnt % ulysses_degree != 0`, UAA pads the head dimension up to the next multiple of `ulysses_degree`, performs the forward/reverse all-to-all, then slices the temporary head padding away after the reverse exchange. The same rule is applied to joint attention tensors.
-
-4. **Hybrid Ulysses + Ring is still shape-constrained.**
- Ring attention expects every rank in a ring group to exchange exactly the same post-Ulysses sequence shape. UAA therefore validates those shapes before entering the ring path and raises a clear error if ring peers disagree on `S_global`.
-
-5. **Tiny scalar gathers stay out of TorchDynamo tracing.**
- `_all_gather_int()` is marked with `@torch.compiler.disable` so the scalar `item()` conversions used by UAA metadata collection do not get traced into `torch.compile`.
-
-### UAA vs `auto_pad`
-
-- `auto_pad=True` pads sequence tokens in `_sp_plan` and requires attention backends that support `attention_mask`.
-- `advanced_uaa` does not depend on mask-based token padding inside Ulysses attention. It is therefore a better fit for non-divisible head counts and uneven Ulysses shard sizes.
-- `auto_pad=True` remains incompatible with Ring attention because the ring backend does not consume `attention_mask`.
-- `advanced_uaa` is still experimental and hybrid mode remains limited by Ring's equal-shape requirement.
-
----
-
-## Approach 1: Non-Intrusive `_sp_plan` (Recommended)
-
-The `_sp_plan` mechanism allows SP **without modifying `forward()` logic**. The framework automatically registers hooks to shard inputs and gather outputs at module boundaries.
-
-**When to use:**
-- Standard transformer architectures
-- Tensor operations happen at `nn.Module` boundaries
-- Predictable sharding/gathering patterns
-
-This is the ideal approach for integrating sequence parallelism into new models, as it is easier to maintain and ensure compatibility with other types of acceleration.
-
-**How it works:**
-1. Declare `_sp_plan` dict in your transformer class
-2. Framework automatically applies hooks when `sequence_parallel_size > 1`
-3. Hooks shard/gather tensors at specified module boundaries
-4. Attention layers handle cross-GPU communication internally
-
-```python
-class StandardTransformer(nn.Module):
- _sp_plan = {
- # Shard hidden_states at first transformer block input
- "blocks.0": {
- "hidden_states": SequenceParallelInput(split_dim=1, expected_dims=3),
- },
- # Gather at final output projection
- "proj_out": SequenceParallelOutput(gather_dim=1, expected_dims=3),
- }
-```
-
-`StandardTransformer` has a transformer blocks list `self.blocks = nn.ModuleList([...])`, and a projection output layer `self.proj_out`. The `_sp_plan` above defines that when SP is enabled, sharding the input tensor to the first transformer block, and gathering the sharded tensor at the final output projection layer.
-
-**Requirements:**
-- Tensor operations that need sharding/gathering must happen at **`nn.Module` boundaries**
-- Inline Python operations (e.g., `torch.cat`, `pad_sequence`) **cannot be hooked**
-
-**Solution for inline operations:** Extract into a submodule (see Step 2 below).
-
-### Step 1: Understand Module Boundaries
-
-Identify where tensors need to be sharded or gathered in your model's forward pass:
-
-```python
-class MyTransformer(nn.Module):
- def __init__(self):
- self.patch_embed = PatchEmbed() # ← Boundary 1
- self.pos_embed = RoPE() # ← Boundary 2
- self.blocks = nn.ModuleList([...]) # ← Boundary 3
- self.norm_out = LayerNorm()
- self.proj_out = Linear() # ← Boundary 4
-
- def forward(self, x):
- x = self.patch_embed(x) # ← Shard before this?
- pos = self.pos_embed(x) # ← Shard RoPE outputs?
- for block in self.blocks:
- x = block(x, pos) # ← Blocks process sharded x
- x = self.norm_out(x)
- output = self.proj_out(x) # ← Gather after this?
- return output
-```
-
-### Step 2: Handle Inline Operations
-
-If your `forward()` contains inline tensor operations, **extract them into submodules**.
-
-**Example: Z-Image concatenates image + text features inline**
-
-```python
-# ❌ BAD: Inline operation - hooks cannot intercept
-class ZImageTransformer(nn.Module):
- def forward(self, x, cap_feats):
- # This concatenation happens inline - _sp_plan can't shard it!
- unified = torch.cat([x, cap_feats], dim=1)
-
- for layer in self.layers:
- unified = layer(unified)
-
- return unified
-
-# ✅ GOOD: Extract into submodule
-class UnifiedPrepare(nn.Module):
- """Submodule to concatenate image and text features."""
- def forward(self, x, cap_feats):
- return torch.cat([x, cap_feats], dim=1)
-
-class ZImageTransformer(nn.Module):
- def __init__(self):
- super().__init__()
- self.unified_prepare = UnifiedPrepare() # Now a module!
- self.layers = nn.ModuleList([...])
-
- def forward(self, x, cap_feats):
- # Now _sp_plan can shard the output of unified_prepare!
- unified = self.unified_prepare(x, cap_feats)
-
- for layer in self.layers:
- unified = layer(unified)
-
- return unified
-```
-
-**Other common cases:**
-- `pad_sequence()` → `PadSequenceModule`
-- `torch.cat()` → `ConcatModule`
-- `tensor.reshape()` → `ReshapeModule`
-- Complex preprocessing → `PreprocessModule`
-
-### Step 3: Write `_sp_plan` for Your Model
-
-Create a class-level `_sp_plan` dictionary specifying where to shard/gather tensors.
-
-Typically, there are two patterns for diffusion models:
-
-**Pattern 1: Shard at first block, gather at output projection**
-
-Most common pattern for standard transformers:
-
-```python
-from vllm_omni.diffusion.distributed.sp_plan import (
- SequenceParallelInput, # For sharding (splitting) tensors
- SequenceParallelOutput, # For gathering tensors
-)
-class StandardTransformer(nn.Module):
- _sp_plan = {
- # Shard hidden_states at first transformer block input
- "blocks.0": {
- "hidden_states": SequenceParallelInput(split_dim=1, expected_dims=3),
- },
- # Gather at final output projection
- "proj_out": SequenceParallelOutput(gather_dim=1, expected_dims=3),
- }
-```
-
-**Pattern 2: Shard RoPE embeddings separately**
-
-When RoPE is computed in a separate module:
-
-```python
-from vllm_omni.diffusion.distributed.sp_plan import (
- SequenceParallelInput, # For sharding (splitting) tensors
- SequenceParallelOutput, # For gathering tensors
-)
-class TransformerWithRoPE(nn.Module):
- _sp_plan = {
- # Shard RoPE module OUTPUTS (returns tuple of cos, sin)
- "rope": {
- 0: SequenceParallelInput(split_dim=1, expected_dims=4, split_output=True), # cos
- 1: SequenceParallelInput(split_dim=1, expected_dims=4, split_output=True), # sin
- },
- # Shard transformer block INPUT
- "blocks.0": {
- "hidden_states": SequenceParallelInput(split_dim=1, expected_dims=3),
- },
- # Gather at output
- "proj_out": SequenceParallelOutput(gather_dim=1, expected_dims=3),
- }
-```
-
-**Pattern 3: Shard RoPE for Dual Stream Attention**
-In some cases, different streams in attention may need to handle sequence parallelism differently. For example, we may want to shard the image embeddings, while replicating the text embeddings to correctly configure joint attention.
-
-```python
-class DualStreamTransformer(nn.Module):
- """
- Dual-stream model where we need to replicate the text components, but shard
- the image components to correctly handle sequence parallelism.
- """
- _sp_plan = {
- # In this case, the rope_preparer returns a tuple of len 4, where the
- # first 2 items correspond to the text, and the second 2 correspond to
- # visual inputs, so we only shard the second.
- "rope_preparer": {
- # Outputs 0, 1 (text) - NOT sharded (replicated)
- # Outputs 2, 3 (image) - sharded
- 2: SequenceParallelInput(split_dim=0, expected_dims=2, split_output=True), # img_cos
- 3: SequenceParallelInput(split_dim=0, expected_dims=2, split_output=True), # img_sin
- },
- # Shard transformer block INPUT
- "transformer_blocks.0": {
- "hidden_states": SequenceParallelInput(split_dim=1, expected_dims=3),
- },
- # Gather at output
- "proj_out": SequenceParallelOutput(gather_dim=1, expected_dims=3),
- }
-```
-
-NOTE: be careful to test adequately when refactoring classes that take this style of plan, as changing the order of the return values will break sequence parallelism.
-
-### API Reference
-
-**SequenceParallelInput Parameters:**
-
-| Parameter | Type | Description |
-|-----------|------|-------------|
-| `split_dim` | int | Dimension to split (usually `1` for sequence) |
-| `expected_dims` | int \| None | Expected tensor rank for validation (optional) |
-| `split_output` | bool | `False`: shard **input** params; `True`: shard **output** tensors |
-| `auto_pad` | bool | Auto-pad if sequence not divisible by world_size (default: `False`) |
-
-**SequenceParallelOutput Parameters:**
-
-| Parameter | Type | Description |
-|-----------|------|-------------|
-| `gather_dim` | int | Dimension to gather (usually `1` for sequence) |
-| `expected_dims` | int \| None | Expected tensor rank for validation (optional) |
-
-**Module Naming Conventions:**
-
-| Key | Meaning | Python equivalent |
-|-----|---------|-------------------|
-| `""` | Root model | `model` |
-| `"blocks.0"` | First element of ModuleList | `model.blocks[0]` |
-| `"blocks.*"` | All elements of ModuleList | `for b in model.blocks` |
-| `"rope"` | Named submodule | `model.rope` |
-| `"outputs.main"` | ModuleDict entry | `model.outputs["main"]` |
-
-**Dictionary Value Types:**
-
-| Key type | `split_output` | Description |
-|----------|----------------|-------------|
-| `"param_name"` (str) | `False` | Shard **input parameter** by name |
-| `0`, `1`, ... (int) | `True` | Shard **output tuple** by index |
-
----
-
-## Approach 2: Intrusive Modification (For Complex Cases)
-
-For models with dynamic sharding logic that cannot be expressed via `_sp_plan`, manually insert shard/gather calls.
-
-
-**When to use:**
-- Dynamic/conditional sharding logic
-- Complex tensor manipulations that can't be encapsulated
-- Temporary workaround during development
-
-```python
-from vllm_omni.diffusion.distributed.sp_sharding import sp_shard, sp_gather
-
-def forward(self, hidden_states, ...):
- if self.parallel_config.sequence_parallel_size > 1:
- hidden_states = sp_shard(hidden_states, dim=1)
-
- # ... computation ...
-
- if self.parallel_config.sequence_parallel_size > 1:
- output = sp_gather(output, dim=1)
-
- return output
-```
-
----
-
-## Testing
-
-After implementing Sequence Parallel support, thoroughly test your implementation to ensure correctness and performance across different configurations.
-
-**Test Different `sp_size`:**
-
-Test your model with various sequence parallel world sizes to verify correctness and identify optimal configurations:
-
-```bash
-cd examples/offline_inference/text_to_image
-python text_to_image.py \
- --model Your-org/your-model \
- --prompt "a cup of coffee on the table" \
- --num-inference-steps 50 \
- --ulysses-degree 2 \
- --ring-degree 2 \
- --output sp_test_image_ulysses=2_ring=2.png
-```
-
-**Verify:**
-
-1. **Correctness:** Output should be identical across all `sp_size` values
-2. **Speed:** Throughput should remain stable or improve (especially for large sequences)
-3. **Logs:** Check for any shape mismatch or communication errors
-
-**Test with Tensor Parallel:**
-
-Sequence Parallel can be combined with other parallelism strategies:
-
-```bash
-cd examples/offline_inference/text_to_image
-python text_to_image.py \
- --model Your-org/your-model \
- --prompt "a cup of coffee on the table" \
- --num-inference-steps 50 \
- --ulysses-degree 2 \
- --tensor-parallel-size 2 \
- --output sp_test_image_ulysses=2_tp=2.png
-```
-
----
-
-## Troubleshooting
-
-### Issue: Shape mismatch errors
-
-**Symptoms:** `RuntimeError: shape mismatch` during forward pass.
-
-**Causes & Solutions:**
-
-- **RoPE dimension mismatch:**
-
-**Problem:** RoPE embeddings not sharded, but hidden_states is sharded.
-
-**Solution:** Shard RoPE outputs in `_sp_plan`:
-```python
-_sp_plan = {
- "rope": {
- 0: SequenceParallelInput(split_dim=1, expected_dims=4, split_output=True),
- 1: SequenceParallelInput(split_dim=1, expected_dims=4, split_output=True),
- },
- ...
-}
-```
-
-- **Sequence Length not divisible by sp_size:**
-
-**Problem:** strict Ulysses sequence parallel requires divisible shapes. If the shard length is uneven, or if the model head count is not divisible by `ulysses_degree`, the strict path will raise an error.
-
-**Solutions:**
-
-1. Use `ulysses_mode="advanced_uaa"` for Ulysses-SP when you want the experimental uneven-shape path without relying on attention-mask padding.
-2. If the model already uses `_sp_plan` token padding and the attention backend supports `attention_mask`, set `auto_pad=True` and add attention-mask plumbing.
-
-> **Experimental Feature:** `ulysses_mode="advanced_uaa"` is experimental. It is intended to relax Ulysses divisibility constraints, but hybrid Ulysses + Ring still requires equal post-Ulysses sequence lengths inside each ring group.
-
-> **Experimental Feature:** `auto_pad=True` is an experimental feature and may be changed in the future. We plan to improve this solution to involve minimal changes to model files. More details are [here](https://github.com/vllm-project/vllm-omni/issues/1324).
-
-**Constraints of auto_pad:**
-
-| Constraint | Description |
-|------------|-------------|
-| **Attention Backend Compatibility** | The attention backends must support `attention_mask`. Currently only `TORCH_SDPA` and `FLASH_ATTN` (default for diffusion models) are supported. |
-| **Ring Attention Limitation** | Ring attention does not support `attention_mask`. Therefore, when using `auto_pad=True`, the combination of Ulysses + Ring attention is not feasible. |
-
-1. Enable `auto_pad=True` for all sequence-dimension inputs in `_sp_plan`:
-```python
-_sp_plan = {
- "rope": {
- 0: SequenceParallelInput(split_dim=1, expected_dims=4, split_output=True, auto_pad=True),
- 1: SequenceParallelInput(split_dim=1, expected_dims=4, split_output=True, auto_pad=True),
- },
- "blocks.0": {
- "hidden_states": SequenceParallelInput(split_dim=1, expected_dims=3, auto_pad=True)
- },
- ...
-}
-```
-
-2. Create attention mask dynamically when padding is applied:
-```python
-from vllm_omni.diffusion.forward_context import get_forward_context
-from vllm_omni.diffusion.attention.backends.abstract import AttentionMetadata
-
-# In model forward(), before transformer blocks:
-hidden_states_mask = None
-ctx = get_forward_context()
-if ctx.sp_original_seq_len is not None and ctx.sp_padding_size > 0:
- batch_size = hidden_states.shape[0]
- padded_seq_len = ctx.sp_original_seq_len + ctx.sp_padding_size
- hidden_states_mask = torch.ones(batch_size, padded_seq_len, dtype=torch.bool, device=hidden_states.device)
- hidden_states_mask[:, ctx.sp_original_seq_len:] = False
-
-# Pass mask to attention layers
-attn_metadata = AttentionMetadata(attn_mask=hidden_states_mask) if hidden_states_mask is not None else None
-output = self.attn(query, key, value, attn_metadata)
-```
-
-**Important Quality Considerations:**
-
-While `auto_pad` enables generation for irregular resolutions, be aware of potential quality impacts:
-
-| Aspect | Impact |
-|--------|--------|
-| **Training Distribution** | Models perform best on aspect ratios seen during training (e.g., 1:1, 16:9, 4:3). Unusual ratios like 700x400 (1.75:1) may produce lower quality results. |
-| **Padding Overhead** | Padded positions consume compute even when masked. For best efficiency, prefer resolutions divisible by `sp_size`. |
-
-**Recommendations for users:**
-- Use standard aspect ratios when possible (e.g., 768x432 for 16:9 instead of 700x400)
-- Ensure post-patch dimensions are divisible by `sp_size` for optimal quality
-- Test generation quality when using unusual resolutions
-
-### Issue: Inline operations not sharded
-
-**Symptoms:** Some tensors remain full-sized, not sharded.
-
-**Causes & Solutions:**
-
-- **Operations happen inline in `forward()`, not at module boundaries:**
-
-**Problem:**
-```python
-def forward(self, x, cap):
- unified = torch.cat([x, cap], dim=1) # ← Inline operation!
- # _sp_plan can't hook this
-```
-
-**Solution:** Extract into submodule:
-```python
-class ConcatModule(nn.Module):
- def forward(self, x, cap):
- return torch.cat([x, cap], dim=1)
-
-class MyModel(nn.Module):
- _sp_plan = {
- "concat": {
- 0: SequenceParallelInput(split_dim=1, expected_dims=4, split_output=True),
- 1: SequenceParallelInput(split_dim=1, expected_dims=4, split_output=True),
- },
- ...
- }
- def __init__(self):
- self.concat = ConcatModule() # Now hookable!
-
- def forward(self, x, cap):
- unified = self.concat(x, cap) # ← Can be sharded via _sp_plan
-```
-
----
-
-## Reference Implementations
-
-Complete examples in the codebase:
-
-| Model | Path | Pattern | Notes |
-|-------|------|---------|-------|
-| **LongCat** | `vllm_omni/diffusion/models/longcat_image/longcat_image_transformer.py` | Dual-stream | Text components replicated, image components sharded |
-| **Qwen-Image** | `vllm_omni/diffusion/models/qwen_image/qwen_image_transformer.py` | Dual-stream + preprocessing | auto_pad, separate RoPE |
-| **Wan2.2** | `vllm_omni/diffusion/models/wan2_2/wan2_2_transformer.py` | Dual-Transformer + RoPE | Video transformer |
-| **Z-Image** | `vllm_omni/diffusion/models/z_image/z_image_transformer.py` | Unified sequence | Concatenated input |
-| **SP Plan Types** | `vllm_omni/diffusion/distributed/sp_plan.py` | Type definitions | SequenceParallelInput/Output |
-| **Hook Implementation** | `vllm_omni/diffusion/hooks/sequence_parallel.py` | Hook mechanics | How hooks work |
-| **Tests** | `tests/diffusion/distributed/test_sp_plan_hooks.py` | Test examples | Validation patterns |
-
----
-
-## Summary
-
-Adding Sequence Parallel support to a transformer:
-
-1. ✅ **Choose approach** - Use `_sp_plan` for standard cases, intrusive modification for complex cases
-2. ✅ **Identify sharding boundaries** - Where should tensors be split/gathered? And which module boundaries need to be moved to facilitate this?
-3. ✅ **Extract inline operations** - Move `torch.cat`, `pad_sequence`, etc. to submodules
-4. ✅ **Define `_sp_plan`** - Declare shard/gather points as class attribute
-5. ✅ **Use `auto_pad` for variable lengths** - Support non-uniform sequences
-6. ✅ **Test** - Verify with different `ulysses_degree` and `ring_degree` combinations
diff --git a/docs/design/feature/teacache.md b/docs/design/feature/teacache.md
deleted file mode 100644
index 8577cff1f05..00000000000
--- a/docs/design/feature/teacache.md
+++ /dev/null
@@ -1,491 +0,0 @@
-# TeaCache
-
-This section describes how to add TeaCache to a diffusion transformer model. We use the Qwen-Image transformer as the reference implementation.
-
----
-
-## Table of Contents
-
-- [Overview](#overview)
-- [Step-by-Step Implementation](#step-by-step-implementation)
-- [Customization](#customization)
-- [Testing](#testing)
-- [Troubleshooting](#troubleshooting)
-- [Reference Implementations](#reference-implementations)
-- [Summary](#summary)
-
----
-
-## Overview
-
-### What is TeaCache?
-
-TeaCache speeds up diffusion inference by caching transformer block computations when consecutive timesteps are similar. It provides **1.5x-2.0x speedup** with minimal quality loss.
-
-The core insight is that the modulated input (after normalization and timestep conditioning) changes gradually across timesteps. By measuring the L1 distance between consecutive modulated inputs and comparing it to a threshold, TeaCache decides whether to execute the full transformer blocks or reuse the cached residual from the previous step.
-
-vLLM-omni provides a **hook-based** TeaCache system that requires **zero changes to model code**. The hook completely intercepts the transformer's forward pass and implements adaptive caching transparently. This design allows easy integration with any transformer model by simply writing an extractor function.
-
-### Architecture
-
-The TeaCache system consists of three main components:
-
-| Component | Purpose | Location |
-|-----------|---------|----------|
-| [`CacheContext`](https://docs.vllm.ai/projects/vllm-omni/en/latest/api/vllm_omni/diffusion/cache/#vllm_omni.diffusion.cache.CacheContext) | Dataclass containing model-specific information for caching | `vllm_omni/diffusion/cache/teacache/context.py` |
-| [`EXTRACTOR_REGISTRY`](https://docs.vllm.ai/projects/vllm-omni/en/latest/api/vllm_omni/diffusion/cache/teacache/extractors/#vllm_omni.diffusion.cache.teacache.extractors.EXTRACTOR_REGISTRY) | Maps transformer class names to extractor functions | `vllm_omni/diffusion/cache/teacache/extractors.py` |
-| [`TeaCacheConfig`](https://docs.vllm.ai/projects/vllm-omni/en/latest/api/vllm_omni/diffusion/cache/#vllm_omni.diffusion.cache.TeaCacheConfig) | Configuration including thresholds and polynomial coefficients | `vllm_omni/diffusion/cache/teacache/config.py` |
-
-The hook handles all caching logic automatically, including:
-
-- CFG-aware state management (separate states for positive/negative branches)
-- CFG-parallel compatibility
-- L1 distance computation with polynomial rescaling
-- Residual caching and reuse
-
-
----
-
-## Step-by-Step Implementation
-
-To add TeaCache support for a new model, you need to:
-
-1. Write an **extractor function** that returns a `CacheContext` object
-2. Register the extractor in the `EXTRACTOR_REGISTRY`
-3. Add model-specific polynomial coefficients to `TeaCacheConfig`
-
-### Step 1: Model-Specific Preprocessing
-
-Extract and process model inputs. This typically involves:
-- Embedding image/latent inputs
-- Processing text encoder outputs (if dual-stream)
-- Creating timestep embeddings
-- Computing positional embeddings
-
-**Example (Qwen-Image):**
-
-```python
-def extract_qwen_context(
- module: nn.Module,
- hidden_states: torch.Tensor,
- encoder_hidden_states: torch.Tensor,
- encoder_hidden_states_mask: torch.Tensor,
- timestep: torch.Tensor,
- img_shapes: torch.Tensor,
- txt_seq_lens: torch.Tensor,
- guidance: torch.Tensor | None = None,
- **kwargs: Any,
-) -> CacheContext:
- # Validate model structure
- if not hasattr(module, "transformer_blocks") or len(module.transformer_blocks) == 0:
- raise ValueError("Module must have transformer_blocks")
-
- # Preprocessing: embed inputs
- hidden_states = module.img_in(hidden_states)
- timestep = timestep.to(device=hidden_states.device, dtype=hidden_states.dtype)
- encoder_hidden_states = module.txt_norm(encoder_hidden_states)
- encoder_hidden_states = module.txt_in(encoder_hidden_states)
-
- # Create timestep embedding
- if guidance is not None:
- guidance = guidance.to(hidden_states.dtype) * 1000
- temb = (
- module.time_text_embed(timestep, hidden_states)
- if guidance is None
- else module.time_text_embed(timestep, guidance, hidden_states)
- )
-
- # Compute position embeddings
- image_rotary_emb = module.pos_embed(img_shapes, txt_seq_lens, device=hidden_states.device)
-```
-
-### Step 2: Extract Modulated Input
-
-The modulated input is used for cache decisions. Extract it from the **first transformer block** after normalization and modulation.
-
-**Example (Qwen-Image):**
-
-```python
- # Extract modulated input from first transformer block
- block = module.transformer_blocks[0]
- img_mod_params = block.img_mod(temb)
- img_mod1, _ = img_mod_params.chunk(2, dim=-1)
- img_modulated, _ = block.img_norm1(hidden_states, img_mod1)
-```
-
-**Key Points:**
-
-- Use the **first block** to extract modulated input early
-- Apply the same normalization and modulation as the actual forward pass
-- The tensor should represent the processed features that will change across timesteps
-
-### Step 3: Define Transformer Execution
-
-Create a callable that executes all transformer blocks. This encapsulates the main computation loop.
-
-**Example (Qwen-Image dual-stream):**
-
-```python
- def run_transformer_blocks():
- """Execute all Qwen transformer blocks."""
- h = hidden_states
- e = encoder_hidden_states
-
- for block in module.transformer_blocks:
- e, h = block(
- hidden_states=h,
- encoder_hidden_states=e,
- encoder_hidden_states_mask=encoder_hidden_states_mask,
- temb=temb,
- image_rotary_emb=image_rotary_emb,
- )
- return (h, e) # Return both image and text hidden states
-```
-
-**Example (Single-stream model like Flux):**
-
-```python
- def run_transformer_blocks():
- """Execute all Flux transformer blocks."""
- h = hidden_states
-
- for block in module.transformer_blocks:
- h = block(h, temb=temb)
- return (h,) # Return only image hidden states
-```
-
-**Key Points:**
-
-- Return format:
-- For single-stream models: return `(hidden_states,)`
-- For dual-stream models: return `(hidden_states, encoder_hidden_states)`
-
-### Step 4: Define Postprocessing
-
-Create a callable that applies final transformations to produce the model output.
-
-**Example (Qwen-Image):**
-
-```python
- return_dict = kwargs.get("return_dict", True)
-
- def postprocess(h):
- """Apply Qwen-specific output postprocessing."""
- h = module.norm_out(h, temb)
- output = module.proj_out(h)
- if not return_dict:
- return (output,)
- return Transformer2DModelOutput(sample=output)
-```
-
-### Step 5: Return CacheContext
-
-Package all information into a `CacheContext` object.
-
-```python
- return CacheContext(
- modulated_input=img_modulated,
- hidden_states=hidden_states,
- encoder_hidden_states=encoder_hidden_states, # or None for single-stream
- temb=temb,
- run_transformer_blocks=run_transformer_blocks,
- postprocess=postprocess,
- )
-```
-
-**CacheContext Fields:**
-
-| Field | Type | Purpose |
-|-------|------|---------|
-| `modulated_input` | `torch.Tensor` | Tensor used for cache decision (similarity comparison) |
-| `hidden_states` | `torch.Tensor` | Current hidden states (will be modified by caching) |
-| `encoder_hidden_states` | `torch.Tensor | None` | Encoder states for dual-stream models, `None` for single-stream |
-| `temb` | `torch.Tensor` | Timestep embedding tensor |
-| `run_transformer_blocks` | `Callable[[], tuple]` | Executes transformer blocks, returns `(hidden_states, [encoder_hidden_states])` |
-| `postprocess` | `Callable[[torch.Tensor], Any]` | Applies final transformations to produce model output |
-| `extra_states` | `dict | None` | Optional dict for additional model-specific state |
-
-### Step 6: Register the Extractor
-
-Add your extractor to the `EXTRACTOR_REGISTRY` in `vllm_omni/diffusion/cache/teacache/extractors.py`:
-
-```python
-EXTRACTOR_REGISTRY: dict[str, Callable] = {
- "QwenImageTransformer2DModel": extract_qwen_context,
- "Bagel": extract_bagel_context,
- "ZImageTransformer2DModel": extract_zimage_context,
- "YourModelTransformer2DModel": extract_your_model_context, # Add here
-}
-```
-
-**Key:** Use the transformer class name (`module.__class__.__name__`)
-
-### Step 7: Add Model Coefficients
-
-Add polynomial rescaling coefficients to `vllm_omni/diffusion/cache/teacache/config.py`:
-
-```python
-_MODEL_COEFFICIENTS = {
- "QwenImageTransformer2DModel": [
- -4.50000000e02,
- 2.80000000e02,
- -4.50000000e01,
- 3.20000000e00,
- -2.00000000e-02,
- ],
- "YourModelTransformer2DModel": [ # Add your model's coefficients
- # 5 polynomial coefficients (can reuse similar model's coefficients initially)
- ],
-}
-```
-
-
-**Initial approach:** Start with coefficients from a similar model architecture, then tune empirically following [Customization](#customization) section.
-
----
-
-## Customization
-
-### Coefficient Estimation
-
-While you can start with coefficients from a similar model architecture, estimating custom coefficients for your specific model typically improves TeaCache performance.
-
-**Why Estimate Coefficients?**
-
-The polynomial coefficients rescale L1 distances between consecutive modulated inputs to better predict when cached residuals can be reused. Model-specific coefficients account for:
-
-- Architecture differences (layer count, hidden size, attention patterns)
-- Training data characteristics
-- Noise prediction behavior across timesteps
-
-| Approach | Performance | Effort |
-|----------|-------------|--------|
-| Using defaults from similar model | Within 5-10% of optimal | Low |
-| Estimating custom coefficients | Best performance | Medium |
-
-#### Implement Data Collection Adapter
-
-Add an adapter in `vllm_omni/diffusion/cache/teacache/coefficient_estimator.py`:
-
-```python
-class YourModelAdapter:
- """Adapter for coefficient estimation on your model."""
-
- @staticmethod
- def load_pipeline(model_path: str, device: str, dtype: torch.dtype) -> Any:
- """Load your diffusion pipeline."""
- from your_model_package import YourModelPipeline
-
- pipeline = YourModelPipeline.from_pretrained(
- model_path,
- torch_dtype=dtype,
- )
- pipeline = pipeline.to(device)
- return pipeline
-
- @staticmethod
- def get_transformer(pipeline: Any) -> tuple[Any, str]:
- """Extract transformer from pipeline."""
- return pipeline.transformer, "YourTransformer2DModel"
-
- @staticmethod
- def install_hook(transformer: Any, hook: DataCollectionHook) -> None:
- """Install data collection hook on transformer."""
- from vllm_omni.diffusion.hooks import HookRegistry
-
- registry = HookRegistry.get_or_create(transformer)
- registry.register_hook(hook._HOOK_NAME, hook)
-
-
-# Register your adapter
-_MODEL_ADAPTERS["YourModel"] = YourModelAdapter
-```
-
-#### Collect Data and Estimate
-
-```python
-from vllm_omni.diffusion.cache.teacache.coefficient_estimator import (
- TeaCacheCoefficientEstimator,
-)
-from datasets import load_dataset
-from tqdm import tqdm
-
-# Initialize estimator
-estimator = TeaCacheCoefficientEstimator(
- model_path="/path/to/your/model",
- model_type="YourModel",
-)
-
-# Load diverse prompts (paper recommends ~70 prompts)
-dataset = load_dataset("nateraw/parti-prompts", split="train")
-prompts = dataset["Prompt"][:70]
-
-# Collect data
-for prompt in tqdm(prompts, desc="Collecting data"):
- estimator.collect_from_prompt(prompt=prompt, num_inference_steps=50)
-
-# Estimate coefficients
-coeffs = estimator.estimate(poly_order=4)
-print(f"Estimated coefficients: {coeffs}")
-```
-
-Note: some models may require the vLLM context and config to be initialized to initialize vLLM modules. To this end, you may need a workaround like the following to be able to run coefficient estimation.
-```python
-from vllm_omni.diffusion.forward_context import set_forward_context
-from vllm_omni.diffusion.distributed.parallel_state import (
- init_distributed_environment,
- initialize_model_parallel,
-)
-from vllm.config import VllmConfig
-...
-
-if __name__ == "__main__":
- os.environ["MASTER_ADDR"] = "localhost"
- os.environ["MASTER_PORT"] = "8192"
- os.environ["LOCAL_RANK"] = "0"
- os.environ["RANK"] = "0"
- os.environ["WORLD_SIZE"] = "1"
-
- vllm_config = VllmConfig()
- init_distributed_environment()
- initialize_model_parallel()
-
- # NOTE: you may have to pass an initialized OmniDiffusionConfig as a kwarg
- # here to make current sp checks happy; if this is the case, just create one
- # .from_kwargs() with the model name to get around this check for now,
- # since your estimator subclass should handle the actual model configuration.
- #
- # This will be cleaned up in the future
- with set_forward_context(vllm_config):
-
-```
-
-
-**Data Statistics Guide:**
-
-| Metric | Good Range | Warning Signs |
-|--------|------------|---------------|
-| **Count** | 2000-5000+ | < 1000: too few prompts |
-| **Input Diffs (x)** | 0.01-0.10 | Very small (<0.001): model may not modulate properly |
-| **Output Diffs (y)** | Should correlate with x | No correlation: check extractor |
-| **Coefficient magnitude** | -1e6 to 1e6 | > 1e8: numerical instability |
-
----
-
-## Testing
-
-After adding TeaCache support, test with:
-
-```python
-from vllm_omni import Omni
-from vllm_omni.inputs.data import OmniDiffusionSamplingParams
-
-omni = Omni(
- model="your-model-name",
- cache_backend="tea_cache",
- cache_config={
- "rel_l1_thresh": 0.2,
- "coefficients": [1.33e6, -1.69e5, 7.95e3, -1.64e2, 1.26], # Your coefficients
- }
-)
-
-images = omni.generate(
- "a beautiful landscape",
- OmniDiffusionSamplingParams(num_inference_steps=50),
-)
-```
-
-**Verify:**
-
-1. **Check logs** - Look for TeaCache initialization messages
-2. **Compare performance** - Measure speedup vs baseline (expect 1.5x-2.0x)
-3. **Verify output quality** - Visually compare cached vs uncached outputs (should be nearly identical)
-
-See more detailed examples in [user guide for teacache](../../user_guide/diffusion/cache_acceleration/teacache.md).
-
----
-
-## Troubleshooting
-
-### Issue: "Unknown model type"
-
-**Symptoms:** Error message indicating the model type is not recognized when enabling TeaCache.
-
-**Causes & Solutions:**
-
-- **Extractor not registered:**
-
-**Problem:** The transformer class name doesn't exist in `EXTRACTOR_REGISTRY`.
-
-**Solution:** Check the class name and add to registry:
-```python
-# Check transformer class name
-print(pipeline.transformer.__class__.__name__)
-
-# Add to EXTRACTOR_REGISTRY
-EXTRACTOR_REGISTRY["YourTransformer2DModel"] = extract_your_context
-```
-
-- **Transformer class name mismatch:**
-
-**Solution:** Ensure the registry key matches exactly with `module.__class__.__name__`.
-
-### Issue: "Cannot find coefficients"
-
-**Symptoms:** Error when initializing TeaCache about missing model coefficients.
-
-**Causes & Solutions:**
-
-- **Missing coefficients in config:**
-
-**Solution:** Add coefficients to `_MODEL_COEFFICIENTS` in `config.py`, or pass custom coefficients:
-```python
-omni = Omni(
- model="your-model",
- cache_backend="tea_cache",
- cache_config={"coefficients": [1.0, -0.5, 0.1, -0.01, 0.001]}
-)
-```
-
-### Issue: Quality Degradation
-
-**Symptoms:** Output images look noticeably different or have artifacts compared to baseline.
-
-**Causes & Solutions:**
-
-- **Threshold too high:**
-
-**Problem:** `rel_l1_thresh` is too aggressive, causing cache reuse when outputs differ significantly.
-
-**Solution:** Lower the threshold:
-```python
-cache_config={"rel_l1_thresh": 0.1} # Try 0.1-0.2
-```
-
-- **Coefficients not tuned:**
-
-**Solution:** Estimate model-specific coefficients using the coefficient estimation process described above.
-
----
-
-## Reference Implementations
-
-Complete examples in the codebase:
-
-| Model | Path | Pattern | Notes |
-|-------|------|---------|-------|
-| **Qwen-Image** | `vllm_omni/diffusion/cache/teacache/extractors.py` | Dual-stream | `extract_qwen_context` |
-| **Bagel** | `vllm_omni/diffusion/cache/teacache/extractors.py` | Omni model | `extract_bagel_context` |
-| **TeaCache Core** | `vllm_omni/diffusion/cache/teacache/` | Base implementation | Hook and config |
-| **Coefficient Estimator** | `vllm_omni/diffusion/cache/teacache/coefficient_estimator.py` | Estimation tool | Adapter pattern |
-
----
-
-## Summary
-
-Adding TeaCache support:
-
-1. ✅ **Write extractor** - Create function returning `CacheContext` with model-specific preprocessing
-2. ✅ **Register extractor** - Add to `EXTRACTOR_REGISTRY` with transformer class name
-3. ✅ **Add coefficients** - Add polynomial coefficients to `_MODEL_COEFFICIENTS`
-4. ✅ **Test** - Verify with `cache_backend="tea_cache"`
diff --git a/docs/design/feature/tensor_parallel.md b/docs/design/feature/tensor_parallel.md
deleted file mode 100644
index bcafde7e73a..00000000000
--- a/docs/design/feature/tensor_parallel.md
+++ /dev/null
@@ -1,279 +0,0 @@
-# Tensor Parallel
-
-This section describes how to add Tensor Parallel (TP) to a diffusion transformer model. We use the Z-Image transformer as the reference implementation.
-
----
-
-## Table of Contents
-
-- [Overview](#overview)
-- [Step-by-Step Implementation](#step-by-step-implementation)
-- [Testing](#testing)
-- [Troubleshooting](#troubleshooting)
-- [Reference Implementations](#reference-implementations)
-- [Summary](#summary)
-
----
-
-## Overview
-
-### What is Tensor Parallel?
-
-Tensor Parallel (TP) is a model parallelism technique that **shards model weights** across multiple GPUs. Each GPU holds only a portion of the model's parameters and computes only part of each layer's output.
-
-Diffusion transformers contain large attention and MLP layers. We can use Tensor Parallel to shard the model dimension across multiple GPUs, allowing larger models to fit in memory while achieving near-linear speedup.
-
-### Architecture
-
-The Tensor Parallel implementation relies vLLM's Parallel Layers:
-
-[vLLM Parallel Layers API Reference](https://docs.vllm.ai/en/latest/contributing/model/basic/?h=column#3-optional-implement-tensor-parallelism-and-quantization-support)
-
-**Parallel Layer Types:**
-
-| Layer Type | Purpose | Weight Partitioning |
-|------------|---------|---------------------|
-| `ColumnParallelLinear` | First FFN layer, separated QKV | Columns (output dimension) |
-| `RowParallelLinear` | Second FFN layer, attention output | Rows (input dimension) |
-| `QKVParallelLinear` | Multi-head/grouped-query attention QKV | Handles head replication automatically |
-| `ReplicatedLinear` | Layers that shouldn't be sharded | No partitioning (replicated) |
-
----
-
-## Step-by-Step Implementation
-
-
-### Step 1: Identify Linear Layers
-
-Find all `nn.Linear` layers in your transformer that need to be sharded.
-
-**Key questions:**
-- Which layers should be column parallel (weight split by columns)?
-- Which layers should be row parallel (weight split by rows)?
-
-### Step 2: Replace Linear Layers with Parallel Equivalents
-
-Replace `nn.Linear` with parallel layers from `vllm.model_executor.layers.linear`.
-
-**Example (MLP Block - Up-Down Pattern):**
-
-```python
-class FeedForward(nn.Module):
- def __init__(self, dim: int, hidden_dim: int):
- super().__init__()
- # Column parallel: weight split by columns [hidden_dim/N, dim]
- self.w1 = ColumnParallelLinear(
- dim,
- hidden_dim,
- bias=False,
- return_bias=False,
- )
- self.act = nn.GELU()
-
- self.w2 = RowParallelLinear(
- hidden_dim,
- dim,
- bias=False,
- input_is_parallel=True, # Input already sharded from w1
- return_bias=False,
- )
-
- def forward(self, x):
- # x: [batch, seq, dim] (replicated on all GPUs)
- # w1 outputs sharded [batch, seq, hidden_dim/N]
- x = self.w1(x)
- # act operates on sharded tensors (no communication)
- x = self.act(x)
- # w2 outputs full dim [batch, seq, dim] via all-reduce
- x = self.w2(x)
- return x
-```
-
-**Example (Attention - QKV-Out Pattern):**
-
-```python
-from vllm_omni.diffusion.attention.layer import Attention
-class YourModelAttention(nn.Module):
- def __init__(self, dim: int, num_heads: int, num_kv_heads: int):
- super().__init__()
- self.head_dim = dim // num_heads
-
- # Column parallel: QKV weight split by columns
- # Each GPU gets num_heads/N heads
- self.to_qkv = QKVParallelLinear(
- hidden_size=dim,
- head_size=self.head_dim,
- total_num_heads=num_heads,
- total_num_kv_heads=num_kv_heads,
- bias=False,
- return_bias=False,
- )
-
- # Row parallel: output weight split by rows
- self.to_out = RowParallelLinear(
- dim,
- dim,
- bias=False,
- input_is_parallel=True, # Input sharded from attention
- return_bias=False,
- )
-
- self.attn = Attention(
- num_heads=self.to_qkv.num_heads, # Each GPU gets num_heads/N heads
- head_size=self.head_dim,
- softmax_scale=1.0 / (self.head_dim**0.5),
- causal=False,
- num_kv_heads=self.to_qkv.num_kv_heads,
- )
-
- def forward(self, x):
- # x: [batch, seq, dim] (replicated)
- # to_qkv outputs sharded [batch, seq, (q+k+v) * head_dim/N]
- qkv = self.to_qkv(x)
- # Split into Q, K, V (each sharded on heads)
- q, k, v = qkv.split([...], dim=-1)
- # Attention computed independently on each GPU
- out = self.attn(q, k, v)
- # to_out all-reduces to full dim
- out = self.to_out(out)
- return out
-```
-
-**Key Points:**
-
-- `ColumnParallelLinear` → `RowParallelLinear` is the standard pairing
-- Set `input_is_parallel=True` on `RowParallelLinear` when input comes from `ColumnParallelLinear`
-- Use `QKVParallelLinear` for attention projections (handles head replication automatically)
-
-### Step 3: Validate TP Constraints
-
-For correct TP operation, these dimensions **must be divisible** by `tensor_parallel_size`:
-
-| Dimension | Reason | Example Error |
-|-----------|--------|---------------|
-| `num_heads` | Heads sharded by QKVParallelLinear | `num_heads=30, tp=4` ❌ (30 % 4 ≠ 0) |
-| `num_kv_heads` | KV heads sharded by QKVParallelLinear | `num_kv_heads=30, tp=4` ❌ (30 % 4 ≠ 0) |
-
----
-
-## Testing
-
-After adding Tensor Parallel support, test with:
-
-```python
-from vllm_omni import Omni
-from vllm_omni.diffusion.data import DiffusionParallelConfig
-from vllm_omni.inputs.data import OmniDiffusionSamplingParams
-
-parallel_config = DiffusionParallelConfig(tensor_parallel_size=2)
-omni = Omni(model="your-model-name", parallel_config=parallel_config)
-
-output = omni.generate(
- "a cup of coffee on the table",
- OmniDiffusionSamplingParams(num_inference_steps=50),
-)
-```
-
-**Or via command line:**
-
-```bash
-cd examples/offline_inference/text_to_image
-python text_to_image.py \
- --model Your-org/your-model \
- --prompt "a cup of coffee on the table" \
- --negative-prompt "ugly, unclear" \
- --cfg-scale 4.0 \
- --num-inference-steps 50 \
- --output "tp_enabled.png" \
- --tensor-parallel-size 2
-```
-
-**Verify:**
-
-1. Check the `e2e_time_ms` in the log for speedup
-2. Compare generated image quality with TP disabled
-3. Verify memory usage is reduced proportionally
-4. Record comparison results in your PR
-
----
-
-## Troubleshooting
-
-### Issue: TP not activating
-
-**Symptoms:** Model runs on single GPU, no memory savings or speedup.
-
-**Causes & Solutions:**
-
-- **Still using `nn.Linear`:**
-
-**Problem:** Linear layers not replaced with parallel equivalents.
-
-**Solution:** Replace with parallel layers:
-```python
-# ❌ BAD
-self.proj = nn.Linear(dim, dim)
-
-# ✅ GOOD
-self.proj = RowParallelLinear(dim, dim, input_is_parallel=True)
-```
-
-### Issue: Dimension mismatch errors
-
-**Symptoms:** `RuntimeError: shape mismatch` during forward pass.
-
-**Causes & Solutions:**
-
-- **Missing `input_is_parallel=True`:**
-
-**Problem:** RowParallelLinear expects sharded input but receives full tensor.
-
-**Solution:** Set `input_is_parallel=True` when input comes from ColumnParallelLinear:
-```python
-# ✅ GOOD: Correct pairing
-self.w1 = ColumnParallelLinear(dim, hidden_dim, return_bias=False,)
-self.w2 = RowParallelLinear(
- hidden_dim,
- dim,
- input_is_parallel=True, # Input sharded from w1
- return_bias=False,
-)
-```
-
-- **Incorrect split dimensions:**
-
-**Problem:** QKV split sizes don't match sharded dimensions.
-
-**Solution:** Use `self.to_qkv.num_heads` (local heads per GPU):
-```python
-# ❌ BAD: Uses total heads
-q_size = self.total_num_heads * self.head_dim
-
-# ✅ GOOD: Uses local heads
-q_size = self.to_qkv.num_heads * self.head_dim
-```
-
----
-
-## Reference Implementations
-
-Complete examples in the codebase:
-
-| Model | Path | Pattern | Notes |
-|-------|------|---------|-------|
-| **Z-Image** | `vllm_omni/diffusion/models/z_image/z_image_transformer.py` | Standard TP | Full implementation with validation |
-| **FLUX** | `vllm_omni/diffusion/models/flux/flux_transformer.py` | Dual-stream | Image + text streams |
-| **Qwen-Image** | `vllm_omni/diffusion/models/qwen_image/qwen_image_transformer.py` | Standard TP | With RoPE |
-| **TP Tests** | `tests/e2e/offline_inference/test_zimage_parallelism.py` | E2E testing | TP correctness and performance |
-| **Constraint Tests** | `tests/diffusion/models/z_image/test_zimage_tp_constraints.py` | Unit testing | Validation logic |
-
----
-
-## Summary
-
-Adding Tensor Parallel support to a transformer:
-
-1. ✅ **Identify linear layers** - Which layers should be sharded?
-2. ✅ **Replace with parallel layers** - Use QKVParallelLinear, ColumnParallelLinear, RowParallelLinear
-3. ✅ **Validate TP constraints** - Ensure dimensions divisible by TP size
-4. ✅ **Test** - Verify with `tensor_parallel_size=N`, check memory, speed, and quality
diff --git a/docs/design/feature/vae_parallel.md b/docs/design/feature/vae_parallel.md
deleted file mode 100644
index e330b41a68f..00000000000
--- a/docs/design/feature/vae_parallel.md
+++ /dev/null
@@ -1,459 +0,0 @@
-# VAE Patch Parallelism
-
-This document describes how to add **VAE Patch Parallelism** support to a diffusion model.
-We use **Qwen-Image** as the reference implementation for decode parallel, and **Wan2.2** for encode parallel.
-
----
-
-## Table of Contents
-
-- [Overview](#overview)
-- [Step-by-Step Implementation (Decode)](#step-by-step-implementation-decode)
-- [Encode Parallel Implementation](#encode-parallel-implementation)
-- [Testing](#testing)
-- [Reference Implementations](#reference-implementations)
-- [Summary](#summary)
-
----
-
-## Overview
-
-### What is Vae Patch parallel?
-
-**VAE Patch Parallelism** is an acceleration technique for both **encoding** and **decoding**. Instead of processing the entire tensor at once, the tensor is:
-
-+ Split into multiple spatial tiles
-
-+ Distributed across multiple ranks
-
-+ Encoded/Decoded in parallel
-
-+ Merged to reconstruct the final output
-
-This approach:
-
-+ Distributes computation across multiple devices
-
-+ Reduces peak memory usage per device
-
-+ Accelerates encoding/decoding latency
-
-### When to Use Encode vs Decode Parallel
-
-| Operation | Use Case | Example |
-|-----------|----------|---------|
-| **Decode Parallel** | Text-to-Image, Text-to-Video | Latent → Image/Video |
-| **Encode Parallel** | Image-to-Video (I2V) | Image → Latent (for conditioning) |
-
-### Architecture
-We introduce **DistributedVaeExecutor** as the core component responsible for distributed VAE encoding/decoding.
-
-The executor is model-agnostic and accepts three function parameters:
-
-+ split – Partition the latent into tiles
-
-+ exec – Decode a single tile
-
-+ merge – Combine decoded tiles into the final output
-
-#### Execution Flow
-
-+ Call split(z) to generate a list of TileTask and a GridSpec
-
-+ Dispatch tasks across ranks using workload-based balancing
-
-+ Each rank executes exec(task) on its assigned tiles
-
-+ Gather decoded tile results to rank 0
-
-+ Rank 0 performs merge(...)
-
-+ (Optional) Broadcast final result to all ranks
-
-This design separates:
-
-+ Distributed execution logic
-
-+ Model-specific tiling and merging logic
-
-#### Why split / exec / merge is necessary?
-
-The latent tensor cannot be arbitrarily partitioned.
-
-During decoding:
-
-+ Each output pixel may depend on neighboring pixels
-
-+ The receptive field is model-dependent
-
-Therefore:
-
-+ Tiles must include overlap
-
-+ Merge must perform blending to avoid seams
-
-## Step-by-Step Implementation (Decode)
-
-### Step 1: Implement DistributedAutoencoderKLQwenImage
-`QwenImagePipeline` use `AutoencoderKLQwenImage` for vae, so implement a distributed version:
-
-
-```
-class DistributedAutoencoderKLQwenImage(AutoencoderKLQwenImage, DistributedVaeMixin):
- @classmethod
- def from_pretrained(cls, *args: Any, **kwargs: Any):
- model = super().from_pretrained(*args, **kwargs)
- model.init_distributed()
- return model
-```
-**Key points**:
-+ Inherit both AutoencoderKLQwenImage and DistributedVaeMixin
-+ Call init_distributed() after loading weights
-
-### Step 2: Implement split/exec/merge
-Reuse `AutoencoderKLQwenImage.tiled_decode` logic and divide it into three stages. And we need return tiles with `GridSpec` and `TileTask`:
-```
-class GridSpec:
- split_dims: tuple[int, ...] # Tensor dimensions being split (e.g., (2, 3) for (B, C, H, W))
- grid_shape: tuple[int, ...] # Tile grid layout (num_rows, num_cols)
- tile_spec: dict = field(default_factory=dict) # Metadata required for merging
- output_dtype: torch.dtype | None = None # Final output dtype
-```
-```
-class TileTask:
- tile_id: int # task id
- grid_coord: tuple[int, ...] # Tile position in grid
- tensor: torch.Tensor | list[torch.Tensor] # The tile tensor
- workload: int | float = 1 # Used for load balancing (e.g., tile area)
-```
-And tiled base split/exec/merge as follow:
-```
-def tile_split(self, z: torch.Tensor) -> tuple[list[TileTask], GridSpec]:
- # mostly copy from AutoencoderKL
- _, _, num_frames, height, width = z.shape
- sample_height = height * self.spatial_compression_ratio
- sample_width = width * self.spatial_compression_ratio
-
- tile_latent_min_height = self.tile_sample_min_height // self.spatial_compression_ratio
- tile_latent_min_width = self.tile_sample_min_width // self.spatial_compression_ratio
- tile_latent_stride_height = self.tile_sample_stride_height // self.spatial_compression_ratio
- tile_latent_stride_width = self.tile_sample_stride_width // self.spatial_compression_ratio
-
- blend_height = self.tile_sample_min_height - self.tile_sample_stride_height
- blend_width = self.tile_sample_min_width - self.tile_sample_stride_width
-
- # Split z into overlapping tiles and decode them separately.
- # The tiles have an overlap to avoid seams between tiles.
- tiletask_list = []
- for i in range(0, height, tile_latent_stride_height):
- for j in range(0, width, tile_latent_stride_width):
- time_list = []
- for k in range(num_frames):
- self._conv_idx = [0]
- tile = z[:, :, k : k + 1, i : i + tile_latent_min_height, j : j + tile_latent_min_width]
- time_list.append(tile)
- tiletask_list.append(
- TileTask(
- len(tiletask_list),
- (i // tile_latent_stride_height, j // tile_latent_stride_width),
- time_list,
- workload=time_list[0].shape[3] * time_list[0].shape[4],
- )
- )
- tile_spec = {
- "sample_height": sample_height,
- "sample_width": sample_width,
- "blend_height": blend_height,
- "blend_width": blend_width,
- }
- grid_spec = GridSpec(
- split_dims=(3, 4),
- grid_shape=(tiletask_list[-1].grid_coord[0] + 1, tiletask_list[-1].grid_coord[1] + 1),
- tile_spec=tile_spec,
- output_dtype=self.dtype,
- )
- return tiletask_list, grid_spec
-
-def tile_exec(self, task: TileTask) -> torch.Tensor:
- """Decode a single latent tile into RGB space."""
- self.clear_cache()
- time = []
- for k in range(len(task.tensor)):
- self._conv_idx = [0]
- tile = self.post_quant_conv(task.tensor[k])
- decoded = self.decoder(tile, feat_cache=self._feat_map, feat_idx=self._conv_idx)
- time.append(decoded)
- result = torch.cat(time, dim=2)
- return result
-
-def tile_merge(self, coord_tensor_map: dict[tuple[int, ...], torch.Tensor], grid_spec: GridSpec) -> torch.Tensor:
- """Merge decoded tiles into a full image."""
- grid_h, grid_w = grid_spec.grid_shape
- result_rows = []
- self.clear_cache()
-
- result_rows = []
- for i in range(grid_h):
- result_row = []
- for j in range(grid_w):
- tile = coord_tensor_map[(i, j)]
- if i > 0:
- tile = self.blend_v(coord_tensor_map[(i - 1, j)], tile, grid_spec.tile_spec["blend_height"])
- if j > 0:
- tile = self.blend_h(coord_tensor_map[(i, j - 1)], tile, grid_spec.tile_spec["blend_width"])
- result_row.append(tile[:, :, :, : self.tile_sample_stride_height, : self.tile_sample_stride_width])
- result_rows.append(torch.cat(result_row, dim=-1))
- dec = torch.cat(result_rows, dim=3)[
- :, :, :, : grid_spec.tile_spec["sample_height"], : grid_spec.tile_spec["sample_width"]
- ]
- return dec
-```
-
-### Step 3: Override tiled_decode
-We need to override tiled_decode, the main logic is:
-+ check distributed is enabled
-+ select split/exec/merge
-+ Invoke self.distributed_executor.execute to decode
-```
-def tiled_decode(self, z: torch.Tensor, return_dict: bool = True):
- if not self.is_distributed_enabled():
- return super().tiled_decode(z, return_dict=return_dict)
-
- logger.info("Decode run with distributed executor")
- result = self.distributed_executor.execute(
- z,
- DistributedOperator(split=self.tile_split, exec=self.tile_exec, merge=self.tile_merge),
- broadcast_result=True,
- )
- if not return_dict:
- return (result,)
-
- return DecoderOutput(sample=result)
-```
-`broadcast_result` is set to True or False depending on the model; when enabled, the result will be used even on ranks other than 0.
-
-### Step 4: Modify Pipeline
-Change vae model from AutoencoderKLQwenImage to DistributedAutoencoderKLQwenImage
-```
-class YourModelPipeline(nn.Module):
- def __init__(
- self,
- *,
- od_config: OmniDiffusionConfig,
- prefix: str = "",
- ):
- super().__init__()
- ...
-- self.vae = AutoencoderKL.from_pretrained(
-- model, subfolder="vae", local_files_only=local_files_only).to(self.device)
-+ self.vae = DistributedAutoencoderKL.from_pretrained(
-+ model, subfolder="vae", local_files_only=local_files_only
-+ ).to(self.device)
-```
-
-## Encode Parallel Implementation
-
-For models that require VAE encoding (e.g., Image-to-Video), you can also parallelize the encode operation. We use **Wan2.2** as the reference implementation.
-
-### Step 1: Implement encode_tile_split
-
-Similar to decode, split the input tensor into tiles. Key considerations:
-
-+ **Patchify handling**: If the model uses `patch_size`, scale tile parameters accordingly
-+ **Temporal chunking**: Video VAEs may have temporal compression (e.g., 4x)
-
-```python
-def encode_tile_split(self, x: torch.Tensor) -> tuple[list[TileTask], GridSpec]:
- _, _, num_frames, height, width = x.shape
- encode_spatial_compression_ratio = self.spatial_compression_ratio
-
- # Scale tile parameters for patchified coordinate system
- tile_sample_min_height = self.tile_sample_min_height
- tile_sample_min_width = self.tile_sample_min_width
- tile_sample_stride_height = self.tile_sample_stride_height
- tile_sample_stride_width = self.tile_sample_stride_width
-
- if self.config.patch_size is not None:
- # When input is patchified, scale tile parameters accordingly
- encode_spatial_compression_ratio = self.spatial_compression_ratio // self.config.patch_size
- tile_sample_min_height = tile_sample_min_height // self.config.patch_size
- tile_sample_min_width = tile_sample_min_width // self.config.patch_size
- tile_sample_stride_height = tile_sample_stride_height // self.config.patch_size
- tile_sample_stride_width = tile_sample_stride_width // self.config.patch_size
-
- latent_height = height // encode_spatial_compression_ratio
- latent_width = width // encode_spatial_compression_ratio
-
- tile_latent_min_height = tile_sample_min_height // encode_spatial_compression_ratio
- tile_latent_min_width = tile_sample_min_width // encode_spatial_compression_ratio
- tile_latent_stride_height = tile_sample_stride_height // encode_spatial_compression_ratio
- tile_latent_stride_width = tile_sample_stride_width // encode_spatial_compression_ratio
-
- blend_height = tile_latent_min_height - tile_latent_stride_height
- blend_width = tile_latent_min_width - tile_latent_stride_width
-
- tiletask_list = []
- # Use temporal compression ratio from config instead of hardcoding
- temporal_compression = self.config.scale_factor_temporal
-
- for i in range(0, height, tile_sample_stride_height):
- for j in range(0, width, tile_sample_stride_width):
- time_list = []
- frame_range = 1 + (num_frames - 1) // temporal_compression
- for k in range(frame_range):
- if k == 0:
- tile = x[:, :, :1, i : i + tile_sample_min_height, j : j + tile_sample_min_width]
- else:
- tile = x[
- :, :,
- 1 + temporal_compression * (k - 1) : 1 + temporal_compression * k,
- i : i + tile_sample_min_height,
- j : j + tile_sample_min_width,
- ]
- time_list.append(tile)
- tiletask_list.append(
- TileTask(len(tiletask_list), (i // tile_sample_stride_height, j // tile_sample_stride_width),
- time_list, workload=time_list[0].shape[3] * time_list[0].shape[4])
- )
-
- grid_spec = GridSpec(
- split_dims=(3, 4),
- grid_shape=(tiletask_list[-1].grid_coord[0] + 1, tiletask_list[-1].grid_coord[1] + 1),
- tile_spec={
- "latent_height": latent_height, "latent_width": latent_width,
- "blend_height": blend_height, "blend_width": blend_width,
- "tile_latent_stride_height": tile_latent_stride_height,
- "tile_latent_stride_width": tile_latent_stride_width,
- },
- output_dtype=self.dtype,
- )
- return tiletask_list, grid_spec
-```
-
-### Step 2: Implement encode_tile_exec
-
-```python
-def encode_tile_exec(self, task: TileTask) -> torch.Tensor:
- """Encode a single sample tile into latent space."""
- self.clear_cache()
- time = []
- for k, tile in enumerate(task.tensor):
- self._enc_conv_idx = [0]
- encoded = self.encoder(tile, feat_cache=self._enc_feat_map, feat_idx=self._enc_conv_idx)
- encoded = self.quant_conv(encoded)
- time.append(encoded)
- result = torch.cat(time, dim=2)
- self.clear_cache()
- return result
-```
-
-### Step 3: Implement encode_tile_merge
-
-```python
-def encode_tile_merge(
- self, coord_tensor_map: dict[tuple[int, ...], torch.Tensor], grid_spec: GridSpec
-) -> torch.Tensor:
- """Merge encoded tiles into a full latent tensor."""
- grid_h, grid_w = grid_spec.grid_shape
- result_rows = []
- for i in range(grid_h):
- result_row = []
- for j in range(grid_w):
- tile = coord_tensor_map[(i, j)]
- if i > 0:
- tile = self.blend_v(coord_tensor_map[(i - 1, j)], tile, grid_spec.tile_spec["blend_height"])
- if j > 0:
- tile = self.blend_h(coord_tensor_map[(i, j - 1)], tile, grid_spec.tile_spec["blend_width"])
- result_row.append(tile[:, :, :,
- : grid_spec.tile_spec["tile_latent_stride_height"],
- : grid_spec.tile_spec["tile_latent_stride_width"]])
- result_rows.append(torch.cat(result_row, dim=-1))
-
- enc = torch.cat(result_rows, dim=3)[
- :, :, :, : grid_spec.tile_spec["latent_height"], : grid_spec.tile_spec["latent_width"]
- ]
- return enc
-```
-
-### Step 4: Override tiled_encode method
-
-Override `tiled_encode` instead of `encode`. The parent's `_encode()` handles patchify before calling `tiled_encode()`, so input `x` is already patchified.
-
-```python
-def tiled_encode(self, x: torch.Tensor) -> torch.Tensor:
- """
- Encode using distributed VAE executor.
-
- Note: x is already patchified by parent's _encode() before calling this method.
- """
- if not self.is_distributed_enabled():
- return super().tiled_encode(x)
-
- self.clear_cache()
- result = self.distributed_executor.execute(
- x,
- DistributedOperator(
- split=self.encode_tile_split,
- exec=self.encode_tile_exec,
- merge=self.encode_tile_merge,
- ),
- broadcast_result=True, # Latents needed by all ranks for diffusion
- )
- self.clear_cache()
- return result
-```
-
-**Key differences from decode parallel:**
-
-| Aspect | Decode Parallel | Encode Parallel |
-|--------|-----------------|-----------------|
-| `broadcast_result` | Often `False` (only rank 0 needs output) | `True` (all ranks need latents for diffusion) |
-| Patchify | Applied in merge (unpatchify) | Handled by parent `_encode()` before `tiled_encode()` |
-| Temporal chunking | Frame-by-frame | Chunk-based (e.g., 1 + 4n frames) |
-
-## Testing
-Verify numerical consistency between:
-+ vae_patch_parallel_size = 1
-
-+ vae_patch_parallel_size = N
-
-Example:
-torch.allclose(output_1, output_n, atol=1e-5)
-
-Testing requirements:
-+ Fix random seed
-+ Use identical tiling strategy
-
-```python
-m = Omni(
- model=model_name,
- vae_use_tiling=True,
- parallel_config=DiffusionParallelConfig(
- tensor_parallel_size=2,
- vae_patch_parallel_size=1, # or 2
- ),
- )
-```
-When vae_patch_parallel_size is larger than the DiT world size, it will automatically fall back to using the DiT world size instead.
-
-## Reference Implementations
-
-Complete examples in the codebase:
-
-| Model | Path | Decode Parallel | Encode Parallel |
-|-------|------|-----------------|-----------------|
-| **Z-Image** | `vllm_omni/diffusion/distributed/autoencoders/autoencoder_kl.py` | ✅ | ❌ |
-| **Wan2.2** | `vllm_omni/diffusion/distributed/autoencoders/autoencoder_kl_wan.py` | ✅ | ✅ |
-| **Qwen-Image** | `vllm_omni/diffusion/distributed/autoencoders/autoencoder_kl_qwenimage.py` | ✅ | ❌ |
-
----
-
-## Summary
-
-Adding VAE Patch Parallel support to diffusion model:
-
-1. **Implement Distributed VAE** - Inherit from base VAE class and `DistributedVaeMixin`
-2. **Decode Parallel** - Refactor `tiled_decode` into `tile_split`/`tile_exec`/`tile_merge`
-3. **Encode Parallel** (optional) - Implement `encode_tile_split`/`encode_tile_exec`/`encode_tile_merge` for I2V models
-4. **Change VAE model in pipeline** - Use the distributed version
-5. **Test** - Verify numerical consistency with `vae_patch_parallel_size=1` vs `N`
diff --git a/docs/design/figures/omni/E2EL_s_vllm_omni_vs_transformers.png b/docs/design/figures/omni/E2EL_s_vllm_omni_vs_transformers.png
deleted file mode 100644
index 15112d5862a..00000000000
Binary files a/docs/design/figures/omni/E2EL_s_vllm_omni_vs_transformers.png and /dev/null differ
diff --git a/docs/design/figures/omni/Mean_AUDIO_RTF_Baseline_vs_Batch.png b/docs/design/figures/omni/Mean_AUDIO_RTF_Baseline_vs_Batch.png
deleted file mode 100644
index 2f0615f77bb..00000000000
Binary files a/docs/design/figures/omni/Mean_AUDIO_RTF_Baseline_vs_Batch.png and /dev/null differ
diff --git a/docs/design/figures/omni/Mean_AUDIO_RTF_Batch_CUDA_Graph_vs_Async_Chunk.png b/docs/design/figures/omni/Mean_AUDIO_RTF_Batch_CUDA_Graph_vs_Async_Chunk.png
deleted file mode 100644
index 62d8bc79b6b..00000000000
Binary files a/docs/design/figures/omni/Mean_AUDIO_RTF_Batch_CUDA_Graph_vs_Async_Chunk.png and /dev/null differ
diff --git a/docs/design/figures/omni/Mean_AUDIO_RTF_Batch_vs_Batch_CUDA_Graph.png b/docs/design/figures/omni/Mean_AUDIO_RTF_Batch_vs_Batch_CUDA_Graph.png
deleted file mode 100644
index 5838b45319e..00000000000
Binary files a/docs/design/figures/omni/Mean_AUDIO_RTF_Batch_vs_Batch_CUDA_Graph.png and /dev/null differ
diff --git a/docs/design/figures/omni/Mean_AUDIO_TTFP_ms_Baseline_vs_Batch.png b/docs/design/figures/omni/Mean_AUDIO_TTFP_ms_Baseline_vs_Batch.png
deleted file mode 100644
index 24be814b7e9..00000000000
Binary files a/docs/design/figures/omni/Mean_AUDIO_TTFP_ms_Baseline_vs_Batch.png and /dev/null differ
diff --git a/docs/design/figures/omni/Mean_AUDIO_TTFP_ms_Batch_CUDA_Graph_vs_Async_Chunk.png b/docs/design/figures/omni/Mean_AUDIO_TTFP_ms_Batch_CUDA_Graph_vs_Async_Chunk.png
deleted file mode 100644
index c8df58ebcdf..00000000000
Binary files a/docs/design/figures/omni/Mean_AUDIO_TTFP_ms_Batch_CUDA_Graph_vs_Async_Chunk.png and /dev/null differ
diff --git a/docs/design/figures/omni/Mean_AUDIO_TTFP_ms_Batch_vs_Batch_CUDA_Graph.png b/docs/design/figures/omni/Mean_AUDIO_TTFP_ms_Batch_vs_Batch_CUDA_Graph.png
deleted file mode 100644
index 2d1a04e9c2c..00000000000
Binary files a/docs/design/figures/omni/Mean_AUDIO_TTFP_ms_Batch_vs_Batch_CUDA_Graph.png and /dev/null differ
diff --git a/docs/design/figures/omni/Mean_E2EL_ms_Baseline_vs_Batch.png b/docs/design/figures/omni/Mean_E2EL_ms_Baseline_vs_Batch.png
deleted file mode 100644
index e598b543431..00000000000
Binary files a/docs/design/figures/omni/Mean_E2EL_ms_Baseline_vs_Batch.png and /dev/null differ
diff --git a/docs/design/figures/omni/Mean_E2EL_ms_Batch_CUDA_Graph_vs_Async_Chunk.png b/docs/design/figures/omni/Mean_E2EL_ms_Batch_CUDA_Graph_vs_Async_Chunk.png
deleted file mode 100644
index 54452013eb4..00000000000
Binary files a/docs/design/figures/omni/Mean_E2EL_ms_Batch_CUDA_Graph_vs_Async_Chunk.png and /dev/null differ
diff --git a/docs/design/figures/omni/Mean_E2EL_ms_Batch_vs_Batch_CUDA_Graph.png b/docs/design/figures/omni/Mean_E2EL_ms_Batch_vs_Batch_CUDA_Graph.png
deleted file mode 100644
index 04c5ad7396a..00000000000
Binary files a/docs/design/figures/omni/Mean_E2EL_ms_Batch_vs_Batch_CUDA_Graph.png and /dev/null differ
diff --git a/docs/design/figures/omni/RTF_vllm_omni_vs_transformers.png b/docs/design/figures/omni/RTF_vllm_omni_vs_transformers.png
deleted file mode 100644
index d93ba0b2af5..00000000000
Binary files a/docs/design/figures/omni/RTF_vllm_omni_vs_transformers.png and /dev/null differ
diff --git a/docs/design/figures/omni/Summary_E2EL_ms_vs_features.png b/docs/design/figures/omni/Summary_E2EL_ms_vs_features.png
deleted file mode 100644
index 04087b5910f..00000000000
Binary files a/docs/design/figures/omni/Summary_E2EL_ms_vs_features.png and /dev/null differ
diff --git a/docs/design/figures/omni/Summary_RTF_vs_features.png b/docs/design/figures/omni/Summary_RTF_vs_features.png
deleted file mode 100644
index c2c8ad40834..00000000000
Binary files a/docs/design/figures/omni/Summary_RTF_vs_features.png and /dev/null differ
diff --git a/docs/design/figures/omni/Summary_TTFP_ms_vs_features.png b/docs/design/figures/omni/Summary_TTFP_ms_vs_features.png
deleted file mode 100644
index 3dcc1c55379..00000000000
Binary files a/docs/design/figures/omni/Summary_TTFP_ms_vs_features.png and /dev/null differ
diff --git a/docs/design/figures/omni/TTFP_s_vllm_omni_vs_transformers.png b/docs/design/figures/omni/TTFP_s_vllm_omni_vs_transformers.png
deleted file mode 100644
index 9a5b6c9bdaf..00000000000
Binary files a/docs/design/figures/omni/TTFP_s_vllm_omni_vs_transformers.png and /dev/null differ
diff --git a/docs/design/figures/tts/Mean_AUDIO_RTF_vllm_omni_vs_transformers.png b/docs/design/figures/tts/Mean_AUDIO_RTF_vllm_omni_vs_transformers.png
deleted file mode 100644
index 68f0ef17e88..00000000000
Binary files a/docs/design/figures/tts/Mean_AUDIO_RTF_vllm_omni_vs_transformers.png and /dev/null differ
diff --git a/docs/design/figures/tts/Mean_AUDIO_TTFP_(ms)_vllm_omni_vs_transformers.png b/docs/design/figures/tts/Mean_AUDIO_TTFP_(ms)_vllm_omni_vs_transformers.png
deleted file mode 100644
index 44be96e96da..00000000000
Binary files a/docs/design/figures/tts/Mean_AUDIO_TTFP_(ms)_vllm_omni_vs_transformers.png and /dev/null differ
diff --git a/docs/design/figures/tts/Mean_E2EL_(ms)_vllm_omni_vs_transformers.png b/docs/design/figures/tts/Mean_E2EL_(ms)_vllm_omni_vs_transformers.png
deleted file mode 100644
index 2e5d1482bd7..00000000000
Binary files a/docs/design/figures/tts/Mean_E2EL_(ms)_vllm_omni_vs_transformers.png and /dev/null differ
diff --git a/docs/design/figures/tts/Mean_mean_e2e_ms_baseline_vs_batch.png b/docs/design/figures/tts/Mean_mean_e2e_ms_baseline_vs_batch.png
deleted file mode 100644
index 04d8f0bac53..00000000000
Binary files a/docs/design/figures/tts/Mean_mean_e2e_ms_baseline_vs_batch.png and /dev/null differ
diff --git a/docs/design/figures/tts/Mean_mean_e2e_ms_batch_vs_cuda_graph.png b/docs/design/figures/tts/Mean_mean_e2e_ms_batch_vs_cuda_graph.png
deleted file mode 100644
index eb85ec0dd4f..00000000000
Binary files a/docs/design/figures/tts/Mean_mean_e2e_ms_batch_vs_cuda_graph.png and /dev/null differ
diff --git a/docs/design/figures/tts/Mean_mean_e2e_ms_cuda_graph_vs_async_chunk.png b/docs/design/figures/tts/Mean_mean_e2e_ms_cuda_graph_vs_async_chunk.png
deleted file mode 100644
index 6f0e0e2529d..00000000000
Binary files a/docs/design/figures/tts/Mean_mean_e2e_ms_cuda_graph_vs_async_chunk.png and /dev/null differ
diff --git a/docs/design/figures/tts/Mean_mean_rtf_baseline_vs_batch.png b/docs/design/figures/tts/Mean_mean_rtf_baseline_vs_batch.png
deleted file mode 100644
index 89ea30a8643..00000000000
Binary files a/docs/design/figures/tts/Mean_mean_rtf_baseline_vs_batch.png and /dev/null differ
diff --git a/docs/design/figures/tts/Mean_mean_rtf_batch_vs_cuda_graph.png b/docs/design/figures/tts/Mean_mean_rtf_batch_vs_cuda_graph.png
deleted file mode 100644
index 2b207b88987..00000000000
Binary files a/docs/design/figures/tts/Mean_mean_rtf_batch_vs_cuda_graph.png and /dev/null differ
diff --git a/docs/design/figures/tts/Mean_mean_rtf_cuda_graph_vs_async_chunk.png b/docs/design/figures/tts/Mean_mean_rtf_cuda_graph_vs_async_chunk.png
deleted file mode 100644
index f5f7ad72c8f..00000000000
Binary files a/docs/design/figures/tts/Mean_mean_rtf_cuda_graph_vs_async_chunk.png and /dev/null differ
diff --git a/docs/design/figures/tts/Mean_mean_ttfp_ms_baseline_vs_batch.png b/docs/design/figures/tts/Mean_mean_ttfp_ms_baseline_vs_batch.png
deleted file mode 100644
index 6f8c1da4a5b..00000000000
Binary files a/docs/design/figures/tts/Mean_mean_ttfp_ms_baseline_vs_batch.png and /dev/null differ
diff --git a/docs/design/figures/tts/Mean_mean_ttfp_ms_batch_vs_cuda_graph.png b/docs/design/figures/tts/Mean_mean_ttfp_ms_batch_vs_cuda_graph.png
deleted file mode 100644
index b0fe1d02a9d..00000000000
Binary files a/docs/design/figures/tts/Mean_mean_ttfp_ms_batch_vs_cuda_graph.png and /dev/null differ
diff --git a/docs/design/figures/tts/Mean_mean_ttfp_ms_cuda_graph_vs_async_chunk.png b/docs/design/figures/tts/Mean_mean_ttfp_ms_cuda_graph_vs_async_chunk.png
deleted file mode 100644
index 008ba9bf78f..00000000000
Binary files a/docs/design/figures/tts/Mean_mean_ttfp_ms_cuda_graph_vs_async_chunk.png and /dev/null differ
diff --git a/docs/design/figures/tts/Summary_mean_e2e_ms_vs_features.png b/docs/design/figures/tts/Summary_mean_e2e_ms_vs_features.png
deleted file mode 100644
index 7c65aa11770..00000000000
Binary files a/docs/design/figures/tts/Summary_mean_e2e_ms_vs_features.png and /dev/null differ
diff --git a/docs/design/figures/tts/Summary_mean_rtf_vs_features.png b/docs/design/figures/tts/Summary_mean_rtf_vs_features.png
deleted file mode 100644
index 71bb2c54680..00000000000
Binary files a/docs/design/figures/tts/Summary_mean_rtf_vs_features.png and /dev/null differ
diff --git a/docs/design/figures/tts/Summary_mean_ttfp_ms_vs_features.png b/docs/design/figures/tts/Summary_mean_ttfp_ms_vs_features.png
deleted file mode 100644
index cef2546d6fe..00000000000
Binary files a/docs/design/figures/tts/Summary_mean_ttfp_ms_vs_features.png and /dev/null differ
diff --git a/docs/design/index.md b/docs/design/index.md
deleted file mode 100644
index 31420550fbd..00000000000
--- a/docs/design/index.md
+++ /dev/null
@@ -1,18 +0,0 @@
-# Design Documents
-
-This section contains design documents and architecture specifications for vLLM-Omni.
-
-## Architecture Documents
-
-- [Architecture Overview](architecture_overview.md)
-
-## Feature Design Documents
-
-- [Disaggregated Inference](feature/disaggregated_inference.md)
-- [Ray-based Execution](feature/ray_based_execution.md)
-
-## Module Design Documents
-
-- [AR Module](module/ar_module.md)
-- [DIT Module](module/dit_module.md)
-- [Entrypoint Module](module/entrypoint_module.md)
diff --git a/docs/design/module/ar_module.md b/docs/design/module/ar_module.md
deleted file mode 100644
index 5e0aa5b0713..00000000000
--- a/docs/design/module/ar_module.md
+++ /dev/null
@@ -1,387 +0,0 @@
-# AutoRegressive (AR) Module
-
-## 1. Overview
-
-The AutoRegressive (AR) module in vLLM-Omni handles autoregressive generation stages, primarily used for text, chain-of-thought(COT), and audio latent tokens generation stages in multi-stage models like Qwen2.5-Omni, Qwen3-Omni, BAGEL, .etc. Unlike some representative non-autoregressive generation stages (e.g., Diffusion), AR stages generate tokens sequentially, one at a time, following the standard transformer decoder pattern.
-
-The AR module of vLLM-Omni extends vLLM's core components to support:
-
-- **Multimodal inputs/outputs**: Processing images, videos, and audio alongside text
-- **Direct embedding transfer**: Passing pre-computed prompt embeddings between pipeline stages via serialized payloads
-- **Additional information flow**: Carrying per-request metadata (tensors, lists) through the pipeline
-- **Hidden state exposure**: Exposing per-request hidden representations for downstream stages
-- **Basic generator support**: Support some basic heterogeneous architecture such as Convolution, LSTM, etc.
-
-As shown in the [end2end example](../../user_guide/examples/offline_inference/qwen3_omni.md), AR module can be widely applied across multiple stages, generating text tokens in thinker(AR), audio latent tokens in talker(AR) and audio wave in code2wav(Convolution).
-
-## 2. Relationship with vLLM
-
-The AR module builds upon vLLM main framework through inheritance, extending core classes while preserving compatibility with vLLM's scheduling, batching, KV cache management, and execution mechanisms.
-
-### Inheritance Hierarchy
-- Scheduler
-
-```mermaid
-classDiagram
- class VLLMScheduler {
- +schedule() SchedulerOutput
- +update_from_output() EngineCoreOutputs
- }
- class OmniARScheduler {
- +schedule() SchedulerOutput
- }
- class OmniGenerationScheduler {
- +schedule() SchedulerOutput
- +update_from_output() EngineCoreOutputs
- }
- VLLMScheduler <|-- OmniARScheduler
- VLLMScheduler <|-- OmniGenerationScheduler
-```
-- Worker
-
-```mermaid
-classDiagram
- class GPUWorker {
- +init_device()
- +model_runner
- }
- class GPUARWorker {
- +init_device()
- }
- class GPUGenerationWorker {
- +init_device()
- }
- GPUWorker <|-- GPUARWorker
- GPUWorker <|-- GPUGenerationWorker
-```
-- ModelRunner
-
-```mermaid
-classDiagram
- class GPUModelRunner {
- +execute_model()
- +sample_tokens()
- }
- class OmniGPUModelRunner {
- +_update_states()
- +_preprocess()
- +_model_forward()
- }
- class GPUARModelRunner {
- +execute_model()
- +sample_tokens()
- }
- class GPUGenerationModelRunner {
- +execute_model()
- }
- GPUModelRunner <|-- OmniGPUModelRunner
- OmniGPUModelRunner <|-- GPUARModelRunner
- OmniGPUModelRunner <|-- GPUGenerationModelRunner
-```
-- InputProcessor/OutputProcessor
-
-```mermaid
-classDiagram
- class InputProcessor {
- +process_inputs() EngineCoreRequest
- }
-
- class VLLMOutputProcessor {
- +process_outputs() OutputProcessorOutput
- }
- class MultimodalOutputProcessor {
- +process_outputs() OutputProcessorOutput
- +_route_and_normalize()
- }
- VLLMOutputProcessor <|-- MultimodalOutputProcessor
-```
-
-### Key Extensions
-
-- **Scheduler**: `OmniARScheduler` extends `vllm.v1.core.sched.scheduler.Scheduler` to enrich scheduled requests with omni-specific payloads
-- **Worker**: `GPUARWorker` extends `vllm.v1.worker.gpu_worker.Worker` to initialize AR-specific model runners
-- **ModelRunner**: `GPUARModelRunner` extends `OmniGPUModelRunner` → `vllm.v1.worker.gpu_model_runner.GPUModelRunner` to expose hidden states and handle multimodal outputs
-- **InputProcessor**: Stage-0 uses upstream `vllm.v1.engine.input_processor.InputProcessor`; `AsyncOmniEngine` then restores omni-specific payloads (for example `additional_information` and `prompt_embeds`) when building `OmniEngineCoreRequest`
-- **OutputProcessor**: `MultimodalOutputProcessor` extends `vllm.v1.engine.output_processor.OutputProcessor` to route and accumulate multimodal outputs
-
-## 3. Scheduler Design
-
-The AR module provides two scheduler implementations: one for standard autoregressive generation and one for basic heterogeneous architectures.
-
-### Request Flow
-
-The following diagram illustrates the request flow through the AR module components:
-
-```mermaid
-flowchart TD
- A[InputProcessor stage-0 in AsyncOmniEngine] -->|EngineCoreRequest then upgraded to OmniEngineCoreRequest| B[OmniARScheduler]
- B -->|schedule: OmniNewRequestData| C[GPUARWorker]
- C -->|SchedulerOutput| D[GPUARModelRunner]
- D -->|execute_model: None| E[Model Forward Pass]
- E -->|hidden_states, logits| D
- D -->|sample_tokens: OmniModelRunnerOutput| F[OmniARScheduler]
- F -->|update_from_output| G[MultimodalOutputProcessor]
- G -->|RequestOutput| H[Client/Downstream Stage]
-
- style A fill:#e1f5ff
- style B fill:#fff4e1
- style C fill:#e8f5e9
- style D fill:#f3e5f5
- style G fill:#fce4ec
-```
-
-The flow follows vLLM's standard pattern: input processing → scheduling → worker execution → output processing, with omni-specific enrichments at each stage.
-
-### OmniARScheduler
-
-`OmniARScheduler` extends the base vLLM scheduler with minimal modifications, focusing on enriching scheduled requests with omni-specific payloads.
-
-#### Modified API: `schedule()`
-
-The scheduler wraps base `NewRequestData` entries with `OmniNewRequestData` to include prompt embeddings and additional information:
-
-```python
-def schedule(self) -> SchedulerOutput:
- scheduler_output = super().schedule()
- # Rewrap base NewRequestData entries with OmniNewRequestData
- new_list = []
- for nr in scheduler_output.scheduled_new_reqs:
- request = self.requests.get(nr.req_id)
- omni_nr = OmniNewRequestData(
- req_id=nr.req_id,
- prompt_token_ids=nr.prompt_token_ids,
- # ... other base fields ...
- prompt_embeds=getattr(request, "prompt_embeds", None),
- additional_information=getattr(request, "additional_information", None),
- )
- new_list.append(omni_nr)
- scheduler_output.scheduled_new_reqs = new_list
- return scheduler_output
-```
-
-The `update_from_output()` method remains unchanged, inheriting standard request lifecycle management from the base scheduler.
-
-### OmniGenerationScheduler
-
-`OmniGenerationScheduler` implements a fast-path scheduling strategy for basic heterogeneous architectures that process all input tokens in a single step.
-
-#### Modified API: `schedule()`
-
-Allocates all input tokens for a request at once (or 1 placeholder if zero), falling back to default scheduling if budget is insufficient:
-
-```python
-def schedule(self) -> SchedulerOutput:
- # Fast path: allocate all input tokens at once
- while self.waiting and token_budget > 0:
- request = self.waiting.peek_request()
- required_tokens = max(getattr(request, "num_prompt_tokens", 0), 1)
- if required_tokens > token_budget:
- break # Fall back to default scheduling
- # Allocate and schedule...
-```
-
-#### Modified API: `update_from_output()`
-
-Marks requests as finished immediately after one step, since generation models complete in a single forward pass:
-
-```python
-def update_from_output(self, ...) -> dict[int, EngineCoreOutputs]:
- # ...
- # Diffusion request: completes in one step
- request.status = RequestStatus.FINISHED_STOPPED
- kv_transfer_params = self._free_request(request)
- # ...
-```
-
-## 4. Worker and ModelRunner Design
-
-### GPUARWorker
-
-`GPUARWorker` initializes the AR-specific model runner while maintaining standard device initialization:
-
-```python
-class GPUARWorker(GPUWorker):
- def init_device(self):
- # ... standard device initialization ...
- self.model_runner = GPUARModelRunner(self.vllm_config, self.device)
-```
-
-### GPUARModelRunner
-
-`GPUARModelRunner` follows vLLM's two-phase execute/sample flow while exposing hidden states and multimodal outputs.
-
-#### Two-Phase Execution
-
-**Phase 1: `execute_model()`** - Runs forward pass and stores state:
-- Computes logits from hidden states
-- Stores `ExecuteModelState` with hidden states, logits, and multimodal outputs
-- Returns `None` to defer sampling
-
-**Phase 2: `sample_tokens()`** - Samples tokens and builds output:
-- Retrieves stored state from `execute_model()`
-- Samples tokens using logits
-- Extracts per-request hidden states and multimodal outputs
-- Builds `OmniModelRunnerOutput` with `pooler_output` containing hidden states
-
-```python
-def sample_tokens(self, grammar_output) -> OmniModelRunnerOutput:
- # Retrieve stored state
- hidden_states, multimodal_outputs = self.execute_model_state
-
- # Sample tokens
- sampler_output = self._sample(logits, spec_decode_metadata)
-
- # Extract per-request hidden states
- pooler_output = []
- for rid in req_ids:
- hidden_slice = hidden_states_cpu[start:end]
- payload = {"hidden": hidden_slice}
- # Add multimodal outputs if present
- pooler_output.append(payload)
-
- return OmniModelRunnerOutput(
- pooler_output=pooler_output,
- # ... other fields ...
- )
-```
-
-### GPUGenerationModelRunner
-
-`GPUGenerationModelRunner` implements a simplified single-phase execution for basic heterogeneous architectures:
-
-- No logits computation or token sampling
-- Direct generation from forward pass in model implementation
-- Returns outputs via `pooler_output` immediately after forward pass
-
-### OmniGPUModelRunner
-
-`OmniGPUModelRunner` provides shared functionality for both AR and Generation runners:
-
-#### Prompt Embeddings Overlay
-
-During prefill, overlays custom `prompt_embeds` from request state onto `inputs_embeds`:
-
-```python
-def _collect_additional_information_for_prefill(self, num_scheduled_tokens_np):
- for req_index, req_id in enumerate(self.input_batch.req_ids):
- req_state = self.requests[req_id]
- pe_cpu = getattr(req_state, "prompt_embeds_cpu", None)
- # Overlay prompt_embeds for prefill portion
- if pe_cpu is not None:
- src = pe_cpu[num_computed_tokens:num_computed_tokens + overlay_len]
- self.inputs_embeds[start_offset:start_offset + overlay_len].copy_(src)
-```
-
-#### Additional Information Processing
-
-Decodes and manages `additional_information` payloads:
-- Decodes serialized payloads → CPU tensors in request state
-- Passes runtime information to model via `runtime_additional_information` kwarg
-- Processes model-provided updates via `postprocess()` hook
-- Merges updates back into request state
-
-#### M-RoPE Position Initialization
-
-For multimodal models using M-RoPE (e.g., Qwen2-VL), computes position encodings from multimodal feature metadata (image grids, video grids, audio features).
-
-## 5. Input/Output Processing
-
-### Processing Pipeline
-
-The input/output processing pipeline handles serialization, routing, and accumulation of multimodal data:
-
-```mermaid
-sequenceDiagram
- participant Client
- participant AsyncOmniEngine
- participant InputProcessor
- participant Scheduler
- participant ModelRunner
- participant MultimodalOutputProcessor
- participant Client
-
- Client->>AsyncOmniEngine: prompt + prompt_embeds + additional_info
- AsyncOmniEngine->>InputProcessor: process_inputs()
- InputProcessor->>Scheduler: EngineCoreRequest
- AsyncOmniEngine->>AsyncOmniEngine: _upgrade_to_omni_request() + serialize_additional_information()
- Scheduler->>ModelRunner: OmniNewRequestData (with payloads)
- ModelRunner->>ModelRunner: Decode payloads → CPU tensors
- ModelRunner->>ModelRunner: Overlay prompt_embeds on inputs_embeds
- ModelRunner->>ModelRunner: Forward pass with runtime_additional_information
- ModelRunner->>ModelRunner: Extract hidden states + multimodal outputs
- ModelRunner->>MultimodalOutputProcessor: OmniModelRunnerOutput (pooler_output)
- MultimodalOutputProcessor->>MultimodalOutputProcessor: Route by output_type
- MultimodalOutputProcessor->>MultimodalOutputProcessor: Accumulate tensors in OmniRequestState
- MultimodalOutputProcessor->>MultimodalOutputProcessor: Consolidate tensor lists
- MultimodalOutputProcessor->>Client: RequestOutput (with multimodal_output)
-```
-
-### Stage-0 Input Processing
-
-Stage-0 now uses upstream `InputProcessor` directly, and `AsyncOmniEngine` upgrades the request to `OmniEngineCoreRequest` while restoring omni-specific payloads.
-
-```python
-request = self.input_processor.process_inputs(
- request_id=request_id,
- prompt=prompt,
- params=params,
- supported_tasks=self.supported_tasks,
-)
-request = _upgrade_to_omni_request(request, prompt)
-```
-
-### MultimodalOutputProcessor
-
-`MultimodalOutputProcessor` routes outputs by modality type and accumulates multimodal tensors.
-
-#### Output Routing
-
-Routes `EngineCoreOutput` by `output_type` attribute:
-- `"text"`: Standard text generation path
-- `"image"`, `"audio"`, `"latents"`: Extract from `pooling_output` or `multimodal_outputs`
-- Fallback: Heuristic based on presence of `pooling_output`
-
-#### Tensor Accumulation
-
-`OmniRequestState` accumulates multimodal tensors across multiple steps:
-
-```python
-def add_multimodal_tensor(self, payload, mm_type):
- # Normalize payload to dict
- incoming = {mm_type or "hidden": payload}
-
- # Accumulate: convert tensors to lists for deferred concatenation
- if isinstance(v, torch.Tensor) and isinstance(existing, torch.Tensor):
- self.mm_accumulated[k] = [existing, v] # List accumulation
-```
-
-Before final output, consolidates tensor lists via concatenation:
-
-```python
-def _consolidate_multimodal_tensors(self):
- for k, v in self.mm_accumulated.items():
- if isinstance(v, list) and isinstance(v[0], torch.Tensor):
- self.mm_accumulated[k] = torch.cat(v, dim=0) # Concatenate
-```
-
-The consolidated tensors are attached to `RequestOutput.multimodal_output` for consumption by downstream stages or clients.
-
-## 6. Summary
-
-The AR module of vLLM-Omni extends vLLM through strategic inheritance and minimal API modifications:
-
-### Key Design Patterns
-
-1. **Inheritance over composition**: Extends vLLM classes to preserve compatibility with existing scheduling, batching, and execution mechanisms
-2. **Payload serialization**: Uses serialized `additional_information` payloads together with prompt-embedding handoff for efficient inter-stage transfer
-3. **Two-phase execution**: Maintains vLLM's execute/sample separation for AR models while supporting single-phase execution for generation models
-4. **Multimodal routing**: Routes outputs by `output_type` and accumulates tensors incrementally to support streaming
-
-### Differences from vLLM
-
-- **Payload support**: Serialized additional information and prompt embeddings enable direct transfer between pipeline stages
-- **Multimodal handling**: Extended input/output processors support images, audio, and other modalities alongside text
-- **Hidden state exposure**: AR model runners expose per-request hidden states via `pooler_output` for downstream consumption
-- **Generation scheduler**: Fast-path scheduling for basic heterogeneous architectures that complete in one step
-
-The AR module seamlessly integrates with vLLM's existing infrastructure while adding the necessary extensions for multi-stage, multimodal generation pipelines.
diff --git a/docs/design/module/async_omni_architecture.md b/docs/design/module/async_omni_architecture.md
deleted file mode 100644
index 92b13a3da08..00000000000
--- a/docs/design/module/async_omni_architecture.md
+++ /dev/null
@@ -1,203 +0,0 @@
-# AsyncOmni Architecture (Qwen3-Omni Example)
-
-## 1. System Architecture
-
-```text
-• ┌─────────────────────────────────────────────────────────────────────────────────┐
- │ API Layer │
- │ ┌─────────────────────────────────────┐ ┌──────────────────────────────────┐ │
- │ │ AsyncOmni (EngineClient) │ │ Omni │ │
- │ │ • generate() / abort() / shutdown() │ │ • generate() │ │
- │ │ • _final_output_handler() │ │ | │
- │ └─────────────────────────────────────┘ └──────────────────────────────────┘ │
- ├─────────────────────────────────────────────────────────────────────────────────┤
- │ Engine Layer (Proxy) │
- │ ┌───────────────────────────────────────────────────────────────────────────┐ │
- │ │ AsyncOmniEngine │ │
- │ │ • _bootstrap_orchestrator() & _initialize_stages() │ │
- │ │ • add_request() / add_request_async() -> input_processor.process_inputs() │ │
- │ │ • try_get_output() / try_get_output_async() │ │
- │ └───────────────────┬─────────────────────────────────▲─────────────────────┘ │
- │ request_queue (janus.Queue) output_queue (janus.Queue) │
- ├──────────────────────┼─────────────────────────────────┼────────────────────────┤
- │ ▼ Orchestration Layer │ │
- │ ┌───────────────────────────────────────────────────────────────────────────┐ │
- │ │ Orchestrator [background thread] │ │
- │ │ • _request_handler() │ │
- │ │ - stage_client.add_request_async() & _prewarm_async_chunk_stages() │ │
- │ │ • _orchestration_output_handler() │ │
- │ │ - _process_stage_outputs() -> output_processors[i].process_outputs() │ │
- │ │ - _route_output() & _forward_to_next_stage() │ │
- │ └──────────┬─────────────────────────┬────────────────────────┬─────────────┘ │
- ├─────────────┼─────────────────────────┼────────────────────────┼────────────────┤
- │ │ Communication Layer │ │
- │ ┌───────────────────────┐ ┌───────────────────────┐ ┌───────────────────────┐ │
- │ │ StageEngineCoreClient │ │ StageEngineCoreClient │ │ StageDiffusionClient │ │
- │ │ • ZMQ ROUTER / PULL │ │ • ZMQ ROUTER / PULL │ │ • ZMQ ROUTER / PULL │ │
- │ │ • Msgpack codec │ │ • Msgpack codec │ │ • Msgpack codec │ │
- │ └──────────┬────────────┘ └──────────┬────────────┘ └──────────┬────────────┘ │
- │ ▼ ZMQ IPC ▼ ZMQ IPC ▼ ZMQ IPC │
- ├─────────────────────────────────────────────────────────────────────────────────┤
- │ Execution Layer │
- │ ┌───────────────────────┐ ┌───────────────────────┐ ┌───────────────────────┐ │
- │ │ StageCoreProc │ │ StageCoreProc │ │ DiffusionEngine │ │
- │ │ [background process] │ │ [background process] │ │ [background process] │ │
- │ └───────────────────────┘ └───────────────────────┘ └───────────────────────┘ │
- └─────────────────────────────────────────────────────────────────────────────────┘
-```
-
-## 2. Execution Flow (Arrow Steps, one generate request)
-
-```text
-[1] App
- -> AsyncOmni.generate(prompt, request_id)
-
-[2] AsyncOmni
- -> _final_output_handler() (started on first request)
- -> AsyncOmniEngine.add_request(stage_id=0, ...)
-
-[3] AsyncOmniEngine.add_request
- -> (if stage-0 is llm and input is not EngineCoreRequest)
- InputProcessor.process_inputs()
- OutputProcessor[0].add_request()
- -> request_queue.put(add_request_msg)
-
-[4] Orchestrator._request_handler
- -> _handle_add_request(msg)
- -> stage_clients[0].add_request_async(...)
-
-[5] Orchestrator._orchestration_loop (loop)
- -> poll stage output
- - llm stage: await get_output_async()
- - diffusion stage: get_diffusion_output_nowait()
- -> (llm stage) output_processors[i].process_outputs(...)
- -> _route_output(...)
- -> if finished and not final_stage and non-async-chunk:
- _forward_to_next_stage(...)
- -> next_stage.add_request_async(...)
- -> output_queue.put(output)
-
-[6] AsyncOmni._final_output_loop (background coroutine)
- -> AsyncOmniEngine.try_get_output_async()
- -> route by request_id to ClientRequestState.queue
-
-[7] AsyncOmni._process_orchestrator_results
- -> read from ClientRequestState.queue
- -> _process_single_result(...)
- -> yield OmniRequestOutput
-
-[8] Exit condition
- -> receive result["finished"] == True
- -> generate() ends
-```
-
-## 3. Runtime Sequence (one generate request)
-
-```mermaid
-sequenceDiagram
- participant APP as App
- participant AO as AsyncOmni
- participant ENG as AsyncOmniEngine
- participant ORCH as Orchestrator
- participant S0 as Stage-0 Client
- participant SN as Next Stage Client
-
- APP->>AO: generate
- AO->>AO: start output_handler once
- AO->>ENG: add_request(stage_id=0, ...)
- ENG->>ENG: input_processor.process_inputs()
- ENG->>ORCH: request_queue.put(add_request)
-
- ORCH->>ORCH: _handle_add_request
- ORCH->>S0: add_request_async
-
- loop poll route forward
- ORCH->>S0: get_output_async / get_diffusion_output_nowait
- ORCH->>ORCH: _route_output
- alt need forward to next stage
- ORCH->>SN: add_request_async
- end
- ORCH-->>ENG: output_queue.put
- end
-
- AO->>ENG: try_get_output_async
- ENG-->>AO: message
- AO-->>APP: yield OmniRequestOutput
-```
-
-## 4. Comparison
-
-Previous topology (reference):
-
-```text
-┌────────────────────────────────────────────────────────────────────────────┐
-│ Main Process │
-│ ┌──────────────────────┐ ┌────────────────────────────────────────────┐ │
-│ │ generate() │ │ final_output_handler() │ │
-│ └──────────────────────┘ └────────────────────────────────────────────┘ │
-└──────────┬─────────────────────────┬─────────────────────────┬─────────────┘
- mp.Queue (in_q/out_q) mp.Queue (in_q/out_q) mp.Queue (in_q/out_q)
- ▼▲ ▼▲ ▼▲
-┌───────────────────────┐ ┌───────────────────────┐ ┌──────────────────────┐
-│ Worker Proc-0 │ │ Worker Proc-1 │ │ Worker Proc-2 │
-│ (Thinker LLM) │ │ (Talker LLM) │ │ (Vocoder) │
-│ ┌────────────────┐ │ │ ┌────────────────┐ │ │ ┌────────────────┐ │
-│ │_stage_worker │ │ │ │_stage_worker │ │ │ │_stage_worker │ │
-│ │_async() │ │ │ │_async() │ │ │ │_async() │ │
-│ └────────────────┘ │ │ └────────────────┘ │ │ └────────────────┘ │
-│ ┌────────────────┐ │ │ ┌────────────────┐ │ │ ┌────────────────┐ │
-│ │output_handler()│ │ │ │output_handler()│ │ │ │output_handler()│ │
-│ └────────────────┘ │ │ └────────────────┘ │ │ └────────────────┘ │
-└──────────┬────────────┘ └──────────┬────────────┘ └──────────┬───────────┘
- ZMQ ▼ ▲ ZMQ ZMQ ▼ ▲ ZMQ ZMQ ▼ ▲ ZMQ
-┌──────────────────────┐ ┌──────────────────────┐ ┌──────────────────────┐
-│ EngineCore Proc-0 │ │ EngineCore Proc-1 │ │ EngineCore Proc-2 │
-│ (Thinker) │ │ (Talker) │ │ (Vocoder) │
-└──────────────────────┘ └──────────────────────┘ └──────────────────────┘
-```
-
-Current topology:
-
-```text
-┌────────────────────────────────────────────────────────────────────────────┐
-│ Main Process │
-│ ┌──────────────────────────────────────────────────────────────────────┐ │
-│ │ Main Thread │ │
-│ │ ┌──────────────────────┐ ┌─────────────────────────────────────┐ │ │
-│ │ │ generate() │ │ final_output_handler() │ │ │
-│ │ └──────────────────────┘ └─────────────────────────────────────┘ │ │
-│ └──────────────────────────────────────────────────────────────────────┘ │
-│ janus.Queue (request_queue) ▼ ▲ janus.Queue (output_queue) │
-│ ┌──────────────────────────────────────────────────────────────────────┐ │
-│ │ Orchestrator Thread │ │
-│ │ ┌──────────────────────┐ ┌──────────────────────────────────────┐ │ │
-│ │ │ _request_handler() │ │ _orchestration_output_handler() │ │ │
-│ │ └──────────────────────┘ └──────────────────────────────────────┘ │ │
-│ │ ┌────────────────────────────────────────────────────────────────┐ │ │
-│ │ │ _orchestration_loop(): poll/process/route outputs for all stages│ │ │
-│ │ └────────────────────────────────────────────────────────────────┘ │ │
-│ └───────┬─────────────────────────┬─────────────────────────┬──────────┘ │
-└──────────┬─────────────────────────┬─────────────────────────┬─────────────┘
- ZMQ ▼ ▲ ZMQ ZMQ ▼ ▲ ZMQ ZMQ ▼ ▲ ZMQ
- ┌──────────────────────┐ ┌──────────────────────┐ ┌──────────────────────┐
- │ EngineCore Proc-0 │ │ EngineCore Proc-1 │ │ EngineCore Proc-2 │
- │ (Thinker) │ │ (Talker) │ │ (Vocoder) │
- └──────────────────────┘ └──────────────────────┘ └──────────────────────┘
-```
-
-
-Test scripts:
-```bash
-# enter offline inference folder.
-cd examples/offline_inference/qwen2_5_omni
-python end2end.py --output-dir output_audio --query-type use_mixed_modalities
-
-cd ../qwen3_omni
-python end2end.py --output-dir output_audio --query-type text --async-chunk --enable-stats
-
-cd ../bagel
-python end2end.py --prompts "A cute cat"
-
-cd ../text_to_image
-python text_to_image.py --prompt "a cup of coffee on the table" --output output.png
-```
diff --git a/docs/design/module/dit_module.md b/docs/design/module/dit_module.md
deleted file mode 100644
index b0c7e9fc7fb..00000000000
--- a/docs/design/module/dit_module.md
+++ /dev/null
@@ -1,945 +0,0 @@
----
-toc_depth: 4
----
-
-# Diffusion Module Architecture Design
-
-The vLLM-Omni diffusion module (`vllm_omni/diffusion`) is a high-performance inference engine for diffusion models, designed with a modular architecture that separates concerns across multiple components. It provides efficient execution for non-autoregressive generation tasks such as image and video generation.
-
-This document describes the architecture design of the diffusion module, including the diffusion engine, scheduler, worker, diffusion pipeline, and acceleration components.
-
-
-
-| Metric | vLLM-Omni | HF Transformers | Improvement |
-| --- | --- | --- | --- |
-| E2E latency (s) | 23.78 | 336.10 | ~93% reduction |
-| TTFP (s) | 0.934 | 336.10 | ~99.7% reduction |
-| RTF | 0.32 | 3.776 | ~91% reduction (~12× faster) |
-
-- **E2E latency**: 23.78 s vs 336.10 s - **~93%** reduction
-- **TTFP**: 0.934 s vs 336.10 s - **~99.7%** reduction
-- **RTF**: 0.32 vs 3.776 - **~91%** reduction (~12x faster)
-
-**Qwen3-TTS** (H200, concurrency 1):
-
-
-
-| Metric | vLLM-Omni | HF Transformers | Improvement |
-| --- | --- | --- | --- |
-| E2E latency (ms) | 941 | 15,513 | ~94% reduction |
-| TTFP (ms) | 64 | 15,513 | ~99.6% reduction (242× faster) |
-| RTF | 0.16 | 2.64 | ~94% reduction (~16.5× faster) |
-
-- **E2E latency**: 941 ms vs 15,513 ms - **~94%** reduction
-- **TTFP**: 64 ms vs 15,513 ms - **~99.6%** reduction (242x faster)
-- **RTF**: 0.16 vs 2.64 - **~94%** reduction (~16.5x faster)
-
-### Stacked optimization summary
-
-Each optimization stacks on the previous one. The summary plots below show the cumulative effect at each step, with one line per concurrency level (1, 4, 10).
-
-**Qwen3-Omni** (A100):
-
-
-
-- **E2EL reduction**: ~74% at concurrency 10 (410,054 ms -> 104,901 ms); ~90% at concurrency 1 (426,529 ms -> 41,216 ms)
-- **TTFP reduction**: ~96% at concurrency 10 (409,705 ms -> 16,482 ms); ~99.7% at concurrency 1 (426,078 ms -> 1,164 ms)
-- **RTF reduction**: ~74% at concurrency 10 (2.83 -> 0.74); ~90% at concurrency 1 (2.08 -> 0.21)
-
-**Qwen3-TTS** (H200):
-
-
-
-- **E2EL reduction**: ~85% at concurrency 10 (12,141 ms -> 1,767 ms); ~29% at concurrency 1 (1,323 ms -> 941 ms)
-- **TTFP reduction**: ~96.5% at concurrency 10 (12,141 ms -> 425 ms); ~95% at concurrency 1 (1,323 ms -> 64 ms)
-- **RTF reduction**: ~86% at concurrency 10 (2.19 -> 0.31); ~30% at concurrency 1 (0.23 -> 0.16)
-
-**Benchmark environment:**
-
-| | Qwen3-Omni | Qwen3-TTS |
-| --- |-----------------------------| --- |
-| **GPU** | A100 | H200 |
-| **Model** | Qwen3-Omni-30B-A3B-Instruct | Qwen3-TTS-12Hz-1.7B-CustomVoice |
-| **vLLM** | v0.17.0 | v0.18.0 |
-| **vllm-omni** | commit 199f7832 | v0.18.0rc2 |
-| **CUDA** | 12.9 | 12.8 |
-
-This post walks through each optimization in the same order they are typically enabled in practice, then ends with deployment playbooks for both models.
-
----
-
-## Pipeline Batching
-
-### How stage-wise batching works
-
-For both Qwen3-Omni and Qwen3-TTS, batching is a pipeline-level optimization:
-
-- Requests are grouped per stage using `runtime.max_batch_size`
-- Each stage executes batch inference with its own scheduler/worker
-- Stage outputs are routed to downstream stages with per-request mapping preserved
-
-**Batching strategy by stage:** The understanding and decode stages (Thinker for Omni, Talker for both) use **continuous batching**: requests can join and leave the batch over time. Code2Wav uses **static batching**: once a batch is formed, the stage runs the whole batch before starting the next. This matches the decode pattern of Code2Wav and keeps implementation simple while still improving throughput.
-
-### Batching results (Baseline vs. Batch)
-
-Batching alone greatly reduces E2EL and RTF across all concurrencies. The biggest gains appear at high concurrency where requests share GPU resources.
-
-**Qwen3-Omni** (A100):
-
-
-
-| Metric | Concurrency | Baseline | + Batch | Improvement |
-| --- | --- | --- | --- | --- |
-| E2EL (ms) | 1 | 426,529 | 307,719 | 1.4× |
-| E2EL (ms) | 4 | 407,213 | 376,934 | 1.1× |
-| E2EL (ms) | 10 | 410,054 | 234,844 | 1.7× |
-| TTFP (ms) | 1 | 426,078 | 307,262 | 1.4× |
-| TTFP (ms) | 4 | 406,843 | 376,466 | 1.1× |
-| TTFP (ms) | 10 | 409,705 | 234,557 | 1.7× |
-| RTF | 1 | 2.08 | 1.51 | 1.4× |
-| RTF | 4 | 2.55 | 1.83 | 1.4× |
-| RTF | 10 | 2.83 | 2.28 | 1.2× |
-
-At concurrency 10, E2EL drops from ~410 s to ~235 s; at concurrency 1, from ~427 s to ~308 s.
-
-**Qwen3-TTS** (H200):
-
-
-
-| Metric | Concurrency | Baseline | + Batch | Improvement |
-| --- | --- | --- | --- | --- |
-| E2EL (ms) | 1 | 1,323 | 1,339 | 1.0× |
-| E2EL (ms) | 4 | 5,171 | 1,471 | 3.5× |
-| E2EL (ms) | 10 | 12,141 | 1,705 | 7.1× |
-| RTF | 1 | 0.230 | 0.234 | 1.0× |
-| RTF | 4 | 0.908 | 0.255 | 3.6× |
-| RTF | 10 | 2.186 | 0.292 | 7.5× |
-| Throughput (audio-s/wall-s) | 10 | 3.99 | 33.53 | 8.4× |
-
-At concurrency 10, batching alone brings Qwen3-TTS RTF from 2.19 (slower than realtime) down to 0.29 (faster than realtime), and throughput from 4.0 to 33.5 audio-sec/wall-sec.
-
----
-
-## CUDA Graph on the Critical Decode Path
-
-### Why CUDA Graph helps here
-
-In decode-heavy serving, repeatedly launching many small kernels from CPU can become a visible overhead. CUDA Graph reduces this overhead by capturing and replaying stable execution graphs.
-
-In stage configs, this is represented by `enforce_eager: false` for stages where graph capture is desired (Thinker/Talker), while Code2Wav keeps eager mode depending on stage behavior.
-
-### CUDA Graph results on top of batching
-
-**Qwen3-Omni** (A100):
-
-
-
-| Metric | Concurrency | Batch | + CUDA Graph | Improvement |
-| --- | --- | --- | --- | --- |
-| E2EL (ms) | 1 | 307,719 | 61,613 | 5.0× |
-| E2EL (ms) | 4 | 376,934 | 79,019 | 4.8× |
-| E2EL (ms) | 10 | 234,844 | 126,867 | 1.9× |
-| TTFP (ms) | 1 | 307,262 | 61,257 | 5.0× |
-| TTFP (ms) | 4 | 376,466 | 78,634 | 4.8× |
-| TTFP (ms) | 10 | 234,557 | 126,534 | 1.9× |
-| RTF | 1 | 1.51 | 0.32 | 4.7× |
-| RTF | 4 | 1.83 | 0.43 | 4.3× |
-| RTF | 10 | 2.28 | 0.90 | 2.5× |
-
-For the larger Qwen3-Omni model (30B-A3B), CUDA Graph provides a significant improvement. At concurrency 1, E2EL drops from ~308 s to ~62 s; at concurrency 10, from ~235 s to ~127 s.
-
-**Qwen3-TTS** (H200):
-
-
-
-| Metric | Concurrency | Batch | + CUDA Graph | Improvement |
-| --- | --- | --- | --- | --- |
-| E2EL (ms) | 1 | 1,339 | 733 | 1.8× |
-| E2EL (ms) | 4 | 1,471 | 987 | 1.5× |
-| E2EL (ms) | 10 | 1,705 | 1,197 | 1.4× |
-| RTF | 1 | 0.234 | 0.124 | 1.9× |
-| RTF | 10 | 0.292 | 0.203 | 1.4× |
-| Throughput (audio-s/wall-s) | 10 | 33.53 | 47.15 | 1.4× |
-
-At concurrency 1, CUDA Graph reduces E2EL from 1,339 ms to 733 ms and RTF from 0.234 to 0.124 - nearly a 2x improvement. The benefit is consistent across all concurrency levels.
-
----
-
-## Async Chunk and Streaming Output: Earlier Audio and Cross-Stage Overlap
-
-### Why this step matters for first-packet latency
-
-Two mechanisms work together to improve user-visible latency:
-
-- **Streaming output**: audio streaming emits audio chunks as soon as they are decoded (lower **TTFP**). Without streaming, the client waits for larger buffers or end-of-sequence.
-- **Async chunk** is the main enabler for *earlier* audio: instead of handing off whole-request results between stages, each stage forwards **chunks** so the next stage can start as soon as the first chunk is ready. For Omni: Thinker -> Talker forwards hidden-state chunks; for both: Talker -> Code2Wav forwards codec chunks; Code2Wav decodes and emits packets incrementally. This **overlaps compute and communication** across stages and directly reduces time-to-first-audio-packet (TTFP) and end-to-end latency (E2EL).
-
-So in practice: streaming output defines *how* bytes are sent to the client; async chunk defines *when* the pipeline can produce the first bytes.
-
-**Dependency between the two:** Async chunk and audio streaming output are mutually dependent. Without async chunk, **audio streaming output cannot truly take effect**. Without audio streaming output, async chunk's **TTFP advantage is not fully realized**: the client would still wait for larger buffers or end-of-sequence instead of hearing the first packet as soon as it is ready. We therefore recommend enabling **both** on top of batching + CUDA Graph; the benchmarks in this post use both.
-
-### Results: Batch + CUDA Graph vs. Batch + CUDA Graph + Async Chunk + Streaming Output
-
-**Qwen3-Omni** (A100):
-
-
-
-| Metric | Concurrency | Batch + CG | + Async Chunk | Improvement |
-| --- | --- | --- | --- | --- |
-| E2EL (ms) | 1 | 61,613 | 41,216 | 1.5× |
-| E2EL (ms) | 4 | 79,019 | 67,584 | 1.2× |
-| E2EL (ms) | 10 | 126,867 | 104,901 | 1.2× |
-| TTFP (ms) | 1 | 61,257 | 1,164 | 53× |
-| TTFP (ms) | 4 | 78,634 | 3,152 | 24.9× |
-| TTFP (ms) | 10 | 126,534 | 16,482 | 7.7× |
-| RTF | 1 | 0.32 | 0.21 | 1.5× |
-| RTF | 4 | 0.43 | 0.34 | 1.3× |
-| RTF | 10 | 0.90 | 0.74 | 1.2× |
-
-Enabling both brings TTFP down sharply (concurrency 1: 61,257 ms -> 1,164 ms, **~98% reduction**; concurrency 4: 78,634 ms -> 3,152 ms, **~96% reduction**). E2EL and RTF also improve at every concurrency.
-
-**Qwen3-TTS** (H200):
-
-
-
-| Metric | Concurrency | Batch + CG | + Async Chunk | Improvement |
-| --- | --- | --- | --- | --- |
-| TTFP (ms) | 1 | 733 | **64** | **11.5×** |
-| TTFP (ms) | 4 | 987 | **119** | **8.3×** |
-| TTFP (ms) | 10 | 1,197 | **425** | **2.8×** |
-| E2EL (ms) | 1 | 733 | 941 | 0.8× |
-| E2EL (ms) | 10 | 1,197 | 1,767 | 0.7× |
-| RTF | 1 | 0.124 | 0.160 | 0.8× |
-| RTF | 10 | 0.203 | 0.314 | 0.6× |
-
-The TTFP improvement is the headline result for both models. For Qwen3-TTS at concurrency 1, users hear the first audio in **64 ms** instead of 733 ms - an **11.5x reduction**. For Qwen3-Omni at concurrency 1, TTFP drops from 61 s to 1.2 s - a **53x reduction**.
-
-### Why E2EL and RTF are higher with async chunk (TTS)
-
-The table above shows that enabling async chunk + streaming *increases* E2EL and RTF for TTS compared to CUDA Graph alone. This is expected - the two configurations optimize for fundamentally different metrics:
-
-- **CUDA Graph (no async chunk)** generates the entire audio end-to-end before returning. No chunking overhead, so total compute is minimized.
-- **Async Chunk + Streaming** splits the pipeline into incremental chunks, adding overhead from chunked transport, context overlap in Code2Wav (`codec_left_context_frames=25`), and smaller effective batch sizes per chunk.
-
-**The tradeoff is intentional.** Async chunk trades ~30% higher total compute for **11x faster time-to-first-audio**. For interactive applications (voice assistants, chatbots), TTFP determines perceived responsiveness. For offline batch processing, CUDA Graph without async chunk is the better choice.
-
----
-
-## TTS-Specific: Code Predictor Re-prefill + `torch.compile`
-
-Qwen3-TTS has a **code predictor** - a small 5-layer transformer that generates residual codebook tokens (groups 1 through Q-1) autoregressively. Each AR step operates on very short sequences (2 to ~16 tokens).
-
-The naive approach uses a KV cache for this small transformer, similar to the main Talker. But the KV cache machinery (block tables, slot mappings, paged attention) introduces significant overhead relative to the tiny model. Two optimizations replace that:
-
-### Re-prefill (stateless forward, no KV cache)
-
-Instead of maintaining a KV cache across steps, the code predictor **re-feeds the full growing sequence** at each AR step using `F.scaled_dot_product_attention`. With sequences of at most ~16 tokens through 5 layers, the O(T^2) attention cost is negligible - and removing the KV cache machinery (block table management, `set_forward_context`, slot mapping) saves far more time than it costs.
-
-### `torch.compile` on the code predictor forward
-
-The 5-layer transformer forward pass launches ~60 small CUDA kernels per step. `torch.compile(mode="default", dynamic=True)` fuses these into fewer kernels via Inductor:
-
-```python
-self._compiled_model_fwd = torch.compile(
- self.model.forward,
- mode="default", # no Inductor CUDA graphs, avoids conflict with vLLM's CUDAGraphWrapper
- dynamic=True, # sequence length grows each step (2, 3, ..., num_groups+1)
-)
-```
-
-`mode="default"` is used instead of `mode="reduce-overhead"` to avoid conflicts with vLLM's own CUDA graph capture on the main Talker model. `dynamic=True` handles the growing sequence length without recompilation.
-
-These optimizations are always-on in the current codebase - all Qwen3-TTS benchmark results in this post include them.
-
----
-
-## TTS-Specific: Dynamic Initial Chunk for Faster First Audio
-
-In the async chunk pipeline, the standard `codec_chunk_frames` is 25 (each chunk = ~2 seconds of audio at 12 Hz). Waiting for 25 frames before forwarding the first chunk to Code2Wav adds unnecessary TTFP. The **initial codec chunk** optimization sends a smaller first chunk so Code2Wav can start decoding earlier.
-
-**Dynamic initial chunk sizing (default behavior):**
-
-Rather than using a fixed initial chunk size, vLLM-Omni dynamically selects it based on current server load. The initial chunk size is chosen from power-of-2 steps [2, 4, 8, 16] based on load factor (`active_requests / max_batch_size`):
-
-| Server load | Initial chunk frames | Rationale |
-| --- | --- | --- |
-| Low (e.g. 1/10 active) | **2** (~167 ms of audio) | Minimize TTFP when there's headroom |
-| Medium (e.g. 5/10 active) | **4-8** | Balance TTFP vs decode efficiency |
-| High (e.g. 10/10 active) | **16** | Larger first chunk to amortize decode cost |
-
-After the initial chunk, all subsequent chunks use the standard `codec_chunk_frames` (25) size.
-
-**How it works in the pipeline:**
-
-1. Talker generates codec tokens auto-regressively
-2. The stage input processor checks current load and picks an initial chunk size (e.g. **2 frames** at low load)
-3. After that many frames, the first chunk is forwarded to Code2Wav
-4. Code2Wav decodes this small chunk and emits the first audio packet
-5. Subsequent chunks use the standard 25-frame size for efficient batch decoding
-
-**Per-request override:** Clients can also set a fixed initial chunk size via the API:
-
-```json
-{"initial_codec_chunk_frames": 2}
-```
-
-This overrides the dynamic calculation for that request.
-
-**Config (server-side):**
-
-```yaml
-runtime:
- connectors:
- connector_of_shared_memory:
- name: SharedMemoryConnector
- extra:
- codec_streaming: true
- codec_chunk_frames: 25 # standard chunk size (~2s of audio)
- codec_left_context_frames: 25
- # initial chunk is computed dynamically by default
- # set initial_codec_chunk_frames: 2 to force a fixed value
-```
-
-The 64 ms TTFP result reported above for Qwen3-TTS at concurrency 1 uses the dynamic initial chunk, which picks `initial_codec_chunk_frames=2` at low load. At higher concurrency the dynamic sizing increases the initial chunk to maintain decode efficiency.
-
----
-
-## Live Demo: Streaming TTS over WebSocket
-
-vLLM-Omni supports real-time streaming audio output for Qwen3-TTS over WebSocket ([PR #1719](https://github.com/vllm-project/vllm-omni/pull/1719)). With `stream_audio: true`, the server sends chunked PCM audio frames as they are generated, so clients can start playback before full sentence synthesis completes.
-
-The WebSocket protocol uses `audio.start` / binary PCM chunks / `audio.done` framing per sentence:
-
-```json
-// Client sends:
-{"type":"session.config","voice":"Vivian","response_format":"pcm","stream_audio":true}
-{"type":"input.text","text":"Hello world. This is a streaming demo."}
-{"type":"input.done"}
-
-// Server streams back per sentence:
-{"type":"audio.start","sentence_index":0,"sentence_text":"Hello world.","format":"pcm","sample_rate":24000}
-
-
-...
-{"type":"audio.done","sentence_index":0,"total_bytes":96000,"error":false}
-{"type":"audio.start","sentence_index":1,"sentence_text":"This is a streaming demo.","format":"pcm","sample_rate":24000}
-
-...
-{"type":"audio.done","sentence_index":1,"total_bytes":72000,"error":false}
-{"type":"session.done","total_sentences":2}
-```
-
-
-
----
-
-## Deployment Playbook
-
-### Qwen3-Omni
-
-#### 1) Serve with the default 3-stage config
-
-```bash
-vllm serve Qwen/Qwen3-Omni-30B-A3B-Instruct \
- --omni \
- --port 8091
-```
-
-Notes:
-
-- `runtime.max_batch_size` controls stage-level batching.
-- Thinker/Talker commonly use `enforce_eager: false` for CUDA Graph paths.
-- Code2Wav often remains eager (`enforce_eager: true`) depending on runtime behavior.
-
-#### 2) Enable async chunk
-
-```bash
-vllm serve Qwen/Qwen3-Omni-30B-A3B-Instruct \
- --omni \
- --port 8091 \
- --stage-configs-path vllm_omni/model_executor/stage_configs/qwen3_omni_moe_async_chunk.yaml
-```
-
-#### 3) Key config knobs
-
-```yaml
-async_chunk: true
-stage_args:
- - stage_id: 0 # thinker
- runtime:
- max_batch_size: 64
- engine_args:
- enforce_eager: false
- max_num_batched_tokens: 32768
- custom_process_next_stage_input_func: >-
- vllm_omni.model_executor.stage_input_processors.qwen3_omni.thinker2talker_async_chunk
-
- - stage_id: 1 # talker
- runtime:
- max_batch_size: 64
- engine_args:
- enforce_eager: false
- max_num_batched_tokens: 32768
- custom_process_next_stage_input_func: >-
- vllm_omni.model_executor.stage_input_processors.qwen3_omni.talker2code2wav_async_chunk
-
- - stage_id: 2 # code2wav
- runtime:
- max_batch_size: 64
- engine_args:
- enforce_eager: true
- max_num_batched_tokens: 51200
-```
-
-#### Reproduce Qwen3-Omni benchmarks
-
-```bash
-vllm bench serve \
- --dataset-name random \
- --port ${PORT} \
- --model ${MODEL_PATH} \
- --endpoint /v1/chat/completions \
- --backend openai-chat-omni \
- --max-concurrency ${MAX_CONCURRENCY} \
- --num-prompts ${NUM_PROMPTS} \
- --random-input-len 2500 \
- --ignore-eos \
- --percentile-metrics ttft,tpot,itl,e2el,audio_ttfp,audio_rtf \
- --random-output-len 900 \
- --extra_body '{"modalities": ["text","audio"]}'
-```
-
-### Qwen3-TTS
-
-#### 1) Serve with async chunk (recommended)
-
-```bash
-vllm-omni serve Qwen/Qwen3-TTS-12Hz-1.7B-CustomVoice \
- --omni \
- --port 8000
-```
-
-The default config (`qwen3_tts.yaml`) enables the full optimization stack:
-
-- Batching with `max_batch_size: 10` on the Talker stage
-- CUDA Graph on the Talker (`enforce_eager: false`)
-- Async chunk with streaming transport
-
-#### 2) Serve without async chunk (for comparison)
-
-```bash
-vllm-omni serve Qwen/Qwen3-TTS-12Hz-1.7B-CustomVoice \
- --omni \
- --port 8000 \
- --stage-configs-path vllm_omni/model_executor/stage_configs/qwen3_tts_no_async_chunk.yaml
-```
-
-#### 3) Key config knobs
-
-```yaml
-async_chunk: true
-stage_args:
- - stage_id: 0 # Talker (AR decoder)
- runtime:
- max_batch_size: 10
- engine_args:
- enforce_eager: false
- max_num_batched_tokens: 512
- custom_process_next_stage_input_func: >-
- vllm_omni.model_executor.stage_input_processors.qwen3_tts.talker2code2wav_async_chunk
-
- - stage_id: 1 # Code2Wav (vocoder)
- runtime:
- max_batch_size: 1
- engine_args:
- enforce_eager: true
- max_num_batched_tokens: 8192
-
-runtime:
- connectors:
- connector_of_shared_memory:
- name: SharedMemoryConnector
- extra:
- codec_streaming: true
- codec_chunk_frames: 25
- codec_left_context_frames: 25
-```
-
-#### Reproduce Qwen3-TTS benchmarks
-
-```bash
-GPU_DEVICE=0 \
-MODEL=Qwen/Qwen3-TTS-12Hz-1.7B-CustomVoice \
-NUM_PROMPTS=50 \
-CONCURRENCY="1 4 10" \
-bash benchmarks/qwen3-tts/vllm_omni/run_stacked_benchmark.sh
-```
-
-This cycles through four configs (Baseline -> + Batch -> + CUDA Graph -> + Async Chunk + Streaming), benchmarks each at the specified concurrency levels, and generates all comparison figures automatically.
diff --git a/docs/examples/README.md b/docs/examples/README.md
deleted file mode 100644
index 4594d2bed2f..00000000000
--- a/docs/examples/README.md
+++ /dev/null
@@ -1,6 +0,0 @@
-# Examples
-
-vLLM-Omni's examples are split into two categories:
-
-- If you are using vLLM-Omni from within Python code, see the *Offline Inference* section.
-- If you are using vLLM-Omni from an HTTP application or client, see the *Online Serving* section.
diff --git a/docs/features/comfyui.md b/docs/features/comfyui.md
deleted file mode 100644
index ff766cbb3d5..00000000000
--- a/docs/features/comfyui.md
+++ /dev/null
@@ -1,71 +0,0 @@
-# vLLM-Omni ComfyUI Integration
-
-vLLM-Omni offers a ComfyUI integration on top of its online serving API.
-It can send model inference requests to either a locally running vLLM-Omni service or a remote one.
-
-## Requirement
-
-- Python 3.12 or above
-- [ComfyUI installed](https://docs.comfy.org/installation/system_requirements)
-- [vLLM-Omni installed](https://docs.vllm.ai/projects/vllm-omni/en/latest/getting_started/installation/) on either the same device or another device discoverable via the internet.
-- No need to install additional packages apart from those already required by ComfyUI.
-
-!!! tip
- If you run both ComfyUI and vLLM-Omni on the same device, you can create separate virtual environments and use different Python versions for them.
-
-
-## Installation
-
-Copy the `apps/ComfyUI-vLLM-Omni` folder to the `custom_nodes` subfolder of your ComfyUI installation. Your directory should look like `ComfyUI/custom_nodes/ComfyUI-vLLM-Omni`.
-
-If you are running ComfyUI during copying, you should restart ComfyUI to load this extension.
-
-!!! tip
- You can use utility websites such as https://download-directory.github.io/ to download a subdirectory of a repo. Also checkout community discussions (e.g., https://stackoverflow.com/questions/7106012/download-a-single-folder-or-directory-from-a-github-repository) for more info.
-
-On the device and virtual environment you run ComfyUI, launch ComfyUI with
-```bash
-cd ComfyUI
-
-# The regular way
-python main.py
-
-# If you are mainly using this node, launch it faster with
-python main.py --cpu
-```
-
-On the device and virtual environment you run vLLM-Omni, start a model service with
-```bash
-vllm serve The_Model_ID_to_Serve --omni --port 8000
-```
-
-Check **ComfyUI's sidebar -> Node Library**. There should be a new folder named **vLLM-Omni**.
-If no, check your shell running the ComfyUI process. There may be some error messages before the line `Import times for custom nodes:` and the line `To see the GUI go to: http://127.0.0.1:8188`.
-
-## Quickstart
-
-This extension offers the following nodes based on the output modalities:
-
-- **Generate Image** for text-to-image and image-to-image tasks
-- **Generate Video** for text-to-video and image-to-video tasks
-- **Multimodality Understanding** for multimodality-to-text and multimodality-to-audio tasks
-- **TTS** and **TTS Voice Clone** for TTS tasks
-
-This extension also offers example workflows (at **ComfyUI sidebar -> Templates -> vLLM-Omni**)
-
-!!! info
- The node UI and feature designs are intended to match vLLM-Omni online serving interfaces. It cannot offer more than what the interfaces support.
-
-To build a simple workflow yourself,
-
-- Drag a generation node onto the canvas.
-- Depending on your need, grab built-in multimedia file loader nodes, such as **image->Load Image**, **image->video->Load Video**, **audio->Load Audio**
-- Depending on your need, grab built-in multimedia file preview nodes, such as **image->Preview Image**, **image->video->Save Video**, **audio->Preview Audio**, **utils->Preview as Text**.
-- If you want to tune sampling parameters, grab corresponding nodes from **vLLM-Omni-> Sampling Params**.
- - For multi-stage models, you can connect multiple **AR Sampling Params** and **Diffusion Sampling Params** nodes to a **Multi-Stage Sampling Params List** node, and connect this node to the generation node.
- - For some multi-stage models like BAGEL, [only one stage's sampling parameters are exposed and tunable via vLLM-Omni's online serving API](https://docs.vllm.ai/projects/vllm-omni/en/latest/user_guide/examples/online_serving/bagel/). Thus, these models are treated as single-stage ones. Please check the vLLM-Omni documentation on how to correctly set each model's sampling parameters.
- - For multi-stage models where all stages are either autoregression or diffusion, you can also connect only a single Sampling Params node, indicating that this set of sampling parameters will be used for all stages.
-
-## Examples & Screenshots
-
-Please read the [ComfyUI integration's README](https://github.com/vllm-project/vllm-omni/tree/main/apps/ComfyUI-vLLM-Omni) for more info.
diff --git a/docs/features/custom_pipeline.md b/docs/features/custom_pipeline.md
deleted file mode 100644
index dc8b645e45a..00000000000
--- a/docs/features/custom_pipeline.md
+++ /dev/null
@@ -1,151 +0,0 @@
-# Custom Pipeline Extension Guide
-
-Transformer already support Custom Pipeline via
-https://github.com/huggingface/diffusers/blob/main/docs/source/en/using-diffusers/custom_pipeline_overview.md
-
-This guide demonstrates how to use the newly added features for extending vLLM-Omni's diffusion pipeline with custom functionality.
-
-## Overview
-
-Three main features enable custom pipeline extension:
-
-1. **`WorkerWrapperBase`**: A wrapper class that enables dynamic worker extension with custom functionality
-2. **`load_format`**: A parameter that controls how diffusion models are loaded, including support for custom pipelines
-3. **`CustomPipelineWorkerExtension`**: An extension class that enables pipeline re-initialization with custom implementations
-
-## Features
-
-### WorkerWrapperBase
-
-`WorkerWrapperBase` is a wrapper class that creates `DiffusionWorker` instances with optional extension support. It enables dynamic inheritance, allowing you to add custom methods and functionality to workers without modifying the base worker class.
-
-**Key capabilities:**
-- Dynamic worker class extension via `worker_extension_cls`
-- Support for custom pipeline initialization via `custom_pipeline_args`
-- Method delegation to underlying worker
-- Attribute access forwarding
-
-**Location:** `vllm_omni/diffusion/worker/diffusion_worker.py`
-
-### load_format Parameter
-
-The `load_format` parameter controls how diffusion models are loaded. It supports the following values:
-
-- **`"default"`**: Standard model loading using the model registry (default behavior)
-- **`"custom_pipeline"`**: Load a custom pipeline class specified by `custom_pipeline_name`
-- **`"dummy"`**: Skip model loading (useful for testing or when pipeline will be initialized separately)
-
-**Location:** `vllm_omni/diffusion/model_loader/diffusers_loader.py`
-
-### CustomPipelineWorkerExtension
-
-`CustomPipelineWorkerExtension` is a mixin class that extends `DiffusionWorker` with the ability to re-initialize the pipeline with a custom implementation.
-
-**Key method:**
-- `re_init_pipeline(custom_pipeline_args)`: Re-initializes the pipeline with custom arguments, properly cleaning up the old pipeline first
-
-**Location:** `vllm_omni/diffusion/worker/diffusion_worker.py`
-
-## Usage Example
-
-### Step 1: Create a Custom Pipeline
-
-Create a custom pipeline class that extends an existing pipeline. In this example, we extend `QwenImageEditPipeline` to add trajectory tracking:
-
-```python
-# custom_pipeline.py
-from vllm_omni.diffusion.data import DiffusionOutput, OmniDiffusionConfig
-from vllm_omni.diffusion.models.qwen_image.pipeline_qwen_image_edit import QwenImageEditPipeline
-import torch
-
-class CustomPipeline(QwenImageEditPipeline):
- def __init__(self, *, od_config: OmniDiffusionConfig, prefix: str = ""):
- super().__init__(od_config=od_config, prefix=prefix)
-
- def forward(self, req, prompt=None, negative_prompt=None, **kwargs):
- # Call parent's forward to get normal output
- output = super().forward(req=req, prompt=prompt, negative_prompt=negative_prompt, **kwargs)
-
- # Add custom trajectory data
- actual_num_steps = req.sampling_params.num_inference_steps or kwargs.get('num_inference_steps', 50)
- output.trajectory_timesteps = torch.linspace(1000, 0, actual_num_steps, dtype=torch.float32)
- output.trajectory_latents = torch.randn(actual_num_steps, 1, 16, 64, 64, dtype=torch.float32)
-
- return output
-```
-
-### Step 2: Use the Custom Pipeline with Omni
-
-Initialize the `Omni` engine with custom pipeline configuration:
-
-```python
-from vllm_omni.entrypoints.omni import Omni
-from vllm_omni.inputs.data import OmniDiffusionSamplingParams
-
-# Initialize with custom pipeline
-omni = Omni(
- model="Qwen/Qwen-Image-Edit",
- diffusion_load_format="dummy", # Skip initial loading
- custom_pipeline_args={
- "pipeline_class": "custom_pipeline.CustomPipeline"
- },
-)
-
-# Generate with the custom pipeline
-outputs = omni.generate(
- ...
-)
-
-# Access custom trajectory data
-output = outputs[0].request_output
-print(f"Trajectory timesteps shape: {output.metrics['trajectory_timesteps'].shape}")
-print(f"Trajectory latents shape: {output.latents.shape}")
-```
-
-### Step 3: Run the Example
-
-The example provided in this directory demonstrates the complete workflow:
-
-```bash
-cd examples/offline_inference/custom_pipeline/image_to_image
-
-# Run with custom pipeline
-python image_edit.py \
- --model Qwen/Qwen-Image-Edit-2511 \
- --image cherry_blossom.jpg \
- --prompt "Let this mascot dance under the moon, surrounded by floating stars" \
- --output output_image_edit.png \
- --num-inference-steps 10
-```
-
-## Advanced Usage
-
-### Custom Worker Extension
-
-You can create custom worker extensions to add new methods beyond pipeline re-initialization:
-
-```python
-from typing import Any
-from vllm_omni.diffusion.worker.diffusion_worker import CustomPipelineWorkerExtension
-
-class MyCustomExtension(CustomPipelineWorkerExtension):
- def custom_method(self):
- """Your custom worker method."""
- return "custom_result"
-
- def another_method(self, data: Any):
- """Another custom method."""
- # Access worker internals via self
- return self.model_runner.some_operation(data)
-
-omni = Omni(
- model="Qwen/Qwen-Image-Edit",
- diffusion_load_format="dummy",
- custom_pipeline_args={
- "pipeline_class": "custom_pipeline.CustomPipeline"
- },
- worker_extension_cls=MyCustomExtension,
- # Note: worker_extension_cls is an internal parameter
- # CustomPipelineWorkerExtension will automatically init pipeline when custom_pipeline_args is provided
-)
-```
diff --git a/docs/features/sleep_mode.md b/docs/features/sleep_mode.md
deleted file mode 100644
index b4eec162d31..00000000000
--- a/docs/features/sleep_mode.md
+++ /dev/null
@@ -1,243 +0,0 @@
-# Sleep Mode & ACK Protocol
-
-vLLM-Omni’s **Sleep Mode** allows you to temporarily release most GPU memory used by a model—such as model weights and key-value (KV) caches—**without stopping the server or unloading the Docker container**.
-
-This feature is inherited from [vLLM’s Sleep Mode](https://blog.vllm.ai/2025/10/26/sleep-mode.html) and extended with the **Omni ACK Protocol** to support multi-stage pipelines and heterogeneous hardware backends (NVIDIA, AMD, Intel, Huawei). It is especially useful in **RLHF**, **dynamic model switching**, or **cost-saving scenarios**.
-
----
-
-## 1. Feature Documentation
-
-### Overview
-Omni Sleep Mode provides a mechanism to "sleep" specific model stages. When a stage enters sleep, its physical VRAM is reclaimed by the system, while the process state is preserved for rapid "wake-up" without full re-initialization.
-
-### Sleep Levels
-We support two levels of hibernation to balance recovery speed and memory efficiency:
-
-| Level | Name | Mechanism | Recovery Speed | Memory Freed |
-| :--- | :--- | :--- | :--- | :--- |
-| **Level 1** | **Weight Offloading** | Offloads weights to Host CPU RAM. | **Fast** (DMA) | Substantial |
-| **Level 2** | **Full De-mapping** | Physically releases memory pages via VRAM scavenging. | **Moderate** | **Maximum** (up to 95%+) |
-
-### Supported Platforms
-
-Omni Sleep Mode is optimized for high-performance computing backends:
-
-* **NVIDIA**: Supported via Virtual Memory Management (VMM).
-* **AMD (ROCm)**: Fully supported with physical page de-mapping.
-* **Intel XPU**: Supported via Level Zero memory management.
-* **Huawei NPU**: Supported via Ascend memory scavenging.
-
-### Hardware Requirements
-* **Memory Considerations**: System RAM must be sufficient to hold offloaded weights during sleep.
-* **TP Support**: Tensor Parallel groups synchronize sleep/wake transitions across all workers.
-
----
-
-
-## 2. Usage Examples
-
-### Python API Example
-You can programmatically control the lifecycle of stages using the `AsyncOmni` engine.
-
-```python
-
-import asyncio
-from vllm_omni.entrypoints.async_omni import AsyncOmni
-
-async def run_sleep_demo():
- # 1. initialization
- engine = AsyncOmni(
- model="ByteDance-Seed/BAGEL-7B-MoT",
- enable_sleep_mode=True
- )
-
- # 2. sleep mode level2
- acks = await engine.sleep(stage_ids=[0], level=2)
- print(f"Freed {acks[0].freed_bytes / 1024**3:.2f} GiB on Stage 0")
-
- # 3. wake up
- await engine.wake_up(stage_ids=[0])
-
-if __name__ == "__main__":
- asyncio.run(run_sleep_demo())
-
-```
-
-### server command Example
-Start the server with sleep mode enabled:
-
-The first method
-
-```
-
-vllm serve ByteDance-Seed/BAGEL-7B-MoT \
---omni \
---enable-sleep-mode \
---trust-remote-code \
---gpu-memory-utilization 0.7
-
-```
-
-The second method
-
-```
-
-python3 -m vllm_omni.entrypoints.openai.api_server \
- --model ByteDance-Seed/BAGEL-7B-MoT \
- --omni \
- --enable-sleep-mode \
- --trust-remote-code \
---gpu-memory-utilization 0.7
-
-```
-
-
-
-
-### Test Scenarios & Commands
-
-#### Scenario 1: LLM Engine Sleep
-
-Objective: Verify VRAM reclamation for Stage 0 (Thinker).
-
-Trigger sleep (Level 1 or Level 2) via client:
-
-```
-
-curl -X POST http://localhost:8000/v1/omni/sleep \
- -H "Content-Type: application/json" \
- -d '{"stage_ids": [0], "level": 2}'
-
-```
-
-Tip: Open a new terminal and run rocm-smi or nvidia-smi or to observe the immediate drop in VRAM usage.
-
-
-
-#### Scenario 2: Diffusion Sleep
-Objective: Verify VRAM reclamation for Stage 1 (Diffusion).
-
-Trigger sleep (Level 1 or Level 2) via client:
-
-```
-
-curl -X POST http://localhost:8000/v1/omni/sleep \
- -H "Content-Type: application/json" \
- -d '{"stage_ids": [1], "level": 2}'
-
-```
-
-
-
-#### Scenario 3: Multi-Stage Coordinated Stress Test
-Objective: Test concurrent sleep and rapid wake-up across multiple stages.
-
-Concurrent Sleep (Stage 0 & 1):
-
-```
-
-curl -X POST http://localhost:8000/v1/omni/sleep \
- -H "Content-Type: application/json" \
- -d '{"stage_ids": [0, 1], "level": 2}'
-
-```
-
-
-Rapid Wake-up:
-
-```
-
-curl -X POST http://localhost:8000/v1/omni/wakeup \
- -H "Content-Type: application/json" \
- -d '{"stage_ids": [0, 1]}'
-
-```
-
-
-#### Scenario 4: Full Lifecycle Memory Audit & Functional Integrity
-Objective: Audit the complete flow from Sleep to Wake-up followed by an Inference validation.
-
-Check Initial State: Observe baseline VRAM usage.
-
-Trigger Deep Sleep (Level 2):
-
-```
-
-curl -X POST http://localhost:8000/v1/omni/sleep \
- -H "Content-Type: application/json" \
- -d '{"stage_ids": [0], "level": 2}'
-
-```
-
-Wake-up Model:
-
-```
-
-curl -X POST http://localhost:8000/v1/omni/wakeup \
- -H "Content-Type: application/json" \
- -d '{"stage_ids": [0]}'
-
-```
-
-Verify Functional Integrity (Inference):
-Ensure the model still generates valid output after reloading weights.
-
-```
-
-curl -X POST http://localhost:8000/v1/images/generations \
- -H "Content-Type: application/json" \
- -d '{
- "prompt": "A huge swimming pool, with many people swimming.",
- "model": "ByteDance-Seed/BAGEL-7B-MoT",
- "response_format": "b64_json",
- "extra_body": {"sampling_params": {"num_inference_steps": 4, "seed": 42}}
- }' > post.json
-
-```
-
-
-
-
-## 3. API Reference
-
-
-### Methods
-
-| Method | Arguments | Return Type | Description |
-| :--- | :--- | :--- | :--- |
-| **sleep** | `stage_ids: List[int], level: int` | `List[OmniACK]` | Triggers hibernation for specified stages. |
-| **wake_up** | `stage_ids: List[int]` | `List[OmniACK]` | Reloads weights and re-maps memory. |
-
-
-
-### OmniACK Dataclass Fields
-
-| Field | Type | Description |
-| :--- | :--- | :--- |
-| **task_id** | `str` | Unique identifier for the operation. |
-| **status** | `str` | `SUCCESS` or `ERROR`. |
-| **stage_id** | `int` | The ID of the stage that responded. |
-| **rank** | `int` | The rank ID within the Tensor Parallel group. |
-| **freed_bytes** | `int` | Actual amount of physical VRAM reclaimed. |
-| **metadata** | `dict` | Additional platform-specific metrics. |
-
-Metadata Field Analysis
-The metadata field is a dynamic dictionary containing hardware-specific telemetry and audit data, primarily used for verifying memory reclamation on various backends (e.g., AMD ROCm, NVIDIA CUDA).
-
-```
-"metadata": {
- "source": "Platform_AMD_Instinct_MI300X",
- "total_freed_gib": "78.57",
- "rank_residual_gib": "2.07"
-}
-```
-
-#### Core Utility:
-**VRAM Reclamation Audit (total_freed_gib)**: Converts raw freed_bytes into human-readable GiB. It serves as the primary metric to verify that Level 2 sleep has successfully purged model weights from VRAM.
-
-**Residual & Fragmentation Monitoring (rank_residual_gib)**: Reports the remaining VRAM footprint after memory de-mapping. A low residual value (e.g., 2.07 GiB) confirms a successful "clean" state, ensuring the device is ready for high-memory co-located tasks like training or diffusion pipelines.
-
-**Backend Traceability (source)**: Identifies the underlying hardware driver or audit source. This is critical for debugging synchronization issues in multi-stage, distributed environments.
-
-**Performance Analytics (Roadmap)**: Future updates will include latency_ms (context-switch overhead) and cuda_graph_recalled (graph engine status) to optimize performance in high-frequency sleep/wake scenarios.
diff --git a/docs/getting_started/installation/.nav.yml b/docs/getting_started/installation/.nav.yml
deleted file mode 100644
index 0fcee9a008c..00000000000
--- a/docs/getting_started/installation/.nav.yml
+++ /dev/null
@@ -1,4 +0,0 @@
-nav:
- - README.md
- - gpu.md
- - npu.md
diff --git a/docs/getting_started/installation/README.md b/docs/getting_started/installation/README.md
deleted file mode 100644
index 89562c53c51..00000000000
--- a/docs/getting_started/installation/README.md
+++ /dev/null
@@ -1,10 +0,0 @@
-# Installation
-
-vLLM-Omni supports the following hardware platforms:
-
-- [GPU](gpu.md)
- - [NVIDIA CUDA](gpu.md)
- - [AMD ROCm](gpu.md)
- - [Intel XPU](gpu.md)
- - [MThreads MUSA](gpu.md)
-- [NPU](npu.md)
diff --git a/docs/getting_started/installation/gpu.md b/docs/getting_started/installation/gpu.md
deleted file mode 100644
index d08f134b5d6..00000000000
--- a/docs/getting_started/installation/gpu.md
+++ /dev/null
@@ -1,107 +0,0 @@
-# GPU
-
-vLLM-Omni is a Python library that supports the following GPU variants. The library itself mainly contains python implementations for framework and models.
-
-## Requirements
-
-- OS: Linux
-- Python: 3.12
-
-!!! note
- vLLM-Omni is currently not natively supported on Windows.
-
-=== "NVIDIA CUDA"
-
- --8<-- "docs/getting_started/installation/gpu/cuda.inc.md:requirements"
-
-=== "AMD ROCm"
-
- --8<-- "docs/getting_started/installation/gpu/rocm.inc.md:requirements"
-
-=== "Intel XPU"
-
- --8<-- "docs/getting_started/installation/gpu/xpu.inc.md:requirements"
-
-=== "MThreads MUSA"
-
- --8<-- "docs/getting_started/installation/gpu/musa.inc.md:requirements"
-
-## Set up using Python
-
-### Create a new Python environment
-
---8<-- "docs/getting_started/installation/python_env_setup.inc.md"
-
-### Pre-built wheels
-
-Note: Pre-built wheels are currently available for vLLM-Omni 0.11.0rc1, 0.12.0rc1, 0.14.0rc1, 0.14.0, 0.16.0, and 0.18.0. If you need a newer unreleased revision, please [build from source](https://docs.vllm.ai/projects/vllm-omni/en/latest/getting_started/installation/gpu/#build-wheel-from-source).
-
-=== "NVIDIA CUDA"
-
- --8<-- "docs/getting_started/installation/gpu/cuda.inc.md:pre-built-wheels"
-
-=== "AMD ROCm"
-
- --8<-- "docs/getting_started/installation/gpu/rocm.inc.md:pre-built-wheels"
-
-=== "Intel XPU"
-
- --8<-- "docs/getting_started/installation/gpu/xpu.inc.md:pre-built-wheels"
-
-=== "MThreads MUSA"
-
- --8<-- "docs/getting_started/installation/gpu/musa.inc.md:pre-built-wheels"
-
-[](){ #build-from-source }
-
-### Build wheel from source
-
-=== "NVIDIA CUDA"
-
- --8<-- "docs/getting_started/installation/gpu/cuda.inc.md:build-wheel-from-source"
-
-=== "AMD ROCm"
-
- --8<-- "docs/getting_started/installation/gpu/rocm.inc.md:build-wheel-from-source"
-
-=== "Intel XPU"
-
- --8<-- "docs/getting_started/installation/gpu/xpu.inc.md:build-wheel-from-source"
-
-=== "MThreads MUSA"
-
- --8<-- "docs/getting_started/installation/gpu/musa.inc.md:build-wheel-from-source"
-
-## Set up using Docker
-
-### Pre-built images
-
-=== "NVIDIA CUDA"
-
- --8<-- "docs/getting_started/installation/gpu/cuda.inc.md:pre-built-images"
-
-=== "AMD ROCm"
-
- --8<-- "docs/getting_started/installation/gpu/rocm.inc.md:pre-built-images"
-
-=== "Intel XPU"
-
- --8<-- "docs/getting_started/installation/gpu/xpu.inc.md:pre-built-images"
-
-=== "MThreads MUSA"
-
- --8<-- "docs/getting_started/installation/gpu/musa.inc.md:pre-built-images"
-
-### Build your own docker image
-
-=== "AMD ROCm"
-
- --8<-- "docs/getting_started/installation/gpu/rocm.inc.md:build-docker"
-
-=== "Intel XPU"
-
- --8<-- "docs/getting_started/installation/gpu/xpu.inc.md:build-docker"
-
-=== "MThreads MUSA"
-
- --8<-- "docs/getting_started/installation/gpu/musa.inc.md:build-docker"
diff --git a/docs/getting_started/installation/gpu/cuda.inc.md b/docs/getting_started/installation/gpu/cuda.inc.md
deleted file mode 100644
index ca228246b1f..00000000000
--- a/docs/getting_started/installation/gpu/cuda.inc.md
+++ /dev/null
@@ -1,112 +0,0 @@
-# --8<-- [start:requirements]
-
-- GPU: compute capability 7.0 or higher (e.g., V100, T4, RTX20xx, A100, L4, H100, etc.)
-
-# --8<-- [end:requirements]
-# --8<-- [start:set-up-using-python]
-
-vLLM-Omni depends vLLM. So please follow instructions below mainly for vLLM.
-
-!!! note
- PyTorch installed via `conda` will statically link `NCCL` library, which can cause issues when vLLM tries to use `NCCL`. See for more details.
-
-In order to be performant, vLLM has to compile many cuda kernels. The compilation unfortunately introduces binary incompatibility with other CUDA versions and PyTorch versions, even for the same PyTorch version with different building configurations.
-
-Therefore, it is recommended to install vLLM and vLLM-Omni with a **fresh new** environment. If either you have a different CUDA version or you want to use an existing PyTorch installation, you need to build vLLM from source. See [build-from-source-vllm](https://docs.vllm.ai/en/stable/getting_started/installation/gpu/#build-wheel-from-source) for more details.
-
-# --8<-- [start:pre-built-wheels]
-
-#### Installation of vLLM
-
-vLLM-Omni is built based on vLLM. Please install it with command below.
-```bash
-uv pip install vllm --torch-backend=auto
-```
-
-#### Installation of vLLM-Omni
-
-```bash
-uv pip install vllm-omni
-```
-
-To run Gradio demos, also install the optional extras:
-```bash
-uv pip install 'vllm-omni[demo]'
-```
-
-# --8<-- [end:pre-built-wheels]
-
-# --8<-- [start:build-wheel-from-source]
-
-#### Installation of vLLM
-If you do not need to modify source code of vLLM, you can directly install the stable 0.20.0 release version of the library
-
-```bash
-uv pip install vllm==0.20.0 --torch-backend=auto
-```
-
-The 0.20.0 release of vLLM ships CUDA 13.0-compatible binaries by default. If you need a different CUDA variant or want to reuse an existing PyTorch installation, build vLLM from source instead.
-
-#### Installation of vLLM-Omni
-Since vllm-omni is rapidly evolving, it's recommended to install it from source
-```bash
-git clone https://github.com/vllm-project/vllm-omni.git
-cd vllm-omni
-uv pip install -e .
-```
-
-To run Gradio demos, install with optional extras:
-```bash
-uv pip install -e '.[demo]'
-```
-
-
-
-# --8<-- [end:build-wheel-from-source]
-
-# --8<-- [start:build-wheel-from-source-in-docker]
-
-# --8<-- [end:build-wheel-from-source-in-docker]
-
-# --8<-- [start:pre-built-images]
-
-vLLM-Omni offers an official docker image for deployment. These images are built on top of vLLM docker images and available on Docker Hub as [vllm/vllm-omni](https://hub.docker.com/r/vllm/vllm-omni/tags). The version of vLLM-Omni indicates which release of vLLM it is based on.
-
-Here's an example deployment command that has been verified on 2 x H100's:
-```bash
-docker run --runtime nvidia --gpus 2 \
- -v ~/.cache/huggingface:/root/.cache/huggingface \
- --env "HF_TOKEN=$HF_TOKEN" \
- -p 8091:8091 \
- --ipc=host \
- vllm/vllm-omni:v0.18.0 \
- --model Qwen/Qwen3-Omni-30B-A3B-Instruct --port 8091
-```
-
-!!! tip
- You can use this docker image to serve models the same way you would with in vLLM! To do so, make sure you overwrite the default entrypoint (`vllm serve --omni`) which works only for models supported in the vLLM-Omni project.
-
-# --8<-- [end:pre-built-images]
diff --git a/docs/getting_started/installation/gpu/musa.inc.md b/docs/getting_started/installation/gpu/musa.inc.md
deleted file mode 100644
index a7cbc848f58..00000000000
--- a/docs/getting_started/installation/gpu/musa.inc.md
+++ /dev/null
@@ -1,65 +0,0 @@
-# --8<-- [start:requirements]
-
-- GPU: Moore Threads GPU with MUSA SDK installed (validated on MTT S5000)
-
-# --8<-- [end:requirements]
-# --8<-- [start:set-up-using-python]
-
-vLLM-Omni for MUSA requires building from source. Pre-built wheels are not currently available.
-
-!!! note
- MUSA platform requires vLLM-MUSA to be installed first.
-
-# --8<-- [start:pre-built-wheels]
-
-# --8<-- [end:pre-built-wheels]
-
-# --8<-- [start:build-wheel-from-source]
-
-#### Prerequisites
-
-- **MUSA SDK**: Download from [MUSA SDK Download](https://developer.mthreads.com/sdk/download/musa)
-- **torchada**: CUDA→MUSA compatibility layer for PyTorch (`pip install torchada`)
-- **mthreads-ml-py**: MTML Python bindings (`pip install mthreads-ml-py`)
-- **MATE**: MUSA AI Tensor Engine ([GitHub](https://github.com/MooreThreads/mate))
-
-#### Installation of vLLM-MUSA
-
-```bash
-git clone https://github.com/MooreThreads/vllm-musa.git
-cd vllm-musa
-git checkout v0.18.0-dev
-pip install . --no-build-isolation -v
-```
-
-#### Installation of vLLM-Omni
-
-```bash
-git clone https://github.com/vllm-project/vllm-omni.git
-cd vllm-omni
-VLLM_OMNI_TARGET_DEVICE=musa pip install -e . --no-build-isolation
-```
-
-For Gradio demos:
-
-```bash
-pip install -e '.[demo]' --no-build-isolation
-```
-
-#### Environment Variables
-
-```bash
-export MUSA_VISIBLE_DEVICES=0,1
-export VLLM_WORKER_MULTIPROC_METHOD=spawn
-export VLLM_MUSA_CUSTOM_OP_USE_NATIVE=false
-```
-
-# --8<-- [end:build-wheel-from-source]
-
-# --8<-- [start:build-docker]
-
-# --8<-- [end:build-docker]
-
-# --8<-- [start:pre-built-images]
-
-# --8<-- [end:pre-built-images]
diff --git a/docs/getting_started/installation/gpu/rocm.inc.md b/docs/getting_started/installation/gpu/rocm.inc.md
deleted file mode 100644
index 608c259af1c..00000000000
--- a/docs/getting_started/installation/gpu/rocm.inc.md
+++ /dev/null
@@ -1,155 +0,0 @@
-# --8<-- [start:requirements]
-
-- GPU: Validated on gfx942 (It should be supported on the AMD GPUs that are supported by vLLM.)
-
-# --8<-- [end:requirements]
-# --8<-- [start:set-up-using-python]
-
-vLLM-Omni current recommends the steps in under setup through Docker Images.
-
-# --8<-- [start:pre-built-wheels]
-
-#### Installation of vLLM
-
-vLLM-Omni is built based on vLLM. Please install it with command below.
-```bash
-uv pip install vllm==0.20.0+rocm721 --extra-index-url https://wheels.vllm.ai/rocm/0.20.0/rocm721
-```
-
-#### Installation of vLLM-Omni
-
-```bash
-# we need to add --no-build-isolation as the torch
-# is not obtained from pypi, we have to install using the
-# torch installed in our environment
-uv pip install vllm-omni
-
-# Optional if want to run Qwen3 TTS
-uv pip uninstall onnxruntime # should be removed before we can install onnxruntime-rocm
-uv pip install onnxruntime-rocm
-```
-
-# --8<-- [end:pre-built-wheels]
-
-# --8<-- [start:build-wheel-from-source]
-
-#### Installation of vLLM
-If you do not need to modify source code of vLLM, you can directly install the stable 0.20.0 release version of the library
-
-```bash
-uv pip install vllm==0.20.0+rocm721 --extra-index-url https://wheels.vllm.ai/rocm/0.20.0/rocm721
-```
-
-The pre-built 0.20.0 vLLM wheel targets ROCm 7.2.1. If you need a different ROCm stack or want to reuse an existing PyTorch installation, build vLLM from source instead.
-
-#### Installation of vLLM-Omni
-Since vllm-omni is rapidly evolving, it's recommended to install it from source
-```bash
-git clone https://github.com/vllm-project/vllm-omni.git
-cd vllm-omni
-VLLM_OMNI_TARGET_DEVICE=rocm uv pip install -e .
-# OR
-uv pip install -e . --no-build-isolation
-```
-
-:/app/model \
--v ~/.cache/huggingface:/root/.cache/huggingface \
---entrypoint bash \
-vllm-omni-rocm
-```
-
-# --8<-- [end:build-docker]
-
-# --8<-- [start:pre-built-images]
-
-vLLM-Omni offers an official docker image for deployment. These images are built on top of vLLM docker images and available on Docker Hub as [vllm/vllm-omni-rocm](https://hub.docker.com/r/vllm/vllm-omni-rocm/tags). The version of vLLM-Omni indicates which release of vLLM it is based on.
-
-#### Launch vLLM-Omni Server
-Here's an example deployment command that has been verified on 2 x MI300's:
-```bash
-docker run --rm \
- --group-add=video \
- --ipc=host \
- --cap-add=SYS_PTRACE \
- --security-opt seccomp=unconfined \
- --device /dev/kfd \
- --device /dev/dri \
- -v :/app/model \
- -v ~/.cache/huggingface:/root/.cache/huggingface \
- --env "HF_TOKEN=$HF_TOKEN" \
- -p 8091:8091 \
- vllm/vllm-omni-rocm:v0.20.0 \
- --model Qwen/Qwen3-Omni-30B-A3B-Instruct --omni --port 8091
-```
-
-#### Launch an interactive terminal with prebuilt docker image.
-If you want to run in dev environment you can launch the docker image as follows:
-```bash
-docker run --rm -it \
- --network=host \
- --group-add=video \
- --ipc=host \
- --cap-add=SYS_PTRACE \
- --security-opt seccomp=unconfined \
- --device /dev/kfd \
- --device /dev/dri \
- -v :/app/model \
- -v ~/.cache/huggingface:/root/.cache/huggingface \
- --env "HF_TOKEN=$HF_TOKEN" \
- --entrypoint bash \
- vllm/vllm-omni-rocm:v0.20.0
-```
-
-# --8<-- [end:pre-built-images]
diff --git a/docs/getting_started/installation/gpu/xpu.inc.md b/docs/getting_started/installation/gpu/xpu.inc.md
deleted file mode 100644
index 8822e3a7c2a..00000000000
--- a/docs/getting_started/installation/gpu/xpu.inc.md
+++ /dev/null
@@ -1,48 +0,0 @@
-# --8<-- [start:requirements]
-
-- GPU: Validated on Intel® Arc™ B-Series.
-
-# --8<-- [end:requirements]
-# --8<-- [start:set-up-using-python]
-
-vLLM-Omni currently recommends using the Docker image setup steps below.
-
-# --8<-- [start:pre-built-wheels]
-
-# --8<-- [end:pre-built-wheels]
-
-# --8<-- [start:build-wheel-from-source]
-
-# --8<-- [end:build-wheel-from-source]
-
-# --8<-- [start:build-docker]
-
-#### Build docker image
-
-```bash
-DOCKER_BUILDKIT=1 docker build -f docker/Dockerfile.xpu -t vllm-omni-xpu --shm-size=4g .
-```
-
-#### Launch the docker image
-
-##### Launch with OpenAI API Server
-
-```
-docker run -it -d --shm-size 10g \
- --name {container_name} \
- --net=host \
- --ipc=host \
- --privileged \
- -v /dev/dri/by-path:/dev/dri/by-path \
- --device /dev/dri:/dev/dri \
- -v ~/.cache/huggingface:/root/.cache/huggingface \
- --env "HF_TOKEN=$HF_TOKEN" \
- vllm-omni-xpu \
- --model Qwen/Qwen2.5-Omni-3B --port 8091
-```
-
-# --8<-- [end:build-docker]
-
-# --8<-- [start:pre-built-images]
-
-# --8<-- [end:pre-built-images]
diff --git a/docs/getting_started/installation/npu.md b/docs/getting_started/installation/npu.md
deleted file mode 100644
index 0d538f25d7b..00000000000
--- a/docs/getting_started/installation/npu.md
+++ /dev/null
@@ -1,33 +0,0 @@
-# NPU
-
-vLLM-Omni supports NPU through the vLLM Ascend Plugin (vllm-ascend). This is a community maintained hardware plugin for running vLLM on NPU.
-
-## Requirements
-
-- OS: Linux
-- Python: 3.12
-
-!!! note
- vLLM-Omni is currently not natively supported on Windows.
-
-=== "NPU"
-
- --8<-- "docs/getting_started/installation/npu/npu.inc.md:requirements"
-
-## Installation
-
-### Set up using Docker
-
-=== "NPU"
-
- --8<-- "docs/getting_started/installation/npu/npu.inc.md:pre-built-images"
-
-### Build wheel from source
-
-=== "NPU release"
-
- --8<-- "docs/getting_started/installation/npu/npu.inc.md:installation-release"
-
-=== "NPU from main"
-
- --8<-- "docs/getting_started/installation/npu/npu.inc.md:installation-main"
diff --git a/docs/getting_started/installation/npu/npu.inc.md b/docs/getting_started/installation/npu/npu.inc.md
deleted file mode 100644
index c5b13dd73f7..00000000000
--- a/docs/getting_started/installation/npu/npu.inc.md
+++ /dev/null
@@ -1,129 +0,0 @@
-# --8<-- [start:requirements]
-
-For detailed hardware and software requirements, please refer to the [vllm-ascend installation documentation](https://docs.vllm.ai/projects/ascend/en/latest/installation.html).
-
-# --8<-- [end:requirements]
-# --8<-- [start:installation-release]
-
-The recommended way to use vLLM-Omni on NPU is through the vllm-ascend pre-built Docker images:
-
-```bash
-# Update the vllm-ascend image
-# Atlas A2:
-# export IMAGE=quay.io/ascend/vllm-ascend:v0.18.0rc1
-# Atlas A3:
-# export IMAGE=quay.io/ascend/vllm-ascend:v0.18.0rc1-a3
-export IMAGE=quay.io/ascend/vllm-ascend:v0.18.0rc1
-docker run --rm \
- --name vllm-omni-npu \
- --shm-size=1g \
- --device /dev/davinci0 \
- --device /dev/davinci1 \
- --device /dev/davinci2 \
- --device /dev/davinci3 \
- --device /dev/davinci_manager \
- --device /dev/devmm_svm \
- --device /dev/hisi_hdc \
- -v /usr/local/dcmi:/usr/local/dcmi \
- -v /usr/local/bin/npu-smi:/usr/local/bin/npu-smi \
- -v /usr/local/Ascend/driver/lib64/:/usr/local/Ascend/driver/lib64/ \
- -v /usr/local/Ascend/driver/version.info:/usr/local/Ascend/driver/version.info \
- -v /etc/ascend_install.info:/etc/ascend_install.info \
- -v /root/.cache:/root/.cache \
- -p 8000:8000 \
- -it $IMAGE bash
-
-# Inside the container, install vLLM-Omni from source
-cd /vllm-workspace
-git clone -b v0.18.0 https://github.com/vllm-project/vllm-omni.git
-cd vllm-omni
-pip install -v -e . --no-build-isolation
-# or VLLM_OMNI_TARGET_DEVICE=npu pip install -v -e .
-
-export VLLM_WORKER_MULTIPROC_METHOD=spawn
-```
-
-The default workdir is `/workspace`, with vLLM, vLLM-Ascend and vLLM-Omni code placed in `/vllm-workspace` installed in development mode.
-
-For other installation methods (pip installation, building from source, custom Docker builds), please refer to the [vllm-ascend installation guide](https://docs.vllm.ai/projects/ascend/en/latest/installation.html).
-
-We are keeping [issue #886](https://github.com/vllm-project/vllm-omni/issues/886) up to date with the aligned versions of vLLM, vLLM-Ascend, and vLLM-Omni, and also outlining the Q1 roadmap there.
-
-# --8<-- [end:installation-release]
-
-# --8<-- [start:installation-main]
-
-You can also build vLLM-Omni from the latest main branch if you want to use the latest features or bug fixes. (But sometimes it will break for a while. You can check [issue #886](https://github.com/vllm-project/vllm-omni/issues/886) for the status of the latest commit of vLLM-Omni main branch on NPU.)
-
-```bash
-# Pin vLLM version to 0.18.0
-git clone -b v0.18.0 https://github.com/vllm-project/vllm.git
-VLLM_TARGET_DEVICE=empty pip install -v -e .
-
-git clone -b v0.18.0rc1 https://github.com/vllm-project/vllm-ascend.git
-pip install -v -e .
-
-# Install vLLM-Omni from the latest main branch
-git clone https://github.com/vllm-project/vllm-omni.git
-cd /vllm-workspace/vllm-omni
-pip install -v -e . --no-build-isolation
-# or VLLM_OMNI_TARGET_DEVICE=npu pip install -v -e .
-export VLLM_WORKER_MULTIPROC_METHOD=spawn
-```
-
-# --8<-- [end:installation-main]
-
-# --8<-- [start:pre-built-images]
-
-vLLM-Omni offers Docker images for Ascend NPU deployment. You can just pull the **prebuilt image** from the image repository [ascend/vllm-omni](https://quay.io/repository/ascend/vllm-omni?tab=tags) and run it with bash.
-
-Supported images as following.
-
-| image name | Hardware | OS |
-|-|-|-|
-| image-tag | Atlas A2 | Ubuntu |
-| image-tag-a3 | Atlas A3 | Ubuntu |
-
-Here's an example deployment command that has been verified on 4 x NPUs:
-
-```bash
-# Atlas A2:
-# export IMAGE=quay.io/ascend/vllm-omni:v0.18.0
-# Atlas A3:
-# export IMAGE=quay.io/ascend/vllm-omni:v0.18.0-a3
-export IMAGE=quay.io/ascend/vllm-omni:v0.18.0
-docker run --rm \
- --name vllm-omni-npu \
- --shm-size=1g \
- --device /dev/davinci0 \
- --device /dev/davinci1 \
- --device /dev/davinci2 \
- --device /dev/davinci3 \
- --device /dev/davinci_manager \
- --device /dev/devmm_svm \
- --device /dev/hisi_hdc \
- -v /usr/local/dcmi:/usr/local/dcmi \
- -v /usr/local/bin/npu-smi:/usr/local/bin/npu-smi \
- -v /usr/local/Ascend/driver/lib64/:/usr/local/Ascend/driver/lib64/ \
- -v /usr/local/Ascend/driver/version.info:/usr/local/Ascend/driver/version.info \
- -v /etc/ascend_install.info:/etc/ascend_install.info \
- -v /root/.cache:/root/.cache \
- -p 8000:8000 \
- -it $IMAGE bash
-```
-
-!!! tip
- You can use this docker image to serve models the same way you would with in vLLM! To do so, make sure you overwrite the default entrypoint (`vllm serve --omni`) which works only for models supported in the vLLM-Omni project.
-
-Or build IMAGE from **source code**:
-
-```bash
-git clone https://github.com/vllm-project/vllm-omni.git
-cd vllm-omni
-# A2
-docker build -t vllm-omni-dev-image:latest -f ./docker/Dockerfile.npu .
-# A3
-# docker build -t vllm-omni-dev-image:latest -f ./docker/Dockerfile.npu.a3 .
-```
-
-# --8<-- [end:pre-built-images]
diff --git a/docs/getting_started/installation/python_env_setup.inc.md b/docs/getting_started/installation/python_env_setup.inc.md
deleted file mode 100644
index 06794f8d312..00000000000
--- a/docs/getting_started/installation/python_env_setup.inc.md
+++ /dev/null
@@ -1,6 +0,0 @@
-It's recommended to use [uv](https://docs.astral.sh/uv/), a very fast Python environment manager, to create and manage Python environments. Please follow the [documentation](https://docs.astral.sh/uv/#getting-started) to install `uv`. After installing `uv`, you can create a new Python environment using the following commands:
-
-```bash
-uv venv --python 3.12 --seed
-source .venv/bin/activate
-```
diff --git a/docs/getting_started/quickstart.md b/docs/getting_started/quickstart.md
deleted file mode 100644
index dfebe8b6154..00000000000
--- a/docs/getting_started/quickstart.md
+++ /dev/null
@@ -1,122 +0,0 @@
-# Quickstart
-
-This guide will help you quickly get started with vLLM-Omni to perform:
-
-- Offline batched inference
-- Online serving using OpenAI-compatible server
-
-## Prerequisites
-
-- OS: Linux
-- Python: 3.12
-
-## Installation
-
-For installation on GPU from source:
-
-```bash
-uv venv --python 3.12 --seed
-source .venv/bin/activate
-
-# On CUDA
-uv pip install vllm==0.20.0 --torch-backend=auto
-
-# On ROCm
-uv pip install vllm==0.20.0+rocm721 --extra-index-url https://wheels.vllm.ai/rocm/0.20.0/rocm721
-
-git clone https://github.com/vllm-project/vllm-omni.git
-cd vllm-omni
-uv pip install -e .
-```
-
-For additional installation methods — please see the [installation guide](installation/README.md).
-
-
-!!! note
- It is important to install the same major & minor version of vLLM and vLLM Omni, otherwise things may not work as expected. If the versions are misaligned, you will see a warning when you import vLLM Omni.
-
- If you are seeing strange behavior with the `vllm` command not handling the `--omni` flag correctly, you most likely have a version mismatch with vLLM < `0.20.0` and vLLM Omni `0.20.0`, as vLLM Omni no longer hijacks the vLLM entrypoint. Updating vLLM should resolve this issue.
-
-## Offline Inference
-
-Text-to-image generation quickstart with vLLM-Omni:
-
-```python
-from vllm_omni.entrypoints.omni import Omni
-
-if __name__ == "__main__":
- omni = Omni(model="Tongyi-MAI/Z-Image-Turbo")
- prompt = "a cup of coffee on the table"
- outputs = omni.generate(prompt)
- images = outputs[0].request_output.images
- images[0].save("coffee.png")
-```
-
-You can pass a list of prompts and wait for them to process altogether, shown below.
-
-!!! info
-
- However, it is not currently recommended to do so
- because not all models support batch inference,
- and batch requesting mostly does not provide significant performance improvement (despite the impression that it does).
- This feature is primarily for the sake of interface compatibility with vLLM and to allow for future improvements.
-
-```python
-from vllm_omni.entrypoints.omni import Omni
-
-if __name__ == "__main__":
- omni = Omni(
- model="Tongyi-MAI/Z-Image-Turbo",
- # stage_configs_path="./stage-config.yaml", # See below
- )
- prompts = [
- "a cup of coffee on a table",
- "a toy dinosaur on a sandy beach",
- "a fox waking up in bed and yawning",
- ]
- omni_outputs = omni.generate(prompts)
- for i_prompt, prompt_output in enumerate(omni_outputs):
- this_request_output = prompt_output.request_output
- this_images = this_request_output.images
- for i_image, image in enumerate(this_images):
- image.save(f"p{i_prompt}-img{i_image}.jpg")
- print("saved to", f"p{i_prompt}-img{i_image}.jpg")
- # saved to p0-img0.jpg
- # saved to p1-img0.jpg
- # saved to p2-img0.jpg
-```
-
-!!! info
-
- For diffusion pipelines, the stage config field `stage_args.[].engine_args.max_num_seqs` is 1 by default, and the input
- list is sliced into single-item requests before feeding into the diffusion pipeline. For models that do internally support
- batched inputs, you can [modify this configuration](../configuration/stage_configs.md) to let the model accept a longer batch of prompts.
-
-For more usages, please refer to [offline inference](../user_guide/examples/offline_inference/qwen2_5_omni.md)
-
-## Online Serving with OpenAI-Completions API
-
-Text-to-image generation quickstart with vLLM-Omni:
-
-```bash
-vllm serve Tongyi-MAI/Z-Image-Turbo --omni --port 8091
-```
-
-```bash
-curl -s http://localhost:8091/v1/chat/completions \
- -H "Content-Type: application/json" \
- -d '{
- "messages": [
- {"role": "user", "content": "a cup of coffee on the table"}
- ],
- "extra_body": {
- "height": 1024,
- "width": 1024,
- "num_inference_steps": 50,
- "guidance_scale": 4.0,
- "seed": 42
- }
- }' | jq -r '.choices[0].message.content[0].image_url.url' | cut -d',' -f2 | base64 -d > coffee.png
-```
-
-For more details, please refer to [online serving](../user_guide/examples/online_serving/text_to_image.md).
diff --git a/docs/mkdocs/hooks/generate_api_readme.py b/docs/mkdocs/hooks/generate_api_readme.py
deleted file mode 100644
index 3214abd56ea..00000000000
--- a/docs/mkdocs/hooks/generate_api_readme.py
+++ /dev/null
@@ -1,280 +0,0 @@
-# SPDX-License-Identifier: Apache-2.0
-# SPDX-FileCopyrightText: Copyright contributors to the vLLM-Omni project
-"""
-Hook to automatically generate docs/api/README.md from the codebase.
-
-This script scans the vllm_omni module for public classes and functions,
-categorizes them, and generates a summary README file.
-"""
-
-import ast
-import logging
-from pathlib import Path
-
-logger = logging.getLogger("mkdocs")
-
-ROOT_DIR = Path(__file__).parent.parent.parent.parent
-API_README_PATH = ROOT_DIR / "docs" / "api" / "README.md"
-
-# Category mappings: module prefix -> category name and description
-CATEGORIES = {
- "entrypoints": {
- "name": "Entry Points",
- "description": "Main entry points for vLLM-Omni inference and serving.",
- },
- "inputs": {
- "name": "Inputs",
- "description": "Input data structures for multi-modal inputs.",
- },
- "engine": {
- "name": "Engine",
- "description": "Engine classes for offline and online inference.",
- },
- "core": {
- "name": "Core",
- "description": "Core scheduling and caching components.",
- },
- # "model_executor": {
- # "name": "Model Executor",
- # "description": "Model execution components.",
- # },
- "config": {
- "name": "Configuration",
- "description": "Configuration classes.",
- },
- "worker": {
- "name": "Workers",
- "description": "Worker classes and model runners for distributed inference.",
- },
-}
-
-
-class APIVisitor(ast.NodeVisitor):
- """AST visitor to extract public classes and module-level functions."""
-
- def __init__(self, module_path: str):
- self.module_path = module_path
- self.classes: list[str] = []
- self.functions: list[str] = []
- self._class_stack: list[str] = [] # Track nested class definitions
-
- def visit_ClassDef(self, node: ast.ClassDef) -> None:
- """Visit class definitions."""
- if not node.name.startswith("_"):
- self.classes.append(f"{self.module_path}.{node.name}")
- # Track that we're entering a class
- self._class_stack.append(node.name)
- self.generic_visit(node)
- # Remove from stack when done visiting
- self._class_stack.pop()
-
- def visit_FunctionDef(self, node: ast.FunctionDef) -> None:
- """Visit function definitions - only collect module-level functions."""
- # Only collect if we're not inside a class (stack is empty)
- if not self._class_stack and not node.name.startswith("_"):
- self.functions.append(f"{self.module_path}.{node.name}")
- self.generic_visit(node)
-
- def visit_AsyncFunctionDef(self, node: ast.AsyncFunctionDef) -> None:
- """Visit async function definitions - only collect module-level functions."""
- # Only collect if we're not inside a class (stack is empty)
- if not self._class_stack and not node.name.startswith("_"):
- self.functions.append(f"{self.module_path}.{node.name}")
- self.generic_visit(node)
-
-
-def parse_file_for_symbols(file_path: Path, module_path: str) -> tuple[list[str], list[str]]:
- """
- Parse a Python file and extract public classes and functions.
-
- Returns:
- Tuple of (classes, functions)
- """
- try:
- # If this is __init__.py, use parent module path
- if file_path.name == "__init__.py":
- # Remove .__init__ from module path
- if module_path.endswith(".__init__"):
- module_path = module_path[:-9]
-
- with open(file_path, encoding="utf-8") as f:
- content = f.read()
-
- tree = ast.parse(content, filename=str(file_path))
- visitor = APIVisitor(module_path)
- visitor.visit(tree)
-
- return visitor.classes, visitor.functions
- except Exception as e:
- logger.debug(f"Could not parse {file_path}: {e}")
- return [], []
-
-
-def scan_package(package_name: str = "vllm_omni") -> dict[str, list[str]]:
- """
- Scan the vllm_omni package and categorize public symbols.
-
- Returns:
- Dict mapping category names to lists of symbol full names
- """
- categorized: dict[str, list[str]] = {cat["name"]: [] for cat in CATEGORIES.values()}
-
- try:
- # Find the package directory
- package_path = ROOT_DIR / package_name
- if not package_path.exists():
- logger.warning(f"Package path not found: {package_path}")
- return categorized
-
- # Walk through all Python files
- for py_file in package_path.rglob("*.py"):
- # Skip __init__.py and private modules
- if py_file.name.startswith("_") and py_file.name != "__init__.py":
- continue
-
- # Get module path
- relative_path = py_file.relative_to(ROOT_DIR)
- module_path = str(relative_path.with_suffix("")).replace("/", ".").replace("\\", ".")
-
- # Skip excluded modules (avoid importing vllm during docs build)
- excluded_prefixes = [
- "vllm_omni.diffusion.models.qwen_image",
- "vllm_omni.diffusion.quantization",
- "vllm_omni.quantization",
- "vllm_omni.entrypoints.async_diffusion",
- "vllm_omni.entrypoints.openai",
- "vllm_omni.model_executor.models.voxtral_tts.configuration_voxtral_tts",
- ]
- if any(module_path.startswith(prefix) for prefix in excluded_prefixes):
- continue
-
- # Handle __init__.py - use parent module path
- if py_file.name == "__init__.py":
- # Remove .__init__ from module path
- if module_path.endswith(".__init__"):
- module_path = module_path[:-9]
-
- # Determine category from module path
- category = None
- for prefix, cat_info in CATEGORIES.items():
- if prefix in module_path:
- category = cat_info["name"]
- break
-
- if not category:
- continue
-
- # Parse file for symbols
- classes, functions = parse_file_for_symbols(py_file, module_path)
-
- # Filter out internal implementation classes
- # Skip classes that look like internal components (DiT layers, etc.)
- internal_patterns = [
- "Block",
- "Layer",
- "Net",
- "Embedding",
- "Norm",
- "Activation",
- "Solver",
- "Pooling",
- "Attention",
- "MLP",
- "DecoderLayer",
- "InputEmbedding",
- "TimestepEmbedding",
- "CodecEmbedding",
- "DownSample",
- "UpSample",
- "Res2Net",
- "SqueezeExcitation",
- "TimeDelay",
- "TorchActivation",
- "SnakeBeta",
- "SinusPosition",
- "RungeKutta",
- "AMPBlock",
- "AdaLayerNorm",
- ]
-
- # Add classes (filter out internal ones)
- for class_name in classes:
- class_short_name = class_name.split(".")[-1]
- # Skip if it matches internal patterns (unless it's a main model class)
- if any(pattern in class_short_name for pattern in internal_patterns):
- # But include main model classes
- if not any(
- main_class in class_short_name
- for main_class in [
- "ForConditionalGeneration",
- "Model",
- "Registry",
- "Worker",
- "Runner",
- "Scheduler",
- "Manager",
- "Processor",
- "Config",
- ]
- ):
- continue
- categorized[category].append(class_name)
-
- # Add important functions (parse, preprocess, etc.)
- for func_name in functions:
- # Include functions that match certain patterns
- if any(keyword in func_name.lower() for keyword in ["parse", "preprocess"]):
- categorized[category].append(func_name)
-
- # Sort symbols within each category
- for category in categorized:
- categorized[category].sort()
-
- except Exception as e:
- logger.error(f"Error scanning package: {e}", exc_info=True)
-
- return categorized
-
-
-def generate_readme(categorized: dict[str, list[str]]) -> str:
- """Generate the API README markdown content."""
- lines = ["# Summary", ""]
-
- # Generate sections for each category
- for prefix, cat_info in CATEGORIES.items():
- category_name = cat_info["name"]
- description = cat_info["description"]
- symbols = categorized.get(category_name, [])
-
- if not symbols:
- continue
-
- lines.append(f"## {category_name}")
- lines.append("")
- lines.append(description)
- lines.append("")
-
- for symbol in symbols:
- lines.append(f"- [{symbol}][]")
-
- lines.append("")
-
- return "\n".join(lines)
-
-
-def on_startup(command, dirty: bool):
- """MkDocs hook entry point."""
- logger.info("Generating API README documentation")
-
- # Scan the package
- categorized = scan_package()
-
- # Generate README content
- content = generate_readme(categorized)
-
- # Write to file
- API_README_PATH.parent.mkdir(parents=True, exist_ok=True)
- with open(API_README_PATH, "w", encoding="utf-8") as f:
- f.write(content)
-
- logger.info(f"API README generated: {API_README_PATH.relative_to(ROOT_DIR)}")
diff --git a/docs/mkdocs/hooks/generate_argparse.py b/docs/mkdocs/hooks/generate_argparse.py
deleted file mode 100644
index e3cfb1b6a86..00000000000
--- a/docs/mkdocs/hooks/generate_argparse.py
+++ /dev/null
@@ -1,260 +0,0 @@
-# SPDX-License-Identifier: Apache-2.0
-# SPDX-FileCopyrightText: Copyright contributors to the vLLM-Omni project
-
-import ast
-import logging
-import re
-import sys
-from argparse import SUPPRESS, Action, ArgumentParser, HelpFormatter, _ArgumentGroup
-from collections.abc import Iterable
-from importlib.machinery import ModuleSpec
-from pathlib import Path
-from typing import Literal
-from unittest.mock import MagicMock
-
-from pydantic_core import core_schema
-
-
-class _FlexibleArgumentParser(ArgumentParser):
- """Fallback parser for docs when vllm is unavailable.
-
- Accepts the 'deprecated' kwarg used by vllm CLI and emits warnings
- if a deprecated argument is actually provided.
- """
-
- _deprecated: set[Action] = set()
- _deprecated_warned: set[str] = set()
-
- if sys.version_info < (3, 13):
-
- def parse_known_args(self, args=None, namespace=None):
- namespace, args = super().parse_known_args(args, namespace)
- for action in _FlexibleArgumentParser._deprecated:
- if (
- hasattr(namespace, dest := action.dest)
- and getattr(namespace, dest) != action.default
- and dest not in _FlexibleArgumentParser._deprecated_warned
- ):
- _FlexibleArgumentParser._deprecated_warned.add(dest)
- logger.warning("argument '%s' is deprecated", dest)
- return namespace, args
-
- def add_argument(self, *args, **kwargs):
- deprecated = kwargs.pop("deprecated", False)
- action = super().add_argument(*args, **kwargs)
- if deprecated:
- _FlexibleArgumentParser._deprecated.add(action)
- return action
-
- class _FlexibleArgumentGroup(_ArgumentGroup):
- def add_argument(self, *args, **kwargs):
- deprecated = kwargs.pop("deprecated", False)
- action = super().add_argument(*args, **kwargs)
- if deprecated:
- _FlexibleArgumentParser._deprecated.add(action)
- return action
-
- def add_argument_group(self, *args, **kwargs):
- group = self._FlexibleArgumentGroup(self, *args, **kwargs)
- self._action_groups.append(group)
- return group
-
-
-logger = logging.getLogger("mkdocs")
-
-# Define root and doc output directories
-ROOT_DIR = Path(__file__).parent.parent.parent.parent
-ARGPARSE_DOC_DIR = ROOT_DIR / "docs/generated/argparse_omni"
-
-# Ensure the repo root is in sys.path for dynamic imports
-sys.path.insert(0, str(ROOT_DIR))
-
-
-class PydanticMagicMock(MagicMock):
- """`MagicMock` that's able to generate pydantic-core schemas and avoids _mock_name=None errors."""
-
- def __init__(self, *args, **kwargs):
- name = kwargs.pop("name", None)
- super().__init__(*args, **kwargs)
- self.__spec__ = ModuleSpec(name, None)
- self._mock_name = name or "mock"
-
- def __get_pydantic_core_schema__(self, source_type, handler):
- return core_schema.any_schema()
-
-
-# --- Static extraction for CLI argument docs ---
-
-
-def extract_omni_serve_subparser_init():
- """
- Statically parse vllm_omni/entrypoints/cli/serve.py to extract the subparser_init method
- and return a callable that adds arguments to a parser. This avoids import and mock issues.
- """
- serve_path = ROOT_DIR / "vllm_omni" / "entrypoints" / "cli" / "serve.py"
- with open(serve_path, encoding="utf-8") as f:
- source = f.read()
- tree = ast.parse(source, filename=str(serve_path))
- # Find class OmniServeCommand
- for node in tree.body:
- if isinstance(node, ast.ClassDef) and node.name == "OmniServeCommand":
- for item in node.body:
- if isinstance(item, ast.FunctionDef) and item.name == "subparser_init":
- # We'll exec this function body in a dummy context
- func_code = ast.Module(body=[item], type_ignores=[])
- code = compile(func_code, filename=str(serve_path), mode="exec")
- # Prepare dummy context
- local_vars = {}
-
- # Provide a dummy subparsers with add_parser returning our parser
- class DummySubparsers:
- def add_parser(self, name, **kwargs):
- return _FlexibleArgumentParser(prog=name)
-
- dummy_subparsers = DummySubparsers()
- # Provide globals for exec
- # Extract DESCRIPTION from the source file (assume it's a triple-quoted string at the top)
- m = re.search(r'DESCRIPTION\s*=\s*([ru]?""".*?""")', source, re.DOTALL)
- DESCRIPTION = m.group(1)[3:-3] if m else ""
- exec_globals = {
- "_FlexibleArgumentParser": _FlexibleArgumentParser,
- "FlexibleArgumentParser": _FlexibleArgumentParser,
- "make_arg_parser": lambda parser: parser, # no-op for doc
- "_ensure_vllm_platform": lambda: None, # no-op for doc
- "nullify_stage_engine_defaults": lambda parser: None, # no-op for doc
- "VLLM_SUBCMD_PARSER_EPILOG": "",
- "logger": logger,
- "DummySubparsers": DummySubparsers,
- "argparse": __import__("argparse"),
- "json": __import__("json"),
- "DESCRIPTION": DESCRIPTION,
- }
- exec(code, exec_globals, local_vars)
- # Get the function
- subparser_init = local_vars["subparser_init"]
-
- # Return a callable that mimics OmniServeCommand().subparser_init
- def parser_factory():
- class DummySelf:
- name = "serve"
-
- return subparser_init(DummySelf(), dummy_subparsers)
-
- return parser_factory
- raise RuntimeError("Could not statically extract OmniServeCommand.subparser_init")
-
-
-OmniServeCommand = type("OmniServeCommand", (), {"subparser_init": staticmethod(extract_omni_serve_subparser_init())})
-
-
-class MarkdownFormatter(HelpFormatter):
- """Custom formatter that generates markdown for argument groups."""
-
- def __init__(self, prog: str, starting_heading_level: int = 3):
- super().__init__(prog, max_help_position=sys.maxsize, width=sys.maxsize)
-
- self._section_heading_prefix = "#" * starting_heading_level
- self._argument_heading_prefix = "#" * (starting_heading_level + 1)
- self._markdown_output = []
-
- def start_section(self, heading: str):
- if heading not in {"positional arguments", "options"}:
- heading_md = f"\n{self._section_heading_prefix} {heading}\n\n"
- self._markdown_output.append(heading_md)
-
- def end_section(self):
- pass
-
- def add_text(self, text: str):
- if text:
- self._markdown_output.append(f"{text.strip()}\n\n")
-
- def add_usage(self, usage, actions, groups, prefix=None):
- pass
-
- def add_arguments(self, actions: Iterable[Action]):
- for action in actions:
- if len(action.option_strings) == 0 or "--help" in action.option_strings:
- continue
-
- option_strings = f"`{'`, `'.join(action.option_strings)}`"
- heading_md = f"{self._argument_heading_prefix} {option_strings}\n\n"
- self._markdown_output.append(heading_md)
-
- if choices := action.choices:
- choices = f"`{'`, `'.join(str(c) for c in choices)}`"
- self._markdown_output.append(f"Possible choices: {choices}\n\n")
- elif (metavar := action.metavar) and isinstance(metavar, (list, tuple)):
- metavar = f"`{'`, `'.join(str(m) for m in metavar)}`"
- self._markdown_output.append(f"Possible choices: {metavar}\n\n")
-
- if action.help:
- self._markdown_output.append(f"{action.help}\n\n")
-
- if (default := action.default) != SUPPRESS:
- # Make empty string defaults visible
- if default == "":
- default = '""'
- self._markdown_output.append(f"Default: `{default}`\n\n")
-
- def format_help(self):
- """Return the formatted help as markdown."""
- return "".join(self._markdown_output)
-
-
-# Function to create parser using subparser_init style CLI class
-
-
-def create_parser_subparser_init(subcmd_class):
- """
- Create an argparse parser using subparser_init style CLI class, with MarkdownFormatter.
- Compatible with both AST-extracted static parser_factory and real class instance method.
- """
-
- class DummySubparsers:
- def add_parser(self, name, **kwargs):
- return _FlexibleArgumentParser(prog=name)
-
- dummy_subparsers = DummySubparsers()
- # If subparser_init is a zero-arg static function (AST-extracted), call it directly
- subparser_init = getattr(subcmd_class, "subparser_init", None)
- if subparser_init is not None:
- import inspect
-
- sig = inspect.signature(subparser_init)
- if len(sig.parameters) == 0:
- parser = subparser_init()
- else:
- parser = subcmd_class().subparser_init(dummy_subparsers)
- else:
- parser = subcmd_class().subparser_init(dummy_subparsers)
- parser.formatter_class = MarkdownFormatter
- return parser
-
-
-def on_startup(command: Literal["build", "gh-deploy", "serve"], dirty: bool):
- """
- Entry point for doc generation. Builds doc directory and outputs markdown for each CLI command.
- """
- logger.info("Generating vllm-omni argparse documentation")
- logger.debug("Root directory: %s", ROOT_DIR.resolve())
- logger.debug("Output directory: %s", ARGPARSE_DOC_DIR.resolve())
- if not ARGPARSE_DOC_DIR.exists():
- ARGPARSE_DOC_DIR.mkdir(parents=True)
-
- # Register all CLI parsers; you can easily add more commands here
- parsers = {
- "omni_serve": create_parser_subparser_init(OmniServeCommand),
- # "another_cmd": create_parser_subparser_init(AnotherCommandClass),
- }
-
- for stem, parser in parsers.items():
- doc_path = ARGPARSE_DOC_DIR / f"{stem}.inc.md"
- with open(doc_path, "w", encoding="utf-8") as f:
- f.write(super(type(parser), parser).format_help())
- logger.info("Argparse generated: %s", doc_path.relative_to(ROOT_DIR))
-
-
-if __name__ == "__main__":
- logging.basicConfig(level=logging.INFO)
- on_startup("build", False)
diff --git a/docs/mkdocs/hooks/generate_examples.py b/docs/mkdocs/hooks/generate_examples.py
deleted file mode 100644
index b4c92893654..00000000000
--- a/docs/mkdocs/hooks/generate_examples.py
+++ /dev/null
@@ -1,346 +0,0 @@
-# SPDX-License-Identifier: Apache-2.0
-# SPDX-FileCopyrightText: Copyright contributors to the vLLM project
-import itertools
-import logging
-from dataclasses import dataclass, field
-from pathlib import Path
-from typing import Literal
-
-import regex as re
-import yaml
-
-logger = logging.getLogger("mkdocs")
-
-ROOT_DIR = Path(__file__).parent.parent.parent.parent
-ROOT_DIR_RELATIVE = "../../../../.."
-EXAMPLE_DIR = ROOT_DIR / "examples"
-EXAMPLE_DOC_DIR = ROOT_DIR / "docs/user_guide/examples"
-NAV_FILE = ROOT_DIR / "docs/.nav.yml"
-
-
-def fix_case(text: str) -> str:
- subs = {
- "api": "API",
- "cli": "CLI",
- "cpu": "CPU",
- "llm": "LLM",
- "mae": "MAE",
- "tpu": "TPU",
- "gguf": "GGUF",
- "lora": "LoRA",
- "rlhf": "RLHF",
- "vllm": "vLLM",
- "openai": "OpenAI",
- "lmcache": "LMCache",
- "multilora": "MultiLoRA",
- "mlpspeculator": "MLPSpeculator",
- r"fp\d+": lambda x: x.group(0).upper(), # e.g. fp16, fp32
- r"int\d+": lambda x: x.group(0).upper(), # e.g. int8, int16
- }
- for pattern, repl in subs.items():
- text = re.sub(rf"\b{pattern}\b", repl, text, flags=re.IGNORECASE)
- return text
-
-
-@dataclass
-class Example:
- """
- Example class for generating documentation content from a given path.
-
- Attributes:
- path (Path): The path to the main directory or file.
- category (str): The category of the document.
- main_file (Path): The main file in the directory.
- other_files (list[Path]): list of other files in the directory.
- title (str): The title of the document.
-
- Methods:
- __post_init__(): Initializes the main_file, other_files, and title attributes.
- determine_main_file() -> Path: Determines the main file in the given path.
- determine_other_files() -> list[Path]: Determines other files in the directory excluding the main file.
- determine_title() -> str: Determines the title of the document.
- generate() -> str: Generates the documentation content.
- """ # noqa: E501
-
- path: Path
- category: str = None
- main_file: Path = field(init=False)
- other_files: list[Path] = field(init=False)
- title: str = field(init=False)
-
- def __post_init__(self):
- self.main_file = self.determine_main_file()
- self.other_files = self.determine_other_files()
- self.title = self.determine_title()
-
- @property
- def is_code(self) -> bool:
- return self.main_file.suffix != ".md"
-
- def determine_main_file(self) -> Path:
- """
- Determines the main file in the given path.
- If the path is a file, it returns the path itself. Otherwise, it searches
- for Markdown files (*.md) in the directory and returns the first one found.
- Returns:
- Path: The main file path, either the original path if it's a file or the first
- Markdown file found in the directory.
- Raises:
- IndexError: If no Markdown files are found in the directory.
- """ # noqa: E501
- return self.path if self.path.is_file() else list(self.path.glob("*.md")).pop()
-
- def determine_other_files(self) -> list[Path]:
- """
- Determine other files in the directory excluding the main file.
-
- This method checks if the given path is a file. If it is, it returns an empty list.
- Otherwise, it recursively searches through the directory and returns a list of all
- files that are not the main file.
-
- Returns:
- list[Path]: A list of Path objects representing the other files in the directory.
- """ # noqa: E501
- if self.path.is_file():
- return []
- # Binary file extensions to exclude
- binary_extensions = {
- ".wav",
- ".mp3",
- ".mp4",
- ".avi",
- ".mov",
- ".mkv", # Audio/Video
- ".png",
- ".jpg",
- ".jpeg",
- ".gif",
- ".bmp",
- ".ico",
- ".svg", # Images
- ".pdf",
- ".zip",
- ".tar",
- ".gz",
- ".bz2",
- ".xz", # Archives/Documents
- ".exe",
- ".so",
- ".dll",
- ".dylib", # Binaries
- ".bin",
- ".dat",
- ".db",
- ".sqlite", # Data files
- ".pyc",
- ".pyo",
- ".pyd", # Python compiled
- ".npy",
- ".npz",
- ".pkl",
- ".pickle", # Serialized data
- }
- excluded_dirs = {"__pycache__", ".git", "node_modules", ".tox", ".mypy_cache"}
-
- def is_other_file(file: Path) -> bool:
- if any(part in excluded_dirs for part in file.parts):
- return False
- return file.is_file() and file != self.main_file and file.suffix.lower() not in binary_extensions
-
- return [file for file in self.path.rglob("*") if is_other_file(file)]
-
- def determine_title(self) -> str:
- if not self.is_code:
- # Specify encoding for building on Windows
- with open(self.main_file, encoding="utf-8") as f:
- first_line = f.readline().strip()
- match = re.match(r"^#\s+(?P.+)$", first_line)
- if match:
- return match.group("title")
- return fix_case(self.path.stem.replace("_", " ").title())
-
- def fix_relative_links(self, content: str) -> str:
- """
- Fix relative links in markdown content by converting them to gh-file
- format.
-
- Args:
- content (str): The markdown content to process
-
- Returns:
- str: Content with relative links converted to gh-file format
- """
- # Regex to match markdown links [text](relative_path)
- # This matches links that don't start with http, https, ftp, or #
- link_pattern = r"\[([^\]]*)\]\((?!(?:https?|ftp)://|#)([^)]+)\)"
-
- def replace_link(match):
- link_text = match.group(1)
- relative_path = match.group(2)
-
- # Make relative to repo root
- gh_file = (self.main_file.parent / relative_path).resolve()
- gh_file = gh_file.relative_to(ROOT_DIR)
-
- # Make GitHub URL
- url = "https://github.com/vllm-project/vllm-omni/"
- url += "tree/main" if self.path.is_dir() else "blob/main"
- gh_url = f"{url}/{gh_file}"
-
- return f"[{link_text}]({gh_url})"
-
- return re.sub(link_pattern, replace_link, content)
-
- def generate(self) -> str:
- content = f"# {self.title}\n\n"
- url = "https://github.com/vllm-project/vllm-omni/"
- url += "tree/main" if self.path.is_dir() else "blob/main"
- content += f"Source <{url}/{self.path.relative_to(ROOT_DIR)}>.\n\n"
-
- # Use long code fence to avoid issues with
- # included files containing code fences too
- code_fence = "``````"
-
- if self.is_code:
- main_file_rel = self.main_file.relative_to(ROOT_DIR)
- content += f'{code_fence}{self.main_file.suffix[1:]}\n--8<-- "{main_file_rel}"\n{code_fence}\n'
- else:
- with open(self.main_file, encoding="utf-8") as f:
- # Skip the title from md snippets as it's been included above
- main_content = f.readlines()[1:]
- content += self.fix_relative_links("".join(main_content))
- content += "\n"
-
- if not self.other_files:
- return content
-
- content += "## Example materials\n\n"
- for file in sorted(self.other_files):
- content += f'??? abstract "{file.relative_to(self.path)}"\n'
- if file.suffix != ".md":
- content += f" {code_fence}{file.suffix[1:]}\n"
- content += f' --8<-- "{file.relative_to(ROOT_DIR)}"\n'
- if file.suffix != ".md":
- content += f" {code_fence}\n"
-
- return content
-
-
-def update_nav_file(examples: list[Example]):
- """
- Update the .nav.yml file to include all generated examples.
- This function completely regenerates the examples section based on the actual
- folder structure, ensuring consistency between the examples folder and nav file.
-
- Args:
- examples: List of Example objects that have been generated
- """
- if not NAV_FILE.exists():
- logger.warning("Navigation file not found: %s", NAV_FILE)
- return
-
- # Read the current nav file
- with open(NAV_FILE, encoding="utf-8") as f:
- nav_data = yaml.safe_load(f) or {}
-
- nav_list = nav_data.get("nav", [])
-
- # Find the "User Guide" section
- user_guide_idx = None
- examples_idx = None
- for i, item in enumerate(nav_list):
- if isinstance(item, dict) and "User Guide" in item:
- user_guide_idx = i
- user_guide_content = item["User Guide"]
- # Find the "Examples" subsection
- for j, subitem in enumerate(user_guide_content):
- if isinstance(subitem, dict) and "Examples" in subitem:
- examples_idx = j
- break
- break
-
- if user_guide_idx is None or examples_idx is None:
- logger.warning("Could not find 'User Guide' -> 'Examples' section in nav file")
- return
-
- # Get existing Examples section to preserve non-example items (like README.md)
- existing_examples_content = nav_list[user_guide_idx]["User Guide"][examples_idx]["Examples"]
-
- # Preserve string items (like "examples/README.md") that are not example categories
- preserved_items = [
- item
- for item in existing_examples_content
- if isinstance(item, str) and not item.startswith("user_guide/examples/")
- ]
-
- # Group examples by category
- examples_by_category = {}
- for example in examples:
- category = example.category
- if category not in examples_by_category:
- examples_by_category[category] = []
- examples_by_category[category].append(example)
-
- # Build the new Examples section - start with preserved items
- examples_section = preserved_items.copy()
-
- # Add examples grouped by category, sorted by category name
- for category in sorted(examples_by_category.keys()):
- category_examples = sorted(examples_by_category[category], key=lambda e: e.path.stem)
- category_items = []
- for example in category_examples:
- doc_path = EXAMPLE_DOC_DIR / example.category / f"{example.path.stem}.md"
- rel_path = doc_path.relative_to(ROOT_DIR / "docs")
- category_items.append({example.title: str(rel_path)})
-
- if category_items:
- # Format category name (e.g., "offline_inference" -> "Offline Inference")
- category_title = fix_case(category.replace("_", " ").title())
- examples_section.append({category_title: category_items})
-
- # Update the nav structure
- nav_list[user_guide_idx]["User Guide"][examples_idx]["Examples"] = examples_section
-
- # Write back to file
- nav_data["nav"] = nav_list
- with open(NAV_FILE, "w", encoding="utf-8") as f:
- yaml.dump(nav_data, f, default_flow_style=False, sort_keys=False, allow_unicode=True)
- logger.info("Updated navigation file: %s", NAV_FILE.relative_to(ROOT_DIR))
-
-
-def on_startup(command: Literal["build", "gh-deploy", "serve"], dirty: bool):
- logger.info("Generating example documentation")
- logger.debug("Root directory: %s", ROOT_DIR.resolve())
- logger.debug("Example directory: %s", EXAMPLE_DIR.resolve())
- logger.debug("Example document directory: %s", EXAMPLE_DOC_DIR.resolve())
-
- # Create the EXAMPLE_DOC_DIR if it doesn't exist
- if not EXAMPLE_DOC_DIR.exists():
- EXAMPLE_DOC_DIR.mkdir(parents=True)
-
- categories = sorted(p for p in EXAMPLE_DIR.iterdir() if p.is_dir())
-
- examples = []
- glob_patterns = ["*.py", "*.md", "*.sh"]
- # Find categorised examples
- for category in categories:
- globs = [category.glob(pattern) for pattern in glob_patterns]
- for path in itertools.chain(*globs):
- examples.append(Example(path, category.stem))
- # Find examples in subdirectories
- for path in category.glob("*/*.md"):
- examples.append(Example(path.parent, category.stem))
-
- # Generate the example documentation
- for example in sorted(examples, key=lambda e: e.path.stem):
- example_name = f"{example.path.stem}.md"
- doc_path = EXAMPLE_DOC_DIR / example.category / example_name
- if not doc_path.parent.exists():
- doc_path.parent.mkdir(parents=True)
- # Specify encoding for building on Windows
- with open(doc_path, "w+", encoding="utf-8") as f:
- f.write(example.generate())
- logger.debug("Example generated: %s", doc_path.relative_to(ROOT_DIR))
-
- # Update the navigation file
- update_nav_file(examples)
diff --git a/docs/mkdocs/hooks/url_schemes.py b/docs/mkdocs/hooks/url_schemes.py
deleted file mode 100644
index 8798b11db20..00000000000
--- a/docs/mkdocs/hooks/url_schemes.py
+++ /dev/null
@@ -1,121 +0,0 @@
-# SPDX-License-Identifier: Apache-2.0
-# SPDX-FileCopyrightText: Copyright contributors to the vLLM project
-"""
-This is basically a port of MyST parser’s external URL resolution mechanism
-(https://myst-parser.readthedocs.io/en/latest/syntax/cross-referencing.html#customising-external-url-resolution)
-to work with MkDocs.
-
-It allows Markdown authors to use GitHub shorthand links like:
-
- - [Text](gh-issue:123)
- - <gh-pr:456>
- - [File](gh-file:path/to/file.py#L10)
-
-These are automatically rewritten into fully qualified GitHub URLs pointing to
-issues, pull requests, files, directories, or projects in the
-`vllm-project/vllm-omni` repository.
-
-The goal is to simplify cross-referencing common GitHub resources
-in project docs.
-"""
-
-import regex as re
-from mkdocs.config.defaults import MkDocsConfig
-from mkdocs.structure.files import Files
-from mkdocs.structure.pages import Page
-
-
-def on_page_markdown(markdown: str, *, page: Page, config: MkDocsConfig, files: Files) -> str:
- """
- Custom MkDocs plugin hook to rewrite special GitHub reference links
- in Markdown.
-
- This function scans the given Markdown content for specially formatted
- GitHub shorthand links, such as:
- - `[Link text](gh-issue:123)`
- - `<gh-pr:456>`
-
- And rewrites them into fully-qualified GitHub URLs with GitHub icons:
- - `[:octicons-mark-github-16: Link text](https://github.com/vllm-project/vllm/issues/123)`
- - `[:octicons-mark-github-16: Pull Request #456](https://github.com/vllm-project/vllm/pull/456)`
-
- Supported shorthand types:
- - `gh-issue`
- - `gh-pr`
- - `gh-project`
- - `gh-dir`
- - `gh-file`
-
- Args:
- markdown (str): The raw Markdown content of the page.
- page (Page): The MkDocs page object being processed.
- config (MkDocsConfig): The MkDocs site configuration.
- files (Files): The collection of files in the MkDocs build.
-
- Returns:
- str: The updated Markdown content with GitHub shorthand links replaced.
- """
- gh_icon = ":octicons-mark-github-16:"
- gh_url = "https://github.com"
- repo_url = f"{gh_url}/vllm-project/vllm-omni"
- org_url = f"{gh_url}/orgs/vllm-project"
-
- # Mapping of shorthand types to their corresponding GitHub base URLs
- urls = {
- "issue": f"{repo_url}/issues",
- "pr": f"{repo_url}/pull",
- "project": f"{org_url}/projects",
- "dir": f"{repo_url}/tree/main",
- "file": f"{repo_url}/blob/main",
- }
-
- # Default title prefixes for auto links
- titles = {
- "issue": "Issue #",
- "pr": "Pull Request #",
- "project": "Project #",
- "dir": "",
- "file": "",
- }
-
- # Regular expression to match GitHub shorthand links
- scheme = r"gh-(?P<type>.+?):(?P<path>.+?)(#(?P<fragment>.+?))?"
- inline_link = re.compile(r"\[(?P<title>[^\[]+?)\]\(" + scheme + r"\)")
- auto_link = re.compile(f"<{scheme}>")
-
- def replace_inline_link(match: re.Match) -> str:
- """
- Replaces a matched inline-style GitHub shorthand link
- with a full Markdown link.
-
- Example:
- [My issue](gh-issue:123) → [:octicons-mark-github-16: My issue](https://github.com/vllm-project/vllm/issues/123)
- """
- url = f"{urls[match.group('type')]}/{match.group('path')}"
- if fragment := match.group("fragment"):
- url += f"#{fragment}"
-
- return f"[{gh_icon} {match.group('title')}]({url})"
-
- def replace_auto_link(match: re.Match) -> str:
- """
- Replaces a matched autolink-style GitHub shorthand
- with a full Markdown link.
-
- Example:
- <gh-pr:456> → [:octicons-mark-github-16: Pull Request #456](https://github.com/vllm-project/vllm/pull/456)
- """
- type = match.group("type")
- path = match.group("path")
- title = f"{titles[type]}{path}"
- url = f"{urls[type]}/{path}"
- if fragment := match.group("fragment"):
- url += f"#{fragment}"
-
- return f"[{gh_icon} {title}]({url})"
-
- # Replace both inline and autolinks
- markdown = inline_link.sub(replace_inline_link, markdown)
- markdown = auto_link.sub(replace_auto_link, markdown)
-
- return markdown
diff --git a/docs/mkdocs/javascript/edit_and_feedback.js b/docs/mkdocs/javascript/edit_and_feedback.js
deleted file mode 100644
index 0acbcfd965b..00000000000
--- a/docs/mkdocs/javascript/edit_and_feedback.js
+++ /dev/null
@@ -1,47 +0,0 @@
-/**
- * edit_and_feedback.js
- *
- * Enhances MkDocs Material docs pages by:
- *
- * 1. Adding a "Question? Give us feedback" link
- * below the "Edit" button.
- *
- * - The link opens a GitHub issue with a template,
- * auto-filled with the current page URL and path.
- *
- * 2. Ensuring the edit button opens in a new tab
- * with target="_blank" and rel="noopener".
- */
-document.addEventListener("DOMContentLoaded", function () {
- const url = window.location.href;
- const page = document.body.dataset.mdUrl || location.pathname;
-
- const feedbackLink = document.createElement("a");
- feedbackLink.href = `https://github.com/vllm-project/vllm-omni/issues/new?template=100-documentation.yml&title=${encodeURIComponent(
- `[Docs] Feedback for \`${page}\``
- )}&body=${encodeURIComponent(`📄 **Reference:**\n${url}\n\n📝 **Feedback:**\n_Your response_`)}`;
- feedbackLink.target = "_blank";
- feedbackLink.rel = "noopener";
- feedbackLink.title = "Provide feedback";
- feedbackLink.className = "md-content__button";
- feedbackLink.innerHTML = `
- <svg
- xmlns="http://www.w3.org/2000/svg"
- height="24px"
- viewBox="0 -960 960 960"
- width="24px"
- fill="currentColor"
- >
- <path d="M280-280h280v-80H280v80Zm0-160h400v-80H280v80Zm0-160h400v-80H280v80Zm-80 480q-33 0-56.5-23.5T120-200v-560q0-33 23.5-56.5T200-840h560q33 0 56.5 23.5T840-760v560q0 33-23.5 56.5T760-120H200Zm0-80h560v-560H200v560Zm0-560v560-560Z"/>
- </svg>
- `;
-
- const editButton = document.querySelector('.md-content__button[href*="edit"]');
-
- if (editButton && editButton.parentNode) {
- editButton.insertAdjacentElement("beforebegin", feedbackLink);
-
- editButton.setAttribute("target", "_blank");
- editButton.setAttribute("rel", "noopener");
- }
- });
diff --git a/docs/mkdocs/javascript/mathjax.js b/docs/mkdocs/javascript/mathjax.js
deleted file mode 100644
index eb89ace0695..00000000000
--- a/docs/mkdocs/javascript/mathjax.js
+++ /dev/null
@@ -1,20 +0,0 @@
-// Enables MathJax rendering
-window.MathJax = {
- tex: {
- inlineMath: [["\\(", "\\)"]],
- displayMath: [["\\[", "\\]"]],
- processEscapes: true,
- processEnvironments: true
- },
- options: {
- ignoreHtmlClass: ".*|",
- processHtmlClass: "arithmatex"
- }
- };
-
- document$.subscribe(() => {
- MathJax.startup.output.clearCache()
- MathJax.typesetClear()
- MathJax.texReset()
- MathJax.typesetPromise()
- })
diff --git a/docs/mkdocs/javascript/mermaid.js b/docs/mkdocs/javascript/mermaid.js
deleted file mode 100644
index 63676de9db5..00000000000
--- a/docs/mkdocs/javascript/mermaid.js
+++ /dev/null
@@ -1,21 +0,0 @@
-// Initialize Mermaid for diagram rendering
-mermaid.initialize({
- startOnLoad: false,
- theme: 'default',
- securityLevel: 'loose',
- flowchart: {
- useMaxWidth: true,
- htmlLabels: true
- }
-});
-
-// Render Mermaid diagrams when page content is ready
-document$.subscribe(() => {
- const mermaidElements = document.querySelectorAll('.mermaid');
- if (mermaidElements.length > 0) {
- mermaid.run({
- querySelector: '.mermaid',
- nodes: mermaidElements
- });
- }
-});
diff --git a/docs/mkdocs/javascript/slack_and_forum.js b/docs/mkdocs/javascript/slack_and_forum.js
deleted file mode 100644
index 320e44910aa..00000000000
--- a/docs/mkdocs/javascript/slack_and_forum.js
+++ /dev/null
@@ -1,56 +0,0 @@
-/**
- * slack_and_forum.js
- *
- * Adds a custom Slack and Forum button to the MkDocs Material header.
- *
- */
-
-window.addEventListener('DOMContentLoaded', () => {
- const headerInner = document.querySelector('.md-header__inner');
-
- if (headerInner) {
- const slackButton = document.createElement('button');
- slackButton.className = 'slack-button';
- slackButton.title = 'Join us on Slack';
- slackButton.style.border = 'none';
- slackButton.style.background = 'transparent';
- slackButton.style.cursor = 'pointer';
-
- slackButton.innerHTML = `
- <img src="https://a.slack-edge.com/80588/marketing/img/icons/icon_slack_hash_colored.png"
- style="height: 1.1rem;"
- alt="Slack">
- `;
-
- slackButton.addEventListener('click', () => {
- window.open('https://slack.vllm.ai', '_blank', 'noopener');
- });
-
- const forumButton = document.createElement('button');
- forumButton.className = 'forum-button';
- forumButton.title = 'Join the Forum';
- forumButton.style.border = 'none';
- forumButton.style.background = 'transparent';
- forumButton.style.cursor = 'pointer';
-
- forumButton.innerHTML = `
- <svg
- xmlns="http://www.w3.org/2000/svg"
- viewBox="0 -960 960 960"
- fill="currentColor"
- >
- <path d="M817.85-198.15 698.46-317.54H320q-24.48 0-41.47-16.99T261.54-376v-11.69h424.61q25.39 0 43.47-18.08 18.07-18.08 18.07-43.46v-268.92h11.69q24.48 0 41.47 16.99 17 16.99 17 41.47v461.54ZM179.08-434.69l66.84-66.85h363.31q10.77 0 17.69-6.92 6.93-6.92 6.93-17.69v-246.77q0-10.77-6.93-17.7-6.92-6.92-17.69-6.92H203.69q-10.77 0-17.69 6.92-6.92 6.93-6.92 17.7v338.23Zm-36.93 89.46v-427.69q0-25.39 18.08-43.46 18.08-18.08 43.46-18.08h405.54q25.39 0 43.46 18.08 18.08 18.07 18.08 43.46v246.77q0 25.38-18.08 43.46-18.07 18.07-43.46 18.07H261.54L142.15-345.23Zm36.93-180.92V-797.54v271.39Z"/>
- </svg>
- `;
-
- forumButton.addEventListener('click', () => {
- window.open('https://discuss.vllm.ai/', '_blank', 'noopener');
- });
-
- const githubSource = document.querySelector('.md-header__source');
- if (githubSource) {
- githubSource.parentNode.insertBefore(slackButton, githubSource.nextSibling);
- githubSource.parentNode.insertBefore(forumButton, slackButton.nextSibling);
- }
- }
- });
diff --git a/docs/mkdocs/overrides/main.html b/docs/mkdocs/overrides/main.html
deleted file mode 100644
index 94d9808cc76..00000000000
--- a/docs/mkdocs/overrides/main.html
+++ /dev/null
@@ -1 +0,0 @@
-{% extends "base.html" %}
diff --git a/docs/mkdocs/overrides/partials/toc-item.html b/docs/mkdocs/overrides/partials/toc-item.html
deleted file mode 100644
index 656c2158998..00000000000
--- a/docs/mkdocs/overrides/partials/toc-item.html
+++ /dev/null
@@ -1,21 +0,0 @@
-<!-- Enables the use of toc_depth in document frontmatter https://github.com/squidfunk/mkdocs-material/issues/4827#issuecomment-1869812019 -->
-<li class="md-nav__item">
- <a href="{{ toc_item.url }}" class="md-nav__link">
- <span class="md-ellipsis">
- {{ toc_item.title }}
- </span>
- </a>
-
- <!-- Table of contents list -->
- {% if toc_item.children %}
- <nav class="md-nav" aria-label="{{ toc_item.title | striptags }}">
- <ul class="md-nav__list">
- {% for toc_item in toc_item.children %}
- {% if not page.meta.toc_depth or toc_item.level <= page.meta.toc_depth %}
- {% include "partials/toc-item.html" %}
- {% endif %}
- {% endfor %}
- </ul>
- </nav>
- {% endif %}
- </li>
diff --git a/docs/mkdocs/stylesheets/extra.css b/docs/mkdocs/stylesheets/extra.css
deleted file mode 100644
index a29352f5bfa..00000000000
--- a/docs/mkdocs/stylesheets/extra.css
+++ /dev/null
@@ -1,221 +0,0 @@
-/* Warning for latest docs */
-.md-banner {
- background-color: var(--md-warning-bg-color);
- color: var(--md-warning-fg-color);
-}
-
-/* https://christianoliff.com/blog/styling-external-links-with-an-icon-in-css/ */
-a:not(:has(svg)):not(.md-icon):not(.autorefs-external) {
- align-items: center;
-
- &[href^="//"]::after,
- &[href^="http://"]::after,
- &[href^="https://"]::after {
- content: "";
- width: 12px;
- height: 12px;
- margin-left: 4px;
- background-image: url("data:image/svg+xml,%3Csvg xmlns='http://www.w3.org/2000/svg' width='16' height='16' stroke='gray' viewBox='0 0 16 16'%3E%3Cpath fill-rule='evenodd' d='M8.636 3.5a.5.5 0 0 0-.5-.5H1.5A1.5 1.5 0 0 0 0 4.5v10A1.5 1.5 0 0 0 1.5 16h10a1.5 1.5 0 0 0 1.5-1.5V7.864a.5.5 0 0 0-1 0V14.5a.5.5 0 0 1-.5.5h-10a.5.5 0 0 1-.5-.5v-10a.5.5 0 0 1 .5-.5h6.636a.5.5 0 0 0 .5-.5z'/%3E%3Cpath fill-rule='evenodd' d='M16 .5a.5.5 0 0 0-.5-.5h-5a.5.5 0 0 0 0 1h3.793L6.146 9.146a.5.5 0 1 0 .708.708L15 1.707V5.5a.5.5 0 0 0 1 0v-5z'/%3E%3C/svg%3E");
- background-position: center;
- background-repeat: no-repeat;
- background-size: contain;
- display: inline-block;
- }
-}
-
-a[href*="localhost"]::after,
-a[href*="127.0.0.1"]::after,
-
-/* Hide external link icons for all links */
-a[href^="//"]::after,
-a[href^="http://"]::after,
-a[href^="https://"]::after {
- display: none !important;
-}
-
-/* Light mode: darker section titles */
-body[data-md-color-scheme="default"] .md-nav__item--section > label.md-nav__link .md-ellipsis {
- color: rgba(0, 0, 0, 0.7) !important;
- font-weight: 700;
-}
-
-/* Dark mode: lighter gray section titles */
-body[data-md-color-scheme="slate"] .md-nav__item--section > label.md-nav__link .md-ellipsis {
- color: rgba(255, 255, 255, 0.75) !important;
- font-weight: 700;
-}
-
-/* Custom admonitions */
-:root {
- --md-admonition-icon--announcement: url('data:image/svg+xml;charset=utf-8,<svg xmlns="http://www.w3.org/2000/svg" viewBox="0 0 16 16" width="16" height="16"><path d="M3.25 9a.75.75 0 0 1 .75.75c0 2.142.456 3.828.733 4.653a.122.122 0 0 0 .05.064.212.212 0 0 0 .117.033h1.31c.085 0 .18-.042.258-.152a.45.45 0 0 0 .075-.366A16.743 16.743 0 0 1 6 9.75a.75.75 0 0 1 1.5 0c0 1.588.25 2.926.494 3.85.293 1.113-.504 2.4-1.783 2.4H4.9c-.686 0-1.35-.41-1.589-1.12A16.4 16.4 0 0 1 2.5 9.75.75.75 0 0 1 3.25 9Z"></path><path d="M0 6a4 4 0 0 1 4-4h2.75a.75.75 0 0 1 .75.75v6.5a.75.75 0 0 1-.75.75H4a4 4 0 0 1-4-4Zm4-2.5a2.5 2.5 0 1 0 0 5h2v-5Z"></path><path d="M15.59.082A.75.75 0 0 1 16 .75v10.5a.75.75 0 0 1-1.189.608l-.002-.001h.001l-.014-.01a5.775 5.775 0 0 0-.422-.25 10.63 10.63 0 0 0-1.469-.64C11.576 10.484 9.536 10 6.75 10a.75.75 0 0 1 0-1.5c2.964 0 5.174.516 6.658 1.043.423.151.787.302 1.092.443V2.014c-.305.14-.669.292-1.092.443C11.924 2.984 9.713 3.5 6.75 3.5a.75.75 0 0 1 0-1.5c2.786 0 4.826-.484 6.155-.957.665-.236 1.154-.47 1.47-.64.144-.077.284-.161.421-.25l.014-.01a.75.75 0 0 1 .78-.061Z"></path></svg>');
- --md-admonition-icon--important: url('data:image/svg+xml;charset=utf-8,<svg xmlns="http://www.w3.org/2000/svg" viewBox="0 0 16 16" width="16" height="16"><path d="M4.47.22A.749.749 0 0 1 5 0h6c.199 0 .389.079.53.22l4.25 4.25c.141.14.22.331.22.53v6a.749.749 0 0 1-.22.53l-4.25 4.25A.749.749 0 0 1 11 16H5a.749.749 0 0 1-.53-.22L.22 11.53A.749.749 0 0 1 0 11V5c0-.199.079-.389.22-.53Zm.84 1.28L1.5 5.31v5.38l3.81 3.81h5.38l3.81-3.81V5.31L10.69 1.5ZM8 4a.75.75 0 0 1 .75.75v3.5a.75.75 0 0 1-1.5 0v-3.5A.75.75 0 0 1 8 4Zm0 8a1 1 0 1 1 0-2 1 1 0 0 1 0 2Z"></path></svg>');
- --md-admonition-icon--code: url('data:image/svg+xml;charset=utf-8,<svg xmlns="http://www.w3.org/2000/svg" viewBox="0 0 16 16"><path d="m11.28 3.22 4.25 4.25a.75.75 0 0 1 0 1.06l-4.25 4.25a.749.749 0 0 1-1.275-.326.75.75 0 0 1 .215-.734L13.94 8l-3.72-3.72a.749.749 0 0 1 .326-1.275.75.75 0 0 1 .734.215m-6.56 0a.75.75 0 0 1 1.042.018.75.75 0 0 1 .018 1.042L2.06 8l3.72 3.72a.749.749 0 0 1-.326 1.275.75.75 0 0 1-.734-.215L.47 8.53a.75.75 0 0 1 0-1.06Z"/></svg>');
- --md-admonition-icon--console: url('data:image/svg+xml;charset=utf-8,<svg xmlns="http://www.w3.org/2000/svg" viewBox="0 0 16 16"><path d="M0 2.75C0 1.784.784 1 1.75 1h12.5c.966 0 1.75.784 1.75 1.75v10.5A1.75 1.75 0 0 1 14.25 15H1.75A1.75 1.75 0 0 1 0 13.25Zm1.75-.25a.25.25 0 0 0-.25.25v10.5c0 .138.112.25.25.25h12.5a.25.25 0 0 0 .25-.25V2.75a.25.25 0 0 0-.25-.25ZM7.25 8a.75.75 0 0 1-.22.53l-2.25 2.25a.749.749 0 0 1-1.275-.326.75.75 0 0 1 .215-.734L5.44 8 3.72 6.28a.749.749 0 0 1 .326-1.275.75.75 0 0 1 .734.215l2.25 2.25c.141.14.22.331.22.53m1.5 1.5h3a.75.75 0 0 1 0 1.5h-3a.75.75 0 0 1 0-1.5"/></svg>');
-}
-
-.md-typeset .admonition.announcement,
-.md-typeset details.announcement {
- border-color: rgb(255, 110, 66);
-}
-.md-typeset .admonition.important,
-.md-typeset details.important {
- border-color: rgb(239, 85, 82);
-}
-.md-typeset .admonition.code,
-.md-typeset details.code {
- border-color: #64dd17
-}
-.md-typeset .admonition.console,
-.md-typeset details.console {
- border-color: #64dd17
-}
-
-.md-typeset .announcement > .admonition-title,
-.md-typeset .announcement > summary {
- background-color: rgb(255, 110, 66, 0.1);
-}
-.md-typeset .important > .admonition-title,
-.md-typeset .important > summary {
- background-color: rgb(239, 85, 82, 0.1);
-}
-.md-typeset .code > .admonition-title,
-.md-typeset .code > summary {
- background-color: #64dd171a;
-}
-.md-typeset .console > .admonition-title,
-.md-typeset .console > summary {
- background-color: #64dd171a;
-}
-
-.md-typeset .announcement > .admonition-title::before,
-.md-typeset .announcement > summary::before {
- background-color: rgb(239, 85, 82);
- -webkit-mask-image: var(--md-admonition-icon--announcement);
- mask-image: var(--md-admonition-icon--announcement);
-}
-.md-typeset .important > .admonition-title::before,
-.md-typeset .important > summary::before {
- background-color: rgb(239, 85, 82);
- -webkit-mask-image: var(--md-admonition-icon--important);
- mask-image: var(--md-admonition-icon--important);
-}
-.md-typeset .code > .admonition-title::before,
-.md-typeset .code > summary::before {
- background-color: #64dd17;
- -webkit-mask-image: var(--md-admonition-icon--code);
- mask-image: var(--md-admonition-icon--code);
-}
-.md-typeset .console > .admonition-title::before,
-.md-typeset .console > summary::before {
- background-color: #64dd17;
- -webkit-mask-image: var(--md-admonition-icon--console);
- mask-image: var(--md-admonition-icon--console);
-}
-
-/* Make label fully visible on hover */
-.md-content__button[href*="edit"]:hover::after {
- opacity: 1;
-}
-
-/* Hide edit button on generated docs/examples pages */
-@media (min-width: 960px) {
- .md-content__button[href*="docs/examples/"] {
- display: none !important;
- }
-}
-
-.md-content__button-wrapper {
- position: absolute;
- top: 0.6rem;
- right: 0.8rem;
- display: flex;
- flex-direction: row;
- align-items: center;
- gap: 0.4rem;
- z-index: 1;
-}
-
-.md-content__button-wrapper a {
- display: inline-flex;
- align-items: center;
- justify-content: center;
- height: 24px;
- width: 24px;
- color: var(--md-default-fg-color);
- text-decoration: none;
-}
-
-.md-content__button-wrapper a:hover {
- color: var(--md-accent-fg-color);
-}
-
-/* Slack and Forum css */
-.slack-button,
-.forum-button {
- display: inline-flex;
- align-items: center;
- justify-content: center;
- margin-left: 0.4rem;
- height: 24px;
-}
-
-.slack-button img {
- height: 18px;
- filter: none !important;
-}
-
-.slack-button:hover,
-.forum-button:hover {
- opacity: 0.7;
-}
-
-.forum-button svg {
- height: 28px;
- opacity: 0.9;
- transform: translateY(2px);
-}
-
-/* For logo css */
-[data-md-color-scheme="default"] .logo-dark {
- display: none;
-}
-
-[data-md-color-scheme="slate"] .logo-light {
- display: none;
-}
-
-/* Outline for content tabs */
-.md-typeset .tabbed-set {
- border: 0.075rem solid var(--md-default-fg-color);
- border-radius: 0.2rem;
-}
-
-.md-typeset .tabbed-content {
- padding: 0 0.6em;
-}
-
-/* Hide link icon in header logo */
-.md-header__button.md-logo :is(img, svg) {
- pointer-events: none;
-}
-
-.md-header__button.md-logo::after {
- display: none !important;
-}
-
-/* Hide link icons in content tabs (tabbed content) */
-.md-typeset .tabbed-set > label::after,
-.md-typeset .tabbed-set > input:checked + label::after {
- display: none !important;
-}
-
-/* Hide link icons in navigation tabs */
-.md-nav__link[href]::after,
-.md-nav__item--nested > .md-nav__link::after {
- display: none !important;
-}
-
-/* Hide link icons in top navigation tabs */
-.md-tabs__link::after {
- display: none !important;
-}
diff --git a/docs/models/supported_models.md b/docs/models/supported_models.md
deleted file mode 100644
index b81ff5b992c..00000000000
--- a/docs/models/supported_models.md
+++ /dev/null
@@ -1,70 +0,0 @@
-# Supported Models
-
-vLLM-Omni supports unified multimodal comprehension and generation models across various tasks.
-
-## Model Implementation
-
-If vLLM-Omni natively supports a model, its implementation can be found in <gh-file:vllm_omni/model_executor/models> and <gh-file:vllm_omni/diffusion/models>.
-
-## List of Supported Models
-
-<style>
-th {
- white-space: nowrap;
- min-width: 0 !important;
-}
-</style>
-
-| Architecture | Models | Example HF Models | NVIDIA GPU | AMD GPU | Ascend NPU | Intel GPU |
-|--------------|--------|-------------------|------------|---------|-----|-----------|
-| `Qwen3OmniMoeForConditionalGeneration` | Qwen3-Omni | `Qwen/Qwen3-Omni-30B-A3B-Instruct` | ✅︎ | ✅︎ | ✅︎ | ✅︎ |
-| `Qwen2_5OmniForConditionalGeneration` | Qwen2.5-Omni | `Qwen/Qwen2.5-Omni-7B`, `Qwen/Qwen2.5-Omni-3B` | ✅︎ | ✅︎ | ✅︎ | ✅︎ |
-| `BagelForConditionalGeneration` | BAGEL (DiT-only) | `ByteDance-Seed/BAGEL-7B-MoT` | ✅︎ | ✅︎ | | ✅︎ |
-| `InternVLAA1Pipeline` | InternVLA-A1 | `InternRobotics/InternVLA-A1-3B` | ✅︎ | ✅︎ | | |
-| `HunyuanImage3ForCausalMM` | HunyuanImage3.0 (DiT-only) | `tencent/HunyuanImage-3.0`, `tencent/HunyuanImage-3.0-Instruct` | ✅︎ | ✅︎ | ✅︎ | ✅︎ |
-| `QwenImagePipeline` | Qwen-Image | `Qwen/Qwen-Image` | ✅︎ | ✅︎ | ✅︎ | ✅︎ |
-| `QwenImagePipeline` | Qwen-Image-2512 | `Qwen/Qwen-Image-2512` | ✅︎ | ✅︎ | ✅︎ | ✅︎ |
-| `QwenImageEditPipeline` | Qwen-Image-Edit | `Qwen/Qwen-Image-Edit` | ✅︎ | ✅︎ | ✅︎ | ✅︎ |
-| `QwenImageEditPlusPipeline` | Qwen-Image-Edit-2509 | `Qwen/Qwen-Image-Edit-2509` | ✅︎ | ✅︎ | ✅︎ | ✅︎ |
-| `QwenImageLayeredPipeline` | Qwen-Image-Layered | `Qwen/Qwen-Image-Layered` | ✅︎ | ✅︎ | ✅︎ | ✅︎ |
-| `QwenImageEditPlusPipeline` | Qwen-Image-Edit-2511 | `Qwen/Qwen-Image-Edit-2511` | ✅︎ | ✅︎ | ✅︎ | ✅︎ |
-| `GlmImagePipeline` | GLM-Image | `zai-org/GLM-Image` | ✅︎ | ✅︎ | | |
-| `ZImagePipeline` | Z-Image | `Tongyi-MAI/Z-Image-Turbo` | ✅︎ | ✅︎ | ✅︎ | ✅︎ |
-| `WanPipeline` | Wan2.1-T2V, Wan2.2-T2V, Wan2.2-TI2V | `Wan-AI/Wan2.1-T2V-1.3B-Diffusers`, `Wan-AI/Wan2.1-T2V-14B-Diffusers`, `Wan-AI/Wan2.2-T2V-A14B-Diffusers`, `Wan-AI/Wan2.2-TI2V-5B-Diffusers` | ✅︎ | ✅︎ | ✅︎ | ✅︎ |
-| `WanImageToVideoPipeline` | Wan2.2-I2V | `Wan-AI/Wan2.2-I2V-A14B-Diffusers` | ✅︎ | ✅︎ | ✅︎ | ✅︎ |
-| `Wan22VACEPipeline` | Wan2.1-VACE | `Wan-AI/Wan2.1-VACE-1.3B-diffusers`, `Wan-AI/Wan2.1-VACE-14B-diffusers` | ✅︎ | ✅︎ | ✅︎ | ✅︎ |
-| `LTX2Pipeline` | LTX-2-T2V | `Lightricks/LTX-2` | ✅︎ | ✅︎ | | |
-| `LTX2ImageToVideoPipeline` | LTX-2-I2V | `Lightricks/LTX-2` | ✅︎ | ✅︎ | | |
-| `LTX2TwoStagesPipeline` | LTX-2-T2V | `rootonchair/LTX-2-19b-distilled` | ✅︎ | ✅︎ | | |
-| `LTX2ImageToVideoTwoStagesPipeline` | LTX-2-I2V | `rootonchair/LTX-2-19b-distilled` | ✅︎ | ✅︎ | | |
-| `LTX23Pipeline` | LTX-2.3-T2V | `dg845/LTX-2.3-Diffusers` | ✅︎ | ✅︎ | | |
-| `LTX23ImageToVideoPipeline` | LTX-2.3-I2V | `dg845/LTX-2.3-Diffusers` | ✅︎ | ✅︎ | | |
-| `HeliosPipeline`, `HeliosPyramidPipeline` | Helios | `BestWishYsh/Helios-Base`, `BestWishYsh/Helios-Mid`, `BestWishYsh/Helios-Distilled` | ✅︎ | ✅︎ | ✅︎ | |
-| `MagiHumanPipeline` | MagiHuman | `SII-GAIR/daVinci-MagiHuman-Base-1080p` | ✅︎ | ✅︎ | | |
-| `OvisImagePipeline` | Ovis-Image | `OvisAI/Ovis-Image` | ✅︎ | ✅︎ | | ✅︎ |
-| `LongcatImagePipeline` | LongCat-Image | `meituan-longcat/LongCat-Image` | ✅︎ | ✅︎ | ✅︎ | ✅︎ |
-| `LongCatImageEditPipeline` | LongCat-Image-Edit | `meituan-longcat/LongCat-Image-Edit` | ✅︎ | ✅︎ | ✅︎ | ✅︎ |
-| `StableDiffusion3Pipeline` | Stable-Diffusion-3 | `stabilityai/stable-diffusion-3.5-medium` | ✅︎ | ✅︎ | | ✅︎ |
-| `CosyVoice3Model` | CosyVoice3 | `FunAudioLLM/Fun-CosyVoice3-0.5B-2512` | ✅︎ | ✅︎ | | |
-| `MammothModa2ForConditionalGeneration` | MammothModa2-Preview | `bytedance-research/MammothModa2-Preview` | ✅︎ | ✅︎ | | |
-| `Flux2KleinPipeline` | FLUX.2-klein | `black-forest-labs/FLUX.2-klein-4B`, `black-forest-labs/FLUX.2-klein-9B` | ✅︎ | ✅︎ | ✅︎ | ✅︎ |
-| `FluxKontextPipeline` | FLUX.1-Kontext-dev | `black-forest-labs/FLUX.1-Kontext-dev` | ✅︎ | ✅︎ | | |
-| `FluxPipeline` | FLUX.1-dev | `black-forest-labs/FLUX.1-dev` | ✅︎ | ✅︎ | | ✅︎ |
-| `FluxPipeline` | FLUX.1-schnell | `black-forest-labs/FLUX.1-schnell` | ✅︎ | ✅︎ | | ✅︎ |
-| `OmniGen2Pipeline` | OmniGen2 | `OmniGen2/OmniGen2` | ✅︎ | ✅︎ | | ✅︎ |
-| `StableAudioPipeline` | Stable-Audio-Open | `stabilityai/stable-audio-open-1.0` | ✅︎ | ✅︎ | | ✅︎ |
-| `Qwen3TTSForConditionalGeneration` | Qwen3-TTS-12Hz-1.7B-CustomVoice | `Qwen/Qwen3-TTS-12Hz-1.7B-CustomVoice` | ✅︎ | ✅︎ | ✅︎ | ✅︎ |
-| `Qwen3TTSForConditionalGeneration` | Qwen3-TTS-12Hz-1.7B-VoiceDesign | `Qwen/Qwen3-TTS-12Hz-1.7B-VoiceDesign` | ✅︎ | ✅︎ | ✅︎ | ✅︎ |
-| `Qwen3TTSForConditionalGeneration` | Qwen3-TTS-12Hz-1.7B-Base | `Qwen/Qwen3-TTS-12Hz-0.6B-Base` | ✅︎ | ✅︎ | ✅︎ | ✅︎ |
-| `NextStep11Pipeline` | NextStep-1.1 | `stepfun-ai/NextStep-1.1` | ✅︎ | ✅︎ | | ✅︎ |
-| `MiMoAudioModel` | MiMo-Audio-7B-Instruct | `XiaomiMiMo/MiMo-Audio-7B-Instruct` | ✅︎ | ✅︎ | | |
-| `MiMoV2ASRForCausalLM` | MiMo-V2.5-ASR | `XiaomiMiMo/MiMo-V2.5-ASR` | ✅︎ | ✅︎ | | |
-| `Flux2Pipeline` | FLUX.2-dev | `black-forest-labs/FLUX.2-dev` | ✅︎ | ✅︎ | | |
-| `FishSpeechSlowARForConditionalGeneration` | Fish Speech S2 Pro | `fishaudio/s2-pro` | ✅︎ | ✅︎ | | |
-| `DreamIDOmniPipeline` | DreamID-Omni | `XuGuo699/DreamID-Omni` | ✅︎ | ✅︎ | | |
-| `HunyuanVideo15Pipeline` | HunyuanVideo-1.5-T2V | `hunyuanvideo-community/HunyuanVideo-1.5-Diffusers-480p_t2v`, `hunyuanvideo-community/HunyuanVideo-1.5-Diffusers-720p_t2v` | ✅︎ | ✅︎ | | |
-| `HunyuanVideo15ImageToVideoPipeline` | HunyuanVideo-1.5-I2V | `hunyuanvideo-community/HunyuanVideo-1.5-Diffusers-480p_i2v`, `hunyuanvideo-community/HunyuanVideo-1.5-Diffusers-720p_i2v` | ✅︎ | ✅︎ | | |
-| `VoxtralTTSForConditionalGeneration` | Voxtral TTS | `mistralai/Voxtral-4B-TTS-2603` | ✅︎ | ✅︎ | | |
-|`DyninOmniForConditionalGeneration` | Dynin-Omni | `snu-aidas/Dynin-Omni` | ✅︎ | | | |
-
-✅︎ indicates the model is supported on that backend. Empty cells mean not listed as supported on that backend.
diff --git a/docs/serving/audio_generate_api.md b/docs/serving/audio_generate_api.md
deleted file mode 100644
index afe693ae4e2..00000000000
--- a/docs/serving/audio_generate_api.md
+++ /dev/null
@@ -1,338 +0,0 @@
-# Audio Generate API
-
-vLLM-Omni provides an API for text-to-audio generation using diffusion-based models such as Stable Audio.
-
-Unlike the [Speech API](speech_api.md) which targets text-to-speech synthesis, the Audio Generate API is designed for general-purpose audio generation from text descriptions (sound effects, music, ambient soundscapes, etc.).
-
-Each server instance runs a single model (specified at startup via `vllm-omni serve <model> --omni`).
-
-## Quick Start
-
-### Start the Server
-
-```bash
-vllm-omni serve stabilityai/stable-audio-open-1.0 \
- --host 0.0.0.0 \
- --port 8091 \
- --gpu-memory-utilization 0.9 \
- --trust-remote-code \
- --enforce-eager \
- --omni
-```
-
-### Generate Audio
-
-**Using curl:**
-
-```bash
-curl -X POST http://localhost:8091/v1/audio/generate \
- -H "Content-Type: application/json" \
- -d '{
- "input": "The sound of a cat purring",
- "audio_length": 10.0
- }' --output cat.wav
-```
-
-**Using Python:**
-
-```python
-import httpx
-
-response = httpx.post(
- "http://localhost:8091/v1/audio/generate",
- json={
- "input": "The sound of a cat purring",
- "audio_length": 10.0,
- },
- timeout=300.0,
-)
-
-with open("cat.wav", "wb") as f:
- f.write(response.content)
-```
-
-## API Reference
-
-### Endpoint
-
-```
-POST /v1/audio/generate
-Content-Type: application/json
-```
-
-### Request Parameters
-
-| Parameter | Type | Default | Description |
-|-----------|------|---------|-------------|
-| `input` | string | **required** | Text prompt describing the audio to generate |
-| `model` | string | server's model | Model to use (optional, should match server if specified) |
-| `response_format` | string | "wav" | Audio format: wav, mp3, flac, pcm, aac, opus |
-| `speed` | float | 1.0 | Playback speed (0.25 - 4.0) |
-
-#### Diffusion Parameters
-
-| Parameter | Type | Default | Description |
-|-----------|------|---------|-------------|
-| `audio_length` | float | null | Audio duration in seconds (default value is the max ~47s for `stable-audio-open-1.0`) |
-| `audio_start` | float | 0.0 | Audio start time in seconds |
-| `negative_prompt` | string | null | Text describing what to avoid in generation |
-| `guidance_scale` | float | model default | Classifier-free guidance scale (higher = more adherence to prompt) |
-| `num_inference_steps` | int | model default | Number of denoising steps (higher = better quality, slower) |
-| `seed` | int | null | Random seed for reproducible generation |
-
-### Response Format
-
-Returns binary audio data with the appropriate `Content-Type` header:
-
-| `response_format` | Content-Type |
-|--------------------|--------------|
-| `wav` | `audio/wav` |
-| `mp3` | `audio/mpeg` |
-| `flac` | `audio/flac` |
-| `pcm` | `audio/pcm` |
-| `aac` | `audio/aac` |
-| `opus` | `audio/opus` |
-
-## Examples
-
-### Basic Generation
-
-Generate audio with only a text prompt (model defaults for all other parameters):
-
-```bash
-curl -X POST http://localhost:8091/v1/audio/generate \
- -H "Content-Type: application/json" \
- -d '{
- "input": "The sound of ocean waves crashing on a beach"
- }' --output ocean.wav
-```
-
-### Custom Duration
-
-Specify an explicit audio length in seconds:
-
-```bash
-curl -X POST http://localhost:8091/v1/audio/generate \
- -H "Content-Type: application/json" \
- -d '{
- "input": "A dog barking",
- "audio_length": 5.0
- }' --output dog_5s.wav
-```
-
-### High Quality with Negative Prompt
-
-Use a negative prompt to steer generation away from undesired characteristics, and increase inference steps for higher quality:
-
-```bash
-curl -X POST http://localhost:8091/v1/audio/generate \
- -H "Content-Type: application/json" \
- -d '{
- "input": "A piano playing a gentle melody",
- "audio_length": 10.0,
- "negative_prompt": "Low quality, distorted, noisy",
- "guidance_scale": 8.0,
- "num_inference_steps": 150
- }' --output piano_hq.wav
-```
-
-### Reproducible Generation
-
-Set a `seed` to get deterministic results across runs:
-
-```bash
-curl -X POST http://localhost:8091/v1/audio/generate \
- -H "Content-Type: application/json" \
- -d '{
- "input": "Thunder and rain sounds",
- "audio_length": 15.0,
- "seed": 42
- }' --output thunder.wav
-```
-
-### Full Control
-
-Combine all parameters for precise control over generation:
-
-```bash
-curl -X POST http://localhost:8091/v1/audio/generate \
- -H "Content-Type: application/json" \
- -d '{
- "input": "Thunder and rain sounds",
- "audio_length": 15.0,
- "negative_prompt": "Low quality",
- "guidance_scale": 7.0,
- "num_inference_steps": 100,
- "seed": 42
- }' --output thunder_rain.wav
-```
-
-### Quick Generation (Fewer Steps)
-
-For faster generation with slightly lower quality:
-
-```bash
-curl -X POST http://localhost:8091/v1/audio/generate \
- -H "Content-Type: application/json" \
- -d '{
- "input": "Birds chirping in a forest",
- "audio_length": 8.0,
- "num_inference_steps": 50
- }' --output birds_quick.wav
-```
-
-### Python Client
-
-```python
-import httpx
-
-response = httpx.post(
- "http://localhost:8091/v1/audio/generate",
- json={
- "input": "Thunder and rain",
- "audio_length": 15.0,
- "negative_prompt": "Low quality",
- "guidance_scale": 7.0,
- "num_inference_steps": 100,
- "seed": 42,
- "response_format": "wav",
- },
- timeout=300.0,
-)
-
-with open("thunder.wav", "wb") as f:
- f.write(response.content)
-```
-
-## Parameter Tuning Guide
-
-### `guidance_scale`
-
-Controls how closely the generated audio follows the text prompt.
-
-| Range | Behaviour |
-|-------|-----------|
-| 3 - 5 | More creative / varied output |
-| 7 (default) | Balanced adherence |
-| 10+ | Strict adherence to the prompt |
-
-### `num_inference_steps`
-
-Controls the number of denoising steps in the diffusion process.
-
-| Steps | Quality | Speed | Use Case |
-|-------|---------|-------|----------|
-| 50 | Good | Fast | Quick previews |
-| 100 | Very Good | Medium | General purpose |
-| 150+ | Excellent | Slow | Final / critical audio |
-
-### `audio_length`
-
-Duration of the generated audio clip. For `stable-audio-open-1.0`, the maximum is approximately 47 seconds. If omitted, the model uses its own default length.
-
-### `negative_prompt`
-
-Describes characteristics to avoid. Common negative prompts include:
-
-- `"Low quality, distorted, noisy"`
-- `"Silence, static"`
-- `"Music"` (when generating sound effects only)
-
-## Supported Models
-
-| Model | Description |
-|-------|-------------|
-| `stabilityai/stable-audio-open-1.0` | Open-source audio generation model, up to ~47 seconds, 44.1 kHz stereo |
-
-## Error Responses
-
-### 400 Bad Request
-
-Invalid or missing parameters:
-
-```json
-{
- "error": {
- "message": "Audio generation model did not produce audio output.",
- "type": "BadRequestError",
- "param": null,
- "code": 400
- }
-}
-```
-
-### 404 Not Found
-
-Model mismatch:
-
-```json
-{
- "error": {
- "message": "The model `xxx` does not exist.",
- "type": "NotFoundError",
- "param": "model",
- "code": 404
- }
-}
-```
-
-### 422 Unprocessable Entity
-
-Pydantic validation failure (e.g. invalid `response_format`, `speed` out of range):
-
-```json
-{
- "detail": [
- {
- "type": "literal_error",
- "msg": "Input should be 'wav', 'pcm', 'flac', 'mp3', 'aac' or 'opus'",
- ...
- }
- ]
-}
-```
-
-## Troubleshooting
-
-### "Audio generation model did not produce audio output"
-
-The model finished but returned no audio data. Verify the server started successfully and the model loaded without errors.
-
-### Server Not Responding
-
-```bash
-# Check if the server is healthy
-curl http://localhost:8091/health
-```
-
-### Audio Quality Issues
-
-- Increase `num_inference_steps` (e.g. 150).
-- Add a negative prompt: `"Low quality, distorted, noisy"`.
-- Increase `guidance_scale` for stronger prompt adherence.
-
-### Generation Timeout
-
-- Reduce `num_inference_steps`.
-- Reduce `audio_length`.
-- Check GPU memory with `nvidia-smi`.
-
-### Out of Memory
-
-- Lower `--gpu-memory-utilization` (e.g. 0.8).
-- Reduce `audio_length`.
-
-## Development
-
-Enable debug logging:
-
-```bash
-vllm-omni serve stabilityai/stable-audio-open-1.0 \
- --host 0.0.0.0 \
- --port 8091 \
- --gpu-memory-utilization 0.9 \
- --trust-remote-code \
- --enforce-eager \
- --omni \
- --uvicorn-log-level debug
-```
diff --git a/docs/serving/diffusion_chat_api.md b/docs/serving/diffusion_chat_api.md
deleted file mode 100644
index d0e2990ad6c..00000000000
--- a/docs/serving/diffusion_chat_api.md
+++ /dev/null
@@ -1,78 +0,0 @@
-# Diffusion Chat Completions API
-
-vLLM-Omni supports generating and editing images via the `/v1/chat/completions`
-endpoint using diffusion models. This page explains how to pass generation
-parameters (such as `num_inference_steps`, `height`, `width`) to diffusion
-models through this endpoint.
-
-!!! tip
- For dedicated endpoints that accept generation parameters as top-level
- fields, see [Image Generation API](image_generation_api.md) and
- [Image Edit API](image_edit_api.md).
-
-## Passing Generation Parameters
-
-The `/v1/chat/completions` endpoint follows the OpenAI Chat API schema, which
-does not natively include diffusion-specific fields like `num_inference_steps`
-or `height`. How you pass these extra fields depends on your client.
-
-### curl / Python `requests`
-
-Wrap generation parameters inside an `"extra_body"` key in the JSON body:
-
-```bash
-curl -s http://localhost:8091/v1/chat/completions \
- -H "Content-Type: application/json" \
- -d '{
- "messages": [
- {"role": "user", "content": "A beautiful landscape painting"}
- ],
- "extra_body": {
- "num_inference_steps": 50,
- "seed": 42
- }
- }'
-```
-
-### OpenAI Python SDK
-
-Use the `extra_body` **keyword argument**. The SDK automatically merges these
-fields into the top-level request body:
-
-```python
-response = client.chat.completions.create(
- model="Qwen/Qwen-Image",
- messages=[{"role": "user", "content": "A beautiful landscape painting"}],
- extra_body={
- "num_inference_steps": 50,
- "seed": 42,
- },
-)
-```
-
-!!! note "SDK `extra_body` vs. JSON `extra_body`"
- These two `extra_body` usages look similar but work differently under the
- hood. The SDK flattens the dict into the top-level request JSON, while the
- curl/requests approach sends it as a nested `"extra_body"` key. Both are
- handled correctly by the server.
-
-!!! note "About the `ignored fields` warning"
- You may see a log message like:
-
- ```
- WARNING: The following fields were present in the request but ignored: {'height', 'width', ...}
- ```
-
- This is **harmless**. It is emitted by vLLM's request validation layer
- because these fields are not part of the standard OpenAI
- `ChatCompletionRequest` schema. The fields are still stored internally
- and correctly forwarded to the diffusion pipeline.
-
-## Model-Specific Examples
-
-For complete examples with full request/response details, see the model-specific
-guides:
-
-- [Text-to-Image (Qwen-Image)](../user_guide/examples/online_serving/text_to_image.md)
-- [Image-to-Image (Qwen-Image-Edit, Qwen-Image-Layered)](../user_guide/examples/online_serving/image_to_image.md)
-- [GLM-Image](../user_guide/examples/online_serving/glm_image.md)
diff --git a/docs/serving/image_edit_api.md b/docs/serving/image_edit_api.md
deleted file mode 100644
index 79303e1a690..00000000000
--- a/docs/serving/image_edit_api.md
+++ /dev/null
@@ -1,207 +0,0 @@
-# Image Edit API
-
-vLLM-Omni provides an OpenAI DALL-E compatible API for image edit using diffusion models.
-
-Each server instance runs a single model (specified at startup via `vllm serve <model> --omni`).
-
-## Quick Start
-
-### Start the Server
-
-For example...
-
-```bash
-# Qwen-Image
-vllm serve Qwen/Qwen-Image-Edit-2511 --omni --port 8000
-
-
-### Generate Images
-
-**Using curl:**
-
-```bash
-curl -s -D >(grep -i x-request-id >&2) \
- -o >(jq -r '.data[0].b64_json' | base64 --decode > gift-basket.png) \
- -X POST "http://localhost:8000/v1/images/edits" \
- -F "model=xxx" \
- -F "image=@./xx.png" \
- -F "prompt='this bear is wearing sportwear. holding a basketball, and bending one leg.'" \
- -F "size=1024x1024" \
- -F "output_format=png"
-```
-
-
-**Using OpenAI SDK:**
-
-```python
-import base64
-from openai import OpenAI
-from pathlib import Path
-client = OpenAI(
- api_key="None",
- base_url="http://localhost:8000/v1"
-)
-
-input_image_url = "https://vllm-public-assets.s3.us-west-2.amazonaws.com/omni-assets/qwen-bear.png"
-
-result = client.images.edit(
- image=[],
- model="Qwen-Image-Edit-2511",
- prompt="Change the bears in the two input images into walking together.",
- size='512x512',
- stream=False,
- output_format='jpeg',
- # url格式
- extra_body={
- "url": [input_image_url1,input_image_url],
- "num_inference_steps": 50,
- "guidance_scale": 1,
- "seed": 777,
- }
-)
-
-image_base64 = result.data[0].b64_json
-image_bytes = base64.b64decode(image_base64)
-
-# Save the image to a file
-with open("edit_out_http.jpeg", "wb") as f:
- f.write(image_bytes)
-```
-
-## API Reference
-
-### Endpoint
-
-```
-POST /v1/images/edits
-Content-Type: multipart/form-data
-```
-
-### Request Parameters
-
-#### OpenAI Standard Parameters
-
-| Parameter | Type | Default | Description |
-|-----------|------|---------|-------------|
-| `prompt` | string | **required** | A text description of the desired image |
-| `model` | string | server's model | Model to use (optional, should match server if specified) |
-| `image` | string or array | **required** | The image(s) to edit. |
-| `n` | integer | 1 | Number of images to generate (1-10) |
-| `size` | string | "auto" | Image dimensions in WxH format (e.g., "1024x1024", "512x512"), when set to auto, it decide size from first input image. |
-| `response_format` | string | "b64_json" | Response format (only "b64_json" supported) |
-| `user` | string | null | User identifier for tracking |
-| `output_format` | string | "png" | The format in which the generated images are returned. Must be one of "png", "jpg", "jpeg", "webp". |
-| `output_compression` | integer | 100 | The compression level (0-100%) for the generated images. |
-| `background` | string or null | "auto" | Allows to set transparency for the background of the generated image(s).
-
-#### vllm-omni Extension Parameters
-
-| Parameter | Type | Default | Description |
-|-----------|------|---------|-------------|
-| `url` | string or array | None | The image(s) to edit. |
-| `negative_prompt` | string | null | Text describing what to avoid in the image |
-| `num_inference_steps` | integer | model defaults | Number of diffusion steps |
-| `guidance_scale` | float | model defaults | Classifier-free guidance scale (typically 0.0-20.0) |
-| `true_cfg_scale` | float | model defaults | True CFG scale (model-specific parameter, may be ignored if not supported) |
-| `seed` | integer | null | Random seed for reproducibility |
-| `reference_image` | string or array | null | Reference image for inpainting |
-| `mask_image` | string or array | null | Mask for inpainting (white areas will be inpainted) |
-
-### Response Format
-
-```json
-{
- "created": 1701234567,
- "data": [
- {
- "b64_json": "<base64-encoded PNG>",
- "url": null,
- "revised_prompt": null
- }
- ],
- "output_format": null,
- "size": null,
-}
-```
-
-## Examples
-
-### Multiple Images input
-
-```bash
-curl -s -D >(grep -i x-request-id >&2) \
- -o >(jq -r '.data[0].b64_json' | base64 --decode > gift-basket.png) \
- -X POST "http://localhost:8000/v1/images/edits" \
- -F "model=xxx" \
- -F "image=@xx.png" \
- -F "image=@xx.png"
- -F "prompt='this bear is wearing sportwear. holding a basketball, and bending one leg.'" \
- -F "size=1024x1024" \
- -F "output_format=png"
-```
-
-
-## Parameter Handling
-
-The API passes parameters directly to the diffusion pipeline without model-specific transformation:
-
-- **Default values**: When parameters are not specified, the underlying model uses its own defaults
-- **Pass-through design**: User-provided values are forwarded directly to the diffusion engine
-- **Minimal validation**: Only basic type checking and range validation at the API level
-
-### Parameter Compatibility
-
-The API passes parameters directly to the diffusion pipeline without model-specific validation.
-
-- Unsupported parameters may be silently ignored by the model
-- Incompatible values will result in errors from the underlying pipeline
-- Recommended values vary by model - consult model documentation
-
-**Best Practice:** Start with the model's recommended parameters, then adjust based on your needs.
-
-## Error Responses
-
-### 400 Bad Request
-
-Invalid parameters (e.g., model mismatch):
-
-```json
-{
- "detail": "Invalid size format: '1024x'. Expected format: 'WIDTHxHEIGHT' (e.g., '1024x1024')."
-}
-```
-
-### 422 Unprocessable Entity
-
-Validation errors (missing required fields):
-
-```json
-{
- "detail": "Field 'image' or 'url' is required"
-}
-```
-
-## Troubleshooting
-
-### Server Not Running
-
-```bash
-# Check if server is responding
-curl -X http://localhost:8000/v1/images/edit \
- -F "prompt='test'"
-```
-
-### Out of Memory
-
-If you encounter OOM errors:
-1. Reduce image size: `"size": "512x512"`
-2. Reduce inference steps: `"num_inference_steps": 25`
-
-## Development
-
-Enable debug logging to see prompts and generation details:
-
-```bash
-vllm serve Qwen/Qwen-Image-Edit-2511 --omni \
- --uvicorn-log-level debug
-```
diff --git a/docs/serving/image_generation_api.md b/docs/serving/image_generation_api.md
deleted file mode 100644
index 747cef99567..00000000000
--- a/docs/serving/image_generation_api.md
+++ /dev/null
@@ -1,249 +0,0 @@
-# Image Generation API
-
-vLLM-Omni provides an OpenAI DALL-E compatible API for text-to-image generation using diffusion models.
-
-Each server instance runs a single model (specified at startup via `vllm serve <model> --omni`).
-
-## Quick Start
-
-### Start the Server
-
-For example...
-
-```bash
-# Qwen-Image
-vllm serve Qwen/Qwen-Image --omni --port 8000
-
-# Z-Image Turbo
-vllm serve Tongyi-MAI/Z-Image-Turbo --omni --port 8000
-```
-
-### Generate Images
-
-**Using curl:**
-
-```bash
-curl -X POST http://localhost:8000/v1/images/generations \
- -H "Content-Type: application/json" \
- -d '{
- "prompt": "a dragon laying over the spine of the Green Mountains of Vermont",
- "size": "1024x1024",
- "seed": 42
- }' | jq -r '.data[0].b64_json' | base64 -d > dragon.png
-```
-
-**Using Python:**
-
-```python
-import requests
-import base64
-from PIL import Image
-import io
-
-response = requests.post(
- "http://localhost:8000/v1/images/generations",
- json={
- "prompt": "a black and white cat wearing a princess tiara",
- "size": "1024x1024",
- "num_inference_steps": 50,
- "seed": 42,
- }
-)
-
-# Decode and save
-img_data = response.json()["data"][0]["b64_json"]
-img_bytes = base64.b64decode(img_data)
-img = Image.open(io.BytesIO(img_bytes))
-img.save("cat.png")
-```
-
-**Using OpenAI SDK:**
-
-```python
-from openai import OpenAI
-
-client = OpenAI(base_url="http://localhost:8000/v1", api_key="none")
-
-response = client.images.generate(
- model="Qwen/Qwen-Image",
- prompt="a horse jumping over a fence nearby a babbling brook",
- n=1,
- size="1024x1024",
- response_format="b64_json"
-)
-
-# Note: Extension parameters (seed, steps, cfg) require direct HTTP requests
-```
-
-## API Reference
-
-### Endpoint
-
-```
-POST /v1/images/generations
-Content-Type: application/json
-```
-
-### Request Parameters
-
-#### OpenAI Standard Parameters
-
-| Parameter | Type | Default | Description |
-|-----------|------|---------|-------------|
-| `prompt` | string | **required** | Text description of the desired image |
-| `model` | string | server's model | Model to use (optional, should match server if specified) |
-| `n` | integer | 1 | Number of images to generate (1-10) |
-| `size` | string | model defaults | Image dimensions in WxH format (e.g., "1024x1024", "512x512") |
-| `response_format` | string | "b64_json" | Response format (only "b64_json" supported) |
-| `user` | string | null | User identifier for tracking |
-
-#### vllm-omni Extension Parameters
-
-| Parameter | Type | Default | Description |
-|-----------|------|---------|-------------|
-| `negative_prompt` | string | null | Text describing what to avoid in the image |
-| `num_inference_steps` | integer | model defaults | Number of diffusion steps |
-| `guidance_scale` | float | model defaults | Classifier-free guidance scale (typically 0.0-20.0) |
-| `true_cfg_scale` | float | model defaults | True CFG scale (model-specific parameter, may be ignored if not supported) |
-| `seed` | integer | null | Random seed for reproducibility |
-
-### Response Format
-
-```json
-{
- "created": 1701234567,
- "data": [
- {
- "b64_json": "<base64-encoded PNG>",
- "url": null,
- "revised_prompt": null
- }
- ]
-}
-```
-
-## Examples
-
-### Multiple Images
-
-```bash
-curl -X POST http://localhost:8000/v1/images/generations \
- -H "Content-Type: application/json" \
- -d '{
- "prompt": "a steampunk city set in a valley of the Adirondack mountains",
- "n": 4,
- "size": "1024x1024",
- "seed": 123
- }'
-```
-
-This generates 4 images in a single request.
-
-### With Negative Prompt
-
-```python
-response = requests.post(
- "http://localhost:8000/v1/images/generations",
- json={
- "prompt": "a portrait of a skier in deep powder snow",
- "negative_prompt": "blurry, low quality, distorted, ugly",
- "num_inference_steps": 100,
- "size": "1024x1024",
- }
-)
-```
-
-## Parameter Handling
-
-The API passes parameters directly to the diffusion pipeline without model-specific transformation:
-
-- **Default values**: When parameters are not specified, the underlying model uses its own defaults
-- **Pass-through design**: User-provided values are forwarded directly to the diffusion engine
-- **Minimal validation**: Only basic type checking and range validation at the API level
-
-### Parameter Compatibility
-
-The API passes parameters directly to the diffusion pipeline without model-specific validation.
-
-- Unsupported parameters may be silently ignored by the model
-- Incompatible values will result in errors from the underlying pipeline
-- Recommended values vary by model - consult model documentation
-
-**Best Practice:** Start with the model's recommended parameters, then adjust based on your needs.
-
-## Error Responses
-
-### 400 Bad Request
-
-Invalid parameters (e.g., model mismatch):
-
-```json
-{
- "detail": "Invalid size format: '1024x'. Expected format: 'WIDTHxHEIGHT' (e.g., '1024x1024')."
-}
-```
-
-### 422 Unprocessable Entity
-
-Validation errors (missing required fields):
-
-```json
-{
- "detail": [
- {
- "loc": ["body", "prompt"],
- "msg": "field required",
- "type": "value_error.missing"
- }
- ]
-}
-```
-
-### 503 Service Unavailable
-
-Diffusion engine not initialized:
-
-```json
-{
- "detail": "Diffusion engine not initialized. Start server with a diffusion model."
-}
-```
-
-## Troubleshooting
-
-### Server Not Running
-
-```bash
-# Check if server is responding
-curl http://localhost:8000/v1/images/generations \
- -H "Content-Type: application/json" \
- -d '{"prompt": "test"}'
-```
-
-### Out of Memory
-
-If you encounter OOM errors:
-1. Reduce image size: `"size": "512x512"`
-2. Reduce inference steps: `"num_inference_steps": 25`
-3. Generate fewer images: `"n": 1`
-
-## Testing
-
-Run the test suite to verify functionality:
-
-```bash
-# All image generation tests
-pytest tests/entrypoints/openai_api/test_image_server.py -v
-
-# Specific test
-pytest tests/entrypoints/openai_api/test_image_server.py::test_generate_single_image -v
-```
-
-## Development
-
-Enable debug logging to see prompts and generation details:
-
-```bash
-vllm serve Qwen/Qwen-Image --omni \
- --uvicorn-log-level debug
-```
diff --git a/docs/serving/speech_api.md b/docs/serving/speech_api.md
deleted file mode 100644
index 8f78d6a2001..00000000000
--- a/docs/serving/speech_api.md
+++ /dev/null
@@ -1,616 +0,0 @@
-# Speech API
-
-vLLM-Omni provides an OpenAI-compatible API for text-to-speech (TTS) generation. Supported TTS models include:
-
-- **Qwen3-TTS** (`Qwen/Qwen3-TTS-12Hz-*`) -- Qwen3-based TTS with CustomVoice, VoiceDesign, and Base (voice cloning) task types. Output: 24 kHz.
-- **Fish Speech S2 Pro** (`fishaudio/s2-pro`) -- Dual-AR TTS with DAC codec. Supports text-to-speech and voice cloning via reference audio. Output: 44.1 kHz.
-- **Voxtral TTS** (`mistralai/Voxtral-4B-TTS-2603`) -- AR + FlowMatching TTS with preset voices. Output: 24 kHz.
-
-Each server instance runs a single model (specified at startup via `vllm serve <model> --omni`).
-
-## Quick Start
-
-### Start the Server
-
-```bash
-# Qwen3-TTS: CustomVoice model (predefined speakers)
-vllm serve Qwen/Qwen3-TTS-12Hz-1.7B-CustomVoice \
- --deploy-config vllm_omni/deploy/qwen3_tts.yaml \
- --omni \
- --port 8091 \
- --trust-remote-code \
- --enforce-eager
-
-# Fish Speech S2 Pro
-vllm serve fishaudio/s2-pro --omni --port 8091
-
-# Voxtral TTS
-vllm serve mistralai/Voxtral-4B-TTS-2603 --omni --port 8091
-```
-
-### Generate Speech
-
-**Using curl:**
-
-```bash
-curl -X POST http://localhost:8091/v1/audio/speech \
- -H "Content-Type: application/json" \
- -d '{
- "input": "Hello, how are you?",
- "voice": "vivian",
- "language": "English"
- }' --output output.wav
-```
-
-**Using Python:**
-
-```python
-import httpx
-
-response = httpx.post(
- "http://localhost:8091/v1/audio/speech",
- json={
- "input": "Hello, how are you?",
- "voice": "vivian",
- "language": "English",
- },
- timeout=300.0,
-)
-
-with open("output.wav", "wb") as f:
- f.write(response.content)
-```
-
-**Using OpenAI SDK:**
-
-```python
-from openai import OpenAI
-
-client = OpenAI(base_url="http://localhost:8091/v1", api_key="none")
-
-response = client.audio.speech.create(
- model="Qwen/Qwen3-TTS-12Hz-1.7B-CustomVoice",
- voice="vivian",
- input="Hello, how are you?",
-)
-
-response.stream_to_file("output.wav")
-```
-
-## API Reference
-
-### Endpoint
-
-```
-POST /v1/audio/speech
-Content-Type: application/json
-```
-
-### Request Parameters
-
-#### OpenAI Standard Parameters
-
-| Parameter | Type | Default | Description |
-|-----------|------|---------|-------------|
-| `input` | string | **required** | The text to synthesize into speech |
-| `model` | string | server's model | Model to use (optional, should match server if specified) |
-| `voice` | string | "vivian" | Speaker name (e.g., vivian, ryan, aiden) |
-| `response_format` | string | "wav" | Audio format: wav, mp3, flac, pcm, aac, opus |
-| `speed` | float | 1.0 | Playback speed (0.25-4.0) |
-
-#### vLLM-Omni Extension Parameters
-
-| Parameter | Type | Default | Description |
-|-----------|------|---------|-------------|
-| `task_type` | string | "CustomVoice" | TTS task type: CustomVoice, VoiceDesign, or Base |
-| `language` | string | "Auto" | Language (see supported languages below) |
-| `instructions` | string | "" | Voice style/emotion instructions |
-| `max_new_tokens` | integer | 2048 | Maximum tokens to generate |
-| `initial_codec_chunk_frames` | integer | null | Per-request initial chunk size override for TTFA tuning. When null, IC is computed dynamically based on server load. |
-| `stream` | bool | false | Stream raw PCM chunks as they are decoded (requires `response_format="pcm"`) |
-
-**Supported languages:** Auto, Chinese, English, Japanese, Korean, German, French, Russian, Portuguese, Spanish, Italian
-
-#### Voice Clone Parameters (Base task)
-
-| Parameter | Type | Default | Description |
-|-----------|------|---------|-------------|
-| `ref_audio` | string | null | Reference audio (HTTP URL, base64 data URL, or `file://` URI with `--allowed-local-media-path`) |
-| `ref_text` | string | null | Transcript of reference audio |
-| `x_vector_only_mode` | bool | null | Use speaker embedding only (no ICL) |
-
-### Response Format
-
-Returns binary audio data with appropriate `Content-Type` header (e.g., `audio/wav`).
-
-### Voices Endpoint
-
-```
-GET /v1/audio/voices
-```
-
-Lists available voices for the loaded model.
-
-```json
-{
- "voices": ["aiden", "dylan", "eric", "ono_anna", "ryan", "serena", "sohee", "uncle_fu", "vivian", "custom_voice_1"],
- "uploaded_voices": [
- {
- "name": "custom_voice_1",
- "consent": "user_consent_id",
- "created_at": 1738660000,
- "file_size": 1024000,
- "mime_type": "audio/wav",
- "ref_text": "The exact transcript of the audio sample.",
- "speaker_description": "warm narrator"
- }
- ]
-}
-```
-
-`uploaded_voices` is always present (empty list when no custom voices have been uploaded). Fields `ref_text` and `speaker_description` are omitted per-entry when not provided at upload time.
-
-```
-POST /v1/audio/voices
-Content-Type: multipart/form-data
-```
-
-Upload a new voice sample for voice cloning in Base task TTS requests.
-
-**Form Parameters:**
-
-| Parameter | Type | Required | Description |
-|-----------|------|----------|-------------|
-| `audio_sample` | file | Yes | Audio file (max 10MB, supported formats: wav, mp3, flac, ogg, aac, webm, mp4) |
-| `consent` | string | Yes | Consent recording ID |
-| `name` | string | Yes | Name for the new voice |
-| `ref_text` | string | No | Transcript of the audio. When provided, enables in-context voice cloning (higher quality). Without it, only the speaker embedding is extracted. |
-| `speaker_description` | string | No | Free-form description of the voice (e.g. "warm narrator", "energetic presenter"). Stored as metadata and returned in `GET /v1/audio/voices`. |
-
-**Response Example:**
-
-```json
-{
- "success": true,
- "voice": {
- "name": "custom_voice_1",
- "consent": "user_consent_id",
- "created_at": 1738660000,
- "mime_type": "audio/wav",
- "file_size": 1024000,
- "ref_text": "The exact transcript of the audio sample.",
- "speaker_description": "warm narrator"
- }
-}
-```
-
-Fields `ref_text` and `speaker_description` are omitted when not provided at upload time.
-
-**Usage Example:**
-
-```bash
-curl -X POST http://localhost:8091/v1/audio/voices \
- -F "audio_sample=@/path/to/voice_sample.wav" \
- -F "consent=user_consent_id" \
- -F "name=custom_voice_1" \
- -F "ref_text=The exact transcript of the audio sample." \
- -F "speaker_description=warm narrator"
-```
-
-## Streaming Text Input (WebSocket)
-
-The `/v1/audio/speech/stream` WebSocket endpoint accepts text incrementally and generates audio per sentence as boundaries are detected.
-
-> Note: text input is always streamed incrementally. Audio output remains sentence-scoped:
-> use `stream_audio=false` for one binary frame per sentence, or `stream_audio=true` for one or more PCM chunks per sentence.
-
-### WebSocket Protocol
-
-Client -> Server:
-
-| Message | Description |
-|---------|-------------|
-| `{"type": "session.config", ...}` | Session configuration (sent once, first message) |
-| `{"type": "input.text", "text": "..."}` | Text chunk |
-| `{"type": "input.done"}` | End of input, flushes remaining buffer |
-
-Server -> Client:
-
-| Message | Description |
-|---------|-------------|
-| `{"type": "audio.start", "sentence_index": 0, "sentence_text": "...", "format": "pcm", "sample_rate": 24000}` | Audio generation starting for a sentence |
-| Binary frame | Raw audio bytes (one or more PCM chunks when `stream_audio=true`) |
-| `{"type": "audio.done", "sentence_index": 0, "total_bytes": 96000, "error": false}` | Audio complete for a sentence |
-| `{"type": "session.done", "total_sentences": N}` | Session complete |
-| `{"type": "error", "message": "..."}` | Non-fatal error |
-
-### Session Config Parameters
-
-All REST API parameters are supported, plus:
-
-| Parameter | Type | Default | Description |
-|-----------|------|---------|-------------|
-| `stream_audio` | bool | false | Stream one or more PCM chunks per sentence over WebSocket |
-| `split_granularity` | string | "sentence" | Text splitting granularity |
-
-
-```bash
-DELETE /v1/audio/voices/{name}
-```
-
-Delete an uploaded voice sample.
-
-**Path Parameters:**
-
-| Parameter | Type | Required | Description |
-|-----------|------|----------|-------------|
-| `name` | string | Yes | Name of the voice to delete |
-
-**Response Example:**
-
-```json
-{
- "success": true,
- "message": "Voice 'custom_voice_1' deleted successfully"
-}
-```
-
-**Error Response (404 Not Found):**
-
-```json
-{
- "success": false,
- "error": "Voice 'unknown_voice' not found"
-}
-```
-
-**Usage Example:**
-
-```bash
-curl -X DELETE http://localhost:8091/v1/audio/voices/custom_voice_1
-```
-
-## Examples
-
-### CustomVoice with Style Instruction
-
-```bash
-curl -X POST http://localhost:8091/v1/audio/speech \
- -H "Content-Type: application/json" \
- -d '{
- "input": "I am so excited!",
- "voice": "vivian",
- "instructions": "Speak with great enthusiasm"
- }' --output excited.wav
-```
-
-### VoiceDesign (Natural Language Voice Description)
-
-```bash
-# Start server with VoiceDesign model first
-vllm serve Qwen/Qwen3-TTS-12Hz-1.7B-VoiceDesign \
- --deploy-config vllm_omni/deploy/qwen3_tts.yaml \
- --omni \
- --port 8091 \
- --trust-remote-code \
- --enforce-eager
-```
-
-```bash
-curl -X POST http://localhost:8091/v1/audio/speech \
- -H "Content-Type: application/json" \
- -d '{
- "input": "Hello world",
- "task_type": "VoiceDesign",
- "instructions": "A warm, friendly female voice with a gentle tone"
- }' --output designed.wav
-```
-
-### Base (Voice Cloning)
-
-```bash
-# Start server with Base model first
-vllm serve Qwen/Qwen3-TTS-12Hz-1.7B-Base \
- --deploy-config vllm_omni/deploy/qwen3_tts.yaml \
- --omni \
- --port 8091 \
- --trust-remote-code \
- --enforce-eager
-```
-
-```bash
-curl -X POST http://localhost:8091/v1/audio/speech \
- -H "Content-Type: application/json" \
- -d '{
- "input": "Hello, this is a cloned voice",
- "task_type": "Base",
- "ref_audio": "https://example.com/reference.wav",
- "ref_text": "Original transcript of the reference audio"
- }' --output cloned.wav
-```
-
-### Upload Voice
-
-Upload voice (speaker embedding only):
-```bash
-curl -X POST http://localhost:8091/v1/audio/voices \
- -F "audio_sample=@/path/to/voice_sample.wav" \
- -F "consent=user_consent_id" \
- -F "name=custom_voice_1"
-```
-
-Upload voice with transcript (in-context cloning, higher quality):
-```bash
-curl -X POST http://localhost:8091/v1/audio/voices \
- -F "audio_sample=@/path/to/voice_sample.wav" \
- -F "consent=user_consent_id" \
- -F "name=custom_voice_2" \
- -F "ref_text=The exact transcript of the audio sample."
-```
-
-### Use Uploaded Voice
-```bash
-curl -X POST http://localhost:8091/v1/audio/speech \
- -H "Content-Type: application/json" \
- -d '{
- "input": "Hello, this is a cloned voice",
- "voice": "custom_voice_1"
- }' --output cloned.wav
-```
-
-## Batch Speech Generation
-
-The batch endpoint synthesizes multiple texts in a single request, returning all results as JSON with base64-encoded audio.
-
-### Endpoint
-
-```
-POST /v1/audio/speech/batch
-Content-Type: application/json
-```
-
-### Request Parameters
-
-| Parameter | Type | Default | Description |
-|-----------|------|---------|-------------|
-| `items` | array | **required** | List of items to synthesize (1–32) |
-| `model` | string | server's model | Model to use |
-| `voice` | string | null | Default voice for all items |
-| `response_format` | string | "wav" | Default audio format for all items |
-| `speed` | float | 1.0 | Default playback speed (0.25–4.0) |
-| `task_type` | string | null | Default TTS task type |
-| `language` | string | null | Default language |
-| `instructions` | string | null | Default voice style instructions |
-| `ref_audio` | string | null | Default reference audio (Base task) |
-| `ref_text` | string | null | Default reference transcript (Base task) |
-| `max_new_tokens` | integer | null | Default max tokens |
-
-Each item in the `items` array requires only `input` (the text). All other fields are optional and override the batch-level defaults when set:
-
-| Field | Type | Description |
-|-------|------|-------------|
-| `input` | string | **required** — text to synthesize |
-| `voice` | string | Override voice for this item |
-| `response_format` | string | Override format for this item |
-| `speed` | float | Override speed for this item |
-| `task_type` | string | Override task type |
-| `language` | string | Override language |
-| `instructions` | string | Override instructions |
-| `ref_audio` | string | Override reference audio |
-| `ref_text` | string | Override reference transcript |
-| `max_new_tokens` | integer | Override max tokens |
-
-### Response Format
-
-```json
-{
- "id": "speech-batch-abc123",
- "results": [
- {
- "index": 0,
- "status": "success",
- "audio_data": "<base64-encoded audio>",
- "media_type": "audio/wav"
- },
- {
- "index": 1,
- "status": "error",
- "error": "Input text cannot be empty"
- }
- ],
- "total": 2,
- "succeeded": 1,
- "failed": 1
-}
-```
-
-### Examples
-
-**Basic batch with shared defaults:**
-
-```bash
-curl -X POST http://localhost:8091/v1/audio/speech/batch \
- -H "Content-Type: application/json" \
- -d '{
- "items": [
- {"input": "Hello, how are you?"},
- {"input": "Goodbye, see you later!"}
- ],
- "voice": "vivian",
- "language": "English"
- }'
-```
-
-**Per-item overrides (different voices and formats):**
-
-```bash
-curl -X POST http://localhost:8091/v1/audio/speech/batch \
- -H "Content-Type: application/json" \
- -d '{
- "items": [
- {"input": "Hello!", "voice": "vivian", "response_format": "mp3"},
- {"input": "你好!", "voice": "ryan", "language": "Chinese"}
- ],
- "response_format": "wav"
- }'
-```
-
-**Voice cloning with shared reference audio (Base task):**
-
-```bash
-curl -X POST http://localhost:8091/v1/audio/speech/batch \
- -H "Content-Type: application/json" \
- -d '{
- "items": [
- {"input": "First sentence in the cloned voice."},
- {"input": "Second sentence in the cloned voice."}
- ],
- "task_type": "Base",
- "ref_audio": "https://example.com/reference.wav",
- "ref_text": "Transcript of the reference audio"
- }'
-```
-
-Setting `ref_audio` at the batch level applies it to all items, avoiding the need to repeat it per item.
-
-**Decoding the response in Python:**
-
-```python
-import base64
-import httpx
-
-response = httpx.post(
- "http://localhost:8091/v1/audio/speech/batch",
- json={
- "items": [
- {"input": "First sentence."},
- {"input": "Second sentence."},
- ],
- "voice": "vivian",
- },
- timeout=300.0,
-)
-
-for result in response.json()["results"]:
- if result["status"] == "success":
- audio_bytes = base64.b64decode(result["audio_data"])
- with open(f"output_{result['index']}.wav", "wb") as f:
- f.write(audio_bytes)
-```
-
-### Configuration
-
-| Parameter | Source | Default | Description |
-|-----------|--------|---------|-------------|
-| `tts_batch_max_items` | engine kwarg | 32 | Maximum number of items per batch request |
-
-All items are fanned out to `generate()` concurrently. The engine's stage worker automatically batches them up to the configured `max_batch_size` and queues the rest — no client-side throttling needed.
-
-For best throughput, set both stages' `max_num_seqs` to ≥4 via `--stage-overrides`:
-
-```bash
-vllm serve Qwen/Qwen3-TTS-12Hz-1.7B-CustomVoice \
- --omni --port 8091 --trust-remote-code --enforce-eager \
- --stage-overrides '{"0":{"max_num_seqs":4,"gpu_memory_utilization":0.2},
- "1":{"max_num_seqs":4,"gpu_memory_utilization":0.2}}'
-```
-
-The bundled `qwen3_tts.yaml` uses `max_num_seqs: 1` (single request) on both stages. Bumping to 4 yields roughly 4× throughput on the talker and lets stage 1 batch chunks across in-flight requests.
-
-## Supported Models
-
-### Qwen3-TTS
-
-| Model | Task Type | Description |
-|-------|-----------|-------------|
-| `Qwen/Qwen3-TTS-12Hz-1.7B-CustomVoice` | CustomVoice | Predefined speaker voices with optional style control |
-| `Qwen/Qwen3-TTS-12Hz-1.7B-VoiceDesign` | VoiceDesign | Natural language voice style description |
-| `Qwen/Qwen3-TTS-12Hz-1.7B-Base` | Base | Voice cloning from reference audio |
-| `Qwen/Qwen3-TTS-12Hz-0.6B-CustomVoice` | CustomVoice | Smaller/faster variant |
-| `Qwen/Qwen3-TTS-12Hz-0.6B-Base` | Base | Smaller/faster variant for voice cloning |
-
-### Fish Speech S2 Pro
-
-| Model | Description |
-|-------|-------------|
-| `fishaudio/s2-pro` | 4B dual-AR TTS with DAC codec (44.1 kHz). Supports text-to-speech and voice cloning. |
-
-Fish Speech uses `ref_audio` and `ref_text` for voice cloning (no `task_type` needed). The `voice` field should be set to `"default"`. See the [Fish Speech online serving example](../user_guide/examples/online_serving/fish_speech.md) for details.
-
-### Voxtral TTS
-
-| Model | Description |
-|-------|-------------|
-| `mistralai/Voxtral-4B-TTS-2603` | 3B AR + FlowMatching TTS. Supports text-to-speech with preset voices. |
-
-## Error Responses
-
-### 400 Bad Request
-
-Invalid parameters:
-
-```json
-{
- "error": {
- "message": "Input text cannot be empty",
- "type": "BadRequestError",
- "param": null,
- "code": 400
- }
-}
-```
-
-### 404 Not Found
-
-Model not found:
-
-```json
-{
- "error": {
- "message": "The model `xxx` does not exist.",
- "type": "NotFoundError",
- "param": "model",
- "code": 404
- }
-}
-```
-
-## Troubleshooting
-
-### "TTS model did not produce audio output"
-
-Ensure you're using the correct model variant for your task type:
-- CustomVoice task → CustomVoice model
-- VoiceDesign task → VoiceDesign model
-- Base task → Base model
-
-### Server Not Running
-
-```bash
-# Check if server is responding
-curl http://localhost:8091/v1/audio/voices
-```
-
-### Out of Memory
-
-If you encounter OOM errors:
-1. Use smaller model variant: `Qwen/Qwen3-TTS-12Hz-0.6B-CustomVoice`
-2. Reduce `--gpu-memory-utilization`
-
-### Unsupported Speaker
-
-Use `/v1/audio/voices` to list available voices for the loaded model.
-
-## Development
-
-Enable debug logging:
-
-```bash
-vllm serve Qwen/Qwen3-TTS-12Hz-1.7B-CustomVoice \
- --deploy-config vllm_omni/deploy/qwen3_tts.yaml \
- --omni \
- --port 8091 \
- --trust-remote-code \
- --enforce-eager \
- --uvicorn-log-level debug
-```
diff --git a/docs/serving/video_stream_api.md b/docs/serving/video_stream_api.md
deleted file mode 100644
index 88f74affca9..00000000000
--- a/docs/serving/video_stream_api.md
+++ /dev/null
@@ -1,93 +0,0 @@
-# Streaming Video Input API
-
-vLLM-Omni provides a WebSocket API for streaming video frames and optional audio chunks into Qwen3-Omni, then asking questions over the buffered session context.
-
-Each server instance runs a single model specified at startup with `vllm serve <model> --omni`.
-
-## Quick Start
-
-### Start the Server
-
-```bash
-vllm serve Qwen/Qwen3-Omni-30B-A3B-Instruct \
- --deploy-config vllm_omni/deploy/qwen3_omni.yaml \
- --omni \
- --port 8000 \
- --trust-remote-code
-```
-
-### Run the Example Client
-
-```bash
-python examples/online_serving/qwen3_omni/streaming_video_client.py \
- --url ws://localhost:8000/v1/video/chat/stream \
- --video /path/to/video.mp4 \
- --query "Describe what is happening in the video."
-```
-
-## API Reference
-
-### Endpoint
-
-```text
-WebSocket /v1/video/chat/stream
-```
-
-### Protocol
-
-| Direction | Type | Required fields | Description |
-|-----------|------|-----------------|-------------|
-| Client -> Server | `session.config` | none | First message. Configures output modalities, frame sampling, EVS, and prompts. |
-| Client -> Server | `video.frame` | `data` | Base64 JPEG/PNG frame. |
-| Client -> Server | `audio.chunk` | `data` | Base64 PCM16 16 kHz mono audio bytes. |
-| Client -> Server | `video.query` | `text` | Ask a question over the buffered frames and audio. |
-| Client -> Server | `video.done` | none | End the WebSocket session. |
-| Server -> Client | `response.start` | none | Query generation started. |
-| Server -> Client | `response.text.delta` | `delta` | Incremental text output. |
-| Server -> Client | `response.text.done` | `text` | Final text output for the query. |
-| Server -> Client | `response.audio.delta` | `data`, `format` | Incremental generated audio, base64 WAV. |
-| Server -> Client | `response.audio.done` | none | Audio output finished. |
-| Server -> Client | `session.done` | none | Session closed. |
-| Server -> Client | `error` | `message` | Recoverable protocol or generation error. |
-
-### `session.config` Fields
-
-| Field | Type | Default | Description |
-|-------|------|---------|-------------|
-| `model` | string or null | null | Optional model name. Usually omitted because the server hosts one model. |
-| `modalities` | list[string] | `["text", "audio"]` | Output modalities. Use `["text"]`, `["audio"]`, or both. |
-| `num_frames` | integer, 1-128 | `4` | Number of buffered frames sampled for each query. |
-| `max_frames` | integer, 1-256 | `50` | Maximum retained frame buffer size. Oldest frames are evicted first. |
-| `system_prompt` | string or null | null | Optional custom system prompt. |
-| `use_audio_in_video` | bool | `true` | Include streamed audio chunks in multimodal video understanding when audio is present. |
-| `sampling_params_list` | list or null | null | Optional per-stage sampling parameter overrides. |
-| `enable_frame_filter` | bool | `true` | Enable EVS near-duplicate frame filtering. |
-| `frame_filter_threshold` | float, 0.0-1.0 | `0.95` | EVS similarity threshold. Higher keeps more frames; lower drops more near-duplicates. |
-
-### Legacy Aliases
-
-The server accepts these legacy field names and rewrites them before validation. New clients should send the canonical names above.
-
-| Legacy field | Canonical field |
-|--------------|-----------------|
-| `num_sample_frames` | `num_frames` |
-| `evs_enabled` | `enable_frame_filter` |
-| `evs_threshold` | `frame_filter_threshold` |
-
-### Environment Variables
-
-| Variable | Values | Default | Description |
-|----------|--------|---------|-------------|
-| `VLLM_VIDEO_ASYNC_CHUNK` | `on`, `off` | `on` | Wire-level streaming switch. `off` buffers server-side deltas and emits coalesced outputs at the end of a query. |
-| `VLLM_VIDEO_AUDIO_DELTA_MODE` | `fast`, `slow` | `fast` | Audio delta extraction strategy. `fast` emits only newly produced chunks; `slow` recomputes from accumulated audio and exists for A/B verification. |
-
-## EVS Semantics
-
-EVS compares downsampled frames and drops near-duplicate frames before they enter the session frame buffer. `frame_filter_threshold` controls retention: higher values are more permissive and keep more frames; lower values are more aggressive and drop more similar frames.
-
-## Known Limitations
-
-- Session KV reuse and incremental prefill are not implemented in this PR. Each `video.query` rebuilds the model prompt from the retained frame and audio buffers.
-- Back-to-back short replies can still expose an engine-layer scheduler race. The PR notes an observed workaround of at least 200 ms idle between turns when clients repeatedly see idle timeouts.
-- If the audio buffer exceeds the server limit, the server emits `Audio buffer overflow` and clears the currently buffered audio for the session.
-- The API is intended for Qwen3-Omni streaming video understanding; other models may not support the same multimodal processor arguments.
diff --git a/docs/source/architecture/ar-dit-main-architecture.png b/docs/source/architecture/ar-dit-main-architecture.png
deleted file mode 100644
index 200fddf2b7f..00000000000
Binary files a/docs/source/architecture/ar-dit-main-architecture.png and /dev/null differ
diff --git a/docs/source/architecture/ar-main-architecture.png b/docs/source/architecture/ar-main-architecture.png
deleted file mode 100644
index 642c3c00868..00000000000
Binary files a/docs/source/architecture/ar-main-architecture.png and /dev/null differ
diff --git a/docs/source/architecture/async-chunk-architecture.png b/docs/source/architecture/async-chunk-architecture.png
deleted file mode 100644
index 7b3e95e4df9..00000000000
Binary files a/docs/source/architecture/async-chunk-architecture.png and /dev/null differ
diff --git a/docs/source/architecture/dit-main-architecture.png b/docs/source/architecture/dit-main-architecture.png
deleted file mode 100644
index 97672e145ef..00000000000
Binary files a/docs/source/architecture/dit-main-architecture.png and /dev/null differ
diff --git a/docs/source/architecture/omni-modality-model-architecture.png b/docs/source/architecture/omni-modality-model-architecture.png
deleted file mode 100644
index 53978b32366..00000000000
Binary files a/docs/source/architecture/omni-modality-model-architecture.png and /dev/null differ
diff --git a/docs/source/architecture/qwen3-omni-async-chunk.png b/docs/source/architecture/qwen3-omni-async-chunk.png
deleted file mode 100644
index e73ca84b283..00000000000
Binary files a/docs/source/architecture/qwen3-omni-async-chunk.png and /dev/null differ
diff --git a/docs/source/architecture/qwen3-omni-non-async-chunk.png b/docs/source/architecture/qwen3-omni-non-async-chunk.png
deleted file mode 100644
index 47a9ba66a5e..00000000000
Binary files a/docs/source/architecture/qwen3-omni-non-async-chunk.png and /dev/null differ
diff --git a/docs/source/architecture/vllm-omni-dataflow-between-stages.png b/docs/source/architecture/vllm-omni-dataflow-between-stages.png
deleted file mode 100644
index 74abc81ff07..00000000000
Binary files a/docs/source/architecture/vllm-omni-dataflow-between-stages.png and /dev/null differ
diff --git a/docs/source/architecture/vllm-omni-diffusion-flow.png b/docs/source/architecture/vllm-omni-diffusion-flow.png
deleted file mode 100644
index 92a4cfe649a..00000000000
Binary files a/docs/source/architecture/vllm-omni-diffusion-flow.png and /dev/null differ
diff --git a/docs/source/architecture/vllm-omni-main-architecture.png b/docs/source/architecture/vllm-omni-main-architecture.png
deleted file mode 100644
index 98b7a979242..00000000000
Binary files a/docs/source/architecture/vllm-omni-main-architecture.png and /dev/null differ
diff --git a/docs/source/architecture/vllm-omni-user-interface.png b/docs/source/architecture/vllm-omni-user-interface.png
deleted file mode 100644
index 867b3ae2fca..00000000000
Binary files a/docs/source/architecture/vllm-omni-user-interface.png and /dev/null differ
diff --git a/docs/source/logos/vllm-logo-only-light.ico b/docs/source/logos/vllm-logo-only-light.ico
deleted file mode 100644
index 27528ceebff..00000000000
Binary files a/docs/source/logos/vllm-logo-only-light.ico and /dev/null differ
diff --git a/docs/source/logos/vllm-omni-logo.png b/docs/source/logos/vllm-omni-logo.png
deleted file mode 100644
index c054ff46fb5..00000000000
Binary files a/docs/source/logos/vllm-omni-logo.png and /dev/null differ
diff --git a/docs/source/performance/qwen3-omni_e2e_performance.png b/docs/source/performance/qwen3-omni_e2e_performance.png
deleted file mode 100644
index 823662fb124..00000000000
Binary files a/docs/source/performance/qwen3-omni_e2e_performance.png and /dev/null differ
diff --git a/docs/source/performance/qwen3-omni_rtf_performance.png b/docs/source/performance/qwen3-omni_rtf_performance.png
deleted file mode 100644
index 6e8d9c16274..00000000000
Binary files a/docs/source/performance/qwen3-omni_rtf_performance.png and /dev/null differ
diff --git a/docs/source/performance/qwen3-omni_ttfp_performance.png b/docs/source/performance/qwen3-omni_ttfp_performance.png
deleted file mode 100644
index 75f30621947..00000000000
Binary files a/docs/source/performance/qwen3-omni_ttfp_performance.png and /dev/null differ
diff --git a/docs/usage/faq.md b/docs/usage/faq.md
deleted file mode 100644
index 0539e158b01..00000000000
--- a/docs/usage/faq.md
+++ /dev/null
@@ -1,21 +0,0 @@
-# Frequently Asked Questions
-
-> Q: How many chips do I need to infer a model in vLLM-Omni?
-
-A: Now, we support natively disaggregated deployment for different model stages within a model. There is a restriction that one chip can only have one AutoRegressive model stage. This is because the unified KV cache management of vLLM. Stages of other types can coexist within a chip. The restriction will be resolved in later version.
-
-> Q: I see GPU OOM or "free memory is less than desired GPU memory utilization" errors. How can I fix it?
-
-A: Refer to [GPU memory calculation and configuration](../configuration/gpu_memory_utilization.md) for guidance on tuning `gpu_memory_utilization` and related settings.
-
-> Q: I encounter some bugs or CI problems, which is urgent. How can I solve it?
-
-A: At first, you can check current [issues](https://github.com/vllm-project/vllm-omni/issues) to find possible solutions. If none of these satisfy your demand and it is urgent, please find these [volunteers](https://docs.vllm.ai/projects/vllm-omni/en/latest/community/volunteers/) for help.
-
-> Q: Does vLLM-Omni support AWQ or any other quantization?
-
-A: We plan to introduce GGUF FP8 prequantized models and online FP8 quantization in version 0.16.0. Support for other quantization types will follow in future releases. For details, please see our [Q1 quantization roadmap](https://github.com/vllm-project/vllm-omni/issues/1057).
-
-> Q: Does vLLM-Omni support multimodal streaming input and output?
-
-A: Not yet. We already put it on the [Roadmap](https://github.com/vllm-project/vllm-omni/issues/165). Please stay tuned!
diff --git a/docs/user_guide/diffusion/attention_backends.md b/docs/user_guide/diffusion/attention_backends.md
deleted file mode 100644
index 692bcc0f9d0..00000000000
--- a/docs/user_guide/diffusion/attention_backends.md
+++ /dev/null
@@ -1,120 +0,0 @@
-# Diffusion Attention Backends
-
-This document describes the diffusion attention backends available in vLLM-Omni, how to select them, and how to use SageAttention.
-
-## Overview
-
-Diffusion attention backend selection is controlled by the `DIFFUSION_ATTENTION_BACKEND` environment variable and resolved in `vllm_omni.diffusion.attention.selector`.
-
-This backend is used by diffusion attention layers such as the DiT attention in video and image generation models.
-
-On CUDA, the practical choices today are:
-
-- `FLASH_ATTN`: FlashAttention backend. This is the default on supported CUDA systems when FlashAttention is installed.
-- `TORCH_SDPA`: PyTorch `scaled_dot_product_attention`.
-- `SAGE_ATTN`: SageAttention backend, if `sageattention` is installed.
-
-If `DIFFUSION_ATTENTION_BACKEND` is unset, vLLM-Omni asks the current platform to choose the default backend. On CUDA, that normally means `FLASH_ATTN` when available, otherwise `TORCH_SDPA`.
-
-## Backend Options
-
-| Value | Notes |
-|---|---|
-| `FLASH_ATTN` | Default on CUDA when FlashAttention is available. Good default for most diffusion workloads. |
-| `TORCH_SDPA` | Most conservative fallback. Useful for debugging or compatibility. |
-| `SAGE_ATTN` | Requires `sageattention`. Can improve performance on some workloads, but output quality must be validated model-by-model. |
-
-## Selection Priority
-
-Diffusion attention backend selection follows this order:
-
-1. `DIFFUSION_ATTENTION_BACKEND`
-2. Platform default
-
-Example:
-
-```bash
-export DIFFUSION_ATTENTION_BACKEND=SAGE_ATTN
-```
-
-## SageAttention Installation
-
-vLLM-Omni expects SageAttention to be installed into the same Python environment as vLLM-Omni.
-
-Build from source:
-
-```bash
-git clone https://github.com/thu-ml/SageAttention.git
-cd SageAttention
-
-export EXT_PARALLEL=4 NVCC_APPEND_FLAGS="--threads 8" MAX_JOBS=32
-pip install . --no-build-isolation
-```
-
-Quick check:
-
-```bash
-python -c "import sageattention; print(sageattention.__file__)"
-```
-
-## Usage
-
-### Enable SageAttention
-
-Example: HunyuanVideo-1.5 text-to-video
-
-```bash
-DIFFUSION_ATTENTION_BACKEND=SAGE_ATTN python examples/offline_inference/text_to_video/text_to_video.py \
- --model hunyuanvideo-community/HunyuanVideo-1.5-Diffusers-480p_t2v \
- --prompt "A dog running across a field of golden wheat." \
- --height 480 --width 832 --num-frames 33 \
- --num-inference-steps 30 --seed 42 --guidance-scale 6.0 \
- --tensor-parallel-size 2 \
- --output ../tmp/hv15_modelopt_sage.mp4
-```
-
-Example: Wan2.2 TI2V 5B
-
-```bash
-DIFFUSION_ATTENTION_BACKEND=SAGE_ATTN python examples/offline_inference/text_to_video/text_to_video.py \
- --model Wan-AI/Wan2.2-TI2V-5B-Diffusers \
- --prompt "A dog running across a field of golden wheat." \
- --height 704 --width 1280 --num-frames 49 \
- --num-inference-steps 30 --seed 42 --guidance-scale 5.0 \
- --tensor-parallel-size 2 \
- --output outputs/wan22_sage.mp4
-```
-
-### Compare Against FlashAttention
-
-Unset the backend override, or explicitly use `FLASH_ATTN`:
-
-```bash
-python examples/offline_inference/text_to_video/text_to_video.py \
- --model Wan-AI/Wan2.2-TI2V-5B-Diffusers \
- --prompt "A dog running across a field of golden wheat." \
- --height 704 --width 1280 --num-frames 49 \
- --num-inference-steps 30 --seed 42 --guidance-scale 5.0 \
- --tensor-parallel-size 2 \
- --output outputs/wan22_fa3.mp4
-```
-
-## Validation Guidance
-
-Do not assume that a faster attention backend is numerically interchangeable with `FLASH_ATTN`.
-
-Always compare:
-
-- End-to-end runtime
-- DiT / diffusion stage runtime
-- Output quality against a known-good baseline
-
-At minimum, keep the same:
-
-- model
-- prompt
-- seed
-- resolution
-- frame count
-- inference steps
-- parallel config
diff --git a/docs/user_guide/diffusion/cache_acceleration/cache_dit.md b/docs/user_guide/diffusion/cache_acceleration/cache_dit.md
deleted file mode 100644
index eaaca84ad6d..00000000000
--- a/docs/user_guide/diffusion/cache_acceleration/cache_dit.md
+++ /dev/null
@@ -1,292 +0,0 @@
-# Cache-DiT Guide
-
-
-## Table of Content
-
-- [Overview](#overview)
-- [Quick Start](#quick-start)
-- [Example Script](#example-script)
-- [Acceleration Methods](#acceleration-methods)
-- [Configuration Parameters](#configuration-parameters)
-- [Best Practices](#best-practices)
-- [Troubleshooting](#troubleshooting)
-- [Summary](#summary)
-- [Additional Resources](#additional-resources)
-
----
-
-## Overview
-
-Cache-DiT accelerates diffusion transformer models through intelligent caching mechanisms, providing significant speedup with minimal quality loss. It supports multiple acceleration techniques that can be combined for optimal performance:
-
-- **DBCache**: Dual Block Cache for reducing redundant computations
-- **TaylorSeer**: Taylor expansion-based forecasting for faster inference
-- **SCM**: Step Computation Masking for selective step computation
-
-See supported models list in [Supported Models](../../diffusion_features.md#supported-models).
-
----
-
-## Quick Start
-
-### Basic Usage
-
-Enable cache-dit acceleration by simply setting `cache_backend="cache_dit"`:
-
-```python
-from vllm_omni import Omni
-from vllm_omni.inputs.data import OmniDiffusionSamplingParams
-
-omni = Omni(
- model="Qwen/Qwen-Image",
- cache_backend="cache_dit", # Enable Cache-DiT with defaults
-)
-
-outputs = omni.generate(
- "a beautiful landscape",
- OmniDiffusionSamplingParams(num_inference_steps=50),
-)
-```
-
-**Note**: When `cache_config` is not provided, Cache-DiT uses optimized default values. See the [Configuration Parameters](#configuration-parameters) section for details.
-
-### Custom Configuration
-
-To customize cache-dit settings, provide a `cache_config` dictionary, for example:
-
-```python
-omni = Omni(
- model="Qwen/Qwen-Image",
- cache_backend="cache_dit",
- cache_config={
- "Fn_compute_blocks": 1,
- "Bn_compute_blocks": 0,
- "max_warmup_steps": 4,
- "residual_diff_threshold": 0.12,
- },
-)
-```
-
----
-
-## Example Script
-
-### Offline Inference
-
-Use the example script under `examples/offline_inference/text_to_image`:
-
-```bash
-cd examples/offline_inference/text_to_image
-python text_to_image.py \
- --model Qwen/Qwen-Image \
- --prompt "a cup of coffee on the table" \
- --cache-backend cache_dit \
- --num-inference-steps 50
-```
-
-See the [text_to_image.py](https://github.com/vllm-project/vllm-omni/blob/main/examples/offline_inference/text_to_image/text_to_image.py) for detailed configuration options.
-
-The script uses cache-dit acceleration with a hybrid configuration combining DBCache, SCM, and TaylorSeer:
-
-```python
-omni = Omni(
- model="Qwen/Qwen-Image",
- cache_backend="cache_dit",
- cache_config={
- # Scheme: Hybrid DBCache + SCM + TaylorSeer
- "Fn_compute_blocks": 1, # Optimized for single-transformer models
- "Bn_compute_blocks": 0, # Number of backward compute blocks
- "max_warmup_steps": 4, # Maximum warmup steps (works for few-step models)
- "residual_diff_threshold": 0.24, # Higher threshold for more aggressive caching
- "max_continuous_cached_steps": 3, # Limit to prevent precision degradation
- # TaylorSeer parameters [cache-dit only]
- "enable_taylorseer": False, # Disabled by default (not suitable for few-step models)
- "taylorseer_order": 1, # TaylorSeer polynomial order
- # SCM (Step Computation Masking) parameters [cache-dit only]
- "scm_steps_mask_policy": None, # SCM mask policy: None (disabled), "slow", "medium", "fast", "ultra"
- "scm_steps_policy": "dynamic", # SCM steps policy: "dynamic" or "static"
- }
-)
-```
-
-You can customize the configuration by modifying the `cache_config` dictionary to use only specific methods (e.g., DBCache only, DBCache + SCM, etc.) based on your quality and speed requirements.
-
-For image-to-image tasks, use the example script under `examples/offline_inference/image_to_image`:
-
-```bash
-cd examples/offline_inference/image_to_image
-python image_edit.py \
- --model Qwen/Qwen-Image-Edit \
- --prompt "make the sky more colorful" \
- --image path/to/input/image.jpg \
- --cache-backend cache_dit \
- --num-inference-steps 50 \
- --cache-dit-max-continuous-cached-steps 3 \
- --cache-dit-residual-diff-threshold 0.24 \
- --cache-dit-enable-taylorseer
-```
-
-See the [image_edit.py](https://github.com/vllm-project/vllm-omni/blob/main/examples/offline_inference/image_to_image/image_edit.py) for detailed configuration options.
-
-### Online Serving
-
-```bash
-# Default configuration (recommended)
-vllm serve Qwen/Qwen-Image --omni --port 8091 --cache-backend cache_dit
-
-# Custom configuration
-vllm serve Qwen/Qwen-Image --omni --port 8091 \
- --cache-backend cache_dit \
- --cache-config '{"Fn_compute_blocks": 1, "residual_diff_threshold": 0.12}'
-```
-
----
-
-## Acceleration Methods
-
-For comprehensive illustration, please view Cache-DiT [User Guide](https://cache-dit.readthedocs.io/en/latest/user_guide/OVERVIEWS/).
-
-### 1. DBCache (Dual Block Cache)
-
-DBCache intelligently caches intermediate transformer block outputs when the residual differences between consecutive steps are small, reducing redundant computations without sacrificing quality.
-
-**Example Configuration**:
-
-```python
-cache_config={
- "Fn_compute_blocks": 8, # Use first 8 blocks for difference computation
- "Bn_compute_blocks": 0, # No additional fusion blocks
- "max_warmup_steps": 8, # Cache after 8 warmup steps
- "residual_diff_threshold": 0.12, # Lower threshold for faster inference
- "max_cached_steps": -1, # No limit on cached steps
-}
-```
-
-**Performance Tips**:
-
-- Default `Fn_compute_blocks=1` works well for most cases. Some models (e.g., FLUX.2-klein) use a larger value for `Fn_compute_blocks` for a balanced performance.
-- Increase `residual_diff_threshold` (e.g., 0.12-0.15) for faster inference with slight quality trade-off, or decrease from default 0.24 for higher quality.
-- Default `max_warmup_steps=4` is optimized for few-step models. Increase to 6-8 for more steps if needed.
-
-### 2. TaylorSeer
-
-TaylorSeer uses Taylor expansion to forecast future hidden states, allowing the model to skip some computation steps while maintaining quality.
-
-**Example Configuration**:
-
-```python
-cache_config={
- "enable_taylorseer": True,
- "taylorseer_order": 1, # First-order Taylor expansion
-}
-```
-
-**Performance Tips**:
-
-- TaylorSeer is **not suitable for few-step distilled models**.
-- Use `taylorseer_order=1` for most cases (good balance of speed and quality).
-- Combine with DBCache for maximum acceleration.
-- Higher orders (2-3) may improve quality but reduce speed gains.
-
-### 3. SCM (Step Computation Masking)
-
-SCM allows you to specify which steps must be computed and which can use cached results, similar to LeMiCa/EasyCache style acceleration.
-
-`scm_steps_mask_policy` options (number of compute steps out of 28):
-
-| Policy | Compute Steps | Speed | Quality |
-|--------|--------------|-------|---------|
-| `None` (default) | All | Baseline | Best |
-| `"slow"` | 18 / 28 | Moderate | High |
-| `"medium"` | 15 / 28 | Balanced | Good |
-| `"fast"` | 11 / 28 | Fast | Moderate |
-| `"ultra"` | 8 / 28 | Fastest | Lower |
-
-**Example Configuration**:
-
-```python
-cache_config={
- "scm_steps_mask_policy": "medium", # Balanced speed/quality
- "scm_steps_policy": "dynamic", # Use dynamic cache
-}
-```
-
-**Performance Tips**:
-
-- SCM is disabled by default. Enable it by setting a policy value if you need additional acceleration.
-- Start with `"medium"` policy and adjust based on quality requirements.
-- Use `"fast"` or `"ultra"` for maximum speed when quality can be slightly compromised.
-- `"dynamic"` policy generally provides better quality than `"static"`.
-- SCM mask is automatically regenerated when `num_inference_steps` changes during inference.
-
----
-
-## Configuration Parameters
-
-In `cache_config` passed to `Omni` constructor, it accepts the arguments of `DBCacheConfig` ([Cache-DiT API Reference](https://cache-dit.readthedocs.io/en/latest/user_guide/CACHE_API/)). Key parameters are listed below:
-
-| Parameter | Type | Default | Description |
-|-----------|------|---------|-------------|
-| `Fn_compute_blocks` | int | 1 | First n blocks for difference computation (optimized for single-transformer models) |
-| `Bn_compute_blocks` | int | 0 | Last n blocks for fusion |
-| `max_warmup_steps` | int | 4 | Steps before caching starts (optimized for few-step distilled models) |
-| `max_cached_steps` | int | -1 | Max cached steps (-1 = unlimited) |
-| `max_continuous_cached_steps` | int | 3 | Max consecutive cached steps (prevents precision degradation) |
-| `residual_diff_threshold` | float | 0.24 | Residual difference threshold (higher for more aggressive caching) |
-| `num_inference_steps` | int \| None | None | Initial inference steps for SCM mask generation (optional, auto-refreshed during inference) |
-| `enable_taylorseer` | bool | False | Enable TaylorSeer acceleration (not suitable for few-step distilled models) |
-| `taylorseer_order` | int | 1 | Taylor expansion order |
-| `scm_steps_mask_policy` | str \| None | None | SCM mask policy (None, "slow", "medium", "fast", "ultra") |
-| `scm_steps_policy` | str | "dynamic" | SCM computation policy ("dynamic" or "static") |
-
----
-
-## Best Practices
-
-### When to Use
-
-**Good for:**
-
-- Production deployments requiring fast inference
-- Diffusion transformer models (DiT architecture)
-- Scenarios where 1.5x-3x speedup is valuable
-
-**Not for:**
-
-- Non-DiT architectures (use model-specific acceleration instead)
-- Models already using few-step distillation (< 10 steps)
-
----
-
-## Troubleshooting
-
-### Common Issue 1: Quality Degradation
-
-**Symptoms**: Generated images have visible artifacts or lower quality
-
-**Solution**:
-```python
-# Reduce aggressiveness - use more conservative settings
-cache_config={
- "residual_diff_threshold": 0.20, # Lower threshold (closer to default 0.24)
- "Fn_compute_blocks": 8, # Use more blocks for better decisions
- "max_warmup_steps": 6, # Longer warmup
- "scm_steps_mask_policy": "slow", # More compute steps
-}
-```
-
----
-
-## Summary
-
-Using Cache-DiT acceleration:
-
-1. ✅ **Enable Cache-DiT** - Set `cache_backend="cache_dit"` to get 1.5x-3x speedup with optimized defaults
-2. ✅ **(Optional) Customize** - Adjust `cache_config` parameters for specific speed/quality trade-offs
-
----
-
-## Additional Resources
-
-- [Cache-DiT documentation](https://cache-dit.readthedocs.io/en/latest/)
-- [Cache-DiT API reference](https://cache-dit.readthedocs.io/en/latest/user_guide/CACHE_API/)
diff --git a/docs/user_guide/diffusion/cache_acceleration/teacache.md b/docs/user_guide/diffusion/cache_acceleration/teacache.md
deleted file mode 100644
index 026b86ec7f9..00000000000
--- a/docs/user_guide/diffusion/cache_acceleration/teacache.md
+++ /dev/null
@@ -1,194 +0,0 @@
-# TeaCache Guide
-
-
-## Table of Content
-
-- [Overview](#overview)
-- [Quick Start](#quick-start)
-- [Example Script](#example-script)
-- [Configuration Parameters](#configuration-parameters)
-- [Best Practices](#best-practices)
-- [Troubleshooting](#troubleshooting)
-- [Summary](#summary)
-
----
-
-## Overview
-
-TeaCache accelerates diffusion model inference by caching transformer computations when consecutive timesteps are similar, providing **1.5x-2.0x speedup** with minimal quality loss. It dynamically decides whether to reuse cached outputs based on input similarity, making it ideal for production deployments where inference speed matters without sacrificing generation quality.
-
-See supported models list in [Supported Models](../../diffusion_features.md#supported-models).
-
----
-
-## Quick Start
-
-
-
-### Basic Usage
-
-
-```python
-from vllm_omni import Omni
-from vllm_omni.inputs.data import OmniDiffusionSamplingParams
-
-omni = Omni(
- model="Qwen/Qwen-Image",
- cache_backend="tea_cache",
-)
-
-outputs = omni.generate(
- "A cat sitting on a windowsill",
- OmniDiffusionSamplingParams(num_inference_steps=50),
-)
-```
-
-### Custom Configuration
-
-```python
-omni = Omni(
- model="Qwen/Qwen-Image",
- cache_backend="tea_cache",
- cache_config={
- "rel_l1_thresh": 0.2, # Controls speed/quality tradeoff
- },
-)
-```
-
-### Using Environment Variable
-
-You can also enable TeaCache via environment variable:
-
-```bash
-export DIFFUSION_CACHE_BACKEND=tea_cache
-```
-
-Then initialize without explicitly setting `cache_backend`:
-
-```python
-from vllm_omni import Omni
-
-omni = Omni(
- model="Qwen/Qwen-Image",
- cache_config={"rel_l1_thresh": 0.2}
-)
-```
-
----
-
-## Example Script
-
-### Offline Inference
-
-Use python script under `examples/offline_inference/text_to_image/` or `examples/offline_inference/image_to_image/` with CLI:
-
-```bash
-# Text-to-image example
-python examples/offline_inference/text_to_image/text_to_image.py \
- --model Qwen/Qwen-Image \
- --cache-backend tea_cache
-
-# Image-to-image example
-python examples/offline_inference/image_to_image/image_edit.py \
- --model Qwen/Qwen-Image-Edit \
- --image input.png \
- --prompt "Edit description" \
- --cache-backend tea_cache \
- --tea-cache-rel-l1-thresh 0.25
-```
-
-See the [text_to_image.py](https://github.com/vllm-project/vllm-omni/blob/main/examples/offline_inference/text_to_image/text_to_image.py) or [image_edit.py](https://github.com/vllm-project/vllm-omni/blob/main/examples/offline_inference/image_to_image/image_edit.py) for detailed configuration options.
-
-### Online Serving
-
-```bash
-# Default configuration
-vllm serve Qwen/Qwen-Image --omni --port 8091 --cache-backend tea_cache
-
-# Custom configuration
-vllm serve Qwen/Qwen-Image --omni --port 8091 \
- --cache-backend tea_cache \
- --cache-config '{"rel_l1_thresh": 0.2}'
-```
-
----
-
-## Configuration Parameters
-
-In `OmniDiffusionConfig`
-
-| Parameter | Type | Default | Description |
-|-----------|------|---------|-------------|
-| `rel_l1_thresh` | float | `0.2` | Similarity threshold for cache reuse. Lower values prioritize quality (less caching), higher values prioritize speed (more caching). Suggested range: 0.1-0.8 |
-| `coefficients` | list[float] \| None | `None` | Polynomial coefficients for rescaling L1 distance. Must contain exactly 5 elements if provided. If `None`, uses model-specific defaults based on transformer type. |
-
-Users can find the default model coefficients in [`vllm_omni/diffusion/cache/teacache/config.py`](https://github.com/vllm-project/vllm-omni/blob/main/vllm_omni/diffusion/cache/teacache/config.py), for example:
-
-```python
-_MODEL_COEFFICIENTS = {
- # Qwen-Image transformer coefficients from ComfyUI-TeaCache
- # Tuned specifically for Qwen's dual-stream transformer architecture
- # Used for all Qwen-Image Family pipelines, in general
- "QwenImageTransformer2DModel": [
- -4.50000000e02,
- 2.80000000e02,
- -4.50000000e01,
- 3.20000000e00,
- -2.00000000e-02,
- ],
- ...
-}
-```
-
----
-
-## Best Practices
-
-### When to Use
-
-**Good for:**
-
-- Production deployments requiring faster inference, tolerant of minimal quality loss
-- Scenarios where 1.5-2x speedup is valuable
-- Useful for single-card acceleration
-
-**Not for:**
-
-- Maximum quality requirements where no degradation is acceptable
-- Very short inference runs (< 20 steps) where caching overhead may outweigh benefits
-
-
----
-
-## Troubleshooting
-
-### Common Issue 1: Quality Degradation
-
-**Symptoms**: Generated images show artifacts, reduced detail, or inconsistent quality compared to non-cached results
-
-**Solution**:
-
-```python
-# Lower the threshold for more conservative caching
-cache_config={"rel_l1_thresh": 0.1}
-```
-
-### Common Issue 2: Limited Speedup
-
-**Symptoms**: Actual speedup is less than expected (< 1.3x)
-
-**Solutions**:
-1. Increase the threshold to enable more aggressive caching:
- ```python
- cache_config={"rel_l1_thresh": 0.8}
- ```
-2. Ensure you're using sufficient inference steps (35+ recommended)
-3. Check that your model architecture is supported (see Supported Models section)
-
----
-
-
-## Summary
-
-1. ✅ **Enable TeaCache** - Set `cache_backend="tea_cache"` to get 1.5x-2.0x speedup with optimized defaults
-2. ✅ **(Optional) Customize** - Adjust thresholds and polynomial coefficients for specific speed/quality trade-offs
diff --git a/docs/user_guide/diffusion/cpu_offload_diffusion.md b/docs/user_guide/diffusion/cpu_offload_diffusion.md
deleted file mode 100644
index 1d3f1811aed..00000000000
--- a/docs/user_guide/diffusion/cpu_offload_diffusion.md
+++ /dev/null
@@ -1,202 +0,0 @@
-# CPU Offloading for Diffusion Models
-
-## Overview
-
-vLLM-Omni provides two offloading strategies to reduce GPU memory usage for diffusion models:
-
-1. **Model-level (Sequential) Offloading**: Mutual exclusion between DiT model and encoder - only one is on GPU at a time.
-2. **Layerwise (Blockwise) Offloading**: Keeps only one transformer block on GPU at a time with compute-memory overlap.
-
-Both strategies use pinned memory for faster CPU-GPU transfers. The strategies are **mutually exclusive** for now - if both are enabled, layerwise takes priority.
-
-
-## Model-level (Sequential) Offloading
-
-### How It Works
-
-Model-level offloading implements mutual exclusion between DiT transformer and encoder modules using pre forward hooks:
-
-- **When encoders run**: DiT transformer is offloaded to CPU
-- **When DiT runs**: Encoders are offloaded to CPU
-- **VAE**: Stays resident on GPU
-
-Before each module's forward pass, the hook automatically moves it to GPU while offloading the other module group to CPU. Transfers use pinned memory for speed.
-
-### Usage
-
-**Python API:**
-```python
-from vllm_omni import Omni
-
-m = Omni(model="Wan-AI/Wan2.2-T2V-A14B-Diffusers", enable_cpu_offload=True)
-```
-
-**CLI:**
-```bash
-vllm-omni serve diffusion Wan-AI/Wan2.2-T2V-A14B-Diffusers --enable-cpu-offload
-```
-
-### To Support a Model
-
-Implement the `SupportsModuleOffload` protocol to declare which
-submodules participate in offloading:
-
-```python
-from typing import ClassVar
-from vllm_omni.diffusion.models.interface import SupportsModuleOffload
-
-class MyPipeline(nn.Module, SupportsModuleOffload):
- _dit_modules: ClassVar[list[str]] = ["transformer"]
- _encoder_modules: ClassVar[list[str]] = ["text_encoder", "vision_model"]
- _vae_modules: ClassVar[list[str]] = ["vae"]
- _resident_modules: ClassVar[list[str]] = [] # optional
-
- def __init__(self):
- super().__init__()
- self.transformer = ... # DiT — stays on GPU during denoising
- self.text_encoder = ... # Encoder — offloaded to CPU during denoising
- self.vision_model = ... # Encoder — offloaded to CPU during denoising
- self.vae = ... # VAE — always on GPU
-```
-
-- `_dit_modules`: attribute names of denoising submodules (kept on GPU
- during the diffusion loop).
-- `_encoder_modules`: attribute names of encoder/vision submodules
- (offloaded to CPU during the diffusion loop).
-- `_vae_modules`: attribute names of VAE(s) (always kept on GPU, not
- part of the mutual exclusion hooks).
-- `_resident_modules`: attribute names of small submodules that must
- stay on GPU during layerwise offloading (e.g. embedders, connectors).
- Optional — defaults to `[]`.
-
-All attribute names support dotted paths for nested submodules
-(e.g. `"pipe.transformer"`, `"bagel.time_embedder"`).
-
-Both DiT and encoder lists are needed because the offload hooks use
-mutual exclusion: when one group runs, the other moves to CPU.
-
-### Limitations
-- Cold start latency increases
-- Adds overhead from CPU-GPU transfers between encoder and denoising phases
-- Support single GPU only for now
-
-
-## Layerwise (Blockwise) Offloading
-
-### How It Works
-
-Layerwise offloading keeps only one transformer block on GPU at a time.
-
-As each block completes, the next block is prefetched to GPU while the current block is freed. The pre and forward hooks utilized by layerwise offloading apply a separate CUDA stream (`copy_stream`) to overlap weight transfer with computation, and retain flattened tensors in pinned CPU memory for block parameters re-materialization. Encoders, VAE, and non-block DiT modules (embeddings, norms) always stay on GPU.
-
-**Execution Flow:**
-
-| Block | Pre-forward Hook | Forward | Post-forward Hook |
-|-------|------------------|---------|-------------------|
-| block-0 | Prefetch block-1 (async) | Compute block-0 | Free block-0 |
-| block-1 | Prefetch block-2 (async) | Compute block-1 | Free block-1 |
-| ... | ... | ... | ... |
-| block-(n-1) | **Prefetch block-0** (async) | Compute block-(n-1) | Free block-(n-1) |
-
-Each transformer block has a `LayerwiseOffloadHook` that prefetches the next block before forward and frees the current block after forward.
-
-Layerwise offloading is primarily recommended for large **video generation models** where the compute cost per block is high enough to effectively overlap with memory prefetch operations. For example, Wan2.2 T2V and I2V pipelines.
-
-### Usage
-
-**Python API:**
-```python
-from vllm_omni import Omni
-
-# Text-to-video
-m = Omni(model="Wan-AI/Wan2.2-T2V-A14B-Diffusers", enable_layerwise_offload=True)
-
-# Or image-to-video
-m = Omni(model="Wan-AI/Wan2.2-I2V-A14B-Diffusers", enable_layerwise_offload=True)
-```
-
-**CLI:**
-```bash
-# Text-to-video
-vllm-omni serve diffusion Wan-AI/Wan2.2-T2V-A14B-Diffusers --enable-layerwise-offload
-
-# Or image-to-video
-vllm-omni serve diffusion Wan-AI/Wan2.2-I2V-A14B-Diffusers --enable-layerwise-offload
-```
-
-### To Support a Model
-
-Models must define the blocks attribute name for layerwise offloading:
-
-```python
-class WanTransformer3DModel(nn.Module):
- _layerwise_offload_blocks_attrs = ["blocks"] # Attribute names containing transformer blocks
-
- def __init__(self):
- self.blocks = nn.ModuleList([...]) # Transformer blocks
-```
-
-For models with multiple block types:
-
-```python
-class Flux2Transformer2DModel(nn.Module):
- _layerwise_offload_blocks_attrs = ["transformer_blocks", "single_transformer_blocks"]
-```
-
-### Limitations
-- Cold start latency increases because of
- 1) components are loaded to CPU first at the very first during initialization,
- 2) weight consolidation and pinning
-- Performance depends on compute cost and H2D bandwidth as well
-- Support single GPU only for now
-
-
-### Implementation Notes
-
-**Module Discovery**
-
-The offloader discovers pipeline components in two ways:
-
-1. **Protocol-based** (preferred): If the pipeline implements
- `SupportsModuleOffload`, its `_dit_modules`, `_encoder_modules`,
- `_vae_modules`, and `_resident_modules` class variables are used
- directly. All attribute names support dotted paths (e.g.
- `"pipe.transformer"`, `"bagel.time_embedder"`) for nested submodules.
-
-2. **Fallback attribute scan**: Otherwise, the offloader scans for
- well-known attribute names:
- - **DiT modules**: `transformer`, `transformer_2`, `dit`, `sr_dit`, `language_model`, `transformer_blocks`, `model`
- - **Encoders**: `text_encoder`, `text_encoder_2`, `text_encoder_3`, `image_encoder`
- - **VAE**: `vae`, `audio_vae`
-
-**Hook System**
-
-Both strategies use vLLM-Omni's hook registry system (`HookRegistry` and `ModelHook`) to register pre/post forward callbacks on modules, enabling automatic swapping without modifying model code.
-
-**Backend Architecture**
-
-```
-OffloadBackend (base class)
-├── ModelLevelOffloadBackend → uses SequentialOffloadHook
-└── LayerWiseOffloadBackend → uses LayerwiseOffloadHook
-```
-
-Factory function `get_offload_backend()` selects the appropriate backend based on configuration.
-
-
-## Supported Models
-
-| Architecture | Example Models | DiT Class | Model-Level Offload | Layerwise Offload | Blocks Attrs (Layerwise specific) |
-|--------------|----------------|-----------|---------------------|-------------------|-----------------------------------|
-| LongCatImagePipeline | `meituan-longcat/LongCat-Image` | `LongCatImageTransformer2DModel` | - | ✓ | `"transformer_blocks"`, `"single_transformer_blocks"` |
-| NextStep11Pipeline | `stepfun-ai/NextStep-1.1` | `NextStepModel` | - | ✓ | `"layers"` |
-| OvisImagePipeline | `AIDC-AI/Ovis-Image-7B` | `OvisImageTransformer2DModel` | - | ✓ | `"transformer"` |
-| QwenImagePipeline | `Qwen/Qwen-Image` | `QwenImageTransformer2DModel` | ✓ | ✓ | `"transformer_blocks"` |
-| StableDiffusion3Pipeline | `stabilityai/stable-diffusion-3.5-medium` | `SD3Transformer2DModel` | - | ✓ | `"transformer_blocks"` |
-| Wan22I2VPipeline | `Wan-AI/Wan2.2-I2V-A14B-Diffusers` | `WanTransformer3DModel` | ✓ | ✓ | `"blocks"` |
-| Wan22Pipeline | `Wan-AI/Wan2.2-T2V-A14B-Diffusers` | `WanTransformer3DModel` | ✓ | ✓ | `"blocks"` |
-| BagelPipeline | `ByteDance-Seed/BAGEL-7B-MoT` | `Qwen2MoTModel` | - | ✓ | `"layers"`, `"customized modules"` |
-
-**Notes:**
-- Model-Level Offloading is expected to be supported by all common diffusion models (DiT and encoders) naturally
-- Layerwise Offloading requires DiT class to define `_layerwise_offload_blocks_attrs` pointing to transformer blocks
diff --git a/docs/user_guide/diffusion/frame_interpolation.md b/docs/user_guide/diffusion/frame_interpolation.md
deleted file mode 100644
index 349af50c51c..00000000000
--- a/docs/user_guide/diffusion/frame_interpolation.md
+++ /dev/null
@@ -1,92 +0,0 @@
-# Frame Interpolation
-
-## Overview
-
-vLLM-Omni supports post-generation frame interpolation for supported video
-diffusion pipelines. This feature inserts synthesized intermediate frames
-between adjacent generated frames to improve temporal smoothness without
-rerunning the diffusion denoising loop.
-
-Frame interpolation runs in the diffusion worker post-processing path instead
-of the API server encoding path. This allows the interpolation step to reuse
-the worker's current accelerator device and keeps the FastAPI event loop free
-from heavy synchronous PyTorch work.
-
-For an input video with `N` generated frames and interpolation exponent `exp`,
-the output frame count is:
-
-```text
-(N - 1) * 2**exp + 1
-```
-
-The output FPS is multiplied by `2**exp` so the clip duration remains close to
-the original generated video.
-
-## Supported Pipelines
-
-Frame interpolation is currently supported for:
-
-- `WanPipeline` (Wan2.2 text-to-video)
-- `WanImageToVideoPipeline`
-- `Wan22TI2VPipeline`
-
-## Request Parameters
-
-The video APIs `/v1/videos` and `/v1/videos/sync` accept:
-
-| Parameter | Type | Default | Description |
-|-----------|------|---------|-------------|
-| `enable_frame_interpolation` | bool | `false` | Enable post-generation frame interpolation |
-| `frame_interpolation_exp` | int | `1` | Interpolation exponent. `1=2x`, `2=4x`, etc. |
-| `frame_interpolation_scale` | float | `1.0` | RIFE inference scale |
-| `frame_interpolation_model_path` | str | `None` | Local directory or Hugging Face repo ID containing `flownet.pkl` |
-
-## Execution Flow
-
-For supported Wan2.2 pipelines, the execution order is:
-
-1. Diffusion worker finishes denoising and decodes the raw video tensor.
-2. Worker-side model-specific post-processing runs.
-3. If frame interpolation is enabled, RIFE interpolates the decoded video
- tensor on the worker side and records a FPS multiplier in `custom_output`.
-4. The API server receives the already-interpolated video and only performs
- MP4 export.
-
-This design keeps interpolation close to the generated tensor and avoids
-introducing another heavyweight GPU context in the API server process.
-
-## Example
-
-Start the server:
-
-```bash
-vllm serve Wan-AI/Wan2.2-T2V-A14B-Diffusers --omni --port 8091
-```
-
-Run a sync request with interpolation enabled:
-
-```bash
-curl -X POST http://localhost:8091/v1/videos/sync \
- -F "prompt=A dog running through a park" \
- -F "num_frames=81" \
- -F "width=832" \
- -F "height=480" \
- -F "fps=16" \
- -F "num_inference_steps=40" \
- -F "guidance_scale=1.0" \
- -F "guidance_scale_2=1.0" \
- -F "enable_frame_interpolation=true" \
- -F "frame_interpolation_exp=1" \
- -F "frame_interpolation_scale=1.0" \
- -F "seed=42" \
- -o sync_t2v_interpolated.mp4
-```
-
-## Notes
-
-- This is a post-processing feature. It does not modify the diffusion denoising
- schedule.
-- Higher interpolation exponents increase post-processing time and memory usage.
-- If the interpolation model weights are not available locally,
- `frame_interpolation_model_path` may point to a Hugging Face repo containing
- `flownet.pkl`.
diff --git a/docs/user_guide/diffusion/lora.md b/docs/user_guide/diffusion/lora.md
deleted file mode 100644
index 256698752a1..00000000000
--- a/docs/user_guide/diffusion/lora.md
+++ /dev/null
@@ -1,149 +0,0 @@
-# LoRA (Low-Rank Adaptation) Guide
-
-LoRA (Low-Rank Adaptation) enables fine-tuning diffusion models by adding trainable low-rank matrices to existing model weights. vLLM-Omni currently supports PEFT-style LoRA adapters, allowing you to customize model behavior without modifying the base model weights.
-
-## Overview
-
-LoRA adapters are lightweight, model-specific fine-tuning weights that can be dynamically loaded and applied to diffusion models. vLLM-Omni uses a unified LoRA handling mechanism similar to vLLM with LRU cache management.
-
-## LoRA Adapter Format
-
-LoRA adapters must be in **PEFT (Parameter-Efficient Fine-Tuning)** format. A typical LoRA adapter directory structure:
-
-```
-lora_adapter/
-├── adapter_config.json
-└── adapter_model.safetensors
-```
-
-The `adapter_config.json` file contains metadata about the LoRA adapter, including:
-- `r`: LoRA rank
-- `lora_alpha`: LoRA alpha scaling factor
-- `target_modules`: List of module names to apply LoRA to
-
-## Quick Start
-
-### Offline Inference
-
-#### Pre-loaded LoRA
-
-Load a LoRA adapter at initialization. This adapter is pre-loaded into the cache and can be activated by requests:
-
-```python
-from vllm_omni import Omni
-from vllm_omni.lora.request import LoRARequest
-
-lora_path="/path/to/lora_adapter"
-
-omni = Omni(
- model="stabilityai/stable-diffusion-3.5-medium",
- lora_path=lora_path
-)
-
-lora_request = LoRARequest(
- lora_name="preloaded",
- lora_int_id=1,
- lora_path=lora_path
-)
-
-outputs = omni.generate(
- prompt="A piece of cheesecake",
- lora_request=lora_request,
- lora_scale=2.0, # optional arg, default 1.0
-)
-```
-
-!!! note "Server-side Path Requirement"
- The LoRA adapter path (`local_path`) must be readable on the **server** machine. If your client and server are on different machines, ensure the LoRA adapter is accessible via a shared mount or copied to the server.
-
-## Wan2.2 LightX2V Offline Assembly
-
-This workflow is LoRA-adjacent: it uses external LightX2V conversion plus
-`Wan2.2-Distill-Loras` to bake converted Wan2.2 I2V checkpoints into a local
-Diffusers directory, instead of loading LoRA adapters at runtime.
-
-### Required assets
-
-- Base model: `Wan-AI/Wan2.2-I2V-A14B`
-- Diffusers skeleton: `Wan-AI/Wan2.2-I2V-A14B-Diffusers`
-- Optional external converter from the LightX2V project (not shipped in this repository)
-- Optional LoRA weights: `lightx2v/Wan2.2-Distill-Loras`
-
-### Step 1: Optional - convert high/low-noise DiT weights with LightX2V
-
-Install or clone LightX2V from the upstream repository
-(`https://github.com/ModelTC/LightX2V`). After cloning, the converter used
-below is available at `<lightx2v_root>/tools/convert/converter.py`.
-
-```bash
-python /path/to/lightx2v/tools/convert/converter.py \
- --source /path/to/Wan2.2-I2V-A14B/high_noise_model \
- --output /tmp/wan22_lightx2v/high_noise_out \
- --output_ext .safetensors \
- --output_name diffusion_pytorch_model \
- --model_type wan_dit \
- --direction forward \
- --lora_path /path/to/wan2.2_i2v_A14b_high_noise_lora_rank64_lightx2v_4step_1022.safetensors \
- --lora_key_convert auto \
- --single_file
-
-python /path/to/lightx2v/tools/convert/converter.py \
- --source /path/to/Wan2.2-I2V-A14B/low_noise_model \
- --output /tmp/wan22_lightx2v/low_noise_out \
- --output_ext .safetensors \
- --output_name diffusion_pytorch_model \
- --model_type wan_dit \
- --direction forward \
- --lora_path /path/to/wan2.2_i2v_A14b_low_noise_lora_rank64_lightx2v_4step_1022.safetensors \
- --lora_key_convert auto \
- --single_file
-```
-
-If you are not using LightX2V, skip this step and either keep the original
-Diffusers weights from the skeleton or point Step 2 at any other converted
-`transformer/` and `transformer_2/` checkpoints.
-
-### Step 2: Assemble a final Diffusers-style directory
-
-```bash
-python tools/wan22/assemble_wan22_i2v_diffusers.py \
- --diffusers-skeleton /path/to/Wan2.2-I2V-A14B-Diffusers \
- --transformer-weight /tmp/wan22_lightx2v/high_noise_out \
- --transformer-2-weight /tmp/wan22_lightx2v/low_noise_out \
- --output-dir /path/to/Wan2.2-I2V-A14B-Custom-Diffusers \
- --asset-mode symlink \
- --overwrite
-```
-
-`--transformer-weight` and `--transformer-2-weight` are optional. If you omit
-them, the tool keeps the original weights from the Diffusers skeleton.
-
-### Step 3: Run offline inference
-
-```bash
-python examples/offline_inference/image_to_video/image_to_video.py \
- --model /path/to/Wan2.2-I2V-A14B-Custom-Diffusers \
- --image /path/to/input.jpg \
- --prompt "A cat playing with yarn" \
- --num-frames 81 \
- --num-inference-steps 4 \
- --tensor-parallel-size 4 \
- --height 480 \
- --width 832 \
- --flow-shift 12 \
- --sample-solver euler \
- --guidance-scale 1.0 \
- --guidance-scale-high 1.0 \
- --boundary-ratio 0.875
-```
-
-Notes:
-
-- This route avoids runtime LoRA loading changes in vLLM-Omni when you choose to bake converted weights into a local Diffusers directory.
-- Output quality and speed depend on the replacement checkpoints and sampling params you choose.
-
-
-## See Also
-
-- [Text-to-Image Offline Example](../examples/offline_inference/text_to_image.md#lora) - Complete offline LoRA example
-- [Text-to-Image Online Example](../examples/online_serving/text_to_image.md#lora) - Complete online LoRA example
diff --git a/docs/user_guide/diffusion/parallelism/cfg_parallel.md b/docs/user_guide/diffusion/parallelism/cfg_parallel.md
deleted file mode 100644
index 5541106680a..00000000000
--- a/docs/user_guide/diffusion/parallelism/cfg_parallel.md
+++ /dev/null
@@ -1,169 +0,0 @@
-# CFG-Parallel Guide
-
-
-## Table of Content
-
-- [Overview](#overview)
-- [Quick Start](#quick-start)
-- [Example Script](#example-script)
-- [Configuration Parameters](#configuration-parameters)
-- [Best Practices](#best-practices)
-- [Troubleshooting](#troubleshooting)
-- [Summary](#summary)
-
----
-
-## Overview
-
-CFG-Parallel accelerates diffusion models by distributing positive and negative classifier-free guidance (CFG) passes across different GPUs, providing ~1.8x speedup when CFG is enabled. It's ideal for image editing tasks that require guidance scales greater than 1.0.
-
-See supported models list in [Supported Models](../../diffusion_features.md#supported-models).
-
----
-
-## Quick Start
-
-### Basic Usage
-
-Simplest working example:
-
-```python
-from vllm_omni import Omni
-from vllm_omni.diffusion.data import DiffusionParallelConfig
-from vllm_omni.inputs.data import OmniDiffusionSamplingParams
-from PIL import Image
-
-omni = Omni(
- model="Qwen/Qwen-Image-Edit",
- parallel_config=DiffusionParallelConfig(cfg_parallel_size=2), # Enable CFG-Parallel
-)
-
-input_image = Image.open("input.png").convert("RGB")
-outputs = omni.generate(
- {
- "prompt": "turn this cat to a dog",
- "negative_prompt": "low quality, blurry",
- "multi_modal_data": {"image": input_image},
- },
- OmniDiffusionSamplingParams(
- true_cfg_scale=4.0,
- num_inference_steps=50,
- ),
-)
-```
-
----
-
-## Example Script
-
-### Offline Inference
-
-Use python script under `examples/offline_inference/image_to_image/image_edit.py`:
-
-```bash
-cd examples/offline_inference/image_to_image/
-python image_edit.py \
- --model "Qwen/Qwen-Image-Edit" \
- --image "input.png" \
- --prompt "turn this cat to a dog" \
- --negative-prompt "low quality, blurry" \
- --cfg-scale 4.0 \
- --output "edited_image.png" \
- --cfg-parallel-size 2
-```
-
-### Online Serving
-
-Enable CFG-Parallel in online serving:
-
-```bash
-# Default configuration
-vllm serve Qwen/Qwen-Image-Edit --omni --port 8091 --cfg-parallel-size 2
-
-```
-
----
-
-## Configuration Parameters
-
-In `DiffusionParallelConfig`
-
-| Parameter | Type | Default | Description |
-|-----------|------|---------|-------------|
-| `cfg_parallel_size` | int | 1 | Number of GPUs for CFG parallelism. Set to 2 to enable CFG-Parallel (rank 0 for positive, rank 1 for negative branch) |
-
-
-!!! info
- Most models support `cfg_parallel_size=2` (positive branch on rank 0, negative branch on rank 1). **Bagel** is an exception: it supports `cfg_parallel_size=3`, which adds a third branch on rank 2 for full three-way CFG parallelism.
-
-
----
-
-## Best Practices
-
-### When to Use
-
-**Good for:**
-
-- Tasks requiring classifier-free guidance
-- Multi-GPU setups (at least 2 GPUs available)
-- Combining with other parallelism methods (sequence/tensor parallel)
-
-**Not for:**
-
-- Single GPU setups
-- Models that don't support CFG-Parallel (check [supported models](../../diffusion_features.md#supported-models))
-- Workloads without negative prompts or classifier-free guidance
-- Very short inference runs (< 10 steps) where parallelism overhead may outweigh benefits
-
-### Expected Performance
-
-| Configuration | Speedup | Quality | Use Case |
-|--------------|---------|---------|----------|
-| CFG-Parallel (2 GPUs) | 1.5~1.8x | No degradation | Large model, VRAM limited |
-
----
-
-## Troubleshooting
-
-### Common Issue 1: No Speedup with CFG-Parallel
-
-**Symptoms**: CFG-Parallel enabled but no performance improvement
-
-**Solutions**:
-
-1. **Ensure CFG scale is set correctly:**
-```python
-# Bad: No CFG effect
-sampling_params = OmniDiffusionSamplingParams(num_inference_steps=50)
-
-# Good: CFG-Parallel will work
-sampling_params = OmniDiffusionSamplingParams(
- num_inference_steps=50,
- true_cfg_scale=4.0 # Must be > 1.0
-)
-```
-
-2. **Add negative prompt:**
-```python
-outputs = omni.generate(
- {
- "prompt": "beautiful landscape",
- "negative_prompt": "low quality, blurry", # Required for best results
- "multi_modal_data": {"image": input_image}
- },
- sampling_params
-)
-```
-
-3. **Check model support:**
- - Verify your model in [supported models](../../diffusion_features.md#supported-models)
- - Some models don't support CFG-Parallel
-
----
-
-## Summary
-
-1. ✅ **Enable CFG-Parallel** - Set `cfg_parallel_size=2` in `DiffusionParallelConfig` to get speedup when using CFG
-2. ✅ **Set CFG Scale** - Ensure `true_cfg_scale > 1.0` in `OmniDiffusionSamplingParams` for CFG-Parallel to take effect
-3. ✅ **Check Model Support** - Verify your model supports CFG-Parallel in [supported models](../../diffusion_features.md#supported-models)
diff --git a/docs/user_guide/diffusion/parallelism/expert_parallel.md b/docs/user_guide/diffusion/parallelism/expert_parallel.md
deleted file mode 100644
index 7d26d1e5c4f..00000000000
--- a/docs/user_guide/diffusion/parallelism/expert_parallel.md
+++ /dev/null
@@ -1,87 +0,0 @@
-# Expert Parallelism Guide
-
-
-## Table of Content
-
-- [Overview](#overview)
-- [Quick Start](#quick-start)
-- [Configuration Parameters](#configuration-parameters)
-- [Best Practices](#best-practices)
-- [Summary](#summary)
-
----
-
-## Overview
-
-Unlike Tensor Parallelism which shards every layer's weights, Expert Parallelism (EP) only shards the MoE expert MLP blocks. This significantly reduces the memory footprint of MoE models (e.g., HunyuanImage3.0) while maintaining constant dense-equivalent compute efficiency.
-
-During the forward pass, a gating mechanism routes tokens to their designated experts, requiring all-to-all communication to dispatch tokens to the correct ranks and combine results.
-
-See supported models list in [Supported Models](../../diffusion_features.md#supported-models).
-
-!!! note "EP Size Constraint"
- The effective EP size equals `tp × sp × cfg × dp`. At least one of TP/SP/CFG/DP must be set when EP is enabled.
-
----
-
-## Quick Start
-
-### Basic Usage
-
-```python
-from vllm_omni import Omni
-from vllm_omni.inputs.data import OmniDiffusionSamplingParams
-from vllm_omni.diffusion.data import DiffusionParallelConfig
-
-omni = Omni(
- model="tencent/HunyuanImage-3.0",
- parallel_config=DiffusionParallelConfig(
- tensor_parallel_size=8,
- enable_expert_parallel=True,
- ),
-)
-
-outputs = omni.generate(
- "A brown and white dog is running on the grass",
- OmniDiffusionSamplingParams(
- num_inference_steps=50,
- width=1024,
- height=1024,
- ),
-)
-```
-
----
-
-## Configuration Parameters
-
-In `DiffusionParallelConfig`:
-
-| Parameter | Type | Default | Description |
-|-----------|------|---------|-------------|
-| `enable_expert_parallel` | bool | False | Enable Expert Parallelism for MoE models |
-
-EP size is derived automatically as `tp × sp × cfg × dp` — configure at least one of those to set the EP degree.
-
----
-
-## Best Practices
-
-### When to Use
-
-**Good for:**
-
-- MoE models (e.g., HunyuanImage3.0) with numbers of experts
-- Memory-constrained multi-GPU setups where only expert blocks need sharding
-
-**Not for:**
-
-- Dense models (no MoE layers) — EP has no effect
-- Single GPU setups
-
----
-
-## Summary
-
-1. ✅ **Enable EP** - Set `enable_expert_parallel=True` in `DiffusionParallelConfig` for MoE models
-2. ✅ **Set parallelism degree** - At least one of `tensor_parallel_size` / `ulysses_degree` / `cfg_parallel_size` must be > 1 to define the EP size
diff --git a/docs/user_guide/diffusion/parallelism/hsdp.md b/docs/user_guide/diffusion/parallelism/hsdp.md
deleted file mode 100644
index 96a357c86b3..00000000000
--- a/docs/user_guide/diffusion/parallelism/hsdp.md
+++ /dev/null
@@ -1,149 +0,0 @@
-# HSDP Guide
-
-
-## Table of Content
-
-- [Overview](#overview)
-- [Quick Start](#quick-start)
-- [Example Script](#example-script)
-- [Configuration Parameters](#configuration-parameters)
-- [Best Practices](#best-practices)
-- [Summary](#summary)
-
----
-
-## Overview
-
-HSDP (Hybrid Sharded Data Parallel) shards model weights across GPUs to reduce per-GPU memory usage. This enables inference of large models (e.g., Wan2.2 14B) on GPUs with limited memory.
-
-Unlike Tensor Parallelism which splits computation, HSDP uses PyTorch's FSDP2 to shard and redistribute weights at runtime. Each GPU only holds a fraction of the model weights, and weights are gathered on-demand during forward passes.
-
-See supported models list in [Supported Models](../../diffusion_features.md#supported-models).
-
-**Operating Modes:**
-
-- **Standalone Mode**: HSDP alone without other parallelism. Must specify `hsdp_shard_size` explicitly.
-- **Combined Mode**: HSDP overlays on top of other parallelism (Ulysses-SP, CFG-Parallel). HSDP dimensions must match world_size.
-
----
-
-## Quick Start
-
-### Basic Usage
-
-Simplest working example (standalone HSDP, shard across 4 GPUs):
-
-```python
-from vllm_omni import Omni
-from vllm_omni.inputs.data import OmniDiffusionSamplingParams
-from vllm_omni.diffusion.data import DiffusionParallelConfig
-
-omni = Omni(
- model="Wan-AI/Wan2.2-T2V-A14B-Diffusers",
- parallel_config=DiffusionParallelConfig(
- use_hsdp=True,
- hsdp_shard_size=4, # Shard across 4 GPUs
- ),
-)
-
-outputs = omni.generate(
- "A cat playing piano",
- OmniDiffusionSamplingParams(num_inference_steps=50),
-)
-```
-
-### Combined with Sequence Parallel
-
-```python
-omni = Omni(
- model="Wan-AI/Wan2.2-T2V-A14B-Diffusers",
- parallel_config=DiffusionParallelConfig(
- ulysses_degree=4, # Sequence parallel
- use_hsdp=True, # HSDP overlays on SP
- ),
-)
-```
-
----
-
-## Example Script
-
-### Offline Inference
-
-Use Python script under `examples/offline_inference/image_to_video/`:
-
-```bash
-# Standalone HSDP: shard across 4 GPUs
-python examples/offline_inference/image_to_video/image_to_video.py \
- --model Wan-AI/Wan2.2-T2V-A14B-Diffusers \
- --use-hsdp \
- --hsdp-shard-size 4
-
-# Combined HSDP + Sequence Parallel
-python examples/offline_inference/image_to_video/image_to_video.py \
- --model Wan-AI/Wan2.2-T2V-A14B-Diffusers \
- --ulysses-degree 4 \
- --use-hsdp
-```
-
-### Online Serving
-
-**Standalone HSDP** (shard model across 4 GPUs):
-
-```bash
-vllm serve Wan-AI/Wan2.2-T2V-A14B-Diffusers --omni --port 8091 \
- --use-hsdp --hsdp-shard-size 4
-```
-
-**Combined with Sequence Parallel**:
-
-```bash
-vllm serve Wan-AI/Wan2.2-T2V-A14B-Diffusers --omni --port 8091 \
- --use-hsdp --usp 4
-```
-
----
-
-## Configuration Parameters
-
-In `DiffusionParallelConfig`:
-
-| Parameter | Type | Default | Description |
-|-----------|------|---------|-------------|
-| `use_hsdp` | bool | False | Enable HSDP |
-| `hsdp_shard_size` | int | -1 | Number of GPUs to shard weights across. `-1` = auto (requires other parallelism > 1) |
-| `hsdp_replicate_size` | int | 1 | Number of replica groups. Each group holds a full sharded copy |
-
-**Constraints:**
-
-- `hsdp_replicate_size × hsdp_shard_size == world_size`
-- HSDP cannot be used with Tensor Parallelism (`tensor_parallel_size` must be 1)
-
----
-
-## Best Practices
-
-### When to Use
-
-**Good for:**
-
-- Very large models (e.g., Wan2.2 14B)
-- Multi-GPU setups where memory reduction is the primary goal
-- Combining with Sequence Parallelism for large video models
-
-**Not for:**
-
-- Models that fit comfortably in single-GPU memory
-- Use cases requiring Tensor Parallelism (HSDP and TP are mutually exclusive)
-
-### Adding HSDP Support to New Models
-
-For detailed instructions on adding HSDP support to new models, see the [HSDP Contributing Guide](../../../design/feature/hsdp.md).
-
----
-
-## Summary
-
-1. ✅ **Enable HSDP** - Set `use_hsdp=True` and `hsdp_shard_size` to reduce per-GPU memory for large models
-2. ✅ **Combine with SP** - Use together with `ulysses_degree` for video models requiring both memory reduction and sequence parallelism
-3. ⚠️ **Incompatible with TP** - `tensor_parallel_size` must be 1 when HSDP is enabled
diff --git a/docs/user_guide/diffusion/parallelism/overview.md b/docs/user_guide/diffusion/parallelism/overview.md
deleted file mode 100644
index 90d0b9660ef..00000000000
--- a/docs/user_guide/diffusion/parallelism/overview.md
+++ /dev/null
@@ -1,16 +0,0 @@
-# Parallelism Acceleration Guide
-
-This guide covers the parallelism methods in vLLM-Omni for speeding up diffusion model inference and reducing per-device memory requirements.
-
-## Supported Methods
-
-| Method | Description |
-|--------|-------------|
-| **[Tensor Parallelism](tensor_parallel.md)** | Shards DiT weights across GPUs to reduce per-GPU memory |
-| **[Sequence Parallelism](sequence_parallel.md)** | Splits sequence dimension across GPUs (Ulysses-SP, Ring-Attention, or hybrid) for high-resolution images and videos |
-| **[CFG-Parallel](cfg_parallel.md)** | Runs CFG positive/negative branches on separate GPUs for ~1.8x speedup on guided generation |
-| **[VAE Patch Parallelism](vae_patch_parallel.md)** | Distributes VAE decode spatially across GPUs to reduce peak VAE memory |
-| **[HSDP](hsdp.md)** | Shards full model weights via PyTorch FSDP2 to enable large-model inference on memory-constrained GPUs |
-| **[Expert Parallelism](expert_parallel.md)** | Shards MoE expert blocks across GPUs for MoE models (e.g. HunyuanImage3.0) |
-
-See [Supported Models](../../diffusion_features.md#supported-models) for per-model compatibility.
diff --git a/docs/user_guide/diffusion/parallelism/sequence_parallel.md b/docs/user_guide/diffusion/parallelism/sequence_parallel.md
deleted file mode 100644
index e69b541f2ed..00000000000
--- a/docs/user_guide/diffusion/parallelism/sequence_parallel.md
+++ /dev/null
@@ -1,233 +0,0 @@
-# Sequence Parallelism Guide
-
-
-## Table of Content
-
-- [Overview](#overview)
-- [Quick Start](#quick-start)
-- [Example Script](#example-script)
-- [Best Practices](#best-practices)
-- [Troubleshooting](#troubleshooting)
-- [Summary](#summary)
-
----
-
-## Overview
-
-Sequence parallelism splits the input along the sequence dimension across multiple GPUs, allowing each device to process only a portion of the sequence. vLLM-Omni provides 1.5x-3.6x speedup for large images and videos using DeepSpeed Ulysses, Ring-Attention, or hybrid approaches. Use sequence parallelism when generating high-resolution images/videos that don't fit on a single GPU or require faster inference.
-
-See supported models list in [Diffusion Features - Supported Models](../../diffusion_features.md#supported-models).
-
-**Supported Methods:**
-
-- **DeepSpeed Ulysses Sequence Parallel (Ulysses-SP)** ([paper](https://arxiv.org/pdf/2309.14509)): Uses all-to-all communication for subset of attention heads per device
-- **Ring-Attention** ([paper](https://arxiv.org/abs/2310.01889)): Uses ring-based P2P communication with sharded sequence dimension throughout
-- **Hybrid Ulysses + Ring**: Combines both for larger scale parallelism (`ulysses_degree × ring_degree`)
-
----
-
-## Quick Start
-
-### Basic Usage - Ulysses-SP
-
-Simplest working example with Ulysses Sequence Parallel:
-
-```python
-from vllm_omni import Omni
-from vllm_omni.inputs.data import OmniDiffusionSamplingParams
-from vllm_omni.diffusion.data import DiffusionParallelConfig
-
-omni = Omni(
- model="Qwen/Qwen-Image",
- parallel_config=DiffusionParallelConfig(ulysses_degree=2) # Enable Ulysses-SP
-)
-
-outputs = omni.generate(
- "A cat sitting on a windowsill",
- OmniDiffusionSamplingParams(num_inference_steps=50, width=1024, height=1024),
-)
-```
-
-!!! note "Experimental UAA mode"
- `ulysses_mode="advanced_uaa"` is an experimental extension to Ulysses-SP. It lets Ulysses attention handle arbitrary sequence lengths and arbitrary attention head counts without relying on `attention_mask`-based token padding.
-
- In hybrid Ulysses + Ring mode, Ring still requires every rank in the same ring group to observe the same post-Ulysses sequence length. If that condition is not met, vLLM-Omni raises a validation error instead of entering the ring kernel with inconsistent shapes.
-
-To enable the experimental UAA mode, use a model/configuration that requires it. For example, `Tongyi-MAI/Z-Image-Turbo` has 30 attention heads, so `ulysses_degree=4` requires UAA because 30 is not divisible by 4:
-
-```python
-omni = Omni(
- model="Tongyi-MAI/Z-Image-Turbo",
- parallel_config=DiffusionParallelConfig(
- ulysses_degree=4,
- ulysses_mode="advanced_uaa",
- ),
-)
-```
-
-### Alternative Methods
-
-**Ring-Attention** (better for very long sequences):
-
-```python
-omni = Omni(
- model="Qwen/Qwen-Image",
- parallel_config=DiffusionParallelConfig(ring_degree=2) # Enable Ring-Attention
-)
-```
-
-**Hybrid Ulysses + Ring** (for larger scale):
-
-```python
-omni = Omni(
- model="Qwen/Qwen-Image",
- parallel_config=DiffusionParallelConfig(ulysses_degree=2, ring_degree=2) # 4 GPUs total
-)
-```
-
----
-
-## Example Script
-
-### Offline Inference
-
-Use Python script under `examples/offline_inference/text_to_image/text_to_image.py`:
-
-**Ulysses-SP:**
-
-```bash
-python examples/offline_inference/text_to_image/text_to_image.py \
- --model Qwen/Qwen-Image \
- --prompt "A cat sitting on a windowsill" \
- --ulysses-degree 2 \
- --width 1024 --height 1024
-```
-
-**Ring-Attention:**
-
-```bash
-python examples/offline_inference/text_to_image/text_to_image.py \
- --model Qwen/Qwen-Image \
- --prompt "A cat sitting on a windowsill" \
- --ring-degree 2 \
- --width 1024 --height 1024
-```
-
-**Hybrid Ulysses + Ring:**
-
-```bash
-# Hybrid: 2 Ulysses × 2 Ring = 4 GPUs total
-python examples/offline_inference/text_to_image/text_to_image.py \
- --model Qwen/Qwen-Image \
- --prompt "A cat sitting on a windowsill" \
- --ulysses-degree 2 --ring-degree 2 \
- --width 1024 --height 1024
-```
-
-### Online Serving
-
-**Ulysses-SP:**
-
-```bash
-# Text-to-image (requires >= 2 GPUs)
-vllm serve Qwen/Qwen-Image --omni --port 8091 --usp 2
-```
-
-**Ulysses-SP with UAA mode** (for models with non-divisible head counts):
-
-```bash
-vllm serve Tongyi-MAI/Z-Image-Turbo --omni --port 8091 --usp 4 --ulysses-mode advanced_uaa
-```
-
-**Ring-Attention:**
-
-```bash
-# Text-to-image (requires >= 2 GPUs)
-vllm serve Qwen/Qwen-Image --omni --port 8091 --ring 2
-```
-
-**Hybrid Ulysses + Ring:**
-
-```bash
-# Text-to-image (requires >= 4 GPUs)
-vllm serve Qwen/Qwen-Image --omni --port 8091 --usp 2 --ring 2
-```
-
----
-
-## Configuration Parameters
-
-In `DiffusionParallelConfig`:
-
-| Parameter | Type | Default | Description |
-|-----------|------|---------|-------------|
-| `ulysses_degree` | int | 1 | Number of GPUs for Ulysses-SP. Uses all-to-all communication. |
-| `ring_degree` | int | 1 | Number of GPUs for Ring-Attention. Uses P2P ring communication. |
-| `ulysses_mode` | str | `"default"` | Ulysses attention mode. Set to `"advanced_uaa"` to handle arbitrary sequence lengths and head counts without padding. |
-
-**Notes:**
-- Total sequence parallel size equals to `ulysses_degree × ring_degree`
-- Degrees must evenly divide the sequence length for optimal performance (or use `ulysses_mode="advanced_uaa"` for Ulysses-SP)
-
-
-## Best Practices
-
-### When to Use
-
-**Good for:**
-
-- Large images (1024x1024 or higher) or videos
-- Fast inter-GPU communication, larger bandwidth (e.g., NVLink)
-
-**Not for:**
-
-- Small images (<1024px) - overhead exceeds benefit, use single GPU with cache instead
-
-
----
-
-## Troubleshooting
-
-### Common Issue 1: Performance Not Scaling
-
-**Symptoms**: Adding GPUs doesn't improve speed proportionally, or higher parallelism degree is slower
-
-**Diagnosis:**
-```bash
-# Check GPU topology
-nvidia-smi topo -m
-
-```
-
-**Solutions:**
-
-1. Check inter-GPU communication - NVLink is better than PCIe
-2. Reduce parallelism degree if over-parallelized:
-```python
-# If 4 GPUs is slower than 2
-parallel_config=DiffusionParallelConfig(ulysses_degree=2)
-```
-3. Try to switch between Ring-Attention and Ulysses-SP
-
-- Ring-Attention has advantages, like communication-computation overlap, but the block-wise loop overhead is relatively higher, especially for short sequences
-- Ulysses-SP: can benefit from larger bandwidth (such as NVLink), with two major constraints, the sequence length should be divisible by usp size, and the number of heads should be divisible by usp size (or use `ulysses_mode="advanced_uaa"`)
-
-
-### Common Issue 2: Out of Memory (OOM)
-
-**Symptoms**: CUDA OOM errors or process crashes with memory errors
-
-**Solutions:**
-
-1. Increase parallelism degree to split sequence more:
-```python
-parallel_config=DiffusionParallelConfig(ulysses_degree=4) # From 2
-```
-2. Combine with other parallelism method, e.g., tensor parallel, and memory optimization methods, e.g., cpu offloading.
-
-
-## Summary
-
-1. ✅ **Enable Sequence Parallelism** - Set `ulysses_degree` or `ring_degree` for long sequence generation
-2. ✅ **UAA mode** - Use `ulysses_mode="advanced_uaa"` when head count is not divisible by `ulysses_degree`
-3. ✅ **Troubleshooting** - Check GPU topology with `nvidia-smi topo -m`, reduce degree if performance doesn't scale
diff --git a/docs/user_guide/diffusion/parallelism/tensor_parallel.md b/docs/user_guide/diffusion/parallelism/tensor_parallel.md
deleted file mode 100644
index 8e6851412cf..00000000000
--- a/docs/user_guide/diffusion/parallelism/tensor_parallel.md
+++ /dev/null
@@ -1,151 +0,0 @@
-# Tensor Parallelism Guide
-
-
-## Table of Content
-
-- [Overview](#overview)
-- [Quick Start](#quick-start)
-- [Example Script](#example-script)
-- [Configuration Parameters](#configuration-parameters)
-- [Best Practices](#best-practices)
-- [Troubleshooting](#troubleshooting)
-- [Summary](#summary)
-
----
-
-## Overview
-
-Tensor Parallelism (TP) shards some model weights across multiple GPUs, usually the Linear layers. This enables running large models that don't fit on a single GPU. It's essential for memory-constrained setups or very large models.
-
-See supported models list in [Supported Models](../../diffusion_features.md#supported-models).
-
-!!! note "TP Limitations for Diffusion Models"
- We currently implement Tensor Parallelism (TP) only for the DiT (Diffusion Transformer) blocks. This is because the `text_encoder` component in vLLM-Omni uses the original Transformers implementation, which does not yet support TP.
-
- - Good news: The text_encoder typically has minimal impact on overall inference performance.
- - Bad news: When TP is enabled, every TP process retains a full copy of the text_encoder weights, leading to significant GPU memory waste.
-
- We are actively refactoring this design to address this. For details and progress, please refer to [Issue #771](https://github.com/vllm-project/vllm-omni/issues/771).
-
----
-
-## Quick Start
-
-
-### Basic Usage
-
-Simplest working example:
-
-```python
-from vllm_omni import Omni
-from vllm_omni.inputs.data import OmniDiffusionSamplingParams
-from vllm_omni.diffusion.data import DiffusionParallelConfig
-
-omni = Omni(
- model="Tongyi-MAI/Z-Image-Turbo",
- parallel_config=DiffusionParallelConfig(tensor_parallel_size=2), # Enable TP
-)
-
-outputs = omni.generate(
- "a cat reading a book",
- OmniDiffusionSamplingParams(num_inference_steps=9),
-)
-```
-
----
-
-## Example Script
-
-### Offline Inference
-
-Use Python script under `examples/offline_inference`, and enable TP:
-
-```bash
-# Text-to-Image with Qwen-Image
-python examples/offline_inference/text_to_image/text_to_image.py \
- --model Qwen/Qwen-Image \
- --tensor-parallel-size 2
-
-# Image Editing with Qwen-Image-Edit
-python examples/offline_inference/image_to_image/image_edit.py \
- --model Qwen/Qwen-Image-Edit \
- --image input.png \
- --prompt "Edit description" \
- --tensor-parallel-size 2
-```
-
-### Online Serving
-
-You can enable tensor parallelism in online serving via `--tensor-parallel-size`:
-
-```bash
-# Text-to-Image with Qwen-Image on 2 GPUs
-vllm serve Qwen/Qwen-Image --omni --port 8091 \
- --tensor-parallel-size 2
-
-# Text-to-Image with Z-Image (TP=2 only)
-vllm serve Tongyi-MAI/Z-Image-Turbo --omni --port 8091 \
- --tensor-parallel-size 2
-```
-
----
-
-## Configuration Parameters
-
-In `DiffusionParallelConfig`:
-
-| Parameter | Type | Default | Description |
-|-----------|------|---------|-------------|
-| `tensor_parallel_size` | int | 1 | Number of GPUs to shard model weights across. Must divide number of heads. |
-
-
----
-
-## Best Practices
-
-### When to Use
-
-**Good for:**
-
-- Large models that don't fit on a single GPU, especially for models with large DiT blocks (transformer layers)
-- Memory-constrained environments
-
-**Not for:**
-
-- When maximum throughput is needed and memory is sufficient
-- Models with incompatible dimensions (e.g., Z-Image `num_heads=30`, which now supports `tensor_parallel_size=2`)
-
-
-## Troubleshooting
-
-### Common Issue 1: Out of Memory (OOM)
-
-**Symptoms**: CUDA OOM errors during model loading or inference, process crashes with memory errors
-
-**Solution**:
-```python
-# Step 1: Enable TP with smallest degree
-parallel_config=DiffusionParallelConfig(tensor_parallel_size=2)
-
-# Step 2: If still OOM, increase TP degree
-parallel_config=DiffusionParallelConfig(tensor_parallel_size=4)
-
-```
-
-### Common Issue 2: Divisibility Error
-
-**Symptoms**: Error like "Model dimension X not divisible by tensor_parallel_size Y"
-
-**Solutions**:
-1. Check model-specific constraints (e.g., Z-Image only supports TP=2)
-2. Use a smaller TP size that divides model dimensions
-3. Consult [Supported Models](../../diffusion_features.md#supported-models) for compatible TP sizes
-
-
----
-
-## Summary
-
-1. ✅ **Enable TP** - Set `--tensor-parallel-size` to reduce per-GPU memory
-2. ✅ **Increase TP size** - Only increase if OOM persists
-3. ⚠️ **Text encoder not sharded** - Known limitation
diff --git a/docs/user_guide/diffusion/parallelism/vae_patch_parallel.md b/docs/user_guide/diffusion/parallelism/vae_patch_parallel.md
deleted file mode 100644
index 4e8513eabf4..00000000000
--- a/docs/user_guide/diffusion/parallelism/vae_patch_parallel.md
+++ /dev/null
@@ -1,200 +0,0 @@
-# VAE Patch Parallelism Guide
-
-
-## Table of Content
-
-- [Overview](#overview)
-- [Quick Start](#quick-start)
-- [Example Script](#example-script)
-- [Configuration Parameters](#configuration-parameters)
-- [Best Practices](#best-practices)
-- [Troubleshooting](#troubleshooting)
-- [Summary](#summary)
-
----
-
-## Overview
-
-VAE Patch Parallelism distributes the VAE (Variational AutoEncoder) decode/encode computation across multiple GPUs by splitting the latent space into spatial tiles or patches. Each GPU processes a subset of tiles in parallel, significantly reducing peak memory consumption during the VAE decode stage while maintaining output quality.
-
-This is particularly useful for:
-- **High-resolution image generation** where VAE decode can become a memory bottleneck
-- **Memory-constrained environments** where the VAE decode activation peak exceeds available VRAM
-- **Multi-GPU setups** where you want to leverage distributed resources for the VAE stage
-
-See supported models list in [Supported Models](../../diffusion_features.md#supported-models).
-
-
-VAE Patch Parallelism uses two strategies based on image size:
-
-| Strategy | Use Case | How It Works | Overlap Handling | Output Quality |
-|----------|----------|--------------|------------------|----------------|
-| **Tiled Decode** | Large images (triggers VAE tiling) | Distributes existing VAE tiling computation across ranks. Each rank decodes a subset of overlapping tiles. | Uses VAE's native `blend_v` and `blend_h` functions to seamlessly merge overlapping regions | Bit-identical (same logic as single-GPU tiling) |
-| **Patch Decode** | Small images (no VAE tiling) | Splits latent into spatial patches with halos. Each rank decodes one patch with boundary context. | Halo regions provide edge context; core regions are directly stitched without blending | Near-identical (diff < 0.5%, visually imperceptible) |
-
-
-VAE Patch Parallelism **reuses the DiT process group** (`dit_group`) and does not initialize a separate ProcessGroup. This means:
-
-- **Shared ranks**: VAE patch parallelism uses the same GPU ranks as DiT parallelism (Tensor Parallel, Sequence Parallel, etc.)
-- **Combined usage**: VAE patch parallelism is typically used together with other parallelism methods
-- **Configuration alignment**: The `vae_patch_parallel_size` should be no greater than the size of your DiT process group
-
----
-
-## Quick Start
-
-### Basic Usage
-
-Simplest working example:
-
-```python
-from vllm_omni import Omni
-from vllm_omni.inputs.data import OmniDiffusionSamplingParams
-from vllm_omni.diffusion.data import DiffusionParallelConfig
-
-# TP=2 for DiT, VAE patch parallel also uses these 2 GPUs
-omni = Omni(
- model="Tongyi-MAI/Z-Image-Turbo",
- parallel_config=DiffusionParallelConfig(
- tensor_parallel_size=2, # Enable tensor parallelism for DiT
- vae_patch_parallel_size=2, # Enable VAE patch parallelism
- ),
- vae_use_tiling=True, # Required for VAE patch parallelism
-)
-
-outputs = omni.generate(
- "a futuristic city at sunset, high resolution, 8k",
- OmniDiffusionSamplingParams(
- num_inference_steps=9,
- height=1152, # High resolution benefits from VAE patch parallel
- width=1152,
- ),
-)
-```
-
----
-
-## Example Script
-
-### Offline Inference
-
-Use Python script under `examples/offline_inference/text_to_image/`:
-
-```bash
-# Text-to-Image with Z-Image
-python examples/offline_inference/text_to_image/text_to_image.py \
- --model Tongyi-MAI/Z-Image-Turbo \
- --prompt "a futuristic city at sunset" \
- --height 1152 \
- --width 1152 \
- --tensor-parallel-size 2 \
- --vae-patch-parallel-size 2 \
- --vae-use-tiling
-```
-
-### Online Serving
-
-You can enable VAE patch parallelism in online serving via `--vae-patch-parallel-size`:
-
-```bash
-# Text-to-Image with Z-Image, TP=2 + VAE patch parallel=2
-vllm serve Tongyi-MAI/Z-Image-Turbo --omni --port 8091 \
- --tensor-parallel-size 2 \
- --vae-patch-parallel-size 2 \
- --vae-use-tiling
-```
-
----
-
-## Configuration Parameters
-
-In `DiffusionParallelConfig`:
-
-| Parameter | Type | Default | Description |
-|-----------|------|---------|-------------|
-| `vae_patch_parallel_size` | int | 1 | Number of GPUs for VAE patch/tile parallelism. Set to 2 or higher to enable. Should typically match `tensor_parallel_size` as they share the same process group. |
-
-Additional requirements:
-
-| Parameter | Type | Default | Description |
-|-----------|------|---------|-------------|
-| `vae_use_tiling` | bool | False | Must be set to `True` when using VAE patch parallelism. |
-
-!!! note "Automatic VAE Tiling"
- When `vae_patch_parallel_size > 1` and the model has a distributed VAE (`DistributedVaeMixin`), the system automatically sets `vae_use_tiling=True` if not already enabled.
-
----
-
-## Best Practices
-
-### When to Use
-
-**Good for:**
-
-- High-resolution image generation and long video generation
-- Memory-constrained setups where VAE decode causes OOM
-- Multi-GPU environments
-
-**Not for:**
-
-- Low-resolution images/videos where VAE decode is not a bottleneck
-- Single GPU setups should use vae tiling decode, but not parallel vae tiling decode
-- Models that do not support vae patch parallel
-
----
-
-## Troubleshooting
-
-### Common Issue 1: Model Not Support VAE Patch Parallel
-
-**Symptoms**:
-```
-WARNING: vae_patch_parallel_size=2 is set but VAE patch parallelism is NOT enabled for xxxPipeline; ignoring.
-```
-
-**Root Cause**: VAE Patch Parallelism requires the model's VAE to implement `DistributedVaeMixin`. At startup, `vllm_omni/diffusion/registry.py` checks whether the instantiated pipeline has a `.vae` attribute that is an instance of `DistributedVaeMixin`. If it does not, the setting is silently ignored:
-
-```python
-vae_pp_size = od_config.parallel_config.vae_patch_parallel_size
-is_distributed_vae = hasattr(model, "vae") and isinstance(model.vae, DistributedVaeMixin)
-if vae_pp_size > 1 and not is_distributed_vae:
- logger.warning(
- "vae_patch_parallel_size=%d is set but VAE patch parallelism is NOT enabled for %s; ignoring.",
- vae_pp_size,
- od_config.model_class_name,
- )
-```
-
-**Solutions**:
-
-1. **Use a supported model** (recommended): check [Supported Models](../../diffusion_features.md#supported-models) for the VAE-Patch-Parallel column.
-
-2. To add support for a new model, implement `DistributedVaeMixin` on its VAE class (contributions are welcome).
-
-
-### Common Issue 2: `vae_patch_parallel_size` Exceeds DiT Process Group Size
-
-**Symptoms**: Shows warning message, and vae patch parallel size is resized to DiT process group size
-
-**Root Cause**: VAE Patch Parallelism reuses the DiT process group.
-
-**Recommendation**: Always set `vae_patch_parallel_size` to be no greater than your DiT process group size.
-
-Note that the size of DiT process group size equals to:
-```text
-dit_parallel_size = data_parallel_size
- × cfg_parallel_size
- × sequence_parallel_size
- × pipeline_parallel_size
- × tensor_parallel_size
-
-```
-_sequence_parallel_size = ulysses_degree × ring_degree_
-
----
-
-## Summary
-
-1. ✅ **Enable VAE Patch Parallelism** - Set `vae_patch_parallel_size`, `vae_use_tiling=True` in `DiffusionParallelConfig` to reduce VAE decode peak memory
-2. ✅ **Use Long Sequence** - VAE patch parallelism benefits are most apparent at long sequence decoding
-3. ✅ **Combine with other parallelism methods** - Suggest to use together with Tensor Parallel or CFG-Parallel for maximum memory savings
diff --git a/docs/user_guide/diffusion/step_execution.md b/docs/user_guide/diffusion/step_execution.md
deleted file mode 100644
index f8c9fa8ddb2..00000000000
--- a/docs/user_guide/diffusion/step_execution.md
+++ /dev/null
@@ -1,61 +0,0 @@
-# Step Execution
-
-Step execution is an opt-in diffusion execution mode enabled with
-`step_execution=True` when constructing `Omni`.
-
-It is not a generic diffusion toggle for every pipeline. Only pipelines that
-implement the stepwise contract support it today.
-
-## Quick Start
-
-```python
-from vllm_omni import Omni
-from vllm_omni.inputs.data import OmniDiffusionSamplingParams
-
-omni = Omni(
- model="Qwen/Qwen-Image",
- step_execution=True,
-)
-
-outputs = omni.generate(
- "A cat sitting on a windowsill",
- OmniDiffusionSamplingParams(
- num_inference_steps=50,
- ),
-)
-```
-
-## Supported Pipelines
-
-| Pipeline | Example models | Step execution |
-|----------|----------------|----------------|
-| `QwenImagePipeline` | `Qwen/Qwen-Image`, `Qwen/Qwen-Image-2512` | Yes |
-| All other diffusion pipelines | `QwenImageEditPipeline`, `QwenImageEditPlusPipeline`, `QwenImageLayeredPipeline`, GLM-Image, Wan, Flux, etc. | No |
-
-## Current Limitations
-
-- `step_execution` currently supports `batch_size=1` only.
-- `cache_backend` is not supported together with step execution.
-- Unsupported pipelines fail early during model loading.
-- Request-mode extras such as KV transfer are not wired into step mode yet.
-
-## When To Use It
-
-Use step execution only when you specifically need the pipeline to run through
-its stepwise request state machine. For normal diffusion inference, leave it
-disabled unless your workflow depends on this mode.
-
-If you are looking for general diffusion speedups, see
-[Diffusion Features Overview](../diffusion_features.md).
-
-## Troubleshooting
-
-If model loading fails with a message mentioning `prepare_encode()`,
-`denoise_step()`, `step_scheduler()`, and `post_decode()`, the selected
-pipeline does not support step execution.
-
-## For Model Authors
-
-If you want to add step execution support to a new diffusion pipeline, see the
-implementation guide:
-[Diffusion Step Execution Design](../../design/feature/diffusion_step_execution.md).
diff --git a/docs/user_guide/diffusion_features.md b/docs/user_guide/diffusion_features.md
deleted file mode 100644
index 3e9ddb94261..00000000000
--- a/docs/user_guide/diffusion_features.md
+++ /dev/null
@@ -1,281 +0,0 @@
-# Diffusion Advanced Features
-
-## Table of Contents
-
-- [Overview](#overview)
-- [Supported Features](#supported-features)
-- [Supported Models](#supported-models)
-- [Feature Compatibility](#feature-compatibility)
-- [Learn More](#learn-more)
-
-## Overview
-
-vLLM-Omni supports various advanced features for diffusion models:
-
-- Acceleration: **cache methods**, **parallelism methods**, **startup optimizations**
-- Memory optimization: **cpu offloading**, **quantization**
-- Extensions: **LoRA inference**, **frame interpolation**
-- Execution modes: **step execution**
-
-## Supported Features
-
-### Acceleration
-
-#### Lossy Acceleration
-
-Cache methods trade minimal quality for significant speedup. Quality loss is typically imperceptible with proper tuning.
-
-| Method | Description | Best For |
-|--------|-------------|----------|
-| **[TeaCache](diffusion/cache_acceleration/teacache.md)** | Adaptive caching using modulated inputs | Quick setup, balanced quality/speed on single GPU |
-| **[Cache-DiT](diffusion/cache_acceleration/cache_dit.md)** | Multiple caching techniques: DBCache, TaylorSeer, SCM | Fine-grained control, tunable quality-speed tradeoff |
-
-
-#### Lossless Acceleration
-
-Parallelism methods distribute computation across GPUs without quality loss (mathematically equivalent to single-GPU).
-
-| Method | Description | Best For |
-|--------|-------------|----------|
-| **[Ulysses-SP](diffusion/parallelism/sequence_parallel.md)** | Sequence parallelism via all-to-all communication | High-resolution images (>1536px) or long videos with 2-8 GPUs |
-| **[Ring-Attention](diffusion/parallelism/sequence_parallel.md)** | Sequence parallelism via ring-based communication | Videos, very long sequences, memory-constrained, with 2-8 GPUs |
-| **[CFG-Parallel](diffusion/parallelism/cfg_parallel.md)** | Splits CFG positive/negative branches across devices | Image editing with CFG guidance (true_cfg_scale > 1) on 2 GPUs |
-| **[Tensor Parallelism](diffusion/parallelism/tensor_parallel.md)** | Shards model weights across devices | Large models that don't fit in single GPU, with 2+ GPUs |
-| **[HSDP](diffusion/parallelism/hsdp.md)** | Weight sharding via FSDP2, redistributed on-demand at runtime | Very large models (14B+) on limited VRAM, combinable with SP |
-| **[Expert Parallelism](diffusion/parallelism/expert_parallel.md)** | Shards MoE expert MLP blocks across devices | MoE diffusion models (e.g., HunyuanImage3.0) |
-
-#### Startup Optimization
-
-| Method | Description | Best For |
-|--------|-------------|----------|
-| **[Multi-Thread Weight Loading](#multi-thread-weight-loading)** | Loads safetensors shards in parallel using a thread pool | All diffusion models; reduces startup from minutes to seconds |
-
-**Note:** Some acceleration methods can be combined together for optimized performance. See [Feature Compatibility Table](#feature-compatibility) and [Feature Compatibility Tutorial](feature_compatibility.md) for detailed configuration examples.
-
-### Memory Optimization
-
-Memory optimization methods help reduce GPU memory usage, enabling inference on resource-constrained hardware or larger models.
-
-| Method | Description | Best For |
-|--------|-------------|----------|
-| **[CPU Offload](diffusion/cpu_offload_diffusion.md)** | Offloads model components to CPU memory | Limited VRAM, large models on consumer GPUs |
-| **[Quantization](quantization/overview.md)** | Reduces transformer stages from BF16 to FP8/INT8/etc. | Limited VRAM, minimal accuracy loss |
-| **[VAE Patch Parallelism](diffusion/parallelism/vae_patch_parallel.md)** | Distributes VAE decode tiling across GPUs | High-resolution generation with reduced VAE memory peak |
-
-### Extensions
-
-Extension methods add specialized capabilities to diffusion models beyond standard inference.
-
-| Method | Description | Best For |
-|--------|-------------|----------|
-| **[LoRA Inference](diffusion/lora.md)** | Enables inference with Low-Rank Adaptation (LoRA) adapters weights | Reinforcement learning extensions |
-| **[Frame Interpolation](diffusion/frame_interpolation.md)** | Inserts intermediate video frames after generation for smoother motion | Video generation pipelines that need higher temporal smoothness |
-
-
-### Execution Modes
-
-Execution modes control how the diffusion pipeline processes denoise steps.
-
-| Method | Description | Best For |
-|--------|-------------|----------|
-| **[Step Execution](diffusion/step_execution.md)** | Per-step denoise execution with mid-request abort support | Request cancellation between denoise steps, fine-grained execution control |
-
-**Note:** Step execution is currently supported by QwenImagePipeline only. See [Supported Models](#supported-models) for details.
-
-### Quantization Methods
-
-| Method | Configuration | Description | Best For |
-|--------|--------------|-------------|----------|
-| **[FP8](quantization/fp8.md)** | `quantization="fp8"` | FP8 W8A8 on validated transformer stages | Memory reduction, inference speedup |
-| **[INT8](quantization/int8.md)** | `quantization="int8"` | INT8 W8A8 on validated transformer stages | Memory reduction, broad GPU compatibility |
-| **[GGUF](quantization/gguf.md)** | `quantization="gguf"` | Native GGUF transformer-only weights (Q4, Q8, etc.) | Memory reduction on consumer GPUs |
-
-## Supported Models
-
-The following tables show which models support each feature:
-
-- **🔀SP (Ulysses & Ring)**: Includes both Ulysses-SP and Ring-Attention methods
-- ✅ = Fully supported
-- ❌ = Not supported
-
-> Notes:
-
-> 1. CPU Offload has two methods: Module-wise (default for models with DiT + text encoder) and Layerwise. The tables below show **Layerwise support** only.
-> 2. The **💾Quantization** column is collapsed for readability. See [Quantization Overview](quantization/overview.md) for per-method and per-model support details.
-
-### ImageGen
-
-| Model | ⚡TeaCache | ⚡Cache-DiT | 🔀SP (Ulysses & Ring) | 🔀CFG-Parallel | 🔀Tensor-Parallel | 🔀HSDP | 💾CPU Offload (Layerwise) | 💾VAE-Patch-Parallel | 💾Quantization | 🔄Step Execution |
-|-------|:----------:|:-----------:|:---------------------:|:--------------:|:-----------------:|:------:|:------------------------:|:--------------------:|:--------------:|:----------------:|
-| **Bagel** | ✅ | ✅ | ✅ | ✅ | ✅ | ❌ | ✅ | ❌ | ❌ | ❌ |
-| **FLUX.1-dev** | ✅ | ✅ | ❌ | ✅ | ✅ | ✅ | ❌ | ❌ | ✅ | ❌ |
-| **FLUX.1-schnell** | ❌ | ✅ | ❌ | ✅ | ✅ | ✅ | ❌ | ❌ | ✅ | ❌ |
-| **FLUX.2-klein** | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ❌ | ❌ | ✅ | ❌ |
-| **FLUX.1-Kontext-dev** | ❌ | ❌ | ❌ | ❌ | ✅ | ✅ | ❌ | ❌ | ❌ | ❌ |
-| **FLUX.2-dev** | ✅ | ✅ | ❌ | ✅ | ✅ | ✅ | ❌ | ❌ | ❌ | ❌ |
-| **GLM-Image** | ❌ | ❌ | ❌ | ✅ | ✅ | ✅ | ❌ | ❌ | ❌ | ❌ |
-| **HunyuanImage3** | ❌ | ✅ | ❌ | ❌ | ✅ | ❌ | ❌ | ❌ | ✅ | ❌ |
-| **LongCat-Image** | ✅ | ✅ | ✅ | ✅ | ✅ | ❌ | ✅ | ❌ | ❌ | ❌ |
-| **LongCat-Image-Edit** | ✅ | ✅ | ✅ | ✅ | ✅ | ❌ | ✅ | ❌ | ❌ | ❌ |
-| **MagiHuman** | ❌ | ❌ | ❌ | ❓ | ✅ | ❌ | ✅ | ❌ | ❌ | ❌ |
-| **MammothModa2(T2I)** | ❌ | ❌ | ❌ | ❌ | ❌ | ❌ | ❌ | ❌ | ❌ | ❌ |
-| **Nextstep_1(T2I)** | ❓ | ❓ | ❌ | ✅ | ✅ | ❌ | ✅ | ❌ | ❌ | ❌ |
-| **OmniGen2** | ❌ | ✅ | ❌ | ✅ | ❌ | ❌ | ❌ | ❌ | ❌ | ❌ |
-| **Ovis-Image** | ❌ | ✅ | ❌ | ✅ | ❌ | ❌ | ✅ | ❌ | ❌ | ❌ |
-| **Qwen-Image** | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ (decode) | ✅ | ✅ |
-| **Qwen-Image-2512** | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ (decode) | ✅ | ✅ |
-| **Qwen-Image-Edit** | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ (decode) | ❌ | ❌ |
-| **Qwen-Image-Edit-2509** | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ (decode) | ✅ | ❌ | ❌ |
-| **Qwen-Image-Layered** | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ (decode) | ❌ | ❌ |
-| **Stable-Diffusion3.5** | ❌ | ✅ | ❌ | ✅ | ✅ | ❌ | ✅ | ✅ (decode) | ❌ | ❌ |
-| **Z-Image** | ✅ | ✅ | ✅ | ❓ | ✅ (TP=2 only) | ✅ | ❌ | ✅ (decode) | ✅ | ❌ |
-
-> Notes:
-> 1. Nextstep_1(T2I) does not support cache acceleration methods such as TeaCache or Cache-DiT.
-> 2. `Tongyi-MAI/Z-Image-Turbo` and `SII-GAIR/daVinci-MagiHuman-Base-1080p` are distilled models with minimal NFEs; CFG-Parallel is not necessary.
-
-### VideoGen
-
-| Model | ⚡TeaCache | ⚡Cache-DiT | 🔀SP (Ulysses & Ring) | 🔀CFG-Parallel | 🔀Tensor-Parallel | 🔀HSDP | 💾CPU Offload (Layerwise) | 💾VAE-Patch-Parallel | 💾Quantization | 🔄Step Execution |
-|-------|:----------:|:-----------:|:---------------------:|:--------------:|:-----------------:|:------:|:------------------------:|:--------------------:|:--------------:|:----------------:|
-| **Wan2.2** | ❌ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ (encode/decode) | ❌ | ❌ |
-| **Wan2.1-VACE** | ❌ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ (decode) | ❌ | ❌ |
-| **LTX-2** | ❌ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ❌ | ❌ | ❌ |
-| **LTX-2.3** | ❌ | ✅ | ✅ | ❌ | ✅ | ❌ | ❌ | ❌ | ❌ | ❌ |
-| **Helios** | ❌ | ❌ | ✅ | ✅ | ✅ | ✅ | ✅ | ❌ | ❌ | ❌ |
-| **HunyuanVideo-1.5 T2V I2V** | ❌ | ✅ | ❌ | ✅ | ✅ | ✅ | ✅ | ✅ (decode) | ✅ | ❌ |
-| **DreamID-Omni** | ❌ | ❌ | ❌ | ✅ | ❌ | ❌ | ✅ | ❌ | ❌ | ❌ |
-
-**Frame Interpolation Support**
-
-- **Supported**: Wan2.2 text-to-video, image-to-video, and TI2V pipelines
-- **Not supported**: Wan2.1-VACE, LTX-2, LTX-2.3, Helios, HunyuanVideo-1.5, DreamID-Omni
-
-### AudioGen
-
-| Model | ⚡TeaCache | ⚡Cache-DiT | 🔀SP (Ulysses & Ring) | 🔀CFG-Parallel | 🔀Tensor-Parallel | 🔀HSDP | 💾CPU Offload (Layerwise) | 💾VAE-Patch-Parallel | 💾Quantization | 🔄Step Execution |
-|-------|:----------:|:-----------:|:---------------------:|:--------------:|:-----------------:|:------:|:------------------------:|:--------------------:|:--------------:|:----------------:|
-| **Stable-Audio-Open** | ✅ | ❌ | ❓ | ❓ | ❌ | ✅ | ❌ | ❌ | ✅ | ❌ |
-
-
-## Feature Compatibility
-
-**Legend:**
-
-- ✅: Functionality is supported
-- ❌: No support plan
-- ❓: Not verified yet and Not Recommended
-
-| | ⚡TeaCache | ⚡Cache-DiT | 🔀Ulysses-SP | 🔀Ring-Attn | 🔀CFG-Parallel | 🔀Tensor Parallel | 🔀HSDP | 🔀Expert Parallel | 💾CPU Offloading (Layerwise) | 💾CPU Offloading (Module-wise) | 💾VAE Patch Parallel | 💾FP8 Quant | 🔧LoRA Inference | 🔄Step Execution |
-|---|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|
-| **⚡TeaCache** | | | | | | | | | | | | | | |
-| **⚡Cache-DiT** | ❌ | | | | | | | | | | | | | |
-| **🔀Ulysses-SP** | ✅ | ✅ | | | | | | | | | | | | |
-| **🔀Ring-Attn** | ✅ | ✅ | ✅ | | | | | | | | | | | |
-| **🔀CFG-Parallel** | ✅ | ✅ | ✅ | ✅ | | | | | | | | | | |
-| **🔀Tensor Parallel** | ✅ | ✅ | ✅ | ✅ | ✅ | | | | | | | | | |
-| **🔀HSDP** | ❓ | ❓ | ❓ | ❓ | ❓ | ❌ | | | | | | | | |
-| **🔀Expert Parallel** | ❓ | ❓ | ❓ | ❓ | ❓ | ❓ | ❓ | | | | | | | |
-| **💾CPU Offloading (Layerwise)** | ✅ | ✅ | ❌ | ❌ | ❌ | ❌ | ❌ | ❌ | | | | | | |
-| **💾CPU Offloading (Module-wise)** | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ❓ | ❓ | ❌ | | | | | |
-| **💾VAE Patch Parallel** | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ❌ | ❌ | | | | |
-| **💾FP8 Quant** | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ❓ | ❓ | ✅ | ✅ | ✅ | | | |
-| **🔧LoRA Inference** | ❓ | ❓ | ❓ | ❓ | ❓ | ❓ | ❓ | ❓ | ❓ | ❓ | ❓ | ❓ | | |
-| **🔄Step Execution** | ❌ | ❌ | ✅ | ✅ | ✅ | ✅ | ❓ | ❓ | ✅ | ❓ | ✅ | ✅ | ❌ | |
-
-!!! info
-
- 1. Tensor Parallel and HSDP are not compatible.
- 2. TeaCache and Cache-DiT are not compatible.
- 3. CPU Offloading (Layerwise) and CPU Offloading (Module-wise) are not compatible.
- 4. CPU Offloading (Layerwise) supports single-card for now.
- 5. Using FP8-Quant as an example of qunatization methods.
- 6. Step Execution is not compatible with cache backends (TeaCache, Cache-DiT) or LoRA.
-
-
-## Multi-Thread Weight Loading
-
-Large diffusion models can take several minutes to load weights at startup (e.g., ~3 min for Qwen-Image, ~5 min for Wan2.2 I2V 14B). Multi-thread weight loading speeds up this process by loading safetensors shards in parallel using a thread pool instead of sequentially.
-
-This optimization is **enabled by default** with 4 threads. No configuration is needed for the default behavior.
-
-### Configuration
-
-| Parameter | CLI Flag | Default | Description |
-|-----------|----------|---------|-------------|
-| `enable_multithread_weight_load` | `--disable-multithread-weight-load` | `True` (enabled) | Pass the flag to disable multi-thread loading |
-| `num_weight_load_threads` | `--num-weight-load-threads` | `4` | Number of threads for parallel weight loading |
-
-!!! tip
- The default of 4 threads balances speed and disk I/O contention. On fast NVMe storage you may benefit from more threads (e.g., 8). On HDD or network storage, the default of 4 avoids saturating I/O bandwidth.
-
-### Online Serving
-
-```bash
-# Default (multi-thread enabled, 4 threads)
-vllm serve Qwen/Qwen-Image --omni --port 8091
-
-# Custom thread count
-vllm serve Wan-AI/Wan2.2-I2V-A14B-Diffusers --omni --num-weight-load-threads 8
-
-# Disable multi-thread loading
-vllm serve Qwen/Qwen-Image --omni --disable-multithread-weight-load
-```
-
-### Offline Inference
-
-```python
-from vllm_omni import Omni
-
-# Default (multi-thread enabled, 4 threads)
-omni = Omni(model="Qwen/Qwen-Image")
-
-# Custom thread count
-omni = Omni(
- model="Wan-AI/Wan2.2-I2V-A14B-Diffusers",
- num_weight_load_threads=8,
-)
-```
-
-### Benchmarks
-
-Measured on NVIDIA H800:
-
-| Model | Before | After | Speedup |
-|-------|--------|-------|---------|
-| **Qwen/Qwen-Image** (53.7 GiB) | 168s | 27s | **6.2x** |
-| **Wan-AI/Wan2.2-I2V-A14B-Diffusers** (64.5 GiB) | 283s | 56s | **5.1x** |
-
-## Learn More
-
-**Cache Acceleration:**
-
-- **[TeaCache Configuration Guide](diffusion/cache_acceleration/teacache.md)** - Parameter tuning, performance tips, troubleshooting
-- **[Cache-DiT Advanced Guide](diffusion/cache_acceleration/cache_dit.md)** - DBCache, TaylorSeer, SCM techniques and optimization
-
-**Parallelism Methods:**
-
-- **[Parallelism Overview](diffusion/parallelism/overview.md)** - Tensor Parallelism, Sequence Parallelism, CFG Parallelism, HSDP, and Expert Parallelism
-
-**Memory Optimization:**
-
-- **[CPU Offload Guide](diffusion/cpu_offload_diffusion.md)** - Offload model components to CPU, reduce GPU memory usage
-- **[VAE Patch Parallelism Guide](diffusion/parallelism/vae_patch_parallel.md)** - Distribute VAE decode tiling across GPUs for high-resolution images
-- **[Quantization Overview](quantization/overview.md)** - Overview of quantization methods for diffusion, multi-stage omni/TTS, and multi-stage diffusion models
-
-**Extensions:**
-
-- **[LoRA Inference Guide](diffusion/lora.md)** - Low-Rank Adaptation for style customization and fine-tuning
-- **[Frame Interpolation Guide](diffusion/frame_interpolation.md)** - Worker-side post-generation video frame interpolation for smoother motion
-
-**Execution Modes:**
-
-- **[Step Execution Guide](diffusion/step_execution.md)** - Per-step denoise execution with mid-request abort support
-
-**Startup Optimization:**
-
-- **[Multi-Thread Weight Loading](#multi-thread-weight-loading)** - Speed up model startup by loading safetensors shards in parallel
-
-**Advanced Topics:**
-
-- **[Feature Compatibility](feature_compatibility.md)** - How to combine multiple features for maximum performance
diff --git a/docs/user_guide/examples/offline_inference/bagel.md b/docs/user_guide/examples/offline_inference/bagel.md
deleted file mode 100644
index 0d3498b28d9..00000000000
--- a/docs/user_guide/examples/offline_inference/bagel.md
+++ /dev/null
@@ -1,287 +0,0 @@
-# BAGEL-7B-MoT
-
-Source <https://github.com/vllm-project/vllm-omni/tree/main/examples/offline_inference/bagel>.
-
-## Setup
-
-Please refer to the [stage configuration documentation](https://docs.vllm.ai/projects/vllm-omni/en/latest/configuration/stage_configs/) to configure memory allocation appropriately for your hardware setup.
-
-## Architecture
-
-BAGEL-7B-MoT is a Mixture-of-Transformers (MoT) model supporting both image generation and understanding. It offers two deployment topologies:
-
-| Topology | Stages | Description |
-| :------- | :----- | :---------- |
-| **Two-stage** (default) | Stage 0 (Thinker, AR) + Stage 1 (DiT, Diffusion) | Thinker handles text/understanding via vLLM AR engine; DiT handles image generation. KV cache is transferred between stages. |
-| **Single-stage** | Stage 0 (DiT, Diffusion) only | The DiT stage contains a full LLM, ViT, VAE, and tokenizer internally. All modalities are handled within a single diffusion process. |
-
-Both topologies support all four modalities: `text2img`, `img2img`, `img2text`, `text2text`.
-
-## Quick Start
-
-```bash
-cd examples/offline_inference/bagel
-
-# Default two-stage mode (auto-detected)
-python end2end.py --model ByteDance-Seed/BAGEL-7B-MoT \
- --modality text2img \
- --prompts "A cute cat"
-
-# Single-stage mode
-python end2end.py --model ByteDance-Seed/BAGEL-7B-MoT \
- --modality text2img \
- --prompts "A cute cat" \
- --deploy-config vllm_omni/deploy/bagel_single_stage.yaml
-```
-
-> **Note**: These examples work with the default configuration on an **NVIDIA A100 (80GB)**. For dual-GPU setups, modify the deploy YAML to distribute stages across devices.
-
-## Modality Control
-
-Control the mode using the `--modality` argument:
-
-| Modality | Input | Output | Description |
-| :------- | :---- | :----- | :---------- |
-| `text2img` | Text | Image | Generate images from text prompts |
-| `img2img` | Image + Text | Image | Transform images using text guidance |
-| `img2text` | Image + Text | Text | Generate text descriptions from images |
-| `text2text` | Text | Text | Pure text generation (language model mode) |
-
-### Text to Image (text2img)
-
-```bash
-python end2end.py --model ByteDance-Seed/BAGEL-7B-MoT \
- --modality text2img \
- --prompts "A cute cat" \
- --steps 50
-```
-
-### Image to Image (img2img)
-
-```bash
-python end2end.py --model ByteDance-Seed/BAGEL-7B-MoT \
- --modality img2img \
- --image-path /path/to/image.jpg \
- --prompts "Let the woman wear a blue dress"
-```
-
-### Image to Text (img2text)
-
-```bash
-python end2end.py --model ByteDance-Seed/BAGEL-7B-MoT \
- --modality img2text \
- --image-path /path/to/image.jpg \
- --prompts "Describe this image in detail"
-```
-
-### Text to Text (text2text)
-
-```bash
-python end2end.py --model ByteDance-Seed/BAGEL-7B-MoT \
- --modality text2text \
- --prompts "What is the capital of France?"
-
-# Load prompts from a text file (one prompt per line):
-python end2end.py --model ByteDance-Seed/BAGEL-7B-MoT \
- --modality text2text \
- --txt-prompts /path/to/prompts.txt
-```
-
-## Think Mode
-
-Think mode enables the model to generate `<think>...</think>` planning/reasoning tokens before producing the final output. This improves generation quality for complex prompts.
-
-- **Two-stage**: The Thinker (AR) stage decodes think tokens, then transfers the augmented KV cache to the DiT stage for image generation.
-- **Single-stage**: The DiT's internal LLM generates think tokens in-place before proceeding to denoise.
-
-```bash
-# Think + text2img: plan before generating
-python end2end.py --model ByteDance-Seed/BAGEL-7B-MoT \
- --modality text2img \
- --prompts "A futuristic city with flying cars" \
- --think \
- --max-think-tokens 1000
-
-# Think + img2img: reason about the edit
-python end2end.py --model ByteDance-Seed/BAGEL-7B-MoT \
- --modality img2img \
- --image-path /path/to/image.jpg \
- --prompts "Make it look like a watercolor painting" \
- --think
-
-# Think + img2text: reason before describing
-python end2end.py --model ByteDance-Seed/BAGEL-7B-MoT \
- --modality img2text \
- --image-path /path/to/image.jpg \
- --prompts "What is happening in this image?" \
- --think
-
-# Think + text2text: chain-of-thought reasoning
-python end2end.py --model ByteDance-Seed/BAGEL-7B-MoT \
- --modality text2text \
- --prompts "Solve: 23 * 47" \
- --think
-```
-
-Think mode parameters:
-
-| Argument | Default | Description |
-| :------- | :------ | :---------- |
-| `--think` | `False` | Enable thinking mode |
-| `--max-think-tokens` | `1000` | Maximum tokens for think generation |
-| `--do-sample` | `False` | Enable sampling (vs. greedy) for text generation |
-| `--text-temperature` | `0.3` | Temperature for text generation sampling |
-
-## Classifier-Free Guidance (CFG)
-
-CFG controls the trade-off between prompt fidelity and diversity. These parameters apply to image generation modalities (`text2img`, `img2img`).
-
-```bash
-python end2end.py --model ByteDance-Seed/BAGEL-7B-MoT \
- --modality text2img \
- --prompts "A photorealistic portrait" \
- --cfg-text-scale 6.0 \
- --cfg-img-scale 2.0 \
- --negative-prompt "blurry, low quality, distorted" \
- --cfg-interval 0.4 1.0 \
- --cfg-renorm-type global \
- --cfg-renorm-min 0.0
-```
-
-| Argument | Default | Description |
-| :------- | :------ | :---------- |
-| `--cfg-text-scale` | `4.0` | Text CFG scale (higher = more prompt-adherent) |
-| `--cfg-img-scale` | `1.5` | Image CFG scale (for img2img) |
-| `--negative-prompt` | `None` | Negative prompt for CFG conditioning |
-| `--cfg-interval` | pipeline default | CFG active interval `[start, end]` as fractions of total timesteps |
-| `--cfg-renorm-type` | `None` | Renormalization type: `global`, `text_channel`, `channel` |
-| `--cfg-renorm-min` | `None` | Minimum renormalization value |
-| `--cfg-parallel-size` | `1` | CFG parallel size: `1` = batched (single GPU), `2` = 2-branch parallel, `3` = full 3-GPU parallel |
-
-## Deployment Topologies
-
-### Two-Stage (Default)
-
-The default topology auto-detected from the model. No extra flags needed.
-
-```bash
-python end2end.py --model ByteDance-Seed/BAGEL-7B-MoT \
- --modality text2img \
- --prompts "A cute cat"
-```
-
-The pipeline is defined in [`bagel.yaml`](https://github.com/vllm-project/vllm-omni/tree/main/vllm_omni/deploy/bagel.yaml). Stage 0 (Thinker) and Stage 1 (DiT) share GPU 0 by default. For dual-GPU setups, customize the deploy YAML and set `devices: "1"` for stage 1.
-
-### Single-Stage
-
-Pass the single-stage deploy config via `--deploy-config`:
-
-```bash
-python end2end.py --model ByteDance-Seed/BAGEL-7B-MoT \
- --modality text2img \
- --prompts "A cute cat" \
- --deploy-config vllm_omni/deploy/bagel_single_stage.yaml
-```
-
-See [`bagel_single_stage.yaml`](https://github.com/vllm-project/vllm-omni/tree/main/vllm_omni/deploy/bagel_single_stage.yaml) for configuration details. The `pipeline: bagel_single_stage` field selects the single-stage topology from the pipeline registry.
-
-### Tensor Parallelism (TP)
-
-For larger models or multi-GPU environments, customize the deploy YAML (see [`bagel.yaml`](https://github.com/vllm-project/vllm-omni/tree/main/vllm_omni/deploy/bagel.yaml)) and set per-stage `tensor_parallel_size` and `devices`:
-
-```yaml
-# Example: TP=2 on GPUs 0,1 for the Thinker stage
-stages:
- - stage_id: 0
- tensor_parallel_size: 2
- devices: "0,1"
-```
-
-Then pass the custom deploy YAML:
-
-```bash
-python end2end.py --model ByteDance-Seed/BAGEL-7B-MoT \
- --modality text2img \
- --prompts "A cute cat" \
- --deploy-config /path/to/custom_bagel.yaml
-```
-
-### FP8 Quantization
-
-```bash
-python end2end.py --model ByteDance-Seed/BAGEL-7B-MoT \
- --modality text2img \
- --prompts "A cute cat" \
- --quantization fp8
-```
-
-## Command Line Reference
-
-### Core Arguments
-
-| Argument | Type | Default | Description |
-| :------- | :--- | :------ | :---------- |
-| `--model` | string | `ByteDance-Seed/BAGEL-7B-MoT` | Model path or HuggingFace name |
-| `--modality` | choice | `text2img` | `text2img`, `img2img`, `img2text`, `text2text` |
-| `--prompts` | list | `None` | Input text prompts |
-| `--txt-prompts` | string | `None` | Path to text file with one prompt per line |
-| `--image-path` | string | `None` | Input image path (required for `img2img`/`img2text`) |
-| `--output` | string | `.` | Output directory for saved images |
-| `--steps` | int | `50` | Number of diffusion inference steps |
-| `--seed` | int | `None` | Random seed for reproducibility |
-
-### Think Mode Arguments
-
-| Argument | Type | Default | Description |
-| :------- | :--- | :------ | :---------- |
-| `--think` | flag | `False` | Enable `<think>...</think>` planning/reasoning |
-| `--max-think-tokens` | int | `1000` | Maximum tokens for think generation |
-| `--do-sample` | flag | `False` | Use sampling instead of greedy decoding |
-| `--text-temperature` | float | `0.3` | Sampling temperature for text generation |
-
-### CFG Arguments
-
-| Argument | Type | Default | Description |
-| :------- | :--- | :------ | :---------- |
-| `--cfg-text-scale` | float | `4.0` | Text CFG guidance scale |
-| `--cfg-img-scale` | float | `1.5` | Image CFG guidance scale |
-| `--negative-prompt` | string | `None` | Negative prompt for CFG |
-| `--cfg-parallel-size` | int | `1` | CFG parallel GPU count (1, 2, or 3) |
-| `--cfg-interval` | float[2] | pipeline default | CFG active window `[start, end]` |
-| `--cfg-renorm-type` | string | `None` | `global`, `text_channel`, or `channel` |
-| `--cfg-renorm-min` | float | `None` | Minimum renormalization value |
-
-### Engine Arguments
-
-| Argument | Type | Default | Description |
-| :------- | :--- | :------ | :---------- |
-| `--deploy-config` | string | `None` | Path to deploy YAML (auto-detected if omitted) |
-| `--stage-configs-path` | string | `None` | [Deprecated] Legacy path to `stage_args` YAML; prefer `--deploy-config` |
-| `--worker-backend` | choice | `process` | `process` or `ray` |
-| `--ray-address` | string | `None` | Ray cluster address |
-| `--quantization` | string | `None` | Quantization method (e.g. `fp8`) |
-| `--log-stats` | flag | `False` | Enable statistics logging |
-| `--init-timeout` | int | `300` | Initialization timeout (seconds) |
-| `--batch-timeout` | int | `5` | Batch timeout (seconds) |
-| `--enable-diffusion-pipeline-profiler` | flag | `False` | Profile diffusion stage durations |
-
-## FAQ
-
-- If you encounter OOM errors, try decreasing `max_model_len` or `gpu_memory_utilization` in the deploy YAML.
-
-**Two-stage VRAM usage:**
-
-| Stage | VRAM |
-| :---- | :--- |
-| Stage 0 (Thinker) | **15.04 GiB + KV Cache** |
-| Stage 1 (DiT) | **26.50 GiB** |
-| Total | **~42 GiB + KV Cache** |
-
-**Single-stage VRAM usage:** The DiT loads the full model (~42 GiB) in one process.
-
-## Example materials
-
-??? abstract "end2end.py"
- ``````py
- --8<-- "examples/offline_inference/bagel/end2end.py"
- ``````
diff --git a/docs/user_guide/examples/offline_inference/cosyvoice3.md b/docs/user_guide/examples/offline_inference/cosyvoice3.md
deleted file mode 100644
index d0638f4140f..00000000000
--- a/docs/user_guide/examples/offline_inference/cosyvoice3.md
+++ /dev/null
@@ -1,81 +0,0 @@
-# CosyVoice3
-
-Source <https://github.com/vllm-project/vllm-omni/tree/main/examples/offline_inference/cosyvoice3>.
-
-
-## Setup
-
-Install dependencies:
-```
-uv pip install -e .
-```
-
-> **Note:** This includes required libraries such as `soundfile`,
-> `onnxruntime`, `x-transformers`, and `einops` via
-> `requirements/common.txt` and platform-specific requirements files.
-
-Download the model snapshot:
-```
-from huggingface_hub import snapshot_download
-snapshot_download('FunAudioLLM/Fun-CosyVoice3-0.5B-2512', local_dir='pretrained_models/Fun-CosyVoice3-0.5B')
-```
-
-Add `config.json` in `pretrained_models/Fun-CosyVoice3-0.5B/`:
-```json
-{
- "model_type": "cosyvoice3",
- "architectures": [
- "CosyVoice3Model"
- ]
-}
-```
-
-> **Why `config.json` is required:**
-> `AutoConfig.register("cosyvoice3", CosyVoice3Config)` only registers a class mapping.
-> The loader still needs `model_type: "cosyvoice3"` from `config.json` to select that class.
-> If no `config.json` is present, model type cannot be inferred automatically.
-> If your downloaded checkpoint already includes a valid `config.json` with
-> `model_type: "cosyvoice3"`, this manual step can be skipped.
-
-Run the offline verification script:
-```
-python examples/offline_inference/cosyvoice3/verify_e2e_cosyvoice.py \
- --model pretrained_models/Fun-CosyVoice3-0.5B \
- --tokenizer pretrained_models/Fun-CosyVoice3-0.5B/CosyVoice-BlankEN
-```
-
-## Implementation Overview
-
-CosyVoice3 runs as a **2-stage Omni pipeline**.
-
-- **Stage 0** (`talker`) converts text + prompt audio to speech tokens.
-- **Stage 1** (`code2wav`) converts speech tokens + prompt features to waveform via flow matching and HiFiGAN.
-
-Key components live in `vllm_omni/model_executor/models/cosyvoice3/cosyvoice3.py`.
-
-- `CosyVoice3MultiModalProcessor` builds the multimodal inputs:
- - Tokenizes `prompt` and `prompt_text`.
- - Extracts speech tokens and mel features from the prompt audio.
- - Extracts a speaker embedding.
-- `CosyVoice3Model` implements both stages:
- - Stage 0 uses `CosyVoice3LM` and outputs speech tokens + conditioning features.
- - Stage 1 runs the flow model (DiT-based CFM) and HiFiGAN to synthesize waveform.
-
-Pipeline topology lives in `vllm_omni/model_executor/models/cosyvoice3/pipeline.py`;
-runtime tunables (batch size, memory limits, sampling) live in
-`vllm_omni/deploy/cosyvoice3.yaml`. The deploy config auto-loads by
-HF `model_type` and defaults to `async_chunk: true` (shared-memory
-streaming). Pass `--no-async-chunk` on `vllm serve` to switch to the
-legacy sync path where stage 1 runs `text2flow` over the full
-speech-token sequence.
-
-- Stage 0 emits latent speech tokens.
-- Stage 1 consumes them via `sync_process_input_func` (sync mode) or the
- shared-memory connector (async-chunk mode) and outputs audio.
-
-## Example materials
-
-??? abstract "verify_e2e_cosyvoice.py"
- ``````py
- --8<-- "examples/offline_inference/cosyvoice3/verify_e2e_cosyvoice.py"
- ``````
diff --git a/docs/user_guide/examples/offline_inference/fish_speech.md b/docs/user_guide/examples/offline_inference/fish_speech.md
deleted file mode 100644
index 0d5c538beb4..00000000000
--- a/docs/user_guide/examples/offline_inference/fish_speech.md
+++ /dev/null
@@ -1,85 +0,0 @@
-# Fish Speech S2 Pro
-
-Source <https://github.com/vllm-project/vllm-omni/tree/main/examples/offline_inference/fish_speech>.
-
-
-This directory contains an offline demo for running Fish Speech S2 Pro (`fishaudio/s2-pro`) with vLLM Omni. It supports text-only synthesis and voice cloning with reference audio.
-
-## Model Overview
-
-[Fish Speech S2 Pro](https://huggingface.co/fishaudio/s2-pro) is a 4B dual-AR text-to-speech model by FishAudio. It uses:
-
-- **Slow AR**: Generates semantic tokens autoregressively (Qwen3-based backbone)
-- **Fast AR**: Predicts residual codebook tokens from semantic tokens
-- **DAC Decoder**: Converts codec codes to 44.1 kHz audio waveform
-
-The model produces high-quality speech with voice cloning capabilities.
-
-## Prerequisites
-
-Install the `fish-speech` package for the DAC codec:
-
-```bash
-pip install fish-speech
-```
-
-## Setup
-
-Please refer to the [stage configuration documentation](https://docs.vllm.ai/projects/vllm-omni/en/latest/configuration/stage_configs/) to configure memory allocation appropriately for your hardware setup.
-
-## Quick Start
-
-### Text-Only Synthesis
-
-```bash
-python end2end.py --text "Hello, this is a test of the Fish Speech text to speech system."
-```
-
-Generated audio files are saved to `output_audio/` by default.
-
-### Voice Cloning
-
-Provide a reference audio file and its transcript to clone a voice:
-
-```bash
-python end2end.py \
- --text "Hello, this is a cloned voice." \
- --ref-audio /path/to/reference.wav \
- --ref-text "Transcript of the reference audio."
-```
-
-## Streaming Mode
-
-Add `--streaming` to stream audio chunks progressively via `AsyncOmni` (requires `async_chunk: true` in the stage config):
-
-```bash
-python end2end.py --text "Hello, this is a test." --streaming
-```
-
-Each DAC decoder chunk is logged as it arrives. The final WAV file is written once generation completes.
-
-## Configuration
-
-| Argument | Default | Description |
-|----------|---------|-------------|
-| `--text` | `"Hello, this is a test..."` | Text to synthesize |
-| `--ref-audio` | None | Path to reference audio for voice cloning |
-| `--ref-text` | None | Transcript of the reference audio |
-| `--model` | `fishaudio/s2-pro` | HuggingFace model path |
-| `--stage-configs-path` | `fish_speech_s2_pro.yaml` | Path to stage configs YAML |
-| `--output-dir` | `output_audio` | Output directory for WAV files |
-| `--streaming` | False | Enable streaming via AsyncOmni |
-| `--stage-init-timeout` | 600 | Stage initialization timeout (seconds) |
-
-## Notes
-
-- Output audio is 44.1 kHz mono WAV.
-- The DAC codec weights (`codec.pth`) are loaded lazily from the model directory.
-- Voice cloning encodes the reference audio using the DAC codec to extract semantic codes, then prepends them as a system message.
-
-## Example materials
-
-??? abstract "end2end.py"
- ``````py
- --8<-- "examples/offline_inference/fish_speech/end2end.py"
- ``````
diff --git a/docs/user_guide/examples/offline_inference/glm_image.md b/docs/user_guide/examples/offline_inference/glm_image.md
deleted file mode 100644
index c6ac6e33ffd..00000000000
--- a/docs/user_guide/examples/offline_inference/glm_image.md
+++ /dev/null
@@ -1,87 +0,0 @@
-# GLM-Image Offline Inference
-
-GLM-Image is a 2-stage image generation model (AR + Diffusion) supported by vLLM-Omni's
-declarative config system. The pipeline topology and stage structure are declared in
-`vllm_omni/model_executor/models/glm_image/pipeline.py`; deployment knobs live in
-`vllm_omni/deploy/glm_image.yaml`.
-
-## Architecture
-
-```
-Stage 0 (AR Model) Stage 1 (Diffusion)
-┌───────────────────┐ ┌─────────────────────┐
-│ vLLM-optimized │ prior │ GlmImagePipeline │
-│ GlmImageFor │──tokens──►│ ┌───────────────┐ │
-│ Conditional │ │ │ DiT Denoiser │ │
-│ Generation │ │ └───────┬───────┘ │
-│ (9B AR model) │ │ ▼ │
-└───────────────────┘ │ ┌───────────────┐ │
- ▲ │ │ VAE Decode │──┼──► Image
- │ │ └───────────────┘ │
- Text / Image └─────────────────────┘
- Input
-```
-
-## Text-to-Image
-
-```python
-from vllm_omni.entrypoints.omni import Omni
-
-if __name__ == "__main__":
- omni = Omni(model="zai-org/GLM-Image")
- outputs = omni.generate(
- "A photorealistic mountain landscape at sunset",
- sampling_params={
- "height": 1024,
- "width": 1024,
- "num_inference_steps": 50,
- "guidance_scale": 1.5,
- "seed": 42,
- },
- )
- outputs[0].request_output.images[0].save("output.png")
-```
-
-## Image-to-Image (Image Editing)
-
-```python
-from vllm_omni.entrypoints.omni import Omni
-
-if __name__ == "__main__":
- omni = Omni(model="zai-org/GLM-Image")
- outputs = omni.generate(
- {
- "prompt": "Convert this image to watercolor style",
- "multi_modal_data": {
- "image": "input.png",
- },
- },
- sampling_params={
- "height": 1024,
- "width": 1024,
- "num_inference_steps": 50,
- "guidance_scale": 1.5,
- "seed": 42,
- },
- )
- outputs[0].request_output.images[0].save("output.png")
-```
-
-## Generation Parameters
-
-| Parameter | Type | Default | Description |
-| --------------------- | ----- | ------- | ----------------------------------- |
-| `height` | int | 1024 | Image height in pixels |
-| `width` | int | 1024 | Image width in pixels |
-| `num_inference_steps` | int | 50 | Number of diffusion denoising steps |
-| `guidance_scale` | float | 1.5 | Classifier-free guidance scale |
-| `seed` | int | None | Optional random seed |
-| `negative_prompt` | str | None | Negative prompt |
-
-## VRAM Requirements
-
-| Stage | VRAM |
-| :---------------- | :--------------------- |
-| Stage-0 (AR) | **~18 GiB + KV Cache** |
-| Stage-1 (DiT+VAE) | **~20 GiB** |
-| Total | **~38 GiB + KV Cache** |
diff --git a/docs/user_guide/examples/offline_inference/helios.md b/docs/user_guide/examples/offline_inference/helios.md
deleted file mode 100644
index f83ebc2de25..00000000000
--- a/docs/user_guide/examples/offline_inference/helios.md
+++ /dev/null
@@ -1,203 +0,0 @@
-# Helios Video Generation
-
-Source <https://github.com/vllm-project/vllm-omni/tree/main/examples/offline_inference/helios>.
-
-
-Helios is a text-to-video (T2V), image-to-video (I2V), and video-to-video (V2V) diffusion model. This example demonstrates end-to-end video generation using vLLM-Omni with three model variants:
-
-| Variant | Description | Key Features |
-|---------|-------------|--------------|
-| **Helios-Base** | Base model, Stage 1 only | Single-stage denoising, `guidance_scale=5.0` |
-| **Helios-Mid** | Mid model, Stage 2 pyramid | Multi-stage pyramid denoising, CFG-Zero* support |
-| **Helios-Distilled** | Distilled model, Stage 2+3 | Few-step inference with DMD, `guidance_scale=1.0` |
-
-## Setup
-
-Please refer to the [stage configuration documentation](https://docs.vllm.ai/projects/vllm-omni/en/latest/configuration/stage_configs/) to configure memory allocation appropriately for your hardware setup.
-
-## Run Examples
-
-Get into the example folder:
-```bash
-cd examples/offline_inference/helios
-```
-
-### Text-to-Video (T2V)
-
-**Helios-Base** (Stage 1 only):
-```bash
-python end2end.py \
- --model BestWishYsh/Helios-Base \
- --sample-type t2v \
- --prompt "A dynamic time-lapse video showing the rapidly moving scenery from the window of a speeding train." \
- --guidance-scale 5.0 \
- --output helios_t2v_base.mp4
-```
-
-**Helios-Mid** (Stage 2 + CFG-Zero*):
-```bash
-python end2end.py \
- --model BestWishYsh/Helios-Mid \
- --sample-type t2v \
- --prompt "A dynamic time-lapse video showing the rapidly moving scenery from the window of a speeding train." \
- --guidance-scale 5.0 \
- --is-enable-stage2 \
- --pyramid-num-inference-steps-list 20 20 20 \
- --use-cfg-zero-star --use-zero-init --zero-steps 1 \
- --output helios_t2v_mid.mp4
-```
-
-**Helios-Distilled** (Stage 2 pyramid + DMD):
-```bash
-python end2end.py \
- --model BestWishYsh/Helios-Distilled \
- --sample-type t2v \
- --prompt "A dynamic time-lapse video showing the rapidly moving scenery from the window of a speeding train." \
- --num-frames 240 \
- --guidance-scale 1.0 \
- --is-enable-stage2 \
- --pyramid-num-inference-steps-list 2 2 2 \
- --is-amplify-first-chunk \
- --output helios_t2v_distilled.mp4
-```
-
-### Image-to-Video (I2V)
-
-**Helios-Base**:
-```bash
-python end2end.py \
- --model BestWishYsh/Helios-Base \
- --sample-type i2v \
- --image-path /path/to/image.jpg \
- --prompt "A towering emerald wave surges forward, its crest curling with raw power and energy." \
- --guidance-scale 5.0 \
- --output helios_i2v_base.mp4
-```
-
-**Helios-Mid** (Stage 2 + CFG-Zero*):
-```bash
-python end2end.py \
- --model BestWishYsh/Helios-Mid \
- --sample-type i2v \
- --image-path /path/to/image.jpg \
- --prompt "A towering emerald wave surges forward, its crest curling with raw power and energy." \
- --guidance-scale 5.0 \
- --is-enable-stage2 \
- --pyramid-num-inference-steps-list 20 20 20 \
- --use-cfg-zero-star --use-zero-init --zero-steps 1 \
- --output helios_i2v_mid.mp4
-```
-
-**Helios-Distilled**:
-```bash
-python end2end.py \
- --model BestWishYsh/Helios-Distilled \
- --sample-type i2v \
- --image-path /path/to/image.jpg \
- --prompt "A towering emerald wave surges forward, its crest curling with raw power and energy." \
- --num-frames 240 \
- --guidance-scale 1.0 \
- --is-enable-stage2 \
- --pyramid-num-inference-steps-list 2 2 2 \
- --is-amplify-first-chunk \
- --output helios_i2v_distilled.mp4
-```
-
-### Video-to-Video (V2V)
-
-**Helios-Base**:
-```bash
-python end2end.py \
- --model BestWishYsh/Helios-Base \
- --sample-type v2v \
- --video-path /path/to/video.mp4 \
- --prompt "A bright yellow Lamborghini speeds along a curving mountain road." \
- --guidance-scale 5.0 \
- --output helios_v2v_base.mp4
-```
-
-**Helios-Mid** (Stage 2 + CFG-Zero*):
-```bash
-python end2end.py \
- --model BestWishYsh/Helios-Mid \
- --sample-type v2v \
- --video-path /path/to/video.mp4 \
- --prompt "A bright yellow Lamborghini speeds along a curving mountain road." \
- --guidance-scale 5.0 \
- --is-enable-stage2 \
- --pyramid-num-inference-steps-list 20 20 20 \
- --use-cfg-zero-star --use-zero-init --zero-steps 1 \
- --output helios_v2v_mid.mp4
-```
-
-**Helios-Distilled**:
-```bash
-python end2end.py \
- --model BestWishYsh/Helios-Distilled \
- --sample-type v2v \
- --video-path /path/to/video.mp4 \
- --prompt "A bright yellow Lamborghini speeds along a curving mountain road." \
- --num-frames 240 \
- --guidance-scale 1.0 \
- --is-enable-stage2 \
- --pyramid-num-inference-steps-list 2 2 2 \
- --is-amplify-first-chunk \
- --output helios_v2v_distilled.mp4
-```
-
-## Common Parameters
-
-| Parameter | Default | Description |
-|-----------|---------|-------------|
-| `--model` | `BestWishYsh/Helios-Base` | Model ID or local path |
-| `--sample-type` | `t2v` | Generation mode: `t2v`, `i2v`, or `v2v` |
-| `--prompt` | — | Text prompt describing the video |
-| `--negative-prompt` | *(see source)* | Negative prompt for CFG (includes anti-static terms) |
-| `--image-path` | — | Input image (required for `i2v`) |
-| `--video-path` | — | Input video (required for `v2v`) |
-| `--height` | `384` | Video height in pixels |
-| `--width` | `640` | Video width in pixels |
-| `--num-frames` | `99` | Number of output frames |
-| `--num-inference-steps` | `50` | Denoising steps (Stage 1 only) |
-| `--guidance-scale` | `5.0` | CFG scale (`1.0` for Distilled) |
-| `--seed` | `42` | Random seed |
-| `--fps` | `16` | Output video frame rate |
-| `--output` | `helios_output.mp4` | Output file path |
-
-### Stage 2 / Pyramid Parameters
-
-| Parameter | Default | Description |
-|-----------|---------|-------------|
-| `--is-enable-stage2` | off | Enable pyramid multi-stage denoising |
-| `--pyramid-num-stages` | `3` | Number of pyramid stages |
-| `--pyramid-num-inference-steps-list` | `10 10 10` | Steps per pyramid stage |
-| `--is-amplify-first-chunk` | off | DMD amplification (Distilled) |
-
-### CFG-Zero* Parameters
-
-| Parameter | Default | Description |
-|-----------|---------|-------------|
-| `--use-cfg-zero-star` | off | Enable CFG-Zero* guidance (Mid) |
-| `--use-zero-init` | off | Zero init for first steps |
-| `--zero-steps` | `1` | Number of zero-init steps |
-
-### Memory & Parallelism
-
-| Parameter | Default | Description |
-|-----------|---------|-------------|
-| `--vae-use-slicing` | off | Enable VAE slicing |
-| `--vae-use-tiling` | off | Enable VAE tiling |
-| `--enforce-eager` | off | Disable torch.compile |
-| `--enable-cpu-offload` | off | CPU offloading |
-| `--enable-layerwise-offload` | off | Layerwise offloading |
-| `--ulysses-degree` | `1` | Ulysses SP degree |
-| `--ring-degree` | `1` | Ring SP degree |
-| `--cfg-parallel-size` | `1` | CFG parallel size (1 or 2) |
-| `--tensor-parallel-size` | `1` | Tensor parallelism size |
-
-## Example materials
-
-??? abstract "end2end.py"
- ``````py
- --8<-- "examples/offline_inference/helios/end2end.py"
- ``````
diff --git a/docs/user_guide/examples/offline_inference/hunyuan_image3.md b/docs/user_guide/examples/offline_inference/hunyuan_image3.md
deleted file mode 100644
index 636aa0c11d5..00000000000
--- a/docs/user_guide/examples/offline_inference/hunyuan_image3.md
+++ /dev/null
@@ -1,35 +0,0 @@
-# HunyuanImage-3.0 Image-to-Text Inference
-
-Source <https://github.com/vllm-project/vllm-omni/tree/main/examples/offline_inference/hunyuan_image3>.
-
-
-This example demonstrates how to run HunyuanImage-3.0 Image-to-Text with the vLLM-Omni.
-
-## Local CLI Usage
-
-Download the example image:
-
-```bash
-wget https://vllm-public-assets.s3.us-west-2.amazonaws.com/vision_model_images/cherry_blossom.jpg
-```
-
-Run example:
-
-```bash
-python image_to_text.py \
- --image cherry_blossom.jpg \
- --prompt "<|startoftext|>You are an assistant that understands images and outputs text.<img>Describe the content of the picture."
-```
-
-Key arguments:
-
-- `--model`: Model used. Default is: tencent/HunyuanImage-3.0-Instruct (Optional).
-- `--image`: Path to input image (required).
-- `--prompt`: Text description used to guide image understanding (required).
-
-## Example materials
-
-??? abstract "image_to_text.py"
- ``````py
- --8<-- "examples/offline_inference/hunyuan_image3/image_to_text.py"
- ``````
diff --git a/docs/user_guide/examples/offline_inference/image_to_image.md b/docs/user_guide/examples/offline_inference/image_to_image.md
deleted file mode 100644
index b066eaee32f..00000000000
--- a/docs/user_guide/examples/offline_inference/image_to_image.md
+++ /dev/null
@@ -1,69 +0,0 @@
-# Image-To-Image
-
-Source <https://github.com/vllm-project/vllm-omni/tree/main/examples/offline_inference/image_to_image>.
-
-
-This example edits an input image with `Qwen/Qwen-Image-Edit` using the `image_edit.py` CLI.
-
-## Local CLI Usage
-
-### Single Image Editing
-
-Download the example image:
-
-```bash
-wget https://vllm-public-assets.s3.us-west-2.amazonaws.com/omni-assets/qwen-bear.png
-```
-
-Then run:
-
-```bash
-python image_edit.py \
- --image qwen-bear.png \
- --prompt "Let this mascot dance under the moon, surrounded by floating stars and poetic bubbles such as 'Be Kind'" \
- --output output_image_edit.png \
- --num-inference-steps 50 \
- --cfg-scale 4.0
-```
-
-### Multiple Image Editing (Qwen-Image-Edit-2509)
-
-For multiple image inputs, use `Qwen/Qwen-Image-Edit-2509` or `Qwen/Qwen-Image-Edit-2511`:
-
-```bash
-python image_edit.py \
- --model Qwen/Qwen-Image-Edit-2509 \
- --image img1.png img2.png \
- --prompt "Combine these images into a single scene" \
- --output output_image_edit.png \
- --num-inference-steps 50 \
- --cfg-scale 4.0 \
- --guidance-scale 1.0
-```
-
-Key arguments:
-
-- `--model`: model name or path. Use `Qwen/Qwen-Image-Edit-2509` or later for multiple image support.
-- `--image`: path(s) to the source image(s) (PNG/JPG, converted to RGB). Can specify multiple images.
-- `--prompt` / `--negative-prompt`: text description (string).
-- `--cfg-scale`: true classifier-free guidance scale (default: 4.0). Classifier-free guidance is enabled by setting cfg_scale > 1 and providing a negative_prompt. Higher guidance scale encourages images closely linked to the text prompt, usually at the expense of lower image quality.
-- `--guidance-scale`: guidance scale for guidance-distilled models (default: 1.0, disabled). Unlike classifier-free guidance (--cfg-scale), guidance-distilled models take the guidance scale directly as an input parameter. Enabled when guidance_scale > 1. Ignored when not using guidance-distilled models.
-- `--num-inference-steps`: diffusion sampling steps (more steps = higher quality, slower).
-- `--output`: path to save the generated PNG.
-- `--vae-use-slicing`: enable VAE slicing for memory optimization.
-- `--vae-use-tiling`: enable VAE tiling for memory optimization.
-- `--cfg-parallel-size`: set it to 2 to enable CFG Parallel. See more examples in [`user_guide`](https://github.com/vllm-project/vllm-omni/tree/main/docs/user_guide/diffusion/parallelism_acceleration.md#cfg-parallel).
-- `--enable-cpu-offload`: enable CPU offloading for diffusion models.
-
-> ℹ️ If you encounter OOM errors, try using `--vae-use-slicing` and `--vae-use-tiling` to reduce memory usage.
-
-## Example materials
-
-??? abstract "image_edit.py"
- ``````py
- --8<-- "examples/offline_inference/image_to_image/image_edit.py"
- ``````
-??? abstract "run_qwen_image_edit_2511.sh"
- ``````sh
- --8<-- "examples/offline_inference/image_to_image/run_qwen_image_edit_2511.sh"
- ``````
diff --git a/docs/user_guide/examples/offline_inference/image_to_video.md b/docs/user_guide/examples/offline_inference/image_to_video.md
deleted file mode 100644
index 6e105741a7e..00000000000
--- a/docs/user_guide/examples/offline_inference/image_to_video.md
+++ /dev/null
@@ -1,90 +0,0 @@
-# Image-To-Video
-
-Source <https://github.com/vllm-project/vllm-omni/tree/main/examples/offline_inference/image_to_video>.
-
-
-This example demonstrates how to generate videos from images using Wan2.2 Image-to-Video models with vLLM-Omni's offline inference API.
-
-## Local CLI Usage
-
-Download the example image:
-
-```bash
-wget https://vllm-public-assets.s3.us-west-2.amazonaws.com/vision_model_images/cherry_blossom.jpg
-```
-
-### Wan2.2-I2V-A14B-Diffusers (MoE)
-
-```bash
-python image_to_video.py \
- --model Wan-AI/Wan2.2-I2V-A14B-Diffusers \
- --image cherry_blossom.jpg \
- --prompt "Cherry blossoms swaying gently in the breeze, petals falling, smooth motion" \
- --negative-prompt "<optional quality filter>" \
- --height 480 \
- --width 832 \
- --num-frames 48 \
- --guidance-scale 5.0 \
- --guidance-scale-high 6.0 \
- --num-inference-steps 40 \
- --boundary-ratio 0.875 \
- --flow-shift 12.0 \
- --fps 16 \
- --output i2v_output.mp4
-```
-
-### Wan2.2-TI2V-5B-Diffusers (Unified)
-
-```bash
-python image_to_video.py \
- --model Wan-AI/Wan2.2-TI2V-5B-Diffusers \
- --image cherry_blossom.jpg \
- --prompt "Cherry blossoms swaying gently in the breeze, petals falling, smooth motion" \
- --negative-prompt "<optional quality filter>" \
- --height 480 \
- --width 832 \
- --num-frames 48 \
- --guidance-scale 4.0 \
- --num-inference-steps 40 \
- --flow-shift 12.0 \
- --fps 16 \
- --output i2v_output.mp4
-```
-
-Key arguments:
-
-- `--model`: Model ID (I2V-A14B for MoE, TI2V-5B for unified T2V+I2V).
-- `--image`: Path to input image (required).
-- `--prompt`: Text description of desired motion/animation.
-- `--height/--width`: Output resolution (auto-calculated from image if not set). Dimensions should be multiples of 16.
-- `--num-frames`: Number of frames (default 81).
-- `--guidance-scale` and `--guidance-scale-high`: CFG scale (applied to low/high-noise stages for MoE).
-- `--negative-prompt`: Optional list of artifacts to suppress.
-- `--boundary-ratio`: Boundary split ratio for two-stage MoE models.
-- `--flow-shift`: Scheduler flow shift (5.0 for 720p, 12.0 for 480p).
-- `--sample-solver`: Wan2.2 sampling solver. Use `unipc` for the default multistep solver, or `euler` for Lightning/Distill checkpoints.
-- `--num-inference-steps`: Number of denoising steps (default 50).
-- `--fps`: Frames per second for the saved MP4 (requires `diffusers` export_to_video).
-- `--output`: Path to save the generated video.
-- `--vae-use-slicing`: Enable VAE slicing for memory optimization.
-- `--vae-use-tiling`: Enable VAE tiling for memory optimization.
-- `--cfg-parallel-size`: set it to 2 to enable CFG Parallel. See more examples in [`user_guide`](https://github.com/vllm-project/vllm-omni/tree/main/docs/user_guide/diffusion/parallelism/cfg_parallel.md).
-- `--tensor-parallel-size`: tensor parallel size (effective for models that support TP, e.g. LTX2).
-- `--enable-cpu-offload`: enable CPU offloading for diffusion models.
-- `--use-hsdp`: Enable Hybrid Sharded Data Parallel to shard model weights across GPUs.
-- `--hsdp-shard-size`: Number of GPUs to shard model weights across within each replica group. -1 (default) auto-calculates as world_size / replicate_size.
-- `--hsdp-replicate-size`: Number of replica groups for HSDP. Each replica holds a full sharded copy. Default 1 means pure sharding (no replication).
-
-
-
-> ℹ️ If you encounter OOM errors, try using `--vae-use-slicing` and `--vae-use-tiling` to reduce memory usage.
-
-For Wan2.2 LightX2V-converted local Diffusers directories and related LoRA
-assets, see the [LoRA guide](../../diffusion/lora.md#wan22-lightx2v-offline-assembly).
-
-## Example materials
-
-??? abstract "image_to_video.py"
- ``````py
- --8<-- "examples/offline_inference/image_to_video/image_to_video.py"
- ``````
diff --git a/docs/user_guide/examples/offline_inference/internvla_a1.md b/docs/user_guide/examples/offline_inference/internvla_a1.md
deleted file mode 100644
index 83906a037a3..00000000000
--- a/docs/user_guide/examples/offline_inference/internvla_a1.md
+++ /dev/null
@@ -1,205 +0,0 @@
-# InternVLA-A1
-
-Source <https://github.com/vllm-project/vllm-omni/tree/main/examples/offline_inference/internvla_a1>.
-
-
-## Setup
-This example is adapted from: https://github.com/InternRobotics/InternVLA-A1/blob/master/tests/policies/internvla_a1_3b/open_loop_genie1_real.ipynb
-
-This example runs the single-path vLLM offline inference workflow for InternVLA-A1 open-loop action prediction.
-
-Before running the script, export the required local paths:
-
-```bash
-# hf Jia-Zeng/InternVLA-A1-3B-FineTuned-Place_Markpen
-export INTERNVLA_A1_MODEL_DIR=/path/to/InternVLA-A1-3B-ft-pen
-# hf download InternRobotics/InternData-A1 real_lerobotv30/genie1/Genie1-Place_Markpen.tar.gz --repo-type dataset --local-dir /path/to/Genie1-Place_Markpen
-export INTERNVLA_A1_DATASET_DIR=/path/to/Genie1-Place_Markpen
-export INTERNVLA_A1_PROCESSOR_DIR=/path/to/Qwen3-VL-2B-Instruct
-# hf tenstep/Cosmos-Tokenizer-CI8x8-SafeTensors
-export INTERNVLA_A1_COSMOS_DIR=/path/to/Cosmos-Tokenizer-CI8x8-SafeTensor
-```
-
-The shell entrypoint also accepts these variables as defaults, so you can keep the command line itself short.
-
-`INTERNVLA_A1_COSMOS_DIR` is expected to contain:
-
-- `encoder.safetensors`
-- `decoder.safetensors`
-
-Reference Hugging Face repo: `tenstep/Cosmos-Tokenizer-CI8x8-SafeTensors`
-
-## Run examples
-
-Get into the example folder:
-
-```bash
-cd examples/offline_inference/internvla_a1
-```
-
-### Run one sample
-
-This runs a single sample through the maintained vLLM registry path.
-
-```bash
-bash run.sh --num-samples 1 --num-episodes 0
-```
-
-### Run open-loop evaluation against GT
-
-This runs one episode, writes evaluation metrics, and saves prediction-vs-GT plots when `matplotlib` is available.
-
-```bash
-bash run.sh --num-episodes 1
-```
-
-Outputs are written under:
-
-```bash
-outputs/internvla_a1/vllm_infer/
-```
-
-Typical files:
-
-- `summary.json`: top-level run summary
-- `registry/log.json`: per-episode GT comparison metrics
-- `registry/plots/*.jpg`: prediction-vs-GT figures
-
-### Eager float32 validation
-
-Use eager attention and float32 when you want the most stable numerical comparison baseline.
-
-```bash
-bash run.sh \
- --num-episodes 1 \
- --attn-implementation eager \
- --dtype float32
-```
-
-### Optional runtime switches
-
-- `--dtype {bfloat16,float32}`: choose inference dtype
-- `--attn-implementation {eager,sdpa}`: switch attention backend
-- `--enable-regional-compile`: enable regional `torch.compile`
-- `--enable-warmup`: run pipeline warmup in initialization
-- `--skip-plots`: skip plot generation even if `matplotlib` is installed
-
-### Collect results and performance logs
-
-Use the helper below when you want to collect one-sample output, forward latency, GT comparison, plots, timing logs, and optional pytest output into a single result directory:
-
-```bash
-bash collect_results.sh
-```
-
-The script writes a timestamped directory under:
-
-```bash
-outputs/internvla_a1/collected_results/
-```
-
-Typical result files:
-
-- `env_summary.txt`: environment and path summary
-- `sample_run.log`: one-sample inference log
-- `forward_benchmark/forward_latency.json`: isolated `pipeline.forward` latency summary
-- `eval_run.log`: open-loop GT evaluation log
-- `eval_outputs/summary.json`: top-level output summary
-- `eval_outputs/registry/log.json`: GT comparison metrics
-- `eval_outputs/registry/plots/*.jpg`: prediction-vs-GT figures
-- `*_time.txt`: timing output
-- `*_gpu.csv`: sampled GPU usage
-
-### Benchmark forward latency
-
-Use the dedicated mode below when you want the isolated `pipeline.forward` latency instead of end-to-end script time:
-
-```bash
-python end2end.py \
- --model-dir "$INTERNVLA_A1_MODEL_DIR" \
- --dataset-dir "$INTERNVLA_A1_DATASET_DIR" \
- --benchmark-forward \
- --dtype bfloat16 \
- --attn-implementation eager \
- --warmup-iters 3 \
- --benchmark-iters 10 \
- --output-dir outputs/internvla_a1/forward_benchmark
-```
-
-The output JSON is written to `outputs/internvla_a1/forward_benchmark/forward_latency.json` and contains:
-
-- `cold_start_ms`
-- `warmup_summary`
-- `benchmark_summary`
-- `benchmark_samples_ms`
-
-### Reference results
-
-Reference run collected on `1x NVIDIA H200`, `bfloat16`, `eager`:
-
-- one-sample end-to-end run: `38s`
-- one-episode GT evaluation run: `45s`
-- `average_mse = 1.7173260857816786e-05`
-- `average_mae = 0.0011860118247568607`
-- `average_mse_joint = 7.42028441891307e-06`
-- `average_mae_joint = 0.0010777723509818316`
-- `average_mse_gripper = 8.544408774469048e-05`
-- `average_mae_gripper = 0.0019436875591054559`
-
-The reference plot filename is:
-
-- `eval_outputs/registry/plots/vllm_registry_open_loop_ep0.jpg`
-
-## Measure latency and VRAM
-
-You can collect end-to-end runtime and peak host memory with:
-
-```bash
-/usr/bin/time -v bash run.sh --num-episodes 1
-```
-
-For GPU memory snapshots, use:
-
-```bash
-nvidia-smi --query-gpu=name,memory.total,memory.used --format=csv
-```
-
-Run `nvidia-smi` before and during inference to record the peak device memory for your PR report.
-
-## FAQ
-
-If `matplotlib` is missing, evaluation still runs and only plot generation is skipped. To enable plots:
-
-```bash
-pip install matplotlib
-```
-
-## Example materials
-
-- `end2end.py`: main offline inference and GT evaluation entrypoint
-- `run.sh`: shell wrapper with local path env vars
-- `collect_results.sh`: helper to gather result summaries and performance logs into one directory
-- `internvla_a1_common.py`: dataset, evaluation, and plotting helpers
-
-## Embedded source listings
-
-??? abstract "collect_results.sh"
- ``````sh
- --8<-- "examples/offline_inference/internvla_a1/collect_results.sh"
- ``````
-??? abstract "end2end.py"
- ``````py
- --8<-- "examples/offline_inference/internvla_a1/end2end.py"
- ``````
-??? abstract "internvla_a1_common.py"
- ``````py
- --8<-- "examples/offline_inference/internvla_a1/internvla_a1_common.py"
- ``````
-??? abstract "run.sh"
- ``````sh
- --8<-- "examples/offline_inference/internvla_a1/run.sh"
- ``````
-??? abstract "standalone/outputs/qwena1/standalone_infer/log.json"
- ``````json
- --8<-- "examples/offline_inference/internvla_a1/standalone/outputs/qwena1/standalone_infer/log.json"
- ``````
diff --git a/docs/user_guide/examples/offline_inference/mammothmodal2_preview.md b/docs/user_guide/examples/offline_inference/mammothmodal2_preview.md
deleted file mode 100644
index 85227b74809..00000000000
--- a/docs/user_guide/examples/offline_inference/mammothmodal2_preview.md
+++ /dev/null
@@ -1,46 +0,0 @@
-# MammothModa2-Preview
-
-Source <https://github.com/vllm-project/vllm-omni/tree/main/examples/offline_inference/mammothmodal2_preview>.
-
-
-## Run examples (MammothModa2-Preview)
-
-Download model
-```bash
-hf bytedance-research/MammothModa2-Preview --local-dir ./MammothModa2-Preview
-```
-
-### Text-to-Image (T2I)
-
-```bash
-python examples/offline_inference/mammothmodal2_preview/run_mammothmoda2_t2i.py \
- --model ./MammothModa2-Preview \
- --stage-config ./vllm_omni/model_executor/stage_configs/mammoth_moda2.yaml \
- --prompt "A stylish woman riding a motorcycle in NYC, movie poster style" \
- --height 1024 \
- --width 1024 \
- --num-inference-steps 50 \
- --text-guidance-scale 4.0 \
- --out output.png
-```
-
-### Image Summary
-
-```bash
-python examples/offline_inference/mammothmodal2_preview/run_mammothmoda2_image_summarize.py \
- --model ./MammothModa2-Preview \
- --stage-config ./vllm_omni/model_executor/stage_configs/mammoth_moda2_ar.yaml \
- --question "Summarize this image." \
- --image ./image.png
-```
-
-## Example materials
-
-??? abstract "run_mammothmoda2_image_summarize.py"
- ``````py
- --8<-- "examples/offline_inference/mammothmodal2_preview/run_mammothmoda2_image_summarize.py"
- ``````
-??? abstract "run_mammothmoda2_t2i.py"
- ``````py
- --8<-- "examples/offline_inference/mammothmodal2_preview/run_mammothmoda2_t2i.py"
- ``````
diff --git a/docs/user_guide/examples/offline_inference/mimo_audio.md b/docs/user_guide/examples/offline_inference/mimo_audio.md
deleted file mode 100644
index 1cba2f77dcf..00000000000
--- a/docs/user_guide/examples/offline_inference/mimo_audio.md
+++ /dev/null
@@ -1,219 +0,0 @@
-# MiMo-Audio Offline Inference
-
-Source <https://github.com/vllm-project/vllm-omni/tree/main/examples/offline_inference/mimo_audio>.
-
-
-This directory contains an offline demo for running MiMo-Audio models with vLLM Omni. It builds task-specific inputs and generates WAV files or text outputs locally.
-
-## Model Overview
-
-MiMo-Audio provides multiple task variants for audio understanding and generation:
-
-- **tts_sft**: Basic text-to-speech generation from text input.
-- **tts_sft_with_instruct**: TTS generation with explicit voice style instructions.
-- **tts_sft_with_audio**: TTS generation with audio reference for voice cloning.
-- **tts_sft_with_natural_instruction**: TTS generation from natural language descriptions embedded in text.
-- **audio_trancribing_sft**: Transcribe audio to text (speech-to-text). (note: the upstream task name uses the spelling 'trancribing', don't fix it)
-- **audio_understanding_sft**: Understand and analyze audio content with text queries.
-- **audio_understanding_sft_with_thinking**: Audio understanding with reasoning chain.
-- **spoken_dialogue_sft_multiturn**: Multi-turn spoken dialogue with audio input/output.
-- **speech2text_dialogue_sft_multiturn**: Multi-turn dialogue converting speech to text.
-- **text_dialogue_sft_multiturn**: Multi-turn text-only dialogue.
-
-## Setup
-
-Please refer to the [stage configuration documentation](https://docs.vllm.ai/projects/vllm-omni/en/latest/configuration/stage_configs/) to configure memory allocation appropriately for your hardware setup.
-
-### Environment Variables
-
-The `MIMO_AUDIO_TOKENIZER_PATH` environment variable is mandatory due to the specialized architecture:
-
-```bash
-export MIMO_AUDIO_TOKENIZER_PATH="XiaomiMiMo/MiMo-Audio-Tokenizer"
-```
-
-## Quick Start
-
-Run a single sample for basic TTS:
-
-```bash
-python3 -u end2end.py \
- --model-name XiaomiMiMo/MiMo-Audio-7B-Instruct \
- --query-type tts_sft
-```
-
-Run batch samples for basic TTS:
-
-```bash
-python3 -u end2end.py \
- --model-name XiaomiMiMo/MiMo-Audio-7B-Instruct \
- --query-type tts_sft \
- --num-prompts {batch_size}
-```
-
-When enabling multi-batch processing, if the total number of tokens passed to the next stage exceeds the `max_model_len` value in the `mimo_audio.yaml` configuration file, you must also synchronously update the `max_position_embeddings` value in `MiMo-Audio-7B-Instruct/config.json` to match the modified value.
-
-Generated audio files are saved to `output_audio/` by default. `--num-prompts` also can be used to all tasks below.
-
-## Task Usage
-
-### tts_sft (Basic Text-to-Speech)
-
-Generate speech from text input:
-
-```bash
-python3 -u end2end.py \
- --model-name XiaomiMiMo/MiMo-Audio-7B-Instruct \
- --query-type tts_sft \
- --text "The weather is so nice today."
-```
-
-### tts_sft_with_instruct (TTS with Voice Instructions)
-
-Generate speech with explicit voice style instructions:
-
-```bash
-python3 -u end2end.py \
- --model-name XiaomiMiMo/MiMo-Audio-7B-Instruct \
- --query-type tts_sft_with_instruct \
- --text "The weather is so nice today." \
- --instruct "Speak happily in a child's voice"
-```
-
-### tts_sft_with_audio (TTS with Audio Reference)
-
-Generate speech using an audio reference for voice cloning:
-
-```bash
-python3 -u end2end.py \
- --model-name XiaomiMiMo/MiMo-Audio-7B-Instruct \
- --query-type tts_sft_with_audio \
- --text "The weather is so nice today." \
- --audio-path "./spoken_dialogue_assistant_turn_1.wav"
-```
-
-### tts_sft_with_natural_instruction (Natural Language TTS)
-
-Generate speech from text containing natural voice descriptions:
-
-```bash
-python3 -u end2end.py \
- --model-name XiaomiMiMo/MiMo-Audio-7B-Instruct \
- --query-type tts_sft_with_natural_instruction \
- --text "In a panting young male voice, he said: I can't run anymore, wait for me!"
-```
-
-### audio_trancribing_sft (Speech-to-Text)
-
-Transcribe audio to text:
-
-```bash
-python3 -u end2end.py \
- --model-name XiaomiMiMo/MiMo-Audio-7B-Instruct \
- --query-type audio_trancribing_sft \
- --audio-path "./spoken_dialogue_assistant_turn_1.wav"
-```
-
-### audio_understanding_sft (Audio Understanding)
-
-Understand and analyze audio content with text queries:
-
-```bash
-python3 -u end2end.py \
- --model-name XiaomiMiMo/MiMo-Audio-7B-Instruct \
- --query-type audio_understanding_sft \
- --text "Summarize the audio." \
- --audio-path "./spoken_dialogue_assistant_turn_1.wav"
-```
-
-### audio_understanding_sft_with_thinking (Audio Understanding with Reasoning)
-
-Audio understanding with reasoning chain:
-
-```bash
-python3 -u end2end.py \
- --model-name XiaomiMiMo/MiMo-Audio-7B-Instruct \
- --query-type audio_understanding_sft_with_thinking \
- --text "Summarize the audio." \
- --audio-path "./spoken_dialogue_assistant_turn_1.wav"
-```
-
-### spoken_dialogue_sft_multiturn (Multi-turn Spoken Dialogue)
-
-Multi-turn dialogue with audio input and output:
-
-```bash
-python3 -u end2end.py \
- --model-name XiaomiMiMo/MiMo-Audio-7B-Instruct \
- --query-type spoken_dialogue_sft_multiturn \
- --audio-path "./prompt_speech_zh_m.wav"
-```
-
-Note: This task uses hardcoded audio files in the script. The audio files used in examples are available at: https://github.com/XiaomiMiMo/MiMo-Audio/tree/main/examples
-
-### speech2text_dialogue_sft_multiturn (Speech-to-Text Dialogue)
-
-Multi-turn dialogue converting speech to text:
-
-```bash
-python3 -u end2end.py \
- --model-name XiaomiMiMo/MiMo-Audio-7B-Instruct \
- --query-type speech2text_dialogue_sft_multiturn
-```
-
-Note: This task uses hardcoded audio files and message lists in the script.
-
-### text_dialogue_sft_multiturn (Text Dialogue)
-
-Multi-turn text-only dialogue:
-
-```bash
-python3 -u end2end.py \
- --model-name XiaomiMiMo/MiMo-Audio-7B-Instruct \
- --query-type text_dialogue_sft_multiturn
-```
-
-Note: This task uses hardcoded message lists in the script.
-
-## Troubleshooting
-
-### Tokenizer path
-
-- **`MIMO_AUDIO_TOKENIZER_PATH` not set or model fails to find tokenizer**
- Export the tokenizer path before running:
- ```bash
- export MIMO_AUDIO_TOKENIZER_PATH="XiaomiMiMo/MiMo-Audio-Tokenizer"
- ```
- See [Environment Variables](#environment-variables) in Setup.
-
-### Other
-
-- If the model or stage config fails to load, check [stage configuration documentation](https://docs.vllm.ai/projects/vllm-omni/en/latest/configuration/stage_configs/) for memory and GPU settings.
-- For errors when reading/writing WAV (e.g. unsupported format), ensure input files are standard WAV/MP3 and that `soundfile` is linked to a working libsndfile (see above).
-
-## Notes
-
-- The script uses default model paths and audio files embedded in `end2end.py`. Update them if your local cache path differs.
-- Use `--output-dir` to change the output folder (default: `./output_audio`).
-- Use `--num-prompts` to generate multiple prompts in one run (default: 1).
-- Audio files used in multi-turn dialogue examples are available at: https://github.com/XiaomiMiMo/MiMo-Audio/tree/main/examples
-- The script supports various configuration options for initialization timeouts, batch timeouts, and shared memory thresholds. See `--help` for details.
-
-## Example materials
-
-??? abstract "end2end.py"
- ``````py
- --8<-- "examples/offline_inference/mimo_audio/end2end.py"
- ``````
-??? abstract "message_base64_wav.json"
- ``````json
- --8<-- "examples/offline_inference/mimo_audio/message_base64_wav.json"
- ``````
-??? abstract "message_convert.py"
- ``````py
- --8<-- "examples/offline_inference/mimo_audio/message_convert.py"
- ``````
-??? abstract "process_speechdata.py"
- ``````py
- --8<-- "examples/offline_inference/mimo_audio/process_speechdata.py"
- ``````
diff --git a/docs/user_guide/examples/offline_inference/qwen2_5_omni.md b/docs/user_guide/examples/offline_inference/qwen2_5_omni.md
deleted file mode 100644
index c54976b540d..00000000000
--- a/docs/user_guide/examples/offline_inference/qwen2_5_omni.md
+++ /dev/null
@@ -1,84 +0,0 @@
-# Qwen2.5-Omni
-
-Source <https://github.com/vllm-project/vllm-omni/tree/main/examples/offline_inference/qwen2_5_omni>.
-
-
-## Setup
-Please refer to the [stage configuration documentation](https://docs.vllm.ai/projects/vllm-omni/en/latest/configuration/stage_configs/) to configure memory allocation appropriately for your hardware setup.
-
-## Run examples
-
-### Multiple Prompts
-Get into the example folder
-```bash
-cd examples/offline_inference/qwen2_5_omni
-```
-Then run the command below. Note: for processing large volume data, it uses py_generator mode, which will return a python generator from Omni class.
-```bash
-bash run_multiple_prompts.sh
-```
-
-### Single Prompt
-Get into the example folder
-```bash
-cd examples/offline_inference/qwen2_5_omni
-```
-Then run the command below.
-```bash
-bash run_single_prompt.sh
-```
-
-### Modality control
-If you want to control output modalities, e.g. only output text, you can run the command below:
-```bash
-python end2end.py --output-wav output_audio \
- --query-type mixed_modalities \
- --modalities text
-```
-
-#### Using Local Media Files
-The `end2end.py` script supports local media files (audio, video, image) via CLI arguments:
-
-```bash
-# Use single local media files
-python end2end.py --query-type use_image --image-path /path/to/image.jpg
-python end2end.py --query-type use_video --video-path /path/to/video.mp4
-python end2end.py --query-type use_audio --audio-path /path/to/audio.wav
-
-# Combine multiple local media files
-python end2end.py --query-type mixed_modalities \
- --video-path /path/to/video.mp4 \
- --image-path /path/to/image.jpg \
- --audio-path /path/to/audio.wav
-
-# Use audio from video file
-python end2end.py --query-type use_audio_in_video --video-path /path/to/video.mp4
-
-```
-
-If media file paths are not provided, the script will use default assets. Supported query types:
-- `use_image`: Image input only
-- `use_video`: Video input only
-- `use_audio`: Audio input only
-- `mixed_modalities`: Audio + image + video
-- `use_audio_in_video`: Extract audio from video
-- `text`: Text-only query
-
-## Example materials
-
-??? abstract "end2end.py"
- ``````py
- --8<-- "examples/offline_inference/qwen2_5_omni/end2end.py"
- ``````
-??? abstract "extract_prompts.py"
- ``````py
- --8<-- "examples/offline_inference/qwen2_5_omni/extract_prompts.py"
- ``````
-??? abstract "run_multiple_prompts.sh"
- ``````sh
- --8<-- "examples/offline_inference/qwen2_5_omni/run_multiple_prompts.sh"
- ``````
-??? abstract "run_single_prompt.sh"
- ``````sh
- --8<-- "examples/offline_inference/qwen2_5_omni/run_single_prompt.sh"
- ``````
diff --git a/docs/user_guide/examples/offline_inference/qwen3_omni.md b/docs/user_guide/examples/offline_inference/qwen3_omni.md
deleted file mode 100644
index 2d856f7380a..00000000000
--- a/docs/user_guide/examples/offline_inference/qwen3_omni.md
+++ /dev/null
@@ -1,148 +0,0 @@
-# Qwen3-Omni
-
-Source <https://github.com/vllm-project/vllm-omni/tree/main/examples/offline_inference/qwen3_omni>.
-
-
-## Setup
-Please refer to the [stage configuration documentation](https://docs.vllm.ai/projects/vllm-omni/en/latest/configuration/stage_configs/) to configure memory allocation appropriately for your hardware setup.
-
-## Run examples
-
-### Multiple Prompts
-Get into the example folder
-```bash
-cd examples/offline_inference/qwen3_omni
-```
-Then run the command below. Note: for processing large volume data, it uses py_generator mode, which will return a python generator from Omni class.
-```bash
-bash run_multiple_prompts.sh
-```
-### Single Prompt
-Get into the example folder
-```bash
-cd examples/offline_inference/qwen3_omni
-```
-Then run the command below.
-```bash
-bash run_single_prompt.sh
-```
-If you have not enough memory, you can set thinker with tensor parallel. Just run the command below.
-```bash
-bash run_single_prompt_tp.sh
-```
-
-### Modality control
-If you want to control output modalities, e.g. only output text, you can run the command below:
-```bash
-python end2end.py --output-wav output_audio \
- --query-type use_audio \
- --modalities text
-```
-
-#### Using Local Media Files
-The `end2end.py` script supports local media files (audio, video, image) via command-line arguments:
-
-```bash
-# Use local video file
-python end2end.py --query-type use_video --video-path /path/to/video.mp4
-
-# Use local image file
-python end2end.py --query-type use_image --image-path /path/to/image.jpg
-
-# Use local audio file
-python end2end.py --query-type use_audio --audio-path /path/to/audio.wav
-
-# Combine multiple local media files
-python end2end.py --query-type mixed_modalities \
- --video-path /path/to/video.mp4 \
- --image-path /path/to/image.jpg \
- --audio-path /path/to/audio.wav
-```
-
-If media file paths are not provided, the script will use default assets. Supported query types:
-- `use_video`: Video input
-- `use_image`: Image input
-- `use_audio`: Audio input
-- `text`: Text-only query
-- `multi_audios`: Multiple audio inputs
-- `mixed_modalities`: Combination of video, image, and audio inputs
-
-### Async-chunk (offline)
-
-For true stage-level concurrency -- where downstream stages (Talker, Code2Wav)
-start **before** the upstream stage (Thinker) finishes -- use the async_chunk
-example. This requires:
-
-1. A stage config YAML with ``async_chunk: true`` (e.g.
- ``qwen3_omni_moe_async_chunk.yaml``).
-2. Hardware that matches the config (e.g. 2x H100 for the default 3-stage
- config).
-
-The async_chunk example uses ``AsyncOmni`` instead of the synchronous ``Omni``
-class, which enables the async orchestrator to receive stage-0 intermediate
-outputs and trigger downstream stages early. Chunk data flows directly between
-stage workers via the in-worker ``OmniChunkTransferAdapter`` / connector,
-**not** through the orchestrator.
-
-#### Single prompt
-```bash
-cd examples/offline_inference/qwen3_omni
-bash run_single_prompt_async_chunk.sh
-```
-
-#### Multiple prompts with concurrency control
-```bash
-bash run_multiple_prompts_async_chunk.sh --max-in-flight 4
-```
-
-#### Text-only output (skip audio generation)
-```bash
-python end2end_async_chunk.py --query-type text --modalities text
-```
-
-#### Custom stage config
-```bash
-python end2end_async_chunk.py \
- --query-type use_audio \
- --stage-configs-path /path/to/your_async_chunk.yaml
-```
-
-> **Note**: The synchronous ``end2end.py`` (using ``Omni``) is still the
-> recommended entry point for non-async-chunk workflows. Only use the
-> async_chunk example when you need the stage-level concurrency semantics
-> described in PR #962 / #1151.
-
-## Example materials
-
-??? abstract "end2end.py"
- ``````py
- --8<-- "examples/offline_inference/qwen3_omni/end2end.py"
- ``````
-??? abstract "end2end_async_chunk.py"
- ``````py
- --8<-- "examples/offline_inference/qwen3_omni/end2end_async_chunk.py"
- ``````
-??? abstract "run_multiple_prompts.sh"
- ``````sh
- --8<-- "examples/offline_inference/qwen3_omni/run_multiple_prompts.sh"
- ``````
-??? abstract "run_multiple_prompts_async_chunk.sh"
- ``````sh
- --8<-- "examples/offline_inference/qwen3_omni/run_multiple_prompts_async_chunk.sh"
- ``````
-??? abstract "run_single_prompt.sh"
- ``````sh
- --8<-- "examples/offline_inference/qwen3_omni/run_single_prompt.sh"
- ``````
-??? abstract "run_single_prompt_async_chunk.sh"
- ``````sh
- --8<-- "examples/offline_inference/qwen3_omni/run_single_prompt_async_chunk.sh"
- ``````
-??? abstract "run_single_prompt_tp.sh"
- ``````sh
- --8<-- "examples/offline_inference/qwen3_omni/run_single_prompt_tp.sh"
- ``````
-??? abstract "text_prompts_10.txt"
- ``````txt
- --8<-- "examples/offline_inference/qwen3_omni/text_prompts_10.txt"
- ``````
diff --git a/docs/user_guide/examples/offline_inference/qwen3_tts.md b/docs/user_guide/examples/offline_inference/qwen3_tts.md
deleted file mode 100644
index 7226ac1fe4b..00000000000
--- a/docs/user_guide/examples/offline_inference/qwen3_tts.md
+++ /dev/null
@@ -1,172 +0,0 @@
-# Qwen3-TTS
-
-Source <https://github.com/vllm-project/vllm-omni/tree/main/examples/offline_inference/qwen3_tts>.
-
-
-This directory contains an offline demo for running Qwen3 TTS models with vLLM Omni. It builds task-specific inputs and generates WAV files locally.
-
-## Model Overview
-
-Qwen3 TTS provides multiple task variants for speech generation:
-
-- **CustomVoice**: Generate speech with a known speaker identity (speaker ID) and optional instruction.
-- **VoiceDesign**: Generate speech from text plus a descriptive instruction that designs a new voice.
-- **Base**: Voice cloning using a reference audio + reference transcript, with optional mode selection. The `ref_audio` field accepts a local file path, HTTP URL, or base64 data URL.
-
-## Setup
-Please refer to the [stage configuration documentation](https://docs.vllm.ai/projects/vllm-omni/en/latest/configuration/stage_configs/) to configure memory allocation appropriately for your hardware setup.
-
-### ROCm Dependencies
-
-You will need to install the dependency `onnxruntime-rocm`.
-
-```
-pip uninstall onnxruntime # should be removed before we can install onnxruntime-rocm
-pip install onnxruntime-rocm
-```
-
-## Quick Start
-
-Run a single sample for a task:
-
-```
-python end2end.py --query-type CustomVoice
-```
-
-Generated audio files are saved to `output_audio/` by default.
-
-## Task Usage
-
-### CustomVoice
-
-Single sample:
-
-```
-python end2end.py --query-type CustomVoice
-```
-
-Batch sample (multiple prompts in one run):
-
-```
-python end2end.py --query-type CustomVoice --use-batch-sample
-```
-
-### VoiceDesign
-
-Single sample:
-
-```
-python end2end.py --query-type VoiceDesign
-```
-
-Batch sample:
-
-```
-python end2end.py --query-type VoiceDesign --use-batch-sample
-```
-
-### Base (Voice Clone)
-
-Single sample:
-
-```
-python end2end.py --query-type Base
-```
-
-Batch sample:
-
-```
-python end2end.py --query-type Base --use-batch-sample
-```
-
-Mode selection for Base:
-
-- `--mode-tag icl` (default): standard mode
-- `--mode-tag xvec_only`: enable `x_vector_only_mode` in the request
-
-Examples:
-
-```
-python end2end.py --query-type Base --mode-tag icl
-```
-
-## Voice and Language Control
-
-### Supported Voices (CustomVoice)
-
-Predefined speaker voices are set via the `speaker` (or `voice_type`) field in `additional_information`. Available speakers depend on the loaded checkpoint; check `talker_config.spk_id` in the model config for the full list. Common voices include `vivian`, `ryan`, `aiden`, `ethan`, `serena` (case-insensitive).
-
-Pass the speaker name in your request:
-
-```python
-additional_information = {
- "text": ["你好,我是通义千问"],
- "task_type": ["CustomVoice"],
- "speaker": ["Vivian"],
- "language": ["Chinese"],
-}
-```
-
-### Supported Languages
-
-The `language` field controls the codec-level language tag. Use `"Auto"` (default) for automatic detection.
-
-Supported values: `Auto`, `Chinese`, `English`, `Japanese`, `Korean`, `German`, `French`, `Russian`, `Portuguese`, `Spanish`, `Italian`.
-
-```python
-additional_information = {
- "text": ["Hello, nice to meet you."],
- "task_type": ["CustomVoice"],
- "speaker": ["Aiden"],
- "language": ["English"],
-}
-```
-
-### VoiceDesign and Base
-
-- **VoiceDesign**: Use `instruct` for natural-language voice description; no `speaker` needed.
-- **Base**: Use `ref_audio` and `ref_text` for voice cloning; `language` is optional.
-
-## Streaming Mode
-
-Add `--streaming` to stream audio chunks progressively via `AsyncOmni` (requires `async_chunk: true` in the stage config):
-
-```bash
-python end2end.py --query-type CustomVoice --streaming --output-dir /tmp/out_stream
-```
-
-Each Code2Wav chunk is logged as it arrives (default 25 frames; configurable via `codec_chunk_frames`
-in the stage config). The initial chunk size is dynamically selected based on server load for reduced
-TTFA, and can be overridden per-request via the `initial_codec_chunk_frames` API field. The final WAV file is written once generation
-completes. This demonstrates that audio data is available progressively rather than only at the end.
-
-> **Note:** Streaming uses `AsyncOmni` internally. The non-streaming path (`Omni`) is unchanged.
-
-## Batched Decoding
-
-The Code2Wav stage (stage 1) supports batched decoding, where multiple requests are decoded in a single forward pass through the SpeechTokenizer. To use it, set `max_num_seqs > 1` on both stages via `--stage-overrides` and pass multiple prompts via `--txt-prompts` with a matching `--batch-size`.
-
-```
-python end2end.py --query-type CustomVoice \
- --txt-prompts benchmark_prompts.txt \
- --batch-size 4 \
- --stage-overrides '{"0":{"max_num_seqs":4,"gpu_memory_utilization":0.2},"1":{"max_num_seqs":4,"gpu_memory_utilization":0.2}}'
-```
-
-**Important:** `--batch-size` must match a CUDA graph capture size (1, 2, 4, 8, 16...) because the Talker's code predictor KV cache is sized to `max_num_seqs`, and CUDA graphs pad the batch to the next capture size. Both stages need `max_num_seqs >= batch_size` in the stage config for batching to take effect. If only stage 1 has a higher `max_num_seqs`, it won't help — stage 1 can only batch chunks from requests that are in-flight simultaneously, which requires stage 0 to also process multiple requests concurrently.
-
-## Notes
-
-- The script uses the model paths embedded in `end2end.py`. Update them if your local cache path differs.
-- Use `--output-dir` to change the output folder.
-
-## Example materials
-
-??? abstract "benchmark_prompts.txt"
- ``````txt
- --8<-- "examples/offline_inference/qwen3_tts/benchmark_prompts.txt"
- ``````
-??? abstract "end2end.py"
- ``````py
- --8<-- "examples/offline_inference/qwen3_tts/end2end.py"
- ``````
diff --git a/docs/user_guide/examples/offline_inference/text_to_audio.md b/docs/user_guide/examples/offline_inference/text_to_audio.md
deleted file mode 100644
index a31a4d7a4d5..00000000000
--- a/docs/user_guide/examples/offline_inference/text_to_audio.md
+++ /dev/null
@@ -1,66 +0,0 @@
-# Text-To-Audio
-
-Source <https://github.com/vllm-project/vllm-omni/tree/main/examples/offline_inference/text_to_audio>.
-
-
-The `stabilityai/stable-audio-open-1.0` pipeline generates audio from text prompts.
-
-## Prerequisites
-
-If you use a gated model (e.g., `stabilityai/stable-audio-open-1.0`), ensure you have access:
-
-1. **Accept Model License**: Visit the model page on Hugging Face (e.g., [stabilityai/stable-audio-open-1.0]) and accept the user agreement.
-2. **Authenticate**: Log in to Hugging Face locally to access the gated model.
- ```bash
- huggingface-cli login
- ```
-
-## Local CLI Usage
-
-```bash
-python text_to_audio.py \
- --model stabilityai/stable-audio-open-1.0 \
- --prompt "The sound of a hammer hitting a wooden surface" \
- --negative-prompt "Low quality" \
- --seed 42 \
- --guidance-scale 7.0 \
- --audio-length 10.0 \
- --num-inference-steps 100 \
- --output stable_audio_output.wav
-```
-
-To reduce per-GPU memory for multi-GPU inference, launch with HSDP:
-
-```bash
-python text_to_audio.py \
- --model stabilityai/stable-audio-open-1.0 \
- --prompt "The sound of a hammer hitting a wooden surface" \
- --negative-prompt "Low quality" \
- --seed 42 \
- --guidance-scale 7.0 \
- --audio-length 10.0 \
- --num-inference-steps 100 \
- --use-hsdp \
- --hsdp-shard-size 2 \
- --output stable_audio_output.wav
-```
-
-Key arguments:
-
-- `--prompt`: text description (string).
-- `--negative-prompt`: negative prompt for classifier-free guidance.
-- `--seed`: integer seed for deterministic generation.
-- `--guidance-scale`: classifier-free guidance scale.
-- `--audio-length`: audio duration in seconds.
-- `--num-inference-steps`: diffusion sampling steps.(more steps = higher quality, slower).
-- `--use-hsdp`: enable HSDP weight sharding for the Stable Audio DiT.
-- `--hsdp-shard-size`: number of GPUs used for HSDP sharding.
-- `--hsdp-replicate-size`: number of HSDP replica groups.
-- `--output`: path to save the generated WAV file.
-
-## Example materials
-
-??? abstract "text_to_audio.py"
- ``````py
- --8<-- "examples/offline_inference/text_to_audio/text_to_audio.py"
- ``````
diff --git a/docs/user_guide/examples/offline_inference/text_to_image.md b/docs/user_guide/examples/offline_inference/text_to_image.md
deleted file mode 100644
index 3a97ffbf74b..00000000000
--- a/docs/user_guide/examples/offline_inference/text_to_image.md
+++ /dev/null
@@ -1,285 +0,0 @@
-# Text-To-Image
-
-Source <https://github.com/vllm-project/vllm-omni/tree/main/examples/offline_inference/text_to_image>.
-
-
-Generate images from text prompts using vLLM-Omni's diffusion pipeline entrypoints.
-
-- `text_to_image.py`: command-line script for single image generation with advanced options.
-- `gradio_demo.py`: lightweight Gradio UI for interactive prompt/seed/CFG exploration.
-
-## Table of Contents
-
-- [Overview](#overview)
-- [Quick Start](#quick-start)
-- [Key Arguments](#key-arguments)
-- [More CLI Examples](#more-cli-examples)
-- [Web UI Demo](#web-ui-demo)
-
-## Overview
-
-This folder provides several entrypoints for experimenting with text-to-image diffusion models using vLLM-Omni. Note that `NextStep-1.1` has a different architecture, so it is treated differently regarding running arguments and pipeline.
-
-### Supported Models
-
-| Model | Image Shape | Peak VRAM (GiB) * | Model Weights (GiB) |
-| ----- | ----------- | ----------- | ----------------- |
-| `Qwen/Qwen-Image` | 1024 x 1024 | 60.0 | 53.7 |
-| `Qwen/Qwen-Image-2512` |1024 x 1024 | 60.0 | 53.7 |
-| `Tongyi-MAI/Z-Image-Turbo` | 1024 x 1024 | 24.8 | 19.2 |
-| `stepfun-ai/NextStep-1.1` | 512 x 512 | 71.8 | 28.1 |
-| `meituan-longcat/LongCat-Image` | 1024 x 1024 | 71.2 | 27.3 |
-| `AIDC-AI/Ovis-Image-7B` | 1024 x 1024 | 71.8 | 17.1 |
-| `OmniGen2/OmniGen2` | 1024 x 1024 | 20.1 | 14.7 |
-| `stabilityai/stable-diffusion-3.5-medium` | 1024 x 1024 | 20.1 | 15.6 |
-| `black-forest-labs/FLUX.1-dev` | 1024 x 1024 | 77.6 | 31.4 |
-| `black-forest-labs/FLUX.2-klein-4B` | 1024 x 1024 | 72.7 | 14.9 |
-| `black-forest-labs/FLUX.2-klein-9B` | 1024 x 1024 | 37.1 | 32.3 |
-| `black-forest-labs/FLUX.2-dev` | 1024 x 1024 | 65.7 | >80 (CPU offload required) |
-
-!!! info
-*Peak VRAM: based on basic single-card usage, batch size =1, without any acceleration/optimization features. FLUX.2-dev requires `--enable-cpu-offload` on a single 80 GiB GPU.
-
-Default model: `Qwen/Qwen-Image`
-
-## Quick Start
-
-### Python API
-
-Single-prompt generation:
-
-```python
-from vllm_omni.entrypoints.omni import Omni
-
-if __name__ == "__main__":
- omni = Omni(model="Qwen/Qwen-Image")
- prompt = "a cup of coffee on the table"
- outputs = omni.generate(prompt)
- images = outputs[0].request_output.images
- images[0].save("coffee.png")
-```
-
-### Local CLI Usage
-
-```bash
-python text_to_image.py \
- --model Qwen/Qwen-Image \
- --prompt "a cup of coffee on the table" \
- --output coffee.png
-```
-
-## Key Arguments
-
-**Common arguments:**
-
-| Argument | Type | Default | Description |
-| -------- | ---- | ------- | ----------- |
-| `--prompt` | str | `"a cup of coffee on the table"` | Text description for image generation |
-| `--seed` | int | `142` | Integer seed for deterministic sampling |
-| `--negative-prompt` | str | `None` | Negative prompt for classifier-free conditional guidance |
-| `--cfg-scale` | float | `4.0` | True CFG scale (model-specific guidance strength) |
-| `--guidance-scale` | float | `1.0` | Classifier-free guidance scale |
-| `--num-images-per-prompt` | int | `1` | Number of images per prompt (saved as `output`, `output_1`, ...) |
-| `--num-inference-steps` | int | `50` | Diffusion sampling steps (more steps = higher quality, slower) |
-| `--height` | int | `1024` | Output image height in pixels |
-| `--width` | int | `1024` | Output image width in pixels |
-| `--output` | str | `"qwen_image_output.png"` | Path to save the generated image |
-| `--vae-use-slicing` | flag | off | Enable VAE slicing for memory optimization |
-| `--vae-use-tiling` | flag | off | Enable VAE tiling for memory optimization |
-| `--cfg-parallel-size` | int | `1` | Set to `2` to enable CFG Parallel |
-| `--enable-cpu-offload` | flag | off | Enable CPU offloading for diffusion models |
-| `--lora-path` | str | — | Path to PEFT LoRA adapter folder |
-| `--lora-scale` | float | `1.0` | Scale factor for LoRA weights |
-
-**NextStep-1.1 specific arguments:**
-
-| Argument | Type | Default | Description |
-| -------- | ---- | ------- | ----------- |
-| `--guidance-scale-2` | float | `1.0` | Secondary guidance scale (e.g. image-level CFG) |
-| `--timesteps-shift` | float | `1.0` | Timesteps shift parameter for sampling |
-| `--cfg-schedule` | str | `"constant"` | CFG schedule type: `"constant"` or `"linear"` |
-| `--use-norm` | flag | off | Apply layer normalization to sampled tokens |
-
-> If you encounter OOM errors, try using `--vae-use-slicing` and `--vae-use-tiling` to reduce memory usage.
-
-> Qwen-Image currently publishes best-effort presets at `1328x1328`, `1664x928`, `928x1664`, `1472x1140`, `1140x1472`, `1584x1056`, and `1056x1584`. Adjust `--height/--width` accordingly for the most reliable outcomes.
-
-## More CLI Examples
-
-### Tongyi Models
-
-```bash
-python text_to_image.py \
- --model Tongyi-MAI/Z-Image-Turbo \
- --prompt "a cup of coffee on the table" \
- --seed 42 \
- --guidance-scale 0.0 \
- --num-images-per-prompt 1 \
- --num-inference-steps 9 \
- --height 1024 \
- --width 1024 \
- --output outputs/coffee.png
-```
-
-`Tongyi-MAI/Z-Image-Turbo` is a distilled version of Z-Image. Distilled diffusion models usually require less number of inference steps (4~9), and Classifier-Free Guidance (CFG) is usually NOT applied. Similar distilled models are `black-forest-labs/FLUX.2-klein-4B` and `black-forest-labs/FLUX.2-klein-9B`.
-
-### NextStep Models
-
-NextStep-1.1 supports extra arguments for dual-level CFG control:
-
-```bash
-python text_to_image.py \
- --model stepfun-ai/NextStep-1.1 \
- --prompt "A baby panda wearing an Iron Man mask, holding a board with 'NextStep-1' written on it" \
- --height 512 \
- --width 512 \
- --num-inference-steps 28 \
- --guidance-scale 7.5 \
- --guidance-scale-2 1.0 \
- --cfg-schedule constant \
- --output nextstep_output.png \
- --seed 42
-```
-
-### FLUX.2-dev Models
-
-To run FLUX.2-dev on a single GPU, `--enable-cpu-offload` is required because the model weights exceed 80 GiB:
-
-```bash
-python examples/offline_inference/text_to_image/text_to_image.py \
- --model black-forest-labs/FLUX.2-dev \
- --prompt "a lovely bunny holding a sign that says 'vllm-omni'" \
- --seed 42 \
- --tensor-parallel-size 1 \
- --num-images-per-prompt 1 \
- --num-inference-steps 50 \
- --guidance-scale 4.0 \
- --height 1024 \
- --width 1024 \
- --enable-cpu-offload \
- --output flux2-dev.png
-```
-
-### Batch Requests (Multiple Prompts)
-
-You can pass multiple prompts in a single `generate` call.
-
-```python
-from vllm_omni.entrypoints.omni import Omni
-
-if __name__ == "__main__":
- omni = Omni(model="Qwen/Qwen-Image")
- prompts = [
- "a cup of coffee on a table",
- "a toy dinosaur on a sandy beach",
- "a fox waking up in bed and yawning",
- ]
- outputs = omni.generate(prompts)
- for i, output in enumerate(outputs):
- output.request_output.images[0].save(f"{i}.jpg")
-```
-
-!!! info
-
- Not all models support batch inference, and batch requesting mostly does not provide significant
- performance improvement. This feature is primarily for interface compatibility with vLLM and to
- allow for future improvements.
-
-!!! info
-
- For diffusion pipelines, the stage config field `stage_args.[].runtime.max_batch_size` is 1 by
- default, and the input list is sliced into single-item requests before feeding into the diffusion
- pipeline. For models that do internally support batched inputs, you can
- [modify this configuration](https://github.com/vllm-project/vllm-omni/tree/main/configuration/stage_configs.md) to let the model accept a
- longer batch of prompts.
-
-### Negative Prompts
-
-vLLM-Omni supports dictionary prompts for models that accept negative prompts:
-
-```python
-from vllm_omni.entrypoints.omni import Omni
-
-if __name__ == "__main__":
- omni = Omni(model="Qwen/Qwen-Image")
- outputs = omni.generate([
- {
- "prompt": "a cup of coffee on a table",
- "negative_prompt": "low resolution"
- },
- {
- "prompt": "a toy dinosaur on a sandy beach",
- "negative_prompt": "cinematic, realistic"
- }
- ])
- for i, output in enumerate(outputs):
- output.request_output.images[0].save(f"{i}.jpg")
-```
-
-You can also pass a negative prompt via the CLI argument `--negative-prompt`:
-
-```bash
-python examples/offline_inference/text_to_image/text_to_image.py \
- --model Qwen/Qwen-Image \
- --prompt "a cup of coffee on a table" \
- --negative-prompt "low resolution, blurry" \
- --output coffee.png
-```
-
-### Advanced Features
-
-#### CFG Parallel
-
-Set `--cfg-parallel-size 2` to enable CFG Parallel for faster inference on multi-GPU setups.
-See more examples in the [diffusion acceleration user guide](https://github.com/vllm-project/vllm-omni/tree/main/docs/user_guide/diffusion_acceleration.md#using-cfg-parallel).
-
-#### LoRA
-
-This example supports PEFT-compatible LoRA (Low-Rank Adaptation) adapters for diffusion models. Pass `--lora-path` to use a LoRA adapter and optionally `--lora-scale` (default `1.0`); omit it to use the base model only.
-
-```bash
-python text_to_image.py \
- --model Tongyi-MAI/Z-Image-Turbo \
- --prompt "A piece of cheesecake" \
- --lora-path /path/to/lora/ \
- --lora-scale 1.0 \
- --output output.png
-```
-
-LoRA adapters must be in PEFT format. A typical adapter directory structure:
-
-```
-lora_adapter/
-├── adapter_config.json
-└── adapter_model.safetensors
-```
-
-## Web UI Demo
-
-!!! note "Gradio is an optional dependency"
- The Gradio demo requires the `[demo]` extras. Install them first:
-
- ```bash
- pip install 'vllm-omni[demo]'
- ```
-
- Or, if installing from source: `pip install -e '.[demo]'`
-
-Launch the Gradio demo:
-
-```bash
-python gradio_demo.py --port 7862
-```
-
-Then open `http://localhost:7862/` in your local browser to interact with the web UI.
-
-## Example materials
-
-??? abstract "gradio_demo.py"
- ``````py
- --8<-- "examples/offline_inference/text_to_image/gradio_demo.py"
- ``````
-??? abstract "text_to_image.py"
- ``````py
- --8<-- "examples/offline_inference/text_to_image/text_to_image.py"
- ``````
diff --git a/docs/user_guide/examples/offline_inference/text_to_video.md b/docs/user_guide/examples/offline_inference/text_to_video.md
deleted file mode 100644
index a09dbfc979f..00000000000
--- a/docs/user_guide/examples/offline_inference/text_to_video.md
+++ /dev/null
@@ -1,156 +0,0 @@
-# Text-To-Video
-
-Source <https://github.com/vllm-project/vllm-omni/tree/main/examples/offline_inference/text_to_video>.
-
-
-A unified script for text-to-video generation. Supports multiple models with model-aware defaults.
-
-For backend selection and SageAttention usage, see the [Diffusion Attention Backends](../../diffusion/attention_backends.md) guide.
-
-## Supported Models
-
-| Model | Default Resolution | Default Frames | Default Steps | Guidance | VRAM (BF16) |
-|---|---|---|---|---|---|
-| `Wan-AI/Wan2.2-T2V-A14B-Diffusers` | 720x1280 | 81 | 40 | 4.0 | ~60 GiB |
-| `hunyuanvideo-community/HunyuanVideo-1.5-Diffusers-480p_t2v` | 480x832 | 121 | 50 | 6.0 | 1×A100 80GB |
-| `hunyuanvideo-community/HunyuanVideo-1.5-Diffusers-720p_t2v` | 720x1280 | 121 | 50 | 6.0 | FP8 + VAE tiling required |
-
-## Local CLI Usage
-
-### Wan2.2 (default)
-
-```bash
-python text_to_video.py \
- --prompt "Two anthropomorphic cats in comfy boxing gear and bright gloves fight intensely on a spotlighted stage." \
- --negative-prompt "<optional quality filter>" \
- --height 480 \
- --width 832 \
- --num-frames 33 \
- --guidance-scale 4.0 \
- --guidance-scale-high 3.0 \
- --flow-shift 12.0 \
- --num-inference-steps 40 \
- --fps 16 \
- --output t2v_out.mp4
-```
-
-LTX2 example:
-
-```bash
-python text_to_video.py \
- --model "Lightricks/LTX-2" \
- --prompt "A cinematic close-up of ocean waves at golden hour." \
- --negative-prompt "worst quality, inconsistent motion, blurry, jittery, distorted" \
- --height 512 \
- --width 768 \
- --num-frames 121 \
- --num-inference-steps 40 \
- --guidance-scale 4.0 \
- --frame-rate 24 \
- --output ltx2_out.mp4
-```
-
-### HunyuanVideo-1.5 (480p)
-
-```bash
-python text_to_video.py \
- --model hunyuanvideo-community/HunyuanVideo-1.5-Diffusers-480p_t2v \
- --prompt "A cat walks through a sunlit garden, flowers swaying gently in the breeze." \
- --height 480 \
- --width 832 \
- --num-frames 121 \
- --guidance-scale 6.0 \
- --flow-shift 5.0 \
- --num-inference-steps 50 \
- --fps 24 \
- --output hunyuan_video_15_output.mp4
-```
-
-### HunyuanVideo-1.5 (720p)
-
-```bash
-python text_to_video.py \
- --model hunyuanvideo-community/HunyuanVideo-1.5-Diffusers-720p_t2v \
- --prompt "A serene lakeside sunrise with mist over the water." \
- --height 720 \
- --width 1280 \
- --num-frames 121 \
- --guidance-scale 6.0 \
- --flow-shift 9.0 \
- --num-inference-steps 50 \
- --fps 24 \
- --output hunyuan_720p.mp4
-```
-
-### HunyuanVideo-1.5 with FP8 Quantization
-
-```bash
-python text_to_video.py \
- --model hunyuanvideo-community/HunyuanVideo-1.5-Diffusers-480p_t2v \
- --prompt "A dog running across a field of golden wheat." \
- --quantization fp8 \
- --height 480 --width 832 --num-frames 121 \
- --guidance-scale 6.0 --flow-shift 5.0 \
- --output hunyuan_fp8.mp4
-```
-
-Quick test (smaller resolution, fewer frames):
-
-```bash
-python text_to_video.py \
- --model hunyuanvideo-community/HunyuanVideo-1.5-Diffusers-480p_t2v \
- --prompt "A serene lakeside sunrise with mist over the water." \
- --height 320 --width 576 --num-frames 17 --num-inference-steps 30 \
- --flow-shift 5.0 \
- --output quick_test.mp4
-```
-
-## Key Arguments
-
-### Common
-
-- `--model`: Diffusers model ID or local path.
-- `--prompt`: text description (string).
-- `--height/--width`: output resolution. Default depends on model.
-- `--num-frames`: number of frames. Default depends on model.
-- `--guidance-scale`: CFG scale. Default depends on model.
-- `--num-inference-steps`: sampling steps. Default depends on model.
-- `--fps`: frames per second for the saved MP4.
-- `--output`: path to save the generated video.
-- `--vae-use-slicing`: enable VAE slicing for memory optimization.
-- `--vae-use-tiling`: enable VAE tiling for memory optimization.
-- `--cfg-parallel-size`: set it to 2 to enable CFG Parallel. See more examples in [`user_guide`](https://github.com/vllm-project/vllm-omni/tree/main/docs/user_guide/diffusion/parallelism_acceleration.md#cfg-parallel).
-- `--tensor-parallel-size`: tensor parallel size (effective for models that support TP, e.g. LTX2).
-- `--enable-cpu-offload`: enable CPU offloading for diffusion models.
-- `--enable-layerwise-offload`: enable layerwise offloading on DiT modules.
-- `--frame-rate`: generation FPS for pipelines that require it (e.g., LTX2).
-- `--audio-sample-rate`: audio sample rate for embedded audio (when the pipeline returns audio).
-- `--quantization`: quantization method (`fp8` for FP8, `gguf` for GGUF).
-- `--flow-shift`: scheduler flow_shift parameter.
-
-### Wan2.2-specific
-
-- `--negative-prompt`: artifacts to suppress.
-- `--guidance-scale-high`: separate CFG scale for high-noise stage.
-- `--boundary-ratio`: boundary split for low/high DiT (default 0.875).
-- `--flow-shift`: scheduler flow_shift (5.0 for 720p, 12.0 for 480p).
-- `--cache-backend`: `cache_dit` for acceleration.
-
-### HunyuanVideo-1.5 Optimal Configs
-
-| Variant | flow_shift | guidance_scale | steps |
-|---------|-----------|----------------|-------|
-| 480p T2V | 5.0 | 6.0 | 50 |
-| 720p T2V | 9.0 | 6.0 | 50 |
-| 480p I2V | 5.0 | 6.0 | 50 |
-| 720p I2V | 7.0 | 6.0 | 50 |
-| CFG-distilled | (same) | 1.0 | 50 |
-
-> If you encounter OOM errors, try `--vae-use-slicing`, `--vae-use-tiling`, `--enable-cpu-offload`, or `--quantization fp8`.
-
-## Example materials
-
-??? abstract "text_to_video.py"
- ``````py
- --8<-- "examples/offline_inference/text_to_video/text_to_video.py"
- ``````
diff --git a/docs/user_guide/examples/offline_inference/voxtral_tts.md b/docs/user_guide/examples/offline_inference/voxtral_tts.md
deleted file mode 100644
index 1a4f2c21b4c..00000000000
--- a/docs/user_guide/examples/offline_inference/voxtral_tts.md
+++ /dev/null
@@ -1,69 +0,0 @@
-# Voxtral TTS Offline Inference
-
-Source <https://github.com/vllm-project/vllm-omni/tree/main/examples/offline_inference/voxtral_tts>.
-
-
-`end2end.py` runs Voxtral TTS end-to-end offline inference using vLLM. It supports both blocking (`Omni`) and streaming (`AsyncOmni`) generation, batched prompts with configurable concurrency, and voice selection via preset name or reference audio file.
-
-When `mistral_common` has `SpeechRequest` support, prompt token IDs are built via `encode_speech_request`. Otherwise, the script falls back to manual token construction.
-
-## Usage Examples
-
-
-```bash
-# Basic single-prompt with cheerful_female voice preset
-python3 examples/offline_inference/voxtral_tts/end2end.py \
- --write-audio --voice cheerful_female \
- --model mistralai/Voxtral-4B-TTS-2603 \
- --text "That eerie silence after the first storm was just the calm before another round of chaos, wasn't it?"
-
-# 32 replicate prompts with cheerful_female voice preset
-python3 examples/offline_inference/voxtral_tts/end2end.py \
- --num-prompts 32 --write-audio --voice cheerful_female \
- --model mistralai/Voxtral-4B-TTS-2603 \
- --text "That eerie silence after the first storm was just the calm before another round of chaos, wasn't it?"
-
-# Streaming with neutral_female voice preset
-python3 examples/offline_inference/voxtral_tts/end2end.py \
- --streaming --write-audio --voice neutral_female \
- --model mistralai/Voxtral-4B-TTS-2603 \
- --text "That eerie silence after the first storm was just the calm before another round of chaos, wasn't it?"
-
-# 32 prompts, 8 concurrent requests per wave, streaming with neutral_female voice
-python3 examples/offline_inference/voxtral_tts/end2end.py \
- --num-prompts 32 --concurrency 8 --streaming --write-audio --voice neutral_female \
- --model mistralai/Voxtral-4B-TTS-2603 \
- --text "That eerie silence after the first storm was just the calm before another round of chaos, wasn't it?"
-
-# Short debug prompt with reference audio
-# Note: Reference audio capability is not yet released.
-python3 examples/offline_inference/voxtral_tts/end2end.py \
- --write-audio \
- --model mistralai/Voxtral-4B-TTS-2603 \
- --text "This is a test message." \
- --audio-path path/to/reference_audio.wav
-```
-
-## Arguments
-
-| Argument | Description |
-|---|---|
-| `--model PATH` | HuggingFace repo ID or local directory path (default: `mistralai/Voxtral-4B-TTS-2603`) |
-| `--text TEXT` | Text to synthesize (default: `"This is a test message."`) |
-| `--audio-path PATH` | Path to reference audio file for voice cloning |
-| `--output-dir DIR` | Directory to write output WAV files (default: `output_audio`) |
-| `--deploy-config PATH` | Override the deploy config path. If unset, auto-loads `vllm_omni/deploy/voxtral_tts.yaml` from the HF `model_type`. |
-| `--num-prompts N` | Number of replicate prompts to run for measuring performance (default: 1) |
-| `--streaming` | Use streaming generation via `AsyncOmni` (default: blocking `Omni`) |
-| `--concurrency N` | Max concurrent requests per wave (must be used with `--streaming`, must evenly divide `--num-prompts`) |
-| `--voice NAME` | Voice preset to use instead of reference audio file (e.g., casual_female, casual_male, cheerful_female, neutral_female, neutral_male) |
-| `--write-audio` | Write generated audio to WAV files |
-| `--profiling-mode` | Enable profiling mode (reduces max tokens to 50) |
-| `--log-stats` | Enable detailed statistics logging |
-
-## Example materials
-
-??? abstract "end2end.py"
- ``````py
- --8<-- "examples/offline_inference/voxtral_tts/end2end.py"
- ``````
diff --git a/docs/user_guide/examples/offline_inference/x_to_video_audio.md b/docs/user_guide/examples/offline_inference/x_to_video_audio.md
deleted file mode 100644
index cec8d47c591..00000000000
--- a/docs/user_guide/examples/offline_inference/x_to_video_audio.md
+++ /dev/null
@@ -1,94 +0,0 @@
-# X-To-Video-Audio
-
-Source <https://github.com/vllm-project/vllm-omni/tree/main/examples/offline_inference/x_to_video_audio>.
-
-
-The `DreamID-Omni` pipeline generates short videos from text, image and video.
-
-## Local CLI Usage
-### Download the Model locally
-Since DreamID-Omni combine multiple models, and without any config, so we need to download them locally.
-
-```bash
-python download_dreamid_omni.py --output-dir ./dreamid_omni
-```
-After download, the model directory will look like this:
-
-```
-dreamid_omni/
-├── DreamID-Omni/
-│ ├── dreamid_omni.safetensors
-├── MMAudio/
-│ ├── ext_weights/
-│ │ ├── best_netG.pt
-│ │ ├── v1-16.pth
-├── Wan2.2-TI2V-5B/
-│ ├── google/*
-│ ├── models_t5_umt5-xxl-enc-bf16.pth
-│ ├── Wan2.2_VAE.pth
-│
-├── model_index.json # create by download_dreamid_omni.py
-```
-
-### Run the Inference
-```python
-python x_to_video_audio.py \
- --model /path/to/dreamid_omni \
- --prompt "Two people walking together and singing happily" \
- --image-path ./example0.png ./example1.png \
- --audio-path ./example0.wav ./example1.wav \
- --video-negative-prompt "jitter, bad hands, blur, distortion" \
- --audio-negative-prompt "robotic, muffled, echo, distorted" \
- --cfg-parallel-size 2 \
- --num-inference-steps 45 \
- --height 704 \
- --width 1280 \
- --output out_dreamid_omni_twoip.mp4
-```
-In the current test scenario (2 images + 2 audio inputs), the VRAM requirement is 72GB, regardless of whether cfg-parallel is enabled or disabled.
-The VRAM usage can be reduced by enabling CPU offload via --enable-cpu-offload.
-
-
-You could take reference images/audios from the test cases in the official repo: https://github.com/Guoxu1233/DreamID-Omni
-
-For example, single IP ref resources can be found under https://github.com/Guoxu1233/DreamID-Omni/tree/main/test_case/oneip, you could download them correspondingly to your local and use them for testing.
-
-```python
-# Example usage for oneip, ref media from the official repo DreamID-Omni
-python x_to_video_audio.py \
- --model /path/to/dreamid_omni \
- --prompt "<img1>: In the frame, a woman with black long hair is identified as <sub1>.\n**Overall Environment/Scene**: A lively open-kitchen café at night; stove flames flare, steam rises, and warm pendant lights swing slightly as staff move behind her. The shot is an upper-body close-up.\n**Main Characters/Subjects Appearance**: <sub1> is a young woman with thick dark wavy hair and a side part. She wears a fitted black top under a light apron, a thin gold chain necklace, and small stud earrings.\n**Main Characters/Subjects Actions**: <sub1> tastes the sauce with a spoon, then turns her face toward the camera while still holding the spoon, her expression shifting from focused to conflicted.\n<sub1> maintains eye contact, swallows as if choosing her words, and says, <S>I keep telling myself I’m fine,but some nights it feels like I’m just performing calm.<E>" \
- --image-path 9.png \
- --audio-path 9.wav \
- --video-negative-prompt "jitter, bad hands, blur, distortion" \
- --audio-negative-prompt "robotic, muffled, echo, distorted" \
- --cfg-parallel-size 2 \
- --num-inference-steps 45 \
- --height 704 \
- --width 1280 \
- --output out_dreamid_omni_oneip.mp4
-```
-
-
-Key arguments:
-- `--prompt`: text description (string).
-- `--model`: path to the model local directory.
-- `--height/--width`: output resolution (defaults 704 * 1024).
-- `--image-path`: path to the input image list.
-- `--audio-path`: path to the input audio list, indicate the timbre of the output video.
-- `--cfg-parallel-size`: number of parallel cfg parallel (defaults 1).
-- `--num-inference-steps`: number of denoising steps (defaults 45).
-- `--video-negative-prompt`: negative prompt for video generation.
-- `--audio-negative-prompt`: negative prompt for audio generation.
-- `--enable-cpu-offload`: enable CPU offload (defaults False).
-
-## Example materials
-
-??? abstract "download_dreamid_omni.py"
- ``````py
- --8<-- "examples/offline_inference/x_to_video_audio/download_dreamid_omni.py"
- ``````
-??? abstract "x_to_video_audio.py"
- ``````py
- --8<-- "examples/offline_inference/x_to_video_audio/x_to_video_audio.py"
- ``````
diff --git a/docs/user_guide/examples/online_serving/bagel.md b/docs/user_guide/examples/online_serving/bagel.md
deleted file mode 100644
index aa8b33de802..00000000000
--- a/docs/user_guide/examples/online_serving/bagel.md
+++ /dev/null
@@ -1,339 +0,0 @@
-# BAGEL-7B-MoT
-
-Source <https://github.com/vllm-project/vllm-omni/tree/main/examples/online_serving/bagel>.
-
-## Installation
-
-Please refer to [README.md](https://github.com/vllm-project/vllm-omni/tree/main/README.md)
-
-## Architecture
-
-BAGEL-7B-MoT is a Mixture-of-Transformers (MoT) model supporting both image generation and understanding. It offers two deployment topologies:
-
-| Topology | Stages | Description |
-| :------- | :----- | :---------- |
-| **Two-stage** (default) | Stage 0 (Thinker, AR) + Stage 1 (DiT, Diffusion) | Thinker handles text/understanding via vLLM AR engine; DiT handles image generation. KV cache is transferred between stages. |
-| **Single-stage** | Stage 0 (DiT, Diffusion) only | The DiT stage contains a full LLM, ViT, VAE, and tokenizer internally. All modalities are handled within a single diffusion process. |
-
-Both topologies support all four modalities: `text2img`, `img2img`, `img2text`, `text2text`.
-
-> **Note**: These examples work with the default configuration on an **NVIDIA A100 (80GB)**. We also tested on dual **NVIDIA RTX 5000 Ada (32GB each)**. For dual-GPU setups, modify the deploy YAML to distribute stages across devices.
-
-## Launch the Server
-
-### Two-Stage (Default)
-
-The default pipeline is auto-detected from the model. No extra flags needed:
-
-```bash
-vllm serve ByteDance-Seed/BAGEL-7B-MoT --omni --port 8091
-```
-
-Or use the convenience script:
-
-```bash
-cd examples/online_serving/bagel
-bash run_server.sh
-
-# Launch a single stage per terminal
-bash run_server_stage_cli.sh --stage 0
-bash run_server_stage_cli.sh --stage 1
-```
-
-To use a custom deploy YAML (note: `--stage-configs-path` is deprecated in favor of `--deploy-config`):
-
-```bash
-vllm serve ByteDance-Seed/BAGEL-7B-MoT --omni --port 8091 \
- --deploy-config /path/to/deploy_config.yaml
-```
-
-See [`bagel.yaml`](https://github.com/vllm-project/vllm-omni/tree/main/vllm_omni/deploy/bagel.yaml) for the default two-stage deploy configuration.
-
-### Single-Stage
-
-The DiT stage contains a full LLM, ViT, VAE, and tokenizer, so it can handle all modalities (text2img, img2img, img2text, text2text, think) without a separate Thinker stage:
-
-```bash
-vllm serve ByteDance-Seed/BAGEL-7B-MoT --omni --port 8091 \
- --deploy-config vllm_omni/deploy/bagel_single_stage.yaml
-```
-
-See [`bagel_single_stage.yaml`](https://github.com/vllm-project/vllm-omni/tree/main/vllm_omni/deploy/bagel_single_stage.yaml) for configuration. The `pipeline: bagel_single_stage` field selects the single-stage topology from the pipeline registry.
-
-### Tensor Parallelism (TP)
-
-For larger models or multi-GPU environments, enable TP via CLI:
-
-```bash
-vllm serve ByteDance-Seed/BAGEL-7B-MoT --omni --port 8091 --tensor-parallel-size 2
-```
-
-Or set `tensor_parallel_size` per stage in a custom deploy YAML.
-
-### Multi-Node Deployment
-
-Deploy each stage on a **separate node** for better resource utilization. Replace `<ORCHESTRATOR_IP>` with the actual IP address of your orchestrator node.
-
-**1. Launch Stage 0 (Thinker / Orchestrator)** on the orchestrator node:
-
-```bash
-# API server port for client requests: 8000
-vllm serve ByteDance-Seed/BAGEL-7B-MoT --omni \
- --port 8000 \
- --stage-id 0 \
- --omni-master-address <ORCHESTRATOR_IP> \
- --omni-master-port 8091
-```
-
-**2. Launch Stage 1 (DiT)** on the remote node in headless mode:
-
-```bash
-vllm serve ByteDance-Seed/BAGEL-7B-MoT --omni \
- --stage-id 1 \
- --headless \
- --omni-master-address <ORCHESTRATOR_IP> \
- --omni-master-port 8091
-```
-
-Or use the convenience script:
-
-```bash
-# Terminal 1: Stage 0
-bash run_server_stage_cli.sh --stage 0
-
-# Terminal 2: Stage 1
-bash run_server_stage_cli.sh --stage 1
-
-# With extra args
-bash run_server_stage_cli.sh --stage 0 -- --tensor-parallel-size 2
-bash run_server_stage_cli.sh --stage 1 -- --gpu-memory-utilization 0.9
-```
-
-**vllm serve arguments:**
-
-| Argument | Description |
-| :------- | :---------- |
-| `--stage-id` | Which stage this process runs (0 = Thinker, 1 = DiT) |
-| `--headless` | Run without the API server (worker-only mode) |
-| `-oma` / `--omni-master-address` | Orchestrator master address |
-| `-omp` / `--omni-master-port` | Orchestrator master port |
-
-> [!IMPORTANT]
-> **Startup Order**: Stage 0 (orchestrator) must be launched **before** Stage 1 (headless).
-> Stage 0 will appear to hang on startup until Stage 1 (worker) connects — this is expected behavior.
-
-### Inter-Stage Connectors
-
-When deploying stages across nodes, configure the connector type in the deploy YAML:
-
-- **SharedMemoryConnector** (default): Used for single-node deployments. No explicit configuration needed.
-- **MooncakeTransferEngineConnector**: For multi-node setups with RDMA hardware. Defined in [`bagel.yaml`](https://github.com/vllm-project/vllm-omni/tree/main/vllm_omni/deploy/bagel.yaml) under `connectors.rdma_connector`.
-
-To use Mooncake, create a custom deploy YAML that binds `output_connectors` / `input_connectors` on each stage to the `rdma_connector` defined in the `connectors` section.
-
-## Send Requests
-
-```bash
-cd examples/online_serving/bagel
-```
-
-### Text to Image (text2img)
-
-**Python client:**
-
-```bash
-python openai_chat_client.py \
- --prompt "A beautiful sunset over mountains" \
- --modality text2img \
- --output sunset.png \
- --steps 50
-```
-
-**curl:**
-
-```bash
-curl http://localhost:8091/v1/chat/completions \
- -H "Content-Type: application/json" \
- -d '{
- "messages": [{"role": "user", "content": [{"type": "text", "text": "<|im_start|>A beautiful sunset over mountains<|im_end|>"}]}],
- "modalities": ["image"],
- "height": 512,
- "width": 512,
- "num_inference_steps": 50,
- "seed": 42
- }'
-```
-
-### Image to Image (img2img)
-
-**Python client:**
-
-```bash
-python openai_chat_client.py \
- --prompt "Make the cat stand up" \
- --modality img2img \
- --image-url /path/to/input.jpg \
- --output transformed.png
-```
-
-**curl:**
-
-```bash
-IMAGE_BASE64=$(base64 -w 0 cat.jpg)
-
-cat <<EOF > payload.json
-{
- "messages": [{
- "role": "user",
- "content": [
- {"type": "text", "text": "<|im_start|>Make the cat stand up<|im_end|>"},
- {"type": "image_url", "image_url": {"url": "data:image/jpeg;base64,${IMAGE_BASE64}"}}
- ]
- }],
- "modalities": ["image"],
- "height": 512,
- "width": 512,
- "num_inference_steps": 50,
- "seed": 42
-}
-EOF
-
-curl http://localhost:8091/v1/chat/completions \
- -H "Content-Type: application/json" \
- -d @payload.json
-```
-
-### Image to Text (img2text)
-
-**Python client:**
-
-```bash
-python openai_chat_client.py \
- --prompt "Describe this image in detail" \
- --modality img2text \
- --image-url /path/to/image.jpg
-```
-
-**curl:**
-
-```bash
-IMAGE_BASE64=$(base64 -w 0 cat.jpg)
-
-cat <<EOF > payload.json
-{
- "messages": [{
- "role": "user",
- "content": [
- {"type": "text", "text": "<|im_start|>user\n<|image_pad|>\nDescribe this image in detail<|im_end|>\n<|im_start|>assistant\n"},
- {"type": "image_url", "image_url": {"url": "data:image/jpeg;base64,${IMAGE_BASE64}"}}
- ]
- }],
- "modalities": ["text"]
-}
-EOF
-
-curl http://localhost:8091/v1/chat/completions \
- -H "Content-Type: application/json" \
- -d @payload.json
-```
-
-### Text to Text (text2text)
-
-**Python client:**
-
-```bash
-python openai_chat_client.py \
- --prompt "What is the capital of France?" \
- --modality text2text
-```
-
-**curl:**
-
-```bash
-curl http://localhost:8091/v1/chat/completions \
- -H "Content-Type: application/json" \
- -d '{
- "messages": [{"role": "user", "content": [{"type": "text", "text": "<|im_start|>user\nWhat is the capital of France?<|im_end|>\n<|im_start|>assistant\n"}]}],
- "modalities": ["text"]
- }'
-```
-
-### Python Client Arguments
-
-| Argument | Default | Description |
-| :------- | :------ | :---------- |
-| `--prompt` / `-p` | `A cute cat` | Text prompt |
-| `--output` / `-o` | `bagel_output.png` | Output file path |
-| `--server` / `-s` | `http://localhost:8091` | Server URL |
-| `--image-url` / `-i` | `None` | Input image URL or local path (img2img/img2text) |
-| `--modality` / `-m` | `text2img` | `text2img`, `img2img`, `img2text`, `text2text` |
-| `--height` | `512` | Image height in pixels |
-| `--width` | `512` | Image width in pixels |
-| `--steps` | `25` | Number of inference steps |
-| `--seed` | `42` | Random seed |
-| `--negative` | `None` | Negative prompt for CFG |
-
-Example with custom parameters:
-
-```bash
-python openai_chat_client.py \
- --prompt "A futuristic city" \
- --modality text2img \
- --height 768 \
- --width 768 \
- --steps 50 \
- --seed 42 \
- --negative "blurry, low quality"
-```
-
-## Configuration Reference
-
-### Deploy YAML Files
-
-| File | Description |
-| :--- | :---------- |
-| [`bagel.yaml`](https://github.com/vllm-project/vllm-omni/tree/main/vllm_omni/deploy/bagel.yaml) | Two-stage default (Thinker + DiT on GPU 0) |
-| [`bagel_single_stage.yaml`](https://github.com/vllm-project/vllm-omni/tree/main/vllm_omni/deploy/bagel_single_stage.yaml) | Single-stage (DiT only) |
-
-### Key Deploy YAML Fields
-
-| Field | Scope | Description |
-| :---- | :---- | :---------- |
-| `pipeline` | top-level | Override auto-detected pipeline (e.g. `bagel_single_stage`) |
-| `stages[].stage_id` | per-stage | Stage identifier (0, 1, ...) |
-| `stages[].devices` | per-stage | GPU device IDs (e.g. `"0"`, `"0,1"`) |
-| `stages[].max_num_seqs` | per-stage | Maximum concurrent sequences |
-| `stages[].gpu_memory_utilization` | per-stage | Fraction of GPU memory to use |
-| `stages[].enforce_eager` | per-stage | Disable CUDA graphs |
-| `stages[].tensor_parallel_size` | per-stage | TP degree for this stage |
-| `connectors` | top-level | Define available connector instances (SHM, Mooncake) |
-| `platforms` | top-level | Platform-specific overrides (e.g. `xpu`) |
-
-## FAQ
-
-- If you encounter OOM errors, try decreasing `max_model_len` or `gpu_memory_utilization` in the deploy YAML.
-
-**Two-stage VRAM usage:**
-
-| Stage | VRAM |
-| :---- | :--- |
-| Stage 0 (Thinker) | **15.04 GiB + KV Cache** |
-| Stage 1 (DiT) | **26.50 GiB** |
-| Total | **~42 GiB + KV Cache** |
-
-**Single-stage VRAM usage:** The DiT loads the full model (~42 GiB) in one process.
-
-## Example materials
-
-??? abstract "openai_chat_client.py"
- ``````py
- --8<-- "examples/online_serving/bagel/openai_chat_client.py"
- ``````
-??? abstract "run_server.sh"
- ``````sh
- --8<-- "examples/online_serving/bagel/run_server.sh"
- ``````
-??? abstract "run_server_stage_cli.sh"
- ``````sh
- --8<-- "examples/online_serving/bagel/run_server_stage_cli.sh"
- ``````
diff --git a/docs/user_guide/examples/online_serving/chart-helm.md b/docs/user_guide/examples/online_serving/chart-helm.md
deleted file mode 100644
index 9b077a74796..00000000000
--- a/docs/user_guide/examples/online_serving/chart-helm.md
+++ /dev/null
@@ -1,226 +0,0 @@
-# vLLM-Omni Helm Chart
-
-Source <https://github.com/vllm-project/vllm-omni/tree/main/examples/online_serving/chart-helm>.
-
-
-Helm chart for deploying [vLLM-Omni](https://github.com/vllm-project/vllm-omni) on Kubernetes. vLLM-Omni extends vLLM with omni-modality model serving, supporting text-to-image, multimodal chat, text-to-speech, and more.
-
-## Prerequisites
-
-- Kubernetes 1.24+
-- Helm 3.x
-- NVIDIA GPU nodes with [NVIDIA Device Plugin](https://github.com/NVIDIA/k8s-device-plugin)
-
-## Quick Start
-
-```bash
-helm install my-release ./chart-helm \
- --set model=Tongyi-MAI/Z-Image-Turbo
-```
-
-## Configuration
-
-### Model Selection
-
-Set the `model` value to any supported HuggingFace model ID:
-
-| Model | Type | GPUs | Notes |
-|-------|------|------|-------|
-| `Tongyi-MAI/Z-Image-Turbo` | text-to-image | 1 | Small, fast (default) |
-| `stabilityai/stable-diffusion-3.5-medium` | text-to-image | 1 | ~6GB VRAM |
-| `Qwen/Qwen-Image` | text-to-image | 1 | Large, ~40GB+ VRAM |
-| `Qwen/Qwen2.5-Omni-7B` | multimodal | 2 | Text + audio + image + video |
-| `Qwen/Qwen3-Omni-7B-Chat` | multimodal | 2 | Latest omni model |
-| `Qwen/Qwen3-TTS` | text-to-speech | 1 | TTS |
-
-### HuggingFace Token
-
-For gated models that require authentication:
-
-```bash
-helm install my-release ./chart-helm \
- --set model=Qwen/Qwen2.5-Omni-7B \
- --set hfToken=hf_xxxxx \
- --set resources.requests."nvidia\.com/gpu"=2 \
- --set resources.limits."nvidia\.com/gpu"=2
-```
-
-### Omni-Specific Flags
-
-Enable VAE memory optimizations for diffusion models:
-
-```bash
-helm install my-release ./chart-helm \
- --set model=Qwen/Qwen-Image \
- --set omniArgs.vaeUseSlicing=true \
- --set omniArgs.vaeUseTiling=true
-```
-
-Enable CPU offloading:
-
-```bash
-helm install my-release ./chart-helm \
- --set model=Qwen/Qwen-Image \
- --set omniArgs.enableCpuOffload=true
-```
-
-Pass additional raw CLI flags:
-
-```bash
-helm install my-release ./chart-helm \
- --set model=Qwen/Qwen-Image \
- --set omniArgs.extraArgs[0]="--enable-layerwise-offload"
-```
-
-### Model Cache
-
-By default, a PersistentVolumeClaim is created for the HuggingFace model cache to avoid re-downloading models on pod restarts:
-
-```yaml
-modelCache:
- enabled: true
- storageSize: "50Gi"
- storageClassName: ""
-```
-
-To use an ephemeral volume instead:
-
-```bash
-helm install my-release ./chart-helm \
- --set modelCache.enabled=false
-```
-
-### Custom Command Override
-
-To fully override the container command:
-
-```bash
-helm install my-release ./chart-helm \
- --set image.command[0]=vllm \
- --set image.command[1]=serve \
- --set image.command[2]=my-model \
- --set image.command[3]=--omni \
- --set image.command[4]=--host \
- --set image.command[5]=0.0.0.0
-```
-
-## API Endpoints
-
-Once deployed, vLLM-Omni exposes the following OpenAI-compatible endpoints:
-
-| Endpoint | Method | Description |
-|----------|--------|-------------|
-| `/health` | GET | Health check |
-| `/v1/models` | GET | List available models |
-| `/v1/chat/completions` | POST | Chat completions (text/multimodal) |
-| `/v1/images/generations` | POST | Image generation |
-| `/v1/images/edits` | POST | Image editing |
-| `/v1/audio/speech` | POST | Text-to-speech |
-
-## Files
-
-| File | Description |
-|------|-------------|
-| `Chart.yaml` | Chart metadata (name, version, maintainers) |
-| `values.yaml` | Default configuration values |
-| `values.schema.json` | JSON schema for validating values |
-| `templates/_helpers.tpl` | Helper templates for common configurations |
-| `templates/deployment.yaml` | Kubernetes Deployment |
-| `templates/service.yaml` | Kubernetes Service (ClusterIP) |
-| `templates/secrets.yaml` | Secrets (generic + HuggingFace token) |
-| `templates/pvc.yaml` | PersistentVolumeClaim for model cache |
-| `templates/configmap.yaml` | Optional ConfigMap |
-| `templates/hpa.yaml` | HorizontalPodAutoscaler |
-| `templates/poddisruptionbudget.yaml` | PodDisruptionBudget |
-| `templates/custom-objects.yaml` | Custom Kubernetes objects |
-
-## Running Tests
-
-This chart includes unit tests using [helm-unittest](https://github.com/helm-unittest/helm-unittest). Install the plugin and run tests:
-
-```bash
-# Install plugin
-helm plugin install https://github.com/helm-unittest/helm-unittest
-
-# Run tests
-helm unittest .
-```
-
-## Example materials
-
-??? abstract ".helmignore"
- ``````
- --8<-- "examples/online_serving/chart-helm/.helmignore"
- ``````
-??? abstract "Chart.yaml"
- ``````yaml
- --8<-- "examples/online_serving/chart-helm/Chart.yaml"
- ``````
-??? abstract "ct.yaml"
- ``````yaml
- --8<-- "examples/online_serving/chart-helm/ct.yaml"
- ``````
-??? abstract "lintconf.yaml"
- ``````yaml
- --8<-- "examples/online_serving/chart-helm/lintconf.yaml"
- ``````
-??? abstract "templates/_helpers.tpl"
- ``````tpl
- --8<-- "examples/online_serving/chart-helm/templates/_helpers.tpl"
- ``````
-??? abstract "templates/configmap.yaml"
- ``````yaml
- --8<-- "examples/online_serving/chart-helm/templates/configmap.yaml"
- ``````
-??? abstract "templates/custom-objects.yaml"
- ``````yaml
- --8<-- "examples/online_serving/chart-helm/templates/custom-objects.yaml"
- ``````
-??? abstract "templates/deployment.yaml"
- ``````yaml
- --8<-- "examples/online_serving/chart-helm/templates/deployment.yaml"
- ``````
-??? abstract "templates/hpa.yaml"
- ``````yaml
- --8<-- "examples/online_serving/chart-helm/templates/hpa.yaml"
- ``````
-??? abstract "templates/ingress.yaml"
- ``````yaml
- --8<-- "examples/online_serving/chart-helm/templates/ingress.yaml"
- ``````
-??? abstract "templates/poddisruptionbudget.yaml"
- ``````yaml
- --8<-- "examples/online_serving/chart-helm/templates/poddisruptionbudget.yaml"
- ``````
-??? abstract "templates/pvc.yaml"
- ``````yaml
- --8<-- "examples/online_serving/chart-helm/templates/pvc.yaml"
- ``````
-??? abstract "templates/secrets.yaml"
- ``````yaml
- --8<-- "examples/online_serving/chart-helm/templates/secrets.yaml"
- ``````
-??? abstract "templates/service.yaml"
- ``````yaml
- --8<-- "examples/online_serving/chart-helm/templates/service.yaml"
- ``````
-??? abstract "tests/deployment_test.yaml"
- ``````yaml
- --8<-- "examples/online_serving/chart-helm/tests/deployment_test.yaml"
- ``````
-??? abstract "tests/ingress_test.yaml"
- ``````yaml
- --8<-- "examples/online_serving/chart-helm/tests/ingress_test.yaml"
- ``````
-??? abstract "tests/pvc_test.yaml"
- ``````yaml
- --8<-- "examples/online_serving/chart-helm/tests/pvc_test.yaml"
- ``````
-??? abstract "tests/secrets_test.yaml"
- ``````yaml
- --8<-- "examples/online_serving/chart-helm/tests/secrets_test.yaml"
- ``````
-??? abstract "values.yaml"
- ``````yaml
- --8<-- "examples/online_serving/chart-helm/values.yaml"
- ``````
diff --git a/docs/user_guide/examples/online_serving/diffusers_pipeline_adapter.md b/docs/user_guide/examples/online_serving/diffusers_pipeline_adapter.md
deleted file mode 100644
index ac88071d53f..00000000000
--- a/docs/user_guide/examples/online_serving/diffusers_pipeline_adapter.md
+++ /dev/null
@@ -1,93 +0,0 @@
-# Diffusers Backend Adapter Example
-
-Source <https://github.com/vllm-project/vllm-omni/tree/main/examples/online_serving/diffusers_pipeline_adapter>.
-
-
-This example demonstrates how to serve any 🤗 Diffusers pipeline through vLLM-Omni
-using the `diffusers` load format.
-
-## Supported Models
-
-Any model loadable via `DiffusionPipeline.from_pretrained()` should be supported, including text-to-image, image-to-image, text-to-video, image-to-video, and text-to-audio.
-
-## Limitations
-
-The diffusers backend is a black-box adapter. The following features are NOT yet supported.
-It is not guaranteed whether they will be supported in the future.
-
-- CFG parallel execution
-- Sequence parallel execution
-- TeaCache / Cache-DiT acceleration
-- Step-wise execution (continuous batching)
-
-For these features, it is recommended to use natively supported pipelines instead.
-
-## Usage
-
-### Option 1: CLI arguments
-
-```bash
-vllm serve "stable-diffusion-v1-5/stable-diffusion-v1-5" \
- --omni \
- --diffusion-load-format diffusers \
- --diffusers-load-kwargs '{"use_safetensors": true}' \
- --diffusers-call-kwargs '{"num_inference_steps": 30, "guidance_scale": 7.5}'
-```
-
-`--diffusers-load-kwargs` and `--diffusers-call-kwargs` are only valid together with `--diffusion-load-format diffusers`.
-
-### Option 2: Stage config YAML
-
-```bash
-vllm serve stable-diffusion-v1-5/stable-diffusion-v1-5 --stage-configs-path examples/online_serving/diffusers_pipeline_adapter/stage_config.yaml --omni
-```
-
-The particular fields of interest are `model`, `diffusion_load_format`, `diffusers_load_kwargs`, and `diffusers_call_kwargs` under `engine_args`. They are the same as the CLI arguments.
-
-## Send a Request
-
-```bash
-curl http://localhost:8000/v1/images/generations \
- -H "Content-Type: application/json" \
- -d '{
- "model": "stable-diffusion-v1-5/stable-diffusion-v1-5",
- "prompt": "a photo of an astronaut riding a horse on mars",
- "n": 1,
- "size": "512x512"
- }'
-```
-
-Or refer to other documentation pages on how to request a particular input/output modality, such as `examples/online_serving/text_to_image/openai_chat_client.py`.
-
-## Configuration Reference
-
-For the diffusers adapter, set options under **`engine_args`**:
-
-### `diffusion_load_format: "diffusers"`
-
-This field selects the Hugging Face diffusers adapter path (see `DiffusersPipelineLoader`).
-
-### `diffusers_load_kwargs`
-
-Passed to `DiffusionPipeline.from_pretrained()`.
-
-This is suitable for model-specific configurations not available through the vLLM-Omni interface (such as `Omni.__init__()`, `vllm serve` CLI arguments, and stage config YAML fields outside `diffusers_load_kwargs`).
-
-When a parameter is available in the vLLM-Omni interface, it will be adapted here.
-But if that parameter is simultaneously set in both the vLLM-Omni interface and `diffusers_load_kwargs`, the **latter** will take precedence.
-
-### `diffusers_call_kwargs`
-
-Passed to `pipeline.__call__()`.
-
-This is suitable for sampling parameters not available through the vLLM-Omni interface (such as `Omni.generate()` and online serving payloads).
-
-When a parameter is available in the vLLM-Omni interface, it will be adapted here.
-But if that parameter is simultaneously set in both the vLLM-Omni interface and `diffusers_call_kwargs`, the **former** will take precedence (because it is set at request time).
-
-## Example materials
-
-??? abstract "stage_config.yaml"
- ``````yaml
- --8<-- "examples/online_serving/diffusers_pipeline_adapter/stage_config.yaml"
- ``````
diff --git a/docs/user_guide/examples/online_serving/fish_speech.md b/docs/user_guide/examples/online_serving/fish_speech.md
deleted file mode 100644
index 2a15ef44ac8..00000000000
--- a/docs/user_guide/examples/online_serving/fish_speech.md
+++ /dev/null
@@ -1,199 +0,0 @@
-# Fish Speech S2 Pro
-
-Source <https://github.com/vllm-project/vllm-omni/tree/main/examples/online_serving/fish_speech>.
-
-
-## Model
-
-| Model | Description |
-|-------|-------------|
-| `fishaudio/s2-pro` | Fish Speech S2 Pro -- 4B dual-AR TTS model with DAC codec (44.1 kHz) |
-
-## Gradio Demo
-
-!!! note "Gradio is an optional dependency"
- The Gradio demo requires the `[demo]` extras. Install them first:
-
- ```bash
- pip install 'vllm-omni[demo]'
- ```
-
- Or, if installing from source: `pip install -e '.[demo]'`
-
-An interactive Gradio demo is available with text-to-speech synthesis, voice cloning, and streaming support.
-
-```bash
-# Option 1: Launch server + Gradio together
-./run_gradio_demo.sh
-
-# Option 2: If server is already running
-python gradio_demo.py --api-base http://localhost:8091
-```
-
-Then open http://localhost:7860 in your browser.
-
-Features:
-
-- Text-to-speech synthesis
-- Voice cloning from uploaded audio or URL
-- Streaming mode (progressive PCM playback)
-
-## Launch the Server
-
-```bash
-vllm serve fishaudio/s2-pro --omni --port 8091
-```
-
-The deploy config is auto-loaded from `vllm_omni/deploy/fish_qwen3_omni.yaml`.
-
-Or use the convenience script:
-
-```bash
-./run_server.sh
-```
-
-## Send TTS Request
-
-### Using curl
-
-```bash
-# Basic TTS
-curl -X POST http://localhost:8091/v1/audio/speech \
- -H "Content-Type: application/json" \
- -d '{
- "input": "Hello, how are you?",
- "voice": "default",
- "response_format": "wav"
- }' --output output.wav
-```
-
-### Voice Cloning
-
-Provide a reference audio (URL or base64 data URL) and its transcript:
-
-```bash
-curl -X POST http://localhost:8091/v1/audio/speech \
- -H "Content-Type: application/json" \
- -d '{
- "input": "Hello, this is a cloned voice.",
- "voice": "default",
- "ref_audio": "https://example.com/reference.wav",
- "ref_text": "Transcript of the reference audio."
- }' --output cloned.wav
-```
-
-### Using Python
-
-```python
-import httpx
-
-# Basic TTS
-response = httpx.post(
- "http://localhost:8091/v1/audio/speech",
- json={
- "input": "Hello, how are you?",
- "voice": "default",
- "response_format": "wav",
- },
- timeout=300.0,
-)
-
-with open("output.wav", "wb") as f:
- f.write(response.content)
-```
-
-### Using the CLI Client
-
-```bash
-cd examples/online_serving/fish_speech
-
-# Basic TTS
-python speech_client.py --text "Hello, how are you?"
-
-# Voice cloning
-python speech_client.py \
- --text "Hello, this is a cloned voice." \
- --ref-audio /path/to/reference.wav \
- --ref-text "Transcript of the reference audio."
-
-# Streaming PCM output
-python speech_client.py --text "Hello world" --stream --output output.pcm
-```
-
-The CLI client supports:
-
-- `--api-base`: API base URL (default: `http://localhost:8091`)
-- `--model` (or `-m`): Model name (default: `fishaudio/s2-pro`)
-- `--text`: Text to synthesize (required)
-- `--ref-audio`: Reference audio for voice cloning (local path or URL)
-- `--ref-text`: Transcript of the reference audio
-- `--stream`: Enable streaming (PCM output)
-- `--response-format`: Audio format: wav, mp3, flac, pcm, aac, opus (default: wav)
-- `--output` (or `-o`): Output file path
-
-## Streaming
-
-Set `stream=true` with `response_format="pcm"` to receive raw PCM audio chunks as they are decoded:
-
-```bash
-curl -X POST http://localhost:8091/v1/audio/speech \
- -H "Content-Type: application/json" \
- -d '{
- "input": "Hello, how are you?",
- "voice": "default",
- "stream": true,
- "response_format": "pcm"
- }' --no-buffer | play -t raw -r 44100 -e signed -b 16 -c 1 -
-```
-
-**Note:** Fish Speech outputs at 44.1 kHz (unlike Qwen3-TTS which outputs at 24 kHz).
-
-## API Parameters
-
-Fish Speech uses the same `/v1/audio/speech` endpoint as Qwen3-TTS. See the [Speech API reference](https://docs.vllm.ai/projects/vllm-omni/en/latest/serving/speech_api/) for full parameter documentation.
-
-Key parameters for Fish Speech:
-
-| Parameter | Type | Default | Description |
-|-----------|------|---------|-------------|
-| `input` | string | **required** | Text to synthesize |
-| `voice` | string | "default" | Voice name (use "default" for Fish Speech) |
-| `response_format` | string | "wav" | Audio format: wav, mp3, flac, pcm, aac, opus |
-| `ref_audio` | string | null | Reference audio URL or base64 data URL for voice cloning |
-| `ref_text` | string | null | Transcript of reference audio (required for voice cloning) |
-| `max_new_tokens` | int | 4096 | Maximum tokens to generate |
-| `stream` | bool | false | Stream raw PCM chunks |
-
-## Prerequisites
-
-Install the `fish-speech` package for the DAC codec:
-
-```bash
-pip install fish-speech
-```
-
-## Troubleshooting
-
-1. **No audio output**: Make sure the `fish-speech` package is installed for the DAC decoder
-2. **Connection refused**: Ensure the server is running on the correct port
-3. **Flashinfer version mismatch**: Set `FLASHINFER_DISABLE_VERSION_CHECK=1` if you see version warnings
-4. **Out of memory**: Reduce `--gpu-memory-utilization` or use a GPU with more VRAM
-
-## Example materials
-
-??? abstract "gradio_demo.py"
- ``````py
- --8<-- "examples/online_serving/fish_speech/gradio_demo.py"
- ``````
-??? abstract "run_gradio_demo.sh"
- ``````sh
- --8<-- "examples/online_serving/fish_speech/run_gradio_demo.sh"
- ``````
-??? abstract "run_server.sh"
- ``````sh
- --8<-- "examples/online_serving/fish_speech/run_server.sh"
- ``````
-??? abstract "speech_client.py"
- ``````py
- --8<-- "examples/online_serving/fish_speech/speech_client.py"
- ``````
diff --git a/docs/user_guide/examples/online_serving/glm_image.md b/docs/user_guide/examples/online_serving/glm_image.md
deleted file mode 100644
index 4cc49e84602..00000000000
--- a/docs/user_guide/examples/online_serving/glm_image.md
+++ /dev/null
@@ -1,189 +0,0 @@
-# GLM-Image Online Serving
-
-GLM-Image is a 2-stage image generation model (AR + Diffusion) supported by vLLM-Omni's
-declarative config system. The pipeline topology and stage structure are declared in
-`vllm_omni/model_executor/models/glm_image/pipeline.py`; deployment knobs (GPU placement,
-memory, sampling params) live in `vllm_omni/deploy/glm_image.yaml`.
-
-## Start Server
-
-```bash
-vllm serve zai-org/GLM-Image --omni --port 8091
-```
-
-The config system auto-detects the pipeline from the model's `model_index.json` — no
-manual `--stage-configs-path` or `--deploy-config` needed.
-
-By default, stage 0 (AR) runs on GPU 0 and stage 1 (Diffusion) on GPU 1. To colocate
-both stages on a single GPU, override per stage:
-
-```bash
-vllm serve zai-org/GLM-Image --omni --port 8091 \
- --stage-0-devices 0 --stage-1-devices 0
-```
-
-## API Calls
-
-### Text-to-Image
-
-```bash
-curl -s http://localhost:8091/v1/chat/completions \
- -H "Content-Type: application/json" \
- -d '{
- "messages": [
- {"role": "user", "content": "A photorealistic mountain landscape at sunset"}
- ],
- "extra_body": {
- "height": 1024,
- "width": 1024,
- "num_inference_steps": 50,
- "guidance_scale": 1.5,
- "seed": 42
- }
- }' | jq -r '.choices[0].message.content[0].image_url.url' | cut -d',' -f2- | base64 -d > output.png
-```
-
-### Image-to-Image (Image Editing)
-
-```bash
-curl -s http://localhost:8091/v1/chat/completions \
- -H "Content-Type: application/json" \
- -d '{
- "messages": [
- {
- "role": "user",
- "content": [
- {"type": "text", "text": "Convert this image to watercolor style"},
- {"type": "image_url", "image_url": {"url": "data:image/png;base64,$(base64 -w0 input.png)}"}
- ]
- }
- ],
- "extra_body": {
- "height": 1024,
- "width": 1024,
- "num_inference_steps": 50,
- "guidance_scale": 1.5
- }
- }' | jq -r '.choices[0].message.content[0].image_url.url' | cut -d',' -f2- | base64 -d > output.png
-```
-
-### Using the OpenAI Python SDK
-
-```python
-from openai import OpenAI
-import base64
-
-client = OpenAI(base_url="http://localhost:8091/v1", api_key="none")
-
-response = client.chat.completions.create(
- model="zai-org/GLM-Image",
- messages=[{"role": "user", "content": "A beautiful sunset over the ocean"}],
- extra_body={
- "height": 1024,
- "width": 1024,
- "num_inference_steps": 50,
- "guidance_scale": 1.5,
- "seed": 42,
- },
-)
-
-img_url = response.choices[0].message.content[0].image_url.url
-_, b64_data = img_url.split(",", 1)
-with open("output.png", "wb") as f:
- f.write(base64.b64decode(b64_data))
-```
-
-For general-purpose request methods (curl, OpenAI SDK, Python `requests`), see
-the [Text-to-Image](text_to_image.md) and [Image-to-Image](image_to_image.md)
-guides.
-
-## Generation Parameters
-
-When using `/v1/chat/completions`, pass these inside `extra_body` in the curl
-JSON, or via the `extra_body` keyword argument in the OpenAI Python SDK (see the
-[Diffusion Chat API guide](../../../serving/diffusion_chat_api.md)).
-When using the dedicated [`/v1/images/generations`](../../../serving/image_generation_api.md)
-or [`/v1/images/edits`](../../../serving/image_edit_api.md) endpoints, pass
-the supported generation controls as top-level fields directly. For image
-dimensions and count, use `size` and `n` rather than `height` or `width`.
-
-| Parameter | Type | Default | Description |
-| --------------------- | ----- | ------- | ----------------------------------- |
-| `height` | int | 1024 | Image height in pixels |
-| `width` | int | 1024 | Image width in pixels |
-| `num_inference_steps` | int | 50 | Number of diffusion denoising steps |
-| `guidance_scale` | float | 1.5 | Classifier-free guidance scale |
-| `seed` | int | None | Optional random seed |
-| `negative_prompt` | str | None | Negative prompt |
-
-## Response Format
-
-```json
-{
- "id": "chatcmpl-xxx",
- "created": 1234567890,
- "model": "zai-org/GLM-Image",
- "choices": [
- {
- "index": 0,
- "message": {
- "role": "assistant",
- "content": [
- {
- "type": "image_url",
- "image_url": {
- "url": "data:image/png;base64,..."
- }
- }
- ]
- },
- "finish_reason": "stop"
- }
- ],
- "usage": {}
-}
-```
-
-## Extract Image
-
-```bash
-cat response.json | jq -r '.choices[0].message.content[0].image_url.url' | cut -d',' -f2- | base64 -d > output.png
-```
-
-## Architecture
-
-GLM-Image uses a 2-stage pipeline:
-
-```
-Stage 0 (AR Model) Stage 1 (Diffusion)
-┌───────────────────┐ ┌─────────────────────┐
-│ vLLM-optimized │ prior │ GlmImagePipeline │
-│ GlmImageFor │──tokens──►│ ┌───────────────┐ │
-│ Conditional │ │ │ DiT Denoiser │ │
-│ Generation │ │ └───────┬───────┘ │
-│ (9B AR model) │ │ ▼ │
-└───────────────────┘ │ ┌───────────────┐ │
- ▲ │ │ VAE Decode │──┼──► Image
- │ │ └───────────────┘ │
- Text / Image └─────────────────────┘
- Input
-```
-
-## VRAM Requirements
-
-| Stage | VRAM |
-| :---------------- | :--------------------- |
-| Stage-0 (AR) | **~18 GiB + KV Cache** |
-| Stage-1 (DiT+VAE) | **~20 GiB** |
-| Total | **~38 GiB + KV Cache** |
-
-## FAQ
-
-- If you encounter OOM errors, adjust `gpu_memory_utilization` in the deploy config:
-
-```yaml
-# In vllm_omni/deploy/glm_image.yaml, reduce from default 0.6:
-gpu_memory_utilization: 0.5
-```
-
-- The first request may be slow due to model warmup. Subsequent requests will be faster.
diff --git a/docs/user_guide/examples/online_serving/image_to_image.md b/docs/user_guide/examples/online_serving/image_to_image.md
deleted file mode 100644
index f40173c4fd5..00000000000
--- a/docs/user_guide/examples/online_serving/image_to_image.md
+++ /dev/null
@@ -1,444 +0,0 @@
-# Image-To-Image
-
-Source <https://github.com/vllm-project/vllm-omni/tree/main/examples/online_serving/image_to_image>.
-
-
-This example demonstrates how to deploy Qwen-Image-Edit model for online image editing service using vLLM-Omni.
-
-For **multi-image** input editing, use **Qwen-Image-Edit-2509** (QwenImageEditPlusPipeline) and send multiple images in the user message content.
-
-## Start Server
-
-### Basic Start
-
-```bash
-vllm serve Qwen/Qwen-Image-Edit --omni --port 8092
-```
-
-!!! note
- If you encounter Out-of-Memory (OOM) issues or have limited GPU memory, you can enable VAE slicing and tiling to reduce memory usage, --vae-use-slicing --vae-use-tiling
-
-### Multi-Image Edit (Qwen-Image-Edit-2509)
-
-```bash
-vllm serve Qwen/Qwen-Image-Edit-2509 --omni --port 8092
-```
-
-### Start with Parameters
-
-
-Or use the startup script:
-
-```bash
-bash run_server.sh
-```
-
-To serve Qwen-Image-Edit-2509 with the script:
-
-```bash
-MODEL=Qwen/Qwen-Image-Edit-2509 bash run_server.sh
-```
-
-## API Calls
-
-### Method 1: Using curl (Image Editing)
-
-```bash
-# Image editing
-bash run_curl_image_edit.sh input.png "Convert this image to watercolor style"
-
-# Or execute directly
-IMG_B64=$(base64 -w0 input.png)
-
-cat <<EOF > request.json
-{
- "messages": [{
- "role": "user",
- "content": [
- {"type": "text", "text": "Convert this image to watercolor style"},
- {"type": "image_url", "image_url": {"url": "data:image/png;base64,$IMG_B64"}}
- ]
- }],
- "extra_body": {
- "height": 1024,
- "width": 1024,
- "num_inference_steps": 50,
- "guidance_scale": 1,
- "seed": 42
- }
-}
-EOF
-
-curl -s http://localhost:8092/v1/chat/completions \
- -H "Content-Type: application/json" \
- -d @request.json \
- | jq -r '.choices[0].message.content[0].image_url.url' \
- | cut -d',' -f2 | base64 -d > output.png
-```
-
-### Method 2: Using OpenAI Python SDK
-
-```python
-import base64
-from openai import OpenAI
-
-client = OpenAI(base_url="http://localhost:8092/v1", api_key="none")
-
-with open("input.png", "rb") as f:
- img_b64 = base64.b64encode(f.read()).decode()
-
-response = client.chat.completions.create(
- model="Qwen/Qwen-Image-Edit",
- messages=[{
- "role": "user",
- "content": [
- {"type": "text", "text": "Convert to watercolor style"},
- {"type": "image_url", "image_url": {
- "url": f"data:image/png;base64,{img_b64}"
- }},
- ],
- }],
- extra_body={
- "num_inference_steps": 50,
- "guidance_scale": 1,
- "seed": 42,
- },
-)
-
-img_url = response.choices[0].message.content[0].image_url.url
-_, b64_data = img_url.split(",", 1)
-with open("output.png", "wb") as f:
- f.write(base64.b64decode(b64_data))
-```
-
-### Method 3: Using Python Client Script
-
-```bash
-python openai_chat_client.py --input input.png --prompt "Convert to oil painting style" --output output.png
-
-# Multi-image editing (Qwen-Image-Edit-2509 server required)
-python openai_chat_client.py --input input1.png input2.png --prompt "Combine these images into a single scene" --output output.png
-```
-
-### Method 4: Using Gradio Demo
-
-!!! note "Gradio is an optional dependency"
- The Gradio demo requires the `[demo]` extras. Install them first:
-
- ```bash
- pip install 'vllm-omni[demo]'
- ```
-
- Or, if installing from source: `pip install -e '.[demo]'`
-
-```bash
-python gradio_demo.py
-# Visit http://localhost:7861
-```
-
-## Request Format
-
-### Image Editing (Using image_url Format)
-
-```json
-{
- "messages": [
- {
- "role": "user",
- "content": [
- {"type": "text", "text": "Convert this image to watercolor style"},
- {"type": "image_url", "image_url": {"url": "data:image/png;base64,..."}}
- ]
- }
- ]
-}
-```
-
-### Image Editing (Using Simplified image Format)
-
-```json
-{
- "messages": [
- {
- "role": "user",
- "content": [
- {"text": "Convert this image to watercolor style"},
- {"image": "BASE64_IMAGE_DATA"}
- ]
- }
- ]
-}
-```
-
-### Image Editing with Parameters
-
-Wrap generation parameters inside `extra_body` in the request JSON:
-
-```json
-{
- "messages": [
- {
- "role": "user",
- "content": [
- {"type": "text", "text": "Convert to ink wash painting style"},
- {"type": "image_url", "image_url": {"url": "data:image/png;base64,..."}}
- ]
- }
- ],
- "extra_body": {
- "height": 1024,
- "width": 1024,
- "num_inference_steps": 50,
- "guidance_scale": 7.5,
- "seed": 42
- }
-}
-```
-
-!!! tip "Using the OpenAI SDK"
- When using the OpenAI Python SDK, pass these parameters via the `extra_body`
- keyword argument. The SDK merges them into the top-level request body automatically:
-
- ```python
- client.chat.completions.create(
- model="Qwen/Qwen-Image-Edit",
- messages=[...],
- extra_body={"num_inference_steps": 50, "guidance_scale": 7.5, "seed": 42},
- )
- ```
-
- For details on how generation parameters are handled across different clients, see the
- [Diffusion Chat API guide](../../../../serving/diffusion_chat_api.md).
-
-### Layered Image Generation (Qwen-Image-Layered)
-
-Qwen-Image-Layered generates multiple decomposed layers from a reference image and a text prompt.
-Start the server with:
-
-```bash
-vllm serve Qwen/Qwen-Image-Layered --omni --port 8093
-```
-
-=== "curl"
-
- ```bash
- IMG_B64=$(base64 -w0 input.png)
-
- curl -sS http://localhost:8093/v1/chat/completions \
- -H "Content-Type: application/json" \
- -d "$(jq -n --arg img "$IMG_B64" '{
- messages: [{
- role: "user",
- content: [
- {type: "image_url", image_url: {url: ("data:image/png;base64," + $img)}},
- {type: "text", text: "a rabbit"}
- ]
- }],
- extra_body: {
- num_inference_steps: 50,
- cfg_scale: 4.0,
- seed: 0,
- layers: 4,
- resolution: 640
- }
- }')" \
- | jq -r '.choices[0].message.content[] | .image_url.url | split(",")[1]' \
- | while IFS= read -r b64; do
- ((i++)); echo "$b64" | base64 -d > "layer_${i}.png"
- done
- ```
-
-=== "OpenAI SDK"
-
- ```python
- import base64
- from openai import OpenAI
-
- client = OpenAI(base_url="http://localhost:8093/v1", api_key="none")
-
- with open("input.png", "rb") as f:
- img_b64 = base64.b64encode(f.read()).decode()
-
- response = client.chat.completions.create(
- model="Qwen/Qwen-Image-Layered",
- messages=[{
- "role": "user",
- "content": [
- {"type": "image_url", "image_url": {
- "url": f"data:image/png;base64,{img_b64}"
- }},
- {"type": "text", "text": "a rabbit"},
- ],
- }],
- extra_body={
- "num_inference_steps": 50,
- "cfg_scale": 4.0,
- "seed": 0,
- "layers": 4,
- "resolution": 640,
- },
- )
-
- for i, item in enumerate(response.choices[0].message.content):
- _, b64_data = item.image_url.url.split(",", 1)
- with open(f"layer_{i}.png", "wb") as f:
- f.write(base64.b64decode(b64_data))
- ```
-
-=== "Python requests"
-
- ```python
- import base64
- import requests
-
- with open("input.png", "rb") as f:
- img_b64 = base64.b64encode(f.read()).decode()
-
- payload = {
- "messages": [{
- "role": "user",
- "content": [
- {"type": "image_url", "image_url": {
- "url": f"data:image/png;base64,{img_b64}"
- }},
- {"type": "text", "text": "a rabbit"},
- ],
- }],
- "extra_body": {
- "num_inference_steps": 50,
- "cfg_scale": 4.0,
- "seed": 0,
- "layers": 4,
- "resolution": 640,
- },
- }
-
- resp = requests.post(
- "http://localhost:8093/v1/chat/completions",
- json=payload,
- timeout=600,
- )
- data = resp.json()
-
- for i, item in enumerate(data["choices"][0]["message"]["content"]):
- _, b64_data = item["image_url"]["url"].split(",", 1)
- with open(f"layer_{i}.png", "wb") as f:
- f.write(base64.b64decode(b64_data))
- ```
-
-The response contains multiple images in `choices[0].message.content` — one per generated layer.
-
-#### Qwen-Image-Layered Parameters
-
-| Parameter | Type | Default | Description |
-|-----------|------|---------|-------------|
-| `layers` | int | 4 | Number of layers to decompose |
-| `resolution` | int | 640 | Resolution for dimension calculation (640 or 1024) |
-| `cfg_scale` | float | 4.0 | Classifier-free guidance scale (alias for `true_cfg_scale`) |
-| `num_inference_steps` | int | 50 | Number of denoising steps |
-| `seed` | int | None | Random seed for reproducibility |
-
-### Multi-Image Editing (Qwen-Image-Edit-2509)
-
-Provide multiple images in `content` (order matters):
-
-```json
-{
- "messages": [
- {
- "role": "user",
- "content": [
- {"type": "text", "text": "Combine these images into a single scene"},
- {"type": "image_url", "image_url": {"url": "data:image/png;base64,..."} },
- {"type": "image_url", "image_url": {"url": "data:image/png;base64,..."} }
- ]
- }
- ]
-}
-```
-
-## Generation Parameters
-
-When using `/v1/chat/completions`, pass these inside `extra_body` in the curl
-JSON, or via the `extra_body` keyword argument in the OpenAI Python SDK (see the
-[Diffusion Chat API guide](../../../../serving/diffusion_chat_api.md)).
-When using the dedicated [`/v1/images/edits`](../../../../serving/image_edit_api.md)
-endpoint, pass the supported generation controls as top-level form fields
-directly. For image dimensions and count, use `size` and `n` rather than
-`height`, `width`, or `num_outputs_per_prompt`.
-
-| Parameter | Type | Default | Description |
-| ------------------------ | ----- | ------- | ------------------------------------- |
-| `height` | int | None | Output image height in pixels |
-| `width` | int | None | Output image width in pixels |
-| `size` | str | None | Output image size (e.g., "1024x1024") |
-| `num_inference_steps` | int | 50 | Number of denoising steps |
-| `guidance_scale` | float | 1.0 | CFG guidance scale |
-| `seed` | int | None | Random seed (reproducible) |
-| `negative_prompt` | str | None | Negative prompt |
-| `num_outputs_per_prompt` | int | 1 | Number of images to generate |
-| `layers` | int | 4 | Number of layers (Qwen-Image-Layered) |
-| `resolution` | int | 640 | Resolution, 640 or 1024 (Qwen-Image-Layered) |
-
-## Response Format
-
-```json
-{
- "id": "chatcmpl-xxx",
- "created": 1234567890,
- "model": "Qwen/Qwen-Image-Edit",
- "choices": [{
- "index": 0,
- "message": {
- "role": "assistant",
- "content": [{
- "type": "image_url",
- "image_url": {
- "url": "data:image/png;base64,..."
- }
- }]
- },
- "finish_reason": "stop"
- }],
- "usage": {...}
-}
-```
-
-## Common Editing Instructions Examples
-
-| Instruction | Description |
-| ---------------------------------------- | ---------------- |
-| `Convert this image to watercolor style` | Style transfer |
-| `Convert the image to black and white` | Desaturation |
-| `Enhance the color saturation` | Color adjustment |
-| `Convert to cartoon style` | Cartoonization |
-| `Add vintage filter effect` | Filter effect |
-| `Convert daytime scene to nighttime` | Scene conversion |
-
-## File Description
-
-| File | Description |
-| ------------------------ | ---------------------------- |
-| `run_server.sh` | Server startup script |
-| `run_curl_image_edit.sh` | curl image editing example |
-| `openai_chat_client.py` | Python client |
-| `gradio_demo.py` | Gradio interactive interface |
-
-## Example materials
-
-??? abstract "gradio_demo.py"
- ``````py
- --8<-- "examples/online_serving/image_to_image/gradio_demo.py"
- ``````
-??? abstract "openai_chat_client.py"
- ``````py
- --8<-- "examples/online_serving/image_to_image/openai_chat_client.py"
- ``````
-??? abstract "run_curl_image_edit.sh"
- ``````sh
- --8<-- "examples/online_serving/image_to_image/run_curl_image_edit.sh"
- ``````
-??? abstract "run_server.sh"
- ``````sh
- --8<-- "examples/online_serving/image_to_image/run_server.sh"
- ``````
diff --git a/docs/user_guide/examples/online_serving/image_to_video.md b/docs/user_guide/examples/online_serving/image_to_video.md
deleted file mode 100644
index 781f0c2a5ed..00000000000
--- a/docs/user_guide/examples/online_serving/image_to_video.md
+++ /dev/null
@@ -1,284 +0,0 @@
-# Image-To-Video
-
-Source <https://github.com/vllm-project/vllm-omni/tree/main/examples/online_serving/image_to_video>.
-
-
-This example demonstrates how to deploy the Wan2.2 image-to-video model for online video generation using vLLM-Omni.
-
-## Start Server
-
-### Basic Start
-
-```bash
-vllm serve Wan-AI/Wan2.2-I2V-A14B-Diffusers --omni --port 8091
-```
-
-### Start with Parameters
-
-Or use the startup script:
-
-```bash
-bash run_server.sh
-```
-
-The script allows overriding:
-- `MODEL` (default: `Wan-AI/Wan2.2-I2V-A14B-Diffusers`)
-- `PORT` (default: `8091`)
-- `BOUNDARY_RATIO` (default: `0.875`)
-- `FLOW_SHIFT` (default: `12.0`)
-- `CACHE_BACKEND` (default: `none`)
-- `ENABLE_CACHE_DIT_SUMMARY` (default: `0`)
-
-## Async Job Behavior
-
-`POST /v1/videos` is asynchronous. It creates a video job and immediately
-returns metadata like the job ID and initial `queued` status. To get the final
-artifact, poll the job status and then download the completed file from the
-content endpoint.
-
-The main endpoints are:
-- `POST /v1/videos`: create a video generation job (async)
-- `POST /v1/videos/sync`: generate a video and return raw bytes (sync, for benchmarks)
-- `GET /v1/videos/{video_id}`: retrieve the current job status and metadata
-- `GET /v1/videos`: list stored video jobs
-- `GET /v1/videos/{video_id}/content`: download the generated video file
-- `DELETE /v1/videos/{video_id}`: delete the job and any stored output
-
-## Sync API (Benchmark / Testing)
-
-`POST /v1/videos/sync` is a synchronous alternative that blocks until generation
-completes and returns the raw video bytes (`video/mp4`) directly in the response
-body. It is designed for benchmark and testing scenarios where one-shot
-request/response latency measurement is needed.
-
-The sync endpoint accepts the same form parameters as `POST /v1/videos`. It does
-not create any stored job record — the response is purely the generated video
-file. Metadata is returned via response headers:
-
-- `X-Request-Id`: unique identifier for this generation request
-- `X-Model`: model name used for generation
-- `X-Inference-Time-S`: wall-clock inference time in seconds
-
-```bash
-curl -X POST http://localhost:8091/v1/videos/sync \
- -F "prompt=A bear playing with yarn, smooth motion" \
- -F "input_reference=@/path/to/input.png" \
- -F "size=832x480" \
- -F "num_frames=33" \
- -F "fps=16" \
- -F "negative_prompt=low quality, blurry, static" \
- -F "num_inference_steps=40" \
- -F "guidance_scale=1.0" \
- -F "guidance_scale_2=1.0" \
- -F "boundary_ratio=0.875" \
- -F "flow_shift=12.0" \
- -F "enable_frame_interpolation=true" \
- -F "frame_interpolation_exp=1" \
- -F "frame_interpolation_scale=1.0" \
- -F "seed=42" \
- -o sync_i2v_output.mp4
-```
-
-## Storage
-
-Generated video files are stored on local disk by the async video API.
-Local file storage behavior can be controlled via the following environment variables:
-
-- `VLLM_OMNI_STORAGE_PATH`: directory used for generated files (default: `/tmp/storage`)
-- `VLLM_OMNI_STORAGE_MAX_CONCURRENCY`: max concurrent save/delete operations (default: `4`)
-
-Example:
-
-```bash
-export VLLM_OMNI_STORAGE_PATH=/var/tmp/vllm-omni-videos
-export VLLM_OMNI_STORAGE_MAX_CONCURRENCY=8
-```
-
-## API Calls
-
-### Method 1: Using curl
-
-```bash
-# Basic image-to-video generation
-bash run_curl_image_to_video.sh
-
-# Or execute directly (OpenAI-style multipart)
-create_response=$(curl -s http://localhost:8091/v1/videos \
- -H "Accept: application/json" \
- -F "prompt=A bear playing with yarn, smooth motion" \
- -F "negative_prompt=low quality, blurry, static" \
- -F "input_reference=@/path/to/qwen-bear.png" \
- -F "width=832" \
- -F "height=480" \
- -F "num_frames=33" \
- -F "fps=16" \
- -F "num_inference_steps=40" \
- -F "guidance_scale=1.0" \
- -F "guidance_scale_2=1.0" \
- -F "boundary_ratio=0.875" \
- -F "flow_shift=12.0" \
- -F "enable_frame_interpolation=true" \
- -F "frame_interpolation_exp=1" \
- -F "frame_interpolation_scale=1.0" \
- -F "seed=42")
-
-video_id=$(echo "$create_response" | jq -r '.id')
-while true; do
- status=$(curl -s "http://localhost:8091/v1/videos/${video_id}" | jq -r '.status')
- if [ "$status" = "completed" ]; then
- break
- fi
- if [ "$status" = "failed" ]; then
- echo "Video generation failed"
- exit 1
- fi
- sleep 2
-done
-
-curl -s "http://localhost:8091/v1/videos/${video_id}" | jq .
-curl -L "http://localhost:8091/v1/videos/${video_id}/content" -o wan22_i2v_output.mp4
-```
-
-## Request Format
-
-### Required Fields
-
-```bash
-curl -X POST http://localhost:8091/v1/videos \
- -F "prompt=A bear playing with yarn, smooth motion" \
- -F "negative_prompt=low quality, blurry, static" \
- -F "input_reference=@/path/to/qwen-bear.png"
-```
-
-### Alternative JSON-Safe Reference Input
-
-Use `image_reference` when you want to pass a URL or JSON-safe image reference
-instead of uploading a file. Do not send `input_reference` and
-`image_reference` together.
-
-```bash
-curl -X POST http://localhost:8091/v1/videos \
- -F "prompt=A bear playing with yarn, smooth motion" \
- -F 'image_reference={"image_url":"https://example.com/qwen-bear.png"}'
-```
-
-### Generation with Parameters
-
-```bash
-curl -X POST http://localhost:8091/v1/videos \
- -F "prompt=A bear playing with yarn, smooth motion" \
- -F "negative_prompt=low quality, blurry, static" \
- -F "input_reference=@/path/to/qwen-bear.png" \
- -F "width=832" \
- -F "height=480" \
- -F "num_frames=33" \
- -F "fps=16" \
- -F "num_inference_steps=40" \
- -F "guidance_scale=1.0" \
- -F "guidance_scale_2=1.0" \
- -F "boundary_ratio=0.875" \
- -F "flow_shift=12.0" \
- -F "enable_frame_interpolation=true" \
- -F "frame_interpolation_exp=1" \
- -F "frame_interpolation_scale=1.0" \
- -F "seed=42"
-```
-
-Frame interpolation is also available for supported Wan2.2 I2V requests. See
-[Frame Interpolation](../../diffusion/frame_interpolation.md) for worker-side
-execution details and feature constraints.
-
-### Frame Interpolation Example
-
-```bash
-curl -X POST http://localhost:8091/v1/videos/sync \
- -F "prompt=A bear playing with yarn, smooth motion" \
- -F "input_reference=@/path/to/qwen-bear.png" \
- -F "width=832" \
- -F "height=480" \
- -F "num_frames=33" \
- -F "fps=16" \
- -F "num_inference_steps=40" \
- -F "guidance_scale=1.0" \
- -F "guidance_scale_2=1.0" \
- -F "enable_frame_interpolation=true" \
- -F "frame_interpolation_exp=1" \
- -F "frame_interpolation_scale=1.0" \
- -o sync_i2v_interpolated.mp4
-```
-
-## Create Response Format
-
-`POST /v1/videos` returns a job record, not inline base64 video data.
-
-```json
-{
- "id": "video_gen_123",
- "object": "video",
- "status": "queued",
- "model": "Wan-AI/Wan2.2-I2V-A14B-Diffusers",
- "prompt": "A bear playing with yarn, smooth motion",
- "created_at": 1234567890
-}
-```
-
-## Retrieve, List, Download, and Delete
-
-### Retrieve a job
-
-```bash
-curl -s http://localhost:8091/v1/videos/${video_id} | jq .
-```
-
-### List jobs
-
-```bash
-curl -s http://localhost:8091/v1/videos | jq .
-```
-
-### Download the completed video
-
-```bash
-curl -L http://localhost:8091/v1/videos/${video_id}/content -o wan22_i2v_output.mp4
-```
-
-### Delete a job and its stored file
-
-```bash
-curl -X DELETE http://localhost:8091/v1/videos/${video_id} | jq .
-```
-
-## Poll Until Complete
-
-```bash
-while true; do
- status=$(curl -s http://localhost:8091/v1/videos/${video_id} | jq -r '.status')
- if [ "$status" = "completed" ]; then
- break
- fi
- if [ "$status" = "failed" ]; then
- echo "Video generation failed"
- exit 1
- fi
- sleep 2
-done
-```
-
-## Example materials
-
-??? abstract "run_curl_hunyuan_video_15.sh"
- ``````sh
- --8<-- "examples/online_serving/image_to_video/run_curl_hunyuan_video_15.sh"
- ``````
-??? abstract "run_curl_image_to_video.sh"
- ``````sh
- --8<-- "examples/online_serving/image_to_video/run_curl_image_to_video.sh"
- ``````
-??? abstract "run_server.sh"
- ``````sh
- --8<-- "examples/online_serving/image_to_video/run_server.sh"
- ``````
-??? abstract "run_server_hunyuan_video_15.sh"
- ``````sh
- --8<-- "examples/online_serving/image_to_video/run_server_hunyuan_video_15.sh"
- ``````
diff --git a/docs/user_guide/examples/online_serving/mimo_audio.md b/docs/user_guide/examples/online_serving/mimo_audio.md
deleted file mode 100644
index c8752f5782e..00000000000
--- a/docs/user_guide/examples/online_serving/mimo_audio.md
+++ /dev/null
@@ -1,72 +0,0 @@
-# Online serving Example of vLLM-Omni for MiMo-Audio
-
-Source <https://github.com/vllm-project/vllm-omni/tree/main/examples/online_serving/mimo_audio>.
-
-
-## 🛠️ Installation
-
-Please refer to [README.md](https://github.com/vllm-project/vllm-omni/tree/main/README.md)
-
-## Run examples (MiMo-Audio)
-
-### Launch the Server
-```bash
-export MIMO_AUDIO_TOKENIZER_PATH="XiaomiMiMo/MiMo-Audio-Tokenizer"
-
-vllm serve XiaomiMiMo/MiMo-Audio-7B-Instruct --omni \
- --served-model-name "MiMo-Audio-7B-Instruct" \
- --port 18091 \
- --chat-template ./examples/online_serving/mimo_audio/chat_template.jinja
-```
-> ⚠️ **Important**
-> **MiMo-Audio is not compatible with the default chat template.**
-> The provided `chat_template.jinja` implements MiMo-specific role, audio token, and instruction formatting and **must be used for all inference**.
-
-
-### Send Multi-modal Request
-
-Get into the example folder
-```bash
-cd examples/online_serving/mimo_audio
-```
-
-#### Send request via python
-
-```bash
-# Audio dialogue task
-python openai_chat_completion_client_for_multimodal_generation.py \
---query-type multi_audios \
---message-json ../../offline_inference/mimo_audio/message_base64_wav.json
-```
-
-The Python client supports the following command-line arguments:
-
-- `--query-type` (or `-q`): Query type (default: `multi_audios`)
- - Options: `multi_audios`, `text`
-- `--message-json` (or `-m`): Path to `base64` multi rounds audio messages json file
- - Do not pass any value for "text" query type
- - Supports local file paths (automatically encoded to base64) or HTTP/HTTPS URLs, only for "Are these two audio clips the same?" task
- - Example: `---message-json ./examples/offline_inference/mimo_audio/message_base64_wav.json`
-- `--prompt` (or `-p`): Custom text prompt/question, only for query type is "text"(TTS task)
- - Attention! Do not pass any value for "multi_audios" query type
- - Example: `--prompt "What are the main activities shown in this video?"`
-
-
-For example, to use multi rounds audios with local files:
-
-```bash
-python openai_chat_completion_client_for_multimodal_generation.py \
---query-type multi_audios \
---message-json ../../offline_inference/mimo_audio/message_base64_wav.json
-```
-
-## Example materials
-
-??? abstract "chat_template.jinja"
- ``````jinja
- --8<-- "examples/online_serving/mimo_audio/chat_template.jinja"
- ``````
-??? abstract "openai_chat_completion_client_for_multimodal_generation.py"
- ``````py
- --8<-- "examples/online_serving/mimo_audio/openai_chat_completion_client_for_multimodal_generation.py"
- ``````
diff --git a/docs/user_guide/examples/online_serving/qwen2_5_omni.md b/docs/user_guide/examples/online_serving/qwen2_5_omni.md
deleted file mode 100644
index b3a2c9f2ac9..00000000000
--- a/docs/user_guide/examples/online_serving/qwen2_5_omni.md
+++ /dev/null
@@ -1,234 +0,0 @@
-# Qwen2.5-Omni
-
-Source <https://github.com/vllm-project/vllm-omni/tree/main/examples/online_serving/qwen2_5_omni>.
-
-
-## 🛠️ Installation
-
-Please refer to [README.md](https://github.com/vllm-project/vllm-omni/tree/main/README.md)
-
-## Run examples (Qwen2.5-Omni)
-
-### Launch the Server
-
-```bash
-vllm serve Qwen/Qwen2.5-Omni-7B --omni --port 8091
-```
-
-If you have custom stage configs file, launch the server with command below
-```bash
-vllm serve Qwen/Qwen2.5-Omni-7B --omni --port 8091 --stage-configs-path /path/to/stage_configs_file
-```
-
-### Send Multi-modal Request
-
-Get into the example folder
-```bash
-cd examples/online_serving/qwen2_5_omni
-```
-
-#### Send request via python
-
-```bash
-python openai_chat_completion_client_for_multimodal_generation.py --query-type mixed_modalities --port 8091 --host "localhost"
-```
-
-The Python client supports the following command-line arguments:
-
-- `--query-type` (or `-q`): Query type (default: `mixed_modalities`). Options: `mixed_modalities`, `use_audio_in_video`, `multi_audios`, `text`
-- `--video-path` (or `-v`): Path to local video file or URL. If not provided and query-type uses video, uses default video URL. Supports local file paths (automatically encoded to base64) or HTTP/HTTPS URLs. Example: `--video-path /path/to/video.mp4` or `--video-path https://example.com/video.mp4`
-- `--image-path` (or `-i`): Path to local image file or URL. If not provided and query-type uses image, uses default image URL. Supports local file paths (automatically encoded to base64) or HTTP/HTTPS URLs and common image formats: JPEG, PNG, GIF, WebP. Example: `--image-path /path/to/image.jpg` or `--image-path https://example.com/image.png`
-- `--audio-path` (or `-a`): Path to local audio file or URL. If not provided and query-type uses audio, uses default audio URL. Supports local file paths (automatically encoded to base64) or HTTP/HTTPS URLs and common audio formats: MP3, WAV, OGG, FLAC, M4A. Example: `--audio-path /path/to/audio.wav` or `--audio-path https://example.com/audio.mp3`
-- `--prompt` (or `-p`): Custom text prompt/question. If not provided, uses default prompt for the selected query type. Example: `--prompt "What are the main activities shown in this video?"`
-
-
-For example, to use mixed modalities with all local files:
-
-```bash
-python openai_chat_completion_client_for_multimodal_generation.py \
- --query-type mixed_modalities \
- --video-path /path/to/your/video.mp4 \
- --image-path /path/to/your/image.jpg \
- --audio-path /path/to/your/audio.wav \
- --prompt "Analyze all the media content and provide a comprehensive summary."
-```
-
-#### Send request via curl
-
-```bash
-bash run_curl_multimodal_generation.sh mixed_modalities
-```
-
-## Modality control
-You can control output modalities to specify which types of output the model should generate. This is useful when you only need text output and want to skip audio generation stages for better performance.
-
-### Supported modalities
-
-| Modalities | Output |
-|------------|--------|
-| `["text"]` | Text only |
-| `["audio"]` | Text + Audio |
-| `["text", "audio"]` | Text + Audio |
-| Not specified | Text + Audio (default) |
-
-### Using curl
-
-#### Text only
-
-```bash
-curl http://localhost:8091/v1/chat/completions \
- -H "Content-Type: application/json" \
- -d '{
- "model": "Qwen/Qwen2.5-Omni-7B",
- "messages": [{"role": "user", "content": "Describe vLLM in brief."}],
- "modalities": ["text"]
- }'
-```
-
-#### Text + Audio
-
-```bash
-curl http://localhost:8091/v1/chat/completions \
- -H "Content-Type: application/json" \
- -d '{
- "model": "Qwen/Qwen2.5-Omni-7B",
- "messages": [{"role": "user", "content": "Describe vLLM in brief."}],
- "modalities": ["audio"]
- }'
-```
-
-### Using Python client
-
-```bash
-python openai_chat_completion_client_for_multimodal_generation.py \
- --query-type mixed_modalities \
- --modalities text
-```
-
-### Using OpenAI Python SDK
-
-#### Text only
-
-```python
-from openai import OpenAI
-
-client = OpenAI(base_url="http://localhost:8091/v1", api_key="EMPTY")
-
-response = client.chat.completions.create(
- model="Qwen/Qwen2.5-Omni-7B",
- messages=[{"role": "user", "content": "Describe vLLM in brief."}],
- modalities=["text"]
-)
-print(response.choices[0].message.content)
-```
-
-#### Text + Audio
-
-```python
-from openai import OpenAI
-
-client = OpenAI(base_url="http://localhost:8091/v1", api_key="EMPTY")
-
-response = client.chat.completions.create(
- model="Qwen/Qwen2.5-Omni-7B",
- messages=[{"role": "user", "content": "Describe vLLM in brief."}],
- modalities=["audio"]
-)
-# Response contains two choices: one with text, one with audio
-print(response.choices[0].message.content) # Text response
-print(response.choices[1].message.audio) # Audio response
-```
-
-## Streaming Output
-If you want to enable streaming output, please set the argument as below. The final output will be obtained just after generated by corresponding stage. Now we only support text streaming output. Other modalities can output normally.
-```bash
-python openai_chat_completion_client_for_multimodal_generation.py \
- --query-type mixed_modalities \
- --stream
-```
-
-## Run Local Web UI Demo
-
-!!! note "Gradio is an optional dependency"
- The Gradio demo requires the `[demo]` extras. Install them first:
-
- ```bash
- pip install 'vllm-omni[demo]'
- ```
-
- Or, if installing from source: `pip install -e '.[demo]'`
-
-This Web UI demo allows users to interact with the model through a web browser.
-
-### Running Gradio Demo
-
-The Gradio demo connects to a vLLM API server. You have two options:
-
-#### Option 1: One-step Launch Script (Recommended)
-
-The convenience script launches both the vLLM server and Gradio demo together:
-
-```bash
-./run_gradio_demo.sh --model Qwen/Qwen2.5-Omni-7B --server-port 8091 --gradio-port 7861
-```
-
-This script will:
-1. Start the vLLM server in the background
-2. Wait for the server to be ready
-3. Launch the Gradio demo
-4. Handle cleanup when you press Ctrl+C
-
-The script supports the following arguments:
-- `--model`: Model name/path (default: Qwen/Qwen2.5-Omni-7B)
-- `--server-port`: Port for vLLM server (default: 8091)
-- `--gradio-port`: Port for Gradio demo (default: 7861)
-- `--stage-configs-path`: Path to custom stage configs YAML file (optional)
-- `--server-host`: Host for vLLM server (default: 0.0.0.0)
-- `--gradio-ip`: IP for Gradio demo (default: 127.0.0.1)
-- `--share`: Share Gradio demo publicly (creates a public link)
-
-#### Option 2: Manual Launch (Two-Step Process)
-
-**Step 1: Launch the vLLM API server**
-
-```bash
-vllm serve Qwen/Qwen2.5-Omni-7B --omni --port 8091
-```
-
-If you have custom stage configs file:
-```bash
-vllm serve Qwen/Qwen2.5-Omni-7B --omni --port 8091 --stage-configs-path /path/to/stage_configs_file
-```
-
-**Step 2: Run the Gradio demo**
-
-In a separate terminal:
-
-```bash
-python gradio_demo.py --model Qwen/Qwen2.5-Omni-7B --api-base http://localhost:8091/v1 --port 7861
-```
-
-Then open `http://localhost:7861/` on your local browser to interact with the web UI.
-
-The gradio script supports the following arguments:
-
-- `--model`: Model name/path (should match the server model)
-- `--api-base`: Base URL for the vLLM API server (default: http://localhost:8091/v1)
-- `--ip`: Host/IP for Gradio server (default: 127.0.0.1)
-- `--port`: Port for Gradio server (default: 7861)
-- `--share`: Share the Gradio demo publicly (creates a public link)
-
-## Example materials
-
-??? abstract "gradio_demo.py"
- ``````py
- --8<-- "examples/online_serving/qwen2_5_omni/gradio_demo.py"
- ``````
-??? abstract "run_curl_multimodal_generation.sh"
- ``````sh
- --8<-- "examples/online_serving/qwen2_5_omni/run_curl_multimodal_generation.sh"
- ``````
-??? abstract "run_gradio_demo.sh"
- ``````sh
- --8<-- "examples/online_serving/qwen2_5_omni/run_gradio_demo.sh"
- ``````
diff --git a/docs/user_guide/examples/online_serving/qwen3_omni.md b/docs/user_guide/examples/online_serving/qwen3_omni.md
deleted file mode 100644
index 413c80b7e50..00000000000
--- a/docs/user_guide/examples/online_serving/qwen3_omni.md
+++ /dev/null
@@ -1,306 +0,0 @@
-# Qwen3-Omni
-
-Source <https://github.com/vllm-project/vllm-omni/tree/main/examples/online_serving/qwen3_omni>.
-
-
-## 🛠️ Installation
-
-Please refer to [README.md](https://github.com/vllm-project/vllm-omni/tree/main/README.md)
-
-## Run examples (Qwen3-Omni)
-
-### Launch the Server
-
-```bash
-vllm serve Qwen/Qwen3-Omni-30B-A3B-Instruct --omni --port 8091
-```
-
-The default deployment configuration situated at `vllm_omni/deploy/qwen3_omni_moe.yaml` is resolved and loaded
-automatically via the model registry, obviating the necessity for the `--deploy-config` flag in standard deployment topologies.
-Asynchronous chunk streaming is **enabled by default** within the bundled configuration.
-
-To explicitly utilize a custom deployment YAML, specify the configuration path:
-```bash
-vllm serve Qwen/Qwen3-Omni-30B-A3B-Instruct --omni --port 8091 \
- --deploy-config /path/to/deploy_config_file
-```
-
-### Launch individual stages (stage-based CLI)
-
-Adopt the stage-based CLI architecture to independently instantiate execution processes per functional stage.
-The example below pins Stage 0 to GPU 0 and Stage 1/2 to GPU 1 via
-`CUDA_VISIBLE_DEVICES`.
-
-**1. Stage 0 (Thinker + API server)**
-
-```bash
-CUDA_VISIBLE_DEVICES=0 vllm serve Qwen/Qwen3-Omni-30B-A3B-Instruct --omni \
- --port 8091 \
- --stage-id 0 \
- --omni-master-address 127.0.0.1 \
- --omni-master-port 26000
-```
-
-**2. Stage 1 (Talker)**
-
-```bash
-CUDA_VISIBLE_DEVICES=1 vllm serve Qwen/Qwen3-Omni-30B-A3B-Instruct --omni \
- --stage-id 1 \
- --headless \
- --omni-master-address 127.0.0.1 \
- --omni-master-port 26000
-```
-
-**3. Stage 2 (Code2Wav)**
-
-```bash
-CUDA_VISIBLE_DEVICES=1 vllm serve Qwen/Qwen3-Omni-30B-A3B-Instruct --omni \
- --stage-id 2 \
- --headless \
- --omni-master-address 127.0.0.1 \
- --omni-master-port 26000
-```
-
-Add `--deploy-config /path/to/deploy_config_file` to every command if you want
-to override the bundled deploy YAML.
-
-For the regular one-process launch, stage-specific CLI tuning is usually done
-with `--stage-overrides`, for example:
-
-```bash
-vllm serve Qwen/Qwen3-Omni-30B-A3B-Instruct --omni --port 8091 \
- --stage-overrides '{"1": {"gpu_memory_utilization": 0.5}}'
-```
-
-For the stage-based CLI, you usually do **not** need `--stage-overrides` for
-that kind of change. Since each command launches one stage, just pass the knob
-directly on that stage command:
-
-```bash
-CUDA_VISIBLE_DEVICES=1 vllm serve Qwen/Qwen3-Omni-30B-A3B-Instruct --omni \
- --stage-id 1 \
- --headless \
- --gpu-memory-utilization 0.5 \
- --omni-master-address 127.0.0.1 \
- --omni-master-port 26000
-```
-
-### Send Multi-modal Request
-
-Get into the example folder
-```bash
-cd examples/online_serving/qwen3_omni
-```
-
-#### Send request via python
-
-```bash
-python openai_chat_completion_client_for_multimodal_generation.py --query-type use_image --port 8091 --host "localhost"
-```
-
-The Python client supports the following command-line arguments:
-
-- `--query-type` (or `-q`): Query type (default: `use_video`). Options: `text`, `use_audio`, `use_image`, `use_video`
-- `--model` (or `-m`): Model name/path (default: `Qwen/Qwen3-Omni-30B-A3B-Instruct`)
-- `--video-path` (or `-v`): Path to local video file or URL. If not provided and query-type is `use_video`, uses default video URL. Supports local file paths (automatically encoded to base64) or HTTP/HTTPS URLs. Example: `--video-path /path/to/video.mp4` or `--video-path https://example.com/video.mp4`
-- `--image-path` (or `-i`): Path to local image file or URL. If not provided and query-type is `use_image`, uses default image URL. Supports local file paths (automatically encoded to base64) or HTTP/HTTPS URLs and common image formats: JPEG, PNG, GIF, WebP. Example: `--image-path /path/to/image.jpg` or `--image-path https://example.com/image.png`
-- `--audio-path` (or `-a`): Path to local audio file or URL. If not provided and query-type is `use_audio`, uses default audio URL. Supports local file paths (automatically encoded to base64) or HTTP/HTTPS URLs and common audio formats: MP3, WAV, OGG, FLAC, M4A. Example: `--audio-path /path/to/audio.wav` or `--audio-path https://example.com/audio.mp3`
-- `--prompt` (or `-p`): Custom text prompt/question. If not provided, uses default prompt for the selected query type. Example: `--prompt "What are the main activities shown in this video?"`
-
-
-For example, to use a local video file with custom prompt:
-
-```bash
-python openai_chat_completion_client_for_multimodal_generation.py \
- --query-type use_video \
- --video-path /path/to/your/video.mp4 \
- --prompt "What are the main activities shown in this video?"
-```
-
-#### Send request via curl
-
-```bash
-bash run_curl_multimodal_generation.sh use_image
-```
-
-## Modality control
-You can control output modalities to specify which types of output the model should generate. This is useful when you only need text output and want to skip audio generation stages for better performance.
-
-### Supported modalities
-
-| Modalities | Output |
-|------------|--------|
-| `["text"]` | Text only |
-| `["audio"]` | Text + Audio |
-| `["text", "audio"]` | Text + Audio |
-| Not specified | Text + Audio (default) |
-
-### Using curl
-
-#### Text only
-
-```bash
-curl http://localhost:8091/v1/chat/completions \
- -H "Content-Type: application/json" \
- -d '{
- "model": "Qwen/Qwen3-Omni-30B-A3B-Instruct",
- "messages": [{"role": "user", "content": "Describe vLLM in brief."}],
- "modalities": ["text"]
- }'
-```
-
-#### Text + Audio
-
-```bash
-curl http://localhost:8091/v1/chat/completions \
- -H "Content-Type: application/json" \
- -d '{
- "model": "Qwen/Qwen3-Omni-30B-A3B-Instruct",
- "messages": [{"role": "user", "content": "Describe vLLM in brief."}],
- "modalities": ["audio"]
- }'
-```
-
-### Using Python client
-
-```bash
-python openai_chat_completion_client_for_multimodal_generation.py \
- --query-type use_image \
- --modalities text
-```
-
-### Using OpenAI Python SDK
-
-#### Text only
-
-```python
-from openai import OpenAI
-
-client = OpenAI(base_url="http://localhost:8091/v1", api_key="EMPTY")
-
-response = client.chat.completions.create(
- model="Qwen/Qwen3-Omni-30B-A3B-Instruct",
- messages=[{"role": "user", "content": "Describe vLLM in brief."}],
- modalities=["text"]
-)
-print(response.choices[0].message.content)
-```
-
-#### Text + Audio
-
-```python
-from openai import OpenAI
-
-client = OpenAI(base_url="http://localhost:8091/v1", api_key="EMPTY")
-
-response = client.chat.completions.create(
- model="Qwen/Qwen3-Omni-30B-A3B-Instruct",
- messages=[{"role": "user", "content": "Describe vLLM in brief."}],
- modalities=["audio"]
-)
-# Response contains two choices: one with text, one with audio
-print(response.choices[0].message.content) # Text response
-print(response.choices[1].message.audio) # Audio response
-```
-
-## Streaming Output
-If you want to enable streaming output, please set the argument as below. The final output will be obtained just after generated by corresponding stage. We support both text streaming output and audio streaming output. Other modalities can output normally.
-```bash
-python openai_chat_completion_client_for_multimodal_generation.py \
- --query-type use_image \
- --stream
-```
-
-## Run Local Web UI Demo
-
-!!! note "Gradio is an optional dependency"
- The Gradio demo requires the `[demo]` extras. Install them first:
-
- ```bash
- pip install 'vllm-omni[demo]'
- ```
-
- Or, if installing from source: `pip install -e '.[demo]'`
-
-This Web UI demo allows users to interact with the model through a web browser.
-
-### Running Gradio Demo
-
-The Gradio demo connects to a vLLM API server. You have two options:
-
-#### Option 1: One-step Launch Script (Recommended)
-
-The convenience script launches both the vLLM server and Gradio demo together:
-
-```bash
-./run_gradio_demo.sh --model Qwen/Qwen3-Omni-30B-A3B-Instruct --server-port 8091 --gradio-port 7861
-```
-
-This script will:
-1. Start the vLLM server in the background
-2. Wait for the server to be ready
-3. Launch the Gradio demo
-4. Handle cleanup when you press Ctrl+C
-
-The script supports the following arguments:
-- `--model`: Model name/path (default: Qwen/Qwen3-Omni-30B-A3B-Instruct)
-- `--server-port`: Port for vLLM server (default: 8091)
-- `--gradio-port`: Port for Gradio demo (default: 7861)
-- `--deploy-config`: Path to custom deploy config YAML file (optional)
-- `--server-host`: Host for vLLM server (default: 0.0.0.0)
-- `--gradio-ip`: IP for Gradio demo (default: 127.0.0.1)
-- `--share`: Share Gradio demo publicly (creates a public link)
-
-#### Option 2: Manual Launch (Two-Step Process)
-
-**Step 1: Launch the vLLM API server**
-
-```bash
-vllm serve Qwen/Qwen3-Omni-30B-A3B-Instruct --omni --port 8091
-```
-
-If you have custom stage configs file:
-```bash
-vllm serve Qwen/Qwen3-Omni-30B-A3B-Instruct --omni --port 8091 --deploy-config /path/to/deploy_config_file
-```
-
-**Step 2: Run the Gradio demo**
-
-In a separate terminal:
-
-```bash
-python gradio_demo.py --model Qwen/Qwen3-Omni-30B-A3B-Instruct --api-base http://localhost:8091/v1 --port 7861
-```
-
-Then open `http://localhost:7861/` on your local browser to interact with the web UI.
-
-The gradio script supports the following arguments:
-
-- `--model`: Model name/path (should match the server model)
-- `--api-base`: Base URL for the vLLM API server (default: http://localhost:8091/v1)
-- `--ip`: Host/IP for Gradio server (default: 127.0.0.1)
-- `--port`: Port for Gradio server (default: 7861)
-- `--share`: Share the Gradio demo publicly (creates a public link)
-
-## Example materials
-
-??? abstract "gradio_demo.py"
- ``````py
- --8<-- "examples/online_serving/qwen3_omni/gradio_demo.py"
- ``````
-??? abstract "openai_chat_completion_client_for_multimodal_generation.py"
- ``````py
- --8<-- "examples/online_serving/qwen3_omni/openai_chat_completion_client_for_multimodal_generation.py"
- ``````
-??? abstract "qwen3_omni_moe_thinking.yaml"
- ``````yaml
- --8<-- "examples/online_serving/qwen3_omni/qwen3_omni_moe_thinking.yaml"
- ``````
-??? abstract "run_curl_multimodal_generation.sh"
- ``````sh
- --8<-- "examples/online_serving/qwen3_omni/run_curl_multimodal_generation.sh"
- ``````
-??? abstract "run_gradio_demo.sh"
- ``````sh
- --8<-- "examples/online_serving/qwen3_omni/run_gradio_demo.sh"
- ``````
diff --git a/docs/user_guide/examples/online_serving/qwen3_tts.md b/docs/user_guide/examples/online_serving/qwen3_tts.md
deleted file mode 100644
index 95f234f02de..00000000000
--- a/docs/user_guide/examples/online_serving/qwen3_tts.md
+++ /dev/null
@@ -1,451 +0,0 @@
-# Qwen3-TTS
-
-Source <https://github.com/vllm-project/vllm-omni/tree/main/examples/online_serving/qwen3_tts>.
-
-
-## 🛠️ Installation
-
-Please refer to [README.md](https://github.com/vllm-project/vllm-omni/tree/main/README.md)
-
-## Supported Models
-
-| Model | Task Type | Description |
-| -------------------------------------- | ----------- | ----------------------------------------------------- |
-| `Qwen/Qwen3-TTS-12Hz-1.7B-CustomVoice` | CustomVoice | Predefined speaker voices with optional style control |
-| `Qwen/Qwen3-TTS-12Hz-1.7B-VoiceDesign` | VoiceDesign | Natural language voice style description |
-| `Qwen/Qwen3-TTS-12Hz-1.7B-Base` | Base | Voice cloning from reference audio |
-| `Qwen/Qwen3-TTS-12Hz-0.6B-CustomVoice` | CustomVoice | Smaller/faster variant |
-| `Qwen/Qwen3-TTS-12Hz-0.6B-Base` | Base | Smaller/faster variant for voice cloning |
-
-## Gradio Demo
-
-!!! note "Gradio is an optional dependency"
- The Gradio demo requires the `[demo]` extras. Install them first:
-
- ```bash
- pip install 'vllm-omni[demo]'
- ```
-
- Or, if installing from source: `pip install -e '.[demo]'`
-
-Two interactive Gradio demos are available, both supporting all 3 task types:
-
-| Demo | File | Transport | Streaming Quality |
-| -------- | ------------------------ | ------------ | -------------------------------------------------- |
-| Standard | `gradio_demo.py` | HTTP chunked | May have small gaps between chunks |
-| FastRTC | `gradio_fastrtc_demo.py` | WebRTC | Gapless streaming (requires `pip install fastrtc`) |
-
-```bash
-# Option 1: Launch server + Standard Gradio together
-./run_gradio_demo.sh # CustomVoice (default)
-./run_gradio_demo.sh --task-type VoiceDesign # VoiceDesign
-./run_gradio_demo.sh --task-type Base # Voice cloning
-
-# Option 2: If server is already running
-python gradio_demo.py --api-base http://localhost:8000
-
-# Option 3: FastRTC demo (gapless streaming)
-pip install fastrtc
-python gradio_fastrtc_demo.py --api-base http://localhost:8000
-```
-
-Then open http://localhost:7860 in your browser.
-
-## Run examples (Qwen3-TTS)
-
-### Launch the Server
-
-```bash
-# CustomVoice model (predefined speakers)
-vllm serve Qwen/Qwen3-TTS-12Hz-1.7B-CustomVoice \
- --deploy-config vllm_omni/deploy/qwen3_tts.yaml \
- --omni \
- --port 8091 \
- --trust-remote-code \
- --enforce-eager
-
-# VoiceDesign model
-vllm serve Qwen/Qwen3-TTS-12Hz-1.7B-VoiceDesign \
- --deploy-config vllm_omni/deploy/qwen3_tts.yaml \
- --omni \
- --port 8091 \
- --trust-remote-code \
- --enforce-eager
-
-# Base model (voice cloning)
-vllm serve Qwen/Qwen3-TTS-12Hz-1.7B-Base \
- --deploy-config vllm_omni/deploy/qwen3_tts.yaml \
- --omni \
- --port 8091 \
- --trust-remote-code \
- --enforce-eager
-```
-
-If you have custom stage configs file, launch the server with command below
-```bash
-vllm serve Qwen/Qwen3-TTS-12Hz-1.7B-CustomVoice \
- --stage-configs-path /path/to/stage_configs_file \
- --omni \
- --port 8091 \
- --trust-remote-code \
- --enforce-eager
-```
-
-Alternatively, use the convenience script:
-```bash
-./run_server.sh # Default: CustomVoice model
-./run_server.sh CustomVoice # CustomVoice model
-./run_server.sh VoiceDesign # VoiceDesign model
-./run_server.sh Base # Base (voice clone) model
-```
-
-### Send TTS Request
-
-Get into the example folder
-```bash
-cd examples/online_serving/qwen3_tts
-```
-
-#### Send request via python
-
-```bash
-# CustomVoice: Use predefined speaker
-python openai_speech_client.py \
- --text "你好,我是通义千问" \
- --speaker vivian \
- --language Chinese
-
-# CustomVoice with style instruction
-python openai_speech_client.py \
- --text "今天天气真好" \
- --speaker ryan \
- --instructions "用开心的语气说"
-
-# VoiceDesign: Describe the voice style
-python openai_speech_client.py \
- --model Qwen/Qwen3-TTS-12Hz-1.7B-VoiceDesign \
- --task-type VoiceDesign \
- --text "哥哥,你回来啦" \
- --instructions "体现撒娇稚嫩的萝莉女声,音调偏高"
-
-# Base: Voice cloning
-python openai_speech_client.py \
- --model Qwen/Qwen3-TTS-12Hz-1.7B-Base \
- --task-type Base \
- --text "Hello, this is a cloned voice" \
- --ref-audio /path/to/reference.wav \
- --ref-text "Original transcript of the reference audio"
-```
-
-The Python client supports the following command-line arguments:
-
-- `--api-base`: API base URL (default: `http://localhost:8091`)
-- `--model` (or `-m`): Model name/path (default: `Qwen/Qwen3-TTS-12Hz-1.7B-CustomVoice`)
-- `--task-type` (or `-t`): TTS task type. Options: `CustomVoice`, `VoiceDesign`, `Base`
-- `--text`: Text to synthesize (required)
-- `--speaker`: Speaker name (default: `vivian`). Options: `vivian`, `ryan`, `aiden`, etc.
-- `--language`: Language. Options: `Auto`, `Chinese`, `English`, `Japanese`, `Korean`, `German`, `French`, `Russian`, `Portuguese`, `Spanish`, `Italian`
-- `--instructions`: Voice style/emotion instructions
-- `--ref-audio`: Reference audio file path or URL for voice cloning (Base task). Local paths are automatically base64-encoded by the client before sending to the server.
-- `--ref-text`: Reference audio transcript for voice cloning (Base task).
-- `--response-format`: Audio output format (default: `wav`). Options: `wav`, `mp3`, `flac`, `pcm`, `aac`, `opus`
-- `--output` (or `-o`): Output audio file path (default: `tts_output.wav`)
-
-#### Send request via curl
-
-```bash
-# Simple TTS request
-curl -X POST http://localhost:8091/v1/audio/speech \
- -H "Content-Type: application/json" \
- -d '{
- "input": "Hello, how are you?",
- "voice": "vivian",
- "language": "English"
- }' --output output.wav
-
-# With style instruction
-curl -X POST http://localhost:8091/v1/audio/speech \
- -H "Content-Type: application/json" \
- -d '{
- "input": "I am so excited!",
- "voice": "vivian",
- "instructions": "Speak with great enthusiasm"
- }' --output excited.wav
-
-# List available voices in CustomVoice models
-curl http://localhost:8091/v1/audio/voices
-```
-
-### Using OpenAI SDK
-
-```python
-from openai import OpenAI
-
-client = OpenAI(base_url="http://localhost:8091/v1", api_key="none")
-
-response = client.audio.speech.create(
- model="Qwen/Qwen3-TTS-12Hz-1.7B-CustomVoice",
- voice="vivian",
- input="Hello, how are you?",
-)
-
-response.stream_to_file("output.wav")
-```
-
-### Using Python httpx
-
-```python
-import httpx
-
-response = httpx.post(
- "http://localhost:8091/v1/audio/speech",
- json={
- "input": "Hello, how are you?",
- "voice": "vivian",
- "language": "English",
- },
- timeout=300.0,
-)
-
-with open("output.wav", "wb") as f:
- f.write(response.content)
-```
-
-## API Reference
-
-### Voices Endpoint
-
-#### GET /v1/audio/voices
-
-List all available voices/speakers from the loaded model, including both built-in model voices and uploaded custom voices.
-
-**Response Example:**
-```json
-{
- "voices": ["vivian", "ryan", "custom_voice_1"],
- "uploaded_voices": [
- {
- "name": "custom_voice_1",
- "consent": "user_consent_id",
- "created_at": 1738660000,
- "file_size": 1024000,
- "mime_type": "audio/wav",
- "ref_text": "The exact transcript of the audio sample.",
- "speaker_description": "warm narrator"
- }
- ]
-}
-```
-
-Fields `ref_text` and `speaker_description` are omitted per-entry when not provided at upload time.
-
-#### POST /v1/audio/voices
-
-Upload a new voice sample for voice cloning in Base task TTS requests.
-
-**Form Parameters:**
-- `audio_sample` (required): Audio file (max 10MB, supported formats: wav, mp3, flac, ogg, aac, webm, mp4)
-- `consent` (required): Consent recording ID
-- `name` (required): Name for the new voice
-- `ref_text` (optional): Transcript of the audio. Enables in-context voice cloning (higher quality).
-- `speaker_description` (optional): Free-form description of the voice (e.g. "warm narrator", "energetic presenter"). Stored as metadata.
-
-**Response Example:**
-```json
-{
- "success": true,
- "voice": {
- "name": "custom_voice_1",
- "consent": "user_consent_id",
- "created_at": 1738660000,
- "mime_type": "audio/wav",
- "file_size": 1024000,
- "ref_text": "The exact transcript of the audio sample.",
- "speaker_description": "warm narrator"
- }
-}
-```
-
-Fields `ref_text` and `speaker_description` are omitted when not provided at upload time.
-
-**Usage Example:**
-```bash
-curl -X POST http://localhost:8091/v1/audio/voices \
- -F "audio_sample=@/path/to/voice_sample.wav" \
- -F "consent=user_consent_id" \
- -F "name=custom_voice_1" \
- -F "ref_text=The exact transcript of the audio sample." \
- -F "speaker_description=warm narrator"
-```
-
-### Endpoint
-
-```
-POST /v1/audio/speech
-Content-Type: application/json
-```
-
-This endpoint follows the [OpenAI Audio Speech API](https://platform.openai.com/docs/api-reference/audio/createSpeech) format with additional Qwen3-TTS parameters.
-
-### Request Body
-
-```json
-{
- "input": "Text to synthesize",
- "voice": "vivian",
- "response_format": "wav",
- "task_type": "CustomVoice",
- "language": "Auto",
- "instructions": "Optional style instructions",
- "ref_audio": "HTTP URL, base64 data URL, or file:// URI for voice cloning",
- "ref_text": "Reference audio transcript",
- "x_vector_only_mode": false,
- "max_new_tokens": 2048
-}
-```
-
-> **Note:** The `model` field is optional when serving a single model, as the server already knows which model is loaded.
-
-### Response
-
-Returns binary audio data with appropriate `Content-Type` header (e.g., `audio/wav`).
-
-### Voice and language (summary)
-
-- **Speaker**: Use the `voice` request field to select the speaker (e.g., `vivian`, `ryan`, `aiden`). List available speakers with `GET /v1/audio/voices`.
-- **Language**: Use the `language` field for the codec language tag (`Auto`, `Chinese`, `English`, etc.). Default is `Auto` for automatic detection.
-- **CustomVoice**: Requires a valid `voice` from the model’s speaker set. **VoiceDesign**: Use `instructions` to describe the voice. **Base**: Use `ref_audio` and `ref_text` for voice cloning.
-
-## Parameters
-
-### OpenAI Standard Parameters
-
-| Parameter | Type | Default | Description |
-| ----------------- | ------ | -------------- | ----------------------------------------------------------- |
-| `input` | string | **required** | Text to synthesize |
-| `model` | string | server's model | Model to use (optional, should match server if specified) |
-| `voice` | string | "vivian" | Speaker name (e.g., vivian, ryan, aiden) |
-| `response_format` | string | "wav" | Audio format: wav, mp3, flac, pcm, aac, opus |
-| `speed` | float | 1.0 | Playback speed (0.25-4.0, not supported with `stream=true`) |
-
-### vLLM-Omni Extension Parameters
-
-| Parameter | Type | Default | Description |
-| ---------------------------- | ------ | ------------- | -------------------------------------------------------------------------------------------------------------------- |
-| `task_type` | string | "CustomVoice" | Task: CustomVoice, VoiceDesign, or Base |
-| `language` | string | "Auto" | Language (see supported languages below) |
-| `instructions` | string | "" | Voice style/emotion instructions |
-| `max_new_tokens` | int | 2048 | Maximum tokens to generate |
-| `initial_codec_chunk_frames` | int | null | Per-request initial chunk size override for TTFA tuning. When null, IC is computed dynamically based on server load. |
-| `stream` | bool | false | Stream raw PCM chunks as they are decoded (requires `response_format="pcm"`) |
-
-**Supported languages:** Auto, Chinese, English, Japanese, Korean, German, French, Russian, Portuguese, Spanish, Italian
-
-### Voice Clone Parameters (Base task)
-
-| Parameter | Type | Required | Description |
-| -------------------- | ------ | -------- | ----------------------------------------------------------------------------------------------- |
-| `ref_audio` | string | **Yes** | Reference audio (HTTP URL, base64 data URL, or `file://` URI with `--allowed-local-media-path`) |
-| `ref_text` | string | No | Transcript of reference audio (for ICL mode) |
-| `x_vector_only_mode` | bool | No | Use speaker embedding only (no ICL) |
-
-## Streaming
-
-Set `stream=true` with `response_format="pcm"` to receive raw PCM audio chunks as they are decoded
-(one chunk per Code2Wav window, default 25 frames; configurable in the stage config):
-
-```bash
-curl -X POST http://localhost:8091/v1/audio/speech \
- -H "Content-Type: application/json" \
- -d '{
- "input": "Hello, how are you?",
- "voice": "vivian",
- "language": "English",
- "stream": true,
- "response_format": "pcm"
- }' --no-buffer | play -t raw -r 24000 -e signed -b 16 -c 1 -
-```
-
-**Constraints:**
-- `stream=true` requires `response_format="pcm"` (raw 16-bit signed PCM, 24 kHz mono).
-- `speed` adjustment is not supported when streaming.
-- Requires the server stage config to have `async_chunk: true` (default in `qwen3_tts.yaml`).
-
-## Streaming Text Input (WebSocket)
-
-The `/v1/audio/speech/stream` WebSocket endpoint accepts text incrementally, buffers and splits it at sentence boundaries, and generates audio per sentence.
-
-When `stream_audio=true`, each sentence is emitted as `audio.start`, one or more binary PCM frames, and `audio.done`.
-
-### Quick Start
-
-```bash
-python streaming_speech_client.py \
- --text "Hello world. How are you? I am fine."
-
-python streaming_speech_client.py \
- --text "Hello world. How are you? I am fine." \
- --simulate-stt --stt-delay 0.1
-```
-
-### WebSocket Protocol
-
-Client -> Server:
-
-```jsonc
-{"type": "session.config", "voice": "Vivian", "task_type": "CustomVoice", "language": "Auto", "split_granularity": "sentence", "stream_audio": true, "response_format": "pcm"}
-{"type": "input.text", "text": "Hello, how are you? "}
-{"type": "input.done"}
-```
-
-Server -> Client:
-
-```jsonc
-{"type": "audio.start", "sentence_index": 0, "sentence_text": "Hello, how are you?", "format": "pcm", "sample_rate": 24000}
-// binary PCM frame(s)
-{"type": "audio.done", "sentence_index": 0, "total_bytes": 96000, "error": false}
-{"type": "session.done", "total_sentences": 1}
-```
-
-## Limitations
-
-- **Single request**: Batch processing is not yet optimized for online serving.
-
-## Troubleshooting
-
-1. **TTS model did not produce audio output**: Ensure you're using the correct model variant for your task type (CustomVoice task → CustomVoice model, etc.)
-2. **Connection refused**: Make sure the server is running on the correct port
-3. **Out of memory**: Use smaller model variant (`Qwen/Qwen3-TTS-12Hz-0.6B-CustomVoice`) or reduce `--gpu-memory-utilization`
-4. **Unsupported speaker**: Use `/v1/audio/voices` to list available voices for the loaded model
-5. **Voice clone fails**: Ensure you're using the Base model variant for voice cloning
-
-## Example materials
-
-??? abstract "gradio_demo.py"
- ``````py
- --8<-- "examples/online_serving/qwen3_tts/gradio_demo.py"
- ``````
-??? abstract "gradio_fastrtc_demo.py"
- ``````py
- --8<-- "examples/online_serving/qwen3_tts/gradio_fastrtc_demo.py"
- ``````
-??? abstract "openai_speech_client.py"
- ``````py
- --8<-- "examples/online_serving/qwen3_tts/openai_speech_client.py"
- ``````
-??? abstract "run_gradio_demo.sh"
- ``````sh
- --8<-- "examples/online_serving/qwen3_tts/run_gradio_demo.sh"
- ``````
-??? abstract "run_server.sh"
- ``````sh
- --8<-- "examples/online_serving/qwen3_tts/run_server.sh"
- ``````
-??? abstract "streaming_speech_client.py"
- ``````py
- --8<-- "examples/online_serving/qwen3_tts/streaming_speech_client.py"
- ``````
-??? abstract "tts_common.py"
- ``````py
- --8<-- "examples/online_serving/qwen3_tts/tts_common.py"
- ``````
diff --git a/docs/user_guide/examples/online_serving/text_to_audio.md b/docs/user_guide/examples/online_serving/text_to_audio.md
deleted file mode 100644
index b1ec33a202d..00000000000
--- a/docs/user_guide/examples/online_serving/text_to_audio.md
+++ /dev/null
@@ -1,193 +0,0 @@
-# Text-To-Audio
-
-Source <https://github.com/vllm-project/vllm-omni/tree/main/examples/online_serving/stable_audio>.
-
-This example demonstrates how to deploy Stable Audio models for online text-to-audio generation using vLLM-Omni.
-
-## Supported Models
-
-| Model | Description |
-|-------|-------------|
-| `stabilityai/stable-audio-open-1.0` | Open-source audio generation, up to ~47 seconds, 44.1 kHz stereo |
-
-## Start Server
-
-### Basic Start
-
-```bash
-vllm-omni serve stabilityai/stable-audio-open-1.0 \
- --host 0.0.0.0 \
- --port 8091 \
- --gpu-memory-utilization 0.9 \
- --trust-remote-code \
- --enforce-eager \
- --omni
-```
-
-## API Calls
-
-### Method 1: Using curl
-
-```bash
-# Run all curl examples
-bash curl_examples.sh
-
-# Or execute directly
-curl -X POST http://localhost:8091/v1/audio/generate \
- -H "Content-Type: application/json" \
- -d '{
- "input": "The sound of a cat purring",
- "audio_length": 10.0
- }' --output cat.wav
-```
-
-### Method 2: Using Python Client
-
-```bash
-cd examples/online_serving/stable_audio
-
-# Simple generation
-python stable_audio_client.py \
- --text "The sound of a cat purring"
-
-# With custom duration
-python stable_audio_client.py \
- --text "A dog barking" \
- --audio_length 5.0
-
-# With all parameters
-python stable_audio_client.py \
- --text "Thunder and rain" \
- --audio_length 15.0 \
- --negative_prompt "Low quality" \
- --guidance_scale 7.0 \
- --num_inference_steps 100 \
- --seed 42 \
- --output thunder.wav
-```
-
-The Python client supports the following command-line arguments:
-
-- `--api_url`: API endpoint URL (default: `http://localhost:8091/v1/audio/generate`)
-- `--text`: Text prompt for audio generation (default: `"The sound of a cat purring"`)
-- `--audio_length`: Audio length in seconds (default: `10.0`, max ~47s for `stable-audio-open-1.0`)
-- `--audio_start`: Audio start time in seconds (default: `0.0`)
-- `--negative_prompt`: Negative prompt for classifier-free guidance (default: `"Low quality"`)
-- `--guidance_scale`: Guidance scale for diffusion (default: `7.0`)
-- `--num_inference_steps`: Number of inference steps (default: `100`)
-- `--seed`: Random seed for reproducibility (default: `None`)
-- `--response_format`: Audio output format (default: `wav`). Options: `wav`, `mp3`, `flac`, `pcm`
-- `--output`: Output file path (default: `stable_audio_output.wav`)
-
-### Method 3: Using Python httpx
-
-```python
-import httpx
-
-response = httpx.post(
- "http://localhost:8091/v1/audio/generate",
- json={
- "input": "The sound of ocean waves crashing on a beach",
- "audio_length": 10.0,
- "negative_prompt": "Low quality, distorted",
- "guidance_scale": 7.0,
- "num_inference_steps": 100,
- },
- timeout=300.0,
-)
-
-with open("ocean.wav", "wb") as f:
- f.write(response.content)
-```
-
-## Request Format
-
-### Simple Generation
-
-```json
-{
- "input": "The sound of ocean waves"
-}
-```
-
-### Generation with Parameters
-
-```json
-{
- "input": "A piano playing a gentle melody",
- "audio_length": 10.0,
- "negative_prompt": "Low quality, distorted, noisy",
- "guidance_scale": 8.0,
- "num_inference_steps": 150,
- "seed": 42,
- "response_format": "wav"
-}
-```
-
-## API Reference
-
-### Endpoint
-
-```
-POST /v1/audio/generate
-Content-Type: application/json
-```
-
-### Generation Parameters
-
-| Parameter | Type | Default | Description |
-|-----------|------|---------|-------------|
-| `input` | string | **required** | Text prompt describing the audio to generate |
-| `model` | string | server's model | Model to use (optional, should match server if specified) |
-| `response_format` | string | "wav" | Audio format: wav, mp3, flac, pcm, aac, opus |
-| `speed` | float | 1.0 | Playback speed (0.25 - 4.0) |
-| `audio_length` | float | null | Audio duration in seconds (max ~47s for `stable-audio-open-1.0`) |
-| `audio_start` | float | 0.0 | Audio start time in seconds |
-| `negative_prompt` | string | null | Text describing what to avoid in generation |
-| `guidance_scale` | float | model default | Classifier-free guidance scale (higher = more adherence to prompt) |
-| `num_inference_steps` | int | model default | Number of denoising steps (higher = better quality, slower) |
-| `seed` | int | null | Random seed for reproducible generation |
-
-### Response Format
-
-Returns binary audio data with appropriate `Content-Type` header (e.g., `audio/wav`).
-
-## Tuning Tips
-
-1. **Audio Length**: Keep under 47 seconds for `stable-audio-open-1.0`.
-2. **Quality vs Speed**:
- - 50 steps: Fast, decent quality (quick previews)
- - 100 steps: Good balance (general purpose)
- - 150+ steps: High quality, slower (final / critical audio)
-3. **Guidance Scale**:
- - Lower (3 - 5): More creative / varied output
- - Default (7): Good balance
- - Higher (10+): Strict adherence to the prompt
-4. **Negative Prompts**: Use to avoid unwanted characteristics such as `"Low quality"`, `"distorted"`, `"noisy"`.
-5. **Seeds**: Set a fixed seed to get deterministic, reproducible results.
-
-## File Description
-
-| File | Description |
-|------|-------------|
-| `curl_examples.sh` | Curl examples covering common use cases |
-| `stable_audio_client.py` | Python client with full CLI argument support |
-
-## Troubleshooting
-
-1. **Audio generation model did not produce audio output**: Verify the server started successfully and the model loaded without errors.
-2. **Connection refused**: Make sure the server is running on the correct port.
-3. **Generation timeout**: Reduce `num_inference_steps` or `audio_length`, and check GPU memory with `nvidia-smi`.
-4. **Out of memory**: Lower `--gpu-memory-utilization` or reduce `audio_length`.
-5. **Audio quality issues**: Increase `num_inference_steps`, add a negative prompt, or raise `guidance_scale`.
-
-## Example materials
-
-??? abstract "stable_audio_client.py"
- ``````py
- --8<-- "examples/online_serving/stable_audio/stable_audio_client.py"
- ``````
-??? abstract "curl_examples.sh"
- ``````sh
- --8<-- "examples/online_serving/stable_audio/curl_examples.sh"
- ``````
diff --git a/docs/user_guide/examples/online_serving/text_to_image.md b/docs/user_guide/examples/online_serving/text_to_image.md
deleted file mode 100644
index 69c1480e39f..00000000000
--- a/docs/user_guide/examples/online_serving/text_to_image.md
+++ /dev/null
@@ -1,314 +0,0 @@
-# Text-To-Image
-
-Source <https://github.com/vllm-project/vllm-omni/tree/main/examples/online_serving/text_to_image>.
-
-
-This example demonstrates how to deploy Qwen-Image model for online image generation service using vLLM-Omni.
-
-## Start Server
-
-### Basic Start
-
-```bash
-vllm serve Qwen/Qwen-Image --omni --port 8091
-```
-!!! note
- If you encounter Out-of-Memory (OOM) issues or have limited GPU memory, you can enable VAE slicing and tiling to reduce memory usage, --vae-use-slicing --vae-use-tiling
-
-### Start with Parameters
-
-Or use the startup script:
-
-```bash
-bash run_server.sh
-```
-
-### Start with Parallelism Acceleration
-
-Enable Tensor Parallelism and VAE Patch Parallelism for faster inference:
-
-```bash
-# With Tensor Parallelism (requires >= 2 GPUs)
-vllm serve Qwen/Qwen-Image --omni --port 8091 --tensor-parallel-size 2
-
-# With Tensor Parallelism and VAE Patch Parallelism (requires >= 2 GPUs)
-vllm serve Qwen/Qwen-Image --omni --port 8091 --tensor-parallel-size 2 --vae-patch-parallel-size 2 --vae-use-tiling
-
-# With Sequence Parallelism (Ulysses-SP, requires >= 2 GPUs)
-vllm serve Qwen/Qwen-Image --omni --port 8091 --usp 2
-
-# With Ring-Attention (requires >= 2 GPUs)
-vllm serve Qwen/Qwen-Image --omni --port 8091 --ring 2
-
-# Combined: Ulysses + Ring (requires >= 4 GPUs)
-vllm serve Qwen/Qwen-Image --omni --port 8091 --usp 2 --ring 2
-```
-
-For more details on parallelism acceleration, see the [Parallelism Acceleration Guide](https://github.com/vllm-project/vllm-omni/tree/main/examples/diffusion/parallelism_acceleration.md).
-
-## API Calls
-
-### Method 1: Using curl
-
-```bash
-# Basic text-to-image generation
-bash run_curl_text_to_image.sh
-
-# Or execute directly
-curl -s http://localhost:8091/v1/chat/completions \
- -H "Content-Type: application/json" \
- -d '{
- "messages": [
- {"role": "user", "content": "A beautiful landscape painting"}
- ],
- "extra_body": {
- "height": 1024,
- "width": 1024,
- "num_inference_steps": 50,
- "true_cfg_scale": 4.0,
- "seed": 42
- }
- }' | jq -r '.choices[0].message.content[0].image_url.url' | cut -d',' -f2- | base64 -d > output.png
-```
-
-### Method 2: Using OpenAI Python SDK
-
-```python
-from openai import OpenAI
-import base64
-
-client = OpenAI(base_url="http://localhost:8091/v1", api_key="none")
-
-response = client.chat.completions.create(
- model="Qwen/Qwen-Image",
- messages=[{"role": "user", "content": "A beautiful landscape painting"}],
- extra_body={
- "height": 1024,
- "width": 1024,
- "num_inference_steps": 50,
- "true_cfg_scale": 4.0,
- "seed": 42,
- },
-)
-
-img_url = response.choices[0].message.content[0].image_url.url
-_, b64_data = img_url.split(",", 1)
-with open("output.png", "wb") as f:
- f.write(base64.b64decode(b64_data))
-```
-
-### Method 3: Using Python Client Script
-
-```bash
-python openai_chat_client.py --prompt "A beautiful landscape painting" --output output.png
-```
-
-### Method 4: Using Gradio Demo
-
-!!! note "Gradio is an optional dependency"
- The Gradio demo requires the `[demo]` extras. Install them first:
-
- ```bash
- pip install 'vllm-omni[demo]'
- ```
-
- Or, if installing from source: `pip install -e '.[demo]'`
-
-```bash
-python gradio_demo.py
-# Visit http://localhost:7860
-```
-
-## LoRA
-
-This example supports Peft-compatible LoRA (Low-Rank Adaptation) adapters for diffusion models. The LoRA adapter path must be readable on the **server** machine (usually a local path or a mounted directory).
-
-### Using Python Client with LoRA
-
-```bash
-python openai_chat_client.py \
- --prompt "A piece of cheesecake" \
- --lora-path /path/to/lora_adapter \
- --lora-name my_lora \
- --lora-scale 1.0 \
- --output output.png
-```
-
-### Using curl with LoRA (Images API)
-
-The `/v1/images/generations` endpoint supports a `lora` field in the request body:
-
-```bash
-curl -X POST http://localhost:8091/v1/images/generations \
- -H "Content-Type: application/json" \
- -d '{
- "prompt": "A piece of cheesecake",
- "size": "1024x1024",
- "seed": 42,
- "lora": {
- "name": "my_lora",
- "local_path": "/path/to/lora_adapter",
- "scale": 1.0
- }
- }' | jq -r '.data[0].b64_json' | base64 -d > output.png
-```
-
-### LoRA Parameters
-
-| Parameter | Type | Description |
-| ------------ | ----- | ------------------------------------------------------------------------- |
-| `name` | str | LoRA adapter name (optional, defaults to path stem) |
-| `local_path` | str | Server-local path to LoRA adapter folder (PEFT format, required) |
-| `scale` | float | LoRA scale factor (default: 1.0) |
-| `int_id` | int | LoRA integer ID for caching (optional, derived from path if not provided) |
-
-### LoRA Adapter Format
-
-LoRA adapters must be in PEFT (Parameter-Efficient Fine-Tuning) format. A typical LoRA adapter directory structure:
-
-```
-lora_adapter/
-├── adapter_config.json
-└── adapter_model.safetensors
-```
-
-## Request Format
-
-### Simple Text Generation
-
-```json
-{
- "messages": [
- {"role": "user", "content": "A beautiful landscape painting"}
- ]
-}
-```
-
-### Generation with Parameters
-
-Wrap generation parameters inside `extra_body` in the request JSON:
-
-```json
-{
- "messages": [
- {"role": "user", "content": "A beautiful landscape painting"}
- ],
- "extra_body": {
- "height": 1024,
- "width": 1024,
- "num_inference_steps": 50,
- "true_cfg_scale": 4.0,
- "seed": 42
- }
-}
-```
-
-!!! tip "Using the OpenAI SDK"
- When using the OpenAI Python SDK, pass these parameters via the `extra_body`
- keyword argument. The SDK merges them into the top-level request body automatically:
-
- ```python
- client.chat.completions.create(
- model="Qwen/Qwen-Image",
- messages=[...],
- extra_body={"height": 1024, "width": 1024, "num_inference_steps": 50},
- )
- ```
-
- For details on how generation parameters are handled across different clients, see the
- [Diffusion Chat API guide](../../../../serving/diffusion_chat_api.md).
-
-### Multimodal Input (Text + Structured Content)
-
-```json
-{
- "messages": [
- {
- "role": "user",
- "content": [
- {"type": "text", "text": "A beautiful landscape painting"}
- ]
- }
- ]
-}
-```
-
-## Generation Parameters
-
-When using `/v1/chat/completions`, pass these inside `extra_body` in the curl
-JSON, or via the `extra_body` keyword argument in the OpenAI Python SDK (see the
-[Diffusion Chat API guide](../../../../serving/diffusion_chat_api.md)).
-When using the dedicated [`/v1/images/generations`](../../../../serving/image_generation_api.md)
-endpoint, pass the supported generation controls as top-level JSON fields
-directly. For image dimensions and count, use `size` and `n` rather than
-`height`, `width`, or `num_outputs_per_prompt`.
-
-| Parameter | Type | Default | Description |
-| ------------------------ | ----- | ------- | ------------------------------ |
-| `height` | int | None | Image height in pixels |
-| `width` | int | None | Image width in pixels |
-| `size` | str | None | Image size (e.g., "1024x1024") |
-| `num_inference_steps` | int | 50 | Number of denoising steps |
-| `true_cfg_scale` | float | 4.0 | Qwen-Image CFG scale |
-| `seed` | int | None | Random seed (reproducible) |
-| `negative_prompt` | str | None | Negative prompt |
-| `num_outputs_per_prompt` | int | 1 | Number of images to generate |
-
-## Response Format
-
-```json
-{
- "id": "chatcmpl-xxx",
- "created": 1234567890,
- "model": "Qwen/Qwen-Image",
- "choices": [{
- "index": 0,
- "message": {
- "role": "assistant",
- "content": [{
- "type": "image_url",
- "image_url": {
- "url": "data:image/png;base64,..."
- }
- }]
- },
- "finish_reason": "stop"
- }],
- "usage": {...}
-}
-```
-
-## Extract Image
-
-```bash
-# Extract base64 from response and decode to image
-cat response.json | jq -r '.choices[0].message.content[0].image_url.url' | cut -d',' -f2- | base64 -d > output.png
-```
-
-## File Description
-
-| File | Description |
-| --------------------------- | ---------------------------- |
-| `run_server.sh` | Server startup script |
-| `run_curl_text_to_image.sh` | curl example |
-| `openai_chat_client.py` | Python client |
-| `gradio_demo.py` | Gradio interactive interface |
-
-## Example materials
-
-??? abstract "gradio_demo.py"
- ``````py
- --8<-- "examples/online_serving/text_to_image/gradio_demo.py"
- ``````
-??? abstract "openai_chat_client.py"
- ``````py
- --8<-- "examples/online_serving/text_to_image/openai_chat_client.py"
- ``````
-??? abstract "run_curl_text_to_image.sh"
- ``````sh
- --8<-- "examples/online_serving/text_to_image/run_curl_text_to_image.sh"
- ``````
-??? abstract "run_server.sh"
- ``````sh
- --8<-- "examples/online_serving/text_to_image/run_server.sh"
- ``````
diff --git a/docs/user_guide/examples/online_serving/text_to_video.md b/docs/user_guide/examples/online_serving/text_to_video.md
deleted file mode 100644
index b918aac19d0..00000000000
--- a/docs/user_guide/examples/online_serving/text_to_video.md
+++ /dev/null
@@ -1,394 +0,0 @@
-# Text-To-Video
-
-Source <https://github.com/vllm-project/vllm-omni/tree/main/examples/online_serving/text_to_video>.
-
-
-This example demonstrates how to deploy text-to-video models for online video generation using vLLM-Omni.
-
-## Supported Models
-
-| Model | Model ID |
-|-------|----------|
-| Wan2.1 T2V (1.3B) | `Wan-AI/Wan2.1-T2V-1.3B-Diffusers` |
-| Wan2.1 T2V (14B) | `Wan-AI/Wan2.1-T2V-14B-Diffusers` |
-| Wan2.2 T2V | `Wan-AI/Wan2.2-T2V-A14B-Diffusers` |
-| LTX-2 | `Lightricks/LTX-2` |
-
-## Wan2.2 T2V
-
-### Start Server
-
-#### Basic Start
-
-```bash
-vllm serve Wan-AI/Wan2.2-T2V-A14B-Diffusers --omni --port 8091
-```
-
-#### Start with Parameters
-
-Or use the startup script:
-
-```bash
-bash run_server.sh
-```
-
-The script allows overriding:
-- `MODEL` (default: `Wan-AI/Wan2.2-T2V-A14B-Diffusers`)
-- `PORT` (default: `8091`)
-- `BOUNDARY_RATIO` (default: `0.875`)
-- `FLOW_SHIFT` (default: `5.0`)
-- `CACHE_BACKEND` (default: `none`)
-- `ENABLE_CACHE_DIT_SUMMARY` (default: `0`)
-
-## Async Job Behavior
-
-`POST /v1/videos` is asynchronous. It creates a video job and immediately
-returns metadata like the job ID and initial `queued` status. To get the final
-artifact, poll the job status and then download the completed file from the
-content endpoint.
-
-The main endpoints are:
-- `POST /v1/videos`: create a video generation job (async)
-- `POST /v1/videos/sync`: generate a video and return raw bytes (sync, for benchmarks)
-- `GET /v1/videos/{video_id}`: retrieve the current job status and metadata
-- `GET /v1/videos`: list stored video jobs
-- `GET /v1/videos/{video_id}/content`: download the generated video file
-- `DELETE /v1/videos/{video_id}`: delete the job and any stored output
-
-## Sync API (Benchmark / Testing)
-
-`POST /v1/videos/sync` is a synchronous alternative that blocks until generation
-completes and returns the raw video bytes (`video/mp4`) directly in the response
-body. It is designed for benchmark and testing scenarios where one-shot
-request/response latency measurement is needed.
-
-The sync endpoint accepts the same form parameters as `POST /v1/videos`. It does
-not create any stored job record — the response is purely the generated video
-file. Metadata is returned via response headers:
-
-- `X-Request-Id`: unique identifier for this generation request
-- `X-Model`: model name used for generation
-- `X-Inference-Time-S`: wall-clock inference time in seconds
-
-```bash
-curl -X POST http://localhost:8091/v1/videos/sync \
- -F "prompt=Two anthropomorphic cats in comfy boxing gear and bright gloves fight intensely on a spotlighted stage." \
- -F "size=832x480" \
- -F "num_frames=33" \
- -F "fps=16" \
- -F "num_inference_steps=40" \
- -F "guidance_scale=4.0" \
- -F "guidance_scale_2=4.0" \
- -F "boundary_ratio=0.875" \
- -F "flow_shift=5.0" \
- -F "seed=42" \
- -o sync_t2v_output.mp4
-```
-
-## Storage
-
-Generated video files are stored on local disk by the async video API.
-Local file storage behavior can be controlled via the following environment variables:
-
-- `VLLM_OMNI_STORAGE_PATH`: directory used for generated files (default: `/tmp/storage`)
-- `VLLM_OMNI_STORAGE_MAX_CONCURRENCY`: max concurrent save/delete operations (default: `4`)
-
-Example:
-
-```bash
-export VLLM_OMNI_STORAGE_PATH=/var/tmp/vllm-omni-videos
-export VLLM_OMNI_STORAGE_MAX_CONCURRENCY=8
-```
-
-## API Calls
-
-### Method 1: Using curl
-
-```bash
-# Basic text-to-video generation
-bash run_curl_text_to_video.sh
-
-# Or execute directly (OpenAI-style multipart)
-create_response=$(curl -s http://localhost:8091/v1/videos \
- -H "Accept: application/json" \
- -F "prompt=Two anthropomorphic cats in comfy boxing gear and bright gloves fight intensely on a spotlighted stage." \
- -F "width=832" \
- -F "height=480" \
- -F "num_frames=33" \
- -F "negative_prompt=色调艳丽 ,过曝,静态,细节模糊不清,字幕,风格,作品,画作,画面,静止,整体发灰,最差质量,低质量,JPEG压缩残留,丑陋的,残缺的,多余的手指,画得不好的手部,画得不好的脸部,畸形的,毁容的,形态畸形的肢体,手指融合,静止不动的画面,杂乱的背景,三条腿,背景人很多,倒着走" \
- -F "fps=16" \
- -F "num_inference_steps=40" \
- -F "guidance_scale=4.0" \
- -F "guidance_scale_2=4.0" \
- -F "boundary_ratio=0.875" \
- -F "flow_shift=5.0" \
- -F "seed=42")
-
-video_id=$(echo "$create_response" | jq -r '.id')
-while true; do
- status=$(curl -s "http://localhost:8091/v1/videos/${video_id}" | jq -r '.status')
- if [ "$status" = "completed" ]; then
- break
- fi
- if [ "$status" = "failed" ]; then
- echo "Video generation failed"
- exit 1
- fi
- sleep 2
-done
-
-curl -s "http://localhost:8091/v1/videos/${video_id}" | jq .
-curl -L "http://localhost:8091/v1/videos/${video_id}/content" -o wan22_output.mp4
-```
-
-## Request Format
-
-### Simple Text-to-Video Generation
-
-```bash
-curl -X POST http://localhost:8091/v1/videos \
- -F "prompt=A cinematic view of a futuristic city at sunset"
-```
-
-### Generation with Parameters
-
-```bash
-curl -X POST http://localhost:8091/v1/videos \
- -F "prompt=A cinematic view of a futuristic city at sunset" \
- -F "width=832" \
- -F "height=480" \
- -F "num_frames=33" \
- -F "negative_prompt=low quality, blurry, static" \
- -F "fps=16" \
- -F "num_inference_steps=40" \
- -F "guidance_scale=4.0" \
- -F "guidance_scale_2=4.0" \
- -F "boundary_ratio=0.875" \
- -F "flow_shift=5.0" \
- -F "enable_frame_interpolation=true" \
- -F "frame_interpolation_exp=1" \
- -F "frame_interpolation_scale=1.0" \
- -F "seed=42"
-```
-
-## Generation Parameters
-
-| Parameter | Type | Default | Description |
-| --------------------- | ------ | ------- | ------------------------------------------------ |
-| `prompt` | str | - | Text description of the desired video |
-| `seconds` | str | None | Clip duration in seconds |
-| `size` | str | None | Output size in `WIDTHxHEIGHT` format |
-| `negative_prompt` | str | None | Negative prompt |
-| `width` | int | None | Video width in pixels |
-| `height` | int | None | Video height in pixels |
-| `num_frames` | int | None | Number of frames to generate |
-| `fps` | int | None | Frames per second for output video |
-| `num_inference_steps` | int | None | Number of denoising steps |
-| `guidance_scale` | float | None | CFG guidance scale (low-noise stage) |
-| `guidance_scale_2` | float | None | CFG guidance scale (high-noise stage, Wan2.2) |
-| `boundary_ratio` | float | None | Boundary split ratio for low/high DiT (Wan2.2) |
-| `flow_shift` | float | None | Scheduler flow shift (Wan2.2) |
-| `seed` | int | None | Random seed (reproducible) |
-| `lora` | object | None | LoRA configuration |
-| `enable_frame_interpolation` | bool | false | Enable RIFE frame interpolation before MP4 encoding |
-| `frame_interpolation_exp` | int | 1 | Interpolation exponent; 1=2x temporal resolution, 2=4x |
-| `frame_interpolation_scale` | float | 1.0 | RIFE inference scale; use 0.5 for high-resolution inputs |
-| `frame_interpolation_model_path` | str | None | Local directory or Hugging Face repo ID with `flownet.pkl`; defaults to `elfgum/RIFE-4.22.lite` |
-
-## Frame Interpolation
-
-Frame interpolation is an optional post-processing step for `/v1/videos` and
-`/v1/videos/sync`. It synthesizes intermediate frames between generated frames
-without rerunning the diffusion model. If the generated video has `N` frames,
-the interpolated output frame count is `(N - 1) * 2**exp + 1`. The encoder FPS
-is multiplied by `2**exp` so the output duration remains close to the original.
-
-Frame interpolation runs in the diffusion worker post-processing path instead of
-the API server encoding path, so it can reuse the worker's current accelerator
-device without blocking the FastAPI event loop.
-
-Example: generate 5 frames and interpolate to 9 frames:
-
-```bash
-curl -X POST http://localhost:8091/v1/videos/sync \
- -F "prompt=A dog running through a park" \
- -F "num_frames=5" \
- -F "fps=8" \
- -F "enable_frame_interpolation=true" \
- -F "frame_interpolation_exp=1" \
- -F "frame_interpolation_scale=1.0" \
- -o sync_t2v_interpolated.mp4
-```
-
-## Create Response Format
-
-`POST /v1/videos` returns a job record, not inline base64 video data.
-
-```json
-{
- "id": "video_gen_123",
- "object": "video",
- "status": "queued",
- "model": "Wan-AI/Wan2.2-T2V-A14B-Diffusers",
- "prompt": "A cinematic view of a futuristic city at sunset",
- "created_at": 1234567890
-}
-```
-
-## Retrieve, List, Download, and Delete
-
-### Retrieve a job
-
-```bash
-curl -s http://localhost:8091/v1/videos/${video_id} | jq .
-```
-
-### List jobs
-
-```bash
-curl -s http://localhost:8091/v1/videos | jq .
-```
-
-### Download the completed video
-
-```bash
-curl -L http://localhost:8091/v1/videos/${video_id}/content -o wan22_output.mp4
-```
-
-### Delete a job and its stored file
-
-```bash
-curl -X DELETE http://localhost:8091/v1/videos/${video_id} | jq .
-```
-
-## Poll Until Complete
-
-```bash
-while true; do
- status=$(curl -s http://localhost:8091/v1/videos/${video_id} | jq -r '.status')
- if [ "$status" = "completed" ]; then
- break
- fi
- if [ "$status" = "failed" ]; then
- echo "Video generation failed"
- exit 1
- fi
- sleep 2
-done
-```
-
-## LTX-2
-
-### Start Server
-
-#### Basic Start
-
-```bash
-vllm serve Lightricks/LTX-2 --omni --port 8098 \
- --enforce-eager --flow-shift 1.0 --boundary-ratio 1.0
-```
-
-For multi-GPU memory reduction, you can enable HSDP:
-
-```bash
-vllm serve Lightricks/LTX-2 --omni --port 8098 \
- --enforce-eager --flow-shift 1.0 --boundary-ratio 1.0 \
- --use-hsdp --hsdp-shard-size 2
-```
-
-#### Start with Optimization Presets
-
-Use the LTX-2 startup script with built-in optimization presets:
-
-```bash
-# Baseline (1 GPU, eager)
-bash run_server_ltx2.sh baseline
-
-# 4-GPU Ulysses sequence parallelism (lossless)
-bash run_server_ltx2.sh ulysses4
-
-# Cache-DiT lossy acceleration (1 GPU, ~1.4× speedup)
-bash run_server_ltx2.sh cache-dit
-
-# Best combo: 4-GPU Ulysses SP + Cache-DiT (~2.2× speedup)
-bash run_server_ltx2.sh best-combo
-```
-
-#### Optimization Benchmarks
-
-Benchmarked on H800, online serving (480×768, 41 frames, 20 steps, `seed=42`).
-"Inference" is the server-reported inference time; excludes HTTP/poll overhead.
-
-| Preset | Server Command | Inference (s) | Speedup | Type |
-|--------|---------------|---------------|---------|------|
-| `baseline` | `--enforce-eager` | 10.3 | 1.00× | — |
-| `compile` | *(default, no --enforce-eager)* | ~10.3 (warm) | ~1.00× | Lossless |
-| `ulysses4` | `--enforce-eager --usp 4` | ~10.3 | ~1.00× | Lossless |
-| `cache-dit` | `--enforce-eager --cache-backend cache_dit` | 7.4 avg | ~1.4× | Lossy |
-| `best-combo` | `--enforce-eager --usp 4 --cache-backend cache_dit` | 4.7 avg | **~2.2×** | Lossless + Lossy |
-
-**Observations**:
-- **torch.compile**: On H800, warm-request inference time matches the eager baseline (~10.3s).
- The first request pays ~6s compilation overhead. Benefit depends on model architecture and GPU.
-- **Ulysses SP (4 GPU)**: No measurable speedup alone for 41-frame generation at this resolution.
- Communication overhead outweighs gains at this sequence length.
-- **Cache-DiT**: Inference varies per request (6–10s) due to dynamic caching decisions.
- Average is ~7.4s (~1.4× speedup) with slight quality tradeoff.
-- **Best combo**: 4-GPU Ulysses SP + Cache-DiT synergize well — Cache-DiT reduces per-step
- computation, making the communication overhead of Ulysses SP worthwhile. Average ~4.7s
- (~2.2× speedup).
-- **FP8 quantization**: Reduces VRAM but does not speed up LTX-2 on H800 (compute-bound).
-
-**Deployment Recommendations**:
-- For **production with quality priority**: use `baseline` with `--enforce-eager`
-- For **maximum throughput** (4 GPUs, quality tradeoff): use `best-combo` (~2.2× speedup)
-- For **single-GPU throughput**: use `cache-dit` (~1.4× speedup)
-- `--enforce-eager` is recommended to avoid torch.compile warmup latency on first request
-
-### Send Requests (curl)
-
-```bash
-# Using the provided script
-bash run_curl_ltx2.sh
-
-# Or directly
-curl -sS -X POST http://localhost:8098/v1/videos \
- -H "Accept: application/json" \
- -F "prompt=A serene lakeside sunrise with mist over the water." \
- -F "width=768" \
- -F "height=480" \
- -F "num_frames=41" \
- -F "fps=24" \
- -F "num_inference_steps=20" \
- -F "guidance_scale=3.0" \
- -F "seed=42"
-```
-
-## Example materials
-
-??? abstract "response.json"
- ``````json
- --8<-- "examples/online_serving/text_to_video/response.json"
- ``````
-??? abstract "run_curl_ltx2.sh"
- ``````sh
- --8<-- "examples/online_serving/text_to_video/run_curl_ltx2.sh"
-??? abstract "run_curl_hunyuan_video_15.sh"
- ``````sh
- --8<-- "examples/online_serving/text_to_video/run_curl_hunyuan_video_15.sh"
- ``````
-??? abstract "run_curl_text_to_video.sh"
- ``````sh
- --8<-- "examples/online_serving/text_to_video/run_curl_text_to_video.sh"
- ``````
-??? abstract "run_server.sh"
- ``````sh
- --8<-- "examples/online_serving/text_to_video/run_server.sh"
- ``````
-??? abstract "run_server_ltx2.sh"
- ``````sh
- --8<-- "examples/online_serving/text_to_video/run_server_ltx2.sh"
-??? abstract "run_server_hunyuan_video_15.sh"
- ``````sh
- --8<-- "examples/online_serving/text_to_video/run_server_hunyuan_video_15.sh"
- ``````
diff --git a/docs/user_guide/feature_compatibility.md b/docs/user_guide/feature_compatibility.md
deleted file mode 100644
index ea05fe81ec1..00000000000
--- a/docs/user_guide/feature_compatibility.md
+++ /dev/null
@@ -1,218 +0,0 @@
-# Feature Compatibility
-
-This guide explains the compatibility matrix of different diffusion features in vLLM-Omni. You can use cache methods together with parallelism methods and other features to achieve optimal speed and efficiency.
-
-## Overview
-
-vLLM-Omni supports combining:
-
-- **Cache methods** (TeaCache, Cache-DiT) with **Parallelism methods** (Ulysses-SP, Ring-Attention, CFG-Parallel, Tensor Parallelism)
-- **Multiple parallelism methods** together (e.g., Ulysses-SP + Ring-Attention, CFG-Parallel + Sequence Parallelism)
-- **LoRA adapters** with most acceleration features
-- **CPU offloading** with other memory optimization features
-
-See the feature compatibility matrix in [Table](diffusion_features.md#feature-compatibility)
-
-## Common Combinations
-
-### 1. Cache + Sequence Parallelism (Recommended)
-
-Best for: **Large images (>1536px) or videos**
-
-Combines cache acceleration with sequence parallelism for maximum speedup on single-device-challenging workloads.
-
-**Using TeaCache + Ulysses-SP:**
-
-```bash
-python examples/offline_inference/text_to_image/text_to_image.py \
- --model Qwen/Qwen-Image \
- --prompt "A beautiful mountain landscape" \
- --cache-backend tea_cache \
- --ulysses-degree 2
-```
-
-**Using Cache-DiT + Ring-Attention:**
-
-```bash
-python examples/offline_inference/text_to_image/text_to_image.py \
- --model Qwen/Qwen-Image \
- --prompt "A futuristic city" \
- --cache-backend cache_dit \
- --ring-degree 2
-```
-
-### 2. Cache + CFG-Parallel
-
-Best for: **Image editing with Classifier-Free Guidance**
-
-Accelerates both the diffusion process and CFG computation.
-
-```bash
-python examples/offline_inference/image_to_image/image_edit.py \
- --model Qwen/Qwen-Image-Edit \
- --prompt "make it sunset" \
- --negative-prompt "low quality, blurry" \
- --image input.png \
- --cache-backend cache_dit \
- --cfg-parallel-size 2 \
- --cfg-scale 4.0
-```
-
-### 3. CFG-Parallel + Sequence Parallelism
-
-Best for: **Large resolution image editing with CFG**
-
-Combines both CFG branch splitting and sequence parallelism for maximum GPU utilization.
-
-**CFG-Parallel + Ulysses-SP:**
-
-```bash
-python examples/offline_inference/image_to_image/image_edit.py \
- --model Qwen/Qwen-Image-Edit \
- --prompt "transform into autumn scene" \
- --negative-prompt "low quality" \
- --image input.png \
- --cache-backend cache_dit \
- --cfg-parallel-size 2 \
- --ulysses-degree 2 \
- --cfg-scale 4.0
-```
-
-### 4. Hybrid Ulysses + Ring + Vae tiling
-
-Best for: **Very large images or videos on multiple devices**
-
-Combines Ulysses-SP (all-to-all) with Ring-Attention (ring P2P) for scalable parallelism.
-
-```bash
-python examples/offline_inference/text_to_image/text_to_image.py \
- --model Qwen/Qwen-Image \
- --prompt "Epic fantasy landscape" \
- --cache-backend cache_dit \
- --ulysses-degree 2 \
- --ring-degree 2 \
- --num-inference-steps 50 \
- --width 2048 \
- --height 2048 \
- --vae-use-tiling
-```
-
-### 5. Cache + Tensor Parallelism
-
-Best for: **Large models that don't fit in single GPU memory**
-
-Reduces per-GPU memory usage while maintaining cache acceleration.
-
-```bash
-python examples/offline_inference/text_to_image/text_to_image.py \
- --model Tongyi-MAI/Z-Image-Turbo \
- --prompt "A cat reading a book" \
- --cache-backend tea_cache \
- --tensor-parallel-size 2 \
- --num-inference-steps 9 \
-```
-
-## Online Serving
-
-### Cache + Sequence Parallelism
-
-```bash
-# TeaCache + Ulysses-SP
-vllm serve Qwen/Qwen-Image --omni --port 8091 \
- --cache-backend tea_cache \
- --cache-config '{"rel_l1_thresh": 0.2}' \
- --usp 2
-
-# Cache-DiT + Ring-Attention
-vllm serve Qwen/Qwen-Image --omni --port 8091 \
- --cache-backend cache_dit \
- --cache-config '{"Fn_compute_blocks": 1, "max_warmup_steps": 8}' \
- --ring 2
-```
-
-### Cache + CFG-Parallel
-
-```bash
-vllm serve Qwen/Qwen-Image-Edit --omni --port 8091 \
- --cache-backend cache_dit \
- --cfg-parallel-size 2
-```
-
-### Multiple Parallelism Methods
-
-```bash
-# CFG-Parallel + Ulysses-SP (4 GPUs total)
-vllm serve Qwen/Qwen-Image-Edit --omni --port 8091 \
- --cache-backend cache_dit \
- --cfg-parallel-size 2 \
- --usp 2
-
-# Hybrid Ulysses + Ring (4 GPUs total)
-vllm serve Qwen/Qwen-Image --omni --port 8091 \
- --cache-backend cache_dit \
- --usp 2 \
- --ring 2
-```
-
-
-## Limitations
-
-### Incompatibilities
-
-- **TeaCache + Cache-DiT**: These two cache methods cannot be used together. Only one cache backend can be active at a time. Attempting to enable both will result in an error.
-
-### Partial Support
-
-- **Tensor Parallelism — Text Encoder Not Sharded**: TP currently only shards the DiT blocks. Each TP rank retains a **full copy of the text encoder weights**, leading to significant GPU memory overhead proportional to TP degree. Tracked in [Issue #771](https://github.com/vllm-project/vllm-omni/issues/771).
-
-- **CPU Offloading — Two Modes Are Mutually Exclusive**: Model-level offload (`enable_cpu_offload`) and layerwise offload (`enable_layerwise_offload`) cannot be used simultaneously. If both are set, layerwise takes priority and model-level is silently ignored.
-
-- **CPU Offloading — VAE stays on GPU**: Both offloading strategies keep the VAE on GPU at all times. For high-resolution generation, VAE decode can still cause OOM. Mitigate by combining with `vae_use_tiling=True` or VAE Patch Parallelism.
-
-- **VAE Patch Parallelism — DistributedVaeExecutor Required**: VAE Patch Parallelism is only enabled for models that have `DistributedVaeExecutor`. Unsupported models will silently ignore `vae_patch_parallel_size`, and use sequential vae tiling instead.
-
-### Configuration Constraints
-
-- **GPU Count Must Match Parallel Degrees**: Total GPU count must satisfy:
- ```
- total_gpus = ulysses_degree × ring_degree × cfg_parallel_size × tensor_parallel_size
- ```
- Any mismatch will cause a configuration error at startup.
-
-- **VAE Patch Parallel Size ≤ DiT Process Group Size**: `vae_patch_parallel_size` reuses the DiT process group and cannot exceed it. Larger values are automatically clamped with a warning.
-
-- **Model-Specific TP Constraints**: Some models impose divisibility constraints on TP size. For example, Z-Image Turbo (`num_heads=30`) only supports `tensor_parallel_size=2`. Check [Supported Models](diffusion_features.md#supported-models) for per-model constraints.
-
-## Troubleshooting
-
-### Performance Not Scaling
-
-**Symptoms:** Adding more GPUs doesn't improve speed proportionally
-
-**Solutions:**
-1. Check GPU communication bandwidth (use `nvidia-smi topo -m`)
-2. Reduce parallelism degree if communication overhead is high
-3. For very long sequences, prefer Ring-Attention over Ulysses-SP
-4. Ensure batch size is large enough to saturate GPUs
-
-### Out of Memory with Parallelism
-
-**Symptoms:** OOM errors when combining methods
-
-**Solutions:**
-1. Enable Tensor Parallelism to shard weights
-2. Reduce resolution or batch size
-3. Combine with memory efficient methods, such as cpu offloading
-
-### Configuration Errors
-
-**Symptoms:** Errors about invalid parallel configuration
-
-**Solutions:**
-1. Verify total GPU count matches: `ulysses × ring × cfg × tp`
-2. Check model supports all enabled methods
-3. Ensure divisibility constraints (e.g., Z-Image TP=1 or 2 only)
-
-## See Also
-
-- [Diffusion Acceleration Overview](diffusion_features.md) - Main acceleration guide
diff --git a/docs/user_guide/quantization/autoround.md b/docs/user_guide/quantization/autoround.md
deleted file mode 100644
index 2261d79a57c..00000000000
--- a/docs/user_guide/quantization/autoround.md
+++ /dev/null
@@ -1,127 +0,0 @@
-# AutoRound Quantization
-
-## Overview
-
-[AutoRound](https://github.com/intel/auto-round) produces pre-quantized
-checkpoints for LLMs, VLMs, and diffusion models. vLLM-Omni reads the
-checkpoint's `config.json` and auto-detects
-`quantization_config.quant_method = "auto-round"`.
-
-AutoRound is static quantization: no `--quantization` flag is needed at
-inference time when the checkpoint already contains the quantization config.
-
-## Hardware Support
-
-| Device | Support |
-|--------|---------|
-| NVIDIA Blackwell GPU (SM 100+) | ✅ |
-| NVIDIA Ada/Hopper GPU (SM 89+) | ✅ |
-| NVIDIA Ampere GPU (SM 80+) | ✅ |
-| AMD ROCm | ⭕ |
-| Intel XPU | ✅ |
-| Ascend NPU | ❌ |
-
-Legend: `✅` supported, `❌` unsupported, `⭕` not verified in this
-guide. AutoRound is Intel-supported.
-
-## Model Type Support
-
-### Diffusion Model (Qwen-Image, Wan2.2)
-
-| Model | Checkpoint | Scope | Scheme | Backend |
-|-------|------------|-------|--------|---------|
-| FLUX.1-dev | `vllm-project-org/FLUX.1-dev-AutoRound-w4a16` | Diffusion transformer | W4A16 | GPTQ-Marlin or Intel-supported AutoRound backend |
-| Qwen-Image | Not listed | Diffusion transformer | W4A16 | Not validated |
-| Wan2.2 | Not listed | Diffusion transformer | W4A16 | Not validated |
-
-### Multi-Stage Omni/TTS Model (Qwen3-Omni, Qwen3-TTS)
-
-| Model | Checkpoint | Scope | Scheme | Backend |
-|-------|------------|-------|--------|---------|
-| Qwen2.5-Omni-7B | `Intel/Qwen2.5-Omni-7B-int4-AutoRound` | Language-model stage | W4A16 | AutoRound |
-| Qwen3-Omni-30B-A3B-Instruct | `Intel/Qwen3-Omni-30B-A3B-Instruct-int4-AutoRound` | Thinker language-model stage | W4A16 | AutoRound |
-| Qwen3-TTS | Not listed | TTS language-model stage | W4A16 | Not validated |
-
-AutoRound support is checkpoint-driven. A model is supported when its
-checkpoint uses a compatible INC/AutoRound config and the target stage maps to
-vLLM-Omni's runtime module names.
-
-### Multi-Stage Diffusion Model (BAGEL, GLM-Image)
-
-| Model | Scope | Status | Notes |
-|-------|-------|--------|-------|
-| BAGEL | Checkpoint-defined diffusion or transformer stage | Not validated | Requires a compatible AutoRound checkpoint |
-| GLM-Image | Checkpoint-defined diffusion or transformer stage | Not validated | Requires a compatible AutoRound checkpoint |
-
-## Configuration
-
-Python API:
-
-```python
-from vllm_omni import Omni
-from vllm_omni.inputs.data import OmniDiffusionSamplingParams
-
-omni = Omni(model="vllm-project-org/FLUX.1-dev-AutoRound-w4a16")
-
-outputs = omni.generate(
- "A cat sitting on a windowsill",
- OmniDiffusionSamplingParams(num_inference_steps=28),
-)
-outputs[0].save_images("output.png")
-```
-
-CLI:
-
-```bash
-python examples/offline_inference/text_to_image/text_to_image.py \
- --model vllm-project-org/FLUX.1-dev-AutoRound-w4a16 \
- --prompt "A cat sitting on a windowsill" \
- --num-inference-steps 28 \
- --output outputs/flux_w4a16.png
-```
-
-## Parameters
-
-| Field | Type | Description |
-|-------|------|-------------|
-| `quant_method` | str | Must be `"auto-round"` |
-| `bits` | int | Quantized weight bit width, usually `4` |
-| `group_size` | int | Quantization group size |
-| `packing_format` | str | AutoRound packing format, for example `auto_round:auto_gptq` |
-| `block_name_to_quantize` | str | Checkpoint block names that should map to runtime module names |
-
-The checkpoint should contain a config like:
-
-```json
-{
- "quantization_config": {
- "quant_method": "auto-round",
- "bits": 4,
- "group_size": 128,
- "sym": true,
- "packing_format": "auto_round:auto_gptq",
- "block_name_to_quantize": "transformer_blocks,single_transformer_blocks"
- }
-}
-```
-
-## Validation and Notes
-
-At load time, vLLM-Omni builds an `OmniINCConfig`, remaps checkpoint block names
-to runtime module names, and selects the matching vLLM compute backend.
-
-Example checkpoint creation:
-
-```bash
-auto-round \
- --model black-forest-labs/FLUX.1-dev \
- --scheme W4A16 \
- --batch_size 1 \
- --disable_opt_rtn \
- --dataset coco2014 \
- --iters 0
-```
-
-Use the generated output directory directly as the `model` argument. See the
-[AutoRound documentation](https://github.com/intel/auto-round) for all
-available schemes and options.
diff --git a/docs/user_guide/quantization/fp8.md b/docs/user_guide/quantization/fp8.md
deleted file mode 100644
index e89bc76ca77..00000000000
--- a/docs/user_guide/quantization/fp8.md
+++ /dev/null
@@ -1,121 +0,0 @@
-# FP8 Quantization
-
-## Overview
-
-FP8 quantization converts BF16/FP16 weights to FP8 at model load time, or loads
-a checkpoint whose target stage already declares an FP8 quantization config.
-Online activation scaling is the default and does not require calibration.
-Static activation scaling is supported when calibrated scale information is
-available.
-
-Some architectures can quantize all linear layers. Others have
-quality-sensitive layers that should stay in BF16 through `ignored_layers`.
-Image-stream MLPs (`img_mlp`) are a common sensitive target because denoising
-latent ranges shift across timesteps and small per-layer errors can compound
-in deep DiT blocks.
-
-## Hardware Support
-
-| Device | Support |
-|--------|---------|
-| NVIDIA Blackwell GPU (SM 100+) | ✅ |
-| NVIDIA Ada/Hopper GPU (SM 89+) | ✅ |
-| NVIDIA Ampere GPU (SM 80+) | ✅ |
-| AMD ROCm | ⭕ |
-| Intel XPU | ⭕ |
-| Ascend NPU | ❌ |
-
-Legend: `✅` supported, `❌` unsupported, `⭕` not verified in this
-guide. FP8 on Ampere may use a weight-only path where available.
-
-## Model Type Support
-
-### Diffusion Model (Qwen-Image, Wan2.2)
-
-| Model | HF models | Online | Pre-calibrated | Recommendation | `ignored_layers` |
-|-------|-----------|:-------:|:------:|----------------|------------------|
-| Qwen-Image | `Qwen/Qwen-Image`, `Qwen/Qwen-Image-2512` | Yes | Yes | Skip sensitive image-stream MLPs when quality regresses | `img_mlp` |
-| Wan2.2 | Wan2.2 diffusion pipelines | Not validated | Not validated | Validate against BF16 before documenting as supported | TBD |
-| Z-Image | `Tongyi-MAI/Z-Image-Turbo` | Yes | Yes | All layers | None |
-| FLUX.1 | `black-forest-labs/FLUX.1-dev`, `black-forest-labs/FLUX.1-schnell` | Yes | Yes | All layers | None |
-| FLUX.2-klein | `black-forest-labs/FLUX.2-klein-4B` | Yes | Yes | All layers | None |
-| HunyuanImage-3.0 | `tencent/HunyuanImage-3.0`, `tencent/HunyuanImage-3.0-Instruct` | Yes | Yes | All layers; use the Hunyuan stage config for multi-stage runs | None |
-| HunyuanVideo-1.5 | `hunyuanvideo-community/HunyuanVideo-1.5-Diffusers-480p_t2v`, `720p_t2v`, `480p_i2v` | Yes | Yes | All layers | None |
-
-### Multi-Stage Omni/TTS Model (Qwen3-Omni, Qwen3-TTS)
-
-| Model | Scope | Format | Status |
-|-------|-------|--------|--------|
-| Qwen3-Omni | Thinker language-model stage | ModelOpt `quant_algo=FP8` | Tested for thinker memory reduction |
-| Qwen3-TTS | TTS language-model stage | Checkpoint config | Not validated |
-
-Audio encoder, vision encoder, talker, and code2wav stay in BF16 unless a
-model-specific guide says otherwise.
-
-### Multi-Stage Diffusion Model (BAGEL, GLM-Image)
-
-| Model | Scope | Status | Notes |
-|-------|-------|--------|-------|
-| BAGEL | Stage-specific transformer or DiT module | Not validated | Route FP8 to the intended stage before enabling |
-| GLM-Image | Stage-specific transformer or DiT module | Not validated | Validate quality against BF16 baseline |
-
-## Configuration
-
-Python API:
-
-```python
-from vllm_omni import Omni
-from vllm_omni.inputs.data import OmniDiffusionSamplingParams
-
-omni = Omni(model="<your-model>", quantization="fp8")
-
-omni_with_skips = Omni(
- model="<your-model>",
- quantization_config={
- "method": "fp8",
- "ignored_layers": ["img_mlp"],
- },
-)
-
-outputs = omni.generate(
- "A cat sitting on a windowsill",
- OmniDiffusionSamplingParams(num_inference_steps=50),
-)
-```
-
-CLI:
-
-```bash
-python text_to_image.py --model <your-model> --quantization fp8
-python text_to_image.py --model <your-model> --quantization fp8 --ignored-layers "img_mlp"
-vllm serve <your-model> --omni --quantization fp8
-```
-
-## Parameters
-
-| Parameter | Type | Default | Description |
-|-----------|------|---------|-------------|
-| `method` | str | - | Quantization method (`"fp8"`) |
-| `ignored_layers` | list[str] | `[]` | Layer name patterns to keep in BF16 |
-| `activation_scheme` | str | `"dynamic"` | `"dynamic"` selects online activation scaling, or `"static"` when scales are available |
-| `weight_block_size` | list[int] \| None | `None` | Block size for block-wise weight quantization |
-
-The available `ignored_layers` names depend on the model architecture, for
-example `to_qkv`, `to_out`, `img_mlp`, or `txt_mlp`.
-
-## Validation and Notes
-
-FP8 quantization can be combined with cache acceleration:
-
-```python
-omni = Omni(
- model="<your-model>",
- quantization="fp8",
- cache_backend="tea_cache",
- cache_config={"rel_l1_thresh": 0.2},
-)
-```
-
-Compare generated outputs with a BF16 baseline before adding a new model to the
-supported table. GLM-Image and Helios are not listed as FP8-supported diffusion
-models until they have method-specific validation.
diff --git a/docs/user_guide/quantization/gguf.md b/docs/user_guide/quantization/gguf.md
deleted file mode 100644
index cd2e8b87509..00000000000
--- a/docs/user_guide/quantization/gguf.md
+++ /dev/null
@@ -1,107 +0,0 @@
-# GGUF Quantization
-
-## Overview
-
-GGUF support loads pre-quantized diffusion transformer weights while keeping
-the rest of the pipeline on the base Hugging Face checkpoint. Use the base
-model for tokenizer, text encoder, scheduler, and VAE, then pass the GGUF file
-for the transformer.
-
-GGUF is static quantization: the quantized weights are produced before serving.
-
-## Hardware Support
-
-| Device | Support |
-|--------|---------|
-| NVIDIA Blackwell GPU (SM 100+) | ✅ |
-| NVIDIA Ada/Hopper GPU (SM 89+) | ✅ |
-| NVIDIA Ampere GPU (SM 80+) | ✅ |
-| AMD ROCm | ⭕ |
-| Intel XPU | ⭕ |
-| Ascend NPU | ❌ |
-
-Legend: `✅` supported, `❌` unsupported, `⭕` not verified in this
-guide.
-
-## Model Type Support
-
-### Diffusion Model (Qwen-Image, Wan2.2)
-
-| Model | HF base model | GGUF input | Scope | Adapter |
-|-------|---------------|------------|-------|---------|
-| Qwen-Image family | `Qwen/Qwen-Image`, `Qwen/Qwen-Image-2512`, edit and layered Qwen-Image pipelines | Local `.gguf`, `repo/file.gguf`, or `repo:quant_type` | Transformer only | `QwenImageGGUFAdapter` |
-| Wan2.2 | Wan2.2 diffusion pipelines | Not validated | Transformer only | No validated adapter listed |
-| Z-Image | `Tongyi-MAI/Z-Image-Turbo` | Local `.gguf`, `repo/file.gguf`, or `repo:quant_type` | Transformer only | `ZImageGGUFAdapter` |
-| FLUX.2-klein | `black-forest-labs/FLUX.2-klein-4B` | Local `.gguf`, `repo/file.gguf`, or `repo:quant_type` | Transformer only | `Flux2KleinGGUFAdapter` |
-
-Generic FLUX.1 GGUF checkpoints are not listed here; the implemented adapter is
-for the FLUX.2-klein path.
-
-### Multi-Stage Omni/TTS Model (Qwen3-Omni, Qwen3-TTS)
-
-| Model | Scope | Status | Notes |
-|-------|-------|--------|-------|
-| Qwen3-Omni | Thinker language-model stage | Not validated | GGUF is not documented for omni/TTS AR stages |
-| Qwen3-TTS | TTS language-model stage | Not validated | GGUF is not documented for TTS stages |
-
-### Multi-Stage Diffusion Model (BAGEL, GLM-Image)
-
-| Model | Scope | Status | Notes |
-|-------|-------|--------|-------|
-| BAGEL | Stage-specific transformer weights | Not validated | Requires a model-specific GGUF adapter |
-| GLM-Image | Stage-specific transformer weights | Not validated | Requires a model-specific GGUF adapter |
-
-## Configuration
-
-Offline:
-
-```bash
-python examples/offline_inference/text_to_image/text_to_image.py \
- --model Qwen/Qwen-Image \
- --gguf-model QuantStack/Qwen-Image-GGUF/Qwen_Image-Q4_K_M.gguf \
- --quantization gguf \
- --prompt "a red paper kite hanging from a pine tree in a winter courtyard" \
- --height 1024 \
- --width 1024 \
- --seed 42 \
- --num_inference_steps 20 \
- --output outputs/qwen_image_q4km.png
-```
-
-Online:
-
-```bash
-vllm serve Qwen/Qwen-Image \
- --omni \
- --port 8000 \
- --quantization-config '{"method":"gguf","gguf_model":"QuantStack/Qwen-Image-GGUF/Qwen_Image-Q4_K_M.gguf"}'
-```
-
-## Parameters
-
-| Parameter | Type | Default | Description |
-|-----------|------|---------|-------------|
-| `method` | str | - | Quantization method (`"gguf"`) |
-| `gguf_model` | str | - | Local GGUF file, explicit Hugging Face file, or `repo:quant_type` selector |
-
-`gguf_model` accepts:
-
-| Form | Example |
-|------|---------|
-| Local file | `/models/z-image-Q4_K_M.gguf` |
-| Explicit HF file | `QuantStack/Qwen-Image-GGUF/Qwen_Image-Q4_K_M.gguf` |
-| HF repo plus quant type | `owner/repo:Q4_K_M` |
-
-## Validation and Notes
-
-1. `OmniDiffusionConfig` receives `{"method": "gguf", "gguf_model": ...}`.
-2. `DiffusersPipelineLoader` resolves the GGUF file.
-3. A model-specific adapter remaps GGUF tensor names to vLLM-Omni transformer
- names.
-4. Only transformer weights are loaded from GGUF. Missing non-transformer
- weights are loaded from the base model repository.
-5. vLLM's GGUF linear method performs dequantization and GEMM at runtime.
-
-Unsupported models fail fast with a clear "No GGUF adapter matched" error
-instead of falling back to a generic mapper. Many GGUF repositories do not
-include `model_index.json`; always pass the normal base model through `--model`.
diff --git a/docs/user_guide/quantization/int8.md b/docs/user_guide/quantization/int8.md
deleted file mode 100644
index 85bee9a5f08..00000000000
--- a/docs/user_guide/quantization/int8.md
+++ /dev/null
@@ -1,107 +0,0 @@
-# Int8 Quantization
-
-## Overview
-
-Int8 quantization supports W8A8 diffusion transformer inference on CUDA and
-Ascend NPU. It can quantize BF16/FP16 weights at load time, or load serialized
-Int8 checkpoints that already contain quantized weights and scales.
-
-Only online activation scaling is currently supported.
-
-## Hardware Support
-
-| Device | Support |
-|--------|---------|
-| NVIDIA Blackwell GPU (SM 100+) | ✅ |
-| NVIDIA Ada/Hopper GPU (SM 89+) | ✅ |
-| NVIDIA Ampere GPU (SM 80+) | ✅ |
-| AMD ROCm | ⭕ |
-| Intel XPU | ⭕ |
-| Ascend NPU | ✅ |
-
-Legend: `✅` supported, `❌` unsupported, `⭕` not verified in this
-guide.
-
-## Model Type Support
-
-### Diffusion Model (Qwen-Image, Wan2.2)
-
-| Model | HF models | CUDA | Ascend NPU | Mode | Recommendation |
-|-------|-----------|:----:|:----------:|------|----------------|
-| Qwen-Image | `Qwen/Qwen-Image`, `Qwen/Qwen-Image-2512` | Yes | Yes | Online W8A8 | All layers |
-| Wan2.2 | Wan2.2 diffusion pipelines | Not validated | Not validated | Online W8A8 | Validate before enabling in docs |
-| Z-Image | `Tongyi-MAI/Z-Image-Turbo` | Yes | Yes | Online W8A8 | All layers |
-
-Other diffusion models may work if their transformer uses supported linear
-layers, but they are not validated in this guide.
-
-### Multi-Stage Omni/TTS Model (Qwen3-Omni, Qwen3-TTS)
-
-| Model | Scope | Status | Notes |
-|-------|-------|--------|-------|
-| Qwen3-Omni | Thinker language-model stage | Not validated | Prefer checkpoint-supported ModelOpt FP8 or AutoRound paths |
-| Qwen3-TTS | TTS language-model stage | Not validated | No Int8 TTS stage support is documented |
-
-### Multi-Stage Diffusion Model (BAGEL, GLM-Image)
-
-| Model | Scope | Status | Notes |
-|-------|-------|--------|-------|
-| BAGEL | Stage-specific transformer or DiT module | Not validated | Requires explicit stage routing |
-| GLM-Image | Stage-specific transformer or DiT module | Not validated | Requires quality comparison with BF16 |
-
-## Configuration
-
-Python API:
-
-```python
-from vllm_omni import Omni
-from vllm_omni.inputs.data import OmniDiffusionSamplingParams
-
-omni = Omni(model="<your-model>", quantization="int8")
-
-omni_with_skips = Omni(
- model="<your-model>",
- quantization_config={
- "method": "int8",
- "ignored_layers": ["<layer-name>"],
- },
-)
-
-outputs = omni.generate(
- "A cat sitting on a windowsill",
- OmniDiffusionSamplingParams(num_inference_steps=50),
-)
-```
-
-CLI:
-
-```bash
-python text_to_image.py --model <your-model> --quantization int8
-python text_to_image.py --model <your-model> --quantization int8 --ignored-layers "img_mlp"
-vllm serve <your-model> --omni --quantization int8
-```
-
-## Parameters
-
-| Parameter | Type | Default | Description |
-|-----------|------|---------|-------------|
-| `method` | str | - | Quantization method (`"int8"`) |
-| `activation_scheme` | str | `"dynamic"` | `"dynamic"` selects online activation scaling; static is not supported |
-| `ignored_layers` | list[str] | `[]` | Layer name patterns to keep in BF16/FP16 |
-| `is_checkpoint_int8_serialized` | bool | `False` | Set by checkpoint config when loading serialized Int8 weights |
-
-## Validation and Notes
-
-Int8 quantization can be combined with cache acceleration:
-
-```python
-omni = Omni(
- model="<your-model>",
- quantization="int8",
- cache_backend="tea_cache",
- cache_config={"rel_l1_thresh": 0.2},
-)
-```
-
-Only add a new model to the supported table after comparing the Int8 output
-against a BF16 baseline and documenting any required `ignored_layers`.
diff --git a/docs/user_guide/quantization/msmodelslim.md b/docs/user_guide/quantization/msmodelslim.md
deleted file mode 100644
index c03628b9d4d..00000000000
--- a/docs/user_guide/quantization/msmodelslim.md
+++ /dev/null
@@ -1,95 +0,0 @@
-# msModelSlim Quantization
-
-## Overview
-
-[msModelSlim](https://github.com/Ascend/msmodelslim) is an Ascend compression
-toolkit for producing pre-quantized model checkpoints. In vLLM-Omni, these
-checkpoints run through the Ascend/NPU path with `--quantization ascend`.
-
-msModelSlim is static quantization: quantized weights are generated offline
-before vLLM-Omni inference starts.
-
-## Hardware Support
-
-| Device | Support |
-|--------|---------|
-| NVIDIA Blackwell GPU (SM 100+) | ❌ |
-| NVIDIA Ada/Hopper GPU (SM 89+) | ❌ |
-| NVIDIA Ampere GPU (SM 80+) | ❌ |
-| AMD ROCm | ❌ |
-| Intel XPU | ❌ |
-| Ascend NPU | ✅ |
-
-Legend: `✅` supported, `❌` unsupported, `⭕` not verified in this
-guide.
-
-## Model Type Support
-
-### Diffusion Model (Qwen-Image, Wan2.2)
-
-| Model | Base model | Scope | Hardware | Notes |
-|-------|------------|-------|----------|-------|
-| Wan2.2 | Wan2.2 diffusion weights | DiT or diffusion stage | Ascend NPU | Upstream msModelSlim provides a Wan2.2 quantization recipe; vLLM-Omni inference validation is not listed |
-| Qwen-Image | `Qwen/Qwen-Image`, `Qwen/Qwen-Image-2512` | DiT or diffusion stage | Ascend NPU | Not validated in this guide |
-| HunyuanImage-3.0 | `tencent/HunyuanImage-3.0`, `tencent/HunyuanImage-3.0-Instruct` | DiT or diffusion stage | Ascend A2/A3 NPU | Generate quantized weights with the HunyuanImage-3.0 msModelSlim adaptation |
-
-Public Hugging Face quantized weights are not available yet. Use the
-[HunyuanImage-3.0 msModelSlim adaptation](https://gitcode.com/betta18/msmodelslim/tree/hyimage3_mxfp8)
-to generate the checkpoint manually.
-
-### Multi-Stage Omni/TTS Model (Qwen3-Omni, Qwen3-TTS)
-
-| Model | Scope | Status | Notes |
-|-------|-------|--------|-------|
-| Qwen3-Omni | Thinker or language-model stage | Not validated | No msModelSlim omni checkpoint path is documented |
-| Qwen3-TTS | TTS language-model stage | Not validated | No msModelSlim TTS checkpoint path is documented |
-
-### Multi-Stage Diffusion Model (BAGEL, GLM-Image)
-
-| Model | Scope | Status | Notes |
-|-------|-------|--------|-------|
-| BAGEL | Stage-specific diffusion or transformer weights | Not validated | Requires a model-specific Ascend adaptation |
-| GLM-Image | Stage-specific diffusion or transformer weights | Not validated | Requires a model-specific Ascend adaptation |
-
-## Configuration
-
-Offline inference:
-
-```bash
-python text_to_image.py --model <quantized-model-path> --quantization ascend
-```
-
-Online serving:
-
-```bash
-vllm serve <quantized-model-path> --omni --quantization ascend
-```
-
-## Parameters
-
-| Parameter | Type | Default | Description |
-|-----------|------|---------|-------------|
-| `--quantization` | str | - | Use `ascend` for msModelSlim-produced checkpoints |
-| `model` | str | - | Path to the quantized checkpoint generated by Ascend tooling |
-
-Example msModelSlim command for a Wan2.2 W8A8 checkpoint:
-
-```bash
-msmodelslim quant \
- --model_path /path/to/wan2_2_t2v_float_weights \
- --save_path /path/to/wan2_2_t2v_quantized_weights \
- --device npu \
- --model_type Wan2_2 \
- --config_path /path/to/wan2_2_w8a8f8_mxfp_t2v.yaml \
- --trust_remote_code True
-```
-
-For HunyuanImage-3.0, use the Hunyuan-specific adaptation linked above.
-
-## Validation and Notes
-
-1. Run with the Ascend/NPU installation and environment.
-2. The `ascend` quantization method expects weights produced by the Ascend
- tooling; it is not a load-time CUDA quantizer.
-3. Keep the quantized checkpoint aligned with the same model architecture and
- stage config used for BF16 inference.
diff --git a/docs/user_guide/quantization/online.md b/docs/user_guide/quantization/online.md
deleted file mode 100644
index 3dcb8297e60..00000000000
--- a/docs/user_guide/quantization/online.md
+++ /dev/null
@@ -1,93 +0,0 @@
-# Online Quantization
-
-## Overview
-
-Online quantization means vLLM-Omni computes quantized weights and scales while
-loading the model. Use it when you want memory savings without preparing a
-separate quantized checkpoint.
-
-This mode is different from pre-quantized checkpoint formats such as GGUF,
-AutoRound, msModelSlim, or serialized Int8 checkpoints. Those formats are
-prepared before serving and are documented in their method-specific guides.
-
-## Hardware Support
-
-| Device | FP8 W8A8 | Int8 W8A8 |
-|--------|----------|-----------|
-| NVIDIA Blackwell GPU (SM 100+) | ✅ | ✅ |
-| NVIDIA Ada/Hopper GPU (SM 89+) | ✅ | ✅ |
-| NVIDIA Ampere GPU (SM 80+) | ✅ | ✅ |
-| AMD ROCm | ⭕ | ⭕ |
-| Intel XPU | ⭕ | ⭕ |
-| Ascend NPU | ❌ | ✅ |
-
-Legend: `✅` supported, `❌` unsupported, `⭕` not verified in this
-guide. FP8 on Ampere may use a weight-only path where available.
-
-## Model Type Support
-
-### Diffusion Model (Qwen-Image, Wan2.2)
-
-| Method | Guide | Example models | Status |
-|--------|-------|----------------|--------|
-| FP8 W8A8 | [FP8](fp8.md) | Qwen-Image; Wan2.2 is not validated | Validated for Qwen-Image family and other DiT models |
-| Int8 W8A8 | [Int8](int8.md) | Qwen-Image; Wan2.2 is not validated | Validated for Qwen-Image and Z-Image |
-
-### Multi-Stage Omni/TTS Model (Qwen3-Omni, Qwen3-TTS)
-
-Online quantization is not currently validated for the omni/TTS stages. For
-Qwen3-Omni and related models, prefer checkpoint-declared ModelOpt or
-AutoRound paths when available.
-
-### Multi-Stage Diffusion Model (BAGEL, GLM-Image)
-
-Online quantization must be routed to the intended stage. BAGEL and GLM-Image
-need model-specific validation before they are listed as supported targets.
-
-## Configuration
-
-Python API:
-
-```python
-from vllm_omni import Omni
-
-omni_fp8 = Omni(model="<your-model>", quantization="fp8")
-omni_int8 = Omni(model="<your-model>", quantization="int8")
-```
-
-CLI:
-
-```bash
-vllm serve <your-model> --omni --quantization fp8
-vllm serve <your-model> --omni --quantization int8
-```
-
-Per-component routing:
-
-```python
-from vllm_omni.quantization import build_quant_config
-
-config = build_quant_config({
- "transformer": {"method": "fp8"},
- "vae": None,
-})
-```
-
-## Parameters
-
-| Parameter | Methods | Description |
-|-----------|---------|-------------|
-| `method` | FP8, Int8 | Quantization method, usually `"fp8"` or `"int8"` |
-| `ignored_layers` | FP8, Int8 | Layer name patterns to keep in BF16/FP16 |
-| `activation_scheme` | FP8, Int8 | The runtime value `"dynamic"` selects online activation scaling |
-| `weight_block_size` | FP8 | Optional block-wise FP8 weight quantization size |
-
-## Validation and Notes
-
-1. Compare the online-quantized output against a BF16 baseline with the same
- seed and generation parameters.
-2. Use `ignored_layers` for quality-sensitive MLPs or output projections.
-3. Document any required skipped layers in the method page before marking a new
- model as supported.
-4. If a model already ships quantized weights, use the matching pre-quantized
- method guide instead of online quantization.
diff --git a/docs/user_guide/quantization/overview.md b/docs/user_guide/quantization/overview.md
deleted file mode 100644
index 762fb2fc68d..00000000000
--- a/docs/user_guide/quantization/overview.md
+++ /dev/null
@@ -1,134 +0,0 @@
-# Quantization
-
-vLLM-Omni exposes quantization through the unified `quantization_config`
-path. The same configuration entrypoint is used across diffusion-only models,
-multi-stage omni/TTS models, and multi-stage diffusion models, but each model
-type has a different quantization scope.
-
-## Quantization Modes
-
-| Mode | Guide | Description | Methods |
-|------|-------|-------------|---------|
-| Online quantization | [Online Quantization](online.md) | vLLM-Omni computes quantized weights and scales while loading the model. | FP8 W8A8, Int8 W8A8 |
-| Pre-quantized checkpoints | Method-specific guides | The checkpoint or an offline quantizer provides quantized weights and scales before serving. | GGUF, AutoRound, msModelSlim, serialized Int8 |
-
-## Hardware Support
-
-| Device | FP8 W8A8 | Int8 W8A8 | GGUF | AutoRound | msModelSlim |
-|--------|----------|-----------|------|-----------|-------------|
-| NVIDIA Blackwell GPU (SM 100+) | ✅ | ✅ | ✅ | ✅ | ❌ |
-| NVIDIA Ada/Hopper GPU (SM 89+) | ✅ | ✅ | ✅ | ✅ | ❌ |
-| NVIDIA Ampere GPU (SM 80+) | ✅ | ✅ | ✅ | ✅ | ❌ |
-| AMD ROCm | ⭕ | ⭕ | ⭕ | ⭕ | ❌ |
-| Intel XPU | ⭕ | ⭕ | ⭕ | ✅ | ❌ |
-| Ascend NPU | ❌ | ✅ | ❌ | ❌ | ✅ |
-
-Legend: `✅` supported, `❌` unsupported, `⭕` not verified in this
-guide. FP8 on Ampere may use a weight-only path where available.
-
-## Model Type Support
-
-### Diffusion Model (Qwen-Image, Wan2.2)
-
-These models run a diffusion transformer as the primary inference module. The
-default quantization target is the transformer; tokenizer, scheduler, text
-encoder, and VAE stay on the base checkpoint unless a method guide says
-otherwise.
-
-| Method | Guide | Mode | Example models | Status |
-|--------|-------|------|----------------|--------|
-| FP8 W8A8 | [FP8](fp8.md) | Online W8A8 or checkpoint FP8 | Qwen-Image; Wan2.2 is not validated | Validated for Qwen-Image family and other DiT models |
-| Int8 W8A8 | [Int8](int8.md) | Online or serialized W8A8 | Qwen-Image; Wan2.2 is not validated | Validated for Qwen-Image and Z-Image |
-| GGUF | [GGUF](gguf.md) | Pre-quantized transformer weights | Qwen-Image | Validated where a model-specific GGUF adapter exists |
-| AutoRound | [AutoRound](autoround.md) | Pre-quantized W4A16 checkpoints | FLUX.1-dev; Qwen-Image/Wan2.2 not validated | Checkpoint-driven |
-| msModelSlim | [msModelSlim](msmodelslim.md) | Pre-quantized Ascend checkpoints | Wan2.2 recipe; HunyuanImage-3.0 inference target | Ascend/NPU path |
-
-### Multi-Stage Omni/TTS Model (Qwen3-Omni, Qwen3-TTS)
-
-These models combine an AR language model with audio, vision, talker, or TTS
-stages. Quantization is scoped to the AR language-model stage when the
-checkpoint contains a supported `quantization_config`; the non-AR stages stay
-in BF16 unless the model guide explicitly adds support.
-
-| Method | Guide | Scope | Example models | Status |
-|--------|-------|-------|----------------|--------|
-| FP8 | [FP8](fp8.md) | Thinker or language-model checkpoint config | Qwen3-Omni thinker | ModelOpt checkpoint path |
-| Int8 | [Int8](int8.md) | Not currently validated for omni/TTS stages | Qwen3-Omni, Qwen3-TTS | Not validated |
-| GGUF | [GGUF](gguf.md) | Not currently validated for omni/TTS stages | Qwen3-Omni, Qwen3-TTS | Not validated |
-| AutoRound | [AutoRound](autoround.md) | Thinker or language-model checkpoint config | Qwen2.5-Omni, Qwen3-Omni | Supported through AutoRound checkpoints |
-| msModelSlim | [msModelSlim](msmodelslim.md) | Not currently validated for omni/TTS stages | Qwen3-Omni, Qwen3-TTS | Not validated |
-
-### Multi-Stage Diffusion Model (BAGEL, GLM-Image)
-
-These models split generation across multiple stages. Quantization must be
-attached to the intended stage rather than applied globally.
-
-| Method | Guide | Scope | Example models | Status |
-|--------|-------|-------|----------------|--------|
-| FP8 | [FP8](fp8.md) | Stage-specific DiT or transformer module | BAGEL, GLM-Image | Requires model-specific validation |
-| Int8 | [Int8](int8.md) | Stage-specific DiT or transformer module | BAGEL, GLM-Image | Requires model-specific validation |
-| GGUF | [GGUF](gguf.md) | Stage-specific transformer weights | BAGEL, GLM-Image | No validated adapter listed |
-| AutoRound | [AutoRound](autoround.md) | Checkpoint-defined stage | BAGEL, GLM-Image | No validated checkpoint listed |
-| msModelSlim | [msModelSlim](msmodelslim.md) | Ascend-generated stage weights | GLM-Image | Requires model-specific adaptation |
-
-!!! note
- "Online quantization" means vLLM-Omni computes the quantization data while
- loading the model. "Pre-quantized" means the checkpoint or external
- quantizer provides the required quantized weights and scales.
-
-## Quantization Scope
-
-### Diffusion Model (Qwen-Image, Wan2.2)
-
-The default target is the diffusion transformer. Component routing is available
-through `build_quant_config()`:
-
-```python
-from vllm_omni.quantization import build_quant_config
-
-config = build_quant_config({
- "transformer": {"method": "fp8"},
- "vae": None,
-})
-```
-
-| Component | Default quantized? | Notes |
-|-----------|--------------------|-------|
-| Diffusion transformer | Yes | Primary target for FP8, Int8, GGUF, AutoRound, and msModelSlim |
-| Text encoder | No | Keep BF16 unless a method-specific guide documents support |
-| VAE | No | Keep BF16; storage-only paths are method-specific |
-| Scheduler/tokenizer | No | Loaded from the base model repository |
-
-### Multi-Stage Omni/TTS Model (Qwen3-Omni, Qwen3-TTS)
-
-| Component | Default quantized? | Notes |
-|-----------|--------------------|-------|
-| Thinker or AR language model | Yes, when checkpoint config is supported | ModelOpt FP8/NVFP4 or AutoRound checkpoint config |
-| Audio encoder | No | BF16 |
-| Vision encoder | No | BF16 |
-| Talker or TTS stage | No | BF16 unless model-specific support is documented |
-| Code2Wav | No | BF16 |
-
-### Multi-Stage Diffusion Model (BAGEL, GLM-Image)
-
-| Component | Default quantized? | Notes |
-|-----------|--------------------|-------|
-| Selected diffusion or transformer stage | Method-specific | Must be routed to the intended stage |
-| Other generation stages | No | Keep BF16 unless separately validated |
-| VAE, tokenizer, scheduler | No | Loaded from the base checkpoint |
-
-## Python API
-
-`build_quant_config()` accepts strings, dictionaries, per-component
-dictionaries, existing `QuantizationConfig` objects, or `None`.
-
-```python
-from vllm_omni.quantization import build_quant_config
-
-build_quant_config("fp8")
-build_quant_config({"method": "fp8", "activation_scheme": "static"})
-build_quant_config("auto-round", bits=4, group_size=128)
-build_quant_config({"method": "gguf", "gguf_model": "/path/to/model.gguf"})
-build_quant_config({"transformer": {"method": "fp8"}, "vae": None})
-build_quant_config(None)
-```
diff --git a/examples/offline_inference/bagel/README.md b/examples/offline_inference/bagel/README.md
deleted file mode 100644
index 9955fd90db9..00000000000
--- a/examples/offline_inference/bagel/README.md
+++ /dev/null
@@ -1,277 +0,0 @@
-# BAGEL-7B-MoT
-
-## Setup
-
-Please refer to the [stage configuration documentation](https://docs.vllm.ai/projects/vllm-omni/en/latest/configuration/stage_configs/) to configure memory allocation appropriately for your hardware setup.
-
-## Architecture
-
-BAGEL-7B-MoT is a Mixture-of-Transformers (MoT) model supporting both image generation and understanding. It offers two deployment topologies:
-
-| Topology | Stages | Description |
-| :------- | :----- | :---------- |
-| **Two-stage** (default) | Stage 0 (Thinker, AR) + Stage 1 (DiT, Diffusion) | Thinker handles text/understanding via vLLM AR engine; DiT handles image generation. KV cache is transferred between stages. |
-| **Single-stage** | Stage 0 (DiT, Diffusion) only | The DiT stage contains a full LLM, ViT, VAE, and tokenizer internally. All modalities are handled within a single diffusion process. |
-
-Both topologies support all four modalities: `text2img`, `img2img`, `img2text`, `text2text`.
-
-## Quick Start
-
-```bash
-cd examples/offline_inference/bagel
-
-# Default two-stage mode (auto-detected)
-python end2end.py --model ByteDance-Seed/BAGEL-7B-MoT \
- --modality text2img \
- --prompts "A cute cat"
-
-# Single-stage mode
-python end2end.py --model ByteDance-Seed/BAGEL-7B-MoT \
- --modality text2img \
- --prompts "A cute cat" \
- --deploy-config vllm_omni/deploy/bagel_single_stage.yaml
-```
-
-> **Note**: These examples work with the default configuration on an **NVIDIA A100 (80GB)**. For dual-GPU setups, modify the deploy YAML to distribute stages across devices.
-
-## Modality Control
-
-Control the mode using the `--modality` argument:
-
-| Modality | Input | Output | Description |
-| :------- | :---- | :----- | :---------- |
-| `text2img` | Text | Image | Generate images from text prompts |
-| `img2img` | Image + Text | Image | Transform images using text guidance |
-| `img2text` | Image + Text | Text | Generate text descriptions from images |
-| `text2text` | Text | Text | Pure text generation (language model mode) |
-
-### Text to Image (text2img)
-
-```bash
-python end2end.py --model ByteDance-Seed/BAGEL-7B-MoT \
- --modality text2img \
- --prompts "A cute cat" \
- --steps 50
-```
-
-### Image to Image (img2img)
-
-```bash
-python end2end.py --model ByteDance-Seed/BAGEL-7B-MoT \
- --modality img2img \
- --image-path /path/to/image.jpg \
- --prompts "Let the woman wear a blue dress"
-```
-
-### Image to Text (img2text)
-
-```bash
-python end2end.py --model ByteDance-Seed/BAGEL-7B-MoT \
- --modality img2text \
- --image-path /path/to/image.jpg \
- --prompts "Describe this image in detail"
-```
-
-### Text to Text (text2text)
-
-```bash
-python end2end.py --model ByteDance-Seed/BAGEL-7B-MoT \
- --modality text2text \
- --prompts "What is the capital of France?"
-
-# Load prompts from a text file (one prompt per line):
-python end2end.py --model ByteDance-Seed/BAGEL-7B-MoT \
- --modality text2text \
- --txt-prompts /path/to/prompts.txt
-```
-
-## Think Mode
-
-Think mode enables the model to generate `<think>...</think>` planning/reasoning tokens before producing the final output. This improves generation quality for complex prompts.
-
-- **Two-stage**: The Thinker (AR) stage decodes think tokens, then transfers the augmented KV cache to the DiT stage for image generation.
-- **Single-stage**: The DiT's internal LLM generates think tokens in-place before proceeding to denoise.
-
-```bash
-# Think + text2img: plan before generating
-python end2end.py --model ByteDance-Seed/BAGEL-7B-MoT \
- --modality text2img \
- --prompts "A futuristic city with flying cars" \
- --think \
- --max-think-tokens 1000
-
-# Think + img2img: reason about the edit
-python end2end.py --model ByteDance-Seed/BAGEL-7B-MoT \
- --modality img2img \
- --image-path /path/to/image.jpg \
- --prompts "Make it look like a watercolor painting" \
- --think
-
-# Think + img2text: reason before describing
-python end2end.py --model ByteDance-Seed/BAGEL-7B-MoT \
- --modality img2text \
- --image-path /path/to/image.jpg \
- --prompts "What is happening in this image?" \
- --think
-
-# Think + text2text: chain-of-thought reasoning
-python end2end.py --model ByteDance-Seed/BAGEL-7B-MoT \
- --modality text2text \
- --prompts "Solve: 23 * 47" \
- --think
-```
-
-Think mode parameters:
-
-| Argument | Default | Description |
-| :------- | :------ | :---------- |
-| `--think` | `False` | Enable thinking mode |
-| `--max-think-tokens` | `1000` | Maximum tokens for think generation |
-| `--do-sample` | `False` | Enable sampling (vs. greedy) for text generation |
-| `--text-temperature` | `0.3` | Temperature for text generation sampling |
-
-## Classifier-Free Guidance (CFG)
-
-CFG controls the trade-off between prompt fidelity and diversity. These parameters apply to image generation modalities (`text2img`, `img2img`).
-
-```bash
-python end2end.py --model ByteDance-Seed/BAGEL-7B-MoT \
- --modality text2img \
- --prompts "A photorealistic portrait" \
- --cfg-text-scale 6.0 \
- --cfg-img-scale 2.0 \
- --negative-prompt "blurry, low quality, distorted" \
- --cfg-interval 0.4 1.0 \
- --cfg-renorm-type global \
- --cfg-renorm-min 0.0
-```
-
-| Argument | Default | Description |
-| :------- | :------ | :---------- |
-| `--cfg-text-scale` | `4.0` | Text CFG scale (higher = more prompt-adherent) |
-| `--cfg-img-scale` | `1.5` | Image CFG scale (for img2img) |
-| `--negative-prompt` | `None` | Negative prompt for CFG conditioning |
-| `--cfg-interval` | pipeline default | CFG active interval `[start, end]` as fractions of total timesteps |
-| `--cfg-renorm-type` | `None` | Renormalization type: `global`, `text_channel`, `channel` |
-| `--cfg-renorm-min` | `None` | Minimum renormalization value |
-| `--cfg-parallel-size` | `1` | CFG parallel size: `1` = batched (single GPU), `2` = 2-branch parallel, `3` = full 3-GPU parallel |
-
-## Deployment Topologies
-
-### Two-Stage (Default)
-
-The default topology auto-detected from the model. No extra flags needed.
-
-```bash
-python end2end.py --model ByteDance-Seed/BAGEL-7B-MoT \
- --modality text2img \
- --prompts "A cute cat"
-```
-
-The pipeline is defined in [`bagel.yaml`](../../../vllm_omni/deploy/bagel.yaml). Stage 0 (Thinker) and Stage 1 (DiT) share GPU 0 by default. For dual-GPU setups, customize the deploy YAML and set `devices: "1"` for stage 1.
-
-### Single-Stage
-
-Pass the single-stage deploy config via `--deploy-config`:
-
-```bash
-python end2end.py --model ByteDance-Seed/BAGEL-7B-MoT \
- --modality text2img \
- --prompts "A cute cat" \
- --deploy-config vllm_omni/deploy/bagel_single_stage.yaml
-```
-
-See [`bagel_single_stage.yaml`](../../../vllm_omni/deploy/bagel_single_stage.yaml) for configuration details. The `pipeline: bagel_single_stage` field selects the single-stage topology from the pipeline registry.
-
-### Tensor Parallelism (TP)
-
-For larger models or multi-GPU environments, customize the deploy YAML (see [`bagel.yaml`](../../../vllm_omni/deploy/bagel.yaml)) and set per-stage `tensor_parallel_size` and `devices`:
-
-```yaml
-# Example: TP=2 on GPUs 0,1 for the Thinker stage
-stages:
- - stage_id: 0
- tensor_parallel_size: 2
- devices: "0,1"
-```
-
-Then pass the custom deploy YAML:
-
-```bash
-python end2end.py --model ByteDance-Seed/BAGEL-7B-MoT \
- --modality text2img \
- --prompts "A cute cat" \
- --deploy-config /path/to/custom_bagel.yaml
-```
-
-### FP8 Quantization
-
-```bash
-python end2end.py --model ByteDance-Seed/BAGEL-7B-MoT \
- --modality text2img \
- --prompts "A cute cat" \
- --quantization fp8
-```
-
-## Command Line Reference
-
-### Core Arguments
-
-| Argument | Type | Default | Description |
-| :------- | :--- | :------ | :---------- |
-| `--model` | string | `ByteDance-Seed/BAGEL-7B-MoT` | Model path or HuggingFace name |
-| `--modality` | choice | `text2img` | `text2img`, `img2img`, `img2text`, `text2text` |
-| `--prompts` | list | `None` | Input text prompts |
-| `--txt-prompts` | string | `None` | Path to text file with one prompt per line |
-| `--image-path` | string | `None` | Input image path (required for `img2img`/`img2text`) |
-| `--output` | string | `.` | Output directory for saved images |
-| `--steps` | int | `50` | Number of diffusion inference steps |
-| `--seed` | int | `None` | Random seed for reproducibility |
-
-### Think Mode Arguments
-
-| Argument | Type | Default | Description |
-| :------- | :--- | :------ | :---------- |
-| `--think` | flag | `False` | Enable `<think>...</think>` planning/reasoning |
-| `--max-think-tokens` | int | `1000` | Maximum tokens for think generation |
-| `--do-sample` | flag | `False` | Use sampling instead of greedy decoding |
-| `--text-temperature` | float | `0.3` | Sampling temperature for text generation |
-
-### CFG Arguments
-
-| Argument | Type | Default | Description |
-| :------- | :--- | :------ | :---------- |
-| `--cfg-text-scale` | float | `4.0` | Text CFG guidance scale |
-| `--cfg-img-scale` | float | `1.5` | Image CFG guidance scale |
-| `--negative-prompt` | string | `None` | Negative prompt for CFG |
-| `--cfg-parallel-size` | int | `1` | CFG parallel GPU count (1, 2, or 3) |
-| `--cfg-interval` | float[2] | pipeline default | CFG active window `[start, end]` |
-| `--cfg-renorm-type` | string | `None` | `global`, `text_channel`, or `channel` |
-| `--cfg-renorm-min` | float | `None` | Minimum renormalization value |
-
-### Engine Arguments
-
-| Argument | Type | Default | Description |
-| :------- | :--- | :------ | :---------- |
-| `--deploy-config` | string | `None` | Path to deploy YAML (auto-detected if omitted) |
-| `--worker-backend` | choice | `process` | `process` or `ray` |
-| `--ray-address` | string | `None` | Ray cluster address |
-| `--quantization` | string | `None` | Quantization method (e.g. `fp8`) |
-| `--log-stats` | flag | `False` | Enable statistics logging |
-| `--init-timeout` | int | `300` | Initialization timeout (seconds) |
-| `--batch-timeout` | int | `5` | Batch timeout (seconds) |
-| `--enable-diffusion-pipeline-profiler` | flag | `False` | Profile diffusion stage durations |
-
-## FAQ
-
-- If you encounter OOM errors, try decreasing `max_model_len` or `gpu_memory_utilization` in the deploy YAML.
-
-**Two-stage VRAM usage:**
-
-| Stage | VRAM |
-| :---- | :--- |
-| Stage 0 (Thinker) | **15.04 GiB + KV Cache** |
-| Stage 1 (DiT) | **26.50 GiB** |
-| Total | **~42 GiB + KV Cache** |
-
-**Single-stage VRAM usage:** The DiT loads the full model (~42 GiB) in one process.
diff --git a/examples/offline_inference/bagel/end2end.py b/examples/offline_inference/bagel/end2end.py
deleted file mode 100644
index a6ce1f1314f..00000000000
--- a/examples/offline_inference/bagel/end2end.py
+++ /dev/null
@@ -1,292 +0,0 @@
-import argparse
-import os
-
-from vllm_omni.inputs.data import OmniPromptType
-from vllm_omni.model_executor.stage_input_processors.bagel import (
- GEN_THINK_SYSTEM_PROMPT,
- VLM_THINK_SYSTEM_PROMPT,
-)
-
-
-def parse_args():
- parser = argparse.ArgumentParser()
- parser.add_argument(
- "--model",
- default="ByteDance-Seed/BAGEL-7B-MoT",
- help="Path to merged model directory.",
- )
- parser.add_argument("--prompts", nargs="+", default=None, help="Input text prompts.")
- parser.add_argument(
- "--txt-prompts",
- type=str,
- default=None,
- help="Path to a .txt file with one prompt per line (preferred).",
- )
- parser.add_argument("--prompt-type", default="text", choices=["text"])
-
- parser.add_argument(
- "--modality",
- default="text2img",
- choices=["text2img", "img2img", "img2text", "text2text"],
- help="Modality mode to control stage execution.",
- )
-
- parser.add_argument(
- "--image-path",
- type=str,
- default=None,
- help="Path to input image for img2img.",
- )
-
- parser.add_argument(
- "--output",
- type=str,
- default=".",
- help="Output directory to save images.",
- )
-
- # OmniLLM init args
- parser.add_argument("--log-stats", action="store_true", default=False)
- parser.add_argument("--init-sleep-seconds", type=int, default=20)
- parser.add_argument("--batch-timeout", type=int, default=5)
- parser.add_argument("--init-timeout", type=int, default=300)
- parser.add_argument("--shm-threshold-bytes", type=int, default=65536)
- parser.add_argument("--worker-backend", type=str, default="process", choices=["process", "ray"])
- parser.add_argument("--ray-address", type=str, default=None)
- parser.add_argument(
- "--deploy-config",
- type=str,
- default=None,
- help="Path to deploy YAML. If unset, auto-loads vllm_omni/deploy/bagel.yaml based on the HF model_type.",
- )
- parser.add_argument("--steps", type=int, default=50, help="Number of inference steps.")
-
- parser.add_argument("--cfg-text-scale", type=float, default=4.0, help="Text CFG scale (default: 4.0)")
- parser.add_argument("--cfg-img-scale", type=float, default=1.5, help="Image CFG scale (default: 1.5)")
- parser.add_argument(
- "--negative-prompt", type=str, default=None, help="Negative prompt for CFG (default: empty prompt)"
- )
- parser.add_argument(
- "--cfg-parallel-size",
- type=int,
- default=1,
- choices=[1, 2, 3],
- help="CFG parallel size: 1=batched (single GPU), 2=parallel with 2 branches (text CFG only), 3=parallel (3 GPUs).",
- )
- parser.add_argument("--seed", type=int, default=None, help="Random seed for generation.")
- parser.add_argument(
- "--cfg-interval",
- type=float,
- nargs=2,
- default=None,
- help="CFG interval [start, end] (default: pipeline default)",
- )
- parser.add_argument(
- "--cfg-renorm-type", type=str, default=None, help="CFG renorm type: global, text_channel, channel"
- )
- parser.add_argument("--cfg-renorm-min", type=float, default=None, help="CFG renorm min")
- parser.add_argument(
- "--enable-diffusion-pipeline-profiler",
- action="store_true",
- help="Enable diffusion pipeline profiler to display stage durations.",
- )
- parser.add_argument(
- "--quantization",
- type=str,
- default=None,
- help="Quantization method (e.g. 'fp8').",
- )
- parser.add_argument(
- "--think",
- action="store_true",
- default=False,
- help="Enable thinking mode: AR stage decodes <think>...</think> planning tokens before image generation.",
- )
- parser.add_argument(
- "--max-think-tokens",
- type=int,
- default=1000,
- help="Maximum number of tokens for thinking text generation (default: 1000).",
- )
- parser.add_argument(
- "--do-sample",
- action="store_true",
- default=False,
- help="Enable sampling for text generation (default: greedy).",
- )
- parser.add_argument(
- "--text-temperature",
- type=float,
- default=0.3,
- help="Temperature for text generation sampling (default: 0.3).",
- )
-
- from vllm_omni.engine.arg_utils import nullify_stage_engine_defaults
-
- nullify_stage_engine_defaults(parser)
- args = parser.parse_args()
- return args
-
-
-def main():
- args = parse_args()
- os.makedirs(args.output, exist_ok=True)
- model_name = args.model
- prompts: list[OmniPromptType] = []
- try:
- if getattr(args, "txt_prompts", None) and args.prompt_type == "text":
- with open(args.txt_prompts, encoding="utf-8") as f:
- lines = [ln.strip() for ln in f.readlines()]
- prompts = [ln for ln in lines if ln != ""]
- print(f"[Info] Loaded {len(prompts)} prompts from {args.txt_prompts}")
- else:
- prompts = args.prompts
- except Exception as e:
- print(f"[Error] Failed to load prompts: {e}")
- raise
-
- if not prompts:
- prompts = ["A cute cat"]
- print(f"[Info] No prompts provided, using default: {prompts}")
-
- from PIL import Image
-
- from vllm_omni.entrypoints.omni import Omni
-
- omni_kwargs = {}
- deploy_config = args.deploy_config
- if args.think and deploy_config is None:
- deploy_config = "vllm_omni/deploy/bagel_think.yaml"
- print(f"[Info] Think mode enabled, using deploy config: {deploy_config}")
- if deploy_config:
- omni_kwargs["deploy_config"] = deploy_config
-
- omni_kwargs.update(
- {
- "log_stats": args.log_stats,
- "init_sleep_seconds": args.init_sleep_seconds,
- "batch_timeout": args.batch_timeout,
- "init_timeout": args.init_timeout,
- "shm_threshold_bytes": args.shm_threshold_bytes,
- "worker_backend": args.worker_backend,
- "ray_address": args.ray_address,
- "enable_diffusion_pipeline_profiler": args.enable_diffusion_pipeline_profiler,
- }
- )
- if args.quantization:
- omni_kwargs["quantization_config"] = args.quantization
-
- omni = Omni.from_cli_args(args, model=model_name, **omni_kwargs)
-
- formatted_prompts = []
- for p in prompts:
- if args.modality == "img2img":
- if not args.image_path or not os.path.exists(args.image_path):
- raise ValueError(f"img2img requires --image-path pointing to an existing file, got: {args.image_path}")
- loaded_image = Image.open(args.image_path).convert("RGB")
- think_prefix = f"<|im_start|>{GEN_THINK_SYSTEM_PROMPT}<|im_end|>" if args.think else ""
- final_prompt_text = f"{think_prefix}<|fim_middle|><|im_start|>{p}<|im_end|>"
- prompt_dict = {
- "prompt": final_prompt_text,
- "multi_modal_data": {"img2img": loaded_image},
- "modalities": ["img2img"],
- }
- if args.negative_prompt is not None:
- prompt_dict["negative_prompt"] = args.negative_prompt
- formatted_prompts.append(prompt_dict)
- elif args.modality == "img2text":
- if args.image_path:
- loaded_image = Image.open(args.image_path).convert("RGB")
- think_prefix = f"<|im_start|>system\n{VLM_THINK_SYSTEM_PROMPT}<|im_end|>\n" if args.think else ""
- final_prompt_text = (
- f"{think_prefix}<|im_start|>user\n<|image_pad|>\n{p}<|im_end|>\n<|im_start|>assistant\n"
- )
- prompt_dict = {
- "prompt": final_prompt_text,
- "multi_modal_data": {"image": loaded_image},
- "modalities": ["text"],
- }
- formatted_prompts.append(prompt_dict)
- elif args.modality == "text2text":
- think_prefix = f"<|im_start|>{VLM_THINK_SYSTEM_PROMPT}<|im_end|>" if args.think else ""
- final_prompt_text = f"{think_prefix}<|im_start|>{p}<|im_end|><|im_start|>"
- prompt_dict = {"prompt": final_prompt_text, "modalities": ["text"]}
- formatted_prompts.append(prompt_dict)
- else:
- think_prefix = f"<|im_start|>{GEN_THINK_SYSTEM_PROMPT}<|im_end|>" if args.think else ""
- final_prompt_text = f"{think_prefix}<|im_start|>{p}<|im_end|>"
- prompt_dict = {"prompt": final_prompt_text, "modalities": ["image"]}
- if args.negative_prompt is not None:
- prompt_dict["negative_prompt"] = args.negative_prompt
- formatted_prompts.append(prompt_dict)
-
- params_list = omni.default_sampling_params_list
- # Bagel exposes 1 sampling param set for single-stage (DiT-only) and
- # 2 for two-stage (Thinker + DiT). This heuristic may need updating
- # if future pipelines break that 1:1 mapping.
- is_single_stage = len(params_list) == 1
-
- diffusion_params_idx = 0 if is_single_stage else (1 if len(params_list) > 1 else 0)
- diffusion_params = params_list[diffusion_params_idx]
-
- if args.modality in ("text2img", "img2img"):
- diffusion_params.num_inference_steps = args.steps # type: ignore
- diffusion_params.cfg_parallel_size = args.cfg_parallel_size # type: ignore
- if args.seed is not None:
- diffusion_params.seed = args.seed # type: ignore
-
- extra = getattr(diffusion_params, "extra_args", {}) or {}
- extra["cfg_text_scale"] = args.cfg_text_scale
- extra["cfg_img_scale"] = args.cfg_img_scale
- if args.cfg_interval is not None:
- extra["cfg_interval"] = tuple(args.cfg_interval)
- if args.cfg_renorm_type is not None:
- extra["cfg_renorm_type"] = args.cfg_renorm_type
- if args.cfg_renorm_min is not None:
- extra["cfg_renorm_min"] = args.cfg_renorm_min
- if args.negative_prompt is not None:
- extra["negative_prompt"] = args.negative_prompt
-
- needs_text_gen = is_single_stage and (args.think or args.modality in ("text2text", "img2text"))
- if needs_text_gen:
- if args.think:
- extra["think"] = True
- extra["max_think_tokens"] = args.max_think_tokens
- extra["do_sample"] = args.do_sample
- extra["text_temperature"] = args.text_temperature
- diffusion_params.extra_args = extra # type: ignore
-
- omni_outputs = list(omni.generate(prompts=formatted_prompts, sampling_params_list=params_list))
-
- img_idx = 0
- for req_output in omni_outputs:
- # 2-stage think mode: text output from thinker stage
- ro = getattr(req_output, "request_output", None)
- if ro and getattr(ro, "outputs", None):
- txt = "".join(getattr(o, "text", "") or "" for o in ro.outputs)
- if txt:
- if args.think:
- print(f"[Think]\n{txt}")
- else:
- print(f"[Output] Text:\n{txt}")
-
- # Single-stage DiT: text from custom_output
- custom = getattr(req_output, "_custom_output", {}) or {}
- if custom.get("think_text"):
- print(f"[Think]\n{custom['think_text']}")
- if custom.get("text_output"):
- print(f"[Output] Text:\n{custom['text_output']}")
-
- images = getattr(req_output, "images", None)
- if not images:
- continue
-
- for j, img in enumerate(images):
- save_path = os.path.join(args.output, f"output_{img_idx}_{j}.png")
- img.save(save_path)
- print(f"[Output] Saved image to {save_path}")
- img_idx += 1
-
-
-if __name__ == "__main__":
- main()
diff --git a/examples/offline_inference/cosyvoice3/README.md b/examples/offline_inference/cosyvoice3/README.md
deleted file mode 100644
index 704b49614fb..00000000000
--- a/examples/offline_inference/cosyvoice3/README.md
+++ /dev/null
@@ -1,71 +0,0 @@
-# CosyVoice3
-
-## Setup
-
-Install dependencies:
-```
-uv pip install -e .
-```
-
-> **Note:** This includes required libraries such as `soundfile`,
-> `onnxruntime`, `x-transformers`, and `einops` via
-> `requirements/common.txt` and platform-specific requirements files.
-
-Download the model snapshot:
-```
-from huggingface_hub import snapshot_download
-snapshot_download('FunAudioLLM/Fun-CosyVoice3-0.5B-2512', local_dir='pretrained_models/Fun-CosyVoice3-0.5B')
-```
-
-Add `config.json` in `pretrained_models/Fun-CosyVoice3-0.5B/`:
-```json
-{
- "model_type": "cosyvoice3",
- "architectures": [
- "CosyVoice3Model"
- ]
-}
-```
-
-> **Why `config.json` is required:**
-> `AutoConfig.register("cosyvoice3", CosyVoice3Config)` only registers a class mapping.
-> The loader still needs `model_type: "cosyvoice3"` from `config.json` to select that class.
-> If no `config.json` is present, model type cannot be inferred automatically.
-> If your downloaded checkpoint already includes a valid `config.json` with
-> `model_type: "cosyvoice3"`, this manual step can be skipped.
-
-Run the offline verification script:
-```
-python examples/offline_inference/cosyvoice3/verify_e2e_cosyvoice.py \
- --model pretrained_models/Fun-CosyVoice3-0.5B \
- --tokenizer pretrained_models/Fun-CosyVoice3-0.5B/CosyVoice-BlankEN
-```
-
-## Implementation Overview
-
-CosyVoice3 runs as a **2-stage Omni pipeline**.
-
-- **Stage 0** (`talker`) converts text + prompt audio to speech tokens.
-- **Stage 1** (`code2wav`) converts speech tokens + prompt features to waveform via flow matching and HiFiGAN.
-
-Key components live in `vllm_omni/model_executor/models/cosyvoice3/cosyvoice3.py`.
-
-- `CosyVoice3MultiModalProcessor` builds the multimodal inputs:
- - Tokenizes `prompt` and `prompt_text`.
- - Extracts speech tokens and mel features from the prompt audio.
- - Extracts a speaker embedding.
-- `CosyVoice3Model` implements both stages:
- - Stage 0 uses `CosyVoice3LM` and outputs speech tokens + conditioning features.
- - Stage 1 runs the flow model (DiT-based CFM) and HiFiGAN to synthesize waveform.
-
-Pipeline topology lives in `vllm_omni/model_executor/models/cosyvoice3/pipeline.py`;
-runtime tunables (batch size, memory limits, sampling) live in
-`vllm_omni/deploy/cosyvoice3.yaml`. The deploy config auto-loads by
-HF `model_type` and defaults to `async_chunk: true` (shared-memory
-streaming). Pass `--no-async-chunk` on `vllm serve` to switch to the
-legacy sync path where stage 1 runs `text2flow` over the full
-speech-token sequence.
-
-- Stage 0 emits latent speech tokens.
-- Stage 1 consumes them via `sync_process_input_func` (sync mode) or the
- shared-memory connector (async-chunk mode) and outputs audio.
diff --git a/examples/offline_inference/cosyvoice3/verify_e2e_cosyvoice.py b/examples/offline_inference/cosyvoice3/verify_e2e_cosyvoice.py
deleted file mode 100644
index a5dc564ec3b..00000000000
--- a/examples/offline_inference/cosyvoice3/verify_e2e_cosyvoice.py
+++ /dev/null
@@ -1,179 +0,0 @@
-# SPDX-License-Identifier: Apache-2.0
-# SPDX-FileCopyrightText: Copyright contributors to the vLLM project
-import argparse
-import os
-
-import numpy as np
-import soundfile as sf
-from vllm import SamplingParams
-from vllm.assets.audio import AudioAsset
-from vllm.multimodal.media.audio import load_audio
-
-from vllm_omni.entrypoints.omni import Omni
-from vllm_omni.model_executor.models.cosyvoice3.config import CosyVoice3Config
-from vllm_omni.model_executor.models.cosyvoice3.tokenizer import get_qwen_tokenizer
-from vllm_omni.model_executor.models.cosyvoice3.utils import extract_text_token
-
-
-def run_e2e():
- parser = argparse.ArgumentParser()
- # ""FunAudioLLM/Fun-CosyVoice3-0.5B-2512
- parser.add_argument(
- "--model",
- type=str,
- required=True,
- help="Path to CosyVoice3 model directory (e.g., pretrained_models/Fun-CosyVoice3-0.5B/).",
- )
- parser.add_argument(
- "--deploy-config",
- type=str,
- default=None,
- help="Override the deploy config path. If unset, auto-loads "
- "vllm_omni/deploy/cosyvoice3.yaml based on the HF model_type.",
- )
- parser.add_argument("--prompt", type=str, default="Hello, this is a test of the CosyVoice system capability.")
- parser.add_argument(
- "--prompt-text",
- type=str,
- default="You are a helpful assistant.<|endofprompt|>Testing my voices. Why should I not?",
- )
- parser.add_argument("--audio-path", type=str, default="prompt.wav")
- parser.add_argument(
- "--tokenizer",
- type=str,
- required=True,
- help="Path to tokenizer directory (e.g., <model_path>/CosyVoice-BlankEN).",
- )
- args = parser.parse_args()
- # Ensure tokenizer directory exists
- if not os.path.exists(args.tokenizer):
- raise FileNotFoundError(f"{args.tokenizer} does not exist!")
-
- if args.deploy_config is not None and not os.path.exists(args.deploy_config):
- raise FileNotFoundError(f"{args.deploy_config} does not exist!")
-
- print(f"Initializing cosyvoice E2E with model={args.model}")
-
- omni = Omni(
- model=args.model,
- deploy_config=args.deploy_config,
- tokenizer=args.tokenizer,
- log_stats=True,
- )
-
- sampling_cfg = {"top_p": 0.8, "top_k": 25, "eos_token_id": 6561 + 1}
-
- print("Model initialized. Preparing inputs...")
- if args.audio_path:
- if not os.path.exists(args.audio_path):
- raise FileNotFoundError(f"Audio file not found: {args.audio_path}")
- # Load at native sample rate
- audio_signal, sr = load_audio(args.audio_path, sr=None)
-
- # Validate sample rate before processing (similar to original CosyVoice)
- min_sr = 16000
- if sr < min_sr:
- raise ValueError(
- f"Audio sample rate {sr} Hz is too low. "
- f"Minimum required: {min_sr} Hz. "
- f"Please provide audio with sample rate >= {min_sr} Hz."
- )
-
- audio_data = (audio_signal.astype(np.float32), sr)
- else:
- audio_data = AudioAsset("mary_had_lamb").audio_and_sample_rate
-
- prompts = {
- "prompt": args.prompt,
- "multi_modal_data": {
- "audio": audio_data,
- },
- "mm_processor_kwargs": {
- "prompt_text": args.prompt_text,
- "sample_rate": audio_data[1],
- },
- }
-
- print(f"Generating for prompt: {args.prompt}")
-
- config = CosyVoice3Config()
- tokenizer = get_qwen_tokenizer(
- token_path=args.tokenizer,
- skip_special_tokens=config.skip_special_tokens,
- version=config.version,
- )
- _, text_token_len = extract_text_token(args.prompt, tokenizer, config.allowed_special)
- base_len = int(text_token_len)
- min_len = int(base_len * config.min_token_text_ratio)
- max_len = int(base_len * config.max_token_text_ratio)
-
- # Build SamplingParams for each stage (GPT, S2Mel, Vocoder)
- gpt_sampling = SamplingParams(
- temperature=1.0,
- top_p=sampling_cfg["top_p"],
- top_k=sampling_cfg["top_k"],
- repetition_penalty=2.0,
- min_tokens=min_len,
- max_tokens=max_len,
- stop_token_ids=[sampling_cfg["eos_token_id"]],
- # allowed_token_ids=list(range(6561+3)),
- detokenize=False,
- )
- # Not used
- s2mel_sampling = SamplingParams(
- temperature=1.0,
- top_p=1.0,
- top_k=-1,
- repetition_penalty=2.0,
- max_tokens=256,
- detokenize=False,
- )
-
- sampling_params_list = [gpt_sampling, s2mel_sampling]
-
- # Start profiling (requires VLLM_TORCH_PROFILER_DIR env var)
- if os.environ.get("VLLM_TORCH_PROFILER_DIR"):
- print("Starting profiler...")
- omni.start_profile()
-
- # Generate (Omni orchestrator requires a per-stage SamplingParams list)
- outputs = list(omni.generate(prompts, sampling_params_list=sampling_params_list[:2]))
-
- # Stop profiling and get results
- if os.environ.get("VLLM_TORCH_PROFILER_DIR"):
- print("Stopping profiler...")
- profile_results = omni.stop_profile()
- print(f"Profile traces saved to: {profile_results}")
-
- print(outputs)
- # Verify outputs
- print(f"Received {len(outputs)} outputs.")
- for i, output in enumerate(outputs):
- try:
- ro = output.request_output
- if ro is None:
- print("No request_output found.")
- continue
-
- # Multimodal output may be attached to RequestOutput or CompletionOutput.
- mm = getattr(ro, "multimodal_output", None)
- if not mm and ro.outputs:
- mm = getattr(ro.outputs[0], "multimodal_output", None)
-
- if mm:
- print(f"Multimodal output keys: {mm.keys()}")
- if "audio" in mm:
- audio_out = mm["audio"]
- print(f"Generated Audio Shape: {audio_out.shape}")
- out_path = f"output_{i}.wav"
- sf.write(out_path, audio_out.cpu().numpy().squeeze(), 22050)
- print(f"Saved audio to {out_path}")
- else:
- print("No multimodal output found.")
- except Exception as e:
- print(f"Error inspecting output: {e}")
- omni.close()
-
-
-if __name__ == "__main__":
- run_e2e()
diff --git a/examples/offline_inference/custom_pipeline/image_to_image/custom_pipeline.py b/examples/offline_inference/custom_pipeline/image_to_image/custom_pipeline.py
deleted file mode 100644
index b1c74e2b345..00000000000
--- a/examples/offline_inference/custom_pipeline/image_to_image/custom_pipeline.py
+++ /dev/null
@@ -1,80 +0,0 @@
-# SPDX-License-Identifier: Apache-2.0
-# SPDX-FileCopyrightText: Copyright contributors to the vLLM project
-
-import logging
-from typing import Any
-
-import PIL.Image
-import torch
-
-from vllm_omni.diffusion.data import DiffusionOutput, OmniDiffusionConfig
-from vllm_omni.diffusion.models.qwen_image.pipeline_qwen_image_edit import QwenImageEditPipeline
-from vllm_omni.diffusion.request import OmniDiffusionRequest
-
-logger = logging.getLogger(__name__)
-
-
-class CustomPipeline(QwenImageEditPipeline):
- def __init__(self, *, od_config: OmniDiffusionConfig, prefix: str = ""):
- super().__init__(od_config=od_config, prefix=prefix)
-
- def forward(
- self,
- req: OmniDiffusionRequest,
- prompt: str | list[str] | None = None,
- negative_prompt: str | list[str] | None = None,
- image: PIL.Image.Image | torch.Tensor | None = None,
- true_cfg_scale: float = 4.0,
- height: int | None = None,
- width: int | None = None,
- num_inference_steps: int = 50,
- sigmas: list[float] | None = None,
- guidance_scale: float = 1.0,
- num_images_per_prompt: int = 1,
- generator: torch.Generator | list[torch.Generator] | None = None,
- latents: torch.Tensor | None = None,
- prompt_embeds: torch.Tensor | None = None,
- prompt_embeds_mask: torch.Tensor | None = None,
- negative_prompt_embeds: torch.Tensor | None = None,
- negative_prompt_embeds_mask: torch.Tensor | None = None,
- output_type: str | None = "pil",
- attention_kwargs: dict[str, Any] | None = None,
- callback_on_step_end_tensor_inputs: list[str] = ["latents"],
- max_sequence_length: int = 512,
- ) -> DiffusionOutput:
- """Forward pass for image editing with dummy trajectory data."""
- # Call parent's forward to get the normal output
- output = super().forward(
- req=req,
- prompt=prompt,
- negative_prompt=negative_prompt,
- image=image,
- true_cfg_scale=true_cfg_scale,
- height=height,
- width=width,
- num_inference_steps=num_inference_steps,
- sigmas=sigmas,
- guidance_scale=guidance_scale,
- num_images_per_prompt=num_images_per_prompt,
- generator=generator,
- latents=latents,
- prompt_embeds=prompt_embeds,
- prompt_embeds_mask=prompt_embeds_mask,
- negative_prompt_embeds=negative_prompt_embeds,
- negative_prompt_embeds_mask=negative_prompt_embeds_mask,
- output_type=output_type,
- attention_kwargs=attention_kwargs,
- callback_on_step_end_tensor_inputs=callback_on_step_end_tensor_inputs,
- max_sequence_length=max_sequence_length,
- )
-
- # Get actual num_inference_steps used
- actual_num_steps = req.sampling_params.num_inference_steps or num_inference_steps
-
- # Create dummy trajectory data
- dummy_trajectory_latents = torch.randn(actual_num_steps, 1, 16, 64, 64, dtype=torch.float32)
-
- # Inject dummy trajectory data into output
- output.trajectory_latents = dummy_trajectory_latents
-
- return output
diff --git a/examples/offline_inference/custom_pipeline/image_to_image/image_edit.py b/examples/offline_inference/custom_pipeline/image_to_image/image_edit.py
deleted file mode 100644
index 7c91c03239c..00000000000
--- a/examples/offline_inference/custom_pipeline/image_to_image/image_edit.py
+++ /dev/null
@@ -1,281 +0,0 @@
-# SPDX-License-Identifier: Apache-2.0
-# SPDX-FileCopyrightText: Copyright contributors to the vLLM project
-
-"""
-======================================================
- Qwen Image Editor (via vLLM-Omni)
-======================================================
-
-Example CLI for Qwen-Image-Edit and compatible models.
-
-This script edits, combines, or layers images according to a text prompt
-using the vLLM Omni diffusion backend.
-
-Examples
----------
-Single image edit:
- python image_edit.py \
- --image input.png \
- --prompt "Let this mascot dance under the moon, surrounded by floating stars and poetic bubbles saying 'Be Kind'" \
- --output output.png
-
-Multiple image composition:
- python image_edit.py \
- --image input1.png input2.png \
- --prompt "Combine these into a single magical composition" \
- --output combined.png
-
-Accelerated with cache_dit:
- python image_edit.py \
- --image input.png \
- --prompt "Edit description" \
- --cache-backend cache_dit \
- --cache-dit-enable-taylorseer
-
-Layered RGBA output:
- python image_edit.py \
- --model "Qwen/Qwen-Image-Layered" \
- --image input.png \
- --prompt "" \
- --output layered \
- --layers 4 \
- --color-format RGBA
-"""
-
-import argparse
-import asyncio
-import json
-import os
-import time
-from pathlib import Path
-from typing import Any
-
-import torch
-from PIL import Image
-
-from vllm_omni.diffusion.data import DiffusionParallelConfig
-from vllm_omni.entrypoints.omni import Omni
-from vllm_omni.inputs.data import OmniDiffusionSamplingParams
-from vllm_omni.outputs import OmniRequestOutput
-from vllm_omni.platforms import current_omni_platform
-
-
-def parse_profiler_config(value: str) -> dict[str, Any]:
- try:
- config = json.loads(value)
- except json.JSONDecodeError as e:
- raise argparse.ArgumentTypeError(f"--profiler-config must be valid JSON: {e}") from e
- if not isinstance(config, dict):
- raise argparse.ArgumentTypeError("--profiler-config must be a JSON object")
- return config
-
-
-# ===========================
-# Argument Parser
-# ===========================
-def parse_args() -> argparse.Namespace:
- parser = argparse.ArgumentParser(description="Edit or generate images using Qwen-Image-Edit.")
- parser.add_argument("--model", default="Qwen/Qwen-Image-Edit", help="Model name or local path.")
- parser.add_argument("--image", type=str, nargs="+", required=True, help="Input image file(s).")
- parser.add_argument("--prompt", type=str, required=True, help="Edit description prompt.")
- parser.add_argument("--negative-prompt", type=str, default=None)
- parser.add_argument("--seed", type=int, default=0)
- parser.add_argument("--cfg-scale", type=float, default=4.0)
- parser.add_argument("--guidance-scale", type=float, default=1.0)
- parser.add_argument("--output", type=str, default="output.png")
- parser.add_argument("--num-outputs-per-prompt", type=int, default=1)
- parser.add_argument("--num-inference-steps", type=int, default=50)
- parser.add_argument("--cache-backend", type=str, default=None, choices=["cache_dit", "tea_cache"])
- parser.add_argument("--ulysses-degree", type=int, default=1)
- parser.add_argument("--ring-degree", type=int, default=1)
- parser.add_argument("--tensor-parallel-size", type=int, default=1)
- parser.add_argument("--layers", type=int, default=4)
- parser.add_argument("--resolution", type=int, default=640)
- parser.add_argument("--color-format", type=str, default="RGB")
-
- # Acceleration + Optimization Options
- parser.add_argument("--cache-dit-fn-compute-blocks", type=int, default=1)
- parser.add_argument("--cache-dit-bn-compute-blocks", type=int, default=0)
- parser.add_argument("--cache-dit-max-warmup-steps", type=int, default=4)
- parser.add_argument("--cache-dit-residual-diff-threshold", type=float, default=0.24)
- parser.add_argument("--cache-dit-max-continuous-cached-steps", type=int, default=3)
- parser.add_argument("--cache-dit-enable-taylorseer", action="store_true", default=False)
- parser.add_argument("--cache-dit-taylorseer-order", type=int, default=1)
- parser.add_argument(
- "--cache-dit-scm-steps-mask-policy", type=str, default=None, choices=[None, "slow", "medium", "fast", "ultra"]
- )
- parser.add_argument("--cache-dit-scm-steps-policy", type=str, default="dynamic", choices=["dynamic", "static"])
- parser.add_argument("--tea-cache-rel-l1-thresh", type=float, default=0.2)
- parser.add_argument("--cfg-parallel-size", type=int, default=1, choices=[1, 2])
- parser.add_argument("--enforce-eager", action="store_true")
- parser.add_argument("--vae-use-slicing", action="store_true")
- parser.add_argument("--vae-use-tiling", action="store_true")
- parser.add_argument("--enable-cpu-offload", action="store_true")
- parser.add_argument(
- "--profiler-config",
- type=parse_profiler_config,
- default=None,
- help='JSON profiler config for torch/cuda profiling, e.g. \'{"profiler":"torch","torch_profiler_dir":"./perf"}\'.',
- )
-
- return parser.parse_args()
-
-
-# ===========================
-# Core Logic
-# ===========================
-async def main():
- args = parse_args()
-
- # ---- Load input images ----
- input_images: list[Image.Image] = []
- for image_path in args.image:
- if not os.path.exists(image_path):
- raise FileNotFoundError(f"Input image not found: {image_path}")
- input_images.append(Image.open(image_path).convert(args.color_format))
-
- # Single or multi-image input
- input_image: Image.Image | list[Image.Image] = input_images[0] if len(input_images) == 1 else input_images
-
- # ---- Torch setup ----
- generator = torch.Generator(device=current_omni_platform.device_type).manual_seed(args.seed)
- parallel_config = DiffusionParallelConfig(
- ulysses_degree=args.ulysses_degree,
- ring_degree=args.ring_degree,
- cfg_parallel_size=args.cfg_parallel_size,
- tensor_parallel_size=args.tensor_parallel_size,
- )
-
- # ---- Cache Config ----
- if args.cache_backend == "cache_dit":
- cache_config = {
- "Fn_compute_blocks": args.cache_dit_fn_compute_blocks,
- "Bn_compute_blocks": args.cache_dit_bn_compute_blocks,
- "max_warmup_steps": args.cache_dit_max_warmup_steps,
- "residual_diff_threshold": args.cache_dit_residual_diff_threshold,
- "max_continuous_cached_steps": args.cache_dit_max_continuous_cached_steps,
- "enable_taylorseer": args.cache_dit_enable_taylorseer,
- "taylorseer_order": args.cache_dit_taylorseer_order,
- "scm_steps_mask_policy": args.cache_dit_scm_steps_mask_policy,
- "scm_steps_policy": args.cache_dit_scm_steps_policy,
- }
- elif args.cache_backend == "tea_cache":
- cache_config = {"rel_l1_thresh": args.tea_cache_rel_l1_thresh}
- else:
- cache_config = None
-
- # ---- Initialize Omni ----
- omni = Omni(
- model=args.model,
- vae_use_slicing=args.vae_use_slicing,
- vae_use_tiling=args.vae_use_tiling,
- cache_backend=args.cache_backend,
- cache_config=cache_config,
- parallel_config=parallel_config,
- enforce_eager=args.enforce_eager,
- enable_cpu_offload=args.enable_cpu_offload,
- diffusion_load_format="dummy",
- custom_pipeline_args={"pipeline_class": "custom_pipeline.CustomPipeline"},
- profiler_config=args.profiler_config,
- )
-
- print(">>> Pipeline loaded successfully")
-
- # ---- Profiling + Info ----
- profiler_enabled = args.profiler_config is not None
- print(f"\n{'=' * 60}")
- print("Generation Configuration")
- print(f"Model: {args.model}")
- print(f"Inference steps: {args.num_inference_steps}")
- print(f"Cache: {args.cache_backend or 'None'}")
- print(f"Input(s): {len(input_images)} image(s)")
- for idx, img in enumerate(input_images):
- print(f" • Image {idx + 1}: size={img.size}")
- print(
- f"Parallel config: Ulysses={args.ulysses_degree}, Ring={args.ring_degree}, "
- f"CFG Parallel={args.cfg_parallel_size}, Tensor Parallel={args.tensor_parallel_size}"
- )
- print(f"{'=' * 60}\n")
-
- if profiler_enabled:
- omni.start_profile()
-
- # ---- Generation ----
- t0 = time.perf_counter()
- outputs = omni.generate(
- {
- "prompt": args.prompt,
- "negative_prompt": args.negative_prompt,
- "multi_modal_data": {"image": input_image},
- },
- OmniDiffusionSamplingParams(
- generator=generator,
- true_cfg_scale=args.cfg_scale,
- guidance_scale=args.guidance_scale,
- num_inference_steps=args.num_inference_steps,
- num_outputs_per_prompt=args.num_outputs_per_prompt,
- layers=args.layers,
- resolution=args.resolution,
- ),
- )
- t1 = time.perf_counter()
- print(f"Generation completed in {t1 - t0:.2f}s")
-
- if profiler_enabled:
- omni.stop_profile()
-
- # ---- Output Validation ----
- if not outputs:
- raise ValueError("No output produced from omni.generate()")
-
- first_out = outputs[0].request_output
- req_out: OmniRequestOutput = first_out
-
- # Verify trajectory data (from custom pipeline)
- print(f"\n{'=' * 60}")
- print("TRAJECTORY VERIFICATION:")
- assert hasattr(req_out, "latents") and req_out.latents is not None
- print(f" ✓ trajectory_latents shape: {req_out.latents.shape}")
- print(f" ✓ trajectory_latents dtype: {req_out.latents.dtype}")
- print(f" ✓ trajectory_latents mean: {req_out.latents.mean().item():.6f}")
- print(f" ✓ trajectory_latents std: {req_out.latents.std().item():.6f}")
- assert req_out.latents.shape[0] == args.num_inference_steps, (
- f"Expected {args.num_inference_steps} latent snapshots, got {req_out.latents.shape[0]}"
- )
- print(f"{'=' * 60}\n")
-
- # ---- Save images ----
- output_path = Path(args.output)
- output_path.parent.mkdir(parents=True, exist_ok=True)
- suffix = output_path.suffix or ".png"
- stem = output_path.stem or "output"
-
- images = req_out.images
- if args.num_outputs_per_prompt <= 1:
- img = images[0]
- if isinstance(img, list): # Layered
- for i, sub_img in enumerate(img):
- save_path = output_path.parent / f"{stem}_{i}{suffix}"
- sub_img.save(save_path)
- print(f"Saved layer {i}: {save_path.resolve()}")
- else:
- img.save(output_path)
- print(f"Saved: {output_path.resolve()}")
- else:
- for idx, img in enumerate(images):
- if isinstance(img, list):
- for sub_idx, sub_img in enumerate(img):
- save_path = output_path.parent / f"{stem}_{idx}_{sub_idx}{suffix}"
- sub_img.save(save_path)
- print(f"Saved composite: {save_path.resolve()}")
- else:
- save_path = output_path.parent / f"{stem}_{idx}{suffix}"
- img.save(save_path)
- print(f"Saved: {save_path.resolve()}")
-
-
-# ===========================
-# Entrypoint
-# ===========================
-if __name__ == "__main__":
- asyncio.run(main())
diff --git a/examples/offline_inference/custom_pipeline/image_to_image/run.sh b/examples/offline_inference/custom_pipeline/image_to_image/run.sh
deleted file mode 100644
index d62efae28cf..00000000000
--- a/examples/offline_inference/custom_pipeline/image_to_image/run.sh
+++ /dev/null
@@ -1,6 +0,0 @@
-python image_edit.py \
- --model Qwen/Qwen-Image-Edit-2511 \
- --image cherry_blossom.jpg \
- --prompt "Let this mascot dance under the moon, surrounded by floating stars and poetic bubbles such as 'Be Kind'" \
- --output output_image_edit.png \
- --num-inference-steps 10
diff --git a/examples/offline_inference/dynin_omni/README.md b/examples/offline_inference/dynin_omni/README.md
deleted file mode 100644
index d28b360714e..00000000000
--- a/examples/offline_inference/dynin_omni/README.md
+++ /dev/null
@@ -1,110 +0,0 @@
-# Dynin-Omni Offline End2End Example
-
-This folder contains a unified offline inference entrypoint:
-
-- `end2end.py`
-
-## 1. Environment Setup
-
-Run from repository root:
-
-```bash
-cd <REPO_ROOT>
-```
-
-If needed, install this repo in editable mode:
-
-```bash
-pip install -e .
-```
-
-## 2. Extra Dependencies (EMOVA)
-
-Install the following packages for EMOVA-related components:
-
-```bash
-pip install \
- "phonemizer==3.3.0" \
- "Unidecode==1.4.0" \
- "hydra-core==1.3.2" \
- "pytorch-lightning==1.1.0" \
- "wget==3.2" \
- "wrapt==2.1.1" \
- "onnx==1.20.1" \
- "frozendict==2.4.7" \
- "inflect==7.5.0" \
- "braceexpand==0.1.7" \
- "webdataset==1.0.2" \
- "torch-stft==0.1.4" \
- "editdistance==0.8.1"
-```
-
-## 3. Hardware and VRAM Requirements
-
-This example uses a 3-stage pipeline on one GPU by default
-([`dynin_omni.yaml`](../../../vllm_omni/model_executor/stage_configs/dynin_omni.yaml)):
-
-- Stage-0 (`token2text`): `gpu_memory_utilization: 0.5`
-- Stage-1 (`token2image`): `gpu_memory_utilization: 0.1`
-- Stage-2 (`token2audio`): `gpu_memory_utilization: 0.1`
-
-### Requested GPU Memory Budget from `gpu_memory_utilization`
-
-| Stage | Utilization | A100 80GB | H200 141GB |
-| :-- | :-- | :-- | :-- |
-| Stage-0 (token2text) | 0.5 | ~40.0 GB | ~70.5 GB |
-| Stage-1 (token2image) | 0.1 | ~8.0 GB | ~14.1 GB |
-| Stage-2 (token2audio) | 0.1 | ~8.0 GB | ~14.1 GB |
-| Total requested budget | 0.7 | ~56.0 GB | ~98.7 GB |
-
-### Observed Runtime Signal (from your log)
-
-- Stage-0 reported: `Model loading took 15.12 GiB memory` (weights footprint signal).
-- Stages 1/2 can still add runtime memory depending on task path and backend allocations.
-- Keep extra headroom for CUDA/PyTorch overhead and temporary allocations.
-
-### GPU Compatibility
-
-- Confirmed target GPUs for this setup: **NVIDIA H200**, **NVIDIA A100**.
-- CI/e2e coverage in this repo also includes CUDA **L4** markers for Dynin tests.
-
-## 4. End2End Run Examples
-
-```bash
-# t2t
-python <REPO_ROOT>/examples/offline_inference/dynin_omni/end2end.py \
- --task t2t --model snu-aidas/Dynin-Omni --text <INSTRUCTION_TEXT>
-
-# i2t
-python <REPO_ROOT>/examples/offline_inference/dynin_omni/end2end.py \
- --task i2t --model snu-aidas/Dynin-Omni --image <IMAGE_PATH> --text "Please describe this image in detail."
-
-# s2t
-python <REPO_ROOT>/examples/offline_inference/dynin_omni/end2end.py \
- --task s2t --model snu-aidas/Dynin-Omni --audio <AUDIO_PATH> --text "Transcribe the given audio."
-
-# t2i
-python <REPO_ROOT>/examples/offline_inference/dynin_omni/end2end.py \
- --task t2i --model snu-aidas/Dynin-Omni --text <INSTRUCTION_TEXT>
-
-# v2t
-python <REPO_ROOT>/examples/offline_inference/dynin_omni/end2end.py \
- --task v2t --model snu-aidas/Dynin-Omni --video <VIDEO_PATH> --text "Describe this video in detail."
-
-# i2i
-python <REPO_ROOT>/examples/offline_inference/dynin_omni/end2end.py \
- --task i2i --model snu-aidas/Dynin-Omni --image <IMAGE_PATH> --text <INSTRUCTION_TEXT>
-
-# t2s
-python <REPO_ROOT>/examples/offline_inference/dynin_omni/end2end.py \
- --task t2s --model snu-aidas/Dynin-Omni --text <INSTRUCTION_TEXT>
-```
-
-## 5. Notes
-
-- Outputs are saved under task-specific directories in `/tmp` by default.
-- You can override output path with `--output-dir`.
-- If you want to force local config resolution, pass `--dynin-config-path <PATH_TO_DYNIN_OMNI_YAML>`.
-- If you see the warning
- `max_num_batched_tokens (32768) exceeds max_num_seqs * max_model_len (4096)`,
- reduce `max_num_batched_tokens` in stage config (for example, `4096` in CI config).
diff --git a/examples/offline_inference/dynin_omni/end2end.py b/examples/offline_inference/dynin_omni/end2end.py
deleted file mode 100644
index 82cff0c0015..00000000000
--- a/examples/offline_inference/dynin_omni/end2end.py
+++ /dev/null
@@ -1,1451 +0,0 @@
-#!/usr/bin/env python3
-# SPDX-License-Identifier: Apache-2.0
-
-from __future__ import annotations
-
-import argparse
-import json
-import os
-import re
-import sys
-import time
-import types
-from importlib.machinery import ModuleSpec
-from pathlib import Path
-from typing import Any
-
-import numpy as np
-import torch
-from PIL import Image
-
-TASK_CHOICES = ("t2t", "t2i", "t2s", "i2i", "i2t", "s2t", "v2t")
-
-TASK_DEFAULT_RUNTIME = {
- "t2t": ("mmu", "mmu", 0, "text"),
- "t2i": ("t2i", "t2i_gen", 2, "image"),
- "t2s": ("t2s_mmu_like", "t2s_gen", 1, "audio"),
- "i2i": ("i2i", "i2i", 2, "image"),
- "i2t": ("mmu", "mmu", 0, "text"),
- "s2t": ("s2t", "s2t", 0, "text"),
- "v2t": ("v2t", "v2t", 0, "text"),
-}
-
-TASK_RUNTIME_FALLBACKS: dict[str, dict[str, Any]] = {
- "t2t": {
- "output_dir": "/tmp/dynin_end2end_outputs",
- "prompt_max_text_len": 1024,
- "max_new_tokens": 1024,
- "steps": 1024,
- "block_length": 16,
- "temperature": 0.0,
- "cfg_scale": 0.0,
- },
- "t2i": {
- "output_dir": "/tmp/dynin_t2i_outputs",
- "prompt_max_text_len": 128,
- "image_token_count": 1024,
- "mask_token_id": 126336,
- "codebook_size": 8192,
- "timesteps": 20,
- "guidance_scale": 3.5,
- "temperature": 1.0,
- },
- "i2i": {
- "output_dir": "/tmp/dynin_i2i_outputs",
- "prompt_max_text_len": 128,
- "mask_token_id": 126336,
- "codebook_size": 8192,
- "timesteps": 64,
- "guidance_scale": 3.5,
- "temperature": 1.0,
- "image_resolution": 336,
- "use_train_i2i_prompt": True,
- },
- "i2t": {
- "output_dir": "/tmp/dynin_i2t_outputs",
- "prompt_max_text_len": 128,
- "max_new_tokens": 128,
- "steps": 128,
- "block_length": 2,
- "temperature": 0.0,
- "cfg_scale": 0.0,
- "mask_token_id": 126336,
- "codebook_size": 8192,
- "image_resolution": 480,
- "remasking": "low_confidence",
- },
- "s2t": {
- "output_dir": "/tmp/dynin_s2t_outputs",
- "prompt_max_text_len": 1024,
- "max_new_tokens": 128,
- "steps": 128,
- "block_length": 2,
- "temperature": 0.0,
- "cfg_scale": 0.0,
- "mask_token_id": 126336,
- "codebook_size": 8192,
- "remasking": "low_confidence",
- },
- "t2s": {
- "output_dir": "/tmp/dynin_t2s_outputs",
- "runtime_task": "t2s_mmu_like",
- "prompting_task": "t2s_gen",
- "prompt_max_text_len": 1024,
- "t2s_token_length": 512,
- "mask_token_id": 126336,
- "codebook_size": 8192,
- "audio_codebook_size": 4096,
- "steps": 512,
- "block_length": 128,
- "temperature": 1.0,
- "cfg_scale": 2.5,
- "t2s_condition": "gender-female_emotion-neutral_speed-normal_pitch-normal",
- },
- "v2t": {
- "output_dir": "/tmp/dynin_v2t_outputs",
- "prompt_max_text_len": 1024,
- "max_new_tokens": 128,
- "steps": 128,
- "block_length": 2,
- "temperature": 0.0,
- "cfg_scale": 0.0,
- "mask_token_id": 126336,
- "codebook_size": 8192,
- "image_resolution": 224,
- "num_frames": 5,
- "remasking": "low_confidence",
- },
-}
-
-DEFAULT_I2T_QUESTION = "Please describe this image in detail."
-DEFAULT_S2T_INSTRUCTION = "Transcribe the given audio."
-DEFAULT_V2T_QUESTION = "Please provide a detailed description of the video."
-DEFAULT_T2T_PROMPT = "Explain multimodal LLM inference in 3 sentences."
-DEFAULT_T2S_INSTRUCTION = "Convert the given text into spoken audio."
-DEFAULT_T2S_PROMPT = "Hello. This is a default text-to-speech sample."
-
-DYNIN_SPECIAL_TOKENS = (
- "<|soi|>",
- "<|eoi|>",
- "<|sov|>",
- "<|eov|>",
- "<|t2i|>",
- "<|mmu|>",
- "<|t2v|>",
- "<|v2v|>",
- "<|lvg|>",
- "<|i2i|>",
- "<|ti2ti|>",
- "<|v2t|>",
- "<|v2s|>",
- "<|s2t|>",
- "<|t2s|>",
- "<|s2s|>",
- "<|soa|>",
- "<|eoa|>",
-)
-
-
-def bootstrap_repo_path() -> Path:
- repo_root = Path(__file__).resolve().parents[3]
- repo_root_str = str(repo_root)
- if repo_root_str not in sys.path:
- sys.path.insert(0, repo_root_str)
- return repo_root
-
-
-def ensure_safe_import_for_vllm() -> None:
- os.environ.setdefault("TRANSFORMERS_NO_TORCHVISION", "1")
- try:
- import torchvision # noqa: F401
-
- return
- except Exception:
- pass
-
- import enum
-
- class _InterpolationMode(enum.Enum):
- NEAREST = 0
- BILINEAR = 2
- BICUBIC = 3
- LANCZOS = 1
- HAMMING = 4
- BOX = 5
-
- tv_mod = types.ModuleType("torchvision")
- tv_mod.__dict__["__version__"] = "0.0-stub"
- tv_mod.__spec__ = ModuleSpec(name="torchvision", loader=None)
- transforms_mod = types.ModuleType("torchvision.transforms")
- transforms_mod.__spec__ = ModuleSpec(name="torchvision.transforms", loader=None)
- transforms_mod.InterpolationMode = _InterpolationMode
- tv_mod.transforms = transforms_mod
- sys.modules["torchvision"] = tv_mod
- sys.modules["torchvision.transforms"] = transforms_mod
-
-
-def sanitize_repo_id(repo_id: str) -> str:
- return re.sub(r"[^a-zA-Z0-9._-]+", "_", repo_id)
-
-
-def is_hf_repo_id(value: str) -> bool:
- return isinstance(value, str) and value.count("/") == 1 and all(value.split("/", 1))
-
-
-def ensure_local_model_dir(model: str, cache_dir: Path, localize: bool) -> Path:
- model_path = Path(model).expanduser()
- if model_path.is_dir():
- return model_path.resolve()
- if not localize:
- return Path(model)
-
- from huggingface_hub import snapshot_download
-
- cache_dir.mkdir(parents=True, exist_ok=True)
- os.environ.setdefault("HF_HOME", str(cache_dir / ".hf_home"))
- local_dir = cache_dir / sanitize_repo_id(model)
- if not local_dir.exists():
- print(f"[end2end] Downloading model into local cache: {local_dir}")
- snapshot_download(
- repo_id=model,
- local_dir=str(local_dir),
- local_dir_use_symlinks=True,
- resume_download=True,
- )
- return local_dir.resolve()
-
-
-def resolve_local_only(
- override: bool | None,
- source: str,
- default: bool,
-) -> bool:
- if override is not None:
- return bool(override)
- return default or Path(source).expanduser().is_dir()
-
-
-def load_text_tokenizer(tokenizer_source: str, local_files_only: bool):
- from transformers import AutoTokenizer
-
- kwargs = {
- "trust_remote_code": True,
- "padding_side": "left",
- "local_files_only": bool(local_files_only),
- }
- try:
- tokenizer = AutoTokenizer.from_pretrained(tokenizer_source, **kwargs)
- except TypeError:
- kwargs.pop("local_files_only", None)
- tokenizer = AutoTokenizer.from_pretrained(tokenizer_source, **kwargs)
- return tokenizer
-
-
-def preprocess_image(image: Image.Image, resolution: int) -> torch.Tensor:
- w, h = image.size
- short_side = min(w, h)
- scale = resolution / short_side
- new_w, new_h = round(w * scale), round(h * scale)
- image = image.resize((new_w, new_h), Image.BICUBIC)
- left = (new_w - resolution) // 2
- top = (new_h - resolution) // 2
- image = image.crop((left, top, left + resolution, top + resolution))
- arr = np.array(image, dtype=np.float32) / 255.0
- tensor = torch.from_numpy(arr).permute(2, 0, 1)
- return (tensor - 0.5) / 0.5
-
-
-def load_vq_image_encoder(source: str, local_files_only: bool, device: torch.device) -> Any:
- from vllm_omni.model_executor.models.dynin_omni.dynin_omni_common import get_dynin_magvit_attr
-
- MAGVITv2 = get_dynin_magvit_attr("MAGVITv2", source=source, local_files_only=local_files_only)
- vq_model = MAGVITv2.from_pretrained(source, local_files_only=local_files_only).to(device)
- vq_model.requires_grad_(False)
- vq_model.eval()
- return vq_model
-
-
-def encode_image_tokens(
- image_path: Path,
- vq_model: Any,
- device: torch.device,
- resolution: int,
-) -> torch.Tensor:
- image = Image.open(image_path).convert("RGB")
- image_tensor = preprocess_image(image, resolution=resolution).unsqueeze(0).to(device)
- with torch.no_grad():
- token_ids = vq_model.get_code(image_tensor)
- token_ids = torch.as_tensor(token_ids, dtype=torch.long).detach().cpu()
- if token_ids.ndim == 2 and token_ids.shape[0] == 1:
- token_ids = token_ids[0]
- return token_ids.contiguous()
-
-
-def encode_video_tokens(
- video_path: Path,
- vq_model: Any,
- device: torch.device,
- resolution: int,
- num_frames: int,
-) -> torch.Tensor:
- import cv2
-
- cap = cv2.VideoCapture(str(video_path))
- frames: list[np.ndarray] = []
- while True:
- ok, frame = cap.read()
- if not ok:
- break
- frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
- frames.append(frame)
- cap.release()
- if not frames:
- raise ValueError(f"Video has no readable frames: {video_path}")
- if len(frames) < num_frames:
- raise ValueError(f"Video has {len(frames)} frames, requires >= {num_frames}: {video_path}")
-
- indices = np.linspace(0, len(frames) - 1, num_frames).astype(int)
- token_list: list[torch.Tensor] = []
- for idx in indices:
- pil = Image.fromarray(frames[int(idx)])
- frame_tensor = preprocess_image(pil, resolution=resolution).unsqueeze(0).to(device)
- with torch.no_grad():
- token_list.append(torch.as_tensor(vq_model.get_code(frame_tensor), dtype=torch.long))
- merged = torch.cat(token_list, dim=1).detach().cpu()
- if merged.ndim == 2 and merged.shape[0] == 1:
- merged = merged[0]
- return merged.contiguous()
-
-
-def load_vq_audio_encoder(source: str, local_files_only: bool, device: torch.device) -> Any:
- from transformers import AutoModel
-
- kwargs = {
- "trust_remote_code": True,
- "local_files_only": bool(local_files_only),
- "low_cpu_mem_usage": False,
- }
- try:
- model = AutoModel.from_pretrained(source, **kwargs)
- except TypeError:
- kwargs.pop("low_cpu_mem_usage", None)
- try:
- model = AutoModel.from_pretrained(source, **kwargs)
- except TypeError:
- kwargs.pop("local_files_only", None)
- model = AutoModel.from_pretrained(source, **kwargs)
- model.requires_grad_(False)
- model.eval()
- if hasattr(model, "to"):
- model = model.to(device)
- return model
-
-
-def encode_audio_tokens(audio_path: Path, vq_audio_model: Any) -> torch.Tensor:
- encoded = vq_audio_model.encode(str(audio_path))
- if isinstance(encoded, dict):
- for key in ("input_ids", "token_ids", "codes", "tokens"):
- if key in encoded:
- encoded = encoded[key]
- break
- encoded = torch.as_tensor(encoded, dtype=torch.long).detach().cpu()
- if encoded.ndim == 1:
- encoded = encoded.unsqueeze(0)
- elif encoded.ndim > 2:
- encoded = encoded.view(encoded.shape[0], -1)
- return encoded.contiguous()
-
-
-def build_chat_prompt(content: str) -> str:
- return (
- f"<|start_header_id|>user<|end_header_id|>\n{content}<|eot_id|><|start_header_id|>assistant<|end_header_id|>\n"
- )
-
-
-def resolve_task_text(
- *,
- task_name: str,
- text: str,
- instruction: str = "",
- raw_prompt: bool = False,
-) -> str:
- text = str(text or "").strip()
-
- if task_name == "t2t" and not text:
- return DEFAULT_T2T_PROMPT
- if task_name == "i2t" and not text:
- return DEFAULT_I2T_QUESTION
- if task_name == "s2t" and not text:
- return DEFAULT_S2T_INSTRUCTION
- if task_name == "v2t" and not text:
- return DEFAULT_V2T_QUESTION
- if task_name in {"t2i", "i2i"} and not text:
- return "A high quality detailed image."
-
- if task_name != "t2s":
- return text
-
- if not text:
- text = DEFAULT_T2S_PROMPT
-
- if raw_prompt:
- return text
-
- instruction = str(instruction or "").strip() or DEFAULT_T2S_INSTRUCTION
- return build_chat_prompt(f"{instruction}\n{text}")
-
-
-def load_universal_prompting(
- *,
- tokenizer: Any,
- tokenizer_source: str,
- max_text_len: int,
- cond_dropout_prob: float,
- local_files_only: bool,
- max_audio_len: int = 512,
- max_audio_len_short: int = 256,
-) -> Any:
- from vllm_omni.model_executor.models.dynin_omni.dynin_omni_common import (
- DYNIN_REMOTE_SETTINGS,
- resolve_remote_attr,
- )
-
- UniversalPrompting = resolve_remote_attr(
- "UniversalPrompting",
- module_name="prompting_utils",
- settings=DYNIN_REMOTE_SETTINGS,
- source=tokenizer_source,
- local_files_only=bool(local_files_only),
- fallback_module_names=("modeling_dynin_omni",),
- )
- init_kwargs: dict[str, Any] = {
- "max_text_len": int(max_text_len),
- "special_tokens": DYNIN_SPECIAL_TOKENS,
- "ignore_id": -100,
- "cond_dropout_prob": float(cond_dropout_prob),
- "use_reserved_token": True,
- "max_audio_len": int(max_audio_len),
- "max_audio_len_short": int(max_audio_len_short),
- }
- try:
- return UniversalPrompting(tokenizer, **init_kwargs)
- except TypeError:
- init_kwargs.pop("max_audio_len", None)
- init_kwargs.pop("max_audio_len_short", None)
- return UniversalPrompting(tokenizer, **init_kwargs)
-
-
-def _runtime_fallback(task: str, key: str, value: Any) -> Any:
- if isinstance(value, str):
- if value.strip() != "":
- return value
- elif value is not None:
- return value
- return TASK_RUNTIME_FALLBACKS.get(task, {}).get(key)
-
-
-def _validate_generation_args(*, task: str, max_new_tokens: int, steps: int, block_length: int) -> None:
- # Keep i2t/v2t generation constraints aligned with i2t.py/v2t.py.
- if task not in {"i2t", "v2t"}:
- return
- if max_new_tokens <= 0:
- raise ValueError(f"{task} requires max_new_tokens > 0.")
- if block_length <= 0:
- raise ValueError(f"{task} requires block_length > 0.")
- if steps <= 0:
- raise ValueError(f"{task} requires steps > 0.")
- if max_new_tokens % block_length != 0:
- raise ValueError(f"{task} requires max_new_tokens % block_length == 0, got {max_new_tokens} % {block_length}")
- num_blocks = max_new_tokens // block_length
- if num_blocks <= 0:
- raise ValueError(f"{task} has invalid num_blocks.")
- if steps % num_blocks != 0:
- raise ValueError(
- f"{task} requires steps % (max_new_tokens // block_length) == 0, "
- f"got steps={steps}, max_new_tokens={max_new_tokens}, block_length={block_length}"
- )
-
-
-def make_prompt_payload(
- *,
- task: str,
- text: str,
- image_tokens: torch.Tensor | None,
- audio_tokens: torch.Tensor | None,
- video_tokens: torch.Tensor | None,
- image_placeholder_tokens: int,
- audio_placeholder_tokens: int,
- image_token_offset: int,
- speech_token_offset: int,
- mask_token_id: int,
- use_train_i2i_prompt: bool,
-) -> tuple[Any, str]:
- runtime_task, prompting_task, _, _ = TASK_DEFAULT_RUNTIME[task]
- del runtime_task
-
- if task == "t2t":
- payload = ([[]], [build_chat_prompt(text)])
- return payload, prompting_task
-
- if task == "i2t":
- if image_tokens is None:
- raise ValueError("i2t requires image tokens")
- img = image_tokens.view(-1).long() + int(image_token_offset)
- payload = ([[img]], [build_chat_prompt(text)])
- return payload, prompting_task
-
- if task == "s2t":
- if audio_tokens is None:
- raise ValueError("s2t requires audio tokens")
- aud = audio_tokens.long() + int(speech_token_offset)
- if aud.ndim == 1:
- aud = aud.unsqueeze(0)
- payload = ([aud], [build_chat_prompt(text)])
- return payload, prompting_task
-
- if task == "v2t":
- if video_tokens is None:
- raise ValueError("v2t requires video tokens")
- vid = video_tokens.view(-1).long() + int(image_token_offset)
- payload = (vid.unsqueeze(0), [build_chat_prompt(text)])
- return payload, prompting_task
-
- if task == "t2i":
- image_placeholder = torch.full(
- (1, int(image_placeholder_tokens)),
- fill_value=int(mask_token_id),
- dtype=torch.long,
- )
- payload = ([text], image_placeholder)
- return payload, prompting_task
-
- if task == "i2i":
- if image_tokens is None:
- raise ValueError("i2i requires image tokens")
- src = image_tokens.view(1, -1).long() + int(image_token_offset)
- target_len = int(image_placeholder_tokens) if image_placeholder_tokens > 0 else int(src.shape[1])
- image_placeholder = torch.full(
- (1, target_len),
- fill_value=int(mask_token_id),
- dtype=torch.long,
- )
- if use_train_i2i_prompt:
- labels_placeholder = torch.full(
- (1, target_len),
- fill_value=-100,
- dtype=torch.long,
- )
- payload = ([text], src, image_placeholder, labels_placeholder)
- return payload, "i2i"
- payload = ([text], src, image_placeholder)
- return payload, "i2i_gen"
-
- if task == "t2s":
- audio_placeholder = torch.full(
- (1, int(audio_placeholder_tokens)),
- fill_value=int(mask_token_id),
- dtype=torch.long,
- )
- payload = ([text], audio_placeholder)
- return payload, prompting_task
-
- raise ValueError(f"Unsupported task: {task}")
-
-
-def _to_1d_int_list(value: Any) -> list[int]:
- if value is None:
- return []
- if isinstance(value, torch.Tensor):
- tensor = value.detach().to(device="cpu", dtype=torch.long)
- else:
- tensor = torch.as_tensor(value, dtype=torch.long)
- if tensor.ndim == 0:
- tensor = tensor.view(1)
- elif tensor.ndim >= 2:
- tensor = tensor.view(tensor.shape[0], -1)[0]
- return [int(v) for v in tensor.tolist()]
-
-
-def _run_uni_prompting(uni_prompting: Any, payload: Any, prompting_task: str) -> tuple[list[int], list[int]]:
- prepared = uni_prompting(payload, prompting_task)
- if isinstance(prepared, tuple):
- prepared_input_ids = prepared[0] if len(prepared) > 0 else None
- prepared_attention_mask = prepared[1] if len(prepared) > 1 else None
- else:
- prepared_input_ids = prepared
- prepared_attention_mask = None
-
- input_ids = _to_1d_int_list(prepared_input_ids)
- attention_mask = _to_1d_int_list(prepared_attention_mask)
- if not input_ids:
- raise RuntimeError(f"UniversalPrompting returned empty input_ids for task={prompting_task}")
- return input_ids, attention_mask
-
-
-def _get_special_token_id(uni_prompting: Any, token: str) -> int:
- sptids = getattr(uni_prompting, "sptids_dict", None) or {}
- if token not in sptids:
- raise KeyError(f"Special token not found in UniversalPrompting.sptids_dict: {token}")
- token_ids = _to_1d_int_list(sptids[token])
- if not token_ids:
- raise ValueError(f"Special token id is empty for token: {token}")
- return int(token_ids[0])
-
-
-def _tokenize_chat_query(tokenizer: Any, text: str) -> list[int]:
- encoded = tokenizer(build_chat_prompt(text), return_tensors="pt").input_ids[0]
- token_ids = _to_1d_int_list(encoded)
- if not token_ids:
- raise RuntimeError("Failed to tokenize chat query text.")
- return token_ids
-
-
-def _flatten_media_token_ids_with_offset(token_ids: Any, token_offset: int) -> list[int]:
- media_ids = token_ids
- if isinstance(media_ids, torch.Tensor):
- media_ids = media_ids.detach().cpu().reshape(-1).tolist()
- else:
- media_ids = np.asarray(media_ids).reshape(-1).tolist()
- return [int(x) + int(token_offset) for x in media_ids]
-
-
-def _scalar_token_id(value: Any) -> int:
- if isinstance(value, torch.Tensor):
- if value.numel() == 0:
- raise ValueError("Empty special-token tensor.")
- return int(value.view(-1)[0].item())
- if isinstance(value, (list, tuple)):
- if not value:
- raise ValueError("Empty special-token list.")
- return int(value[0])
- return int(value)
-
-
-def build_v2t_input_ids(
- *,
- video_token_ids: Any,
- tokenizer: Any,
- uni_prompting: Any,
- question: str,
- image_token_offset: int,
-) -> tuple[list[int], str]:
- media_ids = video_token_ids
- if isinstance(media_ids, torch.Tensor):
- media_ids = media_ids.detach().cpu().reshape(-1).tolist()
- else:
- media_ids = np.asarray(media_ids).reshape(-1).tolist()
- media_ids = [int(x) + int(image_token_offset) for x in media_ids]
-
- sptids = uni_prompting.sptids_dict
- task_id = _scalar_token_id(sptids["<|v2t|>"])
- soi_id = _scalar_token_id(sptids["<|soi|>"])
- eoi_id = _scalar_token_id(sptids["<|eoi|>"])
- sot_id = _scalar_token_id(sptids["<|sot|>"])
-
- prompt_text = build_v2t_chat_prompt(question)
- query_ids = tokenizer(prompt_text, return_tensors="pt").input_ids[0].detach().cpu().tolist()
- input_ids = [task_id, soi_id] + media_ids + [eoi_id, sot_id] + [int(v) for v in query_ids]
- return input_ids, prompt_text
-
-
-def build_i2t_input_ids(
- *,
- image_token_ids: Any,
- tokenizer: Any,
- uni_prompting: Any,
- question: str,
- image_token_offset: int,
-) -> tuple[list[int], str]:
- image_ids = image_token_ids
- if isinstance(image_ids, torch.Tensor):
- image_ids = image_ids.detach().cpu().reshape(-1).tolist()
- else:
- image_ids = np.asarray(image_ids).reshape(-1).tolist()
- image_ids = [int(x) + int(image_token_offset) for x in image_ids]
-
- sptids = uni_prompting.sptids_dict
- task_id = _scalar_token_id(sptids["<|mmu|>"])
- soi_id = _scalar_token_id(sptids["<|soi|>"])
- eoi_id = _scalar_token_id(sptids["<|eoi|>"])
- sot_id = _scalar_token_id(sptids["<|sot|>"])
-
- prompt_text = build_i2t_chat_prompt(question)
- query_ids = tokenizer(prompt_text, return_tensors="pt").input_ids[0].detach().cpu().tolist()
- input_ids = [task_id, soi_id] + image_ids + [eoi_id, sot_id] + [int(v) for v in query_ids]
- return input_ids, prompt_text
-
-
-def build_v2t_chat_prompt(question: str) -> str:
- return (
- f"<|start_header_id|>user<|end_header_id|>\n{question}<|eot_id|><|start_header_id|>assistant<|end_header_id|>\n"
- )
-
-
-def build_i2t_chat_prompt(question: str) -> str:
- return (
- f"<|start_header_id|>user<|end_header_id|>\n{question}<|eot_id|><|start_header_id|>assistant<|end_header_id|>\n"
- )
-
-
-def make_mmu_prompt(
- *,
- task: str,
- text: str,
- tokenizer: Any,
- uni_prompting: Any,
- image_tokens: torch.Tensor | None,
- audio_tokens: torch.Tensor | None,
- video_tokens: torch.Tensor | None,
- image_token_offset: int,
- speech_token_offset: int,
-) -> tuple[list[int], list[int]]:
- query_ids = _tokenize_chat_query(tokenizer, text)
-
- if task == "i2t":
- token_ids, _ = build_i2t_input_ids(
- image_token_ids=image_tokens,
- tokenizer=tokenizer,
- uni_prompting=uni_prompting,
- question=text,
- image_token_offset=int(image_token_offset),
- )
- token_ids = [int(v) for v in token_ids]
- return token_ids, [1] * len(token_ids)
-
- if task == "v2t":
- token_ids, _ = build_v2t_input_ids(
- video_token_ids=video_tokens,
- tokenizer=tokenizer,
- uni_prompting=uni_prompting,
- question=text,
- image_token_offset=int(image_token_offset),
- )
- token_ids = [int(v) for v in token_ids]
- return token_ids, [1] * len(token_ids)
-
- if task == "s2t":
- if audio_tokens is None:
- raise ValueError("s2t requires audio tokens")
- audio_ids = _to_1d_int_list(audio_tokens.long() + int(speech_token_offset))
- token_ids = [
- _get_special_token_id(uni_prompting, "<|s2t|>"),
- _get_special_token_id(uni_prompting, "<|soa|>"),
- *audio_ids,
- _get_special_token_id(uni_prompting, "<|eoa|>"),
- *query_ids,
- ]
- return token_ids, [1] * len(token_ids)
-
- raise ValueError(f"Unsupported task for validation-style MMU prompt: {task}")
-
-
-def iter_mm_outputs(outputs: list[Any]):
- for omni_out in outputs:
- req_out = getattr(omni_out, "request_output", None)
- req_list = req_out if isinstance(req_out, list) else [req_out]
- for item in req_list:
- if item is None:
- continue
- mm_out = getattr(item, "multimodal_output", None) or {}
- if mm_out:
- yield mm_out
- completions = getattr(item, "outputs", None) or []
- for completion in completions:
- c_mm_out = getattr(completion, "multimodal_output", None) or {}
- if c_mm_out:
- yield c_mm_out
- omni_mm = getattr(omni_out, "multimodal_output", None) or {}
- if omni_mm:
- yield omni_mm
-
-
-def _to_token_list(value: Any) -> list[int]:
- if value is None:
- return []
- if hasattr(value, "detach"):
- value = value.detach()
- if hasattr(value, "cpu"):
- value = value.cpu()
- if hasattr(value, "flatten"):
- value = value.flatten().tolist()
- if isinstance(value, tuple):
- value = list(value)
- if not isinstance(value, list):
- return []
- out: list[int] = []
- for token in value:
- if isinstance(token, bool):
- continue
- try:
- out.append(int(token))
- except Exception:
- continue
- return out
-
-
-def extract_text_output(outputs: list[Any], tokenizer: Any) -> str:
- for mm_out in iter_mm_outputs(outputs):
- text = mm_out.get("text")
- if isinstance(text, list) and text:
- text = text[-1]
- if isinstance(text, str) and text.strip():
- return text.strip()
- for key in ("text_tokens", "token_ids"):
- token_ids = _to_token_list(mm_out.get(key))
- if not token_ids:
- continue
- decoded = tokenizer.decode(token_ids, skip_special_tokens=True)
- if isinstance(decoded, str) and decoded.strip():
- return decoded.strip()
- return ""
-
-
-def extract_image_output(outputs: list[Any]) -> torch.Tensor | None:
- for mm_out in iter_mm_outputs(outputs):
- image = mm_out.get("image")
- if isinstance(image, list) and image:
- image = image[-1]
- if isinstance(image, torch.Tensor):
- return image
- return None
-
-
-def tensor_to_pil_image(image: torch.Tensor) -> Image.Image:
- arr = image.detach().cpu().numpy()
- if arr.ndim == 4:
- arr = arr[0]
- if arr.ndim == 3 and arr.shape[0] in (1, 3, 4):
- arr = np.transpose(arr, (1, 2, 0))
- if arr.dtype != np.uint8:
- arr = arr.astype(np.float32)
- if arr.max() <= 1.0:
- arr = arr * 255.0
- arr = np.clip(arr, 0.0, 255.0).astype(np.uint8)
- if arr.ndim == 3 and arr.shape[-1] == 1:
- arr = arr[..., 0]
- return Image.fromarray(arr)
-
-
-def extract_audio_output(outputs: list[Any]) -> tuple[np.ndarray, int] | None:
- for mm_out in iter_mm_outputs(outputs):
- audio = mm_out.get("audio")
- if audio is None:
- audio = mm_out.get("speech")
- if audio is None:
- continue
-
- def _to_wav_array(value: Any) -> np.ndarray:
- if isinstance(value, torch.Tensor):
- return value.detach().cpu().numpy().reshape(-1).astype(np.float32)
- return np.asarray(value).reshape(-1).astype(np.float32)
-
- if isinstance(audio, list):
- chunks = [_to_wav_array(chunk) for chunk in audio]
- wav = np.concatenate(chunks, axis=0) if chunks else np.zeros((0,), dtype=np.float32)
- else:
- wav = _to_wav_array(audio)
- sr = mm_out.get("sr", 24000)
- if hasattr(sr, "item"):
- try:
- sr = int(sr.item())
- except Exception:
- sr = 24000
- elif isinstance(sr, list):
- sr = int(sr[0]) if sr else 24000
- else:
- sr = int(sr)
- return wav, sr
- return None
-
-
-def save_audio_wav(path: Path, wav: np.ndarray, sr: int) -> None:
- try:
- import soundfile as sf
-
- sf.write(str(path), wav, int(sr), format="WAV")
- except Exception:
- from scipy.io import wavfile
-
- wav_i16 = np.clip(wav, -1.0, 1.0)
- wav_i16 = (wav_i16 * 32767.0).astype(np.int16)
- wavfile.write(str(path), int(sr), wav_i16)
-
-
-def parse_args(repo_root: Path) -> argparse.Namespace:
- parser = argparse.ArgumentParser(description="Dynin-Omni unified offline end2end example.")
- parser.add_argument("--task", type=str, required=True, choices=TASK_CHOICES)
- parser.add_argument("--model", type=str, required=True, help="HF repo id or local model directory.")
- parser.add_argument(
- "--stage-config-path",
- type=str,
- default=str(repo_root / "vllm_omni/model_executor/stage_configs/dynin_omni.yaml"),
- help="Path to stage config yaml.",
- )
- parser.add_argument(
- "--dynin-config-path",
- type=str,
- default="",
- help="Path to DYNIN config yaml (passed through additional_information).",
- )
- parser.add_argument(
- "--model-cache-dir",
- type=str,
- default="/tmp/dynin_localized_models",
- help="Cache directory used when --model is HF repo id.",
- )
- parser.add_argument(
- "--localize-model",
- action=argparse.BooleanOptionalAction,
- default=True,
- help="If true and --model is HF repo id, snapshot it under --model-cache-dir.",
- )
- parser.add_argument("--text", type=str, default="", help="Prompt/edit/question text.")
- parser.add_argument("--instruction", type=str, default="", help="Optional extra instruction.")
- parser.add_argument("--raw-prompt", action=argparse.BooleanOptionalAction, default=False)
- parser.add_argument("--image", type=str, default="", help="Input image path for i2i/i2t.")
- parser.add_argument("--audio", type=str, default="", help="Input audio path for s2t.")
- parser.add_argument("--video", type=str, default="", help="Input video path for v2t.")
- parser.add_argument("--image-resolution", type=int, default=None)
- parser.add_argument("--num-frames", type=int, default=None)
- parser.add_argument(
- "--output-dir",
- type=str,
- default="",
- help="Directory for generated outputs.",
- )
- parser.add_argument("--output-prefix", type=str, default="")
- parser.add_argument("--seed", type=int, default=0)
- parser.add_argument("--dtype", type=str, default="auto")
- parser.add_argument("--max-tokens-per-stage", type=int, default=1)
-
- parser.add_argument("--runtime-task", type=str, default="", help="Override runtime task key.")
- parser.add_argument("--prompting-task", type=str, default="", help="Override prompting task key.")
- parser.add_argument("--detok-id", type=int, default=None, help="Override detok id.")
-
- parser.add_argument("--prompt-max-text-len", type=int, default=None)
- parser.add_argument("--cond-dropout-prob", type=float, default=0.0)
- parser.add_argument("--max-new-tokens", type=int, default=None)
- parser.add_argument("--steps", type=int, default=None)
- parser.add_argument("--block-length", type=int, default=None)
- parser.add_argument("--temperature", type=float, default=None)
- parser.add_argument("--cfg-scale", type=float, default=None)
- parser.add_argument("--remasking", type=str, default="low_confidence")
-
- parser.add_argument("--timesteps", type=int, default=None)
- parser.add_argument("--guidance-scale", type=float, default=None)
- parser.add_argument("--noise-type", type=str, default="mask")
- parser.add_argument("--noise-schedule-name", type=str, default="cosine")
- parser.add_argument("--noise-schedule-params", type=str, default="{}")
-
- parser.add_argument("--mask-token-id", type=int, default=None)
- parser.add_argument("--codebook-size", type=int, default=None)
- parser.add_argument("--audio-codebook-size", type=int, default=None)
- parser.add_argument("--image-token-count", type=int, default=None)
- parser.add_argument("--t2s-token-length", type=int, default=None)
- parser.add_argument(
- "--t2s-condition",
- type=str,
- default="",
- )
- parser.add_argument(
- "--use-train-i2i-prompt",
- action="store_true",
- help="Use i2i training prompt template (default behavior of i2i.py).",
- )
- parser.add_argument(
- "--no-use-train-i2i-prompt",
- dest="use_train_i2i_prompt",
- action="store_false",
- help="Use i2i_gen prompt template.",
- )
- parser.set_defaults(use_train_i2i_prompt=None)
-
- parser.add_argument("--tokenizer-path", type=str, default="")
- parser.add_argument("--model-local-files-only", action=argparse.BooleanOptionalAction, default=None)
- parser.add_argument("--tokenizer-local-files-only", action=argparse.BooleanOptionalAction, default=None)
-
- parser.add_argument("--vq-model-image-path", type=str, default="")
- parser.add_argument("--vq-model-image-local-files-only", action=argparse.BooleanOptionalAction, default=None)
- parser.add_argument("--vq-model-audio-path", type=str, default="")
- parser.add_argument("--vq-model-audio-local-files-only", action=argparse.BooleanOptionalAction, default=None)
-
- parser.add_argument("--disable-hf-xet", action=argparse.BooleanOptionalAction, default=True)
- from vllm_omni.engine.arg_utils import nullify_stage_engine_defaults
-
- nullify_stage_engine_defaults(parser)
- return parser.parse_args()
-
-
-def main() -> None:
- repo_root = bootstrap_repo_path()
- ensure_safe_import_for_vllm()
- from vllm_omni.model_executor.models.dynin_omni.dynin_omni_common import (
- DYNIN_PROMPT_SOURCE_KEY,
- DYNIN_PROMPT_SOURCE_OFFLINE_PREBUILT,
- )
-
- args = parse_args(repo_root)
-
- if args.disable_hf_xet:
- os.environ.setdefault("HF_HUB_DISABLE_XET", "1")
-
- np.random.seed(args.seed)
- torch.manual_seed(args.seed)
-
- model_dir = ensure_local_model_dir(
- model=args.model,
- cache_dir=Path(args.model_cache_dir).expanduser(),
- localize=bool(args.localize_model),
- )
- model_source = str(model_dir)
-
- task_name = str(args.task)
- dynin_config_path = str(Path(args.dynin_config_path).expanduser())
- os.environ["DYNIN_CONFIG_PATH"] = dynin_config_path
- default_runtime_task, default_prompting_task, default_detok_id, final_modality = TASK_DEFAULT_RUNTIME[task_name]
- runtime_task = args.runtime_task.strip() or str(
- _runtime_fallback(task_name, "runtime_task", None) or default_runtime_task
- )
- prompting_task = args.prompting_task.strip() or str(
- _runtime_fallback(task_name, "prompting_task", None) or default_prompting_task
- )
- detok_id_default = _runtime_fallback(task_name, "detok_id", None)
- if detok_id_default is None:
- detok_id_default = default_detok_id
- detok_id = int(detok_id_default if args.detok_id is None else args.detok_id)
-
- output_dir_default = _runtime_fallback(task_name, "output_dir", args.output_dir)
- resolved_output_dir = str(output_dir_default or "/tmp/dynin_end2end_outputs")
-
- image_resolution_value = _runtime_fallback(
- task_name,
- "image_resolution",
- args.image_resolution,
- )
- if image_resolution_value is None:
- image_resolution_value = 336
- image_resolution = int(image_resolution_value)
-
- num_frames_value = _runtime_fallback(
- task_name,
- "num_frames",
- args.num_frames,
- )
- if num_frames_value is None:
- num_frames_value = 8
- num_frames = int(num_frames_value)
-
- prompt_max_text_len_value = _runtime_fallback(
- task_name,
- "prompt_max_text_len",
- args.prompt_max_text_len,
- )
- if prompt_max_text_len_value is None:
- prompt_max_text_len_value = 1024
- prompt_max_text_len = int(prompt_max_text_len_value)
-
- max_new_tokens_value = _runtime_fallback(
- task_name,
- "max_new_tokens",
- args.max_new_tokens,
- )
- if max_new_tokens_value is None:
- max_new_tokens_value = 256
- max_new_tokens = int(max_new_tokens_value)
-
- steps_value = _runtime_fallback(
- task_name,
- "steps",
- args.steps,
- )
- if steps_value is None:
- steps_value = 256
- steps = int(steps_value)
-
- block_length_value = _runtime_fallback(
- task_name,
- "block_length",
- args.block_length,
- )
- if block_length_value is None:
- block_length_value = 2
- block_length = int(block_length_value)
-
- temperature_value = _runtime_fallback(
- task_name,
- "temperature",
- args.temperature,
- )
- if temperature_value is None:
- temperature_value = 0.0
- temperature = float(temperature_value)
-
- cfg_scale_value = _runtime_fallback(
- task_name,
- "cfg_scale",
- args.cfg_scale,
- )
- if cfg_scale_value is None:
- cfg_scale_value = 0.0
- cfg_scale = float(cfg_scale_value)
-
- remasking = str(_runtime_fallback(task_name, "remasking", args.remasking) or "low_confidence")
-
- timesteps_value = _runtime_fallback(
- task_name,
- "timesteps",
- args.timesteps,
- )
- if timesteps_value is None:
- timesteps_value = 20
- timesteps = int(timesteps_value)
-
- guidance_scale_value = _runtime_fallback(
- task_name,
- "guidance_scale",
- args.guidance_scale,
- )
- if guidance_scale_value is None:
- guidance_scale_value = 0.0
- guidance_scale = float(guidance_scale_value)
-
- mask_token_id_value = _runtime_fallback(
- task_name,
- "mask_token_id",
- args.mask_token_id,
- )
- if mask_token_id_value is None:
- mask_token_id_value = 126336
- mask_token_id = int(mask_token_id_value)
-
- codebook_size_value = _runtime_fallback(
- task_name,
- "codebook_size",
- args.codebook_size,
- )
- if codebook_size_value is None:
- codebook_size_value = 8192
- codebook_size = int(codebook_size_value)
-
- audio_codebook_size_value = _runtime_fallback(
- task_name,
- "audio_codebook_size",
- args.audio_codebook_size,
- )
- if audio_codebook_size_value is None:
- audio_codebook_size_value = 4096
- audio_codebook_size = int(audio_codebook_size_value)
-
- image_token_count_value = _runtime_fallback(
- task_name,
- "image_token_count",
- args.image_token_count,
- )
- image_token_count = int(image_token_count_value) if image_token_count_value is not None else 0
-
- t2s_token_length_value = _runtime_fallback(
- task_name,
- "t2s_token_length",
- args.t2s_token_length,
- )
- if t2s_token_length_value is None:
- t2s_token_length_value = 383
- t2s_token_length = int(t2s_token_length_value)
-
- t2s_condition = str(
- _runtime_fallback(task_name, "t2s_condition", args.t2s_condition)
- or "gender-female_emotion-neutral_speed-normal_pitch-normal"
- )
-
- _validate_generation_args(
- task=task_name,
- max_new_tokens=max_new_tokens,
- steps=steps,
- block_length=block_length,
- )
-
- use_train_i2i_prompt = _runtime_fallback(task_name, "use_train_i2i_prompt", args.use_train_i2i_prompt)
- if use_train_i2i_prompt is None:
- use_train_i2i_prompt = bool(task_name == "i2i")
- use_train_i2i_prompt = bool(use_train_i2i_prompt)
-
- if task_name in {"i2i", "i2t"} and not args.image:
- raise ValueError(f"--task {task_name} requires --image")
- if task_name == "s2t" and not args.audio:
- raise ValueError("--task s2t requires --audio")
- if task_name == "v2t" and not args.video:
- raise ValueError("--task v2t requires --video")
-
- text = resolve_task_text(
- task_name=task_name,
- text=args.text,
- instruction=args.instruction,
- raw_prompt=bool(args.raw_prompt),
- )
-
- tokenizer_source = args.tokenizer_path.strip() or model_source
- model_local_only = resolve_local_only(
- args.model_local_files_only, model_source, default=Path(model_source).is_dir()
- )
- tokenizer_local_only = resolve_local_only(
- args.tokenizer_local_files_only,
- tokenizer_source,
- default=model_local_only,
- )
- tokenizer = load_text_tokenizer(tokenizer_source, local_files_only=tokenizer_local_only)
- text_vocab_size = int(len(tokenizer))
-
- image_tokens: torch.Tensor | None = None
- audio_tokens: torch.Tensor | None = None
- video_tokens: torch.Tensor | None = None
-
- device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
-
- vq_image_source = args.vq_model_image_path.strip() or "snu-aidas/magvitv2"
- vq_audio_source = args.vq_model_audio_path.strip() or "snu-aidas/emova_speech_tokenizer_vllm"
- vq_image_local_only = resolve_local_only(args.vq_model_image_local_files_only, vq_image_source, default=False)
- vq_audio_local_only = resolve_local_only(args.vq_model_audio_local_files_only, vq_audio_source, default=False)
-
- if task_name in {"i2i", "i2t", "v2t"}:
- vq_image = load_vq_image_encoder(vq_image_source, vq_image_local_only, device)
- if task_name in {"i2i", "i2t"}:
- image_tokens = encode_image_tokens(
- Path(args.image).expanduser().resolve(),
- vq_model=vq_image,
- device=device,
- resolution=int(image_resolution),
- )
- if task_name == "v2t":
- video_tokens = encode_video_tokens(
- Path(args.video).expanduser().resolve(),
- vq_model=vq_image,
- device=device,
- resolution=int(image_resolution),
- num_frames=int(num_frames),
- )
- if hasattr(vq_image, "cpu"):
- vq_image = vq_image.cpu()
-
- if task_name == "s2t":
- vq_audio = load_vq_audio_encoder(vq_audio_source, vq_audio_local_only, device)
- audio_tokens = encode_audio_tokens(Path(args.audio).expanduser().resolve(), vq_audio)
- if hasattr(vq_audio, "cpu"):
- vq_audio = vq_audio.cpu()
-
- noise_schedule_params: dict[str, Any] = {}
- try:
- parsed = json.loads(args.noise_schedule_params)
- if isinstance(parsed, dict):
- noise_schedule_params = {str(k): v for k, v in parsed.items()}
- except Exception:
- noise_schedule_params = {}
-
- image_token_count = int(image_token_count)
- if image_token_count <= 0:
- if image_tokens is not None:
- image_token_count = int(image_tokens.numel())
- else:
- base_res = int(image_resolution)
- image_token_count = max(1, (base_res // 16) ** 2)
-
- uncond_input_ids: list[int] | None = None
- uncond_attention_mask: list[int] | None = None
- if task_name == "t2t":
- messages = [{"role": "user", "content": text}]
- if getattr(tokenizer, "chat_template", None):
- prompt_text = tokenizer.apply_chat_template(messages, add_generation_prompt=True, tokenize=False)
- encoded = tokenizer(prompt_text, return_tensors="pt", add_special_tokens=False)
- else:
- encoded = tokenizer(text, return_tensors="pt", add_special_tokens=True)
- prompt_token_ids = _to_1d_int_list(encoded["input_ids"])
- prompt_attention_mask = _to_1d_int_list(encoded.get("attention_mask"))
- if not prompt_attention_mask:
- prompt_attention_mask = [1] * len(prompt_token_ids)
- else:
- max_audio_len_for_prompt = int(max(t2s_token_length, 512))
- if audio_tokens is not None:
- max_audio_len_for_prompt = max(max_audio_len_for_prompt, int(audio_tokens.numel()))
- max_audio_len_short_for_prompt = max(256, max_audio_len_for_prompt // 2)
-
- uni_prompting = load_universal_prompting(
- tokenizer=tokenizer,
- tokenizer_source=tokenizer_source,
- max_text_len=int(prompt_max_text_len),
- cond_dropout_prob=float(args.cond_dropout_prob),
- local_files_only=bool(tokenizer_local_only),
- max_audio_len=int(max_audio_len_for_prompt),
- max_audio_len_short=int(max_audio_len_short_for_prompt),
- )
- prompting_text_vocab_size = int(len(uni_prompting.text_tokenizer))
-
- is_mmu_task = task_name in {"i2t", "s2t", "v2t"} and not args.prompting_task.strip()
- if is_mmu_task:
- prompt_token_ids, prompt_attention_mask = make_mmu_prompt(
- task=task_name,
- text=text,
- tokenizer=uni_prompting.text_tokenizer,
- uni_prompting=uni_prompting,
- image_tokens=image_tokens,
- audio_tokens=audio_tokens,
- video_tokens=video_tokens,
- image_token_offset=prompting_text_vocab_size,
- speech_token_offset=prompting_text_vocab_size + int(codebook_size),
- )
- else:
- prompt_payload, prompting_task = make_prompt_payload(
- task=task_name,
- text=text,
- image_tokens=image_tokens,
- audio_tokens=audio_tokens,
- video_tokens=video_tokens,
- image_placeholder_tokens=image_token_count,
- audio_placeholder_tokens=int(t2s_token_length),
- image_token_offset=text_vocab_size,
- speech_token_offset=text_vocab_size + int(codebook_size),
- mask_token_id=int(mask_token_id),
- use_train_i2i_prompt=use_train_i2i_prompt,
- )
- if args.prompting_task.strip():
- prompting_task = args.prompting_task.strip()
-
- prompt_token_ids, prompt_attention_mask = _run_uni_prompting(
- uni_prompting,
- prompt_payload,
- prompting_task,
- )
-
- if task_name in {"i2t", "s2t", "v2t"}:
- prompt_attention_mask = [1] * len(prompt_token_ids)
- if not prompt_attention_mask:
- prompt_attention_mask = [1] * len(prompt_token_ids)
-
- if task_name in {"t2i", "i2i"} and guidance_scale > 0:
- uncond_payload, uncond_prompting_task = make_prompt_payload(
- task=task_name,
- text="",
- image_tokens=image_tokens,
- audio_tokens=audio_tokens,
- video_tokens=video_tokens,
- image_placeholder_tokens=image_token_count,
- audio_placeholder_tokens=int(t2s_token_length),
- image_token_offset=text_vocab_size,
- speech_token_offset=text_vocab_size + int(codebook_size),
- mask_token_id=int(mask_token_id),
- use_train_i2i_prompt=use_train_i2i_prompt,
- )
- uncond_input_ids, uncond_attention_mask = _run_uni_prompting(
- uni_prompting,
- uncond_payload,
- args.prompting_task.strip() or uncond_prompting_task,
- )
- if not uncond_attention_mask:
- uncond_attention_mask = [1] * len(uncond_input_ids)
-
- runtime_info: dict[str, Any] = {
- "task": [runtime_task],
- "detok_id": [int(detok_id)],
- DYNIN_PROMPT_SOURCE_KEY: [DYNIN_PROMPT_SOURCE_OFFLINE_PREBUILT],
- "dynin_config_path": [str(dynin_config_path)],
- "attention_mask": [prompt_attention_mask],
- "prompt_max_text_len": [int(prompt_max_text_len)],
- "prompting_max_text_len": [int(prompt_max_text_len)],
- "cond_dropout_prob": [float(args.cond_dropout_prob)],
- "prompting_cond_dropout_prob": [float(args.cond_dropout_prob)],
- "tokenizer_path": [str(tokenizer_source)],
- "text_vocab_size": [int(text_vocab_size)],
- "model_local_files_only": [bool(model_local_only)],
- "max_new_tokens": [int(max_new_tokens)],
- "steps": [int(steps)],
- "block_length": [int(block_length)],
- "temperature": [float(temperature)],
- "cfg_scale": [float(cfg_scale)],
- "remasking": [str(remasking)],
- "mask_id": [int(mask_token_id)],
- "mask_token_id": [int(mask_token_id)],
- "codebook_size": [int(codebook_size)],
- "audio_codebook_size": [int(audio_codebook_size)],
- "timesteps": [int(timesteps)],
- "guidance_scale": [float(guidance_scale)],
- "noise_type": [str(args.noise_type)],
- "noise_schedule_name": [str(args.noise_schedule_name)],
- "noise_schedule_params": [noise_schedule_params],
- "seq_len": [int(image_token_count)],
- "condition": [str(t2s_condition)],
- "vq_model_image_path": [str(vq_image_source)],
- "vq_model_image_local_files_only": [bool(vq_image_local_only)],
- "vq_model_audio_path": [str(vq_audio_source)],
- "vq_model_audio_local_files_only": [bool(vq_audio_local_only)],
- }
-
- if task_name in {"t2t", "i2t", "s2t", "v2t"}:
- runtime_info["prompt_length"] = [int(len(prompt_token_ids))]
- if uncond_input_ids is not None:
- runtime_info["uncond_input_ids"] = [uncond_input_ids]
- if uncond_attention_mask is not None:
- runtime_info["uncond_attention_mask"] = [uncond_attention_mask]
-
- if task_name == "t2s":
- runtime_info["max_new_tokens"] = [int(t2s_token_length)]
-
- prompt = {
- "prompt_token_ids": [int(v) for v in prompt_token_ids],
- "additional_information": runtime_info,
- "modalities": [final_modality],
- }
-
- from vllm import SamplingParams
-
- from vllm_omni.entrypoints.omni import Omni
-
- stage_config_path = str(Path(args.stage_config_path).expanduser())
- omni = Omni(model=model_source, stage_configs_path=stage_config_path, dtype=args.dtype)
- sampling_params_list = [
- SamplingParams(max_tokens=int(args.max_tokens_per_stage), temperature=0.0, top_p=1.0, detokenize=False)
- for _ in range(omni.num_stages)
- ]
-
- try:
- outputs = list(omni.generate(prompt, sampling_params_list))
- finally:
- omni.close()
-
- out_dir = Path(resolved_output_dir).expanduser()
- out_dir.mkdir(parents=True, exist_ok=True)
- stamp = time.strftime("%Y%m%d_%H%M%S")
- prefix = args.output_prefix.strip() or f"{task_name}_{stamp}"
-
- if final_modality == "text":
- text_out = extract_text_output(outputs, tokenizer=tokenizer)
- if not text_out:
- raise RuntimeError("No text output found.")
- out_path = out_dir / f"{prefix}.txt"
- out_path.write_text(text_out + "\n", encoding="utf-8")
- print(f"[end2end] text saved: {out_path}")
- print(text_out)
- return
-
- if final_modality == "image":
- image_out = extract_image_output(outputs)
- if image_out is None:
- raise RuntimeError("No image output found.")
- pil = tensor_to_pil_image(image_out)
- out_path = out_dir / f"{prefix}.png"
- pil.save(out_path)
- print(f"[end2end] image saved: {out_path}")
- return
-
- if final_modality == "audio":
- audio_out = extract_audio_output(outputs)
- if audio_out is None:
- raise RuntimeError("No audio output found.")
- wav, sr = audio_out
- out_path = out_dir / f"{prefix}.wav"
- save_audio_wav(out_path, wav, sr)
- print(f"[end2end] audio saved: {out_path} (sr={sr}, samples={wav.shape[0]})")
- return
-
- raise RuntimeError(f"Unsupported final modality: {final_modality}")
-
-
-if __name__ == "__main__":
- main()
diff --git a/examples/offline_inference/fish_speech/README.md b/examples/offline_inference/fish_speech/README.md
deleted file mode 100644
index 9af853096c5..00000000000
--- a/examples/offline_inference/fish_speech/README.md
+++ /dev/null
@@ -1,75 +0,0 @@
-# Fish Speech S2 Pro
-
-This directory contains an offline demo for running Fish Speech S2 Pro (`fishaudio/s2-pro`) with vLLM Omni. It supports text-only synthesis and voice cloning with reference audio.
-
-## Model Overview
-
-[Fish Speech S2 Pro](https://huggingface.co/fishaudio/s2-pro) is a 4B dual-AR text-to-speech model by FishAudio. It uses:
-
-- **Slow AR**: Generates semantic tokens autoregressively (Qwen3-based backbone)
-- **Fast AR**: Predicts residual codebook tokens from semantic tokens
-- **DAC Decoder**: Converts codec codes to 44.1 kHz audio waveform
-
-The model produces high-quality speech with voice cloning capabilities.
-
-## Prerequisites
-
-Install the `fish-speech` package for the DAC codec:
-
-```bash
-pip install fish-speech
-```
-
-## Setup
-
-Please refer to the [stage configuration documentation](https://docs.vllm.ai/projects/vllm-omni/en/latest/configuration/stage_configs/) to configure memory allocation appropriately for your hardware setup.
-
-## Quick Start
-
-### Text-Only Synthesis
-
-```bash
-python end2end.py --text "Hello, this is a test of the Fish Speech text to speech system."
-```
-
-Generated audio files are saved to `output_audio/` by default.
-
-### Voice Cloning
-
-Provide a reference audio file and its transcript to clone a voice:
-
-```bash
-python end2end.py \
- --text "Hello, this is a cloned voice." \
- --ref-audio /path/to/reference.wav \
- --ref-text "Transcript of the reference audio."
-```
-
-## Streaming Mode
-
-Add `--streaming` to stream audio chunks progressively via `AsyncOmni` (requires `async_chunk: true` in the stage config):
-
-```bash
-python end2end.py --text "Hello, this is a test." --streaming
-```
-
-Each DAC decoder chunk is logged as it arrives. The final WAV file is written once generation completes.
-
-## Configuration
-
-| Argument | Default | Description |
-|----------|---------|-------------|
-| `--text` | `"Hello, this is a test..."` | Text to synthesize |
-| `--ref-audio` | None | Path to reference audio for voice cloning |
-| `--ref-text` | None | Transcript of the reference audio |
-| `--model` | `fishaudio/s2-pro` | HuggingFace model path |
-| `--stage-configs-path` | `fish_speech_s2_pro.yaml` | Path to stage configs YAML |
-| `--output-dir` | `output_audio` | Output directory for WAV files |
-| `--streaming` | False | Enable streaming via AsyncOmni |
-| `--stage-init-timeout` | 600 | Stage initialization timeout (seconds) |
-
-## Notes
-
-- Output audio is 44.1 kHz mono WAV.
-- The DAC codec weights (`codec.pth`) are loaded lazily from the model directory.
-- Voice cloning encodes the reference audio using the DAC codec to extract semantic codes, then prepends them as a system message.
diff --git a/examples/offline_inference/fish_speech/end2end.py b/examples/offline_inference/fish_speech/end2end.py
deleted file mode 100644
index 60830d06b7f..00000000000
--- a/examples/offline_inference/fish_speech/end2end.py
+++ /dev/null
@@ -1,277 +0,0 @@
-"""Offline inference demo for Fish Speech S2 Pro via vLLM Omni.
-
-Generates speech from text using the fishaudio/s2-pro model.
-Supports both text-only synthesis and voice cloning with reference audio.
-
-Usage:
- # Text-only synthesis
- python end2end.py --text "Hello, this is a test."
-
- # Voice cloning with reference audio
- python end2end.py --text "Hello, this is a test." --ref-audio ref.wav --ref-text "Reference text."
-
- # Streaming mode
- python end2end.py --text "Hello, this is a test." --streaming
-"""
-
-import asyncio
-import logging
-import math
-import os
-import time
-
-import numpy as np
-import soundfile as sf
-import torch
-
-os.environ["VLLM_WORKER_MULTIPROC_METHOD"] = "spawn"
-
-from vllm.utils.argparse_utils import FlexibleArgumentParser
-
-from vllm_omni import AsyncOmni, Omni
-from vllm_omni.model_executor.models.fish_speech.dac_utils import DAC_HOP_LENGTH, DAC_SAMPLE_RATE
-from vllm_omni.model_executor.models.fish_speech.prompt_utils import (
- build_fish_text_only_prompt_ids,
- estimate_fish_voice_clone_prompt_len_from_normalized,
- normalize_fish_voice_clone_texts,
-)
-
-logger = logging.getLogger(__name__)
-
-DEFAULT_MODEL = "fishaudio/s2-pro"
-DEFAULT_STAGE_CONFIG = os.path.join(
- os.path.dirname(__file__),
- "..",
- "..",
- "..",
- "vllm_omni",
- "model_executor",
- "stage_configs",
- "fish_speech_s2_pro.yaml",
-)
-
-
-def build_prompt(
- text: str,
- ref_audio_path: str | None = None,
- ref_text: str | None = None,
- model_name: str = DEFAULT_MODEL,
-) -> dict:
- """Build a prompt for Fish Speech S2 Pro.
-
- Uses the same text-only / structured-clone protocol as serving.
- """
- from transformers import AutoTokenizer
-
- tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
- if ref_audio_path is None and ref_text is None:
- prompt_ids, normalized_text = build_fish_text_only_prompt_ids(tokenizer, text)
- additional_information = {
- "text": [normalized_text],
- }
- return {
- "prompt_token_ids": prompt_ids,
- "additional_information": additional_information,
- }
-
- if not ref_audio_path or not ref_text:
- raise ValueError("Fish Speech voice cloning requires both --ref-audio and --ref-text")
-
- normalized_text, normalized_ref_text = normalize_fish_voice_clone_texts(text, ref_text)
- ref_audio_wav, ref_audio_sr = sf.read(ref_audio_path, dtype="float32", always_2d=False)
- semantic_len = _estimate_fish_ref_code_len(ref_audio_wav, ref_audio_sr)
- ph_len = estimate_fish_voice_clone_prompt_len_from_normalized(
- tokenizer,
- normalized_text,
- normalized_ref_text,
- semantic_len,
- )
-
- additional_information = {
- "text": normalized_text,
- "ref_text": normalized_ref_text,
- "ref_audio_wav": torch.from_numpy(np.asarray(ref_audio_wav, dtype=np.float32)),
- "ref_audio_sr": int(ref_audio_sr),
- "fish_structured_voice_clone": True,
- }
-
- return {
- "prompt_token_ids": [1] * ph_len,
- "additional_information": additional_information,
- }
-
-
-def _estimate_fish_ref_code_len(wav: np.ndarray, sample_rate: int) -> int:
- """Estimate Fish semantic token length from local reference audio."""
- n_samples = int(np.asarray(wav).shape[0]) if np.asarray(wav).ndim > 0 else 0
- if sample_rate <= 0 or n_samples <= 0:
- raise ValueError("Reference audio must contain samples and a positive sample rate")
- resampled_len = max(1, math.ceil(n_samples * DAC_SAMPLE_RATE / int(sample_rate)))
- return max(1, math.ceil(resampled_len / DAC_HOP_LENGTH))
-
-
-def _save_wav(output_dir: str, request_id: str, mm: dict) -> None:
- """Concatenate audio chunks and write to a wav file."""
- audio_data = mm["audio"]
- sr_raw = mm["sr"]
- sr_val = sr_raw[-1] if isinstance(sr_raw, list) and sr_raw else sr_raw
- sr = sr_val.item() if hasattr(sr_val, "item") else int(sr_val)
- audio_tensor = torch.cat(audio_data, dim=-1) if isinstance(audio_data, list) else audio_data
- out_wav = os.path.join(output_dir, f"output_{request_id}.wav")
- sf.write(out_wav, audio_tensor.float().cpu().numpy().flatten(), samplerate=sr, format="WAV")
- logger.info("Request %s: saved audio to %s (sr=%d)", request_id, out_wav, sr)
-
-
-def main(args):
- """Run offline inference with Omni."""
- output_dir = args.output_dir
- os.makedirs(output_dir, exist_ok=True)
-
- stage_configs_path = args.stage_configs_path or DEFAULT_STAGE_CONFIG
- model_name = args.model or DEFAULT_MODEL
-
- inputs = [
- build_prompt(
- text=args.text,
- ref_audio_path=args.ref_audio,
- ref_text=args.ref_text,
- model_name=model_name,
- )
- ]
-
- omni = Omni(
- model=model_name,
- stage_configs_path=stage_configs_path,
- log_stats=args.log_stats,
- stage_init_timeout=args.stage_init_timeout,
- )
-
- t_start = time.perf_counter()
- for stage_outputs in omni.generate(inputs):
- request_output = stage_outputs.request_output
- if request_output is None or not request_output.outputs:
- continue
- _save_wav(
- output_dir,
- request_output.request_id,
- request_output.outputs[0].multimodal_output,
- )
- t_end = time.perf_counter()
- logger.info("Total inference time: %.1f ms", (t_end - t_start) * 1000)
-
-
-async def main_streaming(args):
- """Run offline inference with AsyncOmni for streaming audio chunks."""
- output_dir = args.output_dir
- os.makedirs(output_dir, exist_ok=True)
-
- stage_configs_path = args.stage_configs_path or DEFAULT_STAGE_CONFIG
- model_name = args.model or DEFAULT_MODEL
-
- prompt = build_prompt(
- text=args.text,
- ref_audio_path=args.ref_audio,
- ref_text=args.ref_text,
- model_name=model_name,
- )
-
- omni = AsyncOmni(
- model=model_name,
- stage_configs_path=stage_configs_path,
- log_stats=args.log_stats,
- stage_init_timeout=args.stage_init_timeout,
- )
-
- request_id = "0"
- t_start = time.perf_counter()
- t_prev = t_start
- chunk_idx = 0
-
- async for stage_output in omni.generate(prompt, request_id=request_id):
- mm = stage_output.request_output.outputs[0].multimodal_output
- if not stage_output.finished:
- t_now = time.perf_counter()
- audio = mm.get("audio")
- n = len(audio) if isinstance(audio, list) else (0 if audio is None else 1)
- dt_ms = (t_now - t_prev) * 1000
- ttfa_ms = (t_now - t_start) * 1000
- if chunk_idx == 0:
- logger.info("Request %s: chunk %d samples=%d TTFA=%.1fms", request_id, chunk_idx, n, ttfa_ms)
- else:
- logger.info("Request %s: chunk %d samples=%d inter_chunk=%.1fms", request_id, chunk_idx, n, dt_ms)
- t_prev = t_now
- chunk_idx += 1
- else:
- t_end = time.perf_counter()
- total_ms = (t_end - t_start) * 1000
- logger.info("Request %s: done total=%.1fms chunks=%d", request_id, total_ms, chunk_idx)
- _save_wav(output_dir, request_id, mm)
-
-
-def parse_args():
- parser = FlexibleArgumentParser(
- description="Fish Speech S2 Pro offline inference with vLLM Omni",
- )
- parser.add_argument(
- "--text",
- type=str,
- default="Hello, this is a test of the Fish Speech text to speech system.",
- help="Text to synthesize.",
- )
- parser.add_argument(
- "--ref-audio",
- type=str,
- default=None,
- help="Path to reference audio for voice cloning.",
- )
- parser.add_argument(
- "--ref-text",
- type=str,
- default=None,
- help="Reference text corresponding to the reference audio.",
- )
- parser.add_argument(
- "--model",
- type=str,
- default=None,
- help=f"HuggingFace model path (default: {DEFAULT_MODEL}).",
- )
- parser.add_argument(
- "--stage-configs-path",
- type=str,
- default=None,
- help="Path to stage configs YAML.",
- )
- parser.add_argument(
- "--output-dir",
- default="output_audio",
- help="Output directory for generated wav files.",
- )
- parser.add_argument(
- "--log-stats",
- action="store_true",
- default=False,
- help="Enable writing detailed statistics.",
- )
- parser.add_argument(
- "--stage-init-timeout",
- type=int,
- default=600,
- help="Timeout for initializing stages in seconds.",
- )
- parser.add_argument(
- "--streaming",
- action="store_true",
- default=False,
- help="Stream audio chunks as they arrive via AsyncOmni.",
- )
- return parser.parse_args()
-
-
-if __name__ == "__main__":
- logging.basicConfig(level=logging.INFO)
- args = parse_args()
- if args.streaming:
- asyncio.run(main_streaming(args))
- else:
- main(args)
diff --git a/examples/offline_inference/helios/README.md b/examples/offline_inference/helios/README.md
deleted file mode 100644
index 2c7ba525ef6..00000000000
--- a/examples/offline_inference/helios/README.md
+++ /dev/null
@@ -1,193 +0,0 @@
-# Helios Video Generation
-
-Helios is a text-to-video (T2V), image-to-video (I2V), and video-to-video (V2V) diffusion model. This example demonstrates end-to-end video generation using vLLM-Omni with three model variants:
-
-| Variant | Description | Key Features |
-|---------|-------------|--------------|
-| **Helios-Base** | Base model, Stage 1 only | Single-stage denoising, `guidance_scale=5.0` |
-| **Helios-Mid** | Mid model, Stage 2 pyramid | Multi-stage pyramid denoising, CFG-Zero* support |
-| **Helios-Distilled** | Distilled model, Stage 2+3 | Few-step inference with DMD, `guidance_scale=1.0` |
-
-## Setup
-
-Please refer to the [stage configuration documentation](https://docs.vllm.ai/projects/vllm-omni/en/latest/configuration/stage_configs/) to configure memory allocation appropriately for your hardware setup.
-
-## Run Examples
-
-Get into the example folder:
-```bash
-cd examples/offline_inference/helios
-```
-
-### Text-to-Video (T2V)
-
-**Helios-Base** (Stage 1 only):
-```bash
-python end2end.py \
- --model BestWishYsh/Helios-Base \
- --sample-type t2v \
- --prompt "A dynamic time-lapse video showing the rapidly moving scenery from the window of a speeding train." \
- --guidance-scale 5.0 \
- --output helios_t2v_base.mp4
-```
-
-**Helios-Mid** (Stage 2 + CFG-Zero*):
-```bash
-python end2end.py \
- --model BestWishYsh/Helios-Mid \
- --sample-type t2v \
- --prompt "A dynamic time-lapse video showing the rapidly moving scenery from the window of a speeding train." \
- --guidance-scale 5.0 \
- --is-enable-stage2 \
- --pyramid-num-inference-steps-list 20 20 20 \
- --use-cfg-zero-star --use-zero-init --zero-steps 1 \
- --output helios_t2v_mid.mp4
-```
-
-**Helios-Distilled** (Stage 2 pyramid + DMD):
-```bash
-python end2end.py \
- --model BestWishYsh/Helios-Distilled \
- --sample-type t2v \
- --prompt "A dynamic time-lapse video showing the rapidly moving scenery from the window of a speeding train." \
- --num-frames 240 \
- --guidance-scale 1.0 \
- --is-enable-stage2 \
- --pyramid-num-inference-steps-list 2 2 2 \
- --is-amplify-first-chunk \
- --output helios_t2v_distilled.mp4
-```
-
-### Image-to-Video (I2V)
-
-**Helios-Base**:
-```bash
-python end2end.py \
- --model BestWishYsh/Helios-Base \
- --sample-type i2v \
- --image-path /path/to/image.jpg \
- --prompt "A towering emerald wave surges forward, its crest curling with raw power and energy." \
- --guidance-scale 5.0 \
- --output helios_i2v_base.mp4
-```
-
-**Helios-Mid** (Stage 2 + CFG-Zero*):
-```bash
-python end2end.py \
- --model BestWishYsh/Helios-Mid \
- --sample-type i2v \
- --image-path /path/to/image.jpg \
- --prompt "A towering emerald wave surges forward, its crest curling with raw power and energy." \
- --guidance-scale 5.0 \
- --is-enable-stage2 \
- --pyramid-num-inference-steps-list 20 20 20 \
- --use-cfg-zero-star --use-zero-init --zero-steps 1 \
- --output helios_i2v_mid.mp4
-```
-
-**Helios-Distilled**:
-```bash
-python end2end.py \
- --model BestWishYsh/Helios-Distilled \
- --sample-type i2v \
- --image-path /path/to/image.jpg \
- --prompt "A towering emerald wave surges forward, its crest curling with raw power and energy." \
- --num-frames 240 \
- --guidance-scale 1.0 \
- --is-enable-stage2 \
- --pyramid-num-inference-steps-list 2 2 2 \
- --is-amplify-first-chunk \
- --output helios_i2v_distilled.mp4
-```
-
-### Video-to-Video (V2V)
-
-**Helios-Base**:
-```bash
-python end2end.py \
- --model BestWishYsh/Helios-Base \
- --sample-type v2v \
- --video-path /path/to/video.mp4 \
- --prompt "A bright yellow Lamborghini speeds along a curving mountain road." \
- --guidance-scale 5.0 \
- --output helios_v2v_base.mp4
-```
-
-**Helios-Mid** (Stage 2 + CFG-Zero*):
-```bash
-python end2end.py \
- --model BestWishYsh/Helios-Mid \
- --sample-type v2v \
- --video-path /path/to/video.mp4 \
- --prompt "A bright yellow Lamborghini speeds along a curving mountain road." \
- --guidance-scale 5.0 \
- --is-enable-stage2 \
- --pyramid-num-inference-steps-list 20 20 20 \
- --use-cfg-zero-star --use-zero-init --zero-steps 1 \
- --output helios_v2v_mid.mp4
-```
-
-**Helios-Distilled**:
-```bash
-python end2end.py \
- --model BestWishYsh/Helios-Distilled \
- --sample-type v2v \
- --video-path /path/to/video.mp4 \
- --prompt "A bright yellow Lamborghini speeds along a curving mountain road." \
- --num-frames 240 \
- --guidance-scale 1.0 \
- --is-enable-stage2 \
- --pyramid-num-inference-steps-list 2 2 2 \
- --is-amplify-first-chunk \
- --output helios_v2v_distilled.mp4
-```
-
-## Common Parameters
-
-| Parameter | Default | Description |
-|-----------|---------|-------------|
-| `--model` | `BestWishYsh/Helios-Base` | Model ID or local path |
-| `--sample-type` | `t2v` | Generation mode: `t2v`, `i2v`, or `v2v` |
-| `--prompt` | — | Text prompt describing the video |
-| `--negative-prompt` | *(see source)* | Negative prompt for CFG (includes anti-static terms) |
-| `--image-path` | — | Input image (required for `i2v`) |
-| `--video-path` | — | Input video (required for `v2v`) |
-| `--height` | `384` | Video height in pixels |
-| `--width` | `640` | Video width in pixels |
-| `--num-frames` | `99` | Number of output frames |
-| `--num-inference-steps` | `50` | Denoising steps (Stage 1 only) |
-| `--guidance-scale` | `5.0` | CFG scale (`1.0` for Distilled) |
-| `--seed` | `42` | Random seed |
-| `--fps` | `16` | Output video frame rate |
-| `--output` | `helios_output.mp4` | Output file path |
-
-### Stage 2 / Pyramid Parameters
-
-| Parameter | Default | Description |
-|-----------|---------|-------------|
-| `--is-enable-stage2` | off | Enable pyramid multi-stage denoising |
-| `--pyramid-num-stages` | `3` | Number of pyramid stages |
-| `--pyramid-num-inference-steps-list` | `10 10 10` | Steps per pyramid stage |
-| `--is-amplify-first-chunk` | off | DMD amplification (Distilled) |
-
-### CFG-Zero* Parameters
-
-| Parameter | Default | Description |
-|-----------|---------|-------------|
-| `--use-cfg-zero-star` | off | Enable CFG-Zero* guidance (Mid) |
-| `--use-zero-init` | off | Zero init for first steps |
-| `--zero-steps` | `1` | Number of zero-init steps |
-
-### Memory & Parallelism
-
-| Parameter | Default | Description |
-|-----------|---------|-------------|
-| `--vae-use-slicing` | off | Enable VAE slicing |
-| `--vae-use-tiling` | off | Enable VAE tiling |
-| `--enforce-eager` | off | Disable torch.compile |
-| `--enable-cpu-offload` | off | CPU offloading |
-| `--enable-layerwise-offload` | off | Layerwise offloading |
-| `--ulysses-degree` | `1` | Ulysses SP degree |
-| `--ring-degree` | `1` | Ring SP degree |
-| `--cfg-parallel-size` | `1` | CFG parallel size (1 or 2) |
-| `--tensor-parallel-size` | `1` | Tensor parallelism size |
diff --git a/examples/offline_inference/helios/end2end.py b/examples/offline_inference/helios/end2end.py
deleted file mode 100644
index 88c3b865d42..00000000000
--- a/examples/offline_inference/helios/end2end.py
+++ /dev/null
@@ -1,355 +0,0 @@
-# SPDX-License-Identifier: Apache-2.0
-# SPDX-FileCopyrightText: Copyright contributors to the vLLM project
-
-"""
-Helios video generation example supporting T2V, I2V, and V2V.
-
-Usage (T2V, Helios-Base, Stage 1 only):
- python end2end.py \
- --model /path/to/Helios-Base --sample-type t2v \
- --prompt "A serene lakeside sunrise with mist over the water." \
- --height 384 --width 640 --num-frames 99 \
- --num-inference-steps 50 --guidance-scale 5.0
-
-Usage (I2V, Helios-Base):
- python end2end.py \
- --model /path/to/Helios-Base --sample-type i2v \
- --image-path /path/to/image.jpg \
- --prompt "Description of desired animation." \
- --guidance-scale 5.0
-
-Usage (V2V, Helios-Base):
- python end2end.py \
- --model /path/to/Helios-Base --sample-type v2v \
- --video-path /path/to/video.mp4 \
- --prompt "Description of desired transformation." \
- --guidance-scale 5.0
-
-Usage (Helios-Mid, Stage 2 + CFG-Zero*):
- python end2end.py \
- --model /path/to/Helios-Mid --sample-type t2v \
- --prompt "A serene lakeside sunrise with mist over the water." \
- --guidance-scale 5.0 \
- --is-enable-stage2 \
- --pyramid-num-inference-steps-list 20 20 20 \
- --use-cfg-zero-star --use-zero-init --zero-steps 1
-
-Usage (Helios-Distilled, Stage 2 pyramid + DMD):
- python end2end.py \
- --model /path/to/Helios-Distilled --sample-type t2v \
- --prompt "A serene lakeside sunrise with mist over the water." \
- --guidance-scale 1.0 \
- --is-enable-stage2 \
- --pyramid-num-inference-steps-list 2 2 2 \
- --is-amplify-first-chunk
-"""
-
-import argparse
-import time
-from pathlib import Path
-
-import numpy as np
-import torch
-
-from vllm_omni.diffusion.data import DiffusionParallelConfig
-from vllm_omni.entrypoints.omni import Omni
-from vllm_omni.inputs.data import OmniDiffusionSamplingParams
-from vllm_omni.outputs import OmniRequestOutput
-from vllm_omni.platforms import current_omni_platform
-
-
-def load_image_as_tensor(image_path: str, height: int, width: int) -> torch.Tensor:
- """Load an image and return a (1, C, H, W) tensor normalized to [-1, 1]."""
- from PIL import Image
- from torchvision import transforms
-
- image = Image.open(image_path).convert("RGB").resize((width, height))
- transform = transforms.Compose(
- [
- transforms.ToTensor(),
- transforms.Normalize(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5]),
- ]
- )
- return transform(image).unsqueeze(0)
-
-
-def load_video_as_tensor(video_path: str, height: int, width: int) -> torch.Tensor:
- """Load a video and return a (1, C, T, H, W) tensor normalized to [-1, 1]."""
- from torchvision import transforms
- from torchvision.io import read_video
-
- video_frames, _, _ = read_video(video_path, output_format="TCHW")
- video_frames = video_frames.float() / 255.0
-
- transform = transforms.Compose(
- [
- transforms.Resize((height, width), antialias=True),
- transforms.Normalize(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5]),
- ]
- )
- video_frames = torch.stack([transform(f) for f in video_frames])
- return video_frames.permute(1, 0, 2, 3).unsqueeze(0)
-
-
-def parse_args() -> argparse.Namespace:
- parser = argparse.ArgumentParser(description="Generate a video with Helios (T2V / I2V / V2V).")
- parser.add_argument(
- "--model",
- default="BestWishYsh/Helios-Base",
- help="Helios model ID or local path (e.g. Helios-Base, Helios-Mid, Helios-Distilled).",
- )
- parser.add_argument(
- "--sample-type",
- choices=["t2v", "i2v", "v2v"],
- default="t2v",
- help="Generation mode: t2v (text-to-video), i2v (image-to-video), v2v (video-to-video).",
- )
- parser.add_argument("--prompt", default="A serene lakeside sunrise with mist over the water.", help="Text prompt.")
- parser.add_argument(
- "--negative-prompt",
- default=(
- "Bright tones, overexposed, static, blurred details, subtitles, style, works, paintings, "
- "images, static, overall gray, worst quality, low quality, JPEG compression residue, ugly, "
- "incomplete, extra fingers, poorly drawn hands, poorly drawn faces, deformed, disfigured, "
- "misshapen limbs, fused fingers, still picture, messy background, three legs, many people "
- "in the background, walking backwards"
- ),
- help="Negative prompt.",
- )
- parser.add_argument("--seed", type=int, default=42, help="Random seed.")
- parser.add_argument("--guidance-scale", type=float, default=5.0, help="CFG scale.")
- parser.add_argument("--height", type=int, default=384, help="Video height.")
- parser.add_argument("--width", type=int, default=640, help="Video width.")
- parser.add_argument("--num-frames", type=int, default=99, help="Number of video frames.")
- parser.add_argument("--num-inference-steps", type=int, default=50, help="Sampling steps (Stage 1 only).")
- parser.add_argument("--output", type=str, default="helios_output.mp4", help="Output video path.")
- parser.add_argument("--fps", type=int, default=16, help="Frames per second for the output video.")
-
- # I2V / V2V
- parser.add_argument("--image-path", type=str, default=None, help="Input image path for I2V mode.")
- parser.add_argument("--video-path", type=str, default=None, help="Input video path for V2V mode.")
-
- # Stage 2 (pyramid multi-stage denoising)
- parser.add_argument(
- "--is-enable-stage2",
- action="store_true",
- help="Enable pyramid multi-stage denoising (Stage 2). Required for Helios-Distilled.",
- )
- parser.add_argument(
- "--pyramid-num-stages",
- type=int,
- default=3,
- help="Number of pyramid stages for Stage 2.",
- )
- parser.add_argument(
- "--pyramid-num-inference-steps-list",
- type=int,
- nargs="+",
- default=[10, 10, 10],
- help="Inference steps per pyramid stage.",
- )
-
- # DMD
- parser.add_argument(
- "--is-amplify-first-chunk",
- action="store_true",
- help="Enable DMD amplification for the first chunk (Helios-Distilled).",
- )
-
- # CFG Zero Star
- parser.add_argument(
- "--use-cfg-zero-star",
- action="store_true",
- help="Enable CFG Zero Star guidance (recommended for Helios-Mid).",
- )
- parser.add_argument(
- "--use-zero-init",
- action="store_true",
- help="Use zero initialization for the first denoising steps with CFG-Zero*.",
- )
- parser.add_argument(
- "--zero-steps",
- type=int,
- default=1,
- help="Number of initial denoising steps using zero prediction (default: 1).",
- )
- parser.add_argument(
- "--enable-diffusion-pipeline-profiler",
- action="store_true",
- help="Enable diffusion pipeline profiler to display stage durations.",
- )
- parser.add_argument(
- "--quantization",
- type=str,
- default=None,
- help="Quantization method (e.g. 'fp8').",
- )
-
- # Memory & parallelism
- parser.add_argument("--vae-use-slicing", action="store_true", help="Enable VAE slicing.")
- parser.add_argument("--vae-use-tiling", action="store_true", help="Enable VAE tiling.")
- parser.add_argument("--enforce-eager", action="store_true", help="Disable torch.compile.")
- parser.add_argument("--enable-cpu-offload", action="store_true", help="Enable CPU offloading.")
- parser.add_argument("--enable-layerwise-offload", action="store_true", help="Enable layerwise offloading.")
- parser.add_argument("--ulysses-degree", type=int, default=1, help="Ulysses SP degree.")
- parser.add_argument("--ring-degree", type=int, default=1, help="Ring SP degree.")
- parser.add_argument("--cfg-parallel-size", type=int, default=1, choices=[1, 2], help="CFG parallel size.")
- parser.add_argument("--tensor-parallel-size", type=int, default=1, help="Tensor parallelism size.")
-
- return parser.parse_args()
-
-
-def main():
- args = parse_args()
- generator = torch.Generator(device=current_omni_platform.device_type).manual_seed(args.seed)
-
- parallel_config = DiffusionParallelConfig(
- ulysses_degree=args.ulysses_degree,
- ring_degree=args.ring_degree,
- cfg_parallel_size=args.cfg_parallel_size,
- tensor_parallel_size=args.tensor_parallel_size,
- )
-
- omni = Omni(
- model=args.model,
- enable_layerwise_offload=args.enable_layerwise_offload,
- vae_use_slicing=args.vae_use_slicing,
- vae_use_tiling=args.vae_use_tiling,
- enable_cpu_offload=args.enable_cpu_offload,
- parallel_config=parallel_config,
- enforce_eager=args.enforce_eager,
- enable_diffusion_pipeline_profiler=args.enable_diffusion_pipeline_profiler,
- quantization=args.quantization,
- )
-
- # Validate I2V / V2V arguments
- if args.sample_type == "i2v" and not args.image_path:
- raise ValueError("--image-path is required for I2V mode.")
- if args.sample_type == "v2v" and not args.video_path:
- raise ValueError("--video-path is required for V2V mode.")
-
- # Build extra_args for Helios-specific parameters
- extra_args = {}
- if args.is_enable_stage2:
- extra_args["is_enable_stage2"] = True
- extra_args["pyramid_num_stages"] = args.pyramid_num_stages
- extra_args["pyramid_num_inference_steps_list"] = args.pyramid_num_inference_steps_list
- if args.is_amplify_first_chunk:
- extra_args["is_amplify_first_chunk"] = True
- if args.use_cfg_zero_star:
- extra_args["use_cfg_zero_star"] = True
- if args.use_zero_init:
- extra_args["use_zero_init"] = True
- extra_args["zero_steps"] = args.zero_steps
-
- if args.sample_type == "i2v":
- image_tensor = load_image_as_tensor(args.image_path, args.height, args.width)
- extra_args["image"] = image_tensor
- elif args.sample_type == "v2v":
- video_tensor = load_video_as_tensor(args.video_path, args.height, args.width)
- extra_args["video"] = video_tensor
-
- # Print generation configuration
- print(f"\n{'=' * 60}")
- print("Helios Generation Configuration:")
- print(f" Model: {args.model}")
- print(f" Sample type: {args.sample_type.upper()}")
- if args.sample_type == "i2v":
- print(f" Image: {args.image_path}")
- elif args.sample_type == "v2v":
- print(f" Video: {args.video_path}")
- print(f" Prompt: {args.prompt[:80]}{'...' if len(args.prompt) > 80 else ''}")
- print(f" Video size: {args.width}x{args.height}, {args.num_frames} frames")
- print(f" Inference steps: {args.num_inference_steps}")
- print(f" Guidance scale: {args.guidance_scale}")
- if args.is_enable_stage2:
- print(f" Stage 2: enabled (stages={args.pyramid_num_stages}, steps={args.pyramid_num_inference_steps_list})")
- if args.is_amplify_first_chunk:
- print(" DMD amplify first chunk: enabled")
- if args.use_cfg_zero_star:
- print(f" CFG Zero Star: enabled (zero_init={args.use_zero_init}, zero_steps={args.zero_steps})")
- else:
- if args.use_cfg_zero_star:
- print(f" CFG Zero Star: enabled (zero_init={args.use_zero_init}, zero_steps={args.zero_steps})")
- print(" Stage 2: disabled (Stage 1 only)")
- print(f"{'=' * 60}\n")
-
- generation_start = time.perf_counter()
- frames = omni.generate(
- {
- "prompt": args.prompt,
- "negative_prompt": args.negative_prompt,
- },
- OmniDiffusionSamplingParams(
- height=args.height,
- width=args.width,
- generator=generator,
- guidance_scale=args.guidance_scale,
- num_inference_steps=args.num_inference_steps,
- num_frames=args.num_frames,
- extra_args=extra_args,
- ),
- )
- generation_end = time.perf_counter()
- generation_time = generation_end - generation_start
-
- print(f"Total generation time: {generation_time:.4f} seconds ({generation_time * 1000:.2f} ms)")
-
- # Extract video frames from OmniRequestOutput
- if isinstance(frames, list) and len(frames) > 0:
- first_item = frames[0]
-
- if hasattr(first_item, "final_output_type"):
- if first_item.final_output_type != "image":
- raise ValueError(
- f"Unexpected output type '{first_item.final_output_type}', expected 'image' for video generation."
- )
-
- if hasattr(first_item, "is_pipeline_output") and first_item.is_pipeline_output:
- inner_output = first_item.request_output
- if isinstance(inner_output, OmniRequestOutput) and hasattr(inner_output, "images"):
- frames = inner_output.images[0] if inner_output.images else None
- if frames is None:
- raise ValueError("No video frames found in output.")
- elif hasattr(first_item, "images") and first_item.images:
- frames = first_item.images
- else:
- raise ValueError("No video frames found in OmniRequestOutput.")
-
- # Unwrap batch list from postprocess_video: [numpy(T,H,W,C)] -> numpy(T,H,W,C)
- if isinstance(frames, list) and len(frames) > 0 and isinstance(frames[0], np.ndarray):
- frames = frames[0]
-
- output_path = Path(args.output)
- output_path.parent.mkdir(parents=True, exist_ok=True)
- try:
- from diffusers.utils import export_to_video
- except ImportError:
- raise ImportError("diffusers is required for export_to_video.")
-
- if isinstance(frames, torch.Tensor):
- video_tensor = frames.detach().cpu()
- if video_tensor.dim() == 5:
- if video_tensor.shape[1] in (3, 4):
- video_tensor = video_tensor[0].permute(1, 2, 3, 0)
- else:
- video_tensor = video_tensor[0]
- elif video_tensor.dim() == 4 and video_tensor.shape[0] in (3, 4):
- video_tensor = video_tensor.permute(1, 2, 3, 0)
- if video_tensor.is_floating_point():
- video_tensor = video_tensor.clamp(-1, 1) * 0.5 + 0.5
- video_array = video_tensor.float().numpy()
- elif isinstance(frames, np.ndarray):
- video_array = frames
- else:
- video_array = frames
-
- if isinstance(video_array, np.ndarray) and video_array.ndim == 5:
- video_array = video_array[0]
-
- export_to_video(video_array, str(output_path), fps=args.fps)
- print(f"Saved generated video to {output_path}")
-
-
-if __name__ == "__main__":
- main()
diff --git a/examples/offline_inference/hunyuan_image3/README.md b/examples/offline_inference/hunyuan_image3/README.md
deleted file mode 100644
index 3cd8fa01b2e..00000000000
--- a/examples/offline_inference/hunyuan_image3/README.md
+++ /dev/null
@@ -1,161 +0,0 @@
-# HunyuanImage-3.0-Instruct
-
-## Set up
-
-Please refer to the [stage configuration documentation](https://docs.vllm.ai/projects/vllm-omni/en/latest/configuration/stage_configs/) to configure memory allocation appropriately for your hardware setup.
-
-## Run examples
-
-**Note**: These examples work with the default configuration on **8x NVIDIA L40S (48GB)**. For different GPU setups, modify the stage configuration to adjust device allocation and memory utilization.
-
-Get into the hunyuan_image3 folder:
-
-```bash
-cd examples/offline_inference/hunyuan_image3
-```
-
-### Modality Control
-
-HunyuanImage-3.0-Instruct supports multiple modality modes. You can control the mode using the `--modality` argument:
-
-#### Text to Image (text2img)
-
-- **Pipeline**: Text → AR (CoT + latent tokens) → DiT (denoise) → VAE Decode → Image
-- **Stages Used**: Stage 0 (AR) + Stage 1 (DiT)
-- **KV Transfer**: AR sends KV cache to DiT for conditioned generation
-- **Default Config**: `hunyuan_image3_t2i.yaml`
-
-```bash
-python end2end.py --model tencent/HunyuanImage-3.0-Instruct \
- --modality text2img \
- --prompts "A cute cat sitting on a windowsill watching the sunset"
-```
-
-#### Image to Image (img2img)
-
-- **Pipeline**: Image + Text → AR (CoT + recaption + latent) → DiT → Edited Image
-- **Stages Used**: Stage 0 (AR) + Stage 1 (DiT)
-- **KV Transfer**: AR sends KV cache to DiT
-- **Default Config**: `hunyuan_image3_it2i.yaml`
-
-```bash
-python end2end.py --model tencent/HunyuanImage-3.0-Instruct \
- --modality img2img \
- --image-path /path/to/image.png \
- --prompts "Make the petals neon pink"
-```
-
-#### Image to Text (img2text)
-
-- **Pipeline**: Image + Question → AR → Text description
-- **Stages Used**: Stage 0 (AR) only
-- **Default Config**: `hunyuan_image3_i2t.yaml`
-
-```bash
-python end2end.py --model tencent/HunyuanImage-3.0-Instruct \
- --modality img2text \
- --image-path /path/to/image.jpg \
- --prompts "Describe the content of the picture."
-```
-
-#### Text to Text (text2text)
-
-- **Pipeline**: Text → AR → Text
-- **Stages Used**: Stage 0 (AR) only
-- **Default Config**: `hunyuan_image3_t2t.yaml`
-
-```bash
-python end2end.py --model tencent/HunyuanImage-3.0-Instruct \
- --modality text2text \
- --prompts "What is the capital of France?"
-```
-
-### Inference Steps & Guidance
-
-Control generation quality for image modalities:
-
-```bash
-python end2end.py --modality text2img \
- --steps 50 \
- --guidance-scale 5.0 \
- --height 1024 --width 1024 \
- --prompts "A photo-realistic sunset over the ocean"
-```
-
-### Key Arguments
-
-#### 📌 Command Line Arguments (end2end.py)
-
-| Argument | Type | Default | Description |
-| :--------------------- | :----- | :----------------------------------- | :----------------------------------------------------------- |
-| `--model` | string | `tencent/HunyuanImage-3.0-Instruct` | Model path or name |
-| `--modality` | choice | `text2img` | Modality: `text2img`, `img2img`, `img2text`, `text2text` |
-| `--prompts` | list | `None` | Input text prompts |
-| `--image-path` | string | `None` | Input image path (for `img2img`/`img2text`) |
-| `--output` | string | `.` | Output directory for saved images |
-| `--steps` | int | `50` | Number of inference steps |
-| `--guidance-scale` | float | `5.0` | Classifier-free guidance scale |
-| `--seed` | int | `42` | Random seed |
-| `--height` | int | `1024` | Output image height |
-| `--width` | int | `1024` | Output image width |
-| `--bot-task` | string | auto | Override prompt task (e.g. `it2i_think`, `t2i_recaption`) |
-| `--sys-type` | string | auto | Override system prompt type (e.g. `en_unified`, `en_vanilla`) |
-| `--stage-configs-path` | string | auto | Custom stage config YAML path |
-| `--enforce-eager` | flag | `False` | Disable torch.compile |
-| `--init-timeout` | int | `300` | Initialization timeout (seconds) |
-
-------
-
-#### ⚙️ Stage Configurations
-
-| Config YAML | Modality | Stages | GPUs | Description |
-| :---------------------------------- | :-------- | :----- | :----- | :------------------------------------ |
-| `hunyuan_image3_t2i.yaml` | text2img | 2 | 8 | T2I with AR→DiT, 4 GPU each |
-| `hunyuan_image3_it2i.yaml` | img2img | 2 | 8 | IT2I with AR→DiT, 4 GPU each |
-| `hunyuan_image3_i2t.yaml` | img2text | 1 | 4 | I2T (AR only) |
-| `hunyuan_image3_t2t.yaml` | text2text | 1 | 4 | T2T (AR only) |
-| `hunyuan_image3_t2i_2gpu.yaml` | text2img | 2 | 2 | T2I for 2-GPU setups |
-| `hunyuan_image3_moe.yaml` | text2img | 2 | 8 | T2I with MoE AR→DiT KV reuse |
-| `hunyuan_image3_moe_dit_2gpu_fp8.yaml` | text2img | 2 | 2 | T2I with FP8 quantization |
-
-------
-
-## Using MoE Config
-
-The `hunyuan_image3_moe.yaml` config enables AR→DiT KV cache reuse with 8 GPUs (4 for AR + 4 for DiT).
-
-```bash
-python end2end.py --model tencent/HunyuanImage-3.0-Instruct \
- --modality text2img \
- --stage-configs-path hunyuan_image3_moe.yaml \
- --prompts "A cute cat"
-```
-
-------
-
-## Prompt Format
-
-HunyuanImage-3.0 uses a pretrain template format:
-
-```
-<|startoftext|>{system_prompt}{<img>}{trigger_tag}{user_prompt}
-```
-
-- `<img>`: Placeholder for each input image (auto-inserted by `prompt_utils.py`)
-- Trigger tags: `<think>` (CoT), `<recaption>` (recaptioning)
-- System prompt: Auto-selected based on task
-
-The `prompt_utils.build_prompt()` handles this formatting automatically.
-
-------
-
-## FAQ
-
-- **OOM errors**: Decrease `gpu_memory_utilization` in the YAML stage config, or use a smaller `max_num_batched_tokens`.
-- **Custom image sizes**: Use `--height` and `--width` flags (multiples of 16 recommended).
-
-| Stage | VRAM (approx) |
-| :---------------- | :------------------- |
-| Stage 0 (AR) | ~15 GiB + KV Cache |
-| Stage 1 (DiT) | ~30 GiB |
-| Total (8-GPU) | ~45 GiB + KV Cache |
diff --git a/examples/offline_inference/hunyuan_image3/end2end.py b/examples/offline_inference/hunyuan_image3/end2end.py
deleted file mode 100644
index 2cea303888e..00000000000
--- a/examples/offline_inference/hunyuan_image3/end2end.py
+++ /dev/null
@@ -1,265 +0,0 @@
-"""
-HunyuanImage-3.0-Instruct unified end-to-end inference script.
-
-Supports all modalities through a single entry point:
- - text2img: Text → AR → DiT → Image
- - img2img: Text+Image → AR → DiT → Edited Image (IT2I)
- - img2text: Image+Text → AR → Text description (I2T)
- - text2text: Text → AR → Text (comprehension, no image)
-
-Usage:
- python end2end.py --modality text2img --prompts "A cute cat"
- python end2end.py --modality img2img --image-path input.png --prompts "Make it snowy"
- python end2end.py --modality img2text --image-path input.png --prompts "Describe this image"
-"""
-
-import argparse
-import os
-
-from vllm_omni.diffusion.models.hunyuan_image3.system_prompt import (
- get_system_prompt,
-)
-from vllm_omni.entrypoints.omni import Omni
-from vllm_omni.inputs.data import OmniPromptType
-
-# task → (sys_type, bot_task, trigger_tag)
-_TASK_PRESETS: dict[str, tuple[str, str | None, str | None]] = {
- "t2t": ("en_unified", None, None),
- "i2t": ("en_unified", None, None),
- "it2i_think": ("en_unified", "think", "<think>"),
- "it2i_recaption": ("en_unified", "recaption", "<recaption>"),
- "t2i_think": ("en_unified", "think", "<think>"),
- "t2i_recaption": ("en_unified", "recaption", "<recaption>"),
- "t2i_vanilla": ("en_vanilla", "image", None),
-}
-
-# Modality → prompt_utils task mapping
-_MODALITY_TASK_MAP = {
- "text2img": "t2i_think",
- "img2img": "it2i_think",
- "img2text": "i2t",
- "text2text": "t2t",
-}
-
-
-def build_prompt(
- user_prompt: str,
- task: str = "it2i_think",
- sys_type: str | None = None,
- custom_system_prompt: str | None = None,
-) -> str:
- """Build a HunyuanImage-3.0 prompt using pretrain template format."""
- if task not in _TASK_PRESETS:
- raise ValueError(f"Unknown task {task!r}. Choose from: {sorted(_TASK_PRESETS)}")
-
- preset_sys_type, preset_bot_task, trigger_tag = _TASK_PRESETS[task]
- effective_sys_type = sys_type or preset_sys_type
-
- system_prompt = get_system_prompt(effective_sys_type, preset_bot_task, custom_system_prompt)
- sys_text = system_prompt.strip() if system_prompt else ""
-
- has_image_input = task.startswith("i2t") or task.startswith("it2i")
-
- parts = ["<|startoftext|>"]
- if sys_text:
- parts.append(sys_text)
- if has_image_input:
- parts.append("<img>")
- if trigger_tag:
- parts.append(trigger_tag)
- parts.append(user_prompt)
-
- return "".join(parts)
-
-
-# Modality → default stage config
-_MODALITY_DEFAULT_CONFIG = {
- "text2img": "hunyuan_image3_t2i.yaml",
- "img2img": "hunyuan_image3_it2i.yaml",
- "img2text": "hunyuan_image3_i2t.yaml",
- "text2text": "hunyuan_image3_t2t.yaml",
-}
-
-
-def parse_args():
- parser = argparse.ArgumentParser(description="HunyuanImage-3.0-Instruct end-to-end inference.")
- parser.add_argument(
- "--model",
- default="tencent/HunyuanImage-3.0-Instruct",
- help="Model name or local path.",
- )
- parser.add_argument(
- "--modality",
- default="text2img",
- choices=["text2img", "img2img", "img2text", "text2text"],
- help="Modality mode to control stage execution.",
- )
- parser.add_argument("--prompts", nargs="+", default=None, help="Input text prompts.")
- parser.add_argument(
- "--image-path",
- type=str,
- default=None,
- help="Path to input image (for img2img/img2text).",
- )
- parser.add_argument(
- "--output",
- type=str,
- default=".",
- help="Output directory to save results.",
- )
-
- # Generation parameters
- parser.add_argument("--steps", type=int, default=50, help="Number of inference steps.")
- parser.add_argument("--guidance-scale", type=float, default=5.0, help="Classifier-free guidance scale.")
- parser.add_argument("--seed", type=int, default=42, help="Random seed.")
- parser.add_argument("--height", type=int, default=1024, help="Output image height.")
- parser.add_argument("--width", type=int, default=1024, help="Output image width.")
-
- # Prompt configuration
- parser.add_argument(
- "--bot-task",
- type=str,
- default=None,
- help="Override prompt task (e.g. it2i_think, t2i_recaption). Default: auto from modality.",
- )
- parser.add_argument(
- "--sys-type",
- type=str,
- default=None,
- help="Override system prompt type (e.g. en_unified, en_vanilla).",
- )
-
- # Omni init args
- parser.add_argument("--stage-configs-path", type=str, default=None, help="Custom stage config YAML path.")
- parser.add_argument("--log-stats", action="store_true", default=False)
- parser.add_argument("--init-timeout", type=int, default=300, help="Initialization timeout in seconds.")
- parser.add_argument("--enforce-eager", action="store_true", help="Disable torch.compile.")
-
- from vllm_omni.engine.arg_utils import nullify_stage_engine_defaults
-
- nullify_stage_engine_defaults(parser)
- return parser.parse_args()
-
-
-def main():
- args = parse_args()
- os.makedirs(args.output, exist_ok=True)
-
- # Determine task for prompt formatting
- task = args.bot_task or _MODALITY_TASK_MAP[args.modality]
-
- # Determine stage config
- stage_configs_path = args.stage_configs_path or _MODALITY_DEFAULT_CONFIG[args.modality]
-
- # Build Omni
- omni_kwargs = {
- "model": args.model,
- "stage_configs_path": stage_configs_path,
- "log_stats": args.log_stats,
- "init_timeout": args.init_timeout,
- "enforce_eager": args.enforce_eager,
- }
- if args.modality in ("text2img", "img2img"):
- omni_kwargs["mode"] = "text-to-image"
-
- omni = Omni(**omni_kwargs)
-
- # Prepare prompts
- prompts = args.prompts or ["A cute cat"]
- if not prompts:
- print("[Info] No prompts provided, using default.")
- prompts = ["A cute cat"]
-
- # Load image if needed
- input_image = None
- if args.modality in ("img2img", "img2text"):
- if not args.image_path or not os.path.exists(args.image_path):
- raise ValueError(f"--image-path required for {args.modality}, got: {args.image_path}")
- from PIL import Image
-
- input_image = Image.open(args.image_path).convert("RGB")
-
- # Format prompts
- formatted_prompts: list[OmniPromptType] = []
- for p in prompts:
- formatted_text = build_prompt(p, task=task, sys_type=args.sys_type)
-
- prompt_dict: dict = {"prompt": formatted_text}
-
- if args.modality == "text2img":
- prompt_dict["modalities"] = ["image"]
- elif args.modality == "img2img":
- prompt_dict["modalities"] = ["image"]
- prompt_dict["multi_modal_data"] = {"image": input_image}
- prompt_dict["height"] = input_image.height
- prompt_dict["width"] = input_image.width
- elif args.modality == "img2text":
- prompt_dict["modalities"] = ["text"]
- prompt_dict["multi_modal_data"] = {"image": input_image}
- elif args.modality == "text2text":
- prompt_dict["modalities"] = ["text"]
-
- formatted_prompts.append(prompt_dict)
-
- # Build sampling params from defaults
- params_list = list(omni.default_sampling_params_list)
-
- # Override diffusion params if applicable
- from vllm_omni.inputs.data import OmniDiffusionSamplingParams
-
- for i, sp in enumerate(params_list):
- if isinstance(sp, OmniDiffusionSamplingParams):
- sp.num_inference_steps = args.steps
- sp.guidance_scale = args.guidance_scale
- if args.seed is not None:
- sp.seed = args.seed
- if args.modality in ("text2img",):
- sp.height = args.height
- sp.width = args.width
-
- # Print configuration
- print(f"\n{'=' * 60}")
- print("HunyuanImage-3.0 Generation Configuration:")
- print(f" Model: {args.model}")
- print(f" Modality: {args.modality}")
- print(f" Stage config: {stage_configs_path}")
- print(f" Num stages: {omni.num_stages}")
- if args.modality in ("text2img", "img2img"):
- print(f" Inference steps: {args.steps}")
- print(f" Guidance scale: {args.guidance_scale}")
- print(f" Seed: {args.seed}")
- if args.modality == "text2img":
- print(f" Output size: {args.width}x{args.height}")
- if args.image_path:
- print(f" Input image: {args.image_path}")
- print(f" Prompts: {prompts}")
- print(f"{'=' * 60}\n")
-
- # Generate
- omni_outputs = list(omni.generate(prompts=formatted_prompts, sampling_params_list=params_list))
-
- # Process outputs
- img_idx = 0
- for req_output in omni_outputs:
- # Text output (AR stage or text-only)
- ro = getattr(req_output, "request_output", None)
- if ro and getattr(ro, "outputs", None):
- txt = "".join(getattr(o, "text", "") or "" for o in ro.outputs)
- if txt:
- print(f"[Output] Text:\n{txt}")
-
- # Image output (DiT stage)
- images = getattr(req_output, "images", None)
- if not images and ro and hasattr(ro, "images"):
- images = ro.images
-
- if images:
- for j, img in enumerate(images):
- save_path = os.path.join(args.output, f"output_{img_idx}_{j}.png")
- img.save(save_path)
- print(f"[Output] Saved image to {save_path}")
- img_idx += 1
-
-
-if __name__ == "__main__":
- main()
diff --git a/examples/offline_inference/image_to_image/image_edit.py b/examples/offline_inference/image_to_image/image_edit.py
deleted file mode 100644
index 7837fe16dca..00000000000
--- a/examples/offline_inference/image_to_image/image_edit.py
+++ /dev/null
@@ -1,566 +0,0 @@
-# SPDX-License-Identifier: Apache-2.0
-# SPDX-FileCopyrightText: Copyright contributors to the vLLM project
-
-"""
-Example script for image editing with OmniGen2.
-
- python image_edit.py \
- --image input.png \
- --model "OmniGen2/OmniGen2" \
- --prompt "Change the background to classroom." \
- --negative-prompt "(((deformed))), blurry, over saturation, bad anatomy, disfigured, poorly drawn face, mutation, mutated, (extra_limb), (ugly), (poorly drawn hands), fused fingers, messy drawing, broken legs censor, censored, censor_bar" \
- --num-inference-steps 50 \
- --seed 0 \
- --guidance-scale 5.0 \
- --guidance-scale-2 2.0 \
- --output outputs/image_edit.png \
- --num-outputs-per-prompt 2
-
- Note: For OmniGen2, `guidance_scale` works as `text_guidance_scale`,
- and `guidance_scale_2` works as `image_guidance_scale`.
-
-Example script for image editing with Qwen-Image-Edit.
-
-Usage (single image):
- python image_edit.py \
- --image input.png \
- --prompt "Let this mascot dance under the moon, surrounded by floating stars and poetic bubbles such as 'Be Kind'" \
- --output output_image_edit.png \
- --num-inference-steps 50 \
- --cfg-scale 4.0 \
- --guidance-scale 1.0
-
-Usage (multiple images):
- python image_edit.py \
- --image input1.png input2.png input3.png \
- --prompt "Combine these images into a single scene" \
- --output output_image_edit.png \
- --num-inference-steps 50 \
- --cfg-scale 4.0 \
- --guidance-scale 1.0
-
-Usage (with cache-dit acceleration):
- python image_edit.py \
- --image input.png \
- --prompt "Edit description" \
- --cache-backend cache_dit \
- --cache-dit-max-continuous-cached-steps 3 \
- --cache-dit-residual-diff-threshold 0.24 \
- --cache-dit-enable-taylorseer
-
-Usage (with tea_cache acceleration):
- python image_edit.py \
- --image input.png \
- --prompt "Edit description" \
- --cache-backend tea_cache \
- --tea-cache-rel-l1-thresh 0.25
-
-Usage (layered):
- python image_edit.py \
- --model "Qwen/Qwen-Image-Layered" \
- --image input.png \
- --prompt "" \
- --output "layered" \
- --num-inference-steps 50 \
- --cfg-scale 4.0 \
- --layers 4 \
- --color-format "RGBA"
-
-Usage (with CFG Parallel):
- python image_edit.py \
- --image input.png \
- --prompt "Edit description" \
- --cfg-parallel-size 2 \
- --num-inference-steps 50 \
- --cfg-scale 4.0
-
-Usage (disable torch.compile):
- python image_edit.py \
- --image input.png \
- --prompt "Edit description" \
- --enforce-eager \
- --num-inference-steps 50 \
- --cfg-scale 4.0
-
-For more options, run:
- python image_edit.py --help
-"""
-
-import argparse
-import json
-import os
-import time
-from pathlib import Path
-from typing import Any
-
-import torch
-from PIL import Image
-
-from vllm_omni.diffusion.data import DiffusionParallelConfig
-from vllm_omni.entrypoints.omni import Omni
-from vllm_omni.inputs.data import OmniDiffusionSamplingParams
-from vllm_omni.outputs import OmniRequestOutput
-from vllm_omni.platforms import current_omni_platform
-
-
-def parse_profiler_config(value: str) -> dict[str, Any]:
- try:
- config = json.loads(value)
- except json.JSONDecodeError as e:
- raise argparse.ArgumentTypeError(f"--profiler-config must be valid JSON: {e}") from e
- if not isinstance(config, dict):
- raise argparse.ArgumentTypeError("--profiler-config must be a JSON object")
- return config
-
-
-def parse_args() -> argparse.Namespace:
- parser = argparse.ArgumentParser(description="Edit an image with Qwen-Image-Edit.")
- parser.add_argument(
- "--model",
- default="Qwen/Qwen-Image-Edit",
- help=(
- "Diffusion model name or local path. "
- "For multiple image inputs, use Qwen/Qwen-Image-Edit-2509 or Qwen/Qwen-Image-Edit-2511"
- "which supports QwenImageEditPlusPipeline."
- ),
- )
- parser.add_argument(
- "--image",
- type=str,
- nargs="+",
- required=True,
- help="Path(s) to input image file(s) (PNG, JPG, etc.). Can specify multiple images.",
- )
- parser.add_argument(
- "--prompt",
- type=str,
- required=True,
- help="Text prompt describing the edit to make to the image.",
- )
- parser.add_argument(
- "--negative-prompt",
- type=str,
- default=None,
- required=False,
- )
- parser.add_argument(
- "--seed",
- type=int,
- default=0,
- help="Random seed for deterministic results.",
- )
- parser.add_argument(
- "--cfg-scale",
- type=float,
- default=4.0,
- help=(
- "True classifier-free guidance scale (default: 4.0). Guidance scale as defined in Classifier-Free "
- "Diffusion Guidance. Classifier-free guidance is enabled by setting cfg_scale > 1 and providing "
- "a negative_prompt. Higher guidance scale encourages images closely linked to the text prompt, "
- "usually at the expense of lower image quality."
- ),
- )
- parser.add_argument(
- "--guidance-scale",
- type=float,
- default=1.0,
- help=(
- "Guidance scale for guidance-distilled models (default: 1.0, disabled). "
- "Unlike classifier-free guidance (--cfg-scale), guidance-distilled models take the guidance scale "
- "directly as an input parameter. Enabled when guidance_scale > 1. Ignored when not using guidance-distilled models."
- ),
- )
- parser.add_argument(
- "--guidance-scale-2", type=float, default=None, help="image guidance scale for image-to-image generation."
- )
- parser.add_argument(
- "--output",
- type=str,
- default="output_image_edit.png",
- help=("Path to save the edited image (PNG). Or prefix for Qwen-Image-Layered model save images(PNG)."),
- )
- parser.add_argument(
- "--num-outputs-per-prompt",
- type=int,
- default=1,
- help="Number of images to generate for the given prompt.",
- )
- parser.add_argument(
- "--num-inference-steps",
- type=int,
- default=50,
- help="Number of denoising steps for the diffusion sampler.",
- )
- parser.add_argument(
- "--cache-backend",
- type=str,
- default=None,
- choices=["cache_dit", "tea_cache"],
- help=(
- "Cache backend to use for acceleration. "
- "Options: 'cache_dit' (DBCache + SCM + TaylorSeer), 'tea_cache' (Timestep Embedding Aware Cache). "
- "Default: None (no cache acceleration)."
- ),
- )
- parser.add_argument(
- "--ulysses-degree",
- type=int,
- default=1,
- help="Number of GPUs used for ulysses sequence parallelism.",
- )
- parser.add_argument(
- "--ulysses-mode",
- type=str,
- default="strict",
- choices=["strict", "advanced_uaa"],
- help="Ulysses sequence-parallel mode: 'strict' (divisibility required) or 'advanced_uaa' (UAA).",
- )
- parser.add_argument(
- "--ring-degree",
- type=int,
- default=1,
- help="Number of GPUs used for ring sequence parallelism.",
- )
- parser.add_argument(
- "--tensor-parallel-size",
- type=int,
- default=1,
- help="Number of GPUs used for tensor parallelism (TP) inside the DiT.",
- )
- parser.add_argument(
- "--enable-expert-parallel",
- action="store_true",
- help="Enable expert parallelism for MoE layers.",
- )
- parser.add_argument("--layers", type=int, default=4, help="Number of layers to decompose the input image into.")
- parser.add_argument(
- "--resolution",
- type=int,
- default=640,
- help="Bucket in (640, 1024) to determine the condition and output resolution",
- )
-
- parser.add_argument(
- "--color-format",
- type=str,
- default="RGB",
- help="For Qwen-Image-Layered, set to RGBA.",
- )
-
- # Cache-DiT specific parameters
- parser.add_argument(
- "--cache-dit-fn-compute-blocks",
- type=int,
- default=1,
- help="[cache-dit] Number of forward compute blocks. Optimized for single-transformer models.",
- )
- parser.add_argument(
- "--cache-dit-bn-compute-blocks",
- type=int,
- default=0,
- help="[cache-dit] Number of backward compute blocks.",
- )
- parser.add_argument(
- "--cache-dit-max-warmup-steps",
- type=int,
- default=4,
- help="[cache-dit] Maximum warmup steps (works for few-step models).",
- )
- parser.add_argument(
- "--cache-dit-residual-diff-threshold",
- type=float,
- default=0.24,
- help="[cache-dit] Residual diff threshold. Higher values enable more aggressive caching.",
- )
- parser.add_argument(
- "--cache-dit-max-continuous-cached-steps",
- type=int,
- default=3,
- help="[cache-dit] Maximum continuous cached steps to prevent precision degradation.",
- )
- parser.add_argument(
- "--cache-dit-enable-taylorseer",
- action="store_true",
- default=False,
- help="[cache-dit] Enable TaylorSeer acceleration (not suitable for few-step models).",
- )
- parser.add_argument(
- "--cache-dit-taylorseer-order",
- type=int,
- default=1,
- help="[cache-dit] TaylorSeer polynomial order.",
- )
- parser.add_argument(
- "--cache-dit-scm-steps-mask-policy",
- type=str,
- default=None,
- choices=[None, "slow", "medium", "fast", "ultra"],
- help="[cache-dit] SCM mask policy: None (disabled), slow, medium, fast, ultra.",
- )
- parser.add_argument(
- "--cache-dit-scm-steps-policy",
- type=str,
- default="dynamic",
- choices=["dynamic", "static"],
- help="[cache-dit] SCM steps policy: dynamic or static.",
- )
-
- # TeaCache specific parameters
- parser.add_argument(
- "--tea-cache-rel-l1-thresh",
- type=float,
- default=0.2,
- help="[tea_cache] Threshold for accumulated relative L1 distance.",
- )
- parser.add_argument(
- "--cfg-parallel-size",
- type=int,
- default=1,
- choices=[1, 2, 3],
- help="Number of GPUs used for classifier free guidance parallel size (max 3 branches).",
- )
- parser.add_argument(
- "--enforce-eager",
- action="store_true",
- help="Disable torch.compile and force eager execution.",
- )
- parser.add_argument(
- "--vae-use-slicing",
- action="store_true",
- help="Enable VAE slicing for memory optimization.",
- )
- parser.add_argument(
- "--vae-use-tiling",
- action="store_true",
- help="Enable VAE tiling for memory optimization.",
- )
- parser.add_argument(
- "--enable-cpu-offload",
- action="store_true",
- help="Enable CPU offloading for diffusion models.",
- )
- parser.add_argument(
- "--enable-layerwise-offload",
- action="store_true",
- help="Enable layerwise (blockwise) offloading on DiT modules.",
- )
- parser.add_argument(
- "--vae-patch-parallel-size",
- type=int,
- default=1,
- help="Number of GPUs used for VAE patch/tile parallelism (decode).",
- )
- parser.add_argument(
- "--use-hsdp",
- action="store_true",
- help="Enable HSDP (Hybrid Sharded Data Parallel) for diffusion models.",
- )
- parser.add_argument(
- "--hsdp-shard-size",
- type=int,
- default=1,
- help="Number of GPUs to shard weights across for HSDP.",
- )
- parser.add_argument(
- "--hsdp-replicate-size",
- type=int,
- default=1,
- help="Number of HSDP replica groups.",
- )
- parser.add_argument(
- "--enable-diffusion-pipeline-profiler",
- action="store_true",
- help="Enable diffusion pipeline profiler to display stage durations.",
- )
- parser.add_argument(
- "--profiler-config",
- type=parse_profiler_config,
- default=None,
- help='JSON profiler config for torch/cuda profiling, e.g. \'{"profiler":"torch","torch_profiler_dir":"./perf"}\'.',
- )
- return parser.parse_args()
-
-
-def main():
- args = parse_args()
-
- # Validate input images exist and load them
- input_images = []
- for image_path in args.image:
- if not os.path.exists(image_path):
- raise FileNotFoundError(f"Input image not found: {image_path}")
-
- img = Image.open(image_path).convert(args.color_format)
- input_images.append(img)
-
- # Use single image or list based on number of inputs
- if len(input_images) == 1:
- input_image = input_images[0]
- else:
- input_image = input_images
-
- generator = torch.Generator(device=current_omni_platform.device_type).manual_seed(args.seed)
-
- parallel_config = DiffusionParallelConfig(
- ulysses_degree=args.ulysses_degree,
- ring_degree=args.ring_degree,
- cfg_parallel_size=args.cfg_parallel_size,
- tensor_parallel_size=args.tensor_parallel_size,
- enable_expert_parallel=args.enable_expert_parallel,
- )
-
- # Configure cache based on backend type
- cache_config = None
- if args.cache_backend == "cache_dit":
- # cache-dit configuration: Hybrid DBCache + SCM + TaylorSeer
- cache_config = {
- "Fn_compute_blocks": args.cache_dit_fn_compute_blocks,
- "Bn_compute_blocks": args.cache_dit_bn_compute_blocks,
- "max_warmup_steps": args.cache_dit_max_warmup_steps,
- "residual_diff_threshold": args.cache_dit_residual_diff_threshold,
- "max_continuous_cached_steps": args.cache_dit_max_continuous_cached_steps,
- "enable_taylorseer": args.cache_dit_enable_taylorseer,
- "taylorseer_order": args.cache_dit_taylorseer_order,
- "scm_steps_mask_policy": args.cache_dit_scm_steps_mask_policy,
- "scm_steps_policy": args.cache_dit_scm_steps_policy,
- }
- elif args.cache_backend == "tea_cache":
- # TeaCache configuration
- cache_config = {
- "rel_l1_thresh": args.tea_cache_rel_l1_thresh,
- # Note: coefficients will use model-specific defaults based on model_type
- }
-
- # Initialize Omni with appropriate pipeline
- omni = Omni(
- model=args.model,
- enable_layerwise_offload=args.enable_layerwise_offload,
- vae_use_slicing=args.vae_use_slicing,
- vae_use_tiling=args.vae_use_tiling,
- cache_backend=args.cache_backend,
- cache_config=cache_config,
- parallel_config=parallel_config,
- enforce_eager=args.enforce_eager,
- enable_cpu_offload=args.enable_cpu_offload,
- enable_diffusion_pipeline_profiler=args.enable_diffusion_pipeline_profiler,
- profiler_config=args.profiler_config,
- )
- print("Pipeline loaded")
-
- profiler_enabled = args.profiler_config is not None
-
- # Time profiling for generation
- print(f"\n{'=' * 60}")
- print("Generation Configuration:")
- print(f" Model: {args.model}")
- print(f" Inference steps: {args.num_inference_steps}")
- print(f" Cache backend: {args.cache_backend if args.cache_backend else 'None (no acceleration)'}")
- if isinstance(input_image, list):
- print(f" Number of input images: {len(input_image)}")
- for idx, img in enumerate(input_image):
- print(f" Image {idx + 1} size: {img.size}")
- else:
- print(f" Input image size: {input_image.size}")
- print(
- f" Parallel configuration: ulysses_degree={args.ulysses_degree}, ring_degree={args.ring_degree}, cfg_parallel_size={args.cfg_parallel_size}, tensor_parallel_size={args.tensor_parallel_size}, enable_expert_parallel: {args.enable_expert_parallel}"
- )
- print(f"{'=' * 60}\n")
-
- generation_start = time.perf_counter()
-
- if profiler_enabled:
- print("[Profiler] Starting profiling...")
- omni.start_profile()
-
- # Generate edited image
- outputs = omni.generate(
- {
- "prompt": args.prompt,
- "negative_prompt": args.negative_prompt,
- "multi_modal_data": {"image": input_image},
- },
- OmniDiffusionSamplingParams(
- generator=generator,
- true_cfg_scale=args.cfg_scale,
- guidance_scale=args.guidance_scale,
- guidance_scale_2=args.guidance_scale_2,
- num_inference_steps=args.num_inference_steps,
- num_outputs_per_prompt=args.num_outputs_per_prompt,
- layers=args.layers,
- resolution=args.resolution,
- ),
- )
- generation_end = time.perf_counter()
- generation_time = generation_end - generation_start
-
- # Print profiling results
- print(f"Total generation time: {generation_time:.4f} seconds ({generation_time * 1000:.2f} ms)")
-
- if profiler_enabled:
- print("\n[Profiler] Stopping profiler and collecting results...")
- profile_results = omni.stop_profile()
- if profile_results and isinstance(profile_results, dict):
- traces = profile_results.get("traces", [])
- print("\n" + "=" * 60)
- print("PROFILING RESULTS:")
- for rank, trace in enumerate(traces):
- print(f"\nRank {rank}:")
- if trace:
- print(f" • Trace: {trace}")
- if not traces:
- print(" No traces collected.")
- print("=" * 60)
- else:
- print("[Profiler] No valid profiling data returned.")
-
- if not outputs:
- raise ValueError("No output generated from omni.generate()")
-
- # Extract images from OmniRequestOutput
- # omni.generate() returns list[OmniRequestOutput], extract images from request_output.images
- first_output = outputs[0]
- if not hasattr(first_output, "request_output") or not first_output.request_output:
- raise ValueError("No request_output found in OmniRequestOutput")
-
- req_out = first_output.request_output
- if not isinstance(req_out, OmniRequestOutput) or not hasattr(req_out, "images"):
- raise ValueError("Invalid request_output structure or missing 'images' key")
-
- images = req_out.images
- if not images:
- raise ValueError("No images found in request_output")
-
- # Save output image(s)
- output_path = Path(args.output)
- output_path.parent.mkdir(parents=True, exist_ok=True)
- suffix = output_path.suffix or ".png"
- stem = output_path.stem or "output_image_edit"
-
- # Handle layered output (each image may be a list of layers)
- if args.num_outputs_per_prompt <= 1:
- img = images[0]
- # Check if this is a layered output (list of images)
- if isinstance(img, list):
- for sub_idx, sub_img in enumerate(img):
- save_path = output_path.parent / f"{stem}_{sub_idx}{suffix}"
- sub_img.save(save_path)
- print(f"Saved edited image to {os.path.abspath(save_path)}")
- else:
- img.save(output_path)
- print(f"Saved edited image to {os.path.abspath(output_path)}")
- else:
- for idx, img in enumerate(images):
- # Check if this is a layered output (list of images)
- if isinstance(img, list):
- for sub_idx, sub_img in enumerate(img):
- save_path = output_path.parent / f"{stem}_{idx}_{sub_idx}{suffix}"
- sub_img.save(save_path)
- print(f"Saved edited image to {os.path.abspath(save_path)}")
- else:
- save_path = output_path.parent / f"{stem}_{idx}{suffix}"
- img.save(save_path)
- print(f"Saved edited image to {os.path.abspath(save_path)}")
-
-
-if __name__ == "__main__":
- main()
diff --git a/examples/offline_inference/image_to_image/image_to_image.md b/examples/offline_inference/image_to_image/image_to_image.md
deleted file mode 100644
index 1c1a5ff3a79..00000000000
--- a/examples/offline_inference/image_to_image/image_to_image.md
+++ /dev/null
@@ -1,56 +0,0 @@
-# Image-To-Image
-
-This example edits an input image with `Qwen/Qwen-Image-Edit` using the `image_edit.py` CLI.
-
-## Local CLI Usage
-
-### Single Image Editing
-
-Download the example image:
-
-```bash
-wget https://vllm-public-assets.s3.us-west-2.amazonaws.com/omni-assets/qwen-bear.png
-```
-
-Then run:
-
-```bash
-python image_edit.py \
- --image qwen-bear.png \
- --prompt "Let this mascot dance under the moon, surrounded by floating stars and poetic bubbles such as 'Be Kind'" \
- --output output_image_edit.png \
- --num-inference-steps 50 \
- --cfg-scale 4.0
-```
-
-### Multiple Image Editing (Qwen-Image-Edit-2509)
-
-For multiple image inputs, use `Qwen/Qwen-Image-Edit-2509` or `Qwen/Qwen-Image-Edit-2511`:
-
-```bash
-python image_edit.py \
- --model Qwen/Qwen-Image-Edit-2509 \
- --image img1.png img2.png \
- --prompt "Combine these images into a single scene" \
- --output output_image_edit.png \
- --num-inference-steps 50 \
- --cfg-scale 4.0 \
- --guidance-scale 1.0
-```
-
-Key arguments:
-
-- `--model`: model name or path. Use `Qwen/Qwen-Image-Edit-2509` or later for multiple image support.
-- `--image`: path(s) to the source image(s) (PNG/JPG, converted to RGB). Can specify multiple images.
-- `--prompt` / `--negative-prompt`: text description (string).
-- `--cfg-scale`: true classifier-free guidance scale (default: 4.0). Classifier-free guidance is enabled by setting cfg_scale > 1 and providing a negative_prompt. Higher guidance scale encourages images closely linked to the text prompt, usually at the expense of lower image quality.
-- `--guidance-scale`: guidance scale for guidance-distilled models (default: 1.0, disabled). Unlike classifier-free guidance (--cfg-scale), guidance-distilled models take the guidance scale directly as an input parameter. Enabled when guidance_scale > 1. Ignored when not using guidance-distilled models.
-- `--num-inference-steps`: diffusion sampling steps (more steps = higher quality, slower).
-- `--output`: path to save the generated PNG.
-- `--vae-use-slicing`: enable VAE slicing for memory optimization.
-- `--vae-use-tiling`: enable VAE tiling for memory optimization.
-- `--cfg-parallel-size`: set it to 2 to enable CFG Parallel. See more examples in [`user_guide`](../../../docs/user_guide/diffusion/parallelism_acceleration.md#cfg-parallel).
-- `--enable-cpu-offload`: enable CPU offloading for diffusion models.
-- `--strength`: **Z-Image only** - controls the denoising start timestep for I2I (default: 0.6). Range: [0.0, 1.0]. Lower values preserve more of the original image; higher values allow more creative changes.
-
-> ℹ️ If you encounter OOM errors, try using `--vae-use-slicing` and `--vae-use-tiling` to reduce memory usage.
diff --git a/examples/offline_inference/image_to_image/run_qwen_image_edit_2511.sh b/examples/offline_inference/image_to_image/run_qwen_image_edit_2511.sh
deleted file mode 100644
index d6e66ec7daa..00000000000
--- a/examples/offline_inference/image_to_image/run_qwen_image_edit_2511.sh
+++ /dev/null
@@ -1,8 +0,0 @@
-python image_edit.py \
- --model Qwen/Qwen-Image-Edit-2511 \
- --image qwen_bear.png \
- --prompt "Add a white art board written with colorful text 'vLLM-Omni' on grassland. Add a paintbrush in the bear's hands. position the bear standing in front of the art board as if painting" \
- --output output_image_edit.png \
- --num-inference-steps 50 \
- --cfg-scale 4.0 \
- --cache-backend cache_dit \
diff --git a/examples/offline_inference/image_to_video/README.md b/examples/offline_inference/image_to_video/README.md
deleted file mode 100644
index a458850a02b..00000000000
--- a/examples/offline_inference/image_to_video/README.md
+++ /dev/null
@@ -1,80 +0,0 @@
-# Image-To-Video
-
-This example demonstrates how to generate videos from images using Wan2.2 Image-to-Video models with vLLM-Omni's offline inference API.
-
-## Local CLI Usage
-
-Download the example image:
-
-```bash
-wget https://vllm-public-assets.s3.us-west-2.amazonaws.com/vision_model_images/cherry_blossom.jpg
-```
-
-### Wan2.2-I2V-A14B-Diffusers (MoE)
-
-```bash
-python image_to_video.py \
- --model Wan-AI/Wan2.2-I2V-A14B-Diffusers \
- --image cherry_blossom.jpg \
- --prompt "Cherry blossoms swaying gently in the breeze, petals falling, smooth motion" \
- --negative-prompt "<optional quality filter>" \
- --height 480 \
- --width 832 \
- --num-frames 48 \
- --guidance-scale 5.0 \
- --guidance-scale-high 6.0 \
- --num-inference-steps 40 \
- --boundary-ratio 0.875 \
- --flow-shift 12.0 \
- --fps 16 \
- --output i2v_output.mp4
-```
-
-### Wan2.2-TI2V-5B-Diffusers (Unified)
-
-```bash
-python image_to_video.py \
- --model Wan-AI/Wan2.2-TI2V-5B-Diffusers \
- --image cherry_blossom.jpg \
- --prompt "Cherry blossoms swaying gently in the breeze, petals falling, smooth motion" \
- --negative-prompt "<optional quality filter>" \
- --height 480 \
- --width 832 \
- --num-frames 48 \
- --guidance-scale 4.0 \
- --num-inference-steps 40 \
- --flow-shift 12.0 \
- --fps 16 \
- --output i2v_output.mp4
-```
-
-Key arguments:
-
-- `--model`: Model ID (I2V-A14B for MoE, TI2V-5B for unified T2V+I2V).
-- `--image`: Path to input image (required).
-- `--prompt`: Text description of desired motion/animation.
-- `--height/--width`: Output resolution (auto-calculated from image if not set). Dimensions should be multiples of 16.
-- `--num-frames`: Number of frames (default 81).
-- `--guidance-scale` and `--guidance-scale-high`: CFG scale (applied to low/high-noise stages for MoE).
-- `--negative-prompt`: Optional list of artifacts to suppress.
-- `--boundary-ratio`: Boundary split ratio for two-stage MoE models.
-- `--flow-shift`: Scheduler flow shift (5.0 for 720p, 12.0 for 480p).
-- `--sample-solver`: Wan2.2 sampling solver. Use `unipc` for the default multistep solver, or `euler` for Lightning/Distill checkpoints.
-- `--num-inference-steps`: Number of denoising steps (default 50).
-- `--fps`: Frames per second for the saved MP4 (requires `diffusers` export_to_video).
-- `--output`: Path to save the generated video.
-- `--vae-use-slicing`: Enable VAE slicing for memory optimization.
-- `--vae-use-tiling`: Enable VAE tiling for memory optimization.
-- `--cfg-parallel-size`: set it to 2 to enable CFG Parallel. See more examples in [`user_guide`](https://github.com/vllm-project/vllm-omni/tree/main/docs/user_guide/diffusion/parallelism/cfg_parallel.md).
-- `--tensor-parallel-size`: tensor parallel size (effective for models that support TP, e.g. LTX2).
-- `--enable-cpu-offload`: enable CPU offloading for diffusion models.
-- `--use-hsdp`: Enable Hybrid Sharded Data Parallel to shard model weights across GPUs.
-- `--hsdp-shard-size`: Number of GPUs to shard model weights across within each replica group. -1 (default) auto-calculates as world_size / replicate_size.
-- `--hsdp-replicate-size`: Number of replica groups for HSDP. Each replica holds a full sharded copy. Default 1 means pure sharding (no replication).
-
-
-
-> ℹ️ If you encounter OOM errors, try using `--vae-use-slicing` and `--vae-use-tiling` to reduce memory usage.
-
-For Wan2.2 LightX2V-converted local Diffusers directories and related LoRA
-assets, see the [LoRA guide](../../../docs/user_guide/diffusion/lora.md#wan22-lightx2v-offline-assembly).
diff --git a/examples/offline_inference/image_to_video/image_to_video.py b/examples/offline_inference/image_to_video/image_to_video.py
deleted file mode 100644
index e46db4de456..00000000000
--- a/examples/offline_inference/image_to_video/image_to_video.py
+++ /dev/null
@@ -1,558 +0,0 @@
-# SPDX-License-Identifier: Apache-2.0
-# SPDX-FileCopyrightText: Copyright contributors to the vLLM project
-
-"""
-Image-to-Video generation example using Wan2.2 I2V/TI2V models, LTX2, or HunyuanVideo-1.5.
-
-Supports:
-- Wan2.2-I2V-A14B-Diffusers: MoE model with CLIP image encoder
-- Wan2.2-TI2V-5B-Diffusers: Unified T2V+I2V model (dense 5B)
-- LTX2 image-to-video pipeline
-- HunyuanVideo-1.5 I2V: SigLIP + VAE dual image conditioning
-
-Usage:
- # Wan I2V-A14B (MoE)
- python image_to_video.py --model Wan-AI/Wan2.2-I2V-A14B-Diffusers \
- --image input.jpg --prompt "A cat playing with yarn"
-
- # TI2V-5B (unified)
- python image_to_video.py --model Wan-AI/Wan2.2-TI2V-5B-Diffusers \
- --image input.jpg --prompt "A cat playing with yarn"
-
- # LTX2 image-to-video
- python image_to_video.py --model /path/to/LTX-2 \
- --model-class-name LTX2ImageToVideoPipeline \
- --image input.jpg --prompt "A cinematic dolly shot of a boat" \
- --num-frames 121 --num-inference-steps 40 --guidance-scale 4.0 \
- --frame-rate 24 --fps 24 --output ltx2_i2v.mp4
-
- # HunyuanVideo-1.5 I2V (480p)
- python image_to_video.py --model hunyuanvideo-community/HunyuanVideo-1.5-Diffusers-480p_i2v \
- --image input.jpg --prompt "A cat playing with yarn" \
- --flow-shift 5.0 --guidance-scale 6.0
-"""
-
-import argparse
-import json
-import time
-from pathlib import Path
-from typing import Any
-
-import numpy as np
-import PIL.Image
-import torch
-
-from vllm_omni.diffusion.data import DiffusionParallelConfig
-from vllm_omni.entrypoints.omni import Omni
-from vllm_omni.inputs.data import OmniDiffusionSamplingParams
-from vllm_omni.outputs import OmniRequestOutput
-from vllm_omni.platforms import current_omni_platform
-
-
-def parse_profiler_config(value: str) -> dict[str, Any]:
- try:
- config = json.loads(value)
- except json.JSONDecodeError as e:
- raise argparse.ArgumentTypeError(f"--profiler-config must be valid JSON: {e}") from e
- if not isinstance(config, dict):
- raise argparse.ArgumentTypeError("--profiler-config must be a JSON object")
- return config
-
-
-def parse_args() -> argparse.Namespace:
- parser = argparse.ArgumentParser(description="Generate a video from an image (Wan2.2, LTX2, HunyuanVideo-1.5).")
- parser.add_argument(
- "--model",
- default="Wan-AI/Wan2.2-I2V-A14B-Diffusers",
- help="Diffusers I2V model ID or local path (Wan2.2 or HunyuanVideo-1.5).",
- )
- parser.add_argument(
- "--model-class-name",
- default=None,
- help="Override model class name (e.g., LTX2ImageToVideoPipeline).",
- )
- parser.add_argument("--image", required=True, help="Path to input image.")
- parser.add_argument("--prompt", default="", help="Text prompt describing the desired motion.")
- parser.add_argument("--negative-prompt", default="", help="Negative prompt.")
- parser.add_argument("--seed", type=int, default=42, help="Random seed.")
- parser.add_argument("--guidance-scale", type=float, default=5.0, help="CFG scale.")
- parser.add_argument(
- "--guidance-scale-high", type=float, default=None, help="Optional separate CFG for high-noise (MoE only)."
- )
- parser.add_argument(
- "--height", type=int, default=None, help="Video height (auto-calculated from image if not set)."
- )
- parser.add_argument("--width", type=int, default=None, help="Video width (auto-calculated from image if not set).")
- parser.add_argument("--num-frames", type=int, default=81, help="Number of frames.")
- parser.add_argument("--num-inference-steps", type=int, default=50, help="Sampling steps.")
- parser.add_argument("--boundary-ratio", type=float, default=0.875, help="Boundary split ratio for MoE models.")
- parser.add_argument(
- "--frame-rate",
- type=float,
- default=None,
- help="Optional generation frame rate (used by models like LTX2). Defaults to --fps.",
- )
- parser.add_argument(
- "--flow-shift", type=float, default=5.0, help="Scheduler flow_shift (5.0 for 720p, 12.0 for 480p)."
- )
- parser.add_argument(
- "--sample-solver",
- type=str,
- default="unipc",
- choices=["unipc", "euler"],
- help="Sampling solver for Wan2.2 pipelines. Use 'euler' for Lightning/Distill setups.",
- )
- parser.add_argument("--output", type=str, default="i2v_output.mp4", help="Path to save the video (mp4).")
- parser.add_argument("--fps", type=int, default=None, help="Frames per second for the output video.")
- parser.add_argument(
- "--vae-use-slicing",
- action="store_true",
- help="Enable VAE slicing for memory optimization.",
- )
- parser.add_argument(
- "--vae-use-tiling",
- action="store_true",
- help="Enable VAE tiling for memory optimization.",
- )
- parser.add_argument(
- "--enable-cpu-offload",
- action="store_true",
- help="Enable CPU offloading for diffusion models.",
- )
- parser.add_argument(
- "--enable-layerwise-offload",
- action="store_true",
- help="Enable layerwise (blockwise) offloading on DiT modules.",
- )
- parser.add_argument(
- "--ulysses-degree",
- type=int,
- default=1,
- help="Number of GPUs used for ulysses sequence parallelism.",
- )
- parser.add_argument(
- "--ring-degree",
- type=int,
- default=1,
- help="Number of GPUs used for ring sequence parallelism.",
- )
- parser.add_argument(
- "--tensor-parallel-size",
- type=int,
- default=1,
- help="Number of GPUs used for tensor parallelism (TP) inside the DiT.",
- )
- parser.add_argument(
- "--cfg-parallel-size",
- type=int,
- default=1,
- choices=[1, 2],
- help="Number of GPUs used for classifier free guidance parallel size.",
- )
- parser.add_argument(
- "--vae-patch-parallel-size",
- type=int,
- default=1,
- help="Number of GPUs used for VAE patch/tile parallelism (decode).",
- )
- parser.add_argument(
- "--enforce-eager",
- action="store_true",
- help="Disable torch.compile and force eager execution.",
- )
- parser.add_argument(
- "--audio-sample-rate",
- type=int,
- default=24000,
- help="Sample rate for audio output when saved (default: 24000).",
- )
- parser.add_argument(
- "--cache-backend",
- type=str,
- default=None,
- choices=["cache_dit", "tea_cache"],
- help=(
- "Cache backend to use for acceleration. "
- "Options: 'cache_dit' (DBCache + SCM + TaylorSeer), 'tea_cache' (Timestep Embedding Aware Cache). "
- "Default: None (no cache acceleration)."
- ),
- )
- parser.add_argument(
- "--use-hsdp",
- action="store_true",
- help=("Enable Hybrid Sharded Data Parallel to shard model weights across GPUs. "),
- )
- parser.add_argument(
- "--hsdp-shard-size",
- type=int,
- default=-1,
- help=(
- "Number of GPUs to shard model weights across within each replica group. "
- "-1 (default) auto-calculates as world_size / replicate_size. "
- ),
- )
- parser.add_argument(
- "--hsdp-replicate-size",
- type=int,
- default=1,
- help=(
- "Number of replica groups for HSDP. Each replica holds a full sharded copy. "
- "Default 1 means pure sharding (no replication). "
- ),
- )
- parser.add_argument(
- "--enable-diffusion-pipeline-profiler",
- action="store_true",
- help="Enable diffusion pipeline profiler to display stage durations.",
- )
- parser.add_argument(
- "--profiler-config",
- type=parse_profiler_config,
- default=None,
- help='JSON profiler config for torch/cuda profiling, e.g. \'{"profiler":"torch","torch_profiler_dir":"./perf"}\'.',
- )
- return parser.parse_args()
-
-
-def calculate_dimensions(
- image: PIL.Image.Image,
- max_area: int = 480 * 832,
- mod_value: int = 16,
-) -> tuple[int, int]:
- """Calculate output dimensions maintaining aspect ratio."""
- aspect_ratio = image.height / image.width
-
- height = round(np.sqrt(max_area * aspect_ratio)) // mod_value * mod_value
- width = round(np.sqrt(max_area / aspect_ratio)) // mod_value * mod_value
-
- return height, width
-
-
-def main():
- args = parse_args()
- generator = torch.Generator(device=current_omni_platform.device_type).manual_seed(args.seed)
- model_name = str(args.model).lower() if args.model is not None else ""
- model_class_name = args.model_class_name
- is_ltx2 = "ltx2" in model_name or (model_class_name and "ltx2" in model_class_name.lower())
- if model_class_name is None and is_ltx2:
- model_class_name = "LTX2ImageToVideoPipeline"
-
- # Load input image
- image = PIL.Image.open(args.image).convert("RGB")
-
- fps = args.fps if args.fps is not None else (24 if is_ltx2 else 16)
- frame_rate = args.frame_rate if args.frame_rate is not None else float(fps)
- guidance_scale = args.guidance_scale if args.guidance_scale is not None else (4.0 if is_ltx2 else 5.0)
- num_frames = args.num_frames if args.num_frames is not None else (121 if is_ltx2 else 81)
- num_inference_steps = args.num_inference_steps if args.num_inference_steps is not None else (40 if is_ltx2 else 50)
-
- # Calculate dimensions if not provided
- height = args.height
- width = args.width
- if height is None or width is None:
- # Default to 480P area for Wan2.2 I2V, 512x768 area for LTX2
- max_area = 512 * 768 if is_ltx2 else 480 * 832
- mod_value = 32 if is_ltx2 else 16
- calc_height, calc_width = calculate_dimensions(image, max_area=max_area, mod_value=mod_value)
- height = height or calc_height
- width = width or calc_width
-
- # Resize image to target dimensions
- image = image.resize((width, height), PIL.Image.Resampling.LANCZOS)
-
- # Configure cache based on backend type
- cache_config = None
- if args.cache_backend == "cache_dit":
- if is_ltx2:
- cache_config = {
- "Fn_compute_blocks": 2,
- "Bn_compute_blocks": 0,
- "max_warmup_steps": 8,
- "residual_diff_threshold": 0.12,
- "max_continuous_cached_steps": 1,
- "max_cached_steps": 20,
- "enable_taylorseer": False,
- "scm_steps_mask_policy": None,
- }
- else:
- cache_config = {
- "Fn_compute_blocks": 1,
- "Bn_compute_blocks": 0,
- "max_warmup_steps": 4,
- "residual_diff_threshold": 0.24,
- "max_continuous_cached_steps": 3,
- "enable_taylorseer": False,
- "taylorseer_order": 1,
- "scm_steps_mask_policy": None,
- "scm_steps_policy": "dynamic",
- }
- elif args.cache_backend == "tea_cache":
- cache_config = {
- "rel_l1_thresh": 0.2,
- }
-
- profiler_enabled = args.profiler_config is not None
- parallel_config = DiffusionParallelConfig(
- ulysses_degree=args.ulysses_degree,
- ring_degree=args.ring_degree,
- cfg_parallel_size=args.cfg_parallel_size,
- tensor_parallel_size=args.tensor_parallel_size,
- vae_patch_parallel_size=args.vae_patch_parallel_size,
- use_hsdp=args.use_hsdp,
- hsdp_shard_size=args.hsdp_shard_size,
- hsdp_replicate_size=args.hsdp_replicate_size,
- )
- omni = Omni(
- model=args.model,
- enable_layerwise_offload=args.enable_layerwise_offload,
- vae_use_slicing=args.vae_use_slicing,
- vae_use_tiling=args.vae_use_tiling,
- boundary_ratio=args.boundary_ratio,
- flow_shift=args.flow_shift,
- enable_cpu_offload=args.enable_cpu_offload,
- parallel_config=parallel_config,
- enforce_eager=args.enforce_eager,
- model_class_name=model_class_name,
- cache_backend=args.cache_backend,
- cache_config=cache_config,
- enable_diffusion_pipeline_profiler=args.enable_diffusion_pipeline_profiler,
- profiler_config=args.profiler_config,
- )
-
- if profiler_enabled:
- print("[Profiler] Starting profiling...")
- omni.start_profile()
-
- # Print generation configuration
- print(f"\n{'=' * 60}")
- print("Generation Configuration:")
- print(f" Model: {args.model}")
- print(f" Inference steps: {args.num_inference_steps}")
- print(f" Frames: {args.num_frames}")
- print(f" Solver: {args.sample_solver}")
- print(
- f" Parallel configuration: cfg_parallel_size={args.cfg_parallel_size},"
- f" tensor_parallel_size={args.tensor_parallel_size}, vae_patch_parallel_size={args.vae_patch_parallel_size}"
- )
- print(f" Video size: {args.width}x{args.height}")
- print(f"{'=' * 60}\n")
-
- generation_start = time.perf_counter()
- # omni.generate() returns Generator[OmniRequestOutput, None, None]
- frames = omni.generate(
- {
- "prompt": args.prompt,
- "negative_prompt": args.negative_prompt,
- "multi_modal_data": {"image": image},
- },
- OmniDiffusionSamplingParams(
- height=height,
- width=width,
- generator=generator,
- guidance_scale=guidance_scale,
- guidance_scale_2=args.guidance_scale_high,
- boundary_ratio=args.boundary_ratio,
- num_inference_steps=num_inference_steps,
- num_frames=num_frames,
- frame_rate=frame_rate,
- extra_args={
- "sample_solver": args.sample_solver,
- "flow_shift": args.flow_shift,
- },
- ),
- )
- generation_end = time.perf_counter()
- generation_time = generation_end - generation_start
-
- # Print profiling results
- print(f"Total generation time: {generation_time:.4f} seconds ({generation_time * 1000:.2f} ms)")
-
- audio = None
- if isinstance(frames, list):
- frames = frames[0] if frames else None
-
- if isinstance(frames, OmniRequestOutput):
- if frames.final_output_type != "image":
- raise ValueError(
- f"Unexpected output type '{frames.final_output_type}', expected 'image' for video generation."
- )
- if frames.multimodal_output and "audio" in frames.multimodal_output:
- audio = frames.multimodal_output["audio"]
- if frames.is_pipeline_output and frames.request_output is not None:
- inner_output = frames.request_output
- if isinstance(inner_output, OmniRequestOutput):
- if inner_output.multimodal_output and "audio" in inner_output.multimodal_output:
- audio = inner_output.multimodal_output["audio"]
- frames = inner_output
- if isinstance(frames, OmniRequestOutput):
- if frames.images:
- if len(frames.images) == 1 and isinstance(frames.images[0], tuple) and len(frames.images[0]) == 2:
- frames, audio = frames.images[0]
- elif len(frames.images) == 1 and isinstance(frames.images[0], dict):
- audio = frames.images[0].get("audio")
- frames = frames.images[0].get("frames") or frames.images[0].get("video")
- else:
- frames = frames.images
- else:
- raise ValueError("No video frames found in OmniRequestOutput.")
-
- if isinstance(frames, list) and frames:
- first_item = frames[0]
- if isinstance(first_item, tuple) and len(first_item) == 2:
- frames, audio = first_item
- elif isinstance(first_item, dict):
- audio = first_item.get("audio")
- frames = first_item.get("frames") or first_item.get("video")
- elif isinstance(first_item, list):
- frames = first_item
-
- if isinstance(frames, tuple) and len(frames) == 2:
- frames, audio = frames
- elif isinstance(frames, dict):
- audio = frames.get("audio")
- frames = frames.get("frames") or frames.get("video")
-
- if frames is None:
- raise ValueError("No video frames found in output.")
-
- output_path = Path(args.output)
- output_path.parent.mkdir(parents=True, exist_ok=True)
-
- try:
- from diffusers.utils import export_to_video
- except ImportError:
- raise ImportError("diffusers is required for export_to_video.")
-
- def _normalize_frame(frame):
- if isinstance(frame, torch.Tensor):
- frame_tensor = frame.detach().cpu()
- if frame_tensor.dim() == 4 and frame_tensor.shape[0] == 1:
- frame_tensor = frame_tensor[0]
- if frame_tensor.dim() == 3 and frame_tensor.shape[0] in (3, 4):
- frame_tensor = frame_tensor.permute(1, 2, 0)
- if frame_tensor.is_floating_point():
- frame_tensor = frame_tensor.clamp(-1, 1) * 0.5 + 0.5
- return frame_tensor.float().numpy()
- if isinstance(frame, np.ndarray):
- frame_array = frame
- if frame_array.ndim == 4 and frame_array.shape[0] == 1:
- frame_array = frame_array[0]
- if np.issubdtype(frame_array.dtype, np.integer):
- frame_array = frame_array.astype(np.float32) / 255.0
- return frame_array
- try:
- from PIL import Image
- except ImportError:
- Image = None
- if Image is not None and isinstance(frame, Image.Image):
- return np.asarray(frame).astype(np.float32) / 255.0
- return frame
-
- def _ensure_frame_list(video_array):
- if isinstance(video_array, list):
- if len(video_array) == 0:
- return video_array
- first_item = video_array[0]
- if isinstance(first_item, np.ndarray):
- if first_item.ndim == 5:
- return list(first_item[0])
- if first_item.ndim == 4:
- if len(video_array) == 1:
- return list(first_item)
- return list(first_item)
- if first_item.ndim == 3:
- return video_array
- return video_array
- if isinstance(video_array, np.ndarray):
- if video_array.ndim == 5:
- return list(video_array[0])
- if video_array.ndim == 4:
- return list(video_array)
- if video_array.ndim == 3:
- return [video_array]
- return video_array
-
- # frames may be np.ndarray, torch.Tensor, or list of tensors/arrays/images
- # export_to_video expects a list of frames with values in [0, 1]
- if isinstance(frames, torch.Tensor):
- video_tensor = frames.detach().cpu()
- if video_tensor.dim() == 5:
- if video_tensor.shape[1] in (3, 4):
- video_tensor = video_tensor[0].permute(1, 2, 3, 0)
- else:
- video_tensor = video_tensor[0]
- elif video_tensor.dim() == 4 and video_tensor.shape[0] in (3, 4):
- video_tensor = video_tensor.permute(1, 2, 3, 0)
- if video_tensor.is_floating_point():
- video_tensor = video_tensor.clamp(-1, 1) * 0.5 + 0.5
- video_array = video_tensor.float().numpy()
- elif isinstance(frames, np.ndarray):
- video_array = frames
- if video_array.ndim == 5:
- video_array = video_array[0]
- if np.issubdtype(video_array.dtype, np.integer):
- video_array = video_array.astype(np.float32) / 255.0
- elif isinstance(frames, list):
- if len(frames) == 0:
- raise ValueError("No video frames found in output.")
- video_array = [_normalize_frame(frame) for frame in frames]
- else:
- video_array = frames
-
- video_array = _ensure_frame_list(video_array)
-
- if audio is not None:
- from vllm_omni.diffusion.utils.media_utils import mux_video_audio_bytes
-
- if isinstance(video_array, list):
- frames_np = np.stack(video_array, axis=0)
- elif isinstance(video_array, np.ndarray):
- frames_np = video_array
- else:
- frames_np = np.asarray(video_array)
-
- if frames_np.ndim == 4 and frames_np.shape[-1] == 4:
- frames_np = frames_np[..., :3]
-
- frames_u8 = (np.clip(frames_np, 0.0, 1.0) * 255).round().clip(0, 255).astype("uint8")
-
- audio_np = audio
- if isinstance(audio_np, list):
- audio_np = audio_np[0] if audio_np else None
- if isinstance(audio_np, torch.Tensor):
- audio_np = audio_np.detach().cpu().float().numpy()
- if isinstance(audio_np, np.ndarray):
- audio_np = np.squeeze(audio_np).astype(np.float32)
-
- video_bytes = mux_video_audio_bytes(
- frames_u8,
- audio_np,
- fps=float(fps),
- audio_sample_rate=args.audio_sample_rate,
- )
- with open(str(output_path), "wb") as f:
- f.write(video_bytes)
- else:
- export_to_video(video_array, str(output_path), fps=fps)
- print(f"Saved generated video to {output_path}")
-
- if profiler_enabled:
- print("\n[Profiler] Stopping profiler and collecting results...")
- profile_results = omni.stop_profile()
- if profile_results and isinstance(profile_results, dict):
- traces = profile_results.get("traces", [])
- print("\n" + "=" * 60)
- print("PROFILING RESULTS:")
- for rank, trace in enumerate(traces):
- print(f"\nRank {rank}:")
- if trace:
- print(f" • Trace: {trace}")
- if not traces:
- print(" No traces collected.")
- print("=" * 60)
- else:
- print("[Profiler] No valid profiling data returned.")
-
-
-if __name__ == "__main__":
- main()
diff --git a/examples/offline_inference/internvla_a1/README.md b/examples/offline_inference/internvla_a1/README.md
deleted file mode 100644
index bb7fd3abb54..00000000000
--- a/examples/offline_inference/internvla_a1/README.md
+++ /dev/null
@@ -1,30 +0,0 @@
-# InternVLA-A1
-
-Full usage and result-reporting guidance lives in [docs/user_guide/examples/offline_inference/internvla_a1.md](../../../docs/user_guide/examples/offline_inference/internvla_a1.md).
-
-Quick start:
-
-```bash
-export INTERNVLA_A1_MODEL_DIR=/path/to/InternVLA-A1-3B-ft-pen
-export INTERNVLA_A1_DATASET_DIR=/path/to/Genie1-Place_Markpen
-export INTERNVLA_A1_PROCESSOR_DIR=/path/to/Qwen3-VL-2B-Instruct
-# hf tenstep/Cosmos-Tokenizer-CI8x8-SafeTensors
-export INTERNVLA_A1_COSMOS_DIR=/path/to/Cosmos-Tokenizer-CI8x8-SafeTensor
-
-bash run.sh --num-samples 1 --num-episodes 0
-bash run.sh --num-episodes 1
-bash collect_results.sh
-```
-
-Expected files under `INTERNVLA_A1_COSMOS_DIR`:
-
-- `encoder.safetensors`
-- `decoder.safetensors`
-
-Reference Hugging Face repo: `tenstep/Cosmos-Tokenizer-CI8x8-SafeTensors`
-
-Key entrypoints:
-
-- `run.sh`: wrapper for offline inference and GT evaluation
-- `collect_results.sh`: collect sample output, latency, metrics, plots, and logs
-- `end2end.py`: underlying Python entrypoint
diff --git a/examples/offline_inference/internvla_a1/collect_results.sh b/examples/offline_inference/internvla_a1/collect_results.sh
deleted file mode 100644
index 6f4556a3409..00000000000
--- a/examples/offline_inference/internvla_a1/collect_results.sh
+++ /dev/null
@@ -1,220 +0,0 @@
-#!/usr/bin/env bash
-set -euo pipefail
-
-ROOT_DIR="$(cd "$(dirname "${BASH_SOURCE[0]}")" && pwd)"
-REPO_ROOT="$(cd "$ROOT_DIR/../../.." && pwd)"
-TIMESTAMP="$(date +%Y%m%d_%H%M%S)"
-RESULT_ROOT="${INTERNVLA_A1_RESULT_DIR:-$REPO_ROOT/outputs/internvla_a1/collected_results/$TIMESTAMP}"
-
-: "${INTERNVLA_A1_MODEL_DIR:?Please export INTERNVLA_A1_MODEL_DIR=/path/to/InternVLA-A1-3B-ft-pen}"
-: "${INTERNVLA_A1_DATASET_DIR:?Please export INTERNVLA_A1_DATASET_DIR=/path/to/Genie1-Place_Markpen}"
-: "${INTERNVLA_A1_PROCESSOR_DIR:?Please export INTERNVLA_A1_PROCESSOR_DIR=/path/to/Qwen3-VL-2B-Instruct}"
-: "${INTERNVLA_A1_COSMOS_DIR:?Please export INTERNVLA_A1_COSMOS_DIR=/path/to/Cosmos-Tokenizer-CI8x8-SafeTensor}"
-
-EVAL_OUTPUT_DIR="$RESULT_ROOT/eval_outputs"
-GPU_MONITOR_INTERVAL="${GPU_MONITOR_INTERVAL:-1}"
-
-mkdir -p "$RESULT_ROOT"
-
-export INTERNVLA_A1_MODEL_DIR
-export INTERNVLA_A1_DATASET_DIR
-export INTERNVLA_A1_PROCESSOR_DIR
-export INTERNVLA_A1_COSMOS_DIR
-
-write_env_summary() {
- cat >"$RESULT_ROOT/env_summary.txt" <<EOF
-timestamp=$TIMESTAMP
-repo_root=$REPO_ROOT
-result_root=$RESULT_ROOT
-python=$(command -v python || true)
-python_version=$(python --version 2>&1 || true)
-model_dir=$INTERNVLA_A1_MODEL_DIR
-dataset_dir=$INTERNVLA_A1_DATASET_DIR
-processor_dir=$INTERNVLA_A1_PROCESSOR_DIR
-cosmos_dir=$INTERNVLA_A1_COSMOS_DIR
-pwd=$(pwd)
-EOF
-}
-
-capture_gpu_snapshot() {
- local output_file="$1"
- if command -v nvidia-smi >/dev/null 2>&1; then
- nvidia-smi --query-gpu=index,name,memory.total,memory.used,utilization.gpu --format=csv >"$output_file" 2>&1 || true
- else
- echo "nvidia-smi not found" >"$output_file"
- fi
-}
-
-start_gpu_monitor() {
- local output_file="$1"
- if ! command -v nvidia-smi >/dev/null 2>&1; then
- echo "nvidia-smi not found" >"$output_file"
- return 1
- fi
-
- (
- echo "timestamp,index,name,memory.total [MiB],memory.used [MiB],utilization.gpu [%]"
- while true; do
- local now
- now="$(date '+%Y-%m-%d %H:%M:%S')"
- nvidia-smi --query-gpu=index,name,memory.total,memory.used,utilization.gpu --format=csv,noheader,nounits \
- | awk -F',' -v ts="$now" '{gsub(/^[ \t]+|[ \t]+$/, "", $0); print ts "," $0}'
- sleep "$GPU_MONITOR_INTERVAL"
- done
- ) >"$output_file" 2>/dev/null &
- echo $!
-}
-
-stop_gpu_monitor() {
- local monitor_pid="${1:-}"
- if [[ -n "$monitor_pid" ]] && kill -0 "$monitor_pid" 2>/dev/null; then
- kill "$monitor_pid" 2>/dev/null || true
- wait "$monitor_pid" 2>/dev/null || true
- fi
-}
-
-copy_eval_outputs() {
- local source_dir="$1"
- local target_dir="$2"
- local source_real=""
- local target_real=""
- source_real="$(realpath "$source_dir" 2>/dev/null || echo "$source_dir")"
- target_real="$(realpath "$target_dir" 2>/dev/null || echo "$target_dir")"
- if [[ "$source_real" == "$target_real" ]]; then
- return 0
- fi
- mkdir -p "$target_dir"
- if [[ -d "$source_dir" ]]; then
- cp -r "$source_dir"/. "$target_dir"/
- fi
-}
-
-run_with_artifacts() {
- local name="$1"
- shift
-
- local log_file="$RESULT_ROOT/${name}.log"
- local time_file="$RESULT_ROOT/${name}_time.txt"
- local gpu_file="$RESULT_ROOT/${name}_gpu.csv"
- local status_file="$RESULT_ROOT/${name}_status.txt"
- local monitor_pid=""
-
- monitor_pid="$(start_gpu_monitor "$gpu_file" || true)"
- set +e
- local exit_code=0
- local start_ts=0
- local end_ts=0
- start_ts="$(date +%s)"
- if [[ -x /usr/bin/time ]]; then
- /usr/bin/time -v -o "$time_file" "$@" >"$log_file" 2>&1
- exit_code=$?
- if [[ ! -s "$time_file" ]]; then
- end_ts="$(date +%s)"
- {
- echo "timing_mode=usr_bin_time_empty_fallback"
- echo "start_ts=$start_ts"
- echo "end_ts=$end_ts"
- echo "elapsed_seconds=$((end_ts - start_ts))"
- } >"$time_file"
- fi
- else
- "$@" >"$log_file" 2>&1
- exit_code=$?
- end_ts="$(date +%s)"
- {
- echo "timing_mode=shell_date"
- echo "start_ts=$start_ts"
- echo "end_ts=$end_ts"
- echo "elapsed_seconds=$((end_ts - start_ts))"
- } >"$time_file"
- fi
- set -e
- stop_gpu_monitor "$monitor_pid"
-
- echo "exit_code=$exit_code" >"$status_file"
- if [[ $exit_code -ne 0 ]]; then
- echo "[error] command failed for $name, see $log_file"
- return $exit_code
- fi
-}
-
-write_manifest() {
- cat >"$RESULT_ROOT/README.txt" <<EOF
-InternVLA-A1 collected results
-
-Key files:
-- env_summary.txt: environment and path summary
-- sample_run.log / sample_run_time.txt: one-sample functional run
-- forward_benchmark.log / forward_benchmark_time.txt: pure pipeline.forward latency benchmark
-- eval_run.log / eval_run_time.txt: GT evaluation run
-- pytest_e2e.log / pytest_e2e_time.txt: offline e2e pytest result
-- gpu_info_before.csv / gpu_info_after.csv: point-in-time GPU snapshots
-- *_gpu.csv: sampled GPU usage during each run
-- eval_outputs/: copied output directory from the GT evaluation run
-
-Important outputs:
-- forward_benchmark/forward_latency.json
-- eval_outputs/summary.json
-- eval_outputs/registry/log.json
-- eval_outputs/registry/plots/
-EOF
-}
-
-write_skip_artifact() {
- local name="$1"
- local reason="$2"
- echo "$reason" >"$RESULT_ROOT/${name}.log"
- echo "timing_mode=skipped" >"$RESULT_ROOT/${name}_time.txt"
- echo "exit_code=0" >"$RESULT_ROOT/${name}_status.txt"
- echo "skipped_reason=$reason" >>"$RESULT_ROOT/${name}_status.txt"
- if [[ ! -f "$RESULT_ROOT/${name}_gpu.csv" ]]; then
- echo "skipped,$reason" >"$RESULT_ROOT/${name}_gpu.csv"
- fi
-}
-
-write_env_summary
-write_manifest
-capture_gpu_snapshot "$RESULT_ROOT/gpu_info_before.csv"
-
-run_with_artifacts \
- "sample_run" \
- bash "$ROOT_DIR/run.sh" \
- --output-dir "$RESULT_ROOT/sample_outputs" \
- --num-samples 1 \
- --num-episodes 0
-
-run_with_artifacts \
- "forward_benchmark" \
- python "$ROOT_DIR/end2end.py" \
- --model-dir "$INTERNVLA_A1_MODEL_DIR" \
- --dataset-dir "$INTERNVLA_A1_DATASET_DIR" \
- --benchmark-forward \
- --dtype bfloat16 \
- --attn-implementation eager \
- --warmup-iters 3 \
- --benchmark-iters 10 \
- --output-dir "$RESULT_ROOT/forward_benchmark"
-
-run_with_artifacts \
- "eval_run" \
- bash "$ROOT_DIR/run.sh" \
- --output-dir "$EVAL_OUTPUT_DIR" \
- --num-episodes 1
-
-copy_eval_outputs "$EVAL_OUTPUT_DIR" "$RESULT_ROOT/eval_outputs"
-
-if python - <<'PY' >/dev/null 2>&1
-import importlib.util
-raise SystemExit(0 if importlib.util.find_spec("pytest") else 1)
-PY
-then
- run_with_artifacts \
- "pytest_e2e" \
- python -m pytest -sv tests/e2e/offline_inference/test_internvla_a1.py -m advanced_model
-else
- write_skip_artifact "pytest_e2e" "pytest is not installed in the current python environment"
-fi
-
-capture_gpu_snapshot "$RESULT_ROOT/gpu_info_after.csv"
-
-echo "Results written to: $RESULT_ROOT"
diff --git a/examples/offline_inference/internvla_a1/end2end.py b/examples/offline_inference/internvla_a1/end2end.py
deleted file mode 100755
index a7799d7cea8..00000000000
--- a/examples/offline_inference/internvla_a1/end2end.py
+++ /dev/null
@@ -1,327 +0,0 @@
-#!/usr/bin/env python3
-from __future__ import annotations
-
-import argparse
-import json
-import os
-import statistics
-import sys
-import time
-from pathlib import Path
-
-import torch
-
-_WORKSPACE_ROOT = Path(__file__).resolve().parent
-_REPO_ROOT = _WORKSPACE_ROOT.parents[2]
-if str(_REPO_ROOT) not in sys.path:
- # Keep the shared helper import clean by doing script-only path bootstrap here.
- sys.path.insert(0, str(_REPO_ROOT))
-
-from internvla_a1_common import ( # noqa: E402
- A2DOpenLoopDataset,
- collate_open_loop_samples,
- make_shared_noise,
- run_open_loop_evaluation,
- select_indices,
- tensor_dtype,
- tensor_sha256,
-)
-
-from vllm_omni.diffusion.data import OmniDiffusionConfig # noqa: E402
-from vllm_omni.diffusion.models.internvla_a1 import ( # noqa: E402
- InternVLAA1Config,
- InternVLAA1TrainMetadata,
-)
-from vllm_omni.diffusion.models.internvla_a1.config import OBS_STATE # noqa: E402
-from vllm_omni.diffusion.registry import initialize_model # noqa: E402
-from vllm_omni.diffusion.request import OmniDiffusionRequest # noqa: E402
-from vllm_omni.inputs.data import OmniDiffusionSamplingParams # noqa: E402
-
-
-def _required_path_arg(env_name: str, cli_value: str | None) -> str:
- value = cli_value or os.getenv(env_name)
- if not value:
- raise ValueError(f"Missing required path: set --{env_name.lower().replace('_', '-')} or {env_name}.")
- return value
-
-
-def parse_args() -> argparse.Namespace:
- parser = argparse.ArgumentParser(description="Run vLLM InternVLA-A1 inference on a few samples.")
- parser.add_argument("--model-dir")
- parser.add_argument("--dataset-dir")
- parser.add_argument("--num-samples", type=int, default=1)
- parser.add_argument("--num-episodes", type=int, default=0)
- parser.add_argument("--seed", type=int, default=1234)
- parser.add_argument("--dtype", choices=["bfloat16", "float32"], default="bfloat16")
- parser.add_argument("--device", default="cuda")
- parser.add_argument("--compile-model", action="store_true")
- parser.add_argument("--attn-implementation", default="eager")
- parser.add_argument("--enable-regional-compile", action="store_true")
- parser.add_argument("--enable-warmup", action="store_true")
- parser.add_argument("--strict-load", action="store_true")
- parser.add_argument("--output-dir", default="outputs/internvla_a1/vllm_infer")
- parser.add_argument("--skip-plots", action="store_true")
- parser.add_argument("--benchmark-forward", action="store_true")
- parser.add_argument("--warmup-iters", type=int, default=3)
- parser.add_argument("--benchmark-iters", type=int, default=10)
- return parser.parse_args()
-
-
-def build_od_config(args: argparse.Namespace, processor_model_name: str) -> OmniDiffusionConfig:
- return OmniDiffusionConfig(
- model=str(Path(args.model_dir).resolve()),
- model_class_name="InternVLAA1Pipeline",
- dtype=tensor_dtype(args.dtype),
- custom_pipeline_args={
- "device": args.device,
- "dtype": args.dtype,
- "compile_model": args.compile_model,
- "attn_implementation": args.attn_implementation,
- "enable_regional_compile": args.enable_regional_compile,
- "enable_warmup": args.enable_warmup,
- "strict_load": args.strict_load,
- "processor_model_name": processor_model_name,
- },
- )
-
-
-def build_dataset(args: argparse.Namespace) -> tuple[A2DOpenLoopDataset, InternVLAA1Config, InternVLAA1TrainMetadata]:
- model_dir = Path(args.model_dir)
- config = InternVLAA1Config.from_pretrained(model_dir)
- config.device = args.device
- config.dtype = args.dtype
- config.compile_model = args.compile_model
- config.attn_implementation = args.attn_implementation
- config.enable_regional_compile = args.enable_regional_compile
-
- train_meta = InternVLAA1TrainMetadata.from_pretrained(model_dir)
- with open(model_dir / "stats.json", encoding="utf-8") as f:
- train_stats = json.load(f)["a2d"]
-
- dataset = A2DOpenLoopDataset(
- args.dataset_dir,
- config=config,
- train_stats=train_stats,
- )
- return dataset, config, train_meta
-
-
-def run_one_path(
- pipeline,
- dataset: A2DOpenLoopDataset,
- config: InternVLAA1Config,
- args: argparse.Namespace,
- indices: list[int],
-) -> list[dict[str, object]]:
- results: list[dict[str, object]] = []
- for index in indices:
- sample = dataset.get_sample(index)
- batch_inputs, _ = collate_open_loop_samples([sample], device=args.device, dtype=tensor_dtype(args.dtype))
- noise = make_shared_noise(
- args.seed,
- index,
- (
- batch_inputs[OBS_STATE].shape[0],
- config.chunk_size,
- config.max_action_dim,
- ),
- args.device,
- )
- pred = run_pipeline_forward(pipeline, batch_inputs, noise)
- pred = pred[:, :, : dataset.physical_action_dim].to(torch.float32).cpu()
- results.append(
- {
- "path": "registry",
- "index": index,
- "episode_index": sample.episode_index,
- "task": sample.task,
- "seed": args.seed,
- "shape": list(pred.shape),
- "mean": float(pred.mean().item()),
- "std": float(pred.std().item()),
- "action_sha256": tensor_sha256(pred),
- "first_action_prefix": pred[0, 0, :8].tolist(),
- }
- )
- return results
-
-
-def run_pipeline_forward(
- pipeline,
- batch_inputs: dict[str, torch.Tensor],
- noise: torch.Tensor,
-) -> torch.Tensor:
- output = pipeline.forward(
- OmniDiffusionRequest(
- prompts=[""],
- sampling_params=OmniDiffusionSamplingParams(
- extra_args={
- "batch_inputs": batch_inputs,
- "noise": noise,
- "decode_image": False,
- }
- ),
- )
- )
- if output.error:
- raise RuntimeError(output.error)
- if output.output is None:
- raise RuntimeError("InternVLAA1Pipeline.forward returned no output tensor.")
- return output.output
-
-
-def _synchronize(device: str) -> None:
- if device.startswith("cuda") and torch.cuda.is_available():
- torch.cuda.synchronize()
-
-
-def _latency_summary(values_ms: list[float]) -> dict[str, float]:
- sorted_values = sorted(values_ms)
- p50_index = min(len(sorted_values) - 1, round(0.50 * (len(sorted_values) - 1)))
- p90_index = min(len(sorted_values) - 1, round(0.90 * (len(sorted_values) - 1)))
- return {
- "mean_ms": float(statistics.mean(sorted_values)),
- "stdev_ms": float(statistics.pstdev(sorted_values)) if len(sorted_values) > 1 else 0.0,
- "min_ms": float(sorted_values[0]),
- "max_ms": float(sorted_values[-1]),
- "p50_ms": float(sorted_values[p50_index]),
- "p90_ms": float(sorted_values[p90_index]),
- }
-
-
-def benchmark_forward(
- pipeline,
- dataset: A2DOpenLoopDataset,
- config: InternVLAA1Config,
- args: argparse.Namespace,
- index: int,
- output_dir: Path,
-) -> dict[str, object]:
- sample = dataset.get_sample(index)
- batch_inputs, _ = collate_open_loop_samples([sample], device=args.device, dtype=tensor_dtype(args.dtype))
- noise = make_shared_noise(
- args.seed,
- index,
- (
- batch_inputs[OBS_STATE].shape[0],
- config.chunk_size,
- config.max_action_dim,
- ),
- args.device,
- )
-
- _synchronize(args.device)
- cold_start_begin = time.perf_counter()
- pred = run_pipeline_forward(pipeline, batch_inputs, noise)
- _synchronize(args.device)
- cold_start_ms = (time.perf_counter() - cold_start_begin) * 1000.0
-
- warmup_ms: list[float] = []
- for _ in range(args.warmup_iters):
- _synchronize(args.device)
- begin = time.perf_counter()
- _ = run_pipeline_forward(pipeline, batch_inputs, noise)
- _synchronize(args.device)
- warmup_ms.append((time.perf_counter() - begin) * 1000.0)
-
- benchmark_ms: list[float] = []
- for _ in range(args.benchmark_iters):
- _synchronize(args.device)
- begin = time.perf_counter()
- _ = run_pipeline_forward(pipeline, batch_inputs, noise)
- _synchronize(args.device)
- benchmark_ms.append((time.perf_counter() - begin) * 1000.0)
-
- pred = pred[:, :, : dataset.physical_action_dim].to(torch.float32).cpu()
- summary = {
- "mode": "forward_latency",
- "model_dir": str(Path(args.model_dir).resolve()),
- "dataset_dir": str(Path(args.dataset_dir).resolve()),
- "sample_index": index,
- "episode_index": sample.episode_index,
- "task": sample.task,
- "device": args.device,
- "dtype": args.dtype,
- "attn_implementation": args.attn_implementation,
- "enable_regional_compile": args.enable_regional_compile,
- "warmup_iters": args.warmup_iters,
- "benchmark_iters": args.benchmark_iters,
- "output_shape": list(pred.shape),
- "cold_start_ms": cold_start_ms,
- "warmup_summary": _latency_summary(warmup_ms) if warmup_ms else {},
- "benchmark_summary": _latency_summary(benchmark_ms) if benchmark_ms else {},
- "benchmark_samples_ms": benchmark_ms,
- }
- with open(output_dir / "forward_latency.json", "w", encoding="utf-8") as f:
- json.dump(summary, f, ensure_ascii=False, indent=2)
- print(json.dumps(summary, ensure_ascii=False, indent=2))
- return summary
-
-
-def main() -> None:
- args = parse_args()
- args.model_dir = _required_path_arg("INTERNVLA_A1_MODEL_DIR", args.model_dir)
- args.dataset_dir = _required_path_arg("INTERNVLA_A1_DATASET_DIR", args.dataset_dir)
- output_dir = Path(args.output_dir)
- output_dir.mkdir(parents=True, exist_ok=True)
- dataset, config, train_meta = build_dataset(args)
- indices = select_indices(dataset, args.num_samples)
- od_config = build_od_config(args, train_meta.processor_model_name)
-
- eval_summaries: dict[str, object] = {}
- pipeline = initialize_model(od_config)
- if args.benchmark_forward:
- benchmark_forward(
- pipeline=pipeline,
- dataset=dataset,
- config=config,
- args=args,
- index=indices[0],
- output_dir=output_dir,
- )
- return
- results = run_one_path(
- pipeline=pipeline,
- dataset=dataset,
- config=config,
- args=args,
- indices=indices,
- )
- if args.num_episodes > 0:
- eval_summaries["registry"] = run_open_loop_evaluation(
- mode="vllm_registry",
- policy=pipeline,
- config=config,
- dataset=dataset,
- train_meta=train_meta,
- collate_samples=collate_open_loop_samples,
- run_sample_actions=lambda policy, batch_inputs, noise: run_pipeline_forward(policy, batch_inputs, noise),
- num_episodes=args.num_episodes,
- seed=args.seed,
- device=args.device,
- dtype=tensor_dtype(args.dtype),
- output_dir=output_dir / "registry",
- skip_plots=args.skip_plots,
- )
-
- summary = {
- "mode": "registry",
- "model_dir": str(Path(args.model_dir).resolve()),
- "dataset_dir": str(Path(args.dataset_dir).resolve()),
- "device": args.device,
- "dtype": args.dtype,
- "attn_implementation": args.attn_implementation,
- "enable_regional_compile": args.enable_regional_compile,
- "seed": args.seed,
- "indices": indices,
- "results": results,
- "output_dir": str(output_dir.resolve()),
- "eval_summaries": eval_summaries,
- }
- with open(output_dir / "summary.json", "w", encoding="utf-8") as f:
- json.dump(summary, f, ensure_ascii=False, indent=2)
- print(json.dumps(summary, ensure_ascii=False, indent=2))
-
-
-if __name__ == "__main__":
- main()
diff --git a/examples/offline_inference/internvla_a1/internvla_a1_common.py b/examples/offline_inference/internvla_a1/internvla_a1_common.py
deleted file mode 100644
index 806e145380d..00000000000
--- a/examples/offline_inference/internvla_a1/internvla_a1_common.py
+++ /dev/null
@@ -1,471 +0,0 @@
-from __future__ import annotations
-
-import hashlib
-import json
-import math
-from collections.abc import Callable
-from dataclasses import dataclass
-from pathlib import Path
-from typing import Any
-
-import numpy as np
-import pyarrow.parquet as pq
-import torch
-import torch.nn.functional as F
-import torchvision
-
-from vllm_omni.diffusion.models.internvla_a1.config import ( # noqa: E402
- OBS_IMAGES,
- OBS_STATE,
- OBS_TASK,
- InternVLAA1Config,
-)
-
-
-def tensor_dtype(name: str) -> torch.dtype:
- return torch.bfloat16 if name == "bfloat16" else torch.float32
-
-
-def select_indices(dataset, num_samples: int) -> list[int]:
- indices: list[int] = []
- for _, episode_indices in dataset.episode_start_indices(max_episodes=num_samples):
- if episode_indices:
- indices.append(episode_indices[0])
- return indices[:num_samples]
-
-
-def make_shared_noise(seed: int, sample_index: int, shape: tuple[int, ...], device: str) -> torch.Tensor:
- generator = torch.Generator(device="cpu")
- generator.manual_seed(seed + sample_index)
- noise = torch.randn(shape, generator=generator, dtype=torch.float32)
- return noise.to(device=device)
-
-
-def tensor_sha256(tensor: torch.Tensor) -> str:
- array = tensor.detach().contiguous().cpu().numpy()
- return hashlib.sha256(array.tobytes()).hexdigest()
-
-
-def _clamp_index(index: int, start: int, end: int) -> int:
- return max(start, min(end - 1, index))
-
-
-def _load_parquet_rows(path: Path) -> list[dict[str, Any]]:
- return pq.read_table(path).to_pylist()
-
-
-def _load_json(path: Path) -> dict[str, Any]:
- with open(path, encoding="utf-8") as f:
- return json.load(f)
-
-
-def _stack_stats(stats: dict[str, Any], keys: list[str]) -> dict[str, torch.Tensor]:
- result = {}
- for stat_name in ("mean", "std"):
- values = []
- for key in keys:
- values.extend(stats[key][stat_name])
- result[stat_name] = torch.tensor(values, dtype=torch.float32)
- return result
-
-
-def normalize_vector(values: torch.Tensor, stats: dict[str, torch.Tensor]) -> torch.Tensor:
- denom = torch.where(stats["std"] == 0, torch.ones_like(stats["std"]), stats["std"])
- return (values - stats["mean"]) / denom
-
-
-def unnormalize_vector(values: torch.Tensor, stats: dict[str, torch.Tensor]) -> torch.Tensor:
- return values * stats["std"] + stats["mean"]
-
-
-class TorchvisionVideoReaderCache:
- def __init__(self, backend: str = "pyav") -> None:
- self.backend = backend
- self._readers: dict[str, Any] = {}
- torchvision.set_video_backend(backend)
-
- def get(self, path: str) -> Any:
- reader = self._readers.get(path)
- if reader is None:
- reader = torchvision.io.VideoReader(path, "video")
- self._readers[path] = reader
- return reader
-
- def decode_frames(self, path: str, timestamps: list[float], tolerance_s: float = 1e-4) -> torch.Tensor:
- reader = self.get(path)
- first_ts = min(timestamps)
- last_ts = max(timestamps)
- reader.seek(first_ts, keyframes_only=self.backend == "pyav")
-
- loaded_frames: list[torch.Tensor] = []
- loaded_ts: list[float] = []
- for frame in reader:
- current_ts = float(frame["pts"])
- loaded_frames.append(frame["data"])
- loaded_ts.append(current_ts)
- if current_ts >= last_ts:
- break
-
- query_ts = torch.tensor(timestamps, dtype=torch.float32)
- loaded_ts_tensor = torch.tensor(loaded_ts, dtype=torch.float32)
- distances = torch.cdist(query_ts[:, None], loaded_ts_tensor[:, None], p=1)
- min_dist, argmin = distances.min(dim=1)
- if not torch.all(min_dist < tolerance_s):
- raise RuntimeError(
- f"Video timestamps are outside tolerance: query={query_ts.tolist()} "
- f"loaded={loaded_ts_tensor.tolist()} path={path}"
- )
- return torch.stack([loaded_frames[i] for i in argmin]).float() / 255.0
-
-
-@dataclass
-class A2DOpenLoopSample:
- index: int
- episode_index: int
- task: str
- state_raw: torch.Tensor
- action_raw: torch.Tensor
- inputs: dict[str, torch.Tensor]
-
-
-class A2DOpenLoopDataset:
- image_keys = [
- "observation.images.head",
- "observation.images.hand_left",
- "observation.images.hand_right",
- ]
- state_keys = [
- "observation.states.joint.position",
- "observation.states.effector.position",
- ]
- action_keys = [
- "actions.joint.position",
- "actions.effector.position",
- ]
-
- def __init__(
- self,
- dataset_root: str | Path,
- *,
- config: InternVLAA1Config,
- train_stats: dict[str, Any],
- image_offsets: tuple[int, int] = (-15, 0),
- tolerance_s: float = 1e-4,
- ) -> None:
- self.root = Path(dataset_root)
- self.config = config
- self.info = _load_json(self.root / "meta" / "info.json")
- self.dataset_stats = _load_json(self.root / "meta" / "stats.json")
- self.data_rows = _load_parquet_rows(self.root / "data" / "chunk-000" / "file-000.parquet")
- self.episode_rows = _load_parquet_rows(self.root / "meta" / "episodes" / "chunk-000" / "file-000.parquet")
- self.task_rows = _load_parquet_rows(self.root / "meta" / "tasks.parquet")
-
- self.state_stats = _stack_stats(train_stats, self.state_keys)
- self.action_stats = _stack_stats(train_stats, self.action_keys)
- self.image_offsets = image_offsets
- self.tolerance_s = tolerance_s
- self.video_reader = TorchvisionVideoReaderCache(backend="pyav")
-
- @property
- def num_episodes(self) -> int:
- return len(self.episode_rows)
-
- @property
- def physical_action_dim(self) -> int:
- return 16
-
- def episode_start_indices(self, max_episodes: int | None = None) -> list[tuple[int, list[int]]]:
- rows = self.episode_rows if max_episodes is None else self.episode_rows[:max_episodes]
- result = []
- for ep in rows:
- start = int(ep["dataset_from_index"])
- end = int(ep["dataset_to_index"])
- result.append((int(ep["episode_index"]), list(range(start, end, self.config.chunk_size))))
- return result
-
- def _task_text(self, task_index: int) -> str:
- return self.task_rows[task_index]["__index_level_0__"]
-
- def _episode_for_index(self, row: dict[str, Any]) -> dict[str, Any]:
- return self.episode_rows[int(row["episode_index"])]
-
- def _state_vector(self, row: dict[str, Any]) -> torch.Tensor:
- return torch.tensor(row[self.state_keys[0]] + row[self.state_keys[1]], dtype=torch.float32)
-
- def _action_vector(self, row: dict[str, Any]) -> torch.Tensor:
- return torch.tensor(row[self.action_keys[0]] + row[self.action_keys[1]], dtype=torch.float32)
-
- def _query_rows(self, idx: int, deltas: list[int]) -> list[dict[str, Any]]:
- row = self.data_rows[idx]
- episode = self._episode_for_index(row)
- start = int(episode["dataset_from_index"])
- end = int(episode["dataset_to_index"])
- return [self.data_rows[_clamp_index(idx + delta, start, end)] for delta in deltas]
-
- def _decode_camera_history(
- self, episode: dict[str, Any], camera_key: str, rows: list[dict[str, Any]]
- ) -> torch.Tensor:
- timestamps = [float(r["timestamp"]) for r in rows]
- shifted = [float(episode[f"videos/{camera_key}/from_timestamp"]) + ts for ts in timestamps]
- chunk_idx = int(episode[f"videos/{camera_key}/chunk_index"])
- file_idx = int(episode[f"videos/{camera_key}/file_index"])
- path = self.root / self.info["video_path"].format(
- video_key=camera_key,
- chunk_index=chunk_idx,
- file_index=file_idx,
- )
- frames = self.video_reader.decode_frames(str(path), shifted, tolerance_s=self.tolerance_s)
- return frames
-
- def get_sample(self, idx: int) -> A2DOpenLoopSample:
- row = self.data_rows[idx]
- episode = self._episode_for_index(row)
- image_rows = self._query_rows(idx, list((-15, 0)))
- action_rows = self._query_rows(idx, list(range(self.config.chunk_size)))
- camera_images = [self._decode_camera_history(episode, camera_key, image_rows) for camera_key in self.image_keys]
- state_raw = self._state_vector(row)
- state_norm = normalize_vector(state_raw, self.state_stats)
- action_raw = torch.stack([self._action_vector(action_row) for action_row in action_rows], dim=0)
- task = self._task_text(int(row["task_index"]))
- inputs = {
- OBS_STATE: state_norm,
- OBS_TASK: task,
- f"{OBS_IMAGES}.image0": camera_images[0],
- f"{OBS_IMAGES}.image1": camera_images[1],
- f"{OBS_IMAGES}.image2": camera_images[2],
- f"{OBS_IMAGES}.image0_mask": torch.tensor(True),
- f"{OBS_IMAGES}.image1_mask": torch.tensor(True),
- f"{OBS_IMAGES}.image2_mask": torch.tensor(True),
- }
- return A2DOpenLoopSample(
- index=idx,
- episode_index=int(row["episode_index"]),
- task=task,
- state_raw=state_raw,
- action_raw=action_raw,
- inputs=inputs,
- )
-
-
-def collate_open_loop_samples(
- samples: list[A2DOpenLoopSample],
- *,
- device: str,
- dtype: torch.dtype,
-) -> tuple[dict[str, torch.Tensor], dict[str, Any]]:
- first = samples[0]
- batch_inputs: dict[str, torch.Tensor] = {}
- for key in first.inputs:
- values = [sample.inputs[key] for sample in samples]
- if isinstance(values[0], torch.Tensor):
- tensor = torch.stack(values, dim=0)
- if tensor.dtype in (torch.int64, torch.bool):
- batch_inputs[key] = tensor.to(device=device)
- else:
- batch_inputs[key] = tensor.to(device=device, dtype=dtype)
- else:
- batch_inputs[key] = values
-
- metadata = {
- "indices": [sample.index for sample in samples],
- "episode_indices": [sample.episode_index for sample in samples],
- "tasks": [sample.task for sample in samples],
- "state_raw": torch.stack([sample.state_raw for sample in samples], dim=0),
- "action_raw": torch.stack([sample.action_raw for sample in samples], dim=0),
- }
- return batch_inputs, metadata
-
-
-def plot_prediction_series(
- *,
- series: dict[str, np.ndarray],
- output_path: Path,
- title: str,
-) -> None:
- import matplotlib.pyplot as plt
-
- first_series = next(iter(series.values()))
- num_dims = int(first_series.shape[1])
- num_cols = 2
- num_rows = math.ceil(num_dims / num_cols)
- fig, axs = plt.subplots(num_rows, num_cols, figsize=(16, max(6, 3 * num_rows)))
- axs = np.array(axs).reshape(-1)
- x_values = np.arange(first_series.shape[0])
- styles = [
- ("Ground Truth", "blue", "-", 1.5),
- ("VLLM", "green", "-.", 1.4),
- ("Predicted", "red", "--", 1.4),
- ]
- style_map = {name: (color, linestyle, linewidth) for name, color, linestyle, linewidth in styles}
-
- for dim in range(num_dims):
- ax = axs[dim]
- for name, values in series.items():
- color, linestyle, linewidth = style_map.get(name, (None, "-", 1.2))
- ax.plot(
- x_values,
- values[:, dim],
- label=name,
- color=color,
- linestyle=linestyle,
- linewidth=linewidth,
- )
- ax.set_title(f"Dimension {dim + 1}")
- ax.set_xlabel("Time Step / Sample Index")
- ax.set_ylabel(f"Value Dim {dim + 1}")
- ax.legend(loc="upper right")
- ax.grid(True, linestyle="--", alpha=0.7)
-
- for dim in range(num_dims, len(axs)):
- axs[dim].axis("off")
-
- fig.suptitle(title, fontsize=16)
- plt.tight_layout(rect=(0, 0, 1, 0.97))
- output_path.parent.mkdir(parents=True, exist_ok=True)
- plt.savefig(output_path)
- plt.close(fig)
-
-
-def summarize_prediction_metrics(
- *,
- gt_tensor: torch.Tensor,
- pred_tensor: torch.Tensor,
- joint_dims: int = 14,
-) -> dict[str, float]:
- return {
- "mse": float(F.mse_loss(gt_tensor, pred_tensor, reduction="mean").item()),
- "mae": float(F.l1_loss(gt_tensor, pred_tensor, reduction="mean").item()),
- "mse_joint": float(F.mse_loss(gt_tensor[:, :joint_dims], pred_tensor[:, :joint_dims], reduction="mean").item()),
- "mae_joint": float(F.l1_loss(gt_tensor[:, :joint_dims], pred_tensor[:, :joint_dims], reduction="mean").item()),
- "mse_gripper": float(
- F.mse_loss(gt_tensor[:, joint_dims:], pred_tensor[:, joint_dims:], reduction="mean").item()
- ),
- "mae_gripper": float(
- F.l1_loss(gt_tensor[:, joint_dims:], pred_tensor[:, joint_dims:], reduction="mean").item()
- ),
- }
-
-
-def summarize_metric_list(values: list[float]) -> float | None:
- return float(np.mean(values)) if values else None
-
-
-def run_open_loop_evaluation(
- *,
- mode: str,
- policy,
- config,
- dataset,
- train_meta,
- collate_samples: Callable[..., tuple[dict[str, torch.Tensor], dict[str, Any]]],
- run_sample_actions: Callable[[Any, dict[str, torch.Tensor], torch.Tensor], torch.Tensor],
- num_episodes: int,
- seed: int,
- device: str,
- dtype: torch.dtype,
- output_dir: str | Path,
- skip_plots: bool,
-) -> dict[str, Any]:
- output_dir = Path(output_dir)
- output_dir.mkdir(parents=True, exist_ok=True)
- plots_dir = output_dir / "plots"
- plots_dir.mkdir(parents=True, exist_ok=True)
-
- mse_values: list[float] = []
- mae_values: list[float] = []
- mse_joint_values: list[float] = []
- mae_joint_values: list[float] = []
- mse_gripper_values: list[float] = []
- mae_gripper_values: list[float] = []
- per_episode: list[dict[str, Any]] = []
-
- plotting_available = True
- if not skip_plots:
- try:
- import matplotlib.pyplot as _plt # noqa: F401
- except ModuleNotFoundError:
- plotting_available = False
- print("[warning] matplotlib is not installed; plots will be skipped.")
-
- episode_specs = dataset.episode_start_indices(max_episodes=num_episodes)
- for episode_index, indices in episode_specs:
- print(f"[{mode}] episode: {episode_index}")
- pred_chunks = []
- gt_chunks = []
- visited_indices = []
- task = None
-
- for index in indices:
- sample = dataset.get_sample(index)
- task = sample.task
- batch_inputs, meta = collate_samples([sample], device=device, dtype=dtype)
- noise = make_shared_noise(
- seed,
- index,
- (batch_inputs[OBS_STATE].shape[0], config.chunk_size, config.max_action_dim),
- device,
- )
- with torch.no_grad():
- pred = run_sample_actions(policy, batch_inputs, noise)
-
- pred = pred[:, :, : dataset.physical_action_dim].to(torch.float32).cpu()
- pred_phys = unnormalize_vector(pred, dataset.action_stats)
- if train_meta.action_mode == "delta":
- pred_phys[:, :, :14] += meta["state_raw"][:, None, :14]
-
- gt_phys = meta["action_raw"][:, :, : dataset.physical_action_dim].to(torch.float32).cpu()
- pred_chunks.append(pred_phys[0])
- gt_chunks.append(gt_phys[0])
- visited_indices.append(index)
-
- pred_tensor = torch.cat(pred_chunks, dim=0)
- gt_tensor = torch.cat(gt_chunks, dim=0)
- metrics = summarize_prediction_metrics(gt_tensor=gt_tensor, pred_tensor=pred_tensor)
-
- mse_values.append(metrics["mse"])
- mae_values.append(metrics["mae"])
- mse_joint_values.append(metrics["mse_joint"])
- mae_joint_values.append(metrics["mae_joint"])
- mse_gripper_values.append(metrics["mse_gripper"])
- mae_gripper_values.append(metrics["mae_gripper"])
-
- if not skip_plots and plotting_available:
- plot_prediction_series(
- series={
- "Ground Truth": gt_tensor.numpy(),
- "VLLM": pred_tensor.numpy(),
- },
- output_path=plots_dir / f"{mode}_open_loop_ep{episode_index}.jpg",
- title=f"{mode} Ground Truth vs VLLM",
- )
-
- episode_log = {
- "episode_id": int(episode_index),
- "task": task,
- "visited_indices": visited_indices,
- "num_pred_steps": int(pred_tensor.shape[0]),
- **metrics,
- }
- per_episode.append(episode_log)
- print(json.dumps({"mode": mode, **episode_log}, ensure_ascii=False))
-
- summary = {
- "mode": mode,
- "num_episodes": len(per_episode),
- "mse": mse_values,
- "mae": mae_values,
- "average_mse": summarize_metric_list(mse_values),
- "average_mae": summarize_metric_list(mae_values),
- "mse_joint": mse_joint_values,
- "mae_joint": mae_joint_values,
- "average_mse_joint": summarize_metric_list(mse_joint_values),
- "average_mae_joint": summarize_metric_list(mae_joint_values),
- "mse_gripper": mse_gripper_values,
- "mae_gripper": mae_gripper_values,
- "average_mse_gripper": summarize_metric_list(mse_gripper_values),
- "average_mae_gripper": summarize_metric_list(mae_gripper_values),
- "episodes": per_episode,
- }
- with open(output_dir / "log.json", "w", encoding="utf-8") as f:
- json.dump(summary, f, indent=2, ensure_ascii=False)
- return summary
diff --git a/examples/offline_inference/internvla_a1/run.sh b/examples/offline_inference/internvla_a1/run.sh
deleted file mode 100755
index 3ae9f776f8f..00000000000
--- a/examples/offline_inference/internvla_a1/run.sh
+++ /dev/null
@@ -1,23 +0,0 @@
-#!/usr/bin/env bash
-set -euo pipefail
-
-ROOT_DIR="$(cd "$(dirname "${BASH_SOURCE[0]}")" && pwd)"
-REPO_ROOT="$(cd "$ROOT_DIR/../../.." && pwd)"
- : "${INTERNVLA_A1_MODEL_DIR:?Please export INTERNVLA_A1_MODEL_DIR=/path/to/InternVLA-A1-3B-ft-pen}"
- : "${INTERNVLA_A1_DATASET_DIR:?Please export INTERNVLA_A1_DATASET_DIR=/path/to/Genie1-Place_Markpen}"
- : "${INTERNVLA_A1_PROCESSOR_DIR:?Please export INTERNVLA_A1_PROCESSOR_DIR=/path/to/Qwen3-VL-2B-Instruct}"
- : "${INTERNVLA_A1_COSMOS_DIR:?Please export INTERNVLA_A1_COSMOS_DIR=/path/to/Cosmos-Tokenizer-CI8x8-SafeTensor}"
-INTERNVLA_A1_OUTPUT_DIR="${INTERNVLA_A1_OUTPUT_DIR:-$REPO_ROOT/outputs/internvla_a1/vllm_infer}"
-
-export INTERNVLA_A1_MODEL_DIR
-export INTERNVLA_A1_DATASET_DIR
-export INTERNVLA_A1_PROCESSOR_DIR
-export INTERNVLA_A1_COSMOS_DIR
-
-python "$ROOT_DIR/end2end.py" \
- --model-dir "$INTERNVLA_A1_MODEL_DIR" \
- --dataset-dir "$INTERNVLA_A1_DATASET_DIR" \
- --output-dir "$INTERNVLA_A1_OUTPUT_DIR" \
- --num-episodes "${INTERNVLA_A1_NUM_EPISODES:-1}" \
- --attn-implementation eager \
- "$@"
diff --git a/examples/offline_inference/magi_human/README.md b/examples/offline_inference/magi_human/README.md
deleted file mode 100644
index 2b89093d941..00000000000
--- a/examples/offline_inference/magi_human/README.md
+++ /dev/null
@@ -1,72 +0,0 @@
-# MagiHuman Generation
-
-MagiHuman is an advanced, omni-modality model that generates both high-quality video and lip-synced audio from a text prompt.
-
-Because MagiHuman is a very large model featuring a powerful DiT MoE backbone and a ~9B parameter T5Gemma text encoder, it natively supports **Tensor Parallelism (TP)** in vLLM-Omni to run efficiently across multi-GPU setups, reducing device memory bottlenecks.
-
-## Setup
-
-### Install MagiCompiler (recommended)
-
-MagiHuman relies on [MagiCompiler](https://github.com/SandAI-org/MagiCompiler) for custom-op registration used by the DiT attention kernels. While the pipeline can fall back to stub implementations, installing MagiCompiler is **strongly recommended** for correct behaviour.
-
-```bash
-# Clone the repo
-git clone https://github.com/SandAI-org/MagiCompiler.git
-cd MagiCompiler
-
-# System dependencies (optional, for FX graph visualization; Debian/Ubuntu)
-sudo apt update && sudo apt install -y graphviz
-
-# Python dependencies
-pip install -r requirements.txt
-
-# Install MagiCompiler
-pip install . # end users (recommended)
-# pip install -e . # developers (editable install)
-```
-
-### Hardware requirements
-
-Ensure your hardware has enough VRAM. For a standard node with 80GB GPUs, running with `--tensor-parallel-size 4` is recommended to shard both the MoE weights and the T5Gemma text encoder across 4 GPUs, reducing the per-GPU peak VRAM overhead significantly (by roughly ~13.5GB per GPU compared to single-device inference).
-
-Please refer to the [stage configuration documentation](https://docs.vllm.ai/projects/vllm-omni/en/latest/configuration/stage_configs/) for further details on allocating memory.
-
-## Run Examples
-
-Get into the example folder:
-```bash
-cd examples/offline_inference/magi_human
-```
-
-### End-to-End Generation (Text to Video+Audio)
-
-Generate a video with synchronized speech natively generated by the model.
-
-```bash
-python end2end.py \
- --model /proj-tango-pvc/users/zhipeng.wang/workspace/models/daVinci-MagiHuman \
- --prompt "A young woman with long, wavy golden blonde hair..." \
- --tensor-parallel-size 4 \
- --output output_magihuman.mp4
-```
-
-## Common Parameters
-
-| Parameter | Default | Description |
-|-----------|---------|-------------|
-| `--model` | *(Required)* | Local model path or HuggingFace ID |
-| `--prompt` | *(built-in demo prompt)* | Highly detailed text prompt dictating visual look and dialogue text |
-| `--tensor-parallel-size` | `4` | Tensor parallelism size (Number of GPUs) |
-| `--height` | `256` | Initial resolution height |
-| `--width` | `448` | Initial resolution width |
-| `--num-inference-steps` | `8` | Denoising steps |
-| `--seed` | `52` | Random seed |
-| `--output` | `output_magihuman.mp4` | Output video with audio path |
-
-## Example materials
-
-??? abstract "end2end.py"
- ``````py
- --8<-- "examples/offline_inference/magi_human/end2end.py"
- ``````
diff --git a/examples/offline_inference/magi_human/end2end.py b/examples/offline_inference/magi_human/end2end.py
deleted file mode 100644
index 64f11c4658b..00000000000
--- a/examples/offline_inference/magi_human/end2end.py
+++ /dev/null
@@ -1,122 +0,0 @@
-import argparse
-
-from vllm_omni.diffusion.utils.media_utils import mux_video_audio_bytes
-from vllm_omni.entrypoints.omni import Omni
-from vllm_omni.inputs.data import OmniDiffusionSamplingParams
-
-
-def parse_args():
- parser = argparse.ArgumentParser(description="End-to-end inference script for MagiHuman.")
- parser.add_argument("--model", type=str, required=True, help="Path or ID of the MagiHuman model.")
- parser.add_argument(
- "--prompt",
- type=str,
- default="",
- help="Text prompt containing visual description, dialogue, and background sound.",
- )
- parser.add_argument(
- "--tensor-parallel-size", "-tp", type=int, default=4, help="Tensor parallel size (number of GPUs)."
- )
- parser.add_argument(
- "--output", type=str, default="output_magihuman.mp4", help="Path to save the generated mp4 file."
- )
- parser.add_argument("--height", type=int, default=256, help="Video height.")
- parser.add_argument("--width", type=int, default=448, help="Video width.")
- parser.add_argument("--num-inference-steps", type=int, default=8, help="Number of denoising steps.")
- parser.add_argument("--seed", type=int, default=52, help="Random seed for generation.")
- return parser.parse_args()
-
-
-def main():
- args = parse_args()
-
- print(f"Initializing MagiHuman pipeline with TP={args.tensor_parallel_size}...")
- omni = Omni(
- model=args.model,
- init_timeout=1200,
- tensor_parallel_size=args.tensor_parallel_size,
- devices=list(range(args.tensor_parallel_size)),
- )
-
- prompt = args.prompt
- if not prompt:
- prompt = (
- "A young woman with long, wavy golden blonde hair and bright blue eyes, "
- "wearing a fitted ivory silk blouse with a delicate lace collar, sits "
- "stationary in front of a softly lit, blurred warm-toned interior. Her "
- "overall disposition is warm, composed, and gently confident. The camera "
- "holds a static medium close-up, framing her from the shoulders up, "
- "with shallow depth of field keeping her face in sharp focus. Soft "
- "directional key light falls from the upper left, casting a gentle "
- "highlight along her cheekbone and nose bridge. She draws a quiet breath, "
- "the levator labii superiors relaxing as her lips part. She speaks in "
- "clear, warm, unhurried American English: "
- "\"The most beautiful things in life aren't things at all — "
- "they're moments, feelings, and the people who make you feel truly alive.\" "
- "Her jaw descends smoothly on each stressed syllable; the orbicularis oris "
- "shapes each vowel with precision. A faint, genuine smile engages the "
- "zygomaticus major, lifting her lip corners fractionally. Her brows rest "
- "in a soft, neutral arch throughout. She maintains steady, forward-facing "
- "eye contact. Head position remains level; no torso displacement occurs.\n\n"
- "Dialogue:\n"
- "<Young blonde woman, American English>: "
- "\"The most beautiful things in life aren't things at all — "
- "they're moments, feelings, and the people who make you feel truly alive.\"\n\n"
- "Background Sound:\n"
- "<Soft, warm indoor ambience with a faint distant piano melody>"
- )
-
- sampling_params = OmniDiffusionSamplingParams(
- height=args.height,
- width=args.width,
- num_inference_steps=args.num_inference_steps,
- seed=args.seed,
- extra_args={
- "seconds": 5,
- "sr_height": 1080,
- "sr_width": 1920,
- "sr_num_inference_steps": 5,
- },
- )
-
- print(f"Generating with prompt: {prompt[:80]}...")
- outputs = omni.generate(
- prompts=[prompt],
- sampling_params_list=[sampling_params],
- )
-
- print(f"Generation complete. Output type: {type(outputs)}")
- if outputs:
- first = outputs[0]
-
- if hasattr(first, "images") and first.images:
- video_frames = first.images[0]
- print(f"Video frames: shape={video_frames.shape}, dtype={video_frames.dtype}")
-
- audio_waveform = None
- mm = first.multimodal_output or {}
- if mm:
- audio_waveform = mm.get("audio")
- if audio_waveform is not None:
- print(f"Audio waveform: shape={audio_waveform.shape}, dtype={audio_waveform.dtype}")
-
- output_fps = float(mm.get("fps", 25))
- output_sr = int(mm.get("audio_sample_rate", 24000))
- print(f"Using fps={output_fps}, audio_sample_rate={output_sr} from model output")
-
- video_bytes = mux_video_audio_bytes(
- video_frames,
- audio_waveform,
- fps=output_fps,
- audio_sample_rate=output_sr,
- )
- with open(args.output, "wb") as f:
- f.write(video_bytes)
- print(f"Saved MP4 ({len(video_bytes)} bytes) to {args.output}")
- print("SUCCESS: MagiHuman pipeline generation completed.")
- else:
- print("WARNING: No outputs returned.")
-
-
-if __name__ == "__main__":
- main()
diff --git a/examples/offline_inference/mammothmodal2_preview/README.md b/examples/offline_inference/mammothmodal2_preview/README.md
deleted file mode 100644
index 44b20c76a14..00000000000
--- a/examples/offline_inference/mammothmodal2_preview/README.md
+++ /dev/null
@@ -1,32 +0,0 @@
-# MammothModa2-Preview
-
-## Run examples (MammothModa2-Preview)
-
-Download model
-```bash
-hf bytedance-research/MammothModa2-Preview --local-dir ./MammothModa2-Preview
-```
-
-### Text-to-Image (T2I)
-
-```bash
-python examples/offline_inference/mammothmodal2_preview/run_mammothmoda2_t2i.py \
- --model ./MammothModa2-Preview \
- --stage-config ./vllm_omni/model_executor/stage_configs/mammoth_moda2.yaml \
- --prompt "A stylish woman riding a motorcycle in NYC, movie poster style" \
- --height 1024 \
- --width 1024 \
- --num-inference-steps 50 \
- --text-guidance-scale 4.0 \
- --out output.png
-```
-
-### Image Summary
-
-```bash
-python examples/offline_inference/mammothmodal2_preview/run_mammothmoda2_image_summarize.py \
- --model ./MammothModa2-Preview \
- --stage-config ./vllm_omni/model_executor/stage_configs/mammoth_moda2_ar.yaml \
- --question "Summarize this image." \
- --image ./image.png
-```
diff --git a/examples/offline_inference/mammothmodal2_preview/run_mammothmoda2_image_summarize.py b/examples/offline_inference/mammothmodal2_preview/run_mammothmoda2_image_summarize.py
deleted file mode 100644
index a742b535f69..00000000000
--- a/examples/offline_inference/mammothmodal2_preview/run_mammothmoda2_image_summarize.py
+++ /dev/null
@@ -1,121 +0,0 @@
-"""
-Offline inference example: MammothModa2 image summarization (single AR stage).
-
-Example:
- uv run python examples/offline_inference/mammothmodal2_preview/run_mammothmoda2_image_summarize.py \
- --model path/to/MammothModa2-Preview \
- --stage-config vllm_omni/model_executor/stage_configs/mammoth_moda2_ar.yaml \
- --image /path/to/input.jpg \
- --question "Please summarize the content of this image."
-"""
-
-from __future__ import annotations
-
-import argparse
-import os
-
-from PIL import Image
-from vllm import SamplingParams
-from vllm.multimodal.image import convert_image_mode
-
-from vllm_omni import Omni
-from vllm_omni.engine.arg_utils import nullify_stage_engine_defaults
-
-DEFAULT_SYSTEM = "You are a helpful assistant."
-DEFAULT_QUESTION = "Please summarize the content of this image."
-
-
-def parse_args() -> argparse.Namespace:
- parser = argparse.ArgumentParser(description="MammothModa2 image summarization (offline, AR only).")
- parser.add_argument("--model", type=str, required=True, help="Path to model directory or model id.")
- parser.add_argument(
- "--stage-config", type=str, required=True, help="Path to stage config yaml (single-stage AR->text)."
- )
- parser.add_argument("--image", type=str, required=True, help="Path to input image.")
- parser.add_argument("--question", type=str, default=DEFAULT_QUESTION, help="Question/instruction for the model.")
- parser.add_argument("--system", type=str, default=DEFAULT_SYSTEM, help="System prompt.")
- parser.add_argument(
- "--max-tokens",
- type=int,
- default=512,
- help="Max new tokens to generate.",
- )
- parser.add_argument("--temperature", type=float, default=0.2)
- parser.add_argument("--top-p", type=float, default=0.9)
- parser.add_argument("--seed", type=int, default=42)
- parser.add_argument("--trust-remote-code", action="store_true")
- parser.add_argument(
- "--enable-diffusion-pipeline-profiler",
- action="store_true",
- help="Enable diffusion pipeline profiler to display stage durations.",
- )
- nullify_stage_engine_defaults(parser)
- return parser.parse_args()
-
-
-def build_prompt(system: str, question: str) -> str:
- return (
- f"<|im_start|>system\n{system}<|im_end|>\n"
- "<|im_start|>user\n"
- "<|vision_start|><|image_pad|><|vision_end|>"
- f"{question}<|im_end|>\n"
- "<|im_start|>assistant\n"
- )
-
-
-def main() -> None:
- args = parse_args()
-
- if not os.path.exists(args.image):
- raise FileNotFoundError(f"Image file not found: {args.image}")
-
- pil_image = Image.open(args.image)
- image_data = convert_image_mode(pil_image, "RGB")
- prompt = build_prompt(args.system, args.question)
-
- omni = Omni(
- model=args.model,
- stage_configs_path=args.stage_config,
- trust_remote_code=args.trust_remote_code,
- enable_diffusion_pipeline_profiler=args.enable_diffusion_pipeline_profiler,
- )
- try:
- sp = SamplingParams(
- temperature=float(args.temperature),
- top_p=float(args.top_p),
- top_k=-1,
- max_tokens=int(args.max_tokens),
- seed=int(args.seed),
- detokenize=True,
- )
- # NOTE: omni.generate() returns a Generator[OmniRequestOutput, None, None].
- # Consume it inside the try block so the worker isn't closed early.
- outputs = list(
- omni.generate(
- [
- {
- "prompt": prompt,
- "multi_modal_data": {"image": image_data},
- "additional_information": {"omni_task": ["chat"]},
- }
- ],
- [sp],
- )
- )
- finally:
- omni.close()
-
- lines: list[str] = []
- for stage_outputs in outputs:
- ro = getattr(stage_outputs, "request_output", stage_outputs)
- text = ro.outputs[0].text if getattr(ro, "outputs", None) else str(ro)
- lines.append(f"request_id: {getattr(ro, 'request_id', 'unknown')}\n")
- lines.append("answer:\n")
- lines.append(text.strip() + "\n")
- lines.append("\n")
-
- print("\n".join(lines))
-
-
-if __name__ == "__main__":
- main()
diff --git a/examples/offline_inference/mammothmodal2_preview/run_mammothmoda2_t2i.py b/examples/offline_inference/mammothmodal2_preview/run_mammothmoda2_t2i.py
deleted file mode 100644
index bd1282a2117..00000000000
--- a/examples/offline_inference/mammothmodal2_preview/run_mammothmoda2_t2i.py
+++ /dev/null
@@ -1,250 +0,0 @@
-"""
-Offline inference example for MammothModa2 Text-to-Image (T2I) generation.
-This script uses the vllm_omni.Omni pipeline with a multi-stage configuration.
-
-Workflow:
-1. Stage 0 (AR): Generates visual tokens and their corresponding hidden states.
-2. Stage 1 (DiT): Consumes the hidden states as conditions to perform diffusion
- and VAE decoding to produce the final image.
-
-Example Usage:
- uv run python examples/offline_inference/run_mammothmoda2_t2i.py \
- --model path/to/MammothModa2-Preview \
- --stage-config vllm_omni/model_executor/stage_configs/mammoth_moda2.yaml \
- --prompt "A stylish woman riding a motorcycle in NYC, movie poster style" \
- --out output.png
-"""
-
-from __future__ import annotations
-
-import argparse
-import json
-import logging
-import os
-from pathlib import Path
-from typing import NamedTuple
-
-import torch
-from PIL import Image
-from vllm.sampling_params import SamplingParams
-
-from vllm_omni import Omni
-from vllm_omni.engine.arg_utils import nullify_stage_engine_defaults
-
-logging.basicConfig(level=logging.INFO, format="%(asctime)s - %(levelname)s - %(message)s")
-logger = logging.getLogger(__name__)
-
-# ---------------------------------------------------------------------------
-# Constants
-# ---------------------------------------------------------------------------
-_PATCH_SIZE = 16 # AR image grid patch size (pixels per token)
-
-
-class T2IGenConfig(NamedTuple):
- eol_token_id: int
- visual_token_start_id: int
- visual_token_end_id: int
- top_k: int # AR sampling top-k (covers the full visual generation vocabulary)
- # Qwen2.5-VL special vision tokens: <|image_pad|>, <|video_pad|>, <|vision_start|>, <|vision_end|>
- visual_ids: list[int]
-
-
-def load_t2i_generation_config(model_dir: str) -> T2IGenConfig:
- """Load T2I token IDs from t2i_generation_config.json and config.json.
-
- Supports both local directory paths and HuggingFace Hub model IDs.
- """
- model_path = Path(model_dir)
-
- def _read_json(filename: str) -> dict:
- local = model_path / filename
- if local.exists():
- with local.open(encoding="utf-8") as f:
- return json.load(f)
- # Fall back to HuggingFace Hub when model_dir is a repo ID.
- try:
- from huggingface_hub import hf_hub_download
- except ImportError as exc:
- raise ImportError(
- "huggingface_hub is required to load configs from HF Hub. Install it with: pip install huggingface_hub"
- ) from exc
- cached = hf_hub_download(repo_id=model_dir, filename=filename)
- with open(cached, encoding="utf-8") as f:
- return json.load(f)
-
- gen_cfg = _read_json("t2i_generation_config.json")
- llm_cfg = _read_json("config.json").get("llm_config", {})
-
- return T2IGenConfig(
- eol_token_id=int(gen_cfg["eol_token_id"]),
- visual_token_start_id=int(gen_cfg["visual_token_start_id"]),
- visual_token_end_id=int(gen_cfg["visual_token_end_id"]),
- top_k=int(gen_cfg["top_k"]),
- visual_ids=[
- int(llm_cfg["image_token_id"]),
- int(llm_cfg["video_token_id"]),
- int(llm_cfg["vision_start_token_id"]),
- int(llm_cfg["vision_end_token_id"]),
- ],
- )
-
-
-def parse_args() -> argparse.Namespace:
- p = argparse.ArgumentParser(description="Run MammothModa2 T2I (AR -> DiT) with vLLM-Omni.")
- p.add_argument("--model", type=str, required=True, help="Path to the model directory.")
- p.add_argument("--stage-config", type=str, required=True, help="Path to the multi-stage YAML configuration.")
- p.add_argument(
- "--prompt",
- type=str,
- action="append",
- default=None,
- help=(
- "Text prompt for image generation. Can be provided multiple times "
- "to generate multiple images with shared height/width/CFG settings."
- ),
- )
- p.add_argument("--height", type=int, default=1024, help="Output image height (must be a multiple of 16).")
- p.add_argument("--width", type=int, default=1024, help="Output image width (must be a multiple of 16).")
- p.add_argument("--num-inference-steps", type=int, default=50, help="Number of diffusion steps for the DiT stage.")
- p.add_argument(
- "--text-guidance-scale", type=float, default=9.0, help="Classifier-Free Guidance (CFG) scale for DiT."
- )
- p.add_argument(
- "--cfg-range",
- type=float,
- nargs=2,
- default=(0.0, 1.0),
- help="Relative step range [start, end] where CFG is active.",
- )
- p.add_argument("--out", type=str, default="output.png", help="Path to save the generated image.")
- p.add_argument("--trust-remote-code", action="store_true", help="Trust remote code when loading the model.")
- nullify_stage_engine_defaults(p)
- args = p.parse_args()
- if not args.prompt:
- args.prompt = ["A stylish woman with sunglasses riding a motorcycle in NYC."]
- return args
-
-
-def tensor_to_pil(image: torch.Tensor) -> Image.Image:
- """Convert a normalized torch tensor [-1, 1] to a PIL Image."""
- if image.ndim == 4:
- image = image[0]
- image = image.detach().to("cpu")
- image = (image / 2 + 0.5).clamp(0, 1)
- image = (image * 255).to(torch.uint8)
- image = image.permute(1, 2, 0).contiguous().numpy()
- return Image.fromarray(image)
-
-
-def _format_prompt(user_prompt: str, ar_width: int, ar_height: int) -> str:
- """Build the AR-stage prompt string including the image grid header."""
- return (
- "<|im_start|>system\nYou are a helpful image generator.<|im_end|>\n"
- f"<|im_start|>user\n{user_prompt}<|im_end|>\n"
- "<|im_start|>assistant\n"
- f"<|image start|>{ar_width}*{ar_height}<|image token|>"
- )
-
-
-def _collect_images(outputs: list) -> list[torch.Tensor]:
- """Extract all image tensors produced by the final (DiT) stage."""
- images: list[torch.Tensor] = []
- for out in outputs:
- ro_item = getattr(out, "request_output", out)
- for completion in getattr(ro_item, "outputs", None) or []:
- mm = getattr(completion, "multimodal_output", None)
- if not isinstance(mm, dict) or "image" not in mm:
- raise RuntimeError(f"Missing image in multimodal output: {mm}")
- payload = mm["image"]
- for tensor in payload if isinstance(payload, list) else [payload]:
- if not isinstance(tensor, torch.Tensor):
- raise TypeError(f"Expected image tensor, got {type(tensor)}")
- images.append(tensor)
- return images
-
-
-def _save_images(images: list[torch.Tensor], out_path: str) -> list[str]:
- """Save image tensors to disk.
-
- Single image: written to *out_path* exactly.
- Multiple images: suffixed as ``<base>_0<ext>``, ``<base>_1<ext>``, …
- """
- if not images:
- raise RuntimeError("No images to save.")
- base, ext = os.path.splitext(out_path)
- ext = ext or ".png"
- paths = []
- for i, tensor in enumerate(images):
- path = out_path if len(images) == 1 else f"{base}_{i}{ext}"
- tensor_to_pil(tensor).save(path)
- paths.append(path)
- return paths
-
-
-def main() -> None:
- args = parse_args()
- os.makedirs(os.path.dirname(args.out) or ".", exist_ok=True)
-
- if args.height <= 0 or args.width <= 0:
- raise ValueError(f"Height and width must be positive, got {args.height}x{args.width}")
- if args.height % _PATCH_SIZE != 0 or args.width % _PATCH_SIZE != 0:
- raise ValueError(f"Height and width must be multiples of {_PATCH_SIZE}, got {args.height}x{args.width}")
-
- ar_height = args.height // _PATCH_SIZE
- ar_width = args.width // _PATCH_SIZE
- gen_cfg = load_t2i_generation_config(args.model)
- expected_grid_tokens = ar_height * (ar_width + 1)
-
- logger.info("Initializing Omni pipeline...")
- omni = Omni(model=args.model, stage_configs_path=args.stage_config, trust_remote_code=args.trust_remote_code)
- try:
- ar_sampling = SamplingParams(
- temperature=1.0,
- top_p=1.0,
- top_k=gen_cfg.top_k,
- max_tokens=max(1, expected_grid_tokens + 1), # +1 for hidden state of eoi
- detokenize=False,
- )
- dit_sampling = SamplingParams(
- temperature=0.0,
- top_p=1.0,
- top_k=-1,
- max_tokens=1,
- detokenize=False,
- )
-
- additional_information = {
- "omni_task": ["t2i"],
- "ar_width": [ar_width],
- "ar_height": [ar_height],
- "eol_token_id": [gen_cfg.eol_token_id],
- "visual_token_start_id": [gen_cfg.visual_token_start_id],
- "visual_token_end_id": [gen_cfg.visual_token_end_id],
- "image_height": [args.height],
- "image_width": [args.width],
- "num_inference_steps": [args.num_inference_steps],
- "text_guidance_scale": [args.text_guidance_scale],
- "cfg_range": [args.cfg_range[0], args.cfg_range[1]],
- "visual_ids": gen_cfg.visual_ids,
- }
- inputs = [
- {
- "prompt": _format_prompt(p, ar_width, ar_height),
- "additional_information": dict(additional_information),
- }
- for p in args.prompt
- ]
-
- logger.info("Starting generation...")
- # omni.generate() returns a Generator; consume it to run the full pipeline.
- outputs = list(omni.generate(inputs, [ar_sampling, dit_sampling]))
-
- logger.info("Post-processing and saving image(s)...")
- for path in _save_images(_collect_images(outputs), args.out):
- logger.info(f"Saved: {path}")
- finally:
- omni.close()
-
-
-if __name__ == "__main__":
- main()
diff --git a/examples/offline_inference/mimo_audio/README.md b/examples/offline_inference/mimo_audio/README.md
deleted file mode 100644
index 5615dea5176..00000000000
--- a/examples/offline_inference/mimo_audio/README.md
+++ /dev/null
@@ -1,201 +0,0 @@
-# MiMo-Audio Offline Inference
-
-This directory contains an offline demo for running MiMo-Audio models with vLLM Omni. It builds task-specific inputs and generates WAV files or text outputs locally.
-
-## Model Overview
-
-MiMo-Audio provides multiple task variants for audio understanding and generation:
-
-- **tts_sft**: Basic text-to-speech generation from text input.
-- **tts_sft_with_instruct**: TTS generation with explicit voice style instructions.
-- **tts_sft_with_audio**: TTS generation with audio reference for voice cloning.
-- **tts_sft_with_natural_instruction**: TTS generation from natural language descriptions embedded in text.
-- **audio_trancribing_sft**: Transcribe audio to text (speech-to-text). (note: the upstream task name uses the spelling 'trancribing', don't fix it)
-- **audio_understanding_sft**: Understand and analyze audio content with text queries.
-- **audio_understanding_sft_with_thinking**: Audio understanding with reasoning chain.
-- **spoken_dialogue_sft_multiturn**: Multi-turn spoken dialogue with audio input/output.
-- **speech2text_dialogue_sft_multiturn**: Multi-turn dialogue converting speech to text.
-- **text_dialogue_sft_multiturn**: Multi-turn text-only dialogue.
-
-## Setup
-
-Please refer to the [stage configuration documentation](https://docs.vllm.ai/projects/vllm-omni/en/latest/configuration/stage_configs/) to configure memory allocation appropriately for your hardware setup.
-
-### Environment Variables
-
-The `MIMO_AUDIO_TOKENIZER_PATH` environment variable is mandatory due to the specialized architecture:
-
-```bash
-export MIMO_AUDIO_TOKENIZER_PATH="XiaomiMiMo/MiMo-Audio-Tokenizer"
-```
-
-### Flash Attention (audio generation)
-
-For **audio generation** (e.g. TTS variants, multi-turn spoken dialogue with audio output), install the **`flash-attn`** package with a build that matches your **CUDA** and **PyTorch** versions. On GPU, omitting **`flash-attn`** can cause **generated audio to be noise-only or otherwise unusable**. See the [FlashAttention](https://github.com/Dao-AILab/flash-attention) project for installation options and prebuilt wheels.
-
-## Quick Start
-
-Run a single sample for basic TTS:
-
-```bash
-python3 -u end2end.py \
- --model-name XiaomiMiMo/MiMo-Audio-7B-Instruct \
- --query-type tts_sft
-```
-
-Run batch samples for basic TTS:
-
-```bash
-python3 -u end2end.py \
- --model-name XiaomiMiMo/MiMo-Audio-7B-Instruct \
- --query-type tts_sft \
- --num-prompts {batch_size}
-```
-
-When enabling multi-batch processing, if the total number of tokens passed to the next stage exceeds the `max_model_len` value in the `mimo_audio.yaml` configuration file, you must also synchronously update the `max_position_embeddings` value in `MiMo-Audio-7B-Instruct/config.json` to match the modified value.
-
-Generated audio files are saved to `output_audio/` by default. `--num-prompts` also can be used to all tasks below.
-
-## Task Usage
-
-### tts_sft (Basic Text-to-Speech)
-
-Generate speech from text input:
-
-```bash
-python3 -u end2end.py \
- --model-name XiaomiMiMo/MiMo-Audio-7B-Instruct \
- --query-type tts_sft \
- --text "The weather is so nice today."
-```
-
-### tts_sft_with_instruct (TTS with Voice Instructions)
-
-Generate speech with explicit voice style instructions:
-
-```bash
-python3 -u end2end.py \
- --model-name XiaomiMiMo/MiMo-Audio-7B-Instruct \
- --query-type tts_sft_with_instruct \
- --text "The weather is so nice today." \
- --instruct "Speak happily in a child's voice"
-```
-
-### tts_sft_with_audio (TTS with Audio Reference)
-
-Generate speech using an audio reference for voice cloning:
-
-```bash
-python3 -u end2end.py \
- --model-name XiaomiMiMo/MiMo-Audio-7B-Instruct \
- --query-type tts_sft_with_audio \
- --text "The weather is so nice today." \
- --audio-path "./spoken_dialogue_assistant_turn_1.wav"
-```
-
-### tts_sft_with_natural_instruction (Natural Language TTS)
-
-Generate speech from text containing natural voice descriptions:
-
-```bash
-python3 -u end2end.py \
- --model-name XiaomiMiMo/MiMo-Audio-7B-Instruct \
- --query-type tts_sft_with_natural_instruction \
- --text "In a panting young male voice, he said: I can't run anymore, wait for me!"
-```
-
-### audio_trancribing_sft (Speech-to-Text)
-
-Transcribe audio to text:
-
-```bash
-python3 -u end2end.py \
- --model-name XiaomiMiMo/MiMo-Audio-7B-Instruct \
- --query-type audio_trancribing_sft \
- --audio-path "./spoken_dialogue_assistant_turn_1.wav"
-```
-
-### audio_understanding_sft (Audio Understanding)
-
-Understand and analyze audio content with text queries:
-
-```bash
-python3 -u end2end.py \
- --model-name XiaomiMiMo/MiMo-Audio-7B-Instruct \
- --query-type audio_understanding_sft \
- --text "Summarize the audio." \
- --audio-path "./spoken_dialogue_assistant_turn_1.wav"
-```
-
-### audio_understanding_sft_with_thinking (Audio Understanding with Reasoning)
-
-Audio understanding with reasoning chain:
-
-```bash
-python3 -u end2end.py \
- --model-name XiaomiMiMo/MiMo-Audio-7B-Instruct \
- --query-type audio_understanding_sft_with_thinking \
- --text "Summarize the audio." \
- --audio-path "./spoken_dialogue_assistant_turn_1.wav"
-```
-
-### spoken_dialogue_sft_multiturn (Multi-turn Spoken Dialogue)
-
-Multi-turn dialogue with audio input and output:
-
-```bash
-python3 -u end2end.py \
- --model-name XiaomiMiMo/MiMo-Audio-7B-Instruct \
- --query-type spoken_dialogue_sft_multiturn \
- --audio-path "./prompt_speech_zh_m.wav"
-```
-
-Note: This task uses hardcoded audio files in the script. The audio files used in examples are available at: https://github.com/XiaomiMiMo/MiMo-Audio/tree/main/examples
-
-### speech2text_dialogue_sft_multiturn (Speech-to-Text Dialogue)
-
-Multi-turn dialogue converting speech to text:
-
-```bash
-python3 -u end2end.py \
- --model-name XiaomiMiMo/MiMo-Audio-7B-Instruct \
- --query-type speech2text_dialogue_sft_multiturn
-```
-
-Note: This task uses hardcoded audio files and message lists in the script.
-
-### text_dialogue_sft_multiturn (Text Dialogue)
-
-Multi-turn text-only dialogue:
-
-```bash
-python3 -u end2end.py \
- --model-name XiaomiMiMo/MiMo-Audio-7B-Instruct \
- --query-type text_dialogue_sft_multiturn
-```
-
-Note: This task uses hardcoded message lists in the script.
-
-## Troubleshooting
-
-### Tokenizer path
-
-- **`MIMO_AUDIO_TOKENIZER_PATH` not set or model fails to find tokenizer**
- Export the tokenizer path before running:
- ```bash
- export MIMO_AUDIO_TOKENIZER_PATH="XiaomiMiMo/MiMo-Audio-Tokenizer"
- ```
- See [Environment Variables](#environment-variables) in Setup.
-
-### Other
-
-- If the model or stage config fails to load, check [stage configuration documentation](https://docs.vllm.ai/projects/vllm-omni/en/latest/configuration/stage_configs/) for memory and GPU settings.
-- For errors when reading/writing WAV (e.g. unsupported format), ensure input files are standard WAV/MP3 and that `soundfile` is linked to a working libsndfile (see above).
-
-## Notes
-
-- The script uses default model paths and audio files embedded in `end2end.py`. Update them if your local cache path differs.
-- Use `--output-dir` to change the output folder (default: `./output_audio`).
-- Use `--num-prompts` to generate multiple prompts in one run (default: 1).
-- Audio files used in multi-turn dialogue examples are available at: https://github.com/XiaomiMiMo/MiMo-Audio/tree/main/examples
-- The script supports various configuration options for initialization timeouts, batch timeouts, and shared memory thresholds. See `--help` for details.
diff --git a/examples/offline_inference/mimo_audio/end2end.py b/examples/offline_inference/mimo_audio/end2end.py
deleted file mode 100644
index 9c652fe2b05..00000000000
--- a/examples/offline_inference/mimo_audio/end2end.py
+++ /dev/null
@@ -1,446 +0,0 @@
-# SPDX-License-Identifier: Apache-2.0
-# SPDX-FileCopyrightText: Copyright contributors to the vLLM project
-"""
-This example shows how to use vLLM for running offline inference
-with the correct prompt format on MiMo-Audio-Omni.
-"""
-
-import copy
-import json
-import os
-from typing import NamedTuple
-
-import soundfile as sf
-from message_convert import (
- get_audio_data,
- get_audio_understanding_sft_prompt,
- get_s2t_dialogue_sft_multiturn_prompt,
- get_spoken_dialogue_sft_multiturn_prompt,
- get_text_dialogue_sft_multiturn_prompt,
- get_tts_sft_prompt,
- to_prompt,
-)
-from vllm import SamplingParams
-from vllm.utils.argparse_utils import FlexibleArgumentParser
-
-from vllm_omni.entrypoints.omni import Omni
-from vllm_omni.inputs.data import OmniTokensPrompt
-
-SEED = 42
-
-MAX_CODE2WAV_TOKENS = 18192 # Maximum tokens supported by code2wav model
-
-
-class QueryResult(NamedTuple):
- inputs: dict
- limit_mm_per_prompt: dict[str, int]
-
-
-def get_codes_query_from_json(codes_path: str) -> QueryResult:
- with open(codes_path, encoding="utf-8") as f:
- data = json.load(f)
-
- if isinstance(data, list):
- code_final = data
- elif isinstance(data, dict) and "code_final" in data:
- code_final = data["code_final"]
- else:
- raise ValueError(
- f"Unsupported codes json format in {codes_path}.\n"
- "Expect a JSON list[int] or {{'code_final': list[int]}}."
- )
-
- if not isinstance(code_final, list) or not all(isinstance(x, int) for x in code_final):
- raise ValueError("code_final must be a list[int].")
-
- if len(code_final) > MAX_CODE2WAV_TOKENS:
- print(f"[Warn] code_final len={len(code_final)} > {MAX_CODE2WAV_TOKENS}, truncating.")
- code_final = code_final[:MAX_CODE2WAV_TOKENS]
-
- return QueryResult(
- inputs=OmniTokensPrompt(
- prompt_token_ids=code_final,
- multi_modal_data=None,
- mm_processor_kwargs=None,
- ),
- limit_mm_per_prompt={},
- )
-
-
-def get_tts_sft(
- text="The weather is so nice today.",
- instruct=None,
- read_text_only=True,
- prompt_speech=None,
- audio_list=None,
-):
- res = get_tts_sft_prompt(
- text,
- instruct=instruct,
- read_text_only=read_text_only,
- prompt_speech=prompt_speech,
- )
-
- prompt = to_prompt(res)
- final_prompt = {
- "prompt": prompt,
- }
- if audio_list is not None:
- final_prompt.update(
- {
- "multi_modal_data": {
- "audio": audio_list,
- },
- }
- )
- return final_prompt
-
-
-def get_audio_understanding_sft(audio_path, text="", thinking=False, use_sostm=False):
- audio_list = []
- audio_list.append(get_audio_data(audio_path))
- res = get_audio_understanding_sft_prompt(
- input_speech=audio_path, input_text=text, thinking=thinking, use_sostm=use_sostm
- )
- prompt = to_prompt(res)
- final_prompt = {
- "prompt": prompt,
- "multi_modal_data": {
- "audio": audio_list,
- },
- }
- return final_prompt
-
-
-def get_spoken_dialogue_sft_multiturn(message_list, system_prompt=None, ref_audio_path=None, audio_list=None):
- res = get_spoken_dialogue_sft_multiturn_prompt(
- message_list, system_prompt=system_prompt, prompt_speech=ref_audio_path
- )
- prompt = to_prompt(res)
- final_prompt = {
- "prompt": prompt,
- "multi_modal_data": {
- "audio": audio_list,
- },
- }
- return final_prompt
-
-
-def get_speech2text_dialogue_sft_multiturn(message_list, thinking=False, audio_list=None):
- res = get_s2t_dialogue_sft_multiturn_prompt(
- message_list,
- thinking=thinking,
- )
- prompt = to_prompt(res)
- final_prompt = {
- "prompt": prompt,
- "multi_modal_data": {
- "audio": audio_list,
- },
- }
- return final_prompt
-
-
-def get_text_dialogue_sft_multiturn(
- message_list,
-):
- res = get_text_dialogue_sft_multiturn_prompt(
- message_list,
- )
- prompt = to_prompt(res)
- final_prompt = {
- "prompt": prompt,
- }
- return final_prompt
-
-
-query_map = {
- "tts_sft": get_tts_sft,
- "tts_sft_with_instruct": get_tts_sft,
- "tts_sft_with_audio": get_tts_sft,
- "tts_sft_with_natural_instruction": get_tts_sft,
- "audio_trancribing_sft": get_audio_understanding_sft,
- "audio_understanding_sft": get_audio_understanding_sft,
- "audio_understanding_sft_with_thinking": get_audio_understanding_sft,
- "spoken_dialogue_sft_multiturn": get_spoken_dialogue_sft_multiturn,
- "speech2text_dialogue_sft_multiturn": get_speech2text_dialogue_sft_multiturn,
- "text_dialogue_sft_multiturn": get_text_dialogue_sft_multiturn,
-}
-
-
-def main(args):
- model_name = args.model_name
-
- # Get paths from args
- text = getattr(args, "text", None)
- audio_path = getattr(args, "audio_path", None)
-
- instruct = getattr(args, "instruct", None)
-
- # Get the query function and call it with appropriate parameters
- query_func = query_map[args.query_type]
-
- omni = Omni(
- model=model_name,
- deploy_config=args.deploy_config,
- log_stats=args.enable_stats,
- log_file=("omni_pipeline.log" if args.enable_stats else None),
- init_sleep_seconds=args.init_sleep_seconds,
- batch_timeout=args.batch_timeout,
- init_timeout=args.init_timeout,
- shm_threshold_bytes=args.shm_threshold_bytes,
- )
-
- thinker_sampling_params = SamplingParams(
- temperature=0.0,
- top_p=1.0,
- top_k=-1,
- max_tokens=2048,
- seed=SEED,
- logit_bias={},
- repetition_penalty=1.1,
- )
-
- code2wav_sampling_params = SamplingParams(
- temperature=0.0,
- top_p=1.0,
- top_k=-1,
- max_tokens=4096 * 16,
- seed=SEED,
- detokenize=True,
- repetition_penalty=1.1,
- )
-
- sampling_params_list = [
- thinker_sampling_params,
- code2wav_sampling_params,
- ]
-
- # Build query result based on query type
- # Notice: The audio files used in this example are available at: https://github.com/XiaomiMiMo/MiMo-Audio/tree/main/examples
- if args.query_type == "tts_sft":
- # python3 -u end2end.py --stage-configs-path ${config_file} --model ${MODEL_PATH} --query-type tts_sft
- query_result = query_func(text=text, read_text_only=True)
- elif args.query_type == "tts_sft_with_instruct":
- # python3 -u end2end.py --stage-configs-path ${config_file} --model ${MODEL_PATH} --query-type tts_sft_with_instruct --instruct "Speak happily in a child's voice"
- query_result = query_func(text=text, instruct=instruct, read_text_only=True)
- elif args.query_type == "tts_sft_with_audio":
- # python3 -u end2end.py --stage-configs-path ${config_file} --model ${MODEL_PATH} --query-type tts_sft_with_audio --audio_path "./spoken_dialogue_assistant_turn_1.wav"
- audio_list = [get_audio_data(audio_path)]
- query_result = query_func(text=text, read_text_only=True, prompt_speech=audio_path, audio_list=audio_list)
- elif args.query_type == "tts_sft_with_natural_instruction":
- # python3 -u end2end.py --stage-configs-path ${config_file} --model ${MODEL_PATH} --query-type tts_sft_with_natural_instruction --text "In a panting young male voice, he said: I can't run anymore, wait for me!"
- query_result = query_func(text=text, read_text_only=False)
- elif args.query_type == "audio_trancribing_sft":
- # python3 -u end2end.py --stage-configs-path ${config_file} --model ${MODEL_PATH} --query-type audio_trancribing_sft --audio_path "./spoken_dialogue_assistant_turn_1.wav"
- audio_path = "spoken_dialogue_assistant_turn_1.wav"
- text = "Please transcribe this audio and repeat it once."
- query_result = query_func(text=text, audio_path=audio_path, use_sostm=True)
- elif args.query_type == "audio_understanding_sft":
- # python3 -u end2end.py --stage-configs-path ${config_file} --model ${MODEL_PATH} --query-type audio_understanding_sft --text "Summarize the audio." --audio_path "./spoken_dialogue_assistant_turn_1.wav"
- query_result = query_func(text=text, audio_path=audio_path)
- elif args.query_type == "audio_understanding_sft_with_thinking":
- # python3 -u end2end.py --stage-configs-path ${config_file} --model ${MODEL_PATH} --query-type audio_understanding_sft_with_thinking --text "Summarize the audio." --audio_path "./spoken_dialogue_assistant_turn_1.wav"
- query_result = query_func(text=text, audio_path=audio_path, thinking=True)
- elif args.query_type == "spoken_dialogue_sft_multiturn":
- # python3 -u end2end.py --stage-configs-path ${config_file} --model ${MODEL_PATH} --query-type spoken_dialogue_sft_multiturn --audio_path "./prompt_speech_zh_m.wav"
- first_turn_text_response = "我没办法获取实时的天气信息。不过呢,你可以试试几个方法来查看今天的天气。首先,你可以用手机自带的天气功能,比如苹果手机的天气应用,或者直接在系统设置里查看。其次,你也可以用一些专业的天气服务,像是国外的AccuWeather、Weather.com,或者国内的中国天气网、墨迹天气等等。再有就是,你还可以在谷歌或者百度里直接搜索你所在的城市加上天气这两个字。如果你能告诉我你所在的城市,我也可以帮你分析一下历史天气趋势,不过最新的数据还是需要你通过官方渠道去获取哦。"
- audio_list = []
- s1_audio_path = "weather_of_today.mp3"
- s2_audio_path = "spoken_dialogue_assistant_turn_1.wav"
- s3_audio_path = "beijing.mp3"
- audio_list.append(get_audio_data(audio_path))
- audio_list.append(get_audio_data(s1_audio_path))
- audio_list.append(get_audio_data(s2_audio_path))
- audio_list.append(get_audio_data(s3_audio_path))
-
- message_list = [
- {"role": "user", "content": s1_audio_path},
- {"role": "assistant", "content": {"text": first_turn_text_response, "audio": s2_audio_path}},
- {"role": "user", "content": s3_audio_path},
- ]
- query_result = query_func(message_list, system_prompt=None, ref_audio_path=audio_path, audio_list=audio_list)
- elif args.query_type == "speech2text_dialogue_sft_multiturn":
- # python3 -u end2end.py --stage-configs-path ${config_file} --model ${MODEL_PATH} --query-type speech2text_dialogue_sft_multiturn
- s1_audio_path = "weather_of_today.mp3"
- s2_audio_path = "beijing.mp3"
- audio_list = []
- audio_list.append(get_audio_data(s1_audio_path))
- audio_list.append(get_audio_data(s2_audio_path))
- message_list = [
- {"role": "user", "content": s1_audio_path},
- {
- "role": "assistant",
- "content": "Hello, I can't get real-time weather information. If you can tell me your city, I can help you analyze historical weather trends, but for the latest data, you'll need to get it through official channels.",
- },
- {"role": "user", "content": s2_audio_path},
- ]
- query_result = query_func(message_list, thinking=True, audio_list=audio_list)
- elif args.query_type == "text_dialogue_sft_multiturn":
- # python3 -u end2end.py --stage-configs-path ${config_file} --model ${MODEL_PATH} --query-type text_dialogue_sft_multiturn
- message_list = [
- {"role": "user", "content": "Could you recommend some tourist attractions in China?"},
- {"role": "assistant", "content": "Hello, which city would you like to travel to?"},
- {"role": "user", "content": "Beijing"},
- ]
- query_result = query_func(message_list=message_list)
- else:
- raise ValueError(f"Invalid query type: {args.query_type}")
-
- prompts = [copy.deepcopy(query_result) for _ in range(args.num_prompts)]
-
- print("prompts", prompts)
- omni_outputs = omni.generate(prompts, sampling_params_list)
-
- output_dir = args.output_dir if getattr(args, "output_dir", None) else args.output_wav
- if args.query_type is not None:
- output_dir = os.path.join(output_dir, args.query_type)
- os.makedirs(output_dir, exist_ok=True)
-
- for stage_outputs in omni_outputs:
- output = stage_outputs.request_output
- if stage_outputs.final_output_type == "text":
- request_id = output.request_id
- text_output = output.outputs[0].text
- # Save aligned text file per request
- prompt_text = output.prompt
- out_txt = os.path.join(output_dir, f"{request_id}.txt")
- lines = []
- lines.append("Prompt:\n")
- lines.append(str(prompt_text) + "\n")
- lines.append("vllm_text_output:\n")
- output_text = str(text_output)
- if "<chinese>" in output_text or "<english>" in output_text:
- output_text = output_text.replace("<chinese>", "").replace("<english>", "").strip()
- lines.append(output_text + "\n")
- try:
- with open(out_txt, "w", encoding="utf-8") as f:
- print("lines", lines)
- f.writelines(lines)
- except Exception as e:
- print(f"[Warn] Failed writing text file {out_txt}: {e}")
- print(f"Request ID: {request_id}, Text saved to {out_txt}\n")
- elif stage_outputs.final_output_type == "audio":
- request_id = output.request_id
- audio_tensor = output.outputs[0].multimodal_output.get("audio")
-
- if audio_tensor is None:
- continue
-
- output_wav = os.path.join(output_dir, f"{request_id}.wav")
-
- # Convert to numpy array and ensure correct format
- audio_numpy = audio_tensor.float().detach().cpu().numpy()
-
- # Ensure audio is 1D (flatten if needed)
- if audio_numpy.ndim > 1:
- audio_numpy = audio_numpy.flatten()
-
- # Save audio file with explicit WAV format
- sf.write(output_wav, audio_numpy, samplerate=24000, format="WAV")
- print(f"Request ID: {request_id}, Audio saved to {output_wav}")
-
-
-def parse_args():
- parser = FlexibleArgumentParser(description="Demo on using vLLM for offline inference with audio language models")
- parser.add_argument(
- "--model-name",
- "-m",
- type=str,
- default="XiaomiMiMo/MiMo-Audio-7B-Instruct",
- help="Backbone LLM path.",
- )
- parser.add_argument(
- "--text",
- "-t",
- type=str,
- default="",
- help="input text",
- )
- parser.add_argument(
- "--query-type",
- "-q",
- type=str,
- default="tts_sft",
- choices=query_map.keys(),
- help="Query type.",
- )
- parser.add_argument(
- "--audio-path",
- "-a",
- type=str,
- default=None,
- help="Path to local audio file. If not provided, uses default audio asset.",
- )
- parser.add_argument(
- "--instruct",
- type=str,
- default=None,
- help="instruct",
- )
- parser.add_argument(
- "--enable-stats",
- action="store_true",
- help="Enable writing detailed statistics (default: disabled)",
- )
- parser.add_argument(
- "--init-sleep-seconds",
- type=int,
- default=20,
- help="Sleep seconds after starting each stage process to allow initialization (default: 20)",
- )
- parser.add_argument(
- "--batch-timeout",
- type=int,
- default=5,
- help="Timeout for batching in seconds (default: 5)",
- )
- parser.add_argument(
- "--init-timeout",
- type=int,
- default=5000,
- help="Timeout for initializing stages in seconds (default: 5000)",
- )
- parser.add_argument(
- "--shm-threshold-bytes",
- type=int,
- default=65536,
- help="Threshold for using shared memory in bytes (default: 65536)",
- )
- parser.add_argument(
- "--output-dir",
- default="./output_audio",
- help="Output audio wav directory.",
- )
- parser.add_argument(
- "--output-wav",
- default="output_audio",
- help="[Deprecated] Output wav directory (use --output-dir).",
- )
- parser.add_argument(
- "--num-prompts",
- type=int,
- default=1,
- help="Number of prompts to generate.",
- )
-
- parser.add_argument(
- "--sampling-rate",
- type=int,
- default=24000,
- help="Sampling rate for audio.",
- )
- parser.add_argument(
- "--deploy-config",
- type=str,
- default=None,
- help="Override the deploy config path. If unset, auto-loads "
- "vllm_omni/deploy/mimo_audio.yaml based on the HF model_type.",
- )
-
- return parser.parse_args()
-
-
-if __name__ == "__main__":
- args = parse_args()
- main(args)
diff --git a/examples/offline_inference/mimo_audio/message_base64_wav.json b/examples/offline_inference/mimo_audio/message_base64_wav.json
deleted file mode 100644
index 1ddcf70791f..00000000000
--- a/examples/offline_inference/mimo_audio/message_base64_wav.json
+++ /dev/null
@@ -1,56 +0,0 @@
-{
- "messages": [
- {
- "role": "system",
- "content": [
- {
- "type": "text",
- "text": "Your voice should be:"
- },
- {
- "type": "audio_url",
- "audio_url": {
- "url": "data:audio/wav;base64,UklGRiRKAwBXQVZFZm10IBAAAAABAAEAwF0AAIC7AAACABAAZGF0YQBKAwAFAP3/CAD7/wkAAAD9/wgA+v8JAP//AQADAP//CAD+/wEABAABAP7/BgD8//7/BgD0/wYA/f/8/wMA9f8GAP///P8DAPz/AAAFAP3//v8CAP7////+////+/8IAP//AQAAAAMABgD6/wUA+v8DAAcA+/8AAAMAAAAAAP3//v8DAAMACgD8/wQACQD9/wUA/f8BAAcABQADAAAABAADAAEA+v8AAAIAAAAFAPz//f8DAAAA/f8AAAMA/v8FAP7/9v8GAP7//f8EAAAAAQAIAPv/+/8AAP3////+//3/AAAHAPr//v8BAPz/AwD///n/AAACAPr//f/8//7/AAD//wAA+f8GAPz/9v8CAPX/BgACAPv/AQD//wQA///7/wAAAAAHAAQA/f8FAAAAAgAAAPv/BAAGAAAABgACAP7/DQD7//3/BAD//wkA//8DAPz/AwAHAPf/AwAAAAAABAD7//f/AwD8/wAA/f/5/wQA/P8AAPr//P8AAAAA//8AAP////8DAPL/AQD9//r/CwD4/wEAAgD9//7//P/9//7/AAD//wAA/v8DAPr/+v8CAPr///8CAPz///8GAPr/AAAEAP//AgADAP//AAAHAPz/BgD//wUACwD//wYAAgABAAQABQD8/wgABgACAAUA//8CAAQAAAADAP7/AQAIAPr/AwD+//v/AgACAPv/AQAJAPf/AQD+//n/AgAAAP///f8CAAAA/P8DAPf/+/8HAPv///////7//f8AAP3//P8BAPr/AAD6//z/AAD5/wIAAAD7/wIAAgD4/wAA/v/6/wQAAQAAAAAABwAAAAAAAwD+/wIABQADAAEABAADAAAAAwABAAAABAAGAAEAAgAGAAAABQD///7/BQAAAAMAAQAAAAIABAD8/wMA/////wQA/f8AAAEAAQD//wMA+/8FAPr///////P/CwDz/wQA/P/6/wIA8/8AAPH//P/+//f//v/+//n//P/8//L//v/7//r////7//3//v/5//v/AAD5/wMAAAD8/wYA/P///////////wAABwD6/wwAAQD+/wUA/P8GAP7/AwD+/wUABwD+/wUA//8FAAMAAgD//wUAAAAEAAcA+/8KAAUAAgAEAAAA//8HAAAA+v8EAAIAAQAEAPz/+/8EAP7//////wAAAQABAP//+///////AAD9/wEA/f8DAAAA+P8AAPj/AQD+//v/AQD8/wIA/v/6/wAA/////wIA/P///wMA+/8BAPj///8CAAAAAwD+/wcAAAAFAP3/AAAFAP7/AwABAP7/AAACAPv/AwD+/wMABAD9/wUA/v8AAAEA/v8AAAIAAQAAAAAAAAD8/wIA/v/8/wMAAAD///3/AAD5//7/AwD2/wgAAAD8/wQA+f8CAP7/AAAAAP//AwD//wAA/v//////AAAAAAAAAwD9/wIA+//9/wQA+/8DAAAA//8AAP///f/+/wAAAAABAP//BgD8/wIAAgD3/wwA//8AAAkA/f8EAAAA//8BAAAAAwADAP//BQD///z/AwD8/wEAAwAAAAEAAQAAAAAA/v8BAAAAAQAGAP7/AAD///3//v8AAAAAAgAGAP//AgAAAP3////9/wAAAQACAAAAAQD///3/AQD9/wAABwD//wMABAD8/wEAAwD+/wIABQD+/wEAAwD6////BAD5/wYAAAD+/wgA+f8CAP3///8DAP7/AgAAAAAA/v8EAPv/AAAHAPv/CQACAP7/BgD//wIAAAADAAAAAgAEAPz/BQD8/wQA/P/+/wMA+f8EAP3//P8AAP////8AAPv/AgD8/wAAAgDz/wgA/f/7/wQA+P8BAAAA+v8BAP7/AAACAP3/AAACAP7/AQAEAPj/BwAAAAAABgD7/wcA+v8CAP7/+/8IAP3/AQACAAAAAQACAAAA/v8CAAcA/f8HAAIA/v8IAPv/AQAAAAAABAD+/wQAAgD//wMA/P8AAAAA//8BAPr/BQD9/wAA///4/wIA+/8AAP3//v8EAPr/AAD9//r/BQD3/wEA+v/6/wYA8/8BAPz/9v8CAPn/+f/+//3//v/+//3//v///wAA/P/7/wAAAAD//wAA//8AAP7/AgD4////BAD7/wYAAAADAAAAAwAAAPr/BQD6/wUABAD//wcA/f8EAPz//P8FAPv/BQADAP//BgAAAP//AQAAAAAAAgAAAAEAAwAAAAAA//8AAAAAAAAAAP7/BAD///7/AgD8/wAAAQD8////AQD9/wQA/v///wIA//8BAPv/AQD9/wMA/v/8/wQA+f8DAP3/9/8EAAAA/P8GAPz/AwAEAP//AAD8/wQAAAAGAAAAAgAFAAEABAD8/wEAAQADAAAAAgADAAAACAD7//7/BQD9/wUAAAD+/wcAAAABAAAA/f8DAAMAAAAAAAEA/v8AAAAA+f8AAAEA//8AAP//AAD7/wUA9//6/wQA9/8BAP3//f8AAP7/AAD7//3/AwD+//v//v/7//3/BAD3//r/CAD8/wIA/v/6//3/AQD+//j/AAAAAAgAAAD///v//f8BAP7//v/9/wEA//8EAAAA//8BAAEAAAD+/////f8AAP7/AgD9/wQABQD4/wIA/f/5/wAA/P/9/wEAAQABAPf/AAD8//7/AQD5/wAA/f8BAPf/+f/7//b/AwADAPz///8BAPn//P/4/////P8AAAAA+P8JAAAA/f/8//3/AAABAAAA8v8EAAMAAAACAPn/BAAOAAcA+//t////DwAEAAIA/f8HAAYADAD7//f/BgD//wwA//8BAAEADwAEAPv/BQD1/xEA//8DAP//9/8LAPn/AgABAAMABAAEAPz//f8FAPb/BAD+//r/CwAAAP7/BQD4////BAD4/wEA/v8AAAAA/v/+//z/BAABAP//BQD+//z/AQD7/wAA/P8DAAUAAAAHAP//AQD9////AAABAP//AAACAAQACAD+/wYA//8DAAcA/v8CAAEABQADAAIAAgACAAUABQAAAAAAAgAAAAAAAwABAAAABQAAAAYABgAAAAEA/v8EAAAA/P8GAP7/BAAGAPn/AQABAAIA/f8EAPn///8GAPT/BgD5/wAAAgD8/wQA+v8BAPv/9/8AAP3/AAAAAPz/AQD9//r////6////AAD9/////f8AAPz/AAD9//z/CQD5/wUA+v/7/wIA9P8FAPn/AQADAP3//v8AAP3/+/8DAPr/AQABAAAA/f8BAAAA9/8EAP7///8GAPr///8BAPz/AQD9/wAABQD//wEAAAD9/wMAAQD7/wAAAwAAAAMAAAD+/wMAAQAAAP3/AAABAP//AgD+/wEAAQAHAPv///8EAPb/CQD//wAAAAAAAAUA9v8JAPf///8FAPr/AwD9/wIA+v8DAP//+P8GAP////8EAPv/+/8EAPv/AAD+//7/AQD//wEA+/8AAAAA/v8CAP///P8GAP////8DAPv/BgAAAAAAAgD//wEA//8CAP7/AgAAAP//BgAAAAEAAgAAAP//BwD6/wIABAD6/woA+/8EAAAAAAAEAPv/BgD//wIAAAABAAMAAAAHAPf/BwAAAPr/BwD4/wQAAAAAAAAAAAD//wAAAAD7/wcA/v8AAAAA///+/wIA///7/wkA+/8GAAAA/f8BAP//AgD9/wYA//8FAAQA//8CAPz/AQAFAPr/AwAAAP//BgD5//7//v8CAPv/AAD9//b/CAD4//z//v/6/wAAAAD+//z/AAABAP///v////3/BwABAAAAAAAAAAUA/f8DAPb/AAAIAPv/AwD9////BAAAAPf/+/8AAPv/AQD7//v/AAABAP7/+v8BAPn/AQACAPr/AQACAAEA/f8FAPv/AAAFAPj/AAABAPv//P/+//n//v////r//f/+//r/AAD0//b//f/0/wMA9//+//7//f8BAPP/BAD6////AwD8/wEAAAAKAPf/BwACAPz/DAD9//3/AwAGAPn/BwD+//3/DgD7/wAAAAD7/wYA/f/5/wQA+v8GAAgA+P8IAAMAAwAKAP//AQAFAAMABQAAAAUABQAGAAcA//8IAPr/AgAAAPX/BAD+//3/BAAAAPX/AwD5//T/AwD3//n/BgD6//z/BAD3/wAAAAD+/wAA//8AAAAA/v/+//7///8BAAAAAAABAP7//v/+//b/AAD8/wAAAAD+/wEA/f8CAPr/AQD7/wAABQD7/wcA//8FAAcAAgAIAAUABAAGAAcAAwAGAAQABAAKAAkABQAIAAUABwADAAMAAAACAAMAAgAFAP7/DAABAAgA/v/+/wYA/P8KAPj/BAAGAP7/CQAAAAEACAAEAAUA/P///wIA+/8DAP7///8FAP//AAD7/wAA/f/2/wIA9P/9/wMA8v///wAA+/8DAAEA/P8CAP7//v/5//r/CAAAAAkABgAAAAUABwD+//3/CwD//w4ABwAAAAkAAgAJAPz/BwALAAEAEgD//wAACgABAAcAAgAFAAcABwAGAAAABAAEAAoAAwAIAAsABQAMAAAAAQACAAkABwAGAA4ACwAKABMAAgAAAAoA/f8JAAAABAADAAsACQD9/wQA+/8AAPf//v/z//r/AQDv//3/8f/w//r/8f/0/+//9P/u/+j/8v/g/+7/8f/r//X/8f/x/+7/7v/m/+v/7v/3//D/8//4/+3//v/z//b/9//7//n/9f8BAPT//P8AAPj/AAADAAAAAAD+/wIA+f/8/wQA+v8DAAcA/v8AAA8AAAAFABEA//8NAA4ABwAHABAAEgAKABgAFAARABYAFAARABIAHAAXABIAIAAYABQAIgAUABEAIQAXABUAGgAVABMAFwAVAAgADQAJAAkABAAJAAkAAAAKAPz/+f/3//z/8P/2/wAA8/8CAP7/8//0//j/7v/t//r/9f/5/wMA7//0//z/8v/7//D/+//5//r/AQDz//3/9v/3//v/+P/+//j/AAD0//X/+f/x//n/+v/x//T/8//l//f/6v/t//b/9f/z//v/+v/r//7/5v/t//n/8v8KAAcADQASAAIACwAAAP3/CwAKABEAIwAiACAALQAdAB0AFQAWABoAIQApABsAIwAaABgAFgAQAA8AEAAIAAQA///8////9f/2//P/9v/2//b/6v/i/9//3v/c/9//6P/d/+v/3//e/9r/z//c/8n/4P/g/9z/9f/e/+7/5//f/+7/4f/y/+v/9P/6//P//v/2//n/+P/4//n/9f/8//z//f8HAAAA//8AAAAABQADAAEAAAAEAAIAAAACAAAACgAOAAcABwAMAAkACgAEAP7/DQAUABgAHQAUABsAHgAVABoAFQAfACAAGQAaABoAIAAlACoAFwAbAB4ADgAYABAABwAbABUAGgAdAA0AFAAFAAMAAAAAAAkAAAAEAPr//P8AAP7/+f/2//H/8v/w/+H/8//l//P/+v/r//b/6//p/9//5P/f/+T/6//k/+7/7P/l/+r/4v/h/+7/4f/x/+n/8P/9//H//f/8//n/+/8GAPr/BwAGAAIAEgABAA8AEQAQABsAGAAWABYAEgAOAA4AEwAgACoAJQAsACAAEgARAPz/DAARAB8AJAAXABMABwD9//X/8//4/wAA9P/6/+r/4v/n/9f/2//g/+z/5f/b/87/xP/I/8j/2P/h/+H/7v/g/9j/2v/a/+H/4P/z//b/AAAGAAEA//8HAAAACwAQAAcAIAASACEAGAAkACUAHAAuABgAIQAiACYAJwAlACkALQAeACUAGwAYACEAGgAYABEAFgAIAA8A//8CAAUABQAAAPX/8//s//X/5v/y/+f/7f///+z/7//s/+j//P/8//r/CAAHAAUABwD+/wAAGwAcACIADQAGACEAEgAUABgACgATABYAEAAIAAEAEwAKAAMABAD7/wYA8//v//j/7v8LAAUA+//s/9b/7v/d/+H/9//y//T/7v/e/87/z//a/+f/2f/e/+H/1v/Y/8j/yv/W/+X/8f/v/9f/3v/d/97/7f/3/xIAFAAVAA4AAQACABUACgAfACIAKQA5AB4AJQAQACUAHwArAC4AFgAoAA0AFgAVABcAJAAoACUAEgATAAsABQAKAA8AEQAUABMAFQAGAP7//P/v//X/9/8BAPn/6v/m/9n/1P/V/+X/4P/c/9z/0P/F/8j/z//N/83/0v/q/+L/4f/k/9X/2v/f/+7/9P/z/wAA/f/y////AwANAAYAAwACAPn/CQAKAB0AFQATAB0ACAALAAgAEwAVABIAHgAkABgAIAAZAAAAGgAZACwAMgASABIABAAAABEAHAAiABcAEQAVAPT/AAAAAO//CQANACIAIQALAAwAAwD5/wcACQASABEAJgAcAAwAHgANACIAGAAWABsAGAAZACMAJgATACUAJAAeABoAHwALABIAHAALABoAEgAcABEADQALAPz/EAAHAAIABgADAAkADQABAAEACgD+/woABQDz//L/8P/v/+r/+P/6/+z/5P/l/+b/5P/i/+D/3P/Z//L/9f/a/93/7//l/+v/7//j/9L/2f/p/9//5f/q//f/2f/X/97/0f/V/9T/6v/g/+L/8P/j/9H/4f/t/+X/4//v//D/4P/t/+z/+f/z/wgADgDu/wEAAwDz//j/CQAHABsAEQALAA0A9f8EAAwA/f/9/w0AAwD6/////f/w/wAA/P/1//r/9//4/+7/7f/t//3/+f/9/wEA+f/s/+j/2v/V//f//f/0//f//v/2//3/+P/j/+X///8PABkAGgAYABMADAATABwAKQAeADEAKwAcACgAIwAoABwAMgA0ACYAKAAbACAAEAAbACEAFQAdACcAJAAEAAgADAABAAwACwAHAAQAAgAMAPz/9v////r//v/o/+7/+P/g//v/AwDn/+T/7//r/+f/7P/n/+D/1f/z//j/7P/5//b/AAD7/wMAAgD0//3/CQAiABcAHQAmACEAFwASABkABAAcADkAOQAmACUAJQAkAD0AJgAaACMAIQA1AEIAKAAfAC0AMQAwACgAJQAfACIANAAoACoAKQAfACcAFQAJAAoAEwAHAPj/+P/r/+f/8//6/+v/3v/k/+z/4v/Y/+D/0//c//P/7P/q/9D/0f/i/9H/0v/f/9T/z//i/+n/2v/b/+z/3v/Y/8n/0P/T/9H/5P/T/8//0P/k/9f/v//E/8D/yv/o/+//2v/b/9X/5//m/+D/9//a/9//9//y/+n/7/8FAPf/6f8AAPr/9/8EAAcA9P/j/w0AGAANAAcADQAPABUAJgAWAAAA/P8aADAAJAAkADIAEwASAAcA8f8BAAoAHQAXABIAAgAIAAEA8f/z/+r/CQAFAPn////r/+L/3//x//j/7P/6/+//2f/i//b/+//+/+j/DAAIAPX/IAD7//3//v8UABUA/f8bAAUAHAAeAB8APQAgAB8AJQAbAB8ARABGAD8ARAAyAEEAOAAzADEALgA+ADcAQgAzADAAOQArAEcAOwA0ADcAGQAPAAMAGwA1AC0AKQAYAAoA/f/8/xIAAgAIAB4AIgAZAP3/DQD6/9v/BQAbAA4A///6/+j/2//y/w0AAADt/wkABgD2//j/8v/3//r/AAAQAAEA+v8BAPT/5//w////8f/s/97/1v/r/wEAAADi/+b/5v/Y/+P/5v/M/9P/AAADAPX/7f/j/8//wv/n//j/7//0//D/8P/q//3/BwDq/+r/9P/6//X/9/8MAPX//f8CANj/4v/u/+f/1v/Q/93/4f/e//P/3P+m/8z/8P/x/+D/6P/f/6D/zf8KAO7/yf/o/+7/xf/U//T/zv+l/+n/AADx/+T/9P8EAML/6f8QAPj/6P8MAAsA4f///wwADwDk/wIAGQD8/wYAAAAJAAcAIgApABEACgAjACMAFgAdAAUAFgAsACAA+/8CABAADAAaAA0A/v/1/woADQD9//L/EQAdAAsACAADAPj/9f8WAAcA9/8KAAwA+v/s/wAA9f/t/woAAQD8//P/BAD5/+X/DgAcAA0A+/8SAAQA8f8XAB4ABAAJACYAJgAQAAQAFgAFAAwATABGADYAMAAgADsAKgA1AEkANQBLAEoASAA9ADAALwA8ADAAKAA+AEAASwAvACEAMQA4AEkAUwBIAB8AIgBCAEoAIwAPACsAFQAhACQAIgDu/+D/GgDp/+X/6f/z/+L/zv/j/87/rP+5/8z/kv+h/77/rP+W/5f/l/+F/5//sP+b/2v/hf+l/4j/eP+H/4r/if+6/8T/d/9a/5T/r/+g/6L/p/+m/6//t/+w/57/o//G/9T/pv+V/7T/yv/I/7T/xv/Y/83/1//j/7f/pf/T/woA5P+3/87/t/+m/6D/tP+0/6P/wf+8/6r/of+W/5n/nP+s/7P/vP/G/7r/oP+d/6v/mP+c/8D/0f/H/+z/7f+f/7T/1//Y/9P/3v8mABMA7f8MAOn/t//8/0IAJAAHACgAOwAQABQAPAAlAAQAUQCQAGMARQBNAGUAYAB+AMoAvACLAKQAtgCsAJwAvgDZAMMAzADmAPwAzgDKAOQA2wDpAA4BHwEAAeEA+QAXAQkBBgETARkBEAEUAQ8BDgH/AAYBIgEeASoBAgEQAQoB3QD5AN8A4QD+AAEB+wDPALYApACbAK0AjABgAG8AgwByADQAIwAmAB4ANAAeAAsA7P/h//7/3f+u/63/4P/p/7P/nf+E/4T/pf+f/5L/Zv9s/5v/iP9B/x7/Tf9d/0L/Pf8Y//T+F/80/z3/9/75/j3/AP+w/q/+4/7S/uH++/7G/qv+v/7J/p/+TP5n/tn+3f6h/of+cf40/lj+hP5M/g3+Fv6B/l7+Hv44/hb+Mv5r/lf+8v37/Xv+bP5N/j/+C/4A/kL+jf5A/tL9Hf6T/pL+X/5r/lb+M/6G/pT+av56/sH+rf5+/rr+2f7q/vT+Hv8L//L+Rv9a/wf/Gf97/2H/iv///7P/If93/+D/xP+5//T/LwDk/woAiQAfAK7/NACSAJkAvwDcAM8A3gBGAVEBPQFkAe4BQQIYAv0BCwJ6AssCAQNDA0UDUQOAA7wD/APrAxAEpATZBPMEMQV8BbIFrgXpBTAGWQaIBtQGEAfzBg8HWgeJB48HfAehB6QHmwfIB98HtgdyB3MHkAdNBxMHAwe4Bm0GIwb3BZoFFAXlBL0EZATsA6QDLAOpAmACMQL1AXkBNQHfAHMAIAD2/67/L//t/qH+YP4a/tn9p/1z/VH9EP3W/I38V/wr/Bn8IvwU/B/8Jfz8+7v7tfvW+/j7EPwH/Ar8APzi+9v7s/ul+7371vva+8D7nfsp++/6B/vy+tP6yfpT+qb5r/md+cn4Kvgb+Nn3dveV95f38fYp9hr24vXm9Kb08/R09LfznfNb877ymPLJ8qPyL/Lc8cnxXvG68ErwCvBh8OTwHfHm8Lvwx/DM8HXxifLe8p/ze/ca/Ir91/zp+9P64vvrACgGlQfTBtsHKwpUDAwP3xDNEEMRQRTGF2IYThdwFzsYXhq9HTgfyR1JGyAacBr5GmMbSxuZGqoZ0RiEF4EV1RNVEhcRyQ8PDvgL4wl5CNkG8wRZAx0ChgCC/kD8ufmu97H2yPaX9kT1nPNI8l/xBPHu8JPw7O+j7yzwtvDG8Mrw//Cn8cDy+PPY9Ar1QvUR9mv3/fh4+v37bP2s/rj/1wDSAYACegPWBEkGnwcMCVoKMAvfC6MMSw3vDXAOyA78DkoP4w9IEKsQqRA6EKYPJA+YDuINgA0zDc4MPAzcCyoL2wmrCIgHjgapBeoEBwTeArkB+QCZAN3//f4r/jz9PPyM+/36YvoX+ib6WfpN+vj5bvkA+b/4sfgF+Xz5uvkC+k76aPpd+lv6h/pU+kH6Y/qj+tP6sPql+m36E/qp+Sf5P/hK96z28vVd9Ur1IfWK9NfztPLu8BjvEO587czsauwH7NzqOOmY573lIuSB41rjPuO+48vjp+JU4d3gt+HA4hjkneVR5mTnJepp7oPyAvU/9k/2FPf0+ksAwQQnB7gIGAtIDrMStRYrGJgY1BqQHoYhVSMzJHMkfiUUKNgqXiv8KYMoWScGJ1YnPCccJj4kpSISIeEeTxyXGcEWBRR6EeEOFQw7CYEGqgPjAHT+7/uJ+Qf39/M78TTvAO4+7T3sEuuJ6VHo6+fN56Pnbud55wPoKelv6kPrBuwl7aLug/Br8hP0KPWI9rD4tPrb/CL/FgGoAh4EwgUTByoIugk1C14Mcg2IDnMP1w+bEL0RUxJdEhsSmxEcEdQQChFcEfkQKxBnD3gOHA3TC/UKFAoCCWgIBAgmBwIG5ASIAx4CbAHsAD0AX/+J/h3+RP6a/qH+Uv71/dD9e/1r/Xb9e/31/cf+pP/i/w0AeQCNAHIA7QCpAQgCTwKjAuAC3QJBA5oDUgPKAo0CYgLuAdgBnwEoAawANQCJ/1n+O/0N/Nj66/kT+e/3pvZm9ejzV/Ll8GTvp+3066Hqr+n46ATo0ub75KTiHuE64Ejf+91B3FPaJdhl1vPUXtNw05zVjNe017LWSdVm1G7Wb9vI357in+Zu7DvyMvYu+HT4AflE/jAIeRDOE0MVKhegGtEgiSdhK8QrcizBL+UygzRjNSs2RTdpOaA7GzvMN90zHjGWL4UuPi0bK+0nKyQ+IOwbrhe/E+wP7QthB4ACKP7E+rH3gfRC8WDuh+ua6CvmkeO44EHfk9+J4BPhGeEe4Q7hyuHB49vlp+eM6SDsAu/h8fj0xPeg+vP9JgEXBKkGzQjECjINABCNEs8U4RZZGO8YPhmFGYIZeBm2Gb0ZIhkIGPQWnhXME48SqRFoEFIOxws7CXcGmgScA2ACegCT/vn8K/t7+Uj4NPcK9oT1lPVk9Rf1LPVC9Uv12fX99jv4XfmM+mX8o/5PAEECcQSmBmMJ4gvsDIsMsQxKDqUQ2xLVFOsV7hWwFQgVMhSVE4MTaBPdEvwRmBC7DpAMiQqtCAkHbAUYAwkAS/0F+w75lPft9e/zePEY79LsRuqJ6NDnbedV5uTksuNW4jLhMOAW38rdG92y3SXee92c3Ajc4tox2hPaftcO0+LQPdA1ztvMIM60zpLN188M0hPPyszgzxXVw9l75RH1yP1UAI0BEQCH+0sAEw54GYse2CP1J68n/yxqNEc2YTXfORlA5T+QPJY68znzOVI8Yj/kPgk5qjGdKnAjwB7xHC0cKhp5FrsQuwmxA2f9Yvc381fw1ezM6JLlNuJb3wLe/t0W3jze7t5e3jHcc9sN3lXi8eZc7HDxRvRL9kb5lPyL/4wD7QjsDTcS+BX9GBcbEx2cH/4hiiMsJPUj0CJdIRUgNh+iHm8dLhu9F0wTUA6FCa4FeAJj/1b8g/kp9hDySe4j66LoruZQ5fvjmeLD4ZHhCuIE46DkEudZ6V/ru+3o713yx/UW+qT+JgNZB9kKvg2RENoT6BZwGRwcqR4BIaEjRiXcJSQmWyZbJpYljyQOIxwhjh5/G/wXeBTuEWkPaAwPCWoFmwFV/qn7KPkt9771cfTq8nrxNvAD7x7uru2/7SfunO4Q72LvzO/J8Pzx8fK083/0E/VD9an1nPaA9yL4fPhZ+Kv3k/ZR9YnztvHo787tdusa6CbkgODm3HzYfdMQz8vKQMdGxRPEqcIzwRvB8cC7waTG8s6Y3ILwWgLUCEYEtvrm9M/7Dg3aHZYmXCl2LHwwIjV5OfI5nzdlOIw9ikBLPbU2WjBzLL4svi8wL/8n2h2CE10J2QBP/BT7Hfqa+MD1G/Ce6DLi79202pDYLtiw2drbet2d3n7fkuFB5jXtLfTQ+CH7s/xK//YDmwpDEpMZYh9WI/QlEifrJucmpyfbKPgpryrWKdUmUCJOHcwYmxThECANHgjqAUn7IfUA8PzrEelx5kvj7t+k3J3ZeNfK1lTXH9ka3HrfiuLu5F7nZOpI7lLzG/nX/iQEEAlsDWMRdhWKGWsd/iDhI/0lXCfJJ5gnuyZtJW4k9iKPIEYdVBnIFPUPsQtZCA0GqgPCAKf98/lI9tbzgvJQ8YHwIPFk8kHzHvRB9Tr2g/d4+hL+5gAjAyoF8AZRCHgKDQ3wDi0QCRE+ETgQ7w75DRMNNQw5C7YJMAcnBAsBgv37+fv2LfRk8c/uIOzQ6F3lgOII4ODdqNyg27XZZdc01Z3SU9Bdz6LOd81QzA3Kh8W0wYzB28PRx8rMPM8pz7jP59NS3BDqjAF9Hxw4E0HYOUgoDBg5GAMpoTnkPvA99zyeO4c55zbrL38lhiC6IsghDRexCOH7I/EP7NTuU/PT8h/vt+nk3zXUi86X0Z7Y9+BZ6lLxI/Sq9Rv4C/qC+1MAVAkdEx0bnSDmIsci2yMmKCgu5jKgNGIyPyyqJM8d9xg/FrsUMhOdEGEMxgUU/fzzNexx5ivjG+KX4Qjgmt1/20zavNqG3ULiFufO6tntn/AK8zX2YPvRAXoIJQ9KFcgZIRwkHakdvx0NHiUfJCB9Hyod1RmKFdMQegzdCF8FoQHp/QL6cfW18P/sVOp96L7nQ+hR6Q7qxeqh67Ps8u4D8/z3wvxiAQAGYApWDzYVphpFHkIgUiGcIbAhmyHSIF8fSh6/HYocIxrBFsESQQ6ECfEE1QB2/dD6rvik9qL0RPOY8hnyf/HI8Fnwp/CH8dfyj/RH9vX36vnM+xL9pP2j/Zr9qP3v/Xz+wf5p/qf9qfwT++j4rvab9BzyYu+q7H3pDeaf4infi9sk2GfUO9AQy+nFjsJYwZvCzMSVxrjGU8l10XblgwXuI3U6mEGCOLknghoYGn4h5yadJXUiLCOpJmApPSf3HeEQjQesBN0BXfsE87rqPOMm3kvegOHJ5Dvo2+uq7ULtUe8i9SH7a/+JA5gIqw0BFNgbDyKaJFIlwiZqJwEmgCMwIHobbRZOE2URdw71CW0Euv059jLwoexK6ivomObY5W7lqOUW5zfpi+uX7tbypvdq/BkBXwXsCEAM9g/wE8AXChs8HaAdahx1GgMYERXMEUQOSgosBmgC7v5p+9D3XPQk8UfuC+ye6rbpRume6bjqbOzP7vzxi/Ur+dj8jwAxBKMH8goSDtIQAROtFMAVLBYIFnUVfBT2EukQYQ6lC9QIHwYVBOoC9gFoAIT+v/wO+6b5BvkM+WX5bfpn/MH+mAD6AX4DAgVDBn8Hjgj4CAAJBAnUCAQIywbBBbQEYgPhAWgAzv4h/cD7k/pv+V/4zPdx9wj3yPbU9iT3n/dL+On4VPmB+aH5ufmR+Tj5efg298z1bvT98nHxtu+q7Zzr6+km6HTl4+GO3qTcCdwt3Jzchdz821TcRN8p5dzwyQRNHXYzKz+PPQ4yaiSoHGkbqhpxFTMOMgqdCsgMDA2rCDcAzvh39un2m/Vp8efr5eVZ4Mzdc99k5PrrD/aDAKwIyw5SFI4YshloGPUWbhZIF4gZnRsYG+EXbRTaEXUPlQwjCbkEJf9r+VX0nO8P663nLeZa5mnoc+yK8UH2+/nc/AP/4QAnA+UFfQjCChgNfg+YETYTORQ3FBwTcRF+D+4MkAmCBdMAyfsP90zzrvAQ713ukO5T733wL/Ia9NT1R/ew+F76WPy7/nwBSgTKBgUJEAvBDAwO3A4ZD3kOAw0GC5MIzgXjAhYAn/1++9T5xPgx+Pb31/ev96H34Pel+B76OvwM/7wCsQb+CVIMCA5kD1UQsRB0ENAPxg5eDdcLBAqRB8YEFgKs/6T9Dfy6+ov5jfjz98D3ufcd+Dz52/qT/Dz+8P+SAfMCBwTOBCgFKwUWBdoEMATsAkMBf//N/Un84vp8+Sb4BfcP9iv1T/R787/yRvIl8hzyIfIM8qHxFfGI8Ljvh+4B7fbqsejR5qzlb+XY5RrmDuY75g/naOmn7+f8VxF8KBM6sD/eOAYrwR48GA0U6QykAvD5ivbJ9xX62fn69czx9vF+9gz7nfxF+2f31/En7RTs5u6Y9Nn8bAYuD1YWzRz0IUIjXyC+G0YXHRMqDxoLyAVJ/+f5cvcb9433rPgP+of6zPnC+H/3evU68/fxG/LA8473RP07A/cHpQvfDlERzxJ4E+MSoxBXDeYJegbnApv/Nf2v+//6Qvsd/Kb8Q/wX+zn56Pbk9MDza/Om86v0sPaF+d38eADkA6EGswhFCiwLDwsICloILQbRA8gBagCj/2b/nv/0/xsA9P+H/7/+jv0g/Mb60flV+WL56fnd+lb8V/6mANkCyAR3BmwIKwvVDdIO5A0SDBcKjAjaB14HbgZKBW4EqwNZApAABf/M/Z387vsU/JX8Jf3f/an+HP+F/3YA1QHjAloDdAM3A8YCUAIDApEB9gCRAGQAHABm/1r+D/2n+276nfkr+cr4c/gr+L/3Xvcz9yb3FvcR9yT3CvfC9mb22fXT9JnzzvIr8vjwDe+h7ALqy+eC5rLlhOQ9483iIeR852Pt/PfVCPUddzHwPCI9bjQJKckfkBi7D/sDgPhR8Srv7u/i8FrwiO9t8UP3Z/5SA8YE9QJh/oX4JvTi8kX0zfeG/bsEPAzhEzUbESDXIIweQBtGFwkSogtFBCn8w/Rp8JDv4PCS83P3nvvf/iYBnAJ/AoUAwv1f+7n5LflQ+rj8Yf82AtMFDQrvDeQQkhJZEhgQkgxiCH8DRf7B+aT2A/X/9JH2APk/+/f8Lf6s/nb+2f0B/bn7TPpv+W/5Rvro+0v+HgEVBAsHvAmJCwcMPQtgCZ8GawNfAML9vvuA+jD6oPqc+/L8T/5j/wAAOgASAIL/n/6h/bL8EPwq/D79+v4zAUwEVwhsDE4PfhAoENQOKg1+C3wJzgYKBOoBYwD+/s79RP0x/VX93/23/kT/cP+T/53/Vf8j/7H/pgBfAdEBOQJtAlwCTwI0AsgBGwGtAGwA2/8H/zz+cf2U/PH7rvuA+yX7n/r1+Rj5Kvh19/32q/aG9qn24fbm9sT2g/ba9Yr0EvPj8aDwsO4Z7G3pIOd+5dTkveRR5ODj/OQm6PXsWvV6BBEZuyxiOSg86DWQKwIjuBy6E1oGZ/mq8dPuoe5R78LuLe2S7n/1Qv7xAz0GHgbAAv38lfgW95H20/bS+Vz/iwWkDAEVaxtVHeAchRwBG8MWqhBOCR0AEPer8Qvw6O8N8Xv01vhz/Mb/EgN7BDwDQAGt/+39OfzK+y78Qvz2/NT/KwR5CIkMFRDFETsRhw/dDG8IwQKD/Vr5N/a59Dv1ovYE+Lj52fux/fH+5/9DAIH/CP7Q/O37P/s9+y38wv3c/8cCAQaNCP8JfAr8CWQIJwakA+cAHf7Z+4T66PkA+un6QPyY/dz+EgAHAW0BOQGDAGb/Nf6F/b79Pf/6AUIFJAhZCjMMpQ14Dm4Odw29C48JLgeLBJgBtf6i/Kj7mfs//Fr9e/5e/wwAhACuAJ4AuAD9AB0BDwEMASQBIwEZASkBUgGGAdMBBQK2AegA6v/1/gb+NP2W/A78avuq+vz5Rfl6+Nn3f/dh92T3pPf79yX4Eviu9//2MfZh9Xv0XfPy8TvwI+6k6wLpreb15PzjleNz49LjqOVG6WnuEff8BYkZnCuoNjQ46TE+KcwiYh02FPkG2frf82fxOPFK8d3veu5V8fn4lwCwBMgFcQRJACf7FPjc9sH1uvWB+DH9xAIhCj8SwhcLGqUbGR0yHGAYlBKaCvoA7PjB9BjzffKq85T2nflz/M7/hQLeApUBWwAa/1P93/sQ+/D5+PgH+mH9qAEpBtUKlw5uEM8QHxC0DWIJdgT5/+r72fh090r3c/cN+KH5oftv/fv+FQAUAAX/xf2Y/En7IPrP+V/6qvvc/cwArQPrBaUHyQgFCVMIDgcrBbkCPgBC/tL80PuN+w38+fwP/lT/hgAxAVEBEQFwAAkA3wCFAowD0ANOBDsFegYKCEwJiwkmCeAIVggMB4YFFwRlAp4Ar/+u/67/lv+1/5z/Pf9l/ywAqgCRAG8AcABeAGwAtgC2AEMABQAlAAkAj/8e/63+7P1Z/Vn9dv1d/Uj9Jv2a/N77Tfu2+s753fgd+GD3y/a59u/20PZt9jH2GPa29cj0hvPy8dnvqO2v64bpHOfx5FHjL+Ki4UXiT+Qy5xTrnfL1ANUUJyhkNLg2TjE0Kt4l+iGCGUgM6f/L+HX2KfY59afyl/An81b6FgEOBO0DuQFa/ZD4w/V89EDz7PIZ9SX5j/4OBl4OehQUGHwbjB72HhgcpBaODu4EM/0X+S33MfbU9uD4A/ty/X8ArQJ/Ag0Byv9Y/mP8fPqm+FT2y/T39ZX5Gv4QA0UIfQwpD8gQOBF2D88LsgeRA5n/iPzn+vn5RvmR+RX7Dv3n/pcAcgHNAFT/3/1B/D76o/js9/b34fj7+tf9igACA2wFTQdKCKIIXggIB8gEeAKDAOv+Af4p/g3/KwBxAcUCxgNnBAAFOQWdBHYDRwIlASYAlv98/8T/jgAfAu4DRwUsBswGQweEB3wH4QanBTEE3QLBAeEAWwAXAA8AOACdABsBcAGPAWQB+gB9APX/Tf+Q/sb9FP2B/DP8O/xy/MP8E/1Q/XP9eP1k/Rb9bfym+/r6Zvqh+b74A/hx9w732fa79nb2HPal9bn0efM68r7wpe5A7CfqQegQ5n7j/+Ak34HeVt+a4QDl1upz9+QLZCGqL0Y01jHfLMIpnSfaIAAUJAdCAPj9BPwq+Uz2pPTN9sf9YATvBQoEnQHk/Vj42PNY8THvhO217ovyLPeG/e4FwA02E5YYPx66INUeKxqQE/UKTAMb/+z8Mvv0+uf87P6ZAPQC2QSBBOIC2QE3APz8Pfnr9Y3yA/CU8MvzzPdp/C8CqQdqCxgOtg8qD54MygnvBlwDAgAQ/gL9IPxo/E/+bQAKAoQDXQSbA9EB8f+s/cH6L/jK9in2M/Z69835M/yt/pQBRQQXBhoHWwdrBqIE+QLtAVIBCQE0AaYBXwKfAzAFVgbaBvcGsQb2BdwEewPtAXgAPP9n/h3+c/5V/5UADwKoAxIFDwa/BvcGgwaFBUoE8gLGAQ8BqgBnAHMA/gDMAYwCGANRAyQDsgINAgsBnP8P/q/8iPux+kL6RPqe+jb74Pti/L388/z0/J788fsL+wX6D/k++Hz32fZv9ib2HvZN9i32bPVW9DXz0fEM8CHuIOzw6cTnuOWG4xPh7t7c3d7d7t714b7pkPkvD8gi1i2cLygswSjWJ6UlUx4gFAsMZwecA7//pPyr+5r96wHrBYgGhwUlBYMDBP5m9oHwSu2O7J7tEu8d8NbyP/lvAfMIkQ/aFfYZ3hqMGfcVDxCOCRUFfALwAAkBsQJmBH4FAAdTCF0IrQcFB1wFuAFL/dH4R/SP8Crv6O+28QP16Pnn/sUC6QVOCCYJtAiyBwUGhAM5AcX/xv49/t3+wAD6AhoFAwcfCPoH4QYaBXICPP9Y/BL6M/gP9xH38fdh+V37sv3j/7UBGwPaA8kDKANpAnIBUgCD/27/FABUAUMDfgWTB2AJvQpgC/wKvQkMCPoFoQN+Adv/i/6h/Yn9L/4//54AFwI4A9cDLQQfBGADMgIRASUAgP9C/2z/zf9gAEUBTAIgA70DJQQqBKwDswJlAcX/Hv7C/Kb7yfo8+hX6LPpU+nX6fvpd+iT68/mK+dn4HfhO9072YvXY9IL0T/RR9D/08/OM8w/zWvJr8T/wq+6k7GzqGOis5SXjguDs3QXcANwG3/PnwvgeDcodxSZAKAAlMiKVIoYioR7UF9EQpAo9BtYEQwUxBpkHHgoXDBYMfwsECrwFd/4w97rxSO5e7fHtOu4P7gvwK/UT/G8DPwpZD3URjRElEBMNGQnFBfID3QLqAkcEmAYwCbQL0w2DDk4Ozg24DBIK+gU+AQj8Uvf684HylPIT9Nn2//n8/H//ngHIAsgC5AEXAO399fvA+jr6dvql+5v9SgBhA4IG+gh4CucKIwplCP4FYwPOAJr+7vza+2X7kPuP/C/+HwAOApgDRgTrA8kCLQFx/xv+kv3J/a/+EAChATsDvwQjBlcHOAiZCEoIVAf4BWUEywJZAUMApf+G//L/twCiAXkCHAN3A4sDfwMhA04CIQHa/6/+2f2R/bn9Gv6r/mD/BQCeABcBTwFLAQcBegCd/43+fv2C/JP7ufr8+YL5VvlS+Vn5UPkq+ef4gfgC+Gz3mfaq9bP0ufPF8u3xRfHS8J/whvBb8PHvQO9I7hTtl+vM6aXn8OTU4Q3fjN2g3mjlDPPFAx0TqB3LIPgdnhp8GaQZKxpWGaoV7Q/TCj0IiQi6CyoQ8BNEFQIUsRGkDtMKTQaEAWP8W/du86PwX+8P8NLyl/aV+sv+tgLoBdQHJQhKBtcCVv8K/Yz8ef1v/7AB+ANZBgkJHQz/DmIRhBKYEXoODApoBWwB4f56/d78y/xQ/Wj+1f+UAUADewSvBKADYQFB/vf6Dvgc9jL1VPVd9gv4Sfrj/J///gHFA9MEIwWiBGMDugHx/2D+Yf1Q/Sv+wv/ZAREE+QVJBwUIEgiPB7YGkQUrBJ4CJAEHAIT/v/+cAOoBRwNWBPcEFgXDBCYEYwN6AmsBSQAp/yf+hP1m/dH9uP7S/9IAfQHKAbwBdQERAZAA/P9T/7r+Tf4S/v79Hf52/uX+S/+X/7L/pP94/y//1f5e/tb9Sv2u/An8dvv/+q76h/p3+oL6i/py+kz6K/oC+sX5g/k6+c34Vfj29573PPfw9tP2tPZk9uv1WvWe9NDzGPNj8o/xaPD57o7tj+za7E/vwPOn+WYAGwbJCHAIzAahBcAFpgZRByYHJAYmBfIEYgVUBkwI4woFDW0O3w7ODXALOwlUCDwI6Af9BuAF2QRWBNYE4QXpBiMIjQluCjIK8wgTB/UEIgMBAnIB5QBGAPX/AgA8AIcA8ABjAeUBPwIbAmUBKADW/tH9J/3E/KX82/xV/QL+yP6Q/0MA0gA1AVsBGwFlAIv/t/7//ZD9cP2c/Qv+xP6h/2YAAwGIAQoCZwKYApICTwL2AZsBVgEsASkBdAECApwCDwNUA3gDgANhAxkDuQI/Aq4BGwGtAHIAWgBtAKUA7QBBAZEBtwG7AckB3gHmAbcBbgE1AfgAxQCpALUA4AAQAUkBdgGHAYMBcwFdAT4BDgHIAG8AFwDa/6v/e/9I/xv//P7i/r3+if5V/iP+8f20/Wf9Ef24/GL8DvzQ+5f7Xvso+wP7+/r0+tz6rfp++lL6GvrL+WP5//ic+DL4vPc/98P2RPbF9UH1qvTy8/vy1fGn8I3vtu6Y7jzwD/RS+Kv6tfrW+ZP5lPpY/Aj+f//DAP0B8QLyAlcCRgJIAysFwAc+CnYLSQvXCkALMAy4DMQM/AxcDaQN7Q3VDTENxAwsDc4N7Q1CDRMM0gqpCeQIZwjJBwwHrwaYBh8GIwXrA/gCbwIKAnwBogCQ/23+d/2b/NL7avuF++n7TfyP/K38ofyC/Iz8uvzJ/I78SPwc/PH70fvV+wb8cfwo/Qj+tf73/hb/Zv/p/3QA6QAqAU8BkwHrAS8CXAKrAjwD8gOVBPwEPgVZBVQFUQVhBV4FIgXVBKAEiwRyBEMEAgTEA50DcwMiA7ACWwIsAvgBsAFiARoByQB8AEAADADk/63/e/9O/xn/3/6c/m7+Wv5c/lr+Rf4r/ij+Lv4m/hf+/v32/eb9xv2q/Yn9cP1u/Xn9d/1t/Vn9PP0R/d/8q/x5/Dv84/uV+0j76vqQ+jv69Pmm+UT5zPg6+Jv3+/Zs9s/1IfV+9NHz7vLT8ZbwWO827rftJO+u8mb2RPgz+Hz3XfeB+Fn6HPzA/Wb/FgE6AjoCtwHmAQID5ARcB4MJewpBCvMJmQrvC+sMgA0+Du0OZw/DD68P9g6BDtgOTQ8TDwcOlwwgC/cJXAklCbwIHgjbB7MHDQf0BbYEvQMtA7IC5AG3AHL/R/5m/a/8CvzD+/z7Vfx6/Gz8Ufw7/A/8CPwu/CH81PuP+2X7WPtg+4T7wvsl/MD8U/2z/c796P1F/tT+Wv+x/+X/AgA1AIYA7ABQAcABVQIDA4kDxAPiA/oDIQRUBJAErwSpBJsEoQTCBOQE9wT/BAEF7ATHBHwEFgTFA4cDVgMNA6ACKAK4AVMB8gCnAGwAJwDf/4//Nv/V/mv+Gv7l/bH9fv1E/QX95Pzc/OL86Pzj/O38//wK/Qz9EP0h/T79TP1I/TP9Af3C/I38cPxR/DH8CPzQ+5L7SPv9+q76a/o5+vz5lfn9+E34o/cF92b20fVA9ab0//NC81/yW/E+8BnvSO7e7qDxCvUD92r3AvfQ9tT3jvkj+7D8W/78/zwBmQFDAT0BAgKcA9UF2AcHCTUJ7whPCaoK7guFDEcNNw7GDiIPQQ+2DicOWA7fDvsOQw4PDc4LvQocCvMJugkpCdQIoQgXCCIH4QW+BCgE1wMdAxEC4gCm/5/+6f1c/eX80vzz/PD8rvxO/Pj7pfuD+6H7wfuZ+0v7G/sH+wz7I/tX+6v7G/yO/On8Hv03/Wr93P2A/g3/ef/J/wIAQACiAB8BgAHzAX8C/gJIA1sDYQN8A7sDBARIBHMEfgSCBJUEngSvBMEExQS6BIoERgT4A6kDWAMhA/kCugJjAvkBiQEsAd4AigA4AOr/mv9A/97+ef4m/uv9s/13/UP9Cf3X/K/8nPyb/I78ifx//ID8i/yE/IL8ifyT/Jr8k/xw/ET8Gvzz+9b7sPuD+1v7Lvv8+r/6fvo4+u/5oflG+dr4WPjT90f3u/Yo9o718fQ89Gbzc/J98XrwiO/A7+jxjfQU9pv2d/Y+9jD35/hj+tr7g/0L/xoAlACcAM8AYgG2ArgEcwaEB+wH0AcTCHAJywp/C2QMcQ0FDmkOuQ5nDvoNGA54DowOBQ4XDQgMIAuTCnEKQQrOCZ4JegnkCAEI4AbHBT8F8ARBBFYDaAJfAV4AqP8Y/6b+df5k/jn+1v1h/ev8cfwq/Cr8NvwQ/Mv7nPuF+4H7lPuw++z7Svyo/On8Af0K/Tf9tv1a/s/+Dv9U/57/9P9cAMEAIwGHAfgBTwJ6ApYCqALKAg4DYgOoA8sDygPMA/IDHAQyBDQEMQQ3BCIE6QOgA2EDNgMTA+gCqgJZAvkBlQE7Ae4AnABHAO3/kf8u/9X+fv4l/vD9zf2k/Wr9Kf3x/Mv8uPyp/Jr8lfyO/IX8evxx/HX8fPyE/Ij8f/xp/D38DPzw+9n7vPui+4v7a/s8+wT7xfqN+lT6EvrE+WT5+fiL+Bb4pfcu97H2LfaM9dL0FvRh857ygfLo89716fZO92P3IPfF9035fvp0+8D8H/4T/63/DgByAOsA+QGyAxQF1AU3BlgGhAaFB+kIrQlnCmcLGwyIDAkNFw3dDCkNog3cDZgN6wwNDEgL6QrOCpMKIgr9CecJWQmYCMkH2AYoBtcFSgV2BKQDzwLyAU0B1gBZAAYAx/96/xj/pP4f/qP9Zv1S/Tv9Cf3I/If8YPxi/Ij8ovyz/O38Iv0q/Sn9NP1Q/a79Nf6M/sP+9f4o/2//1v9AAJEA8ABJAYoBtgHSAe4BFgJoAr8C/AIQAxEDHwM1A14DgAONA48DiQNwA0UDFQPlAsUCswKWAlcCCAKxAVEBBQHBAHIAJQDV/4L/M//o/p/+Zf5H/jH+CP7P/ZX9Wf00/Rz9Ef0J/QD98vzZ/Mv8tfyy/Lr8uvzA/Lz8rvyY/If8e/xu/Gb8dPyY/Kv8n/xy/E38SPwy/OX7fPsc+8L6hPpS+gb6pfkk+Zj4AvhL94P21/VM9S/1EPZI98338PcS+MH32ff5+Pv5q/qs+9H8hv3u/Wz+5v5L/ycAsQH4Ap8DJQSZBM4EZwWHBkwH4QetCFsJ0wl1CuAK7wo/C68L9wvuC5ML/QpmCi0KNgonCtkJuQmhCS8JrwgvCI0H9gayBk4GlQXjBDQEdAPaAoICKgLHAXUBGQGlACQAqf8z/9n+qP5z/iv+5v2j/WL9Tv1s/X/9c/11/Y39jP2D/Zj9o/2u/en9Mf5c/nb+lv7H/v3+Of95/57/v//j/wIAJwA8AGQAmgDQAAMBKAFAAU4BaAGQAbkBwgG8AbQBpAGIAWQBSgEtARwBBQHkALMAYgAVAOn/xv+P/1D/D//K/oL+R/4K/rz9if15/WL9P/0d/fj82PzP/Nb86fz+/BL9Lf1H/Vj9YP1w/Yb9lv2q/bP9p/2L/WP9Nv0P/Q/9Nf0l/dT8q/zK/Lz8Z/wd/OD7l/tG+/76svpU+gf67PnD+Uj50vh1+D34j/gr+ZL54fkT+ub59fmV+g77U/v/+7L87fw6/eL9Yf6r/mD/fAA0AYkBDQJ6AocC9gLvA5MEBQXFBW8GvwYwB6sH9QdUCL0IAwkVCesInAhfCD8INwgtCBwIGwj+B7kHcgcjB7gGcAZOBvcFcAX7BIsE/wOnA3kDLgPmAqoCUALaAXEB/ACRAEIAAAC5/2X/G//U/pr+ff58/mz+U/5J/in+/v3k/dT90P3p/Rb+KP4l/i3+Kf42/l/+hP6Z/rr+4P7w/vr+Av8a/0P/e/+6/+L/7f/4/wcAEQAsAFgAaABYAFYAXgBmAGoAWgBFADcAMQAZAM3/cP80/yT/GP/y/sn+of6C/oP+dv5i/lL+Rv5Y/lD+I/4E/gf+Af7n/cr9uP25/an9kP2M/Yn9kP3I/dj9pP2p/e79FP73/d397/0S/iP+9/3H/Z79k/2z/Yv9Qv0u/Uv9Tf0X/cD8hfyS/KL8bPwJ/Mn7z/vU+437gvu4+9T7Hfxa/CP80Ps//OD83/z4/HL9tf3J/Sz+nf67/hD/0v9eAH4AuQAhAUQBbwH4AWYCowIaA5ADxAMRBHMEwAQFBUsFgwWaBaoFlwV2BW8FewWOBY0FjwWBBW4FXwVCBRYF7ATRBJwEWAQVBL8DawM8AxYD1wKxApgCYAIhAu8BqwFvAVwBPAHuAKcAiABcADgANwApAA0ADgAfAAkA4P+//5//f/+C/6H/lf9t/2L/Yf9R/1H/Zv9i/2D/cv9v/2D/Tv9O/1P/UP9Z/3L/hv9//4X/lP+R/5z/t/+5/6v/rf+s/6T/nP+i/7z/r/+S/4H/Yv9P/1n/W/8r/xT/Pf9A/x7/Bv///vv+AP8a/wn/7v7u/vH+8P7i/un+Bv/8/tf+5P7z/u/+9/7+/vD+7P4D/+7+y/6t/p7+uf67/q7+r/6a/o3+iv5q/kL+MP4p/iH+D/7j/cD9wv2y/X/9ZP1R/S79Gf0J/ff87vwO/UL9R/01/UD9UP1H/V79kf2v/c79B/4p/jH+nv56/10A9gAtAf0AsQB5AFcAcQC6ACMBaAF/AYUBgAGYAf0BhwLqAjoDZQNLAwsD3QLOAs0C9AIoAzgDKgMPA/YC5QLcAu8CGwMdA/cCuQJ2AkMCKgJCAlkCWAJNAj0CHQLqAdUB1wG6AZUBkQGDAVkBNQEVAQ4BNAF5AaUBewEeAd0AywDEAL8AtgCgAHoALwDe/9H/AwBBAGEAZQBeAPf/av9N/2H/m/8aAHgAcQAZAMH/h/9I/07/p//d/wAATgBpANf/O/9O/7X/7v8KAEUAKwDj/8z/k/9j/6H/CAAKAKv/d/+q/73/nv+d/7T/y//G/7f/Pv+M/vv+PQBBANj+Pf4S/5T/ev/6/3YA6P/I/hP+O/7y/sr/sP+U/kj+A/9x/+X+cf4x/mz93v0g/43/qf5g/dL9g/58/Sn80Pyh/s3+X/11/MP8vfzS+5n7NPwN/Yz+4f/R/0f+v/wz/eT+LP/p/XT9WP7B/iP+/v3i/sf/tADiAR8CPgGwADIBaAHtAEoBJAL0AYsBPQK7AuMBjAH5AiUErgNvA+gDyAIoATEC8gNZA14CSgOtA3MB7/+wAeAD2wMoA94C2gKWAicBxgA2AbsBOQLRARYC7wEIAS8BQwL8AC//sAGkAyIAL/2BAYEGvgLf+7f9fQKdAP7+pAH6AiYAE//QAZQBCP+u/v8AVAL/ACwAwf94/9v+Af56/wUC0gFO//r/8gJ5AGz77PzpAhkEzf90/kIBUgDm+2L+lQRAAwL/T/8BAUUA4P59/jP/HwHMAiMBxv2+/YoA8QAk/s7+4QHOAMn97v5JAhwAHPyU/dsA4v/s/bsBgwNa+5b2Rf36AwkC5fvT/LUAzP1p+z3+5f5X+/v7VQGxASH99Psy/cD79/vo/2QArfwq+uz6UPzi/E7/aP4r+YX5A/6H/Tj5CPiE+1sACAGC/Vz7cPw3AMkCt/8C+y77mv5GADAAfgBOAfwAxP+k/7kA6wHTAjwEqQWpBKABBQBKAaMDBQUpBZwE2QPlAkcCVgN+BS4GpgQ3AxMDuwLBAZcCswQ3BAsC+gG5AvcA/v8WA5IF5gOLAZIAg/9l/2YB3QJ2AXH/DgC6AUUAK/5XAL4DjgKR/qP9yP5X/0MA+wC7APcAYgFa/8n8Xv3BANQDJwM2AakBHQHK/Zr9TwE7AkEA9P8KAu0C7P9A/Rr/tQC4/7oAqwIaA1kDcgKb/gv7HP6OBP0EDgCT/Uz/FADB/8oBQANGAXT/Rf/5/vP9sf4JA14Dyf26/BECxAHF+rj7IQLgAMb9RwG8AEH5bPlsACwBNv33/NH9yfyU/OX9Of7o+1L7JP7m/s/7Yvnd+fn77v6Q/7v9gPwp++/5VvmX+Yz7Cf9DAJ36Z/SJ9rP70vp79nH2A/tn+1j5UP2c/+H7rvv7AKABwPxe/XECGgLL/c79DgAD/z3++wAbBCkFxAVcBiwFeQNSA+kDAQW4Bt4GsgTDAosCZgOvBFYG7QfRB9wFGwRiAwED6wKsA58EkQQDBIwDgwL1ACQApADpAWkDVwQeAxcAbP4Z/40AjADY/vT9b/8iAjYCc/+d/UX/iQGp/7P8Tv3E/9X/QP8rAe8B4P76+8n9MwHZAX8CHARwAcT8e/6TA6oDjwBjAEMB5gAQASUBtwB/APcAnQEwAqgBUwAwAtkEjwOp/+X9wgCoBGMEPwCq/qoANwLDAtMBuf4B/e7/5QLtAR4BHwH4/0T+Q/3j/3oBjv7Y/ToAIgAx/pj8Rvqh+lEAxwS8/zT3ufdI/q7/H/yO+qz6Ivrw+e77xf06+tb2J/v8/aT3/fMA+jf/F/2395z0bPUz98f3ufYW9dL0tfSb83bzcfdJ/YD/sP9RABj/lfyO/NX+3gCzAdQAzP9eAJsBaAJDA1wFewi1Cm4KfQgCB4YGhgbPBlUHtAfCB4EHIAc/B6cHnwfiB9II8ghQBzMFcgSABIQDOwKLAoEDrgNjA/wCBwL7AEIBvgHiAXgCKwL2/yn+df74/oL/PgApAC4ACQH8ACT/6f0D/3cAUQBb/43+5/42AEwA0f5M/vH/iQHLAaIBRAEAASMCUgO7AqIByAGGA9AEtgNqAVcAdwGyAzEEDgJ0AH4BkAOWBOoDoAKOAiUDWwPcAi4BTQCVAeACNgJeAGoAggICA58B3QDlAVsC5P8c/1wBDABr/TH/jACV/qr9hv8RABH9J/q3+5AA/gCj/CL66/ra/HL7Wveu9+H7pvzj+cr4PPhj9k/1FvY6+Mj5t/kl+G31hPLS75zunPGj9cjyuOtT62bx7/U4+ab++QPTA1r+uPon/Fv/awHLAvsC8wD3/p7/wQKxBqUKXA6VELwPhAwICucJugoAC7cK+AnXCDsI0ggBCsgKOwuvC18LvgmMB+EFjgQzAy0CcAHFAGkA2gC3AVUCbwLhAcIA7P/1/wEAJP/f/fv8U/w+/Dj9LP5e/pj/1gHWAWT/RP50/7//if5i/q7/lgBoAAkA9/9aAF0BSQKOApcCFwMDBLcE5ARQBEYD6QKmA4sEqQRlBGoERgSUAxUDXQPMAxQECQRnAwwDOgMoA3sCUQFoAFYAdQDM/wP/lf8/AQICwwCy/9cArQHD/1n9l/0JAA4BGf9O/PD6Pfv0+1b9BAEnBLMAM/ow+Xz7A/sh+YT5+Pl89071wfWA9Uj0MfUi9rX0YPIQ8NXuvu8m8GXtPuqb6RjpgeYC5Zbnuexa8qL4m/5PAXoA2/5s/Uj8pf12ASoEugNDAlcCCAR9BkQKQRDkFd4X0RWkEcAN2gujDGwOxw5wDfMLPAvWCrAKYQvBDLsN6gzqCdAFNwL0/9v+X/7P/R39r/y3/N/8/vxT/Yj9N/1s/H/7qPru+Z75rPn8+av62ftd/df+IQAlAeoBLgLpAYkBgAHWASgCZgKJAnUCkAJlA5wEcgXwBagGWgcRB9oF0ASLBIUEPwQtBKoEIwXtBF8EHwT9A8sDuAPzAycEvAPSAt0BIgGTAEcAkgD5AMsAFQBL/6z+pv5m/xMAEgDs/xAA2f+h/kn9m/04/1X/hv2M/DH9aPzq+Qr6YPwZ/LP56vg8+YP4m/dB9872CPaZ9OPyV/Gi8IPxWfLU8Fftyuqu6uHqWegE5KXhBuJQ4/Llv+xf92AAHARAA3P/zPtY/EwBlQXfBTMERQM1A7gDfgaADDEUwhrrHWccLBcIEvoPlBA4EZYQNg+YDQkMKAuGC6YM7A3nDp0O+AtrBwkD+/8t/h79Pfxs+/P6Jfuv+yL8lfz2/Pb8h/zU+/b6Hvqb+Wv5h/kx+qj7l/2J/0kBkwJ2AwIEIwQJBCYEnwQdBVsFaAVrBbgFsAYcCIYJvAqlC/wLjQt4CiIJIQjaBw0IJQjFBwMHBgYnBbAEjASPBHUECwQeA7cBTgB+/17/hf+Z/6f/gf/Q/gj+u/3p/TP+hP7i/g//DP8Z/zz/Rf8o/x3/F//B/h3+Wf1h/Ab7I/rV+i38B/wt+rj4bfgl+FD31fXO88/xdPBf7zDunO0U7ZjrZOla54PlnuIr31XdDt754EHnYvJ+/j0FCQVWAeH99fzb/3MEkQf+B5oGLwXxBC0HdwywFIAdtCLpIWscVhZSEv4QeRHDEaMQfw6ADC0LBgsSDJsNmw4PDi0LPQYOAU/9W/sv+tj4effa9kX3afjE+dj6S/vT+u/5JfmK+C34Pfib+AT5w/kv+z39u/9bAo4EDQa/BowG/wXsBYEGPAevB70HvAc7CHkJGAuHDIIN+g3MDcYMKAuUCcYIugiTCLAHYgZBBZUEeARSBJcDYgL2AGn/2/2h/Ov77/tL/HL8OPzJ+4j7dfuo+/H73fuG+0j7fvv++3v8Jv0Q/uP+Jf/j/mL+tv3w/Eb8zvv8+rT5ivje92X3s/aw9Uz0r/JY8ULwqO6U7B7rE+oF6OjkQuKY4IzeqNuC2efZQt2e5O7wLP5vBrgHNQRL/9P8Cv+KA+0GAgibB70GTgYKCFMNKhb6H0Im6yXbH0sY0RLDEPoQ8hCCD6YNcgxkC50KAguUDDAO6Q18CqUE1f67+mL4/Pap9YL0EfSz9Cn21/dq+WT6hPrZ+cz44/eL9xz49fij+Wb6sfvJ/ZQA3gPfBiIJRwodCk8JxQj3CJwJawohC5wLEQzWDNgNuA5lD7MPXg9aDvsMnwt3CpUJrwirB7MGwgXTBOEDxAJRAcr/ff5e/Wn83/u/+8H7sfuE+2j7cPuW+7f7wfun+2r7R/tc+8T7n/zc/QL/mf+q/2D/4P5H/tL9Rf05/Oj67Plp+Xf46Pa69Rz16vPc8Q/wvO5z7T/sJevd6L/kv+Bb3jPcCNlC18rZWeBs6i/3oQJfCLIH2gPPACwBIAQkB+gI6QgXCH0HXQjzC9cSVRy8JDQoSSWhHl4YoBR1E7MSzRBEDmkMUQt4CqUKEgwdDhsPHw0CCNQBDP0v+oH48fYP9YbzJPMy9AP2Ffj8+SD7QPtz+lX5ffiA+E/5SPpC+0v8rP2j/1oCcAVRCI0KewtXC+wK5QpTCwIM2AyIDSAOpA7WDsEOoQ7EDhkPMQ+5DnkN1wteCiUJEgjyBsMFcgQcA4cBm//T/YT80ft4+0b7+/qz+rv6+foo+xz79/rA+ov6Pvr2+f75f/qB+6f8uP1Z/pv+yv7k/tz+n/4N/gL9nPsF+l34E/di9rv1kvQp877xEPAs7pDsdOsN6q/ngeRR4SzedtrX1hrVuNZM3AHnQvWJAY0HEwdDA+H/CABBA3IG6AejB/oGUQbbBj8KLBHpGnkjPifCJHoebRjZFLYTiBJvEAsOJQyyCpMJuAklCzANMg41DAsHvADE++/4oPeB9sX0EvNU8rvy7PO39b33GPli+bb4r/fy9g/3DvhC+Y761Ps+/Rb/hAFhBCcHWQk7Ch8K6AlIClYLmQy/DaEONw9LD+QOOw7WDSAOwA7GDqENxQseCioJcQh6BxQGZQSlAtQA1f7M/E37jPpC+uT5Lvml+LT4S/nu+UP6Ovrk+Yn5N/kN+RX5n/nD+g78KP3m/Wj+1f5I/5P/d//O/sL9s/yn+2j6zPgY93b1JvQy88TxY/D771XvY+3K6nzoI+ZF43Tgfd382dfW/dXJ2LfgEO4S/FMF+QfZBUMClAAzAtgEkgYWBzIHwgYdBpAH1wwDFr8f3SXeJeMg7xqQFjgUuBITES0PVw3kC8AKbgpnC3INOw90DnEKrARh/9f71Pmc+Dz3yPXR9JD0IfV99pH4e/p/+1r7NfrO+AH4aPir+WT7K/2d/un/agGIAyAGrQhpCgkLKAtpCwcM4wzzDQcPyQ/9D3QPeg7rDUYODw9uD9AOWQ26C14KDwmeBx0GsQQ0A3IBYf8o/Y/75frX+sr6ffou+g36PPpz+pj6nfqN+o/6c/pZ+m769Pr++0T9YP4H/2//zf9EAJoAhgAYAFP/1v2q+3X6afpG+Sn3Cvb39HryIPDW7+nwbPEd8Nbsaekr5z/lfOIf3zfcVtpd2q3eHelu9iwBlwbYBv8DFAEgAacDAwajBjcGyAXRBHQECwdvDsoYEiG5I3sgzhoAFoQTXRL3EIEPLg67DNcKkAkOCjsMJQ9dEPANZwhyAmH+Rfw1+z/6LvlS+JD3Dfc696D4u/po/O78FPx6+vX4hvhH+b76evzy/RL/CwBuAVkDgQVLB1QIAQmfCUoKEwsODBkN5g0vDscN/QxuDI0MFw1dDdUMkAvvCUgI2AapBcYE2gOOAskAsf6r/DH7nvqH+mL60vkX+dv4KPnC+XT6LPuU+4T7L/vY+rP62vp0+0z8JP3O/fn9ZP17/IL9CAHCAQX+avtc+6P6+Pim+P/4tfcq9UfznfKf8jHzUvMI8iTwte517a/rSOnN5h3lWOP44FjfFuBx5UPvS/o5AkAEIAKE/8L+xP8AAkAErgR6BHMExQP5AuAFcQ4DGFUd2xzrGGQUPhEWEFUPQw6NDYIN1wwAC5MJFgqxDFMPRA+lCwsGSAGY/lX9mfwq/Cf82fsA+wz67PkZ+/X8ev5v/v38APt7+Rz5Afrg+9j9V/8OAHAAAAEbAqADDgVZBl8HEgiDCPwIxQnDCo0LrgsMCxgKdwlxCYgJMAm4CBwI3gZUBTEEXQNqApIBEwFPAKT+s/yn+6X7p/tW+377Ifyd/P/8yv2a/rb+M/7v/eH9u/zC+tf6lf15/hr93f0zAIj/wPtH+oH87v2D/Sn+jv5O/Gz5EvgF+Eb4BfgS9xP2qfUK9nT2cvay9mv3QvYH8jDv9+/68J/vKO4c7l3sc+ig5oHqNfKD+kICVgcfB5YCW/9n/zkAeAD9ALkC4wNOAy8CfQOaCJkPbhUCF28USxBRDegLxArmCd0JeApZCj0JCwj4B+wJxgwyDsQMHAn+BMkB9P9B/2T/JgDYANAAIQCw/xgAOgGgAnYDNQPpAVgAD/+l/nX/6AAiAm4COQIrApAC2QLMAnkD4gQKBpIGUwbUBeMFWQajBlYGtgXQBNIDJAP1AtECVALsAQkCsgLGAvUBAAGsAAoBDwECAEP+ov0T/hj+/P4IAd0A7f7E/sP/kv8S/vr9Sv91/8P+5/6d/gH8+vpQ/JL8Hf37/kP/RP1n/Q4Abf55+Tn5mvtW+g/6if7x/kv4DPVi+Mz5AvhK+l3+avuA9az1qfjA9xT3CPqG+gn3HvSc8zj0yPVG92L29PMW8wv1jfgI/V4BowLAAOf/1gAAACr+l/7QADEC3gG9AK7/UgB1A8QHoQrQCqIJ9wd1BngFEgUWBZsFiAarBuIFBAV5BXoHYQnMCY0IjQaIBBQDhAJ2ApsC3AI1A20DYQM1AzYD8AP8BEIFEwTBAUj/Sv3O/UkBEASGA7EB6gA+ADn/1P7y/58CSwW7BekDnAGz/4X/NgFwAoICpQJuAkIBZgDg/67/OQFOAs3/UP3a/6sDFwOPAD8BxALp/zj8Kf0sACkAg/8QAesB9gDA/uT8bv0o/+T/DP///Rj+of2f/GX8sfvB+k/8xv+KAW//0PrT+J/6N/0B/vn7FvoR/B/8h/aA+OUBBgJU+1T5Pvo8+o/56viE+x4A9f/5+qP3aPgD+639Z/9//8L9nvtx+nP5xviI+bj7QP3s/JX6iPiW+h/9K/yu+0z/VQIeAPP96v9MAU7/wP3z/br9Tf68AIcC9QEtARcCIQMaA6ICyQLrA1QFdAWWAwoCrQIDBGAEIAQmBG4EvgRfBdoFjwVDBTUFYwTBAvkBYALnAhoE/wVWBkYEvQKcA0EEMQKq/9z/MAJxBGYElQLqAX4CjAFg/x4BawS6A9kBzgGTAqkBmf8AADoDqgRjAogADgHjACj/agCkBBAFtgDh/Nj8HgC7A5UEeAPkARoAkf6K/c3/vQKaALD9k/9nAYb/J/57/X3+nQLWAr/9M/t8+6b8y/+E//n7Xfsj/9oBOv5U+8z+VADG+8b6M/9X/zX7tvulAMUA8vr5+Ln94AGQAS0A8f6k+lf4k/6CBNP/zfnx/bADEQCM+SP6bv6/AHkDOQTX/nn5rfmZ/WgAwQDzAJT/sfto+0P+L/xg+g8ACgT7/dr2evpAAaH/Pf34AeQEeP5B+Cb6OP6eAMUCvAN0Abb9Kvzn/JL/rgOcBaQDjQBG/+P+eP64/0gDJgaqBEcBvwDjAsADAgKrAREEIgR6AGn/GgQECDAFUwAEAYEEQANGAF4CtAUKBNr/gv6MAZEFIAaPA/MBywJiA/ICfgJhAYH/OgAjBH0Epf9U/YQBMwU7A90CZAWQAKT46vpwA74FbgEsAHcDGwHW+Oj4mwJ+BkABl/+NA0QA0fac91sCJwanAPb8uvsO+3b+XQRKBTT/XPkx9nD4AQG8BSsDOf6W/AX+BP3S+Qv7UALPBccA1/ue+1H8Vv9KA38AK/vU/Pz/yP5K/ysCBgH3+uH5SgD5Adj8PP3AA9ACQfwf+yz+Tv8p/vj+pgDA/2j8Y/rV/JkA8QCW/bv8ogBvAt3+1PwU/g/9PPyi/sz/n/8hAM79pPtp/dD/XACcAboCfQB+/JT4y/rZAWoFVANP/wv9Xfwz/tEAqgDZ/80C1wXIAVn8a/8FBIwA9PwjAf0EmAEa/30DbwWoAOX+5QJlBIsBcQGTBHYFmQPOAuID6gK4/wf/kAH4A/gEZAaACCYIsgWcA2QBd/9dAhkHDQRcAOYFjwjq/736KwNLDIwHgQBtBWQIqgAh/R0BGgHu/2wClQLPAA8CwwIPAI4ADASfAVn7iP1nBVUDxfoq/ckGKgRk+bD7pAYLBan7rv3NBEQCtf2k/wcBbP5v/okCHgRp/zX7Gf+rA80BdP+b//D+9f5i/wX9nv2VATICsv+F/Vn8qfyjAUQEUQBZ/dP7Xfs6/mEBCwCo/BD8j/4m/2T65voyA2AFMP/P+V/5pvon/W4CJQPN/Ff6rP1k/Uv7yP3N/iL7Avu7/pT/C/60/DL7Wflj+24B/wGx+6/4vfuQ/Vn9BP6W/kH/Ef68+jz7VP+i/9P8RP0qADEASf1h/Mz9kv0d/+wE7AMP+7v4hv6NAtUBYAFpAjABpP40/jP+iv4vA90GIQL8+pP8ngNsBC4BqAEmA4QBEf82/kEAiwULCPoCg/zl/JICEQWZAtgAWwEXARoBWgMYBIUBjf56/2kFLAgSA5L9YQDHBR4DtP4G/63/Pf6l/yoD6gDy/UIAEv/w+M/7TwQiAfL56P5aBaf+KvcB/YsDMP1K+eUC+AUq+0b0nfk/AtQB9f3FAKcC0Pym+U8AJgOb/XD6bP+4BtEFZ/7w+oj+YgFm/+z89/9IBZAElf3v9JjzJ/1aBhYGrQDM/Z78hvnb+q0B2AKy++z4qP/8A0YAtfhg973+gQNhAYD7dflx/jQBnP2P/Ij/cf1V+i/+JAI0/0H7P/2p/3D9zPyx/vX+9/0u/GH7/P3rASUBs/zD+3H+mv/Z/JT7W/9sAWz+avym/n4BkgLjAacB1wFRANsA6APHAxsA3f5KASYDUAMqA3UD/gPxBAQEKAHlAfAG4gl9BQUAhwAGBGEHwAjkBhAEswRaByMIwgjuCc0I6QTPAv0DjgXFBs4HCAfnAzcA6f47A1wJCAl8AzsBUwP6BOoFUwdFB8wDbv+1/4sDgQR2A9kC5v80/Bz+0QGNAZ4CKAK8/OX6af6gAEUAagCZ/k37r/u//m8ABADS/xb/Av1B/Tn/ZP9f/ZD7Sv2bAUED3v72+ff8bwQLBUP/hPzx/HX7iPuVAGgDpf5f+Kf4wvt4+9r7aP9T/3f5S/Z7+db9Uv92/pX88PlQ+QL71fob+qP7Lv0f/FD4vfXy90z7BPuw+bD6R/tq+Qj4nvms+jD4y/YJ+bz5ufa79Fj2VPlm+1b8vfzi/Gn9WP4j/rL80Pzd/nYBKQSXBOoBLwB3AqgFUgYXBkUHOgj+BkAFxQSWBSUHqQjTCHQHQwYWBnsG7gYMB5sGuAbvB+QI9gjTCCgJrgnbCVgJiwgbCG8HLwYyBUcFzwUYBoYGOAfYBzwIkwibCKsH7gXKBFUEtgM9A3gDCAT+A98D2gOGA6YD/wO4AicAIP8xAM0BQQJRAf7/If9n/93/hv8Z/xv/Qf8l//j9W/wC/Df9Fv8uAC7/m/yJ+/X8Ov6//b38Evx6+4v7kfxu/SH9hfyM/Jn8mPuG+ib7GfyZ++j6QPun++n7ePxv/JH6xfej9uz3qfkq+sn5ePhR9kH1yvbC+DD4avas9dv1mfZG+JL5ivhY9mv1QfYR9932OPbB9K/yr/EF8hfyk/Bw7pHu8PEk9un4lvqt+zb8Av3I/kIBGQS/BpEHEAYgBO8DXQUJB+4HNgi2CIUJEwprCUgIuAdoB9UGGgY1BaUDFwJDAW0B0gLlBOQGBwj0ByoHrQYbB/gHNAm5ClwL/AqYCtMKkQs2DJEMlww1DAELCgkmB80FbAXvBZUGZAZfBWgEKAR2BHgEJgTeA8QDqQM/A54CagLlAjUDpwKUAe0A+AAhAfEAJAAe/4r+qv5V/w0AnwAWASMBiACw/yH/O//3/60AeQBY/z/+m/0G/WP8P/zM/Er98/zX+7r6Qfqr+qv7X/xp/AX8ofuV+9L79vsV/Ev8h/yb/Fr8SvxU/Cb8rvts+5j7cPvp+kb62vna+OP2ZPWr9fT2Kff69bD0p/Sz9XX2Zfbb9R/1qfR+9Rv32/fK9833CPi99/H2tfbn9kT2g/S+83/1HPjh+cj65Pq4+qb71v1TAGwCqgNaBCcF+QU1Bk4GSwdhCfQKyQqDCeYHLgeeB80HCAeTBjwHMAgFCI4GQwUcBXQGagiOCZEJYwllCaIJyQlICUMJqwp5DPkMFQz7Cu4KBQwYDRkNLQx4CxELfwqBCTMIDgegBp8G1gUfBGUCIQKqAyoFVwWGBMADUAPMAlgCRAJrAnACKwIgAZH/v/40/1oA/QAaALX+vf4gAG8BbgFKANX+t/3//IH83Pyz/UD+TP6K/en7VPow+jX7M/xP/IX7qvq/+aX4y/e392z4iPlV+lv6uvn2+C/5qfoD/Sb/5f9J/2X92fpP+bb5Ivtt/NX8A/w4+u73oPZe93X5ffvG/DX96Ptc+WD3Jvef+K/5gPnG+EP3/PT98pvyFPTH9of5O/vn+5/7z/r/+Xn5N/mX+MP3aPfY90D4FvgM+Jv4gPma+rH8Dv8IAUIDtAXFB2wI8gfyByUJhAo5C1YLCAtDCi8JZgjxB5IHXgerBxEI0gfkBisGhgZlB+oH/QeuB3gHyQcaCGMIXgkDC9sM6w3sDcoN2A2mDQQNmQwdDAULKwo5Cj4KFQlWB2QGewZ5BggGGwZ2BtcFQgTjAqwCogOsBBwF2QTVA/YCIAOZAz4DdAIbAlcCWwJjATUAh//E/kf+kP6+/pv+XP5P/n/+5P0G/YL9nP64/gX+ev2D/U79OfyM+wj83Pyg/WP+pf5//Wn7Rvrg+u77OPxj/Iz8kPtm+eD3zfj0+k781/zh/Ff8rvtc+9b7aP1a/nr9Zfz4/Hj+af5X/DD6qvkU+w/9/f1h/TH7tfi79wT4Rfim92f2iPXD9JjzaPMm9Z/3AvmT+NX3Svhj+dn5svlp+aj4wPdo9gD1yvM+8rLxxvK49C72U/ZW9ij4MPvb/SoBzAS2BzAJxwieCNYI9AgxCqILOguvCEkFlwKoAYYB+gB0AF0ATADp/2D/U/9bAFQCywQQB2MItwj9CGIJegmICf4JJgvOC0ELKQqkCW8KvgtqDMcLcQr2CI8HjwawBe0EGgRJA+wCuwJ7AmwCIQNBBPIEKgU7BT4FkgQgA98BfgG5ASIClQK7AjICGQEoAPX/FwDf/xr/Uv4g/v/97v0F/ib+YP4n/uv9IP6i/gb/9/4u/pb8hPuY+5T8lf0r/d/7T/vz+538cfzA+1T71fua/B79Wv1v/ab9xP6r/3D/BP9//mH+Vf52/qj+N/7Q/EP7VPoU+YX4Tvmd+gr7tPk9+Zz6nvsI/G/8l/yh/Mn8/vwo/Qb8YPpC+q76ffrS+Tz6HftM+436z/iT94n2g/Y690j3tfbo9a/2tfe199/2Avap9df0xPSN9nP5U/uR+2D7U/sU/MP9LADLAoYEkQWXBvsGHQYOBekELQVIBaQEpgO5Ap0BYwBU/9f+Ff8LAN4AGwEkAXwBSwJRAz0EFwVyBtQHeggqCKAHlgf2B38IcAj0B98HJgj1B4AGhQTwAzEFrgYVB8cGmAaVBmsG9gWkBfcFqwYVB+MGJAYaBXIEeASKBCQEpAPuA68EqASHA58CzAJGA0UD+gI5A8QD2gNSA4sC7QFZAcIAegBMADkAXADbAH8BfAHrAEgAoABHAcUAkP/s/mf/2v92/7D+fP63/tP+A//k/rP+OP+V/4z/ff9C/5b/SwBuAIkAaAFTAW7/r/2W/fn+1//N/tL96P3I/S7+Df8b/5X+Tv6P/u/+bf7N/db+5/8v/8X9o/23/v/+x/25/N/8Yv1J/Zb8Q/yB/NT8Iv3r/Sn+HP11/A39wf0z/S38vfxa/qf+wP3a/IH8z/xP/Lb6dfnS+IT4q/hq+b36L/wr/QT++v6j/24AxAG4AnkCmwHxAP0AOQG8ABkAcgAnARUB0gAsARUCoQKEAu0CJATRBHwE/AOtA2IDZQNiA+cCLQJNAawAdwDGAG8BPAK4AsACygL4AkYDYQM6A+oCrQKIAn0CjgLZAu0CeQKXAm8DFQQTBPUDDgRDBBwEVwOVAgsCkAFdAW8BMAGtABwAs/+i//L/nwAhAeQAPAD9/y8AJADR/9r/GABVADEAcf+9/nL+pv4l/4b/jv97/5n/Wv/V/pr+Kf59/Wb9tv2Z/VX9m/04/sP+5f6v/iP/RACJAOj/Zf/1/nf/kQBcAC3/SP55/nP/pv+2/tn+w/+u/3v/Yv8L/+D+WP8YAGkA2v86/9H/XQCS/53+C/9cANoAEQB7/0kAPAEFAVMA9/99/8j+k/7j/uz+Uv6k/aT96P2n/f/9af8LAJj/Iv86/9H/tf8J/9H+Vv60/bv9xv1P/cT8evyr/A39CP0B/S79/fxy/Of7Svsf+4z72vsM/Kn8nv01/qj+jf+cAIABBAKJAmMDFAQvBLsD/wJiAlAClAJrAssBHQGbAHMAmgDoAEEBhgG1AdIB7AEGAuoBwgHwATYCagJ0Aj4CGwL6AbwBmwGWAaQB1AE4Ao0CYQIZAkACrQK6AlIC+wH6AUMCEgJuAUkBlAHuAS8CYgLhAosD8QPeA3QDuwLzAVEBbwB7/yT/fP+5/3H/Rv/F/0oAiQDBAMYAqAC6APEARAGRARABSwBQAG8ABwBx/9b+qf7m/vP++v45//z+JP5v/rr/XQD0/z3/8f7x/vv+Cf9z/57/U/8p//3+//5a/4H/wv8/ALP/2/5O//L/3v+H/+H+uv46/xP/Wv4m/oj+dv7x/eD90v7S/4v/6f7e/iH/c//o/9P/DP+D/oP+9P4V/7H+nP4K//v+c/6Z/gv/jP/C//D+Iv54/ir/D/9S/of9m/0d/qn9F/0m/SD9wPyh/Lj8XPzu+x38c/z/+yz76vo8+9b6C/l09wj3lPeX+J/5f/qV+2L9sv9PAtMEwgbtB+QItAm+CRsJDwjjBsMFogSGA4ACpgHiABcAiv+S//r/fgAnAasBBAJwAu8CVQNuAyQDxgLQAg4DCQPBAqsCugK+AtUC8gIRAywDWAN4A1gDAQOXAiECdwG8AFkAFgCE/+P+nf7Q/iT/SP9s//r/vABdAesBYAIRAxwEEQVmBfsEdQQ7BOYD9AKsAagAMgDe/xn/P/4H/mb+ov6z/gr/f//6/1cAMwDm//L/EADv/8X/hP9r/5z/t//y/yUACgD8/0cAWgAVAPj/s//3/pT+t/6F/kj+av6L/lr+Iv7d/cD9Jf5W/hz+AP4y/jf+MP5p/lv+4/3Y/Yr+Ev8X/9z+m/4p/oP9if1C/lj+t/2M/bL9of2c/b790P3P/Sz+n/4+/r39EP5A/s/9gv2d/cT9qv1B/Q39E/3D/G/8Wvxg/Hj8gPxl/Cf8j/vm+qb6r/p7+uP5JPnv9+P2Kfb89IjzOfLM8JXu+uz77j31MfyRAJsDSQeMDMMSRxdVGCMXjBZVFikUkA9CCsMFKQKi/5f9Z/uq+VD5F/ql+mX7o/3ZABIDywMwBM8EZwVnBdYEBQSNA/EDsAQLBdYEsQTiBC8FiwUABhYGcAV5BHADXgIrAQsA1f5v/Wj8+/sG/BX8cvxh/YH+qv/7AEYCIwPBA2QE5AQUBRIF7QRWBDgDHgJjAekAxQAHAUUBawHuAdUClwPyAxgE6ANXA5gCrQF/AD//RP6H/SX9LP19/QP+sv6K/2kAUwE1At0CJgMzAyoD1wI4AooB3gAmAIH/B//Q/sf+0v4L/03/jP+6/83/sv9p/wX/j/4v/sv9Sf3w/Ov89vza/OT8d/0b/o3+Jv+6/+T/2//5/wAAgf+e/gb+mf3a/Er8Lvz5+6r70ftr/CH9hP2U/bL9wf2t/a/9t/02/WP8EPzK+936EfrJ+Tv57/h9+Qf6Cvqy+Sn5A/mj+Hf3jfZv9XDzQ/Fj7w/tQupO5xDkZuA73UffSelS9xYCywiAD1oYFyS9LrszETJjLrYrHCdgHh4SHAbY+4f0u+9S63vni+VC55vq0O7J9Hb8PQMWB8EJjAuaDDsMuwqHCEEGUwV1Be4FVAXjBIcF9QapCB0KPQvKCnUJ1wf3BVkDMAA4/T76vvcE9mr1LfVt9eP2Zfla/EL/XgIGBeoGMwgvCYoJ8gjhB2kGuQTJAvYATf/C/bH8UPx0/Jz8GP3t/cb+Q/+K//b/VgCeAKcAZgDm/8v/XQAlAfwBUAMKBT0GwgYpB5IHlwchBzUG8gScA1gC8wBd/yX+mP2L/an9Df65/oX/ggCQAWUC5wJsA9sD2gNbA6EC8QEyAXwA6P+G/17/Xv+I/9H/NwCsAPsAFwEeAQsB4QCCAOX/Pv+U/hr+vf1u/Tj9MP1y/cP9Df5X/q/+4f7n/sv+lP5R/s/9MP2r/C/8i/v/+q76dPpb+kL6Jfon+k36dvpU+vj5fvk5+e/4O/hX9yf2d/SZ8szwv+6O7CHqTecm5BDhyt152oTXjNb6223ql/0DDCUVBx2BJtoyDT1YQE47mTMfLbIlZhq7Cm77L+/y5yTkwOBS3dzb19+35pbu3vZk/8sGvwtZD9sQtxCODuwLtwnCBw8HRAf+B9cHYghJCpYMdw6UD1wQdA9tDbYKhAdHAzr+3vnq9W3yuO++7uHu7u+i8rf2VfuU/+EDlAc3CucL8QwiDRAMjwrJCLMGJgTUAeb/Iv78/JT81PwP/Y39Sv78/lb/WP8q/1r+NP0L/B77P/q7+fX5wPoF/KX9qf+jAY4DZQX8BioIogiICN0H6gYyBvkFcwXWAygCeQFmARIBjAAyAE0A7wCHAXIB7gDPAAoB/gBvAPj/xv+p/7T/2v8OAGQAQQFNAgsDqwNQBMsEywSKBDgEwwMDAwUC9ADj//f+LP53/e38yvwK/Wn9xP0j/qD+BP8z/zH//f6g/jD+t/0v/b78d/xf/Gb8gPy//A79TP1o/WH9F/2d/Bf8YPuK+q353Pjn97f2nPWM9IvznvKX8Vfw+O6p7WPsrupx6KzldeLi3qDbtdkp2cfcn+gd+/UK8hSoHQEnSzJaPCNAMDuOMfgpRSNeGd0JW/nq7InlreKN4OHdNNw04IzpQvPF++QC2gkTD2ASrxM5ElgOOAkMBgAEsgJWAs4C3QNfBRQJQA0pEHwRhhI2E8gR9w72CukFvf8m+sv1avGh7Zvr/uuA7WPw+vQr+v/+RgOkB9QKbgzxDLsMhgtUCT0HAQVqAsv/Iv5O/cD88vzY/RX/DAAaATUCpQIwAjYB7P/p/an7p/kU+Mf2Mvbh9kD4Cvo7/Oj+kQHYA+0FmAeBCIYIDggWB38FkQOSAaL/8P0J/c/8zfwS/Rj+AQA2AkMECwZzBykIOgjHB4IGlwSYAtsASv8L/mT9P/2m/cn+mQBxAvYDRgU4BqIGggbxBcQECQNeAfj/tv6V/dn8vPwj/f/9Lf9ZAFcBJALBAuoCigLJAbEAY/8G/sf8tPvV+l36X/q0+lT7Nfwn/fP9of43/3v/Y//6/lT+Xv0e/Mj6j/lh+DP3NPaF9Qn1t/SQ9Hn0X/RI9C70mfOG8h7xg+9n7dfqDOgd5WbiQeBY33zfMuPG7a39NwweFt4eOShVMgs65joENAgqyiI2HOYRjQJJ85XpO+WQ5P7j5uKv49rpS/Re/cYDMQiTDO0P4hBxD9sKnQSo/sD7u/oh+sb63PzZAM8F/guHEb4UvxZUGCUZ6RZQEosM/AU+/wX5+PMJ70frLeqV61nu3fHC9g/86AA9BfoISQuCC8EKjAm+B0YFzwLKAOD+ov11/SH+G/9qAGcCaQToBdYGPwewBhcF8wJLAC797vk890f17vOd83v0M/Zs+DH7S/4tAZkDkgX7Bn8HOQd3BkEFlwPUAUIA6f79/cH9Nf71/u7/PgHAAgIE3gRyBZoFkAWKBUIFNQTJAsIBPQHuAIEAIAAcAMEA4QHpAoED8QORBBIFFAWMBLMDrAKSAYgAmf/Y/mf+Xv6r/jv/EAAIAdwBYQK/AvoC4gJeAm4BSQAM/9/9zvzT+w77t/rf+kv77vu+/Kb9hf49/7n/2f+k/yn/h/6p/aL8oPud+rT58Phn+Pz3nPds92j3c/di9zr32fY+9nb1gfRL87Tx7e8l7ljscup/6F3mgeQf447iA+Pn5DTrfPcOBuAQKxiJH/EnFzCvM+4v7yZMH1kbOBa4C5r9LvNQ73zvAvB77gPtZu8897X/GgRvBc8GnwkeC5oJFQXA/kD5efaQ9uf2Tvej+Wb+qgTgCpgQjhTPFrwYIRpWGRcVTA+JCdgDPP72+Gz0qfAG7/7vdvJY9ZH41PwfAZwEKgeECGII5QYyBWIDBQF3/nb8S/uv+gz7a/xE/lgA1QK3BREIdQkXCvEJugiCBsoDkwAD/b75Rvee9a/02fQR9vD3R/r//MD/+wG5A/4EnAVkBYMEPwOeAeb/av5h/b38oPxQ/Zv+PgAUAgsE1wU4BxQIQwjzBxMHrAU1BAYD9gHRAA0AAwChAIABPQLLAogDswSsBa8FzgTrA2YDugKDAQEA0f5H/lr+p/7b/kn/VQDPAQYDrgMIBCEE6QNKA1cCHQHC/4L+af2S/O/7lvuI+8H7XPwe/dn9d/73/mb/q/+b/yz/jv7h/Sn9X/yK+9L6Sfrt+bf5lfmE+YP5dvlZ+T35AvmF+MT38vYZ9hX11vNr8gfxwe+17qPtVezk6o/pZOg35yHmj+XJ5eXmSesQ9UgBsAooERkYCCCAJ3UrEikBIn8cPRsSGSIRXgWe/A76z/of+wH5k/b392r+LAX8BoIFRgVeB3EIBQaFALz5nfTZ8jbz+/KM8uf0hPoZAcAGXgsiD1ISkhUPGMcXdxRaEOoMKgmFBNb/7/s9+TL44Pg1+qD7zv3xAOkDowWABpsGkQWpA30BMv95/PH5SfhY9/T2Z/fj+N76Of0fAEgD+AXbBywJrgk1CeEH5wVSA14Axv3C+y/6Mvkg+fX5Uvsk/TP/EwGaAt4DyQTbBCgE+gJ7Ab7/5f1H/P36MPol+uv6KPy+/dL/JgJnBHAGFAgICT0J6QgjCNUGQgXNA7wCJQIoAqUCJAOkA3MEeAUkBjIGzAUwBXoEmgNfAroAPf9j/hD+4v3I/RT+3v7u/w4B/wG0AkEDqAOyAyoDRgJHATwALf9T/rf9Nv3n/Nv8D/1e/a398f0o/mP+i/6J/jX+sv1U/Qf9jPzp+1T75fqc+lz6Gfra+bX5tfmU+UT57viY+Cn4fPe19vf1NvVb9G7zh/Kt8ePwGPBQ71buIe3t68bqsOnN6IjooujQ6WvuNvbR/aQDoAmNECoXCxwVHeoZRBY4FtIX1hVlD50IdwW3BYAGfAUUA58CTQapC8cNxAvOCXQKzwvPCrYGuwAb+xL4+fZa9dryBfJW9Dj4y/tZ/j8AdAKpBRIJswr/CZAIxAf9Bh4FgQIgAKv+dP4s/wcAowD6AYkELAfYCLAJQwpJCpUJTghmBgwEyAHu/yb+QvzL+hv6A/pT+iP7Z/zG/Rz/VAAlAUYBAgGQALD/VP7b/KH7lPre+a757/mU+rf7Uv34/m0AygEdAycEpgS0BF4EnwOxAr8BtwCz/wD/3P4M/3H/JwAfATcCTgNcBDQFvAXwBdUFWwWABJIDrgLZAT0B9gACAUUBpAH2ASUCWwK2AiMDZQNaAwwDgwLbAScBcADS/2T/Qf9R/2z/n//3/3gAFQGmAQcCJAIAAqgBLwGQAOz/Wf/V/lT+4f2Q/V39W/14/bL9Cv5Z/on+kf6M/oT+Zf4i/sX9Vv3l/HX8//uk+2f7SvtY+2j7dvuE+4z7pPum+4n7V/sM+7j6UPrV+U/5xPhM+NT3Tve59gv2W/Wo9PfzPPN/8t/xh/G+8ZzyHfR99iP6S/4TAbEB1wBu/z3+XP61/3wA4v8e/yf/wf/GAEkCuQMABTkHdAq9DBEN4QygDfAOrg9pD+QNYgtHCWQI7gcIB4QG/Aa6B1kI4QgaCbwIegjoCB0JMgiOBtgEGQNnAd7/W/7c/PT7+PtD/Ff8hvw0/Sf+EP/h/1MAOADg/5b/Jf9Y/oj9+vyG/Bb85Pvv+wv8dfxq/Zn+rf+qAIwBMQJ1AooCXQLAAe4AJwBv/5T+3f1//Wr9kv0G/sD+fP8oAOAAlQEQAlQCcgJLAtQBQwGmAO3/Pv/U/rP+vf4V/8D/jgBNAQYCwwJiA9sDLARTBEYEHgTfA2wDxAILAl4BzgB8AIMA0gA6AbUBPALBAjMDdAN8A0cD9QKXAgwCXAGwADAA5/+2/6v/yP8FAFYAtQAWAV8BpQHDAa8BcwEXAaAAAQBb/9D+aP4E/rX9h/2B/Zz9tP3O/dP92v3c/b39gv0s/cf8Ufzh+2377Ppp+vf5oflq+VP5UPlJ+T75SvlW+VX5Mvny+JX4Iviq9yX3lvb79Vn1s/T780bztvJm8mHyu/J38/f06PfD+5H+9/7Y/a78R/wO/bP+6v+6/xT/B/9N/8f/5wBoAsoDuAWBCKEK8gqgCj8LegxUDYcNkgxxCo0IKwhvCDYIMQgHCfUJggoVC2ELAguxCiYLeAueCg0JWgeIBcYDiwJiAfD/8/7l/h3/+v79/mT/y/8gAH8AdACX/4X+zf0W/RT8QfvG+kj65Pnw+TD6XPrd+vj7IP0A/s/+fP/K/9z/9//i/2f/2/5+/ib+wf2i/c/9Hv6f/l//NADYAHIBGwKcAuYCFwMjA88CTALXAVABvABPAB4AIgBOALsAOQGcAQkCjgIVA4ED2wMIBOcDmANFA+MCagIAAqoBVwEhASQBSAF7AdABSQK1AvoCJAMgA+oCpgJgAvgBeQEMAbAASQD4/+n/+P8YAFIAoADhAAgBKwEuAQYB0QCNACEAo/8u/8n+bv4k/v796v3j/en9//0P/iH+N/43/h3+9P3D/XH9Fv3F/Hj8IvzR+4T7Ovv9+s36qPp++lb6KPrx+bH5cfkq+cb4TPjc92/34vY99pv1DPV69O7zXvPD8jHyzvHf8WDyi/MI9pb5d/xT/a381fuY+2H8IP7P/0wA9f/p//L/7v+xAEgCzwNABV8HUAnVCbkJYwqdC38M/QzPDFALZAmzCPYI6QjpCJQJLApECnQKzQqaCjUKhQr1CnIKNAnQByUGbARcA6ACbgFIAPP/4/+O/3T/xf/8/wsAXwB7AMX/yP4s/qT91/w8/Nn7O/un+ov6sPq++hH77PvP/Hr9JP67/vH+DP9W/2v/Gv+8/nr+KP7O/b/96v0W/nr+Hf+//0EA0QBsAeYBRwKdAscCmQJNAhUCxgFkASEBBwH/AA8BVQGtAQMCawL1Ao0DDwR0BJIEXAQEBKoDSwPaAnICLAL1Ac0BwgHMAf4BUAKqAvECGwMjAwkDxwJ4Ai0CygFbAekAiAA5AP3/5v/l/wUAPwB3AJoApACmAJcAaQAfAM//av8B/57+SP4E/tD9sv2n/a39vf3Z/ev9A/4Y/hH+9P2+/YP9Rf3//LX8bvwv/O/7vPuV+3z7ZftI+yn7+vq++nv6Rfr/+aP5Nvm/+DP4iffw9mL21/VG9bf0KPR+883yTPIl8lvyKfMf9TT4FPtU/Oj7CPva+sr7kv1E//v/5//Q/8//yP9IAKQBLAONBEcGAwjQCO4IeQmtCugLwgz3DAMMYAqFCbUJ6QncCS4KjQp5CmcKiwpzChYKIwqOCmgKeAk0CLMGHQUQBHQDhgJOAZEARQDi/5L/lf+l/6T/yf/h/3D/lP77/aL9Jv2w/FP81/tF+wD7CfsT+0H7z/t+/AX9gv32/Tb+Wf6d/t/+3P6r/oL+Vf4a/gz+Kv5Z/qH+B/97/+H/TgDJADwBpQEJAmACcgJSAikC+AHMAa8BnAGPAZsBzgEcAm8C2gJWA8oDGQQ5BD4EMgQQBN0DogNRAwIDrAJXAh4CDgIoAkMCVwJ0ApcCqQKaAngCVQIkAtYBawH5AJkAUgAVAN7/uv+s/73/zf/W//D/BwALAPP/zP+T/0v///6w/mf+KP73/cL9mf2I/Yn9mv2k/b390v3Y/c79ov19/Vj9KP3x/Kj8W/wd/O37vPuU+237UPsx+wj74Pqq+mz6J/rb+YD5B/l8+Nv3N/ep9i/2ufUy9Zn07/NB877ykvLQ8q/ztfWX+NP6c/vo+mX6xvop/P39Y//d/8T/xf/K/8f/aADQASgDVgTHBQwHlgfQB5wI8wkxCwgMKgxBC/UJhQnqCScKJgpVCmIKGAryCQUK3gmbCckJKArvCQQJ1QeLBkcFhAQJBCMD/wExAcAASgDk/8L/uP+k/6L/jP8S/2L+5f2h/Un97PyX/Bb8jPtE+zn7TvuB++D7Xvy//Bb9Zf2b/dT9Gf5a/m/+WP43/hT+/f0G/jX+cP6w/gn/Z//G/zEAngANAXYB1AEmAlECWgJCAikCKgIiAhYCGgI9AnMCtgIEA04DiwO8A/UDIQQvBCoEEATXA5UDUwMMA7oCcAJPAj4CNQIxAi4CNQI7Aj8CRgInAuoBrAFlARgBxAB2AC0A6f+y/4v/bf9d/2j/fP+Q/5b/kv+E/2D/Of8M/9r+qP5n/i/+/P3S/b79q/2o/a/9wv3U/dL9xf2w/aP9jv1n/Tn9/fzB/Iv8VPwj/PD7vvuO+2P7PPsa++/6ufp/+i76z/lk+eb4VfjN91T33PZV9qz1BPVs9OHzdfNR84XzSvQd9nz4JvqT+lb6Qvr0+m/8CP4p/5v/tv/R/9r/+v+0AAMCMgM3BFoFZQb6BlMHDgg/CYAKUQt1C84K4AmbCQ8KagpyCnsKYQoeCt0JyAm2CYQJjQm5CZYJxQiWB3sGegXFBEwEngOZAqkBEQGjADMA4v/L/7b/hv8//9v+U/7g/Z/9YP0W/cb8YPzm+4n7bfuT+8/7EPxd/Kf86vwk/V39mP3Y/Rj+Qv5A/jD+Ff4E/h/+Tv6R/tj+Hv9f/63/EQCDAPUAXAG+AQcCNwJHAkICPAI5Ak0CYwJsAoECqQLaAggDPwN4A6UD3AMHBBYECwT4A9gDoANkAx8D4AKiAm0CTwI6AjACJgIeAhICCwL/Ad8BqgFvATwB/AC4AGoAJADl/6z/gf9c/1H/Tf9M/07/Tv9N/0T/Kv8F/+T+wP6R/l3+Jf76/dr9w/2v/aL9p/2t/bT9tP2t/ab9mP2B/V/9NP39/Mj8l/xj/Dr8BPzH+5f7Zvs6+wv71fqU+k76Cvq/+Wr5+/h4+OL3SPfE9kr2xfUr9ZT0H/Ts8xr0xfRA9jb4nvkl+jP6SPry+k38xP3N/nf/yf/Q/7//5f+nAN0BCAP9A+8EwgVqBvcGjweKCLwJpQrZCnMK3AmXCd8JOwpnCnQKVQoRCsIJmgmWCZIJgwl3CV4J0AjHB7UGxgUHBYAE9wMmAysCZQHlAHkAGgDv/9f/nP9D/+r+ff4O/sb9j/1O/f78n/ws/MT7lPul++D7IvxW/IL8svzj/CL9Y/2v/fv9JP4x/if+GP4N/hv+TP6Q/tn+Hf9U/4//4/9aANsAQgGnAQcCPgJZAmMCbgJ9Ap4CvQLSAu0CBQMaAy0DUAONA9UDAAQYBCcEJgQcBPkDzwOiA3kDQwPzAqgCbwJWAj8CJwIVAgwC/gHcAbABfwFmAT4B9wCwAG4AMgDy/7D/eP9c/07/QP8t/xn/Hv8e/xH//f7n/tT+rv6B/lP+J/4M/u790P26/aX9n/2Z/Yv9iv2O/Yz9d/1X/Tb9D/3n/Lj8ivxb/Cb85fuk+237OfsP+9j6lPpQ+gn6v/lh+fj4jPgZ+JT3DveN9v/1Z/XZ9IP0g/Tr9O71bvfS+KL5DPpT+rz6tPsF/R/+6f53/6P/jv+i/y4AMAFHAkADIQTzBLMFZwb+BqAHoQiyCTkKIAq0CVAJSwmWCeYJBQrwCcQJhglPCTwJUAlbCUIJKQnwCEcIVgdjBogF4ARUBLMD2QLtAS8BqQA/APX/2v+v/13/Df+9/mn+Gf7a/aH9W/0U/a38LPzJ+6X7vfvo+x38Tfxy/J382vwc/WX9vf0L/i3+Nf41/ir+Jf4w/lr+kP7G/v/+Mv9j/7r/NQC2ACYBiAHZAQ8CPQJhAnkChwKYAqoCqwKxAsYC5AIHAzcDagOXA8QD6QP1A/YD+APtA84DnQNfAxoD3QKpAnICQwImAg0C6gHXAcMBqgGPAW8BTQEjAfEAqQBgACEA5P+p/3//VP8z/yX/IP8a/w3/Cv8G/wH/5v7E/qb+ev5T/i7+Bv7b/br9pP2V/Yz9hv19/W39Wv1H/Tj9E/3j/LL8efw0/Nz7hfs2++P6jvo2+u75m/lN+fr4m/gw+Gb3dvaE9ZD0O/Pj8V3w9u1N7I3shu5C8RD0nfa/+Az7If5SAsAFdAbZBYsG/wcZCDcHCwZ+BAwEUgaJCMIHrQZoCGMLXg33DrgPtg4SDugOYw6ACxUJxQcABgwE7AKwARYA6//RAB0BPAEwAsoCKgKZAUwBYwBC/1f+u/yE+jb54fh8+BT4XPhB+XD6E/y//cH+kv/8AJcCWwNyA1ID1gI5AvEBzQFJAeYAKgGKAcMBWAJJA/kDjQRmBfcFygVaBcsEpQNPAmQBYwDy/qz95vw6/Oz7afwc/Zb9TP5Y/ykA0wCGAcIBkwGbAb0BggEpARcBKAFeAQUC0AJgAwoEBgXfBWYG0wYAB7kGPga/BfsE8QMIAzwCcQHqAKwAZQAbACkAcQCcAKsAlQBRAPn/pf8y/4X+7P2N/Vz9Vv1l/XX9pf0s/sv+S//D/y0AbQBuAGIANgDH/0f/2P52/v79f/0O/dv87fzx/Mv8ePw0/Ab8wPtH+4v6u/kN+XL4n/d29mf1w/Qu9FTzZPKo8fvwNfBZ7znuFO0X7N3qCOnL5hPlR+Rv5ELlWOiB8Gz7/AJKBkkJNg70Fr0hciZEIoEd6B1jHsQa5BSoDqMKFgwnD/QLSQXeA4oHlgqyCzQLdAcHAzsB9/58+ar0FPM88Tjuz+w+7VPuSfFX9r36Qf7cAmoHRAmBCXIKZwt0CyUL5gn/BpUEeQRHBcEFxwaGCOMJ7Ar5CzkMZAuQCrsJsweQBCUBV/1O+Wb26vTu83rz3PN09Cr19faH+bv7lP1F/00AhAB8ACwAUv+h/qT+8v4q/53/ZQBfAekCLwVuByAJaAoDC8QKJgp2CVYIwgYTBTgDcQE5AIj/Pf+Z/5kApAFxAjgDvgPqAzIEWATNA9UCygF/ABv/Tf4K/uz9Qf4F/7j/SgAPAfgBsgJPA7wDhwPAAvEBJwFRAKf/R/8N/+r+Cf9F/4j/DwDLAGkBygHcAYABzQD6/yX/Qv5m/Zb80Psi+4v6KvoE+in6iPrP+sD6Vvrl+Yn5N/mu+Oj3PfeG9p71oPTM8z3z9vKx8gHyQ/HD8Bzw7e577Rjsguqt6GvmtuN/4Ujhv+LC5Szuy/w6Cq8QZxPRFjoe+Cq8NGUyiigeIsgfaBt1E9UJtwGL/4QCUgIJ/FH3N/kK/qIBVgPpAbz9X/rg937z3+7F7YDure3Z7ILuSPIO+CYAGAjxDW8TShmlHGwcLRugGeYW0xOkEKgLVQXLANP+C/5O/p//ewBgAKEAHwGYAFf/Jv5T/FL5OfZV8zfw0O1d7X7uhPC483735/pT/nsC0wZcCuoMYQ6HDm8NvguiCUYHSQWwAz0CKAGeAFQAaQAzAVECIgObA8oDJgOKAcn/Sf7c/J/72fo8+sb5J/qk++j9oACsA3EGoAhSCmULswtqC84KlAnKB8wFpANxAbT/t/5m/rb+UP/P/wgAagAiAcMBJAIPAnsBnADG/wr/ZP79/eP9Gv6T/jT/0/9tACIB4AF4ArECbQKdAV4AAf+5/X/8Y/uC+rH54vhG+A/4V/j0+Gb5bvlO+VT5Ovmj+Mb3Avdr9qH1hvRb81jyvvFF8XbwsO9n7/Duiu2l67Hp3Ofd5W3jC+Hr3xnhMeRv69H5jgrsFCgY+xmEH7UrejgwOgEwiiSuHuIa0BPjCAP+7Phi+v37HviL8jvybvdd/UEA/f/E/V37uPgz9EnvZ+3x7mfwNfBm8IvzofobBCQNCxS+GR8f/yLwIxQiZR6/Gd8Usg+FCXQC8ftI9/f07/SA9mz4u/mC+j77Ifzb/OH81/vN+UD3tvRe8qPwE/AF8WrzC/d6+xMAnAT8CCANzBCGE9cUiRR8EhQPGwsOBz8D2f8E/aj67/gt+GH4Vvm/+lT8oP11/s7+qv4P/gX9zfuc+uX5CPrM+sP7B/0v/1cCAAaTCdsMyA/AETISWhHDD7oNWgtsCNQETQFs/iz8ifq1+fD55/oo/F39YP5s/4cAVQGFAUsB8AB6ANr/Gv+H/nP++v7J/4oAOwHqAZkCJQNtA1MDvAKlASkAa/6V/Ob6kfmt+Pz3afcZ9zr33feV+A/5OflO+Yf5qvlC+Q34X/bt9PTzFvMN8u3w9O8h71zuku247NXr5eqp6fnnDuZs5HDjk+NT5Tvpn/K5AmQS/BlYGw4dnCOOL/44ATfgKyIhTRtZFggOMAM6+qz2W/dO947zIPCy8QT3Vfub/Jz8MPzj+sn3AfP97oDuRPGR87fzQfSC+JYA4AlNEtgYyh3YIZckrCTqIX4dAhi9ESsLyQR5/nb47PN28TPx7fKe9ar3pfiT+eD63PsD/HP78fm094P1xfO68uDyh/Qp93/6wP7DA6wI+QybEDoT2hRoFXEUoBGHDQMJigRmANb8D/rm92n26PVY9ob3Rfky+7H8nf1U/s7+uf4a/if9DvyC+wz8O/1z/sr/3AGoBPIHOAvaDf8P0RFXEvwQog7hCw8JIQbHAjj/KPwa+t34MPg++Ev5DPv0/Jr+8v8LAeUBXQJKAvABkgEqAYMAwf9U/4L/LAD1AKYBNwK9Ai0DSQPmAhsC/wCY/9/9Efx1+hr5Cvg698P2xfYy97b3HPhu+MD4F/kv+eX4Tvhh9//1Z/QD8+7x8PDO73DuEu0J7E/raerU6PbmjOUT5WfluuYx6ZnttvebB3YVUBtNHDYeoCQBL5I1vTHFJh8d9hfsEnwKZgDs+Dj21Pa19rrzjPHM83f4DvsR+/D6+/oo+lP3ofJ67uvt6/C/86/0MfYL+84CeAuBE7AZHB6DIZ4jPyNrICAcchaiD7wIpgIg/RP4LfSc8dXwRPIG9Uv3hviW+bP6UvtI+7D6Vvl297H1PPRU86PzhfVW+Kb7rv9dBEMJzQ1/EcsTphSAFGoT/hBEDegIUQTq/z/8gfl+9yv2wfU19lT3Cvnv+oX8v/2M/s7+oP45/pP9svwS/Cj8Cv10/hwAGAKUBI8H1wquDZUP0hByEfAQ6A7rC74InQWQAlv/Jvyi+U34APg3+N/4KfoO/CD+4f8NAbYBGwI/AgECdQHbAEsAz/93/2X/wP9sAD8BAgKTAvECCgO3AuABoQAe/3P9yvs++sn4h/ez9lH2Ufac9gr3mPdA+M34/vjT+Hr4+fc49/n1WPS68lHxIvDq7n3t6Our6nzp8efL5ojmHedm6I/qku2j8xwAnA/vGcwcLx3aH9wmOC8jMdkpOh8qGC0ULg4xBZr8nfe/9sj3Bvd99GH0zPf8+hL7D/oK+kH6P/nH9Z/wBu3Q7XDxK/S79eL4Hf8gB2IPfxZ1G/AekCGMIgUhoR30GMQSrAsPBZn/9PpA95f00vKf8lv07fba+BH6Hvun+2T7ovp8+dH3AfZq9BHzlPK/82/2vvld/Y8BQQYSC4QPyBIwFEIUjhPQEeYOLAsEB5gCfP4+++n4a/fT9hD3y/cD+bf6f/zo/b3+7f6d/in+l/3N/Oj7Vvte+wL8l/07AEoDEga+CFQLjw2eDykRXhEsEPsNDQvHB5AEaQFd/rH70vnf+Kr4JPkL+j/71/zC/oYAsAEsAhYCrwEsAbsAQQC5/0n/CP8U/5L/YQBGARkCqgLxAtkCYAKNAUEAmf7i/EP7vvlt+HX31/Z79k72d/YL98T3S/hd+Bf4r/dP97/2qvU+9LTyNvGy7yzul+wg6/7pBukZ6DfnAefe5/jpYO1Q807+mAx3F8Ab3BzBHvIjZyuxLs0pgCAjGakUFA//Bt7+jfkn+Bf5+vjx9mH27PjI+/H7d/q4+Zv5AvlD9iHxeeys63ruivG98+32jvwRBEQMuxM4GR8dDiB2IZog9x0eGrcUFg6BB+IBVv33+aT35vU09TL2PPjz+Q/79Ps8/I/7Q/qh+LL21fQt85rxnfA08afzFvfr+hn/ogN5CEoNKRE9E8wTcRMyEs4PlgzrCO0EHgHw/YX75vlC+YX5MfoW+0P8g/2V/k//Uf+F/nb9ePxy+2r6nvlQ+bb5CftX/XIA0APjBq0JHgwjDtoP7hC0EBkPkQyFCWoGdAOWAPz9+fu5+jX6Vfrz+uH7CP1r/tX/5ABrAW0B/ABXALP/If+s/lj+O/5Y/r3+bf9cAFgBKAKoArYCUQKdAZwAO/+j/Qn8ifo8+Ub4o/ck99T27fZf9/H3bvh1+Pz3avf/9mT2QfWy8wfygfAY773tMuxu6tbo2Od050/nkueu6P/qCu8g94YEEhKhGfgb9hxUH/0kKitMK00kCRy2FjgStgszBOv9j/qd+tL7LPvE+bn6TP0N/i/8KPon+ZP4HvcK8yjtV+n96QTtx++q8if3kP1kBZQNUBT3GHQc2B4oH50dLBuBFzYSNQykBgICrP62/Fr7PfpC+pT7Bf3U/Tb+GP4C/R77xPgW9orzk/HZ7zbuou3+7vbxxfUD+lz+4wLDB2gMvQ9gEdgRbhEQEN4NKwsUCO4EQQIWAHb+q/3N/XX+Nv8GANoAcgGKARoBGgCP/sv8B/te+Qj4W/do9yT48Pm5/Nb/wwJxBQ0IwQpjDQAP2Q5fDXcLYwkMB4YEAQLD/xP+Af1l/FL88vwK/h3/+v+8AGUBuQF9AZ4Aaf9s/tH9UP3M/Hv8h/wC/d/95/7q/88AegGzAWsBuQC8/4v+Of3B+zH64fjw9y33mfZu9q32LPe29/T30/eM9zD3pfba9Zf0APOQ8QjwFe5K7Mvq+egP59bljOUp5iLoduvE8Av7NgnIE50XkRgLGlkegiWKKVwl+RxbF64UthBtCgkE2v9U/0UB7gE7AJv/zAGRA8AB8v0A+1n5LfhQ9U3vGOkV5xjpqevD7b/wePUR/PIDJwswEAoUXRcVGeEYwxc3FogTwQ/CCxIITgULBJMDywJCAskCrwPpA3oDjALGAD/+PPvK9270/fE18ELumOxg7O/ty/BK9ML3Avur/t4Cfwa4CNEJUQpMCtgJBwnQB4EGkwUCBXsENwSTBG4FTwbxBjgH8AZaBrgFggReAvn/zP2w++z50/g2+A34F/ky+xj9zv4zAegD7AVCB/UHyAdLB9wGxwXIA+cBxwAHAGr/Ev8n/8f/5gD1AXECxQJaA7gDWgNcAhEB2v/s/iP+P/1n/Cb8dfzv/IL9Mf7c/mv/yf+9/zj/Z/6E/Wz8Cvux+Yr4ffeW9hf27/Xu9SD2c/al9rv24Pbr9pb2zPWo9JzzvfJn8aXv7e0T7DHqoehm58bmU+dT6azs+fJw/jULkxLTFJAVwBY+G/QhvyMlHl0XDhQCEn0OugkSBaoCCQTgBmIHSAbbBuYI/Ai3BUkBmv1h+9j5+PUw77vp0uiu6qrsku7g8Hv0UvotAWsGvQmnDNIObg8YD5EOrg1jDCELsQlECOcHxQiqCQEKeAooC3kLLAstCjYIWAUJAjr+MPoD9wf1XvOa8WDwIPAV8S7zgfUp94j4j/re/Hj+Of9y/2n/g//x/0UAhgBpAQcDqwQPBpwHaQlLC/kM3Q2pDfQMWQyBC9kJZQfLBJ4CBAHi/wT/kf7G/l7/1/8rAIoAAwGDAaMBIgFPAJ//Cv9T/nb9xfyi/PX8lP1M/g3/AgAVAQQCmQLvAiwDPwMFA3UCtwHyAGAA/f+t/43/l//H/xIAWgB/AHoAUADl/z7/Yf5b/SD8n/oF+Y/3S/Ye9SX0bPPY8nPyU/JI8jfyQfIi8vvxCvKb8YPwd+9M7qTsD+uZ6enn/Ob253Tq4e4i+DAFzw6oEn8UcxWJF4odeCLiHyEZ6xQLE5YQBA2oCNUEZATHB7wK0gqyChYM/gxGC3IH6QID/+L8k/o29bzuZ+uf6yXt3e5d8O3xavUw+3EAUgMUBZkGMwcaB98GMAZPBS4FuQUlBuwG6QhNCwoNVg6DD04QnxBuEBMPZQwyCbwFywEe/oP7rPkn+Cb3nPZz9hP3PPjw+OT44PhM+aj5mPn3+OL3Affn9nP3LPhZ+Wj7BP66AHAD9gU3CH8KhgySDacNUg3HDAIMAAu2CVkIPgelBnQGOgbaBZ4FkQV5BT8FpASTA1kCGwHM/2v+Hf0E/Dz7zvqg+pb6x/pS+xf84/ya/TP+sP4b/3H/j/9//3H/cP9w/3j/m//h/1kA5QBSAZ4B2QEZAk8CPQLTAT4BkQCV/y/+kvz/+pn5TfgC95L1LfQ/86Dy4fEB8WHwHPDW7xrv0u0+7MbqiukC6Njli+Nt4nbjMuaI6/D1cwJVCuoNERDCEIkTOBoSHrMaoBXqE/ATbhODEbINSgqPC80QaRTCFH0UehTNE7MRYQ04B+oB9P7j+6v2UPGO7mXus+8/8dHxSfLi9DX5Uvz9/G/8mfvM+or6VvpQ+Yf4ffng+8b+YgKiBnEKjg0zEAsSChOYE4ETFhK2DzoNpwr1B5sF3QOQAvMBKAJ3Ao0CmAJjAlcBe/9r/V/7a/mP94v1ZvPa8YHxD/L48jT0FPZw+O76Y/2C/wIBQAKFA0wEfQSwBB0FmwVGBi8HEgj6CBMKEwutCxYMVwwbDHgLngpfCboHBQZTBLgCaAFcAGT/gv7s/Yf9If2g/BT8g/sH+7D6Pvqw+T35Efkd+VD5mPns+XD6Gvvh+7D8df0a/pP+8f5C/4T/ov+w/6//iv9c/yb/rv4B/mj9wPzT+9T64vnX+L73qfZ49Tz0SfN+8iDxF+8e7XbrtunU59zlK+Tt40/mbuyD9Qb9XgAhAqUDJwXJCCcNuA1GC3EK2ws2DaUNHQ3LC8ALGA/IE7EWNhhXGYIZkhiiFvMSZg75CmsISQWhAdD+Jv1Q/CL82Psi+/D66vvJ/F788frM+GL2UPTG8kXx6O+d74rwOfKP9KH31fq6/XsA4QKwBB8GSwfKB5EHQAcEB9AG2QZBB7sHXQiSCeUKzgthDKMMPwwqC7cJ3AeoBYsDjwGm/w3++fxD/OX78Pv8+/37LPx5/JP8fPxG/MD7J/vN+rT6wPoc+9b7vfz0/WP/vQD2ASgDMQTuBIAF1gXiBcIFnAVrBSMFGAUpBQkF3ATQBLEEXATxA1YDcgJiAVkATP83/jL9UPyU+/v6n/pj+j76JvoE+uz52/nH+ab5f/lJ+Qn50Pif+JT4s/jj+Cz5ffm6+ez5Mfp2+pb6l/pu+hD6nvk7+b749fcR9xj26/Tl8wLzt/EY8B7vW+8V8W71X/sr/2QAPwGxASsCOwTyBacEsgL/AkIERAUSBuUF5wSNBeQIYQytDocQrBHfEQQSzBHgD04NfAvhCUUIWQcHB10GyQW8BYUFSQWgBRcGpwWMBDkDSQEg/x/98fqU+OT2OvYA9k/2MPc5+DH5UPp5+xr8k/wZ/Vf9T/1B/T79I/1S/dX9YP4u/2QA5QFnA+UENAb5BmkHnweABwoHeAbRBQYFeAQ4BBgE/wPrA9IDrwPEAwMEEgTNA10D0wIeAoEB4AD+/yb/pf5i/kH+ZP6T/qT+0/4k/2T/gP+o/7v/ov+g/6X/h/9w/4L/nv+//wkAVwCRAMoA/gAEAdsAqwBRAOf/eP8C/4f+Cf7B/X39Q/0b/fX83fzh/Pv8+vzw/N38ufyH/Gj8VfwZ/N770vvS+8T76fsa/C38bPy6/P38S/2H/Y39iv18/Tj95/yZ/DH8mPv++lv6mPnV+Dz4avi/+Yb74vzQ/Sj+/f1n/nH/0P9T/9b+rP7v/rz/aQBPAAAAbQCXASMDwAT3BbAGegd4CA0JEwnBCCEIZQf5BvEG4wbFBr4GvgbUBiMHmAfTB8cHjQcbB5YGAwYnBdoDZAIeAQsAPP+z/jL+u/2K/aD9xP3M/cb9ov19/Xr9dP1Y/Sz9Av3d/M788Pwt/Wv9zP1O/s3+Wv/v/1oAlwDJAOYA6QDjANgAuQCbAJcApwC9ANYA6wD2AA0BJgFDAVsBXAFUATUBCwHjAKwAaAAwABIA///5//3///8AAAgAHAAuAEQAYQB5AJUAvQDfAPYADgEXARcBHQEiARgBCwH5ANoAugCUAG0AQAATAOX/uv+f/4L/V/8o//T+v/6V/m3+R/4b/vv93P3I/cX9vf3E/cL90/3t/Qj+Iv4z/lD+XP5n/nP+df5t/m7+f/6D/pn+rf63/r7+wP6+/rD+oP58/kr+Gf7d/Yz9N/3V/GH8HPxD/KT87Pw5/XD9Xf19/er9Gv71/d391f3e/Sz+iv6w/q3+4P5a//n/rgBPAckBOwLKAkQDjgO0A68DmAOHA6UDxAPBA84D2APcA/YDKgRMBEkENAQJBM0DhAMoA5gC9gFmAeUAgwBDABgA/f8OAEwAkgDHAPsAEwETARUBBgHdAJkAUwAKAMb/lf91/2j/dP+e/9X/FQBhAJoAuwDJAL4AoQBxAC8A5f+U/0f/Ev/l/sP+uv7D/tn+Av8t/1P/cv+N/6D/lv+O/3b/Vv89/yj/H/8W/y7/U/+B/8D/BwBSAJQA3wAZAT8BYAFvAXABZgFRATEBEwH5AOIAzwDEAL8AtwC3ALEApQCVAHsAVgAuAAEAzP+Q/1L/GP/l/r7+nP6F/nf+cf59/ov+nP6q/rn+yv7T/tz+3/7d/tz+2f7Y/t3+4P7o/vr+Ef8q/0b/ZP93/4z/m/+Z/5T/fP9g/zr/Ev/o/rr+k/5v/lb+Of4j/hP+Ef4h/jP+Q/5J/k7+Sv5O/l/+Wv5N/k3+Uv5j/ob+rf7R/vz+M/93/8P/CgBJAIAAtwDoABABKQE0AT0BPwFNAWEBcgGBAZgBsgHJAeYB/QEXAiACIgIfAhICBALmAcMBnQF6AWQBUQFCATYBLQEsATUBPAE8AUEBQQE6ATIBIwEQAfUA3gDFAK4AmQCIAH8AdgBvAGQAYQBVAEYAOwAkAAsA8P/T/7T/k/9r/1D/Pv8n/xX/Cf8A//3+/v4D/wb/C/8V/x7/Jv8t/zr/Sf9Z/2//hf+V/67/zP/r/wYAJgBHAFwAewCUAKUAswDBAMoAyQDOAMsAygDHAMMAvgC6ALIAogCVAIoAegBoAF4ARwA0ACYADgD+/+r/2//K/7P/qf+a/4z/jP+E/33/ev98/3n/eP9+/3r/gf+D/4P/hf+M/5L/k/+Z/5n/nv+f/5//mv+X/5X/jv+I/4L/ev9x/2b/XP9X/0v/Qv89/zL/Kf8g/xn/FP8M/wX/Av/9/vX+8v7x/vH+9/73/gL/Df8a/yb/M/9F/1P/Z/9w/4T/lf+j/7j/yf/c/+7/AQASACoAOgBMAFwAagB4AH0AigCLAI4AkQCOAI8AjwCTAJcAmQCdAKAApwC0ALkAwgDKANIA2ADaANsA2gDYANUA1gDYANYA1QDbANgA3ADeAN8A3QDTANMAywDBALQAqwCeAJEAggB3AG8AXwBXAEkAPwA0ACgAHwARAAUA+//x/+L/2//T/8v/xf+6/7X/sf+w/7X/t/+7/8T/x//Q/9P/1f/Z/97/6v/u//f//P8AAAYADAARABYAGQAaABwAGwAhABsAGwAeABoAGgAVABgAFgATAA8ADQALAAMAAAD9//j/9//0/+//6//o/+n/5//l/+P/4//i/+H/4//g/+D/3v/k/+H/3//l/97/4//l/+T/5v/j/+L/4P/f/97/3v/W/9P/0v/J/8b/wf+8/7z/uP+3/7b/s/+z/7T/s/+z/7P/tP+0/7T/tf+z/7f/uv+7/7//wv/J/9H/2f/h/+n/7//2/wAABAAJAA8AFwAcAB0AGgAdABsAHgAlAB0AIgAnACQAJQAmACoAKgAqACoAKgAnACUAIgAhACIAHQAiACAAHwAdAB8AIwAiACYAJwAqACoAKwAsAC4ANAA5ADkAOAA8ADkAOwA8ADsAPQA5ADwAOwA9ADwAOwA8ADcANAAyACwAJgAjAB8AHQATAA4ADQAJAAYAAAD+//z/+f/2/+3/6v/n/+L/5v/f/9r/2//a/9b/1//U/9L/0//R/9b/1//V/9H/1f/a/9f/2//f/9v/3P/h/+L/5P/l//D/7v/v//f/9P8AAAIAAgABAAAAAAD+/wAA9//w/+z/5//f/9j/0f/R/9n/4v/t//b/BAAUACcAOgBHAFIAWgBcAGAAWQBGADUAIgAUAAYAAAD4//D/+P8AAAAACQAZAB4AKQA3ADgANQAwACQAFQACAO//4P/V/8z/0v/Y/97/7f/5/wUAHQAxAC8ANgBAADoAKgAsACcADgAJAAMAAAD8//r/AwAJAAwAEwAgACEAHQAqACYAGgAaAAwACAABAPr/9f/m/97/3P/x//r/9//1//D/7P/w/wYACgD4//D/9//4/wEACAD9//P/8P/4/wMADAAFAAoAEAARABkAGgAbABoAGAAhACcAJwAtAC4ALAAqAC8ANgAxAC4AJgAbABMAEgAKAAAA+P/q/+f/2v/P/8r/uP+j/5v/i/9y/2T/VP9N/0j/Sf9K/0//Yf9b/0j/Uf9X/2z/qv/M/8D/vf/y/yMAUQByAHIAcABuAIcAlwCKAG0AYQBSACQABAACAPT/6f8AAP//6f/b/+L/5v/k/+7/7P/s/9z/y//W/+L/AAAgACwAOwBXAFkAawCLAGIARAA+AC4AHQAOAOv/xP/G/7//wf/P/77/m/+u/9P/4P8KADIAQwBdAIQAmgC0AMIAqACoALAAmwCGAH8AbQA/ACUAMwAcAAsAKAAkABEAHAAvACUAMAApABAAEAAIAPD/xv94/wr/t/6P/of+of7f/gH/OP+b//b/RgCVANIAzADgAOcArQBTAP7/xP+R/4T/ev9t/2f/iv/Q/ykAbACHALIAxgDYAOEAzwCgAG8ANgD8//P/0P+j/5T/qf+1/8//EwA3ADkASQBxAHoAhQCUAG8AMgALAP7/8//2/8n/mP+I/3L/c/+o/8f/p/+6/9z/zP/f/xYAIgDv/+3/DAAMABcAFwDw/63/rf/A/77/wP+h/4P/gv+s/9r/EQAnACwAQQA8ACYALABFACgAGAATAAsA8//3/w8A+f/f/+7/EQAeADMAFwD9////5f/i/xgAKwAhADoAMwADAPP/EAA7AGUAMwATAAMAv/+0/9v/7P+v/6H/q/+N/5L/vf/p/w4A/P8dAGYARABZAHQAWwAsACkAHwAEAN3/lv+i/43/l/+V/57/yv+w/9f/QABVABcAJQBFADYANwA+ABEAx/+u/6b/av9P/0X/ZP9t/0j/bv9W/xT/pP5c/n/9Tv1Z//IAdgFtAi4DegKrAr8DhwOyAiACbwFiAGL/bf7e/V39A/0u/fD9mv7g/sb/qwALAT0BxgH9AbEBjgFEAdgALQCE/x7/+f6g/kP+l/71/jn/mv8GAHgApQCiANMA7wC7AIsAVAAUALj/ef+6/87/VP82/4P/gf+z/xMALAA5AGwAsgCTAGMAVAA6AFIAUQA0ACEA+/+r/63/2P+e/6L/2//s/83/4f8nABsADwAAAAwACgDk/+n/5P/B/4H/if/e/6P/W/+6/+z/q//Y/0IACgDZ/xMALwAyACsA+v/c//r/5f/e/z8AIQC0//f/VQAsACkARADi/8v/IwBLACwACgDU/6r/4v/5//3/6//H/9L/CAAsAAoADQATABgAAAABACEAGADz/8z/EAAjAAcAJwAyAP//AABGAFIAQQAQACUAUAAqABQALgAvAPL/4P8DAAwAHABRAFcAGwAYAD4APABEAEoAQAA7ADUAQQBWAGUAYQCFALsAzwDoAAkBGQEMAUkBqwG3AbkB6gEZAj4CVgJbAm8ClgIIA8kDVwOqAgkDgQLfAXcBgQBj/0f+i/26/PT7D/tE+un5JPq++kX75fuF/GP9Jf5X/4kA5gCwAGcA7gDfAEsA6P9G/6n+KP4H/iX+Wv49/nL+WP/9/3cA2QAhAX4B2gGHAWkB1wFPAaEA5QCMAeYAQACmARgCVAFkAXwBMwGuALIAXAA+/0P+av21/OL7Z/u4+oX6MvuG+/D7d/yR/Yz+Ff9PAD0BIwFCAQMCTQIYAucBhQHNAE4ASQBgAEcAEAAwAHAAsAD3ADYBeAF7AY4BzQECAukBhwFaATABowApAAcAnP8y/0L/Tf9W/2f/Y/+Y/6j/i/8MADkAEACpALEAfQDdANMArQCrAMYAqQD6AE8BCwGBAaYBkQHMAdEBuAGwAa8BsgGkAWQBaQE5AS0BRwE1ASYBbQEcAgQC3QHtAa8BQgG4AHwAAADr/vj9jv0P/Qz8OvvY+qv6ofqq+jT7o/uU+9r7l/wi/Rn9QP0w/dj83fxR/Kn7MPtn+sD5Pvnz+KT4HPjL9+b3Rvhp+G/4rPj5+ED5jPn2+Tv6PvpK+rT61Puh/Uz/mgC6AZICrwNTBWMH8QgvCWMJTQpSC/QL2Qv5Cs8JRAloCXQJDwk3CIkHTQdDBxgHdAbJBWIFIAXTBDcEgwPHAuIB2gDA/7T+3v1L/c78S/yo+xn7Avsn+0X7gPvt+3v8av10/jf/QQByAT8CGQNZBGwFHAYOB/AHHAhACLwIFwn/CKMIgwhmCEsIQgjqB10H7QaUBiEG2gV7BccENwS6Ax4DPwJgAa0A4v8N/xL+k/1H/Tj8hPtX+836QvpD+i367PnM+cz5AvrU+Zr5g/ml+Yv59Pje+LL4HfhW97T2APa99PDzZvN08kHxLPBG7wfu4ezE67fqM+qq6X3pW+oq7KHv+/TU+Lv6D/6HATgFIgsMEFMRihGWEwwW0BYAFiQUlxGKD5wP/A+EDpgMeQv5CpcKKQr0CfoJQAqmCk8KGAniB9EGMgXXAlEA7P2s+/P5gvhE9qTz7fEn8cbwBPEE8ifzUPT/9Sb4VPqT/MT+gAD9AcEDqwUuB+sH7QefB3EHpQfdB6IHLwcFByoHTAdUB30H6Qd0CB8JHwoaC1sLfAvKCzALGgqMCeIIhgfWBREECwLd/w7+l/w2+xD6Tfn/+Bn5jPki+tT6q/vK/Aj+Zv/yAL0BGgK8Ag0D+ALIAoQCFAJ5AcYAGQBX/2n+yP0d/UX8rPsH+4T6DPr++Kz3Z/b/9IHz3fHo7+7t5Otw6Rvn3uRV4vjfFd6+3C7c5Nzl3kfjeelp7afwhvY0/E8CHwukEh0Wlhi3HHcg6SG7IXEg/x18G2sa4hhbFZoROw5MCwMJWgdSBp4FaAUqBSsE/wKIAo4CBwLsAK3/G/5U/L/67/g+9jjzt/D37u7tmu2+7ePtKu4V7/Lw1fN+91373/5YAjUGHgqIDSsQIhJ2E4MUYhWrFQ8VoRPJEaUPWA0FC/oIYwfdBTwEGQN1ArQBagHHAdcB5QGyAmgDcwNCA9wCHgIuAVgAdv9n/kT9D/zN+s/5SPkJ+TD5uflz+nz74/xr/vD/cgEBA5EECgZBBw8IkAioCFYIpQepBn8FGwRyAoQAb/5K/Cb6//fK9XXzHvEF7x7tIetD6YjnxuVK5ArjqeFg4HTf3d4l31PgQOIa5kXr0u4S8kz3a/wpAvcJgRBFFLgXHRwOIJQi3iPiI+IinyGgILYeRRuNF7wTxQ8tDCsJbgbQA4oBOv+p/Kb6yvlx+eP4avgl+L/3dfdt9zr3nfYa9r31X/Vp9cn1//XO9b31F/b/9r34D/s2/Qz/PwHmA8UGqQlZDLYO2BDWEnQUghUCFvMVVhUyFKkS1xDZDrUMHApgB/EEogKWAPv+g/0h/D777Pq++rT6/Ppu+/P7fPwV/br9av74/kH/iP/h/zEAcwChAKQAlwC+AA0BPgFxAbMBAwJ0AtwCMAOEA90DEgQaBOQDjgM3A4wCigFIAM7+Lf14+4T5I/eU9ArygO/H7BjqmecF5a7is+Cx3unc0Ns821vbe9x93k3i0+dV7FjwH/YH/DgCHQr/EEUVFxl1HTkh0iM/JUwlMCR6Iowg9x1dGoEWiRItDg0KoQauA9oAP/6/+1b5uvcr9w731vat9tP2CfdM9733Efgx+EX4Ivje9933Bfjz96z3Y/dB96j3xPgk+lr7kfwp/kMAygJ6BRkIbwqUDMgOvRBSEpYTYBSEFBQUWBNLEsMQvw6YDFAKrgcbBeUCqABu/qr8L/vU+ev4hfhk+Gr4ofgH+a75svrN+7/8s/3K/sj/tQCXATACpwIYA3EDkgOSA4MDVwMtA90CawIGAsABcgEDAX0A8f98//v+Xv6h/b38t/uk+mf53Pco9j30FPLF72ft6upj6OXlXOPz4OLeK90P3OzbfNxZ3mjiteYs6iTvOPUH+zMC1QmEDx0UHhksHjgi+iSSJugm8iVsJK8iyx8CHDQY+BMmD8UKIwd2A9n/rfzK+XL3DfZq9Qb1uvT79M71xPbU9+v45vm3+lv74fta/MD87vzI/Fv8xftY+1z7j/uo+8r7UPw+/Y3+OgAZAvgD5gUgCGoKgAx9DlsQuRGzEpMT+RPHE3UT2hJfEWkPmg19CxwJ9AarBAkCkv+k/ff7bvor+Tj4m/dM92L3wfdY+FP5mvri+xT9XP7K/yUBTgJAAwIEogQhBXcFcgUVBZMEHQSMA68CngGiAKb/ev5g/Un8KfsW+gL5zPdy9h/11vNs8sLwAu8w7ULrT+lk523lcOPF4cvgUOBf4BviN+XW58jqge9g9GT5zf/fBX4KFw9tFFgZMh06IEgiBiOpIjciaSFoH8UcyhnxFZMR6Q28CiUHXgPH/4X8yfnK91b2E/Ua9NjzWfQb9d71tvaf95X4ofne+h/8B/2k/Qj+J/4Y/j7+pP66/oP+bv6W/tr+cf9bAE0BLQJAA68EHAaXBzgJwQohDHMNqw7dD+MQTBFAEe0QXhCnD7wOSg1KCysJFQcNBf0C0gCu/rL82fpL+SP4RPfD9qv2zvb/9qL3wvjg+Q37QPxv/bn+AQAsAQcCgwLlAkkDdwNAA8YCHgJLAVcARf8v/vz8ovsl+pL4+PZc9cvzHPI48D7uVOxz6p/o8+Y35XnjGuJg4TzhreG848TmMumG7G/xAvaV+hUA8gTiCGUNXxKLFoUZwRtNHcMdfB1jHfYcVhsrGbMWXRPqD4ENbAuhCHEFWAKf/2v9o/s3+tX4mvcq91j3e/du94739Pd5+EP5VPo4+5r73/tU/LX8EP2q/S7+Jf7x/SD+lP4Z/9L/qQBfAQgC6AIJBCsFZAbSByYJVQqMCwINVw4yD+IPbBCXEJQQgRDZD40OKw3lC3gKvgjPBrUEiQJtAJb+/fx++zn6PflS+KH3d/e89yz4sfhV+Qv65/r5+xz9E/7V/qH/bwD0ACwBRAE8AQIBqgA7AIr/nf6O/Wf8F/uf+Sv4pPbH9KvynvB77ljsdeqK6IHmoeQm4zLi5OFX4ivk/uaY6Rzt/PFz9t76+P+FBHcIAw3gEbIVRBgoGnYb8RvbG+EbZxvCGbEXbRV2EoEPhQ3LC1sJbQaYAyQBEP9p/RD8rvp1+fz4Dfnk+Jb4k/je+GD5KfoK+4z7t/sE/J/8L/2r/S7+Zf4r/vH9KP6U/vn+dv/s/0gAwQB3AVgCRgNvBM8FBgdECPYJogvnDEMOjA9HENsQZhFhEc0QHxBWD0UO6Qw+C1EJCwfDBN8CAgEL/z79i/vc+YX4zfeD90P3BPcD9073zvdy+Dn5B/rA+pT7aPwB/W391v02/mH+YP4+/uT9XP29/PH78/rG+Xr48PYI9fnyzfCP7mvsPOrd56nlzuNK4mXhWuGL4uPkhufo6qzvVPSN+GL9LAJbBvkKExAmFLsWjxgNGtoa7BoPG9oaZhlMFzUVpBLUD+0NhwxnCpMH3wSbAocAsv47/eD7kvrq+dD5fvn9+M34I/m4+V76B/tn+4776fui/Fv92f02/lX+DP7J/fn9Tf6D/rj+9P4l/23/AAC1AIMBmALeAyQFowZnCBQKyAufDSQPOhA3EfARLxIuEgkSkhG9EJoPJw5dDEAKOwhbBmIERAIdAAv+IPyp+qL5wfjY9xr3vfap9r32+fZN97f3WfgX+bD5NfrH+mT77Ps//Hf8kPyO/G/8K/yl+9/6+vm8+C33Y/Vl80fx/u6j7BnqjudY5aHjbuLe4YniiOQM5zDq1e6o89b3Y/wfAXEFAApAD6MTSBb3F2cZbhqzGvUa2Rp8GWYXdhVcE9MQ8w6lDdgLVQnQBq4EqQLUAFf/AP6t/N37jPsQ+1n68/ko+pz6Fvt8+5r7j/vT+5D8U/20/c/9w/16/T79Xv2W/an9rv2+/dj9Hf6e/kr/IQApAWwC/APJBYYHSQlfC00N5g5QEHYRLRKwEiwTKROwEuoR+BDHDzYOewyYCqMIpQaZBFUCIwBZ/s/8Xfvt+ab4pvf+9n32Jvbe9bD1zfUX9oL20vY297n3RPi9+Ar5WPmg+eH59fnW+YX58/gh+Pn2kvXh8/Tx6u+f7SrrxOiS5rvka+Pb4mHjHeV656jqHe+S84731/ssAEcE2wjsDfIRPBSiFewW8Rd6GNoYohhEF3IV3hMdEh0QpQ6cDRQM5wm4B8kFAARbAgYBvv9i/nP9+PxU/G778/oA+0b7g/t/+0z7Jvte+wv8pPzJ/Kj8Wfzz+7r72fv3+9/7tvuc+6n77vuA/EH9If46/9IApgJJBDYGZwhNChcM8Q1jD1YQSxEzEoISSBLzEZMR3hDSD7wOTg12C74JJwhHBjsEdQLqAED/df3e+4r6S/k/+HX3m/a79Tv1BfXQ9Kr0zPQJ9UD1fPXA9RD2Z/bT9iH3NPcP99z2gvbG9cn0lPMX8mzwh+5X7D/qVei85oTlAOWq5UznnOni7BXx5fR6+IT8ewAxBG0ICw1cEDMScBOUFFsV4hWCFkcW9hSVE58SXxH1DzoPvQ67DSoMhwrpCF0HMwZQBR4ElAKDAegAIwA2/4z+I/7a/bj9bP3g/GL8ZfzQ/Az92vx6/Af8gftG+1z7WPss+wj75frg+iL7wfuQ/G39q/48ANABgQN3BUIHzAiICkgMlw2dDpIPPBB3EHUQhhBxEAgQhw/YDsYNhAxcCyUK0whwBw0GmQT6AmoB9/+E/gf9xPum+m75U/hs96z28/Vz9SL11fSO9Gj0bvR99Kf0zfTa9Mj0n/Rt9BP0kPPa8vDxzfB67/7tZOzb6m7pU+iv5+nnM+k46wzupvEP9bn3zfpt/rkBFAWwCI0LCg3fDd8Oog+zD+YPNRCMD0gOoQ1HDaUMewzlDPYMXQyyCxMLTQqSCTYJ2AjIB6UGAQZwBaIE6gNZA6QC3gEkAWMAlv/8/s3+sP4b/jP9ZPy4+y773/qW+i/63vms+ZX5pfkB+sb67fsV/Sb+Yf+RALMB/wJ4BNsF+AbfB4kI/AhHCaIJ+AkPChEKKAoJCpsJNQnbCHYIFgi0BxcHSwaKBfoEdASrA9AC9QELARkAR/+F/rb9+/xJ/JL7uvr0+V/54vhj+PH3jvcU95T2H/ap9Rj1hfTc8w/zGPIP8RHw/O7W7bPsoOvE6lvqqOrJ66HtWPBD8zj1jvZZ+ND6a/0FAD0CWAOCA8oDggTWBKkE1gQlBbkETAR3BLwEOAWDBi8IMgmuCU4KAwuQC0YMSw3nDbINYg1mDVsNPA0XDa8M/QstC1IKVAk7CDsHpgYJBgUFswMxAvkAFABo/5z+jP2X/Pr7wvvN+/v7VPz0/Hb9sP3d/UX+Dv8AANMAQwFcAVMBkQESAmwCpQL4AkgDbQOeA+8DWQTcBGQFvAXFBaAFmAWsBZoFUQX+BJQE5QMwA4IC4wFIAZ4A3v8A/yT+c/3p/Dv8f/vV+iL6Z/mo+Ob3Dfc49mD1X/Q68xXyEPEH8PHu1+3R7Pnrf+um62Ts1e0p8L7yXPQl9Vv2SPiX+hT9Mv8QAP//SABAAeQB5QEnAo8CaQJEAqoCDwOMAwUFAAczCLIIZQlpCkYLLQxnDSkOHw4MDjcOJg7pDfYN6w1iDX4MnwvWCvYJPgm3CPkH0gaIBVwEIwMZAlwBhAB5/33+2P18/U39W/2w/Qf+Bv79/R7+Wf6+/j3/of+q/3v/Z/+Q/8n/+f83AG4AggCmAAQBfgETArsCTAOZA7oD3wMRBDQELwQjBO0DdQPuAnACAwKSARUBfgDE/wr/YP7N/Un9tvwm/H37rvrb+Qz5QPhi93X2XvUT9MfynvGC8FzvPe5P7aTsXOzN7ATuCPBO8srzf/RJ9cz27vhQ+0n9K/44/lf+Hv/n/x0AVgC/AMgAwQAjAY0BHwJmAzkFqQZkBw4I9gjlCdEKEQwiDVoNTQ1lDWgNVQ1wDX4NFA1QDH4L1QorCpAJKgmeCKkHjgaGBW4EeQPRAjQCZwF/AL3/Qv8R/yL/Z//C/+P/tv+f/8n/HwB/AKoAmQBRAN3/pf+0/7f/q/+u/7X/rf/G/x4AnQAqAbwBKAJjAoYCwAIZA1YDaQNjAywDwQJjAhsC1QF0AfcAcQDc/0P/s/40/rD9LP2e/OH7E/tV+qP54vj69+32vfWA9FPzOfIO8cXvqO7v7ajt3u3R7pvwlvLO81n0H/Vk9jf4gfpz/D39Nv1s/S3+xv7s/jb/jP+A/4r/CACGAAsBbAJhBNQFngZhB1kISAlMCrAL4AwfDQgNLw1KDTENRQ1bDd8MBQxJC7wK/glBCdoIcwinB5QGlwWUBJkD/QKUAvYBJgGDADkALwBOAJoA6gDfALAAvQDsACIBUAFkAS8BtAA8AAYA3v+e/3D/WP84/xL/Of+R//T/aQDgAD0BcAGjAe8BPQJiAnICWwIPArUBYwEjAdMAeAAMAIL/+/6C/h/+vf1E/cf8PPyL++b6V/qq+dL46/fu9s31rvSZ84LyQfEN8DvvvO6b7iPvivBq8s3zV/TQ9LP1G/cq+UD7T/xN/D38sfxe/az9x/0a/jv+Kf6B/hH/lv+fAG0CMgRZBTYGLQdECFoJnwoODOcM9wz8DCgNIQ0wDV0NGQ1XDHkLwgopCoYJ8giICPkHGQckBkMFbATOA3QDCgN/AvcBmwGOAaoB2wEkAjQC9wHMAdcB5gHwAfYBuwE2AacAQwAHAML/bv81/xX/7v7z/jj/if/s/2sA4QAnAWMBpAH/AUYCTgJJAhMCsAFVAREBvgBMANn/XP/J/jv+zf11/RD9m/wq/LH7IvuS+hb6b/mn+N/3+Pb39ez07fPb8q3xnPD2783vGvAk8cHyDvR19M30vfUL98z4rvr2+zv8K/yd/E39lv2W/f39Wv5J/nH+AP+R/2kABQLSA/0EpQWSBuYHCQkMClMLYQyjDLEM8Ay6DE4MXwygDF4MbQt3CuEJaAkQCd4IPAj+BvcFegUFBWUE1ANhAwADzgLCAqoCeAJ2As4C+QKvAk8CEwLlAdYB1wGGAdoAKwDU/6f/Wf///sn+uP6g/tr+QP98/8z/RgDYADEBcAHBAQsCLQI0AkAC+wFyAQUBuwBQAL//O/+q/gr+h/0y/d38Xfzq+4v7Ifub+iT6tvkL+Vf4m/fL9tT13fT2893ysPGs8DvwRvC38N3xS/Mn9Fv04PTj9RP3mvgd+v76H/s9+8D7X/yw/Af9vv0N/g7+Vf78/tL//gChAhAEAQWqBawG/wcFCfYJMQsQDC0MQQx8DGcMOgxQDDwMggtjCqcJOAmpCD0I/wdzB5QG/QWaBRgFqARuBDgE2wOWA3IDQAMVAx4DNQP3AokCMwLeAZ0BjAFkAQEBcgDt/6L/WP8Q//P+9f4C/yf/ff/c/zAAogA7AcQBDAI8AngClwKFAn4CYQLpAWIB/QCcABkAjP8U/5X+Cv6m/V798vyD/C/82vtl++v6cPrg+UL5j/jI9+b27vUB9Rz0BvPc8Rrx7/Ap8fPxN/MJ9B70SvQQ9Rb2XffY+Ov5Svp7+vr6rftB/Mb8j/0g/l/+sP5G/ywAQgGfAvQD+gS7BXEGeweTCGwJWgpcC8QLtAvNC/YL8QvpC/oLlwuhCsgJdQk0CcEIggg4CIIHzwZsBg4GnQVOBQ0FoAQnBMwDigNQAxcD9gKwAjgCygFwASIB6wDKAJAAMwDD/2D/NP8g/x7/Jv87/1j/hf/r/0MAkADpAD8BeAGVAawBuQGwAY0BagEWAZ8ANADj/47/KP/P/nP+G/7I/Yr9Sf31/Kb8Uvzw+3j7+/p++ur5O/mI+M33//Yh9kv1Z/Rl82jy0PG48eXxkPKK8wb06fMo9Ov02PUm9334Tvmc+QP6r/p2+zP8+PzK/Uf+ov4W/7T/lgC/AfoC9gPCBE0F0gW0BsEHkQhfCSAKSQpFCn8K1Qr1CgELEQu6CgsKhQljCSwJ3wi3CGAIrAcGB6oGRwbfBZEFMwWjBBMEtQN4Az0DCQPHAlkC6gGaAVMBHQH+AN8AuQCMADQA4P/W/+//AAAHAAcABAAjAG0AqwDQAOwAGwEnAR4BHAEeARMB9wDeAIsAMAD3/8j/if8+//z+rv5m/hP+0P2R/Uf99PyL/A78i/sh+6n6I/qG+d74Ofh/98L2CPZP9YD0xPNw81vzfvMd9NL09vTw9GD1B/bh9h34QvnF+R36ufpq+yT85/y6/Vb+uf42/8b/WAAkAT8CJgPaA5sEIwWuBYEGZAcDCKQIQQlvCX8JwQkeCkMKTwpMCgIKiglHCUYJCQmwCHoIIAiMBw0HsQZHBvAFpgUrBYcE8AOHA0wDGgPPAm8C+wGKAU8BKwECAeIAwACLAGUASAAeABQALgA+ADMALAAeACAASABtAIcAgAB0AHYAeAB3AHAAcgBPABkA6f+u/4X/bP9R/x7/3f6g/mT+Lf7x/bH9cv0Z/bb8SvzU+2v7BvuZ+gL6YvnZ+FX40/dK98X2LfaS9Sf1+/Tv9Bf1n/Ua9ir2Nvab9hD3vvfT+LT5Dvpw+gr7jfsn/Ob8s/0//q7+Of+s/yEA8AD5AacCQAPjA08EsQRkBS8GpAYrB60H0QfWBxIIbAiUCKkItQiGCCUI/gf7B8cHlQdzBysHrwY3BtYFfQU5Be0EegTzA3UDCAO8ApACUgL+Aa8BaAEcAeQA7AD1ANYAtwCXAGQASgBgAHAAXwBKADsAIQAGABAAIgAnAC0AJwAKAO//AAAGAAAA///m/77/l/+I/3H/YP9S/y3/8v65/ob+U/4r/uj9kf0t/cr8bfwF/K/7YvsY+736X/oM+sf5pvmQ+Xr5Uvki+f346PgE+TH5ffnj+Sb6MvpQ+qj69/qE+0P8tvzS/Bn9i/3c/UX+0/5N/4D/x/8yAHAAuQBcAf4BOQKPAgoDPANsA/gDcgSWBNQEGQUYBRgFUwWcBa4FuwXOBaIFbQV4BYYFWQU/BTkF/gSiBFwEJATUA6QDggM0A8wCeAI4AvwBywGWAUUB9AC0AH4AZwBbAFUAQgAoABgAEAArAEIAVwBqAGgAYwBvAIwAqgC9AMIAyADBAMAAwwDCAMgA0gDaAMAAoQCWAIYAbQBVADgADQDb/7b/lP9y/1H/Kf8H/9z+rf6K/nb+T/4X/uv9w/2l/Xj9Vf09/SD9Ef37/ND8n/yl/Lb8lfx8/Gz8Ufwq/Cn8T/xa/GD8e/yX/In8fPyt/ND82Pz8/C/9Tf1h/YX9j/2I/aL96f0m/kH+eP63/tH+B/90/7//4P8eAHoAuADmADABcQGkAdMBAAIhAj0CbgKWArQC4QL8AvcC/wIfAyMDGgMiAyEDAwPyAu0CzwKnAokCegJJAg8C5AG3AZkBiAFcASQBEAH/ANMAoQDcAAYBSAKrBeUGjQPc/0z/cv9j/zMB5QLkAQAA7/+IAD4ANADMANcAKAAcAAcBnAEaAVkA1v+Z/8f/ZgCZAJb/c/9+AFgAMv97/4cA3/8M/4D//P+V/xP/C/+b/mL+Sv4x/sP+o/7o/Z793v3v/ez96P1h/Sz9Cf2Y/KH83Pxx/Cf8v/wU/V78Evyn/KP8m/x1/c/96vwj/O78cf6D/oD9Of2s/Q/+ev7y/gn/fv78/YX+kv8NANT/uv+a/9X/ugD1AO4AQgG2AV4BLAF2AtQCfAFkAe4CswLiAZECegLKAQ0CwALbAgcCowHEApIC5QCsASsD/AIcAUwA/gIEA+D/xgB1A9ABqP/yAIsCrQFQ//cAOwMeAXIAnADHAEYBbAGkAr0A9/9SAswBYwFvAdEARwF+AiUC9wFgBEEDkwDRAEkB3wDmAMgC2QJS/7P8SQAjBLf/3v2MAlcBafzj/sAD4QCT/R8ABgEP/W/9AQKGAMX9Pf26/av/FP9E/JX9HgEF/ur7Zf7C/YL88P2C/zH9tPqa/KT9tvwG/fD8Jfza+9H8P/3Q/JL9qv3x/ET8Tv0t/0b/Rf5a/Dz9MP8w/6z/b//K/pf90v6xAOj/VgASAMb/8P4RALkCqAG7AJEAHwEPAcwBUQNiAiUBwABUAk4CWwHnAjADyQAVAIgCXAJzAeAB+AGkAAYAWgNZA/L/Bv80AtkDcQCZ/90B7wH+/6QA0wLeAYP/xgBfA20A1/62ApMDqQHJ/3wATAH7APEDvwIn/yIAZgHxAZgBwAF+AQwALQErADgAQAO4AZH/Lf5DATcES//V/o4BIQFp/iIACwMR/lT+rP9p/rAAEQBA/hv+9v53/v39TP94/9r9gfyu/1z+jvpV/3AAcPwQ++D95P5w+zL8mP4T/yD79vlL/ir+G/zS+8z++/3s+V/83wBg/jD6IP48AEv8RfwAAbkAO/s5/UACZ/+0/FsA2wEd/4z+awAoAQMAVQAOAhMBPf/VAFIDNgI9ACMBfgLDAV4BjQLwAjsBRwD4AngD4QALAWACFgMfAgQAEwFdA78BPAD5AfUBTABKAd0CRQHm/3oB/wHsACwCMQK1AI0AEQFKAxoDEwHkABUBJAEXAq8CIgL9AOz/uQEfAz0B+ADMAiMBsf7aAVwEfgAC//QB6AHd/8z/9gLfAdb8OQDaBFEALPzt/gwCOwGM/W//QAGI+yj+LQPD/Sn5G/4bA9j9iPlr/4YBJfpJ+jgBoP9m+/n78f3k/sr6W/owAIX/a/qo+vT+NP0n+1X+9P5l+1P6d/5aAPH9cPs+/dT+N/5j/0z/Ov4m/ikAeAC8/vb+lv/kAKgA2P/HAFQBVAFOALgABANyApkAWQEkAt8BAAJ0AvECmAGbABIDAQQcAWcApQNLA4kA/wGAA+0AL//EAhkEkwAXAAcCTgEqALMBdgJkANr/0AEbAVIAhQKfAbf/aQK6AncAPQGiAMkBpgR1AqMAHwEHAmACs/8UAvQF4/9X/IQBVwVsAvX+kgEIA+//1f9yAygC6f+lAToBpf72/mgBvQJuAB785P6GABL9qP8pAXH7FfqF/+n/m/tX+of/x/9d+IH7SwD2++H7kv76/HX5Ivn0/h7+TPj7+bf7Jvpj+pD7hvtW+x/6afrR/N78Sf2k/tD89vor/k4B6//0/cn+tAA1AHn/EwETATf/CgE4A9gA0/8vAtICLALpAt0CbwG/AUoEywQPAjkC8gT1A5EBrAKBBF8DCgJTA+8DzQHpALoCfQNEAZ8ABQOhAhoAXgAUAukB1wA1AX8BfwA0AFsAcQBOAd0BEwFwAPYADAE0AU0C1QKNAaEAoAJxA3cBzgF1A2ECygGoArIC+AGvAREDWgLZAMYBmwMiBUkFCAVwA5cCBAODAfAATQLCAdz+7/5UAPj+pv6T/v39gvwv+z39qvxb+tj72/u5+Ib4pfku+RL6N/p2+Ln2r/Zi+En4A/fu9o/2bvVi9vj3B/dH9sH3LfkH+bP56vtw/D/8Sv7bAOUBLAKcAmAC9QE5A/wExQTpAwYErQM0A9kD8wRYBXAF7gXVBXEF9AULB9IHKwgTCEMHWwY2BnkGNQaTBQcFsAP/AZkBmgH8AIEATgDd/1T/Dv8v/6n/AADl/5D/R/8z/13/JP+r/rX+Jv9r/0L/Qf/M/ywARgCAARYDTQMYA58DPgSLBMoFJgexBqUFMAXHBAkFEQa3BR4ETwOjA9QDEAPeAl8DWgOVAgIC7wHZAEoAfQFyAeX+1fwS/bb9nPyd+vb5MPnq93n4yPhh9pb0t/VO99H2cvQr9E71A/TM8lfzBPOQ8eLwkfCt71DvjfAw8v/ycfSM9tv3Pfl1+5j+ZgIJBW4FvQToBNgGhgnMCt0JEAgxB7MHNggrCC8IYwiuCPAI8gjICDUJfQrLC/8LQwt2CroJGQmfCPAHkwbqBCcD+wAU/1L+8/0Q/TL8lfsW++H6Ffub+0n8Kf3+/TD+zP1i/Zb9gv4+/wD/K/7w/Yv+O//d/78AjQFeAgIEiAUCBr0GPQiYCYAK8Qq/CmcKPgryCYQJCAlGCEQHbwa2BfIEaQQWBJID6AJSAqUBFgHEAGQAl/+o/tz9uPxQ+3D6EPpL+Tf4bffW9q/1lfSI9Kb0KfRs86Py7vGS8VDx7fBC8F3vhO687RDt0uy37GDsFu3R74TzlvXz9W/3NPoo/tID4AfyBy4HqQgBDFQP2xASEMgN0gtZC0cLogooCi4KFgp3CX4INghJCTQL+Qx0DYIMZQviCqQKMwoWCQgHlAQgApn/RP2F+zL68/gf+J/3LfcK9yX3mfe7+Hb64Ptg/DD83Psz/Gr9l/6y/g3+fv2e/bj++//yAFgCzAPmBIMGPgi7CcULyg2YDsEOEw8nDyQPEQ9SDgANpwtcCv0IuQedBogFkASdA5cC0gFIAZQAwP8T/0b+SP0w/NH6bPlg+KL3lvYV9a/zvPIf8pbxH/HJ8InwXPBD8OfvTu/v7rPuF+4P7QDs+uoW6l/pAukj6enpx+yV8cL0XvUG98n6hgCpCOIOhg/1DacOjBHtFOAWsRVQEmEP4A2fDD0LiwqeCn4KcAnsB28H0AhUC2gNkQ0wDMkK/QlYCV4IuAYwBGQBbf5F+7P42PY19ePzc/OQ897zd/Tk9GP1R/dm+gX9Wv6K/m7+Jf+iAOEBJAKxAS4BpgBoABoBcgLuA9UFeQfPB8kIaQvhDR8QIhJxEpERSxEnEXUQrQ9mDjEMzgmiB3QFsQOXAr0B5gAjADb/XP4m/kD+Sf4l/qD9n/yF+336XPkt+Af33/Wk9FjzKvJN8crwtvDh8OzwtPBQ8OTvhe8g737ucu0b7Mzqqelk6D/n9+Z3563p2O7W8yf13vUS+ZT+bAdoEDQTTBHPEPESORYiGfoYrBU1Ev4Pxw1yC1AKkgotC8YKEAllB7UHFgrKDOEN7gw3C+AJzgiBB6QFAQMyAF39VPpf98r0hvLj8KrwdfF28lzzyfM29B/2m/kM/Uv/dADxAHIBeAJvA98DDgQ/BOYD7QIcAmECQASJBicIoAnYCuQLDw6XECsSkRPPFGgUwxIkEWkPuw1PDD0KRgd2BPABrP9L/qH9Sv1M/R79ZvwD/GH83fwv/VD9uPyQ+2v6LPnR98P2EPYo9Qj08PIA8obxofEQ8nrysfKB8gfyg/HO8NTvue5l7dbrMepZ6G/mcuX+5T7oMu0A8xv1VfVV+BT+ygZ2EOcUkhM+ErUTWRaNGIsYvhU7EnAPhgw3CXoHBAhDCX0J8AcpBnwGEgneCwsNXAzYCtUJ3gj7Bj0EAwEW/oP72Pj99S/zvvD17rDu7e/Q8bXz9fS49Sr3R/oX/gsB3gKwAwQEPgRmBFQEXwTZBO8EAQSEAo4BGwKWBNkHqglVCvgLzQ1eD7IRQhNsE+cTxhN/Ec8OcgzWCb8H/gVZA3cAaP6R/DX7/PpA+5P7T/zn/M783Pw//XX9wP0D/l393ftD+s74xvdI9+H2IvY19YD0LfQ99I/0BPV39cP1lfXQ9LvzafLj8FTvwe3P63bpJecj5evjUeTf5sPrvvF79cL2Svlo/o0GXRBOFncWzxSGFLEVehfIF2YVNRI/D/cLpAilBrQGOAi/CZ0JWwgRCJ8J9guHDYANIgx9CskIcAY1A5L/PfyG+Sz34fSC8iXwcu4w7qfvSfIs9VT3ovgR+m78gv93AtYEIQZuBi8GfAWzBHoE8gRRBQkFJgQuAyUDmgQhB6gJjAv2DJAOWBBuERgSkxJqEvwRFRGoDlkLfAjaBWUDewGZ/7z9avxp+4r6W/oG+xz8d/2C/p7+WP5m/q/++/42/6X+Q/31+9r64vlD+fn4pfhL+P73ifc29zX3dfe196L3Dvcq9jf15/P+8cTveu2C67PpReee5JDiyOGk4h/lXek873r0Pvf9+Yz+dwXBDjUWPRisFo0VIBZXF9IXJRY4E1MQiQ2FCssHJwdzCEMK5woLCkYJwAl8C68MYwzoCukI1AYrBOAA8Pwh+S32uPOp8dvvRO727HPshO0J8HDzoPbi+K36vvx5/0ICvASJBmkHsAdGB2UGjgV8BSgGkgZJBpkFVAX2BXwHYgkSC2AMmA1fD+QQ2hDlDxsPZg7GDeAMYgqbBnkDLAHv/h/9qPtp+vP5t/kE+br4qvlh+yH9YP6j/qr+Wf8LAFAAQADq/1X/uf4I/hv9W/z1+8T7kPtE+/P6ovpN+un5oflC+b34F/jk9lT1mPNR8ZXuNuwt6hXo7+X44qLfH9633m7giuMo6AnuuPOO9zz7ZAClByARzxivGgMZShgLGScaihqUGCgVWBIxEEYNNApdCXkK7gubDOwLxQrHCuALLAz8CvYItAYqBO0A4vwy+AP0KPH47ijtyuvA6gbqM+oa7FXvXfNq9576C/2E/5YCbQXDB7gJ0AoFC6oK1gnKCH0ICwl7CWcJIwkgCbQJ9QpoDIENfg5KD84PFhD1D6MPZA74C4wJaQdhBYQDEAHU/U371vms+B/4/PcM+N346Pmb+oL7Ef3Y/lIAOQF2AcEBZwLgAsICIwKFAR0B/wDSAF4ADADe/8b/yv+6/3v/Lv+0/sn9rPxl++P5QPgv9sDzYfHW7uXrHumd5ibkA+LV33rdAdwz3MTdOuDV44rpWvEL+Aj8KgCpBVANKRc2HjIfkx1LHQoewR5CHrEbxBiwFoQU4hBHDSQMIA1rDiMOEAzfCSoJeQmQCN4FiAKC/7L8cPlz9cPww+x66i/pfehn6M/oZumy6n7tWfHl9Yn6bP5tASoEHAeFCWMLMA2ODh8P6g75DbYMhQxhDeUNtQ1KDRoNhA1RDowOCw67DaQNEQ30Cy8KCgh7BtME1gGt/mv8pPqJ+XT4pPZH9Sn1yvWc9nL3XfjT+an7Bv0k/o//JwGIAncD3gMJBKAEVAVoBQsFuASaBKUEnARLBM8DbQMmA60CAwJZAYcAXf/q/Tj8Yfqs+Nz2qvRg8vPvQ+2+6nvoKebz4wfiMuBH3qDcWttU2k/a0ttp3gTifOdy79f3cv3JAV0HEg5AF+MgTyWuJKkjhiNUI9AiwiBMHRsaHRcWE/QNUQqeCR8K+QkYCEoFZAMLA7ECfgAg/QX6g/fs9MPx4e3P6SvnMebh5U3mwueW6YPrN+4C8sr2TfymAe0FHQkmDBYPLRG9Eh0U+BT/FB0UbRKzEA8QKRC/D5cOYw3FDKUMhQyJC+MJvwjXB3EGkAQtApT/tf3n+zn5r/YX9Vf0Q/RE9OLz6PMS9QL3//jE+oH8Wf51AJ0COQRLBXEGzAfRCE4Jcwl5CZQJ1gnrCWsJ2QiOCEoI0Af8BucF1AQBBAQDgAGi/7r99Psz+lL4RvZA9HDyyPAL70zt1Ouf6oLpc+hQ5+7lq+TX4xfjQOJS4Vbgud8Z4NDhl+QU6Hntc/bc/4MFmgl1DmUUvx3gJ+ErBCq0J2wmASX/Ik4faBppFk0T7A6vCNkDogKkA1EEJgO8APb+GP+p/xX+tfq897v16vPN8a3usOoS6ITnB+ic6UHsLu/38X71//na/hkEZgnwDV4RHBT5FWUWPhZtFnkWmxXIExwRYg7UDD4MTAu9CZIIHwgKCMkHkgZyBJICcQE7AOb9v/oX+DH2aPSM8ibxvfBy8dPyBvTr9Hv2iPlO/VQAfwJkBH4GxAhKCtwKLgugCygMcgz4CyALtgqJCksK8QmHCVgJUAnpCP4HxwaCBWcEPAOtAan/aP0++yn5MPdy9dvzj/Kh8eDwUvD979vv5e8c8FbwWfA68BHw1e9C7yDupewy6/npFuk/6MvmCuXd47HjuORU5wLryO/g970BCwhFC9EOHBMgGnQjjiieJjki2h5JHOEZgRYVEhIOjwszCfIEsQB2/2kBGQQdBSUEaALYAWMCoQFE/iX6MfcM9SPzvPAz7f/pFekx6mLsme+Q81r37voC/1wDiwe4C4wPHBJmE7cTvBLcEDcPVw6IDf0L4QmrB04GTgbXBr4GMAY8BtIGLweSBqIE6wGe/7b9L/v59+b0W/Jh8FLvxe5/7rbvDfPf9qr5Lfz3/gQCuQVeCVELrAv7C0MM8gtECzsKEQljCCsIqQcNBwQHagcCCIQIrgiVCJ8Irwj5B1QGPAQuAj4Ab/6b/GP6FvhK9hT1RvT18xv0cvTv9JT1NvbM9oz3Tvi7+Lb4S/il99n2Avb29IHz8vGP8CnvrO1F7AzrDuo/6SXou+af5RXlPeVG5k7o8eqt7z34pgD1BFcH8wkRDtsVbh78ITsgIh0XG6sZ0hcrFVESdRC0D7YNowloBgwGOAh7ClUKQAg7BogFLwX5AoP+5PnA9rL0AvOy8ILtM+vs6hHsJ+5m8V31Jfm3/AcA1wKiBb8IjQttDXUOaA46DcMLxwqKCpIKXAqiCdkI7AjUCbsK0gpnCjcKWgo4Cu0IWgYjAzkAu/3Z+qv30vTA8pPx/fBr8EDwpvFW9Ib3vfqD/dX/+wEzBBkGUAdKCBsJQQnaCGQI0weEB9oHcwg7CQsKswpFC9oLVwykDIYM2AvkCo8JwweaBTsD4QD0/of9OfwL+yv6qPll+WP5kPm8+Qb6VPpz+jP6rfko+Zb4G/i391z3CPfO9rr2sfbC9uz2L/dU9z/39fZH9gj1cfO08cTvvu2Y6z3pt+YP5I7hz99B33nga+Op57XudvjcAFkGkArZDZYS5hqkIi4l9SIMHzkbFhi+FVUT1xCLD5cPpA4gDHEKNAv/DYYQLBGDD3YMDwrPB8IDxP2399nyQu/r7NvqtOh55xjoSuqN7Q/yZvd9/MwAEAQiBoQHyggRCsMKpgruCYQIpQZnBX8FrQZ6CF8KAgyBDV0PVBF9EoYS3xG0EM0OLAyFCO0DNv8K+2P3DPRr8dvvVu+j70/wHfF/8ur05/fL+u38//1v/pT+sf7I/tb+QP+bAKQC/gOqBKEFIgeQCQwNXBAdErMS1hJZEj0Rng/mDSkMQgooCIkFsgJ0ADv/vP6X/pv+rf7l/ib/QP/R/ub97fzz+wb7APq8+EL37fUe9cT09PSS9Yj2uvcP+VH6Lvvd+2T8u/y7/Cn8+/pW+Y33t/XU87Pxj+++7STsvOpg6dXnI+Z+5Bjj++EA4dvgWuLy5DTpB/FI+sYAQAUnCRsMxBB0GGYf4CF5IA4eHRv4F/EV/hQyFJcT9RN5E0kRlA/wD38RPBIGEuMPwwsDCMoEngAY+6f1/PBE7Wbr4equ6s3qCOwQ7lnwpvPZ9wP8ef/tARIDwwJEAmUC0QJtAzwE7QQIBTIFbQajCIUL0g69EXwTgRQ3FSEVEhQtEn0PDgxdCJEEggB6/Bj5ZPYr9K3y9/H48Zny0/Pr9FH1WPVg9XX1ifW99cP1j/WJ9cf1ffbi9zP6V/3RAKIEIggCC7ENGhAbEn8TRhQ1FIITbRK1EMkOzwwKC8MJ7QhqCAgIrQcgB5MG0wXTBMcDkwIhAUr/UP0Y+9n4Afe09fT0jfSN9Mb0PvX29dT2x/eg+Hr5Mfq4+gD7/vrz+tP6x/rR+tb69vpA+5L7tvuw+1D7uvr1+cf4O/da9SfzqfAb7nHrkujd5ZTjq+Hz35fe09323cLfIOO46KPxXPvTAk4IGgztDYQQsRXOGj0dDx1iGxgYPRQ9EkkSahNnFUwYYRphGt4Z8xkSGpUZhhifFSIQHApYBHP+kPhW88/uy+qk6KXo8Okl7AbvsPFE85L0HPad9/f4GvqQ+pn5+ve49jP2+/aS+aX93QG7BYcJHA2cEGkU9BcjGsUaGBoaGBgVsxE8Dp0KFQcEBFIB/f57/en82/wD/SX93fwD/PD61Pll+HL2GPRe8XPuE+zC6l7q6ep37LLucfHC9Jn4yfw+Ac0F0AmdDDkOGA9nD60PThBqEM4PJQ+GDvsNEA7uDvQP1hCaEfERUxEDEG8OSwyyCecGygNCALX8u/lp98L1zvRq9Gr06vQS9lj3YPgl+Xn5TPnY+GP45Pd491H3ZPeK9+H3u/gI+sn7+/08ABYCVAMBBAoEgAOIAjYBdv9B/fL6mfgY9rrzyvEg8IvuUu1h7C/r3umL6BLnJeXr4hfhs99B3yvgzOJA6CPwcvi7//wFZAoQDZ0QaBWYGR8cZh0QHU4aGRc+FagUNBVSF4QasBxyHaIdNx0UHK8aHhnTFZwQtgpcBM/98/dc80nvt+uy6fvoP+nQ6nTtB/Cr8cnyWfMU86DytvIT8ybzVvPT81X0afUk+ID8mAEpB6oMExFIFOwWFBk/GpQaNxqyGAoW/xIXEEcNBQuuCcAIxAfUBggGDAUCBAoDqQFs/1v83fjv9Arx1e1T63DpEeiN58rnteis6oXt2PBI9J73bfqQ/Fb+5f88AX0CKwSBBlMIZAkjCzUN+w6DEZcU0hYIGNsY9xi7FwYWTxQgEl8PfwzJCfYGawSaAjcB8P8A/y/+xPxQ+2f6mPly+Ef3GfZ+9OryC/Km8ZjxVPKb8930B/Z09zP5+/rx/AT/swC8AWsCygLAArUC2ALeAocCFwKrAQYBWgDg/0D/T/4//er7DfrU97T1e/Px8HTuB+xv6dHmueQD417hAeAa37De2d5T4Ejj7+ct75T3Qv/TBYIK7QxiDoMQChMcFd4WCBjaF7AW6xUyFngX9RmSHRMh9CJLI2Ai8B+PHAQZ5BR1D04JJgP7/IT3zPOI8QDwPe8/72/vvO+Z8L3xXPJG8rfxV/BA7mDsautq63Ls1+4O8mD1D/l5/U8CTAddDNMQ0xNWFdMVXRUvFAETEBIbESEQZw/bDlUOPQ65Dj0PTQ/GDlUNtgpVB7UD7/8G/EP4tfRE8UfuPOw36xrr7eti7QDvgfDY8fzy5PPB9KT1W/bJ9ib3mPdD+Ib5kvtD/qcB5QUtCtEN9hCMEz8VMhbGFqEWiBXgE/ARqg9JDW4LLAonCWII9geQB/kGZgbBBcYEggP0Acf/+vw6+tL3yPVR9JjzZ/Og82/0tfU09+j4yfqB/Lj9c/7X/tr+pf6M/pn+q/7Y/jL/of83ACEBQwJJA/wDSgQTBD0D+gFwAKL+qvyh+p/4jPaG9OPyffE78DbvRe4y7Qfs9erQ6YnoNOe25RvkneKt4bHh2+JZ5RjqSvFI+fsA9AfQDCEPkxAFEg4TtBNNFHIUhhNaEucRRxKpE3QWaRorHqQgqiHpIDIefhqfFjMSAw2oBzsC0vxr+L/1mfSB9GL1vva490L4iPhY+HT3HvaR9G7yzu9i7Z3ruupA64/tBfHu9Cb5cP1mAQkFgAhTC/gMkg1IDSQMfAoTCVwIVAgZCaIKcwwDDlsPixBEEXARCRG5DzENsQm8BZ0Bvf2e+lX4uPa79Vz1Z/Wm9TT28/aU9933q/f49qH1BPSf8qLxOPF68VTylvNE9XL3GPrw/N7/zAJsBckHqAmjCgELEAvCCoUKwQojC4oLDwyxDDUNlQ37DS0O/Q1jDWQM7wr4CL0GkQTIAmUBbQDJ/yD/hv4N/qX9Sf0E/cb8aPzv+2f7yfo6+uf52/kZ+o36Jfu7+z78zvxk/fv9gf7W/v3+8f7K/q3+hv5a/kP+KP7y/bP9Yf3s/Gz80PsZ+0T6Ofn595z2RPXT81fy9PB67+/tpOyW643qoOnb6BvoWOfX5ubmhOfk6JLrOvCS9kj9mgPTCJkLZQzeDFMNzw2DDmsPBxD3DwUQphDSEeIT+xa+GvAdgh9aH0odnRl3FakR8w0mCpMGCgO4/zr99vvG+0H8M/3q/eb9D/1i+zr5tfYj9PPx7+8P7qTs6OsU7ITtZPAm9Bn4wfvY/ikB0wIwBBsFhgWNBUwF7ASQBJ8EcwUXB4IJagxED18RdhKmEgcSxBADD+AMNgowByEETAEC/3f90fzK/A/9Xv1p/fL8APzB+k35vPcV9mr0u/Il8Qzwr+8p8HzxbvOj9dH3zfmP+wz9Rf5S/ykAxgAvAXkByAFSAswDTAYACb0LVw7iD3MQ0BDFEFEQug/hDo4NrQunCb0HNQZHBfUESAW5BeEFrwUPBQAEtQJZAab/v/35+1v6DPlU+D/4m/ht+aH6x/vN/LD9Q/6U/on+Fv5s/ZT8vPs1+yr7h/tJ/FD9VP47//z/jQDYAMUAZACi/2r+4/wp+3P59vfO9hv2ovUx9cT0OvR283vyW/EV8JbuA+156+vpZegK5x7mpOXK5e/m/+gC7L/wdve3/nkFGAsbDnAOtg3+DK0M+AzFDd0Org9VEF0R+xJGFTwYBRybH1Yh4CBRHskZWhR6D3oL6wfVBBsClv+G/U/8Pvz0/OX9lv6K/lT92Pq593T0Q/HD7jXtT+zo6xbsGu0I7w3yIPaE+mD+OwEQA+0DKAQlBBEE/wP5A04E9wThBVIHcQkmDCMP/xERFMkUDBQ0Er4P+gwyCowHAwWXAo0AFf8t/uL9Kf6v/vP+rf6q/eD7g/n+9rP0xPJK8Ujwr+9679rvB/Hy8lT14vc7+g38TP0R/oD+wf4K/4L/LAD7AO0BEQNmBDQG1wjjC9kOXhHLEu4SLhK/EAAPXg24C1gKMgkECPgGHgatBYIFpgXqBaAFvgRjA6wB5P9b/gX9yfvI+v35ivmj+Tb6Lfty/LH9of4X/yb/0f5e/hz+2/2o/XX9Lf0G/Sv9xv3L/vr/DAHIAQ4C1wE5AWkAd/9o/lX9N/wC+8j5yfgS+LL3qvev93737/YD9rv0IvN28cnvA+5P7MHqdemU6AXo3OcS6GXo3uiq6d7qnuwi7wXz4fim/xwGrAu9DgEPKg6rDRMOdA9qEUATXRTFFBQVpRXKFoEY1Rp5HcEeyx3kGksW1xANDJkI5gVeA9sAUv7f+wn6QvlV+b357fmN+V34MvaK8xPxAe+M7QrtOu3L7aHu8O8J8uj0kvix/GcACQOIBEkFqAXzBWsGCQekB1AISwmQCgIMuw20D74RbRNTFAkUWxK3D7AMygknB7IEZQI7AEr+zfzm+2f7Lvv/+pP6ofkO+Ab2xvOk8ezv3+5i7lfuvu6D78bwg/LU9Ib3Hfpi/Ar+LP/q/30AMgH3AecCCgRYBb8GOAjZCZALZA1ND9cQrRHZET0R6g9oDtEMCAtMCb4HSAYMBT8EqAMoA8wCRQJuAWkAC/9f/e778vpY+h36K/op+hb6T/rV+qT7wPz7/Qb/y/8+AEgAMwAqAD8AkAACAWYBnQG6AdEBAwJVArkC/ALuAowC5wELAQcADv8q/kH9XPyB+4/6rfnv+Ez4wvck92r2dfVe9EjzL/It8UbwZO+S7sft/uxh7OTrm+uL64Prcesv69zqoOqX6ifrmezl7mPykvd+/jMGQA2JEs4UHxRsEicR8xDtETsTGhRRFAYU2BM0FFQVJxeJGdoblRzhGtUWJxH7CsUFIgJi/+78kfpp+LH2z/UF9vr2DPjA+Mv45vck9urzz/Ek8BfvBe/A7xbx/PJ19av4gvy+ANIEEAj/CaoKtwqUCmsKXwpZCkUKZwoOC0cMzg1qD/EQEhJ6EsgR3A/VDB8JfwVUAqL/Nv0E+y351/c09y73hPfD96X3F/f89W70o/Lv8KLv7e7r7pbvy/Bw8pH0J/cB+v781P8lAsADqAQeBVUFlQX7BYUGOQcYCDkJiwrqCygNQw5UDxoQNhCdDzAO5QtjCSMHGwVYAwMCAgE7AMH/fv9a/zT//f6q/gj+H/0K/Ar7TPoE+kf60fqQ+3T8bP2O/uz/VAGjArIDUwSQBH8EQATxA7kDvQPTA+cDCgQLBOoD4wPmA7sDYgPFAtEBrABo/yH+7vzG+7f61PkU+W74/Pez92j3Gve89jD2c/Wp9NfzDfN68gbylfEz8dnwkfBU8DDwGvDs77DvUu/z7pLuF+6R7Qnth+wT7ETscu2h7zvzbPga/7EGwg3wEhwV7BMiEekOMg4VD8cQDRJIEswRfRHUEeYS0xQ/F2QZQBrUGOYUKw/mCJQDAAC7/Qv8fvoJ+QD4uPdc+JT5tPpP+yn7KvqR+Kz23fRi81Ty+PGI8v/zUvZ1+R79/gC7BO0HFQr2CtMKNgq3CYQJfAlcCQMJxQgZCUkKDgzjDUcPzQ9mD+4Ndgs4CJUEJgFL/h38VfrI+I/34Pbj9mz3IPiB+Dn4YPcs9sr0cPNK8pDxXvHK8e3yo/Tf9ob5YPw+/78BtQMNBcYF+wXpBdwF7wUvBo0GCQevB5IIvwn3CvcLagw4DBUM4QvhCpkJ6QcrBZ8CHQHp/xz/Ef88/1P/Z/+K/0P/rP5a/vX9qv2K/SL95vwf/Xf9G/42/0gALQFMAogDiARKBccF2wWEBR8FxwRpBC4E/wPlA9UDfwMLA5gCGQKlAVQB2wD//9/+pv1o/E37gPrf+WH5Afmz+Gr4NPj997T3jvdd9wn3sPZV9tz1X/Uf9eD0e/Qs9Nzzj/N283jzbPMk867yD/JF8Y/wsu+a7sDt7ew37Czse+zy7BnuFvDR8gT3Nf2RBJIL+xBeEw8SAg+3DCoMng1jELoSxBO4E08TOBOpE9oUqhZTGMsYOxdJE5ANYQdNAgf/Av20+6D6kPnl+Pz4ovls+u/63Poz+kD5QPhJ93H2uvUr9f70o/VO9/75jv17ATAFMAgtCgMLzwoWCnIJSAmNCdkJzAlLCbsIwAiXCesKLQzADFwM/grLCAEGxgKD/6r8e/r9+AT4Wvft9uv2Vffs91X4Svi89+P2GvZ+9RL1z/TQ9EL1Q/by9zv65/ym/ywCOgSdBVIGjgaBBk8GLQYeBiMGMwZRBo4G8gagB5UIbwnUCaQJrghEB8gFNASgAjkBCAAp/8z+yP7S/vP+QP+S/+v/NAAvANr/Tv+5/o7+2/5b/0wAZAEPAqsCcgMEBIkEVwUVBmMGTgb0BUQFcAT/A+cDzwOyA4QDKgOeAvwBcQHeAC0AdP+u/s793fwd/I77Dvuv+m36J/rd+bz5t/my+aL5Zvnz+Hn4Hvj39wX4Ivgy+BD41/eL9y336vag9lD24PUm9UX0ffPB8hvywPFG8VXwPu8h7tXs/+vn6+br8OsS7Cns0uyd7rTxovYx/YQEqwvYEJoSVBGXDrEMJw2yDxYTfBUHFokV3hTGFHAVdxaXFzwYuxesFcwRdwzQBhAC2P7h/KX70vo8+vL5Ofra+g77mPqi+X74pPdM91P3SPfO9iX24vWT9rX4H/wwABgEJwcwCR8KGgqOCdwIhAi6CEkJzQnQCXIJHQlGCRkKGgujC0oLFQo6CAkGhgO/AOn9W/uW+aH4VfhX+IH4vfjo+On4j/jc9wD3VPYB9gf2K/ZU9p/2RfeW+Jv6G/2v//YBrQPFBE8FaQVGBRQF+gT8BCEFaQXEBTIGqwYuB8kHYAikCHsIyQd2BgoFvwN+AmwBiwDm/8b/KgCNAMEAsABVABEAIwBAAAYAqP9d/2r/tf8iALsABwF3AVwCTQMJBHsEygQJBQkF8ATlBIgEMQQvBEAEIwTPA4sDKgOvAlMC+wFrAaEA4f8m/1/+pP0d/Z78MPzv+7H7YPvw+pb6TPoJ+sP5Yfnz+JD4Vvg0+Cf4JPgM+Or3tvd890f38PaR9i/2cfWE9LLz1fIf8sLxn/GG8RXxcvCh72XuQu2P7PbrkeuI65XrvuuA7FHuP/HQ9Wf8EwR/CxURLxPPEZ0ORgypDDMPrxKBFVsWwRUcFTUVtBVBFvMWKxdMFlwUIBFhDAQHiAJ1/2L9IfyK+037gfs7/Pz8yfx8+8r5NfhU93L3H/iG+Bb4U/fv9nv3o/k3/S0BnwQyB7QIFwmuCAwIZwcJB08HEQjGCBkJPwltCdIJaArxCtcK5gmICAoHaQVtAxEBcP4C/F76zPn5+WT6yvro+qT6/vkT+fr3A/d49mv2pPbf9iT3evcz+I35c/uO/YX/LgFeAhQDbwOIA20DNQMiA1cDygN+BFUFJQa/BjEHmAfDB6cHTgebBqIFuwTWA+oCMAK6AZEBvAERAkMCEQK2AYABOQHkAIcAFADT//L/RgC4ABoBPwF/AeIBOQKSAgIDjAP7AyAEHATzA6UDmwPQAwUEDwT7A9EDbQPmAmQC6AFTAcUARAC6/yT/ov4u/rH9Sv3x/Ir8BfyU+y77tfo/+sH5K/mc+Ez4NPgn+Az4B/gD+Lv3Uvfr9mr23vV49RX1e/Sd89TyUPLG8WrxXfEz8eXwe/Dg79Huau1G7Ffr0+oG65LrYeyt7aHvgfK39tj8WARoC4YQSxJrEPcM7grSC9wOdBI1FS4WzxWFFecVRxY2FvoVeRVXFGISnQ/pC7YHDwRwAYb/Hv55/YT9Jv4F/0v/TP4a/KP5xfcB94/3rvhE+Qb5XfgK+Lz44fol/m8B3gODBXwGtwZuBgIGpQVoBcIFuQbLB5AIMAneCWAKmApcCpoJaAhBB2cGeQUNBAYCuP+7/ZX8U/yY/OL87PyQ/M37u/p++Uv4W/f59vz2L/d599/3b/gu+UT6i/vL/Pj9Bf/6/70AOwGJAZ0BlgG5ATICBwMOBBIF5gVkBn4GiQaZBn8GTwb5BWQF2wR7BBQErANvA4oD9gN3BIoE8QPqAvYBkAGZAb8BogFSAQgBxQChAL8AEAFuAegBPwI6AhACCwJDAokCvgLsAgQDGwNSA4QDmwORA00D6wJ7AgoCswFuARQBmQAHAGb/3f5r/iT+CP7Q/XD90fwV/Gn74/qT+kH64fmC+Sb52PiV+GD4OPj897f3XvfS9kL2zfVK9Zj0/fNq87/yOPL48cXxafFH8TXxufDi7+7utu1+7L7rYOtT63br0euu7IDuXPFZ9dz6vgGICJYN8w8JD+0LgwkuCoMNjRHZFJkWpRYRFisWshaXFsEV6hQKFLASyhBSDisLrwfLBNkChAGvAIIA0QAVAboAVP/2/Fj6UPhv9933AfnD+Yb5tvgj+HH4APqo/Gr/VgF+AloDAgQvBA8E8wPpAz0EUQXeBjAIGwnGCUgKWwrzCVYJkgjfB24H/QYSBnQEdwLEALj/Xv9q/0z/2v4K/vX8xfuP+m75dfjb97X32PcS+Fz4vfgf+Yv5F/rP+pf7a/xr/WD+GP+Y/+//LwCHADkBNwJRA08EFwWgBe8FKAZbBnoGfgZ8BnAGdAZtBkkGIAYKBhsGUwZqBs8FwASkA60CJgIKAgEC6gEmAoACmwKFAhwCbQHlALsAqACsAAMBdAG0AcQBtgGoAc4BQQLVAiMDGAPdAn4C/gF2ARoB8wDdAMkAtAB6AA8Ar/9X//v+qP5h/vr9bv3n/ED8hfvb+jz6vvmI+Yf5eflF+ef4Z/jF9xb3dvbu9Xn1DvWT9PXzS/Oo8iDyqfFU8SDx6vC78Hfw3+/47vft6uwC7HDrLetG68/rdOx87XTvNvId9uz7GQNmCWYNbg5jDBwJvAcGClsOuBIGFpUXaxfGFsUWtBbTFYMUoxPxEtkRhxDWDlQMWQn2Bj0F1wP3AtQC7QKHAmABNf9T/Kb5Fvju9974FPqC+t350PhM+Mr4XvqY/Jv+zv+NAGsBJwJnAlcCYwKhAk8DzwSlBg0IAwnICSYK4wlFCcAIWQghCCkI8QcIB4kF/APWAiwC6wHGATsBTQAs/+v9ovxx+2n6hvkE+ev4EPk1+U75YvlU+Tb5R/mh+Sz68vrx+/T8rP0m/pf+Av+R/3QAgAF+AlAD9AN/BO8EZAXVBTAGhAbpBl0HwwcdCF4IjwiNCCcIiQfCBuYFVAUuBQwFmATxA0oDgwLXAdoBvAK5A/MDegNFAmoAHv9H/xwAvwBEAdMB/AGTAVIBZQGCAZoB1QHoAYwBHQH7AP4AwwBoAC4AOwBoAIoAoACCAAgAN/9O/pX9NP0L/e/8xfw3/EX7afr6+cT5i/l/+Xb59/gG+CX3Yval9f30gvQR9Gzz2PJn8vDxY/Ha8GzwFvCp7y7vxO4H7vjsAOxc6wLrNevk64Xs8OzF7ZnvL/I89kz8FQPaCHMM8QyECmwH4AYECukOrRMNFzgYpRfoFsoWWBYUFbQT4hJKErMRMBEIENsNNQvXCNsGQwVcBBkE4QMcA34B6P7n+3P5Pfhm+IX5oPq7+qD5Mvhz98v3TPll+yv9JP7S/sX/hwC+AL4AwAD1ANYBjAOEBRcHPwgWCW4JHwmYCDwIGghFCI4IfgigB0AG8ATyA28DRQMGA14CTgEGAKn+Sf0f/Cn7VfrN+a75svmW+Xf5OPnI+Fz4NPho+OD4sfm9+rn7aPzS/Cr9hv0c/gb/GQAYAfIBoQJEA+wDkAQ2BcsFXQbyBogHBAhyCPUIQQkYCaUI/QcdB30GaAZ1BiAGrgWGBUcFpgQzBAcEfAPRAnQC/AECATgAQQB3AFcAOgBPADsAEQBDAIoAfQBGAE4AXgAsABUAKgA6AC4AGwACAOv/5P/1/wAA6P+7/0//wv5S/u79e/0Z/ej8sPxQ/Ar83Ptc+7T6O/rR+Sv5cPjv91H3b/bR9Vf1mPT286PzOfOK8tbxKfFz8NnvZ+/O7gHudO0X7ZLsEeyp6xjrjOqc6kTr1esD7d7vmvNJ+KD++gQzCaUKzQnSBzsGdgcVDGURaxXGF4EY6RfIFjEWuBWDFHgTYBNsE+YS6RGEEF0O4AvvCVgIzAaiBQAFRATZAsYAJv58+8n5bPn0+aX6xvr4+Un4y/aP9nn3HfkT+8D8r/0p/r3+Kf/7/sr+L/8HAFcBMwMrBaIGngdYCKwIaAgSCBYIRwiSCLYIWwhZBx4GPAXABHsEVwTyA/cCnQErAL3+Wf1Q/K77LfvC+pX6WfrQ+S35mPgO+Jb3lPf896j4fvln+iT7evuu+/r7f/w//U3+aP9PABIB0QGUAk4DKQQGBcEFbAYnB7gHOQjlCGYJcgkpCawI8AdyB3kHmAdFB5EGwQXFBB8EdARTBbYFUwVJBIECiAB+/5b/EAB/AOgA2gATAD3/8f4L/zL/Yf9+/0f/7v7y/iL/I/8I//b+8v76/jD/df+c/5j/TP+v/gT+tP2w/cb91v2l/Qb9Mvyi+1H7GfsG+wz7tvr3+ST5L/gu92H20PU89ZD04fMy83Hyt/Ep8aXwBvBk79vuIe4v7T/sbOvD6l/qW+qq6tLqpuqD6rDq8OuW7uzybvneACUH2wpCC7gIcgUHBVEJow/LFBoYshjrFpgVIBYJF1MWyBQKFHsT9RLvEpcSuRCvDUkLxAkkCNAGXQbxBX0EQAKl/6L8H/o5+er5H/u5+x77LfnM9or1Bfbm92H6P/z3/Db9xv2h/g3/Bf8J/y7/9f/KASIE9gUIB+kHgwhwCCUIRAiYCOwIXAllCXgI5gajBSAFDAUuBRgFSQTNAjQBxv91/mL9l/zx+2b7Fvvj+nL6xfkP+Uj4j/dF94X3HPji+Nz5t/oT+zL7ZvvD+2n8cf2a/oX/JgDCAHsBOgIgAxgE7gSYBT4G7AZ5B98HUgjxCFIJYAlNCfIIXggHCP8Hwwc5B7MGPwazBTYF4gSCBAoEhgPeAv4BFQFxADAAIgASAOb/rv+Z/5z/n/+I/1P/G//9/gH/Ev8g/yT/Lv9A/zT/D////vn+7f7v/ur+rf5P/hb+5f2q/Y/9Zf0b/cj8c/we/Lf7Lvuk+if6l/n5+D34i/fP9u/1HfVf9JLzpPLw8VHxgvCs7xjvq+737Q/tI+w26ynqfel36WbpIek86a7pCeof65PtZ/GP92AA9giCDSANogiiAi0AYgTdDLAUhRkqG+gZZRfcFW8VZhTSEnQSbBMBFNITfRMcEhQP1QutCeUHTAbiBTMGqwWYA3QAxfxo+en3yPjh+oL8Xvwk+vL2vvTc9Oz2xvlW/Lj9Hv5w/vb+6v4j/rf9Lf5u/4cBTATCBjMIFwmICQ0J/AdqB9EHswiSCe8JNwmFB+sFOQU5BWgFagXTBG0DngHo/1P+Bf1F/OX7pPt9+2j7Dfs3+jH5Jvgj95D20fax99f4F/ov+7T7j/tV+3b7+fv4/Ej+bf82ANQAjQFVAhAD4AOrBEUF1AVdBt8GTgeaB/AHYwjZCBUJGgnNCP0H9QYoBrsFUAULBUEFxgX5BcMFVgU3BJMCSQHIAJkAiQDxAGgBPwGkADYABADQ/8H/7//r/57/a/97/4P/av90/6j/z//H/6b/af8i/9P+k/5u/lT+UP46/ir+C/6X/fT8Xvzj+3f7TPtU+zD7x/od+kH5Wvh696n29fVZ9cn0QfSl8/PyYfLj8RPxGfA77xDu0uwy7ODrN+th6trpaOnG6JLoK+n96SDrS+2Z8Nf0x/rnAbQHjQoACgoHVAQeBRAKdBDCFdcYWBkfGLwWFxaRFWAUiBOkE7ITQBOtEs0R1Q9IDTELUQlVB+kFXQXDBEAD+AA1/kD7FvmW+Hn5m/oh+336n/iQ9q31dPZf+Jn6XvxV/dX9ff4C/wj/5P4h//r/WwFiA4oFKAdFCBgJYwnuCGIIXgi/CDMJfglDCTQIxgbJBVkFHgXgBG0EcQP1AV4A3v6E/XT80Pta+/b6u/p1+vP5Pvl5+Ln3G/f/9nz3TvhR+WP6OPub+8H7CvyH/ET9TP5d/0AA8wC1AYkCUAMXBNcEewX8BX4GFAeWB/MHTgi/CB8JIwnzCLoIIwhrBw0H4AZ8BgEGoAUPBTgEsAOtA5IDHQN6Aq8BpwDZ/7L/1v/z/wkAQgBKAAUAz/++/7L/k/+Q/5z/kf+O/7T/0f/O/7f/jP9W/zD/I/8Y/w3/7P6l/kH+6/24/Zn9gv1h/Rn9gvzK+zX7yvpq+vv5d/m2+Nf3Gfdt9qH1zfQU9GDzjPKi8fnwefC677buvu2t7IbrBOv46ofqwOlC6T/pcunX6YjquevV7fjwxvXj/JEEDAptDJYLwAc3BF8FIQvFEcAWshk4GocY6haJFt4VBhSbEsoSIRN1EpkRnRBwDpQLbAnQBwMGogRWBAQEXwKU/1r8Zvmk96r3FPmz+mn7mvqj+Mb2KfYN9wr5YPtC/Uv+Bv8SAMQAnQA2AGsAOQGOAqoE4gZmCDQJyAnWCSgJdQhtCO4ITAlWCbwITAehBY0EOgQRBMUDQgM8AsoAQf/A/VX8NPuC+hj65Pn6+QX6t/k0+ZP4yfci9xz3vfe/+Ob5HPsQ/HX8s/wj/dD9nP6G/40AVQHpAZwCcAM0BOIEiwUjBp8GIAesBx8IZwimCNoIvAhgCAsIlwfyBncGHwaaBe8EUwQLBB8EVQRtBCgERgPqAdgAbAA6AC8AeADeANgAaQAdAA8AGQBAAH4AgwAxAPj/HgBDABsA4v/o/w0ABwACAAgA6f+m/1b/Af+O/ij+A/7//eL9gP3x/Gf88ft++xX70PqJ+gD6R/mD+Lv32Pbv9Tb1d/SD85Xy7vFA8WvwrO/x7iruSe187OfrX+uw6rHp5eir6FXoKugQ6RnqM+vt7UvyAPhb/ysHhAyHDRELKAfxBEQHTA2pEwQY/hkLGhkZJRhcF/gV4xNiEjISHxJAET0Q3A51DJwJdwfwBVsEgAOBA88CgwBR/Sb6gvc69uv21fhn+rv66vlX+Pn2+PZr+Hr6WPzs/VD/kwDOAY8CUwLVAQwCAAOLBIoGdgixCU0KjQo4ClkJwAjcCEcJXgndCLgH+wVWBGEDBQOjAg8CaQFwABn/qv1S/O/6s/n1+LH4tPj6+FD5Vvn8+Gf40vd296T3cvid+ef6GfwL/Z39DP60/oT/XAAyAfsBmwIaA8EDfgQPBYUF/QVsBs8GQQfFBx0IJwgkCBsI4Qd7Bx8HwgYwBrIFfwVIBdUESQTDAw0DQwL0AR8CKwLqAYMB7QAtALT/1/8cADwAcQC8AOEA0QDLAOQA9wDvAOAAygCTAFoAUgBXADkACADj/8r/tv+W/2j/Jv+u/hL+g/0i/d78t/yw/H/8EPx0+876K/qN+RD5i/jZ9xn3V/Z19Zr05/Mu81DydPGv8L7vwe4a7q7tS+3Y7EvsfetM6kPp0uh56F/oA+n/6YPrNu4I8gr3Jv6yBkkNpw9WDngKrwYxB3YMmxLAFgoZGxq/GeQYixiYF/QUShJYEesQpA86Dh4NAAvnB5oFUQQQAzkCUAIRAiEA+vy9+d72FvVT9Tr3Yvmw+rz6vPnB+Nz4G/rR+2z96P45AKMBagO5BMAENQRFBAkFKQa3B3sJkQrcCukKiwqKCYcIYgjFCM4INQgHBz8FSgPzAUUBqwDz/1H/k/6h/aT8l/tU+gH5Ivi397z3RPgC+Xn5i/ll+R754PgC+dP5+fou/HD9if40/6H/UgAvAfUBtQJxA/gDVQTBBE8FnAWkBc4FFgZuBtsGfwcICBwI2gdYB6YG+wW9Bc0FrgVPBd8EYAS8A0AD6gJiAu4B1AHdAa8BaQEeAaEAOgAvAGIAjQDEABwBVgFbAVQBYgFzAYMBtgHQAZQBNAHVAG8ACADH/7L/rf+q/6n/e/8P/5P+DP51/en8jPxH/Ab80vuS+yX7m/om+s35X/nQ+Ev4ofe59tr1E/Vc9Krz4vIw8mfxZ/CJ78/uMe6U7SPtzOwG7MzqrenK6Abo4Ode6BXpQeqd7C3wyfQl+5ED0guuEH0R3w5kChoI3QqREEEVzxc0GZIZTBlhGTgZSxcgFOgR3hBeDzgNWQtZCX8GzgNAAkEBowDvAIQBywA//tL6gfcA9TL0S/V094P5sfrQ+oP63/og/NL9aP+uAK4BvgJpBBcGtAZiBjsGxAa4BwIJiQqaC9YLlQv/CsYJQwhuB2sHhgceByUGkwStAiQBHQBE/1r+e/3J/DH8oPvv+v758vgZ+Kj3q/cy+Cv5E/qe+uD64PrB+un6m/us/Nv9D/82AAABeAH8AaUCUAP2A54EDwVcBbIFCwYhBgAG7wULBlQGsQYkB00HLwf6Bp0G2AXMBBYEpQNeA14DWQP4AoYCVgJkAs4ClQMLBMwDIgMcAgIBjADuAHwB/gGRAt0CowIxAiECSwJYAkgCMQL4AYMBSQE2AcAAEACq/5z/iv91/33/Wv/m/lL+m/3X/FD8HPwb/PD7jPv8+k36wfl4+Wr5XPk0+cj4AvgV90b2ifWg9MzzIPNQ8oDx/PBb8HrvwO7l7dHs8ut76//qQups6W7obuf65nbnpOiS6sLtS/I9+H0AJwqaEXgUDRPDDpgKpAoJD98TvhYvGO4YAxkrGYYZkRjoFUQTvREKEDQNNAp3B1YEKAEu/z/+yv1a/tb/iwA4/1387vi89c/z5POL9bH3gPl6+uP6lfsn/Un/UQHnAgME5gT4BTwHxwdRB9IGDwfwBwoJeArSC1cMMAyMCyQKBghQBpwFXAXoBAEEqwL3AHj/dv61/en8Kfyo+0b7wvoR+jD5Nfh39yb3R/fd9wf5Wfpw+zb8kfyl/K/8Iv31/eX+7f/7AMgBMQKRAhsDtQNdBBIFmAXVBegF6AXJBY8FWAUyBTEFawXABRAGWAZbBvkFeQUBBXsEBASvA1cD+AKsAnwCcwKHAp0CpQKSAlgCCALoAdMBlQFVATQBNwFYAYIBsAHbAf8BKwI7Ah8CzQGCAVcBDAGZAAEAe/8H/7T+f/5L/hH+zv2S/TT9y/xj/Pn7oPs6+8T6T/r/+bf5cfk9+QL5ofgh+Kb3FfeA9vv1VvWA9Irze/Jr8YDwyO9R7+Puae7I7bLscetL6kbpdejc53rnR+dc5/7njulk7NjwVvdwAOkKBBOjFu8VyRFfDbwMERC+E+8VexdWGGcYvhhaGbEYkRaDFO0SpBA3DaUJRQaTAvH+Xfz/+sX6Fvxf/vj/mP9g/SX68Pbm9HD0YvUx9+n4vPkz+kT7Ov3U/5wCHAWqBnQHSggNCfUIDwhOBy8HawccCH8J9ArNCyUM2QtdCiIISQY3BXoElgNUApwArf4m/UD8v/uM+4j7lPuI+zL7dfpp+WH4pfcp9wP3ifep+B76lfvn/Mr9JP6C/iD/2v+CAEcB8QEmAigCOAKVAjEDEwQLBcMFKQZaBpIGjwY3BrwFSwXtBL0E4QQHBQsFKAVBBSMF1wSCBCUExgN+AzID4wKgAn4CdAJqAlgCUwJoAn4CgAJNAvUBkAFNATUBMAFCAU8BWgFuAYwBjwF4AVkBGwG5AEkAzP89/7j+Wf4V/sT9ef03/f780vyj/G/8/vt9+xT7uPpM+uH5m/lB+fX4zPiJ+Av4hvci97j2N/ah9fP0DfQL8wryFvFC8HPv0e5k7uHtNe2A7Hrrx+kn6Dfnceb05Vnm6OZd5w/poOy28XD5nwSkD0kWOhgGFjURMA6wD0MTchWGFoMXwBehF00YFRmcGLAXHxdOFU0Rkwx+CI4ElQBw/fH6RPmo+Qn8hP6q/zv/M/0n+of3Pvb69aX2Jvgh+d34tfjj+VX8qf+ZAw8H4witCUkKQQosCScI4wfBB6QHHwgsCQ8K6grTC8MLaQrXCLUHqAaCBSEEMAKt/1P9oft5+gz6hfp1+yf8avwG/PH6vPnx+Gr4zvd19633UPgz+X/66/sO/Rz+ZP+WAFoBEwK3AvMCzgKcAoICgAIdA1sEvQX+Bv8HigiZCI8IhwhfCBIIwAc9B2gGrgU2BdkEvgQLBVwFXgUhBbkECAQjA18CtgEIAYgAXABLAFMAfQCqAL0ArQCeAJUAjQCYAKUAewAoAO3/0v/b/yUAiADGAM8AqwBJAJ3/8f5h/uX9hP03/eb8evwV/ND7l/tS+/T6lPo3+tP5Vfmo+On3Gfdr9gD2zPWl9W71PvXd9Dv0dPOl8uDxIvFw8Lbv5u4U7obtMe3O7CvsIOuE6aDnS+ak5ZPla+Yc6F3qAe719H3/xAq4E7oYQBi/E4AQnBAlEtcTtBXbFhgW4RSwFKcUABUCF1IZsxjmFPsPuAq2BfcBfv8K/fP6yPra+wb9Uf5n/1T/F/60/Cv7mPk5+R36kvrS+fv4k/jf+B/7Vf+uA+8GcAneCmYKBQkdCMEHgQefB/AHlgcDByIH1wdwCOcIgAmMCd8I3gdwBmYEFwL0/8T9sft2+j76tvq4+9j8R/37/Hn80vsD+2L6Hfru+Zb5avls+YD5KPq++8j9t/+MARcDCgRsBJwEsgSlBLgEGgWJBdwFawZABy8ISgmFClsLowt9C7wKkQlQCCEH5gXABPEDPAOQAh8C8wHRAaYBlwFnAfIAZQDs/13/sv5Q/jL+Kv5F/ov+1P4X/3X/1P8EAA8AEAADAOj/0//E/6H/ff9k/0P/G//0/sH+fv43/t39V/2w/Af8WfvJ+lj67/mS+Rb5ifjz92v37/Zo9uL1TfW59D/0DvTo85/zXfML82/ysfEX8Vvwo+89787u8O3k7AXsOOtd6ovpkOi25ozkTuN54w7lAOo79N8AMQzyFIcYZRVTEc4QuBHiEgIVABdoFkgUQBNYEq8RUBS4GfAc2huKGJATAw04B8QD9QAI/lT9Ov4l/r79ZP4x/zv/X/9//2v+G/39/Mj8N/tk+dX3YvZC9mT4xvtW/zgDuAY7CBMI0Af6B6kISgo7DIUMtApTCCwGZAQpBB4GtQjNCjkMFwzWCYEGqQNnAXH/Gv4k/df7gfrA+Tn5Avl6+Xn6W/vT+xH83vs5+6H6HPqB+UX54vld+039p/8jAvoDIgULBqwG9wZpBw8IZgg7CMgHDgciBp8F2wWeBpMHcwjNCHEIdgcxBvsE5gMYA20CuQHpAPz/Gf93/iL+Hf5m/rv+9/75/sb+e/4q/uL9rv2J/Wv9dv20/QX+VP65/hT/X/+//x0AagChANgA4QCXAC4Al//g/jP+r/1G/c/8W/zi+1j7y/pY+vr5qvlR+fP4ePjK9/v2RPa49VL1HfXt9Nb0u/Sz9NX03fTL9LL0b/T884Hz6vJG8pfx7PAu8HDvwu7y7RztNuwj67/pe+jI53fp3++f+dsDcAxZEOIOPwzBCgEK9QqkDZkQExKYEYMPZAy9CgQNYRJcF6AZHBnFFfcP7AnJBWADzAKfBHkGPwbFBHIDqgKUAoQDuQRIBQ0FKgRCAob/If1w+4/6jPoh+0T85P3T/20BTwLCAuECkgIbAvsBFQI6AoACgwLbAfAA5QDnAT0D/wTmBv8H9QcSB3QFTwO5ATgBTQF+AcABzQGOAVgBNwFmAR8CPgM2BHsE5AOAArgARP+E/ln+uf6V/4kAFQE/AVkBXQFfAacBMAJhAicC2AFKAaMAQgB1APUAnwGUAl8DwgOwA2sDAwOHAi8C4wGWATUB0gBoAOb/Z/8a/xH/Pf+H/8b/1v+4/3L/D//G/oz+T/46/kf+Qf4m/hH+8P3W/eH9GP5f/oT+k/5w/ij+w/00/bT8UvwQ/NL7lvtC+9T6h/pg+l/6Tfow+v35tPlm+Rz5/fjr+OL4wfiU+GH4Y/ic+Mr4Ffl6+bf5g/kv+b/4BPhT9/r2s/ZA9uD1l/Uq9Xn0svP/8knyh/EL8WvwZu/x7ejs4u6I80j5bQBeBjkIkwjACGwHUwYJB/MIxgoDDI0McwtcCeUIIAs9DigR8BMyFXwTzQ9DDPYIOQYlBtgHsQjLCJsIhwfSBa4EuQRjBTEG5AaxBh0FqgIrADL+9/yi/FP9lf6R/+r/5v+y/5z/4P9kAAcBagGeAakBQwF6AM7/3/90AEQBfALcA9oEkwVABkIGtgVXBTAFEgULBSIFBwW8BHgEGwTGA60DvAPXA9ADigPaAt0B2QDa/w7/nf6R/p3+m/6f/pv+dv5L/lb+c/6R/tz+G/8R//H++v4J/xH/ZP/v/3wABAFzAZsBegFIASwBGQHMAI0AYAAGALb/lv+G/2X/Pv8f/wP/1f6V/kP+KP43/g/+0/3x/Vf+ef4l/qf9aP1v/en9ov6t/t79DP3r/PX8jfyQ/Hv9Kv4p/u/9gf2v/PT71/sg/Ef8LfxJ/J385vzw/L/8sfwR/aP9lP3s/JL8kPz++037bvvH+9/7Mvx+/K77ffqp+jj7bfpx+ZD5nfnq+Jf4J/mM+Vr5c/nO+TD54PeZ9+r3Ufdv9pr2vvcT+Wr7G/+wAWwCOANhBN0E1QQbBZMFkAUtBbIEAASvA2oE/wX8B9EJ/gpNC/MKIgrbCLEHWweIB40HXwcMB10GjAU1BUsFgQXeBUQGLAZdBVYEUgM1AlQB8gDlAOsA5QDkALkAeQB0ALoANAGtAQkCPgIkArsBUwEZASwBdAHZAXACAwNTA3UDigOrA/sDWQRyBCMElwMSA7oCeQJHAhMCCAI/AmQCRQICAqgBGQGZAFQAOAAOAMv/Zf/E/kf+C/4S/qf+qP/9/1P/zf7G/p3+6f1r/df9/f2+/YX+sf/P/2v/zP8vAHP/hv5s/mX+o/2P/bv/GAKJAYv/Bv8d/23+6f2C/h3//P4h/9f/qv/y/uX/4wCE/9P9x/1c/jr/RgCk/+T9Rv6//y7/lv2C/db+Rf8g/oH95P1+/ab9z//oAPn+O/1L/pr+WPuX+XD9RwHl/5X9TP6k/rH8Afwf/x0CawF7/4D+i/3O+1v6MfrW/NEA3QEHAHj+UP7Q/Rr9Kv1f/Vf+sv8BAHz+xvxk/QD+6/xl/HT9RP6f/tf/yP+X/aP86P1i/nv8YvsJ/TX+Nf2//BD+4v7m/uf/NgEhAcsAfgHAAcgADgBJAEcA1/98AMcBVwLDArID8QO+AjQCagNtBBYEGwQPBU8FcAS/A5cD7AJUAqkCoQN3BKkEcATQAyQDxAJcAhMCrAIbBMsEwQNCAoQB+wBRAIsApQG5ArIDAQT4AssBzgH8AYUBegF4AjsDjgIyAVgAkwBOAXwBoQEQAjoCNwJaAtgBggD1/z8AAAD0/0oB6QG9ACP/m/58/37/Cf+S/1QAUACl//T+/f1B/vL/YgC6/lP9+P2v/u/+p/+R/6D+xP3J/SX/RQC1/1X+Z/4m/9H9efzF/f/+vP6o/+cAdv/y/V3/NwCs/tj+4gDw/wz+S/9cAML++/2fABICP//p/MP+ngBy/x//ngAXAHb9Gv4wAOv+Lv94AugCuf8t/Zj8dfye/Tz/Jv+a/9YBCQFj/K78lQGpACn8Z/7xAsL/Svt3/m8CAACs/fMAzQJn/vX7VgAbAsb9Zv38ARcDhP+1/XT/vf93/jT/UgEyAeL/HgBA/+38pv2sAG0ATv4N/zEAZ/4i/hQBiwAs/RH+TAE0ABj9w/3w//L+Tf1//ycCrgAj/qL+zP9F/5b+Rf7i/i8A9f9k/r7+NwGVAVwA2AD/AL/+/PzA/ggBlQClABoCmAHr/lz+oAA3ATIAQQCuAaYB0ABkAaIAKv8NAGgCAQIUADkBmgMqA28AfP9yALAArgBHAoED8AGPACUCJAP8AKH/kQE1A3kBpgBxAxQE8ACDALICigBu/Dr+0QISA9cAVABOAcsBTQDZ/okAIQNGAgP/Iv/QAb4AB/0p/jEDXwKs/af+ogLGAVH+I/+AAQMA7f3h/gcB1AFVAKr9Xf13/ywB6gEgAbj+k/2m//AB1AGwAFIAiv9y/cr7F/zy/hoDIAWzAmT+1/tX/JP/pQLyAr8ANv+L//j/MP/V/MP8ygBrA9L/WfyZ/2AC4f8P/Sj/WwIGAPH8y/6lAfj/5fxv/d/+rP/8AA4B0/4I/kUAGQBq/cX+lQEh/2r81f+RAg3/Pf3PAHICqf4C/Pr+bgHS/zv/ogEIAt0ArABw/n/7hP3kAVUBSv/ZAcgCS/2j+sb/YQOXAEv/xgD6/o38m/6QARsAEP6c/w8B7f9u/2MAzP+A/hL/ov95/tr++wGtATX+GAARA5D++/pP/6wCof9X/dwAgAJW//b+LAFyAKv+KgCvASIAPf9zAFgADP78/VMAQwH6AEr/Mf7c/9sAzv+j/zMBrAD9/e7++ALtAlb+S/2YAE0BNgBQAGAAkv6h/UoBLATTAUn/jwB0ATn/XP3a/gkCywJ6ATgACf+a/90AX/8g/i8BpgSBApz+ngA7BAwBV/sL/CkBLQLR/5cAbwEz/9z/OQMTAhD+x/4gAuIA2f5jAYsD5QB1/WH9Vv5q/ysCrgM8Ap//nf2Y/Sb/BAEiAXEBCgQTBJ//Ovyg/ZP/b//ZADMCPP+E/YgCVAWE/9r73P/tAjgBGP9//r7/3gKSA13/Ffxo/fz+ZwDWAmkDQgBO/K79ZgK4AHX71P7NBUEDffwm/aAB4/+y+lf8JgE/AfP/XgHfAZ3+e/zb/rkBDAHUALMBhv6I++j9nwH0AjkCjQAt/vH7PPyf/3ACswCK/g4CKgXLAC78f/0dAIEAGwGGAmoBWP5//eX99PzG/SIASAJOA8YA9/1Q/j4A0gFMASj9G/wTAmUEBAAo/Y7+df8b/cH7Z/7DApIDXwEAAWMA6/ya+/v/3QKIAED/5QCNAPP8EPzY/4wCVgLn/w79BP+jAyQD4Pyf+hr/mgENAWIBBwJt/4n8xf/TAlD/tftx/akB9wL3AIX/gv8D/+b9gv/GAXUASwHDA3r/HfqT/XIDUwIqADcDVgPi+hr2Of/3BpMAavueA+gJ9wDv9wn8yALIASUAHgKj/9/7uP6sAg4AAf1uAk8GGgAO/IABlgQN/yP98QFYAlX9Ov3+AjcEz/3D+YYArgaHACj6SQCaB5wDtv3J/7wBJf3k/NUDDgRZ/YP9XwKlAK78nf52AfcA7QGtBKEC5Pzy+80APgMiAI/+aQAPAoEBFP+D/Gv8CgHbA8UBiQCaABH/w/47AoMC9v1c/fYAUQGJ/tH9/v4kADQBsgExAbv+uf2VAe0D/v+e/Mj/iQJc/2f8hv4LAogB5P8MANf+o/1v/w0BPv7L/WgDpgLM/FIAdwarAP345/1XBGL/KPogACUGPwFV++b+1wL6/UT73wG/BMz+Nvz7AJED9/+3/WP/rP9M/4r/qP1U/rQDTAOv/Mf8BwGV/4b+lAIlAuP8dv7pAz0BjfnB+54EkQOQ/JP9QgLQACQAEwK5/Rj5Uv6uBbUDWP5V/tAA3gB5/ysA0QAU/sH7J/9YA8L/6voaAD8HAwM7+3X9/AKuACn9TAD6AlQAKP0f/WH/uwCEATkCuwF2AHr+A/3O/5UDxAJjAQwCcACT+iH59wAiBZ8Atf+qAzgBsfsw/+QDxv61+9UCrwVI/2v9YAFy//367P/ABKD/4vsbAZ8E2f5n/KgCOwMR+wn8YwX2A0X6dvpvBXgG+fvc+14FZwO7+Vz8uAQcA/H8Nf0ZAeYAtP9qAPYAWgFRAXD/zPwQ/1oEcwSn/1H+rwEjAaz6tvgjAZAHFgOy/akAIwKn+wr70gPjBuT9OPkPAgcHxP6++csABQSH/Tv7eAAeA6gATwDTAe/+yPsLAGkEFADH/LoBrAQB/zT77f81A5D/OP0nAMgB1/+T/0AAcP5b/owCxgMB/qf8zAGoAcn+TQDHABr9J/3OAQkC0P1G/68DP/9b+icAtgU1Ad/7cf2nADUBzgC/AAEAKf+H/yUAqP9K/4f/bv9G/14ADAFm/9//LgO/Aob+XP02AM4AgPwy+w8AfQN1ADT9RAGDA+v+s/1OApoCWfwd+qH/cgVsA5H+wv6+/1n+1v2t/qP/ygEsA98BpP7o+8f/2gVJAqb5kvkvAuwEZf8X/+ED9gKV/Gj7BgC5AfP/2f45ABcCYgJLAJL9Z/56AoAE3f/e+jn+XQQDAy38ZfqB/70EbwRi/wv9oAFeBSoANfmU/ZwIrgXD+Jn5dwQlBF77Bv1MBV8CHPnV/C8HpQSN/VYA4AMK/5z8wgCP/1P7WP3rAbsEMQRkAUn+qPvJ/QoCXgK5AFMCNAQzAXj9e/yE/T7/4wKJBLL/7Pv2/w8FVgB1+lwAngXn/QP5NgO/CFf/Y/lB/0UEEf+r+48BnwVFAij+4f4UAFP+Z/6+AcQBxf6L/wkDwwFh/Hn9bwNlAw//ef8LAoH+Zvr6/SUDFAIUAJUBJgEm/hH+PQBWABIAygIDA7v9gftY/+MBcv/L/Tb/2wBUAMn+bQHzA/wAuPxK/loEIQM9/Gn7IwDVAbb+QP56AEz/6v37AMkD2wAM/dX+hgK0AAj80v1zAtABHP87/6AAmADI/xv9Z/py/bIDGwRW/1P+ugAV/wT8Rv+5BF8DDf0O/CgANwGy/rL8WP4mAWEBdAB2ADYAcP5R/U/+SgFQBLUChf7J/XX/8P58/Av9KwFIBB0Dov6K/In+3P42/wADLwIe/Rz/fgT0ABH70/4ZBF7/W/vCAtYEp/uV+l8Fywcu/Pn4iAPiBof+kfyfAdX/a/wg/2ECCwD1/d8C2gXg/6b6Av8RA2L/b/04AUcDWgExAY4B9v3X+9T/4gReA079L/1LAhYELgEE/8f/nwAAAR8A8/4i/1oA7P80/gQBSAW9AZf6OPxyAn8Cs/8dAKkAxv4+/tj/3P+1/kIBqAT3AOP6qfvm/+ABkgKYAED9tv4FAcb/T/6h/4wCKALE/sn9LgB/ABf+Pv5sACMA7/0n/2ECqAEX/6T/IAKX/0r69/zyA1oDRP0Q/uUClQAO/W0AbAM3AAD+lf/9/qn9OgCiAcH+aP5MAuACUv7s/Df/Of9a/9ACagSu/uX5mv6nA9T/+Prr/tEF+AR6/tX8KAAMAFv9DP4oAcgCEQFn/kX/RQJMAuT+gv37/wABu/5a/pEA3/5U/JP/CQORAPv8AwAFBSgDr/1Q/e4AMwGr/7kAMQFl/hv+eQJlAxT/lv09ADYAcv1y/0YE0AJ//joA1QP+AND8Y/4nAo8Bbf6a/7IAYv3w/OoAmQEs/28B5ATbAcL96v9nAr7+IPzp/t4BqgHq//j+n/4K/3wAJgHt/2EBmQTxAXf91v5kAs8AHv00/70DYALU/Dz9swIIAlj9Bv4tAuoBKf4U/ikCfQQHAgP+o/3QAJIBTv/f/ssApQFm/+n88P4gA6QCNf+g/78CjAJB/4H+1gDAAJ/+h/+JAdoAPP+DAFcDgQHA/Br9cgHyAYr/iABpAkX/hPsf/skC/gHN/UH+HAK/AHb8m/3bAWYBqP1o/ncCQALK/mz+9v+d/pv9igCgAkQAFP6Y/0QAuv3T/QADpQTg/zb+zADR/1D8QP1RAfABS/9b/vb/3wACAKj/tQDTAMT+xv4IApUBdf0H/hQCawFr/h7/6gFvAav9pv1tAKv/wP2W/7YBdwDF/vz+jgB5AIP/FwCqAD4Auf8o//n9YP5mAJMAM/5j/ZwA+QEZ/xn+OQHMAlb/5/yP/2UBqv+1/4oBzQD9/pT/oQCk/4/+s/6c/4UAvgAbAQgChgGg/+j+K/+2/wgAYf/m/64BIQFa/u38m/7iAJ8AvP8JAOkAMwHc/9n+Qf86ACoAJf97/3MA4P/q/gEA0AAD/1L+JgEVA8IAW/77/3oC3wE9AJ8AsQGfALr+DP+wAMYAxv/G/1wATgHVAaEAiP5A/+kCcAJX/u7+HgPZAhX/bf+SAmwBjv0f/mIBJQGa/4gAaAGwAIcAaADH/mf+TQHUAgEAQf69AB0CcP+d/UL/0/8e/g/+SP8O/0X+Vv+FAJcA/wBjAC//cQA6AyUDFgAs/2MBxQHg/l79CgCMAyoDiP+d/Xj/jQH8AAkAwQDIAdAAlP5//nEA2gBn/zj/QgABAGP/9v+f/+/9Rv7jALsA1P25/lQC/AH2/gL/NAF0AED9Y/2gAKAAr/2m/X4AAgGr/mb+PAEQAuT/mf+YAewBcgDr/1cA2v/t/ob/pgDl//f+xf/s/yb/m/8WAfUAsv8sAP0AiADV/08AigAJ/3j+ov8mAAz/if60/1EAuv+B//j//P/z/wMAav/+/sH/pgAlAEP/cf89AF0ADQA8AEkACADZ//b/GwD1/+X//f96APAAlgAAAL7/0//t/7z/av8Z/x//Af9T/nz+pv8JAFL/V/8AAPH/3/85AIMANAAdADoBpQH4/8T+vf97ALH/XP8bAFkAzf8vAMQB3QFIAN7/nABgAMn/VgDdAEYApP/M/7//F/88/2cAWgD1/vP+RABIANn+gf6h/yEAQ/+E/un+X/91/6j/BAAyABgACgA0ACkAqf+i/6YAWwFwAF3/xP/DAMsAKwBpACAB5ABjALkAFwHmAMsAWgHpAYABdwD1/y0AWwAAAGn/nP8pAOz/Qv9x/ykAFADW/z8ArgBTABIAsQAJAZQAIQA4ABAAbf97/xAA9v9Y/2X/CwAfAMr/+v98AJ4AkQDgACgBBQHVAMIAeAAdADYAIABv/xz/r/9FABkA0v8ZAJcAkAAqAG4ALgExAVMA5f9vAK4AAACE//T/XgANAO7/jgDoAIoAnwAxATQB2gDlABYBpwA0AJEA+gCtAGQAvgD8AIkARQDXAC0BoQD2/woAVQAOAN7/CwDo/2X/YP/6/0UABwD2/ywAbwCJAFYAMABYAIMAVAAQAOj/wf+O/0P/NP9d/4r/mP/F/1IArwDAANwAHwFAARgB+AAJARwB6gCiAFwAEQDk/8n/rP+W/6H/6f86ABwA8f8bAD0ANQBQAHcAUAAkADMAKADL/5D/pf+N/1v/e/+3/4f/SP+r/ykAGAD0/z4AjwBgACEAVwB8AEAAMQBMAAUAh/9x/3f/Jv/M/t3+OP8m/87+0P4i/zr/QP+f/xAAEgCU/0L/VP81/9/+Dv9v/zv/x/5y/h7+r/0+/SL9R/0x/Rn9WP2V/ZT9oP2n/XP9OP0R/QX97/zC/J78jvxc/Nn7Xvsk+x77Cvvs+uz62/qx+mH6RPo6+hH6Avr6+c35gflV+VP5q/mW+vH7gP1Z/yEBpAJoBGYGJAjFCZ0LBg3fDZ0OFg8BD8UOtg5rDuENXA3HDBYMiQtLCywLLgtcC5cLvwvRC+AL2QuqC1YL5wozCj8JPggeB+AFpgR1A0QCGwEjAGP/0P59/m7+nv7e/iv/nP8MAGwA0wA8AYABqAG/AbsBlAF1AWoBPQEQAe8AyAChAJUAqAChAKsAxgDIAMMAvAC4AJYAXgAQAKH/Hf+T/gH+VP2t/A/8Xfuz+if6mPkU+a74YPgf+Nz3o/d+9133J/fo9rL2d/Y89gD2wfV+9Sr10vR49Bz0xPNX8/7yzvKs8pXya/JD8h/y4PGG8SfxxvA88KXvIe+G7ojtZuxs60bq/ugi6KnnDOew5ifnEujX6cvt6/IH9xD7uP9UA9EGOAy4ER4VDBhFG6QcjxzgHOIcsxtqGtsZuBiQFqsUeRN7EosRZRF/EewQVhBhEHIQ5A9xD0UPKQ49DIYKnAj7BTYDxAD6/ab6s/dV9QLzyvCI7/buYO5l7kjvX/CB8XrzIvaJ+OH6kf0XAPEB2QPaBS4HDAj6CMgJ+QnvCQsK9gmQCV8JfglhCTYJfgneCQEKPgqtCvIK8godCzgL6QptCsYJ1Ah0BwAGnwT9AlUBz/9U/tH8avtq+pn59vjC+OD4FfmR+Vb6Hfv8+wT9Gv4W/xEAFAHwAakCVwPzA1EEogTrBBcFMAU3BTAFEAXaBJwEWgT8A6IDUAP0AoQCCgKNAf0AZwDa/1D/sf4Y/pD9Af1t/OT7b/v7+pX6QPrt+aP5ZPkY+dn4lPg0+OL3lvc/9832S/bC9Uv1A/W89H/0OvTL82/zL/Pk8nryGfKa8crw3O/c7ovt+uuN6kzpD+gS56bmueYO6JLrZPCu9Ij4q/w6AEAEsgrrEUQXZhtfH5shPiIzIwskdyMuIl4h1R+0HG4Z0BZFFK4Rwg88Du8LsQmgCAwILwdzBj0GPwV4AyICFwGW/+P9dvxa+kL3RfTN8VHvyez06pHpA+gA5/3mbOcZ6MjpcOw37wnyUfXX+C382P/TA1AHAwpgDHUO5A/REJ8RBRKnEf8QRhAmD6YNSwwtC+0JrwjEB+EG5wUmBbUEMQSLAxYDrwIIAkgBuAAUADf/MP4p/Q381vrb+Rz5aPi691f3PvdH94f3Q/hV+Yn6F/zu/cD/lQGxA9UFzQemCVALmwyaDXoOCg8sD/MOcw6aDYAMUAsECpgIHgezBTQEqwJFAQsA7f7o/Qr9KfxW+6P6GPqm+UP58/ia+FP4I/gP+BH4KfhI+GH4gPih+NT4EflL+Yv5yvnv+Q/6Hvoh+iX6GPr++bT5Uvnm+H74Gviq9xv3SPZF9T/0PPMO8tHwbu+y7dbrKOpv6LHmb+Vb5ILjVOMi5ELmJOop71/z+/YJ+1z/tQQLDKIT2hhhHLEfAyJzIx4lbyY8Jv0k1CPyIb8eTBt7GNwV1RL9D0oNYAq3B0IGiwU1BJwCYAEgAK3+8P3w/Wz9Nvzh+gv5g/ZS9PzytPHw70nu0exJ6zDqFOqI6hrrYeyF7gLxmvPG9ov6V/5IAlkG/AkADfYPDROiFWQXchi3GCoYQhdFFuIU5BKfEEIOoQviCFgGFAT2AR0AnP4x/fL7/vpq+vT5j/l3+Wv5RPku+Uj5TvlF+UX5KPnn+KX4u/gN+Vj5uPk3+uH6r/vL/ET+0f+RAY0DggVRBx0J5QqBDPQNPg8NEGEQghBOELgPzw6eDRYMTwp3CIcGhQSNAq8A1v4W/Yn7KvoL+SP4fPcM97P2hfZ/9pv25PZZ9+H3aPju+If5K/rJ+mf7AfyH/AD9fv3c/SH+XP6J/qX+nP6B/kn+2v1f/en8Sfx5+5v6xPnO+LT3n/Zz9SD0tvJj8QvwZe6k7PzqWOmm5wXmq+R/40nig+GQ4RfiWuNK5g7rI/BS9Fz40vyeAdcH/A+pF5Ec7B9cI0cmVyhcKt4rXSuqKTcoGiZQIkgeChtNF+ES+g6KC7QHTARfAq0A+f1b+//59fj59wn4lvgf+M722fXp9JHzzvLe8mDy7fCl77zuwe0q7ZjtTO7Z7hzwbfL19HH3lfo6/toBiQWaCYENzBAkFHIXyRn3GpEbuBs7G1kaOxk6FxsUnxAwDYoJwAVWAij/6vv3+Jf2cPR+8jfxkPAd8NzvLfDU8JPxo/Lm8/b0wPW49vT3Oflt+pL7kfxA/fD97v4IAB8BZQLhA1EFpgYiCLgJSAvbDHUO0A/BEJERKRJZEhwSfRFvEPwOWA2FC28JHAejBBUCif8W/fL6EPlj9/r1z/Ts81bzIfNC86XzQPQV9Q72GvdF+ID5tfrq+xj9JP4f/xEA6wCSARACbAKgArcCwQKyAm0C9gFcAZwAsP+t/pn9WPzy+n757/dR9rn0NfOf8ejvO+6c7A/rlukX6KDmReXi46biv+EG4WXgOeDS4PLhpOOs5oPrJ/Fo9kn7MQBKBZoLxhMHHBAi9iVTKTgsbi5YMHsx2zDDLo8svSlEJfAf9hoQFrgQogvTBsYBG/3C+Rr37vPO8MPusO0y7Y7tc+6t7lHuXe697hTv1e8w8UbyfPJ58qvy3fJn87P0XfbK92j5yPtj/u0A1gMzB5QK9A2UEQYV1BdgGs8cYx7HHnMewh2IHMUajxhZFfAQGAxmB8sCKP7A+aH1kfHb7dfqYOhi5j/lFOVy5TXmhudL6U/rqu1Z8CDzzfWY+Ij7Lv6GAMAC0wSgBkEItgkSC18MqQ30DvYPrhBYESMS4RJ5E/cTNBQSFJkT2BK1ER8QWg57DDUKiwe6BNwB6/4T/G/58/a09O/yovGk8P/vxe8D8KDwqfEg88f0lfaO+I/6gvxz/mEAKgLJA0EFfwZlBwIIawiVCIwIUAjnBy4HRwZIBRgEzQJYAc7/LP6D/NP6Cvkk9zz1avN+8Yzvye1G7Nzqeukg6MPmcuVx5NrjT+Ou4iri7eHX4fDhXeIt42vkYeZ26ZPt7vI5+WT/1gToCZsPdRZyHm8mrCxeMG8yIzRdNb41FzUCM3Mv4SqdJTsf0hd5EL0JWwPo/LD2AfHx6zXolOVD4y/hEOCZ4FvixuSH5wTqB+wd7trw4vPl9v/51fzk/hsAIwE9AnMDFAX2Bq0ICQpxCxsN0Q6WEKISxRSyFm0Y7Bn/GoAbfBvKGiIZsxb3E/QQbA07CVYEx/73+JDzzu6D6prmT+OV4HveON3p3J7dRt8Q4qzli+mM7eXxn/Zt+zAAvwTgCHIMiQ9HEmIUoxVIFnAWLhaQFcIU2xO0EloR2A9ADqsMXwtcCn4JnAiRB3YGLAXJA4ECNgHC/zj+oPzr+iP5evcX9tz04fNR8yrzWPP98//0Nva494z5vfsY/pkAHANsBXwHUwn4CkIMQw39DU8OIQ6DDZIMUAvKCRsISAZDBC4CHwAV/g38GvpP+J72HvXa88fy5PEx8abwMvDO75vvle+l773v2e/27/rv++/q77zvnO+L72fvFe+s7mDuFO7T7ajtee1y7dftAu/C8Ony7vWH+pYAegYLC5sOaxJ9FyweUiUXKncrCCt/Ks8pPCjSJRMi3Rw3F20RlwqcAnD7CPZb8c3spug85b3iB+IN40DkD+Wh5vjpbe4y8+X33vva/nUBWwQmB1sJXgs1DQ4OpQ2kDK4L2gqECuEKJgvGCjsKMApgCqwKYAtUDPkMIg09DQ4NRAwIC2wJEgf1A7sAtv2H+vb2SfN877HrieiL5mbl7ORJ5XXmF+gX6vzsu/As9Rz6Qv8QBDwIIAzSDwwTfhVCF0IYWxjAF5UWuRQbEiEPBwzHCIEFigL7/6P9fPvC+XX4ivdA96j3aPg0+Qr64vqi+2b8Y/1Y/gH/dv/M//P/9P8HADIAXQClACcBvAFKAvsC6gPgBMQFsgamB4cIRwnuCTUKCwq0CTYJhQihB5UGUgXRAzICggDJ/hf9k/tA+vj4v/e49uj1OPXL9Jz0i/Sl9PP0dPUI9qb2WPcO+MP4b/kv+tP6Nvt0+137+vps+tT5Lvlf+Fz3DfaD9NnyXPEc8NruqO2Q7Jnr9urM6kLrQez07cLwMvVC+4gBmQYuCroNnRIpGUogmSXBJ2AnWSZZJcUjOiFdHXcYLBOmDWkHQwCK+V70cfAt7Uvq9+eX5sXmXOhF6uLrt+3f8EP1B/pu/sMBAASeBUUH/ghsCp4LhgyxDOILegoaCSgI3wdSCPEIGQnrCPYIRwnACVAK2QoSC8IKMgpNCdgHwgUaAwEAkfxE+Vj2l/Pa8CLuqOuj6XHodeiU6YvrMu5U8aH0CPjQ+ykA1ARTCWINnxDqEpEUpBUPFpwVbhStElsQoQ2PCkAHtQNBACf9ZvoS+Ez2NPWG9DP0PvSP9DH1Qvbs9+D51vuJ/dv+AAAGARkCJwMJBLgEPgWlBdgF+gUoBnYG1wZJB8YHMAiZCPQIIAn7CJUIMwjTB0UHdgZXBeQDVQLSAGb/D/7a/OP7DvtA+pn5LvkJ+Tf5qPkz+rr6WvsQ/Kj8KP2e/fj9PP5u/o3+nP53/jD+1/1m/fD8hvwl/Kz7FvtR+lr5QvgY9/P12/Th89/yjvEC8HbuIu0S7CTrPOpu6ffoDenZ6U7rN+3O7w70jfoXAp8IPQ3gEFwVyxtoI5wpRiy4K8EpwidsJe4h1BxfFrIPJwkaAiX6bvJj7CboHOXG4h/heOCT4YbkGuhC61HuZfK+97D9PAN1BxsKwwtNDeQOPBApEZMRKRHNDwoOUwznCiEKBQoaCuIJWAngCIcIMwjtB4IHmAYoBXkDnwFe/3/8LPmM9f7xIe8R7YnrSupb6e7oN+mb6kbt/fBd9RX67/6AA7YH3AsIENkT6hb9GNMZjhlsGKMWGxS+EN8MygiwBLEA5/w6+cb15PLF8HXv3u4N797v/fBI8qfzJ/Xe9tj4/vrm/Fv+U/8EAKAAMwHvAbUCYwMDBKYEcQWLBg8IsgkpC3wM3w1LD14Q7RDYEBcQ2Q49DTgLtAjRBbwCh/8s/Az5ffaP9GHzv/J+8qnyjvM19Ub3jfn1+2n+tgDUAqkECQb0BokHtwdtB9AG+QX5BMUDagIAAaj/k/7I/TD9p/wy/OP7nvtk+z/7Jfv8+qb6Hvpq+Yj4f/dc9vr0VvOq8Rfwve6w7dLs5+vv6irq1Okf6grrkOy17kPxQfT89xf90AMDCxARDxXdFxobuB+5JMAnciclJNYfzBu6F8ESaQxoBc7+9PhM87Dt3eix5XHkZeTy5BTmNejR62rw2PRg+Hz7L/+tA1MI7gvVDVEOPA5UDqsO6w6zDgIO5gyXC1QKQAmECCcIFQjgB1wHkwajBZsETAOwAab/Rv3e+p/4fvY79Nfxeu+Q7ZHswuz17bfvwvEO9Nb2Kvog/n4C0wbdClgOIBEVE0YU1BStFL8T/RF9D2QM9whqBbUB6f07+gr3lfTo8uXxQPHy8A3xqvHm8pH0hfaQ+HP6I/yR/bv+xf/HALMBfwIYA3wD1QM9BLQESAXmBYgGTQcaCOwIlgnlCeYJjwnvCBYI/AaDBaYDcwHz/lP8vvlo92f1wvOZ8tbxhfG/8ZryKPRA9sX4nPut/t4B+wTaB2YKrAyVDvIPshCpEAAQ/g6VDcQLkgkZB5UEKQLb/8D95vty+nb5wfhE+Az4M/jQ+LD5k/pl+zH8FP0M/u3+lv8dAJAAAQFnAaABwAHYAfsBFwIRAhECFAIQAgEC0wGZAU4B8ACWABcAe//o/k3+qf39/GD81ftd+/36ovpb+jb6OvpJ+lj6cPqb+sj67voA+wH7+vrg+rD6XPr1+XX52vgZ+Cf3Evbq9OfzR/MS8yvzf/Mm9CD1q/Zp+bv9/QLfB4MLGQ6uEC0URRhaGykc6RqrGEAWhRPiDyELswWWAGf8sPjq9G/x+e627Y7tMu5R7zjxU/Qr+HX7vP28/xgC5QSoB74JngpPCsgJpQmPCQgJLQhnB9QGiwZhBikG3wWjBYwFcAVLBQUFegSPAzsCcAA6/ur75vk9+Kn2C/V380DyqPHq8QXzt/TJ9jr59/vs/hACGgXYBzMKMgytDYkO0Q5sDkcNcAs/CeIGdAQNAsf/nf18+6T5TviD90f3gPcB+Kb4bPlR+j37L/wW/dH9Xf7B/h3/bP+Z/7f/0P8CAF0A+gDPAasCnAN+BEwFBgahBi8HfwduB/EGAwa7BDIDhwGy/8H90fsC+n34Sfdz9ub1x/Uw9gX3Qfjd+bv7l/1q/z0B+AJ3BKgFkgYlB0YH/wZuBpkFnQSHA2sCSQEgAB7/UP63/UH99fzM/Mv86vwd/UL9U/1c/Uz9Of0g/QH93fy1/Jj8jPyb/N38U/31/bn+jf+DAH4BhAJ+A0oEAAV7BbcFqQVYBdoEEAQXA/cBwACP/2D+Tv1r/Lv7Nfvi+uD6Gvt9+wf8sPxr/TH++v62/1oA3wBIAZYBzwHqAfEB/AH7AfYB/QEMAi8CaAK2AhoDcQOUA4cDXwM1AwkDuwIjAkABRgBT/2r+j/3O/Db82vu6+8X7Bfx5/Cr9Bf7h/rH/hgBiARwCnwLKArkCmgJ5AkwC7AFmAckAOwDW/5L/Xf82/zv/UP9r/47/u//v/xwAQQBTAEkAOgAhAPP/rf9R/wD/yv6r/pf+hf50/nb+i/63/uj+JP9d/3v/jv+H/23/Pf/5/qH+Jf6F/db8HPxD+1L6UPld+KX3N/f09sP2mvau9iD39/cs+Zv6Mvzu/RUAwAKyBWQIVwq2C+cMNA5mD+APPg+8DdgL1gmrBygFUwKU/zr9QfuK+QD4/Pa19gD3qfeF+LT5Rvsc/dP+KAAwATUCdgOpBIcF2wXGBbMFwQXSBcIFiwVIBRsF7gSyBFMExwM/A6sC+gEqATsAT/9G/iz9FvwL+0z63/m0+bb50vkk+tH60fsV/X/+1P8ZAVoCfwNtBBcFegWUBW8FCAVzBKcDrAKgAYkAff+U/tr9S/3l/Jr8bvxd/H/8zvwz/Zr98v03/nb+tf7z/i7/Tv9y/5X/xv8MAEwAlADXADABlAHzAUwCiAKpAq0CiQJFAuIBZQHQACIAYf+X/tb9Mv22/F38Kfwf/D38jfwE/Zj9P/7n/p7/UgDyAIYB7wE5AmQCbQJrAksCGgLdAZkBUwENAc8AjgBdADMABgDe/6z/ff9G/wn/zP57/jr+/v3J/aX9i/2K/Zn9yP0V/oL+Av+P/ycAvwBXAd8BVgKzAvMCEwMKA+QCmQI4AscBRwHBADkAv/9O//T+tf6L/nf+d/6T/sL+9/4l/1f/jv+y/9T/8v/6/wMA///6//j/+f///wQAHgAyAFAAdgCcAMIA2gD5AAUBBwH8AOMAvQCNAE8AEgDY/5L/Zf80/xL/Af/7/g7/Iv9H/3j/p//V//3/IgBMAGEAcQB3AHEAbABcAFgATAA8AC8AKAAsACoAOABDAEgAUwBTAFMATwA+AC4AFgD8/93/wP+k/4n/d/9o/23/dP+E/5//wf/t/w8AMQBYAHYAjgCgAJ0AmAB/AGYAQwAZAPP/yP+r/43/dv9h/13/Wv9g/27/eP+O/5//t//J/9P/3f/i/+b/3//Z/9b/yv/J/8f/zP/T/9v/6//2/xAALgA8AE4AWgBnAGcAVwBVAEQAKgAUAPv/4f/D/7D/qP+f/5n/nf+r/73/0//u/wwAIQA0AEgAWQBhAGMAZABaAFAARAA6ADIAIwAZAAsABwAFAAMADQAMABQAIAAhACwALwAvACwAKgAtAB8AGAAVABMAFAALABEAEwAWABgAHQAkACIAJQAlACkAHAAKAAcA/P/r/9f/zf+8/6v/qP+b/5n/nP+e/6X/qf+2/8X/1f/e/+v/AAALABMAGAAkACgAKgAuACoAMgAwAC4AMwAqACcAJwAgABcADQAGAPj/6//g/9D/yP+6/7T/s/+r/6z/uv/K/9H/3//1/wQAEwAfAC8AQQA/AEkAUwBMAEYAQQA+ACsAHAAZABEADQAEAAUACwABAAQADgAWABUAFQAaABcAGgAZABkAEAAIAAQA/v/5/+//6//j/+L/4v/h/9v/2P/Z/9T/3//j/+L/3P/e/9//zv/I/8z/0P/K/77/zP/Y/8r/x//T/97/2P/X/+r/5P/j/+b/7v/u/+D/6f/p/+n/3P/d/+//5P/l/+z/8v/z//T//v8AAAIAAwALABEAFgAXABYAGQAUAA8AEAATABcAGQATABoAFwAWABoAFwAVAA0ACQAHAAYA/P/4/+7/6P/m/+D/4P/a/9z/4v/j/+r/9v/6/wAACAAZACYAKAAxADkAQABDAEMAQwBEAEQASABCADsAQAA7ADgALQAnACcAIwAhABkAFAATABEADgAKAAEAAAD1/+7/6v/i/+f/3v/Z/9n/1P/S/9L/2P/b/97/4f/n/+3/9f/7////CwAPABgAGgAcACMAIAAlACIAJAAaABgAFgARABAACQAPAAkAAwD///7//v/8/wEAAAD+//v//f8BAP7/AgAFAAEABAD//wIAAQABAAQAAAAHAAsACgALABMAGgAbABsAHgAoAC0AMgA9ADQAPwCpAJMBlgIlA0sDUQOAA6YDYAOTApYBuwDj/8j+dv1e/Kn7Tvsh+x77cfsq/Br96f2r/ov/ogCcAS4CTwIqAv4BuAFBAaUAHgDA/4v/W/9D/1P/i//a/xcAYwDAABoBPQEWAccAawAQALH/K/+c/iX+zP2Y/X79mP3e/Ub+t/4+/9n/bwDpADcBagGMAaMBkQFYAQABngA4ANv/j/9d/0//Tv9b/3j/uP8FAEgAfACZALAAvwCuAIEAPQD5/77/hv9T/zP/If8k/zf/V/+a/+z/RQCOAMMA7gAQAScBHwH9AMsAlwBXABgA2v+k/4b/aP9e/13/c/+e/8L/6f8FACgAQwBYAF4AWgBHACsAFwD8/+v/1//M/8H/xP/T/+P//f8WADIAUwBnAHgAigCIAIMAaABNADAABgDp/8X/rP+S/4H/gv+B/5T/qP/A/97/+v8eADEAPQBNAFQAUwBMAD0AMAAdAAUAAAD2//T/8v/x//v/AgAYACgALwA4AEEAQQA+ADYALAAiAAkA9f/g/9X/0v/O/8T/yf/S/+X/9P8BABEADAAYACEAKAAhAA8AFAADAPX/5v/d/9//0v/X/9j/3//u////CQAPACQAMwBHAEUAQAA1ACUAJAAQAAEA7f/b/9X/yv/C/7z/vv++/8f/x//P/9r/4//v//P//P/6/wIAAAD3/+//7f/y/+3/7v/o//D/7f/u//X/+P8AAAAACAAJAAsAEQAPABEAEAANAAoABgACAAkABAD6//j///8BAAAA9P/1/////f/5/+//+P/7//D/6//n/+7/9//t/+j/7P/1//3/8v/z//7/EAAPAAkAEAAZACUAGwAUABgAIAAdAAkAAAAIABAADQD4//H/AAADAP3/6v/u////BgD6/+7/+/8MAAwA9//u//P//f/y/9z/4//t//H/7f/k//D///8DAP//+/8MABcAGgAOAAcAFwAZABIABgAMABIACwAFAAMACwASAA8ABwAKAA8AFQAMAAMADAARAAkA/v/+/woACAD9//f/9v8CAAUAAAAAAAAABwAKAAIACgAQABAAEQARABcAGgAWAA8AEAAQABgAFQAPABMAFgAgABcAGwAlACwAKgAdABcAGwAiABYAEQAIAAgACAD4//T/7v/1/+//5v/o/+n/8f/u/+3/7f/0//v/+f/6/wAACAAKAAcACgANAA0ACQABAAEABQAEAPz/9P/w//D/8P/r/+j/8//w/+r/7v/q//L/8f/s/+7/7//z//L/7//y//T/+//7//b//v/7//7/+f/1//z/+//7//b/8//0//L/7v/v//D/9v/x//L/9f/5//7////5//n/AQD8//7/9//3//v/9//3//T/AAABAPz//f/+/wMACAAEAAIABAAEAAEAAwD///3/AQD7//r/+f/6//f/9f/6/wQACwD//wEABgAKAAUABQAMAAkADwALAA4AEAAPABIAEAALAAcADgAJAP///v8AAAAA/v/9//r/BgADAAAAAgAAAAgABAADAAcACgAQAAQABgAJAA0ADQAJAAoACwATAAQABQAFAAoAFAAMAAwADQAMAAMAAAD5//n//P/7//n/+v8GAAoABgADAAEABQADAPv//v8BAP3//P/+//z/BQAFAAAA/f/5////AAD//wIAAgAHAAQAAAAKAAsADwAJAAYACwAKAAYA/f/9//j/+f/0//f//f/8//z/9////wQACQAGAP//AQAHAAAA/f/6//v//f/6//b/8P/2//f/+P/2//b/AAABAP7/AAAGAAsABwAAAPz/AAAAAAAA9v/8/wcABAAEAPn//v/7//X/9v/4//3/+v/5//H/9//2//j/9P/y//b/+P/5//b/+/8AAAkAAwAAAPj/+P/4//P/9v/z//n/+P/3//f//P/8//z/9//4//3/+//+//z/AQAEAAAA+v/3//P/+f/5//n//v8AAAUAAwAAAAAAAgAGAAkABwALAAoACQAJAAkABwAJAAYAAwAFAAgADwALAAoACQAQAA4ADQAIAAAAAAD8/wIAAwACAAIAAAABAAcAAwAHAAgACgAMAAoAEAAQABIADgASABUAEgAXABAAFAASABMADQAEAAUA//8FAAQAAAAFAP7//////wAAAQAFAAoACAAJAAUAAwAAAAAAAgAAAAAA+P/7//v/9v/8//3//f/+//3/AAACAAMA/v/4//X/9f/6//X/9P/4//L/8v/r//D/9f/y//v/9//7////+P/8//n/+//5//P/7v/z//f/8v/y/+7/8P/x//b/9//4//r//P/8//r//P///wUAAAD///r/+P/8//v//v/7//3/+//8/////v8EAAAAAQAFAAYABwD/////+v/3//r/+v8DAAEAAAAAAAAABQABAAEAAwAIAAsABwAHAAgACAAHAAAA/P8AAP7//f/6//r/AAAEAAAA//8EAAYACgACAP7/BAADAAcABAADAAoABQAFAP7//f8BAPz/AAAAAAYAAwAGAAQABAAHAAMAAgD8/wAAAAADAAAAAgAEAAAA/v/4//3/9//+//X/+v8CAAIABAAAAAcACwANAAcAAwAGAAYAAwAEAP3/AQACAPr//P/4/wMAAgADAP//AAAHAAMACgACAAcABwAGAAwABQAKAAQAAAADAAQABwAFAAUAAwAHAAoABAALAAwAEQATAAcACAAJAAwADgAKAAsADwAUABIADQAFAAQAAAACAAUAAgAJAAAA//8EAAEAAwAAAPz/AAD9//r/+f/1//r/+f/4//j/8//1//X/8v/x//T/9v/4//b/9//2//b/9f/w//L/8v/0//X/9v/2//f/9f/6//7/+v/4//H/9f/1//T/9//3//7/AAD4//X/9v/4//z/+f/3//j/+f/5//j/+P/4//j//f/8//z////9/wIAAAABAAIAAgD8//r/+f/y//n/9v/8//v/+/8AAPz/AAAAAPz/AAD9//X/+//0//j//f/4//3/+v/7//v//P/7//v///8DAAQACwAMAAkACwAAAAAAAAABAAUAAwAEAAAABAACAAMACgAGAAYABgAEAAMABgAEAAgACAAGAAYAAwAGAAUADAAJAAsADwANABIACwANAAgAAwAFAAEAAAD///z//v8BAAAABAAGAAgADAANAA4ACQAGAAIAAAAAAP7/AQABAAAABgAAAAEA/////wgAAQAIAAUABwALAAIAAAD8//j/+//5//T/9//y//z//f/4//7//v8FAAkACQAIAAsAAAABAPz/+v/9//X//P/0//7/AwACAAoAAwAJAAoACAAMAAcABwAHAAgACQAEAAIA/v8AAAEAAAACAAMACQALAAgABwACAAMABgADAAcAAgD/////+/8AAAAAAAD/////AAAEAAYAAgADAAAAAwACAAEAAgAAAAAA/f/8//r//f/8//3//f/+/wYABQAFAAIAAgADAAAABAABAAAA+//1//f/8v/x/+v/7//x//L/9P/r//X/9f/6//z/+f/8//j/9v/t/+7/7f/x//b/7P/w/+7/8//5//T/+f/5//z//P/7//z//v/9//z//P/2//j/+P/5//r/+P/5//f/+//7//7/AAD8/wUAAAAEAAYAAAALAAMACAAAAP7/BAAAAAcACgAHAAQAAAD//wkACQAKAAcAAwAJAAwAEAANAA8ACQAJAAQAAQAGAAQACAAFAAcACwAJAAoACQAHAAoACgAIAAkAAwADAAMAAAADAAEAAgABAAMAAQADAAEABAAKAAgADgAGAAoADAADAAoAAgACAAkAAAAAAAIA/v8HAAUAAQAFAAAAAwD///3/AAD//wEA/////wAAAAAAAP//AAAAAAUABgABAAUAAgAAAAMA/P/9////+v/+//n/9v/6//j/+//5//j/+v/8////AAD/////AAD8//z////6//7/+//3//z/+f/7//r/+f/5/wAAAAD8//z/9v/6//r/9f/2//n/+f/7//X/8v/2//b/+f/2//j/AAAAAAQAAQABAAgABgAJAAYACQAHAAgAAwD//wUAAQAGAAMAAwADAAAABQADAAUABAAEAAMAAwAEAAMAAwD9////AAAAAAIAAAAAAAEAAgABAP///v/9/wQABgAAAAIA+f/5/wAA+/8BAPj/9v////n/AgD8//n/AAD6/wAA///+/////v/9////AAD9////AAAAAP7///8AAP///v/3//n/+v/7//v/+v/6//f//P8CAAIABAAAAP3/AAD//////P/0//r//f8AAAYAAQAMAA8AFQAfABsAIAAUAAcACQADAAMA9v/q/+P/6P/4/wIABwD6/wIAEgAfABIAAQALAA0AFQD///f/+v/u/+7/7/8AAP3/9v/6/wAABgD//wUADgASAAsACQAJAAMA///6//3//P/3//H/7//w//X/9//5//n//f8IAAcACgALAAkAEQAMAAoACgABAAIA///+//3/9//+/wEAAQAAAAIABwANAAQACAAOAAoACQD9///////9//z/9v/3//X/+P/6//3/+//7////AAAFAAMABgADAAIAAgADAAQAAgADAP3////7//z/+//5//z//P////z//f/9//7//v/9/wAA/f/9//n/+v/6//f/+//6//v/9//1//3/+v/7//r//P8EAP7//f/9////BQAAAAAAAQAAAAUABwAEAAcABwAMABAACwAKAAoACgAHAAMA//8DAAAAAAABAP7/AQAAAP7/AAAAAAAAAAD6//z//f////7/+//+//3/AAD+/wAAAQAAAAAA//8AAAAA///9//n/+v/9//n//P/6//z/AgD9////+f/6//z/+//+//3/AAAAAAAAAAACAAEAAwACAAMACQADAAcAAQAEAAMA/f8EAAAACAAHAAIABgACAAQABQAEAAcABAACAAAA/f/9//z//f8BAAEAAAAAAP3///8BAP7////7//3/AAAAAAIAAAD9/wAA/f///wAA//8CAAAAAAAAAP//AAAAAAAAAAABAAIAAgACAAIAAgADAAIAAAAEAAIAAwAAAP3/AQAAAAcABQACAAQAAAACAAMAAAD//wAA/v///wEAAAAAAAEAAAACAAEAAAD///3//f////7/+v/6//v//v/4//n/9v/3//3/+f/9/wAA/P8AAP7/+v/5//T/+//4//r/+P/z//r/+//+/wMA//8BAAIA//8FAPz/AAAAAP3/AAD3//v/+//4//f/+f/4//7//v/3//3/9v/9//3/+P/3//T/9//2//L/8//z//D/9f/x//z//P/5//3/+P8AAAAAAAAAAAAAAwABAAEAAAD//wEAAAAAAAAAAAAAAAEAAAAAAAEAAAAIAAMABQAGAAQACgAIAAoACAAIAAgACQAJAAkACAAIAA0ACAAKAAgABQAIAAYABgAIAAcABwAFAAUAAwAEAAUAAgAIAAIAAwAAAAAAAgAAAAUAAAAGAAUABAAFAAcACgAEAAcAAwAKAAgAAgAEAAMAAgAAAAEA//8FAAMAAwAEAAEABAD//wAA+v///wEAAAD8//v//P/5////9P///wAA//8CAPz/+//7//z/+P/5//X//P8AAPz//v///wsABAAEAAEAAgAHAPr////3/wUA/v/+/wIA/f8IAPr/AQAAAP7/AQD8/wMA///9/wEA/f8DAP3/AgACAP7/AAD9/wMAAAADAAAAAAAEAAEAAAD+//3/AgACAAQAAgABAAQAAAADAP7//////////f///wAA+/8AAPn/AAD7//3/AQD8/wAA/P8AAAQA/v8AAAEAAgAHAAEABQAGAAcACgAGAAgABwAFAAYABAAAAAEA/P8AAP//+/////v/AAD+/wEAAgAAAAIAAAABAAAAAAAAAP7/AAD9//v//f/9/////f/9//7///////3//f/+/////v/+//7////+//7//v/+//7//v/+//3////8///////6/wAA/P8AAAAA/v8FAAEABQADAAEABgACAAMAAgD+/wMA//8AAAAA/P8EAAAAAwACAP//BAACAAYABQAFAAYABAAFAAYACAAKAAoACAAMAAoADQANAAsADQALAAwACgAIAAYACQAFAAgAAgACAAUAAAAFAAEAAAADAAAAAAAAAPz/AAD+//7//v/6//3/+//9//z/+//7//3//P/7//z/9//6//v/+v/9//n/9//7//n/+v/6//n/+//7//z/+v/7//v//P/9//3//v/5//z/+f/6//v/+v/4//j/9P/y//j/8f/1//P/8P/y/+7/8P/y//L/8v/y/+7/8v/w//T/9//0//f/9//1//r/+P/2/wAA9//+//3/+/8AAPv//P/8/wAA//8EAAAAAgAEAAIACQACAAgABgAGAAoABAAFAAUAAgAEAAMAAgADAAQAAwADAAYABAAHAAYACgAJAA0ACwAJAA0ABQAKAAUABgAFAAIAAwAAAAMAAQABAAAAAAAAAAAA/P/8//7//P/+//z//f/9/wAA/v///wEAAgAHAAcABwAHAAgABQAHAAUAAwAEAAIAAgABAAYABAAEAAQAAwAIAAkACQAIAAkABwAHAAUAAwAIAAQABQAAAAAABAAAAAYAAgAGAAgABAAGAAQABQAEAAQAAQADAAAA/P8CAPz/BAADAAAABgAAAAsABwAJAAwABwAOAAoACwAJAAoABAAFAAAAAQAFAP//AgD6//7//P/8//n/9f/7//j/+f/3//f/+f/+//v/+P/8//j//P/6//X/+f/2//j/9f/2//b/9//6//T/9//3//n/+P/6//n/+v////r//P/6//v//f/9//v/+//9//7//v/+/wAAAAAFAAMAAgAFAAUABQAGAAQAAwAKAAMABAAAAP7/AgAAAAAAAAAAAAEAAAAAAAAA+v8EAP////8DAPn/AQD8//3/AAAAAAAAAAABAAIABQACAAUAAwAHAAkAAgALAAQAAwAIAPz/AgABAP7/AgD+/wEAAAABAAAAAAAEAAAABQABAAMAAwABAAUA/P8DAAAAAAAHAAAAAwADAAEAAgACAAEAAgADAAEAAQACAAIA/v8BAP//AQAFAAAAAwABAAMAAgAEAAIAAgACAAIAAQABAAIA/v8CAAEAAAACAAEAAQAGAAUAAAAIAP//AAADAPz/AQD7//3/+P/5//n/9P/6//P/9f/3//X/+f/3//n/+v/7//3//P/+/////v/8//7/9f/5//n/8v/7//T/9v/6//X/+v/7//r/AQD+/wMAAwACAAcAAgAFAAUABQAGAAUAAAADAAIAAQACAAEAAgACAAgAAgAJAAcAAwAJAAMABwAHAAUABAAFAAIAAwACAP//AgD+/wIAAAABAAEAAgACAAEABQAAAAQA/v////7/+v/7//b/9f/1//T/8f/2//P/+f/6//b//P/3//z//f/6//3/+//+////+//+//3//f8AAPz///8BAPr/AQD+/wAABQD//wIAAAAAAAEAAAAAAP///v/+//7//f/9//3//f/+//z//v/9//7//////wIAAAAAAAAAAAAAAAAA//8AAAAAAAAAAAAAAQAAAAAAAAAAAAMAAAAAAAAA/v8AAP7//P/+////AAAAAP//AAAAAAEABAACAAQAAwAFAAMABAADAP//BAD//wEAAAD+/wEA//8BAAIAAQADAAMAAwAEAAMAAwADAAMAAgAAAAEAAQAAAP//AAD+/wAAAAD//wIAAwACAAMAAgACAAYAAgADAAEAAAAEAPz/AAD9//7/BAD//wEAAQADAAgACQAFAAkABwAIAAoAAwAIAAUABQAEAAAAAgABAAQAAwACAAQAAwAFAAMABAAEAAQAAgADAAEAAQACAP3/AQD8/wAA///7/wAA+v8AAP3/+f/8//f/9//6//f/+f/7//f/+v/5//j//P/8////AQAAAAMABAACAAkAAwAGAAsABAAKAAgABgAIAAUABwAIAAgACgAJAAoACwAMAA0ACgAJAAkABAACAP///f/9//r/+f/z//j/9//3//n/9v/7//r//P/6//z////+/wAA/P/9//7//P/6//f/+v/5//n//P/2//z//f/5//3/+v/+//7////9//3/AAD//wAAAAAAAAAABAD+/wAAAAAAAAEAAAAAAAAAAQD+/wEA/v8BAPz//f8BAPj/AgD8//3/AgD7//7////7/wAAAAD8/wAA+/8AAP///v8AAP7/AQAAAAAA//8AAP7//v/+//r//f/8//z//P/9//z//v////z/AQAAAAAAAgD+/wAAAAADAAAAAAAAAP//AAD///7//v8AAPz/AAD+//7/AAAAAP////8AAP7/AgAAAAAAAAAAAAAAAAAAAAAAAQAAAAEAAQADAAQABAADAAUAAAAEAAMAAAAEAAAAAgACAAAAAQACAAIAAgACAAIAAgABAAIA/f8BAP///P8AAPn//v/+//v//v/8//////8AAAAAAAADAAEAAgAAAAIAAQAAAAAA+//9//3/+P/7//n/+P8AAPr//v8AAP7/AwAAAAEABAADAAYAAAACAAUAAAAEAAAAAAABAAAAAAD+/wAA//8AAAEAAAAAAAUAAQAHAAcABQAMAAoADQANAAwACwALAAoABwAIAAYABgACAAIAAAAAAAIA//8CAAAABgACAAUABAACAAkA/v8EAP///v8CAPr//v/7//z//v/8//7/AAABAAIAAAAAAAAAAAD+//7/+P/5//n/8//5//L/+P/5//j/AAD+/wQABAAHAAoACgAMAAcACwADAAUAAQD8////9f/+//X/+f/5//b//v/4/wAA/P8AAP///P8AAPn/+v/3//L/8//v/+v/7v/o/+3/7f/r//P/8P/3//n/+v8AAP7/AgADAAEABQACAAQAAgACAAIAAQAEAAEACAAEAAYACwAHABAACgAQAA0ADAARAAYADwAEAAYABQAAAAEA/P////j//f/5//n//P/4//z/+v/6//v/+f/6//r/+v/8//r/+f/7//r//v/+//7/AQAAAAMABAADAAUABwAKAAsADwAPABMAFAARABkAEQAaABUAEwAYAA4AFQAMAAwACQAJAAcABwAIAAIACgACAAQAAgD//wIA+//9//T/8v/w/+n/7P/k/+j/6v/l/+r/6P/p//P/8P/4//r/+v8CAP3/BQABAAMABwADAAkABgAIAAoACQAIAAsACAAMAA4ACQAPAAsADQANAAsADAANAAwACwAOAAkADQAIAAgACQAFAAkAAQAEAAAA///+//n/+//1//n/9f/2//b/8v/3//T/+P/3//f/+//5//v/+v/6//z//P/8//3/+//9//7//v8BAAAAAQACAAIABQACAAQAAQABAAEA/P/+//n/+P/6//X/9//5//f//P/8/wAAAgADAAcABgALAAcACQAGAAQABQAAAAIA///+/wAA/f8BAAEAAQAFAAQABQAFAAgAAwAHAAIAAAABAPr//v/3//j/9v/5//r/+///////BQADAAkACQAMAAwACQAMAAgABAAEAP7//v/9//j/+f/4//f/+//6//v/AAD//wEAAgAAAAMAAAAAAP3//P/8//j/+f/2//f/9//6//r//f8AAAAABwAFAAgACwAIAAwACQAJAAcABwAEAAUAAAABAAIA//8FAAAAAgAHAAEACAAEAAQABgABAAIA/P8AAPj//P/5//X/+//0//3/9//8////+/8EAP3/AAAEAPr/AQD6//j//v/z//v/9P/5//v/+/8CAAAACQAIAA4ADgARABIAEAARAAoACwAEAAEA/f/6//j/9P/0//D/8//0//X/9f/3//j/+v/6//n/+//7//n/+P/3//f/+f/2//j/+P/7//7//f8BAAEAAQAFAAQAAAAGAAEABAAEAP7/BAABAAMABAAEAAgACQALAAsACgAMAAwACQAFAAUAAgD//wAA9//6//n/9v/7//f/+/8AAP////8CAAEABAACAAEAAQAAAAAA/f/9//n//f/+//7//////wUABQAJAAwACwAOABAADgAOABAADAAMAAkABQAEAAMAAAD+/wAA/f8CAAAAAAACAAIABgAAAAQAAAADAAAA///8//n/+v/0//f/8v/0//b/9P/2//r/+v8AAP//AQAFAAIACAAEAAMABQAAAAAAAAD4//7/+P/5//n/9P/8//b////+//z/BAAAAAUABwABAAkAAwAFAAUAAAACAP7/AAD8//z//P/8//3/+//9//z//f////v//v////z//v/5//z//P/7//v//P/8//7/AAD+/wIAAAAFAAEAAwAEAAMABQACAAUAAgAFAAMAAwAEAAQABQAEAAQAAwAGAAEAAwAAAP//AAD4//z/9v/5//j/9//6//n/AAAAAAMABQAKAAwADwAPAA4AEgANAAwACAAGAAQAAAAAAPv//P/9//r////+/wEABAAGAAkABwALAAcACwAJAAIABAD9/wAA+f/1//f/8v/z//X/8v/4//v//P8BAP//BQAHAAkACAAJAAoACQAGAAIAAwAAAAQA///+/wAAAAADAAAAAgAFAAkACAAGAAkACQALAAUABQABAAUAAgD+////+v8BAPz//P/+//7/AAAAAPz/AAD///7/AAD2////9//3//b/7//3//L/9f/1//P/+v/4//v//v/9/wIAAAACAAIAAQAEAAAAAAACAP7/AgAAAAAABwABAAYACAAGAAwADAAKAA4ACwALAAsABgAHAAQABAABAP///P/9//n/+v/5//T//P/1//b/+P/y//f/9v/1//b/9//6//3//f/+/wAAAwAGAAYABQAJAAcACQAHAAAABwAAAAMAAAD+/wAAAQAEAPz/BwACAAoACAADAAkABwALAAMABQABAAQAAgD//wAA/f8EAP//AAAAAAAABwACAAAAAwD+/wAA/P/2//j/8f/1//D/7f/y/+z/9P/x//H/+v/1//z//P/9/wAAAAACAAAAAgABAAEAAwAEAAMABgAIAAgADwAJAA4ADgALABIACAAOAAkACQAMAAIACAAFAAUABwADAAcACAAEAAoABAAEAAYA/f8AAPb/+P/z/+7/7f/o/+//6P/x/+v/8f/4//L//v/4/wAAAAD9/wAA/f8AAPz/+//9//n/AQD9/wAABgAFAA0ADAAOABQAEAASAA4ACQAPAAIABgD///v//f/2//n/9f/6//n//v///wAAAgADAAQAAAAAAP///v/3//n/9P/1//X/8f/2//b/+P/8//z/AAABAAEABgAFAAUAAgACAP7////9//f//v/9/wAAAgABAAUACwAIAAsACQALAA4ABQAKAAAAAQAAAPf/9//0//j/9v/8//r//v8EAAEABQACAAIAAgAFAP3//f/9//r//f/y//j/9v/9//3//P8CAAIACwAJAAkACQANAAoACAAFAAIABAAAAP///P/9//z//P/+//n//f/9///////+//3/AAACAP7/AAD+/wEAAAACAP7/AAAEAP//AAD7////+/////n/+f////v/AAD//wQAAgALAAkACgANAAcADgAIAAgAAAADAAAA/f8AAPj/AQACAAMABwAGAA8AEQASABEAEAATAAwACAADAPv/+f/0/+7/7P/s/+7/8P/1//P/+v8BAAIACAAJAAkADQAMAAMABAD9//3/+P/0//X/8f/6//X/+v8AAAEACgALAAsADwAQAA0ADAAHAAMAAAD+//n/9v/0//P/9v/3//j///8AAAYABQAEAA4ABwANAAQABgAGAP3////z//r/8v/0//f/8f/6//v//v8AAAIAAgAKAAIACAAJAAEACwD8/wAA///5////9P/+//r//v8AAAEABwADAA0ABgAJAAkABwANAAAAAAAAAP7/AAD6//z//P/5//v//P/+/wsAEQAJAA8ACQALAAwA+f8AAAAA+f/3//L/+v/0//D/7v/2//3/AAAIAAkAEgASABUAFgAOAAoAAwACAAIAAAD4//P/8f/0//v/9f8DAAoAAAAKAAgABwAHAA4ACwAAAP7/+////+//7f/q/+r/7P/r//j/+v8AAAcAAAAHAAkAAwAKAAUAAwAHAPz//f/9//v/AgD6//n//v/+/wMA+/8IAAgA/v8MAAAACgAKAAYAAwD4/wMAAQAMAAAA9/8CAPv/+v/w//P/9v/3//X/7//z/+3/9P/0//H/9f/5//f/8P/+////8v/v/+3/8f/9//v/+v8HAAsADgANAAUABwAbABAACgATAAsAFQAZAAgAFAAfABMAIgAQABoAAAAVAAkACwD+/wcAHADl/z4AuP9IAK7/Ef/7/8D/cQBdADkAwP82/43/vP8lAA8AMAAcANH/6v/Z/+z/9v8JADsALQASAAkAKAAWAPz/FAAMAAgA9f/5/wcAEQARAAQAGQAKAA0AGgAdACIAMAAXAPz/BwAAAAEACgANAP3////o/+j/+//8/xEADgABAPv/AQD1/wIADQAAAPj////w/+j/8P/e/9//5P/9/+H/EwDm/woA3f+2/tMA9wFn/oT+ZwJvAI79rgCKAf/+Yv++AGwAqP9c/0UA8gB5/1b/8ABMAHr/KwB5ABcA1f8lAEgA+v/M/xYANgDY/9T/LwAdAKT/4P86AOX/wP8FABEA1//t/wwA8//p//b//P/3//3/8//t//X/8P/o/+3//v/x/+3/BQD6//b/BwASAA8ABwALAAYABQAFAPz/AwAGAP3/CgASAA4ADQAMAA8AEgAJABEAHAAMAAMACQAMAPf/8v/8//n/7v/u/wEA///2//n///8EAP///f/5/+3/8v/2//L/7P/2//b/7//x//L/7P/m/wAA/P/9/wUA/f/9//v//P/3//f/AAAFAAoADQALABYADgANABYAKgAPACEACADS/y0A+//v/xoABAAJAPr/CAD8//n/9/8KACYACgAHABYACgD1//3/+f/o/+b/3f/k/+z/5f/q/+n/7P/y//X//v8AAAkABwANABQAEAARAAkAAgD6//7//f/4//3/DgALAPr/CAAUABUAEQAZABEABwAFAAEAFAASAA4ADAADAAEA+f/7//r///8GAAAABAAMAAQA+f/5//j/7P/t/+3/6v/y//L/9f////n//f8BAAMABgD+/w0ACQD//wsABwD7//z/BAD+//b/9v/+//v/AAALABUAHQAVAAsABwAHAAYADwAEAAYACAD4//H/7f/9//X/7//9/wQAAQD1/wsACwAAAP7/+P8HAAEA+/8DAPv/7//+/wUABwADAP//BwD3//3/DAANAAAA+P8AAP7//P8CAAoABAAGAAUABQAHAAQACgD9//T/9v/0//r/7//t//H/6//4//z/AQAIAA0ABwAAABUADgAJAAQA/P8JAPT/7P/y/+z/7P/v//v/BgAFAAQAEAAIAAwAEAAMAAsAAQAEAP3/7v/p/+D/3P/b/+D/8//4//j//P8EAAIADwAeABsAJgAeAA4ADgAJAAAA/P/7//7/+v/2/wAAAAAFABEACAAOABAABwAPAAYAAADv/+3/7v/d/+T/3//g/+//8v/t//3/DwAaABsAFgAcABIABgD9//P/8P/t//f/8f/v//n/+f////r/BwAPABUAIgAqACIAFwAVAP///v/5/+//5v/p//j/+v/4//r/AQADAAYADgARAA0AGwATABkAGgABAPr//f8AAPT/8v/x/+7/7f/w//n/8v/2/wAA+//4/wAABgAHAP7//v8HAP7///8BAPf/9f/u/+j/9v8BAAEADAAMAA4ADgANABYAGAAnAB4ADwAGAAEAEQAIAPn/+f/w//H//v/0//H/8v/5/wEAAwABAAUABQAAAAwACwAEAPr/AAD9//P/9f/9//7/5//s//r/8v/m//D/BQAIAP//AgAGABAAFQAGAAMABQD//+z/7f/y/+v/9f/x//3/CwAUABkAKAAoACcAMQASACsA+//n/xkA9f/M/73/5v/W/7z/5P8GAP//9/8kADkAFQAGABwAGgDz/9n/8P/m/7r/s//R/8//xv/i////DgASACsAQgA4ADIANQAwAB4ADAD6/+f/4v/g/9n/z//X/9T/2v/v/wUAGgAcACIAKQA1ACgAIgAcAAsA+//1//j/7P/1//D/5//o/+3/AAACAAEAIAAeAAQADwAGAAAAAADy//H/4v/W/97/4v/j/+H/8f/7/wAAGgAlAA8ACQAMAP//AQD8//T/+f/w//r/CwACAAUABwALABgAJAAzACcAHAAXAAQAAADx//3/AADm/9//3//z//v//v8NABYAHwAoACQAKgArABQA/P/8/wAA7f/q/+j/6v/c/9D/5//+//j/+P8NAPv/+v8DAA4AEAAHAAYA+v/2//H//f/6//X//v8EAAoACQAXABcAEgAWABsAHwASAAAAAgAEAPH/7v8LAAQA9f8FAAAAAAAAAAsADQD2//z/DAAGAPr//v/+//f/5//g//P/9v8AABcAGwAVABgAGgAIAPn/8//1//P/6v/l/+D/2f/Z/9H/2P/8/wQAAgANABsAIAAiACgAJgAdAAQA/P/2/+f/4v/w/wYAAAADABAACwAIABUAGgAlACYAHgAWAAQABQDw/+j/3v/d/+z/3//o//P/BgANAAAABAD5/+z/8v/4//X/6v/n/+n/8P/u/+b/7f/6/wMAAAATACEAJAAkAAgABgAJAPf//P////H/AAAAAAYADgAHABAAEwAXABkAHQALAPz/AQAEAPT/4f/s//D/3//e/wAADgASABcAHQAfABoAHQAPAAAA+f/0/+j/5//o/+L/3v/m/+7/6f/x/wUAHwAVABkAFgAIAAQA9f/y/9T/1f/f/9//8P/2//T/8/8NACgAPgBBADkAMQArACEAEAD6/+D/0//Q/9T/xv/b/+n/9P8SAA8AIgAoADEANgAZAA4AEQADAO3/7f/w/83/wf/c/+n/8P8DADIAPAA4AD4ANgArABQA9v/s//L/3f/e/9v/1f/M/7//4v/5/wcACwAPACMAGQASAAgA+//3/+H/5P/x/+z/7P/3/w8ADQAUACQAGQATABgAGQALAPv/5v/g/+X/9P8AAPr/+f/6/w4AGAASAB0AMQArABoADgD8//z/5//k//r/+f/0/+r/+v8FAAcAAwACAAoAEAACAPf//P/1//L/4f/h//T/BAD2/+f/DgAWAPv/+/8SABUABQD//wQA/P/m/9f/3//q/+j/AQAOABYAFQARACYAIAAlACkAIQAUAPv/9//2/+f/3f/d/+b/6P/l//b/AgAEAAYA/v///wkABQAIABQAEwD9//H/+f/2//n/8//1/wIAAAD6/wAADAAMAAMA+P/4/+//7f/+/woAFAANAA8AEAANABMAGAAkAAwA/P8AAPL/8f/j/+X/6f/g/+//9f/4//r/CwAiACAAIwAiABYADwAHAAkABwDy//D/7f/q/9n/zv/h/+b/+P8BAAQAEwAPAAIADAAQABgAHgANABMAFgAIAO7/6//w/+//9v///woADwABAPH/AADx/+//AwAGABUACgAaABsA/P/6//H/5P/Y/+7/BQD6//D//f/9/+X/3f/q//v/CwAVAAoAHAAeAAsAAgD4//X/8f/6/+b/5//x/+r/3//m/wAA9v8CACEAKgAnACcAMwA8ADkAMQA/AFAAPgA1ADkAIgATABMAIgAbAAQABwACAPX/7v/q/+v/5P/O/8T/y//H/7b/uv/C/8X/zP/c//P/AgAIAAAACgACAAYADQD9/wgAJgBDAD4ASABPAEkAUgBhAGoAUABMAFYAUwA/AC4ANwApADIAMwA5AEAAOQBDAEkAUwAzADkAPgAkAAAA8v8PABUAPwBKACoAIwBCADgAFgDw/+3/4P/B/7z/lv82AET+o/gt9337r/2g++76J/2C/vP9zP28/oT/FQDRAaQDZQMiApMCJgQYBLoCMgLwAh8DXgI6AlcCgQHKADkBXwGjAEkAbgA4ACUAggBdAJv/TP+0/8L/av9c/0v/CP/j/u/+0f6V/pX+sf7a/hz/XP+W/wgAiQDNANwAxgDQAOYACQE9AQUB6wDWAFEARgAPADj/jP+nAIwA1/+z/7X/fv+P//H/DgAXAHcApQCKAF8AWgCnANEAhgA2AHUA2P9p/kX+Fv/u/uv9G/7h/pH+FP5D/pD+0/42/43/zf/h/xMAnQDrAIIAIgB+APcAnAD//0cAlQBbAFYAigB4AD8AfgDTAKwAcACbALIAewBZAAYArf+K/3z/pv+s/4X/Yv+B/87/vv95/6b/GgD//87/FgA9AO3/2f88AFAA+f/x/0kAWwBNAGcAtQCvAG4AfgB6AG8AiACmAH8AOgAUAC4ARQAEAOT/DwBeAFkAFwAzAGAAJgD+/xIA4/+h/83/BQDB/4n/qf+q/4j/p//g/9j/pv+U/+v/UQBMANv/mv+H/x3/Av/j/x0A1f5N/lv/MADP/5r/6v/+/+//2//j/+P/DABHAIQAlABMAAUAqP8//9T+1v5b/3j/Mf91/xYA6/93/7j/HAAmAFwAzQCtAGcApwC5ADoA9f/n/5j/hP/E/57/Mv9i/8v/yf+3//L/SQCoAOwA6wDLALUAmgBsAHIAkQBtAGMApACLACwAKgBkACkA0f/m/+//1f/Z/wUAFADh/+H/HAAzACEAEgA1AFcAHgD2/ywALwAAAP7/KwBCAB0AOQBjAE8APgA8AFoAegBxAGgAZQBbADoACAD4/wcABADq/+r/AAANAAwA8P/h/wAADwDq/8r/z//T/7r/pP/G/9T/uv/E/+z/BQDc/9z/JQBAAAAA1/8KAB4A9P/k/w0ABQDX//j/PwBhAEwAOAA2ACoAKwAgADgAWwBkAEkACgD+/+7/5f/p/xsADQCZ/nv9bv6Q/3L//f4d/47/4f/9/5b/LP+d/ywAKwAEAOf/0/8uAJ4AdgBDAGYAaQAYACoAhgA6AOj/QABrAAAA1/8bABwA1P+z/7T/n/+S/6v/uP+n/4T/jv/d/+7/hf9R/4L/mP+T/7v/5P/O/+D/KQBNAGIAcgCJAJwAiwBsAFIAagBwACEA/f8xAH4AlgBxAFYAKwAjAEwAaABkACwA/f/3/xIA+P+j/6P/5P8BAAMA8f/Y/8b/w//O/7n/r/+1/7j/1//+//H/u//X/xoAFgDu/+f/AgAnAEwAPwA3AGIAgQB6AEYAHAAjAF4AXgAeAB4ATgBdACQA//8MADoAWQAnAOT/x//n//H/v/+e/7n/6f8LAB8A9f/V//L/FwD6/7L/wP/v/9//x//D/9H/5v/2/xIAHgAtADQAKwAuAHkAvwCSAHYAjQB6AFoAPwA2ACoA4P/N//n/IAAFAL//0P8QACwAAgDV/7r/sP/A/8r/tf+N/6j/2f/a//T/KwBJADYAFwAdACYAJwATAOL/rv+X/6j/pf+1/83/xf/g/xEAIAAZADAAUgBVACMA7//R/63/iP94/3r/fv+L/4v/jP+n/77/1/8FACYAQwBKACYADwAUACUA9/+x/7X/0//p//n/HgA0AB4AIQBEAFcAQgA0AEcAQgAZAAwAIwA+ACYABgAgAEcATAAaAO//y/+6/73/zv/Y/73/vf/I/9f/6/8FABYAEgAiACcACQDy/+z/z/+q/7f/6/8AAA8AMgA0ADYAVgB1AGkATgA7ADEADQDZ/+D/7//M/6P/pv++/9L/6/8OABcAEQATABYAAwD0/wEA6v/H/6r/qv+c/4H/kf+6/wAANABaAHgAegBwAFgAOgD9/8P/qP9q/0b/YP91/3//t/8xAGoAWgB0AHkAWAA8ACsABADK/6n/lP+i/7j/y//C/7//7P8aAB4AIwBXAFcALQASABcAJAAkACoAIQAPAB4AOgBFADYACAABAAgAAgAGAAwA/v/G/6P/r/+v/63/tf/I/+b/9f8UADsAXwB6AHMAZwBfAFQARAAuABQADgAvAEQAMQAVAAoANQBaAFwAQwAOAND/qP+g/4v/eP9r/5D/uv/N//v/EgAeAC8ASwBRABsA6P/l/wEAEAD+/93/2P/3/w8APgB5AI4AdgBAABYADAAWACwASABGACMAGAAWACQADgDL/6n/sf/T/87/3v/w/+n/3P/H/8D/lf9t/2//ff+C/47/wf/9/yoALgAmABMA8f8CACUAPwBDADsAKwAlADwATgBlAHcAfACJAHYASAA1ACEABwDj/9n/9v8cAEIAWABPAB4ACwAUAAIA3P+4/6v/lf9t/1v/R/8q/zz/dP+1/9r/9v8yAE8AXgBhAEgALgAHAPf/+f/p/+f/AgAeAC0ANQBdAIYAhgBSACAAEAD6/9z/l/9T/zT/Q/9l/4D/sP/V//P/BgAKAAoAAQAJAAAA3v+2/6P/tv+0/8H/zf/t/xsAMwBsAJkAowCZAI8AbwBBAC4ADQDj/7z/rf+w/7D/vP+t/7f/4v8VAEoAVgBQADkAPAA+ABgA5f+y/5z/mP+h/8r/3//1/yMAPQBfAGMAbwCEAGwASgAbAA8ADwAWADIANQAvABQACAAkACIAIwAxAC8AJwD3/9H/0//H/8L/1P/U/9v/vv+t/87/2f/3/wkAIQA8ADwARgBCAAoAwv+V/4n/lv/H/woARwB0AIYAdQBXAFIAQgA7ABAAxf+K/37/nP+Q/4v/h/+U/8X/8/8rAEAANwA4ACYAEwAKAAsADgD2/9D/uv+8/8v/7/8wAF8AbAByAH0AgQBnAFUAMwD3/8z/rv+t/5f/fP+G/4r/qv/H//H/GgA7AGgAawBYACoAFgDw/yEAT//b/N/8mv50/+MAiwLtAm4C5AEtAbcAKgA1/4j+0/2A/fz9hf7E/nH/fgATAXgBBQIbApEB3QAVADf/o/6p/s3+6P4L/z3/zv+CAPwARAFcAS8B1gCSAGcAGgCl/zb/Hf9M/4D/pP/F/9f/+P8qAEUAZAByAIQAlACZAIQAfwB/AEsAEwDD/3//Wv9e/3z/qf/c/yAAewC6AOkA9gDhAJsAPwDh/3L/G/8C/yz/dP++/xkAggDNAOYA1wC2AHQAIADR/5z/ZP9T/2f/eP+h/8b/AwA8AH8AnACPAG4ALwDp/6L/hv9m/27/bv9m/3P/fP+p/8T/1f/Y/9z/DgBXAH8AigB8AFAAHQDY/5D/XP9H/0X/V/95/6j/2P8DAEYAfACEAGMAQgA2ACUA/v/Q/8H/yf/e//D/DAAjACsAKwAvACwAHQASAOr/tv+K/3//kP+p/7//2v8aAFAAZQBXADYAKgAkADcATwBMAEoAQABHAEoAQABJAF4AagBfAEQAFgDx/93/2P/W/8H/oP9v/2P/df+E/5//ov+4/+T/8P/8/xcAOABQAF8AVQA5ADAAIgAPAP7/AwAdACQAIAARABwADwAKABMADQAiAAcA8//d/8H/s/+w/9L/7v8LAA8ACgABAAYAIAA1AEsAPQBAADQAFgALAAAACgAYACAACgALABMAGQAtADEAJQAMAP//6f/h/9n/3//b/8v/xv/P/+P/4//z/xEANwA3ACwANwBAAE4AVQBeAFsANwALAPT/2/+//8f/5P/w//L/4//c/+T/0P/I/9r/5f/a/8v/0f/O/8v/3//r/+//6v/f/+H/3//n/97/yf++/6f/s/++/9L/7P/x/wkADgAdADAAQABSAE4ALAAEAOr/zP+//7j/z//v/w0AJQA4AEcATgBnAGsAbgBcACIA3/+j/5L/jv+Q/7L/5v8HAA4AAAD5/xMAMQA8ADkAIQAHAP//DgAMAOj/zP/A/8P/zv/s/yYAVgBnAGoAWwBSAEcAUwBrAF8AOAASAOz/zv/e/wcAMQAkABsAOgBlAGYAVwBRACMA+f/N/8H/sf+W/6L/wv/o//b/AgAZADgAPQA0AD8AJgD1/63/b/9V/z7/Uv+F/8z/9v8hAEkATQBfAHEAkwCNAH8AaQAuAOP/nP+A/3//kP+g/7D/wP/H/9n/8P8IAC8ATgBPACoAAgDy/9D/pv+J/3r/gf+U/7b/5f/4/xIAKgArACsAFQAiAB4ABwD8/9//2v/a/+H/AQAIAAcAGwAkACYAFgApAC0AIQAqACMAGgDr/+D/9P/6/+//9f8PACAALgApADAAIgANABwACgDg/+b/+//m/8r/z//z/wcAEQAgAC8AUgBrAIsAmwCBAFIAKAAXAO3/1v/t//3/BADz/+n/7f/a/9P/1f/a/93/1P/O/8H/uf+f/6L/qP+p/8r/6P8VABgAGwAKAAIAAwAXAC0Ajf5h/Q7/gQCEAMMAZAF+AZsARABHAfQAcv+W/9z/vv5b/jT/ev88/8D/eQC3AAYBjwG7ASUBbgALAKn/Pf/7/vn+3f7T/iT/nf8CAF0ArwDGALkAmwCKAHIATgAJAND/wv+s/8f/3P/d//L/EAAaADwAfQCmALEApgC1AKAAfwBdABoA4P+t/5v/mf+a/6L/xP/m/wAAHwBFAFwASQAwAPn/vP9+/1T/T/9c/4X/qP/M//v/MABkAIgAkACTAHsAVgBAAB8A9//C/57/l/+X/7z/6f8FAB4AJwAfAB0AJwAOAPb/zf+y/67/nf+c/57/uv+7/7r/xf/I/8f/wf/D/7b/u//E/9j/6v/u/wAAAgALAAQA/v8cABsABwD3/+r/3//T/9L/0P/Z/+r/AAAGAAMA/v/7/xMAHQAlADcAKwAaAAUA8//3//n/AwAUABMADAABAP7/CAAbADUAOwAtABcACgAGAP7/CAAsAFQAaABnAHUAdwBtAHgAYwBNADMAEQAQAAgAAQAbACEALwBIAEMARAAyACgAHwAKAPn/4//T/77/tf+c/5T/o/+w/7r/sP+4/9L/2P/s/wgAEgAfAAwAEQAfACwARwBCADcA/v/V/8H/y//y/wQAGwAYACAAIQArADcAMgA/ADIAMgAYAOr/2f/C/7//y//b/9v/4f8AABcAGAANAAoAEQA0ADAAGgARAPz/8//w//7/6//v/w8AEwAUABMAGAAfACAAFgAUAA4ACQAHABAACwDu/+D/3//v//b/AAD+//j/8//q/+f/2v/I/73/yP/b/+j/6f/w//7/BQAOABQAHAAjACMAFAD3/+n/2//U/+H/5P/q/+r/4v/j//v/CAATAA0A8f/m/8//wP+z/6r/t//A/7z/xP/X/+n/+v8GAA8ACwAGAPb/z/+r/67/wv/J/8//z//Y/+v//v8OABoAFgAFAPj/5P/k/+r/6f/r/+L/6v/k/9r/3f/o/w8AHAA2AE8AVgBfAE0ATwA/AC8ASwBYAEgAMwAgABoAHQADAPv/EAAOAAgAAAD4//X/8f/x//z/AgAAAAoADAAOABkAMABPAF0AawBwAGMAVwBMAEoAPwAsACgAGQAOAA0ABAAFAAcAEgAWABcAJgAeAB4AIwAgAB0ADQAJAP7/7//t/+X/0//J/83/yv/H/8n/xf+6/7L/v//Z/+3/BwAYABoADwAHAA8AGgAsACkAIgAtABkABAAGAPv/9P/t/9r/zv/E/7D/r//F/9r/4//9/wgA+f/+/wkAFwAAAOj/7v/p/9f/v//E/87/z//M/8T/w//B/9T/8f8MAB4AIQAxAEgATgBHADUAGQACAOX/1f/S/9H/3f/Y/+X/+f8GABIAFAAaABkADwD4//v//f/s/+H/1P/e//b/DwAcACYAKQAhACYAIgAQAAEA/f8HAAYA/f/y//T/+/8DACQAMgA5ADkAHAD5/87/yf/O/8v/0//K/+P/9P/4/wMABQARABQAGgAiACMAEQAAAP3/6v/M/6z/o/+Y/5j/vP/O/93/8////wgAHAApADUANAAxAC4AIQAoACAAIQAnACMAGwAXACAAHQAWAA4AFwAKAPX/7P/g//X/CQAbADEAMAAtACkAMAAtABMA+//g/8j/q/+b/5//of+g/6//x//a////IgBKAF8AZQBrAGMAZwBPAEgARwAyACwAJAAfABcAIQAbABsACgD3//3/AAAMAPn/4//X/9f/3v/h/97/2//q/+n/4//v//X/9v8FAAsABwD7/+7/4v/g/9z/2v/h/+f/AwAHAAUABgANAB4AKwAuACwALQAfACEAHwAXAAgA/P/r/9T/yf/F/8f/1f/f/9r/1v/W/9D/3v/0/wAABwD3//D/5//r/w8AJQAxADAALgAlABEACQADAAgAFwAWAAAA6//m/+j/5//a/9v/1//P/9b/2//h/+b/6f/6/xQAHQApACgAHQAXABQAGAAWABsAGQAUAAcAAgAKAAwAGQAmACkAJwAoACoAFQADAOz/yf/C/8L/vv+7/8v/0//M/+z/EgA3AEcASwBLADUAJwAUAAUA+//j/9P/zP/N/8X/zv/t//P/FAAyAEMAUQBIAEoAQAA5ADYAIgAUABAACAADAAIA/v8BAA4AEQASABwAFAAPAAEA9v/3/+X/6P/i/9//6//s/wIAEAAUACEAGQAbABoABwACAPr/5//Y/8b/vf/G/87/5f/1/wEADgACAAYACgABAAIA+f/8/+//1v/I/7n/wf/D/8T/vv+9/7r/uv/M/9P/1P/L/9j/6//8/xYAHQAeABEAEAApACgAKgA0ACsAEAD8//7///8AAAIADAASAA0ABAARACcAKQAnACkAMAAwACgAKAAcAP7/6//P/8r/w/+u/6z/pP+s/67/wP/U/+n/FQAjAEEAUwBQAFwASAA4ACQAFQAVAA0ACwD2//D/7f/p/wYAFAAkADQANgA5ADEAIwAdABYABwD3/+T/0P/F/8v/3//p//D/9f/k/+L/5//4/wgADAAIAPz//f/k/+L/8P///xUAHgAkAB0AGwAVABgAIQAkABoABQD+/+7/4f/u//X/BwAZACgARgBKAE8AQwA8ACsAFwAfAAcA7P/O/67/of+n/7z/1P/o/+///v8RABIAHQAmABcACAD8//H/6//f/+T/5//j//H/9v/6/wEAGQAmADEAMwApADoAMAAgABQADAAMAAQABgABAAAACQAMABUAGwARAAgA+f/r/+D/3P/T/7//x//E/77/vf+3/8P/xP/S/+X/8f8AAPv//f/6/wgACQAGABAA///1/+z/BAAKAA4AEQAVABwABgAPABAAHAARAAQABgD6//r/6//y//v/AAAPAAUAAgD4//T/7v/g/9//4P/j/9v/2//n/+v/9P8JABAAFwAUAA4AFgAWABMACgD9/wUACQARABsAEAATAA8AEwAFAAMADgAKAAkA/P////z/+/8GABkAHQATAAoAAgD+//r/AAAIAAQA7//d/9j/2f/X/9r/5//w//P/+v8AAAcAFwApACoALgArAB4AHQAFAAAA/v/5/wEA/v/w/+r/7f/o/+//+P8AAAgACwALAAwAGwAnACwAKAAgAB8ADQANABAACwAQAAQA//8AAAEADQARABIACwACAPz/9f/w/+X/7//x/+n/6P/f/9n/1v/R/8//2//k/+f/6f/r/+v/7f/0//z/+v/9/wYADgAXAA8ABAD9/wIABgD///7/7//n//L/8v///xUAGwAmAB4AJAApABkAGwAPAAgAAAD2//b/8v/8/wAA/f8BAPz/9//w/+3/9P/x/wAAAgDz/+7/6P/j/+b/+f8NACAANQBHAFEASABJAEcAQAAyACEACAD3/+r/0f/L/9D/5//v/wAADQAOABgAEgAbAA4ACQAKAP3/AADt/+j/6v/o/+3/6//w//n/9/8FAAcAAgALAPj/9P/y/+//5f/Z/9z/1v/S/9P/6P/x//7/DQAZACUAJQAuACsAHQAJAPv/9f/x/+j/5v/g/9//6v/q//j/AAAFAAsACQAJAA8AEwAHAAgAAQD4/+//8v////7//v/5//r/9//w/+//7//3//L/+P8FAPr/8f/4//r///8GAAgAEwAQABEAFAALAA4ABAABAAsAAwAEABEAEwAhABsAEQARAA8AFwANAAsA+P/t//T/7v/z//7/AwAEABAAFQATAAoABwALAP7/+f/6/+3/6//t/+X/6//y//D/7f/0//r/+v/4/+7/9//3/+7/8f/4//T/9v8AAPf/AAAZAB4AIwA4ADcAOAA0ACkAKAAfABAAAgABAO3/4//j/+b/7v/w//n/AAAEAAQACwAGAAkA/f/+/wAA+P8AAPz/+P/z//j/8f/z//P//v8AAPv/DQAJABEABwAEAAMA/v/6//j/BQD7//3/AAD+////AgAIABMAGwAVABgAGgAOAAQAAgD5/wAABwAJAAkAAgAJAA0AGwAhABUADgAFAPP/9P/r/97/4P/Q/9L/zP/P/9z/5P/u//H/+P///wgACwAUAAsA+//z//L/7//v//n//P8EAAwAFAAkACkAJgAxACkAFgAKAPP/4P/Y/9T/1v/Q/87/3v/j/+z/8P/u//z/+//5/wEA9v/w/+v/6P/m/9//6P/4/wAAAgATABgAKAAmACQAKwAXAA0ABwD///D/7P/d/97/3f/Y//T/AQARABQAGQAhABoACgAJAAUA+P/1/+z/6//q/+z/9//8//7///8NABoAGgAbABIABQAFAAEA+v/0//v/AwD+/wYABAAJAAwABgASABQAHwARAAcACQD+/wAAAAAEAAYAAwAEAAEABAD7//b/BQD//wAACwABAAIAAgAAAAoACAAJABQAFgASAAsADAAGAP3//f/9//f/7//v//b/9f8AAP//BgAMAA4AEQAAABAACQAMABQADAAOAPr/9f/p/97/4f/l//T//f8BAAUABgAOABMAFgAdACMAIwAYAAsA/f/y/+n/7P/q/+X/6P/i/9z/3//n/+n/7f/2//b/9f/8/+7/6f/1/+//+P8BAAMAHAAYAB8ALAAiACUAIwAnACQAGQAOAP7/8//z//D/6P/j/97/6P/w//H/+P/0//z/9f/j/+r/6P/o/+X/8//0/+///P/8/wsAEQAeACEAIwAkAB0AKAAlACsAJgAeACQAIgAZABkAJAAiAB8AGQAPAAoACAABAAUACAAGAPr/6//k/9j/3f/a/+b/7P/w////AwAIAPr/+//5//P/9P/z//X/7P/o/+v/4//r//T/8f8AAAUADQAXABgAFwAPAAkAFAAYAAkABQD+//n/9f/r/+r/8P/5//7/BAAIABQAFQAIAAAA8//z/+3/9f/4/+7/9P/3//b//v8DAAwAFAAGAAQAAwAGAAgA///7//n/+v/5/wAA+//0//7/+v/9//v/8//2/+3/4//o/+r/5f/l/+X/7v/2/wAADwAbAB8AIQAiABcADwAFAAgAAwD///v//P8DAAUABgABAA8ABAAKABAABwANAP///f/y//H/8P/u/+j/4//i/+D/8P/q//b/8//s//D/7P/y/+3/9//3//j/AQD8/wMABQAGAAwAFwAdABMAGQAXABIADwAGAAIAAAD3//3/AAD0/wcABgAPABYAFQAgAB0AIwAXABoACwD4//D/1//b/9T/1v/l/+b/5//4/wUACwAaAB4AIwAWAA8ACQAAAAYAAAAHAP//+/8CAP3/AgAMAAgAAQAHAPX//P///wAADAADAAQABgAPAAsAEQATAA0ACAABAAAA9//1/+7/5//j/9//5v/r/+z/+f8BABEAFwAiACoAKAAmABwAHAABAAIA/P/v//3/7P/2//r/8P/1//D/6v/u/+//5v/l/+P/3//e/93/2f/e/+X/4f/u//D//f8NAAkAEQASABoAHAAYABsAEwATABcAFQAWABUAEgATAAoADAAWABIAEAAOAAwADgALAAQA///5//T/7v/r/+P/3//V/9D/2//P/9//5P/c/+T/4//v//n//v8MABMADgAWABgAIAAjABsAHgAeACMAIwAoACcAJgAjABsAGQAPAAwACQABAAQAAAD6//z/+f/y/+//8//3//r/+P/4/+7/7//t/+D/5f/d/+X/5P/e/+f/7v/2//v/AwD+//3/AAD///f//f8BAAQACAAAAAsAAgANAAoACgAaAA0AHAATAA4ADgAHAAoAAgABAAQABAABAAQA+v/9//3/9f/6//H/9P/4//D/8f/x/+7/8f/0/+///f/8//v/AAD3/wEA/f/+/wAA+/8AAPb/BAABAAIACAAGABQADQAWABMADgANAAAA/f/6//n/+/////v/+f/6/wAABQAMAA8AEwATAAkABAACAAEA+f/4//b/9f/2//r/9//0//b/9f/8//3/+//+/wIA/v8HAAUAAwAMAAcAEAAPAA8AFQAUABAAEQANAAQAAwAJAAMAAQAFAAMADAAAAAAABAAAAAUAAAACAPz/+v8AAPb/9//9//j//v/7//3/CAAHAA0ABgADAAAAAQABAPj/AAD9/wAA///6/wAAAwABAAIAAgACAAwABAAFAAEAAgAEAAgADQAGAAwABwALAAgACAAPAAkACwADAP7/+f/2//H/7//y/+7/9//1//P/9f/z/////v8EAAUABAAHAP//9//7//n/9P/8/+7/+f/1//f//P/5/wIA/f8JAAIABQALAAgACAAHAAUA/f8GAAYABwAJAAYABQD9//n/+//1////9v/5//r/7f/5/+3/8f/z//H/8f/t//P/8P/2//7/AAACAAAA/v8DAAIAAAADAAMABQALAAsABwALAAwADAATABEADAARAAMABAAKAAEACgAAAAAAAAD4//r/8v/z//H/7v/t/+3/8P/t//D/7f/0//T/9/8AAPr/AwAAAAcADAAJABEADAANABQAFAASABUAEgATABMADwARAAsADgAOAAgACgAIAAwABAACAAEA///+//j/+//x//v/8//0//r/9/8GAPn//f/7//v/AwD//wAA//8FAAAAAwABAAUACgACAAcAAgAFAAQAAwAEAAAACAAHAAYACQAEAAsACQALABYADAAVAAkACwAOAAQAEgAGAAoACQAAAAMAAQD+/wQA/f/9/wIA9//9//f/9f/1//L/7//r/+z/5v/w/+j/6//z//H//v/0//n//P/7/wAA+v8AAP3/9//9//r/AwAIAP7/BgD7//r/AAD//wgABQAEAAsACQAJAAsAAAAEAP7/AAD///v/AwD4//7/+//7//3/+/8CAP////8AAP3//f8CAPb/AAD8//X/AwDy//3/+v/z//7/7v/6//P/8f/4//T/9//1//n/8f/z/+3/7P/z//H/9P/y//L/8f/y/+v/7v/0//X/+P/0//b/9v/2//n/8//+//7/AAD///X//P/5//z/9v/7//7/AAAAAPj////1/wAA9f/z//T/7P/1/+b/6f/j/+X/5//h/+P/4P/g/9n/3P/V/9n/2P/V/9f/1f/Z/9v/2v/Z/9v/2//f/+D/6v/l/+r/8f/t//r/+P8AAAQAAQAFAAUABAAIAAoACwAFAAYACAAGAA0ABQAOAAsADAALAA0AEwAPABkAEAAUABMAEQASAAUACAAFAAEABwAFAAcADgAQAAoAFQANABAAFQAMABQAEAAVAA0AFAARABAAGgAUAB8AHAAgACAAHgAjAB0AHgAhABsAGwAaAAwAFAAWAAsAHgAUABgAJgAYACEAHQAWABkAFAAKAA0ADQADAAYAAAAEAAQABwAMAAsAGAAVABMAFgATAAkAEAADAAAABwD6/wMA/v8AAAcACwAHAAcACQAGAAoABQALAAcAAwAFAPz/+f/9//r/AQAAAAIABgAAAAIA//8AAP7//v8AAPv////6//f//P/5//v//f/8//z//P/9//v//v/9//f/+P/9//f/+v/7//P/+v/y/+//7//u//H/9P/5/+7/8//y//D/8f/r/+z/7//w/+j/7f/r/+3/7//t//H/8//6//X/9P/1//L/9P/1//H/+P/9//b////9//f/AwD///7/BAAAAAAABQACAAEABQADAAgABQABAAYA//8EAPv/+/8DAPr////7//3/9v/9//v/+v8IAPj/AwD6//j/AAD6/////P8AAAAA//8AAAAAAQADAAQAAgAFAAUABQAHAAMABQAFAAUAAwABAAAAAgAAAPz/AAABAAEAAQAAAP//AgD9//3/AAD9/wcAAAABAAAA/v8AAP3//v/+/////P/+//3/+v//////AAADAAMABAAIAAUABQAIAAYABwAGAAsABAAHAAUA/f8BAAAAAQAAAAYABAAEAAYAAwAEAAUABAADAAUA/v8BAAAAAAD+/////v/4/wAA+P/6//3/+v/+//z///8AAAMA///6/wAA/f///wAA/f8AAAAA/v8AAAAABAAHAAIABAADAAQABAABAAEAAQACAAEAAQD//wAAAAD4//z/+v/4//3/9//3//v/+P/5//v/9/8AAP//AAADAP3/BAAAAAQACAAFAAsACwAJAAkABwAGAAcABQAAAAIAAgABAAQA/v8CAP////8IAPz/AAAAAP7/AAD+//v///////b/AAD6/wAABAD//wIA/v8BAAAAAAD//wAAAQABAAAA/v///wEAAAAAAAIAAAAIAAQAAQAAAP7/AAD+//3//v/+//z////0//z//P/7/wUA/P8CAAEAAAACAAAAAAAAAAIAAAAAAAAA/v8AAP3/+v/9//z//v/8//z//v/+/wAA/f/+//7//f/+//f/+f/7//j/+v/0//T/+f/1//n//P/4/wAAAAD7/wAA/////wMAAgD+/wkAAwACAAkAAAAFAAIAAAAAAAAAAAD//////v/8//v//v/1////+v/4////+v////7////9/wEAAQAAAAIAAQD+////AAD3/wIA/v8AAAkABAAJAAcABAAEAAYABgAGAAcABwAHAAgABgAHAAYACQAFAAAABQD6/wAA///z//7/+v/2/wAA+f///wQA/P8AAP7/////////AAD//wIABQACAAMABwACAAcAAgADAAYAAgAIAAMABAABAAUABgAHAAoABQAMAAcABwAGAAIABgADAAEAAQD//wEABAD+/wMAAAABAAwAAAAJAAcABgAPAAMACAAIAAgACQAEAAYABAAJAAAAAQACAAAABgD8/wUAAQAFAAgA/v8GAAAAAwADAAEAAgAEAAAA/v////r//v/6//7/+v/6//3/8/////P/+v/9//T/AQD2/wEA/v/9//7/+v/8//T//f/5/wAA//8BAAYAAAAHAAMABAAHAAEAAwAAAP7////+//n//P/+//z/AgAAAAEAAAABAPr/+//8//f//f/z//n/9v/2//n/9v/9//n//P8AAP3/AQD9/wAAAAAAAAQAAAAHAAEABwABAAMACQACAAsAAwAJAAcABwALAAIABgAHAAUACQAEAAQABwAAAAMAAQAAAAIAAAD9//r//v////3/AAAAAAMABQAAAAMA/v8AAAIA/v8BAP//AQAAAP3/AQD//wMABQACAAUAAwAGAAMABgAIAAQACAAGAAQABgAEAAMABgAAAAIAAgACAAQAAgAEAAIAAwADAAQAAgAFAAIAAgAEAPz/AwD//wAAAAD8/wAA+/8AAP7/+v8BAPj//P////T/AAD3//r//v/4//7//P/+///////+/wEA/P8AAPz/+f8BAPf/AAAAAP3/BAACAAEAAwABAAIAAgAAAAAA/f8AAPv/+v/9//r//v/9//v//f/9//3//f/7//z//f/8//z/+//5//7//f/9/wIA/P8EAAIA/v8FAAAABAAEAAEAAwADAAAAAwAAAP7/AgD//wEAAgD//wMAAAD//wEA/v8AAP3/AAD8//n//f/6//z//P/7//v////9//z/AAD8/wAAAgD7//7/AAD5/wAA/P/8/wAA/v8AAP7/AgD//wUABgAAAAUAAgABAAAAAAD9/wIAAwAAAAQAAAABAAIA/v8AAP7//v/+//7/+//9//r/+P////f/AAD8//3/AAD4//7/9f/+//n//P////r/BQD9/wAAAAAAAAUAAAACAAAAAgADAAEAAwADAAEAAwABAPn/AwD9/wAAAgD8/wUAAAABAP//AQD//wEAAAD9/wAA+f////b//v/4//3/AAD5/wIA+f8BAPv/AAABAAAABQADAAgAAgAGAP//BAAAAP//AwD+/wQAAQACAAAAAgACAAcAAQAGAAYAAAAIAPz///8BAP3/AAAAAPr/AQABAPz/AgD//wAAAQABAP7/AwD+/wEABAD//wQA/v8DAP7//f8CAPz/AgABAAAABAACAAYAAwAHAAMAAgALAAAACAAAAAAABQD//wUA//8FAAYAAAADAAAA/v8DAP3//P8DAPr/AQD9//7/AgAAAAcA/f8EAAMA//8IAAAAAgAEAAEAAQADAAMAAQAHAAAABAAHAAIABgADAAUABQAGAAIABQAEAAIABAD9/wMAAAAAAAIA/P/+/wMA+v/+/wAA9f8DAPX//P/8//f/AwD2////+//8/wIA/P8AAAEA//8AAAEA//8AAAEAAAABAAEA/P///wAA/f///wEA/f8GAAAAAQAFAAAACQACAAMAAgADAAAAAAD9////AgD+/wEA/f8AAAAAAAD+//r/AAD9//v//v/5//z/AAD2//v//v/5/wIAAQD8/wUAAgD//wYA/v///wYAAAADAP//AgD/////AwD8/wgABAAFAAcAAwADAAQABAD//wQAAAD//wAA/f/8/wAA/v/+/wYA/f8CAAIA/f8BAP//+/8BAP7//P8GAPr/BQD+/wAACQD8/woAAgAEAAoAAgAEAAYAAgAEAAYA/f8EAAEA//8FAP//BAAGAAQABAADAAMAAQACAAAAAAABAAAA/f/+//3//v8CAP7/AwD//wQAAgAAAAMA/v8GAAEAAQABAAAAAQAAAP7/AAACAAEABAABAAIAAAAEAP//AQADAAAABAD//wEAAAABAAAAAQAAAAAAAAADAAAA//8EAPr/AgD8//z/AAD4/wAA+//8//7//P8AAP3/AAD+//v/AgD7////AQD6/wQA/f/9/wAA/v8AAP//AQD+/wIAAAD9/wIA/////wAA/P/+/wAA/P/9//7////9//3//f/7/wAA/P/7//3/+v/+//z/+f/9//z//f/8//r//v/8/wAA/f/8/wAA//8CAP////8CAAMAAgABAP7/BAAAAAAAAAD//wQA//8BAPv/AQAAAP//AQD9/wMA//8BAP3//f8AAPv////7//v//f/+//j////9//z/BAD8/wEAAAD//wEAAAAAAAAAAAAAAAAA//8AAAAA/P8DAP7/AAAFAPr/BgD+/wAABQAAAAQAAAADAAAAAgAAAAAAAAAAAAAA//8BAP7/AQABAP//AwAAAAQAAAABAAQA/v8HAP//AwAGAP//BQADAAEABQADAAAABAACAAIABAABAAIAAwADAAEAAwAFAAEABAAAAAAABAACAAEABAABAAEABAD+/wMA//8AAAEA//8CAP//AQAAAP7/AgABAP//AwD/////AAD9/wAAAAD9/wAAAAD//wQA/v8CAAAAAAAEAP//AQAAAAEAAAAAAP////8FAP7/AgABAAAABwD+/wMAAgABAAMA/f8AAAAA//8CAP7///8FAP7/BgD9/wAAAwAAAAcA/f8HAP3/AwABAPz/BAD//wMA//8CAP7/AAABAPz/AwD7/wAAAAD7/wEA+//+/////P////z//v/+/wAA/f8BAAAA/v8FAPz/BAAEAAAABwAAAAUABAADAAMAAQAGAAAAAwABAP3/AwAAAP//AQAAAAAABAAAAAIABAAAAAIAAAABAAIAAgAAAAAAAwAAAAQAAAAAAAIAAwAAAAIAAAD//wUA/f8AAAAAAQD+/wAAAAD9/wcA+/8BAAEA/f8AAAEA//8AAAIA/f8CAP7//f8AAP7///8BAP7/AAABAAEAAgABAAIA//8GAP///v8BAP3/AQD///////8AAAAA////////AAD+//z//v/9//7////5/wMA/f8EAAEA/f8JAPv/CAD9//3/AwD5/wAA+f/9//v//f/8//z//v/+/wAA//8AAP7//v/8/wAA+f8AAPz/+/8BAPr/AwD9/wAA//8AAPz//f/+//n/AAD1//v//f/6//7//f/7/wIAAAD//wEA/f8AAPv//P/6//f//f/5//n//v/4//7//v/6/wAA/P/////////9//7//P/8//7/+//+//3/AAD9//z//v/6////AAD+/wgABwAHAA0ABwAGAAYABQD9//v/9//w/+//6v/q//L/8f/v//z/AAAEAAwACwATABMAEwAJAP///P/t/+v/4P/c/+L/4P/g/+T/6f/0//3/BAAOABkAIgAjACIAFgANAAIA9P/t/+n/4P/c/+L/3//q//L/9v8FABUAJwAiACAAHwAXAA4A8P/a/9v/1f/C/8j/w//R/+b/3f/o//D/+v/2/+//6P/k//L/7f/o/+j/7f/4//3/9f/4//3/DQAAAPX/8v8BADQARwAdAWcCWwPyAyYEGQRTA0ACdAGkAHj/Mv5m/ab8pvsf+4b7aPxG/YH+HgB6AWcCBwN8A38DCQOKAsQBmQBa/3D+q/2z/Dj8c/wJ/Zb9Rv5a/4AAfgEWAnsC7wIFA0MCXwHYAPz/lv7M/ef9uv1l/eT9Fv/j/yEAXQD8APcBRQKaAWcB2gFHAeD/LP88/7j+4P1Z/jz/CP+n/ij/fP9+/2YALAEdAU4BlgFIAZEA5/8QAKgANwAZ/9j+6v+BAHT/b/5i/24BTwEh/+X+sgDEACj/bP9oAdEAl/57/4wBtQCe/gf/9gCDANL+Tf/uAFwBogCvAPsBeAKGAfX/qv7Y/qH/UP+V/gX/ZQDGADkA5/9vAHABgwGFANH/RwBCADEAAwCW/nH+w//H/wv/KgC4AN3+FP5h/7j/PP5g/fT9+/7g/xoB7wA2/jf+xgF5Abz9iP7jAgEDX/4b/WsBKQK3/fX9ngJiAcn8Ov57AUkAVf6Z/w8CuwFvABYBxwCJ/nH9kP9sAvACIQEB/4P/MgH2ALP+l/0p/0sBPgIhAI79Dv++AowCzP1F/E0ACQKv/t/9oAKbA2z9WvuuAT8ECf9z/ZMBCALi/sj/fgLLAHf+PAD3//b7Qf2+AVQBiP5p/7MB1v/G/qwBDQK8/XD9/gNpBPb8kftMAdwBQv5X/4cCVQEw/Yf+RAMNAu/+9gA/A9T/Pv0gAQED/v7d/JT/4gCb/Yb88wFLBYcAyPzR/4QBQv+3/s3/uP6b/Er+uAJdBJ0Akf7ZAs4D5P5I/SgBHQJq/hf9SP8dAND98v2KAf8BZ/7Y/noDWQL8/ef+IwKSANL9owC0Avf9Q/q2/sMEuQNo/2MABwMUACD9tv9ZAqYAwP79/wsBV/8J/mn/bf/t/Tj/jgHSANf/qgF5AkMBKgEOAdL8WvqVAJMFtP8X+Mb7eANtAdP7Yv6WBLIEMwKdA1IDaP4p/ToBWgGC/H78JAFZAVz9BP6TAWH/+Pu0/rsCogAh/soBAgTk/+v9rwPeBen9RfkgANUFWQAV+9b/2APr/p76Ev5xAowBpv/n/7wASADw/lr/VACYANMAdAC2/3//pP8v/4n+zv+xAWwAfP4rAfACHf7++af9xAO7AVn8Rf8aBQYDCP1//eMB4gFd/jb9vf+UAU//xP2YACMDigEu/aj8hQE6BPn+1Pp6AK8FTgFt+vz8iAOCAW77UP1RA1EBOP0oASwHoQTR/Nf8OAKKAff95f+MAhn/C/1bABEBqf1P/UcBJQOVAvcBpv+h/kECpQQrAKf7Vf5kAU/+rPvs/yAEWwG6/RT/QgM3BGMAXP34/zMEKv9r9wX7bwTWBCD6t/YuApEJfwBB+JMAzAsyCLL8Mv2AAxf/qPft+Xj+mPtT+80BRgRYAEz+YQGXBGgEYgK5AKEAXgJ3AGD5h/dK/1IDPPw3+OcA7QeMAKD5OgBzB7QCv/xwAAME1wHe/zIAKP5z+l/7Qv9OATwAfQAJA/QBj/6J/6oDuwNTAXIC/gOvAIX8z/01AAX8uPZI+yIErAKz+pz+kgsjCxP/ifx2BGgGDf8L/E8BvwKe+xL2z/jS/d7+rv2+/tIBxwLKAU4D8AZyBUP/b/40A7UC/vvJ+d79K/7M+Fb5RwGxA/z+7/4ABGkFNwNmAu8BLwCvABcB7fxH+dP80wJVADz6PP0FBRgD5vqy/ksIOAao/XP9IANwAKP5I/zdAyADbf3b/lsDsQI6/+L+NQGuAccA2wCiAAwAPv8T/gf+8v9QAQYA4v/LAKz/fv5o/tn+ev8oAVEDcwIMAGgAdQG4//38oP1iAQ4Cqf4o/tkCbwN+/E35wf5MAw4A3Ps9/koEHwZpAuj/5QHgAgcA9/7A/n/7GftlAEEBx/pd+WUAWQMO/ob9DAUVB28BWgFEBqUE6v4j/o4AlP9k/IX6m/pP+0X82f7RARUD5wJ5AycElQJCAFcA3QHxAA7/N/9l/+z9f/06/3f/Av3Q/HMBTQSsAcn+1/8JAjgBQf9d/0cBOQIKAY7/C//e/4cAb/+H/oP/+wDQAM//Iv9B/kH+Vf+i/w//XwAHAgkAyv1qADkFrgNj/SL9qAJCA9L91vtL/yMCsQBC/jL+jP91AL7+u/wv/4EEfgVLAUsAggM7A47/T/9OAkEB6v3I//cCUQAz+8T7pP9hAD7/if/WAngFugRrA60CzAFBAHMANQJYAb3+qv2G/z8BXf8I/fj+LwNLA9QA+wGnBMUDoQC1/2sBQwL9/379hP5FAcABCf///Kf+vAImA2T+xv26AiwE0v/G/fn/VABz/gj+c/55/dv9hf8m/xP9Fv5EAv4ByP3b/bQBWABI+mv5h/0i/Q/4P/eh+xn93flY+Yv8Zfw2+bH5yf04/o76zvkY/K/7iPj+98T5rvke+PT29/aD+D76bvpl+hP8BP72/c/8vP14AOcBjQGWAQsDhwM0ApcB2gIcBKIDPgOwBAQGqwXBBUQHOwgqCOAIywqbC+kKhQqwCu8KAAuzCnQKxgrSCnQJ+gcxCAMJhwjRB2EI6AhMCN8HsAgbCWUIzAcJCGkIggfHBQcEygKCApYC7wGpAEYABQEsAXb//v2c/vb/SgD8/y8A6wCmATMBb/8v/XT8sP0//lL9Vfww/N77yvrX+Sb5wPi++PH41PhS+G34Tfmt+bT49Pd1+Ev4q/bB9PHzMvPa8NPude/i8QTy5u8Q8ALz1/P/8Nzv/vF88i7vLu0f70zww+7f7XzvkPG78qP0qPdX+u786P86AuADBAYmCPsIVAmtClIMnQwvDLsMww3GDWANGA5ZD9UPHRA1EYgSRxO5E2UUBRUnFfcUqRQbFFgTThILEcIPlQ6gDWcMogp7CJEGKQWeA5sBDQDb/wUAOf8O/ub9NP5j/fP7Yfti+6f6JPkh+L/3FvcA9lH1Y/V09Sj17vR19Vb2uvaY9q72ifdB+Bb41Pdy+IT53/mB+bj5r/pi+6P7RPyN/cD+iv9MAGEBNQKiAnkD9gRpBvAG+wZ/Bw4IuwdVB8gHiwjCCIYIzgiECbQJHgmjCNAIywjYB8AGbgarBkMGWQXFBNcDagJQAVcBEwHV/+n+5v4i/zP+vvwM/AX8Wvvs+cr4NPhx9/H1TPTO8pDxWfAQ78vtkezS69TqN+kf6B7oVOi25yLnWueX50bn2+bU5jDmGOUX5bPlgeUN5UDmz+jZ6insR+5T8RL0gvZx+fj8XgBLA8cFLwioCsoMPg5eD3kQfBFPEuoStxN0FPAUjBVqFmsXNxj9GMQZYhrBGhYbqRsFHM8bVxsJG4IaTBl+F5oVohNJEdYOqQzMCn8I9gXZAzQCoQC9/jn9bfzU+/r6Nvre+d/51flu+SD5APnk+Ij45feg95P3X/cm9xr3TPd793j3nPcn+N/4m/lw+pH76vw+/o7/5gBUAucDfQUTB9EIbgq8C/oMLA5SD0cQ/BCZEQkSQBJeElUSARKPESMRsxAfEH0P2Q48DqQNBw1yDM4LLQt9CqoJsAi2B6gGWwXKAzUCswD0/vH87PoW+dj2P/Qi8l/wGu7U64nquOms6JTnAOeG5r/lreRq41biPuEV4BffNt4m3S7cW9u72rfaN9pO2SnZ/9kQ2yncot514jnmAem76/ruXvIR9mD6Av8LA4AGwwnYDKAPQhJVFNsVWBf8GKca3hvuHAUe3x5vHzEgQCEMIpIiNiP9I5kkDyVnJYQlMyWOJMojviJEIYgfbh3nGlAYshUDE/kPrAxkCfoFxQI0APn9sftv+YH3+PV/9DvzK/Jf8d/whvB38FjwUfBe8Dfw8+/b7/jv/O/q79fv8+8h8GHw6PCn8VXyDvMr9Jf1Nffv+Ob68vwZ/4gB/ANRBoYIsQraDNcOqxBeEtIT7hS7FVsWtRarFnUWEBZxFZ8UqhOmEnQRXBBKDzsOQw1WDGYLQwoyCTQIEQfZBaAEdAM6AsEAV//r/VL8pPrm+Cj3PvVd83TxNu/F7DzqiOe25O/hxt9J3rXcTduJ2iPakdkV2VbZsdmR2VnZLtns2GjYqtf81pTWt9bt1w/aZ9yl3szgCePY5RPqdu/s9MX5Tf7vAkwHdgubD1YTKhaoGGYb+x36H2YhhyIxI2AjsCMBJPgjtSOJI38jUSMrIxQj7iJ3IuYhlyErIZYg6x/uHkYdYBt/GT4XYxQsEd8NVwrOBnMDOQDB/BX5oPV38r/vae2C6+Lpieir5z7nHeca51Dn2+eF6F/plurV6/fs9u367gbwAfEB8ujym/NL9ED1TPZc93/4wfkl+5f8X/6FAMwCPwXhB8YKpQ1jED4T/RWRGOwa/BzEHicgKyHTId8hUCF9IDUffh20G7IZfxc+FfkS0BCwDqsM3QoNCVUHyQVJBLsCJQG2/0P+x/xX+8v5BPg99qf01fK08KXusOx56tznYuU84xnhvN413K7ZVddp1dHTr9L30YTRN9EK0ejQt9AW0dXRiNIq1HXXcNtO3jjgyuJe5svqAPAP9gH8uwDUBA8JxA1uEi0W8Rh3G2EeByHpInkkxyWqJusmSSciKNkoFSkSKXApyinXKZspTSnWKCAoayetJuUl2CRqIzwhyB5mHM0ZuRYmE7QPHAyBCAoFkQH3/Qr6TfYF81DwDe4D7BfqY+ga5zTmneU/5S7lXuXI5Y/moefL6M3pturX6w3tY+7G7wrxRvJ989r0Svan9w/5lvod/MD9uv8CAmgE5QZ0CQMMiA4EEaETUBbnGFQbZx0fH64g6SHUIlgjZCMRIzAi+SBoH4EdYhvvGEAWVxNxEMINOgvOCHkGNwQcAhYAFv40/ID6B/ma9x32qvQj85Hx/u9d7rDs1erG6H7mQeQr4i3gDd6Q2/7Yi9ZD1PbRxM8GzpnM48pDyYPIO8geyJLIZMruzTnSBNYt2ZTcr+Cx5Tjs4PPt+jgArwSUCbYOvhM5GKgbQh7ZIJ8j2CVtJ20o8ygJKR0pmyngKcspsinGKdEplSlBKQoptCgtKMgneiftJvQlvSTgInUg+x11G5EYLRV5EYQNjwmpBa4BSP2z+Hj0w/B77Z7qKOjM5YbjreGq4Cfg6d8E4IDgZeGW4gjkrOVF58zod+pH7DfuIfDi8V/zzfRW9t33OPl++tn7IP2U/lYAXgJ9BKIGxwgHC40NMxALE+wVuRhBG5AdlB9eIQQjPiQdJWglJiVgJA4jbyGUHzsdWhozF/ITjBAuDRAKCAcCBAwBYf7f+4H5WPd49eXzZPLf8HLvU+497Qnsyeqp6Ybo+eYU5TnjnOHf373dOtuz2CPWWNOt0FzOKMzCyWXHVsWxw3/CBcJSwkbEO8jEzIHQmtPA1wrdxuNR7Ez10Pw8AnUHiQ3RE6AZRR6QITAk8iaWKXAreCzDLJssOyzyK8grVyunKgoqmSkiKWUohycLJ6UmWCZPJiomsiXhJKoj4iHYH9QdnRvEGE0VkxGJDVgJBAVeAFf7SPbO8cztOur+5tzj1+BA3pjctdte217bxdvW3FPeJuBa4qrk+OaJ6U3sIu/18Xz0vvbK+MT6r/xa/sD/7wAiAmIDyARmBg4IkAkHC9EM/Q5sERAUuxZaGdYbKB5rIJ8iqyRRJn0nGig3KMAnwSZ3Ja0jRiFEHtMaSBejE+MPIwxtCNUESgHk/dL6G/iT9UHzU/HA72juIe0j7IHr+Opg6qvp9+gy6PPmhuU55M7iGeHh3mTctdnj1vjTRdG+zubL/chPxinEesKMwY7BDsOWxv/Kl85k0VzVJdu94gLsw/Xd/bADfglhENcX3h5BJPon8ioMLrwwdTJUMz4zpTK/Mf8wITDLLnYtMiwrKwgqeygAJyAmoiVcJXUldiX7JAQk1CJ8IQIgdB6aHBMa5RY4ExwP0wpfBnoBDvy39uTxmO2O6XnlkuEL3inbR9lR2PvXCNhz2KDZjtvk3XngV+Nq5sbpce0Q8Xv0mPdb+ur8Yv+eAXkD2gT/BRQHIghJCVQKUQtbDGANvQ6HEH4SrRTrFlQZkRuyHfQfGiIwJOElJSfbJwUolCeoJl4ljSMVIdwdWxqHFo0Seg5DCiUGFgI4/qD6aPeW9Pzxp+/G7TnsB+sc6n3pHOm86FPo4+db55jmueWy5IPjN+Kv4M/ee9zV2RXXTNST0dLOFswrySfGmMOhwXXAEcBswRfFf8nPzI3P1tMG2gzi5+sx9on+gQSeCvIR5hk3IX8mLCpXLW0w5DKVNHM1CDXhM7UykzEQME8upSwLK5Mp1iesJcojxiI2IuchzSGMIdcgox97Hk8dAxyIGokY9hW1EuAOsQqABv8BsPwd98nxBu3E6J3kleCy3DnZp9YX1XXUf9Tl1PLV4NdW2ivdTuDF46XntuvS7+Dzoffk+tT9ngApA04F/AZTCFcJOgoUC90Lmww8DRcOOA+cECwSyxOfFbQX9hkvHD4eECDkIawjCSX5JUImyiXHJG0jsiFQHzgcoRjBFKAQUAztB5ADe/+n+xD40/Tu8Xjvae3M65Tqpun66HDoJegJ6PDn2Oen51DntubA5arkbOP24V7gZd4J3FnZb9Z204XQu83RysbH+8RlwlfAWb9pv0bBgsWYylTOUNEK1uHcpOVo8Df7ZwMiCVcP/BYEHxsm0yrOLWAw1TKmNOE1Eza+NPYycTH5L+8tASyUKg0pkSf7JfAjMyJoIT0hYSF/ITghOyC9HkUd3htEGl0Y0BVmEmgO+AlmBdMArPvU9Qbw1upB5kXiqd4n28nXPtU+1ELU+dQ+1v3XZNpp3engpuSO6KPs4vAv9WD5L/1sADQDrwXqB7oJBgv4C7MMPg28DU4O0Q46D88P1RAaEr4TvRXWF/8ZHhx7HqIgnyJ1JMklzyY4Jx0nVibiJPoikSCjHSIaKRbeEYoNLAnMBJUAr/wf+fj1avNN8ZXvOO5S7dbsquzS7BntdO3X7SruTO4w7uTtVO137B3rLOn45qHkS+Ky353cRNna1XzSQs9nzLTJ+8Z6xIDCQcEbwR/CZ8VAy0PRfNUn2c3eQubJ7zD7uwUCDeYRthexHsQllCvULnsw4DE7MyQ0zzRrNHQyfjAVL40tjis5KrUp7igZKAAncSUrJL8jCiRwJFokXyOcIWQf9hxmGo0XHBS1D64KNwWh/2P6FfUo7+ToVOPG3njbRdlw167VMtTV09PUxNZs2ZfcPuBR5JDo4Oz38Nb0wPiT/A4AEAOOBW4H4QgtCk0L/QscDDYMrgxTDSEOKw8pEBoRhhKlFBAXfRkDHIke0yD0IvEkPybmJlAnNSdOJrMkYiJHH5gbqhduE8gO/wlOBeUA3vxL+Qj2NvMM8Zrv2+6b7uHuTu/s78/wz/HR8pLzFPRd9Fz03vMQ893xQvBe7g/sXekr5tPint+v3PbZDdfo09vQKc7Wy/XJcsg5xxXGDMXbxPnF0MeYyyTSlNh/3LDf2uRS677zcv4CCMINOxHaFbsbDSJVJ/spPSuALNUtES+OMPIwvy/ULoMu0i21LG8sziykLDksQCsuKRwnriXoJB0kJCIcH4MbYBfpErMOeAqLBdb/Gfqv9F/v2urI5iHiWN2W2SXXB9Y41t7WT9eu1wXZftuB3gfiveVq6QbtmvAl9Cr30/mh/Fb/ngGJAzwFpgYFCKUJTQtvDDoNSA7jDwUSaRSrFm0Y2xmBG7Ad7h+uIdMiYiN6I2wjIiPkIaAf3hwDGt4WXhOxD7ILgAeSAxQApPxJ+ar24PSo8+zyevIr8jvyBfNT9IX1c/Y799X3Pfic+LP4I/gV9831YvS68ufwDe8V7QbrDOn85s3kqeKy4Dbf5N2R3DHbkNnW1wbWaNTG0vDQ4s6jzFnKuMhiyOfIFMy/0TbWOdgJ22Lg/Oa08LX8YQYmDDERChhvHy8ndy13MDsyKjTSNTE3QDh8NzE1RDOXMT0v0CxnK34qYCkbKPclFSOOIBAfsx7gHaAbjhg0FVEROA1aCQMFaf8l+Z/zbu546ULlLuGP3O3XvdRf007TiNSx1onYVtpZ3VnhwOVY6hvv4PNR+LH8tADbA5cGPgmaC1QNgg5rD1EQaBHNEhIUgRSHFEQV0hbFGAUb7xz6HYserB8iIcghzyE9IeAfHB5PHBwa6xYCE9kOqAqHBqUC//6/+wD5yPb49Gfzd/JB8uzyTfTm9Vn3s/g6+g78+v1Z/wwAPgAsAPn/iP+3/mL9pfvt+VD4uPZf9Tz0P/NP8o7x0PC0757uru2b7Gfr8ekA6Knl2+KP37jbzNfp0+LP5svaxxTEcMFywG3BAcZIzW3TzNeB3f7k0O17+tMIyBN3Gu8f3yXpK1cycDakNn01hjRqM44yvzF4L24sGSq/KIUnXyZMJksnwyiRKf4oaSdiJbQjviKeIEgcoxZNEJgJswIH/Nz0dewm5JDdh9it1ILSTdEp0GnPctCJ0wbY690X5EPpvu2h8p330/tL/zQCeQQQBnEHiAj8CC0J4wn4Cu8L1wxIDpMQshO4F3gb8h2vH88hVCRjJooncyelJcEiByDzHKcYaRPkDTsIxQJJ/m/6rfaI80rxqe/L7vfu6u9Y8XDz6/Uz+Pn5l/tA/Zz+1P+CAIgAHwCV/3P/XP/b/jf+t/2A/f79BP8fABMBFgJdA4EEhQUvBjoG3gUdBcgDpwG+/hH74fZ08oXtO+jy4ujdE9l11DXQGcxtyG7FLcOXwXTA4b/Gv8TAK8PFxgTNj9Yg4MfmlOz98ov5DQOXDwAacx9dIpElLyktLvIyFDRYM2ozOTRjNcI2YDfHNgk23jVTNUkzuzDiLmkt5yoaJrYfdhggETALfQVZ/kj2oO496A/jD9/P2yLYStQL0tPR4NIu1YzYkdt73WnfYOLU5cXpIO6r8VT08vYX+lD9LAAtA3gG0wmRDbMRohVSGQEd3SAlJOsl3SavJ0oowShNKOUlniHmHOMY4hSCELYLOQa7AH/8l/n/9mb0PfK28Inv4e7T7uXuLu/X72vwc/AQ8NfvEfC/8NTx9PLL8+D0w/aE+aX8pf+yAtEFIQnSDIUQgRN1FcIWfhebFzMXNBZcFM0RCw8KDK0IGgWxAZn+k/va+Fr2x/M18Qfv+ex46qHnjOQZ4VLd69mV1uzSXc8JzMvIZ8WlwtvAzL+LvyHASsE2w+nGT8w91CjgVe7z+SkCYgqqEbYZ6CUOMiQ5pDo7Ot05hTrFPHE82DgQNW0yZzF6MWkxYjCgLtsslStnKd0ktx9uGw0XeRBxB5P9gfPq6pfkq9731zLRjswwy2TMYs+00ufU79al2tnfeeWB61jxevXA95355vs7/ukA8gPIBqMJCA1tET8W5RqhH0YkaSgrLHAvoTGGMoEyWzGxLZUntCAWGt4T0g1VBw4Ar/jV8ljvMe1+6/HpuuiH6JfpSuuV7Obs8ewX7bzsUewH7N/r+euZ7AXur+/t8Yj1fPoAAKcFLguEEA0WhxugIF8kQiawJh0m6CQNI7Qgdh1aGScVQxGdDSgKQwfCBHACfQDB/uf81Pqx+GX2a/PI78vrrefx48HgqN1D2svWBNRa0qPRrtFG0jnTVtSo1XvXN9ko2tfavNtU3DLc+tsP3KHc3d2Q4LHkhurh9asElRDjGGMfoyMOKGAx6jvOQI4+ajlHNAgwxy3xKXIj0BzjFz0W4BXGFL4T9BKxEu8SxhF1DYYHKAPW/5P6sPIr6nTi4dyX2hnaOtl315nX5dvH4svq0/L0+PH8PACMA1YGxQhWC/4MvgzIC30L0AvCDKwOhhG+FCYYiBxTIaokiiZ1J/kmriS8INMbKhZlEMAK6QOB+znzM+0C6rToLOhp50fmWeas6N/r8O1M7uztue3Q7QXu3u1H7U7tB+8I8n71KPlr/d0CVwkmECYW3RrRHn0imCU8J8ImcySzISsf3RyYGqIXRRRKEXEPSA4ODbsLEgqMCDQHawV7Ao/+dPqP9tHyy+6x6gLnhuSI43/jx+Mh5CblYud96pHtze8E8cXxdfK08iTymPA77sXrDeoJ6ezn6OZ15m3meOaR5uTmZ+eh52Pn/+bQ5SrkZeOR5O3m8evq9sACEAqkDlcRFRJIFkYgQikeK+0m/yF6HqQdMB5RHJsYAxWKFNwXfxqWGgoajhlPGfEYORb+D9YI7ANCAJL6wfK162Tnlubx6OzrTexc6ofqvu5S9Fn51/yB/Sv8o/rJ+Tj52viw+ZD7rf2XAJ8E+AgJDd4QuRTVF/8ZUBwmHusd7BsBGfsUuA9ICjEGpwNBAmwB3/8K/Uf6a/k/+tr66vlL943zT/Cu7mHt5eq/57zlsOUD5xrpuOuS7i7yRPcw/VICDAbfCVoOARLEEyEUoxMmE1YUuRYXGLcXGhdOFzAYuBnTGoIagBmzGJAX7hSLEGYLbAbiARb+sfop9+rzHvLQ8ZLx8/Ce8A3xNfKK8/fz3PLE8AXveO5v7kHuAO4c7hDvBfG/8zP2D/ga+lD8pv2m/aT8hPp590X0RvHs7S7qSudb5WrjHeFP33be0N1Q3a3dZt0i24LZt9kB20veqeYG9Y8ClgojD3IQSBAPFWwfhijtKT4lUiGxH5YgIyP3I8AioiG1IzsoTCqzKNUlLyLAHe8YJBKoCGz/Ufnp9LDubOfM4gDi6uSh6q7vO/DE7BTql+oe7FXtSu7T7UDsc+uq7JfvVfOv+LH/8wZYDg8WphyWIAci1CEEIP8coBoeGSIX3RQeE1URoA7oCw4LxQt5DDkM5wntBJ3+Tfln9TTx2+tF5onhrN6B3hPgk+HU4jDlIemR7Yfx3/Qn93345fnI+7L9j/+bAjIH9gsZECQUZBg0HMkfYiOiJaYljyQGI0ogFxxdF98SnQ4zCzIJBwimBgMFqQMkAs3/QP3Z+gz4I/WW8jTwhe09617qx+ot7GbuJfHJ8072C/lp+6D8A/1H/XD9df21/Sf+Y/6i/m//vgDkAaoCgAPoAwQDAgE3/oH69vV28XftrOkz5mjj4OAi3lTbB9nP19fWmNYD1wLWntMr0XLQGdIm1nDdvOlh+jAKbhXMG5Ydxxz1H4EoIzDlMeEtlSmSJ18oYyuXLVEuaC4RMCkzKTPnLaolcRxTE5sKUwE69+jtf+dh44nfjdtf2Xvaht5v5Gbp+Onj5fvgR9613ejeJOKB5vLqHfDy9jX/bwcWD4MWMh3dIscnRCvsK4IpjyWkIXYe0ByuHPIcMh2MHTgdvBoHFrgQ4wvvBggByPnr8Nbn1OAw3d3buNre2VnaXtxw363ivuQ+5XzlsOYV6b/rVe4/8bH0Bfld/m0EowogES8Y4x6rIy4mlyZUJeYj+CJsIm0hgh9THVEbbhlaFxUVaBJaDwwMVQjfA0/+evhC8+zuvev56YfpFuqD6x3t/O067u/un/DP8rz0+fWe9g33+Pfq+ab8vv8KA6UGHwqaDCUO0Q7PDm8OtQ2gDC8Logn1B/sFswNlASn/Lf2h+xD69ffy9DfxB+256KvkJuFu3j3cWdqv2D/XStbA1dzVo9aI14zYZdnh2VvaONut3Z/i+emf80sBIhPVIrsrny6eLIcoVyj1LfkzUzQPL1QqaSg/KHwpdSr0KVYn9SS/IyUfIRVcCdX+HPVY7HjldeD33JLbVtzD3IXb0trv3CDh8+VQ6gXs7emw5kjmRemu7on26/+xCN8PvxYOHqQj+SW3JicnEyf0JisniCZ7I2kfuhw0G78ZNxjMFs0UhxGvDMEFufyJ88PsPuhe5GvgvtwW2jDZkto43RPf3d884a3jIOby51bpoepJ7HrvBvXe+64CjwlYEBgWNhofHUUfgSBfIXYiCCMgIiMg8x32G1EaRxmIGAsXqxT6EXwOcQlaA0v99/d68xXwqO1V6yfp5+e8593nM+hX6TXrqe3B8OzzJ/a596f5+ft9/mMBAAXhCFMMiA9oEgwUeBQkFXwWURfvFgIWqBQ9ElUPtgwwCjMHTgQzAiUASP3N+Wr2FfO/7+jsr+rI6BrnweVO5Hvi1eDv37ff+9/j4NfhZ+Im42jkeeXH5VLmquf56DDqq+s+7b/u7O/N8JrxMPJu8yr3Kf2TAzULwxYpIz8q1Sp6JrAeJhiYGM0ddSDsHMIX+BUAFpoWbhckF1YUjxAXD10NywZr/RP2IvHY7DfqReq565DtX/BK87Lz2/E68R3z2fXQ+Ij7QfyX+kH5zfp+/nYDsQmwD3sTfxXTF/QZRxkbFjETfBGyECARbRJiEhUQ3A0JDfMLZgmYBmsEEgLf/u36Mfbh8PPsCezX7Cvt6+wA7YPtY+6l74/wVPDN76PwzvIW9Rf3LflR+2f9RQBhBI8I4guUDsMQsRFXEacQ6g/qDiEOSg4ED0EPvg70DfMMgQu3CccHagX1AkEBDABn/ub7Qvle97f2IvfO9/b3s/fI90j4hvhC+Dv4+fiC+vT85f+DAqgEIAfkCasL9wvfC1UMCQ2LDcsNig2vDO8L+ws3DK4LhgqCCWsIgwbCA6IAif3P+tD4T/fZ9XL0nfNV8+jyMPJi8cLwXvAr8BLwnu8J7/bufO/07ybwvvC58c3ym/P98xP0pvP58pDyQ/KP8cHwJvB573fuh+0g7fLsv+xy7LnrWuo16VfpNutb7l7yFPl6BK4RghrVHMAZfRIUDDYNZhTnGe0ZJBjCGE0arBvMHfYe4hycGSwZuhnSFVQO4gfDAlH9Ufmi+GT53fm1+qf7Dvp+9T/xge9q73zwxfIg9OvyIPGJ8frzUffU+3sAdgOIBdoIoAzaDTgMeQpKCkYL1A3aEd8UExVKFFsUshMREQgONgzZCt8IggarA8z/8/sk+tz5AvkW91/1UfQ88yny+fD17mjsFOvl69bt7u/38cPzA/VW9qD4cvvU/dz/IgJJBNYFEgc1CAwJxglKC4YNOQ/9D48QHREWEVQQEA8eDbgKEwmsCGwIWwcABswEVQNoAYT/Gf74/CL8s/sR+5r5MPgH+Mf4U/mG+Qf69fpI/Fj+4QC0ApUDggSNBfcFFQbKBggI9QiKCU4KswpSCvYJFAq8CXkIIAc8BgoFOAOKAQsAU/6J/GT7q/qh+Xn4lvek9jj1u/PA8iTyqvF78WXxG/Hs8C/xk/Gr8aHxrvHg8SfybPJG8pjxBvHg8A7xS/FH8QvxrPCt7zPu9ez365jrXOyJ7ZPtMuyc6hTqF+ve7UnyWfdL/ksJQhVVHLIc6RetELwLYQ3dE0EZSxo5GkocJx6AHn4eBx6KGzwYaxc1FzgTtwyTB20Dcv6Q+vL5FPuh++n7aPym+rT1t/BU7s3tj+728FTzpvO/8m/zCfbn+KD7FP4dAFMCuQWKCTMLUgoiCWYJwQoJDVwQKxNzFAgVgxWEFHwRZg7IDOoLmQoWCWQH3AQLAjcA/v7C/Lf5cvc99jH1J/Q084Hx7+757L7sxe0O723w6/EQ8xf0ofV39+D4Lfo0/Nf+YwGYA4wFBAdPCPIJqwvPDE4NAg4gDx4QnxBZECYPgA1sDAsMjguBCmQJkgiRBzIGhARjAuf/+v0o/a780Pv0+rz6rfo7+qn5Ufk3+bT5Svsx/Tz+r/7A/2QBnQJfAwsEtASHBc0GTgggCR0JRAnQCekJSAmTCC8IwgcOBxUGlgS2AlQBkQCm/zX+1/zw+x/7Avqw+FL35vXs9Hf09PMr86Py0/Ij8wzz6vLr8tPyzvL78vTykvJY8l7yR/K28XLxjPFL8Ufxi/HJ8U7xMvDU7t/s/uqJ6ozrPuzT69Dq7Ols6dvpB+wd73Hy/fczAnYOBRfTGdIXNxJ9DNgLaBARFbMWpxfHGgEegh+DIAAhGh/QG8Ia9hpzGHITLg+HCzMGvQC0/b38bvwP/ef+Hf/C+/n2ZPPo8Ffvfu878O3vJe/x73HyFvV492j5v/pl/J7/3gPRBqEHzwdGCLYIpwnhC4cOrRA3EyUWdxdMFkgU7xK5EdYP2g0IDLgJfAdjBsMFyQN+AIP9UfuJ+Rv4D/d29cDyBvAx7gLtLOzg61/sWu2p7pPwpfIm9GX17PaT+Cz6tPtp/Vf/nAFlBA4H5ggaCpALew1PD70QfhFhEbQQdRCrEEkQNw8ZDkYNXQxdC4EKgwk2COIGjwVkA38AKv4m/bL87Pv5+gf6TfkW+Xf5o/ko+eH4o/ln+yf9iP7h/yABCwK+AnIDRQRkBf4GqgiQCZEJTwmHCfAJAAq1CUQJ7giSCAgIBQd6BcYDRALkAGz/8P3B/PX7HfvW+Sn4ivZc9af0GfRL81jyl/EY8bPwT/DZ75rvq+/u70HwdPCd8L/w0/CM8BLw2u8O8Hzwu/CM8OfvTO+z7lTuOe4G7tzt3u3Y7TbtLOxI6zXrLOwB7s/wNPU3/G8FYg5MFPoV8ROmEBUPARDTEeASbBPTFBAXXhmlG54dch4yHgce+R3OHFIajhdBFG8Pnwl0BM4AmP4A/g7/cwCQAHT/3f0A/P35Ovh89vbz2/Bp7qztZe7S72fx5fKh9E/34/pZ/ukAkQKKA8oDnAN7A7cDjQR6BkoJ7AvtDZ4PfhEzEz4UZBSSE9QRmw/FDUEMYgoGCLAFngPYAbkATQAGADT/xP30+775JPdt9PLxuO/17fnspuzi7KztIO/88MfyQfRS9Tr2Tfe5+C/6Tvsf/Pn8Pv4KAEkCxQQyB3MJrAu1DTYPHBC4EGkR4hGzEQ0RCxDMDvAN2A0GDq8NvgzMC/oK2wlnCNUGHAUPA/sALf9Q/V77/fl9+WT5hvno+Zv6fPs3/J/8nfxr/E38gPzn/Fr93v1z/jD/EwAdARwCCwMzBDwF0gX3BcwFegXHBNMD3ALhAekALQDA/03/pP7i/UT9p/zc+/v6FPof+Qf42Pao9Yj0ovMP88LysfKs8rLyzvIA8x3z+/Lx8u3yw/J08ivyA/Lg8dfx7vEc8hfy5/HJ8bfxf/H98Gfw3+9A78Tu7u6+7x7xkfO99zz9mgLBBmMJgAqiCuUKwQtYDBkMrAvnC8cM5A1kDzwR+xKgFJ4WzBhkGj0brxuCG+EZ7RZiE60PLQx0CcwHvgbFBQQFsQSGBGsETAS8AzMC3/9k/ej6efgo9vTzy/ED8BvvH+/E7wPx6vIi9S/37Phm+mn7IfzB/Dz9T/3//N/8Rv03/pL/PQEQA8YEegZZCCcKfQtHDJcMUQx+C1cKHQnABz8G3ASeA3ACewHZAHEALQABALn/IP9L/lr9Yvxg+0f6Gvnj99L2K/YF9jX2kvYj9/D35fj1+Rz7QPxL/Sj+4f5r/6v/z/8LAGIArwAMAYYBGALvAvkDEgX4BZQGBQdCB1QHNgfiBlEGogXqBBcEOQN0Au0BkQFYAT8BKAElATsBXgFwAVIBEgHSAKoAdQBBACgAFAARABgAKABJAH0AywAXAUQBaAGCAZgBsgGnAYABTgEPAdgAoABnADQACgDm/8X/q/+R/5P/mf+f/57/g/90/3H/gv+Q/53/qP+0/9b/7f8fAGAAmADsAEUBngH1AUkCogLhAg4DKAMxAygDBwPXApsCWwIcAuEBjgEvAcMASgDE/z3/uf4z/sP9Vf0C/cP8kvyp/Cj9+P35/gkADAHwAcECpwOLBGsFIgbABmwHAgiwCHgJUgo/C0EMZA2bDtgPExFSEl4TFRSFFJkUWxTREwgTLRImEfMPpQ5LDe0Lhwo5CdIHSQatBAIDRAF6/7P90/vi+d/3+vUv9IzyRPE+8InvFO//7knvyu+W8KXx1/Ia9FX1nPbh9wv5Mfo0+xz81/xv/fj9Xv6j/sz+0P6Z/jj+kf2r/Hr78fkd+O31hfPq8DLueOvD6BrmguMD4bTeodzT2l/ZVNi213LXodcu2BPZRtqq20rdGt8z4Z/jbua06X3tv/Fr9mb7ggCsBcYKzw+mFDAZdB1dId0k9ieaKrgsRy45L3ovHS8zLt4sOStTKVYnWSV6I9khcCBLH1MebB2KHJIblxqFGXQYWRc0FhEV4hPAEp0RbRAVD6gNGAxmCpgItgbPBNcC5QD8/hr9SPub+RP4qfZg9Tz0Q/N08sfxPPHG8Fnw9O+H7yfvuO5B7s/tU+3a7FHs2+tw6w/rvupj6hnqyOmK6V7pK+kV6QTpA+kj6VTps+k46tTqnOt87Gjta+5174LwlPGd8pbzh/Rk9S72AffB93v4OPnv+bH6YPsS/Mb8dP0d/rX+Uf/V/1gAygAzAZcB2AEVAk4CewKjAtUCBQM6A3ADswMOBI8EIgWYBQEGOQZpBpkGuAbcBukG5wbgBukG/AYjB1EHiQfOBx8IiQjvCGMJ0gkwCmAKXQofCp0J9QgrCGEHjQbABRQFiAQuBAIE+AMDBBEEFAQUBBYEEAT5A9ADiAMeA7ACQQLBAVoBEwHcAMEAuACsALkA0gDtAP4A8ADWAKYAcAA+AAsAxf+I/0P/9/66/o/+dP5X/lT+RP5G/kj+SP5U/kr+Rf4r/g/+AP7i/c39yf2+/br9tv2y/bL9vP3Q/er9A/4U/jP+Xf6S/r3+6f4d/0D/cf+e/8T/4P/x/w8ALQBEAF8AhwClAMYA7wAoAVsBlQHYAfoBHQIsAk8CZwJpAn0CdgJ1AlsCQwJGAjsCRgJIAkkCPQIkAikCKQIqAhcCCgLyAcQBogF8AWYBRQEmAQcB3AC6AKAAiQB2AF0APAAhAAoA8P/O/77/qv+H/2b/S/9N/0H/M/82/yv/Hv8X/yv/Nf8g/xn/IP8a/wr/A//9/vP+0v6x/qL+iP5r/lr+N/4O/uf9wf2r/Yr9YP00/QD9svxh/B384vuh+1z7Jvvd+n/6Ovr8+bb5dPku+e74mPg8+Nv3ivdW9yL3+Pbc9tn27PYp9473O/hM+Zz6H/yW/cb+0P/SAM0BsAJeA8oDEARaBJ0E5AQxBYcF6QVWBuwGjAdFCBQJ6AmjCgsLJQvzCnoKxgntCO0H6QbeBewEQwTQA6kDtQPaAwUEOASSBP8EVgWPBZYFVQXjBE0ElgPGAvQBNgGqAEQA+P/h//P/KwB6AMcA/AAbAUIBWwFfATwB/gCLAPv/bf/e/lz+4f2P/Vf9Sf1Q/YX90P0H/kT+Y/5//nv+Xv42/gv+z/18/Sz91fx+/Ef8Ofws/Dj8VPye/Bf9of03/r3+Nf+P/+D/IwBZAH4ArADyABgBMAE5AUUBbwGeAc0B9gEfAlYCqAIBAzwDVQNcA1ADLwPzAq4CZwInAvcBvgGGAWMBTgFTAVoBUgFjAXMBqgETAlcCfwKkAs4C2wLWAtICugKTAkgC5wF1Ad8AZAATANH/hf87/wb/9P7f/s3+0P6f/n3+bP5h/kr+KP48/kT+bP6M/pf+sf7C/tn+5v7j/rj+fP41/sD9LP2H/Mf7/Po1+mr5qPgI+Gr3w/Yc9mb1wfQp9Inz0PIM8hzxA/D07vLtLe3G7NrsRu0F7n/vLfJN9nj71wCkBXsJhQxTDxMSYxTaFWcWUhbiFUkVoxQFFHYTIBMeE1wT3BO7FA0WmxfHGPkYABjlFQoTtg8hDDcI9gOh/2b7wvfo9O7ypvHe8Hjwl/Bu8d3yufSM9hD4G/mf+Zr5KvmP+AP4wfew99L3Jvjv+GX6efzk/kMBaAN5BaIHswmOC9IMRw3gDLwLBwrSB14FyAJXAA7+Avxd+h35V/jt98v3r/d99zH38va09lb22PX69MHzSvLk8L7v+O6R7pruKO8/8BDybfQr9xP6+PzE/1MCnASKBiQIcwl9Cg0LHgvMCkgKzwldCQkJuAiHCHkIhQh9CCgIkwevBogF+AMhAiAADv4Q/Bj6M/h09hv1MfTF87zzA/Sq9JP1ufbp9wn5FPoD++T7m/wt/cP9VP4G/7r/YAAKAZ8BSQL0AoUD8wNDBHQEjARwBBYEnQP0Ah4CKQEtAEf/h/7k/WX9+PyL/EP8+vuv+2D78/pk+rT55vjz9/D20fW29InzUvIk8Srwbu/A7ijude237AXsb+vI6gDqNOld6MTnAehk6TLsK/Hv+CkDDQ7AF3sfaiVrKmAvtjPmNVE11jKnL+ErSSe4IYkbeBV1EPoMwAqcCc0JQgusDLAM4gqrB6QDcP85+4H2F/Fu61XmQOJf38XdbN0x3jTg7OOS6cXwrvh5AEkHtAzxEBEU6RWgFrUWbxa/FYMU5hI6Ee4PVg8tD/QOng7CDs4PSRFSEiYSdxBvDYAJ7gSm/8/56vOX7t7p1eWx4o/gtt8x4OfheeTb5yPsI/GB9pb75v8pA1cF2QbuB8UIdAn/Ca0KgwvIDJoO0BAvE6EVQRjpGpAd4R+tIc8i8yIfIi8gPx2/GR8WvBKpDw0NDQvzCd0JrwpQDIwOLxHVE0wWixiFGiwcch34HYsdYBzUGi8ZYBeNFaUTnRGND2ANEguXCO4FEwPl/zb8T/g69Anw5+uZ50Pj/94N27nXEdUG06PR3tCF0IbQv9BE0e3Rm9JL0+fTi9RI1Q7W+tb81wHZNNp2293cad4B4I3h8eIg5OTkQOUz5c7k/ePC4inhP98s3RLbH9lR17XVEtQ20i/QS87VzK/LvMrFySPJGslPymHNgdLF2t3nRPoWDSAcPCfpLo811zyUQ7lGz0SNP4w5YDO2Ky0iTxfYDLIEcP9R/NX6vfvz/rsC0gSIBMQCuQCH/9r+X/1++g73aPQk80Hzy/SL90L7ZQC9B00RFBzXJiAw5TYXO0U9qj3AO8Y3dDJFLD4lOB16FKkL6QP1/XD5kfWP8pDx+/LT9YD42/m8+Q75nfg2+Cr3kfU69Krz3vOy9CT2Ufiy+4MAVwaNDPASnBkVIHkl/igyKv4o4yWHIUUcLBZIDyEIEwGe+ij1xvBc7ePqquna6WDr1e298IXz2/XW90r5JfqE+un6uPvg/Hn+WQCdAp8FcgmlDXgRtBSUF1IaohwLHvgdVRxzGZ0V7RBvC+4FJAE//RL6efeS9dD0X/X39s74pvrQ/Gr/TALQBKQG0QeaCB4JTQkKCZcIRQgnCNwHEgfpBZcEVAPoASMA/f22+2v5NPfe9Eryve907a/rSupY6dvoz+g66dbpXOqx6trq3Opv6mnp3ucH5irkH+LE3y7dzNoR2RXYdtf/1pHWNNZV1uPWr9eb2A3ag9yM4GXmOe+2/F8Ntx0vKm0xMTVFOO07ND7JO9czCSlQHswT/wd3+qjsSOEx2k3XTte42RXfu+Zz7j30zPdT+jL91AAdBIEFFQU9BAIEdwSUBWMH3gkmDbsR8BfOHuokCyk5Kjwo9iNRHh4XKw4ZBB767fBr6JPgydkN1XLTI9Ut2bfe4uXr7hX5mwIbCioPZxLxFOUWfxdnFkMU7BHLD8cNqwuXCQoIrQdKCDwJ3gn7CYYJ8AcDBbgAZPud9RzweuvZ51XlIOR05HHmJOpQ75b1j/waBPcLpBNmGk0fNSIZI3gipyCgHdsZmhVoEYEN9QngBkkEbgJkARkBNAGlAYYCvwPrBH0FJwUqBCADZAIQAkICeQNWBlEKEQ6tEEcScBNgFOAUPhRgEs4P1wxHCb8Eqv/Y+gj3Y/So8sfxA/Jy82n1CvcE+Ln4gflG+tD6+/rM+mn6z/nb+Jn3W/aV9Vj1ZPWC9aT1yvXP9XP1n/Rl8wry6fD97y/vW+6H7dbsXOwM7L7reeuA6/zrwuyB7dXtuu1N7dLsI+wm6wnqIOnr6MrpO+zE8Lj4CgWDFcgmvDOFOtk86j1KPzA/ODpNL/0gARNaBjL5gOoJ3G3R/sxszpvT8dpu5I3vn/psAykJuAxfD/kRqBMjE1MQqQx9CRcHpAVLBSsGOQjMC58QURUdGOsXrRTODnMHX/9s9ovs2+Lz2nzVGtJD0F7QbtMx2jTkxu9r+6QGTRGaGjshUiT6I1Qhmh0lGXcTiwxjBQT/3vnB9YvyWvCm77Lw+PJT9dj2dfc891X20PTY8sfwGu+X7n7vofHF9Mb4kf0XAyIJPg/SFFMZixw4HuEdMBtAFrQPYwgJAQ/6mvML7gzq9eeV55Lorurr7U/ynfcY/e8B3AX6CHsLLQ3pDQEOzQ1eDWEM2go1CR8IIAgCCS4KhwpACZUGcQNKAAz9zvnZ9sH0p/Nz8/bzQfWM9+f6Ef9YA0YHtgqdDU0PFg/+DMQJSAbFAlD/G/x9+an3lfYd9jP27/Zu+I36zPzG/loAbAHJAUwBIADI/or9Xvw7+yj6Ivk5+Gz3mPa+9QL1evTT8+ry1PHL8Nbvpe797P/qL+no52vnauf458zpEe5x9o8EfRdyKQc1PzliOYA5TDqdOJIwgyKJEqQEbPi76jvbas0WxrfGPM1o1s/gLe3C+jsHKRAvFcwX6BkAHHkcKxqDFXUQLAz/CEQH/wZBCNUKzw4vExQWBRasEscMWAWM/Yv1Fe3L5GPe9toc2u7aK93j4Qjqf/VnAmAObhiyIEInKCtRK5knOiH1GcISbAtpA1T7UPQd77jrzOk+6Tzq/+wG8RL17Pds+Q36KPrv+V/5rvhM+Oz44frN/SUBpQRpCHQMqhCQFFsXjhgRGPQVHxJzDEYFcf369Z/vrOoK58/kbuQ15u7p1u5S9DH6eAAABxENwBGbFKcVLxWQE/0Q0Q15CosHRwXoA1sDGwPTAioCMgH4/43+Cv2q+6n62fkU+V/4Lvjm+Lz6cf2RAOcDKQceCjAMwwzJC7IJAgfZA1wA1Pye+Qz3N/Ue9M/zcvQU9qH4mfuI/icBOAOPBPQEeQRMA7YB1P/P/dX7//ln+PH2pvWP9O7z1/Mv9KX03/Td9IL0xfOa8hfxnu8S783vpfBS8Kruoewe63zqruor7PnwSfuPC48dlyr7L1gwMDAwMSgxaixMIogVDwlj/WvwoeHQ03nLm8qnz+vX4OG47Yf6NwbdDh0UPReUGbAbYxxbGrQV7g9zCvgFHQMtAigDpgVzCbkN6hCRESkPcwpbBAP+qvcv8ezq3uXV4qXhA+IA5IToFvA6+lQFiw8VGOUeuSPHJY0kXCBdGr8TKA10Bln/Zfhz8hjuautm6hDrWe3v8Bn17fi++4f9e/7S/rT+SP7i/eD9if7Y/4oBZQOJBQEIxgqpDSUQuBH6EdsQSQ5FChAFO/9p+Sr06+/f7BbrmOqW6xfu7PG19t37FgFFBgcL6Q50EWoSCxKWEHUO/QtrCS0HgwVjBGIDRQI5AbMA7gBbATwBPADX/pv9lvyf+7P6UvrZ+jH88v3u/yACYQR1BvYHtwipCAEIzQbYBDMCRv+K/C76RvgY99X2YPeP+Cn6APzo/bv/PwFNAs4CwwIyAgYBXP9b/Ur7Yvm091r2afXm9Kr0p/Tg9C/1afV19VH19/RN9DvzwfEC8Ffu5eyN6xnqgugs53rmC+d56R7v5fnvChEfIC/rNtY3tzZlNmg1py90I6MTLQTt9pDpidpNzNDDs8NkysLUpOBO7ub8HgqsEwQZrxtJHXwe/B2ZGqsUFw52CDEE0AF/AToDdga0CiQPIBI7EvwOIQnMAWT6W/Nv7Ojl0uAn3uXdyN/T44zqHfTg/wEMlRb3HiIl1ShEKR0mBCBXGGIQrQgBATT5B/KA7Cbp1edQ6HHqAe6a8l73ZPsf/qr/XgBjAOb/M/+5/sf+lf/5ALkC0ARSBzsKPQ0BEPMRkBKkETYPaQtMBjkA6vkK9DHvtOuo6RvpEuqB7EPwFfW6+uwA9gYjDBAQjhKwE5ITMxLFD60MZQlDBpcD5gFJAUMBGwGyAJIAGwHDAZkBhAAT/+H95fzu+zX7EPvC+yv9Cv8gAVsDtQXMBw4JRgm0CJYH1gViA3sAo/0w+yb5nvfb9gH38/dl+SL7Gf0d/+sAOALmAvQCfQKUAS4Adv6Z/M36Kfm395D20PWH9Y31uPX69Wj24PY+91L34vYD9tD0bvPY8Q3wWe7J7EnrvelT6Ezn8ObS58zqqvFT/tgQBCT0MGY1uDQKNGI0izJ/KrQcHg1R/xzzZ+Vq1jbKkcUQybPRNtzV5171OwOwDskVWRlkGxIdxB2wG4QWug+ZCeUEmgH2/3UAMgNnB0YMLRCuESoQFwxhBt7/Svmk8irsjebA4gnhL+Ft4zXo8+8N+icFhw8eGNoeiCNkJdMjbx9JGYwSrgubBE39Tva68ALtEuuz6vvr4e7o8kL3BvvA/YD/hQDQAGsAqf///sP+DP/R//EAZAJmBFoHLQvpDj0ReREFELsNzAqsBjQBLfu29XDxSO7867LqKOu77eDxovaQ+9YAVQZ4C8IPRBNyFZQV4BMeEe8Nigr8BnIDaAD8/WX82PsY/Ij80fxC/fL9n/4M/3D/7/9WAIoAyAA4Ac8BgwJeA0YE8gRYBXMFOwVyBPoCGgFG/7H9MfzI+qr5C/nx+FH5J/pb+8v8Wv7m/zgBGQJwAkQCigFeANj+FP07+3j57/ep9q31AfWh9J30+PSB9Qb2e/bI9tL2lvbp9aX02vLh8PXuGO1D60/pcOf/5cTld+cZ7OH1ZQaqGiQrNDNrNPwz6zTuNKgvniNhFBkGuPlj7NHcss4vx13Ia8/F2Dfj5O8Z/nwKtBIXF+0ZPxxvHbkbpBb7D/IJawXOAX3/e/9LAhcHWAyeEJ0SBxIXD0wKIQRV/Wf2iO9q6dfkMOJg4bziuuaG7bX2CwH/Cm4TLRoFH0khcSD9HPkXMBIYDMEFUP9Q+Z70iPHh74PvjfAD80z2pPlK/Pv95/44//X+GP78/CH8zfse/P/8Sv4TAH8CewWgCIML1w1CD4YPdw4XDJAIQgSz/0b7NvfR82zxN/BB8G3xnvO79rP6/v7+AnEGSgl1C5YMnQzwCzELXgogCZ0HRAZ6BVAFdAUkBSoE8wL8AUABMACp/if9Ifxy+/z69fq2+yP91/6VAF8CNgTDBdgGTQcbB2UGWgXxAx0CDwAI/k384Pq++QP54vhZ+SP6HftA/IP9wP68/2MAwgDlAMUAOAAh/5r9/fuB+in5+vf89iz2ivU79Tf1SfVL9Tv1EfXg9KX0KPQ686Hxc+8C7cfqvOiT5oTkR+Oq43bmHu5u/cUScSa2Me00RjU+N1c5ZjbBK4Ic8A14AR/0d+Pm0nfIRsf1zADV/91v6YP3kARxDY4SYRYqGo4cnxvZFnkQGwtTBwMEIAGFAEUDjggnDlMSKxS0E28RWw2eB7EASvnr8Tnr+eWN4hvh4eEz5QjrIfOg/C0Glg5bFVkaAx0YHQYbdxfZEokN6AdgAob9wvkh9271u/Q79cn21fjJ+kn8Fv1B/ez8IPwJ+wD6Rfn4+Er5ZPo4/Ir+QwFWBIAHggr7DJoOGg9qDqcM6QlhBmYCYf6Q+lz3+vSR8z/z6fN/9fb3Gfti/q8BQAX5CPsLcg2FDfcMSwwzC1UJ9wavBNwCeAFCADH/ef5C/oT+7v5A/4z/6/8cAOj/iP9w/8f/OQCRAPYAlQFfAg4DfAOxA7wDkAMGAxMCxQBW/9n9Y/wO+wP6cvli+br5Ufod+yn8cv2z/rv/cwDFAMIAWQB+/zX+q/xA+x36Ifkc+Aj3IPas9Zr1kvV09WD1efWe9YD16/QO9B7z3/EC8GDtV+pn5xTlhuO14sfiGeXy7SMAyhYQKGovoDC1Muo3pjofNSQoqhn0DTkDo/R64mvT+czpzl/UBdqW4ZHtSPtGBWQK4g3TEhAY6Rm1Fq8QuQszCWYHhgQkAlMDvQgqEHkWrxlgGYYWBhI6DGQFyv3Z9UbuD+iw40Dh5eAS4/HnCO+L904AQQi6DmgTshV1FZ4TPxGPDhcL/AbzAvr/Yf6//Zr90v3A/iwAdwEDArkBtwAd/x391/rE+D33TvbA9a/1l/Z3+Nz6Zf0dAOQCfwWwB1AJcQreCkQKpAiIBqgEPgPNAQoAbP6K/a/9ff5K////9AAhAhIDjQO4A+MD/gObA7QCxQEtAeIAigAEALP/BQD4ABAC0QIqA2QDsQPwA+UDfAPcAh8CTwGCANr/Xv/2/rH+m/62/v3+UP+f/9n/9f/6//H/x/9z/wH/e/7x/Vr9vfw+/Pv73/vR+/r7dvwn/cD9Av7g/Yv9Vv08/er8Q/xs+4z6yPlB+dv4f/g7+Pn3mvc+9xL3F/f19m/2yPU/9cT03vNW8kHw9e2f6yfpZOZx4+nggODJ5hf2CwkEF7oddCJ7KnM0ZjiPMp0nUh7VF+oODgDx7lLjht+S3/jed95y4+rusPo9AGwBuwT4CycSIhKJDdAJFgpvC5MJ3AT4AUcEZAn0DHINOQ03DigPeA3DCOED2ACZ/tz6+PVN8mjxufJQ9H/1Zfc7+x4AIQRtBrUH5Qi3CYsJRAiKBhMF8wPaApoBegDn//D/RQCXAMgACQGiAU4CSQJFAdT/qv4K/rH9Jf1y/Dr85Pzq/Yz+wf5e//gAEAOiBEUFmwUcBnkGCwbTBJEDuAI1Aq0BAgFXAAQAMQCdAAsBZwHhAYMCAgMcA+ICjQImApgB4gA3AMz/gf84/wr/Gf9l/+D/cwACAW8BtQEBAkUCNwK7ASkBtwBNAM3/O//U/qP+m/6b/q3+zf7f/vb+GP8t/wD/mv4n/sD9Xv3r/Ib8Rvwa/N37nPty+1/7g/vH+/37G/xC/Jb8B/0p/cj8Rfzt+777cPvi+jv6tflT+df4Q/jI93L39vZP9sj1W/Xb9BT07PJi8cLvcO4q7arr0ulF55Pk4eXy7zwApQ6zFZUW9xZWG7gh9yPeIDAcgxisFL4NpQN2+of2RPcg+BT2ifP19Cv5U/s9+lP5xvv1ABEFzQTGAXMAlgL8BTgIZQnJCvgM4g7lDv4MKQvHCp0KCAlMBoMDDQHW/tz8Mfs8+oj6z/sO/aP9v/3l/Vj+Uf+ZAG4BpQGpAacBmwGzAeAB2QHwAWAC1AIJAyEDKQP/AtkC5wIyA5cD3QP1A6sD6gIIAnUBLAEUARkB6ACZAGAAKgABADgAugAPAT4BPwH9AJkAQQAIAOX/4/8AAEgAtQBBAdIBRgK+AjoDfwOCA1oD8QJXAqgB2gD4/zP/r/5b/hf+yv1+/Wf9tv07/rb+Hf9f/5D/7f9oANQAJgExAfoAswBjAAYAsf9N/8b+Pf60/Ub9LP1a/Yv9tv3G/Zr9Xv08/SD99/zH/Iz8X/xG/E38b/yi/Nz89fzf/Lf8l/xx/GT8afxN/B381/tp+wj74vrY+t/6yvpi+vH5kvlG+fv4pfhN+Pb3lvf+9kf2VfVw9Ab0r/Mj82XySPH577fvkPG09cL7zwEJBmEILwqNDGoPPhLpEw4UshLnD1YMYAj1BAcDnAJwAowBNgC9/vj9Bv4+/ln+7/5OAI8BKAL2AYABcwFTAgsEkwW/Bt4HzQgMCZ0I5Ac/BxQHIAfJBr8FUAQAA/cBNAG8AJMAoQDAAOEA2wCgAGsAcQCpAPIAOAFjAXUBmAHCAa0BkAGjAckBAAJHAo4CsgK1ArcCygLZAtQC0wK9Ap8CdAIJApABOQHwAMQA0QDlAO4A9ADHAKYAigBCABEA9P/S/6f/af8Z//H++f4D/zf/m//i//3/LQBeAIgAwADzABgBJwEbAcYAVQDt/3v/LP/4/s/+oP5y/mP+cf6h/sr+3f7m/hL/Tf9r/5T/dP8D/4n+T/6B/vX+Vv9u/2v/Mv/e/rP+t/7U/rz+eP76/VH9pPw+/FD8gPyy/N/8Jv2H/Zj9Xf0h/RH9Mf1p/Y79c/0T/Y38O/w0/DP8VfzC/Az9zvx4/BT8b/sz+0P7D/vN+nP67vmJ+UH57/iV+Ff4PPg5+GH4eviX+J/4Efgh9xz2fvUi9l/4K/te/TP/WQBYAVMDigXCB+UJQgthC1cKmwicBooFfwX5BVwG1wXlBL0D4gKVAnoCngLHAhkDCwO7AogCYgK7Ak4D4gMOBPoD+wMsBKIEvASlBHwERQRFBGAEsATVBMcEmwQiBJEDDAPxAgQDYQPjAwIEJAQ5BFEEbQSWBLEEkQRiBOkDYgPQAjECrAFQARIB1gDEAJ0AcQBTAA8Aw/+l/6P/nv/M//7/BwAVADMASQBvAL8A3wDwAAMB0gB3AA0Ao/9W/03/Rv9A/yj/r/4x/t/9s/3F/SL+gP6v/rb+wf7//h3/Lv+G/9j/9f/x/63/X/8l//3+Ev8s//T+3P7i/lj+qv2L/Qv+4P5Q/yv//v68/oP+4/7P/7oAEwGIALb/fv+r/xcAnAC9AJcAWgASANb/y/9DAOIArQC///L+bf5j/sH+1/78/j//Hv+d/ir+T/4f/ycATgC+/y3/0v5S/y0ALgBC/83+TP/K/3YAdgHtAfoASv9//pr+1v5r/3sAmwBU/wH+E/5//4wA6f8j/nz9XP7W/mn++v0V/iH+4P2F/V/9BP7Y/qD/FwA2AP//jf8lADQBMQG6ACoBCgL2AQYBlAC2AGAAh/8w/1j/Qf8F/xH/lf9/AKoBVALyAX4BmgG6AdAB9AH3AZUBPwEuAZMAtf/c/z4BzwFGAT0BUgG4ANX/kf+Q/yT/Q/9dAA0BnQBMAMwAwAAGAPP/vv9R/i39F/7i/8cALAF5AdQAYP9n/gL+M/0p/GD8j/11/hX/d/9v/9L+QP41/tH9wfzo+0j8oPyh+3j7q/3N/+H+xPw6/N77RPu1+xn9e/1K/Ez7Pvtf/Ir9uPw4+8370fyH/AX9qf7z/hX9F/xq/CX8Zft4/AIAMgHu/kb9w/xq+536qfy8/wIAdv6J/u3+tP2i/CT+dP///fj8/f49ARUAGP74/eL92vyj/SUAEgEHAQYB2ABG/4n9Mf46AFwCxwKYAUj/hv0y/yoCXAIAAVsDpQa1BLQAlf///7cAvQPZBzgI7QQkAiQBRwCxAGwEEQiQB6EEGQOqAYUBGgXcCDoJkwf/B/QIAAh3BqgGAAmFC8MMxwyJDVUPQhA/ENkPHg/oDr0P/hH8EwUUgBKFEAIQDRE6EvISIxTcFBQT8Q6DC8YKaAoUDMAP+g5GCUcFUQU9BLQBvALABYkGXAXEA9QA8PxQ+w39dP8j/7X9Vf1p/Of5H/kX+7j71vpn+pz5Wva686z1UPiE9wf2+vW19An0sfbc9+zz//Bb8uzxxO1e7LHwmfPC8FbuiPA68gnxIPEJ80ny8+9T8dnz9/I08oL1f/c59erzPvVM9fL0Kfgq+g/3g/OT9N/2J/eb93D3cfck+H/5svm/92X2n/VU9cb0cfQ+9b/3//hK9rPyb/EJ8xD0lPSK9DnzFvEh7t/tOPHA8tvwrvHd82Xx1ezU7MHwTPJL8SbyjvOn8RHv+fBm9XP3B/im+aT6/PZz8/r1i/rA++X76f89AtP9vPqN/u4Bjv/V/lcFmQn1BRgDDQXGBq4G9gnMDzkQdAtPCScMHw6zDjYQJRCKDjcOahA9EUAPAw9OEMoOHg14D9QR2A+ADR4PmxGvEXkR8hQdF9AStQ9xE/oWThWsFbIZcRoDGGwXwBidGKIYKRtlHfMbLhpHG3wbCRrvGfEbRh2CHR0dPhvdF9IUlRW/Fh8VOhOQE4EUKhINDw8OSQ6kDbEJQQW0BaUIOgY3AdAAMgHR/5sATwGm/tL8kvxa+cf0d/SB97H4iffF9hj2J/Ti8Ujxu/OQ9ALxz+6T8CHyCfCb7rDw2/Eo8JzumO/p8afwU+ys7Rj00fU18Rzu9e7h7iLw9PM79R/ziPJg9Gvy1/CV9c34r/RD8jz39Pe28LfwtPok/Wn1hvM9+bD5mvUC9nn5s/if9yz8cfvd9O/0U/o8/Kn6Qfv8/H/86PnJ+Fz6e/sE/toB+/9/+TD37fl7/dj/v/91/LP5QfwH/z7+Bf5yAIUD7AFD/Wr7j/yv/af/bwR9BuoC5v01/RIApwE/AVABigTNBLn/mP2nAl0HzwPG/6QA5gGEAUQD1gY+BAUARQBlAPL+sv9ZBYMJSgbVAIj/9wHQA58EGwXUBX8FMQIzAXoDdQJC/2ECEwiyB24BoP7pBHAG/QFtBDQJAAVnAIkGYAl1Ajb/YQO3BAgC/wRZCbkFTwJFBtsGQwAQ/zQGQQneBZgENgcbBcL9f/2IBUkJsANQAUUF6gaVA14BDwVvBrsC2gAxA68DsQLnBPAE+P+s/VcCuwVUBPkFJQosBhD+lv0kAXACsAPHBmkHbQIL/t8AdAMD/9z+HQf0CV4FaQJbASAARgChAe0CtQVRCEgGgAFK/un+UwLOBOkE5AMLBpYGEwE3/tb/8ADrAdQFjgekBPIBdwBM/13/1wA2ATwCXwTKA5UBt/99/K76J/2wAFUCDQIOATv/K/wR+U74dvtAAX0EUAA4+Ub3n/qe/J/6x/uT//z/0fxB+ob6lPj391r9WgKh/6v5Mfpq/AL5PfZQ/MICLQAR/ZD90vk981X1HP96AlX/Of/o/lz5M/cN/Vv94vfR+1UD0f/293n79ACx+7z2rPo+AMj8l/q7AO0CeP3e9hL6UAAl/vP4gvw0BW0Ax/ZF+UkASP/G+or9GAMeAp/+2P8k/1r55/h2/jkAKQCNAfkAuf6k/a7+ov9AAGYBUwGB/gz9vf9zAXr//v4SAbEAY/60/5IDugJR/nX9WAHjA8gBRABiA1kElP+c/XcALQMNAsz/SgFZA2oCQ/8N/6gCLQVQBEgCHARXA6X88ftUAlIEoAHnAi8FdwJX/i4BBgT6/Uz+0gb9BbH8Z/tZA0sFowBg/gn/GQEqA/sC+f+w/gkBfQM3AzD/E/6vAaoCUgH0AGUCdQKx/h/9/P+WACn++ADFB5QGo/3N+Zf+sAKLAlIBMQG9AqsCUwC2/UD+4wF6A0MDvgRIBDf/Lf4kAyQEZgJSBG8Eev/y/eIErQiuA84A1QRoCDcFkf+mAEoIhAsbBUj/vgIkBjgDngSlC9sIdv4uAIMJiggsAeQBXAhQCAYDyQAhAy8D8gEsBcQH9QWWAm8AH/+aAnMGjQM7AUgDkAP6/3/+FwDJASEBHwH7A5QBmfkq++oG8QdQ/9P+RwPr/rb3dfsCAFb+qAABBAv/3vii+zH/af72/74CeQGg/KP6LfyU/Hn7dPy4/wz/Gfvs+9j/Jf96/fz9TPsH+W//KgT4/HH1/Pfq/TH96/lD+lH+vwJyAZf5jfTu+Nn9+fxf+7f+bAD9+Yb35/w+/Cr28/qnA6r8qvTo+gL/Xfpe+lcA+P3c9hD5D/9M/sT6Qv5eARz8yveC+3r/K/1s/ND9zf0S/cD8NP4I/kX+7f+//Sn6k/2XAw4BoPxe//sBOvsY9rj+iAZaAbj75gEnB4X/Lvnn/YkBZv3U/LgEUggMAYP6u/8VBlIBivvm/1oIhwUz/dr+3QPnArv/zwDxAi0DIQMVAscBtAK4ATX/h/+UAyIFXAFZArcHrgQ1/hAB5AX5AC79JASdCToFHQFrAUEAqP4xASIFWQRQAhMESgR7AHcAuQPMAdH/3QUhCB3/gPstBqoImPo1+A8HvQo0AEwA2gVcAJj7lwO6CbAAqvkbAlUIX/9d+74EWQb0/KX8WgXCA4r8IwGCByUAL/v2ApQFNf4M/ZMG9ga8+k35fgTQBGv5K/3FCiQEy/PK+ScM8gfq9mP8yQr9Ab32UAFzCBv94/d4A1AHcPxF+SkC2ARQ/Zn/0weKAbH3VfzlBUkDFfws/5wGOAIU+J39dweG/hf22QGnC7wAFPj8AfQHXPx59CoB6Qje/dX52QX6Bjj3sPT7AUcILgKx/ToBNgHC+lf8RQUCA6/5xPqFA0QEW/1W/SYA6v+sAbYAo/m1+WwEIgUM+x79Mwh7Aq3zfvgfB6QDvvee++AFLwQs+0752P19AO8B3wDy/BD9EAIQAnr7ePuvAQoBo/yO/7MFwgFh+uf9tgJr/3D9IQBn/Xn8nAXbBhr7SfjRAyYFA/rO+cAEagRo+kn9CgYrAqr6k/9xBcz9rfhxARYIdQFs+jT/dQID/TH+yAW1AQ342P61CTEDRvkw/aUDogFn/4sAOwCK/UP+qgMYA/36RPmaA6IIfAGS/W4BgAPC/1f9Hv9bAnkBGP/EAbEBuPus/I0G1AYl+y/3+AGhCCb/tvkrBNMGXPpq+NIC+gMv/Ir+JAcwA7D5IfvEA6ID5v3o/8gEXwJP/cj+rwHC/5/8fv19AOMBrwAQ/mb/JwTtA7796vtCAXQE6/8Y/WYCewWqAdb7TPkv/LYBbwPe/wYAPgXuBd79+vj6/6kDH/yC+9oEnwXn+0v5eQQGCDn8D/iEAgwHsP3l+jAE5QSQ+cv3ZwTwBsb69PkUCE8Hufb79msGngcb/IX77ADf/zP+RwFUA7T+p/zFAFcBcvzN/qEEQ//i+TEAYAbx/0X6QgJNBgv8IPgLA2UGWf0w/KAD2AOb/Xj8Nv8d/dD7XwMbCGcBsvtY/zYC3fxh+AD/cQj5Bu39xPuf//39LPvF/qMEJgNc/IH8rwR/BaT69/h2A+oFIf8Q/kIBRf97/Av/QwFw/hv+dgEBA2ID0v4r+ZX9swNgAHj8aQFjBTwB2/zL/ZAADwA2/+L/nwBOATsBVwDK/k3/BgJPA14A5PsU/V4C4AJM/9L+QwGAAWr+8v35AcADOgFI/yoAEAL4Aev+4Pwf/7YAq/8cAVwCm/+f/nkCRANG/xn/2wEBAJ38ZACbBVgBDP39Ao8HgwBD+K39Nwh3BGn4Efy8CYIGC/iX+LIGkgXo+P77PwkNCf/8wfujAyUCjvny+6EFpgSs/y0C2gPs/XL76P94AWT/VgBIBaYEff6d/ZMCpQJG/X381AEnB08CYvm6/QAJVAQS+Cr8Hwe9BAv81f/tBiICDvoc/MMCXwE//uYAkwK2/2//GANzAsv8EPy7AY8CNP4k/3oCKgAZ/SoBjwalAbT5mP1XA8D94vo+A/QGwP16+Kj/UwSPAGn9DgDdAkkBsf7m/64C6//K+079hAFPAgz86PimAQkJOAH0907+zgY4AS752P5SBfL/nPvW/+8AdvxP/l8DEQEr/Z/+iwA3ADf/Y/6l/bf+lAFeAqD/8/ux/IAAagFv/5j9Cv6AAJQCgQAr/PD8iAFqAfz9MQBuA3/+jPqqAP4CJvsE+ooEkQbX+8n4CgGHBBH/sv1sACEAK/9c/xL9bfvOAHADx/2/+3kDbQTm+rP6YQOQAmL6U/6YBa7+Vfh2/3EFOf66+LkAkwR4/Fz9EgdPAkv1SvhLA6oBgf0zAjYDdvtS/KwF8gDz9Wj8AwmdAw73LvvuBbEB4vhG/iUG//6q+bsEfAnv+yn19wFsCJz98vf4//IEQwBo/UMAjACW/9IBIQILAB8AaQLIAF39l//mAwABwPtZAKgG/AC8+D79SwW/A38ArgEqAucBWQJt/zf7sf3cA+ADUQFRBDsEHPwv/NcE2gAa+J/+PgojCb7/Qf4HAUz/i/7JAJ0CPQMaBHwE+QIaAQv90/vKAhUFZv6u/WIGKwluAgX+HgC9AMv9cf+9Aq4A9QBKB7QGZv+u/ZP/xP9aAf4DXgNiArUDRQMS/978zADQBB4DbACFAmsECgI5ATkDtQHh/iUC+gMk/9b/FQjsB4z9j/w0BNwC7Pz6AIMGyAAW/3AGKQTP+WH8FggEBLj4vv0dCOoDNPsl/mACtf5W+m797APUAgkASgC1/zL+j/vt+uj8f//K/+H+pgB3AXL+a/tz/K79nPsn++QAzwTs/y38Qv/Q/vv46PoBACT9Sfo7AHkGRAIQ+WX1sfoTAHj+GvwC/8IDeQEv+UT4g/4wAIn9F/+7AYz+tvsE/FP8T/xe/x4Ck/8u/KD8jwAHAK38Lf5wANX+O/2l/rkAhQAp/uP+sADd/rP8pv8+Asr9IfxnAaoDQ/4d/GMB4gNVAIf96P81AcMAMwEI/6j+0QJtAeb63fvGAQQCQADPATYB6/4fAOgB9f/3/IH+6wE4AsEAAwB3AH//D/09/90C1wBh/p//xgBS/7kAdwMPAG7+6QPrBSH9Nfi1AI0EG/4B/7EGAgNP+nz97wNIATv+iwOmBj3/SPoNAUwFQ/0U+1gF/wXt++H6tgKjA7b+kP41A6MGFwSC/2z8Qf2QArMEXwBn/cgAigEh/P77+AO2BiUByQCjBSUB5/dR/KwHZgSc+pv/bQi3Apv6iP7eAjL8Y/h0AWsILAP2/CIBfgTl/ej6ewFmBM7+G/3VAMAAcv3h/c0ApP+K/S0BCQY7Arn8vv9zA5/+hvkR/3sEDQH8/SQBRwEj+jT6zQGCAo79Rv+VBcoCIfuR+jD/MgB2/RkANwYpBTj8v/bS/GkDNQDN+6r/oAXGAXr6qPzuAkkCp/0C/2gEegNl/OH6sAFzBNL9Z/l8/0MFjQFF/rUArwAl/bX9FQKCARf9d/5zA+EBoPxA/14DZf7g+rYBwwUR/bz4AAGxBev/hvweA00GcADk/E0AGwMOAX//JwD8AEoBbf7Y+lL+uQWaBJn9of/MBpgDuvq5+/cCbgLH/ZkAVQQS/zT7TwKNB5YAJvpDAEoIhQX2/gX+Yv+f//wBSwOu/1j9LwA7AyEBPv0t/mQCWAIa/2cA1AQ+BCAAgABSAvD9XPpfAG0Fxf/w+q8AKwXqAAn/tgJVAqD9GP7YAn0CuP1q/O0ACgRDAIr8dQDkBUwDK/7d/i8B6f90/m8AnQF4/lT+RAN4A6v+U/6PAqYB6fwS/94DUQDA+2MAuATK/n36gAGeBUMA7vyx/2MB1v+qAP8CCQKL/+/+VgALAuEA0P7F/8sAo/7p/Af/ZAAX/43+5P/jAO/+4/wY/68CywEB/oL9jv8mAIz/9/4i/r397f4OAFkACABe/i/8cf2fAZoAsPuS/Y4DbAFM+o77EQJLAYD9RQBxAyj/QPrY+07/GQAoAG8A5v9q/zf/hv6k/en9Sf/V/wb/ef/fAesBF/8q/qgACwLX/sv7jP4ZAnQAwf6iANAB2v/y/noAnP/s/Qv/rQBO/0r9j/5e/9n9d/7xANAAsv8hASMBYP0p/Ob+gf9r/Zr9c/9p/yb/qQCfAUz/WP7gAT4DC/9r/MUAfwNx/1L9rwDKAWn+wv5fAqoBzv6C/+0Atf/N/+YBZgLXAeYBOwGO/0//RwGFAisCEwIZAQAA8wB5AQ8AQv8MACgAhP/1/+//GP+L/3EA0v8V/jv92/1+/xwA2P4i/lv+wv3D/Hn9LP8wAP0A2wHjAbAA8v9xADYBnwFfAfAAGQGoAS0BawBZAXUC1AHvACwBxADH//D/iQB4AAMAMABLAFv/5P4QALoAof9X/3gAgAA1/+7+EQCRAOX/4//1AJ4BRwHJAAoBUgEOAZgALwB0AGQBLQJNAhkCRQJvAgwCrwEgAlMCKAF7ADABQwFDAA8AJwGMAZEAOgDRAGIAbf9PAN0BawFWANQAegFzAKz/qgD9AM7/sP/qAN8Azv9RAFEBewDz/60BuwJ/ATkBrAKRAuQAgAAhAUEA/f7F/8cA9f88/0cA4ACz/0n/lAApAQwAUf/E/4r/nf6L/nb/tf+7/lj+/f5H/wD/Ef+q/yIADAAKAF4AmgB/AEwAOQA7AEgA/P+k/7n/AQAAANP/IACkAIkA5v/C/w4AAgCa/2H/Xv8N/5L+bf6Z/q/+hP5U/mP+bP4w/tr9t/3f/fD9v/2z/dH9xv2U/WL9Vf1l/Vf9N/1U/Y39dv1F/WP9nv2Y/bP9H/5v/ov+mP7e/iX/Sf9l/5H/wP/x/0EAawCTAM0ALwGaAfoBawLLAhkDWAOxA+ID0QOxA60DnwN0A2gDWQMyAwID+ALZAqcCvwLoAukCzgK5AqgCXwL0AbUBqAGwAcABxgHCAcMBvQG0AdQB/gH5AesB/QEGAsoBhwGOAbcBsgGNAZgBpwGVAWsBPQEeAQEBwgBYABUA7v+y/4f/YP8T/3z+yf05/b78OfzB+2L70fpQ+vD5cvn8+I/4JPh496H2wfXU9MLzcvIE8Xjvz+0t7ILqvOj85nHlLeQ246fideLr4r3jbOYD7Yr2VwGrC9sUqBt2IG8lECqJLWEvyi8LLpUptCOAHTMYaBTbEr8SAhJ5ELgOgA2nDFcM5AzUDDkLNghWBH7/+vlR9ZzxI+7s6l3oWuam5DjkseV06Ofr4O8q9Az4c/vW/hICtAShBlEIhAkICmIK3gp3CwAMwgyWDQoOUQ7BDmEPyQ8CEAoQgA8nDkkMJQp4B2sERQH7/Xr63/ah8+rwte5F7Z/si+zI7GjtdO6g7wjxt/KJ9ED2wvdE+aX6APyN/U//HAHfArkEjAZBCPIJtQtuDQIPZhCeEYQSERNeE28TLBNxElUR3Q8VDhcMHAoaCAcGFQQ2AncA6P6a/Yz8uvsW+5v6QPrm+cH51/ke+o36D/us+0D81/yX/XH+Vf9IAEIBKwLgAnAD4QM3BGUEZgRDBMEDAgMGAtoApv9Y/gv9wPt2+iv5/Pfl9u71EvVF9IbzuvL28UjxsPAj8JvvCe9z7ujtcu0O7ZzsIOx9653qhOkv6LnmD+Vq49rhSuCy3ujcHdtZ2dDXlNZM1lvXJ9tc5IzytwLoEM8bhCPzKP0uGDawPI5AaUCBPPk0kSswIuQZnBNbD8YMBQpMBoECIAA4ACMCSAXhB0YISgbDAr7+ZPo49ozy2+7M6tTmA+TF4lzjOeYe60/xCvh2/2YHHA87Fm8cgSG/JBQmFybzJNwi/x+nHKAYtxOmDgcKawYBBLUCRwLuAWQBvgAcAFn/Sv75/BT7Ovhs9BPwlutg5yrkQ+J/4ZDhduJn5Grnmuvq8PL2F/33AlcIBw3GEIQTexWRFpsWoBXDEywRLg5PC8UIfAZwBKECOAEzAHn/Df++/kn+b/0c/En68fdW9bvyHvB/7f3qw+gN5x3mFuYa5x3p8uuf7+Dzd/g6/QMCwwYzCwcPDxIUFCcVkRV5FewU8RO/EloR6Q+CDj8NLwxEC68KUAoaCs0JMQkECEEGHwS3AVX/E/0O+2r5DfgO94j2k/Z29xX5Q/vB/UQAewJMBNEF9QbRB0UIaAgqCIgHuQa9BdIE/QNjA/8CqwJmAioC9QGlASgBawBv/zL+wPw5+6b5Bvhk9rz0GPOR8SHw1+647bvszeu16l3pzedH5tTkdOML4nLgrN6/3D/bq9q826ze3+TC76T9vwtXF3sfviSoKXkwMzg+Pp8/vzvbMwcqnSA4GL0Q6QnnA8X+uPkC9YvxUvCF8TT0VfdT+Xb5RPiq9iv1VPMB8SvuKOvL6PHnQ+kz7AvwV/QS+aX+aAWWDWIWVR44JMEnQykNKaYnYSU5Iu8dTRiWEQ4KYQK8+932APR58o3xy/A28D3wGvGi8hv07fTp9D70PPMM8s3wje9v7rDttu2/7sTwzvPi99H8JgJiB0sMxxDCFCsYrBq7G/kafhjIFGUQuAv6BikCYf3e+Pf0+/EB8CPvS+9V8OjxwfOs9W73CPlU+kb7zfvW+5P7Ovv0+uD6Hfu7+9P8Z/6FADgDUwapCdMMhw+HEcISTBMdExsSIRA7DYkJXQULAdv8B/nM9S3zwPES8qLzl/U195X4NfrB/Pr/GwNOBU8GoAZ9BigGqwVhBU8FhAVPBsMHewn5Cl8MeQ0iDhQOdw1vDNIKtAjPBSkC7/0K+j33k/XD9Hb0pvQB9cv1KPcD+S/7S/1I/9UAsAHaAaABVQECAbcAgABIABQAAQAjAD8AIwCx/xj/lv7+/Uj9LPyJ+nH4JPbt89Px/O9+7lXtP+wV6/TpEOmN6HLofOhm6AXoaufQ5iHmhuXz5LTkRuXz5qPqnPHK/OgKtxj/IscoCCwJMHM2YT3MQLs9rTThKIsd6hM4C0AC+/hz8OvpxuW343Xj8+T358DriO+58jT1Afcg+HH4xPdO9vX05/Sp9gv6Z/7cAuAGywqaDzMWXh5nJkAspS7ELeQqHiesItYcBRWwC/sB6PjM8MDp7eO135Xdkt1K3x3iuuU06jjvJfQ8+E77vv33/xMCpgMsBJ4DxQKyAhYErwbMCc4MbQ/UES8UbBYiGMcYCRjmFXkS6g1QCAICW/u39J/uYelM5YziVuHY4efjIucY66Dvq/Qa+qT/qQSMCA8LeAw1DZ8Nnw0WDRAMuwqNCbgIXwhOCF8IjQi2CMIIZQh7B/8F5wM9ARP+kPrg9k7zNfCs7eHr6urq6hzshu4R8ln2HPvt/44E5gi+DO8PLxL2E34VSRZrFZISpw7kCh0ILAY9BKEBxf55/BT7L/pJ+Yb4V/jm+Kz5KPpA+nn6UPuU/M392f4iABACdQSrBjUINAkcCkgLcwz+DHYM+AoSCeAGYASSAcT+WPxm+sr4NvfO9fb08/Sd9ZP2bvcp+P/4//n5+m/7evtj+3L7r/va+9n7tvvC++j7Dvzx+5P7Pfvb+lf6XPkH+KL2T/Ud9NzydvEU8BHvTO6w7Tnt0ey87Pnsf+0H7szui/Db8x75LgCQCDwRTRkCIAAlVihGKi0rmyr0J74iLRs/Eg8JdgCy+MPx2euD51DlX+VP54DqZe6T8sv21vpl/kEBNgNFBK8EzQQeBeYFQwckCU0LrQ1OECYTGhbiGBgbWhwkHCgaYhYUEaoKswOE/E/1je6l6B/kV+FR4Obg+uKH5nDravHm90f+CATpCM4MpA9QEfcRrBGVEPoOFw03C4IJMghcB9wGjwZABrgF8ATFAx0C5f8I/aj57/Ur8qbutuuJ6WToduje6bDswfDO9Wb7LAHXBiYMuhBNFKkWqxdqF/MVgBNCEIIMkwi9BEABRf7h+w/64vg1+OP3yfes94L3NPfA9jv2oPUQ9ar0oPQZ9S727PdD+if9fgAUBL0HOgs/DpsQDhKJEvQRXRDfDZUKzga7Aq7+1/pq95n0kvJc8fTwXPFc8uvzxfXV9/H54/sN/qIASANPBZIGhAceCeAL3Q5LEJUPEg5UDQ0OeA8gENoOGAz2CLoFFQI4/gr7rfiI9hz0KfKM8ZryDfUP+Nr6Qv0yAAsEzQckChALSgsQCzMKzwgjBxoFyQJ3AHz+vvxZ+6/6g/oh+hr5xPeq9tz1N/Wa9OzzM/Oo8rjyUvM19F715fa2+Gz69/tC/SX+mv61/l7+Qv26+z360Pgf9wn1B/NC8Rbw4u9l8OLw8PBg8ezyifXj+BL9DAJwBzMNOhPzGEQdlR8SIO8efBwEGbkUlw9eCX4CEfzn9hnzd/AE79Pu3u8u8pH1bfkK/QgAdQI9BFMFowV0BUoFOAVsBQ4GMwe/CJMKrwzIDn8QfBGoEQ0RdQ+8DPAINgTO/h/53POP71/saurG6aLq7+x88AH15vnC/lUDdQfrCn4N6w4oD3IOCA0tCwgJ1AbCBAYDzAEUAbUAewBXAC0A2v8g/+b9QPw++h34F/ZT9PLyFPII8u7y0PSb9wj76P79Ag0HywrqDRoQMBEiEQkQBg5DC/sHXgTLAIL9uvqO+A33QvYc9oL2RPdD+ET5Kvrr+nv7yfvk++j76vsm/LX8sP0H/7oA0AICBUAHVAn5CgwMWwzmC60KtAgWBvoCnv9P/D/5pPaz9HfzDvN185r0TvZR+IL6t/y3/nMAzQHMAnUDwAM2BF8FWgcbCdsJ4gnPCScKsAoZC4gKtwhjBmYEAgOiAQ8AfP4s/SX8m/vc+9r8Jv5p/6oAvwGWAnIDfwSDBQYGDwYjBm4GngZlBuIFDQXlA5ICOAHl/2L+zfxN+/n53PgY+NP35Pcb+Ff40/iV+Wv6Jvuz+yf8YPx5/G38Pvz0+4j7LPu2+iL6o/lZ+Sr5zPhh+PP3gvck95j2pfWB9KPzC/N78vXxxfE18jfzb/RL9d/11fbA+Lb7Gv+5Av4G6wv9EJ4VcBn9GzMdPB2jG/sXuRIBDXYH3AEh/Lv2RPIY74vt2+1578Txx/SX+Kj8OAAjA30F/AZhBz0HTQeQB90HbAhyCd0KcgwyDvcPBREFETEQqw4YDB4ITwNA/hr5HPTD75Hsr+pC6obrXe428pD2UPtBAMQEWQj5CqwMVA0BDRkM1wo+CYEH+AXaBA4EkANbAzwD6wJIAl0BCQAj/rL7D/lz9gb0FfLf8JPwOvHp8pz1Cvnc/OEA4ASACHYLgw2ZDrAO3A1ADA8KdwejBPoBrf/U/XT8ifsJ+9L60fre+uX6y/p++hr6sflV+Sb5Pvmv+ZL6+fvO/fr/VAK5BAYH/wh4CkcLWQuuClIJZAcLBXICuv8q/fP6Lvnq9yr38vYt99z3xvjb+ej6Fvwa/vQAjQPWBDkFZAXMBY8GnQdNCDUI+gcTCEAIkAdrBrAFGwX8A5cCMAK7AvsCPQL7ANn/Cf/s/jX/1/7P/Wn9Qf5X/8v/RwCTAeYCUgNWA7gDOQRABL8DwwIwAW//Ov5v/Wv8R/vB+uH6Efsa+zf7hfuO+zj76Pqp+jb6n/kZ+Yr40PdH9zf3WfeC99X3SviV+Nz4W/nu+Q/6wflQ+ab4uveH9mX1ofR+9O/0bfVv9QH1GfUZ9oz31vgD+hH8w/88BWcLDBG8FVwZBhxDHXYcOxlTFPEOpgl6BCT/CPrN9d/yYPFr8bHyr/Qt9yD6Rv33/+EB2ALaAicCXgElAZ0BlgInBLQGIwrfDUERyBMhFSsVDBTJERUO9QgoA3T9Pfiq8+Xvae2L7Fvtuu8w8wT3xPpV/nwB4QM6Ba4FcAXQBEYECgQ7BLUEjAXPBmII6Qn1CkoLrAooCdIG0AMaAN37tfcS9Fnxo+/+7oXvKfHv83b3SPvt/hICsgSzBvUHbwhKCK4H7wZIBtUFmQV4BZAFyAUCBg4GlgWUBP4C6ACI/uP7Lvmc9ov0R/Ps8nbzxfTV9mT5X/xw/zoCiwQsBkoH0AfWB2gHqAbQBfwEdgQgBPYD9wMhBEEENwRQBHEEDASQAlQAAv75+3T6fvkb+UH5Q/ol/HT+igBRAkgEDgYRBzwHFwfvBocG4wUMBRcERQP0AgUD9AK1AncCXQIFAiABBgD9/u39uPyk+/762vo3+/T73fzN/bz+l/85AHgATgDz/3n/rP63/fT8Y/zW+0r79PoH+0b7dfug+5T7U/vQ+sz5Wvjl9uP1I/V99P3zufPg8w70/vPr8zL0/PTA9bz17vRQ9FT0fvSC9FP0PvQM9Vz3dPuYAdsJmRMIHcQjJCbNJGchrxz1Fg0QGQj1/y75zfR98m/xJfHX8b/zoPb6+S/9Sv/f/0P/Gf6t/Bz74fl6+YH6Xv0nAmwIEg8lFScahR1+Htcc7hhpEwcNbgb4/935pfQE8WLvme8C8SrzzPW5+JL7uf22/l/+Nv3g+/f6sPo0+678Kf+zAgIHpAvCD70SWhRWFKkSbA/bCnYF5P/W+sP20fP88VHx2/Ft84z1tfeX+fn60vs0/Bn8jPvm+qr6P/vT/Dz/OgKTBRMJcgw6D/UQSxE6EPMNvQrqBsICqv4T+2D4ufYR9jj29vYh+HT5vfqq+wj88ft/+/r6h/pW+p76rfvc/RMBAgX+CG4MPA+7EcETWBT5EhUQlAwoCfQFzgLI/yn9mPv++qj6Yvp4+j77Bvw4/PP7qfu5+xn8i/zk/ID94P4RAWkDUQXgBjoIMglyCeUIvQcWBhYE6QGm/4b94fvH+v35R/mm+Ef4N/g8+Cv4FPgB+P33DPgy+GD4oPgA+Yb5FfqG+gH7c/t6+9r6+/kz+V/4i/e19p71TvR780vzy/Ko8W3wXO+K7lnuE+9u8AryzvMP9gL6dAGCDHMYQCF2JAojwB8EHYwadxbkDxgI8gHC/uP9q/0B/f/7kPtU/Ff9Vv25+//46vUw81zxZPA18AXxj/Mq+Dz+/ATuC38SABipG8Uc+RreFhgS3Q0wCqMGMAN8AC//P//r/wIADv+P/UP8IvtK+Vr20PKx7xjude5h8EDz5/Z6+8sAIgasCuINoQ84EOcPpg5qDIMJuQbLBNcDkwOZA5IDcwMvA4kC5gAX/pX6E/ck9MrxAvDd7snuPPA28y73PPvx/kQCKwVrB68I4wg5CEcHnAZBBh0GIAZ0BkEHUQgyCXoJygg9Bw4FTQIJ/1j7xPfV9AzzhvIM83n00Pbr+T39WwAbA34FcgeZCOIIrAh7CKwIIwmbCQcKlgpjC/4L1gvXClUJgQdEBbgCAQBx/Wz79/kA+XH4b/gU+Rn6F/sE/Pf81/2L/ib/v/9kACEB4AFzAscCCwMtA+0CQgI/AQ4Awv5U/dP7XvoV+RH4Qvd59rD1BvVm9L3zTvME83zy9fHH8dvx7PH+8RDyKvKB8t3yA/Ou8s7xnfCi74Hva/AJ8gX0pfb3+g0DVg9+HEMlbiaGIRkbzxaUFKsR0gtDBF//OP/XAfQD7gOvAsMBFwJhAkYAQPsV9VXwq+2m7NDs9+1r8Hf0QvqKACwGNAvXD7wTrRULFQYS/Q3xCvgJdQraCgELnAsKDYIOgQ4SDGgHZAKF/nb74/dU8wPvfuyc7N7u7fHD9HL3mPrc/UgAJgHfAHIAogC3ARADMwRXBTUH9AnlDBwPJBASEC4PpQ0NCxMHSAL8/Q/7ffmJ+LH39fbE9n33iPj2+Gz4kPcJ9/j2Aff49hH35vcg+m396wDvA38Gwwi0CvkLOAyRC2MKUAmhCBEIcgfKBlgGTAZuBjYGRgXjA3ECKQHa/yr+QvzH+lH6zvrA+8z8+P1X/8wA3wFRAoMC6wKcAxwEQQReBOkE4QXZBlcHSwcfB+8GfQZeBa0D6gFrADT/Nv5m/cH8cfxD/AL8ovtF+/D6h/oG+oD5Hfm++Jb4mPh9+ID4sfjE+Kf4ePhm+EP4qfex9ov1WfQz83PyEfKV8fDwMfBI7xXu4uwK7Kzrlevc6yLtDO8F8rv3HgE5Dc0Y4R/9Hy4bJBbgE+wTFBPGD5wLwwlJCxYOTA+IDaYK0wjxB+wFywAo+bLxJe3r66/sMu7g7xryBvUQ+F764/t2/bT/hAKfBDIFvQSYBOkFqQj7C8MOCxE6ExkVkxV4E0UPmwpNB90FBQVxA9YAaP4n/fD8v/yd+9D5HvgJ9xf2jfSC8vvwHPEb8y32FvlV+zL9CP/bAEACCgOoA5gE+QVGB/cH9Qf1B5MIwwndCgILMAq8CCsHhAVgA9QAgP4J/Yj8WPy0+4z6QPlz+DL4DPiZ9wD3x/ZW96r4GPpj+7b8o/6JAasEEgenCMkJfAr1CjYLLgs9C7gLbAySDB4MlAsbC20KMAl2B5YF4ANmAuoACv8x/RP8r/up+6/7o/t3+0P7IvsT+yf7jftJ/CP99f3A/mH/qP+8/6//cf8c/9L+cf7j/Xr9Tf0G/ZX8Ffx0+7H6nvlP+OT2NvWa8zLy0/CS76ju4+3H7HjrVepg6UjowuYa5fDjPeQr5tLpge8L904BZg1FF5EamhfcEigQlhFdFYUXOxZIFH8VTxlqHF4czRmvFmoUnRI+DpcFXfsv9NHxnPJW9PX0BfSh8p/xWfD87e7rvOuj7bDwg/N89d/2Vfmb/WkCdAafCW0Mog4AECkQBQ/vDbAOthH8FIEWzhWREyQRQg+aDQoLiwc7BLEBd//e/NT5x/bd9L/0ffV49QP0sPGE7yDuyu1X7orvmvGK9L33MPrL+zf99f42Ab8DwgXoBsYH4wg/CoMLuQz7DUsPbxC6EJkPEw03Cu8HSQYoBVYEdwNaAhMB9v/9/uj99vww/Fv7YPqT+RP5w/jk+Lr5Mfu+/Dz+eP8pAIEA2QCMAakC+ANPBW8GQQf+B6YIOwmVCYsJNgmjCNgH8wYLBiYFigQpBPQDnwP1Av8BhgDh/lX97fuh+lz5Lfg893n2x/U19bn0TvTn85DzG/Nv8ufxd/HY8EDwte9273jvee947/LuB+4g7WXsbetP6uLpQero64rvAfXu+zwF+w5wEzkRuAtQB5gH2gzZEjoU8RFxEesUnRnjG4caKRcqFdYV8xXbEI0Hwf9w/WYA0wQ/BgoDEv56+v/3A/V78eLuXu5J8B3zaPTx87jzX/Uc+IX6Afx2/HP8l/wX/ar9Pv80A8QIsA0jEOEPCA5oDDYMkwxUDNYL/wvODGoNHg2cC54JfAhxCAwIwQW9AVH9+Pl++Hb4ufiz+KH4a/iV9+711fP88UPx9PFF80j0/PTb9Sv3A/lC+5X9qv9lAaACLQNTA90DQAVoB+MJNQxVDr4PERCQD5IOxQ2pDeYNtw3BDHULRwpQCZMIxAfGBosFHgRdAjQAH/5x/I37XvuW++b74/tw+7z6KvoK+mj64vo6+1n7f/vx+7X8tP2N/j//yf8WAC4ADgDN/5v/q//b//n/0v8W//T9ufyo+/H6Kfo3+fr3cvbQ9B7zwPGE8GnvLO5i7FzqS+jC5rDl1eTd5CLm9uhB7cvyYvnc/nYAo/4e/Hj7Tv70AzEJKQtcC2oNrhHsFVEYbRjFF34YfRrtGqwXrBLQDwoR8hTIF5MW7BH6DMIJggfhBJ8Bm/4U/Qf97Pwf+yr46PUP9f/0hPT78qHwme647fLtN++w8RD1MvgM+m769fm8+aD6U/wE/qf/uAFYBOIGsQizCXMKuAt5DZEOBw40DGQKxQl9CroLcAxRDMoLBguvCXAHlAT6AT4AcP/b/rr9JPy8+vP5r/ml+Xr52PjF94n2jPWH9UP2MveM+AH6TfuB/JX9Nf5i/vP+VwAGAn4DrASfBbsGFQh+CaIKJgsqC+YKnQpPCtkJWwkoCUEJPQnvCDcIFAe5BXMEVQM4AhoBAADT/p79s/ze+yn7q/oe+mf5hvjC9xz3hPZS9mb2gPaQ9oL2VvbM9Q71aPTs85XzPvP68ojyyfH48EHwiu+q7t3t1Oxk6ybqZunN6Z3rI+6+8cb31P0d/938+/nw93j5zf4SBAUFCQTzBf4Jsg39D4sQZBD9EaQVSBd8FAwQIw5aEFwVhxlbGe4V3hJ3ET8QHA6UC2oJpwhnCXkJNAfmA8QB8ABjAGf/Gv3P+Zv2LvR08qnxwfL69IP2ePZJ9afzevJo8qvynvIO8+v0hPd++WP6xvrY+1/+fAEqA5sCMAGfAJkBrQPGBUAHkAhfCgoMSwwCC0EJMQhgCE8J3AlhCWwIMwjJCAEJwgg9CCUHAgYJBcYDHALnANEAbAEXAnYCHQLqAMf/E/+b/lH+M/42/lb+0P5o/8j/FACBAN8A9gC/ACEAVP/3/jn/4P+mACoBUwEqAdIAawDo/1P/1/6F/lD+Iv7A/Sr9r/xi/CH8v/v8+tn5rvjA9y/3qfYm9qT1E/WF9D/0JvSs8t7w5e+97q7t5+y07Cvscevx7CPvZ/AZ87/3LPrs+JT3gvbT9d73D/zS/uT+AgDmAjMFwga6Bw8IvQhGC8oNdQ2uC88K6wvaDlsSGxQZE9ARdREXEQsQ9w6JDooOiQ+gEDIQgw4yDZ4M/QtiC0cKTgj6BRYErQJyASsBnAGEAY4AL/+E/X77wfl8+E/3rfYI95L3Y/fN9mP2Xvby9tD36Pch95X24fYQ+Gf5cvpj+078sP2A/7QABwEGAVgBRQJkA3AEKAXMBRAHpwjaCVUKHAqnCX8J3Qk8CgcK0wniCeoJ9AnLCTgJPwhXB8oGRwZnBVIEdAPrAqQCdgL1Ae8A5P8Q/2z+s/3d/Cv8rvuL+5P7h/tH+/n6v/qo+q36d/r8+c757Pkc+qP6KPso+xL7E/sD+x/79vqw+pf6mfq/+rz6wfqu+nT6IvrT+aX55/jI91r3P/ee9ub1j/Uw9XX0AvSU86DzTfS99dz5PfxW+hH5W/iz9934rfrn+4v7Nfy4/oX/X//G/+EAtAIpBa4GnAUOBPgDFAXaBgkJhwrGCloLFwymC9cKrAoqC8kLpgxjDSINYgwjDEsMMAxnDEQMJgvNCXYIfwe1Bl0GXwbhBWgF8wTzA10CpACY//H+lP5t/s799fxm/ET8Qfw2/Cr82Pt5+0b79Pp/+lL6sPpH+yv8Zv3w/ez9Fv5A/pj+HP+q/ygAhQAhAbsBAQJNAqwC+QJCA4kDkwNMAxMDCQMcA1MDbQM+A+0CuAJrAvcBjAFDAQYB2QAiATkB1QA8ANv/3v/O/5P/cv8V/0v+F/54/rP+CP4d/tH+W/67/YD9gv0Q/Rz9pP2l/QP95/xs/SL9jfyk/JL95/zc+438BP2n/CT80fxT/XD8NPzn/J38efue+0T8Ivy0+877Qfyf+1L75/ux+wb7BPtM+/f6svrb+tz6f/pb+nL6Mfsf/QD+Zf0k/bz8Xfwe/Q7+Lv65/TH+hf/m/6n/wP8KAL4A8gG7Ao0CAALxAVoC+wLoA3AEgQTsBF4FWAUXBRMFLQUxBYcFAwYUBqwFVQUdBQwFQQUwBZAE6gOeA14DCAPUArQCdQJiAmgCDAImAa4AygBVAPb/QQBTAM3/k/+//5v/df+w/+7/i/88/7H/zf8n/wj/rP/5////AgALADQAJgAGAFoAnAB+AGsAwAA1AaEAggBSAe0AXAAaAWQBygChAP4A9QDqAPsAzACiAFMAxwCNAJr/hf8yAEIAl/+U/7r/2f89/wT/bv/6/qj+0/6D/lr+Z/5r/mb+Q/74/dL9g/4g/nb9m/0F/hr+xP0G/gz+6P2T/dr9N/7G/aP9w/0n/ib+/f39/S7+df4R/gn+PP5Z/jv+rv0p/oX+OP4a/in+gf5q/i3+Xf69/jX+Af64/uj+gf4S/rT+Kf+8/pL+J/+I/yD/Pv+0/5r/Uv+W/w8ACgD7/0kAWgAwADcAdwCxAK8A1wA/AUUB6gAvAZ4BeQFbAZoBBQLrAY0B0QECAusB/gEQAjQCIQLsAQgCKwIbAtAB3AEMAtEB+gHrAZUB7wGEAe8AjAHMAUUBwgA7AdABDwGUAB0BNwF8ANUASQGGAGoAwQAZAakAQAD3AAIBhgCqAB8BjgA/ACcBDQEwAIAAfQHqAPn/hgAoAdcA//+GACsBIQD6/8EApwDh/9H/NwBUAOD/b//L/xMA8/8j/3j/AQA//07/j/9l/+z+EP+2/zD/jf4q/6v/7f6v/nz/c/8B/0X/V//k/qP+Sf95/+j+2v77/j//bf9G/0n/Uv8Z/1r/R/9B/4L/Mv8v/1j/gv9i/y//KP/D/8j/Cv81/6f/5f8w/2P/JgDO/5T/pP8FANv/iP9y//v/IwCT/zoARAD0/xMAzP8dAIYAGQC5//T/NgBZAFAA5/9QAIEAmv8qABwBPwBr/38ALAFhAO7/KwCcAJoAXwAxAIMA0gB5AJYAigBLAJMAnQCOALUA0gCDAJwA7gCrAEkAVgAQAQwB6P8AABUBsAC6/zkAFwFkAML/UQC7AC8Azf9dAIkAWgAAANb/fQBjAGj//P+pAPP/of8iAHgA7f/e/xkATQCmACIAnv8aAMEAMgCU/54AOQHm/23/pABCAUkAgP9eABYBPwBz/2MA/wAfALz//v8OAJf/yv/Y/57/+f+m/4b/cf+E/5H/4/7V/0gAvv7R/rv/qf/m/iz/9v9J/zL/lv8V/yj/2P/L/3b/Hv97/0MAk/9V/2cAAQAV/zYAWgAb/xgA1QD5/7f/NQB2ADgAzf9p/34AowAX/4b/ywCAAFH/2v+EACYAn/8B/3YAmwAV/8D/LwD1/7X/rv+WAA4AQf+S/5EAQAAj//T/VQDX/4z/sAASAKf+twAoAaT+xP5yASUB8/67/5kBnQBJ/97/YwFtAC3/swAtASYASf+UAIIA9v8PAE4ABgEA/xMAmQETALz+ewB4Ahn/ff52AUEBmv6o/pQB6AFm/if++AEZATP+Tf9FASUAt/41/0cBPgCp/VIAKAF8/9X+KAA5AfD+Kf/IAA0AVf9nAPoAT//0/uAApwBg/zH/hACoAK7/MACQ/28ArwCf/x0A4gBrAL/+zf8cAkoA5v3mALECNP8I/uAADQGA/xr/yf/WAGQAvf5u/5QB1f+P/a7/HQJI/7D9NQDwALn+Pf9nAAEA+v/w/qf/vv+g/zz/xf99ANn/df8HAP4AD/+N/tMAOwEQ/73/EgHl/zT//f9iACgAKwDD/0sBtv+e/jUBxgB7/9r/ZABl/9IATgFN/vT+SwHWAAz/Gf9KAev/4P4iANn/HwCX/tT/MAHd/3X/4/6W/4QAJQAX/x8BwgDg/ev/RAFAAP7+Ff71AtEBivskAZQCBP8B//P/sAGmAEsAgf5MAMEBCACRAA3/OwBeAY//F/+gAG4BMP/JABMBmv7y/9H/LgG2/3T+6AA2Abb/Jv4oArgAZv3zAB8Atv/3ACf+tgAfArz9tv+cAiL/kf10AZEBHv8LANcDeAEv/KIBfgSo/6z8NQDiAuX+eP0tASYCnfxR/+sBDv6p/xEAvv+P/6v/NgG+AGf+Gf6TAckAdP7L/tf/rwAQAOUBWP6O/VgCRgBf/3r/QgCeAJL//P+3AJL/bP4HAiIBkf0iAAgB4/+4/zUAuv9xAIgCFP64/QEDUgAL/FsAJwNiANH+ef6iAOUCf/+V/ckBAAHL/rgACwDH/oMBUwGp/vr/dQEBAIP+vv/CAWz/i/6IAs7/z/0xAJsAWwAC/y8AygDm/mL+FwH1AEn9a/9FAjAACv3U/n8BhAAf/4X95gF9Ap78RP+RAc3/y//p/o3/jgG3/zb9cQFjApj9Uv9XAfUAJP/e/tkBGgF2/g8A/AHp/hsABQFe/t8AfQIG/wv+Qv8LApwDKvxU/HMF+QOc+m78JQUNAZH9zf7LAEEDC/4C/tYCewAA/LEAQAOX/a/+XwD8/+YAuv8m/4D/fP8bAQgBVP67/WcC6wD0/fkBr//a/loA0wB1/u3/8QM2/fP7DASIBCz7Yvs4BW4EmPq3/b8FPgE1+73+4QTAAPP7g/9lBLUAwvuf/2AEiv+s+4MCOAMs/hr92QENA+T9kf9+AA7/4P/dAcgBVf3Z/k0BFwIAANT9wQEGAAQANQDR/0gBtf2e/xQCRADN/bUA/gLh/bn9AgGjAi//af3pAAwBkgD4/+/9HAHdAiT9Lf7+AwT/uPs6AqIBLv8L//H/HgFk/iwA2wIO/jv89QORAvr7Hv9RA/D/GPwb/8oEzgOV+Wr8Zwb5Acn5LP7zBWkAyPrh/5MDOf/c/JYAgQMe/2D7OgBRBaP/oPrjAYgCVf5E/noAcQKb/oL+SwI3AVL9yf41A+gAY/6NAE4CpP8M/fgB2QPR/CD8LQXzAqP5Yv7vAygDuv21+4cDLwRd/Ez7dwWiAq35iAFrBSj8L/pLBc8DufkQ/WoEkAPJ/Ej9SwJzAST+If8BAUUA+QGm/Xz7JQStA+/7k/3PAggBOv3q/usCDAES/MP/qAQq/3T8NAFoAmL97/7ABE8AEfq9/g0I1wBD98wBnAeA+z35wQX8A/j4of2+B70BFPefADIJdPvz96sEXQWO/G/8twJW/+j8rgM9BMj7pvuIBhADBvij/A8IqwMl+Cf91QUWAh/8PP6MArwAnP6EAb8AUP+OAJQBi/8t/yIEtv7c+5cDcwM6/d77CQLbBHT/XfvP/y0DfP+T/hoB/ADi/ZH/zgF8AP3+Ev5QAWYBLv/n/+v+0f7JATYBn/4XAfYAPf1M/04CbAA4/SP/DAQNA2T8AP1BAqf/n/9VAjsCWv2b/B4FmAFD+8b+fAFGAOT/o/9V/lkAvABx/wD+E/+OBEIBV/vi/10B/v5NAmoC9/3G/MwAQAR5/1v7EQDTBHkA8fmWAGQFP/1C/EUDDATW/U/9WgFqAOj91v5zA0gBx/s7/+0CVAFi+8H7SwXrApL6H/zRBMEDr/uE/Z4AqQLwAFH9l/0iAVoCm/1N/icE2ABO+iAAiATV/+P7Vv6GAi4DRv8G/rQCrf9Z+ywBSQUG/5f75AB7BXn8x/oqCCECt/fC//gGxP99+UD/YwXOABH8OwHNBLz+A/viA5EFCfxg/O4FaQb5+yP6IwJ+BrwCS/yz/YYA4P89/2YBRQPQ+hD9JgZnATP9YPze/vIDwwNf/o/85v0ZARwGTQDY+WIAQwTmAQMADvsY/fsFiwVK/Kf8+gVEAv34YP5aBwQAn/p8AqIFpP5T94f/YgswA5X0sP3HChIBtvbV/G0J8AMC+AL+cQZlAED5WgI7BFr6E/5hBTABJ/mBAHcIQfu5+bUEqgFS+9L/hgJe/Fn/AQUd///40gC6BZv9f/sPAWAEs//R/HMBp/8C/tMCkAJw+7D70gVZAjD6Ov6cAr4AeP94AML+7v+K/kP/LQQI/nz8oQC1AJgCUv2W+WoEBgjK9+D21AccBh37lfkcAy8GOvtU+xoGGQKy9o8ACwtB/vbzxf8bC3sCGfct/N4IZwJr+eb/CgHm/fIB/wQ9/Hv50wTGBa755/lCBUIFrP2L+ykAzQGcAX8D7P66+GH+1AYGBAH88/fOApUIAv4h+rD+zAJ9AvUAAP8pAD0CngEq/SL52gKvCgoBq/j0/hAEBQER/rb+5gGK/2f+RgWOAu/63vykA0cFj/x7+nUEGQaG+yz6HQSTBmv/RfsT/0kDWAMK/eL6MwTHBdb/if/j/iz/6QMDA+r7vv9kBTb+9forA2kI/P2B9zYBIwRU/k/9KwOFATj4c/9gCKUA7fcO/h0HTADy+Qn9OgV0BNv4hf3EBRf+2fu8AiwB2/nV/V4HvgPV+dj3TAT9CDP99/ii/g0GDgN9+3X9tgO6Aij8ev8+AiH9l/+rBEn/7vdm/h8J0QOY9kn68wQnA6n9aP/6Aqz8gvxdBfYDEPtI/e4EhADO/N//iwPT/nb7yALkAk37kv3xCJ8E0ved/rgIJ/0g9xsEJgfS/ez7IwR1AVH66/+3Bj8Ac/YpAMMIHv7g+IQD6wWQ+dn4oAcPCfv2jvMsBecJevwF+3YCWQL1/oH9Yv8g/3sA4gIsAcj8D/49AlwAugFaAT76cv1+BWIDu/zO+u8BEQbIAIb+bgWbAKD0DwExDCD/dvQrALcOkwLk8K36iAv/Bxj6OfWx/3kJ6QFZ+kj/Ev9P/fUDIgSa+6f5/wHfBrIAx/p6/qsGfgaI/WX7Qv+DASgDtQKY/gj7Af+ZA9QCuf9N/7IAx/1B/4EEeQK3+xr5+AGjCWkBs/dW/S8EVAC5/Ar9fAPVBAf8m/x+BNcEEv6t+1X+HAKWA0r+NP21AfEBwv4w/CX/ZAOLAIT+wQHf/xv+BgI//xj8JAGBBE0AqfxX//gAaf9P/UUAgQMH/8/8I/8iAVMA4P2T/icAof/8/zkCa/7/+43+Kf6OAkYFfwBu+2H8jgHGAbQAqQBx/7r+UAM/Bfb7h/h1AvwFsf0H/RgDn/9J+vv/bQS6/tD8oQL6A5f/ifut/IwDfwPw/jj/8wH2AXj9CPzr/ogBEgEKAtEDdAEs/Tb8AwHjA0QCL/+Y/iQB3QEi/qb7dAFtBW8B0/4AAAIA5fwU/1oE1v81+98BXQflAEH6Bv3mAIz+Pv3jBFgGDvv29x7/PAOgAjb/Jf3s/hAAr/+SAHT/8P54BGsDt/qm/UAEeQG7/fH+FgTPBJL+4Pu3/pAAQgJEA3kAtf5mATQCCP4I/L4AYwW+AP764v9cBTsC6/1i/vH/YP9MAVADtQBa/JX8qQIIA4L9ZfvIAFcFev/w+p79bAHjAlEBN/65/PEB/gNA/gX9QgF7A5P8w/gUAs8HAwL9+7n+MABo/gcBIQNpAdf+ngDRAkIBBP9Z/mYCfgTkABH/kf4y/ZX+ZQGPAHX/0QE3A5L8jfNz+jEGwgCM94D+KwgqAlX7tv49Ak7+6fuzArsE1/34+jsAcwPX/4v+KAFFAEr9of43AmQAx/+eBL0CUf2J/gkDwAGy+9j6owDlBBQBvf0BABIBLgDS/7gAlf/h/fb9sf0y/hX/vgCVAP39+/2MACwBqP65/aX9Fv4lAo0ETQHV/ucBuQPdAbMAQQCD/wz/RAGoA74CzgH7AkUD+AAF/xv+ofwQ/qEBJgEi/sn+QAGKAMf+Tf4nAGYB5v6a+wr9WAG4ARkAb/8fAHUAvQAMAPX84vv7/UEBPgKMAc4BOQPMAf796P5UAPH/kwAGAeL/Gv+uAEABLACj/kn+hf/h/2T/7P9kAHT/RP/c/2UAfgBBAMQAdQB4/6v/NP82/n7/CwLnApcBEABcABABov/o/nMAlgFlAS0BkgE2Ab7/Zv+TAXICFQFUAXoBaf6d+838cgCSAygDHgBn/qH+ef78/FX8r/1T/98AvgGFAOP9i/yC/l0AKwBBAAEBkgDd/rv9xf6VAQ0DWQFH/of+vAFzAhwAO/7W/Qf/kQKPA78A7P6S/2wCGgIb/g/98f4LALD/LwAAAZ0APwAkAFv//v5sAEgBLwBz/9IA1AHoAEgABQHLAW8BqwB9/8b+e//MAEEBDwFKAf3/Jf7+/V//5QCXAKL/k/+BAHkA4f6j/qv/VQAhAHD/BP+L/jz+rP7A/04AuP8L/xH+j/06/kP/YgB6AHj/u/4s/0b/ov4q/3kA8QCaAHz/v/6f/+z+Bf42AZwDYACA/Qr/KgBP/+3/FgJNAnUAmACkAtgBcP9AAIkCWwI6ASEClQLVAKIATAKnArABfAHPAaQA7/7i/skA9wH9AIkApgDr/0f/6P7n/oH/AwBlALAA9gDnANn/o/4U/kH+hP/UADMAN/+T/x8AnwAEACT/uf91AGoA0//r/8kAwQD8/xMA7ABpAaMBfgE7AMP+W/42////2P/6/0sABgB2/4z/RgApAAP/3v5SAAUBMQBD/5z/dgCCAPj/Ef83/iT+7P48/5j/SQFhAh8BU/8z/6r/e/8bAAQBXgAb/9L+aP9F/xz/v/9BAEUAq/9R/yL/wf4K/9//ZgB9AD8Anf/A/mL+X/4P/tz9Av6B/oj+EP7w/Y39D/0A/UH9OP3+/CH9Q/1h/Xn9o/3H/Xb9Jf1+/RL+zv0Q/Wz9hf4A//v+r//PAA8BKQF3AWQBSAEcAmoD8gMDBFUE3gQpBW8FowViBW0FZwYbB9IG1gaVB+MH2wcACLgHWgdhB3AHIwffBjwHwQd7B5cGDwbWBYMF+wRaBP4DjQPrApoCaAIzAvYBdAEFAcwASwDI//H/YwAwAND/BgAOAID//v7l/uX+yP7B/on+DP7d/Q7+ZP6L/nD+Q/7G/Vr9X/1w/X39Yf1c/XD9Zf1q/V79if2X/Rb9gvxA/CX8APz7+/b7Afz2+6n7evtL+5/65fn4+TL6wPnx+M34Wvk0+VH4rPeG95j3yvdm9zX2svUn9jD2hfXr9F30KfSW9Nz0UvQr847ysPLe8QTwXu6d7EzrvO7r+ToF8wVQ/vD3SPZN+lgCngZFBPICWggMDlsNnQnyCK0MgxF3FLcTExACDngOaA6PDvwR/BYcGA8Ufg5+Cq4JCQsbCxQJQAhzCsoLDwlwBEIBaQCKADIAwP71/FL8M/wd+zb6YPuX/T7+i/z1+TT4VPjD+bL6yfr3+xL/ggFQAdX/FP+g/xcBlgJcA7sDjwTvBfgGZwcbCLQJrArhCXkIUge7BskGQwezB8oHBAgRCM0GpQSbAvEAxP9S/3r/if9c/xD/eP7Y/ZD9Vv3b/DP8yful+6n7Cvy9/Kj9nf54/+L/xP9I/6z+bv7G/o//YgAgAa8BBQLjAU4BuAA4APH/zv+1/2j/7f62/rH+lv5h/hX+sv0A/fD7/PpQ+tX5h/l3+Yb5Zvny+J/4jPgB+N721PUq9a30mvT59C31B/UQ9TD1zvT/84XzWfPu8jTyaPGF8F/vhe4p7qjtpOxM67HpV+hL5ozjf+DE3uvoUADYDvUJe/+t9gn0If2mCPAI9QJVCIwW1RslFuEPDhEzF5YdHSFGG+MT8hOsFesSLxAOFjIe4x8UGx4RNAhbBhwJJwjaAkMC9QYUCq0HTAGs+6r4d/kh+wn5PvYA9lD2F/WJ9Jf3XftZ/Q3+NPz6+Az4w/nB+vX6Sv61A4gHEQkQCTEIGAcOBxcIxwhNCWIKyArCCfsIpwmbCvIKoAokCcoGuQTlAroAV/93/xwAeQClAD4A3/4Q/YP70/qx+vH6ZvtJ+zP7R/wB/vr+T//C/+3/9f9RAOUAeAFJAuwDswX/Bg0I4AgNCZsIRAgPCKsHTgcWB60G/gV0BQYFVASzAxUD/wF+AAH/vf2r/Oj7fPs9+9r6Vfr9+aX56PhT+BP4+vdV+Or4dvm++Tf66/pj++H7TPyY/LL81vwW/Rj9Lf1Z/Vv9O/0Y/Q39Bf16/Fv7bvqy+c34IPi497T2HPUD9GfzYvL08JLvHO5z7EbqIegX5qfjlOFE4OHevNyu2t3agt0E4Rbrrv+4DzwPBAjAAU/9qQFMDiAWRxQbFR8eriQTJA8hRSGBI9YlainBJmodBBb0EiURDw/AERwWCRZ1EhILmQH++d737vdd9d3zTfXh9gf2wvNx8XjuAe4G8X3zVvNE8k/yU/JI82/3//zZAXcF6QcLCOIGQwc1CPMI1gqEDjASPhRUFdcU0BJGERwRshD6Dg4NaQqJBjQDewHhAKcAigDU/1f9Efom9xf05fDu7vvug+8H8O7wePFg8bzxSfPw9Kz2Sfmi+7n8v/2o/6UB/gNeB2EKfgxzDioQyxCvEOcQOxGHEdIRBBKqEX8QPA+1DdcLJQqICIYG6ANmARj/6fyB+6z66fk1+bv4LfhN95v2VvZF9lH2vfan98f4CvpJ+2b8kf0G/6QAAQIEA6gDDgSABB8FwAUdBmgGrgaKBhUGdAVtBEEDMwIrASYAMv8g/qP8//qf+Xb4T/f39Vv0svJZ8Xjw4+9y70DvGe9d7iztWOys67jqZuqt6oXqA+rk6fvpb+mX6LXnNeZa5M3jweSk5QbmNece6invW/yUEg0iqyFyGpgSygyGD/cYUh0kGVUYyB7KIt4gqhxxGq4ZpBq+HWcamg9+BfL/s/yO+l79xgE7Az8Ccf7q95PxJvDx8MPvMO9b8Yn0FPYk97n39vaG+PX9oAOwBVEF0wTBA9ADqQbjCmEOahHGFNQVdhT0EhURkg6uDKUMrwyQC0YKYwg4BeUBewD//6H++fyW+vr2KfPU8AzwkO8N8JTx3/KR8wn0NvSM81TzmfSJ9o/4zPof/dv+hADZAnAF1Af9CdsLnAxcDBIMogsFC6AKwQr2CtIKsAr+CW8InQYSBZ4D6AF0ACX/wv2L/JD7pfql+Sf5Nvkw+Sf5S/l6+fD59vpY/Nr90f/9AbYDGgUxBvQGZgfoB5wIwQgOCVsKgAueC0ML6QqwCocK4wnVCG0HrgVCBNoCCwFx/3v+t/2p/JX7nfrL+Rr5cfiy9+32ifaJ9qb2ivaK9gz34fem+F35KPrD+kr76fub/A39JP1L/af91f3B/cL9mv1J/dL8QfyB+2b6MPkX+BX3vfUd9Ify6vD37vTsauv+6Q/o1eVX5DXj5uEP4avg0t9Y303hseRZ6Mbsk/U3BkgXZx6LHGgW1w+IEIUZCyHKH+IbOB1vIPAhQSH6HpQcQxyyH+Yfuxf2Cz0Cvfto9+L2TPhB+K33sPbj877uMOuY68nsde2E7jvwB/Hh8XL0o/ad+Lj8uQOYClMOjg93DncMKQytDnUS2xSKFqwXaxdOFp0UQxJRD1gNdAz1CjgIOQSj///6s/d89vL1hPX79MDzSPFe7qDsAOxL7Jftiu9g8ePypPRa9rf3XfkB/G7/zQLABdIHxQg8CQ8Kdwv+DHsOkw/fDzsP9Q1oDHUKhggIB70FZQTxAisBzv48/Cj6nviS9+32f/b39S71ffQI9PDzk/Qt9ij46/ma+3n9q/8HAh0ExQUlB70Iugp1DGkNmA2HDY0Nzg0RDtgNJg0WDM4KQgm/B1AGsQRKA/kBDwEQAIz+R/0m/CL7i/qQ+qr6lPqA+r76Rftq+9b7Dv3e/TL+of70/j//pP/q/ywAswDoADMBqQGWAUQB3ACOADUAxv83/6P+J/56/a/8Cvy8+077v/pJ+pX5r/jk9z33g/bi9Wz1+PSY9BT0WvN48qbxDvFT8D/vEO7g7MrrF+vM6obq6ulS6UrpaelG6Vrp9+lQ68Tt5/HY9pj7+QIWD8caEyDkH3scDBgaF98avh0qG+4WiBUFFjAWeRXvE8gRBhGsEtUSkw1XBIH79/TN8LfvevDT8OPwIPKy88fzkfO79MT2nPiC+mX8tvxr/Gj9Zv+2AfcELwrID/sTUBZkFoQUPRKAEacR+hCPDwUOXAyRCu8IKgfLBMQCDwLIAUsAMf0b+bH0EvEl77Xuv+4R7ybwbPFF8hHzLfSP9Tz3Z/mo+zP9Kf4g/w4ACQGsAiwFGwjeCigNgA55DrgN4QwJDP4K0AmmCEQHqQUcBIICwgA//1D+xv0N/f37d/pr+Fn2zvTv86Dz8vPl9A72KvdE+FL5cfrF+139Ff+qAD8C4gNcBXUGfgflCKsKgAz1DaUOZw6vDeQMGQweC/0J9QgMCAkH3AWjBFUDKgJBAYcAtv+o/nj9N/wT+0P69PkR+l/62vp++xb8pfwz/az9Iv6//mv/2v8PADYAYACCAM4ATQGlAegBEgL8AZIB+ABnAMj/Ov/d/qT+X/4N/sf9eP07/RH93vyb/ET82vtZ+976cfoH+r/5s/mv+ZD5avkZ+Z/4DPiJ9wj3QPZw9dT0RfSZ8wbzsvJq8iLy9vHz8cvxnPHL8QHysvHm8E7wAPDa71/woPEg8970UPc5+qH99gKVCmoSRBjwGk4atxdyFbUUtxRrFKcTmRJREeoPrw4sDn8OXw9CEN4PNQ2ACAkDuf3c+CT1yPKw8dbxJPPq9Bv26fbd9z35BPv//Nv+0v/W/1//zv6N/kf/kwEqBT8J8Ax8D6QQqhA8ELsPEA8KDqUMAwv0CKUGZQRmAgQBgADYAE4BQAFhAKX+O/x2+eb20vRr897y//Jw8/DznPSj9Sv3MPly+5f9Ov8sAIAASgDf/67/BgAnAdoC6QTkBnIIkAktCmQKKAqrCdsItgdDBmkEYwJcALT+wP2A/b/9Qv6h/pz+H/4m/fj7uPqj+ef4h/hy+IT4zfhg+Uj6oftz/YD/hgFWA7UEkgXXBcUFoQWNBcYFNwazBjAHmwfsBxsIHAgECN4HmQcEBw0GuwQqA4oBEQDi/vT9aP0N/cn8kvxg/Dr8A/zn+9v73Pvp++777/v1+xP8VPzG/F39If7x/q//TgCvAOoADAEKAf8A4wC6AIMAMADg/4r/SP8d//X+2P6p/mz+Fv6q/S39sPxR/P37vfuL+1r7NPsW+wL7C/sd+x77GPsT++z6wvqd+lP6Bfqt+Wb5QPk++WH5hflh+fj4sPiW+Kn4vfjV+MP4U/jO92L3NvdL95j38/dL+Kv4PPkp+o/7qv1JADIDxQWOB2oIdghKCD8IdAiZCIUIEQhwBykHbgccCO8IwAlrCggLmQvcC34LVQqZCLgGBgXXAwkDZALWAVgBGQEuAZkBOALvAo4D8wMDBLMD/ALuAdMAxv8E/6z+u/4A/0T/lP/2/10AygBCAZEBmAFRAd0ARQB//6v+8P1w/UP9iv0p/tn+cv/l/0MAjAC7ANcA0gCdAEIA8P+a/zr/9v7Z/u7+Rv/M/2EA5QAsAVQBWAEyAQUBzwCQAEQA8v+i/1r/I//6/vP+CP8q/2j/qf/S/87/r/98/zj//f6//pf+cf5U/ln+X/58/rD+8/47/4f/z/8RADoAPQApAAMA2f+1/6n/nv+d/6j/s//W//H/CAAWABsAJwAuAC0AGAAIAPr/7v/j/9v/2v/Z/+v/HABTAHgAiwB+AHgAhQCdAL8A0gDgAOsA8wAGARsBJQEzATwBUQFoAWcBaQFZAT0BHwEFAfkA6wDVAL0ApAB+AFQAJwD4/8T/nP99/2f/RP8c/wf/7P7c/t7+4/7m/ur+8P74/vT+8v7x/uT+6P7n/u/+9/74/vT+7/7v/ur+8/72/vP+3/4l/7H/tf+K/4D/Av9Q/hr+//26/bT9EP56/oj+Zv5d/jb+1/2L/X79mf3E/dT9zf2p/Vv9FP30/Mn8lfx+/HD8ZfxX/D78Efzb+6P7Uvv9+tb62vrl+tX6xPrH+r76wfrt+jP7aPuj+xP80PzN/dn+8f8DAdwBfwIkA9oDngRUBdcFHQYsBj0GWAZ7BsMGBAdBB5MH+QdgCKQIvQiRCD4I6QeOBygHowYGBl4FrAQJBJIDNwPrArACkwKAAlUCCwKnASIBfwDk/1//4f5f/vL9lP1E/RH9A/0a/Tn9af2z/QD+Nv5d/mP+Vf44/hD+Bf4B/gH+Dv4y/l/+nf71/lX/tf8HAF4AoQDMANgAwwCaAF4AMgAIAOj/3v/W/9v/5v/+/yMAPwBbAGIAVABGAB0A1/+G/zL/3v6e/m3+Uv5F/lL+Yv58/qH+vv7o/gT/IP8X//n+4P6w/pP+jv6D/of+n/7V/hv/SP+K/9X/IQBuALoABQE4AUoBQwExAQsB7AD0ABEBNgFaAXQBjgGgAccB+QEVAiQCMwI4Ai0CIAL8Ac0BjwFqAWoBaAFwAWwBaQFfAUYBPAEwARgB/ADcALkAjABbACIA4/+7/5f/iP9v/1f/Sf8m/xL/Af/y/tr+xP61/qf+nP6R/oz+Iv/i/yoABQGwAWEBhAHhAe8Av//x/9UATQFSAT8BwwCf/03+rf3q/XH+Gf9i/5j+Qf1d/PH7rvux++P7C/y6+zf7Avu++mz6XvqT+rL6o/qj+rD6Zvr4+ef57/nd+cH5rfmW+WD5DfnC+Lz47Pjr+LL4e/hQ+Dz4dfjK+A75aPnh+dP6TvxH/lcAFQJqA3IElQXfBjUIOgmdCW8JJgkuCYsJ9gkaCg8KDgp8CmcLewwgDegMSQyTC+AKNApKCfUHRAaYBEQDQQJHATgAXP/U/qj+z/7+/tf+Mf5K/XD8tPsD+1n6q/n8+Hn4Tfh5+ND4UfkX+hD7Nfx5/bb+tP87AIsA0AAXAWMBngHXAQYCPAKlAj4D0ANJBMAERgXKBTcGbQZEBrEF3QQRBDkDUgJfAXwAvf8a/63+S/7t/Zn9WP1E/Tj9Hv3h/IL8+Pti++j6fvoz+gr6CfpC+qb6KvvM+3T8Lv0I/uf+vP9vAPYAVwGIAboBAwJRArcCIQOMA+cDQASeBAgFdwXOBR0GRwZKBjIGAAakBR4FkAQFBIQDDgO2AlwC6QF1ASQB1QCIAFkALADt/5T/S/8A/6b+T/4V/gX+/v0W/kn+Yf5s/on+v/73/jH/ev++/+b/AAARAAwADAAFABIAJQAvADQALAAXAOz/zP+q/4v/aP9O/zH/9/61/mf+H/7U/Yn9Yf03/QH93vy8/Iv8Xfw//Bb88fvT+777q/uA+1v7Jfvi+pH6Uvo6+hH67vnF+Xr5F/m4+Gj4BviS9yP3zfZ29hH2kvX89Gj07vPD88/z8fMe9HH0M/WD9pz4lvsC/yUCjgQ6BncHywhVCrsLcwxMDKsLSAtxC9wLJwwuDD8M1gwuDugPNRFtEZAQNg/pDY4M8QrwCIAG+AO7AREAxf6F/Xr8+Psm/Mn8i/0H/u79Of1A/GH7kfrI+QX5TfjG95X30feK+KD57fqK/Hb+cwBUAtQDpwTKBIgEQQT8A7oDgAM9AxAD/QIrA4sD6wM6BKEEPQXMBRoG7QUtBeoDbgL0AIX/J/7g/N37Pvvp+s/63Prg+gv7cPsD/JX8Af0n/fv8nfwg/L37aPtF+2f75vun/IP9e/5e/0sAMwElAgEDrwMpBEsEJgS0AxsDdwLoAXgBOwE9AWkBqQHqASsCWQJ/AqkC0ALtAtwClAL5ARQBIQBI/7b+df53/qf++P5z/w8ArAAmAX8BtQHoARYCJwIhAssBQQHCAGkARABPAI8A5wBAAYsBzwEBAv0B0gG6AaMBbQE5AeoAgAD6/4r/Tf8g/2H/+f+YABgBVwGDAVoB3ABsAAwApf8y/9b+bv7c/Tn9r/xo/Ef8T/x0/Kn8z/zP/ML8ufzG/Or8If1N/Xr9pf24/bL9q/2y/Zv9nf3I/dH9qf1C/b38NfyY+/z6gvoZ+qD5Ifmg+Bz4hvf09nL26fVs9R/1+vSs9EX04vN28yzzBfPr8tPy+PJ982v0l/Xh9pv4IPv+/kMEXwpOENUUjRfjGLUZZBp+GmkZzhYXE0YPHAxyCaAGcAN2AOj+Pf+UAKMBSwFf/+D81fp6+Tb4gfaA9NfyTfIf8+z0+fZR+XX8vgDnBe0K8A5AEfgRuREAEe8PZw5bDBQK/AdHBgkFGgROA5sCPQIzAjkC9QHnAP7+SfxC+Wz2CvRQ8jfx5vBs8cvy7vSR92D6Ov02AD0DAgYcCDgJTQmaCH0HWQZKBWEErgNbA1oDcwOBAzYDuAIwApYB0wCx/xP+A/zZ+dj3Jfb89HT0vfTh9av34/k3/HT+mACDAjYEjAVlBtMGzgZfBp8FtwTFAwEDkAJgAlcCXAJZAjYCyQEPARgA9/7K/av8sfvP+jv6LPqj+lr7I/z3/Pj9aP8qAeYCKAT7BKUFPAbJBgMHswYaBoQFEQWtBCMEXANfAl8BiADL/wf/Pv6F/fv8mPxj/Ez8Rvx8/OP8gP1F/hT/7f/KAJEBMQKgAuEC+wL9AgED4QKhAjQCqgENAWQAw/8X/3X+5f1d/dP8VPzQ+2L7KPsu+2r7zPtF/K/8JP2b/Q7+Vv57/pf+gv5Z/iT+xv1U/e/8oPxd/Bj82PuK+0f7FvvF+nP6HPq2+Yn5fvlM+Sj5PPlL+Vf5h/lz+Q35zvjS+N741/i5+Dz4affU9oj2Lfar9T71+PT59Kf1+fa4+N/64f3sARUHOg0yE6MXwBnyGToZexicF3sVWhGLC7sFRwFt/lL85Pl390z2dPdr+lL9h/7h/bD8d/xl/XP+sP4L/qX9uP5aAbAEzgdiCv0MERBlE+4VgBbrFKgRkA1FCfIEfgAO/B/4C/U686Py4fK58w71xvbN+Oz6uvzj/UD+H/71/RL+vv7t/4EBawOVBfAHPgosDG8N6w2YDWoMcwqtBy8ESQBV/Lv4zPWz85/ygfIt83L0A/bB94b5R/vX/Cj+Jf/Z/4YAFgGsAVgCIQMhBGMF3QYzCDQJmglRCWwI6gbrBHECsf/o/E/6HPhj9jH1m/Sp9FX1jPYh+Of5pvtG/cf+KwBYAUECEgPdA6UEXAUoBh8HFQgdCSUKoQr1CV4IcwZDBA4C///X/cT7aPrS+Zj5jPm4+VH6evsb/b/+DgAYAeIBdALPAggDTgO+Az0EsgQFBR0F9QSOBOsDFwMlAiUBIQAW/+792fwI/HP7Nvtc+977kfxa/Sr+7v6D/+D/JQBLAGsAlgCjAHMAJwDq/7n/jf9h/y//B//f/p3+NP6y/TP9w/xl/Bj8zvuW+3X7WPs2+/z62/rU+tr6APsY+w/7E/s3+0v7S/td+377nvvM+xn8dPyA/CD8i/vl+mv6Lvr2+b35cPnX+ED46vdK9132IPas9ir3UvdR9x73Bfe390L5ifuC/lkCYgdMDfUSHRdbGcwZGhn6F40WWxR7EPEK3wSG/4H7qPiX9kf17vQQ9qz4mvuZ/Tn+Jv43/gH/PgA5AccBEgLeApwEIAfnCX0M0w7pELISuRNBE+kQBw03CDkDnf6H+gb3GfQM8jHxh/Ha8tb0P/fj+Yz8+f7wADoCxwLWAsEC3wJVAz8ElQUcB40IsQl+CskKcgpjCZAHDwXvAYv+I/vV9+30vfKM8XPxe/Jk9M/2ZPnj+z7+TgACAkUDIQScBMcE6AT/BBUFIwU9BXkFtAXeBcIFJgX2A0UCKADZ/Xz7M/lD9+D1HfUL9bP14PaH+JH6xPwG/x8B5gIxBPoEXAVPBREF9gQRBTMFLwUcBfcEyAR4BNwDEAMpAjYBKQAm/xj+2fyO+3j60/nK+a76Zvx9/mYA6QFbA54EWgWiBaUFkgVjBRcFogTjA+QC8wFuAUUBLQEQAfYAqAD//yz/a/69/Rr9sfyp/P/8hf0r/t7+g/8oAOsAxQFvAr0CyAKIAukBIgFmAKb/9v6M/kv+Df7c/cj9qf1O/Qf9Av0d/Sv9GP0k/SD98/zP/Nn85PzU/AT9W/1y/TT9EP0D/dr8m/xl/Er8BvzK+7X7jftW+1X7tPso/En8Jfw+/KT8uPxM/LH7E/uE+ir6Bfqp+Ub5Uvmi+aL5P/nN+In4hPis+Bj5p/kH+iL6Z/ra+oH7rvyG/jMBjQR9CNcMFBFLFMIVthWgFAITChG+DpoLFwcxAgf+K/sg+X/3svbu9kb4ivo//Ur/HgBQANEAvAGhAnUDQQT/BNYFKQf7CLcK3AvMDI0N4g2BDSwMxQksBhQCJv7J+uf3m/VH9NHzLfQ/9Q73N/lf+5X9xP+/AT0DUQQFBVQFZQWGBeQFXwb1BpMHCAgSCJsHuQZTBVwD/QBp/tT7Wfk596r1qfRD9JD0uPWH97T5E/xo/nIAEgJwA3IEBgVHBVkFWAVQBU4FQwUXBcEESgSyA+wC0QF0ANj+Bv0w+4L5Lvg197j21PaP98n4XPo8/CL+7/+SAfECBQSlBOsE8QSkBDME2gO7A7YDtQOxA50DTQO3Ai4CxwFFAVwAQP9P/rP9f/2B/VP9Av02/Ur+AwC/AS8DXARFBe4FJgbHBQAFKARmA7wCNAKpAQsBbwDi/4//aP9u/5z/nf9R/+j+kv5Z/hn++v0w/qb+Uf8LAOQAfgHFAQQCOAJEAh4C/QGuAQQBOwCd/yP/ov40/vj91f3A/cP9wf2c/U79Dv38/On83vz2/Bn9Lf1S/br9Ef4m/ir+Mv4q/t39eP0H/Wv84ft3+zX77/rj+kX7n/u/+/D7X/ye/I78jvyl/Hz8Ufx4/Kj8g/wX/Nz7u/uC+2X7kvu2+5n7sfsD/AP8kPs1+zT7O/sf+9T6kPqf+vr6Tvt++8j7bfye/Zr/ggLrBUkJiQxeDwERdBFnEfQQhw8pDa8KOQhNBR4CSv///C/7Jvpe+ln7Sfw5/Wb+X/+1/9D/MQC3ABwBzQEGA1wEjAXYBlgInQl/CkQLuwtyC0QKeQguBkkDMQBg/Rz7SPkl+Nf3Evi1+Kn5/vpl/LP9//5AAFkBJAK3AjsDqQMHBJIESwX8BZMGDAc4B+MGBQbBBAYD9ADH/rH81/o3+QH4Wfcr93P3RPh7+fL6cvz7/Wv/kgB9ATcCxAIiA3AD0QM4BIIEwQTfBM8EeQTXAwcD4gF/AP3+cP36+576mPkC+dT4GPnL+dL6D/xu/c3+FwAhAfUBlQL2AioDLAM1A2YDwgNIBLoE+ATZBGkE+APQA9EDbgNhAtMAXP9g/vD9k/3k/Gn8vPwL/sn/UAFVAhQD6QOaBNwEowQqBLkDSQPiAoUCFAKwAVQB7ACGAEcAZQB7ABwAXv+q/kr+Av7b/dr9+/1e/gj/3P+DAPkAVwGdAbQBpgGYAW4B+wBIAJr/Hf/M/on+VP4a/t/9zP2y/WP98/yw/Kf8hPx+/MX8Gf1b/aX9Bv40/kj+i/7M/oz+8P2K/RP9Ufx++/f6wvqv+tf6Mvth+1z7r/s5/Gj8HfwF/F78hPx1/I78ovxz/Fj8lPy2/HP8a/za/CP9B/39/PH8XPyN+zv7Sfv3+nj6kPo1+8f7Rvzd/Cz9Yv1V/nkANwPSBUgIuAq9DNwNYA6gDicOwgwrC/YJjAhnBtUDTgHi/uX8Bfw4/JX8s/wo/RP+2/4k/2X/z/8iAKwA3wF+A74EogWeBqYHaQj5CJUJ2QlqCW8IPweZBVQD7QC8/tz8Tvtc+h76J/pX+tD6kPtU/Br9Dv4Z/wUAyQCVAWYC/gKSA0AE1QRXBcEFJgZDBuQFLgUQBJoC7wBC/7f9SPwB+yL6pPlr+Yb58vmY+ln7OfxM/V3+Mv/3/7QAVgHuAXkCCwOOA+oDSgSABG4EHgSSA9ACwgGJAFT/K/4O/RT8a/v8+sn65PpN++/7q/x6/Vb+L//b/3wACQFnAbgBBQJdAp8CzwIKA4ADKgS6BOwEzwRcBJ0DVwO3A8kDiwJ/AMr+pf0l/Wf9zP3J/RX+jf93AV0CSQJsAuQCLANSA5sDqwMAA1ECCAKfAQYB9gBzAX8B+QC7AOUAoQDM///+if4y/hb+fP7o/tn+xP4a/4H/tP8CAIEAxQDIAMwA8ADZAHEALwAAAL//of+o/4r/Gf+p/mn+Jf7M/X/9Xf0n/dv8u/y1/KX8qfzq/C39U/2B/c395f2t/X79X/0y/fv81vyb/DX88vv4+wv8Dfxj/Oz8Sf2S/dP9+P27/WT9WP1n/WD9Vv1X/Rn9uPx+/GT8MfwI/EX8o/zi/P/8Iv0+/Uj9dv2g/Y79VP1T/Zj9yf2u/Yb9ev2L/Rb+i/+UAZADlwWpB3YJrQp8C9wLbgtnCm0Jqwi5B1QGogQAA2sBHwBZ//3+yP6v/u/+TP9L/wz/5f7O/tL+G//W//gAKgJMA3wEfQVDBuEGVQeMB08H1AYZBggFpQMiArUAY/9M/ov9Iv3u/OL87fz2/PT8Bv00/Xz95f1s/hz/1/+pAJIBawItA84DWwTIBOsEyARaBJYDmwKCAWIASv9M/nr95/x7/DD8EPz++/X7Afwt/Gz8xfwv/a/9VP4I/8r/nABuATIC7gKFA+QDBgTpA48D/QI9AmQBegCW/9P+Kf6o/Uj9Bf3i/Mr80fz1/Bf9QP14/cn9K/6J/vn+ff8CAKQAVQH9AbMCiAOCBD8FbAVABTIFbgWLBSAFEQR7AtkAv/8f/6X+PP41/oL+1P4t/4r/9f8vAFQAngD7AEwBmAHMAbsBmwGpAQsCYwKPAp8CjQJUAuMBXgGwAOr/Qf/R/o7+Yv5D/j/+Mv4v/lX+lf7i/in/Wv9w/4D/jf/J//3/HgBQAHUAngCgAIYAVADv/4P/KP/I/m/+Ef64/WT9I/0D/ez81Pyn/KT8xvzu/AT9FP0m/TH9Rv03/RX99vz8/CT9M/0z/Ur9i/3F/eX9AP7q/b/9o/17/Ub9F/0P/Sn9Wv2K/ZH9Z/0b/RH9Pv1G/UT9O/08/U/9TP1H/U79U/1l/XT9bv1y/Zv9vv2I/Un9lv24/pwA1QIWBUoHWwnzCtUL5Qs6C0YKLwnYB1QG0gR1A0cCHwEKADz/3f7x/j3/a/9R/xn/xP5u/hT+4f0I/pX+nP/7AIwCAgRNBVAG+AZKB1UHHwd7BokFZwQvA/MBuACm/9P+OP7X/bb9ov11/Tv9/fyy/G/8Wvx//OX8gf1W/mD/ewCRAY4CZAMKBGgEiARvBP8DYAOSArIB2wABAE3/vP5D/tb9ff0x/d78fPwY/M37k/uF+7z7IPyt/Gz9WP5a/0YAKgH/AacCEQNGA0MDBwOgAi0CtwEhAZUAJQDG/2z/D/+4/lX+2/1y/R390fyc/Hr8h/y6/Bv9n/0w/sz+Zf8EAKQAHwFvAawBygHQAcYBpAGBAUEBBgHPAIkAXwA4AAwAvP8//8v+fv6E/gj/1/+RADMBGAI5A9oDsgMnA40CLQIVAvMBhAHgALAA7AD2AIsAJQBFAHoAiAB9AFIA/P+Q/0f/Af++/t3+b/8FAEcAeADVAAwB9ADSALMAjwCEAIoAhABBAPL/3f/H/53/jf+m/7j/qv+X/3v/R/8A/9L+yP7L/ub+Gf9M/17/av+X/7n/t/+5/9P/3f/G/5n/e/9k/yH/AP/9/uf+3P7S/uP+3/7J/tP+3P7Z/sb+y/7c/tj+6P4F/w3/Bv8a/0D/S/9P/1b/W/9N/0b/Y/9Y/xX/yP6D/kv+K/4p/hf+Wv4AAMUChwTPA5wBov9V/pH99/xn/EL8Ef1//hT/Xf6e/fz9of6d/m3+yv5k/1n/p/6v/Qj9Df20/U7+JP4J/oD+xP4O/qH8oPtO+0b7VvtY+zb7Bvsa+1j7g/s2/Ez+rAFrBboIHwtDDBkMJgvpCZIILAcmBrEFUgW3BOAD4QKOAUsAj/9D/w7/uv5k/tj9/fwU/Kj70Ptr/LX9gP9UAfUCYARXBawFsQW6BdgF4gXFBYUFEwVnBK0D7wIpAlcBpQAZAF//kf6v/dD8/ftT+w/7Gftw+xf8AP3Z/aP+dv8wAMYAMQGsAR4CgALSAgoDDAPSArkCiwI5AtABXwHmAEUAmv/m/jf+kf38/Ir8Ovwj/Eb8hfzI/A79dP0F/pf+Hf+j/yUAmwAGAXsB4QEgAlQClgK2Aq4CkwJ4ApgC6gJfA5kDXwPhAj4CiwHmADsAe//6/rL+p/5n/mz+/P7y/tv+Rf8FAJIAzwAKASwBTgFfAaEB4AHNAfIBOwI0Ah4C6QGRAVIB7AB+AEsAMQAFAKr/U/8Q/8X+hv5V/jL+Iv4m/kT+dP6r/tX+4v7x/gb/Hf8Z/wj/6v6c/k7+GP7j/bH9h/1X/ST9/vzk/LH8YPwY/OX7xvu5+5r7Zfsu+/v6yvqb+nz6cvqL+s367/rn+sX6c/rd+Rf5Z/js98P36feH+Dr50PnY+g/8U/3l/ncBfgX8CV8NwQ5sDikNvQtdCl8I/QV9BEYEjATwA3kCHwFPAOv/cv/a/kn+A/79/X79cfyw+xr8gP0Q/5YAOwIiBNYFxgbfBlsGCQYnBmIGOQa5BV4F+gRoBIkDlwK9AfgAcADW/+v+6P0X/XX84/ux+wP8sPyD/Vz+Mf/e/10AxAAqAXMBswEZAokC4gIHAwkDAAPWAp4CZQIOApEB/QBoALb/A/9q/uz9ff02/Rz9Fv0f/SX9P/1Q/X/94P1a/tL+Sf/A/yEAhADRAB4BUwF9AaUBtQGiAXsBZwE4AeoAmgBfADEABwDM/4j/O//d/qv+df4n/vH9+P0l/j3+TP55/sf+Bv9F/4n/yP8WAGIAlgCmAJ8AqwC4AKYAnACGAI4AjAB+AHYAQAAWAND/j/9a/y3/F//y/tL+rf6b/pb+lv6e/rn+7f4S/x//Kv9F/3n/tf/Y/+n//v8jAFAAZQBgAGAAYgBbAEcAJgATAAUA7f+p/2j/UP9A/zT/GP8D/xv/O/9U/1v/VP91/6r/1////xoAPABQAFcATQA7AEAAUABYAFIAWwBZAD4AFgDh/6n/av9J/zb/Mv8k/xH/BP/8/g//Mv9l/4D/uP8AADoAYgBeAF4AaQByAIEAlACgALAAsgCPAF0ARwA9ABwA7P/B/5//of+y/43/Xv9b/4X/uv/Y/9P/3v8AABQAJQATAAcAJwBJADsALwA7AFAAYwBcAEcARABfAGsAWQAuABMAGgAoACsALAAxACYAFgALAAYADQAgAB8AHwAkAD8AjADRAP8A/wDUAKkAnQCjAJEAcgBtAI0AwQDdAMwAqwC6ABEBjQHaAcIBeQE4AQkB3AC6AK8AwgAFAT8BZwFYAR4B/ADWANAA7AA4AVkBRwFAAR4B9wDXANwA6wD8ABUBQgFTATABDgHSAKYAoQCrAKMAhABfADEA/v/I/6z/lP+T/6D/nv+c/4T/g/+P/4z/mP+1/8f/wf/T/9z/xf+4/6H/lf+W/4D/WP8v/wf/7/7q/sb+hf5H/v39u/2a/VX9+/zQ/Ln8gPw4/O77gvs1+xD76/rd+tj62/q6+m36Ivr1+RP6W/q3+ij7Wvs1+//6/Po6++L7Df1d/tj/sgEqBIgGigeVB0sH5gapBm8GtgWVBCEEWQRHBJkD3AJvAvIBgAH5ACAAYP/7/rr+H/6r/SL+CP+2/zgApQADAZEBKQJkAkMCRgKhAgADLQNJA3UDcwNSA0gDJAO+AjUCsQEUAZkAhQBxACMA4P/E/63/h/9i/zX/Df8F/y7/R/9F/1b/hP/K//H/JQBdAH4ArgC1AIgAZgBbAF8AZwBmANQA2wHjAjMDtAL1ATUBfwCy/7L+AP4f/rr+4v6D/lz+l/7Z/t/+t/6L/pX+uf6H/jH+If6R/lL/2v84AKYA+wAZAfoAqgBhAFoAegCGAGgAVABMADYAGAD+/+r/q/+A/2H/Lf/x/s/+yv6//vD+PP9k/1j/Sv9K/zr/RP9e/4H/q//v/yYABADx/ygAZACBAIAAagBIADgADwDJ/6b/s//N/9n/7P/v/9//wv9+/0X/SP9i/2H/Rf9B/2z/of+1/77/5v8MAAsA///m/9n/+/8RABkAKwBiAIIAcABWAFwAjgCOAHIATgAqABMAAwD1/9v/4P8GAAYA4f/d/+f/1/+m/4n/kP+l/7f/uv+r/47/o//A/7j/t//A/7f/sP/A/9X/1f/U/+//JgBlAH0AfQBmAEgANgAoAPn/6P81AEMAJwAkABYAFAABAN7/s/+t/9D/6f/U/6z/y//l/93/9P8XADoAUgBiADsAAwASADsAOQAuAEsAYwBmAGkAMgDu/9v/+f8AAO7/FgArADYAPwBNAEYAMABEACYAFAAMAAsADwAaAE0AYQBkAGgAZwBKABsA+v/n//D/BQAQABIAEwAIAPf/4//N/7v/uP/M/9L/1v8EABEACQAoADcASgByAHoASAAXABUADAACAPz/EgA0AEkAYwBOABwACgAgABoAAAAnAD8AFgD2//L/8/8RAE4AVgBCAEIAUQA6AOb/w//L/+H/DAA4ADgAJAAwACMADQASADcARAAZAAAA8//j/9D/1//7/xIARwB+AGkAKwD//83/mf+c/9f/8v/5/xMAEwAFAAAABgDo/8v/8f8LAP7/7//o/8//tv/N/9b/zv/k//X/3P+w/6X/kv+I/6n/1//p/+L/8f/p/9D/xv+0/67/0//2//b/5f/g/+3/BQASAAkAAAD4/wAA8//H/6L/j/+h/8v/2//O/8j/1v/q/+j/5v/u//r/GAAeAAIA5v/r/+n/2//j//H/GgBCADMADgAEAPz/EAA1AB4ACwAhABYA2//H/6//lf+5//H/EwAlAE8APAAGAPb//P8JAA0ABADx//n/AAAQAAkA+/8BAAIAHgA2ABAA0//V/9v/1//t/wAA6v/y/ycABQDa//3/GwD5/9X/4v/u//L/9P/n/9z/HAB8AGYAFgD0//X/8v/u/+3/6/8VAEAARAAlABwAFADz/+P/2//J/6T/qf++/8b/8v81AFoAcwCCAD8A9//Y/9n/1/+8/9r/GABiAIgAYgBAADUARgAqAPH/y/+8/9H/0P/L/8///P8ZAAUA6//g/+L/r/+R/5T/jP+h/9L/9/8wAHYAUQAXAAcA9f/w//b/9f8KAFgAkgCHAGcAdwBnAEMANwAZABcAHAArAC0AKgA5AEsAWQA+AE4AXQBBACAA6v/Q/9P/LACRAKIAvwDcAPkA6ADDAJgAYABSAEYATwBeAH0AigB9AH8AcwB+AHAAWgAwAP3/7P/Y/wkASQBKAEwAagBiAEwAWwA5APH/4/8IABQAIgBFAF4AUQBdAIcAgQBZAC0AHADv/93/BgAnACwAKQBIAEAAKgAnACoACQDK/8b/xP+s/6n/1P8BAPv/GQBOACQA2v+2/6n/dv9r/6//rP+l/+j/KwAaAPv/BADf/6n/pv+o/37/ev+b/5b/r//j/wUA///X/8L/nv9m/0//Vv9M/3P/xv/a/9f/0v/H/6D/k/+j/4v/b/9O/0L/Mv8b/xD/Hf8b/xf/Of/x/ob+b/5v/lH+Pf5l/nT+cP6a/qf+av5Y/nH+Q/4P/vL9zv3R/eP9+/0O/jr+g/6f/o3+RP72/fv9Wf6l/if/RAD4ADIBYQFyAYsBvwHsAdAB5AFRApoCdgJtAsoC+gI7A14DNAP5ApEC9wFkATkBZwGsAdAB7QEJAt8BawH5ALcAjgCHAHwAagBjAGwATwAcADoAhACpAJMAdwA4APf/0f+n/7X/EACMAMoA8gAWAfkAqQBdAGwAhAB3AJAAlQCZAKkApQCEAGIAiACMAEEA/f/W/6//fP+A/7z/7P8BAP//3v+Z/1z/K//r/tb+/f4c//f+B/9B/1P/Tf9P/3H/f/9u/0D/Hv8Y/1b/t//x/xgAQABZACUA9//5/+n/zf/T//b/DwAKAPn/+v8AABwANgARANn/sv+R/4X/fP+Z/9T/4f/d/97/4/+//3v/Xv9m/1//Z/+E/3T/ef+e/7v/wv+y/8H/0f+y/5v/rf+m/5v/0/8FAAAABwAgABEA/f/0/+T/0P/c//r/CgAeACYAKgAYAAMA9//t/9z/xf+9/7X/uf+8/7P/xv/o//T/4v/P/8j/vv+9/6D/k/+4/+H/9v/7/woAKABEAC4AHwAPAPb/CQATACMARwBKADQAOwBbAEkAJQAgABMAEwAsACYA8P/m/xAAFgAMADYAQgAPAO3/7f/h/7r/x//t//f/CABEADsA+v8AAB0AGAABADsAZAA2ACgASQBbAF0AiAC6ALkAygAEAewAogCiAMMAtwDPACwBOQEHAfQA5wDHALMAtQCtAK4AsgC+ALQAmwCpALUAtQCyALwAqQB8AFgAMwAtADwATABVAFUAWwBcAEgALgAXAAoADgALAPn/6f/c/8//w//P/+n/7P/b/8z/t/+l/5z/kf+Q/5v/qP+W/3b/YP9T/0P/Nv9E/0v/UP9X/0L/Lf88/y//G/8n/yX/Jf8j/x7/HP8a/zv/T/9L/13/b/9i/z7/Mv8+/zn/Lf86/z7/JP8c/zT/Mv8v/0//Wf8//zL/Tv9B/xv/M/9f/1z/Wf9s/1//Xf9e/2P/dv9z/33/hv+H/4T/jf+R/4D/g/+g/6//kv96/4P/cv9f/2z/bP98/4v/dP91/2//Zf90/4n/nf+8/+n//v/z////CQD2/wIALQA/AFMAegCIAJcAtgDSAOoAAAErATQBLgE9AUMBTwFaAXABkwG0AboBvQG0AZwBgwF4AXQBXAFlAXIBagFjAXEBbAFEASQBGQH6AMQAvQCmAJEAjACKAIMAhACZAIMAawBdAFIAOQAiACsAIQA2AHwAeABIAE4AQwAPAOn/6//t/+P/AAAqACwAJgBNAHUAZgBHAEcATgA4ACAAGQAZAAwAGABCAEgASQBZAGsAbQBUAEEAMwAYAAcA/P/3/+f/0v/T/8f/xP/H/8T/xf+2/6j/n/+V/4D/d/9v/23/bf9d/13/R/8w/yb/Hf8Z/wT/+v71/uX+1/7U/sP+sv6l/pD+iv58/nz+fP50/nL+cf6C/nz+ff6E/oH+iv6Q/pH+lP6c/pv+mP6Z/pn+pP64/sv+0v7b/uf+9f75/gf/K/81/03/cf+A/5v/tf/K/93//P8SACYASQBfAHkAiAClAL4A0ADlAO0A/wAMASABLgEzAUYBYgFtAXwBiQGaAbIBpAGvAb4BxQHKAcQBxQG4AasBoQGQAX4BegFzAWgBVwE2AS8BIQEHAfoA6gDUAMEAugCqAJAAhgCAAGwAXQBMAD0AMgApACAAFAAPAAQAAAD4//H/7P/q/+D/0//O/8P/zP/Q/83/xv/F/8z/x//I/8n/yP/H/8r/uf+2/7D/rP+y/6j/s/+1/7//vP+7/7v/sP+0/6z/tf+7/8D/x//M/87/1v/o/+f/7//5//3///8DAAoAAwAEAAoABwAFAP///P/7//b/9//v/+v/6v/w//f/7v/q//P//f/4//v//v/v//X/AQD///r//P////f//f8CAPr/9v/y//D/7P/t/+n/6//w//P/8v/0//z/AgAEAAIA/v/3//v/+//5/+//7//t//H/7//s/+j/2f/f/9D/1v/W/8z/0v/O/9f/1//g/+j/7f/5/wEACgAOABQAGgAZABUAHQAgABwAGAAVAAsA//8AAPb/8f/v/+r/6//i/+T/6P/m//D/7//u/+7/8//0/+3/8P/p//j/+f/7//b/6//z//X/+//1//j/8f/5//r/9P/2//H/9//w/+7/7v/x//H/8P/0//L/9v/1//T/9//5/wMAAAACAAUAAAAAAPf//f/z//H/7f/n/+j/4v/l/9r/3P/g/93/4f/l/+n/6P/v//n/+/8KAAwACAAUABAAFgASAAwADwAPABMAFQAcABQAFgASABQAGAAYABUACgALAAQACgAJAAYABgARAA0ACQANAAYAEAAKABgAFgAVABkAFAAcABcAIAAcACAAJAAhAB8AGgAfABsAEwAWABgAFAAXABMADAAMABcAFwASABYAFgAbABYAFwAZABQAFAAVABEAEQARABMADwAFAAoACAARABAAEgAWABkAIQAVABMADgASABUAFAASAA0ACQAEAAIA+v/0//L/8f/t/+f/6P/l/+L/4f/j/+n/3f/g/+L/5v/v/+n/8f/o/+7/9P/u/+7/4//r/+b/5v/l/+X/6//k/+T/5P/l/+X/4v/q/+3/5//u/+//8P/1//H/+f/9//f////+//r////4/wMAAgAAAP7/9f/7//X//P/3/wAAAwD6/wAA+/8AAP3//v8AAAkAEQAQAA4AEAAUAA8AGAATABIAFAAKAAMAAgACAAMABQD7//v/+//4//T/9f/4//z//P/+/wYABQACAAMAAgABAAcAEAARAA8AEgAdAB4AFQAUABcAFgAMAAgABAD7//3//v/3//r/+//3//j/9f/0//X/9v8AAP3/+v8BAPn/AgADAP7/CwAMAA4ACwARABIADgAFAAUADAAKAAUAAwABAAEABwD8////AAAAAP//AQAMAAcAAgALAA0ABQAPAA0AEwAMAA4AEwANABgADwAXABIAAwARAAwAAwADAAEABwAIAAUABgAAAAAAAAD7//r/8//5//n/8P/2//T/9P/2//P//P8CAAAABQAGAAoAAwD9/wQA/v/+//P/+f/+//n/7//s//r/6P8vAEcA6f/b/xcAFwDI/8n////9/9L/7P8PAPD/4v8BABsAAgD3/xYAJQAJAAMABAAIAPL/5P/1/+n/4v/g/+r/7f/n/+b/8P/y/+z/9//7//j/9//9//3/+f/7/wAAAAAAAAAABgAIAAIAAwAGAAEA+f/3//7/+P/v//f//f/5//L/+P/1//P/9//4//z//P/+/wMAAQD9/wAABQAIAPr/+f8AAPj/8//p/+j/8P/n/+D/4f/c/97/3//c/97/4v/p//L/+f/2////BQAHAAgABQAMAA8ADAAGAAkADQAFAAUAAgD///z/9v/3//H/8v/v//D/9f/x//v/+f/+/wMAAAACAAcADgASAA8AEQAbABYAFwARABQAGwASABkAFwASAA8ACwAIAAAA/v/9//j//f/4//j/9P/x//j/9v/4//P//P/9//r/AAD7//z/AgABAAAABQAAAAkADQANAA8ADwAUAA8ABwAKAA0ADAAMAAoADQAFAAAABgD9/wAAAgD9/wkACgAHAAsACAAJAAIABgAQAAcADwAPABAADwAAAAUACAACAAIAAwAEAAcAAQADAAAA9/////z/BQAGAP//AQAGAAMAAQAEAAcADwAJABAAEAANABEADwAGAAUACQD7////+P/5//3/8//8//f/+P/5//j/+v/2////AAD9//z//v8EAP7//v/9//r//v/7//3/+/8AAAQABwAMAAkADQAPABAAEQAWABMAFQASAAoADAACAAAA+P/0//f/8f/x/+//6//t//L/7//w//P/+f/8//z/AgD///3/AwAEAAAABAAKAAYABgAAAPz/+//3//P/9f/v/+7/8f/1//L/7f/y//D/+//6//z/AgD8/wQAAAD6//r//P/+//z/AAAGAAMA+f/9//v/9v/1//T/9//t//T/9f/w//b/9//6//r////7/wAAAAD8////AgAMAAsAEAAQAA8AFAAXABQAFwAXABIAHQAVABAAEQAHAAwAAQD8////9f/4//L/9P/4//n/AAABAAMAAwARABgAHAAaABsAGwAYAB8AFgARAA8ADAALAAUAAgD///v/+f/5//b/9P/7//T/9P/1/+3/9v/z//P/8f/v//b/9//3//j/AQAGAAAAAwAEAPb/8P8BAAoA+f/v/wkACQDy//f/AAAGAPr/+v8FAAYA/////wsA/f8BAAoACgALAAcADQALAAoACAANAAsADQAPAAsAEwANAA4ADQARABEADgAYABQAEgASAAoAAwADAAEA///5//j/9P/z/+//7P/2//T/+v/+/wAABwAJAAsADgACAAUAEQAFAAAAAAAFAP3/+v/7//P/8f/z/+3/6P/0/+f/7P/p/+b/8v/t/+v/8//0/+v/7f/7//f/8P/2//z/+v/r//f/9v/y//L/7v/2/+X/5//o/+L/3v/e/9v/1//Y/9b/4//l/+j/5P/n/+z/7P/y/+//8v/1//n/+P/0/+///v8EAPj/+f/8//r/9P/4//f/8f/5//3/+/8EAAQAAwADAAcADAAKAAgABAAKAAUA//8BAAAAAgD///v//f/9/wAAAAD0/wAAAgAAAAAA/v8PAAUA/f8AAAgAAAD0//j/AAAAAPH/9P/8//b/6f/q//X/+f/t/+r/9//0//T/+P/2//T/8P/8/wAA+P/6//r/AAD7/+f/8v/8/+z/6//5//j/6f/s//n/9//q/+v/9//1/+7/7//0//L/6//u//v/+f/t//H/+v/4//3//v/8/wEA/P/6//f/+//7/+3/7//z//b/7//k/+7/7//n/97/8P///+v/6v/7/xIACQDz//7/DwAKAPn/+v8TABUAAwADAAkAFAAJAPn/CAAOAAEA+P/5/wMABQD6/+3/9f/+//z/BQAFAAkACQAFABEAGQAtADEAKgAlAEUAWQBaAHIAoADaAOsAIgFfAcQB9AFjAokCBAN6BfsGTQVpAucB/AJXAmEALv9O/4P/6P4E/lz9nP2v/R/+HP41/Yz9Cv/g/3v9m/1sAP/+Dvxq/SkA2f44/JP8OABMAJb8qf2MAcYAx/x3/fIB+gAY/aX+xv+//ygAL/96/+T/cgDc/0UAlQBLAKEA6/9L/zIAkQIjAav+6P+GAXMALP9XAOoBuf+a/8QAcf8QALUAegEf/zH/RAGrAFAAGf8RAKQAbQBA/1kAPwJT/77++//uAYkBuf4K/r3/3gMuAVr8x/7jAicCCf1R/ToCsALw/5T9Dv6dAOUBnQF1/g/86AD1BFwATfwg/fcAOgPW/6P98f6aAHUBJQDP/rT/6QDZAJP/OACUARUA0/2BAM0Cj/9L/4oB9gDN/bn/VgPSAKr8sf4eBLACa/0l+3ABIwZEAVv7j/sgAkQE/wHI/9b73ft/ApEG7AA3+vT9EwO7ASgAmACz/f37SQPwBVL9zPihAZAHaQC1+Y/9/wMAAw0B7P9Y/Sj9EQHqBBgCI/yG/DQCYwQCATL7ufzqAz8D1f0W/YgBpgH2/tT+WP9F/zYAzQI8/pP6sQEWBRr8yvpOBBQCxPnW/hkHiv549/wB6QeC/VL2TQEiCqj/C/hTAIEEk/5W/ggEzwBB+kX+0AbCBB/6pvmZAgAGHwB//OL/ygCt//gAdQHT/ez+yAISAfH+rf8jAW3+1/57AzgBkfsp/o8FnQII+xj+0APoAJb9xP9NAXD/if8IAjgBR/4I/lUA6gHOAfD/pv2N/pQBAgF7/8T/uv+o/woA2QBZ/7T+AAB6/+T/SgF4/4X9IQBJAqf/N/4mAPEA9P88//wAgwDx/rX/hv9JAM8Ayf+J//4AaAHF/lT+EABJAN7/fAD1AjsBl/1Q/7oAk//o/5oBKACM/tMAYQLD/2b99f/NAJL//gAPAt7/4fxz/wkCCv9R/s4ATwHC/u/+QALMAIv9wP20ADcBJwCbARYBY/56/Pz/FAT4ANz9k/4tAaMAi/0ZABYD1f8V/VoAuwLk/6n+pwBTAAf+yf5LAK4AigGVAbz/Av0J/mkBUwHb//IAUQAT/WH9DQHOAm8Ahf5Z/3UA3f8gAPQBDwDM/DT+LALhAUP/zv+SATgA2/3B/v4AhgHE/z//xP/c/zoAAAAxAHwAzP99/in/BQG7AYMAxv3+/er/uAAKARcB1ACO/4r+Xv8MAa8ALf9P/3UALwAj/6IA1QErABj/c/+c/4cAKgK9AHL9V/6PAYQBxP9XANUBgQC7/p3/6QCYAEsAsAC0/+f+rQA8AXT/Bf8EANcAuwC9AM0ByQHa/1T/QQBPARcC4gHDAo8Czv/M/Yv/eALhAVgADQACAKb/MgBTAUoAuP4r/3oAhgD2//j/n//+/ir/CwAWAOH/sgAgAG/+lP7O/9P/zv6q/lD/W/+l/98AQQHo/6/++f5U/+j/UAF4AVcAo/8s/+L+q/8bAeQBwABm/x0AJAGMAHH/1P87AMn/PgCSAaYB5P/1/lb/wP/p/+7/1AB/ASQADP9Z/5b/A/+X/tP/2AC0/1D+1/45/1D+//3w/uD/m/+G/9T/If/z/eb9kv76/tz/BACk/ij+N/+B/5f+h/6f//7/ov+w/9X/AP9E/l3/+P8B//H+8/8HAJb/kf85/6v+1f4SAMgADQCQ//X/SgAlAOX/AQBjAKkAxwB/ALn/Gv8x/6b/y/9+/zr/lv8AAN7/l/+R////OgAhAC8AQgD1/5b///8GAHf/gf/L/8f/bf8+/13/Wv87/5P/GgAwACAAawBvACYAawC/AJYAgQDnABYB1wDfADkBTwFzAeQBJAIKAtgBzQHRAQECLwLZAVkBlgFAAhkCtwEPAicCmAGQAR8C9AFAAe4AEgHsAGMAfAB/AP//5P8uAFkAHwD1//7/9v/C/4f/yv9JAHoALADr/+P/4v81AIYAqgB3APT/hv+Z/10AvgBJABQAVwBYABgACwAAAL7/d/+P/+H/4v/Q/53/Vv/v/m/+rv5w/6v/D/9N/ij+Uf4u/kD+A/9g/9z+l/6r/pH+U/79/Xr9Zf3o/Rr+7f3b/cT9WP0g/T397vxZ/C78PPx1+5P6gPog+mr5bPm3+Tb5f/hR+DX4pfcU9yz3IPeZ9mD2WPbU9fb0qPRK9Qz3OfoF/nwApQDR/xf//P5WAJECUwRYBW8G0AeXCB8J8AmhCp8L8gwUDnsONA4WDtkNFw1ADOELBQyUDHQNjw0dDOsJBAipBr4FSgUUBYgEuwPzAtQBVwDx/sz9/vxg/OT7efvQ+hj6XPm3+D34KPir+Fn5/vlu+on6PPrl+fj5fPpr+5P8s/23/o3/NwDYAEYBqgEfAswCuQN0BO4EOAWmBXoGjweuCMAJWwo0CuUJfAnFCC0IEggqCP0HzAesBy8HjAYaBo8F4AQvBJED+wI5ApoB/QAyAJD/R/9J/zr/J//s/nn+Bf6b/Vv9O/1L/Yv9rf2//db9xf2t/Zr9mP2e/Y39mv2Q/U79+/yK/PP7UPvY+pj6Ufr5+ab5Jfk2+CD3Tvas9SL1ovQI9DrzVvJq8UnwFu8H7kTt6+wP7VHtUu0c7Z3s/Oub6+Lr/+zJ7hLxF/Ts9zb8BQAqAq4CeQLYAt8E+gfjCtIMBw5bD9kQehL4ExgVZRYFGG0Z9BlYGS8Y7xagFVcU3BJ2EYYQKxC8DzEOqwu5CCYGXQQSA+ABTwCG/sr89/r3+BP3d/Vd9Nnzt/Oo823zUPM38y3zLvNx8zb0QvW09jD4f/l6+k77VfyK/RT/3gDLAo0ECAZABzUI7giICSUKkQruCnEL7wstDAgMoQvyCigKhwncCBEILwdCBgUFjgMIAoQAN/8O/jP9Xvxu+3z6pvnV+PP3WPfu9u72n/f1+Cv6rvoN+7H7kvyn/QX/NgDpAOoBZAOMBFQFKAZOB2cIewm3CpELCgxhDK0MkwwQDKQLXQsOC7kKTQp8CVcIRAdcBkkFLAQtAxUC4ADR/+T+rP1Y/EP7XvqT+fj4gfjd9zr3t/Yg9mn1uPQy9MDzWPML88fyj/KH8pbycfJA8izyEPL58dzxifED8Xzw1u/57jLuju0W7fDsNO147Yztyu0K7v3tAe607g7wGvIB9Sb5w/5nBB0ITgnXCP0HnAi4C1APIBFwEekR8hIYFFUVAxY/FhwX2Rh/GpEaOhmDF4YVBhMqEDwNkgogCQsJpgiDBj4DVQBQ/ib9pPzl+3P66vjP93v2kfSx8krxg/CF8EzxSPIy83H0+/UL9773ovj2+aP7hf2a/ygBGALvAvAD9wQoBtAHnQkqC3IMhg0ZDjcOGA6tDeMMDAyCCwoLTwpeCTcIqgYdBckDiQI8AQwAEP/i/Wz82vpN+cz3svYB9mz17fSx9OX0OPW+9W/2CvcA+Jb5efs+/b/+CQBCAaQCKQSQBboG5QdPCcgKDQwLDcwNiQ4iD4IPpQ9PD9YObQ7TDd4MuQtTCuQIuAejBn0FHgTtArcBZAA5/wb+yPyf+8D68PkN+T34jvfy9n/2Mfba9W71GPXq9NL0wfSz9MT03PTw9Oj0z/Sl9G/0VvRL9Cz0/vPK827z5fI98mjxlPDL79DuvO2t7LLr9uqn6orqJerP6cTp/+nM6nTs1O7M8cP2FP6vBAQI/AjsCJQITwqWDvMRLRLKEe0SLBQPFS4W3hY2F6sYlRunHUEdJRxhG50ZNRZpEpMOwgrECJUIOQePA/H/qf3x+wv7MvvL+m/5fPgX+KL2HvQY8qPwXe/O7mnvKfAI8fDyQvXf9gb45/ky/Fz+4ACIAysF6QW8BnwHzQdrCOEJRwtBDGANoA5QD5UP9A+pD44OhQ3qDAIMcwriCAsHnQRHAn0Awf4C/en7Rftf+if5GvgN9+n1LfXI9D30v/Pv85H0AvWI9ZD2uvc1+UH7R/0C/8EAxALLBKEGNghxCYQKqQvWDOsNwA5fD+EPLhAiEPYPqA8UD2kOww3QDHwLFwq5CEsHvQVJBLkCHgG6/4/+fv1X/F37afp0+bf4Jvie9yT3y/Zz9hn2vfWE9Vz1UPWC9cv1E/ZN9pn24PYa92H3lfeZ92z3MffV9lD2uvUg9Xv0wvMM8zHyGfHf75/uau0+7AjrlOlA6FTnsuZZ5hjm0OW05WPmEuiS6l7uvvQM/csDagcACWgJ6AkXDQESsRSEFGIUYhX3FaUWkRf1F5oY3Ro/HiAgHyDlH6IfzR1aGlIW5xHaDccLowqSB9ICmP7P+8z5BvlS+f34P/gY+Nr3QPb580TywvA9727uPO4n7pruPfAd8mbz9vRY9zX6Pf3BABkEPAaPB7EIWQl5Cf0JDwvdC1MMAg2rDfoNaA7qDs8OSg4DDtENHA3gC3EKggjoBUsD3wBd/jD8vfq6+Yj4OPc79mr16vQO9aX1+/U29tb2o/dS+Av58/mH+hP7Svzh/Wz/NwFVA1QFLQf1CJUK9wtFDZ8Otw87EEsQ+w9gD6AO6Q0NDf0LCgseCkkJagiAB4EGXwVDBBsD5AGPAEH/9P2b/Ef7FPoA+Rr4jfdM9z33LPdR95L32vc2+Jf44fj3+Cn5R/k4+Sz5Gfnx+ML4ofhe+AX4uvd39zz38vaO9iL2mfUD9Vv0bfMq8svwke8w7qrsCOs26VTnceWe48XhZuAS4HjgKOEu4rbjyeVs6V7w3PknAiQHFgq6C7wMwA+bFIwXThfcFkoX+Ra5Fo0XUBgNGWEbsh6fICEhGyIDIw0ibB/TGygXZxJvD1UNqAmMBPH/RPxL+fr3Lvhk+Ez4r/jw+N73X/ZZ9TL0nvJj8YrwaO+o7j/vgvB+8eLyNvXo9+f6y/77AjIGcwhCCmMLqAsqDCANiQ1kDVINSQ3FDGsMvwzpDKQMqwz1DKMM5QtJCy0KFwiuBUkDkgDJ/cX7MvpE+Gr2MfVs9AT0bfRo9Vj2WPfR+FT6JPvH+5j8LP25/Y/+av8kACABowIjBHUF/AbBCIoKQgzlDS4P4Q8eEBwQrQ/VDuINwgxQC9cJhgguB9YF4QQPBCgDdwLZARoBRwCD/6z+fv03/CD7DvoX+WD40PdY9xb3J/eG9wP4mvhn+ST6l/rp+jz7Tfs9+zz7E/u7+lv64vlU+fn4ufh4+DP4EPi79yj33PZ+9tb1FvVw9Kzzi/I58eDvZu727IrrF+rZ6HbnC+YH5frjU+Kg4H/fDN843xvgG+JZ5dHqRfOY/G0DhQfNCn0NVxD+FN0ZiRsSG4EbDBuxGF8XzxdfGIsZZBwAH1ofSB/IINIhniCiHncc0hjMFEgSgw+RCiUFBgEP/Tf5z/dE+EX4Mfjp+OH4T/dE9kv23fUF9db0mvQp88DxfvGC8Zrx5vI79U33jPnu/GsACANqBdcHdAk7CmULvwwpDSINOQ2uDEULPQrzCaQJbgnSCSYKqgkhCdUILggbB/8FpgSoAogAt/7s/Cf72vnX+AD4kfe392n4ZfmT+sb7+Pzo/br+mv9FAL8AOwHWATwCkAI5A0kEnQXvBkYIfAldCikL6gtkDJMMhwz9C+UKhAn+B3MGGAUMBCIDSQKMAeMAQwDG/4r/Wv/8/nL+0v0G/Rr8TfuG+pr54fhv+Aj4wPfV9yj4ivgS+ZL5AfpW+rD69voc+zf7CPui+v35cPkI+ZT4N/j298r3mPea95z3bfde94r3dfcG9572DfZB9Xv0mvNn8kHxHvDW7qbtzexE7Kfr8eoD6tbopedn5ivl1OON4lDivePZ52rvpvco/RkB9AQzB54J8g5bFJgW6ResGV8YzBQFE9cShBIsE98VKRhtGMsYohrVG6wbGxxgHFwaohcmFioUOhA4DL8IHASI/5H9P/2R/G/8dv1Y/bz7/PoF+3D6IPoH+0L7mvnU98L2X/Uk9K30Hvbo9un3K/pZ/Lv9x/9jAu4D3QSiBgIIJghbCMgILAjbBj8GwwW1BDsEBQWKBXgFCQZ+BhUG9AXlBmoH2QZlBt8FTgRvApUBAwEEAJD/wP+I//7+I/+z/+n/YABgAQEC8gHkASkCBQK5Ae4BCwK4AbMBPwKNArcCUAPZA/cDGQRVBEYE+wPUA30DpAKmAaUAk/+i/jf+Ff7v/dD9t/2T/X/9sv3i/fP94v25/Wn94vxd/N77UPvl+q76g/pj+mP6o/rY+vj6HPsx+wb7ufqf+m/6Kfrv+ar5Tvnk+ID4Qvg2+DL4JfhN+Hn4Ofjj99/31/eT95T3t/dy9/T2lvY+9qX1JfX79L30RvTM82Hz4vJK8p7xKfG08N/v7O7t7dnsI+tc6qrt/vP3+Bv9jALXBNUDKwY0C5sM2ww8ESYTOg8QDYUNDgseCOwKBw8cD2YP9xG4Eu0Q+hEmFdEUJBOtE4ETNRCvDVMN6AoCB7oFkQVzA7wBwgJkA0ECWQIaA8sB2P8FAHIANf+l/vT+oP0U+xb6HPoy+QX50/oy/ED8C/19/oL+Rf7U/2UBtAFTAmUD+wLkASICngJOAq8CMwQRBVwFTwZGB08HSAcLCHgIDAjkB7gHggb8BB8EVgPkAdEAswBsAAAANACZAE4A+v9jAHsA6/+X/4z/2/7n/YH95vz/+5T7qPu0+/P7qPxc/eT9cP4b/2L/if/X/73/Yf8W/9z+ZP7W/aL9sP3M/fj9Yv7Y/h3/av8BAF4ALgAsAHMADgA1/73+XP6p/cL8evxx/P/72/sf/Cv8tPuv+9v7cfsg+0X7pPuz+7D7XPtC+or51Pk++sv5Ovni+dr66/rQ+lP7Dfyx/ED9gv1Q/ZP8Ivx0/Cr8BPug+mX7DPyf+9b64Pr2+mv6ovqw+0H8T/yI/L38Hvz2+iX6xfk6+ar4e/hR+Fn4v/if+cr6hvwN/88AwQEiA14EgwR2BM0ElgRKBJkEgwTpA8MDPAT0BPsFSAdQCEEJNwqJCm0Kfgp+CiEKvAmACSoJiQi1BwEHuAaSBogGswa9BnAG+AV+BecEYwQaBN4DbwPuAoQCzwHXAC4A9f+2/3X/cv+C/3b/iv/0/0sAcgC5ADsB1AFQApkCyQIQAw8DngJiAlsC2gFwAbQBnwECAfkAuwEtAh4CLQJ5AogC9gESASQA0P/8/5n/uf6q/ij/y/7Z/bf9mP5y/t/8Wfxz/Yb9CfwM/LD9fP3l+wL8gf0G/Vv7v/zn/sP+yP1w/qL/2P4I/vn+e/8t/uX+rgDo/8H+Ev8XAGAAwwCEAXUBagB5/5EA+gCY/8MAyALhAZYA4ADCAIsAvQHYASoA9v8HAqwCh/92/dgAVQP5/nz8RgHVAysAov0HAJ8Bqv44/W0AYALz/yr+QADpARcAFv5rAJMDNQL//hL/8QEmAvT+N/39AD4EPQFp/uv/jgIqAhv/gP0KAJUCLQBE/aH+LAHtAEsAewHpAd//VP4AADEBBwAAAF0AJ/+Z/kP+pfzi/C7/q/8B//D+lf9w/yr/IwBq/0D+M/4h/7n/5v23/br/G//7+zX82/+TALf/6wC+AWj/EP5YAakCy/4o/Ir/TAPgAN/9zf9EApsBYwApAQsCtAHAAWsCKQGB/oIAIASfAp//bv86AUACmQKuAV7/AABGA4YD/gD5AMgBvgEcAkcCqwHB/6kA3gKQAU3/Sf8LAooDlgEG/8YArwTGATD9NwDuA/P/Wvuf/2AEtgAj/TcAFQQYASj7KvyQAaQC2ABPAFv/7f+DAeT+avvK/m0DYv95+uj9nQOB/6b3XvukAqwAbvz2/2gCRv54/U0BUgEd/aP9ggLCAur9bP1eADv/F/5R/zD/NP4g/zUBBAG4/mj/vwHLAeABjwJGAYj/sv8G/+D94/2D/54AEP9P/48ATf9y/en+aQIpAiL/Av+rAMz/Uf7m/rH/E/9M/oj/SwKKADr8Qv3aAgUEO/0N/FQClwIY/mT+rAIdAlz9ef2q/0r9lPyVAbYDTf9i/qwCJwJh/eP8QQHjAfX+XP6I/wv/2fv2/bQDEQLX/A3/BgS0/0P7RwCbAQX8B/05AxgBlvqF/V4D3f/x+ln/CAND/sn8TgJdAqr8w/2ZAg0CCP5j/qsARP6J/RABJQMDAN797P/A/xr+MP7k/yUBuwFaAiUAff1n/9cBMwAq/8wBgQKO/7X+DgGLAaL/r/4NAI0BHwFKAFoAAgLPAzID6//k/vwA/v9C/mn/xADy/1n/PAJLBA8DgQDU/wUBFgByAKkBHgDx/gYA2gDA/in/mgD//dj+swPiA7X/sv9nAyMCd/2U/rkCvAB7/fv/vQJjAA/9T/58AW7/PPwdAe4FDQKd/nQBIwMn/5/8IgF5BDH/q/wdA6cDx/tc+8oDUgKx+k4AKQlpAlX47ADXCAP+iPeHAx0Kn/xV+LkF8QYx+XT3VgO8BPb7FvypBUUGW/yL/CQFowT2/B79igI5ALP8JAB8Av79R/0RAmr/MPoR/sYDJAHn/YACkgUXABr71f+YA+L9fftgAGwBXfzX+5EAAQGK/Qv/gQNDAfD8NwBbBJYAr/7OAk8C0/xq/nQD0P/m+Wf8cgPBAgv+Lf9JAgEAdfwN/5sCcQDc/Pn/mgNSAA78Kf3/AOz/xv3Q/1kBlQBc/gP9+P5mADL9Rvs0APQCx/9TACoDjAAP/PL9fgOYAWr8m/6lAmj/NftC/hcBX/4n/14EEANS/dv9fAGQ/rL7TgCiBK4BZv3Q/8gBmP3N+5EAtQJm/wf/swBMAHEAuwCG/17+GACIAZL/jwBMBGwBGvyP/tQBaf79+hwAfgQxAGb9fACkA6QA1v1QAKMBiQASAZACVgAF/p7/gAGBAKP+JAGkAof+UP0VASICzv6w/kQCEwNI/6X9mwLaA2f+Nf3/ARACEv4bAJICKf/i/KsApwO//5H9SAGWAq7/k/5MALsCyQKZ/2X+agBvAgIAD/7+AXYCsPzj/AYF/gR3/IX+uQZMAxX7T/3iBPYBS/ty/3AFjwBp+hb92AD2ADsATQHRAOj+uP9eAIIAjQC0AOsBjQHT/jn9N/8NANX9R/9TAgv/+Pvi/yAC5P4A/+EBfgGr/x//BQCqAFMADv67/df/NwDq/hH+xACZAiIAH//TAfoBNv67/BUANAJq/gj7fv7YA1UCWf4pAEoD7ADP/DL9XwDyAdMAfP9SAq0EGf/3+or/owLW/AX5cwAcBeD+Sfp2/6gDCP+9/CcBeASaAPb8HwHHAm796fshAn8D2fyK+5QB4AF6/N/8vQHXAjP/+f4XAsIAgP3l/r0Bm/9s/WMAEgJZ/t78qAGtAnD94/yVArwCsPye/k0FWgNm/Hr8JgFxAbX+7/yG/xgCov8m/eT/wwM/ANL8SAGaAxz+BfxpA8EEAf1d/ZgDWAKR/e39UAD5/xH/jgAMAt/+zv10ArsBI/3d/u8D5ANAAGEB6AS8AUf8+f3LATz+LPuVALIDnf/N/AkA8gFyANAASwExAdAB1gKcAIj+owCSAJP+Dv/2/07/9/1p/8ABs//T/lcCVwOG/47/XAIXART/JQAvAiUAZf7f/0MB0f65/YIBvQCa/Br+9APhAtf8cf73A40BUPzj/qYD9ABC/U8A6gLc/937q/5UAof+uPpp/7YElADu/JAAZgOW/4r8OgGHA5j9bf6MBeABmPsw/5EDVP5l+T7/zARqAfX81f88BIsBcf19/7gCMQBp/EX9+ADvABD+Mv3EACYG7QJf/Zn/twNpADj7Tv7UAtf/IPwI/3UAJ/0N/HQArQPVAd3/pAEMBJgAQP3B/0QBmv0d+zv+cgE//1z8YwDFBJQByPzw/xQFmgBi+0f/zgPn/ir6J//vAuH+AfufAJcEN/7L/BQD9gTM/3n/RQODANv8B/9fAgT+APoO/6MBfv0n/SUCZQIs/h4AtwXpA5P9kf7qBDMBPPl4/bIEmgDW+Yr9GQPW/x39/QG3AyD++f5cBkoEr/t4+44DKgWE/Iv6iALHAuf6Z/uMA5cDW/xv/T8GUwRp+lf+UQdSA937gv6mA5z+y/hl/q0EEwDv+9gAMAWHApT9+v61A7gBbPwq/kMDFwFq/fr++AG6/xz8MQDnAjb+/vyjAhMDE//hAHcEtgGR+xL92AKiArT99/zYAJkB9f/q/Qf/RgJtALH8J//PBF8CTP1JAa8DJf5q+1gAUQNZ/TD8XwFUAb3+lgDFA6ABOf/QAM4BBf4U/Nn/kgEF/0H9NgETA4z+6f1OAhgCUv1X/j8B0wCp/pT/1wN6AZf9Sv58Aq8AsvtwAagFtQDC+if+EgaRAYL5m/5xBaMAk/qx/YgD/QGb/W//BANK/xf7yv+lBPgAEPvk/XIFJwN1+538zQJFARn8//7vATX+6PwKAzIFk/8n/WoAIQI8/sH9SgEiATj+AP/w/x/8N/ywApsEMv+W/fEBswKH/Rf/DgXSAIP6MQAQBtT+T/lQ/58C0fxZ+44CjwUj/379FwTkA0/9W/2CAxUEL/40/jED8P8I++b9BQHt/Gz6y/9mBE4D0v9FAoYDIQBhAQwDrf+G/An+Vv+R/pf+/P7f/jz/s/+TAEsBBgBr/z0CLAMx///+8gPCA8b9LPzLAPsBJv0R/V4CBQJ4/s3+4AC/ABQANwJ3ARr/xgOoBen8IvttBEsEo/q6+xQFxQIn+vD8mQWNAJD4lAINCLz78fZjA+8IOPyX93wDzgYD+2r5YQVDBQL6SPr2BCwE6vtH/SUDdgIZ/Xn+vgOfA47++/oaAL8CIP04/gIIsQZ694H3DAc1Bj71OvX/B3gJO/oD/GUJ6wTs+NX9jQYaAgL7C/2JAzgDG/xB+ssAAQVM/+b5sAEOCHL+rPnKAisEjvzn/c4EmP+d+Pv+UQNt/WX8RgSlA4X9mv8SApj/rv5pAlsCdP7l/ZQB6gJi/jz8qP7/AA7+lPka/XcFBAa7/0X+cQPhBIH8NfvxBN4EvfgV93EE/wUA+Xj34gQ6CR/+QftlBNsDXPo1/FYFZgLZ+v//iwYjAcD7kwD3Aif8Dv1sBOb/pPhIAfgJdf5x9kIDDAp7/OTz5wAnCdH86/aCAzoIM/s49uX/XAUmAev9KwJUBk0DQv5S/28D4gCp+G75xQNvA1z4ZfpKCXcKzvve9mwEHwvZ/p76iAXnCDQAgfs5AWMHqgVN/v36Rf4iAPH8y/xhAwQG0/8g/CEBfAJ/+0/6owM+Bj79RftsAsMAivdh+7QGAgVN/bcAEAcWAeD5O/6kBg4EufiJ+EIDmQUE/sL6k/7ZAL7/ev/KAHUDCgPV/j/+lwB//rH4e/yWBqUFb/57/ucDgQJP+gf4XQCVBvYBY/5vAasCXfwB+C4Auwh8BAz+iwJeBLz69PY6/p4Cl/0B/sUGoAYq/Z36CgM5BAv7HfryApwC4vgy+UkBbwCR+rD+1AdtBYr8X/4FBX0B/PgX/E8FygMp/Gb+uQfUBt3/+gC4BUEBi/pn/C/+b/r7+Nr9qQCX/Vv90QKDA3b/OAEdBn4FswAi/ywBH/9b+qX8mgFgAEX7j/nc/UcCkwJ4AboC3gMsAjn//f3F/3H/Ovzi+8r+Zv+A+875W/4iAUj+U/4LBckIMwRhATYFjgb8/477L/5I/Yj62PzC/3AAzwEmBO8DgwMJBS4EwQBF/x4B4gEv/nb8qP/5/3X7h/rn/3sBu/zQ+qr/CARsAd3+fgHkArP/qf33/vD+If0C/b7/ugC2/0sBWQNnA4oBtwAgAYX/wP3f/VT/tgDnARoCmwA4AIoCLgO1AMcBRwXTAzT/Wf6MAGT/TPzh/DH/vf6Y/bgAAgWDBXYELwSDA2QBv/+5/kr9+fzy/ab+A/8dAOwAzP+g/s7/7wB3/8X9jf4XAE0A9v/f/0YAFAGhALP+F/6p/rD9L/2N/z4AD/6F/toBVQKv/9//aAJFAdL96v5dAb3+s/yM/yAB6P2f/OIACgM5AHD/CgKaAYn+uf7jAPb/sf2p/okAvP9+/nMAMAPNAe3+EQD2AhIC/P4z/6ABpQA//lv/pAEPAZT/RQEBA0QBvf6z/un/sv6H/ej+wf/H/qz+9P/q/w3/Uf8IAJP/wf6W/4EA///k/8YAKgEZAAf/EP8W/xD/Zv8nADcA2P8rAYACywGGAYQDBAS3ARsBvAKvAlMA9f/DAXYAyv29/kQAkf68/BL+EwCi/03+E/+PAEsA+P9kAPT/fv5k/cf9LP4I/a38gP66/zb/Mv9uACEBCQFtAZ0BKAEuAW4BEAGuALcAYABE/+n+dv8b/87+AAA0ARIBpQCLAH0AOgCf/wj/Qv6d/Qn97/tE+8D7x/xh/Un9XP0R/nD+1/37/V3/sv+1/iT+Av5j/Qb9kv3d/X39hv30/eX92P2C/ib/ZP+c/wYAQwDr/7z/HwCaAIMAGQApADUAw/9d/zT/Av/i/pX+0f2Q/Tf+kP4x/g3+h/5+/rL9Pv02/ez8cfxR/Gr8Vfzx+5T7ivuS+4P7g/vj+1/8ifya/P38p/0t/nX+Bv/r/6gAfQGpAucD8QQEBmUHqwjFCdIKywuIDAoNkQ3fDe0N6A3jDeMNzQ2uDWsNFg3NDIoMWwwkDPIL2QuSCwwLcgq4CeQI7wcFByIGNQVsBKMD0wIXAq4BWAHhAJQAigCMAHAAegCkAJAAPAD3/7z/XP8A/+v+7v7N/sv+J/92/1n/Q/+M//f/EwAFACIAWwBDAOT/rf+k/5P/Tf///r/+iP5Q/gn+t/1u/TP9y/xG/Lb75PrK+ef4cPjO99P23vUZ9W70p/Ph8lnyIPIT8gTyH/Jp8ofyY/Ib8tHxW/HA8E3w2O8z70Pu9OyS60Xqr+go5+zlp+QT4+XhTuGy4LPgPuK35o/tLfU//UoFNgtDDzgVexvnH+wjlCcTKTEn9yRSI/ofgxxOGyYbSBnYFrsVERQNEjoSWRQUFskWnheEF/EUcRGCDkkL9AbUAk//4/rA9XHxNu7O6vDnIOdC5x/nr+ew6a3rSu0g8Lvzc/ap+GD79v0l/wUAawECAtoBRwJlAxAEoAQaBtkH+QhDCkkMAA4rD6cQVxITExETBBNvEsYQlQ6gDC0K8wbwAykBA/7r+uL4afcU9nb1gfW39QT24vYl+E35hvoP/Gn9NP7u/p3/+v83ALAAQAHMAYsCigOlBL8FKgfVCG4K9QuDDd0Oog8QEB0Qow+cDlAN4Qv5CdkHugWBAywBFf9h/ej7sfrq+Xj5Bfmr+Hn4Qfj498L3oPdk9/n2iPYR9nz16/SR9FD0J/RF9IX0s/Ty9Ev1lvX39Tz2afaF9mL2BPZ09dj0C/Qs82nyb/FB8Bnv5e177O/qXOmN52Xl4+IY4CbdINp913/VzdPc0ojTWNf13qboHvN0/fAFQgyQE6sc5SQdLF0yETY8NjY0FjLQLlIqEyc6JYwinx5fG6wY7RX1FHEWmxiEGYsZWxlGF6MTcxBnDVMJZQSN/xf6jPMo7dvnI+OG3mfbOdrp2ajaGt3N4MXkUen87sT0yfmj/rADGQhuC1sOmxBlEW8RkhHKEY4RThGQEYURTRGNEWASOhMKFFwVlRYDF6YW4RVgFMsR9w7kCwEIcwOU/on5QPQT78bqO+dF5Evik+HX4cDi3uQV6KzrdO+m8wb4vfs4/9UC6wUlCBoK4gvmDHMNLA4PD6UPSBBZEWYSQBNDFJoVtxZ4FxEYMhhYF6gVpBMsEfwNgwomB3oDeP+8+2v4X/Xw8lvxWPCu73Hvxu9l8D7xePLe8yz1SvZY9zT4z/hX+Qz6wfo1+8/7fvz5/H39Rf4x/w8A6wDEATICLQIAAloBRAAH/2T9XfsB+Tb2N/M+8FvtkuoT6NzlfuMw4Rnfqdwg2t3X3dUm1JTSZtFs0IDPAc/Dz0XSxda93v/px/XOAAALHxPaGeohIiuHMy06cT4AQGo+FTvMN+wzWi8aK30nLCMAHnEZtRWwEpIQnw/5DuQMAgpgBz8EhgAI/bz5qvW+8OzriOc04z7fjNy32hfZotgJ2t7cp+CE5Ujr+vCL9pz8BwMFCY4OCRTFGAQcHx4/H0MfiR7LHUkdTByqGtwY9BblFAoTzxG5EGAP+A2FDKoKJAh0BaUCTv+i+9n3zvNy7zHrbucc5DnhH9/83aDdHd6330DimuWw6WnuevN4+JT9yQLHB2EMjxAKFJcWjhgOGjgb+RtWHIUcVxzEG/4aJRo3GScYDBfNFRIU5xFfD4oMXgkcBugCgv8W/MT4tPXe8o/w8u7v7Yftpu1c7nPv0PCj8rz07PY0+Vr7b/1J/+kAbwKzA8YElwVOBswGHgdtB5cHqweTB3IHIweEBtgFDQXpA3MC2ADQ/kn8lvmt9onzc/Bo7VbqZeeY5Bri0N/T3UTc/Nrd2dbY+dcH1x/WiNUv1eXUqNSr1AbV6dXL12fbc+HJ6i33cwOsDXsWLx0eI74q/zIZOv4+20CQP907VjeaMhIt7ibWINoawBTfDvUJAAbzAtIAbf9N/qH85fqq+Wz4+vZy9Zbz0fCA7Y3qWOis5m3lxuRf5EjkauVz6ADtOvLi9579BgNqCCkOFxRRGaEdKSFaIxAkdCPlIZMfwhztGfoWjROgD9gLiAicBUMDegHZ/zH+uPyC+2X6HPm99yn2KfTp8bjvq+2l69rpbehW56bmqeab52Hp3Osr7yfzbPfp+4wAHAWCCaINcBGgFNsWLRjBGLcYIRhAFxMWkhTZEhQRZw/DDWgMVQtxCqIJ0gj3B+IGlgUuBJMCwQDe/uT84foB+WD3HPYx9aD0nfQT9ff1Xvcf+ST7Q/1o/4cBfQM/BawG0AeYCP4IIwkDCaEIFwh+B70G6AX6BBUEPQNTAocBsgDQ/9f+zf2Y/Dj7v/kk+HH2nfTV8gbxOe+A7QLsxeqZ6bbo+udd5+3mxubn5v/mHOc35zTn6eaA5iTmvuVm5Rnlz+Rs5D3kY+Qh5ezmIeqe77T3MwE5CkoSrhhCHWoivSiJLsIylzSIMyowqCviJrAh9xviFfkPnArkBVQCzf/9/db8Tfxn/LP83vwN/Tf9Gv19/GL7hvno9kb0H/LE8Krvmu7T7ULtlO197xTzXPee++H/AAQgCHIM4BDLFKMXhhmYGoQabhmqF14VqBKbD6oMswmcBtYDpgEFAM/+Av5u/fv8rPyl/Nz81vxs/Jr7WPrT+Ev3zfVS9MLyPvH27wjvve4l70vw7/EW9ML2xPkA/TcAeAOPBlUJtguTDbsOMQ8tD7wO7g3LDIYLPgr+CAMIXQfpBpwGdgaSBvMGbgfzB1IIZggRCGQHfgZDBeMDewIFAZv/Tv4z/Vv81Pu0+wP8qPyJ/ZL+uP/cAP8BIAMOBK4EBgUcBfgErgQ+BLQDEwNoAr4BIQGaACEAwv9w/x7/1P6G/iH+r/00/ZL8zfvW+rL5lvhs90T2MfUw9C7zLfJm8cTwNfDP74bvQu/j7oruO+7V7Wjt7uxf7IvrhOp36VvoQucz5kflZeST4wHjv+Iv43LkyOYN67Txl/mEATkJkQ8iFNgYbB6eI90njyrlKgYpHiYxI/YfHhzkF6kTuw+MDLkKuwnnCD8I5AfYB+IH6welB/UGyQVCBFwCtP9F/Jf4dvXs8sbwsu7r7J7r5+qy6/Tt3/DK89z2Jvp1/fQAsQRRCAAL6QxpDjcPUw/0DlUOLQ2rC10KPgklCDkHxQagBpgGyQYvB3IHkAfIBxoIHgiTB4MG6ATaApsAb/4m/KP5Dvej9KLyD/EX8Jvvne8p8D7xzPKY9Jn2qfjR+tT8qv5AAHYBZgIEA4MDxQPTA9YD7wMuBKIEWAVGBlUHagitCQsLewzSDf8OvQ/rD8IPMw9JDvMMVAuZCb4H7gVPBNICdQFLAHT/3/5//lL+Q/5Y/mr+h/6g/ob+Sf77/aH9Of3C/E784fuJ+037O/tb+4H72vtB/LP8MP2h/Sb+hv7O/v3+AP/e/oP+Dv58/cb8EPxG+3r6r/ny+EX4ivfh9kT2rvUW9YD06PMz82jykfG68NPv0+697ZPsQevp6cjorueu5uzlM+W05I/k0uTF5YLnkOpI7/X08/rkAOMFvQlyDXERSBWfGBYbGhyqG5IakhlzGNkW4xTZEhURFBAkEMEQPhF8EcERKRJ4EmIS5BH4EKYPGw4sDKIJZQbkArD/1/w/+tP3hvV28wDyiPEF8uHyw/PS9P71J/eD+Db61/v9/Of9rv4k/0//Wf9i/zP/7f4G/2z/5f+FAHkBvwIbBKEFMweECJgJmwrEC6MM+QzaDCgMCgu3CVkI0AYCBRwDTwG1/0X+Av0B/EH7tfpv+mf6g/qi+sj6Bfs4+1r7WPs6+wb7r/px+lD6M/or+l/6wvpV+y78Q/13/qL/AQGQAh4EnwUABywIEQmzCTMKegpjCiEKzAldCdIISwi2BwsHWgbJBVoFywREBNQDZQMAA58CPQLKAS8BjwDx/0H/i/7a/Tb9pvwr/Nj7oftv+2T7hvu8++n7LfyE/M38Bv03/Wb9aP1M/S/9Av21/HP8Ofz/+8P7m/uT+377c/t4+4L7b/tD+xP71/p8+vv5fvnm+Cv4bvew9uD1AfU39Gfzj/K28c3wAPBW77XuM+7d7bvty+1p7tPv6vGv9PT3Yvtj/oIAswGqAk0DqAOEBDMFMAWwBGgEogTJBMoEyATcBDkFWwZdCFkKxAvrDCkOQQ/xD1gQbBAtENAPpA9tD6oOYQ0SDPsK5AniCBQIVgeXBh0G/gUFBvAFyAWWBSwFowRPBB4EogPiAhwCSQFqAJ//7f4x/lH9qfxw/F78TPxF/Gb8nvzo/FH9pv23/aD9q/3O/ev97f3W/az9Z/04/SP9Av2+/JD8iPyX/Lz87fw5/XL9uf0e/pH+BP9b/7X/DQBeAKIA1QAAAQoBAAEOAS8BTAFmAaAB3AEmAoUC7QJGA4oD6AM7BJME5AQeBUcFWgVeBVMFNQX+BNQErQSWBJMEfwRuBFsEWgRoBF0EXARTBEMENQQgBAMEyAOHA0UDAQOrAkYC8wGrAWABEAHBAHMAIADL/4L/M//d/o7+TP4I/sH9e/06/f78t/yG/Ev8CvzO+5z7b/s0+w372vqf+nH6SPol+vn5uvmA+Uj5A/m8+HX4IfjA92n3FPfH9mD25vVt9dT0MfSQ8/DyR/Kj8RfxlPAd8KvvXu9s7+Tv3vCS8tf05PZb+Gf5E/qj+m37fvx1/f/9f/5L/0wADQF1AeQBcwKOA4AFAAhOCisM8w26Dz8RNxK5Et4SyBKtEsUSsBLhEbgQtw/cDg4Oag3+DJ4MQAwtDFgMSQzrC4IL/Qo6CmUJsQjzB9MGWQXoA4MCAgGp/3P+R/0r/GX7Cvuw+kj6BvoJ+iP6ZPrJ+gr7IfsJ+xv7L/sF+776XfoF+rL5c/k7+Rr56vjO+Pb4MfmY+QT6pPpY+wf83/ym/Vv+6f5v//v/awDFAAoBOQFJAVoBjAHEAesBLwJ7AusCewMaBNQEdAUNBpsGKAeaB+QHGgg8CEQIIQj2B7sHUwfhBoYGOQbvBbUFqAWeBZYFmQWSBYoFbAVFBQ0FxwRqBA0EpAMJA14CtAEjAZUADgCl/1L/EP/d/sv+s/6H/m/+Zf5U/jr+Ff7z/cn9iv1P/Rb9vfx3/En8F/zw+8H7pfuc+3z7dPt6+3H7XftM+0T7EPvY+ob6LvrV+Vr58vh6+PT3evcD95r2IPaU9Q31c/Tc8z7zl/L68VPxwPBA8MzvW+8H7/zuX+9G8M3x6PP19ar3zPiG+UH6+fri+9/8of1J/h//PQBLAQQCgwIhAz0E4QUaCGkKaAwmDscPPREWEl4SPhIBEsgRohGMESgRXhCCD9YOTA7ODWINLg0eDScNPQ1CDfgMQwxpC1wKJwkFCOwGrwU/BL0CWQEPAMD+if2F/K37GPvp+uf62vq/+qX6q/q5+rz6pvp0+jP68/nK+Zz5SPne+Ir4VPg8+E34gfjF+B35nPkw+sz6a/sF/KL8Qv3t/YP++/5j/6P/1v///yYAPwBaAHgAmgDjAEABsgEeAowCHAOwA0kE6gR4BfAFQQaFBrUGvwazBo8GZgYyBgcG0gWcBWYFOQUxBTcFTgVlBZMFugXGBcgFqQVwBRoFuwRBBMYDUgPNAkMCrwEwAcEAcAAqAPz/7f/Z/9b/y/+0/43/U/8X/9P+f/4k/sX9X/0E/az8V/wQ/NX7qvuS+437jPuY+6H7oPuk+6L7iftu+0X7/frF+nf6E/q3+VX5+fib+Ef4A/iz92b3Jffg9pb2QvbZ9Vj10PQ59KHz8/I98pLx5fBZ8NPvau8f7xjvcu9J8Nfx6PMc9vT3Kfny+Z/6U/tD/Dn9/f2l/mr/lADQAbQCQAPZA9cETQZeCJ0KiwwwDrQPHREAEjMS9hGLETURBxENEe0QVBCmDyQPug5TDuENnw2JDWwNYg1hDRMNUQxNCw8KqwhHB/UFqgRMA+cBqACW/33+df2D/Lj7NPsB+xX7IPsV+wf7+vrs+sn6ffol+r75YvlA+R75BfnM+I74gviE+Lf4+Phf+d35YvoO+8L7W/zO/ET9t/0j/oL+5v4y/2L/l//R/xYAMABgAJMA1AAyAZYBLwKqAh8DoAMaBJME8ARTBaoF4AX7BQsGFwb8BdQFtAWMBWsFTgUtBRoFCAUABQ4FJgU9BT0FRQVIBScF+wTCBGQE9AN4AwsDpgI1AtQBfQEoAdkAqQCKAHAAWABRAEwAOQAOAOD/ov9M/wL/pf5J/uT9j/08/fb8v/yB/F/8RPw4/C/8N/w7/Dj8M/wd/AL83vuo+2j7JPvV+n76KfrW+Xn5IfnT+If4RvgF+Mv3ifdE9xL3yfZ29hr2ofUc9Yf09fNb86Ty+vFZ8bzwK/Cz72DvDu8H72LvQvCw8Y7zwfWe9/P43/ms+mT7IPwR/en9sf50/5AA5gHfApMDRAQsBWkGIAgwCiwMzg1KD6wQoBHwEcARYhHvEJkQihCVEEYQww9bDwwPsQ40DtgNmA1YDRoN+wzFDB0MJAv3CZYIIAewBVoEGQPeAd0A+f8i/03+a/2q/BL8r/uA+3P7ZvtG+yX7BvvW+ov6E/qk+Ub5AvkB+Q/5Ifks+Tr5YfmR+cb5Efpu+tr6W/vr+3H83fws/Xf9y/0W/mb+u/4Q/13/uv8hAIUA3AAgAWsBtwEOAnUC4gJBA58DAQRNBIcEtQTqBB8FSwWCBbAFygXMBbsFrAWjBY4FawVPBTAFIwUiBRkFBAXkBM8EswSZBHsESQQYBMoDfgNAA+sCjwI/AgoC1wGjAXcBTQEhAf8A7ADYALkAgwBkAC8A5f+i/1f/HP/P/pH+VP4U/tz9rP2W/Xr9Vv08/S39C/3r/Mz8ovxu/Dj8APzE+4j7Ofvw+qX6VfoJ+sT5efkz+QL5yfiQ+FH4C/jH9373Mffh9oj2KPa69VL16vRs9NTzMfOi8v/xd/EM8ZzwO/DW76nvse8I8MXw+PG786r1gvf++A760fqL+2/8Z/1U/h3/9P8LAVIChgOQBGYFOwZSB9kIswqHDC4OkQ/aEM0ROBIpEq8RJhG6EIwQjxBnEBoQ2A+eD0wP7A6RDjgOyQ1MDfsMngwLDB8L8wmYCAAHaAXgA38COQE4AGz/sf4I/lP9qPwb/KX7XftD+yv7FPv5+t/6s/pl+gX6iPkJ+aL4d/iD+Kz40PgE+Uf5ivnj+Tj6jvr1+mv7/fuX/BT9df3E/Q3+Tv6H/sT+/v46/5f/AABrANgALwGPAeIBPAKYAvwCcAPZA0sEnwToBBYFKAVFBVUFYwV1BX0FgQVxBVEFQQU2BRwFCAX2BN0E3ATdBOEE3gTIBKkEgARVBAgEwgNxAxwD1QJ/AjsC7QGsAYkBawFRATcBKwEgARABCQEJAegAtgCJAE4AAACd/0f/Bf+y/mn+L/74/cX9nv2N/Xn9a/1d/UT9Nf0f/fb8zPyR/En8A/yy+2L7Efu9+m36I/rg+Zn5XPka+d/4sfiI+F74Ivjj96f3a/cc98n2dPYE9pX1NvXT9FT0xvMx853yEfKR8SjxwfBV8Arw6e/x7zvw3/D98YrzYfVI9+D4Cvrv+tX7z/zW/cz+pf+GAHsBuwIaBD4FHAbpBv4HSwnjCqIMRQ7CDwcRHBK9EuASiRIYEqURVBEzEQURkRGTEWQQmw94DxwPHw5zDScNkgzmC2oL2QqdCRAIuwY7BXUDxQF9AGD/NP44/VL8WPs2+kL5p/hP+EX4cvjY+Dj5kfn3+TL6QPoO+rn5XPkL+e74FPlb+Zj59PlZ+s76PfvB+4b8V/1E/jX/DwCuAAgBPwFsAYoBiQGLAZgBtAHmATICjgLuAjYDcwOmA8gDBARHBI8EzATpBN8EqQRgBAcEuQOcA4kDeANxA04DKQMMAwwDGAMdAyYDGQMLA/kC8QL1AukC1AKtAo8CZQI+AjUCTgJwAn4CowK3Ar4CvgLpAjYDKQPzAuICywJkAggC4wG9AWoBGQHyALcAigCaAK0AgwA1AOz/hv/3/nL+Dv69/WP9//y2/GL8DfzZ+6f7YfsG+7b6ZPoB+p/5SPnn+In4IviX9xP3pfZh9hn2zPWR9TX1xPRV9Ozzd/P78pLy9fEb8Unweu+U7p3twezO69XqIera6d3puul86XTp9+kT62DtU/FY9nX7yP+iAi4DLAKHAcEC/wVcCh8PIhN/FYUWJReRF3QXDRcOF5sXZBhxGZoaJxtTGmQY7hUhE2oQpw4+Dm8Ofw4ADokM2wlYBiQD0AAx/+f9q/w2+435Cvj39mD2+fWc9Uj1JfVT9bv1VPbF9uT2zfbe9oX31fjP+gv9Rv8ZASICkgK9AhQD0QMwBfgGkAifCRgKMgoQCs4JiwlHCdUIaQgsCAAIqwfsBt4FdgTfAl8BJgBc/8P+Ov6N/aH8mPuV+sb5Pfn6+M74mPhH+Oz3rPeb9+D3Zvga+df5m/qY+6v8xP2z/n7/JwDbAO0BQQOSBK0FrwaVB0cI0QhOCaAJ0gkUCmYKsArGCtYKwQpmCsEJ7QgfCFkHtQZGBgUGnQUDBVUEkQPDAvIBPwGnABIAfv///of+C/6X/TD90/x6/Cr8+vvj+837v/u3+8H70/v/+zT8YfyF/IX8f/yI/Jj8ufz6/D79bP2C/XH9SP0J/a38ZPwn/N37iPtC+/j6d/ri+Ub5vPgr+JL3+/ZD9oP10vRC9Ljz+PIw8mzxo/DB777uzO2b7FzrbOr76bXpeOlU6eroC+gT5//mDOhx6hDu6vIH+DH8/f7a/x7/FP4t/6ADowoCEm4XqhnHGJIWSxWbFQIX8hjwGsMc1h0GHi4dGRtkGA4W2hSRFKQUVRT7EoQQeA2dCk4InwZqBVoE2gKFAFz99vku97H1sPW29sL3C/hE94L1ovNG8vnxw/JH9En2U/gS+mX7H/xd/Hn8CP2E/q0AIgNRBcIGbQe5BxcIxAifCVkK5wr8CqcKFApSCcUIgAhVCCAIngeSBgMFNANsAe//3f5L/hT+0v1R/XT8Ovu/+Uj4T/f49hz3hvf79zb4KfgK+Bj4h/gz+QP6x/po+yL8Kf2K/uL/8ADhAfUCPARzBTgGZAZqBt4GCgiYCdoKbgthC/IKVArGCWMJNAlBCWwJdQkqCWcIWAdGBi0FTwTHA30DRAPgAkYCbwGGAMf/Sf/v/p3+MP67/Tz9wvyK/IX8pvyx/J78d/xM/Bf87fv3+yT8fPzZ/Cn9Rv02/RL97Pza/N38E/1L/XT9cv1B/eb8gvw//Pj7qftZ+wj7ovpE+u35fvnu+Fb41vdP97j2Jvaj9QP1N/Rq86Ty+vGc8VXxkPAJ70nt/Os76yHrkOu36/nqsel36JXnZOfO6P/rhu8L87/2K/qE/GX9lP2X/QD/nAM1C8USxxYQFwsV5xLnEkoVohjXGnEbxxsRHNYbEBvPGUUY6RaGFuAWqRbWFOQR4w6CDHYLTgvKCtIIhgXJAUz+n/sS+qH5pfmv+Vb5Vfix9rr0NfNi8nryfvP99Fn2JPeM99L3R/g6+bz6hPwU/oL/xgDHAcQC+AOUBU4HsgijCf4JowkgCesINAnGCUgKqAqGCt8Jsgg1B5cFJgRSA9sCjwL+AQwBzP9o/jf9Qvx4+6/69PlF+bf4UPga+Aj4BPgw+Gf4hPiQ+Jn4y/hV+S/6Tvtf/ET9Nf4r/w8AtQANAYgBXQLKA8YFVwe8B0kH/gZUBzkIRAk7Co8KOQrRCW4J3Ag8CDoIkgidCBMIbQevBpoFiwQYBAcE2gPMA4sDxAJfAUEA0v+a/2b/TP8z/6b+7f1O/QD9yPyX/Jz8l/xw/Er8IvzW+5f7j/vK+wj8KPwd/Ov7xPvR+/j7D/wi/C/8JPzx+9T7yPvA+8D7yfvI+4D7GvvA+oz6cfpP+h762/lt+df4VPjU90f3rPYp9rP1EfVV9JTzuPKS8VbwTe+G7gDupu1e7dXsz+uL6pzpYOkl6v7rjO6+8LHydvXH+Nv7p/03/k/+qv84BBQLLxH9E9QTdBKrEe4StxUTGPAY9RiXGZgaBxugGjIZSBf1FRcWtxYwFhQUSxHqDkMNkgwtDKcKpgciBDAB8f40/QX8PPt9+qb56fjg92f23PTE81nzlfNs9Iv1ZfbE9gf3Yfca+EL50fpW/Ij9u/7g/xgBeAIABIcFvgaUBycIawiACLYIDwmLCfYJTQpjCgAKOwkaCN8GwwX9BJMEJgR9A4QCUgEqACD/Tv57/X38kvvP+jj6v/lr+S75+/jI+Lf4tviM+Gj4b/jI+KD52vro+138k/wY/fr9Af/z/5EAAgHmAZgDWAUeBgsG3QULBrAGyAfUCEsJggm5CcAJQwmBCCAIJwhXCIUIZAjJB+wGIQZbBawEXARMBCYEnQPIAsYB1QBCAPn/wP9O/8j+Sv64/Qr9lvxu/C788PvZ+9T7j/sj++b62PrR+vH6Rftg+z37Kvte+4n7kfus+8b71fvt+yL8VPxp/Gj8Z/xw/G38T/wS/Ov76fvp+8X7ffsv+7X6XPr7+Vn5sPgO+Jj3/PYz9nH1i/S08+7yFPJA8UfwN+/07dzseuxu7GnsJOxz65bqpeqa7FLv2PHI9Ob3cPr6++n8ff1V/rUB3gdODhkS2hIAErgQtxD6EhIW+xexGFoZMhovGnkZhBhPF18WYRY3FxwXShWqEmEQlw5qDeQM5wt6CSAGIgPGANn+ef3F/Cn8QftD+gP5Vvem9Yz0MfRs9Av15fV29o/2mvbN9lv3U/jG+Wf7pPyu/cD+4f8SAX4CCARPBS4GtgYsB3gHvgdCCOAIcgnJCeQJpQntCPcHEQdOBsYFcwUVBWsEZwNDAhkBHwBZ/6P+zf3j/CP8dPvO+kz6BvrA+X35QfkV+dr4t/j5+FX50vlC+uH6bfsA/NP8nf1s/uL+gv+EAMkB3QKZAzAElQQkBQQGCAd4B5kHKgj7CDEJ2giWCHMIegixCBsJzAjcBzQH9waKBs0FdQVQBQIFUAS2AxEDFwJJAdUAeQDY/1H/9P5q/pj99/y0/G/8Afyw+337Kvvx+sz6v/qg+pX6uvrC+rv6yPrz+hz7T/uD+7z75fsB/Cv8Rfxg/J/85/wJ/Qf9/Pzk/Lf8r/zU/NT8lPw9/Oj7d/sF+7r6Wvq9+Q75e/je9yX3d/ap9Wv0R/Ot8jvyjfFi8Bzv4O0i7S7tEO177HHr3Op66xPtNe/H8IHyH/Xz96n6g/xN/b79of+MBJQK5w64EMEQFhDND4cRahRfFhcXpRfaGHYZKBmoGMIXkxYGFqYWMRc+Fi4UORKZEPAO0w3lDAYLMQhZBU8DegHP/6/+2P3T/Jn7X/rn+FT3GvaJ9XD1jfXm9VP2gfaG9qP23PZo93b44Pk6+0r8Vf17/pL/vgAaAlQDKgTIBHcFFwadBjgH4AdjCKoI3AjkCJkI+AdJB8sGVwYJBrgFPQVzBGgDcQKFAb8ABQBS/5P+w/0c/Yf8/Pt/+wn7oPpE+gP64vna+dn51/nu+Tv6yPpt+x38vvw5/bP9Mf7H/pD/ngD2ASsDvwPdA/YDTwQaBRYGAAfWB0IIXAgwCLYHUwdxBx0IwQjACCwIlwfxBj0G1AWjBX0FTAX0BGoEhANwAswBbgH0AHQA9v94/9H++f1m/Q39vvxw/CP8y/tN+/D6yPq0+o/6ifqv+q36jfqM+qX61PoD+zP7aPuE+7z77/sI/CP8WPyY/Lb8xfzK/NT8yfy5/K38lfxb/CX8Cvyz+0X7zvpr+uz5Ofmn+Bn4bfem9gD2GvXo88DyuPH08EPwt+8X71DuVu1K7HnrFuta6z7sze1y78DwVfLg9K73Lfro+9X8vv0GANAEVQo9DrQPlQ8TD18PZREOFMwVgxY8F3MYPRk1GZ4YehddFi0W+haCF6sW2BT3EjkRqg+XDnENaQu1CDcGWASjAhMB3//O/oz9Ofz6+ob5/PfG9if26/Xo9Rv2ZfZ09lL2RfZp9vX29fdU+an6vvu0/MD91f79/zMBNgIRA74DhARXBQcGvQZQB7wHCAhECGQIOwjIB0YH5gaWBm4GMAakBc4E0QP0Ah0CZwHCABEAWv+m/hX+fv3R/C/8l/ss++X6vfqn+nD6PPoo+kT6ifoL+8X7iPzo/AD9Wv3y/eb+CgAVAbQB+QGHApMDfwTjBCYFlAUjBsYGbgfOB78HggeyBxEIAgi8B4MHawcuB/MG4AaYBvMFRwXjBGUE4AN9AxwDfgK1ASEBnAD5/0D/tP43/rv9Tf3n/IL8/fuU+0b7EfvZ+q/6rvqZ+nz6cvqe+rT6v/rp+hP7PftW+5v71Pvl+wv8Yfyu/LH8tPzA/L38tfzO/PP82fyE/Er8Nfzc+1L7DPva+mL61/lf+cT4yvcH98b2Q/Yi9RT0I/Pz8e3waPAa8EfvO+507YvsqetW69vr1Oz17aDvdfGN88D18vcL+kr7fvx1/gMC3gYlC+UNtQ5EDggOFQ+GEdwTXBVNFhgX3BcUGPEXXBd2FggWfBZDFzwXExZPFHoSwhB6D3QO+Ay/CkQIHQZjBOQChQFSAAz/tP1q/Ar7h/kn+DH3tPaN9n72mPaM9mD2N/Ym9mn2GPc5+H75tvqv+5j8iP2K/q7/uwCpAYICUwMfBPAEqQVGBsgGLgeBB8EH1QetB2gHEgfTBqcGdwYeBngFrATOAwgDUwKzARoBcwDg/z3/n/7y/Uf9ofwQ/LP7dftd+yz7+vq8+pn6sfoP+777Yvy3/NP8Lv3M/ar+kP9BAMkAPAEDAhQD4AM8BHME1ARqBR4GtwYfB18HbAeKB7MHsgeUB4cHmweRB1QHHAfbBmMG0AVNBesEkwQwBNkDVwOMAtcBRQHGADMAl/8O/4v+C/6S/ST9mvwW/Kz7Zvs4+wP71/qp+ob6ePqB+o76nfqk+qf6zvoG+0L7Uvts+5n7tvvn+xj8SvxI/D38T/xV/EH8RvxG/BL8yft1+0v7EPvO+n769vlO+bP4T/jT90v3lfZy9Wb0gPOx8ubxLfGE8LLvzO7s7Tftbuwj7JDsV+1R7nXv+/AS86v1H/g9+nj7MPy3/d8AdAXTCaMMzg3VDYMNMg4fEBcSeBOcFPAVLRebF14XphaGFeEUbhWBFuEWExZ8FLwS4RBJDysO5QwPC/kIIQd/BcgDGAKsAHP/Sf44/SL8ufo6+RH4Svfd9q72wvbs9t32svZ69mb2y/bD9w/5S/ph+1X8Kf30/dv+y/+kAHwBdwJ7A1IE/wSBBeQFKAaPBg4HUwdbByAH4AaWBlIGKAbfBXAFzwQsBIMDsAL4AVQByABOAM3/Sf+l/vj9SP2q/Dv8//vw+8r7i/tO+yP7LvuN+yT8gPys/PL8hf1A/tn+bf/e/00AEQErAhoDfAOdA/ADaQTiBJYFRwaoBtcGFAdKBywHBgckB0kHOwcyB04HGQeSBhIGvwVaBdcEpAR5BP0DTQPAAjkCfwHgAGsA6v9H/7H+WP7j/Tb9vfxZ/AH8qvtn+0D78fqw+pf6lPqF+oT6j/qN+or6lPq5+uT6BfsS+yD7NPtb+4X7k/uY+577n/uZ+437evtE+wX73frM+qj6TPrv+Xj5+fh8+Av4yvcz94T2vvXC9NHzw/Lt8SPxifAP8FzvvO7j7fHsL+xH7H3t/u618N/yLPUB95L4K/pN+0j8jv7MApkH8grKDGcNwAxDDGUNqA+QEeQSfhRJFvQWiBb+FRMVDhQsFIwV0RamFlsV2xMAEukPeg6CDSYMeAroCH0HwwWpA98BjQBm/4v+wv2Q/BD7kPln+Iv3AffY9u32FfcY9/r2lfZa9sL2sPf1+DD6Xftj/Bb9v/1+/iv/0P+xAOEBBwPnA4YE6QQcBVQFxgVTBqgGwQbABowGRgYABrQFYwXvBIIEGgSFA80CEAJbAccAWADx/4r/DP9k/sD9Lv2i/Fj8P/wV/O/71fvY+wL8Nfxo/KX82vxV/Q7+tf4q/3r/+f+hAGQBBgKJAtkCHwOmAzEEwgQoBXYF6gVGBoAGngacBo8GigadBsUG2AavBlwGBgaXBSwF0wR6BEAE8QOTAzoDsAL/AVkBxAA6ALX/R//w/nH+4v1L/cz8Vvzk+6P7Y/sx+/H6wvqf+nH6ZfpX+mD6bfpo+oD6jPqN+ov6k/q1+tn69vrw+vX6/fry+t760Prb+sP6e/pl+kP63vmY+XD5Q/nN+F/4I/ie9/P2cPbB9bL0x/Mk83jyzfFr8dLwsO+L7vXtiO0j7eftZe9s8JHxvPMr9uX3bfkv+2P8QP3I/0UEPQhoCsoLkwxKDDIMnw1+D3YQQBFDE38VKBbyFZYVkBRgE2wT3BTlFXgVmBSfE+sRyw9ADhUNegvbCcUIzQdHBloEsgIcAaf/r/79/R393fup+m75PPhQ9+/29vYL90z3XPco9/j2NPfQ92r4TvmC+sH70Pym/V/+sP7f/nD/bwCKAXoCWwMBBFkEjgTXBCAFOwVTBZEFzQXGBaEFVQXpBGUE7QOqA1ED3wJjAtgBRQGzADgA0f9q//7+q/5Z/vX9fP0O/cX8mfyr/Nj8HP1b/Y39zf34/Rj+Sv6o/jT/5f+bAB8BdgGqAfABOwKDAvMCYQPdA2ME0wQSBRUFGQUtBUsFcwWjBbQFkQVxBVEFGQXRBI4EVwQUBNQDmQNMA9kCXAL0AYUBGQGuADcAtP8d/5T+IP6i/S39xPxr/BX8vft5+zL75fqi+oH6Z/pW+lb6S/o6+h36FvoG+ur56fnp+fP59Pn2+fT53PnV+dH5wPmQ+XP5bPlV+Sf51vir+Gv4K/gb+Pr3qfcF95L2JPZX9Y/08PNu87PyQfIV8nzxePCU7zjvD+9u75nw/vFO8xX1Wfd5+Qb7H/wn/VT+hQC9A/AGOgmfCnkLzQtEDAoNuw1SDioP3xDEEhUUuxSPFL4T7hLVEj4TfBNGE+gSYxJiEQgQrg4zDXwLBQr+CBMI3wZ8BScEuQJKAT0Adf+J/nX9Y/xQ+yb6E/ld+P/3yvfN9//3JfhO+Hf4nfjQ+Bn5q/mW+qv7sPyD/Rj+df7P/kb/xP9TAPwAtwFvAgwDngPyA/UD+gMPBC0EPwRVBF8EMQTgA50DYgMMA7ECbgItAs8BbwEWAboARgDe/5r/Y/83//n+tv5p/g/+2v3S/en9Av4//pX+3/4Y/0L/bP+T/87/IQCDAN4ANQGJAdgBEQJFAoYCvAIIA08DhwO/A+gDDwQzBFUEbgRzBGkEYQRMBB8E8gPKA6MDgQNnAz0DFAPIAmICEgKlATsB3AB0ABIApv82/8j+Tv7I/Ur92/xy/Bj8x/uG+0L7+vrF+on6WPou+gT62/m0+Zf5evls+WH5UPlG+UX5RPlC+Tb5L/ks+Sr5L/k5+Tn5Kvkg+Qv56vjQ+Lj4r/ij+Hf4Qvjl93X3APds9uH1ZfXl9GD06PNs8+vycvIX8gPyLPKs8pHz3/R49if49vmr+w39Nf5m/88AXAICBKsFNgdgCDQJDQquCv4KRAvHC4gMag1tDnsPQRCAEJMQnBBvECMQ4g+kD1oP4w5iDtwNAA34CwkLNgpUCXUIqQfdBu0F2gTqAwADBwISAS4AU/9t/qL9/Pxg/Lj7LPvL+pT6iPqV+rj65PoN+zf7Z/ud+9f7Evxj/KT88vxJ/ZP95f0t/nr+xv4e/3L/x/8BADoAcQCWALkA1QABARQBKQFDAVABUgFTAVMBSwFDAUIBUAFQAVoBZAFhAV4BYAFUAT8BPQE8AT0BRQFlAYQBkQGZAaEBnwGbAaUBwwHYAd0B+QEDAvgB7wHhAd8B1wHZAe4B+gEAAv4B9wHtAegB9QEEAhACFgIbAhsCDgIGAvwB7QHkAdkBzwHDAawBkAFzAUQBHAH2AMMAlABPAA0AwP9w/yb/2f6R/j3++P2r/Vj9Ev3E/Hz8OPz4+7n7d/sw++b6r/pn+iP67fmr+XP5PPkH+dH4nfhk+D34Gfjz9+H3w/em95D3efdk91r3Sfc+9zT3Fvfm9pH2NfbK9Vj14vR/9Cv00POM80rzBvPO8s/yJ/PY89j0Nvbi94f5C/tL/ET9/P2w/qT/2gAyAmgDiQR8BS0GwQZjByAI/QgOClsLzAwBDuUOiA/PD9oP1g/kDwQQChALEAgQ0w9cD6wO/g1IDZ4MLAy6C0MLmwrQCecIzweqBn4FbgRYA1sCawGAAKH/xf7z/SX9g/wA/Kf7avs6+wv73fqr+n76Wfo1+jL6Qvpe+oT6sfrc+gr7Lvtf+6P78ftD/Jf89fw8/YX9yf0L/k/+lP7p/kH/l//f/ykAbQClAOIAIQFhAZYB1QETAkACdwKVArQC0QLoAg0DNANsA58D3wMEBBEEHQQSBBAEGgQcBBsEHQQNBPQD0AOSA2kDSgMoAxwDDAP7AuECvAKQAmYCQAIZAgwC6wHIAasBhgFmAUABIAEFAfcA6QDYAM0AugCfAIQAaQBUADkAEwDu/7r/gv9H/xD/3v6o/nP+Rf4U/tf9oP1a/SL96fyu/Hz8QPwD/LT7a/sX+8P6dPoc+tj5iPk4+fP4mfhI+Pv3r/d690H3C/fe9qP2bfY39gH23fW39Y71WvUZ9dD0dfQI9I3zIPO38mTyLvL88dPxyvH28XPyXPOR9DT2DPjC+VD7h/x8/V/+QP9RAK4B/wItBEEFGwbCBlcH9QfPCOQJEQuADOwN/w7DDzcQaxB0EHkQkhC0EL4QoRB9EB4QfQ/KDgcOZA3oDIAMGwyTC+AKAAoCCecHyAazBaIEoQOnAqkBrAC1/8j+5v0c/Yj8GfzP+5P7VvsY+9H6lfpo+kL6JPoj+jX6S/pj+oP6pfrJ+vX6M/uE+9j7NfyO/Nj8FP1U/ZT92/0n/nP+0P4p/3//z/8ZAFsAnADgACQBaQGpAfMBOQJvAqYC0wL6AhYDNgN2A7QD9wMvBFgEZgRqBIkEpgTBBM4E1QTSBMAEoQR7BFkENQQRBPcD3wO+A54DcgNDAw4D3AKwAokCVgIbAuoBqQFxATYBAwHTALAAkAB0AFUAKwAQAOP/xf+p/4b/Z/85/wf/0/6i/nP+Qv4N/ub9wf2U/XT9TP0h/fv8z/y0/JH8aPxA/An8yfuC+zz78/q0+mn6Jvrb+YT5MfnU+ID4JvjQ94P3RvcO98z2jvZG9v/1vPV19Tb17fSo9Fj0/fOQ8w7zlvIS8qPxR/EI8e3wAPFR8fTx/fJa9BH24vd5+dX69/vy/AD+Jf90AMwB+wIMBAIFzgVzBisH8wfxCCYKiAsADTcOIw/ND0YQixDOEBYRURF0EXERVhEPEYwQ5A8zD4YO8Q2IDTYNuQwRDDsLUQpVCUIIPQdABj8FOAQvAxkC/wDl/+3+Dv5O/bz8UfwC/K77W/sC+7f6e/pL+i36EfoM+hD6FPoi+jT6U/qA+rT6/vpT+5r78fs1/Gr8qvzh/DP9fP3D/SX+dP7Q/if/cP++/wMATwCeAOcANwGOAd0BJgJqAq4C4wIiA10DnAPnAyYEagSZBMgE6wQWBTwFWQVxBXYFgwV7BW8FZAVQBSoFAQXVBJwEbgQ3BA0E3QOdA2wDOwPyAqkCZgIgAtkBhwFHAQgBwgCAAD4AAADA/4j/Vv8l//X+w/6Q/mH+Kf71/cb9mf1t/UH9GP34/Nv8s/ya/Ib8cvxb/Ef8OPwc/Pj71vuy+4X7YPs0+wP7wPpu+ij65fmd+V75HPnU+In4MPjq96H3XPci99z2mfZO9vT1o/VN9fD0jPQb9K3zNvO68jjyufEy8c3wwfAJ8aDxZPJn87L0HPaI9+j4DvoS+xn8Tf23/hUATwFeAjYD3wOTBGYFXAZgB3QIsgn8CigMJA3rDYQODQ+NDyAQohADES4RIRH8EKEQOxDJD1EP1Q5XDvoNow0YDVIMewuaCrgJ1ggHCDUHPQYyBSMEEQPpAd4AAAAx/33+4f1s/fb8c/z9+5j7P/v6+tH6rPqU+mX6VfpH+jH6PvpI+nz6qPrh+iL7VvuP+7b76fsX/FP8mvzg/Dn9hP3U/Sn+c/7H/hv/dP/V/zAAiwDtAFABngHqAT8ChALUAhsDYgO3A/EDLwRlBJIEugTkBBcFRQV3BaYFyQXfBdgFxAW2BY8FZwU/BQ8F3wSoBGYEKATeA5gDXAMeA+EClwJZAgACrwFmAREBxQByACYA3v+V/0v/Cf/E/oT+S/4W/uX9rP19/U79IP32/NL8tfyX/ID8ZvxP/Dn8HfwK/PX76Pvb+8z7xPuv+5X7evtU+y/7BPvM+qD6Z/oo+u75s/ly+Sz58/i++I/4YPgw+P33v/eD90r3EffB9nf2LPbU9Y/1OvXj9IX0EfSi8znz4PK48s/yMfMJ9EL1ofbs9/741/mI+lb7ZPyo/f7+PgBlAU0C7QJxA/IDfwQtBUEGfQe+COwJzwqEC+8LYQzsDIYNKg7ODm8PvQ/ZD78Paw/9DpIOSg4aDuMNpQ1EDasM9gs1C3EKrwn7CFMIqAfuBhoGJwUVBAADBgItAX8A+/+D/wH/cv7r/WP96vyR/EX8DvzX+6v7gPtC+xP77Pri+uL6+vom+0/7cPuB+5L7mfuf+7z74/sK/Er8gvzL/A/9TP2n/fP9Vf7H/kD/vP8hAHcAxwAZAWIBwwEqAokC7gJFA5wD3gMeBF8ElQTUBAYFSQWHBa0FxQXeBesF6AXnBdEFuAWNBVkFIgXgBJkETwQJBLkDawMlA9sCggIwAs4BdAEZAboAZAD9/6H/Ov/Y/n7+Jf7T/YP9P/0B/cX8gvxJ/AX81vu3+5r7jftz+2b7X/tV+1P7UvtY+1/7Zftv+237cvt1+3j7ifuf+8j71PvX+9P7x/vM+7b7lvtz+1X7TvtC+xP7vvpd+gj6vvlo+Rb52fil+Hb4MPjj95f3Q/f+9r/2g/Y99vz1t/V79Yz1+PW89o73OvjR+Fb5yPlU+hL75/vX/MT9vP6T/y8AzQBnAfQBiwJuA34EhQVlBigH3gdiCOgIhQkqCrwKXwsWDJsM9QwoDUENJw30DNkM0wzGDJoMcwwdDLELQQvaCn8KCAqgCSkJmAjrBzQHdQakBeEELASXAwoDhAIAAnUB+QB9AA0Apf9K//f+pv5X/v39qv1L/QD9wPyH/GT8VfxG/CT8D/z1+9v7vPuu+6f7rvu5+8r78PsA/Cv8Xvyc/O/8Q/2q/fr9Rf6X/uv+Sv+p/woAbADLAC4BjAHmAUAClwLuAkADjAPRAw0EOARgBIQErATQBO4EBAUKBQsFAQXjBMAEmwRxBEUECgTCA3YDIgPSAnsCHQLFAXEBHQG+AE4A4P91/wz/pv5G/vX9qv1m/Sj95fy1/JT8d/xk/Fv8Y/xz/Gz8VvxT/Gb8j/yn/K/8tPyx/LX8qfyp/MD85vwJ/Rv9HP0Y/R79I/0V/fn87Pzr/Pj86/zd/M38nPxb/Bv89vvR+6f7ffte+1H7RPs6+yD77vrP+rr6m/p0+k76Ovob+u75t/l2+TX5Ffk2+ZH5D/qT+gP7Pvtu+7T7Gfyg/Cb9w/1Y/t3+Xv/I/yoAgQD0AHwBHQLTAnQD/ANYBJ4E6ARMBcYFVwbYBlIHyQcpCHcImgi6CMYI3wgCCRkJKAkPCewIrwh1CEoILggVCOQHtQdwBx0HrQYmBp0FDwWTBCoEyANtAxIDrAI9As8BbwEfAd8AmQBSAAMAtP9x/yf/5f6w/o3+cf5t/mb+Wf5B/h3+B/7w/eL91v3L/b79r/2p/a39tP3G/ev9DP47/mf+kv6z/sn+7f4L/zb/ZP+P/87/AAArAF0AeACkANYAAAEyAVABbQGCAZMBngGoAbYBywHdAekB9gHvAe8B3AHOAccBtAGtAZIBhQF1AWUBWgFBAS8BHgETAQQB9ADeAMkAsgCKAGQARAAlABYABQDn/8//n/9x/0//MP8S//D+0f6r/o3+a/5O/jX+Iv4Y/hf+F/79/ej96P3h/eD93/3W/dv91/3V/dP90f3E/bT9t/2o/Z39nf2R/YT9bv1T/VD9Rv05/TL9Lv0z/Sf9LP0u/SX9Kf0m/Sv9I/0b/R39GP0T/Qf9Av0B/e/85Pzd/NH83vz3/Bn9N/1R/Wj9fP2N/Z79yP3p/RT+Sv56/rb+5f4c/1f/jv/a/ycAagCzAOsAJwFhAYkBwgH4ATYCdQK2AvACKwNhA5EDvAPWA/gDEAQpBDsERQRPBFAESARPBFUEUwRdBFcEUgREBC4EGwT6A9kDuQOiA4sDbANVAz4DIwMIA+4C1wK/AqQChAJhAjMCBgLhAbQBjQFmAUMBIwH/AOAAuQCYAHEASgApAAEA4f++/6D/gv9u/1j/Qf88/y7/K/8l/yD/Hv8a/x7/Hf8l/yr/N/9D/1f/X/9v/4T/jP+o/7v/0f/r//3/EQAjADwATABhAHQAfgCaAKEArQC2ALIAuQC8ALsAvAC4AK4ApgCaAI4AiAB3AGkAWgBCADMAHgAFAPT/4v/T/8n/uf+v/6b/mP+Q/4f/ef9s/2L/UP9J/zj/Mf8k/xn/Ef8A//n+4f7V/sz+v/62/qr+l/6T/ob+f/5//nH+b/5l/mX+X/5W/lP+Rv5A/jb+Jf4p/hv+FP4R/gT+Av79/f79+v3+/fT9+v38/fj9Af7+/QL+A/4F/gn+Ef4V/hf+H/4d/iH+Jv4l/i3+M/48/kj+VP5l/nL+fv6N/pr+rf6+/s7+6P7+/hf/Ov9Y/3z/of/E//P/FAA+AGgAjgC6AN8ABQEnAUcBZgGNAbYB3QEGAiYCSAJoAokCpQLBAtwC6QL9AgEDEAMVAxIDHAMXAx8DGAMWAw8D/gL2AuEC0gK4AqECjQJ4Al4CRgIzAhsCCwLwAdUBvQGiAYwBdwFcAUYBLwETAf4A5ADRALsApQCQAHsAaQBWAEYAMAAeAA0A/f/s/9z/0f/O/8n/xf/I/8D/xP/E/7//xP++/8H/xf/D/8H/yP/N/9T/4v/h/+z/8P/0//3///8DAAYACQAKAAgACQANAA4ACQADAP///P/1/+z/6P/h/93/2f/V/8f/vf+z/6b/n/+N/4z/g/94/2z/YP9Z/03/T/9D/0H/O/81/zP/K/8l/x3/Hv8X/xf/Fv8X/xf/F/8a/xj/IP8b/yL/Hv8b/x7/Gv8i/xr/G/8e/x3/Hf8g/xv/Hv8i/x3/IP8U/wv/DP8C//7++/72/vT+7P7p/uL+4P7f/tv+3f7W/tf+1/7V/tn+2f7h/uL+4v7q/u3+9P78/vz+Bf8O/xH/Iv8m/y3/Ov9B/03/Uf9e/2P/cf9+/4f/l/+Z/6b/rP++/83/3P/z//v/EgAmADUAUgBjAHcAkgCdALQAyADaAPcACAEaASsBPAFOAWEBcgGAAZIBmwGoAbgBugHIAc0BzQHVAdYB3gHjAd4B2gHaAdcB1gHRAcEBvAGwAawBqAGZAZEBhQFtAV4BTgE7ATYBHwERAQAB8gDkANAAwgCqAJ0AjQB3AGkAVwBJAEIAMQAnABsADQACAPX/6f/f/9X/yv/F/7j/sf+1/6v/p/+h/5v/nf+X/5v/mP+Y/5f/lP+Y/5j/m/+j/6X/of+k/6P/p/+m/6n/qf+p/6v/rf+2/7T/u/+8/7v/vf+7/7z/vP+5/7b/vP+5/7j/t/+y/6r/p/+m/6T/pP+j/6H/of+f/5z/mv+Z/5X/lP+X/5D/kf+T/5H/kv+Q/5H/jf+R/5H/k/+Z/5P/kv+S/47/kP+S/47/j/+M/4r/if+M/4b/iP+H/3v/g/92/3f/e/9x/3r/cP9v/2j/Zv9q/2L/av9j/2X/Y/9h/2L/Y/9i/2D/ZP9i/2n/bP9y/3T/dv99/4H/iv+Q/5j/nf+m/6r/r/++/77/zP/T/9f/6//s//b/9v/6/wEACwAbAB4AKwAyADkARwBNAFoAZgBqAHcAegCDAI0AkACbAJ8AqACxALgAvAC9ALsAvgDAAL0AwgC+AMEAwgDCAMIAwQDBALkAuQCuAKsAsACkAKMAnACOAJAAhQB8AHcAbwBpAGIAWgBSAE8ASABBADcALwArACIAIAAaABUAFAANAAwABAAEAAIAAQAAAP7/AQD///7/+//6//n/+//7/wAAAAABAAcACQAKAAkACwAHAAoACAAKAA0ADwAQABQAGAAUABYAEgAQAA4ADwASABIAFgATAA8AEQAFAAcACgAIAA0ABQAAAP3/9//3//n/8v/w/+z/5v/o/+T/4//h/9v/2v/a/9v/2P/S/83/x//J/8b/w//C/73/u/+6/7r/uv+7/7b/tP+1/7L/tP+1/7P/tv+x/7b/s/+z/7f/sf+4/7X/t/+5/7r/uf+8/73/uf+7/7T/tf+x/7L/rf+v/7D/rf+x/6r/rf+p/6j/o/+h/6L/nv+g/5z/nv+f/5v/m/+b/5j/nP+b/5n/nv+W/53/m/+c/6D/nf+t/6n/sv+1/6//uv+3/7//yP/M/9n/3P/i/+X/6v/1//T//f/+/wMACgANABkAFwAjACgAMAA1ADAAPgA6AD0ARQBBAEwAUwBPAFsAXABbAGQAYQBkAGUAZwBmAGMAZgBgAGcAZABhAGMAYABhAGEAYgBdAF4AWQBZAFYAUgBZAFEAVgBUAEwATABEADwAPwA6ADoAOwA2ADUALAAuACsAKgAqACcAJgAjACIAHwAhAB4AIAAhAB4AHgAfAB0AHAAZABcAGQAXABsAGQAWABMAEgASABAAEQAPAA0ADQAMABAADwANAA4ACQAKAAkACgAQAAoACgALAAUACgACAAAA/v/7////+v/+//X/9//3//L/9P/1//X/8v/1/+v/8P/w/+3/5//k/+L/4//k/9z/4v/e/93/2//X/9j/1//R/9P/zv/M/8//yv/L/8L/wP/A/8D/uf+2/73/s/+0/7P/t/+1/67/sv+s/6j/p/+o/6z/qv+p/6b/qf+j/6H/o/+b/5//of+g/6D/m/+b/6b/pf+d/6j/sv+w/6z/pv+p/6//qP+v/7n/r/+3/8j/vP+5/8X/yP/C/8D/0v/Z/9L/0P/Y/+D/2//l/+7/5P/i//X/+//v//D//f8IAAQAAAAJABAAFwAaACgANgA3ADEASQCCAJwAvwAJAXwBBQKqApwDzwSKBXkF/gT3AzYCLgCz/q793fxF/CT8X/yM/Pv82v0a/yYAEQFGAjIDIQNNAosBfgA6/3T+Kv7M/Wb9tP1f/rz+5/6r/5EA/QBAAdEBYQK+AQsBBgGuAKv//P4E/+z+Ef81/9P+4v7w/xUBBAFJADwBtQLwAYwAIAHvAYkAzf4c/xEAO/8l/mn/bwEtAT4A1QA8AdEArQBWAeAB3wA6/+r+av9s/4r/dgBbAS4C+QLrAkoC3gEvAUwApf+o/hr+cf2h+637V/3i+yj7Vf5HAJX/k/81AUABLgCiAPoBWgF5/vL8X/0H/lv+mv6h/kf++P5RAAcALP/x/wIBSQGOAdQAnf/Y/5sARQBb/87/YgB2/lf8H/6LAR0ChgANAPwAGAAi/1wAowCq/9b/kwEqAHH8gv3u/9n+nv6jAQcCOP+C/1cBEABl/br+UwIVAXH9Kf8WA3YBOf9EAFf/k/0m/2MBkQAFAEkCqgLt/3//6wH3AjMAEP4AAD39Evl4/rwDLgDm/eIDHgaa/cv5nwJNBt/7Mfp2BgQGIvpR+mwD4gFH+SH9qwZaA8L8of+vAt//cf9WAp7/IPtd/2kG5QII/Ab/bwRqARr82/7IAXH/jP7QAWUC3v3L/uUCNAAJ/BYB9wSR/1P9BAEMAtT9df3+AksExv1W+7kC3wPz/Jb8fAKtBEX/nfwOApsCRv4bAS4ENP5E+8UDXwbE/K76hAN0BGj60foWBh0DQvde/cIK6gSJ+jMA4ASH/L34kwCQA9X7TfrjAvUDHvxN/BMEuAFE+qD/dwkqA1T2WP2XCnwB+/Id+4gH7/5d994D3gl3/cT4qATSB8P7uPmwA5IGlgAS/cEAuwKo/eL8rQLRAcn7DP8eB9MERPzR+5cCFQJ7+1P9kASqAgv9vP/lAob9i/qZAFoCOf3K/D4CoQJn/uH+hgEw/8n75v9/BNwArPyy/xcDAADr+1r8Ef9ZAGEAh/9C/38BaQISAaMAdQFtAncAmv35/gAAwPwh/KD/Rv9S/bIA6QNaATH/2gEuAor+gv8kA0gA3ftq/1gD1P6R+2MBhwSy/ib8+gCmAk7/cQCNAy8ABfzH/bYBGwIYAUMCXQLa/9X9Y/9+Abb+JvvT/WAC3gBP/sIAXQK0/6r/UwNgAu3+cwAgAWD9+/3pAa3/oPso/3QExgHO/Gf/NwTQAQP+GAK9BVz/wPohATcErfvm95oAQwSY/QD+VQZLBJT6Gf3IBaQB0voMAs8IKf9g97P/KQQt+2f5WAMUBPL6jfxABjQDPvrd/kIHsQEY+fj+lQZW/+/2+v0XBoj+mfchAFwGjv4u+lYCiQaH/0j9zgQ6Bgv+Uvvh/8b//ftY/X0BegF1/5IARwLIAJv+xv4hABcBYgEyAFz/kwBlAV0AEgDgAekAvfy8/KcAsQDK/YX/qAMFA3r/1f8DAroAsv/+ADEAm/2d/koBbv92/JP+vgGNAO/+KQB+ABX/JwBfAswA1/6KAMUBm/99/aP9af2T/I79P/8P/xT++P6UAIgAJgC3AHsACQByABYANf/y/o//KACA//b9FP40ABkAmf3g/Z0B6QKjAC0ASAJJAsj/f//bABIApP4r//D/nP67/dL/NQGt/yP/eAF8AjIAHf9wAZoCjwAsAOsBjQGw/5v/0gDKAFwA8wCFAeMA4f+AAOgBZAEEALYAsQJjAp4AVwGOAgwBd/+9AIAB5f+l/xgBfwHwANUB6AJCAgAC7QLHAjIBVAGTAs8BbQBNAGoABADH/3IASQFIAW4BNQHF/4v/AQE7ARUAqf9eAJ0AbP/F/pP/9v87/9v+C//d/Sz8dPwI/lb+uPxW/OT9kv0U+7b6/vzO/Xr8V/zG/Tn9B/tG+8P8tfvq+cL69vtv+tH4H/oC/Gj7Z/rC+0D9ffzN+179w/4z/gL+zP/eAK7/Rv8DATYC2QFvAkcE2gRMBBkF2AbbBtgFZwaSBzEHSwavBlcHrQbmBUsGxgYfBn4F6gVNBu8FiAXKBckF+QQ6BOIDZAOLAtsBkwE0AXUAAgBnAN0AvgDVAHIBDwJbAqgCHAMpA6QCNAI4AvMBZAEkAVcBgwFMAWsB5QEiAhkClgJGA1QDRwNmA6kDsAONA84DLQTrA4gDgAMdA1wCvAGZAV4BnQDr/6L/pP84/5H+lv66/kf+1/21/Xf9Bf1F/HH7RPtT++H6+flJ+TH5wvim9/H2Ave19sH1RPUl9Zj06vO387jzV/O/8lzyHPKt8QDxV/D072Xvgu7m7ZvtNe3b7BXtvu2r7lbwH/NM9ij5y/sw/j8AAwIOBG4GVAhrCQEKbAqlCqMK2wpLC5EL6wu3DOENAw8mEHkR4RL0E4YUzxS2FBMUOxNeEk0R0Q/oDeELvAlpB0AFsQOLAlYBMABp/8f+EP65/bn9bv2r/Pn7jfsb+2j6rfkc+Wn4w/dX9wj3w/af9tz2afcb+Nn4s/md+pT7svzu/RT/CwDpAKsBXALqAm0DzQP5AwYE6APYA8EDrQOtA7sD1gPqAw0EOARsBKUE+gRvBQMGqQY8B5EHsgfVB+AHyQeiB2oHCweeBjsG7wWYBTAF7gS4BIUEZgRVBGAEdwSDBJAEgAREBPkDqwNfAxMDuwI5Aq0BQAHhAHYAGQDs/87/fv8n//z+sf4G/mL9A/2h/Bj8Yfvt+rP6F/o8+ZT4GPhh94X24PVT9YL0f/OQ8qjxi/Bp75vu1e3Z7MfrxOrY6eLoBeh7513nh+fc58PoqOps7WzwS/Pv9S74Lfrs/K8AFwSbBpkIEwr9Cv4LXA1IDn8O0g57DxgQ6BAHEiIT/BPvFAgWuRYWF4MX/Rc/GD8Y3RfKFggV5RKjEDcO1AuICfwGRQSRARb/5fwW+5f5GfiU9k/1n/RZ9DT0FvTb83PzBvPW8rfycPIx8jXyWPKA8snyFPNX89vz0vQI9jv3hvj++Yb7L/36/rMAKAJkA5oEvAXABrIHawjQCPQI4wihCEkIDAjNB3QHMgcSBxwHIwdBB3MHiwekB9gHHAg6CEgISQgnCMQHOgeIBpIFqAThAwgDGAJHAZgA7f9j/x//8P7N/uD+J/96/8T/JgB5AKMAvQDEAJYAPADd/1T/rf4K/kD9VPx/+7D6APpw+fz4pPhE+Pf3rvdW9+L2Tvaf9b/05/Mh8zfyCPG+723u7Oxi6/Tpoegr57Llp+QA5LDj/eMs5WHnYuqK7ZrwnfOY9t75Bv7SAgAHGAqfDKAOEBCYEQATbhNJE14TkhOuExUUyBQxFWwVAxbDFk4XDxhdGZ8afhstHGEcvBuaGlwZ1Rf4FfEToRGeDjELxgdgBB4BDP43+2P4w/Xi87Dy8PFk8e/wj/Bb8InwIfHL8WPyA/Oo8yD0bfSl9LT0xfQP9Y/1B/Z/9iH35PfU+BP6jfsK/Yb+RgBIAk4EWAZeCCQKfAuiDJoNSA7NDiYPOQ/xDnQO7Q0/DYEMvgsCC2IKwglNCRIJ2gisCK4IkAhUCCgI8Qe8B20HGgedBsgF6wQJBP0C9AH8AAAACP8y/or95vxa/BD84/u9+837CfxF/IL81fwN/Q79GP39/LL8Tvzt+2v7t/oe+m35lPjE9w/3Q/ZT9YL0rPON8n/xiPBx70PuIe0H7KvqaelS6CLn8OXl5Bbkj+On45PkgOY/6djrE+518AjzBfY++kf/gwPHBtwJlgzQDjIRcxOgFBsV5RWwFvkWYRfWF7IXMRcdFy8X0hbTFpsXVxi1GCsZVhnDGA4YoxchFzkWOhXgE68R/g4/DGEJPQYpAwAAlvxN+ZP2aPRV8l3wtu5K7Tzs8es/7LfsZ+1e7lnvWPB48Yvyh/OE9Mv1E/cJ+NL4gPkc+q/6avsg/L78VP0r/l3/ggC7AQMDPgR0BbcGIgiDCd4KLwxDDQcOnQ4XD1QPXQ81D+cOXA6rDeoM8QvwCugJ4QjOB7MGxAXqBDAEgAPlAkcCmgEYAbgASgDp/6T/Sv/f/nD+Df6F/fr8e/zm+1P7yfpP+r/5QfnZ+Hn4FPjN97v3nPeQ9533sPe899L36ffp9973r/dl9+/2S/Zw9XT0ZvMi8q3wG+967aXr3elE6LDmHOWj44zi5OGz4VfiMeTb5nnp1etp7h/xG/Rg+KL9IgKiBQEJ4QsvDsYQSxOQFCsVBhatFs4WBxdcF+EW7xWIFUQVhxRBFNUURxVQFY8V0RVXFcUUyxTDFEoU0RMTE2QRJg/hDFcKcQeKBIEBD/5/+mH3p/Th8Tbv3eyq6tro/Ofk5wnoXegf6SjqReur7Ezu9++78bPzt/Vd97X4/fkK++v7xvyb/Sb+hP4f/7r/PADLAHwBFgKrAo8DrgTvBTsHpQj7CQ8LPAxtDXMOcw9JEOgQPhFJER4RtxACECQPLg7mDIALIgq4CDQHyAVsBAkDvwGzAPz/Yf8D/97+t/6y/s/+/v41/2v/rv/Z/93/0f+n/1f/9/6I/vj9Uv2i/O/7Jftk+sH5Ifmm+FH4Ffj69/j3//f49+j3tvdd9/b2ffba9ev0zvNr8s/wNO+K7bzrwOnn51nmMOXC5G/lJefn6FjqKuxc7tjwu/QO+vD+1wKwBkQKXw3QEFcUuxYyGKoZ4xqAG/YbTRygGzAaKBkvGKcWXBXsFFIUNxONEhYSDxEbEBIQPBATEB4QKBB1Dz8OIA3cCyAKWAhvBtcD2AAK/l37W/gk9RryD+8o7CDq2ei559DmWeZa5qjmeOfz6LDqoewO77TxOfSc9vr4Pvs3/T7/KQGfAsAD0AS2BR8GbAaYBnoGOQYaBjMGPgZiBrgG+wZEB7kHdQhpCXoKoAurDKQNeA5FD+oPPBBvEFoQ7w8+D1oOJQ2kCwcKTQhgBlsEhQLQAD7/3/2//MT7+PqW+oj6sfoC+5H7Nvza/Iz9Pv7R/jj/lf/F/7L/df8T/3H+p/3M/NP7w/qt+Z74iPd29n31ffRm81/yTvFI8F/veO6Y7ZjsgOtt6k/pOugm5wLm3+T+43bjkePB5I3mCOhG6fjq1uxf75jzZ/iG/DcAwgMOB4sKcw7iEXMUvRa9GGUa7BtcHRMeph0gHckc0RunGhwadRkIGLAWpRUNFDISDBFJEEQPeA4CDhwNwguPCn4JHAi3BoQF9QPWAdL/Bv7i+5b5T/fP9CryBvCK7ijt0uvC6uHpLOkH6YTpTOpT68vsq+6U8KTy9vRF93j5y/tN/pMAnAKZBGoG0gf4CPcJkwrlCi0LWQteC0kLKgviCmoKEgrZCcsJ6AkXCloKiwrCCikLiwvZCy8MZwxmDFAMNQzQCyMLVgpvCUEI5waYBTEEvgJVAQgAr/5S/UL8a/ut+ij69PnM+br59PlC+oz67vpj+7n7+/tG/Gz8ZPxH/Bj8wvtK+8r6JfpT+WH4Uvcm9tn0d/MB8ozwJe+u7RfseOrd6C/nlOUq5MfiZeFA4InfRd/l37Ph3OOR5VTnmekj7Mfv5fQD+kr+MgLVBXQJjg2dEdcUVxd7GS0bxRx/HrUfrh/3Hn0etR17HKgbLBvuGT4YDRexFd0TcxKkEaQQlg8TD4UOhg13DIsLZQoECf8H4wY2BXID2QHh/4j9W/se+Y72C/QN8nbw5+537TzsHetg6kXqqupd61nsx+2H757x8/M29pD4Efuw/UQAzgJTBYIHUQnwCkoMQQ38DY8O3Q7LDqUObw4EDnMNzgw3DK4LSwsWCxkLCgv4CiYLaQuwC/gLWgyWDLwM4gzVDJIMGwyHC6sKoQmJCEUH0AVVBOMCWgG+/z7+9Pyk+5362fkd+Zj4OvgX+Pz3DPhH+Hz4u/gK+Vj5c/mM+Yv5VfkH+bL4Kvhq94j2evVN9ObycfHY7yvul+zl6hzpPedc5W7jpeEH4GXe+dzq21bbctvK3NvekOAg4jXkq+bW6Zvu2fNd+F/8/f+bA7AH5AtfDxASJhSwFUkXBBlmGqca0hntGNkXdxZ3FcYUZBN4EeQPSg5/DCgLQwpACT4InwdIB8gGPAbMBQIFDQRfA8YC0AGnAGX/yv0E/C/6PPjs9ZfzpPHY70Tu2ux26xzqH+m/6NLoR+kc6l7r5+zP7jLxwfNO9vT4xvuj/oQBZgQmB4EJdQskDYYOmw9rEAARNREZEdgQbhDqD0gPmw7vDUsN6gzODM4M3wwSDWUNzw1aDgEPpQ8+ENwQWRGdEboRpxFSEcEQBxAbD+8NnwxJC80JIwiFBvcEZAP7AccAtf++/gD+cv0D/dD8uPzQ/AH9R/2k/e39OP55/o7+lP6O/mL+/f1k/ab8oPtq+gz5fffE9Qv0RvJJ8EruR+wt6iboYua75C7jAuJE4Vrhn+Kg5G/mFOgi6mTsle9F9EX5ov1MAZwEAAjUC6gPzBIXFX0WkBfZGFoadBt6G50abxk4GBYXfxYFFugUhBNEEhsRIRCaDzwPqA4dDt0N2g3oDd4Nhw2vDJILnQrDCZoIIQdTBRsDuABN/tj7H/lb9snzcPF379HtTuzi6trpWulU6cjpq+rn63XtXu+q8Q70Xva2+Bv7d/3F/wYC9wObBd8GwQdUCKMIvQibCDkImQfwBj0GjgXsBFUEyQNsA28DuAM1BOAEqgV8Bm4HhAikCakKiAtHDMgMFQ0aDdUMQgxbCzgK2QhHB48FxAP2ARMAMf50/Ov6j/l4+LP3FvfG9rL23vZG99j3mvhf+T76Ifv0+6r8Nv2e/c/9y/2f/T79q/zc+9P6l/kx+LX2IPV389jxU/C27iftuetS6irpJOg655LmLuY55uvmoujm6uHswu668Nfyo/WH+Z79CwG3A98FIQi7ClsNWg93EOAQEBGcEZgSXRNdE6MStRHyEIkQrxD+ENsQbRAdEO0PAxBVEJEQfRApEO0P3g/HD30Ppw4wDVQLdAm7B+AFyANFAXn+p/sH+Y72EPSx8Xzvqu1m7IvrAuvB6q7q+eqv67bsCO6M7zDx7fLF9If2Fvh8+cv68vvx/NH9if4E/z7/Uf9D/yb//f7c/r/+r/7D/gP/ef8LALgAcwFVAngDygQzBpMH0AjTCcgKrwtoDMgMxgyQDA4MYgt7Ck8J6QdOBp8EAQN2AfP/qv5z/Wr8lPsF+8T6vvr2+lf77fuM/GD9N/7+/r3/RQC9ACEBVgFcASkBsQAFADP/Of4n/Q382vqX+Vv4KfcH9u/09PMo82nyyfFP8b/wOvDD7zbvuu5C7qvtC+2J7C7sVOxG7ZTuvO+l8ILxlvJo9DH3TfoI/S//DAE2A+kFzghFC/EM9Q3zDn8QfRJWFE4VcxVQFVwVwRV1FhUXGhe5Fk8WNRZLFlsWMRaUFcAUChSwE20T8BLfETEQRg5sDNEKQQljBx4FoQI5ACP+Svx3+nD4h/b19N7zTfMC89/yxPLn8ljzHPQX9S/2XPeN+MP5+voS/P/8yP1W/s7+Ov+V/8z/6//7//X/1//I/9P/5v8XAGcA5AB0AR0C5AK2A3UERgU+BikHBQixCDYJfAmaCZUJTwnQCP4HDQf+Be4EzwOKAjIB3/+p/pr90fww/L77bvtK+1H7kPvv+1P80/xL/c79Qv6h/u/+Ff8H/97+lv4l/pL94fwt/F37hfq1+e34SPit9xb3wvaG9kv2RPYo9gz28/XN9br1ivUr9bP0JfRO83LymPGa8Jzvq+4A7qjtC+5B79/wZvLV83b1VvcM+nn94wDCA/IF3wcKCm8MlQ76D2sQRxA5EMIQpBE6EgISJBFREAIQQhDhEGcRixGHEaoRNxLrEmsTaxPZEggSPxGuEAMQww7DDCYKSgevBGUCCQB//ef6bvhe9vf0EfRD84DyAfIX8szyxvMf9YP2X/c2+Hn5vvqh+178Df1r/VX9SP2D/Vr9vvxe/FH8KfwI/GD8J/3N/UT+Of+CAJABfwLMAyMF6QWWBk0HvQe/B4AHNAekBs8F3gQoBHoDjQLAARIBWgDS/5//sf/U//3/PQCjAB8BhAHyAUACZQKMApwCiQJUAvUBZAHcAEgAmP/9/nz+Cv6u/XX9XP1r/YL9u/3//Tv+iP66/sf+v/6//nz+Av5o/Zz8sfuw+rX5pviE9172Q/Ut9DDzUfKg8RbxvfB18BzwCvAM8BzwLPBH8HbwnfAf8Szy1POt9V/3pPi++RH7u/wQ/4IBgQPSBNgFJAfLCIoK1gtcDF4MmgxyDdoONBDfEMsQchB+EPgQmhHgEZER6BA+EN4Pig/jDqwN3AvuCUUI/gbYBW4ErQKVAIL+w/yf+6z6fvlX+Fb3xPan9vr2P/cx9xf3N/fN95z4jPlH+qX66Po/+8P7OfyE/KL81PxC/cb9bf4i/8n/YgABAcwBuQKuA5gEdwVFBtkGPweAB44HWgcHB48G/wVfBaQE+ANUA50C2wFSAeQArQDLACgBjAG+AfEBDQI+AnoCqAKyAngCLALrAacBbQE7AbkAUgAnAB0AWgCxABYBSgGMAfUBPwKRArwCuQJzAuwBewHPAAgAQv9G/jT9QvyT+w37gvr4+bf5nPl++Yn5o/mh+Xz5JvnE+EP4gPeg9qX1qPSZ83jyVvEw8C3vZe7i7V/tNe1g7ZvtU+6p74Tx9PPw9uX5cvym/r4A0gJHBe4HtAlyCssKNwu+C1YMoAwZDBALiwoPCzkMZg0jDlEOag4RDwcQvBDgEGUQcA9sDoYNYAx/CuIH/gQZAqr/uv0R/ID62vhm91n2BvZP9rv2Afcv9533Vfh1+ZP6OvtZ+/j6xvr6+lj7ivt1+2n7ofsw/P/8Df4C/+j/+gBeAvADXQWMBmMH+wdJCFEIFwiqBwcHKAYnBRsEBQPjAdcA8P8I/yX+l/1g/XP9s/0K/mr+zP4s/6P/VwAKAZgB1wHwAQ4CJwJbAngCZgIuAhoCagL+ApYDCQRkBL4ENQXOBWYGnwZ/BjMGxwVCBYUEjwNaAgUBrv94/ob9wfzo+zj7zfqe+rL62/ou+1n7lfvT+/z7G/zV+3P77PpP+l75SvhJ9+L1SPTZ8rPxh/Bw76zuD+6E7TrtNu1C7Ynt/u2H7oDv3/B08mv0NvcD+8P+iwGoA1wFGQd+CX0Mwg41D8QOtQ54D6AQRhGgEMAOYw3JDUYPrBATEU8QBw95DtcOyA6bDWML1wh5BqEESQNjAaT+lfsS+Wr3qPad9oj2G/bD9RP2E/dk+KD5PPoq+jn69PpH/Hn9J/4p/t79Cf7o/hwA6QCDAWYCpgMsBdUGJwjbCDoJqQkwCmgKTArQCQAJBAjrBpAF3QMrApsANf/+/Qj9Ovxs+9/6pPpw+kD6X/ru+rD7qfyr/XL+Sv9kAJ0BnAJOA9YDUQTsBNUF0gZcB5wH4Qc7CKAICQlnCVoJGgn7CNwIgQjeB/4GyAV5BGgDfgJZAToATv9q/pX9Kv34/Jb8avxR/DT8J/xE/Cj8ePvJ+kD6ifmS+M73+vbJ9dX0PfSR88DyAvJG8Vjwr+9p7x3vtu5b7gXuPu1b7P/rquv16qrqQuub7OTuvvKU+Pj++QNTB98Jxgz6EOwVYxnEGS8YBxc9FwsYuhfEFKYPjAvWCpAMNg4TDnQMrwozCjwL7At4CkQH6gM+AWT/+/3r+5P4zPTu8VPwpu/l78/wyfET8zP1K/hv+0X+QwA8AewBHgPFBAUGVwYSBoMFIwU5BYcFdAULBUkFkwZBCJ4JnwozC2ALXgv2CtMJ3ge7BdkD8gGy//H8CPpr95P1dfSe89nyk/It85D0sfYh+Uz7DP2j/joAFwItBPoFEgd1B8AHWggXCbUJAQrECUUJPwn7CccKDgvaCk0KxAlTCckI+ge6BkEF1QOJAlQBKQAB/7v9f/zB+1j7EPv++ij7UPss+/P6wvp2+tP5DvlE+Gz3tfb39Qj1IPSV8/Dy//FK8aXw2O/+7jDuTO1Q7F7rN+rP6GvnJebD5GbjY+IG4tfiC+Uj6fPvs/nqA2ELBxCLE8sX0h0bJOQmrCRzIAEe0x2nHd8aDhR8C+oFxwVdCIUJTwhUBl8FRwZPCJAISQU2APb7P/kM97T0+fGS7kHrg+mS6X7qMewc77XyrPaW+3UBGwdpC0UO2g+bEEURHBIrEt8QFg+0DZwMWQvdCRIIVAaIBfwFqgazBlUGIAb0BQ8FMwMzAG78DfmX9lP0f/GC7kfsJ+sI66/rkuyF7TPvSfJm9lj6y/3kAMIDdgbnCM0KzQtnDFsNjw6XD0wQrRDOENwQChEDEWYQdQ+NDqgNZwyeCkUIjgXIAk4AGv73+z/6OPnS+PL4jflY+hv7A/wu/X3+g/8xAIgAZADg/+7+i/2++/X5fvhB9zf2afXq9Lv0C/W99Uj2jvao9qz2ZvZT9ZXzEPG47STqsuYo4yzfWNsh2ITVYNMz0vPS2dXY27PmhPa7BkESDRkcHpokZS1uNX43TzISK9Um1iUVJKMdERJ3BWD+qP7OAYsCrQB//6QA0QPcBpMG9wHJ+1H3lfTD8U/ueOqt5trjPeOn5P7mj+rG72b25v2WBhwQNRibHbIgPyKRIisiDCEbHoIZ3BQsEZ8NLQlFBM//jvwp+2j72Puy+/P7L/02/rX9r/u/+K71WfO/8bjvyOw/6m7pDepf6yntTO8i8nj2kfwgA8gIjw3CESAVaBfcGEMZSxhgFl4UWBIEEL8Nkws6CboGzASoA+ICeAKLArUCuAL1AioD1QIaApIBLwGbADMATwCOAMwANAGHAZYBlQECAoMCkwJvAkACzAH5AOn/cP6g/P361/nq+PL3NffH9qH2yfYt94X3j/dp9x/3k/ak9Tr0D/L47jHr9OZe4tDdz9l31lPTd9A/zoLNQ8/I07bbo+jP+tcMkRkfIY8mnS3ENsM+iEDdOoYycywkKaEkGhuyDDX+m/Xc84j0aPMC8XLwwPKm9tL5Nfrq93/15vQS9Sb09vGd78Pt4uxq7eDuEvGt9GD6uQHoCd4Ssxu2Igknhyn+KjMrCyoSJ9Uh5RroE3ANXwYi/rX1m+7Q6Z7nRed+5yPoIOp87evwZvML9X/2Ivj2+Wz7p/vN+iv6f/ok+477+vv6/Cv/7wLKB3cMUBCKE34WxRj3GSkaMhnwFtsTXRAxDG0HjgLr/YL5nvXy8q7xv/EV82f1MPhn+zj/JwOXBpoJTwxKDmUPwA9GD+ENzAtJCUgGAwMGAMH9DPyc+qH5Jvkx+bj5ZPr4+qz7pvyu/WX+aP7+/V/9hvx3+xb6c/ix9in10/NP8q7w+e487UHr5egl5injhuA+3u3bVdng1vDUK9Tp1MnXLt6t6iP9MA7kGBceRiIXKvw0Qj4ZQGo6ojJ5LawqNSVDGWwIBvkk8OHsqOrW5i/jkOJR5Xjpk+zQ7cvun/Fa9pn6e/yB/FT8zvy//YP+qP7D/kMA5wMKCdoOrhSgGdUcsR5PIPch+yJaInYfXBpDFE0OCAhCAOb2m+075qDhVd843qPdNt7f4DLlBeqs7obzA/n+/rQE9AhLC1IMJg3ZDY8NCwzgCSIIgAfeB3UIcQgBCNkHRQgECZ0J3AmdCeYI4AdVBvoD9ADQ/cL63/d/9erzR/Ow8yz1Rfey+bX8ZAB5BJAIYgx8D7sRPxP3E5ATshGiDuMK4wb5AjL/efv+9zP1YfN38l7yB/NZ9En2y/ik+zX+JQCMAXECpwIwAh8BaP9B/eX6TPhn9ZzyDPCQ7TvrH+k+51vlfuMX4i3hWOAn35rd+9vn2k3br92i4rjrafrZCrYWfBy1H70l6i+fOhRAtT32Nsow+CwpKModig2x/PLw7eoZ53vizd1P2xrcAN/s4TDkJOfB7J70JvwBAU4D/gRRB9cJWAtNC3AKmArCDAsQLxNzFZ4W2RbfFpMX1hjfGdQZFRiAFK0Pngo6Bab+7vZh72DpYOXO4gDhk98Q34Xg1+Mq6Pjsv/KV+fYACwinDVURlBN+FRkXghc8FsQTChGPDlYMxQl4BroCpf/T/fD8l/yW/N/8Ov2p/fD91P2N/Y39zP3e/cb9pv3S/WT+S/8XALUAyQGmAx0GsQgFC7kM1A2LDgwP/A75DRAMdQmUBp4DmgBu/TP6Sfcj9czzUPOp86r0RPZl+Mv6Ev0i/+QAYAJOA4cDIgMlAqYAiv72+wj59fUL80bwm+0W69To0ub05F7jJ+JG4Xbgdt9Y3oTd0d3439zkyu3j+4ILeBZkGyIeJyRnLiI5zD7/PN02nTBCLLEmxRvkCxX8LvHB6rflKuAq287YctnH2xPejOAe5S/tK/eb/5sE9wY8CZMM+g++EWIRQxA1ENgRuxOdFBEUlxI9EdwQtBHkEqMTVhO+EcIO0QqABqQBE/wx9vzwtOwp6QrmQ+NF4b7gIuIY5Qnp1O0K9Hr7HQPECa8ONxJKFWYY2BqPG2Aa9Bf0FLIR7A0+CesD6P4l+6j43PaO9d303fSE9Xf2hPfF+KD6O/3Z/7kB0wKHA1gEWwUaBjYGCgZgBmwHrAh/Cb8JogmICcMJ9wnACeYIeQfEBccDjgEI/3H8Ffop+Nn2DfbY9Sr28PYl+Lb5gftT/Sf/7QBPAgoDDQNtAloB0//k/X77wvgI9mLz6PBx7v3rt+mX57jlKOT74iTiMOHw347evd133kjh5OaW8Oz+Rg1YFkQabh2xJKcv7zk7Pm07FzUNL5EqsiNPFxAHcfj67uToXuM33TLY4NV01qbYNtsV39Dl0O9R+i8CeQb9CDQMPxDJE0EV2hQKFCAU6RT1FKETJxGaDgYNAQ0NDiAPZg+GDnYMRAnEBT4CaP4r+uX1DvJ17tHqIucI5C7iOeL347rmlOqv7zz2hv1KBLYJ9A3uEUsWfBoTHWUdxRseGdYV1hHrDCEHVQF7/NP4w/X78s3wpe+T717wy/HG86n2cvpj/oIBnQMlBasGYQjBCUMKAwqxCbUJzQl+CZoIfwejBlUGbgZfBuUF+gTBA0MCjwDT/iX9qftp+lf5bPjR96T35feS+JH53fpV/PL9jf/XAJEBlAEhAWsAev8g/kT8APqI9xP1gfL172ntD+si6V3nx+VV5DHjF+LX4Ibfdt7U3lHhv+Y+8Bj+1AtBFNMX5xo9Im0tCzi9PFc6djSiLggqCyPvFmoHkvmE8GTqeuTQ3V7YldWE1SnXztli3v/lafCc+tgBmQU/CAgMmxCOFFgWVBbFFb0V5BUBFcYStw8eDd8LUgyxDaIOXg7MDFAKXQeXBPUB+f58++H3ZPSN8Drs5eeI5PHiPOMA5Y3n/er07zj2zPy6AqAHOwxjEf4WyxtEHjwemhwwGhwXHRMWDmEI7AJH/jj6P/Z88q7vQ+4i7v/upfAZ85v2sPpk/gYB1QK2BDIHEQoWDHQMvQsSC+8K5Ao9CucIsgcpBzEHIAd9BmcFKQT1AqoBNADF/pH9mvyA+wj6i/i098v3c/hV+Tj6S/vA/F/+4v/XAC8BHgH2AKYA7/+O/nr8DPpk9670+/Ft7/ns1Or06DfnnuX444viTuFl4K3f29/N4UTmq+5v+yQJABK8FWAY4h4WKlc1SzvCOWA00C5sKl0khxlVC839vvSa7nnoYOEl28vX7dby1yLakd7g5Xvv6Pg4/4MC9gT8CAEOXhKvFAAVtxSvFPIUNBRUEtIP0w1GDUEOHxAYEWcQMg6DC/8I1ga4BN0BQ/44+kX24fHa7PznYeTa4hfjeORr5lPpvO2I86r5HP8oBIAJrg8UFhcbYR1FHQocaxo3GNkUZxBHC0AGswFW/dv4pvS28U3wKPDL8ATy8PO89gX6y/y//l8AmQJ5BQsIRAklCakIjAjtCAEJfAjLB4wHBwixCOYIPQg6B2MGpwWnBDsDqgECAEf+L/zi+en3wvaW9tr2SvfQ97f4P/og/N/9CP/E/2MAEQFkAdwAdP9m/Q77jPjh9RXzUPCx7Ufr6+il5oHkveKE4aXgy9/s3h7fW+HF5lzw/P20CrERlBTWF+QfvismNuQ52jaJMeksCikKInIWmwjp/Kr1PvAN6tjicN3e2mDaKttu3X7iDurs8gn6uv04/3YBzAVrCssN8w7gDuwOtg+TEEAQ/Q6mDYcNBw/lEakUbRUFFIIRMg82DWALxwjSBBYANvtg9tfw7erf5b7iteEF4gvjluSf53TsMfKi95D86wExCA0P+hSBGFcZ1Rg6GGoXrBWSEq4Ohwq5Bi8Dfv/G+8T4NvfN9hP3o/eF+OH5pfsl/eD9R/4C/3AA3QGIAicCTgHyAGsBXwIYA7sDtQRUBjYIkgkbChcKGwoXCrMJjAivBnUECQJe/2n8k/lr90L2wPV79Vv1kfV+9hD40vlK+238f/19/hP/5/7w/WH8evpq+AX2TvOO8Pbtlus/6fbm0OTz4oDhleDp33vfOeDx4p/oefIAAK0LihEGFKwXESCGK6I0nzanMocthSmIJesdeRL6BUn8tPYl8mTs7OWk4Rbg/d/y4IXjrOh+72/2AftT/Hj8Af5yAbkEswYdB+MGSweyCFkKDAs/C9wL2g2CERIWrxlxGtcYmxbuFIYTYxGkDUQIWwKp/PT2fPD56QzlVuKZ4efhu+Jh5Lfnr+zj8X72//ppAKAGpAzmEIgSWRLiEeoRmhE7EOgNRAvgCAAHXQV7A70B1AAHAdMBpAJHA6QDtgN4A8MCngFsAHf/o/52/e37QfoE+dj43vmP+0H9Lf+GAT0E7gYsCbkKsQtwDNgMkAxBCxsJjQbeAzgBiv4S/Dz6Iflx+Nb3a/d890n4gfmd+lb7svvy+/77svvF+kf5ffea9a/zifFQ7wrtzOqm6MzmVuXy42zi+ODS32Dfb+Bp4z3pa/MGAQYMGRFvE48X0SDoLKw1ujZLMsEttSrzJuQeIhNXBxv/0vrD9snwRupR5iHlA+XH5Tjo3+yd8rf3BfpT+VT4NPml+6/9lP6M/nL+g//YAX8EewZLCO0KEg/eFCQboh+JIPMeRR1DHCEbkhjEEywNeAZaAPv5w/Lb6/PmceTA48XjKOSM5bboIu0q8YX0Jvjj/CgChwbGCL0I7wfUB5AI7whsCIkH2wb0BsQHyQh9CSsKcAtaDV8PuRDzEOwPIQ4TDIoJUwbQAoD/fPyR+a32MfTR8gTzZPQi9vX3VPqX/UYBeQSPBrwH0AgeCvQKngpBCXkHrwXuAyUCYADt/gv+mP04/dP8qvzX/Bn9If3Y/Fv8tPvi+r/5J/g69jD0JPIA8ALubez96lXpX+d65dTjbuLX4Nve4dzb29ncHuAU51nzqgHICqsNnQ+bFcshoC9DN8w1gDBFLdwrIygZHwcThAjnArwABv2o9sXwJO5s7dXsT+3n71T0nviS+qX4jvQ48qDyvPO788XyqvG/8Rj04PeN+8j+iwKlB34O+RYLH6Qj9SPTIusivCM7I1YfORiIEIgKigUi/1n3pPDO7Ffr0uoi6p/p6uoz7mjx0PKh88n1SPlX/DL9y/vR+WH5pPrn+yr8R/xu/fP/fQMkBzsKKg2SEB8U/BbBGGkZ/RiPFx4VmhE1DbkItAToAPr89PiC9W3zAPN/8xf03vRf9sT4a/uw/S7/KgA0AUMC9wIIA7wCXQLqAUoBogA+AEAAjwDTAOEA2gDnAPAAyQBhAKf/qP5+/Q/8Pvpg+KL2wfTJ8h3xu+9k7intDOy56hvpgefY5SHkSOIg4O3dnNyd3CPdHeA96RP3hAIlCNkKPA8MGo8ohzExMe4sMSuwKwkqQCIDFp0LwwZUBYUBsPqc9Rr1mfZN9u70Y/Vs+fz+IQGw/SP4hvW+9Wv1x/Kq7qfr2uvX7qzxR/OX9ff5AADYBkIOJRUsGvUc+x0sHg4ejB15G0MXFRJNDbUItgMU/4H7Mvnr91j3D/dq9wz5zfoP+wf6d/ka+hP7+/rf+MD1vfPO8570+PSg9XL3Qvqp/WoBKwUDCfsMHhDYEe8S4xMbFBITvBCKDXIKEggEBqYDKQEw/wD+c/1h/Z39+f1s/tL+/P4J/yn/Fv+g/u79Qf3G/KT82fwB/fX89/xe/Rz+/v65//v/5//j/wAA5v9f/4n+qf3u/D78a/ti+mP5uvhR+J73kvbF9Vn19vRF9AzzffEZ8OLuW+1J68PoF+am40jhsN6v28nZ592s6hP5aADFAXECpwcpFLchYifNJeMkySZbJ2EjvxqtEecM2AxrDO8HRQNvAtADDgPy/1v+vQBsBmcKAwjEAAL7t/lw+Ub3evPO75fuwPCh8wb0ofOD9aP51/6kBC8K+A0IEOUQYRAxD8AOCg93DtcM2wpUCI8F6AOhA44DfQPfA6IEmwXYBkwHqAU+A/cBrwF5AeYAXf/h/Cr76PoJ+2z70PzF/nUA8QEYA+kD5QTMBbEFxgQZBK4DDwMIApsAF/9L/sj+2P/RALIBgwI+A/cDlQTXBNMEmgQZBCoD7gG2AIT/d/6e/f/8wfwL/av9H/48/hb+A/5F/pD+af6d/Zf8q/u5+r752fgm+JH3WveF98r3GPhH+E/4UPhs+J/4rfhB+GX3TfYU9a/zS/L28Ibv7+1V7N3qNemd55bl2+Pl53Dz8fxf/1f/sv7FAQYL5xI/E+UQhBLjFJgUCxFfCz8IRwmHDKwMwQlUCX8L1gxgCuAG7gVRCGEMWwwgByUB6f4M/7b9yfs0+tn5ifsO/o3+TP3h/Yr/BQEIA1oFrgb5BvoGcwVOA5sCIANeA1MDpAM0A2oCcAIfA8IDhASmBUAG+wZpCOAIcAfHBRoFoARNBAEEwgIgAWAACABd/yH/3f+9AGAB6gG3AR8BGAEdAUwAO/+4/kL+u/1L/bD8Kfxc/E/9Lf4C//b/lwD9AGQBrQF9ASgB6ACEAAkAkP8O/33+Rf5i/m7+if7F/gX/Nv9D//r+eP4g/uH9Tv0x/A77H/qG+Ur5wvjv93X3sfcc+Dz4P/gd+BL4JfgZ+LH3GvfK9kv2g/Xj9Cf0JfNX8tXxJPE28Hrvpe5m7QTsL+p+6lfxjfnK+7b7GPyI/YIDlwqyCzUJwQpwDogPKA5WCl4HTAh+C1QMsQmqCHIKTQzJC2QJsgclCLQKeguTCAkFBwSKBH4DjwHg/yD/JAD8ATwC2gDVAJ0BrgEBAsUCAAMPA7cDaQNKAgECLQIXAoACyQOZBBYFsAXOBbYF9AWMBtIG1wbnBkwGLgV/BAEEOAN+Ah4C2gG7AbkBUwHmABUBgAGgAZABgQE+Ac8AaADQ/xT/jP4k/pH98fyd/I38sPzq/Bz9UP2p/Qn+Qv5//sv+Cv8e/yz/J/8l/1b/hf+q/8z/CgBPAHYAjwCIAHQAUwAdANn/ZP+R/n/9xPxj/NH7IvuR+i76Kvpj+lz6DPrx+UH6r/rC+n76X/qV+q76SPqd+ej4Xvgt+AD4T/eV9kr2Afbf9cX1XfXW9Cz0SPMy8h/yBPVE+Vn7oPvO+/n85P+YA7AFTAWKBVAHJAjrBpQEagM4BJMGXQiiB5EGOQefCD4JRQlHCaEJlwrnCo8JXwdJBpIGuQZ2BjUG6AWGBWgFHwWEBLQEfAXUBawFdwUGBUEE6QNYBBUFagU9BaoECgT/A3oEzASEBHIE2AS7BDUExANgAxsDPQNpAxEDsgKHAhcCmgGwAR0CYQKbAo8CJgL0Af8B2wGrAZUBVwEEAZ4ACwB8/x3/qv4l/sr9kP1k/RH92vy9/K78+/wp/dD8mfzZ/MP8dPyi/Of8Hf15/fL9SP4o/i3+pv7S/mD+Xv6y/oj+f/5B/rj9qP1y/tL+XP10/Ar9Lv3d/Eb9mf2J/Pn7c/wH/AH7B/tg/DH8ovpW+xH8m/rT+Z76nvpY+an4U/mv+Xj4Uvio+bf5DPmW+R36Qvnr+J35pPqf++r79/vx+7L7VfzY/W7+O/63/gQA5AAGAQYB1gBHAZwC0AP6A7wDNAScBH4EbASoBCQFxQVFBuYFMgVDBZcFtwWRBUkFHAUvBb8FFwaTBRUFcQUDBj0GVwZ8Bm4G4gVwBZ4FDQY1BtoFZQXpBHgEbgR0BGME8wOLA8AD7AOyAxIDYQIeAmwCnQJNAvIBiQEXAd8ADQFOAScB0QDlADMBCgHCAHUAFgAGAMb/jf+W//f+e/6G/kv+H/4y/kz+ef62/sb98PyE/Vf99fxH/ZD9Vf2e/E/8+/yh/fj94v0V/VL9rv2x/dH9vf09/SL8h/yY/nr//P2T/Kn8uP1I/o/9yf3M/rr9MfyF/fH+9f2e/Ef9ef4O/fX7fP3S/e777Puz/f/9Y/0y/fT8FfyJ/E3+c/6M/An7Efwg/cn8tfzn/Ar9CP0Y/V39o/3U/WH9/fs9/DD+v/6g/ej82/3j/qX//P9y/4r+3f5sAND/A/5X/mQAFQH3/2r/SADUAeIBEgH3AHgBegLvApUCCQLkAWsCWAP8A98DYQNMA9IDEQRwA2ADWQSuBEYE3APQA/gDQgS1BCIEMQOdA0oE2AMqA3ADZAOjAr4C0APsAysCsAFSAzsErwO4AtwBVgFDAekBbgEsACUA1ADOAdYArgBtAWwAnACmAD7/yv9YAXD/gv4f/1X+3P+PARwBVv1n+pT/BAKI/DH98wKVAJr5SP34Bc7/ZvYA/vQDQ/tS+a//xv+z+1/8WgLkAPf5lf1sBfv/ZPfp/QAFYwEF/mX6k/n/ACsFDgDG+kP9+ACxAbj/W/45/nP6BP2tAVn+5fsjALYBGvpR+wYG9gOB97L3SwNEA8H8jv0KAaT/QvzH/4ACc/6//AoBzAEH/VD/0wTLAGv7+P6EAzwCmf4w/y4Bif5O/QABYgJW/vv9fgN1AdP65v4sA9b/O/4SAOH/yfyz/ksEFQRe/ZL8YgPKAx/+Iv/UBIICQ/4dARwDQwGCAVwCUQIHAOX9XQLPBRsDVf/A//8B6wPsBI0B7QGfA7IAEQFpAlkB/QCRArkB2/30ALwGEwV3/Rf6bQAaBG8AeP5ZAvoC7vzv/HUFwwUT+jP5BgVDB+7+dvwD/5n+rAAZBooCXfoY/nIDtQDVACsDx/xt+tsCdQSHAI/98P1MAJb/twOeA3/5Fv2bBqv+VPcIARoI6f249vX/hAVU/QL9pgN+/Yj9KQJN/qD+9f9nAwEA8fZxAGoHP/wt+CECVAfE+z/2IgIJCBP+FPiOAKUDA/6q+iT/xAQnASz+mv9Z/jH9/gEbBE7/xP0e/1gBGQHV/9kAJv1x/jYCQgCZ//3/sP+H+6kASQim/OL1rQX7CKD2zPZ6BoEGFvdQ+bwI6QDb9uP+gAad//f78QIpBIkAXPo7+1gFegWo/Dn85wBYANcAZAR4ATz77fq0AxwJ9v869B/6zgxEB571tvz3B639Q/XKBG8LF/l69fIHygg795/5ngnbBKX1nvzKDa4DNfMZAC0Nuv7F80sBqAms+5j17wbCB2L19/nCCF0D3PYc/UMImgBE+a4DZwjC+qv4ugjGC+H3z/KuCPgKifVk9OAH3QgH+EX57Qj0Ahj4K//LBXkFcP2U+3QDFQfSACD2CP2fCEUEcPqp/EMEhgAhAl0Agvk6AfgFGAFR/W7+jABpBAkFB/3I+rwANAXQAIf5wP9vA9r8sABABPr98/vqAr8Cffof/t8JFQRH8xX8GgqMAYL5c/+cA+T+AP9aBJUCRvgb/egJiQKz+TT8qgPPBMT9a/54A4kCpvwh/q0HSAOV9j7+8Aro/5v0Lf8aCBn/tvaQAjIJGfnU9V4IQwcT9Z/5MgacAzH7o/9tBVX/Gv4h/6IAQgNCAY/7k/0HBvf/IPvZBQgF2Pa7+zsMwAKa8Yf9qwzwAWr3Yf5ZBFH+LvwgBfUD9fgn/S4L+gIb8sP6oQ1YBj7zFPipBzUIp/g/+NwHQATk+E/9pwacAAv3hgEgCmf77/ObBo0QS/uh7xQAowek/3H8OgNqAY35DgJTCH/9L/WRAUALlfvm9XMDBgjjABD8+gCmAgX9b/7+BRYFl/rE+BUDjAdmAQD8Ev5KARoDhgLW+9X+RAZa/uf6xQNrBvP+ePrd/6EEgwRe/7H4kf3OBe4DEf3M+QH/kQOYAXX+7QJaBFz6OPo3BSkKgP3Q9DgDsQqr/rv2fQJtCUz7BPd+BasL8f1+8+L9FgptAo36BAHIAhkAZv/+AG4BF/0Y/fUCVwF4+lf/FgW3/EL6ngalBJX0c/utC14ABPNvAV8Ka/oQ+OYGZALM8/T+nwyN/CL0hgQOCPv5a/xJCHEAmfX5BKYOyPRM7EMKhhWV99jmZwL4FfT8D+1aBXILy/V5+DANvAag8GT6wQ6iABXvqv+3D0j+kPF/AJUI+fsj/QgLAv8h84sB9g9RAFjtpP8PDZj/iPV3//AJpwFG+sH+1we2BD36APxyBswETvlb/poIkAP39yr9HQkvAdH5hgA/BeoAIvhR+vQIOwmI+Xf28QRGCYf8g/x2AwT9GfzbBzEF7/XH+osJbAdF+U33aAQNBtUAWf9A+yf8egMqB+f/pvlCATQGJv8a+wYA2gSyAPL8x//tAL8BKAOxAN36/v7VBvkAH/pA/6kDWfsQ+08HqgNS9xT7kgY2A+X47v3vBB4CFwBG/739MwALBbIA7/gJATgJ5v6O9lT/gglJAgP5Vf8cBzABW/k+ACQHfv9P+Pz/agiBAVn5tv6VAGP7oAEbBnz72/Z5BBoLJPxy9fAEmggD+aP4sAZRBo/2P/YdCb4L1PoG9fwCMwmk/E/5ZAS0A3n4dvwtBV4BZ/1BAB4ECP/t/cwGhwPm9wb5IwODBCb9x/zKAy0CQPk4+50E1wPQ/Oz8eQPxAGv7tAGmBRX9HPkLAusEuP/g/T//sQCbASUBUP7m/D//3AMEAqr7+P2hAhX/Gv43A/UAUPo7+88FCgjf+Cn25wWpCNb9FPuKAIwBs/8iAuYA/vyj/k0E4gSV/Db8QgWuA4T6JPsTBEQELPzx/IsDfwD3+dkCKQm4+5r2twNVCoYAlfm1/5wBn/wlABYDffoW+hQImghA+Vz3JATjBuv7lPlFBHEExPtC/ksFwgFl/WYDdwTz/W/7ggHqAjv7m/88BdL9pPovBEgG8fv3+hkEGAVj/AP/nwWVAHv8Tf99A54BSwGzAYr9cv5VAccBIgCT/h3/MABQAxIEuP2Z+jYBPwUcAKz+wwDL/bv8KQGTAx8Aj/6cADT+O/2VAb8DegF/+fP9UQnSANH26P5ECNr/3vedAEgHqP7b+cYDiQRn/Bj/iAEL/uT8of4AAtwB4ABOAKb9EfpiAGkIy/ws9j4D0gco+ePzdQWeDNX8rfeAAwcBg/dR/m0Htv809nEB4Ak6/RX4+AUCB174HfspCOYDhPdy/l4JEQD/9YL+mgg7AEj5KwDvAUP+XgFaAzH8UfqnAf8E+AGc/Q38s/1QAQAE6wER/K/7KQIDBW0BLvoS+18EBQaG/5z9kQARAIb/DwFPAssB+PzE+4oCOgQpAKX/JwKFAPr9jgKhBUwAx/pWAZIICwLj+/D9lgB5ACoBYwIuAQH/aP5pAJT+4PuY/5YCHgG9/qz/qgBV/wwBegHe/jT/wQGCACD8xv23AooDuwAY/tEAYAKU/yn/8/4s/A79lATBBZ/9dPsCA10E7f3l/dj/FgHcAzoFdf7H9LD8uAiRATH48v8sBuD8Dvh/AtYGu/od+VcG0AYS+7L4bAFrBe3/ff7KAK/8bPtJAJ7+PvvNADYFSAEh+wv+MQYdBI3+2wJZBOL+JABgAS7+JfyaAXYH/QNS/kX9NANHA7f5/vefAfcHZAOA/QP+8P6+/jACWwJR/TD8FgPkA+r2nPg3B7YFsvvT+mT++P5lAlsDQv0/+D796QifB6H6d/Wf/pwI0wRy+gb7KgcACE755/ZvBFEGz/u8+yIDXgKm//EBdQGP/Rv+6wOKA+f86vwvAbEAiP4z/sAAKQR1AUL/PADk/nX8bQAsBav/qf1jAFcAOQINAtf+mP3D/oIDrwOq+/T7IgXtA9/6HPxfBMsDf/2S/6wBtPtk/OsHIwUJ9Wf5ngkYCGr56fiBBSgEB/od/ycJhwCo+JcBKQK3+ST9lgdJB6352PV8AyQH9PzC+7YDaQRI/HH7ggO5A6/8efzZAhkDTP9wACMBZf/s/hwAOQF4AbABeQBz/RH8mAElB84Am/oV/9EBdP6y/YQAuQAA/hD/TgTDAyv9M/z2ASADl/5l/CP/awKzAcT+Xv3X/zIClwH2AIj/Tv3I/dIA3AGZ/tL9fAEiAZL93P+dAqD+t/u2/SAADQB2AHgA8P1y/rgBUQKLAOcA5APaAMr5Ff79B+oDVPsaAKEDZ/0//d0FFQN99L747glBCEL5EfcdAr0Fu/97/ZYBV/9S+80BtwWx/7j4wvxzBEUD/AG4AA/6JvokBFUGCADW/RIB/f+n+8oAagbPAOP6GwBCAkX8xAC4BtX/6Pkn/2cEwgC5/NH/ewKg/YL9YAIzABz+GQCwAR0B9gBcAiH/+fsVAAQEnACG/XsBUgIy/Nv8uwV4BNz5PvukBaIDOf1cAeUDJf9l/WsDhwNh+gT6yAHnA1j/fgBUAxb8ZflHAacEq/3f+yYCEgMLAf79If76/7gABANkAhoBGv+R/nX/o/+q/5X/IQMdApz+ogAQAQoAqgF/AtP+1fqF/4MEnv/U/X//iP62AMkEkgKQ+WL51gKmAzT8hf1nAtL8v/mQAtoHsABz+cL9OAOr/y7+rgFYAMj7Lf5SBNYDGf/k/84Cxfzy96n9kgVqAwr9Rv8RAF/+ywDuAs0B4fwd++IAPANi/7v9zv4p/zEA6gFYAcQAzAByAOb7b/lv/+YDhwSbANf6avxEBF4DB/um+xEALwEMARIA1/6j/Tv+ngKJA9YB9gOAAk78FPuc/h//VwGFBBsD//5h/ssELQTM/H79cwKIAFz8XgDLA9H/Xf0gAGEBu/54/wUBnf9H//L+VP8lAf8BgwH9/qj9CgHCAl//4f1MARICs/6W/dv+sgBkAaEBBAJsAaz/7/zk/ZD/8v8MAxAD6P6J/BUAowa0BQ39DfuIA+UFt/8y/n7/8P6g/iMA1gGp/1j/7AGv/mX6T/yj/ssAPwXPAl39Z/1b/gMAGwEqAlIDAgDF+5b9JwJ3AVz/jACKAd//8v9KA8oB/fqQ+1kF3AYD/mn9ZwTNAgj7efyhA5UCMP5U/58BSP8w/jQCRwKE/PD9xgXCAt/6f/ygAfgA4/+WAlYBQv34/CoAoABa/qv+kAGvAX7+vf9EAMj+AwNDBZ7+Rfrc//ACtv5E/fYAjwKE/2v+tQF+AX/+4f2D/lQAYQH5AqcCFwBM/Un9OQKXAzYCTf/4/Kb9yf4FAvkB6P7K/hQB5gED/on+2gDN/Jn7Pv4dAQ8CLwHs/hL99P4LASoCJAH0/jL/iQB8AJX/QgHGBD4CEP6e/kX/k/5R/mcAvADk/jr/eQHKAp0B5fwn+fz8kANlBMD+C/3CAMgCcAEEAOr/Wf/7/0gAZACL/6b+5v+vAEkA9wAlAkUB9f+G/Jr6jf9pA6UAt/+gAc8AIAElAQ4AaACg/wj/b//X/sH/lAHbAKkAuwD7/s8AUQMg/1P6rvrw/ZoCwgTSASb/of6t/Yz+ZQG5/3L7ov7EA83/eP0CBOUD+Pp4+cUAUgPo/4T/KAKK/137IwGmBkECz/34//kBsP5b/YgBmwPp/Xf7kwBUAYkA2gP8A/r9nfvn//gAmf22/psCDwDK/J0B6QUVADz8Hf8DAEsAH/+S/pgAeADm/w8D3gTpAf//Jf0X+h39oAEKA5MC/QGuAOz+3/5NAWICt/0U/D0BSwGE/XcABQXCAyX/UP0jAd4CzP4o/QX/K/8JAPMDPQVGAHf+WAKRAOL7cv0ZAYL/z/0fAjgDf/28+2ABEgRE/zz8MP4GABL/0/4qAloCf//c/6QBrQHU/zX+z/6xAKwAQgFuAyYDnAJ6AXb/eP4M/Z/9ZQJ+A0/+zv2rAe0Ak/24/ZT/7P/P/7j/h/76/BH+EQDX/4n/wwE+Af/8eP0yABIAUwAiAef/Qv8tAlIEKQIc/fr7PQGCA6cAVv4vADADGAKFAJ0DIwYfAFn7Ev84As0AXwD8AeEAVgAZAkYCS/8p/N/8ogAuBIcBZf2e/5UB3gAYAAH/B/5r/Tf/uQK5AsL+yv2mAFAAN/+8AakC8v7P+in87wAKBFgDvADo/mr9FQD1ApL/v/ug/aYASgBaAUEBNv7R/L39IwDE//r+MAC9/mb8Cv0k/zD/IP4p/k//SADZ/mP8EPsd+8v9LAEnAQD/Xf1V/b39Cv6C/i//j/+t/aP9EP++/qT+iP49/qL+XADIADz/D/+U/vv85v0/AAMBdADb/3YAygAX/wv+BQBeAe8AoQGQAfr/6/8rApkDWgI0AecCSwTZAUYACgPXBFkClwD5AsAFXQVMA5ACfAPnA5UEOAY1BQQC8QGrBbgGyAOhApMECgXgAqMCGgR1A8cBMgLRAjQDLARSA///Fv0dAHEDxAEvAYoCrAFr/oz+XQCP/y7+x/5oAdkAq/1//Tj/G/6W+wf97f/M/Qv6VfuX/Xz7cfkj+4n88fsP+1z6RPkc+An5Hfq5+Oz3G/k4+WD38fWB9mH3MfYZ9cL2h/ef9EDyz/P89a70f/JL8gPy5vHj8qr0NPnU/iUAYf0m+m335vba+o0BkwUiBdMEKgcxCV0IUQapBeAHsgx1ECYQZw0FDP0MDQ9KEQMSdBDgDgUPKQ/eDWAMDAy9DNANmg7BDTILBAkVCG4H7AYLB0YHJgcBB8MGlAVNA3cCtAM+BLICrAD0/w4AhwBaAQgClAGzAJsA0QA9ABT/9P5qAGUC+AIkAjMBhgAyALIAXQEnAeMAUQG2AQMBfgDoAKcAWf9R/sf9WP1p/T79Nvzz+hv6RPlA+Ab3q/Um9dj0hPNd8sjyTPMi8pXvTO2S7Mfsoez06+Pqwelc6I/m3uTz5E/n6+ri8//9vPy+8ijrxug167T04gGqCCQF2QFKBcMH7gVCBAYGbwpxELEWgxj2E4cOtA79EzYZkBrMGDIWZhTvE/0SnxFzEk0VJxeNFkoTJQ5ACRwHzQc9CGkHigZkBm0FGALL/Sz6m/hi+YT6NPqo+DD2HPTQ86f0yPUG9iz2Vfdn+IP4lPgd+dn5sftr/msBNgOVA/cDvgQcBnsHwQgDCtcLqQ3CDvcOcA77DZYN4Q0aDpENYQy4C9ULSgvFCdYHiAY9Ba8D4QEPAHT+WP2v/Hj7n/kn9xD13fMD88bxW/BC77rue+4p7Srri+nu6BTpWek66UroxuZZ5XTkg+N34gLiEOK14srk7+ga8rr7PfsE89rqOObj6A/1uARxDAgJbwWTBz4JgwgECJAI+gr+EQAbXx7pGYYTrBGZFGAZ3hsfGmsWbBSqFEoUKxOCE+sUPBVhFAMSJQ2BB6gELQUsBjUG1wVOBSoDU/8o+zr37fRC9cj2p/dT95n1TfOl8WvxPPKD8onyePOZ9F71k/aa+Fr70f0m/y4A7AAVAe4BMwRDB/YJIQyUDqAQhxHdEesRcREYEY0RRxLrElUTOBM/EuoQww80DuwL0AlcCAUH/gVGBR8EDwLY//n99vuu+Wr3tPVm9K/zRvNX8vfwh+9h7u7s5ur76LHnHOda59znl+ch5vfjNuL84AzgjN/z30LhL+MQ5vXs7Pa6+ZzzIex954ToKfLLAaYM2AvKBloHXwplC90LJwwoDScSSBsYIfgegxgvFNMUJhmoHdcduBkMFvIVfxbGFVwVbxWhFBkTlhE3DrQIOwRyA3ME6gS2BIIDowBD/Ev42fRN8g7yZPOb9Mn01POj8e3uXO327TXvAvAS8Tjy7fLS8+H1i/h++n78uP8tAkICygF3AlIEywcFDdwRgRPgEmUSChKhEbkR+hLvFPIWWRi0FwAVBBI5EGwPCg85Ds0MKQulCV8IVga0A6EBfwAy/9D85flO96X1DPXy9D/0qPK18A3vke3T6zzq+Ogd6M/nnudo5+fmn+Wh47fhi+AT4A7gs+B+4djhLuP05hHvqPZm9cPuQOlh5/br7fedBdML9gg9BjkIjAl4CRkKQgs4DnYVIh61IBwcnxVNEmITthfKG3AbABg4FvkWuRZDFTgU3xLoEJgP5Q4ODBUHsgN+Ax8EHgRIA+YAp/wo+Dz1BvPN8Wry5POu9Fv0zfLb78TsfevO7Nbun/CX8hH0ovQn9Sv2Vfe9+Db7kv5EAZQDoAVGBrAGyggEDPcOaxGXE0wUHxO4EqcTjRRjFZwWbhe3FkoVlhNEEUwPqA5RDpYNvwxpC04JnAZgBIYCjgAw/4T+Yf07+0f57/fU9rv1uPSQ8+fxe/Ch7wPvGe437V3sMOsi6qXpb+l+6E/nOuZx5cLkQeRy5FHkJuQt5bfnl+wl9J73cPON7Srq2+sI9J4AsAqyCzEHGwYZCKkIWwn2CjENEBIcGpgfWx1PFpYQzQ9DE5AYlhvFGYwWzRUWFpUUYRLNEFYPPQ5eDukNZAq/BXQDhwOgA+ICPwEH/rr5p/ZT9Wz0UvQw9fT1tPVv9Ejydu9c7bftZ/Aw8171Bfd99yL3MfcD+CX5p/oX/ZMACARcBhkHtwdTCdAKHAyzDTkPQhB/EY4T7RRIFHcTtxOeE/0SRxJKERQQmg/DD7AOdgyhCkQJfge8BWUE5AJVAYcADgBf/tH7Cvo7+VT4UfeB9qH1vfQ89M7zzfKc8dPwefDQ79Tu9O387HPsreyo7JLr6+mX6L3nCOdq5ivmH+a+5qfoVOym8oH2aPP87b3qiusG8g/9/QZ8CewFPwS4BVkGrgb5Bw4KZg4RFgwcqxoEFCAOkgwmDz0UFBh7F5YUsRNLFNUS7g/EDYUM6AuIDB0NvgogBtoCTgJNAo8BEQBw/dz5N/d39tn1CvUG9Xn1WvV69OzyrPCH7mXuA/Ep9EL2ePfh93z3QPfe9wL5ivrF/On/6AKKBAIFYAXUBfoGwAmADEUNEg1vDVMOVQ+LEOIR1hGQEAUQuA9YDuEMigzWDAENrwxVC6IIsQUEBEYDfAIHAtMBJgH0/2v+gPxR+gX5Ofmx+UL5ZfjO90L3iPbH9eD04PNU81DzLPMf8mvwRO8Q7zPv2e6E7Y7r0ukD6Zjo8Odx5zznF+j46bTtgvMv9QLx1Oxo65ztBfWx/3sHnAf5A6cD2ATHBLIF3gd6CoAPLxcGGwUXvA9ECy0LoA45FLwXoBYSFOoT6hMTEacN1QtxC/MLpQ1fDjQLKAYuA6ICMQI4Adv/qP3r+oD5bvmA+Bj3tvYC99/2LPbv9CHzqfFS8kH1/vda+ev58PmM+Zb5Z/qc+0b9pf+xAjIF5AUvBT8E9gMDBagHjQqJDIgNtQ1rDWAMVwt/C4AM2A1JD94PuQ6lDMsK+QmRCS0JNAn8CEAICQeCBYMD4AFTAWIBbQG/ALf/n/68/Tj9/vyr/Dr8QfxH/OT77/rx+YH5cvmG+Uf5VfjI9k71GPQn85LyUvId8iPxY+927ZDrK+q66ZjpXOmJ6X7qeey/8Jn0I/Ps7p/stO218hH7XANZBrUDAwKcAxgEwQMgBa8HVAtKEeQWIhbGD0AKTwmPC5EP8RNNFZYTfhIJE3kRXw16CjoKSgu/DDcOMg3ICHsE8QKJAnoBPQA9/+H9cvwS/If7qfn79+H3e/h5+Nf3vfZy9fX0fPbv+Dj6dfqI+q363PpN+wL88vxi/pQACQNABMEDiwLSAS4CpgOABc0GaweJB84HNAhPCMoH4QYFBwcIzwhjCbcJHQkTCMAH+Ad0BxsGngW6BXUFQgU4BXcEDANIAugB3wDK/9T/UgBbAFAANACK/6X+df6K/gX+c/2k/SL+6f0V/RT8v/p3+cz4Pvjz9kr1HPSo8xPz6fFp8FzuouyR6+rqe+r76avpFuoN637sDvDu8rnxJ+8G7mrv/fP5+j0BEQMJAXkALQJ4AkECyANHBn0JeQ56EhwR6QtHCGkIgQquDS4RghKfERcRJhEfD1oLJQmNCRULlQyHDQQM8QdwBCQDogKGAaAAYwDq/x3/gf5g/S77jPmv+Zb65fph+n35i/gk+Pz4YPrv+uX6JPum+wT8H/wt/Jr8sv1//1sBHgKMAaYAUgC7AMoB+ALnA5EE7gQSBb4E1AMAA+sCtgNSBREHsgeuBhAFFgQ+BP0E0gWfBtQGlgaZBngGXQUWBKIDPgT7BAoFngSKA4ECLgI/AvQBhAGoAR8CMwKYAe0AVwAqAH8AuAA5ADH/rv6E/gv+GP0H/Cn7TPpf+VD4CvfF9er0OvRB88zxRfA271/ume3u7JLspewt7f7tOu+E8VLz/fIu8j/yd/PP9vv7ZABqASsAQACPAdYBPwLYA58FIAgNDMYOWg2wCd4HuwisCjkNww9yEMsPtA+ZD6ENsApmCQcKRgtVDJ8MEwv7B44FqQQWBCIDfgJcAg8CZwG1AID/hf0Z/Az8jfyV/AH8L/tn+gT6Wvrw+vz60foW+5D73fvk+8z7APzM/CH+Xv/S/3P/Bf8g/7D/hwBdARICugJQA6kDjAP8AoYCsgKBA3UEAQXxBFwEuQNBAxYDcQMtBHwEYARYBBcExAPhA4QE4gSDBFcEnQRRBLADmQOVA1MDUQO1A48DhALEAakBiQFhAbEB9gGgAT0BEgGjAOH/lf/Z//j/v/+Q/1T/sP4G/qP9Sf2s/CL8xfsU++T5nfh09zH2L/WZ9BX0CfOV8WPwT+9y7lfu2O5H78LvCfEs83r0F/Sj8wT0Y/U6+CL8F/+Z/xD/mP+dANAAIwGFAkcEeQZjCTcLXwpJCLAH0whWCv4Ljg0rDvMN8Q3JDVQMNwpVCdoJkArvCrcKfgllB+IFaQXvBPYDEAO7AmUCtAGxAG3//f34/Ob8B/2J/Jj7tPot+hD6Mvpn+lT6PfqR+gT7LPvy+t/6UPs1/FX9Qv6P/mj+cP7g/nv/DQCwAGsBMALhAjwDIAO4AosC9gKhAzAEcQRoBCgE3wOqA2YDIQPuAgYDNwMvA9QCPAK9AV4BSgGIAaUBVAHbAKQAeQBEAD4AZQBkAEIAcgCdAE0A3v/f/x0AOwCEAOEA4gCLAH8ArgCNAG0AuQAbATMBMwE9ARkBvACrAM4AxgCqAL4A2wCTACAAzf+T/z//BP/Z/mb+vf0f/Zj80PvN+vn5RPk0+OD2d/VD9LLzfPMh847yx/H78NzwlPHT8gr01PTy9U/3D/il+LP51Prn+2f9LP92AMIA3QBwAdABTwKYAy0FSwYkBw8IoAizCMMIYQkKCokKVQv6C9ALAgtbCtEJOAnBCKYIpQgpCJMH7QYLBvQEFASiAycDmgLgASABOAA+/33+0f0v/br8k/xS/Pv7qftd+0D7Tfub+wH8Qvxv/KP80Pzz/CL9d/3o/WH+1/5C/4L/m//K/xwAhAD6AGwBzwEGAhoCLwIuAjACNwJVAnoCfAJrAjUC7wGhAXMBWgE2ARQB7gDHAIMAOwD6/77/lv+C/4P/ef9L/yT/C/8J/yr/VP+N/7v/7P8wAHIAjwCnANoAHAF7AcUB9QH5Af0BGQImAigCKwJeApwCuwK5ArACpwKhAqwCswKlAoYCiQKUAm4CFQLCAZEBYgE2AfgApgBWABMA7P+j/0D/8/65/or+R/71/aD9UP0E/c38hPwX/MD7a/sf+7P6Qfrz+Y75Ivmu+Dr4pPcB92X2wfV59X71i/V89Wz1h/US9h/3IfgE+dv54PpS/Mj9Af/D/yoA9wBCAkcDwwMiBIoEFQXaBbgGMAdHB7IHkQhbCaQJuAnECccJ7Qn8CacJ7wg3CMoHYgfKBgkGWAWrBB8ExQNAA4QCqgEaAcAAPQCV/9f+NP6s/VD93/xO/L77Xvti+2f7YftV+1v7lvvw+1P8lvy8/Aj9gv30/VL+kf7N/iH/hP/z/0kAdACxABcBggHSAQUCLgJZApMCyQLfAtQCwgK+AsoCwQKcAnECRgItAhgC9gG9AX0BUgEwARMB1QCBAEMABADN/5v/W/8U/9j+s/6Z/m/+TP4u/hj+IP4Y/hb+Cf79/Qz+Gv4k/hz+If4z/kr+aP59/ov+pP7R/g3/RP9o/4D/rv/l/xUASQBfAHYApADUAP8AEgElAT4BXQGDAaIBvAHSAeEB8gEJAhoCDwIEAhMCEAL5Ad8B1wHRAawBlwGLAXQBTwE7AS4B+QDIAK8AmQBnADwAJwD8/8//r/+d/4r/Zf9U/0//NP8i/yb/Jv8i/x//Kv80/zT/Mv87/0f/Rf9L/17/bv9o/2f/Zv9h/1P/Qv84/yf/Dv/3/tv+rP57/lb+L/75/cf9mP1o/SH92fyi/Fz8Cfyy+2X7BPuA+hT64Pml+XL5efmk+d75PPq++kz7y/tX/CP97P2L/iX/ov8LAH0A4AAvAWMBrQEVAoUC7AJHA6ADAAR4BOsETAWQBccF7QUEBv8FyAWRBVAFFAXYBI4ESAQDBM0DlwNuAz8DCAPiAq4CeQI4AuIBfwElAdIAgAAtAOL/pP9h/z7/F//q/tz+zP7M/s/+0P7U/sz+zv7Z/tr+2f7Z/uX++/4A/xL/Kf89/27/if+g/8D/2//1/wcAGwAmADMAOgBGAFEAVQBZAFYAYABuAH8AigCRAJoAnACYAJoAlQCBAHcAYwBWAFAAPAAqAB0AEQACAPz/9P/s/+r/5f/b/9X/zv+6/67/qP+Y/4T/c/9k/2L/Xf9V/1f/U/9Y/2X/Zv9r/3X/df97/4P/h/+N/5H/mf+c/6n/r/+2/8P/zf/j/+7/+f8IABQAIwAtADEANAAxAC0ALAAkABcAEAAOAAIA///2/+7/8f/p/+P/4//g/93/1P/O/8j/uv+y/63/qP+f/5n/kP+N/4z/iv+U/4v/kP+Z/5n/pP+o/7L/uP/D/8z/1f/n//H//v8HABMAIgAyAD4ASwBYAF0AZQBwAG4AaQBuAGcAXwBVAEwAQAA0ACoAHwAXAAIA/v/w/+f/4v/X/8//xP+7/7b/sP+q/6r/ov+k/6T/oP+e/5n/nv+e/6D/p/+r/7X/vv/G/8f/2P/j/+n/9v/2/wIADQAVAB4AJQAmAC4ALgAxADcAOgA+AEAATABIAFAAUgBVAFkAWQBcAFoAXgBeAFwAXwBfAF8AZQBeAGIAYwBhAGIAVgBZAFQATQBGAD8APgAyACgAIQAXABYADQD+//z/7P/h/9v/0//N/8D/xP+7/6//rP+f/6H/m/+b/53/lf+Y/5f/m/+f/6b/qv+s/7H/uf/B/8T/1P/Z/+H/4v/u//7//v8JABAAFAAVACYAKwAwADsARQBLAEcAUABTAFMAUgBYAFYAWQBbAFwAXwBcAFwAWwBcAFQAUwBUAFMAUQBHAEgAQwA7ADgALgAmACQAGQAPABEACwACAP3//P/x/+z/8f/j/9v/1P/P/8z/yP+//7v/uf+u/7D/sP+p/6z/q/+x/7f/q/+q/6z/qv+p/6f/r/+z/7T/tP+0/7z/vv/E/8T/xv/Q/87/0//U/9b/3f/g/+T/6v/v//P/7f/q/+n/9f/5//L////5/////f/8/wUAAQAHAAgADAAIAA4ADQARABMADQARABAAFQARABYAFwAZABYAEQAdABwAGAAaAB8AGgAYABoAGQAaABgAGwAjACUAJAAoACgAKAAsACIAJAAhABkAHwAWABQAFwAZABEAEAAUABEAEwARABEACAAHAAsABQAFAAIA/P/8/+7/6P/o/+T/5f/l/+j/4f/l/+X/5P/p/+n/6P/t//H/6f/z//H/7v/z//D/+P/5//P//P/8//b/+v8AAAMAAwADAAMAAAABAAoAAwAGAA4ABQANAAwACAASAA0ACgANAAoACwAKAAsACgAMABMADwANAA0ACQAKAAsACgALAAoACwAUAA8ADQAOAAgACgAKAAsACwAAAAcAEgAMAAwABwAAAAAA/v/9/wEAAgACAAgAAgD5//f////7////CAAAAAAAAAAAAAAA//8FAAgAAgADAAQA/P/6/wAA/v/4//3/9v/5//r/8f/4//b/8P/u//P/9//3//f/9f/4//H/7v/z//H/8v/y//L/8v/y//f/8f/v//T/8f/z//H/8v/1//j/+f/1//b/9P/6//r/8P/4//P/7//x/+v/6//j/+n/7//u//D/6f/u/+n/5f/q/+3/+P/v//H/+P/3/wAA//8FAAgAAwALAAsADAARAA4AFQARAAwAEwAUABEAEAAWABgAEwAUABEADwAMAAcABgAEAAUAAAABAAAA+//8//b/9//y//L/7v/u/+v/5P/r//D/+f/y//L/+P/z//T/9v/8////AgAFAAsADwARABcAGwAaABkAGgASABYAHwAeABwAHwAgACQAKgAkAC0ALgAmACIAIQAnAB8AGgAUABMAEwARABkAFwAMAAoAEQAMAAgAAwD///7/9//9/wQA+v/6//v/8v/6//f/9//6//L/8v/u/+//8v/y//f/9P/1//P/9P/0//X/8//1//T/9f////f//v/8//z/AwD9/wAAAQACAAMACwALAAsACwAOAA0ACQAOABAAEQAEAAsADAACAAkABwAKAAYAAgAAAAAAAAD9////9//w//L/8f/q/+r/6f/q/+n/5v/j/9//2//Z/9z/2//e/9f/2//e/+D/4P/f/+L/4f/q/+j/6//r//L/9P/w//D/8P/5//P/+v/+/wAABQACAAoADAAEAA4ADgAGABQADwAPABYADAAPABAADgAPAA4AEAANAA8ADQALAAMAAgAJAAAABAAAAP///v/4//n/+f////v//P/2//X/+v/7//7/+f8AAAEAAAAFAAAAAAAEAAgACgAKAA0ADAAOABAAEAARABIAEwARABUACQALAA0AFgAYAAMADQAIAAMABgD//wcAAgD8/wIAAAABAP3/+f8AAPb/+f/2//T/+//w//b/9v/2//f/7v/z//T/9P/1//X/9P/0//T/9v8AAAAAAgABAAMACAAEAAgAAgADAAQABQANAAkABgAMAA4ACQALAAkACwASAA8ADQAKAAoACQAKAAgAAgAFAAcABQAIAAUABwAFAP7/AQADAAMAAgD7////AAD9//n/8v/4//j/+P/z//H/9v/1//T/7P/x//L/8//2/+z/8v/y//H/8//x//P/7P/p/+3/7v/x//D/9v/4//H/+f/6//X/+P/1//j////7//r/+v/5//j///8AAPv//f8AAAYA/P/6/wEA+P/4//z//P/6/wMABAD+/wAA/f8AAP7////9/////P/3//j/+v/6//n/AgAAAAIAAQAFAAYAAAABAAAAAAAAAAgABgABAAMAAgABAAcACwAIAAgADAAQABAAFQAQAA4ACgAPABQAEAAVABYAFgATABsAGgAUABUAEQAWABMAFQARAAcADQALAAwADQADAAkACAAEAAcABwAGAAIA/f/5/wAA/f8AAAAA9v/9//j/+P/8//n/+v/7//n///8BAP3////+//3/+//5//v/+f/7//r//f8BAAAA/P8EAAMAAQAJAAAACAALAAkABgD+/wMABQADAAgAEAAKAAsADgAPABQADwAOAAwABQAFAAYACgAJAAMABAADAAEA+//8/wkABQADAAMAAwABAPj/AAD///j/AgAEAPz/+f/+//v/9v/4//7//f8EAAUAAAAEAAUABgACAAUAAAD6//7/+v/+////+v/6//3/AAAAAP3////6//T/8f/2//v/+//6//L/+P/2//j/8v/w//L/7P/x/+b/6v/u//D/8f/s/+n/4//o/+n/8f/z/+//8//w//L/8P/y/+z/6v/6//n/+P/1//X/9P/3//3//P8DAAAAAAAAAAAACAAEAAEABQABAAgACgAGAAYABQAHAAUABwAEAAUACgAGAAcABwAEAAwADgAKAAkACQAHAAAABgAGAAIAAQAFAA8ABwAHAAgADgANAAgAEQARAAwACgAKAAsACQAKAAoACQAKAAkADgASAA0ADwAMAAEADQAHAAkAEQAKAA4ACgARAAkAAQADAAUABgABAAMABQACAP3/AAD5//7//P/1//3/+v////j/9v/6//r/+v/y//X/9//2//j/+P/0//T/8v/2//T/8v/s/+z/7v/n/+7/7f/w/+//9f/1//n/+f/1//7/9//7//r/+//+//3////8//7//P///wQAAQAAAAAA//8AAAAA//8BAP7/BgAFAAYACQAGAA8ACAANAAcABQAKAAcADQAHAAkABAAAAAEAAQACAAMABAAAAAgACAAHAAUABQACAPz/AQAAAAIA+v////z/9//5//P//v/7//7//f/9/wAAAAD1//f/9v/w//j/8P/y//b/8v/w//T/8v/5//v/9v/4//v////6//v/+f/5//n/AwD///z/+//x//r/+P/3//r/+P/6/wAA///7/wAAAQAIAAQAAgAFAAAAAwABAAIAAwD+/wUAAgD5/////f/8/wAA+/8FAAAAAgAEAAIACQAGAA0ABwAHAAkABgAHAAYABgAEAAgACQAJAAYABwAFAAoADgANAA0ACQAJAAsACgAMABQADQAQABAADgAXAA0AEgAQAA8AFgATABEAEgAQAA8ACwAFAAgABwALAAgAEgAQAAcACwAAAAEABwAPAAoACwAJAAsADgAAAAEAAgAEAAIACQAGAAYABgAEAAIA+f8AAPr/+v/9//v//v/6//v/+//7//z/+v/8//X/9/8AAP3////9//v//P/7//z/+//7//z//P/8//j/9P/6//L/9P/3//L/+P/v//L/9P/z//b/8//4//b/9f/u/+7/8//w//z/+v/2//b/9f/5//n/+v/5//7/AAD9//7/+//7//z/+//9//z//P/7//3//P/9/wQAAAAAAAAAAgAGAAIABQACAAIAAgD7/wAA/////wAA+P/5//z/+v///wYAAAAAAAAA//8AAAAAAAAAAP//AAAAAP///f/1//z/+//6//z/8//3//n/+P/7//j/8////wEA/f8CAAAAAAAAAAQABgADAAUABwAHAAYABAABAAEAAQACAAIAAQACAAEABAACAAYACwAFAA0ACAAIAAsACQASAAwADQACAAAABgADAAAAAAACAAAADAAKAAUABwADAAYABQAGAAUABgAFAAYABQAGAAUABQAFAAMACQAKAAsADAAJAAwAEAAQAA8ABgAFAAoACAALAAsABwAIAAAAAAAGAAIADQAMAAYACgAFAAcACQAHAAcAAwAAAAQABQAEAAYABAD9////AQABAAMAAAABAAEAAwAKAAcABgAHAAcABgAIAAYACgAOAAgAEQANAAwADgAHAAsACQALAAkAAgAEAAUACAAGAAgAAAABAAAA/v8AAPj//v///wEAAgACAP//AAD7//r//v/8////9P/7//T/9v/5//D/+f/x//L/9P/v/+z/7v/z//H/9f/w/+v/7//v//L/7//t//D/7f/x/+//8v/1//L/8v/u/+z/7//z//T/9P/z//P/8P/z//P/9v////n/AAD9//7//f/+////+f8CAAAAAAACAAAABgAGAPz/AAABAAMABAAIAAUAAAAEAAIAAQADAP///P/+//f//f/7//b/+f/4//j/+/8BAP7/+//8//f/8//6//r/+/////r//f/6//P/9v/4//X/9//5//r//f/9//r/+v/7//r/+v/6//z/AAAHAAEAAwAHAAAACgAHAAYACQAGAAYABAAHAAYACwALAAcABAAFAAoACAAJAAgABwAIAAUABwAIAAYACgAGAAQABQAFAAYABgAHAAUABgADAAMACAAIAAoABgAAAP//AQADAAEA/v////v/AAAFAAcACAAGAAsACQAPAAgADQAMAAAACgAGAAgACQAEAAoACQAHAAkACAAGAAQAAgAFAAMACgALAAgACQAEAAMAAwADAAAAAwADAAQACwAFAAUABQACAAQAAwD9//7/AQD//wEA/P/8//v//v8GAAAAAgD7//v/AAD8////AAD9//n//f/0//b/9v/z//j/9f/3//T/9P/z//P/9//z//H/7//n/+//8P/v//D/6f/x/+3/6//t/+3/8v/s/+//8v/u//f/8//z//j//f8CAPX/8v/3//j/+P/x//T/9v/3//j/+P/5//v//v/9////AAABAAAA/f8CAAQAAQD+/wYABgANAAoABwAPAA4AFwARABIAFgASAA4ABgAIAA0ADQANABcAFQAZADMAXQC0ABoBaQGSAZ8BqwGSAVMBHwENAQsB6gDAAJEAVAAfAPz/1v/B/9f/8f/3/+3/+f8GAOv/yv+0/53/dv87///+1P7D/r3+tf66/tv+CP8S/xf/Kf8//1P/Vf9e/2z/cv9o/1r/SP9O/2T/bP9+/6P/1P/5/w0ALABKAGIAbABoAHsAgQB4AGoAVQBSAFkAUQA8AEIASQBNAEYAPABBAEcAPQApACcAEwD9/+L/w//A/8L/u/+0/7f/v//G/8X/xv/T/+P/5f/n/+f/7P/z/+j/5P/q//P//f/4//7/DAAXACYAKgA9AE8AVgBWAFMAWQBWAFUARQBFAEwAQQA5ADQANgA+AD0AOQBGAEUASQBCADUAOAAvAB8AEwAEAAAA///v/+3/5v/o/+j/3f/l/+X/6f/j/+D/4//f/9j/y//K/8j/xv/D/7n/u//A/77/yP/O/93/5f/k/+n/7v/0//H/8P/v//f/+//5//j/+v///wQABgAJABUAFgAZABUAGwAeABoAFAAOABQADgAMAAEA//8EAAIABQAFAAYABAABAPn/+f/1//L/6//n/+X/4//j/9f/3//Z/9n/2f/U/+P/5P/q/+v/7f/2//n/+//+/wIAAwAFAAUACwAQABIADgAMABMAEgAZABcAHAAiAB8AIAAbACAAIAAcABUAFwAZABkAGAAPAA0ACgACAAIA/v8AAAIA9v/1/+7/7v/r/+X/5//h/+j/4//f/+z/6//t/+//8v/3//7/9//4/////P8EAP3/AAAEAAYABwAFAAoADAANAAoADwAMAA4ADAAJAA4ADAALAAkAAQACAAYAAAD/////AwAJAAYABQAIAAsABwAIAAQAAwAEAAIABQADAAUA///8/wAA//8BAAAA//8AAAEAAAAAAAAAAAAAAAAAAAABAAMA+P/4//z//P////v/9f/4//v/9//6//n/+/8AAP3//P////3//P/9//3/AgADAAEAAQAEAAcABAAFAAIABAAGAAQABwAFAAkABwAFAAcAAwAEAAMABAAGAAYABAAFAAcABwAGAAUABAAFAAYABAAEAAUABgADAAMAAgACAAEA+v8AAP7/BgAGAAAABgACAAkAAwABAAAACAALAAgAEgAHAA0ACgAFAA8ADQAMAAUABAAEAAYAAwAAAAIAAAD//wAAAQD//wAA+//4//7//f/6//X/9//5//n/9//y//b/+P/3//z////8//3/9//y//v/AgD//wAA//8BAAcAAAABAAEAAwACAAEAAwAFAAoABgAEAAYABAABAPz/+v8AAPj/+//1//T/+//3//3/+v/8//j/8f/t/+3/8f/y//X/9//+////9v/4//b/+/////r/AAABAAYABAAFAAQABwAKAP7/AAAAAAEABAADAAUACwALAAUABwAFAAUAAwAAAAMAAQACAP7/+f/+//r//P/+//r//f/+//z//f/9//7//f/+//r/+f/1//D/9//4//n/+f/4//j/+P/8//j//f////7//v/9//z/+//7//X/+f/8//z//P/7//7/AQAFAAMAAgADAAAAAQABAAAAAwD8//3/+f/+//z/9v/+//n/AwABAP3////8///////9/wAA///8//n/9v/4//n/+//2//7//P/8//r/8P/6//b/+f/3//j/8//y/+//7f/7//b/AAD5//j/AAD7//7/AAADAAcADAAEAA4ACgAKAA8ACAARABAAEQAQABIAEgAZABYAFAAXABQAEgAJAA8ACwAOAAkAAwAJAAQABgD///7/AQAAAP///P/8/wMAAwAAAAMABAAFAAMAAAAAAAIAAgABAAAAAAABAAAA/f/+/wAAAgAAAP7//v/+//7//P//////AwAAAP///v/7//f/8//y//f/+//6//r/+//8//r/AAD8/wEABAAAAAAAAAABAAEA/v/6//z//P/+//v/AwAAAAIAAgAAAAcAAQAGAAEACAAMAAoADgAFAAcABwAFAAYABwAHAAcACQAFAAcACQAAAAIAAgADAAQA///+////AAAAAP//AAABAP//AAD8////BwAAAAMAAgAAAAUA/v/+//////////z////+//7//v/8/wIAAwADAAQAAgAIAAAA/////wAABAABAAAAAgABAAAAAAD6//7////+/////v8AAAAA/f/9/////v/+//r/+P/+//r/+//8//n/AAD7//7//P////7/9//9//f/AAAAAP7/AQD//wEA/f8AAP////////r/AAADAAIA+//9//z/AAACAPv/AwABAAIAAQD//wEAAQAAAP7/AAACAAAA/P/5//f//v/5//r//f8AAAMA/P/7//v//v/8//7//f8DAAUAAAAAAAAAAQAAAAEAAAAIAAcAAgABAPv/AAD6//j/9//4////9f/0//n/+f/7//n/+P/+/wIA/P8AAAIABQAKAP3//f8AAAAAAQD//wAABgAIAAIABAADAAUABwAAAAcADwAIAAcAAgD//woABQD//wMABAAEAAQA/f/7/wMA+P/7//3/+/8DAPn/+v/8//z//f/1//j/AAAAAP///P///wIAAgD6//3/AAD+/wEA9v8CAAUABwAGAAAACwAGAAcABAAHAAsADgAGAAEACAACAAUA/v///wQAAgD+//r////7//z/9//3/wAA/v/5//n/+P/4//b/7v/2//r////8//j//f/6//z/9//7/wAAAAD6//z/+/8CAAAA+f8EAP//CAD+//z/AAAGAAcAAgAIAAUADQD///3/AAABAAcAAAACAAgABQAEAAEAAgALAAgABgAIAAoADQAHAAEABAAKAAUAAgAEAAMACwAIAAMACQAJAAgABAAEAAYABwAEAP3/AQAEAP7//v/2//7/AwD7/wAA/v8HAAYA/v8DAAAABgACAPr///////3/+v/6//3/AwD///X//P/8//z//P/7//3/BQAAAPr/AQD4//r/9//v//z//P/5//f/9v/6//j/9v/1//j//f/4//r/+v8AAAAA/P8BAAAACQAEAAMABAAIAAkAAAAGAAIADQAMAAQACgAIAAoABwAGAAwAEQAOAAoADgAQAAwACwABAAcADQAHAAkACAAIAAoABAAAAAYABwAHAAIABAAGAAQAAwD7/wAA///8//r/9v/8//n/9//0//v//P/7//P/8v/4//X/9//w//b/+P/1//L/7//z//b/9P/y//3/+f/7//n/9f8AAAAAAAAEAAYADwALAAYABQAFAA0ACQAIAA0ADQANAAcAAgAKAAUABwADAAIADwAJAAgACAAGAAkABgD//wMABwAEAAUAAwAEAAgAAAD8//7/AAABAP///v8CAAEA///3//T/+//z//L/9//2/wAA+v/x//X/9f/0//L/8//1//7/+f/2//v/+v/+//X/+P/7////AQD3//3/AAD+//n/+v/9//7/AQD1//3/AQD7/wAA9f/+/wEA///9//z/AQD+//7/+f/8/wMA/v/6//7//v8AAAAA/P///wIAAAD9//7/AAAGAAAAAwACAAUACAD7/wEAAAACAAAA/f8AAAAAAgD2//7/+v/6//z/7//5//r/9//3/w=="
- }
- }
- ]
- },
- {
- "role": "user",
- "content": [
- {
- "type": "audio_url",
- "audio_url": {
- "url": "data:audio/wav;base64,UklGRgrVAABXQVZFZm10IBAAAAABAAEAwF0AAIC7AAACABAAZGF0YebUAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAEAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA//8AAAAAAAAAAAAAAAAAAAAAAAAAAP////8AAAAAAAAAAAAAAAD//wAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAP////8AAAAAAAAAAAAA///p/9T/xv/G/8b/yf/K/8r/zP/M/83/zf/O/83/zf/P/8//z//O/87/z//P/8//z//P/8//z//P/8//z//P/8//z//Q/9D/0P/Q/9D/0P/R/9H/0f/R/9H/0f/R/9H/0f/R/9L/0v/S/9L/0v/S/9P/0//T/9P/0//T/9P/0//U/9T/1P/U/9T/1P/V/9T/1f/V/9X/1f/W/9b/1v/W/9b/1v/W/9b/1//X/9f/1//Y/9j/2P/Y/9j/2P/Z/9n/2f/Z/9n/2f/a/9r/2v/a/9v/2//b/9v/2//b/9v/3P/c/9z/3f/c/93/3f/d/93/3f/e/97/3v/e/9//3//f/9//4P/g/+D/4P/g/+D/4P/h/+H/4f/h/+H/4f/i/+L/4v/j/+P/4//j/+P/4//k/+P/5P/k/+T/5P/l/+X/5f/l/+X/5f/l/+X/5f/l/+X/5v/n/+f/5//o/+j/6P/o/+j/5v/n/+f/5//o/+j/6P/o/+n/6f/p/+j/6P/o/+j/6P/p/+n/6f/p/+n/6v/q/+r/6v/q/+r/6v/q/+r/6v/q/+r/6//r/+r/6v/r/+r/6v/p/+r/6v/r/+r/6v/r/+z/7P/s/+v/7P/r/+v/6//s/+v/6//r/+v/6//t/+z/7f/t/+3/7f/r/+z/6//s/+v/7P/s/+z/7P/s/+z/7P/t/+3/7f/s/+z/6//s/+r/6//q/+z/7P/t/+3/7v/u/+3/7f/t/+z/7P/s/+z/7P/t/+3/7f/t/+3/7f/t/+3/7f/t/+z/7P/s/+z/7f/t/+3/7f/u/+3/7f/t/+3/7f/t/+3/7f/u/+3/7f/t/+3/7f/t/+3/7f/t/+3/7P/r/+z/6//t/+z/7f/t/+7/7f/u/+7/7f/t/+z/7P/t/+z/7P/t/+3/7P/t/+7/7v/v/+7/7v/t/+z/7P/t/+3/7v/u/+7/7v/v/+//7v/u/+3/7P/u/+z/7P/s/+z/7f/u/+7/7v/v/+7/7v/s/+z/7P/t/+3/7f/u/+7/7f/u/+3/7v/t/+3/7f/t/+3/7P/t/+z/7f/u/+3/7//u/+7/7f/t/+3/7f/u/+//7v/v/+7/7v/t/+7/7f/v/+7/7v/t/+7/7f/t/+3/7v/u/+7/7v/v/+3/7v/t/+z/7P/r/+z/6//t/+r/7P/t/+7/7v/u/+7/7f/s/+z/6//s/+v/7P/t/+3/7//w//D/7v/w/+7/7v/s/+3/6//t/+v/7f/u/+//7//u/+//7v/u/+r/6//q/+v/6//s/+7/7v/w/+//7//v/+3/7f/s/+v/7P/s/+3/7f/u/+7/7v/u/+3/7P/r/+z/7f/s/+z/7P/t/+3/7P/t/+3/7v/s/+3/7f/t/+z/6//r/+z/7P/s/+z/7P/t/+z/7f/t/+z/7v/v/+7/7P/s/+z/6//u/+3/7v/u/+7/7f/u/+3/7f/t/+v/7f/r/+v/6//s/+3/7P/u/+7/7v/v/+7/7v/u/+z/7P/r/+3/6//t/+3/7v/t/+7/7v/v/+7/7v/t/+3/7P/t/+7/7v/v/+3/7v/t/+3/7f/s/+z/7f/s/+3/7f/t/+7/7v/u/+3/7//u/+7/7f/s/+z/7P/s/+v/7P/t/+3/7f/v/+7/7v/u/+3/7f/t/+3/7f/u/+7/7v/u/+7/7//u/+7/7v/t/+3/7f/t/+3/7f/u/+//7//v/+//7v/u/+7/7v/u/+7/7v/u/+7/7v/t/+7/7v/u/+7/7v/u/+7/7f/t/+3/7f/t/+7/7f/t/+3/7P/u/+3/7v/t/+7/7v/u/+7/7v/v/+7/7v/v/+7/7v/u/+7/7v/u/+3/7f/u/+3/7v/u/+7/7f/u/+3/7v/u/+7/7f/t/+7/7v/v/+7/7v/u/+3/7v/t/+3/7f/t/+3/7f/u/+7/7v/u/+3/7v/t/+3/7P/t/+3/7f/u/+3/7v/u/+//7v/u/+7/7v/u/+7/7v/u/+7/7f/u/+3/7f/u/+7/7f/u/+3/7f/t/+3/7f/t/+3/7f/s/+z/7f/t/+3/7f/t/+3/7P/t/+3/7f/t/+z/7P/s/+3/7P/t/+3/7f/u/+3/7f/t/+3/7f/t/+7/7P/t/+3/7f/t/+3/7f/t/+3/7f/t/+3/7f/t/+3/7f/t/+3/7f/s/+z/7f/t/+3/7f/t/+3/7f/t/+z/7P/t/+3/7f/t/+3/7f/t/+3/7f/t/+3/7f/t/+z/7P/s/+3/7f/t/+3/7f/t/+3/7P/s/+z/7P/t/+z/7P/s/+z/7P/s/+3/7P/t/+3/7f/t/+3/7f/t/+z/7P/t/+z/7P/s/+z/7P/s/+z/7P/t/+z/7P/t/+z/7P/s/+z/7P/s/+z/7P/t/+z/7P/s/+z/7P/s/+z/7P/s/+z/7P/s/+z/7P/s/+z/7P/s/+z/7P/s/+v/6//s/+z/7P/s/+z/7P/s/+z/7P/s/+z/7P/s/+z/7P/s/+z/7f/s/+z/7P/s/+z/7P/s/+v/6//r/+z/6//s/+z/7P/s/+z/7P/s/+z/7P/s/+z/6//s/+z/7P/s/+v/6//s/+z/7P/s/+z/7P/s/+z/7P/s/+z/7P/s/+z/7P/s/+z/7P/s/+z/7P/s/+z/7P/s/+z/7P/s/+z/7P/t/+z/7P/s/+z/7P/s/+z/7P/s/+z/7P/s/+3/7P/s/+z/7P/s/+z/7P/s/+z/7P/s/+z/7P/s/+z/7P/t/+z/7P/s/+z/7P/t/+z/7P/s/+z/7P/t/+z/7P/s/+z/7P/s/+z/7P/s/+z/7f/t/+3/7f/t/+3/7f/t/+3/7f/t/+3/7f/t/+3/7f/s/+3/7P/t/+3/7P/s/+z/7P/t/+z/7f/t/+3/7f/t/+3/7f/u/+z/7f/t/+3/7f/t/+3/7f/u/+3/7f/t/+z/7P/s/+z/7P/t/+z/7v/t/+7/7f/t/+7/7f/v/+z/7f/r/+3/7P/t/+3/7f/u/+7/7v/v/+7/7v/u/+z/7f/s/+7/7f/u/+3/7f/v/+7/7//u/+7/7//t/+//7v/u/+z/7P/s/+7/7f/w/+3/7f/u/+//7f/u/+7/7//s/+//6//w/+3/7//u/+3/7v/s/+7/7P/u/+//7v/x/+z/7//t/+3/7f/u/+//7//u/+7/6//w/+3/8f/t/+//7v/v/+7/7v/u/+//7v/w/+3/7v/t/+//7//t/+7/7v/w/+3/7P/v/+3/7//t/+//7v/w/+7/7//y/+3/7v/v/+3/7//t/+7/7P/v/+3/9P/w/+3/6//r//D/7//w/+3/8v/t/+7/7f/v/+3/7f/v//D/7f/t//D/7v/u/+3/8P/v/+7/7v/w/+z/7//r//L/7v/x/+3/7v/u/+7/7//t/+//7f/v/+7/7f/v/+7/7f/u/+7/7f/v/+//8P/u/+3/7//u/+//7f/v/+z/7f/v/+3/7v/p//D/7f/x/+7/7v/s/+3/8P/v/+//7f/r/+7/7P/t/+3/7v/t/+3/7f/u/+7/7//t/+7/7f/u/+3/6//s/+z/7f/t/+3/7//s/+//7f/y/+z/7v/s/+3/7P/v/+3/6//r/+3/7P/u/+//7f/t/+7/7v/v/+z/7f/r/+//7f/w/+z/7f/v/+v/7f/s/+7/7v/v/+z/7P/u/+z/7//s/+3/7f/u/+7/7f/w/+z/7v/t/+3/7v/t/+3/7P/u/+7/7v/s/+z/7f/v/+3/7v/t/+3/7f/t/+7/7P/t/+3/7v/v/+z/7f/u/+3/7v/v/+z/7v/t/+//7f/u/+7/7v/u/+7/7f/u/+7/7//t/+7/7P/u/+7/7f/v/+z/7//s/+3/7f/u/+//7v/u/+3/7v/v/+z/7//q/+//7P/u/+7/7P/x/+z/7v/r/+7/7v/t/+7/7P/w/+7/7P/u/+z/7v/r/+//6v/u/+3/7v/t/+3/7f/t/+3/7P/u/+z/7v/t/+z/7v/s/+z/7v/t/+//7v/w/+3/7P/t/+3/8P/s/+3/7P/s/+//7f/v/+z/7v/u/+7/7v/v/+7/7v/u/+3/6v/r/+3/7P/s/+3/7f/t/+//7//v/+v/7f/w/+3/7f/t/+3/8f/r//H/7f/w//D/7//x/+z/7//u/+//7P/s/+3/6//s/+v/7P/u/+z/7f/r/+//7//x/+7/7v/w/+z/7P/s/+3/7v/t/+7/7P/w/+7/7//t/+b/6P/r//P/8v/2/+//8v/q/+//AAAOAA8ABwDw//r/9f///+X/2f/h/wAA/P/W/8b/vf9TAAsBqgA2/3v/9P8vAAAApf+w/wIAQQA3AOX/xv8QABIA+P+V/8r/HwAJAOn/2////yIA+f/U/9v/9f8TAML/v//u/zcAIQDf/7n/4P/4/9X/xv/e/x4AEQBw/3X/HACRABwA1P97AGAAGQBmAJb/Rv9zANcAVAD0/7P/gQC9AFMA6f+u/0oANwDb//j/NgAsACEATQC8/9X/5//5/9X/M/+//4IApv+6/wIAcf95/9D/zv/v/6P/zf94/9H/1P99/8f/x/+//93/bf/8/9f/9f/y/xv/x/+MAL7/agB3/7L/dwBW/7D/Df+zAIoA9/8e/8P/0wAKAA7/kADf//7/8v9o/zH/hADV//T/Av9+/xEBCgAD/rb/pwBt/7f/3/7I/3EAff+Y/wMAqf9ZAU3/3v70/6cATv8s/+7/lgBy/8H/LwA0/7H/9f9FAUH/1P4hAMoAAgAW/+j/hQCJ/mf/4wDb/8r+bQBB/ykDPv8w/kEAdgAYAAUAw//2/nMAuf9IANf/GP8OAKcAVwC3/eb/GgBtAHr/BP++/7sBJ/89/yj/UAH+/4z/Nf/JAOgAMP/l/4UA7f9gAFAAK//l/9oAgv+e/ykAuf97AXgAYP7I/fACs/+l/u8AlwAgAJb/NP5cAt4ASf7N/9EBfP+p/zwAVwB9AL//3/6oAZEAkQABAZL/uv88/5kBbgC8ADn/Nv+JAa//o/4qAeP/Qv/eAFsAMQBp/63/fAC3/jX/IwEr/7D/9/8t/xsAKwAwADH/0f71/vQBVgEg/k3+zgAvAqf9wP+UAdP+v/8DAZv+AQDUASgA3/7x/hMBOwCm/Zz/MgIEA5b8TADsAcr9kP/fAbn/v/4s/9EBvv8q+74BOwKGAMr8hgBCAlAAn/4a/a7/ewC8ASQA+/8b/qD+KgHX/zL/zf1QAksBUf/r/jMBO//F/BMC7wDE/W394wEpApP+9ftnAzIBL/9vAA7/1f/mAtv9Sv5QAPP/1wEpAHf9Jf5aBGD/k/9U/uf+AwKkAdv+gPxFAfwCYv5R/NwBqP9SAkj/JP2mAe4A+f5TAEIAWgAYANX+X//gAML+6wHzA5777ADrArj+0wDo/ff+RAKV/MsB7wHy/LsAmv3U/QQGqv1EAEQBNPxzBDwBHP4//tYAaf+xAYn+rP1rAZ8BgP6KAe4Amv7JApH+6v1fASsBYQAl/hb/zQCO/iP/SP99Atf/GP/n/mn+9wBS/0kD3gKXANoEBADQ+B4ANAbCB378/Py1/oUG4/9rANT8aQCdAHIAM/+d/4X8vfxcBmz/iPoQ/ngFGv6C/vz/zfs7AfcB/f4C/7L/gv6gAWj+pv8sACb/SwEv/k4CBv/H+rQBZgISAfX8Mf9G/4wElgEw/DT6mQQiBTj9Gv2E+5wFCwEK/zD8S/1zBKYCJPpSBDMARgDD/+UAnP6K/egEYAGr+u//XwFmACkCuvt4BIECQf3aBH0AwPo6/WwH7P0J/nL/mgPq//T+OfwfBVcBy/70/0D+//81Avv96QAD/8wB6fvo/5UDbv0MBFsBfv5XAMv6BAi5Bf/8NP6qAKAAFgLVAokBMwBN/tkAif8a/EIAzgTkA7z9NfnQBcQBYwKEA7j5PgFU/mP/8wbZAP36SQBdB+v9rQDpBB/+Gf8e/F4BzgJYATUCXvwI/JQB0gml+/P7bQLD/IwD+P57+v3/xwRd/6X7DwK0BXX+vAEZ8xf8pQXiDKj5AP1n/DcCIgOe9Uz6mwr3BXf5AQIO+Kb/PgZq/HH7OQZG/2YCGvqD+/gFmADb+lEA+fwYAA0KLP7k+lv8FQVf//wCLP6J84wDhgbZ9n38zwOVAEH9xv7KAHL/o/xrA+MCI/4i+uQDiwBV/573swPzAy0Bbfr6/lMEXgBz95cDmgVd+SP+Ef98+gwGK/uF+98I/fgj+4MK4/dz+v8Gw/xJAIf3pgMUBu8B2fq1/T38zAIEBRb5OgEL+6kAOwRS+6L3XARBAXf7wvck/8ADZgWn+Tr5F/9SA1b9CfrxArD2jwaKCbv0YgBF95H9cAltA939K/599NoEugmm88T8rga1Bw4DKfm09HoKEwP0+sT+nvrH/gUO3fz79agATfh+BNgDhfvB8gQCMwYn/bP/S/rx+yQDRgF1CFb88PWM+MwGtgQJAqX5+/+dA5IDiv4e9pMAuQpKAV33N/sKAXcMOAEFAS/3V/x4DvYFRv5Z/lUC3wQQ/if6UgASBJ8CUP98/g75tAB6CLIBLgDJ+Zr+RANN+rL/fwNo/Xj8tgBZCtwE1vsB/4AFVvq0+hoENwHN/ykBLwbO/lgCjvw7/ssCnfq3AAcHHfxg/XQGpAIO+mr8DABpBM8Ac/5cBgsACPlS90wGEQjdBX4Ab/OJAer/dQUfAnP3GvzR/ZkE8gISAF8ELf8U+cX2lwM2BeH/iwG98qH7iQUZB3f9KQGlAIf9GAif/B34T/5/B/IAVQJ/Axf/5QVO+1T4VQC1/FkEbQMg/IMAvQNVBe/97/tN/wQGjAKFAgX3G/IxCWYG8wEL/Q4DxwTyCcb5evNW+LoHKwaYAS3+BgFPCMX/evzg/OP4bgHyEZgB0PgmAbr5ZvcRDi4KiQvA+Lv4dfyhAjn9svy2A2MFZQCCBm8DXQMC/2z5TPf2+iwG4wVlCPj7BfgHAcr94wDuBosIhfkL7cgDZAZ0BWr76fvxBAEHXAhe/jPzTfakCxQDdP8E/GT+AQOz/3/zoQDaCp8GxP5E/RP7rfx4DbUA9vzt/Ez/GwlXBtcAr/5/AMf+Of0fBSADEf6J/bz85/wfA98EDAQtAkv7JPi3/z//gv9P/mX6q//NBSoA5P58A8L+w/tm/0P5LALLBKH8u/xj/bwEMAReAqb+Jvr++w/+kf38/0QCkv25+uQDKgEx/4n9RPrY/l8GTv/NAK8Auv41AUj/gADrBl8CWQKaADH8mP4DArQCgQH0/U4CdwFuAaD9Xvs5/PL8lQP7B1UDsfyK/6YAef4XAe4C6ALwAvb/0f9DAPoBKAFyAUEE7gJt/BQBzP+lAC/7Xv3mAm0J0AWbAgQA+fhK+iwDPQfmBvwAJv/N/Lv/LQBmAUkDlQDFAU0CP/w+AG0Bnf5q/G0CIgTEA3EGtf5a+Zn5RP+2BcYFHwf9/gX+LP9K/rAC+P4G+qX+rwG/AswEVf8M+z0CwQHh/8QCGgDm/qQBafvj/SsAnQOYA5MBlQGSAsT9S/5u/w/+uvzGAf8C5AGZ/yv+/fxr/s7/1wEV/BP8yAFs/pT8Ovqy/Pf/JAKr/SX+ovtf+E/75Pve+1f7m/8rAuj+6/ye/bz8Yftw9638wv1RAXD/Of1F+tD2GPfR/Mn/Q/6p+pf8qvk5+1H7Rfrp/Gb97PkB/Av6xfnv+5T6AvrV+rb8SvwH/sj69PY69jX46/t1/gD+Ev4T/Fb8e/u9+7X7cfhF+Yj8Wf2K/Vz/Iv8V/6//x/5t/xP/wf2AAF//TQFfARIFCAf8BHcF2QVNCHMIEAn+CGgI7gkzDI0NPA4wEOIPDxAXEL4Pvg8/EpURgRE0EuwSPhTFE7sTGxIIESER8xABE9cS0xECESURdBCXD6AOsg4sDcQMgwy5Cy0LgAqQCo8IuAZCBh4F/AW2A7wCsAHNAVAB/QDsAMD9w/xE/E/8xftZ+pT7MPth+r35D/YM9/34pPoy+Bj1/PO48xf0LvXR80ryYvE+95T1ePRA8mrx9/GF8a3wM/Bu8frx8fCX7Ubu9+/Y9Bb0+PFq7uHwAvDG7fPr3+gb607upfBL8IPuvO3e6sDmEOX75LPozOre6u7pdec75vjlB+Z95uDm9ufW5oDjCeRR45rk4+QK5nXm6+OE4ezeE9y13rLgFuHQ5+X4UwTJAmP9+PNL6pTqo/LrAP8OyRkhHFcXwxEjEfEV2RpnHRIfcyD8JZAqky4XMGctXy8nMyg1/DSEMYYt9CrGLGIyTjjPPZI70DQ2K0El8iEYIyclDCbDJkYmpCMbIgsdBxfREBMNGw3fDKwMTAtcCEoF1gSSA4oDSgIY/9L68vYL9Yv3y/g3+xz8xvpp98/0UfLA8Ovx0PJ19Ln3ovp/+3H6zfdj9or1gvZl+KD6J/1y/pT+6f6+/uf+2QCwAKX/jv5H/tn+SQC+AEsBcwJyAywDWAHp/87+vP53/8cA3gJIBGkDhQJNAAEAuv6T/qz+nP9sADABTgKyAu4B2P9R/lP93v20/XT9uP4n//X+Xv2u/P38yvx0++n5cPq3+4f7wfqv+Dj3P/c39hz1zPMw813yf/Cc78rsretT6yjr3upj6Qvm8uPS4qDigOFL32PfcN7x3IraT9nO2MfXsdbx1L7TbNNA02rSItFi0IXQQ9BSz4nNessGyNvEc8JLyffcw+/J9DnyHOwj3pzUm9e44xH5JA2KFoMU4A77C+sJZAu/D2AWXh8iJnMqgiy5LaYsYC2IM9w4nzsqO1g2RjEGL8YxTTkfQwFI70VXPuYz0ivsKK8pySyiMRcz5DJYL1Ap/yL5HNMY6Ra1F8YY8hh3FxMUwhABDs8MAQ2MDMkJ8AR6APH9tv2u/5ACvAOQA1kAB/yx9/b0wPMQ9Rb3rvmw+9v75/kW94v0gvKQ8qr09fZ+9z73DPYi9SL1OvZI93/4zvjo91/2G/VW9dH2MPnI+xP9Af1t/Gf7S/rd+WL7yv2pAOQCaAPcA94C3gEcAvQCVQQWBnYH1wc6BzEHqwc+CDIKGQvCCskKugk/CdQHeAevB5cINQmlCO8H3waVBPACEAEbAN//1P+E/5n+b/3o+1j5B/jF9mv1t/OJ8fbvue537lrtJOwZ6qDoPOe15CXi5ODw3jfeid3T3JPcY9vH2lrY89Vr06HSw9Ly0X3RDNHCz7TPpc6GznXNDcxjy2LJt8cPx6zFxMUOxCHEKsj+1U3lMet+7A7pId/l1I/YmOKA9HgIxBKNEwgR/QzICV0Kcg7tFGUfpCjkLZkzOzWBM/UxZDKANEw3UTr+Or85bDrYO2s/d0RHSMpHS0JeO7Y0nzD5L9QxHjX1N6o3hzUVMEcpyiI7HcMaOxvnHNEe9x7bHbIZgxQqEKcN3AvACjkJzwcoBh4FZQTuA9QDogILAKb8VPmw9gf1CfXP9Sn3O/iM+P32mvQL8tPvDO4u7nDvP/El8xf0h/Na8sLwve/L743wGfHO8UnyWfKV8qr0FPYM91/4/PhF+U746ffR+Cf7kvzV/icAOwIxA1kDVQLVAaQCCQRrBWMHegkNCxoLhAq2CucKBQv3CjkLRQvpC3wL8wp1Cs4KPwp/CbYIPQgSB5YFugOeArIBHQEJAIz/xP7r/Dr7Lfne9p31K/R085vy/fGF8M7uLO1L67LpIehT5h7l9+Pf4uzh7+Dv3z/eet213CTbKdpw2KXWSNW30yfTSdLd0fzRfdFZ0H3PHc6vzDHKhckeyD3IBcjex5nKg9Jt2o3eouIx4wndVdpA2/XgZ+55+0MDfwdJCMQEtACTAZ8ECwtnFGkdtSSpKgAtdixLKn0ogicYKdYsCTFSNiw66DuaPKc9Mj0gPMg61zm6OIQ35jbpNro24zVqNCcyhy8GLboqWCi6Ju4kBiQcI34i1CF5IAAdCBoIF6kT9BG0EKkPjw44DQAMYQoaCHMGIgSWAaP+1fy8+/z6JPvS+iz5avfb9ZX0NfM+8l/ybvJF8gvy9fE78U7wdu8576Xu9O6C78zvVPDp8Lzw0vDE8aDyaPNZ9Mn0BfWO9Un1uvVD95X4f/m2+rT7/Puj/DP9Yf3a/cn+lf+9AOEB0gJ3A4cDngMDBI8EOwXBBS0GqgbOBqsGUwYtBtYFBgZEBj0GSwaxBbgEvAPpAggCcAEOAdsAbQAQAN/+jP1k/NP68fmc+Uj5zvhq+LD3Qfao9Ozyk/HK8P7vne8d7zvuGu3g69nq5+kz6VzoBueT5UbkJ+P84TThS+AI3+HdDt0E3NzaEtrd2NjX1Nac1Z/UhtNn0hfS6dH50UrTydX41z/bcN4C4NfgY+F34Wzi7eSA6MTstPCn82f2d/jH+Qn8if8/A+8HbwwFEMgSrxTzFeQWrhioG2cfhyPaJ7crhS7bL9IwvzGsMswzRDUwNp02uTbWNZU0bTOHMvoxFzJoMssy5jLYMS0wPS5RLGAqHykaKEUnOCbPJAgjzCCNHm4cNxqhGB0XZRWTE5YRGg8fDHgJFwcFBTcD1gF0AC3/k/36+7r64fnF+MP3kPZP9fXz4fLP8arw4O8Q72fu++2x7Xvtk+2C7TLtRu1D7Tbtgu3v7Sbume4R77rvM/CF8P/whfES8tryyfPJ9B72KPfo95n4JvmO+UX6Bvv/+zD9Hf7+/uT/jQAAAYUBSAInAx4EvAQCBSAFGQX0BMcEtASdBFgEDgTmA9UDqgOeA0YDtQIUAmMBoQDy//f+Iv5//cb8w/vs+uz5u/io94P2fvWF9GLzFfLj8KDvTO7s7ITrHerc6Gzn6+Wf5EPjDuLn4L/fld5d3Tbcxtpv2f7Xr9Y91eHTwdKt0YvQz88C0PbQJNNE1jva89yG3mffBd/w3fveK+Fr5GHpMe5O8UL0PPZR90D5VPwwAE0FWgpmDjAR8RIGEzUTuhSIF8wb8iAVJhsqVyyRLaItxC2DLgIwyjHwM0Q1QDVcNHIySTD2Lu0uqy9cMdgyXjPDMoUwCS5+K6op5CiSKC0ojCckJqYjACGzHoccMRuEGr0ZphgbF34UPREGDhoL6wgmBw8GJwUhBJ4C/gBI/+790vzD+976JPoq+Z/3S/ak9PjyxfHy8F/wEfC872HvB++f7lvuVO477oLuyu7z7h/vR++H77nvGvDB8JHxH/K68nHz+POT9E/1DPYG98r3hfg1+ej5a/oP++H7vfzi/Qj/8v+cAH0BAQKXAgcDawPGAygEcwSFBHoEXAQdBNsDmQOJA2gDPgP8ArMCUQLMATcBiQDW/yb/Zv6Z/cn86/vr+v35B/ka+A73RfZJ9Tv0M/MM8tDwo++I7nrtiOyB60jqHOnp56jmguVm5HLjieKL4Xvgi99p3lfd/9ue2kTZ6tet1rfVwdQB1EDT0NLe0sHTWda12R3deN+D4QvifOGS4DjieOR0587rdPDG81z2X/i0+bb7yP60AkAHwgsxD60RBhN2E3EUURYNGQId3yGZJt8pRSxYLV8try2YLsUvbTE7Mx402TO1MvcwLS/0Lf8t6i4FMBYxPDFkMGMuLSznKfcnqyYBJnUlryRQI3AhNB/DHM0abRlNGD0XPBbcFIIS8w89DWwK8wf5BdQE/gMDAxEC8ACG//L9xfzH+8L61/nZ+Mj3sPZ49SD0HPMe8k/xtfBe8BLw6e/x78bvvu+p78Dv5e/17w/wOfB38MnwJPG38TvyyPJS8xT05fSm9Vb2+faQ9zD4tPhZ+QP6x/pw+yv85Py4/Yf+Pv/v/6wAWgH6AYoC5QJHA2YDhgN4A2cDaANxA2EDTgM7AwQDlQIgAsUBcQH9AKAANgCf//n+Kf5L/Wz8m/uu+tH5//g9+E/3WfZi9WH0XvNi8oDxk/Ct78fu4+397AzsDusg6k3pd+ij59Hm9+Ub5T/kPeNd4o7hxODY3w/fM95F3WTcXNtx2o7Z9diF2ETYrtjN2ZzbBd5x4M/id+Rd5RLlcuWP5kjo5upI7kHx/vNd9lz4OfrM/E7/WgLmBWIJMQx6DiEQFhFcEmYU/RZSGnAe+iHsJPEmaihOKRcqDSs5LMotJi/8L0Aw0y+vLrIt/CylLAUt1i1YLksuuC2FLLsqDimUJ5YmzyUFJRwkwSIAIQofMB1hG+MZrRiSF1IW1hTqEnwQ8g1uCz8JjQdBBk8FXAQjA9cBXQDz/on9Zvx2+7j6F/pj+VX4O/cG9sf0wfMG86DyafI/8hHyzfF38Snx+vDo8OLw8fAk8VjxiPHG8QjyVPKz8inzv/NJ9OT0ZvXY9U/20vY698T3UfjS+GT57fl2+hf7xvtw/Bz9xP1d/vX+XP+z/wUAVQCYAM8AIgFEAV0BdQF4AXMBagFUAUgBHAHXAIEAIACs/zv/vf5O/vX9kf0b/Yv86fse+1X6lfnV+Az4SPep9uf1HPVP9IXzwvIR8nfx5/Bd8K7v/u4/7nbttuz+61Hrt+ol6pbpDemJ6NrnS+fJ5kjm2eWN5Trl6OSG5B3kuuNT4w/j1OK74qHif+Ky4kzj6uPy5IDmA+g/6aLqxOug7LvtCO+E8JLyqfTP9hP59/rc/Of+0QDhAmcFzgcbCl8MHg66D2kRAxPdFB8XWBnMGxseCCDEIVwjeiSRJcUmzyfMKKYpRCqHKmAqKCreKXwpTyk3KTIpDym7KAooKCcYJuckuSO1IqIhmCCFHzYe8Bx5G9cZRBjXFlsV4ROJEu0QKQ9rDXYLlAnbBzAGrgReAwgCwgCL/yz+zPyr+6X6qPnR+BP4Ufdx9qH1zPQF9GXz8fKL8k7yHfLr8bzxifFt8UDxKPE/8WrxpvHQ8SDyX/J/8tXyQfPD80v07/SG9QH2d/bv9kj3uPc0+LT4QPm6+Vb6z/pE+6n7EPxv/P38e/3g/UD+lf7i/i3/c/+r/9L/+v8DACUANQATAPf/5/+y/57/nv99/zf/F//M/mn+CP69/V39+vyw/F788vt3+xj7j/r5+Wn56/hi+Nv3TPfN9jr2h/UK9Zv0KPSb8z7zuPIn8sXxc/E28QnxvPBC8Pvvsu927yDv7+6v7o3unO6z7rzucO5O7nXume6R7qbu3O4N70Pvou8b8HXwvPDr8D7xhfHJ8Tzy0vJJ8/7z+/T29fj2FfgR+f75Avv3+xH9Sf5n/7gA/wEoA3EEvQXpBuoHYAmZCskLCw1mDnAPcRCGEYkSdRNfFE0VQxYbFwEY5BimGUIavBowG40b2RscHDocVhxSHBQc5huJGyMbthogGqkZOxm+GC0YnBcPFx8WVhV8FJETsxLgEQERERAQD/8N9AzwCwwLLAo5CUQINgc0BiMFLwQyAzsCTAFmAKv/A/9T/qL99PxL/LH7Eft1+vT5l/kQ+a34afgf+N33dfcm9+b2uPaA9or2ffZx9m72fPaF9or2k/az9tD24PYO9zv3g/el9/X3R/iI+M746fj4+Ev5j/nH+Qf6K/pR+nD6s/rQ+jr7nPvX+xf8W/xk/Hj8efyH/J38p/yy/Pb8IP3z/Ov86/zu/Mv87vzl/ML8jvyb/Hn8O/wx/Ar85vua+3H7avsn+/n69PrU+rP6w/p/+nH6Zfo8+tT5lPlP+dT4jvjx+Mb4wfik+HX4K/j89xb4Nvgr+OH3Avg2+BL46/cf+Er4Kfhu+If4c/jM+Bj5Ivkb+YP5tfm++RL6jPrN+kL7zvtU/Bn8Wfyn/K387fx1/Zv9Bf6X/gL/j/8FAHMAwgAeAYAB4QFUAl0CjALfAhIDdAMQBF4EugQABV0FgAW9BdUFBwZtBqsGwgb2BgkHFAcvB0oHfQejB8IH6AcCCPsHFAhdCFcIIAhPCE4IKgjnB+YH+QfPB8wH3gd6B2sHXAcvBx8H/AbhBiYH3wZWBnIGfwY5Bi0GIwb0BfEFtwW+BakFWgVGBRMFuwTDBJ0EfQSjBEcEKwQkBOYD1QPSA20DPwNYAx8DzQJoAhsCAALiAfIB6AECAsIBegFfAVMB3gBpAE8A4v/h//f/KgDk/2f/Ev++/nj+V/4g/vH9Hv5K/gr+2P3L/T395/yd/Ej8TPxw/FP8G/wG/A/89fu1+4D7ZftW+zr7IPvx+rL6tvqp+qr6wPrx+rr6hfqg+pL6T/r1+fD5HPoy+kj6nPqD+pL6jPqC+oT6gvqS+pz6qfqo+u36IPtA+0v7Z/uH+2/7iPvc+/X7UPxo/IH8qPz1/N38wfzC/FL9gv3E/Rr+S/6V/v/+R/+p/7z/LwBhADQAQwAWAKkA+QBoAZIBugEHAuwBAQJGAj4CNQKSAsgCCgM0AwgDFgMCAxwDCgNFA6YD0gMgBJgDrgPaA4MDeQORA30DkAPaA6ED/gIGA04DvAKHAlYCPQI+AkoC3QIUAyUD4wKZAvAC7gIuA6kDNwNKA3AENAgDDQYLJQduADL+vPvM/H/9MgG+AgoDTQLSAogASv0t9eP3Gv2pAOsAkgohDr4IDgjeBVH+0/6lArwB3v24AToEIv8b/JgAkgZqCY0MaAwmBfMItQl7A5T+Yf6B/V8JNg/rC9QQ0QZR/l38eP1I99j7GAO6CFUFkAUGBTX9E/3x/GAA+AJjAeT8gPkT87/4E/xmAzAFiAkuBpj/ofLX8iL0jve+9mj+zQE1BfwFIgEO/DP7ovUh+n77aP0cAPkBbQB8/LcBlACzAAP+s/p8+lj64/gT+Uv8d/6r/xIC/QBg/JD72PZC9gf2ufha/YP+ZP4L/Yb9uPrj+OH5dfr7+bP/9f4l/sT8G/5e/nH9V/0uAtAA4P6P/5wAT/03/XX/YAErAhYFvgVwAon/FP91AF8BTAKnB8cGJQYYBbgD6wG7ATIDFAMJBY0GYQYbBswBYwLKAZMDmAKzAiQCLwGAARUBLACPALkCUwEaAIMB+wCGAF/9Cf2f+Sb9u/8dANUAPwEd/8X8mfmp+fX4HPpj+jr9CP+y/9H+AP0G+o73Jvh++R/7G/vK/Rv8L/mI+pX69vkF+nH52fn995b4gfj8+Mv4TPpB+gT5bvlh+b33UPiY92v4yfnP+UD54PjL+oD3n/hJ+Zn5Q/gH+b/4ffqI++b69PqY+Fr4PPf1+Gr56fuO+rv7T/tN+qD5G/o1+dj5ovpw+ln8ify4/qP+O/6d+g/6G/uM+7z81/9Z/4v/Gv7J/Tj+ef1j/qH9N/7L/kYBwAFZAMn9RPxX/R/+VwBrADcDDQOs/4D+zv1J/P4AiACUAgcBuAHUAdD/eP9oAKACfQKLAlz/Ev+P/Vf/0gD+AqYDlAS8A+kBxP9yAJL/RwD0A8AESgZmBJIF+APeAEwCwwSdBTQI3giuBocFjwUJBWYECgVLB/AICQicBtIFJgU5AkcEGgUxBlIHygbsBvIDKwRdAyEDYwQNBj8GlQXPA2wDogKIASsCOQLUBJYFrgVsA4MAnAC8/4UCTgPlAiQCigKkA2gCCgO5Aj0D1ALHBIMCMwGHAWICmQICAt8B9QOvAzYD9wIEAjYB+gG6ASkArQC9AgYCHAITAmkA/AEoBFMBJgIe/5v+U/7z/4EBJAE2ApEBNALDAgwBDwBi/3//sP9XAXsCe//Y/7sAVgQHBNYERwJwAZ//+v3BAegAOwCSAEgBuwLPAsUDwQJV/wn+/v7t/jkA+QDRAy8Cx/5H/qL+6v6f/az/Dv/W/v/9vv7i/b77Dfu1+wr9Dv+o/mb95PiS+Zz6F/uI/Sj/jv1U+9/5m/db+Sn6b/56/ab7x/v9+f/5F/xA/x7+O/3j+gX6Wfr3+az6x/sy+4T77PyV/zcAnv3b+z75/vpx+0X+ZP2T+uj5tPsA/Df8vvum+n77ZPuE+2b9Xv1I+gD6EPr8+/r7Bf2y/1793fuI+wT7hfkZ+4D/dABX/av8ifr8+Fb5a/yWAOoBPQEDAYb8WPqt+QL8of4yAJIBIANIBKb/e/+w/x7/iQC7A8kDYAO9BDoFfgQeBMAE2gRtBRAF3AXyBjwGDwZ+By0J0ghtCvwIbgf2B+IHvAc1CLwJ1QmNCtQLYQstC2QKignDCSUKhQsmDEsNXw1HDaYNTA2HC3cLwAsHDYwM3AtnDAULtQtHDVYMgQt+CxYLDws9CrYJvwmuCVsJPQlwCrEJJwiMBywGKgboBZoHBghSB54GpgTjApkDMwP5A/gCZAIPAuUCBAP1AID/Df/w/Lr8Af0B/ST+lv4//wD+9/0O/SP8ffsi+nf3vPcx+Zb6lvx9/fT8l/qM+Xb53fnm+F35Nvka9xT39/cb+t37Ofxg+0j5EPcI9g32Hvat9175L/ql+6/6Jvu9+L/20/Rv9Kb16fWf9Qr32vi7+Dj5jfdN9Qz0e/Js8Z3xXPKJ8v/zdPV59134B/Z09Gvvj+5N7pjwGfKo8/70z/Ql9Ofyr/H77qHwK/Aj74PuUPAx8ijzv/PH867wle487TTsP+7Y8FXzk/Rk9N308vKw8czvqu9P7wPxG/PQ9QD2TfRP9Ov1Lvbz9373bPkX+Qr4rfpl/nH/4QHYBIMEngO4A/IDpwMTBfAIZw6qECkQyBBoDg4NSg4DENcSnhTCFVQXLxZYFr4WhRf2FyMZCho3GmcalhprGjEaMRm5GTAbuRu3G74aLBllF/EV3xZvF2kYSxnCGGkX0hTbEwYUQhMjE1MTPxNXEzASZhF1EJ8OJA7dDVIO4g20DXILlgm0B0AIYQnTCeAJgggtB2EEcQNZAp8DsgTyBA4E7gIVAQIAwv8b/+P+1f6C/nD+1/1Q/Rz8Avta+aj4X/nf+UT6c/n097T29/bB9wD4ufga+Iz3yvYT9oL1ovWc9R72JvYT9qL1HfV19QD1mPQk9b/0KfVN9d30D/XC8yLzxPKG81vzXvOQ82PzK/Nr8pzxwfEx8mPzVPNR8g/xn+9k74fv7u6q7ovuIO8a7wXwve4W7Vfsausi6zDsGuzG7LTtH+4r7kztSO2K60Hq2OhX6d/ptuoL63fr4uvH63LrSuve6ZTprui559zn4OhW6ifsuuwJ7EHqXOcR5qrnHel267Lt0vAq8rfyPvPZ88TxCvS191L7CP8EAN8CkQTnBCkHzAr0C3UOmxFREmoSuhOMFf0YGRoVG24d8h08HtEfSiATIWUhniMhJRMlwyQbJAgkniPnIxYlFCVxJIok/iLIIe8gtSFtIksiPCJmIakffR4YHgIdtRwKHKEckBwbHPQaHxoiGb0X0hYEF+sWMxczF0UV/hPqEekQNxAIEFsPrg77DQAM7Qo5CrwJ3giGBzwG7ASrA50CrwHNAMn/mP7o/Zz8Rvxx+pX52Ph297j2VPat9Qv1AvTU8rDy5fH38VfxSfEG8TvxRvGQ8ZzxffEf8cTwuPAE8VLy+fJ1807zZvIA8jbynPIQ8yX0fPRl9Dj0G/PG8gLyofHv8UPyd/LR8krycvEr8AbvV+/y7vDuB+8v73LuCO1Q69DpQOlU6VjplemL6SDo2uaU5YnlEOaS5qPnrudX54zlv+Oh4aTg/uBb4kPkTuVi5JbjEOEl3qbc8dxY3fTejN+Z34HeZ92M26jbxdyE3efddd3f3Lnbm9ss3B7enuF+5LfnIexb77Tt0O6r8IzzIfeb/X4EsglwCYQMPg1kDxkSzhUGGpMdtyEIJRgmHSWkJ9UnEykoKp0sFC8tMQkwfS6oLtQuYDASMkgy2DE+MLAtJiyKKxgsFS0LLX8r2SnMJ+4lEiViJcAkDSSgI/QhxCHSIF4fNx78HDUcOBzmGzwcxxtNG54Z1hfZFrEXbheeFzQWOBX4E30SahD/DxgQWw8dDuEMFgzHCvUIagZdBJ0CdQJaAdMAFQCV/x/9tvpC+Eb44Pek9uT1VvQZ9A7zofJY8j/zJfO+8vrw2/DQ8JTx7PEn8ofyfPMb9GD0DvW79TX1PfXH9RX3xPho+u367vo3+qX55fm4+aT6P/sV+5n7aPs/+5v6Mvr5+OL3kvZw9Q/1E/Uq9Mfz4fL78Vjwe+/J7RbtduvQ6afoCeiS51vmO+Vh5DTj7uI54gfi+ODy3sfdqtxx3FrdPN6n3ePbxNlG2ZTYhNhO2IzXqdUk1GHT5NOw1R3Xq9bw1F3SQtA00AfR19GI1PvSBdIqz7LQlNUY4YTnrOys7njwYvAt8ArxIvrsAMQG4g5IFAoZUB0/HWUe2B8EIWolWisTLtsyaTPEMUIyDDQtNkg5uDn8Nxs39DRAMw404TXVN784izZjNbsyri9ILQArtCmzKQgpYCrdKvMo3CXOIXYf6R1THlwf1B83Hysd9RqaGmMbZBwZHIcbfxkxGG4WWhXVFNYVVBUfFkgVjxSFE/UPNwxKCScIFgilCAIJoQhLBiYDAf/r/Dz75Pre+cr45fc29hL1lPOU8hvyLfHs75zvAPB774PvT++T7g/wk/Bl8hrzWvOQ8xP09vN39F32tfjJ+rb7PfzN/CP9L/1u/fP+j//xALEBqQG5AdEBiwGRAbwAAAEtAVwASP+6/WP82/te+sX60vpq+4P5dPex9CvzFvI08XnxovAI8E3v5+2j7JzrGOpZ6ObmgOad5uXlM+X44yniQ+AC3+/dUt3q3N3bK9vp2IvXDtdw1mXV+tM90pLRDtCRzkjO2s3uzPLLtcsKyzbKyciWyLjGG8fMxUbGfMX+yGnHzsu1z8jc4+jm7+by6PQm8irvxfQv+YgJPRapH2EiNSVpJPAnEiiGKbQutzKJM6Y2kzeaPRc9eDrpOME8HT3ePfw5pTfjNa4ypzG8NJo2jDitNwkywixfKbYlSiQMJJIkwCWIJF0i9iAsID4dFxxFGQIaKBuVGoEZaBlZGBMYDRmNGcsb2xvCGKoVPhMXEZoRchIIE9ESHxKZDzANvwlpCJAFeQOTAW8BPgEkAHf9f/sX+Zz2FvVI9Pfzs/OV8UTvnu1W7cHsaO277dfu7O7d7Qztd+067jTwk/Hn8q/1Ofcb+QP6o/pf+6D8Cv14/nAA/gJeBI0ELAUuBrEGZQaSBiwHZwcUBn8FQQWfBTIFrARnA/4CYgLpAAUA6f6r/ZX8PftP+jP68/kA+SX4APZt9fzzbfOV8pLyrPEQ8efvQe+67ovuu+0q7Trr5+mp6e7neufL5mzlXuPl4eHfqt7p3Kraedkp2OLV0NRk1GHTg9Fqz0PNjcukyZrIqMdKxirHjMWuxPXCoMFbwIfAkb62voe8Obtdum+8vr50zyzgFe6x9ev7hPnH77roR+7f/LsK2xvkJz4vITHhMF8wXzLKL6Yz6zTDN0s56TyJPXxANz8jQXdC80JDPkE5ZjKuLPQqVSyPM803kjmAN4gwPyg2JOkf5x7jHR4ezB5bH7AdXBxBG/EZtRg4GO0XZRoWGeYWAxQtFGwV4xgmG88dTx7eG04WyRG4DhcPYg/3Dk4Q2hAqESYORQpMBuEDxAC1/kz+Qv0T/Cr5wfZ19Zz1zvTz8/Pxfe+x7Bvq9OiU6cHr7+yC7g7vXu+N7k7tBe3Y7fDvEPLu9cf40fo6+7P8cv2B/2YAMAIOA7IECgWXBj8HSAn4CvILSgzHDHYL0Al1CDMIfAhlCU0KkQpbCnQILQZEBKYC+gGYAXQAsf/f/k3++fwo/Ff7cfqM+Y/4Cfdv9sv0lPTr88D0ePWJ9hP2PfWk82DxDPAF73vvePC68FHwFfDk7WLs4+nd5wTmwuSr4yPjpOHc3wXef9yq2ULYI9eM1v7UAdNy0HDP/M1IzTXMSMzSzGDL28nZxzPGD8VUxBLDWcTfwbfBtr+6vvu868uo2Xzw5vyCBMsAKPgo6X3qzfJMAZkX/yX7KfAvcjCZMNsuHSpXLRMwJTD/L9wzTjT2Nn0zOzYzPFJBxT4oOsEvWCeDIX0fvSPpLCAzczUBMt0sWChJIm4bCBeeF+cYiRoAGi4blRueGsoYUBqJG6EdKRuIFm8SPxAED5sRORW0GcwcaBwyGcsVwRATDOsH4wYrCC8KvAqjCWAIEQZuA4UA4v8q/5r8bfnH9W3zI/Lf8RjycPOS9CL0zfJQ8Jbt/ep06WDoNOpf7Mvum/DX8TjyT/IT8mjz1PTP9Qj3N/gw+bz6d/wp/kwBZQMjBSAGfQb7BVUFAgW7BWoHNQi2CSEKaQoxCnoJDAmhCEAIjgepBs8F1QTSA+oCfAKTAscCjQLWAYcAeP4K/Iv6zfmX+Qj6Cfq7+Xf5VfjB92j2mvUQ9aH0v/Nm8/LyW/Kd8eHwVvCo8Cjw/e+R71fu7exL6/Lpqukz6X/oDOjq56bnHOd35oTmM+WB5L/i+eFj4cXhwOEc4ujhPuLj4W/hBuFL4QTh1uCn4Njgz+CU4NDfed9Y3jbedt2q3UndSt9u4gPqxe869dP5c/tf+ZL4cvnE+qD+EAP1BpEKJw1ID0IRyhL8E1AVWRbLFtAXohjSGOIXehg+GqYbJR5JIRQjLyPEIhsi/iECIoMhlyFxIhQjYiMfJIwkpiNFI1gi1iE9IcogtB9yHv8cQBwMHCIcTBx8HEwcLxtmGlwZXRjqFjgV3hNqEpURsBDND3cORw0TDB0LfApACeUHWwaqBBIDpgG5AOb/I/8a/uP9QP22/PL7/Pq0+bj4u/ch95n23/V79b30Q/QV9CL0//PO85bzTvM38yPzRPN286Lz2vNh9Pf0lvUW9rP2Jvd+95j3//eF+E35BPq7+mn7U/z7/KD9BP6G/g7/dP/V/4UAJAGdAesBFQJcAtICJANWA9MDFQQYBBAE8AOYA2YDJAPpAr4CuwKXAlkC/wGBASUBvwBjAPT/h//a/mX+zv0+/bb8LPzR+x37lfoZ+pL56fhC+Lr3HPeR9v/1dfWu9OLzE/N98szxWvHf8EDwlu/67kruvu0L7Z3sE+ye6wzrf+rk6VTpvehD6NjnnedR5+LmSOaf5czkP+TN42LjAePV4qDiaOK54s3jzeVB6Izqs+x67sjuqe7C7gbw6PF49Nf3/PpB/fn+WwBDAYgCAAXJB8UKwQ3gD4ARthGfEXMSPxRmFtoZNB3WHxohqyF1IWMhxyHnIl4kySWtJs4m3iV/JEwjeCKFIvsikyMMJN4jjyInIY4f5h3yHJEcGByBG5saDxk7FzoVlxNKEqUR+BBGEBoPgQ1vCzUJSwemBZAEmQPVAr0BmwAa/6z9YPyA+xf7mfou+pb5mPhf9xT2+vRF9NTzsfO1863zdvMT86jyPPIf8jvyc/LI8gLzLfNb83rzwvMd9Jz0JPW/9V32//a190P40vhm+cj5O/q9+lX72fts/Ab9hP3y/UH+rf74/lv/wf9SANUATgG6AQICKAI9AlgChwKfAr8C1ALPAsUCoQJ/AkYCJgIPAvIBsgFrARMBkgAWAKv/Zv8e/+P+kv5F/rX9Kf2o/CH8m/s1+7T6MvqV+fz4Wfi59wz3cfbT9Sf1e/TR8yfzjfL48YDx/fB18NfvR++x7gLufO0B7YfsKeyx60PrzOpM6rPpQunS6IvoOujF53PnBeef5lPmRebL5sfnZem46zvtwe5H8ITwL/Au8Vry4/MO9p34qPpW/EP9bf7A/1gBhwNFBs4I4gpSDE8Nsw3eDVMPJxExE9QVdBgpGhsbyRt8HE4dOB5uH6UguCEMIrchVCGoIM4fxh8nIHsg6iAPIVQgRx8aHiQdTBzhG38bHxtWGgUZghcMFn0UPRNsEswRMhEqELUOHQ0rC24JCgjeBskF0ATJAzgC7gBt/yD+SP2Q/Cz8xvs++4L6svms+Mv3D/eW9j/2APaa9T71yfRU9Dn0HvRM9K302/Tz9Af12vTM9NT08PRL9ej1hPb29mT3yvcA+GD4+fil+UT6zPpD+2X7kPux++/7TPzH/EH9vP0O/j7+YP6B/rv+BP9q/97/QABbAGQAWAAvABcADwAzAG0AhQCTAHIAHgDi/5L/Zf9L/zP/Cv/F/mP+DP6m/Vn9Gv0L/ev8r/xj/Pn7ifsV+7f6Y/ob+rH5R/m4+BH4a/fU9kv20fV/9S/1sPQ99KjzEvON8hzyyvF/8SXxuPBH8M7vZ+8b7/Hu1O6v7nPuO+7p7YntR+0U7fns7Ozc7OLs4Oz27Ajtbu1l7nDvhvDp8RzzufNv9Dv1HfZG94n4Cfqy++f8+v1D/y8APwH3ArUEUAbZB2wJiwo+CwAMDA07DmwP8BCaEuAT4xTtFecWqBdbGHkZXRrwGnYb3RuxG5YbehtnG2AbZxt9G4obMxusGioapBntGHQYMhiVF+UWKhYiFQUU3RLgEfcQGBBdD5cOlg1+DFYLIQrhCNAH6gbvBfsE/wPuAuQB2ADZ/w7/bv7i/Tr9qvwk/ID74PpD+rT5Nfm1+Cv4wvdo9/v2mPZY9i/2CPYC9gv29/X89QD2B/YT9iz2RfZe9oz2x/b+9k33gPfG9x74aPip+Nf4Cfk7+Xz5v/n++UX6ifrF+v76L/tw+6j74Psj/HL8rPzv/Bf9QP1u/ZT9u/3R/fv9Ev4Z/hz+Bv7z/eP92P3i/c/9qP2I/W/9Uf0s/Qj93PzE/Lr8kvxj/CX80vuY+237N/v/+tL6j/pK+vf5nflK+RP55/jO+Jz4dvg4+Ab4vPdz9yv3Jfcx90X3JPcE9+z2yPa19qP2v/bo9gr3HfcH99r2ofaT9or2mfa79sv20PbT9vH2BPce91P3sfcH+ET4d/jC+AH5WfnE+Xj66fpr+zz85Pxa/Rv+1/5K//v/1gCNAVYCOQMXBBEF0wWYBkwHLwgJCeQJsAp0CyEM3wx0DfINrw6CD+APghBEEZkR4xFVEpoSzhIIE/0SDBMdEzITOBMeE/kS0BKgEj0S8RHBEVcR5RCYECgQqQ8hD48O7A1RDckMPAytC/wKegrrCTgJoAgrCGQHvQYgBoQF6AQYBFYDpwIKAlYBugAoAKD/GP+N/gX+jv0B/YT8BPyS+yT7qvpA+uP5g/k/+Q/50Pin+G34L/jh96L3hPeC91P3Ovch9wP39vbs9vb27Pbv9hH3H/co90z3Zfdk92z3gveW96336/cE+CL4W/iR+NP49fg1+W35e/mj+eH5Kfpc+n76rfrp+g77QPtl+6b74PsD/Cz8TfxQ/FT8UPxZ/Hb8q/zU/Nn85PwM/SL9E/01/VX9V/1Y/Wz9fv1Q/U39Zf2A/Yn9k/3C/bn9uv3I/cP9rv3A/fv95/2v/dn92/2u/c395f3o/RD+Sf4//hr+EP5D/oH+jv5k/iz+B/7g/Tf+Av5C/cX9jv5X/sn9cf0I/on+1f5a//L+J/5A/uj+G//t/rr+AP9P/1P/Jv9B/2H/rf9fAK0AfgCkAMYAwwD7AD0BQAGKAQoCPwJMAnECnQLLAiQDYgN8A0kD6AOwBN0E+wT+BAgFTwWrBaEFVQWBBfYFOgaXBoMGaQahBtMGBgdBB1IHKgcWByAHIAfnBu0G4Qa7BrcGuQbBBqEGgwaRBocGcwZmBgQG2gWpBWkFIQXyBM8EfwQ9BEAE/wOzA1kDKgMRA9cCigIfAskBagEXAb8AZwA7ACAA4P+4/7z/af8Q/+z+u/5s/lr+SP6//Yj9bP09/R/95Py//K/8j/x7/Db8Ivws/A38+PvN+5j7jvuT+337cvuH+1r7RPtj+0j7XPuf+3H7RvtV+0f7J/sf+zj7bft0+4b7uPvX+5r7n/vG+wf8JPwr/Ff8sfyv/Hz8mfzW/NT87PwF/Qn9Zv3O/en93f2v/eb9Xf5h/hz+Nf6F/qz+2P73/g3/Rf9X/2//b/+j/+n/+P/R/wgACgAUAC0ARAB4AJcAxADmAOEAwADXAPQA6gCoALEAJAGEAXcBSwEnAVABjAGSAYwBdgFzAasBvQGoAaUBbQFcAVwBWQFWAYEBZAEgAZcBpgFqAVABKwEtAQYB4QAYAREB+gBBARwBsgB/AMoAuwCcAKwArADCALwAkgB2AIEAdgCeAE0AHwAVAAgA5P/f/wUA8P/7/ykAIAAPABoARgBXABcADQD2/8D/5P/t/zgAHgBsAFIAHgAiAB0ALQAbAE4AggCWAI4AuwCRAK4AdwBRAKkAxQDsAPYA8ADeAPEADAHDANMAvwCwANcA5wDTAPkA8gCuAIoAbQBhAFsAXgAeAGwAogCXAFoA/f/X/6r/nP8EACYAhgB0AIAAgwBBAKEAjwAAAXgBTQGuApsDBwbeCncOcQhIA1YBUP0W+uz58fwb/tgCcga7CLcFi/8sAOABCAJe/YoEuQfVBJcDJQd7AocBhQadA67/bPz9+DH4iffg+3QBUwMTA0gAjf8t/lX+rPua+6D7Avzx/v7/6/9a/0cBpQAI/x388vkh+F35EvrO/AkBqgGQBHcC9P+S+3z8ifqB+4j9JQCcAnoDcAEdAa4A1v4b/wwAiQAAAL8AaQFcAr0DJwYzBPwDUAEtAp//KP4pAeMFNwZlCFMNUgkiA0kDwf7q/VoDVgeqCgwJXAdSBQEE6ADR/03+If99AQoB9gCTADMCiQJ3APr/eP9p+6r2E/aE+Mr6lQBrAvgC3wHu+yj3QPYs9YP3UPqL/EQBwQE9AC7//voA99f5E/mR9oT8wf6k/mj+aP+G/pP8q/ot+Wn4Ufr+++r82P9hAA3/Ev+T/Dn6B/uZ9434l/0fABj9yv4NAKL+iPu/+ZT3PvpM/Ff9bPwa/qD9sPy1+jj5n/lE/A35JvsF/CH6o/rG+7/62/vK/dP4r/jE95n3c/nt+uT74P/B/lf7+Pds+FL4kvh597v7nP7n/cH8/vzy+UD4PflW+jD9a/wS/ZgAf/6z+eb8+fxh+7b7A/2M/RX89f22/yb+Nv3f/br/ov1o/B/9iPyb/Ir9Rf5VAoD/A/9HADD+yvzV/af+E/7e/skA/P/h/qz/2wC//yb+B/2z/6QAowBUANkAUALEAQoCw/9cALsB0wLXATUDbwP7BFwCigL4A/sDwwS0BLsDPgKdAtMDJgSoBdEF0wVSBOsDKAQbAmsC5AOlBGIGoQbUA30D2QMmBJwE+wOqBUcFngSlBFIEsgMhBFkHkgYUA9EDpwM/Az0CNwM8BkEHewWnBYcDtQAAAa8CagJIBHgFmASoBNgC4gItAr8AgQEfA7UDKAQxBHYDJQOZAtwBm/+dAaICXwEfAREDpgIgA78BEwBP/2gAXAL2AXoBVwDrAOkCUgPHAqwAJ/5//eT/mv+8AQoEEwIHAEgAKf7g/WwBpgEQAWQATv8K/2X/xv30/VT/pP8/AzoC2P9c/eL8gfzP/jMDgwLbAE/+r/tV/dX9HQEFA3kB+v/O/sj+uPuh+v388/74Aq8F7QVSAYL9S/u6/EP/DgFiBBgF1wCp/+0ACgJdAOoA4QApAQwClQIJBMUAWP99/7j+fwExBCsErwTlAYYABgG7At0Amv8YAEUAaQIkA7MBcQB7AYP/m/+t/0L/rf8U/4v/HQLZAjsC2P4E/Tb8Hf+4ATgCQgFR/5IAvwB7ABwAt/8lAUYCPAAzAX0AZ/6a/Y3/+ABVAdQBywInAfr+wvvV/Kv+OgChAM4ByQFtASL/SP87/nT9FP+zAAUB3gBZABP/tP6CAAQCSQHK//v9o/4h/6z+Cv4RAf8DiAN5A93/Of2V+yD+QADjAsYEugVCA3P/Rv7o/lr+5//eApkEMANLAqAA9AB0/27+Tv45AE0ATAAHAiEAbP/1/vj/JQC9/3j9+f3c/Tb+ugAPAGj/mgCsARkD5wHL/lf7vvrA+93+oQM6Bd8EIwLt/Vj7kPvl/bX+iwBTAqwBoQA3/yL+Svtb+4P84f57AVQBAv+9/GD72PqA/EIAZgGr/9T88vk5+0/8Gf2N/xoAiP9L/sn7U/qa+8r84f7b/XX+kf9l/wr+bvwr/A78zv2I/00BDQAJ/q/8HfuV+8r+4P+lAPYA6v8t/kj98fup/P79Rf3F/AH/2P7A/rz8+vve/LL8Qv4o/vv8gvwc/EX7i/zU/mX/2P5S/Wb8uPtb/Nr9yf6C/z7/if7B/kj+Uf7m/b38pPyw/ecAxwLXAfMAvv7R/iL+2v6w/lYBtAEDAmAB6gEJAhAC3gCc/9z/mACDAvEC9gL6AbYBsAAeATcCXAIIAj0BzQD0AcMCBAIFA6wDgQSiBeMDawOeA2kCOwJ8A1UFKwYGBQAEhgMTAj0BogKZA7IDCgQGBE4DMQOEA5oDwwNNBNUDYAKCAeYBlgIGAzMEcwTGBVMFWARkApAACAD5AcQDwgTIBJEDRQESAq8BkQFrAhkDdgJzAikCmgFJAvUBXAFgADT/0f80AjwDcQTdA9cCXgJkAVMASAAvAE4A1AL6A2MDtgIiAwkDMgJSAXn/CAB4AGUBnQFUATACPQPfAhUBm/4w/AL9uv5MAH4BmAJPAs8B9wCK/pH+gf5F/6EAiQHwAqYCeQLQAUUAZP56/d/9uf95/wkARAG/AU8CogEkALH+L/0T/W79mv70/pj/lP+w/03/of0I/dr8ifz1/Mn9mP0a/vX9Wf2K+7b6N/ut+zz8/voo+pD6T/pR+7r8Z/1A/Jf6svny+MH5+vnu+Tn5UvkF+sn6IvuZ+rT5oviC+Gb5Zfro+3b56/cq90v42vm4+qT6tvn390j4M/nc+eT64vpv+2H5zfi/+Ib59/nB+Rf6WvpP+zf8tfw7+y75jPjO+Jb5t/ou+wb7cvph+0r7Hfvn+rn7Rvwm/Vj9xv0K/u39SP0I/hz9uf3P/5L/Sv8X/+f/AgCMAGgBQgIOAj4ChgIeAuIBfwK9AtADbgQqBNcEnAXQBMUEfATOBGsFigVlBdwG+QaYB+cHIAe7Bo8GlQYKB6kHYwjYCcQIuQgaCfkJrQndCpQKiApZCj4KmArtC5oLGAxmDDwM3wu5C9EKuQrlCu8KhQu1C4wLtArkCSIJDwmYCTUJKwkDCacIdwgMCA8I+weQB5wGtAWcBDUFPgUnBQ0FYAUkBcQEKgRaA4sCIgISAvQBlwJWApMB3wBYAGD/A/+r/mv+gf6e/hr+yv3d/Wz9D/0y/Lj7vvv7+0f7CPu0+U/5v/jD+Jf4nvhe+PL3Kfdn9r/1N/U99FL0GfSW9Bj1LvWM9NvzWvP38tjy+/LS8sbyT/Lh8eXxOvL48S/yH/Fp8PjwJ/Io85zzNPJp8dXwwPBF8Jzxq/Hm8anxMfH88HvwCfC97yjwI/AN8crxAvIf8QbwYO9178PwW/G98YLxs/B28I3wF/HL8W/yvvLD8gXzN/PX86Pz+/K18eTxjPHU8+f1a/mb+n/85v4cAFP+l/1N/SD/OAImB98JLg1GDoMOpQ4gDhQNuw+cEnMTwRUVF1MZbxqfGpkZfRm7GRcbZxzIHZwdNR90H1kgNSCpIGYgoB8NHu8dxx2GHhYf6h/nHxQfbB2BHCMbLBoPGdMYHRkbGqkZfBjfFiQVGRQFE6ESuhL3E9ATiBNlEecP0Q6BDc0M4guGC58LYwscChkJ9gbnBeMEHASlA10DNwJFAfP/PP5q/Rv8xvun+7n6a/mp+O/3xvc590H2ivUQ9TL0L/QH89byx/IA8/LywfJI8hnycfF+8Ijw/fB98Tzyu/JH8qPxxPCH8B3xi/HW8eby9PJM81vyZfFc8MTviO8M8MnwIPG08d7wHPAS78btWe0a7ezs3uwX7WrtLu2n7IXsF+zh6ojp8OiA6BXoWOiS6JrpvOku6UrpkefG5fnj7uLY4jblQOcj6WDpdOji5afk0uPy4xHk7OXn5V/nOeYE5mHm1+ig6avs6e0M7zjub+838C/2aPmM/UcA6gCKAacCLwKPA1UJ7gxhEeUTghXIFuUWtxO3EywWXRhTHRkfByBNIL4fIh7TH/ofOCH9ImYiuiFGIo0h/iGuI8UjOCXsJIEjiyIsIdMeeR6iHl4gUyNuI9AiUiHSHpAcYht+Gk0c7R2THk0eQx1OG9QZ6hd+FokVphWaFMwVuxR/E34Rew+5DR0NAAyVCmIJ3wflBW0ERQPYAkMCBgKQAO/+E/1r+/X5gfiM95n3t/fa9132fPUq9LHypvHL8Xry7fO18wX0bvOf8jTxe/GK8ebyYvM59Hv0UfUg9Tn13/Ty80v0kvTC9FX1qfWW9Xj1t/RL9Yf1jfWX9fj01fMJ883xuPHA8e7xNvFf8Vvw1+9776DuG+6p7Rbtx+y87MzrwOq96QLptui26GLoJOiY5mnlKORU44TixOKl4iriSOET4SLgf98T38jeJt483ozebt5E3lre3d3U3W/c79wP3IDcMtu23G7dVuDk4bnoqO2F8j71wfRh82j0Nvaf9zsBPQf3EP0TbxRZEksUuBLhFOUXUhtlIHgjNiTjJNIkbyNzJCojaCVeJycpjifAKMEmFyiGJ70nWynbKSco7SabJdckxCWdJK0lkyZHJ0UmJyVvIjAiziBSIPUgaSJcI9wjpCGlH8sfbR6eHtsdVx3THMsb6Bi7GPwWsxb8FcEUMRNWEn0PugxLCvYHGQdOBh8FLgUhBEUBxf7P+5L67Pnv+HX4lvg+92v2hPVo8y/zQPKK8afxTfFI8NPx6/Es8qby6vJJ88Xz0fIC82XzSvPr9IP1gfbF96X45vfq+E/3HvdP9+P3PvhW+ff4SPlT+c/4ffhz+A73s/ZA9e/0mvSG9L/0S/X19Ef0f/MV8tvwg+/I7i7uuO1K7VLttewx7NLqsOni5wbnjuV65eDj1+Mf433iZOJD4vfg6d5M3F3alNiV10vWJNdY2KjZo9lJ2MjW8tNz0kbQsND0zk3RzNA+0jPRINM+0VjVdtl53mbn/+0173jwEvRL8Nj1Z/z/Az0N5BMRFj0ZMxq3GNccBB4OIYAlnydAKlYs2SodKhorRSkILekuji5sLs4shCogK64qRCtyLv8u+iy9K8AoUCeWJpUmcyZeKAgnKyfgJh0lbCMQIhYgBCA8IbMgeSI+Idsf6B6KHkQe0B4aHyMeNx2fGoYYdRZeFSoVrRQnE4IRBRDvDb0LmQeHBG0CrgAvAGD/4f4//fj6W/gm9k31hvSe8yPzvvHX8PTwkPA18Wjx1vB38JPvhO/b76TwwvD88UTyD/Sr9Jj1h/YE94/2Wfed+Jf56vug/AL99fza/Pn8kP01/qz+df+e/iD/VP8y/xn/fP4d/af8M/xq+1T7m/qS+rX57vhA+Ff4Ivhx9/D1sPSg8xXyIfJa8aLwo+/87gztH+yl6mfpH+i55pLkH+Qi4xTiiOC03yfexdyG2rrYhtfc1Q/VBdRM02jSDtKt0eTRvtB70DXPV83GymHLvcq/zAbLSctOzG3QTc5i0mPY6eMg6p7wjfc//EX3KfeP+6n8dQg3EqMaQyHuIv4ivyRfIdchaibWJr0p3SuRLukveS/bK50uLS9sLgwvhi5UK7sqzihzKUksCy5BMJIvfCyrKDAncyTmI2wkWyW9JmsnDCalJGojaSHiH68e6R57HxAgsx6HH00dxRxAHPUbhRuzG5EYKxZHEkYR3g8KD2sOxQ1yDL4JDgcYBPkBl/+D/RH8Ffvc+UT5uvdf9lr0FfMO8j7xAPGn8Nvveu9t7yHwF/F18UfyXPKu8gXyUfMT84/0PvX19gX4Hvmg+Yb6LPsL+3b8vvyo/YP+i/9z//QAXgDaAV4BCgE7AasBCQG9AK4A0gDNAZAArQDU/9X+b/0P/Ej7pPtM+zT7zvqN+uT5BvnB96322/UR9Tr0L/N88kXxM/DM7WPsC+tn6cDnXebx5Kzi/uH831rfNt5J3Yvb39hO10vWl9Uy067SANFY0KbO183izFXNnczfyk7KVsmhyCfHMsYTxL7Fq8ixyorSB9qX5MDw8fa18Sv2ePSg8Q70hf8zCq0ZmxxGImkiGSCWHEAfxR+UI5cnkyjMK/wsNC4RLukt5yywMHEvFSyWKewnIidjKHkqhy+2My0zLi9EKywmaSNLIQAipyM+JqkmASYlJRUk3iHAIJweJh4jHvgdZx3vHEkcHx3DG74cxByrG0wYMxOiD0cObA3GDMQNLg0FDH0JHAYOA57/9vzc+in6hfmj+V/51fdr9un0rPNg8zfyrPFa8dXvA+8q7xXwTfE787PzifSt8wnzuvJE8y30Ifbf99/59fre+xz9dv0S/QT+8/6K/zgAKAGYAToCYQOlA6wE7gQUBX8ESQNfAnUCZQJYA18CPgOxAhwCIgGJAD7/rv5W/Zr89fwy/Gz8SPw0/GL77vri+E74/vac9mX1fvVw9In0f/Of8mHw4+6z7FHrq+kL6cHn/ub+5D7kd+J/4Lvfc96b3ETbyNnH2CvX4dXm1FrU0tTa0oHTftF60PXOZs41zGTObsw4zVfLwcogyeXItdA73inrivC++pH2vfBs6rnutfIlAfMIwRMVF7sa7Rq7GwsYuBgMHKEefyBEIl0m1yjhJRsnpypLLZorkioVJxUjzSAmIYAlEysSMJQx8y8aLC8myyIOHpUdux6VImgjWiRBIj4iISAeHnkdHR3WHMUcuhpmGSgZnBhsGaka2ho6G7AYfBS7DykM2woPC34L3AwADiQMkgkpBeEBFP90/GL7xPvq+x37kPpN+KX3+PZR9tX19/QO9OryIvEO8Mjw7/HS8tbzFPVn9kH1x/RE9DP0ZPUK92X4i/p0+9D7CPyF+zr8Jf2w/Wj+xv8TAJMAXQCIAL4BvgLiAm4ELAShA8cCiAFpAZMB6QFtAoADAwPsAn4BkgDG/0f/V/5T/r/9Tf1A/XD8TvyR+xH7efoD+qn5xfg5+IT3DPdK9w73uvb29dj0FPMb8qnwP/AH76bu6+117UfsWOtH6v/o5ecj5+zlcOUN5JzjBuMv4r3hHuGV4JTf894S3qDd0dx83IDb6tp+2kTZgtgN15HXRdaz12PcWuTl5SLtwfC+8Brw8vBP8tP1Wvlk/e0DfQasCPcMQg1eDTwQDRKEEzwUZhWGGZwZ/hlOHCYfLB/KHyEg6h/2HkIerh8qIewilyRuJlglHiRhInQhXx+/HZMexR7XHV4deB1XHUUcrRv9G3cb3RqaGRMZ2RfhFaEVmxVTFWAVwBTjEzASDBA7DvgMBwuOClsKuQnDCGIHBQbFBDIDrgEgASUAxv4E/sD93vz/+7j7s/vZ+jH6ovk1+c/3J/cq99X2HPeM9+z35veB9wj3OPcV92D3F/jv+GP55fkC+lf6S/qA+r76MfsO/Bn8mPxR/Nn8uPx2/a/9av7M/tH+r/6T/jP+Cv4d/j7++v4F/17/Jf+x/nH+M/6f/Qv+pv3u/T791PxA/CX83vuq+9H7jvvD++H6yfpm+lz68vn9+ZH5a/mn+Gb4vPc095j2Ivaa9fv0SPSh88nyHfL88K3wI/Bk7/nuIu6G7cvsOuxw6+vqbuo26nDp2uiJ6AboVuef5tHlhOVY5MHjAOO74iPhteGd4YjkVuZ46Gjr5Oyx7G/uefCC8IXyDfXD9jH5h/pO/LT+rf92AesD4wW4BlEJlwp0DFUNYQ/pEOwRbxKvFLUVDRZwFxQZmRrRGyMdHx4+HxYfKR9RHyQfmB4SH/QeZx58Hq8dlR0wHdEc4Rw1HWccYxwDHE4baxqlGbsYNRhvF14W/hW5FPgTwxIBEhIRAxDtDgUO3QxHC3YKNAksCOQG2gX/BCUESQO7AggCKAGfAO//Rf93/q/9Af07/J773/qB+t/5fPkv+bf4UPih94P3KPc89xf3I/fv9vD29/ai9oj2c/Zm9pH21PZJ91X3tfet9+33/feO+KP4z/jh+Bv5HvlH+Zj5xfkj+lL6r/q2+vX6/PoW+yH7QPtw+4b7mPt1+3T7TPsW+xH7B/st+zT7Rfs2+0T7Lfv1+r/6jvps+gT6yPky+a/4Kfib9w33n/ZL9tb1TvXW9F703/M4847yDvJi8bzwFvB67/Puau7p7XntIO2Y7B7srutL67LqUOqs6aHpGekF6c7o3+jY6IfpPeqI68jsEu4i73Xw4/Dq8SvzdvS+9ZL3Cfl1+uf7Gv3P/vn/qAF6A2oF5AaKCA0KWguQDNsNVw/ZEAsSbhPNFNQV2hb0F/4YGBrWGu8bPRyGHLYcyRy1HK4cvxy4HL4cahw9HPkbyhtOG1EbBBu6Gk0arhnpGBwYUReUFs0VLRWXFKMTrhKJEZ4Qsg/YDvkNKQ0/DB0L6wnECKwHigazBbQEBgRAA5UCxAEKAVQAwP8x/3f+3P08/Yr83PtH+7b6Wvqt+WT57via+Dr42/d19z33APfi9rj2fvZa9gH25/Xi9ev1D/Y19k32dfaO9oP2vPbj9hD3afei98H38PcN+BP4TPh3+Lv4B/lL+Zf5zfkK+iD6TPqF+pT6yPrb+gn7FfsO+yv7Ivsr+0T7O/st+zf7Jfv9+tH6f/pL+gr6wPli+Qz5ovgv+PL3ivdP9xP3xvZU9vX1ifUD9ZD0LvTG82bz//KV8jXys/Fg8QTxpfBl8Djw/e+/73HvQ+/y7qvuZO5Y7lXuee4N74vv2e948OfwcfHx8aPynPO69I71k/aj92D4Ovk0+l/7evyp/TH/YwCVAcoCBAQ8BXUGrAcUCU8KSAt4DKwNrg7eDxQRQhJnE1kUKRUbFqUWMxfMF0MYrBjyGFsZhhmVGZQZtxm0GaIZmhmAGVAZ/Bi9GEAY1xcuF7MWLhaAFbAU7hMlE0ESZxGmEPgPLA9PDn0NnQyoC7MK3Qn6CBsIOQdoBoIFowTPAxQDTQKSAfEAQgCY/9/+NP6k/Qv9Zfze+0b7tPor+qX5J/m4+E74BfjE93n3NvcA97z2hvZX9jn2KfYY9vz1B/b19Q/2G/ZB9lP2ePaX9rz22PYH9y/3Zfef99D3+fcu+Ff4ivi++Pj4M/l/+db5G/pv+pj6zPrn+gr7IPtE+2T7hvuf+8j70Pvb+9X70vu/+7X7qvuR+2H7M/sC+9L6pfpp+jH6+/nJ+Yj5SPn++Lr4dPgl+OT3n/dI9wH3p/ZY9hb20fWX9Vj1GvXm9Lb0jPRb9Dn0IPT/8+jz0fOz85jzdvN483Hzm/Pg8z30l/Ql9Yn13/U+9qT2LffH93n4UvkQ+sb6mvth/Bj9DP74/gwAEAH6Ae4C4gOjBJ0FiwaUB5AImAmCCoALTQwlDRMO4A6yD5sQTxH5EX0S5RJcE68TBBRiFJIUxBTnFOEU6hTOFMUUoxSCFGQUKhTWE3wTFxOyEj4SxBFSEc8QRxC6DzMPiQ7yDWUNvAwqDHULvwoLCjwJiwjaBwoHXwabBdMELgSCA9kCRgKyARkBeQDT/zj/of7//XX98fxl/Or7Zvve+nf6//mj+Uv5+/iw+GH4F/jr96j3Y/dN9xD37vbO9tb21Pbk9tv26Pb69gv3Gfc891f3eveT97b32vf39y74Vfh7+LP48/g1+WT5pfnI+fr5JPpL+nb6pPrK+vj6EftC+0b7V/ta+177b/uD+4j7ovup+7D7qPuj+6j7svuX+4j7ZvtP+zP7D/vm+tf6tfqn+pD6gPpe+j36Gfrn+cn5lflz+Tn5Cvnt+OH4w/jT+Lb4mPh1+GH4Wvg3+E/4RPhG+D34MPgY+CT4MPhG+Ff4mvjI+Ab5W/ms+f/5KPqD+sz6SvvV+0/80/xE/av9Rv6p/nL/6//KAEwB7gGaAjMDzwN6BAQFvQVkBusGoAcMCNoIIgkYCksKMguFCy8MpQzzDGkNsg2yDSIOPA7IDt8OKw9SD00PeQ9AD6YPWw+ZDx8PMA/2DtoOkQ5HDvANsA1aDRQNvwxpDLILUQukCncK8wmjCf4IpgjUB1gHqwZCBm0F+AQTBPUDMQPDAhECQQGYABwAfv9n/1b+9P2S/f4A+P9I/j77nPrI+cL6/vmU+nv5fPnr+Rv5YPh/+DD4mfhw+Af4Sfdf90D3s/eX93X3Qvfz9lT3vPey9yD41vcL+CL42vdL+Gz4ufgR+QL55vhD+YP5cfnj+RL6b/o0+1v7gvt3+9z75vvS++v75ftk/HT8svzN/Mj8+fwS/Vn9Wf2o/cz91/0F/qH9pv3K/dj9mP3z/cz9kf2q/b79m/2c/Xf9nf1r/Vj9R/1T/V79FP0d/bT8n/xG/Pf8qfzf/GX8yfzQ/Lb8ovxU/ND8gvy6/HD8evwW/cH8+vwi/WX9Uv2k/bL96/2M/nX+gv4t/wz/RP+a/xgAAwAZAKIAFgE8AbUBwgHZAngCHgOlAhIDbQO5A1sEIAQBBQYFbwXXBY0FsAU9BsQGrwbGBlsHkAf5B74HCAh2CHAIvwiWCIYIrgjWCKwI9wi+CAQJywi3CGEI4whnCIsIRQgBCP4HvweVB0AHZwfQBgcHcwZ3BcEFpgVxBcQEwQTwA28EJAQhA/sCGQMpAlEC6wGRATQBRwFKACH/tP/B/2r/9P6Z/gj+yP5x/qD9W/1a/fz89Py5/J/7o/wo/QH7W/vk+6D7G/vS+gr7xfrx+i/7sfpq+xP6zfqu+/L6JvrC+5H7r/po+QP7kvtc/FL8/fqe+5D8cvx/+xH8Df17+1v8kf0O/A79K/64/M79x/xf/Hf/Ev95/In+Vf6D/j7+GP6J/gwAn/7o/hf/lf68/kP/dP4HADUAx/4x/vL+X//LAIj+Ev4UAZP+uP+CAJD9b/71/8z96/71/bP/Zf8e/a/90/4y/uz+r/4Q/hD+Hv4T/gUAvP48/Nv98wGl/bP81/xi//MAW/+U+ar/SgGB/ir/hP4H/g7/z/+xAJEAj//Z/oz/DgC9/w0BkAAW/SwAYgRP/6wADwAqAF8DPQKi/8kC0AIEAEYA9APrAkkDPQEqAQQFqwOa/vMDegMBAiUEwgJbAYUE8AS4Ay8Hof7c+9MKXAdj/m0CwwJnAzUJNwNXAUICzgD7AdIG3wRO+6IGzQWu/tQCJAPwAdQDS/47As0EMAFe/0oB5AN0Bsr+Ov+T/ggEKP0K/u8AfgGZ/8sAqQFC/QL8XgDhAg/9FP1b/DX/2AB++wP+Uf8o/nX9uf31+UD8i/1S/7L9Vvts/rT+Yfzg/+/++/v4+Nf5gvum/hoG/fqQ97j+Hvxu+uYAl/aH/swDRvpGA2IEWPdy9jkK2AKp9NH4DfsNCPYB3wR//uf4LP+PAxwDe/nK+5f/Hf7d/c8Fz/6K/qoDfPpN/6cCMPvP/un+ev+2/SD/PgUd/zkCof1n9AwCnP8PAPv8jvxwBc4Cx/qtAlkCw/t8Bvv8Pvqf/HcERQAkAc//PP6DAlMCTQAQ/kz8iv26+8X/IAWrA4j40ASEA2P8Hv6Z/EP79QIZBM3+4v4IAcECFf93/Rz+Yv34BfECT/ruAvYByP+9BnMBHv3j/WoCOwI0/8j8Sv+DCB0H/ACp+MIBgwMW/+L/SgPK/aYHfwfc+oP7ogWBB6YAGgBVAWYEawEPAqADrf6o/j8IOAsg+ZH+yAAf+b8A+QSfBxoGCQEn+lMG8Qd28In5IAZaCdQCtwH7+zP/HwE6+0oC7wT/+vb+xwGJ/G39VAPq/978UALQ/38AygI39yP4iQXI+Wz7AgVmBPr7Nv6//nP+kvxd/JwCJv2l/HAAd/+E+8/+J/+C/C7+8fur+i0HDQKP+n36NPeGAOgDlAGA/EH/iwBn/jgBm/329kr/cgBW/6j+k/8rBOECGf+f+Xb+owIO/MEC3AP9+3X6zwLBAdIG6QMR+Jb/4P4V/oQCJv5YAKT/Gv8yB+UFFPsLAG4Glf7K9vgBzP/+/LIDbAflAJP+UPn0AbsDOv8s/RUDiwKL/33+RP9zAWICYwOx+vn7kf6xBegCgP3s/G4ALwPtAcH+4f+o/ZT7hvyX/wQFHQlR/6/3ufxR/BYGvQN0/5n+T/4z/LX9uQRnA5X/ZwG//gUDrAGu/9b77vjRA/YIKghV/PQCjADz9Fz8CgD3CNQJy/6P/ygAcAHcAdT+pP4p/5cFCwX3BdsAE/1Y+eYANQY1AksG4AVt/KL52v7sBcECbwR1AiEBaANx/Rn8+wAl//7/CQX5ABkC+QENBxz6TPt6AH0DEAbq/QP+gwO5/mv8tgCoAeD6bvsq//4CSv6TAM/+mPu5AwcAgf10/jr7XfuS/nT9e/4TAIkA0v3pABT90/rM+YL6k/sz/pcAAgCq/hn/ov05+sX5IwBQ/T/75fo7/cP/rP/wAgn9Of5SAHD7ePyv/z/8dgDyAoT9EQCzBfQCav1z/rz8lvz8AcUDY//zALMEcALG/OL+Nf/b/KP9ZgAoAq8G6AOw/Nj8lv1m/BIAMAPDBPb+Pf03+/b5MAKCBjgEtwC0+dL+DwL2AaP6Df6X/j0GbQlZAIn9PPfX9iEALAXUAfUCOwJp/5z+8Pt3/UoBN/94ArgDjv01/48CcPx8AQUCLPwRA8AHW/z5+7/9n/qK/xcFEgUDAsICvf7q+mT7Qf+x/f0AXQczBlUAoQLjAIn7g/89Avz//QOdArEBPgG5/sH73f/fCnUFhQLm/tAAhv8xAVQDWwCdASUB1wHpBfsBRv/p/FEAIwKZBCQFkgHt/Hn6NP4YAH4CmgehBmL/yfyD/+z+hP6jAAcBPAXdA8L/Wv+V/Tr/awQMArwAZADx/JcBIQCs+7L8VQLdACkCpf8H/fz+/f8F/UT5/vzD/psCPwX3/9b6tvuX/MP9GP+1/jX89v00A0P+cv3a/Sf6K/ou/Sv8d/+BAjoAKQFrBMn7YfyVAIwBU/yy/R/+9gB8BKsDTwIo+7//PwCu/Tb9Ov11/ZT+Pf5vBE8FrwZrAqL7PPtW/B39TQKBBcUHDAR9BEsBW/ty/gr/6f0yANUDIwOzAt8AoQHm/gf6wP2YAcgBXgBYAc8Agv8D/VMBrAMVAkgANv8V/Mz5qP3UBBUDbwIj/aj/D/8WAOcDAv+0/cL8yQCBATIBrAET/3f/VQIe/jsBTgMa/3v6wvtRAecCigMEBH0B9P63/bH7Zvu7/gwELgAt/3T/ogFfAdAE/ADf/tgC/QDTAH0ALP4y/aEB9Qb6BDsD/gEhBDsA5vxZ+k4BBAH3A/oE6QJ3AWIBpgAX/wD+hvyG/jUGCgSQAVYBf/+k/R78HQBJAcQAHwGlAe8B9wCc/Cf/eP5L/C76JADtAWAAOwLf/Gb6uvvs/h4EcALy/rr2YPnS+83+9gKtAMj+Z/vB/mMAj/8P/0v0jfYu+FL/hwZhBAMB6fwI+kv5YPzQAuL9ZvzI+jr4O/6PAYoEiQOe/ov6rvj1+Qn80P0R/2f/JP1Y/9H/AAEp/on6BPgf+93/NQMr/scB/wFO/pn/NQDR/ooABAIE/NX7w/19AxsFtgVqAOP8Uv7S+xT7Tf7G/+cB2QNHBcL/ZfsL+pv8d/w7/6QBrAVkBcgD2/tr+KT5kPs+BJQGUgJPAOz+rf7F/fcBEf7N/Hz/AQCsAAwAtv///fn7zf2A/d7/UgSfAV3+tf1w+JP71AA/AaIAiQCl/DT8OP58AL4ArwAhAJz8y/qB+of9S/+X/ZkDdQSdAev/0f5R+4v6wPvA/HcCewRQBNoETAGj/H38wv7z/s3/o/4cAAUBywHXBMwE9QLwAUgCtP9L/9v+oP7oAVIDjgRaCbMGZgMjAdn/5v2u/Q4BXAS/BG0FywLv/ioAdwDMAXQBMgBn/rL/w//pAJsANQGqAukCqwN9Aa79rvzG/BD+aAAuAq8FYQUeAnIA3v2l/KL9Lf9UAIIE0AXZA7sCLAJX/lX/sf/G/7wC/wKzAe0DWQLYAl8CUAGjAsEDZgKXAfH/wf+5ANUBKAWfBZ0EGQQsAtcAXf1C/Kn+YwB+A9AGqQeNBYwCGADT/XP9If4MAZoCbQK3BFUF+gVkBccAhP1d/ur/4gIbBt0FDATvAvL/jf8GA+kE6QVLA7YBhgD1/g8C6QQbBicEtAJ3Ai0C2gDV/4b+sf7QAc4EhQYGBwADoQD5/fX75vwVAJEBVAJUAnUCQgIIBLIBsv6D/Nj6jvwLAGYBrgFbAVcASf8tANL+sP6g/gH9T/sJ+2X8QwAOAnAA1ACz/xv98fyJ/Ln8Zfs++p785P4DAR0DqQOJ/m/5Zvju+Yf9ZP8TAYv/qf06/n7+7v7t/uf9Jf1i/Sz8V/y7/UT9Jv07/Rr82/y8/53/Gf6r/vX7lvm2+RP7mP1T/lr93v1N/oX8lvwa/of8gvqC+Fn6ufoi/Ub/iv77/Ff7nfrK+kD79Pvu/G78evwC/Oj9Cv49/M76GfrH+wn9hP9J/6z9n/6f/3b+bv4//mb9rP2z/bj+pv7A/y8BaQETAYkAhf8r/13/Gf4v/iT/MgFTAt8CtAK5AUoAKv8p/p3/WADyAM0B8gIRA8sCLQRRAnEAtP9E/04ATAGMAvgDJgXqBCwEnAKIAUMAgQCuAl0DpwO0BG8FBQURBIMDWwPzA2IEpARHBYoEEASJBDsERgX8BfIHcggNCB8G9wPZAyQEYwW1BQwHiAh6CIUHggYRBTUDiwPoA9YExwU/BtgFHgUlBIgDigLiAvkCtwImA4kCAgJMArUC2AKJAnEBGACj/9D+Av6Q/tL/zv9kABUAO/7b/XX94fwt/Sv84vxO/g4AAP7J+wj6ivmg+4L8cPy5+8n7mvtA+/P6lvov+Tz4J/lj+Yv6+/wN/Uf77vgW9ir1zfUU93/50fkx+MX3Wfee92r5gPqy+aL3g/V89Lr1FvU09Rz2n/dl+HD4QfcI8+/y+PNN9TP2wvYK9yv3F/ec9rH0RPIL8T3yofRL9+X3Y/bv8xHz7vGx8UDyUvMR9OXybfGp8OHvNPIQ90D9oQJdBBQCv/3x+N/2uPohAa0G8gz1EDIRMxHpD6sOmg1fDAQO+xJWF9saBB2JHZgbKRlpGPcYHxvAHf4eLh6eHKEanRk/GsIamRrKGhUaThfSFFQSBxDJDtoNfw2TDTQNPAz6CbQGFQOy///+6P9TAHkAU/+y/Dn6Kfhn98L3jPe99+f4+fhU+fz5qPlU+af4g/iS+TT7Cf01/28AgABVAIAAWgERAxgFUwaDBjQGVwY2BwYIeAmMClwK1AlNCTwJeAl/CTMJzQj3CJ4IVAj0B44GxQTxAuIBlQExAbABZQFhANP+v/wo+xT60/gH+Mv3p/d79wj3HvYZ9bXzfvIJ8oHyIvM89Ev1GfVM9CrzRfIF8rjyUfTa9R33MPiF+DX4tffZ9jv2svaS9474YvlJ+mb6Bvrj+Mn3BfcP99L3O/hw+BL4Affi9Rf1A/S888PzZfP38uHxmvAC8Gjvu+567n3tr+tv6gnpHOj457PnWefa5tvlTOXv5Avkr+NF4kjgjd7c3NnbYtt829vbT97M5IfvRPu5AWr/PfaZ6JDfsuHw73oDmxRyHsYcBhfBEPgNOg5OEdgUCBkkIL0nZy5QNMkyVivlIwwhOSJkKHAwgDRKM9Qtgif7JBMnQykOKn4ohSPoHO0Y/ReQF54XjxZuE+oRGREiDzsMfQdcAPr5XPfw91v7tv9GAX/+wvnv8wDv1ey+7DjuVvB08u/zvvUM91z2bPQa8tDvje+X8Wf27Pqz/Qf+ev0z/cP9jP+qATAD7gMyBLUEOwaECHUK7wsGDVIN5w04Dt0NKA1uDF0LXAvXDNEOuxCjEUwQ7w2NCjkHIwW3BHsF3gbWBygIaAeBBUEDZQC+/Tr8Y/u9+/38y/34/UP9k/uy+aX4WPiD+Fv4V/hs+Fr4S/i1+OL49/gJ+RL5ofka+nb6yPow+2n7ofsw/Pz8R/1u/X39Qf32/DX99/2N/hr/+P5f/tz94vzq+yz7WPrw+V75fvmN+RL5cPgm97n1FPRy8lLx3vA18R/x9/Ak8EruFuwU6vzoaugN6DTo/uc45zzmDuX047niBeJ+4aDgMuCL3+7enN573Yvca9vH2hfasdkD2gXa+NiS1p/SF8+9zEDTtuGL9V0HAA+CCSX4M+MN1j7dMPBpB9kc2yfxKAAmyiFlH7MfBh18GV8awyDHLHs7sUTARRA9FDFyKPUpKDKiOww+VDr8MY0p2yamKbstJS+hLBsmhx+xGl0X2BQTES0LAAf5BbgIVAwxDVUIAP/K86rrQOl+7MHyXfcj+UL3iPNl76vspOtz63Lreewg70Tyz/TZ9oX3e/e79wn4X/qI/Wr/dwCpAE4AmgDbATwECwhRC7AMhQ2zDRYNLAzOCngJBAnrCSYM7Q7qEKgQFA6sCtEHSAYjBjoH1AcrB98FnQSnA0oDTgJpASAAj/7G/QT+cP6U/tz90vzr+/P7pfx1/Zf+ev5E/QP8S/sz+1L81f1U/6gAgQG5AeABogE2ARkBZAGuAU8CWQOCBIkFzQVzBZMEXgOKAoYC2QJYA+oD6AP1Ai8CQwHnAMgAfADH/5b+YP0j/Fn7F/sI+8r6hvpU+pb52/jo9xb3JvYK9fbzIvOt8mryq/I+8xTz+fEK8NntGewN6yXrxOsz7B3sxusN6wTqjOg15/jlH+Xj5HTks+MC4x7iaeEJ4bLg/99y32LeN90s3KbaUdnu19vWtdb41rXXKdgM2DDWUtLDzw3OgNJZ34byywX9EpgR0gRx8Tviyd9t7dICixluK7Mw8y+ILN0qqCqgKSMmByOqIwQqsjUwQ6dJukeqPSgyjiwtLrk12T0iQN457i95JgIjWySOJvwmqCR8H8sZahbWE4cRrQy8BSUAE/1C/N/+egHqAP/6XfOE7FPp9Ola7MPv9fFs8ervU+8r7wHv7u2z7Mfs2O4z8rn2s/pi/NX7pvp6+l786f4+AmAFLwflB0AIzAjRCRELCQzCDZ4OCw8JDx8P5A5iDkANMwzgC1cL4gq9CjQKhQndB9YFoANDATL/+f2N/Xb90fzL+wv6bPiD9mj1u/Qp9KzzcvOo82b0FPWF9fL19PW49RX2Ffeo+EH6vfvp/Lz9qv5i/5AAAQJ/A+EEFgZmBxQItAgRCVYJGgrBCv4LNQ0YDmAOvQ3LDLILvwpKCjIKhgp/ClkKjAl0CCcHcwU0BCcDLwJrAXMAxP+O/pD9nPxg+3b6Jvlp+P/39Pcj+Jf3D/fP9d70HPS48wv0LfRu9GP0SvRH9NLzyPM+8wbz1/J68lTyJ/Lc8aLxPvEA8ZPwIPA671nuW+157HTr8+rC6q3q6urU6jnq6egu51Dli+Ny4jniNuLu4ezgAeCT3svdKd3p3AfdYNyN253aANmf12jVg9NA0bHPfdGK1mHhifAnAhkNexDBC2D98+/v6FHtB/wqDV8dDChQLFwtvS5+MbIyTDLjL2Ys6CrfLHoz9Dl2PUc9CjouNrc1HTiqPKQ/1z1UN8ItZCMjGygYVBj0GgIeVR8RH7wbVRVBDmwGNAAR/Fr5vvdi9s70RfMq8i/ykvF48CbuN+zo6gnrJuw47QXtVOsG6bDnnOgd7Cnxjfa8+kH8K/xJ+2f6mfrj+4/91v9qAjoFUAhhC78Nag8rEN8PGQ+dDqMOLA/AD0kQiRAKEMgOBA5dDQUNBA2cDOoLngpjCPkFPwMuAPb9Fvz0+nH6Q/oI+oT5g/gA9zv1QfN68SnwMu+/7nbuVO6k7vDukO9S8AzxyfG68ubzLPXM9uf3aPi9+Nn4fvnc+kP9VwCDA34GzAiPClYLhwt8C1wLpgtQDIUNFQ+FENMRvhKKE90TnhMhE0MSdBG3EAYQnQ/ZDv4NFQ0lDG8L3wpHCnYJdwgmB0sFWgNAAWv//f3g/C/81PuT+xT7qPrv+Qr5IPjx9jv2dfXD9DP0mvNa803zqfMe9Jn0P/WK9Qj24/WS9Rf1+/M384fyQ/K48lXzP/TE9AX1/vRX9KbzsvLO8c7w0+/+7jju2O2I7Xvtqe1j7Sztd+w56/Hpxui/57HmWeUL5HDi/+Bs4ILgJOEo4sfi5+LI4tvh0eA64FnfKt+33iTeaN3521naYNkP2oLfLuhr9IYCvw3ZEXwPzQfv/CP4Cfg4/UIIFhI2G7giVCf2KwUwZzK5Mj8xCy7tKjUp+SgfK9AtQTDnMRAypDG/MTEyPDNgNJ8z0DCvK88jBhwyFc0QDRBREU0TKBUhFT0TahBUDIEITwRl/236v/Un8nzwRvBq8Q/zH/Re9OTz9PIe8t7xX/FJ8XjwEu9/7Z7svOx77pDxk/Wk+Yr8TP7t/r/+Z/4d/mD+zv54/0IARAFhAkwEfgaXCL4KAgypDGUMeAtHChYJqQe5BiYG3QUhBuIGiQc6CBYIiAd6BpYEkwKcAKr+S/0i/Kn7Zvsa+6T6EvpS+a/4V/gB+LP3LPdI9hj1CvT38rLyrPIl8+vzzvTS9Wf21PYb9y73SPd29/f3g/ho+VL6n/sT/Xb+PQCbAdsCGQTEBMkFiAYtBwIIzghyCSkK3AptCy8M3QyXDWsO+Q5fDzgP8w5DDpEN0AwsDKILJQv+CtMKhQpCCncJeQhBB+AF3AS8A9ECAgI0AVsAmv/g/if+hf3+/Gb8Cfx1++b6Vfp9+cX4OvjU93D3afeE96r3HfiW+Pf48vio+Db4n/eg94/3sfcA9yn2afW99LL05vRU9mn4pfpd+/D6Xfkz98X0G/PK8Tvx//Bj8WnyTfMp9Tj3PviM+ED4kfaM9FDyJPB87cXqg+qX6mbr6+3H8FvzufU/9zH3gvWQ82Xx7+2i62HqB+ot6qzqVey57pPw7/Kr9IH1j/Ux9FfyFvBL7Wzr9+nk6Jrppet+75b1X/x6AycJUgxTDb0LIwmrBr0EMQQnBbwGqgl9DUESoRc0Hf4hZiX/Jl4mdSSzISofdx2KHJwcmR3lHn4gIiJyI8MkSCV9JRgluiPjIf0epBt0GDYVuBKhEPcO/g2rDPsLVAvtCp0K8QnlCD0HvwTfAZH+OftQ+AX2ZvSo89zzr/Qg9o73k/hK+Rb5Yvhc9w323/S78w3zBPOH8470DPaH9/b4Lvo3+8b7V/yT/BT9fv3c/V3+lv7Q/gn/S//f/7oAaAFBAqcC3wIDAw0DIgNYA1UDJQPFAh8CbwHRAHMAOwA+AEQANgAkAND/fP8N/3P+2/06/er8nvxZ/G78GPzZ+3P7tfpK+sX5kPmL+Xn5rfko+pb6Ifuy+zn8p/yd/Gz8Dfyn+3r7ePul+yz8yfyy/Y/+nf+BAIcBhQINA5EDnQNbAzMD4gK3Ah4DjgN/BFsFVwYSB38H3wfyB/8HGgi+B4EHMQe4Bg4GsgVBBfwE/gQDBf8EBQXSBL4EaAQDBKkDRwPQAi0CZgFKAEf/T/52/VP9X/13/cD9xv32/bL9e/1L/cX8Tvy++3L7m/ug+xD8Afwy+9/5Z/iJ98X3qPjI+G/5CvoU+7j8WP05/hT+sP2n/JX6ovjb9c7zCvN49LT0//Ui97b5T/wW/sX+nP5R/Xf6Q/fy80ryPfEE8QLzCPVS9nT3ivgL+db5PPp8+T/5t/nI+ID3evZB9TP0HvOW8jrzB/RZ9OH1U/eB+MT5xvo/+1v7lPoy+VD2ZvPs8EPvW++y8BzymPRI9lr3Tvjx9z737fYo9vD1XPZu91H5I/tb/XP/IwHyAqMEoQacCC4KrgvSDLkNhw72D1oR3BKYFL4VvxbZF2gYIBkEGs8aXxxMHVQeKB/+Hm0eBh17GyEaxBgTGJsXSxciF4IW0BXgFN0TcxL6ECMPJg1cC0UJKgdFBVUDmwEwAB7/XP7D/eb88/uS+jz5RPiS9zv3EvcO9/L2lfZd9uX1ofVl9Wv1pPX39bL2Qfft96T4WPki+sf6i/tN/Ln8FP2H/Y/92f3s/T7+xv56/+7/rgB0AeMBOgJMAj4CHQISAicC7AGyAW4B/QDWAH8AUABRAPn/4f+K/33/Lf/f/rL+gv5d/i3+v/0l/Zz8GfzP+737jvto+yL70vqp+rH6B/uK+0f8ovzi/OH8svxb/Ev8NvwU/Ez8Ufw2/KX84Pxk/UT+Cf8AAOMAeQHiAUUCJQLxAZcBYAFwAZYBpAEIAqcCZgMtBPcEpwVdBooGvwbkBnYGPgbXBYUFFwVbBBAEqgNeA2cDpAPEAxwEaATEBNgEwARNBMMDAwMkAjwBdgDt/53/cP9F/7z+Wv5W/kv+hv7L/h7/L//6/tf92fzJ+yr7TPuU+5z7vPtI+0D7c/vk+zH8I/xG/Lv7ffve+4H7UPvZ+hH7zfqf+iH6//kg+nX63/oO+0X7ffvf/OD7yfq1+FD5C/r2+fj5GvrS+R/5lfiC+J75ZPov+tv5Bfku+Pf3vPfQ94j4U/nW+Pr3H/cA95P2uvVA9jX3hvZf9iX2ffb99i73BPef9hH2YfYt9lH1bvVj9QP1R/Xh9OD0gfXs9aP2y/az9sr2LfaX9SD1xvSn9FT0ufT99U33z/ne/HYAQgRsByYK6QvSDBINQQ02DS0NQw1cDXgNDw4GD8YQ8xI0FfIXURocHF4dth22HSodQBxbGzwaRxlEGG0XDxbrFJ8TeRLdEW4RWhEyEXYQ0Q+zDt4NmwxaC7MJyweZBSYD3ACf/v78x/uQ+hX6u/mY+W35IfkL+Q/57/jt+AP5Gfk6+T/5EPmU+EP4Ifjr9933/Pf/91j4wfiA+eH6Hvyt/QH/JAAEAWIBcgEpAYwAEQCN/x3/Bf/1/iT/Z//b/1QA2gCZARYCWwI6AgcCzAGDAfcAWQDg/z7/nP7f/S79gvw0/Bz8KvxZ/Iv80fy2/BP9Sf1v/Wf9Q/0J/bf8KPyn+zT7BfvJ+rz6uPoW+2L7qfvj+xf8QvzP/Fj96P1y/t3+Jf86///+4f6a/qT+lP6x/pb+8P5x/yoA9gD+AfwCjgMQBHsE4gQHBTIFPgVtBXEFpQXuBfsFDQZMBkoGXQZIBjUGMwYyBg4GDQY4BjkGUQY0Bp0FFQUpBIMDBwOzAm0CNwJDAi8CEgLWAVQBmAC2/33/D//a/j7+Iv4O/sD9sf28/Xb9FP29/HX8gfyS/Kf8qfxl/Dr8cvyB/Hv8pfyp/Kb8qfyw/Gn8Vvwn/Lr82vwd/Qv9FP1O/ZT9ZP36/ID8yvtY+9/69vpG+5X7Nvul+v75lPnm+fX5QvpA+sz5xPmt+b35Bvoa+u344fZA9ST06/Pf8oDzY/QT9kP3O/dk97n2ifUc9VX1j/U79fL1/fVG9mz18/Tm8ynzEfTH9ED0XvMA86fyq/KB8sLzT/XM9Qv2jPYQ9lv1o/WO9av1e/Vx9Zr1nfWq9Rv3L/jC+Qj8b/5OARQEbQflCpUNtQ+uEcoSIxMzE00TZROuE9ITbhTxFJkVshblF9sY/RnCGk0b9RspHHYcbxzDGygbWxrqGEcXXRU+E0kRKw8lDXMLxgnYCBoIrgd1B9cGIQZEBSoEAgPUAX4APf/I/UP87PqD+ZH43fdH9wr3y/b39in3jff096z4l/lk+i771/ti/Hv8avxy/FD8IvxM/IH8/vxU/Qr+r/5E/+f/mABdAR0C1QJ7A88D8AP/A+YDrwNhAxIDpwITApkBEQGDAAUAlf9M/xj/9P7R/p3+XP7s/ZL9Mf3Q/KD8YPzz+5L7NfvQ+oH6GvrN+Zf5Xvk7+R35Hfkv+W/53vlX+vv6afvJ+yD8Z/yY/ML8Ef03/XH9uP37/Uj+bf6e/un+Pv+x/1AA6gCVATQCtwIgA2oDtQP1A0IEngTKBP8E+gT1BPYE/gQdBVcFlAW6BegFOgZxBscG8QYDBwQHFwcaB+kGwAaHBkkG9gWrBVQFGwXhBLEEaQQmBL0DjQNyAzwDIwMMA+YCxgKcAn4CLgLOAWIBzgBMALn/Sv/K/lX+O/40/gr+9P39/Qj+JP4c/hz+Cf4x/gz+2/1s/fT8mfxB/Oz7gPtD+w372foe+wH73PrR+uP66vom++H6yPrF+m/6JvrM+V75Bfmo+Kv4ofi3+H/4T/go+PL31ven91r38Pbp9nr2AvaJ9Tr10/Rd9Pvz5/Or81PzLPP08qDyS/I48iHyCPLc8QbyGfII8sHxdfFw8TLxEvH68OTwnfBw8GTw9u9v70/vEe/97jvvre9J8NbwN/HV8U3ymfIl8030mPVZ9wX6Hf1xAMUD9QblCd8LlQ0YD6IQQhLgE8MVRhdhGD8Z9xk3GoIa0hpNG6sbLBzCHIcdGx6SHvce5h5oHoIdNxyjGp4YsxbKFBkTTRG2D+IN6AvpCeEHDgZ4BBEDLwJhAcsAJACG/67+tP2s/Jr7qPq7+QT5ifgN+Nr3tve+97P3uPfY9wf4afjo+M/50foI/Hb9xP72/9sAfQH5AUcClALhAjMDfwPIAwMEFgQtBBwEHwQHBCIESARwBLUE2AT7BAIF3QShBBEEYAOQApgBoQCp/9H+Cf42/Xj8s/vp+if6cfnb+G34Pvg0+F34ifjC+Nj45/jf+Nb4xfiq+Lr4vfjz+B75WPmV+dT5JPqC+ur6gPso/Oz80/3A/sD/sgCCAUQCxQI7A2kDmwPIA/UDNgRsBKoE3QT9BBsFKAUzBTwFUQV8BZ4F2AXqBdMFpwVeBRwF0QSEBDQE+gO3A5wDjAOoAwMEgwQbBaMFDwZLBlUGaQZ5BsYG3gYxB1gHbAdLB/cGiAb3BXsFFwXLBJEEdQRqBG4EVAQ7BA8E4wO5A24DOAPWAoACOwL3AZkBNQHEAEkAvP8h/6f+Nf75/dn9xv2t/X/9T/0H/cT8evxt/Ev8N/w0/O770vuV+1b7Dvux+mL6F/rK+Zv5X/k5+fr4wviL+Fj4LPgJ+Ob3sfd991j3Kvfv9rT2YfYL9pz1JPWx9En05fOB8ynzwfJ58grywPFr8TPxC/Ho8NLwtPBx8APwnO857+Duve6T7nruTu7x7ajtQ+3R7IHsK+z465frZus36xPr4urb6sDqgOoa6hTq3uny6RHqsepA60Dsyu0P8IfzkvdT/GQBqAU6CZcMbg8YEg0VORgkG2UdCR/7H/8fqB9hH18fhh/HH30gSyGkISIigiKlIqcihiJhIuEhFyEvIP0eQB0iG5MYphUQEn4O7wqcB7gEJwIjAB/+Pfyv+lD5VPig92n3n/fV90P4jvjB+I/4PPjx9533V/dK91n3ffes9x34p/hr+Tj6Qvt1/O39rv+rAeMD3QW0BxQJMgr0CpILAgxeDFYMRQzBCxYLHwoICe8HyQbnBSYFiQQdBJcDNgOpAicCkwHnACoAXf+P/qn9s/yZ+0r6wfg094P1BfSv8r/xEvG68JrwrvDV8D3xxfGY8qbz6/RL9p731Pj3+d36uPtl/Pf8cf3V/Vb+0f5l////hwAjAbIBaQJBA0EEcQWKBrYHqQh1CQEKYwqbCqgKlQpZCvsJVQmvCMcH5wb4BQgFJgRYA6gCMgLJAZUBYgFBASkBDwH9APEA8ADqAAYBBQECAcwArgCfAMMAIwGuAU0C6wJvAxUEsgR1BUMGKgffB4wIHgl2Ca4J3QntCeAJuAlfCQQJfAj5B3IH+wZ+BvcFegXvBHMEGATMA5IDRgMAA4ICEQJ3AQ8BgADp/1P/qv74/TL9b/yx+//6X/rX+WD5Afmt+Hv4Qvg9+Bn4+/f99+b38Pf69xD4Fvgb+AT42ffF96b3l/eH93L3Ufce9+z2vvac9oL2aPZP9hn23fWA9Rf1svQf9KfzEPOG8uvxQ/HY8ELwze9h7+nub+4C7rbtbu1O7UHtK+0y7f7s6+zI7IDsQuwJ7MbriusZ68PqR+qY6eTohugO6IjnIufN5mjmOeYv5krmoeat5pPnqOjB6sLtGvI99w/8zQDhBAMIsguGD7oUhBnKHfwgqyKxI8AjdiQlJZsl+iXiJZQlCCWCJKEkNSQeJIsjVCMvIz4jvSPRI10jQSJvIDceiBsmGdIWcBSzEVsOjQphBnoCEv9j/FP6ZPjH9lL1NfSZ84jz5vM19LX0WfUf9lr3fPjN+V36r/qu+p/63voq+9f7gPwM/ZH9Av6U/j3/UgDZAaQDpQWDB04JxQr1CwsN9A20Dv0OCg/RDkgOfw1kDM8K7AjEBskE1wJhAeD/kf4v/dj7tfqo+R/5lPhS+B347Pe/92r3B/dv9qX18fQs9Irz5fJo8vDxePEM8bjwgfCd8BzxEPJJ8870cfYQ+MX5ivt0/Uv/GwHTAloEpQXXBroHbAisCLUIeghNCAEIzAejB2gHEwfIBooGcwZbBpAGzwYSB2QHgwekB1cHGwfBBjoGjgW3BLUDewIbAb3/Ov69/Eb7CvoM+Uj4rPdJ9x33DPcq95r3Yfhk+QD7sfyv/ocAawIOBL4FgActCesKZAyDDRYOOQ5JDj8OUw5SDg4Oog3jDHIM7At3C/QKhQokCqUJbwk1CQMJlggRCFQHjgawBR4FaAS1A5cCTAHf/zn+2PyZ+6D6q/mq+OH37fY19q71hPVx9YP1pPXG9e71Nva09gv3Vfdw95H3pvfJ9yX4afiU+HH4Ofgj+Bz4cPi0+Bv5P/lj+T/5QPk7+Uz5Mvke+cr4a/jt90/3h/bP9e/08/Pd8ujx4/Db7/buCO447Vnst+ss6+3qweqz6o3qfep36rnq6+o161brZete6zXrJ+sU6+Dqhuog6uHpmelN6ULpIun36PzoR+m/6SLqs+pq6/zrq+xw7Qjv4PCa8433RPyNANMEQwi2C5sOXBNbGI4dZSEWJJYlWiZbJ54ouCnJKfAoHyghJ/IlHiUdJNki5SBvH3MeGh4JHhUe0x2vHBobqxmWGHgXjhaEFcQTLREIDr8KhAdGBLUBVf/5/B76sPeg9Tb0QPPU8o/ybfKW8q3zSfUA94f4tPmp+pL74vy0/mkAsQFoAp4CnAJhArkCFQOJA8gDKwRoBJgE3wSCBU0GJgf0B+YImQlFCukKnQviC4UL3wr+CTwJVwinB2IGiQQ+Atj/tv3l+3H6OPnX93L2GPUU9GjzCPPp8g3zM/OK8wf0rvRP9cf1PvZy9rj29/Zr9/X3YPiR+Ib4ePiA+N74pfmR+nj7S/wZ/Qv+Nf+LAAoChgPmBDIGaQdjCC4J2glACn0KewpuCgwKmAnrCDQIRgcsBhsFLwRoA70CHwJ8AcYADACP/zX/Ff/+/tL+lv42/uf9kP1U/Qr9tvxM/ML7Sfvm+m/6FvrE+av5j/mj+eb5Rvrn+tP78fxW/gIA+gEmBDIGTQgVCs8LOQ28Dj8QjxFgEpYSQRKAEVUQVQ9ODjwN5As/CnIIngbHBFQDEAIFAQIAP/+h/iT+vP2H/Uz9Ev3V/Lr8sPyx/IX8LPyJ+5X6mPnK+Db4x/c+95v20/UC9Xf0VvSO9AX1n/U89tn2lveM+KT5zfra+978rf10/gP/dP+5/5D/RP+3/v/9Xv2//P37EPvr+af4Yfdl9r71R/XN9Br0ifPX8mbyCvIQ8vPxwPFs8QjxfPAF8IbvPO+67gHuKO2O7Pvrq+u062Dr+uqI6knqPeqo6kLrGOyd7O/s/uxZ7bvtSe4e77Tvsu+g703vSO8a70TvCO+u7j3uA+5I7ubuAfDo8d30qviz/NwAZwRpBzcLIhCiFfUaoR/iInIk8iVaJ0spWirTKh8qECltJ+kljyT8Isggpx7fHFwbZBoAGs8ZKhkYGBsXSBbJFacVpRV0FQ8UJRKrDz0NfQr4B9sFdwOPAGD9OPo89+70XvNQ8mrxk/BT8MLwu/ES84X09vUz9//4Nvu3/dD/hgHTAncD/AOCBBEFkwXQBRcGCQaxBRcFnwR8BKcEJwXDBUAGmgYFB5IHPgjhCG8Juwn7Cf4J6QmUCcUImwccBl0EkgKyAPP+GP00+0H5PvdO9bvzmfL68cPxyfHM8c7x4vE98gPz+fMm9Rn21PZ49+73ffjo+FX5lvm/+cf56vkm+m36wvoa+3f7BvzN/OT9Ov+lAB0CfQO+BAYGTAemCOEJ+wrKCwYMAAynCzILmgoCChsJDwisBnAFKQTtAtsByQDW/wf/Z/77/bL9iP1f/V/9Wv1p/bL93P0K/vH92f2m/Vv9Gv38/AP9CP0Q/QP9P/2Z/Uj+h/8aAboCQQSzBRMHiAgpCuILgA3MDpEPCBApEPMPlA80D1cOPA0ZDMcKQgl8BwoGbgTpAloBQgBt/8n+Nv7V/T79tvwn/Ef8cvyx/LT8kfwR/Gf7zfp7+vf5Xvm9+AL4JPdf9sv1YfX09KD0fPSr9AD1e/Ux9vD2lfdR+BX5Afr4+uP7uPxM/Xz9Xv1S/f/8uPxH/L378fra+cP4xffU9vH1G/Vv9LDzL/O18m/yS/L18cfxjvFh8WLxY/GA8WPxL/HC8DPwpe8k79vuqu5O7uPtVu3c7FfsXOyU7PLsVe2w7dXtFe5k7vTufu8a8IXwGfFy8bbx0fHj8c3xovGd8anxn/Fc8SbxCvHb8JjxE/O79Uv5Av2UAGgDTwZmCTwOrxP6GHsdiiCPIvojsyWuJ/soiin+KAMoeSbgJG4jvyHPH5cdthsaGhIZfxjxF04XaBaUFc4UVRRAFDsUGxRGE6IRhQ8jDdAKtAi4Bn8ExAHH/qn7//jO9k71I/QY82ryQvLD8tvzQfW09jD4m/le+5L96v8UAtAD8QTEBS4GfQbEBvQGAgf9BroGNQaDBcoETAQqBIAEAAV6BbQFDwZ+BjoH9QeOCOEI+QgLCe8Isgj1B7IG/AQhAzkBgP/T/Sb8KvpE+GD20vSV88DySfIX8iHyfPID85rzSvQG9f716Pbn9834jfkb+lP6gvp5+nf6WvpK+mH6gPq8+gr7S/uf+yv8Cf05/oH/wQAdAnwD1AQeBjYHEgi1CEkJtQkACvgJegnECJ0HlwaDBXgEZANQAiwBJgBA/5H+Gv7J/Zj9qP3b/RX+df7Y/lT/oP/Y/wIAOQB5ALwA9wD+AMYARQAUAEAAuQBIAd8BQAJ4AhsD9wMfBQ8GSQeOCGUJLQrOCnsL0Qv4CwoM9AunC+0KNApwCSYI4AaTBaMEZQNvApUB0ADZ/xD/e/4N/r39uv3N/bL9Y/0c/dT8h/zr+5T7N/uk+tX5F/lX+Hb3nvYD9pP1Q/Xw9N305PQB9Tv1qPVR9tv2k/df+CL5lvke+m36sfqt+oj6YvoN+pH59fha+IL3gvax9Rb1uvRV9Bn07PPB86Hzs/P182n0u/Qj9Vj1h/Wr9bf1svV09Sn1u/RC9MrzQPO48hbykPH08JvwWvAy8D7wdvDW8DzxkPHz8Z/yYfMx9Oz0svUD9iL2HPYM9s31YvUX9Wn0v/Pu8oHyC/KD8UHxTfHO8abytfMX9XD2V/ix+lb+8QGNBRcJ6QucDlcRZBSUF/IZ5xsSHbcdzR3HHe0d/h2dHRwdWxyBG7UaMhrMGUAZ1BhmGGoYPRgKGPgXgBfCFsEV0hTAE0oSyxAPD0IN8gqqCEkG9wPtAScAx/5S/f/7+foQ+rL5wvlC+ur6Y/sQ/L78k/1n/jn/BwBsALQA+AAxAYABogHAAZ8BXgFQAWQBswEPAqUCMAO1AyUEzQRtBTYG1wZ+B9wH8gfdB6YHQweUBtQF8QT4A7YCcgEpAOj+uv2c/Jn7rfrf+X/5JfkD+d/4y/jN+NP4Gfls+a/52Pnd+dr5tvmd+Y75cvlU+S/5/fgB+QX5Rfl5+dT5Rvrb+qT7bvxK/TD+Dv/q/6AAaAEaArACJgN+A6MDoQOSA1wDNAPwAscCaAIbAr4BhQFlAV8BVQFRAVQBZwF/AbYB5AEAAhQCCwIXAvEB6AHIAaQBbgEMAdgAswCoAKcAyAD1ADsBcwEEAp8CVAMZBMwEhQUFBtEGdgf9BykIMwgsCOEHcQcpB3wGuAWJBMkD1QIQAhwBjADX/0j/r/5z/jH+F/4M/hL+8/25/aL9k/1q/SL91/yC/Ar8a/sW+5/6JfqP+SD5vfhz+Dn4MvhE+E74cPh4+Kr44vgU+X/5tfny+d758vnw+QX6Gfoc+vr5zPlo+Ub5H/kS+cj4qfh/+FT4Ofgg+CD4O/gt+Df4Qfgw+CT4Kfhn+EL4Ovgr+Fv4Kvg3+Ev4fviO+Ln4yfj5+O349vgu+WX5rfnu+Q36H/pN+mj6v/q/+uv6F/tB+4L7s/sK/Cz8dPyb/I/8ufy7/BL9Pf2G/ZL9Sf0R/Un9sf0z/n7+vv6p/mv+Rv5G/sr+wv7e/oL+bf5C/hj+L/7X/W39Vf2d/Sz+vP6z/1kA3wCcAd0CCwWkBkwIfAmQCnELdAwkDjkP5g/5D/sPqg9eD3cPtA8yD4oOrw1DDaUMcgxkDHkMAAySC1oLWwt8C5MLxQtoC5sK8AmOCR4JmgjpB2cHEwbtBOgDVwPVAkYC4gFPAckAawB1AIcAlQC7AAgBTQF0AdkBSgJhAl0CSgJRAj8CJAIFAroBVAHFAIAAVgARAPr//v8NAOL/2v/t/9j/zf/Y/yYANQAWAPn/qf9V/xL/v/6W/hL+ov1V/QH9ufxj/Df8Dvzq+wb8Vvyo/O78Qf19/bz93P03/ob+0/7v/vL+w/5t/jD+/f3A/Zn9S/0Y/dL8jvyU/K383vz9/C79eP3b/Uz+uP74/jX/Ov9r/53/vf/y/8b/l/9P/xn//v7Z/ur+1/7x/uH+8/4k/0T/iv/U/xkAdgCWAPUABwEgAUEBNwFEASIB+QAoAdEA2AB6AE4AJgDs/zcAGQA/ACkALgA/AEYATgBpAFoAWgA3ADgAGwAGAMj/ov9f/1j/HP8g/wT/A//Z/p/+t/55/vX+L/9r/4b/cv+Q/4P/mv8KAOD/2v+Y/23/SP/v/jf/2P63/k7+Fv4O/s39u/1T/Vz9A/1o/W39PP1V/Qv9w/0x/YL9MP0Y/Wv9CP3H/Wb9Qv2O/Q/9o/1A/Yj9fP3p/IT9gP3M/bz9iv2X/QT+bP69/sj+2P6o/qL+uP4i//n+Rv88/+b+Kv8O/+v/SP90/wr//f5W/9r+CP+N/uP97v2W/cf9rv2m/WH+3P0X/j/+jf4P/xf/a/9z/2z/+v/2/70A9//+/7P/Sf9+AAkANQDX/tP+qv6J/kv/Nf8R/8P+6f7Y/jj/eP+uAML/DQDl/7UA+QDyAGYBFwHNAAwBmADFAFgA6v/c/5n+d/7M/YL+ef5D/l/+if7T/pb/cgCPAaQBGwL/AUICjgKDAuoCnAFZASMABgAaAOj+2f7a/ZD91f26/QX/rP7w/lL/rv8kAacBkAI5AqYCAQOVA8kD0AO1A7gDNANVA/ICBgPgAksCLgI/Af0B7gEdAgwC1gHmAfMB5QFoAoQCvgKWAkACsALEAuoCVwPwAvsCjgLcAvoCZQLGAloCTgKVAYoB1AHWAZ8BgAGTAZsB4AEWAn0CMAJqAqsC2wIdA8ICIwOvAqACcQKQAocC+wFFAUYB+ADmANEAXgByAJX/KAAWABcAbADo/xkA1v8XAL0AUADNAPn/VQBlAFsAvgCy////p/87ADIA+v/4/z3/Gv/T/kr/Wv8Q/8j+YP6w/o7+tv4Q/3b+uP6C/qD/vv/q//L/mf+q/47/wf+1/6b+g/6e/fz9Hf41/if+o/0c/iH+pf4D/wb/7f4+/yf/m/8d/7D/xP9f/4n/ev/C/6j/y/+O/x3/I//u/g3/6/6o/vP9pv0P/pz9rv2B/Y/9N/2+/S7+i/6t/g3/mv9F/4P/n/8QAM//0P8r/9/+wP4X/ln+Y/40/gz+vv0q/iv+z/78/sb+1f7Y/sP/NQCjAIAALwDFAIIAugDjAFIAkP/C/iX/gP5D/r39Tf0A/af8SP31/Cv95fzM/WP+p/59/xEAYwDNAPAAjAEMAVcB1AB9APv/hf/T/lP+EP6v/W/9e/2q/Y79NP6B/pH+wf5C/xAAlQDVAL4A4gDhAPQADgFjAe0AVwBKAF4A4//e/8X/Qf8N/9n+cf8H/w//jf4x/zv/i/8c/7T/IABEAPsAHQF2AVYBsAErAgkC8AFXASYBwABgAGwA8v9s/4j+5P6U/vr+GP96/iP/Uf+/AL0AKAGPAUYBpAHLAToCBgLZAWgBDQG1AM8AeQAZAJb/Bv9f/1r/Xv+a/6//9f/N/5AA4QD9AUcBxQE+Ac8B5gGDAYEBxQASAecA0wATALT/pP/e/2YAJQApAMz/hAB+ADgBAAH1ADABOAEgAusBGQIRApABogH+AQQCxQFJAe8AjgC+AIcA0P8F/xb/6P4E/8v+g/4q/0H/9v/e/5EA5QAFAb0B3gEMAuwBiQGYAQkBAwFiAJj//v7O/sT+1v7u/on9Lf4J/r7+7f5e/7z/qv88AOIA5wAsAV0BNAFDATgBfAEvAdUAEQALAM//N/8q/07+Q/6B/fL9yf1i/dD9Yf63/i//rf+2//z/rwCcAUcBwgGJAaEBlQFDASsBjwCMAMD/ef+Y/zX/tf5d/mX+k/7l/kj/RP8m/5T/OwDn/5EAmgA0AbUAeQAfAHn/w//Z/tn+r/54/iX+Kv6k/rT+Lf8dAVgAsACZAZoCNwPgARAC+gAWArIBnQBq/7n9ef2l/Dz93fwq/P77BPyS/K398/6V/yD/RgDFABoD7gJdA74CoAIoA6UCdQKqAcD/O/9//v79h/2W/Jn8j/tR/LL8XP2l/Xj9Qv5t/xoBTAGPAaUB7AE0AksC3AI/AWEBdgC0AAAAvf9l/5b++v68/jz/Yf/1/vP+lv+rAFwAgwBCAAUB0QAaAeMAtQBbAA4AOgA9AOf/u/97//r+R//O/8UA9/8dAMT/0QDnAAoBpAAKAFwAPAAkABwADADk/5b/of/r/y4AiwD8/x8A2f8oAe4AcQD+/3wAtACZAE8AgP9L/zz/Tf+a/uv+of7b/lH+if4i/4T/wv+i/7X/TwDqAL0AuwAkAM8AxwBkAYQAWQCiAG8AYgAvAP3/GABw/7b/lv/7/ygAmv+p/3v/JwBIAJcAFQC4/6D/iP8GABT/SP9a/wP/zP4S/1v/ff9Z/2z/Mv+3//7/0v9f/2L/Zf+0/9b/OADE/0MAhQD6/7UAUwGfAeYAOwEGAfoAHgHPAB0A8//G/0j/rv5a/uP+tP5R/z/+mf7i/qz/yP/x/w4AUgCyABcB9wCyACcBFwH1ANEAnwBNAPb/m/9b/33/n/85/5X+8f6D/wQAq/+2/7f/LQBDAMcAxQBUAMQAywDAABsAWAAJAN3/Jf8c/9b+Kf5t/Yz9aP1X/hf/Cf9g/3YA6AGwApQDmAONA8kD0ANuAzwCsQFnAAX/Ef5j/ZX8Y/ww/NT7APz+/C/9tf1C/w8AFQG3AWsCygImA0EDgQKQAiwCagEbAMP/7P66/WH9R/2I/C/89fzz/DH9i/3a/hEA7QBjAR8CNQOmA/QDAgQNBH4DMgPOAt4BCgHv/wv/a/7P/Wf9Iv0Q/ZX8pvzy/S/+Rf7Q/hkAkQArARwC6AG4AeYBKwKdAV0BVwBo/8T+Hv7l/Xz9Jf2U/H78bv3x/Yr++v5B/xkAnwB0Ap0ChgJvAjYCNQITAjICLwGGAGj/Xf8+/zr+2v2I/X792v1c/l//ZP9gAMcArQGrAiEDXgO3AmsCMAIHApYA5f4W/nb99vzI/GD8pvv++w39Mf46/7b/VgH4AREDfgPZAwgElgPDApgCbwJjAbX/zv5v/bH9jP1r/Zv8UvwF/bX9Y/6U/ur/4ABjAUQCuAJ9A4QDCQPFAoUCUQI5AfT/1v4W/t392vzo+4b7ffzo/OP9pP25/dH+SACLAZ8BQAKbAiUCswGcAZkBEgHc/9n+xv06/sP9cv2G/F38+Pzz/cz+G//8/58ANgHuAYYCTQMLBIUDvgIaAuAB9ACd/1D/Qv53/QD9Uvx6/Jv8Of1A/Z79xv4KALkAQQG1AS8CdAKnAnACxgKRAqQBHAEQAPr/w/9q/zX+wv25/Qz+1v3l/ab+Dv81/3X/RgC/AK0BvQFzAVQBiQHeAbgBLAF6AE8AAADF/xn///7a/r/+EP7H/kn/sP8h/1r/gf/L/7UA6wDBACoAegCSAJsALwBUAIYAlADi/8n/MwCRAMX/0v/E/+b/9P/r//f/zf/t/8//u/9a/6H/x//P/7D+sv4c/5f/Ev/J/jb/Lv+t/0MAXQB/AMoA6wAhAQsBpgH9ANsAGgBAAEQAHgA5/2T+Pv4y/mn+Sv6u/sD+QP99/wcAZQAMAToBXwFmAY4BugGaARYBqgCXAEwAzP8T/z3///7l/qH+lP6k/hz/cv+6/+D/LgAyAKIA8wAPAWMBeQEqAd4AGgHwAJkANwDr/4z/Uv+m/xX//P70/gH/Vf+y/5r/4v9aANEAsQCeAQ8CfgHgAGEBKwGdAIwAAAA0/6D+nP6a/qb+vv6s/ib/sP/p/78AKAFnAT8BxAEKArUBKwHGAGcAOQDG/+/++v7D/p/+Vv6U/j7++f2V/gr/+f6d/0EAMgDc/7sAXwGJAS0B4ADoAIAAlABEAOL/j/8z/3b/s//K/4n/uf/i/7//IQDHAHEABwDJ/00ASwA+ABIA4P/l/0P/Vv+s/zb/tv7P/gL/oP6U/hn//f7P/vT+t//x/wkAEQChAOUANAEtAQoB3ACQAOUAvQAlAIn/cv9R/0r/I/96/yz/Hv/4/mX/t/+v/9T/4P8aAAgAigDs/8X/xP/7/1QABACn/xD/Pf8o/0L/Ev8v/2D/o//a/ykAvADUANAACgE7AT8B/QBwANH/Lv9s/y//zP6i/qb+ef6b/iX/hP/E/04AdQD6AEABtAHSAGIANwAiAG4A2P8+/1j+hP6l/n/+C//b/vX+Q//I/1cAqgAWAakA1gAqAYUBwAGDAQQBhgCvADoAvP9t/zv/vf5p/nn+S/7G/vT+Mv9Z/xcAhgC5AP8A7gDsACgBSQHTAHwAFACf/zb/7v5n/g3+//0E/hf+Uf4//o/+Ov/j/2YAygBaAasBnQHKAWcB9wCRAGYAu/81/7T+ZP7k/f79R/5q/nX+jv7Z/rL/YQCBAMQA+AD0APYALgENAW4ASQAuAMH/of+J/5H/W/9Z/63/HwBMADIAQgC0APoA2ADEAJwAfwBqAEAA4v+S/2v/bP98/2L/Yv+l/+P/w//h/34A7wDKANoAEAEcAfEA6gCEACQAJwAbABUA5f/c/xMAQgAoAHMA2AA9AXcBjQGnAaABkAFwAVYBMAEBAbUASgDl/6f/f/9d/1//K/8t/1T/c/+A/63/xv/X/+z/OQCKAF4ABgC1/5//zf/w/8f/e/95/4z/t//5/wQAJQBVAGUAoADfAAcBqABmAFAAPABVAEoA9/+7/5H/df+B/6z/zf/n/xcAXgCRALEAugCpAJgAsgDEAJ0AWAALAK7/aP8e/97+5v7W/pv+rP7j/s3+qf63/un+QP+g/9D/0P/F/9P/+/8UAAwA9P/u/9X/hP9M/0j/M////gT/M/+c/63/tf/V/wAAEAA6AG0AkQCGAGwAQwAPANX/sf+Z/2n/Ov8T/wX/3/6p/oj+n/67/sj+6P4z/yr/HP8P/1z/mv/B//T/GAAIAOP/1f8PAAUA/v8QABEA8f/i/+3/8v/0////AAAfADoASgBnAF0APgAbADEAMgAWAPT/1/+X/3r/X/8y/0T/Tv9B/0D/Sf9B/zn/I/87/1H/b/9K/1L/U/9r/3r/if+N/3//lP+6/9L/yf++/7P/vf+6/7j/0P/Z/7j/nP+P/57/i/9z/4z/sP+h/47/mf+X/5j/nP+g/7P/lf9o/0r/Sv8q//3+9v7r/t7+3f4H/zz/SP9Z/5T/5/8OADsAhAC3AL0AywDzAAsBAQH1AA0BIgERAf0ACQEEAQgBNgGEAaYB2QEEAj4ClALiAiwDZQOYA6QDtQPfA+4D4gO5A4gDZQMqA/8CywKYAmECPwI2AjQCKAIZAi0CPQJaAmECewKNAogCcwJqAlcCJgIBAtQBtAGOAVYBJQEAAdEAqQCVAIIAZABHAEAAPgAoABwADwAFAPn/6f/d/87/sf+K/3b/e/9X/07/P/9N/zv/Lf8m/yX/H/8X/xH/G/8F/97+u/6g/m3+NP75/br9bP0f/eH8rPyD/FP8QPwz/CX8FvwU/CH8KPww/EP8RvxC/A/8/vvl+8P7kfti+zz7CfvU+rX6n/qY+pX6rfrf+hT7Rvt++7j75fsY/Dn8W/xz/Hn8e/xo/Eb8IPz/++r72PvJ+7r7pPuM+237Y/t3+437pvun+6r7mvuA+3D7bfty+1b7L/sj+xr7A/v++gr7K/sv+zz7ePuQ+6T7mvuW+4v7Y/tN+1T7Rvsv+7z6o/qv+gn8Ov4PATgDOgREBb8GUwjlClIOFhFnER8RPhGrEZsRoxEKEpoRSRATD5UO8A1IDHkLMQsLC6sKwwoxC9UK/gmeCW4JxgjqB6AHfgexBtkE6AI9AdD/wP54/oj+FP4H/Sv8D/x7/Dv9Tf6F/3YACwGOASwCrAL/Aj0DgAOjA38DRQPwAlACrAEiAewAHgFtAd8BKQIzAgEC6gE2Ap8C5AIHA+wCZgJ1ATMAP/+C/un9N/2b/Nb70Pqb+R75G/lM+Vb5m/kP+nz6vPoY+5T7+PtO/Or8m/0E/vf91v25/YH9fv3X/Tn+T/5g/qD+5v4E/0H/5P+2ADIBggHVAfMBvQGAAX0BdwE4AcgARwCv/+j+P/7E/XL9N/0M/ef8rPyL/H/8nfzY/A79Uf2X/c391f3A/c795/3n/Qb+NP5H/iz+C/5A/o7+zP4Z/5L//P9pAMgANAF9Ab8BCQJ4ArkC2gLWAp4CUQIQAvAB4AG0AXUBRwEXAcsAhABdAFkAcACFAIkApwCgAJQAjAC2APsAGQEoAVwBbAFsAVQBSwFFAUABdQGFAYQBhgF+AXoBlAGzAd8BJgJTAlECSQJaAj0C9gHkAeoBxQFxATEB8gClAGAAGwD6/9b/uf+r/4z/Zf84/yL/Hf8V/yD/Mf8l/+z+yv7K/sb+rf6N/m3+QP4B/sj9q/2c/Y39Zv1H/T/9Nv0u/Rr9FP0b/Rn9/fzg/NH8tPx3/DT89fvd+5X7N/v8+sT6ZPr6+Zz5a/ky+RP59vjD+IH4NPjz97v3jfeA91H3DffV9r/2sfac9pT2ofa89tb2/vYf92H3kfei98j3CPhW+H/4svjm+AT5JPkl+Tb5bPmY+bT5x/nU+cj5nvms+dz57PkD+gP6/Pnh+d75HPo4+kT6TfoG+rn5hflP+RP5yfjo+Gf45vf/99z6nv49AjIG8gi9CdsKbA72E2MY9RuJHXccWRpVGdkatxvwGjMZ5xdYFTQSkBB3EKMPEw7VDUQOSA1ADG4MzAwxDN0K6gkcCcwHowbjBR0E1QBX/cD7QPvT+s/6IPun+in5sfgv+qD80P7aAAgDEQQFBGgEygU6B90HLQhuCNUHrwYBBuYFkAXlBIEE6wRqBa8F5QUWBskFVQV1BR4GRAboBQ4F/gNaAk0Aq/6F/Xv8V/tZ+kj5tfcI9nP11PWt9mT3BPib+PD4XflE+mn7Tvzu/Fv9xf3a/ev93v20/XH9cf2u/Sr+mP4L/0v/iP/O/0AAAwEcAiwDrwOrA0oD3QKEAjsCGwLWAeEAqv9L/lP9kvzy+4L7PvsZ+9f6w/rx+ij7a/u8+zf8rfwP/WD9o/26/XX9Uf0+/TD9Pv19/Zr9e/1N/Xf93v14/kL/EwDLAFQBqwH3AVgCpALeAvIC3wKMAh4CigHKAD0Auf8y/9X+iP5f/iH+6v3Z/ef99P0+/oT+rf7D/rr+1f6a/kP+Sf5E/vP9vf2c/YL9JP37/D/9gv3K/S3+r/4a/1b/pv8oAJkA7wBYAasBqwGNAV4BGAG1AHoAXQAwAAIAyP+O/0f/Gf8b/0n/fv+q/+X/MwBeAFMAXgCfAKYAuwADAUQBIQHIAKwA0AC4ANQAWQHLAWgBTgGgARACGAJsAg8DMgPHAtcCGwM4A7ACcQJ4AnAC8AGuAa0BXQGiAHEAswDYAKIApgDCAIQAGAD4/y8AMADl/+v//P+L/9T+iv6n/mT+Gv4f/jL+vf0p/UL9sP28/a/91P0u/ub9sP3z/ST+4f2l/bz9vv1V/fn8xfxU/ND7hfue+6D7XPsx+zT7Hfvy+hD7d/u2+5b7ivuy+3b7G/vx+vL6sfph+jX6D/q5+S756Piv+Fr4LPgm+DX4Ffjj9+D3yPe29973PPiB+JD4jPiW+IL4a/iF+Af5YPl1+WX5cvlk+Vz5mvkK+kX6XPo0+kP6Yvp2+oT6vfr4+hj7IvtP+2H7X/uA+9v7D/wg/FT8e/xw/JL85vxC/Yr96v2H/rv+CP+j/20AIgGpAVYCEAN2A3oEsAZ7CVULzwxZDtAOVQ/iEAYUmxXpFcsV+RSRE/gS2hIUE4ERmA87DhENLwt8CboImwiYB+YGLQe2BqYFXwWxBZoFFQUNBScF4wQ+BLEDHQMIAiABSAEeAhICegFUAZEBYAG5ATcDsQRjBaIFOAatBrcGBwd7B8AHPQdsBu0FGwUdBGwD4gIKAuAAMAD7/4v/If+//nX+K/7X/fL9WP5V/uj9Uv37/Hv8//vR+777Zfvf+p76avpL+o36FfvX+2/80fx8/Rv+wv6B/zoAtADgANIAFQEgAQgB1ACpAEsAxf86/wv/2/6+/qz+0v7D/oz+Yv6A/rf+7P4K/xX/9P69/nL+If6//Uz9/vzJ/Jv8bPwb/Nn71/v7+3P8HP2v/eb9Jv6d/vr+Vv+1/xsASwAyABgA4f9o/xH/y/7B/rf+ef5F/iz+/f37/Uf+mf7m/gH/Vv+W/6//pf+i/57/gf9V/zT/8v6e/gz+rP1+/Vz9Y/2M/a/9y/3z/TH+k/4N/27/6P9aAIUAlgC0ALsArwCSAHkAYwAdANf/pf+K/2X/V/9i/77/3//s/zgAfACAAK4A7wApARMB/QDeAJYAHADC/5T/c/82/xD/Dv/L/o3+kf73/j3/fv8HAEAAKQA3AIUAygDSANUA1ACsAEAA9P+6/5D/Zv9O/2H/YP8q/1v/kP+h/+f/UACEAJ4A3AAmAT8BIwElATQBEAHaAJUAOwDy/1v/Iv8//xH/uv7n/gX/JP/C/5oAOQFBAY8BQgKnAvkCiAPKA6QDmwODA5UDbwP9AtQCuQJQAhUCKAI5Au8B9AEbAi4CDwI3AngCkQKaApUCZwIjAr4BbAFGASIB9wDNAIUA//+Y/6r/y//S/yYATQAtAK3/kP+c/7//vP+1/4z/L/+7/ob+Uf4p/vr9+P3w/a39gf2j/aH9ov3C/f/9D/7v/e393/2q/UL94vyy/IH8MvwE/Ln7RvvZ+r360fre+t/6/PoW+wP78fol+1L7bftt+2v7V/sO+7/6rvqQ+mT6SfpF+kL6KPob+jD6SfpB+nP65fow+x/7//rx+vX61Pry+ir7Ffuc+jX6yPmM+Wj5qfkD+vf58vns+fD5+Plj+hn7lPuw+7H7rPuf+3L7kfvW+9b7jvuH+6f7vPvQ+y/8lPzE/E/9+/15/s7+Jf9c/2T/pv/7/ysARgAgAAsAzf+K/23/2P9JAH8A1QB1AXwBqQEoAhwD5AN0BCsFRgUaBfYEQgWfBZ8FlQWmBXMFlQUoBuoHuAjeCG8JiwoIC/ALPQ0HDhMOug0FDsINGA2PDAEMEwv4CdkIUwiQB6MGOwY7BtcFngXuBaIG7gYAB2gHyAe2B7oH5wcECL0HJgeZBgsGQQWgBI4EVAT4A6oDkwOlA4kDtAMuBCEEHwQ9BFYEPATOA0oD0gIkAngB+ACBAK7/0v49/sH9av1A/Zz9y/3L/eH9+P0V/ir+df7b/uf+8P7V/pn+Rv7X/aT9j/1j/Ub9J/3o/Mf8wfwH/V79uP0g/oX+1P4U/z7/Uf9w/5P/pv+v/33/F/+b/mP+MP4+/kH+S/4r/hj+H/4//of++/5U/3H/wf8FACAATwCHAJsAiQB6AIEAgwAnADMAQgA9AP7/9f8oAGIAigASAS8BDQGuANgAHgFGAbIB1gGqAeoAiACOAJsAjgBmAFcAEAC9/9f/CABCAO7/8v82ADAAQgByAFUABQDJ/+H/9v/n/77/0P+d/y3/DP8g/0//ZP+K/9n/yf9x/3P/rP/Z////EwD7/57/TP8x/wr/v/5//kn+AP6v/Yz9kf2I/Vn9Rv1Z/X79l/2j/cz9yv3I/eH9Gf4y/jr+RP46/h/+//35/fX93v3a/dH9v/2K/WP9Qf0n/Rj9Df0e/Qf94vzG/M/80/zy/Bf9KP0K/ff8Av0A/Rn9Ff0K/Qb94vzH/LD8nvyI/FX8SPw6/B/8FfwZ/A38G/wq/Ej8Rfwg/Bz8I/wT/Cf8QfxY/FD8Ivwg/EX8SfxP/H/8X/w3/Pj79vsc/Dz8lvzU/Kr8dvxZ/H/8tfz4/B39C/2y/E/8VvxQ/Gr8P/xE/Fv8Mvwz/MX87fwZ/Z39BP5Z/qr+JP+i/9v/FQC3AB0BQgFQAVwBQAH0ALUA/QD2AJgAbwA3ANb/yf9MAMUABwEtAUkBaQFnAZQB5AEkAj4COwJrAlEC8wGhAbUBrgGxAR0CiAKfArEC4AIrA5UDDQSFBN4EzARtBDAEDwSoA2UDOwPdAmICEgIzAuwBvgHTAd4B5gEtAnEC3wLvAt8CzALYAs0CzQLBAmcCzgEvAfkA2wCvAOoA6AC+AJ0AewCbAOYAKQGeAfwBCQIDAv0BFQI5Ah4CIgLgAV4B2QCQADAA2P+b/4D/V/9X/1D/jv/D/9P/KQCXAN8ABgEGAd0AngBdAGwAeABbADsAHQDn/8r/DACFACoBpwElAqcC4AItA78DVgS6BN8E5QSkBEoEDQTuA74DdAMjA9MCVwLzAcEBmgG0AcIB3QENAuwB2QH+ARICVgKQArkC7QL0AusCFwM0A3MDzwMHBDAEOgQuBFgEpAT2BFkFfgVVBeoEagQeBN8DqAOHAysDmgL4AXIBIAEHAREBGgHnAK8AjQCGAMkADwE8AUoBMAH5AOkA6AACAfUAvwB9ACEA9//z/+H/3v/h/6f/hf+P/5X/zf/u/9//rv9e/yb/Cv/l/ur+2P6T/kb+5P2a/Xn9cP1x/W79af1P/RD93Pyi/Ij8mvyt/Mb80vy//HP8L/wA/P77L/xg/Gb8P/zx+637ofvf+0r8o/zR/MX8lvyM/ML8Fv16/aX9jP0y/aH8KfzW+837nvtU+9D6PPq7+ZT5w/kB+kz6hfqO+pL6s/oO+6L7EPxw/Jb8lfx3/EX8Q/xa/GL8a/xx/Fj8K/wO/Bv8JPw//Fv8ZvxZ/Fv8W/yB/Ib8jvyl/KX8nvxq/En8Jvwm/Ej8mfzZ/OD85/y7/PD8L/12/dn9Gv7m/bT9ef1f/Vz9af2S/WH9Dv3a/Mn8z/wZ/Xb93P38/R3+OP6O/q/+4v4x/1X/JP/R/ov+/f2I/VP9UP1G/f/88/wF/TX9vf2k/nT/MwDYAF4BGgJyAtQCWAN2AzkDDgPfApUCIgLyAeQBngFNAVEBVwGNAdoBWAL4AmIDxgNRBMIE8AQ6BYYFqgWbBZQFiwVQBQkF8QQUBTgFSQV7BakFqwWzBQUGcAatBs8G5Qa4BkwGDgbtBcgFgAU7BfcElQRCBBIECgTqA8oD9gMoBEIEVQRbBHkEUgRWBHsEbAQxBAoExANsAy4DBgP3AswCrQKrAq4CrAK/AtMC5wLqArECmAJwAiQCAwLhAaUBawE5ARMBCQH1ACABRQFVAWYBcgGNAboB9AFCAnQCegI1AuUBoQF0AXYBlgGOAUEB2ABwACYAIABXAKUAzQC1AIIANgAaACYAWgCiAK0AewAWAMX/nP/F/zQAkQDAAIwARgABAAQAKQB7AKcAiwBNANH/af8w/x//Q/9j/0P/Av+h/lj+Pv50/tv+Q/9a/1z/RP9D/1P/mv/n/yAAEgDc/5D/Sf8g/zz/VP8z/wb/sP5K/u39uv3N/e/98P3x/fL98/32/T/+nv7l/g//N/9G/zr/Wf9z/2P/Pv/x/rL+eP46/iP+Af7W/Yz9ZP1d/WH9if2u/cv9y/3a/er99v0N/hD+GP70/aL9Rf3o/K38lfyt/Kj8n/yL/Hb8ZvyB/M38J/1e/WL9Rv3s/If8M/zx+7D7ePsd+7n6WPog+jL6fvrU+iD7Vvt0+4v7wfsU/Fr8fvxu/Cr8sfso+7z6ffpN+hT64Pmt+X/5i/nL+Wj66/pr++z7Tvye/Ov8Nv1i/Xb9k/22/Zz9T/0L/dX8zvzo/DD9mf3P/Qz+cv7o/m3/EwClAPQA9gDMAI4AVQARAOD/o/9L/8L+Wf4v/kb+iv73/n3/zf8yAMYAcgEiAq4CIQNYA1wDRwMoAwADmgJeAj4CUAJbAl8CdwJOAkcCjQLfAv8CEgPoAo4CBwKoAXQBRAEPAckAXwD2/4b/gv/P/zYApgAOATwBaAGvASACnQIDAzsDPwP9ArsCggJSAkACEQLuAcEBiAFBAUQBZAGUAbsB/QEhAjECTwJvApQCxAL5AiEDKgMdAyEDCgMHAwoDMQNXA10DPwMtAyEDHwNNA3oDmgOhA6ADmgOeA6sD5AMQBDQETgRLBDgEJwQgBDcERQQ+BC4EAgTdA8QDxgPRA8sDwQOqA5UDhgOEA3sDeQN8A3UDbQNiA0QDGQPuAsUCpgKPAnsCcgJTAjkCGgIHAgcCDwI1AkgCMwIEArkBggFkAVsBSAEZAb4AZgAbAOr/2v/Z/+H/1f+7/6T/mP+P/57/pP+V/3X/Mv/6/r/+gv5d/iX+4v2i/Xr9Vv1C/Uj9Wf19/bH96v0h/kD+Yf57/qH+vv7R/sD+l/5f/in+CP7z/eP91P25/Zf9df1c/V39Zf1x/XT9cv1e/U79RP1W/XH9g/2V/Y/9kP2h/b/9+P0n/lD+dP6K/p3+t/7F/tf+2f7F/rX+gv5P/h3+7/3I/aj9kf2U/ZD9nf3B/eH9Gv5e/pH+w/7q/vL+8/7n/tn+yf6y/pX+bf5O/j3+Pv5A/lX+ZP52/oD+if6a/pz+o/6f/qX+nv6T/pH+k/6Z/qL+sv61/rP+wf7Q/u/+Af8J/wP/9/7l/sj+qv55/kP+Dv7e/cH9qf2c/ZH9iv2R/bb98P0y/nD+oP7T/u7+FP9G/2T/aP9O/xb/4P60/o7+a/43/g7+6v3q/Qv+P/6C/r/+8v4k/2j/v/8PAFcAfABvAF0AQwAhAPv/4P+4/3f/QP8W//n+9f4Z/z//bP+d/9P/FABJAIcAvgDTAOEA5ADyAOoA6gDnAOcA6wD7ACABRgFuAaMB0AH3ARkCKQI4AiUC+gGrAVYB6gB1ABAAv/9+/1z/W/9m/5n/8f99AB0BuwFJArMC7gIUAyYDJgMKA7gCRAK0ARUBhAAbANL/nf9//1v/TP9N/2r/qv/4/00AnQDbAAsBOQFmAZcBtwHHAbYBkAFcAS0BEAEBAe0A4ADGAKwAkgCGAHgAfACCAHEAWwAyAAoA+v/1/xYAOwBpAIwAuADrADIBewHFAQACIAIhAg0C6gHJAZIBVAEJAa4ASwDz/6z/cv9S/0r/T/9q/5L/yP8SAGQAwgAnAXABsAHcAeUB3wHKAa0BfQFFAe8AkgA9AO//vv+e/4//lP+Z/67/1f8MAEQAdQCcALIAwgC9AKoAigBjADsAFQDu/8n/pf+H/27/aP90/5P/p//J/+T///8cAC0AQQBDADYALQAcAPf/2/+5/5z/gf9Z/1b/Sv9I/2b/dv+O/5T/rf/J/+P//P/1/+T/w/+w/7H/sP+o/4//gP9q/1//Zv92/4D/kv+k/5//oP+g/6j/pP+V/4T/Vv8p/wH/7/7n/vH+8/4T/zD/WP+M/7r/8/8gAEIAYABfAFIAQgAwAA8A3f+l/3T/Pf8W/wj/+P7i/tH+zf7c/vT+Ev8v/2b/iv+7/9f/8P8DABsAMAApABEA7//a/8D/qf9//1j/N/8f/x7/IP8h/yn/MP9O/2X/fP+L/6n/sf+n/8z/1P/f/+b/9/8FAOv/tP+s/5n/nP+r/5T/iP81/2b/j/9Z/1r/d/9J/13/Yf9Q/2X/Yf+B/6X/o/+0/9f/9v8uAEsAbwCCAH0AggCbAG0APQAcAPf/yf+3/6T/nP+T/5z/tP+7/+r/HQBJAGcAcwB4AH8AdgBrAGAAPAAYAPj/1//E/6D/n/+t/63/pv+d/6P/pf++/9P/7v/h/+n/7f/1/+3/3//W/8z/w/+5/7T/qv+W/6P/rf/I/+D/BQArAEMATQBnAGwAdQB/AGkASQAUANv/uP+f/4P/b/9Z/1f/Vv9q/4n/sv/W//3/KQA0AFoAgACeALkAwwDGALcAkwB2AFsANQAQAOf/w/+g/3f/af9f/2T/dP+L/7P/3f/+/yoATwB9AJMArAC7AK0AngCQAIQAfgCEAIIAegBjAFYARQA7ADsANwA5ADUAHwAPAPv/4f/A/7z/tv+x/7T/wP/K/83/7f/+/xcAOgBiAIUAmwCpALYArgCdAIgAbQA6AAEAxv+S/1j/K/8P//X+4/7h/vP+Bv8h/0f/bf+V/7z/1f/m/+z/6P/i/93/4v/j/93/2v/Q/8j/yP/O/9T/2v/i/+b/5v/m/+//9P/z/+v/5v/j/+X/6//x/wAABgAQACcAKwA0AEUASwBaAGIAXQBQAEgANAAyABwABwD3/9r/1v/Q/8b/wf/E/8T/0v/d/+P/8//+/yAALAA3AEgAVABXAFMAUQBHADkALwAiABkAAwDo/9P/wv+2/63/qP+U/4n/fP90/3D/bv9t/3H/af9q/3H/ff+S/6j/vv/b//b/DQArAD8ARwBEADAAGwD//9//vv+a/3v/Yf9P/0T/Sv9R/1z/bv9//5T/tf/Q/+//BgANABYAFQAMAAYA+//u/9r/yf+3/6r/pf+x/77/1P/o//n/CAAXACMAJwAmACIAEAAJAPz/7P/k/9n/1P/W/+D/8P8CABMAIwAwADwAQQBDADwALQAfAAcA8P/d/9H/xf/F/8P/zP/Q/9n/5P/u//X/+//+//j/9//0//D/5P/Z/8//w/++/7n/tP+w/7n/vf/I/8//2//o//H/+f////////8DAAUAAQD7//z/8f/v//H/9v/8/wUACwAVAB4AKAAxADoAOgA4ADQALQAkABkAEgACAPn/9P/x//L/+f8AAA0AIAAuADgAQwBNAFMAVwBaAFgAUgBKAD0ALAAbAAwA/f/u/+P/0v/K/8L/v/+7/8H/xv/Q/9b/4v/x/wAAEwAhAC8ANABCAEIAPAA0ACgAFQAHAPT/4f/S/8H/rP+f/4n/eP9o/13/Vv9T/1L/WP9g/27/hf+e/7X/y//a/+v/9/8AAAgACQAGAAQA/v/0/+r/3v/W/8j/v/+2/7L/sP+w/7D/tP+7/8P/0P/g/+//BgAbAC8ASQBhAHUAhQCMAIoAfQBvAFwARgAtAA8A8f/W/8X/tv+x/6r/rf+0/8X/1//o//r/CQAXACUAKgAvACkAJgAiABoAEQAHAPr/8f/r/+b/4f/f/9T/yv/D/73/tv+y/6j/of+d/5b/l/+g/6H/qf+t/7v/x//T/+L/8f///w0AGQATABcAEQAJAAAA8P/f/8v/uv+w/6f/pP+m/6//v//X//D/DAApAD0AUgBfAGUAZQBeAE8APQAnABQABADz/+j/4//g/93/5P/t//n/CAASAB8AJwA0ADwAQABBAD4AOQAyAC0AKgAqACwAMgA1ADoAPQA+ADoAMgAqACAADwD+/+v/2f/K/7v/rf+q/6n/qf+0/8D/z//g/+//AQARABUAHgAeABIACQD9//L/4v/R/8H/t/+w/6//sP+u/7H/tP+7/8D/xf/K/8n/yv/K/8v/zP/O/83/z//Q/9D/1f/e/+X/7P/z//b//P///wIABQAEAP7/9v/q/+L/1//M/8T/uP+x/6r/rP+1/7//y//b/+D/7v///woAFAAbABcAEQAHAPz/8v/h/9n/0P/C/7n/tv+1/77/xf/O/9n/5v/t//X//f8HAAkADAAMAAsABgADAAAA+P/0/+v/4v/b/9X/z//O/8P/wf+//8X/zP/K/8z/z//S/9j/4v/i/+P/5v/s//H/9f/7////CAAGAAYACAAAAPv/+P/4//X/7P/n/+D/4f/g/+H/4P/m/+r/7v/z//z/AQAKAAwADQAQABAACAAHAAIAAQD6//P/8v/s/+X/6f/o/+X/6v/p/+v/6//v//L/9//6////BAALABAAFAAZABsAGAASAA0ABwAAAAMA+f/w/93/0P/G/8L/vP+7/7b/sv+x/7H/uf++/7j/yv/W/9T/4P/m/+X/5v/n/+T/4//b/9T/1v/T/9b/2//a/9f/2v/X/9f/2P/V/9r/3v/g/+P/6f/p//H/9f/2//f/9v/4//b/9v/4//P/8v/1//L/7//u//L/9P/2//n//f8AAAIABwAKAAsADQASABEAEQAPABAAEQAMAAsACQD//wAAAAD//wQAAAD/////AAAAAAAA+//8//r/9v/u/+3/7P/p/+n/6P/j/+D/5f/k/+T/5P/n/+f/7f/v//L/+//7//v//f/6//j/9v/4//f/9P/z//T/8//z//X/9P/4//f/+f/2//X/9P/0//H/7v/v/+j/5//o/+j/5f/o/+7/9P/5//v//P/8//v/AAD///z/+//7//n/+//4//f/+f/9//n/+v/6//v/+f/7//v/+v/1//T/6//q//X/6//n/+3/5P/n//L/7//1//f/9//7//z///8HAP//AQACAAAAAAD8//P/8//x/+X/4f/e/9b/2f/c/9//5v/t/+7/8//5//v//v8AAAIAAwAFAAAA/f/8//r/9//3//f/9//z//T/9//+//n/+f/7//v/+v/7//n/+f/6//j/9//x//D/7//u/+3/6v/o/+X/5f/n/+b/5P/k/+L/4f/g/+H/5f/j/+L/5P/g/93/3//b/9z/3f/b/93/3//g/+T/5P/l/+P/3//d/9v/2P/W/9X/1f/V/9P/1P/W/9j/3P/f/+D/5//m/+X/4f/h/+T/4P/g/+H/3P/c/+L/4f/k/+j/7P/t//D/8P/w/+z/7P/r/+z/7f/u/+7/8v/1//j//P/9//3//v///wEA/f/9//3/+v/3//b/8//z//H/8v/y//P/9P/y//L/9P/1//P/8v/3//X/9P/1//L/8v/z//X/9f/3//f/+f/8//3/+v/8//3/+f/4//n/9v/2//L/8P/w/+7/7v/s/+3/7f/t/+v/6//r/+r/6v/q/+n/6f/n/+X/5P/j/+X/5//q/+v/7P/u//D/8P/x//H/7//s/+v/6f/o/+T/4//j/+L/4P/i/+D/4P/h/+D/4f/i/+L/4//m/+T/5v/l/+j/6P/n/+f/5//m/+f/5v/k/+P/4v/i/+H/4v/k/+T/5P/n/+f/6P/p/+b/5v/l/+b/5f/m/+X/5f/l/+b/5//n/+n/6v/p/+r/7P/s/+z/7v/t/+3/7P/r/+r/6f/q/+r/6f/q/+v/7P/v//L/9P/4//n/+v/7//v/+//8//n/+P/3//T/8v/y//D/7//u/+//8P/w//H/8//0//X/9f/2//b/9P/z//D/7//t/+z/7P/s/+r/7f/u/+//8f/0//b/+P/7//v//P/7//v/+P/3//T/8v/w/+//7P/s/+z/7f/w//H/8v/1//b/9v/4//f/+P/3//b/9v/2//X/9f/2//X/9//5//r//P/9//3//v8AAP7//f/+//v/+v/5//j/+P/3//j/+P/6//v//f8BAAEAAwADAAQAAwACAAIAAAD///3//P/7//n/+P/3//f/9//3//f/9//4//j/+P/4//n/+f/4//f/9v/1//P/8f/v/+7/7P/t/+v/6//r/+v/7P/t/+3/7f/t/+7/7f/s/+v/6v/o/+b/5v/l/+P/4//i/+L/4v/i/+L/4v/h/+H/4f/g/9//3v/d/9v/2//a/9r/2v/a/9v/3P/d/97/3//g/+H/4v/i/+P/4//j/+P/4//i/+L/4f/h/+H/4f/i/+L/4v/j/+P/5f/l/+f/6P/p/+n/6f/q/+r/6//r/+r/6v/r/+z/7P/t/+3/7v/v//H/8f/y//L/8//0//T/9P/z//P/8//1//T/9f/2//b/9//4//n/+v/6//v/+//7//v/+//6//r/+v/6//r/+f/6//r/+v/7//r/+v/7//r/+v/6//r/+P/5//f/9//2//X/9P/0//P/8//y//L/8f/w//D/8P/w//D/8P/v/+//7//v/+7/7v/u/+7/7v/v/+7/7v/v/+//7v/u/+7/7v/t/+7/7f/t/+z/7f/s/+3/7f/t/+3/7f/u/+3/7f/t/+3/7P/s/+z/7P/r/+v/6//r/+r/6v/p/+r/6v/q/+n/6f/p/+n/6f/p/+r/6f/q/+r/6v/r/+r/6v/r/+v/6//s/+v/6//r/+v/6//r/+r/6v/r/+v/6//s/+v/6//s/+z/7P/s/+v/6//s/+v/7P/s/+v/7P/r/+v/7P/s/+z/6//r/+v/6//r/+r/6v/r/+r/6v/q/+r/6v/r/+r/6v/r/+v/6//r/+v/6//r/+v/6v/q/+n/6f/p/+n/6f/p/+j/6P/o/+f/5//o/+j/5//o/+f/6P/o/+j/6f/q/+r/6v/r/+v/7P/s/+v/7P/s/+z/7P/t/+3/7v/u/+7/7v/u/+7/7v/w/+//8P/w/+//7//w//D/8f/y//L/8//z//T/9P/0//T/9P/0//T/8//1//P/8//y//L/8v/x//D/8P/w//D/8P/v/+7/7v/u/+7/7v/v/+7/7v/t/+3/7P/s/+v/6v/r/+r/6v/p/+n/6P/o/+f/5//n/+f/5v/m/+X/5f/k/+T/5P/k/+P/5P/k/+X/5P/k/+T/5P/j/+P/4//i/+L/4f/i/+D/4P/g/+D/3//g/+D/3//g/9//4P/h/+H/4v/j/+P/5P/l/+T/5f/l/+X/5P/l/+X/5f/l/+X/5v/m/+f/5v/n/+f/5//n/+f/5//p/+j/6P/o/+j/6P/p/+j/6f/p/+n/6v/q/+r/6v/r/+r/6//q/+v/6v/r/+r/6//q/+r/6v/q/+n/6v/q/+v/6//s/+z/7P/r/+z/7P/s/+z/7P/s/+v/6//r/+r/6//r/+v/6//s/+z/7P/t/+3/7P/s/+v/7P/s/+z/6//r/+v/6v/r/+r/6v/r/+v/6//r/+v/6//s/+z/7P/s/+z/7P/s/+z/6//s/+z/7P/r/+z/7P/s/+z/7P/s/+z/7P/s/+v/7P/s/+v/6//r/+v/6//r/+v/6//r/+v/6//s/+v/7P/r/+v/6//s/+v/6//r/+v/6v/r/+v/6v/s/+r/+P8BAAAAAAABAP//AAAAAP//AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA"
- }
- }
- ]
- },
- {
- "role": "assistant",
- "content": [
- {
- "type": "text",
- "text": "我没办法获取实时的天气信息。不过呢,你可以试试几个方法来查看今天的天气。首先,你可以用手机自带的天气功能,比如苹果手机的天气应用,或者直接在系统设置里查看。其次,你也可以用一些专业的天气服务,像是国外的AccuWeather、Weather.com,或者国内的中国天气网、墨迹天气等等。再有就是,你还可以在谷歌或者百度里直接搜索你所在的城市加上天气这两个字。如果你能告诉我你所在的城市,我也可以帮你分析一下历史天气趋势,不过最新的数据还是需要你通过官方渠道去获取哦。"
- },
- {
- "type": "audio_url",
- "audio_url": {
- "url": "data:audio/wav;base64,UklGRiQiKQBXQVZFZm10IBAAAAABAAEAwF0AAIC7AAACABAAZGF0YQAiKQAGAAcABwAIAAkACQAJAAoACwAMAAwADQAOAA4ADwAPABAAEAAQABAAEQAQABAAEQARABAAEQARABEAEAAQABEAEQAQABAAEAAPAA4ADwAOAA0ADQANAAwACwAJAAYABQAEAAIAAQAAAP7//f/7//r/+v/5//b/9v/0//X/9f/0//X/9P/0//L/9P/y//D/9P/z//T/8v/x//L/8v/x//H/8P/v/+//7v/u/+3/7P/t/+3/7P/t/+7/7v/u//D/8f/z//X/9f/3//n/+//7//3///8AAAEABAAGAAgACgAMAA4AEAASABMAFAATABQAFAAUABUAFQATABIAEgARABEAEAAOAAwACwAJAAcABgAEAAMAAgABAAEAAAAAAAAA//////7//f/8//v/+f/4//j/9//3//f/9v/2//b/9f/1//b/9f/1//b/9v/2//b/9f/1//X/9P/z//P/9P/z//P/8//0//T/9P/0//X/9v/2//f/+P/4//n/+v/7//z//f/+//7///8AAAEAAgACAAMABAAFAAYABwAJAAoADAANAA4ADwAPAA8AEAAQABEAEgASABMAFAAVABYAFwAXABYAFgAWABYAFgAVABQAEwATABMAEgASABIAEQARABAADwAOAA4ADQANAAsACgAIAAcABAACAAEA///9//v/+f/4//b/9f/z//H/8f/v/+3/7P/r/+n/5//m/+X/5f/k/+T/5P/l/+X/5//o/+r/7P/u//D/8v/1//f/+f/7//z//v8AAAEAAgAEAAQABQAHAAUABQAGAAQAAwACAAEAAgAAAAEAAQD+/wAA/v8AAP7//P////7//f/9/wAA/v/9//7//v///wAA//////////8AAAEAAwACAAIAAwADAAMAAgACAAIAAwACAAEAAAABAAEAAAD////////////////+/////v/9//3//P/8//z//f/9//3//v/+//7///8AAP////////////////////////7//v/9//3//f/8//r/+P/3//j/9//3//b/9f/2//b/9f/1//b/9//3//f/9//3//f/9//3//f/9//3//f/9//3//f/9//3//f/9//3//f/9//4//j/+P/5//n/+f/5//n/+f/5//n/+f/6//r/+//7//z//P/+////AAACAAMABQAGAAcACAAIAAkACQAJAAkACQAKAAoACQAJAAcABgAEAAMAAQD///3/+//6//n/+P/3//b/9v/1//b/9v/2//b/9v/2//b/9//4//n/+v/8//7//v///wEAAwAEAAUABwAJAAoACgALAA4ADAANAA0ADwAOAA0ADwAPAA8ADgARABEAEQARABEAEAAQABEAEQARABAAEAAQABEAEQAQABAADwAPAA4ADQAOAAwADQANAAwADQANAAsADAALAAsACgAJAAkACAAHAAcABQAFAAUAAgABAAEAAAD///7//P/6//n/9v/z//P/8v/w/+//7f/r/+v/6v/p/+r/6f/o/+j/6P/o/+j/6f/p/+n/6v/r/+z/7P/t/+7/7//w//H/8//1//b/+P/5//r//P/9////AAABAAIAAwAFAAYABwAIAAkACwALAAwADQAOAA4ADwAQABEAEgASABMAFAAVABUAFQAVABYAFQAVABUAFAATABIAEQAPAA4ADQAMAAsACgAJAAcABQADAAAA///8//r/+P/2//X/8//x/+//7v/t/+z/6//r/+r/6v/q/+v/6//s/+z/7f/t/+7/7//w//H/8v/z//T/9f/2//f/9//4//j/+f/6//r/+//7//z//P/9//7//v///wAAAAAAAAEAAQACAAMABAAGAAcACQAKAAwADQAPABAAEQASABIAEgATABUAFwAYABkAGgAbAB0AHgAfAB4AHgAdABwAGwAaABkAGAAWABQAEgAQAA0ACwAJAAcABQADAAEA/v/8//r/+P/2//T/8//x//D/7//t/+z/6//r/+v/6//r/+v/6//s/+3/7f/t/+7/7v/v/+//8P/w//D/8f/w//D/7//w//H/8f/w//D/8f/y//L/8v/y//P/8//1//f/+P/5//z//f/8/wAA//8DAAEAAAAEAAIAAQADAAMAAQAAAAEAAAABAAEA/////////v/9//7////9//z//P/9//3//P/8//z//f/+//7//v////////8AAAAAAQACAAIAAgACAAIAAgABAAEAAQABAAIAAQAAAAAAAAD///7//v/9//3/+//6//r/+v/6//r/+f/6//r/+v/5//n/+v/7//v/+v/6//v//f/+//7//v//////AAD///////////7//f/8//v/+//6//r/+f/5//n/+v/6//r/+v/6//z//P/9//3///8AAAEAAgADAAUABQAGAAYABwAIAAkACQAKAAsADAAMAAwADAAMAA0ADAAMAAsACwAKAAkACAAHAAUAAwACAAEAAAD+//3/+//6//j/9//1//T/8//y//L/8//z//T/9f/1//b/9v/2//f/+P/4//n/+f/5//r//P/9////AAACAAMABAAFAAYACAAJAAoACwANAA4ADQAOABEAEAARABEAFAATABMAFQAVABYAFQAXABYAFgAWABUAFAATABQAEwASABIAEQAQABAADwAPAA4ADQAMAAsACwAMAAoACwAKAAkACgAJAAgABwAFAAUAAwACAAEA///9//3/+v/5//j/9P/y//D/7v/s/+v/6P/m/+X/4v/h/+H/4f/g/+H/4P/g/+H/4v/j/+T/5f/m/+f/6P/q/+v/7f/u/+//8f/y//T/9f/3//j/+v/7//z//v///wEAAgADAAQABQAGAAgACQAKAAsADAAOAA8AEAASABMAFAAVABYAFgAXABgAGAAZABkAGgAaABoAGQAZABgAFgAVABMAEgAQAA8ADgAMAAoACQAHAAUABAACAAAA///9//v/+f/3//X/8//x//D/7//v/+7/7v/t/+3/7f/t/+7/7v/v//D/8P/x//L/8//0//X/9f/2//f/9//4//j/+f/5//r/+v/6//r/+v/6//r/+f/6//r/+v/7//v//P/8//3//v///wEAAgADAAUABgAIAAsADQAPABEAEwAUABYAFwAYABgAGQAZABkAGAAZABkAGQAZABgAFwAVABQAEgARAA4ACwAIAAUAAwABAP///v/8//v/+v/4//b/9f/0//P/8v/y//H/8P/w/+//7v/u/+3/7f/t/+3/7f/s/+z/7P/t/+3/7v/u/+7/7v/u/+//8P/v//D/8P/x//H/8f/y//P/9P/0//X/9f/1//f/+P/5//n/+//8//z//f/9//7//f///wAAAAAAAAEAAQD//wAA/f8AAPz/+//+//v/+v/8//z/+//7//z//f/+/////v///wEAAQAAAAIABAADAAIAAwADAAQAAwADAAMAAwADAAIAAgACAAEAAAAAAAAAAAD//////v/+//7//v/9//7//v/+//////////////////////8AAAAA////////AAAAAAAAAAAAAAEAAAD///7//////////v/9//3//////////v/+//7//v/+//7//v////////8AAAAAAQACAAQABQAGAAcACAAKAAoACgALAAwADAAMAAwADAAMAAwADAAMAAwACwAKAAkACQAJAAgACAAIAAgABwAHAAYABQAEAAMAAgAAAP///v/9//z/+v/5//f/9f/0//P/8v/x//D/7//u/+3/7f/s/+z/7P/s/+7/7//w//L/8//0//X/9v/3//j/+v/8//3///8BAAMABgAIAAoADAAOABAAEQARABIAEwAUABQAFQAVABYAFAAUABYAFAAUABQAFgAVABMAFQAVABUAFAAVABUAFQAVABQAFAATABQAFAAUABQAFAATABQAFAAUABMAEgASABAAEAAQAA4ADgAMAAkACAAGAAIAAAD8//r/9//0//L/7//t/+v/6f/n/+b/4//h/+D/3v/e/9//3v/e/97/3v/e/+H/4v/j/+b/5v/n/+n/6v/s/+7/7//w//L/8//0//b/9//4//n/+v/7//z//f/+////AAABAAIABAAFAAcACAAJAAoACwANAA4ADwARABIAEwAUABUAFgAXABcAFwAXABcAFgAWABUAFAATABIAEAAPAA0ACwAJAAYABAABAP///f/7//n/9//1//T/8v/w/+//7f/s/+r/6f/o/+f/5v/l/+T/5P/j/+T/5P/l/+X/5v/n/+j/6P/p/+r/6//s/+z/7f/u/+7/7v/v/+//7//v/+//8P/w//H/8f/y//P/9P/1//f/+P/5//v//P/+/wEAAwAFAAcACgALAA4AEAATABUAFwAZABsAHQAfACEAIwAkACUAJgAmACUAJQAkACMAIQAgAB0AGwAaABkAGAAWABQAEgAPAA4ADAALAAgABgAEAAIAAQAAAAAA///+//7//f/8//v/+f/5//j/+P/4//f/9//2//X/9f/0//T/9P/0//X/9f/1//X/9f/2//f/9//4//j/+f/6//v//P/8//3//v///wAAAAABAAIAAwAEAAUABQAGAAcACAAIAAcACAAJAAgACAAIAAgABwAIAAkACQAIAAoACgAIAAkABwAKAAcABgAKAAgABwAKAAoACQAJAAoACwALAAwACgAKAAsACQAIAAgACAAGAAQAAwACAAEA///+//3//P/7//r/+f/4//j/9//3//f/9//3//f/9//3//j/+P/4//j/+P/5//n/+f/5//n/+f/5//j/+f/5//n/+f/4//n/+f/6//r/+f/6//v/+//6//r/+//8//3//P/8//7/AAABAAIAAgADAAQABQAGAAcACAAJAAoADAAMAA0ADQAOAA8ADwAQABAAEAARABAADwAPAA4ADgANAAsACgAKAAgABwAGAAUAAwACAAAA/v/9//z/+v/5//j/9v/1//P/8f/w/+7/7P/r/+n/6P/n/+b/5f/j/+L/4f/h/+D/4P/g/+D/4P/g/+H/4f/i/+P/5P/m/+j/6v/t/+//8f/z//T/9v/3//j/+v/7//3//f/+/wAAAQADAAQABQAGAAcACAAIAAgACQAKAAoACwAMAA0ADAAMAA8ADgAPAA8AEgARABEAEwAUABUAFAAWABcAFwAXABcAFwAWABYAFQAUABMAEgAQAA8ADgAMAAoACAAGAAQAAgABAP///v/8//n/+f/3//T/8//x//D/7v/t/+z/6//q/+v/6v/q/+v/6v/q/+v/6v/s/+7/7f/u//D/8P/x//P/9P/1//f/9//4//r/+v/7//z//f/9//7//////wAAAQACAAMABAAFAAYABwAIAAkACgALAAwADQAPABAAEQASABMAEwAUABQAFQAVABUAFQAVABUAFAATABMAEQAQAA8ADQALAAoACAAGAAQAAwABAP///v/8//r/+P/3//X/9P/z//P/8//y//L/8v/y//L/8v/y//P/8//z//T/8//z//P/8//z//L/8//z//P/8//z//P/8//y//L/8//z//P/8//z//T/9P/0//X/9f/2//b/9//4//j/+v/7//z//f///wEAAgAEAAUABwAIAAoADAANAA8AEAARABIAEgATABQAFAAUABQAFAAUABQAFAATABMAEgARABAADwAOAA0ACwAKAAgABwAGAAUABQAEAAMAAgABAAEAAQABAAAA//////7//v///////////wAAAAAAAAAA//////////8AAAAA//////////////7//v/+//////////////8AAAAAAQACAAIAAgACAAMABAAEAAQABAAFAAUABQAFAAUABQAFAAQAAwADAAQABAADAAEAAgACAAEAAQAAAAAA/v///wAAAAD//wEAAQD//wEA//8CAAAA//8CAAAA//8BAAEAAAAAAAAAAAABAAEA//8AAAAA///+//7////+//z//P/8//v/+v/5//n/+f/5//j/+P/4//j/9//4//j/+P/5//n/+v/6//v/+//8//z//P/9//3//v/9//3//f/9//z//P/8//z/+//6//r/+v/6//r/+f/6//r/+v/6//r/+v/8//z/+//7//z//v///wAAAAABAAIAAwADAAQABAAEAAUABQAFAAQABAAEAAQABAADAAIAAgACAAIAAQAAAP/////+//3//f/8//v/+//6//r/+f/4//f/9v/2//X/9f/0//T/9P/z//P/8v/y//H/8f/w//D/8P/w//D/8P/w/+//7//v/+//8P/w//D/8f/x//L/8v/z//T/9P/1//f/+f/7//z//v8AAAEAAwAEAAUABgAIAAgACQAJAAoACwALAAwADAANAA0ADQANAA0ADQANAAwADAANAA0ACwALAAwACwALAAoADAAKAAkACwAKAAoACQALAAsACgALAAsACgAKAAoACgAJAAkACAAGAAYABQAEAAMAAQAAAP7//f/9//v/+v/5//f/9//2//X/9P/z//L/8v/x//H/8P/w//H/8P/x//L/8f/x//L/8v/0//b/9v/2//j/+P/5//v//P/+/wAAAAABAAMABAAFAAYABwAIAAkACQAKAAoACwALAAsADAAMAAwADAAMAAwADAAMAAwADAAMAAwADAAMAAwADAAMAAwADAAMAAsACwALAAoACgAJAAkACAAIAAcABgAFAAQAAgABAAAA///+//3//P/7//n/+P/3//X/9P/z//L/8v/x//D/8P/w//D/8P/w//H/8f/y//P/9P/0//X/9f/2//f/+P/5//r/+v/7//z//f/9//7///8AAAAAAQACAAIAAwAEAAQABQAFAAYABgAHAAcACAAIAAgACQAJAAoACgALAAsACwAMAA0ADQAOAA4ADwAPAA8AEAAQABAAEAAQABAAEAAQABAADwAPAA4ADgANAAwADAAKAAkACAAHAAUAAwABAAAA///+//z/+//5//j/+P/3//b/9f/0//P/8v/y//L/8v/y//P/8//z//P/8//z//T/9P/1//b/9v/3//f/+P/4//n/+f/5//r/+v/6//r/+v/6//v/+//8//z//P/8//3//v/+//7//v///wAAAAAAAAEAAgACAAIAAgACAAMAAwADAAIAAwACAAIAAgABAAAA//8AAP/////+///////9//7//P////z//P////z/+//9//3//P/7//z/+//8//3/+//8//z//P/7//z//f/8//v/+//8//v/+//6//n/+f/5//j/9//3//f/9v/1//X/9f/1//X/9f/1//X/9f/1//b/9v/3//j/+f/5//r/+//7//z//f/9//7//v/+//7//////wAA//8AAAEAAAAAAP//AAAAAAAA///+////AAAAAAAAAAAAAAEAAQACAAIAAwADAAQABQAFAAUABQAGAAYABgAGAAUABgAGAAUABQAEAAQABAADAAMAAgACAAEAAQABAAAAAAD///3//f/8//v/+//6//r/+v/6//n/+f/5//n/+f/5//n/+f/5//n/+v/6//r/+v/6//v//P/8//z//f/9//7//v/+//7//////wAAAQABAAIAAwAFAAYABwAIAAkACgAMAA0ADQANAA4ADwAQABEAEQASABIAEgASABIAEgASABEAEQARABAADgAOAA4ADAALAAoACwAIAAYABwAFAAQAAgADAAIAAQAAAAAA///+//7//f/9//3//P/7//z//P/7//v/+v/6//n/+f/5//f/+P/3//b/9//2//X/9f/0//T/9P/z//P/8v/y//P/8v/z//T/8//z//T/8//0//b/9v/3//j/+P/4//v/+//8//7///8AAAEAAgAEAAYABwAIAAkACgALAAwADQANAA4ADgAOAA4ADgAOAA4ADgANAA0ADAAMAAwACwAKAAoACQAJAAgACAAHAAYABgAFAAUABAAEAAMAAwACAAIAAQAAAP///v/+//3//P/8//v/+//6//n/+P/3//b/9f/0//T/8//y//H/8f/w//D/7//v/+//8P/w//H/8f/y//L/8//0//T/9v/3//j/+f/6//v//P/9//7//////wAAAQACAAMABAAFAAUABgAHAAcACAAIAAgACAAIAAkACAAJAAgACAAIAAcABwAHAAcABgAGAAYABgAFAAUABQAEAAQABAAEAAMAAwADAAMAAwADAAMAAwADAAMAAwADAAIAAgACAAAA///+//3//f/8//v/+f/4//b/9v/1//T/8//y//H/8P/w//D/8P/w//D/8P/v/+//7//v/+//8P/x//L/8//0//X/9v/3//j/+f/6//z//f/+//7///8AAAAAAQACAAIAAgACAAMABAAEAAQABQAFAAYABgAGAAcACAAIAAgACAAIAAkACgAJAAkACwALAAsACwALAAsACQAKAAkACQAIAAkACAAGAAcABAAHAAQAAwAGAAMAAgAEAAQAAgABAAEAAAABAAEA//8AAAAA/////wAAAwACAAEAAgADAAMAAwADAAMABAAEAAQABAAEAAQAAwADAAMAAwADAAIAAgABAAEAAAAAAP///////wAAAAAAAAAAAQABAAEAAgACAAIAAgADAAQABAAFAAUABQAGAAcABwAGAAUABgAHAAYABQAEAAQABQAEAAQAAwADAAIAAQAAAAAAAAAAAAAAAQABAAEAAQABAAIAAgABAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgADAAMABAADAAIAAgACAAIAAQABAAEAAQAAAP///v/+//3//P/8//z/+//7//v/+//6//n/+f/4//j/+f/6//n/+f/6//v/+v/7//v/+//6//r/+//7//z//P/8//z//P/8//z//f///wAAAAAAAAEAAgADAAMABQAHAAcABwAIAAgACQAJAAkACQAJAAkABwAIAAkABgAFAAcACAAFAAQABwAFAAIAAQADAAAA/////////P/6//v/+//6//n/+f/4//f/9//3//b/9P/0//P/8//0//P/8//0//P/9v/3//b/9v/0//T/9P/0//b/9v/0//X/9f/2//b/9f/0//T/9P/z//X/9f/2//n/8//w//L/8f/x//X/+P/3//f/+P/5//z///8BAAEAAgAFAAcACAAJAAoADQAOAAwACwALAAwACwAJAAkACgAKAAsACwALAAsACwALAAoACQAIAAgACQAJAAgABwAHAAcABwAHAAYABQAFAAQAAwAEAAUAAwADAAMAAwADAAMAAwADAAIAAAD///3//P/6//j/+P/3//b/9f/z//T/9f/1//b/9v/1//T/9P/0//T/9P/2//n/+v/7//z//P/7//z//f/+/wAAAQABAAMABQAHAAcABgAHAAcACAAJAAsADQAOAA8ADwAPAA8ADgAMAAsACgAKAAoACwALAAsACwALAAoACgAMAAsACgAJAAgABwAFAAQAAwADAAUACAAKAAoACgAIAAgACQAJAAgABgAEAAIAAQABAAIAAAD///z/+f/4//n/+v/7//v/+f/4//j/+f/5//r/+v/3//P/8P/u/+7/7//v//D/8P/v/+7/8P/y//T/9f/3//v//P/7//z//f/8//z//f/9//3//f8AAAAA//8AAAMABAACAAEAAgABAAAA//////////8AAAIAAgD///3/AAACAAIABAAFAAQAAwADAAMAAQAFABAADQADAAcADQAEAPj/BgAPAPz/+v8VACIAGAATAAUA8//s/+z/+f8GAAUA+v/0//L/6//m/+7/9v/9//X/5//k/+v/8f/z//n/AQD///L/8f/4//n/AQAGAAIA/v/9////+v/7//7/+//4//f//v8HAAgABwADAP3/+f/2//H/8P/5//3/8P/r//T//P/7//n//f///wEABAAEAAMAAwABAP//AQAEAP3/+f/9//n/7f/t//r/+//2////DAASABcAIwAeAPv/2v/Z/+j/8v8BABIABgDd/8T/0P/g/+j/9/8CAAYAGQA0AD8AQABKAEwALAAAAOr/5//q//n/EQASAPv/5v/d/+D/7P/6/wIA/v/1/+v/4v/l/+///v8LABEADgAFAP7//v/9//n/+f/3//H/7v/r/+L/4f/t//r/AgAKABgAGQAKAP7/+f/6/wMAFQAkAC4AMQAXAPj/9/8IABIA/P8GAB4AAwDp//r/GAApACkADgAAAAMA/f/7/xUAIwAKAAAAEwATAAQACQAQAPr/5P/x/wwAFgAZACYAIgAEAPb/+//4//X/BgAbABgAAgD3//H/5P/f/+r/8f/z//n////7//X/8f/y//P/9P/3//L/5v/n/+z/6//r/+7/7P/w//P/9f/6//7//f/6//X/8//w//D/+P///wIAAQD8//r/+//7////BQAIAAYABQAGAAoADgARABEAEgAPAAgABgAMABIADwAJAA0AFAAUAA8AEQAUAA8ACwANABEAEgARAA0ACQAIAAgABgABAAEACQAOAAoACgANAAcA//8BAAgACAADAAAAAgAEAAIAAAD+//7//v/5//b/9P/x/+7/7v/v/+7/7v/v//D/8f/y//T/9P/z//P/8v/x//L/9v/6//v//v8BAP//+v/2//f//f8DAAYABwAIAAkACAAGAAUABAADAAAA/f/+/wEAAwAEAAcABgACAP///f/9//3//f///wAAAAABAAQABQADAAQABAAFAAQAAwADAAQABwAIAAoACwALAAsACgAIAAYABQAAAP//BAAGAAIA/v/+//3/+//8/wAAAAD+//v/+v/2//P/9f/3//j/9//2//X/9v/3//n//P/7//b/8v/x//D/8v/1//j/+P/4//f/9//1//b/9v/2//j/+f/6//j/+P/3//X/9f/3//n/+v/7//v/+//6//v///////z/+//7//3///8CAAMAAAABAAEAAQACAAMABwAHAAQABAADAAIAAQAEAAMAAAD//wMABAD+/wIAAAAAAPz//P8EAAAA/P8CAAcAAwAAAP//+f/3//j/+v///wAA+//4//n/+//6//z/AAABAP///P/8//3///8BAP///v8AAP7//f/8//z//v////3/+//8//7//P/8//3//P/6//r//P/+///////8//r//f8AAP//AAACAAUABQAEAAQABQAGAAoACQAFAAQABwAKAAoACQAJAAkACQAIAAcABwAIAAcABAADAAQABAAEAAUABgAFAAMAAwADAAMAAgADAAMABAAEAAQAAwACAAEAAQABAAMABAAFAAQABAAFAAUABQAEAAMABAAEAAQAAwABAAEAAgABAP///f/8//v/+v/6//r/+v/5//j/+P/4//j/9//4//n/+v/8//3//v/9//3//P/8//z//f/9//7/////////AQADAAQABAACAAIAAgAEAAYABwAHAAgACAAGAAYACQALAAsADAALAAsACwAKAAsADQAPAA8ADQAOABAADAAKAA0AEAALAAkADgANAAoABgAIAAcABgAHAAcABQACAAEAAQABAAIAAgABAAAA/////////f/9//r/+f/6//r/+//7//n/+f/5//n/+P/2//T/9P/0//b/9v/1//T/8//0//b/9f/1//b/9P/1//f/+P/6//v/+P/2//f/9//3//v//P/8//z/+v/5//v//f//////AAAAAAEAAQACAAIAAwAEAAQAAwADAAQAAwADAAIAAgADAAQABAAEAAQAAwADAAMAAgABAAEAAgACAAEAAQABAAEAAQAAAAAAAAAAAP7//f/9//7//v/+//7//v/+//3//f/8//v/+//6//v/+//6//n/+P/3//f/9v/1//X/9v/2//f/9//3//b/9f/1//b/9//4//r/+//7//v//P/7//v//P/+////AAAAAAEAAQABAAIAAwADAAMAAwAEAAQABQAFAAUABgAGAAcABwAGAAUABQAGAAYABgAHAAcABwAHAAYABgAGAAYABgAFAAQABAADAAMABAAEAAQABAAFAAUABQAEAAQABgAGAAYABAACAAIAAwAFAAcABgAEAAMAAgACAAMAAwADAAIAAQABAAIAAgADAAMAAgABAP///v/9//7///8AAAEAAQD///7///8AAAAAAAABAAMAAwADAAMAAwACAAIABAAEAAQABAAEAAMAAwADAAMABAAEAAMAAQAAAAMABQAEAAEA//8AAAAAAQACAAMABAAEAAMABAADAAIAAQABAAEAAAABAAUABAAAAAEA/v8AAPz//f8CAP///v8BAAIA//////3/+f/6//z/+//9//v/9v/0//j//P/7//r/+//7//n/+P/7//z//P/8//3//v/+//3//f//////AAAAAAEAAQACAAIAAQABAAEA/////wEAAgADAAMAAgAAAP7/AAACAAEA/////wEAAQABAAAAAQAEAAYABAACAAIAAwADAAQABAABAAEABAAEAAIAAgADAP//+//8//3//P/8//7/AAD+//r/+f/5//j/+v/8//z/+//5//b/9P/3//j/9f/2//v/+v/z//H/9v/6//j/9//6//z/+v/1//b/+//9//n/9f/6/wAA/P/6/wAAAAD4//f/+//7//n///8DAPv/9f/5//z/9//4/wQABgD6//b/AAACAPr/+v8AAP7/+f/7/wEAAAD9//3//P/3//j/AAADAPz/+v/+//r/8f/1/wIABQD///v//P8BAP7/+P/4//z/+v/3/wAACgAHAP3/+/////3/+f/9/wUABgADAAMABAAAAPv//f///wUACgAJAAIA/P8AAAEAAAAFABEAEQADAPn/+f/7//7/CgAUABUADwD+/+v/6/8DABQADwAIAAoABAD0//T/BAAMAAUA/f///wUACQACAPj/+/////7/AAAMAA8ABAD4/+7/5//y/xEAGAAHAPn/7v/h/+H/BgAsAB8A8v/h/+j/5v/8/ywAMQD+/9v/5f/1/wQAHwAvABsA6P/N/97///8gADoALgACAOj/7//0//b/GgAzAAsA2v/z/y4AHgD2/w8AIgDn/7f/6P80AEEALQAhAPv/wP+7//T/IwAjAAgAEgAsAP//vv/Z/ygAFgC+/87/JAAuAAcACAAJANn/u//e//r/AgA5AFAAx/84/5f/TwBWAAsAGgATAKD/Zv/T/1IAQAD2/wEADwDD/5H/4P9LAEIA6P/E/w8AHQCg/47/VwCqAPr/0/9aABUAYP+h/0cAEQD8/+AAqgAN/w3/EAHMAFT+af94AgABkP3+/ggCuABq/uf/yAFfAK7+fv+EACoAXwDLABwAk/86AIIAMf/m/qQAXAH5/yb/dQAgAYH/hv46ADACYAGo/3T/sv48/S7+AALoBGgE0gF2/oj66PiE/FwCwASgA2QCsgBQ/Uj7iP0OAXIBYwDuAB4Bjv9A/1wBygE9/5j9kv7B/5r/KwCiAdwBUACk/mT+TP9+ANoAMgC5//n/DACi/wIA+wD0ANX/Hf81/w//Uf/FAJoBmwC7/ycAEQDM/s7+ngBcAS8Aav8zAPcAPwAT/1n/YwBTAJn/w//BAOoA9v8e/2P/UQCAANr/yP+KAG8ARf8W/1gA3gAKAKr/DAD3/4D/jf8bAI4AXQDC/4j/2/8hABgA/v8IAA0A1/+Q/6//NABqABsA8f/6/7z/bv+i/ycAYQBbAEkA3P9E/zv/r/8hAIYAywBzAJL/I/+F/9r/3P8mALoAnwDH/2D/v//7/7n/z/9hAGYA1f+5/xoAKwD7//f/8v+1/5X/3f9JAHcAaAAbAK3/gP+u//b/IABJAHEAPAC0/3X/0f86AEUAOgA6APz/n/+e/+j/LQBXAFkAJgDZ/7//0//k/wIANgBBABQA7//1/wQA+P/t/wEACwD2//b/IQAoAPD/1//w//T/3v/4/zUAPwAXAO3/4/8EAA4A1f/D/xAAQAAXAP7/CwAAAOP/3P/2/yQAMgAPAOb/6P8AAAcADwAlACcAAADi/+X/9v8LAB0AIQALAPr/+P/4/+3///84AEQABwDl//v/CQD9/wUAHQAZACEAIgDt/8P/6v8fABUABwAjABcA1P/V/x0AOwAYAAAA+P/t//H/DgAtACAA8//X/+P/BgAeACEADwD8/+3/2f/l/wkADgD3//H/+//8//r/8P/s//j/AADy/9//+v8VAO7/zv8AAC4ABgDr/wYA5f+Y/7r/JgA+ABAA/v8BANr/uv/f/wsABgDz/wAAHwAdAPv/8f8HAPf/yP/X/yAAQQAbAPT/+f8CAOn/6P8RABIA7P8DAEMAOQDy/9T/9P/6/+L/DgBZAEgA+v/j//X/8v/u/woAIgAQAAYAHwAiAAAA9f8CAAcAGwA3AB8A8f/8/x8ACADs/w4ALQACANT/8v8NAOn/3f8QAC0AEgD2/+v/7////wMA/f8AAAYACgAAAAMAJAAnAPn/2f/k/+j/4v/9/ykALwAYAAcA7v/T/8//5//+/woAGwAqABEA3f/O/+f/BAAJAAIA/v///wEA+v///xkAGwD9/+r/9/8MAAMA/P8GAAgA+P/z/wQACAD3//T/BgATABkAHQAEAOf/8f8PABkAEQAHAPT/4f/r/wwAGgASAAwACwD0/9r/5P8NACQAGQAJAPz/7v/f/+f/CwAZAAIA6P/Y/8v/0f/2/yIAJwAFAOT/2v/f/+n/+v8VACAADAD8/wcACQDy/+X/8f/2//P/BwAhABMA9P/t/+f/3P/p/woAGQABAOr/7P/7/wYAEwAZAPf/xv/B/+v/JABAADIACADR/77/4v8LAAkA8P/n//b/BQAhAFIAQAD0/7L/qP/I/93/GABtAHsAOgDy/7f/gv+L/9v/NABjAFAADwDR/7r/zv/w/xAAHgAXAAAA4f/f/wcAJwASAOz/7/8LAAoA/P/8/wkADwALABEAFQAJAPj/7v/y//7/AgDx/+f//f8dABsA9//M/8T/5/8JABcAHAAUAPr/1f/G/+T/JQBjAGQAIwDV/6j/rv/a/yUAYgBXABwA1v+c/5T/1f87AGkAOwDn/6//rf/l/z0AagA+AN//nv+l/+z/RABjAC4A5P/H/9P/7v8MABEA+P/k//D/CQAZACkANgAvAP7/xv+6/8///v9FAGQAKADh/+T/BgAFAPz/9v/S/6v/0v8+AIAAYAADAKX/fP+v/wYAPgBHADsAJADr/8n/2P/2/xAAIgAXAP3/9P/m/93///9BAE0ABADI/9r/BgAEAPv/FQAsABQA8f8AABsADQDh/8v/6P8TABoAGAApADcAKQD+/9//4f/g/+z/GAA+AEcAQAAcANz/q/+7//z/IQAhACoALwAHAOf/7//g/9X/DwBRAD8ACgD4/97/xv/z/0IATAADALL/ov/W/yYATwAvAOz/q/+N/77/KQBsAE8A+//C/8X/5f8IACsARAA1AP3/z/++/8z/8/8oAFwAUQDp/4L/ev+y//T/LABGACwA3f+u/9r/HgAfAPX/5P/Z/9D/+v9DAFcAJwD3/+3/2//M/+D/9/8FADMAYAA5AAMA9v/a/7X/zv8iAEcAJAD+//n/+//5/wYADQD4/87/qf+7/xgAdAB7AC4Azv+g/5z/xP8kAHUAaAAiAO7/4v/y/wcADgD6/9j/zv/7/0QAZQA+ANT/c/9m/7L/FQBaAHkAWgD//67/of/G/+n/CAAdAB8AGgAOAAoADgAFAOT/t/+n/+H/PgBaADQADgDn/8T/x//2/zcATgAUAL//qP/e/yUAVgBQAAoAuf+p/+X/OwB0AE8A3/+R/7P/GQBzAIEAQgDk/4f/aP+4/0QAlgB5ACAAxv+h/8r/EgBBAD4AHQDz/+b/DwBBAEIA/P+Z/4r/5v82AD8ALAAaAOr/sf/J/y8AZwBKAAEA1f/T/+n/FwBCAEgAGADg/73/uv/o/yQAIADc/7z/4P8GABMALABHACUAzf+Y/6r/3f/6/xwAUwBUABUA1f+8/7L/qf/D/wUASQBgAEQAFADy/+3//f8YAA8A3v+8/8f//P81AFQATAAbANb/q/+0/8j/2P/5/yUAPAAfAPr/8f/r//f/BwD4/9j/yv/Y/wQASwBkADIA7f/W/+r/+v8CAAEA//8CABEANAA8ABMA4//N/8T/uf/V/wMA9//Y//P/JgAlAAAA7f/s/9T/uv/a/xcAUAB5AHsAQwDt/7f/rv+//+X/HwBHAEEAIgAAANP/pf+b/8v///8XADgAQgAPANT/6P8ZAAwA4//V//j/LwBMAD0AAgC3/47/pf/k/ygAYABnABUArf+L/7D//P9TAIYAZgAMALL/hP+t/wgAUQBlAEkAGwDX/4H/cf+9/xMAPwBAAC8ABQDV/9P/8v8MABEACADy/9v/7/8lAEIANQAMAN3/uv+0/9T/DQAxACcADgAMABQAJQAyAP//pv+X/+r/QQBrAF8AEACv/3H/hv/e/zcAXAA+AAMAzv+3/83/DQBLAFAADQDD/77/8P8zAE0AOAANAOH/xv/B/93/BAAeABMA7v/w/wsA+P/i/wUAOQAzAO7/wf/s/zIASABCAEYAJQDf/7z/1P8AAAQA5P/R//f/NgA6ABYAAQDj/8X/zf8HAE0AXwBCADYAPwAXANz/5f8TACgAEQDR/6b/vP8IAGMAdAAqALr/af9m/7r/OACPAH8AJADE/4z/jP/O/zkAggB1ABgAqf+A/7L/FQBpAIYAXwDu/4T/jP/5/1cAVwAiAPf/0P+t/77//P8YAPH/zP/Q/+7/AwAKABAACwAEAPn/7v/q/9T/v//1/1wAhQBDANP/lP+x/wQATABrAEoA9/+q/6L/AwB6AIgANwDO/3L/Uv+k/0YAqQB6APP/g/9u/7v/KABWACcA5P/R//v/VgCdAIAABQCV/4//2f8YACsAIgAYABgAFwD5/8n/xf/Y/9b/yv/M/+P/DQBKAIsAiwAMAGH/Gf9l/wkApgDNAHAA8v+g/53/2f8NAP//zf++//j/UwCEAGkAEwCw/3T/cf+p/wcAXAB7AFgAEwDF/4r/gf/A/x4AWQBTABMA5f8AAC8APAApAPz/yP/B//T/LQBLAEYAJgACAOn/6//5//7/CgATAPz/4f/y/xUAKAAnABQA5f+7/6//x/8CADgAPAASAO3/8P8VADMAMwAoAAcA2//P/wgAYwCHAF0AIAD6/7n/Zv9p/8b/LQBlAGkANADi/6b/mf+8/+z/DQAgAC8AQABCABMAzv/C/+r/8//i/+n/CQAaAA8ACQAKAOz/tP+l//n/ZABsACEA3P/G/9H/6v8QADcALgDv/8H/7P8lAAoA1v/Y/wEADgDu/9n/6v8RACcAIAABANv/wf/T/xYAYwB+AEAA0f+C/5H/5P8pAFQAdwBuAA0AoP+Y/87/+v8TACEAFADs/9H/5f8zAG8ANwC3/2//h//K/wgAOQBIAB4A4P/M/+v/BQD7/+b/8P8TACsAOQBGAEwANwAHAOP/zv+n/5j/3/9KAG8AKADF/5L/lP++//f/LwBNAC4A8P/V//X/HAAWAPr/9f8RACQAHQAOAPn/3P+2/7j/8v8rAD8ANgAgAAMA5f/e//X/FgAaAPj/1f/W//j/GAAmACgAGADs/7//tf/Q//n/EAAKAP7/AgAJAAcADgAYAAUA2f+6/8T/9/8zAF4AbwBPAPf/mf98/6//AwBCAEwALQAPAAUA+f/m/+L/6f/V/7P/x/8aAFMATgA2ABwA5P+j/5D/tP/0/y0AUQBUAC0A///0//3/AwAHAP//4//U//X/PgBqAE8AEgDT/53/k//A//z/JAAoAAEAzv/I/+T/BAAkADcAHgDk/8f/7/8zAFAAQwAlAAMA6v/o//r/FAAdABYACAD+//f/5//U/9r/+f8UABwAHAAjAC4AJAAIAO//2v/R/+T/EwBGAFEAKQDz/9P/2v8AACYALQATAOv/1v/i/xAAMgAtABIA+v/n/9L/1v/2/w4AAgDp/+j/8//9/w4AKAAwABoA+P/c/9L/3v/6/xQAKAA0ACgA/P/U/87/1v/T/93/CgA5ADsAEwDd/77/0P/6/x0AIgAFAND/tv/W/xYAPwAgANv/rP+9//7/NgBBACIA+f/t/xoAYABjABMAvv+h/8L//v8qAC8AFADz/+X/7v/w/9r/uf/B/wgATgBbADwAFQDz/+D/6f8NACYACwDV/9D/EgBcAGIAGQC//4z/pf/0/zUANgAFAM7/yP8OAGQAcAApAM7/n/+r/9X/CwA1ADMAAgDN/9D/CgBIAFMAIADB/2X/VP+u/z0ApgCtAE0Az/+F/4v/0f8gAEMAHADL/5v/wf8lAHoAiwBIANT/e/+C/+X/SQBqADoA6P/H////VABnABgAov9b/3L/5/95AMYAmwAbAKv/jv+8/woASABOABoA3P/F/+r/NQBxAGEA9/94/zX/a/8IAKEA2ACTAAwAl/96/87/TQB6AD0A4/+6/8z/BwBPAGMAGQCf/1r/g//w/18AkQBnAAgAvf++/wQASQBIAAAAsP+a/9b/MgBZAC0Az/98/2j/q/8aAFUARgAaAPP/6P/3/w8AIAAXAP3/6f/l//r/JABSAGMANADM/3b/b/+3/yEAYQBQAAQAv/+3//H/PgBRAPv/ef8//5T/QgDGAM4AVgCz/13/iP8FAGYAbwAyAOb/x//n/yQARwAwAPX/wf+x/8L/6f8YACsAEQDn/9P/0P/f//7/EwAKAN3/r/+u/+3/QgBwAFUAAwC4/6j/3f85AHgAbQAZAL3/qv/l/zYAVwA4APf/s/+F/4r/xf8ZAFgAYQA4APT/sP+J/5j/3f8zAGsAZgAzAPz/1//S/+r/DQAcAAUA3P/H/93/FwBFAE4AMQD3/8H/tP/Z/xIAPwBNACsA9P/M/7//1v8EACYAGwDn/6//n/++//v/OQBVADYA9//U/+b/EgAmABcAAADz//P/CQAwAEIAMAAMAOj/0v/Q/9//6v/n/9j/3/8KAD8ATQAXAMb/mP+1/wAAMgAmAPv/4//6/y0AUgBBAAUA0f/D/9r/9f/9/wAAEAAoADEAHQD4/97/4////xQADADi/73/0f8YAFIATwAVAM//qf+s/8///v8SABIAIwBMAGwAVwAQAM3/wv/2/zcAUQApAOj/yf/e/wcAEwAAAOr/4//g/+b/+/8VADEASABPADkACQDj/+3/HwBBACUA6P/E/9f/BwAiABYA7P/C/7r/5f8gADkAHADp/9P/4f8BABwAIgARAPb/3//e/wIALQArAAAA2P/K/9T/7/8iAE0AOgDy/8j/5P8XACYAAgDR/7b/vf/m/yEAPQAhAPH/2f/g/+L/0v/P//n/MwBaAGUATQARAMj/nv+k/8j/7/8HABUAJQAwADIAJAADANj/tP+u/83/AQAxAFsAcgBvAE4ADwDI/47/ff+h//b/TABwAFcAEwDU/7H/rP/B/+b/CQAoAEgAZABoAD0A7v+u/57/r//I/+v/GQA8AD8AKQAIANf/nv+Q/8L/AQAXABAAFgA2AE8ATQA2ABAA3f+y/6n/vf/O/8r/2/8hAHIAhgBIAOr/l/9z/43/0/8oAFsAUgArAA8ABwABAPX/5f/a/9X/4f8LAD4AVwBIACEAAQDv/+z/+P8OABIA/f/k/+H/+P8QABQACgADAAQAEgAmACsAEgDv/+L/9v8bADsARAAvAP//zP+9/9//DwAdAP7/2f/L/9H/7P8lAFYAUAAZAOb/4f/+/xwAKAAkABIA8//h/+7/DgAgAA0A8f/k/+P/3v/f//H/AwD//+//6//v/+z/4P/i//f/BgD6/+n/7f8CABYAIQAlAB8ADAD4//b/AwD+/+j/5P8FADEAOAAUAN//w//V/woAPAA5APf/r/+b/8X/BwA3ADYACADS/8T/4/8VADEAJAAEAOv/9f8aAEEATwA+AB0A/P/v/+r/2v/G/8b/5v8NAB0ADwDr/77/oP+q/97/GQA4ADgAJgAOAPr/8//9/wsABwDs/9n/5v8HACAAJAAaAAYA6P/T/9n/8P8JABgAHQAYAAMA8v/+/yIALwAEALf/hP+U/9v/LQBWADAA0v+G/5H/8/9cAH0AUwANANj/yP/k/x4ASwBGAA0Azf+z/8n/AgA4AEsAKgDc/4z/cf+f//f/RQBkAEgACQDd/+v/IwBIACYAzf+A/3j/uv8eAGgAbAAxAO7/1P/l//7/BwD//+7/4v/s/wwAMwBMAE4ALwD2/7v/n/+2/+j/DwARAPX/3//r/w4AIwAQAOL/w//U/xQAWQBvAEgACADg/9//8/8FAAEA8f/r//b/DQANAPL/0//I/9j/7//6/wIAFQAmACsAKgAkABAA7//e/+j/+v/7//j/CwAxAEIAKAD+/+P/3f/j//T/DgAiAB8AGwAtAEYAQQAQANL/sf+z/9X/CAA1AEQALAABAOz/+/8VAB4AEgAFAAcAEwAaABUABwDz/+//DAApABoA3f+r/63/4P8VABwA8v/A/7b/5/8yAF4ARQD8/8f/yv/4/y0ASQBAAB0A+v/r/+n/5P/b/9v/6f/y/+b/0f/K/+T/FgBAAEYAGADO/6D/t//6/zQAPQAbAPP/3v/s/xAAJAAQAOT/zP/d/wkAMwBCADQAGQD7/+f/3v/b/9v/5v8FADEATQA5AAsA4//M/8//7f8cADwAOgAiABQAHgAuACcAAgDN/57/jv+y/wQASQBMABcA3v/R/+z/FQA1ADsAHQDz/+P/+/8kADEAEwDh/8L/xf/h/wIACQDo/7D/mv/C/xMAUwBgAEYAGwDx/9X/zf/Y/+f/8v/4////CwAVABgAEgD7/9T/s/+5/+7/LwBLADgAEQDy/+v///8aACQADADa/7v/0/8ZAFcAYgAzAO3/v//N/wwAQgA8APj/sv+o/+b/OABhAEgAAAC//6v/1P8iAGAAZQAyAPH/0P/j/xgAOwAuAPj/xf+6/9z/CwAYAPD/s/+X/73/EQBXAGgASAAZAPn/8f8AABYAFQD6/9n/z//m/wkAIwAeAP3/xv+W/47/s//r/xEAFwAOABIAIwAuACMAAwDW/6b/iP+T/8X/BQA4AFkAaABXACgA7v+//6f/p//L/w4AUQBuAF8AOQAZAAYA7v/J/5j/dv+A/7r/CgBHAFkARAAgAAEA7f/i/9v/5f8IADIASgBBACkAGQASAAsA9f/Q/7D/sf/Y/w0AMQAsAAoA7P/m/+7/7P/j/+H/+v8oAE4AVQAzAPv/zP+3/7z/yv/b/+//AwAbADYARAA4ABwA/f/l/9X/1f/w/xgAOgBGADYAFADs/87/wv/E/8//4P/8/xoAKwAmAA8A+//0//7/CQAJAAcAAwACAAoAHgAlAA4A7f/f//T/FQAgAAsA6v/T/9X/8P8YADwASgA+ABwA9//k/+z/BgAdABsA+f/N/7X/v//r/xsAOAA9AC8AFADw/9D/zv/v/xsAOgBAADMAIQARAAoAAwDy/9j/wv/B/9j/AQAsAEUAQQAdAO7/0f/X//X/EgAXAAcA9v/8/xQAJgAdAPL/w/+6/+L/FwAyACcA///e/9n/8f8aADUAMgANAOD/xf/L/+z/EgAcAAQA3P/G/9//EwA/AEIAJwAPAAkAEQAWABgAFwAUAA4ABQABAAAA+v/7/wkADQD0/9H/yv/x/x8AMwApABYABAD2//z/DwAcABQACgAUADEAQwAyAAsA6P/N/7r/tv/J/+v/CQAdACcAJAAKAPD/8v8HAAwA6/+4/6X/yf8FADAAKQD7/8X/qv+5/+n/FgApAB4ACwABAAAADAApAEwAVAAqAOD/ov+X/7b/2//o/9X/sv+W/6H/2f8YADMAJQARABEAIQAvADkAOAAhAPn/4v/n//r//P/p/9v/3P/n/+z/5f/b/9P/3/8SAFkAfQBhAB4A8v/5/xwANAAxAA4A2v+1/7j/6f8dACAA8P+2/5n/sv8BAGEAkgBtABIAz//P//3/GQADAM//sv/K/wkARwBWACoA6P++/7//1v/p//f/DAApADoALQAGAOL/2v/h/9v/wv+s/7T/6f80AGMATgD8/7D/qv/t/0IAawBQABAA4v/e//r/FAAPAO3/zP/K/+r/EwAnACAACgDw/93/2f/t/xUAQABYAFEALwADAOb/6P8HACYAJwAPAPX/9P8PACkAKgAPAOf/zf/R//D/EQAlACoAKAAmACMAHgAWAAkA+v/q/9v/3P/z/xUALAAoAA8A6v/Q/83/3f/4/wsADgAIAAwAHgAyADcAKAARAPf/5v/q/wUAIwAoABYA/P/l/8b/p/+l/8P/5//5//v/+f/6////BgARABMABQD5//7/DQANAPr/7v8BAB8AIwAPAP7//P8CAAUACQAFAPL/5P/y/x8AQAAvAP//2//W/9//6P/y//z/+P/p/+X/+/8QAAoAAAAKAB8AHQABAO3/9/8SACIAHgARAAMA/f8KACYANwAfAN//nv+E/5P/uf/l/xYAPAA9ABQA5v/b/+z/+f/4/+3/3//e//7/PQB4AHkALgDR/6X/tP/a//r/DwAVAAoAAAAHABIACADn/8//2v/0/wIACAAWACYAIwAIAOn/0v++/7//6/8pAEUAJwD8//b/DAAiACEAEQD3/9D/sf+2/97/AQAEAAAADQAmAC0AHgAFAOf/w/+m/6//4v8VAC0ALQAkABMA9//j/+X/8v/x/9//2f/t/xAALAA6ADkAIADx/8L/tf/F/9z/4//e/93/6f8AABoAMAA3ACIAAgDw//b/EQAqADUALgAUAOj/vv+0/9P/BQAoACwAGwAMAAUA/P/y/+f/3f/P/87/7v8sAFwAYgBEABEA1v+l/5P/q//g/xAALQA3ADYALwApABoA///Z/6//lf+l/+D/LgBiAGIAQwAgAP//6f/h/+X/5f/X/8j/zv/1/yQARABQAEQAGADd/7r/xP/i/+//7f/6/x0AQgBVAFgAUwA9ABoA+//o/9r/xf+6/9T/BgApAC4AKgAsAC8AHwACAOj/0//E/83/9f8pAD8ALQASAAkACgAFAPf/4//L/7H/sP/T/xAAPgBRAFoAZQBkAEUAIAAFAPP/3P/J/87/4v/u//H/+P/+//H/zP+n/5r/pP+3/9H//P8uAEsASAA8ADcAMAAYAAAA+//+/+//0//C/8z/7P8FABMAFQAIAOr/2v/t/wwAEQDs/8f/x//q/xIAKQAqABUA+P/r/wIAIwAZAOf/yP/e/xIAOABFAEYAQQA4AC8AKwAWAOj/uP+3/+v/GgAYAPf/4P/c/+L/7v8DABAAAADr//z/OwBzAG8AMwDy/83/y//h//X/7//P/7b/z/8hAGkAbAAyAO//yf/C/83/6v8NABoACgD4/wUAKAA8ACgA7/+e/1P/P/9///L/TABbAC4A+v/m//H/EQArACwADgDu//L/JQBqAIwAcQAiAMb/iP+G/73/9/8HAOn/xf/P/wwATABSABQAvv+O/6j/AQBmAJUAegAwAPL/5f/7/xoAJQASAO//1//g/w4ASwBvAFoADAC3/5D/sv8FAEwAXgAyAOz/v//M/wsAQgA4APn/v/+0/9n/EgBFAE4AIADe/8L/5f8eAD4ALwD7/8D/of+z/+//IQAXAN3/sP+2/+f/GwAtABgA7P/J/87/AAA6AEQAHgDx/9f/0//c/+r/+P/3/+f/4P/w/xUANwBHAD8AFgDT/6D/pP/Y/xIAIgAGAN//0v/r/xwARQBAAAAAt/+p/+v/TgCCAGkAGwDO/7j/3P8XACwABgDF/5v/pP/V/wcAHQASAP3/8//8/xEAJgAyACgABwDl/93/6/8GAB4AHgABANL/rv+z/+f/JgBEAC8A/f/Z/9z//v8oADUAHQDq/8H/x//w/xcAGAD6/9r/yv/H/9f//P8sAEkARQAtAAwA6P/J/8L/3P8BABgAFQAJAAQA///6//v/BAAEAO//1v/T/+z/EAAnAC0AKAASAPf/6v/3/wYABQD///j/+P/7//7/DgAmACwAEADl/8b/wv/T//L/GQA1ADAAGQARABkAFwD1/83/wP/S//D/FQA+AFIARgAsABgADAD5/9//y//K/9L/5/8NADkASAAiAOf/xf/Q//D/AQD5/+v/6v8FADEAWABUACUA8//Y/9X/0//I/8b/2v/3/w0AEwAQAAgAAgD9//b/6f/U/83/7f8kAEUAPgAfAAIA9v/y//H/7v/h/9j/7/8fAEcARAAcAPb/6v/+/xkAIAAEANv/z//u/x0AMgArABwAFAAIAAEACgAXAB0AGwAdAB4AEgADAAsAKQA0AA4A2v/N/+v/EgAeABUAAwDt/+P/+v8cACAA9f/C/7z/3v8AABAAFwAYAA4AAQAJAC8ASgAyAAEA6v/x/wIAEAApADwAIwDl/8L/0f/g/8r/n/+O/57/uv/d/xEANgApAAQA8////wAA6//k/woAPABUAFYATQAyAP3/xv+q/6j/r/+6/9b/AgAjACwAKgAkABUA+f/i/+H/7//5/wEACAAMAAcA/P/2//j//f8IACQAPgA8ABkA6f/K/8H/yv/o/xQANABFAE8AVgBOACIA4P+y/6X/qP+v/8f/8f8VACUALQA3ACoA/f/U/9H/2f/L/7r/y/8EADQARQBGAEEAJQD4/9j/zv/C/6D/mP/V/zIAZgBVAC0ABADg/8f/xP/W/9z/xP+0/8//+/8RAAoA///5/+n/2v/m/woAJgAsAC4ARQBfAGcAXwBNACgA6/+0/6H/sf/F/8r/zv/c/+3//f8OABIA+v/V/8f/5f8bAEcAXQBgAFEANAAhACcALgAWAOP/vP+6/8j/3f8CACcALgAUAAEAEAAmACUADgD9//j/7f/m//f/GgAoABAA+f/5/wAA9f/p//L/AgD///X/BQAkAC0AFAD5//P/8v/i/9n/7P8AAP3/8v/5/w8AGAALAP///v/x/9n/2/8EADIAOAAdAAAA9v/9/wsAHQAcAPv/1v/V//n/HgAoABcA/v/u/+//9v/7//X/5v/j//X/GQA1ADcAIwAIAPv//f8PAB0AEwD+//f/DwA2AEkANwAEAMH/jf+E/6r/3P/5/wMACQAUACEALgA7AD8AKQD6/9L/yf/Y/+3/BAAbACQAFQAIABQALAAwABUA7f/L/7D/qv/P/xUASQBFABoA+f/1//3/BQAKAPn/zP+i/6r/7f85AFcATwA+ACkABADf/9P/2v/e/9T/1P/r/w0AMwBWAG8AZAAmANT/nf+a/7L/y//g//H/AAAWADsAZABuAEIA+P/B/7H/vf/Q/+D/5v/n//H/EQA2AEQAMgASAPX/3v/P/8v/1P/e/+r/+/8PABkAFgAWAB0AIgAWAAAA9f/5//3/+//4//r//P/9/wUADQD9/9L/sv+6/+D/+f/8//T/9f8BABAALgBCADIABgDq//j/EwASAAgAEQAbAAwA7//e/9P/u/+l/7H/2//y/+z/8P8ZAD0ALgABAOT/1P+6/6n/xf8DACgAJwAnADYANAAQAPL/BAAjACEAAADs/+//9f/v//T/BgD+/9z/y//t/yUAOwAnAAUA7f/W/8f/3f8IAB8ADQD7/wwAMgBHAD4AKAATAP7/9P///xQAGAAJAAQADwAQAPv/3v/N/8z/0P/U/9v/4v/r/wMAJwBCADwAIAALAAwAFQAYABYAEAAOABkANABDACoA7/+z/6D/rP+7/8X/x//N/+L/DAA/AFUAOwADAOH/7f8GAAkA9//e/8v/yf/o/yAARwA0APr/0v/V/+//CAAeACsAFQDn/8//7v8gACoABgDh/9j/4f/6/ysAWQBPAAcAvf+v/9j/AAAQABMADwABAPX/BwAyAEUAIADh/8X/1f/u//z/DQAkACoAGAAPACUAPAAvAAcA7v/x//j/9/8CACAAKwAIANX/vv/B/8H/vv/F/9H/0//V//j/PABsAGMAPgAqAC4AMwAsABkA9/+9/4v/kv/N/wUAEwADAO//2f/E/7r/vP+6/7H/uf/w/0kAkACoAJYAdABPACoACADp/8v/sP+s/8T/5f/0//H/6v/u//n/BwAPAA8AAgDz//H//v8PABcAHgAeABUADQAOABgAFwD+/+T/4//+/yEAPwBPAEoALwAKAPv/+//z/9r/xv/R/+7/BgARAB8AKgAfAAIA8v/5/wAA+f/1/wQAFQAPAAkAGAAvADAAEADx/+X/4f/a/9L/3P/s//L/9P8DAB0AHgABAOT/5P/7/woADwAOAAUA8f/g/+z/EAAsACUADwAKABUAGgATAAYA8v/Q/7D/tf/i/wwAGAAJAAEABAACAAcAGwAuACMAAQD0/woALQA9ADEAEwDn/7v/r//O//f//v/k/9X/5/8RADUAPQAhAPL/wf+p/8D/6/8KABQAGAAjACwAKgAkABcA+v/T/7X/s//N//j/IAA1ADMAHwANAAcABAD7/+L/wv+s/7D/0v8EACkAMAAdAAAA6f/Z/9P/1v/h//D///8TACcANwA4ACkAFgADAPP/7v/0/wAADAAJAP//9//u/9n/v/+1/8X/6P8GABkAIwAmACQAJgAtACgACADT/7P/vP/c//r/BgAKABEAHQA0AE8AVwA0APT/uP+g/6H/pf+r/7z/4v8RAEIAbgCLAHgAPAAAAOL/1//H/7X/s//H/+H//v8hAEAAQwAqAAwA+v/u/9f/x//R/+r//f8FAAwAFgAaAA4A+v/s/+D/3//o//7/FgAbAAwA/f/6//3//P/0/+v/4//b/9z/7P8DAAkA+v/j/9j/3//z/wkAFQAXAA8ACgAVAC4AQQA8ACYADQAKABgAIwAhABIA+f/h/9z/6//8//r/4P/I/8j/3f/9/xkAJgAkABYACgATACgAMwAtABwAEAAUACMANgBGAEQALwAMAOj/0f/F/7n/rP+x/8n/6P/+/xAAHwApACoAKwAwADAAIgARABIAIAAiAA8A8v/b/8//yP/L/9f/4P/f/+L/8v8JABsAIwAfABIA///x/+//8//t/+P/4f/q//z/CgASABIABwD6//v/BQAKAAMA+/8AAA4AFwAZABsAGQAMAPb/6P/h/9T/xP/D/9z/9v8BAAkAHgA4AEoAUgBPADgACwDf/8//3f/l/9T/vP+7/9j/AQAnADwAOQAgAAUACwApADUAIQD9/+///P8IAAoABQDz/9D/qP+U/5v/rf/B/9//BQAeAB0AEwAbACcAJAATAAgACAAMABgALAA3ACQA/f/d/87/wf+x/6L/n/+m/7T/1f8DACkAOAA5AD4AQAAxABYA/P/1//H/7v/3/wIACgAMABIAHQAYAPr/2//O/9P/2//i//H/AQAKABIAJAA4ADsAJgAQAAQA+v/v/+n/8P/7/wAABwAVACgAMQAuACwALwAuAB8ADQADAP//AAD8//H/5//Y/8v/yv/T/+D/5f/v/woALwBOAE8ANQAQAO//2v/a/+L/5v/t/wEALgBbAG4AXgAsAPL/xf+t/6f/p/+p/7T/zf/2/yMASQBgAGEAVAA/ACAA9//S/8P/xP/N/9f/4f/3/xQANwBXAGUAVgAsAP7/3v/J/7b/o/+h/7L/0P/0/yUAXACFAJAAfABYACUA7P/A/6n/nv+Q/4P/lf/K/wkAOABTAGQAYwBNADUAIgAGANz/s/+n/7f/z//m/wQAKgBBAEIANgAnABIA9v/i/+P/9P8CAAEA+//8//v/8f/l/9v/1P/K/8f/3P/+/xwAJQAfABsAGAASAA4AEQAVAAwA+//1//j///8HAA4AEQAFAOz/2//f//D/+v/0/+z/5//p//f/EQApACUABADg/9D/0//X/9X/0//W/+f/CgA7AGYAbwBYADQAGQAJAPT/2P/B/7T/s/++/9X/8P8AAAUABwAMAA8ACQAFAAwAFQAWAA4A///4//n/AAAHAAAA7//e/93/7/8DAAQA9v/l/+H/6P/3/wAA9//l/9f/5v8GACIAKwAqACQAFQD3/93/1//U/8v/w//K/9n/4P/u/w8ANAA3ABkAAQACAAkAAgDz/+j/3v/O/87/8v8lADoAMAAtADYAMgAZAAIABAAJAP7/+P8FAA8AAgDo/+L/7P/l/9T/1P/u/wwAGAAhAC8AMgAXAPb/8f/9//7/9v/9/xgALgA1AD0ASQBJADMAFwAKAP//4P+8/7L/wP/F/7z/vf/S/+3/AgAVACYAKgAbABAAHgA2ADoAKAAWABYAIQAlACAAEADy/87/uf+0/63/l/99/4D/qP/i/x4ASQBcAGAAYgBoAF8APAADAM7/t/+8/8z/3f/m/+f/6f/8/x4APgBBAC4AGgAQAAwACQAJAAkA+f/a/8D/wP/S/+X/8P/+/w8AGAAdADEASwBPAC4A/P/b/9L/1//m////FAAWAA0AEgApADsAMwAYAP3/6v/c/9b/3v/s/+z/2v/O/9v/+P8OABcAGQAWAAsA/v8AAAwACgDp/7//rf+1/8r/6v8XADoAQAA6AEYAZgBwAE0AEgDe/7v/p/+m/7n/x/+4/6L/sf/n/xwALwAqACMAEwD+//v/DwAkACUAIAA2AGMAgAB5AFgAKwD3/8H/mP+G/4L/gf+Q/7j/7f8RACEAKgA3AEYATgBSAFUATQA9AC0AIwAXAP3/4P/J/7r/uP/D/9v/+v8PAB4AMABJAFoAXQBRADIABgDS/6//oP+d/5//qP/E/+v/DwAoADwARwA9ACIACQD///3/+f/3////CAD///X/+f8CAAIA7v/Z/9D/0P/Z/+X/+v8LABAAEwAeADMANgAjAAgA9v/z//D/8f/y/+r/2P/G/8r/4v/7/wIAAAAFAA4AEwAVABcAEAD4/9n/zf/e//P/AAADAAkAEwARABMAIQAzACwACgDw/+f/6f/n/+D/3P/Q/7v/uf/Y/wUAGAAKAPr/+f8EABEAGQATAAIA7f/n/wMALgBJAEcANwAoABkAAgDq/9j/wf+o/5j/of/B/+f/CAAeACgAJAAaABUAFgAUAAYA8f/h/+L/8f8JABwAIAAWAAIA8v/n/+P/3v/b/9//6v/+/xIAJQAyADQALQAgAA0A+f/l/9P/yP+//7r/vv/L/93/9P8QADMAWQBwAHMAYgBFAB4A9f/T/7X/mP9+/37/nv/R/wYALABDAFEAVwBaAFkASgAhAO3/wv+0/7r/x//Y/+7/DQAtAEoAXwBmAEsAFgDg/77/rP+c/5T/nP+3/9X/9f8dAEMAUgBLAEAANgAoAAwA9v/z//f/9P/s/+r/8v/6////BAALAAgACAAPAB8AKAAbAP3/4//U/83/y//N/9f/5f/2/xIAOABbAGYAXQBKADoALAAfABMAAgDt/9j/z//Y/+r/9v/1//H/7v/1/wUAEwAWAA4AAgD8/wgAHQAuADEAJQAZABYAFwAWAA4A9//c/8X/uv+//8z/1//e/+f/9f8LACUAOgBHAEYAOwAoAAwA7v/Y/8X/s/+u/7v/1v/u/wgAIwA8AEkASwBJAEMALQAIAOf/0f+5/5r/ff9v/3T/hP+f/8n/9/8aADgAWAB1AIUAgwBzAF0AQAAfAAUA8//e/8j/uP+z/7r/wP/D/8j/z//Z/+r/AAAZAC0AOgBKAFwAZQBcAEsANgAcAPf/zv+t/5X/hP+D/5n/uv/X//L/FwBBAGMAdgB4AGsAUQA0AB8AFwAMAPD/z/+7/73/yf/Q/87/yP/B/7v/xv/f//T/+P/x//j/FQAxAD8ARgBHAEEAMQAlACQAIgAXAAoABQABAO//1P/D/7//uv+w/67/vP/Q/+b/AQAaACgAKgAoAC4ANAAvACQAGAATABEAEwAWABgAFgAQAA8AEQASAA4ABAAGAAwAEAAVABMADwAHAP7/8//h/8n/tP+r/7D/vv/O/+P/+/8UAC8ASQBcAGIAWwBSAEkAOwApABgADAACAPj/8v/v/+7/7f/r/+n/4//a/8v/vv+5/7b/vv/K/9f/6v8AABkALgA7AEIAPAAyACYAFwAIAO//1P+9/7T/uP/K/+P/+v8UACwARQBQAEYAKgD+/9H/r/+f/57/pf+0/9H/9v8eAD4AUgBXAEoAMwAYAP3/3//F/7z/wv/P/9//7/8FABkAKQA2ADcALgAYAAAA7P/d/83/u/+2/8H/1f/p/wcAKQBHAFYAUQBFAC4ADADu/9j/x/+0/6H/oP+2/9T/7P8BABwANABAAEgATQBFAC0ADQD0/+T/1v/G/8T/1v/r//z/DAAeAC0ANQA4ADUALQAYAPf/2P/G/73/sf+p/6v/u//R/+v/CwAnADgAOwA1ADEALgAkABUACQD+//H/5f/l/+z/8//1//b/+f/6//n//v8JABAACwABAP7/BQAIAAUA/f/1/+z/4//g/+f/7f/p/+P/5//z/wUAFQAjAC0ALQAoACUAKAAoABwABgDz/+n/5v/m/+f/6v/t//P//v8OAB8AJgAmACIAGwAPAAAA7//g/9X/zP/G/8b/0P/i//n/EQAlADIAOAA7ADwAOAAqABUAAQD1//H/9/8BAAsADQAKAAYA///1/+n/4P/Y/9D/yv/N/9f/4v/r//T//f8DAAoAGQAvAEEASABGAEQARAA9AC4AIAAVAAYA8//o/+f/6v/r/+3/+f8CAAQAAgAFAA0ABADz/+b/5//q/+3//v8MABYAFgAcACoANwA3ACwAHQARAAsACAAJAAUA+v/q/+X/6f/t/+n/3f/U/9H/0v/b/+T/6P/p/+f/7//7/wMABgAEAAcAEQAfADAAPwBEAEYAQgA9ADkAKQAPAO//z/+w/5f/gf9z/27/av9s/4D/pv/V/woAPQBlAIIAkgCYAJYAhgBnADoACADc/7b/mv+G/3z/fP+K/6T/yP/0/yAAQwBcAGoAcQBuAGEASQArAAcA4f/A/6r/nf+Y/5//sv/N/+v/BgAgADgASQBQAEwAQgA0ACUAFgALAAEA9f/r/+n/7f/0//b/8v/r/+T/3P/V/9H/zP/H/8j/1P/r/wYAIAA4AE0AXQBkAGAAUQA2ABMA7//P/7X/ov+a/5//r//B/9L/4//2/wkAGQAoADAAMQAsACUAIAAZAA4A/v/x/+v/7f/2/wAACQAOABEAEwAXABoAGQASAAcA/f/4//f/+f/6//7/BAALABEAFAAVAA8ABAD2/+r/4v/c/93/5v/5/xIAKgA+AEsAUABKAD0ALAAVAPX/1P+9/7X/u//K/+D/9/8OACUAPABNAFUAUQBCADAAGwADAOv/1P/B/7L/qP+n/6z/uv/P/+j/AgAaAC8APgBIAEoAQwAxABgA///r/93/0//L/8f/yP/P/93/7/8DAA8AFgAZABwAHQAZABAABAD1/+T/1//P/8z/zf/P/9f/4v/0/wwAJQA6AEcATQBNAEYAOgAlAAwA8P/a/8n/v/+8/8P/yf/L/9n/5f/3/wIACQAWABkAFgAbAB8AGgAMAPv/7//r/+r/6P/q/+3/6v/p//L/AQAIAAgACQAOABMAEwAPAA0ACgADAPz/+P/5//f/8//0//f/+v/6//j/9//5//r/+P/0//D/7P/r/+//9v/8//7//v/+////AQADAAMAAwACAAQACQARABgAHQAfACAAHQAWAA0ABgD///T/5f/W/87/zf/O/9D/1P/b/+P/7////xEAIQAsADMAOQA6ADUAKwAdAAwA+f/p/9//2//b/9z/3v/j/+z/9v8AAAkADwASABIAEAAOAAgA/v/y/+f/4P/c/9z/4P/o//T/BAATACIALwA4AD0AOwAxACAACgDy/93/y/+//7j/uf/G/9v/9/8TACkANgA6ADUAKgAZAAUA8P/d/8//yf/L/9T/4P/u//r/AwAJAA0AEgAVABYAEwAPAAwACwAKAAoACgAMAA0ADQAQABQAGAAaABoAHQAbABcADQAFAAAA8//q/+X/6P/p/+3/+v8FAA0ADgAVABwAIQAjACEAHgAZABYAFwAZABcAEQAHAAIA///8//b/7f/m/+H/4v/r//P//f8DAAgAEgAbAB0AGgAQAAcAAAD7//r/9//x/+//8f/7/wwAFwAeACMAIwAhAB0AEwADAO3/0v+3/6n/pP+n/7T/w//W/+3/BwAkAEAAVABeAF4AVwBKADkAIgAHAOn/y/+z/6T/n/+j/6//wf/Y//L/EAAvAEkAWgBeAFcARgAwABYA+f/c/8H/r/+m/6f/sf/B/9b/7/8IACAANQBFAE4AUgBRAEsAQQAzACMAEQD//+v/1v/C/7D/ov+Z/5b/mv+i/7H/x//k/wMAIwA+AFUAZQBtAG0AYgBNADAADwDv/9P/u/+o/5z/lv+V/5r/pf+1/8r/4v/9/xgAMABEAFEAWABWAEwAOgAiAAoA8v/f/9H/yP/E/8X/zf/Y/+j/9/8EAA0AFAAaACAAIwAkACIAHAAUAAkA/P/v/+H/1P/J/8L/wv/J/9j/7f8GACIAPABRAF8AYwBeAFIAQAApAAwA7v/X/8n/xf/J/9H/2f/j//D///8OABgAHAAbABkAFgASAA4ABwAAAPj/8v/w//D/8//4/wEADAAXACEAJwAqACgAIAAUAAQA9f/o/97/2P/U/9P/1f/c/+b/9f8EABAAGQAgACcAKwAqACQAGgANAAAA9P/r/+f/5v/p/+7/+P8HABkAKAAyADMAMQAoABoACQDz/97/yf+//7v/wP/K/93/8P///xcAKAA7AEIAQgBDADYAJgAaAAsA9v/f/8v/vv+7/8D/yf/Y/+j/9/8IAB4ANQBAAEIAPgA3ACwAHgANAP3/7f/e/9P/0P/U/9n/4P/q//X/AAAJAA8AFAAVABMADQAGAP//+P/0//T/9//6//7/AQAGAAsAEgAYABsAHAAaABcAFAAQAAoAAQD3/+7/5P/b/9X/1P/W/9f/2v/f/+j/9v8DAA8AGQAiACgALQAwADEALQAkABgACwD8/+z/3v/S/8r/xf/H/9D/3f/t//v/BgAPABUAGQAaABcAEgAMAAYAAQAAAP/////9//z//f/+/wAAAQACAAMABAAEAAIAAAD9//f/7//m/9z/0//P/9D/1//i//L/BAAZAC8AQgBMAEoAPQAmAAkA6v/L/7H/nf+T/5T/of+4/9X/9P8QACYANQA8AD0AOQAxACUAFQAFAPj/7//q/+j/6v/u//T/+/8EAA0AFQAYABcAEwAKAP3/7P/b/8//wP+7/73/y//c//T/FAAwAEkAWQBmAGkAZABUAD0AHwD//+P/zf++/7P/rv+w/7v/zP/i//j/CgAaACYAMQA7AD4APAA1ACcAHAAPAAIA9P/m/9z/1//Y/+D/6P/w//r/BAASACAAJwAoACMAGgAPAAUA+f/r/93/z//E/8P/yf/T/+L/7//7/wgAFQAiAC8AOAA7ADoANgAwACoAHwARAAAA7P/Z/8j/vP+1/7L/tf+7/8j/2v/y/wwAJAA4AEYATgBSAFEASgA9ACoAFQD//+r/1//H/7r/s/+y/7f/w//W/+3/CAAlAEEAWQBpAHIAcABkAEwAKQAAANX/rP+J/3D/Y/9i/3H/jf+1/+X/FwBHAHAAkACiAKcAnQCDAF8AMwADANb/rf+M/3X/aP9l/2//g/+g/8T/6/8UADkAVwBtAHcAdwBsAFgAPAAcAPz/4P/K/7z/tf+1/7v/xv/U/+T/8v/+/wYACwAOABEAFAAWABgAGAAXABUAEgAOAAgAAAD3/+3/5v/i/+L/5v/t//f/AwAOABgAIQAnACsALgAtACgAIQAaABQAEAALAAMA+P/r/9//1//R/83/y//M/9P/3//x/wUAGQAsADsARgBNAE8ASwBDADUAJQATAAAA7f/b/8v/vv+1/7D/sf+5/8b/2P/s/wAAFAAoADoASQBUAFcAVABMAEEAMgAgAAsA9f/f/8v/vP+y/6//sv+6/8X/1f/q/wIAGAAqADYAPwBDAEEAPAAxACUAFQAKAP//+P/y//H/7v/o/+v/5//q/+f/4v/k/9//3P/g/+X/5//q//D/+f8GABUAIQAtADYAOQA5ADoAOAAtAB0ADAD6/+j/1//J/7//uP+3/7r/w//S/+L/8v8DABMAIAApAC0ALgArACUAHAASAAgAAAD6//j/+P/5//z//v//////AAD///r/9P/r/+P/3f/a/9n/2f/f/+n/9f8CABIAIwAyADwAPwA9ADYALAAcAAcA8P/a/8b/tv+t/6r/rf+3/8b/2v/x/wkAHwAzAEMATABPAEwARAA1ACIACQDx/9r/x/+4/7H/sP+1/8D/0f/m//3/EgAkADEAOQA9ADsAMwApABoACwD7/+z/3//U/83/yP/G/8j/zf/X/+T/9P8FABYAJgA1AEEASQBJAEEAMgAdAAQA6v/Q/7n/p/+b/5j/nf+q/77/1v/w/woAIgA2AEcAUwBaAFkAUQBCAC8AGwAEAO3/2P/F/7j/sP+v/7X/wf/S/+X//P8SACUAMwA9AEQAQAA6AC8AJAAUAAQA+P/q/9//1v/T/9T/2f/i/+z/+P8FABQAIwAvADgAPAA6ADYALgAjABUABAD0/+T/2f/U/9D/0//Z/+D/7v/7/wgAFQAeACYALAAvADAALQAmAB8AFgAPAAkA///2/+7/5v/h/+D/3v/d/+D/4f/k/+3/9f/+/wkAEQAWABsAHQAeAB4AGgAVAA4ABgD///n/8//u/+r/5//m/+j/6//w//b//P8CAAcADAAQABMAFAARAAwABgD///r/9P/w/+3/7P/u//H/9f/6////BAAIAAsADgAPAA8ADwAOAA0ADAALAAkABwAFAAIA/v/5//T/7//r/+j/5f/k/+X/5//r//H/+P///wcADgAUABgAGwAaABgAEwANAAUA/f/1/+3/5v/f/9v/2f/a/97/4//r//T//f8FAAwAEQATABMAEAALAAYAAAD6//X/8f/u/+3/7f/v//H/9P/3//r//P///wIABQAHAAkACQAJAAcABQADAAAA/f/5//b/8//x//H/8f/z//b/+f/9/wEABQAJAA0AEQAVABcAGAAZABsAHQAdABsAFwAQAAoAAwD8//T/7P/l/+D/3v/e/+L/5//u//f/AQAMABYAHgAmACsALQAuACsAJgAeABQACgD+//P/6v/j/97/2//b/9z/3//k/+v/9P/+/wcADwAXAB4AJQAoACgAJgAiABwAFAALAAMA+//z/+3/5//k/+X/5v/o/+r/7//0//j//v8CAAYACAAOABIAFgAYAB0AHgAcAB0AGAAXAA8ABgAEAPn/7//r/+X/3v/a/9n/2f/d/+T/6v/z//7/BgAPABkAIwAoACoAKwApACUAHgAVAAwAAgD4/+7/5v/i/97/2//d/9//5P/r//H/+P///wUACwAPABIAFAAVABYAFQATABEADgAKAAUAAQD+//r/9v/y//D/7v/u/+//8P/y//b/+v/9/wEABgALAA4ADwAOAA4ADgAMAAkABAD///v/9//z//H/8P/w//H/9P/3//r//v8CAAUABwAIAAkACQAIAAUAAgD+//v/+P/2//X/9v/3//j/+//+/wIABQAHAAkACgAJAAgABgADAP///P/4//T/8f/v/+7/7f/t/+//8f/0//j//P8AAAMABgAKAA0ADwAQAA8ADAAIAAMA/f/3//D/6f/k/+D/3//f/+L/5v/r//H/9//9/wIABwALAA0ADQALAAkABgADAP//+//4//b/8//y//L/8//1//f/+/8AAAQABgAIAAwACgAJAAcABwADAP7//f/5//f/9P/1//b/9//6//3///8CAAcACwAOABIAEwATABQAEwARAA4ACQAFAP//+//5//X/9f/1//X/+P/7//7/AgAEAAcACgALAA0ADQAMAA0ACwALAAoABwAFAAQAAQAAAAAA/v/8//v/+f/4//n/+f/5//z//P/9//7///8AAAIAAgACAAIAAgACAAIAAgABAAAAAAAAAAAAAAAAAAAAAAAAAAEAAQACAAMAAwADAAMAAgABAAEAAAD///3//f/8//z//P/9//3//v///wAAAQABAAIAAwAEAAUABgAHAAgACQAJAAkACQAHAAUAAwAAAP3/+v/3//X/8//y//L/8v/0//b/+f/8////AgAEAAUABgAFAAUABAACAAAA/v/7//j/9v/0//L/8f/x//L/8//1//f/+v/8//7///8AAAEAAQAAAP///f/7//r/+P/3//b/9f/1//X/9v/3//n//P/+/wEABAAFAAcACAAIAAgABgAEAAEA/f/6//j/9v/0//T/9P/1//f/+f/8////AgAFAAYACAAJAAoADAAOAA8ADgAOAA4ADQANAAsACQAFAAIA///8//r/+P/3//f/9//4//n/+v/8////AgAGAAkADAAOABAAEQARAA8ADgAMAAkABwAEAAEA/v/7//n/+f/4//j/+P/5//v//f/+/wAAAgAEAAcACAAJAAsADAAMAAwACwALAAsACgAJAAYABQACAAAA/f/6//f/8//z//P/9P/0//n//P/+/wQABwAOAA8AEAAWABMAEgATABAACwAGAAEA/f/5//b/8f/v/+//7f/t//D/9P/2//j//P8BAAUACAALAA0ADwAQABAADwAOAAwACQAGAAMAAAD9//r/+P/2//X/9P/z//P/9P/2//j/+v/8////AQADAAQABgAHAAgABwAGAAUABAAEAAMAAQAAAAAA///9//v/+//7//r/+P/3//b/+P/4//n/+f/7//z//v///wEAAgADAAQABQAFAAQAAgABAP///f/7//n/9//3//b/9f/0//X/9v/3//j/+f/7//3///8BAAMABAAFAAUABQAEAAMAAgABAAAA/v/9//v/+f/4//f/9f/1//T/9f/1//f/+P/5//r//P/9////AQADAAMABAAEAAMAAgAAAP7/+//4//b/9f/0//T/9P/2//f/+P/6//z//f/+/////v/9//v/+v/5//j/9//3//j/+P/5//r//P/+////AgAEAAcABwAIAAoACAAIAAYABgAEAAAAAAD+//z/+v/6//r/+v/8//3//v///wIABAAFAAcACAAIAAoACgAKAAoACQAIAAYABQAFAAIAAwACAAEAAwADAAMABAADAAQABAADAAQAAgACAAIAAQACAAQAAwADAAQABAAFAAcABgAGAAYAAwACAAIAAQAAAAAA/v/9//7//f/9//3//f/9//7//v/+//7//v/9//3//f/9//3//f/+//7//v/+//////8AAAEAAgADAAMAAwADAAMAAwADAAIAAQAAAP///v/9//z/+//6//r/+v/6//r/+v/7//z//f///wEABAAGAAcACAAJAAkACAAHAAUAAwABAP7//P/6//j/9//2//b/9//5//v//f/+////AAAAAAAAAAAAAP///v/9//v/+v/5//j/9//3//f/9//4//n/+v/8//3//v///wAAAAD//////v/8//v/+v/5//j/9//2//b/9v/3//j/+v/8//7/AAABAAMABAAFAAYABgAFAAQAAwABAAAA/v/9//z//P/8//z//P/9//7///8AAAAAAAD//wAAAQACAAMABAAFAAYACQALAA0ADgAOAA0ADQAMAAoACQAHAAYABAADAAEA///+//3//f/9//7///8AAAEAAwAEAAUABQAGAAcACAAJAAgACAAIAAcABwAGAAUAAwACAAEAAAD///3//P/8//z/+//7//z//v///wAAAQADAAUABwAIAAgACgAKAAoACQAIAAUAAgAAAP7//P/5//r/+f/4//r/+f/9//3//f8DAAIABAAIAAkACQAIAAgACAAIAAcABAADAAIA///8//v/+//5//f/9//3//f/9//4//n/+//9////AAACAAQABAAFAAYABgAGAAYABQAEAAMAAgAAAP///v/8//z/+//6//r/+v/5//n/+f/6//v/+//7//v//P/+//////8BAAMABAADAAMABAAFAAQAAgD///7//v/9//v/+v/5//n/+f/6//r/+//8//3///8AAAAAAQABAAIAAQAAAP////////7//f/8//z/+//6//n/+f/5//j/+P/5//r/+//7//z//f/+//////8AAAIAAwADAAMAAwACAAEAAAD+//z/+v/5//j/9//2//X/9f/1//b/+P/6//v//f///wEAAgADAAIAAgAAAP///v/8//v/+v/6//r/+v/6//v/+//9//3//f/8//v/+v/5//j/9//3//f/9//3//b/9//4//j/+v/8//////8BAAQABAAFAAUACAAHAAYABwAFAAQAAQABAAAA/v/+//7//f/9//7//////wEAAgACAAQABgAHAAkACQAKAAkACQAJAAcACAAHAAUABgAFAAQABAADAAQAAwADAAMAAgABAAIAAQACAAMAAgACAAMAAwAEAAcABwAHAAgABwAGAAcABQAEAAUAAwABAAEA///+//7//f/8//z//P/7//v/+//7//v//P/8//3//v/+////AAAAAAAAAAAAAAEAAQAAAAAAAAAAAP///////////////////////////////wAAAAD//////v/9//3//f/9//3//v///wAAAQADAAMABAAFAAUABQAFAAQAAwACAAAA/v/9//v/+//6//r/+//8//z//f/9//7///8AAAAAAQABAAEAAQAAAP///v/8//v/+f/4//f/9v/1//X/9f/2//b/9//4//n/+v/7//z//P/9//3//f/9//z//P/7//r/+v/6//v/+//7//v//P/8//3//v///////////////////////////wAAAAABAAIAAwAEAAQAAwADAAIAAgACAAIAAQAAAAAAAQACAAQABQAGAAYABwAIAAgACQAJAAoACwALAAsACgAKAAkACAAIAAcABwAGAAUABQAEAAMAAwACAAIAAgACAAIAAgACAAIAAgADAAMAAwAEAAUABgAGAAYABQAFAAUAAwACAAEAAQAAAP///f/8//z//P/7//v//f/+////AAABAAIAAQACAAIAAgAAAAIAAQD//wAA/f8AAP7//P8AAP3//f8AAAAA/////wAAAAABAAIAAQACAAMAAgABAAEAAwABAAAA/////////f/8//z//P/8//z/+//8//3//P/9//7//v//////AAAAAAEAAQABAAEAAQABAAEAAQAAAAAAAAD//////////////v/9//z/+//7//v/+f/6//v/+//7//v//P/+///////+//7/AAAAAAAA/////////v/+//3//P/8//z//P/8//v/+//7//z/+//7//v/+//7//v/+//7//z//P/8//z//P/7//v/+v/7//v/+//7//v/+//7//r/+v/6//r/+//8//z//f/+//7////////////////////+//7//P/7//v/+//7//r/+//8//3//v8AAAEAAQABAAIAAgACAAEAAQAAAAAA//////////8AAAAAAAAAAAAAAAAAAP/////////////+//3//f/9//v/+//8//z/+v/7//3//P/8//z/////////AgACAAMAAgADAAMAAwAEAAMAAwACAAIAAgABAAEAAQD//wAAAAABAAIAAwAEAAMABAAFAAQABgAGAAQABgAFAAUABgAFAAYABgAFAAYABQAEAAUABAAEAAUABAADAAQAAgADAAQABAAEAAYABAAEAAUABAAEAAUABAAEAAQAAwACAAIAAQABAAAAAAD//////v/9//z//P/7//v/+//6//r/+v/6//r/+f/5//r/+v/6//r/+v/6//r/+//6//r/+v/6//r/+f/5//n/+f/6//r/+//7//v/+//7//v/+v/6//n/+f/5//n/+f/6//r/+//8//3//v8AAAEAAgADAAQABAAEAAQABAAEAAQABAADAAMAAwACAAIAAgACAAIAAgADAAMAAwAEAAQABQAFAAUABQAFAAUABQAEAAQABAADAAMAAgACAAEAAQAAAAAAAAAAAAAAAAAAAAAAAAD//////v/+//7//v/9//3//f/9//7//v///////////////////////v/+//3//f/8//z//P/9//3//P/8//z//P/9//3//f/8//z//f/+//////8AAAAAAQABAAEAAgACAAMABAAEAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABgAGAAYABgAGAAYABgAGAAUABQAEAAQABQAEAAMAAwADAAMAAgABAAEAAQABAAEA///+//7//f/8//r/+v/5//j/+P/4//j/9v/2//b/9f/z//X/9P/y//P/8f/z//H/7//y/+//7v/x//H/8f/x//L/8//0//b/9v/3//n/+P/3//j/+v/5//j/+f/5//n/+P/4//j/+P/4//j/+P/5//n/+P/5//r/+//8//3//v///wEAAgADAAMABAAEAAQABAAEAAQABAAEAAMAAwAEAAQABAAEAAQABAAEAAQAAwADAAUABQAEAAMABAAFAAYABQAEAAQABQAFAAUABQAFAAYABgAGAAYABgAFAAUABQAFAAQAAwADAAMAAwADAAIAAgACAAIAAQABAAAAAAD///7//f/8//r/+f/5//j/+f/4//j/+P/5//n/+f/5//r/+v/7//z//f/+//7///8AAAEAAgADAAQABgAHAAgACAAJAAkACgAKAAoACgAKAAsACwAMAA0ADwAPABAAEQASABMAEwATABMAEgARABAADwAPAA4ADgAMAAsACwAKAAkACQAIAAgACAAIAAYABwAGAAYABQAFAAUABAAEAAQAAgABAAEAAQD///3//f/7//r/+P/4//b/9f/1//X/9f/0//X/9f/1//b/9v/2//b/9//3//n/+P/6//r/+v/8//z//P/+//3///8BAAEABQAFAAcACgAMAA8AEQASABUAFwAaAB0AHwAgACEAIwAjACMAJAAlACcAJgAlACUAIwAhACAAHwAcABkAFQAOAAwABwACAP7/+f/1//D/6//n/+L/3f/a/9b/0//P/83/zP/J/8b/xf/D/8P/wf/B/8H/v//A/8L/wv/D/8X/x//J/8z/zv/Q/9P/1v/Y/9v/3v/g/+L/5f/n/+r/6v/s/+3/7v/v//D/8P/w//D/8P/w//L/9P/z//P/9P/2//b/9f/0//L/8P/u/+3/6//q/+r/6v/s/+z/7v/x//X/+/8AAAcADwAYACAAKgA1AEAATABVAGAAbAB4AIMAjwCbAKcAsgC+AMcA0QDcAOIA6QDwAPMA9wD3APUA8wDtAOcA3QDQAMQAtQCkAJAAeQBjAEwANAAZAAQA6f/O/7b/nv+F/23/WP9C/yz/HP8L//r+8P7m/t7+1v7S/sr+xv7A/sD+uv6y/qr+pP6g/pT+iv6A/nb+aP5Y/k7+QP4y/iT+HP4U/gj+Av4A/gD+BP4K/hb+JP44/lL+dP6Y/sT++v4x/3D/uP8HAFoAsAAQAXAB0gE8AqQCDAN0A9wDQASgBPgEUAWgBegFIAZQBoAGmAa4BrgGsAagBoAGUAYYBtAFgAUoBcAEWATgA2QD4AJYAsoBNgGjABIAf//m/mD+0P1I/cT8PPzI+0j70Ppo+gj6qPlY+RD5wPh4+ED4EPjg98D3oPeA93D3cPeA94D3kPew9+D3IPho+Lj4EPmA+fD5cPr4+oj7IPzE/Gj9Fv68/mX/EAC8AGYBCAKkAjQDwANABLAEGAV4BcgFEAZIBnAGmAawBsAGwAa4BqgGkAZoBkAGEAbgBbAFcAUwBegEoARgBCAE3AOUA1ADEAPMAowCSAIEAsQBhAFKAQgBxwCOAFUAHwDx/8X/oP+A/2f/Vv9G/z3/Qf9I/1j/af9+/5f/sv/T//n/JQBJAG4AkwDDAO0AFAEwAUoBXgFsAWwBXAFIAR4B8QCpAFIA7P9x/+D+RP6c/ej8JPxo+6j66Pk4+YD44PdQ98D2YPYA9sD1oPWg9cD18PVQ9tD2YPcI+ND4oPl4+mj7XPxY/V7+ZP9fAFIBRAI0AxAE0AR4BRgGoAYQB1gHiAegB5gHiAdgBxgHuAZABtgFUAXIBCgEkAP8AmQC3AFUAdMAWAD1/4n/T/8A/8r+pv6U/oz+oP7K/vz+QP+K//X/TwDBADoBtgEsArACMAOwAzAEoAQYBYAF6AVIBqAG6AY4B2gHqAfYB/AHEAgQCBAIEAj4B9AHkAdYBxAHuAZYBugFcAX4BFgE0AMYA2ACtgHsADYAX/9w/nD9ZPxA+yj6+PjA95D2UPUw9BDzEPIw8WDwoO9A7+DuoO6g7qDu4O5g7wDwoPBw8WDyYPOA9ND1APdY+Lj5IPuU/AL+X//CABwCZAOYBKgFsAaYB2AIEAmQCfAJQApgCnAKYAogCuAJgAkQCaAIAAhoB8AGKAaQBegEOASUA/QCYALcAVoB4QBuAA8Axv+E/0D/Df/q/tD+yP7S/t7+9P4o/2P/pv/8/0sAnAAGAWwB4AFUArQCMAOcAxgEiATwBGAFwAUgBmgGsAbgBhAHIAcwBygHGAfoBqAGUAb4BZAFCAWIBOgDXAOgAvgBNAFsAKL/zv7g/fD86PvI+rj5iPhw90D2IPUQ9CDzQPJw8bDwMPDg74DvYO9g76Dv4O9w8ADxwPGg8qDzwPQA9jD3gPjg+Uj7pPwK/mf/vgAMAkQDeASQBZAGeAdACAAJgAnwCUAKcAqACoAKUAoQCrAJQAnACDAIgAfQBiAGaAWgBOQDNAOEAtgBRAG2AD8A1v+C/zP//P7a/sb+wP7U/uz+F/9J/4X/2f87AJMABAF2AfoBdAL8AogDCASYBBgFoAUgBqgGEAeYBwAIcAjACAAJMAlgCWAJYAlACRAJwAhgCAAIcAfYBjAGiAXABPADGAM0Al4BcACZ/7b+sP2Y/ID7WPo4+QD4wPaA9TD0EPPw8eDw4O8A72Du4O2A7UDtQO1A7aDtAO6g7kDvMPAw8XDysPMA9WD2wPdI+dj6dPwA/on/AgGAAugDMAVgBoAHkAhwCTAKwApAC6AL4AvwC/ALwAuACyALwApACrAJEAlQCIgHyAYABjgFcASkA+QCNAKCAeIAVQDJ/03/6v6Y/kj+EP7w/dT93P34/SL+XP6e/gD/dP/r/20A/ACMASQCyAJ0AxAEqARIBegFiAYYB7AHMAigCAAJcAmwCdAJ4AngCdAJsAlwCRAJsAggCKAHAAdQBoAFoAS8A9ACygHaANL/1v7Q/bz8oPtY+gj50PeA9iD10PNw8kDxMPBA72DuwO1A7eDsoOyA7MDs4OxA7eDtoO6A74DwkPHA8hD0gPUA92j44Plo+/z8iv4ZAIgB8AJIBJgFyAbQB9AIoAlQCuAKQAuQC7ALwAuwC4ALMAvQCkAKsAkACVAIcAeoBrgF4AT0AxwDRAJmAagA3f81/5T+GP6M/TT93Pys/Ij8fPyY/MD8/PxM/cj9NP7U/lX/EAC1AIABRAIAA9gDoARwBTAG+AaoB4AIIAnQCWAK4ApgC7AL8AsgDCAMEAzQC4ALMAuwCiAKcAmgCNAH2AbYBcgEoAN0Ak4BIAAa//T9qPxo+yD6yPhw9xD2oPRQ8+DxoPBg7yDuIO1g7MDrIOvA6qDqoOrA6iDroOtA7CDtQO6A78DwMPKw81D1APfA+Gj6LPz0/bf/eAEcA6gEEAaIB+AIIAogCwAMwAxgDeANIA5QDkAOEA7QDXAN4AxADIALsArQCeAI2Ae4BqgFmASUA5ACiAGFAJP/wP4I/mD9xPxE/MD7cPtI+zD7OPtI+3j70PtE/Mz8XP38/bz+h/9jAEwBLAIEA/AD4ATQBaAGWAcQCMAIcAkgCpAKAAtgC6AL8AsADPAL0AuAC1AL4ApQCqAJ4AggCFAHcAZYBUAEAAPuAdgA1P++/pj9gPxY+zj6APnA91D2APWg8zDy0PBg7yDuIO1A7IDrwOog6uDpwOkA6kDqoOpA6wDsIO1A7qDvMPHA8nD0YPY4+Bj6CPz8/ez/2gG8A4AFMAfACEAKoAvADKANYA4QD6AP4A/wD9APkA8wD7AOAA4wDVAMQAsgCvAIuAdgBhgFzAOIAkwBEwDy/uD97PwQ/Fj7qPoQ+pj5UPkg+RD5EPko+Wj5yPlI+uj6oPtc/Cz9JP4t/zMATAFUAnQDiASgBZgGiAdwCEAJIArwCqALEAxwDOAMQA1gDZANgA1ADQANsAxADIAL0AogClAJkAigB3gGQAUIBOQCygGNADf/7P3E/Jj7WPoA+bD3QPbg9IDzAPKQ8CDv4O3A7MDr4Oog6qDpYOlg6WDpgOng6YDqQOtg7IDt4O5Q8ODxsPOg9aD3iPmI+4j9hv+EAWQDOAUAB6AIIAqQC8AM4A3ADoAPIBCgEOAQ4BDAEKAQQBDQDyAPQA5QDTAMIAvgCZAIQAfgBXgEMAPQAWUAFP/Y/dD80Pvw+hj6aPnY+Jj4UPgo+Bj4MPiI+Pj4kPkg+uD6sPu4/Lz94v7g/+EAFAI8A1gEaAVoBkgHQAgwCTAK0ApwCwAMoAwgDXANwA3ADdAN0A2QDTANoAzwC1ALsArwCeAIwAeIBlgFOATwApIBTwDu/rj9oPxw+yD6wPhQ9xD2oPQw88DxQPAA78DtwOzA6+DqIOrg6YDpgOlg6aDpIOrg6sDrAO0g7oDvAPHA8rD0kPZ4+Ej6YPxe/m0AVAIwBOAFoAcwCbAK0AvADNANoA5gD9APIBAgECAQwA9wD+AOIA5ADVAMQAsgCuAIiAdABugEoAMwAuQAhv8w/gT94Pvg+vj5GPlg+PD3gPdQ90D3QPeA9+D3gPgw+ej50Pq4++j8Jv5a/7cABAJwA9gEIAZQB3AIgAmgCpALUAwADZANIA6gDgAPEA8gDwAP8A6gDkAOoA3wDCAMUAuACoAJUAhABzgGEAXEAzgCwQB5/1j+NP0M/ND6iPlA+DD3EPbQ9GDz8PGQ8EDvAO7A7MDrwOpA6qDpYOkA6eDoIOmg6UDqIOtA7GDt4O5g8CDy8PPg9cD3yPnY+/D9BAAUAhAE8AWgBzAJoArgCxANEA7wDpAP8A9AEEAQQBAAEJAP0A4wDmANYAxgCxAK0AigB1AG+ASQAzgC4QCR/0r+BP3A+8D6wPng+Cj4cPfg9qD2gPaQ9rD28PaA9zD4APnY+fD6APw8/ZT+6P9YAdwCeATwBWAHsAgACkALUAxQDSAO0A5QD8APQBCAEGAQQBAAELAPIA+ADsAN0AwQDBALAArQCKgHoAaABUAE7AJ+AfT/mv5Y/VT8OPsY+vD40PfQ9rD1oPRw80DyAPHA74DugO1g7KDrAOtA6uDpoOmA6aDp4OmA6iDrAOxA7aDuQPAA8sDzoPWg95j5kPu0/ab/vAHQA9AFkAcwCcAKAAxgDWAOQA/ADyAQgBCgEIAQIBCwD/AOQA4wDSAM0AqQCTAI+AaABfwDhAIIAbH/Vv4A/Yj7OPow+WD4cPeg9gD2cPVA9TD1UPWQ9dD1gPZg90D4SPlg+pD7KP2s/jsA0gFwAzAF4AbQCFAKoAsADUAOYA9AEAARYBHAESASYBJgEkAS4BGAEQARYBCQD4AOYA1QDEALIArQCEgH+AXYBIADMAKcAOz+kP1E/DD78Pmw+HD3YPZA9QD04PKw8YDwYO9A7gDtwOug6uDpQOkA6aDoIOgg6EDo4Oig6YDqoOsA7YDucPBg8lD0gPaw+BD7ZP2v/+ABIARQBoAIUAoADGANkA7AD6AQYBHAEeAR4BHAEUARwBDwDxAPAA7wDIALAAqQCCgH4AVQBLgCEAGS/yD+wPxY+/j5sPiQ97D2wPUQ9VD0EPTg8/DzIPSA9OD0kPWg9qD3sPjg+UD7wPx0/ioA6AGkA3gFMAcACYAK8AtQDYAOgA9AEOAQQBGgEcARABLgEYARIBHAECAQYA9wDnANcAxgC0AKAAmoB2gGKAUIBOACjgEdALj+fP1E/Cj78PnQ+LD3sPaQ9WD0QPMw8iDxAPDg7qDtoOyA68DqIOqg6SDp4Ojg6ADpgOkA6gDrIOyA7SDv8PCw8tD04PYw+aD7+P1IAHgCuAQAByAJ8AqwDDAOgA+gEIARABJgEqASoBJgEsARABEgECAP8A2QDOAKUAnIB0AGuAQEA1oBtf88/sT8OPuw+UD4MPcg9hD18PMg86DycPJg8mDykPLg8pDzkPTA9fD2SPiw+Wj7TP02/yQBGAMoBUgHUAkgC9AMQA7ADyARIBLgEmATwBPgEyAUABSgEwATgBLAEQAR4A/QDsANkAxgCxAKkAjwBpgFWAQkA7QBQQDc/sT9oPxw+zj6CPkA+BD3IPYQ9dDzoPKw8cDw4O+g7oDtYOyA6+DqQOqg6QDpwOjA6EDpoOlA6iDrgOxA7gDw0PGQ84D14PeQ+hT9hf+OAdQDMAaQCLAKUAzADQAPYBBgEQASIBIgEgASABKgEaAQoA9QDjANEAyQCrAI6AYIBZwDIAJ+ALb+2Pxo+xD6wPiA9xD2wPTA89DyEPJQ8bDwoPDA8FDx0PFQ8jDzkPRA9vD3iPlQ+yj9VP/IATAEiAawCPAKMA1QDyARoBIAFEAVQBYAF2AXYBdAFyAX4BYgFgAVwBOgEmARIBCwDhANUAuwCUAIoAb4BCADaAHl/6L+XP0U/LD6ePmQ+MD34Paw9bD00PMA83DykPGQ8IDvwO4g7mDtYOxg64DqAOrA6YDpQOkA6UDpAOoA60DsgO3g7sDw4PIQ9VD3aPnY+1b+7gCMA6gFoAeQCZALcA3gDgAQ4BBgEeARQBIgEsARQBGAELAPwA6QDTAMsAowCaAH+AUwBFwCvAA5/6T9+PtA+rj4cPcw9hD10POw8rDxAPGA8CDwEPBA8MDwkPGA8pDzAPWg9pD4mPqk/K7+6gBQA+gFcAjwCjANQA9AEQAToBTgFeAWoBfgFwAYwBdgF8AWIBYgFeATgBIAEXAP4A1QDNAKMAmQB+gFQATAAkYB7f+Q/jz9GPz4+hD6OPlo+JD3wPbg9SD1UPSQ88Dy8PEg8WDwgO+g7sDtwOwA7EDrwOpA6uDpwOng6UDq4OrA6+DsYO4A8PDxAPRA9nj42Pp0/Q0AhALgBBAHIAkgC/AMcA6gD8AQgBEAEkASIBKgEeAQYBBgD0AO8AyQCyAK0AhIB8AFIAQwArEAK//Y/WT86PpY+Qj4wPbA9dD0wPPQ8hDysPFA8RDxAPFQ8eDx8PLw8zD1oPZI+ED6cPyo/rYAAAN4BRAIoAoADTAPQBFAEwAVYBZgFyAYgBigGGAYwBfgFuAV4BSgEyASgBCwDtAMEAtgCbgH8AU4BKwCUgH4/7T+fP2E/MD78Po4+oD54PhQ+AD4oPcg94D28PVw9fD0YPSg8+DyAPIw8WDwoO/A7gDuQO3A7IDsYOxg7IDsAO0A7iDvYPDA8WDzcPWw9/D5GPw6/nwA0AIYBQgHkAgQCoALEA0wDvAOcA+gD8APwA9gD6AOkA2QDKALkAogCXgH8AWwBHAD+AE/AHD+xPxw+2D6MPmw9zD28PTg8zDzcPKg8dDwQPAw8FDwcPCQ8DDxYPLg82D1APfY+Oj6VP3u/4gC4ARYB/AJkAwwD4ARgBNAFQAXYBggGaAZoBlgGQAZYBggF6AVABSAEgARQA8wDRALEAlwB+gFUASYAggByv/U/vD95PwA/Ej7wPpo+gD6YPnQ+JD4aPgw+LD3IPeA9gD2kPUQ9VD0UPOQ8uDxQPGQ8ODvIO/g7sDuwO7g7gDvgO9g8IDxsPIw9LD1gPeI+bD70P3D/6QBoAOYBUAHsAjwCSALUAxgDRAOgA6gDoAOYA7QDQANEAzgCqAJcAgQB4AFCASsAnABGABe/oT8sPoo+QD4sPZg9fDzsPKg8eDwEPBg78DuYO5g7mDuoO4g7wDwMPHw8tD00PYI+YD7Qv44ATAECAfgCcAMwA+AEgAVIBcAGaAa4BugHAAdwByAHOAbwBpAGYAXoBWgE6ARcA8wDeAKoAiABpAErAIOAY//Nv7Y/LD7qPrY+Sj5ePgI+ID3EPfQ9pD2UPYA9rD1YPUQ9bD0YPTg81Dz0PJQ8qDx8PBQ8ODvoO9A7wDvAO8g72DvAPDA8KDxsPIQ9LD1kPeI+Yj7oP2r/9AB3APIBXgHAAmACuAL8AzADUAOwA4ADwAPkA6wDbAM0AvQCpAJMAiIBhAFwAOMAjwBr/8O/mD8wPow+aD3IPbA9LDzsPKw8ZDwgO/A7qDuwO7g7uDuwO5A73Dw8PGQ83D1gPcQ+qT8lP90AnAFoAjwCxAP4BGAFMAWIBkgG8AcoB0gHgAewB1gHYAcIBtgGYAXgBVAE+AQgA4gDOAJsAeABVgDfgHb/67+YP0U/PD68PlI+aj4OPjQ92D3IPfw9rD2UPYQ9sD1oPVQ9eD0UPSw8yDzsPJA8rDxEPFw8ADwwO+A70DvQO9g76DvIPDQ8LDx4PJg9AD2wPeg+Yj7qP3o/yQCMATwBaAHYAnwCjAMEA3ADWAO8A4AD6AO8A0QDTAMQAsQCrAIAAdwBRgE1AJ6AREAnP4s/aj7QPqo+CD3oPWA9HDzgPKg8bDw4O9A7yDvIO9A72DvwO+A8HDxwPJQ9GD2kPg4+/T9igBEA3gG8AlgDaAQYBMAFoAYoBqgHCAeAB9gH2AfAB9AHuAcYBugGaAXQBWgEsAPMA2gCjAIsAVUAy4BQ/+s/RT80Pqo+dj4MPiw9zD34PbA9hD3YPdg90D3APcA9yD3QPcA99D2MPag9TD1wPQg9GDzwPIw8qDx0PBA8ODv4O8A8EDwkPAA8cDx4PJg9AD2kPdI+TD7IP0q/yIBEAPgBKAGIAhQCTAKAAvAC3AMsAxwDOALIAuACtAJ8AigBzAG6ASsA2wC+ACV/0T+PP08/Pj6cPng95D2kPXQ9LDzcPJQ8aDwYPBA8BDw4O/A7yDwEPEQ8kDzUPSg9eD3kPo8/a3/LAJYBRAJ0AxAEAATwBVgGEAbgB0gH+AfgCAAIQAhgCAAHyAdIBtgGUAXoBRgERAOYAsACYgG5AMeAfL+iP08/Pj6kPlQ+KD3cPdg9xD3gPaQ9tD2QPeg93D3MPcg91D3oPdg98D2IPaw9aD1UPWA9JDz0PKg8nDyIPKQ8RDxAPGA8RDygPLQ8nDzwPRQ9tD3OPmA+gj87P39/+IBRAOABPgFoAcgCeAJUAqgChALkAuwC0ALYAqgCRAJgAhwBxgGgAQIA9gBwAB7/+j9YPw4+0D6MPmw9wD2UPQQ8wDyAPHA74DuwO3A7QDuAO7A7eDtoO4A8NDxgPMg9QD3kPmk/BwAYAO4BmAKIA4AEkAVIBigGgAdQB8AIQAiACLAIQAhQCDAHsAcQBqAF8AUABIgD/AL4Ag4BtwDnAFy/4T94PvY+iD6ePnI+AD4oPeg9/D3QPgY+AD4GPhY+Jj4sPho+Aj48Pfg96D3IPeQ9iD28PWg9SD1gPTg85DzcPNg8yDzAPPQ8uDyQPMA9MD0cPVQ9nD3sPj4+Yj78PyO/k8AFAKsAxAFUAaQB9AIsAlgCrAK0ArACpAKcAoACjAJMAgIB/gFyARgA+ABSgC+/nT9NPzo+nj58PeQ9kD14POA8kDx4O/g7mDuIO4A7gDuQO7g7qDvkPCw8UDzYPWg9wD6dPwd/xwCuAWwCWANoBDAE4AWYBkAHEAeoB+AIAAhACGAIIAf4B3gG+AZoBcAFeARcA5AC5AIOAbYAzwBwv7o/Lj78PpI+oD50PiY+KD4wPjo+OD48PiA+fD5MPoY+sD5wPn4+QD6uPkI+XD4KPjw98D3QPeA9uD1wPWw9WD10PRw9ED0cPRw9GD0UPSg9FD1QPYg99D3kPio+TD7sPwg/p7/KAG0AmAE0AX4BvAH0AiwCVAKgApgCgAKsAlACaAI4AfABmgFGATEAkABq/8Y/qj8WPsA+pD4EPeA9SD00PKA8VDwIO9A7sDtQO0g7YDtQO4A7+Dv4PBg8kD0QPbQ+Kj7Sv4YAVgEEAgQDAAQYBOAFiAZoBsgHkAggCEAIgAiwCEAIWAfYB0gG8AYQBYgE7APMAwACVAG/AOOAU7/RP2Q+1D6kPn4+LD4kPho+GD4QPho+Mj4UPnI+dj5qPmY+aj5qPmw+ZD5YPn4+LD4mPho+OD3oPeg95D3QPeg9iD24PXw9eD1oPUQ9bD00PQw9aD1APaA9iD3IPhA+YD6uPsE/aL+ewA8AqwDEAUoBngHoAhwCdAJ8AnwCaAJQAnACBAI6AbIBYgERAOWAbv/+P10/Bj7wPl4+AD3wPVw9JDzcPIw8RDwQO/A7oDuYO5A7oDuAO+A8NDxMPOA9FD2uPiA+zT+vwCYA8gGgApQDgASQBVAGMAaQB2AHwAhACKAIsAiwCFAICAeABygGQAXIBSgEBANoAm4BvgDRgHa/tD8+Pp4+UD4cPcQ9xD3UPdg92D3YPfA90j40Pgw+Yj5mPmY+bD5+PkY+ij6MPoo+ij68PnY+cj52Pnw+bD5YPkI+dj4mPhA+OD3gPcQ97D2YPYQ9iD2UPaw9kD34Pdg+Ej5kPoE/Jz9HP+9ADwC5ANoBcgGwAdwCBAJYAmgCWAJ0AjoBzAHQAZgBRAEaAKCAL7+WP0Q/GD6uPhw92D2cPVQ9BDzoPFg8KDvYO/A7gDuwO3A7UDuIO9A8GDxwPKg9BD3iPn4+3z+hgEABXAI0AtAD+ASYBbAGaAcgB4AIIAhwCKAIwAjwCEAIOAdoBsAGSAWwBJQD+ALwAigBZwC8f/I/Qz8aPrw+KD30PbA9hD3oPfw9+D3GPio+FD5+PlI+nj6kPqQ+rD6wPqw+qj6yPro+rj6aPoY+tD52PkQ+jD60PlI+ej4sPiI+CD4kPfw9nD2APbA9ZD1YPWg9TD24PaQ91D4MPnI+rz8sv55ABACqANoBSAHgAiQCTAKoArQCqAKEAowCSAIIAfgBUgEcAKZAK7++PxQ+8D5QPjg9oD1UPRA8zDyMPFg8ODvQO/A7oDuoO7g7mDvEPAQ8VDywPOg9QD4SPpo/GL/VAKQBbAIsAvwDsASgBbgGaAcYB7gH0AhwCJAIwAjgCFgH6AdYBuAGEAV4BFgDkALIAjQBH4BsP6c/BD7iPng95D2APYg9rD2QPeg9wD4mPh4+VD6wPoA+1D7qPvQ+/D72Puo+6j78Ps4/DT8oPsI+/D6MPtg+0j7+Pqg+lj6CPrQ+VD5sPgI+HD3wPYQ9oD1MPVQ9bD1IPZw9vD2wPcw+Sj7JP3M/k4ACAL4A9AFUAdwCGAJMAqgCpAK8AkACSAIOAcIBlgEUAJCAIT+BP2Q+8D58Pdg9iD1APSw8kDxIPCA70Dv4O5g7sDtwO1A7iDvIPDg8NDxcPOw9RD4ePrs/KH/nALgBSAJAAygDuARoBUAGQAcAB4gHwAgQCFAIkAiwCCAHmAcQBqgF2AU4BBgDQAK0AbQA5cAeP0g+5D5UPhQ9wD2QPVg9TD2IPfg95D4UPlg+oj7PPx8/Nz8aP34/Uz+Lv64/Yj93P1W/mL+0P0c/ej8FP1Q/Uz91Px8/CT80Pug+wD7IPpg+dj4MPhQ92D2sPVg9ZD14PVA9pD2IPdo+DD6HPzc/Yf/YgFcA0AF8AYwCEAJAAqACrAKMAowCfAHyAZ4BdAD3AGy/5T9wPsw+oD4oPbg9FDzMPIA8eDvAO9g7iDuIO5A7gDuAO5A7gDvIPAg8VDywPOQ9dD3QPrg/M7/AANYBmAJ4AuADsARQBWgGKAb4B2gHwAhwCGAIoAiQCHAH6AdIBsgGMAUIBGgDUAKCAecAy8A6Pxo+pj4UPcQ9iD1sPSw9BD14PXQ9uD38PgI+gj7yPtI/MD8eP0S/lj+Sv4o/vT9AP4y/lD+NP74/bj9iP1k/Xj9gP1A/eD8aPzw+yD7SPqI+aD4sPeg9rD1sPQA9JDzwPMg9LD0kPXQ9nD4cPrE/C//jgG4A9gF8AewCQALAAyQDKAMQAxQCwAKUAhIBjAE/AG5/2D9APvA+MD2APVw8yDy4PDg70DvwO6A7mDuYO6g7gDvgO/A7+DvcPBw8dDyUPTQ9YD3kPlc/JX/CANQBoAJwAzwDwATIBYAGeAbwB4AIcAiACPAIkAiQCFAIIAeYBuAF8ATYBDwDEAJwAVMAiT/iPwQ+uD3MPZg9UD1gPWw9fD1cPaQ9xD5oPrg+6T8KP3g/ar+G/8u/yj/Pf86/yb/2P5i/gr+IP5U/lT+3P1g/Sz9FP0Q/cD8HPwo+zD6aPmg+ID3UPZQ9VD0cPOQ8gDywPEQ8vDyYPTA9TD3CPmA+27+RgHoA2AGoAiQCkAMoA1gDnAOIA6ADSAMQAroB3AF/AKGAPT9QPuA+ED2cPSw8iDxEPBg7+DugO5A7kDuoO4A76DvAPAw8FDwkPBQ8XDysPPQ9CD2CPiA+mD9pQDwA3gHEAvgDiAS4BSgF4AaQB3AHwAiACMAIwAiACEAIGAe4BvgGEAVYBHADRAKSAYwA48AzP3o+mj4wPbQ9ZD1sPUQ9oD2UPdQ+ID50Poc/FD9iv6L/yYAVABoALsASgF8AUQB4gCFAFgAMQACAML/lv9L/9r+NP50/bD8+PtA+1j6APlQ9+D10PQQ9BDz0PHA8ADwoO8A8ODw4PEg8+D0QPfo+XD8/P7WAcAEaAewCXALgAxADbAN4A1gDQAMAArIB3gF+AJGAIj96Ppw+FD2YPSQ8iDxIPCg70DvAO/g7gDvQO/g72DwwPDw8FDx8PFw8vDyoPPQ9FD2OPhA+nD88P4YAsgFsAlADWAQQBMgFuAYIBsAHUAegB+AIMAgACCAHqAcQBqAGIAWgBOQD2ALEAiwBVADdwCA/Qj7ePl4+PD3UPew9hD3UPi4+Zj66Pqo+yT9+v6TAFYBiAGkATgCDANUA+gCRALYAeQBygH+ABgAdv9J/0r/1P68/XD8ePsw+6j6sPlA+MD2sPUA9VD0gPNw8rDxkPGw8fDxIPLQ8mD0kPb4+PD60PwS/84ByARYBxAJMApQC4AMQA0ADfALsApQCZgHgAXUAun/+PyQ+qD4sPZQ9ADygPCg70DvAO9g7gDuIO7g7oDvAPBA8KDwYPEw8vDycPPQ85D0APbg98D5iPuY/WEAmAMwB6AK0A2gEEATIBagGOAZoBqgG+AcwB3gHcAcwBqgGMAWIBUAEwAQkAxQCbgGUATgATT/AP2I+8D6GPpY+bD4oPio+UD7pPyQ/Vr+Xv+7AEAChAMgBFgEmAToBNgESASAA9ACUALOAesAuf+A/rD9VP34/ET8OPsY+lD52PhI+ID3kPaQ9dD0YPTA8/DyMPIQ8lDykPKg8uDy0POQ9fD3OPpE/Gb+5ABsA/AFUAhQCqALkAxwDZAN0AygC1AKsAigBhgEEAHg/RD7sPig9pD0gPIA8RDwgO8g7wDvgO8g8MDwcPEQ8rDyUPMg9CD1wPXw9VD28Paw96D40PlQ+zj9hv8UAqgEAAfQCRANYBAAE+AUIBYgFwAYoBhAGYAZIBkAGGAWwBSgEqAQsA7ADFAKsAc4BewCJAHW/5r+VP0o/Ij7aPtg+3D72Puw/OD9H/8oAAIBzAHAAuwDKAXQBdgFoAW4BdgFgAWgBHwDeAKmAc8AwP94/hT9BPxg+4j6ePkw+BD3gPYg9nD1wPQQ9KDzYPMw8zDzIPPw8lDzUPRA9QD2EPfA+OD6LP1I/1wBVANwBXgHQAmgCoAL8AsgDNALoAoACWAHeAU4A9cAKv5Y+7D4gPbg9GDzEPIg8aDwgPCA8PDwsPFQ8hDz0PNw9AD1gPXw9VD2oPbA9tD2APdw9zj4UPno+vz8Of+yAUAE4AbACSANgBAgE8AUwBWgFiAXgBcgGGAYgBfgFSAUoBIAESAPMA1QC0AJSAegBQgESALHAPH/k//4/uD93Px4/Mz8YP30/Xj+D//a/90A1AHEAsQDsASIBRgGSAYABrAFaAXYBAgE1AKoAWgALv/Q/Uj84Prg+dj4kPeA9rD18PRA9ODz8POg8wDz4PJA82DzgPPA83D0QPVA9nD3sPgo+gj8SP5qADgC+APgBaAHIAlACvAKMAvgCiAK0AggByAFGAPjAJr+8Ps4+eD2IPXA88DyIPLA8bDxoPEg8vDy0PNw9PD0sPWA9gD3MPdA90D3cPeA9+D3wPeA9+D3QPmY+xj+TAAsAmgEkAdAC1AOwBCgEkAUgBUgFkAWABagFWAVwBSAE6AR0A8gDsAMoAtgCrAI+Aa4BbgEmAN8AsgBUgGmANn/Hf9w/vD9EP7Q/kr/Vv+A/0IAYgFgAkADEATgBJgFEAYQBoAF6AR4BOgD5AJmAdb/Uv4A/dD7iPoY+bD3sPYA9nD1sPRQ9ED0gPSg9FD0QPSA9AD1cPXQ9VD24PZw91j4oPkI+2j86P24/54BJANoBNAFSAeACEAJkAkwCWAIUAcYBpgEuAKTAGL+KPz4+cD34PWA9MDzIPPg8tDyIPOg80D0APWQ9fD1sPaA9+D3kPdA93D3wPfQ95D3APeA9uD2iPho+gj86P2lAMgDmAYgCfALwA5AEWATABWAFSAVwBQAFSAVIBSAEsAQIA/QDbAMQAuACQAIGAd4BoAFSAREA7gCiAI8AnwBfwCw/4P/0f8wAFAAPgBiAPIA5gHYAqQDcARABegFWAaIBkgGwAUwBagErAM4ApQA8P5Y/dj7ePow+cD3YPZg9bD0MPQQ9CD0IPQg9ED0kPTQ9AD1YPXw9aD2QPfQ94D4cPnA+lz8CP6v/zIBqAJIBOAFMAcgCNAIMAkQCWAIOAfQBTAEeAKfAJj+YPwg+ij4gPZQ9XD04POg86Dz8POQ9FD1IPbw9mD38Pe4+Ej5KPmw+JD4qPiY+Ij4oPgQ+CD3EPfA+Aj7rPxW/vAA8APABqAJUAygDoAQgBJgFCAVgBSAE4ATgBOgEsAQ8A5QDdALoArQCeAIWAf4BZAFkAXYBNQDUAMoA6gC0gE0AbUAJgDu/2IAzgCeAEYAvAD6ASQD4AOABFAFAAZoBpAGcAbYBQAFQARkA+QB2v/o/Vj84PpQ+eD3sPaQ9dD0gPSA9KD0oPTA9ED1wPUg9lD2oPYA93D34Pdg+AD5oPlI+lD7tPwk/mz/zgAwAoADwAToBbgGIAcgB+gGeAaQBTgEqAL3AEj/lP3Y+xj6cPgQ9wD2cPUg9RD1MPWg9VD28Pag90D4+PiQ+cD50Pn4+ej5iPkI+bD4ePgw+AD44PeA9zD34Pco+vT8Lv8MAWwDWAZQCSAMYA7QD0ARgBJAEwATQBKgESARQBDgDnAN4AtQCmAJ8AhQCBAH+AWYBYgFGAVwBNADUAPgAmAC0AEgAYwAUQCCANwACAEUAVwBLAJ0A8AEsAUoBoAG6AYgB+AGKAZQBUgE7AJgAaT/rP3A+yj6+PgI+BD3IPaw9cD10PUA9nD2EPdQ94D38Pdo+Kj4qPjI+ED5qPkY+qD6aPs8/ED9mv4UAFABWAJkA5AEaAXoBTAGGAaYBdAE7AO4AigBc/+0/Qz8cPrw+JD3cPag9UD1UPWg9QD2oPZQ9wD4uPhg+ej5UPpo+lj6MPrQ+WD56PhQ+ND3kPdw9xD3kPaw9tD3aPmo+2b+AgH0AlAFsAgQDAAOsA7QDwARoBGgEUARgBCQD9AOEA7QDCAL8AlwCWAJEAlACFgH0AaQBmgGGAY4BRgETAPMAigCNgE5AML/1/8eAHQA0gBGARgCcAPwBPAFeAbgBkgHeAc4B3AGOAXIA3QCCgEf/+j88Pqo+bD4wPfg9kD28PXg9TD2gPbA9gD3YPfw90D4UPhQ+GD4gPjA+Bj5qPlQ+hD7HPx8/d7+LQCCAeQCIAQYBcAFGAYYBsAFIAVIBBQDdgHJ/1D+yPwo+5j5QPgw92D28PXQ9RD2gPYA95D3KPiw+Dj54Plo+sD6sPpg+iD6CPrw+aD5KPnY+Lj4gPhY+Hj4APmQ+ZD6RPw8/vL/5gHIBPgHUArwCyAN0A1wDpAPoBCgEFAPcA5ADtANsAyAC8AKUAoACqAJ4AgACIgHgAeAB/gG6AXABLwDGAO8AgwCAAEzABkAdwDAABgBwgG0AsAD2ATIBUAGiAbgBkgHOAdYBvgEYAPQAVYA8P5k/Zj7CPoA+VD4wPdA9xD3IPdA91D3cPeQ99D3CPhY+Ij4aPgw+CD4WPjY+Hj5QPoY+yj8TP1+/sT/LgGIApgDOASgBOAE8ASoBBAERAMsAuAAgP9g/mT9WPww+wj6IPlQ+LD3cPew9wj4EPgY+ED4mPj4+Hj50Png+fj5SPpg+iD68Pkw+nD6UPoo+vj5uPlg+ZD5MPqw+gj72PuE/XD/jgH8A4AG0AjwCpAMYA3gDZAOYA/AD6APUA9QDtAMwAuwC4ALoApwCZAIIAjwB7AHIAcwBmgFAAV4BIgDXAJaAeYA9gAkAeEAPwBDAGQB+AIQBJAECAWwBXgGKAd4B0AHeAaYBZgEJANYAa7/YP5E/RT8wPqA+YD4CPgY+Cj48PeQ91D3cPew99D34Pfg9wD4KPhA+Ej4aPjo+OD5CPsQ/MD8bP10/tz/TAFMAsgC/AIkA1QDRAPUAhwCWAGuAOH/2P64/cz8PPzA+zD7WPpg+bD4mPjY+AD50PiQ+Ij4uPgg+Wj5gPnA+Vj64Prw+sD6yPrw+vD6APsQ+7D6uPkw+aD5CPrQ+dj5APuo/DL+EwDMApgFwAfwCWAMEA5QDmAOQA8AEJAPsA4gDpANkAywCyALUAogCZAIEAlQCWAIEAdYBkAGQAawBZAEMAMUArIBvgGQAeYAPwBmAGoBmAI8A3gDGARoBaAGCAegBggGkAUIBUgEJANAATX/yP0A/Rz8qPpY+aD4UPgw+CD4APjQ99D3WPjY+Mj4aPhA+Ij4CPlY+VD5GPlI+Rj6GPvw+5D8SP0y/lf/iQBsAeQBQAK8AigDIAOUAuYBaAEIAYUAw//M/sD96Pxc/Oj7QPtw+sj5cPko+cj4cPhQ+Fj4oPgI+Sj5GPlQ+fj5kPrg+vD6+PrQ+rD6qPqo+jD6gPlA+Wj5OPnQ+PD4sPng+jT8HP5ZAGQCuASYB1AKAAzADJANQA5wDlAOMA7gDVAN8AxgDGALQArACfAJIAoQCqAJwAjAB3AHgAcIB5AF8APoAmQC9AFOAY8AEgA/AAIBrAH0AVACPAOQBLAFAAagBRAFsASQBCgEFANyAeH/wP70/Sj9OPxI+6D6cPpw+jj60Pmg+cD5+Pn4+aj5IPnA+Mj4EPko+fj44PgY+Zj5OPro+pj7WPw8/UL+Nf/p/3QA9gB6AeYB8AG8AWYBPAEuAfYAcwDK/yP/nv4c/pT9FP18/Nj7OPvA+lD60Plw+Wj5kPmw+cD50Pn4+UD6iPrI+tj60Pqw+pD6UPoI+rj5cPlQ+Tj5APnA+Mj4QPkI+hj7sPy2/t4ACAOABTAIMApgC3AMkA3gDVANAA1gDbANQA2wDFAMgAugCoAKIAtgC6AKsAlACcAI+AcQByAG2ARsA4wCFAIuAfH/O/+R/z0AagBHAJYAjgGwArADUAR4BDAE7AMQBDAErAOAAmIBwgBFAHz/qv4g/sT9XP0M/cT8NPyA+yj7MPsY+4j64PlY+Qj52PjA+LD4mPiQ+ND4aPkA+pj6UPss/Bj91P10/hP/v/9QAK0A2QDuAPgA5ADMALsAiQAeAJ7/RP/4/o7+Dv6U/RT9fPzg+2j78Pp4+hD6+PkI+vD50Pno+Sj6UPpg+nj6oPqg+mD6KPoA+tj5oPmA+YD5cPk4+SD5WPnQ+Xj6iPsg/e7+2QD4AjgFGAeQCOAJEAuQC1ALAAtgC/ALIAzwC7ALQAvACpAK0AoAC8AKEApACbAIQAiYB1AG0ATIA0wDkAJKASkAuf+1/6X/rf/e/wEALgDhAPYBqAK8AqwC7AJAA1wDIAOkAiQCxgGQATABkAAUAP3/9f+z/1L/7v50/vj9vP2g/TD9WPyY+zj76Ppw+iD6+Pnw+fD5KPqQ+uD6CPt4+yz80Pwk/Yj9Fv6U/uL+Fv9a/5b/tv/Z/wsAOAA2ABEA5v+7/3P/Cv+U/hr+hP3c/FD80PtQ+9j6oPqQ+oj6iPqg+sD6yPq4+pj6ePpg+kD6CPqw+Wj5WPlY+UD5IPkg+TD5UPmg+UD6EPsc/ID9Kv/pAKQCSAS4BQAHEAjwCCAJwAjQCIAJEAogCiAKYAqgCnAKYArACsAKUArwCeAJkAmwCKAHqAbQBRgFeASkA5QCsAFaAT4B8QBxADUAZgC9ABABTgFcAVQBYgGaAaoBYgEGAdUA3QDlANIAvQCnAKAAugDLAKEAYABDAD4ADgC0/1r/3P4o/nD90PxI/LD7UPs4+zD7APvQ+sj6sPqI+oj6sPrg+iD7gPvo+wT8+PsI/GD82Pw8/Xj9oP3g/ST+SP4m/vj97P38/dz9kP1A/fz8yPys/LD8wPy8/KT8kPyw/Oj8BP3w/Lz8pPyw/Lj8nPxo/Ej8OPwk/Pj70PvQ+/j7FPw0/Hz85Pxg/eD9lv6O/4QARAHuAbACcAPwA1AEoATQBPgEOAWgBegFIAZ4BuAGCAcIByAHWAd4B4AHiAd4ByAHsAZQBhgG4AWoBVAF4ASQBGAEMATcA5ADiAOsA8QDsAOMA1QDJAMUA/QCsAJQAhAC7AHMAaIBggFYARQB5ADBAJ0AWgAdAP//4P+2/3j/I/+w/ir+sP1I/cj8UPz4+9D7oPto+zj7APvI+rj60PrY+sj6wPro+vj62PoA+4j7+Pv4+wD8JPxo/Ij8mPzc/Dj9jP20/bD9kP2I/cT9Lv6A/q7+yP7o/vb+1v68/vb+Q/9N/zH/SP9x/1b//P7M/uz+Af/Y/qj+nP6K/mD+PP4y/ib+Gv4s/lD+XP5m/oL+sP7a/iT/oP8VAFcAfgDAAPUA6QDgACABggHAAeoBOAKkAuQCAAM0A4QDxAPcA+gD9AMABAgECAQIBAgEAAQgBCgEIAQoBGgEyATgBPAEKAVwBYAFYAVgBZgF0AXYBeAF+AUIBgAG2AWgBXAFWAVIBSAF2ASoBJAEcAQgBLwDeAMsA7AC/gFGAZ8A/v9i/8L+KP6Q/fz8YPyo+zD7APug+vD5SPkQ+dD4KPig98D3EPjQ9yD30Pbw9iD3EPcA9zD3gPfA99D3sPfQ94j4YPnA+fD5ePoI+zD7KPuw+5T8LP1g/aT9Kv6O/qj+wP4X/4D/xf/h//r/BQAOABwAKAA4AFkAfgCcAJ8AowCnAK0AswDMAPEADAEkAUYBXAFWAVIBYgGOAaABsgH0AUgCgAKwAvgCSAOMA8gDGARQBIAEwAQIBTgFSAVgBZgFyAXgBQAGQAaYBtAGCAdIB5gHuAfAB9gH6AfwB+AHyAfQB9AHwAeQB2AHUAcwB/AGkAZQBhAGqAUoBbAEaAQYBJwD/AJMApABvwDM/+L+KP5w/Zj8oPvQ+jD6uPlI+fD4qPhY+LD30PYQ9qD1cPVg9XD1oPWw9XD1APUA9VD1wPUA9mD20PYw90D3YPfQ93j4OPnQ+TD6aPrI+lD76Pt8/Az9qP0i/mL+kv7c/kb/pf/0/zcAYwBwAHQApADuAC4BWgF6AYABegGAAaIBzgH6AQAC4AGwAaoBrAGyAdIBGAJQAjAC7AHWAfABFAJEAowC3AIMAxwDOANgA5wD9ANQBIgEkASYBMgE4AT4BDgFmAXYBQAGQAaYBuAGGAdoB7AHuAeQB3gHgAeIB7AH4AcQCPgHwAeYB2AHAAeoBmAGCAaIBQgFqAQ4BLADQAPEAgACFAFEAIj/pv6s/cz8APwY+yj6mPlw+Vj5EPmI+PD3MPeA9tD1kPWw9fD1IPbw9ZD1QPVQ9aD18PVQ9uD2UPcw9+D2EPew9zD4kPgI+Zj5CPo4+nD66PqQ+1D81Pz8/AT9UP3g/U7+hv7w/oP/zP+0/6v/8P86AGsArgD/ABgB/gDzACABSAFmAZoBygHWAdQB6gH8AfgBCAJIAnACZAJoAqAC3ALwAhADXAOcA8gDGASABNAE+AQgBVAFYAVgBZAF6AUwBlgGoAbwBhAHGAdoB+AHMAhgCGAIcAiQCIAIcAhwCMAIIAkwCfAIsAigCHAIAAiABygH2AZABpAFCAWwBFgErAPsAjQCXgFSAC7/KP44/Uj8UPtQ+oj5CPng+ID4CPig9xD3EPbg9HD0sPTg9LD0wPQA9eD0cPQg9KD0cPUQ9lD2YPaQ9uD2EPcQ93D3ePho+aD5cPnA+Zj6QPuA+9j7jPwg/TD9KP2E/TL+0v47/37/rv/O//b/IABWALQAJAFYAUoBSAF2AaQBqgHaAUACfAJMAiACUAKQApACiALEAgwDLANEA3gDpAPUAygEeASIBKAEAAWABagFmAXgBUAGUAYoBlgG0AYIB/gGEAdgB5gHqAfgB0AIcAhwCIAIgAhgCFAIcAiQCJAIkAiwCKAIQAjwB8gHiAcYB4gGIAaoBRgFkAQgBKAD5AIQAjgBWgBW/0b+RP1U/FD7SPpw+dj4YPgg+PD3kPfA9vD1QPWw9DD0APRg9ND0sPRA9ED0oPTA9ND0UPVA9rD2kPaQ9uD2QPdw9/D3sPg4+ZD5APpo+sD6GPvA+1T8aPxk/Lz8VP2w/dz9Uv7w/kP/V/9d/5D/0v8PAGAAqQC4ALsA1QD1ABgBUAGoAcgB0gH+ASwCLAIMAjACnALkAuAC8AJEA7QD7AP4AyAEcATIBPgEKAVwBcAFAAYoBlAGaAagBvAGMAdgB4AHyAcQCBAIIAiACBAJMAkQCSAJYAlgCTAJMAmACbAJsAmQCWAJIAnACHAIEAiABwgHqAYgBmgFyARgBMwD9AIIAigBIADg/rj9pPyQ+5D6yPkw+Zj4MPgA+JD3wPbQ9TD1oPQQ9NDzIPSQ9JD0UPQg9DD0UPSA9BD1sPUg9kD2UPZw9oD24PaQ91j48Pho+dD5EPpQ+tD6iPsY/GD8vPww/Yj9tP0Y/rj+Qf+D/5//x//q/xUAXgDDABABOgFIAVIBWgFyAb4BEAI4AjwCSAI8AhgCCAJAApACuALIAuwCIAM0AzQDWAOkA/gDEAQoBHgE2AQABQgFQAWgBdAF0AUIBlAGkAbIBhAHOAdoB7AHEAhQCGAIgAiwCMAIoAiQCNAIAAnwCNAI4AjgCIAIEAjYB6AHGAdwBvAFiAUABXAE6ANQA5QCxgHbAMT/qv7A/ez86PvY+hj6mPkQ+Yj4QPgI+ID3kPbA9UD18PSw9LD0APVA9TD1APUA9SD1cPXw9WD2oPbA9uD28Pbw9jD30Pd4+PD4QPmQ+fD5QPqY+hj7qPsI/DD8XPy0/Bz9eP3o/XL+5P4Y/yf/Pv9x/6v/8v9GAIEAlQCnAMQA8AAaAVYBngHEAa4BngG8AewBAAIIAlACsALIArgC5AJEA4wDrAPsA0AEeASQBMgEIAWABbAF4AUYBkgGYAaYBvgGOAdoB7gHEAggCDAIgAjQCAAJAAkgCUAJMAkwCVAJcAlQCUAJUAlACcAIQAjoB6AHGAdwBgAGsAU4BYgEyAMAAwAC8AABABL/9P3g/AD8EPv4+Tj5APnI+Dj4sPdA94D2QPVw9GD0oPSg9LD0APVA9QD1sPTw9HD1wPUQ9pD2wPag9qD2IPew9xj4iPg4+cD56PkI+nj6GPuI++D7MPx0/Kz8/PyE/Qb+av7A/hX/SP8//0X/iP/r/zkAcgCgAK8ArwDcABgBIAEuAX4BxgGaAVwBkAH+AQwC6gEoApQCxALEAgADaAOkA8ADAARwBKgE2AQoBYgF0AUIBjgGaAaYBuAGOAeAB6AH0AcgCGAIkAiwCPAIEAkgCRAJEAkgCSAJEAkwCVAJQAkACeAI0AhgCLgHKAfIBkAGmAVABfAEgASsA9QCCAICAez/9P4i/jj9NPwg+yD6UPng+JD4UPjw94D30PYA9iD1kPSg9OD0EPUg9VD1gPVw9VD1cPUQ9pD24PYg92D3gPeQ9/D3ePjw+GD5APqY+sj64PpI+9j7JPxI/KD8CP0s/Uj9qP0u/n7+qv70/jj/RP8p/0D/gf/H//n/EQAYABoANwBSAGoAkADaACQBQgE4AS4BXAGcAcQB+AFYArwC8AIEA0gDvAMgBGAEyARIBZgFqAXYBUAGkAbABggHYAeQB6AH0AcwCHAIoAjwCEAJYAlACTAJQAlgCWAJcAmQCaAJgAlwCXAJYAkACZAIMAioB+AGQAYABsAFSAW4BBAELAMQAgYBJQA1/0L+eP2I/ED7CPpY+ej4WPjg97D3cPeQ9oD1sPRA9PDz0PMw9LD04PTw9OD0wPSw9OD0YPXg9VD2oPbg9gD3APdQ9/D3oPgw+bj5QPqY+sj6+PpQ+9j7VPy8/AT9QP2U/fD9Vv66/gr/UP95/5X/nv+1/+z/NABlAHQAcQB3AJ8A2AAUAUYBegGmAZgBdAFyAbIBBAJQAqAC4AIIAxQDSAOcAwAEaATQBCAFSAV4BaAFyAUQBogG8AYgBzgHcAfIBwAIQAigCAAJMAkwCUAJQAkwCVAJkAmwCaAJoAmwCbAJcAlACSAJ0AgwCIAHEAegBhAGmAU4BbAEzAPQAvQBDAECAA7/VP5o/ST8+Poo+lj5gPgA+PD3sPfg9iD2gPXg9AD0gPOg8yD0YPSQ9ND04PTA9KD04PRQ9bD1MPaw9hD3EPcA92D3CPig+DD58Pmw+hj7IPtA+5j78PtM/Mz8YP3E/QD+Vv7C/hT/U/+t/xYARgBQAFwAZABcAG8AwQAIARoBLgGKAdIBtgGAAZ4B5gHsAdIB+AFQApACoALMAhADWAOgA/ADMARgBKgE+AQ4BVgFiAXoBTAGUAZwBsAGIAdQB4AH2AdACHAIkAjACPAIEAkwCVAJYAmACcAJAAoACvAJAAoACrAJQAnwCKAIUAjgB4AHEAeABvAFYAWYBKQD5AJIAlYB/f/G/uz9AP3A+7j6QPrI+fj4QPjg93D3oPbQ9UD1wPRA9PDzIPSA9ND0IPVA9SD14PQw9aD1sPXQ9XD2IPcg99D2IPfw94D42PiI+Wj6wPqg+qj6+PpI+6j7OPzA/AD9NP2M/eD9CP5O/sz+JP8o/yL/Jf8b/xD/SP+e/8n/1v///y8AIAD9/x8AXwB1AH8AtwD3AAIBBAFIAZwBuAHiAVwC4AI4A4wDCARgBIAEuAQYBXgFsAUQBqAGGAdIB4gH8AdwCOAIQAmwCSAKQApACmAKgAqwCvAKUAuwC9AL0AuQC0ALAAvACoAKIArACWAJ0AgACEAHyAZIBqgF4AQABPgCwgF9AFD/OP40/Uj8YPuA+rj5GPmQ+AD4cPfg9jD2UPWQ9ED0MPRA9JD0APVA9TD1APUA9SD1YPWw9SD2cPag9sD2APdQ98D3ePhA+dD5EPow+lj6ePqo+gD7gPv4+0j8gPyw/OT8FP1k/cT9AP4S/hL+Ev4E/vj9DP5A/nb+pP7U/uj+3P7s/hn/Pf9I/4n/5/8oADYASwCJAKoAuAD/AHgBAAKIAiQDsAPwA/wDIARoBMgESAXwBbgGQAd4B7AHEAhwCPAIgAkwCrAKAAsQC/AK4AoAC3ALAAxQDHAMgAxgDAAMgAsgC/AKoApACtAJQAmQCMAH8AZYBtgFMAVYBFgDQAIMAcj/mv6U/bT84PsI+0D6kPn4+GD40PdA96D28PVA9dD0kPSQ9MD0APUg9RD1APUQ9UD1YPWA9cD1EPZA9iD2IPZg9uD2YPfQ90j4qPiw+Kj40PgY+Xj58PmI+hj7cPuw+/D7TPys/DT9rP34/QL+8P30/RT+Uv66/iv/fP+q/8z/y/+0/7z/7f8tAF0AjAC9AOgA7QAEAUIBogEEAlwC0AJIA6wD9ANABLAEIAWQBQgGqAZYB/gHoAhACbAJ8AlACpAK8ApgC/ALYAywDAANMA1ADfAM4AwQDUANAA2QDFAMAAxQC7AKcAogClAJgAjgBwgHqAUwBFADwAL2Ae8AFwBh/3D+OP0c/ED7UPog+Tj4sPcg95D2QPYg9vD10PXA9YD1APXA9KD0cPQw9FD0sPTw9DD10PWw9gD38Pbg9gD3APfw9iD3kPcQ+JD4QPnw+Wj6cPpg+rD6EPsQ++j6IPug+9j7APys/IT92P3E/QD+QP68/fj8+Pz4/dj+O/+G/3z/4P5w/vD+k//y/4wAXAFyAegAOAFAAnwC5gF8AmAEmAWYBRAGqAfACNAIEAkQCqAKUAowCvAKkAuQC4AL4AsQDJAL0AqQCnAK4AkgCaAIUAhACEAIMAgwCDAIMAjAB/AGKAaIBbgEGAQ4BIgEEATEAogB0AACANz+4P1c/fj8mPxg/ET86Ps4+4D66Plo+ej4gPhQ+ED4ePjw+DD5SPl4+aD5iPkw+eD42PjQ+DD5OPqY+8j8hP38/UT+VP48/gj+2P28/bz92P0U/kL+HP6c/Rz91Pxc/JD70PqQ+qD6mPq4+lD7EPxs/ET8DPwc/Az8oPtA+zD7MPsI+9j6OPvI+xD8MPzI/Lz9ev7g/if/dv+b/5v/oP/4/54A+gDrADYBMAJIA+wDMAQ4BMwD7AI4AigChAIQAwgEQAUABgAGcAXYBJgEsATYBHgEvAOoAxgFuAewCoANwA/gEIAQoA8AD2AOsA2wDdAOIBCgEEAQcA8ADmALQAiABfQCGQCU/Xj8WPzo++j66Png+PD2UPQQ8tDwcPBg8BDxwPJg9CD1gPVg9nD38Pfw94j4kPlo+kj7CP1T/9EAQgHOAegCPAM4AuwAlQBzAHX/Pv7g/Zz9WPzo+pD6kPoQ+bD2cPUQ9UD0gPNQ9CD2UPfw9xD5aPp4+vD5uPqE/LT9EP7i/hgAvAD+AP4BUAOgAyQD5AIkA/QCTALGAZABIAFyAAYAyP9f/+7++P45/z7/Fv8d/zn/af/V/6IAjAGoAigEyAUIB9AHUAiwCBAJsAlwCuAK8AoQC8ALsAzgDaAPYBFAEsARYBCwDhAN0AvwCyANsA1gDBAKUAi4BmgE2gHl/xr+qPuQ+Qj5SPlg+DD34Pbg9qD1kPNQ8kDy4PIA9PD1kPcI+Bj46Pjo+Vj6qPqA+2D88Pyc/YD+N//h/ygBRAJwAnwBwwBOAMH/Sv9a/1v/nP7Y/Uj9tPx4+1j6uPnw+MD3APcQ9yD3YPcY+Bj5cPmw+Zj6oPvo+wz8dP0y//3/IAC3ADIBoAAzABIBVAIwAnYBfAGUAaAAIP9m/ir+jP2c/Dj8MPz4+8j7yPsA/Bj8HPxg/MD8EP20/fb+7AD4ArgE+AUAB6AHIAjwCAAK4ApgC6ALMAzwDMAMUAywDOAOoBAgEYAQIBCQDgAM0AqwCwANAAxwCsAJsAjIBdwCHAKWAab/IP2Q+7D6sPmg+VD6OPq4+ND2cPUg9NDzIPVA95j4SPkw+qD6OPqo+Yj6HPzs/Dz9yP2k/g//lP/TAFACbAL0ABv/9P2c/aT9Cv7C/kr/iv58/Bj6kPjQ9xD3UPYQ9lD2QPYw9rD24Pc4+ID3EPcA+Pj4kPkg+/D9VADJAIYA5gBgAQIB8gDuAdwCzAKoAlQDmANoArAArv+0/iT9+PsI/GD8FPyg+7D7kPsI++j6mPuI/Bj9Cv6o/5gBlAOwBbAH0AhQCWAJgAkQCpALkA3gDgAPYA5QDTAMkAuADGAO8A+AEEAQsA8gDuALsAkgCZAJkAngCBAIIAe4BGgBdf+W/9T+2PuI+dj5qPq4+dD4ePlA+XD2APTA9HD2EPYw9lD5NPxw+0j5aPmQ+kj6WPok/dH/X/86/rv/vgESAVn/i/9RAF//Bv6O/lD/ZP6w/Yb+ov7A+3D4UPeA9+D2kPag93D4wPfA9vD20PYQ9jD2SPgw+oD6kPos/KT+IADCAPMAxQAmADIAagGAAswCBAPkAwgEIAJZ/8D9TP3c/Hz8ePzQ+wj6wPhw+Zj6MPpA+bD5WPts/ED9zP7uANQCSATwBTAHsAf4B1AJgAuQDeAOMA8QD5AOkA0gDKALwAzwDuAQYBKgE6ASAA/QChAJcAnwCZAKAAzwC2AImAPVAO//iP74/LT89Pxw+yD5YPjY+JD4QPeg9lD2gPXg9ID2YPkg+2j7WPsw+1D6yPnw+kT9Qf/YAOABcAF2/zL+Hf/XAGgB8QAvAAj//P3w/Y7+YP40/RT8EPto+bD3MPeQ99D3wPfA9xD3oPUg9dD20PhY+Sj5qPmo+nD7sPza/rMABgF/AFEAdAACAZ4BbALAArQCHAIKAfL/Jf9y/kT9VPyw+/j68Pk4+Qj5sPhg+Kj4ePnI+QD6gPvY/XX/WwAEAkAEuAV4BlAIwAogDKAMwA3gD4AQMA8gDuANcA1QDfAOgBEAE2ASABEgDxAMYAkQCRAKoAqAChAKoAggBT4B3v68/QD9RP1s/jb+kPtg+CD3UPfQ94j44Pgo+OD2QPcQ+ZD6SPsk/AT9QPww+7D7Jv58ANABWAKWAXz/bP38/YcAZALwATwA1P68/cD8QPyc/PT8aPwQ+5D5QPgQ98D2QPeQ98D2sPVg9SD2APeQ92D4uPh4+Kj4aPrk/DT+uv6m/84AJADW/l3/ZgFsAggCSAK4ApoB3P4I/uL+0v4A/Wj76Pq4+UD4CPgw+Rj5EPgY+CD52PlA+uj7Lv6T/5cAlALoBEAGiAfACSAMgA2gDtAPQBBAD2AO8A7gD4AQYBHgEsATIBPAESAQAA5wC3AK4AuQDUANcAsQCTgFQADU/Fz9R/+C/xr+rPxA+uD1cPMw9Tj4SPhQ9pD1IPaA9hD3sPlw+8j6oPmQ+lz8ZP2e/i4BCAPmAZr/7P4WAGwBZAIUA/wCWAED/6j9dP2w/Yz9KP1s/OD6cPiQ9nD2EPdQ9yD2APWQ9PD0YPVw9dD18PZo+Jj42PiI+gz95P3M/Vv/XAHJACH/nADIA3AEqAKMAqwDeALV/5n/EAE2AMD9oPyc/AD7qPgY+OD4mPgA+Aj5oPq4+sj5QPp4/Bz/9QD8ArgEwAWwBjAJEA2QD5APcA6QDqAOcA4AD2ARoBMAFMATYBPAEiAQYA7QDdANYA1wDbANMAzACNAEsAFd/8z+tP8YAET+WPuI+AD2wPPw8/D18PbQ9aD0gPWQ9oD2IPbw9zD60PpY+kD7YP1u/uD+tQBMA/ACLQBt/yACIARoA9wChAPEAqT/4P2o/l7/eP58/eD8uPrQ90D2gPbA9sD24Pbg9fDzEPMg9CD1YPXQ9vj4SPnA9wj4OPvc/U7+WP6r/4UACQAbAOgBwAOIA9gC7AIoA1ABsP5s/iUAegD0/aj70Prw+UD4EPjQ+aj6sPlY+cj6sPsE/MD9+ABcAqwBLAJIBQAJ8AuQDsAPYA7wC3ALMA1AD0ARQBRgFqAV4BIgEaAQ4A8gD7APwBCQDyAN0AuACnAGeAH4/1ABCAGU/mT9iPyo+KDzgPLw9HD1IPSQ9PD1oPQQ8tDywPUg95D3KPqY/OD7oPrc/H4AqgGUAZwCGAPIAa4BUARYBuAEaAK4AXgBMgBK/9P/wP8A/pj72PkQ+JD2kPbw9zD4MPYA9CDzcPPg87D0YPaw99D3gPcA+ED5aPrI+8D9r/86APD/HQAoAWgCPAPQAxgE6AMAA9ABwwC7ANkA8P8C/hT8MPu4+ij6oPlw+Vj54Pjw+PD5oPsU/cj96v5dACIBoAEIBGAJAA7gDpAM4AqACuAKoA1gEiAWoBWAE0ATIBOgEQARgBOAFCASAA8AD1APIAyQCCAH0AU8AsP/bwCuAEz9yPjg9vD1APTA8gD0kPUg9bDzMPMw8yDzMPTw9sj5IPsQ+yj7APxI/e7+zgAwApwCmAIMA2gEAAXcA4QCJAJsAigCwgG6AfsAgv74+/D6EPpA+CD3IPjY+BD3EPTg8tDy4PKg84D14PZw9gD24PYo+Dj4UPn4+0b+4P4N/9r/hgC5AGgB4AJEA5ACWALYAngC4QB8//r+Iv6k/Jj7aPs4+7D6MPq4+Rj5wPjQ+Sj8+P0q/gT+5v6pAKgC2AVACmANMA0wC/AJ4AmwCiAOoBSAGCAWQBGADyARgBJAEyAV4BWgEiAOAA3QDaAMgAlIBygG/APaAF3/Jf80/aj50PbQ9SD1APSQ87D0wPWw9IDyUPFw8rD04Pbw+LD6MPvQ+vj6HPzE/dj+LAAYAvgDSAREA3gCXAIcAiQBKAGEArADgAIgACz+HPzA+fj4gPow+3j5UPfQ9mD2IPSQ8nDzEPXQ9bD20PeQ92D2IPfA+Xj7OPvg+07+NACzANsAZAE0AdsAiAFEA+QDsAJAAY4ADQDM/jj9UPx0/Fz8uPsI+5j6qPng+Ij5cPtU/dj9Hv5o/ir/YgB4A4AHUArQC8ALsApACdAJUA3AEaAUgBXgFOASIBBAEIATYBaAFcASIBHQD7AN4AowClAKoAjwBGQCcAGK/6D8gPqg+VD30POg8lD0cPUQ9JDyoPLA8iDy4PKA9fD3CPkg+mD70Puw+8T8N/96AeACvAP4A8AD9ANoBAgE9ALMAqgD9APoAnYBAwAq/jj8EPu4+hD6OPlo+JD3IPZQ9CDzEPMw9CD1gPWw9RD2YPZA9gD3CPk4+xD8dPyw/Qz/nv8MADQBLAJYAiwCYAKgAjgCsAEkAfz/ZP48/az8QPzQ+7j7UPtQ+kj5oPnY+qD7PPxA/U7+bP6w/oQBYAbQCYAK0AmgCAgHcAdQDIATwBZAFEARgBCgEOAQIBOgFgAXABRAEWAQYA6wC1ALcAzQCmAGSAN4AvIABv74+3j6gPdg9CD08PXg9aDz0PFQ8dDwwPCw8sD1kPfw9wj4MPh4+ND5qPxi/6QA+wCwAawCIAOIAwgEOATIA2wD2ANgBPADbAKsAPr+UP0w/Mj7yPso+6D50PcQ9rD0APRg9ED1APYQ9qD1MPUQ9fD1cPcA+RD68Prw+9j8hP0s/j//VQDwACQBlAEMApwB7gDWAPcA+v8a/nD9Bv78/Zj88Psk/HD76Pk4+tz8OP5E/fT8dP7g/jr+NgHoBxAMYAkgBegEAAfgCKAMYBIAFSASgA4gD4AR4BFgEiAVQBdAFaARcA+gDpANwAygDEALMAigBTgERALq/sD72Plw+ID3sPeg97D18PKQ8ZDxoPEQ8hD0gPYA9xD2IPZA92j4wPn4+1D+fv8fAE4BbAJ0AhgCgAKwA4AEIAWgBWgFmAOEAUcAg/8G/5j+WP5Q/Wj7QPmw94D2APZw9hD34Pbw9WD1IPXQ9AD1gPYI+MD46Pi4+dD6CPtI+3D8Ev7a/jb/s//2/8L/BACKAPb/lP5K/gX/yP6U/Xj9PP5s/aj7KPw0/mz+WP2o/sIAgv/Y/OL+IAbACmAJsAbYBeAEuAQgCQAQABNgENAN4A6QD2AOMA/gEgAV4BNgEgASoBCgDSAMsAxwDJAKgAlgCSAHjAKo/iz9TPwg++D6CPtI+SD20PPg8jDyEPKg8+D1sPbQ9RD1EPVg9bD24PjI+rD71Pxk/oX/gP9R/+T/qgBaAcwCqAT4BJgD+gEUAUkAkP+0/5sAUQAw/vD7cPpA+Qj4CPgI+Wj5KPiQ9hD28PWw9UD2oPeA+Ej4cPio+ZD6OPpo+kD85P3o/aj9VP4k/xL/Gf+B/wr/fP0E/X7+Nf80/jj9TP30/Aj8mPyy/h0Avf9o/x//8P3w/SACUAiwCqAIKAYgBfAEgAZwC4AQ4BDwDQANoA7wDqAOYBCgEkASgBAAESASQBDADKALEAyQChAJsAlQCugGVAFm/tz9tPxo+0T8FP1Y+tD1oPMA9CD0EPTA9cD3YPdw9VD1wPaQ9+D3YPm4+8j81Pzg/a3/LQBl/0b/dADCAcwCGAToBKQDBgGw/ywAswBeABcA1v9A/qD76PnY+eD5aPlI+WD5mPjg9jD2wPZg93D3cPco+Nj4KPl4+Sj6uPoQ+6j7XPwA/WT9+P3Y/gv/Wv5Q/bz8qPxE/fT9CP4Q/bD7gPsA/BT8fPxE/gQAlP+U/fT8Nf9IAlAFoAjgCQgHFAM4A9gHQAzwDcAOUA+wDXALUAygD0ARgBCAEKARIBEwD4AOAA+wDbAKoAngChALIAkIBxAFpgG4/WT8pP2U/pj9qPv4+ID1QPPQ8/D18PYA9wD3sPaA9aD0wPWQ97D44PnI+/z8mPxc/Iz95v6+/sD+rwDUAiADZAI0AsgBLgD2/uv/xgGUAcL/gv5s/aD7CPpI+nj7cPsw+mj5QPkg+AD3gPfQ+Dj50PhQ+UD6EPpw+Sj6kPvg+6D7RPyI/bz9HP1I/ZD9hPxo+xD8bP2o/Yz8mPsw+4j60PqU/F7+iv48/hD+1P2w/V3/XAPoBjAImAdQBkAErAP4BrAMABDQDqAMAAxwDBANIA8AEmASgBBADyAQoBBAD/ANgA3ADOAKMApgCpAJ2AbAA6YBY/+k/WD9bv4S/kj7UPgQ9tD0gPTg9bD3sPdg9jD1sPUA9hD2QPdA+dj6WPvQ+2D87Pxc/Uz+3P+YABwBPAJ4A5gDoAKuAUYB9QCaAE4BDAL8ANj+UP24/Oj78Po4+3z84PuQ+UD4cPhY+KD38Pd4+Qj62Phw+Dj5kPlw+fj5YPso/LD7OPug+0z8lPyA/JD7yPpA+zj8fPzY+4j7YPsQ+wj8sP4uAAD+WPto/EwAYAPgBOgG2AfQBXwDaATIBxAK8AuQDkAQwA3ACRAKwA0AEeARABKAEaAPoA3ADWAPEA9ADQAMoAvgCkAJIAgQBxAFogE0//r+Nv/s/mT9WPuo+ED2MPUQ9nD3kPcg93D24PVA9QD1sPUA94j4+Pno+hj7IPuw+zz8sPzM/bb/LAFGAYIBQALiARoAQv/ZAEgCmAFHAGQAbgBS/hj8+Pvo/HD8iPvQ+/j7KPrg9xD4oPnI+Zj4qPgg+pj6iPkA+QD64Pp4+oj6wPug/Nj7EPtw+7j7uPoo+tD7YP0o/Lj5mPng+xT+K/9W/yD+8PuI+w3/3ANgBqgGoAY4BqAEOASIBmAKcA2gDtAOkA3gC1ALUA0gEMARgBIAEsAQEA/wDZANkA3gDRAOUA3wCpAIOAcoBsgE0AIOAZP/av6g/ej8ePsg+eD2cPWQ9aD2IPfg9lD2APaQ9bD00PSw9ij5iPo4+4j7MPuY+gj7bP3g/58AtAB2AeQB+wAmAMQA9AHEAY4AOACKAP7/2v5Q/jD+IP1A+5j6oPtI/DD76Pmg+XD5MPgg9xD4wPlg+uD5qPlw+bj4YPiA+Sj7WPvg+uD6GPuA+qj58PmA+nj6GPow+oj6MPss/TL/rP6I+4D5oPtKALgEwAeACPAFTAKmAbgEMAlwDLAO0A8wDiALQAqADGAPoBEAE2AToBEgD6AOsA+AD/ANQA2QDeAMAAuACXAICAaAAvMA7QBtACP/VP58/Xj6UPaA9OD1EPdA94D3cPfQ9WDzIPNg9TD3cPdg+Aj6cPrA+Rj6APxo/XT9GP4HAEwBNAEYAXQBegHEAKoAaAHKAXQBCgG9AMf/VP5g/XT9eP0A/XD82Pvw+hD6wPnY+aj5EPkw+cD56Pm4+aj52Pmg+Vj5gPkQ+vD5sPnw+fj5iPkY+Yj5oPnQ+HD4GPpo/AT9UP2c/Tz96PuE/D4BWAbgB3AGwAWgBcgFYAdQC/AOwA7wDKAMwA0ADjAOABBgEuASYBFAEKAP8A6QDuAOAA+ADRAL0AmwCRAJOAf4BIwCdQD6/mD+Bv54/Ej6ePgg9+D1EPWA9bD2EPfw9cD0MPQg9OD0oPbY+BD66Pkg+gj7sPss/Mj9tf/YAKUAmQCiARQC8gE8AhQDvAKWAfkAcAHKAQABSQCX/27++Pxs/Kj8tPwk/Fj7cPow+Vj4UPjA+Aj5WPmg+TD50Pfw9kD3APhA+HD40Piw+GD3IPbQ9kD4mPgA+ND3wPjo+Sj7yP3cAPoA6P0I/Ib+7AOACCALoAywC4AIoAbgCFANYBAAEuAToBRgEUANwAywD8ASoBOAE2ASkA/gC4AKEAvwCqAJgAhACOAG8APzAGn/Ov5c/KD64Pn4+aj5uPhA98D1kPTw8xD0APVw9oD3wPeA94D34PdQ+GD5uPsi/sz+KP7k/cT+0f94AFIBTAKYAiACvAHiAdIBhgFoAZoBmAHJAOT/+P5q/gD+4P2U/Xj8YPt4+jD6kPkI+TD5kPk4+fD3gPew96D3APfA9kD30PZQ9aD04PVA9xD3YPYg9jD2sPZw+AD8mv70/lz+sv6F//T/rgGYBZAKAA6wDgANUAoACfAKcA+gE0AVYBUAFAASYBBgEMARgBLAEoASwBGADvAKsAmQCSAJUAdIBlAF9ALf/+D9BP3o+uD4YPgY+ZD4gPZw9SD1gPSw83D0UPYg9xD3QPfA98D3KPjo+dD7sPzw/BT+J/87/3H/tgDsAfAByAFEArwCBAJiAd4BOAJgAXAApwDwACEArv5E/iT+8Pxg+7D6wPow+nD5SPlQ+SD4cPbg9TD2EPZg9XD1sPUQ9aDz0PIg83DzkPNA9DD1wPVA9hD40PrU/Lj9JP5F/6MARAKoBJgHoApwDcAP4BCAEBAPMA4QD8ARYBWAGCAZ4BbAE8ARwBBgEIAQIBFAEYAPoAzwCbAHYAXQA4AD+AKoAIT9kPvQ+gD64Pjg94D2kPRw8xD0cPXw9eD1YPag9gD2sPUQ92j5CPsU/Ej9BP6k/Tj9JP7h/ygBCALUAlgD7AIwAkACuALQAowCiAKQAjgCoAFIAe8AKABP/7b+5P2c/Ij7OPsY+3D6yPmA+RD5EPgQ95D2APYw9bD00PSw9ODzYPNw87DzoPOg8+DzUPRg9WD36PmI+1D8UP3m/rIAVAJoBNAGAAnACnAMEA7gDiAPsA/gEAAS4BLAE4AU4BQgFCATQBJAEfAPwA4wDjANcAuACTAIKAeYBcwDIAJDAOT9kPvw+dj4wPew9hD2sPUg9ZD0gPTw9JD1wPWw9bD1IPYg96j4YPok/Kz9fv7c/kL/9//NAL4B0ALgA2AEMAQQBGgE8AQ4BWAFSAXQBNwD8AJ4AhwCjAHHAAYAX/9m/mT9bPyI+6D68Plw+eD4OPiw92D3EPfA9qD2cPYQ9tD1wPXw9SD2UPaw9iD3cPcg+FD5oPqw+3z8UP0w/g3//v88AZwC1APoBOgFyAZQB4gHyAdACMAIMAmgCSAKcApgChAK0AlgCcAIIAiwB0gHuAY4BhgGEAbIBRgFQAR0A9ACXAIMArgBZAFAAUQBGgHpAMMAugCaAE8AIwD//9f/jv93/3T/X/80/w//+P7Q/ob+Pv4I/sz9jP1M/Rj96PzI/Kj8iPxs/Fz8WPxU/Ej8TPxQ/Ej8OPxQ/ID8nPyk/LT82Pz8/Bz9UP18/YT9dP1w/Xz9dP1c/Uz9VP1w/ZT9vP3U/eT98P0Q/iD+LP48/lr+ev6i/tD+A/9D/4P/zv8LADIAUQBpAI4AwwAKAUgBbgGMAawB1AH6ASQCSAJsAowCqALEAtwC+AIMAwgD7ALkAvACAAMIAwADBAP8AugC2ALMAsgCwAK0ArACoAKQAnQCaAJYAlgCVAJMAkwCRAI4AiACBALwAd4BxAGiAZABjAGAAVwBLgEAAdcAswCiAJYAegBPABkA3/+t/4T/bP9b/0T/LP8K/9z+qv6M/nz+aP5M/i7+Iv4W/gL++P30/fj9/P0E/hb+Gv4S/gL++P34/fj9/P0A/vj93P28/aD9mP2U/Yj9eP1o/Uj9HP38/Oj85Pzc/MT8sPys/LT8xPzY/PT8DP0k/UT9dP2o/dj9BP44/nL+rP7c/h3/bP+1//D/KwByALcA9AAsAXYBpAHKAf4BPAJ4AqAC0AIIAywDPANIA1QDVANcA4ADrAPAA7gDpAOYA5ADjAOQA5ADjAOAA2wDUAMoAxADCAPwAsgCpAKIAlgCJALuAb4BiAFGAQgB0gChAGYAJQDo/6v/bP8v//7+2v62/ob+SP4K/tz9yP3A/bj9pP2Q/YT9eP1w/XD9bP14/YD9gP14/Xj9jP2o/bz9xP28/bj9uP28/cj90P3Q/cT9vP3A/cj90P3c/eT95P3g/ez9/P0K/hz+LP5A/lb+fP6q/tz+DP89/3L/p//t/zwAigDLAAIBNAFuAa4B7AEoAmACmALMAvQCDAMkA0ADTANQA1gDZANkA1QDUANQAzwDHAMAA/QC3ALAApwCeAJUAjACJAIMAuoBuAGMAWYBOAEIAeYAzQCbAGgASQAvAAUA0v+7/7H/lP9X/yn/FP8F/+b+yP60/pb+Zv5A/j7+Sv5C/ij+Gv4M/vD93P3Y/ej9+P0A/hL+Iv4W/gT+DP4m/jz+RP5K/lj+ZP5u/oL+lv6i/rD+zP7o/v7+GP8x/0j/VP9q/4P/mP+u/8b/2P/b/9v/5v8AABUAIgA8AGIAdgB2AH4AlgCzAM4A7wAOASIBKgE2AVABbAGCAZIBlgGWAZgBngGcAZoBmAGSAYgBfgFuAVoBPAEWAfwA7ADkAN0AwgCdAH0AaABPADMAIQAUAAoA///x/97/wv+k/5X/mP+k/6j/mf+B/3P/c/90/3P/dv+A/33/av9Z/1X/Wf9b/1j/Vv9Y/1n/Xf9s/3r/d/9m/1r/Wf9g/2r/e/+M/5H/iv+K/5f/oP+p/7P/uf+1/7b/wf/J/8b/xf/R/9n/0//L/9H/1//S/83/0//f/+f/7v/6/wEA/f/4/wIAEwAeACkAPwBWAFkAVwBiAHkAigCPAJoArQC/AM0A4ADyAPoA9QDpAPEACAEcAR4BGAEWAQgB6ADKAMAAuACqAJQAfwBsAFMAOAAjAAkA8//m/9r/y/+6/6r/lf+D/3j/c/9p/1v/Uv9X/17/X/9d/1r/XP9o/3n/gP9+/33/hf+O/5j/qf+8/8z/1P/V/93/4f/n//D///8GAP3/9f/3/wgADwARAA4ACwALAAcABAD+//v/8v/l/+H/7v/7////+v/7//7/8//n/+7/+f/8//v/+P/2//T/9f/+/wMACgATABcAFQAMAAUA+//4/wAAEAAdABoAFgAIAPv/9f/5/wYADQAOAAkABQACAPz/+f/8/wIAAgD6//b//v8DAP//+v///wgACAAGAA8AFQAMAP7/AQAQABAACwAJAAgA///p/93/3v/e/9f/zf/H/8D/uf+9/8H/uv+t/6z/rf+y/8X/1P/Z/9b/2//s//j///8JABgAIgAtADcAQABJAFAAWABbAFwAYgBvAHQAcgBxAGwAZQBcAFwAYQBgAFcARgAyABoADQAKAA4ADgAIAAEA+P/q/9n/0P/O/9P/2P/W/83/xP/B/8b/y//G/8H/vP+0/63/rf+x/7T/s/+r/6j/pf+i/6L/o/+g/5j/kf+M/4//k/+b/6P/nf+W/5j/qf/A/9D/2//i/+j/7f/4/wcAFAAeACsAPwBJAE4AVgBhAF8AXgBpAHcAeABwAGwAaABcAE8AUwBfAFoASQA+ADsANQAtACgALQAuACwAKgAhAA0A/v/7////AwAFAAkAGAAaABsAHQAcABwAJwA4AEUATABQAFoAYQBkAG0AdgB4AG8AZgBgAF4AWQBXAFAARQA6ACwAIAATAAcA+//t/+D/0f/L/8D/r/+i/5f/i/+D/4b/hv96/2f/Xf9e/2H/Zv9y/3X/b/9t/3L/e/+E/4r/kP+T/43/jf+a/6b/sP+7/8v/1//U/87/1v/n/+3/9/8JABQADgAIABMAHwAhACMAMQA+ADwAMgAzAD4AQQA9ADsANwAzADMAOQA+ADsANAAvADEAMgAzADoAPwA8ADUALgAtADQAOwBDAEkASABEAEMAPgA8ADcAMgA2AEAAQQA7ADIAMAA3ADoANwA2ADkANgAtACcAKQAqACgALQA2ADYAKAAcABYADwAEAAAA///1/+T/2P/R/8v/xv++/7L/pf+d/5n/lP+M/4T/ff9x/2b/bP90/3H/ZP9c/2X/cv94/4H/i/+M/4j/j/+j/7X/wf/S/+n/+f/9////CQAaACgAOABJAFIAUQBQAFsAYwBmAG0AeQB8AHQAawBmAGIAWgBVAFUAVwBSAEoAPQAwACQAGQARAAoABwAJAAcACgANAAYA///7/wIABQACAAAAAwAJAA8AFgAeACUAJwArADUAOQA3ADIANAA5ADkAPABBAEQAQQA5ADMAKwAjACAAIQAeABYADQACAPb/7v/s/+3/7v/k/9v/1P/G/7b/q/+l/6D/lv+Q/4//jf+J/4H/fP9y/2v/bP91/3r/e/98/33/gf+C/4n/kv+X/53/pv+x/7f/u//C/8z/1f/i//H///8EAAYACwATABcAHAAlADEAOQBEAEoATgBNAEwAUABVAFcAWABWAFMATwBKAEAAOAA3ADQALQAiAB0AGAATAAoABAADAP3//f8HAA8ADQADAPv/+////wUAEgAkAC8ANAA8AEQARgBHAE8AXQBrAHQAfQCEAIkAiwCKAJIAlACQAIoAgQB2AG0AZQBYAEUAMgAkABcABwD8/+7/3v/L/7v/r/+l/6H/nf+W/4r/fP9y/3D/dv9//4P/ff91/3D/cf92/3X/ef+E/5L/nf+o/7b/xP/L/9H/1f/a/97/6P/5/wwAHAApADMAOAA0ADAAMgA0ADMALwAwADgAPgBCAEoAVABXAFAASABEAEYATQBaAGMAaABoAGsAcABqAFsATAA8ACcAEgALAAUA+v/t/+D/1f/K/7r/rv+w/8H/1P/c/97/3v/o//v/DwAWAAcA9v/1//z/BgAMAA8ABwDm/7D/g/9z/3f/gP+I/5f/sP/P/+D/5//j/97/6P8EADEAUwBeAGkArwAaAVABDgGRADcADwD1/xIAUwBWANT/Ov8x/8D/iAACAeMAJgAq/3j+nP5y/18ADgF2AaoBegEEAbsApwCsAMoAIAFcAQoBIgAK/xj+lP24/Vr+5v7u/pr+5P3Y/Lj78Prg+pD7/PzC/m0AlAEgAjgC6gFWAX8AeP/U/gT/8P8SAQQCqALEAmgCygFKAdoAcABBAFIAmwC7APYAXAGGARIBGQAg/0T+vP3A/TD+iv7M/jn/qf/h/97/7/9FAMgAXgEIApwCBANcA5QDTAOMAsYBOgGhAN3/gf/b/4UAxwCpAGUA/v9+/zf/aP+e/2r/E/8U/2z/x//y/wQA4f9z/wX/3v4E/0H/Z/9f/0X/Rv9o/53/2/8WAD4AXAB0AIkAgABfACoA///p/8f/jf9p/33/wf/3/wMA6f+v/2X/G/8D/wr/D//8/tr+6v5G/8P/NwB/AJ4AjwA6AKj//P5g/uz9vP3k/V7+1P74/tL+bP4G/rz9nP2w/eT9SP7Q/on/awBIARgC1AKUA1AE2ARABYAFyAX4BTAGiAYAB3AHkAdoB/gGOAY4BfQDuAKMAXIAbf+6/j7+yP1o/UD9OP34/Fj8kPu4+uj5MPnw+BD5UPmg+Sj6wPoA+wD7+Pro+qj6aPpw+qD6yPoI+4D74Pv4+xj8iPwM/UD9KP34/JD8EPzI+/j7YPyk/OT8PP10/Rz9nPyI/ND8DP00/Zz9Jv5o/tr+9v+wAaQDIAaACQANIBDAEoAVABjAGQAbYBvgGuAZgBggF8AV4BMAEoAPMAwwCLQDBf9Y+kD2oPIg7+DroOlA6KDnoOeA6EDqYOxg7nDwUPLw8/D1mPjQ+9T+fgEoBJgGcAhwCcAJkAngCOAHqAZABZADwgE7ACb/LP4U/cD7UPqg+LD2sPQg8/DxUPGA8TDyAPPA89D0QPaw9xj5qPo4/HD9nv5AACACnAMQBZgG4AegCCAJwAkACsAJYAngCMAHeAYIBiAHMAmwC8AOYBFAEwAUwBPAEoARoBCQDzAOkAzACuAICAcYBbwCtP9s/Cj5UPVQ8UDuYOyA60DrYOwA7gDvYPCw8gD1gPbg9zj69Pz4/hwBCAT4BiAJ8AqADLAMEAtACeAHQAbkAzgBDf8U/RD7YPk4+ED3MPYw9VD0IPMA8qDxcPIA9ND1gPdA+QD70PyI/gIACgHCAUQCcAIIArYBNAJUA4gEYAXIBTgFiAN0AcP/BP7I+wD6kPnQ+SD6+PuKAAAHgA3AE4AZgBygG0AZIBcAFsAUYBTgFCAUQBGwDXAKAAeIAqj9IPmw82DtgOfg40DjQOVA6aDt8PCg8kDzAPRA9aD2+Pio/AwBeASYBtAIYAtgDaAOMA9ADgALcAaUAkv/yPso+UD48Peg9nD0wPKA8TDw4O9A8NDwcPEQ88D1oPh4+8L+GALABEgGuAZQBkgFwATIBKAEGATcAyAEIAQMA1IBtv/s/dj76Pm4+PD3IPcw94D4IPpY+5z9lALACSAR4BfAHUAhgCHgHiAcABpAGCAXIBYAFCAQcAvgBlQCRP3g91DyAO1A6GDkoOHA4SDl4Org73DzUPa4+Ej6+PuS/nwB7AOYBvAJYAwADWANYA5wDjAMMAi8Awz/cPow90D1oPNA8tDxsPGQ8ADv4O5w8DDyoPMw9bD28PcY+qD9KAGYA7AF+AcwCTAIQAZIBegEeAQYBNgDxAKzAD7/yv7o/ST8EPsQ+3j6oPhg95D30Pfw99D5TP2VADAEwApgEyAaIB5AIQAjACBAGsAW4BUgFIARoBCQD6AK0AMK/1j7kPUA70DrgOmA5iDkAOVg6YDuYPPI+Nz89P14/Q7+i//KAEwC2AUQCoAMoAwwDGALIAmwBTAChP74+RD2YPQA9DDzkPKg8+D0gPSw81D0gPVA9lD3YPkY+wj81P0QAbADeATIBGAF8ATwAiIBZgDM/7z+Hv4+/uj98Pyo/Ez9gP2I/LD7kPsQ+wD64Plw+1T9VP5i//cAVAIIBAAIAA+AFiAcQCCAIgAhIBygFoATgBFAD1ANAAvwBpIBUP3I+rD3IPMg70DsgOng5mDmQOlg7vD0kPs/AEQClAKEAqgCOANoBDgGAAjACYAKcAkwBwgFJAPy/2D7MPdQ9ADygPCg8BDygPMA9QD3QPgg+BD4kPmg+/D85P1k/+YA7AEEA1gE+ASQBLwDyALyADj+WPwM/Jj8BP2I/Xr+1P4U/jj9GP38/Fz88PuI/Aj9zPww/bL+8P/E/wwAFAIIBaAIgA4gFqAcoB/AH4AdYBhgE2AQ8A4QDdAK0AhQBYMAuPwg+oD2IPLA7kDswOmA6ODqgO/A9Lj61gAoBPAD7ALoAnQCrAFMAiAEOAUwBVAFGAVAA5MAMP5Y+4D38POQ8tDykPPQ9DD3iPmY+pj6YPpo+sD6kPvc/Pj9lP4m/0EAogF4ArQCjALsAU0AJP5w/OD7ePyw/eT+lf/N/4j/6P4q/sT93P0C/uz92P24/Tj9iPxY/Pz8YP0E/cD95wCoBVAL4BLgG4AiACQAImAe4BiAEtAOYA7QDcAKSAc4BBMAOPuQ96D04PBA7ODogOfg5+DqgPAw+AEAmAWwB8gGwATwAmwB9QDgAfgCkAPoA+QDNAIJ/4z82Prw90D08PFQ8XDxUPIA9Rj4wPmo+sj7PPyA+0D7zPyE/uL+Af/Z/70ANgHqAagCQALyANj/1v5o/Tj8dPyI/XT+Vf8iACkAm/9k/7n/bP8K/vz81Pxc/Fj7IPuc/Dj+fP64/mwACANABiAMIBXAHcAhgCJAIWAdIBdAEmAQwA5QC8AHwAT2AMz80Pmw9+DzAO9g62DpgOgg6qDugPTo+oQBYAYQBzgFUAQwBNAC6QCsAEgBBgHLAJQBSAGC/nD7mPkA9/DycPCA8eDzgPVQ9yD6PPzA/AD9dP0w/aj8VP2s/p7+dP1Q/aj+0P9TAMwAuABb/5T9sPxU/Pj7nPwQ/3wBNAL6AQAC3gHsABwAEACf/zT+JP0Y/az8mPu4+1D96P1U/cj+SAOQCJAOIBfgH4AjgCEAH4AbwBSADnAN8A2QCngFUAOYAbD8EPjA9rD0IO9g6kDqwOvA7JDwIPjE/yAEEAaIBvAEGAIkAI3/GP+y/iL/owDOAaoBPABA/gj8SPkQ9nDz8PJQ9MD2YPnA+xz9zP1q/nL+bP1E/Dz8dPzw+2j74Pvs/AL+bf+VAPr/Av7Q/Lj8WPzI+6j8lP6f/6L/9v/eAEABLgGQAcoBsQCU/gT9GPwo+8D6+Psk/gP/OP7w/Zj/BANACPAPABnAH0AiQCGgHsAZIBQAEJAOEAwoB9ACVQDg/RD7qPkI+aD14O8g7IDr4OuA7aDyCPoMALwDGAZYBogE2AJoApIBov9Y/or+xv7u/nD/Hf9A/TD7oPlA9yD0cPMA9rD46PmQ+wD+6P4Q/rz96P3g/Ij7+Pv0/CT80Pqo+9T97P7i/iX/Pv8S/qz8mPw8/YT9GP7A/3YByAFwAeABgAIUAgwBdwC5/+T98Pt4+xj8jPwo/U7+4v5Y/vD+WALoB5AOIBYAHeAfgB4gGwAXQBIQD4ANYAuAB/wDGAKl/7j8oPvY+hD3oPHA7kDuQO5A8FD29Py+ABgDkAWgBXACvP99/4D+qPvo+bD6yPtM/KD9P//i/sT82PpA+aD3IPfw+Mj7wP3O/nX/U/9Y/iz9BPzo+hj6iPnI+OD3CPjA+Qj8BP57/0gABwAQ/1z+XP6w/mP/2QBYArwCVAJYArgCZAJcAaAASgAy/0T92Ptw+0j7KPt4+4T8AP2U/MD9VALACGAPwBZAHgAi4B/gGqAWIBJwDUALcAuQCgAH2AMYAp7/tPzw+pD4UPTg74DtAO6Q8AD2gPxwAbAEeAYoBQwBvP2s/FD7+PhQ+KD5YPoI+6z9BgD8/pz8APww+4j4UPfg+QD9yP2C/jgAEQBo/aD7YPvA+dD2IPaA91D3EPZg9+D6KP0S/qn/LAG4ANj/nwC8AW4BKgFMApwD8APoAzgE9APsAvIB3gDu/rj8aPvA+hD6yPnQ+lT84PwU/XL+7gB4BHAKIBMgG8AeIB9gHUAZoBNwDwAOsAwQCvAH8AWUApv/1P5K/tj6sPUQ8oDvwO0g7zD0gPmg/bwB8AQgBGIAfP7O/mT9+PnQ99D3IPgo+WT8wf8QAH7+fP1Q/Oj5gPhg+rD9QP9Y/4f/gf+G/lD9IPw4+tD3YPYA9lD1YPQA9VD30PnQ+5j97v5H/5X/3gB8AhQDSAOIBPAFAAZYBYAFgAXUA3YBbgDM/+D9IPxo/Lz8MPsI+jj78PtY+nD6mP5MAxAH4A2gF+AdgB5AHmAdgBfAD0AN8A2AC0AHWAZoBvQCpv/+/+z+SPnw80Dy4PDg7sDwUPZI+2z+tAFoA1wByv5K/lz9MPrg9wD4OPhI+Lj6Zv6l/wP/Cf+E/qD7mPlQ+xz+9P5A/yQAFACq/pj9AP0Y+5j4EPfw9VD0MPMA9ND1CPio+tT8uP0Q/vb+AwBtADgB3AL4A/wD8AOgBFAFQAUIBbgEQAN7AOz9aPxw+4j6aPqI+4T8EPxY+7D77PyY/tYBEAhwD2AVIBpgHsAfoBwAF+ASABCADOAJ8AggB5QDWAG4AT4BkP1o+bD2kPMg8KDvYPLg9bj5av7eAeABiwBEAID/DP34+iD6oPgA9wj4APvY/PD9RwB4Aar+UPuY+5T9FP7W/lABDAIm/6j81Pw4/Ej5cPeQ92D2UPMA8tDzsPXw9mD5qPwm/qD9oP36/jwASAEIAwgFgAV4BOwD6ATgBaAFmARoA1YBav5k/PD7APzY+xz8uPxA/GD7+Pu8/Y7/VAIQB5AMgBHAFsAbgB2AG2AYwBSgD1ALgApwCpgHMAQoAzwCZf/Y/Bj8UPow9oDz0PPQ9BD2aPkq/gYBDAF9AC0A/v6w/Oj6APrQ+ND2EPVw9Qj4uPqY/DT+Qf8K/1j+Tv+sAcACjALIAmgCof/I+/j58Pnw+BD3UPbg9WD0cPMQ9GD1IPYw9/j5TPwY/RD+3v9EAsAEUAaYBmAF3ANYA1ADbAMQBDAELAPEAeYAhv9k/YD8GP3M/DD6aPhI+dj6OPyr/0AFYApADuASABjAGoAaABnAFoASgA3ACrAK8AqwCYgHcAU0A7X/bPyg+jj5APfg9OD0EPcw+Rj7/P1nAEYAOv6c/Lj7cPp4+TD6QPtI+iD4YPcQ+MD4iPkg+9z8uP28/rgAEAO4BEgFkAQEAib+cPqw92D2sPZw94D38PbA9nD2gPXA9DD14PVA9tD38Pps/ZT+jAGgBqAJUAg4BhAFBANMAP//OAKgAqoBdANgBZQCVv7Q/Rj/vPyY+LD4kPpI+rj7CAEIBjAIkAtgEsAWQBZAFkAY4BbAEUAO4A0ADTALAAugCgAHgAIpAE7+GPuY+Fj4UPhg9wD4UPoA/CD9wv5x/wT+2PsI+8D6wPmg+TD7EPwI+2D5APjg9gD20PaI+ST83P2w/3gCcAXoBrAGcAWMAsD96Phw9lD20PZw9+D4mPkY+PD1APVg9HDzoPNA9iD52Pkg+0X/WAToB5AJwAm4B+gD+gAyALT/S/+aAFQD0AQYBNQCCAKjAMj94PoI+eD3MPjQ+g3/HANoBjAKIA5gEEARoBKgE0ATABJAEcAQ0A+AD2APkA0ACrgG6ANMAKT8MPsA++j5GPkw+lD7QPvg+5z9Cv5A/AD7UPvA+mD5qPmY+3D8cPzk/Jj8wPkA9gD0oPNA9ND2WPuD/xgCiARYB9AIIAjQBQACzPzQ93D18PVQ96D4WPr4+vj40PUA9GDzkPKg8sD04PYQ9yj56v6gBCgHcAiQCZAHHANQAUAChAHj/xYBzAOcA9YBhAKcA2oB8P0c/Jj68Pjw+Qj+vAG0A0gG8AlADGANQA/AEKAQQBCAEIAQ8A9gEGAR4A9gDHAJKAcgBOMA/v6s/RT8ePsw/BT9NP10/VD+nP7k/ej8GPyI+wj7IPpw+ZD5ePrY+pj6kPqo+ZD2sPKg8NDw0PJQ90j+9AMIBkgHMAmgCUAHpANNABD8oPeQ9mj40Pkg+uD6APvw95DzsPEA8vDxQPJg9OD2gPg4+0AAkAToBTAG2AbgBfACfAHUAtwDKAMMAygE/APAAgADkAOOAUL++PxE/ZT8dPz0/uwBYAOwBDAHUAlQCgAMoA4AEKAPkA9gEKAQ4A8ADyAOYAwQCmAIAAfABMoB3v9j/8r+jP3c/ET9HP1o/GT81Px0/FD7mPtE/Aj7KPkA+dj5CPoA+ZD4MPjA9dDyEPHQ8FDyYPbQ/MwC0AVgByAJwAlQCLAFRAL8/bD68Plw+jj6OPoY+/D6QPhw9cDz0PFg8CDxEPPA8+D0QPnG/i4BEAK4A3gE0AIyAVACoANEA5ADQAUoBqAFwAUoB8AGtAO5AGT/pP6Q/YD9O/+yAGIB+AKIBTgHkAfwCIALsAyQDGAN4A4QD5AOEA+QD0AOIAwgCxAKgAcgBSgEGAMuAcD/Sf/g/iL+2P0m/oj9gPyQ+8D66Plo+RD5ePgQ+DD4UPhg98D28PWA9CDyoPAg8XDygPXg+6wDgAjQCTAJ0AhgB6gENALZ/wj9qPog+rD6GPuQ+jD6yPlg9+DywO/A7xDxcPEQ8lD14Pjo+oz9OgEIAywCugEwA6QDfAKIA5AGkAcwBgAGeAeYBwAGAAUgBHYBiv4U/u7+vv6I/igAxAKwA7wDOAVoB6AIwAngC5ANEA1ADGAN4A7wDpAOwA4ADpALMAlACDgHkAVIBDgDggFn/2D+Sv6M/aj8iPwU/LD6OPn4+Aj5ePgg+Ij4OPjg9nD2EPdg9jD0UPOg8wDzMPKA9dD8zALwBUAIQAmABwgFsAR4BCwBIP0E/Pj7iPrI+Uj7NPwY+rD28POg8aDvoO9w8fDyMPSw9lj6tP0DANYBOAOQAyQD5AIsA7ADoAQgBlAHiAeAB+gH+AdYBvADWAIIASX/2P0c/sD+5P4uANQCqATQBKAF4AdgCXAJAAqAC4AM0AwgDvAPgBCgD9AOIA4QDHAJ6AfoBiAFJAPOAd4Ak/+U/m7+Qv4g/eD7OPtQ+gD5SPiI+LD4WPg4+Mj4qPjw99D3cPcA9bDx4O9A8LDxYPT4+U4AcATQBiAIkAeYBfwDlAMEAl7+yPvY+4z8wPwU/TT9qPvA+MD1EPPg8MDvoPAQ8hDz0PSg90j7/v54AXACiAJ0AnwCqAJoA7gEeAXYBdAGyAcACMAHuAeYBtwDdgF+AAcAWv+x/x4BpgHoAUQD+ASwBRAGIAcwCFAIAAlwCnALMAxgDYAOYA7ADeANcA1wC2AJ+AeQBoAEHAOYAlQBY/+M/pr+2P1E/ID7sPvY+mj5+Pg4+cD4sPfA91j4wPfQ9tD2EPew9fDyIPGg8LDwUPPA+GL+wAGUAzAG6AdIByAGOAVEA18Axv6W/tz9NP1U/h3/7Pxg+QD3wPTA8UDwEPGQ8XDxUPMw9zj6PPws/+ABJAIkAVIBfAIcA+gDUAV4BgAHwAewCAAJgAhYB5gFcAPCAYoA2/8zADgBxAGuAZQCWASwBXAGeAcQCGAHAAdwCDAKkAoQCwANgA4gDoANgA2QDBAKMAh4B9AFKAMMAngCngGh/z7/NACa/8j9JP3o/Nj6oPjY+Gj5APiw9rD3gPjw9oD18PXg9TDzIPCg7kDuoO8g9Bj6kv5AAfgDmAaQB6AHMAegBVADXAGoAA8Ayf9xAPgAiv80/Bj5wPZw9GDyYPEA8cDwUPHA8xD3sPno+zD+pv94/wn/4P8kAQQCMAPoBFAGEAcwCAAK0AoQCgAJ2AcgBkAEVANMAxQDoAKUAswC0AIQA0AEmAXwBbgFuAVABvAGyAcgCVAKoArwCrALIAygC9AKkArgCSAIsAYoBogFUAScA2AD3AHY/1//XP/w/QD8ePv4+tD4wPdg+ND34PWw9TD3MPbA84D0EPZg80DvIO/w8RDz0PVc/DYBhAFIAkAGMAiYBdQDqARYAwgAYP9QAV4BoP/n/08A+PxQ+ID20PVw8wDxkPHQ8oDygPMg91D6YPt4/Jz+Jv8Y/vL+UAFcAkgCtAMgBugGIAcQCZAKgAnoB8AHUAcoBawD5AOMA+wBZgGIAiwDJAM4BLgFyAUoBUAFwAXIBVgG8AcACSAJkAngCrALoAuAC1ALkApwCXAIYAcYBsgE3AO0AlYBPwBN/7z+iv4S/oT8mPoI+uj5cPgA9xD3QPfQ9fD0MPZw9kD08PJQ81DyIPDA8aD36PsY/TP/LAIYAzQDwAQwBjAERgGEAWgCfAF4AEAB2AEMAJD9PPxY+rD3IPaw9eD04PKA8iD0wPUQ9+j4QPuw/Ez9gv61/+//dwDSARQDZAP0A+AFmAdACMAIEAmQCJgHEAfYBqAF7AMIA5gCHAI0AlADkAQYBaAFOAb4BWAFkAWABgAH4AZIB1AIMAkACvAKsAuAC+AKYArwCeAISAfwBfgE0AM0AqMAAQAJAOD/Nv9w/mz96PtA+lj54Phg93D1EPXQ9YD1YPQg9GD04PJw8BDwoPFA88D1OPpG/on/7/8kAngEiASUA4ADDAPKAXgBbAKkAlYBVgDq/0j+SPsA+Qj4APdw9VD0IPQQ9GD00PXA9+D4YPlw+tD7xPyk/Sb/qQCYAYgC8AMwBQgGKAeACCAJ8AjACIAI4Ac4B6gGsAWYBDAEcASABJAEAAVIBRAF4AQYBQgFsAT4BNgFiAbwBrgHwAiACRAKgAqQCgAKkAlACYAIQAcgBjgF/AO8AgwCggGQANf/uv8d/0D9oPtY++D6MPmw92D3sPZA9fD0gPVA9GDxQPBA8TDxkPCQ8qD2wPlo++j9uABsAYYBJANgBAgDXgEYApwDSANMAogCiAK6ANz+FP6A/Ij5UPfQ9vD1EPRQ86D04PWA9oD30Piw+Uj6mPsE/bT9Tv6p/y4BcALMA1AFwAbgB8AIEAmwCIAIoAhACFAHeAYABpAFoAWIBkAH6AY4BigGMAaYBdAEuATwBAAFSAVQBoAHIAjACKAJ8AlwCfAIEAkACYAI+AcwBzgGcAUIBUgEFANIAtABkwD4/vj96PxQ+zj6IPpo+XD3kPbA9wD48PXQ88DyQPFA76DvEPKQ81D0MPe4+xz+Rv6F/8QB9gG4ALUAuAF6AQYBXAK0A2QCkgDAAO0A1v4c/MD6gPlg9wD2QPZA9pD10PUQ97D3sPdI+Jj5WPqw+qD71Py4/cL+RgDOASADkARABogHEAiACAAJIAkACcAIUAiAB9gGEAegB8AHqAewB2gHmAbwBagFIAU4BPgDoARABcgF8AZQCPAI8AggCWAJEAmwCLAIUAhgB5gGSAbIBRAFkAQABNwC1gEoAQMAQv4Q/Xz8SPuA+cD4sPjQ97D2cPZw9WDy4O8A8PDwsPDw8FDz0PUA99j44PvU/Rb+wP5aAM0A+v9nACACuAIsAhwCdAL0AegANQBe/0T92PqA+cD4sPfQ9sD24Paw9sD2cPcA+BD4iPiw+aD6OPtU/OD95P7C/24BeAOwBLAFUAeQCLAI0AiwCfAJAAlwCLAIgAiwB9AHoAiACKgHcAdwB3gGYAVIBTAFcARABHAFmAboBnAHkAjwCJAIoAgQCcAI4AfAB9gHOAc4BhAGQAZwBVgEvAPcAjIBtP/6/gD+HPyA+uD5OPkY+KD3UPfA9WDz0PFA8TDwYO/w8HDzsPSw9Rj4iPqQ+4j8Ov7+/jL+XP4pAAYBjgAGAWACVAJWAV4BlgEbAPT9GP0k/MD5CPgw+ED4QPfw9uD3MPiQ99D32Pj4+Nj42PlY+8j7OPzk/bn/swC+AYgD2AQ4BfgFSAfwB8AH8AeACHAI8AcgCNAIIAkACeAI0AhQCLAHWAfQBvgFYAVoBcAFAAaABjAHkAegB8AHwAdwBzAHWAdgB7AGAAbYBaAFMAUABRAFeAQwA1QC4AHEAEH/PP5s/fD7mPpo+jj66Phg96D2oPWA8xDyQPLQ8jDzUPQA9gD3sPc4+Sj7+Pss/NT8mP3Y/V7+kv9TAC8AJwCVAIIAv/9L/xz/OP64/KD7+PoQ+lD5UPl4+Qj5YPhI+Gj4cPiY+Ej58PkY+oj6cPtw/Cz9Dv5L/2sAZAGMAuQDKAUgBvAGkAfYB+gHEAhwCAAJcAmgCZAJoAnACZAJEAnACJAIEAigB6AHyAegB6gHAAgACGAHGAdYB0gHkAZoBrAGQAZoBUAFaAWoBKwDyAP0A6wCGgHLAL8AZ//U/VD90Pxg+1j6mPpA+lj40PZg9rD1IPSA81D00PTg9AD24Peo+Nj4GPqw+wD8uPtM/Cj9WP2Y/Zb+Q/8E/9z+cP+w/x7/Zv7U/fD84Psg+8j6gPoY+vD5APrY+Yj5cPmw+QD6CPoA+jD6mPog+9j77Pz0/dT+1P8WAVwCYANYBGAFQAbYBigHiAcgCLAIEAlgCdAJMAogCuAJ4AnACRAJcAiQCKAIEAjQBzAIcAj4B9AHAAiQB8AGwAYwB4gGgAWABaAFmASoA/QDEATcAhgCnAJwArEAgP/h/5n/+P0c/WD9tPzo+lj6qPpY+bD2wPWA9iD2wPQA9ZD24PbA9kj4MPro+ej4APqg+xj7WPrI+2j9GP3o/GT+Mv8Q/qT9rv5u/pD82Puo/Ej82PrQ+qj7CPvo+Uj6+PpA+pD5WPr4+iD6mPmA+kj7KPuY+/z8Ev6q/tn/dAF0AuwCqAOYBDAFoAVQBiAH2AdwCOAIIAlgCaAJ0AnwCeAJgAkgCdAIoAhACOAHsAeQB3gHeAdwBygHuAaoBsAGWAa4BYgFmAVQBcgEsASIBMQDGAMAA9AC1gHbAMUA2gD9/77+FP6Q/XD8OPuY+sj5KPgQ91D3cPdg9rD1sPbg9wD4SPhY+cD5QPmQ+ej6IPuI+hj7kPwE/bz8ZP1U/iD+uP0c/hr+AP1E/Jz8mPyQ+/D6MPsg+7j6yPoQ+9D6UPpY+mj6CPrA+RD6kPog+9j7yPys/ab+zf+fADQB4gGoAmADGAQgBfgFcAYIB9gHUAhwCMAIQAlwCVAJUAlwCYAJYAlACeAIUAjoB+AH0Ae4B6AHoAeQB2gHSAcgB6AGCAaoBVgF0AQgBLgDkANAA6ACHALUAYABDAHhAKoAtf9q/pj9NP1A/Aj7ePpQ+qj5wPhg+Cj4gPdQ9wj4ePgA+ND3uPiI+Yj5uPlY+rD6oPoo+/D7CPzQ+xz8hPxE/ND70Pvo+7D7qPuo+zj7gPpo+tj68PqY+mD6aPow+gD6IPpQ+mD6uPpo+wD8TPzE/LD9jP4O/6H/XAD5AKgBvALgA4gE6ASgBWAGuAYAB7AHUAiQCMAIQAmACWAJcAnACcAJIAnACMAI0AiwCJAIoAiACEAIEAjgB4AH2AYYBoAF8ARABKwDZANgAyADlAIQArQBdAEeAb4AKwBh/5D+Cv60/RD9KPx4+xD7cPqw+VD5IPng+Mj4+PgQ+ej46Phg+bj52PkI+jj6YPq4+jD7cPto+2D7gPuA+2j7iPuo+3j7SPtI+yD7sPpQ+lj6OPrY+aj5qPmY+cj5aPrY+rj6oPog+4j7kPsA/Mz8EP0o/Qz+S/+1/+X/OAHMAhwDLANIBGAFUAWIBfAGsAc4B5AHQAkACoAJsAmQCiAKEAkwCRAKoAnACCAJ4AlQCaAIQAnACdAIuAewB3AHCAYIBTAFCAUgBMwDOAQYBDgD1ALkAjgCDAFxADYAkf/i/rL+av6g/eT8gPzg+xD7oPpg+tD5WPlw+Zj5WPlw+Qj6QPrY+aj56Pn4+dD5GPqQ+mj68PkQ+mD6IPrY+Wj60PpI+tj5ePrw+kj66Plo+lD6gPmw+dD64Pow+pj6kPtY+5D6APv4++D7wPuw/Hj9VP24/Sn/EQA0AOYATAIMAyAD1APYBCgFWAUwBjgHkAfIB4AIQAlACfAIEAlwCWAJQAlgCaAJcAkQCVAJwAlgCZAIQAhQCKAHiAYIBtgFGAVABFAEmATwAyQDXAOsA9AC4AH0AdIBzAAiAFYA2P9E/mT9oP0s/dD7WPuI+9j6qPmo+SD6gPmw+CD50Plo+Rj5wPkw+tD50PmA+nj6+PlQ+hj7+PqA+sj6MPvQ+qD6IPtA+8D6oPo4+2D72Pqo+gj7MPsI+wD7QPso+wD7KPto+1j7QPuQ+0D82Pw8/dD9ov5C/8f/egA+AcABRAIcA9QDMAS4BJgFcAbwBnAHEAhQCEAIkAgACeAIoAjQCBAJ0AiACLAI8AiwCGAIYAjwByAHyAboBoAGqAWABdAFaAWwBKAEsAT0A0QDZAN4A7QC/gEkAvoB7AAiAPr/g/96/uj91P0w/TD8BPxU/PD7MPsg+0j72PpY+pD6yPpY+gD6YPqo+lD6KPqo+uD6ePoo+mj6aPr4+dj5EPro+Xj5iPko+oj6aPqA+tD6qPow+hD6UPpQ+hj6aPro+vj6wPog+9j7KPxY/Oj8fP2s/ez9vv6G/8j/KAAQAfIBXALoAuwDuAT4BEgF+AV4BogG0AZoB7gHqAfIB0AIgAiACMAI4AigCEAIMAgQCJgHKAcoByAHwAZIBgAG4AWgBWAFIAWQBAAEtAOAAxQDuAKwAowCFAKmAUYBowDr/5v/Yf+m/uD9mP1Y/dT8iPys/Ij8APzI+9D7iPsI++j6+Pqw+kD6KPow+gj6CPpA+jj64Pmw+cj52PnA+aj5iPlw+Yj50PkI+ij6QPpo+oj6gPpg+iD6KPqI+uD66PoI+6D7MPxs/Nj8aP2I/XD97P3G/jL/bf8HAK0AAAGKAWwCHANcA9ADsAQoBUAFeAX4BWgGqAbgBkgHoAeYB5gH6AdACCAIyAfQB/AHyAdwB1AHSAcQB9AGuAaIBhAGmAVQBeAEUAToA7gDeAMkA/gC4AKIAgwCrAE4Ab8AWADq/4H/Uv8z/8z+Qv78/dz9hP0k/fj8sPws/Pj76Ptw+/D6MPuA+yj72PoY+wj7gPp4+vD6+PqI+mD6oPqw+pj6qPqw+qj6oPrA+vD6GPtA+3D7gPtw+3j7oPvI+/j7OPx4/LD8+PxA/XD9mP3o/XD+0P7s/gv/YP+m/9P/MgDCACYBRAGiAVwCzALIAhQDvAP0A9wDUAQYBUgFOAWoBSgGAAbgBUgGeAZIBnAG6Aa4BmAGqAbABjAGyAXwBdAFKAXwBCgF8ARIBAgEAASEA+QCnAJoAv4BqAGaAWAB0wB+AFYA+v+Q/17/Jv/I/pb+jv5o/hT+4P3A/XT9NP0o/Rz94Pyw/GT8APyo+6D7mPtg+1D7aPtA+/D66Pro+qj6cPqY+tD62Pro+hj7KPsw+0j7YPtA+1j7sPvg+8D7yPsg/HD8lPy8/Bz9bP2Y/dz9Kv5c/oL+2v5D/37/qf/3/0YAfwDjAEIBSAFOAdIBlAIAAyQDcAPYAwgEMASQBPgEGAVIBbAF4AW4BbgF6AXwBdAF8AUYBtgFkAXABfAFgAXIBNgEUAUoBaAEiASQBBgEhAOMA5wDGAO4AsgCsAIYAqwBrgFuAd4AlQCcACgAY/8w/2H/Cv9I/hT+VP4Y/nz9SP1I/dz8RPws/DT82Pto+4j78Pvg+4j7cPto+xj7wPrI+uj60Prg+jj7iPuA+3D7oPvI+6j7iPuY+7D70PsU/HT8xPzo/CD9fP3Q/eT90P3Q/fD9LP5a/oz+5P4o/2P/pv8IAGUAjgClAN4AQgF8AZIBxAEgAnwCwAIAAygDSAOIA+ADGAQYBBgEUAR4BGAEQARYBIAEUAQYBEgEkASQBHgEgASABEgEEAQIBOADsAPMA/wD2AN0A0wDPAPgAmwCRAI4AvABpgGGAUABwgB5AHQAOADH/6//r/85/4j+UP5O/vD9hP1o/WD9IP30/Oz8oPwc/PD7EPwI/Nj78Psg/Pj7uPvA+9j7yPvY+xD8KPwI/Pj7+PsE/DD8bPyU/LT8AP1E/Sj9BP0o/Vj9dP2U/dz9GP4o/lD+jP6g/rD++v5J/1r/cf/M/xkANABSAKsA9QAEASIBcAGwAcoB9gFAAnQCnALwAhgD+ALoAiQDXANwA4gDlAOAA2ADaAOQA6ADoAOoA7wDtAOMA2QDZANwA3ADRAMQA/QC2AK8ApACaAJEAiACBALSAZoBZAE8Af0AqACGAJQAZAAHANL/w/+S/yr/3P7U/sD+hP5K/kD+Hv7Y/bD9pP2U/Wz9UP1A/Uj9YP1k/Vz9bP1k/TT9FP0w/WD9TP0k/Uz9pP2k/YD9pP3M/bj9rP3I/dz9yP3k/Vr+pP6c/pz+zP7w/gD/JP9y/5r/pf/F//L/AwAUAFsAsADcAO0A/gASAR4BKAE4AUwBcgGAAW4BggHKAfwB+AH+ATQCUAIwAigCTAJMAhgCDAIoAigCEAIQAiwCGALSAawByAHgAaoBWAFMAWgBTgEcAQIB6wDJAMEAywC7AH8APQAJAM7/uf+6/5b/dv+A/2r/Hv/w/gf/HP8B//L++P7W/rL+tv7A/pb+eP6E/nz+dv6a/sT+nv5a/lz+hP52/lj+ZP6A/pL+sP7i/vD+Av8g/yn/Fv/+/v7+Av8R/0H/dv94/2T/U/9M/1P/gf+v/7X/s/+z/73/yP/Q/8//0f/j/wUAMABVAG4AdQB7AJAAmgCmAMUA8wAQAR4BKgEsASwBJgEmATABRAFUAUIBKgE4AUoBTgFaAVoBQgEuAT4BNgESAQIBDgESAf8ACAEOAe4AxAC1AJoAZABKAEwAUQA6ADAAIwAJAOP/yP/N/83/wf+r/53/hP9s/2D/TP8//y7/EP/c/s7+A/8s/yb/If9N/1P/Hf8X/zb/Pv9H/4v/u/+Z/3T/gf+N/3H/W/9w/4P/gf+O/5T/eP9p/4j/lv+J/4z/tP/Z/8T/vP/f//P/2f/A//j/SwBNADQAUQB6AHUAVgByALcAxgCcAIUAvQDyANgAwADTAOkA1ACxALIArgCfAJsArgC4AKAAiQCZAK0AmgCaAKQAhgA9ACgAVQBCABsAPACAAG0ALgBFAFoAKAD4//j//P/a/7b/oP+z/+j/6P+4/6n/tv+f/2//av94/2b/Wv9v/3b/Yf9I/yr/A//q/vL+Dv80/1b/Wv9D/1r/kf9z/y7/Uf+w/9D/o/+m/+D/2v+6/7b/zf/g/9X/xv+u/6z/uf+1/7T/y/8HAC0AMAA5ADEAFADm/+T/EgAqAE8AgACmAK0AnACbAJ8AuADIALUAmQCUAJ8AjgCHAKgAyQDAALEAvACyAJMAeABkAE0ARQBVAF8AZwCBAHgARAAQAP7/+f/N/7n/7f8OAOL/uf/M/8j/n/+///b/wv+F/9D/BQCm/2v/3P8BAGr/Nf/J//D/cP9n//D/5P9a/2r/zf+n/z3/eP/i/6L/T/+m/+7/iv9C/5L/o/82/xX/hP+8/37/iv/Q/8D/pf/D/9D/r/+4/8n/mv+W/8D/wP+g/9H/CgDc/5v/wf/s/7n/n//k/wcA9f8OAFEAdgBnAH8AsQC9ALwAxACxAIoAiACjAK8AtADMAPUA7gDZANUAwACYAJQAmwCWAJQArwC6AJEAfQCkAK4AdwBrAIMAZQAYACsAXAAzAP7/QgCTAEUAAgBCAGcA+v+9/xoAKgC8/7H/IQAbALv/0P8UANb/hP+s/7j/av9z/+H/zP9f/3v/1f+h/0n/g//R/5f/YP96/3z/V/9e/6X/t/+s/7b/y/+1/5D/uv/O/6j/bv97/6D/fv9m/37/i/9W/1b/wv/z/7//sf/B/7b/pv/U/w4ACgADAB4AUQBfAFUAJwARAFUAfgBYADEAXgCBAEMA+v8QAFoAYwA3ADwAYgBiAGEAfwCNAFoATgCAAIgAWABbAGoAJgAKAFgAkwBZABcANgBeABwA3P/z/xcA/v/S/+n/AADo/9//EAASALr/ff+P/6j/n/+5/8v/wf+6/7L/r/+2/+T/8P/G/8T/8f/n/7T/5v9CADMA7/8BAC8A9v/P/wIA+f+o/7f/LgA4AND/vv/1/7r/XP+Z/wIA7/+g/7n/7/+//47/vP/r/8//u//P/9r/0v/m/xcAMAA3ABAA4v/9/x8AEgADADkASwDn/8n/PQBnAAkA9/9cAFoA7v8QAIoAfwAbAC8AeAA9AAMAUACOAEUADgBEAGcAMgAmAGQAXAALAB4AbgBRAB4ASABtAB0A6v9EAFkABgABAEQANwDx//z/OgAWAM7/8P8sAAoAwv/e/ywANADw/+j/AADl/9X/8P8OAAcAEAAmABEA/f8xAE8AEgDP/9r//P/s////IAD1/67/rf/e/9n/sf/D/+H/w/+i/7//4f+5/5r/wP/g/7b/lf/G/97/rf+i/+j/9v/C/9H/FgA1ABEA9v8BAAoAAAAaADcAHwD3/+z/6v/i/+b/KABEAO7/sP/S/w4A/v/z/zcAaQA0AO7/5v8DABIAJABYAHgAYAAqAAEA9v/x/wcAHQAgABUAAQACAAkA/v/8/xMAJAAFAOz/FAAoABcADwAiACoAFQAeAC0AKwArABgABwAMAB0AKAAbABgALgA5ABgAAgARAAgA6v/8/ycADgDM/8n/CQD8/7z/tv+//47/ev/C/9r/m/+P/8//2f+l/5//yP/R/6f/mv+n/7r/6f8XABUA2f/I//3/CwDi/9b/4P/W/8L/7f8CAN//zv/T/9j/0//R/9n/zv/K/+L/7//2//f/BQD9//7/JAAiANr/vv8MADoABgDz/z4AcgAYAMb/DgBWACEA4P/q/zAARgAuABcA7//V/97/HwBBAC4ADQAVACgABwD3/ysAZQBBAB8AWQCEAGAANABIAHcAcQBXAEkASwBUAEMAKQAdAC4ANQAfABwAJgAQAOP/9/8oACYAEQARAAQAzf/F//3/EwD2/xQAKgDP/5z//f8oAL7/kP8EAB0Abv9B/+n/KgCJ/1P/1//4/57/of8aAB0Aqf+l/w0AFACu/4X/t//p/9f/rf+g/7n/tP+k/83/AAAGAOr/6P/v/9r/2/8TACwAEgD6/xsAPgAzACgANQA1ABEA+f///x0AIQAmAEMAWQBYAFEARwAWAPj//f8iADkAIgAnADYAFwDt/wQALwArAPj/6/8zAFwAIwDn//j/DADo/+H/RQB3ABcA4/9UAIwABQCz/zQAggAJAML/FgA8AM//ov8GADkA+v/K/9f/7f/2/9L/of+O/6b/vv+7/9T/6//v/9n/nf+M/73/7P/c/8X/5P/5/+j/4////+v/r//P/xsADgCx/4//0v/z/8//yf///x0ACgDw/9b/1P/l/wEAHAAlACIAKABKAFEAHgACACAAKwD4/+T/BQAOAPn/+P8GAB8ASABWADEANwCEAHsACgD4/1sAiwBZAE4AhgBtAB4A/v8JAP7/6P8QAD4AQwApAAkADgAsADwAGAD2/wkAKAAXAPT/CwA7ADsABADo//j/+P/L/73/6f8JAPX/7P8WAD0AKADj/83/9P8BAOz/3v/e/9//4P/+/xcAEwD///3/EwAaAAwACAAGAOn/sv+X/57/h/9o/4D/tf/O/9D/8f///5r/If8S/0//Sf8m/33/+/8mAEUA5gAuAQMAQv5s/bD9VP60/3wBTALCAd4AdQAaAID/VP/p/6UA2wCRAG0AgACKAFcACADm/+P/2//N/8X/sP+Y/6D/q/+a/4H/uv8cADEACQD8/wEA4/8IAKcAKgECAWkACQAPACQAOABfALIAIgFOAd4AHACl/4j/Rf/o/uD+Hf9T/3H/mv+Z/1j/Rv+h/xUANAAQABkAUQBiACwAGQBRAG4AaAChAPsA3QBJANj/i/8a/xn/SADqAawCbALeAewAiv+0/ij/9v/5/4r/c/98/xz/jP74/UT9tPys/Nj8DP3A/TX/lAAyATwB+ABwAPL/5f8kAGAAoADiAO8A0wDLAO0ADgEoAUQBOgH5AJQARAAuACgAGgAYAFEArwDcAMIAmQBzAEsAMAA5ACMA3P+8/+v/FQD2//H/UwDJAOUApQBLANz/Tv/G/rD+Of+0/9r/WgAuAXABtwAzAIYAjAC7/0D/4/+yAOUA3QAuATYBlwA0AI0AowCv/9z+Gv+A/yX/0P43/3v//P5s/kz+JP7E/dj9eP7g/vL+av8hAFgAHAAZAIMA2gD6ABQBGgHoAJkAWgA1AB0A/v8HAHgA/AAMAdQA3wAuATgB8wD0ADwBTAE4AUQBPAHZAEoAKABmAHEALQApAHoAgQAWAKz/iv9d/x//If82//T+lP6G/sL+5P7u/jv/nv+9/7L/yf/3/ycAeQDeAOsArwCYAMEAngAfAND/1P/N/5r/hf+m/6L/ef98/47/Yv8U/+j+3P68/or+ZP4q/tD9oP2c/Yj9fP2o/fD9CP4a/oL+F/9w/4b/uP8XAFMAVgBxAMcADgEiAVYBugHcAY4BQgFAATIB1AB4AIQAtwCqAJcA0AAyAVQBOAEyAT4BFgHYAN0AHgFEAUABbAG6AcwBlAF2AaABvgGgAZ4B9gFQAmwCkALwAhgDyAKIArwC8AKwAogC4AJAAywDGANkA4QDHAOUAmwCIAI2AU8A6/98/2L+FP1g/PD7+Pqo+cD4CPjA9gD10PNQ8+DywPKQ8yD1oPag99D4kPoc/Mj8SP1E/vz+0P6m/mT/cQD/AJwB4ALQA2wDkAJIAggC6gC4/4j/rf9L/wX/vf+7ABABRgHwAVgC3gFGAYABOAK4AmAD0AR4BpgHkAjwCQALEAvACrAKUAoACYgHwAZoBsgFEAW4BFAEQAMoArgBggHYAFAAvwB6AaYBpgGUAhgEEAWgBWAG4AaIBqAFKAXQBOQDjAKcASQBNAB2/uD8OPz4+yj78PlQ+RD5SPig9zD48Pig+ED4OPkY+vj4oPcw+PD4YPdw9PDxQO8g7ADrgOzA7aDtAO9g8rD0YPXQ9+D8QAG8A2gGIAmACYAIUAmQC4ALoAkQCVAJOAeUA7oBiAFXAIb+Gv4K/jz8MPqw+tj87P1+/rEApAPIBGgEyAQIBqAGmAYoB7gH4AaQBcAFyAbIBigGmAZYB1AGMARgA4gDCANsAjADIARwA3QCIANABPwDXAMIBJgEhAMAAqoB4gGOAZIBjAI8A9QCVAJsAnwCKAIMAlgCYALwAaIBhAEeAbMAwAAIAdIA7f/w/gL+9Pz4+5D70Pvo+2j76PoY+zD7OPog+UD52PkY+dD3sPfQ9wD2MPQg9TD2IPQw8VDx4PHA7qDrYO7w85D2KPjg/AgC/ALIAvgFcAlwCAAGqAYQCCAGIANkA4gF4AWwBCAEfAMoAXr+oP0S/hD+NP6+/+4BUAMIBCAFyAYQCGAIyAeIBjgFUASoAyADGAPEA4gEsARgBPQDMAMQAoQBuAGEAXkADAAsAXgC3AJUA+AEKAbwBSgFyARABCADlAJgAxgEkAMQA5AD7AMkA3QCzAIEAxQCKAEwAfsAJQAMAFoBTALUAYgBLAIQAngAH/8j/zv/dP64/VD9PPwQ+0j7JPz4+4j7WPzU/Dj7uPlw+uD6QPl4+PD5iPkg9jD1MPi4+MD0wPLg9CD0gO6A62DuQPFA8pD2cv6oAsYBqAIAB8AIaAYIBlAJEAr4BdwC4AOgBNACHALoA7gD5f/8/Cj94PwA+3D7UP9oAqwCTAPQBcgHQAgQCVAK8AnwB3AG4AWwBOgCMALoAmADqALMAVgBhwBs/0b/OgCXAAIAMQCcAZQCtAKIA3AFqAaIBiAG0AXQBHADAANkA2gD6AKwAowCuAGeAGEAAAE2AboAVQBFABEA6v9oAEgBugHmAWQCpAIMAlQBUAGSAVwB/gDLACcA9v4O/tD9WP2E/CD8XPwY/Dj7APt4+0j7QPog+tD6GPoI+KD34Pgw+HD1gPSg9SD0oPDA71DwoO2g6iDuwPXQ+aD7rgGwCFAJeAbgByALgAkYBgAHkAiIBE7/7//4AqIBfv54/2gBcv6o+ZD5XPz0/AT9iwDYBIgFiAQIBmAIUAggB6AHgAggB2AE4ALYAuAC7ALMAwgF+ASQAzQCugFoAeAA5ACyASwC8gEMAvAC4AOQBHAFAAZYBcADRAIkARYAwv+SAKgBHAJcAvACVAMoAxwDpAP4A4gD7AKYAhACPAEIAcABNAKOAZYAWwBSAMj/Y/88AJYB+gF8AWwBaAEwAIr+cv4Z/9j9aPsY+3j80Pt4+XD5aPs4+zD5mPko+3D5QPbQ9vD4UPcw9GD1YPig9sDxwO8g8ODuAO5w8bD2CPqc/awD4AhAChAKIAvQC/AJOAeIBVgE7ALOARYBaADy//j/y/+g/sD84PqI+ZD5QPvg/aQAmAOIBqAIkAlACvAKIAuAClAJKAdgBDQCXgEyATQBwgGgAqgCqAGpABsAof9z//n/ygAmAVQBKAJ4A6AEkAWABrgGwAX4AzQCyADZ/8D/SQCjAGUAKQBWALoAEgGIASgCfAJcAhACzgGgAaoBTAJYA/wDvAPsAiQChAHoAGsAMAAMANr/l/9j/1T/Yf88//L+Bv8Y/xD+VPzA+4D8aPxY+9D7rP1w/RD7WPpQ+xD6IPfQ9tD3MPUQ8dDxkPWg9CDwIO+A8fDwIO5A8MD2SPvw/QgEgAswDfAJwAnQDCAMGAegBAgG8AS+/7j8PP4Z/zz9BP11/4L/4Pv4+RD87P2g/W//sASQCHAIAAjQCTALAArACOAI2AdoBFwBbwC6/1b+eP7AAIwCRAKsAQACBAISAa8AhAHuAS4B4wAkAqADMASQBFgFqAXABFADPAJeAXsAIQCwAHABrAH6AewCsANEA1QCLAKAAjgCvgHEAbAB5ABfAPkArgFSAZUAmgDQAF4A3f8aAI0AkQCvAFIBuAFYAfMAJAFQAa4Aef9e/oT9nPx4+3D6+Pko+mD6WPow+tj5OPno+Gj50PkA+eD3IPi4+HD3sPRQ86DzMPOQ8dDwAPFw8XD0HPyIBGAIIAlwC/AN0AvIBuAE+AXYBCgBa//j/4b++PuU/KT/AwCA/XD8aP3g/Ij6uPrK/mADQAaACMAKgAuACqAJUAnwB+AEzgHL/07+DP3w/Hr+vQCwAvwDWATEA9ACNAIMAtABlgH0AbACBAP8AigDoAPsA8gDSANMArcAM/+S/gz/DAAGARACSAMoBGgEYASABLgEsARQBIgDbAJkAcoAlQCLALIA5QDkAJQAMgDy/6//hf/P/1QApADhAFwBxAGwAY4BwAGqAZMADv+4/Wz8YPsg+7D7PPx4/Mz8zPzg+wj7YPu4+/j66Pkw+eD38PXw9cD3wPdA9QD0gPTQ8uDuIO2A7yDyMPSA+a4BiAcAClAMQA7gDEAJWAewBvgDSwDi/vr+7P24/MT9tf/N/8b+kv4y/oD8iPsw/fr/AAJQBOAHwAoQCzAKMArwCQAIgAX8A4ACEQAW/tz9oP5v/9kA5AIoBAgErAOgA2wDEANcAyAEYAQYBAgEIAS4AwwDzAK4AgQCwgCe/4b+UP2o/Fz9If/kADwCiAPIBDAFsARABDAE7AMEAxwCdgGeALD/qv+WADIB6AB+AGQAzP+S/tj9IP6G/p7+EP8XANYA5gAAAXYBhAG5AJf/wv78/ez80Ps4+1D7wPsA/Pj70PtQ+2D6yPn4+QD6CPkI+ID4KPng99D1wPUA9xD3sPVA9BDygO5g7TDx0Pag+uj+AAYADJAMwArwCqALgAlwBsAEAANe/1T8dPzI/eT9tP3M/hYAof8E/iT9wP16/4QBqAP4BXAIcAowCxALsAoACmAIQAYgBOIBZf+Y/WT9Qv4q/w4AYAHYAuQDiATQBJgEEATsAzAEKASAA8wCbAIkAgACLAIoAkwB+/8v//L+hv7w/Rb+Ef81ADQBPAIUA2wDqAMQBAgENAM8AtoBugGIAYgBygF6AZgAIgBRACkAZ/8+/+L/6P/M/jD+T//TAEoBQAGoAQACiAHeAFkAUf/0/Xz9xP04/fD7oPs0/Dj84Ptk/Oz8+Puo+rj6GPvY+UD4WPgQ+WD4IPcw99D3gPdQ9lD18PNQ8WDuQO0A8JD21P0oAygHMAsADtAN4AswCpAICAaMA4QBuv5A+/j5APwU/6IA2wDXALkAMQA8/27+wP78ABgECAagBqgHgAmwCoAK4AngCOgGSARkAg4BYf8G/oz+kQAUAlACTALAAhwDvAIUAsoB1gHeAeIBDAIsAhACJALcAqwDuAPgAuAB/wDf/6r+CP4o/pr+LP/9/8MAMAG4AfQCUASoBOgDEAOQAiQCrgFuAWgBQAHkAJYAPwCI/4D+yP2s/bz9YP3w/Ej9bP53/yIA6gCoAZoBGgFgAQQCXgHt/5f/z/9w/iz8yPvA/AT8QPqg+hD80Pow+ND4QPt4+gj4MPkg/OD6MPew99D6cPng9CD0IPYQ9KDvkPDA9Qj5gPugAtAKAAxACEAIYAtQCpAFgAM4BHACgP5M/Zr+Yv4g/aT+1AHKAWD+XPzI/Z//5v+EABADEAagByAIEAkACgAKQAmgCGgHWASVALb+7P7+/m7+/P7oADQCMAJ0AmwDqAP8AuACqAPkAywDrAL4AkAD6AJ4AngCZAKEARoAE/+2/n7+JP5K/h7/9f9mAAwBDAKsArwCEAPMAwgETANoAhwCHALeAWwBAAFxALf/OP8a//r+nv6G/gv/kf+D/1v/xf9wAKMAsgAsAVABuABcANIA9QDq/9z+zv48/kT80Ppo+zD8oPuI+yj9Gv7E/KD7ZPyk/Lj6UPlA+rD6+Pig92j4qPiw9uD00PSA9ODyEPIQ83D0wPVY+en/8AZgC7AMMAwwC6AJGAfEA/AAp/9B/1j+xPyo+5D7dPw+/nQAfAGCAFv/FwCqAdwBjAFoAwgHMAkACYAIUAhgBwgGwAWwBZgDXgDu/lT/8v64/Sj+1AAwA8QD0AMwBBAEPAMgAxgEmATQA9wCmAIkAtoACADbABACugFpAN7/1v/U/oz9Lv4XAL8AUgAgAbwCvALGAawCyATQBMQCkgGeAdYAd/+A/3cAggAYAIcA0gC7/2T+dP5B/3j/IP+m/jL+Nv4a/x8AjADzAK4ByAHHANb/ff/W/gr+UP4T/0L+XPz4+zz9rP20/HT8YP1M/bD7uPoA+7D6WPng+LD5QPnw9qD1oPYQ9zD1cPMQ9AD1MPRA9LD3nPywAIgF0AvwDuALCAcQBtgGOATJ/1r+QP+K/rj8DP20/gb/Vv/GAbQDrgFI/k7+DAFYAkgCCARYB+AIQAjYB7gHEAbEA3QDoAQgBKIB9/8aAB4AXP/K//YB5AOIBPgEeAW4BCAD0ALQA/AD7ALEAkwDZAKGAKYAiALMAucA5P9SAGf/FP2c/Gr+O//E/h0A6AJYA5YBtgE4BAgFNAM0AowCIAE2/qj9bv+A/6D96P24AIABCP9Y/Tz+G//I/ln/BgEkAX3/Df99ACoBGgCP/4oAHgEPAMD+av5w/kD+Zv7s/pT+5Pxo+6D79PyU/TD9AP10/YD9aPzQ+rD5MPkw+Yj5qPnw+AD4wPfA9/D2sPUg9TD1cPVg9rD44Pu+/wgFEAuADoANEArYB8AGgAQOAWb+KP0A/HD6YPm4+Yj7KP7nAPQC2AOMA6QCOAK8ApADMAQ4BQAHIAh4ByAG2AX4BQAFaANMAlABoP/o/Wj9GP5I//sAIAPYBIAFeAU4BegEoARYBMgDGAOsAkwCbAGIAMMA4gGEAkwChAEXAID+7P1y/q7+eP5V/0IBHAIuAVAAiwDrAPcAcAEwAtABPgAu/2b/6//o/8b/QwBUASACvgFxAIX/eP98/yb/NP+h/27/ov6k/qD/KgDu/ywAIAFoAZAAuP9t/w7/Xv70/eD9kP3w/KD8zPwU/TD9AP1o/ND70Pv4+3j7mPpw+rj6cPrI+YD5+PiA9zD28PXA9VD0IPMw9LD2KPl0/MgBiAdAC8AMcAzQCVAFRAIgAgACoP84/Vz9Lv4Q/bj7FP03AAQCAAL8AewBeQDQ/t7/aAMYBsgGuAewCTAKEAgQBiAGOAZIBPYBIAFaAEz+CP1m/oYAFAF+AXQD8ATUAywCrAL8A8ADBAOgA2gEnAN8ApAC2AIwAk4BxQCi/5j9LPw8/Jz8sPw8/Zj+CADnADYBMgFSAegBSALOAVQBiAFaASAAfP9VAMMAqf8p/2MAGgEhAIL/MAAWAGb+kP2s/pr/Of/0/oL/2P+u/9z/SQAVAKH/1/8zAOH/Qf/y/rL+Nv74/Sb+9P1c/WT94P2Y/XT84PsU/OD7IPsw+/D7wPug+jj6wPog+gD40PZw9wD4IPdg9gD34PdA+Nj57P2MAnAFKAcgCSAKIAiwBBQDDAPCAVf/iP4v/4b+GP18/jACrAMwAv4BGASABCQCEAH0AoAEEAQ4BAgGwAZgBYgEMAX4BCADrAGKATAB/P8a/wX/Pf8aAOQBoANoBNgEcAVoBXgEyAOkA+QCbgHHADgBDgG6/xH/+P/iAMQApwBEAYQBaQAo/zb/2/+A/z7+xP2c/nP/dP+e/9MADAIQAmABGAHrACkAy//HAAAC9gFiAZQBAAJQAQMANv/E/jD++P1M/gz+CP3Y/Cz+hP+5/6X/FABgAA8A5f9CAEgArv81/wv/qv4E/rD9uP18/Qj94PwA/dj8ZPwA/LD7SPsA+xD7KPvA+gj6aPnY+BD4QPcA9xD3APdQ99D4qPro+1T9XQCYBAAIUAkwCXAIoAb4A5QBXADI/wr/xv7G/94ANAC8/j3/rgE4A8gCcALsAqAClAHyAaQDeARwBIAFsAZIBUQCbAEMA6ADLAJQAewBrAHQ/+L+HgCmASQC7AKIBAAFNAOEAewB1AIYAt4AQAFEAsoBWQD1/3oAdQA7AMgAHgH3/2b+KP62/qb+eP4y/ygAYABoAN0A0ADo/7v/6QCIAYkA5P/uAMwBQAFGAfQC4AOAAkIBkgH9AFb+6PyQ/hkA6P6c/bL+5//6/uT9rP7U/93/CQD6AOAAVP/Q/h8AwgBp/wb+8P3M/cD8HPxo/FT8uPsg/FT9KP1o+3j6OPvA+yj7yPrw+lD68PiY+BD5oPiw9wj4cPnw+bj5uPpI/Q8A+AJwBnAJMAoQCXgHAAYwBAwCMwAF/5D+uP4T/0L/P/9//3EA3AHEAmQCZAEcAagBGAJcAjwDsASQBXAF6AQwBBwDeAIEA8AD/AJGAVcAVQARAKL/HgB2AaQCbAMoBEAEWAOAAswCaAP8AhgCxAGgAd4AQwCVAPEAbQDn/xwA2f84/qD8pPyA/fj9Yv5h/w0AwP+0/9oA6gGwAVwBXAKkA0QDqgHKAOIAjwCt/1n/kv8v/yb+yP0u/iz+sP30/RL/qv9T/xn/aP+A/0X/b//k/8n/Sv8+/3v/Of+w/oD+Uv6c/dD8pPzY/PT8GP1s/Yj9XP1k/ZD9RP2g/Gj8fPwY/Gj7IPvw+tj5YPjA99D3cPdA93D4UPqQ+9j8T/9IAqAEwAYgCXAKgAlwB+gFkASQAowAgP8g/8j+iP6U/pL+kP4A/yAARgHiAVgCLAMoBLgE4AQYBZgFCAZgBrAGkAZgBaQDYAKeAZAATf+w/u7+Gf/W/sr+P//P/4QAygFEAwAE5AO4A+gDAATEA2QDCAOwAjQCYgEWALb+1P18/Vz9WP2M/cD9yP0Q/tz+e/93/4T/WwA8ATABugDdAFQBUgEWAUoBlAFmASIBNAEOAVQA3f9TAPsA4QBEAMv/Rv9i/pz9YP1A/ez8EP3k/Zr+nP6q/on/qgD/ALEAlACXAAYA1P64/Tj97Pxs/Pj76Psc/Dj8QPx8/ND80PyA/Ej8SPwk/LD7UPtA+xD7kPpY+oD6WPrY+RD6aPv4/ED+7P8oAvgDMAWQBsAHYAewBZAEKAQcA6ABPAHWAbYBqQD9//L/tf+E/zwAPgFqARABWAE4AuACdAOoBCAGwAZYBmAFAARUAtoAMQABAJf/CP/k/hf/S//a/0gBLAOYBHAFMAaQBuAFcARMA6gCsAEZAKj+6P10/dD8XPyQ/Dj94P1m/gb/l//B/8T/dwAQAmwDfAMIAygDdAOsAjABVAA/ANb/3v4i/rj9AP1A/ID8lP0a/rD9cP3c/Rr+uP2Q/Vj+ef8KABEAEgAdAPf/pf9M/+z+av7Q/Tz9mPzA+wD74Pqg+7D8VP10/Wj9cP1Y/Rz94Pyw/HD8QPw8/CD8uPsw+/D6SPsY/Lj8+Pw8/fj96P61/6UADAI8A5QD2AP4BCAGyAW4BKgEKAV4BMgCBAI4ArgBkgB9ADgBxgBe/0b/ngAuAawAEgHIAvQDKATwBEgGYAboBAAEaARYBOACggF0AaYBBAE2ADEAegBjAKMAwgGsAlgCmAHSAZgCjALKAZIB9gHKAcwA7f9c/3L+eP1Y/az9JP0I/Az8RP38/dj9UP7c/x4BfAG6ARwCCAKiAdoBbAJAAoYBOgF0AVwB9ADXABYBYAHkAawCCAOkAgwCuAEkAdj/SP7k/Kj7qPpo+tj6QPtY+4j7yPu4+2D7KPvQ+hj6WPkQ+QD50Pjo+Jj5ePro+uj6qPog+pj5oPko+sD6QPsg/DT9Hv4A/xQA+gBYAeABNAN4BEAExAKCAc8AzP+A/tj91P38/bL+mwCwApwDIAQgBkAJsAvADEANgA0QDfALwApgCbgHOAaIBTAFGAQ4ApcAzv+V/2L/3v4M/jz91Pzc/OT8wPzI/HD9rP7g/5YA7gB0AVgCPAPYAxgEGASsA+gC3AGQAPj+fP2k/GT8MPyw+xj7qPqA+tj6qPus/Jz9hP5C/4f/Wv9L/5T/yf+Y/zb/4v54/uD9fP2Y/fT9Vv7i/on/sf8p/4D+TP4y/rj9NP0c/Sz9+Py0/LT8xPzU/HD9vv7L/+f/r/8uADIB6AFIAsQCYAOwA7wD0APIA1ADrAJwAnwCMAJ6AeEAsgC3AKIAeABsAIYAlwCRAHwARADk/4n/dv+Q/5P/if+5/w4AVQCAAI4AaAAJAKr/XP8E/7L+mP6Y/m7+Nv5M/pr+0v4g/8v/fADIAPgAWgGOAVQBNgF8AWQBjwDn/8//XP86/qD9Kv6e/jL+5P1y/gb/QP88AFQCGATIBKgFYAeACOAH2AawBogGUAXMA8gClAFu/5j9OP2E/Vj9HP2w/XL+iv6M/lH/cQA+AegB6ALkAygExANUA/QCZAKoAfYABgCc/ij9aPxA/CT8LPzM/MT9aP60/gb/BP92/ib+nv7W/tT9hPz4+2j72PlA+OD3sPfA9kD2YPeA+DD4aPgw++7+EgFAAvADAAXoA1gCQAKIAoIBXQC8AF4BjwBT/03/CgCgAL4B2ANYBRAFQARIBFgESAMMAtYB1AEIASMA4f+L/9L+Hv8IAcwC9AKgAjADxAMsAywC/AEYArQBMAEYAdoAFgC1/2kAbgHUAeIBUALwAgwDeAKqAQ4BrABaAPn/j/8g/6D+Rv5K/pT+lP4c/rj92P3o/Sj9EPxw+0j7EPvQ+uD6QPuw+zD8IP2c/hgAFgHsASADiARABRAFiATYA3gCbACM/hT9aPt4+UD4GPhg+Jj4MPlo+gT8oP0W/0YAJAHmAYgC4AK4AlgCFALiAcQBpAFUAdEAaQBaAHMASQDg/4v/ff99/1L/Jv82/5f/HQC8AHQBKAK4AjQDxANQBLAECAU4BQgFgATsA2ADxAIMAlABjQDE/yf/1v6w/oj+wv5i/+b/AQAqAK0AFAEkAUYBogGaAfUAXgAsANP/NP/0/m7//v9EAJ4ASAEUAuACuAOgBEgFiAWIBVgF8ASQBGAESAQ4BAgEnAPsAjwCwgFeAdsASQDW/2//+P6C/jT+EP4C/iD+Zv6c/pb+fv5u/jL+tP0s/dT8hPwQ/Lj7ePsI+2j6OPpw+nj6CPqg+YD5KPm4+MD4IPlQ+VD54Pm4+uj6sPog+yD83PxM/QL+pv6G/iD+UP7G/rD+av6+/lf/gv9k/4j/wv/X/0MAOgEUAmACqAJEA7QDqAOIA7wD4AOgA1QDKAPYAlgCNAKwAmgDAASgBHAFGAZoBpAGwAb4BhgHQAcwB6gGwAUIBZgECARIA7wCeAIIAjwBbwDn/3j/If8Y/zH/7v5c/gT+9P24/UD9DP0Y/ez8dPwY/PD70Pug+5j7qPuI+1j7QPsw++D6cPpg+tD6YPvg+1D81PxQ/dT9eP4i/4z/mP+O/6j/qv98/0H/Lf9C/3n/xf/n/57/O/9A/5X/u/+U/5H/uf+5/7X/9f9FADsALACqAH4B0gGiAYIBpgG+AbYBxAGSAdMA8f+w/97/rv8j/x7/z/+DABgBDAJAA/gDYARQBZgGEAd4BggGSAYwBiAF0AP4AhQCzQD5//v/1//G/rz9sP0G/sj9eP30/cD+NP+S/3QAMAEuAVgBiALkA2gEgATwBGAFMAXYBLAEIAToAsIBKAFtACf/BP6I/Vj9MP1k/fT9fP7k/nP/IgCZAOAAQAGQAXAB8QBwANv/9P4A/oD9VP0w/TD9hP3w/Tb+mv5T/x0AswAYAUIB4wACAPL+3P20/JD7iPqY+cj4MPjw9+D3MPjw+Cj6iPvs/Cj+2v4Q/0v/oP+r/1T/Dv/y/pr+9P1k/Rj94Py8/BT90P1y/tD+L/+9/00AygA8AaoBBAI4AkACAAKYAVgBaAGQAaIBzAEwApwC6AI0A5QD1APwAzgEqAQABRAFCAX4BMAEcAQwBPwDoAM0A9ACVALAAVgBLAHtAJAAZgB9AHwARgAiADIAQwBAAFUAgACJAF0AHQDr/8v/r/+L/17/M/8d/x7/JP8a//j+3P7g/v7+Gf8o/0v/m/8IAG4AtADGAJkARwD0/63/Rv+Q/rT97Pws/FD7cPrw+dj5+Pk4+rD6IPuY+0j8GP24/SD+oP5J/7r/1f/B/4T//P52/jr+/P1k/cz8tPzo/BD9YP0E/rD+P//1/9oAcAGcAe4BlAIIAxQDKAN0A4gDUAMwA1ADXANAA0QDZAM0A6wCVAJoApgCkAKQArwC+AI4A3ADoAPEA/gDSASQBMgE6AToBJAEEASwA2wD9AJUAtYBfgEYAZ8APgANAAsAOgCZAAoBbgGuAboBtgG2AcIBqAFoASIBzABUALf/HP+K/hj+8P38/Q7+Bv70/ej92P3Y/fD9+P3M/YT9RP3w/HT8BPyw+2j7GPvo+uj64Pqg+nD6iPrA+vj6QPuQ+7j7wPvY+wD8GPwg/FD8rPz8/Bj9GP0g/Vz91P1s/tz+Ev9J/67/KwCmABQBSgFOAWABpAHiAdIBpgGuAfABTAK4AhgDPAM8A1QDjAOoA6QDoAOkA3gDNAMMA/gC3ALcAiQDiAOsA5wDmAO0A9ADAAQ4BGgEaARYBEAE+ANsA9ACUALgAWYB5gBWALn/Nv/2/ur+1P6e/pj+2v4q/1f/e/+3/+f///8EAP//w/82/5r+LP7c/Xj9CP2k/GD8PPxE/Gj8bPxc/Ij8+Pxo/bT95P0A/vz9+P08/pL+ov5w/lT+VP4g/sj9oP2E/ST9wPzM/Cz9RP0E/ej8JP2Y/Sb+zv5m/77/BwCHACoBqgEEAlACiAKYApgCjAJEAsIBUgEgAQAB0QCyAK8AsgCXAIYArQAKAXwB8AFEAnACoALsAjADTANQA1gDRAP8ApQCMALUAZQBggGOAYgBfAGGAYgBbgFoAbIB/AHmAYwBTgE8AfoAdQD//73/h/9P/yD/5P6O/lz+hP7m/jf/Zv+Z/8v/9v8bACQA9v+x/5D/hv9F/6j+Av6s/Zj9sP3U/fT94P2s/cT9XP4A/xX/yP68/hb/Xf89/9T+Yv4Y/iL+av52/gj+gP1w/dj9KP42/jz+ZP7E/mH/EAB8AJAAtQAkAY4BkAFcAU4BRAHwAHUAPABDADsADADr//b//f/i/9j/BQBUAHgAbgB/AMMA/QAMASIBUgFsAUoBNgFsAZ4BWgHfAMYAMAGeAboBjgFKAR4BTgHGAegBbAHFAJ8A1gDQAGoA6f9z/yH/L/+E/5H/F/+W/p7+Ev9w/4f/ZP8u/yb/nP83AFQA7v+w/wkAoADzAOoArgBTABIAEwAqABQA2v+s/3n/Iv/O/rb+sv6A/kL+Tv6c/sr+pP5u/n7+1P5B/67/AwASAPH/9/9ZAMMAwQBgADMAfgDJAI4A+f+f/6f/u//H//H/IgAeAO//BgBoAJwAfgBUAEUAHADx//r/DAC7/0P/X/8KAIUAXQAUAC8AgwDVADQBlAGKARQB6QBoAeoBqgHeAFoAdgDLAOEAigDk/0f/KP+U/+n/rP8M/6z+0P4y/4n/nP9L/+j+Kv8dAOsAxwAeAO//kABmAbIBTAGZADgAbwDrAPsAcwDZ/47/mP+6/8P/d//e/or+7v6y/wcAuv9f/4D/HgDGAP8ArQBMAFwAvwDdAH8AAADG/9v/DQAqANb/KP/G/hP/hv9n/8j+WP5y/vr+if+x/13/I/+o/4QAzwB0AEoAkQDGAKsAoAC3AHYA9f/e/zMAKABv/7j+lv6+/sr+zv7m/uL+yv4L/6D/+//q//T/VQCgAIwAewDDAAIB4QCWAJsA1ADiAMkArgCRAHgAfwCbAJAATwALAO7/6f/y/wUADQDs/7//zP8TADwAAQCk/53/AgBtAIoAbABZAHgAqADHANYA6QDaAHsADwD6/x4A7v9G/7j+2P5g/6b/WP/I/qD+PP9BAM8AcQCy/4f/JwDiABoBsgACAIf/tP9mAMQAJQAJ/5b+Gf/T//L/ef/w/sb+Nf/9/3EAEwBc/0f/5/+BAHAA3P9Q/1T/BADIAKgAnP/k/lX/QACBAPv/Vv8G/zL/4P+bAIgAlv/g/mD/kwA8AcgA4/+Q/yYAKAGGAdUAvP9b/+7/mQB8AKb/1P6W/g7/2/9DAM//7P7K/sz/CAE6AXUA5f9FACoBtgGoAToByQCnAAwBqgG8AfEACADg/0gAdAACADf/iv5W/rz+Qf81/6D+XP7I/mP/qv/G/wIAMwBEAH8ACAFuAVQB8QDFAAwBZAFUAc4ARwAeACMAGQDn/6f/VP/8/rz+tv7Y/vb+9v7S/tb+Kv+3/x8ATQBrAJEAqQC5APQAMAEWAa8AeQCSAI4AQQDu/6n/QP/o/hD/Wv8H/1L+RP4B/5j/pv+z/wIAGgAWAIYAQgFYAcAAdwDfAFQBVAEQAbwAYgA9AI0AygBdAKH/gP8DAEQA4v9m/2P/l/+I/17/a/+P/37/Zf+V/+T/6v+x/7r/GABWACYA2v/m/zIAUgAiAPf/6//u//D/CAAzAEcARwBQAF0ATQBWAI0AqwBOAMP/qv8SAFUA9v9V/wP/L/+I/7P/f/8G/8D+9P5q/5D/Mv/M/tj+ZP/0/yAA4f+I/5f/OgDuAP0AeAA4ALMAVgFqASABBgESAfQAygDVAOsAowARAK7/nP+U/2z/PP/0/o7+Qv5Y/qj+0v7G/rL+wP4R/7j/VwB4AEgAegAoAZQBagFCAZgB/AHoAZQBYgFIASQBBgECAcsAPgCn/23/kf+s/2D/rP4Y/kT++P4+/7z+Nv5u/hX/gP+s//X/NQBFAF4A0wBYAXABNgEMASABPAE4AQQBrABlAFQARgD5/6X/iv9x/w7/xP7+/mT/Qv/W/t7+ef/z//j/3//R/9b/CwCLANoAkAAmAGIAIAF6ARgBfgAzAEgAhwCzAGsApf8Z/2r/QwCQAPj/Mv8F/3L/6f/1/3b/1v62/lD/DwAuAKv/Tv+O/zwAsACgADIAx//F/0IA1wC2AOH/PP+J/1kAoAAWAGL/Pf+v/0IAewAoAJb/Y//G/1oAigBIAOX/qv/W/2UA2ACkAPr/qP8NAJ4AnwAkALr/xf8eAFIAMADa/6f/r//e/wgADQDm/6f/kv++//f/7v+g/1z/bv/U/0UANwCu/1//5//LAP0AZADj/ygAxwACAbMARgAWADMAcwCHAE8A+P/J/7P/lf96/3r/dP9J/xn/G/8x/y//LP9i/5//l/92/6P/BwAkANv/x/82ALQAzACYAIwAvgDxAAAB7QDLALcAuwC2AHsAKgDz/9L/sf+L/2X/IP/E/qL+9v5a/0b/zP6o/iz/4/8qANX/cf+Q/0AA3gDiAHMAIwBfAN8AJgH9AJcAXwB4AL0ArwAwAJ7/jv/g//v/hf/k/sL+F/91/2v/Gf/m/gn/aP+y/8f/uf+6/93/KwCcAOkAwgByAJIAMAGUAVABxgCwAP0ALAH4AJkANgDn/97/EAArANH/R/8W/3X/7//6/5b/NP8t/5f/KABbAPj/cf+B/zcAywCCALn/X//F/14AhgAZAJb/jP8LAK0AxwBSANf/7f9yANgAtwBLAP7/EQBnAKQAgQAeAOr/IQBqAFUA3v98/2z/i/+c/4r/Uv/w/rD+6P5k/4b/KP/a/g//g/+8/8z/6P8cADcAVwCXAOsALgFEASgB3gC1AOsAPAEMAT0AiP+d/yoARQCn//L+1P49/6P/pf9e/xb/Ef9f/8P/6P+3/3z/o/8OADkA/v/N/wUAcwCmAHsANwAmAGoA0QAKAd8AggBYAIsA8AAQAagA9f+Y/9j/UABEAJv/+P4D/5f/8v+v/x3/7v46/6n/2P+3/3v/Zv+n/xoAcwBdAP7/wf/8/4gA4gCmAAMAof/M/0UAeAAlAJD/Q/94/+f/GQDY/23/Rv+M/wEALQD7/7T/tf8EAF4AfgBZACAADABDAKAA0QCeACwA7v8oAJIApwA7AKT/b/++/y8AKgCw/0T/U//J/xYA9f+K/1P/hP/v/ygABgDM/73///9VAIoAdQBFADYAXwCvANUArwBLABIAMwB3AIUARQAFAOf/8P8SAEcAWgAVALz/wP80AH4AMACw/5T/AgBwAGIA1v9b/2r/2/8aAM//Rv8T/2D/wf/Q/4T/R/9r/9X/HQAgAAoABwAlAF0AtQD2AN8AkgB6ANwASgE0AbAATQBMAHMAeABTAAgAjP8f/yb/jv+h//b+QP5I/uj+Rv/6/oz+iP4J/6X/+P/o/7z/4v9qAAABLgEOAdoA2wAoAZABwAFkAeoA3AA2AUwBxwAiAMv/xf+//53/U//e/nb+eP7w/kX/9v5g/kz+4P6B/6n/bv9J/3j/7f9gAI0AbAA+AE8ApQD5ABAB8QC7AIsAhwC1AOMAqAAMAK7/AwCKAHUAzv9m/7P/KAA0AN//pv+//+f/9f/x//z/BgD9//z/FwA+ADwABQDP/8T/4//v/9f/uv+y/9D/8v/3/9P/q/+2/+f/CwDw/7n/p//O/wgAJQAtAC4ANwBAAEwAYABmAFcANgAeABkAHAAJAOP/w/+v/4z/bP9o/3H/Zv8+/zr/cv+s/57/Yv9m/83/PQBGAPv/3P80AKMAnABMADsAhwCrAIAAYwCQAKUAdABIAGAAewBLAAAA4P/7/w8A+f+5/3v/df+i/6b/Zv8w/0T/Zf9a/07/dP+i/4j/Y/+P/+H/+v/J/77/BgBpAI4AcgBqAJQA8QA+AVABAgGvALQADgE6Ad8ATQAKADQAaABSAOj/eP87/1H/gf90/xL/ov6C/sz+KP83//r+0v4D/4T/4//g/7n/2P9MAMMA5gDhAPwASgGKAZgBjgGIAZQBegFMAQoB3AClAGwAIgDl/8P/kP8//+L+0v7m/tz+nP58/rT+9v4P/xT/Rv+B/6T/v//3/zwATgA4ADoAiADVAMUAYwA5AIAAyQCUABgA5v8lAFAAFACp/3j/qv/N/7z/gP9r/2//c/94/4H/sf+5/7D/qv/n/0cAhwCeAJ0AugDqADABYgFcASAB7QDUANUA3ADLAIMA9/+S/5X/5f/R/zb/mP6Q/v7+Gf++/mz+lP7Y/tz+2P49/+b/MAD5/93/ZAA+AagBUAHWANYAWAG2AYoBBgGlAI8AkgCbAHMAAABf/wX/Hv9J//j+VP4U/nr+Df8Y/7T+ev74/tX/VQASAIz/pv90AEQBTAHQAHMAmgAKATwBFgGgAC8AEQBVAI0AOACD/xn/c/8HAAAAOf+A/rT+jf8YALT/4P6q/mr/XwCOAP3/cP+G/yUAyQAKAbIAHQDl/2wAJAEuAXkA1/8CAKsA+AB9ALT/av/c/30AcQC2/wv/Kv/p/2wATwDU/4//vf9LAN8A+gB2APX/MADnADoBwgAnABAAcgCzAH8ACgCz/9D/MQBfAAwAif9a/6v/GAAmALf/J//0/lP/4f/y/2j/yP7A/lP/3f/e/1H/4v4L/5v//f/j/3v/RP+D/w4AeQBhAAEA5P9oABABPAHJAG4ArAA+AZABYAESAfkAHgEwARgB8gDSAJQAMgDp/+D//P/e/3//D//S/uD+Bf8D/8r+hv54/pT+tv7Q/uT++P4J/zb/fP/D//X/IABkAJ4AxADpACwBWAFYAVYBYgFyAVABEAHgANkAyQCVAEYABQDb/7T/h/9x/27/Wf8O/7T+tv4A/yr/6v6c/rT+F/9K/y//Gv9U/7X/8P8DABAALwBXAHsAqwDcAAwBFgEKAQ4BKgFAATQBDgH5APQA1wCYAFgAQAAuAAIAwv+P/3z/bP9X/z7/Nf82/yH/F/8x/1P/Vf84/y//S/93/4L/bv9h/4T/0/8NAAEA0v/g/zQAiwCLAE8AMQBeALIA3wDFAIEAaAClAOUAxQBUABYAPwCGAGcA8/+j/8j/JwAtALj/Kv8a/47/8P/A/zb/6v42/7v/BgDU/3P/V/+j/x8AXgAxANr/zv8rAKsA0wCQACYAGAB7AOcA3QBQANf//f+EAKwAOwCu/4L/q/+//6f/gf9L/wD/4v4i/5b/tP9U//j+I//m/4EAeQDw/7f/NgD8AEAB0ABcAGsA4wAmAfkAkAAzAB0AUQCRAHQA3/9K/0b/yf8kAMr/FP/M/jz/7f8bAK//Mf9B/9L/aACAACgA3////34A4QDeAIgATgBwAMwA7wCxAFoAQABXAHIAcgA3ANP/hv+5/ykANgCj/xn/O//L/yYA6P9y/zT/bv/v/0kAHgCU/13/vf9bAIIAJwDP/+//YAC0ALkAdAAvAB0ASQBmAEAA8P+8/7f/yv/G/6v/f/9V/0v/W/9q/0v/HP8O/0X/gP+O/4D/jP/P/xUAQQBIAGIAjgC3AM4AyQDJAL0AsQCuAMkA0gCqAGgASQBhAGMAJgDN/6z/vP/G/6z/g/9k/1z/c/+Q/4P/Tv85/2z/nv+M/2r/ev+4/9//+v8rAFYATgA2AGMAuwDjAJwAUgB0ANcABAG4AF8AQQBgAHIASQAPAOj/1P+6/6P/jf94/2L/VP9O/0j/Q/9Q/1//Y/9m/4b/wf/n/+z/9/8tAGcAcwBbAFgAjQDNANkApwBrAF8AegCCAEgA6/+z/6//rv+N/3D/cv98/2r/VP9u/6v/x/+u/5z/xf///wMA5P/4/zkAVwA7AB8AQABvAIEAaQBXAGQAdgCAAHMAXwBPAEwAXABjAFAAIwAOACkARQAxAAIA//8lAD4AIgAGAA8AKgAlABQAFQAVAAAA7f///xEA8P+u/5b/xP/d/6f/Tf8v/2T/nP+b/1n/Lf9L/6D/5P/o/8v/zP/9/zoAZgCBAIgAgACDALAA3ADcALIAkwCcAJ0AhQBbAEcAOAAVAOT/vP/C/9T/vf+H/2b/e/+f/5//gf9w/3X/ff9//43/p/+9/87/5/8IABYAEwAZAEQAcwBzAE8AOgBTAHUAeABdAD8ALAAnACwAIgAEAN3/w/+5/6n/lf+S/6D/pv+h/6P/s/+2/6j/vP8GAD0AIQDe/9z/LwB2AF0AGgADACoARgAhAOP/w//Y//L/5v/C/7D/xP/a/93/3P/c/9H/tv+5/9f/9v/6/+z/7/8MAD8AbQCCAHkAcAB4AIcAjgCXAJYAfgBXAEoAYABjADkA/P/n/+n/2P+v/4T/bP9c/1r/YP9o/1z/Rf9F/2r/nv+t/5f/kP+//wAAGwAGAP3/IgBfAIMAgwBzAGQAYwBqAHoAfgBjACgA//8HAB8AHgDx/8T/uP/R/+7/7//L/6f/tf/e/+v/3v/N/8D/vv/L/+7/BADt/9H/5v8xAFkANQABAAcANABIADAADwAGABQAKQBBAEUAKwAEAPb/DgApACcA/P/X/8//5v/3//L/2/+//7X/x//c/+D/xf+j/6H/zP/x/+f/zv/K/+r//v8BAPv/CQAmADkAPAAwADwAXgB4AHYAXgBLAFEAbQCCAHYATQAtACUAKgAlABAA8v/K/63/sv/E/7z/mP+I/6X/xv/M/8b/0P/0/xQAJgA0AE4AagBwAGIAUgBTAGIAXAAxAAEA7////wcA5/+4/7L/2v/+//3/6f/l//H/CQAmAD4APQAiAB0ARABeADUA5P/K//j/IwAJAL//kf+g/8r/6f/j/77/mv+e/9f/DQAKANn/vf/j/yUARQAlAO3/3f///yQAGgDr/7z/sP/J/+7//P/d/6z/pP/d/x8AIwDn/7P/w//7/xMA7//E/8j/8v8LAAwACgAIAAcADQAmADoALAAAAPn/JQBWAEoAEgD0/w4AQABIABsA9f8DACwAOQAhABQAIgAyADMAMAA6ADQAHwAQACAALgARAOD/0//z/wYA6f+4/6H/q/+1/7D/n/+H/33/if+y/9j/3f/M/8n/4f8BABkAHAAKAAAAGgBTAHUAYgA+AEQAdACZAIcAWAA4ADEAOAAtAAgA0P+u/7P/xP+5/4v/X/9c/4H/pv+m/4T/d/+Z/9X/9v/y/+//DQA9AF4AcQB5AH4AeQCAAJoArQCfAHgAWwBdAG0AZwBBABcAAgD+//b/3P/A/6z/qP+u/6//n/+U/5v/u//e/+X/3P/c//H/EAAlACcAHQAgADMATgBeAGIAZABvAIAAjQCKAH0AcABpAGAAUwBCACwAFQD///r/5f/C/6X/nP+f/4//ef90/3//jv+e/6f/mv+N/6P/1P/3//b/4P/d//f/EgAUAP7/7//0/wYACgD2/97/1f/f/+T/4v/d/9T/zP/S/+j/AwAKAP7//v8hAE0AWwBPAEEARgBSAE8ARAA+AD8AOgArABsAFAAMAP//7P/f/9n/zP+y/5n/lf+l/7b/sv+c/4//pP/M/+T/4P/Q/9H/5P/6/wcABQD5//L//P8RABcACAD8/wAADwAcABwAEgAJABEAKAA4ADAAJQAxAEwAWwBSADoAJwAnADMAOQAmAAQA5v/p//j/7//L/6T/l/+d/6L/mP+D/3z/hf+Y/6v/tP+z/7j/0P/z/w8AFwAWABwAMABNAFMAPQAhABwALgA7ADEAGQAPABcALAA2ADAAIQAZACMALwAqABAA9f/s//v/CgD6/9j/w//R/+r/7v/Z/8T/wv/M/9X/2//Y/9P/2P/6/xIAEwAHAAgAHgAvADUAMQAoABoAFQAaAB8ADgDr/87/0//V/87/sv+T/3//iv+m/6//ov+P/53/tP/O/97/4v/b/+L/BAAhACsAFwAPABUAHwAhABwACAD3/+//8f/w/+n/2v/O/8X/zf/R/9L/0v/V/9n/3v/l//P/+v8CABUALAA6AEYAXwB+AKUAvQDMAOMA9QD+ABYBOgFYAWABWAFcAXgBnAGsAaQBnAGsAcwB1AG+AZ4BlgGgAaABiAFYAToBIgEKAeMAqwB3AEoAIwD+/9T/mv9m/0P/H//0/rj+ev5I/hj+5P2g/Vj9EP3E/IT8UPwU/ND7kPtw+2j7WPs4+yj7OPtY+4j7uPvo+yT8cPzY/Ez9uP0Q/mb+yP46/6T/AwBRAJ4A/QBqAdYBLAKAAuACVAPAAyAEaAS4BBgFcAXQBRAGQAZoBpAGuAbgBvgG8AbgBsAGsAaIBlAGCAa4BXAFIAXIBEgE1ANkA/QCbALiAUoBwQAwAKn/H/+Y/hz+nP0s/cj8aPwM/ND7mPt4+1D7QPs4+0D7SPtI+0D7QPsw+wD70PqY+lj6APqA+fD4YPjQ9zD3cPaw9fD0QPSw80DzwPKA8nDyoPIg88DzoPTA9TD34PjI+uD8Av9EAbgDSAbgCFALkA3AD8ARgBMgFWAWQBfAFwAY4BdgF4AWQBXgE0ASQBAwDuALYAnYBmgEBAKn/1D9MPtQ+aD3IPbQ9MDzIPPg8rDysPLw8nDzQPQw9VD2YPeA+ND5QPuc/Oj9LP9vALAB4AL4A+AEsAVgBhAHmAf4BzAIQAhACCAI4AdoB9AGIAZYBXgEdANkAi4B8v/I/pz9SPzo+qD5iPiw9+D2IPZg9eD0sPTA9OD0MPVw9fD1oPZw9yj40Ph4+Qj6qPpI+5j7oPug+6j70PvA+4D7KPvg+uD6EPtI+3D7uPtA/AT97P0N/1kAxAEsA7AEcAZACPAJgAvwDGAOsA/AEGARwBEAEkASIBKgEcAQoA+ADlAN4AtgCrAI6AY4BaQDEAJ2ANL+ZP00/BD7CPoY+Tj4kPcg9+D2sPZw9kD2UPaA9uD2MPeA9/D3iPg4+ej5mPpA+/j71Py4/ZL+S/8IAM4ApAFwAhgDsAMwBKgECAVoBYgFeAVQBTAFAAWQBAgEaAPQAjACiAHiAB0AXf+K/sD96Pwo/Gj7mPrA+ej4QPiw9xD3UPaQ9dD0QPTg84Dz0PIw8tDx8PFQ8rDyIPPg8xD1kPZQ+DD6IPwq/pMAGAOgBegHQApwDLAO4BCgEuATwBRgFQAWQBYgFmAVIBTgEmARIBCADmAMEArQB8gF5APWAbX/vP0o/Oj6wPmQ+HD3sPaA9nD2YPZg9nD2wPZg9xj42Ph4+SD68PrQ+8D8sP2A/kX/+v/kAN4BqAJEA+ADqASABUgGuAbwBggHcAcACFAIAAhwB/AGgAYIBkAFQAQgAwQC9gDX/6D+RP0E/AD7EPoY+Rj4APcA9oD1MPXQ9FD00PNw81DzQPNA8yDz4PKQ8oDygPKA8lDyIPIw8pDyQPMQ9ND0gPWw9pD44PoM/fD+6wBUAygGAAmgC/ANIBBAEoAUQBaAF0AYwBhAGUAZwBigFyAWgBQAE0ARIA+ADNAJOAcABfACugBo/jz8gPoI+dD3sPag9dD0gPSQ9ID0YPRg9ND0kPWA9kD34Pdw+FD5oPoA/Oz8pP2S/sT/BAEUAgAD2AOwBKgFmAZgB7AH8AdQCLAI4AjQCHAIyAf4BlAGqAXIBHwD5gF/AGH/Uv78/Ij7GPoQ+Sj4UPdA9kD1cPQA9ODzoPMQ84DyQPJw8tDy4PKg8kDyMPKA8sDysPJg8lDyAPMw9DD1EPYg98j4EPug/SEARAJ4BBAHEArwDIAPoBGgE6AVgBcgGQAaIBrgGcAZQBlAGGAWIBTgEcAPoA0gC0AIQAWMAlMAUv5A/Bj6GPiw9sD1IPWA9AD00PPw83D0EPWQ9QD2wPbQ9wD5APrQ+oj7cPyI/bb+xP+EACwB9gEUA1AEUAXYBWAGAAfoB7AIEAkwCRAJMAlQCRAJcAiQB4gGmAWoBGwD2gHz/zj+1PzA+3D68Phw90D2YPXg9GD0oPMA88DyAPMw8yDz8PLg8iDzkPPA84DzAPOQ8qDy8PLQ8jDysPGg8SDyMPOQ9ND1IPcA+Zj7gv5aAQAEwAbwCWANwBBAE0AVIBdAGWAbgBygHCAcYBuAGkAZYBcgFWASkA/QDCAKaAeABLgBOf8c/Tj7gPkA+LD24PWA9WD1MPUQ9SD1kPVA9vD2cPfw94D4IPno+bD6YPvg+2T8OP02/gj/ov9XAFYBkALEA8AEkAVQBjgHMAgQCcAJ8AnwCcAJkAkgCXAIaAcYBqgEPAO4Ac//6P08/OD6gPk4+OD2oPWg9CD0APTg86DzcPOA89DzEPRA9GD0YPRw9JD0cPQQ9IDzAPOw8mDy8PFw8fDwsPAQ8UDyMPQQ9rD3sPl4/PX/qAMgB0AKcA3AEAAU4BYAGcAaQBygHUAe4B3gHGAbwBnAF2AVwBLAD4AMYAmgBgAEgAER/9z82Pow+QD4MPdw9sD1kPWg9dD1APYw9oD2APeA9+D3MPh4+AD5sPlQ+uj6kPto/HT9cv5Q/3oA6AFgA7gE+AVIB6AI0AmgCmALAAxwDIAMQAyAC5AKcAlACNgGGAU8A0ABMP8U/UD7mPkI+KD2cPWQ9NDzMPPg8tDy4PIQ82DzoPOw8/DzUPSg9LD0YPQA9LDzMPOQ8uDxIPGQ8BDwwO/A78DvIPAw8TDz0PW4+Ij7ZP5+ARAFYAmQDQARoBMgFuAYgBtAHQAeQB4gHgAeIB1AG4AYwBVAE+AQEA7gCrAH2ARsAkIAXP6I/OD6cPlw+MD3UPcQ99D2sPaQ9sD2APdA9zD3IPdg9/D3SPhg+Hj4CPnw+ej60PvQ/Nj9Lf/RAHgC3ANABfAGkAjgCeAKsAtQDLAM0AywDEAMUAsQCqAICAdYBaAD2gHn/9j94Pso+rD4UPcg9jD1wPRQ9PDzkPOQ8/DzYPTA9AD1EPUQ9UD1YPVA9fD0gPQg9IDz0PIg8oDx0PAw8ODv4O8A8DDwwPAg8oD0gPe4+oj9RQCQA7gHAAywD6ASQBXgF0AaQBxgHeAd4B3AHeAcgBtAGYAWABSAEdAO4AvwCCAGdAMuAW3/Bv6Q/OD6iPnQ+Fj44PdQ99D2kPaQ9qD2kPZA9hD2YPbw9jD3YPfQ96D4uPkA+2j8xP0m/8IAmAJ4BCgGwAdQCbAKwAuQDDANcA0wDZAMAAwwCxAKgAjYBiAFcAOeAcn/Fv5o/Oj6gPk4+AD3EPaA9SD1wPSA9ID0oPSg9LD04PRA9ZD1wPXA9bD1oPWQ9ZD1QPWg9CD0wPNQ86Dy8PFg8SDxEPEg8SDxUPEA8nDz4PW4+Mj7tP6mAcgEcAhADAAQQBOgFaAXwBmgG8AcAB2AHAAcIBvAGYAXwBTgEWAPMA3QCgAIGAWcAsMAYf8M/tT8qPuQ+rD5WPkQ+ZD4CPjA96D3YPcA98D2oPaA9qD2APdw98D3OPhI+cj6bPwq/uf/jAEkAwAFCAfgCCAKEAsQDNAMEA3wDGAMcAtwCmAJMAhgBkgEbALTAED/tP08/Nj6oPm4+Bj4cPfg9qD2oPbA9uD2APcg90D3gPfQ9/D3APgA+PD30PeQ9zD3sPYg9pD1EPVg9JDzwPIw8qDxMPEA8fDw0PCw8DDxUPIw9KD2iPmY/H3/pAIwBsAJEA2gECAUoBYgGGAZwBqgG+AbYBsgGqAY4BYAFaAS0A8gDTALgAmgB0gFKAOYAYQAv/8Q/wz+1Pz4+0D7mPrA+fD4IPhA94D24PVQ9bD0cPTA9GD1EPbg9vD3gPmI+/T9YgCMApAEoAbACHAKwAvADJAN0A2wDRAN0AtACtAIWAeYBawDwgErAJr+LP0Y/FD7sPpA+hD68PnI+aD50PkQ+jj6KPoI+sj5mPlo+RD5ePjA92D3EPfQ9lD28PWw9aD1gPVQ9fD0oPRw9FD0IPSg8xDzkPJQ8kDyIPLg8dDxoPJw9AD3APoQ/b7/cAIIBmAKkA6gESAUgBYgGSAbABzgG2AbABuAGmAZABfAE+AQ4A4ADcAKMAjIBbwDJALQAKH/gv5w/aj8+Pso+yD6IPkg+ED3gPbw9WD1kPTg88DzQPQQ9fD18PZQ+Aj6KPye/hABUANwBbAHsAkQC+ALYAygDLAMQAxgC+AJ8AcYBoAECAN0AdT/Yv48/Xj8+Puw+4j7gPuw+/j7NPxM/ED8LPwU/Oj7kPsI+2j6iPnI+GD4MPjA9xD3wPYA93D3sPfQ9/D3GPg4+Gj4aPjg9xD3YPbQ9dD0cPMQ8hDxQPDA78DvEPCw8BDy8PTg+PD8dADgA6AHEAygEMAUoBdgGQAboBygHUAdoBsgGsAYQBcAFQAS8A4wDDAK4AiAB8AF/APEAvwBNAFbAG7/Wv74/Ij7MPq4+MD20PRg86DyAPJw8SDxUPEw8sDzIPaA+MD6VP1iAIwDWAagCKAKQAxgDQAO8A1ADQAMwAqQCSAIIAbcA/YBpwC2/97+KP6Y/WD9kP0G/mT+Wv4a/gD+/P2Y/dT80Pu4+nj5YPhw96D2wPUw9TD1gPUA9pD2QPcg+ED5oPro+8D89PzU/KT8TPx4+yD6aPiA9pD0kPLA8ADvoO3A7IDsAO3A7eDu4PBQ9Aj5Dv6cAlAGkAkQDUARQBXAF8AYYBkAGiAaYBnAF0AW4BTgE8ASIBHQDsAM4AugCxALAArwCLAHAAZABLwCAgG0/ij86Pmg9xD1oPLg8KDvIO9g71DwMPEg8uDzoPbw+RT91v9MAoAEmAaQCAAKkAqgCsAK0AoQCoAIwAaABcgEWATMA/gC6gEuASYBlAG+AWwBIgECAcIAGQAU/+T9oPx4+4j6cPkI+LD24PWA9XD1oPUQ9sD2sPfw+ID66Pvw/Oz97v7Z/10AbwDw/9T+rP2Q/FD7gPmQ97D1APRg8iDxEPDg7iDuAO7A7oDvEPAQ8bDy8PQw+Dz8EgA8A1AGsAmgDAAPQBHAEwAW4BYgF0AXIBfAFoAWQBYgFcATwBLAESAQQA6QDDAL8AlwCIgGAAQwAaT+zPzo+pD4MPZQ9ODysPHg8MDwIPHg8TDzEPXQ9nj4ePrw/Gv/iAF0AygFSAYQB9AHkAgQCSAJAAngCGAI2AdwB0AH0AZYBhgGwAUABfQD9ALuAecA4f/O/nD9yPtI+ij5UPiA9wD30Pbg9vD2YPcY+Nj4ePk4+mD7ePxM/cz9PP56/qD+ov6m/mT+7P1g/bz8+Pvw+gD6IPkY+PD28PUA9bDzUPJg8eDwQPBg7yDvYO/A73DwAPJg9BD3mPpO/+gDQAfQCbAMIBBgEwAW4BeAGIAYgBigGAAYYBbAFOATABOgEeAPIA5wDPAKAAogCYgHOAXsAsoAZP7w+7j5oPcw9QDzsPHg8BDwgO8w8JDxUPNQ9ZD3sPmw+w7+6QBgA+AE6AXwBsAHIAhQCJAIkAhwCFAIQAjwB4gHWAdoB2AHAAdoBngF/AM4AqwAVP/Y/RT8UPqg+CD30PUA9eD0UPXg9XD2IPco+HD5kPqI+5D8lP1i/ub+JP/4/pz+gv7M/tz+bv7s/cj9qP1I/dD8dPzY+/j6OPpI+dD34PVA9ADzcPHA76DuIO6A7SDt4O0g72DwkPJQ9hD7jf+wA4gHoAogDSAQwBMgFsAWIBfgF0AYgBeAFuAVYBXgFMAUQBSAEkAQ8A5wDjAN8AqACAgGCAOm/5j8qPmQ9uDzcPJQ8eDvwO6g7kDvYPBA8sD00PZQ+Oj5CPwY/tT/fgE0A6AEmAVoBggHeAdQCKAJ4AqQC7ALgAtAC7AKEApgCYAIQAeABVgDBAHK/gD9mPto+nD5qPjA9wD3gPaA9vD2kPcg+Jj48PhQ+dD5UPrI+lj7MPwU/cz9Lv6O/iH/4P+hAEQBiAF4ASwBvwAOANz+YP3o+5D6EPlg96D10PMA8nDwwO9g7wDvwO4g78DvYPAA8TDyAPSA9gD6Bv6SASAEqAbACRAN8A9gEiAUgBWgFsAXYBggGGAXIBdgFyAXABYgFEASYBCwDhANAAtgCKAFAANOAGD9ePrA95D1IPRQ85DykPGQ8GDwUPHw8oD0sPXg9jj4yPlA+6T8KP7h/7QBaAPgBPAF0AbwB1AJwAoQDLAMcAyQC6AKwAnwCLgHUAa4BAQDKAEv/zj9qPvI+oD6SPq4+eD4APiA95D34Pco+Dj4cPjQ+Cj5YPnI+YD6iPu4/AT+7v4n/0z/6/+tADgBhAF6AfAABwBU/7z+0P1o/FD7qPr4+dD4QPeA9eDzwPIA8lDxUPBg7wDv4O4A72DvcPBw8pD1gPlo/fgAQASAB6AKkA1AEGASgBNAFEAVQBagFkAWwBVgFUAVYBUAFeATIBKAEFAP4A2wC9AI2AXcAtP/yPzY+RD30PRg84Dy4PFQ8RDxYPFA8pDz8PQA9uD20PcY+WD6oPvg/Fj+KwAQAsADCAVwBlAIQArgCxANoA1wDaAMoAvACoAJEAjABngFwAPGAUgALf8e/iz9xPyQ/OD70PrY+ej48PeA95D3UPeA9gD2UPbw9oD3WPiw+Rj7OPxY/S7+hv7C/of/WgCLAFgAMgDT/wD/LP7Y/YD9zPws/LD70Pow+aD3cPZg9SD0MPOQ8oDxcPAA8EDwwPCg8aDzkPbI+dj8UwAgBJgHYAqADDAOQA8gEGARoBJgE2AToBMAFKAUABVAFSAVYBSgE+ASoBEQDwAMAAlgBrgDGAFi/pj7EPlg95D20PUg9ZD0gPSg9ND0APUA9aD0cPQQ9TD2YPfI+Hj6PPwS/jQAhAJ4BDAG8AegCaAK4ArwCqAK4AkACXAIUAgACGgHiAZgBTgEcAPcAgAC2QCx/4j+AP0w+5D5QPhw9xD38PbQ9nD2MPZw9gD3wPeo+KD5UPrI+jD7YPtQ+4D7YPxw/Qj+Ov6Q/u7++P7c/vD+7P6Y/hL+cP0w/FD62Pgg+KD30Pbw9SD1MPRA88Dy4PJA8+DzUPVA91D5gPsu/jAB+AOABsAIUArgClALgAxADuAPIBFAEiAToBMgFKAUYBTgE4ATABPgEeAPgA3QChAI6AVwBAADCgH6/iz9UPuI+Uj4oPfw9kD28PXQ9TD1UPTw8zD08PRA9hj48Plo++j8iv4aAIoBHAPABBAGEAfABwAI2AfgB0AIsAgQCTAJ0AjgB9gGGAZgBXAEmAPwAvYBiwAQ/4j90Pto+hj6aPpw+vD5UPmw+AD40Pco+Ij4mPiw+Ej5sPmQ+Xj54Pm4+rD77Pzc/eT9ZP04/YD9rP2U/Vj95PzQ+4D6gPnA+PD3cPdA9+D2IPZg9cD0EPRw83DzQPRA9VD2IPiI+gj9kv8kAoAEWAboB2AJgAowCzAM0A1wD6AQoBHAEoAToBOAE4ATYBMgE0ASwBBwDtALgAmQBygG+ATEAzACWgCO/uT8WPvQ+Wj4cPfg9pD2IPZA9YD0cPRA9aD2CPhg+Yj6iPuU/LT9uv6A/1wAiAHgAhgEEAXABQAGUAYgBzAIoAiACCAIgAdwBkAFcATsA0gDoAIkAlIB6f+I/pD95Pxo/JD81PxI/Oj6wPlY+Rj5+Pgw+Zj5sPmI+aD5uPmY+aD5OPr4+lj7iPuY+1j7CPsI+1D7UPsI+8D6cPqo+cj4SPgQ+KD3IPfQ9mD2oPXA9GD0UPRw9CD1cPZA+Fj60PxQ/zIBkALUA1gFmAaAB3AIkAnQCjAMAA6wDwARABIgE+ATwBMgE6AS4BFgEKAOUA1QDBAL8AkgCegHIAa4BLgDAAKX/2T9mPvA+TD48PdY+Dj4oPeA98D30PcA+LD4QPl4+QD6EPvg+yT81PxW/s//5gAIAhADaANwA/ADqAT4BAgFUAVIBYAE3AMgBJgEaAQQBBgE1APQAqIBxADo/w//1v4r/0D/ov7U/TT9jPwE/OD70Ptw+/j6wPpg+sj5YPmQ+Rj6iPq4+rj6ePoQ+rD5YPkw+VD5ePlA+aj44PcQ94D2UPZQ9kD2APbg9ZD18PRw9ND0wPUQ9wD5iPvA/TH/gQAgAoQDeARoBaAGiAdgCAAKQAwADkAPwBBAEuASgBIgEsAR4BAgEKAPUA+ADmANgAzAC5AK4AhQB9AFIAREAk8AUv5w/Ej7CPsg+xj7+PqI+oD5QPhg90D3cPew9zj4QPmA+nD76Pv4+/j7mPzg/TX/6/85AJIA+gBMAbIBaAIIA2gDrAPwAwgE0AOgA6QD3AMIBBgE4AMYA0gC/AH6AbwBSgHwAGEATf8U/lD96Pxs/AD84Puo+/j6YPo4+gj6oPlo+Xj5EPlY+Bj4cPiA+Aj44PfQ90D3QPbw9TD2IPYA9lD2wPag9kD2QPYg9vD1YPbw9/j5yPug/Xj/0wC6AeACOAQwBbAFaAaAB7AIQAqADNAOQBAAEWARQBHAECAQ0A+QDzAPQA+ADxAPwA1QDDALAAqgCGgHcAYoBTwDLgF1/zz+hP10/aD9QP1U/ED7IPrI+GD3sPYA9/D3SPmg+nD7MPsQ+gj56PjY+Yj7WP14/rj+kP5y/pj+AP+t/6gAmgEsAkwCOAJMArQCZAMABGAEUATIAxgDmAJoAmQCWAI0AugBcgHgAEAAgP+e/uT9aP0E/bz8qPyU/AT8APsQ+nj5GPnA+Jj4gPhA+ND3gPcw98D2UPbg9XD14PSg9AD1oPUQ9mD2oPbA9uD2YPdg+KD5APuI/Ab+P/9TAHQBmAKQA4gEoAXgBhAIYAmwCvAL0AywDYAOAA8gD9AOYA7QDZANoA3QDaAN8AwQDDALUApgCVAIIAfYBaAEjAOsAhQCqgFAAZgAp/9w/hD9wPuo+tj5ePmw+Uj60PoQ++j6ePrA+Rj50PgY+cD5cPoA+2D7iPuY+8j7NPy0/Cz9lP3Y/Rz+aP7e/p7/mQCCAe4B2gGkAbgB8gEwAnACuALUAqQCTAL2AaIBUgE0ATIBBgGJABIAvf9f/+b+Zv4C/pj9IP2s/GD8QPzo+5j7SPv4+rD6kPp4+jj6APoo+qD6CPtg+7D76Pv4+xT8TPyU/Oj8ZP0g/uz+hv8EAFoAcQBwAI4A6gBsAfoBeALcAjwDmAPcA/wDCAQIBAgEAAQgBFgEgASYBLAEsASQBEgE/AOsA1gDHAMoA3ADuAPkA+wDtAM0A8QCoAKwAtAC6ALgAqgCcAJ8AqwCnAJcAhgC4AGWATYBAAH4AP4A2gCiAFsADgDb/7//nv93/1b/Ov8n/x7/Lv9W/3r/h/+M/3z/WP9B/1b/gP+Z/53/oP+e/4n/Y/9S/0X/IP/+/gL/CP/w/sD+mP5m/iL+3P2k/XT9PP0Q/fz89Pzc/Lz8mPxs/ET8MPwk/AD82PvQ+9j78Psc/Ej8ZPx4/IT8iPyA/Iz8xPwU/WT9pP3Q/eT97P0A/ij+YP6U/sz+/v4z/2n/q//m/xAAOABlAJcAvADqACwBbgGaAcAB9AE0AmwCnALMAgQDOANoA5wDyAP4AxgEKAQwBDgEQARABFAEYARgBFAEMAQYBPgDzAOYA2QDQAMIA7wCeAJIAiQC/gHOAZABOgHnALAAjgBtAEcAKwAKAOD/uP+h/5j/iv+C/3v/af9P/zf/NP87/0H/RP9J/0z/Sf9H/0b/PP8t/yP/H/8X/wP/5P7C/qL+fP5k/lb+RP4o/gb+6P3Q/bD9jP1o/UT9JP0I/eT8xPyo/KD8mPyQ/JD8mPys/Mj84Pz4/Az9HP00/Vj9fP2g/cj9AP44/mr+mP7M/gP/Mf9T/5L/yf/7/y4AawCqANgADAFOAYIBoAHEAfwBLAJYApACwALkAvwCHANIA3gDnAO8A9QD7AMABBgEIAQoBDAEOARABCgEIAQgBBAE+APcA7gDkANcAygD+ALIApACTAIIAsIBhgFOARYB2wCeAF4AHQDf/6z/gv9Z/y3/Av/c/r7+pv6M/nL+Wv5I/jr+KP4S/gT+BP4A/vD93P3I/bj9sP2k/ZT9fP1k/Uz9PP0w/Rz9CP34/PD86Pzk/OT85Pzk/Oz89PwA/Qz9HP0s/UD9VP10/aT91P0A/jL+ZP6O/rb+3v4U/0b/b/+a/83/BAA3AGsAngDGAO0AFgE4AVABZgF+AZYBrgHAAdQB2gHYAdwB5AHuAfYBCAIgAjQCTAJcAmgCbAJwAnwCgAKAAnwCgAJ4AnACbAJoAlwCTAI8AigCCALoAcgBqgGQAXABTAEmAQIB2wCsAH8AVAAoAPT/wf+V/2L/Mv8L/+7+0v6w/pb+gv5u/lj+RP5A/kL+Pv42/jb+RP5C/kT+UP5m/nb+jv6q/rz+wP7M/uj+Av8U/yj/P/9N/1f/Xv9j/2D/Vf9U/1v/Yf9q/3X/df9x/2//dv96/3T/bv9s/3j/iv+Z/6X/qP+i/6v/yP/p/wIAEAAdADAATABkAHcAjgCiALAAsACzAMEAzQDVAOMA7ADjANgA1ADVANcA2QDbANoA1gDYANoA0wDKAMkA0ADZANoA0gDFALMApgCjAKIAnACXAJIAiwCHAH8AbwBkAFkAQwAxAC8ANAAvABwACQD///n/6P/U/8L/sf+a/4L/Zv9M/zf/KP8c/xH/Cf8E//7++v7u/uD+3v7s/vj++P70/vr+Cv8a/yf/PP9c/37/nv++/9b/4f/n//f/EQAsAEMAWABvAHwAgACBAHwAeABwAGkAZABjAF8AUgBBADUALQAkABcABgD5//D/6v/k/9//1v/N/83/0//f/+n/7f/q/+r/9P8AAAwAGAAiADEAOwBCAEgATQBXAF0AXwBfAF8AVQBNAFAAVQBTAFUAWQBYAFMATgBGAEQARgBBADUAJwAiACUALgA0ADQALAAfABYAGAAeACMAJwApACkAJwApACsAMAA3AD4AQwBEAD0ALQAcABQAEQAKAP//8//l/9n/1P/R/8n/uf+r/6D/mP+S/5D/kP+T/5X/mP+b/6H/qP+x/7j/x//Z/+r/+P8BAAYADQAbAC0AOQA4ADAAJwAmACwAOABFAEgAPQArABkAEAALAAkACQAGAPf/6P/e/9v/zv+3/67/nf+O/4L/i/+i/6P/mv+Y/6D/n/+k/7P/vv/F/8X/yP/U/+D/6P/7/xIAIQAhACMANQBLAFYAVQBUAFQAVQBXAF4AZwBqAGEAVgBQAE4AUQBVAFMARgA0ACAAEAANAA4ACQADAAcADwAYABsAFwAPAAcACQAWACYANQBFAFMATgBAAD4ASgBbAGMAVwA7ABwACQADAAgADAD6/9r/uv+i/5D/h/+G/3j/Wv86/yn/Lf9E/2X/e/95/2D/Rf80/0H/cP+m/8f/1//Y/8v/wP/J/+P/BQAoAE0AagBvAFcAOQAoACUAPQB0AK4AxACmAGkAJwD1/+P/9P8fAEEAMwD5/7n/mP+b/7X/zf/L/6//k/+T/6P/rP+k/4//hv+c/8v/DABEAEQA+v+e/3r/qP/+/0kAagBWACAAAgAnAHMAngB9AC0A8f/v/xAASgCkAPgA0wAfAHz/jP8rAMwALAEuAXoAS/+a/uz+6/8IAc4BwAHZALv/LP9r/xwAuADuAOoA5QC0AFQA7v+B/yP/Vv9IAFQBngH1ALb/Zv7E/W7+DwBQAYIB+wAzAF//yP6m/qL+Yv4S/h7+jP4j/73/JAAvAOb/bP/g/qD+DP/U/1wAiACOAG8AGADv/wMA7f+m/6P/KQB4AC4A7P8/AMIA8AD7AKQAcv9C/uT+5ABMAoQCAALpAJX/Kv8RAGQBNAJwAgACggDU/qb++/9IAbABoAEoAdr/Tv7g/ej+/P8RAKf/aP8V/6D+zP6X/+P/MP9c/iL+iv5P/yMAXQCL/3z+Pv7e/ub/6ABCAXUARf/4/nf/AwCJAPcAxQAtAB4AnwAYASoBywA4ANr/7/9LAJMAzQAUAQYBWwC6/8f/+P/r/x0AlACwAEYAyP90/z3/Q/+i/x0AUQBWAE0Azv8B/9j+Uv9z/3T/DwCPACoAff80/zT/Wv+z/x0AQgDz/4r/kP/T/7X/iv/s/2wAaQAcACEANADh/73/MQBwADIAagD0AKAACgBUAJoAMQBQACYBDgEsADkA9AChAKz/2v/bACIB4wDSAGoAjf9J//b/iwCWAGwA4P83/3T/WwBuAKT/Wv+W/3f/Mf9g/9r/IQDt/1r/I/98/1P/6P67/xoBogAr/xT/vv+B/yH/NABeAa0Ahf8aANEAvP8e/3QAQgFSAAoAFgEUAar/P/85AHkA1v8vACIB5wDc/3T/nP/F/7b/zf9UAKkA8P/8/rP/3AD8/1T+3P5tAFEAvP9VAEkAyv6a/mcAJgHf/w3/dP+t/5n/yf8dAEwAZgDc/zD/b//w/yMA+f+o/87/dgBqAJn/xP83AKD/Vv9pAPAAoP/O/h0AXgGJAHT/BgC8AAUAb/8yAFgBMgHc/3b/FgBaAGEAAAEIAev//v41/98AZAJoASb/tv4l/xP/WAAMAvQA5v7e/g7/1P7y/3oBIgHE/7j+Cv6O/vv/xADWAOAAMgDg/pz+l/9QAG0AhQCBADUA1v9M/0X/bAAYAS4Atf9OABQAVv/l/xwBWAEVAGL+uv6MAKQAGQBkAbYBqP7c/E//1AGtAMj+XADmAUT/GP3S/+wBuP+w/p8A7ADo/jz+iP8KAYwBvwB2/+b+Av8e/87/rQCvAC8AMwATAPb+gv4lAP4ByABk/hb/0QDP/yf/OgFmAYr+JP7+ANYBxf+k/r//8wDPAPP/q/+EALAAFv/i/iQBqAE2/6j+/gCQARgAzP9zAB3/wP2o/3ACcAJ9ABn/Qv4k/tn/6gGIAdL/GwBIATb/gPyS/pQCnAKsAI0Abf/U/KT9mAHcAg4BSQDt/9D9qP2eAXgD4f9g/fT/oAH+/8//AAKqAXL+eP4GATkAZv4iASwDjP+U/VoAhgGR//z+MQDf/3L+tv6LAEABPAFMAWj/2Pwc/Tz/xQAgAu4Bff/A/Sz+K/9nABgBBwAh/1//pP9HAEwBPABk/s7+BACwAEgB5QCd/27/M//K/rUAcALuAFP/oP98/+b+xf/9AHgBFgEpAPf/oP9y/oj+9gBQAgQBQf/4/j0AoQAd/wD/BgHEAPj+YACEAr7/JPxk/qQCgAIvAN3/Tf9I/az9gAH4A9ABOv9f/5b+xPxd/+QDLAPg/y///v6g/Qb+1gCsAsoBfwC2/5j9aPx8/9gCaAIsAX4AQv6I/Ob+/AHOAXEAUADa/2b+uv5XAIoBzAGmAHL+rP2X//0AXQBNAMIBzgAM/UT9jgHMASz+lv7kAVgBrP74/pEA///c/uT/ggEqAJD9BP6SAIIBhQDG/8b/QwD9/yX/XQDEAZD/0PwI/4wCwgEeAP0ADgEb/17+Dv+I/+gAGALcAOn/vwDuAJT/Iv9SAJgA6v4o/sIBEAQ+AGj9SP/r/7z+WAH4Aib/bP1mAO8Amv6N//YBWgGV/xH/Z/95/17/EwDKAN//eP+EAegBG/8e/vr+vv7D/wgDMAMxAB3/lv7g/EL+0AIUA4b/NP8wAej/bP3a/rIB6ABs/kX/nAGmAcoA+v8E/hz9Zf9yAaYB+gF2AVr+MPzk/kgCCgHc/nYAjAHA/qT9EwAWAeD/GgBOAc8AKv9Q/lD+8v7PAPACAAOZAOD9rPzY/fb/wwD3ADQCYAKL//j8tP1V/y4AbgEUAlgASP6O/oH/FQD/AGwBXgAs/0//uv9c/xT/pQCgArQBi/9w/wn/VP16/twBsAKIATABaQCK/tz8BP3t//gC9ALKAJ3/Tv9y/vz9FABkA3gC4P2M/OX/MAJAAZUAEAFlAJD+gP5EAMgAbgDFAP3/XP48AEgDvQCw/Dr+cACo/g7/qAIgAtz+yv44ABoAS//a/r//JAEWAMD+TAAOAdj/UwDqANj+DP7T/2wAMgCgAMkAkQBbAGn/9v5GAM4Ae//Y/hgA4QBPAEgA+wAmAEL+SP7i/2AAMgAWARQB7v6o/Y7/NgFRAKz/cwBlAEn/0v7K/uP/+AFQAo4AHP8k/qT9/v6FAGIBoAJ8AhYAav7M/eT8/P0MAQwDgAO2ATL+SP1l/7v/zP5TAAgCkAGVAA4AT//2/nP/Hf8//6wBdAM6AZL+Bv8m/wz+2v4gAWgB2QBgAVYB3v9i/vz9wv7dAN4BYwB6//T/wP6o/TIB8ATgAvz9rPx+/oz/ZgBYAigD4gAT/zD/IP+o/pz+pf9kAUQC/gFcAuEAoPxw+zz+kABgAigE4ALV/5T9IPyw/ZIBwAJKAYoAhv/k/fz9Mf+kAK4BwwDm/hr/QgD+/hz9Gv4UARgCHAF3AK//oP3I/Hv/sAJ0AtL/Sv/sAIkAYP4o/9wBzQAe/hP/TAFeAWoBIAFa/mD9KwBwAR0A/f9WAGP/Cf9mANYBZAHi/kj9mv6gAEYBngAaAJUAWgDg/iP/7gDJAAwAuwCcACj/kP4AAJgCqAKf/7z++v9u/qT9YAGIAsL//P9iAQP/lP3X/7IAt/84/0L/dQBWAXT/7v5mAbAAPv4pAMwBAf+M/Un/6wB4AeEAKgAMAQgBov6s/dT+iv8KALYBsAOkAiL+TPzi/oz/Tv68AQAFWgGA/Yz+4v7Y/BX/+ANwBJkAMP4m/oT9uPy8/ggD4ANeAJz9wP1k/tT+T/9dAIgC8gEM/tz8d/+3AOAAAAJeAYv/Nf+G/9//6gDAAa8AMf9m/9MAMgFwAEAAgv/e/roAKAOuAej9+P1GAcgBZP9m/30ARv8j/14B+AE/AJD++P0Q/2sA6wAQAswBev6M/CT+/f+YAewCIALKAO7+sPug+04A5ALgAWAChAIA//j7/Pyq/zgBDAGaALgBzAJUAWb/pv7E/QL+9/8QAToBsAEjAMj99P77AHIAcf8o/5r+vv7b/6sASgEaAWkAPQC2/1L/PQAcADb+nP7cAIwBMAKQAxADKwCw/BD7NP0KAQADbAO8Avj/aP28/OT86P0DAEIBtQB0/0T+Tv5B/4n/4/8wAVABiv8+/mr+av+2AGgBGAKEA/gCd/9g/fT91P3C/ngDcAaUA9L/rP5g/aj7jPyMAFAEQATSAXsAEv8Y/DD8JABmAaT/5QD4AswATv6F/8b/GP18/U4B4gFP/8D/4AGGAOz9vP7xAHgAsP4L/0wB8AGyAGIAjgD6/rz9Tv+wAFIAIQB6/zr+V/+oAdcAwP6I/tb+E//N/zkA7ABEAuABFgD2/wQBbQAo/nD9vACYBLADtAB2AJEAZv7M/bkAhAIeAdr/pACOAJD+/P3a/94Amv8y/9MAbAGu/+z+8P/A/7j+PP/M/1L+fP1I//0ARQBM////i//0/GD8jP5f/1n/QAKwBL4B7PxM/H7+PP+g/6IBHANwAhoBjf9W/jP/KAF+AToBtgFUAZX/6v4OATgD3AHg/vL+sQArAI7//QBEAe7+fP2g/u7/dv+s/r3/UADA/dD80QA0A78A/v7M/tT8mPw2AGAC2AFYAjgDggEL/8b+j/8X/7j+xwCkAkgCkAK4AxgCZP4w/Bj82P3pAJAD8APKAQ//sP0Q/Uj93f+CAbf/sP5/AFgBOgD3/6oA+P8u/tb+cgGdAPD9kP88AooAyP5TADkA5P0A/vz/SwD2/wIBPgH3/yT/4v6E/h7/egAGARIB6ABAAIL/4P5c//AA2ABy/8oA8AJkARr/jf8pAOz/jgCQAdYBfAFMAOb+4v6G/5L/iv85ABYBFAEfALr+yP3o/c7++v9mAWACLAFS/uD8Av6z/3AAiAEsAxgCfv6s/dj/+v8A/wgAtQCFAJIB7AGcAAoAGf9k/Wz+ugDdAEcAQACsAEwC4gFa/rD9l/+c/qj9VwBkAkAClgHl/3D+pv7Q/vj+8v9HAFAA0AC2AD0A+P8K/1z+N/93APsAWQCh/04AxADV//z/SAGtAHD+MP0q/iQAAgFwAegCgAKA/0j9+PtQ+9D92gGYA2gDZAGI/tD95P3w/HL++gE8ArgAXAEMAqT/+PyY/SoA+QBCAEwBnAIIAR7+QP4eAUAC+wBcAPr/xP0Y/U4AAAOcAhQCHAJpAAz9SPtk/ZkA8QBsAHwC9AMcAQj92Pv4/Mr+EAH8AgADZgFs/1T9pPzS/tgBaAIQAfb/WP9a/+H/cQCXACkAY/86/53/qf89AMIBFAJxADT/b/+q/9L+Mv6o/zgC6ALMAVwB4QCQ/oD8bP0FAKYB1AF+ASoBOACe/gb+tv7a/tj+GwBwAcIB7AFeAaz/yP6s/hj+Uv7x/xABpAHEAX0Aqv8eAA7/+P09ANgB+f8J/7AAWAFIAGf/tP88AOT+TP20/v0AIgEMAU4B7f8q/vT9SP6Y/iUAeAIcAzoBHv+I/ub+d/9eAIQB3AFyAMT+l/9EAaEAwP/wAEQB2P+r/zQAHP8q/n//wAGkArwBkwAMAHz+nPwC/tkAvgD6/6IBQAIXAGr+8P1k/Yz9Af/fAJwC8AJGAbn/H/8s/h7+PACwAXMAMP/v/2wBDAKeAQQBVgCs/vT80P0WACcAc/9oAWgDfgF0/vz9nP5O/jr+gf/HAJgAYgB+ARgCDgFn/6D97PzE/oQB2AJ0AusAw/+I/w7//v74/0MALAAwAcABvgA3/9j9Fv6dANIBZQDU/yYAev7M/Eb+7QAsApoB/v8a//7+0P38/Df/0gG0AQQBkgHqAJ7+sP2M/vT+9P4eANQBYAJUAT0AGwBk/9z9Kv4RAL4A7gB0AkADVAEU/+T+ef9B/4r/KQDR/xMAQAHUABkA+wBMAMD93P0kAB8Acv5q/icAsAE8AjACEgGw/nz8dPwK/rf/wgHsA7ADPAHw/yT/BP10/OT++gB6ASQC2AKAAr8AkP7k/WD+Vv4X/yYBEAKyAdgB4gEMAXz/JP00/Cz+OQDcANoBfAJAAaL/ev7Q/Vb+xP4G/uL+6gEcA/ABOgEJAEj9OPwg/uL/jACiAaACWALGAPD+kP4H/1b+8P2H/yABtAEwAuABlAAA/4z9/P00APsAkAD4AfwCdAC4/Sz+qv9FABIBsgGHANT+0P7l/xAAY//Q/0gB+QDC/lr+6/8EABP/GwAQAgQCcwCz//b/nf+O/pj+OAAwAVcA/f/gAEEArv6N/xoBCgCo/tT+R//w/3EA3P8xAHYB0wC5/ywAv/9Q/ob+YP9K/5P/dgFgA0AClP6Q/b7/TP8Y/R7/eAKCAbb/lQC6AGz/hP9sAFcAkv9J/2UAqAG5AFn/DACBAHH/jv90AVwCtwC0/Uj8mP0d/w8AYALkA2wBRv7k/cz9fP1T/1YBagF0AZgBZABL/y7/MP9F/37/DgA0AUwBBgAcAOoA/v80/+T//f8hAPQBhAIIAVcADwAP/2v/8QDvAEkAYwBMAND/S//u/qb/mwDZ/xb/EAB4AE//8P7E//X/ev92/xYAZwDa/3H/CQCAALr/Ev+a////fP9t/3cAZgEuASkAQf/c/qj+jv6D/14BUALEAd0ALABh/+D+K/+b/9z/bABSAcABdAGUABz/AP56/tf/YAA4AHsAsQAxAMD//f8YADH/+P0O/nD/awDDAHwB0gF+ALb+gv62/3gAPgA6ALcArQAnABUAQgDq/4T/3f8NAGv/S/8RAAoAJP8l//X/RwDG/zn/pf9qACEAef+D/+L/ewA6AR4BQwC9/3P/Tf+y/6IAggGuAQIB3f/2/qz+9P51/2YAqAF4AXr/Tv4J/8L/EQDqAEwBZgBG/4T+HP50/ob/lwDoAMoAEAEaAcj/OP4K/oL+F/+cALQCPAOcAeX/bv9f/yr/pP+VABYBRAH3AB8Aev84/3L/YwDGAPb/dP9d/8L+bv4e/yAAawCx/w//Kv8P/+r+i//x//j/kQCdALf/gf/6/x4ARwCFAGEA/P+j/9//ngDwAPwAVAHIAFD/RP8jAJ7/NP/TAPwB/gA/AJoA///K/rr+QP/A/2oAzQDgAOIANwBd/07/SP8f/4b/rf+H/0UAGAHHAGMAUQCk/7D+Ov6g/vn/BAGuAGkAogDt/0r/9/8+ALL/3P8uAPD/QgAIAfsAVgDs/9T/5f8XAD0AUwA6AB4AOwBCAEAAHgCC/xb/0//SAMgALgC//1H/M/8EAPEAywABAK3/x//h/1AAFAE8AUkAB/++/mr/EACZAAQBqwDy/9H/s/8i/w3/fv+0/wkAowCeANn/Vv/C/38AgwAeABgAw//S/rr+2f+DAGQA+gAQAqABiP/U/aT9Iv6m/pz/MAFcAkQCKgHL/4T+mP1w/Ur+EgDmAVwCXgF1ACoAh/+y/ub+rv+i/0b/+/8gAV4BGAHtAHgAj//G/oD+nv4O/+n/8gB0AVgB/gAkAKT+mP3U/bz+wv/bAMwBAAJKATQA/v4A/hD+Iv8EAMEA5gF4AqwBSwCN/2z/Of/o/iP/BAD7AIwB3AHoAR4By/8E/8j+qv4l/0oAFAFYAaoBrAGVAPj+Gv5a/vr+cv8LAPYAfAEkAXkAzv/c/vT9tP1A/oP/7gCEAVAB8QA2AAn/Cv7k/Vr+/P4dAAQCYAPEAu4Ac/+K/rD9gP24/l8AgAFkAtwCHAJfAKz+sP2Q/Rj+Lf+XAMgBPAL2AfIAgf90/i7+Rv6Q/l//mQBmAVwBHgHgADEAJP9i/jz+sv6w/+IA2gFAAgQCKgHm/6z+AP5C/lH/lQCgAVgCTAIsAb7/2v5s/ib+mP7S/8AA8QAMASABqADO//L+Zv54/gn/7f8MAdYB0gFEAXcAlf8D/+7+KP+W/0IACAGUAYQB6AAwAH//zP5U/mz+Cv/k/6IA6AClACoAfP+q/kL+fP7I/uj+cP9MAJYAIgDU//7/6f94/1n/if9l/zr/z//KAFYBegFWAZUAif8H/zf/of8WALwAcgG6AVABmgD6/2r//P7w/nL/YQAeATQB2wBjAMH/K//c/tz+WP8ZAHgARgD5/83/lv90/6n/6P/i/9D/1f/R/9H/+v8zAFEAJgDE/5D/kf+W/7b/CwBGACEA1f+5/9v/4v+0/6n/x//f////OABHAB8ACAAOAOn/wP/f/x4AOwA+AFMAZQBGACIAKQAsAA0ADwBYALMA7gD4AM8AdQAfACAAYwDBACIBTgEsAfAAwACYAH8AWAA1AE4AjQCcAH8AdQBXAAQAsf+I/23/Zv+Y/8b/yf/T//j/+P++/3P/Kf/Q/qr+Cv/I/3kA2QDDAFsA6/+F/zH/D/9J/9j/bgDAAOEA3ABuAKP/Bf/W/tT+3v4X/3z/t/+J/xH/sP5U/rz9TP1k/Zz9sP3M/Qb+Ev68/WT9UP1U/VD9lP0c/n7+xv4s/5D/zv/w/xYARQCVABIByAGIAhwDVAN4A7gDyAO0A9wDIARIBIAE0AQoBVAFKAXoBKAEMASwA2gDbAOQA6ADrAOkA1QDyAIgAogBKgHvANQADAFmAUwB1wCWAFsA2f9n/1r/gv+n/8r/AgAtAP//dv/y/qb+iP68/vr+pv7c/Tz9DP1A/Vj9PP0Q/Uz8yPqY+UD5GPkA+UD5oPmg+fj4APhQ96D24PXg9cD20PeY+PD4CPnY+JD4kPgg+SD6MPs4/Fz9iv5W/8f/UwD8AK4BwAIYBDgFAAa4BlgH0AdQCNAIMAlwCZAJwAnQCZAJcAmQCZAJQAkgCeAIMAhgB7AGOAboBYgFOAUABaAECARsA8gCPAIEAgAC9gHeAaYBXgEqAQwBAgEAAeQA2wDjAPoA7ACqAGAANgASAP//CQD+/9T/gv/w/kr+6P24/Yj9WP0g/bj8FPxg++D6mPoo+sD5qPmo+XD54Pg4+LD3gPdQ9zD3YPdw9wD3cPZQ9oD28PZA91D3QPfQ9lD2MPZg9gD3SPj4+XD7vPyY/XT9zPyU/ED90P4CAWwDiAWgBrgGmAaYBqgGKAdwCOAJ4AqgCzAMUAzQCzAL4ArQCrAKsAqwCjAKQAkwCFgHmAb4BZgFIAUgBOwCBAI2AWQAu/9n/zL/wP5M/gb+yP1Q/bT8cPyI/Mz8LP2Y/ej9+P3w/Qz+gP4u/+b/ggDrAEABlgH4AWgC/AKcAxgEgAQABXgFkAUYBZgEYARIBDgEcATIBJgE5AMcA3ACeAF3AA8ABgCT/+D+oP5q/nD9GPxA+7j66PlY+Xj5kPm4+KD3IPfA9kD2MPaQ9mD2gPXQ9LD0oPRg9MD08PVw9hD2kPVw9RD14PSg9XD3aPkI+2z8VP1s/RD9IP3Q/fD+tQAkA5gFMAfQB9gHmAdAB1AHYAgwCuAL0AwgDeAMQAygC3ALgAtwCyALsAowCnAJwAggCGgHWAY4BWgExAPkAtYB1wD4/yb/lv5s/kT+0P0o/WT8qPsw+yD7aPvQ+zT8fPyU/Ij8bPxw/LT8MP34/QH/5/9kAHcATgAtAHAAMAFYAoQDSASABFAE6AOIA3ADhAPIAygEkASwBIgEEARMA1ACXAHSALsAvgCzAJAAGwAT/7z9sPwI/ID7EPvQ+tD6ePrI+Wj5IPkw+DD30PbA9oD2APbQ9eD1UPWQ9ED1YPZA9oD1APWA9BD0QPTg9YD4WPpA+4j8kP0I/RD8OPxU/f7+ZAGQBNgHUAmQCKgHKAeABrAGwAiQC5ANkA7QDnAOAA0gC2AKoArgCiAL4AsgDEALgAnYB5gGaAWABFgEQAQoA6ABqAD+/zn/ov56/jr+YP04/Hj7CPtw+iD6qPqo+2j8xPzQ/FD8aPvI+gj7FPxw/eb+LwDSAL4AfQBxAIUAsQAaAfYBLANQBCgFmAVwBZAEkAPsAtQCOAPQA1gEgAQwBIQDrALGAeYAOADV/6n/kP+A/07/xv78/Sz9dPzQ+zD7wPpw+hD6qPmA+Uj52Pg4+LD3MPeg9jD2MPZg9lD2QPZQ9jD2sPUg9RD1YPWw9TD2IPcw+Jj5gPtU/fT9fP3g/Nz8eP0T//YBYAW4B3AIcAhQCJgHuAbYBjAI4AmgC0ANgA6ADjANUAvgCSAJAAmwCZAKwAowCkAJEAigBjAFAAQgA2wC9AHOAY4BxwCk/5L+rP0A/cD8pPxY/MD7GPvg+gD7OPuQ++j7+PvQ++D7RPyo/AD9eP0U/tT+oP9nAAgBPgEmASgBhAEsAgwD/AO4BBAFGAUQBfgEoAQgBMwDuAPcAzgEqASwBBgEFAP2AQIBZAAnACMA+/+L/wf/ev64/dD8EPx4+wD70Prg+tj6YPqI+aD48Pdw91D3kPeQ9zD3wPZQ9uD1gPWg9SD2APZw9SD1MPVQ9aD1cPbw92D5ePrg+yz9dP0E/cj8NP14/qgArAOgBmAIoAhACLAHAAcIB0AIEArgC2ANkA7gDgAOgAxgC5AKIApgCjALsAtACzAKIAnoB3gGUAWYBMADqALkAX4BDAFcALD/B/8E/uz8PPzg+3D78Pro+jj7cPuY+8j7yPtY+9D6wPow+8j7fPxM/eT9Jv5a/sr+Tf+j/+7/UQDEAC4BrAFYAuwCNANgA6gD1APIA6ADfANAA/ACyALwAkADRAP4AngCsAG9AAYAn/9p/zv/Hf8B/67+EP5Q/ZD82PtI+/j64Pq4+oD6IPqI+cj4IPjA94D3QPcg9xD30PZQ9vD1wPWw9aD1wPUA9jD2MPYw9nD24PYQ+CD6PPys/VD+Zv4y/gb+zv7YAIAD6AXQBxAJgAkwCaAIUAigCJAJIAsQDZAOMA/ADqANEAzwCoAK0ApAC5ALYAugCnAJAAi4BqAFuATwA1QDuAL6ARgBIwA4/4D+AP6k/UD9oPzI++D6QPoo+nj6CPtw+5D7cPsQ+7D6mPrI+jj70Puo/KD9bP7O/tb+sv6a/sj+Yv9UAEgB9gFMAnQCoALkAkADfAOYA5wDmANgAyADDAMcAywDIAMgA/wCeAKmAdUAWgA1AEkAZgBXAPL/HP86/nj91PxU/CT8LPwk/PD7mPv4+gj6CPlo+Aj40Pew98D3sPdg9wD3sPaQ9kD2wPWg9aD10PUQ9pD2QPcA+AD5QPqo+/j86P1C/j7+bv5L//0APAOwBbgH8AhQCRAJwAigCPAI4AlgCyANoA4wD9AOwA1ADPAKMApACsAKIAswC8AKwAlgCNgGUAUABCQDpAJkAhwCeAFvADT/CP4k/ZD86Psw+4D68PmQ+Zj56PlI+mD6OPr4+cD5kPmY+fj5oPpg+1T8TP0O/m7+cP5g/n7+5P6x/8QA4gHAAkwDiAOMA3ADZAN8A9wDYATIBAAF+ASgBAAEXAPkAqgCdAJMAiAC1gFCAZYACgCF/wD/gv4S/qz9OP3c/Kj8TPzI+1j7+Ppw+vD5qPlg+Qj5oPiI+KD4YPjA93D3UPfg9qD24PYw9zD30PbA9hD3IPdQ9xj4WPlI+iD7ZPyQ/Tb+uv6B/3EAKgH8AYgDiAUgBzAIAAlQCeAIkAgACQAKEAsADNAMUA0gDWAMoAvwClAKAAogCmAKYAoACjAJEAjIBpgFyAQ4BJQD8AJUAqoBAgFPAKL/+v5G/nj9wPw4/LD7MPvw+uD6APsg+yj7+Ppg+rD5UPlo+fD52Prw+7T86Py8/HT8JPzw+yz8/Pwg/k//XwAQAR4BmwDn/4L/ov9ZAIQBzAK4AwgE5AOAA/gClAKEArgC9AIwA2wDhANYA/ACcAL8AXoB9wCVACsAmf8l/+T+sv5q/iL+3P1Y/Xz8kPsI+8j6qPrA+ij7MPuY+rj52PgY+HD3QPfg95D4APkY+bj40PeQ9uD1YPag91D5GPtg/MD8YPzA+5D7FPxg/Uf/YAEoA1AE8AT4BKgEcATIBOAFgAdACaAKYAtAC5AK0AlwCZAJ4AkwCmAKQArgCVAJ0AhQCNAHMAeIBrgF2AQIBFADtAIsAswBkgEyAX8Alf+u/tD9FP3A/Nz8MP10/ZT9bP0Q/XT8yPto+2D7oPsM/Kz8QP14/Uz9AP20/Gz8XPy8/Fj90P0u/pT+0P64/p7+zv4f/3P/zP82AH8AeABlALEANgGoARQCYAJwAjQC4gHAAd4BCAIwAnQClAJ8AjQC0gFMAcAAVgArACwALAAAAJr/9v4y/mz9yPxI/Lj7GPuY+ij60Plw+RD5qPgg+HD38Pag9mD2UPZw9tD2YPfw96D4UPnA+RD6kPpQ+zz8UP3O/nEAwgHMAswDuARYBdgFqAbAB/AIIApwC5AM4AygDHAMMAzwC9ALMAywDKAMEAxwC5AKQAnIB7AGGAaABRgF6ASIBHQD/gG7AMT/2P4O/qT9QP2s/Bj80Puw+2D78PqI+jD6wPlo+WD5uPko+qj6SPvg+xj8+Pu4+6j70Ptc/HD90v7s/40A4QD5AK4AYgCTABABiAEcAtgCVAMcA1gCwAGAATwB3wCgABYA0v54/fT8YP0s/sb+4v48/pD8aPoQ+cj4GPn4+WD7rPxA/fD8CPzw+sD5APm4+aD7oP01/zEAHwAe/xr+7P2i/p//oQDgAfQCQAMEA8ACXALEAXQB/AH8AswDSAR4BCgEQANwAlQCpALsAhgDLAMIA5ACKAIoAkgCKALoAZwBPAHPAF4A6f97/x3/Bf8o/yb/5v5y/rD90Px4/MD8VP28/cT9hP0o/aT8UPyg/FT9+P2S/kD/0f/w/7r/rv8hAPsADAJgA6AEQAUwBdgEqAS4BBgF0AWgBjgHgAeIB0gHwAYQBmgFAAW4BJAEiARIBMgDKAN4AsYBIAGAAO//gf9A/yf/Qf9e/0T/5P5S/tD9hP10/bT9Qv7Y/iD/Nf/8/mT+pP0k/QD9KP2A/cD93P28/VD9tPwk/LD7SPvo+mj68Pm4+Xj5GPng+Jj4IPiA9wD3sPZw9jD2MPaQ9gD3YPew9xj4SPh4+PD4sPmY+pj7sPzM/dL+vP+9ALABhAJsA6AE6AUgB1AIYAkgCoAK4AqQC1AM8AxgDdAN8A2wDVANIA0ADZAMEAygCyALUApgCXAIcAc4BggFMARUA1QCRgE6AA3//P1Y/fj8jPwE/Ij70Pq4+aD4sPfw9kD2cPbQ9yj50Pmg+YD4YPZA9NDzYPUA+Hj6hPzA/Yj9UPxA++j6KPsI/Pj9qQDsAiAEaATMA1gCGgEuAYwCKARIBeAFyAXIBIQD3AKsAkACiAEQAd8AggD8/6b/Xv+w/rz9IP28/AT8GPuA+lD6WPqY+kj72PuQ+6j64PmI+ZD5GPow+4D8dP0O/pL+6v72/uj+Ov8OADoBsAJABIAFCAYABtgF6AU4BsgGiAcwCIAIcAhQCCAIyAc4B8AGaAYYBsgFcAUIBWAEpAMMA7wCbALyAVoBkAC5//7+iP5o/nz+gv5a/g7+nP0M/ZD8IPzg++j7LPyU/Pz8LP0A/Yj8+PuY+4j70Ptk/AT9eP28/eD95P3I/bj9yP3o/SL+lv5A/+f/dADbADABYgFoAZAB8gFoAtgCaAMQBJgE+AQwBTgFCAXABJAEmATABOAECAUgBfgEmAQoBLgDTAPwAqgCaAIsAtIBgAFEAeMAQgCh/yT/rv5K/hr+Gv74/aT9NP3w/Lz8YPwQ/Pj70PuI+1j7YPto+zj72Pqo+qD6cPpI+oD6yPrI+rD62PoI+wD72Pro+iD7KPs4+8D7aPy4/Oz8OP1o/VD9RP2A/bT9nP2k/SL+ov7i/mf/QgDCAL4AugCJAJX/Qv4G/lD/LgEoAyAFQAaABWADygGWARgCTAOYBTAIoAnQCYAJsAgoB5AFQAVoBgAIYAnACkALIAogCLgGAAaQBVgFkAXgBYgFuAQ4BLADcALsAPD/N/9G/mT9+PzM/GD84Pvw+xT8ePtY+lj5aPiA90D3GPhw+Wj6wPq4+jj6EPng93D3sPdo+JD5GPt0/Oz8lPzI+9j6OPpY+kj7qPzo/cD+Ov9B/+b+eP5K/jT+Ov6q/oX/WwDUAAYBIAEOAcQAtgAKAUABEgH/AFIB0gFEAsACMAMwA5ACygF0AXIBnAEYAuQClAPwAwAE3ANYA4AC5AH6AawCrAPABIAFiAXgBPwDWAMkA0ADpAMoBJgEuASwBIAEGASAA/wCzALkAiADcAOoA6ADXAP8AqwCUALeAWoBBAG2AIQAiACvALMAZQDh/0v/qP4Q/pj9SP0c/fz8+Pz0/Mj8WPyo++D6MPrY+dD5CPpY+oj6gPpQ+hD6uPlw+Vj5cPmo+RD6qPpQ+8D7CPxY/LT8HP3A/aL+k/9lADIBKAIoA/QDoARQBfAFaAb4BsAHYAigCGAI8AeABzgHQAegB+AHoAfQBrgFkARMA0ACeAHEAAYAW//q/nD+oP2U/Jj7oPq4+UD5IPkY+dD4ePhY+Ej4QPho+Kj4wPiI+HD4sPgQ+Xj5GPr4+qj7KPyw/DT9aP1k/ZD9KP74/uf/8wDkAVgCXAJMAmAClALoAoADSAToBFAFqAXYBbgFWAUYBRAFKAVQBZAFuAWoBUAFyARgBPQDgAMoA9wCfAIQAr4BgAEqAb8AaAAnANb/e/8+/xj/2v6Y/oT+nP6+/tb+7v7s/rr+ev5a/lb+YP6I/tL+Gf9H/1r/R/8C/5r+Pv4Y/ij+VP6A/qL+kP5I/vT9pP10/VT9QP08/Uz9VP1M/UT9OP0o/ST9MP1M/XT9mP28/eT9DP5A/pj+A/9f/6n/6v8rAGoAqAD2AGoB6AFMAqQC8AIsA0QDVAN4A7gD+AMwBHAEoASgBIgEgARwBFAEMAQYBOgDpANUAwgDsAJUAvQBoAFMAe8AigAdAJj/+v5e/uD9eP0k/dj8nPxc/Bz84PvA+6j7ePtI+yD7KPs4+3j72Ps8/JD80PwU/Vj9iP2k/eT9TP6y/jT/zP9aAMYAEgFOAXwBnAGqAdwBHAJgAsACNAOIA6ADhANcAzADBAP0AvwCBAPwAtgCuAJ0AhwCyAF+ATAB5QC3AJ0AcgAsAOf/qP9y/0f/Pf9P/2H/YP9b/2v/i/+u/8v/8P8dAEwAiQDXACYBcAGoAdoBGAJUApACyAL0AhADOANUA2wDiAOIA3QDXAM4AwgD5ALEAowCUAIMAsgBeAEmAcwAbgD1/3b/F//U/pj+Yv4q/tT9cP0E/az8YPwY/Nj7wPu4+7D7qPug+4j7WPso+wD76Pr4+hD7MPtQ+1j7YPtY+zj7CPvg+qj6ePpY+jj6+Pm4+Xj5SPkg+SD5QPlg+WD5UPl4+dj5aPpI+4D8pP1o/rz+8P5C/7T/jgAEAtwDkAUIBzAI0AgQCQAJMAmwCYAKkAuwDKANAA7QDUANgAzACyALsApwChAKkAngCAAI+AbQBbAEoAOcArAB3AAEAB7/Lv5c/az8DPxw++D6SPqY+QD5qPiI+JD4oPjA+Mj4wPiw+Lj4yPjw+Dj5sPlQ+gD7qPtA/KT8zPzc/Bz9jP0a/sz+jv89ALcADAFYAY4BngGcAboB9gE0AnwC0AIEAwAD2AK4ApgCfAJYAigC8gGgAWQBTgFAASIB7AC5AHYAKADt/73/gv9K/yr/JP8y/0D/Sv9H/zL/F/8f/0P/dv+o/8b/5f8CABgAOABYAHUAigCqANoACAE0AUYBQAE4AS4BRAFoAYIBhgFwAWQBXAFuAZIBrgGUAWYBNAEKAfEA6gDnANQAqABmADkAFwD3/8T/k/9u/z//G/8a/yf/HP/6/tL+tv6u/sD+8P4M/xH/Df8h/0f/dv+k/8T/xP+z/7f/1v8NAEcAgAC2AOMAAgEkASwBDAHuAOcA/wA2AYwB4AEEAuoBtgGIAWwBZAFuAYgBlgGUAZQBnAGUAXoBWgFAASwBIAEeAR4BAAHNAI0AVwA/AC0AHQAKANr/kP9V/zD/+P66/oT+Wv4a/tz9vP2w/ZT9VP0g/Qj97PzM/MD8tPyY/Hz8fPyM/Iz8iPx4/Hj8ZPxU/Fj8bPx0/Gz8YPxg/GT8YPxY/FT8SPwk/AD8BPwc/Dj8RPxU/HT8jPyQ/Kj82Pz0/PT8AP08/ZD96P1U/vr+sv9JAL4AMAF8AXoBbgHUAeQCWAToBYAH0AhACRAJ4AgACTAJcAkQCvAKkAvwCzAMMAyQC3AKYAmQCNgHSAf4BpgG0AWoBKADwALMAb8Awv+y/nT9RPx4+wj7oPo4+uj5mPkw+aD4KPjA91D3EPcw98D3aPgI+Xj5uPnI+cj5APqQ+jD70Pt4/Bz9nP0A/l7+wv4Z/2z/4P93AAIBWAGKAaABqgG2AfYBXALEAvQC5AKwAnwCOAIAAugB+AEIAvYB2gHGAZgBOgHeAKkAkgB9AIMApACqAHAAFADW/77/tf/I/w0AUgBkAF4AYgB1AH0AiQC3AAoBWAGaAdgB9gHWAZgBdAGMAdABFAJQAnACSALuAa4BogGYAYIBZgFCAQYBtgCAAGIAOQAHAOL/z/+k/0//7v6e/lr+PP5U/pT+zv7q/uj+zP6Q/lD+NP4y/i7+MP5I/oT+vv7Q/tz+3P66/pD+ov7g/hn/M/87/1v/df9+/6r/9P8VAAUA9v/+/wUA/v8TAEQAXgBsAJkA1ADdAMoAuACQAFwAPAA9AF4AgACUAKsAmQBcABsA3v+a/2n/Yv95/5D/pf+w/6v/gv9B/x7/Cv/8/vD+/P4F/+r+2v7k/vT++v4Q/yj/Pf80/yn/Qf9U/13/e/+r/9H/4f/x/wIAEQAmAEgAkwDhABABJAEsASIBIAE+AYoB9gFUApQCsAKsAnwCRAIkAiQCQAJ0ArgC+AL8AtgCoAJUAhwCAAIYAjwCSAI0Av4BtgFuATwBKgEoAQwB0AB+AAoAjP8O/5r+GP6U/Sj9yPxs/Pj7aPuw+tD5+PhI+MD3QPfg9jD2QPVQ9NDz4PNw9DD10PUA9rD1QPUA9VD1MPaQ91D5KPvo/Fr+ef9DANgAhAGcAiAE+AXwB6AJwApQC4ALsAvwC2AMEA2wDQAOAA7QDYANIA2wDFAM4AtQC6AK4AngCMAHsAbIBRAFkAQwBMwDHAMQAtoAq/+2/iz+GP5Q/o7+pv6O/kD+xP08/dD8pPzM/ED98P2Y/hP/SP8s/+z+vP7G/vj+NP9y/5//of+H/4T/iv9w/zX/+v62/lL+5P2I/Tj91Pxw/Dz8NPwQ/MD7UPvI+gD6SPnw+AD5OPlw+bD5yPmo+Wj5SPlQ+XD5oPkQ+rj6YPsE/LD8SP28/UL+Bv/w/8MAZAHmAUQCfALUAnwDWAQgBbAFGAZABjAG+AXIBbAFmAWYBcAF8AUIBuAFgAX4BEgEoAMoA/AC1AKwAngCHAKaAQABfAAbAMX/k/9//3D/UP8g//D+wP6K/lT+TP56/qL+rP7I/u7++P70/iP/fv+0/7X/uv/I/73/rv/e/y0AXAB6AMUABAHtAL8AzQDnANQAxQAAATYBHAHYAL8AoQBFAO3/3v/i/6D/TP8k//7+oP40/gr+BP60/Uz9EP3w/Kj8YPxI/Cz86Pug+4D7aPtI+xD76Pro+uj64Pr4+jj7cPuY+9j7JPw4/Bz8DPw4/Hz8zPxE/eT9Yv6m/u7+PP9r/4H/sv/p/w4AQgC6AEQBpAEIAqgCLANMA4ADEAQwBHgDkAJ0AgwD4AM4BRgHUAgACNgG6AVQBcAEsAR4BWgG6AZYB8gH0AcwB1AGwAVQBeAEyAQoBUgF0AQoBNQDkAM0A+gCpAIgAjwBbwAHAKj/Fv+4/rr+nP4m/qz9SP2w/ND7GPvY+uj6APtA+4j7cPvY+hD6iPlY+WD5mPkQ+pD64Pr4+vj6APsg+zD7UPu4+3T8MP2c/dz9Nv6e/ub+Q//b/1YAZQA9AEYAnQAGAVwBsgH+AQQCsgFCAeIAmABfAEsAhwDyAC4BCgHNAJEAFgBx/wn/Cf9I/4z/2P86AJUAtAChAJgAuQD7ADYBcgHKAUACtAIgA6gDMASABKgE0AQQBUgFaAWABXgFSAUYBRAFMAVoBZAFcAUIBaAEMASMA7gC/gF6ASgB2wBsAOD/Uv/E/kD+6P2U/Rj9aPy4+zD7wPpo+kj6YPpw+kD6+Png+fD58PkI+lj6mPqI+lj6mPow+7D7BPyA/BD9UP1E/Xj9/P1w/pr+wP4L/zz/N/9M/5r/3f/z/xEAOwA+ACEAJQBYAIcAqQC0AI4APQDq/7n/uv/T/8b/nv+K/4r/j/+3/xYAWAAnALb/Z/9I/z3/fv8FAHwAsADpAIQBeAIgA9QC9gFkAS4B3QAeAdACEAUYBhAGaAaoBmAFPAM4AngC4AK0A7AFuAfwB2AG4AQoBMgDVAMYA0gDaAMsA+QCtAJEAnABqQBOAGIAmwCUAAcAAP/8/XT9XP1c/Uz9CP10/OD7oPuA+2D7mPtU/Pz86Pxc/Lj78Po4+lD6OPv4+/j74PuE/Jz9QP4w/rD94PzI+9j66Po4/Nz93v4L/+L+sP6C/kz+HP4K/hT+QP6W/gL/bv/D//H/IgBnAHgAKQDa/+r/GQASAD0A5QCGAZ4BmgHYAd4BUAG2ALsANAGiARgC5AKwA+QDkAMkA6gCGAKsAY4B2AGkAoQDvAOsAyAEiATAA6AC3AK4A2gDwAKUA2gE9AJgAewCoAWYBbwDTAOwA2gCVAAtALwB5AKcA5gEeAQwArr/Mf+C/9r+BP7C/jYAPwA7/xn/jv/o/pT9JP0E/cD7UPqg+sD7EPxY/NT9Ff8e/nz8nPy8/JD6wPgQ+sD7mPsI/EL+0/9a/2j+1P3I/FD7KPts/DT9+P0MADQB2P4k/Ez9DgDy/3z+eP8eAYv/SPzY+0T+5f81/7j+YgA4ApQBef8K/x8AoP9Y/Rz9CwBgAtoB/gCoAQgCJgFIASgD4AMsAocAVgD9/yz/AgAYA+gFgAYABqAFaASIAWL/EQDYAUwCZALgA5gFuAUABbAE5AOgAYP/gf/oAOIBTALgAoQDaAO0AtIB7gDY/4j+nP3U/Rj/gwBsAZoBTgGYAAT/9PwM/Nz8xP2Y/QD+LQA+AZL+yPtw/YkAKP9A++j7fADDAEz8wPtXANoBsv5I/e7+Bf+c/Dj7EPyA/e7+iQAaAWQA6P9L/wD92Pr4+6b+Jv/E/pcABAKP/8z8QP4CAV4ATP5y/ywCgAHk/mT/IgGK/7D9DwDIAjIBsv4B//j/gQAAA5gFnAMQ/8j9aP9p/w7+bv8wA9gE8AN0AwwDHAHV/50AwQBI/97+aAD0AaQCiAOYBDgE6AGZ/03/YAA6AaIB2AFgATIAVv+z/0oBJAO0A2QCgACC/z7/2P4q/tD9cP7p/4YBnAKsAuwBJgFDAJD+nPzg+2D8HP00/qoAOAMwA/cAP/8c/uD7wPlA+uj8W/9kAaADiARIAkT+EPtA+bD4iPqG/hwC+APwBHAEFAE0/Mj4aPgg+1v/1AJYBHQDygAj/zYAiAFUAJz9NPzM/Ej9FP1h/9wDIAUoA3QDKAXgAjT9APlw+Bj6dPzv/xAFQAjABVYA7P2A/uj9KPxs/TYBUAJBANn/QAIIA3kAgv60/2IBIgFsALkAfgHGAcUAE/+m/lj/Lv/K/j4A0AKABIAERAJa/qD7TPwT/ygBlAGwAcgBSQC0/sUASAQQA6z+Iv6gAagCKwB9/wIBzP8k/eP/QAZQB4gC2P4G/gT9ZPzc/ZT/JwAyAVwCwAGwAC4B6gC8/Zj6ePqQ+7j8yQBoBjgGMP9g+jD8Uv4I/Sz97AB8Avj+cPzA/6wDjgHE/KD85f9eAHT+5P5QAYYBl/9U/zQBAAIEAOT8UPtU/Jr+jAD2AYwCcAGJ/2D/7ADTAAj+fPxi/joAPAAUAhAG8AVLAMT85v4UAd3/Cf9bAJMAzv7k/iQCgAQ8A/QAYQDBAL8ALwAX/+T94P0I/xcACAGYAmQDXgE+/jb+wgHAA94AqP2+/i4AiP1Y/AwCmAfwA1z8qPtfALwBXv+K/7wCtANAAPj8qP1c//z9DPwa/hQDsAZoB+gF1gHg+8D4+PpM/cz85//wB1AJEwAw+TT9QAIb//D6sv44BFwCAv5m/pP/zPzQ+uz96ALgBHQCxv5U/QT+Kv4Y/dj9KALoBKQBcP7I/0gAGP6w/dL+J/+AAGADCAV4Alz92Psa/kD+MP3c/2ADZAMQAtQB2gFEAJj95Pw6/vj9pP12AVgFRAOQ/tD9WwDkAfABsAL4A2ACrP3A+qT8hv83ALIBIAbQCGgESPz4+ET8Uv6I+/D78AJIBhACXwAoBMgDcP2w+uT95P7w+hD6KP/UAkACmAJIBFQCdP34+qj7pPxm/uABmAOmAY3/p/8VAHb/rv60/qz+Pv4AACAEgAXIApkABwDo/Wj7cPzO/0ABgwCzACwCuAJqAQAAfP8i/gz8rPzD/wIAnP2I/rwC6AMAAS3/X/+U/rD9Dv84AHr+sPyk/rQC3AP+AND+kwBkAtD/oPwi/9QDeAJY/Wz9KAJsA8MAaAGABdgELf8g/cT+yPwQ+gj+uASYBoAFyARAAtT9QPxk/bz8qPue/pgCfAE4/wAD0AegBIr+Rv4i/9D6QPcg+8wBkAO8AWACmAQUAyf/Ev74/sj9gPuw+/z9qf/VABwDwAWoBVgBePx0/F3/tP7Q+yj9TgGAAhgCAATQBKEA9Pxu/qH/MP1s/J3/bAJgArgBgALgAvL/TPzk/AgAQQDQ/bD9OQCUAbYBCANkA1kAiP2s/fj92Px0/Fb+pAHMAwADdgHCAYIBGv+E/VD9kPxo/akAyAF2AJAB8ANUAhr+gPxE/fT8zPwxADAFuAWpAAz8ZP3OATAC5P7o/pQCbAIM/iT91P/w/+r+FgHEArgBzgEAAgb+yPkg+77+EwBaAfgDGATcAWIBCAEU/dj5TPw+AKIAhAAUA5gEZAJLAMYA1wD0/qT9Lv76/rT/TAIQBqgFKP9A+lD9+gH8/3T8o/+QBFwCTPzI+xMAagA4/Ez8DAJgBOEABP9eATwCHf+M/GD+mgHYAfYAtgG2ACT8+Pns/aQCIAMoAlgDkAOs/gD5EPq0/rj+EP0AAhAIYAQI/bD9jAGC/uD5rP0wBdgE2P6M/lwDOAM4/rj8Of85AD//wf+KAcIBZAGEArgCSQAm/rT91Pwc/F7+JAIEA7cAAP/a/mz+Jv4w/1gAIACI/37/T/9I/2QBeATMA4j+kPoI/BL/kf92/7QBeAQYBOb/4Pw2AHgE3QDY+VD7FAMYBCD+Kv44BQgGTv90/J7+vP0I+1j9pAIQBHgCdAKgAvMAuv94/wD+IPzo+5j9PABEA7AFGAXUAe8AnALr/xj6IPpu/pj+hPz0/1gHsAnIA9D88Pvs/mP/uPxY+yD+kAKkA0cA5P1CAfgFyANY/Lj51P0NAKD96P4gBjAIeQBQ+tD8BwCo/vD+vAOIBBD+sPqo/3AD3wBx//gBbAHI+wj5qP20AsgBWv/sAJQD9AIUAOD9hP2E/kH/uv6i/l0AzgFEAef/uP7Y/Tr+XACQArQCjAEwAT0AXP0Q/YYBsAT6AVz9BPxQ/ZT+lwAoBJgFtAK5/6D+HPxw+YT8GAOgBGoBcQA8AjwBVP18/DQAvALxAIv/tgAMAcT/Qv+b//D/KgHyAYAAnv+MAmAFPAKI/PD6jPxA/eT+eAMYBsgCqP2s/UkAkP4Y+yD9fgECAaL+hP8EAhwC1P74+iD7Av9oAWYBOAKkA9gCMQDI/mT/nv7I+sj41PwEA+AFcAWgBbgH8AXs/ND1UPkd/9z88Piw/dAFCAasApgFIAlqAWD0QPII+98Agv+JAHgGUAigA/b/2v+K/gj8ePyW/hz/2/+EAqgDqgEhAB4BgALSAUz/6Pxw/HD+/QC4AUgBIAK0AwgChP0k/Ob/CAId//D95AEYBAQA6Pvs/VACZALh/0EA7gD0/fj7ef9YAxwDPgFO/9D8QPwM/y4BrACk/xr//f9YA0AFJgEo+2D76/+g/zD7FP1ABZgHKAIz//UA2P8o+yD6Zv5MA6AEiALdAA4BIQCw/Xj9jP46/j7+4v/eATgCEAC8/Rj/XAJ4AkMADQD0AMD9ePkA/XgFUAY3/6T87gFABUYBKP1I/9wCQgH4/Hj8o/98AQYB3//k/sL/XAMwBMj9gPjc/SgGTAIg+Jj5dAPQAxD8eP0gBygHgPyg+aQCgAVY/ID33P10Ajr/+P6ABQAIoAEQ/Nj9kv/w+3j6lgBABdwBlv7CAeAEmAL//7MAYwCQ/Nj5BPyBABgDeALYAMsAsgEeAaX/v//BABMAyPxA+uD81ALABFEAIP30AOgFMAMw/GD78ABsAqT8KPrCANgFNAFI/BsAEAXuAIj5sPuUA+ACOPw8/nAFUATY/Rj9bgDz/4D9mv7cALoAoAEEA8T/gPy//5ADBAJVAAQCEAHY+7j7nAKYBGH/4//gBcwDsPoA+ET9fAEYAnYBqv8F/yQDWAVV/zD69P0sAVT8MPlU/3AG6AQ5ADz/WP34+aT9uATUA6r/uQCUAPj6APhY+8b/hAKoBRAIQAUC/kD7Bf+q/uj4SPrEA5gHqAS0A2gD3v9w/aT9lPzk/CgCGAaOAUj7Tv4gBVIBsPgY/PgE/ALg/EEAGAb8A0D9UPlg+3oBWAPM/hr+GASQBYT+ePqf/zAEHv8w+BT8cAUQBsH/zv7kAfsA1v7W//7/EP4M/9wBpgFtAEQDkAVjAOD4GPnJ/5wDFAJHAFIB4gEGATgA3P5U/gsArv7Y+VD7BAKUA8YAQALABYADxPyo+tj9GP2Y+ZT9yAWQBcAB1AOQBPz8kPcQ/DwCQAGM/Hb+cAVwBCj88PwoBgAG8PsQ+hQCIANI+/j6HAPUA5L+2QAIBlEAYPhA/aAFVgEo+Sz9SAegCDQCMf/y/8z9qPlw+sj+3QCcAbQDkASYAmgBDgCw+6j5PP2s/oj7vP0IB+AJLgFA+uj8pf8o/WD+9AMgBF//RP90AioBgP1G/lIB2P/c/Lz+UAMoBP4BdAGcAj4BHPwo+UT8lgABAEz9hv8oBcAE3P2o/PQCGAOw+ij5gAJwB0wAoPkC/ogF3APQ/Kj9kAWgB+sA+PtQ/BT8sPoY/QgCwAM0A+gEmAWl/xD5QPqA/sz+Df/YAhgEeQC6/p0Ag/94+1z8mgEgA/v/WP4IASgDngD8/XQANAOqAa7/0P5E/RD9aP+QAYQCtALEAb4AOAC4/YD6UPxqAYIBVP6NAOAEWAJ0/Ir+0AUEA8D3gPegAlAFSf+AAKgHYAd0/9j6nPzk/fj7UPz6/5ACxALiAa4ADgEkA/wC0P64+0b+2AFR/6j5QPqGAUAHoAboAo0A1v9M/rj6OPnc/MYBgAPwAvIBLgFoA3AHoAUw/KD1UPnL/5H/ePyv/zgHEAiyAAD9HgGwAhD9+PjI+2sArAG4AAYBpAJoArz+GPvw+8f/KAD0/JT9yAMYB+ACQv4W/8gA1P24+VD7jwDkAb3/cAGwBkAICAQU/rj6cPo4+nD6aP5gBBAHoAXMAmIBdAH6/qD54Peo+8D+rP9sAqAGqAf0AgD8uPp0AHQDnP4Y+wQAeAXYAaT8wAIQC6ADIPVg9gAE2AeO/4z8pAIIA7D6WPh0AHAGEATr/+L+Bv+4/fD7jP0IAvQDDAJtAMb+KPtQ+k8AEAa4ApD7ZPzEAxgGwQA4+yD6mPxOAUgFcAQGAWoB+AKU/vj4cPoVAEgCuwATAO4BLAOmAcL+RPwQ/ZoBgAP5/3D+rwBp/1D7kP3YBEAFKv4E/NQB5API/gT80f8IAz0ARPxg/QIBJALQAvQDZAI+/6j9dPw4+6j8mAHoBSAEhv4C/oACwgFg+wD7XAJIBHj9oPr8/4gEQASkAu4AFv5w+oD6qQD0A2b/bP1IAswDvf86/vr/LQA4/oP/WAWQBdD7gPa0/YgD0AD8AFgGGAUk/pr+IARwAYD5qPlUAKQCYABiAAQDBAMBAGz+Cf+E/9j/BQCi/vD8WPzw/CT/hgE4A2AGMAgwAjD5APik/DD9iPr4/sAJcAuUAFD6qgBQBS8A4PqQ++b+sgD8/rD9fAJACGgESPsY+zwCDgHA96D5AAcACbj8UPlkA1AHRgDg/LABEAPE/FD5HP1q/+D99AAQCLAIhAHA+zD8LP7U/Kz8BAIoBbsApP2GAFoBof+cAjAGtAAI+Pj4QAEkAwj+9P0oBBgFmv5E/LwBYAQc/nj46PzoBJgD4Poo+vgDeAfO/oD6pgEABfj8SPlAAjAHyv54+1gFIAY4+ID1UAQQCu7+oPqoBNAICf+Q+bf/FAKg+sD3LAHQCZgGlf/0/wgCAP5Q+mz82v7g/fT9qgG4AzwAgP0uAaQDof8c/egAeAMg/uD2EPjUAFAF1AEwALgEgAYeAKj6wPzW/mj7iPoYAbAGSAV4AngCQAEa/uj94P5I+2j5ywBACHAEdv4gAxAJjALg9+D32P1u/qj8DQDYBhAJ1AOM/dz8Ov4c/Pj6WgDYBogF+P0g+sT9FAJSAZL+1P74AiAHkAWI/uD5oPv8/VD8EPvW/5gGSAcMAtD9pP00/4n/uP0c/YUA0AMsAtz+7P98A9ACwP0A+7z8EQBIBNgF+QBY/O7/qAP8/Vj4vP0oBSAC0PysAWAIRAJQ9hD3VAK4BEj8qPwwCNAIIPtA9+ACCAdM/KD3QAK4B4j88PUwAmAL0AEA+q4BkAUo+/D1iQCgCGYBgPna/tAFTAFg+6f/UAWEARD82v4YBEQCuP07/2gCC/+g+dD80AXwB80AYPtw/WP/NP1o/YACaAUcAkj9NP1KAZ4ByPvI+YABgAgYBBj7YPqcAD4BqPt4/AgEkAUQADb/xAPAAwL+4PqI/FD9IP5YBBAK6AVk/cj70P50/dj42Pm2AWAHKAacAjoAxP5m/vD98Psw+7j+AASoBOb/0P6YBfgH2P1Q9cj6PAMuAVT8+v8IBZAC1v8cAygE3P1Y+QT9ZgHs/lD7ZP/wBUgEvP0I/cgAYgDo/Jz9xAEAAvb+LgBYAxkAmPug/gQCov5K/hgGoAnQAgT9ov4x/0D74PrG/04BsP0w/bgCGAcYBc0A+P2o+3j7av4K/7T8dv5EA2AD2P9E/xQC2ANwAs7/sP34+7j6cPss/iACAAZ4B/gEWACY/Qz+oP6s/Fj7mP7UAlACDQAIAkAFRAN0/Tj66PuW/5oBowCg/pD/2AMwBTQAiPwe/zEAIPsg+fr/kAboBMgA7AGoBBgBsPlo+FT+hgFM/2j/GAOUAxQBQgG0AvwA+P1o/Nj6gPqe/vwD0ARQA4ADHAM3AOT9lP1M/bD8OP2u/jkA2APQCEAIWgAI+6D9CQA0/Aj5xP3YBEgF/AFsAugDqwA8/Bj85P1k/QD9GgH4BRAFJQCo/XT9lPwc/aEAOAKs/rT8NgGoBJv/aPk0/aAGMAdI/Rj4/v7IBLL+YPcc/QAJgAk7/zj79wCIArD7mPg8/5gFCARMAOIAzgF2/lj7vP0EA9AEZgHE/X7+vAG2AQD+CPyU/skACv/u/jAEOAc4AbD6yPyiAXH/APpI+5ACwAZQBGsAzv7A/kP/Pv/Q/dj9tgE4BBwBlP6gAVQDzP6I+0T94v73/wwD5AOI/8D7OP0IAIL/Ff9+AVYBJv6T/1gEIARbAB7+cPxY++z9DAIMA9AC6ARIBYb+cPeo+rAESAYQ/eD5RAOQCE4AaPpuAHAF6P6w9qj5PANYBSD+kPv8AsAHEAEg+cD6dQAYAez+yv8cAlACcQBg/rT9qf/0ApADDv8I+hD8EANABND+SP5wBPAFjgAm/poAgQAQ/YD7vPzm/iQCaAXwBOIA5v7JAC4BuP0Q+9D8xAH4BGQDvP9W/n7/4wDa/2D84PxgA3AGcwA4+pj7b/8gAPT//wDIAKIBWAUwBOj6QPZ6/vgFgACw+igD8AuwAiD1YPjMA4gEfP10/BgCYARx/9j7tQBwBiQCSPl4+WwBeASqAAr+WP84AHD/nAB4A2wCmP3Q+4D9cP04/eYBMAgIB8L+aPsWARQDSPuw918AQAc2ATj7YgHYB7AByPks/aACNv+o+jj+EAToAwQB0QBcAXn/5PwQ/Dj9IgFYBdADeP0w/LQBRALQ+oD4kgHgCHgEGPyQ+mj/8AJIAb7+wADEA6kA6PmA+YgCsAkoBGj6JPw4BLwCiPv8/FgEMAQg/WD7iwCkAnP/pP1e/h3/eAEABfgE0QDY/db+NQDY/Qj6oPpvAOAE0ALY/2ADmAZpABj62P6wBKL+gPXo+NAEcAhIAcT9XANYBvX/6Pkk/A0AWv4o/JD/dAOYAn8AvACtAC3/iv6C/pD+4QB4BAADMPzI+Oj87ADw/hD+uARwCcgCYPsA/m4BHP04+sT+iALXACP/xQCIA0AEKAL6/qT8KP38/0gA7Pxk/awCGAQqAf4AHAJa/6T8lv44ARMA4P4QAfoBrP4c/d0AZAPx/xz8CP60AmAECALI/Qj8Wv9eAWD94PvqAegFaAIC/3gA2QBw+6D3MP5IBwgGNf+M/iwDSAXEAZD7iPlq/iADJAEs/Uj/eAS8AiD8ePw4A5gE3v7A+zb//AJiAUz9ZPya/vQAiAHV/0H/DAMYBpwCKP3A/K4ArAGI/QD9vAPABdD9aPpcAQgF/v5I+gj/6AW4BXoAUP1c/CD68Pgs/aAEQAe0Atz+mgEYBNj+aPiQ+Wb+m//GAIAEqAMM/TD8yAOoBlr/WPot/+IB2PpY+KADcAugAsj5nP/QBmIByPkA/awDwAKi/hD/MgHcAF4AZgHjAIj9iPsw/ogCMARgA1wB0v4C/mb/dv+A/CD6RPwAAsAFQAT2AO3/RwCX/4z92Pts/N7+YgHsAuAC3gF+AbYAuv4Z/wgC9QBw+5D6dgBYBFwCIQA6AHQAmQBeAesAeP4Q/cb+RgBT/4//CAKkAdD+y/8YA2wC5P3w+rT8kgEQBKABlv54/pv/YwAEAowCbP6A+cD7vALcAzD/Cv60AAQBFwCIAFP/zPxQ/pgB6v8Y/Oz+KAZgBrf/hP0aAWv/0Pj4+QAE4AhsAuj7Xv6IAvb/iPwx/wQD6AKmAb4BEgHK/nz9fv58ACAB6f/E/iUAnAJgAjwBfAGA/0j6ePk8AIAFyALe/k4B4AO3/9j7av7oAPz+qv60AdABIP5C/iAEmAV6/qj5tP1GAUL+2PwsAgAGlgH0/KEAaAXXADD5mPrKABgAFPxW/9AFQAWfAOgA5AM+AcD5kPbA+nAAyAOYBcgFZAO/AND+/Pzo++j72Pw2/9AB5AGMAbADIAX4AmD/qPwI+uj4LPzGATAEPAMABFgF+AG4/Cz9mQBy/jD5SPpoAfAE7AIQAggEjANk/5D7APrY+qD+nAKMApIA+gEIBUADPP0A+/z+2gHK/vD7Of9MA6QBOv7g/2QD7AFk/QT9GgDZ/wL+CgGwBG4BNP2H/3YBTP2o+wgCkAZ8Aqz9Uv41/1z9Rv44AqgCigA4AtADlv44+Vz8OgEhALD/WARwBfz/TP10/7b+cPuk/YQD/AMMAKv/dAKUAYz9IPzM/ez+hP+oAdgDdAN/AGz9LP31/wABUP0I+6//oAVQBHD+SP1AAtAEbP8Y+lD+MAWEAdD3IPmQBdAJ+/8I+roB2AceAbj5RP0gA60AAPzI/UQBVwBu/n7/VgHaARQCjAK4Aar+MPz4+2T8Lv6MAtAEgAGC/lsAIAJO/1D8LP5SAWwAeP0Y/SD/BAIgBdgEd/84+8T9qgH0/zT8tP1MAwgFiwBw/A//aAS0A4T9UPsZ/ygAAPxw/CgEcAdmATD9gAHwBEsAGPsw/YcAZP1Y+jj/gAXoBJwCtANoAlT8UPofADQDjP0w+VT9lAJEA6ADyARUA2gAFP4Y+zj5BPwsAYQDQAMcA4ACkgDk//MAk/8M/Mj78P4gAmAE8AQ8Atj+zP38/Yj9yP24ADQDVAEf/0wBxAIN/0T8gv4pAHT+wv76AYQBlP0u/sACTAKo/Xj95wC/ABL+vv4GAccAk/+o/1QAMAG8AW4A1P7e/h3/G//s/9gAvwAUAaQCSALc/Vj6YP26ASAAcP3QAGAFnAO9/4QALAKs/tj5wPqp/1gC0gGkAQgDlAOOASj+SPzs/Ez+b/+9ACgC7AJsAfT9NP0QAYwDlAFQACgB5P4Q+pD6QAGwBPABnABEA4QDyv9c/Xz9XP1g/Bj9YgGoBaQD1P10/cwBAAL8/Jj6Bv+cAwwBBP1jAFgFWALA+8j6Dv8kAkAB9P9OAXQCxgDc/u7+av/E/pT9JP6cAWgECAMAACv/LAD4/5j91PyS/3oAUP3E/GwBwARsA8ABFAK2ALT8iPqw+1j9x/+0A8gEygAQ/ez++AKoAi3/8v8wBGgCSPto+kQA4QDY+zj9sAX4B34B3P50AzQDOPug+C3/sAJM/kz83ACwA5ACyAPoBVgC7Pz4/Oz9sPlQ94z+gAYIBKL+uAKACZgEuPiw9gH/AANU/nD70v/IA1ABpP0XAEgGEAcGADD64Ptz/zr/uv70ACwC5wCRAAACsgFt/1n/SgHU/1j7sPvKAXgEUwBw/eUAKAS0ALD7NP38ARIBqPxW/rgEQAXW/kj7Zv63ABT+fPwsAMwDlAJbAHAB+AIWAUz9qPtA/Wf/PP9Y/kcAnAPgA8AAdP5U/4MArv5g/TYBKAQy//D5qP00A0IBlP2fAEgFwAIk/dT9OAJIAbT8APwY/2ABzgGWAboB1AJkA70ACPyY+hT+UAHkAFgAKAJgAqL+SPyt/zQDrQDs/KT+mAE9AJL+HwC+AAT/1/8QA2gCJP5c/V0AcAAI/mEAKAUsAxz9VP16AfX/YPug/MYBKAOsAcACoAT+AbD8qPrA+yj8AP0+AYAE/gF1/0wDGAfAAqj7wPrc/AD7OPku/7AGSAU/ABADYAjEAvD30PcNAKYBwPzo/HgCQARMARwBSASwAzj+cPrY+8n/+AGdACL+KP7CALgCJAISASYBGQBo/TT9/P9UAMz80PtgAdAG3AMY/Qj9fgEAAOD6zP0YBpgFrPzI+eT/7AIi/ij85AKIBxgCJPyO/kABFP1g+tP/2AR8Aqr/DALAAzIAzPwM/rD/PP5m/ogCuASkAmgBtgFf/5j7qPti/4wBYABt/xYB8AIEAkv/nP5FAHD/EPww/QQD5ANO/mD8QAFwBEACzP8R/0T9sPuc/fEAOAKMAqwDDAN0/0T9Jv4e/uD87P6IAoQCrQBKAWQCIADU/Mz8wP7i/pT+HgGgAwgCvf8CASACgP5o+qT8bAJUA0H/aP64AYoBPP24/KwBUATeALD9PgCYAxoBVPw8/Hr+8P0g/ugCAAZwAjD/MAG6AdT8IPqQ/sACZQCU/eMAcATiAQr//QDWAaz9kPsiAPwDewDA/JIAKATW/hD5HP0wBDgE+QCjAAwAKP10/a4BbALG/k7+uAEwAcD8OP1UAugCS/+NACAFPAPo/KD8pwCa/gD5KPvcAmgEsgDgATAGpAN8/MD7qv9Y/bD3kPqIA2AGBAM0AqAEYAOY/RD6ePu8/Hj8OP98A4QDbALwBdAHHwAg94D5AgFH/4D5bv5QCMgGwv6E//AEXAIc/Hj8E/+o/Lj6pv8QBXQDlgA8AygFRwBI/G//aAGQ+2D2uPrAArAFyAWIB6gGMv8w+Lj4aPzo/Xf/fAJMA9gBcAF0AVEAef+T/wj/FP7A/qwACgFt/yr/BAG6AZIAVQB4AUACBAIjABT9ePto/Cr+igAcA/gChgDU/yIBZgB8/dz83/+kASX/iP13AHgCnf+w/aMAzAJrAHD+MADhALj9IPxt/xwCbQA7//wB2AMWAez9lP5AAAT//PwQ/gABtgGpAEwBPAOcAjv/+Pw4/SL+4P5UABQCsAL6AdUAtP+k/mz9SPwE/dcAuARYBHwB5gBwAU3/yPzs/cz/LP4w/Oz+gAPIA3IB9gE4A+z/SPtQ/NsATgF0/QD8qv6fALEAOAKQBBgEaAGp/zb+qPsA+xj+4wBfAJAA9ANgBWQBUP16/owBhQD0/Oz8ewBQAuYAff/h/14Aov8u/2AA+gEYAqwApP5U/bz96P5W/7D/vAEIBMACfv4k/YYAyAKRACj+oP5E/yT+dP1S/8QCyARcAxkAjv5//7P/TP3Q+1L+dgGgAYgBqAPcA27/sPt4/ckAOQA0/vr+yQBhAA3/Gv/0/9cAIAL4AkgBKP6k/V3/Jf+k/Sf/fAK0AuL/yP7YABgCUQC4/pX/3QCbAGD/uv6R/6sAVgC3////5f8//+3/ygFIAiQBWgDk/zj+CP0V/7AB2gB8/7IBgANQAMD8Iv6eAIf/Nv5QAJQCqgHJ/7n/PwA4/+z9mv7s/77/TP8TAAgBtAE4AlwBW/9c/lD+dP3g/CD/uAJQA4kARP8KAcABOQABADABaQAs/lD9LP6M/6EARAG0AeABZAG7ADIAGv/g/eD9BP/1/4EAOgFiAUgAjf/CAJgBjP+8/Gz8Qv6TAOQCuAPWAYn/S/9I/7j9MP0v/4IAD//0/ScAaAPIA7gBOgBq/wz+DP04/bj93P7tAHAC7AIkAzgCw/9C/hD/sf8w/sD8vP06/6f/XgF4BEgEuQCp/1wBNP9I+Tj4MP7EArQBDAGIBHAGQAIk/az8AP7I/Ij7ev5EA3gEkAHU/+YBdAPBAHj9MP75/zT+2Ptu/lAD0AM4AXQBZAPgAS7+9Pzc/cz9VP3W/ngBzALAAlQCUAHz/3v/sf8t/wr+Iv6m/7UAhABjAGwB5ALYAocAdP7m/pT/Hv4M/R7/CAIIArD/9v6gAJABjADW/0sABgCW/vj96P6+/93/6v/Y/8X/nACaAbkA8v4+/+AARADY/aj9EQA4AfL/S/9vAMsAT/+S/gMAigFIASgA1f/r/z//VP5y/jn/n/9LAGgCwAQoBCoAkPw4/HD9vP1K/uUAvAPsA2QCrAHOAEz+OPwU/YD/VwCh/wsAEAIMA5wBgf/O/n3/6P8E/zj+R/9KAZwBKgDF/ygBkgHP/2r+Nf+ZALAALACIACYBoQBe/7b+tv7q/pH/qgBEAfoAlAATAA//rv7p/8kApP+6/r7/LgB+/vj9TACqAQAAov7h/1oB3wDm/xkAFABk/tT8XP3i/uv/6QAUAlQCeAG3AD0AEv+s/cz9H/+7/6n/dwDKAfYB8AA9AFoAUAB0/5b+Bv9dAIsAZP96/2QB7AHo/x7/bAGoAv7/RP0U/sH/hP+M/6YBQANIAmwAFv/w/XT9ZP6G/7z/ZgBgAkwDZgEp/1v/KgDk/jz9Rv7wAOgB+ACXAIQBBAIoAeH/Yv/f/0kAT/+w/fz9VwAMAgwCDAKAAp4BgP9W/lT+xP08/bj+HgGAAWsA+QDgAngCf//g/XT+PP4A/R7+uAFwA8YBQQDkAAwBNP/U/Vj+H//4/hr/KgDvAMEAhACkAEgAPv+i/s7+qv7g/cz99P4mAK0AHgFuAYYAiv5o/fT9zv7+/jj/8f91AEsAMACzABYBpgCq//L+Bf+p/yUAYwAeASACRAJKAUUA6f/f//z/UwCSALgAXAHyAVQB8f9C/4b/4v8ZANkA+gEwAiABSgCMAKcAlP+8/p7/HgFeAbIA2AAcAswC8AHtAOIA+QBRALj/bQDcAUwCoAG0AdwCDAOWAd4AIALQAigBxf+lAF4B7v8K//sAFAN8AscAgQCqAHT/zP1g/bD9fP0s/fT9/v7a/hL+rP0Q/dj7IPsQ+0j60Pio+DD6gPuA+3D7QPzA/Kj7IPqQ+Tj5YPgo+MD5XPxE/sz+xv4A/9j+9P1g/dD9XP6A/l3/ZAEYA8gDgARYBbgEAAOoAvADcARkA0QDKAWIBkgGeAbwByAI2AV8A+wCTAPsA2AFGAdABzAGsAVgBdwDPAJ4AsgDQATQA8QDQARABKQDLAPAAvABiAEUAlwClAHKACoBIAIQAtsAYQA2AXQBMQAg/yH/4P64/TD9bv4UADwAAP/U/Uj9aPyY+tj4uPj4+fD6GPuA+xD8EPuQ+BD3MPew9iD14PRA9uD2MPZA9mD3EPcA9SD0YPXw9SD1cPWg95D5WPog+0z8BP0E/Uz9OP7q/oD/LAHAA9AFGAcQCPAIEAmwCIAI4AiwCWAK4ApwCyAMoAzADJAM0AtQCvAIIAiwBxgH2AZgB5gHmAZwBSgFgARwAqUA2wD2AbABBAAP/6L/FABN/5b+Uf9NANj/Uv6k/Vj+0P5W/h7+GP+GAFgBegFaAVwBYgHxAGoAfgDyAOEAiwDlABACNAOkA5wDgAP0AuQBogBx/7D+3P6a/8r/Yv9j////KgBv/6b+/P2Y/ID6OPlA+aj5OPpw+5z8sPwk/PD7aPuo+bD3IPeg98D3wPe4+Aj6SPrA+YD5cPnI+ND3YPdw91D3MPfQ98j4yPnA+tD75PyQ/eD95P24/aD9FP4J/1EA9AHsA6gFgAbQBmAH8AewBwAHGAcgCPAIcAmwCnAM4AzQC+AKcApQCZAH4AZABygHaAZ4BiAHwAYwBbADlAI6Aaf/Af9B/4X/fv9i//r+CP78/GT8+PuI+4D78Pso/Bz8iPxI/Xj9EP0A/Xz93P38/XL+LP+3/xUArABqAegBNAKMAqACQAJMAjgDCAQgBHAEiAVIBpAFOASkA6QDHAMMAm4BxAGQAkADgAMsAxwCewB+/oT8KPvg+mj70Pu4+4D7SPuo+oD5YPjw95D3YPaw9ODzIPSg9LD0APWw9TD2APYw9WD0sPMw8xDzoPPw9OD2sPg4+oD7ePzM/Hz8VPxI/QL/owA0AgAEmAV4BgAH4AfwCLAJEAqwCoAL0AvgC4AMYA2QDRANoAyADEAM0AugC0ALcApwCbAIyAegBsAFiAUwBTgENANwAloB0v+e/gz+iP20/CD8MPxg/DT8+PvQ+2D7YPpI+cD4UPmY+rD7SPy8/GD9rP1A/RD9Av5n/x0AbABUAagCUANYA7gDoARIBXgFoAXwBQgGCAZgBpgGIAZYBfAEsAQ4BPQDSARYBLQDDAPIAqQBRf9U/dD8pPzI+0j78PuI/JD7+PkY+Xj4UPcA9hD1UPSw83DzsPMg9BD1APbw9bD0gPMA86Dy4PGQ8UDysPNA9VD30PnY+5z8jPyE/LD8sPzk/CD+hAAQAwAFqAZQCJAJEAoACjAKwAowC4AL8AvADLANQA5wDmAOwA3gDCAM4AvgC2ALIArACMAHAAcoBqgFiAUgBRAErAKAAU8ADP8W/pD9EP10/Bz8IPwA/ID70PpA+sj5cPl4+ej5iPpI+wT8aPxg/ET8aPzw/Lz9yP7Y/4YA/ACsAbAChAP0AzAEWAR4BKgEOAXwBYAGyAboBtAGOAYoBSAEsAPgAxgECATsA8ADzAI2Afz/Mv/s/TD8YPvA+8j7sPro+Tj68Pk4+ND20PaA9sD0IPNA8+DzYPPw8sDzkPQQ9HDz8PMA9BDzoPJw8/DzUPNw88D1mPiQ+jz8JP4b/6T+TP4q/2MAKAEMAvgDiAbACGAKwAvADDANQA1ADTANUA3ADWAOwA7QDsAOsA5ADoANAA3ADGAMgAsgCrAIgAdwBmgFeATcA0wDdAJ6AZ4A0//U/rT9mPyY+8j6OPq4+Uj5KPk4+Rj58Pgw+ej5aPpw+kD6GPrw+SD6CPtU/Jj9tP7H/7IAUAG2ASACuAJsAxAEoAQwBdAFkAZgBwAIMAjwB3AH0AY4BrAFGAXABLAE0ATIBCgEMAM0AvAARf+U/XD88PuI+wD7gPog+oD5cPhg96D24PUA9YD0QPSg86DyMPKA8tDy8PJQ84Dz8PIQ8gDyYPJA8jDy4PJA9ND14Pcw+gT8BP3I/UL+/P2c/Z7+GAGUA2AFWAeACfAKoAswDOAM8AyQDMAMoA1wDvAOgA/wD8APAA9wDgAOQA1wDOALMAvQCSAICAeABuAF4AT0AywDJALcAMT/Ef9U/jD9CPwQ+zD6iPlY+XD5WPkI+fD4EPkI+fj4IPmI+dD52PkQ+oD6GPvw+xT9iv7h/7MAJgFuAboBCAJcAuQC1AP4BCAG8AaAB8AH0AeYB/gGQAa4BYAFeAWoBdAFqAUQBSgEFAPgAYsAO/9S/tT9aP3k/ET8mPvQ+tj5sPig96D2wPUQ9aD0UPTw87DzkPNw8xDz0PLg8tDyMPLA8SDysPKw8tDysPOg9AD1APa4+ND7cP38/dj+rf+s/8j/CgEcA+gE6AbACUAMAA0ADcANgA4ADlAN8A0QD4APkA9AEAARQBDADjAOEA4ADYALkArQCWAIwAYgBhAGSAXsA/wCQALVAAr/+P2Q/dT8sPvQ+lj6wPkg+fj4OPkw+dD4oPiQ+Gj4WPiw+FD5wPkQ+tD6APwI/bD9Tv4U/7P/HwCtAIoBdAIkA+QD2ATIBYAGGAegB+AHmAcgB8gGuAawBqgGoAZoBtgFKAWgBBAEQANEAlwBlwDA/87+/P1E/Xz8qPvg+hD6IPlA+ID38PZQ9qD1EPWQ9AD0YPMA8/Dy8PLA8pDysPLw8gDz8PIQ84DzsPPg84D0wPUg93j4YPoA/Tr/MgBEAEMApACcASgD4ASABoAI0AqQDDANoA1wDsAOIA6ADRAOwA6QDkAO0A5QD5AOUA3QDJAMYAuwCaAI8AfIBkgFQASMA5wCdgGPAM3/2P7k/RT9OPxI+4D6yPnY+Aj4wPfw90D4ePjA+Bj5KPkg+XD5CPqA+vD6iPtU/BD91P30/hoA5QB8AWQCZAMgBKgEaAUwBqAG2AYgB4gH2Af4ByAIMAgACJAHGAeIBsAF6AQ4BLwDPAPAAlwC3AEIAfb/vP5Y/eD7oPqo+ej4WPgI+MD3QPew9hD2gPWg9MDzEPOA8vDxoPHg8UDyoPLg8iDzYPNg82DzgPOg8/DzoPSQ9bD2aPgQ+8D9of/xABwCnALsAWYBmALwBLgGEAhgCgANkA4QD2APgA8AD0AOIA5QDmAOoA4gD5APEA8wDoANcAwAC8AJAAkQCIgGMAVIBEQD2AGqAAkAd/9w/mD9oPzQ+7j6oPnw+GD40PeA95D38Pdg+Aj5iPm4+eD5IPpY+oj6APvo+7z8bP1W/rD/+AD0AdQCsANYBLgEIAWwBSAGgAboBmAHqAfQBxAIYAhwCCAImAfQBtAF2AQoBLADMAOoAjACwgESARcA7P6k/Tz8yPqo+fj4iPgw+ND3YPfg9jD2UPVg9JDzEPPA8oDyUPJw8pDy0PIQ81DzYPNg84Dz8PNw9MD0YPVw9rD3EPnY+iT9g/8wARwCxAIkAyQDiAMIBRgHAAngCuAMMA6wDhAPkA+AD5AOEA5wDtAOsA6QDuAO8A5QDlANQAxACyAKEAkACLgGOAX4A+wC3gHsADkAjP/I/gb+OP0g/OD62PkY+WD40Peg9/D3WPjI+DD5ePmQ+ZD5wPkg+pj6SPsg/NT8aP0O/u7+6f/5ADACXAMIBEgEoAQoBagFEAaIBhAHWAdoB5AHyAegByAHwAZwBsAFyAQgBMADRAOUAtABEgEhAA3//P3s/Nj76PoY+lD5mPgA+HD3sPbw9UD1oPTQ8wDzgPJQ8kDyIPIw8mDygPKg8tDy8PLA8sDyEPNw8+DzwPRQ9sD3UPmY+yL+v/83ALMAVgGEAawBIAPIBTAI4AmQC2ANYA6ADmAOIA4ADuANAA5ADqAOQA/QD7AP0A7gDeAMkAsACtAIIAhIBxAG8AQYBDgDLAJMAa4A2P+I/kD9TPx4+6D66PmI+Uj5KPk4+Vj5cPmw+RD6QPoA+uD5YPoQ+4D7HPwc/ez9Rv7g/gYAIAHoAbQCmAMIBBgEgAQ4BagFwAUwBtAGEAcQB2AHuAd4B8AGGAaABZgErANoA2QDAANYAr4BBgHS/3r+dP2g/Kj7qPrg+Uj5sPgg+KD3APdQ9qD1APVg9NDzgPNQ8xDz0PKw8rDywPLQ8vDyMPNw86DzwPMw9PD08PUw9+D48Pr4/Kr+HwAGASIBDgHeAYQDCAWQBtAIQAuwDGANQA4gD+AOAA7gDaAO8A7ADhAPwA+wD7AO8A1gDTAMsArACWAJYAiYBjAFaARkA/wB8ABxALz/ov6s/QD9HPzg+gj6uPko+VD48Pdg+BD5YPmw+QD6QPpQ+nj64PpY++D7mPyE/Vb+Df/0/ygBSAIMA7ADOASIBKgECAWwBTAGaAawBiAHgAegB7AHeAfQBvgFcAUABUgEgAMgA/gCTAIqAS8Ad/9s/jj9YPyg+6j6iPnA+CD4gPfg9lD2oPXA9ODzUPOw8hDyoPGQ8WDxQPFQ8ZDxwPHA8fDxMPIw8jDy0PLQ8wD14PaQ+Rz84P0z/y0AfgBXALUAIAIwBEgGkAjwCuAM8A2ADuAO4A6ADiAOcA4QD6APIBCAEIAQ8A8QDwAOwAyAC3AKkAlgCCAH6AXQBLwDtALAAcEApf+K/pT9mPyw+9j6IPp4+dj4aPhA+Gj4wPgg+Yj5wPnY+fD5KPpw+vD6uPuU/GD9JP4b/zQAUAE0AtwCZAPQAzAEeAToBJgFUAawBtAGGAeIB6gHcAcoB9AGMAZoBeAEiAQwBNADZAPAAsoBtgDa//7+7P3w/Cz8SPsg+gj5cPjw9yD3YPbQ9UD1YPSA8xDz0PJQ8uDxoPGA8WDxcPGw8fDxEPJA8sDyMPPg8zD14Paw+Ij6kPxW/kf/iP/j/8EA9AFQA0AFwAfwCXALsAygDRAOEA4gDkAOUA6ADgAP0A9AEGAQABBADxAOwAywC+AKAArgCMgH4AbgBbgEtAPcAtQBlABW/0D+OP1M/KD7IPuY+vD5cPlQ+Tj5MPlo+aD5sPmg+dj5aPr4+mj7DPzw/Kj9Jv7M/tz/5ACOAUACPAP8AzgEgARIBRgGeAagBvAGMAc4ByAHOAdAB+gGcAYgBsAFKAWYBDgElAOQApABvADe/97+8P04/Wj8cPuQ+tD58PjQ99D2APYg9TD0gPMg87DyUPIg8gDyoPEQ8bDwkPBw8FDwgPDg8HDxMPKw88D1wPeQ+Uj7iPzw/Oj8nP02/+sAgAKYBBgHIAlgCoALoAwwDRANAA2ADSAOoA6AD6AQIBHAEAAQYA+ADiAN8AsgC4AKgAlgCIAHsAawBYAEYAMgAr8AXP9C/nj9yPwI/GD70PpI+sj5aPkw+SD5EPkA+QD5OPnA+TD6ePr4+tD7lPwM/az9rP6J//T/eQBwAVQC5AKEA5gEmAUIBhgGSAaQBqAGqAa4BsgGuAawBsAGqAYgBmAFqATwAzgDhALUARQBJwAu/2b+mP2I/HD7sPoQ+ij5IPhA94D2YPVA9GDzAPOg8kDyIPIQ8uDxkPFA8fDwkPAg8CDwoPCQ8UDzUPWA92j52Pq4+xj8dPwk/Rr+T//vAFQDAAZACOAJQAuADCANAA3QDAANcA2wDTAOYA9gEMAQgBBAELAPYA7QDJALoApgCQAIMAewBgAGEAVgBKgDbALrAI3/VP4M/ej7QPvg+oj6UPo4+jD6IPow+kj6KPoA+ij6iPrY+iD7wPu0/Jz9bv5J/zEA3ABAAboBdAIwA7gDaARIBQgGWAaABrgG4AbABpAGoAawBogGQAYQBsgFKAVoBMADAAMMAhgBZgDK/wD/Jv5I/Vj8SPtI+mD5kPiw9+D2IPZg9ZD00PNQ8/DyUPLQ8aDxcPFA8QDxAPHw8LDwgPDQ8ODxkPPg9YD4ePpQ+5j7GPyI/Nj80P2+//wBEAQoBoAIcAqQCxAMcAxgDOALwAuADIANYA5ADyAQQBCQD8AOEA7wDGALAApQCZAImAfgBogGGAYQBagDSAL9ALv/mP7I/Qz9bPwQ/OD7iPsQ+8j6wPqA+gj6+Plg+sj6+PpY+wj8oPzw/Gz9VP4b/5D//v+vAGAB6AF4AigD7AOIBAgFcAWQBZAFoAXIBdgFsAWYBagFqAVwBQgFqAQQBDQDVAKYAekAFABh/9r+RP5o/Vz8ePuY+oD5aPiQ98D24PUQ9XD0APSA8yDzwPIQ8mDxEPEw8eDwIPAA8JDwIPFw8ZDyAPWg9zj5GPrw+pD7iPvI+wj96P6YAFQCsARQB3AJsApgC6ALoAtwC3ALsAtQDIAN0A6gD9APsA9gD5AOIA2wC4AKUAlQCIgHCAeIBugFSAVoBCgDtgFwAGD/Uv5w/ej8fPwM/MD70Pvg+7j7cPtg+2D7QPsQ+0j7yPto/AT9vP2Y/nT/SgAAAa4BNAKQAtgCLAOcAzgE2ARQBbgFGAZ4BogGYAZIBkAGAAaABSAFAAXABDAEiAMAA3gCqgG0AMv/HP9o/oT9kPzg+0j7aPo4+UD4oPfw9tD10PRQ9LDzkPLw8YDyMPPA8qDxEPEA8XDwwO8Q8JDxQPPw9OD2yPjg+Sj6YPrQ+jj7BPzQ/UQAhAKABJAGcAiwCVAKsAoAC/AK8AqgC5AMYA0QDuAOcA9AD6AO8A0QDfALEAtgCoAJQAhIB7AGKAZABUAETAMgAuAAAgCR//T+Jv58/fT8YPzI+3j7kPuo+6D7uPvo+wT8DPxc/Nz8NP10/fz9vv51/zkALgEIAkQCUALEAngD6AMQBGgE8AQwBTAFYAW4BbgFeAVgBVgF2ATsA0gDJAPIAvgBJgGmAA8APv+I/hD+ZP1k/HD7oPqg+XD4kPcQ95D2sPXA9PDzUPMA8xDzMPPw8nDyAPKA8cDwYPDw8PDx4PJA9KD2+Pg4+pD6APto+2D7oPsA/Tf/agGQA9AFyAcgCRAKsAqwChAKwAkwCuAKYAsgDJANkA5gDqANAA1QDBALsAngCFAIcAeABvAFiAXIBNgD7ALgAbQAyP9P/+j+SP6o/XT9ZP0Q/bD8uPzU/Ij8KPxY/Nj8CP0Y/Yz9Qv6+/j3/LQAuAbQB1gEkAnwChAKcAjwDGASABLAEEAV4BXgFSAVABYgFeAUQBZgEKASwAzgD+AKwAiACSAGgABoAZf+A/rz9FP04/Cj7MPp4+ej4ePgQ+CD3oPVQ9PDzEPQA9KDzgPPw8rDxoPCg8FDx4PGw8mD0YPag91D4UPlI+oD6WPrg+iT8yP3K/1ACqAQ4BlgHYAgACQAJAAmACQAKEApgCoAL4AyADXANYA0gDWAMYAtwCsAJEAlwCLgHyAboBWAF8ARABGADpALwAQwBCABh//b+Xv6k/Uj9YP1Y/SD9KP18/Zj9VP08/XT9mP2I/cD9nP6R/yQApwBeARgCaAJoApgC4AIMAzQDrAM4BGgEgATYBCgFCAXIBLAEaASsAxQDFAMEA3ACtgFcAdcA0f/k/oT+8P2s/Hj72PqA+uD5EPlg+HD3QPYQ9VD08PPw8xD00PPg8tDxQPEQ8TDx4PEA8xD04PQg9vD3UPmI+YD5CPro+pj7iPxo/tgA+AKQBAgGSAfAB5gHcAewB0AIIAnwCdAK0AugDBAN4AwwDEALQApACWAI2AeQB0gH4AZgBtAFGAUYBPQCAAIiATIAXP8Q/0T/df8p/5j+NP4K/tD9YP0Q/QT9EP0E/Rz91P0a/2wAOAGGAcgBEALwAXgBTgHcAYQC2AJcA3gEaAWABSgFGAXgBBAEQAMsA2gDSAPoApQCTAL8AaoBSgG5ANb/uP6Q/Zz8APyo+yD7cPrw+Xj5iPhA91D2oPXg9KD0MPXA9QD1cPNw8iDywPFQ8RDy4POw9cD2sPeY+AD52Pgw+UD6GPuQ+8j8Hv+CASwDYASgBYAGsAagBgAHyAeACPAIcAkwCvAKgAuwC6ALUAvQCnAKAAowCUAIoAcYB2gGoAU4BQgFqAQgBLQDNANYAkwBZQDM/4P/g/9//0P/Ef8Y//7+lP50/ur+K/+2/oj+Zv9dAHIAVQD5ALIBegH0AFwBcALYAmgCRALYAlQDRAMwA2wDiAMoA6QCZAIsAr4BXAE+ARQBgQDf/6P/hf/c/sj9/PyQ/OD76Po4+sD56PjQ90D3YPdQ97D2MPYw9iD2cPVg9IDzIPNw8xD0wPRQ9VD24PcI+Yj5CPrY+mj7kPv4+/j8Hv5G/7cAXALcAxgFMAboBggH8AbwBgAHOAfoB/AIoAnQCRAKgAqgCvAJ8AgACEgHmAYYBvgFGAYgBuAFaAXoBEAEWANQApgBVAEsAecAygD2ABIB1gCaAIUASwDL/1//Xf+P/8r/VAAyAdQBvgE6Ad4AxQC0AKwA+wCmARQC8AG6AfYBYAI4Ao4BLgE+AQIBdABbAM8AyQDt/1T/tf8cAFf/FP58/Rz9yPs4+sj5+PnA+WD50Plg+tD5YPgw90D28PTg8xD0IPXg9aD1APXQ9FD1UPYg98D3WPgY+dj5cPr4+nj78PuA/Gz9wP5SAOIBLAMABIgE8AQ4BVgFWAWgBWAGQAfIBzAI4AjgCUAK0AkwCZAIgAcIBngFSAZAB0AHuAaYBrAGSAaQBQgFaAREA+oBXgHSAVgCWAIwAiQCtgHtAG4AcwBoABgAEQCBAMYAhQBXAJoA4wCwAD0AFAA9AFEAMgBEANkAfgGSATwBMAFOAd4A4f8p/xz/RP8p/yH/i//2/8r/Df9a/sz9CP3Y+9D6kPro+uD6OPrw+Vj6MPqw+FD3YPew9/D2YPZw92D4QPcA9lD3wPkY+hD5cPnw+jj7mPoQ+4D8mP2u/ngAgAGmANH/8QCoAtQCVAI4A/AEoAWgBXgGmAeQBwgHWAfAB9AGqAXQBYgGeAaQBtgH0Aj4B6AGoAaYBsgEuALQArQDiAMMA4gDUARoBOADDAP4ASQB3QB1AJj/4v/oAfwCFAEk/4QA7AJ8AqcAEgGUAnwBiP78/Y0AfAK0AckAJALEA9ACdwD3//YAGwBM/UT8Tv4uALn/5v5P/0P/oP1o/Oj8BP0w+0D52PjQ+BD4EPiw+SD7yPrw+eD5SPkQ92D1EPZw93D3QPfQ+Mj6OPvw+oj7EPzI+jD5yPkc/KD94P2K/hwAMgFAAWYBOAK8AigCcgHUAfgC0ANABAAFIAagBvgFKAVgBQgGYAXcAyAEgAZoBxAFVANwBfAHKAa4AkgDmAZIBkgCOAEwBFAFKANkAkAE+AQYA3ABjgEEAu4BBAJQAlgCNALqAR4BbgD9ANABQAFrAO4ABAHa/jT9Av+qAU4Bgf8MALABmwD4/aj9ev70/CD7pPwe/5L+iPwA/GD8rPwA/hn/8Pzg+HD30Pgo+Rj42Pi4+1z9mPyw+yD7yPmw+FD5GPpY+Wj4OPkY+5j8nP2k/vD+tP0o/DD8bP04/lz+vP5t/8H/6f+6AHACOATIBOwDvAJYApgC3AIUA3wDGAToBAAG+AYYB2AGsAU4BYAEvAO4A3gEGAWABWAGWAfYBgAFnAMYA4QC7AFoAugDOAXABcAFIAVsAxoBM/8+/lL+tP/uAbgDuAQ4BYAExgEq/pD7APuc/Iv/HAIMAxwCfgATACgBigGI/0z8IPq4+ej5kPoE/ToAIAESAGcAbgGP/wD7UPdQ9sD2wPcY+hb+2wC7/9T8MPxI/bT8sPqA+tD7IPuY+Ej4UPsU/iD+zP0y/4EAnv/k/VD9ZP3w/AD82Ps8/Sf/YABAAXQCrAN4BEAE/gFq/rT8Uv4MAbgC1AMQBRgFeAMoA+AFaAf8AwAADAFoBGAEkAKsA3gFeAMkAaAEAArwCCwDXAA4AXYB8ADQARgDTAOEAzAECAQMA4AC9gE2ADz+pP0O/lL/kALgBZgEEP+g+zD9fv89/7b+n/+I/yj9CPzG/ogBh/8o+xj6PPwQ/Sz8hPwi/nD+ZP1I/Tj+JP5A/Aj6QPlY+kD8Dv57//b/zv4w/Vj9kP6U/Yj60Pmg/Fr+rP0R/yADdAOK/uD72P4sAeL+tPwq/qT/Tv68/bMAmAO4AosA5gDsAmgDlAEk/8z9Lv6M/9cAVAJ4BGgFPANmAHABcAUQBnIBXP6NAOIBeP7U/eAEUApQBfz9sv/4BbgFhACq/1gD/APd/8T9zgBQAwgBbP5OADAEsAUABYAD/f9Q+4D6WP4NAAz+VAB4B1gHVP2Q91z96AI2/yD7d/+ABFgBfPxs/QX/kPvQ+OD8NAPUA7r+MPv4/Ob/Hf+Y/Hj9EgEcAbz8YPuK/nz/qP1o/n0Arv+S/uQAYANKADj6uPly/sD/WP2Y/vACqAPtAPj/egH6ALT9kPyK/sb+qP1dAFAE0AL8/XT9iAEgBEADcALgArwAmPvI+fz96gGEARgCUAdQClAEsPso+7kAHAH4+6j8KAToBZgAhgB4BtgFWv7o/GgCvALo+7j5df94AwgC3gFIBAgDLP6E/N7+SABfAMQBaALR//D8HP2m/tj+fP4t/7//f/8aAZgEyARkAOT8VPwg+2j5QPsIANgCiAKAApgDKANdAOT9zPwQ+3j50PukAJwBHf/z/ygEwASWAJz9eP0M/bD8nv6VAEL/bP01ALgFYAbFADT9XADcAlr+APoC/rQDIgHQ+37+CAWgBNf/LgE4BtAD2PsY+pT9mPzw+bT+8AYQCQAGgAMcAZz94Pto/CT8GPxd/8wCwAGsAGAFkAnQBLD9nP0U/3D6YPaI+1gEMAaUAlwCeAV4BJX/pP3u/gb+OPvI+7f/8AEcAYgB6ATYBTkAAPpo+7YAMACI+9j7rAB8AnwBlAJ4A8r/8PtU/Zn/5P3o+wL+kAFMAkABqAE4Aob/IPxY/d8AZwA0/aT9QgEQAygDIATEAw8AEP3Q/ej+mP18/OL+iAO4BXgDqADVAHIB9/9A/jj9YPyM/YwAsAFEAbwCeASIAsD+VP20/ST99Pw3AKAExANw/Rj6AP84BdgDfP42/qABfADA+xD73P3Y/nP/ZAI4BEwDpAJeAdj88Phw+ij+5P9QAeADqAQUA/oB1gBk/eD64PzT/3D/zP6EAfgDUAIhAEABeAIyAFj9WP0e/tT90//IBFgFVP6w+S7/sAVAAsD73P2UA6QBSPuw+2wByAG8/NT86AJoBGr/OP3OAIwC2P74++L+xAIYAjoALAFmAEj7gPnb/ygGqASyAI4BBANq/kj5QPyOAYr/cPyQApAJeAR4+xT9KANWABj6gP2wBbAE7PxY/NwCMATu/uz8YgBQAlcA2P6O/xgAagDyAbQC6gD0/qT+bv4e/ob/rAGIATj/qP34/Qr/CAB5ABcAh/+l/5H/Wv4k/koBkARoAgz8MPm0/NYACgEQAKAB1ANQAkD9SPtyAKgEdP9Q+MD78ARABRT+3P0oBRAG5P7A++L+P/8s/GT91ALQBDAClQCyAWwCFgGg/qj8LPyg/KT9EwDMA+AFrAMqAPAAiANfAGj6CPud/x3/MPyk/zAHkAjiAej7AP39AA4BmP3A+zb+iAJoA0L/aPzqAEAHGAXQ/Fj6PP8CAaD9+v4gBrAG5P1o+T//KARiAXP/fANIBED9WPk7/+gEhAJD/zoBGAIA/WD5Fv5IBOwCFv6g/uACIAPO/hD80P15AEQAjP7E/mAAbwBk/xL/iv4s/Wz9VwD8AngCQQAO/wb+YPyU/VwCyAR2Adj82PvQ/fz/GAIIBHwDQwBw/q7+VP24+1r/yAVoBhIBtP3U/m3/hP2I/XYBeATsAoAApQDwAOD+KPyI+6j94gC+Aer/LAB4BJgGwgFo+yj6DPw0/U//gAMABQABJP1j/zgDIgHM/Ez+YAKUAaD+W/8MAvIBov6w+3j8zP/0AawCdAOMA+QB2v84/2z/qP2A+fD3uPxUA8AF2ATABZAIQAa8/PD1QPmO/tj8YPp//wAGAAVcAlAGIAkZAJDzwPNY/mgDpP9c/tgCeAQcAdT/jAFwADD9WP2V/z7/xP20/k4A4P9O//AAIAPoAjoAcP18/KD9Wv/g/5//ngBoAmQBzP1o/c4B7ANaAPD9fADMAUj++Ps//0wDyALNALQBEAKo/uT81gDIBMADXABk/aj7IP1OAZADHALL/zD/GgEYBMADHv6Q+Nj5wP+wAWT+NP6sA5gGBAMp/4b+iP1I+7D74/9YBLgEOgEp/xQB1AKkAQgAV/+e/ir+3P69AK4Bef8k/fv/eAUIBvQBsv+H/zD8iPis/IgE3AMQ/Jj62gE4BigCBv4aALQC2P+I+1D7UP0w/kX/2wDAANMAUAQABtr/kPnk/XgFCgFg9pD39AEQBHz+nQDwCCAHCPzg+dQCWAT4+YD1dP0sA3IA+wC4BzAIWf9Y+qz+twDo+tj4lgDIBakAEPxBAAgFIAM/AIoB4AFI/ZD5UPzeAYQDFgGl/1oBEANMAlABJAKkAj0AAPwo+qj96AJAA+b+vP0QA2gHyAP4/HD8MgGEAfD7qPoaAcAEpQBc/iQDaAWk/nD4JP2wBPABAPus/dgEgANY/VT9FgEqAIz8CP1DAIQBdgHoAGb+MP1eAAgDVAF9//v/PP4w+sj7GAMIBQkA3P8wBYQDQPrA9hz9QAMgAyIAaP63/2QDUAQeAPz8NP8WAR7+iPte/tgC0AIoANb+XP0M/egCUAloBuL+APzg+vD3APic/SAE6AcwCdgHGAIY+qD3CPx0/dD54Pv4BDAJ6AU8Am7/GPxA+2z9R/9QAegE8AXHAPj63PxsAmwAgPq4/cgFWAUNALoA3AOEAbj7KPm8/JgCSANF/23/YASwBNj+QPxiAPQCSP6g+cD9+ARgBL7+NP4MAZAAGf8AAHP/sPw0/QwBgAJ0AYwCmAPm/ij4uPhpAGAFCANG/6v/0gFUAnABrf9W/ir+mPxg+sj8sgHEAiACkAR4BiQDcP1Q+0z8YPtI+uj+2ARABKAC4AWgBXj92PgW/hQDb//w+RD9OATkAuT8PwBwCLgF8PuQ+wwCHgDg9wD5UALgBEQB3AKgBVb/mPiY/ZgEcf9Q9xT86AeQCogDIv5U/Uj8GPtw/dEAZgHKASAEqAQEAhgArv7g++D79//9AHz9vv54BmAIX//g9/D6nwBqAQwCqAR8A4b+EP2U//P/1P0s/uQAIgFS/+X/1ALQA9QBGQBOALj/PPz4+Rz95gG0AVr++v4QA3wC8PxE/NoBkAIg/Nj6jAK4BhEAAPnQ++ACwAJQ/Qz+iAVwCPgCRP3Q+0D7CPvw/QgC/AIoAlQD9AOv/8D60Ps9AM4BVAGqAdkAdP4y/tL/3P6g/O7+MAQgBfoAEv6g/yYB+P4k/cX/jAJeAXX/2P6Y/Qj9yv+cA5gEXALP/3f/g/90/HD5lPzUAvADaAEYAgAEJAFk/Kz9yAIkAej5KPpYAjAFYgFAASgFuARO/7D7ePwA/ib+1P5/AFoBUAE4AfkAXAGcAgQCfv5w/Ab/mAFk/uD42PnUAUAIYAe4Aq3/Hv+A/lD8GPsw/VAAVgGMAJz/GwDwAzAIkAUk/FD2IPoSAMX/jPxe/jgE2AXOAZL/xgH2Abz9+Prg/FMAjAIwA4QCcAFqAH7+QPxo/DT/oACs/84AaAVQB+ACrP1U/bT+xPwg+kz8LAF4Ai4BZAMQCEAItAJo/GD5IPmA+ej6sP40A8gF6AVgBHwCWgEN/4D64Pc4+vz9XgCEAsgE+AT5AED7yPoqAXgFmAGA/Lz99gBM/zT9XAKwBzoBgPYA+bgFIAqcAlz98v9TABj7aPqGAXAGMATIACIAo/+Q/YD8Y/+gA/gDbABw/fD7OPvA/RgEGAeAAYD6HPyEA4gFaP8Q+fj4Dv7wA4gGAATG/8z+bf8g/XD6ePyEAUAEMAP2ABcAQwCz/8z9BPy4/UwDWAYIA8D+rP3A/KD7nP7gA/QDh//M/uQCyAP6/pD7Kv4YAmABvP30/NP/pAIABAAEBAJQ/4T96PvQ+qz8YgHgBMQDWQCw/yQBCv9g+gj7OAHkAqz9UPs3AOAF2AaIA7z+MPsY+iT8rgDuAbD9dPw4AjAGMAMS/zT+Qf8jAFwBJANoAej6KPg0/lgEYATIA+AE0ALy/nv/ngFo/qD5cPvQAAwCGAAnABACoAJ8AUAAN/+K/vL+Df8s/ZD7pPwP/zoBJANABUAHCAaF/xj5oPho+2z8XP2oAvAJEAoyAWD60PwyAZEAtP38/Fj/NAJSAbr+AgGoBUgDFPxI+4QAGwDg+WD7IAUwB+r+GPzMAqgFQQCM/Cn/EAFA/jD82P3k/gz/LAOACAAHwv+4+rj6XPzM/C7+TAJQBPkA4P3s/vH/9P9AAogDpv7w+PD65AGYA3T/Rv5oAlgE+QDm/pwBIAOs/hj6QP0gBKADMPwI+5ADsAd0AMD6Xv98AzD++PkcADAGSAJq/ogCoAKg+UD3RgEQBxABJP2MAnAG4gF4/cL+B//g+tj5SQAgBigESf9y/ygCEAHw/Xj9uP66/i7+6v7v/1//5P5cASgEoAP2ASwCpAH4/HD3sPdg/qwD8AL2ARgFmAbMAeT8TP1k/rj7qPrP/yAFYARqAVIBsgHU/xL+SP1g+yj7YACYBWQDAP/GAZgG+AKA+ij4yPtC/uD+ZAEIBmAIkAR4/ej5GPus/Pj96AFQBuAEkP0Y+dD8UAJcAcD8LP3MA7AImAWO/mj74PyY/QD8aPxkAfgGSAeAAkz+FP4NALwAGf/0/bL/ugHYAEz/wgAQA14BaPzY+ej7JgCABLgFtgEG/oYAKANe/oD4ePrD/ycAV/8QBKAIvAOo+uj5QwAyAcD7lPzABKAF+Pzg+nADgAciAcT8tgDIAdD5QPYUALAIMATQ/kAC2AMk/bj5w/8oBCP/0Pk8/bACQgEC/ogAkAT4At7+pP7ZAE8ArP0Q/fD9TP3A/BIBoAiAChQDkPqY+Tj9zv7s/igBEAScAwgASv45AFsAMPxg+5QCUAgsAzj6iPmK/7YAfPxM/bADSAXTAL//8AJQAhT9KPpo+wz9qf+wBXAJ2ATU/QD9Qf8U/ej4qPocAuAGgAVwAuAAIgDv/1z/6Py4+pj8JgHYApMAmADQBZAHyP84+Lj6iAC6/2D8Av6MASwCAAOYBUgE7P14+pj9mwBw/kj8NwBoBfADbv7w/Ib/0wBIAJUAfAEIAXEAnAE8AVj8uPiA+zb/FP82ASAI0AroBB7+6Psw+0D6YPvY/VL+4P2GAKgFMAggBpACOf/o+xj7QP3c/Wz8Uv6kAvwCOABNAIgDWAWsAyYAxPxA+lj5IPvI/oQCgAWYBngEswDY/lr/Qv9Q/Wz8xv5SAeQAMgBkAngEdALY/VD7pPzn//IBHgEH/1L/nAI4BPUASP0k/RT9cPpY+vX/wAWYBgAFkAS0A0v/ePnw96j7Sv8cAOcA/AJgBJgE2AQoBCYB+Pwo+fD2yPiO/nwDyARQBTAGeASaAG7+qP0w+1j4EPnw/BoBaAVwCcAIwAHg+9D8AP9A/ED5zPxoAygFxAJoApgDzAF+/tz9Zv7k/Aj8t/+gBIAEOQAI/jX/7P+h/1UAhwAg/lT8cP7tAFH/EP11ALgGcAaK/hj56PuI//T8EPot/6AHkAhMAn7+lP/4/jD7oPqm/9wDHAPFACoA3v9c/tz9dAAoBDAFYALc/kD+8v8LALj9fPyW/gwBRgEQAvAEIAX0/6D7uPx2/lj8WPpk/RAD6AWQBHgBsv50/dz9av7I/aj9HACkAjACQgE8AogB8P2Q/HT+o/+gAJwDqARQAMj7CP36AIwB4//D/6v/jP7x/4wDGAQGAcT9SPuA+lj95AHsA5wDWAMYAuD96Pmg+7gBYAMo/tD7uAGYBggDjP7f/5gBDP6Q+dj6kQCMA2ABeAAIBGAFMADA+sj6TP1+/tz/SAIAA1gB0/+e/6T/NwDgASwC5v44+4D8WAHQAkQALgB4AyAElAHOAIYBfv+w+3D6IPzU/mQCuAWoBWgCOABXAFf/fPxQ+6z9nAG0A5gC7/9y/jf/zwCJAEj+bv5YAuQDyv/Q+5j8wP5r/28A/gHkAbQBKAM0Aiz88Pf4+zgCOALu/ywDuAZ2AUj5uPkcAEwCEwCy/4YBigFT/9L+2AG4AycAaPvg++3/pAGGAMH/JgBpAKcARAIIBHACqP2g+jj7kPxW/qgCYAf4BnoBxP0d//D/aPxY+lj+XAKVAI7+PAIYBkADNv4E/lz/HP0A+6j9BAJUA5wCcALcAX3/IP0M/Zj+ugCMAv4BEP/M/ev/pgC4/aj8CAFQBcADvP4k/Jz9IgDrAK0AbgHmAZ7/RPxQ/PYA2ASwAuz9qP2jAIYAcP4GAMwDSAOi/nz8tv5lACf/5P1I/l7/ZgFABHgFjANTADr+TP1I/BD7OPv8/fwBCATYAxgEGAQUAdz9tv4XALT8OPgI+ssAgATAAmIBvAMABYgBgP3k/GT9fPyY/E//dgFcAVoBfAJkAn0AN/8Z/2D/1ADkAuABNP0o+iT8jf9nABoBsAQIB4ADyv5w/gX/pPww+5T9WADyABABIAJ4A7ADFAI4/7D8bPxG/jr/Dv4w/vAAcAJyARYBigEjAPD94P0o/2z/ZP+JADQB7f8I/1IAKAFw/9D9GP+aAcgCMAISANT9kP2Q/or+pv7pAGQDtAOMAvwAdP4Y+9j5dP3UAnAEiAKGAWQCuALLAEj9KPvM/BgAMgFaAO0AxAIQAhH/uv5oAeABEP/M/RQAHAL4AMj+Pv6k/tz+cP8RADMAHgG4AnQC/v9I/hj/+v+c/gD+4gDQAvT/qP1GAKQCNwBQ/VH/4ANYBcwCmP88/aD6MPk0/GgC0AXgAx4B4gEUAxcAkPvQ+gT9Kv4w/6gBJAIV/xj+OAJYBXQCYv6U/jP/0Psw+qT/CAVwAhz+RAAABKQB+PxM/ZcA3QDS/tL+igA6ASYBhAHjACb+MPzY/V4BXAM8A8IBqv+4/pj/2/+4/ZD7tPyxAOQDKAToAsgBbgDU/qz9GP0k/UD+WgA0AmwCgAEMARgBswCUABIBxv94/Gj7Wv5qAdQBUAFiAYoBfAF+AfoANf8g/Zj8oP2w/sn/cAEgAlgBIAGmAc0A9P1Y+6D7/v4wAoACLgGfAM8AIAGoAR4BDv7g+tj7TQDcAggCbAEoAjACYgHPAE//1Pxk/Gj+Nv8u/mP/0AMgBowDPQAy/1z94Pnw+Vf/0AOAAmL/3/9AAuIBuP9k/0oACAA5/1f/oP8K/5D+g/9cASwCSgE1AFcA+QCZANP/iP+E/pT89PwgAbgE7AMyAbcA9gDE/nD8fP3K/yEAWAAwArQCPQDW/gABJAKu/nj7ZP2mAHIAoP/qARAE7gH4/gAADAKx/3D7aPtu/jL/lP7xAIgEgAQIAp4BiAJ4AJj7qPjw+Uz9uADwAwAGcAVMAz4BRv8I/VD7KPuI/HT+HwAsAsgEGAYgBYACEf8w+8D4wPlM/WQACAK0A0gFuAQ8AqcA6/9A/Yj5IPnQ/KUAUAKUAzAFMAWkAmL//PzI+wT8aP24/p3/JAFIAxAEhAKCAMf/Vf/c/bz8cP2k/rT+7P70ACwDHAN0Aa4AjAAj/5j9ZP7Q//j+2P15/3IB4QCGAPgCwAR0Apz+uPww/Mj79PwkAMwCtANwBHAEaAH8/Gj7cPxE/VL++AAYA9wCDAKAAcX/gP2g/cX/cwBl/4X/IgGEASwAZP/M//D/2f/JAAQCmAF//7z9tP0j/1AAEQC0/+4AxAKQAhwASv7o/g0A+v48/YT+bAH7AHj9HP2aAVgEcAFS/vP/KAIcAFD9dv7XADIAbP4I/2sA4f/q/tz/jgEUAhgCjAJAAhQAdP1A/Hz8zP0eACACYALyATwCIAJvAJL+Nv6K/iz+rP0m/ob/kAHMAzgEogGo/nr+wv87/2T9iP0dAOQBAAGb/3QAfAJcAqv/tP0e/oz+qP0o/hABvAIsAfr/tgEsA1ABnP4y/oD+CP3w+yr+tAE0A1gDzAMUA1cAYP78/lv/GP3w+iD8j/9sAkAEYAUABdQCv//A/Oj6EPvA/N7+zwBUAhwDNAMcA4QClwC8/ej7SPw2/noA1gG2Ae4AgQBRAOj/rv8mAHoAsv/m/mf/FACE/+j+u//zADwBNgFYAboARf+E/tb+vv4+/hP/FgEMAmIBzQC5ACIAHv+u/v7+e//a/yMAewCwAF8A6v/b/9L/Zf8z/8z/VACy/9r+p/8wAeQAL//g/j8AEAG8AKcA2QDY//z9kP1B/yIBjgEgAQ4BJAFuAPr+Ev5e/vr+Tv/8/z4BCAJOAbP//v6y/2UAMgD6/zMA2f+a/iL+pP94AdQBZgF+AZIBogAl/yL+7P0g/rL+RgB0AkQD+AGaAHkAQAC0/hT9eP1Y/04AMwAOAawCkAJzAJj+YP7k/gH/BP+7/7UA/gCwAHEASQDX/xH/oP5Y/6QA8wA6AM3/GQAQAD//Bf8MAIQAR/9y/tD/kAGKAdAADAEmAZ3/pP0w/ST+of82ATgC+AHxAGwAXgDN/+r+Ef8qAEwAWP87//L/j/+g/pD/2AF4AiYBcQC9AKn/FP08/Dz+QABXAE4AcAEsAt4BuAGoAXgAov6w/Wj9+PxI/Z//iAJoA8AC8AJcA0YBSP1Q+6z8ov47/6n/JgGYAogCZgGkALgAigAZ/0z93Pz8/Wn/TwDmAG4BugGiAT4BjgCb/9D+bv4S/rT9Uv4nAKwByAGGAeYB9gGMALb+Jv6M/nz+QP5M/zQB4gHqAOz/y/+m/wr/xP5T/wAALAA3AI8A1wCeAO7/M//U/t7+B/9N/wkAIgG+AVgBeQD3/+b/q/9j/77/UQD6/0P/tP/RAOoAWACsAHoBEAG0/0r/6P/G/8D+qv7o/+wAFgFKAbYBkAGyAJv/jP7Q/Q7+Yv/bAJwBzAHCATIBAwAX//j++v6y/ur+8P/dABQB9wDBAFoA/f/s/87/Xv8U/1T/yf8EAEkAzQD6AHwABgDz/5T/tv5i/jv/gwBMAYQBeAH6AOD/qv4c/mr+Lf8AAKgA8QAIAUgBgAHxAIz/Qv7A/eD9WP5+//UAtgGcAYIBhAGlAOL+1P0+/sz+xP4c/1wAbAGMAWQBcgH6AJr/Vv5C/gL/i/+O/4v/6/+JABwBeAF2AQwBTgCZ/0r/L//i/qj+QP++ADQCiALeARYBewCF/0T+5P3k/hMAXABQANEAdgFCAWwAIgBTAOf/4v6K/hv/pP/R/0EA+wBEAfoAswCBAO7/Dv+Q/rT+Hf/C/8MAjAF8AegAYgDJ//T+av6k/lH/3f8wAJcA9ADZADkAk/9V/0v/Kf9A/+T/eQBIAMv/6P+HAM0AcADZ/1n/AP/w/if/jP/7/2cAqQCRAEQA8v95/+r+uP7u/g3/C/9S/+D/JwD5/9b///8CAKP/Qv8w/y3/Dv8X/2//w//P/+b/XADJAIQAoP/e/qD+tv7y/o//gQAKAb4ARgBEADcAcf96/l7+GP/u/7IAZgGuAWoB0wAzAJr/Uv+x/3EADgFsAeYBdAKcAjwCqgEWAZAAYgDFAHgB/gE0AnQCtAJwAq4BWAG6ARgC+AGuAYABWAFUAaIB4gGyAWgBgAGEAdEA5f+u/+v/uP8l/+b+5P5q/pT9SP18/Uj9mPxU/KD8kPzQ+yD76Pq4+kD6EPpo+rD60PpQ+/j7IPyg+zj7SPtI+wj7APu4+8T8mP1Q/gL/gv/H/+z/0P9a/0b/JwBMAb4BKAKAA+gEEAWQBMAEQAX4BGgEsARwBbgFuAVIBhAHKAfoBvAG2AYoBpgFoAV4BagEQAQQBRAGIAbYBQgG8AW4BEgDzAK8AlQCBAJsAggDPAMcAyQDRAMcA4wCvAHsAEkA3f+W/4r/zv8bAPz/bP+8/h7+bP1g/Aj7sPmg+OD3YPdA92D3UPfQ9gD2EPUA9NDy0PEg8eDw8PBA8eDxYPKQ8rDyEPNQ85DzYPTA9WD3wPgY+sD7WP2c/r7/JgG4AiAEaAXoBoAIsAlwClALUAwgDZANAA6wDhAPsA7gDXANQA2gDMALMAsQC8AK8AkgCUAI6AYwBbADuALmAS4B+AAGAbEA6v8S/yL+0PyA+8D6sPrw+mj7RPz8/CT97PyU/DD82PvY+1D8AP3A/Z7+cv/3/3IACAFuAV4BOgFeAcQBKAKgAkgDwAPUA6wDiANgAxgDwAJoAvIBigFqAXwBagEaAckAhQDo/9T+3P1U/Qz9qPwk/MD7kPuA+1D7+Ppw+rj5APlw+Bj4GPhQ+Jj4uPio+Hj4YPho+HD4ePiY+Jj4WPgo+Hj4OPkQ+pD68Po4+3D7iPuo+yT8+PwU/lb/ngDKAbACPAOgA/wDeAQYBeAF6AZACHAJMApQCkAKMAoACtAJ4AkgClAKQAoACrAJMAlwCNAHYAfYBigGiAUQBagEOAS8AwwDNAJuAd4AXwDZ/4P/Y/8X/4L+4P1Q/cD8MPzY+8j76PsI/DD8VPxY/Cz86Puo+5j7sPsE/IT8aP1i/vL++P7y/jb/X/9I/5z/tQAAAuACgAMoBJAEOASkA3ADlAPMAzAEyARIBUgFAAXIBGAEpAPwApwCbAIoAuoB1AFqAZYAzv9I/2L+/Pz4+7D7kPsY+9D64PqY+mj58Pcg95D2APaA9VD1QPUg9RD1MPVw9eD1QPYQ9lD1oPSA9ND0gPXA9qj4yPq0/Iz+RABGAToBwQCOAOcAyAFQA6AFQAiACsALIAzgC0ALgArACXAJwAmACkAL0AsgDAAMUAtACiAJ8AfABuAFkAWQBUgFgASYA9wCPAKcATYB+wCLALr/1P4Q/kD9fPwM/BD8KPwk/Ej8jPyE/CD8oPtI+/j6uPr4+rD7jPxQ/Sb+7P5T/0n/Mv9f/7T/FwC2AKABpAKEA0AEyATwBJgEAAScA4ADoAP8A3gE6ATgBJAEIARsA3wCpgFWATwB+gC/AK8ANQD8/sD97PwA/Lj6EPpg+qj6APo4+SD5qPgQ98D1oPWQ9bD04PNA9OD0oPRg9PD0kPUQ9ZD0EPWA9TD1MPVQ9oD34PfI+BD7uP2d/ywB1AKQA/gCiAJcA8AEEAagB/AJMAyADRAOYA4gDlANkAwwDAAMAAxgDPAMIA2gDPALEAvgCYAIUAeYBvAFQAWIBNQD/AIQAjIBbQDX/1//+P6O/hT+jP3o/Cj8aPvI+oD6kPrQ+iD7kPvg+9j7kPtg+3D7mPvA+yD8qPwg/ZD9Ov4L/8b/bwAYAbAB/AEcAkgCoAIcA7QDUAToBEgFkAXIBfAF4AWoBYAFQAXoBJAEOATsA5gDWAMwA9ACSALKAT4BXQAY/+D97PwA/Cj7uPq4+oj68PlQ+bj4sPdQ9nD1MPUA9XD0MPRQ9BD0sPPg83D0cPTg88Dz4POw84Dz8PMg9VD20PfQ+dj7gP0N/4UALAHlANEAvAFEA/AEUAcgCkAMMA1gDWAN8AwgDNALYAwADZANMA7QDtAO8A3gDKALAApwCJgHaAcgB4gGCAZoBUAEpAI4AT0AYv+O/vT9rP1c/dT8RPzI+yD7aPoA+vD58Pnw+Sj6kPq4+rD62PpA+6j7DPyo/Fj9yP38/Tr+sv5S/xAAHAFQAlAD4AMQBPQDxAOgA9ADQATIBEAFuAUoBjgGAAaQBfgEQASYAyAD3AKoAnwCVAIkArgB8QABAC3/aP6Q/bz8HPyo+xj7cPoA+rD5KPmQ+CD4wPcQ90D2wPWA9eD0YPRw9ND0wPRw9LD0EPXg9JD08PRQ9YD0UPOQ8yD1sPZg+DD7Lv6h/wEAjQASAZsARQC4AVAEYAZACAALkA0wDoANUA1ADXAMkAswDMANUA4wDpAOAA8QDmAMYAuwCkAJgAewBngGoAV4BPwDwAOsAh4BLwCf/47+WP3M/Jj84Pvo+oD6qPqA+kj6qPoo+wD7mPqY+tD6sPqA+gj7BPzQ/Hj9dP58//3/JAB1AO0AQAGaAVwCPAPAAxAEkAQ4BaAFyAX4BfAFkAUYBdgE0AS4BIgEeARYBPQDTAOYAt4BGAFsAPb/ov9A/9T+ZP7g/TD9gPzo+1j7wPpI+vD5sPl4+UD5+PiI+AD4gPfw9lD28PUQ9kD2MPYQ9iD2APbA9eD1gPbg9kD2MPWw9PD0sPVA95D5DPwa/q//twDgAJQAnQAuAdYB9AIwBQAIMAqQC+AMoA0ADaALAAsgC+AKoApgC7AMIA2wDEAM0AuQCsAIaAeABnAFSAS4A4QDDANoAuYBPAEYAOD+Dv5k/aj8EPzQ+5D7IPv4+jj7aPtY+2j7mPuQ+1D7UPuo+wT8UPwA/fz9wP5D/wIA7QBwAYIBtgE4ArgCIAO8A4gEMAWQBfgFYAaABlgGKAb4BaAFOAX4BOgEuARgBBAErAMcA2gCtgEKAWUA3v94/xn/uP5K/sD9CP08/JD78PpY+uD5uPmo+YD5UPkg+dD4OPiA99D2MPbA9cD1IPZg9nD2cPZg9jD2EPZg9pD20PXA9GD00PRQ9VD2qPjQ+zL+b/+GAEgBKAGQAKoAkAG0AkgE6AbgCRAMQA3gDfAN8AywCzALMAswC6ALwAywDbANQA3QDOALIApQCCgHGAboBAgExANoA5gCzgE8AWAAMv86/oz9vPzA+xj7uPpA+vD5MPrA+hj7QPuQ+6D7OPvA+sD6GPuQ+1D8dP2e/nH/FwCuAPgA/gAcAZYBMALcArADkAQwBWAFgAWgBZAFcAVoBYAFaAUoBQAF4ASIBPgDeAMMA4AC3AFWAeoAXgC7/zf/uP4o/pT9IP2g/OD7KPuo+kD62PmA+VD5APlw+Aj4wPdQ97D2UPYw9gD2sPXA9RD2APag9YD1sPWQ9UD1cPUA9jD2APYA9lD2wPYI+JD6YP1i/7EA3gGMAjgC7AGoAhgEgAUYB2AJsAsgDcANIA4ADhAN8AtwC4ALsAsQDLAMEA3gDEAMYAsgCqAIKAfQBYgEaAOsAlAC9gF8AewANgBJ/zr+QP1o/Jj74Pp4+mD6gPrA+gj7YPuo+8D7kPso++D62Poo+9D7wPzY/dj+jf8TAIAAzADyACYBigEoAuACmANIBNgEWAWQBZgFkAWgBagFmAWQBZAFcAXwBGAECATAA1ADzAJsAgQCXAGdAAMAnf8s/7b+Sv7I/SD9aPzg+1D7oPoQ+uD5yPlw+RD56PiQ+PD3YPcg9+D2QPbg9eD1APbg9dD1IPZw9lD2EPZA9nD2UPYg9gD2IPaA9oD3YPno+6r+DgF0AsgClAJUAlwC3AIgBBgGYAigCqAMMA7gDqAO8A3wDAAMUAsgC4ALQAzwDDAN0AzwC8AKMAl4B+gFuATEA+ACQALuAbIBQgGZAND/zP6U/Xj80Pt4+zD76PrY+gj7MPtg+6D74Pvw+8D7oPug+7j7BPyw/Jz9jv5U//T/dwDPABIBXAG2ASACjAIMA5gDOAS4BBAFQAVABRgF2ASgBKAEmARgBCAE8AOoAyADiAIMAnQBlQDR/2b/E/+S/jL+FP68/fz8PPy4+yD7YPoI+jD6GPqw+Yj5mPkg+UD40Pfg95D3APcQ95D3YPeQ9qD2QPcg94D20PaQ94D3wPYA99D3oPfw9mD32PjI+bD6AP3o/5QBMAIMA9gDWAOYAowD0AWwByAJQAtQDQAO4A3wDfAN4AyACyALkAvAC/ALkAwQDYAMUAswCtAIGAd4BXAEpAPAAhgC4AGQAdgADgBO/1j+KP04/LD7UPvw+tD64PoA+wj7KPt4+7D7uPu4+8D7yPvQ+xT8vPx8/Tr+E//1/5wA/ABYAcABBAIkAmgC6AJ0A/gDmAQ4BZAFmAV4BVAFCAWgBGAESAQwBPgDtANsA/gCXALAATABhQDT/0r/4P5s/vT9kP00/ZT82PtI+8D6CPqI+Vj5MPnI+GD4SPgA+HD38Pbw9vD2oPZQ9nD2YPYA9tD1IPZw9mD2cPYA91D3MPcg90D3MPfg9lD30PjQ+vD8Wf+iAegCGAPsAuACFAO8AyAFAAfgCKAKcAzgDVAOAA5wDaAMsAsACxALoAswDKAM8AywDLALMAqwCEAHuAVgBIAD7AJsAggCwAE8ATwACP/w/ej80PsA+7D6oPqA+mD6iPrI+tj62Prw+vD6wPqw+vD6aPvw+8D8zP3G/mP/9P+NAP4ANgGAAf4BhAL4AowDWAQYBYgFyAXoBdgFiAUoBfAE2AS4BJAEaAQoBKwDKAOwAhQCXAGeAAAAaf/Q/kb+4P2E/Qz9hPwA/Hj72Pow+tD5kPlQ+QD52PjA+ID4MPgQ+CD48Pew95D3gPdA9wD3MPeA95D3kPfg90j4OPgA+Cj4aPgQ+LD3GPgo+Vj66Ptg/ucAGAJEAoQCzAKgArwC+APwBYgH8AjgCrAMQA0ADQAN4AzgC8AKsApQC8AL4AuADCANcAwAC9AJ0AgYB0AFQATcA0gDmAKAApgC9AGhAHz/iv5A/ej7YPt4+2j7MPtg+8j7yPt4+2j7kPto+wj7EPuA++D7VPwk/TL+4P46/7f/VwC2ANsANgHGATQChAIAA6gDMASABNAEGAUQBdAEmAR4BDgE5AOwA4wDWAMEA6gCQAKiAdoAEQBh/7j+Fv6g/Uz9AP2k/Dz8yPtA+7D6KPrA+Wj5KPn4+Mj4qPio+LD4qPio+JD4YPgQ+MD3sPfA98D3APhg+KD4sPjA+Pj4EPng+KD4mPiw+AD5APrw+yD+4f8QAcoBCALqAe4BaAIoAzgEwAWQByAJUApQCwAM8AtAC6AKMArACYAJAArwCnALYAtAC/AK0AkQCKgGoAWQBIADBAMMA/wCmAI8ArwBrAA7//j9DP1M/OD7APxQ/Hz8hPyU/ID8KPzY+7j7kPto+5D7KPzU/HD9JP70/nf/nP/S/y8AbwCVAAgBxAFcAsACSAPwA2AEeASQBLAEoARoBEgEWARIBBgE9APUA3wD9AJwAgACdgHUAEsAyP8//7T+Rv7k/Xj9CP2E/PD7SPvA+lj6APqw+XD5SPkQ+fD46Pjo+Nj4qPh4+DD40Peg96D34Pco+ID4wPjQ+ND46PgA+eD4kPh4+Ij4yPiY+UD7QP3S/uH/vwBKATAB3AAuAQQC9AIYBKAFUAeQCHAJMAqQCjAKgAkQCfAI4AgwCfAJwAoQC/AKwAogCuAIiAeYBtAF8ARQBDgEOATkA3QDFANkAjYB9f8G/0D+mP1U/Xz9oP2Q/YD9eP04/dT8fPxA/Pj7wPvo+1z83Pxw/RT+lv7E/sL+tv6w/rj+Af+M/yAArgBEAdQBJAI8AkwCVAI8AhgCKAJYAnQCkALEAugCwAJgAgAClgEMAYEALQDz/6D/RP8E/8j+aP74/ZD9GP2A/Oj7iPtI+xj7+Pro+tD6kPpA+gD60Pmw+aj5oPmI+Vj5SPlY+XD5iPmo+dD50Pm4+cD56PkQ+iD6UPqY+uj6YPs0/FD9Uv47//7/XwBgAHQA+gDIAYACUANQBEgF8AVgBtgGMAdAByAHEAcYByAHQAeoByAIcAiACFAI6AdQB6gGEAaYBUAFAAXYBMgEuASYBFgE5ANEA4ACyAE6AegAwwC5ALYAqAB+ADYA2v9y/wX/nP5Q/hj+AP4I/j7+iP6+/sr+qv5u/iz++P3s/RD+Uv6i/vD+OP9+/63/yP/X/+D/5P/g/+r/FwBhAJwAwADYAOAAygCKAFgAQwAuAAYA3P/O/77/oP+G/3r/cf9D/wH/vv6A/kr+HP4S/gr+9P3U/cT9uP2g/YD9dP1U/SD96PzM/Kj8dPxg/HT8gPxk/FD8QPwc/Mj7aPtI+0D7KPso+2j7uPsY/HT84Pw8/XT9kP2k/cT9Bv50/iL/3P+GABYBngEQAlQCgAK0AuQCEANIA6QDEARoBLAE8AQYBRAF4AS4BKAEiASIBKAE0AT4BAAF8ATYBMAEiARIBCAE+APUA7gDuAPIA8ADkANUAygD7AKMAjgCAALMAZIBZAFMATABAgHFAIoASADy/6L/af9D/yn/D/8D//z+4P66/pr+gP5o/k7+OP4u/ib+JP4m/ir+Jv4a/gb+8P3U/bz9qP2Q/Xz9eP14/Xj9eP14/Xz9eP1s/Wj9dP14/Xj9iP2w/cz91P3g/fj9Cv4I/hL+KP48/jT+NP5G/kz+NP4k/jb+Rv4u/hb+Fv4O/uD9qP2g/aj9kP14/YD9pP2o/bD91P30/QD+Dv40/mT+hP6y/gv/c//J/w8AYACpAOMAGgFkAaoB4gEQAlACoALgAhADSAN8A6gDxAPkA/wDEAQwBFAEeASYBKgEwATQBNAEyATABMgEwASwBKgEqASYBIAEaARgBEAECATUA6ADaAMkA+wCvAKAAkACBALKAYIBNgHxAK0AXQALAMX/fv8w/+r+tP6C/kT+DP7Y/aD9YP0c/eT8uPyY/Hz8cPxs/Gj8bPx0/Hz8hPyM/JT8mPyk/MD87PwY/Uj9cP2c/bz91P3s/QL+Ev4q/kT+Xv5y/oz+sv7O/tz+2v7s/v7+/v78/hP/If8j/yL/Jv8v/xz/CP8J/wT/6v7I/qr+iP5i/kb+Pv42/iT+EP4C/vT96P3c/dz96P34/RD+MP5Q/nL+nv7K/u7+FP9H/4P/xP8JAFMApQDvADQBdAG8AQQCPAJ0AqwC6AIkA2QDpAPgAxgESARgBHgEiASgBLAEwATABMAEwATABLAEoASQBHgEUAQYBOADsAOEA0wDGAPgAqQCZAIkAuABmAFSAQoBxgCGAEYACADP/5T/W/8i/+b+qv5y/j7+DP7c/bD9kP18/Wj9SP0w/Rj9BP30/Oj85Pzg/OD83Pzk/PD8/PwA/QT9EP0c/Sz9OP1E/VT9bP14/Yj9nP24/dT97P0O/jL+Uv50/pT+tP7Q/uL+9v4P/yb/QP9d/3r/jf+a/6D/nP+M/3b/Zf9N/zT/Hf8K//7+8P7i/tb+zv66/qD+kP6S/pr+pP66/uD+Cf8p/0z/e/+s/9n/DABSAJUAzwAOAWABugH+ATwChALEAvgCHANMA3wDqAPMA/ADIAQ4BFAEYARwBHAEcAR4BIgEgARwBHAEaARgBFAEQAQoBAgE5APAA5gDZAMwA/wCvAKAAkAC+gGwAWQBHgHVAIoAOgDs/6X/Yv8d/+T+sv54/jr+BP7Y/bj9jP1k/Uz9PP0k/Qz9AP0I/Qj99PzU/MD8rPyU/JD8nPyg/Jz8mPyU/Iz8hPyE/Hz8dPx0/IT8kPyY/KT8uPzU/Oj8+PwM/ST9NP1I/WD9gP2c/cD98P0c/kL+Yv6M/sD+4v72/g7/Ov9r/5P/vP/u/yUAVQCCAK8A3wAIATQBZAGYAc4BAAI0AmwCqALYAgwDPANwA5wDxAP4AzAEWAR4BJgEuATYBOAE6AToBOgE6AToBOgE4ATIBLAEkARwBDgE/APEA5ADWAMgA9wCmAJMAvwBpgFUAQIBqwBWAAYAvf90/yv/3P6Q/kb+/P2w/WT9JP3o/Kz8dPxA/BT86Pu4+4j7YPs4+xj7+PrY+sj6uPqw+qj6sPq4+sj62Prw+hD7KPtA+2j7kPvI+/j7OPyA/Mj8EP1U/Zz97P1A/o7+2P4j/2z/uP8JAF0ArgD7AEQBjAHMAQQCPAJ4ArAC4AIMAzwDYAN8A5gDtAPEA8wDzAPMA8gDtAOkA5QDhANwA1QDOAMYA/ACxAKcAngCUAIsAgQC3AG0AYgBXgEwAQYB3gC3AJEAbQBNADAAFgABAOz/1//E/7P/qv+k/5v/j/+K/4r/jP+P/5f/oP+q/7L/uv+//8X/zf/V/9j/2f/i/+//+f/7/wkADgARAA4AEAAUAAoAAgAMABcAGQAYABsAEwADAPf/8P/p/9b/vf+u/6b/mf+F/3P/av9e/03/Of8q/x3/Ev8F//r+9P7w/ur+5v7k/ub+5v7i/t7+3v7o/vj+B/8V/x7/J/8r/zD/N/9F/1P/Wv9i/2z/fv+R/6L/sP+4/8H/x//O/9b/4//3/xAAIwAuADgARgBVAGEAaABsAHEAdQB8AIcAkwCYAJgAmACXAI8AhgCAAHwAegB0AHAAbwBtAGYAXABRAEcAQgA/ADoANAAxAC0AJwAeABgAGQAZABQAEgAaACIAKAAwADoAQwBHAEsATwBPAE8AUwBaAGEAZQBpAGkAYgBZAFIASAA8ADUAMAAnABsAEQAGAPr/7f/d/8z/u/+s/5n/h/98/3f/bv9g/1D/Rv87/yr/H/8c/x//Hf8Y/xT/D/8N/w//FP8U/xj/H/8r/zb/Rf9W/2b/dv+G/5P/l/+d/6v/u//G/9b/8P8NAB8AKAA4AEgAUABXAF4AbQB2AIQAkQCeAKQAswC/AL8AtgC5AMkAxAC7AMEAzgDJALkAuAC9ALcApwCgAJ4AlwCWAJkAkQCCAHQAaABWAEUAQQA9ACkAEwAOABkAFgADAPb/9f/0/+j/2v/W/9b/2P/R/8X/u/+3/7v/uP+x/7P/uP+z/7H/sv+2/7r/sv+p/6z/uf+5/7H/s//L/+b/5P/c/+f/+v/9/+7/7v///wsADgAWACQALQAuAC0AMAAuACYAHgAaABQAEgAZAB4AFwALAAsADQAAAO//5v/p/+f/3P/N/8r/yv/L/8j/w//I/9H/0v/P/9j/6P/t/+P/4P/t//r/8//s/+v/7P/p/+r/8f/z//H/8P/r/9r/0P/U/9f/x/+7/8P/yf+2/5L/iv+g/6v/m/+F/4f/k/+L/4T/kv+m/67/qf+t/7n/vv/G/9r/7v/0/wIAHgAxADUAPABTAGUAbwB6AIwAnAClAKwAvADPANcAzgDEANIA7ADyAN4A1ADcAOAAxgCyALYAugCuAKEAoQCuALYApQB3AFYAVQBYAEIAJQAlADIAJAADAPT/8//w/+P/zv+y/6T/tP/F/7j/pv+8/93/x/+d/7T/9P/2/7f/oP/Y//r/0/+r/7T/y/+3/4D/Tv8//1D/UP8S/7j+qv7Y/tL+cv4k/jb+Yv5G/gD+1P3k/Qj+Nv5I/kr+fP7e/jb/Yv+a/+7/KAA3AG8A6wBQAVABTgG8AXgC5AK8AmQCOAIkAuwBzgHCAY4BQgHlAGoA9/8aABsADP7o+pj6tP7kAjgDlgEWAU4B+gCWAbgC6AFw/8j+EAGwAooBIADjAPIByAB6/sT9qP4g/07+cP3A/a7+5P4w/rz9Sv7i/k7+FP3U/MD9gv4s/rD9dv7v/5EAKwAiAPMAngFkAe8ASAFEAtwCuAKsAkwDCATQA6wC7AEYAlACwgEMAfIAGAHlAIUAWAAbAIP/1P5u/j7+DP7U/bj9rP2o/dT9Jv4y/sT9dP2Y/cz9sP2k/RT+mv6+/tj+T//E/+X/GwCJAJMAMgBNADIB1AGcAWABygFgAoACTAIcAv4B/gEIAuQBlAFkAXABZAEuAQoB6ACRABkAuP9w/zr/Kv8r/xT/6v7k/hf/TP9X/z//Kf88/2j/mP/P/ysAnwDjAOgA+gBUAagBlgFaAWQBkgGEAVQBZgGkAbABggFUATAB0AA5ANb/tv+S/y7/wP6Q/qj+uv5y/gD+2P3o/cD9aP1w/cD9BP40/nT+ov6e/s7+Rv+S/17/L/+U/zoAigCQAMgAJgE4ASoBTgGEAX4BdAGOAZYBcgFkAX4BXAH+AMoA4wDRAHcAFQCy/0H/+P4e/1//Rf/w/sT+uv6a/l7+IP74/QL+LP5g/o7+sv7C/tz+Ef9H/z3/FP9I/83/JgA9AHkAAgFcAWABZAF0AVYBFgE8Ab4B5gGSAXABtAHOAYYBQgE0AQ4BqAAyANX/hf9Q/0z/Q//6/qb+mP6c/mT+HP4y/nj+hP5W/l7+vP4u/3D/pP/s/wQA1v+n/7r/8P8dAEQAcACRAI0AeQCYANEA1gCkAJ0A3gD4AL8AmwD1AF4BZAFKAYwB3AGoAUYBUgGsAawBVAEsAWQBegFSATIBNAEmAfMAtgBoAA0Aqv9e/w//qv5S/ir+GP7o/ZT9ZP1c/Tj93Px8/Ej8IPzw+/D7QPyQ/MD8+PxE/Yz9sP3g/Tb+jv7S/hb/c//Y/yAAegD5AIAB4gEsAoQC3AIAAwADEAMsA0QDSANIA2ADjAPMAxAEOARYBGgEeARwBGAEKATcA7wD0APkA8ADnAO4A+gDxAM4A7QCZALeASoBswCNAGoAUQBRACwAoP/Y/vT97PzI+wD70Pqg+ij6uPmQ+Xj5cPnA+TD6GPpg+Zj4WPiY+ED5ePoU/Hz9Rv5+/lr+Fv7o/dj9zP2g/VD9HP04/Zj9AP5O/mT+Gv5s/YD8mPsI+7j6gPqI+uD6aPvw+4D8iP32/kMALAH2AcQCdANABHAF+AZgCFAJQApQCzAMwAwgDbANIA7gDUAN8AwwDRANoAxADOALwArwCHAHgAZgBdgDxAIIAosAiv4w/aD80Pu4+kj6KPp4+VD44PcI+MD3YPfQ99D4QPlg+Sj6UPvY+/j7jPxM/Wj9WP3Q/Zb+EP+F/zcAnAA6AKX/ff9Z/8T+OP4Y/uz9SP2k/Gz8fPyI/Kj8nPzI+2j6mPnA+Tj60PqI+2T8AP1A/Zz9JP52/mb+HP7I/Tz9xPzc/Mj90v5m/yD/+P00/OD6uPr4+hD6EPjA9kD2sPUw9UD2CPnY+7D9Y//eAKgByAK4BcAJwAyQDsAQQBMgFYAWQBhAGuAaYBrAGYAYIBYgFEATYBKAECAOYAxQCpAH0ASIArv/cPzA+dD3MPUg8lDwwO9g7+DuIO8Q8MDwcPHg8lD0APUQ9kj42Pqs/KD+UgGoAzAF8AZACdAKQAuQC1AMAAzgCcAHiAYgBbgCeQA6/yD+oPxo+8D6EPqo+ND2YPVQ9IDzwPJQ8tDyEPRg9TD2APeo+Oj6AP1W/v7+Mv8Z/1j/IQBSAbACMASYBWgG2AZYB3gHqAZQBeQD4gGA/kD70Pmw+eD4KPgw+aD64Pkg9xD10PMA8uDvYO+g7wDvgO6g7wDysPSY+Fz9RwC7AHoBUASQB0AKAA4gE6AWgBdAGGAaIByAHOAcYB0gHIAYIBWAE2AS4BAgD0ANcAowBs4BMv6Q++D5sPhA98D0EPIg8GDvwO/A8ODx0PLA8/D0cPaw90D5oPsy/r//mADuAQAEqAUAB7AIIAoACuAIIAiYBzgGEASYApYBxP9c/eD7cPvQ+sD50PgI+KD2IPWQ9ND00PSg9CD1IPYA99D3EPl4+qj7zPwo/jr/sv8PAMAAcgH8AYACEANcA7QDWATABCAExAKwAeQAAgD2/iD+LP2w+0D6qPm4+XD5yPiQ+Oj46PhA+OD3SPhg+ED3MPaA9qD30Peg93D57Pyx/zYB/AJoBVgHIAlADMAPoBEgEqATgBVgFQAUQBQAFoAWgBWgFKATwBBADaALIAvACNAE2gE6APj9CPtY+UD5GPkI+OD20PVg9GDzAPRw9WD20PYw+DD6wPsA/e7+cAE8AxgE2ASABTAFYASQBAAG+AZoBmgF4ARABNQChgGuAG7/eP3A+5j68PgQ93D2UPeg98D2YPbA9nD2kPXw9aD3gPiA+Gj5cPvg/HD9uv5zAFgBlgFEAugCpAJYAtwCZAMYA+gCLAOcAtAAiP90/zH/EP7w/CT8CPuo+bD4oPdA9kD1kPXA9fD0sPRg9mj4EPko+TD5EPjQ9RD18Pag+aD77P1AAWgEiAYACZAMABDgEmAVQBdAF8AV4BRgFeAVIBaAFoAWwBTgEZAPsA3wCtAHUAUEA7H/EPzQ+dj4IPiw9wj4OPhQ91D2gPZA93D3gPdQ+Dj52PnY+qj8bP7d/7ABzAPgBLgEgASwBIgErAPwAsAChALkAUwBzwAOAP7+2P3U/Pj7EPuw+fD3oPZQ9rD2APeA9xD4kPjI+Dj56Pmo+qj79PzU/Qb+Tv5J/xsASADXACQC6AJgArABHAKwAkwCjAEIAU4A1P5o/cz8NPwg+zD64Pmo+TD5sPgA+ND20PXw9aD2gPYQ9uD2mPjo+Zj6uPsI/Rj94Pvg+uD6iPsE/Zn/cAJ4BPAF+AeQCmANYBBAE6AUABQgE+ASoBIAEuARoBLgEsAR4A8QDhAM0AkACIAGMATzALj9SPuw+Qj5MPmQ+bj5+Pl4+qj6SPoQ+mD68PqQ+0D84PyE/Yr+XgBoAtgDwAQgBaAEnAPkAoQCrgGWAE4AigDb/2j+2P1a/oD+yP0U/YT8QPuI+aD4mPiQ+Jj4CPmQ+bD58PnY+tj7WPzY/Jj9HP4o/nT+KP9w/xj/5v5O/6j/mv+m/wkAOwDs/7f/zP+S/6T+jP28/Pj7EPtg+ij6CPqg+Wj5WPnw+Bj4oPeQ93D3cPeg+Hj6GPuY+vj6bPzY/ID7iPoI+4D7WPuU/Nr/FAMQBSgHQAoQDTAPwBGgFAAWIBUAFMATwBOAE+AToBSAFGASoA8gDbAKAAjQBRgE3gGO/jD7GPkQ+MD3KPgo+eD5wPlA+Tj5oPkw+tj6cPvY+1j8dP3K/sb/5wC4AkAEaAT4AxAE4ANwAhgBQgGEAfX/5P10/Qr+xP3E/FT8NPx4+4j6MPrA+cj4QPjQ+LD5IPpg+rj6+Ppo+6D8MP76/tr+xP4w/4n/bv9C/4D/mv8H/1T+ZP7u/gv/wP7W/ib/pP5c/Uj8sPvY+uD5gPmI+Uj5+Pgw+Zj5cPn4+Oj4KPkw+Vj5yPlg+lD7EP3E/tL+iP3E/AD96Pwk/Fj8Ev4AAFIBDAPIBWAIQArADIAQwBPAFIAUoBSAFIATgBLgEmATYBLAEKAPEA4QCzAIAAfwBSADmf8Y/QD7gPgQ99D38PgQ+QD5aPmQ+Xj5SPqQ++D7iPvw+/D8OP14/R//WAFwAtACwAOIBPQDwAJ8AqwC8gGYAMX/gP/w/uD9LP0o/XD9fP0s/aD8EPyQ+0D7OPtA+yD7APso+2j7gPuo+3j8hP0y/qj+P/9w/6z+7P0y/rr+Gv68/Dz8lPzE/Lj8TP0K/sT9lPwA/Bz8yPvQ+kj6aPpw+gj64PnY+Xj5ePlg+gD7APqY+Nj4MPow+yT84P3A/mj9WPsA+3j7IPso+4D9iADiAWQCWARoB0AKQA3AEIATIBRAFAAVIBUgFGAT4BPAEwASIBAwD5ANwApACOAGCAXqAfL+/Pww+yj54PeQ94D3oPeQ+LD50PmA+UD66Pv4/Ez9/P3e/vT+tv68/9YBQANcAzgDSAPwAhwCdgEMAWcAtv89/1b+1Pyw+7D7MPxI/ET8YPwI/Bj7qPo4+8D7cPs4+wD81Pyg/Pj7QPxo/Uz+uP5s/yoA8P/Y/h7+QP48/pT9HP04/Rz9nPyY/FT9rP1A/SD9SP1s/LD6APq4+rj6UPlQ+KD4wPjg97D30Ph4+eD4wPhI+rj78PtU/Aj+eP++/uj8APwY/DT8iPwo/nUAxAFEAggEkAcgC2ANMA9gESATgBNgE8ATgBOAEgASoBKAEoAQMA7gDFALkAjIBQgE+gHG/iT8OPuY+iD5QPgQ+Tj6WPoQ+nj6QPvg+9j8Dv6O/lz+sP7I/5wA6wCiAdwCiANgA2ADuANcA0QCoAHUAX4Byv/4/TT91Pwk/Az8LP08/uz9BP3k/AT9YPyw+wD8kPxM/OD7MPx4/CD8jPxa/n3/kv5g/bj9Qv5M/Qj8CPxE/FD7UPq4+pj7kPtY+xz8KP0s/Xz8CPzY+3j7+Ppg+rj5YPl4+Zj5OPnw+Dj5sPn4+XD6OPvQ+xj8xPzQ/Rz+mP0w/TT94Pw8/ID89P2K/9QAnALwBBAHEAkgDCAQQBNgFEAUABSAE+ASwBIAE6ASQBHwD7AO8AyQCkAI2AUMA2IAcP6k/FD6ePjw9zj4aPig+GD5EPpw+iD7bPx8/dT9OP4m/zgAAgGwAVACtAIwA8gD8AOsA8ADSAQgBOACigHVAL//yP0g/OD7XPx4/FD8jPz0/Oz8gPxM/HD8hPws/LD7gPug+8D70Pso/AT95P06/g7+4P34/Tb+KP6Y/dT8WPw0/LD72Pq4+oj7CPyI+yj7qPsM/Hj7+Ppo+6D7qPrQ+RD6UPqY+dj4OPnw+Qj6KPrA+jD7SPvo+yz9IP56/tj+Cv88/hz9EP3M/UD+4v7DABgDUAQ4BaAHQAtQDoAQQBJgE+ASwBGAESASYBIAEqAR4BBgDyANsAowCIgFCAPmAPb+NP2A+/D5+Pgg+QD6ePqQ+gj74Pso/Nj7MPw8/QT+cP5w//cA6gEsAoQCIANMAwgDBAOAA9ADhAPIAsQBmwB4/6D+Mv78/bz9WP0w/Vz9hP2s/fj97P0A/ej7oPvw+6j7CPtY+3D8DP0I/Wz9Ev7Q/QD93PxE/fD8BPyQ+7D7UPuA+hD6GPpQ+tD6ePug+yD7APuQ+8j7WPtA+5j7MPsI+kj5cPlQ+dD4yPhQ+Wj5GPlI+RD68PrQ+8z8ZP1Q/Vj93P02/iL+Uv70/r7//AAkA2AF6AaACFALoA7gEGASABTgFGAUABOAEqASYBKAEeAQ4A9wDcAJYAY4BKQC0ADS/gz9QPtY+fD3wPdo+PD4gPmQ+uD7YPwM/Bj8BP1M/pf/7gAMAoQCmALUAjgDeAOcA7wDlAP0AlgCmgFHAM7+Dv7Y/VD9wPzs/HD9OP3U/Fz9UP6A/vz9fP28/Jj7+PpY+9j7BPzM/Az+Tv5w/VD9Pv6A/sT9iP0A/lz9iPuI+hD7iPsA+9j6uPts/BT8kPvo+7T8BP2M/ND7YPsg+6D68PmY+dj5+Plw+fj4gPl4+rj6ePrY+vj74Pzo/Oj8pP2a/gL/4v4A/1v/j//O/+4AJANYBdAG8AfQCUAMUA6gD0ARABPAEwATIBIAEkASwBEAEWAQwA7QC9AIkAZIBJgBsv+k/vz8wPqI+aD5QPmg+Lj5BPz0/Oj7IPtw+6D7oPvs/Db/XgDu/5L/UQBUAdQBPAIIA7gDZAPsAV0AoP9b/8L+FP4w/qD+Ev7A/FD8IP3Y/QD+bv7+/l7+oPyQ+9D7NPws/Kj83P2e/jT+kP2A/bj9zP3g/fT9YP0g/PD6WPoY+vj5OPrY+nj7qPuA+4j7BPzY/Jz9FP4Y/qT99Pw4/Hj7wPpY+kj6GPqg+Uj5SPlI+XD5MPpg+9D7mPv4+/j8gP2M/Rz+4P7Y/rL+1/+aAWgCHANwBXAIIAqwCiAMEA4gDyAQYBJgFCAUwBJgEgAT4BFgD0AN4AuwCVAGnAMIAjMAtP3o+2D7sPo4+Vj4+PgI+qD6CPuA+0D7gPrQ+sD8qv5f/7T/vwDYAQAC+gGkArwDaASgBMAEMAR0AokArf/O/8//G/8a/iz9cPwI/Cz8nPxE/S7+JP9V/3r+gP1g/cT96P3w/VD+nv4S/iD96Pxg/Yj9RP1k/aj91Pzg+lj5APkg+RD5aPn4+ej5ePng+Rj7yPsM/AD9FP6g/TD8qPvw+4j7yPpA+yT8ePvg+bD58PrA+9j7mPzU/Xr+aP5o/or+bP6Q/lH/XAAcAZYB7AFkApgDoAWQB5AIAAmQCSAK0ApADGAO8A8AEYAS4BOAE2ARkA+gDtAMwAkgB0gF4AL1/zD+iP0Q/Nj5APkQ+gD70PrY+pD7qPsI+wD78Pug/Oz87P2A/0EA9//6/9MAtgFUAhwDeAOgAkoBtQCbAPv/L/8e/2r/+v4s/uT94P2c/XT9Vv5//8L/Nv/E/n7+Dv6M/Vz9SP0I/bz8lPw0/Jj7cPsA/KD80Pys/GD8oPtg+mj5MPlY+WD5UPmg+UD6yPog+9D7HP1i/tL+gP7w/RD9APxY+3j7mPsI+yD6cPnw+Jj4APlI+pj7OPzA/Gz9vP2Q/eD9NP+XABwBYgEoAhwDuAOQBCgGyAfACKAJAAtADKAMwAwADgAQABJAE6ATIBOgEQAQkA7wDIAKwAdQBRgDlgAQ/jD84PrI+Rj54PjA+ID4kPgo+eD5UPrA+mj7YPys/RT/HwC+AHYBiAKoA2gE8AQwBQgFQAREA3ACegFAAC//xP6q/jj+dP0Y/XD91P28/Wj9VP18/Zz91P0+/oL+MP7I/fj9kP66/kL+4P3Y/dj9yP28/XT9zPxE/CD8sPuY+vD5OPpY+pD54PgY+Uj5MPn4+fj7LP2Q/ND7PPyQ/Mj7OPvI+xj8GPtQ+tD6WPvY+pD6gPuM/Hz8RPy0/OD8XPyQ/FD+QgAmAdABDAP0A9QD4AMYBXgGAAdgB7AIEAqQCvAKkAzQDkAQYBGgEmAToBIAEYAPoA0AC7AIMAfgBHIBrP54/Vz8sPoI+qj6wPrA+Yj5mPog+5D6yPpU/CT93PyM/c7/dgGOAdgBVANQBOwDmANoBNgEuANAAqQB/wCO/2j+hv7S/i7+dP2c/cT95Pzw+zj86Pyg/Oj78PuI/Kj8rPw4/ej9Jv5W/sr+Df/c/nb+3P0c/bz8wPwY/JD6oPnw+Rj6SPmY+ND4GPkQ+Zj54Pqw+8j7TPxg/az96Pww/BT8EPzg+9D7oPso+/D6kPt8/Lz8TPzQ+6j7gPuA+yj8SP0C/k7+Of8qAQADlAPEA5gEcAVYBSgFKAaQB1AIEAlAC3ANUA6ADsAPgBEAEqARoBGAEUAQ4A1AC8AIIAbcAyQCjAC4/vD8oPuQ+qj5IPlA+aD5GPqQ+gD78Pqw+hD7hPwc/ub+i//dAAgCMAJoAsQDQAVgBRgFcAU4BVQDRAHlABIBPQA3/0j/W/9A/gT9BP2Q/Xj9KP0w/TD94Pyw/NT8/PxI/RL+2v72/qb+Yv78/Sz9ePw4/AD8QPt4+iD6+Pmw+WD5yPnA+nD7QPvg+kj7MPys/KT8uPzA/Aj84PpI+gj6SPmI+Oj42Pnw+WD5kPlo+rD6SPoo+mj6cPrA+jD8Av4J/6b/NAGUA3gFeAZAB+gHuAfgBngG6AY4B3gHsAiwChAMUAygDGANAA7QDmAQYBEgENANAAxQCnAHSASYApwBrf+o/QT9pPxQ+zj6MPu4/KD8uPvY+2j8TPww/Bj9OP7e/uD/lgGgAogCrAKoA1gECASsA5wD+AKYAZgAVAD6/1v/A/8t/wn/UP6k/XD9dP10/Zz97P3U/ST9sPwc/fT9jP4E/3v/dv/A/g7+4P2c/dD8+PvQ+6j74Pqw+ej48PgQ+cj4YPg4+Dj4IPhY+Ej5cPo4+yT8lP28/pT+dP2k/Kz89PwI/cj8EPxA+/D6IPtA+xj7OPuI+3j7EPsY+6D7HPzQ/GL+SQBeAfoBJAN4BAgFMAXgBZAGyAZIB5AIgAmgCVAKYAyADqAPgBBgEWARABBwDjANcAuACMgFgAS0AwQCvf86/qT9FP1U/Nj7kPv4+kj6UPoA+2D7UPvA+zD95v4QAKYAPAEEAtgCsANgBKAEMASgA3ADXAPgAkQCGAIUApwBugDV/w3/bv5G/sr+Q/8U/3j+Kv5C/nj+4P64/30AiwBGADEA5f/c/qT95Pxg/Kj7CPvg+mD6WPmw+CD5wPnA+XD5gPmQ+Sj52Pg4+SD6APvI+5z8BP1g/ED7mPqA+nD6aPrA+gD7aPqA+eD4QPiw90D4qPkQ+hD5mPjY+Wj7oPwo/xADoAWoBZAF0AaQB7gGaAb4BxAJUAjoB3AJ4AqwCvAKQA2QD9APYA/AD8AP8A1gC6AJEAiwBVADCAIUAaH/Mv6U/TT9bPyo+6j72Pu4+8D7QPzQ/HT90P5dABABWAGAAuwDMATYAxgEOAQcAzgCvAIEA34B8/9EAO4ACQCO/lb+qP5K/tj9Lv5u/uj9pP12/lz/Pv+o/or+6P5Z/+b/aQCFAD8ANgCPAHEAhf9Y/pT91PzY+yj7APtw+gj5wPew99D38PbQ9RD2QPfA9/D3CPmg+lj7oPuk/KD9XP1o/Fz86PzA/Dz8QPyE/FD8qPv4+lj6+Plg+jj7iPsY++j6iPto/Dj9ev50AEACYANoBNAFkAYIBqAFwAZACLAIIAnQCqAMAA2QDaAPoBHAEeAQ4BDQD6AMIAloBzAG6APSASABUAAi/iz8yPvI+wD7ePqY+nD6wPmY+Vj6CPuw+yz9Ff86ALAAXgFMAugCfAOQBJAFmAXgBEgE5ANAA5ACsAJgA5ADtAKwASYB2wBVAPP/HAA8ANP/OP8R/wv/vP6w/pb/vAD/AHYA9/+P/6j+mP3k/Fj8SPsA+mD5KPmI+KD3YPfg93D4gPiw+ED5sPno+Zj6BPwQ/ST9/Pwo/dT8qPtw+tj5iPmg+aD6iPvo+jj5ePho+OD3UPco+JD5uPlw+Wj66PtQ/Pz8uv8wA8AE8ATYBTAHYAcgB/AHAAkQCQAJAApAC2ALYAuADBAOcA4gDvANcA2wC2AJqAdABmgEkAKCAc0AqP9o/uD95P3o/fj9Tv5A/kT9YPyo/Jz9Wv4M/xMAzgDSAPsA3gGwAvQCUAMIBEAEiAO4AiACpAFgAaYB5AFUAVAAov9n/y//Fv9Y/7z/tf9I/+T+jv5A/jj+CP9bAAwBjgDo/+L/z/8e/4z+1v7g/sT9dPwQ/KD7QPoI+Rj5EPnA94D2gPbA9jD2kPaI+Dj6YPrA+kj8FP0g/Jj74PwI/qT9GP28/RL+AP3w+xz8HPx4+qD4UPjo+ID4YPeg94D5UPs8/Jz9uv8yAWgB+AGwA8gEMAR4AzAEWAXgBbAGsAjACtALwAxQDmAPsA6gDXANQA3wC0AKMAkQCEgGmATAA6wCAgHA/4z/P/8e/vD8OPyY++j6EPuw+wD8HPwU/aT+nP8GAPoArALQAwgEAAQgBLQDsAJwAlgDOAQ4BGAEKAVwBWAESANEA1ADhAK2AcoBlgFkAIH/EwDxANYArQBWAZABYgBG/3n/lf8i/mD86Puw+yj6QPig9wD44PeA97D3EPig99D2kPYA94D3EPgI+Yj6FPwA/ST9OP0A/rD+hv7A/XD9RP1k/Cj7iPpo+rD5wPh4+Kj4OPhw95D3ePjY+HD46Pjg+mT9oP+8AaQDkATwBMgFGAeoB4AHyAewCIAJMApwC5AMwAzQDOANgA5QDWALUApwCagHuAWoBKQD2AFRAAQA2f/o/uD9nP2Q/Tz9EP0Y/QD91PwM/Vz9mP1a/vX/rAH0AjgEgAXwBXgFGAVYBUAFcATYAxAEaAT0AxQDrALEAqgCLAKqATABhwDC/0D/+P6u/oz+2v5t//P/UwCmANgA5QDWAIgAov80/tT88PuQ+xD7SPq4+bD5gPl4+JD3kPfw92D3sPYQ9+D3wPeg98j4iPqA++j76PzA/WD9fPxQ/Kj80Pwc/bT9+P2A/fj8hPyw++D6APt4+yD7QPoo+rD68Pqo++j9rQD2Af4BSAK8AnwCHALQAigEKAUQBoAH0AiACTAKMAsgDMAMAA2QDFAL8AkwCaAIyAdQB1AHiAbQBEQDGAJaABj+0PyQ/CT8cPtw+wT8MPwY/ID8ZP0u/v7+7P+3ABoBQgFuAcIBfAIsA1wDYAP4A7AE6ARQBXAGGAdwBrgFmAXwBFwDgALEAowCfgFQATACSAJMAdgAOAHuAOL/av+H/wD/9P1g/RT9CPy4+kD6SPrg+RD5ePjQ9wD3sPYA9wD3kPaw9qD3MPg4+Mj4GPoA+2j7RPww/Rj9VPxQ/Kz8OPxI++j6sPrw+Tj5GPng+BD4wPcw+HD4IPgQ+KD4UPmo+jj9LQAQAjADkATABdgFoAV4BjAIkAkgCoAK4ArwChAL4AtADTAO0A2gDHALMApQCAgGoARIBBgEQAMEAsgATf+k/aD8tPzg/Ez8aPsI+wD7yPqo+mj73PyS/kwAzAGwAjwD4ANQBEAEaAQgBYAFKAVABUgGsAYQBkgGiAeQB5gF1AMwAxgCSQCg/zUAGgBl/5P/NQCs/wj/9f9SASYBKQDX/zv/bP3w+xj8fPzA+yD7sPss/ID7kPpQ+hj6IPnQ9/D2kPag9sD2APeA93j4qPlA+oj6IPvQ+7j7+PrA+kD7iPso+zj7ZPx8/Wj9gPwM/Nj7KPto+mD64Prw+tD6MPt4/Cb+y/8EAQACCAOkAyADPAK8AlgEcAXwBbgHMAowCxAL4AtQDWANkAzgDEANsAtwCbAIsAjYBwgHOAfIBkgEjAE3AC7/bP1A/ED8EPzo+iD6mPpQ+8j7mPwS/i//cP9K/0//qv9AANwAVgEIAgwDuAOQA7ADGAWgBtgGYAaABmgG6AQ0AxADiAPUAvIBgAJwA4gChgCQ/53/Of9y/k7+eP40/rj9nP2E/Tz9AP3k/KT8OPyY+4j6cPnw+Aj54PiQ+MD4OPlA+Qj5IPmo+TD6mPro+hj7OPtY+3D7iPv4+2j8YPw8/Hj8kPy4+5j6IPrA+dD4IPho+OD42PhQ+dj6DPws/JD8LP7Q/4wAegE8A5AEwAQIBWgGkAeIB6gHMAngCiALoAoQC/ALsAvAClAKMAoACVAHkAaABogFqANkAsoBpQD8/jz+Mv6E/Vz8GPxs/MD7cPpY+rD79Pzc/SD/pABGAUQBpgFYAqwCqAIUA/ADoATwBGAFEAboBtAHcAiQCPgH8AbIBcAE7AMgA4gCkALMAoAC5gHeASwC5gEOAXoA7P+I/gj9rPwA/az8JPxg/JT8oPto+gD6aPkA+MD2kPYQ9hD1EPVw9nD3kPc4+HD5iPmo+Jj4SPlg+Tj5gPp0/Fz9VP2k/Qr+nP0c/Tz9UP2g/Az8MPxg/Ej8lPxU/Yz9ZP2c/Rz+Bv78/Sj/5QAMAvACkATQBZAF4ASIBbgG+AYoB9AIAAuQCxALQAvwC1ALEArgCVAKgAnYBxgHsAYYBeQC0gGUAbEAfP++/sT94Psw+rD5oPlo+cD5+Prg+yD8oPx8/eD9AP7a/hwAogDPAM4BQAMwBPAEUAagBwAIEAhgCGAImAeIBugFYAWgBCgEIAToAzQDjAJEAsABwQDH/wD/1P0w/Pj6qPrQ+uj6OPuQ+1j7oPrA+SD5gPgQ+ND3kPcA96D24PaA90j4OPlI+uj66PqA+hj6APp4+kj7FPzs/KT9zP1A/bD8ePwY/FD72Pr4+vD6ePow+qD6OPvA+5j8cP2I/Uj9kP1g/hj///96ARgDOAQ4BUgG2AbQBjgHYAiACRAKwAqwC9ALYAtgC6ALIAsgCsAJcAkACBAGMAXQBKQDMAK2AWYB6f8a/hj9QPyY+mj5kPng+XD5aPmQ+oD7cPuw++D84P0k/tr+ZACMAdQBSAKEA8gE0AX4BkAIQAmACUAJgAjAB2AHKAeoBkAGYAZoBsAF0ARABMQDxAJwAUIAFv+s/WD8iPtA+1j7mPuA+9j6KPqA+Zj4UPeg9uD2QPfg9sD2gPdo+ED4EPgY+Wj6gPro+Rj6sPrQ+vD6HPys/Wr+fv5+/ib+PP2w/KT8PPyQ+5j7EPzw+7j7gPyg/ZT9wPyY/MD8aPwo/Aj9av50/1wAYgEwArQCdAMwBKAEiAVAB4AIsAhQCQALAAxgCxALAAwADCAKoAjgCOAISAfwBUgGWAaoBOQCLAIYAZb+aPwA/Cj8uPtY+9j7OPzg+2D7WPtI+0D70Pvg/Mz9iv6I/6oAoAGgAtgDyARQBdAFeAbgBuAGEAeQB+gHuAdYByAHwAbgBfAESATYAxADDAJcAeUA3f9g/oz9aP3M/ID7yPrY+mD6APkY+CD44Pfg9oD2QPeQ98D2QPbg9nD3APfg9gj4QPlw+Zj5CPuk/OD8dPzs/NT9cP1Y/HT8pP0Q/pT92P3C/oj+JP2w/HT9rP0A/SD9FP4k/lz9hP20/kz/V/8zAJYB3AFWAXIBUAIIA/QDmAU4BxAIsAigCUAKIAoQCoAKcArQCYAJkAkgCVAIMAhwCNAHQAawBIQDTALcAMr/UP/2/lL+eP2o/BD8oPtA+/D68Pog+yj7YPsE/Oz8rP1y/nz/XAD6AMoB9ALYA3AEYAV4BsgGkAbYBpAHoAdIB4AH+AfAB9AGOAbIBeAE0ANQAwADLAJAAV0AK/+M/VD8cPtI+gj5aPgQ+CD3QPZQ9oD2wPXQ9OD08PQg9IDzkPTg9UD2APdA+Sj7GPvI+qj7MPwA+zj6oPt4/fj9gP5AADYBzf8W/hr+cP60/VT9pv7z/3H/hv6+/jD/6P4B/ykA4wBWANH/NwCwAA4BTAJIBHgFqAUYBtAGwAYwBqgG2AdQCOgHEAigCJAI6AfAB/gHcAcwBlgF+ARABFwDCAPYAhQCGgF+AMn/fP5c/Tz9cP0s/QT9kP0M/rD9OP14/Qz+Uv68/r7/wQBSAeAB1AKsAwgEUATIBPAEsATABFAFyAUIBmgGsAY4BjgFaATsA0gDnAJIAgQCYgGHAJ//fv4s/Sj8ePug+pj5+Pio+Bj4MPeg9nD28PUg9cD04PTw9BD1wPUQ9wj4cPjg+Ej5WPk4+Xj5CPqI+jj7bPyc/Sr+SP54/qz+iP5O/pD+Tv/t/ysAVACvAPcAGAE6AYQB5AEAAtABqAH2AawCYAP0A8AEwAUoBsAFgAXYBSgG2AWoBVAG6AaQBggGSAagBvgF4ASIBHAEmAOoAqwCCAOYAroBfAFoAVoA9v58/qz+hv4g/lT+yv6m/i7+Lv6G/pD+oP48/w8AlADVAG4BGAJ8AswCcAMQBDAEOASgBCAFOAVQBcAFGAbgBYAFYAVABdgEWARABEAE2AMoA3gCogGIAFL/Zv7M/TD9gPzo+2j7qPqQ+Yj40PcQ91D24PXQ9eD1wPXw9XD24Pbg9hD3cPeA91D3cPco+Pj40PkI+0T8jPw0/Ej8qPys/ND8HP67/yoA2P9GABIB7ABZAM4A7gFEAhACjAJwA5ADTAPEA5gEmAQgBFgE+AQgBRgFgAUIBggGuAWwBagFQAXgBPgEAAWYBDgEMAQQBJQDLAMIA7AC+gF6AUYB0gArAPH/IwAKAJj/ZP91/0r/7P7u/jv/Wf9R/57/HgBPAEoAigD3ACoBRAGUAfABGAI4AowC6AIQAygDWANwA1QDLAMcA/wC1ALIAtgCxAKAAiACsgEaAWUA1P98/yb/rP48/vD9nP30/CD8gPsY+6D6GPrI+cj52Pmw+YD5ePlw+VD5GPkY+TD5SPlo+bj5OPqw+vj6OPtw+8j7CPw8/Hz89PyI/QT+Tv6S/ur+Qv95/63/DwCJANAA/wBCAZQBzgH8ATQCYAJoAmwCnALUAgADPAOIA6gDjAN4A4ADfANYA2QDrAPcA8gDtAPQA9gDtAOEA3gDZAMwAwwD+ALkAsgCxALQArwCgAJIAhgC4gGmAYwBlgGSAWwBQAEgAf0AwwCTAIcAkgCKAGoAXABkAGAARgA7AEUANAAVAAQADgANAPX/7f///wAA7P/b/+f/6f/U/8H/xf/G/6X/gv92/37/Vv8w/yX/Fv/s/rT+oP6W/mz+PP40/jb+FP78/Q7+Gv4A/tj9yP3A/aj9tP3Y/eT93P3g/QT+CP7k/dz9AP4K/vT99P0U/hb+/P38/Rb+HP4I/gb+IP44/kD+TP5q/n7+hv6Y/rz+3P7w/gz/N/9b/3P/l//N//v/EwAqAFMAewCZALIA1gD+ACABQAFeAXgBkAGyAcoB1AHQAdoB9gEIAhACGAIoAiwCMAJEAlQCVAJUAmACcAJwAmgCcAJ8AnwCfAKIAowChAKEAoQCgAJwAmQCYAJcAkgCLAIYAvgBzgGqAY4BbgFAAQwB6gDJAJsAXQAoAPr/xv+I/1T/L/8H/9b+qv6K/mj+Pv4W/vj92P24/ZT9gP1o/Uj9MP0c/fz81Py0/Kj8nPyM/Ij8lPyY/Iz8jPyY/Kj8pPyo/MT85Pzs/Pj8IP1c/YT9mP28/ez9FP4y/lr+nv7c/gb/Nv94/6z/y//x/zIAdgCbALYA3wAOATABRgFuAaAByAHeAfwBKAI8AkwCZAKMAqACuALcAvwCAAP8AhQDJAMoAzADNAMwAyADHAMcAxgDAAP0AvgC8ALgAtQCxAKsAogCcAJcAkACIAIEAvIB3AG6AZgBdgFKARQB4wC+AJ8AbQAzAAcA4/+1/33/Tf8n//7+wv6K/nD+Uv4s/g7+9P3Q/aj9gP1g/Uz9QP04/Sj9EP0E/QD99Pzc/ND81Pzk/OT85Pzs/Pz8/PwE/RT9KP08/VD9bP2Q/aj9vP3g/RL+QP5k/or+vP70/iL/Sf9x/6D/0f8CADIAZgCZAMcA8AAgAUwBbAGAAaABxAHeAfAB/gEUAiQCKAIwAkACRAJEAkgCVAJcAlwCXAJcAlwCWAJYAlwCVAJIAjwCOAI0AiwCHAIQAgQC8gHaAboBoAGKAXYBXgFQATwBHAH5ANUAtwCXAHIASgApAAkA6P/B/5f/bv9H/xz/8v7K/qr+jP5q/kr+LP4U/gD+5P3I/bT9oP2I/XT9ZP1g/Vj9TP1M/VD9VP1U/Vj9bP2E/ZT9oP2w/cj94P30/RL+NP5a/nj+lv66/uL+C/82/2P/hf+g/7//5/8QADMAWgCIALAA0QDzABgBOAFSAXYBnAG8AdIB6gEIAiQCNAJEAlgCZAJsAnACdAJwAmwCaAJsAmgCWAJIAjgCJAIMAvwB7gHcAcIBqAGOAXIBVAE2ARYB+ADcAL4AoACBAGYATgA2ABsA/v/p/9X/wP+r/5T/e/9m/1T/SP81/yf/I/8j/xr/Df8M/xD/Av/u/vT+9P7q/t7+4v7s/t7+zv7Y/t7+yv62/rr+vv64/rr+yP7U/sz+wP7G/tL+3P7g/ub+8v7+/gv/Fv8e/yn/Of9K/1X/YP9x/4D/iv+V/6H/sf+//8v/2v/w/wUAEQAdAC0AQwBYAGkAeACHAJUAnACiAKwAuwDJANQA3wDnAPEA/AAIARABFAEaASYBKgEmASQBLAE4AToBNAEsASoBKgEkARoBDgECAfMA5ADWAMYAsQCbAIgAeABkAEsAMwAfAAwA+f/n/9j/y/++/67/nP+O/4b/g/+A/3z/ev94/3L/a/9p/2j/Y/9d/1v/X/9k/2b/Zf9k/2b/aP9n/2P/Yf9i/2L/X/9f/2H/Yv9f/1z/Xf9e/13/X/9l/23/dP93/3f/c/9v/27/bv9t/27/c/94/3v/gf+J/5L/mP+e/6X/rf+v/7H/uP/J/9X/2v/e/+j/8v/3//v/BgAUABwAIQAtADkAPwBEAFAAZABtAG4AcQB7AIQAfQB+AIoAlgCSAI8AnQCfAJoAlwChAKQAowCpALEArgCmAKoAsgC1ALMAsgCwAKwAowCcAJQAgwB3AG0AYwBbAFIASQA9ACwAIgAXAAgA+f/r/+P/2//R/8z/x/+6/67/p/+m/6f/n/+U/4//kP+P/43/iv+K/4v/hP97/37/hP+G/47/lf+W/5T/k/+V/5r/ov+p/6z/rv+y/7j/u/+7/7v/wP/K/9D/0P/S/9b/2f/c/9//5f/t//P/+f///wIAAQAEAAwAEQATABcAIQAsADIANAA3AD4ARABIAEkATgBTAFcAWQBfAGgAbwBxAHUAegB/AIEAfwCBAIMAfwB7AHsAeQBxAGkAZgBmAGIAXwBcAFwAWgBaAFsAWgBTAEwASgBLAEoARwBGAEYAQwA8ADIAKgAfABYADgAJAAIA+f/t/+L/2v/Q/8X/u/+z/6z/pf+e/5j/kv+L/4T/fv95/3X/b/9p/2T/Yf9i/2X/Zv9o/2z/cf91/3f/ev+A/4T/h/+K/43/kP+S/5f/n/+n/67/s/+5/7//xP/G/8n/0P/X/9n/1//Y/9v/4P/l/+v/6//o/+T/5P/l/+X/5f/n/+r/6//s/+3/7f/t/+//8//1//X/9f/4//7/AwAJABAAFwAdACIAKAAuADMAOQBAAEkATwBUAFYAVwBZAF0AZABpAGsAbABwAHIAdAB0AHQAdgB4AHoAeQB2AHQAdAB1AHIAawBrAG4AbwBtAGgAZQBgAFgAUwBLAEIAOQA0ACwAIAAWABMACwD4//L/6v/j/9f/0f/W/87/wv/D/8f/v/+y/67/q/+l/6D/of+n/6f/nf+Z/6H/rP+s/6v/sP+4/7v/u/++/8T/zP/R/9b/3f/l/+n/7P/v//P/9v/4//r/+v/9/////f/6//j/+P/4//r//P8AAAMAAgAAAP//AwAHAAgACAAHAAoADQARABUAFwAZAB4AHwAcABgAGgAgACIAIwAiACIAJQAmACgAKgApACcAJwAqAC0ALwAyADcAPQBCAEMARgBKAE0AUABSAFUAWABZAFcAVABSAE8ATQBMAEoASQBHAEQAPgA7ADgANAAuACYAHwAYABMADgAGAP7/+f/0/+3/5P/b/9T/y//E/8H/vP+3/7P/rv+o/6L/n/+d/5n/mf+b/5v/mv+c/5//n/+i/6f/qv+q/6r/rv+z/7X/uP++/8X/yf/L/87/0v/a/+L/6f/s//D/9f/5//v/AAAHAAoACQALAA4ADwANAA0AEQARAA0ACgALAAgA///9////AgAAAP//BgAHAAQAAwAEAP///f8BAAIA/f/+/wsADAAEAAQAEgAWABEAEwAbAB0AGAAXABoAGgAdACEAHwAgACMAKAAqACgALAAtACYAHQAcACQAJwAdABYAFwAYABIADwAQAA0ACwAFAAAA//8AAAUAAgD6//n/+v/z/+//8f/0//T/7f/q/+//9f/3//b/8//2///////4//b//P8CAPr/9f/6//z/9v/w/+z/6P/i/9//4//o/+r/7//2//f/+f8DAAsACQAHAA0AEgASABIAFQAWABYAFgAUABIAEQAYAB4AGAARABMAEwAOAAwADAAGAPz/9f/z//H/6P/f/9X/yf/A/7//wP+8/7X/tf+3/7T/t//B/8P/u/+4/73/xf/J/8r/y//U/93/4P/j//L/BQALAA0AFgAjACoALAA2AEcATwBRAFsAYwBeAF8AawBsAF8AWgBiAF4ATwBHAEgAPwAlAAcA+f8BAA4ACgD2/+b/4v/k/+D/4f/y/wUAAQDs/+H/5f/k/9v/1//e/+n/8f/0//z/DAAaABkAEgAbACoAIQAMABAAIgAdAAIA8f/q/9b/vP+6/8n/xv+9/8T/yf+//8D/3f/6/wMA+//1//D/7P/u/+r/3P/Q/87/2f/t//n/9//9//v/5v/i/wcALwA3AEMAXABWACQA/v8RAB4ADgAcAFoAcQBFADUAaQCOAIsAlACpAJ0AbABKAEsASgATAMj/of+L/1j/JP8m/0P/Rv8h/+r+xv7e/jX/Of/2/n3/oACEAD7/aP8MAWQBJgCM/7//oP8wAOoBGAMcAuL/yP4W/y7/6v66/ygBOAGu/1T+cv64/8wAAAESAbYBMAJ4AVsAggDKAUACtgGQAQACMAKgAaMALABOAOv/1P5G/pb+3v5O/gj9LPxM/IT8RPxo/IT9mv6I/kz9ZPww/ar+5P5s/vD+2v9r/4L+Iv9GANT/xP5k/wwBkAEwAaQBmAIcAq0A6ADIAngDbAIQAgwDNAPAAboAQgGMAaEAtgCkArQDZAIqAU4BegA8/l7+CAIwBOwBAf9q/kL+jP0M/oj/HACX/7r+kP24/FT9zv7V/zAACAAf//T9eP0I/qL/wAFoAl4A+P1M/lEA8QBtAP0A6gFGAR0ArABMAmwC4wD//4IARgHWAYQC5ALwAa//Uv7q/6gChAO8AvYBywD0/vD9sv5cACACqAOMA54AJP1U/B7+iwD6AbAB5wCyAI7/8Px8/Mb/wAIcAnj/6P02/hD/Rf+3/0UAF/+A/cT+TgEMAUz/Rv9j/yD9iPuW/lgDtAMoAOD9RP0o/HD8GACsA5QDZAE+/zz9KPyQ/cEAKAO4A+QCzAAM/vD8Uv4lAAIBpAAi/4D+WwAkAuoASv4o/WT9yP1p/3ACgAPTADz96Pv4/KT+EwAQAlAD6QD8/Dz84P1G/+QAXAJ6AfT+pP1w/o3/kP+6/8YAYwAY/uD91wCIAtsACv8Z/53/2v/4AJACOAI3AHD/+P/P/0QAgAKYA+YBvf8G/+7+9v4EAEQCVAMsAdD9CP2Q/sn/qgDiAbQBSf/I/FD8ZP5OATwCEgHT/2j+4Pxw/TMAYAIkAmQA7P58/uD+LgDUAWwCyAFjAGT+gP1x/2AC4AIKAW//zv5e/nz+IwC4AqwDWAH8/Rz9tv55ANgB2AJoAjsA1P0c/cz+oAEAAwACJQAW//z+Jf9i/wIAzgC7AKH/Iv8sADwBwQB+/0L/3/+l/y//jACMAsoBsP4w/dD+swCQAG8A+AFcAlb/FPzw/JQAbALkAa4BkgHH/5j93P2mAPQCJAKO/+z+VwAEAbEARAHeAfz/EP1Y/TAB4APMAisANP4k/Zz9GwCkAvgClgFm/7T8kPsM/kQCMAS0Ap//CP1A/Nj9BAEYAzQCu/9G/lj+J/9GACgBMgFAAPL+fv7O/8gBAAJJAMr+vP4Z/87/qAHwAkYBQP5w/Qn/SQAKAPX/KAEwAhwBWP6g/Nj9awCcAY4BWAEWAMz9KP0x/1IBggHaAHIArP+2/j7/7AB4AWUAaP9h/8//ZgD/AMgAe/+C/ib/kQAWAdsA5QCcAOD+LP38/fMAQAMAA8kAaP5Y/RT+7v+MARgCfgH6/xL+OP1M/isAWAFuAZUA+P6E/aj9o/+qAdYBXgDi/jD+WP6G/wQBcAHSAE0A5f8c/2r+Fv82AXACFgHu/rT+6P9HAPf/6wBsAkwB9P3M/GP/LAJUAvwA3f/k/tj98P34/5ACGANqAMD8APwq/5wC9AJ6ARwAOP5g/GT9DgFgA4gCWgB2/kT9UP09/xwCaAOIAVL+7PzU/cf/uAGYAnABKf+Q/Xz97P4SAZgC/gFL/+T8EP1f/7ABoALIAYD/HP20/BD/NAJoAzgCIQAe/hj9ZP6SAaADvAJLAIj+6P1Y/hUAYAJEA5YBfv5o/CD9IgCoArAC8wD0/nj9VP2+/gQB5ALYAq8ASv5Q/eD9oP/YASQDZAKd/yD9uP26AKQCLALSAKP/kv4s/nP//AFwA9IBav7k/Kr+OgEcAtgBOgFe//z81Pxh/84BKAI0Afb/qP7M/Vz+WgBQAkgCTgCw/l7+Xv76/loBjANoAsT+kPyM/d//xAGsAggC3f8G/hz+sv+AASgCIAFc/17+BP/qAEwCxAElAMz+UP4E/8EAYAKMApsA6P0o/fT+9QCOAVIBigDq/mT9mP2h/1wB9wCV/2r/2f8F/wD+zv6XAPMAAQCi/9X/Jv9K/jj/CAH/AET/tP7W/zsAPf9U/xoBhgFl/8T9/v5uATQCyQD4/sb+9P+lAIwAzgD5APz/wv4D/5kAlgH3AOz/zf8kAOz/gP/2/x4BcAFTACv/Hv/Z/70AGgFzAGf/9P5O/yoA5QDZAB4AL/+i/kP/lgDwAG4AZQBQAGv/Gv9IAEQBrQCP/2f/AgAxANP/DQCwAEAAU/+Q/zAA1P9S/7j/fABUAED/8P75/7kAQQCU/0b/I/9E//P/3AAWAV4A4P/T/zD/1P48ALIBPgFNACsAif9M/v7+VgEIAk8AKP+8/+L/yv6o/oIAwAFiAJD+FP+wAJkAJf8O/6kABAFf/5D+vP/DAGwAzP+z/8n/tv+//0MA4gDwADUARP80/1QAdAFkAVEAKP80/5YAjAHMAJX/vv/AAMsACwAUAJMARwDo/4EAKgHwAG0ATQBIAPT/9f/XAGoBrACX/1L/hv+K/6X/NQCYAN//nv54/pD/FwCB/3X/NwASANr+ev6T/2EAvf/m/lz/lQDZAPL/IP8e/53/6/8LAIMA/QB5AF3/Of8eANAArAAgAMX/2P8sAHIAqACmAE4Ar/89/7j/0QAkATYARP8Y/zX/d/84ABIB6gCB/zb+Zv7G/+UA9wBtAAUA3f+q/4v/4f97ALAAQgDJ/8r/JQBDAPr/6/9CAFoAGwAiAGkAJQBI/97+q//OAN8AFwCc/2H/5v70/hAA5wBtALf/4v8TAIf/G/+n/5IA1ACJADcA3f+E/7r/SQA6AKb/rf82AFkAMAAfALz/Cv8s/zEAqgA8ABkAWgDy/zv/fP9dAJ0AQwATACQAGwAkAFIAPQDL/5L/CwC9AAYBsADa/0b/pf+DAMEAZABJAHgAVADS/3//wf9OAHcAMAAgAGQAFADw/mT+af+OADAANP8g/4H/W/8N/2P/1f+q/0f/a//Y/wcA6v+t/5L/s//3/zQAZQCDAGsA3/89/4T/qABIAbgA+P/p/y0ANAA9AJcAzACbAEYA2P9p/7n/AAG+AcsANP+6/of/YACEADoABADR/2X/Ev+A/3gAxQD3/13/lv+a/yD/Z/+bAO4As/+a/vr+//9QABUAFQAaAJj/G/+F/3IA3QCXACkAvP9O/2z/XwBSAVoBhQCO/xT/bv9hAAYB2AA7AK7/U/93/ygAugCdABMAmv8//yD/qP+nABgBcwBL/5T+8P4HAM0AwABVAPf/uv+4/wcAhQCdADkA9v8sAGgAVwA9ADIACADY//j/ZACOAF4ARAA7AOz/nP/g/3MAzgDdAKcAAQBP/2b/NwDrAPEAaQDV/53/rP/W/yIAeQCgAGQA9//P/8n/jP99/yQA3QDDAA0AeP82/yv/ff80ALYAdgC+/yn/Ef9a/6z/z//z/zIAHwCk/1T/eP+P/23/hf8HAHoASwCc/wH/yv4K/6j/UgCMABMAU/8A/0L/n//o/ywAQwAnAAAA5P/g/wwAPwA9ADMAYACPAF4A9v/n/1MAjQBcAF0AmQBtAOj/uv/1/zoAYABxAE8ACwDg/+D/2f/Q/wQATQBWADEAFwC+/0D/a/9XAAoBswDn/7P/1v+j/6H/cgAgAagAzP+V/6z/fP+P/1sACAHcADsAvf+C/4j/4P9kALoAqwBdAPX/mP99/8z/IgAkACcAXABSALP/Mv9y//r//f+v/+D/XAAmAET/2P5B/6v/s//O/+T/g/8I/xL/Y/95/4X/5v9FABEAkv99/8//8v/t/z4AuwCzACcA2f8TAGIAaABZAGcAegB8AFoAQgBlAH4AQwD+/x8AhwC8AJEASQAAALD/qf8nALgAwgBiAAcAsf9w/5z/MgCQAGsAOgA1ABAAwf+w/xgAiACMAFkAVgB8AGkAIQANAFcAoAC1ALUAnwBFAMT/nf/p/0QAZABrAGIAAABY/+r+Dv+R/w8AXQBNALb/6v6Q/sj+U//8/3gATwCc/xL/+v4n/3L/AgCUAIsA3v9M/z7/ff/h/1wAmQBXAN//nP+g/9f/LwBjAEsADADY/8L/2/8lAFsAOgDg/83/FwBIADoALgAoAPX/1P8XAHsAawAZAAYADADH/5r/CACqAMMAUwDl/5v/Zf+c/3MAOAEeAV0Ar/9i/1n/qv9tABQB7gAwAHr/D//y/mf/XwAAAaQAzv9n/17/W/+E/xMAjgBzACQA6P+N/yf/TP/y/1gAOQAPAAQAqv8n/zH/p//r/wQAOQAxALT/Pf9C/4L/tf8PAGUASgDW/3//gf+t/+P/CgAcAA8ABgAJAOr/xf+1/7r/5v8/AGoANAAEADIASADm/87/agDsALoAfgDBALoAHQALAPkAegHkAJMABAEIAUQALAAYAV4BpgBoAPsA2gDu/9P/mwDHACgAFQB0AB4AXf9n/wUAHQCi/4r/p/9F/+L+WP/w/5b/7P70/lb/Iv/G/vr+OP/a/oj+vP7I/nj+VP6i/sb+ev5C/j7+IP4Y/mz+kP50/nz+mv5Y/vD9JP62/vT+6v4c/zb/7P7c/mD/tv+f/83/ZwCsAG0AhQAMATQB6QAcAeQBXAJIAmACcAL8Aa4BVAJUA7QDhANcAyADkAJkAvACrAMoBCgEtAMQA4wCaALAAlQDkANYA9ACXAIUAqoBWgGWAfQB0gGEAUIBxAAXAL3/IgCcAF8AqP8t/xD/6P6C/kj+hP6S/tz99PzA/Mj8YPwI/Fj8ZPwo+8j5qPko+gD6qPng+fD56Pjw9yD42PgI+SD5wPn4+YD5WPkg+rD66Pqw+9T8RP0c/Xz9Wv76/n7/ngCgAbAB7AEkA0gEYAR4BDAF4AUIBpgG2AdQCNAHmAfYB8AHmAdQCFAJEAnoB1gHSAf4BtAGiAf4BxgHCAbYBdgFCAVgBBAFsAXYBJgDPAMgA0ACxgGwArADKAP0AaQBkgHTAEgA+gDmAaYB7gBmAJb/Yv58/Wj9YP0M/aD8+PuQ+pj4IPdw9hD24PUA9qD1MPRQ8gDxYPBQ8LDwcPEA8tDxAPFA8FDwoPFA85D04PUQ96D3wPfQ+Mj6ePyw/Wb/hgGAAowCTAMABUAG4AYQCJAJIArgCRAKwArgCsAKIAvQC7AL8ApQCvAJgAkwCRAJoAgQCKgHSAeIBsgF4AUYBogF2ARABfAFeAV4BJgEYAUwBbAEaAV4BuAFkASwBLgFYAVQBNAEwAWgBHwCeAKUA/gCsAHwARgCLAD+/nAASAEK//D8oP0k/qj8dPz8/Sj9mPnw9/D4mPgA99D38PnQ+PD00PKw8gDyQPJQ9YD3gPUA8uDwIPGw8NDxoPU4+AD30PSA9ND0IPVQ91j7nP2g/MD7yPzY/Tj+k/9EAswDnAOgA+AEiAUIBVAFqAagB0gHMAdACCAJUAgwBzgH0AfYB+AHkAgACSAI6AaoBsgGqAbwBpgH4AcgBzAGqAV4BZgFIAaABmgGAAZ4BTAF4ASYBJAE4AQQBYgEfAPgAuQChAIIAvQB5AESAQ8AAQBVAOT/zv7I/iH/mv7w/SD+sv4+/sT9XP7Q/rz93PxY/l//NP4g/WD+Rf/o/GD68PpE/Kj7qPsE/Qj8gPdw9MD18Pco+Ej4CPlw95DzcPHA8rD0gPXg9nD4YPcA9JDyYPTQ9oj4ePqA/Fj8ePrw+Zj7sP06/yQBBAM8AwgCsAHIAiAEEAXYBbAGUAcoB6gG4AY4ByAH6AZwB7AIsAiYB2AH6AfQBmAFsAVIB+AH6AaIBogGWAXoA3gE8AVYBhgGAAbQBZAEjAMABLAEuAToBGgFoATMAjgC/AIAAxACeAKsA/gCxgAYABYBCAHn/+3/CAGUAOz+oP67/zcAcv/m/oL/8/8Y/1b+8P4+ACgAwP4S/nb+5P1g/OD74Pso+zD6IPtU/Dj68PWg84D0EPZg90j4WPjw9UDywPDg8fDzEPYw+Nj4UPew9DDzgPSw9wj7aP34/ST9XPzw+1j8UP50ARAEqAS0AzADSANUA9ADSAUYB8AHMAf4BkgHwAaYBbgFgAfACBAIQAfQB5AHyAUYBYAGYAeABmAGkAc4B+gE6ANABeAFGAVABZgGmAaIBFAD9AN4BMwDrAPQBBgFjAOeAZ4BOAKwARQBvgGMAkQBKv/I/oP/LP+G/hb/pP/W/sD9xP04/vj95P0K/77/Lv+E/oT+vP4s/w8ARABB/zr+Tv5q/sz8kPt8/OD9gP2w++j5oPeQ9TD1sPdY+ij6gPdw9PDyYPLw8vD0iPiw+pD44PSw80D1gPZY+IT80P9+/jD7ePvE/W7+Of/wAjAGEAXwAlgDWAS0A2gEcAeQCNAGGAaIBzAHGAUoBTAHQAeoBSgG6AfIBgAE/AO4BUAFuAO4BBgHeAboAzgDYAQwBBQDSARoBmAGWASMAzgEIARQA/QD4AXYBUAEHANIAyQDQAJEAjQDiAM8Au8AdgBAALz/gv/z/xwARv9S/i7+cv5c/mD+6P5I//j+av64/kT/NP84/xsAyADW/4j+pv7U/kT9KPxc/Zj+JP1o+2D7SPpg9iD0EPdQ+vD5GPhg9zD1YPEQ8TD1oPhQ+PD3cPiQ9hDzkPN4+ND7cPx8/dj+BP3Q+fD6tv9gAiwCJAP4BLQDxQACASAEmAUgBSAGwAeQBuAD0APgBTgG+ARoBUgHQAc4BWAEEAXwBPgDeARYBsgGIAUgBLAEuATAA+gDeAVABngFsATYBJAE6AM4BDAFYAWgBGAEYASsA7gCmAIEA8wC8gF8AaYBAgG6/0H/xv/T/9b+YP7+/i3/Iv7Q/cr+Qf98/ir+KP+6/yj/7v7//1YAhv9v/y4A/P9U/qj9Pv7o/Xj8nPxI/hz9YPkA93D3wPcQ94j4CPuA+TD0gPEQ8+D0gPVg98j5kPig9ADz0PSw9jD4IPtE/uj92PrY+aj7gP34/rQBUAS4A2YBAAF8AgQDHAMABTAHAAc4BcAEYAU4BcgEsAXoBtgGOAYwBkgGeAVYBGgEYAXwBTAGaAYgBkAFGAQQBCAF4AXABUgGsAb4BZAE/AMQBQgG8AWoBeAFUAUIBIgD/AMwBHgDKANcA6wCPAHWAGYBEAH9/+3/TQB0/1D+9v4OAGX/HP6s/s7/J//4/b7+SwD6/9z+G/8ZAPT/1P5q/sz+/P08/Jj7ePxQ/XD8kPr4+GD3cPUg9XD3qPlY+aD2QPSg8rDx0PIQ9rj4aPhg9uD0kPSQ9MD18PhE/Hz9vPyo+/D6WPso/fT/XAIsA/gCkAL+Ad4B0AIoBEgFIAbABqAGgAWABBAFKAZQBggGoAboB5gHwAXIBHgFCAagBRAGkAewB6gFiASgBfgF4AQwBTAHoAeYBZAEcAWQBaAECAVwBvgFUAQQBOAEcATYAsACsANQA7oBLAHEAYQBTwCh/ysA9P+8/kj+N//g/+j+8P1u/gv/cP78/er+0v9a/6T+/v6x/zP/qP40/zb/6P2w/MT86Pxc/Bz8HPzg+kD4YPaA9iD3IPgw+dj4IPYA81DywPOw9dD28Pco+ID2cPQg9ED2qPio+kT8qP00/fD6mPpY/VgADgG0AaADMAQ8AgABKAMwBfAECAUAB5gHYAVIBMAFgAYoBQgFAAd4B/gFiAVoBpAFuANABIAG2AaABaAFoAaABWQD5AMIBngGkAXwBegGsAWwA9wDwAUgBvgECAW4BRAFJAOkArwD+APQAjwCyAIUAnYAx/+NAJsAWf/O/mX/Yf8m/tj9vv4G/z7+9P2w/vr+UP4+/gv/UP++/tj+pf+x/77+5P3E/TT9MPwY/CD9WP2o+3D5CPjA9qD1kPYo+Rj6sPfQ9LDzIPOQ8lD0IPhA+QD3APUw9VD1EPWA97D7gP0Q/HD7PPz4+5j7Wv6EAnAD5gHYASwDnAJIAfACAAZwBhAFaAWoBogFsAN4BKAGsAZwBRgGaAeIBqAEqATYBbAFAAXoBTgHiAbIBLAEwAWwBeAEaAXgBtAGcAUQBaAFWAWABPAEEAbQBZAEKASABOADsAKgAjAD8ALgAWwBPgF5AIz/cP/j/6L/3v6u/i3/8v4k/hr++v5a/77+mP5f/6L/1v7C/rj/IwB3/xr/jv8I/1T9cPxA/Zj96Px4/Pj7+Pkg92D20PfQ+KD4oPhA+DD1QPKw8qD1IPfg9nD3sPeg9VDzwPQg+ND5MPqg+9z8kPv4+Vj7Yv7o/4MA7AEUAyAC5QDyAeQDYARABGgFuAYgBuAEGAXwBbAFUAVIBngHSAdQBiAGSAaYBfgEmAXQBhAHkAYoBggGmAUIBXAFeAbYBnAGIAZABigGSAUgBQAGUAZYBSAFkAWABVAEhAMQBAgEwAIIArgCtAJcAXMAswCQAGL/DP/E/9X/9P7Y/l3//P4k/nj+P//8/mr+2P5v//T+fv40/5r/mP6A/XT9SP1U/BD8tPzo/JD7UPmQ9+D2wPZg93D42PjA9yD1sPKQ8jD0kPWg9oD3IPcw9XDzYPTA9kj4aPkI+/D76Pro+eD6JP1e/nX/VgFkAqYB1QCwAdQCXAPMAwgF+AW4BXAFsAV4BfgEaAWoBmAHMAcQBwAHOAY4BVgFYAb4BvgGIAdgB1gGAAU4BYgG8AZIBjgG4AaoBlgFCAXgBcgFAAUoBcAFQAU4BFAEmASgA1ACVALwAnQCvAGsAW4BYgBQ/3X/yP9z/yD/gv/N/wD//P3Q/az++P6i/qr+N/9Y/3b+Iv7Q/g7/Iv5w/cT9sP2Y/Mj7LPxM/KD66PiQ+ED4gPdg92j4gPig9qD0MPSQ9ND00PVA9zD3oPWQ9ND0EPZQ9+D4QPq4+jD6YPpA+zD8MP2w/p4AUAEEAeUA5gGsArACgAPoBGgF0AQgBUgGGAbQBOAEuAZoB5AGuAa4BzgHaAUwBYAG8AZ4BggH+AfgBjAFcAXQBtgGSAb4BsgH+AaoBfgF2AYwBnAFMAb4BiAG+AQwBagFmARQA2gDCARkA0gCWAJkAnAB/f/R/3AASQCJ/3v/FwB8/1b+AP6o/tb+Yv6K/jz/LP8q/gb+vP7U/gr+nP3k/bD9oPz4+zD86PuY+pD5UPno+Aj4kPcA+PD3cPYA9eD0IPUA9WD1gPZw9sD0sPOg9CD24PYg+Mj52PlI+Cj4aPoA/Ij82P3u/zYA2v7u/sEA4AHkASAD2ASYBFADyANIBTAFYAQwBegG0AbgBXAGcAeYBjgFwAUwBzgHmAY4B/AH4AZABZAF+AZIB/AGSAegB5gGUAWQBaAGqAYABiAGcAbIBbgEoAQ4BdgEtANIA3QDDAMwAu4B6gE2ARYAtf8RAPP/dv9e/3X/Ef9M/hT+Vv6K/n7+hv68/pz+QP4i/nz+gP4Y/sT90P2w/QT9gPxQ/ND7sPrw+aj5YPnI+Fj4UPiw94D2kPWQ9bD1wPUQ9lD28PXQ9HD0APXw9fD2OPhQ+dD4CPhQ+Kj56Pr4+6j9C//i/ib+wP4RAOQAbgG0AgAEAARkA6QDeASoBLgEoAXwBhgHgAaYBiAH8AZgBqgGiAewB0AHWAe4B0AHWAZYBjgHoAdYB0AHcAf4BkAGEAZ4BrgGgAZgBnAGMAZ4BRAFOAUgBYgE+APUA8gDAANYAjAC5gEMAZQAqQDZAH8A0P/k/9z/IP96/ur+bv8q/7D+wP7+/oT+CP5E/qb+Pv7A/az9gP3A/Pj7oPtg+8j6CPqo+VD5wPgY+JD3IPew9jD2wPWw9cD1oPVw9aD1cPUA9QD1sPXA9mD3GPgA+Rj5YPi4+HD66Pvo/Pj9J/88/2j+0v6kAOwBJAIMA2AEYASEA7gDGAV4BVAFMAaQB4AHcAaQBmgHUAeABugG+AfoB0gHgAf4B0AHcAbIBsAHuAc4B3AHsAfgBuAFGAbABqAGOAaABngGcAWQBMAECAVQBKADwAO8A7QCxgHIAZAB1gBnAIQAhAD7/5z/m/9q/9T+iP7k/g7/+v7u/u7+yv5u/kz+Yv6G/mb+Jv7Y/Uj9oPwE/ND7gPvg+kj66PmA+bD4CPjw99D3IPdg9kD2UPbw9cD1APZA9rD1MPXQ9cD2MPeQ95D4SPno+LD4sPkw+wz87PxE/vj+ov6K/on/AgG6AVgCSAPQA2gDZANIBBgFQAVwBWgG8AaYBlAG2AYIB2AGUAb4BlAH6AbYBkAH6AYQBvgF0AYgB7gG0AYYB5gGmAV4BSAGUAYABhAGQAagBagEiAToBKgECATsA+wDQANMAhACHAKSAe4ACgE+AcUAGQD0/wEAfv/4/hX/if9t/+7+AP8j/9j+Yv50/tr+vv4w/tz91P04/Vz8BPwA/JD7yPpQ+jD6qPnA+GD4UPjQ9/D2kPaA9mD28PXg9TD2APaA9aD1UPbA9iD3gPco+HD4YPjo+Aj6CPug+0T8CP10/aj9WP6E/4MA5wBYAfgBSAJQAtQC2ANwBKAE8ASIBcgFmAW4BUAGeAY4BlAGuAbYBoAGcAa4BqgGUAZoBvgGGAe4BpgGqAZgBuAFCAaoBrgGMAbwBQAGqAUABeAEMAUABVAE9APIAzgDdAI8AmQCIAKcAXwBjAEgAYcAcQCiAG0ABwAWAE8AKQDI/83/EADu/6D/qv/K/2r/2v6m/pD+CP5E/eT8tPwc/Ej76Pqo+hj6YPnY+JD44Pcw9+D24Pag9jD2IPYw9gD2sPXw9YD2sPbQ9kD30PcI+Dj48Pjg+Xj64Pqo+4D85PxA/SD+C/99/8P/ewBAAZIB9AHAAoQDxAMABKgEOAVYBXAF8AU4BigGOAaoBugGyAbABgAHOAcYBxgHaAeQB0gHGAdYB2gHOAcIByAHMAfYBpgGgAZ4BigG4AWoBXAFAAWIBEgEEASkAzwDFAPkAogCNAIYAgQCuAF2AWYBVAEMAcYA2wDRAJcAawCBAHwAIQDF/6H/bP/m/mL+KP7U/TT9ePwA/ID7wPog+tj5ePnA+AD4gPcA91D20PXQ9dD1cPUg9SD18PSw9MD0QPWw9eD1IPaw9hD3UPfg98j4gPkI+rj6iPs0/KT8PP0C/qT+Jv/U/58ANgHCAWQC/AJoA9QDeAT4BFAFoAUQBlgGYAaQBgAHUAdgB3gHyAfwB9gH4AcQCCAIAAjoByAIIAjwB9gH0AegB2AHQAdIBxgHoAZIBhAGuAVQBQAFuARgBPgDqANoAxQDrAJoAlQCCAK0AYIBeAE8Af8A4QDlAMQAiAB2AG0ALgDN/6X/d/8G/3z+Kv7o/VD9sPxA/Nj7IPtw+hD6sPkA+Uj44Pdw98D2MPYA9uD1gPUg9QD1APXA9JD04PQg9WD1kPUA9oD28PZg9wj4wPhY+fj5qPpo+wj8nPxA/QT+uv5e/w0A1ACMARwCuAJMA+QDYATQBDgFqAUABkgGmAbgBiAHUAeAB7gH2AfoBwAIMAhACEAIQAhQCEAIQAhQCFAIMAjoB8gHqAdoByAH6AaoBlAG6AWgBVAF8ASQBEAEAAScAzAD7AK0AmACDALYAboBeAEsARQBAAHSAJoAfAByADsA7f+//5L/MP+2/mL+GP6g/Qj9nPwc/Hj7yPpI+sj5GPmI+AD4gPfw9mD2APaw9VD1APXQ9LD0gPRw9ID0oPSw9AD1UPWw9RD2oPZA98D3SPj4+KD5KPqw+nD7KPzA/GT9JP7k/oX/OwD7AL4BPALQAnAD/AN4BOgEgAX4BUAGgAbQBigHYAe4BxAIQAhQCGAIgAiQCIAIoAjACMAIsAjACMAIkAhQCDAIIAjYB4AHOAcAB6AGOAbYBXgFEAWoBGgEIAS8A1QD/AKkAjwC8gHOAbIBbgEoAQoB7wDAAJMAjACBAFEADwDX/6X/YP8O/8b+dP4I/oj9GP2w/Cz8mPsI+4j66PlA+bj4QPjA9zD30PaA9iD2wPWQ9WD1MPUQ9QD1IPVA9WD1oPXg9VD2sPYw99D3aPjw+Hj5CPqo+lD7+Pus/GD9CP6q/m7/IwDLAHQBGAK4AkADyANgBOgEUAW4BTAGoAbYBhgHeAfIB/AHIAhgCIAIkAigCMAI0AjgCPAIAAnwCOAI0AiwCIAIQAgACMgHgAcgB8AGcAYABogFMAXgBJAEKATIA2wDEAOkAkgCDALgAZABTAEmAQABugCIAH4AbQA4APv/5P+3/0j/8P60/nz+/P2A/TT91PxA/Kj7QPvA+gj6ePkQ+ZD48PdQ9/D2kPYQ9qD1gPVQ9eD0sPTA9MD0kPSw9BD1UPVg9dD1YPbw9kD3wPeI+Cj5oPlI+iD72Ptc/BT9/P2y/j//+f/WAIwBFAKwAmwDCAR4BAgFqAUwBogG4AZQB6gH4AcwCJAI4AjgCOAIAAkgCSAJMAlwCYAJMAkQCSAJAAmwCGAIUAgQCJAHKAcIB7gGEAagBXAFGAWIBCgEAAScA/QChAJgAhQClgFaAVoBKgHGAJMAigBhABAA7v/0/7n/Yf8j/wP/rv4u/uD9qP1I/bD8TPz4+3D7wPpI+uD5SPm4+FD4APhg97D2cPZA9sD1cPVQ9UD1APXg9AD1MPVA9VD10PVQ9pD28Pag9zD4oPgw+eD5gPoQ+8D7lPxQ/ej9lP5g/wMAnwBOARgCsAIsA7wDYATwBFAF0AVQBsAGAAdQB7gHEAgwCGAIoAjQCOAI8AgwCVAJYAlACWAJcAlACRAJ4AjACGAI+Ae4B3gHCAeYBigGyAVABdAEeAQYBKQDOAPkAogCHAK4AYABUgESAcoApgB6ADMA/v/p/8n/mv9v/0n/C/+2/m7+OP7w/Yj9IP3I/Fj82Ptg+/j6ePrw+XD5CPmI+AD4kPcw98D2YPYQ9tD1kPVg9VD1QPVA9UD1gPXA9fD1MPaA9vD2UPew90D40PhY+ej5iPoo+8j7fPw0/ej9kv5A/+j/ogBaAQQCqAJEA+gDgAQIBZgFKAagBgAHYAfABxAIUAiACMAI4AgACSAJQAlgCWAJcAlwCWAJIAkACdAIkAhQCPgHwAdoB/AGgAYgBsAFSAXwBJgEKASwA0gD8AKMAiwC8gG8AW4BJAH/AN4AmwBcAEYALQD0/7L/gv9X/wf/vP5+/iz+zP1s/Rj9rPww/MD7UPvI+kD60Plo+fD4ePgQ+LD3QPfw9qD2cPYw9hD28PXg9eD1EPZA9nD2oPbw9kD3oPcQ+Ij4EPmQ+RD6oPow+9D7gPww/dj9fP4o/9L/hAAuAc4BbAIIA5wDIASoBCgFmAUABmgG0AYgB2gHuAf4ByAIQAhwCJAIsAjACNAI0AjACLAIsAiQCHAIMAj4B7AHaAcYB9AGaAYQBrgFWAXoBIAEKATIA1wDAAOoAkwC+gG6AXgBLgH1AMgAnwBvAE4AOQAJANX/qf+C/0v/DP/O/oz+Ov7c/YT9NP3Y/Hz8GPyo+zD7uPpA+tD5YPn4+ID4EPiw92D3APew9oD2cPZQ9jD2IPZA9lD2cPaw9gD3UPeQ9wD4iPgA+XD5APqY+iD7uPtk/BD9tP1C/u7+l/8+ANAAfAEoArgCLAOoA0AEoAQABXAF4AUoBngGyAYIBzgHUAeIB7gH0AfgBwAIEAgACPgHAAjwB9AHqAeIB2gHMAfoBrAGcAYgBtAFgAVABfgEkAQ4BOQDmAM4A/ACsAJgAgQCqgFiASoB8gDCAJYAXgAaAOv/v/+L/07/Hv/s/qT+Tv4O/tT9dP0Q/bj8ZPwE/JD7MPvI+lD62Pl4+RD5oPhI+AD4wPeA9zD3APfg9sD2sPaw9sD24PYA90D3gPfA9xj4gPjw+GD54Plo+vj6gPsg/MD8YP38/bD+X//5/5AALgHSAVwC4AJsA+wDWATABDgFoAX4BTgGkAboBiAHYAeoB+AHAAggCEAIUAhQCFAIUAhQCEAIIAgACMAHgAdIBxAHuAZgBhAGuAVgBfgEoARIBOgDhAMsA9QCgAIwAtABggE6AfMApABpADMAAgDD/4//ZP84/wT/zP6a/mD+Hv7c/Zz9UP0E/aj8UPzw+5j7OPvI+mj6EPqw+Vj5APmw+GD4KPjw98D3oPdw91D3QPdA91D3cPeg99D3APg4+Ij44PhA+aD5EPqI+vj6ePsA/JD8IP24/Vz++P6L/x8AuwBUAd4BZALwAngD7ANgBNgEOAWIBeAFOAaABrgG6AYgB0AHUAdgB3gHgAd4B3AHaAdQBygHCAfoBrAGcAYwBvAFqAVgBRAFyARwBCAEyAN8AygD3AKQAkAC8gGuAWYBKAHgAKAAagA1AP7/yv+h/3//TP8V//b+wv6G/k7+Fv7k/Zz9ZP0w/ej8kPxE/AT8uPto+zD78Pqo+lj6GPro+bj5kPl4+Vj5QPk4+Tj5SPlI+WD5iPmw+dD5APpA+oj6yPoQ+2j7wPsc/ID86PxY/cj9Mv6i/hL/j/8MAIsA/wByAeABSAK0AhgDfAPYAzAEgAS4BAgFSAWIBcAF6AUYBkgGYAZwBoAGkAaYBogGeAZoBlgGSAYoBgAG0AWgBWgFOAUABbgEeAQwBOgDoANYAxADxAJ4AiwC6gGiAVYBGAHcAJgASQAJAM//l/9W/xj/3v6g/mL+IP7s/bD9aP0k/eT8oPxg/CT84Pug+2j7MPvw+sD6iPpY+jD6CPro+cj5uPmo+aD5oPmg+bD5yPnw+Rj6UPqA+rj6+PpI+5j78PtE/KT8CP1k/cj9Nv6o/hz/jv8FAHgA5gBOAbgBJAKQAvQCTAOcA/QDSASQBNAEGAVgBZAFuAXwBQgGGAYoBkgGYAZYBlAGUAZQBjAGEAb4BdgFsAV4BUgFGAXYBJAEUAQQBMQDfANEAwADoAJMAgwCvgFeARABywB4ACAAzv+E/zH/0P6C/kD+7P2Y/VD9DP3E/ID8UPwU/ND7kPtg+zj7CPvY+rj6oPp4+lj6QPo4+jj6KPoY+hD6IPoo+jD6SPpw+pD6oPqw+uD6IPtQ+5D72PsY/Fj8qPz8/Ej9oP0E/l7+sv4W/4P/5f86AJUAAAFqAcQBHAJ8AtgCKANwA8ADCARIBIgEwAT4BCgFSAVwBZgFoAWgBbAFwAXIBbgFqAWYBZAFeAVYBTAFEAXoBLgEiARQBCAE3AOUA1gDIAPcApACSAIEAroBZgEWAdMAhgAxAOb/qf9h/xL/zv6W/lj+HP7w/cT9lP1g/TD9CP3c/LD8jPxw/Fj8QPwk/Aj88Pvg+9D7yPu4+7j7uPuo+7D7uPvA+9D72Pvo+wD8HPw4/FT8ePyk/ND8/Pws/Wz9rP3g/Rr+Yv6u/vb+Ov+C/9P/GwBdAKQA6gA4AXYBrAHgASACUAJ0AqQC3AIIAywDUAN0A5QDsAPEA9wD+AMIBAAE+APwA+QD2APUA8wDsAOMA2wDWAM0AwQD4ALEApwCXAIoAv4B0AGaAWwBRgEUAdoApAB5AEwAFQDn/8D/mv9x/0T/GP/u/sj+pP6C/mL+Pv4e/vz90P20/Zz9hP1o/VT9QP00/Rz9DP0A/fT86Pzg/OD83PzQ/NT84Pzg/OT87Pz4/Az9JP08/VD9ZP2I/bj93P3w/R7+Wv6O/qz+1v4c/2T/jf+o//P/MgBYAG4AnwDbAO4AAAFCAYQBigGKAa4BygHUAeQBDAJAAkwCNAI0AlQCeAKAAngCgAKcApwChAKIApwCjAJ8AngCcAJgAlgCWAJIAiAC/gHwAeIBvAGkAZwBdgFGAR4B8ADHALkAogB0AE0AKwD9/8v/qf+U/3v/TP8S//T+5P7G/qL+jP50/mD+VP4w/hD+Gv4S/uz96P3s/cj9uP3U/ej94P3U/dD96P0C/vz9Av4e/jL+Pv5W/mj+gP6e/rj+zv7u/g3/Nv9q/5H/p//K/wAAKQBPAHsApQDMAO0AAAEiAUoBZAF8AYwBkgGUAaABpgG4AcABpgGiAcYBuAGIAZABogF0AVgBZgFoAT4BHAEcARAB8gDYAMgA0QDcALwAkQCeAKsAkQB2AHUAhgByADgAJQBPAEEA7P/f/x0AGgDN/6T/qv+5/6f/d/9V/2j/hf9Y/wr/H/9r/zP/0P4y/4P/Av+w/jH/c//w/rz+OP+B/xT/0v4x/2T/MP8J/zT/d/9S/x//Y/+q/1f/P/+T/73/lP+A/8f/8P+6/5f/9/8sANL/w/9TAG8A5P/r/30AaQABAEEAnQB9ADkAUAChALYAkACEAKUAqgB+AIUAwQDPAKkAZQBuALwAwwBfAEcA5wDYAAoA9f+nAPAAOQDJ/48A2wCY/2j/pgCZALT/2f8wAJ//d/8sAFQAXf/8/iAAjgAk/5j+EQDQAEb/cP70/7EAX//A/gIAdgBL/9z+7v92AHv/7P7U/1wAh/8Z/8n/GQCA/17/2v/O/5X/rv+u/6v/y//Y/8L/g/+l/xkA5f99/9D/CgDB/8n/6P/o/x4AJADA/83/RwBGANz/4/9UAHgAHgDY/0YAqgA5AAYAngC3AEkAawCzAIoAiACqAJsAqACvALYA6QC2AG0A4AAKAXMAewD+AMgAawCgALkAiwBmAF4AkwCbAAoA7P+1AIgAmv/B/2IAPQCk/67/GwDz/5H/1/8UAIz/Yv8vAPX/Fv/b/40AQf/W/ogAVQCc/jj/tQAIANb+Mf8cAP3/T/92//f/lP83/+X/2v8u/8b/CAAG/xL/NQAdABf/Pf8OAP3/Q/8x//n/KwCo/1j/gP8uACkABv81/+4ASwCu/pz/1gAIANj+lf/0AF4ApP6M/4gBBgBC/gIAagG8/8r+QQDoAML//P75//AA3v8H/yoA+gC//xz/PQDrAA4AU//D/+EA7QAX/17/ygH/AHT+vf/oAXsADf+OAHIB9/8s/4cAlAE/AFf/cwDEACkAPAA6AOT/9QD5ADv/qv/mALsA+/++/ysAwwBQAA7/EwBkAeb/pv5gAGwBhf+O/j4AdAERAHz+dP80AU8A9P5z/7MAmgDy/vL+lACUAB7/ff+LAOn/Ef9m/y4AagDe/8j+iv+mACL/5v4YAR4A8P2f/94APv/I/kYAUACE/0j/7v7M/5gAdP85/0oAHwAY/xb/bAC7AGf/O/8yAC8A1/+7/4j/KgDYAIj/0P6/AAgBIP+G/9MAmADc/xX/MgDIATgAnv6OAEQCvv8w/tIA0AJwAMz9pABgAy0AoP0yAUQD8v+q/gQBJAKYAG//dwCOAfkA//8uABQB5ADS/zsAHgGBAHf/QgBgAVcA8P6Y/9ABBAHQ/RP/fAJZAGT9DABUAlb/UP1IACACxf+g/Vv/vAGWACz+Xv77AH4Bbv78/SQBQAEe/kr+OAHuAJT+hP70AEsAIv5i//gAEAAJ/1T/gv9x/+f/ZADj/+D+Ff/bAEwARP4j/3ABjwBg/pP/wABk/23/FgE6AKT+x/8IAcP/zv5mANQB2P+Y/RAACAINAMD+wQDQAdr+Mv6sAQACVP5j/6QCEgAg/mAAvAG7AEH/zP8WAUcAR/+9ABQB3/9lAG4Ai//l/30AdADzAF8AM/+//4IA/f9MAPkAx/8N/3QAmgAp/1EA7wBm/2L/DQDl/00AIgAt/6oAcwDo/an/3AGN/2L+oQCdAJ7+Rv86ADsAz/8I/+z/dgAn/5D+VwCsAIL/E/8E/2MAzgBm/oT+pAGbAHT9Af84AjwAPP1K/yACSgC4/ab/XAGp/6D+EQCSAbL/5P3UAPwBPv6k/pgC8wAe/u3/XAFEAFT/KACKAU4A/P6lAEYBWf+J/34BAAGQ/+D/wgAjABMA8ACqAOL/IQB/AD4A1wAhAMX/UgEiAfj+Jf+aAZgBh/8J/0ABugFU/l7+gAIsAvT9HP4gAsQBKv6q/ogBOgHE/oT++wBoAaz+Qv4GAXQBtv4M/g0AxAFoANT9Kf+UAToAeP1i/0QCNwAg/pn/zwCP/yb/FADl/4kAmQBe/sT+LAFeAa7+nv5cAfwAjP7M/e4BiAJ8/TL+KAKSAOz8lAC0A3b+qPyEARAC9P2Q/tgBKAER/6L+3P+sAJL/k/8WASIAUP6i/xABFgCx/5z/c/9aACYBWf/G/lYBXgE4/hb+yALqAdj8Gf+AA6cA8Pwt/3ACeAF6/tL+xQCcADoAXAAh/yL/OAFFAGr+bAA4Aqz/5PzA/0wDAwBw/GIAlAMv/8D8PwA4Asb/KP46AJIBg/+U/jIA2AC1/0T/dAAiAXL/7P2vACgCWP8W/jUA0AHz/0r+RwAMAXj/ff/BAPr/wP58AOQAov/D/wcA0P+s/2kA0ADJ//j+DwCSAf7/Ev5+AHQCT/+U/TYBMALw/gP/CAFyAW3/fP0yAGgD8gDM/Pr+GAP/AIT8dP54BJQCyPv8/DQDXAKM/Qz/XAKSANT9SP/IAaEAJf/wAHABaP3A/cQDNAKc/N//aANA/oz8QAKgArD+zv7mACIBTP+k/eb/jAOJAED8FADYApj+tP0EAmoBCP7c/t8A6gDQ/sr+5gF8ATz9fP3kASgCDf+g/gQBmwAG/rr+ogFQAbj+vf/aARn/6PzDAAQDof9A/ZsAcAJN//j93v82AfwAEwBS/vD+0gGgAez+2/8iAY7+D/+GAbsAWgAkAQMAh/9GABX/if+8AVoBfgHpAET9wP1cAwwDvP2w/oACvAF+/gD+qgDoAq4BpP2s/ZQBcAIN/0T+lAIMAlT8DP1EA5QCyP3M/kwCIgGs/RT9OACQBIYBePrc/XAFaAAg+f//gAcOAQj5PP3wA7wBNP0ZAOwDkP7I+oP/qAMYAtT9vP3sAYQBwPsi/mAFYALg+zj9NAH/AJr/rv/6AcgBsPtA+wAEYAV4/AT8GAQUAxj76PoIA3gGEwCw+bL+gAVu/7j52wA4BxkAgPh2/kAG2AAw+YD/YAhCAVD2iPwQCGAEyPmY/BgGygFg+Uj+uAVAAgz95/8mAbz9xv5wAuQCPADI/bL+aQAGALAAwAIYAQD9UP2OAXQC2P5E/gADbAL4+mT8SAQYAuj8OwAsAzT/aPvo/RAE+AMU/UD9NAOx/xD7SAJQBZD9MP30Avv/FPy1ADgEzgFk/Sj8AAGYA7D9tP1IBiwCAPgc/mAGjABQ+3z/EAW8AlD68PoABSAFsPvQ/GAEjAEQ+5T9SAXQBHD6YPpYBhgEoPfo/cAJXAFA9woA6AZ8/Rj68AIgBzb/CPmJ/1AGUgAw+coAYAgDAND3Fv+oBlgCQPps/CAHkAR4+KD70AYgA3D6mv7YBLQBePy8/dwCyAIU/qj9JALcAtr+nPyoAEAF4/8o+on/IAf4AjD5MPyIBqQDCPos/jAG5ACY+qH/yARuAej7JP0wBEQD2PoQ/bAFaAO4+kD7vAKUA8z9JP3kA/QDaPog+YAEKAb4+uj7sAYYBOD4yPn4A+gFIP4w+xgCIAUc/QD7jAIQAxL+Sv5eAUoBwf94/pz/gAIPALT82f+QAkT/gP6qAYsA9P0+/o0A/gCC/vr+hAJyAZj74PwwA+QANPwEANAEtwCo+kz9MAMYAtD9wP9cA6j/WPz3APwD9P6E/J4BIARy/zj8cgFwBST/IPpnALgFlABM/KIA1AM7/3D6E/+oBoQCIPog/9AGPv6A9rgB4ApeABD3mP+gBoT/2PkAAcgG1v6g+SgCUAas/Bj6qARQBeD5gPoABTAE+Pyx/0QD8PtY+TwDyAYI/jD7yALkAwD7gPl4AmAG9P9I+0z/GAIN/+j90AFQAtz8fPxeASgDCAFs/uD99v+iAZD+UP0AAhAEdAE8/mj7wPxYA3AFU/9Y/HgB9AMw/WD45gCACa4BgPhq/vAE0v7w+sADYAdQ/HD2jAEwCY4AWPlTAIAGYv6A9ykAAAnsAoT8iv+N/4D7OP+IBngEQP10/MEAQwBs/X4BQAUmANj7cf96AJT8PwCwB1AEOPlQ968AiAagAoT9G/+gAsP/wPnw+yAGoAhA/kj5HwDYAlj8oPxgB7AIyPtQ9Zv/+AdaAVT8dAMYBhj7oPUoAfAK0AMY+kD+MATM/OD3IAOwCsoBUPp4/Tj+WPxYAVgGsALg/BT8tP2t/zwCKAOnAMj9DP5k/uj9+QBgBQgE1P7w+tD58P5YBngGhQDg/PD8Dv6q/lYASAVIBTT9sPlw/8YB4P7GAVAGFgGw9wD66AXIBlT9UP34A93/QPh+/kgH7ANk/Wb+AwAk/Tz99gGQBRgDFPyI+X//WAQiATj+CAGkArD9aPmc/4AH9AJo+pz9EAQXACD7EAAgBkwCMPuo/IACtAL0/j//yALAAbz8GPvsAEAGXAKU/BT+QAHc/hD9jwCsA+AC8P7o+1D91AD2Af7//v8wAgYAcPuk/TAE/ALk/Yj+BABh/9z/pwCGAQgD7v/o+Xz8IAQQBCH/vP38/2gCFP+A+lv/0AW4AQD8gP7SAKn/GgD/ALcAGf9I/cP/uAPYAeD9iv5bAD0ACwBL/zQAiAKsAXn/jP3s/DABEAX0ACj8BwCkA6r/6Pzd/xQC3P/g/mwCSAKO/lH/JgGY/sj8ZgBYBOwD5P6A+6X/hALg/Wb+wARYAhD86v4gBND/WPoo/lAFlAMo+2j8qAWwBAD6gPnYAzgFkP34/UAEsgGQ+lj90ATIAlT8iv7oBdADWPqI+hgEIAWI/OD7kARYBRD9wPo7AHgCK//s/vQB1gGa/jj8XP4UAlYB/P36/hgCAwC0/LL+XAJ6AdD9/PwnAGQCQwBU/tMACAIW/hz8ZgAYBEoBvP1J/9oB1v8I/UQAmATYAXz8eP1QAlQCxv40/zACCgFI/cD92gGoAhEAqP7E/j7/NwCpAH4ACgGYAAT+SP3w/4QBrAE4ASD/Qv76/2//Mv5YAtgEN/9A+4n/2AJEAD7+7wA8A3f/GPs8/sQDVAKe/nb/kwAy/iT94v8kAm4B8P+E/17/YP6s/QUAHAM4Au7+Nv4P/8D+TQDUAi4BFv4B/74AtP9S/3YBpgEe/xD+e/+lAEoAmgDiAS4AvPwM/vgBLAFY/mIAxAILABz9QP6iAMUADACmAE4B2v8Q/oD/0gEwANz9ZAC8A/8AePzI/ZACHAMD/xL+PgFsARz+xv6YAlwB4Pw+/mgDygEo/KD9kAPMAvj8ZPyeAKQBcP9a/wAB6ABM/yD+fv4dAIwBlgF+AA//rP6j/x8AnwA2AREA+v4cAJgBTAFb/5j99v6cAiQCIv7m/mgDKAKU/Gz8NgGAAyABvP7//54BIv/s/NAA9AMWAAD9YgCkAj7/SP3KAAADav80/Ob+FAPKAYT+ef/eAFr+MP2UAJgCmgCj/+IAFwCM/dD9UgH8AkAB6v5u/koAgAGb/9r+rgG2AcT9Ev6gArAC4v5O/ocAFQBy/mYAKAPeATr+nP19/ycAIQBkAfABHADc/hH/3v49/1wBgAKYAGb+rv6TAEAB+P9c/ycAAAD4/nX/EgFWARIAMv+b/4L/OP4D/ywC3AKV/3j9wv4aAOf/bP+ZACQClQBM/Wz97gDeAfD/TADzABz+nPxnAFgDmQDw/Wf/wAAU//z9mAAQA+MAZP1w/Xn/fQAWAfABpgHe/iT8Ev5sAlwCVf9RAGACGP+I+3r+AAOcAksAz/8U/6D92P40AowCSf/E/fL/MgE4/9L+pgFEArj+5Pzl/1AC1QC4/2gBOAFU/XD8WgFABPIAbP5uANgAFP68/qACpAJO/zr+8P86AakAsv9yAFQBa//g/TEAKALpAPf/VQAO/9D8tv7IA+ADJv6U/AgBFgHY/JD+0ANoAmz9lP1YAC0ALP+YAAQCpP9Q/Nj9gALcAg7/Gv43APT/vP0n/1ADOAOO/rD8Mv8NACr/eAEYBBgBhPxA/WkAFgHTADoB/wCl/1z+Xv45ADAC8AHY/yb+bv5HAEAB3wDuAJIA5v4i/k//yAC6ARwCXAAq/mj+qv9IAGIBTAKpAFD+Uv4MAC4B+gBoAJoAhQDc/kb+3AD0AjwBuv78/joAGwDk/y4B0AG2/7z92v7hAMkAAABdAEQAtv7E/UP/tgHsAcz/TP7M/p7/fv/v/2ABaAFa/xr+JP9eAIMAzADmALn/ZP7C/moAagHuAF7/YP4J/xIA9P+j/zYASwAg/1j+/v45AJUAtf8H/zn/Qf8g/yIARgFbAHD+TP4OACIBWAC5/2gAkgB8//7+EwBAAToBoAAEAIj/rv+iAFwB2ADu/8j/ZwDWAHwAaQD/AMsAsf9K/xQAFAF+AfIA1P8r/x//wP/MAEIBwADs/2f/+P7u/qf/dQCHABEAwf8R/xz+sv5+ANMAgP/S/h//VP9F/1z/p//E/27/C/8f/43/KwCVAAkAEf/y/lz/tv9HADYBHAFx/3D+Y/+JAFcAJwDCAI8AT/+6/oL/RQASAOL/XAAhANT+xP46AJIAif9h/0gASgBi/4b/iwCMAMr/6P+JAKsAtwDGANAA8gDOAKAAUAEoAtwBBAEEAcIB6gFmAa4BvAJYAr8AFgGgAvQBfQByAeACpgHh/5gA1gEEAa//9f/mAGIAHv9I/zEAjf82/nT+Mv+o/tT92P1C/kT+7P2I/Wz9fP1w/VT9EP0g/bj9xP2w/FT8KP1I/fT8aP2c/dz8hPz4/Fz9YP0k/Qz9YP2Q/YD9rP0g/i7+9P0I/pr+Vf+i////RgACABYAUAF0AmgCNAKwAiwDhAN4BHgFYAXIBDAFUAaoBoAGKAcQCKgHYAZwBrAHIAi4B6AHWAdoBuAFIAZIBgAGYAXABJgEQAQcAxgCFAJgAt4BiwCy/+r/gP/c/Rz9uP1M/Yj7EPss/OD7iPkw+DD5uPko+ED3aPgA+UD3kPUQ9vD2cPbg9XD2MPfQ9oD1EPUw9kD3EPew9oD3UPjA9yD3iPhw+nj6CPog+5T89Pwo/Vr+vv9CAJ8A/gF0AwgEuAQoBjgHaAfABxAJoApgC5ALMAzgDAANsAzQDAAO8A4QDiANgA2wDaAM0AtQDJAMEAtACQAJQAkACIAGcAY4BiAELAJ0AsACCAFL/zb/zP7k/Oj7vPyk/ID6CPm4+ej5UPhw97D4MPlQ9/D10PbQ9yD3kPZg9wD4APcw9jD3uPh4+ID30PfQ+KD44Pe4+KD6APtw+ZD4cPk4+vj52Pmo+uD6APrA+YD6uPoA+tD56Pro+6D7UPsY/ND8jPyA/Iz94P7c/7oAZgFuAWQBcAIYBBAFsAWoBsAHIAgACGAIcAmgCiALgAvQC/AL0AsADAAMsAvQC1AMcAzQCzALwArwCUAJUAlgCWAIoAewBwAH+AS0AxAEIAT8AuwBsAEoAbP/yv7w/pj+cP00/dD9PP2g+wj7oPtw+3j6kPrQ+9D7QPqQ+WD6uPoY+kj6gPvA+6D6KPow++j7OPvQ+tj7lPzA+xD7LPwE/bj7gPpg+2z8yPtA+wD8yPuQ+UD4sPnA+rD5WPlA+mD58PZw9iD4+Pig+ED5sPpQ+pD4qPhw+oj7UPwW/nD/MP/M/v//sAFUAigDSAXoBqgGwAZQCHAJMAmACTALEAzQC3AMoA1ADbALcAvADEANkAyADAAN4AuwCSAJ4AngCcAIAAjoB+gGCAX8AygEyANgAlwBGgGXAF3/Rv7U/TD9PPzI+8D7kPsQ+5D6+PlI+fD4APl4+Qj6EPpw+Rj5UPmQ+bj5YPpA+3D7EPtQ+yj8TPws/Mz8rP24/Xj9Iv7y/n7+nP0g/tL+YP7U/Sb+bv5k/Uz8cPyU/Gj7ePoo+0j78Pko+cj5cPkg9yD2GPjA+Qj5gPgg+dj4kPco+Nj6bPww/JT8BP5M/qT9rP5yAQwD9AK8A7AFiAYIBngGQAhQCXAJQArQC0AMcAsgCwAMgAwQDDAMIA1ADTAMIAvwCvAKYAqwCcAJ4AngCEAHMAbIBQAF0ANwA/AD6AKtANT/8v+2/iz9IP3o/WT9oPvw+lD7sPp4+bD5mPpI+oD5mPko+tj5SPnA+aj6yPrg+qD7BPyQ+6D7hPwQ/fT8dP18/q7++P3Y/Zz+uv4k/jz+2P6C/oz9OP10/VT9TPxQ+1D7QPtA+jD5MPl4+Yj4MPdg90D4cPfA9eD1gPdY+GD4SPnY+ZD4sPdw+Yz8QP5I/or+xf8MALj/WgFIBAgGaAaQBigHAAiQCFAJ0ArQC7ALEAwgDcANYA3ADLAMIA1gDWANoA3ADRANwAuACuAJ8AlwCnAKUAl4B+AF2AQoBLADfAMcA54B2f8S/1L+AP1Y/Hj84Pto+rj5IPoA+pD4gPfg9zj4APgY+OD4CPkA+HD3UPh4+cD5APog+/D7MPtY+sD7uP3c/TD96P05/+L+CP7c/vj/UP9o/iL/+P9E/wT+3P0m/kT9NPx0/IT8WPsg+sj5sPlI+cj4iPhA+GD3oPbA9hD3APho+eD5CPkQ+FD4wPnY+2D9iv5M/yb/1P6j//oBOARgBdgF2AbAB2AHwAcgCtAL8ApgCoAMcA6QDVAMcA1QDqAMwAsADqAPsA2wCwAM4AvACRAJ8ApQC8AIyAbwBigG0AMMAygE0ANmASgAhgBv//T8MPz8/Hz8wPpo+nj7uPpY+ID3oPjI+ND3SPio+Yj50PdA97D4sPlg+dD5aPvA+8j6oPrw+/D8vPz8/Ez+9v4o/tT90v5s/7r+Kv7i/on/2v4A/hz+8P24/AD8dPyQ/Gj7OPoA+rD5YPiQ92j48Piw93D2oPaQ9qD1EPZo+ND50Pg4+GD5yPkI+bj61P5kAOD+nv7NABgCAAKgA8AGyAeYBkgH0AlQCkAJUArgDDAN4AugDOAOsA5gDCAMEA5QDvAMUA2wDmANcArgCXALQAswCdAIwAmACIAFYAQYBUAEIAKYAUQCLAGg/oj9yP3Q/ND6YPpg+wD7OPl4+KD48Pfg9jD3MPho+ND3sPco+PD3kPco+FD5CPpg+qj64PoY+3j78Pu4/ID9Dv5w/sz+3v7C/tb+Rv+8/8j/uf/M/2//rv5s/nr+7P0w/TD9NP0Q/LD6kPqw+nD5YPgg+ej5qPjg9hD3kPeg9oD2QPlY+5j54PdA+Qj7cPrA+pr+pAE2AC7++v+UAtgCcANYBnAIWAd4BqAI4ApgCqAJUAtQDUAN0AzADVAOQA0QDLAMEA5QDsANkA0ADYALMAogCsAKwArACcAI0AdABsAEOAQgBGQDCAIqAbsAnf/s/fz8kPyw+6j6gPrI+jD6wPgg+Cj4cPfQ9pD3uPiY+MD3oPco+CD48PcA+Wj6sPqY+ij7wPuw+7D7pPzM/Vj+tP5i/3z/AP/8/o//+//3/xgAawA+AE7/qP60/qT+JP6Y/RT9nPwM/DD7UPrw+Xj5qPhA+Kj4yPig9yD2APbA9sD2QPew+RD7QPkw9yD48PqQ/BT9sP6JACoAD/9NAPgCWATQBGAGUAiACMAHgAiACnALAAtACxANUA7ADQANQA2ADQANwAygDZAOIA6gDOALYAtQCoAJAAqQCrAJ0AdYBngFiASYA/gChAKkAYgAdP9g/jz9RPyA+7D6OPoA+nj50PhA+KD34PZw9qD2UPfA96D3kPeg93D3gPcY+AD5APq4+vj6GPtw++D7fPw8/Qb+sv5I/+b/HQDW/6//MwDoAAIB7QAgATQBkQDG/6f/rP8V/2b+WP4o/iz9JPyw+zj7OPpg+aD56PkY+Wj4cPjg95D2UPag91j5KPoY+sj5YPkA+Tj6DP3O/vz+Y/9lAPQAAgEgAqgEcAZwBqgGUAhgCTAJwAkQC6ALUAsADOANkA5QDYAMEA0gDXAMwAzwDfANMAzQCoAKEAoQCeAIUAmACJgGSAXABOgDnALGAYIBugA3/1L+Cv4Q/ZD7oPpg+vD5MPnA+AD5yPiQ96D20PZA92D3kPcw+Ij4CPig91j4YPmw+RD6CPu4+7j7sPuI/Ij9xP3Q/Z7+hP/C/9H/EABRAEAAGABeAMgAswBWABcAyv9Z/+b+jP4i/oz9+Py0/Ez8WPtw+gD6gPm4+GD42PgI+Sj4MPfg9qD2kPYI+Fj6+Ppw+Yj4yPkI+3j7EP2x/58AwP/q/8wBIAN4A8gECAfIBzAHMAiACjALIApAChAM4AygDFANkA5ADoAMAAwQDXAN8AwwDaANgAxwCpAJ8AngCQAJYAj4B7AGCAUwBNgD0AJSAaYAeQBh/8T9+Pyo/Jj7KPqA+XD5CPlQ+Dj4QPhQ9zD2YPZA92D3UPfA9zj4GPjQ91j4UPnA+Sj6CPu4+8j78Pu0/GT9xP0m/t7+kv+8/9X/JgBoAFYATACdANMA2wCpAFgAEgCq/yr/tv6Y/lD+mP3M/Hz8OPxA+zj68PnY+VD56Phw+Yj58PdQ9hD3qPjQ+Pj4iPp4+0j64Pj4+cD8HP54/tr/KAF5AB8AEAJ4BIAFgAVQBgAIAAkACXAJcArACgAL4AvQDFANcA1ADdAMQAwwDLAMMA0gDbAM4AugCqAJcAmACeAI+AeIB9AGSAXIAzADzALAAZEA6P9p/2D+KP2U/PD7sPqg+bD50PlA+bD4WPgQ+JD3QPeg9xD4MPhw+PD4EPn4+GD5APpg+tj6mPuI/OD88PxU/Qj+Sv5e/iP/+v9RAFwAjAC2AHsARQCJANUA1QDRAOAATQBD/9T+DP+s/pT9SP2w/eT8IPt4+uD6OPq4+KD4uPlQ+VD38PYg+KD34PWQ9mj5mPqY+ej4gPnw+dj5ePu2/iMAUP9e/7gAhAHoAVQDuAU4BxgHKAeACJAJsAkwChALkAsgDPAMkA1wDbAMcAyADFAMoAxQDSANEAwgC4AKsAngCMAIIAlwCLAGiAUwBTAEoALsAdQBJAGI/zz+AP6A/ST8IPvQ+jD6OPnw+DD5CPkQ+ED3cPew94D3kPcw+Hj4YPiI+Dj5yPmw+bD5oPrI+0D8cPz8/ID9mP2w/Wr+Rf+a/9n/kwDsAFIA2f9YAP4AAAHTAOcAwgAYAJH/lf9B/3D+HP4k/pD9fPwY/Aj8GPu4+Vj52Plg+YD4wPgA+aD3UPYA92j4gPiQ+Fj6iPvI+UD4aPpI/dj9Iv4lAJABhQDq/3ACWAVoBTAFaAdACXAI0AewCdALYAtgCsALsA0wDfALkAwwDTAMQAsADAANYAwAC5AKUAogCSAIYAiQCKAHMAYQBVgEiAPEAlACvgGtAHb/hv7c/VT9yPwg/FD7iPro+aD5cPkg+cj4iPhQ+DD4OPho+MD48Pjg+CD5uPk4+pD62PpQ+7j78PuA/ID9DP78/UL+/v5r/2r/4v/MACIBtQCnAC4BNgG2AM8AbAFCAUcAFABzANb/hv4o/pb+6P2c/IT8IP0c/Oj5cPkI+mD5UPgA+fD50Pjg9uD2CPjw95D3GPnw+mj6KPnA+Wj7MPzQ/KT+HQD8/6j/+QDoAtQDaASgBfAGSAeAB5AIwAlQCmAKwApAC9ALYAywDLAMUAzAC6AL0AsgDFAM8AsQC/AJAAmwCKAIYAjQB+gGqAVQBGgDFAO8AuoB7wAMAPL+1P1U/RD9SPw4+6j6iPoQ+lD5+PgA+ZD44PcA+Kj42PiQ+ID40PgA+Qj5qPno+nD76Prg+tD7oPy4/Pz8IP4C/4L++P0Z/2QAOQCm/1gAMgFuAID/ggDKAe0Agv8WABIB5/82/qr+5P/O/sj87Pz4/Rj9CPuY+mD7uPrw+AD5aPr4+fD3YPeo+BD50Peg99D5QPsA+ij5uPpg/Dj8VPyE/o8ACQAT/8wASAOwA5ADcAVwB+gG0AVYB/AJMArgCMAJwAvQC4AKEAuADAAMgAqgCgAM4AuAClAK0AqwCcAHeAdgCDAIqAbIBZgFKAQ4AtwBeALuAWgAoP9c/0L+cPzo+4D8DPzA+pD6KPuY+mD5APlg+Tj5kPgo+aj6sPqQ+Xj5KPpQ+jj6MPu8/BT9LPws/Ej9hP0U/QL+o/+2/6r+vv4LAH4Arv+N/5YAxADp/wIACgHoAK7/Nv+4/7P/2P6U/ir/5P5w/WT8bPyA/Oj7WPsY+6D6uPko+TD5UPko+cD4ePh4+JD40Phw+Rj6aPpw+pD6SPuU/Pj97P6L/+z/DQCrABQC4AM4BfAFMAZwBugGoAfwCEAKkApACpAKUAuQC5AL0AvwC5ALAAsgC6ALYAuQCiAKkAlgCLAHAAj4BxAH2AXwBPgDvAIAAhwCzAGVAK3/If/0/bz8bPxw/Nj78Pqo+tD6aPpw+Sj5ePk4+bj4APn4+Wj6CPrI+fj5+PkA+vD6NPyw/Gj8OPyk/Az9CP2I/Y7+/P62/rD+Gf9w/2H/Mf+t/w4Ahf8h/9b/XgCC/3z+pP49/77+yP0a/rj+2P1w/ED8iPzQ+/j6aPvo++D6oPnY+Xj66PlI+eD5gPoI+qD5iPpo+2j7kPtY/PD8FP3Y/XX/eAB4ALoAtAF0AtQC1ANwBZgG2AbYBkAHsAdACEAJMApgCkAKQApgCoAKoArACqAKUApQCkAKsAkACdAIUAhAB6AG2AbYBsAFiAS8A+QC9AF6AYABDAELABb/Xv6g/RT90PyM/Cj8qPsQ+5j6sPrg+oD60PnY+Yj6yPqg+vD6SPvo+oj6OPtE/Jz80PyA/bD9/Py4/LT9xv7u/uj+N/9g/zb/W//g/wMArP95/+L/KADI/6f//P+z/7L+NP5m/oj+eP5W/rD9kPzY+wT8NPy4+0j7WPvQ+rD5kPlQ+lD6uPnI+Tj64Pmg+bj68Puo+yj7BPwk/TT9lP0B/y4AUACMAIQBNAKIApgDGAWYBTgFoAXQBpgHuAcQCLAIAAnwCPAIIAnACRAK0AlwCWAJIAlwCHAIAAnwCMAH2AbYBmgGCAVABNAE2ARMA/oB2AGaAXgAdv9j/2f/ov7U/bD9YP1k/Mj78Pvo+4j7cPug+2j7CPsI+/D6iPrw+kT8kPyI+0j7FPxU/PD7iPzU/RL+TP1Y/Qz+4P2c/eL+LAAc//D9A/8zAGj/iP72/vL+Qv5s/oH/4v+Q/kj9YP2c/eD8vPy8/ez9xPxY++D6aPsE/Pj7iPs4+yD7IPvA+sD6kPss/Mj7mPtA/Lz88PyQ/Wj+Tv7Q/bj+PADwAO4ARAHEAcQBAALoAggEcASABPgEeAX4BGgEyAX4B5gHoAUgBlAIIAhgBtAGwAhgCBAGQAbACEAIwAWIBnAIWAaEA9gESAdIBqQDTAOABIADRAFwAcwCBAJeACcAMADe/qz9Ov48/5j+4Pxw/BT92Pyw+1D7GPy0/Fz8SPvQ+mj7yPuA+9D7hPw4/Ej7IPsM/BT9iPyA+6z8Tv4Y/TD7KPyY/pb+HPxQ+6T92P5k/Sj9Pv5I/bj7sPx8/pz+mP30/Bj9JP2o/LD8yP2w/g7+pPxQ/ET98P2k/aT9Lv4S/qT9hv56/7T+Wv6k/ygAOv/S/xACnAImAdkAcAKkAqQBEAOABbgEtALEA7gFsAREA3AFIAh4BrgD0AT4BjAGSAUAB+AHiAX0AwAG0AdABngEmAWoBhgFfANIBMgFIAUsA1QC6AJAA7ACIALAARQBJQCB/6L/4P9X/5L+QP78/Sj9LPws/Mj8yPzo+wD7GPsQ/Bz88Ppw+ij78Pow+jj7zPwE/HD66Prg+5j7WPts/Iz9LP3w+/D7XP2E/UT87Py6/gb+gPxc/br+4P3Q/PT9TP8I/lT85P3p/z7+OPyk/Sv/KP5g/Zr+Wf8C/hj9Iv7a/vD98P2T/9n/aP70/Sn/OABaADMAAgA5AAQBkAF+AeIB8AL8AmQC+AIIBAgEIARQBYAFUAQ4BMAFEAdABzAGgAWIBngHkAboBQgHUAeYBrgG+AYABtAE8AWoB/AFiAIUA1AGEAbUAsgBVAOgA/IAI/9IAeQCBgCk/ez/swCo/Jj6fv5EAWj80Pf4+6kATPxA99j6RP4g+uD2iPqU/Vj70Pko+7j6MPhY+MD7uP3Y+1j5qPkY+1j7iPsM/BT8FPwE/Ij74Ps8/Rz+JP6k/WT8+PsA/h8A1P9K/uT9QP5+/vD++P+YAFcAcgAuAHD+sP1uAJwDQAPmANj/FwCrABACgANQAzACKAIMA9AC9AH4AjAFWAVsA3ACXAO4BHAFcAXIBJQD/AJABAAG4AW4BHAEuAR4BHgDMAOgBMgFiAQIA/wCAAOAArQCvANgA3ABvADWARACuwBgAH4BggF3/9T93P6CAPr/Tv60/dD9VP3s/KD9sP7k/VD7wPqY/Az9SPsg+yT9NP2Y+mD5gPuQ/Lj6CPoU/Mj8aPrg+cT8xP3Q+nj5pPxu/hD8SPti/pz/BPxI+hD+/gDo/oz8bv5eAR4AqPxU/eIBbAL8/ZT9NAKoA2D+gPscAsgGe/8I+rgDcAnc/bD4gAWQCRz9ePtQB6gH8Pxk/agHYAfU/Dj8sAhwCoj8ePsACvAJoPsk/BAJkAl4/6T9MAVACKgBQP1cA3AJ7ANc/BABIAkgBcj7rP4wCdAG+PrM/EAJUAcQ+0z8UAawBPj7HP2IBUgEIPuY+/gDVALI+Vz8eAScAcj5ePqfAOsAgPsA+1UAhgAA+jj5RwBvAJj52PmJAJsAsPkY+dr/VAGw+nj4J/+AAXj7MPrR/5UAYPvI+q//XwCE/Gj8MgHgAQz8OPpCABQDFv50/YwCYgE0/dD+dgFzAJj/JwAMAdwBLQA6/u8AGAScAez9Pf/YAmQDgwAF/2gC9AOy/1D+SANYBND/VwB4BCwDrP78/sADMAVsAZb/UAK8Atb/WgFABBAC0QBgAjIBTf/4AZAEMALb/+3/8ADmATYBcAAAApACuv+E/vgA3AEUAPH/hAB4ACcA7P7K/toAFgEq/sj9kf+C//7+A/+s/lj+Fv7s/Z7+bv6k/Wb+Cf9k/eD8nv6A/vT8rP3h/2b/dPwU/IT/EAHA/Qj8yP/7ADz9QP18AAMAPv7u/pf/IQCO/3z95P8oA+r+mPuRADgD4P5U/rACSAJo/Sj9FAJoA+P/Df+QAmADsv74/DwCGAUhAEb+AANAA1b/8P4cAvgCGAFQANgBBAK+/xoBGAM+Adn/nAAgASAC4AFO/w0ACAMeARz+9f+AArwBV//W/0gCCgDE/AwBGAXf/yj7lv8ABYgCDPxo/GQDQAOs/AL+fAOAAWj9Vv9kAjEAAP0e/yQDuAHE/Vj+twB7ADj/sv6X//cAJwBy/sb+4v/I/1//Y/9z/xP/ev4l/+kAn//k/C3/wAEH/xz8Bf9MAnf/NPwE/gQC1/+w+3H/pAIw/lD7uv/0AnH/yPtS/hwDDAGI+wz+bAMsAfD91P50AEYB4v4w/awBYASu/jz8VAL4A2D+1PwMAngEeP8c/JYByAXe/3j7/AEYBmr+OPuUAyAGov60/IACAARz/6D9lgGQBLIAAP29ADQDBgCT//oBXgEnAPD/bv/1/xgCtAEK/+L+uABQAfj+iv7KARQCcv4C/sMAUQAe/+IAqgDc/Q3/EgF7/9b+OgDPAO7/wP1Y/iQCjQB8/OL/MANK/kT80ABwAvP/CP1e/mYBcv9U/RABzAK8/Kj7pAFkAhT9KPx4AsQDwPvI+RgDMAXY+yj7UAQAA5D5pPwIBpQCMPoY/XgEKAEI++r+WARCAKj7rv8IAjT+zP5wAoIAVPz4/TQC4AEW/uD9RALyAdj8kP3cAwQD5Pwk/qgEigFA+qMAIAiWAYj6Y/+IBTQCnPyu/wgGYAKo+5MA0AUpAFD9aAIgA2D/of/yAYACUwBm/p8AhAJZ/7T/1AKvALb+1f+GAGUAcQDa/10ADAE1/3r+vv8QAToB4v78/FYA+ALA/oD8wgAoA5T96PqMAsAEJPyQ++ADGAKw+nT9MAWEAsD6BP3wA1ABePv4/qgE2QBA+/j9cAKCAST9tP3UAkgCkPzQ/DQCcAIo/pj9z/+CAKUAlv8c/6oA5wBE/gr+DgDPADgBTQAG/ub/9ACk/fz+WALAAEL+kP+BAMD/8//U/7H/p/+7/4IBOQCo/ZIByAOE/dj76AIoA17+HgBcApwAbv64/UcAWATWAQj9aQBEA5b+1PwMAoADoP8Q/hYAdAKSAeD9gP1EA5QCoPuQ/ugFgAFw+7r+RAI6ATj9QP0ABEgEwPqo+yAFzgG4+lb+3APGAcj8aP3UAdoBzPwo/QgDwgFE/dz+bAGz/zX/xwBs/9z/hAFS/5j+QgG4AdL+2P6vAHgBjgG6/lj+lAJ8AeD84v8gBN//tPwEAXQDTP/E/DIBUAOG/sD8fgE0A8T+EP0qAdACmP04/EADLANU/KT9/gHHACz+vv7DABwBRv/c/TIANgFs/0T/mf9JAJwAs/9o/4wA0gD2/9oA/v9q/n8AeAJwAJz+GAGKAez+JP/AADQCuQCQ/cj//AOd/yD7AAKQBaT98PvsAgwDuP1m/vwBBAJo/zT9egBIBDj/6PooAhAGiPzg+SgE2AT4+4T8HAMIArT9wPznAJgEWv5w+uwCgAQQ+oD8CAaIAQD7+P7oAj0AVP6g/wgBSQA0/iH/RAJdAFj9igAcAhr+3P2EAVsA0v6MAUgAqP1z/9UAPAAKALz/lgD/AG7+7P5UAk4BUP23AMwDAP4Q/YQDYAKg/N7+9gEGASAAYP0Y/+AEAACA+eUAaASU/HL+AAT8/jD9CwBy/zgB4gHM/MD+mAQ9/4j7kgGAAhv/qP9i/17/KAKMAD7+igE8AQz8j//IBOj/nPw2AWwCvv5M/Yn/CASKAZj7s/9wBGr+GPxgA5gDLP0A/qwC9AG1/wL/iv+oAWoBiv4OAEADDwAS/gwB2f/s/QwD5AEI/fYAFAH0/KL/MALA/kQAYwD4+7wBaAT4+XD6QAdEAyj4Hv7YBML/hPxR/2wCuwBg+5j8eAa4BJD3hPwACbIAMPe3/7gG/ADo+8z+hAKkAXD9AP2YA+ADMPss/OAE1ALo+jj9UAS4AhT9MP14AeQC0P0w/VADNAE4++z/0AX0/lj7lAH8AXz+mv9lAAgAVAE0/7z+OgHo/iD/xAOAACj85gEYA/z8fv4cA4IA7P26AAQC2ABf/97+kQDuAWX/GP6QAjgDVv7c/iQCwv6e/lACbAGdAGn/cP4gASwCQv58/tACBgHc/cn/SgFhAJ7/Kv8SANkAZ/+b/x4B3f9W/ikApADo/oUA6wAf//z/a//o/VoB3AL4/MT91APP//j7AAGgAvj9tv7tAFUAiAA+/qr+SAOJAEj7igCwBEz+GP3MAqwAHP4/AFIBnAAt/3T/jgA0Acv/Bv/L//8AtgFc/7z9ZgDoAc3/iv7UAJwBcv43/0YB/f/8/jAATQD0/34A1v7P/wwBav6q/2wBtv6w/kACDABY/HgAQAPM/nT8IAF0Av7+uP4fAEAAJ/+Y//4AmwA///j/cAEd/7D/wgF4/jv/nAJoACD+9wBsAlv/PP2e/4QDAgFQ/Hn/eATL/8D7kgBYAiT/gP74ADgAWv/7/5T+TgCUAsj9sPvsAiQDZP28/ToBsAGK/jD++P8KAaIAX/+w/5n/ov8rADoAQgEc/6j9hwB4AaMAjv9a/gAAfAI6AMz8GgCwA0kAMP1CAYwCSP1R/0gD7AB4/dT/uAKcAeb+MP2GAZwCPP2l/0gE1P7Y/OoBKAL0/Rr+XgHwAsAAWPwP/2AEdQBo+wYBwASi/rD8GALYAu7+cP08AEwD4wC8/Fz/QAUvAPD6swAAAwH/XP7nADIBmgFi/6D7sgCoBBr+oPyoA24B0PzS/+0AzADlADD/CP8iAZkAGP/XAG4ANv+9APH/p/+JAPH/NgApADL+Qv8kAi3/cP14ApoBaPug/aQCyAC2/lD+Ev40AlIBuPoi/uAE9v7A+dkA8ASi/tD6B/8IBPUA8Pnw/kAHKAGo+AT/eAb//zj66QBoBo7/yPrRAJAE7v6M/AwCvANW/8j8kQBkA///LP1MAGgCqwAS/5n/egFGAYb+Vv4cAuIBTv6o/7gCpwDs/QD/9AF0AUz+BwBYAvL/5P35AIQBVv5z/3QB0QDY/Q//dAPzAKj7OP4ABJgAiPyIAFACkv8Q/pr+4gBoAVb/Qv9yAOv/3/+3/8T9XwD0A9z+sPsqAcADev5o+zIB8ATC/sj5/AA4Bej9OPtgAogEWPxY+sgCqAWU/Rj7wAFMAgT9nP0UA0wCWP30/c4BXwBg/TIBQAOO/lD93gHeAZT9of/EA+oBKP2k/b4BRAILAMz/HgFxAGj/YP///2wBJAIm//z9NAEoAmz+LP0wAiAEOP8I+z7/yASnABD8/gC0AwT9CPtgAkgFvP6g+gQB8AUM/QD4zAPYB+T8iPq0ArQBEPzv/xAFWgGQ+0b+8APmAVD98P8UA9f/LP52AH4BdgFUAQ8AEAD+/2T94/94BMwCHP44/SgAtAJp/yz8+AJ4Bej7sPnIA8gE2Pv8/OAEUAKo+CD7yAeQBYj4APswBtQBQPhT/9AHuwDQ+Bz/2AQJ/zz8JgGAA+7/XPyc/VgCEAOo/hb+wgDeAND+rP3bAGAErwCo+sL+8AScAOj7lwD0AyT/VPyeANACbwCy/kv/ygC2/yL/AQBMAJYAsQB0/wz+gv8uARsApv60/3ACcAAo/J7+RAOqAXj86P3kAygCuPtw/XAEAALY+7j+PAIMAAv/zADDABcAL/8M/Xb/WAPuACT+1P5s/0QCVAHA+3b+iATGAAD8QwDQAjoAUf+U/0IAXADM/k0AVAPoACT9Zv+2ARsAJABzAEkAqQDB/3QAPQD4/UEAKANl/4D8aAGwAwv/uPyc/zgCsf+k/XwC/AJM/Xj9ZgFQAKD9iQBUAwQCAP4I/EYBWATA/fT8aARIAoD7T/+gBQIBOPvs/UAExAPI/B7+4AXEA7D5GPtIBtAFwPwg/ugEZgEY+mz+KAekAwD78PzoBOgCkPrc/KAFZAMA+gD8QAU0A3D75PzCAdr/SPzL/zADFQA8/TT9qP7M/zYAJgD0/4T/OP4G/uT+aABCAeP/+P3Q/tUAIwCs/pQAAALI/rT8EwBQA/EAMP6R/xYBmP8q/ukAWAO2ABj99P1EAXgBxv9UAKABBgBk/Vz+8AH0Aa//sP8HACP/ev+aAN8A0ADR/zz+5v4aAcEA/QBwAXT+EP2gAI4BwP6uAOQC8v7g+1r/bAL3AKb+f/+QAX3/cPyP/4AEyAEs/Zr+bAHP/6r+bAGIAggAlP47AGwBJgDa/qUAZAI+ANT9OgC0AgYAov7tAJAAAP5l/ywCRgEf/3X/xf/s/kH/ugBQARgABv+r/4r/fv5PAFgCxv/4/P//aALW/6r+ZQCbANz+7P7pAN4BrQAo/4r/QgDs/qL+ngFkA3AAKP2w/dYAjAIVAJr+ugAeAQz+KP7oAQQCcv5g/gACPgEo/TL+IAPAAtD9FP2PAK4BYQBoANAA7P8Z/+j+lf8AAdoBIgHW/9D+/v5IAFQAwwAEAkAA6P1R/+YBkAF8/3b+Vv+EAYgBPv9q/+YBAgG8/RD+uAAQAjgBe/+F/5EACv+g/QgBNAOJ/xT9AQDsAc3/Vv43AKABz/8O/pb/BALdAPb+GQC1AKL+hP5gASgC4v/u/vr/GgBT/3n/vQDcANf/Sv94/xAAdwCd/zn/fQBZAKr+Vf+EAcMApP64/mYAVwBE/zEAKgHo/zz+Pv/nADwAX/9wAMEACv/2/mwAPgBL/9D/qADv/xz/pf9/AAoALf+t/1UAvP+c/5EAcwBH/zn/KwBbAJf/Ov8MAHkA0/+h/zUA6P/+/oX/OwAsAB0AAQCQ/yH/uv9mAPT/8v9CAJT/8v7f/wgBbwC3//r/NwDZ/4D/RQA4AY4Aa//H/4UAdgCpAOYAeQCf/yX/3P84AXYBXAAJAFwAuv8k/x8AVgEyAX4AJwDG/3X/BAAkAUABGgBz/0EADAGAAAEATQBaAMH/qf97AOkAeADq//b/6v88/1f/wgBuAUIAFP9W/83/hv/f/6oAEQAP/zD/6f8WALz/XP+Q/+b/RP/6/goAYQCU/z//Uv9O/z//2f/uAKgAnv4g/hwArQBm/63/8QA6AMb+Mf96AJMA0f/m/7MAHwDg/pr/cgEmAVf/K/9dAKAA6v8xAD4BmADQ/hX//gA6ARgAUQAcAQoApv6J/x4BHAFUAPv/+f/W/97/OQCaAHQABADb/+P/CgB9AIEA/P/7/wIAyv8fAJ0AhgDr/9n/3//W/x0AbQBXAPX/tf+b/73/5v8nADUA5v9U/zT/s/+0/3r/zP/m/xf/uP5x/8//Xv8D/1j/m/8p/wL/s/8UAF3/9v5u/6X/hP+5/x8AEQCI/0H/nP8HAEIANwAUAP3/5v/N//j/VQBuACoABgAEABMAKQBcAJQAXwAfACIAWwCGAI4AdABGAEMAbQCmAMAAhQBHAE8AOwA0AKkAHgG/AEUASgBBACIARwDDAAYBfwDI/+D/XAA9AOf/HgBmAPb/gv/B/woA2f+F/6b/s/9j/1r/v//5/1v/1v49/4P/Wv9r/9r/6f9d//D+Of/I/7P/w/8NANr/Yf9q/+D/9v/a/+7/JQD+/53/zf8oAOT/pv8JAEgA+v/D////XQAiALn/IADMAKQAJQBeANsAywCfAOEAdAFyAd4AFAGeAcQBegF6AfQB+AGoAXIBxgEMAq4BaAGkAdYBYAEMATwBRAH5AHQAZgDAAF0Axf/2/zoAgf/o/mb/jf/8/qz+9v4W/17+Iv6U/nL+4P3k/W7+FP5s/YD93P1Y/cz8cP3o/ez8NPzw/Aj9EPzw+xT9QP0E/LD72PxM/TT8DPxc/Yz9vPz4/I7+rv6U/Rr+bP+N//r+OQCeAWAB0QBgAXgCnALAAuQDAAXQBFgEEAXgBdgFKAY4B8AHeAdIB3AHEAgQCMgHMAiQCBAIyAfYB5AH6AZQBkAGKAaIBQAFkAS8A5gCyAFAAeIAngDm//j+Fv4w/YT80PuY+6D7APtA+gD6oPnA+DD4gPjg+Fj48PeI+Kj4cPcQ99D3IPjw90D4yPig+OD3wPdw+LD4aPgg+cj5CPm4+Jj5APpA+ZD5CPsg+0j6mPok/Gz8OPvA+/T9gv5c/Rr+TgCZAID/jgBAA9wDEAMIBJAGqAZgBTAHIAowCvAI8AnAC9ALUAvQDJAOcA0QDCANMA6ADfAMkA1gDSAMAAvwCiALIAogCWAIcAcgBmAFoATEA9ACfAFRAHj/0v6w/cT8QPyg+4j60Pno+YD5gPgo+Jj4SPiA9+D30Phg+DD34PcY+XD4sPfg+Cj6gPlY+Bj5WPqw+cj4+Pk4+zD6SPkg+rj6CPpw+TD6CPto+tD5SPqw+oD6SPpw+uj6YPuA+2D7kPsg/CD8FPyE/Ij9Bv64/dD9xP74/mb+DP+ZABwBngDiAAgCbAIMAuACyASABRgFMAboB3AH+AZACBAKwAqwCoALAAyAC2ALoAyQDTANQA2wDQAN8AvwC0AMkAvACoAKAAqwCIAHUAeQBiAFKASwA/QCtAEIAWEAJ/8K/qj9WP3I/Dz86PtA+0j68Pkg+uj5oPmo+bj5MPnI+Nj4KPl4+WD5iPng+dj5ePmI+RD6UPow+hD6aPqo+kD6wPlA+uD6YPrg+TD6APug+qD5qPmg+oj6kPkI+jD7yPqA+dj5WPuI+4D60Ppc/Gz82Pow+0D9WP0Y/ID8hP5Y/oT8IP0o/+r+SP2O/h4BzgAx/zwAaAJ6ATEASAPQBvgFeAQ4BqgHSAZgBgAKkAwAC9AJAAyQDGAK4AowDtAOgAwADJAN4AzwCbAJ8AtQC5AIUAhgCbAHoAToA/gEKAT8AfgBkALpADj+oP1+/uT9kPys/Iz9iPyg+hj6uPrg+lD6YPoo+xD7oPnw+ND5cPoQ+gj6yPoQ+zD6ePkg+sj6cPo4+sD6+PpI+gj6UPpQ+gj6+PlA+pj6SPrI+Rj6CPrA+QD6mPrY+qj6oPrY+vD6sPpA+zz8fPwc/CD8uPzg/KD8HP1i/kz+qP0K/qr+gv7c/YL+7P8YADj/zP+EAfMAx//bAGgDaATIA9AEmAbABfgD2AWACUAKQAkQCkALAAqgCNAKwA1wDdALQAxADbAL0AkAC1AM4ApQCcAJ8AnwBwAG+AUgBqgEmAMgBPgDDAI2ALL/f//K/qr+C/+O/mj9UPyg+2j7sPvQ+9D7mPtA+/j6IPrI+dD66PpY+uD6cPuI+uj5CPqQ+oj64PmA+jj7ePqQ+fD5GPqI+Zj5SPpw+qD5gPn4+Yj5APmY+YD6IPqY+Wj66PoY+sj5MPvw+0j7KPtk/PT8CPzg+0j9+P1c/bD9lP5o/tT9yP1U/ub+F/9b/5D/qv9UAKoASADdAJACWAOQA7gECAbgBaAEkAX4BxAJcAlQCjALYAowCRAKkAwgDVAMoAzADMAL0AqwCgALAAtACnAJIAkwCBAHQAZIBcgEcAR8A8wCtALWAQAAyv7Q/ir/nP4I/gD+aP04/ED7WPvA+5j7mPuY++j6OPoQ+tj5KPrw+rj6IPoo+mj6IPpg+aD5ePpo+rj56Pmg+vj5MPmI+VD6KPqQ+TD60PpY+pD5uPl4+sj6sPq4+oD7iPsI+wj7uPus/JD8VPwg/cj9YP0A/cj9jv6A/kb+2v66/wv/Uv76/lb/H/8d/93/PADs/9X/TwCqAIEAfAE0A8ADGAS4BLAEOATwBAAHoAhQCfAIQAlwCUAJAApgC3AMQAzwC0ALQAtQC1AKMArQCqAK4AgQCJAI6AfABRgEIAVwBUQD9gHMAhgC1P74/bz/yf+Q/ez8VP58/dD6iPqU/Gj8UPqY+hz8MPsw+cj5ePvA+kD5EPqQ++j6cPnw+Rj7QPo4+RD6UPuo+qD5CPqQ+jj6ePn4+fj6uPrA+dD5kPpI+tj5GPrY+vD6aPqY+nj7kPv4+mD7YPyI/ED8kPxw/ZT9BP1s/YT+tv5a/sT+df8s/57+3v6x/43/1v5B/2QAiwDK/+z/DAEIAbgARAKQBPgEtAP8A4gFuAU4BWgHoAoQChAIgAigCrAK4AmgC8ANwAxQChAL0AxgC0AJUArQCyAKyAcQCNAIwAYwBLAE2AVYBDACbALIAn4AVv7q/joAR/+E/aT9Av6Y/Cj70PvU/AT86Po4+7j70PrY+XD6QPu4+uD5UPoA+3D60PlI+pj6CPrQ+Xj62Ppo+vj5WPqQ+hD6GPq4+sj6YPpo+rD6gPpQ+qD6CPv4+tj6MPuY+4j7cPvg+1j8ePyY/BD9iP2w/YD9oP1w/tD+gv6K/kX/i//s/rD+ff/P/5z+TP7F/6gAoP/y/jUA1ACZ/7f/4AK4BPQCRAIwBHAFOASABBAI4An4ByAHcAlACvAIYAlADEANUAtwCtALEAxgCiAKQAsgC6AJIAlQCRAIWAbQBeAFYAWYBCAEWAPiAcEAcQAcAIP/gP9e/17+TP3I/Kj8ZPxI/Fj8FPx4+yD7EPuw+qD60PrI+pD6gPqQ+mD62PkY+qj6OPqw+Sj6cPoA+rj5APp4+hD6uPlQ+pj68Pno+aD6wPpI+kj6yPq4+nD64PqY+2D7GPuQ+xj88Pvw+7j8LP3w/Pz8sP3o/bT9NP7A/ob+Yv7w/j7/qP6u/j7/+v4w/qT+AwDl/87+JP9nAOL/aP/yAUAEqANQAuACqATwBAAFQAeQCcAIUAdgCPAJIAoQCoALMA2wDEALIAvQC6AL4ArACkALEAuQCXAIEAh4B0gGcAWYBZAFOARoAugBnAFHAGf/mP+t/9D+zP1w/fT8LPzw+0D8SPyo+1D7IPuw+lj6kPrA+kD6QPpw+hj6sPmg+Qj6EPqw+bD56Pmw+VD5sPko+vD54PkA+hD68Pnw+Uj6iPqY+rj68Prg+tD6CPtQ+6j76Ps4/Ez8RPyA/MD8AP1o/fj9FP7w/UD+uP7K/pr+Bf+U/3T/Ov+o//z/Y/+m/kv/4v9Z/0//UgCeAIn/Gf8RAEABpAFsAtwDIATAAtQCCAVQBoAGgAfQCOAI2AcwCDAKMAvAClALsAwADLAKAAvgC5ALYAqACgALIAqACAAIAAjIBpgFeAWIBXAE1AIQAsABvACf/4T/p//q/uD9TP34/Hz8+Pv4+zT88Psg+8j62Pqw+oD6gPrA+tD6UPrQ+fj5SPoo+hD6WPpY+gj6qPnY+VD6QPoY+lj6mPpQ+gj6SPqg+sj6oPrI+hD7APvQ+vj6OPtY+5j7sPv4+zj8IPww/JD88Pwo/VT9kP3s/R7+JP5W/qL+rP7k/jn/Rv8x/zf/Mv/s/q7+Gf+t/6L/k//x/9T/Iv+T/04BtAK0ApACfAO0AwwD+ANwBpgHOAdgB3AIoAgQCAAJEAvQC+AK4ArgC6ALgAqgCqALMAvwCaAJ8AkgCYAH0AbgBigG2ARoBFAEUAPeARgBygAxAIf/Uf8u/1L+RP3w/PD8oPw8/Dj8SPyY+9j6yPr4+sj6mPrQ+tD6MPp4+bD5MPrw+bj5EPpA+pj5OPmw+fj50Png+Wj6oPoA+tj5cPqw+nj6yPp4+2j7APsg+5D7oPto++D7gPyA/Ej8iPwI/dz88PyQ/QL+Ev4u/oT+dv50/rj+GP8e/xz/k/+d/zf/JP9n/yT/jP4K/xQA+f8M/zT/8P9//0n/8QC8AgwDaAKIAoQDnAPIA5AFkAdgB8gGOAfgB5AI8AjQCdAKIAvQCpAKoAqAClAKQAogCgAKsAnwCPgHYAfoBiAGgAU4BdgEEATQAtIBVgHyAFMA7P/c/2T/cv6c/WD9TP38/LT8rPyQ/PD7MPs4+4j7cPsQ+zD7QPvQ+nD6YPqY+qD6cPqY+sj6WPoI+jD6cPp4+sD6+PoA++D6sPoA+yD7SPuI+wT8GPyw+8D76Pv4+xT8bPzM/Nz8yPzg/Pz88PwM/bz9Iv4A/gD+bP54/uT9FP4F/zr/qv6U/mD/Nf8q/ib+If9G/0D+UP6t/7j/RP4u/nr/EwBSACYBhALsAtwBwAFoA7gEOAVABlgHiAcYBxgHIAhwCTAKkAoQCyALoApwCpAKkAqgCpAKQArQCSAJcAioB7gGSAYoBogFeATEA0ADSAIIAXoApQBSAF3/1v7G/hz+CP3I/Cz9NP14/Mj72Pu4+xD74PpY+3D76Pp4+nj6kPpI+gD6QPp4+kj68Pnw+fj54Pm4+fD5kPq4+mj6QPqI+qj6oPro+pj76Puo+5j76Pv4+8D7FPzk/DD96Pzo/DT9SP0w/ZT9Lv5k/kj+iP7O/pr+lP4C/2D/PP9S/8H/qP8v/y7/s/9U/47+4v7D/2z/uv4o/8L/+v5M/sb/zAHCAQwBOAIgA1ACJAJABHgGYAbIBegGMAiQB0gHMAnwCtAKIArACoAL0ArgCWAKUAuwCpAJgAlgCVAIAAd4BlgG0AXgBEAEuAOcAl4BnABGABkAxP8t/4z+5P00/bD8mPzU/OD8dPzw+5j7aPtQ+0D7ePug+3j7IPvQ+rD6qPqg+rD62Pro+rj6iPpg+nj6kPqY+tj6GPsw+wj70Pro+ij7UPt4+9j7IPwY/PD7GPxk/IT8jPz0/Hj9eP04/Vz9sP3Y/cT9Jv7M/tD+gv6q/jD/Cf+O/tD+lf+o/wb/Qf/V/0L/Xv6O/kj/Pv+0/h3/u/8i/yb+hP64/zQAcgA0AfwBzAGaAXgCnAOABAAFqAVIBogG2AaIB3AIIAmgCfAJEApwCrAKkApgClAKQArQCYAJYAkQCUAIOAewBlgGwAUwBbAE9APkAsIBCAHAAG4ABgBv/7r+Bv5U/dz81Pzw/KD8FPzI+5j7KPvI+vD6QPsY+7j6mPq4+lj62Pn4+WD6UPoY+jj6UPoo+sD5sPlY+sD6mPq4+vj68Pqg+nj6EPvo+/D7sPss/ID8MPzY+2z8ZP1g/eT8UP3s/YD9+PyQ/Yz+jP4S/lj+M/8C/17+vP55/5P/R/9U/9//CwBL//L+df+n/zb/7v4+/7r/aP9y/q7+w//P/6H/WwCQAbAB/gBqASQD6AOIA0AEkAUQBqgFSAYQCNAIUAiQCMAJMArACdAJgAqwCtAJgAnQCcAJAAlQCAAIgAeoBvAFsAUwBVgEWANcAtQBXAHIAH8AAQBQ/5T+5P1k/TT9JP3g/MD8TPzY+5j7SPsQ+0D7kPtg+0D7OPtA+/j6YPqA+ij7KPvg+jD7aPsA+3D6kPpo+6D7MPuQ+zj8uPvg+jD7HPxc/AT8NPzU/KD86PsM/OT8EP2k/ND8cP1M/dT88Px0/cj9xP3Y/UT+iP6C/nj+iP7M/gP/Kf9K/4P/nf9q//T+/P56/3f/Nf9Q/4H/Pv/Y/tr+k/8oACwAXgDhAEABYAH+ASwD8AMYBBgEsARoBRgG2AbAB4AIYAhgCCAJ0AkQClAKoAqAChAKwAnQCdAJMAmQCFAI8AcIB4AGQAZwBWgEkAPgAlwC0AE4AcoAGAAb/3z+Cv6g/ZT9dP3o/HD8IPyo+zj7EPtI+1j7EPvQ+uD62PqI+lD6aPqA+mj6aPrI+tj6gPow+jj6cPqg+uD6GPtY+zD7uPqo+gj7WPuA++D7DPwA/ND7iPsM/KT8hPxo/PT8QP3E/JD8BP2s/aD9XP0E/rL+aP4Q/rr+cf8z/9b+mP90ABEAof8JAGUADADK/04A5gB3ALr/+v82AOT/HwDoAHABRAEMAXgBCAJYAuwC+ANwBEAEOATABIgFGAbQBrgHIAggCGAIsAgwCbAJ0AnQCeAJ0AmwCUAJ4AjACHAIqAdAB2AHyAaIBYgEEASEA2wC8AEIAoQBQABG//7+kP7g/Xj9nP1U/Zz8DPzY+6j7aPsw+yD7YPtg+xj70PrI+sD6cPog+pj6EPuw+lD6gPqY+ij6APrA+mj7IPvA+iD7WPvA+qD6YPvw+7D7qPss/FD88PvI+2z86Py0/Mj8VP18/Rz9DP1o/Yz9tP0i/or+oP56/oD+sv7K/gL/jv/N/5b/jf+5/3j/Vf+2/wgA3/+J/5P/pf9g/zv/3P9fAAsAHQC7AAwBHAGaAYwCEAMMA2ADWATwBAgFoAWYBjAHYAfIB7AIUAlQCVAJkAnwCQAK0AnwCTAKsAmQCCAIQAggCGgH0AagBsgFYARsA2ADOAMwAlIBGgGZAGj/pv6s/ob+0P1E/Tj9EP1k/PD7+PvI+2D7QPtY+zj7EPsY++D6ePpg+qj6iPoo+mD6oPpI+rj56Plw+jD6yPlI+tD6UPrY+Wj6EPuA+ij6APvQ+3D7IPvQ+yz8yPug+3j8QP30/KT8DP1w/Rj9BP28/Sr+Pv4q/lL+kv6u/rD+8P5V/2T/kv+N/4v/tv+//5b/pP/c/9L/0f++/+r/DgDf/xwAhQC8AM0AQgH0AUgChALsArQD+AMYBOgE+AVgBkgG+AYQCEAIAAjQCCAKIAqACQAK8AqQCoAJwAmgCvAJkAjgCIAJMAiABnAGqAaQBSgECAQoBKgC4wC4AOIA8P8n/yH/yP7M/dT8kPyk/Fz86Pu4+1j78PrA+mD6IPp4+qj6EPqI+dj5GPpw+dj4kPkQ+mj50PhY+Rj6gPnI+KD5oPoQ+oD5QPoA+8D6OPqY+rj7+Pt4+/D7uPyI/Dj8mPww/az9oP1k/dD9Lv7s/eD9ZP78/iz/Cv8//77/t/9f/7f/QQBUAEcAmADUAG4AMABmAI4AbQDGADgBDAGwANgAUAEiAQ4BHAIIA6ACgAKMAxgEoAPEA2AFeAboBdgFUAcQCDAHYAcgCeAJAAnACAAKYAowCZAIsAkgCtAI+AeACIAI8AbQBfAF2AWgBFADMAPsAoABMwD1/+D/MP9i/gT+2P00/Tj8wPvo+9j7YPv4+tD6wPp4+uj58PlA+gj6oPmo+QD6+PlY+Rj5uPng+Wj5ePko+lD6yPnA+Uj6qPpY+mD6UPuw+yD7EPvg+0T8+Psk/AT9cP3Y/Kj8cP2w/ST9QP0q/jb+mP20/Wj+cP7o/WD+Q/8w/6b+HP/g/4X/EP+//4cAGwCs/1AAtgA8AOz/qwBOAeoA2QB+AdoBgAGmAVACvAL4AkADzAMYBDgEqARABZgFIAbYBhAHQAe4B1AIkAiwCEAJ0AmwCVAJkAkACmAJwAjgCEAJoAigB1AHOAdIBgAFsATIBPQDhALUAdQBxwBW//b+Nf+u/mz9AP1Q/cT8kPtQ+8j7WPtw+oD6GPvA+tD5qPnw+Zj5SPnI+Uj6CPpg+VD5gPlQ+Vj5CPpw+iD6+Pko+jD6MPqQ+jj7mPtw+4D72Pvw+9D7SPzg/PT86PwU/YD9pP1c/Wz99P0a/vD9MP6u/t7+nv6M/vz+XP9f/5D/IwBVAPn/0f86AJIAeACJAPkAFAGwAIQA2gAeASoBQAGUAcgBtAHCASAChALYAhQDZAPkA1gEoATgBGgFGAZoBrAGUAfwBzAIEAhwCOAIAAngCDAJcAkACYAIQAhQCBAIkAdIB+AGCAYgBbgEUAS4AxQDcAKuAeQASADA/y//xv6A/uD9GP3g/LT8EPxo+0j7cPsI+3j6qPrQ+iD6cPmg+Qj62PmI+cD5APp4+ej4MPmg+bD5oPnI+fj54Pm4+eD5MPqY+uj6APso+4j7sPuY+8D7WPzc/Kj8kPxI/aD9GP3Y/Ij9DP6w/aT9bv7A/gr+0P2g/gn/vv7Y/p3/9/9d/z7/5f83AOf/FgC5APUAnACGABYBNgEGAWgBLAJkAmwCqAIUA2QDbAPUA5AEAAU4BZgFCAZABmgGwAZYB9gHIAhACHAIsAjACKAI0AgQCeAIcAhgCFAI2AdQBwgHwAYIBkgFAAWwBOwDBAOAAtwB1gBPAHcAJAAp/2z+CP50/Zj8QPzM/MD8mPsI+0D74Pog+iD6kPqQ+tD5YPng+fj5EPnY+HD5iPkQ+QD5iPnI+Vj58Phg+eD52Pnw+Wj60Pqo+oj6CPuo+9D78Ptc/LD8yPzc/Cj9aP2s/ez9Bv4E/ib+lP7K/rr+9v55/2r/F/+H/zgAPAD0/zIAxAC9AFUAqwBmAUwB7AByAQgC1AGgAfwBcAJ4AmgC6AKQA4wDfAP4A1AEYASYBDgFuAXwBRgGeAawBsgGAAdgB8gH+AfwB9gH6AfwB9AHsAe4B8gHaAfoBogGaAbgBTAF8ASoBBgEYAPIAlQCrAHZAEMAHADx/0T/kP4W/qj99Pxo/Fj8bPwQ/Gj7KPvw+mD6GPpA+kj6CPrg+bj5ePlA+Rj5KPk4+Uj5ePl4+SD5CPlQ+VD5QPmQ+QD6KPoI+hj6aPqY+qD6EPuo++D72PsA/FD8iPyg/AD9kP3Y/eT9Dv5S/oL+rv4F/4r/0v/r/xMAQgBqAJEAywASAVgBdAGCAagB1AH6ARgCPAKMAswC7AIQA2ADnAOwA9ADKASQBNAEGAVwBbAFyAXwBVAGwAboBhAHWAeAB3gHcAewB/AH6AewB7gHiAcoB/gGAAfIBjAG2AXIBWAFuARYBBAEQAOUAjgC3gF4AfQAbQC3/7b+HP4c/vD9bP0Q/Zj8yPso+/D66PrA+lj6CPrQ+WD58Pj4+Dj5EPmg+HD4iPi4+Mj4yPjQ+ND4qPiw+Cj5oPng+Rj6YPpo+jD6UPoY+xD8bPxI/Ez8nPzk/Ej9/P2E/q7+0v4Y/zP/XP/R/3UA2AC+AKEA3QBSAbQB+AEIAvgBFAJcArAC5AIgA0QDUAOEA7wDwAPoA3AEqASQBJgE6AQwBTAFMAVgBXAFUAV4BdgF4AW4BcgF+AXYBYgFoAX4BQAGwAWABVgFAAXABLgEwASABNgDfANQA9ACKAL0AQwCwgEOAWcALQCy/9j+cv6i/nz+tP00/Sj9zPzg+0j7qPv4+2j72Pr4+gD7GPpY+ej5sPpo+rD5yPlw+mj6cPko+WD6APsI+gj6ePsA/Gj6gPlg+/D8sPvg+mD9dv6w+8j69P0e/8z8BP3P/3z/4Pyo/a0AOgCI/Sj+lgFqARj+AP+sAqgBTP6Z/wADyAKtAO8A0AIMA1gBOgGIA/gErANQAlQD0ARIBOwCpAPgBZAFFANgAwgG0AWAA/gD4AVoBdwDOAQQBvAFEATcAxgFuAScA4AEgAVoBBwD7AJEA0wD8AIQA3QDqAL3ALkAwAEmASAAzgA2Ab3/cP7u/mL/mP60/bj9Kv5c/Tj8HP24/QD86PoQ/Fj8+PoQ+5j8oPyo+pD5aPpQ+9j6cPr4+7T8SPoQ+Rj7+Puo+gD7WPwY/BD72Pqg+2T8tPy0/Jj8cPy4/LD97P1o/Ur+Jv8i/sz9mv9LAEf/1v8KAY8Auv9sACgClAKQAWIBKALUAUIBXAPIBNwCfAL8AyQD3AEQBGgGQAXUA8wDOASQBGgE4ARgBigGMAQABFgFSAWoBEAF+AR4BBgFwATEA2AEIAWEA4gCVAPEA7QDWAOMAggCrgHzAPEAmAGiAQQBFwAN/xz/eP9E/sj9Xf+0/4D9APzE/ID9lPyg+4D8jP3Q+/j5ePtU/ED64Pm4+4D7aPqI+nj6KPu4+5j5qPiA+8z8oPrI+kj9mPxI+QD5lPxa/oD8+PtM/qj+CPsA+kz+0QAW/jD9IgAPAJD9hP39/+EABQA/AHwBMAEIAMwB7AJQAS4B1AIsA3QDAAREA2ADYARwA5ACIASYBWAFKAQYBCAFpAPEAQAFAAh4BA4B4AN4B5AFFgFaAdgFqAU2ASACwAXAA44ADALwAwQC7f+4ASAEzAJSAB8AogCiAPsAyQA0AMgAuwAr/1j+Gv/h/53/Wf9+/3D+/PyE/Xv/yv6M/Ar+Zv8Q/fj6VP2n/9T8qPrQ/Gb/qPwI+g7+f//g+oj5uP2b/7T8GPtM/Sf/pPzw+UT9ywBe/iz9Zv7k/cz9PP2o/Mj//gHk/bD7IQC6Acj9qPyKAHACYf8U/bsAKARyAOT8MAGoBGr/dP0QBMAFdwAO/xQCVAMEAhgBZAKoBEQDGQA+ASgDoALgApgD5AKUAjgCMAF6AQgEeARgAQ8AbAIQBAwBav/EAlAECAHI/tEArAIcAigBXgDN/woB9QCF/yABMAIQADz/h/+R/8wAEQBe/qYAkgEk/dD8BAE4ARn/UP0A/pX/Uv6o/VsAtgCY+0D7IwBZAAj8sPsqAXwB0PmI+GABgANg+2j6PAJUAbD4aPugBCgCcPrw+1gCfgA4+/T9OANoALj7cv7IAGD+x//2AQ7/nPzo/jQBvwBB/1L/WAErAOT8rv68A1gC3P2U/iADewBg+qIAsAf4AQD7cv4QBLYB8PxU/2AFoAKQ+3r/YAXrAET9XAHUAu7/GwAcAsQCZgEz//3/PAKSADwB7APqAc//PQDIADwBLALiAawB0AFzAN//aACwAfQC7QCw/UoA0ANzAKD9tAB8A5D+CPsYAoAFvP3o+9ACagHY+hz90AREA1j7HPxsAlAA6PqI/rAETAGA+gD8JAEoAYT8gPzyAfABGPxA+40A6AK2/uD79P0gAK4AWf/y/sEARgGo/Qj8g/9sAlgCTQAA/koA8gDc/Ib+hAP8AtT+ZP5cANcAiADj/zcAMwDG/4oBcgBW/iwCvANg/Vj7SAJ8Azb/pAC4AnsAAP0A/AMAWAWgAuz83f9oAoj9BPyEAYgDbgAo/sT+UAFcAQT+RP3YAqgCiPu8/QgGIAMQ/Kz94gEUApD9PP0oBUgGWPuw+rAE5AIE/OT+GAWgAwT9jPzoAfwCtP00/QwDaAKg/dz9ogAEACv/JADk/rn/YgH4/hD+WwDqADT+Tv47AB4BlAFy/iT9fgEaAVz8PP9ABEQAKPzA/5gCUP+4/NIAcAPM/ij8pQBIAwb/qPzhAGgDHv6g+/ACKAR4/Zj9EAHzAG3/Vv+yANYBhwCk/Rr/jgH9AOH/Ev+4AHwBUf9S/nUAOAK2ACMAiv/E/k8AwAGnAPD+ygBuAbj+uP5NAAwC5wB0/WX/oAOe/wj7rAGwBez9mPscAhgDjP52/qABXALo/+j87v94BBEAgPvOAfAFsP0w+hQDSAX0/cz8PAKwAvr+xPx+AEgFov/Q+lACyARw+6T86AQIAoD8gv7GAbcA/v5y/yABdwD0/dL+IAKfAND9bgB2ATD+/P2xAO7/LP+OAQwAqP3O/rf/AgBQAJn/XwBTALD9+v4gAmUA8PzlAGwDxP3M/KAClAJU/TT+RAE4Ae3/WP0PAFgFyv+w+cgAwAS0/YD+5AOhAGD+E//4/hAC4AK0/cb+SAQRACD8wQDEAoAAMP9g/kEA1ALu/+D9/gEIAvD7Lv5wBKIBLP3w/3QCaf9w/Lb+wARIAlD7N/9ABIr+uPs8ApQDfP68/TIBEAJdAJj+CP9mAR4BlP7Z/+AC4gCG/rD/ef/u/swCXAEi/uYB0gDc/HT/HAKM//QAnAB4/LIBtAPA+mj7IAb4Akj50P1QBGgAWPxg/sgCDgFY+gD8UAagBAj4QPywB0oAcPfc/iAGrAGg+7D9fAJaAXj87Py8A8ADwPvA+xQDJAMw/Cz8KAN0A2j9wPzEAUgDxP0Y/fACdgEc/Jj/iAWZAFj8dQCoAXn//v/uAAwBdAEm/x//CgHU/sf/7AOvAPz87gGIAnj9Av/gAuAAIP4LACwCrAFY/6D+agBoAU//ov6AAjwDDP+O/kwBzv6a/uIB2gFkAU7/8P2cALwBfP6y/nACFAEy/j7/iwCEAKn/1P7c/40Abv/Q/8EAqv+W/qf/wf8i/x4B+QAn/97/Ov/I/cMAyAL8/Tj+UAPS//D7LADYAsz+Ov6CANQApgC8/XL+LAOHAJD7CwBwBJj+0PyUAt4A1P1v/1oBMgE5/3r/IwBzAM//WP+Y/4AAFALf/5D98v9WAc3/wP77ABgCqP7M/jABngDc/vD/BgEpAHwAjP8FALgA4P5gAGYBiP66/tQCDAF8/NP/ZANf/0z8LAEkAxn/jP6wAIIAcv4l/0oB5gBn/9T/+ADk/rX/6gFQ/pj+eALWAOz9NQCUAtb/sPwc/6AD5wAI/Mn/qARa/4D7fACMAmz/RP6rAHEAq//k/3L++P/IAuD+mPu6AVgDsP7A/XsAMAI//wD+8P+sARoB6P55/2wAgQDp/3//FAJUAIj9nv88AW4B/P9i/uT/HALx//j8VABIAxUAQP0oAewCMP0k/qgCWgGA/Rn/gAKIAd7+NP34ALYBgPyt/4AE7v6E/PcAxAEi/tD9pgCIAiQBsPyU/ogDTQDQ+10AYAQ+/4T8TgEQA8L/7PxK/0QDRAEY/X3/QAWkAGj7CgBMAo//AP8UAXoBogFe/6j7TACoBAj/2Pz0ApgBUP1s/3sAEAHwAAL/J//5AGAAMv/jABMAxP59AMX/+v8UAQ0ABgCe/+D9SP+AAhAA7P04ArgBSPy0/SgCgAHr//r+Uv5oAgQCwPt4/iAFJgBY+loAqAV7AJj7cP7QA64BiPrc/ogHiAKA+RD+iAVvAKj6mwCYBnIAqPpv/+QDTv94/EABZAPH/7j8h/+wAi4AFP1l/5YBcwDy/nf/PAH9ADj+dP0KAbIBoP7M/1wCBgCw/Vr+GgFIAeb+IwDIAdH/UP2cAOIBYv4m/zgBMAE+/nz+1ALSAQj9PP3IAuQBcP1VAGgCeQDE/tj9OAB0AvgAWP9pAOMABgCC/xT+vAC4BAoAIPyEALgDqf8Y/PwAEAXG/5D6WADIBGL/RPzqALgDfP5Q+y4BaAUi/9D7oACSAfD9Gv5EAgACOP4A/oYAuP+o/VgB0AJk/jj92gBQAZj9Mf9QA6AB5Pyg/WgB4AA4/zwA7ACg/wv/b/+C/y8A9gH4/6z9af/cAQMAHP2IAIQDMACo+zr+QASgAWj8RgDgA0D+KPsKAbgEwQBg/Bf/iARk/2D5AALgBmz+uPusAfgAOP3//9QCBgEe/k7+FgFuART/BQB+ARr/cP52AJ0AmwAcAmIAuv7W/yb+mf9IAygCYf8U/+b+qwAKAaT9eAH4BND9wPqEApgDfP2S/vgC5AEs/Lj7eAQQBbD76PvEA1gB4Pqa/+AEdAEY/FD+aAKz/xj+xgAcAnIANv64/WEAcALb/7z+TgBqAIf/Ov6s/6wCggH4/DD+7AI2AWz9fv+8AowAcP3e/4AB8gA6APr+ZgBUACf/fv+BAAYBxwDV/37+dv9wANP/q/+z/6YB0QAE/WL+tgGOAVb+YP4oAnYBiP0C/sACxgF8/Qj/VAE3ALv/4wCOAO7/TgAU/pD+5AI2Acj+ZwDM/mAAOAKc/Rz+iAMKAYT8KwCuAbn/jwB6/zb/LgE1/+b+MAKAAR7+UP+oAC//5gBfAFn/lAG7/2z/vACG/pj/eAL8/4T9HAHUAdT+/P5h/08AjwAg/u8AcALI/pL+MABz/1L+gABmAR4BgAB0/Rv/1AJY/nT9PAP2AVD92P6QAlYAwP10/XABwANc/Yz9vANkAhD8FPy4AngDDP7k/fQCiAJw+8T8gAQ0Apz8sv6oAwgCQPwE/ZQC4AIY/Rj91AOYAhz9xP3NADYBev4o/54BxADW/2z+qP69ADwBJ/8U/ygCuwA+/n3/AgHSALb/J/+sACACTQAa/vkAXAIP/6z++wAEAoQASv/g/wwB7wDO/s7/OALKALr+A//gAFIBnv8s/68A+AAZ/5z+8wD/AET/sv87AFz/rv+4AM7/Iv+SAEcAcP60/1gAoACfAIz+0P5MAoUAUPzNACgEpv5E/AwBBAIo//D98v9cAqv/UPy2/xQD9v7I/XwBzADo/Xr+nAAqATz/Jf+eAVsAmP0h/+IBXQAm/0wAMgF9ALj9g/+AA1UAzPzFAAwDDf/k/TgC0AHk/W7+fAE0Apn//P2YAdQC4Pyo/NADHANI/Cj/nAMuAJD92P7aAbwBSv5E/pQC2AJY/Xj9SAO4AQz8jP6gBOgBoPxK/t4BIAIA/nT90AIcA7D87Px8A2gC4PuE/ZAEKALA+yL+7AKWAbD9uP3wAawBYP1A/wQDZQD4/aL/WwALAAQA+/8YAjoARP3MADQBsv5RABoBJwAEAAz/CQCgAbL++PxOATQDgv6o/NgB6AIQ/bz87QBsAhQAXP2q/5wDt//I+mQAkARa/+j7+AAoBBX/kPvtAHAD2P58/YEALAMnANz8hQDwAmz+UP2UAbgC3P4s/gQCqAHc/bz95gFiAaT/PABg/ycAhgH0/uz9zgEcAmD9ev44A9QA5P1s/gwBAgEw/r//1gEKAeT9SP5EAVcAOP6iAJwCwP5C/poBRgCQ/ScAgAJ1AL7+Qv8mAaoBkP4W/gwCZgEs/goAWAIaACL/XP8tAJgBGP/M/VoBUAOG/mT99gBJANP/Qv84/xACngFs/XT9uALSAWT8JgB0A+L+iPw8AFgD3/+E/Zv/JALtABj99P54A2gAbPzA/yACiv/0/oYA2AGqAKz88P1sA0gClPxD/zgEIQCQ+x3/gAOIAOj9ywAsAtr+0PwiAUQDBf+8/PgApAOw/vT8lAHkAij+jPwsAqgDmv64/RQCoAKA/Zz86gEwBLn/JP2AAQgDaP00/WAD8gHw/fr+DAEOAVQAdP7+/ngCv/9Q/PIBLAOk/Wj+ygHqAMT8zP0QA6gEqP2o+qwDuAPI+vD80AXgAgj7/v4YBE0A7Pxe/zwDVAEc/JT9sATgAnD7OP4AA8L/VPyc/3QDegEA/QT9jAGNAIT8wP/QBIgAEPth/zgCkP4C/2wBKwBE/7b/P/88AAwBqf+L/zwAbP4OAJwC7f8+/9QAyv9e/lIAaAGD/8wBWAF8/Xj/ggEA/5j/7AKHACr+t/9DAPMA9wBI/nD/zAKr//T84ABgA5n/TP3p/04BBACc/qkA2AJ3/0z8d//sAnEADv5CAKIBq//o/dD+6AF8AQ3/9P7o/4IAM/9q/4wB7gD2/sT+lADoAHj/QgCkAPL/K//d/5gA9P+4AdsArP2q/rgBkgHS/o7/0gE0ABL+Bv/WAZoBCv6Y/uwBPgGY/ez+RANmAVT93P2AAWACKf/E/qQB1wAC/qT+kgHCAc7+gf/MAQYAoP2e/wQCWQAj/0H/UwCEAfT+hv76AcUA7P0u/2ABaADK/1oATABEAND9Av8oAr0AG/90AAoBmP46/lcAUAGFAOD+WAAQAnT+HP28AWQCXP5E/4gBzf/u/nYAqQCp/3L/FgCyAOH/ev/OARgBmP0S/2wBVABK/goBUANA/5z8jv+gAqv/Jv7KAXgBev5Y/lAAbgFx/+z9PAGsArj9aP1oAj4B8P3w/osAHAHo/3T+hgCwAaT+yP4QAfj/qADcAGD+RQAwApT+HP70ATwCF//o/Y0ATALT/2D9LAHEA4z9sPyQAyQCAPyW/rgD0ADY/BUAygFm/0P/hv9eAPMAPP/o/rgBYwAY/XwA/AE4/nD/SgGE/vz+6AEkAIL+cP/Z/7YA/f8w/vr/+AKM/tj8dAL1ALD8JAHsAvT9C/8WASb/SQD2ALj+sP9uAbf/R/86AWP/b//TADX/CACCAOH/bABYAH7+AP+yAZAAdP6IACABSv4c/xQCAgE0/gT/TAH3AN//LP8nADQCa/80/WwBWALi/loApgHE/kj/XAFg/+f/VAKH/1z+agF8Ac7+cP4gAGQCCAHc/KP/5AMy/6j7YgFQBLT9DPzQAtgDVv4g/EIAPAN//4z8cwDsA0sApPyN/4QBVf8J/y0A2gC6Adb/NP2K/mwC3AFg/Tz+/AIYAkj8oP2MA2QBwPx2/lwCbgHU/aj+/gHiAAD9kv4cAq8AIv9DAPIAjP9E/sn/mgGmAMX/OADP/6EA2AAm/hr/3APBAKD8rwCsAgUAWP6M/wQCSgFQ/aD+JAOwAeD8Tv4wAy4BKPx4/tADWAEA/SP/fAGi/xL+LgCoAoUADP0s/3QCXwBQ/c7/2AJkABT+KP80AcAALf9q/2IABgHK/o7+5gG0ARb/vP3I/84B5P+4/dv/sAMUAWj8rP2gAYABVP7o/zwCW//Y/TkAeAGNAIT+0v5qAToBnv7Y/lIBwgDB/0L/gv4EAJoBRAFQAKL+8v6hAFkA//+EANgATAAUAEv/bv9gAGgA9QCHAM//nv8RAFsANQD5/wwAjQCr/ycAtAHL/xL+xACMAsb+AP3CAcwDuP7s/CAB4gF7/1D+yv80AmcArP1OAHAC0P4w/fQANAJX/yr+JwCWAQwAGP6o/4oBOADO/oz/BAF8APb+PP+VANgAIP8S/iIBqALm/oz89ADUA5j+mPsgAZgExv5Q+0ABmATk/rD7JAFMA+z91Px8AoQDRP40/cYAigHc/mb+dAEgAtz+AP6iALYAMP+P/3cAxQB4/4D+BQCIAYIAfP4i/28AswAwAMr+RQAcAuP/dP3Q/soBPAG6/hwAOAKA/7D8gf+wAhoBeP62/poBeAFI/bT92ALMArD9tP3wAZwBOP5G/lwCgAKA/ST9ugHMAhf/Uv66AUQBHP12/twCSALw/nT+iAAYAQL/jv7+ATwCWv50/twA9/8H/6sA6gEtAMT95P16AHACTgAq/un/vwCS/m7+5wCEAYQAKv/4/SH/pAD3/zIA5AEvAMD8Iv4UAtoBkv7m/owBVwDM/bL+cgEUAu3/Sv4y/+z/Qf95AIwCfgEM/hT9TQBcAr8AB/+u/5oB7ACI/bz9WAJcA8H/Ov6v/4wAv/+c/9IBKALG/vT8AQB0AzIB/Pwm/5wD4ACw++b+mAQ4Akz96P0mAZ0AyP6yALwCXwD0/CD+IAKeAQr+Kf8AA9EAgPxk/lwCegHK/pH/IAETAEr+t/9wAqIByP3U/RwCkgFY/t3/eALDAPT9qP3m/7gC0AHY/hj/rABN/wL+kgDQArcA+P3Y/h4BPQCW/n8AnAKXAOT8yP2EAjwDVv9W/sEAiABg/kr/kAKwAoL/+P0r/8T/rP9eAYwCmgBC/gb+R/8CATwBAADY/wEAHP9J/xUAwv+nACQBpv64/aP/5QCUAXABSv7Y/Mr//AA0AN8A9wCN/7T+Iv/O/yIAXwC7AOEArf9U/if//gB0AYoAF/8w/lf/0AGQASf/mP/8AFH/gP2K/3wC7AFq/9j+9/8A/7j91gDYA1sAqPz+/lABrP/y/pcAEgHI/3b+Lv8oAbQAk/+2ADcAtP14/pwBNAKlAJH/+v5L/5T/2P8QAawBmwBB/0b/s/8TAGAA1gBAAU4ARv7G/tAB7gFC/5z+pwCOAK7+g/+mAa4BUf+c/SH/LAGUAHD/MwDoAGL/VP7O/n4AvAE/AH7+bv+EABP/2v4UAUIBKf9a/p3/6ACUAFr/eP+aANf/ev6a//sAUwD4/y0Aq/9h/6n/VgBWASABZv9M//YAVgEmAL7/8gCOAUwAtv9QARQCfgC6/0QBkAHX//v/VAJ8Auv/CP8wAVwC///I/oQBtAIJALb+XAAOAaL/Lv+QABYBZ/9o/s3/tABQ//T9E/+LALH/8P1G/ur/5f8q/mj92P6S/3r+FP4R/zD/Cv6I/WT+Sf/G/vT9gP4O/6L+Av7k/Uv/LgDk/qj93v6JAJf/Mv5n/8YAyf8Q/30AXAFPAND/wgAkAUgASwA8AhwDfgFoAHQBZALOAewBIAMcA/wB0AH4AgwD+AFAApwDfAPoAZgBIAPYA+gCCAIUAjwCNAJ4AtQCkAKwAVABagHIAEYATAEkAioBoP/I/uj+s/+z/77+HP4G/qz9+Pyw/ND8wPz4+0j7YPsw+4D6oPpY+wD7oPno+LD5sPqw+uD52Plw+mj6KPpw+hD7qPvI+3j7CPzs/PT8RP0i/n7+LP56/r3/vwAKAeIADgHCATgCNALEAhgEgAQwBGAEuAT4BHAF8AVABmAGGAZABjAHWAegBtAGoAegB0AHSAfAB+gHiAdIBzgHEAfoBiAH+AZgBvgFmAX4BGgEQAQoBIwD4AKwAsQBCwAR/5//0v9U/rD8gPzY/Jj7CPoY+hj66Pjg9xj4KPhA97D2wPZQ9gD14PSw9TD2EPbg9eD1sPVw9cD14Pag9zD4yPgY+QD5WPlw+qj7yPxU/Vj9Iv5e//n/NQD2AM4BgAK8AswC6AMABaAE4AMoBMAEqAS4BKAFKAbwBHQDwAOgBEAEvAN4BDgF7ANYAtACyAOAAyQD2ANIBFQDsALEA2gEUAMgA6AEUAWoBEAE0ATABVgFUAQYBagGgAbABQAGWAZABqAFAAXIBZAGcAUoBAgF6AVgBHgCbAJ8AygD/gA6AJABQgGe/lT9Ov42/mD8UPvg+9D74PmA+Kj5KPrA9wD2IPdY+ID3MPYg9qD20PXA9MD1QPcQ94D2wPZA94D3sPeI+Hj6GPso+pD6bPyg/cj9VP5z/zwA4/8CAKwB9ALYAtgCaAMQA4gCIAM4BFgExAOcA3ADxAJ4AigDVANAAugBmAIUArYAXAEAAzAC5v/E/3oBFAIEAewAhAJgAjoAKgCEAkgDPAJoAqAD1AOkAoACiASwBaAE8AMYBVgGIAZ4BcAFoAaABsAFKAY4BwgHAAaABdAFoAWwBGAEQAUwBTgDzAEIAiwCHAECAOP/5v+Y/jj9NP3o/Aj78PnI+tj6oPmY+ID4aPhA9zD2gPYg97D2MPZQ9iD20PXw9VD2wPYg91D38PfQ+Ej5oPlI+uj6cPsg/DD9cP5J/63/BwCQAMQAAAEkAoADhAMYA3QD5ANwA8wCYANgBNgDlAK8AnQDlAJaAXQB7AFqAWkArgCoAUwB1P+G/3QAegDa/0cAsAEQAu4AIAACATACKAIcAuAC4APoA3ADuAPoBHgF+AQwBaAGeAfIBmgGUAcgCGgHwAb4B3AJgAjwBlAHIAhABxAGmAYwB/gFUAQoBJgEeAO4ASIB+wDa/8r+GP8M/3D9kPtw+rD5UPmI+dD5WPnw93D2sPVA9QD1gPUA9oD14PTQ9MD0oPSg9DD1APZQ9pD20Pcg+UD5APmQ+cj62Puo/CD+DgCZANT/5/8cAfgBrALIA9gECAVYBNgDSATIBHgESAS4BNgEOASIA1QDKAN8AnwBagEEAvwBlgFYAeAAFgCD/8X/qwA2ATABFgHlAGUAdwAuAcoBQAKYAvQCEAMUA5ADKARYBGAEIAUgBlAGOAbABlAH4AaIBmAHQAgwCMgH8AcwCHgHgAbgBlAHWAZIBYAFmAWABDwDdAIMAgAB6v/1/wEA9v5g/Sj88Prw+Yj5qPmw+eD4oPdg9mD14PQA9QD1cPQw9HD0gPTw84DzsPMg9DD0wPSA9vD3IPig9wD46Pi4+QD78Pyw/gb/8P48/zIANAG+AaAC2ANoBAgEEASoBPAEqAQgBBAEgAR4BCAEQAT4A3wCZAFUAawBvgGWAYwBWAE1APz+SP9CAI4AeACpANwAewA6AN8AtgGwAc4BtAJEAzQDeANoBAgFoATIBAAGoAbABqAHYAjgB0gHAAhgCTAJQAgACSAKIAngB1AI0AjgB3gGaAYoB4gGyAQ4BAAEWAKhAGwAsAAqAKb+5Pzo+1D7QPog+eD4wPjw96D2cPUg9SD1QPQw83Dz4PNw8xDzgPPA8/DyEPLg8kD1oPZw9sD2kPeA95D3EPmQ+3j9nP1s/Yz+pP/3/8MAPAJAAzgDCAPIA1gFeAVoBGgE6ASIBOQDoASgBUAFWAM4AowCaAK+ASACEANAApMAFACDAG4AMwCWABgB3wBNAIYAFgEKATAB8AH6AbYBvAIIBAAEiAMIBPAEOAUgBSgG4AfYB7gGKAdgCEAI0AewCNAJgAkQCOgHQAkwCYgH4AaAB2AHGAY4BXgFGAUUA2QBggGmAR8Avv56/gD+EPwY+tj5cPqg+cD3EPcA9/D1oPSA9ND0IPTQ8tDy8PPg84DyMPIA8wDzIPOg9HD28PZQ9mD2YPeA+Kj5aPsc/bj95P2Q/pD/iQCeAYgC/AJsAwAEsAQoBUgFQAXgBIgEgAQIBZAFQAVwBIgDrAIgAhACMAKcAoQCdAFNAPn/PwBiAFQAnQAMAZ8A1f9lAIwBgAHpAFABeALgApgCFAN4BNAE5AP0A3AFoAbYBjgH2AfwB0AHOAeACJAJkAlQCUAJIAnQCJAIoAiwCGAIuAcAB5AGSAaoBXgEaAPYAjwCKgFhAP//+v4c/bD7aPvw+uD5KPnQ+ND3IPYg9TD1APXg8yDzQPMw86DyoPLA8iDyUPGQ8dDyIPQw9cD14PXA9fD1IPfg+HD6EPxI/Yz9qP2C/uj/DgG+AYwCnAMwBGAEyARQBUAFqASYBFgF4AWABTgFEAVwBBgDHAKYAogDQANQAvgBlgGSAL7/NABcAXwBegBHABIB+AA0AIIAzAE4ApYBpAH4AuwDcAMUA+QDqASYBCgFqAZ4BygHoAbQBnAH6AdgCEAJoAnQCFAIYAhgCEAIUAhACKAH6AZwBkAGeAVoBMwDQAMsAiQB5QB1AAD/TP2A/ND7uPro+aj5MPnA90D2wPWQ9YD0sPPg87Dz0PJA8sDyMPMw8gDxkPEA87DzYPSw9UD2gPUg9aD24PhQ+lD7tPy4/az9pP01/zQB9gFYAlQDSAR4BKAESAWwBUgFwARYBSgGGAaIBUgFyASIA6wC2AJUA1AD5AI4AoIBpwD1/0UAEAEeAdUAygCVAFwAVQCrAKQB7AGUASQCQANEAzADvANYBJAEmASYBSAHoAcwB1gHyAeYB7gH4AggChAKYAkwCQAJkAiACAAJIAlQCIAHSAfIBpAF6ASwBOgDiAK2AYYBvAAH/7T9IP0M/KD6EPow+pD50Pdg9gD2gPVA9KDz8PPw89Dy8PFg8tDyAPIQ8YDxQPKQ8iDzEPVw9oD1cPRg9YD3QPmQ+vD7VP14/fT8Dv4cAF4BLAIUA7wDQARwBLgEkAXgBSgFCAW4BVAGeAbwBegEAAR4A0ADZAOUA5wDQANQAvMANACxADYBJgFUAYAB7QA+AFEALgGwAToBSgGsAjgDgALQAggEMARgA6wDaAWgBngGeAZoB3AHaAaYBnAIoAkgCcAIIAkgCSAIoAegCGAJgAggBxAHKAcgBtgEcARQBDADogFWAWgBCQAg/gj9dPyA+2j6+Png+cj4IPdA9qD14PRg9DD08POQ8wDzoPKA8kDyMPJg8hDyUPKw8yD1oPWA9ZD14PXA9gD4IPpk/BT9vPz0/Dz+cP+HAM4BaANIBJADVAPoBDgGgAW4BHAFQAbgBWAFCAZIBpgExAL8AvADiAPoAjwD+AI2AfL/UgACARYBEgFOAQgBPAAgAPUAYgE6AcYBsALEApgCVAMwBBgEvANQBLAFUAZQBvgG8AeQB4gGAAdgCEAJIAkQCZAJUAkQCLgH0AggCVAIiAegB1gHEAYABfgE0ARsAxgC3gGwAXcA0P68/fj82PvQ+oD6QPoo+cD3wPYQ9kD1oPRw9ED0oPPw8uDy4PJg8uDxAPIQ8uDxkPIg9GD1UPXw9GD1EPaQ9ij4KPvU/IT8QPxI/Xb+Qf+sAJwCnAMgA0QDoAQwBaAEAAXwBcgFKAWIBWgGGAZ4BJQD2ANwA6gCTAM4BCQDJgFzAPUA9wBtAPQADAKiARwA/P8iAVgBzgBgAbgC9AIwAmgCxANQBIQDWAPQBNgFsAUIBigHYAeQBkgGSAdwCJAIgAggCTAJMAiIB/AHgAhgCOgHYAfgBjgGcAUABYgEjAOAAgwCfAGIAIL/gP5s/ST8EPu4+oD6iPmA+MD3sPZw9eD0APXQ9AD0YPOg83DzsPJw8qDygPIA8sDyYPRQ9TD1kPVQ9uD18PUA+AD7aPws/Kj8zP34/Qb+OgDgAlQDfAL4ApAEyAQYBLAE+AXABbAECAVwBkAGgAS8AwgEpAO8AuQC2AOgA/gBxgDjAPUAjQDYANQB6AHJACAAngAqAUABiAFcAvQCwAK0AowDIATYAwAEAAXQBRAGcAZYB/gHKAe4BuAH4AjACDAJ8AkACtAI0AeQCGAJsAj4B2AIAAh4BlgFWAU4BfADwAJsAt4BigB+/9b+qP0M/CD7wPoY+kj5uPjQ90D2EPXg9ND0APSA89DzsPOg8iDyYPKg8jDykPFg8uDzkPTQ9ID1EPYQ9uD18PbI+VT8uPyQ/Fj9Hv5O/jj/2AEABNgD7AKMA/AEGAW4BIAFkAawBbgEkAWABtgFQAR0A3gDWAPcAigDiAOUAjwBoQBSADcA5QCaAZAB7QBYAEMAfgDzANYBpAKMAiwC2ALUA7ADeANYBGgFoAWIBSAGYAfAB/AG2AbABwAIEAgQCbAJIAkQCMgHMAhACOgH+AcgCCAH0AVQBQAFSASQAzQDZAIgAf//hP8U/5z9+PtA+yD7UPpA+bD4UPhA95D14PRg9WD1YPTQ8zD0APQA84DyUPPQ8/DywPJA9LD10PWQ9VD2IPcg94D3uPkg/OD89Px4/ej9aP6r/5gBSAOcA1ADYAPUAzgEOAUYBsAFIAUYBYAFgAUYBagEWARoA0wCuAKkAzQD4AFAARgBVQCt/1oA2gHKAUwAvP9QAJAAjQCAAbgCyAIIAigCLAOgA8gDiASIBagFiAUoBhgHaAdIB6gHIAggCGAIYAnQCSAJQAgwCIAIQAgQCGAIYAgYB3gFCAX4BIAEpAMMA5QCSgGO/7b+yv7w/Tj8IPvQ+kj6KPlg+ED4gPfA9cD0EPVA9aD0EPQA9NDzEPPA8lDzwPOA85DzUPQw9aD14PVg9hD3kPdo+Pj5gPtg/ND8OP20/Yj+BACqAcgC5AKoAuQCYAPQA7gEmAVYBZgEQARgBGgEGATYA8QDEAPeAcgBbAIoAh4BiACAACkA0/8wACIBKgEjAOL/mwD4APoABAJ8A4ADiAJgAqADwAT4BIAFqAbYBhAGUAaQBzAIIAgwCMAIAAnACNAIcAlgCWAI6AcQCCAI2AegBwgHEAboBBgE2ANwA6wCAAIaAZr/TP60/Vj9nPxw+2D6oPno+Cj44PeQ96D2UPWg9ND00PSQ9HD0sPRQ9GDzQPMQ9KD0kPQQ9RD2cPZw9vD2KPjw+BD5GPoE/Cz9UP30/SD/p//n/xQB1AKsA2wDcAMABAgECASwBGgFGAVoBDgEIATAA0QDNAPIAt4BegHGAZQBqQAwADQAyv8w/5j/ugDZAOj/pP99APYA9ACGAcQCOAOsAsgC0APQBAgFmAVYBqgGiAaYBpgHoAjwCLAIsAjQCAAJcAnACeAJkAmwCBAIEAhACPgHoAfYBsAFsATgA6gDVANIAgoBIwAQ/wb+gP30/BT8sPqI+fD4iPjw96D3QPcQ9uD0YPRg9JD0oPTg9KD0sPMw89DzMPQQ9ND0IPag9iD2gPYA+Jj4IPgo+aj77PzQ/HD92v5V/+T+r//+AUwD8AIgA/gD7ANwA7ADgAToBLgEYAQwBNADRAMQA5QC2gHqATgCrgHoALkAcQCY/xH/tf/DAJYA4v8hALsAcABQAIQBjAJ8AiwC6AJABNAEwAQoBdgF8AVQBlgHUAjACKAIoAjACPAI8AhwCVAKcAqwCaAIQAhQCEAI4AfYB5AHEAagBDgEAAT4AtwBXAGyADr/3P14/RD9yPtw+rD5CPlI+AD40PfQ9oD14PSg9BD0EPTA9PD0EPQQ81Dz0POA88DzQPUw9tD1wPXw9iD4MPhI+Oj50Pts/Mz8Ev45/2L/Xv9xADQCPANIA5ADOAQ4BMwDEATIBDAF0ARQBGgEaAR8A6gCuALAAjQCvAHOAcIB6gDg/9n/OQAHACQABAFIAWEAGADoALIBvAHOAbwCXANwA+QD2AQYBcAEQAVABsAGAAewB3AIQAjgBwAIcAigCAAJsAmQCaAI4AfIB7gHSAc4B0AHoAZ4BWgEuAMgA2QCrgEYAUwANP8i/kz9oPzA+5j6oPlg+Rj5MPhQ99D2QPZQ9ZD0wPRQ9RD1YPRQ9DD00POg80D0MPWg9bD1EPag9hD3oPeI+Gj5QPpA+yz81PyQ/XT+Kf+9/50AzAGIApAC4AKMA9ADqAP4A4gEiAQIBNwDEASwA+gCtAKUAuQBUAGOAdgBPAE+ANz/pv8k/0P/eQA2AZYA/v82AH8AhgASAVACLAMoAzgD3AMwBDgE4AToBXAGsAYwB9AHAAjwBzAIoAigCLAIQAnACYAJ0AhgCBAImAcwB2gHgAfgBqgFcASYA8QC+gGcAXoBmgAH/6j97Pxw/Ij7kPoo+sj5qPig92D3MPcw9jD1APVw9UD1sPTA9PD0UPSQ8wD0IPWw9eD1MPaQ9sD24PbA90j5SPq4+pD7bPzg/Hz9nP7g/7MANAHYAYgCxAIgA+QDWAQ4BDgEwATwBIAEMARYBAgEVAMYAywD6AIoAuoBKAKyAasAdQDfAF8A8/+QAIQBfgGgAIYAFgEwAUgBnAIABPgDRANQAxgEqAQgBQAG0AboBqAG0AagBzAIQAhACEAIcAjQCPAI0AiACOAHEAfQBgAHGAegBrgFyAS4A4wC9AHaAXYBhQB1/27+PP0o/Mj7oPuw+oj58PiY+OD3APeg9oD2sPUA9YD14PVQ9bD0wPTg9KD0gPTA9fD20PZg9uD2gPcA+ND4MPpY+4j7uPu0/Mj9XP4P/xgA7AB6AfYBgALkAhwDbAPAA9wD/ANYBHAE8AN8AzgD8AKgAnQCRAIIAr4BSAHlAIcA4P9M/z7/5v/rABIBRwD3/yMA6f8eAJoBWAO8A+gCzAKwAxAEGARABdgGEAdQBqgGAAgwCGgHmAegCAAJkAiQCFAJMAngBxgHYAdQB+AG2AbwBiAGgAQcA7gCrAIUAn4B8ADh/4r+hP3I/BT8iPs4+5D6cPmg+Hj4KPgg90D2QPZA9sD10PVg9gD24PRg9CD1wPXQ9UD2QPeQ9wD3APfw9+j44PkI+/j7LPwo/Oz8CP7e/q7/swBuAYwBvAE8AggDSAMgA2gD1APgA5wDvAMQBMADtALgASwCqAI8AsYBGAL4AYQAWv+3/5kA2QCLAAYBmAHEAMr/aACgAdwBHAIUA/gD+AN0A4gDSATABEgFcAYoB8gGqAYIByAHEAdYBxAIYAgQCOgHYAjoB4AGKAa4BqAG0AXIBRgGCAXQApgBKAIkAvAAXQBoADr/AP34+0j8FPzg+jD6SPp4+Qj4kPfQ93D3gPYw9mD2UPYg9nD2kPbQ9TD1wPWg9kD3sPdI+ID4IPgg+Cj5oPqA+wD8sPw4/WT9rP2s/gUA1ADpABgB4AFkAnQCsAJAA2gD3AKoAlQD0ANAA4gCcAJAAoABCAF+Ad4BHAEtAAkA8v9i/yL/sf9VAFoA/P9IAJoAOQASANEAAALYAmQDzAO8AzADFAMoBJgFWAbIBggHwAbwBfAFGAfQB6AHgAfoB8AH4AaQBgAH2AbABWAF8AW4BYgE6APAA9ACWAHPADYB6gDN/xj/oP5Y/dj7qPsc/MD7wPpI+iD6WPlo+FD4sPh4+AD4EPhA+OD3kPfQ91D4QPgI+HD4KPmQ+bD5GPqI+sj6APug+4T8DP18/TD+sv7E/ub+p/+UAAQBJgGMAeIBygHmAWQCiAI8AhACQAJgAgACyAHwAa4B5gCBAJoAmACtANQA0ABHAG7/V/8tABABcAGOAV4B/wD2AIIBoAK0AyAEKAQgBEAEeAQIBfAFwAbYBmAGeAYwB3AHEAcQB2AHKAeABpgGWAcYB8gFCAUgBeAE+AOYA/wDoAP0AZcAUQAAADz/sP6y/nT+RP3Y+0D7EPvQ+pD6gPpg+tD5CPmA+Ij4sPig+Ij4uPgA+fj40Piw+OD4IPlQ+dD5cPrg+gj7OPtY+4j7BPyk/Ez92P1W/r7+yP7A/iH/x/8mAHUACgGIAYQBBgEQAWYBRAEIAXgBJAIEAk4BtACqAHsACwBGAPoA+ABOAP7//f/q/77/8f/GAGQBQAEaAWQBmAG6ASgC5AKUA/ADIAR4BNgEyAS4BEgFEAZQBmAGkAagBkgGoAWABQAGOAYABvAFsAXQBNgDeAOgA6QDNAPUAngCsAG5AA8Aw/+W/2f/H/+O/sT9JP3E/FD82PvA+7D7SPvg+tD6uPpA+rj5oPnY+cj5uPlA+rD6OPqI+ZD5CPqg+ij7sPvY+3j7OPvA+4D82PxI/dT98P3k/Ub+9P4o/xL/XP/m/xYAEwCmADgB5gAtADQAwADgAPsAZAGAAc4A+/8CAJ4A8ADuAAIB1QBOABYAeQAEAWQBmgGYAWIBRAGyAXQC+AIkA1gDiAOAA8QDgAQwBWAFOAVIBZAFyAUYBoAGgAYQBsAFsAXQBfgF+AW4BSAFaAQQBPADtAN8A0wDqALeAT4BzwBtAAwAsv88/5r++P2k/Sz9gPwo/Pj7qPtI+xj7APug+hj68PkA+uD5wPnw+Sj6EPrg+eD5APoQ+lD6yPoA+yD7aPuo+5D7gPsA/Lz8EP04/aT98P2o/Yj9Jv7i/g//+P5I/7L/j/9W/6z/CgD9//v/RwCJAHYARAA+ADgAMQBuANQABAEKARgB+ADDAPwArgFEAlwCeAK8AtAC0AIsA/QDaASABKAE6AQYBTAFaAWwBdAF0AXQBfAFCAbwBagFQAUABfgE6AS4BKAESASYA9gCeAJwAjwC4gGKAQwBTACv/4D/bf8D/27+DP64/Uz9/Pzw/MD8MPyg+4j7iPtg+1j7aPs4+8j6gPq4+hD7OPtI+0D7CPv4+jj7qPv4+xz8OPwo/Bj8WPzk/ET9aP2E/aD9pP20/R7+sv7w/uz+BP8q/zH/Y/+4/wkAIwAgADcAYgCPANQAHgEmARYBRAGaAdABAAJEAogCmAKQAswCLANwA5wD9AMwBDAEIARABIgEuATQBPAECAXwBLgEsASYBHAEWARQBEAE7AOUA0QD+AKgAlwCOAIAArABWAESAbcAQQDl/7r/rf+C/0r/D//G/lL+8P3o/Rr+IP7s/bz9iP04/fT8AP04/Uj9GP38/Oz8yPys/KT8uPys/Jj8uPzk/NT8rPyQ/Hj8bPyE/LT89Pz4/NT8vPy0/Kj82PxA/YT9mP2Q/ZD9tP30/Tz+kP7i/h3/Z/+m/+b/MgCMANoAIgGMAQACYAKgAuACJANMA4QD2ANQBKAEsAS4BLgEuASwBOAEEAUYBfAEwASYBGgESARABDAE6AOkA4gDYAMgA/QC0AKcAjwC6AHmAdQBfAE6ARgBxwBhABoABwD7/67/RP8O/9L+aP4O/vT92P2U/TD96Pys/GT8GPzw+9j7qPtw+0D7CPvY+rj6sPqw+rD6oPqQ+oj6kPqg+sj68PoY+zj7WPuI+8j7EPxI/JD85Pw0/ZD98P1W/qz+5v4i/6n/RwCxAAYBVgGcAeYBOAKkAiwDiAOwA9gDEARABGgEqAToBBAFCAUABRgFMAUgBRAFCAXwBNAEyATABJgEYAQwBAAEyAOgA6ADlANUAwQD1AKUAkQCHAIgAgQCpAE8AQIBzgCBAEUALwDx/3n/Ff/m/qz+WP4O/tj9kP00/ej8wPyE/DT8+PvI+5D7YPtI+0D7KPv4+tj64Pro+gD7GPtI+2D7cPuQ+8j7FPxg/LD8BP1M/ZT94P06/pL+5P5D/5r/8v9WALEA/AA8AYoB1AEQAkwClALQAvACGANEA2ADYANwA6QDxAO8A7wDxAO4A5gDmAOoA6QDjAN8A3ADUAMgAxADFAMAA9gCwAKsAnwCTAI0AhgC8AHEAZ4BfgFKARAB3wCuAHEANQAMAN3/n/9o/zH/9P60/nz+Sv4e/uj9sP2A/Uz9JP34/NT8sPyI/GD8TPxI/Dz8MPwk/BT8EPwY/DD8VPxw/ID8lPys/ND8AP08/Xz9sP3g/Rj+Vv6S/sr+Bf9H/4T/wP/3/zQAbwCqANcA8gAgAVoBigGoAdwBCAIgAjACSAJ4AogCiAKwAtwC6ALgAuAC7ALoAugC7AL8AvgC2ALEArwCqAKMAngCbAJQAjACEALsAcoBrAGKAWIBOAEQAe0AyQCbAGoAQwATANv/rf+N/2v/N/8B/9L+pP54/lj+Qv4i/vj90P2w/ZT9gP14/XD9ZP1Q/UD9PP1A/Uj9TP1Y/WT9cP10/YT9nP28/dz98P0K/ib+TP5w/pT+vP7e/gP/Lv9j/5f/wP/i/wQALgBWAIIAswDiAAABFgEsAUQBYAGCAaQBtAG4AbwBygHWAdwB4gHoAeQB3AHcAeQB4gHUAcYBugG0AbABqAGgAZoBiAFuAVoBTgFGATgBIgEMAfIA0wC7AKsAlAB5AFgAOwAhAAYA8v/h/8n/pv+H/3H/Xf9G/zP/Jv8Q//L+2v7Q/sz+wv62/rD+qv6Y/oj+hP6Q/pr+mP6W/pr+nv6c/pr+qP68/sT+yv7c/vL++P74/gn/Lv9B/03/Zf+H/6L/qP+2/9X/9v8HAB0ATwBnAG4AeQCVAKoAvADXAPkACAEGARIBJgE0AT4BTgFYAWABZAFuAXQBbAFoAWoBZgFoAWgBYgFaAUYBOAEuASQBGAEGAfcA5QDQALwAqACQAHwAZABOAEQAMwAUAPb/3//K/7X/pv+d/5n/ff9T/0D/Nv8n/yT/Kv8h/w3/9v7q/ub+5v7o/ur+5P7g/uL+5v7m/uD+4v7s/vT++P4D/xP/Gv8Z/xr/I/8z/0L/VP9o/3L/bv90/4j/mv+l/7H/wf/T/93/4v/s//r/BQAPABoAJAAuADkAQABKAFYAXQBiAG8AgQCPAJUAlwCfAKsAsAC2AMMAygDGAMIAxwDLAMgAwwDBALwAswCqAKgAowCXAIcAegBvAGAAUABEADwAMwAlABIAAgD0/+j/3v/a/9X/zf/C/7v/uf+3/7T/r/+u/67/sP+z/7b/uP+6/7r/uf+8/8P/y//Q/9D/zv/R/9f/3f/h/+n/7//y//L/9f/+/wMABgAKABAAEwAPABAAFQAaABwAHAAcABsAGgAXABUAGQAdABoAEgAOAA4ADgARABcAGAASAAsADAAQABAAEAASABQAEQANAAwADAALAAsADQANAAkABgAHAAgABQADAAUACAAKAAwADQALAAUABAAKABEAEwAVABUAEAAKAAcADAARABEADQALAAgABQAEAAQABQAEAAIAAQABAAEAAwAGAAUA//8BAAcADAANAAwACgAHAAQACAAJAAYAAAABAP7/9P/x//v/+v/r//D/8f/x/+f/4//y/+3/3//o//r/9v/p/+b/5v/j/+L/5//y//H/4P/V/9b/2v/W/9T/1//X/9P/z//N/87/z//P/8//0f/W/9j/2f/c/9v/2//d/+D/4//o/+z/7P/o/+X/5v/p/+z/7//z//b/8//v/+//9f/7//3/AAADAAUABgALABEAFAAYAB8AJAAkACQAKgAzADgANwA1ADgAPgBCAEQARwBHAEcARwBJAEsATABJAEgASABGAEIAPwA8ADcALwAmACAAHAAXABAABQD6//D/6P/h/9v/1f/O/8b/vv+6/7b/s/+u/6r/p/+m/6X/pP+k/6X/pv+k/6P/pP+n/6j/qf+q/6v/rP+u/7H/tf+4/7n/uv+8/8H/yP/O/9P/1v/Y/9z/4f/n/+z/8f/0//X/9v/6/wAABQAJAAsADAALAAkACwARABYAFwAUABQAFQAVABUAGQAgACUAJQAoAC4AMwA0ADYAQgBLAE8AUQBaAGUAYABdAGQAbgBsAGgAcgByAGsAYQBjAGMAXwBcAF0AWABMAEUARQBDAD0ANwAyAC8AKgAoACUAHgAXABAACwAKAAYABAD///b/8//w/+z/6f/k/+L/3f/Z/9n/1//R/87/y//L/8//zf/J/8f/wv/A/8P/xf/H/8v/xv++/77/v//B/8j/zP/L/8n/x//H/83/0v/W/9n/2//e/+P/6f/t//D/9P/5//7/BAALABIAFgAXABgAGwAgACYALAAwADAALQAtADAAMwA0ADQANQA2ADUANQA1ADYANgA3ADcAOAA5ADkAOQA5ADkAOAA4ADgAOAA4ADYAMgAuACsAJwAiAB4AGQASAAoAAgD7//T/7P/j/9r/0v/K/8T/vv+3/67/pv+f/5j/k/+P/4z/if+F/4H/f/99/3z/fP9//4H/g/+F/4n/jv+S/5f/nP+j/6n/sP+3/73/xP/K/8//1f/c/+P/6v/w//T/+f/+/wQACQAPABUAGwAeACIAJQAqAC8AMwA3ADkAOgA7AD0APwBCAEQARABFAEQARABEAEYASABJAEgARQBCAEIARABIAEoASQBGAEQARABGAEcARwBGAEQAQgBAAD4APAA6ADcANAAxAC0AKAAjAB4AGQAUABAADQAJAAQA///5//L/7f/q/+j/5v/j/97/2f/U/9D/0P/R/87/y//J/8j/yP/H/8b/x//H/8j/yf/L/8z/z//S/9L/0v/W/9z/4P/i/+T/6P/q/+3/8//4//n/9//+/wIAAgAEAA0AEQANABQAFwAeABsAGwAnACYAIgAqADMAMwAuAC4AMAAyADMANAA6ADsANAAvADIANwA1ADMANAA1ADMAMAAuADAAMAAtACsAKgArACgAJQAjAB8AHAAZABYAFAARAA0ACAADAP7/+v/2//P/8P/t/+n/5f/g/93/3P/b/9n/1//U/9L/0P/R/9L/0P/Q/9L/0//R/8//0f/V/9b/1f/T/9P/1f/X/9j/2f/Z/9n/2f/a/9v/3P/d/97/4P/h/+H/4//l/+b/5//o/+r/7f/x//T/9f/3//n//P///wMABwAKAA0ADwATABgAHAAfACEAJAAmACkAKwAtADAAMgAyADMANAA1ADUANAAzADIAMQAvAC8ALgAsACgAIwAfAB0AGwAYABQAEAALAAYAAQD9//j/8//t/+b/4P/b/9f/1P/Q/8v/xv/B/73/u/+7/7r/uf+3/7X/tf+1/7f/uf+7/77/wP/C/8b/yv/M/83/0v/Y/9z/3v/j/+n/6P/p/+z/8//1//X/+//+//7//P8BAAQABgAJAAwADgAOAA8AEwAXABoAHAAdACEAJAAoACwALgAwADAAMwA3ADgAPAA9AD0APwBBAEEAQwBDAEMAQwBCAEQAQgBAAD8APAA8AD0AOgA4ADUALwAsACsAKQAnACUAHgAXABQADwAMAAsABwADAP7/+f/1//T/8f/v/+z/6v/o/+b/5f/j/+H/3v/d/9z/3P/c/9v/2f/W/9P/0v/S/9P/0//T/9H/z//P/8//0P/Q/9H/0f/S/9P/1P/W/9f/2f/b/93/4P/i/+X/5//o/+r/7P/v//L/9P/3//j/+f/6//v//P/9//7//////////////wAA//////7//v///wEAAwAEAAUABQAFAAYABwAKAAwADgAQABEAEgASABQAFQAWABgAGQAaABoAGwAcABwAHAAcABwAHAAcABwAGwAaABgAFwAWABUAFAASAA8ADAAJAAYABAACAP///f/5//X/8f/u/+z/6//p/+b/4//g/97/3f/d/93/3f/d/93/3f/e/+D/4v/l/+b/5v/l/+f/6v/u//H/8v/x//H/8//2//n/+//8//z//P/8//7/AAABAAIAAwAEAAQABQAGAAYABgAHAAoADAAPABEAEwATABQAFQAYABwAIAAiACMAJAAkACYAKQAtAC4ALQAuAC8AMQAxADIAMgAxADAAMAAxADIAMgAyAC8AKwAqACwALAApACUAIwAgAB0AHgAcABkAEQAOAAoABgACAAQAAAD4//b/8P/w/+r/5P/m/9//2f/a/9z/2f/U/8//yv/I/8j/yf/N/83/yP/C/8P/x//J/8v/zv/Q/9D/0P/T/9j/2//d/97/4P/k/+j/6//u//D/8P/x//T/+P/9/wEAAwADAAMABQAIAA0AEgAVABgAGgAbAB0AIgAmACoALAAtAC8AMQAyADQANAA1ADcANgA0ADIAMgAyADAALAAmACIAIQAfAB0AGwAXABIADAAIAAUAAgAAAP7//P/4//T/8f/v/+z/6f/l/+P/4v/j/+L/3//a/9b/1P/U/9b/2P/Y/9b/0//S/9P/1f/X/9j/2f/Y/9j/1//Y/9r/2//b/9v/2//d/97/3v/e/9z/2//c/9//4//n/+f/5v/k/+P/5f/p/+3/8P/x//L/8v/0//f/+v/6//n/+v/7////BAAJAAsACgAHAAcACgASABoAHwAgAB8AHwAfACIAJQAqAC0ALQAuAC8ALwAtACsAKwAoACgAKAArAC4AKAAhABsAGgAXABYAHAAbABYADgAKAAgACAAJAAkABQD+//v//P/+////+//1//H/8P/z//j/+P/2//H/7v/x//X/9//2//H/8P/0//r/AgADAP7/9v/w//L/+P/9/wAA+//2//X/9P/2//T/7P/h/9z/4P/t//7////y/+D/0v/R/+P/+v8JAAsA///z//D/+f8GAA8AEgAQAA4AEgAYABsAFwAMAAEA//8MAB4AKgAmABQA///1//z/DAAdACMAHAASAAsACgANABEAEgAQAA0ADQARABYAFgAPAAQA/f/9/wUADgATABEABQD4//L/8v/3//v/+//2//D/6v/n/+f/5f/g/9v/2v/e/+P/5v/i/9j/zf/I/87/2//o/+//7P/i/9b/z//Q/9n/5f/u//D/7//r/+f/5f/m/+j/6//u//X//v8FAAcAAwD8//f/+P8AAAwAGAAcABkAEgAMAAsADgATABYAFwAXABcAGAAZABkAFwATAA8ADQARABcAHQAjACUAJAAfABwAGgAcACIAKQAvADAALgApACYAKQAuAC8AKwAjAB0AHQAjACwALgAmABgADAAIAA0AFgAbABkADQD///b/8//0//P/8P/r/+f/5//q/+v/4//V/8n/x//R/+L/8f/0/+v/3f/W/9v/6P/0//n/9v/x//D/9/8BAAUA///1/+z/7f/4/wUADAAEAPP/5f/k//D/AQAMAAoA/f/y//D/9f/5//f/8v/w//b/CQAdACMAFQD6/+D/1//l/wMAGgAfABwAEgASABIACQD0/87/uv/Q/w0ASgBgADoA5P+U/3z/p//8/0EATQAkAO3/zP/N/+X//f8CAPn/+v8UADoATwA4APv/vf+p/9D/HQBgAGwAOgDq/67/pv/O/wYAJwAiAAUA6v/j/+z/8//v/97/1v/l/wsAMgA+ACQA9f/P/8v/6f8UADEAMwAcAP//6v/j/+X/6v/s/+3/8f/4/////P/q/9L/xv/R/+7/EQAjABkA+//c/8//2f/v/wUAEQARAAYA9//m/9n/0//X/+X/9/8GAA0ACwABAPf/8P/v//T/AAAQAB4AJAAgABQABQD3/+7/7f/0/wAACwAPAAoA/v/t/9//2P/Z/+L/8f8DABIAGQATAAEA7P/c/9r/6P///xgAKQAsACEACwD2/+z/8f8AABMAIQAlACUAJQAmACMAGAALAAQACwAeADQAQQBCADkALQAgABYAFAAcACkANwBDAEUAOgAoABcAEAAPABUAIAApACwAIwAXAAoA/f/w/+//AQAUACAAHwAQAPr/7P/w//7/BgACAPf/7f/w//n/+//v/9r/yv/M/93/7v/y/+X/0P/I/9L/6f///wUA///y/+7/9/8FAAoA+f/a/8T/yf/n/wwAFQD2/8L/lf+P/6j/v/+z/5D/gv+v/w4AYQBoAA8Ahf8m/0D/zv9/AOwA2wBnAOP/nf+v//X/NABDACoAFAAiAEkAWgAuAM7/d/9z/9P/YgDFALsAUADN/4f/oP/7/1YAewBoADsAFQAKAA8ADwD9/+L/2P/2/zUAbAB0AD8A6P+h/5f/zv8kAF8AXQArAPH/zP/F/8z/z//J/8P/0P/w/xEAFADu/7b/kP+T/73/9f8YABMA8v/U/8//5P///wkA/P/k/87/yf/X/+//AwALAAUA+//u/+H/2P/V/9n/4f/y/wwAKAA3ADEAFgD2/97/3f/3/x8AQwBQAEIAJAALAP//AgAKAA4ADAAIAAoAFgAjACcAFgD6/+b/6v8MADUAUwBWAEQALgAiACQAKAAlACQAMQBNAGsAcgBSAB0A7v/f//P/GgA3ADkAIAACAPL/9v8FAA0AAQDk/8b/w//h/w0AIQALANf/qf+j/8z/CAApABkA6P/A/7v/2P/+/xMADQD5/+z/8f8CAAgA9//W/7r/uv/b/w4AMQAoAPX/vP+n/8j/CAA4ADIA/P/G/7n/4f8cADkAIQDk/67/qP/Z/x0ARAAyAPH/q/+T/77/DwBOAFMAIwDn/9H/6P8MABAA7v/M/9X/CwBMAGgAOQDf/4//dv+d/9z/HABQAGkAYwA7APn/qv93/3v/wP8uAJIAvgCgAEYA2v+P/4r/xP8SAEoAXABSAD8ALAARAO7/z//J/+D/CgAuADgAKAALAO7/2v/T/9r/8P8RACsAKwAPAO//5f/5/xcAJwAhABEADAAUACQANAA3ACUA+v/M/7H/uv/l/xUAKwASANX/nf+V/8P/BQAnABMA2v+p/6b/1/8bAEUAOAABAMv/vf/d/w4AJQAPAN3/u//K/wIANQA1AP//xP+3/+n/MQBQACYA1f+i/7T/+P87AFEALwDx/7//r/+//9v/9P8DAAUA/P/0//L/+v/+//P/2f/B/8n/9f8mADUAFwDn/9L/6P8WACgACADQ/7L/1v8jAGMAZwAsAOH/tP+4/+X/GQA2AD0AOwAvABUA8v/Z/9n/8P8NAC0ATgBlAGcAVAA7ACMABQDs/+r/BQAxAGEAkACiAHMABwCZ/2v/lf/u/0EAWwA0AO//xf/O//f/GAAUAPT/0P/E/+X/JwBqAIMAWgD9/6b/k//M/yYAXQBQAA8AzP+3/9H/9v///+b/yf/N//L/GwAoAAkAzf+c/5z/yP/+/x4AIAAJAOX/w/+u/63/u//a/wMAKQA6ACsAAwDQ/6j/m/+2//3/VwCQAIYAOQDQ/4z/lP/g/zwAYgBCAAcA6f8AADQAVQA7APT/uv+//wYAWABuADYA4v+9/+z/UwCiAJUAJgCZ/1T/jP8aAJUApABRAOf/sf/B//b/GwARAN7/tv/S/y0AfQCDADwA1/+O/4f/x/8oAGUAUwAIAL//ov+z/9f/8f/r/8z/sv+y/8j/2//b/9D/0P/i//n//v/h/7P/mv+x/+r/IAA2ADEAFQDq/8H/rv+7/+X/GAA6ADgAGwD+//b/+//3/+L/z//V/wEAQABuAGcAJgDF/3b/Z/+f/xIAjwDRAKwANgDF/5r/tP/j//3/AAAOAEUAlADAAI8AEACR/1//k//7/1gAhgCHAG0ARwAdAPb/1P+9/8D/5/8oAG0AkwB+AC4Axf+B/5D/5f89AF8ATwA2ADcAQQAlANn/fv9U/4b/AAB3AJkAUwDX/3n/Wf91/6//7/8kADYAKgAVAAsABwD+//b/9//+/wsAIQA6ADsAEQDU/7H/u//k/xIAKAAiAAYA4v/J/8f/4f8BABUAGQAUABIAEQAMAP//6v/Y/9b/+/8xAE4ANQDx/77/yf8FADwARQAhAO7/2P/v/xkAIgD1/8H/vv/r/xYAFwDw/87/zP/g//7/CwD+/+H/zP/Y/wAAMgBMADkABADG/7H/4v9AAHwAVgDe/3P/cf/j/3QAuAB8APT/iP+I/+H/MwA3APf/vP/E/w8AbQCRAFAA1f95/3P/t/8MADAAEQDO/6r/1P89AJsAowBEAKv/M/8i/4j/LQCuANAAnQBNAAwA5//E/5X/a/9w/7r/LQCQAK8AfgAVAKH/Uv8//2X/tP8TAGgAjwB2AD0ABQDY/7T/n/+l/8n/EgBzAMMAyABpANf/Yv9G/4//FgCLAK0AdQAXANH/u//K/9j/zf+//9n/KQCBAJUATQDV/2r/Rv+B//T/WAB3AGQARwAlAOb/nf97/5v/5/8xAFYATQAfAN//s/+2/9z/+f/u/9L/yP/X/+n/+P////P/zv+u/8D/AQAyAB8A3v+t/6z/2f8QADMAKAD8/+H/+v8wAEwALQDh/6L/oP/e/zgAdgCCAGQAMAD2/83/xf/l/xgASgBgAEYACADP/8n/8/8fACMACQD7////CQANAAwADAANAA8ADwAWACMAMwBFAEgALQADAO3/BQA2AEsAKgDw/9j/AQBHAF4AJwDQ/6H/v/8IAEcATwAdAOL/0//o/+7/3P/c/wsASgBdADgA/P/P/7v/tf+v/7T/1P8QAEwAWAAmANb/of+o/8z/2f/F/8P/+v9KAGMALADa/7D/vf/c/+//8f/t/+7//v8TABQA8P/M/93/HQBWAFMAKgAKAPX/3P/N/9//BgAhACEAGQAWAAkA6P++/6D/n//N/ycAfwCTAEwA5/+1/9T/IABaAFcAIgDs/+j/FQA+AD0AGwD3/97/0P/O/9r/8P8KACgAQAA9ABMA3P+6/7j/wP+9/7//4P8gAFwAdQBWAPn/c/8Q/zD/2P+bAPUAwAA+ALr/Yf9U/6D/EgBdAFoAHQDX/6D/gf+I/8P/EQA1ACAAAwADAAsA9//P/7//0f/y/xgATQCBAHgAJADA/4v/gv+M/6T/3f8iAEoAVQBRADcA/v/G/7//3f/m/9D/0v8PAGMAkgCJAFIA9/+g/4D/sv8FADoAUwBuAIMAZgAWAM3/u//m/zUAfQCOAEoA2/+U/5f/y//0//v/8P/q/wAAKAA7ACEA7v/J/7z/vv/N//T/OgCKALkApABKANH/dv9p/6L/+P88AFEASAAuAAYA2f/A/9D/7/8DAAYACAAFAPb/5v/g/9v/2f///1AAiwBrAAUArf+e/8z/DAA9AD8AHQADAAoAIAAkABoAEQAGAO3/yP+u/7z/9v85AEAA+/+u/7T/DQBkAGIA/v9+/zf/Yv/t/3oAsAB5ABkA0/+0/7j/0f/1/xIAFwAOAA8AIAAyAC8AAwC2/2//bf/G/0gAngCNADgA4v+4/7T/sv+r/7X/5f8zAH0AmQBvAAkAm/9d/2D/lv/j/zMAcgCJAG0AJwDd/7z/yP/h//X/EAA9AGUAXQAhANz/v//R//v/LQBCAB0A0f+k/8b/GwBVAEgA+/+b/2T/jP8LAI4AsABeAOf/pv+2//r/LAAbANf/rv/f/1AApQCbADoAxP9+/4b/yf8HAA8A/P/+/xcAIgAVAA8ADgD7/9D/p/+h/8z/GgBjAHAAMgDl/8f/6v8gACsA+/+7/6r/2P8XADIAJgAXAB8AMgAsAO7/i/9Q/3j/8/9eAHgATwASANz/qv+I/4P/mv/H/xIAZwCCADsAxv+G/5b/wP/X/+//HgBAADYAGwAaABYA3P+F/2n/qP8PAHYAzQDfAG0Apv8o/03/0v8+AGYAWQApAPH/4v8JADkAOAD4/6f/ev+O/+j/WgCmAJcAKwCq/3b/tv8xAIkAhwA/AOn/wP/c/xgAOgA0ACUAKgA3AC8ABgDF/4b/cP+i/w0AZgB5AFMAKAAJAPD/2//O/8n/0v/9/00AnACxAHcACQCT/0f/Rv+c/ycAlQCZADoAvv9t/2v/s/8gAGkASwDh/5T/qf8GAGAAegA8AMP/Zf9w/+L/TgBLAO3/r//k/2QAxAC2AEIApP8y/zn/xv92AMYAjwArAPX/5P/D/4//df+A/5f/wP8iAJgAuABgAO7/vf/F/9z/CQBcAJcAcwASANf/7/8jADkAMAAVAOz/xP+4/9H/7P/v/+//EwBJAFoAJADB/3r/fv/D/w8AOwBKAE4AMwDo/5L/cf+X/+T/LQBXAFcAOgAnACUAEADN/4P/ev+//x8AWwBcAB8Avf9b/yv/Sf+k/yIAkwC1AG0A9P+v/7b/1//i/97/9f86AJcAzAChABQAef8p/zb/e//G/wsASgB2AHkARwD0/6j/f/+A/6n/8/9JAIoAlQBbAPD/iv9x/7r/KABYADkAFAAnAGAAcgA0ANP/lv+u/xYAkADHAI4AEgCt/5X/pP+z/8T/7f8iACwADADx//j/CQAEAPz/BwAVABcAGQAxAD8AIADv/+b/CwAwADYAJAAVAP7/z/+e/5//4P8pAEEAKQAIAPj/8f/u/+n/3f/O/9b/FwBnAHYAJgC4/5j/3/89AFYAKgDy/9b/3/8BACEAFwDj/8n/+/9IAFIACwDD/8f/AQAqACsAEwD4/+P/2P/o/woAKAAgAO3/sP+Q/6v/AQBjAIIALQCX/0T/iP8xALIAqgAwALL/iv/L/y4ASwAHAK3/mv/l/1EAkwB5AA0Amf93/6//BgA7ADEA/P/G/8f/GACLAMQAiwDy/0b/4v78/o//TQDFAMkAiABFABsA+//G/37/S/9o/+H/fQDtAAQByABMALr/Sv8i/0T/nv8QAHIAkQBdABkA9//p/8v/nf+G/6D/9f9vAM4AwwA8AJD/Lv9H/8D/SACIAGQACgDE/7v/2v/6//L/wP+d/8//UgDDAMIAVQDP/2r/Tf+J//v/UgBXAC0AEgD//8j/gf9z/7D/AwArACYAGAAMAPX/3v/t/xwAOgAiAP7//P8QAA0A+v/2//n/5v/I/9n/FwAzAP7/tP+p/97/GQAqABcA9v/W/9X//f8oACIA4P+U/4f/w/8WAEwAWABTAEsAMQD6/8H/s//j/zQAfQCUAGMACADH/9H/CQAmAAIAzf/I/+T/8f/n/+f/AwAgACMAEAAJABYAMABJAEEACgDJ/8D/AwBTAF0AGQDQ/9D/FgBTADUAz/+E/5H/3/8iADoALAAMAPn/BQAMANv/mf+g/wQAZABgABEA1//b//f////u/+v/DgBNAHsAbQAiAMz/of+0/9D/xf+g/63/DABsAGYA+/+c/5f/y//r/+j/6v8JADIAUwBcAEIA///J/+P/LwBPABUAx/+9/97/7P/q////KgBBADoANQA4ACIA6f+r/4r/mP/a/z8AjQB/ABEAlv9q/53/9P8iAA4A4P/Y/xEAaACNAGUAIQD3/+//6v/W/8P/xv/o/x4ARQA2AOn/nf+T/8f/7P/O/6D/t/8bAIQArQB/AAQAZv8L/1T/IADLANQAXwDm/53/ef+B/9P/RgCGAG0AIwDj/7j/nv+i/9j/GQAlAPf/3P/+/yYAFgDh/9L/8f8SACsAWgCVAI4ALwDO/7b/zf/h/+//FQA8ADkAGgAJAP//4P+//8j/7//y/9D/2f8zAJwAtQBzABQAu/+A/3n/tf8DACQALABOAHgAVwDk/4T/iv/l/00AhwB3AB4Av/+1/wEATABJAAwA2f/K/97/BgAgABIA6//P/8P/sv+k/8f/IgCCAJ0AWwDn/4P/YP+D/8f/CgA+AFgAVwA4AAkA4//b/+v/7f/V/8P/3v8bAEoASQAaAN7/xf/9/2AAgAAlAKD/a/+a/+D///8CAP3//f8NACcALAANAO3/6P/s/9j/uP+8//j/VACUAH4AHgDR/+//UQB3AB0AhP8f/yP/hf8XAIwAqABrABQA2v+1/5r/mP/A//D/+//1/xMAVgCMAIkARQDT/2b/Tv+v/zsAfgBTAA8A/P8OABYA/v/Y/8H/0v8SAGIAhgBZAPj/pf99/3T/hv/B/x8AcgCGAFoACgDF/6z/v//b/+j/7/8OAEUAZABJAAgA5v/7/yAALgALALv/Y/9M/6f/RQCqAI4AFACW/2L/mv8hAI0AdgDt/33/iv/w/1gAewBBALz/Sf9S/9j/YgCIAFoAGgDo/8f/y//x/wUA8f/V/+H/FABZAJ4AsABdAL7/Mf8L/1n/7P9zAI8AOwDy/w4AWwBfAAMAlv9o/4n/6/9gAKAAhQA1AP3/9P/1/9j/qv+h/8z///8AAOf/+P87AGgASwACAMH/l/+S/9X/SQCRAHUAKAD+//j/6f/N/8//8/8LAAkAEAA5AFkAQwACAM7/xv/U/+z/HQBeAGwAMgDs/8v/u/+f/6b//P9oAIUASAD4/9P/1f/r/x0AUwBcADIACQAHAA0A5f+m/6z/CABfAFgACgC4/3n/a/+n/wkALwD0/7H/y/8rAHYAdQAyANH/g/+A/9H/PwCDAIQAWAAcAOv/0f/H/8n/3//4/+j/s/+j/+P/PgBwAG8AOwC4/xb/4P5T/wEAYQBsAGEATAAuACgAQAAqAMb/cf+K//3/agCYAJMAZgAYANP/sv+n/5r/of/W/yMAXABjAFAAJgDa/5P/lP/w/1oAegBMAA8A5v/M/8r/5P/3/9T/lf+d/xAAiQCfAGoAIwDV/4f/g/8EAKMAvQBJAMn/mf+n/8z//v8dAP//wv/C/wYAJwDr/5X/hf+0/+v/JABtAK4ApwBHALT/LP/8/kf/7f+FALQAfgArAAQAFgAuAAkAov9U/37/BQB7AKAAhQA0AL7/b/+X/xsAaAArALr/k//M/zIAlgDBAH4A3v9p/4j/DwByAFYA6v+T/5f/7v9fAJ0AdwD+/3b/Rf+o/2YA9gDzAHIA1v9//5H/4v8lAB4A1v+a/6j/+v9KAFQACQCj/4H/vv8UAEgAYQBvAFkAFgDn/wAAJwAUANf/tP+9/9D/9/8xAEoACwCk/3z/qv/q/wAA7//b/+X/DgA7AEcALQD1/5z/NP8G/0//7v+BANYA8ADAAEsA2f+x/7T/mP+A/8X/WwDAAK8AaQA9ACcA/P+5/2L/B//i/iv/3P+IANIAuQB5ADQA8P+x/4P/gv++/xIASgBHADQARwB3AIwATgDN/1f/O/+J/xEAfgCFADIA2//I/+j/9f/a/7f/uP/i/xQANQAvAAYA1v+3/67/uP/U////JgBGAGsAgwBtADAA8//K/6X/kf++/x8AegCVAHMAMQDl/6b/jf+g/8f/6P8KADUAXgBfACUA2P+z/8z/9/8MABkAHgAOAPP//P8eAA8Azv+2/wIAZQBnAA8Avv+n/7X/2P8PAEYAWQA9AAMAyf+w/8z/EgBPAFUAFgCt/1//aP/R/0QAbQBiAFwAUQADAID/P/99//T/TwBzAHQATgAQAPf/DQAbAPX/vf+n/7r/5/8tAH0AqAB5AAAAjv9u/7X/JwBnAEcA9P/K/+n/JQA7AAcAsv+T/9b/PgBuAEYA8P+w/5X/o//b/yUAVgBLABMA0/+u/7z/AABEAD8A6P+S/57/BABqAHkAPwAHAP3/DQAOAAAA+v8DAAsADwAXABAA5f/L//v/QAAuAML/f/+9/ykAVQBDADIAGgDh/77/6f8yAEEAIwAxAHMAigBEAPP/5//1/+D/vP++/+f/EwBDAH4AjgA7ALz/jf/D//j/1/96/1D/j/8KAG8AdwAlALn/fP+U/+7/TwCEAHMANwD+/+D/5/8hAIwA3gCwAPj/Pf8S/23/1/8AAO7/vP94/1r/oP8bAFAAIADq//X/EAAEAPv/EwAOAMT/jf/B/zMAaQBPAC0AIAARAPz/7v/Z/6T/iP/k/5cA/ACxAAUAj/+I/7r/6v8EAPP/sf95/5P/CwCCAJcATADR/1//RP/D/7UAZgE4AVIAdf87/5n/CgAjAOP/qP/N/0wAwgC9AC0Aev8h/0r/rv/y/wcAGwBRAIEAZAD3/4v/cf+a/77/vv+7/+H/OwCiANIAlgDz/1j/Pf+7/2gAxQChADcA2f+l/5X/mv+j/6T/qP/J/xEAWwBrADUA2/+L/2L/av+z/zEArADmAMEAXADn/5P/g//C/yAAVABEABYACQAqAEkAPQALANX/uv/G/+r/BwAUABcAGAAZABIAAQDs/+D/5//2//b/7/8FADsAZABOAA8A3P/W/+3/CwAvAEYAMwABAPH/GAA8ACcA+P/r/+//3P/K//P/QABdAD8AIAAOAMz/X/89/5f/HABfAFgAOQARAN3/u//M//X/AAD6/w8ANwAsAN//qP/Z/z0AWgAhAOn/6f/8//z//v8HAO3/wP/T/04AuQCKAPT/l/+p/9b/5P/7/ysALgDu/8L/7f8dAPT/vv/j/0AAVgANANb/7/8gACQAAADe/8z/1f8QAHEAsACLAPz/X/8S/zT/kf/r/0kAqgDGAF4AuP9v/6T/7f/5/+T/2P/O/9T/HQCYALsAMQB4/0j/pv8MADMAPgBIADMABAD5/xMACgDI/6T/2/8vAEMALQAtADUADAC+/5X/oP+t/8z/NQC2AMoATQDA/53/wP/f//f/KABPACYAzP+c/7X/1//d//T/OAB9AIQAVAAaANj/gP80/0f/yP9WAKAAoQB8ADoA3/+h/5//u/+7/6j/vP8JAF8AjgCSAHMAKwDE/2//Xv+J/8D/2//l//z/IwBCAEYAOAAbAOj/uP+y/97/JQBeAHYAagAxANP/eP9e/6b/JgCGAIUAQgALAOv/uP99/3z/uv/v/wQAPACcAMAAdQAFAL3/ef8j/wT/Xv8AAIEAtQCsAG8AFQDT/7n/rf+f/5f/o//L/x8AjgDEAIQACgC6/6H/l/+f/97/KwAtAOD/pv/D/wUAOgBpAIsAWwDZ/3X/if/Y/+z/yP/O/xMATQBTAE4AXgBdADYADQD1/9H/lf+A/8z/SwCSAIYAXwBKADoADgDO/57/h/+I/6v/9v9QAHkAVgARAOj/6v/8/wcABgDr/63/dv+E/+P/RgB3AIoAlQCDAEIADwALAAcA1f+f/67/9P8tAE0AbwB8AEMAzv9s/03/Vf9o/5v/+/9YAG8APwAMAP7/+//n/+T/EQBJAEMA/f+3/6j/z/8DADIATgBGABYA8P8BADEANwDs/5P/gf/C/xIANwA1ABgA7v/e/w0ATwAzAK//Rf9a/8r/LgBhAHsAegBbAEMATwBHAO//gf98//L/YQBqADMAAgDU/6j/sf8IAFMAKQCz/3//y/9EAHQAPgDe/5//rv/9/0cARQDz/5X/h//t/24AkABGAOz/0P/W/8z/0P8KAEsAQwD//+L/FwBlAHwAMQCH/8r+hv4b/zIA+QD1AFoAuP9n/27/r//1/xUABwD3/woARACSANIA0QBcAJv/C/8V/63/VACVAFAA0/+m/wEAewBvAMD/BP/e/mr/TwAUAUgBywDt/0f/Lf9u/8b/GABQAEsAEADn/wkAWwCTAHIA6P9G/xP/o/+iAEYBLAGHAMP/Of8t/6//RwBbAPz/u//b/xUAKwA7AEEABACR/2T/yf9sANIAxwBfAMX/TP9O/8//UQBQAN//hf+j/yIAkQCQACIAmP9V/4z/HwCuAMwAdwAIAMf/t//A/9L/7P/x/9X/wP/W/xwAZwCOAHYAFQCV/1r/oP8xAJwAkAApALr/if+q/wMAVQBWAOn/Y/9H/8v/lgAKAdwAKwB0/z7/qf9cAL0AiAD5/33/XP+X//D/GgD+/9D/y//p/wsAKQBBADEA8P+4/87/GwBcAG0ARADs/3//RP94/wAAfACXAEYAy/+D/5f/7P9GAGwATwD+/7j/zP8wAHwAWQDr/5X/cv9l/3j/yf9FAJgAmQBpACUAz/97/2L/pv8YAHMAkAB6AEMA7v+Z/3r/rP8AACgACADS/8j/9v8rAEEAMQAJAOD/1P/5/zUAUwA5APz/zf+8/7L/wP/9/0cATgD+/5//fv+i/+z/QQBxAE4A9P/L//f/KAAFALn/nf/B//X/HQA+AEUAKAAFAPP/5f/S/8//7f8OAAsABAApAG8AiAAxAJr/M/9T/9n/RQBCAPD/uP/e/0AAhwBpAP3/p/+q//D/FwD1/8z/4/8kAEcAKgD2/9X/1f/u/wEA7/+1/5n/4/9lAKAAaQAQAOP/2f/J/7z/yP/O/8v/9v9WAJAASwC7/2n/if/x/1cAhQBWAPH/vv/y/z0AMwDt/8//8f8JAAIABQAiAD8ASwBOADIA3v+N/6j/KwCBAEUA1f/L/y8AgwBlAPT/i/9l/5D/9v9MAFMADgDP/97/GwA1AAoA2P/X//L/8v/w/y4AjQCVADMA2//P/+X/9f8vAHwAZgDd/5L/7/9hADYAnP9G/17/n//1/20ArQBbAM3/lv+z/6X/Z/91//r/gwC6AMEArQBcAM//X/9E/2D/mP/6/3AAsACLAD0ADQDw/8T/kP+A/6H/3/8pAHEAhgBPAO3/mv91/27/gv/I/0YAvADYAIcA/P+I/0j/Pv98//3/hQDQAN4A3QC7ADgAfP8U/zr/jP+1/+v/XgCvAI8APQAOANL/Wv8V/3X/BgAZANT/4f9SAJMAbwBGADsADwDF/7P/2//W/4n/gv8ZANMA/QCBAOb/iP9o/3v/wf8oAGMAPQDt/8D/uv+3/7P/yv/o/9r/t//N/x4AUgAyAPz/+f8eAEkAewCjAIIAEgC2/7v/+P8WAAcA9//u/9z/2/8AABgA5f+V/4z/2/8yAFoAZgBfACQAx/+v/wcAZgBUAO7/q/+p/6//v/8OAHQAfAAcANz/EwBqAHEAPAAiACQAAwDU/9//HAAuAPP/yf/n/w0A8v/A/8r/8//o/8D/2/84AGYANwAOAC4ATwAjAN3/yv/G/53/iP/R/zsAUwAcAAAAEwACAMf/xP8YAFwAOwDk/6//uv/4/1MAkgBlANv/dv+G/9n/DwAPAPf/4f/e//r/HAAcAPP/0f/g/wcAJgAzADcAKQD7/8j/tf/c/w8AEQDt/+f/JgB4AJUAbwAcAKn/Pf8v/6H/OAB3AF0ANAAWAN//pf+z/wAAHQDZ/5//yf8eAD4ALwAmABYA4v/B//f/TABWABEA3P/S/7T/h/+v/0AAsgCMAAUArv++/wQAWQCXAGMAoP/W/s7+lf9iAJkAdgBiAE8AAQCk/5j/zv/t/9X/xf/l/xcATwCaAOUA1QA7AHT/Ef84/5H/0P/3/xEAFwAfAFkAqgCrADAAjv87/1H/qP8TAGEAWAAJANj/+P8oAB4A7//S/8b/u//K//v/GgAIAP3/JQBKACEAzv/E/xIAWgBPABUA6f/F/5T/d/+a/+j/HgA2AFkAeABHAMX/cP+n/xYAKwDk/7f/5f84AHwAuwDHAFYAlP8r/2z/1f/n/+L/KAB7AHEANgAjABQAuf9X/3X/6v8QAOD/8v9hAI8AOwDn/9//wP9c/0H/zv+HAMQAlABXAAsAn/9p/8z/fwDCAFsAxP+H/7f/EQBQAFQAGACw/2L/c//j/14AfwBHAPz/y/+q/6n/8/9iAIwASAD0//f/RAB/AG4AHwDP/7r/8v9EAFUADwC7/6L/x/8FADYANAD5/8H/zf8MABUAv/9m/3X/2f9AAH4AogCXADgAtP9w/47/xf/2/0wAvgDZAGwA6f/T/xcALwDy/6P/bf9c/4b//P91AHcA9f92/3D/y/8NAAQA0v+f/4b/tv9IAPAAGAF8AJv/KP9K/67/EwBiAHUAKQDO/+H/UAB0AAkAlP+e//r/QQB3ALgAuQArAGX/CP86/5P/zv8FADoAOQD9/9n///8uABMAyv+w/+z/RQB0AGwATgA3AC4ALgAlAAYAxf96/2X/t/9KAKUAgAAhAPX//v/y/8v/xf/v/w0AAgDv/+n/2f+5/63/uv+5/6f/v/8dAIcArAB2AAEAkv9g/4D/0f8iAHQAvgDCAF0A0/+S/5X/i/9j/2L/sf8wAKgA8wDlAGEAsv9c/4X/1P/k/87/5P8uAFUAIwDL/5v/of+9/+X/IQBaAG4AXQBIADYADwDj/+r/KQBVAD8AJABHAIIAYQDI/zD/FP92//n/UgBpAEIA/f/a/wUAPgAtANv/r//a/woABAD4/yMAXwBfADMAGwAbAA8A+v8DABgAAADE/7b/+f9QAGgANADx/8X/qv+a/6r/4f8KAPj/xv+4/9z/AQAGAPv//f8FAAQAGABEAFQAHwDM/8D/DwBgAF8AKgAJAAcAAADw/+r/5v/R/83///8zAA0Aof9q/7v/QABrAC4A2f+z/73/2v8GADMASgA2AAYA3//d/w0AXgCTAGYA0/9C/zr/0f+OANQAdgDQ/27/kf/+/zEA4/9n/0v/uv9fAMgAxgBfAMD/Sf9O/6j/8/8AAPD/7f/8/ysAigDpAOgAYQCf/wj/4P48//f/tgAEAdIAcgAsAPz/wv9s/xH/5v4r/9X/hADWAMMAfwAmALv/Xf9A/3f/3v9IAI8AlgBhAC4AJAAgAPD/nP9r/5H/CwCSAM0AigDw/2n/P/98//P/WwBzADsA+P/f/+b/4P/G/6T/ff91/8P/XADNALYAPgDY/6T/kv+t//z/UABlAFAAVQBpADsA1v+j/8z/AADp/6//qP/a//n/+f8OADoANwDp/6f/v////xYADgAiAD8AKgD1//H/GAALALT/fP+3/yoAcQBoADgABQDe/93/AQAXAPf/tv+K/57/2/8VADIALgAjAB4ABgDL/5P/nv/6/2IAjwByACEA0f+z/+X/NwBTABwA2f/c/wIAAADX/8v/+v8zAEEALgArAEEAVABQACYA2v+X/5n/5v82ADgA8//B/+j/SwCDAEQAxf+A/6T///8/AE0APAAaAAIACwARANr/jf+V/wkAcgBZAO7/t//Z/xEAHQAJAAoAMwBtAJMAfAAoAMT/j/+c/7H/l/9o/37/9v9tAG4ACAC7/8v/+f/v/8D/u//v/ygASwBbAFYAIwDq//T/JAAdAL7/c/+W/+X/AAD9/yMAYQByAE8ANQAtAAUAu/+J/5X/xv8LAFoAhQBTANT/cP90/8L/CAAUAPD/x//I/woAaQCLAFoAFwAJAB4AGQDv/9D/2/8BADEAVwBRAAgAuP+0//L/DQDL/4v/uv85AIwAewArALz/Qf8L/3v/VwDcAJsA/f+g/5D/if+R/+T/YACXAGsAHwD3/+X/1P/g/x0AUgA0ANn/rP/Y/wgA9P/E/83/AgAcABwANwBkAEcA2f+Q/7H/8f////H/BwAuACsAEwAVABgA7P+3/73/4//U/6b/0P9mAOkA6wCQADEA3f+Z/4v/x/8EAAMA+f8oAFwALgC7/4T/tf8GADgAQwAiAMv/gP+q/zAAjwB1ACoACAAKABUALABDADMA+//Q/8n/wP+s/8n/NwCsALwAWADR/2//P/9F/3z/zv8XAEAAVwBdAEQAGAAAAAAA5P+o/4v/wP8YAEYAPgAeAAMAAQA9AJgAoQAmAJP/bP+v//L//v8AAAsAEgAYACQAIQD3/8v/vv+7/5b/Zf9v/8z/SACXAIsARQAeAFQArQCvACcAbv8F/xv/jP8eAI0ApgBvACEA5/+v/3z/b/+d/9f/7P/2/yYAbwCYAIwASQDX/1z/Mf+O/yIAaAA/AAgABwAXAAgA3f/B/8X/6/87AJkAvAB6AAAApP+A/3P/ef+q/woAYwB9AFoAGADS/6f/pP+1/8D/zf/4/0AAbABcADQALwBJAEsAJwDn/5r/Wf9l/9//gQDJAIQA9f90/0D/e/8QAIsAdQDt/5T/xP8wAG4AWwAFAIT/Kv9e/xIArAC8AGsAGgDk/7P/mf+r/8T/yv/U/wkAWQCeAMYAswBHAJj/Af/e/kf/+/+TAKwATwD8/wkAQgAvALz/R/8s/3f/AQCPANoAuABUAAoAAQALAOn/rf+e/87/BAD7/9T/2v8QAC0ACADM/5//gP98/8L/RACXAHsAKwAJAA8AAgDg/+X/EQAiAAoABAAuAEkAIADY/7v/1P/v/wEAMQB1AH8AOADn/77/nP9u/3v/8/98AJQAOwDd/73/wP/R/wYATQBeADIAFgA1AE4AGwDQ/+D/QwCHAGoAGQDS/5b/fv+x/wwAIgDW/5P/v/8vAHYAZgAaALn/af9l/8L/RwCbAJwAbgA7ABcA9v/Z/83/3v/t/9X/sP/D/x4AfQClAJcATwCs//L+uv47/+//TABVAEwANAAOAAkAKgAWAKf/SP9q/+7/YQCUAKEAigBBAPf/1v/I/6f/mf/S/y8AYgBRADEADgDE/3n/if8BAHMAggBTADMAHwDz/8z/0P/T/5f/Tf9w/wcAhACKAFIAFAC7/1P/U//6/7kA2QBqAAkA+/8SACkARABFAP//q/+0/wkAIADF/2H/Z/+4/wMAOgBvAJIAcQAIAIP/FP/2/kX/4v9uAKEAggBDABYADQAFAMz/af88/5z/TgDKAN8AuwBxAPj/kv+c/wAAJgDJ/2H/d//2/3UAvgC9AFcAo/8n/0r/0v8kAPz/sP+k/+j/SgCWAKAATACy/yH/A/+H/2UAFgE2AdIARQD2/wkARABZACQAxv+J/57/9v9EADUAxv9V/1H/tP8TADYAPAA9AB4A3f/D//r/NAAqAP//BAA3AF8AdgCFAGIA5v9Y/zP/iP/4/y4ANQA/AGQAigCOAF0ABgCY/xr/sP6q/iz/+/+qAAgBGAHJACgAjP9G/zb/HP8o/7v/rgBQAU4B9wC1AIQAMADA/0v/5P7C/h7/7/+yAPMAugBdAAcAsv9b/yH/J/90/+H/NABLAEYAXQCUAK8AbwDh/2D/Pv+P/yAAlACTACwAxv+4/+//EwD+/9z/5P8YAE8AZgBMAAQAtP97/2z/fv+l/9r/DgA+AGgAcgBDAO//pv+B/3L/ff/I/0wAyQD7ANoAhgAaALT/ev+F/7X/2//2/x8ATQBPAAsAtf+N/57/wP/c/wUAHwAHANz/5/8cACAA5P/N/yAAiACFACAAxP+p/7T/0f8IAEsAbwBjADIA+f/V/9//EwBHAEMA8v93/yH/NP+u/y4AXgBTAEkANQDf/1j/G/9m/+v/UgCDAJcAigBfAEQASQA6AO//m/+J/7n/AABLAJIAsABqANH/Sv8t/33/8P8vABUA0P+x/93/KQBFAP7/jv9s/8z/XQCkAHsAHQDZ/8L/1P8KAE4AdgBiACQA3P+q/6f/4f8jACYA0v96/4j//f9wAHcAIQDR/8T/5f/+/wAA/f/8//v/CAAtAEAAGADu/xEAWQBOAOD/l//X/0sAdQBVADQAEgDT/6z/2f8hABwA4f/q/0wAiABOAPD/0f/R/7L/kP+i/9f/AgAvAHcAnwBVAM7/nP/j/ywADwCu/4P/yP9HAKoArABNAMz/e/+E/8z/GQA+AC8AAQDb/83/3v8ZAIUA4AC+AAkASP8V/27/1f/5/+r/xP+H/2j/rf8xAGoALgDn//D/EgAPABUATgBsACsA3//7/1wAgABJAAwA7f/M/6P/lP+V/3n/a//U/50AEgG8APf/ff+M/9r/GQA7AC4A4/+V/57/CQBuAG0AGACo/0X/L/+w/6wAaAE4AUQAYP8v/6D/JABIAPz/m/+a/xYArgDKAD0Aef8V/0L/tf8HABwAJQBSAJIAmQBFAMz/jv+U/6b/mP+B/5b/7v9pALsAoQANAGT/L/+j/10AzQCuADwA3f/A/9f//f8MAO3/vv+6//z/VQBxADQAzP9w/0L/UP+l/zAAswDsAMwAbgD3/5H/cv+0/yQAZABPABMA/f8kAFIATwANALP/ff+M/9H/FQA2ADYAKAAhAB0AEwD9/+r/6P/y/+n/0//f/x0AYABmADQA9//S/8L/yv/3/yoALAD+/+7/IwBaAE8AGAD3/+T/u/+i/93/SwB8AFkALgAXAMv/Rf8I/2T//f9LAEAAJAANAOn/yv/d/wYABQDs/wkAUwBgAAMArf/V/0kAcgA4AP3///8SAAoACQARAOf/k/+L/xMAqgCZAAAAkP+U/7j/v//V/wYABQDA/6L/8v9BABYAxP/f/04AeAAtAOH/6/8jAEIAQQAvAAsA6v8DAF8ArQCNAPX/R//w/g//bf/H/yQAhgCrAEoAnv9F/3X/zf/2//v////x/+j/MwDSACIBngDA/2T/q/8FACEAKQA6ACgA9f/x/ycALQDX/5H/uP8FAAQA1f/b/wwAEwDj/8P/vf+b/4L/2f+AAMoAZADa/8P///8rADgAWQBwAC8Avf+R/8n/BAAFAAIALgBdAEwADwDi/7v/cf8h/yr/ov8rAHcAiwB/AEQA3f+T/53/0f/e/8X/z/8TAGUAlwCsAKUAagD5/4//bv+R/8X/3f/c/9z/6f/7/wwAFwAXAAEA4v/O/9X//P8xAFwAaQBFAO3/g/9U/5//RQDKAMcAYwAKANn/oP9o/3L/u//y////MwCnAPIAxQBTAOr/ef/y/qb+8v60/2wAzQDaAKsAWwAXAO7/zf+j/3T/Vv9s/9n/iQAMAQIBkwAlANf/jv9j/5H/9P8WANf/o//U/zUAfgC1ANMAhQDE/yT/L/+j/9v/wv/P/yoAewCFAH4AkACFAD0A8v/M/6T/Xv9A/57/RACnAJwAcABkAGAAMADb/4z/Uv81/1T/wP9OAKAAigBAAAsA+v/w/+P/0/+y/3L/Rf9v//T/eQC9ANEAzgCjAEIA8f/d/9v/rf90/4T/1f8cAEAAYwB6AEsAz/9Z/yf/Iv8q/1z/0/9XAIsAaQBBAEAAOAAJAOP//v84ADwAAADG/8n/BwBPAIcAmQByABUAyv/T/xIAIwDI/1b/Pf+T/wYASwBVACIAxv+M/8L/MwA/ALn/N/9I/9P/YAC5AOcA3wCZAFYAUwBMAOj/Wf83/6z/LQBLACgADADq/6//lP/O/xQA+P+U/3b/3/9yAKgAXADe/4X/gv/G/xMAHwDf/5b/qf81AMYA0QBRAMb/l/+t/8L/4P8qAHMAbwAtABAAPwB9AHcADgBP/4b+Qv7q/ikAGgEqAYYA0v93/3z/wP8JACYAFAAHAC0AgADhACIBFAGIAKv/AP/4/pT/UQCnAGQA1v+Z//v/kACTAMr/zv5u/vL+AQD/AFoB6AABAFL/O/+K/+b/JgBJAEgALQAkAFcAtgD3AMkAEQAs/8D+OP9EABYBLAGaAMX/Gv/4/nP/CAAOAJb/R/99/+v/NwBnAHsANgCj/1T/s/9qAOQA4QCDAPL/b/9c/+D/dwByANP/Tv9q/wUAmQC4AFYAsP86/1X/+/+mAMQAWQDd/6T/qf/F/97/6f/X/6//n//E/xQAaACjAKUATAC1/0//eP8RAJ8AtQBYAN3/nf+8/yUAiACBAOX/Gf/I/k7/UgASAQ4BVQB1/xT/cP8zALMAiwDs/1z/QP+a/xYAUwAwAOX/wf/a/xIARQBkAFUAEADG/7r/7f8vAFYATgAYALv/af9y//D/kADVAIsA9f+I/4P/0/8/AHsAWADb/2D/X//Z/1IAUgDw/5j/dP9r/4P/4/98APEAAgHIAGsA9v97/z3/dv/7/2wAkQB7AFEADAC4/4j/ov/Y/9r/nv9w/5T//v9fAIQAagAbALz/hv+j/+7/JgAuABYAAgDx/9b/1v8RAF4AZQAUAKz/ff+k/xEAlQDeAKcAHQDG/9v/BgDg/33/Q/9f/7L/EgBlAIMAXAAbAO7/zv+r/5v/v/8AACEAJQBPAK4A5QCRANP/Mf8h/5b/HwBPABoA0v/W/zwArwCxADAAmv9h/5D/y//T/8v/7/80AGEAUQAUAMv/pf/B//n//v+x/3D/s/9gANsAxwBTAOD/nv+Q/7j/+v8PAPX/CQB3AOQA0AA8AKf/c/+x/yIAbwBKAM//gv+w/w0AGQDU/6L/rv/C/8f/3v8LADUAVQB7AIYAPQDO/8b/UADTAKsABwCh/8z/MABUACIAxP9o/0H/gP8CAE8AGQCp/4j/zP8PABIABgAZACIA9v/X/xgAiACeAEcA8v/S/8D/uP8AAHMAdQDU/07/gv8TAD0A5v+Q/3//l//e/2QAxwCPAPX/nv+0/77/hf9s/8f/UACeALEApwBlAN3/WP8j/zr/df/V/2cA9wAwARQB2QCRACMAmf8z/xz/R/+T//L/PABBAP//r/+D/27/ZP+L/w8AtwAMAdwAXwDt/53/d/+e/xcAlQDTAOUA9gDYADcAPP+K/nb+uP4A/3b/NgDkACYBFgHpAHIAlf/e/uT+a/+0/6b/0v9pAOQA5wCsAGoA9f9Y/w7/Uf+o/5v/if8UAAYBhAEwAXsA2P9X/wX/HP+h/yEAMgAHAAUAHwARAN3/w//C/6v/i/+z/y4AowDFAKoAiABgAC4AHAA3AD4A//+m/4b/rv/e/+v/4f/W/9P/7P8mAEwAHgC7/4b/sf8JAFMAgwCTAF8A8/+0/+L/MgAwAN//qv+4/9D/6P84AKQArwA3AMX/0v8hADUACQDu/+n/tf9w/3n/0f8KAOf/wv/h/woA8P/I/+v/MQA1AAYAFgBtAJMATQD7//H//f/U/6b/vf/s/+r/1f8AAFIAZAAkAPL/+//1/7v/m//e/0QAYQAmANX/qf+1//b/TABkABIAn/9//8j/LgBmAF8AMwAFAPj/CAAXAAEA0//B/9f/AQAdACIADwDh/7T/r//v/0AAVAAoAAIAGABRAG4ATgDt/13/2v7I/lD/EQCIAJUAdQBQAB4A8P/5/zMASgALAL//v//9/zYAWwB2AGYACQCk/5//7f8kAA8A3/+8/4//Zv+S/ykAswCzADwAyf+c/6H/0v8jAEYA8P9e/zr/zP+XAPgA6AC1AHUACQCP/1f/dv+v/8z/3/8AACQARgB4ALQArwApAE//qP6e/hf/tv84AH0AhgB0AH8AqwC3AGAAwv9A/x3/WP/C/ysAXQBMACMAGwA0AEYAOwAjAAYA3P+1/6z/xP/i//3/GgAxACAA7v/c/wkARgBEAAEAvv+q/7X/y//o/wkAIQAzAFcAfwBlAOz/af9M/6P/BwAvABwABgAPADsAhQCoAGAAyP9a/2f/uP/t/wUAMwBbAEMA8/+n/3L/R/9K/6f/LQBlAEEAOQCVAOgAswAXAJf/Yf9Y/4P//v+TAM0AnABZAC8A6P9t/x//aP8IAHMAdABFACAABgDl/8v/u/+W/2r/e//1/6EAAgHpAH0ACQCl/2L/bv/L/zkAaQBcAEsAUwBZADsA+P+v/3//e/+m/+f/HAA4AE4AXABDAPn/n/9o/3n/x/8fAEgAMQAEAAUAOwBsAFgABgC1/57/xv8MAEgAUwAxAAsABAAGAOb/nf9S/z//Y/+f/9//EQA1AFMAdQCMAHMAKgDi/9n/EABJAE0AJQDw/8P/r//K/wMAJQABALP/hf+U/83/GwB1ALIAkAAaALz/zf8oAFgAKgDM/3//Xv+D//j/eQCPABcAfP9I/53/KwCbANAAwQB3AB8A/v8kAE4ALgDP/4b/gf+g/7v/1f/2//X/tf9h/0r/gf/M/wcAPgB7AJ4AkgCCAJYAqABzAAEAn/+A/5P/uv/k//f/2f+b/4H/r//0/w0A/v/3/w0ALgBFAEcAJgDb/5H/i//Z/0YAlQCxAJQAOgDF/3P/ZP96/5b/vP8OAIcA6QD+ALsARQDN/3n/V/9d/3z/rv/3/0sAggB0ACoAz/+a/6P/0/8AABcAHwAuAEUAUQBJADsANwAsAAkA5v/j//3/DQD3/8//uf/K/wAATwCOAIcAMgDI/5v/ov+k/4P/aP+D/8T/AQAxAGIAgQBsAC8AAQD4//X/7P/2/yQARwAwAAYABQAkACwA/P/C/6v/sv+8/8P/3v8IACYANABAAEkAKwDo/7n/zP8SAEMARAAgAOz/s/+I/5L/0P8TACsAJQAsAEYAWABOACgA6P+X/1//eP/g/0sAdgBfADYAFQD5/+//+v8GAPj/3P/f/wUAMQBIADgAAgCo/1H/Pf+G//T/NwAxAAsA/f8kAGYAiABdAPr/of+Q/9r/RgCKAIYAUwAcAPn/4v/M/7b/oP+V/5H/nf/H/w8AWwB8AF8AFgDU/7//3v8WADUAFwDP/6D/v/8bAHAAhwBfABkA3P+9/8P/4v8AABAADgAEAPD/2//T/+T/AAAIAO7/0f/c/xEAUwBtAFIAFQDU/6b/m/+4/+7/JgBGAEQAJAD0/8v/x//r/w8ACgDY/7T/y/8XAGUAegBNAAQA1P/h/x4AUwBLAAkAvv+b/6L/t//K/9v/9f8WADoAXwByAE4A/P+t/4//nv++/+D/BAAjADUAQgBTAFgAMgDw/7z/r/+//9L/7/8cAEkAXABJABcA1v+W/2P/S/9T/3H/q////1kAngC1AJ8AdABKACYACwD2/+r/5v/o/+7/9//8//D/2//E/73/zf/y/xsAMgAxABoA/f/q/+v/+f////X/5f/q/wgAIgAbAPf/y/+y/8j/CABUAIAAewBcAEoATwBaAFMAMAD8/8n/pf+g/7j/1f/c/8H/l/9//4X/q//p/ywAVwBZADwAKAA3AFAAWwBbAFcARQAiAP7/6f/d/8n/tv+x/7j/t/+0/9D/BwA0ADYAEwDr/9T/1P/r/xEALAAjAAEA5P/d/+7/CAAWAAwA7v/S/9X//f8uAE0AUQBEADgALwApABsA/P/Y/8j/z//a/9v/0f/P/9r/4//n/+///P8DAAcAEQAjAC0AKAAjACsAMAAjAAwA/f/5//j/+v////3/6v/S/9L/9/8kADQAIQAFAPv/BQAYACEAEADg/6f/lf+5/+3/BAD2/+j/+f8bADcARAA5ABYA5//I/8j/2//x/wkAIwAsABEA3f+5/7v/1v/y/wMADgAaADEAUQBnAF0AMgD5/87/uv+7/8P/yP/K/8v/1v/p//v/CQATACAAKAAjABIA/P/5/wQAFQAmACgAHwAVABMAFgALAO3/y/+8/8f/5v8FABkAHwAZABcAGAAZABUADgAJAAQA+v/0//P/+v8CAAEA+//z//L//f8NABoAGQAJAPH/2//V/97/9P8JABIAFQAUABIAEAAPAA8ABwD+//r/AgAWACEAGAD+/9//yP/F/9D/4P/x/wEAGQAyAD8ANwATAOb/y//P/+n/CQAfACkAJwAjACAAGgANAPb/3//S/9D/2P/r/w0ALgBAADoAHgD5/9n/zP/T/93/4v/j/+//BgAeACUAGQAKAAEA/P/5/wIAFgAtADoAMQAWAOv/wf+3/87/7v/6/+7/4P/j//L/AAAIAAsACQAJABcALQA6ADIAHQAHAPL/3f/H/8L/0f/n//X/+f/3//X/+f8HABsALQAxACUAFwAUABoAGgAPAP7/7f/g/9r/3f/k/+n/5f/c/9v/5P/z/wQAGAAmACgAHgARAAgABQAGAAcA///t/9z/2v/s/wYAFgAYABIADQAKAAgABwAFAP//+P/2//v/AQAAAPf/7f/j/93/3P/j/+7/9P/z//T///8QAB0AHgAXABEADwAQABEAEQANAAcAAwAFAAoACQABAPf/8P/t/+r/5//m/+3/9f/6//r/+f/7/wAABgAKAAkAAwD8//z///8BAPz/8v/s//D///8RAB0AHgAVAAUA8//i/9n/2//l//H/+/8AAAIAAgADAAMA/v/x/+T/5P/4/xIAIwAlAB4AEgADAPP/7P/u//L/9P/4//3//v/8////CwATABAABgAAAAIAAgD9//j/9v/x/+//+v8KABAACQD+//n//v8FAAoACwAKAAoADgAXAB4AGwAQAAQA///+//v/8//r/+X/5P/s//j/AQAFAAUACQARABcAFgANAAQAAgAHABAAFAAOAAMA+P/y//P/8v/s/+r/7P/z//3/BgAMABEADQD///P/7f/v//z/DQAXABQABgD1/+7/7//z//X/9f/7/wUADgATABIADwALAAUA///9////AQADAAIAAAD8//n/9//6//z/+//5//n/+f/4//j//P8GAA8AEQAPAA0ACwAKAAgABQABAPz/+P/6/wAAAgABAP////8CAAMAAwACAAMAAwADAAMAAgD8//X/8f/y//X/9f/z//P/9v/9/wMABwAFAAEA/P/6//r/+v/8/wAABgAJAAUA+//w/+j/6P/v//r/BAALAA8AEgATAA0AAgD1/+3/6v/u//X//P8AAAAA/f/6//r/+v/7//r/+v/8////AgAEAAYACAAIAAYABAAFAAUABQAEAAMAAQD8//j/+P/8/wIABgAJAAoABwABAP3///8EAAUAAAD5//f//f8HABIAFgATAAoAAwABAAAA///8//v//f/+/////v/9//3//v/+//z/+v/8/wEABwAMAA4ADAAJAAYAAwD///n/9P/0//r/AgAJAAoABgABAP3//f8AAAEAAAAAAAMABgAIAAgACAAHAAQAAAD8//z//v8BAAEA/v/9//7/AQAFAAgACQAJAAcABAAAAPv/9//1//b/+P/8/wMABwAHAAcABQADAP///v8BAAEA//8DAAoADAAGAPv/8P/s/+3/8//8/wEA/v/4//r/AQAEAAEA//8BAAUABgAFAAQABAABAP7//P/9//v/+v/6//7/AQABAP///v///wEAAQD///z/+P/1//b/+v///wMAAwABAP////8AAAEAAAD+//3//f/9//7///8AAAIAAAD7//b/9//8/wEAAAD9//v//P8AAAIAAgABAP7/+//5//n/+f/5//n//P/+//7//P/7//v/+v/5//r//f8BAAMAAwABAP7/+//5//n/+v/7//z//v8BAAQABQACAAAA/////////////wAAAQAAAP7/+v/3//b/9//5//v//f///wEAAwAEAAAA+//3//f//P8BAAUACAAJAAgABgACAP7/+v/1//L/8f/x//T/+f///wMAAwD///v/+//+/wEAAwACAAAA///+//7//v///////////////v/9//3/AQAFAAgACQAKAAsACAAEAAIAAAD9//r/+//+//3/+//6//z/AAAEAAYABQACAAEAAgAFAAgABwAFAAUACAALAA0ACwAGAAAA+//6//z//f/+/wAAAwAHAAgABwAEAAEAAAABAAQABQAEAAEAAAACAAUABAABAP3/+f/6//7/AwAHAAcAAwD9//n/+P/5//3///////7//f/8//7///////7//P/7//3///8AAAEAAAAAAAAAAQACAAIAAQD///z/+v/5//v//v8AAAEAAQAAAP/////+//3//P/8//z//f/+//////8AAAAAAQAAAP///v/+////AAAAAAEAAgADAAQABAAEAAMAAQABAAEAAQAAAP///f/7//n/9//2//b/+P/7/wAAAwAFAAQAAgAAAP7//f/+////AQACAAIAAQD///z/+f/3//f/+f/7//7/AAACAAMAAwACAAEA///+//7//v/+//7//v/+////AQABAAAA///+//3//v///wEAAgACAAEAAQACAAMABQAFAAQAAgAAAP7//f/9//3//v//////AAACAAUACQAMAAsABgABAP7///8DAAYABwAFAAMABAAHAAkACAAFAAIAAAAAAAEAAQABAAIAAwAEAAIAAAD9//v//P/+/wEAAwAEAAUABgAGAAMA///9//7/AAACAAIAAQAAAAAAAQABAAAA/v/9//7/AAAAAAAA/////////////wAAAgACAAAA/v/9//7///8AAAAAAQADAAUABgAFAAIA/f/6//n/+f/7//3//v///wAAAQACAAEAAQABAP///v8BAAYABgADAP///P/8//z//P/+//3/+f/2//n//f/+//z/+//9/////////wAAAQACAAEAAgADAAIAAAD+//7//v/9//z//P/+///////+//z/+v/5//n/+v/8//3//v/+//7///8BAAIAAgAAAP3//P/8//z//P///wEAAgAAAP7///8CAAMAAAD7//n/+v/8//3//v/9//z/+//7//z//P/8//3/AAABAAEAAAD//////f/7//r/+v/9//7////+//7//f/8//z/+//6//n/+v/9/wAAAQABAAAA//////7//f/+////AQACAAIAAQD///7//P/6//j/+P/6//3/AAACAAEA/v/7//v//P/9//7/AAACAAQABgAIAAcABQABAP3/+v/4//j/+f/7//3//f/9//3///8BAAMAAwACAAAA/v/9//3//v///wAAAQABAAIAAQD///7///8BAAIAAwAFAAYABwAGAAYABgAFAAQAAwADAAIA///9//3///8CAAMAAwACAAEAAQADAAMAAgD/////AgAFAAgACQAIAAUAAwACAAEAAAD///7///8BAAIAAgACAAEAAQACAAIAAQD///7//v8AAAMAAgABAP7/+//8////AgAFAAUAAgD///7//v/+/wAA///9//v/+v/7//z//f/8//z/+//7//z//f/9//3//f/9//3///8BAAIAAwACAAAA/v/9//3//////wAAAAAAAAEAAQABAAEA///+//7//v/+//7//v///wAAAAAAAAAA/v/9//3//f/9//7///8AAAIAAwADAAMAAgACAAMABAAFAAUABAACAAAA/f/6//j/9//3//r//f///wAAAAD///3//P/8//z//f/+////AAAAAAAA///9//z/+//7//v//P/9//7//////wAA/////////v/9//3//P/9//7///8AAAAAAAD/////AAABAAIAAwADAAIAAQACAAMABQAGAAYABgAFAAQAAwACAAAA///+//3//P/9/wAABQAJAAoACAAFAAMAAwAEAAUAAwABAP//AQAFAAkACgAJAAcABQAEAAMAAgADAAQABQAGAAYABAABAP///f/8//v/+//8//3///8AAP///v/9//7///8BAAEAAAAAAAAAAQACAAEA///+//7//v/+//z/+//7//r/+v/6//z//v8AAP///f/8//3//v/+//3//v8AAAIABQAHAAUAAwAAAP7//P/8//z/+//7//v//f////////////7//f8BAAUABgAFAAIAAQABAAIAAwADAAIA/v/7//z///////3//P/9//7//f/8//3//v//////AAABAAEAAAAAAAAAAAD+//3//v///wEAAgACAAEA///9//3//f/9//z/+//6//n/+v/8//7////+//z/+//7//r/+v/7//3//v/9//z///8DAAUAAwD///3//f/+///////+//3//P/7//v/+v/6//r//P/+////AAABAAIAAQD///7//v///wAAAAAAAAAAAAD//////f/7//n/+f/6//3//////wAAAAAAAP///v/+////AQACAAMAAwADAAMAAgAAAP3/+//7//z///8BAAEA///9//z/+//7//r/+f/5//v//v8BAAQABQAFAAQAAgAAAP///v/+//7//P/7//r//P///wIAAwACAAEAAAD///7//v////////8AAAAAAAAAAP////////////8BAAMAAwADAAUABwAHAAcACQAKAAkABgADAAIAAgAEAAQABAADAAIAAwAEAAQAAgD///3//v///wIABAAEAAMAAwADAAMAAgAAAP////8AAAAAAAAAAP////8AAAEAAAD+//3//P/9////AAD+//v/+P/2//j/+v/8//7//f/7//v//P/9////AAD///3//P/7//v//P/8//z//P/7//z//P/8//v/+//6//n/+v/7//7/AAABAAAA////////AAAAAAAAAAAAAAEAAwAEAAUABQAFAAUABQAEAAMAAwADAAQABAAFAAQAAwACAAIAAQAAAP////////////////7//f/9//7/AAACAAQABQAHAAcABwAFAAEA/v/8//z//f/+//7//v/9//z/+//6//r/+v/6//r/+//8//z//f/8//z//P/7//v/+//7//z//P/9//3//v////////////7//f/9//3//v///wAAAAD/////AAABAAIAAgABAAAA//8AAAEAAgAEAAUABgAIAAkACQAJAAgABwAGAAMAAQD/////AQAEAAcABgAEAAIAAgAEAAUABAABAP///v8AAAMABAAFAAQAAwABAAAA/////wAAAgAEAAUABAAEAAMAAgABAP///v/8//z//P/8//r/+P/2//b/9//5//n/+f/4//j/+f/6//v/+v/7//v//P/8//z//P/8//r/+P/3//j/+//9//3//P/7//z//P/7//r/+f/6//v//v8BAAMABAADAAIAAAD//wAAAAAAAAAAAAABAAEAAQAAAP3/+v/7//7/AAABAAEAAAAAAAIABAAHAAkABgADAAMABAADAAIAAQABAAEA///+//3//v/+//7/AAABAAEAAQABAAEAAQD///3//P/9////AQADAAQABAACAAIAAgADAAMAAQD///3//v///wEAAgACAAIAAAD+//z/+//7//z//P/7//n/+v/9/wAAAQD///3//f/9////AQACAAIAAgABAAEAAAAAAAAAAAAAAP//AAAAAAEAAAD///////8BAAIAAwAEAAQABAAEAAQAAwACAP///v/9//7///8AAAAAAQACAAIAAgABAAAAAQACAAMABAAFAAUABgAFAAUAAwACAAEAAQABAAEAAQABAAEAAQABAAAA///+//3//f/+/////////////////wAAAQADAAUABQAEAAIAAAAAAP/////+//3//f/9//3//v///wEAAgADAAMAAgACAAEAAgACAAIAAgADAAUABQAGAAcABwAFAAQABQAFAAQABAAEAAMAAwAEAAUABQAEAAMAAwAEAAQABAADAAEAAAD//wAAAAAAAAAAAAACAAMABAADAAAA/v/+////AAD///3/+//5//n/+f/4//j/9v/2//j/+f/8//7/AAD9//n/9v/0//j//P/+/wIAAQD9////AgADAAMAAQD9//v/+//6//n/+v/8//3//f/8//v/+//8//r/+f/5//r//P/9//7//////wAAAAAAAP////8BAAQABQADAAIAAwADAAQABQAFAAYABgAGAAYABQABAP3/+//8//7//////////v/+////AAAAAP///f/9/wAAAwADAAEAAAD///7//v/+//7//f/9//z//f/8//z//P/+//7//f/7//r/+v/8/wAAAwAEAAMAAwACAAEA///9//z//P/9////AAABAAAA/f/5//f/9//4//n/+v/7//z//f/9//7/AAADAAUABAADAAIAAQABAAIABAAGAAYABAAEAAUABgAHAAkACgAGAAEA/v/9//7/AAAAAAEABQAJAAwADwAQABAAEAASABYAGwAdAB4AHQAaABcAFQAUABMAEAALAAUA/v/4//X/9//4//n/+v/9/wEABAAEAAMAAQD+//3/AAADAAcADAAPABAADQAIAP//9P/q/+H/2//X/9X/1v/Z/9j/1f/O/8j/w/+9/7f/s/+0/7n/wP/L/9r/7P8CABcAKAAzADcANgAvACUAIwAtAEIAWwBwAHcAYwAmAMD/Nf+a/hj+yP3U/Ub+/P6+/0EAcQBqAFgAXwCRAM8A8ADxAN4A0wDcAPMADAEcARwBBgHjAM8A1QDrAAABBgH/AO0A2ADCAKwAkgBwAD4ABgDT/6r/h/9h/zj/Ef/w/tz+1P7c/u7+Av8U/yH/Lf87/0X/TP9R/1n/Zf93/43/p//F/9//7//0//X/9P/2//v///8EAAkADgASABIADgAIAAEA/v/8//3//v//////AAAGAA4AGAAjACsAMQAyADUAPQBHAFAAVABRAEYAOgAzADIAMwAyACwAJQAiACQAKgAuAC4AKgAkAB8AHQAfACkANgA/AEEAPQA3ADQANwA9AEMARQBAADcAMAAsACoAJgAfABUACwAEAP7/+P/0//D/6//n/+f/7P/z//r//v/7//f/8//z//X/+P/3//L/6v/k/+P/4v/g/9z/1f/N/8X/v/++/8D/xP/G/8T/xf/I/9H/3P/q//P/9f/y/+//8P/0//v/AwAJAA8AFgAhAC0ANgAzACoAIwAcABsAHgAhACIAHgAYABEABwD9//T/7f/m/+H/3f/a/9v/3f/m//T/BAAWACEAJAAlACIAIQAiACMAJwArAC0ALQAnACAAFQAJAAEA+//3//j/+f8AAAoAEgAXABcAEwAGAPj/6v/i/+H/4v/h/93/0v/E/7n/s/+x/7D/rv+r/6r/q/+q/6b/oP+a/5L/if+E/4T/iv+U/57/qv+5/83/4v/3/wwAHQArADQAOAA6ADwAPAA9AD0APAA7ADoAOwA/AEUASQBNAE8AUQBRAFIAUwBQAEsARQBAAD4AOwA1AC4AJQAdABYAEgAOAAsACQAKAA0AFQAbACIAKwAzADoAPgA+ADkAMQAoACEAGgAXABUAFQAUABEACgACAPz/9v/y/+//7P/m/9//1P/K/8D/tf+o/53/lP+O/4v/if+H/4b/hf+F/4X/if+M/5H/l/+e/6j/tv/E/9P/4v/w////CwAUABsAIAAgAB8AGwAYABMAEAALAAcABAAAAP7///8CAAUACgAQABMAFgAVABUAGQAiACoAMwA6ADsAPAA8AEEARABIAEwAUQBWAFoAYABmAGwAcABwAHIAcgB0AHcAfQCFAIkAiQCHAIIAegBxAGgAXQBRAEQAOAArABkABwD0/+L/0v/E/7b/qP+b/4//hP99/3f/cv9t/2j/Zf9h/2D/ZP9q/3D/dP94/3//hv+P/5j/nP+h/6L/ov+i/6D/o/+o/6z/sv+4/8D/x//N/87/yv/I/8X/wf+3/7X/qP+e/47/fv90/2T/WP9S/1j/Xv9p/3n/hv+U/6n/w//h////FgAtAEMAWwBvAH8AlQCpALoAyQDYAOcA+AAMAR4BLgFAAUoBUgFYAVwBXAFaAVgBUgFQAVABTAFEATwBMAEiARIBBAH7APQA6wDdANAAxgC8ALIAowCQAHcAWgA2AAsA4P+z/4P/Tv8V/9b+mv5k/jL+Av7Q/Zz9bP1A/Rz9/Pzg/MT8sPyk/Jj8lPyY/Kj8wPzc/AD9LP1Y/YT9vP3w/Sj+Zv6o/vD+Ov+A/8f/CgBSAJ0A5wAwAXQBtgH4ATwCfAK8AvQCKANYA4ADpAPAA9gD6APwA+gD4APMA7ADmAOAA3ADaANwA3wDlAO4A9wDAAQwBGAEkAS4BOAEAAUQBRAFCAXoBLAEaAT4A3QD3AIoAmIBkAC0/9z+AP4g/UT8cPuo+vD5SPmg+Aj4cPfw9oD2EPbA9YD1UPVA9TD1QPVg9YD1wPUg9pD2IPfA92j4MPkI+vD64PvU/Mz9yv65/54AcAE0AuACiAMYBJgEAAVQBaAF0AUABiAGQAZQBlgGYAZgBlgGOAYoBggG4AW4BYAFSAUIBdAEmARoBDAEAATQA6gDlAOEA4ADiAOgA8AD7AMgBGgEsAT4BDgFiAXIBQAGUAaABrgG0AbYBrgGgAZABvAFoAUoBZgE4AMQAzgCXgFvAGP/SP4k/fj7sPpY+QD4sPaA9VD0MPMQ8hDxQPCg7yDv4O7g7gDvYO/g74DwQPFA8lDzgPSw9fD2MPhw+bD68PsY/T7+Vv9kAGYBWAI8AyAEAAXYBbAGaAcQCKAIIAmQCeAJAAoACtAJcAnwCEAIaAdwBnAFWAQ8AxQC6gDr//7+UP7M/Xz9WP1s/bD9EP6Y/i//0v+LADoB4gGAAuwCTAOEA6wDwAPMA9ADvAOsA5wDpAO4A9wDGARwBNgESAXABTgGuAZAB8AHEAhgCIAIoAiACFAI8Ad4B+gGOAZQBWgEVAM4AiQB+//e/qj9lPxw+3D6WPlA+CD3MPYw9TD0UPOA8tDxUPHg8IDwYPBQ8GDwkPDQ8BDxcPEA8rDyYPMw9BD1IPZg95j4APpg+9z8Rv6w/xIBaAK0AwAFSAaAB6AIkAlwCgALgAvwCyAMEAzgC2AL0AoQCjAJMAgoBxgGCAX0A9wCuAHFAOr/Rv/E/lr+DP7s/fz9HP5c/rD+Pv/U/14A7gBgAewBZALsAlgDlAPcAxAEYASQBMgECAVwBdAFOAaIBuAGQAeYBwAIcAjgCDAJkAmgCeAJ0AnACaAJUAnwCEAIoAfABtAFoARsAxwCfwC8/vT8SPuw+RD4YPaQ9NDyYPEA8ODu4O0A7YDsQOwg7ADsIOxA7ODsgO1A7sDuYO8g8ADxEPIQ8zD0UPWw9jD4sPko+6T8Pv72/6oBTAPgBHAGEAiACdAKAAwgDfANoA7wDhAP0A5wDsAN4AzwC8AKcAkQCKgGQAX0A7QCkAGBAJf/3P5Q/uD9nP18/Xj9rP34/VD+rP4a/5H/BgCTAAYBdgHUASgCiALMAiQDgAPQAzAEmAQIBWgFyAU4BqgGOAfABzAIkAjwCFAJsAkACiAKMApACiAK0AmACeAIMAhwB5AGaAX4A3gC0gAy/3z9sPvw+Qj4QPZQ9HDysPBA7wDu4OwA7EDr4Oqg6sDq4Oog66DrYOwg7eDtYO4g7xDwMPGA8sDzEPWw9jD46PmA+0j9Kf8GAQADsASIBiAI8AlwC+AMIA4gD9APQBBgEEAQABBgD4AOYA0gDMAKcAkACIAGAAWkA0gCKgH3//7+NP68/VD9DP3g/NT8EP1k/bT9CP6E/iH/wf9gAOIAdgEIArACSAPIA1AE6AR4BRAGYAbYBmAH8AdwCAAJYAngCUAKkArACvAKIAtwC4ALQAvwCoAKEAqACaAIoAegBngFGAR0AroA6v4w/XD7cPlw93D1gPOw8QDwYO4A7QDsIOuA6uDpgOmA6cDpAOqA6gDrwOvA7KDtYO5g75DwEPKg8xD1gPYQ+Oj50Pug/WH/JAH8AugEsAYwCMAJMAuwDOANwA5gD9APIBAAENAPMA9gDoANcAwwC9AJcAj4BqAFOATwAq4BkQCx/+L+Uv7M/Xj9SP1A/Uz9iP3Y/ST+kP4H/5L/HgCdAB4BpgEsArgCTAPMA0AEyARgBfAFcAbwBoAHIAjACDAJkAnwCUAKoArgCuAK8ArwCtAKgArwCVAJoAjYB9gGoAU4BNACTgGy/+z9DPxY+nD4sPbA9PDyQPHA74DuQO1A7IDrAOug6oDqoOrg6kDr4OuA7EDt4O3A7sDv8PBA8oDz8PSA9hj40Plw+yj92v6XAFwCCASgBSgHsAgwCoALoAyQDVAO8A5QD3APUA/wDlAOoA2wDLALgApACQAIuAZoBRAE1AK4AcgA3/8q/4z+Gv7c/cz96P0Q/kz+xv5R/+7/ewAUAbYBUAL0AnQD8ANYBMgEMAWIBdAFCAZgBrAG+AYgB0gHeAe4B+gHAAggCEAIcAiACHAIYAhQCBAI0AdYB7AG6AUABfwDyAKGARYAnv4Q/Xj7uPkA+GD2sPQw87DxUPAg70DugO3g7GDsIOwA7CDsYOzA7EDtAO6g7kDvIPAQ8SDyQPOA9ND1QPfA+ED6sPsc/aD+NwDUAVADsAQIBlgHoAjQCcAKkAtQDPAMUA1QDTAN8AygDCAMcAuQCqAJ0AjgB9gGuAW4BNgDFANQAooB3ABqACUA6//F/67/zv8UAGsAsAACAW4B8AFwAtQCLAN8A9QDKARgBIAEkASwBOAE+AT4BOAE6AQABRgFEAUABRgFMAVIBUAFQAU4BUgFOAUYBcgEYAQABHgD5AIYAjwBRwBQ/zb+/Py4+2j6OPnw98D2cPVQ9EDzUPKA8cDwMPDA76DvgO9g74Dv4O9Q8MDwQPHQ8YDycPNQ9GD1cPaw9+j4MPpg+7D8/P1G/4kAyAHkAggEGAUYBggH0AeQCEAJwAkgClAKcAqACmAKIArACWAJ8AhwCOAHOAeQBvAFWAXABCAEkAMQA6gCWAL+AcQBpAGkAaIBtgHYAf4BQAKIAsgCHANYA6wD6AMoBFAEgASYBMAE0ATQBNgEyATIBMgEwASgBIgEgARwBFgEOAQgBAgE7APAA5QDTAMIA7gCVALcAUwBuQAQAFj/iv6k/bz80PvY+uD52Pjg9/D2EPZA9ZD08PNw8xDzwPKA8nDyYPJw8qDy8PJQ88DzQPTQ9ID1IPbg9rD3oPig+ZD6ePto/Gj9aP5g/1MANAEkAhAD6AOgBDgF2AVwBvgGUAeIB6gH0AfgB9AHoAdoBzgHAAewBjgG2AVwBRgFuARIBOADiANMAxQD0AKMAmwCXAJoAmQCYAJwApQCzAL4AhgDPANwA6wD0APwAwAEGAQwBDgEOAQoBCAEEAT4A+ADtAOQA3ADUAMoA/wC1AK0ApgCaAI8AhAC3AGiAVgBCAGoAE0A3P9m/+D+TP60/RT9aPzA+wj7UPqg+fD4SPig9yD3oPYw9uD1oPVg9UD1QPVA9WD1gPXA9RD2cPbg9lD30Pdw+CD50PmQ+kD7APy4/ID9Nv7u/pz/TQAEAaYBRALMAlQD0ANIBJgE4AQgBUgFaAVoBWgFWAVQBUAFGAXwBLgEkARgBCgE+APIA6ADeANUAzQDHAMMAwQDBAMMAxQDJAM8A1QDcAOQA7AD1AP4AyAEOARYBHAEkASgBLAEuAS4BLAEoASIBHAEUAQwBPgDyAOYA2ADLAP4ArgCfAJAAvYBtAFoASQB1wCIADgA3/+J/zL/2v56/hT+qP1A/cT8UPzQ+1j72Ppg+vD5ePkQ+bD4WPgA+ND3kPdg90D3MPcw9zD3QPdw95D30PcQ+Fj4uPgY+ZD5EPqI+gj7gPsQ/Jz8NP3A/VL+4P5t//X/dgDqAFgByAEsAnwCxAIEAzgDZAOIA5wDqAOsA7QDsAOkA5ADfANkA0wDOAMkAxQDBAP4AvAC7ALsAuwCAAMUAygDQANYA3gDmAO4A9gD9AMQBDgESARYBGAEaARoBGAEUAQ4BBgEAATgA7ADgANMAxwD8ALAAowCYAI4AhAC7AHEAZwBdAFSASwBAAHQAJ0AcgA3APf/qf9f/xH/vv5k/gL+oP04/dD8aPwE/Jj7OPvg+oD6OPrw+bD5ePlI+Rj5APno+Nj40PjY+Oj4+PgY+Uj5cPmw+ej5MPqA+uD6QPuo+xT8iPz8/HD94P1S/sT+NP+Z//j/VQCmAPMAPgF+AbgB6gEYAjgCVAJoAngCiAKcAqQCpAKoAqwCtALAAsgC1ALgAvQCCAMcAygDQANgA4ADqAPAA9wDAAQgBEAEUARoBHgEkASYBJgEoASQBJAEgAR4BGAESAQwBBgE9APMA7QDkAN4A1wDPAMcAwQD6ALAAqACcAJIAhwC6AGyAXYBNAHyAKQAVAD6/5//QP/W/nL+CP6c/TD9yPxc/AD8oPtI+/j6qPpo+ij6+PnQ+bD5kPl4+XD5YPlY+WD5ePmQ+bD54PkA+jj6cPqw+vD6QPuQ++D7NPyU/PD8SP2k/QL+YP7A/hn/av+5/wcAUQCWANMACgFAAXQBoAHEAegBBAIgAjwCVAJoAngCkAKoArwCyALYAvACCAMcAzADQANUA3ADgAOUA6QDtAPAA9AD4APsA/QD9AP0A/QD7APgA9ADvAOoA5ADeANcAzwDHAP8AtwCvAKgAoACYAI8AhwC+AHYAbQBjgFqAUYBGgHrALQAfgBFAAkAx/+G/z7/9P6m/lj+Cv64/Wj9EP3E/HT8KPzg+5j7WPsg+/D6wPqY+nj6YPpI+kD6OPo4+kj6YPp4+qD6yPr4+jj7cPu4+/j7TPyY/Oj8OP2I/dz9NP6K/uD+NP+H/9b/JgBwALUA+AA4AW4BoAHQAf4BKAJUAngClAKwAswC6AL8AgwDIAMwA0QDUANYA2QDcAN4A4ADiAOMA5ADlAOUA5QDlAOQA5QDkAOMA4QDeANsA2ADVANIAzgDJAMQA/gC3ALAAqQChAJkAkACHAL0AcoBogF6AUoBGgHrALYAgQBJABQA2/+i/2j/K//y/rj+gP5G/gz+1P2c/WD9LP3w/Lz8iPxY/Cj8+PvQ+7D7kPto+1j7QPsw+yj7IPso+yj7MPtI+2D7ePuQ+7j74PsM/ED8dPyo/OD8GP1Y/Zz94P0i/mb+sP72/j3/hP/J/w8AVgCbANsAHAFaAZYB0AEIAjgCaAKYAsQC7AIQAywDRANcA3ADhAOQA6ADqAOwA7gDuAO4A7QDtAOwA6gDoAOUA4gDeANkA1ADPAMkAwwD7ALIAqQCfAJUAiQC7gG4AYIBTgESAdUAmQBcACEA5/+t/3L/Ov8G/9T+pv50/kj+Hv74/dT9sP2Q/XD9WP1A/Sj9EP38/Oz83PzQ/MT8wPy8/Lj8tPy4/Lz8wPzE/ND83Pzs/Pz8EP0k/Tj9VP1s/Yj9qP3I/ej9Dv4y/lr+gv6s/tj+Af8u/1z/iv+7/+7/IgBWAIoAvQDvACABUgF+AaYB0AH0ARgCOAJYAnQCjAKkArgCyALUAtwC6ALwAvQC9ALsAugC5ALcAtACxAK4AqwCnAKIAnQCYAJMAjgCKAIMAvYB3gHEAawBjAFwAVABNAEQAegAyQCcAHgATgApAP//2v+1/4//af9F/yf/CP/u/tT+vP6m/pj+iP56/nD+YP5Y/lD+Rv5A/jj+NP4w/ir+Kv4m/iT+IP4c/h7+HP4c/iD+IP4g/ij+LP40/j7+Rv5O/lz+bP58/pD+ov60/sz+4P7y/gv/Jf89/1r/df+M/6j/wv/d//j/EwAsAEUAXwB3AI4ApQC6AM8A5AD5AAwBHAEuAUABUAFeAWwBegGIAZQBngGmAa4BtAG6AbwBvAG6AbYBsgGuAaQBmAGMAYABdAFmAVIBQAEsARgBAgHsANQAvACkAIwAdABbAEIAKgARAPr/4f/K/7L/m/+E/23/WP9D/y//HP8L//z+8P7m/tz+1P7O/sj+xv7G/sb+yP7M/tL+2P7c/uL+6P7u/vb+/v4E/wv/Ev8Y/yD/KP8u/zX/O/9D/0r/Uf9Y/2D/aP9y/3z/hv+Q/53/qf+1/8L/0P/g//D/AQATACYAOgBOAGMAdwCOAKEAtgDIANkA6AD2AAQBEAEaASQBKgEyATgBPgFAAUQBRgFGAUIBPgE4ATIBLgEmARwBEgEIAfwA8gDlANcAyQC6AKsAmwCKAHkAaABZAEkAOAAmABUABAD0/+b/1v/I/7z/r/+j/5j/jP+B/3j/cP9p/2P/XP9W/1D/TP9H/0T/Q/9C/0H/QP9C/0P/Rv9J/03/Uv9Y/13/Yv9o/27/dP95/37/gP+F/4r/jv+S/5T/l/+c/5z/n/+e/6D/nf+g/5//nv+e/6L/pP+h/6v/qP+v/7H/tP+//8H/xv/R/9j/2//f/+f/7P/y//r///8EAAkADAARABgAIQAkACoAMwA7AEMASwBTAF0AZwByAHoAhACOAJcAngClAKoAsAC1ALkAuwC9AL0AugC3ALMArgCpAKMAnQCVAI4AhgB9AHMAbABjAFkATgBCADgALQAiABcACwABAPj/7f/h/9b/zf/F/7v/rv+j/5r/kv+J/37/df9t/2b/X/9Y/1H/TP9I/0b/Q/9A/z7/PP88/zz/O/88/z7/Qf9E/0f/SP9M/1H/Vv9a/1//Zf9s/3P/ev+C/4v/k/+c/6T/rf+2/77/xv/O/9b/3v/l/+v/8v/4////BQAMABMAGgAiACoAMQA4AEAARwBRAFsAZwBzAIAAjgCcAKsAugDIANUA4QDsAPYAAAEIARABFgEaARwBHgEeARwBGgEaARQBDAEEAfoA8QDmANoAzgDCALQApgCXAIcAdwBoAFkASwA8AC8AIQAUAAkA+//x/+b/3v/S/8f/wP+0/6v/oP+Z/5D/iP+C/3r/cv9r/2X/YP9b/1b/Uv9O/07/Tv9P/1D/UP9U/1X/WP9b/13/Y/9m/2n/b/90/3j/ff+B/4f/jP+S/5j/nP+h/6j/rf+0/7v/wP/F/8z/0//b/+X/7f/1//7/BQAMABcAHwAnADIAOwBCAEsAVABdAGcAbwB4AIAAiQCRAJgAnwClAKsAsAC1ALgAuwC9AL4AvgC8ALkAtgCyAK4ApwChAJkAkQCJAH8AdABpAFwAUABEADYAJwAZAAsA/v/w/+L/1f/H/7r/rf+h/5T/if9//3X/a/9i/1n/U/9M/0b/Qv8+/zv/Of82/zT/Mv8x/y//Lv8t/yz/Lf8v/zH/M/82/zn/Pf9D/0n/UP9Y/2L/a/91/3//if+U/5//qv+1/8H/y//W/+D/6//0//3/BgAOABYAHQAkACoAMAA2ADwAQgBIAE4AVABaAF8AZQBrAHEAeAB+AIUAjACTAJsAowCrALQAvADDAMoA0ADVANkA3QDeAN8A3wDeANwA2gDWANIAzgDIAMAAtwCuAKUAnACRAIUAeABsAGAAVQBJADwAMAAjABgADAAAAPb/7P/j/9v/0//L/8P/vP+1/6//qf+k/5//mv+W/5H/jf+K/4j/hv+G/4X/hf+F/4b/hv+H/4n/i/+N/43/j/+R/5L/lP+V/5f/mf+c/5//of+k/6j/rf+w/7T/t/+9/8P/yP/N/9L/2v/h/+f/7v/z//n//f8EAAkADQARABgAHAAfACcAJwAvADAAMwA8AD0AQgBLAFAAUwBXAF0AYgBnAGwAbgBxAHQAcwBzAHUAdgBzAHEAcQBwAG4AawBoAGUAZABhAF4AWgBYAFQAUABMAEcAQwA/ADsANgAyAC0AJgAgABgAEQAJAAIA+f/x/+n/4P/Y/9D/yf/C/7v/s/+r/6X/n/+a/5X/j/+M/4n/hv+D/4L/gf+C/4H/f/9+/3//gf+B/4D/gf+C/4L/g/+D/4L/g/+E/4b/iP+J/4v/jv+S/5b/m/+g/6f/r/+3/77/xP/M/9X/3f/k/+v/8f/4//7/BQAMABIAGAAeACQAKQAtADAANQA4ADsAPQA/AEEAQgBBAEAAPwA+AD4APAA7ADoAOQA4ADYANAAzADMAMwAyADIAMgA0ADcAOQA7AD0AQABCAEUARgBHAEgASQBJAEcARABCAD8APQA6ADUAMQAsACgAIwAeABkAFgATAA8ACgAHAAMAAQD+//z/+v/4//f/9f/0//P/7//u/+z/6//o/+T/5v/i/9//3P/b/9j/1//V/9P/z//M/8z/yv/H/8T/wv/B/8H/wP/A/8H/wf/E/8T/xf/H/8j/y//M/8z/0f/U/9b/2f/Z/9z/4f/k/+f/6P/r//D/9f/5//3/AAAEAAkADQAQABYAHAAhACcAJwApAC8AMgAzADcAOQA6AD0APQA9AD8AQgBCAEIAQwBEAEUARQBEAEMARQBGAEUARABCAEIAQQA9ADgANAAwACwAJgAeABgAEgANAAgAAAD5//P/7v/p/+H/2v/U/9D/y//F/8D/vf+7/7n/tv+1/7T/tP+1/7b/tv+4/7r/vP++/7//wf/E/8b/yP/H/8j/yf/J/8f/xf/D/8H/wP/A/8D/wP/C/8P/xf/I/8r/zf/S/9j/3f/i/+j/7v/0//v/AQAIAA4AFAAZACAAJwAtADMANwA8AEEARABHAEcASQBJAEkASABIAEYARwBGAEUARgBIAEsATQBQAFUAWgBgAGYAagByAHgAfwCDAIgAiACIAIgAhgB/AHcAbgBlAFsAUABCADYALQAiABQABQD4/+7/5f/b/8//wv+7/7b/sv+r/6T/o/+m/6j/pf+j/6n/sf+4/7r/vf/D/8v/z//N/8f/xP/D/77/rv+c/43/g/90/17/Sv88/zf/Mv8q/yL/JP8z/0P/UP9Z/2v/iP+l/7b/wv/U/+7/CQAVABcAIQA2AEwAUwBPAFAAWwBnAGAASgA2AC4AJQANAOH/v/+r/6L/jP9x/2T/dP+Y/73/3P8LAGUAxQAoAXoB1gFMAsACKAN4A7wDAAQ4BFgEQAQYBOQDoAMwA5AC2gEoAXUAq//C/uD9HP10/Nj7OPu4+mj6UPpQ+lD6ePrY+lj76Pt0/Az9uP10/iT/tP80ALMAJgF+AawBvAHGAcYBsAF6ATIB7QCvAG4AIQDR/5D/Y/9C/yL/Bf/+/gr/Jf9B/17/h/+/////OgBtAJ8A1gAOATwBWgFwAYYBmgGeAZQBggFwAVwBQAEYAe0AygCrAIsAZwBDAC0AJAAcABMADgAUACgAOQBFAFAAYQB4AIoAjwCKAIoAjQCMAHsAXgBHADcAJgAGAN//wP+v/6H/iv9r/1r/W/9h/1//Wf9h/3r/l/+u/7r/z//2/xsAMwA+AFAAbwCOAJ0AnACfALAAwwDEALQApgCnAK0ApACIAHEAbQBxAGgASwAxAC0ANwA2ACAACgAKABsAIAAPAPr///8RABgABgDw/+r/+f/+/+r/0P/H/9b/3P/J/67/pf+2/7//sP+T/4f/of+n/5r/e/9z/4D/j/+D/2X/V/9m/3r/b/9X/07/Zv9+/4P/cf9x/5H/rf+2/6T/nf+0/87/y/+x/5z/q/+8/7b/mP+A/4z/n/+f/4n/e/+K/6j/sf+l/6P/uv/f//L/8//1/xkASgBkAGwAcACOALoAzgDFAMIA0wDoAOYAxwCqAKkArQCYAGsARAA+AD8ALgAKAPH//P8QABIAAAD9/xcAOwBHADwANwBRAG4AcABZAEQARgBQAD8ADwDk/9T/zv+z/3//UP9C/0X/Of8Z/wL/Cf8l/zP/K/8s/0b/cP+N/5P/mP+1/9//+P/6//b/BAAfAC0AIQAJAAQADwAPAPT/1P/D/8b/x/+1/53/l/+o/7n/u/+5/8f/7v8YADUATABrAKAA1wD7ABABKgFUAXgBiAGCAXwBggGCAXABRgEeAf8A5AC5AH4ASAAiAAUA4f+z/47/fv95/3L/Y/9d/2z/hP+a/6n/t//T//v/FQAmAC0AQABRAF8AUwA/ADYAMgAjAAMA4f/M/7z/r/+Q/3L/aP9m/1//UP9E/0H/Uf9d/2D/W/9j/3f/iv+O/4z/kP+g/6r/qf+f/6D/rf+4/7n/tf+6/8T/0v/X/9X/2P/l//X/9v/y//L//v8GAAIA/f/5/wAABwAEAPz/8v/2//z/9//r/9//3v/i/9n/yv/B/8D/yP/F/7P/q/+y/7//wv+9/7//x//f/+3/9v8BABkAPABdAGwAfgCbAL8A1wDiAOwA9gAMARoBGAEGAQoBCAEKAf4A7gD0APUA/AACAQ4BEgEiATgBOgE+AUYBTAFMATYBEgHxAM8ApABgAA8Awf9v/xv/uv5S/vT9nP1U/QD9tPx8/FT8NPwo/Bz8JPw0/FD8cPyQ/Lj84PwQ/TT9WP14/Zj9wP3g/QD+GP46/mD+lP7A/vT+MP96/9D/LwCPAPwAfAEEApACEAOcAzAEwARIBcAFMAaYBvgGSAeAB6gHwAfAB7AHiAdYByAH0AaABhgGuAVQBegEeAQABIgDHAOkAigCogEYAYkA6v9E/5L+1P0Q/Uz8gPuo+tj5APlI+JD3wPYg9oD1APWQ9ED0APTA88DzwPPQ8wD0UPSw9CD1kPUg9sD2YPcI+Kj4WPkY+uD6qPt0/FD9SP5U/2MAegGwAvADUAWoBgAIYAnACjAMoA3gDgAQIBEgEiAToBMgFGAUgBSAFCAUgBOgEsARwBCQDxAOcAzQCiAJQAdoBWQDhgGl/+j9IPxo+uj4gPcw9gD1APQw85DyEPKg8WDxcPFg8YDxwPEQ8nDy8PKA8/DzgPQQ9cD1QPbg9nD3CPig+Cj5sPkg+qD6+Ppo+7D78Psw/Hz8wPz0/Dj9gP3Q/RT+av6+/in/k/8MAJwAPAHsAagCYANABDAFKAYgB/gH8AjQCdAKsAtQDPAMcA0ADkAOYA5ADiAOEA6gDQANIAxAC2AKgAlQCOAGaAVABBwDvAFFAOD+2P3s/Aj88Pow+qD5aPlQ+TD5IPl4+Rj6yPpw+wj8xPy0/aD+Tf/N/y4ApwD6AAYBvQBJAMf/J/9i/mD9NPwA+9j5oPiA91D2IPVA9IDz0PJQ8uDxsPGw8eDxMPKA8gDzgPMg9ND0gPUw9vD28Pf4+Bj6QPug/Cr+3f+iAXwDaAWIB8AJEAxQDmAQoBKgFIAWIBiAGYAaQBugG6AbIBtAGgAZgBeAFUAToBAADjALQAg4BTQCUP/A/ED64PfQ9TD08PLg8UDx0PDg8EDx4PHA8sDz4PQw9qD36Pgw+kD7ZPw4/Rb+gv64/t7+4P60/kr+yP0o/YT84PsY+0j6gPnQ+ED4oPcg96D2YPZQ9kD2EPbw9fD1EPYw9hD2APbw9RD2UPaQ9gD3kPeI+LD5APt0/AL+7f8sAngE6AZgCeALYA7gEGAToBWgF0AZoBrAG4AcoBxgHKAbYBrgGCAXwBQAEhAPEAzwCMgFZAIt/zz8oPkw99D08PKQ8bDwMPDg7+DvYPBA8VDykPPA9BD2oPco+Wj6YPtY/Bz93P0y/mb+Pv4c/tj9fP3I/CT8aPvg+lD6kPkI+Yj4OPgQ+AD4wPew98D3sPew96D3gPdQ9xD3sPZQ9gD28PXw9RD2UPbg9uD3MPmQ+jj8Tv4OAfADwAagCZAMwA8AEyAWoBjAGsAcgB7AH0AgACBgH2AewBzAGgAY4BTAEYAOEAtAB1QDwv90/Fj5kPYA9PDxQPAg72DuAO5A7qDuQO9Q8IDxAPNQ9LD18PaA+Mj56PqA+wz8pPww/YD9VP34/Kz8hPw8/Nj7WPvg+oj6YPoI+qj5mPlg+Vj5WPkw+QD5qPhY+OD3gPcQ91D2sPUw9QD1EPVw9bD1QPZw9xj58Pr0/BH/8AEoBXAIkAuADsARABVAGOAa4BxgHqAfwCAAIYAgoB8AHkAcABpAFyAUoBAQDbAJOAaQAqL+EPsw+ID1UPMw8UDvAO5g7WDtYO2A7eDtAO+Q8ADyMPNg9AD2wPdg+Zj6QPsc/BD9Dv6I/pD+jP6e/rT+nP48/sT9ZP38/MT8XPzg+2D74PqY+ij64PlA+Xj40Pcg95D2oPWA9JDzMPNQ81DzYPNw8yD0sPWw96j5WPu4/QYBuAQgCEALcA4gEgAWYBnAG6AdIB/AIAAiACKAIUAg4B5AHcAa4BfgFGAREA6QCsAGyAL2/qD7mPjg9XDzIPFA7wDuYO1A7SDtIO2A7YDuwO8A8QDyIPPA9GD20PfA+HD5QPqA+2D80PzI/MD86Pwg/Sj95Pyg/FD8RPww/Oj7kPsY+9D6mPpQ+tD5GPlQ+KD3IPdw9lD1APRQ84DzwPOw87DzMPSQ9aD3uPmQ+7j9uACABGAIkAtwDuARwBVgGSAcIB7AH4AhgCJAI8AigCHgH0AeABwgGQAWYBLgDkALUAcsA/z++PqQ96D08PGg72DtwOvg6qDq4OpA6+DrAO2g7pDwUPLQ87D14PcQ+rD70PzI/er+OgD0APsAwACBAHoAOQCT/67+Av6A/Qz9UPxQ+6D64PmA+fj4GPgQ9yD2gPWw9MDzsPKg8dDwkPDA8ADxYPEQ8qDzkPXQ9zD6xPz4/7ADqAdwC9AOYBIAFsAZAB1AHwAhgCKAI8AjgCOAIgAhIB/gHAAawBaAE/APQAxACCgEMgA8/Gj4IPVQ8gDwAO5g7ODqIOog6oDqIOsA7EDtwO6A8EDyEPTw9eD3qPk4+3z8rP3S/rz/MwB0AHkATQAJAIj//P5M/sT9JP1g/Ij76Ppg+rD5IPlo+MD3EPdw9sD14PQw9HDzEPOw8oDysPKA81D0kPVQ92D52PuG/owB2ARwCDAM4A9AE4AWwBnAHEAfACEAIoAigCJAIkAhQB/AHAAa4BagEwAQEAzwB7QDt//Q+9D3APSw8EDuYOzg6sDpwOiA6CDpYOog7MDtYO+w8SD0sPYg+YD7nP1v/0YBxAKkA1AEsATwBNgEEAQEA9oBqwCE/3j+TP3I+2D6UPlw+HD3gPaQ9cD0EPRw86DywPEA8YDwQPDg78DvAPCg8MDxQPMw9YD3UPo8/aYAWARwCLAMwBCgFGAY4BvgHsAhwCNAJYAlgCWAJAAjACFgHgAbIBdgE6APUAvYBkwCHP4g+mD2sPJA70DsgOrA6QDpYOgg6ODoQOog7EDugPCw8iD18PfA+jT9TP+EAZwDOAVQBugGSAdwB1gHAAfYBSgEgAIQAaD/uP3A+9j5IPig9vD0cPMQ8rDwAPBA72DuYO3A7KDsoOwA7WDtAO4g7wDxEPOA9Uj4iPs5/yAD4AbwCiAPoBPAF2AboB5AIcAjgCWAJgAngCYAJUAjwCDAHUAaYBZAEuAN4AmYBQgBmPyA+BD1kPEg7gDr4Ojg54DngOdg54DnwOhg6yDuQPBw8mD14PhE/HX/GAKABBgHgAkgC9AL0AvgC9ALEAuwCagHQAW4AkUAHv6o+9j4YPYg9DDyQPCA7iDt4Osg68DqQOqg6WDp4OkA6+DrwOzg7eDvMPIQ9fD3MPvS/swCEAcgC1APgBPgF+AbQB8AIkAkACZAJ8AnQCfAJYAjwCDAHUAaIBagERANoAgYBID/+Pqw9sDygO9g7CDpgOYg5UDloOUA5sDm4Ocg6mDtIPFA9AD3UPpq/ogCuAVACKAKAA0AD2AQgBDgDxAPMA4QDaAKUAfQA8YAvP2w+pD3QPRQ8cDuwOzg6iDpoOcg5+Dm4OYA52DnIOhg6WDrgO2g7/DxoPQI+Nj7s/9wA1gHYAuQD6ATYBfgGgAeACGAI8AkwCUAJgAmQCVAI8AgwB1AGoAWYBIQDrAJQAUyAfT8kPhw9ODwwO3A6uDnoOUg5KDjIORg5aDmQOiA6iDuEPIA9tD5kP18AagFwAnwDDAPIBEgE2AUgBRgEwASIBDwDSALuAeIA1z/mPs4+KD0MPEg7qDrYOmA5yDmIOWA5IDkIOXA5aDmwOeA6YDr4O1w8CDzMPaI+Sj9QAFgBXAJcA2AEWAVABmAHKAfQCJAJIAlACYAJkAlwCPAIeAeYBtAF2ATQA/ACigG8gHw/ej5MPag8oDvoOxg6kDoQOYA5cDkAOYg54DoQOoA7TDwEPRo+Fz8MQAABCAI4AsQD6ARwBMgFeAVwBXgFMASIBBQDTAKEAZeAYD8APjw8yDwgOxA6WDmIOSg4qDhQOGg4UDioOMg5cDm4Oig66DuoPGg9OD3WPsi/9wCwAawCqAOYBLgFeAYoBuAHgAhACMAJEAkACRAIwAiACCAHSAaYBaAEnAOQAr4BegBLP6Y+kD3EPTg8EDugOwA60DpgOeA5sDm4OfA6cDrwO0w8JDz4Pcs/EIAKATYB8ALcA+gEsAUABbgFkAXwBbAFMARUA7ACugGXAIA/UD3YPJA7sDqIOcA5KDhQOCA34DfIOAA4cDiAOWA5wDqoOzA7xDzUPa4+Qz9LwB4AxgH4ApQDmARoBTAF2AawBwAH8AgACJAIkAigCFAIKAeYBxgGaAV4BEQDhAKuAWKAdj9iPrA99D0EPLg72DuIO3g68DqwOlA6eDpQOsg7UDvYPHw8xD3GPtx/2ADqAbACZANABHAE0AVIBagFqAWgBVAE+AP4AsQCPwDJf+Q+TD0gO9A6+DnAOVg4kDgQN/A34DgoOEg40Dl4Ofg6uDtsPBw82D22Pk4/ev/ZAIgBWAIoAvQDsARQBTAFoAZIBwAHoAfgCDAIIAgoB9AHkAcgBlgFuASEA8QCygHWAN1/zz8kPlA9/D0EPOw8cDwIPCg78DuwO0g7aDtYO/g8ADyYPNg9Vj4sPs5/zQCGAVQCMALAA8gEcASABSgFKAUYBMAEeANIAooBu4BEP2w9xDyIO1A6QDmYOMg4YDfwN6A3wDh4OKA5ADnYOrg7dDwUPMQ9jj5nPyH/9QBjAO4BYAIsAtQDqAQIBOAFeAXIBqgHEAeAB/gHgAfgB7gHAAbYBhAFYAR0A3wCbAFigFg/sj7EPmQ9vD04PPg8hDy8PHg8WDxgPAQ8GDwYPHw8oD0sPXg9lj5wPzj/8QCoAWQCMALYA7gEIASYBOgE0ATIBJwD+ALwAeQAzf/cPoQ9YDvYOrg5qDkoOKg4MDfAOBA4WDjgOXA52DqoO0A8RD0MPYw+KD6bP3N/3oB5AKQBPAGoAmADPAOQBGgE4AWIBkgG6AcwB0gHuAd4BxAGwAZYBZAE9AP4Av4B2gEMgFa/vj7UPoo+TD4oPdw93D3gPdw9+D24PWg9PDzAPRw9AD1APbg9gD4EPqg/RYBAASABmAJkAxgD8ARoBIAE4ASYBFgD7ALCAd4Agz+MPnw82DuYOmA5UDj4OHg4CDgwOCg4iDlAOjg6qDtkPDQ87D26Phw+hT8IP7f/zABMAJwA/AEMAcQCuAMMA/AEYAUIBeAGSAbgBwAHcAcoBvAGWAXoBTAEVAOMApABuwCIQC4/dj7aPq4+ZD50Pno+dj5MPrI+pj6WPmg90D2cPVA9bD1MPaQ9hD3mPiw+yr/aAKIBXAIMAswDuAQoBLAEmASgBEwD1ALeAasAQj9GPjg8qDtYOhg5CDiQOHg4ADhAOIA5KDm4OlA7WDwYPNA9vD4qPrI+/D8hP7V/6wAOgEgAmgDUAXwB7AKoA1AEMASYBWgF+AZQBvgG8AbgBogGMAVIBMgENAMUAl4BcgBW/+g/Vz8MPuw+jj7APzA/Ej9uP30/TL+3P34++D4sPZQ9mD28PVQ9XD1kPbo+Az8wP/IApAF0AhQDPAOoBDAEQASQBFAD0AMsAdYAlT9WPnQ9CDvwOkg5gDk4OJg4qDioOPA5WDogOuA7gDx8PPA9vj4IPro+nD7APz8/PD9hP7A/rL/vgGgBHAHEArwDGAQgBMgFiAYoBngGmAb4BogGYAWwBMAEUAO4ApoB0AEYgFQ/z7+qP1M/Rj9BP5c/2kArwCyAPMAjQBV/+z8kPlg9vD0QPUQ9bDz0PJw9PD3YPuM/vIBYAWwCGAMYA8AEYARoBEAEcAO4AogBjIB+Psw9/DyQO4g6WDl4OOA40Dj4OOA5QDowOqg7YDw8PJg9SD4MPqg+mD60PrQ+4D8NP30/er+6//2AegEMAggCwAOQBFAFMAWgBjgGaAawBoAGiAYIBUAElAP4AwQCqAGqAOcAUQAav8c/2H/1v+SAI4BqAL4ApgCSALgAUMAIP1A+QD28POA89DzQPMw8vDy0PZo+wD/4AFwBVAJkAwgD8AQIBFgEEAPIA1QCUAEJ/+4+lD28PHg7QDqgOag5KDkQOXg5eDmQOkg7IDuUPBg8rD0oPY4+Pj46PjA+FD5kPrw+yz9Xv75/0wCeAUwCbAMYA/gEaAU4BZAGIAY4BjgGOAXwBXAEuAPUA1ACyAJ0AZABGwCwAFwAWABXAEQAuQCeAPIAzAECAQEA+wBwAA+/uj54PXg84DzUPPw8vDyoPMQ9nj6Bv8sAsAEIAiQC5ANQA6QDnAOEA2ACngHgAOo/ij60PaA8xDwgOzA6eDnYOcg6ADpwOng6uDsIO+Q8NDxoPNw9dD2kPcg+FD4yPgI+sj7qP0t/68ArAJYBZAI4AuADmAQABLgE0AVwBWgFaAVYBVAFEASsA+wDRAMoArgCBgHYAUABEQDLAMoAwwDaAOYA7ADcAOIA2QDcAI4AWj/2PzQ+HD1QPTA9LD0QPSA9OD1yPjY/PQA6AMoBqAIUAsQDYANYA3QDCALcAhABZ4BQP1A+XD2EPTw8GDtoOpg6UDpgOkA6kDq4Oog7KDtYO8A8ZDyIPSQ9eD20Pew+OD5kPvI/bX/bAE4A1AF4AfAClANMA+gEAASIBPgEyAUYBSAFAAUoBKgEKAO4AxQC9AJMAi4BigF8AMwAzADXANAAzwDnAOsAzQDnAI4AsIBbQB4/pD7GPhg9cD0kPXA9YD1EPbg99D6dv5sApAFcAfwCOAKcAxwDJALUArACDgG0AIB/zj7OPjg9ZDzoPCA7SDrIOrg6SDqAOrA6UDqYOvg7GDuEPAg8vDzkPVA98D4GPqQ+8z9GQDaASQDwAQAB1AJUAvwDHAOkA+AECAR4BGAEgATIBPgEgASQBCQDjAN8AswClAIsAZYBQgEYAOAA5wDJAPIAhQDrAMoAygC0gFmAW0AoP7o+8j4cPaA9TD28PYQ92D3cPhI+97+tAJoBfAGQAiwCbAKkAqgCVAIiAYgBBYBMP3I+bD3cPZw9JDxAO9g7UDsYOtA60DrwOrg6YDqQOwA7kDvcPHg87D14PZw+Jj6iPxk/pUAkAKwA9gE2AZQCSALIAwQDRAOcA7ADoAPgBBAEYARgBEgESAQ0A7ADcAMcAuwCZgH4AXwBKAEiARYBPADsAO0A8ADwAN4A+QCWAK8ATsAqP3Q+qj4kPdw9/D3WPgg+Aj4MPoK/uABSASwBfAG8AfACFAJYAkACPAF9AOsAX7+cPvI+cD4IPdg9HDxQO+g7YDs4Osg6+DpAOkg6SDqAOxA7nDwwPIQ9TD32PhQ+lj8EP+OAbACIAPgA0AFGAcACbAKsAsADMAMEA6gD8AQwBGAEsASIBIgEWAQMA+gDRAMcArABxAFuAO4A+ADiAOMA7QDaAMgA9ADmAT4A6QC7gEmAR//ePx4+jD5QPgA+Gj4kPgA+Mj4UPwrAIAC3AMgBUgGGAe4B+gHWAegBYQDUgEo/wj9gPvw+SD4MPbg81DxoO4g7UDsIOtg6QDowOdA6aDrAO4w8GDyEPWw9+j5ePsg/db+iQCyAZQCAAN0A6AEUAYQCFAJUAowC5AMMA7wD0ARIBIgEsARQBGgENAPUA6ADLAK4AjoBiAFOAQwBLAEAAUIBeAE2AQABUgFWAWwBBgDEgFP/7z98Pvw+aj4ePhY+CD4YPjI+fD7EP6hAOACAASQBHgFmAbwBlgGEAV4A4wBFABe/4j+wPzA+hj5QPfw9FDyAPAA7uDrwOmg56DmYOcg6iDtAO/g8DDzAPYI+ST8XP5W/6L/0gB8ArQDGASQBGgFQAagB0AJwAoADNANQBAAEgASgBFgEUARYBBQDzAOMAxgCQgHKAaYBUAEBAMAA7wDMARIBLAEOAVwBTgF0ATMA94B//+6/oD9wPv4+dD4gPiI+CD5UPqA+5j8YP6sAHQCGAOoA7gEAAZ4BqgFYATMAtIBMgFXAAX/jP2w+2D54PbQ9MDy4O/g7EDqIOiA5mDmIOjA6mDtAPAw8iD0sPZY+sz9Jf9E/43/fABsAZQCCAQwBYgF+AWIB3AJIAugDFAO0A+AECAQoA8wD9AOMA5gDSAMUApgCMgGEAbQBWgFsAQIBLwD6ANIBOAEQAUgBZgEyAPYAsIBoQCn/57+RP3I+6D6IPpQ+uj6oPuU/GT9SP53/wgBeAJkA/ADsARIBRAFIAQsA1gCMAHV/4r+fP14+yD5UPeg9YDz0PDg7SDrYOig5gDn4Ogg60DtYO/w8XD0EPew+UT8MP4k/0D/DP+B/yAB+AIoBNAEaAXIBtAIIAsQDXAOcA8AEMAP8A6QDjAOkA1gDEALUAogCbAH2AagBmgGmAWoBEgEUAR4BKgE+AQQBfgEkATcA9AChgGBAPz/If9o/eD7OPsw+wj78Pq4+wT9/P3c/j8AuAEcAyAEOAXwBdgF8AQIBDwDPAIeAdj/pP5E/bj7APpg+CD2oPMA8WDuoOvA6EDngOdg6YDrAO4Q8MDxkPMA9tD4YPtE/Tj+RP70/R3/tgEwBOgEQAWIBnAIMArAC7ANAA+QD5APYA+wDrANMA0wDYAMwAogCRAIgAcAB7gGKAYgBdgDWAOAA5ADeAOcA9ADkAMIA4wCHAJsAewAmgDf/5z+wP3I/fT9qP08/YT9Dv6u/nX/jgBGAZIBLAIgA7wDpAOIA0QDaAIsAVYA2f/I/jj98PvA+qD4IPYQ9ODx4O7g68DpQOgA52DnwOpg7gDw4PAA86D18Pc4+rT8Av5U/Rz99v7YAVwDUAR4BSAHgAjACZALMA1gDuAOQA9gDjANYAzQDEANsAwwCyAKsAlQCRAJkAhoB4gF/AMEA5AC7AGWARQCtALMAowCtAK8ApQCPALcASIBGwA1/8r+nv40/g7+Sv60/if/6/8KARQCsAIwA8wDSARoBDAE4AMoAzACMgFxAJT/VP5I/Xj8IPvA+AD2cPPA8ODtIOvA6ODm4OVA58DqIO4Q8BDx0PJg9SD4YPrw+5j88Pwu/hoA/AE8A/AE8AawCKAJcAoQDLANwA7QDjAOUA3ADIAM8AwgDaAMYAsQClAJ0AhwCGAHCAZoBMwCZgGrAKAA5QA2AVgBoAEAAoQCCANAA7gCvAHWAD0Asf8///j+4v7G/p7+9P7H/7AAMAGOAfoBSAJwArgCPAOQA1ADwAIwAk4BYgDS/3r/iP7U/BD7QPkg92D0oPHg7gDsoOng5wDnYOeg6WDtoPAA8pDycPSg93D6BPyE/OT86P2U/5oBcAMQBaAGEAgwCRAKIAtgDEANcA0ADYAM8AtgCzALkAvACyAL8AngCHAIIAh4B0AGwASIA4wCsgECAfYApgFUAnACHALAAcIBHAJYAgAC7ADk/2P/Xf8l/+b+DP9O/1f/SP/L/8wAvgGAAhwDVAMYA+wCfAMwBPwDCAP8ATYBYQCo/1f/7P64/eD7CPqw98D0sPFg7wDtgOqA6CDowOlA7ADvYPHA8mDzkPTg9mD5kPqg+tD68Pv0/U4AgAJgBNgFcAcACSAKAAvAC4AMgAzwC1ALMAtwCxAMcAwgDDALYAogCtAJIAnQB3AG8ASYA5AC7AFSAd8A0gACAUgBmgHmARACCALWAW4BrADa/4f/sf/E/63/1/9hAAwBkAHyAWACzAJEA5wDrANoA0ADXAN0AwwDMAKqATgBXQBa/9L+kP7M/WD8sPoA+RD3APUQ8+DwQO5A7IDrIOxg7SDvEPGA8kDzAPTQ9QD4qPmA+uD6ePu4/KD+6ADYAjgEYAWgBuAHAAnQCWAKYAoQCoAJEAkACXAJIApQCsAJ0AgQCJgHUAfIBvAFyASMA7ACUAL+AbIBdgE4ARABJgHSAcACZAN0AwQDZALUAZoBrgHAAZIBQgEiAVwBqAHqAfwBygFyAVABbgGYAaABhAFqATYB3ACaAH4AAQBA/6D+jP6A/vD9VP3E/Az80PqA+VD4APeA9YD0MPTg89DzgPRw9aD1IPUA9QD2IPeA95D38Pew+KD5yPoE/Bz9Jv5O/4AAegEsAggD2ANQBGAEiAQQBaAFOAa4BkAHoAfAB5AHYAcgB+AGkAYoBqgFOAXwBMgEuASQBGgEIATkA9QDyAOMAzADxAJ8AkwCTAKIArgC3ALsAiQDVANcA0gDOAMkA/AC2ALwAiQDNANAA1wDZAM8AwAD1AJ0AtQBQAH0AJ0ATQAzAEkAEwBy/7z+8P3Y/HD7OPpo+dD4UPgw+AD4UPdg9uD10PWw9YD1kPXg9RD28PUA9jD2gPbw9nD3GPjI+Ij5YPog+6D7EPzA/ID9Mv7K/nX/IwDUAIABHALMAoQDOAS4BAgFWAXABRgGYAagBsAG0AbgBiAHaAeoB9AHAAgwCEAIIAgQCAAI8AfIB6AHqAegB2gHGAfABlgGyAVQBegEgAQABKQDhANIA/QCsAJoAvYBWgHVAGMA6P9Z//b+tv50/ij+Hv46/gb+fP24/ND74PoY+sD5wPmg+UD5sPjw9zD30PbA9sD2gPYg9uD1sPVw9TD1IPUA9dD00PQQ9aD1YPYQ94D3oPfw97D4yPnw+hT8KP34/Zj+Vv9cAJQBxAK4A3gEIAW4BXgGYAcgCJAIAAmQCSAKkAogC7ALAAzQC5ALgAuAC0ALAAvQCmAKoAkQCdAIUAiAB5AG2AUgBUgEvAOIAyADbALsAb4BmgFQASYBCAGiAPX/d/9L/z//Pv9W/33/bP89/zz/Z/9N/7b+xP3c/Pj7OPuo+lD6APpI+Tj4MPeQ9iD24PWQ9VD10PQQ9EDzwPKA8mDyUPKQ8hDzwPOQ9KD1oPYw91D3wPew+Nj5APtg/MD9rv5Y/1EA2AFkA6gEsAWYBkgHuAdgCHAJUArgCmALEAyQDNAMAA1gDXANAA2gDJAMcAwQDKALQAvAChAKUAnQCGAImAegBsgFCAUwBHQDDAO4AigCigFYAUYB7QBhACUAFACm/w7/0P4c/zr/+v7M/tL+tP6K/pr+nP4Q/gD9GPyI+8j68Pmw+bD5GPnQ98D2IPag9RD14PTQ9ID0sPMw8wDzkPIQ8gDycPLA8gDz4PMw9SD2YPaw9lD3EPgA+Wj6JPx4/UT+LP91AM4BKAPABDAGAAdQB8gHsAigCZAKYAsQDGAMoAwADXANkA1gDQANgAwQDPAL8AvACyALcArQCSAJUAi4BygHOAYYBSgEkAP0AlgC6gF4AfQAkACMAJMAWQASANH/U/+W/lj+2P5n/3T/QP8W/+D+nv60/if/Nv+Q/sD9AP1E/Jj7SPsQ+1j6KPkI+GD34PZg9hD20PUg9UD0kPNA8wDzsPJw8mDyQPKA8mDzgPSA9RD2gPYA97D3kPjQ+Tj7cPx0/Wb+dP/OAGwCEARwBXAGGAfIB4AIQAkACtAKcAvQCzAMcAzgDDANMA0ADaAMIAzAC6ALkAtQC9AKUArgCVAJoAgACEgHSAYoBTgEiAPwAngCJAKqAf4AZQA8AEMAMQAQAOT/f//Q/lT+aP7g/k//k/+5/4b/BP/E/ub+3v5m/tz9ZP3U/BT8gPsg+6D6gPlg+ID38PaA9lD2APZQ9WD0kPMg89DyoPKg8qDyoPLQ8lDzMPQg9fD1gPYA95D3gPio+dD62PvQ/NT93v4yALABQAN4BHAFKAbYBoAHMAjwCKAJIApwCuAKgAsQDGAMoAzgDNAMgAxADBAMsAtAC+AKoApACsAJYAngCBAICAcIBhgFEAQcA3QC2AEmAYcAJgDc/17/DP8O/xn/2v5w/hD+xP1s/VD9qP0k/nr+mP52/hT+sP20/ej90P1M/bT8NPyg++j6YPrQ+QD5OPiA9yD38Pbg9rD2APbw9AD0cPMw8yDzYPOg89DzEPRw9CD18PXA9oD3OPjI+HD5WPpo+1z8PP1I/rD/NAGoAvQDMAUYBrgGcAdACBAJ0AmQCjALcAvACyAMsAwQDRANEA3wDKAMQAwADLALMAuQCjAK0AlQCdAIUAiwB7AGiAVwBIwDoALKATABqAAdALj/mv+H/0j/Ev/w/sD+SP7Q/Zz9kP2Y/eD9SP6G/m7+QP44/iD+Dv78/ej9gP20/OD7SPvI+iD6SPlo+KD38Pag9pD2kPZQ9pD1kPSg8+DywPIA81DzgPOQ89DzYPRA9TD2MPcI+Mj4ePk4+hj7FPwY/RT+L/+AAAQCvANYBXAG+AZ4BxAI4AigCXAKMAuwC9ALAAxgDOAMUA2QDYANIA2wDGAMQAwQDJALAAuAChAKgAkQCaAIAAgoBxAG8ATcA+QCKAKMAfsAdAAbAOb/tv+C/z7/4v6E/iT+xP18/WT9kP3Y/fj98P30/eD9sP2M/YD9VP3s/ID8JPyA+6j66Plw+cj44PcA96D2YPYQ9tD1oPVA9XD0gPPw8tDy8PJA87Dz8PMg9ID0UPVA9hD34PfI+KD5SPoI+wD8+PzM/dL+IgCQAQgDcASYBVAGwAZYB0AIMAnwCaAKMAuAC8ALEAygDCANQA1ADSAN0AxwDGAMUAwADGAL0ApwChAKgAkACYAIqAeIBnAFeAR4A5AC7AFiAbgACgC5/6H/ev8m/8z+hv4c/qT9QP0g/Rz9KP0w/Tz9RP1E/TD9GP3o/Kz8XPwQ/MD7YPvo+lj6uPn4+Dj4gPcQ97D2YPYQ9vD1oPUg9XD04POA81DzYPOw8wD0QPSA9PD0oPVQ9iD3EPgI+cD5WPog++j7rPyc/ej+bgDkAUgDmASwBXgGKAcQCAAJ4AmQCjALwAswDKAMYA0ADkAOQA4wDgAOwA2QDXANQA3ADCAMkAsgC8AKUArwCVAJUAgwBygGOAU4BFgDkALGAQIBfAAqAPv/sP9Y/+z+Zv74/aj9fP1A/fz8xPyk/KD8uPzY/NT8pPxI/PD7mPtY+0j7CPuY+uD5IPlo+MD3MPfQ9oD2IPbA9YD1QPXQ9FD00POA81DzYPOg8wD0MPRw9LD0IPXQ9cD24PcI+fj5oPpI+wT81PzU/Sf/nwD6ATADSARABRAG4AbAB4AIMAngCaAKQAvAC1AM8AxgDYANkA2ADXANYA0wDQANsAxADMALUAvgCnAKAAqACdAI8AcABxgGQAVgBIQDrALSAQYBgAAlANb/hv8k/7z+Vv78/bT9hP1I/ez8hPxI/FT8kPy8/MD8iPwo/MD7cPtA+xj76PqQ+gD6WPmw+Bj4kPcw99D2YPbw9ZD1QPXg9GD0EPTA87DzwPMQ9GD0kPSQ9LD08PRw9UD2QPcY+Mj4WPkQ+vj68Pv0/Az+Lf9tAMwBJANYBHAFeAZwB0AIAAngCdAKwAuADCANkA3wDUAOUA5QDiAO4A3ADbANgA0QDXAMwAsgC4AK0AlACcAIMAhIBzAGGAUYBFgDtAL+ASQBRACM/x///v4B/+z+rP5g/hb+uP1Q/RD9BP0E/fT86PwY/Sz9BP24/Iz8bPwg/MD7YPvo+kj6oPn4+FD4kPfg9jD2oPXw9CD0YPPQ8nDycPKQ8pDykPKw8hDzYPOg8wD0sPSA9VD2MPcA+Mj4kPmg+gj8gP3Q/iMAZgGIAogDiASoBcgG4AfACIAJYAqgCxANMA6gDsAOEA+AD4APsA7gDdANYA6wDnAOsA5gD7APkA5QDIAKUAoQC6ALEAtgCZAH2AUwBJgCqgF0ARQB4/+G/vz9Av70/XD9tPz4+0j72PqY+kD6qPlA+Tj5SPlg+ZD5wPmw+WD5OPmA+ej5yPko+aD4oPjo+Oj4gPjg9/D2oPUw9CDzoPJw8oDyoPLw8nDz4PNQ9ND0cPVA9gD3kPcg+AD5OPrA+yD9cv6X/wQBsAJgBIgFGAaABggH4AfACIAJAArACuALEA0ADpAOYA9gECARABEgEJAOIA3wC/AKAApACQAJ4AiwCOgH+AYgBkgFOAQMA0QC3AFyAY4Ac/9K/jj9GPxg+xj7APuw+oj62PqQ+zz8pPz8/GT9zP0W/n7+/v68/3UACgFWAZgBkgEqAWsAf/9m/hD9mPsA+lj44Pbw9XD1APXg8+DxoO/g7cDsIOzA68DrAOwA7SDvEPJw9bj42PuA/nkANALoA4gF0Aa4B8AI4AkwC6AMMA6QD0AQQBDAD8AOkA2QDGALgAlQBxAGYAZYB+gHAAgQCDAIAAiYB+AGuAV4BHQDrALcAToBYgE0AvQCbAOsA/gDUASYBKAE/APwAuAB6QDm/7T+uP3o/CT8mPt4+3j7MPuo+kD6QPpw+oD6IPqQ+Uj5uPkg+hj6+PnA+qD8Qv6k/vT9mP06/gb/pP7E/HD6EPlw+bD6QPsI+nD3cPQQ8mDwQO9A7kDtIO1A7qDwUPMg9lj5fPyW/nv/ZAA8AogEYAZQB2gHmAfQCAALIA1QDsAOAA/wDoAO8A1ADQAMIApwCGgH8AYIB9AH8AhQCRAJ0AgACRAJkAh4B+gFMAT4ApQCnALUAjgDzANgBMAEEAU4BegE+AOIAukAXv8a/kT9sPwA/AD7IPrQ+fD5CPrA+fD4GPjg9zj4YPgI+OD3cPgo+VD5KPnI+UD72PwS/gr+TP3o/Ej9+P2E/cj74PkI+Vj5YPrA+nj58PZQ9JDy8PDg7kDt4OyA7QDvQPGA9Aj4kPu2/hQBRAJcAyAFIAcwCNAIwAmwCqALEA1QD8AQYBCQD4APwA8AD7ANMAxwCrAI2AfAB9AHqAfQBxAI2AegB/AHUAjgB4gGQAVYBHgD7AL4AjADBAPYAkwDKAR4BGAECAT8AmAB5//Q/pz9QPwo+6j6IPqI+WD5yPnA+Vj54Ph4+ED4GPhI+FD4OPgQ+Hj4GPkA+gD7LPyY/cz+w/9l/97+2v6l/3j/aP0o+8D6DPxI/Yj9uPuY+OD0QPKw8ODugOwg66DrgO2A8HD06Ph0/Pz+IgEwA1AEMAX4BgAJ4AlQCXAJUAugDWAPoBDAELAPkA4wDiAO0AxgCiAIOAa4BHgEsAXwBigH8AY4B4AHYAeQB+gHMAdQBZAD7ALAApgC8ALYA0gESATIBLAF4AUYBfQDgAJoACb+0PwM/AD74Plw+TD5oPiI+DD5gPnQ+MD3gPfQ99D3CPho+Ij4sPiQ+dj64Pu4/Gj+FwAZAPb+vv7u/3YAkf+8/QD8uPqo+nD8yP04/FD4sPSA8tDwAO/g7ADroOmg6kDu0PKg9mj6NP4WAeACWASIBsAIAAqgCqAKgAoQC+AMIA+AEEAQMA8wDoANQA3QDDALYAj4BfAECAV4BSgG4AYoB/AGEAf4B7AIoAggCJAHaAYgBaAECAVQBSgFOAVwBWgFOAWABZAFUARIAmoAsv6o/PD6CPpQ+QD40Paw9vD2YPfw95j4gPjg96D3UPjY+Mj42Pgo+YD5KPqY+0D9eP4p/z4AAAGaAK3/k//P/wL/6PyY+rD5KPq4+9j8YPtQ91Dz8PCA78DtQOuA6WDpwOqA7mDz4Pdw+7r+6gFIBNAFEAfwCLAKYAtQC9AKQAvgDBAPYBBAENAOkA1ADQANQAxACpgHWAVIBHAEQAXgBSgGgAawBuAGWAcwCLAIUAhIBzgGMAVABAgEKAT0A4QDpAM4BLAEGAVoBcAEoAJgAMr+dP2g+yD6KPkA+JD28PWw9mD3oPfA9yj4EPgA+Oj4+Pko+oD5uPmw+kD7YPtk/Dr+dP/T/83/qP9n/9L/6ACdAMz9OPpA+WD6uPuw+xj6cPcQ9BDycPFg8KDtQOvA6mDsIO/A8pD2GPrQ/X4BKARgBdAGUAmwC9AM8AzwDOAMQA2wDmAQIBAwDoAMEAywC6AKMAmQB8AFQAQABGgE4AQgBbAFaAZ4BoAGAAcwCOAIwAggCPgGmAWYBJAE2ASQBJQDFAM4A0wDGAPkAlQCxACW/gD9UPyA+yj6wPiA94D2APbA9tD3MPho+DD5OPrQ+kD78PsM/Ij7YPsw/Hz8CPz0/HL/OgGgAGP/iP+0AGYBCAFg/zj8kPmA+VD7RPwA+zj4QPVg81DyUPHA7sDrgOrA6wDugPDg88D3yPvF/6ADMAZAB7AIIAtgDeANUA3wDPAMIA0gDuAOMA6ADJAL0AtgC+AJsAgQCLAG2AT0AygEmATABGAF4AWQBYAFyAZwCDAJsAiYBygGoAQgBJAE0AQ4BMADvAOAA0gDWAN8A1gCFADc/Tz84Pqw+QD54PdA9vD0EPUg9vD2sPeI+CD5OPmg+Wj60Prg+mD7APzg+6D7fPyE/tX/TQB8ALr/eP7U/t4ARAHg/fD5KPkw+nj6YPqA+tD4kPWg86DzkPJA7wDt4OyA7eDtsPCA9Rj6zP3YAZAFMAcACDAK8AzQDUANkAxwDFAMcAxgDcAN0AxgC2AKAArwCeAJQAmQB5AFSATYA/wDeAQQBWAFMAXABWgHAAnACdAJYAlQCPgG4AWQBVgFyAT8A0QDpAI0AgwCxgE6ATgAwv4c/cD7uPqo+VD4wPaQ9fD0EPVg9QD2APdQ+Ij5EPqI+mD7OPyM/KT8pPw8/Oj7yPyA/jn/wv7O/tv/XAAOAAsA+/9U/hj8iPvA+1j6kPjg+Dj64Pgw9ZDyoPFQ8MDuwO4A7wDvUPAA9ej60P4eAawDYAYQCMAJ8AtwDcAMsAvAC2AMsAyADMAMcAyAC6AKsAoQC3AKAAkoB6gFiAQgBAgEQARoBKAEYAWABsgH0AhQCTAJoAiYB8AGIAZwBagE5ANMA5wC9AHSAdYBPAHa/5b+xP3c/Ij7SPoI+dD3kPbQ9aD1gPWw9UD2YPdQ+ND4GPmw+ZD68PrI+oj62Pqw+3z8aP1s/u7+B//R//IAWgE+AMj+UP78/az8iPtI+7D6aPm4+LD5CPrw99D0oPKQ8EDuYO2A7kDwUPHg89D4MP7iAcgEcAdACXAK0AtADTANEAzgCxANgA1gDEAL4ArACoAKgAowCgAJYAegBpgGEAbwBAgE7AMoBNgE2AXwBsgHoAiACdAJIAkQCGgHGAeIBoAFWAR0A+QCkAJwAjACVAHh/5L+/P2Y/cz8kPsw+pj48Pbg9bD10PXA9bD1EPbw9jD4cPlY+uD6EPsQ+yD7kPuI/FT9hP2U/Qz+dv6u/ln/hAC6ACX/eP08/WT9kPyo+zD7EPo4+MD3QPlg+VD24PJg8QDw4O1A7YDvUPIg9MD2QPtp/4QC+AXQCXAL8AoAC/AMsA7gDpAOMA4wDQAMEAywDEAM0ArgCbAJEAnAB6gG+AWgBSgFcATkA+wDAAWIBvgH4AgACZAIQAigCMAI+AdwBigFKAQcA4gCjAJIAlwBlABMAMb/wP4U/uj9EP0Y+xj50PcA9xD2cPVg9UD1APWA9RD3iPgQ+UD56PmA+qj64PrQ+xT9jP1c/dD9yP5b/37/5v9qAPn/hv7Q/dz9CP2I+xD7ePt4+kD4cPfw+Bj5YPYw8wDxQO/g7aDvUPOg9bD1sPc4/bACqAWIB7AJoArgChAMgA6QD4AOkA2wDfAM8AoQCpAKoAogCbAHcAd4BzAHMAdIB2gGuASkAzgEgAXwBQgGWAbABvgGWAf4ByAIKAfgBTgFsATAA9ACcAJEApwBpAAWAKz/C/9W/qD9uPxw+/j5uPig92D2UPXQ9JD0oPTQ9HD1oPbw9+D4iPkY+qj6QPvg+5j8QP2M/Zz9HP4H/7v/+/9YAKwARQAV/0L+WP74/aj8iPtI+9j66PlQ+VD5EPjQ9BDyIPFQ8ADvgO+w8lD2SPho+qz+QAOABjAJkAtgDNALYAygDkAQQA9gDTAMUAvACvAKUAuQCrAIQAdAB5AHQAeIBpgFgASoA5ADMAQoBeAFWAa4BgAHeAcgCIAIQAhgBwAGwAQgBBAE5APkAmwBjgBpADwAvv8U/xj+jPwo+1D6gPng98D1QPRg8+Dy4PKw86D0YPVw9tD3UPlw+hj7WPtQ+4j7aPxw/QD+YP7o/pL/SQD1AFgBCAH6/x3/uP4A/uj8APxg+7j66Pk4+bj4kPfg9UD0gPJg8ODuAO/Q8KDzgPao+cD87f/8A3AIMAsADDAM8AxADjAPcA/gDkANUAuQCrAKoAoQCkAJIAhQBzgHqAdgBzAGWAXQBFgEUAQYBegF8AXwBcAGuAfYB6gH4AeYB4AGSAWoBPwD6AIAAoYB0ADF/1//W//o/rz9gPyw+9j6oPl4+ID3APZQ9HDzsPMw9ED0YPRg9bD2wPfA+AD6wPqo+qD6qPtA/Sj+iv4S/8z/NACeAEoBkgHUAIH/4P6w/gr++PxI/Oj7IPsw+sD5cPkQ+AD2UPTw8kDxAPCw8ADzEPZQ+cj8GgCsAqgFUAlgDFAN4AygDHAN4A6gDyAPkA2wC6AKgArACqAKcAmoB6gG2AYYB3gGYAXIBIgEOARIBPAEoAXABQgG8AaIB0AH0AYABwgHMAbIBLQD7ALsAVAB+QBwAF3/kv54/ir+LP3g+xj7YPpA+Qj4EPfw9XD0kPPg85D00PQQ9SD2sPfI+LD5yPqA+3D7aPuE/Aj+zP4k/7f/TwCnACgB5AGgASgA2P6s/mL+RP1w/CT80PsY+7D6ePog+eD2IPVg9PDysPDA7yDxcPQQ+ED76P11AGQDKAfQCjANgA2gDNAMcA5AECAQQA5ADBALkApwCpAK4AkwCOAGEAeoBwAHoAXwBPAEiAQYBFAE0ATwBEgFeAYoB4gGyAUgBqAG+AVwBHADoAKQAQQBNAEcAU0Ag/9r/1D/SP7w/Nj70Ppw+SD4APeg9UD0YPNA84Dz4PNQ9DD1IPYw93j4ePn4+UD60PrY++D8+P3+/tD/bgD7AE4BRAHuAFcAcv9Y/pj9FP1A/Dj7MPvY+2j7IPpw+Uj5APiw9WD0sPPQ8WDw0PKg92D6kPtA/sACQAaQCHALoA0QDRAMwA0gEPAP4A3QDIAMEAugCYAJkAlQCBgHUAfIB/AGwAXIBQAGeAWYBFAEmAQIBdAFyAZAB/AGWAYgBkgGWAagBSgElALUAaQBTgHFAB4AT/9c/uT93P2o/ZD8OPs4+lj5KPjQ9pD1UPSA8zDzYPMA9ND0wPXA9sD3yPjo+cD6cPsY/Nz8oP1W/hL/wf9uAKQAUwAFAC4AQABw/1L+vP1k/az8VPzY/NT8YPsw+mD68PlQ97D08POQ82DyYPIw9Yj4cPo0/eABeAVYBsgHgAswDuAN0AyADVAOkA0QDUANAAwQCcgHQAmACnAJ+AeYB2gHuAZgBgAHkAbABGgDCASIBSgGOAYwBhgGoAV4BfgFOAYwBWADNALKAZQBDgFeAKL/mP6c/Uj9ZP0M/Qj8APsg+hj50Pfg9jD2IPUA9IDz0PMw9LD0oPWg9hD3UPcQ+FD5YPoQ+6j7nPyw/br+zP/EACQB0gCPALIAqQDB/07+pP14/dz8APzw+1z8MPw4+4D6+Pk4+MD1gPRg9LDzwPIA9JD3EPuI/ZAAWATYBiAIQAowDYAO4A2gDXAOkA5gDYAM0AswCiAIkAegCNAIuAf4BiAHSAcgB0AHIAcABqAE0ARABhgHiAboBQgGiAbIBpgGGAYABegDUAMYA4gCdgGCAMP/CP8g/lT91Pxw/DD88PtY+xj6oPiw9yD3QPbg9LDzEPMQ88Dz4PTw9WD2kPZw9/j4gPqo+3j8FP2o/Xb+W/8RAHQAXwDr/3r/Yv9f/8r+zP04/Rj9mPzw+/D7ZPwI/Lj6oPnQ+BD34PQg9KD0sPRw9FD2SPq8/QoA9AKABpAIUAlgCwAOIA9gDlAOcA8gD2ANAAzQC0AL8AkwCSAJsAjYB/gHoAgACEAGCAVYBRgGKAawBWgFsAUQBngGuAagBvAF6ASgBNAEKARMAucA3ADSAHT/uP0I/ej8pPx8/Lj8XPzo+sD5iPk4+dD3APbQ9BD0cPNA87DzYPTg9GD1YPbA9+D40PnY+ij8YP0q/ub+wv9RAIMAlAC8AHUAdv+a/mr+Sv6I/fD8tPxU/Kj7gPvo+5D7EPqw+ND3kPYg9eD0wPVw9jD3cPkg/SEAeAJoBVAIoAngCYALEA6QDwAPAA5QDVAMMAvwCuAKMAm4BqAF4AaACIAIcAdQBqgFoAVoBugGUAbQBCAEEAU4BigGSAXgBBAF+AQ4BIAD+AIgAkgBzABaAEX/6P2U/QD+yP2s/Lj7YPsQ+1j6ePmg+FD30PXQ9GD0IPTA83DzwPPQ9AD28PbQ9/j4OPpI+1j8wP3o/mj/l/88APIAEAHBAHAA+P8V/4D+nP6C/oD9fPxc/Gj8APyo+4j7yPoA+XD34PZg9oD1cPXA9hD4gPkk/FIA4AO4BXAHwAnQCwANcA7AD0APAA2AC/ALIAzACvAIAAioB7AHUAjACBAIqAYABjgGAAZYBcgEwAQABWgFsAWgBXAF0AWQBogGkAVwBIADzAKEAkwCWgGo/2b+Xv6G/uT98PxI/ID7cPrg+dj5MPmA9xD2gPXA9EDzUPKw8iDz8PJw8xD1wPbg9xD52Ppc/Cz9Bv5E/xQAWwDFACABBAFoAN3/f/8W/8D+Zv6Y/Zj8QPxs/DT8iPvI+hj6IPk4+LD38Pbg9ZD1kPbQ9/j4yPq0/d0AWAMYBjAJgAvQDGAO0A+QD+ANkAxgDKALAAoACeAIQAigBxAIsAggCLgGSAbYBqAG0AV4BYgFgAWwBVAGeAYIBtAFSAZoBtAFQAWQBHQDTALEAUIBLgAa/4j+6P3I/BT88PtQ+xD6IPno+Jj4APig9zD3APaA9NDzkPMQ89DyUPNw9FD1MPaw93D5CPtU/HT9Yv4s/zAAoAHYAtQCfAHW/zT/bf9o/5L+SP0Q/Hj7IPxI/Xz90Pvo+Wj5uPmQ+cD4CPhw90D3YPi4+tD8AP6y/8QCCAaACJAKkAzADVAO0A4AD9AN0AvACqAKEArgCEAIMAgQCOgHEAjgB/AG6AXIBRgGAAaQBWAFYAWABfgFeAZgBsgFUAVYBWAF8AQQBOQCogHvAMEAQgAQ/6z91PxU/MD7OPuY+oD5aPhA+LD4QPjQ9qD1IPVw9GDzEPNw86Dz0PMg9fD2IPjI+FD6uPw0/qD+Qv/BACwCCAMkA0ACgQDo/qr+AP9M/pT8CPvY+tD7yPys/HD7EPpo+YD5uPmQ+Zj4gPew93j5iPt4/FD9Xf9AArgE+AagCaALkAxADYAOUA8wDpAM4AugC9AKkAngCFAIwAd4B7AHmAeQBogFiAUoBmAGAAaIBVgFcAXwBWgGWAaABbgEgASIBFgEgAM4AukAEgCw/1z/eP5I/WD88Puw+2j7APt4+vD5cPkQ+XD4UPfg9aD0oPPw8iDysPEg8hDzAPSw9MD1QPcA+aj6ePxU/rH/2QB0AgAE+ANMAlMAj/9Q/4b+NP0Q/FD7QPtQ/HD9SP2o+3D6qPog+4D6WPm4+ID4oPiQ+XD7GP0I/pX/bAJwBZAHUAlAC/AMkA3ADRAOwA3ADAAM0AtAC/AJ0AiQCKAIUAjoB2AHgAbIBfAFkAZoBngF8AQwBYAFoAXABaAFwAT8AyAEmAQYBMQCygFOAbMA9/9k/7T+wP0E/cD8nPwc/Gj7+PqA+vD5UPlY+AD3sPXA9LDzkPKw8eDxYPKw8oDz8PQQ9uD2gPj4+tT8lP3+/s4B4AP0AyQDjALQAbsABQBq/9D9sPsw+4z8iP0A/eD7MPvo+gD7YPtY+zD60Pio+ND5KPsc/Az9UP44AKwCUAWQByAJoArwC9AMMA1gDTANoAwQDMALEAvACaAIoAjQCBAI8AZwBlgGCAYYBqgGqAaYBfgEwAWwBlgGQAWwBJgEUAQgBPwDXAMAAvMA1ADJAPL/rP68/UT9JP0E/bz8HPxQ+8D6cPrY+dD4YPfA9WD0cPNw8pDxAPFA8SDy4PKA82D0wPUw9+D4qPog/Gj9Bf+AAYgD0APYAtABIgGmABwALP+c/dj7OPto/Iz9SP0Q/DD7SPvY+xT8mPuY+pj5gPlg+nj7ePxY/bD+0wBcA7AFeAcACVAKgAtADHAMYAwwDCAM8AtwC4AKsAkQCdAI4AjACAAIAAfABjgHYAfIBvgFaAUgBUgFwAXIBegE5AOkA+gD3ANQA4QCsgECAdIAxgAlAOL+4P2s/ZT9JP2E/Aj8gPsA+6D6+PnI+GD3cPag9VD04PJA8lDycPLA8lDz8POA9LD1wPeA+UD6CPv8/FX/TgGcAhQDXAIcAdwATgHXAPj+CP0o/Gz8LP2M/fD8qPsI+3D7KPwo/ID7qPoY+lD6YPtg/Nj8hP1U/9IBCATYBaAHQAlgCmALUAzADHAMIAxgDHAMsAtwCsAJoAlgCfAIcAjQBygHAAeIB7AH+AboBagFGAZ4BkAGmAWwBOgDxAMABMADwAKOAfsA8ADSADwAR/9C/pz9fP18/QD9EPxw+yj7yPoA+hD5EPiw9mD1kPQA9NDy0PHw8cDyMPNA8+DzQPWw9hD4oPkY+yj8lP3r/0ACMAOsAsYBTAFYAUwBbgCK/rj8JPyw/Fj9SP2k/LD7aPs4/HT9kP1Q/Dj7QPsI/MD8aP0A/pD+z/9AAhAF2Aa4B+AIgArAC1AMsAzwDLAMUAxgDDAMQAsgCsAJoAkQCSAISAeoBlAGMAboBTAFaARABLgEEAXwBJgE/ANcA0ADeANIAywC/wCFAHEABABE/5r+4P0w/fj8MP0U/TT8UPvo+oD6gPko+PD2wPXA9AD0QPOQ8iDyQPKw8jDz4PPw9OD1EPfo+Oj6IPzw/JD+qQDUAdYBvAGkAfUASAAuAOX/YP6Y/ET8BP1Y/dT8UPwE/AT8mPyc/dj9tPxw+4j71Pzc/Sj+Zv5m/zgBlAP4BagHcAjwCPAJUAtgDHAMEAzQC+AL0AuAC9AKEApQCaAIAAiYByAHeAboBaAFiAVABegEuAQABUAFAAVwBPgDsANQA9ACTALMAfoAEwCw/5f/D//4/TD9FP0Q/Zj8FPyw+wj7OPp4+dj40Pdw9lD1oPQA9GDzAPPQ8uDyQPMA9MD0oPXg9mj44Plw+zT9xv7b/+gAFAJkAqAB/AAKAQQB+P/A/ij+uP00/Tz9xP2Y/Zz8RPxk/Yb+cv60/UD9KP1M/Qj+A/9u/3P/mAAMA3AF2AawB8AIsAmACkALwAvQC3ALUAtgC1AL0AoQCjAJgAjYB0AHqAYgBsgFkAUoBeAEwASoBIAEUAQ4BBgE0AN0AygD0AJQAogBsgAcAMX/Wv+m/vD9hP04/fj8sPxM/Kj78PqQ+iD6cPlI+BD38PUA9TD0cPPQ8kDyMPKw8nDzYPRQ9UD2YPcI+Rj7AP1I/nP/zACUAaYBigF8AeYA9P9P/wz/bP6Y/XT9zP2I/bz8WPzM/Ez9ZP1k/TD9vPxw/Pz87P10/rL+Yv8KASADGAWwBsgHkAhQCWAKIAtQC/AKwArgCiALAAuACvAJYAnQCCAIoAcQB6AGSAb4BcgFoAVQBeAEiARYBCAEmAMUA+QC3AJ4As4BLgGrACgAqf9Y/+b+OP6I/VT9RP3M/Az8WPu4+iD6oPkg+SD4wPbA9UD1wPQg9KDzQPMA8zDzIPQw9dD1YPaQ90D5GPsA/bb+7f+TABYBsgHyAXABkgDq/3P/3v5K/iL+KP7k/Uj9/Pwo/XT9pP3s/S7+Bv6U/aT9Wv4M/zT/UP8TAGgBDAPQBGAGOAfAB5AI0AnQChAL4AqgCpAKsArQCmAKgAmQCMgHOAfgBngG2AVIBRAFIAX4BJgEcARoBDAE2AOoA6ADbAP4AqgCeALyASYBfwAOAKD/7v40/sD9bP0I/Zj8LPyw+wj7SPrI+Uj5SPgQ9zD2sPUQ9WD0EPQA9ODz4POA9JD1cPZA92j4KPro+6z9jf8MAaYBwAHqARwC2AEsAWcAnv/Q/kz+UP5C/tT9HP3M/Pz8VP24/fz9AP6U/Uz9uP20/mX/nv/m/84APALcA3AFiAYYB1gHEAgwCRAKMArgCbAJ4AkQCgAKkAnwCCAIUAfQBpAGUAbABSgFCAUQBcAEUAQQBAgE4AOcA3wDYAMUA8gCmAIwAmoBpQAfAMz/b//y/lj+qP0s/fT8vPxE/KD78Pog+oD5+Pho+FD3EPZA9QD1APXw9KD0UPSQ9ED1MPYA99D3GPmo+mT8RP7n/9UADgE0AXQBYAHPABgAdv+s/vD9qP3Q/bj9IP2A/Ij8FP1w/Yj9lP2o/YD9kP0Y/gj/kP/H/28AngHgAggEUAVoBvgGSAcgCDAJwAnQCfAJAArgCeAJAArQCfAIEAiwB1gHyAZgBhAGkAUYBfgECAWYBPwDtAPIA6wDVAMIA8gCnAJkAggCRgGVAC4A8f96/wX/lv70/UT95PzI/Dz8OPtQ+vD5YPmI+KD38PZA9qD1UPVg9XD1UPVg9cD1cPYA94D3cPjA+TD7nPwi/nn/LAB/AOIASAEyAYAAx/81/7L+Sv4q/vz9eP0I/Qj9fP28/cD9zP3c/eT9Av5c/tT+Rf/J/4sAlgGkArgD4AQIBuAGUAe4B4AIQAmQCaAJsAnACaAJUAlgCUAJgAioB1gHUAfoBjgGuAVgBeAEeARABBAErAM4AwAD7ALMAoACFAKuAUwB+wCHAPn/e/8X/5z+Fv6Y/Rj9mPwY/LD7OPt4+sD5IPlo+JD3oPbg9WD14PSg9ID0gPSg9PD0cPUA9qD2cPeo+Gj6OPyw/cj+k/8sALMAIAEGAUQAff8v/yr/5v6M/lz+KP7k/fD9fv7o/sj+uP4E/0//VP9Y/63/CQBmAAYB3gGkAmgDgASoBYAGCAegB2AI8AhQCYAJoAlgCTAJIAkQCcAIMAiYBygH8AaoBkAGwAVQBegEoASABFgEAASQA0wDPAMQA6gCLALIAWQB6wB0APL/cP/o/mr+9P10/dj8RPzQ+3D74PpA+rD5SPmg+MD3EPeQ9iD2oPVw9YD1gPVw9ZD1IPbA9jD3oPeY+Aj6oPsI/SD+5P51//7/cwB7ABQAbf/m/rj+tP6W/kT+Av78/ST+Wv6k/sz+zP7i/jv/qv+8/8X/KgDgAFwBwAF8AoQDiARYBTgGMAfYB1AI4AiACdAJkAkwCQAJ8AjACHAI+AeIBygHAAfwBrAGOAa4BXAFKAX4BMAEgAQYBMADlANcAwADjAIgAq4BLAGoAE8A5f9h/9b+Xv7o/Wj9+Pyc/Dz8oPvw+kj6yPkY+Sj4MPeQ9gD2oPWA9YD1cPUw9WD18PWw9jD3oPeo+DD6wPsc/Tr+6v45/1v/y/8UALr/3v5Q/lb+kP6m/n7+Rv4S/jL+tv43/zP/AP8d/4T/vv+2/+j/YQC9AAwBqAGUAnADIATwBOAFkAYIB5AHMAiwCOAI0AigCHAIQAggCPgHoAcwB9gGoAZ4BkgG+AVoBdgEoASgBIAEGATAA4wDSAP0ArACgAIgAowBEAG9AFwA3P9e/97+Sv60/TT90Pxs/Pj7cPvY+kD6wPk4+Yj4sPcQ95D2MPbg9cD1wPXA9dD1YPYQ93D3APgY+Zj66Pv8/CT+/v5K/2n/xP8EAJL/vv5G/lr+hv6M/nT+Rv4m/mL+5v5M/2H/Tv97/9L/JQBrALsAGAFqAdABXAIQA7gDUAT4BJAFMAbABlAH2AdQCKAIsAiQCIAIgAhgCAAIwAd4BwAHkAZYBkAGuAUABZAEeARIBPgD2APEA5ADQAMkAxgDyAJAArIBRAGxAAwAf/8C/3b+2P1Q/ej8lPww/MD7QPuw+gj6aPnQ+DD4gPfg9oD2QPYA9sD1wPXw9TD2cPaw9jD3EPgo+XD6uPvY/LD9UP4H/5X/qP9V//j+uP6Y/oz+jv52/ij+/P1S/uL+Pv9V/3X/zf84AI4AtgDkABYBUgGgAQQCjAIQA5QDKATIBGAF4AVwBggHgAfYBxAIMAhACFAIUAggCMAHaAcoB/AGuAZ4BgAGWAXgBKgEYATcA2QDKAP0AqwCfAJcAv4BdAH5AJ8APADI/2D/AP+I/hT+sP1Y/dz8ZPwE/Jj7CPt4+hD6mPkQ+YD4KPjg95D3UPcg9+D2wPYA91D3kPfA91D4WPlg+mD7SPz8/HT99P2k/hf/AP+4/qj+uv6s/qz+sv6O/lj+hv4A/3P/p//H//z/RAClAPoAGAEeAVwB0AE4AngC2AJgA/QDcAT4BJgFMAbABkAHuAcACCAIQAhgCHAIQAj4B5AHQAcAB8AGeAb4BYAFEAXYBKgEaAQgBLgDeANcA0gDFAOwAjgCugFEAc4ASAC4/xD/fv4M/rj9ZP30/Hj8EPyo+zD7mPoI+oj5+PiA+Dj4APiw92D3UPdQ9zD3EPdA94D3wPdY+Fj5aPog+8D7mPxo/fj9Vv6I/pj+fP6U/uD+Gv8Y/+z+3P4K/1n/m/+3/9f/FQBaAJcA1gA6AXwBqgHaAUwCyAIcA3AD6ANoBLAE+ARoBfgFcAbIBhgHYAeAB5gH0AfoB7gHYAcoBwgH2AaoBmgGAAaIBSgF+ASoBDAEsANEA/ACnAJIAvgBlgEcAZcALADO/2v/AP+K/h7+sP1k/Rz9vPxM/OD7WPuw+gj6kPkw+cj4YPgg+PD3wPew97D3oPdg9zD3UPew92D4IPnQ+Xj6IPvw+7T8TP3I/fz97P3k/Sz+kv6Y/lj+QP5u/qr+5v5K/6T/2/8PAIcAHgFsAW4BdAG8ARACRAJkAqwCHAOIA/ADYATABCAFgAUABngGwAb4BjgHeAegB7AHuAeoB3gHQAcQB9gGkAYoBsAFUAXgBHAEEATIA4wDOAPYAogCOALqAYABAgF8AAkAmf88/+7+ov4u/pj9KP3k/Jz8FPyQ+yj7uPpI+vD5wPlg+ej4mPiI+ID4UPgo+Bj4IPgY+ED4qPhA+eD5gPog+8j7dPzs/DD9ZP2I/ZT9hP2k/QT+Xv6E/pL+xP4T/4T///9mAIoAnwDyAIgBBAIwAjgCXAKwAiQDoAMIBEAEYASgBCgFoAXYBRAGaAbABggHOAdoB2gHUAcwByAHAAfQBrAGoAZ4BiAGwAVoBRAFmAQYBJQDGAOgAjQC2gF4AQgBkQAuAM7/d/8Y/67+MP6o/UD95Px4/Pj7kPs4+9D6WPoA+rj5WPn4+MD4sPiQ+HD4cPh4+HD4aPh4+KD46Pho+dj5SPrA+kD7uPsU/GT8lPyg/JD8tPwM/Wj9qP3g/TT+kP4N/5r/FgBYAIMAxgAmAXIBrAHqASwCbAK4AigDsANABKgE8AQwBXgFuAUABjgGYAZgBlgGiAbABsAGkAZQBigGCAYYBjAGKAbwBagFgAVQBQgFoAQgBKADQAP8ArwCZAL0AZABMgHNAFIA2v9n//T+jP4q/sD9UP3o/JD8PPzg+4D7EPuo+lj6IPrw+aj5WPkg+Qj5+Pjg+MD4uPjA+OD4KPl4+dj5QPqo+hj7ePvQ+xD8PPxo/Kz8+Pw0/WD9kP3Q/Sr+mP78/lD/ov8JAIMA/QBcAaAB4AEoAnQCuAL8AjwDgAPQAzAEkATwBEAFqAUQBkgGUAZYBngGgAaABngGcAZYBkgGWAZoBkgGAAa4BXgFQAUABbAEUATkA4wDSAP4AqQCRALcAXQBDgGsAD0Ay/9d//L+gP4W/rj9YP0I/aj8SPzY+1D72PqA+jD62PmQ+XD5aPlw+Xj5iPmY+aD5qPnA+eD5APog+mD6uPoo+4D70Pss/JD84PwY/Uz9jP3I/QD+Rv6c/tz+GP9x/+f/UACVAOAAQAGkAfgBSAKUAtQCEANUA6AD7AMYBEAEcATABAAFSAWIBbAFyAXYBQAGEAYABuAFyAWwBagFkAVwBTAF6ASwBHgEMATkA5ADPAPwAqQCZAIcAtIBhgE8AfYAtQBuAB4AzP9y/xL/qv5K/vj9mP04/eD8mPxI/AT8yPug+3D7KPv4+vj6APsI+wD78PrQ+rD6sPq4+rj6wPrY+vD6KPuA+9j7DPwo/FT8oPzw/DD9ZP2g/dz9Hv5o/rD+7v4w/3j/w/8OAFUAmQDkAC4BaAGWAcoBDAJQAoQCqALQAgADLANUA3wDoAO8A9gD8AMIBBgEGAQYBCAEKAQgBAgE9APkA8wDpAN4A0gDFAPkAsgCpAJwAjQC/gHOAZwBZgEuAesAoABgACoA9P+1/3P/NP8B/9T+pv5o/iL+6P3E/aj9iP1o/Uz9MP0U/QD96PzE/KD8hPx4/Hz8hPyM/JD8mPyo/LT8uPzA/ND85Pz0/BD9NP1o/Zz90P0I/kD+eP6w/ur+If9Y/4D/rv/k/yUAYACTAMwADAFEAXYBoAHKAeoBCAIgAkACaAKMAqQCvALYAvgCFAMsAzQDNAMoAyADHAMQA/wC8ALkAtwCzAK8AqwCkAJsAkgCHALwAcQBoAGEAWIBPAEYAfsA2QCyAIUATwAWAOX/wP+c/27/Pf8Q/+r+wv6g/oL+av5Q/jT+Hv4K/vT93P3E/az9mP2I/YD9gP2I/ZT9nP2k/az9tP3E/dj95P3s/fT9AP4W/jL+TP5e/nr+nv7I/vD+Gf9J/3b/mP+w/+H/CgAwAFIAeQClAMEA4QAOAS4BNAE6AVQBbAGEAZ4BtgHGAdAB3AHwAQACCAIIAggCDAIUAhgCEAIAAvQB8gHsAdwBzAHEAbYBogGIAWwBUAEwARIB8ADSALEAigBjAEMALAATAPT/1P+4/53/f/9g/0L/Jv8I/+r+0v66/qD+iv54/mT+UP5C/jj+MP4o/ij+NP4+/jr+Mv4y/jz+Sv5O/kz+UP5c/mz+gv6W/qT+tP7M/uj+Bv8b/y3/RP9b/3L/i/+p/8j/6f8LACsARQBiAIUAqwDIAOAA+gAUAS4BRAFYAWoBdAF+AYwBngGsAbABrgGoAaYBoAGSAYIBcgFmAVgBSgE8AS4BHAEIAfUA3QDEAKsAlQCDAHAAXABEACkADgD0/9n/vf+f/4T/cP9f/07/QP80/yj/HP8L//r+6P7U/sT+uv64/rD+pv6g/qT+qv6q/qj+rv64/sD+xv7S/uD+7P78/hT/MP9B/0v/W/9x/4T/h/+N/57/s//A/87/6f/3/wIAEgAvAEgAWwBuAIIAkwCkAMAA2QDoAPIA/wAQASIBLAEuASgBIgEmASwBMgE2ATQBNAE0ATQBNAEsARwBCgH7APMA6wDgANMAwwCyAKUAmQCMAH0AZwBSAEIAOQAsABsACAD2/+X/zv+3/67/qf+f/5P/hf92/2r/X/9Y/1D/Rf85/zL/MP8y/zL/K/8h/xz/If8o/yv/Kv8q/y//NP87/0D/R/9S/1v/ZP9q/27/c/96/4P/iP+M/5b/pv+3/8D/xv/O/9r/5v/w//f/AAANABsAKAA3AEYAUQBbAGcAcwB7AHsAegB8AH8AfgB7AHgAdQBxAG8AcABvAGsAZwBmAGgAaQBnAGEAVwBNAEQAPwA5ADEAKgAoACgAJQAbAA0AAwD9//j/8//v/+z/6P/m/+X/5P/f/9f/zv/L/8r/yP/D/7z/t/+0/7L/sP+w/6//rv+s/63/rv+z/7f/uv+8/8L/yf/O/9D/0v/X/9j/2f/b/97/4//m/+3/9/8DAA0AFQAeACYALQAyADgAPQA/AD0APgBFAFEAXABkAGkAawBtAHAAdABxAGoAYwBhAGEAYABcAFgAVABRAEwARgA8ADIAKgAmACMAHgAaABgAFwAVAA8ABwD+//f/8//y/+7/5//g/93/2//c/9z/3v/e/93/3P/f/+H/4f/d/9r/2v/b/9v/2v/a/9z/3f/e/93/3f/j/+r/7f/s/+r/7P/u/+z/6//l/+H/4f/q//D/9P/6/wQABgABAAkACgAMAAYABAANAAkABgANABAABgD5//j/+//9//3/+v/6//j/9v/7/wQACgAGAAQACwAUABsAGwAZABoAHwAjACMAIwAjACIAHwAdABsAGgAXABQAEQAQAA0ACAABAP3//v8AAAAA///+//7//f/5//b/9P/x/+3/6v/o/+n/6v/r/+r/6f/p/+r/5//i/97/3//h/9v/1P/Q/9X/3P/c/9f/1P/V/9b/1//W/9P/0f/Q/9P/1f/T/9D/zf/N/87/z//R/9b/2//g/+P/5f/p/+7/9f/5//7/AwAJABAAFQAaABwAHQAeACEAJgArAC0ALQAwADUAOQA6ADgAOAA5ADoAOgA5ADgANwA3ADcANQAzADEAMAAzADUANgAzAC0AJgAfABYACwD+//P/6f/i/93/2f/V/9H/zf/H/8D/uf+x/6z/qP+m/6L/nP+Y/5j/mv+a/5f/lf+X/5n/mf+b/57/of+n/67/uv/C/8b/yP/P/9f/1v/X/9z/5P/m/+j/8f/0//X/9f/+/wYADAASABgAHgAlADEAPgBHAEwAUgBZAGQAawBuAG4AbABuAHIAeAB/AIAAgwCFAIgAjwCRAI4AigCGAIgAigCLAIsAhgCBAH8AfwB+AHsAcgBqAGUAYQBdAFcATABAADUAKAAcABUADQADAPr/7v/i/9f/zf/D/7n/rv+j/5n/k/+P/4n/gv95/3P/cP9v/23/af9m/2T/Y/9k/2T/Zv9q/23/b/9w/3H/dP94/3z/f/+D/4j/kP+Y/5//o/+o/67/tv++/8X/zP/U/97/6f/2/wQAEQAdACsAOQBHAFEAWQBhAGkAcQB3AHwAgACCAIQAhwCJAIoAiwCLAI0AkACSAJIAjwCKAIUAgQB+AHoAdQBvAGoAZABbAFAARQA6ADAAJgAeABYADQAEAPv/8v/o/93/0v/J/8D/uP+w/6f/n/+W/4//iP+B/3v/dP9t/2j/ZP9j/2P/ZP9m/2j/af9r/2z/bv9v/3D/cP9x/3T/eP98/4L/if+R/5v/pf+u/7f/wP/J/9T/3v/o/+//9/8EABUAJwA2AEMATwBcAGwAewCIAJAAlwChAK0AtwC/AMUAyQDNANIA1ADUANIA0ADQANAAzwDNAMoAxgDBALoAsgCpAJ8AlwCQAIkAfgBzAGYAWgBOAEMANwAqABsADwAEAPr/7//h/9P/x/+8/7D/o/+Y/47/hv9+/3b/bv9r/2n/Zf9g/1r/WP9V/1L/UP9L/0j/SP9O/1P/V/9c/2X/av9s/3j/ff+I/4z/kv+i/6f/sP++/8n/zP/O/9f/4f/r//P/+P/+/wQACAAQABsAJQAoACwANwBEAE4AVQBbAGMAbQB2AH0AhACKAI8AkgCWAJoAnACdAJwAmwCaAJcAkwCNAIgAhQCCAH0AeABxAGsAYwBaAFEASABAADYALAAjABwAFAANAAYA/f/2/+//5v/b/9L/y//E/7n/rf+j/53/mv+U/4z/hP9//3v/eP91/3D/a/9o/2f/Zv9k/2D/Xv9e/17/X/9h/2X/av9u/3L/df96/4D/iP+P/5b/n/+p/7P/vv/J/9P/3P/l/+//+/8HABIAGwAmADEAPABFAE0AVQBdAGQAbABzAHoAgQCIAI4AkwCXAJwAoAClAKwAsgC1ALcAtwC2ALMArQCmAJwAkwCJAH8AdgBtAGMAWQBOAEEANAAnABkADAD///D/4f/S/8T/uf+t/6D/lP+J/3//dP9q/2D/WP9R/0z/S/9J/0j/Rf9F/0j/R/9I/0v/T/9R/1T/XP9f/2T/af9y/3v/g/+O/5f/oP+q/7f/xv/U/+H/7v/9/w4AHQArADcAQABLAFYAYwBwAHkAhACPAJkApQCuALQAugC+AMQAyQDOANIA0wDUANcA2QDcAN0A2wDZANcA1gDUANEAywDCALoArwCkAJwAkACDAHcAaABYAEoAOgAqABoACAD3/+b/1v/H/7j/qP+Y/4n/ff9x/2X/Wf9N/0H/OP8v/yb/H/8b/xf/FP8S/w7/Dv8O/xD/Ev8U/xj/Hf8k/yv/Mv85/0H/Sv9U/13/Zv9w/3r/hv+T/6L/sf/A/9H/4v/0/wUAFQAmADYARgBUAGIAbwB7AIYAkACaAKMAqwCzALsAwwDKANEA1ADWANcA2ADYANgA1wDVANQA0QDMAMcAwAC5ALEAqACgAJYAjACBAHUAaQBdAE8AQQAzACYAGAAJAPv/7f/f/9H/w/+3/6r/nf+Q/4T/ef9v/2f/Xv9X/1D/Sf9D/z7/Of81/zD/Lf8p/yb/JP8j/yL/I/8m/yv/Mf84/z//R/9P/1j/YP9p/3D/ef+D/5D/n/+u/73/zP/c/+//AgAVACUANQBGAFgAaQB6AIoAmQCnALYAwwDOANcA3wDnAO4A9AD6AP4AAgEEAQQBBAECAQAB/gD8APkA9ADuAOcA4ADYANEAxwC9ALEApQCZAI0AgABxAGEAUgBDADMAIgASAAMA8//j/9T/w/+2/6n/nP+P/4H/df9p/1v/T/9A/zP/J/8f/xb/Df8G/wP//v72/vr+9v74/vb+9v7+/gD/A/8N/xT/Gf8f/yr/Nf9A/0z/V/9j/2//ev+J/5n/qv+3/8X/1//p//v/DAAdADAARABXAGkAewCOAJ8AsADAANAA3wDtAPoABgEQARoBIAEkASgBLAEuAS4BLAEqASYBIAEYAQ4BBAH6AOwA3gDOAMAAsAChAJAAfwBvAF8ATAA3ACMADwD7/+X/zv+3/6L/j/97/2X/Uf8+/yz/G/8L//r+7P7e/tT+yP6+/rT+rv6o/qT+oP6g/qL+pv6q/rD+tv6+/sj+1P7g/u7+AP8Q/yT/OP9O/2T/ev+R/6n/w//d//f/EAArAEUAXwB4AI8ApwC9ANEA5QD4AAoBGgEqATgBRgFQAVoBYgFqAXIBeAF6AXwBfgF6AXQBbAFiAVQBRgE0ASIBEAH8AOcA0QC5AKEAiABuAFMAOAAdAAAA4//G/6r/j/91/1r/Qv8r/xX//v7q/tb+xv62/qb+mv6Q/ob+fv54/nj+cv5y/nT+ev5+/oL+jv6U/qD+qv66/sr+2v7u/gH/Ff8q/0L/W/91/47/qf/F/+P/AQAeADsAVgB0AJAArQDKAOQA/wAaATQBTgFmAXoBjgGgAbIBwAHMAdYB3AHgAeQB5gHmAeYB4AHcAdIBygG+AbABoAGMAXYBXAFCASgBDAHrAMsAqQCFAGIAPgAZAPT/zv+p/4T/YP89/xr/+P7Y/rj+nP6C/mz+Uv4+/ir+GP4K/vz98P3s/eT95P3k/eD95P3s/fT9AP4O/h7+MP5G/lz+cv6M/qj+xv7k/gP/I/9E/2b/iP+s/9H/9v8dAEUAbQCVALsA4AAGASoBTAFsAYwBqgHEAdwB9AEIAhgCKAI0AkACSAJQAlACUAJMAkQCOAIsAhwCDAL2AeIBygGwAZIBdAFUATIBDgHqAMMAmwByAEcAHADy/8X/mf9t/0L/GP/u/sT+nv54/lT+Mv4S/vT92P3A/aj9lP2E/Xj9cP1o/WT9ZP1o/XD9eP2E/ZD9pP24/cz95P0A/hz+Pv5k/or+tP7g/g3/PP9t/57/zv8AADAAYACSAMQA9QAmAVQBhAGyAeABDAI0AlQCeAKYArgC0ALkAvgCCAMQAxgDGAMYAxQDDAMAA/AC2ALAAqgCiAJoAkQCHALyAcQBlgFoATYBAgHPAJoAYwAuAPj/wv+N/1j/JP/w/sD+jv5g/jL+Bv7g/bj9lP10/Vj9PP0k/RD9AP30/Oz86Pzo/Oz88Pz8/Aj9GP0o/Tz9VP10/ZT9tP3Y/QL+LP5S/ob+sP7k/hP/Q/97/6r/2/8TAEcAdQClANoACgE6AWgBkgG+AeYBDAIsAlACcAKIAqACuALMAtgC5ALsAvAC9AL0AuwC6ALcAswCvAKkAowCcAJQAjACDALmAbwBjgFeASwB+gDHAJMAWwAkAO7/t/9//0f/Ev/e/qj+dv5E/hj+8P3M/aj9iP1s/VD9QP0s/Rz9FP0M/Qj9BP0E/Qj9EP0c/Sj9PP1Q/Wj9gP2c/bz93P0A/ib+TP50/pz+yv74/iT/U/+E/7b/5/8aAEwAewCsAN0ADAE8AWgBlAHAAegBEAI0AlgCeAKYArACyALcAuwC+AIEAwwDEAMQAwgDBAP4AugC0AK4AqACgAJcAjgCEALiAbQBggFQARwB6ACxAHkAQAAHAMz/kv9Y/xz/5P6u/nj+Rv4U/uj9wP2Y/XT9VP08/ST9DP34/Oj83PzY/NT82Pzc/OT89PwI/SD9OP1Y/Xj9nP3A/ej9Ev4+/m7+nv7O/gT/NP9p/57/1v8LADwAdwCpAN0ADgFEAXQBpAHUAQQCMAJUAoACqALIAuwCCAMkAzwDUANgA2wDcAN4A3gDdANsA2ADTAM8AyQDCAPsAsQCoAJ0AkgCGALkAbABdgE6AQABwwCFAEgABgDF/4b/SP8J/8z+jP5Q/hb+3P2g/XD9RP0U/ez8yPyo/Iz8dPxk/FT8TPxI/Ej8TPxY/GT8dPyI/KD8wPzk/Aj9MP1Y/YT9tP3k/Rb+Sv6C/rr+8v4q/2T/m//V/w4ARgB9ALQA7AAkAVYBigG6AewBHAJIAnACmAK8AuACAAMcAzQDSANYA2gDeAOAA4QDhAN8A3QDZANMAzQDGAP4AtgCsAKIAlwCLAL8AcwBmgFmATIB+gDCAIkAUAAYAOH/qv90/0H/D//e/qz+fv5Q/ib+/P3U/az9iP1o/Uj9LP0Q/fj85PzQ/MT8uPy0/LD8sPyw/Lj8xPzQ/OD89PwM/ST9QP1g/Yj9rP3U/QD+Lv5c/pD+wP72/iv/Y/+Z/9H/CQBBAHoAswDrACQBWgGQAcIB8gEgAkwCdAKYArgC1ALwAgwDIAM0A0ADTANYA2ADZANgA1gDUANEAzQDIAMIA/AC1AK0ApQCbAJEAhwC8gHEAZYBZAE0AQYB0wChAG4APAAJANf/p/93/0b/F//q/sD+lP5u/kj+JP4I/uj9zP20/Zz9iP14/Wj9YP1Y/VD9UP1Q/VT9WP1g/Wj9dP2E/ZD9oP20/cT92P3w/Qb+HP4w/kr+YP56/pb+rv7K/ub+AP8T/zT/R/9j/3f/jP+q/7z/zf/o//v/BwATACgAOABGAFgAZQB1AIQAkQCjALYAzADbAOsAAgEWASgBPAFOAWIBdgGOAaABtAHKAd4B7AH6AQQCEAIYAhwCIAIgAhwCEAIIAvwB8gHmAdoBygG4AaoBmAGEAW4BXAFIATQBIAEKAfcA5ADRAL4AqgCXAIIAawBSADcAGgD+/9z/uP+X/3b/Vv8y/w3/7P7K/qj+iP5o/kr+MP4Y/gL+8P3c/dD9yP3A/bz9wP3E/cz93P3k/fT9BP4Y/i7+RP5a/nD+iP6i/rj+zv7k/vj+Cf8Z/yf/Nf8+/0b/Tf9R/1X/Wf9b/13/Xv9f/2D/Y/9l/2n/bv91/37/hf+U/6X/uv/T//H/EgA2AFsAhACuANkABgE0AWIBlAHGAfoBMAJoApwC0AIAAzADWAOEA6QDxAPgA/QDAAQIBBAEGAQYBAgEAATwA9QDtAOQA2ADMAP8AsgCkAJMAggCxAGCAToB8ACqAGQAHwDY/4//Vf8M/87+kv5a/iL+7P28/Yz9WP0s/Qz95PzE/KD8gPxk/ET8KPwQ/Pj74PvQ+8D7sPug+5j7kPuQ+5D7mPug+6j7uPvI++D7+PsU/Dj8YPyM/MD8+Pww/XD9sP30/T7+lv7u/kf/pP/6/1cArwAUAYIB9AFgAtACRAOoAxAEcATQBDAFgAXIBQgGQAZoBpgGsAa4BrgGuAawBpgGaAY4BvgFqAVQBfgEoAQ4BNADYAP0AoACEAKeATABwwBaAPj/m/9B/+j+kv5I/gj+zP2Y/Wz9QP0c/fj80Pyw/JD8dPxg/FD8OPwo/BD8BPz4+/D76Pvo++j78Pv4+wD8DPwY/Cz8SPxs/JT8wPzw/Bj9SP10/aD9yP38/Sz+Wv6E/qz+zv7o/vz+EP8h/y3/Nf82/zP/KP8a/wn/9v7g/s7+uv6s/p7+lP6K/oj+hv6M/qD+tv7S/vb+I/9P/4f/xv8QAGQAvAAaAYAB6AFQArwCJAOQA/QDWAS4BBgFaAW4BQAGSAaABrAG0AbwBgAHCAf4BugG0AawBoAGWAYoBvgFuAWABTgF8ASoBGAEEAS8A2QDEAO8AmgCEAK+AXIBIgHWAIYANgDk/4//O//q/pj+Rv74/bD9ZP0Y/dT8kPxQ/BD82Pug+2D7KPvw+sj6mPp4+lj6OPoo+hD6APr4+fD56Pno+eD54Png+eD54Pno+fD5APoQ+jD6SPpw+oj6sPrY+gj7OPt4+7D7+Ps4/IT82Pww/Zj9Av52/ur+Xv/H/z4ApwAYAYoBCAKMAgQDgAP4A2AEuAQYBYgF8AVYBrgGEAdYB5AHyAf4BzAIUAiACJAIoAiQCIAIYAgwCAAIwAeIB0AH6AaQBiAGqAUoBaAEKASsAywDrAIgApQBAgF8AAMAlv8y/9T+cv4U/rz9ZP0Y/dD8lPxc/Cz8APzQ+7D7kPto+0D7IPsA++j62Pq4+qD6iPp4+mj6WPpg+mj6cPp4+oj6oPqw+tD68PoY+zj7aPug+9D7BPw0/Gj8mPzI/Pz8NP1k/Yj9rP3I/dz97P0I/iT+Nv5E/k7+Vv5c/mr+dP6G/pT+nv60/tT+9P4T/0D/c/+r/+r/NACDANgAMgGMAeYBSAKwAhgDgAPkA0AEoAQQBWgFwAUQBmgGsAbgBhAHQAdgB3gHiAeQB4AHgAdoB1AHMAcAB9AGmAZQBgAGsAVgBQAFoARABNwDdAMIA6QCPALQAWYB/wCXACgAv/9i//r+oP5O/gj+vP1o/ST96Py0/IT8WPw4/Bj8+Pvg+9D7yPuw+7D7sPuw+7j7wPvY++D76PsE/Cj8QPxY/HD8gPyI/Jz8rPy8/Mz82Pzw/AD9BP0A/QD9+Pzw/OT82PzA/Kj8kPxw/Fz8SPw4/Cz8KPwk/Cj8MPw8/Ej8VPxw/Kj86Pws/XT9yP0i/oj+8v59/xkAsgA4AcABQAK4AkADxANABLgEMAWoBRAGaAbABggHOAdgB5AHwAfgB+AH2AfIB6gHiAdwB1gHOAcAB8AGcAYgBsgFeAUgBdAEcAQYBMADaAMIA6QCPALYAX4BKgHiAJMAMgDE/13//P6w/mz+LP7w/bT9cP0k/dj8oPx4/FT8KPz4+9D7uPuo+5D7ePtY+0j7SPto+3D7cPto+2D7YPto+3j7mPvI++D76Pvo+/D7BPwc/ED8XPxg/Fj8TPxM/Ez8VPxQ/Dz8GPwA/AD8BPwI/Az8DPz4+/D7+Pss/GD8gPyg/NT8IP2A/fz9fP7s/mH/5f98ABwByAGAAjADqAMQBIgEOAXoBagGKAdwB7gHEAiACNAIAAkQCSAJIAkACfAI8AjgCLAIcAgwCOAHoAdgBxAHkAbwBXAFIAXABEAEyANwAxQDjAIEApwBSAHuAJQAUAD7/4b/Hv/e/rT+gv5e/kb+Fv7U/Zz9jP18/WD9PP0k/fj8zPyk/Jz8fPw8/Pj72PvI+6j7ePtQ+yj78Pqg+nj6ePpw+kj6KPr4+dD5uPnI+ej54Pm4+Zj5mPmQ+Zj5qPm4+aD5ePlw+Yj5kPl4+YD5oPnA+cD5yPng+Sj6SPpw+pj60PpI+/j7zPx8/bz93P1C/hz/WgAgAgAEMAVABagEqAT4BYAIAAsADFALUApgCnALkAxADbANwA1ADYAMUAxwDHAM8AsQCxAKcAlgCZAJAAlwB9gF+ATQBLgEkARABGwDEALHACMACwAaADEAEgB4/3j+qP2M/cz96P2w/WT9GP3Q/Kz8pPyA/Dz8HPws/Cz8APzw+/D7yPtg+xD7APvo+sj6wPqw+kj62PnA+dj50Pmo+aj5wPmo+YD5kPmw+bD5qPng+SD6SPpg+pD60PrY+vD6MPt4+6D7qPvo+wz86Puo+7j7GPxk/HT8YPxs/GT8XPx8/OT8MP0g/Tz9tP1g/tj+TP/T/w4ATQCCAcQDYAWABUAFsAVYBvAGQAhgCvALUAvwCaAJkAqwC8AMsA1gDdALcArACtAL8AvgCsAJIAmwCHAIQAiYBzgG+AR4BFgEEASYA+AC0gGYANj/3f/7/8T/SP+m/tz9VP14/eD90P1I/eT80PzM/NT8CP0g/dz8hPyo/AD9NP0s/VT9UP0M/dT88PxM/Uj93Pxs/Ez8NPw8/ED8HPyo+yj7+PoA+zj7UPtY+/D6YPoA+ij6iPqw+uj6APvQ+kj6CPpQ+sj6+Prw+gj7CPvI+kD6+Pko+rD6KPtA+xj70Pp4+gj6QPpI+2D8mPxk/Iz8zPzU/Cz9yv6WABwBOAHMAvgEmAXoBMAECAYQCAAK4AuQDEALYAmACXALUA1ADoAO8A1ADJAKYAqAC1AM4AvgCtAJoAjgB7gHWAc4BgAFsASwBDAEPAM4AhwB+P+O/9v/IgCo/87+Bv48/az85Pyk/bj9AP1M/Aj8APzw+xj8gPyU/Cj88PsU/ET8aPyo/Lz8ePxA/Hz87PzU/Ej84PvY++D7JPyM/ID8oPuQ+mj6IPuo+5D7UPsQ+4j6+PkI+qj6APvw+vD6APuo+iD6OPoA+3D7KPvY+vD6+PrI+sD64PrI+qD68Ppg+2j7CPvo+vj68PoY+8D7oPzI/Nj8QP3A/ez9nv41APIBJAMYBBgFWAXwBIgFIAigCnALYAtwC3ALEAuQCzANoA6QDvANwA0QDeALQAsADHAMgAswCqAJEAmQBzgG4AWoBdgEKATwAzQDlgEuAMD/nf9E/zT/b//2/qT9nPyA/Mj8AP1g/cj9fP2I/Oj7EPyE/MT8GP2A/YD9CP3E/Aj9OP0c/Tz92P0e/sT9OP0I/fj8rPyM/PT8aP0s/YT86PuQ+2D7ePvY+yD80Pso+7j6mPqg+rj6CPsg+wj7uPq4+vj6APvQ+pj6iPqQ+sj6OPtg+9j6IPrI+dD50PlQ+lD72Pv4+mD5OPkI+uj6yPvM/Pz8NPzo+0T9Xv9nAAQBeALwAzgEaATABYAHgAhgCdAKwAuQC0ALIAxwDdAN8A2ADtAOEA4QDbAM4AzADHAMEAxAC+AJsAggCKAHwAbwBYAF+AQgBCwDWAI4AQUAkv8DADYAe/9u/qj9BP08/Bj87Pyo/WT9jPwI/Kj7WPuQ+zj80PzM/Ij8mPyE/Cj8BPyE/DD9gP2E/VD97Pxo/CD8bPy0/Mj8xPzE/Ij8yPtY+1j7sPvY+/D7APyg+/j6aPqw+jj7WPsw+yj7GPuo+qj6KPtA+3j6wPlI+hj7+Ppg+oj6mPpI+TD4KPkA+4j7uPrw+aD5wPho+Dj65PwY/Uj7YPqQ+6T9FP9LAH4BHAIUAtwC8ASgBmAHAAgQCRAKkArwCrALoAxADWANwA0QDjAO8A1gDdAMoAzQDKAMIAxgC0AK4AjwB7AHkAfgBsAF8ARgBCgDegG8ANQA0gAgAGP/tv70/Sj9mPyY/IT8NPwU/IT8lPzg+9D6cPoA+xD8uPzA/Jz8MPzw++j7iPw8/eT9Fv7I/Yz9OP0c/Tj9dP18/Xz9oP2Q/ST9nPw4/Aj86Psg/MD8DP0s/MD6MPqI+sj6IPuo+9j7uPpg+Yj5yPrw+pD5EPko+uj6YPrI+Zj5qPiA98D38PmY+8j6CPkY+ND3wPcw+Zj7sPyQ+8j58PkE/GD+/P82AboBnAEQAtADGAbgB8AIQAnwCaAKUAsgDDANMA7QDsAOcA6wDhAP8A5ADtANwA2ADQANoAxADOAK4AjYBxAIUAiYB1AGSAUIBGwCXAFYAXAB3wAOAEv/mP6s/eT8pPxo/PD72PuM/Mj8+Pug+sj5+PnI+sj7kPyU/Lj76Pr4+pD7IPyo/Ej9nP1E/aT8ZPyU/MD85Pwg/Sz98PzU/Nj8oPzw+2j7ePvw+2z8qPw8/DD7MPo4+vD6YPtY+0D7aPsw++D6kPrg+ej4SPkg+6j88PvI+WD48PcA+Nj4CPtA/AD7sPig9+D3SPhQ+WD73PzI+8j56Pnw++T9V/8cAXwCkAJEApADIAbAB3AIkAnwCqAL0AuwDOANcA5QDqAOkA8gEOAPgA/ADqANwAzgDJANsA2gDJAKgAgoB6gG2AYAB4AGQAWQA7oBXQDb/xAAdwBEAHT/aP5M/VD80PsA/HD8vPzU/Mz8dPxw+5D6qPq4+7D8GP0o/fD8aPzQ+/j7zPyA/cz9AP4s/vT9UP34/Dz9uP3c/dD9sP18/UT9MP0E/Vz8uPvI+6j8NP3o/DT8YPuQ+iD6yPq4+9j7mPuo+5j7cPrA+Ij46PlQ+7D7UPtg+qD4QPeA9zD5cPqA+uj5CPkQ+HD3CPiA+ZD6wPo4+uj5MPpg+/j8Zv5W/+X/rAAIAtgDkAWQBvAGcAewCHAKAAwgDcANsA1ADSANIA7QDwARoBBAD7ANsAyADDAN4A2gDSAMAAowCCAHsAboBiAHmAYYBRgDfgGGAB4AIQBKAO3/Dv8S/iT9KPw4+xD7wPu4/Oz8TPxg+2D6mPnQ+TD7wPxM/bT84PtQ+xj7WPuQ/OT9ZP7w/Vj9/Pyk/LT8gP1Y/kT+jP0k/TT97PyI/JD84PyQ/Aj8KPyQ/Fz8kPsg+0D7QPvg+iD74Pv4+wj7UPpA+kD6wPmA+YD6iPvQ+jj5YPiY+Nj4IPnI+Sj6QPnA99D3EPnQ+Vj5CPlg+YD5sPnA+nj8qP3g/Uj+Zf+yAPAB0AO4BZAGiAbwBoAIYAoADPAMMA3QDJAMUA2wDqAPsA9QD6AOYA1gDHAMMA1ADWAMIAugCegHiAZoBsgGaAY4BTAEUAOqAeX/Qv/r/2kA+v9B/4j+PP3A+3j7aPws/Tz9JP0g/VD86Pqg+vj7ZP3Y/eT95P1c/YT8hPzA/fj+Mf8H/yr//P5A/sj9QP7k/gv/zP52/hz+lP0c/QD99Py8/Gz8NPw8/Bj8qPvo+mD6cPrA+sj6mPq4+pj6APpY+UD5qPkA+gD6EPq4+bj40PdI+Lj5WPqY+TD4IPcg9xj4sPnI+nD6yPhQ92D3wPjg+rz8mP10/Tj9lP20/skAPANQBUgGQAZYBngHQAngCkAMAA0QDQANgA1gDkAPoA9gD/AOYA7QDWANYA2QDWANMAxACrAIMAgQCKgH4AYgBjAFAASwAqQB7QBaAA8AOwA/AHT/CP7k/GD8XPyc/AD9dP2E/dz8sPvw+gD72Pso/RL+BP4o/WT8LPyQ/GT9Ov4k/2b/pv6s/WD9pP3k/X7+JP8g/wz+vPyA/Pj8EP2k/Jj8oPwU/Fj7MPtI++D6cPqY+hj7KPvI+mD6EPqg+Wj5+Pm4+uD6uPoo+iD5MPho+ND5APsI+zj6KPnw90D3CPgg+qj7WPvw+bD4EPhY+OD5MPz0/YT+QP48/uj+DgCyAZADcAXIBnAHqAcwCGAJkApQCzAMQA0wDpAOcA5gDkAOAA7QDRAOMA4ADkANgAywC8AKoAmwCDAI4AdYB2gGgAWABFADCAIsAe8ABAHqAIsAo/8s/vz8tPwY/Xz9uP3Q/XD9jPzI+7j7MPy4/Ij9VP5e/oD9xPzU/ED9wP1Q/gb/Yf8E/4T+NP70/dT9NP7g/hn/1v5E/mz9jPwY/GT8DP1M/fz8dPyQ+2D6yPlQ+lj7APzQ++j6wPnY+Mj4mPm4+iD7mPqI+Wj4APhA+OD4gPnA+WD5UPhg90D34Pdw+Jj4uPjY+Jj4KPhI+Dj5CPoo+pD66PvY/Ur/BwCtAFAB1AHcAigF8AfACSAKIApQCoAKEAuQDOAOoBCgEIAPQA5wDSANoA2wDjAPkA4QDWAL4AnACGAIcAhgCLgHmAYIBXQDdAIYApYBzABHAEkAEAAW//z9NP20/ET8ZPz4/Dz9zPw8/Mj7IPuo+hD7bPxQ/Zj9aP3U/Mj7IPvg+4D9xv4E/9r+eP5k/WD8mPz8/TP/Zf/o/gb+DP0U/Oj7wPzQ/Q7+XP1s/Jj7MPvw+kD7EPzc/Kj8kPt4+gD6WPrg+nj7yPto+3j6UPkI+Yj5MPpw+gj6iPnY+CD40PdY+GD5sPng+PD38Pdg+Jj4+PgA+sj6wPq4+uD7sP0i/yYAUgGYAjAD3AOIBbgHIAkAChAL4AvwC+ALwAxwDuAPgBDAEAAQcA5ADWANQA7gDtAOQA7gDKAKYAiAB+AHgAhQCDgHgAV0A6QBVQAHAHsA3wCcAJD/JP5w/Pj6gPpY+6T83PwA/Cj7yPoo+mj5iPnY+lj87Py0/Fz80PsA+wD7NPzM/br+BP/o/n7+sP0M/ZD98P4dAHQA9P/Q/rz9UP2Y/Sr+zP4+/xP/FP7Y/ET8ePzU/FD9EP4W/vD8cPsg+4D7uPvI+0D8cPxo+xD6mPnA+aD5wPmI+rj6YPmg9zD3oPcQ+JD4UPlg+Qj40Pbg9sD3ePh4+TD7VPxA/PD7BP3M/jsAngFkAxgFwAVABmgHIAlwCiAL4AtwDLAMQA2gDgAQYBBwDzAOUA0ADTAN0A1ADrANUAxgCoAI+AZgBrAGUAcQB7AFfANGAcn/Uv+a/wsAPwCN/zr+lPwo+4j6uPqg+2j8ePzY+/j6WPoI+ij6CPtI/Az9NP0Q/bj8RPws/Az9kP6e/+3/1/+a//D+nP4//1wAIgFUATYBbgA2/2b+0P7K/zgAHwCo/4b+2Pz4+5D8fP30/dz9fP2A/OD6CPo4+gj7iPvI+7D7yPqA+WD4GPhw+ED5+PkQ+hj5sPfQ9rD2YPdw+Gj5gPnY+Dj4wPeA9wD4mPl4+4D8xPxE/TD+AP8mAOQBkAOIBFgF+AbgCCAKwApgCxAMMAxwDKANUA+AEMAQgBCgDyAOAA0QDRAO4A7QDtAN8AuACXgHwAboBkgHOAdoBqAERAJUAGr/L/8y/2P/WP9+/gD9oPvI+mD6WPq4+jD7WPv4+nj6CPrA+cj5WPog+7j7HPw0/CT88Pvg+yz88PzM/Wr+tv6Y/kL+Bv40/sz+h//i/6j/Jv+a/jD+KP6o/kz/ev/k/tz9/Pyc/OD8sP1s/oL+tP2c/Kj7EPsY+8j7pPzM/Nj7ePqI+Sj5KPmQ+Rj6GPpY+XD40Pdg9xD3UPc4+Pj42PgI+FD3EPdQ92D4wPno+nD7uPso/OD8/P23/9wBgANYBOgEyAXwBoAIUArQC6AM8AwwDbANYA5ADwAQYBAgEHAPoA4ADsANwA2wDfAMoAswCvAI4AcIB6AGYAaQBQAEYAIuAUIAXf+2/nj+Rv64/fD8RPyQ+5j6yPnI+Uj6gPpw+mj6iPpI+rD5gPkA+rj6WPsE/Jj8sPxU/ET8zPxs/eD9jP5q/93/xv+2/+b/GAD+/ygAmwDkAK8AhQBuAPr/Sv8G/1v/a/8A/5z+dv4W/oj9SP1g/Tj9yPy0/OD8lPzI+0D7KPvw+oj6gPrw+vD6QPqY+UD56Ph4+ID4IPmA+Tj52Pi4+Hj44Pew93D4kPmA+hD7aPt4+4D7MPy8/Y3/RAHoAggEIAQABNgEoAZwCNAJEAvwCwAMkAsADCANsA3ADRAOUA6wDaAMYAzwDNAMsAuQCvAJAAmoB/gGCAfIBtAFkARkA/gBkwAeAIgAyAAsAE//dv5s/WD84PsI/Ez8iPyo/Hz8wPsA+9j6GPuA+/j7hPyc/FT8ZPzo/Cz9HP10/TD+pv6Q/rL+R/+h/3L/YP+e/6P/Zf9v/8T/4P+j/0v/Av+M/hr+Cv5G/kz+BP6c/Rj9nPxY/Hz8iPw4/OD70Pug+xD7ePpg+pD6SPrY+cD5APrY+Tj5wPiQ+GD4CPgw+Lj4KPnw+KD4qPiQ+ED4EPjA+BD6UPsE/Ez8gPzo/ID9sv5dAEgC6AMABagFEAagBoAH4AhQCoALYAzgDCANUA2gDQAOQA6QDsAOYA6wDQANwAxwDOALUAvACtAJgAiQBwAHWAZoBZgE6APgAnwBXADt/67/Mf+Q/tj9+PwA/ED74PrI+uD66PrI+nj6KPr4+fj5MPqo+kj7oPu4++j7OPyQ/Mj8OP34/bj+Hv89/3z/4P83AGwAvwAcAVIBRAE4AVQBUAEWAdUAowBhAPr/u/+4/5X/MP+Q/iD+zP1s/Qj9zPy0/Gj84Ps4+9j6aPog+jj6ePp4+hD6kPkg+YD48Pcg+Pj4sPnQ+YD5CPmI+ED4cPj4+ID5EPqg+hD7WPvA+2j8DP2I/Ur+Zf+OAIQBtAIQBAgFaAXABaAGsAeQCHAJcAowC4ALkAuQC6ALsAvQC/ALwAtgCxALwApACnAJoAgACGgHuAYQBngFuATUA+gCHAJgAbAAMgDk/27/uv4Q/oz9MP3g/KT8fPxQ/CD8BPzw+9j70Pv4+yz8WPx0/JD8xPwA/UD9gP3I/Rj+cP62/tz+Bv81/3P/q//4/08AcQBTADEAPgBhAG8AVgBEACoA7P+k/4L/h/94/y7/uP5S/gr+0P2Q/Wz9UP0w/fT8lPwU/Kj7YPtI+zj7KPso+yD74Ppw+gD6wPmo+aj54Pko+kD6KPoQ+iD6IPoA+vD5MPqY+uD6CPto+zD8CP2Y/fT9cv4V/6H/LAAEARwCJAMABNgEmAUQBlgG2AaoB0AIoAgACZAJ4AnACaAJ0AnwCcAJUAkQCeAIgAj4B3gHGAeYBgAGeAX4BFgExANEA9QCaAIMArABMgG1AFkAEgDC/3r/X/9S/yv/7v7M/rT+fv5C/i7+JP4O/vz9HP5W/nj+dP5m/mb+Uv4k/hj+QP5y/qL+2v4b/y3/8P7A/sr+2v6C/hj+GP5i/ob+Vv5s/rz+nv6c/VT8uPvw+4D8sPyA/Hz8yPzA/PD7APvg+lD7UPvo+gj76Puc/ID8JPwg/Cj82PuY+9D7TPyg/OT8UP24/cj9lP10/YT9kP2g/eT9Vv66/gX/WP+2/w0AMgBIAIAA3gA+AZYBBAK0AngD/ANABIAEyATwBBgFYAXoBXAGyAb4BjgHYAdIBwgH0AagBoAGcAZQBjgGGAboBZgFOAXQBGgE/AOEAyADzAJ4AhACogFYASoB+ACUAAMAg/82//z+sP5u/mj+iv6S/mT+IP4O/hb+AP60/XD9fP3M/Qb+/P3w/RD+JP7w/bD9tP3k/ez9yP3E/fj9DP7o/cz93P30/cz9pP24/fT9+P28/ZT9mP2Y/WT9MP08/Xj9pP2c/Yj9gP1s/UD9GP0E/fz87Pzc/Oj8DP08/WT9dP1s/UT9HP34/OD88Pw0/YT9tP3U/Qz+Uv54/nD+eP6m/tT++v45/6z/LwClAAwBagHAAQgCOAJYAnwCwAI8A8ADKASABOAEKAU4BTgFOAVYBXgFmAWwBdAF6AX4BfgF4AWwBWgFKAX4BNAEoASABGAEOAQABLwDfAM4A+QCiAIsAuQBpAFcAQ4BygCVAFYADADH/6X/eP84//b+xP6g/mr+OP4a/gL+6P3k/fD93P2Y/UD9CP3w/Nz8zPzQ/Nj83PzQ/Lj8mPyA/Gj8UPww/Cj8PPxQ/FT8XPx0/IT8iPyA/Iz8sPzM/NT85PwQ/Uz9dP2U/bj96P0O/hz+Kv5S/pD+0P4E/y//Xv+Q/8D/3v/x/xEAQgB1AJkAuADrADABZAF+AYwBogHEAegBCAIwAmACkAKoArwC1ALoAvgCBAMIAwwDFAMcAyADJAMgAxgDDAP4AtwCwAKgAnwCWAI8AigCFAL+AdwBrAF0AUIBHAH9ANsAtwCbAIgAdABYADUAEwDt/8H/lP9x/1r/Q/8j/wP/6v7S/rT+kP5y/lb+Ov4c/gL+8P3o/dz90P3M/cj9zP3Q/dz97P34/fz9AP4E/hT+Jv4y/kL+XP56/oz+kP6Y/rT+3P7u/vL++v4P/yP/Mv9I/2v/iv+c/6T/rv+2/7v/yv/m/wAAEwAkAD0AWQBnAHIAiQCiAK8ArQC1AMYA2ADeAOQA+AACARIBHAEkARYBCAEIARQBGAEYASIBLAEwATIBNgE4ATYBLgEmASgBJgEoASQBGAEKAQIB+gDyAOUA3ADNALwAqwCcAI8AeABdAE0ARwA6ACYADQD5/+z/2v/J/8D/uP+n/5D/f/93/3T/af9d/1j/Sv8x/x7/HP8o/zD/LP8f/xX/Ff8X/xX/E/8a/yn/Ov9E/0r/Uf9a/2D/Y/9p/3X/hP+V/6X/rv+3/8H/zv/b/+P/5v/t//v/BgAMAA8AFAAeACcAMAA5AEQASABHAEUASwBRAFMAUABUAFoAXABaAFoAXQBcAFoAWgBfAGAAWQBRAFIAUQBLAEEAOAAuACUAIgAfABgADAAEAAEAAQD///z//P/9//v/9//0//X/+P/9/wIACAAHAAAA9//2//r//v8AAAQACQAIAAIA+v/1//D/6P/h/93/3v/h/+H/2v/R/8n/wv+6/7D/qP+i/57/mv+Z/53/oP+j/6X/qP+s/6v/q/+w/7n/wP/D/8n/1P/g/+j/7//6/wgAEQATABIAGAAjAC8AOAA9ADsANQAyADgAQABGAEgASgBKAEgARgBHAEkASgBNAFEAUQBNAEsASwBLAEcAQwBBAEAAPQA4ADcANwA2ADQAMQAuACgAIAAZABQAFAAaAB8AHAAUAAwACQAIAAMA/v///wMABgAFAAMAAwAEAAIA/v/2//H/8//2//b/8//1//n//f8AAAMABwAKAAsADgAOAA8AEAATABIADgARABcAFgAOABMAEgAQAAgABgAMAAUA/f///wUABAAAAAAA+f/o/9j/1f/e/97/0v/H/8P/wf+2/63/rP+s/6r/pP+h/6H/ov+g/53/nv+j/6j/rP+x/7n/wf/H/8n/zf/X/+L/6P/r//D/9f/3//f//f8LABwAJQAmACYAKQAvADUAOAA6AD8ARwBNAE8AUQBZAGYAcABvAGsAbQB1AHoAewB5AHcAdgByAG0AagBlAFwAUwBLAEIANwAsACMAHAASAAcA/f/1/+v/3//U/8z/yP/F/8L/vv+6/7P/q/+k/6L/pf+o/6j/p/+r/7H/tf+0/7P/tP+3/7n/u/+9/8H/w//F/8f/yv/M/8z/y//N/8//0f/Q/9D/0f/S/8//yv/H/8X/yf/Q/9j/3//l/+j/6f/q/+r/6v/r/+v/7f/t/+7/8f/3////BQAGAAIAAQAEAAYACQAOABQAGQAbABsAHQAhACMAJQAoACsAKwApACoALwAxADQAOAA/AEEAOAA0ADUANgAwACwAMgA1ADUAMgAyAC4AKwAtADAAMQArACgAJwAmACMAIgAiACIAHwAdAB4AHAAZABIACwAGAAQAAwABAP3/+v/3//T/8v/s/+T/3P/Z/9z/3v/a/9P/zv/N/9D/0P/Q/9L/0v/R/9L/1//f/+f/6f/n/+b/5P/i/+b/7v/0//j/+P/3//n//P/+/wEABAAJAA8AEwAWABcAGgAfACMAJgAoACsALAArACYAIgAgACIAJAAmACUAJAAjACIAHQAWABEADgANAAoACAAJAAoACQAHAAYABgAHAAMA/f/4//T/8P/s/+n/5v/k/+H/3//c/9f/0P/M/8r/yf/E/77/uf+1/7D/rf+r/6n/qP+q/7D/t/+8/8D/wf/C/8P/xv/M/9T/3f/l/+z/8f/0//b/+P/8/wIACQAOABQAGgAdACAAIwAlACYAJAAkACUAJwAnACUAJAAmACoALQAtACsAKQAnACUAJAAjACQAJgAnACcAJwAoACkAKgApACgAJAAfABwAGwAaABsAHQAhACYAKAAnACcAKgAtAC4AKwAmACAAHgAfACMAJQAjAB8AGgAWABEADgALAAkABQAEAAQABQAGAAYABgAGAAUAAQD8//f/8//y//P/9P/y/+//7v/t/+r/5f/i/+H/4v/i/9//2//W/9P/0v/R/87/zP/L/8r/yv/I/8f/yP/K/8v/y//L/87/0v/T/8//yf/H/8j/yv/M/9D/1//f/+T/6v/u//H/8v/0//T/9f/7/wUACwALABIAEwAVABEAEAAVABMAEQAXACAAIgAgAB8AGgAUABAAEQAWABMABAD6//n//P/4//T/+P/9/////v8BAAYACAAHAAgADQARABEAEQAVABkAGwAcACEAKAAtAC4ALgAvACwAJQAeABkAGQAbAB0AGgAUAA0ACgAKAAcAAgD9//3/+//5//j/+/8BAAcACAAGAAIAAAAAAAAA/P/0/+v/5f/f/9f/zP/C/7j/r/+m/57/mf+a/5//pf+q/7D/uf/B/8T/xP/F/8v/zv/M/8n/zP/T/9b/1f/Z/+f/9v/9/wAACQAZACQAJgAnAC0AMgAyAC8AMAAzADUAMwAwAC0AKQAlACEAHQAaABsAHgAgACAAHwAfACAAGgARAAsADgASABIAEwAZACMAKAAoACkALAAtACgAIwAhACMAJAAhABoAFQATABAACgAJABEAGwAdABgAFQAZAB8AIwAkACcAKwAvAC4AJwAhAB4AHQAaABoAHQAjACMAGwASAAsACAABAPf/8//5//7/+f/u/+j/7f/x/+v/5f/q//T/8P/i/9//6P/t/+n/6P/y/wAABwAEAPn/7f/f/8z/tP+g/53/qP+2/8P/1v/y/wwAFQANAAUABgAGAPH/zv+4/7X/rf+Z/43/ov/X/xkAXgCdAMQAxgCiAFEA3v9q/yv/Gv8d/yb/SP+i/ykApwDlAOsA4QDHAIIAFADD/7f/xv+//8P/CABoAJMAhQB3AIQAhABeADgALAAlAA0A6//U/87/0v/X/9n/4v/1/wYABwDy/9P/qv+A/2n/Z/94/5v/yP/5/xwAKAAiAA0A9P/n/+b/2//O/8v/1v/m/+v/5f/o//r/AwDn/7z/q/+0/7X/pP+p/+v/SQB2AGcAXgCDAJQARwDR/7b/DABTAC8A5v/m/ywAXgBeAF0AdQCLAI4AgABiADsAHAD//9D/qv/A/w0ATgBgAG4AmQCvAHkANAAPAOD/eP8M//r+Yv/o/ywALQBUAM0ALAHPAP3/4P+BAHkAh/9X/1gA2gAFAFr/BQD4AMkA7v/X/5MA6wA5AGb/ef8UAB0AZ/8g/wAAFAEiAWsAFgA3ALT/Iv6U/DT8qPwY/aD90P6mAIACwAMoBHwDagEC/sD54PUQ9KD0QPYw+Dj75f+4BKAHkAjgCNAIsAeIBSQDdAHTAOYA4AC1AG4BlAPYBVAGUAXABCgFeASAATL+0Pzc/Cz8wPqQ+mz8mv53/4z/AgDVAAoB/P/8/Rz8cPvg+yz82Ps4/Fj+3gDKAXIBnAFYAgACEQAk/sD9NP70/Uz9xP18/yQB6gFUAvACfANcA7ACCAKEAeYAVwAtAB8A6//9/6IAFAGtACEAXwDgAHMASP/C/ln/zf9E/7r+P/8xAF4A0/+R/wkApAB8AJ7/J/+0/3UAQwBd/w//r//5/xP/GP5o/nX/o//g/q7+v/8UAYIBIgHiAAYB4wAiAEX/3P7m/iD/Uf95/9L/kwBqAbIBXgEgAVgBaAGZAGz/D/+M/7T/J//4/uz/UgEIAigCbALUApACkAGgADQA7P9p//j++v5T/8L/NACPALkAzgDWAJwAGwCk/2r/S/8P/9b+6v5W/7T/v/+8//T/KQAHAK7/X/8O/6z+Yv5K/kT+MP5Q/tL+bP/S/yIAhgDKAMQAuwD4ACYB0wAnAMb/AABkAF4A+f/P/xQASgAWAMn/+f+yADoB+ABbAGMABAEyAVgAYv9x/y4AHwDM/tT9lP4CAFYA8P+DANgBNAJMAYQAqgD0AHsAfv/A/kT+4P3g/SL+DP7Y/Sr+ev78/XD97P3O/qj+uP2Y/dT+CgAwAPL/FABoAIEASQDf//D/wgBQAeQAUgC5AHoBTAFsAGIAsAEMAxgDBAJWAZgBQAH6/iD8EPu4+0j8JPzI/Ob+DgEcApACKAO0A2AD/AEqABn/Ff8T/zL+WP0Q/qb/CgBU/5f/8wA2AbD/Sv6a/rb/5v9S/5j/MgH0AuwDGARIBOgEOAVQBMgCCAIsAgACIgGmAF4BcAKoAiQC2gEMAtgBuQA1/xj+XP1s/ED7uPpY+2D82PzA/MD8EP1M/RD9gPzg+4D7wPuY/KT9+P7tAPQC9APMA6ADMASoBLwD8AE0AdAB9gHmAEcAiAFkA6gDcALmAZwClALJAPj+2P6a/2T/KP6Y/W7+fP+L/wr/5P4P/+7+QP58/Tj9YP0k/Wj8IPz0/Gb+X//O/6oAIAIgA/ACNAKoASoBlQAuACIAHAAiAK4AjAHyAdoBCAJkArYByv84/iD+qP6E/gb+WP6L/1kAOQANAG0AeACI/5z+yv6E/2D/kP6K/on/EACp/87/DgHmAYAB+gAMAesAEQCD//P/fABOAPr/ZAAUAS4BvAByAIwAcQC0/67+CP74/SD+RP6w/pX/cwCKAPL/bP9G/w//jP44/mb+1P4z/9H/2gCMAUwBfQDO/z7/yv7q/rD/jgAiAa4BYALgAswC7AGUAFb/qP56/lj+YP4D/yUA8wAqAXwBHAIQAqcA2P4Q/mD+qP5S/hz+xP6G/4//Wf8NAFgBtgGgAC3/nv7c/hT/hv7M/Rr+of/2ANoAkQDmAdQDvAO4AZcAKgH9AML+CP1E/qAA3ACS/87/6AEgAyACbgC+/7b/Hf/Q/dT8IP2Q/s//BgDe/4cAigF6AYsATgACAQoBi/+0/Tj9Vv7O/2oAVgDIACgCKAOcAlABsQC4AGsAxv+V//3/ZgByAG4AiACBAEYALgBlAI4ARACR/9D+Zv5k/nr+lv7c/lr/1//+/5L/2v6i/hL/dv9a/zP/hf/4//H/mf+b/yYA0QAgATYBYAFgAeoAPAD1/1oA2wDNAIkACgEcAmQCiAGTAIQA2AB9AG3/oP6a/g7/g//3/6sAqAE8AowBQQCo/7L/LP8s/sz9zP00/YD8cP3R/z4BrgDe/0gA5wBVABj/pP4F/z3/IP+R//wAiAIoA8ACRAJIAjwCWAHf/8D+Yv5S/gj+IP56/2YBLAKWASgBggFiAeP/OP7w/Wb+LP6U/fT9Gv/P/+T/EwCbAN4AlQBYAJYA6gDsAMoAmQARAGj/Zv9KAFgBxgGyAZQBXAHBAPn/Ov9o/pT9SP2c/Rz+qP6s/x4B/gGyAaQAe/92/sz9uP0E/jr+dP4u/08ANAHIAWQC2AKIAogBmgDj/+r+xP1g/Uz+l/8gAFUANAFgAqwCCAIuAV0ARv8g/oT9OP38/GT9/P6cAAoBzAD0ADIBegAI/yD+Pv56/iL+zP1i/rD/zwBSAZgB8gEsAgwC1gG4ATgBEQAD//b+uP9FAFIAlQBUAd4BygGcAZoBMgH7/6r+RP6u/uz+uP7a/sP/xAAWAQoBagHUASYBaP/4/bT9Kv54/pT+Cv8cAGYBWAK4AsQCoALyAaYAfv8a/w3/xv6s/mv/igDqAI8AbAC8AMEALACR/0L/sv60/TD9vP2i/vb+9v50/3kAOgFCAewArwCCACkAr/9f/27/uf/t/9n/tf8MANwAYgEcAbkA+gBiAegAyv9P/8z/RgD9/3L/a//Q/wcA5v/B/7z/qf+C/27/if+k/4b/IP+o/oL+4P5y/8D/9P9pAOQAxgAYAJv/z/9PAGQALAAvAIYArwB3ADwAdwD+ACoB1wCcAPUAkAG2AT4BiwDw/1//4v6+/gX/n/9UANYA5QCPAAQAbP/2/sL+qv58/mT+tv5H/4n/c/+H/+j/GAD+//P//P/f/7H/uv+6/2D/Bv8s/6L/xP+m/+n/hgC0AEQA9P9OAM0ApAAGAMj/HABGAO//qv/P/wUA7P/O//7/PgBNAE0AegCvAJsAJQCE/yH/Lv90/2b/Ef8g/8T/SAA8AEUAxAAKAXUApf92/67/u/+6/zIA/wB8AXQBXAGeAQQC8gE6AVsA1P+j/3L/NP8+/8L/bwC0AHcAMAA6AFAAAABm/0T/0/8rAJH/rv6s/mz/vv9C/wb/yv/GAOIAVAAgAGMAQQCG//j+H/9s/zv/8P5W/1cAGgE+AT4BaAFgAbkAvP8C/6r+iv6M/tj+df8eAKIA1gCwAFUA///J/3z/Fv/Q/t7+EP82/4T/JwDwAGgBZgEYAbkAYADu/2X/7v7O/v7+Lf9J/77/rgBuAVQBygCgAMUAiADL/1b/nv8FAM7/Sf+A/6wA1gEYAsQBxAEEArQBtwABAAYAIAC//2P/rv9lAOIAHgFMAVQB/QBbAKT//P7C/gf/Yv9r/4T/IQDAAKMAOABbALMASwBn/xP/g//u/+T/xf/L/7f/jP90/2T/RP89/23/nf+l/4b/g/+T/5n/j/+S/6j/vf++/7P/w//9/zQAQQAwAA0Azv98/13/nP/r//P/u/+W/63/8f9MAKkA8AD3ANEAewAUAMD/qP/D/+j/7//4/yEASwBaAFEAVwBmAFQA4/9D/9D+wv7i/gj/Tv/O/04AVwAfAA8AQQApAKf/Rv9V/3z/Nv/Y/vr+oP8iACwAAAAHAEYAPgDR/4n/4f9ZADcApv+c/zkAlQBeAEAAoQDoAKIATABxAM4A+gDhAMEAogCKAHkAgAC0APwARAE2ARIBEgE2ATQBFAE+AXoBkAF0AYgBxAHWAcABrgF2AQwB3gAeAToBoQDr/+j/bgBFAFP/nP6u/gf/zv4w/rj9jP1o/UD9SP1w/Yz9kP2U/Yj9WP0Y/ej84PwA/ST9IP38/Aj9cP3I/bT9fP3E/Uz+XP7E/Tz9QP24/SL+cP60/gf/cP/O//v/5P/f//D/zf9F/7L+rv4P/13/j/8fAAQBngG4AfoB1AK4A+QDrAPkA5gEIAVABZAFYAZgB+gH6AfYB9gH2AeIB/gGiAZwBkgG0AVYBVAFeAVABcAEiASgBDAE9AK0ASgBAgGBAN3/c/9B//b+nP5c/gj+pP0U/UT8GPsQ+qD5kPmA+Xj5CPqw+rD6MPoI+lj6cPoQ+tD54PnA+VD5KPmQ+Qj6SPpQ+hD6OPnw99D2MPYA9gD2UPZw9iD2wPWw9RD2kPYg99D3UPhY+Dj4ePhI+Vj6aPu8/ET+8P96AfwC8ARoB9AJwAtwDVAPABEgEiATYBRgFcAVoBWAFQAVABRAE+ASABJgEIAOMA2wC6AJqAdoBmgFAARwAmoBywAkAIT/Bv+Q/gL+QP24/GT8BPy4+1j7OPtA+2D7WPtg+8j7iPxA/XT9XP04/Rj9wPwg/Hj7GPvg+pj6KPrY+aj5YPnw+Hj48PcQ9+D14PRg9PDzkPOA87Dz8PPg8/Dz4PPA86DzYPPA8gDyMPKQ8wD1sPWA9gD4WPm4+Vj6+Puw/Uj+gP5E/2AAGgHKASAD6ATABlAIwAkgC+AMEA9AEWASIBMAFAAVYBWgFSAWwBaAFsAVIBWgFGAToBEgEOAOEA2ACpAHAAUAA44BYwBA/37+BP5M/Qj8yPo4+vj5mPlA+Yj5CPoY+hj60PpM/Dj9JP0o/cj9VP7A/eD8DP0W/pb+eP4K/0YApwDC/xr/Nv8P/6z9HPxg++D6QPpw+SD5KPmY+cD5OPlA+HD3IPcg9pD00PNA9ID0IPRw9JD1APaQ9XD18PXA9fD0wPSg9ZD2sPcY+VD6wPpg+/D8sP1U/Uz9Cf8LABf/Fv7o/qQA8gEYBDgHwAmwCqAL4A0AEAARABJgE2AUgBRAFEAUoBRgFUAWYBaAFUAUIBMgEWAOQAygCqAIKAYoBMwC9gDU/pz9iP34/Jj7EPrA+ID3QPag9fD18Pbw97D4OPm4+VD6sPpI+5z8xP3E/UD9hP0s/jD+Lv6J/2YB9AGQAY4BeAEcAJb+FP7s/dT8gPtA+zD7iPpI+gD7cPu4+tj5MPkA+ID2IPag9qD2UPYA9+D3kPfw9nD3KPiA94D2cPbw9nD2kPZo+Gj6uPro+jj8yPyI+0j6APs4/Cz8sPvI+2D7QPqI+gT9tf9KAUADyAYACmALUAzADsARIBMgEyAT4BNgFMAUABYAGMAYoBcgFqAUwBIAELANEAwgCiAHAATaAU8ASP/u/rL+jP3I+yj6ePgw9hD0sPNw9BD1wPUg9xj4SPjo+Kj6GPw4/Kj8DP6W/oT9TP0U/9kAHgGUAXgDyAToA6ACwALwAo4Bo/8S/zr/lv4g/Uz8aPzU/Pz8FP2s/LD7cPpg+ZD4kPfA9tD2wPcI+ND3APiw+Ij4UPfQ9jD38PZw9TD1IPfA+Gj4aPgY+sj7iPso+tj5SPog+9D72PsA+2j6MPtE/Kz8lP1AAEgDaAWAB5AKQA2gDgAQwBJgFCAUQBPgE0AVIBYAF8AXgBegFqAVIBSAETAOMAywCpgHTANKAEv/jP40/Wj8hPws/ED6wPfw9ZD0UPPA8oDzYPUg9/D3kPjw+dD7RP3Y/Ub+Dv+r/1D/QP4I/kP/TAGgAkwDIAToBGgEsAJEAasA6f90/oz9UP2w/Aj7MPoQ+1D8mPxk/Ej8aPuw+TD4kPcg99D2kPeg+ND4iPhI+VD6SPpY+dD4CPgw9tD0APYw+Oj4EPlg+uj7kPso+rj5aPp4+vD5uPlY+VD4oPdw+Bj60Pus/RkAnALoBJgHsAoADaAOgBCgEuAT4BMgFIAVYBeAGGAZ4BnAGWAYoBagFAASwA7wC+AJUAe4A5oAN//M/vD95PwY/Nj6APjw9FDzsPLA8RDxYPIA9aD20PZw9zD54PqY++j7sPxQ/YT9pP0G/r7+tv9EAQgDMAR4BGAElAMkArcA+v9x/0L+KP3s/AT9IPxo+zT8mP28/XT8ePvI+qj5QPgg+Lj46Pgw+eD5qPqY+pD6OPt4+6D6gPkY+fD3kPbw9lj5IPuo+jD60Pr4+nD5cPg4+Sj6cPkw+OD34Pew9+D3KPnY+pj8uv6kAdAE2AcAC6ANYA/AEIASABSAFOAUIBZgGMAZIBpAGiAaQBkgF8AUYBKwDzAMoAjgBfgD7gH3/yH/BP/s/Vj7oPhA9vDzAPIA8WDxwPFA8vDzEPYA96D3KPkA+4D78Pqw+1D95P2w/eT+EAFoAhQDUASwBYgFGAQgA6QCiAETAGX/+v5K/rz9wP2s/Rj9zPwI/cT8gPs4+pD5qPiQ93D3oPiA+YD5iPl4+kD7oPpY+cD4SPhA93D28PZw+KD5MPrA+uj6CPoY+WD5APrw+fj4gPiA+Ej4sPgI+hD7sPqo+lz8xv4kAJIBgAWQCrANcA5gDwARYBLgEkAU4BZAGAAYwBfAGAAZoBfgFYAVwBTAEXAN0AlAB8gEeAICAY0AEQDo/qj8iPnA9iD1QPQw86DyAPOA82Dz0PMQ9hj4uPjo+CD6KPtY+pj52Poo/Vz+C/92ABwC9AJQA/gDMAQwAxwCmgHnAMT/Uv++/6r/wv4u/vD+BP+A/fD7sPuI+3D6ePnA+Uj60PmQ+XD6QPuw+hD6mPoQ+6D5YPcA9wD4uPgA+Rj6UPs4+wD6OPlY+Sj5qPjo+Lj56PkQ+Qj4OPhY+bj6ePuQ+zj70PsA/h4B6ATwCDANQBBgEYAR4BEgEiASoBOAFoAYQBjgF6AYwBigFoAUABSAEiAOAAkoBjgEggHg/+oA0AGy/yD8oPlg9yD0oPGQ8UDyUPJg8kDzIPQA9fD2iPmg+ij68PlA+iD6aPo0/PD+cQBGAcgCUAQgBNgC6AKcAygDaAGQAO4AxADM/2v/BACy/3b+eP1s/bD8GPtI+tj6IPso+rD5SPrI+hj6YPmg+fD5ePkI+WD5YPmY+BD4uPi4+Uj6gPrg+uD6KPqQ+YD5ePlI+TD5MPmw+CD4mPig+Qj6yPlQ+oj7GPy4/Kr/KAXgCZAMwA4AEYAR0A8QD+AQABSAFqAYIBrAGSAYYBdAFwAWgBPgECAOIAqABjgF+ASsAzQCSAKsAZz9WPiQ9QD1wPMQ8nDywPMQ9MDzAPXg9lD3EPfQ9+D4aPiQ93D4wPq8/Cz+AQCeAd4BeAHIAUgC5gFOAaYBUAIEAvoAsgBGAYQBJAGLAK7/pv64/XD9QP3Q/Hz8ePxs/MD7CPu4+qj6OPqo+aD5yPlg+aj4sPiA+fj5kPmQ+Uj6gPrI+Tj5gPnQ+Xj5GPlI+VD5EPkI+Tj5OPk4+dj5MPoI+sj6gP28ADQDKAdwDAAQoA/wDTAO8A4QDwARQBZAGmAaoBgAGOAXYBYgFIASwBDgDRALAAmAB1gGEAboBVgEMgFk/YD5MPaw9OD0UPUA9bD0MPXQ9cD1UPVA9bD1EPbw9eD1oPZw+Jj6fPwW/kD/bv/O/tL+lP8zAIYAWAGoAkADqAIcAvQBogFMAWgB2gCH/47++v67/xv/Gv4O/hz+uPwI+zj6KPro+Yj5yPnQ+Qj5APjA9+D3CPgQ+AD44Pfw90D4UPgo+Fj4OPl4+Yj44PdY+Cj5IPno+Jj5cPqQ+iD6uPrk/Jj/XALIBSAKwA2gDjANIAwwDQAPABFAFGAYgBogGQAXwBYgF8AVIBPgEeAQYA4QC1AJEAnoBzAG6AQ4A33/4PoQ+HD3UPdw9hD2MPbw9SD1UPQQ9AD0UPTw9PD1cPaw9sD3iPlQ+0j8kPzg/Hj9Ev56/gj/awAoAkwDMANUAsoBiAFuATwBHAHAAC8AIwBUAGoA+/90//j+Lv7s/Kj7wPpA+lj6uPqg+pj5wPiQ+JD4APhw98D3WPg4+LD34Pdg+MD4oPi4+Bj5GPmo+Ej48PiY+dD5oPn4+fD6UPsw+1j8ef8kA3AG4AkADQAO0AxQC9ALwA2AECAUwBcgGQAYgBbAFSAV4BPAEsARQBAgDlAMsArwCBAIEAjYBjADnP5o++j5oPjg9yD4ePhQ95D1sPTg8zDzAPNQ9KD1gPXw9KD1MPc4+Cj5YPo4+zD7OPsw/HT9VP5x/0ABLAJ4AboA5wA8ASQBbAFIApQC4AGAAeYBvAGXAPP/CQCe/1j+TP0E/dj8FPxo++D6IPoQ+Wj4WPhY+Cj4APgo+BD4YPeg9pD2IPdg92D3QPdQ90D3QPcA+BD5gPk4+RD5EPkY+SD6YP1oAtAG0AmAC6ALEAoACWAK0A1AEWAUQBdAGaAYwBaAFSAVwBRAFKATABKgD5ANwAwgDOAKUAlQB8wDP/8U/Bj78Ppo+gD6iPng9/D04PIQ8+DzEPRQ9AD1IPWg9OD0gPZQ+ED5yPlQ+lD6APro+kD9lv/WAHIBwAFqAasAgwCEAWwCsAK0AtACjALuAaAB1gEMAqABygC3/4j+eP3c/Jz8bPwA/Cj78PnI+BD4CPhA+Ij4qPiQ+OD34PZg9pD2IPeQ97D3sPdg9wD3UPdg+Dj5SPk4+SD56PhI+aD7NQCwBMgHoAlQCiAJ0AeQCUANwBCgEqAUYBdAGOAWgBXAFcAVYBUAFWAUoBIgEJAOYA6ADRALUAgABkAD0v8c/Sj8OPy4+2D6QPgA9sDzgPLg8rDzEPSA81DzYPOQ86DzoPSA9uD3OPgY+Fj4GPlw+sT87P4BADgAcwDKAMkA7ADSARQDoAOgA6wDhAMUA9QCYAOwA9wCYgExAFb/Uv6U/ZD9wP0k/aD7GPrg+AD4cPeA9wD4EPhg91D2gPUw9SD1UPVA9tD2cPYA9kD2YPbw9fD1EPfI+BD50Plw/RACeARoBCAFcAaoB+AIMAygEKASQBJAE8AVYBZgFQAVgBZAFwAWYBQAFGATwBFgEFAPUA1wCvAHEAYIBL4BDwAA/5T9YPsI+fD2IPXw89DzwPNQ8xDzIPMQ83Dy8PFg8oDzgPRg9YD24Pfg+Ij5WPp4+4D8gP3C/hIACAGGAeABgAIYA2wD2ANQBIAEYAQ4BDgEGASoA/gCKAIMAeD/Fv+S/vT9MP2U/Mj7ePoQ+Sj40PeQ9yD3wPaA9hD2kPUA9dD0MPUA9jD20PWA9YD14PQw9ED1YPiY+8z9OgCQAqgCoQCLAOAEMApQDUAPoBFgE8AS4BFAEyAWQBdgF+AXIBjgFsAUwBMgFMAToBHwDqAMgApgCGgGAAUABIwCx/98/Lj5wPdg9mD14PRw9HDz8PEg8TDxMPHw8NDw4PAg8bDx4PKg9BD2QPdg+Oj4+PjI+aD7uP0j/zwAgAFUAkgCNAJAA/gEAAZQBnAGeAbQBbgECAQgBEgEqAOUAoQBhAAi/5z9pPxc/Nj7oPpo+aD4CPgA9+D1APVg9AD0sPPg84D0IPVw9XD0oPIA8TDxQPMg95T81QAUAhMADP6q/mQB2ASQCUAP4BLgEgARABBAEWAToBXgF0AZABlgF8AVoBQgFOATABOgEcAPcA2gCkAIUAfoBvgETgE4/kD8QPrg97D20PYQ9sDzUPFA8MDvIO8g78DvIPCg74DvEPAA8cDxoPIQ9JD1oPaw9yD5qPpE/Lz98v7b/4gAqgE0A7gE8AW4BngHsAcQB0AGEAaYBvgGoAbQBegEkAM8AkoBqgDq/wD/Sv5c/QD8cPpY+WD4QPdQ9uD1wPVg9XD10PUw9VDzkPGQ8dDycPVQ+Wj9Ev9Q/Xj7sPvY/fgAmAWwCjAOwA6QDdAMgA2QD6ASoBVgF2AXgBYgFSAUIBSAFCAU4BKAEQAQQA5ADPAK8AmgBxAEPAGO/yr+lPxI+xD6GPgw9aDycPHg8KDwkPAw8CDvwO0g7UDtIO4g75Dw8PGA8rDyYPPw9MD2mPiQ+lT8YP0a/nD/rAHMAxgF+AXwBogHaAdgB/gHsAggCbAIyAfoBjAG2AUgBSAE3AIAAp8A6v40/rT9iPxg+sj4YPjQ94D2EPYg98D20PMw8VDx8PPQ9ij56PpY+6D58PfI+Iz8SAF4BZAIwAlACbgHmAfwCYAOABOgFeAVABQAEiARwBHAE8AVYBZgFSATgBBQDoANYA1wDFAK4AdQBcQC8gARADf//PxY+XD2EPUg9EDzwPIw8pDw4O3A64DrwOwA7oDugO5A7kDuoO5A7xDxgPOQ9ZD20Peg+WD7jPzQ/QMABALoAoQDQAUwB7AHgAcwCCAJIAlACJgHqAdoB4AG4AW4BWAFUAS4AoUA1P7o/Qz9qPzI/Fz8aPqA97D1YPVg9XD1YPdw+pD64Peg9XD2qPgo+7L+YAL0A7AC8gHcAlgE6AWACcAOoBHgEAAPMA5ADtAOoBCAE+AUwBOAEuARwBAADxAO8A3ADIAKwAigCFAIyAVMAj3/xPzQ+hD6uPlI+aD3gPQw8aDuoO3A7YDu4O7A7qDtgOuA6sDrIO7A72DwEPFw8nDzEPRg9iD6sPzQ/Kz8GP58AJgCwARIB8AIAAhIBtgFwAZQCLAJoApgCuAI6AaYBVgFaAXQBJADRAJaAWkAyP6A/dD84PsA+rD4CPkA+kD6CPrw+WD5CPgo+Pj6AP7q/kz/0wAQAoYBrQBUArAFgAiACqAMYA0ADCALQAwgDsAOgA8AEQASIBEwD/AO0A7QDVAM4AugC4AKIAmIB4gFwAJ5AH7/7v5k/Uj7MPnQ9nD00PIA8pDx0PCA76DtwOvg6sDr4O1A74Dv4O5A7uDtoO6g8cD10PhY+bD42PgA+hz8/v6YAhgFcAVoBKADQASABTgHEAkwCrAJAAggBxAHMAdQBhgF8ARABaAE1AJiATEAA/9Y/Wz87PyU/Sj9jPxE/ED7+PnQ+aj74P3m/ib/7/+PAEwAOACKAXwDGAWoBjAIQAlgCXAJIArwCkALsAvwDOANAA7wDeANEA2gC7AKsArgClAKMAnQB7gFYAMMArQBJAFX/xz9SPt4+ZD3MPaA9bD0kPPQ8SDw4O6A7mDvkPAA8WDwgO/A7qDuQPAw80D2sPdw9xD3kPfY+MD6wP2RABgCWAIIAowBoAEUA2AFOAdAB5AGKAbYBTgF+AQwBRgFwARwBBAEAANqAUsA9P+h/wv/xv4N/0n/3P4s/oD9VP1U/cT94P4WAIgBQAIoAo4BYAE0AngDEAWABiAIAAnQCHAIsAhQCfAJAAsgDKAMIAygC7ALoAvACvAJEAogChAJaAd4BqAFKAS0AnwB6v/g/Yj8oPxI/BD6IPeA9QD08PEg8RDygPMg82DxAPAA78DtQO4Q8dDzUPTQ8+Dz4PQw9kD3yPjI+qT8iP0k/jD/fgCWAZIBrAH8AkgEAAVwBVgGOAbIBKQD7AMIBXgFiAUYBeADvAFRAO0A4gHMARABoACy/6L+qv68/6AAQgDf/wkAaABmAKwBSARABSgE2AJAA0gEkAVAB+AI8AlACTAIAAigCMAJMAvwC0ALUAogCgAKAArQCYAJ0AhgB/gFkAWABXgEyAI6AUz/NP3Q+wD86Pw8/ED5cPXA8oDxcPHQ8sD0APaA9EDwYOyA7KDv8PIw9TD2cPUA8wDygPSQ+FD6gPrw+6j9lP3Y/IL+JAEcApIBiAGoAnQDEATIBCgFIAS8AgQD8AOIBLAEcAQEAx4B6/9UAIAB/AHSAUAB9P9a/nb+CQBQAZYBTgE2ARwBJAFAAmgEqAVABdAEqAToBCgGUAgACgAK0AhQCNAIMAngCYALgAxgC5AJ4AhwCdAJYAkQCZAI8AbgBAgEYATMAyACGwCe/tj8OPvA+jj7gPsw+UD14PEQ8UDy8PPA9JD0sPPg8MDtgO3A8GD04PXQ9eD0wPNg85D1wPkI/LD7QPt0/JD9bP7c/04BwAEYAXABwAJ8A6gDuARoBeADHAJ0AlgE2ATEAxQDxAKMAQAAjABIAhwCyQAWAC8AZP/C/gwA/gGUAiABowBCASACTAMoBVgGgAWQBJgE4AVYB+AIgAoAC6AJYAjACBAKQAtQDPAMMAxwCtAIsAigCXAKIAoACegGsARkAwAD2AIcAnAA6P3Q++j6kPoo+sj44Pag9PDxgPDA8WD0EPUw82DwYO4g7kDvQPLA9ED1MPTQ8yD0sPSw9nj52PvA+wj7wPug/dT+qv/jAAoBgwDIANwCeARABEwDaAPsA1wD7ALMA+AEYATYAsoBdAF2AawBWAKgAugBsAAgAGcA0wB8AUACuAJwAiQCVAL8AkgEaAXQBUgFoAQoBegGkAggCRAJ8AiQCIAIEAkgChALkAswCzAK4AgQCIAIoAngCaAIyAbgBCQDhAKIArQCsAEK/0D84PqQ+lj64PkA+CD14PLw8VDyMPPg85DzQPIg8IDuwO6Q8PDyAPWQ9aD0kPPw87D14Pfo+XD7hPzI/OT8YP1S/l3/WAB6AVwCMAOAA3wDaAMUA1ADvAMgBEgEiASgBMQDnAKcAagBHAKAAuACzALcAWEA+f+0ALYBBAIwAmQCbAIwAnACUANABKgEoAQIBYgFKAZIByAIMAjoByAIMAlQCpAKcArACoAKoAmgCWAKsAoACuAIQAhQBzAF7AOoBDgFNAMzAND9zPyA/PD7WPsQ+oD3UPSA8oDy8PJw8zDzgPKA8RDwIO8A73Dw8PEg8zD00PTQ9GD0oPTw9QD4IPr4+2T9jP3A/IT8oP0B/4sAnAJQBFgE6AIQAmgCNAOIA5gEgAaQBqgE3AKoArwCqAJQA3gEOAUIBCACUAFAAaIBvAIYBGAEnAMAA8gCNAPMA5AEOAVYBWgF+AXQBvAG6AaAB+gHEAiwCBAKEAuwClAJgAjQCGAJIArgCoAK8Aj4BhgFGATIBKAFEAX0AlsA+P34+4D7gPz0/ED68PUA9ED0MPQg80DzsPOA8rDwIPDQ8NDwkPBw8UDzIPQg9BD1IPYA9sD1IPeg+dj75PxY/Xz9FP34/Dz+OwDoAWgDGARMA74B2QCqAagDQAXQBXgF6AMAAqABOAL0AswDeAQwBOACWgEWAfIBkALkApwD+AMwA8gCeANQBEAE0AOYBPAFMAagBWgGIAjYB4gGoAaQCOAJ8AkQCqAKkArwCCAIAAlgCsAKUAogCfgGUAWgBNgEWAWYBFACmv/Q/Rz94PwI/Nj6qPlw95D0EPOg8yD0oPOw8rDx0PAw8IDwYPFQ8aDwkPEA9HD1UPUA9XD1QPZw9+j5YPwY/Vj8tPwk/kr+BP5+/2wCuAPQAkwCjAKkAuABrAKoBJgF4ASsAyADPAL0AdwCYAS4BHADfAJUAlQCaAL4AtAD4AOUA6QDEAQwBCgEuARYBYAFQAXgBSgHwAdwB/AGMAfQB7AIkAlgCqAK0AkACXAIAAkgCsAKMAogCRAI0AbIBUgFcAVQBcgD8gE3AGr+AP3o/Az9ePvw+JD2wPVA9VD0gPMA8/DxIPHg8WDyYPHA76DvwPDQ8QDzEPWw9gD2APQg9KD2QPlI+/D8uP30/PD7ZPxU/lYAogGcAlQDNAO4ArQC5AI0A1gEsAXwBQAF8AN0A3QDeAP0A9gEwAR0A6QCHAOYA1QD2ALkAlwDuAPMAwgEGATIA4wD1ANQBPgE0AU4BlAGSAbgBcAFqAZgCJAJgAlQCLAHAAhQCOAI4AlQCjAJWAcwBuAFsAWgBagF2ATgAo4AEf9a/sz9LP04/Gj6GPjg9iD28PTg81Dz8PJQ8hDycPKg8hDxIO9A72DxgPMQ9WD2UPaw9CDzcPSY+Cj8DP1w/DT8MPw8/Fj9ef+AAVACQAJIAkwC6AHwAUgDiASwBEgEQARoBDAEeAPwAiwD3ANYBEAEzANAAwwDHAM8AzwDRAOgA1AEAAXABLQDZAPsA4AEMAU4BvAGsAa4BVgFOAYAB8AHQAkwClAJYAewBpgHEAngCUAK8AkgCOgFwAR4BWgGCAbABFwD2gHm/zL+kP2M/Qz9QPtA+cD3UPYQ9WD0APSw8qDxIPJQ8yDzYPHg76Dv4O/Q8MDzUPew9xD1QPPA8/D14Phk/LT+5P0Y+2D6+Px//5AAQgFwAuQCbAI8AgQDuAOUA9QD4ASYBRAFmATQBEgEOAMEAzAEgAVgBSAESAM8A+QC9ALQA0gEWAQ4BDAEUAQoBIgDvAPYBEgFUAXABUgGqAYgBlAF0AVoB4AI8AgQCXAISAfoBtAHcAkwCmAJ8AfwBkAG4AXIBYAF4AQgBMgCCgFl/3z+3P38/Mj7UPoA+bD3YPbw9LDz8PKg8iDzsPNQ89DxAPAA76DvcPFg85D1EPfA9dDy8PGg9DD5cPyo/ND7MPug+hD7uP2eAKoBcgEMAbABWAIwAqgCQATYBLADlAMQBRgGcAX4A0QDdAMABAAFEAaQBZADjAIcA4QDpANoBBAFcASQA3wDzAN4A3gD+AQIBgAFcANABPgFGAZIBbAF8AYYB9gGIAcACOAHCAcIB3AIoAkQCQAIeAdAB8gGCAbABTAGsAWwA9wBPgGBAF3/SP5E/UD80PpQ+TD4IPcw9VDz4PKA8yD0IPTw8iDxgO/g7qDvAPLQ9CD2kPVg84DxUPIQ9gj6CPwY/OD6SPqg+uD7TP7UAMgBRgFgAeIBKAKoAowDkAS4BDAEQATYBcgGWAWgA1wDIAToBLgFYAY4BlgEwgHEAfQDQAUYBRAF8ATMA4gChALsA/AE6AQYBagFOAUABBAESAU4BngG2AZoB4gHWAcYB/gGSAcACNAIUAkQCUAIeAe4BlgG4AZgB6gGeAUwBNQCdgG1AGUA3P+C/nj8EPsI+sD4cPdQ9gD1gPOg8sDyoPMg9BDzQPCA7WDtgPBQ9ND10PQQ86DxIPEQ8yD3iPr4+rj5SPnY+VD6ePsS/o0AxADJ/wsAWAEgAkgCzAI8A2QDMAR4BSAGAAW4A4wDCARoBEgFiAZABrAEbANsA8wDGAToBNgFqAUwBFwD2ANoBFAEcARgBQAGyAU4BRgFQAVYBfAFUAdwCFAIwAewB8gH2AcQCMAIwAkQClAJUAi4BzAH8AYwBzAH2AagBawDRALYAQQBjP+e/tj9/PxI+8D4IPeA9rD1YPRg82Dy8PFQ8nDygPFg78DtIO6w8GDzIPRQ8+DxIPEw8nD0MPcg+dj5cPlQ+bj5kPo4/Ir+hACRAL7/EADUAcwCFALeATwDwATYBMAEQAX4BIwDtAL8A+gFUAaIBeAEUAQgA4wCzAOgBRAGAAXsA3gDgAPAA4gEQAUoBcAE4AQoBTgFWAWIBdAFQAbIBpAHQAgQCJAHiAfgB3AIQAnQCcAJAAlgCEAIQAggCBAI2AcIB8AFsARgBLQDLALRABMAMv+Q/Vj8YPvQ+TD3QPVw9cD1IPRQ8rDykPNw8uDvIO7g7qDwQPLw81D0QPJA8DDxQPSA9oD3oPjQ+VD5CPj4+PD7Bv5A/rb+7/9IAAwA1ABEApAC8AGEAqgE6AUABfgD7APQA3gDMAToBdAGIAbIBKQDGANoA6AEGAZwBlgFUATQA1wDtAPoBKAFgAVIBTAF6ARwBEAEUAWYBsAGsAZAB5gHIAfgBlgHUAgACSAJEAlACRAJkAhQCFAIQAj4B5AHMAeoBogFAAT0ArACsgH3/8r+cP5w/bj6KPhw96D3APZg86DyQPOQ88DycPHg70DuoO2A7+Dy0PNg8gDxkPAQ8eDyYPVg90j44PeQ9yD4IPnQ+iz9iv5I/hj+Fv+lALIB/AEsAnwC4AKQA7gEuAWgBbgE+AMIBMAE2AWoBpAG8AUABRAEAAQwBXgGcAZ4BZgEqATQBHgEmASABdAFEAWABMgESAVoBUAFoAVQBogGgAb4BqAH4AfAB6AHIAjwCFAJMAkwCVAJMAnACGAIUAggCJgH6AaABugFuARQAxgC5gDv/yj/Vv4Y/TD7oPiA9oD1oPRA9PDzIPNw8vDxUPBA7oDtoO7w8IDy4PHg8LDwkPDw8MDyQPVg92j4CPig9wD4APnY+lD9Vf+Z//b+6v4PAKwBdAK8AlQDSASwBNAESAWABUAFsASwBJgFqAbgBkAGaAWYBEgEoASgBaAGiAZYBTgEEARoBOAEUAWABVAFyAR4BJgECAVoBZgFiAVQBbAFkAY4B0gH+AbYBhgHmAdACOAI8AhwCOgHwAfQB/gHEAioB7gGuAUwBdgEGAT4AuIBkQC+/lj9+Pyg/FD7UPlA97D0cPIQ8tDzMPWQ82DwgO5g7qDuIO8w8FDx4PFg8cDwEPEQ8jDzwPSQ9jD44PiY+KD4CPrw+yD9/P2A/+wANAG/ABwBrALYAwgEYAR4BTAG6AWABZAF6AXABbgFcAYIB8gG0AUgBbAEmAT4BJAF8AVwBWgElANcA7ADaAQQBeAE5AMwA3wDMAR4BHAEoAQQBUAFMAWIBVgGuAa4BuAGOAewB/gHEAgwCFAIIAi4B8gHIAhQCHgH6AVABXAFGAW4A4wCHAIyAbD+IPzQ+5j84PtA+TD28POQ8jDyIPNg9LDz0PDg7WDtwO4A8NDwkPEQ8oDxoPDg8ODyAPUA9sD20Pe4+FD5QPqY+7z8YP0g/sH/cAEcAmQC4AIQAwgD3AOIBbgGwAZIBjAGQAbQBdAFuAZ4B3AHCAeABvgFiAWABcgFIAYwBvgFmAXoBFgEYASYBMgECAUoBZgECAQoBJgEuASgBPgEkAWgBTgFkAWYBsAGeAawBiAHQAdQB8AHMAj4BwAHmAYQB1AHuAYIBjAFqARIBAwDngE4ARABY/9s/Mj6YPv4+yD6APfA9NDyUPHQ8UD0APVg8sDuYO1A7kDvQPDg8fDy8PGQ8MDwUPIQ9ID1EPcw+Jj4uPig+Sj7TPxE/YT+zf+wAGYBRAIgA3gDSAO0AzgFgAbwBtgGoAZoBkAGKAbABrAH0AdAB7gGYAYYBtgFuAUABkgGwAXYBIgEoASoBEgE+ANQBKAE+AMYAzQD8ANYBDAEEARYBGgEYASwBGgFAAZIBoAGiAaABnAGsAZIB+AH4Ac4B5gGmAboBqAGyAU4BfgEIAToAmgCBAJuACr+EP3M/Mj7QPqY+Sj5QPbg8YDw8PIw9aD0cPIA8ADu4OxA7nDxUPNg8vDwoPAA8cDxYPPA9WD38Pcg+OD48PnA+jD84P34/of/kAD6AdwCNANEA+QD8ATwBdgGsAfgB0gH6AbwBlAHAAiQCJAIMAh4B9AGcAZYBrAGOAcYB/AFwARwBIAEaAQwBGAEoAQgBAgDdAKYAvQCRAPEAxAEvAMwAxwDzAOIBPAEWAUIBlgG+AV4BagFqAaYB5AHGAfQBoAGIAZQBoAGAAboBOAD7APcAywCKABV/7T+RP3I+2D7OPto+UD28PPg8nDysPIw9PD0oPLA7qDsoO0A8ODxsPKQ8sDxwPDg8GDyUPQQ9sD3sPjI+ND4gPnY+jz8rP0c/2oAAgFeARgC1AIQA1ADUATIBfgGUAcAB4AGGAYoBtAGsAcgCAAIoAfIBvAFqAUYBpgGiAYQBpAFAAVIBPwDUARwBPQDjAOYA6ADJAOoArQCIANsA6wD+AMIBOAD5ANwBBgFkAX4BVAGeAZgBkgGgAYAB4gHmAcoB6AGkAaoBiAGWAXwBLAEGARsA2ACpwCQ/kj9uP3c/dj74Phw96D20PQg86DyYPNw8yDyoPBg70DuAO6A7yDxcPHQ8JDwMPHQ8ZDy4POQ9cD2kPew+LD5QPrw+lj8GP4k/+D/7ABIAhADHANUAzgEWAUoBvAGmAfAB0gH6AYgB6gHMAhgCFAI2AcIB3AGaAagBsgGoAYgBjgFcARABIgEoARQBMgDMAPYArwC/AJAAzgD+ALMAugCNAOsAyAEgAS4BNAE8AQ4BdAFmAbgBtgG2AYgB1gHSAcwBygH+AbQBqAG6AXQBGAEsARgBFACg/+Q/gz//P4s/sD8IPqA9kD0oPRA9gD20PNg8rDxMPBg7uDusPDA8VDxgPBA8FDwkPAQ8jD0EPUw9fD1cPeA+Bj58PlY+8D82P0Z/6MAuAHsAQQCwAK8A8gEAAYQB4gHYAfgBsAGIAeoBzAIsAjQCEAIeAfwBqAGiAbABgAH+AZwBmgFaAToA9gDKASABEgEmAPwAmwCMAJQApgC2AL8AtgCxALwAjADkAMYBIAEsAQQBYgFAAZQBnAGkAbgBkAHmAeoB3AHQAcgB8AGQAYYBggGmAXABMgDLALO/2L+SP/cAJz/iPuw9xD2gPUA9ZD1YPYg9cDxwO5A7gDvgO8g8GDxQPGA72Du4O6Q8CDyEPMQ9DD1wPVQ9pD30PiQ+Wj60PvI/ar/tgAUAUIBigFYAqQDKAVwBhgHIAf4BsgGuAYwBxAI0AjgCFAI+AfYB1AHmAaoBjgHKAeABtgFeAXgBNQDQAOYAwgEwAMsA7gCVALqAYgBlAEYAogCjAJkAmACpAIUA2wD9AOYBBgFWAWwBTAGmAbABuAGYAfoBzAIIAjgB4gHIAfIBrAGwAbIBiAGQAToAYwADQDD/8b/a//8/Zj6MPbA84D0APYA9uD00PJg8IDu4O2g7uDvgPCA8FDwwO9A76DvwPBQ8tDzAPXw9dD28Pfg+HD5IPqo+8j9k//NAJoBLAJ0AugCCARwBZgGWAcACGAIYAgwCDAIcAjQCFAJsAmACdAIEAigBzAH8AbgBhgH8AYQBvgEQATsA6wDfAOIA5QDRANsAq4BggG2AegBAAI8AlgCPAIUAmwCEAOsAygEiATYBAgFcAUABnAGiAawBiAHgAeYB4AHQAeoBlgGiAaABtAF+ASYBKgDlgFC/2r+I/9R/xr+uPu4+KD10PPg8/D0cPVQ9DDy4O9A7sDtgO7A77DwEPHA8ADwoO8g8KDxUPPw9BD28Paw94j4uPng+vj7MP3K/m8A4AEQA7wDEAQwBOgEIAY4ByAI8AhwCTAJgAgwCIAIAAlwCYAJQAlgCDgHoAaoBsgGgAbwBXAFuATAA+QCvAIYAzADvAIcAqQBJgHbAA4BegHqAQwCCALqAcYBGALwAvwDgATIBAAFIAVgBQgG6AZQB0AHcAcACDAIuAdQB1AHQAfQBnAGMAaIBZAEqAOEAnQAkP7M/Qj+8P2w/Jj6cPcg9CDysPLw8xD00PLw8ADvQO2g7KDtYO9A8FDwQPDg70DvYO/Q8BDzMPWg9oD3MPio+ED5cPoE/MD9o/9gAYQCCAM4A6QDgASIBaAGwAegCOAI0AigCIAIgAiwCDAJoAlwCeAIQAiYB7gGKAZYBtAGkAaQBagE+AMMA3AC0AKQA3QDfALEAX4BIAHoAIwBdAKkAlwCMAJsAsgCZANgBCgFQAVQBeAFYAawBjAHwAfgB7gH0AcwCFAIyAdYBzAH0AZYBigGoAVQBAADFAL6AD7/vP1w/Xz9SPzI+TD3wPTQ8kDyIPPA87DyoPAg7yDuQO0g7YDuEPCQ8DDwEPAg8DDwsPCA8iD1EPcA+Jj4MPlw+Qj60Pt8/tMA8AGAAggDYAOsA5AECAZwBzAIoAjwCNAIkAhwCKAIwAjQCBAJMAnACNgHGAd4BvAFsAXgBegFcAWQBJgDvAIMAugBYAK4AlgC2gGoAWwB+AC7AEwBNAKsArQC9AJcA6gD5AOABEAF0AUQBogGOAeAB2AHmAcwCJAIUAjQB6AHiAdABwgH8AY4BuAE0AM0AygCUgC+/nj+fP40/fj6yPiw9oD0cPOw8xD0cPPw8ZDwQO9A7gDuAO8w8LDw4PDg8KDwcPAw8cDyYPTw9VD3kPhI+Zj5UPp4+/T8jP5FAMgBoAIgA5gDEASABCAFCAYQB7gH8AcQCPgHoAd4B8gHIAgQCMAHcAdQBwAHSAbQBZgFUAXoBJgEcAQ4BLgDAANwAhwCGAJYAqACuAKgAmwCIAIEAkgC6AKYAyAEmAQYBUgFSAWABTAG4AZYB9AHMAhQCDAIQAhACAAIoAegB+gHoAfYBjgG4AUIBYgDGALaAKv/5v7c/pz+8Pww+sD34PVg9KDzMPSw9LDzsPEA8ODuIO5g7qDvEPFg8dDwcPBw8LDwsPGA80D1cPZQ90D4APmI+Wj66Ptk/Zr+4P9OAYACIANsA5wD9AOQBLAFEAcACDAI2AdoBxgHEAdgB9gHAAi4BzgH2AaQBhAGeAUYBegEgAQoBCgEMASgA6QC6gHGAcgB2gE4ApwCfALkAWwBfAHiAWACHAMABKgEwASQBKgE8AQ4BbgFiAZYB8gH4AfAB1gH6Aa4BggHSAc4B9gGUAaIBXgEjAPMAhQCAgEFABv/GP7A/ED70Plg+BD38PUw9XD0kPPA8sDxAPHQ8PDw8PCg8HDwgPCg8NDwoPHQ8sDzcPRQ9VD2EPeg94j4yPkI+yT8PP1S/kX/LAA4ATgC1AIYA3ADOAQwBfgFeAbQBvgGuAZYBkgGsAYYBxAH2Aa4BmgGuAUYBeAE2ASgBIAEwASwBAAETAP4ArACZAJwAiQDyAPUA2wDFAPIAqgCPANwBHAFqAW4BegF6AXIBRgG6AaYBwAIcAjgCLAI6AdQB0gHQAc4B3gHuAcoB6AFEAQMAzACWAHSAIEAt/8s/mD84PqY+Tj4APdQ9vD1QPUw9BDzwPHA8HDwAPHw8YDyQPJw8UDwoO9w8LDy8PQg9mD2cPaA9sD2wPeA+SD7NPxk/b7+jP/s/60A8gG8AtwCVAOYBKgF0AXgBWAGuAZgBggGKAZ4BogGwAYYB9gG8AUYBeAE6ASwBHgEmASgBDAEnAMwA+QCpAKwAhgDhAPEA9gDlAP8AsACUAMoBKAEAAWgBRgGCAb4BUAGcAZYBmgGAAeYB6AHYAdABxgHyAaABkgG8AVwBfgEUARYAzACRgGnABQAd/+k/nj92Psw+gD5IPhA97D2cPYA9kD1EPQw87DyQPLg8QDyoPIw81DzQPNg86Dz0PNQ9JD10PZw99D3oPiw+WD60Ppw+1T8XP2M/uv/MgHgASQCUAKUAtACSAMYBBgF4AUwBmAGiAZoBggG8AVIBqgGwAa4BoAGIAbQBbAFsAWYBWAFOAUABagEeARwBEgE1AOQA8QDGAQwBEAEWAQgBKADbAOwAwAEOAS4BFgFiAUYBcgE6AQYBTAFcAXIBdAFgAVABSAF8ATgBPAEsAS8A4QCpAEMAW0A0f9U/7r+3P3o/Aj8UPuA+pD5uPgA+DD3UPbA9aD1sPWg9XD1IPXA9GD0cPTg9BD14PSA9LD0gPWw9uD3+PjQ+Rj6oPkY+Uj5EPoA+2j8tv4KAQACzgFiAdwA3P9Z/7UAlAMoBjAHyAa4BbgEOARIBKgEMAXYBaAGSAdwBxgHeAaoBeAEgAS4BGAFEAZgBkgGyAUwBcAEmATABCgFaAUIBUgE9ANABKAE0AQgBVgFwASYAxgDsANIBOwDHAO8AswC5AL8AiAD7ALyAXQAQ//2/lf/5f8sANL/rv4s/fD7YPtA+zj7EPvA+iD6GPkw+OD3MPiQ+Hj48PeA90D38PbA9hD30PdI+GD4yPiQ+Qj6yPlw+Xj5mPm4+Uj6qPtA/VL+tP7a/tj+lP5K/oj+kv/tALgB0AEkAigDzAMsA2wCuAJIAzQDtAN4BRAG3APwAaQDmAbABvgEgAQYBWgE8AKwApwDoATwBVgH0AYgBFwCZAPYBCgEsAK8AsQD4ANMA4wDSARIBOQD+AO0AzACogBXAKQAtQBSAeQC2APkAmgBMAH9ADv/tP1E/tL+MP4e/lH/QgBBALD/XP5c/Nj6qPo4+6j7BP1e/1b/MPuA99D4APxQ/FD7kPwU/ij8mPg4+DD7fP3c/Lj7lPwK/pT9MPzU/ND+aP5w+4j6eP2IALkA0/+7/0j/Gv6g/oABbAOsAkYBpQCU/yb+wP7qAeAEgAXgBCAEsAI5AAj/fwBoAqQCbAIwA/wD8AMABIAEyANGART/I//SAHgCnANoBKgE3ANIAu4A3gCIAX4BvACPAEgB/AF0AhADmAMEAwQBNv9J/1wAUAB5/4MAYAOAAyL/6PuC/jQCTwAA/CD9DAKOAZj7CPq6/vIAXP5E/Tn/vv9Y/SD78Pro+3D9gv+ZAA4AG/8I/hD8YPpg+9D9gP6Y/nMAyQDg/ND5dPxwAOD/SP1O/jABUACA/ar+XgHY/7j9vABQBEgCHP7c/KD9tf+4BMAI0AU7/wj9Zf9HAKb+gP/wA6gGaAUMA9UA0P5v/7QC7ANaAR//8v/KAagCVAP0A9wCr/8k/cj9OADsARwDOASEAw8AiPy4+5z9uAAkA1QDlAHV/2v/lf/c/nD97Pzc/Sv/KQDaAFQBsAGeAWwAKP7o++D6sPtC/v4BAAUIBXwC7/8U/iD8uPog+yD9nv84AogEgAUIBG4ATPwg+fD34Pks/lQCMAXoBugFLAFA+4D3kPfQ+wgCIAZABvACrv4o/XP/GAJAApcAB/+a/iD+CP2S/swCAAT0AcACiAWQBP7/2PtY+nD79P2GAVgGAAmABez+WPzI/Tr+lP0OACgEoAPy/mT95wDcAuX/fP1R/wwBYP/8/fP/+AIABPoBTP7w+6D78Ps0/UkAhANYBUAFkAHA+iD24Pf8/SADWATcAowAIP2Y+hj9XgG8//D6wPvCAWAE4gFAAMj/OPtA9nj7IAcwCggDfP0M/gz/DP7s/TP/KAC6AG4BGAKwAlAD1AJ7AFj9uPpY+cj7SATgDGALhwAQ+dD6hv7+/nwAwASIBR0ADPzJ/zAFWAOo/VD9EgEyATT+Qv54AcQCaAHWAOYBVALGAMj9qPvA/JIA5ANgBBACiP7A/Mz+VAJgAkT+kPtA/Tn/dv8oAhAH0AVA/XD4VPzlAKkA9/+iAdIBev5s/D//ZAKUADD9BP7oAYAD4wAw/ej7KP1k/r7+DwCAAoACEv7g+Rz8GAOwBWcAsPtY/fD9iPh4+EgFsA9oB8D34PWE/+AC6P1A/XgEIAlcA9D7LP2wATz+kPfQ+cwDgArACQAGugEo+3D2UPkc/ub+sAPQDmAPTP+Q8uD3KAKsARj9uAEwCZgGz//Y/vD+6PlQ9yj+AAigCrgDmPzU/GsAw/8I/Ij8zALYBZEAbP3WAeADTwBm/tz9oPtY/EwC0AiwB47+uPnI/V7/ePtk/LgCsAW0A/QAdACf/4D76PhY/OL/kADsA6AHnAPQ+SD0gPag/VgECAeQBmgDvPyQ9oD2kPpM/pgCkAiACxAFIPnw9Lj8iAKY/cj6BALoBDz+Dv54B5AIAv54+VIA1AJI+RD0Bv7gCbAKWAY4BCgBIPtg98D5dv8ABWAI+AZwAdT8MPxC/t0AIAJeAZL+gPtY/ZgEkAjwBJQAof9I/ZD4OPiE/uAE0AXcAzADkAOCAVT9MPug+5j8jv9YBKgE//8k/moByAOYAcD9+PoA+zv/aARABPz+IPz1/zgFoAOY+7D3vP0oBHAB6PzKAXAI6AKQ9/D2qv7v/3D7q/8AC/AKSv7Y+Kz9+PuA9Bj4AAUQC1gH6gF2/iT8sPvc/LD9fP5rAKoAnPyA+9gDAAtQBZj9xP9UATj5YPOY+4AIgArQApb/7AIsArD8SPy4AbwD0f8k/er+WgBl/74AYAbgCHABkPdY+XQDIAWs/aD7RgEQBHoBvgA8Ap//6Pt6/rQCtAGy/l7+yP8sAHf/TgBoAoEAXPxC/ggEiAMg/aD6wP1pAOABgASIBLn/ZP3DADgCAP4o+kD8dALgBQQDLv81APYBSgDw/pT+PPzI+7b/gAJ8AiQDXAPvAMj9sPsA+jD5YPxwBdANoAkQ+lDwEPfMArADRv4QAfAI8AbM/FD5EPzY+sD5YAAwB9gHaAasA3j9SPjI+Jj70P14AQgGyAYgBOQClgE8/LD3YPp6/yUA1/+0A5gHcAWM/1z8TP1K/tz8CPvI+1EAoAdwDBgH2Pgw8Zj5gAXoBO7+RAKwCEgEiPlQ+IoATALA+rj6YAbwCqABGPoI/igD+v6w99D5fAPoBzAG2AX4ApD4oPGo+FAEgAcoBYAGYAgaAWD2sPY4/fj7OPoIBsAR0AjI+OD5BAPI/VDyQPhQCjANlv7g+FgDsAcA/aD1ZPwYBOEAGPse/oAEyARAAcH/dwB/AKz9EPpI+8gB2AagBZ8AwP14/UT99v7EArwDcwDc/RD+1P04/eUAMAc4B6z+CPgQ+wAAXf8Y/kACAAfMA8j5sPYMAvAK8QDA8gj4wAcwBwD5gPiAB8AKQP6A+f//2/+A+Ej6yAXwCQQCwPvI/ZABOAKWAG//gf+0/SD7GP0gA1gGjALY/Q4B+AY8AmD4OProAdz+SPgS/4ANcA8WAdD0yPgQA9wDBP0A+z4BQAewBNj7wPiqARALaAbw+ZD3ev+GAYj7FP6gC+ANTP3A8SD5jALrAPz/wAjAC8z9kPFI+AgEEATTABgEgAWc/VD2SPtQBHwC8PqU/HgF4AehAGj5IPpB/8kAiP4p/yQD+AM6ATf/RP1A+kj6Lv+4BAAGOAM+AKj8APjw+WgEQAu4BRj7wPaQ+Qj+PAIIB9AIQARe/sj64PYw9Rz9IAlQC8gEfwDm/4T8cPeg+BABKAcABVwCzANkA1z+2PmA+gf//ALaAeD9Ef9wB2AMOAV4+tD2KPhY+YD+IAkQDlgGLPwk/UgDRv9g9vj56ARwBRv/8f8wB4AIKv9g9fD2hv9IAnMAVAJIBdACTP4W/0QDKAEw91DywPrIBAAFLgHwA+AKEAig+IDvKPmQBAQBgPkU/mAGjALA/DgGIBFIBODrgOlM/eAIsgHk/cAH8AuYAFD3aPuM/5D7ePruAEgFGANyAI4AMACQ/VT8yP+YA1ACQv7U/Ej/mgEGAVMAdAJ4BKUAKPq4+pwC4AX6AP7+xAMwBWb+4Pig+8oB5AOgA7AFOAQg++D1cP3wB8AJEAQI/UD5ePumAcgEAAM+/zj8zv4QB7AJRQBA9sj4hAJEA9j60PoIBiAKIAJ0/dkAjv8A9/D07P4ACjAKtgEw/Zz/yP+o+wD8+v/CAJn/cACUA3AEzP7w9xD6uAE4BEQCIAJIAgz8wPTw+RgH4AiA/cD3Kv/4BXoB8PoS/ngEBAII+mj50wBIBfwCkP6A/JL/UAZABij7UPTm/mAN8AeA9+D3wATwA5D4cPxADLAKoPcA9MgGMA5E/cDxQPzQBYD/sPzAB/AM+gCg9kz8sALQ+6D23AHwDHgF+PhI+8AECAQc/cj9uAPsAZD5APkYA9AJMATI+2D8fgFCAGj8CwAABwgGSPzA9dD7SAbwBZj70PcYATAJmAPA+Wj7sASgBGj5QPZkAjAJHf84+PABkAqOAfDzkPjQBygGoPcw+QAI8AjY+8D3lQBQBBz9APkJ/4gFUAXq/wj6SPqt/yQCQAF4AhgEkv9w94D4zAJYBYL+0wDQCkgHMPfA8AD7gAboB1QCkP3+/qgFeAbA/Qj5+P+QBHD9wPd6/5ALQAvUAYD8WPng9RD8QAjgCXgEqAOUAcj50PSg94r+gAVQCvAKWAXo+qD24Pzi/nD30PcABSAMQAh8A1T/yPro+Xj6ePnM/SAIUAz0Awj6pPxwBT0AcPMo+IgGKAV0/JIB8AowBzj6IPOI+JwCQAPo/Mr/cAm4ByD78PZxAOAGRP4g9Aj7MAmgCIj9HPy8ATEAhPzS/1wCjP7w++T9BQAGASgFUAjSAbD2IPXc/jgH0AUFAPT+LwDU/xQAcAHgAsADnv9g+Qj8ZAImAZr+OASwCYgF3Pyw+pj+wP1w+Tz+0AdYBkgB+ATYBUD6APMI/PgGOAWA/ED96AVYA8D38PpgCYAIKPow+OQDIAZQ+hD38AFwBj4BCAJIBkb+YPSE/NAJ6ALw8kD2kAjADugDkPwK/0L+sPcw+CgAkAOKAcgCWAbIBOf/HPz4+cj7zP+w/lj6/P2gCWANcAIA92D34Puw/FcA2AYQBoj+6Pt5//MAev5k/SL/Hf8A/oD/EAIkAjABrgHoAl4BwPuw+Ez9CATYA6z+vP7YBNAEQPzI+mgDAAQI+cD3EAaQDUwBoPRI+sgGAAU4+Sj56AUQDKAEvPyA+1j7wPqI/ZgCeAR4A7gEqAUT/6D2oPfA/3AE6AP4AvIB0P+4/i//6P0Q/Bb/mAToBLb/DPyO/nQCFwDw+ij9KAQQBpgC1P2Y+kD7fv5AAVwDKAQgAhEAGgD0/eD5+PssAxgEVv8v/8IBT/8I++z+oAeABPD2sPWAAuAFUv6g/vAG6Afs/oj4QPtJ/4T+2v7sAigF8AKI/pD7yP0oAxgEtP6Q+7cAQAZ8ASD3kPZ8AVAKUAgEAfj8lP0n/8T90PvI/ZwCUAUEA/j8iPlbAGALcApo/LDzuPqQBJwCcPvw/YgHMAhi/tD6JAJgBYb+sPko/fABSAJyACQByANsA8z++Pqc/CgB0gBo/Ez96AT4B/wAGPui/tQClP6g+ND7ZAPYApT8LP74BqAJtAJw+pD4gPtY/LD7BgDgBsgH3ALG/nP/7AFf/zj5IPkx/14BjP8kArgHqAac/PDzCPhgBNgHnf9w+6EA0ALw+4D5AAbAD3QCAO/g8mAGMAwgAuz9CASYAiD30PQEAQAKcAaoAFgAmwCY/Kj4ZPwgBbAIAAUEASD9cPfg9xgDkAx4BvD4sPe4A0AKPAJQ90D2pP3oBMgGoANJAIoBGAPQ/WD36Ph2AOAFAAUQAXoAlAJcAUz8ePhQ+xwDYAbkAhQBtQCQ+8D3kP7gB+gE0PrQ+hAEEAVw/Mj5PgEIBqgAuPmA+hP/sQCAAtgFOAVfANj7uPiI+Jj9aAUwCZgEIP2c/CABYf/w+Dj7YAZwCUL/cPeY+twBsAbABkwBuPoI+MD7QARgBqD+uPucAoAFtgAw/Yj8uPxe/jADAAnABsD6YPTA+6AC3gHYAmAF3wCA+xgA6AUNAFD3mPoYBHgFKgBo/mwBmAJsANz+iv76/qwB+ANiART9+Pvs/MD9Xv/cA6AJ8Ajm/kD38PnQ/Rj70PkUA7AOAAuI+hD0Dv6ABWIB0PwW/jABrAHo/Sz8vAKQCJgCQPok/TAEav+w9HD60AtgDGD7gPWBAAAGaP9E/EgCUAVk/5j6nPy0/Qz8hwBwCRAKVgCg9xj43P0xADgA0ANoBogBsPsA+wj8Sf+YBpAJjAFg+BD6JALsAmD9wP1IBMgE/P2o/GwDGAZk/uD31P3QB9gEUPjw91AGkAtm/1j43QCYBUz8KPjwAnAIHP5I+lgGmAcA94Dy/AJAC93/CPnUAWAHBf+I+fD/JAMI+5D2qwCACyAIJP7w/P0ARP9A+zz8LQAYAgwCxAIAAx7/GPvY/bwBeAD+/xgEyAUo/5D2MPeVADgFzQB4/rADKAaX/5D6wP39/1D7gPlAAQAIoASS/lb+gQDo/5D+wP0Q+2D7kAKQB0gCLPwEAbAHvAJA+aj4bP0I/xL//gFQBxAJaAMU/ID6OPwY+zD7YAMADZAKAP0A9Zj7CAQaATj6OPwYBsALSAYk/VD6hP3A/pj7kPoCAPAGAAiEAtT8EPwT/6UA1P0o/BIBuAXIAWj7XP3QBNgFBv4g+DD6PgC4BeAFEQCk/JIBEAXE/fD2yPs0A7QBvv78A8AIMAEg9jD4yAKIA5j7HP6gCdgHCPmA9mADgAco/bD5kASACAj7QPN4ANALrAO4+7wByANY+dD1sgEAClwCAPlA/fgEpgFo+5D+qAS8AjT9VP2GAXQCrQAaATYBvPxQ+OD8YAfQCjQDQPtQ+2D9VPzI/VAE+AekA/z8kPxIAYAAAPlA+fAFAA5IBYj4YPi2AFIBCPvo/DgFIAUU/j7+KATgA8j9sPpg+5D6aPwIBtAMCAb4+2D8HAGg/QD2oPc4AwAL4AdIAbz9VP38/uX/3P0w/PD+WAOYAvT8BP2ABpAKiv/Q9GD5FAOQAvz8+P30AdABmgF4BGgDdPyQ+UX/0AM5/4D5PP7IBxAIxf9A+8T9/f/6/jT+3/9WARwB4gGUAt7+CPsc/ZX/bP0w/jgF0AgABEb+6PzY/OD8g/98Av4AOP1w/TAC4AWoBOMAqP2g+0z9ggEeAYT9nv84BBwCcPyQ++H/UARYBbADqgCQ/Aj56Pjo+5IAuAUACGgEMv4g/J7+q/90/Ij6wP6sAwQCQv48ACgF2ASO/lD5YPrK/0ADhgH4/XL+TANgBfwAnP3g/zwA2Prw+Ej/wAQoA/gAoAOgBZgAYPkg+dT+cAHk/4AA0ALmAYf/mQBkA3QDgQCQ/Ej56PlB//gDWAQABLAE5ALI/gD9yP2o/bz8YP20/rP/VAMQCaAIaf/I+ET8fACE/Cj4XP2IBiAIxAMIArQBEv4I+wz9kv+Y/ej7VAHgCKAIXgHo+9D6APtM/RQC0APe/yD+EANQBXT9oPUo+9AHIAmk/QD47v9gBTz9MPWU/DAKsAp5/9D64//oAHj62PjxAFAHmAQWAGsAfACo+3D4MP0ABQgHLAK0/Zb+aAG9ANT9FP30/kf/nP0nACAHgAg0AMD5XP0oAqL+IPmY+9QDQAhgBXoA9P2M/Rb+cP60/Tr+ngFYA8wA2P9MA9QDXv5o+0j99P3i/jAEWAccAjD7+PuqAaQCcf87/9P/nP02/lQD8AW4AxX/YPog+cz86QDcAdACEAbYBTz94PRA+FgDMAaw/Sj6qAKQB/L/GPtYAQgGiP9g98j5jAKQBKr+UP7IBgAK0gCQ98j4dP43ADAAsALgBDADDP8A/Jj7rv6UAyAFUwBY+lj7dgGEAiz+eP7kA1gEV/8G/kABpAE0/vj7aPwe/o4BaAUIBV4AVv4uAXQBJPyw+JD8aAQQCKgECf/Q/ED+MQBM/zj8Fv7gBSAJvAJw+6D69PyW/jUApgFSAcQCyAYABeD6QPX4+zgDLADA/PAEgAxQA4D10PbLALwCXv4m/ygExAM0/bD6JgHQBlQCWPqQ+gIBVAPCAP7+QP8F/4b+rQCQBFAEUv9U/JD8qPuI+9cA0AewB4EAgPyi/7MAiPv4+d0AyAUuAbz8SAEoBroBuPvQ/UABJP4w+vT8/AIYBYgDWAK4ARP/2Pqo+Cj7RAIwCGgGiP90/WIB1gCg+aD3aACACFAG3v5w+7D9iwA5AIL/OAL4AzH/iPhY+ZQCQAl4BEj8CP3gAVn/OPqc/cAFcAag/1z8s/+oAVL/yP06/hL+1P4oAugE0AODAET/IABM/xD8YPog/ZAB2ALiAVgDYARv//D6Nv+wBF0A8Pdo+FwBSAZ4Aij/aALgBMYAVPzM/E7+OP1c/W4BkAQgA2sAHQBDALT+EP2w/C7+kAIwB8gFvv5I+vD7HP7s/HD9vANQCLgDjP1y/qAAkP0Y+9T9AAHrAJ7/tf8UApgE2AMUANT8DP2F/5n/vPys/UgDYAXcAu4BKAIL/2D7FPwK/+T/PQDoAkAEEAFi/m0AzAG4/Zj58PvIAdgEGATAAdv/Zf9C/lD7IPuO/1wD1APEA9wDJAGw+kD2aPoIA6AF4gGB/ywBeAMgAgj9MPrA/UgCSAGk/dj+pAPwAgz93PxAA5gEDP5I+uL+gAR4AxX/Pv4LAEEAPv++/jr/WgE0A9wBIf9s/vn/mgCK/jD+SAK4A3r+DPwYASAEW/+A+oj9WARIBtgCIwDo/kj70PdY+5AEMAmIBKL+mv/EAt3/oPpQ+9D/OgF2AcQDMAM4/Rj6Kf+gBAQDX/9fAPEAmPvY+FUAiAf8Aoj7Bv7QBJwDyPxg+9n/3gFS/6z9Qv9eARQCLAKeAQj/mPvw+jb+XALcA4wBpv60/xwDmAJs/ZD52Pp1/0QDGAQIA4gB9/8h/7D+cP3M/Fz+gABSAUIBWgF+AaoAbP9bAGACPwDo+hD6G/9AA2gDaAIsAUD/ev7m/1ABlADc/rj+iv9K/7v/PALMAkkAkP+sATAC8v5I+9D7uwCQBHQDSQCC/gz+AP/QATwD8P84+7D75ACYA5YBrP+x/6j/AAA+AXoA5P0s/rkAFQDk/Pz9zAMQBhgCSv+wAPT+0PhI+BQBkAjgBUP/Zv5MAf7/JPyo/CYAQAGMAEgBWAI8ATj/9v4LAMr/Hv5c/az+yAAwAmgD0APDAJD7QPpC/qYBxQBa/yQBrAJfABT+cv/cAI3/KP8AAbAAXP0s/XACeAV8AUD9vv68AHz+1PwjAJwDwAHO/s0A/AOwAez8/PxkAHsA8P26/ggCUAJRACoBMAToAxL/YPq4+Sz8pf8cA/gEMASEAt8AwP7g/ID8ZP2Y/nz/yP+iAIgC5AO4A0QCxP90/CD66Ppk/sgBGANAAwADfAFD/x3/lgC3/1D8CPvE/QABDAJcAngD+AMQAlD+EPtQ+kz8QP8gARQCWAMoBJQCLf8M/VD9FP5O/mn/WAG6AXIARgD2AYQCQQCc/Uj9Mv4g/oL+egFQBGgD0ADJ/1r+IPt4+tT+mANYBKgCSgHk/9z9CP0K/uL+QP8aASAD/AH0/hD+Ev+M/woAigEYAqsAfv9h/57+oP3I/lYBOAJ+AUIBcgGRABf/av44/uT9rP5GAXwDKAP9AOb+OP49/0oApP/E/v//SAJMAov/hP3W/oABxAGMAG4BUANkAfj78PlG/pwCfAFq/8ABWASqAUD9CP1g/5v/aP4+/xoB1gAH/5z+6P/yALYAJAAzABEAyP7s/Dz8DP5QAegCvgGiAA4B0gCM/pj8QP1f/4UAWgABACsAWgFIA4wDYwCg/Dj8Vv5s/x3/KgBEAxgFFANn/wL++P4v/wj+eP4iATACUQDj/4wCRAOx//z8vv7JAHz/Jv53AHQDfAJ3/wD/dgA8AOj+Rf9rAA0Aa/8QAYQDMAMxAMT9RP2M/Tj+1f+4AcgCeALoAE7/mP56/oT+/v6A/0P/6P7j/wQC4AIUATT+oPwU/eD+ZwCUAFQAzQA2AWcAK//o/jf//v7g/vr/IAGmAIX/g/9OALYAuwC5AGAAj/8V/2D/gv8m/37//QBIAiACAgHK//7+Av/S/8cANgEYAeIA9wAaAeQA0wAwAUgB1gCkADIBigGdAGr/DwD6AXgCHAHg/4b/f//9/2QBiAK4AYn/Xv7u/pz/dP9q/zQA7ABWALz+4P1q/tT+Jv7A/db+HQCO/1j9uPv4+xj9Bv72/tz/xf8s/mz8IPzA/MT8YPzs/FT+jf8EAOn/cP90/iz95PxQ/ur/MgD0/5kA8gGMArgByQAYAa4BjgHiAVwDgARYBIwDWAMYBAgFcAU4BbgEcAS4BFgF8AVYBvgFeASIA0gECAVYBGgDpAPcA4QC+QBYAUgCDgHY/pb+QP8A/tj70PtU/XD96PvI+mD6qPnI+LD4SPlg+aj40Pdg90D3kPdI+MD48PiA+bD5gPhQ9/D3MPnQ+Bj4yPlA/cL+ZP1o/KT9uv7k/VD9yP6PAEIBKALkAygFWAWgBbgGuAcQCFAIcAjIBxAHkAgADCAOYA0QDBAMMAwAC6AJ0AkgC7ALMAvACuAKYAqQCCgGiATcA4wDTAP4AkQC3wAH/4T9pPwA/CD7UPqo+QD5ePhI+AD4IPdA9iD2IPag9VD1UPbg9zD4QPfA9kD3YPfQ9hD36PjA+ij7wPrg+jD7kPpo+SD5GPow+7D7LPxM/XD+ev5g/dD7cPoI+vj6CP1a/04BcAJQAk4BcwA8AJsApgGAA5AF2AZIB4AHIAjgCHAJIAqgCoAKAAoACnAKAAvAC7AMAA1QDDALcAqgCQAIaAYABnAGcAboBXAF2ARAA/AAyP5I/bT8FP3E/fz9bP1A/MD6WPnQ+Fj5CPr4+aD54PmY+ij7MPvg+nj6MPpg+jD7OPz4/Ej9XP0g/YD8DPx4/ID9Gv7o/Xj9DP00/BD7UPr4+Yj5SPnI+Zj6WPoI+XD3IPZQ9VD1EPYg9xj4+Pj4+bj6SPsQ/NT8DP0s/S7+xP9WATADmAWoB3AIYAiQCJAJAAtQDEAN4A1QDtAOEA8ADwAPEA+gDsANMA0gDdAMoAuQCkAK4AlQCGAG4AR0A6IB5P/u/pT+RP4w/o7+lP4Q/Qj6APcw9eD08PVA+Mj6+PtY+wj6GPlo+MD3wPfY+FD6gPu4/CD+4P6I/sT9TP0A/QD9oP2Q/vz+tP42/qT9zPzY+zj7yPoQ+kD5APkI+Xj4UPdQ9uD1wPUA9rD2kPcY+Dj4yPgY+kj74Ptg/ID91P6w/5gAgAIoBSgHMAjQCHAJIApAC+AMMA6gDoAO4A7ADyAQABBAEEAQgA9ADnAN8AwADAALcArwCdAIkAeQBiAFqAL5/zL+JP1I/Cj8EP3o/Uj9WPv4+GD2APQw86D0YPfg+Tj7aPuA+hD54PeQ9/D36Ph4+lT8Iv6F/0IAHgA2/xL+dP2g/Yz+9//gAFIA9v4Y/uD9LP24+3j6CPrA+Qj5WPjw9+D2APXw86D0APbg9kD3MPew9jD2wPYo+KD5QPtY/RT/Vv8l/14AvAKgBNAFOAegCDAJsAlgC6ANsA5wDjAOcA7wDsAPgBBgEFAPAA4wDeAMwAzQDJAMgAuQCYgH2AVoBCwDKAIMAcn/wv40/vD9nP20/Nj6ePiw9kD2wPbQ90j5wPoo+0D6EPmo+Mj4EPm4+QD7fPzQ/er+zv8rAPf/Z//Y/rr+WP+EAHABmAESAff/hv5M/eT8EP3Y/Mj7gPpw+Vj4QPcg9uD0gPPA8iDzUPSw9dD2gPcQ9+D1IPWA9eD2+Pjg+7r+bgAOAboB5AIABBgFqAZACEAJQApADHAOQA8gD2AP4A/wD9APYBDgEEAQwA7ADVAN8AzQDMAM0AuACfAGAAWwA6ACFAKiAawAWv9s/sT9zPxY+6j58Peg9qD24Pdo+Uj6aPro+bj4oPew9+j4SPoo+9j7gPwE/aD9ov6m/97/SP/k/lj/JQC4ACQBmgGqAc0AXP/s/bD8uPuQ+wT8MPxY+9j5APjQ9cDzkPIw8gDykPJQ9HD2YPcQ92D2UPXg8zDz0PRA+ND7+P5gAXQCHAKkATQCfAMoBWgHAArwCxANYA7QD4AQABCwD8APABBAEAARoBEAEfAPQA/ADvAN0AzQC3AKQAggBugEGAQsA2QC2gH3AFf/nP0I/GD6kPhQ9xD3UPcI+BD5yPlI+cD3kPZg9hD3IPhw+ZD6GPt4+yT8AP18/dD9cP7i/tj+7P64/48AtACNAGgALwB7/3T+hP2E/Ij7APtQ+5j78PpA+fD2YPRQ8lDxgPGg8kD0APYg9zD3cPZw9ZD0cPRw9bD3qPoC/u8AtAIoAzADsAOoBOAFmAcACjAMkA3QDmAQwBGgEeAQgBBgEEAQYBAAEWARwBCQD6AO8A0ADbALQApgCDAGYARYA6ACvAHmAEIAOv+w/Rz8oPrQ+BD3YPbg9rD3YPj4+Cj5gPiA9zD3sPdg+DD5WPpw+xz8xPzI/bD++P4D/2X/CQCKAPkAqgFgAmwCwgH0AFQA4P9S/7z+5P2o/Dj7cPrA+iD78PnQ9lDz8PAQ8JDwUPKQ9FD2oPYA9gD1APRg89DzYPVg98D5+Px0AMACeAOIA7QD7AOIBIgGwAlgDOANIA9gECARABGgEIAQABBwD8AP4BCgEWARYBAgD3ANwAuQCsAJgAjgBoAFUAQAA6gB5gAjAMT+KP0U/OD6IPmA9wD3YPfA9wj4gPig+OD3APcA95D3OPgg+Vj6iPtI/Pj8zP2C/tz+M/+x/xwAqgCSAXACtAJoAhQCogEGAaEAZQDS/6L+UP0o/Nj66PkQ+oj6OPng9YDykPAA8FDwAPJQ9LD1sPUw9cD0EPRw8+DzMPUA95j5KP2cAMACeAOgA5QDiAOABOgG4AlADBAOsA/gEEARQBEgEcAQIBDwD4AQQBHgEeARABGAD9ANkAyQC2AKAAmwB0gGoARUA6gC0gGGABb/0P04/Ej64PhQ+AD4kPeQ9+D30PdQ9wD3IPdg98D3mPio+Wj6APvo+8j8SP2k/Xz+lP9iAAYB2AGIArwCoAJ4AjwC4AGSAVoB5gARACz/LP7s/Jj70Ppw+qD5GPgg9uDzUPFA7+DuAPAw8nD0sPVg9dDzMPKg8fDxEPNQ9Zj4+Pui/scAaAIcA+wCsAKkA8gFgAhgCyAOABDAEOAQwBDgEOAQABFgEcAR4BEAEgASoBHAEIAPIA6QDAAL0AnACDgHoAV4BJwDcAIAAdz/qP7w/Ej7QPqA+Xj4kPcw90D3QPcw90D3MPfw9vD2YPcA+Mj44PkQ+8j7HPy0/JT9bP48/xoAzAAqAXIByAH4AeQB7gH6AYABpwAVAL//8P6o/Yz8qPtg+hj5ePgY+AD34PSA8jDwoO7g7mDxQPSA9UD1cPRA8yDyIPKg8/D1mPhw+3L+9ACkAqgDEAQABFgE0AVACAALwA0gEIARYBEAEQARIBEgEUARwBEgEuARgBGAEQARgA/ADWAMIAugCTAIGAfIBTAEqAKcAXAADv/M/aT8QPuw+Xj4sPcw9+D2APdA9yD3wPaQ9qD2oPbg9tD3UPm4+uD72Pxw/aT9uP1E/kj/YwCaAaQCRAN0A5ADpANYA7wCOAIAApAB0QBVAN7/0v4M/XD7YPpo+WD4cPdg9nD0kPEA7yDuQO+A8cDz0PSA9GDzMPKw8UDyEPSA9ij5wPuS/t4AOALoApQDYARABcgGMAngCzAO8A8gEcARgBFAEYARwBHgEeAR4BHAEWARABHAENAPQA6gDCALYAmABzgGcAWABDwD6AGeAFn/FP7Q/Fj7sPlA+GD3EPcg95D38Pew9/D2YPZA9nD2EPco+Hj5YPoY+xz8IP20/QL+fv4z/9n/0gAsAlgD0AOwA1ADzAJEAhwCSAIkApQBvADZ/4b+GP3g+6j6ePmY+Bj4UPfA9cDzwPHA72Du4O6A8QD0APXA9CD0gPMg88DzgPWg96D50PtG/ooAXAIIBHgFMAaABjAHwAjwCmANoA9AEQAS4BHAEaARoBFgEQARoBBAEEAQgBDAEEAQoA4gDHAJQAf4BWgF6ARABEQD3AE4AK7+TP3Q+wj6cPiA91D3kPfg9zj4MPiQ94D2wPXA9WD2QPdg+LD56PrQ+6j8iP0+/qD+5v5V/yEAQAFoAkgDnAPAA9ADrANUAxQD7AJoAnIBbQCZ/7j+tP3A/Mj7ePoo+VD4kPcg9iD0UPLQ8IDvQO+g8ODygPQw9XD1APXQ8wDzAPSA9hj5UPuc/QcAPAIYBGgFAAbgBTAGqAdAChANwA+gEUASwBHgEGAQgBCgEAARIBFgEUARIBGgEJAPwA2AC2AJ6AcIB3gG8AUQBcgDRAKTANr+SP3Y+3j6SPlo+Bj4OPhQ+DD4wPdA95D2APbg9WD2QPcY+Aj5SPqI+3D8AP1o/cD9EP6g/nP/jQCiAZACRAOcA5wDWAP0ApQCIAKSAeIAYAAEAH//iP5k/Sz8+Pqw+Wj4UPcw9vD0wPOg8kDxAPCg7+Dw8PLQ9BD2kPbw9aD0sPNg9HD2WPmg/MX/MAKoA4gEGAWABeAFiAbgBwAKwAxwD2AR4BFgEaAQ8A+AD4AP8A+AEOAQgBDgDyAPEA7QDDALcAmwB0AGOAWIBPwDbAN0AuMA8P78/GD7EPoY+aD4oPjQ+ND4iPgo+LD3EPeA9lD2oPZg92j4wPko+1j8KP2U/cz98P04/vD+AgAuAUQCKAPAAwAE8AOgAxgDgAIYAuABqgFGAbAA0v+U/iz98Pvo+tD5qPiQ93D2APWw86DyoPFg8KDvIPCA8VDzEPVA9iD2kPRQ88Dz0PWg+LD72P5eAegCvAOABDAF4AXABhAI0AkQDLAOABEgEqARoBCgDyAPYA9AEEARgBHgEEAQUA9QDiANsAsgCpAIGAf4BUAFuAQQBOgCLgEu/1j96PvQ+hj6sPlw+Tj56PiY+Fj4GPiw9zD30PbQ9lD3UPi4+TD7RPzU/AD9IP1w/QT+sv55/1MAPgE4AiADvAPgA5AD1AIEAnYBUgFGAS4B4QA3AAj/qP10/ID7gPqA+aj4wPeg9oD1gPRA89DxwPDA8IDxwPLA9AD3APgA9zD1UPQQ9QD3APqg/boAdAJUA0AEEAVwBbAFmAYwCCAKUAygDmAQABHAECAQQA/ADtAOYA/AD4APIA/gDoAO0A2QDPAKIAlYB+gFEAWoBFAEwAO0Aj4Bpf8O/pT8OPtA+sD5qPmg+ZD5WPkA+Yj4IPjQ96D3gPeg9zD4OPmQ+tj73Pxo/Yj9kP3Y/Xb+PP/5/7YAggFUAggDgAOMAwQDPAKSASwB/QD3AOAATgA1//T98PwY/Dj7WPpY+TD48PbQ9dD0oPNg8rDxoPHw8eDyoPRQ9tD2QPaA9RD1QPXA9tj5bP3b//YAtAGgAmgDKARABbAGIAiACUAL4AwgDtAOEA/wDoAOQA6QDiAPUA8wD9AOQA6gDfAMQAxACxAKwAh4B0gGYAXYBGAEmAOIAj4Bsf/s/WD8WPvQ+pj6iPqA+gj6SPnA+Ij4SPjw98D34Pco+MD44PlQ+4D8SP24/ez98P0i/qr+Xf8MANcA2gHcArwDMAQIBCADCAJEAfoAAAEkASQBrQCU/zz+DP34+/D6APoI+fD30Pbw9SD1EPTA8qDxMPGg8RDzIPXQ9pD3EPcQ9iD1QPUA9xj6HP1h/yQBjAJsA8wDOAQYBTAGWAfACKAKgAwQDhAPMA+gDhAOAA4gDlAOcA6QDlAO4A2gDVANkAxgCwAKcAjQBoAF2ASoBFgEwAPEAlIBfP+o/UT8cPv4+sj6kPpA+uj5sPmQ+VD5yPg4+ND3kPfA94j42PlA+0j8BP14/aT9tP3Q/SD+oP4+/w8AJgFkAkwDfAPoAugB1gAeAAEAXgDJAMwATwBZ//T9fPxo+7j6+Pn4+PD3IPdQ9pD10PTw8/DyYPLg8jD0kPWw9nD3cPeQ9gD2sPaw+Cj7qP3f/3gBRAKUAhwDGARgBbgG6AcACVAK4AtwDVAOcA4gDrANcA2ADQAOYA4gDoAN0AxADNALgAsgCyAKcAh4BuAE4ANsA1wDPANsAgYBX//g/Yz8kPvw+nD6CPrQ+fj5WPqQ+lj6oPmo+ND3gPcA+FD5APtw/Fj95P1A/lr+Kv4k/p7+K/+f/1cAjgHIAkwDDAOMAvgBVAGvAFkAPwBDACEAm//E/qj9cPwY++D5MPng+HD4wPcg94D2YPUA9BDz4PIQ85Dz0PRw9sD3QPhA+CD4GPiQ+AD68Pvg/cb/xgFQAxAEgARABVAGWAdQCGAJUAowCyAMQA0gDmAOQA7QDWANIA0ADbAMQAzgC6ALgAtgC9AKsAnwB/gFoAQQBPADwANUA5wCdAH5/5j+qP0A/Vj8uPtA+wD7CPso+0D7EPuA+rD5GPkY+Zj5OPoI+0T8fP0e/lr+rP70/rD+Ov5s/lf/TwASAcIBRAIsAqIBFAGaAAcAaf8U//D+0P6q/kT+SP3w+8j6+PlA+bj4oPh4+JD3MPYg9YD08PPA8zD0IPXQ9YD2gPeA+PD4CPlo+fj5cPp4+4z91f92AcACUAS4BSAG6AX4BZAGkAcgCSALwAxwDYANgA1ADVAMUAvwCkALkAuwC9ALEAzQC/AKgAngByAGaARgA2QDEASQBHAEiAPsAQMAUv4o/Xj8JPwo/FT8iPzY/Aj9iPxA+wj6oPnY+VD6EPsQ/NT8DP0o/Zz9PP6U/tD+DP8M/8j+8P6z/3cA2QA+AdQB+AE6AUoAtv87/27+sP2g/fD90P0I/Rz8cPvY+uj56PgQ+HD3wPYw9hD2MPZA9iD2EPYg9jD2kPZw96D4uPmg+nD7CPw8/KT83P1y/9UAWAIwBKAF2AVYBWgFaAaoB6AIUAnwCYAKIAuAC2ALEAugCjAKoAlQCWAJgAlgCSAJ8AhgCGgHYAaoBSgFqAQgBGwDhAK0AVQBNgEAAZIAJQCf/8L+uP3g/Hj8TPws/GD89PyU/bj9ZP0U/dz8jPxE/HT8RP0a/nT+mP4S/9T/QwAtAOf/mv8m/5b+Uv7q/gAAmgAXAPT+Ov7k/TT9NPyo+8D7sPtA+/j68PpY+vj40Pdg9zD3wPaw9mD34PeQ9yD3QPeQ93D3gPeg+ID66PuE/Mj89PwQ/ZD98P78AAADOAQ4BIwDhAOIBNAFeAbQBpAHoAhgCaAJsAlwCQAJoAiQCMAI4AjwCCAJQAnwCBAIMAeoBmgGMAbQBRgF6AOEAsgBGALQAggDgAJSAcn/Rv50/aT9SP52/hr+xP2s/ZT9aP1M/Rj9mPwc/BT8ePwU/dj91P5y/z//vP6O/pb+Xv5G/oj+zP6u/rD+Z/8xAOL/pP7o/fz9zP0I/Yz8qPyU/Pj7oPsE/FD8qPtg+jj5UPig99D3yPjg+TD6qPkI+bj4yPgw+cD5CPpA+ij7gPyM/TT+Df8HAHUAMAAMAIcACAFmAWgCkAToBiAIMAj4B8AH4AZYBXAEYAWABzAJ4AlgCsAKQArQCHgH0AZIBoAFCAWQBVgGgAYwBvgFuAXABPACBgH+/9j/HgDGALoBGAI2AREA1f+a/wD+YPwE/eD+Pf+A/v7+BwBe/7D9aP08/mz+XP4g/67/Df+k/oL/2f/E/mD+nP/Y/9T9UPxM/ab+Ov6A/Qr+FP4M/Oj58Png+pD6oPng+fD6SPuA+vD4IPdg9oD3MPlw+eD4aPno+jj7GPqg+WD6gPqA+Rj6xP2WAQwCJAB9/9EAxgFuAZwBIAMABFQDIANQBXAIgAoAC0AKEAhQBdQDcARoBqAIQApgCiAJMAhQCNgHwAW8A0ADSAM8AzAE6AXoBcQDlAJgA8wCwv9m/q0AoAIoARX/5P/EAf4Aav68/Tz/+P/4/ir+jv72/q7+1v7w/3IAN/+k/Zz9VP7E/Uj8NPwW/t3/JwCw/yz/yP0Y++j4SPlg+1z88PsU/Gj9yP0M/PD5SPmA+UD5GPmw+Rj6sPlo+fj5EPvw+zD8mPtQ+nD5sPlg+tj62Pse/l8ALgEUAeEAJQD+/vb+sQCIAgADGAOYBNgGeAd4BtgFIAbABVgE/AP4BRAIsAdIBvAG4AiQCDgG6ARYBVgFgAQoBWgHwAfIBJgBVAG0AgQDbAJcA9AFoAZYBHIB0f/C/qT9ZP2q/r0AOAJMAmwBNgDc/tj92P0G/vj8KPvY+hT9BQBAAc0A2P/8/SD7ePmA+kz83PwE/R7+MP9G/rj7CPo4+hj7sPtQ/PT84PwM/ID7sPuI+4D6uPn4+Xj6ePqQ+lj7QPy0/Kj8MPxY+8j64PpI+wj8zP09AMoBrgGDACP/Vv62/vz/dAHEAnQDTAOAAxAFUAboBFACVAJYBCgEQAKkA1AIYAqYBxAFEAawBhgD/v6h/+wCxAPQA2gHIAzAC4gGcAJNAIT88Phw+1ACMAZABuAHIAvACQQC6Pmg9tD3YPsKAPwDmAUgBVgDuAAM/mj8kPug+jj6IPyN/6ABNAFd/3T9OPwA/Fz8WPx4+2D6GPrg+lD88P0H//r+WP60/eD7APhw9MD1NPygApgDj/9o+yD6sPoo+yj7aPs0/NT84Pw4/eb+OAEUAm4AiP3Y+8j8cP/gAdACVAJ0AWIBZAKkA0gEQAQgBPADYAOYAmgCUAO4BAAG+AYoB7AFdANQAswC2ANYBFgEaAQABcAF0AVoBPgBJAAaAJABfAOwBGgE/AJsAYMALwAZABAAFAD5/9n/KgCzAPEAzABfAJf/fv5Y/WD8RPyk/fj/bgHzAHP/Pv5I/fj7GPsU/KL+4QBuAZEAqP6o+wD5SPnQ/ML/Q/9o/Zj9Lv8f/4T9NP1c/sz9MPvw+hz+OP8Q/Jj6Cv+kA7wBoP1G/gEAMPxw+IT8mAJEAnP/6/9rAAH/vf/IAb3/WPyA/wAG+AQK/nL+UAaABiz9gPoIA/AHUAKQ/dwBqAfgBZQAzwCwBEADCP2Y+wYB+ARoAzQC+AT4BeYBlv98AvgCjP0I+/z/YAQMA8QBaAS4BYQB9Pwg/b7+5P1M/WD/8QA6AAwALAIwBPwCJv/w+0j6GPnw+Tz+fAI8A0AC3gHlAFj+WPy4/ID9zPyw/AP/0gCp/2b+df+UAPv/hf8ZANb/VP5s/eD88PpA+aj7rgFABrgGuARoAQz8gPfQ9zD7BP6eAJwD2ASsA64B0/84/vz8OPyI/Mj+VAKYBKwDXgG5ALEAZv48/Lj9eQCSARwDqAUQBasACP74/ywCkwDU/UT+DgE4A8AEOAZABgAE+v+M/Kj9yAKwBBsAsPvo/VQDgAUoBDwDPAPYAAD8kPk0/CkAKgFaADwBYAMIA0P/UPww/bb+WP3I++T9pgHcAugARP4g/aj9wv5L/xH/vP4C/1b/Yv+3/0r/KP1M/A7/1AGAALT9pP4gAigCFP7I+1j9jP7M/Yb+OgHcAsgCJAKIAOj96PvY+5j9YP8BAGIBoAQ4BkAExgGh/8D6QPXQ9ogAsAhgCFAEmAL5AIz82Pls/dACQAMyABX/sv9W/4P/7gHYBIAFLANG/5j8WP0fAEQBGwC8AOwDoAQqAcD9BP6aAJIBM//8/Lz+lAIwBEwCpP7o+4D7OP78AlAEff+k/DQCsAccAqD2APQs/XgFcAQcAYgBXAEm/kz8pP0p/z//sv+gAQwD8gEG/0D8aPss/aX/wQBeAVQCmALEAZ8APP98/Wj8BP1g/hr/AgA0AtgDLAMOAWr+oPuY+2L/SAL4/3D8fv5YBEgGgAI5/zz/y/9NAAoBrP/4+9j6gf94BegG0AQQBDgENgFM/Lj56PlQ+/j9kAK4B/AIaATH/6n/tf/o++D4SPvh/zACwAPIBjAHigHA+xj8Av4w/Lj7SAEQBqwDoP+bAOwCUwBY+8D6aP7m/0L+/P5cAxgGSARvANj9lPz4+mD6Nv4gBGAFZgG4/tr/rf80/KD7UAFYBRIBiPuQ/TQDLAP8/Wj7ov5MAgABeP1m/igDgAR2AKT8HP1q/7T/V/8qAWgCPwCY/m4A+AEoAGz92Pzo/r4BZANsAmr+KPuk/QQDcAMPAJYA7AOoAWj6ePloAfgFoAEA/1wDoAT+/iD96AFgAlT8uPo+AEgDDgEsAbgEIASg/uD7cP6oAfoB4P6A+oD67AA4B6gGtAE6/6L/5P2I+jT8OAJABKMAmv5BAPD/Sv4kAsAGYgAg9mj4xAJgBPb+IgEwCLgEAPnQ9jf/GAJU/Tz94APYByAFZv/4+lD58Plk/Lb/7ALwBXgGaAHY+sD5AP0j/8T+PP5Q/+QAsgDY/zQBiAJ6/3j5oPf4/PAC7ALSAEQC1AJY/ij8EAKQBiIByPog/Ar/rv6iAEgF+AR9AOAAKAXEA/j9KP1L//j70PcM/YAH8ArIBigE7ANe/rD0MPO0/JAE+AIrACgEQAkIB6T/8PoA+/D66Phg+soB8AgwCRADlPx4+yj+yP6c/V7+JAAgATACbANMAzIBOP7I/E7+sgAcAeH/bwCsAwAE8v5g/MUAMASQAcb+UP6w+5j49PxQCHAOAAfQ+mD26Pjo+mD9KANAB1gERP5M/ED+KP74+hD7fwBIBNQCZAJwBAIBcPjw9cT82AIwAugA8APIBK//NP1vAB0ASPvo/FgF+AflALj6RPwX/z7+7P4QBAgHzAO6/zL/VwBdAAv/mP00/QD+Lf+oAXAF2AYgBFEAzv4e/tD7mPmY+zQBMARcA4wDEARzAOj73PyPABgAMP0K/sIA0/+O/jAC2AWQA3r/2v7O/oz8uPyKAXQDlP6w+1kAsAUQBWoB2P9B//j7sPiY+yADcAY0A6cAcAKUAhT9SPlo/fgChgEs/ED7LQDIBaAGLALA/Zz8cPsY+Gj4QQAgCJgHvAE6/6r+YPoA+G7+CAViAaD7mv4gBOQCmP46/rz/hv7s/CL/KAJAAUcAsAOIBFz9aPhk/rAEKAEY/YYBQAWG/yj6UQDwCHgFkPsQ+iD+7P0e/uQDwAbQAZz9o/9wAgwBqP6o/vr+LP4h/xACxAKlAIn/PwBiAA8AggAeAYQBZgHW/sD6+PqYAXAIsAjgAqz9KPwY/HT83P6AAngEUAMxAEz+PABEApT+qPlE/HgCfgGw+0z9yAYgCkcAkPaw+bMA4/84/a7/JAFA/sz90ALgBmwDQPzI+sD9mPyw+bj9yARABJz90PtAAgAHZAIU/Jj8CP7A+vj5ZQBYBogGEAR3AKD7WPouACAFnAAo+uj9mAUoBJb+JQAwBMoBzP1V/7QBkv5g+uz8EAQoB3gEdAKwAj3/KPgg9sj8yAXwCBAEnP0U/UkA5gGwAqQCYP8w+gD4hPwABZgGCf9c/oAJUAwA/rDyoPcSAD0A4P0nAPAClAJIBUALYAj4+wD2oPjQ9hD0Mv6wDVAPaAU4AQgERwBg9TDygPokAYP/qf8gBnAIoAKx/7wDXAMw+pD04PkUAcIB4P/7/8L/tADIBpAKUAOA+fD4MPyI+gj5Dv7ABGgF6gFWAcQDUAPq/3j9+PuI+1j9E/85/9cA2AN4BBgDRAIkAYj9yPlo+mn/0ANQBCADYAO8A30AAPuw94D5sABwCIAI3QBw++j9SAJqANj7Ov4ABbgEzP3Y+8gALAMD/6j7AP9ABKAEtAFMAOT/qP3A+pD7/gCIBfQDhf/k/rIBRAPyAdD9IPkY+eT91QAMASADQAWYA6UAHf8o/ej6YPs8/ir/gP2i/wgHcAmIAjD99P1o/BD4MPpwAWAEbAKkApAFeARO/jD6APzM/kT9GPp8/PAEkAogCOQCv/8o/ND2UPWI+noAoAOgBiAJGAcYAQT8EPqg+bj5OPyYAEAD/ANABFQDTAL4AkABGPqg9bj63AIABZQCagFYApADGATwAkX/gPtQ+2D9gv6+/wACQANIBCgGCAX3/+j64Pdg9zz8OAUQCcQDRf9YA5AFpPyg9Hj6CASsA1H/gAFoBRgCPPyw/BABhwCw+5D9OAfgCZYAEPqA/VD/iPmA96QBUA0ADEwAiPgQ+pD92P2I/Vf//AAgAYwCiASUAvz8EPo4/dwA+P6Y/OwA0AbgBHj+lPzw/QD9uPzFAMQDcAI4AVAC/wCw+wD5pP0QBIgEbgHU/8T+yP18/rX/wQCEAlwD1QBw/AD7tv68AiwCwQD4ArgD/P6A+1D+0ACI/ej6XP+4BaAGWASIA/IA8PlA9Qj5L//eALwCEAlgDbgHoPvg9Ej59v/e/jj82wBQBvAEfAIIBTAHJgEA9hDyAPn/AKQDsASYBmAGmALI/dj7oPzI/Jz8RP3k/Dj94AEQCLAJuATg+2D2KPmE/oj/Wv5t/zgCwAMwAo3/RwAgAh7/KPvU/eYBKv7Y+LT9cAewB7sAlgBABUsAsPUA98wB8AM0/uAAIAkgBvj6EPkQAPIBpv5cANAEcAJk/ET9DAOsAjT9JP1sAqQDxP9Y/ioBtgGU/cj7EAAEA4AAlf9AAwgEsv54+lT8vP/y////0AIYBOoA+Pyo/L//EAKw/8j7RP7YBXgHCf/g93z80ARcA/D8vP7gBAQD+Puo+6AC+AXnANj7mP0CAav/ZPw6/tAEsAa5/7j6kP/oA27+0PhE/jgGaAI4+UD65gE0A0gBMATIBJj8gPbg/GgFgAJY+jD67/+EArQC6APMA3gADP1Q/Ij9pf+SAXQBUACmAeACHf8w/L4BqAc8Akj4aPhWAQgGIAM2AIgAcAC4/sD9pP5wAVAEkAOL/9z8OPyA+3z90ARQCqgFWPyg+hcA2AEe/sT8PP6o/eT9yAKABqAE+AJIBK4AkPbQ8zj/kAhIA9j7cv7UA+QD+AIIBNwCSP44+vD4iPlY/MoBIAZIBrAEjAMkAbj9YPvI+eD44PmM/dwD0AkwCigFJP8w+tD2wPbA+yQDKAU/AAb/QAVIB1sAYPuo/Bj82PhU/DAFcAb8/87/qAX0Ayz8APsy/1j+KPuQ/rgEOAS5/6n/gAIAArb+eP0P/9f/5P5w/84BAAJaAHIBoATUA9z9uPlw/MsAhAAC/6wByAQgA/D/wf8/AOD9ePo4+lT+YAPgBBQDTAL0A2wDSP3Q9nD3Av5gAxgFAAawBRgBIPsA+3r/eQDa/nQB8AShADD50PpEA7AFdgDc/S0AvwC4/hL+sv4M/pD8TP0wAigHGAU6/hj8egD0Auj94Pcw++wDSAW0ACQB8ATwAkT8GPk8/JIAAgEgAMgBYAMMAg0AOf/U/g7+CP3g/TYBNAMMAlEArf++/zT/Mv6T/3QCRAHo/Nj8rgEgBYAEcAIqAUX/2PsY+lj7Tv6AA5AJ4AnyASD6UPpc/w4AOPyk/SAEEAQg/tT+eARwApj60Pr4AgAFBP8W/ggEnAPA+wD6ygCIA2T+kPvQ/jIBPAHoAxAGqgGA/DD9yP0Y+XD3pv8QCPgFxAAwBEAJdALA9XDzQPt2AO//8gBIBbAGEANh/37/mAH5AJz84PjA+Q7+sALABcAFFANPACr/hP4I/RD8Gv54Af0AUP2s/UQD8AWyAfz81P0jAAz+QPs2/igDIAIM/kD/MARwBDv/4Ps4/cT+Pv4X/1wC4AMsAuMARgHrAOL+8Pz8/DH/AgGCADoAzAKABVgE9P+Q/LT8uP2g/GT9SAOQBkYBNPze/iwCEf/I+3T/aATqAdD84v4wBOQCFP0g+6T9PAAcAXwBfAKwA6ADtwC4+xj5+Pu0AKwC6AJ0AzACAP6w+zX/iAPeAXz9RP2P/9X/tP/VAK0Aev+qAOwClgFE/VD7xPyo/Yj+6AKYBoQDyP6P/zQBhP2A+Yj7bgDEAnwDSAXYBUACHP14+uD5CPpc/bQDqAZcA2MApAL4BMABJPzI+fD5kPnA+0gDYAm4BsQBlAP4BeL+MPXQ9Zj9+QDS/9YBSAYQBkQCxgFUAxAAwPhQ9ZD5wgEwB5gGmALK/7H/cQDj/7z+IP4M/ZD8l//IA2QDBP+4/VAC6AXQATD7QPuW/3v/XP0+AbAHqAbs/sD6gP2K/8j8dPykAuAGQANI/4wA4ABk/BD6Bv74AaoBlgEgBGgEegB8/dz9KP3o+uD8kALoBGQDuALyAbj9kPm4+ij/CAG9/2T/aAE4A1gCxP/4/oz/ZP1o+jj9VANcAz7+rP3AAogFPAOHALr+sPvA+Yj8TgGcA4AEsAV4BEwAYP20/Gj7OPs1/6gD5AOEAkADZAPg/9j7YPvE/Cz91v4gA0gF/ALHAC4B/f9A+4D4YPyMAvgD9gEMAiADuQDc/Nz8QACcAe7+OP1YAPwD3AKs/xT//P5Q/Rb+TALUA9YAPv8uAQoBQP0k/EkAKAM8AEz9ef9YAs4BEAHsAYkAJPy4+hP/dAKl//z8VQBAA5//+Pva/kwDQAOYADT+qPu4+o7+0APUA0kAFQBUAsEAAP2c/ecAmwDM/lgB+ASgAqT96P2yAIz+2PrA/VgEmAVsAhQCdANfAIj7KPxu/+D9uPrs/RgF2AeoBCYBogD4/1T8mPlY+2T+8//6AQgEnAP0AsAEUAQM/eD1YPjE/4gAJv7wAkAJ+AXG/lD+lgAI/qD68PuQ/oj+ff9IBBAHdAM7/2n/S//Q+xD7z/+kArj+yPou/sgE0Ab4BKADtQDo+WD1UPjA/tQCwARwBSAEsAFE/yz9RPzk/JT98P2o/wQDKAV0AwEAfP5U/oz9pP1z//QA9gEQAxgChv5A/Aj9J/96AdwC4AGs/yn/VwBtAJj+OP4+ASgDnwBk/g0A/wCG/qT91wAkA5oBLwBYASwBrP0A/BX/zAGgALv/EAJ8A/0AOv6w/tX/eP4I/RT/JAIoAp4AZAEEA2YBhP3Y+wD9Uv5K/ywB6AKEAvUAQgBKAJL/2P2E/Ij9+QCIA5wCWADg/xYA9v5C/pn/dwDK/pD9CwBwA1ADIgGbAE0AgP0w+2j9uAFkAnz/Mv4RALIBsAGyAagBJgA8/qD9gP04/Zb+ugEoA+QBhgE4A8gCnv6A+zz9nQC8APT+q/+EApwDvgEn/+z93P0w/kv/agHoAngCvgDS/pD9kP1w/jf/RQBUArwDsgHA/Wz9KgHUAiMAnP3U/XT+Bv40/nQAoAP4BEwDSQBs/lT+Bv5k/Oj7cP6IASwD4AQoBlgD1Pzg+BD7B/9JAEcAkAHQAkwC6gDL/wf/zv6d/3gAn/84/gL/+AASAUMAIAFsAmABzP7s/T7/AgBe/0v/TAAaASoBeAB+/1L/jv9H/yL/ev9//43/vwA8AjgCowAg//T9ZPxM/Kr/CANkAvYATAKoAvD+0Psk/WH/Tv9//+IBkANAAgMAXP9B/zb+xP1K/8YAowBDAI0ABAF8AVQB4f9Y/vj98P2c/XT+bgFABFwDyv80/kH/if/o/mb/5v8K/1D+9P5qAMIBEAIgAeT/EP/y/pT/JgDf/yD/1v53/7kAqAGGAVgA5v4O/zoBcAJsAGj9lPw8/jQBuAOEA3YAEP6A/p3/U/85/5cA/QDe/nT9yv9IA8QDrgGU/+j97PzU/bf/swDkAEAB3gGkAqwCvgD8/UT98P5BAKb/Gv8YAO0AGgHAAnAEGAL8/ez9VgCw/lj6IPumAdAFaAScAjAD4AEs/QD6OPuY/Vr+f//IArAFcATY/9D8rP0U/+j9tPyk/hoBagAt/zoBmAPMAXj+Ev7y/vT91Pwq/mcATAGKAUACbAJQAdH/Zv7w/Lj8rP75AI4BLgF0AcoB9ABZ/1j+qP7T/1gAtf+d/9cASAHk/wj/SwCWAXEARv46/lEA3AEQAvQBSgFc/7z9Qv7O/4oArgD4APcA4gCyAVwC4wCI/mL+6/8FAM7+Tf+WAWAC0ADC/2MAlgBz/9L+tv+8AIEAq/9+/7v/av/8/oD/dgCeAHEAhAHMAvwAPPxw+Xj7NP8sATQCpAPEA2QBBf9E/lj9cPtA+zj+wgG8AqIB+QBAAeEAD/8Y/bz8Lv6F/0f/xP76//IBCAJTAEj/jf9b/zj+1P0M/58AVAF2AaQBbAEnAJj+Iv4A/2AAwgG4ArQC0gG8ALT/AP9g/7EAXAH9AD4BgAK0AnAB7QBwAc4A/P6Y/nMAXAKgAiACrgGLALr+Kv5h/5MAywDtADIB+gB8AHEAOwDi/nT9wP0f/63/l/8vAAQBrgBr/6b+tP6W/tj9aP0+/lj/UP/i/qj/2wBMALT+pv6p/9D+ZPwA/Ej+WQD2AIYB6AGmAIL+fP18/Zj9Xv4lAIIBrgHMASwCTAEX/+j93P4JAA4AQwC2AfwCeAICAX0A8wAGAV0A9/9lACABWgHtANcAyAHsAgwDPAI6AS8ATf9v/6IAjgGkAfIB5AIYA8wBdwCTAAYBNwAw/4r/hgC5ANQA0gFYArsALP5E/Qb+bP4i/iL+mP7U/rb+ZP6g/aT8HPwQ/Pj7+Ptg/PT85Pxc/ED8rPz4/Aj9AP2I/Ij7wPo4++z8sP5z/yD/av4I/gb+Vv7s/lr/Zf9Y/8v/4gAAAlwC+AGgAdABZAIIA5ADxAO0A9gDOAQ4BOADGATIBPAEsARQBQAHQAhQCNgHGAewBRAEiAOQBDAGQAfIB4AIAAkQCJgFBAP6AfoBjAHbABwB/gEIAh4BXwCh/7T9+PpY+UD5EPkg+ND3kPjY+LD3gPYA9mD1UPTw87D0MPXg9LD0UPXQ9RD2sPaA9+D3QPgg+SD6gPqI+hj7DPzQ/KD9IP99AKAANgDLAP4BbAIkAjgC0AJMA5QDWARgBbgFUAVABbAFsAX4BCAE7ANgBAAFsAVQBrgGiAbwBYgFcAUgBdAEMAUIBmgGiAYoB8AHYAcgBogFKAbYBgAH+Ab4BrgGkAbwBqAHIAgQCBgHMAUEAywCNAOgBCAFEAXwBOADqAFa/7T9YPww+8D6cPsw/MD7oPpQ+XD3wPSQ8tDxYPJQ8/DzcPQA9fD0UPSA8xDzAPMw8zD04PVw93D4APmw+bj62Puo/Dz9Hv5c/2MA8gB+AVACKAMIBFAFcAZgBngFCAUYBcAEWASwBLAFKAYIBgAG8AXwBFADWAL8AaIBYgGSAd4B3gGiAVgBygCz/5z+IP4e/hL+DP5M/sz+O/+U/9v/yP8U/wL+cP28/W7+9P6h/6QAPgEUAekAZAHGAZABbgEQArwC+AJsA9AEGAZIBjAGsAZgBzAHWAboBagG0AdwCJAIwAjACFAIcAcoB4AH4AfIB5AHIAcQBnAEzAJCAf7/Vv8i/+j+Xv6E/ST8KPrw9zD2APXg8+DygPLA8hDzAPNw8sDxMPHA8GDwYPDw8ODx8PLw8+D00PWQ9mD3ePiA+Uj6OPuw/Ej+cv91AKIBjAIcA9AD6ATYBTAGaAYAB4gHoAfABzAIgAhACMAHWAcAB6AGMAbIBXgFMAXQBEgE4AOAA+QC3gHeAEMA3/9s/w3/1P6y/nL+KP7g/aT9WP0E/eT8+Pwc/Vj9mP3c/Ub+zP5//woAYQCeAAQBugF8AkgDKATwBGgFuAVYBigHEAggCSAKQApgCaAIsAgQCWAJMAqAC3AMQAygCwAL4AkQCGAGgAXwBHgEgASoBAgEMALN/zz9gPpA+DD3EPew9uD1APUA9GDycPAg74DuIO7g7eDtgO4g72DvYO+A7+DvwPAg8sDzMPVQ9lD3IPgA+RD6uPus/XX/xwDMAaQCUAPsA+gEKAZQBxAIsAhQCcAJ8AngCbAJkAmACbAJAAoACtAJUAlwCHgHiAbgBWgFGAWwBOwD9AL8AUIBjADh/1T/rv44/uz90P2I/QT9jPxI/Bz8APwE/FD8gPyE/Jz8/Pxc/cj9YP4i/8z/hgBwARgCTAKgAowDoASQBfAGwAjgCcAJEAmACEAI2AcwCJAJMAsgDLAMUA0wDRAMIAogCIgGUAXYBBAFcAUwBSAEdAIRAED9uPr4+MD3wPbQ9QD1EPTg8rDxoPCA74Du4O2A7WDtYO2g7eDtIO5g7mDvgPCw8fDyYPRw9SD28PZo+Bj6sPtQ/Q3/dQCQAaACvAPoBCAGUAdgCEAJwAkwCoAK4AowC4ALgAtwC3ALcAswC2AKYAmACKgHsAawBRgFgASoA5QClgGuALr/oP58/Xj80PuQ+4j7aPs4+9j6KPpo+Rj5YPng+TD6qPpw+zj8iPzc/Mj96v6j/0gAjAHkAngDsAOABLgF8AZgCCAKgAvQC2AL4ApgCuAJAAogC6AM0A3QDnAPIA+gDXALUAmIB1AGEAagBhgHoAZABQwDAwDU/ED6mPhQ92D24PUw9bDzwPEw8MDuQO0A7MDrAOwA7ADsYOzA7GDsYOwg7aDuEPBQ8bDyMPRA9TD2wPeY+Wj7FP3i/m0AkgGYAvQDUAVQBmgH4AggCsAKQAsADJAMoAxADCAMQAxQDFAMYAxADHALQApQCZAIoAdoBmgFmASwA7ACBAJ+AX0ANP8E/gz9HPxw+3D7oPtg+8j6YPog+tD5mPn4+aj6IPt4+/j7sPwM/Yz9mP7x//4ABAIYA8QD6ANwBPAFkAewCNAJMAuQC/AKgAqQCrAKkAogC5AM4A2ADsAOsA5gDQALsAhQB3AG4AX4BXgGCAYYBKYBJP9M/HD5cPdg9pD1kPTA8+DyYPFg74DtIOwg66Dq4OqA6+Dr4Ovg60Ds4OzA7QDvkPDw8SDzcPTw9WD38PjI+rz8bP7r/3oBFANoBHgFgAawB9AIwAmwCsALcAywDKAMkAxwDCAMAAzwC9ALUAugCvAJMAlgCFgHSAYgBfwD5AIcAnoBwwDI/7z+sP28/OD7YPs4+yD74PqY+lj6yPkw+Sj5kPn4+Vj6QPsg/Gz8mPw4/QL+tv6Y/xwBkAJEA7ADeASABUgGUAfACBAK0ApQC9AL0AtgC/AK8ApQC/ALEA1wDkAP4A6ADcALsAm4B1gGuAWABUgFwAS4AwwC0/80/XD64PfQ9ZD00PNQ84DyYPHg7+DtAOzg6oDqoOqg6sDqIOug6wDsgOyg7aDuwO/w8BDyUPPQ9ID2SPjw+aD7WP0M/5EA+gFUA4gEkAWwBgAIYAmACkAL4AtgDKAMoAzADOAM4AzADIAMUAwADFALcAqwCaAIgAdgBqAFAAX4A+AC4gGoAD//Qv7U/Wz91Px0/DT82PsQ+3j6MPrQ+Zj50PmA+iD7kPvo+1z8oPzM/Ej9Vv6k/+IA9AHYApwDSATIBLgF8AZACCAJ4AmgCjALMAvwCtAKsArgCqALIA2QDiAPwA6gDdALoAnIB9AGYAYYBuAFoAXABOgCUQB8/aD68Pfw9fD0oPQg9HDzQPJQ8CDuQOxA6+DqoOrg6mDrwOvg6yDsIO0A7uDu4O9A8ZDykPPA9HD2UPjw+eD7KP5IAKYBkAJ8A4AEWAV4BiAI0AkwCyAMwAwwDQANwAzQDOAMsAyADKAM0AxADFALYApwCTAI8AYgBoAFoASAA2gCSAHm/6r+2P1Q/dz8cPwc/Kj7GPuQ+hj6mPk4+TD5kPkY+rD6WPvY+wT8RPz0/KT9cv54/8sA5gGYAkgDWARoBTgGIAdQCFAJAArACqAL8AuAC9AKoAoACwAMYA3QDoAPAA/ADRAMIApgCEAHmAYQBqgFUAWIBMQCLgBY/Xj6wPew9cD0UPSg83Dy8PBA70DtoOug6iDqAOrg6SDqQOqg6kDrAOzA7ODtQO9g8HDxsPIw9MD1UPco+Xj76P33/5QB3ALcA8gE2AVQB/AIkArgC/AMgA3wDTAOQA4wDiAOMA4gDtANgA0QDZAMkAtgClAJQAhoB0gGCAXIA6gCdAEUABP/av7o/Rz9YPzg+1D7mPoA+tD5mPkw+ej4KPmo+QD6iPow+8j7OPzo/ND9tv5f/wkA9gC+AbACEASQBbgGgAdACAAJcAnACWAKAAsAC7AKsAowCwAM8AzwDYAOAA6wDCALcAngB6gGyAVABdgEUAR8A+QBn//s/AD6UPdg9VD0kPPQ8tDxoPAA7yDtwOvA6iDqwOmg6QDqgOrg6mDrIOwA7QDuIO9w8NDxEPNw9OD1kPdw+aD7zP3Y/6oBLAN4BMAF6AYgCHAJ4AoADPAM4A3QDjAPIA8AD7AOMA6QDUANAA2gDEAMwAsQC+AJgAjwBoAFAASgArYBBAFMAIz/zv7k/Zz8kPvY+kj6yPmY+aj5mPlg+SD5MPkw+Uj5uPmA+mj7VPxQ/Tj+0P5E/+X/qQCOAdACcAT4BQgHAAjACFAJ0AmACjALkAvQCyAMgAzQDFANMA6wDqAOIA5wDVAM0AowCegH4AYABkgFoAS8AxgCvv/4/Dj6wPfw9bD00PPQ8nDxAPBA7qDsQOsg6mDpIOkg6YDpQOrg6oDrIOzg7KDtwO4w8NDxgPMg9cD2ePg4+hT8Fv4iAOQBaAPwBGgGkAegCPAJUAtwDGANMA7gDjAPUA8wD+AOMA6gDUAN0AxADPALkAvACpAJIAiYBtAENAMAAkQBwQAOAEf/cv6A/WD8OPto+tD5gPlI+UD5ePm4+bj5ePmQ+dD5WPro+uj7LP1W/gj/if8aAK0AjAGcAggEcAWoBsgHgAjwCGAJAArACmALIAygDAAN4AzwDFANkA2gDYANYA3ADIALMAoQCQAIuAagBcAEuAM8AmQAcP5A/Nj50Pdw9iD1sPOA8mDxwO/g7YDsQOsA6gDpoOgg6cDpgOqg66DsAO0A7WDtQO5g7wDxEPNA9UD3IPnw+nz82P1R/6IA3AFkA1AFSAfgCCAKcAtgDOAMUA3wDXAOkA6QDqAOYA6wDfAMcAwQDIAL0AoQChAJ2AdYBhAFxAOIAngBtwD5/yb/Xv6A/ZD8aPtw+tD5gPlQ+Vj5kPnI+aj5iPmg+Qj6cPo4+3T8lP1U/uT+pP8vALAAhgH8AkAEMAU4BkAH2AcACHAIQAnwCYAKUAtADHAMUAxQDJAMcAwQDBAMEAyQC7AKAAoQCaAHGAboBOADoAI2AcP/SP48/AD6CPhg9vD0gPNQ8kDx4O+A7uDsQOvg6QDp4Ohg6WDqoOsA7cDtAO7g7eDtIO5A70DxwPNg9uD4+PqY/Jj9fP5i/28A7AH0A2AGoAhACpALgAzwDFAN4A2QDiAPcA+gD1AP4A4wDrANUA2wDBAMcAuACjAJ2AeQBlAF9AOwArAB1gDb/+D+CP4k/fD70PoQ+nj5APnA+OD40Ph4+Fj4wPgo+Yj5WPqQ+3j88Pyg/ZT+W/8HAB4BiALEA7gE6AUQB+AHYAgACaAJMArgCsALoAwwDaAN0A3ADXANQA0gDcAMYAzQC0ALUApACRAIgAboBEwD/AGZAOj+IP1g+3D5YPeA9QD0sPJQ8RDw4O6A7eDrQOrg6CDowOdg6MDpQOvA7KDtwO2g7SDtYO3A7uDwkPOA9mD5oPsU/RT+2P6A/4EAbAL4BJgHAArgCyANgA2gDfANgA4gD6APIBBAEAAQgA/wDnAOwA0ADTAMMAvQCYAIYAc4BtgEkAN8AmwBTwAn/yD+CP3A+4j6oPkw+fj44Pjg+KD4SPjw9+D3CPiI+Ej5MPoo++j7rPyg/Zz+Zf80ADYBUAJUA3gEwAUIB/AHkAggCcAJcAogC9ALgAwQDWANkA2QDYANQA3gDHAM4AswC5AK0AnQCHAH+AVoBMwCRAHJ/1z+fPyQ+sD4APdQ9aDzMPLg8IDvIO7A7GDrwOmA6MDn4Oeg6ADqwOvg7EDtAO0A7SDt4O2A7/DxsPQw95j5uPtI/TT+Bf8GAGQBQAOYBTAIYArgC8AMcA3QDTAOwA5gD8AP4A/gD5APIA+wDiAOgA2wDJALQAogCfAHsAZ4BTAEFAMAAtwA0f/E/oT9PPwQ+1D64Pl4+UD5IPng+GD4APjw9yj4sPhg+XD6WPsk/Oz81P2e/lD/KgBEAXACdAPIBDAGUAcQCMAIcAnwCXAKIAsQDMAMIA2QDdANwA2ADTAN0AxQDLALQAugCrAJoAhoB+gFQASAAugAYv/I/Qj8UPqI+MD28PRg8wDygPAA78DtoOwA60DpAOjA5wDo4Ohg6kDsIO0g7eDswOxA7UDuUPAQ86D14Pcg+jD8lP2C/mP/pAAsAgAEWAbgCAALYAwwDcANIA6ADiAP0A8gEEAQQBAAEKAPMA+QDuANAA3gC8AKoAlgCBAHAAb4BNADqAK4Aa0AP//M/YT8ePt4+gD6GPoY+nj50PiA+CD40Pfg95D4WPkI+tj64PuY/Bj91P3S/rv/qwD4AVgDkASIBYAGYAf4B3AIQAlQCkAL8AuADBANMA0QDeAM4AzADEAM4AuQCyALUAowCQAIuAYQBXgDAAKMAOb+JP2I+8j5APgg9pD08PJA8cDvYO4A7cDrYOpA6UDoAOig6ODpQOsg7IDsgOyA7KDsgO1A75DxAPRw9vj4GPvA/OT9F/9KAHQBHANwBQAI8AmAC9AMsA0gDnAOIA+wD+AP4A8gECAQoA8gD7AOEA7gDMALsAqQCWAIOAcQBrAEUANEAmQBOwDu/sj9tPyQ+5j6OPoI+rj5SPnY+ID4OPgo+Gj4APmw+Vj6IPv4+9z8pP1s/k//QABCAWgC1AMgBUgGCAfAB1AI8AigCZAKoAtwDBANcA2wDYANQA3gDKAMUAwQDLALQAuACnAJMAjABkgFiAMIAooA1P78/Ej7wPkA+BD2UPTQ8iDxoO9g7gDtIOtA6WDoQOiA6EDpoOqg66DrYOug6wDswOwg7lDwsPLQ9BD3WPk4+1z8eP3a/kIA6AE4BAgHUAnQCgAMEA2wDRAOoA6gD2AQoBDgEAAR4BCAEOAPMA9ADiANEAwgCyAKAAnYB7AGaAX4A6gCdAE0ANL+iP2E/LD7APuA+iD6mPnQ+CD4wPeg99D3QPjo+Ij5KPr4+sD7gPwo/eT9vP69//kAaALYAxgFIAbwBqAHUAggCSAKIAsQDLAMEA1gDZANcA1QDRAN8AyADPALcAvQCuAJgAgYB5gFGARkAsIAEP9E/Zj7CPpQ+ED2UPTw8oDx4O8g7sDsYOug6YDoYOgA6YDpYOpA68DrYOsA64DrwOxA7jDwgPLA9OD20PjA+hz8DP0y/sf/zgEYBKgGEAnQCvALwAyADfANcA4wD9APIBBgEKAQoBAAEFAPkA6ADUAMMAtgCnAJMAgYBwgGyARIA94BsQBb/yL+EP1E/HD7uPoA+mD5oPgA+LD3oPfQ9zD48PiQ+SD6uPpw+xD8mPxk/Xb+s//pAEACnAPABHgFOAYIB+gHwAiwCeAK0AtwDOAMIA0gDQAN4AzwDMAMYAzwC3ALkApwCVAIMAeYBdwDeAIIAT3/UP3o+6j6mPhA9qD0cPPw8RDwQO7A7ODqgOlA6QDqgOrA6gDrIOvA6kDq4Oog7IDtwO7Q8DDzMPXQ9oj4KPoY+zD8CP6HAMwC+ARIBzAJUAoQCwAMAA3ADYAOoA+AEMAQ4BAgEQARIBBQD7AO8A3QDAAMoAvQCoAJEAgYB8gFEASwApIBVwD6/gT+aP2U/Hj7kPrw+SD5UPgI+ED4iPjA+DD5uPkA+ij6sPqw+4D8NP04/oH/rwCYAbQC4APIBGgFWAagB7AIcAkwChALoAuwC8ALIAxgDEAMEAzwC4ALkArACTAJcAj4BnAFQATgAg4BWv/o/WT8iPrI+ED3oPXg81DyAPFg72Dt4OtA6+DqwOpg6yDsQOyA60DrYOsg7MDsQO5Q8ADycPNQ9XD34Pjw+Vj76Pxa/hUArAJQBSAHYAjQCQALkAsQDDANcA4AD1AP8A+AEGAQ4A+wDzAPMA5QDcAMMAxAC0AKkAmQCAgHiAVwBGQDIALxACIAVf9O/hT9PPyQ+8j6EPrQ+dj50PnQ+Qj6cPqg+qj6CPuY+zj83Pzw/Tn/NQDuALgBwAKAAzAEKAV4BoAHMAgACeAJcAqwCvAKYAtwC0ALQAtQCwALMAqQCRAJIAi4BngFgAQYA1wB0/+E/tT8+Ppw+RD4MPYw9NDyoPGg74DtgOxA7CDsIOyg7MDs4OsA6yDr4OuA7GDtAO+w8NDxQPNA9fD24PfY+Hj6HPyU/a7/hALYBBAG+AYwCEAJ8AngClAMgA0QDpAOQA+AD1APMA8QD4AOoA0ADeAMoAzwCzALYAowCZAHKAZABXAETAM4AmoBiQBP/y7+cP2w/Nj7KPvg+tD6sPq4+sj6yPqg+qD6+PqA+yT84Pyw/Yz+Nv/D/50AkgFcAhADCAQIBdgFeAZQBzAIgAigCAAJgAmQCVAJYAlwCQAJIAioBxgHGAbIBLQDlAIQAZb/fv5A/YD70Pmw+ED3YPWw82DyAPFA72DuwO4g74DuAO7g7WDt4OwA7QDu4O6A73Dw4PFA83D0wPVg93j4KPlw+lz8VP4TAPgB4AMoBegF0AYwCHAJUAowCyAM4AwwDYAN8A0gDvANgA0wDdAMgAxADAAMkAuwCpAJgAhwB4AGwAUIBVAEJAP6AR4BaQBh/37+9P2g/SD9iPyI/MD8pPws/Pj7FPwo/GD8CP3s/XD+yP5F/9P/NQDCAKIBfAIAA6wDiARIBbgFWAYQB2gHUAdgB6gHsAeIB3gHgAcgB2gGsAUgBVgEOAMEAgQB2v90/hz9APz4+rD5QPgA97D18PMw8lDxMPEg8fDw0PBg8GDvoO6g7mDv4O9Q8ADxQPJA8yD0QPWQ9nD3GPgY+Xj6JPzo/cz/eAGEAiwDEAQwBUgGcAegCJAJMArQCmAL0AsQDDAMYAxADNALsAsQDDAMwAvwCiAKUAlwCMgHeAcgBzgGMAVwBIQDbAKeATQBpgDO/zj/+P66/kr+BP7k/XT94PzQ/FD9zP0G/lr+wv7o/t7+Mv/8/6oADAFuASQCrALwAlAD/AOQBJgEkATgBCgFGAUYBVAFUAXABBAEqANgA7AC0AE6AX8AZP9A/oj94PzQ+3j6UPlg+ED3EPZA9cD0YPQw9PDzcPPA8jDyEPIw8kDyoPJA8/DzgPRA9TD2APeg91j4UPlg+kD7dPwa/m7//P+aALwBzAJ0AzAEaAVoBsgGMAcgCNAI4AjwCGAJsAmACZAJEAowCsAJcAlgCdAIAAjAB9AHeAewBjgGCAZoBXAE6AOsAxQDRALkAfABqAEMAY4AZAAJAHH/N/9h/4//lP+c/8n/7v/y/w8AYgCKAJcAywBMAb4B8gE4AqgC/AL8AvgCPAOUA6QDmAOcA5gDVAP8AsgCiAIMAn4B4wAhAFP/pP4u/pz9rPyw+9j6+PkA+Uj44Pcw90D2gPUw9fD0kPSQ9ND0oPSw80DzAPTg9GD18PXg9oD3oPcA+OD42Pl4+mD7hPxE/cD90v4kANYADgGcAZACJAOAA4AE+AWwBmgGWAb4BnAHcAeoB2AI4AiQCCAIQAiACFAI8Ae4B3gH8AZ4BnAGkAYgBlgFsARABKADHAMYAxwDlALSAWABHAG2AGgAbgBsABAAov+n/+n/EgARAAQAAAD6/wEAFABbAM4AIAEiAfoA+gA6AaQB2AHSAcQBygHEAZgBggGmAaQBEAFXAAUA5v9s/8r+hv5G/nT9VPy4+3D76PoQ+oj5QPmg+PD3wPeg91D3MPdQ99D28PUQ9gD3cPcQ96D3+PhQ+WD4ePgo+lj7CPvw+jT8fP2A/Yj90P4jABYAof93AAgCyALIAkADQASgBGAEoAR4BeAF0AUQBqgG2AZgBigGsAYIB3gG2AXwBTgG8AWQBagFoAXoBCgEGAQoBLwDUANUA0QDwAI8AhwC9gHIAb4BpgFGAQgBQAGgAX4BCAE8AcoBggHKABQB/gEUAoIBegH6AQgCoAGgARwCKALAAZYBuAGcAVgBPAEkAecAngA9ALD/N/8G/77+Iv54/Qj9tPxI/LD7GPvQ+nD6oPn4+BD5MPl4+HD30PcA+bj4EPcQ97j46PiA95D38Pko+4D5cPho+lD8aPug+kz82P1Y/Qz9sP4UAH//zP4RAMABpAEWARwCmAOgAwQDVANABJgEeATIBHgFmAUoBUAF4AXwBWAFOAWwBdAFcAUYBRAFKAUQBaAEIATUA9gD/APQA1wDIAMUA7gCWAJUAmACQALuAZYBrgH8AdABWgFiAcQB2AF0ARgBagEAAuYBVAFUAcIBrgE0ARgBiAG4ARwBZwBwAOsAsgDk/5f/8//Q/7L+7P1s/t7+0P10/JT8UP2I/PD62PrY+3D7yPlQ+Uj6cPpQ+fD4mPmY+cD4iPhY+cD5YPk4+dD5kPqw+mj6iPoA+6D7KPxM/Dz8yPzg/Xz+Uv5G/ib/EwDy/73/2wAMArwBQAEEAuACxAKsAnwDKATIA1wDGATQBGAECATABCgFeAQgBOAEWAWgBCAEuAQgBWgE4ANoBNAEUATUAwgEKATEA5QD6APkA1ADIANwA3wDFAPgAhgDFAOcAlQCrALYAmACFAJMAmQC/AGeAc4BHAK6AQwBEgFmAQoBVwBrANMAVABe/0v/7/+i/3L+KP7C/nL+MP3A/GD9WP0w/ID7HPx4/ED7APqQ+qj7yPo4+Zj56Ppg+pj46PjI+pj6iPh4+ID60PpA+Uj5APuI+6D6UPoY++D7TPyc/NT84PxA/SD+jP5W/r7+wf/z/47/JABWAZoBKAFcAVgC5AKAAnQCSAP4A+ADvAMYBHAEiASQBOgESAVQBRgFMAVwBXAFUAVgBZgFiAUQBegEQAVoBfgEkASQBKAEWAQIBOgD2AOYA0gDHAPoAogCSAJEAjAC1AFqASABBAECAcQAZwAyAPH/of+O/43/Jv+i/oj+oP5W/tD9sP3g/aj97PyY/PD89PxI/Pj7SPxI/LD7KPto+8j7YPvA+sj6IPvo+pD6qPrg+sj6ePqA+uD6CPvQ+vj6cPuI+1j7uPts/GD8+Ptw/HT9zP1o/ZT9qP5K/9b+sv6//4MAFADi//YA6gGCAQoB2gEAA/ACQAK0AvgDOARoA2wDgAT4BHgEQATwBHAFAAWIBAgFyAVwBYAEuATQBZAFOAQwBGgFYAXwA6wDmASIBFwDCAO8A6wDpAI8ArwCvALAAWoB6gG+AbwAfAAWAQIBEQCu/xEA7P9C/yv/c/8w/4L+Rv6a/pr+3P2A/cz9uP1A/TT9SP3w/JT8nPzE/KT8KPz4+0j8UPzY+7j7MPwo/HD7QPsA/Fz80PuA++j7WPww/Lj7CPzg/Nj8KPxk/Ez9cP0Q/VD9FP5Y/g7+Hv7G/iT/Lf+S/9//1/87ANEA5gDxAFABngHOAfoBWALoAtgCbALoAtADxANUA4QDEARwBEgE1AMYBNgEoATQA/ADwAS4BAAE6ANgBDgEfANEA8QD5AMMA3AC7AJAA2ACjgHMARwCpAHnAL4AJgEQAQwAef8AACQASv+o/uj+Nf+k/uD9IP6i/vz9KP2c/Sz+oP3w/BT9eP1I/cz87PxM/fz8nPz4/DD9vPyQ/Nz85PzE/PT8FP3o/Mz8/Pw8/UT9DP0I/WD9qP2U/Xz9vP0i/jb+/P0Y/sD+Hf+0/pj+ZP/W/33/fv8gAIgAZgBmAN4AXAF0AUwBfAHqATgCMAIYAmgC7AL8AswCDANwA1gDQAN0A6ADlAOQA6gDxAOkA0QDVAPAA7ADOAMcAzADHAPgAqACkAKQAkAC0AHWAeYBegHzANwAAgG7ABoA2/8SAP3/cP8c/zT/J//K/oT+jv6E/jb+Av4K/gr+4P3A/aj9eP2A/aT9jP1Y/Wj9mP2M/VD9ZP20/bj9fP2U/ej9/P3M/dz9Mv5G/jL+Rv5w/ob+rP7i/uT+1v76/jr/Tv8i/zb/pv/R/4L/ff/+/0oAAgDB/zIAjwBJAA0AigAAAZYAPgDVAFAB3QCHAP8AWAEeAfIALAGIAYYBLAEcAWYBvgHCAXABVAGsAeYBiAFcAcAB4gGQAV4BngHQAaIBcgGAAZoBYAEkAVABXgEWAegA8wDaAKYAdQA0AD8AZAAnAOb/5/+0/1//XP9y/3r/R//G/qD+CP8X/6D+jP6w/pD+Yv5G/lT+gv5I/uz9TP6G/vD9vP1Q/pL+Tv40/ij+TP6c/pr+kv7i/uj+pP7y/lb/Sv8//1n/iv/G/73/mv8EAHkAIwDe/0wAqACFAHUAowDVAPwAvQCjAAYBOgHuAMoACAEQAfkA8AAEASQB+ADEAPwAJAHYALoAyACeAMUABAHWAHoAjwC8AHsAiQCIAC8AdgAEAYgAy/9WAOUAhQD+/xkAywCyALP/0//zAJcAYP/L/9cAeACq/7//HAAyAO7/of+Z/93/CQCe/zv/lv8jAGX/ev7F/54A1P7k/ez/2gCU/pz9sP/dAMr+VP1d/50Atv6U/Xf/fwB0/qj9tf+gALT+6P2i/5MAM/9M/gIA8AAY/4D+qgAkAUj/Tf82AUQBmP+9/4ABNgG7/7QAIAIQAcL/5gBQAmQBPwAuAVQCIgGY//MABAMYAqD/ov8IAnQCQwBX/x4BrALTAKD+LwBkAgwB2P7q/9ABvwBu/kf/sgHvAPr+gP+XAKX/Gv+QAN4Azv5U/u0AZgFW/tD95wC2AYT+gP34AMQBIv6k/XwBogHA/Zj9LgHkAXr+TP2RAAQCCf9o/cP/EAFQ/1z+g/87AIb/tP6w/rb/QQAW/3D+Of/U/3r/0v7y/r7/rf+I/pj+BwAtAPT+qP53/+X/b/8d/1n/3f/X/zz/dP/7/9P/d/+a/zIAcQABAMb/VACCANH//v/XAJsARwB2AJ8A9ADBADoA0QBoAYwALAAoAWQBuQCbAOgA7ACdAJsA+ADyAFUALABQAT4Bk/97//0AQgGo/3X/yQCmAJ7/s/9vABoAI/+y/14A4v/H/wAAU/9P/9sAFwBC/o//NAEvAOb+GP8YAKwA8P8m//7/fwCh/9r/TQAFAE4A2f/s/un/cAGIANT+qf8UAXwAEv+A/wIBhgBa/1f/JgC9AMT/XP5o/7gB2P+E/an/VgFl/3z9W/+MAej/JP32/kACof+Q/J//iAJw/+D87P8oArn/VP2Z/3ACNgCE/df/vAJUALT9HgDIApgAEv7i/8QCtAH4/Wr/1APMAUz9j/+YA3IBgP6ZALQCxwCA/ioAPANsAUL+hf/yAbABlv82/4wAQAKOAKT9zP/mAbMAAv9a/68A0ABd/+j9igA8Asz+JP2HAGwCEP/A/KD/oAKjAIz81P2YAoYBfP34/YgB0AHQ/Sz9WAF0AnD+0P1IAYoByP4S/nUALALNALD9wP48AmEASv4sARIBAv4u/xwBhwCH/8f/3/9gAAYA1P1d/wACBgBy/uL/0wCY/wr+r//0AVcACP7i/hABeAEL/4z9qQD8AgH/cPxKAaQDcv4s/WIBwAKc/0D8XAAIBWEAUPsTAOgFtP9A+m8AmAZoAZj5Lv9gB74BKPkD/4AHmAEY+nb+2AUwA5D7FP14BKgD6Pwk/SQD2AJk/Wb+iAJuAWT9qv4gA1gB6PzA/WwDsAKY+wz9OASwATj7ev5oBKEAQPpe/igFCALw+TD8aAVkA9j6OPt8A8gEqPuA+rADAAVw+3D6GARYBEj8EPsEA3wDYPzc/GACvAL4/fz8HwD5ANb/EAByAIz+Av7aAWQBUP1G/jgClgHA/Rb/sgGc/5z+cgFGAeD9I/98AgEA6P2rANAC0P8c/CcAlAP9AJD95P+oA+j+SPz4AWgE3P2I/SAEIAFg/SIAeAKWAZD+sv4oAhwCXP77//wCoQAA/9//sgACASgAyf8cAlgB+P36/toBpACg/+8AawAc//z/0QCk/70A/f9K/hUAmwBn/xMAzQBE/s7/DAE4/Vb/KAKp/+z97f+WAJz+X/+I/4AAowDQ/Q3/kAE1ADT9gv9oAlgAjP0K/ngChAJg/Kj9oASWAYj6dv6QBoYBkPl0/ugFIAKA+vb+CAUdALj76f/4BM3/iPoIAUAF4P1w+2gDiAMs/ZT9kgE4Ag//8P3EAUQCJv6s/swBdgD2/kkARAF1AFz/s//R/6AAFgGFABv/TP/nAF4ACgE1/2j+0AEAAvT9bP2MAswCdv4s/ZQB5AO0/CD7WATABdj7cPmkA4AGvPzw+XgCkAWg/dj5WAIIBkT9EPkEArAGbP1I+bUAkAaZAMj4PP6oBXgBYPn8/UAGWAHg+sD9SAOUAZj8Av4MAcwCyv9I+6//yAN4AZD76P2ABEYBLP2I/EgDWATY+1T9bAMUAjj79f/wBmL+4PnWAVgFsv64/KoBqALJADz+rP76ATwB/v6+ALIB4P7W/tMA9wAQAYj/yP0sANgD2f9I/PwAGANe/lD8MAOsA/D7RP1ABMgCRPwU/FwC8ARC/7D7r/9MA+IBiP4g/W8AGASk/9j7fgFoBVT/wPlgAFgHfwCg+CcAUAhHAND4Ff94BsYBkPp6/iAFdgHg+7r++ALMAMD94v9sAvX/4Pvv/yAERwB0/Dj+NAPqARz96v40ASkAcv9aAOD/gv7OAN8AL//V/wUAlf/M/lwAPAJZ/9j8of94A3kA+Pr+/hgFqwBI+nT/CAXt/6D80v7sAgwCqPtw/RgFuAOw+nD88ATIA1j76PqIBYAGUPvQ+AQDGAYY/gj8FgGkAqz+vP3RADwBX/9XAHIBbP1o/VAEoAJQ+3r/YAUQ/uD5jAPYBdT98Ps8ARgE0v9Q+w3/kAYUAqD5Xv9YBcT+2PtEAxADzPyY/ZgB3ALC/kz8nAGABEz9IPpQAngFWP44+1QB8AI8/cT8gAJwAwz+BP3mAWQBtPxo/nADVAJ4/Bz+FANGAaj9tv5UASQBQwAD/9r+qgAAAvz/9v7Y/4L+rv8QAhAB6P9aACD/2P4YAXb/8P3ZAHQC0AFo/1T8sP1gAzwDHP3U/GYBdAJm/6T9Nf+wAZwB7P0U/YMAcAIYAFj+vwDgAJz8rPwcA/QDKv6E/EoBeANW/+D7VP7ABKADUPsA/FAEEAPg+5b+IAXUAXj6JP1IBKwD7P1Y/uADngBI+4r+MAQIBIb+RP1+AUAC6P02/0gEoAHI/ET+3AEgAiMA7v7KAUQCMPxY+5QDGAY2/sj7iAGUAjz9oPswAogG9wCg+Wj9SAWAASD7mP/wBUgBcPlQ/WgGbAN4+vT8yAXwAqj4SPt4BvAGDPzA+AwCMAT8/KD8wAJMAxb+CP3U/vb/CgH4/3D//QA0/8D8rP7EAQQD1gAI/YD8ewCQAggAQ/+BAMAACP8A/cb//AI1AGj+NAGMAMj8wP2qAcQCjQDs/dz+zQBq/kL+CARUAwT8RP1wA9cApPzvAJgE+AAA/AD9DAMgBPz9VP5gBWAB4PgG/zgHxgHw+6r+CAT4AsD7cPw4BQgFyPtY/KwDogF8/In/IAXwAoj68PoABVAE0Prs/SgGCAE4+UL/YAWk/gD7igGABWr+6Pjr/7AGOgBo+MT+8AYMAfj4pP4QBhwCAPqw+4gFOAQ4+lj8yAUEA1j6BP14BEwD+Pyk/BgCEANy/vz9kAJ2AQz91P2YAtgD9P3Y+1IBwATf/3j6mv7IBNoBKPxI/ygDvv5U/O4BIATE/hj8CQD8A78AAPzX/zAEpQCk/BL/lAIgAUD/pwAAArD/YP3q/wgE+AGw/Oz+YAQMAjD8ZP38AigD5P6M/WUATAK7/6r+kQDC/3T+EgCEAQgAIv/E/yoAcwC1/z7/4v9CADwAigAlAEX/dQAiAcn/2v7+/iQAagE2Aa7+vP3L/4MAU//O/vn/cQBC/z7+ZP6B/2kATAAn/17+B//z/w8AU/9r/woAhv/I/l//LgE0AUP/NP8OAY0Acv5e/+oB8AGx/1T+NgCYAhgBmv4bANwBTP8g/uYB3AMuAGz9JQCuAUb/ev5AAbwCKQCU/lQAugBc/sD+KAKcAaj9EP5UAUYBj//7//f/qP3o/agBWAIr/4r+KAHxAHD9bP3jAFgC0QCC/3//Cv9M/+kAlAHx/1T+af8sAVABWABp/0b/EAC7AIv/Uv4EAJgC/gGe/oD8/P1mAcACaQAW/kb/EgFb/9j8xP5kApwBwv6m/rn/Xv+A/5IB0AFq/oj8AwCcAxACjv6A/uEALgFP/8b+xQCgApgCbQCc/YT9AgHEA3gCtP/S/h8ATgGgAVQB9/+U/1QBZALx/+j9NgEgBfwCJP2Y+///+ANAAwsAov5t//j/if9s/78AdAGX/8z+CAA6/wT9Av/EA7wCYPxA+nb/yAMYART9AP5VAPb+HP38/lYBjABe/uj9Dv7o/FD95wCwAm//aPt4+/D9WP96/xP/lv48/sT9UP30/bn/lQBl/5z9ZP2K/uP/UAEsAuUAkv7k/Tb/rAGcA5ADCAL6AM0ANgE8AqQD+ARgBDACZAEUA7gE2ATYBKAEXANMAjgDiAU4BsAEoAOUAwADNAJ4A1AFGAUwA+4BYAHeAGgB4AJ4A5gBtP78/bj/pwB//5b+Tv58/Qj8aPu8/Mz9iPxo+jD6oPrY+Xj5cPoY+8D54PdQ+LD5cPlY+ID4iPlQ+UD48Pco+bj6cPoY+fj4MPq4+vD68Pv8/Dj9jPyU/Ab+Mv/U/wABQAJ4AtABDALYA/AFGAZwBfAF+AbIB2AI4AhACWAJEAmQCDAJkAogC7AKAApQCYAJkAkgCWAJkAlgCPgG+AZIB8gGGAZ4BagEhAOYArgC4ALeAcwAKAAQ/9j9+P3c/YD82PsM/KD7sPnw97j4+PmY+JD2MPco+JD2APXA9bD28PUw9aD2oPdQ9uD0MPUg9iD2YPag95j4QPig9/D30PhY+SD6CPsY+0j7pPz0/YT9JP1M/sb/FwDk/1ABfAPQA1wChALIBNgFiAWIBjAI8AcgB1AIUApQCuAIAAnACuAKcAmQCYALkAswCdAHsAggCfAHOAeoB0gHIAV4A3QDfAOcAk4B1AC7AFr/YP30/Jz9MP3Y+zD7+PuI/Bj82Pts/KT8HPyA/FD+eP95/zIAwgE8Am4B2AHoAzAF2ARwBIgFiAYQBkAFSAWoBdgEqANwA9wDFANSATEAef/g/ej7wPu8/Gz8iPp4+ND2wPRg8xD0wPVw9qD1UPQg8oDvoO9g8qD00PTA9BD1sPQg9ID1CPiY+ND34PiA+9j8hP1n//MAAACA/iIAxAPIBZgGAAhwCHgG8ATIBiAKwAtQCxALIAvwCcAIwAmwC8ALYApACcAIQAj4B2AIQAhQBugDCAO0AwgEsAMkA9QBTP9E/ZD92v4z/77+QP4s/Qj72Pn4+pT8rPwE/Hj7GPu4+gD74Ptg/Cz84PtI/CD9zP1m/qr+jv6G/sb+Qf9HAAwCDAPUAoQCbAK0AqADiAUoB1AHSAboBbAG4AboBmAHwAeQBogFCAYwBoAFgASYA8gB9P9VAGQBJwDU/ED70Pqg+CD3SPlQ+wD58PQw85DzQPMQ8xD1wPZA9NDwkPGw9ED2wPUg9eD04PSw9Qj48PoM/FD7wPr4+vD7Dv7jALgCNAOUAlQBggGUAxAGoAfABygHqAboBpAH8AgQCrAJwAggCAAIQAiwCOAIgAiYByAGEAVoBdgFWAXAA4ACygFiAUoBJAHjAAUA3v4e/ib+MP4a/ij+AP6c/TT9OP2g/Sr+6P6x/5z/Uv+w/wgB/gEEAngC8AMgBSgFUAVABsgG0AY4ByAI4AjQCeAKEAsACsAIgAjQCEAJcApQCyAJCAUkA/QDyAOkAsACpAL0/oj4sPVg+ND50Paw9PD0sPKg7mDtAO8g76DrQOog7eDuIO2A7CDugO3g6sDqIO+A8xD1EPVw9SD1cPRw9sD6Hv47/ywAyAHYAoADAAXoBgAI0AhACrALcAzwDeAPwA8wDcALEA3QDiAQgBFgEuAPYAtQCYAK8AvQC0AL4AqwCCAFCAMwA0ADDALFAM7/gP6k/Hj7ePvY+ij54Pfw9wD4sPfg97D4uPjA9jD10PXQ97D5QPu0/KT84PrY+ej7EP9yAEQBRAMABXgEkAMYBXgHcAjQCFAKIAxQDHAMwA0QDnAMsAsQDeAOUA/ADtAN0AsQCbgHMAi4B9gFmAR0A+H/ePvA+AD4wPbg9JD1APfg8wDtoOmA6cDoYOgg66DuQO1g6EDmwOcg6ODnwOvg8IDxgO9w8HDzwPQA9aD3RPwQ/g7+tQCABLgFQAUwBsgH0AhgCrANIBFAETAP8A3QDdAN8A5AEcASABIAEAAOsAzwC5ALsAuQC5AKAAm4B5gGGAUgA3ABpgAUAFf/xv5C/sD8SPqQ+FD4oPhw+Ij4aPlg+SD4EPeQ92D4cPjo+Mj6UPz4+5D7CP3C/hH/Z/8KAfACXAMIBDgGEAi4B0AHwAhwCqAKQAtADWAOsA0wDcANEA2AC1AMIA+QD5AM0AqACnAIsAUwBvAH8AVoAY//c/8g/BD38PVA97D1MPIg8bDxAPDg7GDrIOqA5wDmgOgg7ADtoOsA6mDoAOcA6CDs4PAg9HD1wPTw8kDyIPWI+qP/hAJAA7ACFAJMA7gGcAqgDOAMoAzgDOANkA+AEaASwBFgD9ANcA6AEEASgBLgENANkApACQAKQAuQC7AKoAg4BeABggDnAHwBFgGf/1D9sPog+RD5QPlY+BD3YPYg9iD2kPZg97D38PZA9mD2EPdw+LD6+PzY/VD95Py4/V3/TgFYAxgFCAZoBigHIAgwCTAK8ApQC8ALAA1wDkAPEA/QDoAOMA0ADCANEA+wDqAMcAtQCngHaARIBPgF2ASwAGD+OP3g+DD0UPMQ9TD0cPBA7iDvQO4A6oDngOdg5qDkoOYA6yDtoOrg5oDm4Oeg6KDrcPGw9fD1gPTQ8wD1YPfY+gMAQAQoBaAEYAX4BqAIkAqQDJAOgA9wDwAQQBGgEYARQBGAEPAPQBAgEaARoBBQDmAM8AqwCRAJcAmgCYAIMAaUAy4BU/+A/sT+Q/9M/uj7WPmw9yD3QPeQ95D30Pag9QD1YPVg9oD3iPjY+Fj4wPdw+ID6+Pze/tv/IQDW//7/agHEA/gFWAcgCKAIAAlgCTAKUAugDFANQA0wDbANoA7QDnAOEA6gDcAM8AsQDHAMsAsQCoAIWAeABaQDjAJoAXr/JP0A+4D4oPWQ84DyUPFg78DugO9A7kDroOhA52DlAOXg6CDuIO8A6wDoAOmA6kDrYO5A9GD3YPaA9XD3mPmg+hD9pgFYBYgFEAXoBrAJ8AoAC+ALcA3QDnAPwA/wDyAQ4A9AD5AOMA4wDhAOsA0wDQAMwAlQB4gG8AbgBsAFKAS8AtwAtv5k/Wj9fP28/LD7UPqQ+FD3UPfw9yj4sPcw9wD30PYw91D4iPnw+fD5oPqg+0D8SP0N/5sAAgH+AAQCpAPgBNgFQAdwCJAIsAjACSAL0AsADGAMgAwADPALMA1wDmAO0A1QDYAMYAvQCgAL4AowCoAJkAjoBuAEvAN4AngA0v4G/qT8WPlA9iD0oPFA76DvAPIw8sDugOog6MDmYOUA58DqoOyA64DqIOrA6YDpoOug72DycPMQ9TD3CPjY+Hj7gP5GAJwBQAQwB5AIMAmwCkAMUAxwDDAOYBAgEcAQ4BCgEFAP8A0gDhAPQA/QDrANsAtACZAHCAfABqAGkAbABXwD0gBV/6D+7P2I/bT9UP2I+6D5+Pjw+HD4IPh4+Jj4GPjQ95j4mPnw+fj5YPrg+jD7LPzw/Y7/WgDEAEwBxgFQAoQDSAWQBhAHkAdgCDAJoAkgCqAK0ArwCmALAAwwDDAMYAxwDBAMcAsAC6AKIAqwCVAJkAh4B4AGeAX0AwQCjwDI/8L+AP0o+9D4UPUA8tDwMPFg8eDwYPAg78DrgOfg5UDnIOlA68DtIO5g62DogOhg6+DtAPAQ8/D1QPZw9UD2yPhg++D91ABMA3gE+AR4BoAI8AmwCoALkAzQDfAOoA+wD6APcA/QDuANoA1QDuAOYA7wDFALcAnQBzAHYAdQB1gG+AScAxgCgwCF/zX/0P4A/vT84Pu4+uD5APpY+vj5GPmA+Dj4EPhw+JD5uPog+wj7OPug+9j7hPz0/Z3/qABCAdgBdAIIA6QDgAR4BWAGYAcACHAIwAhACbAJwAkgCrAKwApgCkAK8ApQC+AKUAoACqAJgAjYB8gHSAcoBlAFuAQsAy4BBABl/wD+iPvA+cD3sPQQ8pDxYPIw8mDxcPCA7oDqIOdg5+DpAOwA7aDtYO3A62DqwOog7SDw8PLQ9HD14PXg9qj4mPpE/VIAlALEA6AEEAZgBzAIkAmQCyANcA1gDfAN4A4QD8AOsA7ADpAOAA6ADVANEA1gDDALoAlACIgHCAdQBpgFuASMAxwC8QAvAFn//P3Q/FD8wPvQ+lD6gPqg+gj6OPkI+SD5EPlY+UD6OPvQ+0z85PxM/Zz9Pv6C/9sAxgGYAlwDCASwBHAFKAbQBmgH8AdwCMAIEAlACXAJsAngCeAJcAkgCSAJAAnACLAIoAggCEAHmAYQBmgFsAQoBIgDWAIiAR0Asv4Q/eD7sPqo+GD2sPRg8wDyUPHA8RDyQPCg7UDsoOtg6qDqIO3g7gDugOxA7eDuAO9A7/Dx0PQw9TD1QPeQ+YD6yPvK/pIB9AGoAagDqAb4B3AI4AlQC1ALEAvgCwANYA1ADfANoA4QDsAMgAzQDKAM4AsQC1AKYAlgCGgH0AY4BlgFmATMA3gCJgFWAMr/Iv8W/uj8CPxY+8D6ePqA+kj6+PnQ+bj5mPmY+fD5kPo4+wD86Px8/az9aP7G/9AAXAEYAkwDGARABLgEyAWYBvAGmAeQCPAIoAiACPAIMAkACQAJQAlACdAIYAggCLgHQAcIB7AG6AUgBZgEQASUA9gCAAIoAQwA8v4y/hT9mPtQ+hD5kPcg9mD1YPUw9XD0MPMg8vDw4O+A7xDwkPCg8NDwAPEA8cDwEPFg8tDz0PSw9aD2MPeg99D4wPqs/Dr+l/+tAGwBKAIsA2AEaAVYBkgHAAhgCPAI4AmACpAKUAogCuAJkAlQCYAJwAmACeAIQAiIB6AGuAUQBZAE/ANYA8gCOAKSAfQAZwCV/3r+mP0o/dz8YPwU/Ej8kPxk/AT8CPw4/Az84PtE/Pz8kP0m/gP/3v9VAIoA+gCgASQCiAIMA8ADYATYBDgFgAWwBbgFwAXYBcAFgAVYBWgFaAUQBaAEkASYBFAElAPoAmwC7AGIAXYBmgGAAQwBbQD4/5j/Jf+q/jT+qP0Q/Wz8yPtY+zj7GPug+uj5UPng+FD4oPcg9/D28PbQ9pD2cPaQ9qD2kPaw9gD3YPeQ97D38Pdg+Mj4OPnw+QD7IPwM/dj9vP6T/zkAjQD2AMQBkAL8AlwDQAR4BUAGgAawBhAHAAd4BjAGSAZQBjgGkAYwBzgHkAYYBgAGkAWIBNwDzAOkAzAD3AL0AvwCpAIgArIBdgEOAa4AXgAOALv/s//g/+b/zP/N/9v/n/9w/4z/sf+N/2r/rP8RADgAJABLAKAAvgC+AOMAFgEyATwBOAEiARYBFAEiATYBNAEUARIBKgESAboAcQCBAJ8AQQDe/wIARQDf/zT/Ov/H/+D/NP/C/vr+Ff+4/o7+/P5j/0H/mP7M/XD9uP0S/rz9OP2Q/WD+Vv50/fj8QP1g/cD8QPyg/DT9TP1I/Yz9xP28/aT9qP3E/az9eP2g/SD+Yv5Y/mr+xv4x/1z/Wv9s/4z/gP9p/4r/0v8IACwAZADXADABFgHTAO0AMgE4AQ4BDAFEAWQBVAFUAZQBvgGwAaYBwgHYAdgB4gHcAboBsAHcAfwB9AHuAfwBCAIEAuwB3gHiAd4B4gHoAc4BqAGKAXIBcgGqAdwBxgGUAXoBcgFOAQ4BzwDEANsA7ADcAMUA4AAUAfkAdgAgADcATQAVAN7///87ADkAEwAYAD4AHwDH/5L/l/+l/2j/K/84/3b/av8N//b+M/9T/wz/sP6k/rr+mP4q/uz9HP5g/lz+Nv42/kL+Nv4k/iT+JP4U/gD+9P3k/dz9AP44/k7+XP6K/q7+kP5g/nr+uv6+/o7+oP4J/1L/Vf9Z/43/wv/W/+T/8f8AABgARwB7AKMA1QAcAUgBOgEqAUwBegGCAX4BmAHOAeYB4AHoAQACDAL+AeoB7gH2AfYB9gEEAgAC3AHAAbABqAGSAWoBRAEoARIB9gDRALoAsACkAIAAXgBZAE8AHwDj/9n/wv+K/1//YP9n/0L/M/9T/1b/Hv/2/vj+2v6i/p7+2P7+/ub+yP7a/vr+Cv8C/+7+7P4I/yb/HP8A/xL/R/9X/y//J/9d/4P/d/9c/2P/gP95/1D/OP9d/4z/if9u/2z/jv+f/5T/j/+l/7X/mv9t/1r/cf+T/6f/n/+T/6v/1v/j/8T/sP/J/+P/xf+M/4v/wv/u/+f/3//v/wwAHAAbACMANQA5ACkALgBVAHIAgQCTAKkAygDmAPMA9wD7AAoBFgEQAQ4BLAFUAVgBOgE4AVABVgFAATYBRAFCARwB6wDjAOsA0QChAIIAggB9AGAANwAcABEA7v+5/5z/mP+I/2b/Uf9d/2//aP9T/0r/R/9A/zD/JP8c/yj/S/9e/1L/Rf9T/1//Uf9C/1L/cv93/3b/if+n/7r/wP/Q/+v/+//p/9H/1v/1/wYA//8HAC8ASQBBADsAUABZAEQARQBgAFgAMwAxAFcAXwA4ACwAUwBuAFEAKgA0AE0ARQAoACoARwBJAD4ALwAhABMAIAA4ADEAEQAKACIAIQAHAP//EQAYAAoAAQARABkAAQDs//L/BQAVABMA/v/5/xAAJwAfAA0ACwAZACAAGAAiAFAAZgBBABkAIgBJAFEALAAWACsAPgAjAPv/AAAeABIA2/++/87/zv+1/7L/x//L/7X/n/+X/5D/ev9g/1L/Wf9r/23/XP9Q/0r/R/9R/2P/av9k/1f/Vf9l/2f/XP9o/4r/r//K/87/y//x/xsABgDb/+P/GwBEAD8AOQBeAIwAiQBwAHIAiwCUAI0AjACbAJwAiQB9AIwAmQCSAJIApQCqAIAAWwBqAH8AYAAsACgASwBRADYAMgBEAEAAMgA+AEcAKQD7/+X/6v/h/8b/x//s/wYACgAMAAoA///i/8P/wf/Z/9v/w//B/+T/AQD9/+z/8v8PABkACgAEABMAJQAhAAoABwAtAFMAUAA4AD8AYQBoAEwANgA6AEQANgAjACgAPQBCACUAFQAqADcACgDV/9b/7P/d/7j/rv/A/8T/o/94/3T/jv+V/3T/TP9D/03/Xf9k/2b/bP93/3//gv99/3z/jf+g/6T/qf/E/93/4v/g//b/FgAYAAUACwAvAEQAPAA5AE8AZABoAGQAZwBqAGIAWABfAHEAdwBzAGkAXQBZAF0AXgBSADoAJgAbAAwA+f/v/+//8f/r/9r/xf+1/6//sf+m/4n/d/+C/5H/j/+K/5H/mf+V/4z/jf+L/4j/jv+f/63/w//n//7/+P/3/xMADADp/+j/IgBHACgAJwBoAIsAXwA2AEYATQA4AEEAewChAHoARwBdAJwAqgB5AFEAYAB/AHQAPQAeADkAVwA/AA0ACwAxACwA8v/M/97/8f/J/4n/fP+h/6H/Z/8+/1T/ev90/2P/gf/C/9b/nf9d/2L/m/+x/47/c/+V/9r/9//u//z/LwBWAEYAEQDu/+3/9//w/+H/3//q/wUAJwBNAHYAigB5AFsAXQBxAGIANAAhACwAJwAJAAsAOwBYAEEAKAA8AGEAZwBEAB0AEAANAPf/2f/k/xkANQAVAO7/+v8sAC8A8P+6/77/2//U/6b/jf+3/+r/2v+1/97/PQBQAAwA8P8rAFAAEAC7/8P/EABDACgAEABMAL4A/gDMAH8AcQCEAFcA8v/K/w0ATAAoAAgAXwDbANUAYgA/AJ0AuAAZAHH/hP/9/wAAiv9q/+b/TgAaAMj/+f9cADoApP9D/1z/kv+H/2T/d//H/x8AKwDd/57/xP///9X/bv9R/5z/2P/G/8H///89ADsAIwAhAC0AIgDy/8f/w//h/+X/xv/L/wMAJgD7/8f/4/8xAEIA///d/xcARwAaAND/y////xkAAwDy/wQACgDq/9n/7f8AANz/k/91/6L/zf+s/3n/g/+3/7v/eP9M/3//x//E/6D/wv86AKgAnwBOAD4AfwCSAEMA+/8OAFEAZABMAFcAkQCxAJsAkwDKAPQArwAgAOf/NQBzAC8Axf/V/zMAQQD0/8r/AwBBACAAw/+d/8b/6v/Y/7D/k/+M/5b/rv/W/wMAJAAsABUA9P/0/wQA4/+Z/3H/eP98/3f/lv/P/+//6//z/xAADwDk/8f/y//P/8v/0f/w/yEARQA+ABsAAgAEABIACgDu/+n/EAA2ACsADAAXAEgAVwAvABwASABrAEcAHAAxAF0APgDm/+L/WQC2AH4AEQAXAHEAcwAHAMn/BQBTAEIA9f/l/yYAUQAiAND/xv8FACQA7v/A/+7/KgATANH/1v8eADsAAADT/w4AcABxABMA4/80AJUAaQDf/7L/CQBKAB4A9P8qAH4AfgA/ACcAPgA3AO//rv+i/6j/lP97/5v/2P/n/7H/ef96/4X/Wv8J/9b+1P7c/ur+Iv98/8T/2v/m/wYAGAD5/8H/mP+I/3//bf9p/5P/5/83AGIAhQC5AN8AzgCQAFYALQARAPv/7P/l/+D/6P/q/+z/BAAxAEkALQAHAPv/+//k/7r/pP+x/8z/4f/0/yIAawCcAJkAhACMAJ0AhgBPADMAMgAhAAMADABAAFUANgAKAPj/8v/f/8P/s/+2/8X/1//p//z/EgApACsAEgD2//L/9f/3/wcADwD1/8z/yP/v/woA/v/u//3/IQBAAEoARQA+ADgAKgAQAPr/9v/+//j/7P/1/w8AJQAxAEgAYQBkAEwAKAAHAOj/2v/k/wIAEgAHAPv/BgAjACcABwDf/9n/7P/l/7j/lP+c/73/yv+w/5n/qf/X//r/AAD6//3/BADy/9X/y//T/9H/uv+m/7D/1v/0/wgAGwA8AFoASQAbAAoAKgBLADoADAABACkAVABlAGYAdgCXAKwArACWAIQAdwBbACUACAAiAEcAQQAuAEYAdgB/AGMAYwCCAHAAFwDH/77/2//X/6f/h/+e/9j/+f/g/7L/sf/Y//H/4//T/9j/6//j/87/x//F/8b/3f8JACYALAAvAEcAYwBgADsAEgD2/+T/z/+t/5v/rP/V/+j/6f/5/xoAMgAuAB8AGQAWAAkA7v/Y/8j/vf++/8b/y//W//D/BgAAAOr/5P/z/wEA+//u/9T/wP/D/83/x/+0/7H/wP/M/8n/1v/5/wwAAQD4//f/5v/F/6v/sP/C/7j/p/+1/8r/xv+5/8f/2//a/8f/w//H/7z/pP+X/57/nf+L/3b/cv+O/8b/6v/o/93/5/8EAB8AJgAkACwAOgA/ADoANQBJAHAAjwCPAHwAbABpAHUAfAB+AHkAdgCSAM4A5gC9AIgAfgCeAKEAbwA5ADQASABIADwAPQBOAGgAdQBtAEcAEwABAPn/4P+u/5H/lP+j/6b/of+c/6P/wP/T/8r/sf+v/7v/sf+Z/5X/of+e/6X/1f8TAB4AAQAAACsAVgBDACQAFAATABIAGQAgABYABAD1/+n/xf+O/2L/Q/8o/wj/5v68/ob+XP5E/jj+GP7k/dT94P3o/dj9zP3s/Tr+dv6C/oz+vP4S/1f/bv+Q/+P/UgCnAO4ARgG0ARACYAKoAtgC+AIYA1gDjAOoA7wDzAPUA9gDzAOYAzADxAJsAiQCrgEiAbIAfQBkAEsAPAA8AFMAfgCTAIEAcgB6AIoAbABBAEMAbACGAIgArAD8ADIBVAF0AZwBwAHIAdABzAG2AaoBmgF4ARwBrQA/ALf/Fv94/vT9YP20/AT8YPu4+vD5SPmo+Dj40Pdg9xD30Paw9pD2YPYw9hD2IPYQ9iD2UPaQ9gD3wPeY+Hj5YPpY+2j8hP24/vP/FAEoAkwDkATIBcAGmAdwCDAJwAkgClAKgArgCjALUAsgC+AKoApACvAJsAlQCfAIsAigCFAIuAdgB6AHIAiACNAI4AiwCHAIMAjgB2AHyAY4BpgF0AT4AxgDEAIyAcMAiQDc/+j+Jv6g/fD82Puw+qj5uPjA9+D2EPZQ9eD0sPSg9KD0sPTQ9MD0oPSg9LD0gPRA9GD0kPRw9BD00PMA9ID0EPWA9RD2wPaA91D4KPko+mj7zPz0/fj+7f8KATwChAPYBAAG2AZ4BzAI0AhACYAJwAlACtAKMAsAC6AKUAogCsAJAAkACCgHKAagBMQC8ABC/4z92Psw+mD4cPYA9VD0IPSA9HD1wPaQ+Bj7Kv4SAZwDWAbACeAMEA+gEAASoBOgFGAVABZAFiAWABaAFaAUgBNAEuAQ4A6wDFAKAAcIA17/ePyg+XD2sPPA8UDwoO5A7QDswOrg6YDp4OhA6MDnAOig6MDpgOvA7QDwYPKQ9Qj54Ps4/r4AjAMABgAI4AkwCxAMUA3ADqAPMA/ADpAOAA6gDAALgAmoB9AFiAQkA6wAwP1g+5D5YPcw9ZDzUPIw8bDwUPEA8pDywPPw9cD3oPhY+XD6WPvw+8z8/P0S/9P/2ADOARwC1gHOAeIBlgH1AD8Al/+6/vT9SP2s/Bj8qPso+4D66PmA+QD5wPho+Sj7FP08/84BkAQoB/AJYA2AEYAVwBjAGgAb4BngGMAXQBbAFCAUgBPAEWAPwA3QDEALcAlACHAHmAW0AoH/WPwo+YD28PSw8wDygPAA8KDvIO8g76Dv0PAg8rDzIPWw9fD1APe4+Dj6QPuI/Cz+iP+TAGwBOALUArQD6ASgBUAFkASABHgEwANwAloBZABH/yb+TP1U/Bj7oPrw+kD7wPr4+bD5yPm4+UD5qPgQ+AD4qPiY+fj5YPqQ+3j9Of9QAAABdAHiAVgCDANcA0QDwAKMAlgCzgHeAK3/zP4o/nz9XPw4+3D6yPkQ+aD4ePgA+ED3sPbw9lD3wPeQ+Lj6bP0+AEwDuAZQCuANwBGAFcAYgBpAG2AbYBsAG2AaIBngFyAXgBYgFWASgA8ADeAKQAgABZABXv5A+yD4cPUg80Dx4O9A7yDvgO6A7SDtwO0A7xDwEPFQ8rDzYPUg96D42PmQ+wD+fAAUAiQDOARwBWAGKAfQBxAIEAjoB3gHKAZABKACcgE7AKz+8PwI+xj5cPdg9pD10PSA9ND0QPVA9fD04PRw9XD2sPfQ+OD5KPuM/Nj9A/88AJIBwAK0A1AEgAQoBIQDAAOoAigCbAGKAKz/3v7s/ez8wPto+jj5aPiw9/D2APZg9TD1MPVg9QD2EPcY+HD5YPvM/YQAEATgCDAOABPgFuAZABxgHeAegCDAIGAfIB4gHSAbwBdgFAASoA8QDcAKQAi4BPIAIv7A+7j4oPWA88DxoO/A7eDsQOyg60DsgO6w8PDxMPNg9XD3uPjo+Yj7JP1k/rX/3ACIARgCOANwBBAFWAXIBSgGwAXwBCgELAN+AYT/yP08/JD6CPkA+ED3cPbQ9ZD1sPUQ9nD2APeQ9wD4cPjY+BD5YPlI+uj7gP20/ur/TgGUApQDWAQIBWgFkAWgBUAFWARMA2gCfgG6ABsAY/8o/qT8iPuA+hD5YPdA9qD1APVg9BD00POQ8+Dz0PQQ9mD3SPmA+2T9vP/cA0AJIA6gEsAXQBxgHsAeQB9AIEAg4B5gHaAbQBlAFgAUABJgD/AM8ArwCFgGcAM1AJz8ePmw91D2APRg8aDvIO+A7sDt4O0A76DwkPKw9ID2sPfQ+HD6QPyQ/Wb+H//i/44ALAHEATgCwAKsA7gEMAX4BIAEEASYA5AC8gAz/6T9KPzA+nD5WPiQ9+D2kPaA9pD2wPZA9+D3YPiY+Lj48Pg4+fD5KPts/Ej9YP7u/0AB0AEQAvQCyAP0A3wDJAN8AioBpf/O/lz+0P0o/Wj8sPvg+hj6GPng9/D2wPZw9oD1APVg9QD2IPbQ9oj4KPrw+hD8ov54AQgEoAdADSATwBfAGuAcQB4AHwAgwCAAIEAeYBwAGsAWABMAEHAN8AqwCMAGOASxAGj9OPtw+XD3oPWA9IDzMPIA8UDwwO/g7/Dw0PJg9ID18Pao+OD50Pog/MD9Ef8MABQBxgG2AWoBtgE8AlgCQAIkAuIBZAHsAGQAaP/s/cD88Pvw+oj5WPjA92D34PaA9oD2sPYA96D3qPiQ+Qj6EPog+sj66PvQ/GT9HP5C/3UARAHSAUwClALYAlwDrAMUA9IB0wBNALT/2v4g/nz9wPwU/LD7APu4+bD4iPig+CD4YPcg9yD38PYQ96D3MPiY+ND5wPts/c7+VAFgBRAK4A4gFOAYwBtAHaAeQCAAIMAewB2AHCAawBYAFEARUA7QC2AKsAjYBdACdAAQ/gD7QPiA9hD1MPOQ8bDwwO/A7qDu4O+Q8SDz8PQw9yD5aPq4+1T91v4nAGoBYAKwApgCpAIAA2ADuAMIBCAE2ANkA8ACyAGHADH/9P28/Ej7qPkQ+OD2MPbA9XD1kPUg9vD2wPdw+Bj5qPlA+gD72PuA/PT8YP0C/sL+fv8wAOcAoAFgAtwCAAOwAjwCsAE8AaUA0/+4/qT9xPwM/Ej7sPpY+gD6qPkI+QD40PZQ9sD2MPcA97D2QPfw92D4GPmg+kD8Fv7nAPAEAAmwDKAQIBXAGCAbAB0gHmAeAB7AHQAdoBqgFyAVIBOAELANUAtQCeAGSATuAaX/GP2g+rD4EPdw9eDzgPJQ8XDwYPAg8TDyUPMQ9SD3CPlA+ij7SPzA/Sn/PADsACIB8gCSAI0A3AAaASABQAGUAawBVAGhAKD/tP4g/qz9yPw4+9j5APlI+GD3sPag9iD3wPdo+PD4IPkQ+Xj5YPpQ+xD8fPzk/GD9LP7+/nX/3f+vAKoBFALeAXABIgGwADYA8f+T/wH/Mv5I/Wj8yPuA+xj7oPpo+oj6EPro+Cj4kPgo+TD5IPlo+dD58PlQ+hj70Pu0/LD+5AGYBWAJEA3AEAAU4BZgGaAa4BrgGgAbgBqgGCAW4BPgEQAQcA7ADLAKkAjIBvgEzAKFAIj+5PxQ+9D5WPig9tD0YPPA8sDy4PJQ81D0wPUA99D3cPhY+bD6HPw4/Qb+jv7i/uz+2v4V/7X/cQD4AGoBogGKARYBkQBPAC8Auf/g/gL+PP1Y/Bj7APqA+Yj5kPlw+YD5kPlg+SD5UPno+ZD6APto+8D7IPyI/Aj9iP0k/vD+qv/U/6X/lv+z/2//F/8S/yP/tP4U/vz9+P1E/XT8hPwc/dD8uPvY+nD6APrQ+SD6cPpQ+mD6IPvw+xz8WPxU/cT+bADoAhAGMAlADJAPwBIgFYAW4BcAGYAZYBkAGeAX4BXAEwASYBBQDnAMIAuwCWgHAAUkA1ABTP+c/ZD8WPuQ+dD3oPaQ9VD0wPMA9JD0QPUQ9qD20PYg9xj4YPlw+mD7hPxk/YT9eP3E/Sj+WP7G/rb/fACJAPD/gf9r/37/ff8N/07+qP00/Xj8SPsg+nj5MPkw+Yj5uPlo+fD4EPmo+QD6GPqY+lD70Psc/JD8yPy4/Cz9Sv4o/yf/FP92/9v/yP/E/wMA/P/A/7H/xf8w/0j+1P3g/Zz9LP3o/Hj8mPsI+3j78Puo+1D7yPtk/Gz8lPxQ/R7+2v5pAOgCaAW4B6AKAA6gEIASYBQAFqAWoBbgFgAXABZAFMASoBHwDzAOwAyAC/AJUAjYBhAF1ALIAFL/3P0U/Hj6OPmw9yD2APVw9DD0IPSw9HD1APZw9vD2oPdo+Ej5aPpY+wj8xPyQ/RL+ZP7m/rb/ZQDjAFoBoAGGASYB3gCWACoAkP/o/hz+JP0c/DD7SPqI+UD5aPmQ+XD5OPlI+aD54PlA+tj6YPuQ+7j7BPw8/DT8VPwE/eT9kv7+/jf/Lf8//7P/MgAqAOr/EwA1ALX/5v5w/iD+nP1A/Wj9hP3w/Gj8cPyw/Kj8kPyw/Oj8QP3c/YT+5v57/9sAvAKIBGgGkAjACpAMIA7ADyARABKgEuAS4BKAEqARoBCAD5AO0A3QDGALAArgCMgHUAbQBFgDzgFBAOj+uP10/BD7uPmg+OD3cPcg9+D20PYg97D3GPho+Mj4YPkg+sj6MPt4+7j7CPxc/Kz8FP14/eD9QP7A/iL/Hv/G/pj+wP7o/rT+Hv6I/Qz9lPwc/Kj7WPsY+/D6uPqQ+lj6KPoI+kD6qPr4+gj7+Prw+jD7iPvw+0D8vPx4/RD+UP5Q/mz+uv4U/3//AQBNADIA6//B/6v/c/8m/xj/Pf9a/z//4P58/m7+sP7a/sj+pP6k/qD+nv7w/pv/dgB+AegCkAT4BSAHYAjACQALEAzwDKAN0A2QDWANIA2wDDAM0AuQCyALcAqwCcAIuAfIBigGgAWYBHQDUAIoAQYA/v4K/hj9IPxw+/D6cPrg+ZD5iPm4+Qj6YPqo+sD6uPrY+hD7OPto+7D7IPyU/Aj9ZP2s/fD9Ov5+/rz++P4R/wT/1P6s/nT+CP6o/YD9aP0U/ZD8OPwM/Oj7yPvg+/j70PuI+2D7WPtY+3j7mPug+7D7APxA/Cz8DPxI/MD8DP1Q/cD9PP6E/rD+AP87/0D/L/9d/5D/gv9K/zn/W/+T/7T/tv/e/zgAmgDTAOIA+wAyAXwB6gF8AigDxANYBAgF2AWQBhgHiAcwCPAIcAmgCaAJoAlwCWAJUAlACfAIgAhACPgHeAfYBlgG6AVgBdgEaATAA9gC+AFUAbsAAwBT/7T+GP6A/fT8ePwE/Kj7mPu4+8j7yPu4+5j7cPtw+5D7mPuA+6D76Psk/Dz8TPyA/MT8/PwY/Rz9IP0w/Tz9HP30/Nz8zPyo/JT8pPyw/KD8mPzE/Pz8+PzA/Jz8pPys/Iz8dPx8/JT8jPx8/Ij8sPzc/Aj9SP2g/QD+Qv5Q/lD+bv6i/sb+0P7e/vb+C/8p/2X/uv8ZAHAAvAAAATABZAGUAcoBDAJkArQC3AL4AkwDzAM4BIAE0AQ4BZAFyAX4BTgGcAagBuAGCAcQB/gG4AbQBrgGqAaYBngGOAYABsAFWAXgBIAEMATUA1gD2AJgAuQBeAEiAdUAiQA7AO7/mv9D//D+kv4m/rj9cP1A/Qz9zPyk/Ij8XPwk/Aj8EPwM/Pj76Pvw+wT8JPxk/Lz83PzU/Lz8jPxY/Cj8MPxQ/GT8dPyU/KT8gPxg/HT8nPzA/Mj80PzM/MD8wPzE/Mj84PwQ/Uj9dP2k/fT9PP5i/nz+tP7s/gX/F/85/1f/Yf9v/6D/4v8PABgADgACAAAAFAAtAFAAjADqAEABagFmAWwBqAHyASgCUAJsAogCoALAAvQCSAOoAwgEUAR4BIAEiASgBMgE4ATQBMAEuASoBJAEmAS4BNAE0ATABKAEYAQABKQDSAPYAlQC1AF8AUYBJgH5AK4ATwDw/6b/Z/8c/7D+Nv7k/dT98P0S/h7+Cv7w/dD9pP1c/RD9+PwE/QT94PzU/Pj8GP0A/dj8vPyE/ET8MPxk/Jj8mPxs/DT8EPwU/DD8RPxI/FD8ePyI/Hj8bPyA/Jj8nPy4/Bz9jP20/cz9Hv6c/vD+BP8y/4T/q/+P/4j/w/8RADkAUQB7AJoAmQCRAKYA6ABAAZgB8AFIAqAC9AIkAyQDCAPsAvgCEAMoA2gD3AMwBDgEEAQQBCgEOAQwBDAEIAT8A+ADwAOcA4gDmAOkA4ADTAMUA7gCQAL6Af4B7gGaATYBCgH6ANQAngB3AEcA5v96/0r/V/9d/zv/A//O/pD+Uv4q/iL+Dv7o/dD94P3k/cT9qP28/ej94P2g/WD9LP34/OT8GP14/az9pP2o/dT97P3c/dj97P3Y/az9sP3s/Qr+BP4C/hz+Jv4c/iL+Rv58/rb+7v4R/y7/Pv8w/xz/N/9+/6//xf/7/08AggCFAJQAuwDCAJUAbACDAMwAGAFSAYABkAGMAYwBrAHiAQQCBAIMAjgCaAKAAowCpAK0AqwClAKYAsgC6ALEAmACCALoAfQBFAI0AkQCHALGAW4BIgHMAGUAGQAFABcALQAhAPD/r/90/y3/zv6I/pb+zv7Q/pr+dv6C/pT+jP5+/oz+lv6C/m7+dv6Q/pD+iP6K/oj+YP4y/jb+fP7M/uD+pv5y/pT+8P46/zz/EP/g/rT+oP64/vb+Ov9l/3X/ef+I/6P/tf/J//z/RQBjAFEAZgCyAMQAVADW/93/QgCDAJsAwgDbAKoAaAB1ALwA2wDXAOAA9wD4APAA/AAMARQBCgHpAJgATQBaAJ8AswCaAMMAJgFGARIB9QAEAeQAmQCSAMIAwQCeANsAcgG8AYwBRAESAb4AWwBMAI4AyADkAAABBAHLAIYAbABmACgAwP9+/3b/lP/M/xEAKwDz/5z/df91/0r/6v6m/q7+4v4M/zP/Xv9a/yX/AP8g/2D/Z/84/yH/N/84/xb/Bf8l/0T/Qv9K/2P/dv+H/7P/2v/K/6n/u//K/5P/Wf+B/8L/nP9i/6T/JABAAAYA7P/q/7L/Yv9U/3j/oP/R/wYAIQAXAA0A9//E/63/6v9QAIoAkAB5AEYADgACABUAFQAhAHQAqQBfAOb/1v8KAAAAzP/J//T/GwBTAJoAmQA3AOf//v8/AHIAtgAAAfUAmwBeAGAAbwCIANkANgEwAcwAgACgAOQA9gDtAAoBNAEWAaAAOgARAP7/+/8ZAEMAMwDu/7L/h/9c/1L/bf9n/y3/If9d/2j/Hf/o/gj/Gf/g/rj+4P4Y/yL/G/8f/zb/iP/4//T/Yf/q/gj/Wf+Y/+7/MgDy/1L/J/+g/wMA/f/3/yEADQCl/1r/c/+m/7H/lf92/33/tP8IADEAIAAIAPn/4v/O/+n/HwAwAAIA5v8xAKUAsABfADkAZQBoAAYAxP8LAF0ANQD0/y0AhgBfAAEADABoAGQA/P/g/0IAgQBVAE8AoACSAPT/o/8aAKAAgQA+AHgAyQCUADsATQB+AGoAVwCBAJMAYgBeAMwAHgHsAIMAPQD9/8b/6f9xANAAtABqAD8AEgDW/93/SQCgAGgA1P9s/0b/J/8i/3//9//p/3n/ZP+5/8//fP9d/6H/r/9g/0z/kf+j/27/g//W/9P/kP+1/ykAHACW/3v/CwB1AC0AuP/D/y8AewB+AFMABACj/3H/rf89AI0ARQDG/7b/HgBtAG0AgwCyAHoA7P/G/0cA0wDtAMEAhgA3AAMALgCaAMwAjQAOAL3/+v+RAMgARACS/2T/r//+/ykANQAXAO//8v8aADQAPAAyAPv/pP9u/3b/kv++/yAAmACqADsAq/9b/2n/yP8+AIQAbQAPALz/rf/V/+z/zf+W/4r/wv8XAFsAcABAAM//Yf9Z/73/JQBAACIAAgDZ/4r/K/8B/yH/a/+s/7L/f/9S/1//k/+o/3j/Nv8r/1n/iP+r/8H/vf+o/53/r/+0/63/yP/6//T/vf+6/wEARwBaAGIAYwA2AOX/wP/u/yEAIwAVACQAJwD4/8///f9kAGYA1P9J/2b/9v9jAJEAuQDKAH4ABwDZ/+v/GgCOACYBRgHMAEoAHQAPAPv//v8gAD8AZACNAF8A1/+U/9n/EAD6/woAWQBRANn/xv89AFAAnv8R/2n/AgAVABIAbQCGAOL/VP/R/8AA1QAeANf/cQDwAKoARQBJAGAAOgAxAI4A2QC7AIcAogDHAJAAIADJ/5//r/8cAIMAUQCm/zH/Kf85/3X/DACXAFsAjv8K//r+/P4H/2f/3//a/1v/Ef94/x0ARQD4/77/qP99/1j/kP8GADYACgD9/0gAeAA9AOb/zv/Q/8T/9/9wAJEACwCj/xIAnwA6AIH/y//SAC4BqgBjAJsAYgCj/2v/KQDnALgADQDW/x8ASAAhABgATQBjADgAMwB5AHcA4/9V/3r/BwBFAE0AfwCdACkAWv8A/1//9P8dAPf/8v8KAO//uP/W/zkAVgAAALb/xf/e/93/8/8lAC0ADQASAGwA4QAAAaoAQAAKANb/m/+h/x0AsgDZAJMACwBS/+T+fP+UALAA9////6YAKQDm/gL/QQAdAKr+nP4RAFsAW/92/4kASQD2/rz+Yf9L//r+0v/BAEkAiP/e/x8Ab/85/xIARQA3/7b+vf/OALkAXgBsADwAlP8g/07/3P9EADIA6v/w/wAA1v/0/60A9gAPABr/af8oAAQArP8/AOEAbwDH/xQArABiANL/DwCvAJsA5f91/5T/2v8cAH8A0wC0AEUA+f/q/8n/gv9t/57/uf/i/3sAGgHoAAgAdv+F/7//8/9VAHIA9f+S/+3/QgAOAB0ArgCkALn/a/8UAEwArf+W/0IAOQCM/73/pQC5ABQA/v9sAHgACwCZ/1//1f8EAZIBogCn//T/UgCP/wT/xf9nALv/8P4A/zL/Pf/A/4QAdQDe/7j/w/9Q/wb/rf8iAKD/L/+8/1cAPgBKAK8AXQBU/0r/lQBUAawAxv9V/xH/R/99ANABuAGJAA0AzgAwATcAA/8K/+3/JACp/9f/1AD9AMD/0P5e/2MAlAA6ABQABAD0/0IApQBUAHz/L/+I/9r/HwBuABYAHP8P/1wAOAFoACv/9v5H/x//HP/p/6wAhAD8//3/RABXAGgAgwDk/4j+1P2q/iEA4ADyAPYAzgADABb/P/8zAGEAd/8K/9j/fAASAM7/rgBYAaQAp/+N/7H/hP/R/2wAEgBL/+L/VAFuAV8ABwAfADH/bP7J/8YBnAHb/x7/ev9N/+b+ff9dAEEAsf/B/yYANgBPANUA9QAGAOz+9v71/54AwgAQAUYBfQBW/4D/mgCWAHj/Rv9IAK8ALABpAGQBYAE7ALz/LwBUACgAeADZAFEAZP8o/6T/DwAKAMH/ef9y/8H/DgAnAEAACwA7/6T+Pf82ACoArv/P/+D/N/8E//n/jgC9/yL//P+8AB0Ahv9BAPAANQAh/yv/vv/d/+X/NwB6AHwAegA/ALD/gf8LAFgAtf/e/rz+Pf/z/50ApwDC/9r+7P61/1AAngDMAIsA+//m/3EAuwBkAAkA6f/A/6v/DAB6AC0Ag/9t/8v/1v+3//P/LwAOANL/wv+w/6P/zv8EAOz/3P86AHcABACq/0oAHgG6AIL/Jv+0/+j/kf/U/7gA5wAEAE//gP/p/xAAYwD1AAIBRAB3/yL/Gf9R//7/tgDIAF0AJgA5ACQA6v/v/yEAGADf/+D/KQBPAFIAXwBZACUA8P/t/xAASABiABQAmv91/7r/CQALAOX/2P/2/xYACwCu/0P/Z/8TAHwALACq/4v/uv/E/5v/YP8o/0j/7/+LAFoAy//W/1EAVwDa/5T/tP/c/+//HwBkAJ0A0QDZAHkA0P+D/7v/+f///xIAMAAcAAwAZAC4AIcACADL/+D/6P/Z//3/PQBNAFEAiADKAKQALwDh//T/AACm/0r/gf8MADwAJgBeAL0AkwDn/67/OQCyAJ8AdACLALgArwBwABAAn/9//83/OAAxAM7/g/97/37/aP+A/83/+P/X/9H/FQAuAO//y/8YAG4ASADn/9j/EgAsAAQA2P/T/+r/FQBCAFYALgDm/7z/1P/9//3/2f+//83/5/8JADUAWABZADwAAwDo/xoASQD8/4D/cv+x/5z/UP+d/1MAhwAtACIAcwBtABMA9f8JALn/Kv8j/6j/6/+l/3f/yP9CAFwAHgD3/w8AEADy/wQAPwBFAP//yv/Z//7/BQAAAPf/6P/V/9n/4v/g/9r/zP+u/4L/h//O/yMARgBCADAAAQDB/5L/df9L/zv/dv/l/zMAMAAYAAQA7//x/x0ARAA8ACgAOwB3AIwAdgB1AJUAowCcAKMAqQBoAAsA9P8fAAYAnf9x/6b/xP+Q/4D/uP/p/9X/1P8UADUA/v+y/6P/yv/s/+f/8v9HAKYAwgCVAHIAXAA+ABkAEQBHAHsAewBnAHoAkQBuADYAJAAgAPb/0//y/xwADQDw/wgASABTACgABADg/5n/Nf/e/pz+fP6A/pL+hv5y/oD+yP4g/1n/e/+h/+f/UQC/ABwBWAF2AW4BRgEQAewAyAB/ACYAAwAHANj/qf/C/wcACQDH/5D/g/92/37/pf/N/8f/vv/u/ycAMgAjACMAOwBCADAAAQDL/8H/6f8LAAIA+/8iAFMAewC/AB4BTAE2AUgBpAHiAdQB1AEYAmgCeAJ8AqwC1AK8ApAChAJoAgQCZAHGACsAeP/E/jr+5P10/dz8aPw0/CT8FPwg/ED8JPzQ+5D7kPuo+7j7uPvQ+9D70Pvw+1j8yPwc/WT9dP10/Wj9ZP1s/XT9uP0S/hL+mP0w/Qz97PwM/bz9yv53/8P/VQBaAXgCaANQBFAFIAaoBkAH8AewCGAJMArgCmALwAvwCxAM8AugCwAL8AmwCGgHWAZQBUgELAP4AdsANQD+/8X/Wv8x/yv//v64/qr+tv5o/uj9qP2M/Rz9ePz4+6D7+PoA+ij5gPjQ9yD38PYA97D2gPaw9mD38Pd4+BD5sPko+qD6APsI+8j6oPpg+pD5UPjg9iD1EPOA8ZDwoO+A7qDuEPCw8SDzsPU4+YD8mP+IA2gHIArQC0AOwBFgFIAVIBbgFmAXwBdAGIAYoBeAFqAVwBTAEoAQwA4wDcALYAqwCEAGOAQMA0wC4wAX/zj9WPug+WD4QPeA9SD0UPSA9TD28PbY+HD7Ev7ZABAEsAa4B2AIQAmwCbAIUAbwA64BPf+0/Fj6OPhA9pD0wPNQ88DyIPLQ8UDy8PLA85D0kPUA99D4oPow/Oz9mP82AbwC5AM4BOwDjAP0ArYB6v+s/cj6YPcw9CDxgO3g6aDnAOcA56DnIOpg7gDzsPgHABAHYAtwDcAQ4BQAGIAZgBpAGwAaoBeAFsAVQBPQD9ANwA2ADEAJSAa4BLgD8AJ8Al4B2v4U/Oj6+PrQ+jj6YPrQ+6D93P7T/ygBpAIwBAAGWAdIB0gGmAWABTAFIAQEAzACcAHXAFYAg/8q/uz8ePxM/Kj7sPqQ+Uj4QPcQ90D3UPcg95D3mPg4+Tj58Plo+6D8QP0c/jb/rP+t/zcAJgE6AYQAHQDn/8j++Pyo+4j60Pjw9oD10PMA8QDuIOzA6iDpAOhg6ADpAOrA7EDySPh0/TwD8AkQD4ARIBTAF+AZIBpgGkAbIBlgFEARQBGAEbAPoA0wDEAK2AfIBpgGUAUkA7IB4ACN/8T9tPzg/Oj9bv+hACgBlAHcAugEkAZYB5gHSAdwBpgFYAXwBIADAAJQAYIAwv4Q/cD8GP0A/Zz8NPwA+8D4YPfg9zj4EPcw9rD2UPdQ99D3mPkg+9D7iPx4/XD9yPwQ/TT+Ff8I/8b+nv6Y/hf/+v9dAO7/oP+B/5T+2PxY+3D6KPkg9wD1kPJA7yDsgOrg6SDpgOhA6UDrIO5A8ij4Uv/wBeALoBCAE6AUoBXgFyAZABmgF0AVgBGQDuAN8A2QDNAJ4AcYB/gFqATEAwgDGAKCAWwBiAAj/9T+/v9UATwCYAMYBEAECAXQBrAH0AbQBaAFGAVIA7wB+wAbALb+uP1M/UT80Ppg+mD7LPzo+0D7wPp4+mj6WPow+qD5uPhY+ND4gPnY+Sj6KPtc/BD9ZP2M/YT9VP1w/U7+5v6A/rD92P3q/pn/pP/4/9AA/QB4ALD/zv4k/UD7+Pmg+ND1QPKA78DtAOyA6iDqgOpA64DtwPEA93D8jAJQCVAOABHAEqAU4BVgFkAXQBdgFCAQcA1gDKALYAqQCGAGYASEA3QD8AIMAtgBGAK0AdkAYQBlAIIAcAFEA4gESAQYBIgFgAcwCLgHOAeABigFqAOoAoYBw/8E/kD9wPxY++j5WPnA+XD6KPvI+8j7aPsw+6j7+PuY+/j6oPqo+rj6OPso/Bz9uP0w/qr+0P5S/sT9tP30/dj9TP0I/ST9QP2U/V7+P//J/0UA+wD2AO3/xP5K/lT9EPtA+FD1APJg7sDroOpg6eDnAOig6iDu4PFQ91z+iAUAC+AOABJgFOAVQBcgGMAXQBWgEdAOIA3gCyAKQAiYBlAFMARwA7ADeATYBIgECASgAwQDnAIsA0AEWARsA9ACRANABEAFWAYIB5AGkAUQBRAFmARwA3gCdAH8/0T+/Pwo/Gj7wPp4+lD6APrI+ej5YPrY+gD7uPog+tj56PkY+lj60PpQ+7D78Ptg/Pz8NP0Y/VT9zP3w/Zj9nP3w/T7+jP4J/2j/af97/8v/y/86/5T+zP1Y/Ej60Pig91D1MPLg74DugOzA6sDq4Osg7ADtUPHA+G//gARQCfANABEAE6AVwBcgF4AUIBKgEDAO8AqwCCAIcAfwBVgEmANoA8AD0ARABpgGoAWoBIgECAVQBTgFGAW4BBAEpAMYBFAFKAY4BuAFkAUgBXgE6APAA1QDBAJKAML+pP2Y/KD72PpA+mj5sPiw+Hj5SPpY+uj5oPnA+aj5gPng+cD6SPtQ+4D7GPyg/ND8KP20/ej9tP1w/Vz9cP24/dT9zP3c/V7+6P4t/7D/eACuAMv/sv5M/pz9sPug+XD4sPZA8+DvoO4g7qDsYOsg7ODt4O9g9BT8gAOQBxAKwA3AEQAUwBRAFaAUwBGwDiANwAtQCVAHEAdgBzAGoARoBIgFqAYwB5AHCAeoBXgEeAQIBRAFkAQYBAgEIARgBPgE4AWQBrgGYAaoBdgEOASoAwwDJALHAB//fP1c/Kj74Prg+QD5iPiA+MD4OPm4+QD6+PmI+SD5GPlQ+dD5SPqw+gj7cPv4+3T8OP38/U7+NP46/nz+WP4E/jT+pP5e/pD9tP3K/mv/Sv+a/z4ACwDC/sz9dP0Q/HD5YPcQ9nDzoO8g7QDtIO0g7ODrIO7w8QD3mP3gBAAKgAwAD6ASQBWAFSAUgBJgEJAN4ArQCNAG2ATMA9gDvAPoArwCOARQBnAHoAdAB6gG4AWgBdgFgAVYBCgDzAIYA6ADQAQQBegFgAbABqAGGAZgBcgEKAQkA5YBxP8u/uD8uPvY+jD6mPnw+LD4+PhY+Xj5mPmo+Xj5IPn4+DD5oPkg+tD6wPuY/DD9iP0Q/sj+PP8a/5D+HP7E/WD9+PzY/NT8lPxs/Aj9NP7u/u7+P/88AI8AXf/Q/aj8+PpQ+ND14PPg8ODswOqA68DsoOzA7QDyEPgQ/vAD4AnwDQAQABLgFAAWYBRgEXAPkA3ACugHWAZIBTAEyANwBAgFGAXYBbgHUAlACUAIUAfYBlAGmAXgBPwD3AL6ARgC/ALcA0gE2ASwBTAGWAZABhgGYAUABKACWgHF//j9cPxI+1D6cPnw+MD4oPig+Mj4GPlg+Vj5GPnY+Nj4APlo+Qj6yPqA+yj88PzA/WD+vP70/kL/bv/+/nb+Tv5A/sD9RP1E/Vj96PzQ/JT9Ev7E/eT94P7O/uT8CPsA+9j6uPjA9SDzYPBg7aDsoO6g8ODwcPLw9yn/mASwCCANoBAgEuASgBSgFOARkA7wDEAL2AeoBIgDhAPkAnQCYAPgBPAFWAdwCdAKgAogCXAIMAhgB+AFeAREAzQCpgHoAXQCiAKIAkQDiASQBQAGAAbQBVAFaAQ0A8IB7f/U/cj7OPoo+Tj4cPcA9/D2APdg99D3SPiA+Jj42Phg+RD64Pqo+2T8AP1s/az99P1M/ob+dv4w/rT9DP2w/OT8NP0A/aj8CP3M/Sj+Yv4o//j/6f9N/wn/Yv5k/Kj6mPpA+sD2wPHA7gDuoO1g7aDu4PCQ8oD1oPsQAxAIwAqwDUARIBOAE4AT4BKgECANkAoACegGMASgApwCvAJ4AtgCcARgBsgHoAggCTAJwAhQCNgHCAeIBcwDzALwAlgDIAOQArgCkANoBDAFMAbYBlgGgAVoBWAFyAMuAQ//hP2I+3j5SPjA9+D2IPZQ9iD3cPdQ93D3EPig+PD4YPkw+iD72Pt4/CD9qP3U/fz9iv4o/xz/iv4y/lr+lP6A/nj+lv5m/h7+bv4j/3D/G//O/pD+nP0Q/Dj7EPtA+rj44PbQ9ODx4O4g7sDvEPGQ8TDz0Pa4+zQBmAbwCkANkA6AEMASYBMAErAPAA3gCkAJyAf4BSgERAMQAxADnAPIBLAFQAYYByAIcAgACMgH4AcwB6gFYAT4A8QDjAOUA8ADnANoAxgEaAUoBtAFMAXYBIgE2APMAnIBXP/E/MD60Pko+eD3kPYg9nD24Pbw9jD3kPew98D3SPgo+bD5+Pmo+tj7hPx0/Ij8NP3k/QT+HP5a/iT+jP2Y/VL+jv78/aD9/P1i/rr+Nv9q/8T+5P30/R7+IP2A+6D6iPpw+UD3oPQQ8kDwQPDA8WDzUPTQ9VD5iv4QBGAI8AqgDFAOoBCAEsASIBFgDvALUAogCagHgAVwA3wCyAJYA9ADcARQBUgGcAeQCPAIQAhoB0AHEAewBcgDnAJwAngCfAKoApQCXALcAlAEoAWwBeAEgASgBEgE3AKiACL+0Pvg+ZD4oPdw9kD1kPQA9eD1QPZw9gD30PfQ+Oj5GPvo+zT8vPyM/QT+qP04/Sj9PP1o/aj9yP1Q/eD8dP14/qD+DP7k/Vj+wv70/hX/mv5I/Wj8wPwI/bj7GPqo+bj52Pgw94D1YPOQ8dDxUPRA9rD2GPj4+xYBkAVACeAL4AyADUAPoBEAEmAPcAzQCjAKgAlwCMAGuARcA6QD+ASgBWgFcAVABkAH2AcACNAHMAd4BvAFOAUIBPQCzAJYA7ADlAOQAygEIAUABqgGwAYwBiAFcAQgBAADYAAQ/bD6QPnw95D2gPWg9LDzkPOQ9MD1EPYA9uD2cPgA+nD7nPxQ/bT9PP7m/vL+mP6O/q7+ZP4E/uj9gP2o/Gz8CP0k/VT88PvY/Jz9gP2E/eT9fP1o/Iz8xP2E/Vj74PkY+qD5MPeg9GDzQPKQ8TDzgPag+GD5PPwEAjAHoAkwC0AN4A6QD4AQQBHAD2AMAAqQCSAJKAfABFAD1ALkAqQDwASoBfAFMAY4B6AIYAkACSAIcAfYBuAF0AQABFADoAIwAkwCoAIEA5ADWAQIBTgFGAX4BPAEkARUAxYBlv5c/ID6yPjw9kD18PMQ89DycPMw9MD0MPUQ9gj4OPr4+zT9MP7q/lP/sP8ZABgAZf+S/mL+oP5Q/nj9HP00/Qj9aPww/Lz8MP0g/Tz9qP10/cD81PzA/bz9APyg+sj62PoI+WD2kPRQ82DyIPNg9SD30Pfo+Yb+NANYBqAIIAswDaAOABAgEaAQwA4QDSAM8AoQCSgHqAVYBHgDNAMYAwQDTAMYBBgF0AV4BvAG+AaoBkAGoAXQBBAEyAPEA5wDYANgA8gDSATIBDgFeAWgBcAFuAVoBWgExALOALj+qPy4+sD4kPag9EDz0PKw8pDy0PKQ84D00PWg98D5kPvY/AT+bP97ALwAswDUAKEA0v8E/8r+eP6g/cj8fPwI/DD74Prg++T8rPwc/FT8DP1E/Tz9LP1w/Cj7mPo4+/D6iPiA9QD04PMA9FD0YPWQ9uD3uPok/0QDuAWoB3AKYA1gD2AQgBDAD4AOcA2ADPAKkAh4BjAFUARAA0gC1gHoAXgCcAOABEgF4AWABvgGEAfABmAGGAbQBZgFSAWgBPgDtAPQA/QD5APYA/wDWATgBBgFmARgAwACpgBR/8z96Pug+VD3cPVA9GDzgPLA8WDx8PFA8/D0oPZ4+Gj6UPxG/hsAQAGaAaIB7AHWAe4Au/8j/8j++P3w/Pj7IPuA+rD6mPso/Mj7iPuA/Oz9oP5s/vz9aP2o/Cz82Puw+mD4APbw9CD1cPWA9cD14PYo+ST8hf8gAyAGYAiwCpANsA8AECAPsA5gDmANwAtQCvAIGAcwBQgESAMsAk4BjgGYAmwD4APIBEgGeAfIB5gHiAdgByAH6AboBnAGKAUIBNwDSARIBLwDYANoA6gDCARwBEAE6AIsATwA+v8A/wj94Pr4+AD3UPVA9GDzAPLQ8CDxoPIA9DD1MPfA+aD76PzS/u0A6gH+AYAC7AI8AiQB+AA0AdT/UP3A+3j76PoI+vD5IPqY+Uj5kPpw/Mz8APwA/Lj8oPzY+1j7yPoA+RD3oPYw9xD3YPag9iD4sPmQ+8T+cAIQBRAH8AkADYAOUA5ADpAOIA4QDUAMkAvgCZgHEAZABfADRAKaAfYBcALkAtADAAWwBTgGEAe4B4AHCAcoB3gHMAdoBsAF+AQ4BBAEaARABFwD2AIIAywD1AJkAsYBjQBS/8z+fP48/VD7gPnw9yD2oPTg8zDzEPJw8UDyAPSA9VD3mPlI+wj8cP3v/7QB1gGaAewB8gFKAfIAqgAo/9T8qPvI+4D7kPoo+lD6GPoI+vj6EPwc/Mj7PPzk/Lj8APxo+5j6OPkQ+LD3gPcg91D3UPiI+dj6EP0UANgCMAXAB0AKAAwwDSAOgA7gDSAN4AxgDPAKQAnwB6gGGAXMAywDlAIoAlwCWANYBAAFsAVYBuAGMAd4B4gHQAcAB7gGWAbABUgF4ARoBCgEOAQoBLADQAPsAkwChgEWAawApv9U/nz9xPxA+zD5cPfA9fDzkPJw8pDyUPKw8nD04PaY+Oj5YPu4/Mj9QP9SAaQCeALyARwCMAJiAfX/jP5Q/Tz8ePsI+2D6iPkg+TD5YPnI+Wj6GPuw+zT8iPxY/Lj7SPvo+iD6QPnQ+Lj4kPjA+Mj5KPs8/Lj9CgCkAtgEwAawCDAKEAuwC3AMkAzwCyALoAoACtAIeAdQBkAFGAQQA4QCcAJ8AtACmAOQBCAFeAU4BiAHkAdQBxgHKAcoB/AGmAYYBjAFWAQgBEgEvAOUAqABKgHKAE8A6/9l/0r+LP2o/FD8IPsg+TD30PXQ9ED0IPQA9PDzoPRw9mj4gPkg+kD79Py4/lUAqAFIAmQCeAJUAoQBPwD4/sD9lPyg++D66Png+GD4ePho+ED4oPiY+Zj6UPsA/GD8IPy4++D7OPzw+/j6YPqA+uj6YPsk/Bj9LP6Q/6gBEATgBQAHIAiQCdAKgAvQC+ALkAsQC4AK4AngCHAHOAZ4BbAEuAP0AuACFANEA5gDQAToBGgFEAbwBoAHiAeIB8gH4AeQBzAHsAa4BZAEAAS4A9ACVgFOAMb/Jv+I/ir+jP1I/DD7CPvg+oD5gPcw9pD14PSA9LD0IPWQ9YD2UPgY+vj6aPs8/Jj9D/9fAHQB6AHuAfgBGAKsAYwANP/4/QT9SPyQ+4j6YPmQ+Fj4aPh4+Lj4OPno+Zj6OPuA+3D7gPvQ+xj8JPwk/Ez8nPwk/Qr+Fv/w/+YAUAIIBKgFAAcwCCAJ8AnACpAL0AtQC6AKQArACQAJAAjgBogFYATMA4wDFAOIAoACAAN0A+wDoARYBcAFSAYoB8AH4Af4ByAI2AcQB3gG+AXoBJwDyAIYArgAXv/E/g7+nPyg+7j7aPu4+UD4GPjA9yD20PTQ9AD18PTg9cD3yPig+Dj5+Po8/IT8CP1M/k3/1/+kAHoBRgFdAOH/0P9N/0r+XP2Y/LD76PqY+jD6WPmg+Jj48Pg4+Xj5qPmo+cj5QPrY+gD78Po4++D7iPxA/TT+N/8qAEIBqAIIBDAFEAYAB+gHkAgQCXAJwAnQCbAJYAkgCcAIAAgIB2AGCAZwBagEOAQoBPQDuAO4A/gDOASgBFAF4AUwBmgGyAYYBygHGAfABjgG2AWgBRgFCAQYA3wChgEgACn/ov6s/Tj8QPuY+kD5gPeQ9kD2IPXg8yD0oPXA9jD3CPgo+dD5ePrg+0T9nP2k/ab+JQC/AIMAUAA2ALr/VP9h/zP/QP4Y/Zz8bPzo+yj7mPow+uD58Pk4+kj68PnA+dD5CPow+mD6sPoA+4j7bPxs/Vb+Qv9zANABHANQBHgFiAZYB/AHgAgACWAJgAmQCaAJkAkwCZAIAAhwB9gGOAawBTgFsARQBDAEKAT8A9AD+AN4BBAFiAXQBQAGSAaABoAGOAbwBaAFKAW4BFAEpANwAiIBVQDC/6b+UP1o/Jj7WPr4+Aj4MPfA9ZD0YPTg9GD1APYQ9xj4aPjI+Nj5GPvI+zD8GP1S/jb/pf/K/5L/Cf+q/rz+ov7s/Rz90PzI/HT86Pto+/D6gPpw+qj6oPo4+vD5IPqA+rj64PoY+2D72Puc/Hj9IP7A/sv/LgFwAmQDUARIBTgGAAfQB5AIAAkQCTAJkAmQCTAJsAhACLgHCAeIBiAGoAUIBagEmAR4BEAEIAQwBFAEkAT4BFAFiAW4BegF6AW4BZAFUAXYBFAE+AOEA4QCVgGQAPL/9P7U/fT8FPzY+rj5EPkY+JD2UPVA9ZD1kPXA9cD28PeQ+Pj4sPmI+kD7HPxM/TD+iv7W/nH/xf9x/8j+bv5Y/jb+7P2M/Qj9dPzw+5D7QPvQ+mD6IPpI+nj6UPoQ+iD6kPro+jj7yPtk/LT8KP0q/kv/CwCtALgBAAMIBPgECAboBnAH8AewCCAJMAkQCTAJQAngCGAI8AeIB/AGcAY4BggGoAUwBfgE4ATABLAE2AQYBVgFoAUABlgGcAYoBuAF0AWgBRAFaATsA1gDWAJAAXIAj/9g/mD97Pw8/ND6cPnY+Dj48PbA9bD1MPaQ9kD3cPgw+RD5QPmY+vD7JPwY/AD9Rv7m/gL/P/8g/2z+/P1W/nr+tP3Y/MT82PxQ/Kj7cPtI+7j6QPpo+qD6WPrw+Sj6sPro+hD7gPsQ/Gj80Py8/dL+m/9bAIwB6ALoA6gEmAWIBigHkAcQCIAIoAiQCKAIoAhQCOAHgAcIB5gGUAYwBuAFaAUgBQAF8ATQBMgE4ATwBDAFoAXwBeAFyAXgBdAFgAU4BfgEcASUA9QCMAIsAfT/M/+e/pT9NPww+3j6OPmw96D28PUg9cD0oPXA9hD3MPdQ+MD5YPqY+pj70Pxw/ez93v5+/zn/3P4n/2P/3P5O/kj+KP6Y/SD97Pxo/Hj76Prg+sj6aPog+iD6IPo4+qj6CPsg+1D72PuQ/Bj9tP2m/pX/cwCUAfQCCATQBMgF8AaoBwAIoAhQCYAJQAlACWAJAAlQCAAI0AcwB3AGKAbwBWAFyASgBJAEUAQ4BIgE8AQoBWgFwAXoBegFCAYQBsAFOAXIBEgEiAO4AugB9wDi/wf/Vv5Q/fj7uPqY+Vj4EPcg9pD1IPUQ9bD1sPYw94D3EPgA+fD50PrQ+5D8BP24/br+T/8X/7L+uP7w/uz+vv6C/gz+gP0w/QT9lPzw+3D7IPvY+qj6mPpw+iD6GPpo+sD6APtg+/D7lPxY/UT+J//p/9oADAJMA2gEYAVQBigH2AdwCMAIwAjQCAAJMAkgCeAIkAgQCIgHKAeoBgAGaAUIBdAEmARwBFAEOARABHgEuATQBOgEEAUwBQAFmARQBBAEjAPoAlgCpAG7ANb/J/9K/iD9+PsY+xD6wPiQ97D28PVg9YD1MPbQ9iD3kPd4+Fj5CPrI+mj7yPtU/GD9UP6C/k7+Tv5w/mL+Tv4w/uz9hP1E/RT9rPwQ/JD7MPvg+qj6sPqo+nj6YPqQ+uD6EPtg+/j7sPx4/V7+YP9WAEABWAKkA9gE0AXABrgHgAgACTAJcAmQCZAJoAmQCVAJ0AhgCAAIiAfoBlAG8AWgBWAFMAUQBeAEoASgBNgE+ATgBNAE2ATIBHgESAQYBIwD0AJYAhACSAElAFL/rv6w/Yz80PsQ+7D5YPjA90D3MPZg9aD1YPbQ9lD3KPio+LD4MPlI+gj7MPug+5z8eP3w/VL+gP5C/hD+Sv6I/kj+6P24/YT9KP30/Lz8PPyg+5D70Pu4+3D7cPuo+7D74Pt8/CT9iP0Q/iT/RAAAAboB4AIIBOAEwAXYBrAH+AdgCAAJUAkwCUAJkAmgCUAJ8AjQCHAIsAcoB/gGkAboBZAFcAUgBbgEqATQBKAEUARgBHgEOATIA6ADgAP8AlgC8AFuAY0Asf8s/4z+lP2g/OD74Pqo+cD4APgA9zD28PVA9qD2MPfw90D4KPig+Lj5UPpI+rD6kPsY/Fj89Px4/QD9fPwA/cD9jP0A/Sz9gP08/dz89PzU/Cz84PtE/Hz8JPwA/FD8fPxU/IT8HP2A/bT9Uv5X/y4A3QDOAegC3AOwBKgFmAY4B7AHQAiwCOAI8AggCUAJIAnwCMAIkAggCMgHiAcoB6AGIAbwBcgFkAVQBTgFMAUIBcgEmARwBAgEeAMYA+QCbALAASoBqQDj//7+Vv7M/fD88Psw+4D6oPm4+BD4kPcg9yD3kPcI+ID4OPnI+eD56PmA+jj7cPuA++j7ZPyQ/Mz8JP3g/Cj8CPy0/Pz8iPw4/HD8ePww/ED8gPxA/Nj7LPzw/Az9oPyo/Dz9gP14/fD9zv5j/9H/xwDyAYwC4AK8A9gEgAXQBZAGgAfwBxAIgAjgCMAIoAjQCPAIkAggCPgH2AdoB/gG0AagBigG8AUABvgFmAVABSgF+ASIBCAE0ANcA7wCNALQASoBPwBs/8T+AP4k/Xj80PvY+tj5KPmQ+ND3MPcw90D3gPcw+Dj5wPm4+QD6uPo4+1D7mPsA/BD8GPyU/Pj8hPzo+/j7UPwg/OD7FPxE/PD7uPv4+wj8qPuA++j7MPwU/Cj8oPz8/Bz9VP3k/Wj+1P57/1oAEAGQASgC/ALAA1AEuAQ4BbgFQAbYBmAHsAfIB+gHIAhgCGAIQAggCBAI8AfQB6gHUAfoBpAGcAZYBhgGuAVwBSgF8AS4BGAE2ANMA+QCgALoAR4BVQCT/8r+Dv5s/bj82PsA+0j6mPnY+ED48PfQ9/D3iPgw+XD5iPno+YD62PoQ+1D7gPug+/D7ePyY/ET8APwE/BD8BPwA/AT84PvA++D7HPwU/OD72Psc/Fj8aPx4/KT83PwU/WD91P0+/qT+NP/8/7EADgFmARAC3AJ4AwAEqARIBcAFSAb4BmAHYAd4B9gHIAgQCBAIMAggCPAH8AcACMgHeAdYB1AHGAfQBpAGOAbQBXgFIAWYBPwDdAP0AkwClgHqAB8ANf9o/sD96PzY++j6MPpw+bD4KPjg99D38Pdo+OD4GPlI+aD5GPqA+uD6OPt4+8D7HPxU/ET8KPw0/DT8GPwc/ED8NPwM/Bz8UPxY/ED8ZPyY/JT8jPzI/Pz87Pzw/Fz9zP38/UL+3v5w/9L/WgAaAa4B/AGIAmADCARoBPAEoAUQBlgGwAYoBzgHIAdYB6gHoAd4B4AHmAeAB2gHgAeAB1AHKAcgBwAHsAZoBjAG2AWABSgFuAQYBHQD9AJYAooByAAbAFX/gv7g/UD9VPxA+2j6yPk4+QD5IPko+fD4CPmQ+ej50PnA+ej5GPpY+tj6SPs4+wj7WPu4+6D7UPto+6j7uPvQ+xj8QPwg/Bz8WPyE/Hj8hPzI/PT88Pz0/Bj9UP2M/ej9Xv7U/kP/yv9oAPQAVAG6AUwC7AJ4AwAEiAToBCgFgAUABlAGaAaoBggHMAcwB1gHeAdAB/gGCAcoB+gGmAaYBpgGOAbgBdAFmAUQBcAEuARYBHwD6AK4AjwCbAHPAFsAg/+W/h7+qP2g/Ij7GPvo+nD6CPoI+gj60PnI+SD6QPoI+gj6UPqI+oD6iPqQ+oD6aPpw+oD6cPqA+rD68PoY+1D7kPvI+wD8SPyA/Kj80PwM/TT9RP1U/Xz9qP3Y/Sb+kv4B/2r/2v9WAMsAQgHEAUACpAIMA4wDEASABNgEMAWABcgFEAZYBpgGwAbwBiAHOAcoBxgHKAcwByAHAAfoBrAGYAYgBugFkAUwBfAEuARYBMQDQAPAAiAChAESAZwA7P9N/9T+SP6I/dT8VPzg+2j7KPsY+/D6wPrQ+gD7CPvw+uj68Prg+tj68PoA++D6wPrA+sj6wPrY+gj7KPtA+2j7uPvg+wD8KPxc/IT8vPwc/ZD91P0K/lD+jv64/uT+Mf+L/9n/QADHADoBfAG8ARQCcALAAhgDfAPIAwAEUASgBOAECAU4BXgFoAW4BeAFAAYABvAF6AXgBbgFgAVgBTgF+ASoBHAESAQIBMADfAMkA7wCaAIUAqYBLgHeAKoAVQDe/2j/B/+c/ir+uP04/bz8ZPwk/OD7mPuA+4j7iPuA+3j7cPtg+3D7iPuQ+3j7cPt4+3j7gPuY+7D7yPvw+yD8SPxk/JT82Pwc/Uj9cP2k/dT9HP5q/p7+tP7U/h7/ef/E/+//DwA8AIwA+QBcAaoB6gE8ApgC5AIIAxQDKANYA5ADsAPEA+QDEAQ4BGAEcARgBEAEQARoBIAEcARIBCgE+APUA7QDjANIAwQD8ALsAsgCgAI0Au4BqAFWAQwBswA0AK7/U/8H/6D+JP7A/YD9QP30/Lj8lPx4/Gz8dPyA/HD8QPwY/AD88Pvo++D78PsI/CT8RPxk/Hj8hPyM/LD84PwI/Tz9kP3g/Qr+HP4+/mr+kv68/uj+A/8V/0P/gP+a/6n/6P9KAKUA5AAeAUYBWAGKAeQBMAJMAlgCfAKkArwCxALIArwCrAKoAsQC6AIAAwwDCAP4AuAC0AK4ApwCeAJgAlACUAJIAiQC7gHKAcoB0gG4AYABRgEIAckAogCJAGMAHwDr/9T/tP90/zX/Cv/Q/pD+dv6E/oD+ZP5S/kz+KP70/dT9yP3A/cz98P0I/hT+IP4k/hD+/P0G/hz+NP5e/qD+1P7q/vr+Ev8g/xv/E/8l/1H/hf+3/9X/3P/T/8z/1v/q//v/CQAmAFAAdgCLAJcAoQCoALAAwADcAAABIgEuARwB8QDRANAA4wD3AAoBEgESARQBDAHrALcAlwCZAK8AwwDMAMQAtACoAJoAeABRAEUAUwBRADMADgD6/+7/4P/N/7//tf+w/7X/sv+h/4//mv+6/8r/uf+e/5f/o/+w/6X/d/9D/zv/Yf+M/5H/fv9w/2n/af9y/37/hf+R/6z/uf+k/4b/ff+F/4//nP+s/7f/zP/6/x0ABADK/73/7f8dADQAQQBGADUAJAA0AEwARwBFAGIAhwCHAHMAcAB5AIEAiACQAH0AWABOAGIAXgAxAB0AOgBVAEwAQgBJAEEAJQAiACsAEwDn/+//MgBbAFQARgA/ABsA3v+//7//wv/R/wEAMAAyABwAFQAZAPv/xv+j/6D/s//T//3/GgAXABEALABZAGMARAAnACUANQBEAE4ATwA5ACYAKwA+AEQALgAXABIAJAAtACgAJgA4AFIAWgBWAEcAMwAlADEAVABkAF0AYQBvAGUAQQArACEA9v/G/8n/7//3/+T/3v/b/7f/if90/2j/Yv97/6b/t/+m/5r/jv9o/zz/Pv9j/3n/fv+J/4j/b/9X/1b/Vf9V/4D/s/+x/4T/gf+q/7j/pP+d/7L/yv/o/wsACwDe/7r/y//s//v/FQBKAGkAXABIAEAANwA0AE4AdAB6AFsAQQBJAFoAVwBPAGQAlwC6ALAAlgCGAHQAZABoAH8AhgBzAGoAagBTACsAFgAQAPn/6/8AABcAEAAFABMAEQDk/7v/w//a/9f/y//M/8z/1////xQA6f+v/6//1P/o/+j/3v+//4z/cv98/3r/aP9r/4r/kP9y/1j/X/9w/3r/eP9n/1j/XP96/4n/fP9q/2v/ff+N/5b/mv+d/5n/m/+6/+j/8//p//7/KwA3ABUABAAmAEYARABDAGAAcgBkAFkAZQBxAGUAUgBRAGcAiQCoAMcA4wDdAK4AiwCXAKsAlgB/AJ0AzwDRAK8AoACaAIQAdAB3AGoARAA7AGwAkwCEAGAAUABBAC0ALABCAEcAMwAoACwAIAACAPj/EQAuADQAJAAQAPz/5f/V/9X/2f+9/4z/ff+Z/6r/kv9//4//lf92/2f/gP+P/3H/Xv9q/2r/Uv9W/3z/dv9A/y3/Z/+h/5D/YP9a/3z/m/+r/7D/pP+U/6D/yv/x//b/3f/F/8H/0v/c/9v/8v8fACoABQDv/wsAMwBGAE8AUQA/ADcAVwB8AHIASgAuACsARQB1AJUAfwBUAEoAXABbAD4AJgAiADQAUwBsAG4AZwBmAGUAWABFADEAIgApAE0AcwByAEsAFgDq/9z/8/8TABoACQD0/+n/5f/d/8r/sP+b/5f/o/+1/7//t/+g/47/hv+I/5P/pf+z/7v/wv/K/8j/tP+g/6T/vP/S/9H/xv/D/8v/3f/q/+P/zv/N/+n/+v/1//P//P8CAAIAEgAkACMAHgArAC8AFQD//woAKgA+AE4AXQBkAFwAUABQAFgAYwBrAHEAdQB1AHEAcQB6AHgAVQAnACcAVwB2AG8AagB6AHAAQgAjABsAGQAqAGMAjQB2AEkAPAA8AB8A9v/n/+r/7//2/+3/xf+e/5r/nf+M/33/jP+d/5X/mP+0/7n/j/9o/37/rf+4/7D/vv/J/6v/iP+c/9P/3f+z/6T/2v8PAAQA6v/v//r/6v/a/+j/8v/m/+//HQA6ACQACwAZACwALgBBAFwATAAbAA0AIQARAPH/CABHAFcAOwA/AFQARQAqADQATwA+ABIABgAwAF8AXQA8ACYAGgACAO3/9P8KAA0ABQATADIAOQAcAPb/3P/J/8L/1f/7/wsA8v/Y/+z/CgDm/6T/qP/s/woA6v/h/wYACwDh/8v/6P/+/+H/t/+r/7H/o/+F/3//lf+u/7f/wf/Y/9//wv+c/5n/sv++/8j/6/8RABAA7P/Y/+n/BgAQAAsACwAOAAgA//8KACUAMwAtACcAKAAlACIAIQATAPr/8/8BABEAJQBCAEsAMgAdAB4AGwD+//7/MwBaAEUAIgAQAPz/8f8QACUAAwD3/zoAYAAwAB8AZQBsAP//0f8iAD8A9P/s/0MAQgDc/8n/BwDw/57/t/8IAOv/o//L/w8A3/+a/8D/6v+o/2n/o//t/8//nP+x/8//uP+X/53/tP+3/6j/nf+r/7H/m/+S/73/5P/I/5z/tf/s/+j/x//U//L/6//h/wIAJQAWAAUAIABMAFoATAA5ADEANgBCAFIAZgB8AIsAjQCLAIkAdgBeAFwAZQBjAGQAeQCCAGQATABdAHEAYgBZAGkAYgA9AD0ATwA6AB8ARQB0AFUALgBKAGIALgAIADQARgAPAPv/KwAuAPf/7v8NAPv/y//D/8L/sP/M/wQA7v+q/7r/9v/U/4T/kf/S/8f/lP+S/5n/ef9j/4T/o/+Z/4n/h/96/3L/mf+8/6r/hf+I/5j/k/+k/8v/wP9+/3//6P84ACAA8v/n/+D/3/8JAEcASwAeABQASwB3AFwAHAASAEwAbABMAD0AdACWAFQA//8CADsATgBDAEoATwBDAFMAggCJAFIAKwA1AEgAUQBbAEIA/P/w/0YAhgBaACAAOQBcACcA4P/s/xMA/f/Q/9n/7v/Z/9D/BQAgANH/a/9d/5H/qP+f/5//rf+n/4//jv+q/77/qf+Q/5v/qP+B/1P/e//P/9f/mv+F/6b/sv+t/7T/of91/4b/5v8hAA0A+f/8/9b/sf/w/1YAWgAeACYAWABAAAcAFABDADMACAAVADoALwAWAD4AfQB1ACgABAAvAEsAQgBhAKQAkAApABgAbgB8AC8AMQCHAIUALwBHALkAwQBkAFkAkAB4AEgAfwDIAI4AJQAiAFUATQAoACEAEADg/9T/9v8GAAIA///b/53/oP/n//D/tv+x/9z/xv+Q/6P/yv+M/z//d//R/6v/Xf+Y/xgAJADb/9L/5/+z/3j/lf/W/+X/1v/Q/8P/wf/y/x8ACgDV/7z/uf/N/xgAVQAoANX/1/8HAAEA+v8vAD8A+P/d/y0AUAD//9//MwBXAA0A+/9OAFUA8v/j/z8ASQDy/+z/QABYACIADgAbAP7/3v8MAEMAKgD+/wIA+//Q/+D/SQBxAA8AwP/r/yEABgAKAG4AoQA4ALD/kv+3/8f/3P8oAGMAPADY/5H/eP9y/4//yf/k/8P/m/+l/77/tv+x/8r/z/+i/5H/zf/7/+H/xf/i//v/1v+w/8v/BgAJAL7/hP+k/+v/AgDj/9v//v8YABIAEAAEAMb/ov/w/10ASwDq/+j/QwBaABgA5//L/57/rP8WAEQA+v/f/0cAkABTABAALQBbAD4A/f/a//3/cADZAMAAOwD6/zYAcQBtAF4AMwDW/7f/KgCYAHYAJQAuAGAASgABAOb/AQAYABEAAAAOAC0AJgDx/+j/DADX/1b/WP/p/w0Alv+W/0gAZgB+//L+hv8NAJv/Fv9Y/+D////6/woAxP8//zr/7/9xACgAof+H/7H/pv+a/+b/QQA6ABkARABZAO//gP+//14AeAAGANj/MABxAEMAEgAqAEMALAApAGQAggBMABkANwB2AKAAuQCvAFoA+v/5/zoAYwCIALQAdgDa/8j/YgCXADUAXAAMAdgAu/+V/6oAFAE6ALT/DQAUALf/KQAmAQQB1/94/zcAfAC4/zD/mf8eAPL/d/9P/17/RP85/6H/KgA0ANr/sf+4/3P/A/8P/4P/ov9R/0n/u/8HAPz/BQAZAK//8v68/jj/o/+z/9P/HQA1ABMAAQDt/7f/pf8BAH4ArgCiAHEABACW/53/7v/z/67/yP9YAJoAPgDl/+f/y/93/4r/FgA9ANf/6f++ACABfwALAH0AzAAuAIr/ov/J/3X/aP8nAN0AywBsAHIArACBAOL/df+t/zMAhACpAAIBXgE+AYcAz/+o/+r/FAABAN3/q/9k/1H/lv/C/33/Qf+b/x0AEwC0/7f/HQBSADMAGwAoAC8AJwATANj/j/+L/9z/GwD6/7f/xf8rAIQAgQA/AO7/mP9X/2H/pv/Q/6z/YP8x/0H/XP9J/zr/jv/r/6r/M/+G/38AAAHWAMYABAEEAcsA0gAGAfIAuADIAO0AvgBWACgAYQC8ANcAiQAvADYAbgBLAM3/l//f/xUA1v+F/33/gP9V/0z/gP+H/0v/YP8EAIUAUADW/9L/LQBLAAwAxf+n/7D/3f8aABsAx/97/5z/CwBOAEYAOAAuAO7/kf91/5//xP/l/yQATwA7ACkATgBjACEAyv+l/5z/kv+F/1f/+v7a/if/a/9J/xX/Pf+O/77/7/9CAGgAJwDS/8f/7/8AAAgARACbAKQAQgDm/+7/GAD//8v/0P/j/6v/a/+f/w0AJQABACQAdwB6ADcAHwAtAAUAyv/1/28AqACGAGgAYQAcAJr/Wv+Z/+7/4v+G/z//Q/9//9n/UADEAAoBFAHvAKoAWAA4AGgApACWAEwAGAALABYARwCEAH8ANQD3/9n/qf9y/3D/pf/Y/wcATwCGAHoAXwBkAFEA+f+r/57/kf9J/xD/K/9n/4v/tP/q/+j/nf9g/2H/bv9g/2X/lP/N/+n/7P/h/+n/LgCJAJgATwAJAOf/r/9l/1//pP/e//7/PAB6AGAACADu/zUAfABuACkA9v/f/83/3P8tAJMAuACsAMUA6ACrADYAJQB5AJUAZABYAHMATwAJADYAtwDHAFEAEwBQAGgAFADj/yIASgD9/6T/l/+X/3v/n/9AAOIAAAG/AI4AfwBiADgAMABIAD0A+P+4/8D/4P/N/6L/qv/W/+X/uf97/1n/XP9x/6L/+P81ABcAxf+r/83/1f+7/8T/3v++/4//p//d/83/if9h/2D/bf+O/7H/sf+x/+3/OABOAFYAigC/ANMAAAFEATYB1QCpAM8AygBvABwA+P/K/5H/iv+v/8H/0v8aAFkAIACg/3P/sP/e/7//hv9k/0z/Kv8Y/yv/UP9q/53/+f8xAOP/XP9I/6z/5f+//7z/BgAkAPH/5/8nAEMAOgB7AOQAzAA0AOP/JABpAD8A5P+q/3z/Nv8Q/y//SP8g/xr/gP/b/57/Mv9I/8L/AAD//xcAHwDe/7//NAC9AKkARgBgAPAASgFMAVIBggGwAcYB1gG6AVwB2gCOAK4A8gDxAKQAXgBSAEMA6/98/1z/lP/j/yYAWwBZAA0Az//9/1oAZwAqAAUA/P+6/1f/Lv9I/1n/Wf9p/1P/2P5G/hT+MP4s/hz+Qv6I/qz+rP7k/mD/3P9CAK0A/wDcAEgApP9T/yb/2v6E/k7+Ev6M/Qz9BP1g/aT96P2g/qL/RQByANQAqAFgAsgCHANYAwQDUALYAbgBmAF0AYQBuAG8AXoBCAGRAH0A6wCEAeQBKAKAAtQCMAP0A0AFSAaYBmAG+AUoBcADdALkAZoBGAGfAJIAbwDD/xb/LP+2/9L/Wv+8/gr+/Pyw+9j6wPoA+xj7CPsY+0D7OPsY+3j7XPzQ/Dz8kPt4+zD7CPoI+Tj5mPkA+Tj4SPiA+OD3cPdo+DD6IPto+0j8oP1O/nT+Qv/bAPYBAAIcAtQCJAOIAkACKAMYBBgEKARQBXAGaAY4BtAGSAfYBpgGUAfoB6AHiAdwCEAJMAkQCZAJgAmwCHAI4AjQCDAIUAhgCdAJgAnACbAKEAvACsAKcApwCLAFAATYAloA9PwY+iD3APNg78DtQO0A7CDrQOzA7SDuQO7A7/Dx8PMw9vD4OPuU/OT9rP8oAZgBPgF5AHz/PP6c/Ij6SPiA9mD1kPTg84DzoPMg9BD1sPbA+HD6BPxI/jgBxAN4BQAHkAhQCeAIcAggCAgHYAWgBOgEsASwA2gDkATABSAG8AbwCMAKYAvgC9AMIA3QCyAK8AlgCnAJoAcIB+AHEAggBygHwAigCQAJAAlwChALsAmgCIAJ8AlgCJgGKAaoBXwDHAErAGv/GP34+bD34PWg8/DwwO6A7cDsAOzA64DsAO7g7gDv4O8Q8lDzIPPA9Ej5VP3G/lcAeAOoBNQCIAK0AxwDuv5I+/j6GPrA9jD1cPeA+fD4yPj4+kz8yPrA+QD8Ff8PAJYAFAMABsAGcAa4BwAKoAqQCcAIIAjgBVACHABEAL8AZwCHAOwBHAMQA2ADQAVYBzAI0AgACmAKEAn4B3AI8AhwCEAI8AhwCDAGmATQBPgEWATIBIgGQAcwBmAFAAaQBmAGcAYQB+AGKAX4AlQBUwBk/3T+CP5y/gL/mP6Y/YT9/P0s/QD7oPlA+ZD3MPTA8VDxUPDA7YDsYO2g7WDrIOsg70DzcPTQ9iz9IAPwBBAGUAlgCogG0AIgA9wCRv4g+tD6DPxg+bD2YPgY+1D64PgQ+zL+nP24+6z95gH8An4BdAK4BWgGQARQBPAG+AZQAxYBGAIcAov/pP5EAXwDHANwAyAG8AfoBuAFoAYQB7gFYAQwBLwDJALyACoB3gFYAhQD+ANABAgEEAQwBBAEkAQgBpAHMAgQCYAKIAtQCvAJ8AqwC9AKUAkACNAFZAKg/6z+Kv7w/Bj8tPxw/cD8gPtQ+9D7UPuw+Wj4oPfw9VDz0PFQ8lDy4PBA8HDxoPGA7yDvIPOw97j5NPyKARgGQAfoBxAK0AlgBSgBxP/U/Vj58PVQ9nD3IPdA9yD52Prw+kj7GP2+/tL+wv42AGwCnAP4AxAFqAZYB9AGaAZQBjgF7AIcAVsAc/8w/hb+fP+rABAB9gHQAyAFOAVQBdAFqAWIBMwD8AOkA3QC0AGUAmwDbAOUA7AEgAUoBdAEiAVwBqgG8AYgCFAJwAngCYAKAAuwCsAJMAmwCGAHKAXkAiIBnP84/oD9pP3o/bz96P3a/nD/zP40/qT+kv6Y/CD6qPiw9jDzYPDg72DvgO0g7QDwUPKA8RDx4PMQ93j4IPvjAKgFqAYAB8AIwAiwBFwAuP5E/Xj54PUw9XD1sPTQ9KD3wPrw+8j8Pv+KAZoBBgEkAuQDYAR4BNgFWAcgBygG+AXABSgEbALuAXABcP9I/dz8ZP2c/Ub+igAEAwgEoAQgBlAHeAZABXgF8AXIBCQD4AIYA3AC+AEgA8AEMAXYBOgEEAWABLQDyAOwBJAFIAawBogHQAiQCOAIUAmACQAJ+Ae4BmgFGAS0ApIB5QCZACEATf+O/kL+CP50/SD9lP0e/pz9nPw4/JD7OPkA9hD0kPLA78DsoOzg7qDvYO9g8eD0APYQ9tj5WAD0AzAEgAW4B5gGYAL4/7P/aP0Y+SD34PdQ98D0QPQg9/j56Pos/MT+UgDM/2f/tgA0AowCFAP4BMgGuAagBTgFYAWwBIgDLANAA1ACagA4/0P/ff+u//4ATAOYBDAEtAMgBEgEyAMIBEAF0AVIBcAEkAToA/QC2AKoA0gEYASIBLgEgAT4A7gD0AMQBHAE2AQ4BagFYAYYB8gHsAjgCUAKcAlQCFAH2AXQA1wCDALeAfoAJgAXAAYAD//k/ZD9vP1k/Wz8yPvw++j7sPow+Zj40Pfw9ODwgO6g7SDs4Oog7eDxgPSw9PD2APwQAOABcAQgCDAJSAY0A7IB1v7A+XD2IPdQ+ND2IPVw9gD5iPlo+Wj7iP5l/5j+hf8AArgCygHkAmgGUAg4B2gGeAc4BzgE7AGcAmwD2gEuANQA3gEoAXoADAJABKgEGASQBIgFAAV8A+ACbANsA2ACtAE8AqwCKAKqARwCvALAAugCsANYBFAESAS4BBgFAAXYBMgEmARYBGgE6ASQBTAGuAYABxgH+AaQBvAFMAVgBHwDwAI4ArgBPAEMARIB5QBiAK3/yP6s/bj8FPxY+3D66Pn4+ZD58PcA9sD0gPOQ8cDvwO7A7SDtYO5A8oD2uPn8/IYBoAUgB2gGaAUoBKYBGv5w+xD6UPgQ9nD1MPfw+Pj4cPnY+8j9KP1Y/OD98f8nAC0AWALABNAEKAQwBYAG2AV4BHgEuARoA6ABIgFqAToBGgHkAQgDqAPgAyAEOATgA3QDSAMoA+gCrAJ8Av4BSgHmABwBlgEYArgCXAOsA7wDEASoBOgEuATQBFAFUAWwBFAEiASQBFgEmARYBaAFcAWQBfgF8AWoBdgFMAboBVgFKAX4BCgELAO0AhgC6QANAB0A9//C/pT9nP3k/Rz9APwI/IT8ePso+bD3UPcA9mDzoPHw8ODugOsg62DvMPQQ9/D6YgEQBmgGyAXoBogGxAJc/7L+WP04+RD2kPZQ9wD20PWo+BD7uPpg+hz8bP34/Ij9egDgAggDVAMoBSgGGAVABPgEQAXkA5ACYAIQAuoASgAcATgCwAKsA1AFQAawBRgFKAWoBPwCrgGqAYwBbwCl/9z/3P8w/2j/8AAAAu4BOAJ4AzAE5AMIBBAF0AXgBRAGSAawBaAEIAT0A1QDkAKcAvwC8ALkAqQDyARYBcAFsAaQB1AHYAa4BTAFCASIArgBqAEyAS4Atv8sACsADv8a/kr+Uv4A/cj72Pto+xD5EPdw94D3YPSg8KDvYO/g7GDrgO9g9pj6IP3aAfgG4AcABsgFOAYQA4z9QPp4+aD3EPRw8kD04PYI+Kj4GPqQ+8j7aPsA/Ij98v7p/0QBQAPIBBAF6ARYBQAGqAVQBAwDXAKMAU0Alv86AKIByALIAxAFCAb4BUgFwAQwBOQCcAHcANMAaQDV/wIAvgAcASQBngGIAiQDYAPQA3gEwASIBJAE+ARIBSgF2ASQBBgEaAPAAlwCKAIYAmwCEAPIA3AEQAUwBvAGYAfgB3AIYAhQB7AFWARYAxwCjACO/6z/AQBa/2j+vv6v/x7/kP2A/XL+bP3I+jj6oPuw+lD3APYg94D1EPAg7KDsgO6g7yDzsPlK/0gBeAIIBcgGUAXIAqoBlgBo/Xj5UPfA9vD1QPUg9hD4WPmo+RD6wPog+4j7wPyU/jAAngEoA6AEoAUwBmgGYAYQBoAFiAQ0A8wBvwA1ADoA2gDsARQDEAToBKAFAAbYBUgFmATgA+gC1AEGAZUATwAoADQAZwCQAKAA2AB2AWACJAOQA8QD7AM4BKAEKAVwBQgFSASoAwAD6gHJAEEAUgCWABoB/AH0AswD4ARwBugHsAjgCMAIYAhYB6gFyANAAv4A2v/6/sD+Av/+/qb+wP53/5D/lP4C/rT+vv6E/Cj60Pmo+WD3APWQ9BDzQO6A6uDswPFQ9PD25P3oBDAGsATgBWgHaATL/77+zP7o+rD18PRQ93D3IPbQ95j7hPyA+vj5gPuo+zj62PoC/iwAGwCMAMwCsATIBNgEIAb4BrAFgANkAhwCWAF0AOQAYAJIA1QD0AMQBfAF0AWQBaAFYAVwBFADnAI8AsgBMgHMAKkAYwC1/wT/B/+i/1sAIgFMAqgDyASQBVAG+AZABxAHYAY4BaQD/AFgABD/cP6o/mP/YwC0AUwD0AQoBmAHYAjgCOAIUAgIB3gFIASoAsYAiP/t/5MAsP96/gH/+f8T/8z9zv4rALr+XPyc/Hz9YPuo+Hj5UPvY+MDzQPFA8QDwYO6A8KD1CPow/UwBiAUIB7AF+APwAh4B0P1g+lD4UPcg9uD0IPVQ96j50PpY+/D72PuY+tj5yPps/HD9ZP4wADwChANwBMAFUAcwCOAHgAbQBDADmAEgAHX/4v/VAKQBoAIIBDAFyAVIBtgG4AYgBigFYAR8A3QChgHIAC4AxP96/yr/A/83/5v/AgCqAKABeAIEA7ADiAQIBSgFYAWgBRAFpAMIAtEA9v+D/53/DwC8ALgB5ALAA2AEQAUoBoAGcAaoBsAGsAW0A3ACPAKaASsAs//BACwBs//U/j0ARgGd//z9+v6D/4T8WPkQ+nj7WPmg9rD38Pgw9RDwIPCQ80D0cPMw9zL+FAI8AqgDYAYwBeT/nPxc/Qj9APnQ9fD20Pig91D26PjU/GD9gPtI+yz8uPrA91D30PmA++j7Ev5gAngFMAYgB6AJAAuQCSgHmAX0AyQBrP5Y/pz/+AAwAtQDeAVYBogGuAbgBngGiAXYBJgEYAS8A+ACQALGASYBbADj/23/5v60/jn/QgBuAcwCcATQBVAGQAZABlAG6AWYBJwCXAA2/qz8OPzQ/OD9DP93ABwCkAOoBKgFkAboBsAGiAZYBuAFKAWQBNQDqAJ8AcMADwAJ/0b+Mv4c/sj9/P3I/vz+dP5I/oj+/P28/Aj8mPsQ+uD3kPag9ZDz4PHA8hD1gPaA+CD9NAJwBDgFwAZABvIAKPtI+nj7GPkw9bD1KPmA+aD3KPlc/fj9mPrY+Oj5IPmQ9UD0gPeI+yT94P5wA4AIYAqgCYAJYAqACfAFWAKoAJn/7P1M/XL/aAKYA9gDcAWQB7gHOAawBXAGQAbIBPADUAQQBGQC3AB0AAIA1P4k/qb+EP+0/ub+mQCUAqgDqAQ4BoAHeAeoBggGIAUMA2sAVv7c/Jj74Ppw+9z8Xv63/7wBiAQIB0AIkAigCGAISAfgBQAFgASkA1ACAAHs/wP/lv7S/lX/3f+eAJ4BSAIkAoABywDy/7L+NP3Y+7D6QPmw99D2APcA9+D1MPUg9tD2wPWA9Sj5rP70ASwDyASABcgCfP5c/HD78PgA9pD1sPYA9yD38PgY+5D7IPsw+8j6APlg92D3QPhA+XD7ff/EA6gGYAjgCbAK4AkQCFgG6AToAoEAM//H/xwB5AGIAigEUAYwB5gGSAYIBzAH+AVIBWgGSAcABhgEfAPkApQANv4I/u7+ev50/RD+y//FAEwB/AJwBfAGOAdQB1AHaAaYBFgCCQD4/YD8qPtY+/j7dP0+/84AzAJYBXgHYAhQCNAHqAYABbADFAN0Am4BfwD//5r/MP8b/1f/g//U/4UA/QC2AGYA0gAUAfn/Kv74/Cj8gPpY+CD3EPcA96D28Pbw99D3UPaw9WD3KPpI/Gj+OgG8AmgBP/8+/iD9mPow+Uj62PqI+FD2QPc4+Uj50Pjg+aD6yPgw9pD1gPZQ93D4mPtoALAECAdgCMAJ4AogCqAHuAVABVgE2AHm/1MAdAGMAfABQATIBnAHGAegB1AIaAfYBaAFUAbYBUAE9AI8AkoBUgAgADgAtv8A//D+Vf+i/2cAJALYA7gEWAVABngGSAW4A+wCPAK3AB3/hP5w/vT9jP0U/j7/CwCKAIwBWAMgBSgGaAZ4BmgGqAX4A3gCGAIcAmwBVgAYAJ0AtQAoABIAywBQASYB0gCOAOb//v6I/hz+2Pww+wj60PgQ93D2oPeI+KD3cPdo+Zj6APlA+DD7mP7S/pD+2QCUAvD/2PvY+oj7UPrw97D3SPkg+nj5CPlA+pD8jP3o+0j5oPcw9hD0QPPw9TD6MP3f/8gEoAqgDQANkAuQCoAIsASsAMD+pv5I/mT98P3lABgEmAWIBoAIQArACUAI0AfIBzgG8AMoA3QD3AJUAYQA5QBWAQgBQwC//6H/uP8UABYBvAJYBHgFIAaABlgGiAWIBHwDLAKqAGL/dv7A/Wj9nP34/Vj+XP9IATgDgASwBRgH2Ac4BwgGCAX8A4gCYAH7AKgA3f8s/0T/xv8VACwANwAXAM7/vP/l/+P/i/8N/3z+cP2o+7D5kPhI+BD48PfQ+Bj6APrg+Bj52PpQ+1D6QPt+/tP/1P0A/R7/Wf+o+3j5qPvA/Bj5EPYw+Nj6cPk4+ID7UP6w+zD46Pjg+aD2oPNA9qj6aPuQ+zEAsAYQCpALAA7QDvAKcAW0AswBdv+M/Dj8bP5lAKYB7ANAB7AJUAowCgAKEAnwBqAENANwApYB5gAcAeoBRAIoAnwCMAMoA0QCrAGoAUQBhgDWAGwCyANgBCgFWAZQBngETAIQARMAYP6k/ED8EP2g/dz99v4oASwDYASQBdAGyAb4BCQDnAKIAtoBKAFSAcoBlAHhAJkACAGEAbAB2gH4AWgBJwAt/zH/df8M/z7+sP0c/cj7APrw+Nj4QPmo+Tj6CPvA++D7gPtY+6j7APz4+xT8oPzg/Bz8OPug+6T8bPxw+7D7sPxQ/LD6EPqY+lD6ePmQ+dj5WPjQ9aD00PQQ9ZD1EPdo+cj8igFABlAJgAvwDUAOgApABVACzQBk/nj8pP3R/woABADQAqgG8AdYBwAIgAngCGAG2ATIBBgEYAKQASwCbAK0AXoBaAIYA6QCDAI0AlQChgF1AE8A/QDUAdACKARYBaAF4ASEA9oBUQBI/4L+sP0U/Sz90P2y/vv/ygGUA8gEcAXQBZgFoAQ8A/4BdAGGAaoBoAGiAdoBvgH1AEIAWwDbAOoAeQD6/4r/Df+6/tT+Hv/u/gD+1Pwk/Mj7OPuY+oD62Prw+rD6mPrg+kD7kPsM/JT8wPyg/Jz8qPyM/Gj8kPwM/VT9CP1w/Ej8cPzw+9j6oPpw+1D7iPlw+Bj5sPgg9hD1EPfg9zD1UPSI+XwAKARQBwANwBAwDqAJYAiYB+QC9P0c/k8A9v50/JT+fANIBYAEUAbwCTAKIAfwBUAHiAZYAyQC7ANoBEgCFAFQAggD3AFeAdwC1AOYAgoBEgGQARgB2gBEAjgEwAQoBMwDbAP6AQsAOf9l/zL/bP4S/nD+0P4T/+X/SgFwAiADvANYBHAE/AOYA3QDQAPAAhgCggEKAawAWwAyAFUAxQA6AVgBBAFZAH7/qv48/kb+Qv6s/bj86Psw+4j6OPqQ+gj7SPuQ+xT8iPyQ/Kj8HP14/Sz9pPxw/FT8+PvI+0z8LP2w/bj9lP0w/YD80PtQ++j6wPoQ+1j7EPtY+qj5APkw+MD3sPdA9wD2gPWw91T88gHoBkAKAAywDDAMgAloBcwC+AE+ACT9FPw6/vD/g/9uAJAEuAfYBogFKAdwCMAFhAI8A6gFCAWIAmACGAQQBFgCRAIgBMAE7AIqARQBPAFVAIX/OgDMAdgCYAMwBBgFAAWMA9wB6wBxAIr/YP7c/R7+Xv56/kL/9wCIAhwDWAP8A1AElAOcArQCTAMAAwQCxgFYApACEAK+AeQBvAHwADQA5f9k/2z+rP2c/eT9IP5O/mT+Lv6w/Sz9vPyM/KT86Pzc/IT8TPxg/GD8HPz4+/D7qPsQ++D6YPsc/LD8iP3C/pz/ev+0/vT9GP3Q+2j6kPmw+XD6uPr4+Rj5APnY+LD3wPYg99D2kPTA8+D3RP5oAoAFsApgD8AOYAqIBxAGuAJE/jj8dPxg/CD8Bv6iAYgEMAbIB1AJoAmQCDAHwAVgBKADpAOUAyAD/AJoA6gDcAN8A+gD2APgArYB/ABtAA0AXwB2AbgC0AOgBMgEUATAA/gClAESAID/iP/6/hb+Jv4E/03/OP80APoBxAJAAtoB5AFeAV8ARwA4AdgBwgH+AdgCMAN4AoAB8gBYADD/Fv7E/ez9+P0S/sD+tv8yABsA9P+b/5b+KP0s/OD7uPuA+6D7EPxQ/Cz8IPx0/Mz8tPxY/DD8QPw4/DD8oPxQ/Yz9PP0M/Uj9KP1Y/KD7qPvA+yj7mPqw+nD6EPng90D4sPhw9wD2gPag95D3GPiI+yMAzAPwByANUA9gDFAIyAYQBbEALP1g/XL+aP2o/D//KANoBZgGgAggCnAJ4AYYBeAE8ARABJwDMARQBUgFAAQoA3QDfAM8AvkA4wAQAWUAyv+hAEQCSAPgA/AE6AWABRAE1AIEAggB7P/6/hj+WP08/cj9Uv6y/qL/MgFkArQCoAJ4AuIB3QBeANEAWAE2AQABXAHWAbYBLAHTALYAdQD9/6r/sv/2/xUAAQALADoAHABj/6z+kP6m/hz+KP3E/AT9KP3s/Az9zP1M/vT9QP3c/MD8oPyU/FD8uPuQ+0j82Pxw/GD8iP0u/iT9XPw8/Wj9OPt4+Wj6ePvQ+QD40Pgg+sD4YPZQ9jD3cPbg9HD10Phg/cABUAbQC0AQYBDgCxAHwASMAqz+APyU/Kz9VP0q/voBEAbYB7AIUArwCvAIqAVkA+QCEAPUAmQCnAKQAwgEYAP4ArwDeASkAyACpAHQAWYB9gDuAaQDUAT0AwAEeATkAwQCPgCJ/y3/aP7I/fD9Yv5g/mj+Wf+3AHoBxgFcAtgCSAIAASwA8f+n/3P/7v/OAEoBegH2AYACgAIkAu4BjAF2AC//tv4P/3D/gP+J/4n/G/9Y/sz9iP0Q/VT8+Ptc/PD8JP00/aj9MP4k/tj99P0s/sz9UP2Q/bz9pPxg+4D7IPyQ+/j6NPyo/dj8oPvM/Db+lPxw+sj7wP24+3D46Phg+oD3YPMw9ED3gPbA9Jj4aP9UAlwDcAiADlAOMAqwCGAI1APs/ZT96wAMAXL+/P6IAigE4ANoBSAI2AfQBDgDEARQBBQD4ALIBIAGIAbwBLAE8ARQBMwCvgF4AdUAdP+6/qv/OgEsAjAD8AQYBoAFMARwA4gCzgBz/0X/L/+M/l7+IP+Y/yH/0P5q/xIA7/+p/zoAOAGcAYoB8gHEAugCNAKWAVABzwAXAPP/bACxAGoACADt//L/zf9n/x//WP+r/2X/uv5y/oT+fv6K/h3/o/9g/8r+qP6e/vD9DP20/Kz8ePxE/ED8RPxY/KD8yPyg/Kj8DP3w/FD8dPx8/bT9zPy4/Hz9mPxA+tj5WPsA+6D4KPjI+TD5EPZg9HD0MPOw8aD0aPt6AdAFQArQDVAOEAwgCUAGnAOkAYj/gPxo+oD7aP67AOQCQAbQCFAIeAbQBZgF/AOAAlgDEAX4BIgDVAOIBAgFeARwBPgEMATkATQABAD5/3H/4v/+AfwDcARgBPgEWAVIBNQCKAKSAQMASP54/VT9YP0U/nv/ogAYAW4BzAGYAeAAdwCNAKkAsADuADYBQAE4AYABCAJgAkQC2gFSAbcA9P81/8j+zP4F/xn/yv5A/vj9Vv7k/h7/Pv94/0//iP78/Rb+BP5g/Qj9bP2I/cz8IPxM/MD8tPyU/MT85Pys/Jj8BP2Y/eD96P0S/jL+2P0c/eD8QP3s/GD7QPqA+ij6CPjQ9gj4iPjw9fDzgPWw9vD00PWY/RAGkAiwCOAL4A3gCfgEGAVIBpQC7P2Q/gABLP+s/DwAiAagB7gE2ARwB0gGPAIsAjAGiAcQBagEcAewBwgE7gF4A/QDDgHO/pz/OgCO/sD9QgBwA4AE+ATIBjAI2AZQBCwDzAJGAUz/6v7L/+P/D//4/vb/cADB/yD/Gf/I/hD+Qv7M/2wBUAJAA4gEEAX0A0wCUAHJAPb/DP/A/vD+Cf8Q/03/hf9P/+D+yP4t/53/ff/I/kL+Xv6Q/kz+/P0C/sT93PwU/BD8NPzw+xj8IP0K/uT9mP0a/rL+bP74/T7+ev6U/UD8uPuw+0D74Ppg+zT8lPy8/Aj9JP2w/Oj7GPso+vj4cPdg9WDz4PIA9QD5eP10AWAEYAZACMAJMAlwBnAECARsAuj+iP0lAJACGAJAAmgFUAfABAgCdANABQgDRwDyAUAF+AT0AhAECAcQB5AEbAPUA4wChv82/nP/kQBaAHUAvgHsAkwDzAPwBNAFsAWYBAwDhgFzAL3/N/80//r/zgDPAFEAOQBYAP7/rv9LABIB0wBZABIBVAKQAhwCgAKEA5wDdAIoAVcAnv8X/1b/MACZAFEADgAiAC0AIgAzAC4Az/9W/w//qP4q/j7+/v5a/8T+DP7I/Wz9sPyE/DD9qP04/aD8dPz4+/j6oPqI+8T8XP3U/aj+Dv9k/kT9cPwA/OD7yPtA+6D6uPo4+2D7oPtk/DD7UPYw8cDvsPCg8DDyEPmeAbgFwAbQCWAN0AyACWgHuAWsATD9GPyg/ar+jv/+AdAE6AXgBSAGIAZYBTAFSAb4BlgG2AVgBqAG4AVQBXAFuAR0AigAAv9M/qD97P1z/y4BmAIoBLAFsAYYB9gGWAX8AjQBYgCF/7b+Kf9tAGwAM//w/uT/HAA3//b+ov+V/77+6v47APcA4QCSATgDGASUA9QCVAJYAbj/kP5g/mz+Qv5g/ub+Sf9m/9f/zgCEAXYBDAGfANz/qP7E/Zj9kP1A/ej8pPw0/Jj7QPtY+3j7kPvA+1D8LP0i/vb+bv+d/6H/Fv+4/Qj84Pow+nj5UPlg+pD7iPtI+0j8MP34+xj6MPoA+5j58Pbg9aD14PRA9oD77ADkAuQDoAYgCNgFjAO4BLgGAAZoBKgEUAVIBFADqASYBhgGiANAAd//NP5g/Cz8cv7iAZgEWAYQCLAJQApgCQAImAawBBQCzv/M/pT+WP6O/uH/tgHIAvgCAAMoAwgDsAJ8AoQCdAJUAkgC9AESAREAjP9V//b+mv5+/iL+JP1Y/LT83P36/jkAHAL4A8gE2AQoBWgFoATUAhQB/f81/4D+VP7q/pz/vP9K/wD/JP9R/1r/zf/zAOwBuAG1ACQAewDwAP0A1QB1AG//Ev5Y/RD9ZPzA+yT8uPwM/Aj7UPsM/LD7oPuI/WT/zv6Q/TL+Av9k/Vj7yPsE/fD7+Pko+mD70PoQ+WD4KPgA9tDxgO7A7rDyoPd8/MABAAfQCWAJUAgwCCgHeARUArABxQAD/7b+6wD0AwgGAAcQB2gGcAUwBNwCSAIgA0gEYAQwBCAFuAZoBygHwAaABYQCEf9Q/UT9uP14/lgAKAOIBYAGiAZQBuAFuAQcA/oBdgHbABcA5f8pAO7/O/8E/2n/hv9N/4v/RQC8APAAZgEIAlQCZAJwAvoBxACc/zj/K//m/qL+qv7k/kz/FQAeAQACfAKQAkACqgHzAPT/oP6k/Vz9/PzQ++D6GPuw+5D7UPuA+zj7UPpw+hj8uP2o/goAsAHkAdAAdACYACL/7Pxk/Gz8KPpA93D3QPkQ+ZD4cPsv/+T+ZPzU/Jb+sPww+Zj5IPww+1j46PiA+7j7oPvH/yAFeAUcAiQBmAJAAvkAzAKIBsgHwAYwByAJIAlAB6AGSAfQBX4B0P0k/bj96P2u/uYA8AIYA3AC6AJABAgFWAUwBsAGWAXEAmoBtAHuAcIBVAI8A8wCPgGVABQBIgGEAHEAHgFsARYBJAEUAhgDBAPkAcIAAADM/hT9QPwk/Xr+Bf+D/6wAbgH0AIwASAEcAuwBdAHAAUAC6AEkASQB7AFQAuQBNAGCAFz/7P0c/Sz9WP1A/XD9HP6O/pD+xP58/xsAXACQAJkASQD//wcA4/85/6D+Zv5s/Tj7SPmg+Ej4wPeY+Cj7zPyo/Bz9xv7e/qz8gPuc/DD9hPxM/eT/CgF1/4z9BPwo+WD1YPPA81D0EPQQ9KD1APmk/TACiAWwB/AIwAi4BoAE+AOwBCgFaAUQBkAGEAWwAwAECAVgBDAC1ADJAHQAzP+9AHADgAXwBfAFGAZQBdADcANwBLgETAPIAXoBXgGXACIA5ADMAZABswBLAC8A0P+y/4YAtgFIAoACHAPEA5QDAAP0AhQDNAKmAND/uP8t/2D+1P4JAAAA4v7A/ov/RP88/sz+vQCUAfoA0gBcASIBaAClAGgBTAHSADoB8gHEAccAyP/w/kr++P20/UT9FP18/eT98P0+/vb+K/+a/iz+CP5Y/Xj8uPwC/pr+CP5o/Rz9XPww+5D6yPoA+9D6wPoI+zj7QPvQ+yz9Jv7Q/fj8yPyY/Fj7yPlg+Vj5OPjA9qD2IPcA99D3sPvrAKwD5ANwBIgFEAVEA9wCcATIBSgG4AZQCEAJcAnACeAJkAi4BfACMgE2AO3/pAAkAoQDOARYBCAEaANIAlAB9QAKATwB1gE0AwAFYAbYBqgG6AWwBEgDDAIwAdQA7gDiACAAUP+e/7MAHAGyAL8AWgE+AV4AMwDhAMoAvv9m/93/Uv/U/Yz9sv4b/0j+Bv7q/nb/U/8AAGoBtAHSANcA6AHgAS0AA/94/xUA1/+Z/7v/Q//w/fT86PwI/dT8vPzg/Nz8pPyo/CT92P18/tL+tP44/rz9jP3U/YD+Cf+2/qz9yPxo/AD8gPuA+/j7+PtA+7D6APvQ+7D8pP2u/o3/7f+y/xn/jv7w/az84Pp4+aj4gPcg9gD2WPgI/E3/3gFgBIgGKAd4BuAFCAZIBugFEAV4BJgE8AT4BAAFiAXIBagEzAKkAQ4BGgBM//f/vgHwAkQDAAQ4BbgFKAVoBLQDmAIwAVgAeQA+ATgCJAPAA9gDXAN4ApQBBAGzABgAYf9k/0sARAHgAWQCyAKoAlACIAKQAYoA7P/7/7T/yP5c/uz+eP9w/37/w/9m/0j+mP38/bT+B/9O/yQAagFgAoACKAIkAnACLAJGAdgA9ABkAAH/Nv5q/kb+VP28/PD83Pw0/Aj80PyU/bT9zP1G/q7+vv7E/h3/k/+k//L+jP0g/DD7mPoA+oD5ePmY+Yj5mPlQ+jD7wPs0/Pz8nP2c/Vj9UP1U/Qz9nPw4/KD70Pog+qD5OPmA+WD7kv5gAeQC/AMoBZgFAAX4BIAGUAggCUAJsAkQCpAJUAgoBzgGmAT4AWj/7P1o/VD9AP6s/3QBMAI0AqAClAMoBFAEkATQBJgESATABNgFgAaQBmAGiAVwA8wAAv82/pj9LP1Q/cT9Fv6c/oj/YgDaAEIBigEiASYAif+h/9r/7P8xAJQAjQAiAMP/f/8//x7/8v5u/gD+QP7E/uL+GP8BAMcAhgD8/+f/hf96/vj9uv6Q/3L/9P68/mj+0P2E/ZD9aP3c/ED8qPsg+yD70Pus/FT93P0s/hT+2P34/Xj+zP6k/jj+tP08/QD9BP34/MT8kPyA/Fj8EPwI/Jj8ZP3w/SD+Iv7g/Vj9+PwQ/Uj9NP3w/OD85PzA/NT8nP36/koAPAEMAiQDWARQBUAGeAeACAAIkAawBfAFOAYIBkAG0AYIBowDSAFpABIAef9f/ywA7AAEAToBTAK0A8gEOAUIBUgERANoAtwBpgHWAQwCygFAAQIB+ACwAG8AxwBeAWoBGAEcAWwBeAFcAY4B2gG2ASYBlgAEAIj/Vv9l/1H/Gf8s/23/Vv/u/sT+6P7c/qD+rv4//9v/SgDIADgBRgHnAGoA7v9o/+T+kv6S/vb+jv/X/5j/Q/9I/zr/iP6Y/Sj9CP2k/DD8VPzo/DD9BP3U/NT8zPyg/GD8QPxk/Lj8KP3A/Y7+Jf9C/xT/AP8A/9z+lP5E/sT9DP2A/Hj8sPzE/KT8cPwg/KD7KPvw+gj7KPtI+5D72PsI/KD8FP4NAMIB9ALoA5AE0AQQBbgFiAb4BhgHOAdAB/gGyAb4BkgHGAcQBlgEhAI8AYAABAAEAPgAWALQAkwC5gEIAiAC3gHEARQCZAJkAmgC1AKQAxAEAASYAxQDWAJgAboA2QA4ASYB1QCqAEoAhv8K/2r/6//H/2L/dP+v/6r/z/+CABwB7QBZAAwA2v9y/z7/sf8tAO7/S/8O/yP/AP+8/pT+IP4c/RD8kPt4+4j7EPzI/PT8YPzw+xD8OPwE/Nj7APwo/CD8NPyQ/Az9gP3o/R7+5P2A/XT9nP2Q/VD9SP1g/ST9uPy8/Cj9ZP00/SD9aP3E/fT9Rv7i/nT/vP/V//b/FwA1AGwAsADhABIBegH6AWgC7AKoA3AE8AQABeAE0ATIBLAEmATABCgFmAXQBegFCAYIBpgF6AQwBEQDIAIiAaUAfABjAGkAiAByAP7/fv8j/9r+1v5W/+3/IAA/AMcAUgFSAQQB6QC6ACIAmv+k////TwDBAGABsAF+AS4B8gCDAOf/yf9BAKIApACtAOoA5QBtAPf/w/+M//b+Ev4I/TD8+Puk/Mj91P6C//z/RQApAMX/hf+T/4X/Kv/8/o3/jgCSAYACSANoA3wCIAEJAFj/0P54/kL+2P0g/YT8TPww/BD8APzg+1j7qPqQ+kj7NPz0/Kj9Qv58/lj+RP6C/uD+Bf/a/mz+5P14/VD9YP1c/Sj9zPxQ/Lj7OPsw+5j7EPws/AD82PvQ+wz8nPxg/Rb+mP72/kX/oP9HAFQBcAIwA6QDKATQBIAFKAbQBlgHkAeIB3AHcAeYB+AHEAjYB1AHsAYYBngF6AR4BOAD6ALqAUQB9ADIAMsA/AAKAcQAaQA5AE0AkgD8AFwBtAEoArACCAMsA1QDgANQA7QCGAK6AWwBBAGSACYAuf85/67+Dv54/TD9JP0A/bT8hPy0/PD83Py4/Oj8OP04/QD9DP1o/aT9oP2o/cz91P2k/XD9TP0c/dD8gPww/OD7oPtw+0D7EPvg+pj6UPoo+jj6aPqw+iD7qPs4/NT8hP0c/ob+6v5K/4f/vv8mAKAA5gACAT4BlgHWAQQCJAIcAv4B6AHKAYYBbAHMAVACfAJ0ArgCFAMgA/wCIAOEA9wDIARwBNAESAXYBVAGSAbQBWAFGAXIBIAEYARwBFgE/AOQAzgD6AKgAkACsgHvAEUA1f97/zj/J/9D/zD/4P6W/pz+uP60/ob+Wv5K/lb+Yv5+/uL+dP/Z/+P/3/8FABYA3/+m/7D/1v/G/4//Z/9m/3P/b/9H/wX/uv5s/iL++P30/SD+Xv6E/or+oP7S/gX/Nv+F/9v/8//V/9j/IgBzAJsAoQCWAIgAigCxANkA6gDpANUAfwDb/zX/0P6c/lr++P2s/Yz9fP1Q/Qz99PwE/QD9zPyo/Mz8LP2k/SD+pv4O/yz/GP/8/vz+Ef9M/33/Uf/M/mT+Pv4A/qT9nP34/fD9JP1E/Bz8WPxQ/Cz8dPy8/Cj8CPt4+rj6CPtI+wj8XP2M/nX/mQAUAlgDIASoBDgF4AWoBsAHIAmACkALgAtQCwALcArgCVAJwAj4B/AGAAYwBWgExAM4A5gCvAHIAPv/Z/8W//r+9v7c/qj+iv6u/i3/5v+RAOoA9gDVAJwAbwCIAO4AZAGGAUAB3gCpAI8AcgBYADgAxf/a/uj9bP1E/RT93PzU/Lj8OPyw+6j78Pv4+7D7ePtA++j6uPoA+3j7yPvw+wD82Ptw+zj7aPuY+4D7WPtY+2j7gPvQ+1T8zPwU/Rz97Py0/NT8QP28/Rr+dP7W/jH/rf9lACwB1gFQAowClAKYAvgCnANABKAE6AQgBSAFCAUIBRgFIAX4BMAEiARYBDAEEAQIBAAE+APcA8ADsAOkA5wDlAOMA4gDgANwA3QDdANYAyAD9ALUAqACVAIgAgAC3gHEAbYBnAFOAecAkABQACIA9P++/3H/Gv/Q/pz+eP5a/jD++P28/Xz9SP00/VD9gP2w/dT97P0C/g7+BP7g/bD9gP1g/VD9WP10/Zz9vP3E/aT9ZP0g/fD84Pzg/PD8GP1c/aD91P30/Sz+cP6w/sD+vv7I/ur+GP81/zz/Xv/C/xkAEAAFAFUAvACXAB8A7P8CAPf/uv+e/7H/rv+M/1f/EP/Y/t7+Cf8r/z//ff/Y/xIAEAAJAC0AWwBSABoABAA6AGwAXQBCAF8AcQAtAL7/hv9b//b+ev4w/gz+zP2M/YT9lP1w/Sj94Py0/IT8WPxU/KD8KP2g/Qr+vP7V/78AJgFuAewBQAJgAjwDMAVAB5AIoAmwCiALwAqACoAKEArwCPgHeAcAB6AGuAboBlgG+ARwAwwCugCt/xL/rv5K/vD92P3o/TL+pP7o/sL+Vv70/bz96P2O/mP//f9SAI8AgwAgAMv/zf+//zj/bv7g/Yj9TP1A/WT9aP38/DD8QPt4+gD64Png+eD56Pn4+Rj6gPoo+8D78Pu4+2D7APvg+iD7wPuA/CD9fP2A/Vz9XP2Q/aT9fP1A/Rz9/PwM/Yz9YP4d/3X/cv9O/zj/XP/M/2gA+gBsAeIBeAIoA9wDkARABbAFoAVIBTgFkAXoBSAGaAbABsAGSAbABWgFIAXIBHAE9ANQA7QCYAJYAnwCqAKkAkQCnAEGAbEAoADEAAQBUgGiAeQBBAIIAiwCaAJYAugBigGSAc4BAAI4AnwCjAIsAoQBwADv/yH/cv7s/Yj9WP1I/Uz9bP2Y/aD9fP1M/SD9zPxg/FT8uPwY/TD9YP3A/eD9qP2M/aD9gP0Y/cz8tPyk/LD8/PxQ/XD9ZP08/eT8ePxI/HT8sPz0/GD91P0u/nj+zv4P/yj/N/9P/27/qP8DAHQAyQAAASQBLAEQAeMA2gDRAJMAPAAWABwAJwAtAF8AugDxAPIAzQCVAGYARwA2AC0ARAB0AJQApQDJAA4BSgFYATABzQBCAMX/ff9G/xz/Gf8g/9T+OP7M/aT9YP3Q/Ej8DPzg+9j7LPzc/JT9Gv6O/u7+O/+j/2cAZAFAAuwCpANoBDAFIAY4BzAIwAggCZAJwAnACcAJ0AmgCRAJUAi4B1gHGAeYBoAFCATcAv4BGAERAFT/4v5I/oD9JP2Q/Vr+xP6K/vz9YP3Q/GT8RPyU/ED97P1K/nb+yv5Y/8z/xf9P/7T+FP58/Rj9+PwI/QT9tPwE/Bj7aPow+jD6GPrw+cj5mPlg+WD5qPkY+oD6sPqg+nj6iPrg+kj7mPvw+zz8SPwg/Cj8iPz0/ED9gP3c/Ur+0v6O/3oAWgH4AUACRAJEApACNAMIBNAEcAXIBcgFuAXIBQgGKAYYBggG+AXgBfAFUAbIBvgGuAZgBigGAAYIBlAGoAaYBiAGoAVgBSgF2ASIBCAEZANcAnoBEgH+AOsAwACAABoAmP8P/6T+Xv4w/gD+tP1o/VT9jP3s/Vb+vv4Y/zz/C/+w/nz+jP7A/gH/Pf90/53/sf+y/6v/mf9V/8L++P0o/Xj8APzI+7j7kPtY+xD7yPpw+ij6EPoQ+vj5uPmY+aj5APqQ+kj7EPzQ/ID9HP6c/gn/kf83AKUAsQC1AAIBXgF4AYIBpAGOAfkANQCK/wT/ov58/mD+Bv6Y/YD9oP2c/ZD93P1O/ob+kP76/sf/nwBIAeYBcALUAhwDZAOoA+ADKARoBHgEGAScA0QDCAO4AmQCHAK2Ae8A7v8u/+D+1P60/lr+3P14/Sz9BP0o/YT95P0E/vT95P0W/rz+3v/5AKYBDAJoAqACoALQAoADYAToBCgFcAXoBWgG4AYwB0gHGAeABogFkAQ4BJAEyARgBLwDdAMsA2wCjAEkAccAlP/4/Uz99P01/1IAOgHCAW4BQADe/uD9VP0Q/fD8yPyU/Jj8OP1I/h//Sv8L/8L+PP5w/eD8BP2s/S7+Uv5C/iT+AP70/fT9uP04/Yz8wPvg+iD62Pko+rj6CPvo+nD60PlI+ej4yPjY+Pj4+PjA+Hj4UPio+Fj5APo4+ij6cPoo+wj89Pw2/tD/FAGoARwCGANYBFgFOAZAB0AIsAjQCAAJkAkgCnAKgAqACkAK4AmQCZAJsAmACdAIQAj4B6gHSAdAB6AHmAfgBgAGaAXwBEAEZAOcAu4BVAG8ADcA2/+x/3v/Fv96/sD9CP1o/Pj7qPt4+4D7yPsA/Pj74PsY/Hz8zPzw/AT9/Pzo/Pj8OP2k/UL+Ev/U/zgALwDi/3v/B/9+/vj9iP00/eT8rPyU/Kj84PwU/Qj9kPy4+9j6UPpI+pD6IPv4+7j86PzQ/AD9mP0U/jT+RP52/oD+aP6U/kD/GQCtAOcA2ACQACgAsP86/9z+qP6S/l7++P2A/TD9DP0I/Rj9QP10/ZT9kP2M/cj9WP4D/1P/Lv/i/sz+Ff+b/0YAEAHsAZAC2AIMA4wDWAT4BCAF8AS4BKgEoASYBLgEKAWwBfgF6AXABaAFQAWgBBgEwANYA9wCtALYAgwDOAOEA4ADpAJGAU0AGwBMAKoAcAF8AkADeANwA5ADyAPMA1wDjAKwATYBGgEYARoBMAEqAbgA5f8h/8D+lv4q/lz9lPw4/DT8UPyY/Bz9nP2U/Qz9pPzk/Jj9Hv4+/kD+cP6c/qr+3v5y/zMAkQBfAOj/q//c/0MAUQDY/yb/pP4q/pj9LP1A/XT9EP0M/Aj7aPro+WD5CPng+JD48Pdg9zD3QPeA9+D3QPh4+JD42Phg+Qj64PoY/JD9yv6n/2sAQgE8AkADMAToBHAF+AWIBvgGYAfoB3AIgAgACGgHCAcABzgHgAeoB8AHwAfAB6gHuAcACEAIQAgACBAIYAhwCCAI0AeIB+AG6AUIBagEUAScA7AC2AEOARoA/P78/UD9wPws/ID7CPsg+6D7+Pvg+7D7kPt4+zj7SPsI/FD9hP5f/wUAfQCpALwA9gAgAdYAUgAMAPX/gv/U/rT+Jf8+/2j+VP3Q/Ez8KPsI+uj5aPpg+iD6SPq4+gD7cPto/JT9ev7u/gL/5v5B/0YARgHaAaQCsAMABAgDsgEUAYQADP8U/bD78PpI+lj5iPhA+Ej4APjg9jD14POA8wD0oPQw9RD2kPcQ+Xj6XPxW/4gCaASQBFAEsASIBWgGgAfACGAJ0Ai4B/gGmAZgBmAGUAa4BbAEMARQBEgE9ANABCAFYAV4BMwDuARYBiAHKAdwB+AHYAf4BeAEqATgBAgFGAW4BMAD5ALIAtQCXALGAZYBLAHT/2D+Dv7I/n3/w/8OAJgA4wB5AKj/Lv84/xT/TP6Q/bz9mP4v/1L/mv/6/5X/OP7I/Bz82Pto+wj7APsw+0j7aPug+9j7+PsI/Pj7yPvQ+2D8fP2Q/nH/PAD3AD4BswDd/0b/DP+I/rD9GP0k/WT9OP3k/Oz8JP3Q/LD7YPqw+Zj5iPlQ+VD5mPnI+aD5UPko+Rj5+PiY+ND3oPbA9SD2APgA+6j+eALABdgHoAiwCNAIEAlQCWAJ8AhQCCAIUAigCNAI8AiwCJgHwAU4BPwDqASQBagG0AcwCKAHGAegB8AIgAnwCVAKIAqQCKgG4AUQBtgF6AQwBLgDpAImAYAA0wDbAPj/qP4w/WD7wPn4+Ej5GPoY+3D8xP2y/jT/ev9K/2r+WP3E/LT8oPzk/Br+wv9xANv/eP/K/6X/Yv5E/ST9DP1M/Pj70PzQ/RL+Iv5g/qT9ePtA+Uj4GPjg93D4UPqk/OT9PP60/lv/Uv+a/qT++v8SAaUAFADpAMABtwBs/0AAXgFq/4j7SPlQ+ED2kPQQ9pD4wPdA9CDy0PEA8cDvwO9A8eDy4PTw93T85AKACvAPYBAADlAMUAugCdAIMAsgDvANQAswCegHaAV0AggBaACK/kj8JPxk/lgBWASwB1AK0ArQCTAJgAnACdAJoArAC7ALYApgCTAJcAhwBkgEqALXAOr+Xv40/+7/AQAjABAAtP6I/Ej7QPtY+0D7yPvs/ND9IP5s/pz+HP6w/Bj7ePrY+rD7AP3k/qoA/wDA/zj+WP3Y/Hz8hPzw/Ej9UP1A/VD9jP2U/TD9ZPzg+9D70PsA/PT8jP5+/zD/hP5e/l7+FP4I/pT+V/+f/7n/8P/6/2j/jP4A/mD9FPyw+oD6+Pow+qj4CPm4+hD64PZg9fD1YPTQ8FDx4PXA9lDykPCw9RD7hP0MA0ANoBPAEeAOYA8QD1ALQArQDfAOQAoQBsAGwAbIAsb/QAHgAeD9oPoc/bYBiAMoBfAJcA4gDtALUAzADVAMYAkgCTAKMAkoB2AHsAhwB8gDJAFWACf/YP1E/Tf/vQCAAPP/WwCfAMj/qv4O/kT90PvQ+gD7iPuo+wD86PxY/bz8KPyE/Bj9JP0A/UD9hP1w/Wz96P18/qD+kv7g/jj/1P6U/TT8KPuI+nD68Pqo+xD8MPxM/Fj8PPxI/Oj8yP1S/qb+Iv/n/8MAnAFAAiwCKgHJ/6b+rP2g/PD7KPy0/GD8GPsA+qD58PiQ94D2kPag9tD1gPWQ9qD3APcg9tD2cPfA9dDz4PUs/KQDcApgEMATIBNgEEANIArIB7AI4AqgCWAFMASIBmgGEANUArAE1AJM/Mj5jv5kA0gE8AawDcAR4A4gC5ALkAxACpAHMAiACQAIWAXIBLgFMAUMA+wAeP8a/gz9HP1A/qX/UwAXAD//Mv5A/XD82Puo+9j7BPxc/ET9VP7O/oT+cP6e/tz9WPzA+8D8kP1Y/Wz9nP6D/yr/nP6o/oz+cP1I/Mj70Pvg+zT85Pxk/XT9HP14/ND7mPsE/Lz8lP3C/gQA3AA2AWABXgHpAB0AU/9s/jz9JPzQ+yj8ePxA/Nj7gPvI+oj5aPjw98D3gPdg92D3IPfg9jD3UPew9vD1oPWw9PDyMPNw9zj9+ALQCsATYBdAExAO0AywC3gHGAUwCLAKUAg4BdAFyAboBKgC/AFhACj9mPzy/1gEQAggDWARoBGwDlAMQAsACWAGKAZwB/AGuATQA3AEGAQQAokA8/+e/mj8gPvc/BX/sQBsAVYBVwCg/qj8APuQ+pD7ZPwE/ID78Ptk/Ij7oPoA+4D7uPr4+ej6gPw4/cz9LP8fAKf//P44/1//av5Q/fj8+Pyw/Kz8bP0A/pj9zPxY/Bj8sPuY+0T8RP38/Zr+jP93AIwA1P9L/xv/uP7o/Vj9hP3k/cT9JP2g/Dz8gPto+qD5YPkQ+Yj4OPiA+LD4QPiQ93D3YPfQ9vD10PVQ9jD2MPZA+cj/uAYgDGARABaAFbAPgAqACVAJIAiwCDALsAoABzgFIAbYBAIBFgDoAVgBcP46//gEEAogDNAN4A/QDwANUApwCeAIsAfIBmgG4AWABMgCqAFUAQABy/9K/sT9Pv6E/nj+PP+XAPMA0/+C/pD9MPyw+lD6EPt4+0D7qPt8/ED8+PpI+lj6EPqw+eD6HP0e/pD9ZP04/qb+bP7O/tz/EgAV//z9NP1w/Az8sPyU/Yz95Pyw/Mj8dPwA/DD8DP2s/cz95P06/pr+3P4u/6L/yv93/+b+aP4Y/sz9jP0k/Zj82Pvg+uD5CPmg+GD4SPio+Pj4MPjA9mD2oPaA9UD0MPXw9lD2YPYI/LAE4AoQD0AUQBYAEZAJuAeACSAJYAgwC0AOwAyACPAFwARQA44BGAAN/27/3gGoBCAHYApADsAPoA2gCnAIwAYwBRgFsAbgB4gHYAZQBTAEjAKRAEf//v4d/xr/Rv9dANABiAIEAn8Anv74/LD7ePqw+Rj6OPt4++D6EPvI+zD7cPm4+Dj5cPnw+cD7wP0e/uT9wv6n/yz/qP5X/4j/Dv6c/Jj81PxY/Fj8LP0c/bj7qPrA+sD6ePpA+9z8iP0k/UT9Dv48/uD9Nv4A//L+Uv5C/pb+cv4s/lD+HP4Y/QT8qPsw+0D6mPm4+cj5KPk4+ID38PYw9nD1QPWw9eD1YPVQ9XD3cPvMAGAIQBHAFuAVwBHQDuALWAcIBmAKQA5gDHAJoAogC/AFcQDzAOQCOgBQ/XsA+AXQB7AI8AxgEJANoAi4B+AICAeYBGAG8AmACRAGgASABGQCIv+K/vn/sf9e/sv/IAPMA54BUACIADL/2Pvo+VD6yPpQ+oD6uPsY/Fj7GPtw+6D6wPjw9zj5APtE/Oj9q/8jAPz+Gv4w/hT+eP1A/ZT9gP1A/Wj9fP3c/Ez8aPzw+3j6yPnI+uj7wPuw+8D8kP38/Fz8/PzI/cD9kP3o/Vj+fP7i/nH/Wv94/oz9kPxA+1D6CPqg+bD4OPhg+LD3UPbw9YD28PVw9FD0EPXg89DxAPPQ9wz90AKwC+AUABigFPAPgAwgCXAG6AdwDPAO8A0gDKAKmAccA/r/V/8Y/5T+Wv8YAsAFkAlQDWAPoA5wDHAKYAg4BhAGUAhgCmAKcAmgCHgGvALf/y//0v7g/eD9uf+WASACeAIEA1gCz/8g/bj7yPoI+oD6LPw4/QT9yPyc/Cj7uPiA9yj4CPmQ+RD75P0DAPf/iv64/cj9vP1c/bT9+v6p/w7/gP7A/n7+OP04/OD7IPsQ+oj6OPwg/Rz97P34/vj96Pvw+5T9uP28/JT91f/X/+z9sP0j/9j+jPyg+1j80PsA+pD5SPrA+WD4cPhQ+cD4MPdw9jD24PSg8+DzkPSw9AD2ePokAcAHkA1gEiAUwBEQDaAJ0AhwCRALEA2QDfAL4AlgCCgGFAP6AHEAuv+K/oD/cAOQB1AKsAxADiANcAmwBngGOAfIByAJIAtQCwAJWAagBLwCIQB+/uz+IgDNAGQBoAJ8A7wCpgBk/kj8SPoY+cj5HPxC/ub+ov4s/rD8wPlQ94D38Piw+aj69Py6/iT+5Pwg/aD9sPy4+5T8Cv6I/tj+3/+FAOr/BP9a/gD9EPtQ+hD74PsI/Jj8wP1A/pz9tPw4/ND7wPug/BD++P4d/xr/AP9s/rj9jP2k/WT9uPzY+4D6uPhw91D34PcY+Ej48Pig+AD2wPLA8UDysPGQ8QD1IPqk/G7+sARQDQARUA+gDoAPAA1QCAAIEAygDXALoApgDIALMAfcA+QCXQAU/Cj7ef/4BEAIQAvADpAPwAvQBhAF6AXIBuAHMAoADFALEAloBzgGEAQ2AUL/eP5k/oX/0gEoBDgFcASAAST90Pn4+Ej5yPk8/CMAkgHk/uD70Pog+RD2cPV4+MD6iPo4+xr+mP/4/UD8aPyo/DD8YPyg/b7+sP8UAf4BTgGY/zb+DP2g+4D6qPr4+3D9Nv5i/mz+0P1I/Oj6APvo+2D84Pxq/goAEwBA/xv/YP/u/lT+RP6w/ej7EPrw+MD3wPYg94j4APmY+Ej4wPYg8xDwkPDw8nD0sPbg+xABQAPgBKAJ4A7AD3AN0AxADsAN4ArACeALEA3wCtAIMAngCPgEmQBn/7L/Jf9pAIAFkAqAC1AKQAqwCUgH0AVgByAJ0AhgCDAJUAnYB6AGGAb8AzsAqP2A/db+UgEIBXAH4AWeAdj92PrQ98D2mPnw/dT/e/9V/7b+UPsA95D1QPdY+FD4IPqw/WT/3P2E/Fz91P34+0D6YPuI/Tj+nv7GANwCPAI0AD3/gP4Q/Lj5KPpg/FT9OP0a/lf/Sv5w++j5kPo4+xD7IPz0/voArAAyABgBfAHE//z93P3I/fD7GPqA+dj4QPdA9gD34PfA99D2EPUw8qDvgO9w8bDzEPcU/LUAHAPYBLgHMAqQCuAKsAwgDjANAAzQDKAN8AtQCWAI8AcoBjAEUANgAowA8//cAVAE0AWAB6AJ4AmgB/AFWAYIB0gHoAigCuAKUAmACIAIGAc4BCwCOAEXAA0A6AKwBlgHoARaAWL+cPqg9oD2OPoU/mH/W/8//5D94PkQ92D38PhI+Uj52Pqg/ID8qPsY/Oj8hPwM/Pj8yP0k/bz8IP7k/34A5QCSAQoBL//s/Yz9oPzI+/z8/P4a/9T9QP2M/Fj6yPgw+nT8DP2o/bv/mQDm/rj97v6k/0z+lP1A/nj9EPto+jj7IPqQ9zD3YPgA99Dz0PKQ83DyUPBA8eD0sPe4+dz9ZAPABkAHqAdgCeAKkAtgDBAOoA9QD0ANAAvACdAIaAcoBrgFKAWoAywCIAJgA+AEaAaQB8AH6AbwBYgFqAXwBnAJsAvgC4AKMAlACMAG4AQwBIAEUASIAxAEWAbAB3AGIAS4ArQAqPw4+WD5gPus/Hz9Bv/y/sj7gPhA95D2EPZo+Gz8VP0o+2j6UPuA+oj5hPzgAK4AbP3g/Hr+Gv7s/FD+egDM/9T9vP26/oL+sP1w/Sj9YPxw+2D6cPkA+uj7EP1Y/ZL+LAAz/3D84Pvg/cb+Ov5w/ywCVAJT/+z8OPxo+iD30PWg9wj50PcQ9oD1sPSw8uDwIPFw8uDzYPbI+r3/NAOIBegHwAnwCUAJ8AngC0ANsA0wDlAO4AyACvAI8AcIBuQDMANkAxwDIAOgBDgGUAaQBdAEgAMoAuQC0AVwCBAKsAtADPAJWAagBEgEiAOkA3AGMAmgCOAGKAfgB6gFxAFn/xL+ePtA+eD6/v6fAFD+cPuw+QD38PKw8XD1APpw+2j7TPzw+7D4kPZQ+YT91P4A//cA5AEK/yT8QP12/+T+IP6GAAQDcgFK/qj9NP6w/HD6CPpI+mj5IPlI+x7+/v5c/vD9fP14/Az8SP0x/3EAQAEUAtQBqf/A/CD70PoQ+rD4MPjY+Oj4gPfw9UD1gPQA8zDyIPMA9SD3mPob/1gCjAN4BOAFeAa4BuAIAAxQDQAN0A0QD5ANUAoQCXAJIAjQBbgFKAcgBygGmAYQB2AFAAOQAlgD4AMABWAHcAnQCWAJwAhIByAFvAOQAxgEeAWIByAJkAmwCXAJSAe4A9sATP9Y/ZD7sPwIACYBrP7Q+9j5gPYA8qDwwPNg9/j4OPrQ+wj7kPew9bD3yPrc/E7/fAJ4A94ABP58/T7+U/+CARAEIASeAYP/1P4E/sj8XPwY/LD6mPmo+oz8AP3A/Cj9GP24+wD7YPws/gD/5P/4AH4Aav4g/Vj9GP3Q+wj7APso+tD4yPho+Xj4APYg9GDz8PIw83D1yPhA+9z8gv4bABgBQAJ4BPAGkAjwCfAL0A0wDjANMAyQC5AK8AgACHAI4AgQCNgGmAaIBhgFJAPAAsADGASQAygEUAbIB2gHqAa4BogGOAUgBLAEAAboBsAHAAmwCQAJkAcgBkgEFAKWAB4Ay/89/8T+2P3Q+4j5aPjg92D2cPSg82D0sPVQ9wD5yPkI+RD4GPjw+Hj6OP0nANYAU/84/sb+ov9sAFgCcAT4AywBRP87/+7+hP2o/Pz88Pz4+3j7BPx4/Cj8sPuQ+3D7GPsQ+8j7/Pz4/Tb+uP3w/CT8cPsw+2j7qPtw+xD7CPuI+tD44Pbg9ZD1gPVA9mD4SPrI+jD7jPzI/S7+hP+8AvAFqAcACaAKMAuQCnAKMAtQC9AK0AogC4AKQAnQCJAIoAeoBrAG0AYIBoAFyAXIBdAEUAQgBdgFoAVoBagFoAUYBegEaAXwBXAGQAcQCCAIgAfIBkAGqAXIBHgD7gEpABL+PPzI+1z8FPxI+gD4EPXw8ODtoO8g9XD5WPoA+hj5YPaw8/D0uPmQ/dT+6f96AbIB3gBmATwDCARkA+gCHAPUArwB1wCFAC8AH/+c/Wj8HPxo/Ij8ZPwk/Hj7GPoQ+Vj5ePoY+1D7qPuo+7j6oPmQ+YD6YPuw+6j7kPso+9j5EPig9+j4WPoI+yT8yP3w/WD8NPyi/t0AnAEUAxgG6AdYB8AGgAcQCDAIQAnQCiALQArQCcAJAAn4B6gH0AfAB+gHgAiQCKgHiAboBZgFKAXIBMgEMAVwBSgF4AQgBYgFYAUgBZgFcAaQBkgGcAawBigGGAUYBLwC6AAv/zz+yP2g/aT9iPxY+TD1EPKA8LDwgPPw93D60PhQ9XDzYPPw81D1kPho/G7+ev6u/h8ATAE4AUYB1AJQBMwDpAL4ArgDgAJ2ACwA5gA2ALr+nP4c/yL+TPxw+wD74PkY+Yj5EPq4+Vj5YPkI+VD4KPhA+OD34Pfw+Lj5APkI+FD4IPlY+fD5sPtQ/cj9+P3k/hMA7QAIAvQDCAYgB2AHoAdACOAIIAmQCWAKsAoACiAJIAlQCQAJUAggCAAIYAe4BsgGEAfABhgGoAVIBagEEAToAygEYARoBGgEmAT4BEAFmAUIBpAGwAbQBqAGIAZoBcgEAASAAvQAiAD1AMIAkv94/aD5gPRg8aDy0PVQ93D3kPcQ9kDyoO8A8RD00PVg9/j5iPvY+qD6mPyo/kL/LQBYAtQD/ANoBFgF8ARUA7wCbAOMA9ACrAIUA1wCUQCG/oz9rPzA+2j7ePsY+wj6APkw+GD3oPaQ9iD3YPcw9zD3gPdA92D2YPaw90j5QPpY+9j8qP2Q/TT+OgA8AlwDkAQ4BlAHmAcgCDAJ0AkACmAKsAqACiAKIApACsAJUAlACeAIIAioB6AHSAeYBhgGwAUABTgEAAQgBAAE3AP0AwgEAARYBAgFmAUQBogGyAaYBogG6AYIB8AGGAaIBDQCLAGcArwD2gEe/iD7GPhA9LDyoPVI+Xj5cPeQ9UDzwO+A7pDxwPWQ97D3APgI+ND3sPjY+rD8BP6v/zgByAEoAjQD2ANsA2QDiARwBTgFQAXIBRgFBANqAeoAOAAD/37+nv74/Tz8gPoY+bD3kPZA9oD2cPYA9mD1wPRA9BD0YPQg9WD2wPeg+ED5IPpI+2z82P0IAGQCOARoBagG4AfACHAJQAowC+ALUAxwDIAMkAyQDAAMMAvgCtAKMAogCaAIkAi4BxAG0ASIBDgEdAMIAwwD6AJ4AkgCWALEApwDeASIBEAEsARABfgEyATIBTgGIASSAQgCgATgBFACOv+U/Fj5wPZA92D6FPyo+sD3APVw8qDwAPGA89D1QPaw9VD1UPWQ9VD2CPjg+WD7tPwa/hP/d/8JAAIBrgHmAcwCsARABnAG+AVwBXAEQAP8AogDkAPgAgwC8AD0/uz86PtI+1j6mPmI+fj4cPcg9qD1IPUw9AD08PTw9XD2EPfw91j4ePhw+Wj7pP2R/1AByALIA6AE4AWAB9AI8AkQCxAMsAzwDEANkA2gDWANUA1wDUANkAzwC3ALkArgCDgHsAbgBnAGQAWABCAEUANUAlgCHAMQA0wCKAKgAngCBAJ0AlwDEAOmAaEAbwCxAHABIALZAFD94PmI+HD42PhY+gT8APvw9pDz8PJg84DzYPQg9mD28PRQ9GD1QPaA9oD3QPlQ+vj6cPz4/Tr+HP43/70AfAFUAjAEuAVIBRAE/AOYBIgEGARoBMgEEASMAnIBxQCt/0L+YP3k/BT8EPtw+gj6KPnA98D2YPZQ9mD2MPcY+ED48Pcw+Cj5OPpw+1T9e/+3ABwB3AE0A4AEcAW4BkAIUAkACqAKgAsADBAMMAygDAAN8AygDKAMkAywCzAKQAkwCeAIIAiYB0AH4AVABBAE0AR4BGADZAPYAwQDxgE4AkwD7AJuAVcAiP8n/3gAhALaAfT9gPpA+cD4EPmI+yT+5PxY+AD1UPRQ9LD0wPbA+MD3MPVg9KD10PaA93D40PhA+ID4oPro/LT9xP3s/cT9hP3W/tIBQARoBDQDNALIAfoBHAPYBNgFQAWkA1QCpAFcAXIBmgFAAQAAqP7g/aj9VP3M/Oj7kPpA+Qj56PmQ+mD68Pmo+SD5oPhI+RD7lPwU/Tz9qP0s/rb+sv8SAVQCLAPkA5AEKAXwBdgGgAfIBxAIwAhwCdAJAAoQCuAJcAkwCWAJ0AngCWAJsAhgCDAI8AeoB5gHeAfgBjgGGAYQBqAF+ASABNgDtALcAcwBtAG1AGH/fP6o/Zz8HPxs/HD8YPsI+lj5yPjQ9zD3kPcw+Aj4QPfA9sD28Pbw9gD3MPdw98D3GPiI+Cj5uPkQ+kD6wPqA+zz84Pyg/Tr+VP4o/k7+7v53/9r/WQDZANsAaAAWADYAeACJAH0AegA5AOr/yP+9/1//6P6u/qz+nP6C/p7+nP50/lL+av6I/r7+MP/N/0EAXgCLANoAHAFgAfABvAJ8A+gDKARoBKgE4AQYBYgFGAZYBkgGQAZoBmgGIAb4BQgG6AWYBXAFeAVIBeAEoAR4BBgEqAOMA5wDUAOkAgwCyAHMAQgCHAKUAawAFgAGAN7/fP9c/4r/Sv+e/ij+HP4S/sj9mP2M/Wz9HP0E/RT9DP3s/Mz8sPyU/JD8nPyw/MD80Py8/Ij8VPxQ/IT8tPzU/Nj8yPyg/Iz8kPyk/MD8yPzM/Nj83Pzc/PD8/Pz8/PD8AP0w/WT9hP2c/cT98P0S/ij+Qv5s/rL+B/9R/3z/n//L//D/IwBsALAA1gD9AC4BUgFuAaAB8gE4AmACkALMAuAC5AIUA2QDlAOoA8QD7AMABBAEIAQwBDAEOARIBEAEKARABHAEWAQYBOwD6APMA5QDgAN4A0gD8AKwApACWAIUAtoBqgFuASgB9ADDAIoAOQDe/5L/Yv8//xf/3P6o/oj+ZP4w/vD9xP2k/Yj9aP1M/ST99PzM/LD8oPyY/JD8ePxU/Cz8FPwM/AD8+PsI/Bj8GPwQ/Bj8LPxE/FD8YPx8/Jz8uPzE/Nz8CP0w/VT9fP24/ez9Fv44/mL+lP7M/gv/Qf9p/4//x/8FADwAbACtAPIAMAFmAZwB1gEQAjwCaAKUArQC0AL4AhwDLAM4A0gDXAN4A5QDrAPAA9QD5APkA+QD7AP0A/QD6APwA/wD7APQA8QDrAN8A0wDMAMQA9QCnAJ4AkgCCALUAbIBcAEMAboAiwBoADQA9/+4/3H/K//w/rj+gP5Q/ib+8P2s/Xj9WP00/QD91PzA/Kj8kPyM/JD8lPyQ/JD8kPyg/Lz81Pzs/AT9IP00/Uj9ZP2U/dD9Av4e/iz+RP5w/qT+0v7w/g//Nf9g/4X/pf/M//v/JAA9AE8AaQCPALQA2AD5ABIBJgE6AVoBegGOAZIBmAGoAbQBvgHMAdIB0gHUAeAB6AHoAeYB6AHmAdwB3AHkAeYB2gHOAb4BpgGGAXoBgAGEAXgBXgFKAT4BLAEaAQQB7QDSALsAqwChAJYAhABrAFkATwBAACQAAQDq/9v/x/+s/4//b/9I/xv/7v7A/pL+dP5g/k7+Nv4i/hL+/P3k/dj91P3Q/cT9yP3U/dj91P3g/QL+KP44/j7+UP5u/oj+nv66/ub+D/8o/z7/Y/+H/5n/sf/h/wYACQAHACIARQBLAEoAZQCKAJUAigCVALMAxgDJANEA7wD8AAYBFgEmARoBEAEiAT4BQAEwATIBMgEiARYBHgEeARABAAH/AAIB8gDeAM0AtQCjAKMApgCeAJAAjgCOAIsAhQB9AHMAXQBLAFUAawBlAEIAHAAMAAsA+//i/9P/0P+8/5j/hf+N/5b/iP92/2//Wv83/yv/Qf9U/1H/P/8p/xX/D/8T/wz/9v7u/v7+C/8E//b+6v7i/ub++P4Q/xz/HP8f/yT/JP8p/zn/Uv9u/3//hf+d/83/6v/i/9f/7P8SACsAPgBfAIMAlQCeALAAygDZAOUA8gACAQwBDAEMARIBEAEAAfgAAgESAQoB7wDmAPQA+QDpANoA2ADPALkArQCrAJkAeABuAHwAfgBlAEgAOAAmAAkA7P/g/9j/0v/V/9z/4P/X/8b/uP+8/8z/2f/c/+H/6//1//3/BAARABsAHgAfACUAMAA3ADQAJgAhACYAKQAaAAQA9f/q/9z/zf+9/7D/oP+P/4X/gf+C/3v/cf9x/3b/av9Q/0L/RP9E/zz/Nv87/0H/Qv87/zX/O/9O/2D/Z/9l/1r/T/9T/2v/g/+R/5b/m/+b/5X/lf+e/6b/qv+2/8f/0f/S/9v/7v8EABAAGAAlADMAPABEAFQAYwBrAGsAbgBzAHAAZwBjAGkAcQB4AHoAdQBtAGYAZABhAF4AWwBdAFsAVQBTAE8ARQA+AEAAQgA4ACsALwA7ADUAHQANAAoABQD+//3/AgADAAEABwANAA0AEgAgACMAGwAfADkARQA5AEAATQBEACoAJwA6AC4AEAAQACQAHgAOABMAEQDu/83/1f/y/+v/wf+i/53/nv+W/4//kv+W/5L/h/9//3//gP97/2//bP9z/3r/ff+B/4j/jf+J/4L/h/+d/7b/xf/P/9j/2//T/8//2v/2/xMAHQAXAA0AFgA0AFMAXgBUAEgAQQBBAEUATQBXAGQAbgBtAGQAZABwAH4AiwCQAI8AiwCKAJgAtgDIAL8ArACjAJ0AjwCBAHoAcwBgAEwARQBFADgAIgARAAUA/f/8/wIAAwD7/+//5//d/9f/3P/i/9z/zP/M/97/7//5/wMADQALAAYABwAIAAcACAAQABwAJQAsAC4AJgAeACIAJQAgAB0AHwAbAA4A/v/s/9r/1v/b/9j/xv+0/6T/kv+I/5P/pf+f/4n/g/+G/3v/cP9+/5X/mv+P/43/lf+f/6j/rv+r/6X/qP+t/7H/wP/Y/+b/5f/q//b/9//u/+///P8CAAUAGAAyADYAKgAsADoAOwAyAD0AWgBhAFEASwBYAFkAWABjAGgAVQBGAFUAXwBLADkAQwBFADAAKAA1ADAAFAALABcAEgD+/wIAFgAVAPX/1v/J/8//5P/x/9n/qf+X/7P/z//H/67/ov+k/6X/oP+g/6n/tf+3/7L/vf/T/9r/0f/d/wMADwDq/9f///83AEYAIwD6//P/FgA8AD4AJwApAEYAQQAZABUAPQBBAA0A+f8mAD4AHQAGABsAIgD9/+b/AAAZAAkA8P/0////+v/4/wUACAD4/+7/+v8MAA4ABgAFABAAHAAaABYAFQAcACgAKwAlABwAEAAKABAAGgAeABcACAAHABsALgAmAAsA/v8FAAkA///1//L/6v/f/93/5P/j/9H/wf/B/8z/0P/K/7//uv++/8T/yP/L/9H/3//u//X/7//q//T/BQAIAPv/6//r//r/BgAGAP3/8v/o/9r/z//R/+L/8P/k/8r/x//e/+//8v/6//7/2P+Y/5v/9v87ABQA3P/3/xgA5P+//xAAcQBiABQA7f/3/x0AXwCbAJsAXAD7/7n/5v95ANAAXACi/5L/IgB4AEYAGQBLAIwAhgBNACAAFAA9AKEA0ABBADn/xv6r/4gBJAN0AywCLQD4/kH/FgArAIX/Cv8B/xH/Mv+A/4z//v5y/q7+gv86AIkAaQDu/47/7v/5AKgBVAF7AAoANQCDAKUAsAC5AJYANADx/y4ApgCoABQAhv9m/6L///8+AAIATP+6/tj+Tv9p/yz/EP8V/+j+pP7I/mH/r/85/6r+zP44/07/af/d/+r/Hf+i/n3/rwCwAMn/ev/1/zUA//8bAJIAoQA8AD0AxADgAEsACgC8AHIBOAF7AEIAggCcAJAAvADwAMEAWwBAAIkA6wAKAZYAyf9s/9b/bgCaAHYAQgDe/0//Lv/i/8cA4QAXACH/nv62/kD/2/81AB8AnP8R/wr/iv/2/wIAxP9U/w//dv8aABcAgf80/1f/Zv9K/3X/+f88AAUA0f/S/7X/fP+k/0wA5wDoAHkAMgAoABgAIgBeAHsAUwA3AFIASADW/2v/kv8OAD0AJQAEAKr/Lf84/93/OADZ/3//vf8FAMb/gP/P/zIACgDV/yEANACS/z7/x/80AOL/hf+2/zIAeABRAPH/w//j/wkAIwBoAJ8AXwDz/x8AqwCAAM//8P/HAJ8AX/8H/ywACgGqACAAOwBcAPv/r/8dAAwBbgF6ADH/SP9FAD0Aw/+tAMIBBAHa/zYAugDY/zX/WwCeAQYBvv+l/zIAGwCx/9j/IACj/yf/9/8QAXMA2P5o/lH/DAA+AK0ArQBR/xj+3P4LAJH/5v7X/6cA4f+s/zIB3gE/AMj+Z/+rALwACADU/x8AVgCGAPsALgFBANr+xP7+/2gAef9q/7QA2gBN/8D+4/8EAEb/vQCQAoT/QPok/PAEIAj+AID6oPvi/l8AfAIoBJgBbP0M/T//AQDZAIADzAIw/UD7ewBcA+D+aPxgASgEG//Y+8gAeASU/9D6UP5kA84BAP4S/+IBHAFi/48A5gH9/9D9S/8IArwBLv8U/mb/wwCJALv/r/8LAGf/HP60/jgBIAI3ABz+yP1I/zgBVAHT/7j/XAFkAe7+zP07AGgC9wBs/ywBJALG/tj7DP7GAfgB+v+m/+MAwwBg/jj8BP0QACACRgE1/0T/HgHJAGr+Uv6cAIwBvgB4AL8AXgD4/xIBUAJtANT8TP3QAaADbAFQAOsA8f+E/gwALAKOAOD9Fv/4AXQCGAK+Aa7++Ps8/r8Avv8sARgFqgHw+Dj5dAPgCBgESP6c/Aj7ePpMAKAHYAb0/fj4UPvVAHAEJAP+/lD9oP6Y/uz8QP4gA9AF1AIM/tD7cPvo+2n/KAbgCYQDgPdg8xD6UAFIBEAHAAj5AMD3cPf4/fwAVwBQAyAGXAFI/Nr+0wA4/ID7wAOgCAgDmP3a/+oAWPsA+vQBAAdsAvL+3gGgAaD66PgMAngHKP4g9dj9kAuQCFj82PpF/6D8MPtYBLAJuf8Q917+4AaUAbj6wP7QAlT9ePhk/bgEGAUWAEj9hv46/0b+VP5N/+L/jAD2ASAEAAVhAOD5+PuABWAI6AAw/HkA+AL4/aT82ATACcABoPcw+VQC0AVsAqIBgALk/ND2yPzQB/AGcPtw9ND3df9YBaAHoAQw/DD1kPc9/+gDCAcgCWYBkPMg8m0AcAzAC7gFHgHA+/D1QPf0AfAKMAmMAqj/ev54+mD4nP1gBHAFOAOQAa7+cPuA+/D9PABgAswCMv/o+sj8KASoBhQAsPpk/LD9+PwgAtAJoAds/sj7cv74++j5zAIwC5AEEPq4+ygCpAC8/Lv/OARCAUj78PvUAXAExAEe//7/wgEcAbv/iv/K/hb+9QCgBFACSPwQ/HQBQAKI/Wj9xAHuABT96v9ABQwCkPrY+zQDrAMC/pj9uAJIA8T94PvEAVAGDAMj/+//kv9k/OT8IAHEAoQC2ATQBTb/IPfg98b/4AV4BqgC/P3Q++j7aPwo/vgBwAUgBmYBwPrQ91j5UP2gBEALuAek/ED3CPog/XYAuAZACSQCEPqo+xACRAJe/v7+/gD0/eD7vgH4B5AFjv/c/ID6wPe4+kwCqAUIBOQCLAK8/rj6MPvG/+gCmwBw+2D6wf8QBgAIYAVJ/5D3oPOg+KQDEAvACWQDAP1w+aj5hPzAAJAEGAUMA6oB3v/0/Bj8vP2E//UAdALkA8ADmv+o+uD6EP5+/6ABqAW4BT4AaPvQ+rj8lf9YA3AGgAXq/4j6SPpi/hgDiAVoBNMA7PwI+wD9+ADAAngCZAICAdD8qPlA+6P/GAOgBFAEWgFU/PD4gPpB/zwDwAVABpABgPog+aD9ZgFwAvwCEAM2AeD9EPys/SgB8APgA7MAfP3w/Cj+LADEAtwDwgF8/hj9lP2Y/jkA/gHsAQQAjv4Q/oD+1QBcA8IBaPy4+cz8bAEwBPAFsAUYAST8SPz0/gD/bv6SAQAFRAM2/6j+cgBCAI7/vAFkAwIAHPzw/Z4BwQCQ/m0A5AKXAFD97v76ASoARPzk/G0A0QAb/4cAzAOYA5//VPyk/Nz+x/+j/2YB6AMkA1cARwAcApAARPz4+xwBuASgAygCygFn/wz8QPxY/xABGAEuAUMAZP14+xT9WADMAZgAlv7E/Zb+3v8sALD/qv9zADABUAG2AGf/TP6m/isAggGAAvwCdAGC/nD9Qf+oAIwAqAF8AyQCWv5Q/a//4gAj/xr+LACoAkQC5/9u/kr+9P2I/d7+hgFQAlMA1v5//6n/Pv4q/kUAhgHiAHgArAAJADz/4f/yAL4AIAAgAHH/1P0+/p4BKAQUA58AUv8M/jD8lPxSAIQDEAPYAG//av50/Ub+wwDoAboAeP+F/6H/BP/U/sj/mABjABoAGQBz/4D+9v7ZADAC4AGhADX/GP4m/qX/pgEkA9QDYAOIAdr+PP0M/s7/qQAyAf4BZgHA/qz8jP2k/47/vP1k/dD+k/9j/yYAtgHYASIAiv6C/q3/BAHAAbwBhgHKAegB9gDZ/33/Ef+G/iX/XQBjAMT/6v8qAH3/gv5o/kP/7//A/2r/gf++/xAAcAA6ADH/QP4O/lz+If96ANABxAEWALb+HP9fAD4B3AE4An4BBwCW/7cAsgF0ARQBGgFiABf/5v6i/4X/jv5q/nn/MwDd/7D/OAAYALr+pP1A/j4ARAIEAyACIQAA/sj8GP2Q/rkAJANYBEQD7wB+/kj8ePt0/RoBzAMABLQCgAFXAMr++P3g/l4AFAH+AKcAHgD8/kz9JPzY/ED/mgGIAlwCvAE4AA7+AP3I/Tr/uACUAigEKASIAqcAs/+i/9D/NQDFAGsA7v5M/r3/SAGVAEb+nPyM/JT9iP/kASADPAJmAPz+Lv4O/tb+IwAyAf4B7AJgA/wBFf/A/ED8UP2e/2ACwAOEApz/MP2w/OD9tv+GAawCKAInAHD+Nv7w/p3/+v9lAO4A4ADP/5L+Pv7e/rr/fAAGAcEAef9+/vr+9v/1/4j/IwBEAVgBpQC1AEABlwDq/jj+Wf8wATwC5gGkAJv/Of/k/o7+zP5I/2H/o//eADgC3AGX/3D9HP0U/iD/SwD0AfwCFAIMANj+3P5S/y4AXgG6AbgAov/p/xwBnAEcAYgA2P+m/vD9nP6v/1wA8wAqAWsAhv+b/xsA2f8q/z3/+/9yAKoATgGyAawAGf9y/iD+OP3U/Bb+3P9FAKz/3P/aAPsAAwBD/xb//P6A/4QBAASgBPQC2gBC/8j9ZP1E/6IBEALDAM7+ZPyo+sj7JP/GAUgCCAKEAdr/8P0+/r0AkAI4AlgBUgE6AU0AnP8QALgADQCq/mT+kv/lAGABJgGQALX/2v68/un/pgF4As4BkQDY/5v/SP/W/oL+OP6i/mEAHALOARMAaP9BANMAjwCUAPgA2ACKAOUAQAGaADj/Dv6g/Qb+Zf86AcoBJADA/bz8hP1X/4gBTANQA90AuP2U/OD91/+QAUwD+AMIAp7+kPyQ/Oz8EP1i/iQBgAPQA3QCiQCi/kT9MP3K/kAB3AK4AoIBjADR/6z+NP1U/HT8RP1Y/qr//wBiAXEANf9J//wApAKsAn4BcwDK/4j/wAC8AygGSAUwAcz8iPq4+rD8ef+0ATACAgEz/8D9SP38/WX/eAC8AKYAwQDjANoAPAEkAnQCXgG5/7T+GP5k/Xz9gP9gArADqAJLADj9UPrg+fz8TgEIBPgEwASAAmD+QPtI+3z95f88AvgDrANqATL/0P2E/Nj7XP1fALACtAO0AygCVP+c/fD9yP6m/7oB/AOQA7kAwP6M/kD+zP0N/44BiAJGAaX/pv64/Sz9ev5aAZgDhAOCAWv/uP5L/+f/HACrAFoBkgAa/hz8XPy0/Xj+dP8UApAEwAP6/1j99P2D/8H/2P8aAe4B1wB1/6n/YQAxAO3/cgB7AFz/pv4s/1r/XP78/Vv/5QAOAVgAhv+8/rj+CQBgAUQBeABcAKQAsAAIAc4B4gHlAKr/OP6k/Pj8eQDkAzQDeP/Y/GT8RPxU/CL+KgHMAggChwAyACgBXAI4A9gDwAMQArX/Fv+3AMYBPADc/UD9Iv4L/wUAEAGrAFb+dPzQ/Fr+1f+2AUgDNALu/pz9bACQBKAG0AXoAuL+0PtA+2T89P28/2wBFAKoAfgA5f8E/iT8iPsw/CT+GAIIB3AJIAfiARj9MPtY/Cf/4AFcAxADGgF+/sz8pPyk/Oj7mPuQ/Pj9Kf/FADACDAIeAXABiAIcAooADABaAM3/H//S/64ACACq/tz9RP2c/Nz8/P3i/kD/6f8iATwCoAJEAo4B0wAFACz/Cv8kADYBwAC0/9H/TwBY/4D9zPxc/Rb+Zv9IAogF4AYgBrAEQANkAUP/Lv4+/9IBtAMsA4YAPP1I+mD4qPio+3f/AAHs/67+dP5U/qj+FgGABJAF7AO8AgADfAJrALr+cP7G/kL/NAD9ADUAlP3g+jj6oPsE/az9Ov9UAqAEoAPTAID/jP+e/gT9PP1M/78AXgBs/yP/Uv+n/3IAsAGkAtgCmAKAAsACkAIuAdb/PgCeAZoB3f92/k7+7P0Y/QL+6QB0ArgA9P1o/MD72PtE/hwDcAewCLgGpAJC/uj74PyY/34B/AEYAqoBzP90/dT8vP1c/gj/IAFEA8ACSQDI/r7+iv54/kIAiAIUAh7/TP1w/sMAfAIEA6YBTP74+tD5oPqQ/CcA4ASoB6AGzAOEASL/+Pto+rT82wD8AlwC3gCK/zb+VP3A/er+TP8s/kT8mPtk/c0AeAMIBPQCEgEn/wL+HP4J/woAwAAIAc0AagCNAPkAkgBq/xn/SACaAdoBrgGmAeQA+v6U/Qz++P5i/gT9DP2k/iQAAgEMAhwDMAMgAhgBvABtALj/GP8r//D/zQAoAe0APgDw/jT9LPz4/Bv/GAH8AQwCrgGvAFD/Ef+MAPgB3gFiAbwBqgEKAGb+Xv7I/uD9rPxc/Yn/VgFAAtgC8AIAAkMAmv7M/Ur+1P9UAcYBHgHX/0j++PzI/MT9rv7M/hj/hAAgApwCXAIYArYBKgH7ABIBhgBo/8r+5P4N/zP/vv8ZAEr/1P3g/FD80Puc/Kj/ZANYBegEDAOBALj9wPvA+6z9bgDIAsAD+AIcAYP/xP4U/rz8gPuo+5T9dABgA4AF0AUYBLQBHgD2/oD9uPzU/bj/ZwBaACoBPALYASUAmP5k/ST8wPvA/VgBGARwBOQCEAE3AJUAegE0AnACGAIuAR8Ab//+/pD+2v5yAEwCkALWANL+Dv5K/pr+PP/AAAQCLgGQ/rD80Pz4/RX/egAwArQCPgF0/wr/N//Y/tr+aQB0AjADgAIoATT/9Pzw+yT9wP9QAiAEsAQkA/n/FP2A+zD7UPza/moBXALkATQBlACi/6z+bP4N/wUAwwBAAcQBCAJcAVMAfwDAAQACSgDw/Vz8yPtc/JL+XAHYAnQCFAFl/7j9yPwg/Wb++/+iAYQC5gFwADj/GP6s/CD8vP2GAKgC0AN4BEgE4AJAAWkA7P8h/8b+sP8EATQBJAAI/3r+MP4W/mD+3v7q/pD+tv7z/2IBpAEIAe0AogFIAqwCPANoA0ACTwCw/pT96PxM/c7+KQCMAL0AegEcArwBhAAt/xr+3P34/rUAoAEgAfb/8v78/Tz9vP3g/wACPAK7AAX/Gv5C/lf/bgB0ALn/Xv+A/1v/TP9RAP4BzAJMAmYBBgCc/fD6sPk4+kj7xPx6/7QCGATUApQA5P6U/XD8UPyI/Sb/vwC0ApgECAXUAyQC1QB6/7T9NPzo+wz9yP58ABQCUAOkA7QCnAAY/oz8NP2H/7oBEAMwBNgEzAOIAd3/J/9a/rz9XP67/6AAXgG0AugD5ANEAywDSAOcAmYBNwDW/mT9UP1//3wC9ANQA3QB2P7o+1D6ePum/qABVAPIA+wCCAFG/6L+8v5u/5j/bf81//7+eP6U/RT9nP20/nr/EQDwAH4B/ACe/x7+CP3M/ND9Wv8kAM7/5P70/VD9TP3s/cL+Wf/C/wgA7/+o/8D/9P+V/wD/FP+F/3v/TP+//0EA/v+p/2EAggHAAXgBngHoAYgB5ACyAIUA2f9N/7f/2ADOAWwC5ALgAvIBdwCI/7n/pgCmAXQCAAMkA+gCiAIcAn4B1gC3AEwB7gHWAfcACQCF/0H/Ff83/5H/iv8Z/xD/xf+IALoAfwDz/9r+eP28/NT8+Pyc/Aj8sPvI+2z8eP2I/kv/ev/k/sD9yPyU/Oz8jP2M/s3/zgAcAagAev/4/bT86Ptw+3D7dPwu/lX/Xf8X/zn/p/9EAFYBlAIYA2wCIAHE/+D+If+rAKwCIASQBPQDhAJoAbgBLANYBKgEcATgA8AC1AEYAkADeARYBagF+ASYA1gCXAFVAN//6gD0AqgEuAVoBvgFMASMAkwClAIcAlwB/wBbAAD/IP6i/q//ZQDXANIAjv9s/dj7QPvg+qD6CPug+1j7ePpI+uD6KPsI+1D74PvI+8j6sPlI+Vj5sPko+vj60PsA/KD7wPuE/Lj8GPy4+yD8MPzI+1j8JP6D//T/wACiAf0AU/+C/lr+oP0U/SL+uP/+/4//wP8MAID/G//k/+kAPgH2AdwD0AUQBzAIQAkQCZgHeAZQBpAGKAdwCHAJMAnwCHAJkAlwCDAHqAa4BRgEXAM4BGgFGAb4BgAIIAgAB7AFgAS4ArAAvf8sAM0A6QDHAJoAUAAZABAAdv/4/aj8YPyE/ID8sPzM/ND7+PmY+OD30PbQ9eD1MPaA9SD14Pag+TD7oPvA+yj7YPnw9/D3YPgI+Zj6kPx0/QD9IPxw+zD7iPso/Kz8VP02/qD+cv74/mMAEAHIABwBgAGI/wT80PqA/Nz9LP4QAFwDYAQMAs3/R/+K/jD9wP3eAIQDtAMUA4ADcASQBEAE0AQ4BvgGmAbgBgAJQAvQC9ALoAyQDAAKoAbQBAgE6AJsAqwDYAUgBmgGuAZgBjgFMAT4AygEgAQQBaAFmAUQBVAEtANgA/QC4gGAAIj/pv5s/eD8+P06/+j+mP30/Nz8HPwY+9j60Pqw+fD3sPbA9WD0YPOQ84D0UPUw9mD3CPgw+AD5mPq4+1D8bP2K/tT9uPt4+kj6kPmA+Bj5EPs8/Dj8iPys/Wr+Rv4S/mT+rv6K/qL+uP8sAVYB6/+q/q7+nP5I/XT8BP6vADAC/AKoBCgGoAXgA/gCqAJkAbz/Wv/Z/67/L//O/6wBgAOwBGAFyAXgBbAFeAXABRAH0AjACbAJoAngCcAJMAkACaAIEAeYBHgCHAEdACEACAIIBVgHgAjwCJAIyAZ4BOQCJALKAQQCyAIsA9gCrAL8AogC/ACB/6D+ZP3Y+1j7KPwA/XT9sP6KAE4BkQCT/2D+wPtQ+DD24PXA9XD1oPVA9vD1YPRg89DzIPUg9kD3UPng+1z9xP3W/q8A4wD8/uz9dv6Q/Wj64Phw+rj7OPsA/Jj+OP8o/Uz8zP3G/tD+pQCwA4AE/ALeAUoByP+I/i3/BwBC/5L+cv8mAMf/kwAYA4AE3APEA+gEsASkAnoBzAFmAScAQACgARwCEAIsA7gEEAUABdAFYAaYBeAEMAVgBVAFeAZQCHAIIAd4BngGiAXQBPAFIAe4BfACngGcAT4BlgEIBDgHYAgAB7gE9AIoAvQBGALUAswDmAPWAToA+f8BAGP/cP+WAKwAgP7w+9j6uPrA+mD7kPxk/Zj9XP1Q/Ej6SPjg9pD1IPSQ88DzcPPg8lDzMPSQ9KD16Pi4/Jz+Mf8kAKYAk/+I/ib/tP+C/jz9kP34/Qj9cPxk/cz9WPww+8j7lPyM/GT9AgBUAugC5AL4AiACOgDs/vL+cv/U/4IArgHMAlwDFAMoAjgB0gCLADEA4gDsAjgELAM6AYMAZQBa/3T+Wv8UAaQBhAFcAuADwAQoBSgGAAdIBogEzAOIBJgFqAZQCMAJUAmYB2gG4AWwBLADeASIBWgEYAJAAugC1gHqADADmAYABxgFQAQoBJwCBAHmAQgE4ASQBLADxgGs/0T/IQBkAOr/Rv9g/Tj6kPhw+XD6SPrw+gj9Av7Q/Gj70Ppg+TD2wPKw8CDwYPAA8eDxsPNg9vj4MPuw/eX/ZABv/wr/lv97/5L+nP7T/0EACP9c/Tj8YPu4+pD6APvA+3D8uPw8/eT+cgGYA/AE2AWwBcgDFAFm/6r+3P2I/a7+kADGAVAC0ALcAiACXgFuASQCEAMYBPgEKAWQBGQDyAEfACH/CP+E/yEAwABIAdQB3AKQBBAGqAaQBlAGwAUABbgEmAUgB3AI8AiQCCgHEAX4Ar4B2AH4AuADCAQwBIAEnAPEAZQByAN4BcAEIAQwBSgFGALg/9wBsAQoBGQCtALQAvn/fP0M/3IBHgB8/cT9gP6o+1D4CPlI+7D6KPko+oj7MPqw+AD6IPtw+DD0EPIQ8WDvoO7A8GD0kPdQ+oj9iQBMAqgC+AGBALb+QP2I/KT8PP3E/fD9Av5A/jb+tP08/Rj96PyY/Pj8Wv7k/x4BrAKQBGAFYATsAgQCAAFi/1L+sv7A/48ARAFEAjADcAMwAxwDVAM0A6wCtAKAA6wDRAJZAE//6v6O/vT+gwAEApACtALsAtQCmAIQAxgEyAToBAAFMAVYBcAFeAYAB/gG0AaYBrgFQAREA3ADIAToBLAFQAYoBhAFnAOMAhQCFAJ8AnADsAQ4BYgEmAOcA/gDgAPMAvAC+AKkAfb/O/+S/kT9CP14/gr/VP14+xj7CPtg+mj6GPsI+4D6gPpA+vD48PeA9zD1kPAA7UDs4OzA7vDzKPva/xwBAAIwAxACB/9Y/YD9EP3w+0j88P3G/rj+MP/a/1b/AP4w/dj8IPyY+1D8TP6rAPgC2ASYBfAEWAOEAeP/0P6g/hr/nv/i/yEAygDIAbwCjAMoBDgEmAPQAlQC8AGGAXABvAHyAbgBKgF2AOj/DAAKAfwBfALUAvgCWAIsAa0AbgHQAlgE8AUQBygHgAYIBtgFgAUIBZgESAQgBCAEKARIBLAEMAUYBTAECAM4AuYBNAIwA3AEUAVoBdAE0AO0AvYBuAHWARwCCAJeAYUA8/9e/4r+JP5S/tz9cPxg+wj7KPqY+cj7Jf/y/jD74PhI+aD4oPbw9pD4MPZA8KDsoOyA7ADtgPJY+9UAugHEAugEAAQ3AJT+5v/f/4D9lPwu/ur+rP1w/Wv/nAB9/2L+kP4A/kT88PtI/kwBWAMIBYgGUAYABD4BjP++/kj+ZP4w/w8AbwCDABgBeAIQBCgFoAV4BZAEBAOSAdgAqwC0ABYBwAHkARgBLADm/wYAIwByABQBjAGcAbgBWAJIAzAESAWwBrgHgAc4BtAE3AOIA+AD2ATABRAG6AWYBSgFsAQoBKQDHAOkAjACwAGiARQC1AJIA1ADPAP4AlgCvAG6ATQC1AJ8A+ADZAMUAs0A7f/o/rj9GP3s/FT8iPuA+6j7MPsY+6D8/P1c/OD4IPcI+DD5SPng+JD3UPQQ8ADtAOzA7YDyuPiU/dUA9APoBaAEFAJwAZIBUv8w/Aj8zP2A/fj7QP2tALwB4f+A/kj+3PyA+jj6zPze/8IBEANgBBgFoAQ4A8IBywBWAOT/Vv8l/3H/hf8r/4X/VgGUA+AEQAVYBcgECAMaAVgAbwBAANP/BQB1APb/2P66/tv/rwCxAAYBIAL4AgADKAMQBCgF0AUoBpAGkAbwBTgFIAWgBTAGoAawBigGKAUoBHgDHAP4AhADFAPEAlACMAJkApgC7AKAA/AD3AOgA7wD2AOUA3ADyAO4A2wCrQBt/4T+rP1s/Qj+mv6M/jb+lP04/PD64PqA+8D70PuQ+/j58PeA+Bj74PrA9gDzcPGA7iDqgOmg7sD0APlM/ugEgAjQByAGyATWAYD9yPp4+tj6mPtk/WP/WADKAE4BtgCA/lT8iPto+3j76PwnAJQDsAXIBlAHwAbABCwCLgDE/pz9BP1I/Ur+qf8qAZgCEATIBRAH0AYIBRwD0gGSAIX/1f+IAbQCXAJ2AdEAyP9Q/tj9Bv+VAF4B7AHgAogDbANcA0AEoAWgBhgHMAfoBggG+AQ4BPwDGARIBFAEGATUA8gDAARABFAEOATYAxgDJAKUAbYBNAK0AiwDeANUA9wCfAJQAgQCkgEmAbAAIgCt/3v/Qf/Q/oL+SP6A/Sz8QPvo+jD6UPnA+SD7QPsQ+vD5yPro+RD3MPUQ9UD0gPLA8TDxAO/g7XDxwPek/K0AEAbACfgHbAP6ABkADv4o/Lj8Jv7k/ez8XP3A/on/c/8J/4L+zP3c/Pj7UPz4/rACUAWABlAHQAcIBZwBeP8B/9D+bP60/qP/SgDJAO4BmAPIBFgFeAUIBQAEHAO4AmQC7AHIAegBVgGr//z9RP1Y/dz9I/8+ATgDKARIBEgEOAS4A1QD0AMgBTAGYAboBVgF6ASABEAEaATYBAAFoARABBgE6ANMA6QClAL0AhgDuAJUAjwCEAJ4ARwB7gGIA5AEaASoA+wCMAJ4Ab0A4/9J/03/R/9u/pj95P02/iT90Pv4+wD8EPog+LD4OPrQ+cj4kPmg+mj58Paw9TD1APQQ8nDwQO8A7xDw0PIg+H0AkAigC+AJOAeABNv/6PpY+cD68PuI/Cr+AQBJAPH/oQCMAQABE//0/LD7CPzI/d//yAEwBHgGeAYQBKgBjACK/zz+RP74/4gBBAJ8AlADpAOgA5gEiAawBzgHyAXgA5IBi//a/nX/KQB0AKkAzAB/ABIAbACyARQD+ANQBAgEJANcAsQCaARIBogHuAf4BpAFIAQ4A0gDKAQwBagFaAWYBLAD+AK8AiADsAPMA0wDWAIwAQEAOv9M/0YApgHIAnwDsAM8A2wC2gG2AYIBKAEwAToBIgBA/jT98Pzw+6D64Pqw+2j6KPhg+GD6WPrg+Nj52Psw+jD2QPWQ9gD1cPFQ8WDzEPLg7oDwYPZo+uD8WAKgCIAJUAa4BMgDJ/+Q+Zj59P0yAHT/mv+VAGj/MP1A/e7+If+4/Rz90P1U/pz+SQC0AxAHYAggB5AEJAJZAP7+dP5z/xAB0AGyAewBwAKQA6AEaAa4BxgH8AS8AtsAVv8s/4wA/gF4AmwCRAJgAd7/yv62/kH/EgAMARgCJANQBLAFIAdwCPAIMAhwBsAEsAMUAwADqAOwBFAFIAWABOQDOAOUAmgC9AJwAwwDOALuARgCPAKoAsQDqARwBLwDNAOAAoYBNAHIAdwB7AD4/yb/5P2s/ID8yPxY/LD7yPuY+3D6uPlw+vj6APog+SD5MPgA9vD0cPUg9cDzEPSw9SD1sPLQ8bDyMPNQ9Bj5FABQBWAIMApwCRgFvv+I/Hj7uPvM/JD96PxE/HD9K/90/yn/8v+vAMz/Yv5M/lX/jwA8ApgEMAbQBRgEnAK2AZYARv8C/0UAwAFQApACZANABHgEqAQ4BRgFiAO6AekAigD1/+L/7QAMAiAChgHlAAwAH//8/t7/7ADMAfQCSAQIBUgF0AWABpgGGAawBZgFSAWwBGAEkASoBHAEKAT0A7ADNAPMAqACZAK4Ad8AUwBfABQBbALkA8gEIAU4BdgEuANwArwBbAHMAPX/bP/2/iz+TP0M/Tz9IP2s/Fz8RPzQ+9D68Pmo+Yj5GPmo+GD40Pew9uD1oPUg9TD08PNA9HDzYPHg8LDyoPSA9pj7oANgCbAK0AoQCjgFLP3o+JD6jPzo+3T8h//2AC7/iv7BALYByP/W/mcAlQAE/jj9+ACABfgG2AZYB9AGNAMV/5D9yP2k/Uj+IgEoBLgE2AMoBFAFWAVoBCAEQAQ4AxoBqf+X//L/SQAYATgCXAIQAWH/ev5Y/qb+wP/AAfgDgAVYBgAHeAeoB4AH6AbgBXgELANgAhwCYAJEA6AE2AVQBtgFuARoAwACrAC//4z/CQAQAWQCqANgBHAEQAQQBLgD+ALWAdcAVAA9AEkAYQB9AFAArP/K/gr+SP1c/ID7GPvQ+jD6ePkg+Qj5yPhg+BD4oPfQ9hD2oPUg9WD0EPQg9MDzMPOg83D14PcI+/D/2AUACuAKUAnoBX0AAPuA+KD5NPxO/nr/sP94/8z/QQBz//j9+P3w/kL+dPwQ/X4ARANoBFAGkAiABygD2v8//3z+0Pxw/SIBEATkA+ACPAP0A7gDTAOQA8gDHAPiAbwA4P+D/7v/KgCPAO0A6QD8/8D+fv5x/6UA2AG0A8AFmAZABjAG8AYgB1gGwAXYBXAFSAS4A1gE4ASYBHAEEAUwBewDTAKcAZQBOgG7AN0AqgFUArQCOAPkA1AEaASoBBAF6ATgA4wCcAGEAIL/jP7k/XD9GP3U/Lj8sPyU/FT84PtI+7D6EPpQ+aD4EPhw97D28PWw9aD1QPXA9FD00PMw88Dy4PLQ80D2kPqK/0gE0AiADHAM8AcoAtj9ePqw91D4jPzf/4L/1v6TALQBvP90/bz9uv5c/hb+gf90AQgDOAWoB3AIuAYIBIABEf9Q/RT9SP4qAGwCgARABYgEjANEAywDsAIYAqwBQAHEAJQAwQD/AEABlgGCAZ4Ai/8o/0b/cf8oAPAB1APABDAFAAaIBgAGUAWABdgFIAUQBAAEkASQBGgEAAWgBTAF/AMEA0wCTAF+AKcAbgHWAcgBBAKgAgQDFAM0A6ADvANcA9gCZAKSAU4AOP+w/j7+gP3s/PT8KP3o/Fj8BPzI+xD74Png+Gj4CPhg99D2wPbQ9nD24PWg9WD1wPQA9NDz4POw85Dz4PQg+Ej8lAAoBVAJsAqQCMAEcgFc/rD7kPs6/j4AzP8g/6//nv8u/pD9aP5O/vj8RP2N/w4BHgFYAlAFOAeABqgERAMsAhABXwBlAOQAmAFIAsgCIAMwA9wCnAIYA5wD8AJsAboAKAFKAaIAYwAGAWQBwgDh/37/YP9+/18ADAKoA4gEAAWABcAFgAVABZgFMAZYBgAGaAWYBOgD3AN4BBAFIAX4BKgEvAM8AhABngCLAMwAwAHwAmgDPANkA+AD4ANMA/QCFAP4AjACBgHS/8b+Gv7s/fz9AP7g/ZD9AP1M/JD7uPqY+aD4EPig9/D2YPag9jD3cPdg9xD3IPZA9PDyoPJg8sDxoPIw9eD3wPrM//AFQAnACCAHwARPAOD7ePuK/vgA5AE4A2AEIAPz/2T9RPzA+5D7wPuA/Dr+0ADsAvAD6ARABngGuAR8AgoB//83/8v/6gHsA6gEuAToBMgEqAM4AuIBuAJgAyADoAKYAqgCRALEAagBugGaATYBdAB4/wD/s/8OAWgCsAOgBJAEwAN0A/QDeAQABWAG8AcACOAGKAYIBmAFQATMA8wDIAPeAf0AlgAwAA4AqgCKAdoBvAHOAfwB+AH0ATgChAKYApgChALYAYQAKv88/oD93Pyg/MT8zPyQ/HD8VPzY+xj7sPqA+vj5QPm4+Gj4wPfA9sD1EPVQ9FDzoPKQ8oDyAPKg8dDykPVY+TT+5AMACHAIaAawBAgDKgDw/d7+GAGAATIBvAIoBP4BHv7o/MT9CP1g+zT8/P5iAKAARAKIBKAELAM4A3AExANGAU8AzgEQA7ACZAJEA+wDcAP4AmADhAPUAsgC3AM4BMQCIAEOAeAB9AF+AYgBBAL+AWYBEAEuAYwBZALcAwAF4AT0A6wDIARABCAEoASwBTAGEAb4BcgFAAUQBMQD5APAA1AD0AI8AsQB4AEsAhgCFAKcAugCDAL1ANQAKgEEAfoA0AF4ArwBVwCJ/x//bv4G/lj+mv70/QD9QPw4++D5CPnQ+FD4gPcw9zD34PYg9rD1YPXA9DD0APQw85DxkPAQ8TDy8PPw9yT+bANQBcAEVANAAZz+RP1K/kEAogEAA8gEQAUAA6r/wP0k/WT8qPsI/Gz93v4ZADoBAAKEAiQDoANQA5gCWAKMArQCHAMwBDgFaAUgBRAF0ATMA5wCEAL+AdIBtAHsARwC4AGGAYQBoAGEAVABKAH5AAABhgEwApQCBAMABPAE8AQgBLADEASQBKgEWAQ4BJAECAUYBeAE0ATIBFgEpAMUA4gCyAFuAcQBNAIAAp4BvAEYAggCxAHUAQQCEAJUArgChAKSAc8ArAAsANL+yP38/ZD+RP5g/cj8UPx4+4D6yPkY+VD44PcA+Dj40PcA91D2wPUw9aD0MPTQ86Dz0POg9AD2APjg+i7+lwA8AcMATwD4/5P/Xv/W/+4ANAIsA2QD4AIMAggBt/9I/nj9nP34/RD+VP4e/+j/MABlAA4BwgHUAcQBcAKUAyAEIARwBEAFaAWIBMQDCATABOgEoASABFAEiAN4Ar4BPgGgAFoADAEYAmQCJAJEArQCoAIMAvoBfALgAigDzAOIBMAEyAQoBcAF+AXQBcgF4AXABUAFwARwBDgE/AOcA/QCJAKwAYoBQgHFAIUAoQC2ALAAxAAOAUIBTAFsAaYBngFGAdwAlQBQANn/a/9I/2L/Kf9i/mz9oPy4+7j6APqY+SD5YPjQ91D3UPbg9PDzoPNQ8yDzMPNg83DzMPRA9sD42Pr4/Db/7f98/vj8VP1q/qD+FP9QAegDqAQIBGQDcAJ1AHD+vP0I/lL+IP/3ALQC3ALaARIBxgBSALX/qf90AJABXALIAuwC5ALsAiQDRAMkAxgDaAPQA+gD2APMA7QDoAPcAxgEvAMkAwQDMAPwAmwCZAKwArwCnALQAvwCpAI0AmgCCANcA3QD2ANgBIAEOATsA8gDoAN4A1gDUANQAzAD1AJgAggC2gG2AZQBiAFoAR4B0QC5AL8AqwCJAHoAgQB4ADIAqv81/yP/RP8I/5D+ev66/nz+fP18/Oj7gPvY+lD6IPrw+ZD5GPmg+PD3APcg9sD18PVA9nD20PaA94D4WPkA+rD6kPuQ/ET9jP3M/Xj+U/+5/9//fQB+AfYByAGcAZoBTAHHAKYA9gAyATwBZAGSAXYBPgEsARoB6ADwAFQBlgF4AYAB5AEYAtABngHsAVACeAKkAgQDRAM4AxAD7AK0AoACgAKoAtAC/AI8A1wDMAPcAqQCmAKIAngCpAL0AhgD8ALIAsgCyAKcAnQClALMAuAC4AL8AiADCAPcAswC0AK8ApACbAJQAiAC7AHCAaIBeAFSAUIBQAEqAegAnQBdACQAzf+M/3r/cP9P/yf/GP/0/pL+Iv7c/ZT9LP3k/PD8FP0Y/QD9xPxY/ND7gPtA+/j6wPrY+iD7MPso+1D7gPuA+3D7qPsA/Cj8SPyg/Az9TP1s/az9/P0y/lT+dP6G/nz+cv58/pb+tv7u/j3/ff+R/5X/r//W//D/+/8XAFoApADoABoBQgFoAYoBngGgAaoB1gEgAlQCZAJkAnACfAJ8AowCtALUAuwCEAM8A1QDWANoA4ADkAOUA6ADvAPIA8ADwAPEA7gDpAOgA5wDdAM8AxQD+ALUArACoAKUAmQCJAL2AdgBpgFkASwBEgH1AM8ArACVAHMANwDt/7L/f/9D/wP/1P6w/oz+Xv40/gj+2P2o/Yj9bP1I/ST9HP0M/eD8oPxw/Ez8JPwE/AD8EPwI/Pj7APwE/Pj74Pvo+xT8OPww/Cz8UPyQ/MD82Pz4/DD9YP1s/Xz9tP30/Rr+SP6a/t7+9v4I/0T/kP+0/8j/+P82AFoAYwCLANEACAEcATIBZAGGAZQBpgHEAdIB7gEoAmwCkAKUAqwCxALYAuwC/AIIAxADHAM0A0QDQAM8AzwDNAM0A0QDSAM8AyQDEAP4AtgCtAKUAoACbAJUAkACKAIAAsIBggFYAUABGAHnAMIApgBxACQA6f/I/6D/Wf8U//D+zP6a/nr+cv5g/jL+9P3A/aT9pP2s/Zz9iP2M/Zz9kP1s/VD9TP1U/Vj9ZP10/YT9iP2Q/ZD9jP2Q/Zz9tP3M/dz94P30/SL+Qv5I/lL+fP64/t7+9v4N/yn/Ov9I/2X/lP/D/+r/DwBDAHQAjQCZALUA2wD4ABIBMAFWAWYBYgFsAYQBiAF6AXYBiAGYAZ4BqgG6AbwBugHIAeAB6AHiAdwB5AHyAfYB8gHyAfgB/AH6AegB0gG6AaQBkgGUAZgBiAFuAVQBQAEoAQgB6ADUAMMAsACbAIUAcQBZADMABADe/8L/q/+R/3T/YP9P/z//KP8N//L+1P6w/oj+aP5W/jz+Hv4S/hT+Dv74/fT9CP4W/hT+Dv4Y/ib+KP4g/ib+RP5m/nb+eP6A/oj+kP6i/sT+3v7q/vj+Ef8n/zX/T/93/5n/sv/P/+v/9//6/wwAKQA7AD8ATABpAIEAhwCHAI0AlgCcAKIAqgCvALQAvgDNANwA5ADnAOIA1gDOANAA2gDgAN8A3gDfANkAyQC4AKkAnACSAIoAhQB+AHoAfwCIAIUAewB9AIgAjgCNAIgAfwB2AG8AagBbAE8AUABXAEwAPgBCAEkANQAYAB0AJAAYAAsAGAAqABgACAAaACYAEAD6//3/9P/c/9n/8/8EAPL/1v/Q/9f/2f/P/8H/vP+5/7P/o/+R/4v/j/+L/33/ef+C/4f/hP+D/4n/jv+K/4T/hv+Z/63/tP+y/7H/uP+8/8L/z//i/+z/4f/R/8r/0P/b/+T/6v/v//3/EwAkAC0ANABEAFoAYgBZAFQAYwB8AIkAhgCAAIAAhgCGAIYAhwCCAHYAcwB+AIIAfAB3AHYAdwBzAGwAZwBgAFQASQBCAD0AOwA4ACsAFgADAPn/8//v//b/BAAHAAAA+P/9/wAA9v/r/+v/8//4//z//v/8//3//v/9//j/8//u/+X/2//c/+P/4P/W/9D/zv/H/73/vP/B/8r/3f/u/+//5f/f/9z/1P/G/8H/xf/D/7z/u/++/7z/tv+4/77/vP+t/5//m/+f/5//mv+a/6b/rP+k/53/pv+u/6n/qv+9/8v/y//P/+L/8//y/+///f8OAAsA+P/4/wYACwADAAYAGQAfABoAFQAUAAwACwAcACwAKgAmADIAOgAzAC8AOgBDAD8ANwA6AD8ANwAuACkAKgA0AD8AQQA8ADkAQABGAEAAMwAlABkAEgAXACgAKQAMAO3/4//m/+X/3v/i//L/+//5//P/9/8AAAAA9f/u/+7/6f/j/+3/+//7//T/8//z//D/6f/n/+n/7f/4/wEAAwACAAMABgAKABMAHgAjAB4AFgATAA8ACAAJAA4AEwAXABUAEAAVABgABQDs/+r/+f8CAP////8OABkAEgAJAAgACwAIAAQABAACAP3/+v/7//r/8//x//7/EgAUAAAA8v/7/wYA+P/i/9z/5P/j/9X/zf/M/8f/wP/I/9f/1P/D/7v/vv+5/67/r//B/83/zf/N/9P/1f/J/7z/vf/L/9f/3v/k//D/9//6//3////+//3/AgAOABgAGAAXABQAEAASAB0AIwAcABQAFwAZABYAEwAWACAAKAAsADEANAA2ADMALwAxADIAKQAiACYALQAwADcARABSAFkAWABRAFIAWgBhAF4AUgBKAEkATgBUAFsAXABYAE4APgAuACIAHwAeAB4AIQAmACQAGQAPAA0AEwAWABUAEgANAAYA///7//3//f/x/+b/6P/p/9z/zP/K/8r/vP+j/5T/l/+f/6H/of+p/6//rP+i/6D/p/+q/6f/rP+8/77/rf+i/6r/sP+l/5n/l/+c/5r/l/+g/7L/v//I/8//3P/m/+//+v8HAAgABgAPAB0AIgAiADEAMQAfAA0AEwAjABwAGAArADkAKwAiADMAOwAtACUAPQBWAEUAHQAVACYAJQAIAP//GAAmABEA+v8CAAkA9f/Z/9b/5P/g/8z/0v/w//r/6v/o/wQAFgAMAAYAHwA8ADUAGwAQABAACAAHABkAKQAdAAQA/P/4/+L/yP/J/+H/5f/S/83/2v/i/93/2f/d/9r/1v/c/+n/5//Q/8P/yf/F/6r/lv+g/63/q/+k/6H/m/+V/6L/yP/s//b/8P/s/+j/4//l//X//f/q/9j/5//9/+v/wP+3/8//y/+o/67/7/8fABEABgA6AHAAXwA9AGsAwwDcALIAowDCALgAbwBQAIsAugCUAG4AkwCwAGgAAwD9/y8AIADg/+f/RAByAD4AEgAvAEMADgDZ/+//FAD5/8L/wP/Q/6H/Uf9L/4P/l/9x/27/sf/i/7//lP+8/wQAHAAmAF0AnAClAJ4AtgC+AIcAXgCCAKEAewBjAJIAlAAaAJv/m//X/87/nP/H/0gAfQBGAEwAvQDhAHgARACsABQB9wDDAO0AEgHBAEsAJQAmAPD/pv+Q/5L/av8e/+b+2v7S/rr+ov6o/sz+2v60/qL+8v5f/4D/fv+8/wkA+P+x/7X/GgBwAD4Ayf/i/6MA9QAmAHL/HQByAWwC6ANABvgFgQCg+TD3KPm4+8j9oQDsA5gFuAQoAr7/xP6A/nz9qPyM/nwCUATIAooBjAJIAqj+BPw+/uIB6gEhABYBJAOWAdT9pP0UAYgCmgDL/9wB1AKGAGT+K/84ALL+uPyc/REAaACM/mj92P3g/ZT86PtE/dz+oP54/Xj9pv5G/7D+Kv74/kkAYwBe/xb/CQCIAK//7P6O/3gAEAD4/gv/TgACAaEArAAMAlAD4AJ+ATwBjALQA+wDuAMQBCAEBANUAYMAsQC4ABAAef9j/zf/fv6o/ST93PyY/Lj8oP30/s7///8bAGwAqgCdAMEArgHUAgQDZAJYAgwD4AKuATgB6AHiAY4A+f/0AGIBFAD2/hL/0v6I/cD8UP1Q/ir/9/90AC0AUP9q/uT97P0+/pr+Av/C/8EAagGeAYoBFgE0AJH/vP8wAGkA0QDOAYgC3AE4AB7//P4W/zb/2f+HAO3/Kv4E/Tz9jP0o/Sz9KP7A/ij+rP1E/tT+av4q/i7/iQAcAUgBegE0AWAA4v9QACYBvgHkAbYBUgG5AC8AGgB+ANUAvQBsAEAARgBZAGIAKACg/2H/tv/N/wj/YP68/jX/rP6s/Vz9wP3s/bz97P34/jYAfAC8/0b/oP+f/+r+Kv/wAFACJAIAArwCYALm/9j9cv4VAFYA6f+RAHgB2QBk/xr/DACgAEcA+v9tAAYB3AAUANL/YgC2ADYA1P9hAB4BCgGQANAA1gF8AgQCEgGxAPAAHgEIAR4BigHsAboB/gA2AOH/6v/Q/23/Q/+x/ywA+v9Y/w7/Tf+i/7f/4f9WAK4AjABJAGkAwADkAO8AGAEaAacAHwAKAE4AjwC/AMgAVgB+/8j+ev6W/kL/TgC1APj/Ff8F/2j/gf9y/57/1f/N/7r/u/+E/x7/Bv9g/93/WADnAFgBWgHsAEwA0P+6//j/TQC7AEgBdAHyAGYATAAMAED/fv5k/sT+WP8XAKIAdQCi/5j+uP10/Sj+bP9AAJ0AJgGsATwBAQBn/wUA4QAYARYBWgFGAVAAQv9X/1AAtQD8/0H/Qv9F/7r+jP6X//QAKgEVALj+0P2Q/Qj+Kv+TAMABWAIkAh4Bu//g/gj/nv/k/x4A+AD+ARgCOgFQAL7/Hv94/nD+G/++//L/6/+5/zv/hP7g/cj9nv7p/3QA7P9R/0j/S/8D/x3/+//SAOIAgQBtAKsAuQB6ACIAwP9l/2//6v8pAKb/3v6q/u7+1P5I/ib+zv5v/2r/Qf+O/xAAWgDGAJ4BGAJMAdb/Av/+/jH/lf+WAJgBYgESABT/9P7c/o7+4v7v/8QAGgF+AdYBXgFIAJj/kf+V/2z/l/92ALABYALmAbUAv/81/6j+gv6M/1YBcAJ4AhgCqAHfANb/J//8/g3/U/8eAFABNAIkAioB7f8s//D+5v4w/yQAUAHQAY4BEAF7AJX/fP7U/R7+Sv/BALoBuAHEAEr//P2w/dz+uQAUArgCBAPMAoYBk/8y/h7+Av8IAK0ADAFGAd0AV/94/cD8fP2W/lH/FAAGAXIBAAFYAAYAw/9k/2f/CADjAIQBzgGsAR4BawCp/7D+0P3o/Qr/CQAdAMD/pP/M//z/WAAGAXwBEgEQAI7/9/9zAE4AGgCeACQBTwCM/pT92P0I/sj9dP5tAPIBpgFkAJv/Mf+y/hD/NgHcA7AERAMSAVn/Hv5Y/XD9nv4lAOAATgAl/6L+GP/R/yMAQQBrACIAKf9g/rD+sP9pAPsA2AE8AiABQv9o/sj+Kv8z/7X/wABgAW4BmAHGAQoBZf/A/ZD86Psw/LT9pv/eABABhQBs/yz+sP2A/vz/VAFIAuQC8AJcArABmAEEAjACtAHvABgA6P6E/Rz9kv6dAFYBWgDA/mD9jPy4/Fr+0QDMAlwDfALFADv/gv5s/nz+D/9qAGYBygBx/0n/RQCGAJr/Jv/F//f/A/+a/gAA5gGgAnACQALGAVkAfv4w/cT8KP1c/s//mABaAKP/7P4w/oD9XP1A/jwAfAKwA2ADYAKIAboABwBFAIIBcAJ4AlACLAIaAR3/0P3w/Xb+lv7e/r//egAeAMj+QP1I/ET8aP2J/wQCwAPIA2wCqwAx/17+yv6gAKwCfAPoAk4B4P6k/Dz85P3+/y4BbAHGAB3/EP3I+zj8pv4gAnAEEATGAW//sP1s/Gj8cP52AYADlAPUART/9PzU/Ez+BgBwAVACtgFp/2j9nP1M/88AOAKsA3wD1QAc/iD+OwD+AZQCkALcARgAHv5U/R7+nv/SAF4BTAGbAE7/yP3c/BT9eP59AFACNAMIA2ACeAEtAFf/IADYASACZwDm/tr+6P5s/u7+5wDmAVcAJP6g/TL+cP7+/v4AIANQA9YBVwBF/+z93Pyg/d7/hAHOAfABeAIgAmcAmP7A/bD9cv6KAEwDyARABKwC4ADW/vz8VPzE/Ej9rP1c/h7/e//6/y4BEAI6ASr/sP3I/SH/UAGwA9AErAMWAbz+eP0s/Sj+fwD0AlwD8wBM/Xj6QPnQ+YD8UgDEAsgCtgF7AKz+IP1M/igCCAWQBGwC2gCl/4T+0v40AbwD8AOEAWD+fPw0/Mj8FP4tANgBLgGm/hz97P1W/7//FQBMAe4BgQBg/uz9M/9QAKsAKAGQAWUA7P3k/CX/9AJIBUgFEAT0Abr+qPs4++T9IgFkAqYBRADY/sD96P1S/3QAPwBq//7+D/+a/78A9AGwAoQDmAR4BAAC5P5U/Sj9bP2E/toAwAJQAi0AXP5Y/Zz8zPzy/iwC9AMsA2QBSgDd/2D/DP9d/7L/9v5w/cz89P0QAKIBugFZAE7+GP3I/dD/4gGkA8gEMARKAcz9yPto+/D7gP3d/1wB0wBz/9b+vP5I/hr+c//2AZgDSAP6AQYBqwCaAOcAlAHSAbYAaP4g/BD74PuM/jQCMAWwBXwDEgBc/ST8hPyw/lwC2AXoBqgEqwAw/VD78Prg+xr+tQB4AggD+AKEAm4B7v++/gb+gP2Q/RH/+gHYBOAFiAT+AXX/IP2A+yT8eP9cA0gF6AQMA+v/RPxo+qD7WP6iAEgCIAPwAez+yPxA/ez+rP+e/x4ACAEGAQEAIv/2/pj+mP0Q/bD9lP6Q/jz+xP47/yL+HPxA+1j8Ev5x/00AawCi/77+1P7g/y4BlALwA2gEgAPWAb//LP0o+4j7JP4AAcQCcAOMAqD/+PsA+gj7bP5wAjAFkAXYAyYBtv4C/tX/6ALABFAEYALt/8T9PP0M/+4B8APIBOgEwAPpAIr+Pv+QAmgF8AXIBOACoP9g+7j4+Pl4/db/jQBsAUwCDAFc/uz93wC8A7wDOAIuAer/mP1Q/CL+LAEQApAA9v7k/RT8YPoQ+wz+MgDG/8T+2P4k/7T+bv4Z/3D/Uv6o/ND7ePvI+lD6SPso/WT+9v4LAJQBJAIqAdf/av/C/xoAKgAbACsAggAoAboBtgHzAOP/LP+s/pL+FgB8A2AG8AWcAkL/9Pw4+0D77v6IBHgHkAbQBJwDvgGv/3YAUARIBzgHQAYwBjAGsAWQBYAF+ANMAQP/LP2Y+yT8BgA4BHgFuARABBgDBABw/bT9QP8eAFYBIARIBiAFigHw/Vj7aPko+HD4mPqs/Ub/Bv/S/j//ZP4U/Oj6gPsY+yD5kPhQ+gj7gPmY+GD5kPkA+AD3GPgA+tD75P3s/1QAvv6U/HD7FPwA/joAtgH8AcAACv4w+wj6sPrw+1T9RP9iAVgCQAKcAvgDcAVwBqAHkAigB+gEnAKUAugDCAVwBqAIMArwCKgF0AO4BJgGuAfQCEAKsApACTgHGAY4BigHuAcAB2AFMAQQA2IBvwBwAjAEXAOiAagB4gEwAID+FP8DAOD+ZP2M/Wz+yP4L/+z+jP3I+wj7gPpA+fD4YPoQ+4j5oPfg9rD14PPQ86D1YPaA9QD2oPjQ+cD3UPUg9SD2kPbQ9hD48Pmg+kj6OPqI+kD6YPnw+XD8jv6w/mL+Sf8CAGj/Lf/7AFgDeATABMAEAAToAggDcAR4BcAFoAZwB6gGuAT0A9AEGAYACGAKcAsgCsAHWAZwBogHoAnQC5AMsAtwCgAKIApAClAKYApwCagGQAOwAWgCeAOYAyAD0ALiARUAGP/U/+cAxQBQAIEAlgDd/3f/GwDWALAADwDe/nj80Pm4+Bj5APm4+LD52PqA+RD2oPMw8+DyIPNg9eD3MPfg89DxAPJg8oDyoPPQ9ID0EPRw9dD3oPmY+0L+wv+w/rz8dPz4/dn/uAHAA1gFSAXEA7AC7AJEA8gC2AJYBFgF/ANAAuACmAT4BKAEWAUABtAEjANwBIAGsAdgCJAJUApACagHYAdgCGAJwAkQCqAKYApACVAIYAgwCGAGYAQYBKAEEAT0AqACkAJOAcj/8/9gASQCMAKsAogDMAP4AbQBgAKwAt4B7AE8A3wD6AFNAH//DP4Q+4j44PdQ91D1UPOg86D1QPaw9eD1MPZw9ADx4O/g8ZDzsPOw9OD20PYg9GDyQPPw9CD2oPdo+Wj6OPtc/HT9mv6YAGQC6gG1ALIBlAMsA8IB2ALoBOQDJgEKARwDXAPcAQgCdAPkAkIBDAIQBcgGmAbYBlAHGAY4BHgEsAagCNAJEAtgCzAK8AjQCLAI8AeoB2AIoAgACPAHgAggCJgGWAW4BHADrgHbAEIBQAF3ABcAZgDdAGABEAI4AuoBdAKsA8gDMAMABLgFkAX0A2wD7ALe/1T8uPtY+6D3kPMg9OD1UPMg8DDxQPTw81DyEPQQ9lD0IPJQ9LD3IPdA9WD2cPfA9PDxMPMg9lD3MPjg+uj8RPyY+1T9n/8AAMz/8AAYAzAEyAOEA0gEaASkAtwASAHgAtACHAIoA6AEcARoA/wDMAV4BPwCGAMwBKgEqATABYAHYAiQCPAIMAmACGAHMAeYB1gH2AYQB7gHcAfgBiAHiAcABwAGmAUoBeADfAIIAngCtAIgAsQBcAIgA4wC9AHoAigEmAPYAhgEwASoAmIBnAMwBXAC1v88AhAE/f/I+nj5QPig8kDvcPMg+CD2EPOQ9Wj40PSQ8GDzsPeQ9hD0YPZw+YD3sPQg9oD3MPTw8NDyMPZw9sD2iPqQ/if/xv5XAAgChAGuAEgC8ATQBZgFeAZYB8gF1AIyAeoAvf9y/on/cAJYBHgEWARABCgDxgH4AaAD4AQIBTAFGAZIBwAIwAigCaAJYAjQBggG6AXwBagGMAgwCQAJcAhgCBAI6AawBfAE6AOAAqIBggF0ARwB6gBaAegB8gFkASIBOALEAzgESATYBbAHyAZwBNgEkAZIBbwCGAQYBvUAEPjw9ND2YPVA8YDyMPcw9vDwQPBQ9ED1IPNg9JD48Piw9XD0UPbg9gD1sPMg9FD0YPMw89D0MPcY+aD6OPy8/dT+W/+4/90A5AKgBPAE6ASgBRAGIAUYBNQDfAJV/zT9tP28/h//uABkA/gDMAKwAQwDIAP2AZAC4AS4BWAFqAZQCaAKIAqQCUAJAAhQBmAFqAVwBiAHQAfIBogGcAbQBZgE4AOwA/wCegFrAIMAFAFSAaYBcALwAtgCyAJUAxAEwASQBXAGAAdYBxgHuAXUA9QDuAVQBiAFAAS8AqT9kPUQ8VDy0PNA8wD0kPag9rDzcPIQ9PD0sPSw9RD3sPZg9ZD18PVQ9fD0wPRg86DxsPJw9dD2OPjY+zD/EP+0/a7+3QBgAeABYAR4BhgG4ARoBXAG6AVABOwC6gFCAMr+lP7R/2IBGAJMAoACjAIAAoQB6AHgAqgDuAR4BgAIwAhgCYAKEAvwCWAI2AfgBzgHcAbQBmgHwAaYBXgFqAXoBNQDzAPIA3wCQAFWAcABJgHDALgBgAIgAmgC3AOABBgEeAS4BdgF+AQgBsAH4AZQBOgDEAZ4BnAE4AGo/oD5IPSA8fDxgPMg9XD2UPYA9XDzoPLQ8gD00PXA9pD2cPZg91D4CPjQ9hD1EPNw8TDxwPJQ9Xj4uPsI/qT+hP7u/rL/cwCGAXQDGAVgBYgFMAfgCGAIQAaoBBADLwB8/ZT9tP8sAdgBRAMYBSAFWAPoAXoBDAFyANUA5AKgBfgHgAmACtAKAAoQCGgGyAXQBZgFoAVoBhAHGAeABjgGyAUIBYAE7APcApIBegE8AkAClAGmAVQClAKgAmwD/APQA1gEyAUIBvgEQAUQB3AGGAScAxgFMAVwBGgGEAdGAZj4sPRA9PDxEPBQ89D3wPbQ8pDy0PSQ9ADzUPSw9hD28POg9ND3cPmQ+LD2APWw8lDw4O8Q8hD2EPq8/Pz9eP5o/h7+Kv59/64BUAMQBMgEKAZYB5AHwAZQBZwDXgH4/sj9mv5kAGwBxgHAAtQDaAPMATgB3AF+AXEASgEYBDAGAAegCMAKsAqQCEgHWAfABrgFAAZQB6AHGAdYB2gH6AVYBFAEwATEA6QCCANcA0QCLgFqAdoBVgHcAWADZAM8AgADwAWABvAEEAUAB4AGuARABcAGUAWEA5gGYAlQBXD+MPvg+PDyoO4w8qD3QPcQ9VD2MPfQ88DwkPNQ99D24PTw9XD4qPiQ92D3APcA9MDvYO3g7gDzMPcA+1z+FQD0/pj8QPzc/YX/KgHcA6gGsAeAB/AH8AcQBpgD2AF4AMj+Jv74/oz/5/9yAVADaAMMApwBugEyAHz+2v9sA0AFwAWYBzAKQAoACAAHOAdIBiAFQAaQCMAI+AaIBvgG0AWQA8QCdANMA0wCiAI4A5ACSAFEATACvgHm/6b/OAKoBBAEbAIYBJgH0AcwBdgEEAfgBogEKAW4B1gGTAPsA0gGAASg/YD5cPZQ8mDw0PIQ9nD2cPYA9/D0gPEA8nD1QPcg9wD4cPnY+DD4iPmI+TD2cPLA8ODvYO9w8tj4sP0N/wr/0P5Q/dD6+Pog/lgBfAOABSAIgAmgCOAGOAV0A2YBiP+0/gD/4f/HAAwBFgG4AXQC+gFwAFz/Tf9+/9P/ugHwBHAHQAiQCPAI4AjgB+AGGAcwCLAIQAjgB7AHyAYYBRgEKAQYBFwDUAMABMADMAJYAfgB8AEIAToBrAK4Aq4BpAIABQAFOAMwBCAHUAdIBegFgAjAB2gECATwBWAFPAPUAzgF0AEY+4D2QPRQ8sDx4PQo+JD3UPXw9FD1APVA9XD3APkA+MD2cPeo+ND4aPjQ93D1UPHg7kDwMPQw+Nj7kv4A/zz9kPuw+/j8iv6sAPgD8AboB3AHaAfgB5AGTAMIAf8AvACC/6f/xAGcAgIBNgCIAe4BXQC1//AAfgHZAF4B6AP4BdAG+AdQCUAJ6AcoB6gHEAi4B/gHoAhQCMgGaAUABXAEkAN4A0AEEASkAqgB0gGqAbIASAC/APEAaAAQAawCUANIAxAEYAX4BNQDyATABuAG2AXoBvgHCAZAA5wDSAWoAysAhP7M/Cj48PPw81D20PZg9sD2EPaA80DyIPSw9oD3UPfA9wD4wPcg+ID4MPcw9DDxgO+g78Dx8PXA+pT9sP08/MD6KPqw+kz8+v44AtgEcAY4B7AHaAeIBUADBAIQAZj/Sv//AGgC1gE+AYwC3ALHAJr/CAFuAdP/vv+UApAE/APYBOgHIAmAB/AGEAjQByAGaAYACRAKAAlACOgHQAY4BCgEEAWoBJgDwAPgA1wCtgCrAFABCgHTAHQBxgEuASQBsAIgBEgEQAQoBWAGSAYABegESAYYB4gG2AUABngF0AOoArgBIP7Y+GD2MPfw9yD3UPcY+AD2QPJA8VDz4PQg9QD20PeA91D2QPeQ+cD5gPaw8kDwYO/A74DykPec/Dr+LPyA+Uj4kPiI+VT8qQCsA5AEYAXYBmAHEAagBLgDJALuAJoB8AJcA0QDUAMsAhEAyP+AAaQBHwCPAEgCeAKaATQDMAaQBqgFiAawB+AGUAYwCMAJkAhQB0AIEAmgB/AF4AW4BTAEfAPoBOgFwASIAgQCYAJ+AWAAGgH8AiwDogE6AUQCVALAAbgCkASYBCADTAO4BeAG2AVABYAFmAXIBGgEmAS4A4YB6P5k/Gj6MPno+PD4qPjg9yD20PNA8pDyAPTw9SD3cPcQ94D2YPbA9sD3APig9UDxwO6A7zDxkPOA+MT9xP2g+SD4KPr4+qD68P1QA6gEEAPwBMAIgAhgBcgEmAVkA6kA7gHQBKgE7ALIAqgCqgBU/2wAVgFeAJv/vADSAfgBAAP4BJgFcAQYBLAFAAdQB1AIMAqwCgAJAAiwCNAIKAcgBvAGKAeABZAEmAWIBTwDJAGsAZgCGAKOAUgCwAKMAYwAIAFEAkACHAIQA3gE0ASIBEAFmAbQBuAFQAVABegExANwA3gD+AEj/0D9mPzI+ij4cPdI+BD3kPQw9GD18PTw89D1OPiQ9nDzMPSg9tD28PXw9sD2kPLA7iDvMPHA8lD2uPs0/uD7wPlY+nj6IPqg/KgBkAR4BEgFsAf4B8AFeAS4BFQDtAC/AIwDKAUYBIQDsAPaAZD+gP0+/2AA9f+TAMAC3ANMA2QDmAQABfwDtAOwBRAIEAmQCXAKoAogCWAH2AYwB/AGUAZIBjAGkAXwBGAEpAM0AhwB6wDIAJcAxQBiAaIBJgG+AGIB7AGMAYQB2AJ4BLgEkASABUAGQAUYBHgEEAUQBMwCxAJgAmAAAv44/Wj8aPqo+CD4sPdg9sD1YPYw9qD0APTg9aD2EPUA9GD10Pbg9RD1oPVA9BDwAO4g8LDzYPaw+Uj9WP1A+qD4qPkI+6D88v8ABGgFmAQIBUAG4AVIBNwDGAT8ApgBeALgBIgFWAQkAwgCJACK/iD/AAEAAgACSAJ8AjQCQAIEA8gDKARgBFAFKAfACIAJcAkgCdAIeAdgBkgHEAnwCMAHOAcYB6gFsAO8AzgEFAOgAe4BrAJIAqABxgG0AYAARgBmASQCJALkAigESASYAzgEiAUwBQgEaAR4BdgEfAOQA7wD1gFO/0D+5P0c/Ej6yPl4+UD4wPZQ9rD2kPaw9fD0sPQg9RD1kPTQ9GD1wPSw85Dz8PKg8EDuAPBg9ID3kPmw+zD8uPlw91D4sPtw/ggBEASQBRgFiARgBeAFEAXcAzwD7AIgA0gEsAXYBbAESAOAAbf/MP95ABwCaALCAcAB+gH4ASAC9AL4AygE/AP4BAgHoAggCSAJ8AgwCAAHKAfwCNAJEAlQCCAI8AbIBCAEuARIBNQCcALsAmwCKgEAAWYBsgBp/47/AAHmAcwB6AGwAiQDFAMwA2gE+AQ4BLADaAQwBUgEFAPsAkgCCABE/ib+mP3Q+5D6gPrI+aD3YPbA9pD2gPXg9AD18PTA9DD1cPWA9KDzgPMw87DxgPDw8DDy4PNg9lj5gPqw+SD44Pf4+Bj7Mv5gAdADWATgA8gDOAVwBrgFsAToBIAFwASoBLAGsAcoBUQCLAJsAvwAugAMA/gDugFHAI4BRAJIAbIBqAPEA7AC1AOoBqgHKAfQB3AIOAcYBqgHAAoQCjAJgAmACYAHoAUQBhAHAAaABIgEEAX8A0ACMAJAAvoAXP+q/wABQAHKADYBFAKYAfwAiAHcAhgDjAK8AowDyAMwA+ACuALqAYsAgf8E/1T+IP34+0D7cPpA+UD4kPfw9jD2gPVw9UD1kPTw89DzkPMQ86Dy4PKA8rDwoO9g8ODxUPPQ9Qj56PnA93D2KPhQ+vD7oP5cAvADOAOsA3gF4AXoBCAFGAagBbgEMAaQCDAI8AXYBIAE2AIcASACOATQA8oBdgFwArwBbwAWAcACnAKmASADyAWYBhgGyAbIB+gGsAXoBpAJcAqwCbAJ8AmwCNgGcAZIB/gGgAXYBAgFaAQEAygC2gEWAbr/Kf+4/1cAlQCbAF4AGwDT/xIAsABeAeoBLAJYAkQCEAKsAZIBQgGWAO//nP9K/07+TP2g/PD7qPrA+Uj5oPiQ9+D2wPZA9oD10PTA9BD0UPNA8zDzQPKw8DDwQPBw8JDxcPSA94D3UPZA9nD3QPiQ+Vz9SAEkAmABtALYBEAFkARQBcAGQAZYBcgGEAkQCWgHeAYgBqAECAPAA1gFGAVgA4AClALqAdEAHgFYAmQCwAFMAhAEUAVwBXgF8AXgBYAFIAbQB2AJ0AmACSAJsAi4BwgHYAfIB3AHmAZYBmgGeAVQBLQDAANkAYcA7wDqAeQBIgEoAcsAoP/E/oj/rgD/ANYADAFKAdEAnwDHAL4ANwD4/9z/Z/+8/nT+/P24/Lj7kPs4+xD6UPlg+Qj5sPew9qD2QPbg9AD0EPQA9FDzMPKA8fDwMPDg7yDxkPOw9TD2kPXA9ZD2QPcI+VD8bP97AF4AwgHMA2gEWARABXAGSAYQBqAHEAoQCoAImAcgBxAG2ARgBXAGKAaIBHwDIAOAAvABAAJEAu4BpAEMAgwD0AM4BGAEIATgA1AEWAWIBogHUAiwCAAIIAcYB6gH6AeIB3AHeAcYB0gG+AXABYgEJAOEAmQCHALoAUQC+gGvAHb/F/8Y//T+Sf/p//X/av8h/33/i/8r/87+5v4U//b+3v7O/s7+Av7g/Ej8XPxM/HD7yPq4+lj6MPlg+Gj4EPjg9tD1wPXA9aD0sPNw8wDzEPKg8eDyYPTg9AD1QPVw9WD1QPaQ+PD6iPy8/cT+w//FADACXAMgBHgEcAWwBsgHkAgQCVAJcAh4ByAHyAcACIAHSAfoBrgFCAS0A1AE3AOkAmQCLAPwAhACcAKAAzgD+AEgAmQD6AP0A/gESAYABhAFUAVQBlAGCAbYBrAHSAdoBrAGGAcgBugE4AQYBVAEmAPwA1AEJAOoATQBMgF8AKv/EwB9AAEAAP/u/lr/8v4u/gj+jv5S/sz94P1Q/vT98PyI/Kz8iPzw+/D7OPzQ+9j6SPpI+gj6SPnA+Kj4OPhQ97D2YPbw9RD1MPQA9BD0APRg9BD1cPUg9eD0QPUg9kD32PiQ+tj7ePxI/Vr+NP/D/+AAbAJYAwgEMAWYBgAHoAawBiAHIAfIBkgHAAjQB+AGcAZABlgFQAQwBLgEcASsA8wDYAT0AwQD9AKIA1AD1AJgA5AE4ARoBJgEIAXwBFAEqASIBdAFgAWYBegFgAXQBLgE8ASQBPQD4AMgBOgDQAMEA9gCOAJ4AUABbgFIAeQAuACWAAgAa/8y/zn/+v6U/nj+lv5s/vj9tP2Q/UD91PyE/Jz8kPxQ/AT82Pt4+8j6YPpI+hD6kPkg+ej4SPhw9+D2kPYQ9nD1QPVw9WD1IPVA9YD1UPUw9eD14PbA94j4uPnY+jD7oPuY/MT9gP5o/7sA3AFkAvACAATABPgEOAX4BYAGkAa4BkgHgAfoBmAGWAZgBgAGyAUoBkgG2AVQBVgFYAUIBcAE2AQ4BTAFKAUoBUgFMAXgBLgEwATYBPAEOAVgBWAFOAUQBegEuAS4BNAE0ASoBHgEgARABOADqAO8A4gDAAOsAqACeAL+AaIBoAFiAcgALgARAPf/hP8L/+r+vP4A/mz9WP00/bj8FPwM/Pj7YPvY+tj6wPog+pD5cPlY+eD4aPg4+PD3IPdw9hD2wPWA9UD1MPUw9SD14PTQ9PD0YPXw9WD2MPdQ+Dj5mPkQ+gD7+PuE/Fj90v42ANgARgFIAlQDwAMIBPAEAAZYBkgGsAZABzAHwAawBhAHEAewBsgGMAc4B9gGmAagBnAGEAYABlAGaAYgBugF2AXYBagFiAV4BYAFWAVIBXgFaAUgBdAEwASIBFAEQARoBGAEIAQIBPgDtANUA1QDVAMQA6wCqAKoAjACvgG2Aa4BEAF1AGcAWwCz/x//M/8i/17+nP2E/Wj9sPzw+/D7FPxw+7D6kPqo+hj6WPko+VD58Pgo+OD38Pdw95D2APYA9sD1MPXw9CD1MPXA9ID04PRQ9VD1gPVA9kD34Pdw+Gj5cPoY+6j7uPzs/dr+rf/CANABhAIkAxgEAAWABegFgAYIBxgHSAeQB6AHcAdoB7AHwAewB6gHwAeoB2AHOAcoB/gGyAbQBsgGqAZwBmAGWAY4BiAGIAYYBgAG2AXABagFkAVwBUAFGAUABegEqASQBJAEcAQgBPQD+APYA2wDGAP0ArACJALUAcQBigEmAbwAjAA2AKP/L//w/qr+JP6o/VT9+Pxs/Oj7oPto+xj7sPpo+jD66Plo+fj4sPhw+Aj4kPdA9wD3cPbQ9XD1MPXA9ED0EPQA9NDzkPOg8/DzAPQg9JD0YPUQ9uD24Pfo+MD5YPow+yj8HP0w/nv/sAB8AUQCPAMYBLgEaAU4BsAG+AZIB7AH8AfgB+AHIAhACCAIUAiQCKAIYAhACFAIMAjoB9gHIAgQCLAHcAeAB3gHKAcQB0AHMAewBlgGWAYwBsAFcAVwBUgF0ARwBHgEaAQIBKwDnAOEAygDzALQAsQCOAKuAYQBdgEUAagAfgBbANb/M//u/rz+Wv7Y/YT9RP3M/Ez8BPzg+5j7MPvg+qj6YPrw+bj5ePkY+aD4SPgA+JD3IPfA9mD2wPUw9dD0gPQg9NDzsPOg85DzgPPA8xD0YPTQ9JD1cPZA9xj4APng+Zj6cPuo/MD9vv7T//YA4gGMAnQDkARoBfAFmAZIB8gH8AcwCJAI0AjACOAIUAmQCYAJcAmQCaAJQAkQCTAJUAkQCdAI0AjACFAI8AcACAAIsAdABxgHAAegBiAGAAb4BZgFEAXYBNAEiAQYBOgD8AO8A0wDGAMkA/ACgAIgAhQCvAFAAQAB+gDDAFAA5P+0/2H/vv5g/j7+5P1A/dD8qPxY/ND7ePtg+xj7kPoo+gD6sPkw+dD4iPgg+LD3UPcA94D2APaA9RD1kPQg9NDzkPNQ8yDzIPMg8zDzUPOw80D00PSQ9aD2sPdw+Bj58PkY+xj8EP1i/sP/qABUAVQCiANoBAgF6AXwBoAHuAcgCNAIAAngCBAJoAngCdAJAApgCnAKIArwCSAKIArACaAJwAmgCRAJoAiQCIAIQAjoB9AHmAcYB5AGUAYYBpgFGAXABIAEGATUA6QDcAMgA9gCrAJsAiwCCALgAX4BGgHuAL0AewBDACAA7P+I/yr/3v6Q/ir+zP2Q/TT9xPxc/Bj84PuA+yj72PqI+ij60PmQ+UD50PhI+Aj4wPdQ99D2kPZA9rD1IPXQ9KD0IPSw86DzoPNg80DzgPPw8zD0gPRA9SD20PZw93D4kPlw+lD7gPzY/db+tf/IAOgB1ALAA7AEwAWABiAHwAdgCNAIEAlgCbAJ4AkACkAKcAqACnAKkAqwCoAKUApQCjAK0AlwCVAJIAmwCHAIcAhQCNAHcAdYBxgHgAYIBtgFmAUIBZAEcARABNQDjAN8A0wD3AKQAnwCRALUAYIBYgEaAa4AZwBJAAcAof9T/yn/0v5c/vz9yP18/ez8fPw4/PD7gPsY+/D6sPo4+tD5oPlo+QD5kPhY+Bj4kPcg99D2oPYg9rD1cPUw9bD0QPQA9NDzgPNA82DzkPOg89DzUPTg9ID1IPYA9+D3qPiA+Zj6yPvc/OD9+P7//+IAxgHUAvQD4AS4BZgGUAe4BzAI0AhACXAJsAkQClAKQApgCqAKwAqgCpAKsAqwCmAKMAogCuAJcAkgCSAJ8AiACDAIEAioBwAHiAZgBggGcAUABcAEYATUA3QDVAMUA6wCTAIgAugBhgE0ARAB3wCCAC4ACADn/5z/Tf8j/+b+dP4U/tj9mP0s/cD8cPww/ND7ePtQ+xj70Pp4+jj6+Pmw+Wj5IPnY+ID4GPjA94D3QPfQ9oD2MPbg9YD1IPXw9KD0cPRA9ED0MPRg9LD0EPWA9fD1oPZg9yD46PjY+dj60PvA/NT94v65/5AAjAGMAmwDUARQBRAGqAZQB/AHcAjACEAJwAkACiAKYAqwCtAKwArQCvAKAAvQCrAKoApwCiAKwAmQCWAJAAmwCGAIIAiwBygHyAZwBvAFeAUYBcgEWATcA5QDcAMgA6gCaAI4AuoBfAE8AR4B0ABrACYADQDM/2v/M/8L/7L+Sv7w/cD9XP34/LT8gPwk/Lj7YPtA+wD7mPpo+kj6+PmI+Vj5OPno+HD4MPgQ+LD3QPcA9+D2kPYg9vD10PWA9UD1EPUA9eD00PTw9DD1gPXw9YD2MPfg95D4WPkg+vj62Pvg/Pz9Af/x/+EAvgGEAkQDMAQwBfgFkAY4B9gHQAiQCAAJkAnQCdAJEAqACqAKgAqQCsAKsApwCmAKoApwCgAK0AnACWAJ4AiQCHAIAAhoBwAHqAYoBpAFIAXQBGAE6AN8AzADyAJcAgQCrAFEAdUAjgBUAA0Av/+U/1n/D//Y/rz+lP5I/gT+2P2Q/SD93PzE/IT8LPzo+7D7gPsw+/D6yPqQ+kj6CPrg+Zj5WPko+fj4uPhw+Dj4APjA95D3YPcg9+D2oPZw9mD2QPYw9iD2QPZg9oD20PZA98D3MPi4+Gj5MPrQ+oD7cPxo/Sj+3P7T/8YAgAEcAhADCAS4BGAFKAboBlAHoAcQCJAIwAgACUAJoAnACdAJ8AkQCgAK8AnwCeAJ0AmQCWAJMAngCKAIcAhACOAHgAcgB7AGOAbQBXAF+ASIBCgE3AN0AwwD0AKgAlAC5AGWAWABEgG2AG4APwD7/7P/f/9Y/xr/0P6Y/l7+DP64/YT9TP3s/JD8SPwA/LD7cPs4+wj7sPpo+ij6+PnI+Yj5WPko+fD4wPiI+Gj4UPg4+Aj48Pfg98D3sPeg96D3kPeA94D3oPew99D3GPho+Lj4CPlo+ej5UPq4+kj74Ptw/AT9tP1w/kb/7f+yAHwBMALEAkwDCATABFAFwAVIBrgG4AYQB2gHwAcACEAIgAiQCJAIoAjACKAIkAigCKAIcAhQCFAIUAgACLgHmAd4BygH0AaYBlgG6AVwBRAFqARABPADrANQA9wCeAIgAr4BVgEQAc8AeQAfANb/lv9G//j+rP5g/hD+xP2E/UD9+Py4/Gz8FPzA+4j7WPso+/D6yPqY+mD6MPoQ+gD66PnY+cD5qPmY+Xj5ePlw+Vj5QPlA+WD5YPlY+WD5cPlw+Xj5oPnI+ej5CPpQ+pD6wPr4+lj70Pss/IT86Pxo/eT9TP7E/j7/rf8bAJQADgGEAQACcALcAkwDuAMQBFgEsAQABUgFkAXgBTgGcAaoBtgGCAcgB0AHcAeYB7AHwAfYB9gHwAewB6AHkAdYBxgH8AawBlgGCAbABYgFOAXYBIAEMATUA2gDDAPEAngCEAKoAWgBIgG+AF4ALAD9/5f/Pv8L/9L+aP4K/uT9sP1Y/fz8xPyc/FT8BPzI+6D7ePsw+xD78Pq4+oD6YPpY+jD6EPoY+iD6+Pno+fj5+Pno+ej5APoY+iD6KPpY+mj6aPp4+rj62Pr4+ij7cPuw++j7NPx4/MD8BP1c/cz9OP6S/u7+VP++/yIAhAD3AG4B2AEkAnQC9AJkA7gDAARgBLgE2AT4BEAFkAW4BeAFEAYwBkAGWAZ4BoAGeAaQBpgGiAaIBogGaAZABhAG+AXgBbAFcAVIBQgFwARwBBgEwANwAxQDuAJ0AigCtAFGAfEAnAAvAMX/ff9D//b+jP4y/uz9qP1U/Qj9zPyc/GD8IPzw+8D7gPtI+yD7GPsA+9D6uPrI+rj6mPqI+pj6qPqY+pj6wPrQ+sD6yPr4+hj7MPtg+5D7wPvo+wz8RPx0/KT82Pwg/Wj9tP38/TT+bP7A/hX/Vf+c//L/RgCRAOIAMAF6AcIBCAJUApwC5AIoA2QDlAPQAxAESARoBJgE0ATwBAAFIAVABVgFYAVgBXAFeAVwBWAFWAVYBUgFIAX4BOAEuARwBDgEEATcA4wDTAMAA7gCcAIoAuIBmAFGAeIAhgAsANX/gP85//T+ov5M/gL+yP2I/UT9CP3g/LT8gPxU/DT8GPz4++D70PvA+6j7qPug+6D7mPuQ+5j7qPu4+7j70PvY++j7DPw0/FT8ePyk/MT88Pwg/Uz9gP24/eT9Iv5c/or+wP4F/zv/ZP+g/93/CwBGAIUAtQDpABYBQAF0AaQB1AEQAkQCXAKEAsAC2ALgAvgCDAMkAyADHAMsA0gDLAMQAxADGAMAA8wCyALQAqgCgAKAAoQCWAIgAgQC/gHmAboBpAGUAXIBQAEEAe0A6QDAAHsAXQBPABoA6//R/6f/fv9V/yr/D//y/sz+uP6k/nT+TP5K/jT+Iv4u/iL+Bv78/ez9yP3M/ej94P3Y/dz94P3g/eT95P38/Rj+Bv4C/ib+NP4w/lT+bv5s/pT+tP6y/tj+Ev8T/zD/YP9i/2z/oP/F/9f/AAAAAAgARgBcAGQAjgCrAK4A3gAAAQABJgFGAUwBagGGAZIBsAHYAdQB4gEAAuwB8AEQAgAC8AEIAvIB2gHsAeABvgG0AaoBgAFwAVABMAE4ARQB1QDsAPgAngB7AJ4AZAAfACkAMAAGAOb/1f+v/57/ff9Z/1b/Rf8v/x//Ev/s/vj+DP/a/t7+/v7s/rz+zP7u/tT+vv60/tL+9P7Y/rL+0P7q/ub+4P7M/uj+J//4/sD+If9U/+D+A/+D/3n/If83/6z/u/98/43/BAAaAM3/7f87AE4AMgA0AI8AkgBuAHcAywDKAKEAswDgAPsAyQDtABwBGAHlANgALAEcAc0AEgF6AS4B3gAsAVABGgEWATQBUAEYAeAAFAFCASIB+QD/AO8AxwC6AK4AngDFAJYAEgANAHsATgCV/+P/PwDa/0T/D/8IAEMAFv8S/0IAav9O/lr/5f8y//b+fv8x/3r+uP6V/4D/Pv5U/sL/ff/g/SD+AQBz/5T9aP7W/0H/+P3E/uT/Rv9I/p7+5P+R/6j+Kv/u/5T/E/+f//f/c/+X/yYA5v+m//f/EAD2/+////9vAA8Am/9zAK0A/P8YAH8ANwAzAGMAQwBvALoAbQAzAHUAqACHAHYAlgDTAPwAdAAxAOEA6QAwAIEAGAG1AIgA3AC7AMEAzQByAMQA3ABhAMsAMAFrAEkA9wCzADgAegC8AJYAcwBZAIUAnwD+//n/xQBpAH3/NwDPAO//pP8AACIA1/+w/7r/1v/e/5z/vv/S/zr/qv8CAA3/Rf+OAMX/RP7U/4wA+P7k/gEACQB5/zb/MP+0/6j/GP+e/8H/7P6P/zYAPv9k/2UAqv/O/q3/jwDx/17/w/9SAA8APP+o/2IAPgDu/5P/GABiAKH/NP9sALoAm//B/zMAcQDw/3T/JgDgAAsAUP/RAAoBiv+5/8MAkADo/1QAyQDAAEYA4f+RALsAHgD3/+4A1wDs/yYAsgCZAEcA5/8HACgBWQBY/94AdAHI/3X/pACCAAEALgCCAJcA+P+A/4wA1wDe/1MAQgCg/zoApAB7/8f/NAERAHn/if/t/2kAu/9M/57/sQAw/2L+PgBeANj+pP4CAN//5v7U/nr/DwCU/4j+EP+8/7n/Kv8q/1YA2f/0/gf/DgAEAG7/7v/a/9//1/9P/6X/GAFSAOr+WwCJAEL/mABOAX//sv97AJn/oP/ZAFcADgDzALr/Bf9BAHQAEQBCAG4A9/9x/8X/KQA9AEcAs/98/48AzQBm/2r/KAGnACr/yv/GALoARQC7/zoAfgG//wb+mAAUAtP/hv7kAKIBZP8w/i8ARAKh//j9sgDKASz/jP7rANAAfv9j/wIATwDf/+T/1f/Y/xgAEABjAHcA7f9ZANgAUQDx/54A6wD3ABwBb/8kAHAClgCA/p0ABAKi/1z+XAACAdj+3P0v/zoA6v5g/dz9if9+/1j9YP2d/y3/FP7e/mf/B/+Y/k7/LAAhAG7/kgBoAEb/XgDMAIoA/AB2AdcAtv+M/3sAqAGwADr/2gCKARr/EP72AC4Bkv4TAIQBCv8A/t0ADAJDAOT+PQBMAocA4P5EAvADf/8S/ggB3AFx/3r/MANsAYT9Nf92Acr+Ov76Af8AmP4Q/54AQgE6/wMA/gFiAJL+fABMAlUAlQCIAioBUP4y//gBgAF4AEABFgGW//z9S/8kAqQA0P0dAJYBlP02/koB5f/u/hv/qP52/6T/CP6KABACJP2U/GABagAo/XEAeAKM/uD9PP+j/1gAb/+J/yIBHgD4/Er/PgE5/+//FQA9/+v/IAAp//T/NAHi/9j+DACWAOD/0/+hAI0Avv+M/8D/agASAE3/tAGyAYT9Xv+gAkj/8P2MAeQBm/9g/wYA/AD2/67+JAGUAUH/xf+uAVcAXv57APoBqv+w/qABjAH8/tL/9QB0AMD/Vv/E/1gBOQAT/8MAnwAy/9j+S//p/9YAXwAy/0UAdQDS/rT+/QC8Adj+F/8OAZMA5f/g/r7/lAETAEj+6wBQAif/+P5AAbYA/P74/SAA9AJGARj+6P6UAW3/HP3l/yQCQQAA/8D/bP+o/8L/Rv4MAMwCjP/8/Kv/zgFcAGr+BP9KAZYBpP2Q/igDNgHU/S3/xAFL/1z+UAIUAq7/H/8m/0D/WwAqAR0A1QAGAUX/uP72/oIA7AGxADT/LQCbALj+1P8sAlEA0P3P/xgCPADi/q4AyAEU/+z9UACKAXcA//9+AfYAUP7c/VAAmAKEAWz+kv4AAvoB+P3s/coBCAK0/m7+kAFqAfz9kP40ArcAnPxo/qACVAEe/qD+bwDV/xn/7P9HAPv/TABxADP/0v5DANQABQBJAPYABgCM/rz/ZgHv/6z+EwDqAcgA2P10/nIBHgFm/gj/lgGbAMr+bv+XABEAuv5m/24B+wBa/pr+nAGQAXr+dP7LANgAoP+k/04ASQD2/07/BQACAWb/+P7aAGwBtf9c/j//7QCxAPj+lv8GAe3/3P5Y/1f/iv8aAewAE/8C//3/AACY/3L/iAB4Ae7+WP1EAbwCbP6+/vQCjgCM/KP/vAIgAcv/5f8vAEAAUP89/3wBqgFF/xMA/ABw/q7+NAK2Adj+cv+EAN7/k/9pAFgBjQDI/pb+WwD9ABAAcABMAcb/tP2E/pwA+wCWAKgAw/9M/oD+7v+HABQApP9qADMAQv6u/k4BegHs/rr+YgC+//L+0QD2AU4Agv4q/o7/1wD2/9r/lgGtADL+bv7E/wQAdQD8AFcAZP8X/33/OAB0AC8AHQD5/77/+v9SAHEALgAIAAYAOP8E/7AA6gGuAGb/xP8RAID/jv/MAEYBOABy//b/PwCA/6z/XgGMAZH/Mv+QAG8Atf+WAHgBowBC/6P/JAG3ABH/EwDkAef/DP4vAMoBTgDC/mL/kQDh/37+lP+qAYgAXP6u/sn/0P+r/x4AqABrAFj/hP5H/+0AMgFMAP3/PgDp/0X/3v9eAZgBHwA5//f/VAAmAJIA+wCBAIz/KP/t/9UA5gCLAAsAbf8e/67/XwD0AAoB7f/0/gj/of9SAPEAjQCE/0z/dP90//X/vwCYANP/Jv8F/6P/UACpAIkA8P9R/zv/1f+CAJsARwDL/0f/Of/T/3kAnwBgAPn/W//Q/jX/XADrAGwA1/99/x//KP/E/28ASgC5/43/dP8u/43/iACCAFv/EP+i/83/4P9dAKAAx//+/jz/+f9lAGYAigBhAJf/7v46/3AAFAF4ALz/2//8/8P/2f9vAJEAHgAVACUA+f/c/yoAmACUAA8Ai//P/9kAxgDP/8D/kwCBAGj/3P9yARgBWf+J/+MAZwA7/14A5gGsAAT/DwB6AV0AWf/PAN4BcABZ/3cAWAFQAKf/owAWAdn/IP84AAQBBQAR/7r/PACL/wL/g//4/77/df9f/1H/cP+w/7b/gv+A/63/jP9H/3L/6P/B/1j/kv/f/43/Nv98/9D/k/9F/1v/j/9//yb/Cv83/z7/Ff8O/x7/Bv8I/zn/K/8T/zH/e/+a/4b/wP/1/+v/+/9EAIAApwDuADABMgEqAXAByAHOAeQBPAJMAhQCXAK4AoACNAJwArQCfAJIAnQCoAJsAhwCIAJAAu4BbAGWAeABpAFWAVwBRgG8ACQA9P9MAJMAUwAjAAIAXP+c/oT+3P7i/qz+Kv60/Wj97PyQ/Iz8kPwo/Jj7MPsQ+wD7wPpo+jj6CPrQ+bD52Pkw+lD6EPrY+Sj6qPoY+8j7ZPy4/Nj8GP20/ab+lf8wAMIATAGqATQC+AK0A1gE2AQABUgF6AVYBpgG8AYoBxAHAAcoB3gHqAegB4AHOAfgBtAGCAcAB6gGeAZYBvAFeAWIBcAFKAVABAgEKAS4AxQDMAMsAxgC1QDAAAoBjQAHAKb/T/8i/rz8nPzg/Hj8gPvQ+gD6+Pg4+BD4IPhw96D2APZw9fD0sPSg9GD0EPQA9LDzsPNA9MD0oPTA9DD14PVg9jD30PjQ+dD5MPq4+/T8kP3w/tkACAIsAsACUASgBVAGOAewCJAJcAmwCYAKIAswC1ALwAvAC1AL8ArACoAK8AlQCeAIUAiwByAHeAaoBfgEWASYA0gDQAPUAjAC4gGUAT4BDAFSAaYBmgFuAY4BoAGCAaoBFAI4AhACSALAAqAC3AHmAQgCggHpAEoB8AHjAFn/uP7A/sD9kPwQ/cj9fPxY+vD54Pmw+ED3gPdg+ID3oPUg9TD1EPQQ87DzsPQw9DDzQPMA9PDzYPMw9OD1cPZA9kD38Ph4+aD50Pqk/Nz9lv4YABgC7AIIAxgEuAXYBrAH8AgQCmAKIApQCsAKIAuQC+AL0AsAC1AK8AmQCfAI4AjACMgHmAYQBrAFyAQABNgDwAMMA0wCaAKUAvwBdAHUASwCyAG+AWwCzAJsAiwCxAIoA8QCsAJ0A7ADHAMEA5QDeAMwAtIBWAIYAv4A1wBwAUUALP5k/Qb+hP08/Hj86Pxw+9j48PeQ+FD4YPdA91D3gPWA82Dz8POg8xDz8PLA8hDykPEw8iDzUPNA87DzYPQA9TD2oPeo+ED52PkA+1D88P3i/2gBIALQAvgDIAVQBtAHgAkwCuAJIApAC+ALoAsQDNAMQAwwCyAL0AtwCzAK0AngCfAIoAeIB9gHAAewBRAF+ARYBMAD9AMoBIAD2ALoAugC0AIQA4wDgAMgAwgDSAM8AywDtAMABLwDcAOUA4wD7AKcAtQCoALwAW4BSgF/AED/Zv4w/tj99Pzk/Mz8WPuA+bj4WPiw90D3MPfA9jD1IPNw8mDyIPIQ8lDy8PHg8IDwgPDA8FDxQPIg8zDzkPOw9MD1gPag90j5SPoQ+5j8xP4JAK4A2AFsA7gEmAUYB9AIkAmgCQAKwApQC8ALMAyQDKAMAAxgC1ALYAvwCnAKQArwCQAJAAiYB0AHcAawBYAFiAXQBCAEIAQQBHAD6AJgA/ADrAMwA3QDoAMYA9wCbAPYA1gDIAOUA6ADAAO8AhADyALMAXIB0AF8AaIAMQDI/3L+7PwI/YT9LP04/Kj74Pro+JD34Pdg+MD34PYA9pD0IPOQ8uDywPKA8kDywPGw8DDw8PCg8dDxUPJA85DzgPOQ9HD2oPcY+DD5EPtM/CT9xP7MAPIBcAK0A2gF0AaQB6AI8AkwCgAKcAqAC+ALwAsADAAMYAuAClAKkApgCrAJQAngCOgH4AaABpAGIAZ4BSgFAAV4BNADyAMIBBAE1AMABFAECATcAxgEeARYBCAEeASoBFgEAAR4BLAECASIA5gDbAOYAhgCQAIYAusAzv9O/5z+qP1k/aT9OP0c/ND6qPnY+Ej4UPgY+GD3UPYg9QD0APPg8hDzAPNQ8tDxcPGw8HDwAPEA8lDycPIA87DzIPTg9HD24PfI+Lj5QPuc/JD9AP+4AAQC1AL8A5gF4AaQB5AIsAkAChAKsApwC9ALsAugC4AL4ApQCmAKoAowCqAJMAmQCLgHMAdIBzAHqAYgBsgFaAXYBMgEKAUwBcgEqATwBNAEmATYBDAF8ASYBKAEyASoBIAEuASYBPgDfAOMAxwDWAJUAlgCggFdAPf/tf9w/lj9iP3U/cT8ePtQ+8j6MPkI+Fj4kPiA9zD2sPUA9ZDzwPIQ80DzcPKw8ZDxMPGA8GDwIPHw8TDyYPLw8pDzMPRA9cD2APgA+Qj6SPt8/Nz9TP+dAOQB+AIoBGgFeAZ4B4AI8AhQCQAKkArgCgALAAvwCrAKUAowCmAKQArACUAJ0AhgCOAHgAdwB2gH0AYABsAFuAVoBRAFMAWABTgF0ATQBBAFAAXABOgECAXgBKAEsASwBGgEUARABPgDmANkAyQDkAL6AdoBYAFZAKP/c//m/rj9PP1g/cT8ePuw+rD68PmQ+BD4OPhw9/D1MPXw9DD0EPPQ8iDz0PLA8TDxQPEg8fDwcPFw8sDy4PJA80D0UPUQ9lD30Pgg+gD76PtE/bj+DgAsAZQC+AMQBeAF8AYQCKAIMAngCYAK0ArACuAK8ArACoAKcApwCjAK0AmgCUAJoAhACBAIyAdQBwAH2AZYBsAFiAWQBYAFSAVYBXgFQAUIBfAEEAUIBfgEAAX4BMgEcAQwBAAE6APUA4QDIAPQAlgCmgEKAa0AbQDF/9T+Wv4E/hj9PPwA/Lj72Pro+XD5CPkg+DD30PZg9nD1UPTQ85Dz0PJg8iDy4PEg8YDwYPCw8BDxcPEQ8qDy8PJQ8yD0YPWw9gj4YPl4+kD7MPyQ/S7/jADqAUQDaARABRAGGAf4B7AIcAkACjAKQApwCrAKoApwCnAKgApQCgAKAArgCXAJ4AigCIAIMAjYB6gHmAcYB6AGkAaoBqAGcAaABoAGMAbgBeAF+AXYBbgFoAVoBQgFsASQBGgEIATgA5ADBANYAu4BggH0AEUAyf9E/27+nP0Q/ZD8uPvw+mj62Png+PD3cPfg9gD2IPWQ9AD0APNg8gDywPEg8ZDwUPAQ8ODvwO9A8ODwYPHg8XDyIPPg8wD1YPaw99j46PkA+yD8cP3q/k0AvAEIAzAEEAUQBhAH8AewCFAJAApACmAKgArgCvAKwArACsAKwApwCkAKIArwCaAJUAkQCfAIsAhwCDAI8AfQB6AHiAeIB3gHUAcwBxgH8AbABqAGiAZYBhgG2AWQBUgFCAXABGgEAASMAwgDgALoAWoB5QBSAKL/B/9k/sz9KP2I/Pj7UPuY+tj5QPmo+AD4MPeg9vD1IPVw9ODzcPOw8hDygPEw8bDwQPBA8IDwwPDg8GDx8PFw8gDz8PMg9UD2MPdA+Gj5cPqg+wT9hv7L/wQBTAKYA6AEeAWABogHUAjACEAJwAkACiAKUAqQCpAKkAqgCrAKgAowChAK8AmwCXAJUAkgCdAIkAhgCDAIEAgACAAI4AeoB3AHWAcwB/AG4AbYBpgGOAbwBcAFYAUQBdgEqAQ4BKQDLAO0AhgChAEUAaAA8f9Z/9D+Nv6Y/QT9jPzo+yj7ePr4+VD5kPgA+GD3sPbA9SD1oPQA9FDz0PJw8pDxwPBg8FDwMPAg8IDw4PAg8UDx8PHg8sDzsPSw9dD2oPeo+Pj5SPuA/Mj9Nf93AKoB1AIQBDgFIAYAB9AHgAgACYAJAApgCpAKwArwCgALAAsgCyAL8ArACqAKcApAChAK8AnQCXAJMAkgCQAJsAiQCKAIYAgQCNgHyAeIBygHCAfoBpgGIAboBbgFWAX4BKAEUATEAzADvAJAApoBAgGFAOf/Rv+6/jr+qP0M/Wj80PsY+2D6yPkg+XD4wPcQ91D2kPXg9GD0wPMg83Dy4PEw8ZDwIPDg78DvoO/g70DwcPDA8HDxQPIA8/Dz8PQA9vD20PcQ+WD6sPsE/Wz+wP/6AEQCbAOQBKgFqAaIByAIwAhgCeAJQAqQCvAKAAswC0ALYAtQCzALIAsAC9AKoApgCjAK8AnACYAJUAkgCRAJ4AiwCKAIcAggCNgHuAd4BxgH8AbABnAGAAaoBVAFyARgBPwDnAMEA2gC5gFIAZsA9v93//T+Tv6k/SD9hPzY+0D7qPoI+lD5sPgo+ID3wPYw9rD1APVQ9KDzIPOQ8hDykPEQ8YDwEPAA8BDwMPBw8NDwYPGw8UDyMPMw9BD1IPYw9zD4UPmQ+uj7JP2G/uj/LAE8AmADmASwBZAGaAcgCMAIMAmwCTAKkArQChALQAtQC1ALQAtAC0ALIAsAC8AKkApgCiAKEArgCaAJcAlQCSAJ8AjQCJAIUAgQCNAHmAdgByAH4AagBjgG0AVwBRAFsARIBOADYAPQAiwClAH9AIAA6/9W/8b+HP6I/eT8WPzA+xj7gPrY+TD5ePjw92D3sPYA9lD1wPQg9HDz8PKA8vDxUPHQ8IDwQPAw8GDwoPAA8WDx0PFw8kDzQPQg9SD2QPdI+Gj5cPrA+xT9cv6q//QAPAJUA1gEaAWABmAHIAjACGAJwAkgCoAK4AogCzALUAtwC1ALQAtACzALAAvgCsAKkApQCkAKMArwCbAJoAlwCVAJIAngCKAIQAjoB6gHaAcQB7gGcAYIBpAFGAXQBGgE7ANsA+wCWAKoAQ4BjgD6/1n/xv5K/qz9EP2E/Aj8YPvA+iD6kPno+Ej4sPcQ93D2wPVA9aD08PNw8wDzcPLg8XDxIPGg8EDwQPBw8JDwwPBQ8eDxYPLw8uDz8PTw9eD24PcA+Rj6SPuA/Nj9Fv9YAJIBuALMA9AE2AXYBqgHUAjgCGAJ0AlACqAK8AogC0ALUAtQC2ALYAtQC0ALIAvwCsAKoApgClAKIArwCdAJoAlgCSAJ4AiACEAI8AegB1AHCAfABlgG+AWgBUAFyARYBAgEqAMUA4gCFAKCAeQATwDm/2L/yv4m/pT9CP1c/Mj7QPuw+hD6cPnI+Cj4kPcA92D2wPUg9ZD08PNQ89DyYPLg8WDxIPHg8KDwgPDA8PDwMPGQ8VDyAPOg83D0cPVw9mD3cPiY+cD62PsM/Wb+tv/qAAwCOANIBFAFQAYwB+AHkAggCZAJAApACqAK4AogCzALQAtAC0ALQAsgCxAL8ArQCqAKgApgCiAKAArQCbAJYAkgCeAIkAhACPAHqAdQBwAHqAZgBhAGoAVABeAEcAT4A4wDMAOoAggCjAEAAXcA2v9c/+L+Qv6w/RD9fPzg+0D7uPoY+mj5sPgA+FD3sPYg9pD18PRA9LDzEPOA8vDxkPEw8cDwYPBA8CDwEPBQ8LDwMPGg8WDyMPMA9ND04PXw9gD4+Pgw+mj7kPzY/RP/XwB6AYwCkAOIBJAFaAZIBwAIkAgQCYAJ8AlQCrAKEAtAC1ALgAugC8ALwAuwC9AL0AuwC4ALcAtQCzALAAvQCoAKMArwCbAJYAkACbAIYAjwB4gHQAfoBpAGGAaYBSgFsAQ4BLgDSAPEAiwCogEKAYQA8/9u/9j+Jv58/cz8GPxg+8D6CPpA+Yj4wPcA91D2oPUA9VD0sPMA83Dy0PFQ8dDwcPAw8ODvwO+g78DvAPBQ8NDwcPEQ8sDysPOg9JD1kPaw9+j4+Pkw+1z8oP3e/gUAPgFcAngDaARoBVgGKAf4B6AIIAmQCQAKgArQChALUAuQC6ALwAvgC/ALAAwADBAM8AvgC8ALsAuAC2ALQAsAC8AKcApACvAJkAkwCdAIcAj4B4AHMAfQBnAGAAZ4BQAFgAQABIgDDAOUAgQCbgHVAEEArP8Z/4j+2P0o/XD8uPsI+0D6mPnY+CD4cPew9gD2UPWg9PDzUPOw8hDygPEQ8ZDwUPAA8ODv4O/g7yDwgPDw8HDxMPLg8sDzgPSQ9aD2sPfI+Oj5IPsw/FD9Yv6f/7kAvAHAAsgDqAR4BUgG8AaoByAIsAggCYAJ4AkwCnAKoArwCiALQAtgC4ALoAvAC9ALwAuwC7ALoAtwCzALAAvQCoAKMArgCaAJMAnACGAI6AdoB/gGkAYYBpgFEAWQBBgElAMcA6wCPALCAToBqwAVAH7/8P5m/sT9GP18/Mj7GPto+sD5CPlQ+KD38PZA9nD1wPQg9HDzsPIg8pDxEPGg8FDwEPAA8ODvAPBA8IDw8PCQ8VDyAPPA86D0oPWQ9rD36Pgg+jD7RPx4/Yr+l/+fAMgB1AKsA5gEcAU4BuAGiAcwCMAIMAmQCfAJQAqQCvAKMAtgC5ALwAvwCyAMIAxADEAMMAwgDAAM4AuwC4ALQAvwCqAKQArgCXAJAAmQCCAIkAcQB4gGEAaQBQgFgAQIBHwD7AJ8Av4BaAHSAFkAs/8Y/3T+6P1E/ZD88Ps4+5D6yPkw+Yj40Pcg93D20PUQ9WD0sPMQ83Dy0PFQ8dDwgPBA8BDw4O/g7wDwMPCA8PDwgPEQ8sDyoPNw9GD1cPaQ98D44PkA+xz8QP1Y/m//kwCmAawClAOIBHAFOAboBqAHUAjgCGAJwAkwCoAKwAogC3ALsAvgCwAMIAwwDFAMYAxgDFAMMAwQDNALoAtwCzAL4AqQCkAK4AlwCRAJoAggCKAHKAeoBhgGiAX4BGAEzAM4A6wCHAKQAQoBawC+/zP/kP7k/Tz9lPz4+0D7oPr4+VD5oPgA+FD3oPYA9mD10PQw9JDzAPOA8gDykPEw8QDxwPCA8IDwoPDQ8ADxcPHg8XDyAPPA85D0cPVw9oD3kPiQ+aj6yPvo/AT+Fv8oACgBEAIQAwgE6ASwBYAGOAfIB1AI8AhgCcAJQAqQCuAKIAtgC6AL0AsQDEAMYAxgDGAMcAxwDEAMIAzwC8ALgAtAC/AKoApACuAJcAnwCHAI+Ad4BwAHeAbwBWgF0ARABLADMAOQAgQCdAHYAD4Alv/6/kz+oP38/Fj8sPsA+1D6qPkI+VD4oPcQ93D24PVA9bD0MPSw8yDzsPJQ8gDysPFg8UDxMPEw8UDxgPHA8SDykPIg89DzgPRQ9TD2IPcY+CD5MPo4+zj8SP1g/mL/cQB0AWACVAMwBCAF6AWwBlgH8AeQCAAJkAkAClAKsArwCkALcAuwC/ALEAwgDDAMQAxADCAMEAwADNALoAtgCyAL0ApwCiAKsAlQCdAIUAjQBzAHsAYYBogF8ARoBMwDPAOgAgwCeAHpAEYAsP8c/4j+5P04/Zj88PtQ+7D6EPqI+ej4SPiw9zD3kPYQ9pD1EPWQ9CD0oPMw8+DykPJQ8jDyIPIg8iDyQPJw8tDyIPOQ8xD0kPRA9fD1oPaA92D4OPkg+gj78Pvs/OT93P7D/6gAigFgAiwD9APABIAFMAbYBngHIAigCBAJgAnwCVAKoArgCjALgAuQC7AL4AvwCwAMAAzgC9ALsAuAC1ALAAuwCmAKAAqgCTAJsAgwCKgHGAeQBgAGcAXgBFAEwAMkA4gCBAJyAeYATwDH/zv/pv4K/nT95PxE/LD7KPuY+vj5aPno+Gj44Pdw9/D2gPYA9pD1QPXw9KD0UPQQ9ODzwPOw87DzsPPA8+DzIPRg9KD0APVw9fD1gPYA96D3YPgY+dj5mPpo+zz8DP3c/bT+lf9qADwBBALMAowDQAQABagFUAb4BogHEAiQCAAJcAnQCTAKcAqwCvAKEAswC1ALcAtwC3ALYAtQC0ALAAvQCoAKMArgCYAJIAmwCDAIsAcwB6AGGAaIBQAFYATIAywDlAL4AVYByQA5AJz/Bv94/uT9TP24/DD8qPsY+4j6APqI+Rj5oPg4+ND3YPcA97D2UPYA9sD1kPVQ9RD18PTA9LD0sPSw9LD00PTw9CD1UPWg9fD1UPbA9jD3sPcw+MD4YPkQ+tD6kPtQ/Bj93P2m/m3/NwD8ALYBdAIsA+QDkAQoBcgFWAbwBnAH6AdwCPAIYAmwCRAKUAqQCsAK8AogCzALQAtACzALEAvgCrAKgApACgAKsAlQCeAIcAgACJgHIAegBhAGiAUIBXgE7ANYA8wCPAKuARYBiwABAGn/1v5A/qj9HP2I/Pj7YPvY+lj60PlQ+dj4cPgQ+LD3UPcA97D2cPYw9vD14PXA9aD1kPWQ9aD1wPXg9RD2MPZQ9pD20PYg93D34PdY+Mj4QPnA+VD62Pp4+xz8xPxk/RD+xv5y/xUAvgBuASQCxAJoAwgEoAQoBbAFOAa4BhgHiAf4B2AIkAjgCCAJUAmQCbAJ0AnwCfAJ8AnwCdAJsAmACWAJIAngCKAIQAjgB3AHEAegBjAGuAVABcgEQAS4AzwDvAI8AroBOAHDAEcA0/9g/+j+bv7w/Xj9BP2g/Cz8uPtI+9j6cPoY+tj5oPlY+Qj5wPiA+FD4KPgI+PD38Pfg9+D30Pfg9/D3CPgw+GD4kPjI+PD4KPlw+bD5+PlI+rj6GPt4++D7PPyg/BT9kP0W/qL+Ov+//zYAugBCAc4BUALgAmAD4ANQBLgEEAVgBbAF+AVABogG2AYIByAHOAdQB2AHYAd4B5AHiAdoB0gHIAfoBrgGkAZwBjAG6AWYBTAF2ASIBDAE4AOYAzwDwAJIAvwBoAEqAcYAgwAtAMP/hP9h/+T+FP6Q/Xz9TP0E/Rj9/Pw0/Ej7wPqg+oj6uPrA+kD6kPlQ+WD5KPn4+Ej5uPmQ+TD5ePno+dD5kPng+Xj6qPqw+iD7qPuw+4D7sPsk/HD8rPwI/Vz9cP14/bz9GP5q/tz+YP/b/zQAkwAUAagBMAK8AjgDjAPwA3AE6ARgBcAFyAXQBfAFCAYYBmAGoAawBpgGoAagBoAGUAZQBnAGgAZIBggG6AWwBTgFoARYBEgEKAQgBDAEIASgA7wC9AGSAY4BvAHWAYABvgDg/z7/0v58/jj+/P3I/WT96Pxs/PD7YPvI+lD6MPpY+nj6YPro+Sj5iPiQ+Oj4IPlw+ej50PlA+Qj5kPkQ+vj5YPqI+zD80PvY+4j8xPyc/Ez9gP4F/xj/UP9s/z//hP9hAPkAGAFGAbABygHMAVACyAKMAjQCkAIcA0ADdAPgA+QDPAPAAhwDpAPsA2AE6ASoBKAD+AJMA/ADaAQIBWgF6ATMA0gDrAMgBDAEMARQBPwDWAM8A3QDFAMsAroB9AEcAhgCGALQAacAMP+O/v7+uP/v/5j/wv6Q/XD8GPyc/Dj9RP2w/AD8YPvA+pj6EPuA+0D70PrA+uj62PrA+gj7YPto+3D7yPtM/Kj8uPyg/JT82Pxg/fj9nP4O//j+ZP4c/pD+SP/W/2YA6wC/AOP/gf81ACABigHYATAC/AFyAX4BLAKkArAC2AIUAywDLANgA4ADWAMYA0ADsAMIBCgEGATgA2gD/AIwA9QDSAQoBLgDTAMAA8ACtALoAggDzAJoAjACBAK2AWgBTgEwAd0AngCtAKAAJQCP/0b/Lv8P/wX/GP/u/mT+2P2s/cD9zP3E/Zz9PP3M/ID8gPyw/ND8sPxo/Bz86PvY+wD8WPyI/GT8PPxM/HD8iPyw/Aj9VP1o/YT92P0c/hj+Fv5s/tr+Ev9B/4z/xf+//6//3P9JALEA3wDnAPsAEAH7AAIBaAHiAQwCHAJkAowCQAIgApgCIAMgAwwDXAOAAxADtAIgA6gDhAM0A3ADqAM0A7gCCAOUA3AD6ALoAkADCANAAvQBUAKQAlgCKAIcAq4B2wBkALoAOAE6AdwAiwAJACL/jv7s/pn/jv/2/qz+aP6M/cj8CP2s/aj9OP0I/cz8CPxw+8j7ZPxE/OD7BPws/Mj7gPu4++j7wPvg+1z8qPyM/Gz8kPyg/Iz8yPx4/QD+/P3Y/Qj+OP5E/oT+DP+H/7P/v//n/xQAJQBHALwAWgHKAdoBtAGwAeQBNAKUAggDSAMsAxADLANQA3ADqAPsA+wDnAOMA/wDSAQQBNQD2AO8A4QDoAMQBDAE2AN0A0ADEAPcAuACLANYAwgDVAKaAUoBdgG4AbYBbAHkAB0Aef9z/8r/3/+Q/wr/XP64/Xj9yP0+/ir+ZP18/AD8EPx8/PD8/Pxs/Ij7CPto+yj8gPxo/Cj8sPsg+zj7LPzU/ID86Pvo+yj8YPzc/JD9mP3k/Jj8RP0c/p7++P4r/+L+dP6y/q3/lwDpANcAxADPAPgAZAEQAqQCuAJYAiACcAIYA6QD6APkA6ADVAM4A4wDQATYBLAEAASEA3ADnAP0A2AEWATEAzADGANMA3gDhANgA9gCRAJAApACjAIwAtwBagHvANEAFAEkAcEAMQCo/0j/Qf+D/2r/xP48/hz++P2g/Yz9qP1A/Yj8WPyY/IT8NPww/Ej8+Pug+6D7yPuw+4j7oPu4+9D76Pvo+5D7QPuQ+1D8zPzk/OD8rPxA/Dj8FP00/sD+oP5k/lD+Vv6y/n//QQCVAKMAsgDPAPYAQgGkAQQCiAIoA3wDVAMUAxgDHANQAxgEAAUQBTgEoAOgA8AD8AOIBAAFiASgAzQDXANwA2QDdAN0AygD2ALIAtQCwAJgAu4B0AE4ApwCaALcAXwB8ABCAEcAHAGKAdkA9f+A//j+ZP6k/nT/Zf8+/lj9QP1A/SD9bP3A/RT92Pt4+yT8jPxc/Fj8TPyI+6D60Prg+2j8GPyo+0D74PoQ+wT81Pyo/Az80PsM/Jj8gP1c/mT+vP1Y/bT9fv59/3sAwAANAFz/mf9tAD4BCAKAAlQCxAGqASgCvAJAA8gD7ANwAwQDXAMABDgEKAQ4BFAEKAT8AxgESARIBDAEOARABAgErANoA3ADnAO8A8QDqAM8A4wCJAI8ApwCwAKcAkwCqgHkAHcAlgDKALgAegAUAGv/vv56/mb+Ev68/cD94P2A/dz8iPxE/Lj7kPtY/Aj9jPyA+xj7APvQ+gD7+Puc/PD78PrQ+iD7OPuA+yD8PPyo+5j7fPwQ/aT8QPyE/AD9lP2G/mv/X/+W/kb+3P7Q/70ApgEsAsYBFAH0ALIB5ALgAzgEzANUA0wDrAMIBIAE+AT4BIAESASoBAAF4ASgBKgEkARYBIAE2ASwBOwDVANIA3QDrAPgA9wDOANYAgACSAKIApgCrAJYAjYBJgBKACoBWgG/AD8AuP+g/rz9OP5E/zP/QP6c/ST9KPyg+3T8eP04/UT8yPuA++D6iPow+wD8+Ptw+/j6iPoQ+hD6uPpw+4j7OPvY+oD6YPq4+oD7XPzY/JT88PvQ+4j8hP04/rD+DP8C/6z+4P7q/+cAGAEwAdwBbAJQAkwCCAOcAywD1ALQA1gFqAXYBDgE+APYA2gEyAXQBlgGAAUgBAgEQATIBKAFEAaABVAEhAN0A7wD9AMYBAgEoAMwAxwDEAOAAsQBtgEgAkAC+gHUAYIBewBv/0r/mv+D/3f/yv9t/9j9ePx4/PT8GP1o/ej9SP1w+zj6iPog+2D72Ps8/FD7kPnQ+Gj5APog+oj6CPuI+mD5APmY+VD6yPpI+9D78Puw+5j74Ptg/Bz96P2M/uz+Lv9W/2z/vP9cAAQBjAEsAsQC7AKgApwCPAPoAzAEgAQIBTgF2ASoBAgFWAVYBbgFcAZoBogFCAWABfgF0AXIBfgFwAX4BLAECAUIBZAEkATYBGgEhANUA8ADjAO0AlgCkAJcAswBtAG2AeIAw/+g/xUA9v9T/w7/vP6k/Yj8hPwQ/Qz9oPxU/MD7ePqQ+cj5UPpA+uD5mPkQ+Rj4kPfA9yj4WPiA+KD4kPhI+Aj4MPio+HD5UPr4+jj7KPsI+wD7uPss/Z7+UP9s/1//OP9U/zAAogGUAqACoAIEA0ADGANgA0AE8ATwBPgEWAWoBZAFoAUYBnAGQAYoBogG0AagBngGyAbwBnAGyAWgBeAFCAZABngGKAYgBTAEKASgBOAE4AS4BBgE+AIsAjQCdAJMAgACwgEiARIAdP+Y/5//Af88/sj9YP3I/HT8bPwA/Oj64Plg+SD5GPlA+UD5ePgQ9xD28PVw9iD3sPeg9xD3MPaw9RD2YPfY+GD5IPnY+MD4yPig+YD7OP2U/Uj9WP2k/Rr+Vv8oATgCBALIAUAC2AJAAxgEIAWIBWgFqAWABtgGoAa4BjAHiAeoBxAIoAigCMgHAAcQB7AHMAhwCGAIyAeoBvAFWAZQB5gHCAdIBpgF+AS4BDgFcAXoBPgDOAO8AmwCVAI8AugBNgGEAOb/kf+G/zL/UP5c/ez8uPxQ/PD7gPtg+oD4gPfQ9xD4gPfQ9jD2wPQA88DyQPRg9TD1gPSw86DyEPJA88D1oPcY+KD30PaA9lD3aPk8/Fj++P5G/nj98P2w/4wBEAOABIAFAAUgBHgEqAVwBggHYAgQCVAIoAdgCAAJUAjwBwAJEArQCYAJAAqgCfAHQAeQCOAJoAlQCaAJ4AjQBuAFIAdgCEAIsAeYB9AGEAUoBNAEYAXQBEAEUATsA0gCwwCNAMkAfQAbABUAtP9q/sD8uPto+yD7iPrg+RD54Pdg9mD1EPWg9DDzUPGQ8DDxMPLg8uDykPFA7wDuYO9g8tD0MPZw9gD1IPNg82D26PlY/Lj91P2M/LD7dP2zAIACJANgBGAFyAQYBDgF+AaQB5AHMAiwCCAIAAgQCaAJ4AhQCOAIwAnQCcAJ4AngCWAJQAmACdAJEAqACqAK8AkACRAJ0AnwCXAJAAmgCOAHYAegB7gHeAbwBOgESAVoBPgCwALAAm4BAgD+////lP5g/VT9sPyA+hj5qPmI+XD3wPVQ9eDzwPGg8cDy0PFg7+Du4O9g72DuoO9A8VDwYO6A72DyoPPg8zD1YPbQ9ZD1wPco+/j8XP3Q/bL+OP+X/+kA8ALgBIgFMAXwBKAFaAYAB4AHIAgQCMAHIAggCWAJwAiACOAIQAkgCXAJEApACvAJgAkwCfAIkAnACpALgAvwCnAKMArwCfAJYAoQC3ALIAvgCUAI+AawBjAH4AfYB7gG0ATMAj4BjwDjAHABZAE/ACT+iPuY+fj48Phw+KD38Paw9XDzIPHA78DuwO0g7qDvcPBA78DtQO3g7IDsAO6Q8YD0IPVw9IDz8PKg8/D2aPtC/kL+3PxI/Cz9S/8sAaAC7APYBHAEYAOUAwgF8AXYBWAGKAeoBrgFsAZQCNAH4AUYBiAIsAjgB0AIkAkgCWgHaAfQCCAJEAnAClAM8AqwCOAI0ApAC/AK4AugDAAL4AggCSAKIAmwBzAI0AjoBlgEGASABOgC9wAaAcQBYwBG/qT9WP2g+8j5ePkg+WD38PXg9eD1IPTQ8VDwQO+g7uDuIPDQ8ODw4O8A7oDsoO2w8HDz4PTQ9bD1kPOA8hD1kPkg/AT9xP2U/UD8fPyi/5QC5AKIAjwDuANMAxAEGAaoBigFKAQwBSAGSAbgBtgHeAeoBfAEKAbIB2AIkAjwCJAISAfQBlAIIApQCqAJsAlwCoAKMAqgCjALoArQCVAKIAvQCrAJMAngCLAHQAYwBugGqAYgBXADcAK+ATIB3AC0ABAAgv74/GT8OPwQ+wD58Pfg9/D28PSw83Dz4PEA76DtAO9Q8EDwIPBA8ADvoOyA7IDvIPPA9JD10PXw9IDzwPNg99D7uv4//07+RP0c/Tj+hQBAAxgFOAWoBGAEUAQ4BJAE4AVwBhgG6AXQBgAHKAbYBUgGIAaoBRgHoAkACjAIQAegB4gHSAcQCdALMAxQCmAJ8AkACqAJkAogDPALUAqwCUAK8AmQCNAHEAgQCAAHEAaQBcAEUAM0AuQBxAFiAcAAKgBo//z9YPxg+/j6oPqQ+TD4UPcA99D1gPMA8eDuQO4g73DxAPMw8sDvYO1g7MDsoO/g89D20Pbw9IDzUPMg9eD4/PyW/vD9rP0+/lr+mP66AHwDYASUA3ADGAQwBEAESAUIBrgEMAPYA6AFiAZIBugFeAWIBBgECAXIBhAIoAgQCKgGqAVQBiAIkAkQChAKsAkQCUAJcAowC3AKkAnQCXAKAAoQCRAJ4Ah4B+gF2AUoBnAFgAQwBHwDqgGOAAgBVgEtAAv/wv6w/dj7cPsA/OD6aPiA96D3QPbg8xDz4PJw8GDuUPCQ81Dz0PDA76DvoO4A7wDzIPdw99D1YPUQ9mD24PcQ+0b+q/+D/wb/ZP7y/qkAnAKAAwAEOAQQBLwDEARgBAAEdAO0A1AESAR4BPgEMAVQBLgD1AN4BMAFOAfAB7AGiAWABVgGMAdACIAJIAqgCTAJIAlACbAJkAogC9AKMArQCYAJAAmACBAIWAegBmgGOAYwBbgD0AJcAt4BRgFIAWYBoQD6/oD9rPzY+yD76PoQ+1D68Pfg9eD0wPPQ8XDw4PAQ8pDysPKw8vDwIO7A7eDwoPRA9tD2APdQ9iD1wPXQ+Pj7vP2I/gn/tv5G/vj+xQCIAhgDwAI4ApACgAMQBLwDYANAA8ACHALcApgEOAVQBLADxANYAxQDyARQB8AHaAa4BegFgAWoBbgH4AnQCZAIoAgwCcAIgAjACdAK4AmwCPAIYAmQCEgHIAcQB/gF4AToBCAFMATEAgQCrgEYAaMA8AAuAVEA4v6I/Zz8kPvA+oD6iPpA+sD4kPYQ9FDyUPHQ8FDxEPNw9KDzEPEg7wDv4O8Q8nD1IPig97D1UPWA9vD3+PnU/Mz+iP7o/c7+NwCwACABWAIAA3gCVALQA0AFIAUYBDQDcALOAWgCUATYBYgF/APcAswCTAMgBHAFqAbgBhAGgAXQBXgGCAfQB8AI8AiACMAIsAkgCpAJ0AiwCPAIEAlACWAJwAhQB/AFeAVwBUgF2ASIBBgE/AKoATABmAGUAX4As/+7/1z/wP1c/Aj8YPvY+bj48PgI+DD1cPKQ8TDxgPDw8NDy8PNg8iDwAO9g7+DwUPNg9hj4sPdg9vD1IPd4+RT8Jv5g/6H/Kf8f/zwAwAGUAsQCUAOAA0QDkAPwBEAFpANAAnQCFAMMAwgE6AXgBXQDHAJ4AxgFiAVgBugHmAeYBUAFWAfQCHAIcAiwCRAKEAngCDAKoAqwCfAIMAlQCaAIcAjwCHAIcAbIBMgEYAU4BUgEYAOkAswBSAFeAWwBAgFKALn/I/8m/tz86PuA+9j6EPpY+cD48Paw87DwoO+A8ODxcPMg9ODyMPBg7gDvsPBw8rD0QPcA+LD28PVw93D5CPv8/Oz+Rv94/hT/QgGkAlgCEAKMAnACBAL4AugE0AXABOQCiAHpAG4BQANABaAFeATwAlgC4AJIBNgFqAZ4BiAGOAaIBhgH8AfACLAIQAigCOAJkApACgAKwAngCNgHMAggCRAJ8AfoBhAGkASYA0AEIAUwBHwC/AHgARoB4wCgATABIP8y/h//A//k/FD7gPvY+vj4cPiI+DD2QPKg8KDxIPLQ8dDyIPTw8mDwYO+Q8EDyMPRg9tD3sPcg97D34PiQ+mT8Iv4R/7X/KgCvADoBPALsArwCOAJoAkQDAASYBHAEbAPiAXAB4gFcAhQDGASABJwD4AI4AxgEqARYBSAGQAa4BQgGIAfIB+gHQAjACOAIAAmwCUAKEAqwCZAJUAnQCIAIkAhACHAHkAYABngF0ARoBBAEaAM0AmYBwAFoAkgCIgESAKH/0v4Q/rT9IP3A+2D6UPpg+rD4wPWw81DyAPHg8IDyEPRw8wDyQPHg8JDwkPEQ9AD2cPZg9jD3KPhI+bD6BPzM/Dj9Fv4l/3sA4AG4AkwCeAFKAa4B6AG8AiAEiAQkA6gBegGsAaoBdALgAwgE4AKQApwDUARwBCAFEAboBSgFwAUwB6AHYAfYB6AIoAhgCCAJAArQCdAIoAgACfAIYAggCPAHAAfoBWgFWAX4BDgE1AOEA6QCwAGgASQCLAKgAe0AUADJ/xz/YP4I/ej7aPs4+4j6kPk4+ND1oPLg8IDxsPJQ83DzYPMA8kDwYPBA8qDzQPRQ9YD2wPbg9nD4sPq4+7D7HPwE/Qj+g/+gAQQDtAJsAckATAFMAjwD+ANgBBgE6AKsAXYBGAKkAsQCHANkAxQD6ALMA+gEuAQYBHgEkAUoBpgGqAdACJAHAAewB9AIQAmQCTAKIAoQCUAIkAjwCLAI+AeAB+AGIAZwBTgFCAWABGgDbAJMArgCzAJUAhAClAF3AEL/cv+i/5j+zPzQ+6j74Pqo+WD40Pbg81DxsPDQ8WDzwPNQ8yDywPDA7zDwAPIw9FD1YPXQ9cD2sPew+KD6WPxo/ND7+PxN/6kAXgGwAjgDngFKAJgBsAPEAzwDvAPkAzgCRgGQArwDAANUAkQD1AMQAzwDOAVoBpAFoARgBYAGGAeYB7AI0AgQCOgHwAjwCTAKIApAClAKkAmQCFAI0AjwCPAHuAZYBkAGeAWwBGgE+APQAvoBhAIIA1gCrAFAAjwCfADC/tj+B/+Q/ST8ZPyY/Oj66PjA97D1EPIw8IDxUPNA88DyIPNg8hDwIO8g8TDzYPPQ82D1kPbA9jj4IPtM/CD7YPoE/Aj+mP+UAXQDWAOeAcoAhgFkAswCsANYBIQDJAIIAuACDAPEAtAC7AJ4AlQChAPABBAFAAVQBVAFAAXABXAHYAgACMgHUAigCOAI8AkAC6AKYAkwCbAJIAlACHAIwAhoB+gF6AUoBgAF4AMIBPADVAJsAYACJAMcAjABmAEmAUn/cv4k/7T+xPzQ+zT8iPt4+fD30PaA9ADyYPFQ8vDyEPNQ88DyMPEw8PDwEPLg8rDzwPRQ9RD2kPd4+Yj6MPvA+zj8wPw4/moA9gGEAnQCRALKAfwB8AKoA5wDNAMkA9QCmALsAqADiAPcArwCHANsA+gD+ATABYAF8AQYBbgFOAbwBiAIkAgQCNAHkAiQCfAJMAqACiAKQAkACUAJ8AgwCPAHIAhQBwgGeAWIBdgEhAPkAhQDsAJUAsACGAMwArgAEQDI/9b+sP10/TT9DPzo+mD6kPnA95D1APTQ8uDxAPIg88DzgPPQ8nDy8PHA8VDyQPMA9KD0APZQ94D4mPnY+pD7qPvw+yz9nv6y/80A3gFcAigCJAKQAqQCTAJoAgQDOAMEAxwDiAOIAxAD7AI4AzQDPAPgA8gEOAU4BZAF4AWwBYgFCAbgBigHUAcQCOAIIAnwCPAIAAmwCIAIoAhwCLgHOAdoB4AH4AYYBpgF0ATMAyQDMAM4A/wCCAMMA3QCmgESAZAAwP/c/jr+eP2E/Bz8+PtQ+8D5CPhg9pD0MPPQ8jDzcPOA85DzkPMg86DysPIg80DzgPNA9JD14PY4+ID5sPpQ+3j7GPwk/Tz+Gv////wAlgHUASwCtALMAmACIAI4AkQCKAJoAuwCCAPQAuwCPAM4AwQDVAPkAzAEWATwBKAFwAW4BRAGaAZQBngGQAcQCEAIgAgACUAJ4AiwCOAIkAjQB5AH6Af4B5gHUAcgBzAGIAWIBHAEEASYA3gDYAPwAmwCBAKCAXUAVv9g/mD9fPwE/PD7cPto+hj50Pdg9hD1UPTw86DzcPOA86DzoPOA87Dz0POg84Dz0POA9DD1EPZQ92j4MPkY+jj7+Pto/Pz8yP1I/pT+af+DADQBdAHWATgCGAIQAowCKANAAywDmAMgBDAEeAQwBdAFyAWwBQgGWAZYBpgGMAd4BzgHSAfQBzAIMAiACAAJ8AiQCIAIoAhQCPAHyAeIB/gGkAaYBoAG4AVIBdgEGARkAxgDFAOsAjQCSAJYAtQBNAEIAboAuP++/mz+Fv5k/ej8yPw4/AD78PlQ+YD4YPew9pD2QPaw9XD1oPVg9cD0cPRQ9CD04PNA9AD1cPXA9XD2YPcQ+KD4cPlQ+uD6UPsY/Cz9CP7U/rP/dAC8AA4BsgFsAtwCIAOQAwgEKAQ4BKgEIAVoBXgFqAXYBcAFqAXgBTAGCAbQBQgGWAZQBjgGqAYQB/gGqAa4BtAGqAaYBsgGyAZYBhAGAAbYBWgFQAU4BdgEYAQgBPADkANIA1ADRAPgAqgC0ALIAjgCtAFSAcAA/P+b/3T/+v48/sT9bP2Y/HD7qPoY+jD5QPiw93D3APdw9iD24PUg9WD0MPRA9BD04PNQ9OD0EPVQ9SD2APeg9zD4GPkA+oD6IPsY/AD9iP0o/jT/HgC9AFoBOALYAgADLAOkAwgEUASwBFAFuAW4BcgFEAY4BiAGMAaABsgGqAa4BggHWAdYB1gHqAfYB8gHyAf4BwAIuAeQB4gHWAcgBxgHGAfYBnAGGAbIBWAFAAXQBJAEQAQQBPwDxAN4AzgDyAIsAnIB+gCCANb/MP/K/kD+fP3U/Ej8mPtw+mD5iPig97D2IPbg9ZD10PQw9MDzQPPA8pDywPLw8vDyMPOw8yD0oPRg9YD2YPcI+Mj4sPlg+gD72PvM/Ij9SP5P/4AAYAEAAqACMAOEA7QDIATABEgFsAXwBSAGMAZYBqAG8AYwB1AHaAd4B3gHiAe4BxAIYAiACKAIsAjQCNAIwAiACFAIMAgQCAAI+AfwB7AHSAfYBmAGyAVgBTAFAAWwBFAEGATAA0ADwAJUAt4BHAFsAOv/Zv++/hD+iP0A/UT8ePu4+sj5mPhw95D28PVA9bD0YPQQ9FDzgPIA8rDxYPEw8XDxwPEA8mDyIPMA9MD0gPVw9mD3CPjA+Nj56PrI+6T8pP2k/pP/lACcAXwCJAO8A0AEuAQ4BcgFUAa4BggHMAdYB6gHEAhgCHAIgAiwCKAIoAjQCBAJUAlQCWAJcAlgCUAJYAlACfAIgAhQCEAIMAgACPAHoAcIB3gG4AVoBRgF+ATQBHAEAAS0A1gD4AJUAuoBRgGEAPP/ev/c/hj+oP0c/Uj8WPvI+jD6IPnQ98D2wPWg9ODz0POg8+DyQPLg8XDxwPCA8NDwMPFA8ZDxgPJg8wD04PQw9iD3oPdw+MD52PqA+4j8xP26/lb/SQCoAcgClANgBCAFeAWQBegFeAb4BkgHmAf4BxAIIAhQCJAI0AjQCLAIoAigCKAIwAgACVAJcAlgCUAJMAkgCeAIoAhwCEAIEAgACBAI0AdQB/AGmAYABmAFKAUwBfgEgAQwBOwDfAPwAogCGAJsAcwARwDC//r+Qv7I/TD9bPyg+/D6OPpI+SD44Paw9aD08POg80Dz0PJg8vDxYPHQ8IDwoPDQ8ADxkPFQ8vDysPPQ9OD1sPZQ93j4uPmQ+mD7oPzI/Wb+Iv9oAJwBZAJYA4gEMAUYBUgFCAaABpAG8AawB8gHeAeoB0AIQAgACDAIgAgwCLAHAAiACIAIQAigCAAJwAiACLAI4AhwCAAI+Af4B6AHgAegB4gHEAeIBjAGyAVIBQAF+ATABHAEEATQA3QDBAOAAgwCegHNAEEAr//8/jz+pP0A/Uj8mPsI+2j6ePlA+AD3wPWw9PDzoPNQ8+DycPLw8ZDxIPEQ8TDxYPGg8eDxcPIw8xD0EPUQ9iD3EPgg+Tj6WPtk/Ej9KP76/sv/sQDSAQwDCASgBCgFqAUABjgGiAYIB1AHUAeIB+gHEAgACDAIcAhQCPAH8AdACFAIQAiACMAIoAhwCKAI0AjACJAIgAhgCPAHqAe4B7gHYAcIB8gGcAboBYgFcAUwBcAEaAQwBMgDTAMAA9QCTAKYARgBqQAIAE//1P5Q/nD9kPwI/Jj76Po4+oj5ePjg9nD1kPTg80Dz4PLA8lDygPEg8RDx8PDA8ADxYPGA8aDxYPKA81D0EPUw9lD3MPgg+Wj6mPtg/Bz9Fv78/sj/5wBIAnwDGASoBDgFsAUABngGIAeAB8AHAAhQCIAIkAjQCAAJAAnwCAAJEAkwCUAJUAlQCTAJIAkQCSAJIAkgCRAJwAhwCDAI+AfIB4gHOAfoBoAGEAawBWgFIAXYBJgEUATkA3QDIAPEAjwCogE8AdEAOACg//r+Vv6c/eT8RPyo+wj7WPqg+aj4cPcw9iD1MPRg89DyYPLg8YDxIPHg8LDwoPCw8MDw8PBQ8eDxkPJg82D0gPWA9oD3sPjI+aj6iPuY/Iz9Zv5Z/3oAnAF0AjwDGATABDgFqAUoBqAG4AYwB6gHEAhQCHAIsAjACLAIsAjwCBAJAAkQCUAJQAkgCSAJQAkwCQAJ8AjwCMAIcAhQCEAIIAjAB4gHYAcQB6AGSAYQBsAFWAUIBeAEoARABNgDiAMoA6gCHAK2AUwBuwANAFn/yP4M/mj94Pxw/Mj78Pog+kj5IPiw9pD1wPQQ9HDz8PKg8lDy0PGA8WDxQPEA8RDxcPGw8fDxkPKQ84D0MPUg9kD3QPgI+QD6GPvw+6z8mP22/qH/agBsAZwCcAP8A6gEYAXYBSAGgAYIB2AHqAcgCIAIoAigCMAIAAnwCOAIIAlgCWAJQAlQCVAJIAkACTAJQAkwCQAJ8AjACGAIIAgQCOgHiAdABwAHoAY4BvAFyAWIBSAF2ASQBBgEqANMA/QCXAKwATABxQAiAI7/E/+A/rT99Px0/Nj7IPtw+uD58PiQ90D2YPWg9ODzUPMQ86DyEPKw8aDxYPEQ8RDxIPEw8WDxAPLQ8pDzQPQQ9QD20Pag96j4uPmo+oD7aPxc/VD+S/97AKQBkAJcAxgEwARIBdgFYAbYBkAHqAcgCGAIkAjgCBAJEAkQCTAJUAlwCYAJoAmwCZAJgAmQCZAJgAlwCXAJQAkQCdAI0AigCIAIUAggCNAHaAcYB8AGaAYIBrgFaAUgBdAEeAQYBJQDCANoAsgBMgGpAA0AY/+6/h7+gP3o/GD86PtY+5D6kPlo+FD3IPYQ9TD0kPMQ88DygPIw8tDxcPEw8RDx8PDw8BDxgPEA8oDyMPMg9BD18PXQ9tD3uPiY+YD6ePtk/Dz9Mv5H/2gAYAFkAmgDQATQBFgF4AVgBtAGUAfIByAIgAjgCDAJQAlACWAJYAlQCWAJcAmQCaAJwAnQCaAJcAlACTAJEAkACeAIwAiQCFAIAAiwB3gHUAcQB6gGMAbIBWgFCAWoBFgE9AOIAxADkALqATwBrAAnAH7/vP4W/oz9EP2E/Pj7cPu4+vj5QPmQ+MD30Pbg9eD0wPPw8qDyoPKA8mDyYPJA8uDxwPHA8dDxAPKA8iDzsPOA9MD1APfg96D4iPlQ+uj6uPvc/OT9mP53/5MAkAFkAmQDiARIBaAF8AVYBqgGwAYQB5AHAAhACHAIwAjgCLAIgAhgCEAIAAgQCGAIsAjgCAAJMAkwCRAJ8AgACfAIsAhwCGAIQAj4B9gH+Af4B7AHWAcIB4gGwAUoBdgEcATwA5gDZAPQAvwBegEGATAAAP8o/nD9WPxI+8j6cPqQ+aj4GPhg9xD20PTw8/DyEPFA70Du4O3A7QDuoO5A72DvoO8g8MDwcPGQ8uDzEPVg9gD48Pmo+1j9E/9oAFQBJAIgAwgEwASYBaAGSAfAB1AI0AgACeAIsAhQCIgH0AZwBhgGyAXYBSgGQAb4BeAFEAbwBbAFkAXABQAGaAYwByAI4AhwCdAJ4AmQCVAJYAlwCVAJ4AiwCLAIsAjQCAAJAAlgCHAHUAYIBbgDxAIYAk4BagC9/1T/3P5Q/nj9EPxA+qj4gPdw9qD1cPWQ9SD1kPSQ9JD08PNA8/DyYPIA8QDwQPCA8ODvgO9w8GDxoPEg8qDzMPUw9lD3APl4+oD78Pyy/uP/VgBCARgDwASgBSAGyAYQBwAHAAdgB1AHyAZgBlAGKAYQBmgGyAZQBjgFiARwBKgE8ARgBaAFoAXABWgGEAeQB/gHQAhgCGAIsAhACeAJEArgCXAJ8AiQCEAIAAiYB+gG6AUABZAEWAT8A7ADdAO4AnABWgDy/6X/DP9o/gj+oP0M/bD8kPxU/LD72Prw+Sj5qPiA+HD4WPgg+LD34PZA9gD2cPVw9IDz4PIA8uDwUPBg8BDwYO9A7yDw4PAA8jD08PbQ+PD5qPvY/Wz/SQCAARwDgATgBcgHwAnACkAL0AsgDHALYAqwCUAJgAh4BxgHGAfgBlgGyAUYBTAEcAMUA9ACcAJMArAClAN4BDgF+AWwBigHUAdgB6gHAAhACGAIgAhwCDAIEAgQCLgH0AYABlAFeASAA/ACqAIIAgoBZwD1/3T/vv5K/tT9HP1g/MD7UPvo+qj6gPpY+iD68Pmo+WD5EPmw+Aj4kPdw93D3wPbw9YD1YPWw9KDz8PJQ8kDxEPDg7xDwAPAA8FDxAPNg9ED2mPnc/Jr+WP9iAHQB/AH4AggFYAfgCAAKUAuADKAMMAygC7AK0AgABxAG8AXgBRAGoAawBpgFIARMA+gCNAKSAZQBtAHaAaACiAR4BoAH0AfYB4gH+Ab4BsgHsAgACfAI0AiQCGAIYAhQCHgHuAX8A9wCSAIAAvQB9AFaAS8AI/+e/nz+hP5g/tT96PwA/JD7qPsE/Dz88Psw+5D6aPpo+kD6+Pmg+QD5GPiA92D3MPdg9mD1oPTA83DygPFg8QDxgO8g7mDuAO8g78DvwPHg85D1WPiM/HP/6f+HAHgCKARoBIgFwAiQC6AMQA1QDoAOcA2wDGAMoArABzgGmAbwBlgGAAb4BRAFUAMYAn4B/gCqAPYASgFmAfwBoAOgBeAGGAeoBlAGcAboBlgHAAjgCHAJMAmgCJAIoAhACGgHWAbQBFAD0AJIA1wDjAKAAbwAs/+A/uz9JP4q/mD9nPxc/ET8APwE/Ej8BPwY+3j6uPoA+8j6WPo4+vj5KPkY+MD34Pdg9/D1wPQw9JDzkPIQ8lDykPHA7+DugO+g7yDvMPAQ89D0gPVo+JD9agEYAnQCmAMABNwDCAYwCoAMQAywDKAOAA8gDcAL8AuwCmAH+AQYBaAFkAXoBUAG6ARMAvgAJAHcAMD/k/+lAKwBOAJUA0AF2AYwB9AGWAb4BQAG8AZgCGAJgAmACeAJ0AnwCNgHCAcoBtgEeAO4ApwC4AIUA8ACpAEFAIj+tP14/XD9TP08/VD9WP0k/SD9dP14/cD8sPsA+8D62PpA+5j7WPuI+qD58PhQ+ID3gPZw9XD0cPNw8tDx0PGw8bDwYO/g7oDuIO5A7gDwQPLg8yD2KPoA/vX/mgHYA8gEsAOwA/AGkArQC0AMoA1wDlANIAwQDEALoAgYBjAFuATIA4gDeATgBGADIgHt/5L/Mf/c/iz/3/+PAIABGAPoBEAGAAd4B3gHIAcIB6AHwAjwCbAKwApACqAJEAkQCNAG0AXABEQDBALSARwC6AGOAVYBewCg/jD9SP3o/Rz+KP58/qT+bv6c/iP/Qv+6/hz+pP0c/cj87Pw0/fj8RPxY+zj6EPlI+MD30PZQ9fDzMPOQ8uDxcPEA8RDw4O4g7gDuAO6g7gDwsPHw8vD0oPjY/KUAqAOwBaAFoAQYBXAHkAlgC6ANYA8AD2ANsAwQDXAMcArQBygFFAO4ArwDUATcA/wC6AFTAOL+kP66/sz+T/82AJ4ABgHoAtgFcAcYB6AG+AZQB4AHMAhgCRAKEArgCZAJ8AgwCLgHOAcgBmAE4AJEAjAC6AE6AZcA9f8F//D9eP2E/YD9XP2Q/dz93P3w/bT+mf9y/3T+vP2o/XT9GP0M/UT97PwU/FD7uPrQ+eD4UPjA90D2cPRw8yDzsPIQ8uDxcPFg8EDvAO8A7wDvgO8Q8ZDy8POA9qj60P6QAcADeAXgBSgFQAVAB3AKgA2ADwAQIA/wDVAN0AyQC4AJIAcYBewD4AOIBCgFAAX0A+YBYv9w/ez8pP2K/gL/TP/d//oApAJwBIgFkAUQBbgEsAQYBWgGcAgQCkAKgAnACAAIOAeQBigGaAUoBEQDQAOIA0QDpALeAaAA3v5Q/eT8mP2E/tj+iv4w/kD+bv5c/ir+7P2k/Tj9/PwY/Sj9XP2k/cT98PyI+2j6qPnw+Cj4oPfg9sD18PSA9MDzsPJg8oDywPFQ8IDvoO/A7wDw0PDQ8VDy4PNA99j6hP19AEAE4AW4BJwD+ARQB6AJ0AywD+AP4A1ADWAOIA7gC9AJsAi4BjAEgAPgBCgG0AWIBIgCDQDk/VT9CP6a/pb+rP5q/5UA9gFgA5AECAXQBEgEGASgBAgG8AdgCfAJoAnwCDAIWAegBjgG6AVoBaAECATkA7AD7ALaAewA0f9A/kD9lP1y/rD+ev6K/o7+8P1I/UD9XP0U/fj8ZP3A/bz9xP0k/uj9BP0Y/GD7qPoI+vj54Pno+LD3EPeg9mD1EPSQ8zDzEPLw8NDw4PBA8ODvgPDg8GDwQPFg9HD3SPn4+4YA+APQBPgEsAXABaAFUAgwDQAQsA+AD2AQcA+gDPAKEAtQCtAH0AWIBeAF0AXgBZgFyANgAFD9CPxw/Cz9xP20/tn/WgD6/zEAogEEAxQDmALAApADqARYBpAI8AngCQAJEAj4BsgFYAWYBZgFGAW4BJgEQASQA8wCiAGX/+j9ZP2U/ZD98P3U/lf/mP6c/YT9kP34/ID8DP3k/TT+Vv7o/jX/yv5M/iz+rP2A/GD7YPuQ+yD7GPpI+eD44Pcw9rD08PMQ87DxIPHA8cDxgPAQ8ODwoPDA7sDuUPJA9gj4QPpY/tgBQANQBNAF2AVoBYgHsAugDqAPwBCgEaAQgA4QDeALUApACfAI2AcYBogFKAaoBXgD/QDQ/qj8IPs4+yD80Pyo/QH/3/+p/zz/yv+5AEwBxAGgAvwDcAUAB3AIIAkgCbAIEAhAB3AGKAZgBqAGuAa4BnAGiAVABCgDJAK+AHH//v4s/yv/5v7u/hz/1v4I/oD9UP0w/fj8EP2Q/ez9FP4S/hT+5P2o/XD9TP30/Fj80PuQ+1D7uPpA+hD6cPnw92D2kPUA9RD0YPNA84Dy8PCA8NDxoPJw8SDw4PBw8iD0YPcw/Nz/+gBYATwCzAIkA/AEgAhgC5AMcA2ADvAOsA6wDoAO0AwgCpAIkAiACEAIYAgwCFAGQAPbAH3/Tv5s/XT9cP2g/BD8IP2o/uL+Mv7c/fD9yP0o/tf/SAIQBPgEmAUQBgAGsAUABsAG8AZYBgAGiAZYB4AHIAfIBhgGqATsArgBSgEOAf4AFAHiAEMAav/W/j7+dP3A/Kj8wPyw/Nj8bP3Y/Zz9UP0g/dj8SPwo/ID8uPys/Kz84PyA/MD76Poo+vj4wPdA9yD3wPYQ9qD1EPWw82DyEPKA8vDx4PCA8ADxsPFw85D3HPwe/qD9VP0A/vb+gQCsA1AHcAlQCmALwAwwDWANAA5ADsAMoAoQCuAKkAugC1ALMAqIB5gEyAL6ASoBhwBEALP/Zv5g/Xz9Iv4w/pj95Pxw/Kz8zP13/yIBZALgAqgChAL8AvQDEAUwBhAH+AaQBtAGsAcACBAIIAjYB5gGOAUIBTAFsATAA1wD1AK2Ab4AigA1ADP/XP7c/SD9PPwo/Jz8ePzI+5D7iPsQ+9D6aPvI+xj7cPqo+tj6SPro+UD6gPrQ+ej4aPgA+GD3sPZA9uD1MPUw9HDzYPOw81DzgPJQ8qDyEPNg9MD3yPv8/fT9mP3I/UT+8v9EA9gGsAiQCdAKUAywDHAM4AxQDcAMYAvgCoALgAzwDKAMQAvQCEgGgASIA+wCcALmAVIBkACh/7z+Nv4Q/sz95Pzw+wT8YP0d/w0ASQB6ALIApACQADoBkALIA4AEIAWoBagFmAUwBvAG2AZIBjAGcAZABtgFsAWIBegEAAREA5QC2gFCAQABmQC4/7b+DP6s/Rz9VPy4+5j7SPuI+iD6aPqY+gD6YPlY+Tj5gPgg+Jj44Pg4+HD3UPcg94D2IPZw9oD24PVA9TD14PRQ9DD0YPQg9NDzUPQA9nj4MPuI/Sj+VP24/Mj9wf/6AXAEOAcwCfAJYAogCzAMoAywDJAMgAwQDNALwAwADvANMAxwCkAJiAdgBYAEMAUgBXAD6gFOAU0Apv78/Vz+0P1g/Pj7+PyE/YD9RP5X/xb/Hv5U/oj/ZgA2AfgCiAR4BPADkASoBdgFAAYoBwAIYAeYBhAHuAcoBxgG4AWIBVgEJAMkA4AD1AJ4AWgAdP/s/ZT8NPxM/Lj7sPog+tj5OPlg+Aj48Pdw94D2EPZQ9qD2wPbA9vD2wPYg9pD1oPXg9RD2APYg9kD20PWA9QD2oPaA9qD1QPWg9WD2KPgI+6z9nP5g/ij+Kv50/jUAiANIBlgH+AdQCVAKUAqACoAL8AswC6AKYAswDHAMAA1wDSAMQAkwB7gGUAaABYAF+AUYBfgCigEaATYABP++/vL+Kv4A/Tz9dv7O/jj+Dv48/rj9FP2o/SD/MgDWAL4BaAIsAsgBVAJYA7wD0ANoBCgFWAVYBbAF6AWABdgEaATsA0gDCANUA1gDpAKoAc4A7f/y/kD+2P1o/cj8YPwM/Ij72Ppg+jD6uPn4+ID4iPiY+ID4ePiI+ED4oPdA90D3UPdQ94D3wPfQ95D3YPeg97D3YPcQ92D38Pew+Mj5OPtE/Hj8ePz4/LT9ZP5m//cAfAJEA8QDoASQBSAGWAawBggHMAdYB/gH0AhQCWAJQAnwCFAIiAcIB+gG0AagBiAGgAXQBDAEsAMsA6gCNALKAWYBGAHwAL0AiQBWACIAzP9m/17/tf8MADQAWwCcALkApgC/ABABfgGsAfoBYALEAvwCTAOsA8QDhANYA3QDeAN8A5ADsAOUA0gD6AJ8AgQChAE2Ae0AhwANAL//c/8E/17+xP08/bD8HPyg+4D7WPsI+7j6gPog+qD5SPk4+Sj54Pi4+MD4yPio+Mj4CPkI+cD4YPhY+HD42Pig+Yj6+PoQ+0D7gPuo+/j7wPyM/eT9Mv4H/+b/VwClAEIB2gEEAhgClAJMA7wDKASwBAgF6AS4BPAEOAVABUgFgAW4BaAFaAVoBXgFYAUwBQgFyAR4BEgEWARoBEgEGATwA8ADcAM0AxgD+ALQArwCqAJwAjACEAL8AcwBggFKARgB5QCvAJIAhgBlACgA6v+4/4r/Yv9N/z3/J/8D/9T+tv6k/oT+Yv5W/lr+Sv4m/hb+Iv4o/h7+Gv4c/gz+/P38/Qj+/P3w/fj98P3Q/bD9rP2g/YD9aP1o/VD9EP30/Pz89PzA/Jj8nPyc/ID8cPx4/Hj8bPx4/KT8wPzQ/OT8GP00/UD9VP18/aT90P0S/lr+kv62/ur+I/9K/3f/wv8UADoAVQCPANsAHgFkAbgB+gEkAlQClALMAvQCMAN8A7QDxAPcAxgESARYBGgEkASgBJgEkASoBLAEmASQBJAEiARgBEgEOAQQBOQDwAOoA4ADSAMUA+QCqAJkAigC9gHAAX4BQgESAdkAlgBXACQA9P+5/3//U/8t/wP/2v66/pb+aP5G/jb+Kv4S/vT94P3M/bD9jP1o/Uz9OP0o/SD9FP0M/QT9/Pzw/PD84PzQ/ND80PzM/MD8zPzg/OT82PzQ/ND8wPy8/NT8+PwM/RD9GP0s/UD9ZP2I/aj9yP34/Tj+aP6U/tj+Jv9h/4z/yv8UAFgAoAD1AEgBhgG+AQACQAJ4ArAC5AIQAywDVAOEA7QD2AP8AxgEIAQoBCgEOARABEAEQAQ4BCgEIAQQBAAE4APEA6wDhANMAxgD9ALYAqQCYAIcAtwBoAFeASAB3gCTAEgACADS/43/R/8J/87+lP5W/iD+8P3A/ZT9cP1Q/Sz9GP0E/fD80Py0/Kz8sPy0/MD80Pzk/PD8+PwQ/Sz9PP1I/Vz9fP2c/bz92P30/Qr+IP4y/kD+TP5c/m7+gP6S/qz+wv7U/ub+9v4K/xz/NP9W/37/r//h/w0AMABXAIIApwDEAOgAFAE4AVYBfAGoAc4B7gEQAjQCSAJMAlQCZAJ0AnwCeAJ0AnACbAJcAkwCQAI4AigCGAIIAvABzgGyAagBnAF8AVwBTgFAASIB+QDkANQAtACIAGUAVgAuAAIA3P/C/5v/ef9m/0z/G//q/tT+vv6g/oD+bv5e/k7+Qv4+/jL+Gv4Q/hD+EP4S/ib+OP5C/k7+aP58/oj+jP6U/qr+wv7e/gD/Gv8f/yX/Ov9c/3r/g/+K/5v/t//G/83/4f/+/wsA/v/y//j/BQAOACYAQQBHAEIAQwBRAGAAbgB7AIQAjQCiALsAxQDCAMYA2ADvAP4ACgEWAR4BIAEkASoBKgEsATABOgFCAUQBPgFEAUoBOAEaARABHgEoARoBCAEEAQIB9gDmANgAzwDBALEAoQCRAH8AbABcAE4APAApABgADAD8/+L/xf+5/7H/mP9v/1D/QP8q/wf/6v7a/sr+vP68/rz+sP6Y/or+iv6K/oL+gv6S/qr+wP7O/tj+5v7w/v7+D/8o/0H/U/9h/3X/jf+f/63/tf/B/83/2P/i/+r/7v/w//H/9P/6/wQABgD///z/AwAMAA8ADwARABkAHwAiACgAMAA+AEQASQBOAFQAUABLAFQAYgBpAG4AeACHAI8AkwCUAJoApwCuAKcAlQCHAIIAhgCPAJgAlQCNAIgAhwCDAH0AfwCEAIYAgQB/AIAAgAB9AH0AfgB5AG8AZABeAFwAVgBPAEoARQA7AC0AJAAdABQADAAJAAsACAD///T/6v/j/9//3f/Z/9X/0v/R/8r/wv++/7n/tP+y/7P/sv+w/7P/vP+//7T/qf+r/7f/wP/G/8//2P/f/+L/6P/p/+j/6P/q/+T/3v/m//X/9v/l/+f/6P/i/9b/2v/n/93/0f/f//P/7P/e/+D/3//X/9b/5f/y/+b/z//O/+T/9v/1//D/+P8AAP3/9f/1//n/+P/z//P//P8EAAQABgAHAAcABwAJAA8AGAAjACoAKQAkAB0AFQASABkAJQAuADAAKQAiACIALgA+AEIANQAnACUAKAAuADMAPABJAFcAWwBXAFcAYgBtAGoAXgBPAEYAQQA/ADwAMwAdAP//6f/g/9X/xv+6/7X/sP+i/5T/kP+O/4T/d/9y/3T/d/94/3f/df9z/3L/c/9y/3T/ef97/3j/eP+H/5f/mf+W/5r/n/+Y/5D/lf+g/6X/qf+1/8P/xP/D/87/2f/d/+P/7v/3//n/+P/9/wIAAAD8/wcAIAA0ADgAOQA+AEMARwBSAGQAawBfAFQAVgBWAE8AVABnAG0AYABXAF0AXQBVAFIAUQBBACwAJgAuADMAOQBCAD8AKgAcAB8AJQAlACcAKgAmACMAKAAxADQAMgAwAC0AJAAdACEAKwAqAB0ADQD///D/7f/0//f/7f/f/9f/yP+4/7f/xf/I/73/u//B/7//vP/M/9r/0//F/8v/2v/Z/8v/yf/a/+v/6v/e/9n/4//v//L/8v/y/+z/4P/m/wAAEQAJAPz/AgANABUAKgBFAEYALwAnAC4AIAAFABsAVQBqAD4AAgD1/yAAXwB6AFsAJgAYACIADgD9/yoAXgA8APj/CgBSAEoAAgD1/yoANgADAO3/EAAiAPz/1f/a//b/CgAKAPT/2//V/9r/1f/K/9H/2v/Q/8j/0P/U/9H/1P/m//P/6P/V/8L/uP/E/9v/2f++/6H/nP+u/7j/qf+I/3b/hv+m/7X/sP+r/7P/wP/N/+//KABFACgAAQAhAG0AbgAbAP//TwCFAEQA/P8XAE0AMwD4//X/+//M/67/4P8MAN//ov+4//D/9P/n/wwANAANAM//8/9TAHgAfAB7AE8AHQA6AHQAdQBzAKYAfgDJ/7T/8ACwAXQAZ/9aABoBCwDJ/5IBVAKLACf/BQAwASABAgFqAToBXwDQ/7b/8//lAKYBiwDO/iX/zADMAG//n/8aAc4AxP5c/ksAaAGvAGIAqQBi/3D9WP7sAbgDlAEs/pD7ePko+fj7/P5a/tj7WPsY/Ij7UPvQ/UMAWf+o/br+rACzAFwASAGkAXUAdwBEA6gF8AQYA/ACHAO6AYoA9gGQBNgEYAJOAB4AGgBv/9j/dAHYAWUANf8U/3z+hP0c/vz/YADE/sT9lP5V/+b+Wv6Q/v7+1P6C/mT/7wB/AFD+qP0z/yIAaP+H/1wBBAK6/7z9NP+cAUYBx/+XAEQCfgFf/2n/DgEYAcX///+UAbAB+P8B/+r/tQAKAG//JgDzAJMAnv8m/2j/HQCIAAkAUP+D/2oAswDs/zn/bP+c//b+xv4uAJwB7QDy/vj9bv5T/0EAOgHIAUABwP+Q/vb+iQB+ASoByAAKAfwAHgCm/3oAdgESAQIAGgD/AOUAGgBPAP0ANwBm/jr+aQAQAkwBKgA9ALL/2P20/YoAmAJKAW3/pP/H/2b+Yv7oAHQCGAFY/0L/xP+3/7j/awAGAYkAh/9t/0kAmwDf/1//qf+2/3b/OwCGARIBEf9W/oL/LAC7/y8AbAEaAVL/tP6g/+T/df9iABACqgFP/yb+dv8UAQwBZQDFADABRgBP/6T/UgBxAJAA2ACaAOv/zP9/ALoAq/+W/l7/mAFQAjUAJv6w/tz/bv+H/7oBvAJMAHD9gP0o/6f/4P/oAfQCg/+o+zj9PgGQAbP/IQAqAXT/nP1s/wQCrwCY/bj97v+DAIsA7AEUAin/ZPyg/MT+/wCMApwCwABq/lD93P2B/zQBngGrAKb/lv5M/Rj+lAFcA6MAPP04/ej+kP96ACgCOgFY/ZD7Kv5gAcoBwAD7/4j+cPzY/GUA/AJgAngAmv7Q/PD8GQB8A3gDcAAe/lr+Xf8nAPgBgAPCAWz+mP06/wQBVALwAtIBHv8w/S7+IgEMA/wCmgFq/7D9HP5kAGAChAIqAbD/5v60/ij/vABEAroBov9y/vL+AgC2ABoBYAHBAPD+Dv50/9UAkAAtAGYAAwDs/pb+zv92AX4Bzv++/nj/gACBACAAWQDPAH0Aff9E/zsA0wAsAGH/Yf/r/0QA//+l/8j/6/+E/zP/gP/s/+T/pv/f/4sA1gA5AEn/9P5t/1AA0ABvAL7/lf/T/+L/EACoAN8AJgBR/57/hgBvALP/7f+RAMD/Tv7o/hQBogH3/+r+of8gAH3/UP9+AGABqQCh/9X/jwB+ANf/0f/1ANgBuwDg/kr/KgEOAY3/KAAgApYBPv87/0ABOgFK/0D/1ADBAIz/NACuAdAAcP7M/T//hgDYAC4BUAH1/6T9yPxq/vsAbAIIAkkAKP7s/Kz95/9wAfYAmf/K/nz+fP5p/6gAUQCe/iz+3/9EAewAQQDu/9L+kP28/kQCQAREAhv/cv6f/wgAOQCeAXwCtwBO/mz+SgAuAfQA+wCWAOb+5P1H/xoBCAHb/1X/pv8kADoAyf9R/zX/8P5o/gX/7wDYAWgAxv7c/ij/mv4j/0oB8AG9//T9Nv9gAWABBADF/zUAk/8S/5AAVAK4Abj/tv7c/nj/rAAEAuoB+f8G/uT9Tv/NAIQBJgG0/0L+PP55/6EA7ABuAIH/yv78/vP/DAGgAf4ASP8o/hT//ACYAa8ABQAqAO7/O/9S/2sAKgG+AMj/KP8o/4P/+/9zALQAXwCW/yn/oP9lAKwApwCyAE4Ab/9M/xYAVwDa/xoA/ADEAI7/E/90/4b/e/8nAN8AhACn/4n/sf8n/7L+g/+4AMYA3v9S/3//h/8l/xf/i//3/yoARgAQAFv/jv5M/gz/mgDiAY4B0P+G/tz+rf8NAPYAgAJwAv//7P2y/v4A+AFoAbAAEQBn/4H/pQAsARIAtP6+/uP/5QAYAZMAqP+U/vz9mP7v/8gAwwD0/4T+oP2a/rQAzgH7AHv/1v4b/4P/+v+cAAIByADo/zX/j/+rACYBjQDu/xgAmgCwAJQAuACyAB0Auv+JANQB+AHvAD8AZgBZAPn/SAAsAWABqgDY/2j/jv9dAPEAegDC/93/GgBt/+T+6v9GAbsAL/86/zsA4P/Y/kn/kQCuAMb/pf9jADIACf8X/5UAOAFBAG//vf8LAIT/Nv8DAOEAdwBX/97+Gf9o/8v/YgCCAK//zv4Y/zMApgAnALT/qv+I/1L/n/9YAJwAEABx/1//g/+M/9b/RQD3/+z+gP7L/3wBPgE2/wL+tv7X/2oAzwAQAWcA0P7g/fD+4wCQAfQAVgDS/wP/xP7z/2ABMAH0/63/agCvAFAAKgA2AP//+P+CAAQB8AB6AAQAqv/F/4wANAHoAFMAegCxABkAm/88ACoBMAGgAFsAFQBM/+b+6f9KAVABRACC/zz/B/8d/7H/OgAyAOP/n/8+/77+xP5c/6r/a/9p//r/KwBH/zb+WP5p/wkA6P/i/w4Auv8L/9r+S//F/y0AjQB1AMj/P/9Z/7T/EwCfANwAVwCv/5b/1P8IAFkAqQCuAKEAngAoAG7/j/+PAPIARADc/04AVgCA/y//AQCtAFgA+v8/AE4Azv+o/zkAngBkAFAAmwCUAC0ANwC3ANAAkQC6ABYB7wBtAFMAmACeAJAA6gBWATIBrwBpAFEAMABFAKwA7QC/AFsA/f+0/5r/2f8+AE8A+v+D/zj/Jv8y/0//cv97/1L/Mf9I/3T/dP8+//r+/P5q/xUAfgBGAJX/BP8a/6r/EAAkABwAEgDS/2b/Pf+P/wAAIQDs/6H/g/+e/7n/pf+m/9z/8P+y/6L/2//b/4L/hf9DAL8AUQCm/4f/s//k/30AWgGKAa4Ap/93/wUAqAAaAWgBVgG+AA4A5f9VAPMASAEsAewAuQByABwAFABzAMgAswBRABgAHgARAM7/pv/L/+P/wP+t/8//yf9h/wH/+v4u/2//wf/0/6r/Af+e/tj+Tf+E/5X/mP9U/8D+aP6u/jf/jv+g/4j/PP/K/o7+2P51/+//6f+L/0//Yv+C/4//yP8dACYA6v/n/xQA9f+q/8P/GwAyADQAhACtACIAgf+F/+3/SQDcAIABMAHf/+7+df+8AI4ByAGYAcsAw/+r/6gAsAEIAs4BMAFhAPz/bQA6Ab4BwgFOAbsAhADHAP8AAAEUARIBpQB3AP4AWAGeALj/4v9wAEQA8P9TAG8Ac/+c/hn/8P/R/yP/9v4Z/9b+Vv48/o7+yv6s/nr+cP5q/gj+kP20/Vz+uP5i/gT+Ev4C/nz9XP1A/gf/rv74/fj9NP7c/cz9pP5O/+z+ev68/g7/xv66/m7/CQDb/57/5P8bAPz/GQCbAO8A8QAUAVABKgEcAbABaAJ4AiQCMAJkAngCzALEA1gEyAMkA4QDIAT8A8ADUAQgBfgEUAQYBFAEOAQABDgEiARABHgDHANEA/gCIALyAYACZAJKAaoA2QB3AGT/Df+i/57/rP4w/lz+mP0Q/Nj7BP1k/XT8wPvA+zj7GPro+fD6ePvw+nj6gPo4+lD5+PjQ+dD6APuo+kD62Pmg+aD5QPpA+/D7wPsg++D6QPvI+zj8+PzI/cj9OP10/aD+Rf8M/1D/oQCyAZwBhgFMAsQClAJsA4AFmAa4BSAFGAYQB0gHMAjwCVAK4AhACEAJ8AnwCdAKEAxgCxAJ8AewCHAJMAkgCRAJ2AfYBcgECAVQBdgE6AP8AugB3ABNAFkAHAAU/9D9IP3c/Kj8cPww/Hj7UPqI+Zj5+PkQ+uD5gPnA+PD3sPcQ+KD4uPg4+KD3UPdQ91D3QPeA96D3MPew9hD3kPdg98D20PYg9wD38Pag9zj40PdQ93D38Pdo+FD5cPr4+tj6GPs8/Fj9VP7I/0wBOALMAsgD6AToBRAH0AiQCpALQAzQDDANgA1gDuAPABGAEaARIBGgD3AOIA/gEGARABBwDtAMsAoQCSAJgAlwCMgG8AUQBbACMQC3/2IA8v8l/yH/C/+E/Uj7QPqw+sj7wPxQ/QT9kPvA+dj4APoU/OT8IPyA+3D7gPpA+bD5iPvY+2D6qPko+sD5KPiw94D4YPgQ9+D28Peg91D1sPNA9ID1IPVg9OD0QPXQ82DyQPMw9VD1kPSA9RD3sPbw9dD3wPog+wj6cPuY/v3/5f9aAcgDeARwBIgGgAlwCkAKcAswDWANQA0ADyARABHwD0AQABFgECAQYBHAEcAPoA1gDUANYAyQDAANEAvYBlgEqAQABbgEyARABHgBVv4o/bj9sP6M/9n/nP6I/HD7cPvY+xT94P7e/sT8cPsg/LT8UPzI/BD+tP14+3j6oPs4/CD7YPrQ+pj6EPkA+FD40Pjw99D20PbQ9hD2MPVw9eD1IPXg8+Dz8PTQ9AD0EPSg9DD0kPOw9DD2IPaA9YD2APjg96D3mPkA/Hj8KPyY/cH/ewBCAYQDWAWIBQgGIAjwCSAK4ArADKANAA3QDaAPoA/QDpAPwBCgD0AOoA+AEXAP8AuQCzAN0AyAC1ALkAroBjgDPAOABdAFYATsAl4BsP6s/ET9Of+OACsABv9k/Tj8EPy0/PT9Ev+O/+L+6P2E/Wj9BP0I/Tb+H/+C/pT9hP0M/Vj7sPrY+6T8qPu4+vj6cPoI+LD2APgI+SD4cPfw97D3oPVA9CD1UPZA9iD2APfg9iD1IPTg9FD28PZg9xD4MPig96D3qPjA+fj6jPy0/bz96P2N/zQBEAIgA+AEEAZ4BoAHYAmgCsAKcAuADPAMQA2ADvAOcA7QDnAPsA6wDYAOQA+gDOAJYAsgDpAM0AjoB1AHyAN6AYAEoAcYBbUAwP/e/yj9EPzU/1QDXgF8/aj89Pws/KD8AwAgAh4AJP3E/IT9NP2o/Wz/AQA0/kT8NPzo/BD9mPwY/Kj7+PqQ+oj6oPpg+mj58Peg96j4CPlg+AD44PcQ9wD2YPbQ90D4UPdw9kD28PXg9YD2APdg98D3oPeg9nD2sPf4+Fj5IPoI/ND86PsA/CD+IgAeAQQDQAXIBfAEiAXgB9AJAAsQDNAM8AxADfANIA5ADoAPQBBAD3AOQA8gD6AMUAuQDMAMwAoQCkALEAmEA1oBaARIBnAE7ALAAncAkPyc/E0AqgFK/0b+QP8k/nD7yPs4/zgAMv4Y/Rz+QP60/Pz8sP7u/iT9ePyA/ZD9TPyA+1T84Pz4+8j6mPq4+gj6gPmw+fj5iPmg+HD4kPjw9yD3YPcI+OD3IPeg9mD2kPUQ9aD1cPZg9iD2gPZw9sD1sPUA95D4OPnQ+eD6qPvg+4j8Zv5bAJYBzAKYBAAGQAZwBsgHEArgC3AMwAxwDeANkA3ADdAOoA8QDyAO0A7ADzAOwAtQC+ALwAowCdAJwApACIQDegH4AfIBugGIA8AEggGA/PD64PxG/ub+bABoAW7/MPxo+5j8bP1S/lAAPgEe/0j80PvM/Dj9nP2U/qz+7Pxg+0j7ePsA+8j6MPvw+vD5cPnA+cj5SPnQ+Gj44PfA95j4YPn4+ND38PaA9nD2oPZA99D3oPeg9vD1UPbw9lD3sPdw+Lj4UPig+GD6VPwI/Sz96P34/gAAlgHsA8gFSAZYBgAHIAhwCfAKQAzwDDANMA3gDPAM0A2gDgAOEA2QDWAOQA1AC1AK0AlACGgHQAlQChAHSALeACABFAAAAKwC0AQAAtT8wPpo+2z8bv4gAmADKQDg+8j6YPz4/aL/ogEwAj4ApP2I/Oz85P0i/8r/Yf/0/Xj8kPvA+0D82PvI+lD6+PoY+0D6mPmY+cD4QPdQ9xD5IPpQ+Tj4gPdQ9mD1EPbg98j4CPjg9iD2wPUg9nD3uPgY+dj4qPj4+MD5SPsA/R7+hP4O/y4AgAHkAqAEaAZYB4AH0AfwCKAKEAyQDMAMEA1ADQANEA3gDWAOcA3ADCANEA1wCwAKAAqACXAHUAYwCAAJgAUiAaP/9P/D/0oBYATABLj/gPqQ+lz94P41ABADeAON/yD7yPp4/aD/CgGYAiACoP6g+9j7sP2C/nz+xP6y/kT9ePu4+uj6yPpo+nj64PrA+jD6qPkA+Rj4cPew9wj5APrY+Qj58PfQ9iD2oPYA+Bj5OPlo+BD3IPZA9mD3yPjI+eD5gPko+WD5sPp8/MT9kv4t/83/rgAgAtgDUAUgBqgGiAegCMAJ0AqgC/AL4AtADOAMUA2ADZANUA1QDGAL0AtwDHALoAnACEAIAAfIBUgGWAaoA3EAKgBWAZoAmv/bABwCX/9A+1j7nv58AIQA5ACQAKT94Poc/B4A4gEGAef/wP4U/SD8PP1N/yEA2v74/Jj7OPu4+1T8HPxI+2D6sPnI+Zj6EPt4+hD5YPjQ+Fj5qPko+lj6UPnw97D3iPjo+ID4kPgA+VD4IPeA98j4wPjg9zj44Pl4+vD5aPok/BD9FP0U/i4ApAEsAvwCkAQIBuAG0AcQCRAKwApQC8ALgAxQDZANcA1wDbANcA2ADMALAAwgDGALMApgCVAIcAbABGgEgAQYBDgDRAK3AOr+vP3E/eD+ov8fAL3/gP6s/Qr+Gv6o/T7+0f/aAEoA/P5g/rj9CP2c/UD/+f9M/2b+DP1o+3j6MPt8/Lz8OPxQ++j5qPjw+ED6ePqg+Xj5MPoQ+kD5+Pgw+fj4cPjY+MD5+Pkw+SD4UPfQ9mD3kPig+dj5CPkA+HD3GPiw+ZD7nPzU/PD8fP1e/lL/qwB4AhAE0ARIBYAGMAgACRAJcAmQCpALIAzQDKANUA0wDLALMAxgDNALcAtwC9AKYAlQCOgH6AYABbwDlANcA/gC/AKMAlEAWP1w/Fz9+P6UACQCKAIA/2j7mPq4/I3/+AHUAnQBrP40/Jj73PwT/+IAygDi/vj84Pvw+sj6GPxc/WD8MPq4+bj6uPp4+Qj5ePkQ+XD4WPkQ+/j6IPnQ94D3wPco+Ij5APtI+gj4IPaw9VD20PfY+bD6qPmg99D2sPcQ+ej6IP2Q/iD+QP3I/a//cgHwAsAEeAb4BvgG8AdwCUAKkAqQC6AM4AwADZANwA3wDEAMwAzgDOALAAtQCwALIAkQCBAIQAfIBBADSAOYA5gC7gEsAvwA0P2g+zT81P5qAWACSgGs/tj70PpA/Jn/pAIcA+wA7P1w/Pj7cPw2/sUASgHQ/iD8EPv4+uD6ePuM/Gj8uPqg+Rj6IPoQ+aD4SPlo+dD4QPmA+qD6KPnw9wD4QPho+MD5aPvw+pD4wPaQ9mD3qPhg+mj7sPq4+ID3GPjI+TD8ev43/6L+8P1q/t3/5gE4BAAGmAZQBvAGcAjACXAKQAtQDGAMMAzwDAAOIA5QDbAMUAzAC1ALgAtgC5AKoAmwCMgGOAXwBGgECANgAjADTAPsAKr+Sv7I/Xj8rP3aAWADRADM/Fj8tPyk/LD+XAJEA+//4Pws/AD88Pvg/eEA/QD0/QD7CPoQ+oD6sPvo/Ez8OPoA+Rj5cPlo+WD5mPl4+Rj5QPkg+sj64PlQ+JD3GPhw+bD68PoQ+lj4oPZQ9pD3WPmI+oD6UPkI+KD3gPhI+oT8Jv6E/rT9MP2Q/vIAyAL8A4AFmAagBrgGAAgACgALYAsgDMAMsAyADAANQA0wDfAMoAwADHALQAuwCoAJ4AjACKgHsAXABNgEpAPYAfoBGAPGAeb+Lv5F//b+Ev5u/4IBQQBQ/Rz9vP56/tT9wf/MATwAgPxw+wz9Fv5+/sT/9f8M/dD5qPng++D8sPyQ/Az8EPrg92D4YPp4+9j6APqQ+Rj5KPnI+aD6IPrg+GD4OPkw+hj6iPmo+MD3MPdQ94D4mPnQ+UD5WPiQ98D3gPnY+1z9lP2I/aj9Av72/goBjAPwBHAFEAbgBmgH8AdgCUALUAxgDFAMwAzgDJAMcAzwDGANAA0gDGALAAsgCtAIcAjACCAIMAbIBEgEsAM8AlYB5AHEAdr/wv6m/w4A5v5E/lP/3f+G/rT9Qf99AIP/SP5g/uj9TPxw/NT+egAn//j8mPtg+kj5EPrI/BD+jPwo+mj4MPfw9sD4OPug+9j5UPgo+Gj4cPgQ+bD5YPnQ+Bj5sPlY+ZD4KPjA9wD3EPeo+Bj66Pm4+ND3MPcg9+D46PvY/dD9DP0Y/az9dP4pAOQCKAXYBfgFcAYoBwAIMAnACvALcAzgDFANcA0gDcAMkAyQDPAMUA3wDMALgAqgCdAI8AeAB4AH0AYgBawDDANQAiwBrgD0AJcAP//g/sb/HADu/tj9OP6U/lr+7P6WAJAAOP50/Cz8BP3Q/e7+aAC6/8j84Pko+Qj64Puw/fT9LPw4+UD3UPfI+FD6yPow+lD5uPiA+CD4iPhA+Tj5WPh4+Hj5qPn4+HD4KPjQ9rD1EPcY+uD6APmQ92D3MPeQ9wj6RP10/rj9NP2I/dT9vv6kAQAFaAYoBiAGyAZ4B3AIIArgC5AM0AwwDXAN8AxgDKAMIA3wDLAM0AyQDJALIArwCAAIYAcIBzgH4AaIBZwDMAJuASgBCAESAVwBNgGIANz/vf+a//T+eP5g/40AwABXAO7/G//g/JD7tPx2/48AlP9c/qz8+Plo+Ej6/Py4/fj7cPqo+Tj4APcw+Dj6UPpw+VD5oPmI+GD3CPhg+Rj5APh4+Lj5iPkY+JD3gPew9pD2GPjQ+bD5UPig99D30Pd4+PD6dP1A/sj9VP1w/UL+cACMA6AFGAYQBlAGsAaQB2AJgAuADIAMsAzQDHAMUAwADXAN4AxgDJAMwAwQDOAKwAlwCEgHMAfYB4AHAAaYBCgDZAF6AC4BOALuAfQAuAB1ADX/Sv4C/7X/JP++/jYAMAHA/7j9EP0Y/XD8BP1m/woBM//w+5j6CPqY+Xj6uPy0/fj7kPlA+MD3QPdI+ID66Ppo+UD4EPjQ99D3gPgQ+Xj4sPc4+FD5IPkg+LD3EPdw9tD2aPio+Xj5yPhY+OD38Pfo+dz8TP4K/sj9RP7g/u3/kAJYBRAGiAUQBqAHcAhACQALwAygDNALYAyADcANgA3gDdANwAxgDNAM4AzAC4AKsAmwCKAHeAfIB8AGCAW0A8ACogFUAe4BUAKSAYQAJgCV/8r+qP5Q/6//cf+S/87/uv4g/Yj89Pwo/az9uP4b/8D9GPsQ+kj6SPqw+vj7NPyY+tD4IPgo+PD34Pcw+RD6ePmw+Gj4EPiQ99D3SPiA+Jj4+Pgw+TD4APew9uD2QPfA96D4sPgI+MD3UPjY+Gj5kPro+/j8VP2w/Y7+0P8sAbACCAT4BOAFyAaoB9AI0AmgCqALYAygDKAM4AwwDUANIA0QDeAMcAwgDPALUAvwCfAIoAgACBgHWAYABhgFiANYAgACmAEYAVQBxAEaAaf/Cf8g/87+bv5L/3YAMAC8/uz9qP3s/OD8Nv5S/27+0PyE/ED8aPvw+pD7yPt4+rD5UPqI+oj5EPnI+PD3cPdY+Mj50Pn4+Gj44Peg9rD2gPiw+QD5CPjQ9yD3IPbA9oj48Piw9yD3EPjA+OD4APqI+7j7+Pqo+4j9H//5/14BCAMgAwwDUAR4BuAHkAjQCdAK8ArwCvALIA1ADdAMIA2ADUAN0AwgDSANAAzACjAKEApwCZAIIAioB1gGyAQ4BCgERANYAigCWAKsAZsAgAB6AJT/Zv7O/sr/pv/s/rb+fP4o/QD8rPwW/gb+OP3M/Hz8aPuw+jj74Ptw+zj60Pko+ij6GPro+YD5kPgA+JD4ePk4+iD6uPl4+JD3sPdo+Fj5wPmQ+cD4oPfw9nD3OPiQ+KD4qPi4+Oj4mPlw+uj6UPuw+3z8pP0n/6cAuAEoAnwCaAN4BPAFuAcQCcAJwAnwCYAKQAvwC7AMQA0QDaAMYAxwDGAMwAugC2ALkAqQCeAIgAiYB3AG2AWABZgEoAM8A8wC5gFaAUAB+wBdAK//a/86/wr/L/88/6j++P3Q/Wz9AP2Q/UL+9P3U/FD8SPyY+xj7sPt8/Jj7MPpA+rD6EPog+ZD5APoo+XD4IPn4+Yj5yPjA+Oj4GPjw9zj5CPoQ+Rj4GPgA+JD3kPeY+PD4IPhA+ID54Plo+dD5APtw+6j76Pzi/tv/pP9AAHYBOALsAvAE8AagB5AHEAggCaAJ4AngChAMMAzQCxAMgAxQDIALUAtwCwALMAoACjAKUAmAB1gGMAaYBcAEuAToBPQDXAKIAWoBOAG1AMoA6ABMAKH/pv+6/0v/Cf/6/qL+TP5e/uD+uP4U/sD9YP2M/Aj8iPzw/GD8qPuQ+zD7WPrY+Vj6gPrA+VD5wPnA+RD54Pgo+RD5MPgY+Oj4SPnA+Gj4gPgQ+FD3YPc4+Cj4APhg+CD5QPnI+DD5APqg+hD7YPys/S7+cv4j/zgABgH4AXwDGAXwBUAGGAcgCMAIUAkACtAKEAsgC6ALMAwQDJALcAuACzALkAqQCpAK0AmQCMgHWAegBtAFkAVgBZgEbAPwArQCIAK0AWwBYAHtAGwANgAgAN3/e/84/+L+sv6e/oj+Vv4q/tT9GP2U/Fj8ePxA/ND7qPtw+7j6EPoA+gD6wPlg+XD5iPkY+bD40Pjo+Jj4IPhQ+ID4OPgQ+Cj4IPiQ9yD3IPcg9/D2APeg9zj4WPhQ+Ij4yPjw+Lj5KPtU/Mj8PP0W/uz+hP+aADQCgAM4BBgFaAZgB/AHwAjACUAKcAoQCxAMkAyQDKAMsAxQDOALAAxQDBAMYAvACjAKYAmQCCAI+AdAB2AGyAVIBaAE5AN4AwwDUAKkAVYBKAHAAFcA9f+G/+r+hP5y/lb+BP6w/Xj9AP1k/BT8BPzQ+1D7APvo+pj6EPrY+cj5WPnQ+LD42PjA+HD4aPho+AD4gPeg9/D30Pew96D3oPdA99D28PYQ9xD34PYw94D30Pcg+Jj4EPkw+aj5kPqA+1D8GP0K/sr+fP+EALAB1ALQA/gE8AXYBqAHkAhgCfAJoAogC5ALwAtADJAMgAxgDFAMYAwQDLALkAtAC7AKEAqQCTAJcAi4B0gH4AY4BpgFMAXABAAEWAMIA6QCBAJ+AVAB7ABHANn/vP9b/8L+dP5C/uj9VP34/Mj8aPzI+3j7UPv4+oD6SPoY+tD5YPkw+Tj5GPnY+Kj4sPiI+FD4EPgo+CD48PfA95D3gPcQ99D2oPbQ9sD2oPaw9hD3UPdg97D3EPiA+Lj4cPl4+mj76Puc/Jz9gP5q/34A1AHoArADqAT4BegGiAdQCEAJ8AkgCqAKgAvwC/ALEAxgDFAM8AvQCxAMwAsgC+AK0ApQCoAJ8AiwCBAISAfwBrgGIAZgBeAEcAS0A+gCrAKEAuIBNgH8AKgA9v9T/xn/zP4y/qz9mP1U/Zz8EPzg+5D7+Pqw+qj6YPrY+Yj5cPlA+eD40Pjg+KD4SPhA+Fj4GPjQ98D3sPdA9/D2APcA95D2QPZg9jD28PXw9ZD28Pbg9iD3sPcY+ED4+Pgw+hD7mPtY/JT9gv5e/5QA6gHUApgDyAQQBggHoAeQCHAJ8AlgCiAL4AsgDFAMkAzADJAMcAyQDJAMIAzAC5ALMAugChAKwAlACaAIEAjIBzgHiAYQBpgF0AQQBLADRAOsAgwCsgE6AYMA9/+g/zj/iP4a/tT9WP3I/Ej8+PuI+wD7oPpw+hj6qPlo+Sj52PiI+Gj4SPgA+LD3oPeQ91D3MPcg9/D2oPZg9kD2IPbQ9bD1kPVQ9SD1QPWA9cD1EPZw9tD2APdw90D4EPnI+bD6sPuY/Hj9dP6q/9QAygH4AkAEaAVYBlgHQAgACbAJUAoQC7ALMAyQDNAMAA0ADQANEA0ADdAMgAxADPALgAvwCpAKIAqACfAIkAgACFAHwAZIBrgFCAVwBBgEcAOwAjwC4AFEAaUAQgDd/zL/jP4s/sD9IP2Q/DD80PtI+9D6kPoo+qD5MPn4+Kj4SPgg+BD4wPdQ9yD3EPfw9rD2oPag9lD28PXg9cD1cPVA9VD1UPUQ9QD1YPXA9eD1MPaw9iD3cPcw+Dj5EPrA+rD7xPyI/XD+t/8SARACLANYBIgFaAZQB1AIIAnACXAKMAuwCxAMgAzQDNAMwAzQDPAM0AygDIAMQAzgC2ALAAuwCjAKsAlQCfAIYAjABzgHuAYYBngFCAV4BNwDOAPAAjQChgECAXgA/v9i/+b+fv78/WT91Pxs/Pj7ePsY+9D6cPr4+aD5aPkY+cD4ePhY+CD4wPeA94D3UPfw9tD2wPaA9iD2APbw9bD1QPUg9UD1IPUQ9VD1wPXg9fD1YPbw9mD3CPjw+Oj5gPpQ+2j8fP18/oj/wwDqAfACGARABUgGMAcQCOAIgAlACvAKoAvwC0AMoAzADLAMwAzgDMAMgAxADCAM0AtgCwALwAowCoAJEAnACDAIkAcQB6AG2AUwBbgEUASsAwgDnAIUAlQBrwBNANr/Mv+g/iz+sP0I/XD8HPy4+zD7wPpw+hj6kPkw+fj4sPhI+Aj48Peg91D3IPcQ9+D2oPaA9nD2MPbw9dD1sPVg9RD1APUQ9SD1UPWg9dD18PVA9sD2QPcA+Nj4sPlI+hD7LPws/Rj+Kf96AJYBfAKsAwAFEAbQBrgHwAhwCfAJkApwC+ALIAxgDLAMwAywDMAM0AyQDDAMAAzQC3AL8AqgCkAKsAkQCaAIUAi4ByAHqAYgBnAFyARQBOwDSAOgAiQCrgECAX8ADACT//T+XP7g/Wj93PxY/BT8qPsg+6D6UPr4+XD5EPnY+Kj4OPjw99D3oPdQ9xD3EPfg9pD2YPZg9jD24PXA9ZD1cPUg9SD1QPVw9aD1APZA9oD28PaQ9yD40PiY+Zj6YPss/DD9Wv5l/0UAcgGcApwDkATIBdgGmAcwCAAJ0AlQCsAKYAvgCwAMEAxQDHAMQAwADBAMAAyACzALIAvgClAKwAmACfAIUAjQB5AHIAdoBuAFeAX4BDAEtANgA9wCKAKaATYBnQD8/3z/HP+M/uj9fP04/aj8IPzI+3j7APto+hj60Plg+fj4wPiI+DD4wPeg93D3IPfQ9qD2kPZA9vD10PWQ9UD1APXw9ND0wPTw9DD1YPWQ9fD1UPaw9kD3APjY+ID5UPpI+1D8MP0w/mT/ZwBuAYgCzAPYBLAFmAaYB0AI0AiQCUAKwAoQC4AL0AvwCwAMIAxADCAM4AvAC6ALYAsQC7AKcAoACoAJEAmgCCAIkAcgB7AGKAaQBQgFkATsA0wDzAJMAr4BKgGqAC4AlP/+/oL+DP6M/Qj9pPxI/Nj7YPsA+6D6OPrQ+Xj5KPnY+Jj4WPgI+KD3YPcw9wD30Pag9nD2MPbw9bD1gPVg9UD1QPUw9UD1cPXQ9RD2YPbA9lD3wPdg+CD5APrQ+qj7nPyA/Wb+a/+HAKYBqAK0A7AEsAWIBmAHMAjwCIAJEAqgChALYAuQC8AL8AvgC9ALwAvQC6ALUAsQC9AKgAoQCtAJgAkACXAIAAiwByAHmAYoBrAFEAVoBPwDgAPgAlQC1gFAAZ4ACwCP/w7/dP4A/oD9CP2c/Dj84Pt4+xD7uPpo+iD60PmY+UD56PiY+Ej4APiw94D3QPcA97D2cPYg9vD1sPWA9VD1QPUg9RD1MPVg9bD1APZg9uD2UPfQ94j4WPko+vD64Pvo/Nz9zv7L//UABAIAAxgEKAUgBuAG0AegCDAJwAlgCuAKQAuAC8AL4AvgC9AL4AvgC8ALkAtQCyALwApgCiAK4AlgCfAIgAggCJgHCAeYBiAGgAXwBHAE6AM8A6QCDAJ+AdAAJwCa/wj/dv7c/WT98Px4/AT8mPsw+9D6cPog+tD5iPkg+dD4iPhQ+CD40PeQ91D3EPfQ9rD2kPZA9gD20PWg9WD1QPVQ9WD1UPWA9dD1EPZg9tD2YPfg92j4KPkQ+uD6mPuc/KD9iv5t/3kAlgGgAqQDmASYBXAGOAcACMAIUAngCVAKwAoQC0ALcAuQC4ALcAtgC1ALIAsAC9AKgAogCsAJkAlACeAIcAgQCKAHEAegBjgGsAUQBZAEEAR0A7wCMAKuAfUAPAC5/zT/iv74/Yj9GP2I/Aj8sPtY++D6kPpY+gD6gPko+fD4sPho+Cj4CPiw91D3MPcA99D2cPZQ9iD24PWw9aD1oPWg9aD1sPXg9RD2cPbA9kD30PdI+PD4mPl4+kj7JPz8/PD91P7c/8wA0gG8ArQDoAR4BWAGMAcACKAIQAnACTAKkArgCiALUAtwC3ALgAuAC1ALQAsgC/AKwApwCjAK0AlwCSAJwAhgCOgHcAcAB4AG+AVoBdgESASwAwwDaALQASwBjADz/2j/zv4+/sD9RP2w/Cz80Pto+wD7mPpA+uj5aPkI+bj4aPgY+ND3oPdQ9/D2sPaA9kD2APbQ9bD1gPVg9WD1cPVw9ZD1sPXw9TD2kPYQ94D3APiQ+Dj54PmY+nD7VPwo/QT+9v7w/+IA3AHAAsQDkARoBTgGGAfYB2AIAAmgCRAKYAqwCgALEAswC1ALYAtQC0ALIAsAC8AKgApQCgAKsAlQCRAJoAggCLAHQAfQBjAGoAUwBZgE8ANUA7wCDAJWAbgAGwB+/+T+WP7I/Sz9pPw0/ND7WPv4+qD6QPrg+Xj5OPno+KD4YPgY+ND3kPdw90D38Paw9pD2UPYg9gD28PXQ9dD10PXQ9eD1APZA9pD24PZQ97D3OPjY+Hj5KPro+rD7dPxQ/TD+Fv/3/9QAwAGkAnwDWAQwBQgGsAZQB/gHkAgQCYAJ8AkwCnAKkArACuAK4ArgCtAKsAqACmAKQArwCcAJcAkgCcAIYAgACJgHGAeoBiAGmAUQBZgEAARoA9ACNAKYAfgAZQDO/zH/iv74/Wj94Pxg/Oj7iPsY+6D6SPrw+aD5SPn4+LD4YPgY+ND3kPdQ9yD38Paw9pD2UPYg9gD2APbw9eD18PUg9kD2cPag9gD3cPfQ91D48PiI+Sj62Pqg+2T8LP0G/tr+xf+PAGwBRAIcA9gDoARwBTAG2AZoBwAIgAjwCFAJwAkACjAKUAqACpAKkAqQCpAKcApQCjAKAArQCZAJUAkACaAIQAjYB2gHAAeIBgAGgAXwBFgEuAMYA4gC5gFGAZwACgBm/8D+LP6s/Tj9qPwg/Lj7WPvo+oj6SPrw+Zj5QPkA+bD4cPhA+BD40PeQ94D3YPcw9wD38Pbw9tD24Pbw9gD3EPdA93D3oPfg9zj4sPgY+ZD5APqQ+jD72PuA/CT92P2W/lT/EQDJAIQBNALkApQDSAToBIgFGAaoBigHkAfoB1AIsAjwCDAJUAmACZAJkAmQCaAJgAlgCUAJIAnwCKAIYAgQCLgHUAf4BqAGKAawBTAFuAQwBKQDFAOMAvYBZgHbAD0Ao/8O/4r+/P2A/Qj9lPwc/Kj7UPvw+pj6QPrw+aj5aPkw+QD50Pio+JD4aPhI+Dj4OPgo+DD4MPhA+Fj4cPiY+Mj46PgY+Vj5kPno+Sj6iPrg+kj7uPsg/Jj8HP2k/ST+qv48/8n/VgDnAHgBDAKcAigDsAM4BLAEKAWgBRgGeAbQBiAHaAegB9AHAAgwCEAIQAhQCFAIQAggCAAI2AegB2gHKAfoBpgGQAboBZAFIAWwBFAE2ANYA9QCXALkAWYB4wBlAOz/X//g/m7+/P2M/SD9vPxc/PD7mPtQ+wD7sPpw+jj6CPrY+bD5mPmA+Wj5YPlQ+VD5UPlg+Wj5cPmI+aD5wPng+Qj6QPp4+rD68PpA+5D74Psc/ID81Pww/ZD99P1m/sT+Jv+i/xIAcQDTAEQBpgEAAmwC2AI8A5AD2AMoBHAEwAQIBUgFgAWwBdgFAAYQBigGOAZABjgGKAYgBggG6AXABZAFWAUgBeAEqARoBCAE1AN8AyQD0AKAAiwC1gF+ASgBxQBjAAUAsv9Z/wT/sP5W/vz9sP1s/SD90PyI/Ez8FPzQ+6D7ePtY+zD7GPsA++j64Prg+uj6+PoA+xD7KPtY+3D7mPvI+/j7LPxc/Jj81PwQ/Uj9iP3I/QT+TP6W/t7+F/9V/5z/5P8rAHAAuwD+ADwBdAG4AQACPAJwAqQC3AIIAzwDaAOMA6wDyAPcA+gD+AMABAAE+APsA+QD0AO4A6QDhANkAzwDEAPoArgCjAJgAiwC6gG0AX4BQgEIAdEApABrADAAAgDY/6j/dv9L/yb/+v7K/p7+eP5Y/j7+HP78/eD9zP2w/ZT9jP2I/XT9ZP1s/Xj9bP1k/Xj9mP2c/aT9xP3k/fT9+P0a/kL+Xv5s/or+vP7O/uL+Bv8y/z7/Vv+J/73/1P/l/xkAQQBVAHgArQDRAOMAAAEwAU4BVgFyAZoBqgG0AdQB6gHuAewB/gEMAgQC/gH8AfgB6AHYAdYB1AG8AaABiAF2AWoBVgE6ARwBCAHtAMcArACgAJUAbwBBAC0AGAD1/+T/4f/I/6P/hP9u/1L/PP80/yL//P7k/t7+0v6y/pr+mP6Q/nz+cP54/nj+bP5q/nL+cP5y/oD+lv6s/rT+sP7A/uL+9P76/gf/I/89/07/XP9y/4b/k/+g/7b/z//i//f/DAAmAD4AUgBlAIAAmwCwAMIA1QDtAP0AAAEIASIBMAEuAS4BQAFIAUABPgFEAUIBNAEwATwBOAEgARQBEAEIAfEA5gDoAN0AygDAALYApACLAH0AdABlAFMASQBAACkAEQAEAAAA6//R/8L/vf+p/4z/ff96/2n/Rf8w/zD/K/8T/wD//v76/uz+4v7m/vD+6P7g/ub+8P72/vb+/P4O/yP/IP8f/z7/Wv9g/2z/hv+Y/57/sv/I/9D/2//2/wwADgATACkAPQBEAFQAbwB7AG8AdwCQAJUAkACYAKgAqACfAJoAogCkAJcAjgCSAJEAfwBuAG0AcABiAE4AUgBbAEYALwAyADkAJgATACAAKQAYAAIABAAMAAAA7//z//3/6//X/9X/3f/X/8L/t/+5/7z/rP+Z/6D/rf+i/4j/hf+X/5X/gf+D/5n/j/9z/3v/m/+W/3b/ef+l/6P/e/+J/8//0f+S/7D/7//q/7X/0v8mABoA4v8EAEwANAAKADQAYABMACEAMwBzAIIAUwBAAFwAZwBQAFEAcgCEAGQARABXAG8AYABZAHEAfQBhAE4AYwB6AG0AVgBaAFcARQBKAFYASAAzACoAHAATAAcA+//+/wAA9//c/7X/qv/C/8v/uP+n/7D/rf+S/5T/rf+2/6T/o/+z/6X/kf+h/7z/uf+q/6r/rf+u/7j/vv+7/77/wf+8/7b/u//d/+P/v//M//j/3/+//+7/DwD2/+X/BwAiAA8ADAAwAEoAMgAmAFYAegBfAFYAiQCiAHkAawCYAL4ApAB/AJoAwACmAHIAmADHAI4AVQBwAJwAdQA2AD4AaQBdABQADQA6AC8A8//o/xMAIQD+/9b/+f8gANn/p//7/zgA4/+n//H/EwDG/5v/+/9FANb/Zv+//0EA3/9f/8X/JACe/zz/x/9QAL//DP+K/1YAwP/0/t7/qACS/7L+2f+dAIT/Cv8VAHIAPv/w/jEAewA1/+L+UwCDANz+3v6eAJkA6v7i/moAnwBf/x3/OgC6AMX/Jv/p/9YAfgBt/4z/vwDeAIb/TP/+AEgBeP8u//8ASAGf/3//BAEQAY3/Z/8SASQBoP+w/wIBsgBp//X/MgG0AJj/5f/mAI8Aof8dACIBogBx/8v/BAGTAIb/EQAEAVUAR//l/9sATgB7/+D/iADr/yj//v+rALr/Hf/5/0kAWP8x/zQAbwBY/xj/4P8YAF7/Gv8wAHMAJf+8/vT/TwAq/yD/6//c/0P/JP+f/7T/r/+u/3D/X/9+/83/vf9//wgAKQBq/03/QABKAG//DwDbAPz/I//3/wYBTAB//14AFAEEAAn/pAC+AQoAgf8MARgBfP/f/7YBYAECAOn/zAAeAUAALABcAWYBKwDm/9gA9wBvALoAngBaAJkAewAGAEYA9QBuAMT/5v8rAE8AJADi/wUAEQCB/1b/3P8nANr/hv9k/5//0/8l//z+FABQAED/0P6G/9H/NP8L/7r/KgBP/47+iP/z/xT/Gv/n/5b/Bf9c/0r/kv8jAEL/iP6a/1MADP/s/psAnAC+/j7+MADmAEf/8v7EADwByv4q/p4AdAFO//L+LgH4ACL/Nv/hANcApv8FABgBwgCY/2IAWAGUAAAAkADgANMAyQBoALMAbAGSAKD/kwCEAdsA5/+WAKABWQCo/pYAiAIqAA7+UACYAq4AHP40/6gB0ABU/pD/wgEWAGD+8v8eAXb/bv4MAPIAov8W/wYA+v8Q/2n/HQCb/4D/8/+8/zz/JP/G/9X/iP+y/07/Av9d/0cAgf9C/icAugCy/qz9IgDkAQD/vP3Y/6IBQf9o/TQBGAKW/vj99AD2ATT/nP4cAfgBuv8M/qIAfAIiAFz/jADYALwAsf9F/0gBXAKR/2D+TgEsArH/5P5CASQCqf9U/jwBJAPa//D9WAEAAxn/8P0IArwCbv+y/s8AegHn/zH/ZwCGATwAsP4gAN0Ai/+V/4IAXwDJ/3//df95/3gAkQAz/9L++f8CARz/DP5LAH4Bkv/s/Wn/tQATAE7/Kv+d/0QAx//C/qH/ewCZ/4T/dP9o/zwAmP+k/gUAGAG+/kb+tQCyAJL/mP6K/74Aj//m/qEAtgFw/tT9fgHmAbT+DP5EAuQCoP30/PwC6AOw/WD9uANMA2z87P3oBCAD7PwM/tADNAJw/b7/vAN0Acj96P8cAhYAGwDqARQBjv5F/9oBqAE4/yP/+AFgAcD9hP7UAuIBDv4a/igCDgG4+2r/qATbAFD74P0kA9cAgPxw/gwDGAGI+0T+3AIZAFz9sv+TADb+yP7sAHQAoP4G/sP/XACg/QD/6gH1/6j9Tv7d/5v/cv/H/yYA5v84/oL+DgCgAKUAiP8C/rD/rAFK/1r+ZgGYAkj+UPzuARgEiv6o/fwC3AGs/H7+kAQIAxz9wP5kA84A0PxjAIgFFAJk/MD+CAPiARz+Uf84BLAC/Py8/agCbAOY/2j+ggAWAZcAov9rAKoB3QAM/zz+R/8AAUwCGgEA/oz/dACo/dr+/AHuAdL+Pv6V/6v/GwBw/2j/JACW//j/nP40/ggCqAIA/fD6OAFgAgT+7P4EAkYBwPwQ+17/mAMMAXD9eQCkAfD8LPxiASwD6P/o/Zr/tAFsAA7+D/8sA5YBGPx2/sAEWAJk/W3/YALMAPT8Tv6YBNAE+PzQ/AgE0gFE/Nr+iASoAxD+9P2AATACIf+w/owCIAKJ/zT/jQAGAdIACAEO/wUAFAIDAMz+qQDIAtT/WP1z/xQCbAKE/gr+SAIQAZj8/P4IBJkANPyc//QCjv8s/LQAzAOg/lj7DwB4A8z+dPx2ARgDoPyA+sgCGASY/Iz8tAHgAfz8SPw+ASQDKv+4+6f/MALS/sD9+P/0Adn/jP0o/zYBcAD+/qABOgE4/TL+EAIMAo7+GQCQAmv/KP0U/3gDOAIY/Z//cASA//D5JgHwBnP/ePuEAXwDLP4k/TgCWAQMALj73P/ABDf/UPtsA+gGyPz4+KQC2AVS/rz8OAOQAwD9aPqqAQAHUv+o+rQCgAQA+lj7+AVwBMj8rPwyAd4APv56/3wCWgHg/Cj9qgEIAVL+4gA0Ak7+ZPwB/4oAPAF8AuT/IP0G/vL+7f9WAcIAjQCs/9j84P1QAQABlv5oAaYBuPtk/AADVAP8/YT9FwAMAXT/IPzwADAH/f+Y+BL/5ANy/oT/8AS6AWj9bPzw/iAEJANQ/ej/KAWU/vD5bAGYBb4BFP5g/VUAjALu/5b/nANMAWD6HP74BMgBHv4QAoADPP3Q+bf/6Ad0A3D6Sv/IBGT9cPqsAzgGJv6I+7EAjALB/yr+qwDIAmb+sPqVAIgFsgAw/bn/4P5Q/MUAQAJoAOQB3v6I+w7+egD4/8ACCAEA+1MAVANQ+vD6aAcYBdD4uPuIAxwBhP0NAGAEhwA4+Gj7MAhIBoD4jP1QCUj/kPTc/jAKsATw+sD8fAOoAVj74P1QB3gFGPpw+xgFfAOA+yr+wAakA1D6JPxgBXgFhPyY/TAFmwCY+QUAEAj4Afj74/9wATb+Sv4MArQDbgFQ/Rr+agAc/h0A6ASEAOj7HgG0AWj8QP9QBLgAoPvs/WQCrAL4/vT9TgHrAJD7DPwABHgFuP4I/SEAKP0k/F4BgATAAvj80PuwAEQBDP30/ngEqAGg+2j8IAEIA3MAvP2U/pL/2v5OAAgCUwBm/kX/mP6Y/SQBFAOUAR8ASP0o/BoBEARY/+T/sANC/lD7rgFYBOz+mv5MArIBvP5E/OsAuAafAFj5p/+4Bdr+sPz0A1wCvPxY/awBGAOh/2z+pQA8Aij/qPyp/8QD9AOQ/uj7SwBYAs//tP7gAYAC1P0i/jAB3AAb/3j/XwCSAGUAAP5z/+IBZv/C/mD/cP5dAIQDF/+g+tIA0ASG/oj6owD4AyYAZP5Q/0cAWP8Q/64ATAGO/+7+WAGiAI7/MP+U/RQBYANY/iT8WAIgBXD+wPkN/7AF5gEo+w//CAYiAaj6If/IA60A4P1wAZgCaP+Y/c7+MAP0A2D8CProA8AFaP2g++ABeASA/rj7Lf8AAxgDU/9E/o7/EQCN/90ACAT1/8j7qP/IAnAB9P6C/tIB5AOM/vj5hQBABuQAuPs/AJgCBP0w/qAC6gA4/Eb+fAPMAeT8vPysApwBSPok/ogFCgGo/D0A2AHw/JD7SAJ4BlQAYPmT/4AGsv4Y+JQB0Aid/2D4XP8QBsIBsPpc/hgFPgCI+bD/AAmcAWD4Sv78A0n/cPpHAEAIaAXo+ZD2AAJQB1L+XPxoBYgDqPrI+6IB+ANcAQ3/v/+E/wr+n/8QBDACRP0M/qr/UwDoAPQBrAJR/2D74P1kAh0AjP+ABcACOPj4+EgDwAUSACD8rP5ABIz/oPfs/wAKuf8A9Rj/UAnTAIj48v8wCIj/wPOQ/mAOIAUg9aD8AAml/+D0ngCADewCwPXU/JgGXP/I+KACYAmv/5D2IP5YB8IB8PnE/uAEewDo+v7+yAXUAij7VPxkAoUApPwwAngGIP+o+ej9QAMoAZT9aAFQBOT+UPp1ADAEhP4M/gADygH4+rj96AZIBED6UPpoBKgEMPzc/VAFOASY+2j5egGIBcgAwP0YAVgCUv4E/Kb+cATYBCT92PsUA8AD8PtA+zAFOAdY/JD3aAJ4Byz9cPnsAygH0PqQ9jADMAlA/vj4TAEIA+D6IPvgBFgFvPzY+zIBpv+4+4ABOAYBAEj7h//4AWT9kP5oBQAF0PyI+scAxAI7/3f/wAMcA2j9OPt5/1AEeAMu/vz9ZAIMAjD8uPuoBOAH9P5Y+Gb+yATq/2T9IAVwBTD5cPYQA6AIR/+g+oAD4AYY+dDzsATADH4AAPpYABYA6PrZ//gHuARo+8D7lALmAVz9YAFYBpMAcPm4+0wCaAS8AkwBSwAo/CD4Ev/oB2AFNv7g/Kz+Rv7Q+6j+EAmwByj4QPWwAlAFnPyj/8gH8QCw84j4IAowCYD5SPoYBj8AwPOQ/lAOMAZw9fj4oATdAMj6uAEACVwB8PVo+RgF6AVS/k//EASA/xj5wPyYBiAIav/Q+db+uANCAG7+MAOgBCL+IPqC/8ADGAIhACUA3f8o/cT9wgDAAcoBagEL/wD8Nv6MAowBeP2m/rAE/AFw+TD8iAWgBAD7kPt4BRgEmPmo+5AHmASw+DD7gAT4AgT8gP14BHgE0PtA9/D/cAdoAdj78P7YAEgB//8k/Q4A3AM0AIj87//uAZQA0ADlAO7/6P3E/FwBuAWQAQT8DP7xANL/CwDz/2sAUAI6AOD9ZP2o/kwD+AOo/Aj6JALgBIz+GP3QABgB7Pys/CgEMAWg/gb+CAHo/fj5yQDwCCAGuPsI+CABsAVc/VD90AYwA8j45PzwBhQD2Pow/WgF4AJI+PT9kAxQB2D0QPWAB/AI2PsI/eAH8ALw9ND5QAlABuD5FP24B24BYPRA+2ALSAew9UD3AAigBxD6APrMAyADgPps/MAEsATU/sj7Iv6Y/7T+xgAoBeADDPzg+Wv/bAP6AYv/5/90AWAA+PxA/WgDgAWj/4D7UP7oArgCIQCB/w4AUP9a/hIBCAQQAsj9lPzU/icAJwDkAUADlQDI+wD7wf9EA8gCwwBu/rD9oP9XADH/zgAYA1gA6Pug/XgCUASIAKD8Xv+gAnr+nPwoBQAH0Puw9+8ACAUR/8z8zALYBFj8gPfw/5AGOgBs/CwCBAMU/FD7HAIsAwD+yP7wAxQCPPwM/SgCHgHo/ZwAEAT0/yj7hwBIBar+SPqqAZgFEP/Q/DQDEANQ+zD7iAMYBdj9OP3ABLQCSPgI+7AGeASo+fj8iAbEApD5RPwgBcwB+Pik/UAI/AO4+MT84Aa7APD12P3gC9gFcPcQ+tgF8AMA+Qz9UAnQBED3+PpQB8QCcPew/ZAKfAMA9Zj6wAhoBTD5kPsYBUwBKPlH/4AIOAMw+mz8ZgHu/gD+2ARYB6j9sPdM/2gEOADi/uwCkAJ8/DT8xAPABDz8sPrEA9gEWPto+zAHCAeQ+OD12AKQCB7/CPrUAngGsPpg9dQC8AkK/qD3WALABmD7YPcABOAIUPxw9sYB4Ah1//j5GANQBmj7sPgwBDAI3P7o+5wDvAPo+pj6qATABnr+yPrT/1QDmP+g/EIByARO/vD4QwCoB/4BIPuI/UAC4/88/bQCoAYMATD6CP10Av0AzP9QBCAEXPyY+5wCMAOs/ST+aAPEAbD7LP1wBBgE2Pu4+jIBbAFY/TEAIAWIAEj5wPsYBHgETPww++ACMAQw/Jj6ZAIYBSj/UPpu/rAEKAKk/Lz+uAKa/pj7kAMgB4z9gPg6AQAHxP5o+SgCYAnmAAD3RP1IB1wDaPzm/7gCeP3U/JAEGAc8/nD4FQDYBSL+KPkwBPAKOv6Q83D7aAXcApP/8AJIAQj5KPnYAygGvPxQ+ygFGAU4+Cj4mAeQCnD7QPVQAcgHPABo/YAE1APQ+Fj42AQgCHb+oP1QBjgCkPU4+rAK0Ano+tD35gGIBcT+3PwYA+ACuPpI+2gEDAP4+yQAOAV8/DDzRP1ADbAI4PZA9ogEDAPQ97j9MArUA2D3uPtYBIkA+PtQA9AITP3A8lT+AA6QBpD3kPsABfj/yPjQAFALUAWQ+JD4fgBJANL+2AYACmD9IPQk/cgGWAMK//4BbAMs/rD6YP94BWgEsv+o/dT8QP2sAtAGBAKY+8D7x/9OASgAuADEAuABCPxY+j4ANANoAP3/hAHs/YD6iP7QBNgD5Pww+1oBcAOU/cj8tANoBMD8iPo2AYgELwCw/RwBigFU/JT8/AO4Bbj+MPtp/64Bpv4A/kgCGARG/5j7DP7hAE0AWv+NAPgA8P4S/v3/dgEkAKT+dP++/y7/CgCMAfoAzP9KAPr+yPxB/4AEKASE/qT8uf/dAET/uABQBCwCuPvw+zACVAN6/5MASASFAKj52Pu4BJAGt/+I/Pr/iwCo/Tn/sANcAgT9RP1iAfcAPP4BAFgCmP64+hD+1APYAzz/lP3+/mz+4P3gAIQDhgH0/mv/9v/C/nL+hAEUA/3/1P0ZAFgCTAD4/dr+AQCE/zwAZAM4A8T9GPuy/twBQgGGAfQCMgEM/eD7VP+sAnQC4gAUAC3/lv4uAOwBaAGi/9z96P0kAEwDuAP4/4z8vPzu/l0AAAJoA1gBTP2g+7z9hgCGAQQCRALi/xz82PxqAdgCWQCi/qX/wwAVAND/NAFUARf/Uv47AEgC0AIKAeT+lv7U/nH/RAJoBOIBWP10/FH/NgH3AIoBqAL3/3D7PP2YAhwCdP7i/p0AJf9e/moB2AKW/5z8oP2eANwBwgEIAhIBrP00/If/DANkA/ABU//o/LT99ACMAsoBVgAV/zj+vP1F/4gCKANN/8j8Vv63/4AAUAIMAtT+xPyU/R4AkAJYApb/aP1k/ej++gCUAugBrf9k/cz8K/8AAhgDpgGU/sD8Zv50AXQCqAE6AAD+/PzT/7QDnAP2/5T9QP54/2sAdAIYBLgBjPxA+4H/LANkAywCBgBQ/Yz85v5QArgDggHo/VT9dP+9AKUArgCZAEz/WP0O/iwCmAN2/1T8EP6g/2D+jP/QA7QDcP1I+dD8CALOAYb/RgAMAWb+UPzK/uQB/ABU/jT+WgBUAbb/gP6W/2QA+P5k/l4BzANaAWj9pP12APEAggAMAtgCTwDg/eT++QA2AYsA3QAQAQUA0P86Ab4BLQAS/wwAYAF4ARwBMAEAAQIAwP76/moBUANsAdD+Pv8YACb/yv7/AKACdgB4/QD+EADL/+L+cgCkATP/KP1b/4YBuv8G/pn/qADW/nD+YAGkApz/BP3S/k4BvAB2/4MAsgEGABD+B/8oAegAPf98//AAcgAq/oD+rAEMAub+YP0EAMYBWP+k/UgAxAKIAJz9dv52AB0AOP96AO0A2P5E/qIAxgHl/2L+ev/RACwAM/+7/7cAhQDm/1X/5P7K/7IB3gGX//z9Wv80ARQBcACkAPcAfQAJABEAWgDpAIgBfgFWAM3/mABsAeEAs//N/84AHgGpALQAkwBb/wn/dQAeAdH/W/+9AJ8ARP7g/ZEA6gEZADj+qv6u/0r/O/9WACwATP7k/Xv/1P/O/vr+DQBH/1z92P2WAFAB/P6o/b7+iv8R/zn/aAB8AO7+1P28/koAOgCl/00AzQAy/7T9Yv/cARYBtv5O/9gBsgGf/9L/eAGsAPT+NgCoAkwCcgCHAP0AyP9g/7IBTANsATX/2P9YAeMADgDjALYBwgBT/8H/UAGqAaoAvf/K/x0AmAAuARoBywBZALD/jv9qAFQBJgGfAI8AJwAs/4j/PgGYAfT/A//K/zUASf/i/hAAmQCD/7b+Tf+d/8L+cv4o/5r/8P5q/ur+6P4g/vD9sP7c/gj+xP2M/p7+nP18/Ur+dv7s/Qz+1P6i/sT9BP70/qz+Gv4w/4UAAgCO/qT+6P9dAE8AyQB+ARABHwB7AAQC8AK8AowCXAJAApgCeANYBMgEiAS4A8QD6ASwBTAFmAQIBRAFOARoBNAF2AX0A7wCIAN8A+ACFAPYA8QCfQCl/5YARAF/AFL/yP4u/pz9gP08/ej8vPww/FD7KPtQ+4j6YPlI+SD6yPmw+OD4uPm4+LD2MPdw+XD5wPfg92j5oPjw9hj4gPo4+rD46PnQ++j6yPng+zb+aP1Q/HL+GAGUAJL/ygEABCADwAKwBaAI6AeoBoAIwApQChAKkAzADvANcAywDbAPAA+QDVAOoA/gDmANMA2gDUAMIApwCbAJAAk4B6gFuARIA9oAc/8bAOP/RP2w+vj5+Pnw+FD30PaQ9tD0gPMw9OD0APTA8kDykPGw8IDxMPQw9dDy8PAA8mDzkPOQ9PD1kPVQ9LD00PYA+JD30Pdw+VD5SPgA+hj9lP3g+3D7aP2Q/ywAkQDeATgCsAGMAggFIAdIB9gGcAeACHAJ4AqgDCANsAyQDGANYA4AD3APoA+AD+APIBDgDsANkA5gDxAOcAyQDFAMgAnQBmAHQAi4BdACrAI0Auj+8PwA/pj9WPrg+Ej6KPpQ9/D1cPeA99D0UPTQ9mD3oPVQ9bD2UPbw9LD1QPjo+GD3QPd4+JD4wPeQ+JD6MPso+lD5CPrA+mD62Pnw+lz8EPyI+oD68Pvg+5j6ePow/Gz9+PxU/IT8VPyo+xj8QP60/63/HP8e/4f/z/92ABACYARIBeAEUAWYBnAHsAewCIAKMAwQDTANUA3gDJAMAA4AEKAQIBCgD4AOYA0ADTANcA0gDeALMAqACBgHIAYYBdQD6ALWAaz/QP4G/tT8MPoQ+fD5mPnQ98D3GPng98D0gPQg9wD4MPaQ9mj4gPcQ9eD1yPhI+Tj46PhA+iD5gPfI+AD7QPto+qD6KPvg+uj6gPuA+yj7uPsU/Kj7wPuw/Jz8WPvQ+uD7oPww/Ij8iP2w/Oj6gPt4/S7+PP2I/Tn/mP+0/t7+lADvAAwAIAGoBMAG6AVIBYAFSAW4BUAJwA0ADtAKEArQCzAMcAxwD+ARUA+AC4AMgA+QDuALwAywDXAKmAdQCdAKMAcUA/gCdAMOAXT/LgGvAOj7wPhA+sD78Pmw+MD5iPmw9oD1cPdY+BD3sPbQ97D3gPaQ9vD3YPiA97D3EPlg+YD4UPjI+Cj5kPkA+oj6iPo4+kD6cPqA+sj6aPtg+xD7sPs8/FD7YPoo+zT8wPtw+4z8LP1Y+8D5wPvc/WD8kPuK/uH//PzI+/r+UAICAR7/tAFgBNADAARoB6AIUAb4BaAJ0AyADJAMQA5gDuAMAA3AD0ARwBBAEOAP8A4QDmAOYA7ADbAMcAsQCtAIIAhwBigE5AK4AnQBH/8Y/rT9APxI+Zj4ePnI+FD38PYA9/D10PRA9QD2gPWw9GD1QPbw9aD1IPag9lD2kPbg9/j4sPgQ+Gj4GPlo+fD5IPug+yj7iPrw+kz8+Pw4/Bj8PP24/cD8aPz0/ar+7Pxc/GL+Ff8A/SD8IP7G/nz8+PuZ/ygABPwQ+4n/kAJqAHD/RgGqAeD+8//ABuAJ4AVUA7AG0AjAB1AIcAyADtALcArQDQAQ4A0ADUAPABAgDgAOQBAgEBAMkAnQCjAM4ArwCJAIIAdwAywB3gEoAn8A1P4E/sj8QPrI+Jj54PlA+AD3kPcI+PD28PUQ9gD2kPVA9pD3KPhg90D2UPbQ9lD3oPgo+tD5gPgw+BD5CPqA+tD6YPt4+yj7iPtE/HD8TPyw/BD9KP2U/Rz++P1k/Tz9pP3Q/dD9dv6C/vT8uPuk/Mz9UP1k/Ej9tP3o+1D7TP6PANz+rP3R/2wBNv+A/oQDuAdIBuAD6ATIBsgG8AcgDLAO8AvwCSAM8A3ADTAO0A8AECAOwAwQDgAPsA0gDCALAApwCeAJUAn4BhAEhAIoApQBGgG6ABn/cPzg+sj6gPr4+ej5qPkA+DD20PaI+AD4EPYA9hD30PZg9pD3sPiQ9wD28PYI+WD56PiY+Qj6APmo+Dj6FPxI/Ij7SPug+yT8CP3o/dD9qP34/T7+DP5K/h//bv+m/g7+Zv5s/ib+dP6E/jj9sPsg/Lz9cP0o/Pj7APzg+tj6/Pw+/4n/Ev7o/dD9OP3B//AEmAZQBDADkARwBmAHAAkgDCANkAtgCwAN8A1wDnAPcA9wDlAOwA+AEOAOAA2wC8AKwAoQDCAMQAnABRAEaANMAiAC7AKsATb+QPvA+lD7IPtY+oD5WPgw95D3EPhw90D2kPXA9ZD2gPfg95D3gPaQ9eD1QPcY+eD5UPlQ+PD3cPhA+aj6+Pvo+6D6UPrA+9D8uPyc/Ij9+P2E/ej9Mv8X/7j96P1v/6f/dv6A/mv/kP6w/PT8dv6o/Qj8kPxs/Rj8iPqo+9D8EPyY++T9w//U/VD8Av4SAEoAjAGIBBgGQAVQBEgF6AagCGAL4A2ADZALgAsgDWAOQA+AEKAQIA8wDsAOMA8ADtAMsAwADIAK4AnQCRAIMAWEAxwDdAJMAX0AVv+s/HD6QPqw+pj5GPiw9zD3IPZg9eD1EPZA9YD0APXw9QD2oPXA9fD1APZQ9nD38Pig+cj4sPdQ+FD6qPvg+yD8RPwI/AD8QP3O/sT+PP60/sj/qf+L/0sAbwB3/yX/mAA2Afz/C/9P/87+YP24/VD/pv4U/Gj7qPw4/LD6APtY/HD7WPrI+/T9JP2o+2D9Lf9y/hL+mgGgBBgEdAPIBPgFkAU4B5ALAA5ADHAKAAxgDSANQA6gECARMA/ADeANgA7wDUANQA1QDMAKAApwCSAIeAbQBIADzAJkAroBLQAK/gz84PpA+ij6YPq4+SD4kPag9VD1wPWA9nD2wPVg9aD1YPXw9OD1cPeA95D2gPd4+WD5APiw+Mj6OPvQ+hT8pP0I/eD76Pzk/vL+TP6S/5EAcv/S/koAWAGgAFkA9wCDACD/ZP8iAegA1v5s/g7/wP0A/OD8Lv7M/Oj6OPvY+zD6ePnQ+1T98PqI+Zz89v6k/aD8lP7x/2v/GgGYBTAHCATEAhAG4AgwCYAKoA0QDnALIAqADIAPwA9QD3APEA9wDZAMMA0QDpANkAtwCnAKgAkwB5AFkAU4BWADmgFKAbYATP4g/ND70PvA+tj5sPnA+ND28PVQ9kD2sPXw9YD2MPYw9SD1oPVw9cD1cPeA+ND3cPdA+PD4uPhA+UD7ZPzI+4D7nPx0/Yz94P3W/o7/yP8nAN0AGAGJAEcAQAF8AuwCIAIwAXYB3AH/AGcAUAFqAW3/Dv4W/6P/hP2I+2D80PxI+kD5MPx4/bj5IPcg+Yj7SPtI+0j9FP2o+ij7oP8sAiQBZgFwA9wDkAP4BVAJAAowCQAKkAvACzAMcA6AD+AN4AwgDvAO8A2wDTAOIA1QC/AKUAswCgAIaAeABwAG8ANYAwQDKAFe/wD/vP5s/fj7YPvg+pD5gPh4+Ej4gPcQ9xD3sPYg9hD2gPbA9qD24PZQ96D3gPfA95D4cPn4+Rj6UPoA+6j7IPzI/Iz9uP2M/TD+W//h/5j/4/+cAJYAGgDgADQCxAF3ALMAzgFsAY4AWAEYAm0AYP7S/u//D/8Y/ij/Rf/w+/j4YPqk/AT84Ppg+xD7kPiA9+D5HPyI+8j6CPyo/ND7WPwE/4oACgBxALQCaASYBDAFsAZIB3gH4AhAC1AM4AuwCyAMYAyQDKANgA4gDvAMQAxADNALEAuQClAKcAkQCAgHeAaABcADYAIsAvYBlwAD/x7+NP2Y+4D6yPoA+7D5CPig96D34PZA9pD2IPew9hD2QPaQ9oD2kPZQ9zD4YPhY+Oj4mPnw+VD6EPvg+4j8/PxY/cz9Dv6K/jj/1P9PAK4A9QAKARoBLgGcAfABEAIoAjgCEAKYAXIBpAFcAZ4AkgB+AX4BBgCK/lz+VP5Q/Qz9Tv6C/nD8WPoI+sD6CPtI+yj8SPx4+jD5SPpQ/DT9DP1A/dj9Yv4f/2AApAFMApgCaAPQBCAGOAfgBwAIYAhgCWAKMAvgCxAMgAvwCjALAAxQDJALwApQCqAJ8AiQCGAIeAcQBggFgATQA/gCFAJEARgA5v4e/vz9eP14/Ij7ePrA+Zj5sPlo+dD4EPiw97D3wPcI+Gj4ePgI+ND3QPg4+eD5QPqA+tD68PoQ+wT8YP0I/uD9Av60/jX/if8hALkAxwC2ACQBqAGwAXYBigGKAT4BigF8AlgC5QABAFAAQgDz/6wAfgFfAJz9lPw0/tz+UP2c/Gz9wPzg+oD6wPvA+7D5GPnQ+rj7aPoA+jj7OPuo+eD50Pzu/nT+oP1O/j//l//tAHgD6ASIBIAE4AUIB3gHkAggCsAKoArwCsALAAwgDIAMoAzQC3ALIAxADAALsAmQCTAJ0AcQB0gH6AbwBBADyAKsAoIBbwBOAKz/4P2U/Kz81PzI+4D6UPpI+pD5yPjg+PD4QPiQ9/D3qPhw+PD3CPhw+GD4SPgo+Uj6WPrY+TD6APtI+4j7tPzQ/Xz9uPxc/bD+IP8G/27/DADC/3r/NgD2AIEA9/94ABYBuwA5AJQAyAAYAKP/YwDSABwAnf8JAOH//P6o/kP/H/8W/ij+Lf/C/uD8kPyM/Yz90Pwc/QD+VP3Y+xT8nP28/ej8sP0h/8r+oP12/noA+wBTAAoB+AJ4A/gC4AOIBdgFeAWIBjAIoAhACJAIcAlwCfAIoAmgCnAKcAkQCSAJwAhACCAIEAg4B/gFUAUgBYAEkAMIA5gCmAGGACIADwBc/07+uP10/fD8PPwM/Aj8ePuQ+iD6QPow+uj50PnY+Zj5IPkg+bD5APq4+Zj5APpo+oj6sPoY+3D7SPtg+yj86PwE/ez8LP1k/UT9hP2m/oX/S/++/p7+nv66/pX/zADdAK3/Lv+2/+X/0f9sABIBegBd/6H/rwCoAMj/w/9KAN7/N/++/7wAXwAr/+j+U/9s/13/2f8zAID/kv6W/kj/eP9X/4f/wP+L/yP/LP+K/87/8P8oAF4AagBxAJwA2AAAAVgB7gF8AqQCuAIMA2ADwANYBBgFiAWYBdAFUAaoBqAG4AaAB8gHgAdYB3gHWAfgBqAGoAZYBqAFGAWwBPQDAANMAugBTAGAAMH/+P7Y/dT8YPwg/JD7oPro+WD5wPg4+Cj4QPjQ9zD3APdA93D3UPdw97D3wPfA92j4UPmY+Wj5oPmA+iD7ePsw/PD8IP3s/DT9Hv7q/mj/5/9OADMAGQC3AKABLAI0AlACjALQAiwDeAOIA5AD9ANgBEgEGARoBLgEWAT0A2gE6ASYBCAESARoBLQDGAOwA1AEuAO8AsgCLAOkAvABPALQAmACjgGgARwC5gFKAUQBuAGEARgBSgHMAYgB0wCQANcA+wDVAOgAxQBMAMH/gv+U/6b/h/9F/wr/mP4W/tD90P3Y/az9aP00/QD9wPy0/PT81PxU/Fj8AP0o/bD8rPw0/Tz9vPwA/Q7+MP6Q/dj9+v7k/uD9Jv51//v/qv9nAJoBBgFM/1f/JgFQArwCVANAA2wBCwB8AbQD3AMAAxwDDAPEAQ4BSAJoA1QC5gBMAQQCKAFgAPoA7wAW//j9TP8OAZAArv7w/Qr+oP2Y/fT+/v8K/3D9NP0I/n7+fv7q/mj/Df9M/nj+Of+p/6n/av9I/3L/1P81AFgAPAABAMn/z/+EAHABnAHeAEkAfwDvAC4BsAFkAigCGAGVACwBFAJsAjgC6gGSASQBFgGgAfIBmgEOAdQADgEsAdsAVwAnACsAEAAMAD0AOwDK/z7/3P7s/kT/nf+Z/wb/Rv4I/mL+iv54/kj+/P2E/Uj9ZP1k/Qz9hPxY/HT8WPwY/BD88PuY+xj7GPuI+/j78Pt4+wD78PpQ+8j7IPxI/Fj8aPxo/KD8QP3U/Qb+Yv4n/4j/S/9l/3YAgAHOARgCCAPYA6QDmAPABCAGiAbYBtgHkAhACCAIQAmQCsAKYArQCmALAAugCuAK8ApgCuAJ4AnQCfAIwAfgBggGIAWgBGAEmAM4AscAif98/tj9mP08/VD8IPsg+mD52Piw+Lj4ePjw94D3YPdg93D3kPeg95D3sPdA+Pj4OPlY+aD50Png+YD6yPus/Hj8MPy8/FT9ZP2w/ej+ev/c/oz+ZP8wAMD/bv8lAJ8AKwB3AOoBOAKtAIH/PwCkATwCnAIEA1QCzQBqALIBDANQAzQDFANcAoABvgHsAnAD8AJwAlgCVAJYAqwC3AI0AkoBRAEkAsACjAIQAo4B8ACKAPUA4AFUAuYBJgGfAEIANQCxAFwBWgGTAOH/1/8RAAgA2v+8/5//eP9t/3r/X/8J/7j+rP7K/ub+AP/+/s7+dv4k/hL+aP7e/uj+kP40/hj+LP5I/nL+oP6Q/lL+QP5S/lT+Rv5g/pr+nP50/mr+gv54/mj+hv7C/tr+vP66/tz+5v7m/hH/Uf9o/1v/YP+T/9H/3P/X//v/MgBQAG4AlQCqAJoAiwC1APUABgH8AP8ABAHdALAAygAYATwBGgH1AO4A2gC7AM8AEgEeAeoA1QDsAPAAwgCmANkAIAEYAeIAzgDlAOYAzgDaABwBQgEeAfAA+QAEAd0A0AAgAVIBEgG0AL4A9wDQAJAAqgDiAL0AYgBdAIUAZwASAP//PQAhAOT/7P8JALH/PP82/3r/gf9O/0L/JP/W/qT+vv7i/tL+sv66/sL+lP6C/qT+qv6U/qL+zv7u/uz+8P76/gP/Cf8k/2r/oP+e/4j/m/++/9//5f/0/ysAPgArADIAbQCBAE4APAB2ALcArACZALkAsQBWADcAkQDiAN0AswCPAFgAIgBDAJcAogBqAEsASQA4ABMAGABIAEYAEQAFACwALAAYAB4AJQALAPL/FQBuAIkAOwAHAC8AUwBaAHIAmACXAGkAVAB4AKMAqACiAKUAlwB3AHIAhwCeAJwAcwA/ADIARwBRAEEAKwAcAP//0f/P////CwDK/5H/j/+P/3f/gP+g/3v/HP/0/hX/MP8d//z+5v7G/p7+nP68/rz+nP6O/o7+iP6I/pD+jv6M/pb+qP68/sz+3P7u/vr+/v4Y/0f/cP+D/43/of/I//D/BQAdADsAVABlAHsAlACgAKcAuADNAOEA6ADvAPsA+gACAQQBCgEQASABKAEUAQABBAEaASIBGgEYARoBGgEGAfUA/wAQARABBgECAewAxgC0AM4A4wDQAK4ApACbAHcAWgBkAHMAXAA+ADEAIAD4/93/5v/p/8H/mP+T/5L/c/9S/0n/OP8c/xX/Jv8k//7+2v7U/tT+0v7m/gb//P7Q/rr+yP7g/u7+A/8e/xb//v4G/yf/P/9M/1z/av9n/2b/hv+y/8D/tP+8/8//4f8DADEARgA4ADIAUgBrAHoAnADIAL8AlQCdANkA8QDPAOcABAHyAMoA4gAkARAB0ADdABYBEgH7ABgBJAHoALEA1wAmATIBBgHnANIAsQChAL8A4wDQAJ0AeABfAEwASABVAEcAGwD1/+P/4v/f/9D/uf+a/3n/Zv9x/4P/dv9P/yn/Fv8J/wf/Ff8q/yT//P7U/sj+1v7s/gH/B//2/t7+3v74/hD/F/8e/zT/S/9P/03/Yv+J/6X/s/+6/8r/4v/4/w4AKQA4ADgARQBoAIQAiwCPAJ0ArQCwALEAxwDfAOEA1ADNAMwAzADWAOgA6QDUALcAqQCqAK8AsQCvAKAAgQBsAG8AeQB3AGUAUwBKAEcARABFAE0ASAAwACAAKQA4ADkALgAlABsACQACAAwAEQAFAO7/2v/J/7f/t//G/83/tv+T/4H/fv97/3r/gf98/2P/TP9E/0j/S/9H/0v/WP9P/zL/If82/1T/Vv9H/0z/YP9b/0T/Tf9r/3X/Z/9y/47/iv9q/2z/nf+u/5v/n//F/9r/wP+3/97/AwDz/+n/GwA6ACwAKABFAEkAOgBNAIIAlAB5AG4AfQCGAIcAmACqAKoAngCmALgAswCsALEArgCrALUAxwDNALoAqACjAKkAsgC1ALMApACPAIQAhwCKAIgAdABaAFgAWgBTAEcAPgAtABEA//8JACIAHAD0/9r/yv+y/7T/2f/t/9X/qf+I/3//i/+l/7b/qP+I/3b/fP+D/3//gv+M/4P/bf9r/4D/jP+D/3T/af9m/2z/gv+c/5j/dv9j/3T/iv+X/5//pP+h/5r/oP+x/8L/zP/U/9f/1v/e//L///8FAA4AFQAYACMAPABTAFkAUwBaAG4AewCEAJoAqwChAI4AkgClALAAsQCvAKMAjQB/AIYAkwCOAHYAYQBWAEwAPwA2ADEAKQAZAAcA+//y/+T/1f/P/83/xv+8/7X/sf+r/6T/n/+h/6L/oP+d/57/oP+i/6H/nf+b/5//pv+t/6z/pf+g/6X/q/+u/7P/uf+9/7v/uv/F/87/0v/X/+L/6//p/+f/7v/6/wEABAALABQAFwARAAoAEgAhACkAJgAfABcADgARACQAMgAuAB8AGwAfACEAIwAsADUAMwAqACgALAAuAC8ANQA5ADIAKQArADEALwAoACYAJwAlACQAJwAoAB4AEgAOABIAFQAYABsAFAACAPb/+f8DAAMA+//3//L/6P/j/+P/5f/j/9z/2P/T/9D/1P/c/9j/yv/G/8//2P/e/+P/5P/c/9j/5P/v//D/7f/3//f/6f/p/wEADQD4//j/BAANAAMABQAhACAABwAMAC0AOQAwADEANgAvACgANABQAF0ASwA2ADYAQQBCAEEARwBHAD4ANAAyADUANwA0AC8ALAAtACsALAAtACgAIAAeAB4AHAAcAB0AGAANAAMAAAD9//f/8P/v/+7/5P/W/87/zf/N/8j/xP+//7n/tv+3/7f/sf+w/7n/wv+8/7P/tf/C/8z/zv/L/8v/0P/W/9v/4f/m/+j/6//w//P/9//8/wEABwAKAAkACwASABcAFgASABMAFwAcAB4AHQAaABYAFAATABYAGAAYABUAEAAPABEAEwASAA8ADgAQABEADwAOAA8AEQAQAA4ADQAOAA8ADQAMAAwADAALAAoACwANAAwACAAGAAcACgAPABMAEwAQAA4AEAARABIAFAAUABAADAAIAAcABgAHAAcABQD9//P/7P/u//D/7P/j/9z/1//S/8r/xv/G/8b/v/+5/7n/u/+1/6//tv++/73/uP/B/9H/y//C/8v/3v/b/9P/4v/w/+3/4//o/+//7v/w//z////0/+7/9P/8/////v/+//7//f8CAAsADgANAAsACgAOABQAHgAjAB4AHQAhACcALgAxADIAMAAvADYAPQA/AD0ANwA4AEAARABGAEYAQQA7ADsAPQBDAEsARwA5ADQAMQAwADYAOgA3AC4AJAAdAB4AIAAfABoAEgALAAYABgADAP3/9//z/+//6v/n/+j/5//h/9n/0//T/9X/2P/a/9X/zf/J/83/0f/Q/87/zP/L/8r/y//M/8z/y//K/8r/y//O/9H/0f/Q/9L/1f/a/97/4v/n/+r/6//v//b/+v/9/wEABQAHAAgACQANABAAEQARABEAEAAQABMAFQAVABQAEgARABAADwAQABEAEQAQAA8ADgAMAAsACgAKAAoACgAKAAoACQAIAAcABgAHAAYABgAFAAQABAAEAAIA////////AQABAP7//P/7//v/+//7//3//v/9//r/+f/5//r/+v/6//j/9f/y//D/7v/s/+v/6f/p/+f/5P/g/97/4P/k/+f/5P/f/9z/3//m/+//9P/z//H/8//6/wMACQAMAA4AEAATABcAGgAdAB8AIAAhACEAIQAhACAAHQAbABwAHAAbABkAFwAVABIADgAMAAwADQANAAsABwABAP3/AAAEAAIA/f/7//v/+//5//j/+v/6//n/+f/4//f/+/8BAP//+P/4/wAABQAFAAQABgAEAAMACgAQAA4ABwANABEACwAIABYAHQARABAAFQAfABkAFgAkACIAFAAWACYAKgAfABgAFwAXABIADwAYABsADAD7//v/BAABAPn/9//3//P/7f/r/+//8P/s/+n/6v/u/+7/7f/u/+3/7P/t/+//8f/x//H/8P/t/+z/7P/t/+z/6//r/+3/7f/p/+f/6f/s/+7/7v/u/+//7//y//X/9v/4/wAABgAEAP//AQAKABIAEwAQAA8AEQAUABcAGQAaABkAGAAZABkAGQAZABkAGQAWABQAEgATABIADQAIAAUABQAGAAUAAgD+//r/+P/3//j/+//7//j/9f/2//n//P/9//z//P/9//7//////wEAAgACAAAAAAABAAEAAAD///7//f/8//z//f/9//v/9//0//P/9f/3//j/9f/y/+//7v/u/+7/7v/r/+b/4//g/9//3f/d/93/2v/W/9H/zv/Q/9P/0//P/8z/zP/N/83/zv/S/9j/2P/Z/97/5P/l/+X/7f/3//r/+f8BAA4ADAAHAA4AGwAaABQAHQAmACQAHAAgACUAIwAjACoALgAmACAAIgApACsAKQApACgAJQAlACoALQAsACcAIwAlACYAKQArACYAIgAfACAAJAAkACEAHAAYABkAGwAaABgAEQANAA8ADwAOAA0ABwAAAPz/+v/9/wIA/P/w/+n/4//g/+T/5//k/9z/0f/L/83/0P/R/9D/zP/H/8X/yP/M/83/zf/O/87/z//T/9v/4P/g/97/3v/j/+r/8v/3//j/9f/0//r/AQAFAAYABgAIAAgACgAOABIAEwAUABUAGAAcAB4AIAAhACIAJQAoACsALAAtAC4ALgAuADAALwAtACwALAAqACYAIwAhAB4AGwAYABQADgAKAAcABwAFAAEA/P/3//P/7//t/+3/7P/p/+b/4v/f/9z/2//b/9v/2v/Z/9f/1v/W/9b/1//Y/9j/2P/Z/9r/3P/e/9//3v/f/+P/5//q/+v/6//r/+z/7v/x//X/9//2//X/9P/1//j/+//+//3//P/7//z//f8AAAMABgAJAAsACwALAA0AEwAcACIAIwAgAB4AIAAoADIAOQA4ADIALgAwADUAOwA9ADoAMwAtACoAKgAqACkAJAAeABcAEwARAA8ACgAEAAAA/v/9//z//P/5//T/7//s/+//9P/3//b/8f/r/+j/7f/1//f/9f/z//L/8//0//j//f/+//3/+//8////BQAKAAgAAAD+/wQACwAOAA0ACgAEAAAABQANAA8ACgAHAAMA/P/8/wgADgAEAP3/+v/9//v/+v8DAPv/6v/n//L/+v/3/+//5f/b/9X/2v/s//f/6v/W/8//1f/d/+X/7v/w/+j/3v/e/+r/9f/5//f/9P/z//X//P8EAAYAAgD9//v///8GAAwADAAHAP//+//8/wEABwALAAwABgD///z/AgAKABAAEQAPAAwACgAMABAAEwAWABsAHAAXABAADwAWABwAGwAWABEADQAMAAwADwAQAA0ACAAEAAEAAQABAAMAAwD///v/+v/8//3/+//3//T/9P/4//z//f/6//T/8P/w//b//v8BAP7/9//y//P/9//9/////f/5//P/7//w//P/9f/z/+//6//p/+f/5//n/+X/4v/g/+D/4f/j/+L/3v/Y/9X/2P/e/+P/4//g/9v/1//Y/97/5//r/+n/5P/f/93/4v/u//r////6//L/7//3/wUAEgAaABsAGQAWABcAHgArADUAOgA6ADoAOgA5ADsAQgBGAEQAQQBFAEgAQQA5ADYANQAuACoAMgA2AC4AHwATAAoABwAQABwAHQANAPr/7v/v//f///8AAPn/7P/k/+b/7P/v/+v/4v/f/+L/6//w/+r/4f/Z/9r/5v/y//b/7v/g/9v/4P/r//X/8//p/+H/4P/r//r//v/v/9n/zP/X//j/EgAUAPv/1f+8/8n/9P8gAC8AFwDs/8//1f/6/yUAOgAtAA0A9P/2/w4ALQA6ACwAEAACAA4AKQA9ADYAGgD9//X/CAApADwAMAAQAPH/5f/x/wsAIQAiAAwA7f/b/+H/9/8KABAABQDy/+P/4v/x/wEABQD9/+//5v/m/+3/9f/4//D/4//c/+L/7f/w/+r/4P/Z/9r/5P/x//b/7//i/9v/4P/u//3/BgAFAPn/6//m/+//AAAPABUAEAAFAPz/+v8DABAAGAAYABMADwAQABQAFwAYABQADwAOABQAHQAhABoACwD///7/BgASABgAEwADAPP/6v/u//n/AwADAPv/7f/k/+H/5f/t//X/+P/3//P/7f/o/+n/8/8CAA4AEAAFAPr/+v8HABoAJQAhABAAAAD//xIAKgA1ACoAEQD4//H/AQAfADMALQAPAPD/4v/s/wcAHwAjAA8A9f/o//H/BgAWABYACQD8//7/EgApAC0AGAD7/+//AAAmAEcASQAnAPj/3v/q/xQAQgBSADgAAQDU/8//9P8lAD0ALAD+/9X/y//i//7/BgD3/93/zf/Q/+D/6f/c/8H/q/+r/8X/5v/1/9//sv+P/5L/s//Z//L/6v/N/7b/uP/Q/9X/xP+4/8f/7f8ZACwADADG/43/k//h/0cAgQBxACgA0v+l/8X/JgCHAKsAgwA1APr/9P8hAFsAewByAE8AMgAwAEMAUwBOADQAGQAWADAAVgBtAF0AKQDs/8//6v8rAGMAaAA2AO7/vv/B/+7/JgBDADUAAwDN/7H/vv/o/xEAGgD6/8f/of+e/7z/4v/y/+L/uv+W/43/pf/J/97/1/+9/6b/p/++/9f/3v/O/7r/uv/R//H/AwD3/9X/uP+8/+b/HgA+AC4A+//M/8j/8v8vAFgAVAAtAAMA8f8DACcAQgBFADEAFQAHAA8AJAAwACUADgD6//r/EgAzAD8AJQDz/87/1v8KAEIAUQArAOz/wv/I//X/JwA6ACYA+//X/9b/9f8UABwADgD5/+f/4P/x/xUAMgArAAQA2//L/9z/CAA9AF0ASwALAMr/tf/T/wYAOgBfAGAALwDh/6b/o//T/xwAWQBjACoAz/+O/5L/z/8VAD0ANQACAMX/pf+4/+7/HAAhAAAA4P/f//v/GAAcAAEA2f/N/+//LgBbAFEAFwDV/7T/xv8GAFcAhABqABoAyv+n/77/AgBOAHgAZgAhANT/p/+p/9L/CwA4AEMAKQD5/8r/qf+f/7P/5v8lAE8ARwAGALP/gf+V/+b/OgBZADoABQDl/+f//f8IAPn/5//w/x8AWgBoACsAw/94/4T/5/9hAKMAewD4/3D/Rf+d/zkAnwCJAA8AlP9v/7j/OACPAHUA+P9+/3H/3f9tALcAhwD//4D/Zf/I/2IAvACUABEAlf91/7n/KgBvAFYA9P+W/4T/yP8oAFQAJQDB/37/lv/2/1QAbQAwAMz/hP+N/+P/SwB4AE4A7/+c/4v/xv8iAFIALADS/5f/tf8QAFgAUAD0/4P/V/+g/zUAqQCcABMAdf8q/1z/6f97ALEAZQDT/23/eP/X/zgAVgAtAPL/2v/4/yYAMwAQAOL/2f8BADkAUAA3AAYA6f/2/yQAUQBeAEoAJwAPABAAKQBJAFwAUwA2ACEAJwA3ADAAEQD0//j/IgBUAGQANgDY/4T/gf/X/0YAfQBVAPb/mv9x/4v/z/8VACoABgDS/77/0f/o/+r/3f/N/8X/1P8DAD8ATQAMAKn/b/+I/+P/QgBvAFEA9f+U/2r/lf/s/y0ANwAgAA4ABAD3/+H/z//P/+b/HQBeAHoATwDs/5b/jP/Q/zAAcQBvACkA0f+p/9L/JQBVADwA/v/W/97/DQBAAFIALADa/6H/sv8DAFMAZwA3AN3/kv+Q/+b/VgB+ADkAyf+S/7//JgBxAGEA+v+M/3j/2P9kAK8AeADl/2f/UP+p/y8AiAB8AB0AsP+A/6P/8v8xADYACQDW/8z/8/8nADUACADB/5b/tf8eAJMAtwBZALD/Pf9Z//D/mQDoALYAKgCd/2T/mP8GAFsAZgA4APn/x/+x/73/5v8FAP//4v/W/+T/9P/q/9z/6f8OACsAKAAFANP/sf/A/wsAZAB0ACQAu/+Z/9L/JABDACYA8//T/+j/KQBlAF0ABQCh/4r/0P87AIQAgQA3AMj/df9+/97/QwBUABYA4v/t/xQAFADm/7f/sP/g/zYAfwB3AAoAhf9V/5f/BQBTAGgASgABAJ7/Yf97/9n/MgBKACUA8v/Z/97/8v/7/+X/w/+6/+n/QAB2AFQA8/+g/5P/z/8sAHkAhgA8AND/mv/M/zkAhwB/ADAAz/+Y/6//EQCBAJwAPgCs/1//kf8KAGUAYQAVAMT/rP/n/0kAcwA0AMP/k//f/2kAvQCdACMAnf9k/6r/TgDdAOAARQCA/yD/Z/8gANAA+gB8AJ7//v4b/9//sADwAH8A0f9n/2f/p//x/x4AHwAIAPr/+P/p/8L/qP++/+7/CwAIAAUADAAHAOv/zf/O/+7/BwAAAOf/3//3/xUACADN/5z/rv/6/0UAXQA4APf/xf+//+P/BwANAAwAIgBAADQA8f+2/77/9f8hAC4AMQAwABMA3f/H//P/PABeAEcAFwDr/9T/6f8pAF8AUgAUAO///P8HAPT/7/8gAGIAZAAQAKv/if/B/yoAeQBkAOv/a/9c/9H/VQBkAPj/kf+U//D/SgBXABQArf9e/2f/3P97ANgAsgAXAFr/4v4F/8X/rAAaAccA/v9P/xn/Y//s/2AAfgBMAAkA4//X/9j/4f/k/9b/zf/9/18AlABJAKn/PP9T/8//WQCmAJYAMgDC/5j/vv/9/xUAFwAmAC8AFQDu/+7/FQAtABcA+P/w//r/CQAlAEwAVwAyAAQA9/8JAB0ALgBEAEQAFQDW/8f/+v81ADkADwDn/97/5v/v//n/CAAVABkAEgD5/8P/jv+K/9b/RABzAD0A3v+u/8T/8f8HAPr/4v/m/xgAYwCGAE4A3v+S/5r/2v8YACcAEQDz//X/FwAlAPT/mf9p/6j/OgC1AMAAUQC7/1v/YP+4/zMAnADCAIgA/P9n/yP/Zf8VAMIA5QBfAJz/Q/+T/y4AhgBkAAQAwP+5/+D/EQAvAB8A4/+f/4T/nP/h/z8AggBoANj/Nv8Y/6b/bQDNAJgAFwCi/3H/lf/7/14AcQA4APn/4v/q////GgApAAcAuf+O/8z/SwCPAF8A/P/F/9L/7//u/9b/yv/c/xAAUwB2AEkA4f+X/6j/7/8YABAAEgBCAHEAZAAkAPH/4v/g/+X/CwBSAIMAaQALAJ7/Xf9p/8T/SQCdAHUA5f9Y/zT/jf8kAKEArwA1AHv/C/9L/xAAxQDdAFYAn/9E/4D/EgBuAEQAx/9//7j/PwCcAIAABACL/3X/0P9IAHMAQgD5/9b/1//h//X/GAAzACgA8f+v/5H/tf8bAIQAlAAzAKn/cf+5/zoAhQBmAAwAyv/N//3/GgD6/8H/v/8YAHsAcwD0/2X/P/+M/wwAeACbAGAA5P+C/3f/oP+7/93/NACOAHQA3f9d/2n/0f8fADgAQgAuAOn/vv8GAIYAlgAPAIX/cf+u//z/bQDzAAIBPwA3/9D+Sv8SAJwAwwCEAOf/TP89/9f/kADNAH4A9P90/zb/dv82AAABKAF/AI3/DP9D//P/nQDTAHgA2P9+/6z/HwBjAEkAAgDY/+b/HgBYAF0AFQC4/5z/0f8WADEALQAoACEACQDj/8L/rP+t/9r/KgBqAGgAMQDp/6D/V/85/4j/NQDQAOoAcACf/+r+xP5k/2oADAHPAAQAZf9X/8D/SgCTAFQArf81/4D/YADvAJcArv8O/yv/4P+3ADIB6QDb/8j+nv6J/6kAFAG4ACUAuf+E/5f//v9kAEIAqv9h/9v/oADuAJ8AFACY/0T/Vv8DAOwARAG8ANr/Vf9d/7H/HAB2AIIAIwCp/43/2v8fAAYAv/+z/wEAWQBfABYAwv+c/6r/2v8dAF4AcAA0AMn/b/9Y/5H/AwBpAHAACQCY/5X/AABiAFYA6v99/17/rP89AK0AoQAUAGX//v4P/5n/aQAIAfUALgBb/yn/o/8+AHMAMgDQ/7j/CwCJAKkANgCI/zH/Zf/b/zQAUwBLADQAHgAYACMAIQAFAOX/3f/y/yQAbQClAIIA8f9g/1r/6P95AIoANQDv/wQAVACOAHgABgB5/03/z/+mABABtQDv/2H/Nv9N/5H///9iAFwA+/+v/73/7P/2//r/IgA9ABQA1v/k/zEARwD8/63/p//R//n/IgBXAF0A/P90/07/uv9HAH8AXgAlAPr/1//M/+z/EQD8/7j/sf8SAHwAbADk/27/c//W/0YAiQCAACEAsP+g/wcAZgBCANf/xP8kAHIATADk/63/vf/k/xIANQAvAO//qf+k/+D/LABYAFUAGACg/zv/Wv8WAOEA/gA6ACr/pP4X/zYALgFAAWkAWf/q/l7/LQCtAJAADACe/6f/LwC7ALgAFwBc/xv/fP8wALYArQAPAE//Bv93/00A8wAAAWYAc/+2/rr+k/+pADgB+ABGALH/jv/I/w0AFgDi/7X/zf8tAJEAtAB/ABUApf9U/0L/hP8HAIQAqABZAOf/rP/A//b/DQDh/4j/Xf+w/3AAEAH+ADUAO/+6/v7+1v+2ABABugD7/2T/X//j/2sAbQDy/4n/rf87ALAAugBZALP/If8e/8D/eQCqAGkAOQA1APX/cP83/57/PwCKAHgATQALAJr/R/+K/zoApgBtAPT/tf+r/6H/uP8SAGEAOgDK/7H/FwBwAEMAx/95/37/uf8OAGIAbgAJAIT/Y/+9/zEAVAATALD/ef+R/+j/RQB4AHYASgD9/6r/f/+k/wgAfgDAAI4A6v9F/zb/1f+UANEAfgARANf/1P/t/xkAQABBABYA5f/V/+T//v8jAD4AJwDd/5//wP88AKIAfQDi/2n/k/9DANcAywAvAHr/OP+X/0sAsABoAM3/kP/T/xcABADg/xQAfwClAF8AAgDY/9n/3//T/73/rv/H/xgAYQA/ALD/N/9a/+f/MQDu/5j/vv89AHwAPgDm/9T/7v/x/+D/4f/o/9r/2P8EACoA8v+K/4f/BwCGAIoASwAsABMAxv+I/8P/RwB2ACYA1f/m/x8AHQDZ/4v/XP92//7/uwAQAZ4Aw/9A/2z/CwCmAOUAqgAkALv/s//n/xIAJAAuACwADwDs/+L/5v/d/+T/IABnAGEAEQDX/+T/9v/E/3z/c/+5/yEAlwDwALsArf9g/gr+Jf/HAKYBaAGeAMn/GP/K/jf/JQDWANAAWADn/4f/If8C/4T/SwCRACQAr/+4//v//f/O/83/7//t/+X/OwDQAO4AUgCY/2D/jf+5/9r/HgBaAEsAJAAvADsA8f+c/8v/VgBvAOT/bf+T/wsAWgCCAJQARgCa/y//ef8CAB0A8/8dAJEArABEANX/uv/f/yoAngD9AMQA+P9Z/3H/CwB6AHAAFwC7/5z/zv8jAEwALQD0/8j/kf9J/y//jf9FAOEA/wCQAMj/Ev/q/mz/LACaAIgASwAjAAMA3f/T//j/GAAUAAwAIQAtAAkA2//J/7T/if+f/zUA3ADdACIAT/8A/0T/0f9dAJEASQDS/6X/2v8eADEALQA7AD4ADADE/7//IgCeAKgAGABl/0P/4v/KADoBzAC5/7T+gP5I/3IAGgHjADYAof9d/2//u/8WADgACwDL/7z/3P8PAEIAUgAOAIL/I/9p/zMA5wAAAZkAFgDI/7f/uf+8/8L/4P8jAH4AvgCkACIAgP8j/zD/f//O/xAAUQB/AG4ADgCg/3v/pv/Y/+f/+v82AGwAUADu/6P/q//p/zkAlwDPAIgAyv83/2D/IgDSAPIAdQCb/9z+0v6u/80ANgGVAJD/BP9A//b/hQBvAL7/Ff8n//f/4gA4Ac4A9f89/xv/l/8uAFsALQAPACUANQAjACgASQBEAO7/gv9h/6b/JgCfAMIAWgCi/y//cP8qAKEAYwC2/0D/WP/Q/zwAWQAvAAQAFgBXAFwA5f9M/zD/xv+BANIAsgBhAAAAnf9v/4r/sP+4/+v/ewDlAIYAoP8n/2f/wP+//8L/FQBFAAIA0f8uAIQADAAj/9r+Xv/5/2wABAF0AeIAdP+Q/gH/BgCPAJkAkQBbANX/jP8DAMMA5QBKAJn/OP8j/4D/YwBEAUIBQgAi/8D+Nf8OANQAFAGSAKj/Lf+O/0QAkQBnADEAHQAWACAARAA5ALn/IP8n/9//igCiAGIAMgAOANX/sf/G/9v/wf/H/zwAzgDoAHYA5f9t/wb/3v5a/2EAKAEMAUcAeP/0/uj+d/98ADQB7ADm/yH/Kv+9/18AwwCfANL/5P7E/rj/xwDNAOH/G/8+/xUA+gBgAQQB5/+m/kb+Ov+7AIYBLgFiAOH/sP+I/3j/p//W/7T/jP/2/8sAJAGYAMX/Yv9l/4D/0/+IABgBzQDZ/zH/V//k/0oAdgB6AD8Azv+O/8L/GwAoAPn/AwBlALsAkQDt/1H/Lf+A/+n/KQBOAHIAYgDt/1D/AP8t/6n/MQCQAJsAWAAcACQAOgD4/3L/Lf91/xMAngDVAJgA9/86/8j+2P5d/yoA8QAyAa4A0v9h/47/5f/3/9D/wv8CAIkAEAEiAXQAbf/M/ub+av/k/0kArADmAMMAXQACAM7/of+B/5b/5f9BAI8AvgCeAAAAKP/O/lD/LwCTAEoA6//2/08AgQBRAOL/d/9h/9z/ugBOAQ4BLQBv/1H/jv/C/+3/NQBtAEUA6v/S/wsAJgDu/8X/6/8TAPD/vP/X/xMA/v+r/5X/4P8nADIAMABKADkAyP9Y/3X/GwClAKgAVAAKAOT/z//R//D//f/O/5v/1/9qAK4AOwB9/zz/qP82AGwAUAAWAM7/nf/A/x0AMQDN/4T/4P+HAKEADgCG/5z/FABjAGkATAAgAOr/0f///04AdABPAPv/ov9l/3f/9v+eANEANwAz/6D+Bv8gABABGAE6ADL/2v5s/04ArwBYALb/W/+V/0MA7QD3ADgATf8G/4v/VgDSAMAAMgB9/zD/rv+pAFABHgE3ABz/Vv5S/i//cgA4ARABXgDW/8D/6//z/6n/MP/+/mv/WQBAAZwBRgF1AIf/4P6+/h7/zP99AOYA1gBoAAcA8v/9/97/jP9F/0n/v/+MAD4BQgFlACz/Zv6Q/nz/iQAQAdEAHwCB/1v/rf8jAEAA0f9S/3X/VAAwAUQBmgC8/w7/0v5C/y0A2gDDAE0AJwBBAP7/bf9E/8P/TwBaACEAFAAUANH/iP+0/y4AUwD1/6T/wP/6//f/6v8VADQA+P+t/+T/ewCzAEAAsf+b/+j/OABcAFsAJwDH/47/vP8ZADQA6P98/1f/l/8JAGIAcwBVADUAFQDU/4P/Y/+i/x0AkQC6AGkAv/9A/27/HQCXAGgA9P/b/xcARABAAD8AVwBaADIAAwD6/w0AJgA9ADMA4f9x/0z/sP9HAHwAGwCX/43/FQCmAKYAFQB//1T/of8gAIIAfwAXALj/yv8SAPz/kf95/wYAqwC3AEEA5P/j/wAAAADn/9v/8P8pAHAAeQAQAG//F/9M/6z/t/99/47/LgDSAMkAIgCZ/57/5v////D/AwAzAE8AWABeADsAxf9b/5D/OgCWAD0Auv+f/77/uv+//xUAdwBuABMA8v8oAEMA/P+T/1n/Zf/D/28ACgH+ADkAY/8t/5//PQCSAHcADwCx/77/NgCZAIcALgD2/+//3v+2/6D/rv/Q/w8AYwB8AA8Acf9L/7f/EQDe/4H/mP8gAKYA7gDkAE4AKv9Q/sb+WgCiAZIBmQC6/0j/Cv8T/6T/aQC2AG0ACQDi/77/dv9e/8D/PgBDAOP/wP8TAFcAJgDF/63/yv/S/+P/UgDcAM8AGQB//4n/4v8RABsARwBxAF4APABHAEAA3/+A/6j/GAAPAI3/Zf/x/5YArgBiABQAtP9F/zL/uf9MAFQAJgBeAMkAowDk/0//V//D/0YAuwDcAFIAeP86/9X/lACuADcAvv+O/7f/KwCfAKUALgCq/2n/SP8p/1X//f+/APEAbwCs/x7/9P47/87/WwCYAIkAdwBtAD8A+P/f//v/9P+1/5P/0f82AGAARAD4/5H/Uf+v/5MAGAGcAKD/Kf96/wIAQwBFACAA5P/H//T/MAAdAM//qP/D/9n/wP+z//j/fgDfALUAEwCZ/9r/ogAeAcEAzP/q/pT+9v7k/8sABAGCAN7/k/9+/23/eP+6/+//3P/P/x0AlgDPALcAZQDM/wn/tP5V/28ABgG4ACgA5v/e/9X/wv+7/7H/uP8PALAAEgHDAAMAcf9I/07/aP+4/z8ArQC8AHoACwCT/1L/cv/C//D/9v8fAH0ArgBuAAMA3/8DACsAQwBBAPL/V//+/nD/bQASAdwADAAo/7L+DP8tADQBJAENAB3/Lv/7/8sAGgGyAKn/sP6u/q3/uQD1AIUA+/+c/2P/cv/L/wsA8v+4/8D/EgCFAPoAMgHTANP/xv5m/gD/KwAcARoBPQB4/43/QACnAEUAdv/q/gz/2P/cAGgBEgEqAID/hv/t/xEAzP+M/6L/3v/f/8L/3/8zAF0AMQDt/7j/f/9g/7v/fgD6AL8AJwDY/9r/zf+l/7D/8v8NAPP/AQBcAJAAPwCv/2z/lf/P//v/RACeAJwALQDJ/63/hf8o/yD/2//VACQBqQD//57/e/+Z/x0AvQDZAGMACgA4AHIAHAB+/2j/9v+AAJcAZAAQAIv/Kf9o/x0AaADm/0v/Y/8VALcA4QCNANv/G//Y/mL/WgAEAfoAhQAcAPz/AAADAAkAHwAWAMn/d/+I//X/WgCUAMAAoQDG/5T+IP7Y/uz/hQCgAH4AHACy/8r/WABwAKf/1v7q/rb/dgDeAAIBxQAeAJv/nv/M/6j/ev/O/3EAwgClAJAAbQDL//r+4v66/44ApABXADAABACd/3D/0/8qAML/E/8x/ycA7AD1ALsAcgC9/87+vv4EAHQBqgHIAOX/hP+C/8//XACZAB0Agf+2/4wA2wAwAEv/8v4V/2X/4v+DAPMA4gBfAJv/yP5i/sr+1f+3AOwAoQA+ABEALQBcACgAav/K/hr/IQDxABoB4QBlAJL/5v4p/0IA7gBrAHH/Hv+O/zUAwgD/AIgAYf+C/tT+9f+xAGgAp/8z/0r/yP+DABgBCAExABr/ov5C/5wAzgEMAiwB0v8C/zf/AACMAG0A2/9d/2f/DQDTAOsADQD0/q7+Vf8cAH4AqgC9AG0AzP+J//T/XgAnAKH/ev+6/wcAaQDtABoBeACE/yr/nP8uAE8AFgDl/+7/JwBtAJYAgwAbAF3/iP4s/qL+ov+NAA4BJAHKABwAkv+A/4v/O//y/nf/swCSAWwBwQBPADEAGgDr/5z/IP+4/uj+3f/qAEoB6gBYAOX/hP8k//D+If+w/0cAlABzACcAEwBQAJMAZQC2//7+0v5m/2gAOgFAAYEAq/9u/8n/KAAlAOP/xP/v/0gAmQChAEYAsf8w/wD/JP96/9D/CAAyAGsAkgBsAAoAs/+F/2H/Uv+h/1IABgFQASABnwDv/0r//v5A/8v/LwBOAGQAjgCKAB0Ahv85/1T/mv/r/1QAjwBKAMv/sP/0/+v/c/9B/9n/qwDZAF8A3v+o/53/t/8MAHsAuACjAFUA+P+y/6z//P9wAKUAUgCS/+j+1P5o/xcAZQByAI0AjgAJACH/pv4K/9X/bwCwALsAhwAnAPv/JQBGAAcAoP96/6T/8/9gAOgAQAHxAPn/AP+2/j7/HAClAIUA/f+Z/7H/HABSAOX/Jf/i/of/iAAQAdcAMQCU/zX/OP+s/1EAvgCwAEgAyv92/4H/+/+AAIIA3P8v/z3/CQDUAOUATQC0/4T/pP/H/97/9f///+7/6/8YADEA5P+S/87/XwBrAMb/TP+h/0MAfQBsAHkAaQDs/37/uP9HAFMA6P/d/3IA3ACOAAsA8v/9/8D/ef+T/+H/BQAvAKwADAGXAJX/G/+N/ywAKgCf/0T/hv8zANYA9ABoAIj/8P4I/7v/jgAEAegAawDw/6v/nv/d/4MAMgEqATEAFv/W/mn///8tAB0A5P9g//L+Rf8kAJMAMwDI/+r/JQD+/9//JgBLAND/U/+f/2MApwBKAP//AgD+/9f/zv/O/3z/Jf+n//sA3AFWAQIAIf8b/3j/3v9IAHMADQBu/1f/9f+RAIwAEABx/87+kP5c/xQBaAIcAnYA7v6Y/lL/PwCeAD0Amf+C/0kAUAGCAYMAGP9e/rb+nv9VAIIAYQBeAJUApwBBAJP/Kv8v/17/ff+d/+H/TADAAP8AuADE/67+Vv4m/4MAcgF4Ad8AOADJ/57/pf+q/33/S/+D/zwA9QAOAXUAnf/u/pb+qP4x/wgA0ABAAT4BzwACACj/wv4c/+b/hAChAGEALAA7AGAAUQD3/4j/Yv+n/yQAgwCeAIQAVAAsABMA/P/T/7D/wf/0//j/wv+s/+v/NwAwAO7/w//H/8v/z/8FAFAAUAAHAAAAbQDIAJgAKgD///P/sf98/9r/kQDdAKEAbwBhAN//3v5i/gX/JQDDALwAfQAkAJv/K/9C/6z/1v/F/wQAlAC3AAsAWv+H/0QAjAA2APn/JgBQADkANwBVABAAZv86/xoAIAEMARMAZ/9z/5n/iv+0/ykAQADM/5b/FgB3AOb/Gv8z/wwAjwBWAA0AKQBcAEwAGwD4/8z/of/V/44ASgFQAW0AP/+S/qj+I/+i/0AAAAFUAasAev/Y/hj/mv/i/xEANwAJAKv/1P+yADgBfwA//9b+a/8KAD8AZQCaAHQA/P/d/zgASAC2/03/u/9qAHkAFQD8/yQA/f+a/4//yv+t/2r/2v/kAFABiACB/0j/nv/c/w0AhQDeAG4AiP8o/4b/4v/T/9f/TQDEALEAUgAfAPL/bv/U/uD+o/9kALcA0wDgAJQA1f86/z7/m/++/6r/zv89AJoAuADGAMMAYACU/+j+3v5V/9D/EQAqADgAOgArABgABQDZ/5T/cf+b//z/ZACzAN0A0QB0AMj/DP+w/g3/DQAGAUwB7gB6ABoAjf/6/uz+Zf/G/93/MQDpAEwB6gA/AMv/Uf+e/kD+yP7r/90AQAEqAbsAIQCw/4X/gv+J/4v/iv+o/yoA9QBeAe8AGgCY/3D/TP9K/8f/dgCOAPP/a/+A/8v/8/86AKkAkgC2//7+TP8ZAEYA1f+2/yMAbwBOAEAAhACiAF8ALgBFACYAgP/y/kf/NwDRAL8AewBhAEgA//+5/6f/l/9i/1D/tf9qANAAlgATAMH/u//V////LwApALr/O/8//9v/dQCmALQA2gDYAHYAJQAtAC8Awv9H/17/1v8cACoAZACuAIMA0P8n/+b+3v7m/kn/JgD2AAwBfgAFAPP/8v/A/7D/BABrAGsAEgDE/7X/zf/r/xwATQBGAPb/uf/t/2YAkgAbAHD/L/93/+D/HwAzAAsAqP91/+//uADBAMv/2P7I/nL/KwC4ABoBFgGlAFUAiwCyABEAC//C/n7/WACbAH0AVQD0/1//Nf/I/2AAIQBa/xn/xP+xABQBwAAQAHH/Qv+g/y4AXwD9/3P/bP8kAPMACAFgALz/lv+z/7P/xP8nAIsAewAbAPr/OgCEAIYAHwA0/xD+mP2E/lAAnAGgAbQAsv8W//z+V//c/yIAFgAPAEgAnwDvACwBKAGCAFj/cP6A/nb/iAAIAbgA8f+A/+7/tgC7AKv/bP4c/vj+cAC6ARwCTgHW/8b+rP4p/7D/EgBUAF8ANQAaAEoAqwDnAKsA1f/S/nT+R//KANQB0gEGAfH/+v6u/lT/OgBXAMT/i/8FAHwAdQBXAFgABQBF/+j+h/+JABQBAgGXAO7/Mv/0/pL/aAB2ALT/Gv9l/04A/wD3AE8Abf/a/hH/EAASAS4BcwC4/4b/sP/c/+//8P/J/4v/hf/b/1UAnQCqAIwAKgCL/yD/VP8EAJ8AqgA7ALX/af95/+r/fwCtAAwAEf+0/nb/zwC0AZIBigBM/7r+Pv9dABIBzwDu/zf/Iv+V/xsAQwD4/5n/if/O/yQAXwBzAE8A9v+0/8v/GgBXAGIAOQDm/3j/L/9Y//X/ngDXAHUAy/9i/3X/3v9UAJoAhwATAJj/pv88ALAAbwDB/0r/L/8v/0z/u/9kANIA0QCgAGAA6f9D/+b+Ov8JAMIACAHpAIsA8/9W/yP/iP8cAEkA+P+g/6b/BABfAIcAcAAWAKD/a/+y/zUAgABkAA8Azf+j/4L/mf8LAIYAhAAAAHj/Tf97/+X/dADTAJkA+v+y/wAAUAASAJD/Yf+Q/9f/IgB3AJMATADq/7//uv+v/7X/6f8aAAAA1v8SAKsA/gCAAH//yP7y/sb/hgCdACEAo/+v/00A8QDqADMAfP9j/9D/JgAJAMr/zv8RAEkARgAOALn/fP+Q/9r/8f+e/1r/vP+LAPgAtAArAM3/nv+P/7z/CwAOAMz/5f+PABQBtgC4/wL/Bv+g/2cA6QCxAOz/c//J/10ATQC4/2T/l//a//T/GABKAFgARgBOAEoA3P9D/0//LwDyAL8AAwDJ/0QAxACwACsAm/9A/07/3v+RAMAAOQCV/4X/6v8iAOX/mP+Y/73/t//C/zwAzQC9AB0At//M/+b/5v9FAN8A0wD4/3j/BgC9AIgArf8o/yb/Tf+z/4IACAGOAJ7/Tf+k/7j/UP8q/6b/NABxAKcA4wCoANX/FP/s/if/cv/i/30A4wDEAHUAXQBXAA0Alv9d/4D/1f87AK8A6gCnAAkAfP89/yb/H/9e/wkAwwAAAaUACgCO/yz/6P4G/6f/YQDIAPQALAE2AZQAhP/0/jH/iv+S/8X/dgAKAf4AugCmAEsAWP+q/h3///8eAKn/sP9XALgAhQBTAE0A8f9K/xz/jv/M/13/H//o/x4BhgHnABIAhP8q/xD/fP9TANsApwAxABAAHgD4/7T/pP+s/3z/TP+g/1YAtwB5AA8A4//U/8z/BQBzAIoAFgCm/7r/FQAxAAMA1v+z/4L/gv/l/0YAIACp/4z/8/9qAKMAuwC3AFAApv90/xAAxwC9ABoAqf+a/4P/bv/O/2kAawDB/1//2f+JAKIASAAXAA8Ayv+D/7//VQB/AA0Av/8DAFIAGwC9/8v/BgDj/6X/8v+bAMgAUAD//zkAaQAXALf/vf/M/4L/T/+2/0sATQDd/7P/4v/O/27/cv8OAJQAdgAIAMr/0v8HAG0AzwCqAO7/Vv96/xEAcwBtADMA8//I/9X/BwAcAOL/lf+O/87/GQA8ADoAGADO/33/Zf+2/x8AKwDp/9n/NACjAMMAmgBBALD/E//6/qb/ggDQAJcAVAAmANH/fv+i/yQARwDM/2j/qv8nAEAAFgAIAPH/lP9V/63/RABmABgA9v8TAOf/cv92/zUA4wDEACUAy//c/xYAewAAAfsA7P+S/kb+SP9pALYAggBoAEgA1f9p/4L/2v/Y/4L/bP/B/xoAUwCqACgBOAF1AFn/vP7g/l//5v9lAKcAdQAhAEIAyADzAFkAdf/8/hr/nf9PANUAtgAEAHn/i//W/9X/oP+U/6z/u//d/ygATQAQANL/AABYAD8Ayv+z/zYAwwDLAHwAPQD6/4T/L/9n//L/NwAwAFgApwB6AK//G/9h//v/BgCU/1f/jv/m/0kA5QBAAaIAUv+a/hL/2/8XABsAdQDEAJAASwBwAHoAzf8K/zT/AgBOAPj/8/93AKIAIgC+/8v/jv/M/ob+aP+cAAoB0wCQADAAdf/0/m//jAAQAYgAtv90/9D/YgDbAAYBoACv/+L+8P7M/7IA8gCcACEAu/91/4H//v9/AG0Azf9I/2L/AACnAN0AfgDX/3X/q/8vAGEADwCh/4f/z/9UANQA5ABRAJH/Yv/T/ycA4f9t/23/2v9OAKYA7ADWABsALf/W/jn/qf/m/1AA8gAWAW0Aq/+T//3/KQDn/5P/U/8s/2j/QAAqATIBKwAM/9L+c/8iAGoAUADv/33/f/9VAHIBtAGlACj/bP60/n7/WgDyANwAAQAv/1L/OACwACoAZ/9N/73/MwC0AEABRAFVABv/nv4L/6r/CABLAIMAZgD9/87/GABiACUAlf9Y/7T/TQCpAKEAWwAIANj/5v8LAAYAqv8l//b+e/90ABQB3wA1AND/0v/c/9D/4f8PACAABADx//7//v/b/77/t/+f/3b/iP8KALgAEgHSABkAYv8S/0H/s/8cAHwAzgDGAD4Am/9m/4b/fv86/yj/if89AP8AjAGMAb4Amf8B/03/7P8iAPD/3/8mAF8ANQDX/5j/e/9q/4r/+P9zAKEAfQBQADEA9/++/9j/OwBmACEA5f8uALoAwgAAABv/zP40//D/lwDTAH4A3v+N/+n/eQCFAP3/hf+M/8X/4f/+/0gAgABcABYACwAlABcA7P/0/x4ACQCx/47/6v9xAKEAWQDw/6f/e/9r/5z/CQBIABUAtP+d/93/EwANAO7/5P/j/+X/IgCOALwAXAC3/37/4f9bAGoAMwAXABoAEAABAAYA9f+v/4b/yP8gAPL/Vv8T/6H/eQDKAHAA4P+F/3j/rP8NAGQAfgBUABQA8f/5/zUAlQDKAHcAoP/c/uD+yP/nAFQBugCU/9L+Cv/u/4gAKwBH/9L+S/9YAD4BbAGuAGb/fP6o/pL/WQCBAD8A/f/y/z8A3wBoAUABUgAp/3D+gP5J/3kAdgGkAQQBMwDC/6v/kf8u/6L+Wv7K/uX/DgGYAVABkQDF/yf/2P7u/mH/BACaAPoACAHHAHMAOgAFAKn/Nf8B/1j/MgAYAXYBBgEHABP/rv4E/9L/hgCiADUAyf+0/9z/9f/e/4j/Cf/K/kv/aQBKAUIBjwDk/4X/av+h/yIAjQCFAEsAYACtAJYACwCn/7n/3v+r/1//bv/G//L/7v8UAFcAQQC8/2D/lP/4/w4A9v8OADkAJgD2/xAAVQA3AKj/T/+k/1QA0ADdAKQARwDj/73/5/8OAOT/gP9A/2v/4v9WAIgAaQAlAO//wP98/0X/Zv/z/5UA6QDLAFQAzP+G/7f/KwBgAB0Axf/W/y0AVgA0ABQAJwBBAC4ABgAHAC8ATQBFAA0Aqf9K/0L/sP84AFgA/f+p/9f/bwDUAJYA7v94/4L/6P9KAHAATAD0/7n/0f///9f/e/93//P/agBWAOT/q//d/y4ATwBAADcASwBpAHkAWAD5/4D/Ov9X/5T/mP9y/5r/OQDNAMEAMgDF/8n/8v/k/7r/wf/4/ycAQwBfAGAAFAC1/7L/9v/+/5z/VP+X/xEASABSAHgAngB5ACUA//8LAOz/j/9I/1v/tf8vAKoA4wCRANH/O/9D/8P/OgBTAB0A3f/U/yUAnQDAAFoAxv9+/4//rv+5/87//P8qAEwAYgBLAOf/g/+V/w4AUAD+/5f/uP9NALsAtABPAKf/4v6O/jf/fwBCAeUAAQB//3v/j/+v/xAAhgCeAFIACQAEAAkA6v/Z/wcALQDo/2b/Qv+p/xcAJQD//wEAHwAfACAAXgCiAG0A1v+D/77/GQAyACkAQwBYADIA/v/z/+P/nf9q/6D//v8BAM3/+/+cABAB5gBkAPH/k/9Q/2T/2f83ACoADQBFAIkASgCr/1j/jv/1/0MAaABPAN3/b/+Z/0MAvQCQABUAzv/J/+f/GwBGADEA5P+x/7//2//g/wYAdQDYALQADQBf/wf/DP9V/8P/JQBJADgAMwBGADsABgDe/9b/s/9v/2H/wv9DAHcAXgAzABQAEQBYAMgAzQAgAFX/L/+v/zAATwA6ACAAAwDz/wMAEgDn/5f/Y/9b/1P/RP9y////qgD8AMEAPQD2/yoAjQCVAAkAQf/W/iD/9//hAFIBGgF3AN7/jv90/3X/i/+3/9z/5f/4/zQAdgB/ADwAw/81/9D+8v6w/4oA2wCHABUA7f/7/wgAAAD6/wQAKgB3ANAA5ACBANj/Wf81/0r/gv/o/20AygDAAGMA7P+F/0v/Qv9U/2j/if/c/1QAoACGAC4A9f/v//H/6f/X/7n/pP/a/34AMgFcAckA3v8i/+7+Wf8pAL0AkwDg/2r/m/8bAGQANgCr/wb/wv5D/0kAEgESAX4A3v97/0z/Vv+V/9b/9f8JAEkArgD/ABAByAAmAFz/0P7g/pf/jAAoAQwBaADf/83/9f/X/1X/yP6m/hv/8//FACQB6ABQANL/rP+5/67/jP+f/wYAeACSAGoAWQBrAFcA/f+d/27/bP+T/wYApwDxAJ0AAQCt/6j/nv97/4X/zv8KABoAMgBsAHgAHwCp/4T/u//4/xwAUgCaAKUAYgAhAAUA0/94/1//0v9tAJwAXwAkACEAIgASABQAHQDx/57/iv/Q/w4A7/+5/+j/YACUAE0A2f+I/2D/ff/7/5MAsgBBAM//3/89AGAAGwCn/0X/Gf9N/+f/mADmAK4ASQANAPj/2v+4/8L/9v8bAAsA8/8FADIATABIACgAx/8W/4j+sv6I/2AAwQC/AJEARQAAAPr/FwDt/3T/N/+R/z4AvQDjAMMAYwDY/3j/c/+X/6f/w/8kAJgAxACWAFkAEwCc/yr/Nf/J/1IAagBDAC4AGgDm/8X/3//q/57/Tf+K/0sA3gDeAJMAPQDT/2f/Z//6/44AgwADALH/xv8EADMATAA4AN3/fv+F/+//NQAKALb/qf/o/zIAXgBuAF4AFACW/xv/5P4d/6v/TACxALQAawANAOD/+/8lAAUAov91/9v/iQDqANEAcQDp/07//P5C/+3/RgADAKL/s/8pAJUAvwCfACoAhf8y/5P/WADJAIgA9/+d/6T/3f8YACkA8f+F/zD/VP8DANoATgEWAWEArf91/8f/QQB9AGAAFADa/+H/JQBcACgAi/8J/yf/yf9bAI0AiABsACcAx/+i/9n/DgDy/7X/w/8bAGkAiwCOAGEA3f8//wz/dP8RAGoAdQB3AI8AkQBYAPz/pf9R//z+1P4c/8//igDzAAQB1ABXAKH/Ev/0/iD/R/+I/ysABgF6ATgBlwAUAMz/mf91/2f/a/+N//L/nwAuATABoADp/2X/Iv8I/xL/Vf/J/zoAcgBdACoADQAQABgA+f+6/43/q/8WAJoA4QCpABYAn/+X/+H/FQAFANz/4v8dAF0AbwA/ANz/ef9K/2b/tP8EADkATQBTAFMANQD2/7T/kv+L/4r/nv/y/3MA2QDnAKEALwC7/3H/cv+5/wwANwBEAFgAaQBEAOH/hP9p/4v/u//m/xQAKQAMAOb/8/8bAA4A0P+6//7/VgBiACgA8f/c/9P/1//8/zYAVQBGAB4AAQD9/woAIQA4AC4A7f+L/1H/df/p/1cAfgBqAD4AAACk/0j/Ov+P/wcAXQB7AHMATwAdAAEABQAEANz/qP+l/+D/NwCDAK0AqABeAOT/hf98/7z/BAAfAAcA4P/U/+//EgACAKT/Of8u/6L/OwCQAH4AKgDV/6j/vP8HAFIAZwBBAAcA4P/W//H/LABYAEAA3/+I/5L/8/9SAF8AIQDe/7r/tP+7/8n/1P/U/9P/6v8XACsACwDz/x4AXABYABMA9f81AIYAlQBnACwA5f+f/5X/2/8hABYA5P/1/00AggBSAPn/w/+k/4j/if/B/w0APgBZAG8AXwAAAJD/gv/d/zQALwDu/97/KwCeAOkA0gBdAMb/Zv91/9b/LgA5AP3/tv+O/4T/mP/W/zoAiQB5ABAAq/+f/+P/MgBWAEMA/v+o/4z/1P88AFIAAwCq/5D/nv+z/97/HQA3ABUA/P8sAHgAhwBRAB0ACAD5/97/y//B/5//ff+o/x8AbQA9AMz/nf/S/yEATgBZAEEAAQDM/+r/WgCqAIAACQCd/2H/YP+x/0IAogBnAL7/R/9h/9j/OgBPACYA/P8NAGcA0gDgAGAAqv9B/1v/uf8AABYAHAAvAEQALgDj/4v/ZP92/57/wP/c/wQARACSALkAfQDV/yn/Af+C/z8AsQCeAD8A6f/E/9P/+P8JAO//z//l/zQAegB5ADgA4/+Z/2X/Wf+K/+n/QQBqAFcAFQC8/3j/d/+9/xMAOAAoABAAGwBLAG8AYQAdAMX/jv+d/+n/PQBsAGoATAAwABkAAADk/8//y//T/9r/6v8QADsATAAwAPj/vf+Z/53/0f8mAGgAagA4AA8ADAAWAAwA+P/y//T/9f8JAEQAfABxACoA4v+1/4X/Wf93/+//cgCkAIAAOADp/5z/dP+R/8//7v/y/xMAVABtADUA7f/i///////s//7/MQBRAEoARQA+AAsAvP+n/+//OQAdAMT/m/+8/+n//v8TAC0AHADl/9T/DABBACEA5f/i/w4AEwDf/7//3/8RABsABADu/+P/4f///0gAiAB3AAsAnf98/6b/3v8EADIAZwBqABsAtP+N/6r/0f/n//n/CAADAAUAOgCPAJsAJACH/0j/ev/M/wsAOABPADwAEwAFABEAAQDO/7v/9v9LAHIAbQBhAEgABQCq/23/Xv9l/5D//f9/AK4AZAD4/8r/0P/X/9f/5f/4//H/6P8NAFUAewBaACAA///w/9j/xP/R/+z/9P/w/w0AUACBAHYAOQDs/57/Xv9P/3//yv/5/wAABAAgAEcAXgBdAEQADwDH/5T/ov/s/z4AZQBaADkAGwAHAP7//v/2/8//m/+J/7f/EABdAH0AcgA+AOb/jv9w/6L/9f8lAB0AAADx//H/9f8BAA0A/f/N/67/0/8sAG0AawA3APD/p/94/4b/1f84AHAAZgAzAPX/yv+//8j/zP/C/7D/tf/w/1kAswC3AFEAw/9f/0X/af+0/wcAPgBIADgAMgBAAEEAJAD+/93/wf+3/9j/JgBsAHMARQAZAAgAAwD1/9//zv/F/8v/6P8MABQA9//X/+H/EAA3AD8AMgAiABAA9f/W/8X/w//W/wQARAB1AHYASwAaAP//9f/x/+//7v/p/+b/9P8TADMANwAjAAcA6f/D/5v/jf+i/8z/+P8lAFIAYwBNACoAHAAeABUA9P/M/7b/tv/Q/wcASwBuAEsA9v+s/5b/qf/K//H/GQAwACUADgAIABYAIgAYAAEA7v/h/9j/5/8OACwAHADg/7H/u//z/y4ATgBPADkAIQAjAD0ASAASALT/fP+S/9b/EwAtACoAFQD5/+X/3//Q/7P/q//d/zsAggCKAGkAQwAgAAAA7P/t//T/7v/o//r/HQArAAcAwv+H/3T/i/+///P/DgALAAYAHwBVAHMATQD4/63/l/+5//P/LQBOAEQAFgDl/9D/2//t//D/2v+1/53/vf8dAI0AwACTACAArv9x/3X/o//X//b//f/8/wIAEQAeABgA///Z/7f/rv/V/yoAgACgAHcAKwD4//n/DQABAMn/if98/7r/LQCQAJoARADG/3X/df+u//X/KwBGAEkAPQAuACcAKQAkAAgA0P+f/53/4P9NAKQAtABxAAIApf+J/7L/7P8EAP7//v8RACkALwAeAPj/v/+M/4X/tv8EAEoAcABsAEQADQDp/+X/7v/l/8//yv/p/yEAUABZADcAAQDY/9L/6v8FAAcA/f8AAA4AGgAZAAYA6v/R/8n/3P/6/xMAHwAiAB4ACgDl/8z/1//9/yYAOAAxABoAAADv/+z/7f/g/8D/rf/L/xwAcwCaAHkAJADN/6b/t//q/xIAFwAGAPj//v8PAA8A8v/I/67/sf/O//P/FQAuADMAIgAMAAEA//8FABYAJwApAA4A5f/V/+7/GgA0ACsACADm/9b/4v8GACUAIgD4/8b/t//N//b/GQAqACQAAADM/6//xP8CAEUAaABaAB8A1f+m/7L/7/8zAFUARgAbAPL/3v/i//P/AgABAPL/5f/q/wEAIAAuAB8A9v/H/67/vf/r/xYAKQAhAAkA9v/z//f/+f/1/+z/6f/y/wEAEAAZABwAGgAOAPf/5f/j//H/AAAEAAEAAgAPACgAPQA9ABoA6v/O/8//3f/o/+n/6P/s//T/BAASABAA9f/H/6P/n//F/wgARQBiAFkANwAVAAQA///0/93/zP/O/+f/BwAbACEAGgAIAPD/2P/G/73/xP/h/woAKgAvACIAGgAcABMA9//P/67/p/+7/+X/FgA1AD4APgA7ADMAGgD0/9r/4P8MAEMAYABSACUA+P/d/9L/zP/I/8b/y//Z//P/EAAeABsAEQAJAAQAAgAHABoAMwBBADkAJAAQAAQAAQD8//P/5P/c/+j/CAAnACwAEwDw/93/4f/z/wQACgACAPj//P8QACwANQAhAP3/2v/E/7z/yP/q/w8AHwAbABYAGwAdABcABwD0/+H/1P/b//T/BgAGAAAAAAABAPX/3f/M/9T/8P8SACwALAAPAOr/1//i/wAAHQAtAC8AKgAiABwAFQADAOb/w/+u/7b/2P8MAD4AVwBNACQA7//B/6n/qv/F//P/JQBHAE8AOwAbAP7/7P/q//H/+/8KAB0AMAA4ACcABADj/9P/2//x/wYADgAIAP3/9v/v/+D/y//F/9X/7/8FABYAIQAmAB8AEQD//+f/yf+6/8j/7f8TACgAMAAzAC0AGQD6/93/xv+8/8r/7f8ZADcAOgApAA4A7v/N/7L/qf+4/9r/BgAvAEIAOQAdAAAA8P/o/+H/2//d/+r/AgAeADQAOQAoAAcA5f/R/9b/8f8SACYAJgAWAAcAAwAJABIAEwAFAPD/4//q/wIAGwAnACIAEgABAPX/9P8AAAgABAD4//L/9v///woAEgAUAAoA+f/u//H//v8NABcAGgAWAAwAAwABAAcACQABAPb/8f/z//f/+P/2//X/9P/y//X//v8EAAUABgAHAAcABAD+//r/+//8//3/AQALABUAGQATAAcA+//4////CwARAAgA+P/t/+z/8//+/wUAAgD7//X/8v/w/+//8P/2////CgATABgAFQAQABAADwAQAAoA+f/q/+P/7v8HAB0AHgAMAO//1f/Q/+D/+P8MABQAEQAIAP//+//5//n/+//6//v///8FAA0AEgAPAAEA7//k/+j/9f8DAAwADgAKAAUAAgAFAAkAAwD1/+j/5//x/wAAEAAdAB4AEQD9/+//7v/x//P/9P/2//j/+f/8/wMACwANAAYA+v/v/+3/9/8GABEAFQASAAwABwAFAAEA/f/7//v//f8BAAMABQAHAAUAAQD7//f/9f/1//f/9//1//b/+/8BAAIA/P/z/+7/7//4/wQADgATABUAFgAWABMADAAFAAAAAAACAAQABQAFAAMA/P/y/+f/4P/i/+v/9f/9/wAAAgAEAAYABAD8/+3/4f/g/+r/+v8HAA4ADwAKAAEA9//u/+r/7f/y//j//f8DAAoADwASAA8ABAD1/+n/5//w//r//f/8//j/8//u/+z/8P/5/wIACQAMAAsABQD+////BgALAA0ADAAOABIAEQAJAP//9f/r/+r/9v8CAAgACQAIAAoAEAASAA4AAgD4//X/+v8EAA0ADwAMAAgABgAHAAYAAAD5//T/9f/9/wcADwASABAADQAIAAEA+v/z//L/+P8CAA0AEAALAAMA+//4//n/+f/4//n/+////wcADgARAA8AAgDu/+H/3v/m//v/DgAVABIABQD5//X/9f/3//j/+f/9/wMACAAMAAwACAACAPz/9//5//7/BAAHAAUAAgACAAQACAAKAAkABAD///z//P/8//3//v///wAA/v/8//v//P///wEAAQACAAIABAAJAA0ADgAKAAYABAAEAAUABAADAAEAAQAAAAAA/f/3//H/7f/v//P/9//5//z/AAAEAAYABAAAAPn/8//x//H/9f/6/wAABAAFAAIA/P/1//D/8f/2//3/AwAHAAgACQAHAAEA+//1//H/8f/0//j/+//7//n/9//3//n//P/9//3//f/+////AAABAAEAAAD+//3//f8AAAUABwAIAAcAAwD9//n/9//5//7/AwAIAAkABgADAAMABwAKAAcA///4//f//f8IABEAEgANAAYAAQD///7//f/8//3//v8AAAEAAwADAAUABQAEAAEA/v/+/wEABAAGAAYABQAEAAUABAABAPz/+P/5////BgAKAAkABAAAAP7///8BAAIAAAAAAAAAAQACAAIAAwADAAIAAAABAAQABwAJAAYAAQD/////AQADAAQABAADAAEAAAD+//r/9v/0//b/+P/+/wUABwAHAAcABgAFAAMAAQACAP///P8DAAsACgAFAPz/8//x//T/+v8AAAIA/f/4//r///8AAP///v///wEAAgABAAIAAwADAAIAAgACAAIAAAAAAAAAAAD///7///8BAAMAAgD+//r/9v/0//b/+v/+/wEAAgABAAAAAQACAAIAAAD+//z//P/8////AgAEAAUAAgD8//j/+f/+/wEAAAD9//z//f8AAAIAAgAAAPz/+v/5//r/+//8//7/AAABAAAA///9//z/+//6//v//f8BAAMAAgD///v/+P/3//n/+//9//7/AQAEAAYABgAEAAEA//////////8AAAEAAgABAP7/+//4//b/9f/2//j/+v/9/wAAAwADAAAA+v/3//f/+v/+/wEAAwADAAMAAgABAP7/+//4//b/9f/2//n//f8CAAQAAgD+//v/+//9/wAAAAD///3/+//7//v//P/9////AAAAAAEAAAD/////AQAFAAcACAAJAAoACQAGAAUABAABAAAAAQACAP///P/7//3/AAAEAAUAAwABAAAAAQADAAUAAwABAAIABAAIAAsACgAHAAEA/v/+////AAABAAEAAwAGAAYABQACAP///v///wIAAgAAAP///v8BAAQAAwAAAPz/+P/4//3/AQAEAAUAAQD7//n/+P/5//3//v/9//z/+//7//3//v/+//3/+//7//z//f/+//7//f/9//7///8BAAIAAQD///3/+//7//3///8BAAEAAQAAAAAAAAD///7//f/8//z//f/+//7/////////AAD//////v/+////AQACAAMABAAEAAUABQAEAAMAAgABAAIAAgACAAAA/v/9//v/+f/4//f/+P/7//7/AQADAAMAAQD///3//f/9////AQACAAMAAgABAP///f/7//v/+//9//7/AAABAAEAAQAAAAAA///////////+//7//v///wAAAQABAAAA///+//7///8BAAIAAwACAAIAAQACAAMAAwADAAIAAQAAAP///////////////////////wIABQAIAAgABAAAAP7///8CAAUABgAEAAMABAAGAAgABwAEAAIAAAD///////8AAAEAAgACAAEA///8//r/+v/7//3//v///wEAAgACAAAA/f/8//3///8AAAAA/v/9//z//f/+//7//f/9//3//v/9//3//P/8//v/+//7//3///8AAP///P/7//z//f/9//3//v///wAAAQABAP//+//4//f/9v/4//v//f/9//7//v////7//f/+//z/+v8AAAQABAAEAAEA/f/8//z//P/9//3/+f/2//j/+//8//v//P/9//7//f/9//7///8AAAEAAQADAAIAAQABAAEAAQAAAP////8BAAIAAwABAP///f/7//v//P/+///////+//7///8BAAIAAQAAAP7//f/8//3///8CAAUABgADAAEAAgADAAQAAgD///3//f///wEAAwADAAEA///+//3//f/+////AQACAAIAAQABAAEAAAD+//3//v///wEAAQD///7//f/8//3//f/9//3//f///wIAAwAEAAMAAgACAAEAAAAAAAAAAgAEAAQABAADAAEA///+//3//P/8//7/AAACAAMAAgABAP////8AAAAAAQACAAMABAAFAAUABAABAP///v/9//7///8BAAIAAQAAAP7//v8AAAIABAAEAAMAAwACAAEAAQACAAIAAwADAAMAAwACAAMAAwAEAAQABQAHAAgABwAGAAUABQACAAEABAAFAAQAAwACAAEAAQACAAMAAgABAAAAAQACAAQABAACAAEAAAACAAQABAADAAIAAQACAAEA///9//v//P/+/wEAAgABAP7//P/7//3//f/8//z//P///wIAAwACAAAA+//3//b/9//9/wMABAAAAP3/9//y//P/9f/2//f/9f/z//X/9//5//v/+//7//v/+v/6//v//f///////v///wEAAwAEAAMAAQAAAP///v/9//z//P/+/wEAAwADAAIAAAD///3/+//5//n/+v/9/wAAAgADAAIAAAAAAAAA////////AQADAAUABwAHAAUAAgABAAIABAADAAIAAAD///7//v////////////7//f/7//r/+v/9/wIABgAIAAcABAD///v/+P/3//v/AAAFAAkACgAGAAAA+//4//j/+v/+/wIABQAGAAUABQAEAAEA/v/6//b/9//8/wMACwAQABAACgAAAPn/9//4//z/AAAFAAgACAAIAAgABQAAAP3/+//7//z//P8AAAgADgAQAA8ADAAGAP//+P/3//v/BAAPABYAFwAPAAMA+P/x/+//9f///wsAEgASAA0ABQD+//j/9v/2//b/9v/6/wEACAAMAAsAAgD2/+r/5P/m/+///f8KABIAEQAIAPr/6//g/9//6P/2/wQADAAMAAYA/v/4//b/9f/z/+3/6f/r//b/BwAUABsAGQAOAP3/7f/i/9v/2v/d/+X/+f8TAC4APwA4ABgA6v+8/53/kv+k/9r/JAByAKcArwBxAOn/T//4/hb/mP9SAOgAEgHIADcArf9f/1P/e//F/xkAVgBoAF0APgAUAOb/vf+r/7P/yf/s/xMAOQBSAFAAMwAJANz/v/+7/87/8v8YADkATgBYAEsAIQDr/7r/nf+k/9D/DgBBAFcATgAqAPf/xP+n/6z/xv/o/woAKwBCAEEAHwDt/7//p/+u/9j/FABCAE4AOQAQANn/p/+c/8j/GABjAIMAbQAlAMb/ev9s/6n/EwB1AKcAmgBOAOH/iv9r/4b/y/8aAFMAXgBHACoAEgD2/9T/wf/A/8H/y//1/zMAWwBaAEUAJADv/7H/i/+X/87/FABTAHgAdQBBAPX/sv+O/5H/vf8KAFkAhQB+AFAAEADK/4f/Z/+I/9r/NgB/AKUAmQBSAPH/pP98/3D/gP/K/0UAqwDAAI0AQwDx/5D/RP9P/7T/JABmAIEAggBVAP3/wf/M/+D/0f/P//n/GQAYACwAXABmACgA1/+y/73/1//y/xwATABLABoA9f/o/9L/xf/X//7/IQA5AEgAQAAiAP7/1/+e/2L/bf/a/1gAngCyAJgAOwCu/zP/Af8X/1v/y/9iAOgAIgH5AI4A/f9O/6r+aP6u/lL/KQAiAfQBNALSARYB/v8+/lD8ePuw/MH/fANgBtAG0ANw/gj68PgQ+8L+MAIIBAAEuAIGAX3/fv4q/j7+SP50/mz/AAHuAZwBEgECAboApf+U/mL+mP6y/kv/4ABcAmwCTgE5AHP/pv4a/mL+Xv9eAB4BqAG4AfkAtv/E/qD+9v5U/63/FwCYAP0AGgEOAcUA6f+4/vj9Lv48/5gAhAHCAYIBtgB8/4D+aP4W/+L/ZQCtANgAqwAYAJb/g/+z/9z/9P8OADUAPQD7/7T/z/8xAGsAQgDm/7j/wf+q/5L/3v9jAKgAoABwABUAqf9h/1n/ev+i/wgA2gBqAe8A//+b/5n/cf9S/5r//f8GAPj/aAAWATwBrgDY/xr/2v4q/3v/sv8+AMQAhgA3AOcAxgEIAdD+RP24/TT/ZwBEAeABlAE7ADH/gP9dADsAAP86/uT+EgDDADABwgHGAXIAcv5s/Qr+gP/hAO4BbAKUAVL/TP1o/Sr/xwC8AUACqgHN/yD++P26/mP/MgCMASQC7gBi//j+4P6C/iH/+AAMAjQBzf87/9b+GP6O/soAeALuAbkAQQCW/xb+XP2U/isAngAWAdACtAOWAVj+FP1w/dz9vP6dANABVAH5AAgCkAKtABD+MP18/Xj98P1JACgDAASgAi4BZQDc/sT8JPx8/YX/TgGsAjQDdAKNAMz+gv4S/9j+7P0k/jEATAKQArABKgFbABT+KPxQ/ZsAUAJIAV0A9QAWAf//c/+T/5b+9Px0/cYA6AP8A8wBp/8S/kj9bP6jAEQBEgAH/8z+Lf+KAMQCAAR0Aur+KPy4+7z8YP4gASAECAUkA1gARv6w/KD7lPzA/8QCgANgAigBbQBH/8z9nP26/k3/pP+IAaAD/AL2/5z9TP3M/ZL+BgEYBLwD2f+A/ZD+WP8o/jz+NAH8AtIA0v5tAOYB5P/s/TH/5ADH/8T9av4OARgCJAG9ABQBbAAj/6z+qP6u/qL/FgEeAfD//P+SAfYB5/8Q/oj+U//8/rn/BAJQAuj/7v7JAFQBkv6U/Hb+MgE8AXcApAHAAs8AuP14/Tn/R/8o/ln/TAJgAzQC3ABr/yT9CPw4/t4BvAPYAkIAtP0E/Y7+SQDCAF4BDAMYA13/cPsY/Lr/ugEMAnACiAG4/hD9HP7T/+oAqAF0AU0ASADCAUoBbP2A+kj8EQA8ApgDKAWgBNoAAP14+yD7+Pss/2gC/ALsAtADUAM5AAz9QPyw/Iz8GP0QALADqAVwBYwCpP0Q+nj6vP0UAcgC/AJEApUAEf81/6f/sP4m/ob/IAHcAfYBwgCw/sz9yv6cALIBMAEqAHf/Jv5g/Uv/4gFYAtIBbgH6/6j9hPxs/YL/gAH8ArQDAAJM/qT8ZP7G/yT/Nf9cASAD+AGO/zL/vP96/uz9jQBQAtv/SP3q/jgCCAPyAdIA1v5E/Dj8Rf/mASwCAALyAbD/0Pzk/VIB1gEiAOz/XgAi/7z9B//wAegCqgE/AFr+IPyA/A0AEAM8A+YBXADK/gD+sP60/4r/5v59/8AARgHkAagDpAMS//D5mPnM/FH/pAGIBdgHoATK/qD8dP0c/AD6kPwUAmgESAOwArAC1gBG/kz++/8Z/2T88PxLABgBef90AAAEAAUIApv/9P/M/ij60PdY/PQCmAVYBYgFmAQ6AJj6cPgQ++b+agAQAcwDEAbEA1n/0P0u/pT8yPqM/WQDgAWkAvr/xP5o/Rz+sgGwAoP/Nv4VAJP/2PwQ/uQC4ASMAhAAOv8S/rT8gP2t/8QAqAGwAwAEywAc/bj7MPz4/dwAuAMIBVADvv6I+wT96P9Z/y7+VgHoBLQC3P2A/UAAhP/Y+4j8gAKABsAEgQCA/RD8cPt0/LwAmAV4BaoAFv79/4AA0PxI+7H/QANGAZP/7AHgApr/dP11//oA5v4g/VD+nf9bADAD8AVoA5D9gPvg/cb+RP2S/kwDaAU0AnT+FP4S/03/pv9YAHIALQD5/2L/RP9DAK8A4/+0/4gAgAA+/9j+TwCMAecALwBJAKD++PsQ/SQBuAIwApADyAQGAWD6oPiE/XIBawBUAFAEoAVAAMD7F//kA10A+Ph4+ekA2AQ0A1QCQAPWAbT90PqI+8r+tAHCAYH/Q/9AA8gF1AEg/Wz9zP0g+xj8LALQBAwC7ADcAhgCnP1w+zb+ggAP/6j+bgF0AiwB4gGwAmb/0PvI/Hn/r/8v/6gBYAQMAqj9NP6+AT4BzP14/bH/yP/C/pkAaAPEAhcAVf9l/wb+yP1EADABuv5c/nQCkAQMAcT9zv49AID+SPxw/egByAXIBbAC5P4w+8D4uPnM/TQDIAhQCdAFcADY+gD2gPU4+8gDYAkACIwC8//y//j86PiI+sgAqARQA+IARAGqAfj9ePkA+6oBEAYgBRQDeAKv/zj6CPgw+7z+xgBgBIAIWAdqABj7JPzG/nz9nPwkARAEIv+w+1QC4AjoA3D6aPnE/p8AAQBIA2AG+gGA+1D7sv5Z/2D+dgDwA5QDSAFIAlACMPzQ9rD5wADYBGgFGAWwAzz+oPeQ+DMAKASIAmACsAPNAFj7gPqA/+wCdQCM/nQCCAXx/5j6EP0UAq4Bev/CAVAD3P2o+U//cAUKAZj6hv44BlgEEP3A/VgDggBg+PD4qAHgBpgFbAK1/+z9PP3A/Nj8nv6YAGYBCAIABBgG7AN0/ND22Pg4/vcAQAJABXgHUAQi/nD72PuQ+yT9+gHAA4cAzv7WAeAE8AL4/qb+2P7Y+lj5U/8ABBgDlAOABUgCIP0I/Tj/rP1w+gj85gEwBCQCeANgBtoB4PrA+6L+cPt4+fn/yAfQBkMAZf98A3IB0Pqw+sT+jP0w+94A0AmQCZoA8Pu4/cD7OPgm/mgHEAdKARf/aP3Y+Zj7IAOoBqQCv/+OAfD/IPnQ+GQCiAdAAUT8vACQBOf/8Pqg/ugETAKw+uj6zAE4BJYB7wDuAc3/oPsw+9//GAQIBPIBfwDa/tD86PzJ/zABbv58/QgDoAe4Alj6yPrYAcACYP0E/XABfAHI/iQAUAOAAqT+AP3W/vP/EwC0AvgDKf+g+uj8VAEsAsIBiANgBOD+UPeI+FgB+AREArQDmAcwA1D5gPYM/Kb/PP0s/dAEYAtACDIBUP2Y+mD3MPfg++wCGAfgBaADGAQ4A8D+WPoo+ID4YPwUAjgGgAeIBawBAP64++D8lQDfAKD88Pqw/UkAyAJ4B/AKEAds/PDzgPRQ+n3/MAQgCCAI4AR6ARj+EPuw+oD8aP1U/Vr/9ANwBkAEEALcAjoBuPrQ9jD6tP4n/yoAOAYwC5AHxf9I/FD64PQA9Kb+oAnACRgGEAdQBfD6QPJQ9cD9YgHkAoAHYAn4A57++P0o/Dj4UPkn/zgDQAUQB/gERv7g+lj9YP6c/Jv/+AUABbj9FPxvAHoAWPzA/ZgEeAZEAXD9qP1Q/Nj5QP1gBYAJAAac/qD5uPrC/hoAqP/KAXgFOAVj/7j54PqR/9j/6P14AvAK8AkA/UD0OPoYArz+EPo5ABAIAAUk/rv/YAS9AED6+PteAbEAWP2c/qgBvgDI/uMA5AOYAq7/eP5E/aD8Lf8QAgwBav7M/sgBWAN0AgYBS/+Q/ZD9pP0U/FD++AawC1AEgPlw99D8RQAMAHgB2AR4BA7/iPo0/L4BqANmADr/GAJIAbj7YPuQApgF5v4g+RT9JAPEAo4B+ASIBRL+CPjw+tL/gv+O/loBjALg/tj9QATQCcgGLf+A+XD2cPag+rcA2AXQCGAIuASyAYUAFP5w+WD2OPhs/GgAUAaQDbAOOAaA+kDzEPPQ9wD+xAPgB4AI2AUcAhn/VP1w+yD5YPmM/egBGARwBcgFnANKALD+Pv4s/Pj5iPu8/1wCmANgBcAFFAO1/yz9yPqA+Tj7Hv/gAhAFOAUoBLACLAC4/Kj6SPtw/Rj/jQAwAwAF4AKs/24AaALh/6j6qPig+lz9lwAgBrAKAAhU/2D5wPmo+/j7UP1sAeAEKATCAW4BjgES/xz8QPzS/sEA7QChAIoALgA9AHwBmAIYAlsAvP42/pj+8v51/wAAyf8dAOoBGAPYAkgCRgCE/Kj6GPxA/pv/NAEIBFgGaASl/6z9/P1c/ND68Px3AHACIAOgA+QDlAJr//z8RPz4+8z8iv9wAjAEQATOAaj+5P3u/ib/0P3w/ET+AAB0ABwCuAVABmoB4PuY+WD5+PlI/YwDcAjgCBAGoAGQ/GD5yPkc/FL+MAB0AogEkAT4AkACgAFk/vj7pP39/wP/oP2k/5gCMALW/yEAWAKIAcD9oPxi/yYBXgDW/4j/yP1o/Kj9FwDEAUQDMAV4BSACiP2o+6D7oPqY+ur++AQ4BzgFMAOgAiwB+P1g++D6qPv0/ND++gHgBdAHGAYgAjL+SPvY+TD6LPzy/noBTAN4BKAERAMWAdr+fPzI+qD7bP7AAPQBZAO4BPgD4gD4/TD9VP3Q/Nj8Jv9oAvgDWAPmAYMA6v4E/dj7WPwM/rv/2QCaATgCVAJkAeT/1v5O/vT9FP4C/0sAYgHQAXABvAAlAHn/D/+T/zsACgDs/8MALAEpAAv/Gv+T/23/g//1AHwCNALYAB8AnP9k/pT9VP7Q/9gAhAEkAiAC+QBg/6D+vP7C/rr+Q/8iALwAOgGWAR4Bz/+Y/vT96P2I/o3/UwDSAEYBUAGuAOD/SP/I/jz++P2C/rD/2gDWAeQCPAPqAWf/OP1M/Kj8KP5mAIgCtAOsA7wCaAEXAPD+Av5Y/RT9yP3J/3wCYASQBEgDNAHU/tz88PsU/PT8dv6IAHgCLAOsAtgBowCi/rD84Ps8/DT9xP7rAMgCWAOEAvwAhP+W/i7+Cv4w/sD+1P86AVwCvAJsAswBOAG7ADcAuP9T/1b/CABMAUwChAI8AsYBvQA6/1D+jP5j/+X/+P8fADYAuP8A/9j+/P7I/nT+pv4u/2z/NP8E//z+1P6s/gf/5v+DAI0AaAAcAHb/9P4J/33/8P9zAP0AOgEgAboATADu/53/a/+M/83/3v/K/+n/PgAlALv/yf9EAB0AP/+a/rj+KP+T/zkA3gDmAFAA0/+z/3f/Hf8+/9f/YQDZAEQBegGIAYwBeAFCARwBSgG6AQgCHAJcAsQC6AK4AqACwALEAqgCnAK0AoAC6AGaAe4BYAJEArQBBgFUAKn/P/96//T/1P87/xT/e/+J/7D+rP0I/ZT8hPwY/Qb+hP5w/g7+jP38/Hz8RPw0/AD8yPvg+yz8bPyY/Gz82Pv4+jj6CPpQ+oD6oPro+hD7oPoY+iD6uPpI++D7fPwA/Sz9kP1u/kP/8f/jADQCKAOIAxAEQAVwBjgH4AfQCFAJUAlQCfAJkApwCmAK8AqwCwAM0AugC2ALkAqQCfAIYAiwB/gGqAZQBogFYARwA9wCGAIWATEAif/K/gz+iP0o/bz8gPyo/KD8APxw+2j7CPsA+mD5oPnw+bD5oPkI+kD60PlY+Tj5gPjw9nD1sPQQ9FDzQPOw88DzUPPw8nDy4PBA7mDswOvA62DsQO4Q8UDzoPRQ9mD4KPqw+zz9qP4GALIBCAQQB8AK0A7gEiAWoBigGoAbgBsgG6AaQBrgGcAZIBpgGmAagBnAF+AUgBEQDoAKwAY0AzEArP2o+2D6oPmo+ED34PVg9NDygPGg8ADwwO+A8ODxoPNw9aD3+Pnw+2T9KP8SAaACAASIBVAHsAgQCpAL4AxwDTANwAzgC3AK4AioB3AGmARYAj8AHv6A+/D44PYQ9bDygPBg7+Du4O3g7ODsIO0g7UDtwO5A8LDwoPAw8UDy4PKw8yD0wPMA8wD04PaA+Zj62Prg+YD38PXg98j83gEQBtAJoAwQDTAMAAywDAANkA0AD4AQYBEgEoATgBTAFAAVgBWAFMARcA7QC+AI4AVIBHAE+ATIBIAE4AP0AcT+uPuY+fD38Pbw9nD3UPcg9xD42PmA+6D80P2U/oD+Av5S/iv/s////xIBAAMIBegGUAgQCdAIQAjoB3AH0AY4BtAFAAVABFgE+ARQBQgFWAQsA4YBYf9A/VD7mPkQ+PD2oPbQ9jD3APfA9lD20PXw9CD00POw86DzwPPQ9DD2gPeg+Cj52Piw97D2gPWg86Dx4PBw8eDx8PIg9bD2QPWw8cDv8PAQ9Ej42P1cAkgEyAQQBkAIAAqwC5ANQA9AEKARYBOAFAAVQBYAGcAawBqAGSAXoBOAD5AM8AoACgAJ4AegBqgERAKf//T8qPoI+cD3gPYg9UD08PMQ9AD1MPfI+cj7qPyA/AD8NPxo/WD/MgFUA5AFCAd4B2AI8AlAC9ALIAzgDAANEAygCqAJUAjQBsAFKAWoBLwDuAJeAcD/UP4o/bD7gPkw95D1APSg8uDxMPLA8kDzwPNw9ND0gPQQ9LDzsPPQ81D0EPXw9QD30Pd4+Cj5WPmY+DD3wPUg9IDx4O6g7mDw4PHw8XDxMPHA8QD04PjW/nADOAbgB/AIIAlACZAKAA2QD4ASwBWAGOAZYBrgGmAbYBuAGgAZgBYAE1APcAyQCgAJyAdQBsgE5AJEAOT8KPkQ9lD0cPPQ8kDywPGw8QDyYPPw9bj46PoM/ND8eP0M/rb+RACsAugE6AbACJAK4AuwDFANcA3wDFAMwAsQCxAKEAkgCBgHAAYABWAEXANOAcj+1PzI+wD7APrY+CD4IPfA9eD04PQg9fD04PRw9dD1oPWw9ZD2oPdY+CD5APpg+gD6sPmo+cj4kPcA95D30PfA9sD0wPJg8RDxcPEQ8SDvwOxg6+DqwOtg7sDyEPgk/ZgBqAWACGAJoAnwCvAN4BAgE+AUABfgGEAaQBygHuAfAB+AHaAboBiAFKAQ0A0QC6AIEAfYBQwDK/9I/Fj6GPiA9eDzwPLg8CDvAO/g72DwgPEQ9PD20PhY+mj8Lv78/h4AgAJABUAHEAnwCkAMkAwgDVAOMA8wD8AOYA5gDeALMArACFgHwAUwBMACQgFE/3j96PvY+tj56Pjw9+D2sPWw9FD0EPTA84DzkPMA9MD0gPVA9uD2IPeQ94D4sPlA+mD6QPpg+ij6YPmA+AD4wPeA96D28PRg8kDwUPCA8VDxwO7g6yDqgOkg6gDtUPJQ92D72v+oBNAHUAnwCqANYBAAE+AVIBjAGEAZQBugHYAeoB5gH2Af4BwgGUAWQBMgDzALEAmABzAEzv8k/FD5wPbQ9LDzYPKw8MDvwO+A7+DuAO/w8DDzEPVA9wj6fPw2/ksAEAN4BfgGoAgAC+AMkA2gDfANMA5ADpAO8A5gDgANsAuQCuAI8AZYBSgElAKRAAj/uP0E/ED6OPm4+OD30Pbw9YD1MPXw9BD1IPUQ9TD1kPUg9mD24PaA9/D3mPiw+eD6QPtQ+6D7LPzw+6j6SPkg+HD3sPaQ9dDzUPKg8SDxYPCg74DvoO4A7GDpQOlA62DugPLQ90j9TgHQBKAIoAxgD0ARQBNAFUAXoBhAGUAZ4BngGwAe4B5AHiAdYBvAGGAVIBLQDvAKKAcIBBwBzP1Y+pD3sPVg9JDzIPNw8nDxsPDg8HDxAPLw8uD0APfw+CD7tP3z/7IBiAMYBrAI0ApgDOAN4A6AD9APwA8QD4AOYA4ADhANkAsAClAIeAbQBKADPAIwAAz+VPwA+zj5oPeg9nD2MPbQ9eD14PWQ9TD1IPVw9QD2YPaw9qD2kPbw9sD3SPjA+Lj5APuo+4j7UPsw+xj6wPgA+KD3QPbw88DysPLg8SDwQO8A8IDwYO9g7YDrAOqA6oDtYPIg90D7MP8oA7AGIArwDWARwBPgFUAYABogGuAZQBpAG0AcAB2AHeAcABvgGOAWYBRgERAO0AoQBygDxP+Y/Aj50PUw9MDzMPMg8lDxAPHg8PDw4PFg85D0wPVQ92D5aPtk/VT/lgHwA0AGgAhQCuALQA2gDnAPYA8AD9AOgA6QDZAM4AswC5AJGAcABcgD4AJWAWP/wP1A/ID64PjQ9zD3YPaw9dD1APZw9aD0UPSw9DD14PWg9tD2cPZw9mD3EPg4+Ij4oPmg+uD6GPt4+3j7oPoY+vj5YPkA+MD2IPYQ9aDzgPLQ8dDwMPBA8IDv4OxA6qDqQO2w8ED06Pg0/VgAnAPAB5ALAA6AEKATYBZgF8AXYBjAGAAZQBpAHCAdIBzgGmAaYBngFiAUwBGwDtAK+AZYA0X/KPso+GD2wPQQ8+DxIPFA8ODvgPCA8TDywPKw8yD1oPZI+ED6fPzO/iIBpAP4BRAIAAoQDBAOoA+AEKAQQBCgD/AOQA6QDYAMIAuACdAHSAbIBJQDcAI6Acr/Pv6o/BD7cPnw9+D2MPaQ9eD0UPTg89Dz8POQ9HD1MPaA9sD20PYA90D30PeA+PD4cPkw+gj7CPuA+lD6ePpg+rD5MPlw+OD2QPVw9KDzgPKQ8bDxAPLg8ODuQO3g7MDtYPBA9OD3wPoS/jgCIAZgCUAMUA/AEYAT4BQAFoAWwBaAF+AYIBrAGqAaYBrgGUAZYBhgFqAT4BAwDgAL6AaUAuj+FPzI+cD3APaQ9BDz4PFg8dDxgPLQ8gDzsPPg9BD28PYI+Ij5sPtA/m0ACAKgA6AF6AcwCjAMwA2wDqAOQA7ADWAN0AwQDCALMAowCaAH4AV4BKAD+AJIAkYBx//o/SD88Pro+cj4oPfw9kD2gPXQ9LD00PTw9HD1YPbQ9mD2APZg9gD3YPfg92j4+Pg4+ZD58Pno+cD58Pko+vD5WPlo+HD3UPZw9bD0EPSQ88DyoPEw8ODu4O0g7SDu4PCg9ND3gPrA/a4BeAWgCEALIA3ADoAQgBJAFOAUQBUgFmAXgBggGYAZQBnAGEAYwBdAFuATABEwDmAL4Af0AyAAPP0I+zD5EPfw9HDz0PLA8uDy4PIg84DzIPTQ9FD1QPZw9yD52Prk/Nr+bwDUAcgDYAawCJAKMAzADXAOYA4gDkAOQA6wDfAMAAzgCmAJ6AfABrAF0ARgBKQD/AHk/1D+HP2Q+9j5oPjA97D2YPVw9CD04PPg8yD0cPSA9ID0kPRw9JD0UPVQ9uD2IPew94D42Pjg+Pj4gPnI+cD5ePnY+KD3oPYw9tD1UPXQ9HD0UPOQ8QDwgO+g7yDwkPEQ9MD2KPkw/DcAOAQoBwAJ0ArwDDAPYBHgEqAT4BOgFMAVwBZgF+AXQBhgGIAYIBgAF+AUYBJAEAAOEAuAB+wDxgA6/uj7qPlg95D1wPSA9ED0APTg8/DzIPSg9FD10PWA9tD3gPnA+sD7HP0p/1QBYAOoBegH8AmAC5AMUA3ADTAOkA7ADlAOsA2wDIALIAoQCTAIQAd4BqgFmAToAuIAIv/M/cD8cPvo+UD40Pbw9RD1IPSg88DzEPSw8yDz4PLw8vDyIPMQ9DD14PVg9iD3sPfQ98D3QPjo+FD5YPkw+Xj4gPcQ91D3sPdQ94D2kPVw9BDzEPKQ8YDxwPHA8pD0gPaY+ED7mP7iAYgEyAbQCLAKgAyADmAQoBGAEmATQBTgFIAVwBUgFmAWgBagFgAWoBQAEyARAA/ADGAKgAdYBEABiv4Q/Lj54Pew9tD1MPWw9HD0UPQw9HD0IPXg9fD24Pfo+Pj5MPtw/MT9ef9cAWwDkAXgB+AJYAtQDFANUA4QD4APkA/gDuANIA1gDAALkAmgCCAIQAfABTAEoALzAJr/xv7g/UD8cPrQ+ED34PXA9BD0kPMw8zDzEPNg8nDxYPFQ8jDz4POg9KD1UPbA9vD2IPdA95D38PcQ+LD3UPcQ99D2kPaQ9tD20PZQ9rD1EPVA9EDzsPLA8mDzUPSw9WD3cPkI/B7/SAIgBagHAArwC3AN8A6gEEASYBPAE0AUgBTAFAAVYBWgFcAVgBXgFMATIBJgELAOgAywCaAGtAO+APT9mPuo+dD3UPZA9cD0YPQA9NDz0PMA9KD0kPVw9jD3IPhI+Wj6WPt8/CT+DwAYAkgEgAZgCOAJYAuwDLANcA7gDgAPkA7wDSANAAyQClAJoAggCCgH4AWwBLwDjAJUATkABP9g/bj7aPrY+OD2MPVg9ODzYPOw8kDyoPHQ8BDx4PHA8hDzgPOA9JD1IPZA9lD2IPYQ9nD2QPew94D3MPdA97D3APjg99D3wPeg90D3gPaA9aD0YPTA9KD1oPbQ97j5WPw0/+wBcATABhAJEAvADCAOEA/gD+AQ4BGAEgATYBPAEyAUgBTAFOAUYBSgE8ASgBHQD5ANAAtwCNgFHANjALz9iPuo+Tj4EPcw9qD1cPVQ9WD1cPVw9dD1YPZA9wj4qPgg+aD5kPoQ/Pj91v+gAZADoAWQBxAJQApgC6AMsA0wDiAOwA1ADcAMIAxQC3AKgAnACAAIQAcgBtAErAOgAmAB2P8m/mD8wPpw+XD4YPfw9dD0YPQQ9EDzQPLQ8QDyQPKQ8gDzgPPg87D0sPUQ9hD2sPWA9WD14PXw9rD3cPfA9vD2sPfw91D34PYQ9wD3gPbw9ZD1cPXw9RD3aPjo+ZD7sP0HAGgCuATIBpAIMArwC4ANYA7QDqAP4BDgEWASoBLgEiAToBMAFOATIBNAEoARYBCQDkAM8AnAB2AF4AJwABT+4PsY+vD44Pfg9iD24PXQ9bD1oPWg9eD1MPbQ9mD34Pc4+Nj4CPqQ+yT9uv5uADwCAAS4BYAHIAmgCtAL0AxwDcANwA2ADTAN4AxwDMAL4AogCpAJAAlACCAHAAbgBGADqgG//wT+jPw4+wj62Pig92D2gPWg9ODzIPNg8rDxIPHw8PDw4PBA8WDywPNA9NDzYPOA8wD0cPQg9cD1IPZg9tD2APfw9tD2IPeQ98D30PfQ97D3oPdA+ID5uPrY+0T9Sf9OAQgDyATIBtAIoApQDKANgA4wD/AP4BCgESASgBLgEiATIBNAEwATgBLgESARIBBwDoAMkApwCCAG3APKAan/nP3Q+0j62Pig98D2MPbQ9YD1cPVw9WD1sPUw9sD2QPfw98D4sPm4+hj8uP1c/9QASALgA3AF6AZACIAJkApAC6AL4AvwCwAMwAtgC+AKUArQCVAJoAjQB+gG6AWwBEwD1AFwAAn/sP1M/PD60PnQ+PD38Pbg9cD00PMA8yDyMPGA8CDwMPCg8HDxUPLw8kDzcPNw81DzUPOw83D0APWg9eD1kPVA9aD1cPYw92D3sPcA+FD4gPjg+Jj5mPrg+2j99P49AMQBnAOgBYgHcAlAC6AMwA3gDvAPgBAAEaARYBLgEsASoBKAEkASABKAEQAR8A+wDmANwAvQCcgH+AUoBEQCdwDA/tz8CPuw+cD4CPhA99D2sPaA9jD2IPZg9sD2YPcw+Bj5wPlY+lj7rPwO/m///QB4AsQDGAWIBtAH4AjACaAKQAugC8ALwAuQC0ALAAugCgAKQAmwCAAICAfYBcAEuANoAvkAmf9M/hT90Pu4+qD5YPgQ9+D1wPSg84DykPHA8EDwMPCQ8ODwYPFQ8lDz0POw87DzsPOw89DzcPRw9RD2IPYg9nD28Paw92j42Pgw+aD5+Pno+ej5kPqw+7z8gP24/ikAqgEQA7AEkAZQCNAJIAswDPAMoA1ADuAOoA9AEMAQ4BAAESARYBFAEcAQYBDAD7AOEA1wCwAKYAiQBtAEJANcAan/Nv7w/KD7kPoQ+uD5aPnQ+HD4KPjQ98D3IPio+AD5YPkg+hD76PvI/BL+hv/JAPYBKANIBEgFSAZ4B4AIMAmwCSAKYApQCkAKMArwCZAJIAmgCPgHIAdYBpgFoASEA2QCOAHx/6z+gP04/OD6qPmg+ID3MPbg9LDzsPLw8UDxwPBg8HDw4PCQ8UDy0PJA84DzwPPA85DzgPPw8/D0wPUw9rD2IPeA9+D3qPjA+Vj6OPpA+qj6KPtw+/D70PzU/SX/ygBMAmwDiAQ4BiAIcAkwCgAL4AugDEANAA6wDjAPwA9gEAARABGgEGAQQBDADwAP8A2QDEALEArwCEAHaAXYA6ACXgHI/zT+/PwQ/ED7mPoI+oD5APmw+Jj4iPiA+Ij44PiI+Tj60Ppg+wz8AP1U/sf/DAEAAgwDiAQIBggHsAdgCCAJsAnwCTAKUAowCgAKAArQCWAJsAggCHgHoAa4BaAEPAOyAYcAoP9w/vj8sPuo+oD5KPjg9pD1IPTQ8vDxIPFg8ODvAPBw8ODwgPFw8uDykPIw8iDyAPLg8VDyUPNw9CD1kPXg9VD20Paw97D4MPlw+YD5uPkQ+pD6cPus/Bj+qf9KAbwC2AP4BHAG8AcgCRAK4AqQCyAMsAxwDUAO4A6QD0AQoBCAECAQwA9AD6AO8A3wDOALwAqACVAI+AaYBVAEHAPAAVcAE//g/cD82PtY+/j6oPo4+tD5kPlo+Xj5mPnQ+UD68Ppo+7j7RPxc/Yz+mv/BAPgB/ALgA8gEuAVwBvgGeAfoBzAIYAiQCLAIgAhgCFAIEAh4B8AGQAawBagEaANkApgBswCx/9L+6P20/Gj7CPq4+HD3YPZw9YD0kPPg8qDycPJw8rDyIPMg89DykPJw8iDyoPGA8TDyQPMw9ND0YPXQ9SD2cPYA94D38PeI+Nj4EPmY+ZD64Psg/XL+9/9WAVgCYAOgBOgFCAf4BwAJMApACxAMwAxwDTAO4A5wD8AP8A8AEMAPcA8QD4AOwA0ADSAMMAsgCvAIuAdwBjAFOAQwA8IBUAA4/2b+lP24/DD84Ptw+/j6yPqw+nj6cPrY+kj7mPuo+wT8iPw4/Rr+Tv92AF4BVAJkA0gEuAQgBeAFmAbgBggHYAeYB6AHsAcACFAIMAjwB4gHqAZwBVgEoAMMA2AC1gFSAXEAOv/k/aD8OPvA+Xj4YPdQ9iD1IPSA8zDzEPNQ87DzcPPA8gDyYPHQ8IDwAPEQ8tDy4PLw8oDzEPRA9KD0QPXg9RD2UPYA99D3gPiA+eD6IPw0/Wb+yP/5APYBIAOIBLAFmAagB+AI4AngChAMIA3QDUAO0A5QD3APYA9wD4APQA/ADlAOwA3wDBAMUAtwCkAJAAj4BsgFQATkAvQBKAEJAPr+TP7E/Qj9YPwg/Mj7QPvg+uj6IPsY+yD7cPvo+0z86PzA/YL+RP9KAEwB9gFQAtgCrAOABBAFkAXwBQgGIAZYBtgGKAdIBzgHGAfIBgAGGAVQBMADQAO4AiwCqAG+AIP/Nv4I/dj7gPpQ+Sj4IPfw9TD10PSg9HD0IPSg89DyAPJQ8eDwwPAA8VDxsPHg8UDywPIg8zDzYPMA9JD00PTg9HD1gPbQ9xj5iPr4+wz9+P34/hQAKgFUApgDwAS4BbAG+AdACWAKgAuQDEANUA1gDcANIA5ADmAOsA7ADmAOwA0wDZAM0AswC2AKUAkwCEAHSAYYBQgEaAPMAuIB3AAKAF7/mP4E/rj9hP00/cT8gPxs/Hj8pPzs/Ej9vP1A/qz+Gv+o/2kAEAGQAQACeAL4AnQD+ANwBMgEAAUoBTgFWAV4BagFwAW4BXAFAAVwBMQDKAOsAkgCmAHVAAgAKP8y/kj9jPzA+7D6ePlY+GD3oPZQ9nD2cPYg9nD1YPQw80DyQPKg8vDyEPNA83DzcPNQ83Dz0PPw8yD0gPQQ9ZD1UPZw95D4gPlY+kD7CPy4/LD9/v5FAGYBtAIgBGgFUAYoBxAIEAngCaAKcAsgDNAMQA2QDdANAA4QDtANYA3gDGAM0AtAC9AKcArwCRAJMAg4B0gGWAWgBBAEbAOwAu4BRAGhAAUAo/9f//r+jv5W/hz+wP2M/dD9Xv7C/v7+V/+g/7P/uv8iAM0AbAHiAVACpAK0AqACqALkAjQDgAOYA1wDFAPoAuwC0AKoAnACGAJoAZoAAACL/wr/eP74/Yj95Pzw+7D6oPn4+Ij4OPjg95D3QPew9rD10PRg9FD0QPQw9DD0QPQg9CD0UPSw9OD0wPTQ9DD14PVw9vD20Pf4+Aj6wPpo+yz8CP3o/fr+OgBGARwCEANQBCgFkAUoBkAHMAhwCMAIcAkQCiAKQAqgCtAKoApwClAKAAqgCYAJUAmwCOgHkAdQB7AG6AWIBUgFcASQA2QDeAPgAggCvAGqATYBjABgAHMAPwAKADMAPwDz/+X/UQCOAEQACwBjAOQABAEaAcABdAJMAo4BOAG6AVACYAJAAmACdAIEAoYBkgH4ASgC1gEoAUkArP+X/9//8f+3/1z/OP5A/Nj6MPsk/Mj7cPr4+Uj6aPmw9wD3gPeg9/D2kPbg9qD28PXg9XD2UPaw9aD1IPZw9oD24PaQ9yD4UPiI+Lj46Pio+SD7kPxI/ZD94P06/rb+qP/nAAACwAKoA5gE4ATABCAFEAbABhAHaAcQCEAIAAgQCHAIYAgACPgHQAhACNAHcAdIBwAHoAaQBogGKAaYBTAFyARIBPADGARgBBAEiANUAyQDqAIMAtQB8AEgAkQCZAJgAgwCrgGgAZ4BPAHoACgBuAHCAWABXgG+AZYBkgDi/ysArQCRAGEApwDBACQAVv8s/0//0v78/dT9dP7Q/h7+HP24/Mz8NPwQ+5D6GPvQ+8D76PoQ+sj5mPn4+Fj4iPgw+Uj5+PgI+RD5cPjg94j4wPkA+gj5aPj4+ND5WPqI+qj62Po4+6D74PsM/Hj8bP18/uL+tP62/lX/UgAwAcgBOAJwApQCJAPwA0AEMAS4BMgFIAaQBSgF2AXYBhgHwAawBvAGwAY4BhAGeAbYBqgGIAbwBdgFWAXYBAgFSAUQBWAE0AO8A5wDSAPsAqgCqALoAqgCmgH3AI4BJAJeAe//4P9YARgCEgHv/yEAXwDZ/1T/Z/9+/13/JwB4AfQAtP7k/U3/AgCY/gj9zP03AGIBVgBm/rT8APyg/Nj9nv6u/jT+wP2A/dz8FPws/Oj8XP0A/Uz8QPxE/Tz+iP1g+5j5CPoU/GT9SP3U/Lj8OPxI+1D6APoQ+4j92/9K/+D7gPno+gz+QP8i/jz9AP4l/0n/vP6m/qL/6gAGAaz/sv65/zACKAQQBDACYQBsADwCCASIBBgE2AMABOAD+AIwArACgAQwBuAFzANUApACOAPkA5AEgARkA2QCzAK4A3gDdAJYAvgCpAJ8AS4BYAJ4A+ACTgFZAGsA2AACARQBTgGyAZYBxgCR/6r+Mf9NAIEA+//O/5r/rP48/if/OgD+/qj83Pxn/yQA9P0A/dT+x/94/Sj7SPyW/r7+Cv6i/qb+DPxg+rT8Qv8a/ij8dP1s/9j9APv4+1H/qP4Q+0j8AAGtACj7UPpVAJACvPx4+Xb/lAO+/vD6lP5gAfT+Cv5X/9j95PyeAbgEgv4A+Qf/qAZQARD4fP3QCAAF+PjY+sAGgAeM/CD5uALwCMABkPr9/1AIOAU0/HT8mATIBrUAVP6wA7AFaQCI/oADKAUKAff/QAMIBI4BtQDQAjQDUAFQAewCGAKMAKgC2ASQAlP/iP/oAawCpgF+AVwCwgHX/2P/fgAMAIf/bgG8AksAdP3G/lwBYAB4/Yj9UgCvAJz+ev58/5j+lP3m/mf/IP3M/FgAkAJP/6D7dPyo/iT+BP2N/4YBhv5U/JL+nf/A/Mj7jv6/ANX/cP0s/VT/+gAAAID9mPym/lQB/ADY/jz/dwCn/9T+e/8n/0D+dwBMA8IBuP3A/Kj/zAG9ACr/Mf/X//z/QwDH/2f/bAFmATD9EPySAeAEXgB0/DH/7AK7ACT83P0ABIAEAv/g/NsAeANxADz9Hf8ABFgEPf+8/P8AEAU0Ag7++v7MAqgDwQAW/zQBmANcAvL/6P+0AUACdQD8/yQDeATV/4T8yABgBXQCGP0s/mgD2AOU/xj+qwBEAaD/KwC6ADf/MP9oAZoBmP9s/uL+rAB3AFr+dv/mAZ//GPyt/1AFQAJ4+fj43AKoBoL+QPn4/wAGuf9g+CT8uAM8Auj8Lv7sAW4BqPwQ+0b/xAN0AjD9sPvj/8gEKgHI+bD7iANIBMD9gPpm/uQD0ALI/DD8igDmABT+wv74ApwD7PwA+UwB+AdD/wD2gP1gCrgHUPmw9dgBIAi0/2D68f9wBIIBzP3w/o4BkgDQ/Z7+mgGYAs0A8P1u/igCdAIu/rT8kQBABGgDUv/8/T4BYAMwAcD93v6gAzAFXAD4/AQCwASo/wj88QDwBaoBkPwY/9AEDAIg/A3//AIcAHD9IAGIA2r/CPzu/gADMQCo+/b+AAQgAcT8VP6UAXEA2PuQ/GADQASg/Ej7JAOABHD8qPmSAYgF+P2g+YYBaAbM/TD4hAA4Brz9wPdtAFAHAQBY+Gj9eAUwAqj5SPt4BPgEiPyA+t0A+APJ/6D7/P7oBLABCPoQ/CAF0ARA+2D5lAJQB+T94PaR/4AIEALg9xD7aATQBBD98PkuAGAFjgDg+Uj9SATsAjj9xPwMAggEDv4Y+0QBIAUQACj9jAAYAjwB1/+n/73/fP/sAVgEoQCg+rr/yAfIAoD5NP2wCIAGWPmg+UAIkAk4+hj4yAZgCQD7OPioBZAIzPxA+PgByAbx/0D7O/+oAwQCXv6I/Ar/YASEA4z82PoYAiAF9v7o+kAAkAVoAJj6Cf+gBfUAUPoy/5gGdgDQ9vj+8AlYAnD2VPxACHwDcPdo+kAH4AWA+Wj64ARYBLD76PpgAXgEkABA/GD+IAL6AIT+zP4i/xQBFALs/qD94f/UAQABvv4s/ff/WAMdAHD8nP4YAzQCaPzY+loBSAWQ/kj6dgD4BED+WPmAANAEXv7g++ABugEo/Br+UAQkAbj53P04BpQB8PiW/qAIKAOg9/j6SAcwB5j6gPg4BqALJv5A9SEAsAuYBOD3EPvoBxAJnPxQ+FQDwAluACj4Tv7AB4AF4Psw+gAEAAeg/BD5pAHIBv8AIPtQ/cwCqAPE/ej6xv8gBAgCsPuA+xwDkAQI/HD5VAJgBNj84PtsAggEvPz4+Lf/AAbYAGj6fv+QBCn/EPo8/9AEkgDg+uz+kAWAAVD5sPywBkQDQPgI/EAIoARQ+Mj6OAaYBeD4YPioBsAIEPqQ90AG6Adw+lD3WAMQCZT+UPhtAMAGP/+A+KL/UAY0Agj7rPywA+QDFP6I+8ABKAWK/sj6ggDgBZwAAPv6/vgEtAJg+4T9oAV0A9D7Gv5YBWAC0PsO/3gFoAIQ/L7/iAU8AOj6EAHQBicAaPp4ARAHCv9w+NoB8AjY/5j4GP/4BgACsPmk/VAG6APw+Sj7sARYBSD90PmQARAG3v8A+rD94AQIBBr+mPpW/kAEJAKw+xT8WAToBOD6oPikAtAHoP1A9xwCYAmg/bD0XAGQC6z/cPVV/zAJfwBg93T/kAi0AJD26P4gCcv/YPUkAJALpv9Q87z+MAs6AWD1Rv5gCcwB4PUM/dAJ1AIA96T9yAexAOj4wP4wBfgBHPw0/cwBUAIS/9j9nv+mAEUAg/+s/oP/YgH1/1j9Uv9IAsf/SP3FAEwDKwDM/Gz+lAJoA8H/7P1fAHAC7AHq/rT9+ABQBYQB6PlE/nAHTANA+HD7eAegBkj60PaQBPALSP1w81wB8Aty/xD2XQCgCVACsPa4+8AJCAbg9ij6gAkgBrD3cPkgBkgHyPvg94gCsAe8/Sj5qAJQBdj7SPvYAywDoPtk/cAE5AGo+cT82AYEA4j4xP1wB4YBsPi0/ugGlgHg+ST+UAZUA1j6ePtgBKAEAPxo+1ADkAQW/vD6nv7AArwCHP0s/BQD6AJU/Cj7OAGIBLwA4PmA+5AHoAXA9VD3gAkQCQD34PYgBgAHEPqg+UgHEAZA9vD3cArQCFD1sPgQDGgHwPOg9mAKgApA+JD20AdgCpj4oPQgBxANGPsQ9HgE8Avs/DD1LAOQC9//cPed/8AGbwDI/JwCeAJo/H7+2ARQAWz8fADoA0gAzPzg/jQCBALs/pL/FAGa/mz/hAIJADD+xAJQAlz8dP3QAjgCrP0E/lgC2AIW/qD8UAFUAxr/HP00AXACGv+C/1QC+v4Y/DUAOASEASj7UP2wBSgEwPkw+hAFoAUs/Cj6QALgBXj+OPmu/6gFNwDQ+mb+BAMyAaz99P1yAAQCf//Q/eb/RQDX/6YBTgG8/Ij+3AMfAIT88QDkA9T+pPxUAUwDkv8I/FYBGAZI/qj5AANAB7j8iPkYBFgFsPzA+jAD0AYY/Uj45ADAB/b/APja/qAHkAMg+TD7AAYgBID6APwIBvgEYPrg+5AEeAO4+4T8cAMYA4D+ZP0eAXoBxP2J/3wB6P6y/pgC3ADQ+6z/QAT9/wD7df94BO8AIP3+/ogCHwCE/Cz/JAOIAZD9Cf9kAigCfP0g+zwCUAUs/Wj6CAQgB7j7YPZAApAKWv4g9MMAMA2zAGDz0P3ACtACcPUI/IAJoAVQ93D4+AdQCJD3oPSoBjALGPtA9aQCkArw/fD0sv5gCIQCSPm4/VgFQAK4+mj8mAVUA1j6jPxgBZgFKPy4+dwCoAcp/5D4SgHwBzUA+PmGAaAGhP2I+uwBwATY/rz8LAKwA9r+QPvj/9AClP7u/4QDxv4U/EABsANE/ij8OAKgBXH/qPlSATAIuP7w9yACsAjs/eD3AANQCfL+MPbV/zAK1gBw9o7/wAuyAcD0nP1ACRADAPew+/AIgAe4+PD16AUQCrj6cPaABFAISP0A+RsAcAZSATj6tP0oBDACCP1s/g4BNAF+AND9cv7EAbYBBf9Y/aH/YANWAVj65PwgB7QD8PcI+yAHoAWo+eD3rAMACoD9QPTyAVAMcPwg8YgCIBBH/4DvBP6gD4ACAO+s/SAT/AMg7fD6wBFgBeDvuPugELgEwO+o+kAPWAXQ8sj7YAx4BJDz8PrQDAgHsPSA+KAJeAdI+Nj50AgwCDD4APeABsAIIPso+igGyAWw+lD5UAQIB2j9mPt4AvACBP0X/ywD8P/A/tAADgDY++D+QAfcA7D4gPkIBhAF8Pi4+6gH2AZw+ZD1gAJgCVb/4PdEAKgH/P/w9nj7QAhwCBj5QPbIBPAICPuA9igGsAu4+oDxMALwDKT+APZUA5AKCPuQ8nwC8A3TACD2kP/oBVD9SPmcAuAGwv8w+1z+QgAq/3ACAAOc/Qj9/gEEATD7ZP+gB2AEkPmY+AQCEAWr/7T9MAJMA5z9mPn8/aAFyAUg/YD67AGoBDj8EPm4BEAKXv7w9ND+cAmkAFD41AJQCVD7gPNgApAMGQCw9csAoAqc/LDxdAKADpcAAPZC/5AEbP3Y+2gDgAbq/hD65P+wA4L/9v6wAh4BGP5e/rP/rgHQAjYB2ACx/9j62P2oBagEDv6k/VgBqAFE/Lj6UAZQCTj6UPaABVAH0PhI+lAJ0Aeg9aD0cAkwCyD3sPawCZAHQPTg9zAKsAhA+Aj52AaYBKj4mPrIBugGQPtI+DwCuAbE/fj5gALABhr+4PaD/2AJ4AKw9wj9kAjgAlD3XPzQCJgFUPlQ+wAFUAQs/Nj7AARIBID94Pr1/9gEyAHM/HD9UALWAVT8gPwEA5gGDP/g9xf/yAbCAOj43/8QCVABYPaQ/BAJ2AMY+GD9qAbcASj6yP3oBCgEUP3Y+ef/oAXcADD8dv8QAkgCzv4o+xkA0AXXACj7EwCAA+n/2P2w/xwDzAE0/Fb+iATyAaD82v4MAugAvf8m/gkABAOX/3L+VwAW/47/kgFM/7j9eAE2Abz9B/9PAI7/GP/c/o4B2ABg/YX/1gEA/nj7/gAIBLIAtPz0/PwCHAMQ+nj8MAf0Amj4lPx4B1QDcPhQ+igHEAeA9yD5sAlgCCD3MPdQCKAIwPjI+NAIsAhg91D4kAlQBxD3SPkACtAIUPeQ9jgHsAlo+VD24AYwCkD7cPbaAUAIXv+w+e7/MAVCATj6MP0QBfgDIPyo+xADRANI/ST99ALwA3z9oPrmAJgFUwA4+6cACAUX/3j6kP/oBWgC2Pt4/VgDpALM/Dz+gAREA2D8ePscAsgEn//4/O0AyAKC/iD85QBQBEIBDP6Q/j8A3AAYAHb/2gBUAtP/lPzQ/ggCrAIgAMD9YgCAA2r+QPoAA8AHNP7g+N4ACAWk/nj6BgHIBuz+oPd2/2AGRv94+xwC2AP4/Jj69ABwBDv/eP30Av4BMPtQ/LADYANE/vT+cAI6AAj7zv7ABeQBmPtO/zADjv60/PwCqAMI/TD8dAJAA+D8/PxwBUAE6Phw+kAGwASY+fz8cAf8AkD4uPpIBiAFOPqw+5AGyARA+GD6uAc4BTD4yPoACBgFAPgw+vAGqAYI+QD5sAZwBqD46PkgCMgF8PYQ+ZAI2AaA+BD6iAYQBXD5uPrwBYgEqPoQ/SgFVALo+1D+EAMcAfz9LgBgA17/qPwcAgADxP3o/VACfAJu/sT9MAPUA4j7sPkwBGAHoPw4+QAE2AZA+8D37ALwCIz+MPfvAPAIWv6g9ZoBUApW/lD1twBACQ//IPfeANAH5P1g9+EAgAiV/6j4rAHABpz8IPlcAxgHBP7A+tACAAVs/UD6PAKoBZX/iPt8/rgDbAIQ/CT9kARsAlD5XPywBjAEcPt4+xgDmAKI+1T+UAVYA2j7+PzsAr4AKP1mAcgEuv5w/IgB+gGc/e7+AAQ4AnT8oPysAggE+P34/IwCvAFg/DT+KATwAiL+eP2AAcQCMP1A/EwDSAaU/qD6YACEA5oAWPx8/4AFSgHQ+Zj9SAZIAtD50P8QBjj+KPjEALAIYwBo+Jj+QAbBAMD4QP/AB/EAmPiE/ggF9/+o+8MAKAYwAMD3+P0QCKACQPjQ/hAIJQBg92r+IAc4Adj6pQB4BDD9qPmgA0AHjPx4+EgDoAfY++D44AQQCHj7MPdoBKAIuPwI+ZAEWAdg+oD3kATACLD8APlYBDgGUPqI+UgGWAZI+0D64AIwBVz+wPsMAlAEaPyQ+sgEwATo+iD96AWoAvD2WPrgCHAIePhQ91AISAbg9Qj6YArQBcD26PvIByQD4PiY/dAI+AJg9qj7EAqgBUD47PzQBlYBoPfI/fAIwASA+TD7uATCAKD42/9wCb4BgPeg/ZgEJgD0/OkAQAOm/3T8bP58AkACGgAXAAn/lPxv/6ADtAHt/y4Ayv+Q/uD9Tf9cAhAFVAAQ/Mn/PgG4/Sb/2ASsAlj8IPygATgEcf84/KwBUARo/ED6gAMAB1D/MPsXAEAC0P2A/KQDuAYk/gj5of9IBH//8PzoAcADWv4I+/j+AAT+Aej9hv40ADX/nP0nAGgDegGc/SD9qf+DAL7/SAGwAZf/jP0K/p7//gBYAywBXPzw/MABGAI0/lz/TAMqAaj7xPyoA+QD6Pz8/DgDpAG4+qD9cAZwBAj7WPpsAlAEBP7I/RgE1ALI+0D8oALoAmb+/v98A6T/6PrI/pAE4gE4/bD+zgFlACj9n//QAzABGP0K/rQAVAAHAK4B6AG2/1T8IP4MAuQBfQDDABQBWv4g/aj/JAJIARn/1QCmAWT9TPy+ARgE6P8A/sT/UQCf/9L/KgFQAXr/gv6D/yoAaQBIAqYBpP7C/pb/Pf9i/3gC9AP5/4j8Nv7YAeUAVP9UAZYB+P6A/cz/wAHs/5b+5ACEAYj9eP0wAqACFv/I/aH/nADQ/n7+qgGAAtj+rP2h/yEATwBYAA0AzgBkACj+If/wAVIB2v6k/qIA6AAW/0b/qAIsArz8cP3MAnABPP25/8QD+gCY/Jr+FAIgAeT+hv/kATIBlP76/s4BdAEX/7L/7QC5AIgAv/8U/7AA1gHa/87+CADQAHsANf8M/8oARgGe/nj+JgFcAMb+mgBmAV7/6v7b/yYAtACVAL7/if+2/9n/JwDGACwA2/+G/zH/HgAjAEwA8QAZADL+9v5GAdcAlv8PACgAuP7A/usAxAHh/5r+EAC2ACj/9P4sAQACSv/Q/eH/5gA2AIcA2QCl/6j+Cf/k//4ADgHs/77/LQCw/+D+LP/CAEACqwDs/TL/cgG8/x7+pQBAAsr+pPxlAJwDfAA0/D7+LAI6ALT89v4cA7IBdP1s/UYAYACK/hT/ogEcAu7+0PwH/wQCEgF+/q7/EAK2AMz9+v5cArgBCf8y/xYBzwCe/4oA0AG/ALD+AP+GAI8AUgA0AXwBxf80/uD+xgBWAYUAJwB8AHwAPP9i/h4AhAL1AAD+Cf9oAboAmv64/1wC0QAA/bj9pgH+AUH/ef+EAeb/6Pym/pQC/AEY/2H/sAAJ/8z9ggAgAxQB0P2i/uUAVADG/hcAMAKlAMD9IP4OAaABq/9M/5QAVQDU/Qz++gE4AwEALP3W/vQAnP+C/h4BtAPnAOj8oP3WAIgBAgB/AD4BVf/g/bL/+gFWAU3/CP8EAAsAbf8ZAHYBIAHB/7T+fP62/7QBPAKaAKb+rP6+/xgAXgD2ABIB5f/4/g3/w/+fADYBLAHh/+r+Uf+vAFQBpAAuACUAl/8A/zcA1gEUAYL/n/9CAG//Cf//AFwCXAAo/gr/gwBBAF7/3v+lAID/Nv4d/2MAvv8A/2//Qv9a/pj+DwB9ADz/Xv4g/23/ev7s/p4AtQAa/2L+Jv+q/47/j/8DAFwAlv/s/o//pABnAET/S/8fACIAWP+8/ywBJgGw/xr/HwCBAPD/agCGATwB+v8XAOgAswA3APwAFAKcAVwAkADMAbYBwgD4APIB+AEEAeUA0gEkAkoBqgBEAYABFAEmAWYBeAEuAaEABwAWAJMAfQAbACMAGwBT/5z+0v5O/wv/RP4e/nT+6P30/Bz98P3I/aT8QPy0/ND8cPxg/AD9vPyg+6j7wPwQ/Xj8vPxo/fz8ZPws/UD+Hv6k/RT+uP6s/rD+1v/NABUAmP93ACoBNgE8AqwDoAOwAggC3AI4BKAEAAWABTgFSASIBLAFmAbQBoAGcAZQBkAGwAZ4B8AHeAfwBlgGgAY4B2AHwAYoBrgFYATcA+gEkAUgBPIBRgHcAH//NP7M/k7/YP3Y+gj6GPrY+FD3QPcw9/D1cPTQ89DzUPOQ8mDygPIw8uDxMPLA8uDy4PJA8/Dz0PSg9aD2oPeY+ID5cPqA+wT9xP69/4YA3gEMA5ADkAQ4BpgH0AcQCPAIgAmACfAJ4AoQC6AKkArgCsAKEAoQCqAK8AlgCfAJQAowCegHMAjACIAIIAhACfAJkAiAB4AIcAkwCBAH+AeQCSAJmAdYBygHMAXQA7AEaAVQBFQCKgExAAb+APyY/KT9mPso+AD3IPeg9ZDzwPNg9MDyMPAA8EDxgPCg7qDuoO/g7kDugO9g8UDxAPAA8FDxgPLA8/D1sPfw92D34PfA+dj7DP4oABYBHAGSAWgCjAMgBeAG+AcwCDAI4AigCVAJEAmACZAJ8AgQCeAJQAlYByAGOAYoBlAFWAU4BpgFaAPMAtwDAAQwA7wDWAXwBNgDqASQBlgGWAXIBqAIgAhwCIAL4A3QC/AIUAlgCwAMUAywDbANIApwBnAGOAeABsAFUAUQA0n/AP0Q/RT94Ppo+BD3oPXA8zDzgPNQ8oDvAO2A7ADtgO0A7gDugOzA6oDqgOtA7UDvMPDg70DvAPAw8vDzQPVA98j4mPg4+Vz8Xv9FAFQA4gGsAzAESAVwCLAKsAmQCLAJ8AoQC4AL0AzADKAKEAmwCRAKAAlgCEAIEAfgBAgEgAR4BFADnAK4AggCaAGsAWACbAJAAggDoAOAA/ADWAU4BhAGIAdQCeAKQAtQDBAOgA3QC/ALgA2ADlAPIBBAD7ALoAfgBlAIEAjQBjgGOAT1/zD8CPsw+6j6yPgQ90D1APNw8aDwwO8g7mDsgOvg6wDtQO0g7MDqAOqg6aDqAO2A78DwIPCA7xDwAPJA9OD2OPlI+rj6ePsM/Ur/PgFgAsgDqAXgBpAHYAiACZAJcAlwCiAM0AxgDAAMsAsQCjAIgAjwCcAJsAdABlAFwAMQAjwCHANgAu4AuQD3AK7/3P45AMABKAGrAFQCKATsA6wDoAUoB8AGYAfgCiAOkA7QDuAOcA0QCyAMABGgEwAScA8ADWAJ6AaAB0AJUAmwBiwDnf+Q/BD78PrQ+aD3APZg9CDywPCA8GDvQOwA6qDqIOwg7MDrIOxg68DoAOjA6iDuYO+g71DwUPEg8aDxAPV4+OD5WPok/Oj9Wv4+/9YBqARIBVgFGAfQCFAI+AfQCUALgAqwCQALoAvgCUAIsAjACOAG4AWIBkgGxAM0AjwCJgHH/y4AZAGBAK7+Fv9wAMf/2v5IAZQDaALGAXAE+AZwBhgGsAggC1AKgArgDqASIBJgEHAPYA4QDmAQgBNAFCARYA2QCZAG+AVwB+gHCAWOAW7+IPvg9xD3gPcA9oDzQPKA8SDvwOwg7CDsgOpg6QDrYOxA6wDqoOoA6wDqgOqA7UDwoPDg8NDyIPRw8yD08PdY+5T8bP22/mr/hv8UATgE2Aa4B/AHMAjYByAIAArAC/ALEAugCvAJMAlACQAK0AmwB+gFiAVoBZAE3AOoA/YBr/9H/3EA8ADNAOIAmACx/2H/DAEQA8gDUAToBUAGuAWYB1AKsAoACsALEA/gD/APIBJAE0APQAvQDUASABJgD3AOUAyYBqgCKARABuADewDE/tj7oPbw86D1wPaw9CDyEPEg72DsIOtg7CDtAOwA6wDrAOsg68DrgOyg7GDsgOwA7gDxoPOw9CD0cPNQ9DD3CPqs/AP/gv94/kb+egAABLgGgAeoB8AHUAdQB1AJ4AuQDDALYAnwCIAJgAlACXAJsAhQBngEaATwBDgE9AL+AeMAg/9c/7EA9wAeAPf/kQBjAHEAcAKYBJgEKASoBXAHsAdwCFALkAwwC7ALgA/AEUAQABDgESAR4A2wDeAQgBDwCwAKEAuACAwDagH8AvYBLP3o+RD54PbA8wD0EPZQ9KDvwOzA7EDsAOyg7WDvAO7g6WDoQOoA7aDuQO/g7uDtAO6g7/DygPUA9gD1EPUA98j5mPw+/rz+hP5K/sr/RAOoBiAIyAeIBuAFwAYACZALoAzQC/AJgAjYB1AIoAkACtAI6AaIBegEkARQBOwD8AKMAVcAWgAaAXQB0QAiACkArgCYAfACuASYBZgEIAQYBqAIgAlACqAL4AygDFAMkA5AEaAQIA9gEIARgA/gDOAMMA1gCtAG0AbIBygF0gDe/lD9EPlg9aD1kPcA9yD14POg8WDtIOpg68DuwPCw8IDvYOzA6EDoAOwg8CDxAPDg7sDuAO/A8HDz8PTg9AD1cPaI+Oj66Pxg/Tj8iPus/ewBmAVgB4gH2AVwA0gDeAaACpAMMAzACsAIqAYIBtAHEArwCfgHEAbgBCgE8AMgBLQDHAKfAJ0AnAEsAhwCegFKAMD/KAG8A8gFwAYAB6gG4AVIBjAJcAygDZANMA6wDuANMA7gEOASYBFwD9APgBBgDlAL4AogChAG5AKIBLgFrgEw/MD4oPYQ8wDxYPRY+DD3EPKA7eDpwOfA6YDv0PMw8kDtwOkg6YDqAO0w8PDxMPHA70Dv4PAQ8zD0EPSg9AD2oPfQ+aT81P5k/TD6OPoD//gDaAbAB8AHWAUEAmAC4AZQCxANsAzwCsAHEAXABcAIcAqwCeAHQAYABUAEMARoBJwDQAKIAQgCpAKoAkgCuAHwANYAcAIIBSgHuAcgB9AGIAe4B4AJQAyQDgAPQA4QDlAOIA6wDqAQgBEgEMAOkA6gDYAKcAc4B3gGMAMsATwCQAI8/WD38PNw8uDwgPI4+Kj6wPRA7EDpYOqg7MDvwPPQ9JDwYOuA6qDsAO7g77Dy8PPg8RDwkPFg9PD04PNw9MD2APmw+uj8Xv7s/JD64Ppm/rwC+AXIB/AHUAUMAkQCaAbgCvAMoAzACvAHyAUgBjAI4AngCUAIGAZgBIwDuAMYBLAD4ALSAe8AKgEsAnQCoAEEATQBPALoAxgG0AewB5AGgAbwB5AJoAtADoAPMA6gDCANoA4AD0APoBDAEFAOAAzwC3ALMAioBDgECAR8AZ//FwBY/hD3sPCw8JD08PWw9cD2UPVg7wDqIOrA7cDw8PLg9PDzYO4g6gDroO7Q8RD0sPTg8pDwIPAg8qD00PVA9nD24Pao+Jj7jP2w/aD8kPs8/Lz/UAWACRAJsAU0AxADCAVwCUAOwA9QDFgHsAUgB7AI4AkQCzAKAAZsArwCYAXABbwDDAIMAfj/4v/qAagD6AIMAT0ARgGIA1AGgAiwCFgHmAaIB3AJgAxwD0AQoA4QDRANEA7gDiAQYBGAEPANAAxAC9AJOAcoBYAEKANEAeb/Hv7o+cD00PEA8vDzMPXQ9tD24PKg7UDrYOsA7cDw8PSQ9jDzIO1A6kDrgO5Q8jD1MPXg8rDwwO/w8IDzIPZg99D24PZw+Jj6WPyc/cD9WPwo/JP/SAWwCJAIeAYwBFAD4ARgCdAN8A4gDEAImAVIBbAHsAqwC6AJyAXgAowC4AMABSgFrANAAbv/eQBMAgwDbALGAaYBFAJsA3gGUAkwCRgHAAZoBxAKEA2ADyAQMA6QC1ALEA3QDpAPABBAD7AMwAlACNAHOAbQA1ACnAEMAOz9IPxo+cD0IPCg7zDy0PUA+AD4sPSA7cDngOjA7hD1SPgA93DygO3A6iDsUPCw9JD2cPXQ8jDxYPFA8tDzQPbA9zD34PaI+Sz9Tv7w/CT88PxG/vYAwAXQCbAJeAYoBDAEUAaACVANMA+QDBAIWAXIBWgHQAlgCjAJuAUwApIB8ALYA4QD9ALEAZT/iP76/4ACTAOIAgQCnAKwA5AFIAiACeAI8AfACMAK4AwgD4AQcA8gDWAM4A3QDrAO4A5QDyANIAmwB7gHEAbMAiYB+gCQ/4j8YPrA+KD0wO+g7nDx8PVQ+ZD4APMA7IDowOpw8KD2APrg99DxgOyA7ODu4PEQ9dD3wPaw8rDw4PFg8xD0EPZ4+Lj4GPjw+SD9kP34+1D8av7D/4IBmAUwCaAIqAVoBGgFOAegCVAN8A5ADCAISAaoBvgHcAkQCrAIcAXwAnwCWAPkAwgENAPTAAr/Z/9eAdQCVANMA7gCPAIsA0AGQAkAChAJsAigCeAK4AxQD0AQ0A7wDEAMwAyQDVAOkA4wDcAKoAgwB9AEFAPAAi4BHP50/LT8SPsQ9pDx0PCg8HDwMPQw+jD58PCA6iDrYO5g8UD2SPrA9yDwwOyg7vDwgPIA9sj4APag8ODuUPGw86D1APig+Xj44PZY+ID7hP38/Tb+/P5PAIwCgAXwB7AIEAcABQgFAAgwDHAOMA2ACjAIsAbgBoAI4AkwCZAGAARUA8ADxANIA7QCdAGt/7T+rf9QAuADGAO8AcABtAIIBEAGwAgQCmAJ8AgQCrALwAyQDYAOEA5QDUANwA3ADUANoAxACxAJ8AewB1AGnAN2AeT/6PyA+vD6SPtA9wDy0PCA8rDyAPPA9RD3kPKA7cDusPIg8wDz8PUA9+DyIO5g7wD08PUQ9lD2YPRA7yDtkPEo+Ij62PnQ+FD3YPVg9aD6qAD4ApQB0P/i/3wBaARIBzAJoAgYB1AHMAoADRANYAtACSAI4AcgCCAJgAn4B4AFZANUAnACZAMYBBADugAW/wT/FQBgAfAC2AMMA/ABuALABMAGQAigCaAKgApQCiAL4AzQDdANkA2QDZANQA3wDCAM8ArgCOgG0AZoB9gFEAK+/pz8OPuo+dj42Pjg9pDygPAQ8hDzcPKQ8pD00PQA8nDw0PLQ9JDzQPIw83DzAPIA87D2IPhQ9KDvQO7A7kDwIPRA+gz9KPoQ9VDykPLw9dz8CATwBdwBwP3U/TABkATIBwAK4AmgCPAIwAqAC9AK8AngCEgH6AbwCMAKgAlQBpQDTAH8/5oBcAXABqgDu/98/vz+wv/wASAFKAYoBMACMASwBmAIIArgCwAMwArQCvAM0A4AD2AOsA3gDKAMQA1gDbALUAmAB1AGOAWABLQDHAFQ/dD6+Pmo+JD2wPXQ9RD0IPHA8PDywPOQ8nDy0PNw85DxQPLw9GD0EPGw8DDzkPWA9QD18PQg8uDtwOwA8CD0SPiY+wT8APhQ8sDwIPWI/MwCYAWUAygAfv4TADgDEAfgCXAKcAngCWALIAuwCUAJsAkQCCgGyAfQC0ALAAYgAhABRQAWAFgD8AaYBW8AvP2o/tv/4AAIBAAHSAbAA7gDeAYQCdAKcAwgDcALAAuQDCAPwA/gDgAOIA1ADGAMEA3QCzAJOAdIBiAFtAN4AgQB3P2I+hj5qPhA99D1MPVw9CDzYPKQ87D0oPQA9BD0YPQA9ZD1gPWw9LDz8PNw9LD1gPZA9qDz4O9g7uDu4O+Q8kj4IPzg+kD1YPHQ8WD1IPtIAsgF5ALs/rz+rAGEAzgF4AgADPAK4AgQCgAMwAqoBzAHEAhABzAH4AkAC8gGlABE/p7/6QCEAkgFYAXeAID8lPxs/5YBrAMIBvAFYAP8AnAGUArQCyAMkAywC1AKAAzQDyARcA/gDWANMAzgCgAL4AuwCqgH8AUgBSgDsAA2/4T9EPsY+UD4kPdw9nD18PTg87DyYPOw9AD1APUg9pD2UPVA9ED1gPWw83DzIPbA95D1YPMw89DxIO3g6iDv8PQo+Aj6UPpg9kDwYO9A9jr+fgHQApwDkAHe/i4AmASQB1AIMAkAC2ALcArgCiAL4AgIBpgFOAdgCdAKIApQBv8ABP7k/j4BqAOIBbgExABc/cj9jwCYAsgDwAWQBtgEaAToB8AL8AvQCoALwAxwDCANgBBgEuAPYAzAC0AMcAtQC0AMoAvwB2gESAN8AnYAuP6s/Vj7YPjQ9gD3APcg9hD18POw8pDycPRA9tD2kPbw9YD08PIQ8xD14PVg9WD1oPUA9KDxsPBQ8KDuAOyg7QDzUPdg+eD5MPcA8oDv4PPI/AgDMAT0A9AC+//i/lQCwAcAC8ALgAswC7AJgAhQCRAKAAn4BkgGOAcwCPAHUAZgAyoA3v7k/wgCSAMMAwgCeQBg/ygAdAIYBLAEWAVYBlgHcAiQCuAMAA3gC0AM8A3QDiAPwA+gD8ANAAzQC7ALMAqgCPgHmAa0A7YBLgHW/9z8EPrA+JD3gPaw9kD38PWA84Dy4PKg87D0EPeY+BD3cPSw8xD0APSw9PD24Pdg9bDysPJA88Dx4O8g76DtAO2w8CD48Pyg+rD1IPJA8SD04Pv4AygHUAUwAisA3v/AAkAIkAzQDGALMArgCDAIsAlAC2AJwAWABNgFqAZoBoAGaAVEAXj9Iv4iAWgCbAJYA8QDDAJiAAQC+ASwBQAGMAiQCrAKUApADDAO0A2wDLANQA8QD4AOQA9wDxANQAqACVAJ4AeABjgGcAW8Arn/xP24+xj5sPd4+Mj4UPcQ9mD10PPw8aDy4PWg9+D2MPZQ9nD0APIg81D2UPdQ9SD0MPSw8pDwcPEg8yDxAO0A7EDvMPRA+Xz8+Ppg9TDx8PJY+eIAwAYgCPAEiQD5/5gCUAYgCnANsA2wClAIUAgQCQAJQAlQCQAH3AO0A8gF6AW0A0QCtgHz/5L+bAAEAxADCALEAlgEWATUA2AFeAcgCGAJ4AuQDcAN0A0gDqAN8AxQDZAOgA5gDWANMA0gC6AISAd4BqgEVAOQA6ADZgES/uj7EPqw91D2YPfA+MD34PVA9WD18PQw9ZD2QPcg9rD0oPRg9fD1sPbQ9rD0QPKA8WDxUPFw8sDzQPIA7mDs4O4A8mD0ePgE/Jj5cPRA9Kj5hv6KASgF4AakAyoA8AJQCBAKEAkgCsALEArYB9AIYArQCGAG2AXoBZgDWAEwAuwDmAP6ASgBiAAM/zz+fv8MAmAEqAVIBsAFyAQYBUgHwAlQDKAOIA8wDgANAA1QDVANMA0QDhAOkAxAC0AL4AqQCFgFLAPIArwChAKcAroBbv7Y+SD3MPfw9/D3KPh4+HD3oPUQ9fD1MPbw9TD2sPYQ9oD1UPbw9vD1MPSw8jDxYPCw8dDzkPNg8YDvIO6g7GDukPRI+gj7OPlY+Bj4kPeg+gwCyAYYBbgCeAQ4B9gHMAhQCnAK0AeABwALAA3QCqAIMAgQBmwB0P84AmAEIAR0A3wDKAHo/Wj95//UAaQCOASwBdgFkAVYBpAHEAkQCzANEA6QDYAN4A0wDfAMAA7ADvANMAxQC4AKMAlQCOAHkAZwBLgCKAJoARoA5P4o/dD68Pg4+Cj40Pdg90D38PYw9kD1gPWQ9kD3QPdA9yD3YPaw9ZD1sPUA9ADxcPBw8sDzAPNg8jDx4O0g6iDrEPFQ9qD4sPqY+yj4UPSQ9rD9YAIAAwgEQAZQBugFkAhQC1AJaAXQBaAJ4AvQC8AL8AnoBOn/zP6XAOoB8AJgBAAEtQCQ/XD9P//8ACwCnANoBIAEKAXIBmAIcAmQCsAL4AzADaAOoA6QDfAM0A3ADsAOYA4ADpAM8AnoB6AHsAd4BkAFoAT8AiwALv64/ez8EPtQ+eD4APiA9oD2oPcg91D10PTw9WD24PXA9gj48Pbg9OD0kPVA9EDyAPKg8kDy8PHw8pDyIO9g7IDs4O7g8QD2aPpA/Fj6APjg96D5VPzQ//QD8Aa4B1AHiAdQCBAIgAbwBaAHQArQC/ALYArIBnACDAC6AAQCLAIQAnwCCAKdAKb/1f91APcA7AGIA/AEIAaYB+AIwAnwCTAKQAtwDQAPoA4wDXAM4AxgDaANQA7gDWALoAiQB5gHQAeQBlgGqAW0ApH/lv7W/vr+DP5c/Bj6kPdQ9mD3CPlA+fD3UPbw9UD2kPbw9vD3GPiA9lD04POA9FD0UPMQ8/DyMPHg7+DwQPKA8ODtQO7A8EDzEPdw/E3/uPxw+PD3uPpU/kwDQAlgC9AIyAU4BtAHmAdIB7AIAApACbAI4AiwB+QDXgB7//L/zP8IANoBHAMsAt7/vv4z/+r/+gAgA8gFkAcgCJAIcAlgCuAKwAsgDQAO8A1QDTANwA3gDSAN0AygDGALYAnABwgHyAZYBkgG8AWkA3kA7v60/lb+PP0A/Lj6WPmA+Jj4kPiw9xD3EPfQ9oD20Pbg90j4kPcA9oD0sPMg9MD0UPRQ84Dy4PEA8QDxoPHQ8KDuAO4A8ODzUPgI/b7/aP0Q+OD1iPm0/1gF8AjACbgH2AT8A3gGAAngCHgH8AYoB9AGUAYoBqgFzAH4/Nj7Gv4vACwBkAJ4AkD/LPyk/TABbALUAsgFkAgQCHAH0AmQDDAM0AtwDTAOkAwgDUAQwBDADbALgAygDEALgAqACpAIoAUYBdgFGAVEAxACiwC2/hz9IPz4+nD6qPpA+rj4sPcY+MD3cPYg9pD3EPiQ96D30Pdw9pD0cPQg9cD0UPPg8jDzQPOw8oDyYPJA8SDvoO1g7zD0GPqc/rr/HP3A+ID28PnjAFgGcAhwCPAG0ASQBKgGQAlACWAHUAboBWgF0AXIBpAFNAGo/CD7CP3j/xACzAJ2AcT+0Pzs/W4BIATYBEgFwAZwCEAJgApADWAOgAwgC3AMcA7QDkAPYBDgD8AMgArACjALUApgCeAIIAe4BOADIAQ4A+8AGf+c/fj76PoQ++j6CPr4+AD48Paw9ZD1YPbQ9kD3OPjg9yD24PQA9fD08PNg87DzsPNA8lDxwPEA8rDxcPGQ8ADuAOyg7tD1vPyG/7b+yPvQ9/D18Pn6AcAHoAgQCKAHAAZgBOgFkAkwCmgH6AXYBigHsAbwBvAFHgHI+2j7Av/MAfAClAMIAoj+yPx+/4gDcAVgBsAHUAj4B2AJQAzgDWANsAzQDCANsA3gDrAP4A5gDfALsArwCTAKoArgCfgHIAbABIADkAIsAkgBXv9M/Sz84PtQ+zj6OPmY+FD3IPYQ9oD2UPbw9VD2MPew9gD1APXA9YD0cPJQ8lDzgPNQ8vDx4PJw8lDx8PAg8CDuAO5A8gj5Bv5Q/+T9mPrA9xD5Rv6oA/AGQAggCJgGWAXgBYAHIAgQCKAHIAa4BGAFAAewBdoBvP64/QD9kP2xADwD3AHg/tj+ywDYAQgDAAZQCBAIsAfwCWAM0AzQDPANYA4gDQANMA+AEDAPEA7QDbAMMApACaAK8AoACaAHQAc4BUwCPgHoAVIBB/+g/ZT9NPwY+pj5CPo4+ZD3EPeA92D34Paw94j4APhg9lD1EPXQ9AD0MPMw8zDz4PLw8cDxsPGw8aDwIO9g7kDuMPBQ9VT8JgDo/iD6MPcI+Kj77gBwBuAIsAfgBZAFkAbIBuAG8AcgCMgFQASIBTAH2AUcAoP/8P3Y+wz8pP+kArwBIP/W/gUAUgBiAagEGAf4BggHYAnQC0AMQAxADSAN4AtgDLAOIBCQD5AO4A3wC0AJ4AhgCpAKcAnQCBAIqAWoAnYBzAFUAff/bv+8/tT8KPvg+qD6iPl4+Cj4wPfg9hD3cPjg+ND38PYg9tD0kPPQ85D04PNQ8gDy8PHQ8FDw0PHA8qDwYO5g7kDwkPKg98j+egGM/bD4GPjw+rz+rANwCEAJYAYoBZgGQAfgBmAH+AdoBjAEOAQoBiAGlAPyAJT+cPxY/Nj+lAEoAscAkf9k/+n/nAFoBHAGOAfwB1AJ4AogDCAN4A1gDVAM8AzADmAP8A7wDpAOQAzQCYAJQArACbAI4AhwCLAF7AK4AuQCcAELAMn/MP/8/ED7SPsQ+5j5uPgI+Wj4EPew9vD3sPjg9+D2QPYQ9YDzUPPQ88Dz0PIA8mDxgPAA8DDxIPIg8WDvQO5A7nDwEPYo/fQAqP6o+nj4oPj4+0ACiAewCOAG4AV4BkgGyAUwB/AH6AXoA3gEEAYIBngEVAKA/wT8MPvo/foANAK+AcoAvv9G/7IAzANABjgHAAggCSAKEAuADEAOsA6wDSANwA3wDfANgA5AD0AOsAsgCvAJIAkACCAIMAgwBnADYAJ0AlIBzf8U/wD+mPvI+fD5YPrA+VD5MPkI+ND1QPUA9xj40PdQ98D2QPWw86DzoPRg9DDzAPOg8kDxcPAQ8rDz8PKw8KDv4O9g8RD2CP3WAL7+ePqI+Ej5WPzqAZAHEAlgBsgEaAXYBeAFMAfwB2AGIAT8AzgFaAWABLgCUf9w++j66P0AAQwC7AH3AD3/Wv5pADAEcAZYB2AIgAkACsAKwAzQDiAPIA6gDbANsA3gDbAO8A5QDWALQAoACnAJsAhQCGAHcAVcA9ACrALwAfEADACS/hD8YPpI+qD6IPrI+dD50Pjw9rD2OPgA+eD3wPag9tD1kPTw9OD1sPRQ8sDxwPIQ8vDwgPKA9IDy4O5g7mDw0PLA9iT9tgCU/aD4APi4+hD+QALQBsgHgAUwBIAF8AZwBxAIoAdABVQDGARgBRAFOAQ0A9n/+Pto+4T+xAAKAWwBcgETAET/6gFYBSgGwAUQB0AJAApAC0AOIBBADvALQAxwDZANAA7gD/AP4AzQCTAKUAtgCgAJoAhYBwgEEAKgAkwDOAI6ANj+zPwQ+jD5aPrg+vD5QPng+HD3APZw9kj4mPhw9wD3APfw9bD08PRg9WD0APPg8iDzoPKQ8qDzMPMw8WDvIO9Q8LDzOPpu/7z+qPpI+GD4GPpm/nAEKAf4BGADOAWoBtgFGAaoB2AG9AKQAlAFEAZoBHwDVAKG/tj62PvS/j4AewBoAcwBNADr/4ACAAWYBQgGaAcACTAKEAyADlAPUA7QDEAMgAyADRAP0A8ADxANcAuQChAKkAkQCUAIGAZABLAD3ANQA3YBUP9U/Rj7cPkA+nD7kPtg+iD58PeQ9rD1YPYw+ND4WPg4+OD3wPYg9eD0QPXg9MDzUPOg8+DzgPSg9KDzQPGg7wDwQPIQ9oj7o//q/jD7oPjY+BD78v68AyAGqARIA9AE6AaABnAFGAXcA5wBLAJABUAGGASiAXsADP4A+7j7iP+WAfUA0gAQAmQC1AE8A+AFuAYIBkAHwAoQDYANkA5wD0AO0AtQC3AN0A4wD2APQA/gDFAKAAqwCtAJ6AfQBpgFEAT8AjQDwAJTAKj9TPzg+rD54Pmw+qD6+PiA94D24PXw9VD3SPgA+FD3EPdg9gD1YPTA9PD0EPSg8/Dz4PNg87Dz0PTQ85DwQO8g8mD2CPp0/Vj/cP1I+dD32Pos/soAMAS4BogF+ALgA1gGcAYQBAAD/AIAAuABmAQ4BtwCEP4Q/Hz8aPxI/SoAeAK8AVQAPAEIA9wDoARABkAHCAfAB8AKIA5wDxAP8A0QDEAKgAowDaAP0A9wDiANkAvwCXAJsAkgCfAGyAQoBCAEnAPsApoBBP8A/Gj6YPrA+uj6MPug+sD48PaQ9iD3kPco+Pj4CPlw9yD24PWg9VD1UPVw9ZD0YPNQ8+D0MPUA9ADzIPLQ8ADxgPSQ+fz87P24/bj7cPgA+Cz8SAHkAxgFkAWwBBQDeAMABmgGAASEAgQDXANAA6QDiAMkAVz94Pvs/EL+Xv/bAOQBIgHp/40AZAPgBcgG0AZAB2AI4AlADMAOcA/ADXAL0ArQC2AN0A7QDyAPgAxgCsAJEApgCtAJcAgwBvgD4ALcAtQCJAIlAED9SPsg+1D78Pqg+nj6mPmw97D24Pe4+Bj4CPhY+ED3IPVw9ND1gPYw9YD0cPRQ88DyMPRg9iD2YPMw8TDxUPJA9eD5uP0S/6j9aPuo+cD5ePzjAFAEwAXgBVgFaARYBCAFOAVABEQDYANwA7QDWAScA+r/APwA+2j8Pv7u/wACbAIDAHj+xwAIBHAFmAWgBvAHcAjwCUANQA/QDcAL8AoACyALwAzAD6AQwA2gCrAJ8AlgCmAKIAqgCJAFQAOQAsQC4AJYAsQAfP4s/ID6APqg+pD7mPsg+qj48PeQ96D3wPgI+lD5gPcg9qD1MPXw9AD2kPbw9IDyoPIg9BD1IPUw9PDxEPBQ8eD1QPpY/DT9GP0w+9j4aPmo/O//tAIIBfgFCAXEA4gD6AO8AxAD/AIIAzAD8AMIBFgCR//4+0D6IPvI/YcA2gEqAcH/CP/a/yACaAS4BZgGYAdACHAKEA1QDmANAAwgC9AKgAvQDcAQgBCQDVALoArwCdAJQAtgC4AIOAVwBFAE3AIsAggDBAKs/WD6wPq4+2j7OPwg/cj6sPbg9Tj4kPk4+SD6SPuw+FD1UPUg9+D2oPXA9fD1QPQw8yD18PYQ9pDzIPKg8eDyAPbg+Wj8tPxY/Fj7yPoI+8j8vv7mACgD0AS4BEgEIAR4A2AC1AGAAkADhANYAzgDvgEK/7D8IPvA+hT82v42Ab4BrADH/xkAngGAA/gEsAVoBvAHYAowDWAOEA6ADAALsAqQC1ANUA9AEFAPQA3QCnAJoAmACmAKgAgQBmgEdANQA8ADrAKf/3D8APs4+7j7FPz4/OD7oPiA9tD2QPgw+Uj6APuY+WD2EPVA9lD3IPeQ9iD24PQA9ND0MPbw9YD0cPPg8iDzoPRA9xj5uPnw+Sj6mPpo+yD9GP7A/Qj+YgAUA4gE0ARoBJwCTwAWACgC+APkAzQDnALNAMT90Pu4++j7oPwf/+wBSAKXAEAAygGYAowCyAMIBjgHMAgwC5AO8A7ADEAL4ApACqAKwA0gEWARcA+gDfAL8AlQCcAKYAswCbgGMAb4BegEvAP4As8AcP2A+yz8TP1s/TD92PsY+YD2gPZ4+Aj6SPqg+eD3wPUQ9fD18Pbg9mD20PWw9ODzMPQg9SD1IPSQ85DzAPQg9QD3kPjI+HD4aPmg+/T8RP1g/ZT90P0j/wQC6AQwBRwD6gGyAQoBQAFwAwAFUASKAVb/bv4E/YT8rP3A/o7+AP+rAGACwAK4AngDzAOwAwAFoAcQCkAMMA7gDmANwAuAC0AMEA1gDqAPcA9gDiAOQA5wDCAKQAkgCbAHUAaYBsAG8AR4AlgBBwCI/RT83PyU/bj8ePv4+qj58Pew9zD5EPpY+cD4ePiA9zD2UPYA9xD3UPYw9oD2wPXg9AD1MPVQ9AD0wPSg9SD2wPaw93D4iPiY+Wj7fPyM/Kj8TP1m/v3/3gGYA4wDVAJGARQBcgFoAgwD6AJIAv0Aff98/XD8NPwY/aD9GP5I/0YA4gDuAYQDjAOMApYBjAN4B3AKQAyADTANgAuQCkAL4AxQDSANEA6QDrANkA3ADtAOsAuoB2gG+AbwBnAHQAgIBwADLf9S/n7+cP3s/Mz9gP1w++j5GPow+sj4IPjg+PD4OPhg+PD4UPiQ9oD1APYQ9qD1MPbA9qD1UPQw9ID0YPRw9JD18PYQ90D3mPiQ+cj5uPpo/BD99Pyo/Wj/uACEAdQC+AMIA3IBqAGMApwCaAIUAwQD4gBs/kT+kv6w/VD9eP7C/rj9kP7aAUgEdAOYAmwDKAM0AlAEkAlQDXANUAyQCzAKEAlgC8AOAA8QDXAMgA1ADkAOIA4ADXAJGAYoBvgH8AiwCFgHSAQ+AJT9qP3Y/vb+gP6s/eD78PmI+RD6oPmo+Gj4yPiA+PD3aPiY+LD2sPTA9HD1APXg9ND1EPZw9DDz8POQ9MDz0PMA9nD3YPcQ+JD5OPrg+Yj6fPyM/aj99P7TAFIBdgFMAiwDkAJCAXwBjAKwAqACyAK6Aaf/Ov4c/jz+nP10/WD+uP49/1QBzANABBQD7AHAATgCEATgCDANwA0ADGAKQAlACeAKcA3ADnANYAzADQAPkA5ADaALYAkoB/AGoAjgCdAIkAbEA8MAzv5k/gj/Pv9O/gz9CPz4+hD6wPmI+TD5QPig9xD4gPhI+ND3YPcw9vD0kPQw9cD1UPVw9RD2gPVw9GD0APUQ9UD1oPZ4+DD5iPmA+lD7QPuI+xD9fP7g/tn/qgGwAkQCEAJgAsABwgBGAQADNAPEAawAJwDE/mT94P2m/hr+qP1E/3wBQALQAmAEiAQ0AusATAMQBxAKsAyADuAMQAkQCHAK8AyQDVAOsA5wDTAMkA3wDoANUApACJgHQAfgB0AJ0AiYBVwCegD2/tT9XP6W/wL/vPww+wD7aPrA+eD52PmY+ED30PcI+dj4wPdA95D2IPVA9DD1cPZA9vD1IPbA9ZD0MPRg9YD24PZw98j4oPnI+YD6uPtE/ED8OP3e/tn/cQCiAdACpAKsAV4B0AEQAhQCvAJEAyACUABh/+z+GP5o/aD9fv6O/sT+2gA0A1gDlAJAAr4BMAFQAqAGIAtwDGALYArwCOAHQAmgDDAOUA0gDEAMEA2QDcAN4AwwCpgHIAfgByAIIAjIB5gFMAKN/xL/9v6k/rj+lv40/Qj7iPow+wD7ePlI+Bj4sPeg97D4qPmY+HD2kPVw9SD1IPWg9sD3sPbg9ND0kPVQ9UD1kPbA90D3cPco+Xj6kPqI+tD7xPyo/GT9TP+YAAQBrAEoAmQBVACgAPwBdALgAdQBtgFAAKT+PP5u/uD9XP0m/oD/WwBwAXADMAQMA4gBSgFsApgEkAhADKAMsAowCbAIAAmQClANkA4QDQAMEA0wDqANwAwQDAAKcAc4B+AIIAmYB1gG6AQQAhb/qv6D/1r/NP5o/dz8aPuI+uD6yPpQ+cD3kPeQ+BD5APkA+Wj40PZg9TD18PXA9hD3IPfg9gD2cPUA9rD2kPaA9jD34Pfg+Aj6KPu4+1j7WPs0/PD8pP1K//sApgFaAQ4BMgEmAfUAKgHcAbwBIgHrALYAy/8w/sT9NP5W/kj+h/+mAegCgAN0A/wC3AGkAbADuAbgCKAKoAtwCnAIUAgAClALoAtQDDANsAwADLAMcA3wC5AJcAjwBwgHeAfwCIAIQAWiAWoACQAI/+T+bv+a/pz8oPso/OD7APqw+ND4oPjQ9wj4cPnI+UD4IPeg9uD1QPUw9uD3wPeQ9jD28Pag9jD2sPaA96D34Pdo+YD6mPqA+mD7BPyo+/j7yP0R/4D/0f+EALcADgD1/1wAUwACAFoA4gCqAHT/fv4i/pj9GP2Q/WT+If9HAMoBCAMoA3wCZAKkAsQCqAQgCIAKsAogCqAJUAkACfAJcAwwDXAMQAwADRANoAywDLALYAn4BjgHAAkwCdAHaAZ4BLQBHQA3AKkAsf+G/hj+uP2M/ID7OPu4+nD5UPhA+Kj4APlA+SD5MPiw9sD1EPbQ9iD3IPcQ9+D20Pbg9iD3cPeA95D34PeQ+Gj5SPoY+5D7kPuA+/D7IP1u/jn/zf8iAB8AHABGAKkA4gC9AMgA5ABzAP//4/94/67+Cv70/Xr+MP9pAAQC2AJ4AjQC7AGiAZgCAAWYB8AI0AjQCLAIMAiwCKAK0AuACxALUAvAC1AM8AywDNAKYAiABzAI4AjQCDAIkAbwA8YBJgGAATABPgBe/5L+dP2k/ID8TPw4+5j5sPjQ+DD5oPko+uD5KPhQ9vD1wPaA96D3kPdg97D2QPYQ9xD4CPig98D3KPig+Jj5GPsU/Lj7GPtg+zz8YP26/tv/GgCV/1H/6/+WAPcAIgHeACcAu//C/9r/l//0/or+HP6g/Qb+Yf+AAHAB7AHMAWQBCgG+AZgDeAXQBvAHMAjoBxAIoAjgCdAKEAsgCxALUAtgDEANEA3wC1AKAAmgCAAJQAkACcAHGAZIBNwCWAJUAsIBqwB8/1T+kP0o/ST91PyY+/D5APno+Fj54Pn4+Tj50Pew9pD2EPeA93D38PaA9iD2QPYg9/D30PdQ9wD3QPc4+GD5kPpQ+xD7gPrI+tj7NP1o/tz+5v7M/uz+kP93ANoAuQAbAI7/rf8ZAFgAHQCE/4b+8P0Y/hv/MQD3AKgB0AE6AWsABgFwAqgDsAQIBvAGEAcoB+AHwAjgCCAJ4AlACvAJwAqADBAN8AtgCmAJsAhQCKAIMAmgCNAGgAXIBLQD0AJQApoBUQAE/6j+2v6M/pD9nPxg+/j5UPnI+YD6aPqY+eD4YPjQ9+D3aPh4+MD3IPcg93D3oPcI+ND40Pjw95D3UPhg+Sj60PpY+zD7yPpo++T81P30/Sz+gP54/nr+f/+vAI4Ayv+a/6r/fv9+/+r/EQAg/z7+qv4d/yb/5v8cAWoBygBpAPIAxAFgAmwDoAQ4BWgFEAbABkgHwAdQCMAI8AhgCTAK8AowC1AL8AowCoAJMAkACfAI0AgwCBAH4AU4BbAECAQUA0QCXAFpAPv/yv9O/27+dP1Q/Gj76PoA+zj72PoY+oj5IPng+Nj40Pio+FD4IPgo+GD4kPjA+Oj46PjI+OD4UPnQ+Vj6sPrY+vj6MPuw+3z8DP1Q/aD91P0A/kb+hP7k/hf/4P7y/h3/Cv/u/sj+ov56/jT+Hv56/tD+K//R/yUAGAD7/yYAqwBcARwCAAPcA1AEsAQwBbgFMAa4BjAHoAcgCLAIUAmwCcAJkAlQCfAIwAjQCOAIoAggCIAH2AYwBoAF4AQwBHADxAJQAtYBVAHDAOP/1v7c/RT9pPxk/AT8sPs4+6j6KPrA+Wj5EPmw+GD4SPhg+HD4mPio+Gj4IPgQ+Fj46PhQ+bD5+PkQ+jj6uPpQ+7j7GPx8/Oj8PP24/Vj+0P7W/sb+7v4T/zv/Zf9s/0H/BP/c/rj+kv64/iX/d/+d/7T/4v8JADIAjgAEAZgBQAL0ApQDGASIBPAEYAXQBVgG+AaABxAIkAjgCAAJEAnwCMAI0AjQCNAIgAggCKgHIAeYBhgGkAX4BGAE5AN4A/wCZALAAQYBJABg/7z+LP6c/ST9rPwg/Ij7CPu4+mj68PmI+Uj5CPng+Nj44PjQ+Jj4gPiY+MD4APlw+cD52PnY+RD6cPrY+kD7qPv4+yD8ePzw/GD9mP20/dT98P0k/m7+pP7C/pj+YP4e/uj9+P1E/qj+3P4W/07/i/+h/9v/RgC3ACQBuAF8AjQD1ANQBNAEOAWgBTgG8AaYBxAIkAjwCCAJQAlgCYAJYAlQCUAJIAngCKAIcAgQCHgH8AZ4BvgFeAUABZgEEARkA6gC5gESATsAjP/8/nL+xP0g/ZT88PtI+8j6SPrI+UD52PiI+Ej4EPgA+ND3gPdg93D3oPfQ9wD4OPho+ID4wPgw+aj5CPqI+vj6UPvI+0j8wPwE/Tj9jP3c/Rz+Zv6s/sD+kv5y/n7+lP6o/t7+PP+O/67/v//f/xkAaQDDAD4BugE4AtQCfAP4A1gEqAQIBYAFCAaoBlgH0AcgCHAIkAigCNAI8AjwCOAIwAiQCJAIYAgQCLAHMAeoBkAG0AV4BRgFiAToA1ADrALoAS4BgADT/xP/bP7k/Uz9oPwA/Hj72Poo+pD5IPmw+FD4IPgA+MD3cPcw9yD3APcA9zD3gPfA9/D3SPig+AD5aPnY+Vj66PqQ+yz8uPws/aD9AP5K/o7+7P5O/5v/1P/u/+n/0v/b/+v/+/8EACQAVwCaAMwABgEuAU4BdgHEATQCrAIcA5ADGASABNgEMAWgBSAGkAYYB4AH2AcQCEAIcAhwCFAIUAhQCEAIIAgQCOAHkAcoB7gGUAbgBXAFEAWoBBgEfAPsAkACigHVAD8Ap//8/lT+wP0c/Wj8uPsQ+3j62PlY+fj4kPgY+MD3kPdQ9wD3APcA9xD3IPdQ94D3wPcY+Ij4CPmA+QD6mPoo+7j7TPzc/ET9kP3k/Ub+pP7+/lf/j/+9/9n/BQAkAB8AEwAfADIAUgCFAMoAEgFAAWIBhgHCARQCiAIAA5QDAARoBLgEAAVABWgFsAUQBnAGwAYABygHEAfoBsgGuAaoBpgGkAZwBkgGEAbIBWAF8ASABCgEyANsAxwDwAJAApIB5gBHALH/Mf/A/kz+1P1M/bj8JPyo+zD7uPpI+tj5kPlQ+TD5IPn4+Nj4uPio+Kj40PgQ+Uj5iPm4+QD6UPqw+hD7cPvI+yz8jPzw/Ez9sP0Q/mT+pP7U/gf/P/92/6//1v/q//j/EwA0AEIARgBPAFYAXwCCAL0A9QAmAVYBjAHCAf4BYALkAmQDwAMgBJAE+ARgBdgFUAaoBvAGOAeQB+AHEAggCBAI4Ae4B6gHkAdoBzgH8AaABggGkAUYBYgE5ANAA5AC3AEyAYgAxP/w/g7+OP18/Nj7UPvI+ij6ePnY+Dj4sPdA9wD30Pag9qD2sPbg9hD3UPeg9/D3UPjA+Dj5uPlQ+uj6cPvw+4j8JP24/TT+sv4s/5T/AgB5AMkA9QAaAVQBiAGiAc4BBAIoAjACQAJUAlwCZAJ8ApgCzALoAiADVAN8A5ADyAMYBFgEkATABAAFIAU4BVgFcAVoBWAFaAVoBWAFQAUoBQgFyASgBHAEMAT0A7gDeAMsA9ACcAL8AYQBEgGgADgA1v9p//r+gv4O/rD9TP3o/JD8RPzw+7D7iPt4+3D7SPsg+wj7CPsg+2D7wPv4+zD8XPyQ/Mj8CP1Y/Zz91P0i/oz+4v4h/0L/Tf9V/2L/gf+2/93/8P/5/+j/u/+i/5j/j/99/1f/Jv8S/wz/7P6w/mb+KP4I/gT+Gv42/lb+Zv5y/nj+kP7M/ib/gv/k/0YAqAAYAZwBJAKYAvwCZAPYA0gEuAQgBXgFmAWgBbgF2AXwBegF2AWgBVgFCAXABHAE8ANYA7QCEAJsAdQAQwC7/yz/qP4u/qz9NP3E/Gj8EPzY+7D7kPuA+3j7ePtw+2j7aPt4+6D70PsA/DD8XPyE/Kj8xPzo/Bz9WP2M/cT9/P08/oL+wv4A/zj/cf+z/wkAXgC8AAIBRAGAAcIB+AEsAngCyAIIA0ADdAOgA7gDxAO8A6gDoAOYA5ADcANEAxAD4ALAApwCdAJIAhgC6AGsAW4BPAEUAegAtQCIAGMARgAuACEAEQD0/9f/zv/Y/+L/6P/o/+3/6f/v/wIACgAJAAYACwAYACcAMgA6ADEACADk/9D/w/+3/6H/g/9X/xn/3v62/oz+Wv4i/uD9qP18/VT9PP0U/eD8pPyA/HD8dPyE/JT8lPyQ/Jj8vPzc/AT9MP1c/Yz9yP0m/pT+7P4j/2P/kv/G/wgAXgC3AOwAIAFqAaABvAHaAfYB+gEEAjgCiALIAuQC8AL0AugC6AL8AhQDLAM8A0gDSAM0AyQDFAP0ArQChAJoAkwCLAIAAroBWAHkAHoAJQDg/5X/Of/S/l7+9P2U/Tz97Pyg/FD8APzA+5j7kPuA+2j7SPsw+0D7aPuo++j7KPxw/MD8FP10/eT9av7w/mX/1P9JAM4AYAHuAWgC1AI0A5gD/ANYBKAE2AT4BBgFMAU4BUgFSAUwBQAFyASYBHAEWARABAgErANEA9gCcAIEAp4BNgHGAFIA5f+R/zj/vv4y/qT9IP2s/FD8APyo+1D78PqI+jD68PnQ+bj5oPmQ+Yj5kPmo+cD50Pno+QD6OPqQ+vj6iPsI/HD8wPwU/XD94P1a/tr+X//e/2kABgGoAUwC9AKQAyAEmAQABWgF2AVABpAGsAa4BtAG6AbgBsAGoAZwBjAG4AWABRAFgATwA3QD+AJwAgQCsAFWAe0AhgBDABYA+//s//P/FwAeADAARgBbAGoAnADiABYBLgFKAXgBgAFsAVQBNAH5AMkAqACEAEYA6f+Q/yv/tv5a/iD+3P2U/UT9CP3E/ID8OPzw+6j7cPtQ+1D7WPtY+1j7SPs4+0D7YPuQ+8j7EPxU/Jz87PxQ/bD97P0c/l7+rv4N/5X/HQBzAKIAvwDgABABTgGUAcgB5AEMAkACZAJwAnACdAJsAlgCVAJ0ApQCnAJ8AjwC8gHEAbIBqgGaAXYBUgE0ARQB6QC8AI4AXgA5ACMAGgAVABEAAgDf/6//jv+O/6X/u//T/+X/5f/j//H/BgAQAA4AEAAZACUAMwBIAFcASgAoABAADAASABgAHQATAPn/5//i/93/y/+z/5b/dv9Y/0X/PP82/yz/G/8D/+T+zP6+/rb+sP6u/q7+rv6q/q7+tP6w/rD+qv6u/rj+zP7m/vz+DP8Z/yT/Lv9C/2P/hv+f/7L/yP/l/wQAJABDAGUAhwCqANIA9wAgATwBVgFoAX4BkgGoAcQB3gHwAf4BCAIQAhQCFAIIAvoB+AH2AeIBxgGoAYwBcgFgAVIBOAEUAe4AyQCcAGkAQgAkAAMA2/+2/5f/ef9c/0X/Lv8P//D+3v7W/s7+xP66/rb+sP6u/rT+uP64/rj+vv7I/tT+4v7w/vr++v78/gj/H/84/0v/YP93/4b/kv+i/7b/yf/b/+f/8/8DABkAMwBGAE4ATgBdAG8AfwCPAJoAoQCiAJ4AogCgAJ8AoACnAKkApgCzAMkAzwDCAMgAxQDDAMAAyADVAMgAvQDHAMsAuAClAJwAiAB0AHIAeQB4AGUATgBAADEAJQAaABIACgD+//P/6P/V/8b/u/+u/5j/iv+G/3//df9r/17/U/9I/zv/Mv8y/zb/NP8u/yr/Lf8x/zf/Qf9R/1z/Yf9l/3D/gf+Q/5r/o/+r/7n/yf/X/+D/6P/3/wYACQAEAAUAFAAmACwAKwAoACwAOABDAEcASQBKAEoATABNAE0ATQBNAE4ATgBJAEUARgBFAD8ANQAxADEANgA9AEAAOwA2ADYAPABDAEsAVQBeAGIAYgBoAGwAaABgAFgAVABQAEsAQwA6ADAAIQAOAPv/6P/V/8L/rv+e/47/f/9x/2T/V/9M/z//Nf8y/zP/PP9D/0f/R/9G/0f/Sv9N/1P/W/9g/2j/c/9//43/nf+u/7z/xv/K/8//2f/p//T/+P/1//b//P//////BgASABsAIAAmACoALAAuADYARgBOAFQAWwBnAG8AaABnAG8AdwByAHIAgQCCAHwAdgB6AHcAeACDAIwAhgB8AIEAiQCKAIgAigCJAIoAjQCUAJMAiACAAHoAcgBwAHAAcABrAGEAXQBWAEwAPgArABoACwADAAAA9v/m/9f/yv/B/77/t/+r/6H/mf+V/5P/kf+R/5H/g/9x/23/bv9y/37/h/+F/4D/fP99/4T/iv+O/4//kf+Z/6X/rP+t/6z/rv+0/7r/wf/K/9X/2//c/9r/2v/j//D//P8EAAYACQASABsAHQAbABwAIwAtADQAOQA9AEAAQwBFAEQAQwBGAEgASQBMAFAAUwBVAFkAXQBhAGEAXwBfAF8AXABXAFUATgBBADMAKQAgABcADQADAPn/8f/t/+v/4//X/8r/wf+6/7T/r/+v/7H/s/+x/6z/qP+k/6T/p/+t/7L/tv+4/7v/v//C/8T/xf/I/8z/0P/U/9j/2v/Z/9X/0//V/9j/2//c/9r/2f/b/9//4v/k/+f/6//u//H/9P/6//3///8AAAIAAwAEAAkADwAXAB8AJgAvADUAOgA+AEQATQBTAFIASgBFAEYATABVAF0AXwBdAF0AYwBnAGgAaABpAGoAagBqAGoAaQBmAGMAXgBXAE8ARwBCADwAMwAqACUAIAAaABMACwACAPn/8//w/+//7P/m/93/0//J/8T/xf/F/8D/u/+8/73/vP+6/7j/uf+6/7z/wP/E/8r/0f/V/9T/0//a/+b/7//0//n/AAAEAAcACwAIAAIA/f8BAAIAAAACAAoACQD//wMABAAHAAIAAwALAAcABgATAB0AFwAOAAwACQAIAA0AEwAWAA8AAwD+/wEABQACAP///v/+//7//f/8//3//f/8//n/+v///wMABQAEAAEA/////wAAAgAEAAUAAAD5//P/8P/w/+//7//v/+7/6f/j/+H/4//j/9//2v/X/9j/2//f/+P/5//u//f/+//7//7/BgAOABAADQAMAA4AFQAaABsAGwAbABsAHAAdABwAHAAbABsAHAAaABYAEgANAAYA/f/2//T/8f/t/+X/2v/P/8b/wf+8/7n/tv+1/7T/tf+5/7z/vP+5/7f/uv++/8L/xv/K/9D/1f/Y/9v/3f/f/+H/4v/k/+f/6v/t/+//7//u/+z/7P/w//f/AgAMABMAFwAbAB4AIQAjACQAJAAiACAAHwAeAB4AHgAeAB0AGQAVABMAEwAUABMADgAIAAQAAwADAAIAAwAFAAgACAAJAAgACAAHAAgADAAQABQAFwAcAB8AGwAaAB4AIwAiACMAKgApACQAIAAiACMAJAAqAC4AKwAnACkALQAtACwALAArACwALgAwADAALAAoACIAHwAeABwAHQAcABoAHAAdABoAFgAQAAwACgALAA0ACgADAP7/+//9/////P/4//X/9P/2//r//P/8//n/7P/e/9b/0P/L/8n/wf+1/6j/nf+U/43/hf99/3b/cf9x/3H/cP9v/2//cf94/4P/j/+b/6b/sP+4/7//yv/a/+n/9/8EAA8AGwAqADgAQABFAEsAUwBbAGMAaABuAHEAdAB1AHYAdwB3AHYAcwBwAG4AbABqAGkAaABoAGYAYwBhAF8AXABaAFkAVABJAEEAOQAyACgAHQAUAAsABQABAP7/9v/p/9z/zv/A/7b/rf+o/6T/nv+X/47/hv9+/3r/d/94/3n/eP94/3j/e/9+/3//gf+E/4r/kf+Y/57/pP+o/6r/r/+3/8D/yP/O/9X/2//j/+7/+P8CAAsAFQAdACYALQA3AD4ARQBIAEwAUABSAFgAXgBkAGsAdQB/AIYAjACSAJkAogCoAKYAowCiAKIApgCqAK0ArACpAKcApgCmAKMAogChAKAAnACYAJgAmACXAJUAkwCOAIkAggB7AHMAaQBgAFcASgA6ACYAFwACAOz/1v/C/6//l/98/13/O/8c/wL/6v7S/rr+ov6O/nz+av5c/lT+Tv5I/kL+QP5E/kj+Uv5Y/l7+ZP50/oj+nv62/tL+8P4R/y//Uf9u/4n/o//E/+L/AwApAFMAcQB/AJoArADHANoA9QAcAS4BQgFeAXoBhAGOAZwBpgGyAcIB1gHmAeYB2gHQAc4BzgHKAcgBxAG2AaIBjAFyAVwBSgE2AR4BAgHnAMsAsACUAHcAWgA+ACAAAgDn/8z/q/+L/23/UP81/yH/Ef8D//D+1P62/qD+kP6A/m7+WP5E/jT+JP4W/gb+/P30/fD95P3Y/dD90P3Q/cT9uP2o/aT9rP20/cD9zP3c/ej9+P0K/iT+SP54/qz+2v4I/zX/Zv+V/8T//f9DAIgA0QAYAVwBkgHEAf4BOAKAAsgCEANQA4gDxAMIBEAEeASoBNAE8AQABRAFGAUoBTAFKAUYBQAF8ATgBMgEuASYBHAESAQQBNADiANQAxADzAKMAkgCDALCAW4BBgGPAAsAfP/c/hz+RP1g/Hj7iPqo+dj4IPhw97D24PUQ9WD0wPNg8xDz0PKg8pDykPKg8vDygPNQ9ED1EPYA99D3uPjA+ej6MPxo/bj+9/8aARAC/AIABAgFCAbgBqgHUAjACAAJIAlgCaAJEAqQCgALEAsAC/AK0AqwCrAK0ArACqAKUArgCXAJ8AiACDAI0Ad4ByAHuAY4BqgFIAWYBBAEkAMMA4wCCAKEAfYAcgD5/5n/MP/M/nT+DP60/Vz9LP38/NT8uPyY/Hj8PPwI/OD70Pu4+8j70Pu4+4D7SPsY+/D64PrI+sD6mPpo+jj6+Pm4+Zj5qPm4+aj5kPmQ+Yj5ePlw+Yj5oPnY+Rj6WPqQ+sD6APtg+7j7CPxo/Mj8KP10/az94P0Y/mb+yP4e/1b/if/I/wgAOAB1AMYACgE+AWQBiAGuAd4BGAJUAoAClAK0AtAC3ALMAtAC3ALgAtwCxAK0AqQCqAK8AtAC6AIAAxgDGAMEA/AC7AIIAyQDSANoA2wDdAN0A3wDnAPcAygEaASYBKgEuATIBOgECAUwBVgFgAWYBaAFoAWgBZgFiAVwBUAFEAXABFgE5ANsA+wCbALoAWgB3gBKAL3/J/+c/gz+hP3w/Fj8sPsI+4D6EPrA+XD5MPn4+MD4iPhQ+CD4CPjw99D3oPeA92D3UPeA99D3CPhQ+Jj46PhI+ZD56PlY+sj6KPuA+/j7aPzg/Gz9Cv6s/in/r/8qAIcA0AASAWoBtAEEAkwCmALEAugCFANIA4QDvAPwAwgEEAQQBAgEEAQ4BHAEoATQBAAFMAVoBZgF8AVgBrgGEAdgB6gH2AcgCHAIsAgACVAJoAnQCdAJwAnQCaAJcAkgCcAIUAjAByAHcAbQBTgFsAQQBIADvALoARQBNABo/5z+BP58/eT8LPxY+2D6UPlo+ND3cPfw9mD2sPXQ9MDzEPOQ8kDyAPLQ8ZDxMPHA8HDwgPCg8ADxgPEw8sDyUPMQ9OD00PXQ9gD4QPlg+mj7YPxI/QD+wP67/7gAiAE0AswCXAOwA9wDKASYBPAEGAVABVgFQAU4BVgFiAWgBbgF4AUgBjAGIAZYBpAGuAa4BugGIAcwB0AHWAd4B3AHYAeAB5gHeAdQBzgHKAfoBpgGQAbwBagFaAUgBdAEeAQIBLgDZAMIA5wCWAIsAuABagH9AOgAuwB3AFAAbABXAA0A/f/2/9j/f/+N/6z/rP9k/y3/N//6/o7+Sv5Q/jD+2P2s/Sj9TPxo+/j6mPoA+pD5gPkw+Rj48PZA9gD2sPWA9XD1EPVg9PDzAPSA9OD0UPUw9uD2UPfA94j4ePkw+uD6yPvg/Lj9Zv48//3/lAAoAewB1AKcAxAEYASYBLgE4AQ4BbgFIAYoBvAF2AXIBZAFgAWoBcgFqAVwBWAFOAUYBSAFaAVYBTAFEAVQBaAFeAV4BdAFKAYABgAGWAaABnAGiAbwBggH0AbQBigHOAfwBsgGAAcYB+AGqAZQBugFgAVYBUAF4AR4BBAEhAPQAhQCmgFyAWoBFgFpALr//v4w/pj9BP08/FD7uPqQ+iD64PjQ90D3QPbA9PDzcPQQ9XD04PKA8YDw4O9Q8MDxcPLA8SDxkPHw8SDyIPMg9dD2IPdA9zD4wPng+vj7KP30/aD+CwDOAYACbAJ0AjADEASYBCgFAAZgBugFSAUYBUgFqAWgBigHiAZ4BRgFoAXoBdgFCAaYBmgGwAW4BRgGOAYoBjgGYAYwBhAGUAawBoAGCAYABjAGMAYoBmgGiAY4BsgFkAWABXAFcAWIBXgFCAVoBFAEQATQA1wDVANgA8wCBAKeAYoB+wA3AO3/HADY/w3/gP50/hb+MP2w/Hj8APww++D60PoQ+vD4OPgQ+KD3wPZA9hD24PVQ9XD0wPMg89Dy8PJQ8/DygPKA8gDz0POQ9ND18PaA94D3KPjQ+Xj72PwE/qr+lv4Z/+UA/AIgBGgE4ARIBTAFUAV4BqgHoAf4BrgGwAaIBqAGIAcYB0AGkAWgBagFcAVABUAF6ARABPwDiAT4BPAE+ATYBFgEEASQBGgFyAWoBWgFYAVQBSAFiAVQBugGsAZIBiAGQAZgBngG0AbIBlAGqAXIBeAFUAWwBIAEmAQgBHADHAMUA0gCDAGKAM8AzgA5AMD/T/9u/mT9OP2Q/Uz9GPxY+0D7iPpA+bj4IPmw+FD3YPYw9pD1cPTw88DzoPJw8fDxMPOA8lDwoO9Q8EDx0PJw9RD3EPZg9LD0APdg+cj7eP6P/xD+8Pxw/gQBAAOgBCAGQAYIBcAEYAaQBwgHsAbAB1AIwAdoB4gH+AaoBWgFkAZIB6gG8AXoBTAF0AOoAxAFEAawBRAFCAXwBGAESARABRAG4AWoBRgGIAZYBRAF6AXwBgAHgAZ4BpAGMAbgBUAGuAZgBtgFmAVgBfAEeARYBFAEvAPMArQCtAL0AfEAowCRACQAzf/M/8P/0P7A/Wz9mP0s/YT8ePz4+5D6QPk4+Tj5aPiA9wD3YPYA9RD08PNw8wDyIPGg8ZDxwPAg8ADwYO+A7sDvIPOQ9QD10POw80D0wPUw+fz8Mv70/Bz8JP3G/loArAJgBfgFqARQBJgFmAa4BjgHEAggCKgH4AegCPgHSAa4BcgGiAdQByAH2AawBVgESARYBRgG+AXABbAFIAVYBHgEUAXIBfAFIAZQBmAG2AWwBVgGAAfwBmgH6AfIBzAHwAYQB6AHyAdoB0AH2AYgBtgFEAbQBegEYAQwBLQD5AJ4AkgCpgGeAEoAYADY//b+0v7E/rz9dPw8/Iz8yPtg+rj5oPmo+HD3EPcg90D2oPSg84DzoPIw8ZDwsPBw8GDv4O4g7wDvIO7A7WDvoPFg8zD0kPQg9KDzQPXg+ID86P2c/VD9LP5X/+sAZANwBVgGYAZYBlAG0Aa4B5AIEAnwCLAIIAlgCbAIwAcQB/gGmAdwCFAIMAfgBVgFgAWgBZgFCAbIBnAGSAWwBNgEOAWoBUAGoAZYBpgFkAVgBnAG8AWYBsAHwAfQBpAGCAcoB+AG+AZ4BwAH6AW4BTgG6AXABHAEoAQgBAwDgAKoAkACEAEwAHcAUQBf/7D+nP5O/kT9bPxs/ED8KPsY+tD5gPlg+FD34PaQ9pD1oPRA9JDzYPIw8eDwkPDg74DvgO9g76DuAO4g7gDvoPAA85D0YPRw88DzwPWg+AD7FP1G/gj+1P0Z/6gBmAMYBSgGCAcwB8AGUAfACFAJoAjQCBAKcAqwCcAIgAhACKAHwAfACOAIMAfwBeAFsAUgBVAFQAY4BjAFmAQgBUAFoATQBNgFIAagBQAGwAZwBqAFEAZwBwAIqAfIB4AI+AcIB3AHoAiACEgHIAdYB+gG0AWgBSgGmAUIBDwDlAPsAqoBKgEqAUkA8P6S/tr+Yv4E/Wz8qPwo/Oj6OPow+rD5mPjg95D38Pbg9UD1APUw9ADzUPIw8oDxEPAA7yDvYO8g78DuoO7g7SDt4O1Q8NDyEPRQ9ED0APRg9BD3aPv0/fD9eP1G/oz/4wAEA3AFoAYoBoAGAAiACOgHcAjQCeAJEAlQCYAKQApgCHAHIAhQCNgHUAjQCCgHAAXgBDgGqAbQBZgFKAa4BZgE2ASwBYAFIAWgBTgG2AV4BfAFmAZYBuAFqAagB4gHAAcwB2AHAAcAB4gHwAfwBjAGUAZIBlgFiATABOAE3AOAAvAB/gFMASQAxv++/w3/+P2Q/aT9AP3w+6D7+Pto+/j5cPno+WD5wPcQ91D3oPZA9aD0sPTw83DywPHw8QDxQO9A72DwMPAA74DuYO5A7uDuQPEg9OD0YPQw9ND0wPWI+GD8yP7m/kL+iv51/woBwAPoBuAHuAYYBhAH6AeQCOAJ4AowCsAIAAmgCuAKUAnQByAIwAjACPAIwAigB9gFiAUwBggHKAeoBmAG6AUYBbAEgAVgBogGSAbYBcAFAAZABogGuAbYBuAGmAfwB4gHEAcwB6gHwAfAB6gHYAeABqgFuAXYBYgFCAWYBKgDPAKiAQAC5AGtALb/f//S/sT9WP34/Yj9+Pto+9D7WPvo+XD54Pko+WD30PaQ9xD3QPVw9ID00POA8uDxwPEQ8eDvQO+A72DvwO6A7kDuIO7g7oDwUPIA9ID1kPVQ9ID0kPe4+4r+mP8BAHr/cP5O/4QDoAegCKgHWAewB5gHIAiwCTALwAqQCQAKgAqQCTAIIAjACMAI+AfIByAIaAfYBegECAWQBfgFgAZYBoAFGAScA7gEqAXQBagF0AVwBeAEqAR4BXgGuAa4BngGUAY4BtAGYAcgB6AGyAYoB/AGgAYQBoAFyAT4BMAFkAXQA3gCiAI8AioBCAHwAYQBfv/k/Qz+fv7Q/Vj9yP2g/cD7WPqQ+hj7WPoo+eD44PjA92D28PUQ9mD1wPMA83DzQPNg8eDv4O9Q8ODvgO+g74DvQO4A7mDwYPPA9ND0IPUg9RD14PYg+w7/DQD+/jz+3v6xAMwDCAdACEgHAAewB2AI4AhQCRAKMApACjAK4AkwCYAIkAggCFAHcAegCIAIqAbABPADKATQBNAFWAY4BXwD4AKoA1AEWATABEgFUAWoBAAEEAQIBQAGYAZABtgF4AVABrAGOAeYB0AHoAbQBigH6AZYBhAGKAbwBVgF8ATQBEAENANwAjACDAKUAeMAEABL/2b+qP2A/cj91P3o/Mj7GPvQ+hj6WPlY+WD5ePgw97D2UPZw9XD0UPRg9JDzUPJg8dDwoO9g7zDwkPBg7wDuAO5g7kDvEPGg8xD10PRg9AD1MPbw95D7xf/TANT+iP3w/uAB0ARQB5AI6AdoBpAGwAgQCrAJoAlACiAKQAnwCFAJ4AiYB+gGiAfgBzgHsAaIBmAFlANgA/AEIAaABXAE+APQA4wD5AMwBZAFuARABNgEAAWoBOgE4AVgBtgFYAXwBXAGYAa4BmgHUAeoBmgGuAboBrAGqAbQBmAGeAXIBIAEeARwBDAEcANUAngB/gCRAFYAKQC2/7r+xP14/XD9HP1o/Aj8wPvg+vD5gPmI+fD4wPfQ9pD2MPbw9DD0QPTg8+DxUPAg8GDwIPDg7zDwAO9g7IDrIO9Q87DzcPJg8pDz8PMA9Zj4ZPw0/Xz8nP38/iL/uv88AxAHwAcgBrgFOAcgCJAIUAlACkAK0AmwCYAJ8AhACBAIYAigCFAIeAeABugF4AWYBRgFIAWgBYgFuATsAxAEqATwBPgECAXoBLAE0AQwBZgFsAWIBbgFUAaYBnAGKAbQBtgHEAhoB1AHmAeABzgHMAewB5gHyAZABkgGmAWwBJAE+ATQBKADiALEAS4BlwCCAIAA7//m/gr+gP0U/bz8lPxQ/ID7YPqg+VD5GPl4+HD30PZA9jD1EPTQ88DzwPJA8VDw4O8g78DuoO8g8IDtIOpg6wDwQPNw80Dy0PGQ8QDygPUg+9D9tPzg+8D8vP2S/joByAVQCDAHIAWgBaAHwAgwCRAKwAoACkAJkAnwCQAJsAe4B8AIIAnYB8gGmAYQBgAFqAQIBVgFQAWgBPgDmAOYA9QDkAToBHgE6APYA5gEOAVYBbgE4ASQBbgFiAWgBSAGgAagBtgGEAfgBmgGiAYABwAH0AawBqAGOAZwBdgEqASYBFAECASMA7wC0AH6AIoARQAUAOr/nv/k/qz9vPyg/BT93PwE/DD7gPrg+Tj50PhI+JD3wPZQ9sD1sPRw80Dz0PIA8aDvwO/A8ODw4O+g7aDrYOsA7jDy0PRw8wDx0PAw8nD0QPgQ/OT9DP2A+wj8Sv4UAQgEEAdwB6gFCAWoBgAJsAnACcAJ8AngCeAJQAqgCYAI4AdgCKAIIAiYB1AHUAbIBDAEkAQYBUAF+AQIBOwCYAIMA1gE0AQQBJAD1AP4AwgEUAQQBdgFCAawBYAFsAUgBsAGwAdACPgHaAdAB7gHqAd4B6AHMAgQCBgHOAbQBdAFWAUoBfgEWARgA6QCHAJaAaQACwA4AE4Abf8s/nz9SP0g/dT8TPzA+1D7wPrw+Tj5ePgo+Aj4YPcw9lD1wPRA9HDzUPLw8MDvIPBQ8VDx4O5A7KDrYO3g7/Dx0PPQ88DxgPBQ8rD1MPkE/LT9ZP2o+2j7Tv6UAugEwAVQBkAGsAVwBqAI4AmwCUAJwAkwCqAJAAkwCSAJ8AcgB6gHUAjoB8AGmAWIBBgEoASIBaAFcARcAxgDQANMA7wDoATIBCgEhANYA2QD6AMABQgGEAYABXAECAXgBVAGyAZwB8gHkAcgB6AGkAbwBpAHEAjgB/gGCAZYBRAFGAUoBcgESASsA6QCpgHnAMYAtwBhAOf/Tv/q/jb+zP14/ez8qPys/Jj8gPt4+tD5iPn4+Ej4oPew9jD2APaA9dDzcPGQ8EDxcPGQ8GDwMPDg7UDrwOvg7iDygPNg8xDzcPEw8ODyGPn4/Lj8aPsA+zT8wP3J/6QCWAUABngFoAUoBrAGsAfgCGAJYAkQCbAIwAjgCDAIEAeQBiAHEAjYBzgGiAQoBEAEIARwBPgEiARAA3ACgALsAlQD2ANoBCAEuAI4AjADeATYBBgFOAUIBeAEGAXABXAG8AZoB/gH2AdQB/gGGAdQB8gHIAjoB3gH0AaQBrgFEAUIBagFuAWQBFADYALMAUYB/gDqAM0AVwCh/7r+0P1Y/YT9gP30/GT8APww++j5SPlY+ZD4UPfA9iD3cPYw9NDyMPPw8oDw4O5A8ODxsPAA7oDsIOwA7YDvMPNg9ZDzQPAw8DDzoPYA+rz8uP3M/Gj7uPuE/kgCAAWABngGiAVIBVgG4AcwCdAJgAkgCTAJoAlwCWAIoAfQBwAIsAd4B2gHoAb4BNwDUAQIBfAEqAS4BPADYAL8AVQD4AToBMADKAMIA7wCEAOABLAFeAWgBEAEiAQABcAF+AagByAHiAYAB3AHEAdwBrAGuAcgCKgHAAdQBjgFkAQIBcAFkAWIBLgDIAPCASYA7v8gAcwBIAHA/2T+WP0A/Zj9Sv4a/uT80Psw+6j6YPog+qD5qPjw93D3oPbA9XD1MPWQ83DxYPCQ8IDwkPDQ8CDwIO1A6qDrQPCA88DzkPOg8tDwoPCw9MD6yP0o/UT8uPyM/Pj8sgDQBegHoAaYBfAFgAbYBnAI8ApgC7AJsAjwCMAIEAjQBxAIAAhgB/AGkAaABRgEjAPEAxgEWARYBLwDbAJkAV4BOAJwA1gEUAQwA+IBlAGgAhAEEAVwBXAFCAVwBGAEMAVQBjgHwAf4B6gH+AZoBoAGSAfwBzAIMAjgB/gGuAXQBOAEiAXgBaAFsARUA8ABuADQAIIBuAE0AXcArv+i/tD9jP0A/mz+cv7U/XD8IPug+hj78PrI+cD4cPgA+PD2gPZA9tD0wPLg8eDxcPFw8NDw8PHQ8GDtQOvA7MDvkPJw9OD0IPPw8IDxQPXQ+Xj8fP18/Yj86PtA/eIAuAQAByAH8AX4BEAF8AZACdAK8ArQCXAI6AdwCFAJQAmACNAHiAdYB+AGSAa4BQgFOATwA3gECAWQBFADZAIkAkwC1ALAA3AEEAQIAxgCBALQAgAEIAWYBVgFsARYBFAEsASwBfAGyAfQBxgHCAZ4BXAFMAaYB4AIEAjIBpgFsAT8A+wDGAVgBvgF2AMIAv4AfQB+AIwBtAIYAkIAFP+Q/tT9ZP1C/on/Of+E/Sj8wPvw+hD6WPoA+5D6OPkA+FD3cPbQ9AD0MPTQ82DyIPHw8PDwIPCg7gDuwO4A7wDwMPJg9AD08PGQ8VD0APgo+oD7GPzo+4D7JP3IAFwDxAO8A4AEQAV4BTgGAAiACTAJIAhoB3AH+AfgCGAJcAiYBkAFkAWIBgAHSAa4BGgD3AIQA8ADvAN8AywDiAJEAYQAfAEwA1AElANcAnwBMAGeAUQDWAXABfAEWASoBKgEKAQQBZgHUAmwCEAHYAYIBugFuAbACMAJcAgIB3AGaAXwAwAE6AUYB8gFfAMMAiABDwA0APABxAJgAYv/0P48/nz9gP1w/jD/mP4o/TT8gPvQ+pD6uPq4+vj5EPkQ+DD3gPbA9WD0IPMA8/DyMPIw8ZDwEPDg7oDtIO5Q8ODxEPIg8lDyEPLg8uD1YPnQ+rD5wPjw+eT88f9IAngDqAKmATQCYATYBgAJMAqwCRAIYAYoBmgHUAnQCgALIAkIBkgE+ASoBrgHgAcwBpgESAOEAsACrAMwBNgD9AL+AXwBlAE4AmQDCAT4AkIB+wCAAvwDaAR4BLAEyARQBOgDeATABRAHIAiwCMgHKAZQBegFUAeQCPAIUAh4B1AG+AQwBGAEYAVIBkgGkAQsAmMAi/9tANQBBAIkAWwAe/+w/Yj8+Px6/lX/2v4W/jz9uPs4+qD6+Pvo+4D62Png+ej4YPdQ9uD1UPXA9LD04PTA83Dx4O+A72DvUPDA8ZDyAPIA8YDw8PCQ8pD14Pg4+sD48PYw96j5BP2yAGgDaANEAcD/jQBkA9AGIAkQCmAJYAeoBagFWAdwCcAKgAogCcAHGAb4BEgFoAZoB7AGeAWQBNQDCAN0ArgCPANQA/QC1AKcAkQC/gEQAlQCjAKgAswCiAM4BFgEGAQwBKAEEAVgBSAGEAeIB5gHeAcQB4AGsAbQB7AIkAjoB6gHIAfYBQAFMAWwBcAFuAVQBagDVAHq/20AfAGiAX4BSgFAAGL+HP0E/Wz9UP5j/4r/PP4I/Ij6OPpo+vD66PsM/HD6GPhw9mD1EPWQ9VD2MPZg9BDyUPCA76DvUPBA8UDx0PBg8CDwYPBg8SDz0PQg9lD3ePjo+Lj4cPm4+1j+XQD2AVwDoAOoAngCAASQBpAIsAmACkAKQAjoBdgF+AeACsALUAtgCWAG+AOgA2AFYAf4BwgHUAUgAywBfgBwAUQDoAR4BNgC+QANAHwApAGYAigDRAPQAkwCcAJYAwgEYATYBFgFMAXABGAFwAZgB6gGyAWoBTAGuAZYB6AH2Aa4BUgFcAX4BJAEwAQIBWgE+ALIAfcAjwBjANwAbAHDAHv/nP48/rT9WP3A/XT+6v5Q/uj8qPsY+/D6APtQ+2j7YPtQ+qD4MPew9mD2EPYg9gD2MPUw84Dx8PDg8MDwcPDA8IDx4PGw8UDxgPEQ8oDzYPWQ94j5OPqw+Sj5KPqQ/Db/9gFoBFgFMASAAsACGAUACEAKgAuAC8AJgAfgBhAIwAlgC0AMQAvgCEgGIAWwBdgGuAcwCIAHQAXQAoIBuAH4AmAE+AQoBFACQQCt/6oAKAL0AtQCcALWAToB4ADGAYgDkARABIADqAMgBHgE8ATABUAG2AVgBbgFUAYgBrAF2AUgBpgFgAT8A6AEOAWIBDgDEAJwAVgBfgF2AUIBuQDs/0H/0P6C/mj+nP7i/vz+ev50/aD8kPy0/Fz8wPuQ+7j7UPsQ+uD4YPjw90D3wPbA9vD1gPRw8wDzcPJQ8eDwgPEw8uDxoPEA8lDyMPKg8mD0QPZw96D4IPrw+qD62PqY/DD/bgEwA8AEEAUgBIQD+ARgBxAJ8AlwCmAKIAnIB7gH8AgACiAK8AkgCaAHKAawBRgGgAZQBrAFmAQgAwwC+gG0AhQDrALiAQoBQQD8/1AA9gAsASYBBgHJAFUAKQDUABACLANkA1gDLAMEA1ADGAQYBYAFkAWwBdgFwAVABTgF8AWIBjAGoAVwBSgFqAQgBOwD0ANcA/ACtAJkAkwBgACIAKAAPACh/13/2v4+/uz9HP42/pj9CP3E/DD8KPuw+jj7WPvI+gD6SPlA+BD3sPbg9vD2MPZQ9ZD0oPPw8rDy8PIQ8zDzYPOA8zDzMPPA86D04PVQ9+j42Pkw+rD6ePuU/Oz9AADYAZAC6ALIA/AEgAUQBggHEAiQCJAI8AiQCcAJwAnQCcAJwAgACBAIkAjACGAIuAe4BmAFKASUA8gDKARwBFAEWAPEAWwA8/84AA4B8AE0ApQBlQDU/8P/MgDgAOYBrAK4AkACFAJkAtQCTAO4AyAEWARYBIAEyAQIBfgEyASQBFAEUASIBLAEgATgAyADiAIgAuoBCAIgAsoB9AAVAIL/Qf8j/w///P6u/gb+XP0Y/ST9GP3o/KD8QPy4+zj7APsg+zj74Po4+nD5sPg4+PD34PfA90D3oPbw9VD1wPSA9LD0APUQ9dD0oPSQ9ND0IPXQ9bD2sPeI+DD5wPlA+ij7UPzA/SL/EwCuAEYBKAJcA4AEQAWwBRAGcAawBiAH2AeQCPAI4AhwCPgHyAfgBxAIIAgQCLgHKAdwBsgFYAUQBbAEUAQABJgD+AJwAjACIALaAYABXgFoAUIBvgBbAHwA0wDoAOYAJgGeAbgBagFcAcYBPAKUAhQDpAPMA4wDbAO4A9gDqAOgAwgEYAQIBHQDIAPkApgCVAI8AggCpAE8AdoAiwD8/5P/Uv8g/9j+qP5+/ir+yP2M/YD9XP1A/TT9FP2w/Ez8OPxE/DD84Puo+5D7UPv4+rj6ePoQ+qj5aPlA+QD5oPhw+ID4ePgw+AD4CPgY+AD4EPhw+Aj5QPlo+dj5cPrI+vD6cPtM/AD9VP3Y/dL+8P/JAE4BngHMASACjAIMA8gD0ATABeAFaAVYBcAF8AXIBegFYAaoBnAGOAZABgAGaAUgBVAFSAW4BGgEiASYBCAEcAMsA0ADEAOkAmQCeAKcAowCRALiAbQBsAHIAfYBOAJYAlgCSAJcAoQChAJ8ArQCJANEAwQD0ALQAtQCuAKoAqQCgAIwAgQCDALyAY4BOAEQAcwAWQD3/7L/bv8f/8z+iv5W/hj+yP18/Sz97PzA/Ij8VPxA/FT8VPw8/CD88Pug+2j7aPuI+5D7WPsw+0D7WPso+7j6ePqA+pD6WPow+lj6kPqA+jj6IPoo+ij6EPow+oj6wPrQ+gj7aPvI+8D7wPsk/OT8jP30/W7+Gf+7/wwARQCxAEYB5gFoAuACdAMABGgEqATwBDAFcAW4BfgFIAYgBiAGMAZABjAGCAboBcAFgAVIBTAFGAXoBMAEqASABCgE1APEA8gDsAN4A1ADPAMoAxwD8AK4ApgCoAKwAqACfAJkAlQCMAIMAggCEAL8AdYBuAGeAXYBTgE+ATgBHgHjAJcAYAA7ACEAAADa/7D/ff8+/wH/zP6S/kT+8P2w/YT9YP0o/QT99Pzc/Kj8ePxc/ET8HPzo++D7yPu4+7j7yPvQ+6j7iPtw+1j7KPsY+zj7UPtg+4D7qPuw+3j7SPtY+6D74PsU/ET8ePy0/PD8DP0U/Tj9iP3c/R7+aP7K/hn/Tf97/77/AgAxAG0AyQAyAYABtgHyATQCdAKoAtgCBAMwA1wDfAOMA5gDxAP4AxgEGAQIBCAEQARQBEAEKAQoBDAEKAQQBPAD6AMIBBAE8AO4A6ADsAO8A6QDhANoA0QDHAP0AtgCvAKUAmQCNAL8AcQBjAFUARIBwwB1ADAAAgDM/4L/KP/i/rj+hP5I/hD+4P2k/Vz9EP3o/Nz8yPyk/Hz8dPx0/GD8KPwM/BT8GPwA/Oj7+PsE/Pj76Pv4+wz8GPwU/Cz8VPx8/JT8rPzM/Pj8PP1w/Xj9aP2E/cz9Dv4u/mT+vv78/hX/Rf+h/+b/8f8WAH0A5wD+APsANgGYAcIBsgGyAeABEAIsAlgCnALQArwClAKMApgCpAK8AuQCEAMcAxwDHAMAA8QCqAK8AtgC0AKwAqQCoAKMAnACVAI4AhgCBAIEAvQB2gHAAbIBpAGSAX4BWgE6ASwBIAH4AMMArAC9ALkAgwBOAEsASQAVANP/s/+r/5f/dP9R/zH/Df/q/tr+1P7G/qr+fv5O/jj+Pv4+/i7+JP4o/iD+AP7c/dT92P3M/cT93P0I/jD+KP74/dz99P0i/jD+NP5O/n7+ov6c/o7+mP60/sr+4v4V/07/Y/9Q/03/fv+2/8n/yf/l/xwAMwAlACEARABxAIIAhACaAMYA4wDrAO4A6QDMALAArwDKAOYA+gACAQYBAAH6AP4ABAEOASIBNAEsASIBLAE0ARoB9QD7ABwBGgHsAM4A0gDOAK4AlgCaAKYAmgCCAGoAUgA2ACoANgA+ADkAOwBJAD4ADgDg/9n/6//m/9L/1P/z/wIA8f/U/77/oP9z/2X/lv/V/87/jf9i/1r/OP/0/tD+6P4M/xH//P7u/vD+4v7A/pj+iP6s/t7++v78/gH/Bv8A//r+Ef8t/z3/Tv96/7j/7f8FAAgACgAnAFsAfAB5AHQAnADNANgA0wDpAA4BHgEWASABNAE8ATIBPAFMATgBEAH8ABoBKgEYAe0A1wDhAOIAwgCTAIMAhABwAE8ATQBoAGkAPAAVABkAHwAFAPH/+/8IAP//3//B/7T/wP/W/9v/1//i/+v/2P+i/4D/ev+C/5H/s//b/9b/t/+Z/4j/hP+R/8D/8P8GAAAA//8IAAUA7v/i//b/FwAkACMAOABWAE4AIgAOACkAPwAtACUAOQA5AAgA7P8VADcAHgD7/wIAFwADAN7/1v/f/9v/0P/K/77/qf+q/7L/mf9o/1z/ef+U/7H/zv/J/5j/c/+K/67/pf+Q/6v/3//8//f/6v/g/93/6P/x/+//9P8ZADYAIQD5/+v/9f/3//7/GgAzACoACADp/8v/u//J//n/HwAhABIACwAOAAIA5f/Q/9v/BwArAB8A+P/p//z/DgD5/9v/3v/9/xAADwAMABIAEwACAPT/+v8KABAADwAQAAwABwABAAYAFAAkADkAOgAaAP7/EgBNAHQAaQBMAEgAWQBqAGwAXgBSAGUAmgCzAJcAeACFAI0AcQBgAH0AjABbACcAHAAOANT/tP/f//7/uf9e/1b/g/+I/1r/Qv9P/17/YP9N/xb/1v7I/vT+G/8f/xX/Kv8//zb/FP/y/uT+/v44/1P/Qv8z/1L/fP99/2b/av+K/5v/ov+o/7H/u//U/+v/5//f/+//DgAUAA4AIwBDAEwAQQBPAGcAYQBNAFMAZgBlAGoAhQCXAH4AZgBzAJQAogClAKoApgCmALsA0wDTAMoA2gDuANgAtADNAAYBCAHkAOUACgEGAc4AtQDYAOkAygC7AM4AwgCKAHMAkACYAGkATgBvAIsAYwApACYAQgA8ABMA7//o//T/BQALAPT/zf+1/7r/v/+t/5v/of+o/5b/ev9q/3H/gP+H/4b/e/9q/2j/b/90/2n/Vf9S/3X/ov+j/3L/Sf9g/47/j/9o/2P/g/+M/3L/a/+E/5P/lv+o/8L/uP+g/63/0f/T/77/xv/l/+3/3//g/+v/9f8AAAsACAADABQAKAAdAAYAEAAkABEA+P8SADoAKQD0//b/KwBBACcAFQAaABUADQAjAEQASQBCAFgAewB6AFwAVABvAIcAlgCnALEApwCfAK8AuwCoAJAAowDFAMUAowCTAKEAqgCYAH8AfgCHAIYAbgBLADIAJwAZAAIA8P/z//P/6P/b/8v/r/+P/4b/hv9z/1T/Sf9N/0f/O/83/y//Fv8G/xj/Lv8f/wb/B/8d/x3/DP8N/xz/Jf8i/x//Iv8i/yz/Pv9J/0X/Pv9I/1T/Wv9h/3D/i/+b/53/qP+6/8X/xf/K/97/8v8BAA0AGwApAC8ANwA+AEEARQBaAG4AbQBqAHYAjgCOAH4AfACDAIUAiwCfALMAsgCrALIAuwC7ALsAxgDKALsAsAC4AMIAwQDFANMA1gDSANIAzwDAAK0AsQDIAM8AwwCyALEAtgC3AKQAgwB3AIAAhABqAFYAWABeAEsALAAkAB8ADwAKABcAFgDz/83/xv/O/8X/sf+u/7P/p/+V/5b/m/+K/3D/bP93/3P/YP9R/1b/YP9a/0z/Rf9L/1v/aP9n/2D/ZP9o/2H/WP9k/33/hP+B/4b/l/+m/7H/vv/K/8//yv/I/9D/3v/s//f//f/+////BgATABoAHwApADcAOgAuACoAPABVAF4AVgBUAF4AaQBlAFsAVgBVAFIATgBRAFIARwA0ACkALwA0ADAAKgApACcAHgAQAAkAEQAbABgABgD8/wEADAAOAAsAEgAaABoAFAAYAB8AGAAMAAoAEQAYABoAFwAXAB4AIgAbABIAEQAYABsAFAATABkAFgAJAAEA/v/0/+L/3P/g/+T/6//w/+3/3f/T/9P/zv/D/7//zP/P/8T/u/+//8H/uP+0/7j/tv+q/6L/p/+2/73/t/+u/7P/vv++/7H/s//G/9D/zf/X/+r/7v/m/+3/BAAHAPr//v8ZACEACwAHACEAMwAqACMANwA7ACcAEwAVABcAFQAbACQAHwATABgAHwAYAA0AFgAlACMAGgAdACYAHgARABIAHgAoACgAHQAZAB0AKAAuACgAHwAaABkAGAAaACAAIAALAPb/+P8KABIAAgD1/wEAFQAPAPr///8cACIA/v/Z/9z/8f/3//r/BwAOAAYA9v/v//L/8v/v/+3/8/8DAA8ACwD//wQAGwApACMAHQAnACkAFwAIAAsAGAAdAB8AJgAsAB4ACgAOABgAAQDa/9T/8P/8/+f/1f/p/wYAAADr/+v/+v/3/+X/2f/b/9z/0P/J/9H/3v/l/+r/8f/y/+b/2//k//H/5P/G/7//1f/e/8n/t//A/87/zP/G/8r/yP+0/6L/o/+r/6v/rv/I/+f/8//s/+T/5P/i/97/4f/u//r///8AAAQACgARABYAEgANABQAIQAqACwAMQA8AEIAQABFAFEAVQBFADUAOgBDAD4ALgApADoARQBBADwARQBPAEcAOgA5AD8AMgAkACkAMAArACoAOQBIAEcAOAAqAC4APgA/ACsAGQAeADAAOgA/AEwAVABCACEADAAAAOv/1//Y/+f/5v/Y/9n/6f/x/+v/7P/y/+b/zP/E/9H/0//E/8H/zP/B/6T/n/+z/7n/q/+y/9H/2f+9/6v/vf/N/73/rP+7/9X/1v/M/9b/8P/8//z/AwAOAAwA///8/wUADwARAAoAAAD//wgADwAOABIAHQAZAAEA8P/u/+//8////w8ALQBYAHQAVwAeAAoA8v+7/57/4f8yABwA9v89AKQAiAAcAPz/GwD9/6v/rv8EABAAxf/D/y0AYgAeAPD/KQBEANT/Uv9b/7D/u/+T/7T/GABCABgA/P8cAEAAPgAnABoAGwAjACQAGgAfADgASAA8ADEASQBpAFkAJAD3/97/wP+e/5D/oP+1/7j/qf+o/8r/9f///9f/pP+L/4L/cP9b/2L/jf+3/83/1//k//j/BgD//+f/1P/V/93/4P/h/+z/BQAbACwAOgBDAFAAagCDAHkAWABKAE8APAAHAOb/+P8QAAkA+v8HAB4AHwAQAAcADgAZAA4A7v/Y/9b/1P/H/8b/1f/b/9T/0v/i//b/CQAUABAA+v/3/w8AGwAMAA0AQgBzAGEAMwAtAEEAKQDa/43/cf9y/1f/EP/c/vL+P/9x/3r/sv8+ALsArgAyANH/ov8p/zj+qP1K/qH/dADpAJwCwAXwB7AHsAaoBggGrALI/gj+4v9kAMz+Sv4XAFIBLQDQ/ub+sP7M/AD74Ppo+3j70Pvw/Br+2P6R/ygA/P9Q/8r+Jv4g/Xz86PzE/Vj+Af8YAEABCAKAAsACwAKoAlQCcgFoAAYATwCAAIwAFAEMArACtAKUAmQC7gEiATMAZv8O/0D/jv+i/8f/VwDTAJ0AKgAoACEAV/9A/sz92P3A/aj99P2U/ib/qP8cAFUAWwBvAGkA+f9s/0r/ev+b/+H/ggAOAUQBogE0AiQCSAG0AN8AqQCL/9j+i/96AGcAGACuAFwB1wCd/x//Vv8H/wT+eP38/bD+xv6w/lH/XwCnAOj/Xf/J/zQAov/K/uD+pP/v/6v/3v/RAI4BfgE8AXIBvgGAAfIAvgDsAO0AhgAoAEgAtQDjAMAAsADfAOAAXgC4/3r/j/91/yr/O//L/0wAWwBGAGMAaQD7/0//5v7K/qr+Xv46/ob++v42/0T/ff/j/xoAAwDj//X/CAD1//L/KwByAIoAhACNAJ4AlgB5AGgAUQAZAOL/4P8PAC0AMwBYAK8A6ADeANQAAgEqAQABpwCFAJcAaQDw/7j/6f8FANX/0v8oAGEARwA2AF0AUQDf/2n/Of8S/8j+nv62/tL+2v70/jL/Y/+J/83/GQAdANX/k/92/0f/Cf/y/gH//v7a/sz+6v4N/xb/Gv9I/6D/9v8wAG4AyAAWAS4BNAFyAdwBEALwAb4BuAG+AcQB4gHuAawBNgHJAG0ADACx/07/yP40/rz9cP1M/XD95P12/tD++P4t/4z/0v+t/0//Zf/z/zIAAQBEADQBjAHsAJAAKgGoAToB8ACOARQCsAE6AUgBEgFJANb/NABwALP/tv6U/hn/RP/g/rj+Sf8FACUAvP/K/7sAkgFmAdgAFgHYAdIB+QCZADIBogEYAWkAkgAEAaEAmP8b/2L/Y/96/oD9pP22/lT/3v5Q/tb+6f/7//b+WP64/vb+PP50/cD95v6//+z/EQCPAPIAzwB8AHUAbQDQ/97+YP6W/hP/i/8QALkAVgF+ASQB1QAcAYoBJgEZAKn/RQDiAN8A9gC6AYQCpAI4AtgBmAEOAfH/nv7s/TT+vv7k/v7+m/+EAPAAuQB6AJkAzwCNAMb/N/+J/ywABAB3/9n/7wAKAf3/fv8sAJgAt/96/i7+pP7c/mL+1P38/e7+zf/j/8n/WgAgAc4Ae//0/ggA9AAIAMj+i/90AaIBCwC0/3oBjAIWAZH/mACcApQC4ABqAJoBxAGv/+T9rv6VANoAr/81/9b/HABQ/1j+GP52/vT+5v4o/vD9JP9+AEwAWP9m/wQAev8y/iD+V/8aAOP/yP9mAD4BqAF0ASIBSAGIAeAApv+f//cAlgFyAET/lv9PALn/Wv4O/gP/hv/i/mz+Hv8YADsA3v/x/1cAIQA9/6j+6P6S//3/+v/k/ygAkQCVAHQA6gDKAQACHAEUABEAkwAGAD7+8PxU/VT+/P28/Oj8zv7c/+j+HP4n/4sAaQCW/wAAiAFIAqwBVAGkApgECAWkA6gCMAOEAzgC0QBOAbQCvAKUAVQBnAKoA8wCmQD8/pz+SP5A/Xj84Py4/bT97PyY/Ej9MP56/hj+pP3M/WD+pv6y/kP/IABNAOX//f+2ACYBGAE8AcIBGAIsAlQCgAJsAlgCZAIwAtQB1gEcAtwB7AD+/6D/a/+6/tD9sP2C/lX/bP8y/1H/dv/O/qD97PzM/Jz8dPzw/Oj9OP6Y/Vz9fP7y/2cAbQBWAYwCcAICAf3/EABCANz/Yv++/yQBxAKMA2ADPAOIAzgDogEOAK7/if92/nT9Bv6H/0AA5/+9/48AmAFuAdr/Yv5o/hb/oP50/cT9rP/KAEAADwBAASwCagEHAI//r/9j/9j+LP9oAGIBdAFSAeoBsAJsAvsArv9I//r+Nv7Q/Zr+xv/1/2//hv9GAFUAUv90/nb+cP64/UD9+P1H//b/1v+x//f/MwDP/yf/Rf9WAD4BLAG2AKYAkQDY/xH/M/8UANEAPgGgAfgBKAIsAgQCogFEAfsAmgAoABMAcQCtAGAA1P9a//j+sv5+/kL+JP5y/vj+Pf9v/w8AjADu/7D+KP6C/rD+nv4w/2AAJgE8AVgBqAGEAbkA3f9f/yH/IP+K/0MA6ABIAVgBCAGxANsARAEWAUcAr/+t/6//af9L/5T/4P/x/wMARACCAJQAWwDI/yD/4P4T/zv/P/9s/53/av8J/zj//P+wABIBaAGGAdUAgv+I/ob+Av9Q/4X/MABSATQCYAJIAmwCkAIIAt8Ay/9C/wP/yv60/vD+Xv+//xAAggAgAZYBagF6AEf/Vv64/UT9FP04/Zz9Iv6m/i3/uv9nAAgBAgEZAPL+Xv5y/uD+ff9MADABAAKgAuwCuAIsAqABHAFrAN7/5P8mAP7/vv8hAOAACAGpAKAAtwDl/2r+0P2O/k//Ff+q/gX/2f9MAEEAQwCXABQBZAE0AZIA6P9x/wb/qP66/kz/CACxAGQBFAIsAowB5wCyAFoAdP+K/lj+sP7y/gb/eP9pAEQBhgEsAaEAMADE/x//YP74/QD+Nv6K/k//hwCyAXQC8AI0A8wCgAH1/9z+JP6c/bj9wP4nAEYB/AFsAqgCqAJYAngBDQDI/h7+yP2g/Qj+C//T/9X/sv8bAIsASgDL/7L/nf/s/uT9WP2A/ez9iv6n/+cAjgGiAaoBsAFAAVgAg/8L/8L+gv6c/mL/swD8AaACbALEAS4BswAHACX/TP6k/Uj9WP3s/d7+9f/tAIABbgHEAO//XP8U/+j+pv5M/iD+cP4u/9L/AAAbAMAAlgGyAfQAMwDx/8n/TP/k/ir/6v+CAOoAZAHIAdIBrgGmAYwB+AAVAGX/CP/M/rj+7v55/zAAxgDrALsAsgDiAMgALgCp/5j/nv96/6T/TgDDAJ0AhwAMAYoBWAHIAIMAgABbADgAYgCdAJMAagB5AKgAtgCkAJIAeAA3AM3/Qf+2/mb+hP7q/jL/QP9Q/3D/Vf/o/pr+0v4y/x//pP5s/sT+Pv9t/2X/jP/r/zwAUQBUAIkAvwCXABsAt/+l/6f/uP8rAOgAWgFCARIBDgEOAcQAMwCd/1b/dv+b/3T/Wf/N/44A2ACPAEoAOQDw/0v/rv5o/lT+Wv6O/uj+YP/6/84AqgFIAoACSAKqAeQASwAOABgAUgC6ADgBqgH0ASQCOAIIAmYBUwAs/z7+xP3c/Yb+cv89ALwACgE4AR4BsgA6AMv/Pf9+/uT9tP3g/Uj++v7T/3IAwQDnAPcAxwBnABcA1/97/wn/uv6A/mD+pv5c//v/FQAZAFUAbQDT/9j+KP7k/bT9gP2Q/Rb+6P6m/yIAZACbAK8AcgAAAMX/tP+V/3L/j//2/zwAaADeALABZAKMAiwCjgHxAHQANgBPALIAIgFgAXgBiAGgAaYBkgFwATABogDa/1z/Vf95/37/iv+6/+f/9/8eAHQAvgCoAEIAyv9z/1T/Wf9T/z//QP9t/4z/jf+1/yEAWQD6/2D/Ev/8/sj+jP52/pb+wP7S/sT+yP4J/0z/Mv+2/kT+FP4A/gr+bv70/iD/+P4A/0r/bf9B/zT/hf++/33/Bf/i/jb/q/8FAFoAwwAKAQQB9wAcAWABdgFsAZwB8gEMAtgB3AFgAuQCDAMEAwgDAAPMAoQCRAIUAvoBDAIwAjACMAJoApwCmAKgAtACuAIYAqwB1gEoAvYBoAHIASgCKAKwAUQBDAHrALAAYgBRALwAOAEqAa4AcQBsANL/1P5q/pD+FP7Y/CT8YPxI/Bj74Pl4+SD5QPgw96D2kPaQ9nD2APaw9eD1gPbw9jD3sPdY+KD46PgA+qj74Px8/Vr+jP9QAI4A/wDcAZQCCAN0A8wDEARgBNgEQAWgBRAGiAZ4BvgFqAW4BagFcAWwBXAG6AbIBogGuAYQB2gHsAfgB/AH2AegB2AHSAewBzAIYAiACLAIkAjIB0AHkAf4B9gHsAf4BwAIWAe4BqAGkAYoBmAFeAQoA4oBIgAs/4D+xP3w/LD7KPoA+Tj4QPcA9hD1QPSw8rDwQO+g7gDugO3g7YDugO6g7WDt4O0g7sDtAO4g7zDwwPCg8VDzMPUw96D5APw4/WT94P1P/yIBlAK8A/gESAaQB5AI8AjwCAAJMAnACJAHAAbgBKAEuASgBBAEfAM4A1QDkAPwA2AEqATgBCAFUAVgBRAGqAfACVALYAxADdANMA5wDmAOoA3ADKAM0AwwDGALYAvgC+ALcAuAC5AL4AqgCeAIUAgQB4gF2ATYBDAEHANYAroBlAD4/oD9RPzQ+lj5OPhg91D2MPWQ9MD0IPXQ9MDz0PJQ8mDxwO/g7eDsAOzg6oDpAOkg6aDpoOrg6wDtoO0A7qDuwO9Q8UDzgPUY+Aj7BP4YACoBrAIIBegGOAdYBvAFSAYYBxAIAAkACsAKYAsQC5AJmAcABogE5AJKAQIA7v5S/uj+XgB0AawBtgFAAuQC9AKcAoACaAP4BFAGIAdACBAKAAxADfANUA5QDhAO8A0QDgAOwA3gDYAO4A7gDoAOIA7QDbANYA2gDDALkAlgCGgHUAYIBTgEwANUA2QC/gDq/1v/+P7w/Xj8OPtg+lD5GPhQ9xD38PZw9lD2oPZg9jD18PNA82DyUPCg7YDrQOpg6WDowOfA5yDo4OiA6UDqwOsg7pDwQPKQ8wD1MPZQ96j5vP1sAVADqAQAByAJkAkwCZAJgArgCoAKEAqQCTAJ0AmwCnAKAAkIBxAFzAKUABn/DP7U/Bj8rPyc/Wz96PyA/eL+jv8d/wD/lf95AHgB0AJQBJAFKAdQCVALAAwADHAMUA3wDdANgA1wDZANwA1ADrAOgA7wDcANsA0wDeALUApQCeAIMAgIB6gFEAUIBfgE9AN4AnwB5AAtADr/TP5g/aj8+PuI+3j7ePs4+6j6SPoA+kD5oPcw9rD1QPXg8/Dx0PAg8ODu4Oxg60DqAOmg58DmoOYA58DoYOsA7jDwMPLg8xD0sPRA9wD7kP3o/i4B1AMoBagFyAfAChAMYAuwCuAKgApgCbAIEAmQCYAJoAjIBlAEUAI0Afz/fv5o/bT8wPvw+gD7sPsI/AD8qPzc/Wz+QP6A/ur/7AGAA5AE6AXQB7AJsArQCjALQAxADbANMA4QD5APkA+gD0AQ0A+QDqANUA3ADAAMEAtgCuAJQAnACLAHIAYQBfgEmAQwA8IB/ADFAIAASwD3/17/rP46/rD9nPy4+6j70PuI+wj7gPqI+TD4IPdw9iD1IPOA8bDwoO9g7QDrQOlg6GDnwOXA5ADlYOaA6KDroO8g89D0YPXA9tj4wPoA/ZcAEATIBUAGsAcgCgAMYA2gDkAPQA6QDEALEAqgCOAH0AhACbgH6AS8AnYBVgCa/sj8qPuo+oD5YPjQ9/D3gPhQ+QD7/Py8/UT9VP3s/tsAkAEwAiAE2AagCNAIYAkgCwANsA1gDXAN4A3QDUANoA3gDiAP4A0ADVANIA1wCxAKQAqQChAJqAZoBVAFGAVgBOQD3AOAA9ACGAJ0Ae0AgwBgADEA/P+y/5b/CP9a/lz+qv46/pD8MPuY+lj5EPcw9cD0IPRA8iDwwO5g7eDqQOjg5gDmgOQg44DjoOXg6GDs4O8Q82D1kPYg9+D38PlE/ckAMASIB2AKsAtgDAAO4BBAEuAQEA4wDMAL4ArgCaAJwArwCtAIMAbsAzIBrP2I+3D70PqA+HD2EPcQ+GD3gPaQ90D5mPlI+XD5APr4+jD9UgCkAhAEuAWgB9AIwAkwC0AMoAyADTAPQBCwD/APwBEgE6ARIA/QDXANgAygC5AL4AsAC5AJ0AjwB3gGSAQwAxwD6ALIAdEADgFmAXAB+AAAAfcAbQC5/xn/fP6Y/Xj92P0E/nz9tPzg+6D6EPmg92D2kPSA8hDx4O8g7iDsYOrg6EDngOVg5CDkoOTA5uDqoO8Q80D1wPYw9+D20Pew+7cAcAQIBxAKgAyADIAM4A4AEuAR0A5wDMALMAtACnAKYAsACwAJuAasA0X/SPug+cD5OPkA+DD3kPbA9XD1YPbQ9sD1YPUw9wD5+Piw+PD6kv4gAXAC6AOQBYgGkAdgCSALsAsADGAN0A5gD2AP8A/AEAARgBCQDxAOkAxgDOAMcAwAC9AJYAmACAgHEAaYBbAEgAPoApwC3AEwAVoB4gHYAUYBvgBcABcACgBBADsA7f9+/wj/RP4s/ej7kPqA+XD4EPdA9ZDzEPJA8EDuYOyg6sDoIOcA5sDkwOPA5MDoYO2w8CDzIPUQ9RDzAPSg+Hz96f/UAhAIkAvwCuAJMAzQDgAP0A2gDcAMoArgCfALIA5ADbAKEAhYBbwBJP54+yj6qPq4+zj7qPiA9gD2QPbg9YD1wPXA9ZD1wPZQ+Yj7yPw2/qkAgAKoAnQCzAOIBjAJ0AqwC+AMIA4QD8APYBAAEQARYBAAEFAP4A3ADEANEA6ADeALUAowCZgHQAbgBcgF4ATUA4QDHAMUAmABHAL0ArACjAGoAPP/gf+c/y8AgwBqADgArv+w/lD9OPwQ+2j54PfQ9rD1MPTQ8uDxsPDA7qDrgOiA5mDlAOQg4yDlIOpA70Dy4PNg9VD0APHQ8HD2Ov6gAngEeAcAC8ALsAqQC/ANEA9QDsAN0A0QDRAMsAzADmAPoAzAB1gDmwCC/gT9cPzU/CD9HPy4+cD2gPRA82DzIPSw9CD14PVQ9zj54Pr4+4z8hP0Q/1kApgF0AygGEAkACyAMcAyADHAMYA3ADnAPoA/gD/APUA9ADrANkA0gDRAM4AqACegH2AaQBngG8AXwBPwDJAM8AoIBWgGeAdwB+AHoAZIBtADc/+T/owAAAWEAs/94/y//Ov5E/cj84Pv4+TD4gPfQ9hD18PKw8aDwwO5A7KDqAOnA5oDl4OXg5wDrIO8w8zD1MPTw8cDwYPLQ9qT9vANABsAGUAhACuAKgArAC4AOkA9ADjAN4A0wDhAO0A4QD6AMsAe0A8gBoQBo/wn/k//a/pj8kPlw9pDzgPLA83D1sPUw9RD2UPeQ97D3QPlA+2j8hP1+/6gBMAPQBMAHkApgCyALoAtADcAO0A8AEUASQBLgEFAPoA5ADgAO8A3QDWANsAvQCXAIUAfQBYAE6ANoA/QCPALgAXwB2gA9AOv/lf8G/9T+uv66/qL+gP5I/vD9oP1w/Wj98PwQ/Aj70Pmo+MD30PaA9aDz0PGw8KDvwO1A6yDpwOcA58DnAOtg71DyMPNA8yDyYO9g7tDyaPuuAdgDwATABYAF0ASIBkAKcAygDJANIA/wDkANcA0wDyAPgAyACSAHgASoAhwDMAQMA+7/oP0A/Aj5oPWw9AD2IPcg9yD3QPew9gD2cPbQ95j4OPno+jj9BP+rANQCoAR4BQAG4AawB2AIIApgDcAPIBDwD8AP4A6ADWANoA5gD8AOMA7wDaAMsAqQCUAJMAigBqAFGAUwBFQDOAM8AzgCywD4/2//3P5y/tL+U/9T/+D+GP5s/bz8dPxA/Pj7ePuI+sj5QPmI+HD28PMw8jDxcPDA74DvQO0g6cDmQOmA7cDuwO9Q8vDzEPGA7eDu0PPw98j7WAFgBDACN/8qAbAF+AeACFAKoAygDAAMcAxgDYANoA2gDcALsAioBmgGaAYwBoAFaAOp/5T82Puo+zj6EPlY+VD5kPeA9YD10Paw9+D3KPhg+Gj48PiY+mT9z//8AJABhALEA8gE0AWACCAMUA4wDgAOQA4QDvANEA9AESASQBFAEPAPkA7ADFAMAA3ADCALoAmACCAHwAVQBSAFMASQAiIBIQCF/0j/Dv+I/rD97Pw4/Fj7+PpQ+3D78Pro+aD4UPfw9vD2QPbQ9EDz8PFw8MDvAPDg7kDq4OXg52Du8PLg89DzUPNA8GDsIO0w84j5uP2EAeQDcAJ6/mT9cAHYBiAKQAsgDDAMUAvAClALwAwgDYAMQAvQCUAIYAfABxAIAAfAAzsAFP4s/fz8DP2g/HD7yPlI+CD3sPZQ90j4+Piw+Aj4wPdA+Aj6lPze/ob/1v9AAGIAEAEQA0AGIAnACmALQAuQChAKgAsgDvAPgBBAEJAPgA5wDTANYA0wDZAMIAyQC2AKIAlACNgH+AaIBfQDwALYAUIBTAGCAfAA8P6s/Lj76Pvg+2j7KPvQ+rD5QPig95D38PZw9XD0UPMQ8YDvUPAQ8nDx4O0g6aDmwOfg7EDzwPYQ9RDxgO5A7QDu4PKo+ucAeAIKAb7/4P7k/uIBAAgQDOALgApwCkALAAtwCyANUA4gDRAL4AnACNAH2AdQCNAGXANYAEb/wP6o/QD9wPxg+wj5oPeA93D3MPeQ93j4WPgw9wD3yPiY+uD7IP2Y/n7/ef/M/5YBQASoBqAIYAoQC8AKgApgC0ANwA7QD6AQABFAEFAPAA+wDkAOUA0ADcAMMAxwC+AKAApACHgGMAWIBLQDzAJcAkACRgFG/3T9aPz4+/j7fPyM/Fj7cPmI+Hj4kPdw9jD2EPZQ9ADyUPFw8cDw4O8g76Ds4Oeg5uDr4PIQ9SDzQPGA7gDrwOvQ8tD6gP5t/w8AUP5I+gj6QQCIB3AKAAtQCwAKkAcQCBAMYA4gDQAM4AygDBAKgAhgCaAJWAfwBMwD6AKwAUwBDgE2/xT88Pmo+cD5+Pmw+vj6cPkw95D2cPdg+FD5OPsg/Tj9LPxs/Ab+Kf/v/yQCOAXQBtgGUAewCFAJcAnQChANQA4wDpAOQA/QDtANsA0QDsANAA0QDUANUAzgCgAKcAkACIAG0AWwBQAF4ANwA8ACBgG6/sT9KP4q/nT9bPyg++j5SPgA+GD4QPew9CD08PRg82DvAO4A8bDxYO3A6ODo4Oog7CDvoPSg9YDvYOoA7NDw4POQ93D94AD0/WD56PjY+5gAOAYgC1AL0Ad4BWgGAAmgCwAOgA6wDOAKAAtAC8AJ4AigCeAIeAUEA7QDqAQUA+AAe/+o/bD6aPkA+5D8sPvY+fD4APhQ9vD1IPjY+vD7YPvQ+pj6sPpA+6T9uQC4ApQD+APQBJAFYAaAB5AJYAtQDOAMMA2gDfANMA5ADoAO0A4QD4AO8A2gDYANsAxAC5AKAAoACbAH4AZYBkAF8APsAnoBiv+c/vT+lP48/fD7mPpg+LD2cPdQ+ED2UPOQ89D0QPFA7GDswO+A70DrwOig6cDqQOwA8VD1EPIA64Do4OzA8nD3PPx2/wb+8Pjg9sD59P7ABEAK0AwQCqAFUARAB9AKUA0AD1AP4A3QC/AK4AqACtAJ4AlQCVgHuAWgBWgFgAMsARf/fP1o/DD94P6U/vj7ePnI+LD3EPcA+RT8AP2Q+2j6MPqY+VD50Pvg/34BuQDlAFQC4AK8AiAE6AbACFAJQArAC8ALwAoQC6AM0A0QDqAOEA9gDvAMoAxwDTANsAvgChALoAqQCNAGkAZ4BkAFqAO4AlQBdf/a/oH/tP4g+xj4APjY+PD3kPbA9SD0sPEg8KDvYO4A7WDtIO5g64DmQOYg60DvwPAg8YDvAOvg5wDs8PT4+pD7uPtw+6D4IPd4+1QDQAigCbAJ0AgABhgFoAmwDmAP4A1gDvAO8AzgCmALcAzACqAIMAngCdAHGAUoBBQDKwCM/bD9Ef++/hT9+Ptg+vD3sPbg99D5oPpw+lj68PnA+Cj42Pkk/HT9Xv6p/6oApQDsAKACsARgBfgFAAjgCWAKcAqgC4AMAAzQC5ANkA9ADzAOQA7ADhAOMA1gDaANwAxwCyALoArACPAGmAaoBkgFxAJmAXwBMAGH/6j92Pvg+aD48Pg4+UD3oPSA8+DyUPCg7YDtQO5g7CDpwOig6WDpgOrg7jDxAO1A54DnAO0Q8iD2SPqA+1D3wPNg9oz8GgFoBGAIoAlYBqADMAawCtAMsA2AD/AP0A2ADKANcA6wDPAKAAtgC8AKYArQCfAG6ALOAPoAGAHzAGoBTAGE/kj6OPho+Pj42PkE/ED9GPtw9zD2CPiQ+Rj62Ps2/nz+zPyw/Nj+rAAgAfIBWAQABggGwAawCNAJUAlACeAKkAxQDbANoA6ADhANcAxwDUAOsA1QDcANMA3gCkAJUAkwCeAH0AaoBmAFlALRACgBUQCU/aj7SPvg+jj5kPcw9qDzAPFg8DDxwO/g7ODq4Olg6KDnAOpA7QDuQOwA68DpAOiA6VDwoPco+VD2IPSg9DD2yPkVAEgF+AWsA1ADOAUYB0AJQAzADkAOMA1wDVAOUA7ADcANMA3AC8AKYAugC9AJeAdYBSwDOgEUATgCLAIBABj9YPsI+gj5SPmQ+jD7cPoY+YD3QPYg9uD3ePq4+5D7iPs4/Mj8fP36/igBsAIAA8QDqAUoB5AHIAjgCTAL0ArgCiANMA+QDjAN4A0gD7AO4A3QDoAPoA2gC9ALIAyQCqAIQAgQCIAGgAQoA+oBfgDH/+T+fPwo+mD5yPgA95D1EPXA8kDv4O0A78DtQOkA56DpAO1A7YDs4Otg6QDmAOcA7UDy8PNg9FD1UPTQ8RDzOPnR/2ADSAScAzgC6gF4BCAJgAxwDYANgA1gDZANcA7QDqAOAA4wDcAMwAzADNALwAnIBtAEAAQoBMAEQAQ0Aj3/7Pyo+5D78Psc/Pj7kPtg+nD4IPeg9yj50Pn4+fD6EPyQ+9j6gPz+/kb/YP4MAIgDIAVYBHgEmAbYB7gHkAjwClAMIAyADMAN4A2QDDAM8A1AD2AO0AxQDHAMsAtACmAJ8Aj4B1gGQAWoBAQDwQAu/8L+mP0A+xj56Pho+OD1IPOA8cDw4O/A7sDsoOnA52Dp4OxA7oDsIOpg6ADngOhA7RDyMPQA9JDzcPIg8hD1APsJAPIBpAKwAvoBNAKwBRAKAAwwDFANwA4ADqAMQA2wDuAOYA6QDrAOUA2wC9AK0AngBygGaAVwBTgFaARgAkP/+Pxo/Mz8+Pw0/UD98PvY+XD4CPjw97D42PoU/eT8KPvI+vD7rPww/fz+lAEYAwQD/AL0A/AEgAXQBuAIsAogC7AK4AowDAANsAzQDBAO4A4ADuAM4AwQDQAM4AqACtAJ6AfABggHcAYABKwB6AC+/9z90Pxk/ND6GPhw9lD1MPMA8aDwUPBA7UDpYOhA6gDsIO2A7QDroObA5ODnIO3A8KDycPMA8oDvMPAw9Tj6dP3t/7YBKAGF/8IAgAWACaAKAAswDMAMgAwQDXAOwA6ADWAN0A5gDyAOwAxgDDALYAhgBggHEAhoB9gFSATqAaL+uPz0/RsA0P/s/aD8oPuo+UD4+Pj4+ij8+Pvg+8j7IPvA+rj7cP2m/s//EgGyAcABQAJoA5AEYAWYBrAIwAmACZAJkAoQC8AKcAtADSAO0AyQC9ALEAwAC/AJQAoQClAIkAZABnAFLAOGASYBTADs/Rz8yPuo+qD3APVg9BDzsPBA7+Du4OxA6SDoIOsA7uDsIOpA6ODmAOeA6iDw0PKA8cDv4O8w8WDzkPfc/Hf/wv5C/nr/OgF4A1AH4ApQCxAKUAqwDFAOYA5QDrAOUA6gDTAOQA/QDhANcAvgCTAIOAegB4AI0AcYBRgCAwDI/gD/NACOAEj/kPyI+ij6WPrY+WD6DPzU/ND7SPqY+uj7xPxM/Zj+wf/x/7AAfALEA2gDbAPwBJgGoAfgCGAKcAqQCeAJYAsQDOALIA2QDpANEAtACgALwApwCUAJ0AlgCLAFaAQ4BNACeQA//xT/zP1Q+7D5uPig9nDzsPGQ8aDwQO4A7GDrgOvA6yDsgOxg6oDmwOWg6eDuUPEA8YDvwO7g7uDwoPWQ+uT8NP0g/RT9MP70ALgEIAiwCXAJYAlACrALUA0QDnAN4AzgDQAP8A4QDmANkAygCpAIcAgQCmAKcAgwBjgEvAEOAOUA6ALgAiIAwP1A/VD8oPr4+hT9mP0k/LD7bPwc/Mj6UPvM/db+Cv7I/mwBbAIIAc8AsAIwBLgESAbwCLAJ+AcIB5AIMAqAClALwAwQDWAL8AkwCmAKgAkgCaAJQAlwB5gFkARwA7oBmwCGAHr/SP14+zD6YPjg9dDzsPIQ8kDxEPBg7iDsYOvg7ADugOzA6cDowOkg7KDu8PCg8eDvgO5w8AD1WPg4+uD7XP1I/YT8rv6wA0gHMAfYBoAI8AkwCiALgA0wDkAMIAvgDLAOEA7wDMAMgAvQCPgHUAngCcAIaAcQBlgDrgD4AAAD7AKhAGf/4v4I/YD7uPx6/tT9XPyk/Mz92Pyw+/j8G//E/oT95P4yAewBcgE0AogDkANIAwgFuAcQCDAHSAeQCAAJ4AjgCaALAAyQCpAJwAngCWAJIAkgCZAIAAeABcAE2ANsAkwBvwDW/xT++Ps4+sD4QPcg9jD1MPOg8MDuIO6A7QDtwO1g7gDtAOpA6EDpgOvA7ZDwwPIg8QDuYO7A8iD3OPl4+sD7gPzk/Aj/AAJMA8gDMAYACYAJUAmgCjAMoAtACgAL8AyADWANQA7ADeAJmAbIB8AKIAsgCbgHsAZQBOYBDAJYA+AChAEUAYAATv6Q/Hz9Xf9B/1D9UPwc/dj9EP6Q/qj+rP08/bD+7gBIAnwClAL0AuwC6AIgBCAGsAdgCGAImAcYBxAI4AkQC6AKcAkQCTAJwAhQCHAIEAjABlgFsAQwBCAD+gGuAekAPv4o+xD6YPq4+SD4UPZA9IDxYO8A70Dv4O6g7iDvAO4A6wDpIOpA7KDtIPAQ8zDz4O9A7oDx4PUQ+Nj5JP1k/pj88PtH/2wDuAT4BKAGkAjQCCAJoAqQC0AKMAmgCjANsA5gDoAMoAlQB2gHoAlwC/AKEAnQBqgEIAPoAqAD7AMIA9wB6ADC/4j+Yv5W/7L/mP48/aT9Mf/M/xb/Rv7E/cj9EP/cARAE1ANwAkgCHAOoA0gEaAYQCYAJEAhgBwAIoAhQCXAKYAuwChAJwAhQCRAJqAfQBpAGKAYgBegD3AKwAV8A/P58/aD7UPrQ+fj4QPcA9aDygPAA76DuQO8A8GDvYO0g62DpgOjA6YDt0PEg8zDwAO2g7bDwoPOw9hj68PvA+qj5CPzF/yQBKAF4A5gGkAdwB6AI4AmgCEgH4AgQDFANsAxQDOAL4AnQB1AI4AlgCjAKAApwCFAFhAPAA7gEiATEA1wDbAIgAY4AxgDq/7L+Jv+RAK4A0P+C/8L/Yf9o/sb+jwAUArwCeAOcA1QCogHQAigFwAZIB5AHyAegB0AHgAdgCFAJYArACoAJmAeoBkgHyAdQB2gGiAVYBLgCvAF8AesAnP40/GD7IPu4+bD3sPbQ9VDzgO8A7qDvYPHA8EDvgO2g6kDooOkg7qDxwPFA8MDvQO/A7iDx0PXo+DD5oPkI+xD8hPzg/TYAKAJgA7gFIAjYB0gG2AZwCNAIIAnwCiANAA0gC/AJkAlgCCAIcApADBALUAjwBkgGCAVgBIAFqAaIBbgD9AJQAu4AYACaAaACugEvAB4AWADS/8P/lQDaAE0AhQDQAcQCnAK4AsAD7AP8AqADOAbwB7AH+AbwBhgHCAfwB7AJQArQCIgHqAegB8gGMAaIBoAGCAUIA/gBtAGvAEz/Iv7Y/Oj6SPnA+AD48PUw85DxIPHQ8FDwAPBA7+DswOqg6kDswO3g7jDwkPBg74DuoO+w8hD1IPaQ9xj5IPpA++T84P0u/nD/bAJoBagGcAYoBsAFQAVgBnAJ0AuACyAKAAlACHAHqAeQCSALcApQCPAGMAZoBVAFIAZYBkAFEATAA6gDoALKAVwCFAOsAvgBBALcAeoAQABaAfACHAN4AowCEAMMAzgDUARoBWgFEAXABdAG+AaQBggH6AdACEAIYAhQCKgHIAcQBxAHmAYIBrgF+ASsA7ACTAJwAdj/mv7g/az8MPtg+mD58PYg9MDysPJQ8mDxEPFw8CDugOtg66DsAO2A7UDvgPBA7yDtwO0w8SD0YPVQ9uD2sPaw9/D6UP5E/9z+kv+IAUADiARQBpAH2AaQBUgGwAhwCuAKsAowCoAIkAboBqAJsAuwCoAIAAf4BdAEuAQYBhAHEAYIBAgDzAIUAqwBgAJcAwQDHALEAaIBBgGZAD4BXAIEA1ADiANQA6gCwALwA0AF2AUgBqAGAAfQBpgGAAeYB8gHAAiwCEAJwAiAB5AGWAZABtgFwAX4BRgF0AJkASwBOgBQ/iT9TP3g/BD7GPlY+BD2kPHg74DyIPWQ83DwIO6g7MDqwOpA7mDxUPAA7sDu4O8g70DvcPJA9mD3oPYg96j4SPnw+nz+8gBwAD4AdALgBEgFyASIBfAGsAdQCNAJkAowCbAHqAdACHAI0AiQCcAJcAiQBnAFUAWIBdgFGAa4BbgEtAMYA4ACLAJ0AhgDlAN0A+ACDAJAAa4ARAHYAvgD9AOMA4ADhAOAA8gDwATgBWAGmAYoB5AHQAfwBiAHsAdgCOAIEAkQCYAIeAeIBiAGSAZoBvAFMAXIBAgENAJOALP/M/90/dD76Pt8/Hj6kPaw83DyMPHA8ADz0PRA8uDswOng6mDtQO+A8ODwIO8A7aDtcPCg8gD0cPVg9mD2kPZo+DD7BP3Y/bL+jf9IAOQBEAQQBZAESASABTAHUAjACIAIgAeoBhAH+AeQCJAIgAjYB6AG6AUoBlAGkAUwBagFeAVIBGgDqAOwA8wCNALUArQDdAOkAiAC5AGiAbIBwAIgBKgECARYA3gDWAT4BAAFWAUoBvgGYAeoB5gHIAfABigHYAhgCaAJEAnoB1gGOAU4BdgFKAZQBsAF0ANaAR4Ayv/8/rj9tPyg/Pj76Pmw9+D1QPPQ8DDxYPNg9KDyAO+g60DqgOug7iDxUPHA74DuwO1A7sDwQPRA9mD2YPYg9wD4QPmY+0D+Df+8/rD/IALAA8gD0ANoBDAFEAbQBzAJsAjoBvgFkAaQB4AIMAkQCdgHeAYYBjgGUAZABnAGaAagBdgE2AQIBWAEfANkA/gDaARQBFAESASoA4gCNAJIA7gEmAWoBVgFoAQQBHAEgAVYBsAGOAdoBwAHgAaoBigHMAdIBxAIgAhIB0AGqAaoBvgEQAPIA8AEUAToAmACAAKg/+z8UPwE/Wj8UPuw+pj5APeg86DxYPGQ8rDzsPNw8cDtgOsg7GDukPDw8YDxYO/A7aDucPHg83D1wPaA92D3gPdA+aj7ZP16/n3/mQBSASgChAMwBPADMATABYAHUAhQCIAHMAZIBdAF0AdgCQAJYAdIBrgFEAXwBLAFaAYIBvgEeASoBEgEIAPcAvgDsAQoBLgDCARgBOwDRANcAwgEyARoBSgGQAbABWgFWAW4BZgG2AdgCDAIEAgQCHAHeAb4BgAJIAoACYAHKAfoBhAGoAUIBngFKARkA+gDrAOWAQQAX/9g/lj8gPug+yj7KPrA+ND2gPOA8FDw8PKA9ODyMPCA7UDrIOvA7TDxUPKg8CDugO1g7iDw0PKQ9dD2cPbw9ZD2gPi4+mz8nP18/kz/YgDMAawC8AL8AlgDiARgBjAIUAiQBqgEiATYBdAGeAeACLAIoAYQBOADgAUIBlgFuAXwBiAGkAPcAiAEaAR0A9wDWAWYBWgEwANIBDAEXAPkA6gFSAYABigGGAZIBQgFKAZIB7AH4AdgCFAIAAeQBrgHkAhQCHAIAAlwCHAHSAeAB0gGwAQIBVAGyAV8A1gC9AEoATsA+v/4/gj8yPmY+mT8+PpA93D0wPJQ8fDw4PIw9HDyYO7g60DsIO1g7pDwQPIA8SDuIO0A7zDyUPTw9VD3kPew9sD2wPhA+1z93v75/18AVgCPAFIBJAIsA+gEUAaABhgGGAa4BagEkARABugHyAcIB+gGaAZoBAQDcASwBugG0AVwBRAFOAPYAVAD2AXoBSAElANQBHgE1AMIBKAEWATgAyAFOAcIB+gEOARoBYgGAAewB5AIQAjQBogG+AeQCNgHIAiACVAJkAfIBhAIwAjYBpgEqATgBZgF0ATEA94BEQDW//0AfgDk/Tj7gPrQ+nD6uPkQ+OD0UPKA8qDzEPOA8cDwUPDA7iDtoO2g74DwgPDw8ADxoO9A75DxkPTw9XD2kPfI+Ij4OPjw+cT8mP6Y/8oAQgFhAMr/FAGUAxAF8ATwBHgFeAWYBOAD+AO4BMAFiAbABgAGkARYAygD5APwBMAFsAUIBQAEIAOsAugC4AMYBYAFwAT0A+QDCAT8AygEyASABQAGgAawBvAFsAS4BIAGQAjACIAIgAjwBzgHiAewCFAJYAmgCbAJkAggB0AH4AhQCcgHIAYoBSgEzAO4BHgFGASGAbH/8P5O/nD9JP3w/LD72PlQ+HD2MPQw8/DzkPSA86DxQPBA74DugO6A72DwUPBg8ODw0PAw8MDwsPLQ9PD1kPbA98j4IPmg+RD7dPxw/QL/QAFcAlYB6P+DAPACqAQwBYAFuAXoBMQD0APIBHAFgAX4BbgGKAZwBHADAAS4BAAFSAWgBYAFwAT0A5wDeAOMA5gE6AUABugEGAToA9QDIAT4BAAGWAYoBhAG0AX4BHgEwAXIB7AIMAh4B9AGSAaoBugHEAnwCEAIEAigB5gGKAZgB2AIsAcYBggFSARQAxQD4AMgBHwCQwAk/4T+SP1E/Fz8jPxY+wj58PaA9WD0oPPw8xD08PJQ8WDwIPDA74DvoO9w8ADxUPHQ8RDy0PHw8WDzYPXw9tD3sPh4+dD5SPp4+yT9hP5//40AWAFgAS4BugGwAmgD4ANoBPAEgASUA2wDEARABFAE0AQ4BbgEdAPkAmQD7APsA0gE4ASQBLgDUAOcA9gDCASwBGgFSAVwBCgEiATIBBAFqAU4BigGEAZABkAGyAXYBRgHYAiACOgHoAdIB+gGYAeQCIAJMAlQCPgH0AcgB7gGQAfABxgH4AUQBZgEAAQwA8ACFALKAL3/4//r/xL+QPuY+cD5YPpA+vD48PYw9ODx0PFw80D0gPNA8tDwoO/g7kDv8PDA8jDzwPJg8jDyoPLw88D1YPew+ID50PkI+qj62Pss/Uz+KP9HACIBTgGKASACZAI8AqwC6AMABfAEIATEA5gDTAOcA+gEwAX4BNADXANMA0ADuAO4BBgFMAQ8A1QDwAOUA8QDwAQwBVgEnAMQBNAECAXgBFgF0AWABTgF2AWYBlAG0AV4BpgH6AdwBygHYAdoB2AH4AewCHAIeAdIB5AHcAeQBggGQAZwBtgFsATsA2QDyAJIAoABmgAUANb/UP/c/RT8iPoo+nj62PpI+tD3cPRw8jDzsPRw9fD0sPPQ8aDvIO8w8cDzUPSw82DzIPOg8hDzcPUo+Aj5mPjw+Cj66Ppo+7j8PP6u/tj+4P8oAZwBfAG0ARACNAJ0AkAD/APoA1gD3AJEAtgBmALsA1gEhANsAvoBvgHeAagC2AMIBPwCQAJUAqACoAIgAygEkATEAwwDjANIBIAEgAQwBbAFWAUIBYgFQAY4BvgFgAaIB+gHmAdoB5AHoAfIB3AI8AiACNgHuAfoB9gHeAdIBzAHsAbwBWgF+AQ4BKwDvANgAywC/wCwAI0AXv+s/ZD8RPz4+6j7iPsg+jD3gPQQ9ED1QPZw9oD1oPNg8UDwEPHA8uDzsPQQ9RD0kPKA8lD0kPbw9+D4oPm4+Vj52Plo+7D8VP1U/qb/SgDn/7H/QQDlADYBsgGsAhQDjAIQAggC4gFkAYABjAJ0AxgD5gE6ARQBAgFIATwCDAPMAvABZgFoAZQB2gGUAmADfAMEA5wCoALwAowDQASgBLgEuATgBCAFQAVgBRAGyAYABwgHQAdgBzgHMAfAB3AIgAggCCAIUAgACIAHeAewB3gH4AaQBiAGYAWgBEgECARMA5ACJAKKAXEAS/+o/qT9hPww/KT8RPwA+kD3wPWA9dD1kPYw9zD2kPNg8TDxYPKw87D0QPXA9IDzkPIw89D0YPbQ9wD5KPmI+HD4oPko+zz89Pzo/Zr+pv64/lb/+f8cAFwAGgGuAaABcAF6AX4BLAHaABYBsAEQAjgCCAIwAT8AJwD0AAQCWAIwAv4BrgH5APIA3gEEA3wDRAMkAxwDHANAAxgEMAWABVgFUAW4BRgGcAboBlgHkAfQB0AIkAiQCLAIEAkwCQAJIAmACZAJEAnwCDAJ0AjoB2AHgAdIB2AGoAVYBfgE+AMYA9ACWAJGAVgA2v8X/5z9UPwI/DT8uPtQ+pD4gPbg9LD0QPZw93D2APTg8TDxgPGQ8vDzIPXg9LDz4PIA89DzUPVA96j4GPnA+Ij4KPlg+pj7qPyA/SD+0P5b/2X/S/+w/2UA+QBIAbQBIAIIAlABuADmADQBbgHsAYQCWAI4AUIAPgDyAIYBCAKUAnACggECAWwBEAJwAggDpAOcAwwD7AKwA2AEcASwBGgFwAWYBdgFmAb4BrAG0Aa4B4AIgAhQCLAI4AiwCLAIQAnACYAJAAkACQAJcAjIB7gHwAdIB4gG4AVIBWAEgAM8A+QC6gGdANL/av+2/oj9RPyQ+0j7+Pog+lj4YPZQ9ZD1YPaw9iD2kPTQ8rDxIPKg89D0MPXw9ID0sPOA86D04Pa4+DD5CPkw+Yj52PnQ+oT8tP38/Qz+uv5r/4H/gf8dANIA8AD3AFIBkAFcATABKgHbAIEAvACGAeIBcgHZAHMAEwD7/78A3AEcApABPAE6ASABMAEQAnAD6AN4AygDkAMABEAECAX4BVgGCAb4BZgGQAdwB8AHgAjQCKAIkAgQCWAJQAkwCYAJwAlgCfAIEAkwCfAIUAjgB3gH2AZABvAFiAW4BMQD+AJIAqYB7QA3AGT/Rv4k/Uj8oPsg+8j6SPro+ND2APVQ9ND0wPVg9vD18PMw8eDvcPHQ83D1sPUA9eDz8PJA8/D0MPfY+MD5APqQ+SD50PmQ+yT9SP4R/4D/Yv9K//T/zwDuAJ4AHAEoAlwCvgFQAUAB8QBhAGcACAF8AVwBHgG9ANX/B/9m/8wAzgG6ASIBngBfAHsAWAGoAlQDIAP4AkADjAPEA2AEUAXQBbgFoAUoBvAGeAfQByAIMAggCIAIEAmACZAJgAmACVAJAAnwCDAJMAnACEAIuAcAB0gGAAb4BWAFCAT0ApACQAJwAZcA+v8J/7D9iPwY/Mj7MPt4+qj5WPiQ9mD1EPVg9eD1QPag9ZDzwPFw8ZDy8PNA9ZD2sPZA9ZDz8PMg9mD4EPpA+5j7sPro+cD62Px+/jD/lv8dAE4AJwAjAEEAYQDMAL4BjAJEAi4BVQAgAAoABQBaAMwA4QCNADYA2f8///r+uP/nAFIB7wCfAMcAGAFGAbYBZAL4AowDcAQQBfgEkAQABfAFoAYYByAIMAmQCTAJ8AhACYAJ4AngCiAMMAwgCzAKIApACiAKMAqACkAKAAngBxgHgAbwBYgFEAUwBNgCqgHgABAALP9o/nD9LPwg+6D6UPqQ+YD4QPfg9XD0sPOg9AD2APZg9EDy4PCQ8HDxgPPw9cD2cPWw8zDzIPSw9ZD32Pl4+5D7uPpo+uj60PtU/Y3/dgGoAcAA/f/s/ywAqACAATgCYALwAXwBvgC5/xf/VP/a//f/7v/A/23/5P5U/g7+EP6k/r//2wAIAXAAIwBrANwApAHoAmAEWAWwBdgF4AW4BeAFIAcwCYAKAAvQCqAKUAowCrAKsAvgDLANsA2wDEALUApQCgALoAuwCxALYAlgBxgG4AXIBRAFUASgA7wC4wAb/1r+LP5M/aD7ePr4+Yj54Pg4+GD3gPUQ8+Dx4PJQ9AD10PTQ8/DxwO8A78DwgPOw9RD3kPeQ9lD0IPNw9KD3SPv8/dD+uP3A+wj7SPxm/nIAjALoA7wDVALdACcACQCtABwCnAOQAwACVQD0/rj9+PyM/er+rP9B/z7+KP3w+3D7cPxE/n7/o/9c/z3/TP+n//kAsALgA5gEIAWIBdgFqAYQCHAJMAqQCjAL4AsgDIAMcA1QDnAOQA5wDrAOYA4ADtANkA3ADNALgAtAC3AKAAmwB5gGeAVIBDgDgAJeAfr/pv5k/cj76Pmw+ED4IPiA93D2IPVw85DxYPBg8BDx4PFg8kDy8PDg7sDtgO5w8BDzYPUQ92D3MPYA9cD04PVo+Cj8u/9wAbcAqv7s/LD8Sv6CAeAEUAZABRQD9wBG/6j+m/+gARgDjAKBABj++Pu4+uj6OPwo/RT9cPzI+0j7KPuY+2D86PxA/Tr+p/+vAIIB6AJYBNAEeATIBFgGkAigCpAMAA4ADhANkAxADZAOIBCAEaASwBKgESAQ8A6gDrAOIA+QDyAPgA1ACzAJYAf4BRgFqAQIBJwCzwAq/2j9aPu4+aD44PcQ91D2oPUQ9SD04PJg8RDwIO9A73Dw0PGQ8iDy4PCg74DvAPFQ82D1gPZA9zj4MPnA+UD6QPuo/CD+TP97AIYBUAKoArwC+AIQA1gDrAO8A2gDoAJ2ASAAwf89AFYABv/k/HD7uPrQ+cD44Pig+cD5WPn4+OD4WPgQ+AD5EPuo/Ej96P1H/zAB5AJYBFgFIAYoB+AIgAvADVAPQBBgEWASgBJAEqASIBTAFaAWoBaAFQAUgBLgEaAR4BCQD3AOkA0ADMAJWAf4BGQCiQDQ/0n/kP1Y+9D5aPgQ9oDzQPJg8pDyUPJg8jDykPBg7oDtAO7g7gDw4PGw88DzkPLg8aDyAPTA9Vj4sPqI+0D70PuE/RT/AQDsAOABBAKIAbgB3AJABPgEWAVABTgEtAIOAXn/Cv6Q/Uj+Bv9w/nj8MPqA91D0EPKw8hD1YPYg9pD1kPUg9fDz8POg9WD38Pio++T+4QCUAbwC+AToBugHgAlQDPAOIBFgE2AV4BWgFQAWABfAF0AYQBkgGkAZwBdAFgAVIBPAEUARIBDwDaALIAroB3gETAF0/9D9sPvQ+Yj4EPfg9HDz4PKQ8UDvwO3g7SDuYO7A7mDvYO/A7sDuQO/A73DwkPJQ9bD2IPfg9/D4EPqI+7z9o/8NAPv/LgE8A5gEeAVIBqAGoAVQBAAEeASgBHAEuATYBKADLgHo/gz9GPv4+ND30Peg98D2IPVg88DwAO5g7EDtoO+Q8fDyIPQw9YD1sPUw9pD3MPoW/iwCeAWYB8AJIAzgDWAPgBEAFOAVYBcAGcAagBuAG+AbAB1AHUAcABuAGYAXgBUAFEASYBBQDnAMQAoYBwgEsAGJ/+T8UPpA+BD20PMg8pDxcPEQ8XDwoO9g7iDtQO0g7iDv4O+A8WDzIPQw9OD0kPbg9zD5MPts/bz+5v6n//wAKALIAmgDQAToBHgF2AUQBggG+AXoBRAFeAO2AXUAp/9L/07/CP8Y/kz8SPrw91D14PJQ8bDw8PBg8TDxQPDg7qDtQOzA6oDqoOxA8KD0MPgA+6z8GP2Q/eD+cAGgBCAI8AvQDyATYBWgFsAW4BagF6AYQBkAGeAYIBlgGQAZoBhgGEAXYBTgELANEAugCKgG6AVwBfgDegGE/vj70PlI+BD3sPUw9EDz8PKw8tDyEPTQ9aD24PUQ9QD1QPXA9WD3+Pkc/BD9hP0y/q7+zP4N/6D/QQCRAP4AYAF8AXIBvAEoAggCfAHCACwAOf9e/kD+kP6E/sD94Pzo+7D6oPko+ej4iPhA+Cj4oPew9oD1YPRg85DygPJw8gDywPGw8sDzMPPQ8SDxUPKg9GD3uPq8/fn/mAFgAxAFOAaIB1AJkAugDZAPoBFAE6AU4BXgFqAWgBVAFMATwBMgE2ASABKAEuASABKwDxANQAoIB1gE0AJAAkAB0//W/j7+NP1w+yD6gPmY+FD3EPZQ9SD1wPVA9/D4+Plo+oj6cPpQ+pj6QPvg+zz8pPwo/Zj97P2G/kr/y//F/1T/wv4g/tD9qP1o/ST9GP0s/WT9sP3s/cj9TP3E/ID86Ps4+5D6APq4+Sj6+PrA+qD5sPiA+Xj66Plo+BD34PVA9LDzYPRg9QD1cPTw9ND1gPXg9CD2wPiw+zb+QgCkAbwCwASQB8AJgAqgC3ANEA/wD8AQIBKgE4AUIBVAFQAUABJgEOAPQBCAEIAQABDwDmANcAuwCOAF6APoAvoBsQBx/2r+jP38/Pz8MP3g/PD7APto+sj5SPlw+Tj6ePuw/FT9fP14/Yj90P34/fD9hP3s/GD8MPxY/IT8oPyw/Kj8fPww/Kj76Ppw+oD6sPqg+ij6CPpo+iD7IPwE/VD9FP0A/fz8vPwo/Ej8BP1g/ST9+Py0/Ij7qPpo+7z8GPwg+ZD2cPXQ9PDzYPMg86DyUPIA83D0kPXw9kD5yPuA/cj+ZwAkAtQD2AWACIAKcAuQDGAOIBAgEQASABOgE6ATIBNAEqAQgA+ADyAQIBCwD+AOoA3AC9AJIAgQBqgD4gH/ACAArP6M/UD9NP0c/Rz9BP1Q/GD7APsY+yD7APtY+xz82PyA/eD98P0E/pT+Gf/i/uD9CP3A/KT8uPy8/HT8yPtw+5D7sPtg++j60PqY+lD6SPpo+oj6EPs4/Gj9hP0g/fD8FP3w/OT8LP0w/QD93PwQ/Vz8yPr4+dj6wPtQ+9D58Pcg9rD08POQ89DyAPLw8WDy8PIg9FD2APmo+zz+iAAEAvwCwAR4B8AJQAvQDKAOIBBgEYASgBPgE+ATQBTgE0AS8A9QDoANEA3wDAANgAxQCwAK0Ah4B6AF1ANUAvEAm/+K/sT9OP0M/WT9/P1I/hz+DP5s/gn/kv+D/xH/wP7a/hL/J/8+/3z/3v8SAAoAaf9e/mj94Px0/Jj7oPrI+Tj5wPiY+HD4CPjA9yj40Piw+ED4YPj4+Jj5OPqA+3j8lPyE/BT91P2U/Rz9aP1I/nL+4P3Y/OD7ePvA+zD8iPv4+Vj4MPcg9vD0APQg8xDyUPGA8YDy0PPw9UD57Pzg//ABrANIBQgHMAlwCwANAA4wD6AQABKgEkATIBTAFOAUYBRAE0ARAA+QDfAMUAxwC1AKIAkACMAGcAXwA1wC6wDQ/+7+9P3Q/Mj7aPvY+2T8bPw0/JD8qP3A/mv/pv/R/+n/JQBlAFsANwAQAD4AWQAyALP/5v4K/mz9GP0w/JD6OPng+Mj4EPgw99D24PYA92D34PcA+OD3UPio+ZD64PoQ+7j7QPwo/CT8IPxY/MT8+P3G/kL+6PwA/AT8APyo+9D6sPlI+AD3MPZQ9QD0sPLg8YDxgPEg8nDz0PUA+aT82P8YAtQD4AVACGAKIAxgDZAOsA+AEEARoBEAEqASYBPAE4ATYBKgECAPEA4wDQAMsAqQCTAIqAZYBUgE8AJsAbMArAAUALD+vP3c/TT+Dv4e/or+sv7a/sD/AgGAAWwBmgEcAiQClgFAAf4AkQBzAMkAgQAy/+j9XP3Q/JD7UPqI+fj4OPjQ92D3kPbg9UD2QPdg9xD3YPeg+HD58Pm4+rj7XPzo/Lz95P0E/VD83Pz8/Vz++P2I/Qj9RPzA+8D7cPuA+ij5KPgg98D1EPSQ8pDxoPDA7yDvgO8Q8eDzcPdA+8L+jgEwBMgGkAkADAAOkA+gEEARgBHAEaARoBEAEsAS4BJAEoARoBCgD3AOYA1QDNAKQAn4B4AGqATgAsQBDAH5//7+pv5u/sT9iP1E/kT/S//E/ur+2f+ZAAQBcAHmAQQCDAJkAqQCVAKyAXYBpAGgAeQA7f/K/rz9yPzY+6D6GPkA+KD3wPcQ9+D1YPUQ9uD2EPcA93D3gPiI+Vj68Ppw+8j7rPyw/eT9VP2o/OD8dP0s/p7+Tv5M/Xz8oPzA/LD7IPpw+RD5CPhQ9uD0kPMQ8sDwMPDA70Dv4O9Q8rD1IPnA/I4A7APIBsAJ0AxQD6AQ4BHgEiATgBLgEcARoBFAEcAQQBCQD7AOkA2gDOALIAtACjAJMAgwB/AFQASAAiQBPQB9/8L+Nv4M/nD+Jv8HALsAfAE4AtwChANABKgEcATkA4QDRAOYAsgBCAGDAOP/fP9Y//7+LP5w/SD9dPwo+8D5+PhI+FD3gPYg9rD1MPVw9XD2MPdg9+D3IPlI+gD7DPxw/WT+0P4c/z//rv7Q/Wj9qP24/Vz9zPwM/Bj7iPqQ+lj6aPkg+GD3wPaQ9QD0oPJA8QDwAO+g7gDvAPBA8uD1APqw/RABeATwB1ALgA4AEaASYBPAEyAUwBOgEkARgBBAEIAPEA6gDMALIAuQChAKsAkQCWAI8AeAB3AGsAQMA+IB1gC7/6z+MP4w/qD+fv9WAOwAhgGYAhAEUAXIBQAGCAawBfAEAAQIA7YBYgBn/7T+mP1c/Kj7aPvw+vj5CPlg+PD3UPcA98D2EPaA9WD1oPWg9cD1kPbA96j4UPlw+pj7nPzI/VL/ngDCAF8AOwA/AMj/Kv+Y/hL+DP3g+/D68Pno+Bj4wPcw9zD2IPWA9AD04PKA8UDwIO+g7iDvoPAA87D18Pjo/N8AcAS4BxALcA5AEWAT4BSAFaAVIBVgFGAT4BFAEJAOEA2gCzAKAAlACMAHoAewB+gHoAcQB5gGMAYoBagDNAJAAZQAzv99/47/s//M/2cAfgGAAoQD2ARgBkAHUAdABzAHoAaABTgE1AIIASL/uP1w/Mj6OPlQ+PD3UPeQ9kD2YPaA9tD2YPeA91D3QPfw96j4uPiY+AD5uPlA+tD6ePtg/Dz9Jv7o/hT/vP6c/lH/vP9F/wr+BP1o/LD7mPpI+fD3oPbA9SD1sPTA87DyAPKw8QDx4O+A7yDwAPJg9DD3OPok/QAANAPQBhAK0AwwD2ARIBMgFKAUoBQAFAATABLAEFAPgA3QC5AKIAngBxgH0AaIBnAGwAYoB+gGKAbgBZAF2AS0AwwDzAJYAuIBsgGiAUIBQgHoAcgCQAPYA9gEqAWYBTgFQAUgBVgERANMAtAA/P4s/Sj8IPtw+cD3wPYw9rD1UPVg9ZD1sPUg9uD2cPfA91D4aPmI+uD6mPrY+qj7mPwI/Uj9dP2o/QL+Zv6C/kL+8P0S/kj+0P3I/Ij7yPog+mj5WPgw97D1sPRw9FD0sPNQ8jDxUPAA8DDwMPEA8zD1KPjg+6D/dAIoBZAIQAzwDsAQgBLgE6AU4BQAFYAUABMgEQAQ8A4ADdAKMAkQCMgGyAV4BVgF+AQQBaAF4AVYBcAEuASIBNQDPAP8AqACNAIcAmwCXAIkAmwCXANIBKgEKAWoBegFyAWoBXAFuARgAwwC8gBl/7D9EPwQ+/D5cPjw9gD2kPUg9RD1MPWg9fD1gPZw91D48PiQ+ZD6aPug+3D7oPsg/Kz89PxE/Wj9XP14/eD9KP7E/Tz9MP1I/cT88Psw+4D6kPmA+JD3UPag9GDzUPNQ81DyoPCg72DvoO+g8IDy8PTQ94D7m/8EA1AF2AcgCyAOQBDgEUAT4BPgE+AToBNgEkAQkA6QDVAMcArACJgHmAaoBTgFKAXgBMAEOAX4BRAGYAXoBOAEwARIBNgDkAMoA7gCkALEArAChAKwAngDOASIBLAE+AQwBSAFyARABFwDPAIcAeL/ev7E/Dj72Plo+PD2oPXg9ID0YPRg9OD0YPXw9bD28Pcg+eD5iPpY+yD8XPyA/ND8OP1g/YD91P3s/bT9bP2w/cz9dP0E/cz8tPws/KD7APsY+gj5KPjA97D2UPWA9HD0QPQw88Dx0PBw8MDwYPLg9ID3GPo4/dUA7ANgBvAI0AtADkAQwBHgEiAToBKAEkASQBGQDwAO4AygCyAKwAiwB4gGiAUYBUAFYAVgBZAF0AW4BTgFAAXwBLgEYAQgBOADeAMMA/wCNAMcA/ACFANwA8wD2AMYBIAEoAQwBKwDEANgAmgBSwBI/w7+rPxQ+yj68PiQ92D2sPVg9RD1IPWQ9SD2oPZQ91D4SPkA+uj62Ptc/Ij8yPxE/Xz9iP3E/Sb+HP7M/Zj9nP00/ZD8OPwQ/Kj7APuY+mj6uPmg+ND3UPew9tD1APWQ9AD0MPNw8uDxIPEA8SDy4PQY+LD6NP0IABgD6AWACOAKIA0QDwARoBJAEwATgBIgEmARIBBwDuAMcAsACsAIiAcwBvAEeASQBOAEAAUwBYAFiAVgBWgFoAWgBVgFMAU4BdgEKAS4A7QDrANgAzwDRAM8AyADUAOsA4gDAAOgAmwC0AHCAO//Sv9S/hD9+Pv4+pj5IPgw96D20PUQ9RD1kPXw9RD2oPaQ93j4QPkw+mj7CPxM/Mj8ZP20/aD9wP00/l7+HP7k/dT9jP0I/cz8lPwY/Ej7yPq4+kj6UPlI+MD3kPdA99D2QPZg9aD0EPSQ87DyAPKg8pD0MPeQ+ej7Nv6mADQDEAawCOAK8AwgD0ARYBLAEsASABPAEsARwBCQD/ANEAygClAJsAfQBbAEgARoBBAE/ANIBFgEKARIBLAEyASgBNAEGAWoBNwDjAO0A4gDBAPgAtQChAI0AnQC0AKEAggCCAIYAnYBmAAzABkAZP90/rj9AP3I+0D6QPlA+PD2wPVQ9WD1UPVA9bD1YPbQ9nD3cPiw+Xj6GPvg+7T8HP1A/ZT9FP5m/m7+aP4+/tT9QP3g/Jj8EPxg++j6mPog+nD50PhQ+ND3UPcg9/D2gPbw9XD1EPWA9KDzYPPA8wD14PaA+Uj8eP41AFgCGAWoB9AJAAyADoAQ4BHAEiATwBIgEsARQBHwDyAOsAyAC/AJMAjYBuAF0AQQBBgEYAQQBKAD1ANwBIAEcATIBFAFSAX4BOgE2ARgBPQDEAQwBJwD3AK0AsgCjAIcAvABuAEOAVYA+/+u/+r+9P1o/fT8FPzw+gj6MPko+CD3gPYw9tD1wPUg9pD2wPYA96D3aPgw+QD64PqY+/D7SPy4/Ej9iP24/RD+Yv5e/hL+1P2o/Vz97Py0/HT88PtY+9D6YPqY+bj4EPjQ93D3APeg9kD2sPXw9ID0MPQw9PD00PaA+aD7jP2N/5oBkAPQBeAIsAvADXAPYBGgEuASgBIgEsAR4BDAD8AOkA3ACzAKMAlACNAGiAUgBSAF6ASYBHAEUAQQBAgEoAQoBTgFEAUYBQAFkAT8A6gDiAM8A9wCjAIkAqgBfgHCAeQBfgHNAE8AAACg/yv/wP4w/oj9yPxA/Ij7ePpQ+ZD48Pcw93D2IPZw9pD2sPbQ9jD3kPcQ+Oj46Pm4+kj7APyY/Aj9SP28/Sz+Uv44/iL+9P2A/Sj9BP3g/GD82PuQ+0j7mPrY+UD5qPjQ90D3APfQ9nD28PXQ9aD1APVw9JD0cPUA9wD5SPuc/Xj/MAFoAzgGMAnACwAOABCgEaAS4BKgEgASABFAEJAPoA4QDZALkAqgCWAI2AbABSAFwAR4BFAEAASoA7ADIASABIgEuAQABSAFqAQgBLQDRAPsAsgCmAIIAngBdgHeAdoBjAFUATIBzQApANn/gP/Q/uj9SP2w/KD7iPrI+SD5IPgQ95D2UPYA9uD1IPaA9pD20Paw95j4UPkg+kj7MPyk/Aj9pP0q/lL+dv6+/uz+hv4I/sD9mP1A/cj8kPxc/Pj7cPsQ+7D68PkI+Xj4OPjw91D30PaA9jD20PVw9aD10PVw9uD30Pl4+6D89P0FAJgCUAVACBALgA1wDyARQBJAEuARoBFgEeAQ0A+wDqANUAwAC+AJ0AiQB1gGqAUYBUgEfAM8A0ADGAMQA3gD/AMABMQDsAOEA+QCMALuAdgBeAEIAfkAIAESASYBjgH6AdoBjgGOAXAB9QBiACQAt/+0/pT9xPzw+6j6cPmo+BD4MPdw9jD2QPYQ9uD1QPbA9jD30PcI+XD6SPvY+4z8WP2c/bD99P1G/lD+Kv4o/vj9dP30/Pj8FP3U/HD8UPws/Kj7APuA+hj6gPno+Jj4KPhg97D2MPbQ9TD1sPTA9HD1gPbg94j5GPtk/ND95f+cArAF4AjwC2AO8A/AEGARoBEgEWAQ8A+gD+AOgA0gDAAL8AnQCPgHOAdIBmAFGAUABYgE/APUAxgEKAQYBFgEiAQwBJwDVAMUA2gCzgHaAQgCzAF4AbgBOAJgAmwCuALcAngC/gG4AUwBcQCp/yX/Wv4Q/dj7CPsg+vD4APig9zD3wPaQ9tD2EPcw95D3UPj4+Gj5MPpI+xz8dPzE/Dj9lP2k/az96P0M/gL+5P3I/bD9gP10/ZD9mP1Y/fT8qPxE/Ij7wPoY+pD5uPjQ9zD3kPbA9RD10PTA9LD08PTw9XD3wPgo+tj7XP3Q/sMAkAOQBiAJgAuADcAOEA9AD4APQA+gDkAO8A0ADdALAAugCvAJIAmgCGAI8AdYBxAH2AZABqAFoAXgBZAF+ASoBIgEMASUAxADhAIYAugBFAIcAgwCLAKMAvgCQAN8A5QDWAPkAnAC8AFEAWsAi/+m/oz9ZPxQ+2D6oPno+GD4CPjg99D30PcQ+Fj4mPi4+Oj4ePkw+tj6cPsM/GD8fPyU/Lz8sPyI/LT8CP0E/cj8rPzs/Oj8vPy4/MD8YPy4+1D76PoQ+hD5YPjQ9yD3cPYg9sD1APVQ9CD0QPSA9ED1gPbQ9xj5mPow/Kj9V/+yAXgEKAfACUAMAA6QDqAO4A4AD8AOUA4wDsANwAzQC2AL8AoQCnAJUAlQCdAIQAigBxAHeAYoBhgGqAX4BIgEgARgBNADCAN0AjACHAIsAjgCQAJ4AuQCdAPIA+QD3AO8A4gDAANYAoQBoAB5/17+RP04/Aj7+PlA+aj4QPgA+Aj4EPgQ+DD4mPjo+AD5QPnI+UD6ePrg+mD7mPtw+2j7oPu4+7D7+PuQ/NT8tPyg/Nj8BP3k/Oj8FP0I/Yj86PtI+5D6sPnY+Dj4kPfg9kD2wPVg9fD0kPSg9DD18PXg9hj4mPkI+1T82P2N/4QBhAO4BTAIcApADIANQA5wDnAOcA6QDnAO8A1wDRANkAwwDPALkAvgCkAKEAqQCZAIgAfIBkgGoAUYBaAEGAR4AyADCAOsAgwCwgHcAdIBogG+ATwCmAK8AvQCTANgAzgDCAOwAvwBBAE9AIf/ov6k/bT80PsA+0j6yPlQ+ej40Pjo+Aj5CPkA+fD4yPig+Jj4wPgA+TD5iPno+RD6KPow+nD6yPo4+6D78PsA/PD7+Psc/Dj8KPwg/Bz88PtQ+4j64PlI+Yj40PeA90D34PZg9jD2IPYA9vD1YPYA97D3mPjo+Wj7oPzw/Xr/QAH0AvgEYAfACeALYA1gDqAOgA5wDqAOsA5QDgAOsA1ADbAMUAwQDKAL4ApgCgAKcAmACKgHCAd4BtgFWAXQBAgETAPwAtQCbALsAcwB+gH4AewBQALIAggD9AIIAywD/AJkAsoBGgEPAO7+GP6E/bT8yPsY+6D6IPq4+Yj5iPlg+UD5cPnA+bj5YPko+RD5CPn4+DD5gPmo+aj5sPno+RD6WPrQ+lD7qPvI++j7+PsA/Aj8FPwU/Oj7uPto+/j6WPq4+Tj52Phw+Aj40Pew95D3QPcQ9yD3QPeA9xD48Pjg+fj6QPzA/Sf/ewAYAiAEcAagCNAKoAywDTAOYA6ADmAOUA5gDkAOsA0gDfAM8AygDCAM0AuQCzALkAoACkAJYAiAB/AGcAa4BfAEOASMA9gCYAIsAuwBpAGUAcwBIAJUAoQCuALcAsQCdALsATABWABm/3b+tP0Q/XD80PtI++j6oPpo+lD6WPpI+iD6GPoI+tj5mPlA+eD4YPgg+DD4YPho+ID4uPj4+BD5UPn4+YD6wPrQ+hj7MPsI++j6APsA+8D6ePo4+tj5UPnw+LD4cPgo+DD4WPhQ+DD4GPgY+AD44PcQ+HD4+PjI+fD6QPyE/fD+ewAcAtADyAUQCGAKMAxgDfANEA4QDhAOIA5gDlAOAA6ADVANMA3wDJAMQAwQDKALMAvACiAKAAnoBygHkAawBcgEOASsA/ACVAJEAkQCFALuATwClAKgAqQCvAKcAhAChgH4ADQAIv9a/uj9ZP3A/FD8GPyw+zD76Pro+qD6SPoo+gD6gPnw+Mj44PiY+BD44PcY+Dj4YPiw+BD5KPlQ+bD5APoo+mD6sPrg+qj6YPpo+nj6YPow+jj6KPr4+dD5yPmo+VD5IPkY+SD5+Pi4+KD4oPiA+Fj4ePjQ+Ej52PnA+vj7MP1k/tf/fAEoA8AEkAaQCCAKUAsgDMAMAA3wDAANcA2wDaANgA2gDcANsA2gDZANQA2ADPALYAugCqAJoAiwB7AGwAUgBbgEEARMA9ACqAJ4AiwCKAJMAlACNAI4AjQC5AGCAUwB/QAzAFX/2P6O/g7+fP04/RT9sPw4/Oj7qPsw+8D6ePoQ+nD56Pi4+Ij4EPig94D3gPdg93D30PcA+PD3APg4+HD4ePiY+OD4CPkI+QD5QPlw+Yj5oPnQ+fD54Png+ej56Pm4+Xj5WPlg+Vj5YPl4+ZD5mPmQ+bD54Pkg+pD6YPt4/KT9xv4KAGoBwAIoBLAFSAeQCLAJcAowC7ALIAyQDPAMUA1wDXANoA3gDUAOoA6wDlAOgA2wDPALMAtQCqAJAAkQCAAHOAa4BTAFmARABCAE5AN0AyQD8AKsAkwCFALaAYABNgEMAcwAHABn/wX/uP46/sD9jP08/ZT84Ptw+yD7sPpA+vj5oPkg+cD4mPiI+Gj4UPhA+Bj44Pfw9zD4YPhg+FD4UPhI+DD4QPiI+Nj4CPkw+Vj5gPmg+dD5APoo+kD6YPqA+mj6OPoQ+gj6+PkI+kD6ePqY+rD64PoQ+1D7wPt8/ET98P2i/m//SwBCAWwCuAMABTgGYAdwCEAJAAqgCjALkAvwC1AMgAyADLAMEA1gDYANgA1QDdAMIAyAC+AKUArQCUAJkAjIBxgHgAYABogFKAXIBEgEvANQA/gCqAJQAhAC5gGeAUABxAA3AJv/Av96/vz9eP3k/FT82PuA+zD78Pq4+pD6WPr4+aD5WPko+fD48PgA+ej4kPhI+ED4QPhA+ED4UPhI+Bj44PfQ98D3wPfw90D4cPiA+JD4uPjQ+PD4OPmY+dD50PnQ+dD5uPmo+eD5MPpo+qD6CPuA+9D7IPyY/Dj9tP0k/rT+ZP8YAPoALAJ0A5AEcAVgBkgHEAjACIAJIAqwCgALUAuwCxAMUAyADJAMkAxwDFAMYAxwDDAMsAsACyAKQAnACHAI+AdYB8AGQAaoBegEWAT8A5wDIAPgAsgCcALYAUYB4ABgANn/if9V/97+Nv68/WT93PxA/Oj7yPuQ+yj7uPpY+uj5iPlI+SD5+Pjg+PD4+PjY+Kj4oPig+ID4WPhI+Dj4KPgw+Dj4MPgY+ED4oPjY+Nj46Pgg+TD5MPlA+Xj5sPnY+Sj6iPrI+tj66Pog+0j7aPuw+xD8cPzU/Ez90P08/pz+Fv+8/3oAWAFIAjwDEATgBLgFiAZQB/AHkAggCYAJwAngCTAKcAqgCsAKAAswCzALIAswCzALAAugCkAK4AkwCYAIEAjAB3gHGAfABmAGyAUYBXgE/AN0A/gCiAIsAtoBgAEiAbgARgDh/5L/K/+U/uj9VP3Q/Ez8+PvY+8D7iPsw+9D6cPog+vj58Png+bj5kPlw+UD5EPkA+Qj5CPnw+ND4sPiA+Fj4SPhQ+Fj4YPhQ+Ej4OPg4+Ej4ePi4+Aj5SPlo+Xj5cPlw+ZD52Pkg+mD6qPoY+5D7EPyY/Cz9zP1U/r7+Gv97/+r/bgAKAb4BiAJUAxgE6ATQBbAGWAfAB/gHIAhACGAIkAjQCDAJkAkACmAKkAqACmAKIArQCYAJUAlQCTAJAAmwCEAI4AeIB0gHGAfwBsAGeAZABvAFaAWgBMADDAOoAoACcAJEAuABTAGnAPX/RP+c/vj9WP3Q/Gz8FPzA+3j7UPs4+wD7kPoY+rj5aPkY+bj4YPgo+Dj4ePjA+PD4+Pjg+Kj4UPjg96D3sPcQ+Ij4uPio+LD48Pho+dj5GPo4+kD6MPog+jj6mPoI+3D7wPvo+xD8SPy4/Ej9tP3w/T7+yP5w/xIAsQBQAb4BDAKAAgwDjAP4A5AEMAW4BRgGaAagBqAGuAYgB5gHAAhwCNAIEAkACbAIcAhACCAIEAgwCEAIEAiwB2gHMAcAB7gGkAZwBkgGGAbgBaAFYAUgBdgEYASoA7gC6gFuAVABZgF4AV4BEgGlACQAgP+o/sD9MP0A/bT8APw4+7j6mPrw+rj7VPwY/Aj7+PmI+Wj5IPnQ+Lj4sPjQ+FD56Pnw+VD5APmI+Rj6IPo4+qD6gPqw+ZD5gPpI+1j7aPtw+yD7GPsA/Lj8WPwc/Bj96P0c/Uj8WP2G/qT9dPyc/br/7P/a/if/1QCeAQgBEgFIAtgCtAF/AOIABAJsAnQCdAMABaAFeAXwBYgGCAb4BMgESAWIBfgFKAdACPgHEAd4BrgFiAQIBNAEsAXgBRgG4AZgBxAHYAZgBYADLAH8/6sACAIcA2AEyAUIBtgEjAOUAtMAVv68/LT8KP2c/bz+cQAiAYwAFQDI/3b+rPz4+6D7+Pko+Kj4CPvU/Iz9oP6F/xD+6PpQ+cj52PkQ+Wj5APsI/BT8LPxo/ET8EPwA/Kj7UPvg+xD9dP3w/KT8mPw8/OD7CPyI/HT99P70/6X/Ev9D/zr/8P28/CT9BP4Q/rb+MAFwA6gD3AL2AcwAZAC+AQwDIAJBAP//XgGMAjADWARYBVgEKAJ+AdgCCATgA0wDiAOYBBgFIATwAigD4ANgA3QCGAMQBRAGKAXIA1QDIANoAjgCNAPYA+ACpAH4AQwDpAJUAcQBZAM8A0QBPABvAMn/Vv5c/s//9P9q/hD+if8uAHT/Xf96/7j98Pq4+Wj6aPu4+3z84v5mAXYByf/K/lT9CPlg9HD0QPlw/bj+//8kAqQBAP4A/LD91P7A/Jj60PpY+wD74Pu0/koBVAJgAlgB2v6M/FT89PwI/cT94v9uAfIA+//AAIACHAJE/4j9tv5VAIEAQQBjANT/3P5pAIgE0AU8Avr/VAOABvwCaPzw+hT/bAIIA/gDEAV0A74AvwCMArQCZAE2AVQC+AKMAogBMwBb/9v/MAE8AqwCwAK8AqQCNAJCAVIAqP/M/sT9CP5aAMQCdAOgA/gD1AFs/fD7DP9CARf/HP2T/zADVAMUAkgChAHi/ib+kv+o/hj7QPoU/tYBQAJwApgEqAR6AHz8UPtY+nD4ePjI/JACOASwAdwA5AJ8AjD+mPoo+qj6GPuY/QQCvAP7AMb+/P9DAFj9APxK/rf/eP4s/l8A6gGAAET+Ev7w/jT+uPxQ/cH/6AHYAtQCLAKnACD+oPxo/oABnAHg/uz9//+rAGD+sv78AzgHaANG/rr+wgH3AEz9wPx8AGADEAIhAMABeARIBMgBh/+U/mj+Uv4+/2gBeALSAfIB6AJwAtoAkP++/nL+zP/sAmAEPgGw/bH/yAPoAqD/1QAIBGYBWPvY+zACOARmAagCwAZYBNj9nP2kASoAIPtw+63/FwBS/sMAoASQAxMAlv+mAEkAM/84/dj5qPgA/dwCCASAAfwACAJO//j6uPul/4j/rPxk/er/VP7c/IACIAfoAJD4QPrW/1j+MPsYAAAHAAQw/AT8OgCq/nj64PvhANgDMAS0AkD/oPsw+5j9yP7K/rQB4AQkAqD8qPv2/rYAXf+o/roAVAL6ABkAcAJwBK4B+Puw+bT8vP/c/xYBaASYBM4ASwCoBBAFif/A/Gz+yP0Y/J3/0AQgBB4BjAM4B+QDFv5c/hQAWPtg9hD7eASgB6AF4AagCagE+PlQ9sD7Tv+Y/KD7NgGAB0AImATSAf0Akv4Y+nD4HPzEAYAEcAIs/zr/uwDb/zb+Nv4l/8n/3//5/8gA+gD6/gD9Av5JAKj/sPwo/b4BzAKC/nT92gFwA0kAzP78/lj7APY4+CAD8ApwB6v/GP38/Ej7KPzaAZAFpAIk/vT91v9e/kD7jPySAXgDhALIBFAHnALI+nD5WP26/hT99v78AwgE3f/qAEgF5ALg/GD9kAIAA1z+cPyY/gT/LP0A/0gEGAZ4AzIBxACQAJUAhAAo/4j96Pyo/TsAzAPoBUAFQAPMAfsA1v5g+7j64P1FAAABeAPQBagD1f+N/+wAhP8g/Zz9pP5U/UT9DgEgBEgD6gEEAhsA6Pt4+8j/BAEI/Vj7O/9UA0ADeAGWAWoBYP3A+Aj61f98AmMAb/9YAowDyv/c/D7/HAIaAMj7QPpE/SACcARQA/wB0gGO/8j64Pjg/PoBYAJ1AGwBNAI8/nD7pP+AA3MAGP3+/i4Bxv9m/qz/zACP/7j+ygAIApf/Hf9oAyAExP2w+qX/kALW/pD9nALQBHv/kPudALgG6AMO/vD9sP5A/HT9GAOwBCwBh/+MAXgCtACp/6EAdAC0/jj/2gEsAjAAw/+uAKYAJwAiAF4AZgGAAs0A2Pw4+5T+zANQBTQCKf+2/oT+oP3U/fz/mAIoA2kAtP1a/4YBSP4Y+rj8TAIIAjD98PzAA4AHdgHw+oz8Pv84/dj8NADaABL+xP0MArgFQAMo/sj9V/8s/AD5vPx8AngCJv4c/ZYBuATWAZz+Rv/6/qD76Pou/jAB/AIgBAQC5PyA+4wAUAQuAMD7nP+gBNIBlP2c/5ACwgDi/kQBeAOeAAT8UPwgAdADsAKUAtwDSAGQ+0j5RP1sA6AFPAJe/6kAYgE9ACIBOAP+AVT9aPno+0QDQAS4/Qz+aAfACRgBqPqQ+/z8LPw0/UoAhQAq/7QDEAsACa7/hPwQ/eD2wPHY+WgGoAjwA7gE8AgIBXD6MPb4+qj90Pq4+0AC6AQ4AgADmAeoBsj+aPmA+kz84PvY/L7+9P2+/rAF4AqQBtf/wv7M/gD70Pco+gj/hgBY/xYB0AQwBfgCQAHW/6z+Ev54/BD7wPwXADQCEAO0A4QDnAFc/hj8xPxX/yYBlgE8AtQC/AFe/7D7+PkK/tAEYAbaAeD9/v4+ATP/NPzc/hAE2AOw//z+CAJcAjr+aPvQ/d4B4AKuAWIB9AEkAWj+oPxW/kIBLgEf/+L++wDUAyAFNALo/BD7rPwk/VD90f9sAhADYAN0A7IB+v6I/bD9CP0w+9D8wAJoBcACqgGsApf/yPow+wn/CwB8/qH/hAPQBKwBkP62/of/YP0Q+gD7TgBwBAAFoAQABK8AUPsY+dD6mPwM/ogBkAWABhAEvAB4/sj8gPsI/MD9B/8yAEoBfAFMAnAEjAP0/Yj5IPsJ/4sAWQA8AMgAGAKoA8wDegGU/mz9XP1I/R7+lf+6AMACyASYBJwC/v8g/AD5aPs0AkAFcgF+/1AEcAZc/wD5DPw2AbEAPP94AhgFtAHw/Iz9SgFaALD7OP1gBTAI0AIZ/0QAEP9I+UD3PP4AB1AIKANf/07/V//4/aT9ov5I/tD9RQC8A/QDzQBw/k3/KAAe/sz8xP/8AhwC7P/2/57/TP0g/dn/mAESAQIB2gHyAIj9SPuM/RYBDAKGAZ0ADf9y/t7+0v53/6gB9AIUAdz9EP1B/6QAjv/0/wgDdAOx/7T9pv8eAOT8SPuc/sQCzAMQBDgFQAOk/GD4ePr4/ID8Vv5IBeAKYAgkAAD7zPyq/gj8GPu6/4AD2AJYAugEUAcoBDj8APdY+Hz8qf8kAlAEoAXYBPwBdv82/lT93PyE/AD8DP2CAJgEiAewBtYAQPtY+7z9iP2Q/Cz+fgE8A5wBRAB4AkADrv7Y++f/tAKE/Wj4ZPx0A8QD8ABkA1AGyQAw+cD6pgCn/zD8OwAwBngDFP0Y/akAOgCo/mgBSARmAdT8vP1CAWAAVP3G/tgCQAORAO3/cgGDAND88PtH/yYB2/9oANgDsAQoAZj9HP2o/ST9sP2LADADxALk/yD+0v84AlEAQPwY/dQCcARQ/tj5Tv54BNgCcP4gAAgE0AEE/ND79AEoBfgAqPxs/tgBagCY/Kz9IANIBFT/gP36AeQD/P7Y+0cA0AMc/7D56Pvr/37/dgDgBTAHAQCI+iT+0AL+/wj7WPv8/dz+DwBUAxgF4AJa/5j90P3q/s7/J/+4/rcA5gEr/4z97AEYBrAC+PvY+vT+gAHNAFQASgFcAc3/Nv62/ooB2AP4ArYAlv/w/cj60Pr8ADgHuAY0Am8AMgEVACj+NP6I/dD6gPsEAYAEyAP4BEAIyAQI+lD1DPygAYL+sPsC/zQCiAIwBOgGEAZkAQT9ePqg+ID4GPxaAcgEiAY4B+gFkAJg/qj6wPiI+ND5wP4QBvAJQAj8A3z/CPvA9/D4tP6KAbT+wP6oBAAHnAJW/xj/8Ptg9xD6oAL4BIUAmwAgBdgD4P2k/Kr+DP2g+gD+gAOUAzcAYv/6AOcA8P5c/sb/+v9c/sz+TgGaAXb/q/9YA5gEGACQ+wD9ZgCU/xD+dAF4BcgD6v/n/4ABnv+A+3D65P2EAWgCXAKYA0AFkAQXACj6gPfo+ZD+jALABWAHOATA/RD7lP0s/5z+NgGgBagDePzI+lEAEAP3/7z+6AEoAwoAqP2W/ij/VPxA+v7+gAaABtL/OP2oAcAEav8Q+MD5mwCiAS3/GAIIB3gFhP4w+sD7Zv5e/sD+xAGYA2QC8gBnAKj/LP5c/MT8FQCgAjwClgDi/zgAS/8k/eT9BgG1AFT9AP15AIQDcASYBNwD4v+w+oj46Pjo+eT+oAjwDVAIPv7o+gD+xP3A+UT8OAR4BBb+gv5ABUgEcPuQ+cYBkAVKADX/EAUwBXj92PrGAIQDsP5A+wj9UP6c/8AFsAqIBtD/Dv8q/rD2MPJY+rAFOAb0AXgG0A1wCOj58PLw9sj7RPz4/WwDEAcYBVQBjAEABRgF7v7g98D1KPg8/ZgDAAgoBzADsgDT/2D9gPqY/EACeAKg/Cj7gAGoBVoBmPxF/4ADmwBg+0D9EAL1/6D6iPy8A4AF4AA6/n//1P7I+6T8ZgHkAnEA+P8gAmAC6/98/bT8eP10/oj+xP46AfgEcAZcA/7+JP44/nD62PhEAJAHeAR6/iUAsAPQ/wD60PzUA9ACIP0K/0gG6AaIAJj7IPtw/PD9XgBsAxAGcAdwBcj+WPhw+ED9igAAAoAEmAVSAej7SP2oArACMv74/CT/CAC8/xsAQQAxAJIBfAPcAnr/wPzY+7j6QPvaADgGmATVAAgCrAN8/2D5APjY+tT9EAH4BTAJsAb+ANj8mPkA9vD2XP5QBOAC0AD4BKAJoAYG/+j6yPjw84DyOPyACPAJSAWYBwAMoARw9nDyIPnw/Dj78P1QBsAJuAWcA0gGQAVU/BDz4PKI+yAEyAZ4BZgD8gEYANT+4/8eAWj+6PpE/QADPANU/RD7pAGACJgF/P3U/Pv/sP0Q+QD9AAfwCWgC6PvE/SYACPyg+WgAWAdIBcoAZAHAAbD8wPjY+yUAAACNAKgFkAgwBBT/GP4E/HD3MPj1/ygG8AaYBkgG/gGw+jD3MPpI/jD/N//mAcgFAAYUAo3/5f+o/RD56PlgAMQC9P6U/TQCyAVgBDACewBY/LD3aPiU/bgBIASABmgGpAJI/9j9iPsI+Xj6Af8YAngDiAXYBgAEyP7g+/D60Pkg+1MAmATQBJgE0AUgBED9MPcQ+ED9rQBgAugE0AVMApz9kPxP/yYBQ/8k/cD+1AEUAuQA5wCr/xz8iPt5AIgEDAPtACQC8AE0/Vj6MP48AhgA5PwK/xgD8AOAA/wDFAIs/LD4xPwsApQBNP+AAcwD3P/w+pz8LALQBNADWAFE/bj5OPtnAIACywAOAWAD/gFY/TD8K/9YABT/VACMAwgDdf/G/j4ACv64+Vj6f/9UAiQCGAQgB+gE6v7E/MD9OPsA99j4SwDoBVgGgAUIBogE8P7o+QD5sPnI+hj+6gGYAzgFMAlwCuACUPhQ9ij7wPvw+af/gAjQCFgDgAKgBM4B0Psg+tj7cPtQ+7kAIAfoBnQDOAMYA8L+APsw/SAA+Pwo+Gj6BAKYBogH4AjAB1wA8PfQ9bj4NPyO/zgD4AU4BlgENgGk/tz9zP3k/Ez8hP7cAUQCwgCIAewCOAFo/iT+g/9YABIBlAGBANz9BPwk/TEANAIIAhIBYQAIAHP/Rv7Q/SH/KAD2/hj+2v+MAaIATv8MANAAQf+E/Xr+LQCQ/47+5f+mATABGwCZAGQBkAAU/+D+f/8r/07+oP4xALYBrAKAA+gDlAJm/3D8mPu4/J7+qgA4AsACaALEAe0Af/+0/bz8qP3k/6AB/gHKAawBJAEZAIX/i//4/oD94Pyy/rYBnAP8A5gDFAIe/2T8BPyY/fj+Jf9O/1gAfAHiAdgB0AGaAasAIv+g/cT84Py0/ab+2f/UAdADEARQAhgABv/Q/iT+TP2g/TH/kQDlAMIAFAGkAWIBkwBAAD8Ajf9E/nz9jP0U/vT+dABMAmAD2ALKAJj+AP74/tb/0f+7/xAAHwBo/+7+8/+WAeAB1gD+/8z/kv8g/+7+Nf+E/8H/vgAoAkQCiwCe/iD+sv4o/2v/HADeANsAhAB+AFwAmf/Q/uL+nP/v/73//f+2APMAngBZACEAo/8w/2L/FQC1ABoBOgHSAFIAaACIAAgAaf9k/7n/y/+T/7D/dQBsARACBAIoAeP/2P40/jD+G/9HAOAAVAEAAgQCxwA6/4z+lP6g/uT+sf+WAN0AwwDNAMIAFQAQ/4r+tv4e/2X/p/9LADIBqAFQAZ8A9/8//5L+av4f/zAArgB2AHwADgFiAQwBagC+/yD/pv58/tD+if8vAJgA8AAuATAByQAHACv/qv7C/kX/yP8AADMAYgBfAF0AfwBUAKX/DP8W/6P/PQCjAKEAOQDD/6n/3//o/9L/9f8aAOD/pv8HALQA5wCnAGkAOgD8/9j/6f/8////GABYAIoAWgDU/3H/c/+w/8D/bv8K/wH/K/9W/8P/fgDyANcAoQCGAPb/5v5i/hf/LwC0APoAigHQASgBFgB+/1n/R/9m//j/rQDqAKoAeQCZAKMAPQCm/0X/FP/y/h//wv9VAFMA/v/L/6X/Y/8a//j+Af8u/4X/3f8KACUAXQCIAFQA5v+k/6r/vv/H/9n/+v/5/8r/qv/V/0UAkgBnABIA7//V/4z/Ov86/3P/iP92/6j/IwCEAJAAYgAZAK7/aP97/7f/7f8nAHgAnQCEAIsAwADFAIEAYgCLAIcAMgD5/yQAVQAvAP3/GgBWAF0AOgAzADcA+v99/zb/Sf9c/0//Yv/S/zwATwBTAIsAeQDd/27/tf9UALUA+wCEARACRAI4AjgCNALuAbABtgG+AWoBFAEQAToBQgEyATABFAG7AFMA3f9c//b+5v4E/+7+wv7A/uD+uP5E/gD+Dv4U/tD9nP2c/aD9aP1E/WT9jP2k/cz9BP4M/vD96P0A/iT+SP5w/pT+yP4P/07/c/+M/6L/rv/M/wAAWwCnALgApgCHAGkAbACVAMMA0ADqACABYAGIAbYB4gH8AeABsgGcAZ4BkgFqAUgBRAF0AbgB+gFMAsAC8ALYAuACHANEAzwDfAP8A1AEUARQBGAECASMA2gDkAOAAyADmALUAboArP/y/mT+3P2A/Tz9tPzg+yD7qPoY+kj5mPg4+OD3oPfQ9wj4MPgg+BD4GPg4+ID48Pgw+Qj5CPl4+RD6yPrg+zT9Iv5g/pL+Gv+b//b/cgAOAWgBnAEkAvwCoAMYBMAEWAVwBXAF4AWQBrgGiAZ4BngGKAboBTgGsAboBggHcAfgB/gHEAhQCGAIQAgwCFAIQAj4B/gHEAjoB8gH+AdACFAIAAi4BzgHoAYgBsAFWAW4BBAEWAO0AiQCbgFfABD/tP0g/Cj6CPgg9gD0YPHA7oDsYOpg6EDnAOdA50DnwOdg6CDogOeg58DoIOoA7GDvYPNA9hj4oPpk/V3/1QC8ArgE8AUYBxAJMAuADAAOIBAgEiAToBOAE0ASIBBADuAMYAuwCaAIwAeYBmgF0AQ4BEwDmAJYArgBpwDq/7X/Wv/i/j7/WwAoAbgBzALsA0gEeARoBYAGAAdYB1AIEAlACYAJQArQCtAKoAqQChAKwAiQB6AGMAU4A6QBeAA///T9/Pxs/Kj76Ppo+iD6wPk4+eD46PhA+cj5aPog++j7mPwY/aj9SP6q/qb+gv5a/sT98Pxg/Nj7oPrg+ED3UPVg8mDvwOxA6gDooOfA6UDsoO3g7kDwUPBg7zDwkPPQ9nD4CPqw/Lz+wP+iAQgF4AeACZALUA6gDwAPgA7QDrAOwA3ADRAPsA+QDjANUAzACoAI6AZgBkgFRANKAQEAjv74/Kj8yP3+/qr/hACOAcYBQAFSAd4B+AEEAgwDuAR4BXgFyAVwBmAGKAagBigHsAbABUgF4AToAwADFAOQA3AD2AJsAtwBwQCP/+r+mP70/UD9BP0I/dj82PxI/dT9DP5i/qb/3QBGAY4BeAJ4A5wDqANQBOAEWARcA/gCmAJ0ATwA4f+L/xj+8Pso+hD4IPXA8SDvoOyg6QDnoOVg5YDlwOaA6eDsYO/g8MDxgPIg82D0oPZA+Vj7vP3wACgEcAZwCBALQA0wDpAOkA/wD5AO8AxwDIAMAAwQDPAMEA1QC0AJYAg4BwgFXAMAAzACRgDw/u7+yv4k/pD+XADEASgC5ALkAwAEaAOAA1AE0AQYBSgGgAewBygHGAeIB3gHCAcQBzgHWAaQBBADNAJyAY0AUABzAD8AX/+w/lj+tP2o/Pj7NPxA/Oj7qPsQ/GD8gPwQ/Xz+AQD6APQBCAP8A2AE0AR4BQgGOAZoBsgG2AY4BhAFEAQUA/wBsgC5/4L+SPxY+cD2MPQg8YDtYOpg5+DjIOEA4QDjoOWg6CDsYO7A7iDvsPFw9ND1YPeQ+pz9Wf8SAUAE6AYwCBAKUA2AD5APYA+wD7AOgAzAC8AMkAzACqAJcAkgCMAFqATwBCgEfALaAQwCHAFj//T+r//9/y0AkAGIA3gEyATwBUgHoAeIB1AIYAlwCfAIEAlQCYAIIAd4BiAGOAUgBJQDCAOQAff/Mv+0/rD9wPyw/Jz8APww+9j6kPoA+uj5ePoA+yD7UPv4+5T8DP3M/Qb/TgAyASgCTAMoBMAESAVIBkgHEAiQCLAIsAhACJAHeAZwBfwDTAKOACn/3P3w+6D5UPfQ9ODxAO+A7EDpIOXA4aDgIOFg4gDlgOlA7SDvoPBA8zD2APjY+Sj87P2i/gIArALwBFgG2AdACmAMsA2ADpAOYA2gC8AKkArwCcAI8AcwB/gF6ATABJgE2AMoAzgDZAPkAmgCcAKAAmAC7AJgBJgF+AUwBgAHwAcQCIAIIAlwCWAJUAmwCVAJYAhYB8gG+AXABLQD4ALmAa8AwP8N/1r+hP0E/bD8VPzo+6j7cPv4+qD6wPpI+3j7wPtQ/ED99P14/kj/NQD2AMoB5AIABKgE+ARoBdgFUAbgBpAH4Ae4B3gHUAegBngFiATUA1ACUACc/mD9iPsI+TD3wPVw83DwAO7A6wDogOPg4CDhgOKg5KDnAOtg7QDvsPEw9RD4MPqs/BT/iwB+AfgCsATABcAGkAjwCmAM4AzgDIAMkAsACyAL8AoACsAI+AcQB7AFgATkA4QDTAPAA2gEcASwAzADUAOwA0AEMAUgBmAGSAaoBmAH0Af4BxAIUAhwCEAI8Ad4B+gGWAb4BXgFiARIAygCTAGEAMf/D/9g/pD90PyA/Iz8gPwo/Nj7+Psk/AD8sPuQ+7D70Psw/Pj8kP20/QD+0P6l/xQAmwC4AdgChAMwBAgFiAWABZAFOAa4BrgG+AYQB3gGCAX4A2QDgAIyAQkAzv5Y/JD5wPfQ9hD1kPLA7yDsgOeg46DiwOLg4sDjAOeg6uDsAO9g8sD1EPjY+pD+NgGsAfwBcAOQBMgEoAXYB3AJwAlACoAL8AvgCmAKEAtwC6AKkAmACLAGaAQkA/wCtAIcAhQCnALUAtQCcANYBAgFeAVQBjgHiAdYByAH+AboBvgGMAdQByAH8AbwBhgHIAfoBpAGAAYoBRgE8ALUAcEAwP/q/kj+0P1M/ez8vPzw/Gj9zP0A/gT+2P2Q/Uz9JP0E/cz82Pwg/aT9AP5+/iT/x/9uAIoB+AL0AzAEWATQBCAFcAUABsAGqAYoBiAGOAaIBTgEmAMcA9gBVwBj/xz+2Puw+eD4MPjw9SDzgPDA7UDqIOdA5UDkIOTA5aDoYOuA7cDv0PKw9Yj48PsJ/8MAaAEEApwCBAOkA8gE8AWwBngHcAgACVAJ8AmwChALAAvQCoAKgAkgCOAG4AUIBXAEOAQgBBAEQAR4BMAEIAXABWgG0Ab4BgAHyAZgBuAFiAVYBUAFOAUYBfAE6AQQBUAFcAWABVAFyAQwBIADrAK+Ac4A/v8f/0z+pP0k/dT8yPwY/Wj9bP00/Rj97Pyk/GD8RPwo/AT8JPx0/Jz8nPzg/JT9VP4y/2oAlgEkAlQCHANIBAAFWAUABuAG+AaYBqgGsAbIBZgEYAQoBLgCrAB0/17+gPyQ+rD5oPiA9SDyoO9g7cDpIOag5MDkIOVg5gDpYOvA7GDuAPIw9jj5YPuM/aT/qwAiAegBsAIIA5AD+ASIBjgHYAfYB8AIoAmAClAL0AuQC9AKQAqwCeAIoAeoBjgG8AWIBQgFkAQ4BGgEKAUQBpgGmAagBsgGuAZABpAF+ARoBPQDnANkAxwDwAK0AiQD+AOgBNAEkAQwBNQDfAMsA8ACDAIYASgAcf/o/oD+Wv5m/mL+QP4i/gr+uP00/cj8oPyI/Ez8+Puo+3D7QPtA+3j78Puk/Iz9sv75/w4B6AH0AmAEyAWgBjAHuAfwB6gHWAcgB4AGUAVIBMgDAAOKASkAOf8S/lD8mPoQ+cD2cPNA8GDtQOoA54DloOVg5qDnwOkA7IDtIO/A8hD34PlI+zz9kf/FAO0AggF0ArACuAK0AzAFwAXIBYAG0AcQCSAKcAtgDHAMEAywCyALEArwCBAIEAfoBfAESATQA6wDCASwBEgF+AXABiAH2AZYBiAGyAUQBTAEdAPAAtYBFAHNAOMAJgG0AYwCKANwA5AD1APkA6wDeAMoA5wCqAHOADkAwv8s/5j+Tv5A/jb+IP74/aj9NP3A/Iz8ZPws/Nj7ePso+/D6CPuI+zT8BP0m/oL/vQDKAewCGAQQBcgFsAaIB+gH6AfQB6AHGAdwBugFQAUwBAwDKALtAET/0P2I/OD6iPgg9kDzQO9A68DoIOhg56DmAOdg6ODpYOsA7vDwQPNg9YD4cPtA/UL+d/+SAOcAnAHgAuQD4AMgBGAFsAaIB7AIkApADFANQA4QD/AO8A0wDdAM4AtQCsAImAdYBigFeARQBCgESAQIBbAFwAWYBZAFQAV4BPwD0AMoA+QB1QBlAOr/g//F/6UAUAHgAdwC1AMoBBgEYASYBBgEYAMAA4gCZAE0AH3/zv7Y/Rj9+PzY/Fj86PvI+6D7MPsQ+zj7OPvA+lD6MPog+jj6qPp4+1D8TP2c/jMAkgGsAuADMAVQBhAHoAcQCDAIIAjYB1gHkAa4BRAFQATQAhYBsv+a/kz9qPsI+gD4EPXA8eDuwOyA6sDoAOgg6EDogOhg6eDqYOzg7mDykPWA9yj5iPvw/VL/aQDUARADlAMgBPgEaAVQBbAFGAfQCEAKsAsgDRAOoA4gD3APMA+ADvANIA3QCzAKkAgQB7AF8ATABMAEkARoBIgEkARoBEgEIAS0A/QCJAJcAWsAa//E/nz+bP6I/u7+l/8/AAQBFAIsA/QDgAQABTAF4AQ4BJAD1ALAAZ8AtP/o/uj9/PxY/PD7gPsw+xj7GPsY+wD74Pqo+mj6KPrg+cj5APqQ+kj78Pvs/Ej+wv8EAUQC3ANgBaAGoAdwCNAIwAiwCLAIAAjgBsAFsARcA6IBRAD0/nD9oPsY+jj4kPXQ8pDw4O4A7aDrQOsg64DqQOoA60DsoO1A77DxMPRQ9hj46Pmw+4z9o/9WATwCrAJYAzgEwAQwBegF+AZgCCAKMAzwDQAP4A/AEIARwBFgEaAQwA9gDrAM8ApgCeAHmAaQBdgEgAQ4BOwDmANsA0wD+AJgApgBvwDG/87+Dv6M/ST9xPy4/Bj9sP1a/kr/nwAEAjgDKAQIBaAF0AXQBZgFGAUwBCwDMAIeAe7/xv7E/fD8TPz4+8D7gPtA+yj7IPsI+9D6ePpI+ij6OPpw+qj6APt4+0z8WP2c/sD/7wAgAnwD2ATgBZAGAAdQB2AHSAfQBgAGuASQA5ACZgEAAJr+JP0w+yD5QPdg9QDzwPCA78DuoO2A7EDsYOwg7GDsIO4w8FDxEPIQ9ID24Pfo+LD6yPzk/bj+SACCAZABxAFsA2gFKAawBoAI8ArADHAOgBAAEkASYBJAE4ATYBKgEHAPUA6wDBAL0AlwCPgGGAbIBXAFoAQABKQDEAM0AlwBhgBZ/yT+WP3Q/CT8gPs4+1D7qPtU/Ez9NP4o/1cAyAEMA9wDgAQQBVgFSAXgBGgEnAOMAnYBlgDO/+D+7P1U/Sj9JP0I/dj8mPxA/AD84PvI+3j7IPv4+vj6EPsQ+yD7ePtM/Fz9nv7S/+wAEAJEA4AEeAUoBpgG4AbQBngGwAXYBKgDkAKcAWIA4v48/YD7gPlg94D1APSA8hDxwO/g7iDuYO0g7UDtoO1A7mDvkPCw8ZDysPNA9bD2GPiQ+Qj7JPwI/Ub+m/+eAJwBFAPgBLgGkAigCrAMsA7AEGASIBMgE0ATgBOAE6ASgBFAEPAOcA0QDMAKQAnAB7gGGAZYBUAEJAMsAjQBLgA+/1z+TP04/Ij7GPuQ+gD64PlQ+vj6oPtk/Gz9ev6N/8UAJAJYAyAEqAQYBTgFAAWoBDgEbAOAArYBFAFEAGP/yP5y/jD+1P2Q/Tj94PyM/GD8TPwo/OD7mPto+0j7OPsg+zj7uPuI/JT9iP5p/0kAUgF4AoADWATgBEAFgAWABTgFoATcAwAD+AHBAFX/nP3Q+yj6sPhQ99D1gPRg82DygPHg8HDwIPAA8CDwgPDw8HDxEPLw8qDzoPTg9TD3GPgI+Vj6wPsU/Wj+IwDEAUgDIAXAB5AK4AzQDuAQoBLAE4AUABUgFcAUYBQgFGAToBHQD7AOcA3QCxAK4AiwB1AG+AQABNQCLAHB//T+Pv7g/Jj7uPrw+RD5aPh4+Lj4+Pho+XD6kPto/Fj91P56AMgBzALMA5AE4AToBPgE0AQwBHgD5AI0AlABaADD/0j/wP5S/ij+Ev7I/Wz9MP0U/dT8fPwo/Oj7qPtQ+zj7SPuA++j7lPxs/VT+Ev/U/7QApgGIAkQD1AMQBAgE6APAA0QDhAKaAa4Auv+Q/kT98Puo+mj5UPhQ91D2UPWA9MDzMPPA8mDyMPIg8jDyUPKQ8uDyUPPw87D0sPXA9rD3oPiw+Qj7VPys/Tr/BgHMApgE0AaACRAMEA6QD+AQIBIAE6ATABTgE4ATIBOAEkARwA9wDjANwAtQCiAJ2AdYBvAE5APIAlIB/v8h/1r+MP34+xD7UPqw+Uj5QPlQ+Wj5sPlw+lj7KPwo/WL+mP+4AMQBoAIgA0ADZANsAzwDxAJIAr4BEgF3AA8AtP9M/wr/+v4P//b+yv7I/sL+kP5M/jj+FP64/Uj9KP0w/Tz9SP2I/Qj+iv4p/9X/kwAgAbYBVALcAgwD/ALgArwCbALoAVABiwCZ/47+gP1k/DD7APrg+OD38PYg9nD10PRA9PDzsPOA82DzUPNQ81DzgPPw82D00PRw9TD2APfQ98D4uPnI+vj7eP0K/7sApAIABXgHwAkQDDAO4A/AEKARoBKAE6ATIBPgEmASoBFgEFAPAA6wDKALwArACWAIGAcIBiAF3AOgAnIBOQDi/pz9jPxo+zD6aPkQ+dD4iPiA+Mj4YPkI+vD6APzo/MT9tP6k/zMAeACgALsAqwB7AFIADgCy/3z/b/9w/2X/bf+l/83/4/8CACcALAAHANz/qf9Y/+7+oP5a/hz+9P38/RT+Jv5W/sD+T//h/2cA5ABMAYABogGyAZ4BVgHvAH4A8v85/2L+gP2U/KD7qPrQ+QD5UPiw9yD3sPZA9uD1oPVQ9QD10PSg9ID0gPSQ9MD0EPWQ9TD2wPZQ9yj4KPk4+kD7ZPzE/VD//wDwAhgFYAeACXALUA3gDgAQ4BDAEaASABMAE+ASQBJgEaAQABAQD8ANsAzgCwALwAlgCCgH+AXgBMgDpAJEAdn/lP6Q/YD8YPt4+tj5aPkg+fj48PgY+Yj5UPog+9D7ZPwI/Zj9EP5a/n7+jP6K/pj+jv50/k7+VP6U/uj+N/+K/9D/EABWAJ8A0wDiAPIA/wDhAIYAGQCz/2T/Lv8e/yb/Jv8w/1T/kv/O//7/UQC5AAQBFgEMAd0AkAAvALP/Pf+s/hb+eP3I/Bz8cPvA+iD6qPlQ+fD4ePgI+MD3kPcw97D2UPbw9bD1YPVA9UD1YPWQ9RD2wPZA97D3cPhA+UD6QPt8/Jz92v6MAIQCkARwBoAIgAoQDEANgA7QD8AQgBEAEoASYBIAEoAR4BBgEKAP4A4QDiANIAwwCyAKwAiIB3AGYAUIBIgCDgGi/yT+yPyw+8D66PlA+fj42Pi4+ND4OPnI+WD66Pp4++j7QPx4/KT8qPys/MD83Pzc/OD8CP1U/bz9RP7q/m7/yf8nAKgA7QAIASABSgFIAQoBvgB4ABMAmf9d/1P/SP8r/zP/Xv+G/6r/4v8pAFEASQBHAB4AuP8s/6b+HP50/cz8TPzo+2j76PqQ+kD6+Pm4+Yj5WPkQ+cD4kPhI+OD3cPcg99D2gPZg9lD2cPaA9rD2IPfA9zj4qPhY+SD68Pq4+7z82P0B/2IAMAIoBOAFaAcQCdAKMAxQDZAOwA9gEMAQIBGgEaARIBHAEIAQQBCQD/AOYA6QDYAMoAvACnAJ+AeoBpgFQASkAiIB1v+A/kD9SPyQ+8j6KPrg+fj5+PnY+eD5IPpY+nD6ePpw+mj6QPpQ+lD6UPpo+qj6IPuo+zj8+PzU/Z7+VP/1/4AA0ADhABYBVgF4AVYBQgFMAUABEgHpAO0A/QACASIBVAFsAVIBWgF4AWYBJgHRAIUA//9T/7D+GP5s/bT8SPwI/Lj7UPvo+pD6MPrA+Vj5APmQ+CD4wPdQ9+D2cPZA9gD2wPWw9cD18PUA9lD2wPYw94D38PeA+Aj5oPlo+kj7QPxs/QD/2QCkAmAEMAYgCMAJMAuADNANsA5gDwAQgBDAEKAQgBCAEGAQABDAD3AP8A5gDrAN4AzQC6AKgAlACNgGUAXkA4ACDgGs/37+fP10/KD7EPuo+kj6CPr4+dj5oPmA+Wj5UPkY+fj46Pjg+Nj4APlA+Yj58PmI+lj7KPz0/Mz9lP4h/3//7P9JAIUAwQAYAWwBkgGCAYgBsgHkAQwCKAJIAmACZAJYAkACIAIYAggC6gGcAR4BewDV/zP/gv7s/WD91PxU/Oj7iPsI+2D66PmQ+UD52PhI+ND3YPfw9pD2QPbw9bD1oPWw9cD14PUQ9nD20PZQ98D3KPiI+Aj5sPl4+lj7TPx4/fD+ewAEAqgDWAUQB8AIQAqgC9AMwA2QDkAPsA8AEEAQYBBgEGAQQBDwD6APYA/wDmAOsA3gDOALwAqQCUAI4AZ4BSgE6AKsAVwALv88/mj9pPwM/Jj7SPsQ+7j6WPr4+Zj5MPnA+HD4OPgI+OD34Pco+HD4yPhI+fj50PqI+zz82PxY/cD9GP6E/u7+Rf+z/y4AngDsADgBmAHSATAChALwAvgC0ALEAuQC7ALEAuQC8AK8AhACVAHFACYAcP/a/n7+Fv6c/Rz9mPwY/ID7CPuI+gj6iPkg+aj4APhg9/D2sPZg9iD2APYA9gD2APYw9oD2wPYQ92D30PcY+ID4APmw+ZD6oPvk/ED+z/92ASADsARQBvgHgAnQCuAL4AygDTAOwA5QD7AP8A8gEIAQoBCAEIAQgBAgEIAPwA4QDhANsAtQCgAJoAcYBsgEpANsAjIBKgBq/6D+vP0Q/Yz86Ps4+6D6IPp4+cj4SPgA+KD3MPcA9/D2EPcw95D3CPiI+BD5yPmA+gj7cPvo+2D8zPww/bz9Xv7W/kX/0/93APIATAG+AUQCnAK8AtwC2AKwAnQCoAL0AgQDyAKQAnAC5AEMAXEAFgCC/7j+Kv74/Yj9pPzg+4j7KPuA+vj5sPkg+XD40Pdw9xD3YPYQ9kD2QPYQ9vD1MPZw9oD2oPYQ91D3gPfA92j4GPmw+Yj62PtY/bz+GACMASADmAQQBmgH0AjwCRALIAwADbANcA4wD+APgBDgECARQBEgEQAR4BCgEAAQYA+wDvAN8AzAC6AKcAlQCDAHCAbIBHgDWAJUAUQAMf9G/pz92Pzg+wD7WPqQ+aj4APiQ9xD3kPYw9vD14PXw9SD2kPYA94D3GPiY+PD4SPnY+Vj6yPpg+yj85Px8/Tb+7v6n/ywAwgBmAbQB9AE8AmwCbAKcAiwD6ANYBIAEcARIBKAD5AJcAvwBbgHnAKUAXADP//z+WP7U/Tj9jPwA/Gj7ePqA+bD4APhA96D2YPYw9uD1gPVg9UD1APUA9TD1YPVg9ZD10PUw9pD2MPcw+GD5mPro+1T9tP7z/14B5AJoBMgFOAeQCMAJ0ArgC/AM4A3QDqAPYBDgEAARQBFgEYARYBEgEcAQYBCAD5AO0A0ADQAM4ArgCdAIkAdABggF5APAAqIBoQCo/5r+gP2I/Jj7mPq4+fD4QPiQ99D2UPbw9YD1MPUw9XD1sPXQ9SD2kPbg9jD3oPcg+LD4MPnQ+aD6YPsU/Nj8kP06/uj+lf8yAJoA8ABcAdYBNALAAmQDCARABCAEAASwA0gD5AKkAnwCRAIgAuQBhgH5AE0Aqf/w/jb+oP0M/Tj8SPuQ+vj5YPmw+ED4APiw9yD3sPZw9jD20PWQ9bD1wPWg9aD1APag9kD3CPgw+Uj6MPsg/ET9bP5w/5UAEALAAxgFQAaAB8AI0AmgCqALsAyQDTAOAA+wDyAQYBCAEOAQ4BDAEIAQQBDQDxAPYA7QDSANQAxgC5AKcAkwCAgHGAYIBdADxALUAcIAY/8w/iz9GPzo+vj5UPl4+ID3sPYw9qD1EPXg9BD1MPUA9QD1MPVA9TD1gPVA9vD2YPcQ+Oj4iPng+XD6SPsc/OT8sP2E/uD+K//i/+8AwgFsAlAD6AO0AxQDAANoA2wDNAOUA1AEWAS8A0wDFAN4An4B/wD7AJYAtf8n/wD/YP5U/aj8aPzg++j6IPrI+WD5qPg4+CD44Pdg9yD3QPcw9xD3MPfQ94D48Phw+Tj66PqY+4j8mP2k/pr/xAD6AQQD3APIBMgFwAawB7AIgAkgCtAKkAtQDMAMEA1wDbANwA2gDXANMA3wDKAMYAzwC1ALoArwCSAJQAh4B6gG2AXoBPwD9ALqAeUA/v8s/0D+VP2A/MD70Pro+Tj5yPhI+ND3kPeA92D38Paw9qD2wPbQ9hD3gPfg90D4kPgQ+ZD58PlQ+uj6mPtI/Mj8XP3g/Y7+QP/c/2UA6ABwAcgB8gEIAkQCnALIAtwCFANQA0wDJAP4AsQCcAIcAuoBwAFwAfAAdwAEAHf/9P6U/i7+qP0o/dD8cPzg+1j7IPv4+pD6GPrw+eD5yPmw+dD5APoo+lD6mPrg+iD7gPsM/LT8WP0G/rz+W//h/2gAGAHGAVQC7AKsA2AE2AQ4BbgFWAbQBhAHaAfIBxAIMAhwCLAIsAigCJAIkAhgCBAI2AfAB4gHIAe4BngGGAaQBQAFmARABLgDKAOwAlgCwgEmAbUAVwDu/23/If/y/p7+Mv70/cj9aP38/Mj83Pzs/Nj8uPyc/HT8ZPxs/Gz8YPxw/Kj82PzU/Nz8CP00/UD9WP2Y/bz9vP3I/QD+NP40/jD+Uv6I/pr+jP6I/or+hP5y/mL+UP5G/kb+RP4e/uT9yP3Q/dD9sP2Q/ZT9oP2U/Xz9dP18/Xz9gP2A/Xz9fP2U/bj91P3Y/eD98P0G/h7+Ov5W/mr+jP7A/uz+Cv8t/1v/lP/A/+b/FABIAHMAowDeABgBSgGCAcYBBAIwAlQChALEAggDRAOAA7gD4AMQBEgEgASgBLgE6AQYBSgFMAVABVAFUAUwBSAFIAUIBdgEuASgBHgESAQYBPADtANwAzAD+AK0AmQCKALuAawBUgECAb0AdwAoAOf/uf99/zH/+P7O/pr+Sv4C/uT9yP14/SD97PzY/Lj8hPxg/FT8OPwE/Nj72PvQ+7j7oPuw+7j7oPuI+5D7sPu4+7j7yPvw+/j78Pv4+yT8QPxQ/GD8lPy0/Mz86PwM/ST9RP10/az91P3w/SD+TP5+/qr+4v4S/0L/c/+p/+X/DQA7AHAAnADEAPEAIgFOAWQBdgGIAaQBtgG4AcgB2AHiAfIBCAIUAhgCFAIcAiwCMAI0AjgCTAJUAlQCYAJ0AoQCiAKMAqACrAKsArQC0ALoAvAC5ALcAuQC8AL0AvAC6ALoAvQC9ALkAswCwAK8ArACmAKEAngCaAJUAjwCIAIIAvAB2AHEAaoBhgFoAU4BMAEGAdcArQCNAGcAMwD6/8f/kP9Z/yD/8v7A/o7+Vv4w/g7+4P2s/YD9XP00/QT93Py8/Jz8dPxU/ET8NPwY/AD88Pvg+9j72PvQ+8j7yPvQ+9j74Pvo+/j7CPwg/Dz8WPx8/Kj82PwE/TD9YP2M/bz98P0y/nr+uP7y/i3/bf+o/9z/DABDAHcApwDQAPoAJgFKAWwBhgGgAboB1gHsAfwBDAIYAigCMAIwAjQCOAI8AjwCPAJIAkgCSAJMAlgCZAJkAmgCeAKIApACkAKcAqgCsAKsAqgCuALIAswC0ALYAtwC4ALkAvQC+ALwAuQC2ALMArwCrAKgApACfAJkAkwCLAIEAuIBwAGYAWYBMgECAdAAnABoADcAAQDK/5b/X/8j/+b+rP52/kD+Cv7Y/aj9bP00/QD91Pyo/Hj8UPwo/AT84PvA+6j7mPuQ+4j7iPuI+5D7qPu4+9D76PsI/Cj8UPx4/KT8yPz4/CT9WP2E/bj98P0s/mb+mv7Y/hz/V/+F/8f/+/8vAGAAmQDZAAYBMgFsAaQBzAHsARQCMAJIAmACgAKoAsACyALUAugC+AIAAwgDFAMgAygDLAMoAywDMAMsAyQDIAMgAyADFAMEA/wC9ALkAtQCwAKwAqQCkAJ4AlwCRAIoAggC6AHMAbQBkAFkAToBFgH0ANAAqACCAF4AOwAVAOz/vv+T/23/RP8P/9j+rP6I/mT+OP4M/uT9xP2c/YD9YP1E/ST9CP30/Nz8yPy0/Kj8oPyU/JD8iPyA/ID8fPx8/ID8iPyU/Kj8sPy8/ND87PwE/ST9TP10/Zz9xP30/Sz+Xv6O/sL+/v48/3v/tv/w/ywAZwCdANEABAE0AWABjAG2AeQBDAIwAlACcAKQAqQCuALIAtwC6AL0AvgC9ALsAuAC0ALEArQCpAKUAoQCcAJgAkgCMAIYAvwB3gG8AZIBbAFSATYBFgHxANIAtQCQAGwATQAxABEA8v/d/8X/qP+J/3j/cP9f/0r/PP83/yz/EP8B/wH/Af/y/ub+8P7w/uj+3v7i/t7+2P7a/ub+6P7i/uL+6P7w/vb++v4B/wf/C/8V/x7/I/8o/zD/Of9E/1H/XP9l/2n/cP91/3j/e/97/3//f/+E/5L/n/+i/6T/qf+1/8X/zP/Q/9r/6P/y//f/AwAUACYALQAuADoASQBSAGMAegCLAJUAmQCdAKYAsgC9AMUAzADWAOMA6wDrAOgA6gDwAPEA7gDtAOwA5wDgANcAzQDEALwAtwC0AKYAkgCFAH4AcQBdAEoAQQA5ACoAFQD//+z/1f++/6v/mv+I/3b/Zf9a/1P/S/9D/z3/O/85/zX/M/81/zj/Nf81/zz/Rf9G/0X/S/9V/13/Y/9s/3T/fP+G/5P/n/+m/6r/sf+8/8b/zv/Z/+n/+v8GAA8AGQAhACcALQA7AEwAVwBeAGUAbQBvAG8AbwBwAG8AbgBuAGwAagBnAGIAWgBUAE8ATQBHADsAMgAvACwAJQAdABsAFwAOAAUA/v/7//P/7P/q/+3/7P/o/+z/9v///wQABwAPABYAGQAVABQAGQAfACMAJAAkACUALAA3AEQASgBLAEsATgBQAE8ATwBRAFQAVABSAFEATwBIAEEAPgA6AC8AIAAVAA8ABQD5//D/6//k/9f/zP/G/8D/uP+y/7T/uP+7/7v/uv+7/73/wf/G/8v/z//U/9j/3//j/+L/4//p//D/8f/v//T//f8DAAUABAAGAAsAEgAXABcAFAAXABwAGwARABAAFwAcABEACQAVACMAGQABAAoAEQAEAOj/6P/9//P/2f/b//H/6//R/8z/1//U/8D/vv/a/+j/0P+5/8f/3//V/8D/xv/e/97/yf/G/9n/4f/W/9L/5P/2//b/8/8BABQAGgAZACUANwBEAEgASwBaAGMAXQBbAGoAdABtAGwAcwBtAFYASABQAFkASwA3ADoARgBAADAAKwAyADUAKgAaABEADgAHAPv/9v/z/+f/2P/T/9T/z//E/7T/r/+v/6b/m/+U/5P/kv+P/4b/gP+C/4X/gv94/3j/h/+R/4j/g/+S/6L/mf+O/57/t/+8/7D/s//N/9r/0v/P/+P/9f/v/+v/+/8VABoADQAQACkAMwAfABgALwA2ACUAGwAuADwAJgAPABkALwAcAPn/AQAkAB4A8v/x/xIAEgDp/+D/DQAYAOv/2v8VADgACADn/yIAXAA1APX/DABZAE8AAgD+/04AYAAPAPb/RwBvACEA9P9WAI4AMwD3/1MAnABHAAIATwCfAFoABAA4AH8AVQAAABkAaQBIAPb/BgBSACQA4f/4/y8ADwDQ//L/GQDu/7b/5/8VANj/pv/q/xkAzf+d/9v/BgDG/5z/0/8EAND/nv/P/wEA1/+k/8D/7P/P/6D/wf/z/+f/of+0/wQA+f+p/6X/HAAgAK7/mv8YAFQA2/+h/xUAaQDj/7D/IwBXADoALwAxAPL/FACSAH0AxP+4/7cA6gCv/z//hgA0AdX/8v5IAEwBGwDe/vL/PgFOAPD+s/8iAY4AL/+O/9gAnQBy/4D/fQB9AKf/lP80AFEAwf+Q//z/KgDU/6T/0v/1/+j/w//D/+D/4f/g/+n/0v/U/wsADwC7/7H/DwAhALj/lf///zUA0/+B/9L/LQDp/5L/y/8cAPz/t/+1/97/8//d/7z/wf/n/wgA/P/H/7j/BgAiANH/r/8DADwA9f/B//j/MAD8/8P/+/8zAP7/wf8JADoA8P+5/+j/OAAXAMn/1v8pAD4A6P+0/xEAbQAhAJn/9v/JAG0AcP/N/xQBtQBw/8f/JAH5ALb/sv/RAAgBGADW/4gAzwBAAPn/QQBwAHQAKADi/x4AjQB3ANz/1/9vAJMA7P+I/zIAngALAHb/2f96AAcAUv+Y/4gAFAAk/57/YQD8/wb/iP96ABcAF/+A/6oADwAH/5X/sAAzADz/0P+1AFYAUv+7/8cAYgB+/9//1QBZAIT/3v/DAGEAd//N/7cAkQBm/6H/zwCJAE7/h/+dAGwAgP+g/2QANACW/4H/KgBZALT/Wv+f/20AMAA9/xr/dwDiAAv/ov4YABwBmv9M/tn/SAEPAAT+iv+eASEA8P1o/+QBeQD4/f7+0gEOARb+ev6oAZQBjv5U/kwB9AHk/ib+AAEwAoz/ZP7iACAC9/9+/nsACAKWAOz+JQCqAW0APf+BAEwB8P9o/3MA/QD4/3v/WADtAAYA3v7I/xYBNAAK/+H/+AD+/5z+nP8uATYAgv5O/yoBkQBg/pT+CAE0AX7+Pv4mAXoBWP4U/kYBvgHA/oj90ACEAh3/OP2hACwDUf+Q/CEAZANHAIz81/98A5MAjPw4/yQD7ACg/fr+NAI4AUT+rP5eAVIBCP8+/9cAZQAA/+n/AAHS/8j+NQByAW3/5P36/zQC8/8E/Sz/YAIbAMz8NP+UAjIAePym/lQC0AA4/ST+8gFyAdT9lP0qASQC0P4M/t8AqAES/4r+EgGsAdX/sP6bAFIBw/9s/4sAUgGnAOT/jf/t//kANgF0AMj/PQBGAZEAOf/r/7YB7ACT/38ArQBw/wEAsAF4AMr+6/+gATYAUv4SAGwCoQAg/TX/OAK5AEL+k//gAfD/bP6A/4oAnf/s/yYBfP+8/uv/7wDA/9D+XgDfAIz/5P6BAIcAW/8AAK0Az/+K/sH/EAFMAEn/EACbAAv/hP7AAJgBN/9u/t8AQAGc/u7+ywCSAID/yv98AOj/U/8FAHQB+v8g/oYA6gEa/zD+eAHWAUL+kv44ARgBhP6C/twBtAEs/nD9lAHeAVb+VP5AAQgC+v6c/UcAgAKk/5j9uQCgAnP/VP1QAFACHQCA/lsAVgEz/6L+OAEgAvr+AP72ASQCgP0A/iADvAIS/iL+fAHEAcD+lv72AfAB6P66/vYAcwAH/zEAQAEVAA//MQACAAf/pf9YAckAGP6G/gIBJAEG/pD+CAIQAUz9kP20AWoBEP58/tQBSAHE/Fj9MAJsAgr+gP2QAdABBP6k/RoBKAJD/6j9rQAoArr+SP1MAVgDA/9Y/O//7APdAHz8ev+wAwgB6Pts/jAEmAJk/S7+pAI4AsD9kP3uATAEZwAM/Iz/tAOCAaT8nv5ABOoBsPwk/XwD6ALQ/Eb+uAJeAXj8If/IA64ACP1I/0ACp//E/TYA/gHKAHL+Bf8xAMH/tP+gANkAhf9q/93/GQBbAH7/t/8EAVoB9v6k/p4BkAG8/ob+oAIIAmD9aP5UA+wC6P0k/YwBtAPA/wT94/9AA+ABIP6A/dIA6AIw/0z9kgGAA5r+OPuRAHgEjP9A+xsAuARO/xj7cf+wAy4ATPyE/5gCpP8E/e7/SAJB/yz9KgA8ApD/GP3//1AC4/+c/ez+vgE+Abb+8P59ALcAhf8w/ysAwAC5ACL/8P78AAwB7P7C/ngB9AHM/oT9pgDwAv7/QP1lAOQCaP/k/O0AsAN3/zT9TwBEA9z/oPv5/zgFtgHI+qj9WARAAtD7IP3ABGQDuPuQ+8QCqAPQ/cT9rgGmASz+Gv7YAGwBdgD0/5v/MP6D/5wCuQAE/r8AfAIk/oD8BAKYA2D//P0EARwCav4w/S4B5APr//T85wD8ASb+Fv6gAiQCCv40/v0AqgGc/rT+dALMART9MP3qAUQCMv8E/3oBbgBE/Tz+4AH8AT7/cv8+AT7/CP3e/3QC3AAe/oX/YgGw/+D9L/+qASIBT/8A/uT+wAAyAc//U/8RAMj+pP7C/5UAWgHoACT/lP7Z/zL/Gf/zAK4B2AHw/+z8jP1QAiwD3v4k/v4ANAIw/wj9JQDAA94BnPy4/TAC9gGk/uL+CAP4AXT8VPzIAmAE9P4I/ZABOAM0/oj7dADIBXwBAPtq/qAEcgCQ+kMAqAayAcD56Pw4BMgCBP2o/qgE7AAA+9j9wAMgA/z9UP4gApABgPxM/qAE6AL4/NT8wAFEAur+aP6oAmADSPzA+qwCkAUm/uj7wALkA8T86PloAcgG/gDw+WT+SAXo/8j5k//YBoIBKPko/dAFfAKo+XT9+AZgA1D44PoIBrgFyPvg+rwDwAPQ+9j7QAOoBJz+AP37/+sAtf8z/wwBUAIQALz9uv6lAL4BoAHJ/2r+pf8AASoAe/+PAMoBSQCk/f7+xgFDAPL+fAG8AYT+HP10/0wCogEA/0//GgHE/oD9vgGEAmD+vv4UAtf/tPyU/xwDtAGo/bD9QAE6ATj9AP/ABPwAUPpy/jgEUwAQ/PT+KASYAkj7wPuYA8wDhPys/cgDNAGw++T9aASMAwD8OPxIBAQDYPrU/SAGSAIY++r+UATq/ij7CAGgBpQAWPnS/jAG6QD4+Er/0AfiAbD4gP3gBdwCuPpk/BAGIATo+YD7kAVgBHD7hPy8A7gD4PwE/OACEAQA/nj8VAI0A9T9vPwAAtAEfP4I+/4A4AWvAGD6/v6YBcABKPtl/0AFkABw+9n/mATiAFj82P7IA1AB0Psd/2AEZgE0/Br+RALJAPj9rv84A/AA0Pvw/AQD8ALQ/Oz95AM4ArD78PtcAtAD/P4o/dUAkAJE/kz9kgHwAfz+YP57AMMA5/+e/xoA+AB3/5b+vP+jAF8AsQDZAPD+zP6//3YArQC//+j/7wCnADb+dv50AToBUv+L/y4BbgB0/kD/SgH2APb+T//qADkAY/+HABIB9P40/lkAagEvACz/sABIAWT+/PxsAAwDggAI/rn/MAH8/hD9MwD0A0IByPy4/mgCZP+4/I4B6AS0/zD7pP98A1YArP3fAMwCdv7E/HYBjANM/+j9aAEMAez8Ov4AA9gCkv9G/+L/0P3c/UACqAPF/xr+zgDdAFD9Pv6wAgADSP+4/cH/kAAhAKAAWAHR/0j9iv4wAfABRgHx/4b+IP5t/8X/yv9oAWAC4wCw/aD7yP2AAqgDJQDM/VD/hQBm/vD8ywCABNIAIPzs/XABbwAg/8wBZAJ4/eD6NQDABEACiv4X/1cAPP44/ekAWARYAq7/xP4Y/ej8+QC4BPQCJf9c/Q7+Mv+7APACFALg/vj9n/9E/2D+LAJwBbQBAPsg+sP/aATEA4MA+P7Y/sj9HP2O/ygE+AQ+/5D7KP5yALz+k/8YBdgEePwA+Kb+4AVEA4b+KQDOAeT8cPoiAfAGmAOE/XD9mf+w/YT9oAMoB/IBcPtw+8T+KAHMAmgDtAFq/oT8hP3SAIgDTAOLAHz94PxU/j0AqAJ4BDACIP2g+mT8EAHoBIgEXgCs/BT8AP5YABwC5ANYAmj9GPtI/rwB/AFgAkACuP6g+lT8PAOYBU4B6P16/jL+6PxFAKgEpAPQ/sT8nP0S/rb/2AKABDoBmPuA+kX/iAOwAnMAgv/i/nD9EP0KAdAEaAJI/Tj9AQDK/yn/qgHwA8gAkPto/KgBhAMIAYv/HAAk/7j9eP6GAcAD6AE8/hD9zP4hALAAvAEgAuYA5P2Q/Hf/uAKMAv//E/8HAIT/Qv4AAJADfAIG/uD8K/8oAUQBDAFAAakAGP5A/BH/FAPsAgwAev6s/uP/3f8o/+4AXALI//z8gv4yAZ4BoQCT/wz/eP40/isAeAKIAe7+IP5a/sj+eABSAXMA0P+f/13/Uv4w/h4BJAMhANT8DP8sAtwA6v76/xABPP8M/ukAGAN6AUT/B/82/67+oP8MAkQDKgFy/kD+R/97/7YAXAIMAe7+af/jAMH/cv7g/xACKgEq/uz+eAJwAoj+zP34AD4BIv9/ADwDbgGo/VL+mgFKAaL+y/+kA5gCSP10/PkAiAKQ/+j+2AEAAmj+GP3j/wwCdAAM//7/rQCI/x7+Tv+eAVwBoP68/cz/+QADAEn/NgByAJ7+rP3P/94BlADQ/rD/JwBK/vD9vQBcAuf/gP2m/qwAJgDc/jAAgAGC/xj9NP4gAaQBOACp/+f/MP9W/n3/sAH8AW4AaP9l/7r/agA0AZgBKgEaAEf/lv/2ANABxgHNAJL/av9nAOUA5ADSAcABcv8G/s3/0gGaAYIAYQBnAO7+9P0dANQC3gFY/xL/uP/e/oD+bwAQAvUAA/+w/jT/Bf/a/iUAEgHB/yL+hv6l/5b/Yf+J/xz/Xv6i/nj/1//Z/6X/rv64/Sr+ef8FANj/0/+0/3T+PP1a/kkASwAu/7L/nACG//j9XP4cAIoA9P9MABgBjAA+/2L/igCvADsA/QA4AlABbP+6/9YBhALhAEQAeAH8ARIBBAE8AjQCyAClAEACSALpAHYBKAN8AvD/g/+WAegCRAKuAcYBIAECAPb/FAHYAcIBWAHHANr/YP8jANEAmwD3/07/NP+b/93/h/9+/mz9cP2m/iH/Nv6M/dz9RP1Q+7j6gPx+/vD9yPsY+5j7GPuA+hT8fP0g/ED6APus/Gz8aPtU/Jz9jPw4+7z8e/+f/zL+Vv4Z/4z+mv7pABQDwAJ+AYQBQAJkApACWARABugFOAT8A6AFsAYABrAF8AYwB7gFmAWwB1AIQAaQBHgFmAb4BYgFSAZwBmgEuAJMA1gESAT0A8gD4ALEAR4BBgF2AeYBoAFUACH/J//J/0//4P2w/WL+uP00/AD8DP38/GD7IPog+gj6GPkw+Xj6iPpg+GD2sPbg98D38PaQ96j4QPfg9HD1aPhQ+ZD38PYA+Bj40Pew+ST8yPsI+oj61Pz0/dj9Rf9UAfkAdf98AJQDoAUoBvgFqAXgBMgEUAegClALkAngCBAJgAiACGAKYAzQC9AJ0AiQCEAIwAgwCtAJ4AYYBUAGYAfwBXAEkARQBCwC4AB0AtQDXAIXAL3/s/9G/tj9GwDgAfH/8Py8/DT+MP5w/Rr+uv60/YT8EP0e/rj9aPw8/PT8oPzY+6j8lP2U/Aj7sPoo+wj7YPuU/Hj8CPqw+HD6WPvQ+WD5OPtw+xj5aPgQ+sD6SPnI+Fj6YPqI+Nj4oPvI+xj5sPj4+vj78PpY+4z9wP2o+6D7mv5EAJv/JQAkAkgCzQB8AVgEGAbQBUgF8AX4BlgHcAdQCFAJQAlACOgH8AgQCpAJYAhwCHAIIAc4BigHEAjQBhgFmASgBOQDJAN0A8QDyAJQARoBkAFaAccAtQCIAPz/u//J/zIApgBeAGz/Fv+0/zIAJAASAJwAuQCn/wj/DQACAXwADgCGAIwAkf86/yEAoACK/37+/P6b//r+IP5Y/ob+kP1Q/Ej85PzI/AD8mPtI+3D6mPmY+Sj68Pkg+Zj4SPjw92D3EPcg98D3SPiw94D28PVA9sD2APcY+Mj5GPqY+OD3SPmo+mj7CP0x/9H/zP7q/gwByAIIA+ADCAYYB7gGOAfACFAJ8AhwCdAKMAvQCoALgAywC6AJQAlwCrAKIAogCjAK0AioBrgFCAZABsgFkAVgBdQD3AEgAcIB2AEgAYIAMwDg/wP/hv7w/v7+DP5w/eT9Uv4a/uz9Hv4a/jz9kPyA/eD+B/9u/hz+Fv7A/aD9Mv4a/yj/Tv7o/Vr+bv7g/Qj+mP5U/kT9xPxA/cD9hP0E/ZD8kPvw+nD7PPzw++j6WPqw+cj4mPiA+bD5+PiA+Ej4cPdQ9hD3qPh4+BD3wPfY+VD5wPdo+Lj6UPvA+qj8wP/E/2z9Gv4wAawCsAI4BKAGmAbwBFAFIAjACUAJ8AjwCaAKMApACuAKIAswCkAJ0AkAC/AKYAlQCOgHQAdwBogGkAdgB3gF4AOEAyQDbAK4AmwDmAKMAMv/uwDfAL3/TP+x/zz/ZP7U/hsAhv/w/cz9lv54/kz+cP+xAOT/qP1U/bz+Zv9I/83/HQA0//j9KP5c/2//ev78/TD+IP7Y/bD9iP0U/UD8gPtQ+3D7qPuA+1j68Pho+Gj4UPhY+GD48Pfw9gD2oPUA9iD2gPXQ9UD3EPgA95D14PWg95j4+Phg+xL+ZP1A+8j78P4IAXoBRAMABvAFpAOIBHAIsAkACEAIcAtQDHAKAAoADGAMIApQCXALwAwwCxAKkAqwCSgHcAYwCFAJMAhABoAFGAX8A1wDvAPkA0QDsAL8ARABnAAAAesA8/82/33/GgDh/6D/lv+2/hj9QP1d/zMAVf+g/sT+Tv4k/VT95v61/wb/iv6w/g7+QP2o/bL+oP6k/Zj96P04/ST8MPzg/Ij8YPuo+kD7OPvg+Sj5ePkw+bD34Paw96D40Pcw9hD2QPbQ9NDzwPVI+Aj4YPYA9mD2MPYg9uD4cPy8/Dj7oPtI/bj9eP6zAOACrAMIBFgFsAZoBlAGAAiQCZAJgApQDIAMEAtACiALgAsgC6ALcA0ADSAKEAkACrAJ8AcwCAAKsAngBjAFEAbQBdgDlAMoBQAFtAKUASwC3gEaAMn/IgESAYL/8P5u/w3/Hv4u/sz+TP5w/QD+Av+Q/qj93P30/Vj9RP16/pv/Bf/4/az95P2Q/Yj9lv47/3z+/PyE/AT9QP20/Ez8mPz4+5D6+PnQ+hD7iPkI+Bj4gPiw9xD3sPeQ95D18PMg9cD2cPbA9WD2sPZA9aD0sPY4+dD5YPlg+qj76PuU/Hb+4P8eAP8AOAMoBcgFAAZoBpAGoAZgCCALUAxgC3AKYArgCbAJIAtADTAN4ApACYAJgAmwCPAI4AkwCSAHQAbIBogGGAWABAgFmAQcA+gCvAMoAy4BagBIAawBqwA5ALEAJQCe/m7+tP8gABP/cP4S/zf/SP78/eT+Xv+U/h7+sv4r/4r+9P1I/rD+cP4C/hT+IP6k/Qj9yPzg/Mj8iPwI/Ej78PrQ+ij6MPkY+Tj5aPiQ96D3wPeA9rD04PTw9WD1IPRA9fD2gPUg80DzsPUg9+D24Pdo+QD50PfA+Wj9yP5C/r7+yAC8AeoByAPIBugHoAZQBjAIQArgCjALIAwQDJAKoAmgCyAO0A2gC6AK8ArwCcAIoAmQC+AK0AdABvgGEAeIBfgECAaYBWwDKALIAiQD5AHSABYBcAG+APj/7P/o/1D/oP68/mH/uP9N/8b+pv62/oT+Wv6g/kD/e/82/wb/8v6S/jD+fv7o/hX/Av/e/jT+QP0Y/XT9BP2E/Nj80Pxo+0D6uPoA+xj5wPYY+FD6OPnQ9nD2kPZA9KDywPQA+BD30PPw89D1gPRQ8tD06PhI+RD3QPeo+Uj6sPkQ/Nf/+f9u/vH/WANQBLAD6ASAB0AIqAfACGALEAyAChAKcAtQDEAM0AywDSANIAvACWAKQAvgCjAK4AlwCUAI4AaABrAGWAaIBdAEoARoBJQDlALwAY4BfAGqAYIBLgG1ANn/2v6u/m3/+/+v/xH/Jv9U/7D+FP6E/iT/5P6a/if/vv9v/5L+JP5e/rT+8v4e/wL/vv5y/rj98PwM/az9UP3w++j74Pxg/FD6aPng+dD44Pag98D6mPog9jDz8PPg9ID0UPVg99D2MPNw8bDzoPWg9XD2SPgo+KD2EPco+rz8zPzE/Ar+Qv80ABgCYAQgBagE0ARYBlAIwAnACvAKQAqwCRAKIAugDLANAA0AC+AJcAogC7AKMApwCgAK+AcABwAIUAiIBugEEAVoBYAEuAMYBPgD9gE0AIIAzAEcAg4BBgCD/yH/nv6k/j3/1f+R/57+dv70/vj+Rv42/uj+V/9b/5z/EQBQ/+z93P0C/8r/qP+y/53/Mv7c/Bz9Av6I/eT8DP38/Pj7uPrw+rj6gPjQ9kD4OPrA+eD38PVg9KDz8PPA9SD3wPZA9aDzkPIw85D1gPfg99D30PfA9xj4YPpU/Rz+PP3k/aUAeALwAvgDmAXIBUgF6AYACqAL8AowCkAKYArACmAMIA7gDfALgApwCtAKAAswCxALQArgCAAIAAgACDgHIAaYBVAF8ASwBMAEiATcAtsAYgCQAWwC/gEwAWgAY/9Q/lL+TP/6/+H/cP/e/hz+6P0+/p7+rP4K/1r/4v40/pL+SP9S/jT9EP6H/xX/lP30/b7+kP1w+6D7aP34/Dj7SPuk/Nj7cPkI+Bj4YPiA+DD5QPmg9yD1EPSA9HD1cPbQ9hD2oPTw80D0EPWA9hD4uPgI+KD3+Pj4+kT8NP1k/in/r/8yAXQDCAUYBTAFeAa4B6AIIArAC7ALUArgCSALkAwADeAM0AwQDIAKoAlQCkALsApwCeAI0AgQCIgGuAUgBggGsAS0AzAEeAQ8A8wBUAFYAb4AWAAMAZIBswAZ/4T+pP7q/kT/tP/c/3f/7v5C/sT9Kv58/zYAlv/m/hD/Ff9i/lL+MP9b/07+7P3o/tD+kP3k/Ij9QP1o+8D6wPt4/Jj7QPvY+rj4UPZA9nD4oPmg+CD3IPag9ODygPPQ9fD28PVQ9MDz8PNg9PD0sPYo+AD4gPco+Oj5cPv4+3T8Gv7M/9oAGALIA9gE0AToBDgGkAhgCiALIAvQCqAK4AqAC3AMkA0QDsAM0ApwClALMAvwCfAJEAtwCvAHsAaAB0AHKAWgBCgGKAbcA8ACjANEA04BVwCMAUwCKAFnAKoADwDY/sb+e/+S/3X/vP+g/8L++P1K/vj+8v5A/77/M/8e/mj+K/+G/sD9fP6///L+VP1Y/Vr+yP10/Lz8vPwY+xj68Pug/eD7oPiQ9yD4cPfw9qj48Png9yD08PIQ9CD1EPWA9WD2EPXA8mDy0PQQ90D34PaQ97j4oPgA+UD7xP1w/kL+gP++AVQD8APABMAFWAZIBxAJsApgC4ALMAuQCpAKEAygDaAN0AyQDMALEApACbAKAAzQCuAIkAiACJgGCAXoBQgHyAWIA1gDOARQA3oBMgG2AQAB3/9dAIgB5AC4/uD96P56/9D+xP6e/8b/lv6k/Tj+J//2/rT+qP8jANr+2P3m/hUAUv/c/Yj+MwCW/4j9OP1g/gT+JP0Q/ej8qPtg+mj7xPwk/Nj5OPiw90D38PcI+ej4YPfA9bD08PNg9PD1EPcw9nD0EPSQ9ED1YPYg+Nj48PfA93D5aPtQ/AD9SP6e/y4AFgEcAwAFmAWIBSAGgAcQCUAKAAuAC3ALgApACnALAA1gDYAMoAsgC1AKUAmgCcAKsApACcgHGAe4BkgGCAYQBlgFMASAA3ADUAP0AjQCRAG2ANcAHgEOAasACwA3/37+vP6z/yAAkv83/z7/mP7g/WD+wP/7/zb/Nf+t/yj/Vv70/gQAa/8q/oj+u/80/5z9zP3K/vT9IPyg+1D8cPxE/IT8NPwI+pD3QPeA+FD5cPn4+ED34PTA84D0wPUw9jD28PXA9HDzwPOQ9dD2IPdw9zj4oPjQ+DD6PPxw/Yj9Iv4oADgCIAO8AwAF6AUQBsAG4AgAC0ALUApgCmALUAvwChAMwA1wDVALEApgCqAKIAogCrAK0AmgB5gGIAcoBzAGYAUQBXgEeAPoAiwD/AK2AdgArABsABUAIQAgAGn/dP4W/nj+mv6C/rT+0P4s/nT9uP1K/lj+Sv72/i//Yv7s/Wj+A/+m/mL+B/8X/9j9VP3c/n3/NP7Q/KT8iPyI+6j7pP1y/vD7yPjQ91D40PiI+Uj6cPmw9mD0UPSA9UD2MPYA9mD1UPTg86D00PWw9hD3MPeg92D4oPko+yj8hPwM/Vr+RgAMAmgDeAQQBRAFkAVYB5AJsAqgCqAKEAsAC/AK4AswDUANAAwwC2ALEAtQCnAK8AoACnAI2AdwCGAIyAZ4BWgFKAUwBPwDaAQYBMACZgEMAQgBxgC9APgAjgCO/9z+tP7e/iD/H//m/qT+qP6k/kr+3P1E/ib/L/+O/oD+8P6g/vz9GP7M/tr+4P2M/Zb+9P6s/WT8JPwE/HD7cPvM/Lj9yPuQ+ED30PeI+PD4yPmg+RD34PNg85D10PYQ9jD1kPVQ9eDz4PPg9VD34PZg9kD3+PjQ+Wj6GPxE/bj8sPwS/3gCWAQ4BPgDuASgBZgGUAhwCpALYAugCkAKsArwC0ANcA3QDPALUAsAC1AL4AuAC9AJkAgQCXAJUAgYB/AGaAagBJgDeAQoBfgDfAIIAloB7f+T/wYBwgEHAGD+oP74/iL+zP3i/nf/Zv4E/bD90v5C/lj9Cv4d/3b+VP3I/SH/Jf/Q/UT9BP4g/lz9nP3q/rb+xPyA+3D74Pvo+1j8MP3A/ED6APgA+AD5wPno+fD4gPeA9hD2APbw9eD1APYQ9kD1IPUw9pD2EPYQ9jD30PdA+KD5KPxg/eD7GPtc/UEATgF0AgAFWAYIBdgD8AUQCSAKcArgC7AMEAuwCTALYA1wDZAMoAyADEALUArgChAL8AnwCPAIsAiIB9AGwAbYBTgEtAMYBNwDBAOoAmgC+QBq/07/hgDCALf/Kf8k/67+tP2s/Y7+Bf90/vj9gP6Y/vD9rP2Q/gX/Fv6U/ar+x/8H/7z9sP0i/sz9kP2i/l//AP4w/PD7TPz4+xD8NP18/aj7aPkQ+aj5cPko+Yj5MPmg96D2EPcA97D14PRg9QD2oPXA9eD2sPbg9DD0IPYY+Pj4+PlI+1j7SPqg+hj9lv/cAHgCYARoBFQD+ANQBhAIMAmwCgAMcAsACnAKQAywDDAM4AzQDcAMAAvgCrALQAvgCaAJAAowCZgHMAeAB1gGYASwA2AEiASAA3QC0AHuAJr/N/8nAJoAtv+u/kb+xP30/PD89P3A/h7+CP3w/CT9BP00/dT9/P14/Wj93P0K/qT9PP1g/Yz9jP3k/YT+Kv7o/Az8+PtQ/Pj8nP2o/Xj8sPrY+UD6wPqg+kj6wPm4+ND3oPfg92D3kPYw9kD2QPZA9tD2EPcQ9gD1APYw+Bj5gPlI+tD6OPoY+pj8AABaAQgBDAKUA8QD6APwBbAIcAkgCQAKkAvQCxALgAvQDDAN0AwADYANIA0QDGALMAsAC4AKQAogCnAJEAjYBhgGwAVoBfgEcAS0A9wC+gFIAXkA3P/w/2YAUQBO/1b+yP1c/Rj9qP2u/uj+0P3s/PT88PzA/Hz9wv4c/xb+/Pw4/bj9hP2E/WT+7P5+/pz9IP0A/Zz8aPzw/Kj9hP2s/Jj70Ppw+jD6QPp4+lj6iPk4+CD38PZQ9xD3cPYQ9gD28PWw9aD1wPWg9UD1wPWQ91j5sPn4+HD4KPng+tz8Gv96AVQCPAGlACgCIAVgB3AIgAlgCvAJUAnQCiANkA2gDLAM8A3wDcAMoAxgDdAMEAtgChALIAsQCkAJoAgQB2gFKAXABZAFoASUA7ACjAF1ADsAcgBoADoABAAK/7j9VP3c/fz9tP3Y/WT+UP40/Xj8vPwM/TD9EP4S/3z+EP1Y/Jj8EP1c/QL+qv4w/uT8JPwY/AD8ZPxM/Xj9lPyI+zD70Pog+hj68PoI+6D5cPgg+Cj4gPcA90D3IPdA9sD1cPbw9mD2cPVQ9UD2QPcY+Fj5YPoI+vD4EPk4+xr+fgCeAUgCJAJuAUgCKAUgCHAJAAowCjAKQArwCmAMcA1wDYAN4A2ADZAMoAzwDHAMcAsACyALwArQCRAJYAjQBkgFeAUIBngFOARYA5ACJgH8/ysA3gCEAJP/H/+a/oD94Pxk/Rr+5P10/bD9oP2Q/Oj7mPx0/az94P1C/uT9fPz4+xT9Dv7w/fD9eP74/aj8JPzQ/HD9HP0I/UD9yPx4++j6aPtg+7D6IPoA+pD5wPhI+CD4wPfQ9lD2gPbA9qD2YPYg9rD1QPVg9YD2CPj4+Dj5APnI+OD4+Plo/B//oQDcAAABkAFUAqQDeAWQB/AIkAkQClAKQApwCnALgAwADUANQA3QDOALEAsQCzAL4AqQCoAK0AlgCAgHcAYwBrgFKAX4BKAEdAMkAowBTAG0AEwAcAB8AM3/yv5k/l7++P2s/Tj+3P6A/qj9TP1Q/Uj9VP0m/ub+nv6o/Sz9PP1Q/Yz9JP6A/vz9HP2w/Lj83Pz4/BD93PxA/Kj7ePtw+0D7+Ppw+sD5KPnw+PD4oPgI+FD30PZQ9hD2kPYA95D20PWw9eD1APaw9gD4EPnw+Hj4OPmQ+pD72Pz6/kQAEgC3AKACyAR4BYgF4AaACIAJYArgC1AMgAsgC/ALIA2QDbAN8A1QDaALYArACpALkAvQCqAJUAjoBlAGWAZ4BtAFeARgA7wCTAKmAVYBJgGjAKL/1P7i/hj/2v46/uD9vP1w/YD97P0U/qT9OP1M/ZD9vP3c/Rb+DP64/YT9rP3s/fD9+P3Y/Xz9MP1E/Xz9bP38/ID8OPwE/ND7sPuI+yj7gPqo+Rj5+Pjo+Hj48Peg9yD3QPbw9WD2cPbw9dD1YPbg9sD2sPYI+KD44Pcw+ID64PyA/cD9aP5G/47/4gBQBPgGsAboBdgGMAgQCSAKMAyQDdAMYAuwC8AMEA1gDfANcA3QC8AKEAuQC/AKwAnwCEAIUAe4BsAGaAYwBdAD9AJcAvQB4gHmAW4BNQAK/7b+xP68/pL+gv5a/uj9fP1k/XD9dP2I/bT91P24/Xj9eP2Q/WT9ZP3E/QT+2P2A/Uj9MP0c/Rz9ZP18/QT9gPxQ/Bz8yPuo+5j7QPuw+hj6kPkY+cD4gPgQ+HD3IPcQ95D2sPWA9dD1sPVQ9SD2QPcg90D2QPZA97D3kPgA+6j9yP08/HT8ev5xABwCaASQBrgGqAUIBiAIsAmgCgAMAA2gDNAL4AvgDHANAA3QDNAMcAzwC7ALEAsQCjAJgAgwCPgHqAcIB9AFeASgAyQDqAJ4AmgCzAHFAA8Awv9c/7T+jP7i/rr+KP4U/kD+wP0Y/ST9yP0I/tD93P0E/rT9HP04/dj9KP4s/vj9yP2Q/WT9bP2k/dD9qP1E/cT8mPyU/Fz8+Puo+zj7iPoI+sD5ePnQ+Dj48PeQ9xD3oPaQ9jD2UPUw9eD1oPbg9kD3YPeg9iD24PZI+YD7iPxc/Qr+mP1E/SD/QALYBCAGYAagBsgGOAfACLAKwAsgDIAMYAwwDGAMwAzgDJAMUAwwDOALcAtAC6AKEAnwB7gH4AdwB8AGIAYoBcQDqAJkAkQC9AGSAUYBmQB1/8T+gP5o/kT+Pv5S/ib+rP0o/fT89PwQ/UT9dP2I/Uj9/Pzo/Az9KP30/PD8MP1M/fT8sPzo/Bj9yPxQ/Fz8cPxA/CT8MPzY+/D6YPpg+lD6yPmQ+Xj54PjQ92D3sPeA9wD34PbA9jD2APbw9gD4IPiQ94D3CPgg+AD5SPuE/SL+7P3k/WL+nv+cASAECAaIBlgGoAZQB0AIwAlAC9ALsAuQC6AL0AswDGAMMAxwC9AK4AoAC6AKAAoQCcAHkAYwBlgGaAboBfAEuAM8AjgBJAGiAZ4BBgFLAFr/kP4k/j7+kv6e/j7+yP2I/WD9bP2o/dT90P2E/Sz9RP28/fj90P2o/aT9aP0w/Vz9pP3M/ZD9TP0Q/Zj8WPyE/Lj8VPz4+8D7OPuA+gj6IPr4+VD56PjQ+FD4cPdg99D3gPeA9jD2sPYQ9xD3sPeQ+Ij48PcA+AD5GPow++z8cP7c/n7+D/9UAM4BfAM4BZgG4AbgBlgHcAhgCSAKEAuQC4ALkAvAC/AL4AtwC+AK0ArQCrAKoAogCgAJ0AfYBlgGeAaQBlAGmAVABMgCCAL4AfgB8AGuARQBOwBL/+T+Gv8W/7L+gv58/hT+tP3c/UD+Bv5Q/TD9rP28/XT9rP0q/tj9BP3o/GD9gP1c/ZD9zP1k/bz8dPyg/Jj8YPyA/HT82PtI+/j6cPoA+gj6EPqQ+fD4oPiY+Cj4kPew9/D3cPcA94D3IPgo+FD42PhA+fD4+PhA+tj7YPzQ/Eb+bv+c/+X/KAGwAqQDcAToBTgHQAdIB1AIQAlgCZAJgApQC2ALsApgCpAKMArACeAJQArQCQAJEAhgB8gGGAbwBSgGwAWgBLADFAN8AvIBlgFsASYBmwAlAOT/dP/6/rL+eP4Y/gz+eP6k/kj+yP2M/Uj9HP1Y/QD+Zv4C/pj9hP1Y/fz8PP3g/Rb+wP10/Yz9kP0k/dD87Pz8/MD8lPyU/HT8BPxY+9j6oPpw+ij6GPoA+rj5IPmQ+Ij4uPiA+Dj4gPjo+Pj4CPmA+RD6UPpY+vD60PtM/Pz8gv7z/0gAYwD4AAgCBAPgAzAFWAbIBsAGIAeoB/gHgAgwCZAJYAkQCfAIAAkACdAIoAhQCMgHcAcoB9AGcAYIBogF6AR4BBAExAOIAygDpAIsArQBXAEyAQgBzgB6AAIAoP+I/37/XP9g/0X/3P6O/mT+bP6S/or+dP54/lL+BP4U/jb+MP4Y/uj9zP3g/fz96P3g/bz9hP1A/dz8rPzw/AT9sPxU/Bz8qPsQ+8D62Pr4+oD6GPoY+hD6gPkw+YD5kPko+dD4SPnY+fD5KPrg+jj7wPqg+mj7gPxc/Vr+f//n/5D/2P/7AOgBmAKQA8AEQAUQBSgF+AWIBpAG2AZQB2AHOAdgB7AHsAc4B8AGkAZgBjAGSAZgBggGeAXoBGAE+APQA+QD7AOIA+QCYAL6AaYBfgFuATAByABsADEABADY/7T/jP9B/9r+oP7A/uj+0P6q/nL+Kv7k/dz9BP4s/iL++P3s/cj9jP2E/aD9qP2Q/YD9aP1M/Sj9DP34/ND8oPyM/JT8aPww/BD82PuY+2j7ePt4+1j7IPsY+zD7APvQ+tj6APsY+0D7iPvI+/D7EPxk/Mj8DP1w/Rj+wP4m/3X//P+oABoBWAHgAYgC7AIkA4wDIAR4BJAEsAQABTAFKAU4BXgFuAWYBWgFYAVwBVgFGAX4BCAFKAXABFAEMARIBCgExAOYA5QDUAPQApACpAJoAvABwgHwAcABGgHCAPMABAF9AC4AYQBqAP3/rf/Z/97/g/82/0z/b/8X//T+Hf8Q/4r+Sv6K/p7+RP4Q/kr+LP68/ZD9sP2Q/Tj9HP1I/TT9rPxs/IT8UPzg+9D78Pvg+5j7WPtQ+2D7IPvw+gj7MPso+yj7YPuo+8j7uPvY+2D8qPzM/Dj97P1G/mT+yP52/wsAPgCRACoBngHQAUgCCAN0A5QDtAPkAwAEQAS4BAAF6AToBDAFQAUABdAEAAUwBfAEuATYBOgEqAR4BHgEUAQIBNgD2APkA6wDXANEAzQD5AKUAmACNAIcAvwBuAF2AT4B+QC1AHcAOQAGANH/gv9X/0L/9v6U/mj+Rv4G/sT9oP2Q/Wj9IP34/Pj8zPyA/GD8WPw4/BT8DPwE/Nj7sPuw+7j7oPuI+4j7kPuQ+4j7kPug+7D72PsA/Az8FPw8/Gz8mPzQ/Bz9YP2U/cj9Cv5U/p7+3P4p/3X/xf8YAFYAlQDuADoBVAF6AcwBJAJYAnwCsAL0AhwDOANoA6wDzAPkAxAEMARgBHAEgASQBLgEuASoBKgEwATQBMAEmASYBJgEeARABCgEIAQIBNADpAN4AzQD7ALMArQCcAIcAt4BqAFWAf0AywCkAFwABADJ/4//Ov/q/rr+lv5O/vT9vP2c/WT9KP34/NT8mPxg/ET8LPwA/ND7uPuw+5D7cPtw+3D7WPtA+0D7WPto+3D7iPu4+8j72PsA/DT8ZPyg/Nj8FP1M/Yj9zP0a/mT+mv7c/in/dP/B/wsAUACVANcAFgFOAYoBygEMAkQCaAKgAtwCCAMgA1ADdAOMA5wDxAPoA+gD7AMIBCAEEAQIBBAEAATkA9gD5APgA8ADlAN4A1QDLAMMA/ACzAKcAnACRAIIAsgBlgFsASYB5ACxAHgANgD0/7T/eP85//b+sv58/k7+GP7c/aT9dP1E/Rj98PzY/MD8mPxw/Fj8RPw0/CT8HPwM/AD8BPwQ/BT8EPwc/Dz8VPxY/Gj8lPzM/PT8HP1A/Wj9oP3c/Rz+Xv6Y/s7+EP9Z/5j/1/8eAGUAqQDhABoBXAGaAcwBAAI0AlwCiAK4AuQC/AIMAyADOANMA1QDYANsA2gDWANMA0wDQAMoAwgD7ALUArgClAJwAlACLAL8AdABrgGGAVoBLgEGAeAAtQCKAGMAOQANAOL/uP+M/2b/S/8u/w7/5P6+/qD+gP5e/kb+Nv4c/gD+7P3g/dD9wP20/bj9vP2w/aT9qP28/cz91P3c/ez9AP4I/hT+LP5I/lz+cP6S/qz+vP7I/uj+GP8y/0b/aP+U/7j/xv/i/xEAPQBRAGkAoADDANkA7wAWASoBOgFcAYgBnAGYAaYBvgHMAdIB3AHmAewB6gHsAe4B4AHUAcwBwAG0AaoBoAGOAXYBZgFYAUgBMgEaAQYB8wDfANIAxQCsAJAAcgBZAFAAPQAfAAQA8f/Y/7v/pP+Y/5D/dP9K/zH/I/8Q/wn/C/8B/+z+1v7I/sb+yP7K/sb+wP7A/sj+zP7K/sT+xv7Q/tj+2v7k/vD++P76/vr+/P4H/xf/Jv83/0D/P/9J/2H/cP9y/3f/iP+i/7T/vf/G/9f/4//s//f/AwARAB8AJgAwAD4ARgBHAE8AWQBhAGcAbAB3AIAAfgCBAJEAnQCaAJcAoACsAK4ArwC1ALgAuAC8AMkA0ADNAMUAxQDJAMYAvgC8AL0AvQC3AKgAmwCQAIEAcQBpAGMAVwBHADkALgAhABQABgD+//X/7f/o/+P/3v/Z/9H/x//D/8T/xv/C/7r/sv+y/7T/sf+s/63/r/+s/6n/qP+w/7L/sf+y/7n/u/+1/7f/v//F/8b/xv/O/9X/1//T/9X/4P/s/+7/6v/n/+T/5P/r//j//P/0/+3/8P/z/+//7f/0//n/9v/z//X/+P/3//n/AAAFAAEAAAAIABEAEwAUABsAIgAnACoAMQA2ADUAMwA5AEEAQwBHAEgAQgA6ADYAOgA7ADYAMQAyAC8AJwAiAB4AGgAZABoAGAASABAAEgAWABEABAACAAUABwAIAAkABQABAAAAAwD9//f/9P/6//X/5v/m//X/9v/g/+T/6f/n/9n/2f/t/+n/1//e//T/9P/m/+b/6f/k/+D/6P/9/wIA7//i/+j/9P/z//D/9P/8//v/8v/x//n//P/7//j/+f/7//r/+//+//r/8v/w//L/7f/t//T/9f/u/+X/4P/f/+L/5v/t//b/8//q/+f/8v/6//7////9//z/+//+/wAA///6//7/AgD1/+T/5//y/+z/4v/d/9j/0//Q/9b/2v/W/8r/y//V/9X/1//f/+j/6v/t//T//P8EAAgADgATABUAHgAtADYANAA2ADoAPAA7AEEASgBPAE4ARwBMAFUAVwBRAE4AUABLAEcARABJAEkAPQA0ADYANAAkABsAGQAOAAQA//8AAPr/6//j/93/1//G/7r/wP/F/77/q/+q/6z/pf+c/5z/ov+a/47/jf+V/5L/h/+I/5L/l/+R/4z/iP+X/6r/qf+d/6j/x//H/7P/vf/i/+b/yf/h/wkA///d//D/HwARAO7/BAA0ACgA+/8NADYAMwAPABkASQA/AB8AKwBdAEUAJwBDAHAAZQBAAGQAhABtAFEAdQCZAH8AbACTALEAjAB4AJkApgCKAIUAmQCcAIQAeQCIAIsAfABtAGYAZABaAFEAUwBLAEoAMgAdACgANAAcAPL/DwAXAOb/yP/o/w4A4P+w/8P/3f+T/3j/v//J/4v/dv+V/3z/VP90/6L/c/8u/2P/rv9u/x3/Xv+7/3b/GP9k/7//j/86/3D/u/+I/0X/fv/U/6j/XP+J/9v/vf9//6H/3f/J/6j/xv/u/+n/1f/k/wYABgD3/wwAIgAZACQANgA6ADwAOgBKAFsAUQBPAGUAcQBUAFYAeQB9AGQAYgCAAIIAaQBeAG4AeQBoAGQAfQCBAGwAaAB2AHIAZgBrAG8AcAB0AHUAdwBsAFgAWgBfAFQARwBJAEsANQAjACUAHQADAPL/9v/v/93/yP/O/9L/tP+X/5j/rv+o/4j/dv+H/5j/gf9a/3b/lP94/1T/YP+S/4L/SP9P/6r/k/83/2T/t/+H/1H/hP+k/5b/lv+s/7P/oP+z/+L/7v/A/9//EADh/9//IQBEAAwABgA6AD4AJAAaAFcAaABBADUAUwBqAE4ASQBhAIIAZQBGAGcAgAByAE4AdwCaAHUAYAB6AKIAfABmAIUAogCTAH4AoQCTAIEAgQCKAIcAdgCSAIAAeQBpAF0AXABLAEoAQgA0ACAAKwAxAAoA+P8BAPr/6P/I/9D/8P/f/53/m//3/8f/ZP+h/93/o/8Q/3v/FACH//L+bv8+AEn/iv5z/z0AX/92/oD/GgBh/6T+XP8yAGT/gv5V/1cAiv+0/ln/OACp/+T+O/87ABwAGv9D/ywAJABZ/3n/OwBfALH/jf9YAHoAyP/a/5YAgwAJACQAmQCgAFIAWwC9ALMANABlAPMA0ABoAJYA4ACvAHoAjgDSAOQAkwCBANAAxwBlAIkA+QDdAFoAZADBALUAfwBjAIoAigBcADIAUAB8ADMADgATAA0A7f/c/9P/6v/2/4j/iP/R/7n/Yf9o/6P/nf9b/zz/nv+q/zf/Pf+e/2v/D/9h/6L/Rv8l/2P/iv9K/yX/gf+e/0n/C/99/77/SP87/6f/1P94/0v/o//G/6f/gP+0//7/xP+l/9P/FAAVAKn/vf9QAEEArP/7/4MATAD0/yQAbgBXAEAAPwCbAIIANwBPAIkAjgCXANAAQgAoANEA7gALANj/TAGKAfH/a//iAK4Bx/95/zoBhgG//07/EAEWAQoAZf+8AGQBq/8T/18AnAHZ/7b+ZwAoAcf/3v6BAOUAgv+u/uX/8QCn//j+ZwDPAKb+3v6fAFwA+P46/30A+P9I/23/KQAJAFr/Z/9r/wsA+v8y/1X/JwBZANT+7v5RAGsA+P58/vsAfABq/gL/BAHXAAr+Lf8+AZoAYv4F/8ABQAA2/pf/RALu/5z9UAC+Ad3/bv5DAIQB9P+y/jAAygGg/8T+vAFmAdD+M/8cApYB5P6y/9QB4gHq/mr/JALKAVT/L//kAYwBTP+Q/3IBWAHc/3P/dAAAASYAhf9jAKgAAwCf/6z/VACOAPP/CP8OAJAAZ/9B/0gAhQBo/4X/3//V/9f/4//H/5j/qf/k/wAAcv8+/3gAawCY/vz+owD2/8T+bP9UAPf/Gv9I//j//f81/1D/DQCW/zD/CABHAAv/jf93AIH/Av+1/3AA8P9K/5X/dAA8AOT+zf/IAJb/9v5GANIApv+D/yoAjwAGAG3/OABoAN3/MwCQAEkAjP+iAM4Ab//9/wYBfwA+/5EAEAHo/6n/YgAuAYEAXP/N/y4B1QCo/+f/9wDBAPv/rv9pAKABYwDM/goAdgF4ABL/NQB6AVIABv9M/8YAfAB+//H/ZwBuAKn/S/9V/9IAbgDW/rH/vwBKAJ7+R//4AHkAYv72/pwBSwDo/Tb/YgHp/xT+8v+QATAAKP5O/zgBzP9G/tH/DAJBAF7+tf/EAWcAKv6E/6oBLgEy/jr//AKcAcz9If9gAsMA6P3e/4wChAAW/pL/dALCABD+1/88ARgAMv65/+EAfQALACj/jwCz/2f/+//S/8H/AwD8AGv/wv/hAF0Aff/H//4AbQAK/3X/XAFCATz/1P5IAeUAGP/c/qkArAH2/jj+TgB6AT//0v7uAAIB8v4a/jgAMAE5ALT+yv8WAT3/kP5QAVwBjP4j/zgA5//0/r//AAG7AJb/cv6i/44AQP9w/+MAbwBA/9z+KgAQAcz/X/8zAI8A7/95/7j/cADRAF3/xP5TAFoBjP/6/oIAvgAPAAD+P/8EApsATP61/+QCLQAo/Yb/7AL7ALz8lv+QA8wAfPyf/9QDdgD4/ET/vALpAID9LP9MAu0ARv6O//gBuwA6/sL/cgEPAGL+CQBgAqkAPv4V/xwCDgFM/dD+DAMqATD9Uv8EA7MAsPw4/0ADOAGg/Db+CAOYAVz9Sv4wAt4BUP28/SwCxAEs/bT9PAIkASb+aP7SAUsA3Py+/moBpAC8/qr/SADQ/qL+uQDnAN7+JP/4AZAAYP1t/8QC6QB8/swA9gEb/6b+7AGmAcb+qP9UAj4A+P2SAFgDjQAk/Ir/gAL1/x7+CgEUA9j+kP3uAAQCev7q/uwCggAA/gcAFAJIAV//0/93ACEARv8YAO4AbQBAAZYA0v7m/o4AowDR/4QA/gDN/wj/7v9mAXYA7P55/+UAeQCs/sEA0gGM/0j+X//SAHEAlP8f/1YBqwAQ/UD/SAKSAPj9rP8sAcj+cv7P/4wBdQDw/T7/EAEBADD9ZP+6Afr/FP66/qYBOgGw/Sr+MAL5AOj83P6QA0oB5Pyq/rQCXgFc/aj/2AKZ/9z8uP+cAv//Cv4UAboBwP3Q/UACHgFM/t3/QAHy/8b+ZwDYAVMAQP+3AKAAXP5P/6AB1QCB/yEARAGx/yz/nwAaAXn/3P6VADkAVQDq/w4AOgHXAAr/QP6eADoBYf9e/poAlALq/pj9CAIEAz7++Pv6AOQCTP5M/ZgB2AKG/hT9TAHQArr++PzdAFwCfP6c/dEA3ALmAGz+LQD4AScAVP0p/xwCiAC4/vH/vAEAAeb+5P7U/5cA8P88/qT/KgHkAMT+Nv/2AbUAqP7M/SQBiAHM/RX/dAHvAAj+5v+YAqn/9P3V/2ABCP9m/voA8gH2AGj/8/+SABIACgBAAD4AKwCSABkAx//4AGQA9P6A/5gBaQDE/qAAagF8/9D95ACAAsH/5v5gAc4BfP6o/XwA5gGQ/xr+nf8gAeUAcf/O/sr/CgBq/kL+xwAUAs3/Fv4/ALIB6P7E/T4BmAIh/wz+3AC6AZL/Ov9WAbgBcf/w/o8AmAAm/4v/LgFoAFX/oP/ZAPD/cP7q/rj/kQAHAKb/TACv/xn/fv/a/7H/SgAyAS8AU//7/3EAm/9q/9wAdgG0//L+7gDEAcz/QP4pADoBCv8q/rcAxgEK/5T+mQCYAZX/YP2P/8QB4v/U/U4AVAIWAC7+xf88AoUAqP3E/ggBMQDM/rcAGAIeAJD+3v+KAAD/F/9eATwBaP7E/vABYgHU/hgAsgHi/uD8LwDyAWn/fv7PAM4BJ//Q/RcAmgGm/1T+RACLAEb/MADSAasALf8lAHUAzP8r/1oA7AF0APj+DwB2AWsAUP9+ADAB/v5Y/cj/2gGBABv/BgAIATr//P1k/1sAtf/w/nAAxQBv/wQALAHQ/xz+Yv9hAMv/kf9iAbYBof/e/t3/7ABy/yb+kAB4AsL/Xv7pAFQBaf8Z/4wAQgHj/wf/PAAUAff/QP+NAPgABADz/2YAigDe/4P/jP8f/2X/swDrAKD/LgAGAWz/CP4q/10AZP/i/nQAkgFqAD//YABeAdr/qv4dANIA6P4i/5gBtgETAI3/+QCgAFr+Yv4KAVwBfv6K/3wC1AA0/vr+DgG3ADL+9P34AbAC8P18/aoBxAGA/o7+QAFIArj/QP3y/qwBwADs/o0AIAIJAND96P4eAVoBwP9r/wYBKAH6/vL+ZgGwAbX/2P7E/zgBfQBW/1gA9gBS/0T+AgB2AV4BLABu//D/AgC+/4gAKgHi/4v/YgADAJT/hgAWAbT/+P5H/4D/Qv84/0wA5QDt/2j/KgADAA7/4P6Z//r/z/8bALwAxgDf/+T/oAB7/wr+Fv+DAPL/qP/XAPQAeP+4/nD/JABf/5z+7P91ACn/L//kAP8Aiv9b/47/hf9f/zj/AAD6AMYAd//x/zQBvQAsADMADQBG/2z/6gAmAc//2//iAa4BUf98/hgAlwBk/3//YgCfALD/cP8YAZoB4f8D/0UARgC0/Vj+LAI4AkD+OP60AgAD5P0E/cgBwgE4/eD9IAN8Agj+XP9IA1wBBP2W/jwCugBE/dT+VAIuAYD+xf80AroAGP4+/x4BLgCa/g0ATAIKAdz+P/8eAX0Aov4d/6wAkwA7/xP/wv8oANr/Vf+h/xEAy/9s/7b/OgAjAMj/2f8RAK7/a/+r/0cAXwDG/6H/t//h//n/+P/I/7v/FgAMABcATwCDAKwAXgDt/87/WQDeAJUAFgAoAFcASQC4AEIB7gAiAPn/IgCv/zX/yf++AFIAqf9uAAIBhwDB/6T/0//C/27/kv+6ADwBowATAGAAIgD8/vL++/9kAKX/iv+xAMEAM/+Q/uj/NQAg/27/YwDb/8L++P64/63/Of9f/wwA4P8g/5f/XQC5/+7+Zf8lAAcAxP8XAIIAXACp/3n/6P8YAAwA9//T/93/DwDW/7D/ggAYAWAAjv9G/2z/of/F/0QA/gCxAJD/qP91AEwAy/+j/7H/v/+1/6//YQAaAa4AawCfAEoAq/+x/0UAqQCzAJAAvgDyAMoAoQCyAIAAwP+0/2QAiwBBAFMArQBuAMr/2f9bAEgAsv+3/yMAxP9I/+D/4wDXAAEAqf/W/+f/WP9j/wgA/P93/0f/mP/J/77/Vf8F/+T+jv46/kL+uP68/m7+jP72/pL+rP3o/Wz+9P18/ez9jP6m/rD+Ev9D/3T+wP2G/mT/OP80/wgAsACwALUAKgF0AVwBQgFAAXAB2AF4AvACJAOIA9QDVAOMAtACRAPQAnwCXANwBAAELAPcA6gEqANcAjwDYARUAzwCMANABEQDbAJ0AxAEyAKEAeABaAJiAU8AngDQAFv/bv4Q/xD/gP0A/PD7oPs4+jj5gPlI+dD30Pbw9iD3MPZw9cD14PUQ9YD0APWg9eD1EPYQ91D4yPgA+cD5IPsI/GT8gP1t/2QAbgDEATgEaAVoBQgGkAeACDAIkAhwCoAL8ArACoAL8AvACwAMkAzQCwAKEAmACbAJAAkwCcAJ4AhYB6AGOAawBRAFmARABGgDiAL4AsgD7AKsAU4BAAHp//b+7v5w/xv/xP1c/cD9WP1I/Kj7oPvg+nj5uPig+Bj4IPew9kD2QPUQ9KDzYPOw8vDxUPGg8FDwIPHw8SDykPKA89DzkPOA9LD2UPiI+Ej5mPts/fT9bv8gAmwDRAMgBBAGAAdgB/AIIAsQDLALEAxQDYANwAzQDNAMAAwAC/AKYAtQC6AKAApACagHOAaIBYAF6ATQAwQDxAJ0AuIBwgH6AYwB2v+q/ub+eP8k/xf/NgDXAFMA7f97ADoBPAEGAToBbgGKAY4BDAKEAtgC2AJ4AiACugEeARYAlv9f/zr+zPwU/CT8BPxI+0j6APlA9yD14PNw88DywPEg8dDwsPAA8aDxkPJA8xDzcPKA8kDzgPQw9lD4WPrA+5j8BP46ANwB+AJABGAFgAUABiAIoArAC3AM0A2gDgAOYA0QDrAOcA0gDCAM4AvQCoAKQAvgCvAI+AYQBggFlAPUAsgCQAIIATgA/v/s/8X/hf/c/sz9LP0U/Uj9vP3A/pX/yP+o/wEA3ABeAZgBGAJcAuABxgGUAtgDOAQoBJgE4AQQBLQCmAIUA1ACoQCq/xT/nP2c/CD9jP3o+0D5UPdA9WDy0PBQ8WDxwO/g7qDvwO8A72Dv0PDA8ODuYO5A8MDx4PKQ9aD42Pkg+uj7eP7N/70A2AJ4BJgESAUACCALsAzQDTAPsA/ADnAOcA/ADxAPwA7wDlAOQA0gDYANsAygCgAJmAf4BZAEQARIBGgDPAJwAdEA3f8f//7+gP5Q/UT8VPzY/BD9jP2M/iT/6P7+/pr/EABGAN0AzAHwAbQBjAIgBJgE/AM4BLgECAQUA6gCyAI0Av4AVgCa/zj+5Pyg/Fj8GPsY+RD3APXA8jDxUPCA7+DuYO4g7qDtoO1g7sDuoO6g7kDvgO9A8EDyMPUA9yD4oPpQ/aD+bP/yAZAEEAVABYgHwAoQDPAMUA9AEeAQABDAEMAR4BCgD8APABDQDpANAA5ADoAMUApwCVAI6AX8A+QDoAPeAZYA5gCPANr++P1M/tj9OPxw+xT8WPzI+2T8DP60/kz+xP4AAGwAEACUAPYBdAJAArwCCATgBPgEEAWgBagF2ARQBCAE3AOgAroBZAHwAG//iP3s/ED9bPzY+YD3cPVQ88DwYO9g72DvQO6g7QDu4O1A7aDt4O4A78DtwO0g8HDyoPPA9VD50PsU/AT9KwCIAvgCCASQBmAI4AigCjAOIBDAD/APYBFgEQAQ4A8AEcAQ0A4QDqAOIA6wDDAMEAwwCigHwAWIBSAEPAJAAsgCagFG/8z+PP9m/vj87PxM/SD86PqY+wT9VP2A/Yr+QP/Y/qz+rv/ZABYBdAGIAgQD8AKEA9gEiAVABQgF+ARABKQDrAOcA7gCxAF+ATwACv6w/DT9FP24+kD4gPYg9EDxwO/g74Dv4O0g7aDtQO1g7EDtwO6A7kDtoO1A79DwMPLw9Bj4uPmg+qj8Jv+vAPoB8APIBagGmAcQCuAMkA6QD6AQIBEAEcAQABEAEUAQ8A/QDwAPAA4QDlAOEA0AC8AJcAiIBtAEiARQBAQDzgGQARgBlv+w/vj+ov4E/eD7DPxM/BD8lPwA/qb+Yv6u/mb/l/94/1YAlAHmAb4BoAL4A4AEyARwBeAFaAXQBKgEUARMA/gCJANQAnEAcP9L/2L+kPxo+/j6uPhA9dDyMPFA7wDuQO6A7mDtAOyA7GDtoOzg68DswO2A7YDtoO/A8vD0sPZI+YD7mPzs/ToAXAJ0A5gEyAYACWAKAAygDoAQABEAEWARYBHAEKAQ4BCgEKAPcA/ADwAPoA3QDEAMcArYB3AG2AWQBGADSANAA0QCHgGWANP/fP6Q/Uj9uPzg+9j7mPz0/Bj92P2y/r7+av6y/hj/M/+m/94AygEYArQC0ANoBCgEWAToBIgETAPEAhADzALSAZABsgGHAHj+KP2Y/HD7sPnI+FD3MPTg8GDvgO+g7sDtwO3A7YDsoOsg7MDsAO1A7SDugO5A70DxYPTQ9sD4EPsI/fD9JP+gASAEYAWgBtAIwArgC4ANQBDgEaARQBHAEcARwBBgEAARQBEgEAAPEA+gDiANsAvwCkAJkAbIBFAE7APEAhQCDAI2AVH/LP40/rT9YPyw+/D7sPsQ+3j7zPxY/UT93P3M/ub+hP5A/4IAzgAYAUgClAO8A9gDAAXIBUgFwARYBVAF2AMoA7wDoAMYAhAB/gD4/4z9+PvI+/j64Piw9nD0kPFA74DuYO4A7mDtQO2A7KDr4Ovg7GDtYO0g7iDvoO/g8BD0cPdY+fj6RP0i/9v/OAEQBJgGmAfACPAK8AwwDvAPQBIAEwASYBGgEWARoBDAEIARIBFQD0AOMA6ADRAMoAoQCfAGyATYA8gDgAPIAvwB8ABM//D9fP00/bT8CPx4+/D62PqA+6D8TP1o/aD93P3k/Sr+AP8XAJkAEAHYAZgCPANIBFgFeAXYBKgE6ARwBMwD6ANoBGQDAALWAWoBcP+Q/Sj9ZPyg+ZD3wPfg9uDyoO/A76DvYO0g7EDtgO3A60DrAO0A7kDtAO4Q8LDwAPDQ8eD1wPgQ+hj83v5MAAwB3AKQBXAHkAhACuALIA3QDiARwBLAEiASwBFAEQARIBFgEeAQwA/QDhAO4AwQDKALQAq4B1gFQATEAwADGAKmAfMAWP+0/Rz9BP2k/Pj7YPv4+nj6UPoo+3j8EP3o/Pz8lP0e/oD+e/+tAEwBegEMAhgDpANIBEAFuAUIBXAE8ARYBagEOAR4BOQDEALyAAgBCgC8/XD8OPyg+uD3wPag9mD0wPAg70DvwO3A62DsYO7g7SDsgOxg7uDuYO6A71Dx0PFg8jD1APkw+5D81v5eAWACKANQBRAI0AlwCtAL0A2gD+AQABLgEsASIBKAEWARYBEAEUAQ0A9ADwAOwAzwC0AL0Am4BwAG+ATMA5QC5gFgAUMAyv7M/Uz9rPwo/OD7oPvg+mj60PpQ+5D74Pt4/BD9RP2g/Yr+g/9EAKQANgHOAVAC1AKgA4AEwASABHAE0AToBCgEhAOIAzADwAF+AP//kf8u/pT84Pvg+oD4gPbw9dD0EPJg74DuIO6g7ADsoO0A72DuYO0g7gDvgO7g7gDxAPOg8wD1CPgY+xT9EP9mAeACRANIBHAGcAjQCZAL0A1gDyAQABEAEoASIBJgEcAQABCQD5APsA9QD5AOgA3gCyAK0AiwB1gG0ASMA4gCeAGVAAgAif+2/qj9lPyw+zD7EPsQ+wD7CPsY+0D7mPs4/Nj8dP0S/qb+GP+N/2YAbgE4AswCTAOsAwgEmAQ4BVAFAAXoBPAEYAScA4QDcAM0AmsAkv8y/9T9HPx4+8j6WPiw9dD0MPTQ8SDvYO4A7iDsQOtg7YDvQO7g7KDtAO9g7mDuAPHA82D0IPU4+Fj7DP3+/hQC7AOMA/ADqAZwCcAKUAywDiAQIBCgECAS4BJAEqARABFAEJAPkA8AEOAP4A5QDZAL0AmgCIgHYAYYBbQDNALNACsAIwCv/47+cP1o/Fj7oPrg+oj7kPsg+wD7MPuA+xz8OP1A/l7+Mv6i/sz/yQCEAVQCEANEAzwDuAPABIgFiAUgBegEqATgA3gDuAOkAygCOwBo/xb/wP1U/Az8aPvg+DD2cPUA9cDyMPDA70DvwOxg64DtQPCg7yDuoO6g76DuYO5g8aD04PTA9ND3aPvo/DL+igFABOQDJANYBXAI0AkwCwAOIBDwD8APYBHgEgASwBCAEEAQQA+ADjAP8A8QDyANoAtACqAIGAcgBkgFzAMkAkIB0wBkAOT/XP9+/gj9gPvY+vD6SPug+8j7yPvI+8j7IPz0/NT9XP6I/oz+Cv8hAHYBoAJYA5gDqAPMAygEyARoBYgFSAXgBGgECAQQBDgEjAPqAUIAQv9O/gz9cPwY/MD6WPig9pD1EPTA8XDwwO/A7aDrAOwA7oDuAO6g7qDvYO7g7KDuIPJw84DzYPVg+AD6YPuo/iwC/ALQAkgEIAYAB2AIoAuQDjAP0A7wD2ARgBEAEQARwBCwD5AOcA7ADrAOUA6wDQAMwAkQCBgHKAYYBSgEMAPwAe4AewAGAD//qv4A/mz8sPp4+nD76PvI+wT8dPwY/Kj7bPyk/Sj+Wv4V/9X/FwD2AKgC+AMYBOADKARoBKAEWAVABkgGyAWABVAFyARIBCgEnAPqAQQAAP8s/ij9ePzo+1j64Pfw9fD0cPNA8aDvgO7g7GDr4OuA7aDu4O4g7+DuoO2A7cDvAPLw8lD0sPbg+Hj6xPw5AMACeAP4A8AEmAVYB3AKIA1QDhAPYBBAESARYBEAEoARIBBADxAP0A7QDnAPYA9gDfAKsAmgCOgGcAXwBEAEpAIeAaoAcQC1/y3/fP70/Bj7WPrY+lj7WPug+zT8GPx4+4j7iPxs/aT91P12/jP/EgBUAdQCyAPcA7ADwAMwBJAEIAWwBfgFgAXYBLgE6ASYBKgDwALIASoAWv6M/Xz92PxQ++D5iPiA9oD0YPNg8mDwIO4g7eDsgOzg7IDuAPBg72DuYO4A74Dv0PBQ85D18PZQ+Ij68PxO/9IB0ANQBDAEQAWYB/AJEAxQDuAPQBBgEAARwBGgESARwBDQD4AOYA6QDwAQ4A6QDUAMMAqoB2gGUAZIBXQDKAKYAZMAiP+Q/4T/9P2Y+2D6OPr4+fD52PrQ+4D7oPqw+oj7IPx0/BD9wP0C/lT+gP9YAeQCkAPUAwgE6APkA4AEqAVABvgFyAXwBegFOAUABSAFEAT2AUUAr//M/lD9qPyQ/BD7kPgg94D20PRg8hDxYPBA7uDrAOyA7YDtYO3A7uDvwO7A7SDvwPAQ8eDxAPXA94j46Pk4/RAABAFYAqgEsAVQBZAG8AlwDDANkA6gECARgBDAEKARYBHgDzAPUA8AD6AOEA8gD7ANkAsgCiAJgAfgBSAFiAQ8A84BLAH9AJ4AxP+I/ij94Pvw+qj6CPuI+7j7wPvo+xz86PvY+6T8fP1o/Wj9qv5dACQBlgHgAgAEyANgAxAE2ASgBMAEsAUIBlAFAAWgBTgFsAPoAuwCqgF5/6L+uv6g/dj7WPtI+4j5APfw9TD14PKQ8BDw4O8A7uDsIO6g7wDvwO5Q8EDxwO/g7hDxMPOQ87D0EPjA+mD7tPzV/94B3AHcAmgFqAaABgAIoAvwDRAOkA4gEMAQ4A9wD6APQA9QDkAO0A6wDgAOQA2QDDALYAkQCEgHKAa4BIAD5AKMAuwBHAFUAGn/Nv4U/Uj8wPtI+xj7aPvI+9j7GPy0/Nz8aPwM/Hj8LP2Y/Vj+x//8AEoBzAHEAmQDYANsAwgEaAQYBDgEMAXIBYAFAAXQBHgEkAOAAr4BDAH9/6j+0P1E/bD8uPuA+nD58PfQ9fDzIPNQ8sDwoO+g7+DvgO+A7+DwwPHg8DDwQPFQ8mDygPNQ9mD42PjQ+YD8tP75/6oBlAMQBNADQAXYB3AJUAoQDLAN0A2ADTAO4A5wDrANsA0wDUAMIAwADTAN8AvwClAK0AjoBhAG4AUABYgD2AKcAuABHAH0AKAALf+U/eT8iPwU/AT8nPwY/cT8hPz4/Fj9SP1Y/ZT9iP2Q/UT+nf/IAIYBVAIQAzwD/AIsA6gD/APcA8ADEASIBKgEmASQBFAEiAN0ApoBuACl/4T+HP74/UD9IPyA+/j6SPkw9+D1QPXg8yDykPHQ8YDxIPHw8dDycPKg8QDywPLg8lDzkPWg99D3EPjw+Sz8QP1Y/noAPAKQAtACWAToBdgGQAggCsAKQApgCsALkAxQDEAMoAwQDNAKkApAC3ALsArwCTAJ+AeoBmAGcAagBUAESAOgArwBFAEkATwBSwDM/sz9cP04/TD9cP2U/Sz9oPy0/Ej9wP3s/Qj+AP7A/aT9OP56/5oAQAGYAboBwAHqAWQC6AIIA+gCzALIAugCSAPIAwAEkAPEAvQBOAGOAAwArP8N/0z+oP1A/dT8DPw4+0j6APlw9zD2kPUw9eD0wPTQ9LD0YPRA9KD00PSw9LD0UPUw9tD2wPdQ+aj6WPvg+9z89P24/pf/0ADMAWwCPAOABLAFkAY4B9gHIAggCGAIsAjgCOAI4AjwCOAIwAjgCLAIMAiYBwgHYAa4BTgF8ASIBAgEvAOQAxwDfAIEAp4B8QAHAIj/df9n/0z/cf+0/6P/cP9o/2j/KP+4/r7+Cv9B/23/AAC9ADQBSgF4AbYBgAE2ATwBaAFeAX4B7AFgAnACSAJQAjwCqgHpAHEAEwCv/1D/Hv8B/8T+Zv7g/VT9nPzI+wD7WPq4+TD52PjI+Kj4QPgA+PD34PeQ93D3kPfA99D3KPgA+bD5IPqo+kj7mPv4+/T8Dv6c/sz+b/9QALoAEgEcAjQDcANUA7gDSARoBHAE6ARABQgF6ARYBbAFcAVQBZgFmAUABZgEsATQBJAEUARIBAgErAOIA5gDdAMUA+ACzAKAAhgCEAJEAkwCDALuAeoBuAF6AW4BbgEqAdsA0gDsAOYA3QAOASgBCgHcAMcAvQCSAGIAWQBUADIAEAAUABQAAQDf/6X/W/8O/9L+oP6C/mT+Qv4g/vz98P3U/aj9bP0g/dD8kPx8/Hz8YPxI/FT8RPwQ/Oj7+PsA/ND7qPvA++D70Pvo+zD8aPxM/Ej8iPyw/LD80Pwg/VD9WP2E/ez9Kv5I/nD+2v4g/0n/gP/J//3/IwBkAJwAuwDZAC4BkgHAAdQBEAJYAnAChALAAvwCEAMcA0QDYAN4A6wD/AMgBAAEAAQ4BFAESARQBIgEqASQBIgEqAS4BLAEqAS4BKAEaARIBFgESAQYBPAD2AOcA0gDGAP0AqwCPALqAbQBbAEaAdQAmQBCAND/cv8t/+L+lv5S/hr+3P2Y/Vz9PP0Y/eT8qPx4/Ej8FPzo+9j70Puw+5D7gPuA+3j7cPtw+3D7cPto+2j7cPt4+4j7oPu4+9D72Pvo+wj8IPw4/Ej8bPyU/LD80PwI/Uj9fP2s/eT9EP44/nL+vv4Q/13/r//z/yIAWACtAAYBPgFuAboBEAJMAngCyAIcA1QDgAO4A/ADGARABIgEwAToBAgFOAVQBWAFgAWgBbAFoAWYBaAFmAWIBYAFeAVgBSgF8AS4BHAEKATcA4wDLAPEAnACGAKwAUYB5wCHAA4Akv8n/87+dP4Q/rD9VP34/Kj8aPw0/Oj7oPtw+0j7IPv4+uD62PrQ+sD6wPrQ+tj66PoA+xj7MPtI+4D7uPvY+/j7JPxY/Ij8sPzs/Cj9VP14/aj95P0U/jz+Yv6I/rL+4v4R/0T/df+m/9b/BgAyAGIAlADKAP4AMAFkAZYBxgHyARQCOAJUAmwCgAKkAswC9AIUAzQDVANsA3gDjAOgA6wDqAOsA7QDuAO0A7QDwAPEA7gDmAN4A2QDVAM0AxAD8ALMAqQCdAJMAhwC5AGsAYABSgH5AKsAdQBKAA8Axv+R/2j/L//s/rb+mP5e/ib+AP7o/cT9pP2Y/YT9YP1I/VD9UP1A/TD9LP0o/ST9LP08/Uj9SP1c/Xz9jP2M/Zz9rP28/cz97P0G/h7+OP5W/oL+ov6+/tj+9P4L/y3/V/+G/7H/xv/V/+//GgA2AEUAXgB9AJUAmwCvANsABAESARwBKAEqATABRgFoAYIBkgGgAaoBsAHAAdQB3AHWAdQB4gHwAfIB6AHoAeoB6gHqAegB3gHSAcQBuAGmAY4BdgFwAWwBUgEuARYBBgHuAL8AiwBkAEoALQAIAOH/vv+c/3v/U/8v/w3/6P7C/qL+gv5c/jT+Fv4A/uT9xP20/aj9nP2E/YD9kP2Y/ZT9nP20/cT90P3o/QT+Gv4w/lb+hv62/tb+9v4e/0b/Zv+B/53/w//w/xoAPQBfAHsAjwCjALsA0wDkAPAA/QAQASIBMAE6AUABRAFIAUwBTAFQAVQBWAFSAVABWAFgAV4BVAFMAUgBQAEyASYBGgEUAQYB/AD0APIA6gDdANsA2wDQALwApgCaAIsAfABrAF8AWABLADQAHwATAAsAAQDz/97/wP+k/5f/k/+J/3X/Zv9b/0n/MP8c/w//Av/y/uT+3P7S/sj+xv7M/s7+yP7G/s7+1v7c/ub+8v4A/xP/Lv9I/1v/aP97/5P/qv/D/+L/AwAcAC0AQQBbAHAAggCVAKgAuADGANQA4ADpAPIA/gAIAQgBBAEKAQ4BCAH7AOsA3gDSAMYAvQCtAKAAlwCUAIUAbgBjAF8ATgAzADcANwAuAB8AGwAeAAkA9//7//j/2v/D/8n/zv/G/8D/wv++/6n/lv+d/6r/q/+e/5L/kP+R/5H/kf+O/4//kf+Q/4T/fv+B/4T/f/90/2r/af9o/2H/W/9c/13/Vv9P/1P/Yv9y/33/g/+G/4b/hf+P/6P/uv/L/9j/5v/3/w8AKgBCAE8AWABjAHMAfACAAIsAogC0ALUAsACyAL0AyQDIAL0AswCsAKkAqwCuAKcAnACRAIcAfQBvAGEAVQBJADoALQAlABsAEAAAAO3/2//T/9P/1P/P/8r/yP/D/7r/sP+v/6//p/+f/5//qP+t/7D/sf+y/7L/r/+o/6P/of+k/6b/qf+t/7H/rv+o/6T/o/+i/6L/p/+w/7j/wf/C/7r/rv+o/6b/oP+W/4//jv+K/4X/h/+M/4//jf+M/4z/iv+G/4r/l/+q/7j/wf/L/93/7v/3/wAAEQAkAC0ANABFAFYAZABxAIcAmgCdAJ8AqgC4ALkAsgC/ANMA2wDUANUA4wDfANIAygDQAMoAxQDHAMYAtACgAJ8AnwCRAIIAfQB2AGMASwA8ADAAHwAVABMADwAKAAQA+//v/+P/4P/b/8z/uf+v/7L/uP+8/73/sv+c/4//lf+i/6f/oP+a/5z/n/+b/5b/lv+X/47/ef9s/3P/gP+H/47/kv+O/4j/h/+L/5H/lf+Z/57/pf+u/7f/vf/D/8v/1//j/+n/6v/p/+f/5f/m/+j/6//0//z////+//j/8//3//z/9v/y//7/FQAlACkAKwA3AEUARwBGAEoAUgBWAFYAVwBcAGQAbABxAHYAfACBAIQAhAB9AHAAaABsAG8AYABIADwAPgA5ACgAHAAbABsAFAANAAcA+f/k/9X/0f/R/9D/1P/e/+H/3P/T/8r/w/+3/63/rP+x/7X/tf+0/7r/wf/G/8n/yP/I/8r/zf/Q/9L/0//U/9X/2P/d/+D/3//a/9X/1P/X/9r/3v/j/+7/+f///wAA/v////3/9//z//T/8v/z//n//P/9/wMADAATABMAEAAMABEAGwAfABwAGgAdACMAKgAuADEALgAlABwAGwAdABwAIgAtADkAPwBCAEgAUABVAFgAXgBhAFsATwBIAEcARwBGAEkASwBDADgAOAA7ADkAMQAuAC0AJQAXAA4AEAAVABQADQAGAAIAAAD9//j/9f/z//T/8//u/+X/3v/Y/8z/v/+1/6z/nP+P/4r/jv+U/57/qf+t/6L/l/+S/5f/nf+j/6r/uf/O/+D/5f/e/9v/zf/G/9D/8/8YACAAHwAsADcALQAZABAACwAEAP7/BwAYABYABAD6//n/7v/V/8X/yf/L/7//sP+t/67/rf+x/8H/1f/b/9X/0f/V/9b/2f/f/+T/5P/m/+3/9P/6//3///8DAAkAFQAnADUAPwBFAEMAQQBGAFQAZgBzAHcAZwBOAEEASABRAEQAIgAKAAAA/P/v/+X/7f8BABAACgD9/wUAIAAsACEAFAASABIAFgAlADsATQBPAEkAOQAeAPz/4P/F/6f/iv99/3j/a/9I/yD/Bv/4/uz+4P7i/uz+9P7+/hL/LP9I/2D/bP9z/33/mP/J/xcAawC8AAYBQAFgAXIBigGiAbQB0AH8ASQCSAJ4ArgC0AKgAkgCBALQAYgBNgH2ALkAYgAQAOj/x/9r/8j+IP6k/Tj9xPxo/ED8NPwg/Dz8nPz8/PT8CP0A/pb/tgAkAQwC2AMYBegEeATIBEgETgGs/XD8+P3f/8gAGAEwAWgAAP9A/lb+Ev5M/UT9Gv68/i3/CACZALD/Fv6M/RD+Tv5G/gv/WwAGASQBfAHYAdoB1AEIAgACggFGAdABfAKoAlgC6AE8AV4Arv99/7P/tf9i/0j/yv96AMoA/QBYAV4BlwDY//D/lAAiAZwBVALEAoACHAJEApACOAKeAT4B6gBnACMADQCQ/7T+CP6E/bz8BPwE/GT8TPzY+7j78Psg/KD8iP0g/ij+jv6Z//z/af9s/8oAxgEuAXMAGgEoAhgCqAEwAtwCHAKFAOb/fwDdAHYAFAAaAN//Lf+e/rL++v62/tz9OP1Y/dz9Sv6A/qL+rP6O/mz+cv6+/hb/UP9i/5P/5v9GAKUAFAGCAboBnAFqAYQB1AEsAoQC/AJYAzwDsAI8AhAC6AFeAbAAbACjANMApwB4AG0AGwAZ//T9eP2E/Yj9RP00/aD9DP42/mb+5v5N/yv/5P4b/8f/YQDgAKoBdAKsAmgCTAJoAkAC5AHQAQwC+gGaAXIBogG2AWoB3wBSAOP/hv9X/1b/if/S/wIA/v8BAC0AXQBOADIAFwC7/2j/rf9hAOUAHgFQAWgBDgGeAKEA9QDsAKAAbgBWAA0A2v8RADMAqP+0/vz9XP2g/Az8BPzA+8D6kPmg+OD3QPdA98D3APjQ9/D3iPjw+FD5OPpY+/j7APx4/ND9mP9yAUwD+AQQBsgGiAdwCCAJoAlQCuAKEAvwCkALAAyQDCAM8ArACcAI4AdABwAH2AaQBvgFMAVYBLwDjANcA5ACeAEIAT4BnAHwAZwCHAPwAigCKgFeALH/mv+6/97+7PyI+1j7CPuA+RD3UPQw8YDuQO3A7cDuEPDA8EDwoO5A7UDtwO3g7UDuYO9w8EDx0PJw9aD3uPh4+TD60Pro+0z+jgFIBEgGMAjACcAK0AtwDbAOAA8wD/APgBCgECARwBEgEQAPAA2wC0AKwAhACLAIgAhoB4gGOAZoBbQDdAIUApQBqwCGAJIBjAK8AuQCRAMwA4ACQAKsAiQDgANIBGgFQAaoBvgG8AaABggGgAXYBIAEwASYBDAD1AGQAfUAvP4M/Mj5wPdQ9UDzIPLQ8ODuwOzA6gDogOTg4eDgQOEg4mDkQOcg6mDtoPAw80D14Pcg+8z98ABYBcAJwAyQD8ASABTAEuARoBKgESAOEAzwDGAMMAl4B0AI0AaYAVz9CPxQ+lD38Pa4+Yj76PpA+7D9Ef+0/qr/hAJQBIgEEAZwCeALwAwQDsAPkA/gDdAMYAwwC/AJ0AmwCWAImAZoBTAEoAKGAUgBhwAS/0b+0P6M/xcA3QDKARAClAGSAYgCeAR4BsAH6AeQB6gGKAWwA3AC1wCk/Sj7CPq4+ED14PHw8IDvgOng4ADcQNtA3IDfAObg7ODvEPBQ8QDzcPMA9aj5Av9AAewCUAigDwATwBJgEqARQA04B3AFqAeACEgHSAeYB6gE6P8K/gz+MPvQ9gD2WPj4+Tj70v64AvgCGAH/ADwCvALUAwAHMAoAC3ALgA0QD1AOYA0wDUALMAeABCAFWAaABhgHAAh4BowCwf9T/03//v7r/2wBrAF+AegCAAUIBlAGCAcQB4gFuAQ4BpAI4AmACoAKgAgABZgCGAFk/nj7ePpw+bD0IO/A7eDuoOzA5qDhgN3A2EDXAN2A5qDsAPBw87D1sPSg9ED58v5oAZwCKAaACoAN8A/gEkATAA9QCWAFBANEAUIB3AJoA2YBuv5I/ZD8iPuI+sj5MPko+bD6XP2uAFgEmAfQCAAIcAdACAAJoAnQC9AOcA8ADrANcA4gDRAKUAhgB8AElAGEAZQD9AOsAhQC5AE3AJr+SP8cAfgBdALUA/gEWAU4BjAIcAlQCSAJgAmgCZAJcAqAC1ALEArQCJgGLAMTALD+4Pwo+ZD14PMg8uDuQOyA68DpYOSA3kDaQNhA2cDf4Olw8dD0IPeQ+RD6aPmw+9AA4ATABhAJsAxAD4AQoBCAD3ALqAUIAdb+ZP4w/gj+NP7Y/ST8CPog+Xj5oPkA+Yj5qPuM/oYBmASQB5AJcAqQCsAKMAvwC5AM8AyQDSAOkA0QDCALoArwCGgGoAREAzABof/O/2cALAAuAPMA6wBt/+T+ZwDiAaAC8AMIBgAH4AawB3AJ4AlQCaAJMAqACUAIoAhgCUAICAa4BKADjwDM/ND6gPmg9tDyQPCA7mDsYOsg7KDqwORA3sDbwNyA30DlQO4w9tD5KPtg/JD9lv52AHADKAaACPAKAA2QDgAQwA8wDKAG9gGO/iD7IPlo+nz8+PsY+sD5sPoo+uj4gPl4+5z8SP34/5AEkAiQCuALEA3ADEALcApAC6AL0ApwCrAKQArACMgHSAdwBVACfQA5AIj/3v70/wgCSAIWAdYAjgF2AXYBUAMYBqgHEAjQCHAJIAkQCdAJ8AngCFAIsAhACHgH8AfACBgHkAN8AVgASP1o+UD4uPig9hDy4O6A7oDuwO3A7ODpQOSA3oDbQN0A4yDr0PIo+Kj7vP3s/QD+9f90A4gFcAaACJAL4AyQDAAN4AyACbwD6P7Y+0j5wPfo+BD7kPvI+tD6kPto+7j6iPs4/Wj+6P9IA+AHUAugDGANkA2QDFALAAtgC2ALcArACeAJAArACfAIYAeoBEQBnP6c/V7+5f9EAf4BJALaAXoBZAEEAmwD8ATwBagGsAfwCJAJ0AkgCjAKcAlwCDAIYAgQCKAHWAdABlAELAJFAOT9FPww+2j5IPbA87DyAPDg66DrgO/A7+DpYOSA4sDfQN0g4YDrkPPQ9sD6AwCKAer/LgHYBNgFWATwBPgHoAkgCqALYAywCSgEdv4w+jD3EPYA98j4oPoE/Mj8jP12/rD+2P1E/fL+6AGYBLgHwAvADsAOEA1gDDAMYAqACKAIsAlQCUAIYAgACZgHqAQsAnwAmv5I/ez9FwAUAuQC2AKMAmQCWAJ4AlADCAXwBiAI4AigCVAKsAqwCjAK0AiAB6gGEAaQBcAFQAbABTAE7AKaAbj+cPto+jD6UPeg84DyoPJA8MDtIO+A8MDsAOfA5IDjgN9A3sDlAPGg9xj76/9EAwAC1P+yAVgEuAMYA+AFgAlgCiAKwArgCbgEfv7o+oj5aPig9xD5cPu0/Pj8tP0L/3L/+P5D/1IBnAM4BQgHIAoQDQAOoA0ADRAMQAowCGgH4AdACFAIQAiwB/gFgAM+AW//NP4y/if/dwCyAQwDIAQgBIgDeAPsA3AEAAUgBrAH8AigCQAKUArACWAIGAfQBgAHUAZgBdAF2AZIBuwDDAIWAQ3/6Psw+rj5GPgw9cDzQPTw8kDvgO3g7mDu4Ong5cDk4OLA32DhoOoA9cD73QC4BVAGsgFm/sj/JALEAkAEuAdAChAKIAkACOAE6P94+3j40PXw89D0YPjw+yD+oP+7AN8A5f88/7P/BgEYA/AFgAngDDAPsA8gDpAL4AiQBgAFIAXQBrAIMAmQCDgH6AQQAsD/mv6S/mr/CAH0AoAEeAWoBTAFeATcA5gDEASABagHkAmQCuAK0ApQCkAJ8Af4BnAG+AWQBWAFYAUYBSAEwAJiAeX/uP0o+2D5YPjA9pD0oPPQ85DygO/A7eDtoOwA6aDmIOag40DgwOKg7GD2CPwmARgGeAYiASD90v7KAUADsAWwCSAL8AjABjgGAAQB/8j60Phw92D2IPf4+Yj83P1I/7gAHgGBADYA+gCsApAEeAYgCZAM8A5wDvALwAnQB2gFIARoBVgHmAewBmAGsAVgA0AB6QD7AEcALAAMAmAEWAWQBeAFcAXkA8wCmANgBVAG8AZgCOAJAApwCUAJAAmgBzgGGAaABjAG0AVQBpAGIAWYAvUAxP+Y/Qj7wPlY+eD3kPVg9AD0APJg7yDvUPCg7qDqoOig6IDlIOGA40DtYPe4/bQDcAiwBp3/6PuE/ngBzAHgA/AIAAtACCgFcASoAhb+CPpo+PD2EPWw9Vj5hP35/+gBGASoBFgCg/+O/u7/VAJIBZAJoA3gDkAN4AqgCBAGlAM8A+gEKAawBnAHyAe4BpgE/AIIAtcA2v8KAEYB/AKABFAFeAX4BPAD3AJ4AnADEAVQBlgHoAjwCcAKAAuwCqAJwAcQBjAF8AQgBZAF0AVYBTgE6AJsAV//9Py4+oD4IPZQ9PDzIPQg82DxsPCw8KDuwOqg5wDmgONA4cDjoOzA9fj7HALQB8AHSgFQ/B7+/AFkA+AEIAigCTgHQAQIA4AB2P2I+uD4gPdA9qD24Piw++j9uv9gASQC3gEcAQwBXAKYBDAHMArQDLANkAyQCoAImAYoBQAF+AUQB9gHMAi4BzAG2ANqAdv/4f/YAHQB1gH8AkgESASQA4ADtAPwAjQCLAMwBdAGUAiQCrAMMA1gDCAL0AkQCAgGyATQBPAF+AYgB4gGiAWQA5YArP2o+xj6aPjw9iD2kPWA9PDyUPHg74DuAO3g64DqIOgA5YDiIONg5yDv6PgcAlAI4AlABwQCyP2s/dIAhANIBYgHEAmYB8QDggBG/kj7UPgA97D2gPaA99j5VPza/gwCeAQwBMgCBAOIAygDgATwCMAMIA1wDJAMEAvoBvgDOATwBKgECAWQBtAGGAVgA2wCMAHm/9r/bwDOAGAB3ALQBPgFIAbQBQAFoAOkAuwCmASABkAIYApADLAMcAuwCXAI8AYIBRgEkARwBZAFSAXQBJwDWAEG/yj9OPvo+MD2gPWA9FDzUPLQ8QDxgO9A7oDtAOxA6YDmAOWg5GDmAOzg9QIAEAeAClAKWAY8ACj9Af+8AngFUAegCIAISAaAAr7+uPtg+SD3MPUg9UD3mPl4+3j+iAKgBJQDhAJMA7QDzAJgA9gGkArwCyAMwAwwDHAJ4AW0AxQD5ALkAugDcAXIBagE8AKOAR4Alv70/YD+r/80AZADCAYQB4gGoAWQBOACHALYAxgHgAnwCtAMQA5QDbAKsAioBwgGSAQYBPAE8AR4BKgEoAQcA9oAB/+Y/ED5wPbw9VD1QPSg9LD1gPQw8SDvoO6A7ODnoORg5GDkIOTA56DwcPu4A3AIMApACNQC9P2Q/Z4BGAaACCAK8AqACTgFagDM/Mj5cPYQ9HD0kPbY+Fj7uP7QAewCcAJIAsACyALAAvwDeAbACGAKIAxwDWAMoAn4BhgFUAPqAYACcATwBWAGIAZABZwDrgFkAMb/ef+o/28ApgEUA5gEyAUoBuAFAAUQBMADsASIBmAIAApwC1AM4AtACqAImAd4BigFoAQIBUgFwAQYBKADWALT/zD9IPtI+ZD3MPbw9NDzwPPQ8/DxoO/g7wDxYO6A6cDnAOjg5MDhgOYw8jz8GAMgCgAOUAlnAPD8Tf84ATwCCAZACiAK2AZgBJwCvP44+pD3MPaQ9BD0UPaI+mr+ygGQBEAFAASIAuYBGAL0AvgE0AdAClAMUA0wDDAJIAb8A0gCBgH2AVAEiAVwBYAFiAXQA+0APf8C/3T+HP68/8gC8ASIBbgFyAUgBdwDNAP0A8AFuAcwCSAKwAogC9AK8AkQCWAIoAd4BhgFKAQIBOwDdAPwAmQC0AAG/tj7APvY+UD3UPWg9bD1QPNA8RDykPLg74DtAO4g7UDnQOLg44DoYOzQ80ABQAzwDMAHlAMuALD8aPywAUAHgAgACEAIQAd8A1f/AP0I+wD4IPaQ9gj42PnM/PwApAOQA5QCPAIoAjQCTAOoBVAIMApgC7AL8ApQCUgHQAW4A2ADxAPsA+QDOARwBMgDeAJmAXkAJv+8/UT9KP4wAHwCYARoBbgFSAX8A9ACHAPYBPAGcAigCaAK8AqACuAJ0AmQCZAIMAd4BhAGyARsA5ADOAQkA4AA2v6O/kz96PrQ+aD50Pdw9PDygPNQ8uDuAO6A8MDw4Ozg6ODnAObA4uDk4O7g+vADsArADkAMjANA/Fj7Rv6YAXAFMAmACsAIqAVQAh7+4Pkg98D1kPQw9DD2ePq8/uABYASoBaAE5gEeAGsA2gHMA7gGgApADeANkAwgCkAHgASYAtwBJAL4AjAEEAUIBRAEzAKEAfL/Sv6w/XL+nf++AFwCYARIBcAEKAQgBBAE+APABKgGoAjwCQALsAugCwALQApwCVAIIAcoBjAFQASkA1wD7AIUAu4AZ/9c/dD7QPtQ+lD48PYg99D2QPTA8UDxMPCA7YDs4O1A7ODloOGg5IDqYO9A99ACEAugCugFCANuADj9rP0kAwAIsAj4B0AIuAbIAVT9EPu4+OD1MPUw90j5qPp4/VABSAPQAjwCSAI4AtwBaAKgBLgHcArwC1AM0AtgCugHkAVgBMQDWANAA6ADiAN8Ao4BLAFhACz/fP5w/or+I//xAEgDeARoBBAEtANIAxwD5AOQBXgHEAmwCgAMYAzgC/AK0AmQCFgHgAYQBggGYAYQBkAFWAQYA9oAaP7g/Pj7gPow+eD4kPcw9YD0APaA9ZDxAO/A8IDxwO2A6cDnwOWg4mDlgPCo/OgCQAbwCcAJ4AIc/ID8YAC4AqgEsAgwC/AIsARcAlP/0Plw9cD0wPUQ9pD3sPsXAEQCKAN0A8wC8QAS/zz/ugE4BeAIAAzgDfAN8AvwCDgGAATEAsgCuAMoBTAGKAbQBIACQACg/oD9GP1w/Rr+Hv+sAIQC9ANoBBAELAMUAnoB/AGMA+gFwAhwC1ANEA7ADXAMgAqwCFAHYAY4BgAH0AfIBwAH0AUIBIwBCP8o/Rz8yPuI+3D66Pgg+GD3gPWQ8yDzoPIA8EDuMPDQ8IDqoOJg4cDlIOpA8Lj7+AZwCYAFkAJiAbb+0PwsAHAGEAnoB/AGYAYABMr/PPwo+gj4cPUw9DD1YPfo+Rz9yQBkA3ADmgGm/+b+zf9UAugF8AlADaAOwA3wC+AJaAfgBOADkARABZAFmAY4B1AFzAGr/5b+PPwI+rD6KP1i/vb+DAGAA8gDbAKOAXgBXgHmAcADsAbQCXAMQA7wDvAOIA4wDJAJyAcgB+gG6AaYB5AIcAjABlAE7AGj/5D9QPzQ+2D7oPp4+VD4YPdQ9oD08PGA74Dv4PCw8ADvoOxg6eDjwN/g46DvAPvIAsAIsAuQCJABJP1o/WP/HAIwBlAJUAkgB5AEIgFc/WD60Pfw9HDz8PTg9gD4KPu6AEAE0AN0AvQB1wBU/wwBIAawClANMA9gELAO4AqQB9gFsAQIBMgEMAbgBhgGeASAAikAsP3o+3j7wPsM/Oz8DP9oAVwCNAJUAlwCRAHG/z8A/AL4BXAI4AqADaAO8A2wDMALgArgCMgHuAfgB5AHMAfYBugFGAQMAjkAUv7Q/FT8BPwI+yD68PkQ+cD2oPRA9DDzkPAg79DwsPIw8ADrQOZA4+DioOew8Uj9yAVgCXAI+APc/tD7SPzk/+gEUAkgCyAKkAdoBIQAKPxo+ND1YPRA9LD1wPhM/Kz/KAIQAygCnACz/7H/ugBkA+gHYAzADmAPIA+QDQAKQAbABNAE2AQIBRgG0AaQBeQCxwBR/wj9OPrY+MD5kPss/QD/mAGkA6QD6AEqAGv/Vv9rAIADuAeAC9ANAA/wDmANYAvACdAIMAhQCDAJkAkACRAIIAcwBXwCmADO/7z+UP3M/PD8EPxw+lD5MPiw9YDzMPPA8nDwIPBA8zD18PFA7CDoAOSg4CDkAPAc/MwCoAYQCWAG4v4Q+mj7Fv/GAfAEEAlwCrgHaAQoApP/uPug96D0cPMg9OD2EPtu/9gCEASwAkkAzP7c/lcABAP4BiAL4A2gDlAOgA3QCxAJqAbwBWAGSAZwBQgF+ATUA2oBjv+a/vz8GPo4+BD5MPvw/Fr/nAI4BKgCIQBL/6H/TwDgAuAHYAwgDrAOIA9QDvALIAoACtAJUAnQCfAKkAqACKgG4AQwApv/7P5U/+z+1P20/Uj9MPvY+PD3gPew9SD0wPQw9VDz0PGw8gDzQO8g6kDnQOVg5CDp8PPk/YgCEAV4BwAFhP0A+WD7/P+8AsgFQAogC8AG3gFa/wz9gPhQ9HDzwPSg9kD5VP24AbgDUALY/3j+gP58/+QBMAbQCtANEA9gD2AO4AsgCXgHsAZABkAGoAaoBtgFcAS4ApkAiv6k/HD6iPjw9yD5IPv8/FT/6gGcAnAAPP40/rL/MgHcA+AIkA3gDtANEA2QDDALAArQCkAMgAzwC4ALoAowCCgFdANkAiQBIADm/wMA8P68/Pj6MPrY+ID2oPVA95D3kPRA8tDzcPVw8mDuIO5g7qDqQOdg6MDrQO+Q9Vf/OAaQB/gFzAII/kj6mPuPACgFAAkwDFALGAZlAIj8uPiQ9DDzwPSA9uD46PxlANoAa//u/jz+PPzQ+yH/UATACBAMkA/gESARQA4gCxAJsAfoBlgH4AhAChAKqAdIBPsA6P0w+9j4cPew9+j4QPrY+/D9AQB/ADH/Hv5W/j//jwBcA/gHYAxQDpAOgA7gDQAMkApAC/AMgA0wDbAMIAswCEAFoANcAsMAKwCuABwAqP34+8j7uPog+AD3GPjg94D10PSQ9jD2APNA8cDysPJA76DsAO0g7ADpQOng79j4bADIBjAK4AccAUD7kPkg+xD/QAWQCqALEAn4BAMAKPqg9YD0MPWA9ZD2mPkA/bz+cf8gAK//7P30/ID+SAFIBHAI4A3gEUASQBCQDRALUAi4BrAHMAqwC/AKYAmoB0gECP8A+yD68Pko+MD2WPgg+xz8VPyo/Zb+iP0U/HD8eP7RACAEkAgwDNANwA0ADdALsArQCoAMwA3ADWAN0AwQC7gHuAQ8AzQC3ABgAPgA0wBP/7D9nPzQ+mD44PaQ9gD2QPXw9RD3gPbQ9CD0sPNg8YDuAO4A7iDrYOjA6nDxePig/hAFUAh4BMD8APiw9zD6pP6gBKAJ0AqgCFAEbP7o+MD1kPRw9ID1WPio+/j98f/UAf4BEgDI/bD8OP2Q/9wDkAnwDqASoBNAEcAM8AhQB1AHoAhAC8ANwA0gC+gH8AQgARz9+Pow+hD5MPgA+RD76PtE/Gz9xP3o+5D64Ps6/sD/HAJYB0AMcA1ADLALQAtQCgAKsAsQDhAPsA6ADWALcAigBYADKALkAVQCFAK7AJ3/0P74/Dj6iPhw+ND3QPZw9SD2sPYQ9mD1MPUA9QD0EPIA8ADuYOtg6GDooO2A9kL+yALABKwCyPsw9XD0APmO/mQDcAgQC2AIwAJi/mD70Pcw9TD2EPkA+gj6YPxYACACyACG/3v/7v6I/Yr+rAPgCQAO4BBgE8AS0A0QCFgG8AdwCQALcA3wDuAMIAjEA10AjP0I/Bj7uPkA+Rj62PtE/CT85Pys/Kj62PmQ+zj9ev6SAZgGwAkQCnAKMAtwClAJIAowDFANQA4AEIAQcA3wCBgGsATsAuQB9AKQBPQDKAE8/rj8yPrw90D24Pbg9zD3cPag9+D4QPdw9JDzEPQw80Dx4PCw8GDu4OtA7ZDyIPhk/BwApAHm/mj6KPgQ+YD7pv54AqAFMAbcA2v/4PoQ+ID30Pfw97D3cPjo+dj6+PuA/gACuAMYA4QCdAOcA1gDsAZwDUASABJAEeAR4A+ACgAIAAtADVALYAmwCUgHWAHU/az+aP64+lj46PhQ+AD2UPZo+VD7aPtI/Kz9SP3Y/Hb/7APABnAI0ArwDPAMMAwADUAOUA5QDlAPsA8QDmAL0AlgCBAGAATUA0gEFAPMAF3/cv74+zj5MPhw+FD3wPWg9ij5YPnw9sD1IPYA9fDxwPAw8mDyQPAg79DwYPLg8hD1WPk4/Hz8RPwQ/ST9MPzI/E3/egEcAuYB1gCg/aD5YPjQ+YD64PkY+mj6gPcQ81Dz4Pgs/sQBeAYQC/AJxANIAP4BGAUACZAPIBbgFuAS8A+wDvALQAmQCZAKMAjIBMgEsAUoA2r/Pv7I/FD34PHQ8RD18Pa4+MT8V/8k/eD52Pk4+6D7+P1IBGAKQAxADNANIA/gDTAM8AzQDqAOUA1wDUAOEA2gCjAJYAgoBpACGQBr/+7+EP48/TD8wPrQ+BD3cPVQ9MD0IPbw9qD20PUA9eDzEPLQ8EDxYPKQ8oDysPPQ9UD3QPiA+gT9tP30/Oz8Jv70/jL/w/+QAOf/Dv50/Ej76PkI+eD5IPtA+rD3sPVA9CDy4PKo+QwDgAggCfAIIAfMAdz9XgFgCUAPIBIgFeAW4BNAD3ANYA0QDKAKsAowCnAHgAUYBngFMAEA/LD4APYA88DywPYI+xT8aPvQ+mj54Pbw9bD4cP3kAegFkAnwC5AM4AvwCvAKEAyADcAOABDAEKAQYA8QDoAM0Am4B7gGMAV4AiIBgAEiAWD+mPtw+lj4APVw88D08PWg9TD1kPXA9IDy4PBA8ODvMPDQ8aDzUPTw9LD2wPdw91D4CPsc/UD9Iv50AIQBOACL/zUAwP8s/RD7uPrI+oD6OPp4+mj6qPhw9fDy4PIg9Xj4iP3YBHAKsAo4B8QDSAEpAPAC0ArgEoAWwBagFeASgA6wC8ALUAzACpAJ8AmACQAHKASgAmsABPwg93D0MPQA9cD2IPmo+jD6cPig9hD28PZA+ej8mAFgBsAJsAowCvAJYArgCmALAA0AEAASoBHgDwAPcA6QDNAJQAhgB3gFiAPcAogCmQAE/nT8qPqg9wD1cPTw9AD18PQw9dD0UPOw8cDwYPAQ8GDwAPIw9FD1UPWw9VD3WPiQ+AD66PzE/l7+ev73/08A1v5Y/lD/9v70/Oj7fPwQ/ED6kPng+XD4gPXg8+D08Pa4+Sb+PANwBrgG6ARYAmsA/wAYBQAL4BDAFAAW4BOgEGAOEA4gDrANAA2ADPALYApACLAGsAXUAg7+ePrg+GD38PUw9zj6SPpQ9+D1gPZg9VDzkPWA+2f/2gAYBBAIQAhIBigHEAoAC4AL4A7AEiATgBGAEWAR0A4ADIALIAvACNAG4AYABlAC7v6k/eD7CPhQ9ZD14PUQ9KDycPNA89DwQO5A7qDuwO2A7aDvYPJQ84DzUPSA9dD1UPZg+Cj7CP0m/rj/PgGIAfgA/wBMAa4AK/9S/l7+4P20/Pj76PsQ+/j4sPbA9YD18PWQ+HD9KAJ4BNAECASAAZb+6v5MA/AI8A2AEkAVoBOgD0AOIA9QDsAMgA0gD8ANoAogCsAKUAicA3oAHv4o+rD2MPd4+bj5OPmA+Vj4IPQw8fDyQPbQ90j6lP+YAzwDWAJABCgG0AVoBkAK0A1gDvAOgBHgEuAQkA7wDUANAAtgCcAJ4AlQCJAGGAVUAij++PqY+WD4sPbA9ZD1kPSQ8tDwgO9A7iDt4Oxg7cDtgO7g73DxYPIg8yD0MPVw9jj4mPqw/Kj+VQCEAcABXAHyAIEAUwBUAFAA9f+W/yP/Ev5A/HD6QPk4+JD3MPig+sT9ywBoA4AE7AL4/1j+7v48AYgFwAvgECASABHQDxAOwAtgC+ANoA/ADhAOIA/ADuALEAnIB3gF5wA0/RT8ePuY+vD6LPzY+yD5UPaQ9BDzgPJQ9OD3APso/fT+JwA7ABgA8gCMApgEMAcQCnAMEA4wD+AP0A+ADzAPYA5ADaAMgAzQC6AKkAlACLgFaAJ1/yj9oPqg+MD3EPdA9QDzMPGg74DtwOvA6wDs4Osg7GDtYO6g7kDvAPGw8qDzYPUI+KD6ZPw8/vf//gAgATYBaAFUAXQBxgEoAhgCsAHiALv/lP6E/Uj8WPtw+7T8fP69AHADAAVoBGwCMgCY/sb+AAJYB9ALUA6wD1APwAxQCoAKQAygDHAM0A0AD3ANAAtwCgAKGAdwA8IBogAI/kD8FP0G/sT82Pr4+Wj4YPWg87D0sPbg93j5QPxA/kr+BP6Q/kr/uv8gAfQDyAbACJAK0AwgDhAOoA2gDRAN4AswC3AL0AuwC4ALwAqgCDgFLAKx/yz96PqA+dj4wPfg9fDzEPJQ8IDuQO1g7MDrgOvg66DsoO2A7mDvYPBw8XDyYPPQ9PD2SPlg+zz9iP5Z/+7/jwAIARgBbgFMAvACzAKsAgAD1AKcAa4A6QAyAQIBtAG8AxAF0AQ4BGgE9APIAtwCsASQBpAH8AjQCsALMAvQCtAKgAqACVAJ4AkQCrAJ8AmACuAJIAhoBgAFFAMmAXoApAACALz+Iv7E/ZD86PpI+lD62Plw+ej5oPq4+tj62PvI/MD8zPwK/o7/XABKASAD4ARwBagFeAYgBwgHIAcACMAIkAhgCLAIgAhgB1AGuAXoBHQDOAJ0AUcAmv5M/XT8QPto+dD30PbA9YD0kPNQ8xDzgPIA8tDxwPGg8dDxkPKA82D0QPVg9nD3KPjA+HD5MPrA+mD7QPws/fT9rP5w/wkALQAuAEgAegCxADAB/AH4ApwD/ANgBLgE0ASQBGgEgATYBFgFQAZYByAIYAhwCCAIeAfYBtAGKAdYB3AHsAfIBzgHcAYABqgF4AQIBLwDpAMYA3wCdAKIAhQCjAFQAe8AAgBQ/0j/Qf/e/sL+Kv9P/9j+bP5u/kz++P38/Wr+tv6o/sb+IP9O/0H/Zf+i/5v/a/94/7v/1f/u/0oApwCpAHQAagB7AFsALAAsAD4AEQC6/3//T/8E/67+jv6C/jb+wP18/WD9HP3A/KT8rPyE/DT8CPzw+8D7gPuA+6j7oPtw+3D7gPt4+2D7gPvA++j78PsI/Dz8aPyk/AD9WP2I/bD92P0E/jz+jP72/lz/pv/V//b/FwA/AG8AuQAeAYYBzgH4ATACeAKcArgC6AIgAzgDNANQA3wDmAOYA7AD1APAA6ADkAOQA4ADdAOAA4gDdANcA0wDKAP8AtgCvAKYAngCdAJ0AlgCOAIwAiAC/AHQAc4B0gHAAcAB3AHyAeQB1AHuAQAC6gHSAdQB9gHsAewB8AH4Ad4B2gHqAdwBqAGGAYQBYgE4ASwBHgHqAK0AeQBFAPD/iv9L/wb/sP5w/lb+Jv7M/WT9IP3U/Hz8KPzg+6j7aPsg++D6qPpQ+gD6wPmY+YD5WPlA+UD5QPk4+Tj5UPlw+Zj5sPng+TD6iPro+lj70Ps0/Iz85PxM/bz9QP7U/lr/0P9RAMkAKAGCAd4BRAKgAvQCTAOoA+gDEAQwBGAEkAS4BNAE4ATwBAAFAAUQBRAF+AToBOAE6ATYBLAEmASIBHgEUAQgBAAE8APQA6ADZAM4AxQD5AK4AqACiAJsAlgCTAI4AhAC7gHmAeABxgGoAaABoAGUAX4BcgFeATQBCAHvAM0AmgBqADwAEgDm/7r/jP9e/yb/6P6s/mr+Lv70/bj9iP1o/VD9KP3s/LT8gPxM/Bj82Puo+3j7UPso+wD74Pqw+oD6UPow+hD68PnI+bD5sPnA+dD52PkA+jD6aPqg+vD6SPuw+wz8ePzs/Gj93P1S/tz+a//w/3IA+QB6AeYBTAKoAggDbAPAAwAEOARoBJAEqATIBOAE8ATwBOAE0ASwBJgEkASQBHgEUAQ4BBgE9APAA5wDhANoA0gDMAMUA/AC0AK4AqQCiAJoAlgCRAIsAhgCEAIEAv4BAAIMAv4B3gHMAcoBygHKAcoBzgHMAb4BsgGmAZABfAFsAVYBNgEMAd0ArwCDAFUAHgDt/7z/jf9g/zP/Av/K/or+Sv4G/tD9mP1Y/RT90Pyc/Fz8CPyo+3D7IPvY+pD6YPow+vj52PnQ+bD5iPmA+ZD5iPmI+aj54Pkg+lD6iPrQ+hD7YPvA+yz8lPz8/Gz92P08/qz+Hv+C/9T/NwCmAAgBWgGwAQwCZAKoAuQCHANQA4QDrAPMA+AD8AMIBCAEOARQBGAEaARgBFAESARIBEgESAQ4BCgEIAQQBPgD6APgA9QDsAOIA3ADYANMAyQDCAPwAtQCsAKEAmQCTAI4AhgC8AHOAa4BmgGCAWABPgEeAQQB7QDYAL4AnQB+AGQAUwA6ABMA4v+5/5D/XP8f//L+zv6k/mj+Iv7o/bD9bP0s/fT8wPyE/FD8JPz4+9D7qPt4+1D7MPsY+wD76Prg+uj66Pro+vD66Pro+uD66Pr4+gj7MPto+5j7yPsE/ED8ePyw/Pj8UP2g/fD9Sv6w/hL/bP/M/ywAhgDVACIBcAG+AQQCTAKcAuQCHANIA3ADnAO4A9AD8AMYBDAEOARQBGAEaARgBGgEeARwBGAEWARYBFAEOAQoBCAEIAT8A+QDzAO0A4QDZANYA0QDIAMIA/gC1AKgAoACbAJUAjgCIAIMAu4BzAG0AZQBZgFCASoBDgHrAMgArQCJAF0AMQAHAM//iv9Q/yv/Bf/K/or+Rv74/aD9UP0c/ez8sPxs/DT8DPzo+8D7iPtg+0D7GPvo+sj6wPq4+rj6uPqw+qD6mPqg+rD6wPrg+gD7KPtg+5D7uPvo+xz8ZPy4/AT9UP2g/eT9LP56/s7+JP95/87/JgCIAOIAKgFuAboBCAJAAnQCuAIEA0QDdAOkA9gDEAQ4BGAEgASYBLgEyATQBNgE2ATYBOAE6ATgBNAEwAS4BKAEgARYBEgEMAT8A8QDnAN0A0QDDAPcArwCmAJwAkwCIALgAaABcgFSASwB/QDWALkAmwBoACoA7P+3/4P/UP8d//L+yv6a/mz+Pv4U/uD9rP10/UT9GP3w/Mj8nPx0/FD8KPwA/OD7uPuY+3j7WPtI+zj7KPsY+xD7EPsg+zD7QPtQ+2j7gPug+7j72PsA/Cj8WPyQ/Mj8CP1Y/az9/P1S/qb+/P5V/6z/AABUAKoAAgFcAbIBBAJAAnwCuALwAiQDUAOMA8gD+AMYBDAESARgBIgEoAS4BMgEwAS4BLgEyATIBMAEuASwBIgEWAQ4BCgEEAToA8ADoAOAA1gDIAPgAqQCaAIoAvABvgGOAVQBDAHMAJcAZgArAOb/p/92/03/Iv/y/sD+jv5S/hr+9P3c/cD9mP10/WT9WP1I/Sj9DP34/OD8zPzU/Az9KP0Q/eD8wPy4/KD8kPyQ/IT8aPx8/Lz87Pzc/Kj8iPyE/Jj8yPwM/Tz9RP04/UT9ZP1w/WT9cP20/Qb+RP5s/pD+uv7i/if/hv/b/w0AQQCCAMYAEgFmAaoBugHCAfIBPAJwAogCsALcAuwCAANEA6wD+AMABPAD8AMABBgEKAQ4BFAESAQQBMgDiANQAxgD5ALEAtAC8AIIA/ACnAIgAqYBVgEaAdcAmABtACYAnf/2/mL+yP0E/Vj8CPwQ/FT89Pyc/az9BP2E/Lj8UP3c/Wz+/P4v/wD/6P4T/0L/Ov8G/+D+Gv+2/0YAdQCKANYALgEyAe0AtACqANYANgFiAfoAGwBN/8r+fv5m/ob+iP4y/rz9fP1Y/QT9pPxs/FT8KPww/Kj8cP00/vT+xf+kAGQB7AEAAmoBZwCW/0r/X//A/4gAcAHWATYB+P/i/lT+FP4A/pz+6f+pADAAkP84AEQBKgFuAFIAdwCy/9L+fv+CAeQC5AK4AuACmAL2AcoBsgH0AHUAcgEoA+gDuANgA6gCSAFOAIwAUAHEAUACHAPkA1AEmATYBMgEoASwBOgE8ATYBKAEOATkA7gDhAMsA+QCnAIYAmwB4wBlALD/Lv87/0r/6v6S/qb+nP74/Qz9hPxA/Pj70Psk/Kj8zPyw/KD8ePz4+2D7CPvw+uj60Pqw+nD6GPq4+Wj5EPm4+FD44PeA95D3MPjg+HD5GPrQ+hD76PoI+6j7HPxU/ND83P3m/oX/LAAUAdgBMAJkArQCEANkA9gDeAQYBZAF8AUIBvgF8AXYBZAFMAXwBNAEqASIBJAEuATgBOgE6AQIBUgFWAUQBdAE2AQoBXgFyAVABngGUAbwBbAFYAXIBFAESASABJgEwAQIBRgFoAT8A5ADUAMIA+AC+AIcAyADGAMYA/AChALkAQYB7P/O/tj9DP1I/KD74Prw+ZD48PYg9UDzcPHA70DuAO1A7ADsAOyA7IDtQO6g7uDuQO/A71DwYPEw83D10PeI+qz9kwDYAsgEmAbIB0AIcAggCTAKUAvADIAOQBDgEMAQYBBgD7ANkAvQCVAI+Aa4BcAECAQsAxQCxwBL/5T9sPvo+Xj4gPdA94D3QPhA+SD6+PqA+xT81PzA/fL+ewAYAnwD0AQoBmAHMAgACfAJkAqAClAKYApgCgAKwAnwCdAJAAkACCgHEAbQBOQDdAPUAgwCuAGiAU4BwQDWAEABVAEUATIBnAG0AZwB/gH8AtQDUATQBIAFqAXoBMADzALoAYcAJf9Q/pz9qPv4+OD2APWA8qDvYO0A64DnQOSA46DkoObA6eDtgPAA8GDu4O0A7iDv4PKA+Bj99v8QA4gGgAgACXAKoAwADcALQAsQDJAMcA3QDyASoBEQD5AMwAmoBdIBjwDSAEIAO/8t/+z+IP0I+0j64PkQ+PD1YPXg9VD2UPfw+Rz99P6m/xsA+f8t/0z/eAEYBKgFKAdwCQALoAogCtAKQAsACqAIYAjYB3gG0AXQBnAHWAboBOwDdAIKAFj+RP6I/pT++P6+/yMAEACaAMYBrAL4AqQD4ATgBYgGsAdwCRALwAsgDHAMYAxwC3AKAAqQCTAICAY4BFQC3/8c/fj6APnA9RDyQO/g7GDpoOXg46DioOAg4KDjoOgg64DsgO+w8TDwQO5w8HD1iPjA+k//yAR4B4AIEAvgDQAO4AvgCuAKIArgCEAJMAvgDCANMAwwCtgGMAMcAHz9MPvY+cD5GPow+jD6gPqg+kj66PlI+TD4UPeA9+j4uPq8/HT/DAJkA7wDIASoBNAECAVgBuAHgAhwCHAJ0AogC4AK8AnQCQAJUAfIBTgF0ASIBGAEYATMA7wC+gGsAVQB5gDxAAoBKgFcAWACjAMoBMgEAAZIB7gH0AdwCJAJ8AkAClAKIAvAC5ALwAoQCpAJ4Aj4BpAE3AJmAYr+KPtw+dD4cPaQ8nDwwO+g7CDnoOMA48DhIOCA4gDpYO7g75DwEPJQ8tDwoPEA9qD6ZP1YAGAEcAdwCMAJUAyADQAMoAlgCDgH0AXgBeAHgAlQCWAIGAdwBJsAvP1E/Pj6mPkA+Uj5uPlQ+vj6aPtI+0D7gPuA+yD7MPtQ/Bb++P+6AVADWASgBGgEcASoBOAEOAXoBdgGUAcoB8AGmAaoBsAGkAbgBfAEIATEA5QDeAOkAxgEMARwA4ACTAKcAowCSAKkAnwD2AP8A7gEuAUYBjgG8AbYByAIEAiQCEAJkAmgCbAJkAkACZAIkAggCPgGCAYYBcADvAEsAOz+4PxA+ij4UPYw81DwIO9g7uDqQOYA5EDjIOIA48DoAO9A8TDxcPOA9SD0EPPw9tD8Uv9BAHwDSAcgCFAIIAvgDeAMkAlACLgHkAVoA2AEuAYIB9AFGAXYA4sABP2A+/D6qPl4+Lj4aPlA+Sj5SPoI/DT9oP2c/Uz9qPxc/ET9NP9MAdwC5AN4BGAE7AP0A5gEWAXYBegFSAUYBGAD1APgBIAFyAUIBrAFcAQsAwADiAPEAxAEwARQBfAEUASABDgFUAXQBMAEMAVwBUgFmAWABnAH6AdACJAIwAhwCGAIoAiwCDAI4AfgB6gHSAcoBwAHiAWEA6ACLAJBAJD9mPwQ/CD5APVQ80DzwPFA72DuoO2g6aDkYOOg5aDngOmg7ZDyEPWQ9cD2QPjw+Ij5ePvc/Yn/LAGoA1gGUAigCVAKMApgCfAH6AWEA/IB4gGoAmAD+AM4BLgDCALa/07+mP0A/Qz8aPuY+wD82Ps0/B7+fwAOAQ0AU/8v/5L+sP0K/pz/8wBqAWYBeAG+ATgC8AKcAxAEEAR4A6ACPALEAtQDAAX4BbAGwAYgBggFaATQBMgFSAYoBigGOAawBbgEwATABRgGeAVQBbAFYAWoBGgFSAfoB2AHoAdACLgHwAY4B0AI2AfQBuAGYAeYBqAF2AUwBjgFhAOAAp4Bxf9U/YD7GPoI+GD1gPMA8zDygO/A60DpwOeg5YDkYOag6qDtgO/Q8hD3uPiA92D3kPmA+yT86P2AAVgEcAXIBvAIEApQCUAIgAcYBqADugEwAaABZAIkA1ADhAJKARkA9v6I/XD80Ptg+9D60Ppo+0j8AP0g/nb/6P/8/sT9tP00/lD+LP4Z/2wApQDc//D/YAFcApgCXAO4BNAEkAM4A4gEiAWIBTgG2AdQCCAHaAb4BjAH0AZ4B4AIuAe4BUgFWAZABuAE0AQIBggGkAQABOgEsAXwBYgGgAe4B0AH4Aa4BrAGqAaABjAGMAaoBqAGmAX4BDgFSAXkA0gCIAF6/7j8SPog+eD38PVw9LDzEPLg7sDrQOoA6eDmIOXA5YDo4Ovg79D0yPgo+rD5oPmo+sD7yPx+/vUAFAPABEAGmAeQCIAJwAmgCGAGCAQsAk8ARf/E/x4BogE8AQ4BEgFQAKT+IP1I/LD7KPvY+jD7TPyM/T7+jP5E/ykAKQBW/w7/df8//zr+4P20/lP/Ef9L/wwBNAMgBLADVAOkAwgE+AM4BGAF2AZgByAHGAeIB9AH6AdgCAAJ0AiQBzgGsAXYBRgGSAZYBjAGuAVgBegEOAQoBFAFcAYwBogFEAboBmgGQAWoBdgGyAbIBdgFgAboBagE4AT4BZgFyAMQAoUAbP5I/Pj6KPrg+ED3gPUg8zDwAO7A7CDr4Ohg5yDngOcA6aDsIPKQ9tD4APrY+sD6IPrY+kD9sv9iAQwD+ASABmgHAAiQCJAIsAfQBUAD+gCk/xD/Fv8ZANYBtAIMAgoBSQDS/kT8ePpg+qj6cPqw+iz8tP1Y/pD+Cf9C/xX/zP64/pb+UP4G/sT98P2a/qf/uQDsASAD4AMIBDAEeASwBDAFEAaoBtAGUAcgCEAI0AdACKAJQApwCVAIoAeoBoAFSAX4BXAGQAb4BbgF+AQYBAgE0ASwBXgGCAfwBjAGAAbgBogHWAc4B/AHAAjIBqgF4AVQBtgFEAV4BDwD4QCg/gj9iPvo+ZD4MPdg9XDzkPEg72DswOoA6iDp4OeA52Do4Olg7ODwEPag+Vj7cPz0/KT8ePzs/bkAbAMYBSgG6AZIB4AH2AegCNAIGAfwA0ABvf+2/hb+6v7AAKwBJgFXALL/UP5U/FD7iPuY+wj7+PoA/DT9+P18/uT+If9r/6T/Xv/A/pr+pv7c/dj8MP2U/m7/xP84AUgD5ANYAxgE+AWgBrgFWAUIBmAGQAagBlAHcAfQB+AIUAlQCGgHeAc4B/AFEAVoBWgFSAR4AxAE2ASgBJAEyAV4B9AHwAbwBQgGWAYABpAFGAZAB5AHmAaoBaAF8AVQBTgEoAM0A4QBpP5o/Kj7GPtA+TD3UPaA9RDzQO+g7MDrIOvA6cDoAOmA6QDqIOtg7lDzIPjQ+vj7FP3s/Wj90Pyw/lQCoATgBJgFSAcQCNAHUAhACXAIIAYoBHQCOQDs/tL/MgFoAXwB/gFQAQP/WP1o/Yz9oPyw+4D7kPuI+9j78Pye/gYAMwCU/1j/of8h/7z9IP1o/QT9yPsE/AT+jf/c//AAiAN4BZAFaAUIBlAGsAVwBVAGMAdAB3AHUAhQCWAJ4AhwCEAI6AfwBpAFKAR4A4ADqAOkA+wDsASABTgGCAfAB6gH+AaABmgGMAYABmgGkAegCPAIcAjIB1AHmAZYBSAEOAOoAWz/vP0o/Sj86Pk4+ND3kPYw8+DvQO6g7GDqQOkA6oDqwOkA6iDsYO4w8FDz4Peg+1z9YP5O/4P/X/+1AJwDyAUgBhAGIAdACDAImAfAB+AHaAbwAwQC6gC3/7r+4P6R/3j/eP6w/Xz9ZP1U/VT90Px4+0j6GPrQ+oj7ZPzI/Vz/FgDc/1//KP/g/j7+oP0o/Wz8SPuA+vj6sPy6/ssA1AKgBPAFuAbgBogGUAbgBrgH+AeoB9AHsAhgCXAJ0AnQCjALEAogCMAGqAUYBBADnAPwBEAF4ARABWgGMAd4B+AHyAe4BoAFEAXwBPgECAbwB9AIEAhQBwgH4AXcA8QCnAKYAW7/1P0c/Sj8mPoo+bD3oPVw83DxYO9A7QDsgOtA6wDroOtg7KDsQO3A72DzcPZI+cj8e/9aALoAWAK4A3wDkAOgBVgHyAYQBjAHYAiIByAG0AUoBdACzgCdAJ4ACf98/Xj96P2g/Xj9DP5I/mT9XPyo+5j6gPmo+SD7iPyI/YD+9v5w/gj+uv48/4L+hP1Y/dz8EPuw+ZD6iPwk/vH/6AKoBaAGqAYoB7AHaAf4BkAHyAfwB9AH0AfIByAIQAmgCgALAApgCKAGkAS8AiwC5ALYA2gE6ARoBcAFCAbIBtAHYAi4BzgG2ARYBNAE6AVAB1AIoAgACMAGeAVYBEADGAISARQArP7o/GD7aPpw+eD34PUA9BDyoO+A7WDsAOyg60DrgOtA7EDtQO6g79DxwPTg9+D6mP3Y/7IB9AKgAygECAUIBqAG4AZYB/AHyAfoBhgGsAXYBEADrAHCABUAGP8U/nD9HP0M/UD9bP04/ej82Pxk/ED7sPqg+6j8qPwA/aL+lv+C/pD9qP5j//j9pPws/RT9oPqg+Hj5GPt4+9T8RQCYA6gESAXYBrgHsAa4BagGAAhACNgHQAigCHAIgAjQCYALgAvgCTAIyAbgBPACVAIYA/QDWATQBGgFsAXQBWgGOAdwB7AGmAXABGAEkARABSAGAAfIBzAIsAdYBggFGAQoA94BiABz/2D+1Pww+wD6CPmQ95D10PNg8gDxYO8A7iDtIO2g7YDuoO8w8QDz8PTA9vj4yPu8/hIBlAKEA0AEyAQYBYAFSAZIB5AH+AYgBpAFIAVQBGADqAIIAhgB4f/Q/iT+zP2E/Sj94PzA/IT8APyI+3D7aPsg+/j6cPvo+9D7wPtg/CT9VP1A/Vz99PyQ+zD6mPn4+MD3APfg96j5aPuE/UMA+AIgBYgGsAZ4BdgE8AVABxgH4AYQCNAIoAfYBuAIAAsACnAH4AYwB1AFOAJeAeAC3AOAA4QDgARQBWAFeAUwBhAHSAeYBsAFeAXIBfgFEAbgBoAIcAnQCHgHuAZQBmAF/APUAtgBdwDS/lz98PtI+tD40PcQ9+D1UPTg8oDxYPAA8JDwYPEQ8lDzMPXg9jD4APrM/Kz/tAEwA3gEUAWYBQAGuAYoBwgHsAZQBtAFGAV4BDgE7AN8A+gCEALUAHr/Vv5U/Tj8OPvI+qj6ePpw+tj6UPtQ+xD7IPsg+3D6kPlQ+bD5GPpo+tj6IPvQ+ij6YPlg+FD3wPYw9iD1oPRg9oD5FPyu/mACWAVIBQAEkAQ4BmgGsAWgBiAIQAiAB7AHYAjACDAJ0AmQCQAIiAaIBUgEFANYA3AEkATkAzgEcAWwBRgFmAVoB3AIwAfgBsgG4AaYBpAGQAcACEAIQAgACHAHyAYYBiAF/AM4A3ACrwBQ/rz88Puo+uD4sPcw9wD2EPSA8tDxYPFA8RDyQPNA9FD1EPcQ+Qj7ZP0XADwCWAMgBCAFwAXoBSgG0AYYB3gGqAU4BeAEOASAAyAD4AI4AjwBJgDk/lT9wPuw+iD6wPl4+WD5aPmA+Zj5kPlo+SD58Piw+Ej48Pfw9yD4iPgI+Wj5aPno+Hj4KPiw95D2kPVQ9eD1EPco+WD87P+oAnAEqAXoBVgFeAXgBhAIAAjQBwAIYAdIBqAGUAgACSAI0AcQCCAH4ARgA3QD4AP8AygEYARoBMAEkAV4BjAHMAgwCXAJIAnwCOAIMAi4B0AIQAlACZAIEAjYBygHSAaIBcgEjAMgAowAYv4E/Gj6qPng+OD3IPdw9vD0MPOQ8uDyEPMg8yD0wPXA9lD30Phg++T9IgCEAogEYAWQBSgGwAaoBmAGoAa4BuAFuAQQBHwDuAIsAgQCqgGpAFf/+P14/CD7MPqI+Qj5+PhQ+Wj5APm4+Aj5cPko+Yj4KPgQ+ND3oPfg94D44PgA+SD56PgI+DD30PYg9jD1IPUQ9qD2oPcg+xkAKAPcAyAF6AbYBpAFQAbACMAJ8AigCBAJ8AiACMAIMAmACcAJQAlYB4AFSAVoBXAEeAMwBBAFSAQEA0ADgARYBdgF2AbgBxAIuAdYB0AHmAcACFAIgAjQCCAJsAi4BwAHAAfgBsAF4AM0AtMA/P60/BD7aPqo+Tj44PbQ9YD08PJw8jDzEPTQ9OD1IPfw9/j4KPuo/U3/rQC0AlgEgARABAgFIAZgBhgGIAbgBagEPAOoAngC8gFAAb0AFwDw/pz9VPwQ+/j5SPng+Fj4APgI+Cj4IPg4+Kj48PjI+KD4kPg4+MD38PeA+Lj4mPh4+Dj4gPfQ9oD2YPYA9qD1wPWA9hD4cPps/e4AiATQBugGUAYQB6AIAAmwCHAJUApQCbAHMAjQCdAJwAhACZAKwAkwB8AFkAW4BIADjAP0AxQDCALMAoAEAAXoBPgFiAfIB/AGcAZwBhAGyAVoBogH2AdYB0AHsAfABwgHCAY4BXgEMANYARP/KP3w+zj7mPrY+Qj5KPhQ95D2APbA9QD2wPag92D48Pi4+bD6QPxu/q0AVAJMAwgEuARoBfAF+AV4BQAFAAWgBGgDPAIMAkgC4gEmAbgAPwAO/7D93PwU/OD6uPlA+SD5APkI+Tj5MPno+AD5MPmg+KD3EPfw9qD2YPaw9hD34Pag9tD2kPag9RD1QPXw9ED04PRA9+D5ePxKAKgECAcAB/AG6AfwCEAJ0AmwCoAKMAkQCOgH+AfwB0AI8AggCXAIUAfoBYAEzAMYBFAEqAPoAvwCVAM0A4AD2ARYBggHYAfIB5AHeAagBdgFgAbIBtAG0AaYBkgGIAboBWgF4ARwBJQDwAGU/+z9sPxQ+yD6kPn4+LD3IPZQ9SD1MPVw9UD2kPe4+Hj5uPlQ+uj7Iv7b/w4BgAL4A5gEsARIBSAGYAYwBvAFUAUYBAQDiAIQAmoBPgFmAY8AzP64/Xj9fPyQ+mj5sPmI+SD4MPeg90j4CPjA9zj4mPhA+OD30PfA98D38Pc4+CD4APgA+MD3APew9kD3gPfg9pD2wPdI+tj8S/8cAtAEaAa4BuAGgAcwCOAIgAmgCQAJMAjoB9AHsAf4B5AIYAhQB5gGWAZoBbQDtAIIA4ADIAN4AngC9AJkAwgEKAVgBhAHQAcgB8gGOAbYBeAFWAYAB2gHMAdoBqgFcAWIBUgFcAQ4A/QBwQBO/4D9EPyI+0D7SPro+Cj4sPeg9tD1YPaQ9+D30Pe4+Ej6aPsY/Fz9JP/DAAwCTANQBNgEOAW4BQAGoAUgBdAEWASEA9QCXALOASYBzAC1ACUAAP/0/Uj9oPyo+7j6EPqQ+TD58Pjg+PD48PjQ+Kj4kPhY+PD3sPeg96D3oPew97D3UPcw93D3EPcQ9sD1IPYA9oD1wPZg+hD+lAAsA/gFGAd4BqAGcAjQCbAJcAnwCbAJUAiQB1AIEAnwCNAI4AhACIgGAAVYBAgEmANQA1ADOAPIAngCsAJQAxgE0ASYBTAGUAbgBXAFcAW4BSgGiAbQBvgG6AZgBlgF4ARoBZgFKASIAvQBMAHy/gD99PwA/Uj7YPkQ+cj4IPew9SD2UPew99D3cPgQ+bD5CPvM/Bj+Lf/DAEQC9AJUAyAE2AT4BBAFYAVQBVgETAPEAqgCWALKAVgBOgH4ABMAwv6k/dD8yPvI+kD6APoo+WD4mPhw+YD54PjY+Cj5+PhA+OD3wPdw93D30PcY+BD4EPjw95D3cPfg9+D3APeQ9pD3kPmw+/D9qACAA5AFiAb4BtgHEAmQCXAJgAmgCbAIOAfYBqAH6AeIB9gHgAjYB0AGaAUQBTgEeAPIA/gD3ALUAUgCKANEA5ADyATABaAFQAVIBSAF2AQ4BfgFIAbQBcAFiAXYBHAEuAS4BMwDyAJwAtQBKABm/qT9jP38/Lj7sPo4+pj5cPiA96D3aPjA+LD4QPlg+hj7cPto/Cb+i/84AOUA4AGYAvACWAPgAxgECATIA0wDgAKqAToBJgEQAb8AeQBUAPf/AP8S/oz9+Pz4+yD7APvw+mD68Pkg+jj6uPkw+ej4gPgg+FD4cPjA9yD3oPdQ+PD3UPfQ90j4YPdA9qD2YPdQ97D3APoI/Qn/kQCwArgEsAVYBlAH+AdACNAIYAngCLAHGAc4BzAHAAdIB6AHIAcIBkAF0AQgBGgDLAM0A/QCdAIkAjwCtAKUA6gEgAXQBcAFyAUIBiAGAAYABjgGQAboBbAFsAWQBSgF2AS4BDgEJAMMAh4BKgBC/5L+zP2k/Hj7wPr4+dD48PfQ9xD4CPgY+Kj4QPmQ+Sj6aPvU/Mz9fv5+/5sAXAHWAWgCHAOYA9QD8APkA3QD+AK4AoQCCAJyARYBxQAwAIT/7P4+/lz9nPwM/Hj72Ppw+jj6KPpQ+nD6KPq4+Yj5ePkI+cD4SPnI+Uj5kPjA+Cj52PiI+CD5iPmY+LD3CPg4+QD6GPto/RkA9AEcA1AESAXQBUgGUAdQCHAI+AeoB7gHcAfgBqgGAAdIBzAH4AZgBlgFCARoA4wDoAMcA5ACcAKQAqAC6AKwA7AEiAUIBkAGEAaoBWgFgAXABQAGEAb4BcAFeAVgBWAFGAWABMgDJANEAgIBtP/s/n7+2P3o/Pj7OPtg+oj5+PjY+Nj44PgI+WD5sPkI+pD6MPvw+/z8Tv5c/+X/VQACAZABvAHOAQgCPAIUAtgBwAGgAXIBWgFYATIB1gBrAO7/Tf+8/kb+uP34/FD86PuY+0j7IPso+wj7yPqY+kj6wPlQ+Wj5sPmg+aD5MPqw+kj6ePk4+XD5SPnQ+KD4mPiA+MD4CPog/Ij+sgA4AvgCpAPQBMgF0AXABcgG6AeQB2gGQAboBuAGSAZ4BjAH+AbABdgEqARQBGwDxALIAhADEAOsAlACdAIwA/wDWARwBLgEAAXoBJgEsAQIBTAFEAUoBVgFIAWgBGAEiASQBCAEWAN4AngBfADD/x//Vv6c/TD9qPyw+7D6OPoQ+uj5yPkA+mD6cPp4+vD60Puc/Dz9/P0H/+//hQD+AJ4BHAJAAkQCVAJMAggCugGiAaYBpgGiAZgBaAEWAasAIQBd/47+4P0g/Sz8cPtA+zj7CPv4+jj7YPsI+5D6aPpY+hj64PnY+dD54PkI+ij6KPpA+kD6uPnw+Lj4IPkw+Sj5APrA+2D9hP7y/44BnAI0AwAE8ASABaAF0AUQBhgGEAYwBlAGUAZ4BsgGuAY4BtAF2AXQBUgFuAR4BEAEtANEAzgDUANAA0wDuAMgBDAEIAQYBCAEOARoBGgEKATwA+wDvANAA+gC4AK4AkACzgGGAfoALACK/x7/mv7w/WD95PxQ/KD7GPuQ+hD6yPn4+Vj6uPpA+/j7nPwQ/aD9Zv4m/6H/DQCHAOcACgEgAToBQgEcAeoAzwDJAL8AkwBXACUA///K/3b/Fv/G/mj+8P14/Rz9zPyM/Hj8lPyU/Ej82PuA+1D7IPvI+lj6APrw+fD5+Pkg+mj6mPqI+mj6UPog+gj6aPog+8j7VPwI/dD9nP7Z/4QB3AKUA0gEOAXYBcgFsAUABlgGcAaABpgGYAbgBaAFqAWgBWgFIAXIBFgE6AOMAygD0ALUAiQDXANgA1wDfAOgA9ADKAR4BJAEiASQBJgEeAQ4BDAESARABPQDiAP4AkwCogEwAckAOQCW//b+SP5s/bD8PPzw+6j7gPtw+zD7wPqQ+sj6MPuQ+xT80PyI/Qb+ev4a/7P/KACIAN4AGAEgARAB/wD/AB4BSgFIASwBGAHzAIkA/f+p/3b/D/9u/uj9pP1Q/fT8yPzY/Nj8mPxk/Dz8+PuI+zD7IPso+zj7YPuA+5D72PtY/Kj8sPzI/PD8xPxg/Gz86PxQ/YD96P2O/vz+Pv/Z/9AAngE8AsQCLANoA5gD7AM4BFAEYAR4BHgEUARABFgEgASQBJAEkAR4BDAE2AOUA1gDFAPEAoQCaAJUAjgCKAJEAoACrAKoAqQCxALkAuQC1ALsAhAD/ALQAswC0AKYAkgCQAJsAkQCtgEcAaoAIgBz/9j+bP4U/qz9XP0w/Rz9GP0c/Uj9qP30/QT+AP4Y/j7+Rv5S/oD+ov6k/p7+pP6g/pL+nv7O/vr+Gf8x/zb/Jv8e/xr//P7M/rb+oP5Q/tz9iP1E/fD8sPyg/Iz8QPzw+/D7EPwE/PD7EPxE/ED8JPw0/Ez8QPw0/Fj8gPxo/DT8QPyU/PT8SP3E/XT+GP+Y/yoA/AC+ATwCsAJcA/gDMAQwBGAEqATQBPAEGAUwBRgFGAUoBQAFuARoBCgE5AOwA5ADcANMA0QDXAN0A3ADWAMwAxQDEAMIA+QCsAKgArACtAKkApwCoAKUAnQCVAIgAsYBaAEaAc4AfQA3AAAAwP96/1L/Jv++/jr+5P24/WD9+PzI/Mj8uPyw/Oz8PP1w/aj9Bv5o/pb+tP7w/ir/Sf9z/67/yf/F/9D/7f/x/83/uP+u/5P/WP8M/7r+TP7g/ZT9XP0M/az8XPwg/OD7oPtw+zD72Pp4+ij64PmI+WD5aPmQ+dD5IPp4+tD6KPug+xz8gPzU/FD9+P2m/kr/9f/FAJIBRAL0ArADQASgBPAEWAWQBWgFMAUYBfgEyASgBIgEWAQYBPQD5APQA7gDvAPMA9wD7AMIBAgEEAQoBFAEcARoBGgEgASIBHAEUAQ4BAgExAOAA0QDAAOkAkQC6gGcAUoB7QCPADMA1f9v/w3/tP5s/jb+Bv7Q/Zj9cP1g/WD9ZP1w/YT9mP2U/Yj9jP2c/az9sP2s/aD9kP18/Wj9XP1Q/Tj9DP3Y/Kj8cPwo/Oj7yPu4+6j7oPug+7D7wPvQ+/j7JPxY/JT81PwQ/UD9hP3k/Vz+zv5D/7f/GgBvAMwAOAGaAeYBLAJ8AswCAAMkA0gDZAOAA5QDlAOMA4wDkAOIA4QDiAOIA3QDYANYA0wDMAMYAxgDIAMkAyADHAMYAyADPANcA3ADcANsA2ADMAPwArACfAJAAgAC0AGYAVIBCAHLAKIAcQAjAMH/a/8v/+7+oP5q/lz+TP4m/gL+9P3c/aT9jP2o/az9hP1g/Wj9eP1o/WT9gP2c/Zz9nP20/cj9uP2k/az9xP24/az9qP2g/YD9eP2I/ZT9lP2s/dj97P38/R7+Sv5e/mz+kv7A/tj+5v4K/zD/RP9b/4X/qP/A/9b/+v8bADMAUwByAJEAqwDHAOQABgEmAT4BTAFoAZABpgGuAcAB6AHyAd4B4gEAAhQCDAIMAhQCDALuAfgBIAI8AkQCTAJMAjgCKAIcAvoBwgGmAaYBjAFUASwBHgECAdQArwCYAHAAPQAVAPj/zP+X/2n/Tf81/xD/6P7O/sj+wP6q/pT+iP6C/nz+eP54/nj+eP58/ob+kP6W/pT+kv6i/rb+tv6k/pz+ov6i/pT+kP6W/pL+hv6O/pr+lv5+/nb+gv6E/n7+gv6Q/pT+nP66/t7+9P4L/zH/Xf9//5z/uf/X//v/KgBbAH4AmQC1AMsA3QD5ACABQgFcAXoBogHCAdQB4AHyAQgCGAIkAjACRAJkAnwCgAKMApQCoAKUAoQCgAJ8AnACZAJkAmwCbAJgAlgCUAJIAjACDALqAc4BogFsAT4BGgH3ANQAsgCWAHcATAAQANP/oP9w/zn/AP/M/pz+cP5Q/kT+NP4i/hL+BP7w/cz9sP2g/Yz9fP14/Xj9cP1s/XT9hP2E/Xj9eP14/Xj9eP18/Yj9mP2w/dT99P0O/iD+Ov5a/nr+mP66/uD+/v4Y/zf/W/99/6H/zf8CAC4AUwB8AKgAzwDuAAoBJAE4AUoBZgGMAaoBwgHgAQQCIAI4AkwCWAJkAmgCcAJsAmQCYAJgAlQCQAJEAkgCNAIcAhgCDALmAcABsAGgAXQBTAFEATwBGgH5AOMAuwCFAFwARgAsAAQA3//D/6T/g/9m/0n/Kf8O//7+7v7U/r7+tP6o/pT+gv56/nD+YP5U/kz+SP5A/jL+Iv4e/iL+IP4W/hD+FP4W/hb+Hv4w/kL+TP5S/mD+bv5+/pD+pP66/tL+8P4M/yL/N/9W/3n/kf+e/63/yv/t/wwAJAA7AFIAaQB8AI4AoACsALUAwADQAN4A6ADyAAIBFAEkATABOgFCAUgBTAFOAUwBTgFaAWYBZgFiAWABXAFYAVABTAFGATwBMAEqASYBGgEGAe8A4ADSAMAAqQCUAIUAeABmAFIAQgAzAB8ACgD5/+j/0v+8/6v/nf+Q/4D/c/9r/2n/cP91/3f/dP9y/2//ZP9X/0//S/9G/z//O/83/zP/Lf8q/yv/Kv8f/w//CP8P/xf/GP8f/y7/Of85/zf/Pv9G/0f/Tf9h/3T/ff+E/5r/u//S/9//8P8MACEAJAAxAEwAZABqAHkAnACxALIAtADAAMEAugDAAM0AyQDAAMQAzQDNAMsA0ADSAM0AyQDMAMsAwAC3ALAApwCgAJwAlwCMAIIAgQB8AHAAYgBVAEYANAAlAB4AFAAEAPT/5v/d/9n/0f/G/8H/wP+8/7H/qf+u/7D/pf+V/5H/i/+A/4D/iP+L/4X/fP92/3H/bv9u/2v/af9w/33/g/+B/4D/hv+L/4r/iP+J/4//kv+V/5j/nf+i/6f/rv+2/7n/t/+4/77/wf/A/7//xP/N/9X/2f/d/+H/5P/o/+3/8P/x/+//7f/w//X/9//2//r/BQARABkAIAAsADgAQABHAFMAWwBdAF4AZABrAG4AcAB0AHgAewCAAIgAjQCMAIsAjwCRAI8AjQCPAJQAlwCYAJcAkQCHAHoAcABrAGYAXgBUAEwARQA5ACoAGAAKAP3/8f/n/+H/3v/b/9f/0//P/8v/x//B/7r/tP+0/7b/uf++/8n/1P/b/9//5P/q/+n/5v/l/+f/5P/g/9//4v/m/+n/6//w//T/9P/w/+7/8v/4//n/9f/y//H/8v/2//3/AgADAAIABQAIAAgACQAMABEAFwAeACMAJgAoACwAMAAxACsAJQAgABwAFwASAA4ACwAHAAMA///6//P/7f/s/+7/8P/w//D/7f/p/+X/5f/m/+P/4v/l/+n/6//r/+z/7//v/+//7v/r/+n/6v/u/+7/6v/t//P/9v/1//b/+v/4//X/+P/5//P/7v/y//L/7P/r//L/7//k/+b/6f/j/9n/3f/r/+b/4P/t//7//v/4//z/AQD7//X/+/8GAAYA/P/6/wMACgAIAAUACgARABIADgALAAsACgAHAAMAAgADAAMAAgAEAAcACQAKAAkACAAIAAoABwABAPv/+v/7//v//f8DAAcABQD+//r/+P/1/+//6//o/+b/5v/n/+n/6f/s//L/8//r/+T/4//l/+L/3P/X/9T/0f/M/8j/w/++/7f/sP+t/6v/qf+o/6z/tf+8/8L/yf/T/93/5P/s//b/AQALABMAGAAbAB0AIAAkACgALQAyADMANQA6AD8AQAA+ADsAOwA6ADcAMgAvAC8ALgAsACkAJwAlACMAIgAjACcAJwAmACcAKQApACYAIgAhACIAJwArAC8AMgA1ADcANwA2ADUAMwAvACsAKQAlACEAHgAeAB0AGQATAA4ADAANAA4ADQAMAAsACgAHAAMAAAD///7//P/7//z/+//3//b/+//8//b/8v/1//P/5v/f/+P/4//Y/9L/1//W/8r/wf/A/7z/tf+0/7j/t/+z/7T/uP+7/73/wf/F/8f/yf/Q/9b/2f/b/93/4P/i/+L/4v/g/97/3//g/+H/5P/n/+n/7f/z//7/BAAEAAQABwAOABQAGQAiAC4AOAA/AEUATABRAFAARgA7ADMAKgAkACkAMgA5AD0APQA/AEAAPgA4ADIALQAqACgAJgAmACcAKAApACUAHQASAAYA+//v/+P/3f/d/+T/7v/3//z//v////7/9//s/+L/2v/U/87/y//L/8z/zv/P/9D/0f/O/8f/wv/C/8L/wf/A/8P/yv/S/9j/4P/n/+r/6P/l/+X/4v/Z/9L/0f/U/9f/2//j/+z/9f///wsAFgAcACAAJAArADIAOQBCAEsAUQBSAE4ASAA/ADYAMAAvADMAOAA9AEMASABKAEUAPAAzACsAJQAhACIAJQAnACYAJQAnACgAJgAgABsAFwAVABYAGgAhACcAKQAmAB4AFAAJAP//9v/t/+P/2P/T/9P/1//c/+L/5f/n/+b/4v/b/9j/2v/d/9z/2P/U/9P/1P/X/9f/z//A/7P/rP+t/7H/uv/G/9H/2v/k/+z/7f/m/93/1P/I/7j/sP+0/8D/zv/b/+n/8f/y/+//7P/l/9j/zf/O/9//9f8IABkAJgArACcAHQAQAP7/7P/g/93/5P/z/wkAIwA4AD0AMgAgAA8AAQD1/+r/6P/1/wwAJAA6AE0AVgBMADcAIQAJAPH/5P/o//b/BAAWACcAKwAjABQA9f/S/77/w//X/+D/8/8ZADgAPgA2ACoAEQDv/9v/5v///wgAAwAGABIAEgAAAPT//P8KABMAHAAyAFMAcAB8AHsAbwBSACYA+//n/+7/CAAoAEwAcQCKAIYAaAA+AAgAxv+C/1f/Vv97/7D/5P8MACQAJwARAOb/s/+D/1//TP9Y/4j/1f8uAH0AsQDBAKgAcwA0APr/w/+P/2v/Y/96/6f/4P8TAC8AKwAOAOX/wP+n/5//pf+9/+f/GQBFAGEAagBbADEA+v/I/6j/mP+U/6L/yf8IAFMAkwC3ALsApgCGAGoAVgBGADcAMwA6ADsAKgAWAAYA8f/N/6j/kf+J/5P/vv8KAFIAcQBrAGIAaABnAEQACwDg/9X/4//4/xoARwBjAFoANQAUAPz/2P+q/57/vv/e/93/6v85AKQA0wCxAHUAPADv/5D/VP9X/2f/W/9a/6X/IgB7AJIAmACRAEwAyv9u/3//1P8iAGAAnQC6AJ8AagBAAAYAkv/y/nT+Rv5i/rj+Mv+4/yMASgAqAPP/0f/D/67/iP9n/1z/cP+y/xwAegCPAFIA9f+t/4H/cv+I/8D/8v8NACUASwB1AJEAnwCQAFQA/P+2/6j/yf///y0ANQASAOP/1P/w/ycAXwCOAKwAsgCkAJUAhQBcABEAxP+e/6T/uf/n/0IAqgDSAKQAVgAeAPn/2P/N/+r/DAATAB8AZgDWAAgBwwA1AK7/P//c/rj+C/+n/wwADQAAACcAVAA9APP/r/9t/xH/2P4k/9v/YABZAA8A2/+v/3D/Vv+S/9z/1f+h/6z/CgBsAJwApQCMAEYA5/+1/9n/KwBhAF8APwAkABMAAwDw/+L/1f/H/8P/4f8kAHMAqACqAIEAOwDw/8b/2P8JACYALABLAJYA6gAaAR4B9wCmAEEA///8/w8ABgDm/+X/EQBHAHEAlgCbAEgAmP/w/qz+0P4e/33/4P86AH8AuQDeAMkAZwDW/0r/5v68/tr+PP/I/00AlwCVAFwAEQDY/7j/m/9t/z7/Rf+g/yMAgQCiAKAAgwAvALn/ZP9R/1n/Vv9R/2T/gf+m//f/hADtAM0APgDA/5//pP+f/6X/zP/u/9j/vf/j/zUAUwAdAN7/yP+5/5z/sP8bAIcAfQAZANj/6P8OABQACwAIAO7/sf+M/7z/LAB1AGUALgARABAACwAUAEwAlwCxAIkAXgBOADYA9v+m/3f/Z/9Y/13/o/8ZAG0AcwBYAEIAEACy/3X/nv/v/wMA3P/U/w8AVQBzAHEARgDj/3H/Tf+Y/wMAQQBWAGYAZQA3AAQADQBDAE4AAgCe/3z/vf9EAMoA9QCKALT//P7e/kv/wv/z//3/HABfALUABgEmAdwAOACT/0D/Vf+3/z0AsADaALwAiwBwAFkAIgC0/xP/cv4u/qj+zP8EAawBoAEoAZEABwCh/2T/Ov8V/xT/aP8MALYAGAEcAcwAMQBk/7L+iP7+/sX/XwCeALwA3ADfAKcARADP/0f/1P7Q/lf//f8+AB8A/v///+7/tv+H/4v/nv+Y/5T/y/9CAKwAygC4AKgAlgBUAPr/2v/w/9D/av8//57/FQAlAA8ASQCMADoAif9S/8b/NgApAPj/CQAnAAoA+P9LAKoAbwCr/yT/R/+t/+L/FACFAOkA1ABxAFkAnQCvAEQAw/+k/9//OgCqACYBUgHhACAApf+a/6j/hf9K/zj/a//U/2gABAFiAUwBwQABAGv/OP9l/8H/JgBoAFsAEQDl/xcAYgA/AIv/vv5c/mz+uv47/9r/UABkADYAGgAkABQAz/+C/1D/Jf/8/hH/lP9BAI4ASwDV/6P/wv/v//H/yf+Y/3f/l/8VALoA8gBxAKz/X/+R/7L/jP+K/+j/PgAkANb/zP8MAD0AOAAeAAsA/f8SAHQA9wAUAX8Apv9F/3b/oP9p/0v/yv+QAN4AqwCcAO0AGgG8ACsA2P+w/4j/p/9CAN0AwAAUALj/7/8RAJ3/Df8H/0z/Vf9S/9b/vAAyAfUAjABkADsAz/9t/2j/kv+q/9b/PACRAG8A/f+3/7v/yf/A/8b/8P8sAHIAuQDUAKcAXgAtAAQAvf93/3X/tv/7/yUAPQA5AP3/s/+c/7n/vv+N/3j/yP9TALsA7AAAAdwAQABn/w7/i/9RAKEAdgBQAE4ALgD8/xwAhgCmADIAn/9+/7z/9v8hAHAAqABTAJH/Jf9k/7z/lf8x/zH/l//0/y8AiwDrAMMACgBo/0v/av96/6f/HgCBAHgAXACIAKIAKQB0/zv/cf96/1//zv/GAGwBSgHjAK0AUwCl/zH/af/C/5H/Ov+L/1kAtQBZAOf/y/++/5P/lP/h/xQA9f/n/zwAqwC8AHgANwAQAPL/2//O/7//tf/K//L/8//G/7r/CwCKAMgAkAABAGr/EP8f/33/5P8gACsALQA6ADsAGgDj/7P/i/9q/1j/Yv+A/6//AABWAGYAJAD5/y8AZwAbAG7//P4I/07/kP/R//7/8f/T//X/TQBmAAQAeP82/1P/hf+o//D/lABOAXwBAAFyAGEAjABjAOT/dP88/yj/df9VAEABagHNAC0A7f+//4f/qv9OAN0A2wCZAJYAtgCnAIIAcwA9AKj/Kv9u/0kA6QDYAHgAMgD9/8H/nP+8/wYASAB2AJ0AowBdANb/Vf8J/+b+2P7u/kj/zv89AF4AIQC2/23/af+B/4X/gv+j/9z/7P/G/7X/9v9LAE8ABQC1/3T/L/8K/0n/1f8tAAMAjv8y/zX/tf+OADwBKAFTAHH/H/9j/+L/OQArAMH/bf+u/3YALAFQAe8ATwCm/y//O//F/1wAoQCkAK0A1wAMASgB+wBjAIH/tv5w/ur+/P8KAVQByAArABEAPAAeALP/Vf8t/zv/sP+gAIwBtgECARwApf+L/27/R/9u/+3/WwBUACAANwCDAH8A//95/0f/Tv9u/+H/sAA+Af0APQDG/8b/vf9w/0//qf8YACkAEABFAJ4AkQAQAKb/o/+5/7v/+f+LANsAggDt/6L/dv8V/9b+MP/R/xcAAQAIADkAOgAPABYAPQASAKT/jv8EAHgAagAjADQAhACKACgAxv+S/2H/S/+i/0wArAB9ADAANwBiAE4A/P+o/17/Fv8M/4b/VQDzAAwBvgBHAMH/O//w/h3/mf/w//j/BABZAL0A0wCmAGgA6P/+/jz+av5u/2UA7gBGAWoB+gAxAMz/4//F/z///P5m/wwAewDIAPsAugD3/0P//v7o/tT+IP/v/6QAtQByAHMAhAAUAFz/JP+Z/xkASwB4AMEAwABZABYAOAAwAIv/3v4G/97/fwCUAJQAqQBqAMb/YP+e/wYAAgC0/4z/nv/Q/ywAnACnAAgAP/8L/3L/yP+w/3L/ff/V/0UApgDlAO4ApwAYAHL/+P7u/mD/FACsAOgAwQBlACcAMAA0AMv/Gv/U/lv/IwCEAI8ApgCeABIAW/85/8D/JQD3/6z/z/87AJoA5wAWAcgA7P8w/0v/EQCtAJoAJgDX/+f/KQBnAIQAeAA0ALb/U/+J/2UATAF+AeQADQCX/6L/8v9HAG0ANwC1/1P/fv8IADsAv/8j/zD/zv9EAFMAZwCaAHAAw/9I/4H/7//r/5//pP/7/zIAOgBOAEgAxP/w/ob+6v60/0IAZgBsAJoAxQCWAAsAh/87//T+oP6m/lL/SQD7AFQBeAEmATMAMf/Q/vb+Ef89/wEANAHkAawBEgGhAEMAwv9I//T+tv6m/iD/LgA2AZwBUgGuAPL/TP/q/uT+K/+m/zUAqwDYANEAzADHAIUA9P9f/xb/Jv94////kgDCAGIA2P+m/8j/1f+t/5D/vv8gAHgAowCOAD8A2P96/0P/Sv+R/+j/FQApAFcAiABwABgA1P/B/5//Yf9w//X/jgC+AI0ASgAJALb/cP9x/6v/1v/h//r/LAA7AAUAx//B/+X///8iAG8AlgBGAMr/vP8PABgArf9u/9P/cgCeAEsA6P+s/4v/jP+6/wIAPwBbAEgADgDf/+j/HwBVAGEALgC0/y7/HP+x/2cAngBtAFQAUgD1/0b/Af+E/0kAtwDHALoAhQAYAL7/t//W/87/pv+X/7T/8f9FAJUAsgBtANn/P//u/hf/pf8tAE4AGQD2/x4AWwBUAOT/Vf8c/3P/EQCIAJ0AYQALAMj/w/8SAH8AtACEAA8Ajf8z/zn/tP9BAFcA1f9K/1f/9P+PAKkAXAAHANb/t/+o/9D/KABqAGUATQBmAIcAXwAcACwAcwBoAP7/zP8iAHoAYQArAEYAYgAOAJ//q/8RACkA4P/C/wUAMAD4/7v/w//I/5r/jv/l/0oAVgBFAHUAqQBcALz/gf/Y/zkAMgDj/7b/2P81AJ4AuQBNAIv/9P7e/jj/w/84AF0ALADh/7n/xP/7/2AAwACiAN3/Bv/a/lL/1P8KABcAAgCo/03/eP8SAGEAHgDV//H/GgAAAP3/VQCUAFYABQAiAHIAbAAcAOn/yv+Q/27/qP/z/9b/mP/y/9MAUAHtAC4Axv+8/8f/7P9GAIEASQDj/9D/GQBFAB8A4v+j/0X/Cf+E/7QAqgGIAX8AfP8g/2P/3/85ADoA+v/a/x0AmQDDAEgAaP+6/qr+LP/b/14AmACbAHwANgDU/4X/b/9x/2D/Tf9w/9T/TACdAKkAYwDJ/yn/+v51/0QA1gDYAHUACQDB/6P/rP/M/+L/3v/d/wIAQABZAC0A1v+C/0z/Sv+d/0EA6AAyAf0AfgD1/43/av+k/xwAggCaAHAASgBPAGEASgD2/47/Vv9z/8z/KQBrAIYAdQBEAAgA1v+y/6X/v//x/wsADwA5AJgA1ACYAA8AqP+V/6z/0/8hAHoAjQBHAAwAFwArAAgA3f/l/+L/lf9Z/63/UgCKADIA2//L/5v/H//i/kX/8P9UAGAATgAnAOf/wf/q/ywALgAOACoAdgB3AP//lf+4/yQAOADz/9b/AQAOANf/wv/3/wsAzv+5/ygAmgBkANf/sf/s//H/uP/V/04AZwDs/5//AwByADMAtv++/y8AUAABANX/BQA8ADwAMgA5ACsA+//r/yIAbQByAAQAYf/+/hj/fP/Y/zYAqgDXAEoAU//a/iD/k//B/+b/NABVACoALwCuAAIBfACM/yP/YP+y/+b/QgCtAKoANQDs/wgAEwDJ/5b/zv8aAB4AGQBQAG0AEwCS/3T/lf9+/2L/1v+eANUAQACu/7X/8v/0//r/WgCzAHcA5v+z//3/PQAxAC0AXwB8AEYA///w/+X/lP8v/zX/t/9AAIUAlQB5AAwAZP8D/zH/mv/F/7r/2f80AIgAqwC1AKIARACk/yf/KP+O//7/QwBdAFoAOwANAO7/5//d/7r/nv+1//7/VgCVAKkAkQBDAMH/Mv/y/kj/CgCmALEAZQAuAP//lf8n/zT/rv8FABEATwDlAD4B8gBZAOX/fP/+/sr+Pf8XAMYACAHvAI4AAACI/0T/Kv85/2n/nP/H/ycAzQA4AdsA+v9a/zH/MP9G/7r/XQCOACoA0v/1/zMANgBAAHoAcQDi/2L/lf8nAFQAGgAXAGkAlQBuAE4AXgBIAOr/mv+Q/4//Zv9b/8L/YQC2AKYAdABLABUAwv99/3n/q//0/0oArAAIASIB1wBKAMz/jf+M/6//2//q/8n/p/++/wwAQQBAADsAQwAkANT/t//y/y4AEgDb//H/MgBEADUATgBlABgAff8Z/x7/Mf8m/1v/CAC/AOMAfQATAOn/y/+W/43/2f8zADUA6f+u/7n/5//3/+X/y/+y/5H/iP++/xsATgAjAOL/5/8zAHsAnQClAIIAJQDT//H/VQBRALL/Gv8V/3z/6/9JAJMAiwApAOP/EQBEAAAAnP/K/3gA3QCyAHcAdwBRAMv/Zv+e/x8ARAADANr/CQBUAGsAPQDl/4b/XP+Q/wQAYQBeAAsAy//y/0kATgDc/1r/Lf9I/2z/rf8kAIcAcgACALz/2v8hAD8ADAB+/9L+pP5Z/40AVgFEAZAAr//0/qb+9P6U//v/+v/o/xIAYgCpAMsAqwAaAEr/zv4O/9//rAAIAdYATgDr////SAAzAJ7/Bf/s/m3/VgBWAdgBZAEvABj/yv4r/83/XwCuAJ4AVAAsAFUAlQCaAEQAov8N/wX/zP/xAKQBnAEaAVkAiv8b/27/HgBTAPf/vP/4/zkAJQD8/+D/iP/4/tr+jv98AOkAxABqAPr/hv9c/7P/JgAtANf/qP/Z/y4AXgBLAPP/bP8N/zr/7/+sAOgAnAAdAK3/bf9v/53/xP+5/5//t//+/z4AUgBHABoAu/9O/0L/xP9/APYA8wClAEUA8f++/8T/+P8aAO3/lv+A/+n/mAAIAeEAMgBl/wf/Vv8XALgA1gB/AAYAvP+0/9H/3v/L/7j/xP/p/xUAQgBiAEUA4f+K/5z/AABiAJEAigBZAP3/oP+L/9H/KQA/AAoAzf+9/9P/8v8ZAD8AOADe/3P/dP/n/08ARwACANz/wf98/0D/bP/1/2oAiABuADUA0P9Y/yn/ff8cAKgA6gDfAJkAJQCw/3P/if/K//H/4v/I/9z/IwBZAE8AEQDB/33/ZP+a/xEAgQClAHYANQALAO3/2//j//X/8v/a/87/4f8FADMAdACjAH4AFADO/+L/FwAVAOT/yP/f/xcAVAB0AEkA4v+R/4b/mf+d/6T/1v8fAEMAQwBQAHsAiQA0AJn/Hf8i/6D/LwBrAEUA9//N/+T/GwAkAOD/if9y/6v/8v8RACMAPQA/ABIA2P/A/7n/o/+U/6P/t/+m/6D/7v9iAHwALgDj/9b/z/+n/5//7f9DAFcAWwCNAMUAnwAdAKL/d/+w/ysApQC6AF4A+//y/x8AJwAKAP3/BgD5/+z/DgBCAE8ANwA0AD4AGQDV/9X/MQB3AEgA6f/b/ysAeABxADMA9v/P/8P/6f81AGQAOQDZ/6v/zP/3//L/2//W/8n/mf+O//X/fAB/AAUArf+x/7v/qf/X/0gAYQDn/4b/xv81ADAAzv+R/3//aP+C/wcAgwBbAND/lv/I/+H/s/+k/+v/NQBKAFoAbQA9ALH/LP8H/zr/m/8cAKEA6ADMAIwAaABSABgAv/+B/4n/1v9RANcAHAHrAFsAwP9d/zP/LP9Q/7v/SwCtALMAeAAzAOb/lP97/9T/YwC/ANQA0wC5AEQAjv8i/zz/hf+y//j/dADAAJAALQDz/6r/Gv++/iP/6v9VAF8AgwDJALIAMADH/5z/Uv/k/t7+c/8PACoAFABQAKgAkgAIAJH/YP9I/0f/nf9SAOwA+wChADkA2/98/z3/TP+L/7b/yf8CAFoAgwBXAAsA4//X/9X/9f9BAH0AcgA8ABoAHwAmABcA+P/S/7f/zP8XAFYAQQDw/7z/x//1/y8AcQCaAG8ABADH/+7/LAAkAOz/2f/w//P/8v80AJUAlwAfALP/vf8EACYAIwAyAEIAGADc/93/CgAFALX/gP+l/9//4f/X/wYAPwAmANv/0v8XADcA/f/D/9L/9f/s/+f/GQA/ABEAzv/d/yIAMgABAOj/CQAVAO//3P8LAEYARwAaAOP/vP+3/+L/KQA/AAwAzv/E/+P/BQAhAC8AIgADAPj/AgACAOn/1v/k//v/DQAeADEAMQAKANr/y//5/z0ATwAfAOb/5f8ZAEQAPAAFAKz/T/82/5L/JwB4AGMAJQDz/7//jv+V/+T/KgAhAAAAFgBSAG8AYwBGAA8AtP95/6T/CQA8ACEA/P/y/+L/yf/c/x4AOwAFALj/pf/E/+L/BQA+AFcAFQCn/4f/2P83AEIAHQAPABQA9f/B/7v/9P82AEsAQQA6ADQAJwAaABwAFADl/6L/hP+v//r/MwBQAFUAPAAIAN3/2v/s/+b/xf+2/9L/DQBPAHwAcgAuAN//xP/Y//L//P8CAAMA+P/3/xgARQBOADIAFQALAPn/2f/S//T/GwAZAPb/4f/m/+X/zf+w/6r/uf/M/+T/CAAUAOz/tP+w//T/OwBNAC4ACgD4//H/CQAjAA8AyP+M/5b/x//i//D/FgAuAAwA1f/L/+D/2P/M//v/TwBhACcACgA1AEYA9v+a/5P/vv/M/93/MQCdALAAcgBCADIAAwCv/5b/8f9sAKQAlABoADAA7/+4/6P/qP+r/7b/5f8xAHMAggBcABgA2P+q/5n/vv8PAGUAigByAD4AEwD+/+n/x/+n/6n/1/8bAEwAUwA+ACcADADh/7X/pP+0/93/EQA9AEgAIwDl/8D/wf/M/8j/v//J/+f/BgAXAB0AEwD3/93/3P/r//T/7f/c/9j/5v8BACIAKwAWAP3/+v8EAPz/6f/n/wIAKwA9ADgAKQARAO7/2//w/x0ANAAbAO3/0f/J/8v/5P8gAFoAUgAKANP/4/8YACsADwDv/+T/4//4/zUAdQBuABMAq/+H/7P/+v80AFIATwArAAIA9f8LACAACgDS/7D/xP/v/wcABQD+/+v/u/+J/4v/xv/7/wEA9/8HACoANAAkABcADQDs/8H/u//l/xcAMgA4ACkAAgDP/7r/0f/u//D/5//1/xYAMgA7AC4ABAC9/4r/nv/p/ywASQBRAEQADgDE/5//sv/Y/+//AQAvAG4AjwB4ADQA5v+w/6T/xf8AADYAVQBeAFwASwAhAOP/qP+P/6n/5P8fAEQAUgBPADYACADc/87/5v8DAAYABgAZADkAQgAkAPf/1P/I/9T/AAAxADsAEgDc/9D/5P/t/+D/2v/1/xUAIgAkADIANgANAMf/pf+5/+D/+/8OACcALQAKAOn/7v8HAA0A8f/b/+n/DAAmACkAJgAiABcABAD1//P/6v/W/8n/3f8RADkAQQApAAAA1f+0/7f/4v8XAC8AIwASAAcA/v/z/+v/4P/K/7f/zP8MAEYAUQAyAA8A9v/f/9z/9f8VABcAAgAAAA8AFwAOAP7/7f/M/6n/r//q/y4ARAApAAEA6f/r/wIAGQAWAP//6v/t/xIAPABKADUADgDs/9j/0v/b//H/AgADAPb/6//y/wcAGAAQAPX/3f/h//v/FwAoACQACgDl/9D/4v8LACkAJwATAPj/4f/S/9f/6/8AAA4AFQAeAB4ADwD6/+7/8P/0//D/7P/2/wkAGwAZAAgA9//m/9b/zv/a//j/HQAvACsAGAD+/+f/4f/w/wYADgACAPj/AgAZACwAIQD6/9L/w//Y/wUAKQAxAB8AAwDy/+3/6//l/+H/5//w//X//P8HAAEA3f+3/7H/y//t/wgAHAAkABgABQAGABUADwD1/+T/6v/7//7/AgASACAAGgABAOT/0v/P/9f/6f/8/wsAIQA5AEIAOAAbAPn/4//j/+///v8KABYAIAAfABYADwAQAA4ABAD6//7/DwAnADYAMwAkAAsA8v/m/+r/+P8CAAMA/f/9/wgACwADAPT/4//b/+j/CQAqADMAHwADAPT/8//8/wgACgAEAPr/9f/+/w4AFQAOAPT/1v/L/9j/7/8EABQAHAAQAPD/1//d/+z/7//v//7/DQALAP7/+P/z/+L/0//e//3/CwADAAIAEgAZAAkA7v/g/+P/7P/8/xQAKAApAB0AEgAIAAIABAAKAAoAAQD4//7/EQAbABgACgD8//b/9//+/wMA/f/z//n/CgAUAA8AAgAAAAUAAwD7////DQAQAAQA9//z//T/9f/9/w4AFQAJAP7/AQAHAAYABAAIAAkA/v/u/+r/9f8AAPn/5//a/9f/2v/h/+n/7v/o/9n/2P/w/wwAFQAGAPr/AwARABYAFAAQAAIA7f/g/+b/9v8DAA4AGAAXAAMA6v/h/+r/9f/8/wMACwAPABEAEwALAPb/5f/k/+//9v/7/wUADgAMAAIAAgAMABQAEQALAA4AFgAYABMADQAPABEAEQAWABgAEwALAAgADAAIAPn/7f/s//b/AgAKABAADQACAPz//f8AAP////8HAA0ABwD///3/AAD+//P/7P/o/+v/8//+/wgABwAAAPf/8P/u//D//f8KAA4ADwAPAA4ABgD7//b/9P/1//f///8MABIACwD8/+7/5v/s//j/AgAJABAAGwAfABcACgD1/+L/2f/j//z/EgAcABsAEgAHAPz/9//0/+//6//t//b//v8EAAoADAAJAAAA8v/n/+P/6v/8/wwAEgANAAoADQARAAsA/P/1//z/BAAFAAcADAAPAAoA+//w/+X/2f/f//j/EAAWAAkAAAADAAUAAAD8/wEABgAFAAwAGQAbAA4A///7//v/9//w//P/AgAIAAMA+//1//L/8f/z//j/AAAFAAQA/f/7//3//f/4//T/9v/8/wEACAANAA4ABgD1/+v/7P/z//r/AQAEAAQAAAAAAAIAAgADAAQABAD8//b/+v8HABEADAAAAPr/+v/7//v//f8BAAMAAwAFAAsADwAJAP//+//5//r//v8GAA4ADAACAPr//P8GAAwACAABAPz//v8BAAMABAADAP//+f/2//b/9f/v/+r/5v/n/+n/5//n/+z/8//1//L/8//6/wEABQAFAAUAAgD9//v//f////z/9v/2//v/BAAMABAADAADAPv/9P/w//H/+v8FAA0ADwAPAA0ACAACAP7/+//z/+z/7//+/w0ADwAJAAQAAgAAAP3/AQAMABMAEwATABQAEgAKAAYACQALAAYA/f///wgABwD9//r//v////7/BwASABIACQACAAMABgAIAAYAAQD8//v///8GAAsABwD///r/+P/5//r/+f/3//X/9P/6/wAAAQD///n/9v/3//n/+v/4//X/9f/4/wAAAwD///n/9f/2//z//v/7//n/+v/7//3//v8AAAQAAAD0//D/9P/9/wkAEwAUAA0AAQD4//j//v8DAAMAAgAEAAkADAAJAAMA//////////8CAAkADQANAAkABgAFAAYABgAHAAUA///6//v//f/7//n//P8CAAYABAACAAIABAAEAAQAAwADAAEAAAACAAYABAD///n/9//4//j/9f/z//T/9P/0//f/+f/3//T/9P/4//3/AAAAAAEAAgADAAMAAAD7//b/8//0//b/9//6/wAABQAFAP//+P/z//H/9P/7/wMABwAHAAQAAQD8//X/7v/r/+3/8//8/wMACAAKAAcAAgAAAAIABQAHAAcACAAKAA4ADgAMAAsACwAJAAcABgAJAAsACgAIAAUAAgD9//v//P8BAAUACAAJAAkABgAAAPv//f8BAAIA/v/6//v/AQAHAAsACQACAPr/9v/4//r//P/9////AAABAAEAAQAAAAAA//////7//v8AAAIABAAEAAIAAAD///7////+//v/+v/9/wMACAAJAAYAAAD6//f/+f/+/wAA/////wIABQAFAAQABAAFAAQAAQD+/wAAAwAFAAIA/f/6//z///8AAP///f/8//v/+//6//j/+P/6//7/AQAFAAwADAAGAAQAAQAAAPz/+v8BAAEA+//+/wUABAD8//P/7//x//f//f8GAAsABAD6//r/AgADAP7//f8BAAYABgADAAMAAwABAPz/+//9/////////wAAAQAAAP7//P/8//7//f/7//r/+v/7//7/AQAEAAYABAAAAP3//v8AAAAA///8//z//f/+//////8AAAIAAAD8//j/+/8AAAQAAQD8//r//v8BAAIAAQAAAP7//P/9////AQABAAIAAwAEAAIAAQD//////v/+////AwAHAAgABQACAP///v/+/wAABAAGAAcABgAHAAgABQAAAPv/+f/5//n/+f/5//n/+f/4//X/8//z//X/9//6//3//v///////v/8//n/9f/z//f//f8CAAQABAABAP7/+//4//f/9v/3//j//P///wIABQAGAAUAAQD7//f/9//7//7////+//3//P/8//z//v8AAAIAAwADAAQABQAEAAQABgAJAAoABwAHAAgABAD///7/AAAAAP7/AgAGAAUAAgACAAQABgAIAAgABgADAAIAAwAHAAkACAAFAAUABgAIAAgABQABAP3/+//9/wAAAwAEAAIAAwAEAAIAAAD8//r/+f/7////AQD///3/+//8/////v/7//r/+P/5////AgADAAIA/P/2//T/9f/4//7/AgABAAAA/f/8//3//v/9//z/+//8//7/AQABAAAA///+//7///8AAAEAAQAAAP///v8AAAQABgAHAAYABAACAAIAAgABAP///////wAAAQACAAIAAgACAAEAAQABAAEAAAABAAMABAAFAAUABQAFAAQAAgAAAP///v/9//7//v/9//v/+v/5//n/+v/6//v//f8AAAMABAACAAAA/f/6//n/+v/8////AQABAAAA/f/7//j/9//4//r//f///wEAAQAAAP7//P/6//j/9//4//n/+//7//z/+//7//z//P/8//z/+//8//7/AAACAAQABQAEAAMAAwAEAAUABgAGAAUAAgABAAAAAAABAAIAAwAEAAQABAAEAAUABgAGAAQAAAD9//z///8EAAgACAAFAAMAAgADAAQAAwAAAP7//v///wEAAgACAAIAAgACAAAA///+//3///8BAAMABAAEAAMAAgAAAP7//P/8////AwAEAAQAAgD///7///8AAAAA/v/+/wAAAgACAAEAAQABAAEAAAAAAAEAAgADAAEA/v/+/wAAAgACAAEAAQABAAEAAQD///z/+P/3//n/+v/8/wEAAgABAAEAAQACAP///f8BAP///P8CAAYABQABAPz/+f/6//v//P///wEA/P/4//r///////z/+//9/////////wAAAgABAAAAAAABAAEA////////AAAAAP////8AAAAAAAD+//3//P/8//3///8AAAEAAQAAAP//AAABAAIAAQD+//3//f/+////AAABAAMAAwAAAP7//v8BAAIAAAD8//v//f8AAAEAAQABAP///v/+//7//v///wAAAQACAAEAAAD///7//f/7//z//v8BAAIAAgAAAP///f/9//3//v//////AAACAAQABQADAAEA///+//7//v///wAAAQAAAP///f/7//r/+P/4//j/+f/7//3//v/+//z/+f/3//f/+v/9//7/AAAAAAAAAAD///7/+//5//j/+P/6//z///8BAAIAAgAAAP7//v8AAAEAAQAAAP7//v/+//7///8AAAEAAQAAAAAAAAD/////AAADAAUABQAGAAcABgADAAMABAADAAEAAgADAAIAAAAAAAEAAgADAAQAAwABAAAAAAACAAMAAgABAAIABAAGAAcABwAFAAEA////////AAAAAAAAAgADAAMAAgABAP///v/+///////+//7//v///wIAAAD+//3/+v/6//7/AAABAAIA///7//v/+//8///////+/////v/+//////////7//v/+//7//////////////wAAAAABAAEAAQAAAP///v///wEAAgADAAMAAgACAAIAAgACAAIAAQAAAAAAAQABAAEAAQABAAEAAQABAAAA/v/+//7///8AAAEAAQACAAIAAgABAAEAAAD//wAAAAAAAAAA///9//z/+//6//n/+v/7//3//////////f/8//r/+v/7//z//v///wAA///+//3//P/7//v/+//8//7//////wAA//////7//v/9//3//f/+//7//v/+///////+//3//f/8//z//f/+/wAAAAAAAAAAAAABAAIAAwAEAAQAAwACAAIAAQABAAEAAQACAAIAAgADAAQABgAHAAYAAwAAAP////8CAAQABAADAAIAAwAEAAUABQADAAEAAAAAAAAAAQABAAIAAwADAAIAAQD///3//f/+////AAABAAIAAgABAP///v/9//7/AAABAAEAAQAAAP//AAABAAAA///+////AAAAAP////8AAAAA/////wAAAQACAAEA///+////AAAAAAAAAQACAAIAAwAEAAEA/v/9//3/+//7//7///////////8BAP///f8AAP7//P8AAAMAAwACAAAA/v///////v8AAAEA/v/7//z////+//3//P/+//7//f/9//3//v////7///8AAAAA///+//////////////8AAAAAAAAAAP///v/9//3//v////////////7//v8AAAEAAAD///7//f/+//7//f///wEAAgAAAP7///8BAAIAAAD+//3//f///wAAAAAAAP///v/9//3//f/9//7///8AAAAA/////////v/8//z//f/+//////////7//v/9//3//f/8//z//P/+/wAAAQABAAAAAAD///7//v/+////AAABAAEAAAAAAP///v/9//3//f/9//7///8AAP///f/7//v/+//8//3//v///wAAAQABAAEAAAD+//3//f/9//3//v///wAAAAD///7//v8AAAEAAQABAAAAAAD/////AAABAAIAAgACAAIAAgABAAAAAAACAAMAAgADAAUABAACAAMABQAEAAIAAwAEAAIAAQABAAEAAQACAAMAAwABAAAAAAAAAAEAAAD/////AAABAAMABAADAAEAAAD/////////////AAAAAAAAAQAAAP/////////////9//3//P/+/wAAAAD//////P/8//7///8AAAIAAAD+//7//f/9///////+//7//f/9//3//f/+//7//v/+////////////////////AAAAAAEAAgABAAAA////////AAABAAEAAQABAAEAAgACAAEAAQAAAAAAAAAAAAAAAAABAAEAAQABAAAA//////7//v/+//////8AAAAAAQAAAAAAAAD//wAAAQABAAEAAQAAAAAA/v/9//z/+//7//z//v/////////9//3//P/8//3//v///////////////v/+//7//v/+/////////wAAAAAAAAAAAAAAAAAAAAAAAAAAAAABAAEAAgACAAIAAQAAAAAAAAABAAIAAgACAAEAAQABAAIAAwADAAMAAgABAAAAAAAAAP///////wAAAAAAAAAAAQADAAQAAwABAP///v///wEAAgABAAAA//8AAAEAAQABAAEA///+//7//v///wAAAQACAAIAAAD+//3//P/9//3//v/+//3//f/9//3/+//6//v//f/+//7//v/9//z//f/+//3//f/+//7//v/+//3//f/+//3//P/8//3///8BAAEA///+//7//v/+//3//v//////AQACAAIAAAD///7/+//6//3///////////8AAP7//P////3/+v/+/wIAAgAEAAQAAgAAAAAAAAADAAUAAQD8//z///////7///8BAAEA/v/+///////+//7///8AAP///v//////AAAAAAAAAQADAAMAAwADAAMAAgABAAAAAAABAAMAAwACAP////8CAAQAAwACAAEAAAAAAAAA/v///wIAAwACAAAAAQACAAMABAACAAAA//8AAAEAAwAEAAMAAQD///7//v/9//7///8BAAAA//8AAAEAAAD///7/AAACAAIAAAAAAAEA///9//7/AgADAP7/+//+/wEAAgACAAUABwAEAAAAAQAEAAMAAgAFAAgABQABAAQABwAEAAEAAwAFAAIAAAAEAAkABgAAAPz/+//7//3/BAAFAAAA/v8BAAIAAAAAAAQABQD///v///8FAAQA/v/8//3//f/9////AgACAAIA///4//X//P8FAAcAAwABAAEA///+/wEABAACAAEAAgABAAEABgAGAAAA+//7//3/AAACAAMAAwD+//n/+P/5//z/AAACAAEA/P/4//f/+f/8//3/AAD///r/9//6//7//v/7//n/+//8//f/8v/0//v////+//v//f////z/9v/1//j/+f/5//3/CQAOAAMA9P/v//T/+f/9/woAFQAQAAQA+v/0//L/9P8BABMADAD0/+j/8//9/wAABAAKAAYA9f/v//v/BwAEAPv///8HAAcABAAEAAQAAwABAP//+//5/wEACQAIAAIABQAJAP//9f/7/wUABAACAAwACgD0/+j/8P/5//n/+P///wYA///3//H/6f/v////BQD+//j/+f8AAAcACAADAP3/9//1/wAADwANAP7/9//8/wsAGgAeAA4A8P/t/xUALQASAPn/CgAXAAEA8v8MACkAIAARACgANQAPAPb/EAAhAP3/4P/z/xAADgD9//3/AQDj/73/1P8EAAQA/f8NAAwA8//a/8P/yP8KAE4AJACW/1v/3/9AAMD/kf9nAJ8AhP8g/0AA6wAyAKP/CwBHAMj/mP8ZAH4AiQBgAMr/Kv+z//MA5gDI/8v/2gDIAI7/ev+6AP0Arv/w/pf/7f+w/5MA7gEaAR7+GPzk/G3/NAIwBHwDbf9Y+9j65Pxq/pD/aAE0AjsA8P1A/rr/1P+l/7gAjAEkAUIBKAJ8Aer+mP0S/7EAhABhAKoBOAKfAP7+kf98AZQCYAL6AegBpgEWAegADAH1AOsAQAEiAdb/bP5a/kL/lv8e//D+AP84/gz9zPx4/Sr+NP6o/bD9sP78/iT+Bv44/+3/Vv9K/+gAYAKkARgAYwCeAV4BowCwASQDgALrABABLALMAXgAmADuAUACHAEyAF0AZwCo/0f/5v+BAFAApv/g/m7+Bv8WAAwA6P5K/r7+JP/q/gH/5v8tAMT+SP3Y/eP/JgHWAM7/zv4w/lr+dP8YATQCygFAADD/c/8/ANAAXgHQAWgBUgDr/58AMAG6ADYApgD8ACcAov/iACwCSAE0/3j+L/+r//n/TgF8AkQBpP7E/fr+4//p/5IAhgGmAJD+Ov6t/1AA0//q/2oA/f8f/z//IQBcANb/qf8GABYAy//w/2EACQAK//T+NQA4Ad4AAACz/6b/U/92/4UALAF+AMb/CwAeACb/yP4/ALIBEAF9/yP/x//z/6f/2/+GAKsAHQCl/2n/DP8d/wsA1gCAAMH/wf88AOH/pP4q/ov/ggHiAZUAiP9g/87+6P3Y/noBrAJYAZP/sv4O/rT9Ff/aAawCTAA+/rz+fv88/xAA5AGEAc7+yP3u/8YB5QBQ/97+fP4S/of/RALwAt0AnP6A/Rz9Cv65ABwDrAIiAEr+QP4R/wMA+QCaATIBUf9s/Sb+NAEMA/4B4P9m/mz9gP3//zADBAOY/zT9dP12/pv/vAE0A1IBsP2w/Kb+cwCcAQADXAKk/jj8Xv7sAfQCOAKwAXUA6P04/Y8A7AM8A8gAjv+w/gz+rP/cAvwDxAH4/gr+YP4y/zQBOAOQArP/rP3M/Qj/ZQB8AcoBswCW/jj9Cv45AKwBlAFsAMb+eP2Q/XL/8AG8AgABxP7U/bT9Yv6mAPwC2AI3ALT9gP1Q/zwBEAL4AUYBBADi/uT+UgAkApQCLgG0/5P//v8VAE0AxwCdAGX/Nv6G/uj/sABrANv/JP9G/hb+7v75/44AwgBvAED/9P0g/g0AkAH0AGf/sv7W/mD/swAgAuIBFQDi/nL/TgBCAJ0A9AG+Aeb+2PyI/r4ByAKsAa4A+P+E/nz9sP4qASgCJAEhABsA2P++/kb+n/9iATIBUv+o/igA7gBk/4b+TACSAef/av7j/5QBZACk/jP/BAD2/kj+HADsARwBOP9o/jL+3P2O/usABAOQArz/EP2c/Dz+qACoAhwDLgH4/XD8LP48AcgCJAIdAMD99Pwl/5QCvAPgARb/VP1M/Yn/HAOQBMQBQP24+zD+cgHEAowCngFz/4j8+PtS/xwDzAJk/5T9TP48/1kAbAKwAvz+iPsc/SgBpALQAVgBXQCw/Tz85P4MAxAElgHg/hD+XP7s/mkA/AL0A80AUPws/D0AQAIaAAb/bgEwApr+VPxe/1wCHgAY/RL/1AJEAgT/aP6k//j+MP7VAPQDfAJm/oD9gP/6/0P/nQCAAjgBPv7Q/fn/oAGsAfcAvv+s/kH/KAHiAY4ASf+R/4gA/wDsAHUAy/96/37/Pv/0/tb/qgH2AaD/YP30/aj/uf9p/xQBwAIGAXz9xPw//wwB9ABWAQwCfADg/cD9hf8jAA4AfAH0AloBCv50/fz/igFrAID/YgDHAMX/nP/jAFAB+f94/hr+2P6DANQCzAMgAaj8EPv4/RgCEASIA7gBB//I++j6K/8oBRgGbgEY/XD8RP2m/nQCYAYIBFD8mPg8/TADCARUAngBM/8I+6j6xwBoBtgEVP9A/GD8xP1aAJwDOARgAPj7+Puh/0QChAI0Av4A5P3I+2j+hAPoBGIBWP7I/mr/jP6V/+gCeAOs/5T8qP0rAPQA2QBOAdAAaP60/Oj9NgDiABoAGgA4ASIBBv+Y/c7+yABaAeoAYQBS/wb+YP6dADgC5gESAUcAxv64/cr+4gDIAZgBTAFHAGL+yP2R/xABTgBw/yEAeABr/1X/0wDQAE7+AP1l/2QCJALz/xH/7P7g/az9xP/aAaQBFQDU/uj9SP2E/uwB0ANOAYz97Py4/vb/WgAuAdgBewDk/Vz9tf8IAhQCnABL/+r+zf+cAfACKAJq/xD9xP2MAegEWARQAMT8YPxm/iIBgAPcAxwBDP1g+7D9xgGMA/IBtf/o/pz+Ov5C/94BxAK6/2D8gP00AVQC6gAhAKv/7P3o/Er/0AIYA44Aov7c/VD9qP5kAngEEAIc/nz8cP3J//wCsATQAeT8RPz9/44B7v+6AMgDPAJc/BD7twC4BMYB1P2m/q8AbP8k/qsAEAOZALT8lP2OAUwC5v/h/9oBTACM/HT9lAIYBEsA3P23/xQBmv8v/x4BWAE1/yj/cgFYAaj+Qv7yACQC///Y/VT+HAD6AKMA1/9d/7P/GABz/8D+jf+1AG0An//9/+YAwwCQ/9T+iP/BAEIBOAEWAUkA6P6g/kYADAKoAZ7/XP7u/mgArgHOAToAfv7G/kIAgwDC/+//xABIAML+wP67ANYBUwBm/kD+8P4h/2n/QQBkAOz+jP1S/vn/0P+U/tr++f+D/2b+W/9iAR4BvP4I/hcAoAHLAOz/gQCfAF7/Nv+CAXgDGALu/uT91P/sASwCZAG9AA4AM/8U/x4ACgG6ABAAFQATAGL//P5z/6r/cf8bABYBBgCo/XT9Y/9CAMX/VgBQAen/eP3k/aAAogFsAOb/WwDt/1P/TQBkAV0A7P7F/2wB5wBZ/8v/XAHGAI7+hv5AAfgCdgGq/oz9dP7H/5cAKgFsAbsAJ//w/UT+6v8+AfsA7v/d/7QAiwAO/2D+q/8sATQBqACgABEAav7c/e7/9gEKAST/r/9sAeMA4P7k/q4AuADw/jX/9AGwAu7/Av6D/xwBHgA8/80AIAKGAIz+Qf/EABoA5P71/5wBzACg/jb+j/+ZAN8A2ADd/wL+jP2A/2wBLAErAAIAl//4/Vj91v8QA7gCJv8A/WD+hgDuAJ0A5wCaAPb+Nv4fAIACZAKBAHP/b/9O/67/ZAGkAn4BTP+k/mb/BACzAN4BygGL/+D9Gf/3AKYAo/9UADYBGQDG/o//xgAJANz+jf/NAHEAs/9JAMcAk/9U/iz/8AAkAeX/Xf/p/xsAlP9+/zcAqQAXAFr/cP/b/5j/Jv+6/+sAFgHa/9b+Hf/Q/yAAmABeAUoB4f+E/rT+JQBGAVgB2ABdAM3/RP+W/9oAiAGOACf/O/9rALEA9P/S/z8AsP+u/kf/JAGWAdz/TP6O/m7/l//e/+sAYAECAAT+sP1v/y4BOgFfAM//WP/A/s7+9P8iAfQAg/9i/rj+EAASAdkAxv8A/w3/nP9+AGABSgHo/7L+/v4pAK4AgwCDAHoAuf/y/k3/awDmAEkAZP8Y/4j/HABGABAAzv+X/3L/y/+cALUALv+w/cr+oAGIApEAuP7I/lT/bP9HAAgCTAIaACj+tP5KAOUA4QAiAfcAxf/q/tj/TgEAAWT/4v4EACABGgFvAML/OP8Y/9L/+ABsARABjAD5/07/IP/c/+MAfAGEAeMAof+2/iL/VQDhAL4AuABgABb/Gv74/sEARAEgAAL/DP9s/1b/P/+Y/+z/wv9j/03/q//f/4T/PP+a/yUAPQAHANj/zP++/7H/2/86AIgAnwBlAPL/vf///0gARwBcAMoADgGMAL//nv8NAEQAmwBuAagBdQAP/xP/FQCvAMAA3ACHAFv/tP6c/7sAgQDR//P/NgCq/yz/1v+jABUA/v4r/0sAogAPAMD/w/9m/wP/jv/FADQBawB3/yv/OP+J/2YANgH+ANX/8v7+/oD/6P9uAOcAbwAd/2z+G/8cAFUA5v+J/1T/Iv9U//j/TADE/+j+qP5V/1kAwwA7AFD/xP7o/pf/cAD+ANIA4//o/tz+vP+sAOoAYwCI/wX/S/8iANQA2QAxAHT/Qv+n/zwApACqACUAZP8u/+v/yQDcAE0A4P+s/37/0P/CAG4BFgFcADAAaABrAGQA1ABQARwBeQBEAJYAzgCAABsAGwBOAD4ABgAYAEwACwBE/+D+fP9GACoAYf/o/vz+Jf87/5P/+v/D//j+nv4u/+3/HADO/4P/V/8y/1j/+/+bAGwAn/8c/23/EwBkAGcATADv/2X/VP/5/7EAxQBUANz/h/9R/4v/aQAsAQIBEQBH/zD/nv9IAOsALgG2AM7/b//r/44A1wD+ABwB0ABPADUAqgAGAQYBCAEWAfAAzgAUAUIBtQAPAFIAMgGIAS4BrgBEANf/xP9rADQBQgGvAB8Aov9R/63/gQD8AK0A+f90/1r/eP+z/+//7v+5/3L/O/8i/x3/E//c/pz+ev6Q/rr+wP6A/tj9TP1Y/fz9nv6q/hj+ZP0w/XD9wP0A/mz+0v6k/vD9jP0A/ob+wv5G/wwA6v/w/tD+2P+WAFUAjgDWAVwClAFGATwCkAIUArQCaAQIBcwDIAPYA3AEOASYBMAF4AWoBBgEwAQgBcAE6ARwBQAF1AOsA5AEaAQgA5wC/ALAAr4BSgFWAdgAwP9I/1X/sP6A/fz8GP3M/CD8mPuA+0D7kPr4+QD6OPrY+Tj50PiY+CD44Pc4+FD4YPdQ9qD2cPdg95D2YPZQ9uD14PVg9xD5OPkA+OD2cPZA9yD6lP34/uD9sPz0/DT+igBwBPgHgAhoB7AHcAkgCxANQBDgEqAS4BBgEaATgBQAFEAUIBXgFEATYBJgEkARsA5wDeANkA0gC/gHAAbQBBwDYAGnAC8Aiv4I/Nj5UPgw96D2oPYg97D2kPQg8lDxYPKw8xD08PPg80Dz4PFQ8YDyoPOA8/DyEPMA89Dx0PAw8XDx4PCw8HDx0PEw8cDwQPFw8dDwQPEw8+D04PUA9xD44Pew98j5wP35ACgCDANQBHgF4AZACiAPwBKgEyAToBOAFQAYwBpAHkAggB8AHSAcYB3AHqAe4B1gHSAcABnAFQAUQBIAELANIAxQCjgHtAK2/lz8yPqA+Sj4EPcw9TDyYO+A7oDvwPBg8YDxkPFA8XDwYPBQ8ZDy8PPw9Tj4SPmI+BD3kPZg9/D4IPsI/dD8sPog+AD2oPSw9KD2MPn4+KD0wO8g7QDsgOwA73DxwPCg7cDrIOxg7ADsYO6w8sD00PNQ9PD2APn4+dj7X/+QAlgFIAkQDTAO0A1gD8ATwBhAHOAdAB7gHaAdIB5AIEAjACXAIkAeoBugG4AboBqgGcAXIBNgDaAKkApgCYgFLAIYAHz9KPmg9gD38Paw9DDygPLA8mDwoO3A7pDygPVg95D3APVg8CDvIPSw+mj9FP0g+wj4APYg+IT8cP6A/Rz9JP2Y+pD3mPgo+8D5YPYg9XD1gPRg8zDzYPHA7IDpoOvA7oDvQO/A7iDswOhg6SDusPKA9ID18PWQ9HD0+PhR/2ACEAPQBDgHsAgQC6AP4BNAFQAWwBhgG+AbIBwAHgAgACDAH4AggCCAHsAbYBogGeAXQBfAFoAT8A0wCaAGyAWABegEhAKE/Vj4UPYQ9tD0YPRg9vD2kPMw8MDvkPHQ8vDzEPcw+TD4cPeA+Zj62PjQ93D6Sv7o/4n/Cf/Q/ej7OPu8/Hb+GP/2/qT9kPs4+UD3sPVQ9iD4wPdw9HDxQPEw8ODsAOvA7TDwwO6g7SDvAO9A6wDqwO4Q9CD1wPSQ9jj4MPeg96T8SAJgBBAFSAdwCUAKIAwAEEATIBXgFqAZABuAGmAaABsAGyAc4B5AIOAdgBnAFqAVwBSAFGAVgBTAD9AJoAZwBVAEWAPUAtYARPww+AD30Pfg98D20PXQ9RD1MPTA9FD2wPew96D3SPgY+gT8Gv7V/57+sPlg9XD3XP5oBHgEVgAg+8D2MPXI+Ij+gACw/aD5cPYg8/DwEPOw98D3kPLA7oDv4O/A7QDt4O4g7mDrwOzw8XDzIO9A7KDugPHw8hD3HP0C/ij5kPYY+nT/KASACUANsAuYB3AHQAyAESAVQBmgG8AY4BSgFcAYIBogG8Ad4B5gGwAWQBTAFEATwBHAEoASgA6QCagGGAUsA1IBrwA6ABj+cPuI+dD3oPaw9vD2kPYQ93D48Pig91D3iPhA+Wj5oPur/98AYf+s/rL+QPsg99D5ZAFABcQCjP4g+1D3UPWY+NT9AP7w+iD5IPcQ86DwkPIw9aD0YPLQ8XDxIO+A7UDugO5A7QDugPEA9KDyAPCA78DwsPIw9oD68PyE/PD6UPos/HQAEAYACjAK8AgQCSAKAAyAECAW4BcgFsAUIBYAF+AWwBhAHGAcYBgAFoAWABbgEwATYBNgEVANAAvACuAIwAU4BFgD0ACU/ZD8uPyY+6j54PiY+DD3UPZg9xD5GPlo+Kj4SPmo+Qj7IP1+/qT+vP6A/iT9kPsM/ND9iP0A/fD9YP4E/bj7iPoQ+PD0MPUo+qT9sPrg9UDzIPHg7hDw4PTQ96D1EPGg7oDtoOwA7mDykPVA9BDxcPAA8lDzUPQw9lj4YPng+dD7Iv4s//j/VgHYArAEEAhgC5AMMAzwDBAPoBBgEsAVgBigFwAWQBeAGGAXQBbAF0AZABiAFeATABLQDrAM0AxgDHAKgAggBwgEPv+E/KD8gP1o/aT80Prg95D1YPWw9sD3MPl4+vD5APjQ98D5aPtM/Bj+cP+0/Zj79Pwx/8j9WPoA+pD7TPyQ/bAAnwAw+XDx4PDg9dj6bP7E/pj58PCA6wDtQPKQ92j6wPgg8gDsIOsg7mDx8PQg9xD1oPDA71DzMPbg9SD2yPgg+hD6zPxcARgCDv+8/iwD6AfwCQAMoA7ADeAK8AuAEaAVgBZgF6AYIBfgE+ATYBcgGeAXIBdAF6AUYBBgDrAOgA0wC+AKkAtgCVgElAAA/3z9mPyM/k4AAv4A+rD3oPag9cD2WPsY/pj7cPgw+Rj6WPlI+/P/RgE4/cD6eP2R//T86PrI+6j6gPeg+Fz+KgHM/KD14PDg75DyYPmO/8b+EPfA7iDroOyQ8gj5iPsg+GDyIO7A7GDucPLA9iD4cPZw9JDzcPMw9ID2qPi4+Wj7UP7m/9z+zP24/hYBCAQACEAMgA0wC3AJYAvwDmASYBWAFyAYABeAFWAV4BYgGGAY4BdAF+AWQBVAEoAPEA4wDSAMEAyADAALcAYeAUb+8P1E/vr+UQDr/6D7kPYQ9eD28PhY+lD74PrY+FD3SPiQ+tj7SPwQ/ED6SPlQ+0T9bPx4+kD5UPfw9KD2aPyy/qj5APTw8pDyMPIg9hj9zP1w9gDwYO9A8dDyEPd4+6j5oPJg70DyUPSQ81D0cPc4+DD2EPXA9SD14PPQ9qz8e/8a/rD8gPwo/NT80AAAB/AKcApwCFAHuAfQCmAQ4BRAFqAVgBQgFOAUoBaAGAAZoBfgFiAXoBbgFAATYBEQD5AMwAuwDdAOYAtwBXYB3/+o/pb+vQDeAVD+yPhg9iD3APiA+BD6yPrw+MD2MPcQ+Vj6GPtQ+1j6APkI+Uj6SPuA+wj72Pgw9iD2qPjw+Sj5iPiw9xD10PKw9Aj58PmQ95D2MPbQ80DyYPWA+fj4wPRA8wD1sPUQ9QD2UPdA9gD1EPZA94D18PNQ9gj7yP08/SD8qPrA+Sj7/f+ABaAI4Ai4BtgEOAWACOANwBPAFkAVIBLgEGATQBdgGSAaoBmgF+AVwBVgFqAVwBPAEfAPkA6ADsAO4AyACKAE4ALwAaIBwAK4AtT+KPnA9hD40Pmo+iD7APuY+JD1kPWY+Aj7QPvI+nD6oPko+HD3MPkY+0D6APhQ98D3cPcA9sD1MPdA91D1QPVQ9yD3sPTg8/D10PZg9TD1cPfA9+D0EPOQ9KD14PSQ9aD3gPfg9ED0APZA9sDzUPLA9ID4gPvw/Ur+MPoA9WD1TPz0A/AHAAmoB6wDPwDwAuAKABLgFEAVABTAEDAP4BKgGOAa4BkAGWAY4BYAFgAXYBZgEtAPoBHAE0ASwA7wC1AInAMwAngFAAigBQgBUP0w+tD3oPhw/HL+QPzA+AD30PZw9yj5wPqg+oj5SPmw+Sj5GPjg9/D3UPcw93j4KPmA9/D0APQg9GD08PW4+DD58PWQ8lDy0PMQ9ZD2sPgQ+DD0oPHA8jD0YPRg9ZD2YPYQ9PDy0PTg9WD0oPLQ8lD0kPcQ/Ij+ZPxA97D0gPcY/jgFgAkgCQgFygHUAjAHsA3gE6AWoBTgEUARwBJAFcAY4BtAGwAYoBaAGIAYIBXgEiAT4BKgEQASwBJAD5AIqAR4BRAHGAfABvgEFACI+vD4IPtc/ez9mP3o+5D4cPaQ9wD6ePr4+Xj64Ppo+Vj4+PiI+GD2kPWg95D54Pjw9gD2sPTA8vDyUPYw+eD44PZA9SD0MPNg9FD3oPnI+ED2kPSg9JD0cPSg9dD2IPeg9RD1UPVw9aDzEPIg84D1sPcY+tz8CPyw97Dz8PU4/cQDcAagBmgEyACRANgFcA1AEaAR4BFgEgARwBBgFCAZwBkgF+AWoBhgGKAWQBagFcASYBAgEgAVYBMgDoAKUAhABiAGoAiQCZgF7P/M/Ij7GPsc/eH/Nv/Q+nD30PfI+Fj4SPmA++D6WPjw90j5uPhA9lD1APfw9yD3cPcQ+DD28PKA8oD0sPYI+Oj4UPjg9ZDz8PMQ9qD3uPhA+UD40PXw9KD10PUg9cD1EPfw9jD2kPbQ9hD0APGQ8TD1sPfI+dz8jPxg9/Dy4PSY+5gBKAWwBsAEBgBl/xAFcAvgDqAQABKAEUAQ4BCgFEAXABcAFwAYYBggGEAY4BdAFeARQBFgEwAV4BPgEMAMkAiIBmgHIAkACZgGEAMo//D74Pta/kX/ZP1I+yj6yPgI+AD5aPqY+XD3cPcI+RD5kPcQ97D2IPVg9PD14PeA96D1IPRg8wDzYPRw9/D4wPeQ9cD0APXQ9TD3uPi4+AD34PXg9VD2YPaA9nD20PVw9XD2cPfQ9uD0EPMg8rDy4PXQ+pj9APvw9vD0oPWA+RAAoAWQBiwDNQBMAagEQAhQDaARABIgEPAPQBJgFMAVgBZgF4AXwBcAGaAZ4BdAFMAR4BFAE4AUYBQAEkAN4AioBigHQAiACIgHgATU/3z8aPxI/Vj9uPxA/Ej7UPlg+FD5OPlQ98D2KPgI+Uj4wPeA9xD20POQ80D1QPYQ9sD1EPVQ89DygPRQ9mD24PVQ9nD20PUA9jD3QPcw9iD2QPdQ94D2IPcA+KD2cPQw9aD3OPjg9iD2sPXA86Dz0PcQ/LD74Pjg9zj4+PgQ/N4BSAVYAw4BFAJQBFAGUAqgDkAQYA+AD2ARABMAFMAV4BYAFiAWgBjAGeAXgBUgFAATQBJgE2AVYBQgEEAMcArwCMgHcAggCTAHJAN3AH7/eP4M/ZT8mPx4+3j6qPrg+lj5QPew9iD3UPeQ98j4EPlA9/D0EPRQ9ID0EPVw9qD2sPSQ85D08PWQ9TD1MPZg9/D2UPaA9wD4UPZg9bD2oPfQ9nD2aPjo+FD2cPQQ9jD34PVA9cD2YPfw9RD2gPgw+SD3EPfw+UT8rPwU/k0A2QBgAHYBeAQoB/AI8AqwDKANsA6gEGASYBOAFEAVoBUAFoAXgBiAF+AV4BSAFMATABSAFKATgBDADeAMEAyACkAJgAhABpQDoAKoAoABBv9Q/UD86Prw+Wj7TP24+1j4oPaA9jD2cPYw+Ej50Pfg9KDz4POA83Dz0PSg9YD0MPMA9FD1EPUQ9KD00PUA9iD2MPeg9yD24PTA9bD2cPbA9ij44PjA9zD2sPWw9XD1APZg9xj4ePiY+ID3MPaA9ij4OPpk/Hb+H//I/UD9b/9AAoQDCAVgCJAKkArgCkANEA+QDwARQBNAFAAUwBQgFmAWABWgFEAVoBTAE4AU4BSgEuAPgA5wDoAN4AtAC2AKYAdoBEAEwARoAz4BjP9O/oj8SPtc/MD9aPyA+RD4UPcA90D3UPi4+CD3wPTQ8zD00POw80D00PQw9DDzoPOw9BD1UPSg9KD1APZA9jD3OPgg98D18PUw94D3oPeI+Fj5GPmA94D2IPZQ9kD3sPgQ+dD40Pgg+CD3YPcI+cj68Ps4/TL+0P1I/Xb+QAG0ApwDuAVgCFAJwAlAC9AMgA1gDuAQQBMgE8ASwBOgFOATYBNgFCAVIBQgE6ATYBMAESAPMA9ADxANkAsgCwAKQAc4BXAFCAX4AqoAOgAs/1D9oPxE/bj8ePrY+FD4EPhQ94D3CPgg99D0oPOg87DzgPPg84D00POg8jDyMPMg9MD0UPUQ9uD1QPWg9aD2EPfQ9sD2APdg98D3QPjg+HD4sPdg9/D2IPdY+KD5aPlY+KD3cPfw94j4aPqQ+3j7UPtk/FT9iP24/ogATALIAvADEAbgB2AIcAlAC2AMYA0ADyARoBFgEYARoBJgE2AToBMgFMAT4BJgEkASgBFgEIAP0A7QDWAMEAsQCsAI+AaYBQAFMATIAkIB5/+w/qD91Pxg/Lj7cPpI+bD4QPig9yD30PYg9uD00PPA8zD0cPQw9ODzUPOQ8uDycPTA9SD28PWg9WD1MPWw9UD3MPig9xD3UPeQ97D3OPiY+FD4kPeA9yD4iPio+Kj4aPiA90D3IPiQ+Xj6+Pow+zD7WPsg/LD9Lv9zAJIBwALUA+gEUAbABzAJYArQC0ANgA5QD+APgBCgEEARIBIgE2ATIBMAE8ASQBKAEUARIBFgEFAPgA7ADVAMwArQCfAIcAcYBmgFuAQcA1oBPwBi/wL+tPxc/ND7YPoo+cD4KPjg9rD1kPUg9fDzUPPg8+Dz0PIQ8jDycPKQ8oDzEPVg9XD0IPTA9ED1gPWA9oD3gPcw93D3IPho+Jj4APkQ+bD4wPiQ+Qj6iPlA+SD5APno+Nj5IPuI+3D7oPss/GT8GP1+/vP/rwBGAZgC/AMABQgGqAfwCKAJ0AqQDPANcA4gD/APgBCAEGARwBJAE8ASoBLAEiASYBEgESARYBBQD6AO8A2ADPAKEApACegHmAb4BRAFhAPqAc8AsP9A/iz9tPzo+6j6oPkA+Qj4wPbg9VD1sPTw87DzkPPg8hDy0PEA8iDy0PLw81D04PPQ80D0oPTA9JD1kPaw9nD2APcA+PD3oPdA+Oj4wPhw+Bj5yPmA+fj4APkw+QD5SPlI+hD7APsI+6j7QPyE/DT9hv6S/zkABgFwAqwDiATABUAHcAhgCcAKUAxgDQAOkA5QDwAQYBBAESASYBIgEiASABKgEWARIBHAECAQEA9ADpANYAwwC1AKcAlACBAHKAYgBdADQAIeASwA8P7Y/RT9bPwo+wD6KPlg+ED3QPaw9SD1kPQA9KDz8PJg8kDyoPLQ8gDzwPMw9ODzoPMA9JD0wPQQ9bD1IPYQ9kD2IPdw9yD3EPfQ9xj48PcQ+JD4mPgQ+BD4wPgY+SD5yPm4+gj7APuQ+7z8eP3g/dj+TAA6AeoBSAMIBQAG0AYgCMAJ0AqgCwANYA4AD1APQBAgEYAR4BGAEgAToBJgEmASgBLgEUARIBGgEGAPgA7gDQANsAuQCtAJwAhYBygGMAX4A4wCSgFhADr/9P3c/PD74PqQ+aD40PfQ9vD1QPXQ9AD0QPMQ87DyUPJQ8uDyMPMQ8wDzQPNw80DzoPNA9ID0gPTw9JD1kPWg9fD1kPag9oD24PZw91D3EPdQ93D3YPeA91D4APlA+Yj5SPr4+mj7+Pso/Sz+4v64/94ADAIMAzgEqAX4BgAIEAlQCnALUAxADVAOMA+wD2AQIBGgEQASIBJgEoASQBIgEiAS4BFAEYAQ4A8gD0AOcA2wDMALsAqgCZAISAfwBdAE0AOkAmABPwAT/8j9jPxw+4j6ePl4+ID3kPaA9bD0EPRQ84DyMPIg8gDy4PEQ8lDyQPIw8kDycPKQ8uDygPPg8/DzEPRg9LD04PRQ9dD1IPYw9mD2sPbQ9sD20PYw95D34PdQ+AD5kPno+XD6OPsU/Oz88P01/1IAFgHyATgDkASwBfgGUAiQCYAKkAvADMANYA4gDyAQwBBAEeARgBLAEsAS4BIAE8ASgBJgEgASYBGAEOAPIA9ADnANkAyAC1AKEAnwB5gGQAUQBKwCLgHH/47+WP0U/OD6yPmQ+GD3YPZw9ZD0wPMQ82DysPEw8fDwAPEw8YDxgPGQ8bDx4PEQ8jDykPIg85Dz4PMg9KD00PQA9YD18PUg9lD20PYg9xD3EPdg96D34PdY+Cj52PlQ+tD6iPtA/Oz8BP4//3EARgFEAoADoASYBbgGEAgwCTAKMAtgDFANAA6wDoAPIBCgEEAR4BFAEmASgBKgEoASYBIgEgASgBEgEYAQoA/QDgAOAA0QDCALMAoQCbAHYAYIBbADUAImAfD/ov44/RT88PqQ+WD4YPdg9jD1QPSw8xDzQPKw8WDxIPHw8DDxoPGw8ZDxwPEw8kDyMPLA8nDzoPPg81D0wPTg9BD1YPXQ9QD2QPbg9iD3MPdQ96D3APhY+OD4oPlY+uD6gPs4/PD8nP2u/vb/DAH0AQwDQAQ4BSAGUAegCJAJcAqgC7AMYA3gDcAOcA/gD0AQABHAEcAR4BEgEiASoBFgEYARIBGAEPAPkA+wDnANkAwADPAKsAnQCNgHWAbgBMQDxAJYAdT/5P7g/Xz8KPs4+ij5wPeg9tD1EPUw9JDzAPOA8tDxgPFQ8UDxYPGA8dDx4PEg8lDykPKw8gDzUPOg8/DzYPSw9AD1QPWA9eD1QPaw9hD3kPfQ9wj4WPjA+Dj5uPlg+hj74Pus/GD9Iv78/uX/8AAEAhgDGAQgBSgGQAdQCFAJcApwC3AMQA0ADrAOQA/QD2AQwBAgEWARoBHAEeARoBFgESAR4BBAEKAPEA9QDnANkAzQCwAL0AnQCNgHoAZYBTgEMAPyAYsAXf9O/gj9yPvI+tD5sPiQ97D24PUA9WD04PNQ86DyMPIQ8uDxoPGg8cDxwPHg8SDykPKw8vDyUPOg8+DzUPTQ9FD1oPUA9nD20PYg95D3EPiY+Pj4YPng+Vj6uPow++D7lPxY/S7+/v61/10ALAEgAuwCwAO4BLgFiAZQB1AIMAkACqAKcAtADOAMcA0ADoAO0A4QD2APoA/gDwAQIBAgEMAPgA8gD7AOMA6gDRANUAxwC3AKkAmQCKAHqAaIBWAESANEAhoB6//M/rj9hPxo+3D6iPmY+LD3APcg9kD1kPQA9JDzIPPg8pDyUPIg8hDyMPJQ8mDygPLQ8hDzQPOQ89DzIPSA9ND0YPXg9WD2wPYw97D3APho+Pj4oPkQ+oD68Ppw+wD8nPxc/Rr+xv51/04ALAEEAuQC1AOgBHAFUAYwBwAIwAiACUAK8AqwC2AM8AyADeANMA5wDrAOAA8wD0APMA8gD9AOcA4gDtANYA3ADCAMkAvQCgAKMAlQCGAHYAZgBVAEMAMUAgoBAADo/uT90Pyw+7D6wPnQ+MD34PZQ9rD14PQw9NDzcPPg8pDykPJg8iDyIPJQ8mDycPLA8jDzcPOg8zD0sPQA9TD14PWA9uD2cPc4+Oj4MPmY+Uj68PpY+9j7jPwo/aT9Nv4G/6z/MgD3APQBsAJAAxAE+ASwBUgGAAfIB3AIAAmgCVAK8ApwC+ALMAyADNAMEA1ADXANkA2QDVANMA0wDRANwAxgDAAMcAvQCkAKwAkQCVAIiAewBrAFyAQABCgDCAIQAUsAa/9y/pT9uPyw+7D68PlY+ZD4oPcg97D24PUw9cD0gPQg9NDzgPNQ81DzYPNw83DzgPPA8yD0cPTw9HD1wPUA9nD2APdw9wD4qPhw+Rj6oPo4+/D7kPwc/bz9kv5u/wkAlABQARACnAIYA9ADoARIBcAFYAYIB2gHqAcwCNAIMAlwCdAJIApACkAKcAqwCqAKkArQCsAKgApACiAKwAlQCRAJ8AigCPgHgAcoB6gG2AUwBcAEKARQA5gCDAJsAagAw/8H/1r+oP3Q/ED8wPsY+1j6yPlY+dD4MPiw91D34PaQ9kD2APbA9ZD1gPVg9VD1kPXg9RD2QPZw9sD2IPdw99D3SPjw+Hj5APqw+kD7oPs0/Az94P1u/uj+n/9iAMMAPgEcAtwCPAO8A3AE+AQwBYAFEAaIBrAG0AYwB4gHqAfIBxAIMAhACEAIQAhACCAI+AfYB8gHsAeIB1AHAAfABoAGKAbYBbAFWAXIBFAEEASoAwADgAJAAtABFAGDAD8Awv8Y/6r+Wv68/QD9sPyI/Pj7OPsI+wj7iPrQ+bD52PmQ+fD4yPgw+Tj5wPi4+GD5WPmw+LD4cPnI+Vj5kPmo+vD6SPqA+qj74Pto+8j7+PyI/YD9BP7g/ur+tv5o/1YAmgDGAHAB7AHYAeQBfAIUAyADRAPMAzAEIAQoBIAEwASgBIAEqAQYBVAFKAUQBRgF8ASoBJgEqAS4BKgEkARQBMADSAM8A2gDRAPYAogCWAIMAr4BhAFGAQQBwQBtAPv/qP+E/2f/LP/M/mj+GP7o/dj9vP10/SD9/Pzg/Jz8cPyQ/Jz8ZPxE/FT8SPwY/Cj8VPxo/Gz8jPzE/OT8/Pww/Wz9lP20/fz9Ov5s/rr+9P74/vT+OP+N/6T/s//8/0cAOAAvAHkA2gDnALoA6gBCAT4BEAE6AYoBjAF4AYIBrAGiAW4BaAGmAbwBggF6AaYBpAFKAf0AJAFqATIB1AD2ACwBqAAnAIsADAGvABMAOgDGAJsAzv++/5AAiQBi/2//sQDLAE7/3P5VAOQAU/+g/qYAYAEH/0D+qABAAfD+3v4eAeMApP4m/4wB7wBs/gn/2AEuATz+N/9EAjQBRv5T/+wBRAE1/53/RgEuAar/h//nAEQBDQBo/y8A1wBHADr/ev/WAJQAvv7w/gABqgCO/t7+sgAuAGr+zv6nADAAPv6g/mkAtv/8/QL/lQBv//z93P7z/xv/LP4R/xwAL//8/b7+BgBA/zL+Kf9IAJL/lv5H/04A6P8A/2T/hwBgAGz/3P8CAasApP8RACIB1AAhAL4AvgFEATIAdQBwAVABfwAoATQCYAFmAB4BugH4AJ0ANAGEASoBywDvAD4BKgHYALwApwCeAO0A4wBWAIUA3gA1AKr/SACbAPL/3f9nACIALv8G/8n/+v8+/wD/fv9B/3r+6v6j/wj/oP4W/+D+LP6y/qL/NP9Q/lD+8v70/mL+kv6A/2n/cP58/jj/QP/e/iX/ZP9Z/3P/hP9+/7z/GQD0/9r/AQBIAIYAfQBtAIwAqACNAMUA8wDNAOYALAECAfgARAEQAb8AKAG4AXABvwC4AGgBiAHEALYAmAGIAX8AlQBaAS4BrwDpADQB+wB7AFUABAE8AS0Azf+zANQA5f8OAPQAkQBM/xX/KAB/AJX/T/8qAEQAwv4+/nH/AgD+/pj+e/9c/4T+Ov7I/h3/1v6k/ub+Cf98/p7+AP/U/qr+wP7O/h3/OP+o/sr+ov9y/67+7v7Q/xYAcv9g/1oARwAL/9H/hAGWAPD+JwBIAoQBJ/9r/+wB5AGv/yMAJAKIAfD/jQC0AQAB+v+pALYBLAE3AKIAIAGuAGAAlAClAL8A1ABuACgAXwCRAGgAHQA3ACQAzv/r/2oABwAy/wYAeQA7/4b+4f/oAET/GP5Z/78AKf+8/e7/2QCO/rz9AADVAMb+5P27/woB+P5w/cP/UAEU/wj+sf9AAFH/Yv7c/mwAWgBy/rr+oAA3ALz+CP9dAGMARP/2/rIAaAFE/8b+LAGeASj/J/+qAbQBsf+C/yoBiAEcAMr/NAGoATcA6/9GAQ4B+P+WAIwB5gBFAEkAjgBsAHoAyQB4AP7/FADpABsAFP85AIgBbQC+/nj/tgCUAKf/SP/3/6EAxv/c/uf/owC2/2j/m/+4//n/Sf8S/1UAXQCI/vb+pgDj/xn/C/+b/9b/Av8Q/4EAdgDQ/XL+CgE0AAr+1v6KAcIAeP3c/e4BzgFs/UT+iAIIAZD80v5kA/UA7Pzi/sQCeQA4/TMAQAMGAEj9swBcAj7/Wv+UAsYB7P0j/zQDiAKO/oX/6AP8AZj9s/+4BGwC5P3c/wAETgGE/AwByAXmAOD77v9wBLMAyPwWABAEigAk/PP/iAMBAJj9nQA+AY7+Bf9cAVgBuP40/oUAzQAI/jj/NAIsANT9wP4+AAYArf97/+T/EgCW/nL+p//HAIMAkv5g/fb/oAE2/nz9WAEMArz8oPvmAUQDBP1E/IQClgFQ+9z8GAR4AkD73PxYAwIBCPvK/igFNgGg+vT9sANSAWD8LP+ABJYB6Puc/hAEZAJm/k7/+gEoAen/twD4AZgBZwA6AIQAFADlAMgC1gHs/t7/YAHH/9r/ngGCAf7/af+t/4kABgEUAHD/OQA5AFYAa//q/vABVAKs/RT8lgGgAmj+kv66AcoBIP3Y+3gAqAPG/6z8pwC+AWT9XPwgAbACyv60/Hr/6gGU//j84P58Asz/kPue/tADhwAY/L7+tAECABT8Ov6EAyQCmPtk/agDTADo++7+FAM+AVj9gv52Ae0APP78/tgBvwBq//3/XABYANcAKgFR/18AhAKmANT+hwBgA+UAHP5SAKwDgALY/WL/GASqASD9cAAABZkAiPy+AJgEcgBI/EAB6AQr/5D7dgEABR//IPzsATgEmP1Q+ywD0AQA/eD77gFQA7j9BPymAZgDWv4o+4QAEAN4/gz9IQAkAvj+BP3K/7ABlv+4/Q4BBgFE/QT+zAGOAYD96v76Ab//4Pyu/jwDzAAk/DD/3ANe/2j6zABYBcD++PruAAAEOP7w+7IBaATs/vj6EAEQBRD++PowA3AGqPzI+XwD2AW8/Zj71APQBET92Pr4AjAH5P0Y+/gDYAUg+zT88AVgBOT8LP0MA3wCLP7g/jwD8gEw/U7+xAJgARL+jwAkAlH/pP3f/9sAuABuAbv/bP4U/wkA7/98AJUAlQC5/4j9dv+AARkA5P1GAQgCgPy8/KAC5AIY/Qz93QCWAYb+4PsEAWAFZv54+VwAbAN8/UT+VAMMAWj9pPyG/4ADCgEw/MH/GARC/jj76gCgA3oAwP1w/agAcALM/uD+CAPrAND68P6wBCwBdP2+AIQD3P5A+77/SAdgAjD6AADwBdr+yPpsA2AGgP5I+7YB6AQZANz8CgEYBAT/ePu6AcAFu/8M/ZEA0gCI/aAALAI8ALAApv5E/g7/IgCCAEwCJ/9A+zQCEAOI+rj7YAaYA+j4MPxIBPYBuPvI/fgEEAFw9/j7wAgoBGD2TP0gCfX/MPXw/QAJEAOQ+Gz82AXoAcj4EP2gB4QDSPgY/GAG3AKA+WD9mAY8A+D5vPyIBcgDSPvc/eAFuADY+UMAqAeGADj78gBgA+L+UP3WAWQD0AC0/TUA/AEk/i8AoAShAGz8LAIwA4D9EP/AA9wBSP3w/uwCHAPu/lT+PAKwAdj8zP1QBJgDQP5U/kYBTv6A/TQBhAJUAZD9jP0MAf0AMP0G/wwDBQDA/Ar+0QB4Ac3/yP2I/k8A6v5g/xgB/P9A/h//p/9Y/hwAPgGIANX/YP1Q/YgB/AJ0/Xj+gAOc/qj7zQAABOj+DP3DAGwCGACI+wEAYAb8/6D5mQCoBdb+tPz8AvoBHv4C/ogBmANf/6z9zwD4Ajz/rP0YAcwCOAIx/4j9ygBAAkUANP/IAYACWP6r/7wBywBz/yAAHAGAAOkAHP9IAEgBL/9BAAgAQv7K/4wDhf8Q+90ApAO2/kD7NQBUA9j/vP2k/iQBb/+w/UMAsgE+/zT+AgFCAHP/Tv98/XAAVAKE/tj85gFAAxb+aPvU/gAE2QCw+0f/KAXv/1D6pv9sA/v/uPwKAXACIv9I/Sj/VAPQAZj8VPxUAyADTv6A/toAWAJV/8z9kv8wApwCyf8A/5L/tACmANL/tAJGAaD94v4UAhgDuf8a/poBCAR7/2D7ogGwBbAAiPwIAfQDPP0G/jwDvAK8/Lj9IAS0Akz9UPzkAkACwPou/pgFvwCA+6b/LAMs/qD6gwAABscA0Pja/ogGJf8w+K4AaAch/+D4FwCoBU0AyPnQ/tAFif9g+dX/IAgPACj4OP/wAzf/sPp9ADgG3AII+zj68AIABHD9wP1IBMABbPyE/vkAaAKdALj+yf+lAD7/Yf+8AvsAIv7G/93//P84AX4BJgGY/1z9Bv+kAloAyv6IA7wC6Pu4+1ACeAReAJT8Cv8wBdgAWPnU/zAIuP9Q99H/kAg4Abj41P6IB8kAYPXI/gAMwAJw9aD9UAhO/1D2FACACsoAcPYk/uAGqv5I+AQCSAeO/ij4DAAYBpH/4Pnn/5AEH/+A+6QAqARoAJD7bv7MAtH/5PyuARAF7P6A+zn/3AKKAPD8PgH4A0j/IPtGATAEXP0c/WgC9AI8/ED9QAW0AzD7wPqABFgE6PvQ/RgF+APQ+7j6UAK4BHX/iP3QAdAC3P4s/fb+/ALcA8D9wPzMAqQD7Pzo+1AEYAW8/Dj5PAPoBvj8WPpYBMgGsPqQ+KAEEAik/CD6xAMkAxj66PsABsQDIPtk/YADwP8Y+kgB+AVU/nD6DAFoA/j75PzABDgEOPtI+kACpAIo/Sr+zAPcATT8UPxEANABQgEZ/9z+pwDCAKz9uPywAjgFuv+A+tb+gAT6/1z8kAMgBlj78PdAA1AI+v6Y+mQDAAfI+lD2gAVgCiL+8PpcA1YBUPpt//AHsATY+lz8gARkAsj7KAHwBkT/GPp7/5QDZgHTAFQCfgE4/Xj5hwAIB1ADsP2Q/i4AOf/c/X7+EAaIBUj6wPiIAyAEkPsk/7AGQAEA9qj5IAnIBgD4YPoQBzYBMPRu/oALIANw9eD7UAaS/nD4lgGgCLL+EPbI/egFQgFI++MAmAT0/Uj6FP/QBEgDnP5Y/WQAtgEN/zL/ZAKUAtz+zPzCAIwCNADl/6YBWAEE/Yz+PAIEAeL/HAIoAiT9IP2IAuwC1P3E/bAFOASg+XD7WAbABeD6UPzwBmAEmPn4+2AIIAVg+LD7WAYQA4j6bv7wBQwDuPpw+aIBgAVb/9j8+QDe//7+1v8s/o//SAKh/5j85/8YAaL/IACr/y3/Vv58/DIAeAQdAMj7Av/h/8z9iQC0AOj+PQCw/03/Mv7k/JQBUATs/Kj56AIYBWj92PyQAaABZP1k/FAEyAW0/Zz8ZAKtAGj66v9IB+gEfPyA+ngC6ARU/Fz9AAfoArj57P2QBwgDePqo/IgG2AQo+Iz9EAywBjD1UPjgCNgGAPqE/dAJKASw9PD6sAtgBYD2UP1QC8ACgPOw++ALoAWw9Ej5wAmoBbD3CPuYBXACcPhw/IAFDANk/Az8zgBWAFD9xv4YAyAD4Pxo+8r/dAIyAA7+Wf+QAaoAKP2E/bgC7AIo/mD9u/9kAfYAUQASABkABgAh/2wA5AFaAd7/+P2i/g4BpgEHAP7/tAHx/6z8Vv7MAkQDmv+M/Xf/CAK6/4D9MgFoBE4ACPtC/zAErALk/Yr+uAMUA+D7APzABkgGyPpA+pAEMAQQ/ND8GAUQBfD6IPoQBKAEgPuI/sgGOgGQ+Ej9MAVmASj7/gDwBkr+oPcZAHgGiP1Y+pAEUAaI+kD3uARwCKj6kPeABeAGAPnw+TAIwATQ9Sj5UAiIBVD3cPuQCvQDkPGo+aAMiAUA9JT8cAygAgDz4PuQDEgD0PLs/OANlAMw8lz9IA4aAeDvcP1gETAFAPLA+3AMrAOw8sD9UA9gBDDyuPzADfwBoPKX/yAQJALg8Iz98A1UA3D0hP5AC5D/EPT0AWANKADQ9WQA8AZE/BD5SAbgClj74PRsA6gHSPs4+lgGUAYI+UD4WAZIByj4MPeYBxAIEPfg9nAJ8AkA9rDz2AWwCgD6kPWYBsAKgPdw8fAFgAxo+TDzEAYwC2j4wPLQBfALEPlw82AFAAzA+qD1mAYQCiD4QPYACBAKOPoQ+RAI0Afo+LD38AbQCNj7cPkgBPAGgP3I+XwCGAfY/Qj4+gGACRUAcPj8/XgFgwBo+uIBuAeRAHD47P5gBYD/pPyYBAgGaPuI+/AFWAS4+Rj8kAdgBKD4+PsACQgG4PZo+WAH8AOQ+Ej+4Al0AqD1qPpwCAAG4PZA+MAHcAjI+OD22ASoB5z84PbAACAJKADA977/uAb4/DD32ATwCcD6UPQsA2ALNPyw85QCEA16/lDyuf+AC57/MPdgAlgGcPr4+fgHkAqY+tDzxANAC7j7sPSABzAPcPuA8SwAkAmY/wD8oAaYBWD2sPagCfAJkPZQ93AL8Ang8tD0MA0ADpD1cPG4B5ALiPnQ+DAKkAcg83D18AkACjj4mPoADIAFcPAg9hAOIAtA9lD2KAb4BpD62PrQBYgD8PfI+5AIlgGg9jQCAAzQ/EDt/PwgEsAI4PFQ95AMSAPA7+D7ABBwBMDyOP7gCkj+sPNMA+AQtP3A65L+ABWQBRDwRP1gDBj/gPH+/yAQiAWg9Yj6sARs/DD3gAdAEND9IPBw/XAI+/9g+kQCsAa+/mD4dP3oBFAEEgGl/6j7cPkMAsAJIARg/RD+3/9E/pz9HAKQBsAF0P3A+jX/ff8S/uQDcAgL/xD2CPyYB+AGSPug+WgE0AQI+Lj5YAlQCTj6QPeAAeQCePtA/uAJiAag9QD1uAVwCdD8YPp4BHgEwPnI+JADMAgRAOD6vP4WAGT9ef+4BaAE1Pxo+mX/WAMAAi4ANgEpABL+Ov7H/wgBrAPIBZD+UPZw+6AHIAeY/PD7nAJAAED57v6gCdADQPbA+mAHYAKg9wQBAA48AqDvcPaQCpAKyPuQ+xgFuP+w9YT9AApYBCj5Iv7ABej9oPacAdAL1ABg9KD7kAfYBPz8pv+EA5z8cPjBADAHrAGU/fwBSALY+iD4aAJACfIBOPvs/rACgv4c/RACMAMi/vz8EATQBQj9mPkWASAE5P28/KgCGATe/nD7sP0JAJL/ggBgAn0AkP2P/7gBAAD0/ub+4v6W/3wDeAV5ALD7fP1WAY//fP40AwgF//84+xj9YgDj/1UAwANsAoD7WPvOAYQC8P30/IgAwAFE/lz93gFgA4D+OPza/r0AcgE+AcEAaQA8/oT8qgAQBRQCWP2G/uYBawDw/ToBGAbUAVj5nPxABcACYPzo/8AEnP9Q+un/4AV4AZD73P2oApYAfP08AQAF+f8g+iz9iAIUAz4BBv9g/Wz+gwCRAKAALAENAOz9VPwE/nACOASKAAb+dP5U/ST+JAPABHQA0Pxw/KL+LAIoA1gBhf8m/uD9av/+AdACmAKw/5j7PPw5AAgEaAQSAej8XPzK/uAA2AJcA/3/DPx8/SgCVAO3AJv/oQAV/2j8Lf9oBcgFuP54+lj9TgCQAfwDgAT3//j6KPu4/yAEAATZAKn/gf/M/QT9DgAIBPwDkP4I+3f/kANyAEj+vAGOAcj6mPrYBPAJBAHA94j7bALA/4j8KAOgCIABOPhw+r4BIAKi/uT/cAOoAej74PveAcwDmP5o++L/OASiAVT95v7eAcT+aPs8/4AE2AJA/tj9LP8O/iz9LgD8AgIBbP5///EAC/84/eb+ZAHsAFb/UgBIApAB4P0k/GH/RAPuAaT/mgFwAmL+iPvb/zAF7AKs/bD+RAKLAMT9IAG4BK4AyPu0/lADnAEV/zYBvAH0/Jj7CAKQBhACcPzQ/ZwA7v50/VYBAAXGAXz8XPzT/48AVf++AJgCAgAQ+5z8AARoBd7+yPoI/4gC3P6w/DgCwAY8Aej52PopAAgCVgGgAuYB7PxQ+1oAYATaAQj+kP6DALz/av4JALQCoAIUANj8qPsm/3AE4ATG/8D7QP1UANUA8QD4AcgBb//s/TL+I//UAPgCCANN/1z8NP4oArACHAAh//j///+7/1ABUAJcALr+s/9IAMj+Pv8MA+QD9v6A+3z+YAL+Abr/r/9WAMb+9P09AOwBUwD4/sr/vv+k/or/KAI8Ajv/wP0HAP4B/AAlAOwAtADW/oT+ygBYAjIBVf8c/7X/BP+2/sMAhAI1AKz8RP1vANAAwv4j/0oBdQCc/eD9pABxAPj9YP4EATABg/8iABIBFf8A/eb+HALMAZz/rP/lALr/+P0q/3IBHgH0/q7+XADpANr/N/+2/3f/rP4z/6UAqgECAS//Kv7a/hcAogAqAfwBXgHo/sj9zf8wAuYBiwCdAAYBy//U/tAAIAMYAo7/e//DAHYAn/+NAPwB4ACC/rz+sADkAL7/sP/q/8D+1P1c/0oBuQDi/lT+4P7Y/u7+NgAGAd3/bP50/ub+Hv/n/wgB3wDu/oj9Tv7A/0QADgAWANL/wP4q/iX/lwC9ANr/8P6q/vD+jf+qAHwBwQDO/hb+Xf/OAAABfQBzAB0A5v6y/msA4gFuAUoAlv8x/yz/YQBoAuwCNgFZ/z7/dAB0AeoBBAKGAeUAkACQAEgBeAKcAjABFQCNAGwBkgGoAXACTAKXAMX/dAH8AvYBvACcATACzwBEAGACqAOmAZn/YQDOAS4BxgDsAcIBQ/8E/mf/aQBg/5L+Cf9i/jD80Pt8/Yz9YPsY+uj64Pp4+Rj52PkY+QD3oPYQ+ND40PdA9/D30Pdw9lD2SPhI+tD6cPqg+jD7QPuo+1D9tP/3ADIBAAKEA+ADyAPYBTAJcArQCUAKYAywDVANAA4gEOAQ4A8gEKARQBLAEUARwBAAD6ANwA4AEcAQ0A3wCpAIAAYoBZAGQAeYBXQCWv+g/Bj6IPmY+vj60Pdw9CDzwPLw8QDxoPBQ8ODuQO3g7UDvoO4A7WDs4OxA7SDt4O0g7yDv4O2A7WDugO9g8GDxYPLg8lDzQPTw9Rj4KPrw+tj6JPwO/6gBQANgBYAH4Ac4ByAJcA1gEIAQQBHgEuASgBLgFGAYIBngF6AXQBjgF8AWgBfgGKAXIBVAFMATQBIAEYAQIA/AC0AI6AYQB+gFwAO6AXr/KPwY+Tj48Pio+ED2kPPg8aDwYO8Q8GDyIPNQ8IDt4O3A7+DwgPEg81D0sPNw8hDzEPWA9qD2MPcQ+Ij4UPgI+Cj4OPiQ97D2gPf4+Mj4cPeA9vD1APXQ81DzYPQg9vD2YPdQ93D2IPYA+FD7pP6dAL8AgQAgAdgCIAaACvANQA8gD8AOQA8AEeATgBdAGqAZQBdAFkAWoBZgGMAaoBoAF2AToBJgEkAQoA4QD4AOoApIB4gGSAUIAq//Tf/8/VD7UPpI+zj6YPYw86DyMPPw8xD1gPVg9FDy4PCw8ADyEPWw9/D34PaQ9rD24PY4+Nj6pPwg/Hj7pPzA/QT93Pwa/sb+ZP10/Lz97P5o/UD6CPlI+aD4oPfw92j4APew9KDykPCA7qDusPIw91D4IPfg9KDxkPDA9Bz83QCiAdoBcAJ2AbsAQAVgDJAPQA9wD4AQoBCgEWAVgBigFyAVoBVAF4AX4BcAGeAXwBPgEAARwBFgEQARYBAgDGAGCAT4BBAFwAO8AigBlP0Q+pD5aPqI+bD3IPew9vD04PPQ9PD1MPXA82DzsPMg9JD1APjY+GD3YPZw9+D4kPmQ+rj7NPz4+wT8fPww/Gj7JPxQ/XT82PqQ++D8iPug+HD2MPZw9oD2gPeg9xD1gPEQ8IDvoO4A7zDy4PXQ9oD10PMA86DzYPYY+xn/NAGwArwDWAQYBSgHQApADqARQBOgE0AU4BUAF8AWoBagGKAawBqAGqAaYBnAFQATABPgEyAToBGgEEAOgAlgBVgE0ATwA6wBX/8U/XD6iPjw92D38PVA9HDzEPPQ8tDyIPOg8pDxMPGA8VDyoPMw9YD28Pag9rD2cPdo+Kj5WPvM/HD9SP0A/QD9KP2w/eD+OgA4ALT+3Pyo/Bj9xPww/KD7iPoo+AD3UPeA98D1wPPQ8+DzIPGg7QDuYPGw9JD2kPcw9/D0IPMw9Tj6hP4MAsgFAAjYBvgEkAaQC+APgBLgFOAWwBZAFeAVYBgAGWAYoBmgG+Aa4BdAFmAWABUAEgARwBHgEIANcApQCFAFaAIQAqQC2wBA/Yj6OPmw9yD2YPYQ95D1kPNw8zDzoPEg8QDz4PSQ9KDzMPTw9DD0oPSQ9/D5APr4+eD6aPtY+xD82P0t/xH/9P5b/x7/3P6L/xQAWf86/sD9gP3c/ND8dPxw+tD3APdg9+D1oPMA9CD2EPWQ8GDtoOwA7SDvEPSY+Dj4gPTQ8iD0oPWA+Jz+kASIBsgFeAVYBjAIYAtAEAAUoBSgFAAWQBcgF2AXoBigGYAZABkgGcAYgBcgFqAUYBIAEPAOYA4QDRALEAnIBsQDWgEiALL+pPy4+5j7yPnA9jD1kPVg9cDz8PKg86DzoPLQ8gD0MPSg87DzcPQQ9eD1gPdw+Vj6UPpw+oD6EPuI/GL+P/9F/1D/bv/8/oL+QP9UAFoAVf9K/oj97Pzs/Hj9mPwI+mD3UPbw9QD2kPYw98D2sPNA8IDtoOtA7ADxIPbw98D20PTw8/Dz0PTo+N7+MAPQBHgF6AW4BsAIAAzQD6ASwBOAFMAVIBcgGMAYQBmAGWAZ4BjgGOAYIBiAFsAUgBMAEuAQsA/gDTALwAjYBjgFdAO0AUIAKP7Y+3j6gPkg+PD2kPYQ9uD0wPOg88DzkPNA85DzIPRw9PD0wPXA9VD14PWA98D4ePmI+sD7OPzo+yD8/PyI/eD9sP5T//D+bv6o/uz+fv74/bD9+Pzg+7D7dPwk/Mj6mPk4+CD2kPRw9dD2gPYg9WD0YPMg8IDtoO5g8pD1sPfw+OD4sPcA90D44Pou/ugBsAUgCBAJ0AkACyAM8A3AEGATwBTgFWAXgBggGGAXoBfgF4AXQBdgFwAXgBXAE0ASYBAgDqAM4AswChAIgAZYBfAC0P+w/UD8qPog+aj4cPhA94D1MPRw82DyQPGA8eDyAPTw82DzQPPw84D0gPTA9DD2APgg+ej5qPqg+xD8UPzw/PT9+P5h/73/+/9bAIMALgC9/5b/qP8A/xj+FP6g/kz+3Py4+1j7SPpA+LD2YPaA9qD2wPag9jD1kPNg8rDx4PDw8EDzIPYY+Nj4qPmg+Sj5KPrk/Or/IAJwBAgHMAlACvAKwAzQDoAQABKAE6AUoBVgFkAWIBZgFqAWIBZgFaAUABSgEuAQwA/wDnANUAtwCQAIWAaQBAgDuAERABb+SPzA+rj5KPmA+ID3cPZw9VD0YPNA8wD0YPRg9AD14PWQ9ZD0oPTg9ZD20PYw+Ej6QPtQ+wD89PwQ/Qj9xP3u/lf/Sv8vAD4BSAHuAKMAt/9Q/uj9mP4h/zf/fv+g/1j+2Ps4+vD5mPkI+TD5qPk4+YD4WPgI+CD28POg84D0cPRA9AD20PjQ+hj8KP0s/dj7MPvk/Kb/ygGYBLAI4AtQDGALcAtgDCAN0A1QD8ARQBPAEwAUoBRgFAATIBHQDwAPwA0QDbANsA4gDvALIAmABvgD7gH/AN0AmQD7/zD/wP24+/D5sPjA9wD38PZQ90D3wPZw9iD2wPWg9UD2IPdA91D3APio+LD4CPk4+mD7ePtw+4j8DP52/hj+TP4d/8H/0f///5cAJgEKAYoARgAiAL//kP/H/zcASADI/2//EP/w/YT82PuI+/j60Ppw+6j7oPqo+fD58Pmg9xD1IPXw9nD3cPeQ+JD66PtQ/Nz8FP3c/ND8uP0j/9sAhAOABnAIcAlACnAKwAlgCVAKwAtwDNAMMA6gD8AP8A4ADiAN0AuQCrAJ8AiACJAIoAggCOAGkAVoBAwDoAGgABQAf//a/mD+9P2E/dT8BPx4+zj7APuA+tD5gPnA+ej5yPkQ+gD7yPvA+0j7UPvI+zj8RPyI/Cz98P1o/p7+HP/f/0IAFwAdAJ0A1QBOANH/DAClAJcAZQC6ACQBgABz/xT//v6E/tj97P1E/hT+gP0Q/cz8aPzI+7D6aPng+JD5SPrQ+fj4MPlI+QD44PaA9yj5EPpY+kD7pPxk/Tz9cP1C/h3/wv+IAKABBANgBHAFEAaoBkgHwAe4B6AHAAiwCBAJAAkwCcAJAApwCbAIQAjgBygHUAb4BfgFwAU4BdAEgAT0AxQDKAJyAbQA9v+N/3j/Wf8+/zb/Av9s/sT9cP1E/fD8hPyU/Aj9eP2g/aD9uP3U/cT9hP1c/Zz96P0Q/jr+kP7e/iP/Qv9r/5L/f/89/xD/OP9k/4H/Y/9J/0v/Rf8l/9r+vP7O/vD+wv50/kT+Ov4U/pz9HP3k/OT8yPxk/AD8APw4/Pj7YPsY+wj7gPqg+WD5CPqg+qj64Pq4+2j8RPzw+1j8KP1s/WT97P0o/yoAiwD8AOIBvAIAAxADZAPwA0AEeAQABagFCAY4BmgGmAZ4BggGyAXgBdAFiAVgBYAFcAUYBegE2ASgBBAEnAN0AxwDqAJgAlgCRALkAawBiAFQAdMAewBTADYACQAcAFQAGgDd/wwANQDl/6D/xP/7/+T/qv/R/xMAAQDQ/+z/EAD5/8r/wP+4/5b/Y/87/zH/Nf8a//j+5v7M/oz+PP4c/vz9pP1c/WD9iP1k/Rj9+Pz4/Nz8mPx4/Ej88PuY+2D7QPsw+3D7gPsg+4j6YPrA+tD6mPrQ+mD7kPuI+8j7OPx0/IT84PyE/QT+Rv7C/nz/8/8jAGsA7QBqAdIBKAKgAhwDbAOcA+QDMARIBGgEqAToBPgE8AQQBTgFUAVIBVAFWAVgBWAFQAUYBQAF8ATIBKgEoASgBHgEKAQQBPwDvANkAygDCAPUAoACQAIkAuoBjgFOARwB4gCjAFIAAwDa/73/hf9K/yH/Cv/s/rb+fv5O/hj+0P2g/Zj9kP1w/VT9PP0o/RT95Pyo/Iz8nPyQ/FT8LPxM/HD8SPwc/CD8OPwY/Pj7DPwY/Pj70PvY+wD8APzw++j7FPxU/Gz8jPy8/Pz8JP0w/UT9bP20/QD+Sv6O/ub+V/+q/8j/8/9VALIA7gAkAWABmgHYASACaAKsAuwCLANUA2ADiAPIA/QD+AMYBGAEkASABHgEoATQBLgEkASYBLAEqASQBIAEgARoBFAEOAQgBAAE6APIA6QDgAN0A2QDNAP0ArgChAJQAhAC1AGoAXQBLAHdAJsAZAAiAMr/fv85/+b+iP46/gT+wP1s/RT91Pyk/HD8OPwE/Nj7uPuI+1D7KPsQ+/j64Prg+uj66Prg+vj6APsA+yD7SPtw+4D7sPsE/Dz8YPyo/Az9MP0s/VD9oP30/TL+av6k/tD+Av89/23/lv/T/yMAWgB1AKkA9wAoATYBXgGiAcwB5AEQAlgCkAKkAsQC6AIIAyQDQANgA3QDgAOIA5ADnAOsA8gD4APgA8wDxAPIA9QD1AO8A6wDpAOcA4ADZANUA1ADNAMEA9QCpAJ8AlQCLAL6AbABaAEkAecApgBaAAIAsv9z/yP/0P6I/jz+8P2o/Wz9LP3o/KT8bPww/PD7yPuw+6D7iPto+1j7QPso+yj7SPtw+4D7kPu4+/D7KPxU/Iz80PwM/Uz9lP3g/S7+bv6m/uT+J/9j/5j/y/8AADkAbQChANIA+AAWAS4BSAFYAWIBgAGuAdQB7AEIAigCPAJEAlgCdAJ4AngCiAKcApwCiAKIApwCrAKcAogCgAKAAngCaAJkAmwCdAJkAlQCTAI4AhAC9gH8AeoBtgGQAZIBjAFaATABKgEeAe4AsQCVAH4ATwAPAOT/0f+a/2f/Sf8o/9r+mP6G/nr+Tv4Y/gT+7P3E/az9oP2U/YD9dP2A/ZT9jP2M/Zj9lP2Y/bj91P3k/fj9Gv48/lz+eP6Q/qr+uv7S/gf/SP9p/3b/hf+g/8P/1v/t/xEAQABYAFkAbgCcAMIAxQDMAOIA5ADKANAA/AAWARABCAEIAQYBAgEIAQQB8QDxAAYBFgEaARIBBAEAAQQBCgEYARgBDAEMAQwB8QDaANMA1QDaAM0AsACyANEAygCdAHsAdABtAFcASABIAEgAMQAYAAoA/v/o/9j/0//Q/8D/rP+i/5r/gf9e/0j/Tf9T/zv/Gf8a/yr/IP8C//r+BP/+/uj+6P70/t7+vP7E/uT+7P7e/tz+8P4A//r++v4O/x//L/9O/2//h/+R/5T/mP+v/83/3//v/woAKQA/AFMAZQB6AIkAjwCYAKIAsAC/AMQAvgDDANkA6gDlAN0A4wDlAN4A2gDbANwAzwDFAMUAwwDEALkAswC2ALwAqwCQAIwAjwCBAGwAZABoAGIAWQBIADgAMgA2AD4AOgAtABEA/f/4//r/9P/p/+L/3f/O/7f/q/+r/6f/n/+k/6z/rf+q/7D/wP/G/7//vP/F/8//0P/O/9T/1v/S/9D/1v/a/9L/yf/J/9T/3v/q//L/8P/u/+//9P/3//j//P8DAAEAAAAFAAcAAAD//wUACgAEAP3/CQAYABEA+v/1//n/9f/x//L/9//1/+//9f/1//D/7f/y/+3/3//g//f////q//X//P/0/+D/4//3/+X/zv/c//L/5//f//X/+P/j/9j/7v8LAAQA5v/c/+L/4//V/8z/1P/b/9b/zv/M/9L/1v/U/83/0f/a/9n/2P/b/+D/3v/X/9b/2v/s/wIAEwAhACoALAAoACcALgBCAFIAUQBFADkAPQBQAGAAYABQAEYAQgA/ADoANwA5AEYASwA/ADIAMwA9AEIAQwA2ACYAGQARABYAIQAcAP//6P/i/9j/xv+5/7H/p/+U/4X/hf+H/3v/af9d/1f/Vv9a/2P/aP9p/2b/Yv9e/2H/av9t/2j/Xv9l/3T/f/+L/5z/q/+w/7n/xf/N/9b/4P/t//7/CgAVABoAFQASAB0AJAAnADMAQgBNAFIAVQBSAFMAYwByAHEAaABqAGoAYwBqAIIAlQCOAIwAoQCtAJ8AmwCvAMEAvwCyAK0ArQCtAKoAnwCPAIcAgwB1AGQAZwBuAGMAVABbAFoAPgAkACQAIAABAPD//v8KAPD/1f/X/9j/v/+o/7D/wP+w/6P/qv+t/5b/jv+c/5r/g/+B/5r/lf97/3z/lv+R/3X/ev+V/5r/iv+Q/6D/nf+Z/6T/rP+o/5z/kv+K/4//qP+3/6X/iv+R/7f/y//B/7r/y//h/+H/1f/g/wAAFgAEAPT/DQArACcADgAhAFAATwAfABoASwBuAGMAPQAuAEgAbQBxAFsAVwCBAKgAkABoAH0AqACbAG4AewCuAK8AjwCXALkAsgCLAIYAogClAIAAaABwAHEAXgBVAF0AWgBCADQAOwA+ACMA+P/k/+j/2f+y/6T/sf+5/6j/j/+U/5//jf90/3P/hf+B/1n/NP81/0H/Lv8N/w3/Lv9I/0T/Q/9Z/2X/Uv8//0r/aP93/2z/X/9r/4T/iv95/27/if+z/8H/vP/B/97/+//+//z/EAAtADoAMgAyAEUAWABuAIEAhwCFAI0AoAClAJYAjwChALYAuwC1AM0A+QAEAekA4QAIARoB1gCYANIANAEaAZIAeQDsABQBlwBqAPUAVgH+AIEAegC+AMoAZADz/wEAUgAzAL3/wv9eAJwA5f88/4T/8f+I/77+kv7q/gz/5v7q/lD/wP/m/7j/Qv/U/qj+lP5Y/jb+gP7U/o7+Dv5E/g3/WP/2/u7+lf8CAL3/av+A/4X/MP/k/ur+Dv8y/2r/hv9p/4b/KADeAP0AwgC4APEA/gCeAC8AEQAdAOz/lP+Z/y0A7AByAdYBRAK0AigDlAOIA+QCUAIIAlAB4v9k/nD9zPzQ+8D6cPog+yj8sPws/Yj+fwCYAbgBbAK8A9wDhALqAaACnALsAIP/9P+1ACEAbP9BALQBGALWAXQC1AOgBHAEGARABGAElAMIAuoAoQBMAAz/nP1I/cj9yP34/KT8nP2w/oz+0P0S/jL/hv9q/kD9SP24/TD9FPzo+9D8bP0A/Zj8UP2m/lP/L/9A//X/ngCKAB0AJgCsAOYAbgDi/wYAqwDtAJMAWgDHAHgBwAGmAcoBZALgAqwCIAIAAlgCbALqAWwBfAGgATIBigBmALUAxABhACkAcwDaAOQAoABzAJQAugCMADAABgAXAAYAs/92/47/wP/G/6//rP/N//r//P/W/8f/4//j/5X/Kv/8/gb/6P6k/oj+sv7m/uj+2v7q/gz/Hv8E/97+4P4M/xb/+v4D/0v/f/9x/3H/r//u/+z/1//7/1AAiQCPAJcAswDUANIApgCAAJQAsACQAFsAXQB9AIkAmgDeAA4BAgEEATABNgECAfkAHAESAbIAUQA6ACUA0v9v/1D/aP9K/zL/Tv95/3r/cv+J/67/y//U/9T/sf+E/3v/hf9f/zD/NP9a/3f/gP+x/+3/+v/n/9T/x//B/6//d/8v/xb/FP/0/rz+jv6G/pr+tP7U/gL/Lf9k/5T/nv+v/+f/GwACAND/3v8TABkA7v8MAHYArQCCAHQAxwAuAVIBMAEcAUgBcgFEAd0ApACvAJ4APgDu//D/FwAdABQAMQB4ALQA4wAaAUABVgFqAWQBRAE2ASYBAAHhAM8AsACPAHgAbgBjAEMALwBBAFUAQgAhAB8ALgAeAN7/qP+s/6L/U//8/ur+6v6w/mj+bP6o/rT+fv54/sL+AP/+/v7+KP9T/2T/bf92/3//gP+O/6L/t//K/+b/DAAoACwALAA1ADsAOwA3AD8ATwBJACcABQDy/9//yv++/7v/r/+a/6D/vv/n/wQAHwBFAGcAjwC+AOEA5ADrAAQBFgEGAfkA/wD5AN4AxwDOANgAwACmALAAwQDKALQAogCnALoAkQA/ABkAGwACAKz/YP9c/2v/VP8R/w//Uf92/27/ef+p/7z/qf+d/7H/yf/R/87/zv+//7f/uP+z/5n/if+N/4T/XP9C/1z/gP+G/3v/k/+0/7r/rv+u/73/vP+u/5D/e/9q/1H/Nv8O/+b+0P7K/sj+sv6a/p7+rv6+/sj+6v4f/0P/WP+E/7//AQA2AGIAjQC7AOcADgE2AVgBdgGaAa4BqAGeAagBwgHaAdwB7gEIAhQCHAIcAhAC9AHkAdoBxgGiAZQBdgFCAQIB0ACpAFQADAD3/+7/yf+3/9H/1v+3/6f/vf/b/9//z//K/8H/wP+q/5v/i/+B/3r/UP8M/9b+wv6a/j7+8P3A/ZD9OP3g/KT8fPxA/Pj72PvQ+9j72Pvo+wD8KPxM/Hz8tPwc/az9JP6C/ub+gv8mALUALgGoATACsAIcA3wD3ANABLAEAAUwBUgFaAWQBagFkAVgBTAF8ASwBGAECASoA0AD7AKkAkwC8gHCAa4BsgHcASwChALkAkwDyANABKAE+ARABWgFcAVwBRgFWASkA/QCSAI+Adr/jv54/Yj8ePtg+lD5WPhw94D2cPVw9LDzAPNA8pDxAPGQ8CDw4O8g8GDw0PBA8QDyIPOA9ND1IPeg+ID6rPyC/jUABAIgBPgFaAeACKAJoAowC2ALgAtwC0AL8AqQCkAKAAqwCUAJ4AiwCIAIYAggCPAH0AfAB6AHaAc4B0AHIAfYBmAGAAbIBdAF6AXgBRgGeAboBkgHsAcQCGAIoAjgCOAIoAhACNAHIAcwBjgFIAQAA9oBmwA1/7z9LPzQ+jD5MPdA9ZDzMPJg8GDuIOzg6WDnAOUg46DhYOBA34DfQOBA4WDiAOSg5uDpYO3w8ID0CPj4+9z/UAMwBvAIsAtADgAQQBFgEqAT4BRgFaAVoBWAFeAUABTgEoAR4A8wDoAMoAqACFgGSAR0AuwAk/9m/lz9nPxE/CT8MPxg/Mz8hP1w/hX/gP/W/28AXAFQAuQCfANQBFgFSAYIB+AH8AgACvAKoAsADBAMMAwwDOALEAsgCjAJAAiYBgAFpANYAgYB2//Y/tT90PwM/KD7WPvI+jD6oPno+Bj4IPfA9YDzMPEg7+DsAOoA5wDlIOTA40DjIOPg44DlwOdg6kDtQPCg8yD3YPo8/fz/jAKgBGAGsAfgCLAJIAqgCjALwAsADCAMcAwQDcANAA7QDZANgA1wDdAMoAtwCmAJUAjgBlAF3AOkApIBxwBZAA8A7v8xANwAWgH8AZgCaAMgBNAEiAXwBQAGyAXoBRgGAAbYBbgF6AUwBoAGsAaoBrgGAAdoB1gHEAfYBsAGiAYoBrAFKAWABNgDQANkAogBygAuAHP/qv7w/VD9oPw0/AD8mPtY+kj4sPXg8iDwIO1g6qDnYOXA4wDjIOKA4eDhYOPA5WDoAOsg7pDxIPWo+Oj7Bf/kAYgESAZwB3AIMAngCRAKUApQCiAKwAnACQAKAAoQChAKMAoAChAK4AlQCZAI8AeAB7AGqAWIBKADoALWAVoBLAEIAUIBjgH2AaQCaANgBCgFCAbYBoAH8AdQCIAIcAhwCDAI0AcwB8gGgAYYBoAF+ATABIgEUAQQBAgEzAOEA3gDeANoAwAD4ALAAmQC/gHEAYoB6AArALL/Wf+g/tz9VP3s/BT8YPoQ+ND0gPHg7sDswOoA6ODlwORg5ADkAOTA5GDmoOiA62DuIPFQ9MD3UPto/ioBYAPoBBAGaAewCDAJAAnQCOAI0AiACOgHmAeYB+AHMAggCMAHiAfQBxAIAAh4B9AGgAYgBrgF+AQgBEQD2ALcAuwC4AKoAtACcANgBBAFkAUABqAGYAf4ByAI0AeIB3gHkAdAB4AGyAV4BYAFOAXQBHAEOARABGgEcARIBAgEOASQBLgEiARIBBgEtAOQA0wDsAK6AQwB6ACTAI//Vv6w/Uj9UPx4+rD3cPRQ8aDuQOzg6WDnYOXA4wDjAONg40DkgOXg56Dq4O0A8WD0EPi4+yn/BAJABNAFSAegCLAJ0AlwCSAJAAmwCPgHQAe4BnAGgAagBoAGKAYwBpAG8AbgBrAGgAYwBgAG2AWIBegEQAT8AyAEUASYBAAFcAXwBbgGsAdACLAIIAnQCSAK8AmACRAJgAjwB2AHoAaABWgEuANoA7QC+gGcAYYBfAGqAQgCUAKIAvQCpAMABOQDlAO8A6wDUAPIAuoB/ABiAPP/L/+8/bT8cPzQ+9j5APdw9MDxAO+g7MDqwOjA5kDlgOSA5KDkYOWg5oDooOqg7cDw0PMA95D6Ov4YASgDuARoBgAIEAmACVAJwAhACOAHUAd4BrAFMAXIBLAEoASoBNgEMAXABXgGyAYAB0gHmAfoByAIEAjAB5AHkAewB6gHiAeAB7AH4AcQCEAIUAhwCKAIcAgQCKgHOAeYBvAFYAXwBCAEMANYAuABlgE0AdcAeAB9AMIAIgFeAawBOALgAlADlAPAA+AD7APYA7gDKANYAqABGgFYAEj/TP5E/aD7sPmA9wD1sPFA7uDrYOrg6ODmQOVg5IDkIOVA5oDnIOlg60DukPGw9PD3OPtm/gQBbAOQBSAHYAgACeAJIArACfAIIAiIB+AGUAaQBfgEoAS4BMAE4AQQBagFmAZIB6gHEAhwCOAIMAlgCXAJYAkwCQAJ4AigCGAIEAgACOAHsAdwB0gHIAfYBogGQAbABSgFoARIBOwDQAOsAgwCfAHVAE8ADwDx/+v//f8/ALAAOAHMAUQCsAIwA6ADwAPIA5QDdAMQA1QCpAEGARUA/v78/aj86PrA+ID2wPOA8EDt4OpA6eDngOaA5QDloORA5YDmQOgg6oDsYO+w8iD2YPlo/C//6AFgBGAGiAcQCJAIMAlgCcAIwAewBtgF8AQ4BJAD6AJ8AmwC2AJcAxAEAAUYBigHIAgQCcAJUAoAC9ALQAwgDIALAAvACpAKIAqACfAIYAjwB5gHYAfwBmgGEAbABUgFsAQ4BOADgAMUA6ACCAJOAbUAYwA1ABYA+f/t/xkAcAAAAYwB8gFMAsgCUAOYA5gDdANAA7wCIAKQAdQAo/9E/vz8kPug+UD3sPTA8YDuwOvg6UDogOZg5QDlIOUg5UDlgOag6EDrIO4Q8eDzAPdo+uj9zgAEA9gEmAb4B/AIsAngCZAJ8AhACFAHKAboBBgEiAM8A9wCbAJYAtgCGARIBUAG8AboB+AIAAoAC8ALMAxADCAM8AugC0AL4ApgCuAJUAnACBAIcAcoB+gGkAYABmgF2ASQBFgEIAS4A1AD0AJIAsgBUgHiAI4AaQBEAEYAXgCVAPAAZAGoAQQCYAK8AtQC2ALwAuQCZAK6ASABVQBc/1b+LP1g+wj5kPZw9KDxYO6g68DpwOig5wDnYOYg5uDlwOYA6YDrwO0A8EDzkPbo+aj8R/9+AXwDMAWwBnAHmAcACFAIEAj4BrgFwAQgBIQD8AJoAuoBrgHaAagCvAO4BLgFuAbAB8AI0AmwCmALwAsQDDAMAAyACyAL4AqQCgAKQAmACMgHaAcoB7gGIAaIBQgFmAQwBOgD1AOsA0ADyAJoAgQCmAFKARIB5QCtAJkAswDWAP8AUAG2AeIB7AEwAoQClAJ8AkAC+AFgAb0AVQC7/6j+TP3w+zj6APhA9bDyIPCg7aDrgOqA6cDnoOaA5iDnwOeg6MDqgO1A8ADzwPV4+Aj7xP1vAKAC9AMQBUgGMAfQB/AHgAdYBigFQASwA/wCCAJAAdsA4wBEAQAC4AIYBJAFCAdACCAJIAqQC7AMUA2QDYANUA0gDQANsAzQC6AKwAkwCXAIiAfIBjAGYAXABFgECASIAzADTANgAygDsAJkAjQC8gHSAaoBegFEAUwBfgGKAYoBtAH0AQACIAJcApACjAJcAiQC7AF2AfEAeQCg/4b+OP2g+4j5EPeQ9FDyEPAA7iDsgOrg6IDnwOZg5sDmgOdA6WDr4O2g8IDz4PUA+Jj6XP3h/7IB8AJIBJAFgAbwBtAGMAZ4BeAE8AP8AigCjgEaAccA8ABmARACMAPABFgGeAeACLAJAAswDDAN0A0ADvAN8A0QDqAN0AzAC7AKoAmwCMgHyAbABRAFgAToA2AD+ALIArwCzALYArQCjAJ8AmACJALwAcIBpgF6AYoBtAGeAUoBEAE+AWQBbAFCATAB7QCnAJcAagABAGD/7P5c/jj9qPv4+Sj4EPbg8wDyQPBg7sDsYOtA6iDpIOgA6GDogOmg60DusPBQ8kD0oPZA+ZD72P3G/14B9AKABKgFEAYwBigG8AVIBZgE0APkAv4BogGKAUYBAgGIAdACUASgBdgGEAggCVAK0AsQDcANAA5wDuAOIA/ADiAOcA1gDEALMAoQCagHYAaQBdgE9APwAkQC+gHaAdAB+AEMAsYBmgHUARwCEALyAQgCVAJ4AngChAJkAhwC9AEQAhgCogEuAd0AmQAnAKz/YP+4/tD99Pxo/ED7YPmw9zD2oPTQ8kDxAPCg7uDswOsg62DqgOmA6aDqYOyA7rDwUPLw89D1QPig+qz8kP5QABACYAPIBKAF+AXoBSgGYAboBQgFMASAA9ACbAJIAjwCRAL4AmAE2AXQBrAH4AjwCdAK4AvgDIAN0A1gDvAO8A5gDvANgA2gDKALoApgCRAICAcoBhAFuAOYAtwBVgHyAOoA7wB6AP3/7v9AAF4AaQCsAAIBKAEyAYABugGiAXwBlAGuAVYB+ADIAHYA0P8h/3D+mP2U/ND7EPvo+Xj48PaQ9fDzgPKg8YDw4O6g7QDtoOzA64DrIOzg7IDtIO9w8RDzAPSA9eD3IPrI+5T9gf/1APYBQANgBMgE4AR4BTgGCAYoBXgECARoA+gCzAIMAzgDuAMABXAGaAcgCBAJ4AmQCmALgAxwDRAOcA7QDvAOoA5ADgAOQA0wDEALQAoACZAHcAZQBfADYAJ2AQ4BqQAvAO3/zf96/zn/T//D/xkANQB4APkAWgFyAZgBxAHMAZQBdgFoASIBtgAqAJT/tP7g/Rz9OPwg+yj6QPkQ+JD2QPUw9BDz0PGw8ODvwO7A7WDtgO1A7UDtIO5g72DwYPEA8+D0QPbA9/j5GPxY/Wr+CgCWAXQCzAJ8A2gEAAVoBaAFYAWYBPwDyAOsA0QDhANoBIgFkAZYB2AIMAnQCXAKMAsQDNAMgA0QDmAOcA5gDiAO8A1wDbAM4AvgCtAJwAiABzAG0ARwA1wCfgHeAFEA7v+w/3v/XP+H/6r/nP+K/9z/cAC5AM4AIgFSAT4B7QDUAM8AfAAZAKj/N/9y/pj92PwE/Aj76PnQ+LD3cPZA9QD0APMQ8hDxAPAA72DuAO6g7WDtwO1g7iDvAPAw8XDykPPw9ND2oPgY+pj7VP3I/sn/lQCyAZwCLAPsA7gESAUgBcAEcAQgBKgDQAOYA4AEqAX4BjAI8AgwCcAJ0ArQC1AMAA0ADsAO4A4QD3APYA/QDkAOAA4wDSAMUAuAChAJaAcYBhAFxAO0AjwCwAHCAP3/FQBaADUA8f8kAFYALwBFANwAUgEeAesAGAEcAb8AdABhAPb/Iv9o/tD9/Pz4+yD7QPoQ+dD30PbQ9YD0QPNQ8nDxYPBg78DuYO7g7YDtoO0A7mDuIO9A8FDxMPJA89D0YPaw9yj5+Ppk/Fj9Zv64/6UAOgE0AjQDEARoBIgE0AS4BHgESARQBIgEUAXQBmAIYAnwCYAKAAuAC1AMUA0ADkAOsA5wD7APkA9gDyAPgA7ADUANkAyAC4AKoAlgCLgGYAXYBCAE8AIkAtwBfgHNALAAKAFKAewAxAAqAZIBogHGAeIBmgEoAQwBIgHSADkA0f9h/2z+TP2A/ND7kPpA+VD4gPdA9gD1MPQw8/Dx0PAw8IDvwO4g7iDuAO7A7eDt4O6g71DwMPFw8sDz0PQw9sD3SPmA+rj7BP04/gj/zP/DAJwBYALIAkwDgAOMA2ADLANEA4wDCAQIBbgGcAigCeAJQAoAC/ALwAyADSAOgA4QD7APQBAAEIAPIA/ADtAN8AxgDOALoArgCKgHwAaABUgEnAMgA2ACnAFmAXYBPAEOAToBPgEKATQB5AFYAhgCvAGwAYIBCgHeAOwAhwCF/6L+GP40/dD7uPoA+uD4gPeQ9vD1wPQw8wDyYPFw8GDvAO/A7kDuoO3A7SDuYO4A7xDwIPHw8cDyEPSQ9aD20PdA+aD6oPuw/PD96P5//0IAIgGoAfQBkAJAAzAD6AIUA5wD0ANYBBAGMAhwCQAKoAqACxAMsAygDWAOkA7wDuAPYBBgEAAQsA8gD0AOcA0QDVAMAAugCXAIOAfwBRAFeATIA/wCYAIkAtwBogGSAYIBUgFAAXYB3AEQAhgCFALOAVIBHAE0AfYAQQCB/+7+Hv4k/TD8QPsA+pj4kPeg9pD1cPSg87DygPGA8ODvYO/A7kDu4O3A7cDtIO4A7+DvoPBg8XDykPOQ9MD1IPdo+Gj5gPqo+7D8pP22/sj/jgD/AKYBUAKsAtACFANEAygDXAN4BEgGyAcQCSAK8ApwCzAMAA3ADTAOoA5gD+AP0A/wDyAQsA/QDjAO4A1QDXAMYAtACtAIYAdgBqAF6AQIBEwDvAJAAgQCHAIoAsQBZgFgAZYBngGSAagBqAFiASwBOAH/AFQAl/8Z/4b+pP3c/GD8cPsI+sj40Pew9oD1kPTg8xDzAPIg8XDwoO/g7kDu4O2A7cDtYO5g7+DvUPAw8VDyUPNg9MD1APc4+Gj5wPrA+4T8pP0M/ycA2gCmAXQC4AL8AnQD7APkA9QDgAToBVAHgAjACZAK8AqAC6AMoA3wDWAOMA+wD7APwA/wD9APYA8AD7AOEA5QDaAMoAsACoAIgAeoBqgF4ARoBMQD4AJgAoQCnAJQAgQCAAL8AdwB7gEgAgQCpAGUAbYBmgEIAWYA0//U/tD9DP14/KD7gPqI+YD4UPfw9eD0MPRg84Dy4PFQ8ZDwwO8g76Du4O2g7SDuAO9g7+DvwPCw8ZDycPPA9BD24Pbw93j5wPqA+0T8pP3K/oL/cQDOAagCzAIwA8wD4AOEAyAEwAUoByAIgAnQCpAL8AvQDLANEA5wDiAP0A8gECAQYBAAEHAPMA8AD2AOYA3ADAAMsAoQCfgHEAfgBfgEiAQABBgDlAKkAqQCEAKYAYwBbgEOAQYBYgFIAcYAnQC7AGoAxP95/zj/bP44/Yj8JPww+wj6YPno+ND3cPaA9aD0sPOw8hDycPGQ8ODvgO/g7gDuoO3g7WDuwO5A72DwQPHQ8eDyUPSQ9ZD2oPcQ+Tj6KPs0/GT9cP5V/3gAlAF8AlADEAQwBKwDsAOwBOgFGAeQCAAK4AqAC5AMoA3gDQAOoA5wD8AP8A+AEKAQwA8ADxAPAA9ADnAN8AwgDNAKoAmgCFgHEAYwBcgEGARMAwwDFAO0AhgCxgHCAXAB9QDcAOYAvgBqAFgATQD3/4P/Jv+8/hT+TP2k/OD74PoA+nj5sPiQ94D2sPXw9PDzAPNw8tDx8PAQ8IDvAO9g7uDt4O1A7sDuYO9Q8BDxwPHg8kD0sPWw9uD3WPm4+sj7xPzY/cD+u//GAN4BvAKsA4gEyARoBGAEQAVYBlgHsAhACnALIAwQDTAOoA6QDqAOQA+gD+APQBBAEHAPwA6wDqAOAA7wDFAMoAtgCjAJcAiYB1AGIAWgBGAE3ANsA2gDPAOsAiAC/gHWATQB3gDYALcASAD8/w8AuP/0/kD++P18/az86Ptg+4j6iPnY+DD4QPcg9jD1gPSQ85DyAPJg8XDwgO/g7oDuAO6g7aDtAO5A7sDugO9w8FDxcPLQ8zD1oPbg9zj5WPpo+4D8iP1o/jD/bADYAdgCbAPwA1gEeATQBLAF6AYQCEAJwAoADOAMsA2gDhAP4A4AD4APABAAEOAP0A9wD5AOIA4gDrANsAygC9AK0AnACOgHMAdABigFgARgBFAECATQA5gDTAPUAnACHAKcAfYAewBQACoA2/+E/zL/rv7k/UD94PxY/KD74Ppg+sD5wPjg9zD3YPZQ9WD0sPMA8zDyYPGg8MDv4O5A7gDuwO3g7UDuwO5A78Dv0PAA8kDzgPTg9VD3iPiw+cD6qPto/Gz9gv5//5kA5AEAA5ADwAP8A0AEqASgBRAHYAiQCcAKEAwADbANcA7wDgAP8A5gD+AP4A9wDzAP8A6ADjAOEA7QDeAMwAvgCgAK4AjQBygHeAaIBYgEEAT8A6QDNAPoArQCUALwAdoBtAFKAZ8AKgD9/9P/m/9r/yP/fP7Y/Wz98Pws/GD7qPrY+fj4GPhg95D2wPXQ9NDz0PIQ8mDxgPCg7wDvgO4A7sDtIO7A7gDvQO8w8JDxsPLg81D1sPaw99j4UPpY++D7ePyY/dj+8/8wAYwChAPkAzAEaATQBHgFkAbYBwAJYArAC8AMcA0wDhAPQA9AD4AP0A/QD5APkA8QD0AO8A1QDjAOQA1gDNALoArgCOgHuAfgBlAFmASYBDAEPAP0AiwDpAKiAYoB/gGoAe0AuQC7AMv/2P4L/6T/Jv9E/hj+Av5I/Uj82Ptw+1j6MPmg+Cj4QPdA9mD1UPQw81DysPHQ8ODvQO/A7kDu4O0g7oDuoO4A78DvwPAQ8sDzYPVQ9mD32PhI+hD7wPuQ/FD9BP5B/70A2AGQAmADEARABHAEOAVQBvgG2AdwCQAL0AtQDCANwA0ADkAOsA7wDrAOkA6ADhAOcA0wDTANAA3QDIAM4AvQCqAJwAjoB+AGCAaQBfgEKASAA0wD5AIMApoBnAF6AQAB+wBIAQABDwB5/53/kP8U//r+Of+4/rT9UP04/Tj84Ppg+iD6CPmw91D3EPeg9SD0sPNQ8+DxoPCQ8GDwIO9g7sDuAO9g7oDuAPDg8PDw8PEg9LD1UPag96j54Poo+/j7LP34/Xj+u/8yASwCAAMoBCAFUAWgBWAGKAewB9AIQApQC9ALYAzwDGANoA0ADlAOIA7ADaANoA0gDYAMUAwwDCAMQAxQDNAL4ArwCQAJIAgYB0AGkAXIBPwDeAMsA7wCLALGAXgBIgHoAN4A3ACOAP3/gf8r//r+4P7a/qL+Rv7Q/VT9wPw0/Kj7yPrI+RD5qPgI+CD3UPaQ9ZD0cPPQ8mDyoPHQ8HDwIPBg78DuAO+A74Dv4O/w8ADy8PIw9OD1QPcY+Bj5QPoQ+6D7yPws/g7/0v8sAZwChANABCgF0AXwBWAGkAfACHAJUApgC+AL0AtADBANkA1gDWAN0A3QDVANAA3wDHAM0AsADIAMUAywC1ALwApwCSAIgAf4BrgFiAQwBAgETAOIAmQCIAJEAXUAhwClACgAov91/w7/Uv78/TT+MP7M/Zz9nP08/Yz8RPwE/HD7iPr4+Zj5EPmA+PD3MPcQ9lD1wPQw9JDzMPOw8uDxEPGg8GDwAPAQ8JDwIPGA8VDyoPOQ9ED1QPZg9xj4qPjI+fj6yPuk/OD9Of9OAHoBzALIA0gE2ATIBcgGqAeQCJAJcAoQC5ALAAxwDNAMAA0wDUANcA2ADXANMA0ADcAMgAyADKAMgAwQDJALAAsQCiAJYAiIB5AGmAX4BIAEAASUAzQD1AJMAtABggE+AdwAXwD2/6r/W/8O/7z+jv5a/vz9mP1Q/ST9yPw0/Ij74Po4+rD5OPmA+LD3sPbA9fD0cPQA9GDzwPJA8sDx4PBA8DDwMPAA8MDvUPAg8cDxkPLQ8/D0cPUQ9mD3ePgY+fD5SPtA/Oj8RP5LAKIBQAIUA0AE4ARYBZgGIAjgCBAJAAowC9ALEAzADHANcA1QDQAOwA6wDkAOIA4gDsANgA3gDRAOkA3QDHAMAAxAC2AKwAnQCIAHaAbIBUAFqAQgBKAD6AJAAuoBkAH6AD4AwP9O/9D+iP6Y/nb+7P1E/dD8jPxo/HT8YPzo+zj7wPpI+pj5APmA+ND3APdg9uD1QPWg9CD0oPPg8hDysPFw8fDwkPCg8LDwgPDQ8KDxgPJQ81D0QPXw9YD2YPc4+MD4ePmY+sD70Pw2/uj/EgGmAWQCjAOQBGgFqAYACKAI4AigCdAKoAvQC3AMEA0gDSAN0A2gDpAO8A3ADQAO8A3ADRAOQA5wDWAMIAwQDEALQArQCTAJoAc4BugFuAW4BLADbAMYAwQCZgGMAUIB8v8C//j+2P40/vz9Rv7Q/bz8PPyU/IT8APz4+xT8oPvg+rD6ePq4+dD4YPjQ9wD3cPZQ9tD1wPTw86DzEPNQ8gDyAPKg8QDx8PAg8SDxcPFQ8nDzMPTQ9LD1oPYQ94D3YPhQ+Sj6QPvI/Ez+av94AKYBvAK4A9gEKAZIBwAIoAhgCSAK4AqwC2AM4AxADaANIA6QDtAOwA6gDoAOgA5wDlAOMA4ADpAN8AyADCAMcAuACqAJ0AjYB8gGCAZoBZAEjAMEA5wC8AFAAdEAWQB1/6L+SP4e/qj9SP0c/dT8SPz4+wD82Pt4+1D7SPsA+3j6OPrw+Uj5gPgQ+LD3EPdw9gD2kPWw9PDzoPMg84DyEPLg8bDxMPHw8PDw0PDQ8HDxwPIA9OD0sPVw9vD2YPcY+Dj5SPo4+2z81P0V/ywAfgHMAqQDaASgBRgHEAjACKAJcArgCjALAAzwDHANsA0QDnAOcA6ADtAOEA/ADmAOQA4wDsANUA0gDdAMAAwwC7AKIAowCUAIiAeoBpgFuAQoBHgDuAIEAmwBywD//1//1P5U/tD9ZP0Q/dD8lPxQ/Aj8uPtw+0D7IPsA++j6uPpg+uD5gPkw+cD4MPjA91D3oPbg9WD18PQg9GDzEPOw8hDykPGQ8aDx8PBg8GDwwPAQ8dDxQPNw9CD1oPWg9oD3KPgQ+Xj6sPuo/Pz9mf/jANAB9AI4BEgFOAaQB/AI4AlwCiALwAtQDMAMcA0ADnAOwA7wDjAPQA9gD2APQA8QD8AOcA7wDZANMA2gDPALYAvACgAKMAmQCMAH2AbwBTgFgASgA9gCOAKUAb8A7/9C/7L+Av54/SD92Px0/BD84Puo+0j72PqA+lj6QPr4+dj52Pmw+TD5qPhg+Cj4oPcg9/D2cPaQ9dD0wPSQ9LDz0PLA8qDyEPLg8SDyEPIQ8ZDwIPFA8sDykPMQ9UD2sPYg95D40Plw+hD7hPzo/e7+JwDiASwDsAOABOgFSAcwCFAJkApgC6ALIAwADbANAA4gDmAOkA6QDtAOMA8wD+AOsA6gDoAOIA7ADWANwAzwC3ALEAuQCuAJEAlQCJAH4AZIBoAFmASUA8QCFAJ0AdIAKgBy/57+6P1o/RD9tPxM/Nj7cPsg++D6uPpw+vj5mPmI+ZD5iPmI+XD5EPmQ+ED4QPgA+HD3APeg9hD2UPUA9eD0YPSQ8zDzIPPA8mDygPKg8uDxIPFg8XDyQPMA9ED1gPbw9lD3iPgA+tj6gPuo/Aj+B/8wANABMAPoA5AE0AU4B2AIUAlQCvAKIAuACyAMwAwQDVANgA2QDaANAA5gDlAOEA7wDcANgA1gDTANsAzgCzAL4AqACvAJgAkACSAIAAdgBggGSAU4BGgDsAK+AfAAlAAdADP/LP6Y/TT9tPx8/GT8EPx4+yD7CPvQ+nj6QPoQ+qD5aPmg+QD6+PnI+aD5YPkA+dD44PiY+PD3UPfg9mD24PWg9YD18PQw9NDz0PPQ87DzoPNA85DyQPLw8uDzwPTA9RD3APh4+FD5mPqw+2T8OP1q/pT/wgBEArADiAQoBTgGaAeACKAJsApAC1ALcAsADJAM8AxgDaANgA1wDbANEA4gDuANsA2ADTAN4AywDFAMkAvACiAKsAlQCQAJgAjIB+AGCAZgBcgEIARUA3gCkgHCACAAsP8t/27+mP3w/Hj8JPzY+4j7SPv4+pD6UPpA+iD60Pl4+VD5MPko+Uj5iPmQ+Tj5+Pjo+ND4iPhg+FD48PdQ9+D2wPaA9hD2wPWA9RD1oPSg9LD0cPQA9ODzEPQA9GD0YPWw9rD3gPhQ+RD6wPqY+8D83P3c/uH/CgEwAlQDmATIBbgGeAdgCHAJUAoQC6ALAAwADCAMkAwQDWANoA3ADaANQA0wDUANMA3gDJAMQAywCxALoApACoAJsAggCKAHIAeYBhgGcAWQBKgD7AJEAp4BCAF1AN7/Tv+4/hL+cP30/IT8+PuA+2D7QPvw+rD6gPpY+vj5wPnA+bD5iPlw+YD5aPlQ+Wj5mPmA+UD5QPkw+dj4kPiI+FD4sPdA9yD38PZw9iD2MPbw9XD1UPWA9UD14PTA9PD08PQQ9QD2UPdY+Aj5GPrw+lj7APxI/ab+ff9PAHABkAJ4A6AEKAZgBwAIsAigCYAKAAuAC9AL8AvwCzAMoAwQDTANQA0QDdAMoAyQDJAMQAzACyALkAogCsAJYAngCEAImAcAB5AGQAbYBSAFSASIA8QCFAKWAUIBpwDa/17/Mf/I/iD+oP1A/Zz88PvA++j7sPs4++j6uPpQ+gj6IPo4+uj5kPmY+aj5kPmQ+cD5oPkw+Rj5cPmI+VD5MPkY+aj4CPjw9yD48Pdw9zD3EPfA9nD2kPag9hD2cPVw9eD1APZA9iD3KPjY+JD5wPrY+0j8kPxk/WT+NP86ALQBCAPMA3gEmAXgBtAHkAhQCRAKYAqQCgALkAvQC9ALwAvgCwAMEAxADHAMUAzQCzAL4AqgCkAK4AmQCRAJUAjQB5AHUAfYBkgGsAUABWgEEAS4AxgDMAJkAbcAPgD6/+j/v/8u/3T+zP1Q/cz8ePxA/PD7cPsI+/j6+PrQ+nj6OPoQ+gD6APog+kj6QPr4+cj52Pko+mD6gPqo+rD6ePoo+ij6SPoI+oj5YPlQ+fD4kPiQ+Jj4GPiA93D3kPcA93D2kPbg9sD24Paw97j4YPkQ+jj7FPxw/NT8mP1u/i3/SQCqAbwCeANgBHAFYAYoBxAI0AgwCXAJ8AlACnAKkArACtAKwArgCkALYAtACxAL0AqACiAK8AngCYAJ4AhACNAHYAcIB7gGaAb4BWAF0ARwBBgErAMMA0wCnAEUAbYAeABMAAkAo/8g/6j+UP4O/tj9fP0I/Yz8SPwg/AT86PvQ+6D7WPs4+1D7YPsw+/D6uPqQ+nj6uPow+3D7SPsg+wj74PrA+tD68Pqg+hD6uPmg+XD5KPkI+cD4IPiA94D3wPeg9zD38Pag9iD2MPYg91D4IPnI+Wj68PpA+7j7oPyA/Rr+zv7W/+cA5gH8AigEAAWABSAGGAf4B5AI8AhACUAJIAlACdAJcArACuAK8ArACnAKUApgCkAK0AlQCfAIoAgwCOAHoAdAB6AGGAbwBdgFeAUIBZAE/AMoA2QCAALGAWIB6ACbAF0AEADD/4X/P//C/jr+0P2A/Tj97Pyw/Gz8EPyw+6D7uPu4+5j7ePtY+yD78Prg+gD7CPsA+wj7IPsg+wj7EPsY+/D6qPqo+qj6ePow+gj62Plw+Qj50PiY+Dj48Pfw99D3YPfw9rD2YPYA9jD2MPco+Kj4KPnI+UD6iPog+wz80Pxk/TT+TP9OADQBTAKMA3gEIAUABigHEAiACNAIIAlQCWAJ0AmAChALYAuAC5ALgAtQC0ALQAsgC8AKYAoACrAJcAkQCbAIUAjYB1AH8AbIBpAGCAZwBfgEWAS0A0ADDAOQAuIBVgEcAcUARQABAOP/Zv+W/hL+4P2I/Qz9uPx8/AD8gPtQ+2j7SPsQ+/j6yPpg+iD6KPow+hD6APoY+ij6IPoo+kD6OPoI+tj5wPmo+ZD5iPl4+Uj52Phw+Dj4EPjA91D3EPcA9+D2oPaA9oD2UPYQ9lD2MPdI+Bj58PnA+jD7YPv4+wT98P2e/nP/tADqAegCCARABTgG0AZwB1AIMAnACTAKgAqgCrAKAAuQCxAMUAxQDEAMIAwADOAL0AugC0ALwApACuAJkAlQCfAIYAiwBzAH4AaQBjAGwAUgBVAEmAMcA6wCHAKGAfgAYgDT/3r/Uf8V/6D+DP54/eT8dPwk/Nj7YPvY+mD6EPro+dD50PnI+Zj5SPkI+Sj5QPkQ+dD40Pj4+Aj5GPlo+cD5sPlw+Xj5qPmg+Xj5aPlI+ej4gPh4+Ij4aPg4+Ej4WPhA+Cj4KPgI+ID30PZw9pD2MPdY+Jj5iPpA+xz8GP3o/Xj+K/8GALEAVAFUAtQDOAVIBjAHQAhACQAK4AqwCwAMoAtwC/ALgAyQDKAMMA2ADTAN4AxADYAN4AwADJALIAtACoAJYAkQCTAIWAcQB9AGIAaABTAFiARsA4gCNALcAToBrwBsAP//bf8z/3X/jf8x/7z+gP46/rj9SP30/HT8sPsY+/D68PrQ+qD6kPpA+qD5EPng+Jj4APhw92D3cPdA9zD3wPdY+HD4KPgw+Fj4OPjg98D3sPeQ96D38Pc4+Fj4aPiw+OD4qPhI+Bj48Pdw99D2oPaw9qD2QPbw9eD1wPbw+Mj7sP1U/jf/FAGcAhQDmAMQBZgGgAegCKAKwAxADoAPgBCgECAQgBBAEQARsA+gDlAOAA4gDaAMwAxwDHALcArQCQAJ8Ac4B5gGYAXgAyADQAN4A0gD5AKcAlwCKAIoAjgC7AFAAZYAFACF/xP/NP/J/+T/Vf/U/sT+pP4s/rT9KP0A/Ij6uPmg+SD5UPjg97D3UPfA9rD28PbA9jD2sPVw9TD1QPXQ9aD2QPfA95j4oPlg+uj6cPvg+/j7uPuY+8j7HPxs/LD8FP1c/XD9dP2w/ZD9oPxI+2j62Pnw+Bj40Peg99D2gPZw9xj4kPdw9yj5+Pqo+zT9LAEABSAGaAZACJAKMAtQC7AM8A1wDRAN8A5gEQASQBEAEeAQ0A9QDlANkAwgC0AJ2AcgB8gG4AYgB9gG2AXABCgEyAM4A5AC8gFKAdUAFAHgAZwCBANQA2AD6AI4AuoB0AE0AR0AQ//e/rb+zP5V/6//OP8W/kT9uPzo+7D6gPmg+MD38Pag9uD2APfA9mD2QPZA9lD2kPbA9uD2IPfQ96j4mPmw+vD76PxM/cD9Zv7a/pb+Kv4G/gj+qP00/Rz9ZP2s/aD9ZP0s/Rj9uPyg+2j62PmA+Vj4IPdA9wD40PdQ90j4mPng+CD3kPeg+UD64PkA/H8AUATQBuAJEA0QDlANgA2gDtAO8A0gDkAPwA+gD4AQABIAEiAQ8A1ADKAK4AigB5gGGAWsA2gDIATQBBgFWAUoBTAE/AJUAigCDAIIAiACHAIcAswCMAQoBfgE6AO0AkoBzv+0/jj+pP1g/Aj7qPoo+7j76Pu4++j6cPkA+ED3APew9hD2oPWQ9dD1kPaA9wD44Peg95D3oPeA99D32PjY+VD6uPq4+wz99P2E/g3/JP+E/gL+Nv6G/iL+gP1o/Zz9iP1k/aD9uP1U/dT8sPyY/GD8UPws/JD7uPqY+vD60Pp4+pD6qPqg+bD4CPm4+VD5KPmw+rT8RP6CAVAH8AuQDAAMgA3ADsAN8AwwDgAPYA2wDDAPABIAEiARQBEgEFAM8AjACPAIuAYgBNQDeAQwBGAEMAZQB9gFlAPIAqACvAEEAVQBkgHhAKwAHAIQBOAEYARUA9oB5P88/oj9RP2A/FD7cPqI+jD7KPz4/OT8wPsg+sj44Pcw99D2sPZg9iD2wPZA+MD5ePqA+kD6mPmA+OD3SPgI+Uj5YPkw+oD7fPwo/SD+5v6i/oj94Pz0/Pj8mPyw/GT9xP2M/az9Zv7c/nr+Av6o/dT8HPyE/IT9WP1o/Ij8QP20/Hj7qPsE/ID6iPjw+ED62Pn4+GD6HPxg+8j6Nv7IAxgHgAiwCgANMA3gDDAOQA/gDYALQAvQDOANoA4AEOAQwA9ADWALcAqQCVAI6AZgBfwDnAPYBOAGQAhACEAH2AW4BEgEUATQA0QCoAAdAJkAdgGoAvADEAQcAmf/zP1k/ej8wPtY+vD4APgo+ED5mPp4+6j7IPsY+jj50Piw+ED4oPcQ9wD3cPdY+Oj5ePsA/Pj6sPlo+bD5IPlA+Gj4GPkA+dD4WPqo/Gz95PxI/fT9FP2g+xz8jP0Y/bD7EPyQ/dD9qP0X/5sAkP+M/Xj9lv4w/iz97P1e/+b+LP0E/TT+Hv5Y/Dj7OPto+mD40PfQ+Sj7sPkw+KD5fPwi/r0AOAYwC4ALEArAC+AOsA4gDIALQAxgC5AKUA1gEeARoA/QDuAOoAwgCQAIcAgQB0gEoAMQBTgGyAbgB4AI2AZwBLADQASYA8wBcQDo/5H/+/+YARwD8AIIAogBbwAM/gT86Pu4+7j5kPcI+JD52Pmw+Rj7fPxw++D5gPqQ+zj6QPjg+HD6uPl4+Bj6vPyk/Cj7qPvM/Hj7YPno+Rj7YPkQ95D40PsE/BD6qPo4/WD9SPsA+8T84Pz4+nj6PPxM/bz82Pyi/s7/7P7o/cL+MQDd/zj+rP3o/rf/Lf/U/pn/if+g/ej7FPw0/ED6gPgo+Vj6aPkA+BD5ePsE/FD7zPySACAEGAfQCkAOsA4ADVAMUA2wDfAMkAygDCAMMAygDmARYBHwDvAMcAvwCPgGIAeoB9AFiAP0AyAGCAfgBoAH6AcQBhADlAGOATwBegAyAG0AcABuAAYB0AHqAdQA8P4M/cD7wPqw+cD4YPhw+GD4OPig+AD6iPsM/Cj74Plw+Yj5SPnw+Ej5EPpQ+nD6UPtw/KD8DPzQ+6j7kPr4+Gj48Phg+YD50PkY+uj5APpA+0z8APxY+7D76PvA+iD66Ps6/mL+gP06/r3/7f+m/6EAYgEBACz+ov5bAOUAoQAKAUABEwCy/mr+Vv5M/fj7GPvw+YD4cPjQ+cD6cPpY+iD7DPy4/awBEAewCpAL4AuwDBANAA3ADZAOoA1wC7AKcAzwDoAQwBAAECAOcAtQCWAIMAhoB6gFGAQQBHAF2Ab4BwAJ0AggBlwCWwBDAPb/3P58/jb/r//x//wAeAJsAocAPP6Q/Aj7aPlw+ID46PiA+OD3cPgI+hD7GPtA+9j7ePso+tD5aPog+hD5gPlY+9D72PoI+6D8OP0g/Fj7IPsQ+oD4aPhw+dj5qPkA+qD6wPro+tD7hPx4/IT8wPxM/Ij7SPxE/h3/ov7c/jcAxQCBACABTAK+AdL/Ef/H/yIABADDAIABmQDe/ij+/P3s/JD7yPrA+eD3APcY+Kj5QPpg+pD6oPpo+37+fAO4B/AJMAuADGANkA0ADuAO4A5QDdAL8AuQDdAOQA/ADwAQUA4wCzAJIAngCMgGuAQoBEAEYASYBegH4AhYBxAF4APMAg4BrP9f/0P/2P4m/0UA/wD+AO8AggDG/nT80PqY+Sj48PaQ9qD2sPZg98j4sPkg+lD74Pwo/RD8IPuI+qD5QPlA+kD7wPpQ+mj7vPx8/PD7TPwM/AD6IPg4+ND4cPgw+DD5EPqo+Xj58Prs/HT9pPwQ/BT8HPzw+yT8JP1A/qj+8P4PAJwBSAKmAegAtABMAHj/G/+9/6QA+ACTAMD/8v5o/gL+wPyY+rD40PfA9+D32Pho+gj7CPqo+Uz8mQBsAyAFEAigC9AMAAzgDCAPEA9QDEALwAygDQANsA2wD9APEA5gDXAN0AtQCVAIwAcoBiAFeAb4B0AHQAY4B2AIUAdYBUAEKAO7AIL+qv5FAOIAGwDE/3AAzQDd/6b+Qv5E/TD6UPbg9OD1cPaQ9RD1UPZg98D3QPlM/Oj9WPw4+kD6IPtY+jj5EPr4+wT8wPoQ+wT9uP2c/Nj7uPtY+uD3EPdo+DD5OPiw9+D4EPo4+vD61PzM/Zj8EPsg+8j70PsE/Ez9gP7k/p7/gAE0A3QDwALcAdMA0f+z/0QAegBjALUALAEIAXoAxf9G/rD7gPmY+CD4gPfQ93j52Pro+nj7pP0BAGgBpAOYB8AKIAswC8ANQBBQD8AMEA0gD2AO8AugDKAPgA+QDEAM8A6QDlAKMAjQCdAJSAaYBFAGgAbQA5gDCAcgCMgEqAIgBBAEXwD0/V3/EwDs/ST9wP8+ATz/oP2q/rz+WPvA98D2MPbw80Dy4PIg9FD0IPWg9yD68PqQ+9D8UP34+4j62Pqw+0j7cPr4+mD8JP1Q/fz9nv64/QD8IPs4+6D6QPk4+CD4WPjo+DD6mPuc/Fz94P2I/Xz8APwo/OD7OPto+5z82P1c/8IB2AP8A6AClgH9ADkAqP+w/5j/Lv+r/yYBHALIARQB2f9A/VD6OPmA+Uj5APkQ+mj7aPug+0j+SgE4ArACmAUACdAJIArwDPAPUA8ADdAMMA7gDbAMgA3QDnANAAswC0ANUA1wC2AKIArACPAGoAb4BhAG+ASgBegGsAagBRgFUARsAp0A4P8M/7j9iP24/mf/5P7S/jD/Jv6w++j54PjQ9gD0oPKw8lDy8PGQ85D2wPio+bD6wPvg+5j7EPyA/Lj7iPqI+nj7LPzc/BL+Av90/vj8DPzo+6D70Prw+SD5KPhA92D3wPio+uj7jPwY/XD9JP2s/NT8QP3w/AD8sPuo/HD+fACcAigESARUA4QCYAI0AlIBTQDv/zcAoQAsAQgCvAJUApwASv4M/ED6IPnw+GD52PlA+vj6PPwG/v//gAF4AnQDGAUoBxAJsApADFANcA0ADfAMcA2wDaANoA1QDXAMkAuAC+ALYAsQCiAJkAiIB3AGaAbYBgAGaARIBHAFQAXEA3ADsAOeAU7+EP5VAGwA8P04/aT+KP7I+yz8tv5c/UD4QPUA9hD1EPGg71DyAPTQ8sDzYPi4+wD70PpM/fD9mPpo+Lj6WP1s/Pj6aPwu/sz9kP1m/1MA6P0A+6j6OPv4+XD4qPhI+ZD4APiI+Rz8nP3o/fj9lP2M/MD7IPz0/Ej9dP0g/jf/ggAoAvADEAUQBVAEWANcAqIBfAG2AbQBWgEmAU4BrAHgAYABJwAK/gD8qPrw+aD54PkY+8T8wP0c/hb/PAFwA7AEmAXwBjAI8AjwCYALkAwwDIALsAtQDEAMsAuAC5ALMAuQCjAK0AlQCdAIkAhQCPgHmAcwB8AGeAZABsgFMAXABFAEaANgAp4B1wCT/47+kv7w/q7+GP60/TD9jPyY/LD8yPqg9uDy4PCA7wDv0PDw8wD1wPRg93T8qP7w/Aj8OP1s/AD5WPgs/AX/8P0A/eL+SgAN/zr+mv/F/zj8WPig96j4yPhY+Lj4aPmw+VD6BPyU/fj9VP04/AD7IPpQ+nj7+Pxi/pX/QQCoAMwBkAOwBHAEeAOsAsIB1QDeAM4BGAJUAcQAGAFYAekAmABDALr+8PvA+Wj54PlI+gD7gPz4/fj+PAA0AvgDAAXYBRAHEAiACCAJUAqgCyAMEAzgC+AL4AvgC8ALcAvQCjAKwAmgCdAJ8AmgCeAIkAhgCNAHGAegBigGSAWABIAEkAToA1gDNAMcAvn/8P6N/6H/Cv4g/cD9WP2A+yD7sPyo+7D28PFg8MDvQO7g7hDykPSw9AD26Plc/dj9MP3s/Ij7iPlI+YD7dP0i/sr+yP/V/zf/nf9rAH3/2Pyg+oj5yPiA+Ij56Prw+jj6qPo0/Fz9fP0w/Vj88Pro+TD6ePvk/FD+j/8/AOMAIAKYA2AEYARYBAAECAMUAkQC6AK4AvIBvAEoAiwC0gGwAUQBjv8Q/TD7UPrY+bj5mPo0/KT91v5xAFgCyAOYBEAFCAbABoAHkAjACdAKcAvQC0AMoAywDHAM8AtAC6AK0AkgCRAJYAmACSAJ0AjACIAI+AdoB7AGcAUQBJADwAOAA4wC4gGcAbMAZP8A/3L/GP/E/fz84PwQ/PD6UPtU/Cj7sPeg9NDy0PBA7+DvcPGQ8ZDxYPQI+bD7LPzk/LD9lPxw+kD6JPxg/Tj9bP2G/lr/SP9V/9H/e/+c/Vj7EPoQ+lj6MPoA+kD6sPoA+4j7lPx4/Vz9ePzY+8j70PsU/Mj8tP00/qz+3P+AAcgCoANwBPAEqAT0A5wDVAOMAo4BTgGSAaIBnAEMArACaAL2AET/0P1U/Nj6IPqI+nD7YPyg/Y7/rgE8AxAEyAS4BZgGGAeQB1AIIAmQCdAJkAqwC4AMUAzQC3AL0ArgCRAJAAlACdAIIAjwB1AIcAggCKAHsAaABbgEYAToAwwDjAIgAlABIQDs/0EAwP+e/vz9BP5Y/Tz8+Pt0/Mj7sPkA+FD3cPZQ9LDx4O8A7wDvIPCw8jD2wPjA+Wj6DPzA/eD9fPxo+2j74Pt4/Jz9QP9AAB8AoP9n/yT/QP7w/Pj7WPtQ+uD4MPgQ+ZD6MPvw+vD6YPuo+9j7ePw0/RD9PPz4+5z8oP3k/rIAcAJgA8ADeARwBegFgAW4BMgDmAKoAbwBlAJIA2ADSANUA+wCygFyAEb/Cv58/HD7iPt8/KT92v5sAAgCSAMwBDgFYAYwB4gHqAfwB4AIIAngCdAKwAswDCAM0AuQC/AK8AnQCCAIsAdAByAHgAfYB6gHaAcwB8gG+AVwBSgFKASQArYBugEiAQcA5P96AMr/Qv5Q/ob/yP5I/Fj74Pu4+vD3MPcI+JD2wPIA8cDxAPHg7oDvMPPw9HD0YPYA+4D9nPw0/ED9WPwA+sj6jv4kADz+TP04/5IAyf8t/5H/ov6g+6D5KPoI+1j6oPlo+mD7IPuY+qD7aP0A/hD9GPwk/Fj8gPxA/cT+6/8qALUAfAJQBPAEyATQBLgEwAPQAugCfANoA/AC9AIYA7wCFALGAZQBowDu/mz92Pzs/DT9sP2M/n3/GQDTAFQCSASABbAF2AV4BiAHgAcwCGAJIAowCmAKUAswDBAMgAtQC/AK0AmgCIAI0AiQCBAI+AcQCNAHgAeYBzgH6AV4BGADmAL4AaoBYgG/AAUA+f8LAMv/eP9M/3r+sPwo+7D6MPoI+SD4kPdg9nD0MPPw8vDxQPCA73DwkPGg8jD1+Pi4+8j8HP0o/XT82PtM/Fz9oP0g/fj8cP2K/un/vADU/7T9PPwU/Az8cPvw+sD6YPq4+eD5KPtw/PT8MP2I/Uz9ePxE/Ej9Sv5G/ib++v5AAEoBaALUA5AE/AM4A4ADEATwA4wDlAOEA6gC1AH2AWwCOAKEAewAKQAY/2r+hv6y/mb+Qv7M/rj/pADgAYgD0AQ4BUAFoAVgBhgHoAdACMAIAAlACcAJcAqwCmAK4AmQCUAJ8AjACHAIIAjAB4AHUAc4BygHEAeABmAFMARUA7ACDAKuAZABHAFpABcAXQBLAFP/Mv5g/Uz8wPrI+aD5KPnw9wD30Pbg9dDzYPLA8ZDwoO5g7qDwwPLw84D2OPtS/gz+UP0M/gL+8Pso+1j92P5g/aD8+P6cARoBv/86AE8A4P2o+1z8EP04+0D5SPoQ/Jj7sPps/An//P5U/TD9Dv50/XD8ZP1Z/6///P4MAKACEAQgBKgEuAWgBUgEwANgBIAEZAN0AmACLAKSAXIBAAIYAioBGwCN/0X/5P6k/tb+OP+V/zAAOgF8AqgDkARQBcAFCAZ4BjgHIAigCMAIwAgACWAJgAlwCXAJcAkwCcAIUAj4B6gHeAdoB2gHOAe4BkAG+AWIBcgE0APwAjwCxAGQAXgBPgHTAFwA5v9Q/3r+eP1Y/CD7GPpg+ej4aPjg90D3UPbQ9DDz8PEQ8UDwIPBA8UDzUPWg99D68P1t//z+5P3g/Pj7uPuc/OT9SP4m/oL+ef9tAFIBZAG7//D8gPv4+wT80PpA+hj7QPsY+kj69PwR/3j+VP2w/ej9qPwk/Pj9sv8s/0T+m/8oAqwDUAQwBcAF8ATQA5gD3AOQA7wC5AEsAbAAygBaAeYBAAKsAdYA1f9e/3z/aP/8/v7+p/9wACABhAKQBOgFEAYQBsgGaAeIB8AHoAgQCYAIEAiwCNAJ8AmACTAJMAnACDAIIAhQCCAIsAdwB2AHEAdwBvAFaAVwBDADKAKcAVwBNgEAAbEATgDF/zX/ov4M/jT9+PuQ+oj5+PiQ+Cj4sPfw9oD14POA8oDxkPAg8JDwkPEA86D1KPkY/KT9dP76/vj9sPvQ+kT8xP1g/QT9Tv6o/5L/pv9MAZ4BEf84/CT8VP0w/RT84PsE/Ej7IPuQ/FT+lv4u/kr+VP6k/Tz9Gv4X/zP/NP/7/0IBeALQAygFoAX4BDAEOASIBGgE0AMUA0wCyAG0AQQCfALIApQCxAHiAJ0AmAApAI7/df/e/zkA6wCAAlAEIAU4BcgFyAZAB0AHoAdQCHAIEAhACAAJYAlQCXAJkAkgCVAIEAhQCEAIsAcwByAH6AZgBuAFeAWYBDgDFAKEAToBygBaACAA3P9F/3b+3P10/dD8qPt4+qj5EPlQ+KD3cPdA91D2wPSA87DysPGw8HDwEPHQ8dDyQPXg+LD73Pxw/fz9cP3w+0D7TPw8/fj82Pz8/fT+5v5S/38AawBm/rj87Px0/bz8HPxE/AD88Pr4+vj85v4D/27+qP4S/77+Lv5w/hT/Sv9h/xAAfgEEAygE6ARQBTAFsARABDgEWATwA9gC/AHgATQCXAJ4ArgCtAI0AqIBWAEYAZQAIAATAEEAqQCqATADeAQQBXgFMAbIBjAHqAcgCDAI0AfYB3AI4AjgCOAIMAlACcAIYAhQCCAIoAdABxgHwAYYBogFSAXIBMQDnALWAYIBSgHkAGwA/P+a/xP/Sv54/bT82Pu4+sj5MPmw+Cj4sPdw9+D2oPUg9ODyoPFw8ADwUPCw8GDxgPMA98D5UPuY/GT9jPzQ+sD6LPzU/Dz8iPws/in/Nv/T/w4B6AAE/4T9gP34/cj9RP3I/Ej88PsI/MD8nP16/tr+bv7Q/ej9uv4p/+z+7v6N/1cAGgFwAjAESAVIBTAFiAXgBdAFoAV4BRAFaAT0A/QDIARYBHAECARAA9wC6AKQAp4B7QDiAPYACgH0AYgDgASoBBgFKAbIBsAG4AZoB2gH2Ab4BtgHYAhACFAI0AjgCHAIQAhgCDAIeAcIB/AGsAYoBtAFkAXgBNgD8AJMAqwBDAGMAAIAX//M/mz+BP50/dT8IPxI+1j6qPkQ+UD4YPfA9jD2UPUQ9ODyMPKQ8bDwIPCQ8KDxAPMQ9Sj4yPqg+2j7oPvg+yj7oPqQ+7T8GPx4+1T9EQB8AC7/BP+v/7L+8Pxk/QL/Sv6w+wD7iPzs/Nj7NPw0/uT+uP2Y/Sv/of9u/gT+QP/N/xH/ff/+AfQDAAS4A8AEwAWABUAF0AXoBcgEyAMgBNAEcATQA+ADaARIBKwDnAPEA1ADcAIEAiwCeALkAtADyAQoBUgF2AXgBnAHaAdIB2AHgAe4BzAIgAiACHAIgAigCKAIwAjACFAIyAeoB7gHQAeQBlgGSAaIBUgEiANMA8QC8AFyASQBeACi/yb/0v4S/hz9TPxY+zj6UPnQ+Dj4gPfQ9iD2IPXg8wDzEPKw8KDvgO/g76DwcPKA9Uj40PnI+pD7kPu4+oD6UPvo+3D7cPvM/ID+WP+o/+r/fP96/uj9YP7A/hr+KP2k/Gj8NPx8/Cj9jP2k/Qb+nP7E/qz++P5p/0v/4v41/zUAFgHKAawCeAOwA8ADYARABZAFWAUgBfAEoARYBJAEwARwBAAE+AP4A6wDXAM8A+gCHAKQAeoBxAJQA5gDIASoBOgE8ASIBVgGqAZIBjgG2AZoB3gHiAfwBwAIiAdoB9AHAAiYB4AHyAewB/gGqAYIB8AGgAWIBEgErANoApABugGKAV4Adf9x/1j/UP40/dj8XPwQ+9D5QPng+DD4cPcA91D2QPVA9KDzwPKw8eDwwPAA8QDyAPSg9qj4wPmQ+iD7IPvA+sD6KPtA+zj7yPsI/Tb+9v53/1b/nP70/RD+cv44/oD99PyM/Az8+PuY/ET9UP0k/aT9jP70/u7+Gf9t/1f//v5S/2AAVgHsAYQCTAPQA/ADQAToBFAFCAWQBGAEaARgBHAEuATIBEAExAPYAxAEtAP4AqACoAJcAjACyALEAzgEMASYBHAF4AXIBQgGqAYAB8gGwAZAB6gHiAdoB5AHmAdgB0gHgAeQB2gHSAcwBwAHmAZABtgFMAWIBPADUAOIAugBkgE8AZcA7v+F/xj/aP6c/fT8NPwo+zj6oPkA+Tj4oPdQ95D2IPXg81DzYPLg8BDwoPCA8YDykPTQ9+D5yPlo+Tj60Pow+sD5oPqQ+3j74Pvs/c7/uP/O/tr+M/+y/iT+nv4u/1L+/PzU/Jz96P2w/ez9lv68/nj+oP4r/2L/B//c/if/t/9BAPcA3gGcAhQDOANkA+ADqAQYBfgE2AQoBUgFyASwBGgFyAXgBAAEYATwBEAENAM8A3AD2AJUAjQDaARoBOgDYARwBbgFiAXQBVgGYAYoBlgGwAbIBqgG2AYYBwAH0AbgBhAHGAfoBtgGwAaIBkgGKAbIBdAExAM0A/QCVAKWASIBDAGgAAwAsf9k/5r+gP3I/CT8WPtI+qD5MPmw+DD4sPcA9wD2EPUg9ADzsPEQ8SDxsPHg8uD0MPew+DD5kPlY+sD6cPoQ+oj6OPuY+yD8cP26/sT+Rv6M/lH/U//u/ib/gP/M/rT9uP18/mz+xP3w/br+9v6+/h7/r/9f/6D+sP5t/9j/DwDLAL4BNAJUArwCSAOwAxAEeASYBHgEmAQIBTgF+ATYBPAE0ASQBLAEGAXwBAgEYAN8A8QDgANgA/wDwATABIgEIAUIBhgGeAV4BRAGMAbQBQgGwAbYBkAGGAawBtgGSAbgBSgGSAbYBZAF8AUoBpgF6ASQBDgEPAOAAlgCKAJuAa0AjwBoALr/9P50/rT9mPzY+5D7+PoA+kj56Pgw+FD3EPew9kD1YPNw8jDygPEQ8SDy8PMQ9QD2sPeA+cj5OPlA+bj5kPmA+Zj6GPzM/Pj8fP0U/ij+Nv68/hn/tv5G/nL+uv52/gb+/P0E/tj95P18/iT/TP8x/zH/Kf8Q/zb/4P+pACQBhAH0AVgCpAIcA7QDGAQwBGAEwAQIBTAFYAVwBTAF4AQYBYAFmAVIBQAFmAT0A3gDkAPcA9QDwAMYBJAEoASgBOgEMAUIBcgE4AQ4BXAFkAXYBQAG0AWwBfgFaAZ4BjAGAAbwBcAFoAW4BbgFYAXYBHgEMATAAyQDhAL8AXIB5QBfAAIAwf9O/3T+qP0w/cD86Psg+8D6UPpA+SD44PfA99D2sPVA9dD0UPPg8RDyMPOQ8/DzYPWQ94j4uPiA+WD62Pmg+Pj4kPqQ+5j7PPxo/dD9eP3Q/ez+Kf94/mL+OP+B/97+ZP6C/m7+7P0A/tD+av9z/6X/GgAhAKL/iv8ZAKgA4AAyAdgBXALAAlADCARYBFgEiAQABWAFeAV4BXgFSAUYBUAFsAXoBaAFGAW4BIAESAQgBPgD2APQAwgEcATQBAAF6ASwBJAEmATgBDAFYAVgBUgFSAVABSgFQAWABaAFgAVgBXgFmAWIBWAFOAXwBIgEOAQYBAAEpAMYA4gCBAKKARwBywBfAMX/C/9u/vz9nP0Y/VT8iPvw+nj6APqI+RD5ePiA93D2kPXQ9PDzYPMw82Dz0PPA9DD2wPfw+Lj52PlI+fj4cPlI+qD6uPqA+4T87Pwc/Qj+8v6S/oz9uP34/mz/zP6C/tL+lv7I/bz9ov4+/+7+wv41/5r/j/+K/83/7P/d/wkArgB2ATACsALYAsQCBAOkAzAEYASABLgEuASQBKgE+AQQBdAEmASgBJgEaARgBHAEIAScA3QDuAMgBFAEkASwBIgEaASIBPAECAXgBMgE8AT4BAgFOAVwBWAFIAUQBUAFYAVwBZAFkAVYBQgF8AT4BNAEcATsA0wDrAI0AugBkAEkAbIAUADg/3H/Lv/a/jL+TP14/ND7QPvY+oD6CPpY+aj4KPiQ9+D2IPZQ9SD0MPNw86D00PXA9uD3CPlo+Vj5qPlA+ij6gPmw+cD60Ptg/BT9wP3k/aj95P2a/vb+Ef9I/4n/SP/4/hz/W/84//j+M/+J/4r/of8iAIEAOQDX/wYAnAD6AD4BrgEEAhgCNAK4AkwDrAPYA+QD6AMYBIAE4ATgBNAE4ATYBLAEuAT4BNgEWAT0A/QD/APoA/ADGAQYBOQD8ANIBIAEkASYBKAEWAQYBCAEWAR4BHAEiASgBKAEoATYBAAFyARgBCgESARwBGgESAT4A2QDsAI4AgwC3AF6AfoAfwAZAMH/ZP8B/4T+7P00/YT8DPyo+yj7iPrw+Xj5EPmw+Gj4MPig94D2YPWw9HD0gPQA9RD2QPdA+Oj4iPno+eD50Pkg+pj6yPo4+wz8zPwU/Uz9vP0a/ib+dP4u/7z/of9J/zT/PP8Y//7+I/9d/4z/wv8HAC4AMAAtAC0ALgBjAM0AMAF8AcwBLAJoAogC1AJMA6wD5AMYBHAEoASYBJgEoASgBJgEqATIBMgEuASwBIgEOATwA9wD5APYA+AD/APwA7wDsAPkAwAE4APMA/ADCAT4A/QDGAQgBOwD3AMIBCgEGAQIBAgE9APMA6wDoAOAA0gDBAOoAkAC7AGmAVwB+wCqAF8A/v+C/x7/1v5g/tD9SP3c/Fz8yPtQ+/j6mPo4+vj5sPk4+bD4OPiQ97D28PWw9cD1IPYg94j4gPm4+dD5CPow+hD6OPrI+kj7iPvw+8T8hP3c/fT9Gv5g/sT+Sv+1/97/2f/C/5D/T/9i/7z/9P/b/8b//P82AC8AJgBNAHQAfwCzADQBvgHyAfAB+AEkAnAC5AJsA+ADOARoBIAEgASYBNAEyASIBIAEyAT4BOgEwASoBGgEAAToAzgEYARABCgEQAQ4BPAD1AP4A+wDnAN8A6ADuAOkA7AD3APQA5gDgAOcA5QDWAM4AzADCAPMArwCwAKQAiwCxgFsARQByQCfAG8AFACf/zr/4P6Q/kT+/P2U/ST9yPx4/Bz8oPso+8j6ePog+tj5oPlI+cj4KPiw92D3IPcQ94D3aPhA+cj5QPqg+pj6aPqQ+iD7YPtA+5D7dPwg/VT9nP06/ob+Yv6w/pH/HQDf/6D/xf+1/zv/E/94/8v/wf/z/4cAyACMAG0AtADMAJcAnAAcAZAByAH8AVACfAKAAsgCVAOwA8AD1AP4AxAECAQYBCgEIAQYBEAEgASYBKAEqASYBFgEEAQABBgEIAT8A9wDyAO4A6ADoAO8A7gDlAN8A5ADmAOIA3gDcANMAxgDFAM4AzAD+ALQAswCoAJIAhwCGALmAXIBFAHjAKcAXAAvABgAzv9d/wD/xv56/hz+yP1Q/bD8HPzQ+5j7WPsY+/j6wPpo+jD6+PmQ+fD4cPg4+Dj4iPhI+TD6wPoI+zD7UPs4+zD7aPvQ+wz8PPyk/DD9eP2E/aD9wP3s/TT+uP47/1D/D//S/rb+rv7A/vr+Of9i/5P/2P8NACEAJgA5AFcAhwDfAE4BngG2AbQBtgHCAeQBOAKwAhQDTANkA3QDiAOQA5QDjAN8A3gDiAO0A9wD7APUA6ADdANoA4QDtAPMA7wDkANsA2ADVANMA1ADUAM4AxQDFAMsAywDBAPkAtgCyAKwAqACjAJgAhgC3AG6AZYBagFEARQBxwBsABgA0v+I/zj/9v68/nb+Kv7s/bz9gP0w/ez8vPx4/DT88PvA+6D7ePtA+xj7CPsQ+yj7QPtY+2j7iPuw+/D7OPyA/LT8zPzg/Aj9RP1s/ZD9xP38/S7+XP6Y/tL+5v7c/sz+yP7U/t7+8P4A//b+4v7Y/tr+6P78/hv/Qv9o/5v/5/8qAE0AYQB4AI0AiACJALcA+wAsAVgBpgEIAjwCRAJgAoQCiAJwAnwCtALYAtgC8AIgAzwDQANoA7AD0AOwA5wDtAPAA6QDlAOgA6wDuAPcAxAEKAQIBOgD2APIA5wDdANYAywD7ALAAqwCfAI0AvABvgGKAVwBQAEeAeIAlQBiADsAAgC8/3//Qf/0/qL+YP4m/tz9hP04/QD9xPx4/DT8+Puw+1D7+PrI+qj6gPpY+mD6ePqI+pD6qPqw+qj6oPrI+iD7iPvo+zz8bPx8/Kj8+PxI/YD9zP02/pL+3v5A/6D/u/+g/6D/3/8kAEsAfAC6ANYAzwDcABIBOAE+AVABdgGSAZoBogHAAdQB0AHaAQgCVAKgAtgC+AIEAxQDLANMA3gDtAPsAxgEOARoBJAEmASYBJgEoASYBIgEkASoBJgEYAQwBBAE7APQA8QDsAN0AyAD4AK0AnwCKALWAYYBLgHlAK4AfgA+APD/p/9q/y7/7v6m/kz+/P24/YT9SP0Q/dz8pPxc/BD80PuQ+1j7EPvo+sj6uPqQ+nD6YPpQ+kj6OPo4+lj6gPqo+sj68Pog+1D7aPuQ+8D7+Pso/GD8pPzw/Cj9XP2g/fD9Ov50/rj+BP9F/2v/if+0/+D/CwA9AH0AxQAGAToBbgGoAdoBBAIsAlACaAKAAqwC4AIYA0QDfAO4A/ADGARABGgEiASQBJgEuATQBPAEEAU4BVgFYAVgBWgFYAVIBSgFAAXYBLgEqASgBIAESAQgBPADtAN4A0ADAAOwAlwCDALGAXgBLAHgAJIAQAD0/6//bv8p/+D+kP46/uj9nP1c/Rj90PyM/Ej8BPzQ+6j7gPtI+yD7EPsA+/D64PrQ+sD6mPqA+oj6mPqg+rj62PoA+xj7OPto+4j7kPuo+/D7QPyU/PT8WP2k/dz9HP5w/sL+Bv9P/6L//f9WALUADAFOAYoB0gEcAlgClALYAhwDSANoA5ADxAPwAyAEUASABKAEqATABNAE4AToBOgE6ATgBNgE0ATABKgEiARgBEAEIAT0A8QDlANUAwgDuAJwAigC3AGQAUwBCgHCAGwAEAC6/2v/H//O/n7+Nv70/bT9eP1E/QT9yPyY/HD8TPwo/AT84PvI+7D7qPuo+7D7uPu4+8D7wPvI++D7APwQ/Cj8SPxs/JD8rPzM/Oz8BP0g/Uz9iP3I/fz9LP5e/pT+yP74/ij/W/+Q/8f/AgBAAIQAxAD/ADgBbgGmAdoBCAI0AlgCeAKMAqACsALEAtwC+AIMAyADPANMA0wDTANIA0ADLAMUAwQD+ALoAtQCzALAAqQCdAJIAiQC+gHGAZgBfgFiAToBEAHtAMEAhABLACMA+/+6/3v/VP83/w7/2v68/qb+hv5c/kD+Nv4Q/uj93P3g/dz92P3k/ej94P3U/dj93P3Q/cD9yP3U/eT99P0O/h7+Iv40/lT+bv5+/pT+sP7K/uL+Af8j/zv/UP9t/5v/xv/r/xAANgBUAG8AjAC2AN4A+gASASwBUgFqAXoBkgGqAbgBuAHGAegBEAIgAiQCIAIUAgQC/AEAAggCCAIEAgQCBAL+AfAB1AGoAYIBcgFuAWQBVgFMAT4BIgH+AOUAzwCwAIsAcQBgAEcAKwAYAAcA6//H/63/nv+M/2v/RP8j/wX/6P7O/rj+pP6S/n7+aP5W/kT+Lv4c/g7+Av7w/dj9zP3I/cD9uP2w/bD9uP3A/dT98P0C/g7+Hv48/lb+bP6G/qL+uP7Q/vD+FP82/0//aP+G/6P/uf/L/93/9/8ZAD4AYwCHAKcAvgDPAN8A8QD+AAoBGAEyAVABagF6AYIBhgGGAYQBgAGEAYoBlAGcAaQBsAG6AbgBrgGeAZABfgFkAUwBOgEsARgBCAH7APMA4wDNALoAqACTAHcAWQBCACsAFQAAAPH/5//W/8D/q/+e/5P/h/96/2z/Vf8+/y7/JP8a/wv/AP/6/vT+7P7m/uT+4P7a/tb+2v7c/uD+6v72/v7+Af8E/w//G/8j/y3/OP9D/1H/Zv98/4n/jP+Q/5n/pf+z/8n/4//5/woAGgArADYAOwA/AEIARwBPAF4AcACDAJUApACuALEAsAC1ALgAtQCuAKgApQCkAKQApQCiAJ4AngCiAKEAnQCeAJ0AjQB6AHsAegBzAGYAYwBlAFUARABFAEEAJgAJAAAAAgD+//b/8v/u/9//zP/K/9L/0v/K/8X/yv/M/8n/xf++/7f/sv+x/7D/sf+0/7f/tv+y/6z/rP+s/6n/qv+x/7v/v//E/8//4P/v//j/AAAHAAwADQARABoAJQAtADYAQgBNAFYAXQBjAGUAYwBiAGQAYwBgAGAAZQBpAGMAWQBWAFsAYABdAFcAVABTAFAATQBLAEUAOwAxACsAKAAhABcADgAHAP//+P/z/+7/5//f/9T/yP/B/7//wP+//7z/uv+4/7b/sP+r/6b/n/+Z/5j/m/+f/5//nP+Z/5j/mP+U/5L/kv+U/5X/lv+X/5j/mf+a/5z/oP+m/67/t//E/8//1//X/9H/yv/D/73/uf+3/7n/wf/L/9X/4P/r//P/9//4//n//f8BAAcAEwAiACwAMQA3AEEASgBNAE8AVABcAGEAZQBsAHQAeAB5AH4AhQCFAHsAcgBwAGwAYABYAFoAXQBWAFEAVQBUAEkAQQBCAEQAQAA9AD8APgA8AD0AQgBBADkAMAArACYAHAARAAUA+f/w/+r/6P/n/+D/1//O/8X/vv+2/6z/ov+b/5v/nP+d/53/mf+T/5D/kP+T/5f/lP+S/5X/mv+f/6H/oP+e/53/m/+d/6n/tf+9/8b/y//P/9T/2v/h/+n/7v/0//v/BAANABYAGwAcAB0AIAAmACoALQAvADIANAA2ADoAQQBHAEkASgBKAEkASQBLAE8AUABRAFUAXABhAGMAYgBfAF0AWwBZAFYAVABRAE8ATABKAEgARQA/ADoANQAwACgAHgAVAA4ABQD7//H/6P/f/9f/0v/Q/8//zf/O/8//0f/S/9H/zv/J/8X/xf/G/8b/x//H/8f/xP+//7v/uP+2/7b/uf+9/8H/xP/G/8j/yf/J/8n/yf/M/9D/1P/X/9n/2v/a/9r/2f/Y/9f/1v/V/9X/1//c/+H/5f/o/+z/7v/v/+//7//u/+3/6//r/+z/7v/x//X/+v8AAAQABwAIAAgACAAHAAYABgAFAAQABAAIABEAGAAdAB8AHwAgACIAJgAoACgAKAApAC0AMQA0ADMAMgAwAC0AKwAoACUAJAAjACUAJgAnACgAKAAnACUAIwAiACIAIwAmACkAKgApACcAJgAmACYAJgAmACQAIgAiACMAIgAeABkAFgAUABIAEAANAA0ADQAOAA4ADwAUABkAGgAZABcAFwAUABAADQAIAAMAAAACAAQAAgABAAIA/v/3//b/9f/0/+7/7f/z//H/7P/v//L/6//h/93/4f/i/97/2//e/97/2P/W/9z/4f/c/9f/2f/e/97/2//Z/9z/3f/d/97/4v/m/+f/6P/q/+3/7//w/+//7//v/+//7v/t/+3/8f/1//j/+//9/////v/9//z//P/8//z//f///wQACgARABYAGQAcACAAIAAeAB0AHwAhAB8AGwAaABwAHwAeABsAGAAVABMAEgASABIAEwATABQAFgAXABUAFAATABQAEwATABQAFQAVABMADwANAA0ADQANAA0ADgAPAA4ADgANAAsABgABAP7//P/8//v/+v/6//v/+//5//X/8v/v/+z/6f/l/+P/4P/d/9n/1f/S/87/zP/N/9D/0//U/9P/0//R/87/yf/E/8D/vP+5/7n/u/+9/7//wf/C/8L/wv/C/8P/xf/I/8n/y//N/9H/1v/b/9//5P/p/+7/8v/3//3/AwAIAA8AGAAgACQAJwArAC8ALwAuADIANgA2ADUAOAA7ADoANwA5ADsAOwA4ADcANgA1ADUANwA5ADkAOAA5ADwAPgA9ADsAOAA1ADMAMgAyAC8ALAAoACQAIgAfABgAEwANAAkABwAFAAUAAgD+//v/+v/6//n/9P/w/+//7v/u/+3/6v/k/93/1f/Q/8//zf/N/8//0P/T/9b/2f/c/97/3f/d/97/4P/i/+X/5//p/+v/7v/x//P/8//y//L/8f/z//b//P8DAAoAEAATABQAFQATABAADAAHAAUABgAJAA0AEAATABUAFwAYABcAFgAUABIAEgAUABcAGgAcAB4AIQAhACAAHQAZABYAEwAPAAwACAADAP//+//4//X/8v/v/+3/7P/s/+r/5v/g/9r/1f/T/9P/0//U/9b/1v/W/9b/1P/R/8//0P/S/9X/2P/c/97/3v/d/9r/1//U/9L/0f/T/9b/2v/g/+b/7P/y//b/+f/7//v//f/+/wAAAgAEAAYACAAKAAwADgAPAA8ADgANAAwADQAQABUAGwAiACsAMwA6AD4AQAA/ADwAOQA0AC8AKwArAC8ANAA5ADwAPQA9ADwAPAA7ADcAMgAvAC8AMQAzADQAMwAwACsAJQAeABUADAAEAAAA/////wEAAgACAAAA/f/5//T/8P/t/+v/6v/p/+j/6f/q/+r/6f/m/+L/3v/d/97/4P/h/+P/5v/p/+r/6v/n/+P/3v/Y/9b/1//d/+f/7//0//b/9v/y/+n/3//W/8//z//Y/+b/9f8BAAkABwD9//L/5v/d/9b/1v/k//T/CAAfAC4AKgAaAAkA+v/u/+P/3f/g/+r/9v8IAB4AKgAlABcACwADAPr/7//o/+r/8P/7/wgAFwAiACYAJwApAC0AMQA0ADcAOwA+AEAAPwA7ADYALwApACIAHAAWABAACQADAP7//P/7//3/AgAJABEAGgAhACYAJwAjABoADAD+//X/8f/w/+7/7P/s//D/8//w/+f/3P/S/83/z//Z/+X/8////wgACwADAPP/3P/D/6r/mP+T/5v/q/+9/8v/1P/Z/97/3//c/9X/z//Q/9r/6f/5/wEA///2/+z/5P/c/9H/xv/C/8j/1P/j//X/BQAQABcAGwAcABkAEAABAPH/4f/U/83/zv/Y/+f/+P8IABUAHQAfABsAEQAHAAIABQANABkAKAA2AD4APgA0ACQAEQAAAPf/+P8DABEAIQA0AEkAVgBTAEYAOAAsAB0ADwAIAAgADwAcADIASgBUAFQAUgBSAEsANwAkABsAGQAYAB4ALgA3ADQALQApACQAFQD9/+n/3//g/+//BAAYACEAIAAdABsAEQD4/9b/t/+s/7P/w//V/9z/1//J/7r/rP+a/4L/cv92/5T/wv/z/x0AMQAoAAcA3f+5/6T/oP+w/9P/BAA1AF4AdABfABUApf85/wP/Cf88/4r/4f83AIYAwQDWALUAWgDj/3//Vf9q/6T/6v8qAGMAkQClAJMAXwAUAMn/lv+V/9D/MwCZAOcAFAEiAQ4B1gCFACIAu/9t/1j/gv/N/xEAQQBkAHkAeQBgADkADQDn/9f/5v8OADYASQBLAEIAJgD1/77/lv+D/3//h/+h/8f/6P/5/////P/r/9D/wP/E/9P/3f/c/9P/wP+d/3H/Sv8x/yn/OP9n/6//9v8lADQALQAWAPP/z/+1/6n/rv/F/+7/GAApABYA6/++/5r/g/99/4z/sv/q/ysAbQCjAL4AugCbAHEATAAtABcABgD9////CQAdADkAUwBgAFsATwBKAE8AVQBVAFYAXQBuAIkApQCzAKIAdQA/ABkAAwDq/8f/rf+t/8z/AgA7AGQAbgBiAFQATQBGADQAHQANAAYAAgAAAAQABwD7/9z/uP+e/5T/nv+5/9b/6f/y////EAAVAPr/wf+C/1n/Uv9n/4X/nv+s/7X/vf/D/8H/tv+m/5z/of+9/+7/LABnAI0AkQBwADsACADg/73/mP95/3D/jf/V/zEAfwClAKEAhABcACgA6v+p/3X/XP9r/63/GgCLAMwAvgBtAAoAr/92/2L/av+M/8r/RgD6AJIBqgEwAWcAr/9C/yX/Of9a/3X/qP8cALYAFgHtAFYArf8+/xv/M/9v/7b/8v8lAF8AmwC3AI8AKwC//3r/dP+h/+7/OgBmAGkAVABAACkA+v+z/3T/YP9+/7b/8f8gADMAJgAHAOv/3f/S/8T/v//Q//v/MgBaAFwAMADu/7z/r/+7/8P/w//Q//z/PABtAHMASwAMANj/xf/U//L/GABFAHAAkACWAIAATQD+/6L/VP8y/1j/vP8zAIQAkgB3AFgAQwAqAPz/v/+R/5n/5/9iAMMA0ACNAC8A6f+9/5r/ef9i/2b/hf/B/xQAXQB4AGIAOQAaAAoA/v/v/9T/qP93/1n/aP+e/9T/6f/Y/8D/uf+9/6//hf9a/03/cv/A/x0AaQCOAJIAgwBjACQAwv9g/zL/Sf+D/7T/2v8OAE4AcQBfADIADwABAAkALABhAIIAhQCMALIAxgCUADAA4P+9/6r/oP+5/+7/FwAqAFYAqADdAMUAggBbAGEAegCVAK4ArgCJAFsASgBMACkAzP9y/1z/jv/T/wUAJAA8AE0AWgBmAFUAEwC5/4P/jv+1/9P/6f8CABgAIAAsAEsAWAAhALD/Rf8Y/zD/ev/s/1oAggBRABQAFQAkAMz/8P4A/pT92P2u/sn/vAAcAd4AagArABQAw/8e/4D+Zv7q/sX/pgBEAWYB9wA5AKb/hv+v/7z/lP97/7T/PQDiAFgBVgG+AOH/Xv+B/+P/6v+S/2P/qv8pAIQAqQCrAH8AJgDh/+f/EwAsAEcAkQDjAOQAmwBvAIYAgwAnALz/rv/1/0MAfQCsAKsASwDB/33/if+M/2H/Uv+b/wcAUwB7AI4AZQDm/1n/I/9K/4D/qv/z/2UAuwC5AGoAAgCO/x7/6P4P/3D/y/8aAHkAzgDXAHUA3f9c/xH//v4u/5n/EgBZAFsAQAAtAA4AvP89/9j+xv4P/5T/JgCVALoAkwBbAEoAUAA1AOb/ov+j/+D/LgB0AK0AugCGADoAFwAbAAQAtv9r/3H/yP85AJMAxAC/AIYASAA3AEMANAD//8z/wP/R//j/RQCeALkAdgAOANr/8P8qAFgAWwAkANj/xv8RAHAAfgA4AO//1P/S/8r/u/+t/5n/if+g/+n/PwB6AJUAmAB0ACwA7//v/w4ABQC7/2r/XP+k/xAAaQCIAGIAEwDV/8z/7P/9/9r/jv9M/0X/jf8LAIQArgBWAJ//+P7K/hv/ef+D/1r/dv8IANEAYAFuAecA8P8S/9j+Pv+0/8f/uv/m/yYAGADC/3b/Sv8n/yn/k/9NANoA8gDOAKMAUgDI/1b/T/+Q/8L/6/9RAOIAGgGuAP3/jf9y/2r/Y/+R//z/dQDVACABPgH9AGEAxf99/2r/T/86/3T/BQCTAMUArwCYAJ8AogBxABEAtv+H/4r/sf/4/1gAtwDxAO4AqQA5AMP/fP91/4L/b/9A/z//jv8HAHIAvADcAMAAYwD2/7z/wf/d/+n/0/+p/5n/3P9mANYAwwAvAIb/Lf8v/0//Vf83/yf/bP8TANEAOAEcAaAA//9w/xz/F/9R/6L/8P8qADcAIAATACUAGACl//z+pv76/sf/mgAUAQwBhwDI/1D/Y//A/93/mP9e/47/AwA/ABoAz/+N/1H/Of+V/14ABgEUAdYA1gD3ALMADACn/8H/4//A/87/aAAAAdwALACv/4z/ZP9A/5b/VQDRAMUAvgAOATwBxgD5/2n/Lf8J/yD/rv91APEA9QDBAIYARQAKAO7/3v+z/43/v/9PAMsAzQBpAA4A6f/F/27//v6w/qr+C//U/6UA7QCGAP7/6v8lACIAwP9i/07/bf/B/3MAQgGCAfAAGwCc/2f/K/8A/yn/e/+k/8P/KQCZAIcA/v+S/3r/Tv/q/tL+X/8pALAAAgFEAS4BmAD9/+L/BgDh/5j/vf9LAK8ArwCVAHoAFgBy/xn/V//I/wMAOgCxAB4BDgGPACQA5f+D/xL/Gv/L/4sAwwCUAGcAOQDQ/13/Qf9a/zz/BP9c/2IASgFcAdwAbQAvAOX/p/+9//n/3v98/2v/4f9dAF0ABgC0/2b/Bv/i/kP/wf+4/z//J//P/6sAAgG/AD4Asf8p/+T+D/9y/6n/u//7/3MAxACtAGUANQANAMT/jP/O/4cAHgEUAZQAJQDy/8L/ff9Q/13/df9+/6X/AwBgAG8APAD6/7b/df98/wgA1AA4Ad0AMwDl/yYAjwCiAEcA0v+q/+b/WADBAPgA5wB8AOL/e/+T/wMAWwBjADsABgDM/6z/0v8BAK//5P6I/k//swCAAU4BtQBGAPD/lv9+/7z/3f+j/4H/AQDeAFQBGAGFANn/CP9A/hz+2v7r/38AhwCeABABWgHqAOb/7P5Q/g7+SP4j/0sAGAFcAXwBogFSAVAAKP9+/lb+bv74/icAeAEQArQB6wA3ALL/Sf8A/8L+lP7A/o7/xACmAbYBCgEbAFv//v74/hj/Q/+T/x0ArgDrAMsAhQA2ANv/gP9f/5H/8P9NAJEArAB5AAIAk/9k/2X/Y/9m/5j/DwCiAAAB8QB4ANn/Xf8Y/w//Tf/I/0QAggCcAMkA5gCkABIAlP9b/0T/S/+q/1IA2ADqALQAeAA0ANP/fv9u/4//qP+4/+X/JAA1AAEAyP+8/9f/9/8ZADwAMQDx/8r/AABYAFcA/f/F/wcAgQC2AHkAAQCV/2D/cv+2/wAAMQA/AC4ACgDq/97/4P/e/9H/r/99/2b/p/84AKYAlAA6AAwAFQD1/43/T/+b/0IA0QAGAesAkQAVALX/lv+a/4//dv96/7P/CQBVAHsAbQAfAJn/FP/k/jD/x/83ADwABAD2/zsAjwCEAPL/P/8G/3r/LACSAH0AGgC6/5P/xP8xAH8AawALAK7/hP+Q/8v/IgBRABoAmP9T/7P/egD4AL8AHQC4/8P/7v/1/+z/9v8CAAkAOgCcAMUAZwDt//D/TwBmABwAAQBPAH8AQQAFAC0ATgD3/43/rP8qAF4AMgAvAHUAigAxANn/0v/N/5L/e//W/08AZAA0ACwAPwACAIP/Uf+j/woAEgDU/8D/CgCCAN4A2wBqAL//O/8v/5L/DAA9ABAAzf/C/+f/BwAeAFEAgwBKAJT/8P7w/mf/wf/O/8n/w/+h/5T/6/9pAHQAAwC7//H/NwAvACIAWwCIAFYAGAA4AHYAUwDb/4j/dv92/4X/xP/8/9j/m//y/94AdAESASgAkv+R/9T/JAB0AIIAGACW/47/+v81AO7/if9d/07/Zf/9/xYB1gF2AUcAVP82/6z/HwA9AAMAsv+2/z8A4gDcAO3/vP4u/pL+c/8yAIsAlwCSAJkAjABDAM3/af87/z//bf/E/zAAfwCTAGwAFwCZ/yL/Cf92/xoAgQB9AD8AAADJ/6L/pP/P//L/7//n/wwATQBoAD4A7f+g/2z/av+2/0AAvADjALAAUQDq/5H/Zv+J/+X/NwBQAEIARABrAIkAYwD5/4T/TP9v/9X/RgCTAKYAigBgADQAAADA/5f/pf/b/wUAJQBlAMEA3wCCAOz/iv+B/53/w/8HAFIAZwA/ACcAPgA7APL/sP/C/+v/1v+8/wsAlQC1AFMA9//i/6//Mf/0/lf/+P8/ADEAIwAWAOP/uP/g/yYADgCz/6//HwBqAC0A5P8aAIIAcgD//8j/7P8AAOX//P9JAEkA6f/D/y8AjgA4AJH/Y/+q/8j/q//Q/zkAQQDC/3b/2f9XADoA0//U/zUAVwATAOP/AgAjAA8A//8lAE0AOwAeAD8AfwBsANL/Gv/Y/iH/kP/l/04A0QD2AFwAdP8I/zj/ev+K/6z///86AFIAowAwAUQBbQBU/+z+Q/+y//z/XgDLANsAhABFAEMAEQCG/yv/bP/u/y4ARAB5AJEANwCu/3v/if9f/yP/eP9TAOAAsQBSAE4AXwAjANj/5P8IAMr/av+K/y4ApwCeAHkAgwB1AAwAmv+B/47/aP87/4j/SADcAOwAqgBOAMb/JP/S/gz/eP+p/7r/DQCZAPoA+QC7AFsAzf8w/+T+LP/M/1YAlgCeAIgAVQAQANP/sP+h/53/uv8GAGQApgCpAHUAJQDA/0X/2P7O/lz/PgDaANoAfQAnANb/Yv8A/xH/hf/x/zgApgA4AXQBCgFKAJ7/CP+E/mL+7v7z/9UAOAEqAdYAUwC2/yH/xP6+/vD+NP+g/2UASgGqASgBNwB+/xz/5P7w/nH/IgB6AG8AeAC9ANYAjwBFADAA/f9//zH/i/8vAGAAIAAPAFkAiABXABgACwD7/8P/ov/A/9b/qf+J/+f/jgDiALgAdQBeAEcA/f+s/5b/pv+1/9X/LwCjANQAnwBDAP3/zv+q/6L/tv+y/37/Zv+3/08AtwDFALIAkwBEAMb/f/+U/7r/rv+m/+v/QwBVADYAMwA1AOj/Xf8M/yf/W/91/7T/TQDfAOUAbAD7/9f/xf+Z/43/zP8VAAsAxf+h/8L/7f/0//T/CwAgABEACgA9AIEAcwD9/5L/lP/m/zYAaQCOAIQAMADc/+L/EwDY/yz/xv4i/+//nQD5ABIB2QBjABQAIwAmALv/Q/9z/0AA4ADfAJMAWgANAIz/O/96//z/LAADAP7/XADJANwAfADa/zL/0v4E/6j/OwBLAP//6v9TAMMAmQDX/xf/2P4T/4X/FACpAP0A3QBrAAEAyP+w/5f/XP/s/oT+qv6e/+YAngFgAXIAdP/Y/sb+Jf+i//z/MABtALgA5QDaAJwAKwB6/7j+XP64/q//rQAwAQYBeAAKAAMAHwDh/z3/uv7k/sX/8gDYAfgBMAHj/9T+hP7a/nX/BQBtAKUAuADDANkA5QC3AC0AY//Q/vT+2P/2AKIBqgEsAVEAY//g/g7/hP+k/4D/ov8lAJMAogCIAFcA1/8m/+j+c/9HAMIAywCjAFkA8f+w/8v/+P/E/0r/If+T/0sAwQC8AFMAuv9I/1H/1/9mAH8ALwDj/87/1//c/9f/xv+Z/23/gP/a/0UAgwCMAGkAFQCm/3P/sP8tAIMAfwBKABoA+P/i/+j/CwAUAM3/aP9X/9H/kAAIAfAAWwCm/07/iv8bAHYATgDY/4T/jv/c/yMAKwD3/8T/wP/l/xMAPgBeAFUAGgDk//P/MwBeAE4AFQDZ/6T/if+r/wwAaQByACUAyP+d/6L/xf8GAFIAbwAtAMT/qf/m/xYA7P+d/4D/i/+M/5f/6v9zAM0AxAB/ACgAu/9Q/zf/p/9bANwA8wDBAG4A+f94/zL/Uv+g/8X/tv+2//D/SwCIAI0AWQDx/37/Sf+F/wMAawCNAHwAYAA8AAUA0v+7/7f/sf+s/77/5v8aAGIAugDkAJ0ACwCr/7P/4//m/8j/yv/+/0kAhQCPAEcAyf9w/23/j/+d/6f/5P9FAIIAiQCLAJ0AigASAGD/6P4E/6D/TwClAIIAIwDq/wIAMQAPAJf/Nf9E/7H/FgA/AE4AYABcACkA1f+I/1P/Rf9z/8L/9//z/+//IgBcAEIA4v+b/5X/pP+o/8n/HQBkAG8AaQB3AH0AQgDY/4f/e//C/0EArgCnACoAsv+h/9D/3f/B/7f/0f/t/w0ARQBzAGkAPAAsAC4A/f+w/7r/OwCxAJkAKwD6/ycATAAjANn/rf+j/7f/BAB1ALAAeAAQAOz/CwAWAPH/2f/t//X/0v/R/y8AkQByAO3/kv+M/5v/q//4/2YAbwAAALn/+/9aAEkA6f+u/6f/q//S/zkAfwA2AKL/Y/+R/7P/lv+T/+f/TQB4AHwAawAiAJv/K/8g/2f/yP8xAJsA0gCoAFQAIQAOAOH/kv9h/3n/x/8mAIQAtQCMABoAtf+T/5T/jP+c//b/agCVAFwAAQDD/5b/ef+i/yEAoADTAM0AwwCZABQAav8e/1D/pv/o/0QAwwACAckAYQARAKT/+v6O/uL+p/8sAGAAqQAIAQgBjgALALb/U//m/ub+f/8fAEQAOwCEAOcAywAfAHn/K/8R/x//jP9SAO0A9QCgAFAADQCz/2P/Vv91/37/gf/G/0EAiwBxACgA9f/R/7H/sv/j/xUAIAAkAEkAeQB5AD4A6/+Z/1z/X/+x/w0AHwDx/9z/AgAwAD4APgA0AAMAuf+w/w8AeAB8ADEA+v/q/8f/pP/T/z4AZAAdAOD/EABlAHAAPQAeABQA5f+0/87/HwA3APj/zf/v/wkA0f+P/6b/6//3/9v/AQBnAJUAWgAUAAkACQDl/9D/9v8YAP3/4/8cAHQAdwAiAN//3P/T/6f/nf/q/1AAdQBQAAwA0f+7/9r/GgAtAPD/qP+u//z/QwBUADsAFQD0/+b/7P/2//L/7v8EACYAMgAfAAcA+f/e/7j/rP/o/0AAWAAfAOP/6P8dAD8AMQD0/4//NP83/6//QQB3AFUAJgAKAN7/o/+X/83/AQD5/+P//v87AGQAbgBlADYA2P+U/7L/CgAzABEA7P/t/+7/3f/v/zcAaAA8ANv/oP+g/7j/4v8hADkA8f+B/3P/6f9pAH4ATAAsAB8A7P+j/5T/1/8yAGgAegB8AGYAQQAsADIAIADM/2D/NP9s/83/GgBLAGUAXwA2AA0A/v/2/87/lv9//6H/7f9FAIUAhgBEAPP/1P/k//n/+//4//b/8P/z/w4ANABCADUAKAAiAAYA1f++/97/DgARAOn/zP/S/+D/4v/o////FgAZABYAFADx/6D/Wv9r/9H/NABdAFMAPgAsACEALwA6AA4Atf99/5z/6v8hAEEAXwBYAA0Arf9+/3n/dP+C/9b/SQByAEMAIAA6AEAA7/+H/2T/e/+S/8D/MQCvAMkAfwA2ABEA2/+E/2v/2v+DAOMA2wCkAF8ADAC1/4X/gf9+/3f/nP8DAHYApQCCADcA5/+V/1n/bf/W/1MAlQCWAIEAbwBTABcAwP9x/1D/c//I/x4AUABmAHkAfgBWAAAAp/96/4z/0P8kAFkAVgAzABsAEwD7/7//gP9u/4//yP8FADwAXQBcAEoAQAA1ABAA0v+Y/4z/tP/6/0QAaQBYACUA9//e/8L/mP97/5H/3f8xAGcAdQBdACYA7v/c//L/BQD1/9n/3f///yIAQwBqAH0AQwDI/3D/hv/i/ycAMwAmABQA+v/w/xcATAA7ANX/b/9o/7z/IABjAHwAaQAmANn/vf/i/xEAEgDx/+z/FAA7AD0AKAAQAOj/pf9x/3//wf/1/wIADgA0AFIAQgAVAPj/7f/W/7z/w//y/yEANgA2ABsA3/+a/4P/rP/g/+v/3v/n/xMAQQBXAEkAFQDJ/5b/q//3/z0AWwBaAD0A+f+k/3n/j/+9/93/9/8vAIEAuQCvAGUAAgCz/5f/sf/g/wIAEQAjAEAATAAoANn/h/9g/3X/sP/w/yIARwBkAG8AVwAoAAYAAgACAOv/1//o/xwARABBACAAAADy////KABOAEMAAwDJ/8z/9P8BAOP/y//c//v/BwAKAB0AKQAHAMj/qv/C/+z/DAArAE8AUgAjAPP/9P8QABEA6v/O/+D/BQAZABgAGgAiAB0ADQAFAAcA9v/O/7T/zP8GADEANgAdAPH/uv+T/6T/6v8zAE4APwArACEAGQAQAAgA9//T/7P/xf8MAFIAZQBIAB4A+f/Y/83/4P/8/wIA+P///xsANQA4ACMA9f+r/2X/Xf+l/wgAPgAwAAUA6//z/w4AHQAIANz/vf/N/xEAXQCEAHgATgAeAPH/z//C/8z/3//s//D/+v8VADoASwAvAO7/sP+b/7X/5v8VACoAGgDy/9j/6P8SAC4AJAACAOD/0f/b//7/KwBIAEkANQAfAAgA7f/W/9P/5//+/wIA+//9/woAEwAHAPL/4//a/9D/y//Z//r/IQA2ADAADgDY/6n/pf/S/wwAIwANAPX//f8hAD4ANgAKANX/u//O/wcAOgBGACkAAgDq/97/1v/V/+T///8UACEAMgA+ACUA4/+i/5H/rv/d/wYAIAAkABIAAQAGABAAAADe/9H/5/8KACAAMQBQAGoAYQArAOH/p/+M/5D/qP/I/+j/DQA2AFAASAAYANf/rf+s/8b/6v8MACkAOgA1ACIAEgAIAPn/3v/A/7n/2P8VAFMAcwBpAD8ACwDq/+j/+v8JAAkABAANACIALAAdAPb/xf+i/6n/4P8pAFUASwAjAAYABwAZACcAHwADAOD/zP/d/xEAQQBIAB4A3f+s/53/tP/r/ysATgBBABYA+v8AAA4ADQAHAAgACAAAAPr//P/5/+f/2f/l//v/+//p/+v/CwAnACMABgDs/+H/3//m//z/FQAgABgABQDu/9z/1//c/93/1P/J/9f///8nADsANAAlAB0AHQAaAAsA8P/i//X/GwAuAB0A/P/p/+b/4v/a/9//8f8AAAIA/f/7//v/AQAUACwALQARAPX/8P/6/wQADAAZAB0ABgDg/9H/7f8YACgAFAD1/+P/6f8AABYAFADu/77/tv/j/xoAKQANAPL/9P8GABQAGwAXAAAA3P/C/8X/3/8BACMANwAsAPn/v/+m/7j/2f/w//z/CAAZACsANwAtAAwA5f/P/87/2v/r////DgAPAAcABQAOABMACAD1/+//+v8PACMALQAtACMAFQAOAAYA9//n/+T/7//y/+P/1P/W/+3/CQAaABsADgAAAAEAEQAjACsAKwAsACsAIgAVABAAFAAWAAwA/f/0//f/AwARABgAFAAGAPL/3//X/9z/8P8IABYAGAAPAAEA9P/s/+n/5f/j/+v/AAAbACYAGAD4/9f/x//M/97/8P8DABwAOgBRAFEANAD+/8X/p/+1/+j/IABCAEIAKQAJAPD/4//Y/8v/wv/G/9n/+f8gAEYAWQBQACkA7/+7/6T/uf/v/yMANwAvACMAIQAeAAoA6v/V/9b/5f/8/xoAOABKAEQAIQDq/6v/gP+M/8v/DgAqABoAAwD8//r/8P/i/9v/3f/p/wYALQBJAEsAOwAjAAUA3//E/8z/9f8cACYAGQAGAPj/8P/r/+z/8v/z/+3/6//5/xAAHQAZAAgA9P/l/+X/+/8aACsAHQD7/+D/3f/q//3/DQATAA0AAQD6////DQAbAB4AEQD1/+D/5v8HACgAKwARAO//2f/U/93/6f/w/+3/5//r//z/DQAOAP//6//c/9n/6v8KACYAJwAMAPD/7P8BABYAGAAHAPL/6v/0/wgAGwAiABkABwD5//b/+P/7//3//f/5//D/5v/j/+r/7//n/9n/1P/h//v/FAAhAB4ADwD///v/AwALAAgA+v/u//H/BAAbACQAGQD8/9j/uf+t/73/4v8JACEAJwAiABgAEAAMAAoA/f/i/8z/0v/3/yEANAAsABYA+//j/9j/5/8IACcANQA4ADEAIwAVABIAGwAbAAkA9f/0/wQADwAKAPz/7f/f/9z/7/8JABgAFQAMAAwAFAAaABcACwD+//b/+v8LAB8AJwAcAAkA+f/w/+3/7P/u//H/9/8DABIAHAAbAA0A///4//j/+P/0//H/9P///wsAEAAEAO//2v/S/9r/5//x//j//P/8//n/+v8BAAkAAwDp/9D/y//j/xQARQBWAD0ABwDW/8b/2v/5/w0AEwATABMAEwARAA0ABwD6/+b/1v/b//P/EwAoACkAFwD+/+3/7P/4/wEA///5//n//P///wEACAAQABAABAD5//r/CAAaACUAJQAbAA4ABgAKABEADwACAPX/7//v/+7/6//o/+b/4v/e/93/4P/h/+T/7f/7/wYACgAKAAoACwAJAAIA+P/v/+n/6f/u//T/+P/8/wUADgAOAAEA7f/e/93/6/8CABYAHwAaAAwA/P/v/+P/2P/S/9P/3f/t//7/CwAOAAYA9v/q/+3/+v8IABEAFwAbAB0AGgAUABAADQAJAAQABAALABMAFwAWABAAAgDw/+X/6v/8/xEAHwAmACUAGgAIAPr/+f8AAAMA/f/2//f/AgASAB4AHAALAPH/3//d/+j/+P8JABQAGAAVAAwABQADAAQAAwD+//f/9P/5/wMACgAKAAIA9//w//D/9P/3//f/9//9/wgAEgAWABAABAD3//D/8f/6/wMABwAHAAYAAwAAAAAAAwAGAAQA/v/7//7/BgAMAAoAAAD2//L/9P/5//z//f/8//n/9//0//L/9P/6/wAABwAOABQAFQAQAAwABAD8//X/9P/5//n/9//8/wUABgD8/+v/3f/c/+n/AAAWACAAFgAHAAIABQAGAAMAAgAFAAkACgAJAAoACgAFAPz/8//w//H/9v///wcACgAGAP///P/8/////v/9//z//P/9/wEACAAOAA4ABwD8//X/9f/5//3/AAAAAAEAAQABAAIAAwAEAAQAAQD7//f/+/8EAAsACAAAAPj/9v/4//v//P/8//v/+f/7//7/AgAEAAYABgAEAAAA/f/9/wAAAQABAAMABwAMAA4ACwAGAAIA//8BAAUACwAPAA8ADQALAAcAAQD4//H/7f/s/+z/7P/s/+3/7v/t/+v/6v/s//D/9//+/wMABQAEAAMAAQD///r/9P/y//b//f8EAAYAAwD9//X/7//s/+3/8P/1//v/AAAEAAcACgAKAAYA/v/z/+v/7P/1//7/AwADAAAA/P/5//j/+/8AAAQABwAKAAwADQANAA4AEAARAA0ACQAHAAYAAgD+//7//////wAABAAJAAgABAACAAQABwAKAAsACQAFAAIABAAJAAwACwAHAAUABQAGAAYAAwD///r/+f/7////AwAFAAQAAgACAP///P/5//b/9//8/wIABQADAP7/+v/7//7//v/7//j/9v/3//z/AAACAAAA+P/w/+z/7//3/wIACwANAAoABAD/////AAAAAP7//P/9////AgADAAIA/v/6//f/9f/3//v/AAACAAMAAwAEAAcACQAKAAcAAwD///3//f/+//////8BAAIAAwADAAMAAwAEAAUABgAHAAcACAAJAAoACQAHAAQAAgAAAP3/+v/3//X/9P/0//X/9v/2//b/9//5//z//v8AAAIABQAHAAkACAAFAAEA/f/5//j/+f/8//7////+//v/9//0//P/9P/2//r//v8BAAIAAQD+//r/9f/x//D/8P/y//X/+f/7//z//P/8//3//v//////AAACAAQABwAJAAsACwAJAAUAAwACAAIAAwADAAEA///9//z//f///wEAAwAEAAQAAwACAAMABAAFAAMA///7//v/AAAGAAsACgAGAAEA//8AAAEAAQD///7//v8AAAEAAgACAAIAAQAAAP///v/+/wAAAwAGAAgACAAGAAUAAwABAP7//P/9/wIABgAJAAcABAAAAP////8AAP///v///wEAAwAEAAQAAwACAAEA///+////AgAEAAIAAAD//wAAAQABAP///v/9//z/+//6//j/9v/2//n//P///wMABAAEAAMAAwACAAAAAAAAAP7//f///wIAAQD8//b/8//z//b/+/8AAAEA/v/8////BQAGAAMAAwAEAAYABgAFAAYABgAEAAEAAAD///7//f/9//3//f/9//3//f///////v/9//z//P/9////AgAFAAYABQADAAIAAgACAAMAAgAAAAAAAAACAAIAAgADAAMAAQD+//v//P///wEA///8//z//f8AAAEAAQAAAP7//v/+////AAABAAIAAwADAAEA///+//7//v/9//7/AAADAAUABAACAAEAAAD//wAAAQACAAIAAwAEAAUAAwABAP7//P/7//r/+f/6//r/+v/5//j/9v/1//X/9f/2//j/+v/9////AQABAP7/+//6//v//v8AAAEAAQAAAP7//P/6//f/9f/z//P/9f/4//z/AAADAAUAAwAAAP7///8AAAIAAgABAP/////+//7///8AAAAAAAAAAAEAAQACAAMABQAHAAcABwAGAAYAAwAAAP/////+//3//v////7//f/9////AQADAAQAAwACAAIABAAGAAcABgAFAAUABgAHAAcABgACAP///f/9//7///8AAAAAAQACAAEAAAD+//z//P/8//7//v/9//3//f///wEAAAD+//z/+//8////AgADAAEA/v/7//n/+v/8//7///////////8AAAEAAgABAAAA/////wAAAgACAAIAAQABAAAAAAAAAAAAAAD///7//v///wEAAwAEAAQAAwACAAIAAgACAAIAAQABAAIAAgACAAIAAgACAAEAAQABAAEAAQABAAIAAwAEAAQABQAFAAUAAwACAAAA/v/9//z//P/7//r/+f/4//j/9//4//n/+//9/wAAAgACAAIAAAD///7//v///wAAAAAAAP///v/8//r/+f/4//n/+v/7//3//v///////v/9//z/+//6//r/+v/7//v/+//7//v/+//7//r/+v/7//z//f///wEAAgACAAIAAQABAAIAAwADAAIAAAD///////////////8AAAAAAQACAAMABQAFAAQAAQD/////AAADAAUABQAEAAMABAAFAAYABQACAAAA//////////8AAAAAAAAAAP///v/8//z//f///wEAAgADAAMAAwACAAEA/////wAAAQACAAIAAQAAAAAAAQABAAAA///+////AQABAAEAAQACAAIAAQABAAEAAgADAAIAAAAAAAIAAwACAAIAAgACAAIAAgABAP///f/8//z//P/9////AAAAAAAAAgACAAEAAQACAAEAAQADAAUABAABAP///v/9//3//f/+//3/+//6//z//v/+//3//f///wAAAAAAAAIAAwADAAMAAwADAAMAAQAAAAAAAAD//////v/+//7//v/9//3//P/8//3//v///wAAAQAAAAAAAAACAAIAAgAAAAAAAAABAAAAAAABAAIAAgAAAP7///8AAAEA///8//z//f/+//////////7//v/+//7//////wAAAQABAAAA/////////v/9//z//f//////////////////////////////AAABAAMAAwADAAIAAQAAAP//////////AAAAAP/////+//3//P/7//r/+v/7//3//v////7//f/8//z//f/+////AAAAAAEAAQAAAP///f/6//j/+P/4//j/+f/7//z//P/8//z//f/+///////+//7//v/+//7//v/////////////////+//7///8BAAEAAgADAAQAAwACAAMAAwADAAIAAgACAAAA///+//////8AAAAAAAD/////AAABAAIAAgABAAIAAwAFAAYABgAFAAQAAwACAAIAAgACAAEAAgADAAMAAgACAAEAAQABAAEAAAAAAP//AAABAAIAAgABAAAA/////wAAAgACAAEAAAD///7//v/+//7//v/+//3//v/+/////////////v/+/////////////////wAAAAAAAAEAAAAAAP///v/+////AAAAAAAAAAAAAAAAAAAAAAAAAAD//wAAAAAAAAAAAAAAAAAAAAAAAAAA///+//7//////wAAAQACAAMAAwADAAMAAwACAAIAAgACAAEAAAD///7//f/8//v/+//7//z//f/+///////+//7//v/+//////8AAAAAAAAAAP///v/9//z/+//7//z//P/8//3//f/+//7//v/+//7//v/+//7//v/+//7//v/+//3//P/7//v/+//8//3//v/+//7//v/+////AAAAAAAA///////////+//7//v/+//3//f/+////AQABAAEAAAD///////8AAAEAAQABAAEAAgAEAAYABgAFAAQAAwACAAIAAQABAAIAAgADAAIAAQD///7//v/+//////8AAAEAAQABAAEAAAAAAAEAAQACAAIAAgABAAIAAgACAAEAAAAAAAAAAQAAAAAAAAAAAAAA////////AAABAAAAAAAAAAEAAQABAAEAAQACAAMABAAEAAMAAQAAAAAA///+////////////AAAAAAAAAAAAAAAAAAABAAMAAwACAAEAAQABAAEAAQABAAAA/v/9//3////+//z//P/9//3//f/8//3///8AAAAAAQACAAIAAgABAAIAAgACAAIAAQABAAEAAAAAAP///v/9//3//f/+//7//v/+//7//v8AAAEAAAAAAP//AAAAAAAAAAAAAAIAAgABAAAAAQACAAMAAQD///7//v////////////////////7//v/+////AAAAAAAAAAAAAAAA///+//3//v/+//7//v/+//7//v/+//7//f/9//z//P/+////AAAAAAAAAAAAAAAA/////wAAAAABAAEAAQABAAAA///+//3//P/8//3//v/+//7//f/8//z//f/9//3//v///wAAAgACAAIAAgAAAP///v/9//z//P/8//z//P/7//v/+//9//3//v/9//3//f/9//3//f/+//////////7//v/9//3//f/+//7//v///wAAAAAAAAEAAgACAAIAAwADAAMAAQABAAEAAQABAAEAAQAAAP////8AAAAA//////7///8BAAIAAwADAAMAAgACAAIAAgACAAEAAQACAAIAAgACAAIAAQABAAEAAQAAAP//AAABAAIAAgABAAAAAAAAAAEAAgADAAMAAgABAAAAAAAAAAEAAAAAAP///////////////////v/+///////+//7//v/+//7/////////AAD//////////////////////////wAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAQABAAAAAAD///7//v/+//7//v//////AAAAAAEAAQABAAEAAgADAAMAAwADAAIAAQAAAP///v/+//7//v///////v/+//7//v/+//7//v//////AAAAAAAAAAD///7//v/+//3//f/9//z//f/9//3//f/9//3//f/9//3//v/+//7//////////v/+//3//f/9//7//v/+//3//f/9//7/////////////////AAAAAP////////7//v/+//7///8AAAAAAAD///7////////////+//3//v8AAAIAAwADAAMAAwACAAIAAgACAAMABAAFAAUABAADAAIAAQABAAEAAQABAAEAAQABAAEAAAAAAAAAAAABAAEAAAAAAAAAAQACAAEAAQAAAAEAAQABAAEAAQABAAAAAAD/////AAAAAP///v/+//////////7//////wEAAgADAAMAAgACAAEAAQAAAAAAAAAAAP////////////////7//v///wEAAQAAAAAAAQACAAIAAgADAAMAAQAAAAAAAgABAP///////////v/9//3//f/9//3//v///////v/+//////8AAAAAAAABAAEAAgACAAEAAQAAAAAAAAD//wAA//////7//v///wAAAAD///////////7//f/+////AAD///7///8BAAIAAQD///////8AAAAAAAAAAAAAAAD//////v/+//7///////////8AAAAAAAD///////8AAAAAAAD//wAAAAAAAP/////+//z/+//8//3//v/+//7//v/+//7//f/9//3//v///wAAAAABAAEAAQAAAP/////+//////8AAP///v/9//3//f/8//z//P/8//7///8AAAEAAQABAAAAAAAAAAAA/////////v/9//3//f/+//7//v/+//7//f/9//3//f/+//7//////////v/+//3//f/9//3//f/9//7//f/9//3///////7/AAABAAEAAAAAAAEAAQACAAIAAgACAAEAAgACAAIAAQAAAAAAAAAAAAEAAgACAAIAAgACAAIAAgABAAEAAQACAAIAAgACAAIAAgACAAMAAgABAAAAAAABAAIAAgABAAAA////////AAACAAIAAQABAAAAAAABAAEAAQABAAEAAAAAAAAAAAAAAP/////////////+//7//f/9//3//f/+//7//v/+//7//f/9//3//f/9//3//f/9//7//v/+//7///////7//v/+//7//v//////AAABAAEAAQAAAAAA/////////v///////////////v/+//7///8AAAAAAQACAAIAAgACAAEAAAAAAAAAAQACAAIAAgABAAAAAAD///////////////8AAAAAAAAAAP/////////////+//7//v////////////7//v/9//3//f/9//7//v/+//7//v/9//3//f/9//3//v/9//3//f/9//7//v////////8AAAAAAAAAAAAAAAD////////+//7///8BAAEAAQAAAP////8AAAAAAAD///7//v///wAAAQABAAEAAQAAAP///////wAAAQADAAQABAADAAMAAgACAAMAAwADAAMABAAEAAMAAgACAAEAAgACAAIAAgABAAEAAQABAAEAAQABAAEAAgACAAIAAgACAAEAAAD/////AAABAAEA///////////+//z//P/8//3//v///wAAAAAAAP///v/9//7/////////AAAAAP///v/+//z/+v/7//3//f/9//3//v/9//7///8BAAEAAAD+//7/AAAAAP////8AAAEA///+//7//v/+//3//v/+//7//f/9//3//P/8//z//P/9//7//v/////////+//7//v/+///////+//3//v///wAAAAAAAAAAAAD///7//f/9////AAD///7//v8AAAEAAQD///7//v/+////AAABAAIAAQABAAAAAAD/////AAAAAP///////wAA//////////8AAAEAAQABAAEAAQABAAEAAQABAP///v/+//7///////7//v/+//7//f/8//z//P/9//7////////////+/////v/+//////8AAAAAAAAAAP///v/+//3//P/8//3//f/+////////////AAAAAAEAAQACAAMABAADAAEAAAAAAAAAAQABAAEAAgABAAAAAAAAAAAA//8AAAAAAAD/////AAAAAP////8AAAAA/////wAAAAD+//3///////7///8AAP///v///wAA///+/////////wAAAgACAAAAAAAAAAEAAgACAAIAAgACAAMAAwADAAEAAAAAAAEAAwAEAAMAAwADAAQABAAEAAMAAgACAAIAAwAEAAYABgAFAAIA///+/wEAAgAEAAcABwAEAAMABAAEAAQAAwACAAIAAwAEAAQABAAEAAUABAABAP7//f/+//3//P/+/wAAAQAAAP7//f/7//n/+f/6//r/+f/6//z//f/8//z//P/8//z//P/8//3//f/9//7////+//3//P/9///////////////+//3//P/9//z/+//7//7/AQADAAMAAgABAAEAAQABAAMABQAHAAgACQAIAAYABQAFAAYABwAHAAcACAAIAAoACgAJAAYABAADAAMABQAHAAgACAAFAAEA/v/7//v//P/8//r/+f/4//b/8v/v/+7/7v/t/+v/6v/r/+v/7P/t//D/8f/w/+7/7P/r/+v/7P/x//j//P/9///////8//j/9P/z//b/+//9////AQABAP////////7/+v/3//n//f8BAAUACgALAAcAAwABAAEAAgAEAAkACwAKAAoADgATABQAEgARABEAEAARABMAFgAVABQAFwAaABsAGQAVABEADgAPABAADwALAAUAAAD+/wAABQAIAAQA+f/u/+n/6//w//P/8//x/+//7v/w//P/9//+/wcAEAAWABkAGwAYAA8ABAAAAA4AMgBkAI4AmAB0ADIA7v/M/9f/8v8KACwAcgDAANYAkAD9/07/0P7W/l3/DACGAJ8AcAAVAJ//Mv/2/vr+Jv9k/63/8P8SAAYA2f+l/3P/Qv8k/yf/Vv+h/+r/GgAnAA0A3/+v/43/iP+b/7//8f8zAHQAmACQAGgAOgAcABUAKQBYAJQAyADkAOIAzACzAKMAmgCYAJoAnwCnALEAtACqAI4AbABPAD8AOgBBAEkAQgAhAOz/uf+V/4b/kv+y/9T/6//0/+j/tP9X//b+zv76/nf/HACeAKsANwCX/zL/K/9b/57/5v8qAF4AeABtADkA6f+c/23/XP9i/3//tf8CAEkAWAATAJD/Ef/c/gn/c//Y/wsABgDc/6f/ff9s/3z/pv/e/wkAEwACAOn/2//f//X/GgBBAFAAOgAQAPj/CQBCAIwAyQDdALIAVADx/7//2v8zALAAJAFUARIBcQDQ/4b/o//1/1YAsADOAIEA+P+1//L/WQByACYAof8p/wf/a/8rALcAqgA2AMv/lf9//4D/i/+B/3L/nv8iALMA7gCsAA8AVv/M/rb+J//p/7gAQgE6AY8AlP/K/o7+7v6m/1kAyADeAKcANgCc/wH/qv7c/qP/lwAcAfIAUwCp/zj/G/9T/7r/HwByALAAuwB+ABgA2P/Y/+f/6f/1/zUAnAAGAT4BGgGXAAUAyf/6/2MAwADmANYAnQBfAFEAdQCkALEAhQA1APb/6f/+/xUANABiAH0AXAATAOP/1v/J/7L/sv/P/9v/z//j/yYAWAA9AOb/lf9t/2r/l//0/1IAbAApAM3/of+s/77/vv+8/7v/tv+p/67/xf/H/63/gv9i/0X/LP8r/1f/lP+5/7P/jf9b/y3/DP8D/x3/Uv97/3f/Tv8g//j+1v7S/vb+MP8//xP/3P66/sj+7v4i/0j/Vf9P/07/av+S/8T/6v8FACEARwCMANoAJAFkAZgBuAHKAd4BGAJwAsgC/AIAAwADEAM0A1wDfAOIA4QDYAMoA/QC4ALQArgCnAKIAnQCMALQAXgBMAHPAHIAQwBGAEMADACo/0b//P6q/nL+cP6K/m7+Fv7A/Yj9YP0w/Rj9HP0Q/ej8vPyo/ID8NPzo+9D70PvA+7j7uPuw+3D7OPsI+/D6APsg+0j7SPsY++j62PoQ+3j74PsU/CD8MPxY/JT8+PyY/Ub+3v5R/7P/JACfACIB3gHcAsADWATABEgFCAawBkgHAAgACcAJEApACoAKwAoAC0AL8AugDLAMMAywC4ALYAswC+AKoApACpAJsAjwB2gHyAbIBbAE0AMkA5wCMAJuAbX/aP3A+7D71PzM/Tj9sPow94D0EPSA9XD3YPhg95D0IPHg7uDugPCA8oDzAPMA8YDuIO3g7eDvoPFg8vDxUPEQ8bDxEPOA9JD1QPbQ9oD3sPho+gj88PxU/eT9C/+/APACKAWIBpgGGAZ4BhAIMApADNANYA7QDUANoA3QDgAQ4BCAEaARwBDgD8APIBBgEAAQcA+QDqANoAzwC1ALcAowCeAH0AboBTAFSAQQA5YBOgAw/3j+Bv6s/Tz9VPwo+1j6MPpA+hj66Pko+qD6gPoY+hD6ePrY+hj7yPuU/MD8bPyM/AD9KP3k/Nz8TP2I/VD9xPwM/Cj7gPpQ+gD6oPmY+bj5mPjA9RDzgPIQ9OD14PZQ9uDz4PDg7/Dx0PRg9kD2sPVQ9SD1wPWQ98D5cPuE/Ez9pP3c/eT++QDsAvwDoASoBdAGsAdwCEAJ8AlQCvAKwAtgDIAMgAzQDOAMkAwgDFAM8AxADeAM4AugCpAJQAmwCTAK0AnQCLAHoAZgBaAEuAQgBcgEpAOwAhACZAHFANQAIgHBAOL/Yv9x/0//8v7S/hD/Pf9C/2j/h/9l/1T/cf+g/+n/fgACAdkAPQAuAOAAMgG/AEYALgDQ/xv/1P4b/wT/4P2I/Nj7SPsw+iD5qPjw9zD2cPRQ9GD1YPUA86DvYO1g7eDvgPMA9ZDyQO7A60DtwPBA9GD24Paw9TD0YPTA9uj5gPw4/vr+/P4H/10A/AJYBTgGWAYgB9AIsArgCxAM0AvAC2AMgA0AD0AQwBDQDyAOIA2ADZAOYA/AD2APsA1AC/AJcAowC7AKYAmACJAH6AVgBMgDcANwAmgBCgHGAMf/jP7E/Qz9JPzA+0D8yPx8/ND7YPsI+6j6CPtg/Ej9FP2Q/PD8pP3g/TL+Iv/u/7j/ff9PAEwBIAFvAIoAQAFqAfkAtgChAAQAJv/Q/o7+mP1A/JD7YPvI+nD5GPhg9+D2wPXQ89DxUPHw8iD1sPWw86DwgO7A7lDxIPWQ9xD30PRw84D00PZo+Qj8MP58/iD91Pwr/0ACvANABEAFYAbgBtAH4AkwC2AKUAlwCtAMAA7wDcANkA2wDBAMcAxgDeAN0A1gDSAMgAqwCbAJ0AmgCYAJEAlwB5AFsARwBKgDzALUAiQDIAJMAEL/R//k/sj9fP0E/kr+oP0U/ST9+PxY/FD8jP2C/oL+Fv5Q/qD+fP6+/uX/KgFGAdQA3ABcAWoBWgHCAVQCLAKEAVABZgH+ABsAhP8u/5T+hP2Q/MD7uPqY+bD40PeQ9pD1wPRQ8zDx4O+A8BDy8PLQ8mDxoO5g7GDtAPKw9bD10PMQ87Dz8PQQ98D5qPvo+1T8xP0j/8X//QAEA4gEUAVYBvgHAAkwCYAJAApQCiALUA1AD7AOoAzQC+AM4A0gDmAOsA4ADrAMIAwgDEALIAowCiALsAqgCMAGGAbABQAFUAQYBIADSAJMAdAAEgDy/lz+lP62/ir+aP0g/QT9zPyg/KD84Pw0/bz99P3M/Zj9yP12/kH/7P9KAJgAeABWALYAbgG8AXQBdgHsAQQCQAF/AFIAFgA5/1b+BP54/Uj86PoA+vD4sPfw9qD2sPVw80Dx4O8A8GDxgPMw9EDxQO2A62Dt4PDg8+D1YPWA8iDw8PFw9rD5WPp4+mj7IPzM/Er+YgDEAYwC7AP4BYAHEAiACPAIEAlgCfAKMA3ADvAOIA7gDPALcAxgDiAQIBDQDsANEA0wDGALkAswDFAMgAtgCgAJUAfoBbAFQAZgBnAFOAQoA1ACGAFLADAARwAzABgAov+2/sT9ZP3U/UL+TP5s/tT+2v5i/hL+Sv7y/sj/qwAiAe0AaQB9AAQBTgFoAaIBzAGaAWgBWgH1AAoAS/8p/97+wP2E/OD7SPvg+UD4IPdg9oD1cPSA81DyIPDg7aDtoO/A8QDyMPDA7YDrAOug7YDy8PWA9cDyEPHA8RD0cPfA+sz87PyE/CT9tP4dALgBMAR4BnAHkAdACMAJAAsgCyALIAzgDaAPoBBgECAPwA2ADdAOwBDAESARwA9gDjANEAygC3AMgA1ADfAKUAjgBpAGYAbYBWgFyASAA9YBAgHFAPX/xv5i/rb+fv5s/bT84Pz8/ED8iPvY+7T8VP1g/ST94Py8/Dz9XP6A/wQA/f/K/6r/9P+wAKgB5AGIAUYBXAFCAb0AmgDTAFgA8v7Q/YT9MP0c/ND64Pmw+ND2gPVw9YD1QPSw8YDvYO6g7sDvAPFA8RDwQO5g7aDtAO8Q8eDyUPQw9TD1cPRg9DD2KPrc/SH/lP40/jf//QBIA5gFmAdgCEAIUAkgCzAMAAxwDAAOIA9QD4APoBDAEHAPQA6wDuAPgBCgEPAPgA5wDFALsAtgDDAMMAvQCTAICAeABvgFGAVQBOADJAPEAc4A0gDAAIH/Ev6g/eD9uP14/Yj9kP2w/Kj7APww/dT9ZP0o/YT91P3Y/Vj+if8EANH/lf9GAPsAMAFsAcwBzAEqAeoAQAGGATABoQARADz/Lv5o/Sj9cPwo+7j5gPhA9xD2IPVw9JDzUPLg8IDvIO6A7SDuoO+A8HDwgO/g7aDsAO3A74Dz4PUg9kD1cPTw85D16Pmi/nMAV/86/hL/WgHYA0AGAAhwCKAIAArAC2AMQAyQDMAN0A6gD6AQ4BBAEGAPQA9wD0APgA+AEMAQMA+wDHALgAuQCzALsArwCWAIuAbQBUAFQAQcA5ACTAKaAW0AaP/E/iD+jP08/QT9xPy4/KD8OPyY+1D7sPs8/JT85Pw4/Tj9LP2A/Tr+2v4//7T/XQD2ACABGgE+AbABFAJYAoQCnAJIAqYBMgECAZMAvf8O/3j+fP0g/Oj6CPrQ+GD3EPYw9VD0oPOQ8sDwgO5A7SDuAPAg8RDxwO9A7QDrIOwA8KDzoPRA9PDzgPMg84D0aPgk/Oz9Hv4w/mz+C/8IATAEEAcgCGAI4AgQCjAL0AtADAANgA4gEOAQoBDwD5APkA/gD4AQABHAEAAQMA9wDoANgAzgC9ALoAugCgAJsAfwBjgGKAUIBGgD8AI4AloBrQDe/+T+/P3Y/eT9dP3w/PT8DP2c/Az86Pto/Mj8DP2M/QT++P3s/Ub+6P5+//3/xwB6Ad4B1AHEAbwB/gGQAhADOAMAA5QCCAJ6AfcAmwAVACr/Jv5M/UT8+PqY+Vj4QPcg9tD0kPOg8qDxAPAg7oDtQO6g7yDwAPAA7+DswOqg64DvoPMQ9fDz0PKg8iDz8PRQ+Nj77P1w/nL+uP5p/+AAiAPYBkAJ8AmQCYAJcArACxANQA6QD6AQABGgECAQABAgEKAQIBFgEQARQBBgD7AOAA4QDSAMoAtgC7AKkAkgCMgGqAWgBNADHAN0ApoB2wD4/9z++P1Q/eD8iPxk/Gz8YPwI/ID7MPsA+/j6iPts/Aj9LP0Q/ST9gP0C/rb+rv+JAAYBRgGCAcABwgHWAWgCSAO4A1QDyAJoAhQCjgEgAesAXQBA/xT+VP1o/Aj7gPlY+HD3cPYw9UD0EPNw8eDv4O5g7sDu4O/g8KDwwO6A7KDrIO1Q8MDzkPXA9PDysPIw9KD2QPn4+1j+Uv8e/x7/UQAsAogEYAewCbAKgApwCiALYAywDfAOQBAAEUARABFgEOAPABCgECARABGAEAAQAA+wDaAMMAywCwALUAqwCaAIEAeIBaAEEAQgAzwCngEuAVUAO/9Q/tz9XP2k/CD8OPxw/GD8DPyw+3D7OPto+xj85Pw0/TT9ZP2Y/QT+ev5T/ygAtQD9AEgBigG0AfIBPALAAgwD/AKgAlQCJAL0AZ4BFAFUAE3/Ov5k/dT8APzA+iD5cPcw9mD1kPSA80Dy8PCA7wDugO1g7sDvMPCg7yDuYOxg66DsIPBQ86D0MPSA8wDzoPOg9cD4wPvw/U//1f/J//v/tgGIBCAHIAmwCpALUAsQC8ALUA3QDgAQYBFAEsARgBDAD/APoBBAEYARgBHAEHAPAA7gDDAM8AvACzALIArACDgHwAV4BMADZAPUAsYBlwCS/7L+/P1w/Rj9pPz4+4j7kPuw+3D7EPvw+gD7OPto+8D7HPxw/Mz8TP3I/S7+nP48/wAAmQDZAAYBjgEsApACvALcAgQD2AKwArgC7AKkAq4BuAD2/2H/eP6o/dj88PuA+uD4cPcw9mD1kPRw8wDyoPCA72DuIO7g7oDw8PCA76DtIO1A7SDuQPAw85D1kPUw9KDzkPRw9lj56PyS/7QAaQAvAOkAzAIQBWAHsAmgC9AMkAyQC0AL4AxADwARIBKAEgASwBCwD7APYBDAECARQBEAEXAPMA2wCzALEAvgCoAKsAkwCIAG8AS0A9gCTAIgAp4BrQB9/6L+zP0I/Zj8gPx0/Dz8+Pu4+5j7ePuQ+7j76Psk/JD8+Pw8/bT9Sv7w/ij/m/9MAA4BXgGKATgCBANoA0QDOANwA5wDgAOAA4QDWAPAArYBrAAEAIT/0P6o/XT8gPtY+nj44PYg9pD1IPRA8iDxQPAA7+DtIO6A7+DvIO9A7gDuQO2g7GDtAPBA82D1sPXA9JDzkPOg9Sj5zPyL/9QAwwCIACoBhAJwBNgG8AmgDIANoAzACwAMEA3ADsAQoBJAE4ASQBFAEMAP0A+gEKARABJAEaAPsA0ADBAL0ArQClAKgAmACNgGwAQUAzwC9gGqASABeQBk/+D9tPxM/CT8wPt4+4D7kPso+5j6YPqg+sj6CPuI+wD8IPwc/JD8hP1S/pj+4v51/zEAzgBMAcoBEAI4ArACaAO8A3wDOANUA3ADIAOMAvwBeAHeAFsAqP9i/tT8sPvY+uD5cPgA97D1YPQg8/Dx4PBg74DuYO7g7gDv4O7g7oDugO3A7EDt4O7w8PDyAPXA9RD1kPRg9bD3mPqo/UAAqgHSAQQCGAOIBCAGgAhQCzANsA1wDVANYA3ADTAPgBEAE+ASABIAEQAQUA9gD0AQABHAEMAPQA5QDIAKkAmQCcAJcAlwCNAG2AQgA+YBQgH1AMwAbACc/2D+DP0Q/KD7iPug+8j7+PvI+0D7oPp4+tj6aPsA/Jz8GP0U/fj8IP3Y/cz+vf+sAIAB2AHGAbwBIALQAqADkARIBZAFGAVgBKgDOAMoA4wD8AO0A5AC4AAG/zT9EPyw+6D72PqI+dD3oPUw8yDx0PDw8HDwgO8g7+DuYO4A7sDtgO3g7MDsAO7g7zDxYPKQ80D0cPTQ9AD2wPfo+aT8jv9qAfABKALsAkgEAAZQCNAKwAzgDTAOQA4QDlAOcA8gEcASoBOgE6ASIBHQD7APYBAgEWARwBCAD5ANYAvACSAJQAlgCQAJ4Af4BbAD3AHfAI8AegBPAKH/nv5w/Tj8SPu4+sj6QPuI+1j7sPoQ+sj5CPqQ+kD7+Pto/Jj8nPzQ/Gz9Jv4//4UAoAH0AaQBgAHwAcACjAN4BFAFsAVYBbAEEAR4AzgDbAPMA8wDEAPGAeb/3P1Y/PD78Ptg+1D6APnw9kD0APLw8ODwkPDg72DvQO/A7kDuQO4A7oDt4OwA7UDuIPDA8RDz8PNA9LD0oPXQ9kj4ePpE/c7/cgFIAtQCmAPQBMAGUAmACxAN8A1QDlAOcA4gD0AQoBHAEmATIBMgEsAQABAAEGAQgBCAEMAPEA7QCxAKIAmgCFAI2AcYB8gF9APqAUUATf8a/y//BP9g/kj92PuA+vD5GPqQ+pj6iPpg+lD6APq4+Qj6wPqY+1D82PwQ/RT9SP0I/kX/tQDsAYQCcAIsAjQCyAK4A9gEEAbgBrgG+AUoBaAEIAQABHAE8ASoBGQDtAH3//T9IPxQ+2j7OPtQ+pD4UPbg87DxYPDg72DvwO6g7sDuoO5g7uDtIO0g7IDr4OuA7aDvgPEQ8/DzEPQw9MD0wPWQ9wD6BP2y/5IBtAJsA/gD0ASwBjAJcAsADWAOgA/wDwAQQBAgEUASABPAEwAUYBNAEmARQBGAEYARIBFAELAO4AxACwAKEAlwCBAIkAdQBlAEQAKRADL/gv6g/tD+Vv4A/ZD7iPrg+Wj5SPmI+dD56Pno+cj5cPkY+WD5WPp4+zT8lPzU/AT9ZP1G/pD/vwCYAUgC1ALsAsgCHAMgBGgFaAYIByAHgAZoBWgEAATwA1AEuASwBIgDiAEd//D8WPuY+sj6wPqg+WD3MPUA8+DwQO+A7kDuIO4g7mDuoO4A7gDtYOwA7MDrQOzA7cDvoPEg86D0sPXw9SD2MPf4+AD7mP2TACAD0ATYBagGgAdgCLAJwAvwDaAP4BCAEaARgBHAEYASQBPAE6ATQBNgEqARIBHgEMAQIBAwD+ANMAxQCsAIyAdYB/gGYAZYBbQDnAGU/xz+XP0I/fD8zPxU/GD7OPow+YD4MPhA+Nj4iPnQ+bD5ePlY+Zj5OPo4+zT86PxU/bz9NP7Y/sj/BgFcAmAD8AMQBCAEOATIBPAFQAcQCBAIwAcAB/AFCAXQBAgFSAUoBYgEEAOuACT+WPyA+/j6ePqw+Xj4oPaQ9IDykPDg7qDtgO3A7SDugO6A7uDt4Owg7ADsYOwg7UDuwO9w8TDz4PQw9hD3wPeQ+MD5cPvQ/aEASANoBegGAAjgCLAJoAogDOANoA8AEeARgBIgE4ATwBPgE8ATYBPgEkAS4BHAEaARQBFgEBAPUA1wC5AJMAhgB/gGqAYIBuAEHAMIAfr+eP20/Hz8TPzw+3D7sPrA+dj4OPjw9wD4KPh4+Mj44Pjg+CD5qPlI+uD6kPsw/Jz8DP3U/fb+DwAsATQCGAN0A5QD5ANwBDgFIAb4BpgHsAcoB2gGyAU4BdAE+AQoBdgErAPgAfz/Sv68/LD7EPtw+kD5wPcw9nD0YPJA8ODuAO7g7SDuoO4A76DuwO0g7YDsYOyA7GDtwO4g8NDxwPNw9YD2IPfQ96D40PmA+9j9mAAIAyAF6AZACDAJ4AnACgAMMA1wDvAPQBEgEqASIBOAE2ATwBIgEqAR4BCAEIAQoBBAEHAPMA6QDHAKcAjoBhgGmAUYBaAE1AOAAsMACv+k/Zj84PuQ+3D7EPuI+ij60Pl4+Sj5CPkA+Qj5CPko+Zj5GPrY+rj7kPwQ/VD9lP3o/Xj+Wf+KAM4B8ALUA2gEoATABPgEiAUYBrAGKAdwB0gH6AaIBigGoAUYBZAExAOMAgwBqf9e/vj8kPtw+qD5uPiQ9xD2EPSg8WDvAO6g7eDtQO6A7oDuIO7A7WDt4OyA7GDsIO1g7jDwAPLA8wD18PXQ9gD4UPmo+jj8BP74/xQCUARoBjAIkAmwCtAL0AygDWAOIA8gEEARoBLAE0AUQBSAE6ASoBEAEcAQgBBgECAQwA/QDkANYAuACfAH2AYYBnAFoASEAzwCAAHp//7+FP40/WD8iPvo+nj6MPoY+gj6+Png+cj5kPlo+Tj5OPmw+YD6iPs4/Lj8EP1k/az9EP7E/qD/iwB4AXgCXAPsA0AEoAQQBWAFmAXYBfAF+AUYBkAGSAbwBVgFgARgAyACFgE9AEP/Iv7w/Oj7yPqo+aD4cPfQ9bDzoPEQ8ADvgO6g7iDvoO+g74DvIO9A7mDt4Ozg7MDtYO9Q8SDzsPTQ9aD2kPeg+Pj5ePsI/Z7+XwBYAlgEYAZgCDAKoAuwDIAN8A1QDrAOYA+AEOARYBNAFIAU4BMAE8ARABFgECAQsA8wD3AOkA2QDHALYAoQCbgHcAYIBZwDXAJeAYYA4P91/x7/ev5M/eD7ePpw+eD4EPmY+Qj6OPoo+uD5mPk4+TD5gPn4+aD6SPsk/Kj8QP3w/aD+RP/u/6AASAHiAYQCYANIBBAFoAUABjgGUAZwBogGiAZgBhgGuAVABaAE6AMAA7wBXgAV/+D92Pyo+3j6MPnQ95D2MPWw8wDyYPAA7yDu4O0g7sDuQO8g76Du4O1A7eDsQO1A7qDvIPGA8tDzEPVQ9pD3EPmA+gj8pP0z/6oACAKQA2AFkAfQCeALgA1wDsAO8A4wD8APwBDAEeASwBMgFAAUwBMAEwASQBGgEAAQUA+ADoANcAxAC0AKcAmACDAHmAX0A2ACBAESAIn/F/+I/qj9qPxY+yj6SPng+Jj4gPiA+Gj4OPgA+ND30Pfg9xj4kPhA+ej5WPrg+mj7+Puc/Gj9Yv5p/1EAGgHwAbwCkAM4BLAECAVQBZgF6AVIBqAGsAaABiAGmAUIBWAEVAMMAsAAjv+c/sj9AP0M/ND6KPlw9+D1UPTA8kDxIPCA70DvYO/g7yDw4O9A78DuQO4A7iDuwO7A78DwAPKA8zD1sPbw91D50PpE/Nj9VP+wAOYBQAMgBYAHAApADAAOAA9wD7APIBDAEIARQBIAE8ATQBRgFEAUABRgE4ASoBHAENAPwA6ADUAMIAtACnAJkAhoBwAGUASEAgYB9P8a/17+qP3g/PD7yPq4+fD4ePgI+ND3sPeg94D3YPdQ9zD3QPeA9wj4mPgg+bD5SPrY+oj7bPx8/Xr+af9bAD4BBALAAqADgAQQBXAF8AVYBsgGGAd4B7AHcAfwBmgGyAXABLADtAK6AYcAZP94/pD9dPwg+8D5GPgg9iD0kPJw8ZDwEPAA8ADw4O+g72DvAO9g7uDt4O0g7qDugO+g8PDxQPNw9ND1UPfg+Hj6MPzE/Rz/TACgATADCAUwB3AJkAtADYAOYA/wD0AQoBAgEeARwBKAEwAUQBQAFGAT4BJAEoARwBDAD5AOUA3wC7AKoAmgCMAHyAawBWAE5AJyAQwAzP64/dj8KPyI+9D6EPpo+ej4ePgw+Aj44Pew93D3YPeQ98D3IPio+ED52Pl4+ij70Ptg/Nz8gP1I/i3/PgB2AZwCfAMoBMAEMAV4BcgFGAaABtgGQAeAB5AHIAdYBmAFOAREA2QClAGVAJX/jP6I/Yz8ePsw+oj4kPaQ9ODykPGg8EDwIPAg8CDwIPAQ8KDvAO9A7uDtwO0g7kDvoPDw8SDzQPSA9eD2kPhg+kz85P05/3wAxAEwA8gEsAbgCBALEA2wDuAPgBDgECARgBEgEsASYBPAE+ATwBOAE0AT4BJgEsARABHgD4AOAA2ACwAKwAjQBxgHWAaABXgELAOcAQ4AqP50/XD8iPuw+uD5OPmg+FD4MPgg+AD4wPdg9/D2gPZg9nD2wPZA9+D3uPig+Xj6OPvo+2j81Pxc/Sz+Nf9jAJABmAJgA9QDOASgBCAFmAUIBngGmAaABjgG0AU4BXAElAPMAvoBEAEdACz/Dv7M/JD7aPpA+fD3YPaw9ADzoPHA8IDwkPCg8KDwYPAQ8KDvYO8g7yDvQO+g74DwkPGg8uDzMPWA9uD3iPlg+yj9tP4MAC4BQAKcA1AFOAcwCQALgAzQDfAO4A/gEKARIBKAEsAS4BLAEoASYBIgEuARwBGgEUARoBCQD0AOoAzwClAJAAggB1gGoAXoBCAEGAP6AdoAq/9o/hz9+PsA+xD6YPno+KD4iPiI+KD4uPio+GD4EPiw90D38PYQ95D3iPiQ+bD6sPtw/Oz8bP0C/pL+K//k/7sAggE8AgwD4AOABPAEYAXABegFuAVgBfAESASgA0QDEAPIAjQCYAFrACf/2P2s/Kj7oPpo+Sj48Pag9WD0YPPQ8oDyQPIw8jDyAPKA8QDxoPBw8HDwsPAQ8YDxEPIA8zD0gPXg9mj4APp4+8z8KP6I/7cAugH8AoAEKAbwB+AJkAvQDLANgA5QDyAQoBAgEYARgBFAESARABEAESARIBEAEaAQ8A8QD/ANkAwQC8AJkAigB+gGUAa4BfAECAQMAxACDgEUACf/Iv4I/QD8OPug+jj6CPoA+vD56PnY+bD5SPmw+DD48PcA+FD4+PjQ+aj6WPsI/KT8JP2g/Sz+zv5h//D/igA+AfYBtAJsA/QDQARYBFgEQAQYBOADrANcA+gCaALeATwBTgAw/wj+/PwE/DD7ePrA+dj4sPdw9kD1MPRQ87DyUPIg8hDyEPIg8hDy4PGw8ZDxgPGw8RDyoPJQ8xD0EPVQ9qD3MPkI+9z8ov4mAG4BfAJsA3AEqAUoB7AIUArQCyANQA5AD0AQIBHAEQASABKgEUAR4BCgEIAQYBBAEAAQsA8gD1AOUA0gDMAKQAnoB7AGsAXIBAgEOANwAsIBGgFWAHn/iP6A/Xj8gPu4+jD6wPlw+TD5EPkI+fD44PjQ+Lj4oPig+ND4OPmw+Tj6wPpQ++j7jPw4/fz9tv5t/zIAEAHkAZwCNAO0A/ADCAQABBAEGAQYBBgECATcA3wDAANoAroBzQDA/7D+qP2g/Kj72Poo+kj5WPhQ9yD20PSA86DyIPLg8fDxEPIg8vDxwPGA8UDxAPEQ8WDx8PGQ8nDzcPSA9aD28PeY+WD7KP3i/m0ApgGUAngDmATgBXAHEAmQCuAL8AzgDcAOkA9AEAARYBGAEWARIBHAEGAQABCQD0AP8A6gDlAO8A0wDSAMwApQCfgH0AbgBRgFUARwA4gCrgHOAPn/N/9s/pD9qPzQ+wD7WPrI+VD5+Pi4+Ij4UPgw+Bj4EPgY+Ej4oPgY+bD5QPrA+jj7kPsI/KD8aP1O/lT/TAA6AQwCsAIkA3ADqAPYAwAEEAQwBDgEKATsA5gDPAPAAiwCigHKAOH/2v7Q/bz8wPvA+uD5CPkg+DD3MPZQ9YD04POA81DzMPPw8rDyYPIA8rDxcPGQ8eDxUPLw8rDzoPRw9YD2oPcI+ZD6NPzs/Xn/rwCoAawCxAMABXgGMAjQCTALYAxwDWAOMA/AD2AQ4BBAEWARYBEAEaAQIBDQD6APcA8wDwAPkA7QDcAMgAswCvAIuAewBsgF6AQQBEQDiAK6AegALABs/5D+mP2s/ND7APtI+tD5iPlA+fj4sPiA+FD4IPgg+Dj4ePi4+Cj5uPlI+sj6SPvI+0D80PyM/XL+Z/9KABoBzgFQAqwC+AJMA4gDtAPUA+gD6APIA5ADSAPwAowCFAKOAfEAKgBF/17+XP1g/GD7aPp4+Yj4oPfA9hD2gPUQ9aD0QPTg84DzMPPg8qDyYPJA8jDyQPJw8sDyUPMQ9AD1IPZQ97j4SPro+3z94v7t/9wAxgHgAiAEgAUQB4AI0AkACxAMAA3QDXAOAA+QD/APABAgECAQ4A+QD0APAA+wDkAO4A1QDaAM0AvQCuAJ0AjIB9AG6AUIBTgEaAOYAtABDgFOAJX/yv74/ST9XPyY+wj7gPoQ+rD5WPko+Qj56Pjw+Aj5KPlQ+aD5APpg+tj6WPvY+2j8AP20/YL+R/8KAMMAdgEQApwCHAOMA9gDGAQwBFgEYARQBEAEKATsA5wDOAO0AgwCTgFpAGr/av5w/XT8iPug+rD54PgQ+ED3gPbA9fD0QPSg8wDzoPJg8jDyEPIA8uDx0PHQ8fDxQPKg8iDz0PPg9DD2wPeQ+Wj7HP2O/r7/ygDQAeQCEAR4BfAGcAjQCSALQAwwDRAO0A6QD0AQwBAgEWARYBEgEcAQYBDQD0APwA4wDpAN4AwQDDALQApACUAISAdABigFCATsAtYBzQDt/x//WP6U/dj8HPxw++D6YPrg+YD5IPnQ+ID4OPgY+PD34PcA+DD4gPjw+Hj5APqg+lD7GPzs/MD9nP5j/xEApAAoAbIBRALQAlwD2AM4BHAEmAS4BMAEsASABDgE3ANYA8ACAAImAS0AIP8e/iT9NPxQ+3j6kPmY+KD3sPbQ9QD1MPRw89DyQPLQ8XDxMPEQ8QDxEPEg8VDxkPHw8XDyEPPQ89D0IPbA94j5aPs8/dD+IABMAWgCnAMIBZAGAAhwCbAKwAugDIANcA5gDyAQABGAEQASQBJAEgASoBFAEeAQQBCwDxAPQA5wDXAMcAuACqAJsAjAB8AGqAV4BEQDHAL8APb/Av8e/jD9UPx4+7D6+Plg+ej4ePgw+OD3sPeQ94D3cPdw93D3oPfg9zD4uPhY+SD6+PrY+7j8pP2W/ov/cQBKARQCzAJoA/QDeAToBDgFcAWgBcAFyAXIBaAFUAXgBEAEjAO8AtoB7QDq/9j+xP20/KD7kPqI+Yj4gPeQ9qD1wPTg8xDzYPLA8WDxAPHQ8KDwkPCA8IDwsPDw8FDx4PGA8nDzgPTg9XD3MPkQ++T8lP4AAFoBnAL0A2AF4AZwCOAJIAswDDANEA4QDwAQ4BDAEUAS4BIgE2ATQBMAE4ASwBEAESAQUA9wDoANgAygC6AKsAnACNAH2AbQBbAEkANYAiYB/P/u/vT9/PwY/DD7aPqo+QD5gPgg+OD3oPdw91D3MPcQ9wD38PYA9yD3gPcY+Oj4wPmg+nj7XPw0/Qr+9P7r/9sApgFkAgwDkAP8A2AEsATwBBgFMAVABTgFCAXIBGAE0AMgA2ACjgGfAJr/jv5o/UD8GPsA+gD5EPgg90D2YPWQ9ODzQPOg8iDysPFA8fDwsPCQ8HDwgPCw8ADxcPEQ8sDyoPPQ9DD2wPd4+Vj7PP0B/5gACAJQA4gEyAUoB6AIAApAC2AMcA1gDlAPYBBgEWASIBPAEyAUQBTgE4AT4BJAEmARoBDQD/AO8A3wDOALwAqwCaAIuAfIBtgF0AS8A4wCYAExAA3//P3g/Nj74Prg+fj4OPig91D3APfw9uD20PbQ9uD24Pbw9hD3UPew9yD4sPhY+Sj6CPvg+8z8xP3S/uD//AAMAvACpAM4BMAEKAVwBbgF6AX4BegFyAWQBTgFyARIBLgDFANUAoABoACh/3r+WP0g/Pj60Pm4+KD3kPaQ9YD0kPOw8uDxQPGg8CDwwO+g74DvYO+A76Dv4O8Q8JDwMPEQ8hDzcPQQ9uD30Png++D9mP8mAZgC7ANABcAGUAjQCSALQAwwDRAO8A7wDwARIBIgE8ATQBSAFIAUIBTAE0AToBIAEgAR8A/QDoANUAwAC+AJwAjIB8AGuAWgBHwDTAImARMA/P70/dj8uPuQ+mj5SPhg97D2QPbg9aD1gPVQ9UD1UPVw9aD1APZg9tD2YPcA+Lj4gPlY+kD7NPw0/VL+ev+pAMoB2AKwA2AEEAWwBTgGmAbgBgAH8Aa4BnAGEAa4BTgFoATwAyQDLAIqASwAA//k/cD8oPuI+mD5SPgg9xD28PTw8xDzQPKA8fDwcPAA8KDvYO9g74DvoO/g7zDwsPBQ8VDygPPQ9HD2IPj4+dD7oP1Y/+0AWALIAzAFwAYwCJAJ8AoQDBANEA4wD2AQYBFgEiATwBMgFGAUYBRAFAAUgBMAE0ASYBFgEGAPQA4gDQAM4AqwCYAIYAdIBigF/APgAsoBqwCV/2r+KP3g+6D6aPlg+HD3oPYA9oD1IPXg9LD0kPSg9LD0APVg9dD1cPYA98D3kPhg+Tj6OPtI/HD9ov7Z/wABHAIQAxAE+ATYBZAGKAegB+gH8AfgB7gHYAf4BpgGIAZwBbAEzAPYAswBqQCT/37+VP0Y/ND6iPkw+OD2sPWQ9IDzcPJg8YDwwO8A74DuYO4g7iDuIO5A7mDuwO5A7zDwQPGQ8hD0sPVw90D5IPsM/eL+qgBkAhAEmAUwB9AIUAqwC/AMQA6AD8AQwBHAEqATYBTgFGAVwBUAFuAVoBUgFWAUYBNgEmARQBAAD7ANUAzgCoAJQAjwBsgFmARwA0wCKAHw/77+fP0s/OD6mPlo+FD3UPZg9aD08PNw8yDz8PLw8hDzUPOw8zD08PTQ9aD2kPeQ+Ij5oPq4+9j8Av4m/zwAWgFkAnADaARgBVAGGAfIB0AIkAiwCLAIkAhQCNgHQAeYBsAF2ATEA6wCdgFAAAv/0P2c/FD7EPrI+JD3UPYQ9eDzwPKQ8YDwoO/A7kDu4O2g7YDtgO2A7cDtIO6g7oDvgPDg8VDz4PSQ9lj4GPr4+8j9vP+IAUwDAAWYBiAIgAnwClAMsA0QD2AQoBGgEoATQBTgFGAVwBUAFiAWwBVAFYAUoBPAEqARoBBwDyAOsAxAC9AJUAgIB9AFqASEA1wCRgEjAPr+xP2M/Fj7IPro+MD3sPag9dD0EPSA8yDzAPPw8vDyMPOQ8yD00PSw9aD2kPeQ+ID5iPqY+7j83P30/g8AGgEcAhADCATwBNgFmAZAB8gHMAhwCJAIcAhACPAHiAcAB0gGcAVwBGQDOAIEAdL/lv5Y/Qj8uPpg+Rj40PaQ9WD0IPPw8dDwwO/g7iDuoO1g7UDtIO0g7UDtgO3g7aDuwO8A8XDyAPSQ9TD32PiQ+nD8TP4OANQBgAMgBYgGAAiACQALgAzwDWAPoBDAEcASwBOAFCAVoBUAFiAWABbAFSAVQBRgE4ASgBGAEEAP8A2gDEAL4AmgCIgHYAY4BRAE3AK0AXsAS/8S/sj8cPsg+tj4oPeQ9pD1wPQQ9IDzIPMA8/DyAPNg88DzUPQQ9dD1sPag95D4mPm4+tj7AP0g/jj/VwBgAXACfAOABHgFUAYIB5AH+AdQCJAIoAigCGAIAAh4B7gG6AX4BPQD1ALIAZgAc/82/vT8yPuI+lj5OPgg9/D10PTA86DyoPHQ8CDwoO8g78DuYO5A7iDuQO7g7oDvgPCg8fDyYPTg9WD3CPmw+lj8/P2V/x4BjALgA0gFqAYQCGAJwAogDHANwA7wDwARABLgEqATQBSgFMAUwBSAFCAUoBPAEuAR4BDQD8AOoA1wDFALQApACTAIMAcoBjgFOAQwAygCDgHW/3j+IP3A+2D6+PjA94D2cPVw9LDzMPPA8qDyoPLw8lDzwPNA9PD0oPVw9lD3SPhQ+Uj6QPs8/Dj9Nv49/0wAUgFQAkQDIAQABbgFYAYAB2gHwAfgB/AH0AdwB/gGYAbABfgEEAQcAxQC+gDW/8L+rP2M/Hj7UPoY+eD3sPag9ZD0kPOw8uDxMPGA8ADwgO8g7+Du4O5A76DvQPBA8VDygPPA9BD2gPcA+Yj6EPyI/dz+MwCOAeQCOASYBRgHgAjwCTALkAzQDRAPQBBAESASwBJgE8ATIBQgFOATgBMAE2ASoBHAEMAPwA7ADeAM4AvwCvAJAAkQCAgHEAYIBewDuAJ8ASkAvv5I/cj7QPrA+FD3APbQ9PDzMPOg8kDyIPIw8lDysPIw8+DzsPSQ9YD2gPeI+Jj5qPrI++D8AP4b/zYASAFUAlQDWAQ4BRAG0AaABxAIcAiwCNAI0AigCGAI2AdIB4gGuAXIBMwDsAJ2AT8A+v6Y/TT8yPpg+QD4oPZg9SD0APPw8QDxMPCA78DuYO7g7cDtoO3A7SDu4O7A77DwwPHg8jD0kPUQ95j4IPqw+zj9wP5QAOoBqANgBQgHsAhACsALQA2QDuAPIBFAEkATABTAFEAVYBWAFWAVABWgFAAUQBNgEmARQBAwD0AOMA0wDCALEArwCKgHcAYwBdQDaALoAHH/zP0g/Gj6uPgQ96D1QPQg8yDyUPGw8FDwMPAw8HDw4PBw8UDyEPPw8yD1UPaA98D4APo4+2T8mP3G/uv/CgE0AlADWARQBTgGAAegBzAIsAggCWAJcAlQCRAJoAgACFgHiAaIBXAESAMIAqIAOf/U/WT8+PqI+TD40PaA9UD0MPMg8jDxUPCg7wDvgO5A7iDuIO5g7uDugO9g8GDxgPLA8yD1kPYA+Ij5CPuU/Bj+mv8oAcQCaAQABpgHQAnACiAMkA0QD4AQ4BEAEwAUwBRgFeAVIBZAFiAW4BVgFcAUABQAEwASABHwD+AO4A3ADKALcApACQAImAY4BcwDUAKzAPT+HP1A+3j5wPcg9pD0QPMA8hDxYPDA72DvQO9g78DvQPAA8eDx4PIA9ED1kPbw90D5mPrw+zD9YP6T/8IA5AH4AvgD6ASoBXAGIAfAB0AIwAggCUAJQAkACbAIMAiAB7gGwAWgBGwDHALWAFb/4P1g/PD6kPk4+OD2kPVg9FDzUPJg8aDwAPCA7wDv4O7A7qDu4O4g78DvcPBA8VDyYPOg9PD1UPfA+DD60Ptg/QH/jQAwAtADiAUoB+AIcArwC2ANwA4AECARIBLgEqATQBSgFOAU4BTgFKAUYBTgE0ATgBKgEeAQ4A/wDhAOMA1ADEALIArQCHgHGAaoBBwDeAG3//T9JPxQ+qD4APeQ9TD0APMQ8lDxwPBQ8FDwYPDA8EDx4PGw8pDzkPSg9bD20PcI+Tj6SPtQ/Gz9av5p/24AbgF0AlADOAT4BMgFaAbwBoAH8AcQCAAI0AdwBwAHWAaYBbgEsAOcAnYBLgDS/nT9KPzw+rD5ePhA9yD2APUA9CDzUPKQ8RDxoPBA8ADwoO/A7+DvQPDQ8HDxUPIw80D0cPWg9uD3SPnQ+kz80P1e//UAlAIwBOAFkAcgCaAKMAyQDdAO8A8AEQASwBKAEwAUYBSgFMAUoBSAFCAUoBMAE2ASoBHgECAQYA+QDsAN0AywC2AKAAl4B/AFOAR4AqcAtv7Q/Oj6CPlQ97D1MPQA8+DxAPFQ8ODvoO+A7+DvYPAQ8eDxwPKg87D0wPXg9vD3CPko+kj7VPxk/WD+h/+VALYB0ALIA7AEmAVwBjAHyAdQCLAI4AjACJAIMAigB+AGEAYgBfgDvAJqASAAyP5k/Qj8uPpo+Rj44Paw9ZD0gPOg8uDxIPGA8ODvoO9A7+DuAO8g74DvEPDA8IDxcPKA87D0APZw9+j4iPoo/Nj9nP90AVADMAUQB+AIkAowDMANIA+AEKARoBKgE0AU4BRgFaAVwBXAFaAVYBUAFWAU4BNAE4AS4BEgEUAQQA8wDuAMYAuwCdgHCAYYBCACAADk/eD7wPnQ9wD2YPQA8+DxAPFQ8KDvYO9A72DvoO9A8PDwwPGg8qDz0PTQ9QD3MPh4+aD60Pvs/Bb+M/9QAI4BqAK4A7gEwAWwBoAHMAjQCFAJkAmgCbAJgAkACVAImAeoBpgFYAQMA54BIwCk/hz9kPsY+qD4QPfw9aD0cPOA8qDx4PAg8KDvQO/g7sDuwO4A70DvoO8w8NDwoPGQ8pDzwPQA9mD32Phg+gj8xP2J/2YBXANYBVAHMAkAC8AMUA7wDyARQBJgE0AUABWAFeAVABYgFuAVwBVgFcAUIBSgEwATgBLAEQARIBAgD/ANoAwQC1AJcAeQBWQDMAHy/rj8mPqA+ID2sPQg88DxoPDg7yDvwO6g7uDuQO/g76DwgPGA8qDzwPQA9iD3WPh4+aD6yPvY/OD9/P4UADgBSAJkA2AEaAVoBkgHIAiwCDAJkAmwCdAJkAkQCXAImAegBngFOATMAlIB3f9i/sj8QPug+Tj40PaQ9VD0MPMg8iDxUPDA7yDvgO5g7iDuIO4g7mDuwO5A7+DvoPCg8aDy0PMQ9YD2APiI+VD7RP0r/yYBMAMwBTAHIAkAC8AMUA7QD0ARgBKgE2AUQBUAFmAWoBbAFqAWgBYgFqAVQBXAFGAUwBMgE0ASIBEgENAOYA3AC/AJ6AeoBUQD4ACQ/hD8yPmg97D14PNA8vDwwO8A72DuIO5A7oDu4O6A72DwYPFg8pDzwPTw9TD3YPiA+ZD6uPvU/AD+EP8jAEYBYAKIA5gEsAWwBogHUAgACXAJsAngCeAJwAkwCZAIsAeoBngFQATsAloB0/9E/sj8OPug+UD4APfg9cD0wPPQ8uDxEPGQ8BDwoO9A7wDvIO8g70DvgO/g72DwMPEQ8hDzIPRQ9bD2QPjo+aD7fP14/4oBhAN4BWgHUAkQC8AMYA7ADwARABIgEwAUwBRAFcAVABYgFgAW4BWgFUAVIBXAFGAUwBMgEyASIBHwD6AOEA1AC0AJKAf4BJgCMgDI/Yj7SPlA91D1gPPw8aDwoO/g7kDuAO4g7oDuAO+g74DwkPHA8vDzEPVQ9oD3qPjg+RD7OPxQ/Xb+qP/LAOwBBAMoBDAFQAZIByAI0AhgCfAJQApACiAKsAlACZAIiAdoBiAFqAMkAoYA4v4s/YD76Plo+PD2kPVQ9EDzQPJg8aDwAPCA7wDvwO6g7oDuoO7A7iDvgO8A8MDwcPFQ8lDzgPSw9TD3wPhw+lT8UP5UAGwCgASIBpAIYAowDNANcA/gEAASIBMgFOAUYBXgFSAWIBYgFiAWABbgFYAVQBWgFCAUoBPgEuAR4BCgDyAOYAxgCkAIAAaoAzoB0v5o/Pj5sPew9dDzMPLA8KDvoO4A7sDtwO3g7UDuAO/g7+Dw4PEg83D0sPXw9jD4ePm4+uj7FP1M/nb/mgDCAegCAAQIBRgGCAfoB6AIUAnACRAKEAoQCtAJUAmwCOgH4AawBWAE/AKAAeH/SP6s/Bj7kPkQ+KD2UPUA9ODy8PEA8UDwoO8g76DugO5A7kDuYO6g7iDvoO8w8PDwwPHQ8gD0UPWw9lj4KPoE/AL+BgAkAjAEQAZACBAK4AuQDRAPgBDAEQATABTgFIAVABZgFsAWwBbAFuAW4BbAFmAWABZgFcAUABQAE8ARIBBgDmAMUAoACJAF/AKPABz+sPtY+SD3IPVg8/DxsPDA7+DuYO4g7kDugO7g7oDvcPBw8XDygPOg9ND1EPdg+Kj54Pok/HT9vv4EAEoBgAK4A+AE+AXwBuAHoAhQCeAJMApQClAKAAqgCRAJQAhYB1AGKAXIA2ACzgA8/6j9FPyA+tj4UPfQ9XD0IPPw8eDwAPAg76DuAO6A7WDtQO1A7YDtAO6A7gDvwO+w8LDx8PIw9MD1YPc4+SD7MP1A/2wBnAPQBcgHsAmACzAN0A5gEOARIBMgFAAV4BVgFsAWABdAF2AXgBdgFyAXoBYgFqAVABUgFAAT4BFgEMAOwAyQClAI8AWMAxwBmP4I/Jj5cPdw9ZDz8PGA8GDvoO4A7qDtoO3A7UDuAO/g78DwwPHw8jD0cPXA9gD4OPlw+sD7BP1A/mP/pAD2ASADQARABUAGIAfwB6AIIAlgCZAJkAlwCSAJoAjwBzAHQAYgBeADhAIIAYP/FP6c/Bj7iPkI+KD2UPUQ9ODy0PHg8BDwgO/g7mDuAO7A7eDtAO5A7qDuIO/g78Dw0PEA80D00PWA92j5UPtE/Wn/nAHcA/gF8AfQCaALYA0gD6AQABIgE0AUQBXgFYAW4BYgF0AXYBdAFyAX4BZgFuAVQBWAFKATgBJAEbAP0A3QC7AJeAcgBbgCQgDI/Vj7APnw9vD0IPOQ8VDwYO+A7gDu4O0A7kDu4O6g75DwoPHQ8hD0UPWg9vD3UPmo+vj7RP2O/sr/9wAwAmADeASABWgGSAcACKAIIAmACcAJ0AmwCXAJAAlgCKgHyAbABYgELAPAAUQAsv4g/ZD7+Plo+AD3oPVQ9BDzEPIg8WDwwO8g76DuYO4g7iDuIO5A7qDuAO+g71DwEPEQ8kDzoPQw9sD3iPmI+5z91//4AQgECAb4BwAK8AugDSAPoBAAEiATIBTgFIAVABaAFsAW4BYAF+AWwBaAFiAWoBXgFCAUIBMAEqAQIA9ADVALQAkIB5gEFAKd/yD9oPpQ+DD2MPRw8vDwoO+g7gDuoO2A7cDtIO7g7sDvoPDA8fDyUPSw9RD3aPjQ+Tj7jPzk/R7/WwB8AZACoAOQBHgFQAb4BqAHMAiQCNAIAAkACfAIwAhQCMgHGAcwBjAFEATMAnIBCQCi/hT9kPvw+Wj48PaQ9VD0APPw8eDwAPBA76DuQO7g7cDtwO3g7SDugO4A76DvcPCA8bDyEPSQ9TD3+PgQ+yz9Ov9IAVwDYAVABxAJwApgDBAOoA/gECASABMAFMAUoBUgFoAW4BYgF2AXQBcgF8AWQBagFeAU4BOAEuAQIA9ADTAL8AiIBhAEkgEW/6T8QPoA+AD2QPSw8kDxEPBA78DugO6A7sDuIO/A75DwgPGQ8qDz4PQg9oD34PhA+qD7CP1g/sP/BAEwAlwDYARYBUgGIAfIB3AI8AhQCZAJoAmQCWAJEAmQCOgHAAcQBugEsANgAu0AfP/k/Wj80Pow+bD3MPbQ9IDzUPJA8UDwYO+g7iDuwO2A7WDtYO2g7QDugO4A78DvwPAA8mDzwPRA9iD4KPpI/EL+NQA0AigEEAb4B8AJYAsADbAOIBBAEUASQBNgFEAV4BWAFgAXYBeAF6AXgBdAFwAXoBYgFiAV4BOAEuAQIA8gDfAKkAgYBogDCgF8/vD7mPmA96D1wPMg8tDwwO8g76DugO5g7qDuAO/A75DwcPFw8qDz4PQg9mD3sPgA+kj7rPz8/Ub/ZwCKAbQCyAPABKAFeAYoB8gHUAiwCOAI8AjwCMAIcAjYByAHOAZIBTAEFAPWAXkADv+o/Uz80PpA+cD3YPYQ9eDzkPJw8XDwoO/g7mDuAO6g7YDtoO3g7UDuwO6A74DwsPEA84D0EPbw9/j5LPw6/jsALAIoBBgG4AegCUAL4AxgDtAPIBEgEiATIBQAFcAVQBbAFkAXYBeAF2AXQBcAF4AWwBXAFIATIBJgEKAOkAxACuAHcAXcAkkAzP1w+yD5EPcw9ZDzEPLQ8ADwYO8A7+DuAO9g7+DvkPBQ8UDyQPNg9KD18PYw+Gj5uPoM/Ej9gv64/+sADAIQAxAEGAX4BcAGiAcwCLAIAAkwCVAJMAkACaAIEAg4B0gGUAU4BPgCoAE5ANb+XP3I+0j6wPhQ9/D1wPSA82DyQPFQ8IDvwO4g7qDtYO1A7UDtQO2g7QDuwO7A7/DwQPKw82D1YPdo+Vj7VP1D/zIBMAMwBRgH4AiQCkAM4A1wD6AQwBEAEyAUABXgFWAW4BZgF8AXABgAGMAXgBfgFiAWABXAEyASQBBQDjAM4AlgB8AELAKv/zD9yPqQ+HD2kPTw8pDxUPBg78DugO6A7qDuAO+g72DwQPFQ8mDzkPTQ9RD3ePjA+RD7VPyk/eb+HwA8AVACXANQBDgFGAbYBngHEAhwCNAIAAkACfAIsAhgCMgHGAdQBlgFSAQ0AwACogAv/7T9PPyw+hj5oPcw9sD0cPMg8uDwwO/A7iDuYO3g7IDsYOyA7MDsQO0g7gDvUPDA8YDzQPUg9yD5IPsc/RL/+wDgAtgEwAawCGAKAAyQDTAPwBAgEmAToBTAFcAWoBdgGMAYQBmAGYAZYBmgGOAX4BagFQAUIBIgENANYAvgCEgGqAMIAXL+DPzI+bD3sPXg82DyIPEw8IDvAO/A7sDuAO9g7+DvoPCA8bDy4PMQ9WD2sPcY+YD66Ps0/Xj+tv/rACgCVANgBGAFWAYoB/AHgAgACWAJkAmwCaAJUAnwCFAIsAfYBuAFwASIAzQCyABP/8j9IPyI+vD4YPfQ9WD08PKQ8VDwIO8g7kDtgOwA7MDroOvA6wDsoOxg7YDu4O9A8fDy0PTg9tD4qPqQ/Iz+ngCkApgEYAYwCAAKwAtwDfAOYBDgEWAT4BTgFeAWoBeAGGAZ4BkgGiAa4BlgGaAYoBcgFoAUoBKAEDAOwAsQCXAGzAMyAcD+TPzw+bD30PUw9LDyYPFg8KDvIO/g7uDuAO9A7+DvoPCQ8XDycPOg9OD1MPeA+Nj5IPts/MT9If9RAGwBnALAA8gEsAWABjgH2AdQCLAI4AgACdAIgAggCIAH4AYQBiAFGAT0ArwBbgD+/nz98Ptw+gD5YPfQ9VD08PKw8YDwYO9g7qDtAO2g7IDsgOyg7CDtAO4A7zDwkPEg8wD18Pbo+MD6kPyK/pEAgAJQBBAG4AfACXALIA2wDiAQoBEgE4AUoBWgFqAXYBgAGYAZwBnAGYAZABkgGCAXwBUAFEASIBDgDWAL0AhABqwDKAGo/kD8+Png9yD2gPQA89Dx0PAw8MDvoO+A76DvAPCA8CDx8PHQ8tDz8PQw9mD3mPjY+Rj7XPyg/dD++v8WATgCUANIBCgF6AWIBiAHkAfoBwAI+AfIB3AHAAd4BrAF2ATwA+gCugF9ACP/xP1I/OD6ePkY+KD2MPXQ85DycPFA8EDvYO6g7SDt4OzA7MDsIO3A7aDuwO/g8EDy8PPA9bD3mPlY+xT9+v7sAMwCmARoBkAIAArQC3ANAA+gECASwBMgFUAWQBdAGOAYgBngGQAaABqAGeAYABigFiAVQBNgEUAP8AxgCtAHSAW8AkMA2P2I+2D5YPew9RD0wPKg8dDwMPDA74DvoO/A7zDwwPCQ8YDyYPNw9JD14PYQ+FD5mPrg+yz9Vv6A/58AtgG4AqADgARABeAFaAbQBigHWAdQBzgHCAewBkgGwAUYBUgEWANsAlABHADS/oD9EPyg+ij5sPcw9rD0YPMQ8vDw4O/g7kDuwO1g7UDtYO3A7WDuQO9g8KDxAPPA9ID2QPgA+rj7eP0w/wYB1AKQBEgG+AewCXALMA3gDmAQABKAE+AUQBZgF2AYIBnAGUAaQBoAGmAZoBigF0AWgBSAEoAQMA7QC2AJyAY4BMYBc/8w/QD7CPlA95D1QPQQ8yDycPHw8JDwcPCA8KDwAPGQ8UDyIPMA9AD1EPZA94D4yPn4+kD8gP3K/gYAGAE4AkQDOAQABbgFUAbIBhgHWAdwB1gHIAfQBnAG4AVABXgElAOQAm4BQwD0/pj9MPzQ+mj58PeA9hD1sPNg8iDxAPAA70DuwO1g7UDtQO2A7SDuwO7A7/DwQPLQ83D1IPfQ+HD6CPyw/XH/QgEUA8AEcAYwCOAJsAtwDRAPoBAgEqATIBVgFkAXQBgAGYAZwBmgGSAZgBigF4AWABVAE0ARQA8QDbAKQAjIBXwDLgH+/tD8uPrY+ED3wPWA9GDzgPLw8XDxIPEQ8RDxUPHA8VDyEPPg88D0wPXw9hD4QPl4+rj78Pwm/mH/iwCgAbACpAOABEAF2AVQBrAG6AbwBuAGsAZYBvAFeAXYBAgENANEAlABKgD4/rD9aPwg+8D5WPgA97D1YPQg8wDy8PAA8EDvwO6A7mDuYO7A7kDvIPAQ8VDykPPw9ID2EPio+Sj7pPw8/vj/qAFoA/gEoAZQCCAK4AuQDSAPoBAgEoATwBSgFYAWIBfAFwAYABigFyAXYBZgFSAUgBLAEPAOAA0AC9AIqAaABGgCZgBy/oj8sPoI+ZD3QPYQ9SD0YPPA8lDyEPIQ8jDykPIQ88DzgPRQ9UD2UPdY+HD5mPqw+8D82P3w/gAA5wDQAaQCaAMYBKAEEAVgBaAFuAWoBZAFYAUQBaAEGARoA7AC4gH8APH/vP6Q/VD8CPu4+Vj4EPfQ9ZD0YPNA8lDxgPDg74DvYO9A72DvwO9A8BDx8PEA8yD0YPXA9hD4cPng+lT85P18/wwBoAIwBOgFuAeACUAL8AxwDvAPgBHAEuAT4BTgFaAWABdAFyAXwBZgFqAVwBSgEyASoBDwDiANMAsgCSAHKAUsAzoBRP9c/YD74Plw+BD3wPXA9PDzUPPg8qDykPKw8iDzoPNQ9CD1APYA9xj4MPlI+lj7YPxk/WD+Vv9AABIBvAFsAgADhAPsA0gEiATABOgEAAX4BNgEqARYBOgDYAOwAtgB3ADJ/6D+YP0Q/LD6YPkY+ND2oPVw9FDzYPKg8SDx0PCQ8IDwsPAQ8aDxQPIA8/DzAPUg9kD3aPig+fD6WPzA/Sz/qwA0AsgDcAUoB9AIcAogDLANMA+gEOARABPgE+AUgBXgFQAWABbAFUAVoBTAE4ASYBHgD1AOoAzQCuAI4Ab4BPwC9AD4/hD9UPvI+Vj4APfg9fD0QPTQ84DzYPOA89DzcPQQ9cD1kPZg92j4WPlA+ij7+PvY/KT9cv4n/8v/dAAYAZ4BJAKEAvQCUAOwAwAEMARIBGAEQAQABLADEANoApwBogB4/0z+BP2w+1j6CPnA93D2QPUg9EDzcPLQ8WDxMPEQ8TDxcPHA8VDy8PKg84D0YPVQ9lD3YPiA+aj68PtI/b7+TgDiAYwDWAUYB+AIoApADMANMA+gEOARABPgE6AUABVAFUAVQBUAFWAUoBPAEsARgBAgD6ANAAxgCrAI6AYQBSADXAGk/+z9KPyg+kD5IPgQ9yD2YPXg9LD0oPSw9ND0QPXA9YD2MPfw97j4iPl4+kj7CPzA/HT9KP7g/mj/6v9ZAM4ATAGoAQQCSAKAArAC2ALkAtACmAJIAtYBUAGaALz/xv68/bD8mPt4+kj5IPgQ9xD2MPVw9MDzQPPw8tDy4PLw8jDzkPMA9KD0UPXw9bD2kPdw+Gj5ePqQ+9D8Jv6e/y4B0AJ4BCgG8AewCVAL0AxgDrAPABEgEgATwBNAFKAUwBSgFGAU4BMgE4ASgBGAECAPwA1ADMAKIAlYB4gFwAMAAjYAfP7M/Ej76Pm4+KD3wPYA9oD1MPUQ9RD1QPWg9RD2kPYg98D3aPgY+cD5YPoA+6D7MPzA/Ez93P1u/vz+hv/2/20AzwAqAXABogG2Aa4BegEuAcoANwCF/8j+9P0M/Rj8GPsg+jD5QPhg96D28PVQ9eD0gPRQ9CD0EPQg9GD0sPQg9ZD1IPbQ9pD3ePhg+Xj6kPvU/DT+rP84AdACcAQYBrAHQAmwCiAMYA2gDrAPoBBgESASoBIAE0ATQBMgE+ASgBLgESARQBBADxAOsAxAC8AJEAhoBsgEHAN8Adj/Vv7w/Kj7mPqg+dD4MPjA93D3QPcw90D3cPeg9+D3KPiA+MD4EPlg+bj5GPpo+sD6EPtw++D7PPyc/PT8VP24/Qr+VP6c/sz+6P7w/uL+xP6M/jz+2P1c/eD8WPzI+zD7oPoY+qD5KPm4+GD4MPgI+AD48Pfw9xj4WPiw+BD5iPkI+qD6UPsU/OT8xP28/sz/3gD8ARwDOARYBYAGmAegCJAJgApwC0AM4AxwDfANUA6wDuAO4A7QDqAOUA7wDWANwAzwCwALAArwCNAHkAZYBSAE6AKuAYQAaf9k/nT9qPz4+1j72Pp4+jD6APro+eD58PkI+jD6YPqQ+sD68Poo+1j7iPuo+9D7+PsU/DT8YPyA/Kz83PwI/TT9WP1w/Yj9oP2w/az9nP18/Vj9IP3g/Jj8SPzw+5j7QPvw+qD6YPo4+iD6IPoo+kj6gPrA+hD7aPvQ+zz8uPww/aT9MP6k/iT/o/8sAKcANAG+AVAC2AJgA/wDiAQQBZgFIAaYBggHYAe4B/AHEAggCDAIIAgQCOgHsAd4BzAH6AaQBjgG2AVwBQgFoAQoBLgDRAPIAlgC4gFwAQgBnQA7AN3/kf9C/wH/yP6S/mj+OP4K/uz9zP20/aj9nP2E/XD9YP1U/VD9TP1E/Tz9PP1A/VD9UP1Q/VD9VP1Y/VD9RP0s/Rz9BP3s/Mj8pPyI/HD8VPw4/CD8BPz4+/D78Pvw+/j7DPwo/ET8ZPyE/LD83PwQ/UT9eP2s/ez9Kv5u/rD+8v44/4b/0/8gAG0AtwAIAVYBqAHwAUACiALUAiADbAO4A/gDQASABMAEAAU4BWgFkAWwBdAF4AXoBegF6AXYBcgFsAWQBWAFKAXwBLgEcAQoBNwDjAM8A+gCmAJEAvABlAFGAfMApQBTAAQAuf9x/yv/4v6e/lz+Hv7g/aT9bP04/Qj93Py4/JT8dPxc/ET8MPwk/BD8CPwA/PD76Pvo++D76Pvw+/j7BPwU/Cj8QPxc/Hz8nPy8/OD8AP0k/Uz9eP2o/dj9BP4y/mL+lv7I/vj+Kv9c/47/wP/x/yIAVACHALsA5wAQATgBYAGIAawBzAHuARACLAJIAmgCfAKMAqACsALAAtAC2ALgAuQC5ALkAuAC2ALQAsQCuAKoApwCiAJ4AmQCTAI0AhQC9gHYAbwBnAF8AVgBMgESAfAA0ACsAIkAZQBDABwA+P/O/6j/gP9c/zf/Ev/w/tT+tP6O/nr+WP5A/ib+Cv74/eD9zP3A/bT9pP2U/Yz9gP18/YD9hP2I/ZD9mP2o/bz91P3s/Qb+Jv5G/mj+jP6u/tL++P4d/0D/Yf+D/6T/xv/n/wYAIwBAAF4AewCbALkA0QDpAAABHAE2AU4BZgF6AY4BnAGmAa4BtAG2AbIBrAGgAZYBiAF4AWYBUgFAATABGAEAAeoA2ADJALQAnwCKAH0AdQBrAGAAVwBRAEwASgBJAEUAQwBDAEQARgBFAEMAQgBBAEAAPgA6ADkAOAA4ADQALAAkABwAFgANAAIA9//q/9z/zP++/6z/lv+A/2n/Uv87/yP/Cv/0/uD+zP66/qj+mP6M/oL+fP54/nb+ev6A/or+lP6i/rL+xv7c/vb+E/8v/0z/a/+I/6b/wv/c//T/DQAkADoAUwBrAIUAoAC6ANMA6gAAARQBKAE+AU4BWAFgAWYBbAFuAWwBaAFiAVoBUgFGATYBJAEUAQQB9wDlANMAwgCxAKIAjAB6AGkAWgBIADYALQAcAA8AAwD8//P/7v/r/+f/4P/b/9n/1//V/9L/zv/J/8f/wv+9/7b/qv+g/5b/iv+A/3b/bf9m/1z/WP9R/0v/Qv84/zL/Kv8j/x7/Ff8M/wf/AP/6/vj+8v7s/ur+6v7q/vD+8v74/gD/Bv8M/xj/Jv81/0r/Xv9y/4f/n/+4/9H/6v8CABkAMQBKAGEAdwCLAJ4AsgDEANUA5ADyAAABDAEWAR4BJAEqATABMgEyATABLAEmAR4BFAEGAfgA6gDbAMsAuAClAJMAgQBvAFsASAA1ACMAEgADAPX/6P/e/9X/zv/I/8L/vv+6/7j/tv+1/7T/tP+0/7X/uP+7/7//xf/L/9P/3f/p//P//f8GAAwAEQAVABcAFwAWABYAEwAOAAYA/v/0/+n/3v/T/8j/vv+z/6n/oP+X/47/hf9+/3f/cP9r/2j/ZP9j/2P/Zf9o/27/dP98/4X/kP+c/6v/u//M/97/8P8CABMAJAA2AEUAVABgAGsAdAB8AIMAigCQAJYAmwCgAKQApwCpAKoAqgCnAKAAlgCKAH4AcgBmAFgARwA1ACQAFAADAPH/3f/L/7z/rP+e/5L/if+D/4H/gf+C/4X/iv+S/53/qf+2/8T/0//i//H//v8KABUAIAArADYAPgBGAEsAUQBUAFkAXQBfAF8AXwBeAF0AWwBWAFAASgBDADkALQAgABQABwD4/+f/1P/F/7b/p/+Y/4r/ff9y/2f/Xv9U/0z/Rf9D/0L/Qv9G/1D/WP9g/3D/ev+L/5f/pf+4/8P/0P/k//T//v8JABYAIQAsADkARQBQAFoAYQBqAHQAfgCDAIgAjgCRAJMAkwCQAIwAhwB/AHUAaQBcAE0APAAqABcABQDz/+H/0P/C/7X/qP+c/5L/jP+I/4f/h/+K/4//lf+c/6X/r/+6/8X/z//a/+b/8v/+/woAFgAkADIAPQBGAFAAWwBlAG0AcQB0AHkAfgCCAIMAgwCBAH8AfQB5AHIAawBiAFoAUQBFADcAKQAbAAwA+//r/93/z//D/7b/qf+d/5P/iv+C/3v/dv9x/27/bP9s/27/bv9v/3L/dv96/3//hP+K/5L/m/+k/63/tv/A/8v/1f/f/+r/9f8BAA0AGAAjAC0ANQA+AEcAUQBYAF8AZQBqAG0AbgBuAGoAZQBeAFcAUABIAEEAOwA3ADIALgAqACYAJAAjACIAHwAcABkAFwAWABQAFAAVABYAGQAcAB8AIwAnACwAMwA7AEMASQBSAFoAXgBiAGgAbQBuAG4AcABvAGwAaABlAGEAXABXAFIASQBAADgAMAAnAB0AEgAGAPz/8P/l/9n/yv+8/6z/nP+N/37/cf9k/1f/Tv9G/z//Of80/zH/L/8w/zT/Nv85/z//Rf9P/1n/Yv9q/3b/gP+M/5r/pv+z/8D/yv/U/9//6v/0/wAACQASABsAIwAqADIAOAA9AEEARABGAEgASABHAEUAQwBCAEAAPQA7ADkANgAzAC8ALAApACgAJwAlACQAIwAiACIAIgAgACAAIAAhACIAIwAlACgALAAwADUAOQA+AEMARwBLAFAAVABYAFwAYABkAGgAaQBrAGsAagBoAGYAYgBcAFUATQBEADoALwAjABgADQADAPv/8//q/+L/2f/Q/8f/v/+2/6//qP+g/5r/k/+M/4X/gP96/3b/c/9v/2//b/9w/3P/dv97/4D/h/+O/5b/n/+o/7H/u//F/9D/2v/k/+3/9v///wgAEAAZACIAKwAzADoAQgBJAE8AVABYAFoAWgBZAFgAVQBRAE0ASQBFAEEAPQA6ADcANgA1ADMALwAsACkAKAAoACgAJwAlACUAJgAoACkAKgArACsALAAtAC4ALwAwADMANQA3ADgAOAA4ADgAOAA5ADkAOgA7ADsAOgA5ADYAMwAvACsAJQAfABYADQADAPn/8P/l/9r/zv/D/7n/r/+k/5n/kP+J/4H/ev90/3D/bv9s/2n/Z/9n/2n/bP9u/3D/dP96/4D/hv+M/5H/lf+a/5//o/+p/7H/uP++/8b/zf/W/93/4//t//L/+f8FABAAFgAcACMAKAAsADEANQA6AD0APQA9AEIARgBIAEoATwBVAFkAXQBhAGYAawBvAHIAdgB5AHsAfAB9AHwAewB4AHUAcQBtAGgAYQBZAFAARgA8ADMAKwAjABwAFgAPAAkABQABAPz/9//x/+v/5v/g/9v/1f/R/87/y//G/8H/vv+9/7n/tf+v/6v/qP+m/6T/ov+g/57/nP+c/5v/mv+b/57/ov+l/6j/rf+y/7b/uv++/8P/yP/N/9L/1f/Z/9z/3//i/+X/6f/s//D/9P/5////BAAIAA0AEQAVABkAHAAfACIAJQApACwALwAwADIANQA2ADgAOgA8AD4AQgBEAEcASgBMAE4ATwBRAFIAUwBVAFYAVwBYAFcAVgBSAE4ASgBGAEAAOgA1ADAAKQAiABoAFQARAA8ADQAKAAcABAACAAAA/v/9//v/+f/4//f/9v/1//T/9P/z//L/8v/z//P/8f/x//H/8P/u/+7/8f/y//H/8//1//P/8//z//L/7//r/+n/5//l/+P/4//f/9v/2f/Y/9b/0//R/8//zP/L/8r/yf/I/8X/xP/E/8X/x//I/8j/yv/Q/9j/3P/d/9//4v/m/+r/7f/x//X/+v/7//z/AAAGAA0AEQAUABoAGgATABQAGgAeAB0AGQAYABwAIgAkACIAIQAkACgAJwAiAB8AHgAdABkAGQAdACAAHgAZABcAFAAQAA0ACgAIAAUAAgAEAAkACgAKAAkABwAFAAUABQADAAEA/////wEAAAD8//v/+//+/wAA/v/+/////v/7//n/9v/0//D/7f/u//H/8v/s/+P/3P/Y/9b/1f/U/9P/0f/P/83/y//M/83/z//T/9j/3f/g/+P/5//u//b//f////7/AQAEAAoADgASABcAHQAkACoAMAA2AD0AQABBAEMASgBRAFQAVgBZAFoAWABUAFUAWwBgAF0AVwBRAEwAQAAuACAAGgAYABQAEwAXABYABQDv/+X/5P/h/9f/zf/M/9P/2f/U/8z/yP/G/8H/vv/C/8n/yf/C/7//wv/J/87/0P/S/9b/4v/u//T/+P8BAAkABAD4//z/EAAeABwAFwAdACMAHQAYABsAIQAhAB4AHwAiACIAHQARAAAA+P8BAA8AEwAHAPr/7v/k/9r/zv/A/6b/g/9l/1f/Wf9X/0f/Mv8l/yD/If8j/yf/Lv85/0b/Uf9Y/2P/bf9x/3L/iP+6//X/IwBAAEsAOAAFANn/8f97AFABFAKcAjADEAS4BIgELAMiAUr/kv5+/3IBKAPAA1QDlALQAfEA7f/y/hb+XP0I/Wj9WP4x/2//Kv/W/qL+YP78/ZT9aP2E/cD9JP7K/nf/y/+V/x3/3P7s/gr/F/9I/7f/JQBUAFkAZABmAC8A1/+3//3/cQDDANcAywC7AKMAdQBGAC8AMQBFAGgAigCNAGIALQAfAEUAgAC3ANUAwQB+ACkA3/+f/3z/s/9XABgBlAGcATgBeQCf/yH/U/8LAN0AbAGSAT4BowApAB4AYQCPAHsASgA6AGUArADQAKUASwABAOH/3f/p/wEAFAAUAA4AEAADALv/Pv/i/vz+b//S/+f/1v/V/9b/rf9i/zL/Qf98/7z/8P8VACUAKQA9AHEApgCZACIAav/a/s7+X/9QADoBugF+AYoARv9k/kD+uP5q/ykA2AAWAX8AU/94/qD+lv98ALoAXwCh/67+Dv6G/gcAcgGsAbMATf9M/ib+1v7b/3wAeABJAEEAIACt/zT/B/8V/2v/TgB+AQACJgFa/7z9MP3o/Wz/+QD4AUACxgGGAOj+oP3w/Mz8kP2i/1gCCASUA3oBCv8k/Qj82PsE/aj/pAL8A8QCCQC0/eD8eP30/nsAKgHfAGwAigDpALgA4v8h/yv/BAAKAY4BkAGWAYoBxwBa/5r+eP8kASAC7AEIAez/6P6S/l7/zgDOAe4BggEEAacAMwB2/+T+Vv/XABwC8gG0AKv/T/9M/47/PQDjAMsAIADY/0IAjQAIABb/rP4//4cA3AGAAtwBBQD0/QD9zP3G/8ABuAI0AloASv6Q/bb+iQByASABXgDK/zb/qv7i/jwAuAHEAS4Agv4G/mT+tv4o/yQA2AAkALD+Rv5G/ysA6v9V/4n/TQC2AIIAOAAyABIAdf/E/vj+QQB4AaQBPgEsASYBSwDM/uT9Lv5C/4MAlgEMAoABOgAA/27+tP6i/+oA7gHsAa8A/P7w/SL+U/8GAbQCdANkAub/wP1M/Uz+9P/uAbgD4AOqAYr++Py8/Wr/lQAYAVgBMgGDAMf/ef9E/8L+dv4p/8EADALMAeD/fP1Q/BT9+P7WABgCMAJdADz9OPs4/Gv/SAIUA9gBlP+Y/cT8WP3a/pEAmgF4AYMAif/a/jL+vP0q/r7/qgHMAngC6QAm/xz+MP5n/3oBTANMA0IBDf9y/hj/f/9d/9j/aAGsAhQC/P88/uT9hP58/84A+AHSATsAyP6u/mj/4f8HAE0AyAAUAbsAsv+u/pz+df81AHMAvQAaAYQA0v6k/W7+lwBwAigDrALRAPT9+PvM/EEAtAOABHQCmP/I/UD9hP3U/mIBkAMUA+v/zPwQ/HT9lv+eAcQCGAKz/4T9ZP0Y/9cAYgHzAGsABgBa/1z+IP6l//4BtALwAMD+cv6u/2EACwABAKkAqwCM//7+KwCAAdQA3v4w/nD/vgC7ADYARABmAID/Qv68/kQBDAN8AR7+6Pz6/rYBtAJUAl4Bnv+Q/QD9yP5eAcQCXAK6AOr+5P0o/nj/FAEoAuwBZwDW/sL+GABAASQBPAB1/y7/lP+WAHABGgGS/yr+Bv4+/xQBfAJgAnUAEv40/Yr+4wCoAgQD4AHE/w7+Cv6v/5QBYAKiAfP/Vv7Q/bD+VgCgAYwB9v8O/nT9kv4aAM4A1ACpAAgAyv7M/R7+of8sAeIBngFHACz+vPxw/dL/sgGkAY0AAgAcAAoA0f8EAHAAdgBUAM8AtAG2AVsA+P7+/hsAFAGsATgCCAI7AOj9TP3W/sIArAHEAUwBDwCa/lr+v/9YAZYBqgCs/97+CP7o/Wb/rAF8AvUAqv60/Xz+8f/sABQByABrAAoAyv/3/ycAhf9y/pb+gwCAAogCwwDQ/oz9GP0I/pUAOAN0A3oArPw4++T80P/aATwC+wCo/tj8CP34/poAuQBHAHcAwQArAD3/6P4N/z3/5f8oAa4BhgAE/7j+8v6S/qL+cQBcArgBF/+8/cz+IQAPALn/mAC+ATIBBP+g/bT+3wDCATYBwQCHAH7/OP7M/lQB+ALWAcv/bP9SAHoA4f83AJYB+AFeAHr+hv5dANIBaAHS/6r+bv7o/i4A/AGcAsUA9P0o/Qj/WgEoAuQBZAFYANz+eP7y/84BHALUAGj/wP7c/o7/mgA+AcoAlP+e/oD+Lf8SAHIA+/8T/37+rv6G/4gAHAHCAHr/Mv4E/hL/hgCwATQCoAG//7T9bP1Q/54B4ALQAkYBjP7g/GD+dgHMAuIB7ABlAA//pP2C/i4BSAKLAK7+G/99AIIAif+R/6wA1gBz/3b+a/8sAYYBJgDW/vL+2f9HAF0A6QBiAVwAWv7w/Q8ASAIAAvn/xP5X/2IAjwAwAFUAAAEcAUUAmP/g/0oABwDL/08A1gCWABwADAACAI//Rf+8/3YApgA7AJL/+v7M/j7/6P8lAMv/av+I/+r/2v9O/yT/x/93AGsA8f++/5v/+v58/lX/QgFMAkwBWf8w/jz+7P71/zYBygG/ALr+vP2s/nMAUgHSAMv/J/8i/6L/iwBMARoB6P/W/hb/UwAkAcgA2P8d/8r+/v7u/y4BjAFfAJj+3P3K/lQAMAEaAZ0AGQCA/wj/Tf9DAOAAfADf//D/TQAGAE//SP8eAMQAvACWAIgAzf92/gb+av9IAcIB2ADI/xb/nP7A/tb/EgF0AQYBZAC2/xr//v6M/2EA+wAcAa8ACQDW/ywAOwCz/3P/GQDmABQB2wBuAJT/sP7a/hoAIAEeAY4A6f83/9b+O/8FAIYAjwA7AJz/HP9p/zoAdgDZ/0r/Zv/S/zYAdwBSAML/R/9Z/8X/LgCKALwAbgCi/+T+yP5U/yoA1gD4AFoAHv8I/hj+ZP+XAHkAff/g/vD+I/9D/7f/XgB/ANj/L/9f/zsAvgBjAPH/EgBSACoAMwD2AIwBuwA//wz/ZwCMAVoBngBGADQACAAaAMgAkgGeAaoAaP/s/rP/GAHgAXwBYwBQ/9L+Lf8fAOQA9ABGAEP/pP7+/gYAvgCkAEAA2v8i/3r+D/+6AIoBgQAO/9r+qf9LAIgA0wDqADQAN/8r/z8AYAGMAcUArv/w/gD/8/86AdgBKgGr/4D+fv5+/5kACAGXAJH/jv5q/lv/kwAWAZ0Ai/+S/mT+Tv+3AGoB2ACp/+L+/v7C/4QAswB6AD8AHQD//+T/6P/r/9T/2P8XADUA8P+j/67/1v/O/8f/EQBxAIYAWwAmAOn/q/+//zcAwQD5AMkAPQCd/2n/1v+EAN8AwgBjAOf/YP8g/3n/LAC8AOsAnwDg//z+lv4s/2UAPAEUAUEAZv/e/tr+d/+AAEIBGgEwAFT/Ev9W/9L/VAC1AL0ASgC3/47/yP/b/6//sP8JAFwASQDd/2P/DP8C/2//FQBrADAAqv9R/1P/ff+w/+j/HwAyAAQAp/90/6T/+P8eABoAJwA1AAQAsf+Z/9X/FgBLAIYAjQAbAI3/cf+5////HAAoAA8A7//o/8v/cv80/5X/OAB9AEsABACK/+j+8P7x/+wA1AAPAKn/lP9V/17/KgAGAfwAWgD4/9X/jf+K/0oAPAFmAdUASwALAND/oP/m/5IADAHmADsAof9z/7P/DwBvAL4A1wCZABMAzv/9/1IAXABoANQAQAEGAT8A0v8GAIUA7gBiAaIBQgF8APb/EQCLAC4BxAEMApoBqQD3//j/jgBMAdwB6AFKAU0AtP/h/20AugC8ALYAgwDl/yz//v54/8X/kP9E/zL/Bf+Q/j7+QP5I/hD+Dv5M/kD+yP1s/Wj9UP1A/Xj9zP2E/dz8wPws/WT9PP1M/Zj9oP04/RD9eP3k/Qr+Fv5G/mr+Pv4w/pL+JP90/5L/uf/K/77/6v+MAFoB1gEAAugBqAGOARACGAPwAzgEMAQIBLADmANABEgF4AW4BXgFYAUYBdgEMAXgBSgGuAUoBcgEgARgBMAEEAWYBNADgAOUA3wDOAMsA+AC8AH3AOMAYAFUAaIA4f8t/0b+tP3E/fT9nP3U/PD7+Po4+tj58Pnw+Xj5yPjg9+D2cPaw9hD3wPYg9pD1IPWg9FD04PSw9dD1gPVw9YD1YPWg9aD2IPgA+RD5YPng+VD64Pok/ND9H//e/2QA/gBuAeIBBAPQBGgGIAdQB7AHMAjQCMAJIAtQDJAMcAygDPAM4AzwDLANYA4QDkANwAywDGAMEAxADEAMsAvQCkAK0AmACWAJYAkgCYAI8AeIB1AHeAfoB4AHIAYIBQAF6ATkA9wCRAJYAbj/fv4Y/vD86Poo+Vj4IPdA9TD0wPOg8jDwYO5g7YDs4Otg7ODswOug6WDooOhg6YDqQOyg7UDtIOwg7EDtIO+Q8QD0wPUQ9rD1IPbQ9wj6jPzg/lwAMAGSAQgC9AJQBBgG+AeACVAKgAogCsAJMAoQC1AMkA1QDiAOIA1ADNAL4AugDAAO4A5ADiANYAzAC/AK0AoADFANIA1ADIALgApACeAIEApwC9ALYAuQCnAJQAggCBAJ0AlQCmAKUAmQB6AG2AboBsAG6AY4BxAGaAO8AdIBkAFXAMX/fP+E/Tj6IPiA9yD28PNA88DzQPJg7sDrYOtg60DrIOzg7GDrgOiA5wDpwOrA64DtAO/A7gDt4OwA7+DxMPTw9SD3APdg9gD3aPkE/OD93v5w/6z/fP/i/34BuAMwBagFaAUABfgEuAUYB2AIAAkgCcAIEAjgB7AIsAkACiAKoArQCtAJAAmgCaAKsAqACvAKQAtQCjAJcAlQChAKsAlACoAKcAkQCPAH0AjwCEAIyAeAB8gGEAbwBTAGMAawBSgFEAXwBFgEGARgBLAEQAREA9ACMANcA8wCnAJoApYBhQAfABgAfv9k/qz9DP24+pD3EPag9sD2EPbA9KDyEPAg7mDuoO9Q8ODvIO8A7mDs4OsA7SDvAPEg8iDyIPGA8JDxAPRQ9tD34PhY+WD5qPnA+oj8Mv6c/4gAzgCJAJcAWgHEAuQDcASQBIAEwAQ4BcgFWAYAB2gHWAdwB6gH6AcgCHAI4AggCeAIgAigCAAJEAkACRAJcAlQCcAIAAgACFAIYAhQCDAIAAhgB5gGWAb4BkAH2AZoBmgGEAYgBbAEIAWwBUgFEAVgBYgFoAQYBNAESAXoBGgECAUgBVAEAASoBNgEAASoA8QDtAK0AAkAFAEsAT7/TP0w+xj4oPXw9aD3wPfg9ZDzQPGA7gDtgO4w8RDysPGg8GDu4Ovg6wDv0PKg9ND0wPSQ8/DxYPKA9fj4APsM/Cz8GPtQ+aD5XPxM/5QA5QAOAW4ATP8V/7IAlAKgA0AE8ATwBOADRAN4BIgGeAeoByAIoAgQCEAHoAfgCNAJAAowCkAKgAmwCPAI0AkQCpAJMAngCGAI+AfIB+gHyAdIB/AGeAbIBWAFkAWoBRgFcAQABOgDpAOcA/gDOAT0A7AD6AMABMQDtANoBMAEWAQQBFgEgAQQBAAEuAS4BGQDGAI0AgwCHgGhAMYAef+w+0D4oPdg+Gj4OPjQ98D1sPHA7iDv8PBA8vDyMPOQ8WDuIOwA7QDwsPKw9KD1kPQw8gDxgPJg9QD4GPqI+yj7SPkg+BD5QPt0/V3/eQDx/1L+dP30/Vr/6wCEArwD7AMUA2wCqAJwA8gEeAaYB+AHKAeIBrAGaAfgB9AIwAkQCqAJsAhACJAIIAlwCbAJcAlwCKAHWAdoB3AHeAeQBygHOAZ4BVAFYAVABXgFqAXwBKADWAMQBHgEMARgBCgFGAUoBNADgATQBIgEoARQBXgFyARQBOgEcAX4BDgE7APAA9wCzgF4AaABlQAO/nD7UPkg+OD3wPhA+bD3YPRg8SDwMPAA8SDycPNA8yDxoO5g7UDugPBg81D1oPVw9PDykPLA8+D1cPhY+kD7OPsw+iD5aPlw+9T9O/9c/xv/1v5Y/hj+1P6nADgC0AIIAyQD5AKUAkwDOAXgBhAHwAZQB7AHOAdIB5AI0AnQCYAJkAlgCbAIwAjQCVAKYAlACBAI8Ac4B/AGcAewB8gGqAVABQAFmARgBPgEMAVQBCADqALwAggD9AJoAwgE6ANEAwQDUAOgA9gDIASIBFgE1APwA1AEeARYBHgEeAQIBDQDkAJAAgwCwAHnAJT+iPu4+YD5uPmA+QD5wPeA9YDy4PBQ8UDy0PIg8xDzcPFA7yDuoO9A8sDzgPRQ9WD1APRA88D0UPcg+RD6GPuQ+6D6uPnY+gz9MP6u/nn/y//0/jb+7P4dALsASgFoAugCQAIAAhQDEARQBPgESAbIBkAGQAYwB9AHmAfwBzAJcAmgCGAIUAmgCfAIsAgQCfAIwAf4BmgHuAcAB1AGiAY4BiAFgAQABUAFgATgAwgEAAQEA2gCAAOUA0gD+AJUA8QDiANgA9QDOAT8A+gDgATYBLAEgAQABXgFQAXIBKAEgATcA3ADnAN0AwgC/v8U/kT8oPo4+vD6CPso+aD2EPWw80DyAPJw83D0sPMw8lDxwPAQ8NDwUPMg9fD0cPTg9BD1wPRw9cD3kPm4+cD5gPqo+vj5iPqE/KT9QP0c/eT9Pv6o/bz9Ff8VABoAiACGAeoB4gG0AhAEuASoBDAFSAbABqAGOAdgCMAIcAiwCEAJIAnQCEAJAAqwCcAIcAigCAAIAAfoBmgHKAc4BqAFoAUwBWAEMASABFgElAMUAwgDwAI8AigCoALYApwCrAIsA0QDCAM8AwAEQAT4AzgE2AQABZAEwASABYgFsARIBKAEWAR0AygDBAOuAUD/XP2A/Ij7qPpw+kD6oPhQ9tD0EPRA8+DykPMg9DDzoPEg8VDxUPHA8VDzgPRA9MDzQPQA9RD1UPXw9qD4APmg+Pj42Pk4+nj6OPso/GT8dPy0/Bz9YP20/Wz+NP+5/zAABgHIAUgC7ALEA3AE6ASQBXgGEAcwB2gHMAjACMAI0AhgCdAJoAlwCbAJ4AlgCaAIQAjwB2gHEAdIB2AHwAYABsgFkAXQBGgE0ATwBEAEhAOYA6gDEAPQApADIATQA5wDMASQBEAEIATIBDgF2ATQBHgF2AWgBYAFoAWABQgFyATYBJgEAARYAygCTACE/jT9APzg+nD6UPo4+UD3sPWw9KDzoPKw8pDzgPMw8lDxYPFw8UDxwPEQ8/Dz8PPg82D0wPTw9MD1IPcQ+Cj4QPjg+MD5MPqA+gj7kPvY+wT8aPzY/FD99P2e/kf/zv9nAFQBLALUAowDiARABcAFSAYAB6gHEAiQCDAJgAmACcAJMApAChAKMApACtAJIAnACJAI+AdgB2gHiAfoBhgG8AXYBRgFYASYBPgEkAS8A3ADnANMA8AC4AKoA/ADqAOcA/gDIATsA/QDeATIBKgEmAQIBVgFEAWwBLgE4ASQBPQDxAO8A/QCsAFiACX/kP3w+/D6WPqg+aD4wPfA9mD1EPRQ8/DywPKw8pDyIPJw8WDxAPKA8qDyQPNA9KD0kPTQ9KD1QPbQ9sD3oPgA+TD54Pmw+vD6EPvI+4T8qPyo/Cj92P00/pr+aP8oAJ0AKAEcAhADlAMIBLgEgAUYBrAGUAcACIAI0AggCVAJoAngCRAKQApwCoAKIAqgCTAJwAgwCNgHuAeoB2gH+AaQBigGqAVABSAFMAUABXAE6AO0A5wDWAM8A5QDIAQwBOQD2AM4BEgE8AP4A5AE2ASYBJAE8AQQBZgESARgBFAEqAMwAxQDrAKuAX0ATP+Y/cj7kPrg+UD5kPgY+GD38PVQ9HDzEPOg8nDywPLw8nDy8PFQ8uDyIPNw8xD0sPTA9OD0cPUw9qD2YPdg+Oj4APlg+TD6sPq4+gD7yPs4/Bj8RPwg/ej9Ov6w/rH/uAA+AeQB+ALsA2AE2AS4BZAG+AaAB2AIIAlACWAJ4AlACiAKAApwCtAKcArACYAJUAmQCNgHuAfQB4AH4AaIBkgGsAUgBfgEAAXABEAE1ANoA/wCyALcAggDEAMcA1wDYAMcAwADWAOgA4ADfAPcAzgEGATkAxgESAToA2QDWANYA9wCJALEASIBvf/s/XT8SPsg+mj5OPno+PD3sPbA9aD0gPMg83DzkPMA85Dy8PIQ89DyEPMA9KD0cPRw9AD1cPWA9eD14PbA9yD4cPgo+bD54PlA+vD6WPtY+5j7SPzY/Cj9uP3A/qz/PQDqAPAB5AJsA+QDsASQBUgG6AawB3AI8AgwCXAJ0AkQCjAKcAqwCtAKwAqQCkAKkAngCJAIYAj4B7AHqAeIB9gG+AXABdAFcAXYBLAEuAQYBEADHAN8A5gDjAPQAyAE7AOgA6QDyAO0A8gDMAR4BGgEcASwBKgEOATwA+ADjAP4AqwCqAI0AiAB2v+U/gD9MPv4+aD5cPnY+PD3APfQ9VD0IPMA81DzUPPw8uDy4PKw8oDyEPPg8zD0IPRg9OD0APUA9bD10PZw95D3MPgI+Vj5YPnw+bj6APvg+hj7uPsw/KT8jP2a/lD/BQD7AOgBfAIYAwgE4AR4BUgGaAdACJAIAAnACSAKAAowCgALcAswCxALUAtQC2AKgAlQCSAJcAgQCBAI0AcAB1gGGAawBRgF4AT4BLAE8ANsA1ADJAPkAiQDtAPYA5ADkAPYA8ADaAN4AxAEUAQQBAAEcASgBCgEyAP0A+gDRAO8AsQCnAKeAVAAOP8G/kD8sPoY+uj5UPl4+OD38PaA9TD0sPOg83DzIPMQ8/DysPKw8kDz0PMQ9FD0kPSw9KD0EPXw9aD2EPeg96D4OPlg+cD5mPoo+wD7CPuQ+/D74PtQ/ID9cv7Y/o3/4QDcAQwChAKgA4gE6ASQBeAG2AcgCHAIEAlQCVAJsAmQCvAK4AoAC1ALAAswCtAJwAlQCbAIoAjACEAIUAfwBuAGWAaoBYgFsAUoBSAEqAOkA3QDHANQA/QDIATEA6gD8APcA3gDaAPQA/QDyAPkA0gEcAQYBNwD1AOIA+ACgAKAAkgCggF1AFr/2P0Y/Mj6KPrA+Sj5gPjg9/D2oPWw9FD08PNQ89DyoPJw8jDygPJg8+Dz0POw8wD0IPQg9MD0APbA9uD2MPfw93D4mPgw+Uj64PrA+tj6SPto+1j78PsU/dD9Sv48/4wARgGUAXQCoANABKgE0AVIB/AH+AeACEAJgAlwCSAKIAtwC0ALUAtQC7AK4AmgCZAJIAmgCKAIgAjIB/AGmAZgBtgFWAVQBTAFiATIA4QDXAP8AsQCFANgA0QDLAN0A6wDbAMkA0wDhANoA1wDxAMgBPgDpAN0A0wDyAJcAmwClAIkAhwBEQDY/ij9oPv4+sD6MPqA+eD4GPjQ9pD1EPXg9ED0oPOA83DzAPPg8pDzIPQw9CD0cPSw9JD00PSg9UD2cPbQ9qD3OPh4+Pj48Plw+mj6qPoo+zj78PpY+2j8NP3M/dD+IADwAFQBPALIA9gEYAUQBhAHoAfQB2AIUAkACkAKoArwCgAL8ArgCgAL0ApACtAJgAkQCbAIoAiACPgHSAfIBmgGAAaoBZAFmAUoBYAEIAQYBOgDmAOcA7gDoANoA4QD9AMoBBgECAQQBNADmAPAAzAESATwA7ADYAPIAlQCUAKQAiACAgHN/3D+wPxQ++D6+PqA+oD5qPjA91D2APWw9ND0kPQA9MDzoPNA8+DyAPNw85DzkPPw82D0kPTg9HD1wPXQ9UD2EPeQ9wj4wPiY+dj5wPkY+qj64Pro+oD7fPwM/XT9bP63/3wARAGYAiAEAAWABUAG6AZAB8gH8AggCrAKwAoQC1ALQAswC3ALcAsQC4AKMArgCXAJ8AiwCGAIsAfwBnAGKAbIBZAFcAVIBeAEYAQgBAgE6APUA+QD0AOYA3QDpAP4AyAEMAQwBAgExAO4AwAEIATcA5ADWAPwAmgCSAJ0AjgCQgH+/8j+hP0c/Dj78Pqo+tD56PgY+ED3QPaQ9XD1YPUQ9aD0UPQg9ODzoPPQ80D0cPRw9KD0APVQ9XD1oPXw9VD2sPZQ9xD4uPgo+Xj5yPkI+jj6kPoA+1j7wPtc/Dj9FP7m/uv/PgF8ApgD8AQABnAGiAbYBqAHcAhQCTAKwArQCrAKsArQCrAKoAqQCkAKsAkgCeAIsAhACNAHgAfoBjAGqAWIBXgFKAXoBLAEWATwA8wD8AMoBCgEEATwA9gD3AMIBFAEiAR4BFAECATsA9gDtAOkA2QDEAOsAlwCLALqAXIBoQCi/3L+PP0g/Ej7qPoQ+oD5yPgA+ED3wPYw9sD1cPUw9cD0QPQQ9CD0UPRg9JD0wPTQ9MD04PRQ9cD14PUw9rD2IPeA9xD4qPj4+PD4EPlQ+aj5EPqo+lj7sPvo+2T8JP0M/kb/FAHIAuwDoAQwBaAFCAbIBhAIUAkQCmAKsArgCgALQAuQC4ALIAvACoAKIAqwCWAJEAlwCKgHKAf4BrAGQAboBaAFEAVYBBAEIAQoBBAE/AP0A7QDZANUA5gDyAPgA/gDGAQQBNADrAPAA5wDOAPsAuAC1AKgAmQCJAKeAakAn//Q/vT9EP1I/KD7+Pog+mj5yPgo+JD3IPew9kD2sPUw9RD18PTg9BD1YPVg9WD1gPWw9eD14PUg9oD20PYA93D3GPiA+Lj4+PhA+Vj5cPm4+TD6oPoI+5D7APxE/LD8rP00/7YAXALkA9gECAUABbgF2AYACEAJYArQCsAKsArwCkALcAtgCyAL0ApgChAK4AmwCUAJsAggCHAH6AaYBmgGIAawBSAFiAQgBAgEMARQBEgEEASkAzQDDAMwA5QD2AP0A+wDwAOAA0gDSAM0AwQD3AK0AoQCXAIwAuIBNAFSAFf/VP5o/az8EPyY++D68Pkw+XD4kPfg9pD2QPbQ9TD14PTQ9LD0oPSw9OD08PTw9BD1UPVw9ZD14PVA9qD28PZg9+D3OPiA+Mj4EPlQ+ZD5APpo+tD6OPuw+yD8lPxs/eT+rQA8AnQDWATQBOgEWAW4BkAIUAkQCoAK0ArQCvAKgAsgDBAMkAtACxALgAoACtAJkAmwCMgHaAdIB+gGgAZIBugFEAU4BCAEQAQwBCgESAQQBGgDFANEA5gDrAO4A+ADvANEA/ACFAMkA8gChAKIAkgC3gGwAbgBUAFOAHH/zP70/eD8MPzg+0D7YPqY+QD5SPiA9yD38PaA9tD1cPVQ9QD10PQA9TD1QPUw9WD1kPWQ9ZD1APaQ9sD24PZQ9/D3MPhY+OD4aPmY+YD56Plw+tj6EPt4+xz8dPzQ/PT9xv+CAdwCCAT4BDAFYAUYBpgH8AiwCWAK0ArQCsAKMAvQC/ALkAtAC+AKcArQCbAJkAnwCCAIqAdoB/AGcAZQBigGaAVwBPwDEAT8A9gDAATsA1QDtAKoAvQC/AIEA0gDXAPsAoAClALQAqQCVAI4AgwClgEqATIBHgFmAJT/9v4u/jD9jPxc/AT8IPsw+oj50Pjw93D3cPcg93D24PWg9XD1EPUg9VD1gPVQ9SD1QPVw9ZD10PVA9oD2gPag9gD3kPfw90j4oPjY+Pj4QPnI+WD6wPr4+jj7qPt0/Mj9n/+KAdQCkAMYBKgESAVABrAHEAngCVAKkArwCjALcAvgCxAM0AtgCxALoAogCrAJYAnwCEAIoAdIBxAHuAZABvgFkAXQBEgEQARwBGAEMAQQBNwDaAMsA1gDmAOoA6gDtAOIAyQD5ALwAtwCgAI8AjAC9AGAASoB+AB2AIb/hv7g/TD9ePzw+4D70PrQ+fj4YPjg93D3MPfw9nD2wPVg9VD1UPVQ9XD1gPVg9VD1gPXg9TD2YPaw9uD2EPdA98D3UPiw+Nj4EPlQ+Yj5yPlQ+uj6KPtY+9j7wPzw/Xb/SAGoAmAD0AOgBJAFiAbQB/AIwAkgClAK4ApgC6ALwAsADPALoAtAC/AKgArwCXAJ8AhgCLAHSAcIB7AGMAbABWgFCAWYBFgESARIBCgECATgA7ADfANIA2QDiAOUA3QDXANAA/gCvAKQAmgCNALwAbwBeAEKAYwAAQBa/5T+0P04/bT8FPxo+6j64PkY+Wj44Pdw9wD3gPYQ9sD1gPVQ9UD1QPUw9RD1APUQ9UD1gPWw9eD1EPZQ9oD24PZw9/D3QPiQ+Nj4APko+Yj5GPqA+uD6aPuQ/MD9Bv+BANIBnALgApwD2ARABmAHUAgwCbAJwAkgCvAKYAtwC1ALgAtgCwALsAqgCkAKgAnwCJAIEAiYB1gHKAeoBugFeAVABRAFyASgBJAEUATgA7QDyAPQA8wD2APMA4ADIAMQA0ADPAMEA9ACgAIEApQBaAFaAQ4BgQDc/yD/Tv6g/Sj9yPwg/ED7YPqo+fD4cPgY+LD3EPdg9vD1sPWA9XD1cPVA9fD0sPTA9AD1MPVw9bD10PXQ9RD2oPYg93D34Pc4+Gj4iPjw+Gj5yPkA+oj6SPsI/Bj9qP4uAAgBpAF0AmwDYASoBUgHkAgQCVAJ4AmwCjALsAswDHAMMAzQC7ALkAtAC+AKcArgCSAJgAhACAAIiAcAB4AG8AVgBSAFGAUIBcAEaAQgBLwDhAOgA+AD4AOwA2QDFAPMAqwCxALQApQCKAK6AUgB3wCmAHYA//9b/6L+/P1Y/dT8bPzo+zj7aPrA+TD5qPgw+LD3IPeA9gD2sPWQ9YD1cPUw9eD0oPSg9ND0APUw9WD1gPWg9eD1UPbg9lD3sPfg9yj4iPgI+Yj54Pk4+pD6QPtI/MD9Sv+CAGwBGALgAqwDuAQgBogHYAjwCJAJAApwCuAKcAvgC/AL0AuQC2ALEAuwCmAKwAkgCZAIMAjYB1AH6AaABugFUAX4BMgEmARwBEAEAASsA2QDUANcA1gDPAMcA+ACnAJ4AmgCWAIoAugBiAEkAdwAogBnABQAmP8A/1r+wP00/aj8FPx4+8j6KPqg+SD5sPgg+JD3IPew9mD2MPYg9vD1oPVQ9UD1UPWA9cD1EPZA9lD2cPbQ9iD3gPcA+HD4uPjo+ED5yPlA+qD6CPuQ+zT8GP1o/sH/zQCWAUwCCAO0A7gE+AUgB/AHoAggCaAJEAqACgALQAtgC0ALEAvACpAKYAoACmAJ0AhACNgHeAcoB9AGWAbIBUAF4ASoBIgEeARQBBgEzAOYA3wDdANwA2QDRAMAA7wCkAJoAkQCFALYAXgBHAHOAIcANgDM/07/uv4e/oD9+Px4/PD7aPvg+lj6yPlI+cD4QPjQ92D38PaQ9lD2IPbg9aD1cPVg9VD1YPWQ9cD18PUw9pD20PYw96D3GPh4+Lj4IPmg+Rj6iPoY+7D7RPwQ/Sj+ZP9/AGQBLAIEA9gDyATIBeAG4AegCEAJ0AlQCtAKQAuAC7ALsAuAC0ALAAuwClAK4AlQCcAIQAjAB1AH2AZYBsgFQAXIBGgEMAQABMwDjANcAywDAAPoAvAC+ALcArACkAJoAlQCPAIQAsgBTgHaAG0ACgCv/1v/9P5a/rD9CP2E/AD8ePsA+4j68PlA+bj4UPjg95D3QPcA97D2YPZA9iD24PWw9ZD1gPWA9aD14PUQ9lD2kPbQ9iD3cPfw93D42PhA+cD5SPqo+gj7mPtI/Az99P0b/y8ACgHCAZQCeANIBBAF8AXoBrgHcAgACaAJEAqACuAKMAtACzALEAsAC9AKcAoQCpAJAAmQCCAIuAdIB9AGUAbIBUgF6ASYBGAEGATQA4wDUAMUA/AC0AK8ApgCaAI4AgwC1AGQAVgBDAG1AFYAAACo/0P/3P5y/vj9YP3Y/Gj8APyY+zD72Ppg+uD5cPkY+dD4iPhA+AD4wPdw9yD3APfw9uD2wPaw9rD20Pbw9iD3UPeQ99D3GPho+ND4OPmg+QD6ePrY+kD7uPtM/Nz8dP0o/hD/8/+8AHwBOALkApADWAQwBfAFiAYYB8AHUAjQCDAJoAkAClAKgAqQCnAKUAogCvAJoAlACfAIkAgwCNAHeAcYB6AGMAbABVAF6ASABCgE1ANwAwQDqAJYAggCvAF0ASoB0wB8AC4A2v97/x7/yP56/ij+0P2A/Sj9uPxM/PD7qPtQ+/j6sPpY+gj6qPlY+Qj5yPiQ+GD4OPgY+PD34PfQ98D3sPeg95D3kPew9+D3GPhQ+Ij4wPgA+VD5sPkQ+mD6wPoo+5D78Ptc/OD8aP3w/Yr+Mf/l/5QATgH6AZwCIAO8A3AEIAXIBXAGGAewByAIcAiwCAAJQAmQCcAJ4AnQCbAJkAlgCTAJAAnACFAIAAjIB3gHEAeYBkAG6AWQBSAFyARwBAgEmAMkA6wCPALWAXgBGgG0AEgAzf9K/9j+fv4s/tT9bP0E/aD8NPzI+2j7IPvQ+oD6MPro+bD5gPlY+SD56PjI+KD4iPh4+ID4iPiQ+JD4mPio+MD48Pgg+Vj5iPnA+Qj6WPqo+vD6SPuo+xj8fPzo/Ez9qP0K/nj+8P5j/8//UwDYAEIBmAEEAogC/AJ0A+ADUAS4BBgFgAXoBUAGgAa4BgAHQAd4B6AHuAfIB9AH0AfAB6AHgAdgBzAH8AawBmgGGAbIBXgFGAXABGgEEATIA3gDJAPEAlwC9AGaAT4B3QCDACkA0f9u/xD/xP54/jD+6P2c/Uz9/Pyo/Gz8OPwM/OD7oPt4+1j7MPsA+9j6yPqw+pD6ePpw+mD6UPpY+nD6gPqA+pD6sPrY+vD6CPs4+2j7oPvg+yj8dPyo/Oj8LP18/cz9KP6E/tL+E/9g/8X/FwBZAKUA+ABEAY4B0AEMAjgCZAKkAugCIANUA4wDxAP0AyAEQARgBGgEgASYBLAEyATQBNgE2ATQBMAEwATABLAEkARoBFAEMAQIBNADoANsAyADxAJsAjgC/AG2AW4BHgHEAGwAIADh/53/Wv8a/97+pP50/jz++P20/YT9aP1I/Rz96Py4/JD8aPxI/Cz8DPz4+/D76Pvg+9D7wPvI+9j72Pvg+wD8OPxo/Hz8kPy4/Oj8EP04/WT9mP3Q/Qj+Ov5q/pb+yv4K/1D/jv/A//D/JABYAIQAswDqACQBUgF+AbgB9gEkAkQCcAKkAtQCBAM4A1wDbAN8A5gDsAPAA8gD2APwAwAE/APkA8ADqAOcA5ADcANMAywDBAPYAqQCcAI0AvYBugGEAU4BFAHTAJEAUwAZANf/lP9e/yz/9P60/n7+Wv40/gj+3P28/aT9iP1o/Uz9MP0Y/fj84PzU/ND8xPy8/MT81Pzc/Nz84Pz0/AT9FP0s/Uz9bP2E/Zj9sP3c/Qj+PP5u/pb+tP7Y/gb/N/9h/4z/xP8CADkAaACbAM8AAAEsAVgBegGWAbQB2AH4AQgCFAIgAjACNAIwAigCIAIUAgwCBAL6AeYBzgHAAbABnAGQAYgBfAFqAVoBTgFCATABGgEMAfkA4QDGAK0AlAB6AGIASgAxABUA/f/y/+b/1P++/63/nv+O/3v/af9V/0f/QP84/yz/Hf8U/wz/9v7Y/tT+zP7C/rj+tv68/q7+pv6u/qz+lP6I/pb+ov6q/rb+wv7I/sT+zv7u/g7/I/8w/0P/X/93/4r/nP+w/9D/8v8OAB8AOQBdAHsAkAClAL0A1gDpAPoACgEeASYBJgEsAToBUAFgAWQBZgFoAWQBWAFSAVQBXgFcAVQBTgFMAVIBVAFMAUQBPAE2AS4BFgH/AO4A4wDPAKsAhABoAFYAQgAhAP3/4P/L/7r/p/+X/4X/fP96/3L/Y/9R/0n/SP9E/zv/Mv8t/yr/J/8e/w3//P72/vj++P7w/ur+6v7u/vD+8P72/gD/Av8E/w3/Gv8j/yf/Kv8z/z//Rf9I/1D/Wv9d/13/Yf9q/3D/b/9w/3v/jP+h/7H/xP/l/w4AMwBLAGAAgACkAMMA2QDvAAgBJAE+AVQBZAFwAYIBlAGiAaIBpAGsAboByAHIAboBsAGuAa4BmgF6AWIBWgFIASQB+QDbAMQArwCUAHYAVQA3ACAACQDn/8P/r/+q/53/gv9r/2j/c/9h/0H/Mv81/zH/HP8A/+T+zv66/p7+eP5Y/kT+NP4g/gr+AP4C/g7+Iv48/lr+gP6u/tr+/P4Z/zj/Vv9p/3P/e/+D/4n/hP94/2r/WP9D/yv/Ef/y/sz+mv5q/jj+9P2o/XT9UP0w/RT9JP18/RT+sP5a/zUALgEYAvQC6AP4BPgFqAYYB4gH+AdQCEAIyAdgBwAHcAZ4BUAEMANIAkoBDwDa/vT9TP2w/AT8cPsg+wj7CPsQ+yD7WPvI+1D8yPwk/ZT9LP7S/lP/qf8AAHEA2wAaATQBTAFyAZIBkgF2AVwBSgE0AQ4B0wCXAGsATAApAPX/wf+i/53/mf+A/2f/af+D/5T/kv+M/5X/r//F/8n/xv/P/+L/7f/n/9f/x/+9/7D/oP+L/3b/af9g/1H/O/8v/zP/Ov85/z3/TP9s/4z/p//G//D/IABKAGoAigCyANcA6gDwAPoACgEOAQAB7ADbAM0AsACFAGAARQArAAcA5//R/8X/vf+4/8D/zP/X/+T/+/8TACQAMQBAAFUAZwBsAGcAZQBpAGcAWwBDACkACwDs/8v/qv+K/2z/VP89/yb/Ev8G/wH//P70/vL+9P78/gX/FP8p/z7/Vf9v/4z/p//C/+L/AgAgAD4AWgB3AI4AnACmAKsAsgC3ALcArQCcAIwAewBlAEcAKAANAPf/3//C/6X/k/+N/4v/hv+A/4T/kv+o/7n/wf/J/9r/7/8AAAYAEQAjADwATwBZAGAAbwCFAJQAlQCRAKAAqgCwAKsApQCnAJ8AlACHAG8AUAA6ACwAEwD2/9//zP+2/5r/gf94/3b/cf9k/1n/Xv9q/3b/gP+M/6f/yP/m//n/FAA5AF4AewCRAKcAwQDVAOEA6ADuAPAA5wDeANUAywC5AKIAigBzAFkAPAAjABQACwD9/+v/4P/e/+X/5//k/+P/5//t/+//5v/e/93/3v/X/8H/rP+f/5j/jv95/2T/Wf9W/1P/Uv9W/13/av97/4z/nf+v/8T/3f/y/wUAGAArADwASwBYAGEAaAB0AIEAiQCLAIoAiQCGAH4AdgBwAGcAWABIADkALAAZAAEA6P/Q/7r/of+G/2//Xv9T/0r/Rf9H/1L/Yv92/43/qv/M/+3/DAAqAEUAWwBpAHIAeAB9AH8AfgB6AHQAbgBlAF0AVgBJAD0AMwAsACQAGgATABQAHAAjACEAHQAhACwANQA1ADMAOAA8ADoANAAsACMAHAAUAAcA8v/X/8L/sP+b/4H/av9f/1j/TP88/zP/Of85/zz/P/9J/1f/Zv90/3r/f/+M/6D/qv+r/6n/qf+r/6v/o/+b/5f/k/+S/4z/hP+A/37/ev91/3P/ef+A/4n/lf+k/7r/1P/s/wIAFAAmAD8AWQBuAHoAfwCJAJYAnwCeAJkAmACaAJkAkQCOAJYAnQCeAJ4AnwCjAKwAtwDEANEA3ADhAOUA6wDxAPMA7QDlAN8A2gDPAL0AqACXAIoAegBnAFMAQQA1ACoAGgAKAP7/+v/6//b/6P/c/9j/1v/L/7X/oP+V/47/gv9x/2L/Wv9X/1L/Sf9D/z//Pf86/zX/Lv8p/yj/Kf8q/yj/Kv8x/zn/Ov84/zv/R/9Q/1P/Vv9e/2r/d/+E/4z/l/+o/7//1//s//3/EQAqAEQAWwBvAIkAqADHAOEA9wAKARwBKgE0ATwBQgFEAUIBPAE2ASoBHAEKAfcA4QDKALIAmgCEAGwAVAA6ACMAEAD9/+j/0f+//7P/p/+d/5j/lP+W/5n/nv+j/6z/sP+z/7j/u/+3/7H/rP+o/6D/mP+K/3//dv9n/1b/R/8//zb/Lv8j/xz/Fv8Z/yT/MP84/z7/Rv9U/1//Z/9s/3X/fP+D/4v/kf+Y/5//qf+z/7f/uP+7/8P/yv/T/9//7v/+/w4AIgA0AEUAWABrAH4AjgCgALAAuQC/AMIAxQDMAMwAywDJAMgAywDNAM0AzwDUANoA3ADcANwA2wDgAN8A1wDMAMAAugCyAKIAjwCAAHIAYwBQADsAJAAVAAgA9//k/+D/1//Q/8P/uf+z/6X/nP+c/5n/jP+G/4r/h/99/3L/Zv9d/1P/S/9K/0X/Ov8n/x3/HP8Y/xL/Bf/8/vb+8P7w/uj+7P74/gj/GP8w/0n/av+Q/7b/3f8DACgARgBnAIUAnACrALMAvADFAM0AywDJAMcAxQC3AKIAkQCEAH0AcwBiAFkAWwBnAH0AkgCvANkADAE+AW4BogHcARwCVAKAAqACxALcAvQC+ALwAuACxAKgAngCTAIUAuQBqgFyATIB9ACwAGYAHgDP/37/JP/C/lr+5P1o/fT8ePwA/Jj7MPvg+pj6WPow+jj6QPpo+qD68PpA+7j7MPys/Cz9sP0o/pT+7P40/2j/ev90/1L/Hv/c/oj+Kv7M/Xj9PP0Y/QD9AP0w/Xz97P12/gv/v/+MAIIBdAJoA2AEYAV4BngHYAgwCfAJsApgC/ALUAygDAANUA1wDXANYA1ADRAN0AxQDKAL4AoQCjAJAAi4BmAF9AN4AsgAA/8k/Uj7cPmQ96D14PMQ8mDw4O6A7UDsQOuA6uDpoOmg6QDqYOpA6yDsYO3g7pDwcPJg9GD2ePio+rz8uP6kAIQCMASwBfAGAAjgCGAJ0AnQCbAJUAnACBAIMAcwBigFGAQgAyQCMgFiAMf/Zv8b/xf/QP+E/yUA1gDEAcgC1AP4BGgG6AdQCbAKAAxgDaAOwA+AECARwBFgEqASQBLAEUARwBDQD4AO4AxQC7AJ8AfgBawDagFv/5T9oPuA+XD3wPVQ9PDycPEQ8ADvQO6A7eDsIOyA60DrQOsg6+DqwOrg6kDrwOtA7MDsgO3g7nDw8PGw88D1MPjY+pD9LgCsAlAF2AdgCnAMMA6QD8AQoBEAEgASwBEgEWAQYA8ADmAMoAoACVAHmAXcAyACpgBW/xb+0PyY+4D6qPng+CD4YPfA9mD2MPYQ9gD2MPbA9pD3mPjI+VD7LP1h/6wBEASYBkAJ4AtQDsAQABMAFcAWABgAGaAZ4BnAGSAZIBjgFiAVIBPAEDAOYAugCPgFPAN+AMz9iPuA+ZD3wPUA9JDyYPFA8CDv4O3g7ODrQOuA6qDpwOgg6IDnAOeA5uDlwOXg5aDmgOfA6GDqwOzg7yDzkPYw+sz9lAFIBZAIkAuQDiARYBMAFeAVIBYAFoAVoBSAE+ARIBAADsALgAmQB5AFfANyAb7/dP5I/QD8oPqA+bD4GPhA9wD2IPWA9DD0sPMg88Dy8PKw86D0oPWA9mj48Pr0/ZoAVANoBgAKoA3AEKATABbAGAAbwByAHcAdgB0gHSAcYBogGIAVIBNgECANoAmABpwD0wBC/rD7aPmQ9zD28PSw82DykPHQ8CDwIO8g7kDtQOxg62DqQOkg6EDnYObg5SDl4ORg5WDmwOeA6eDrwO5w8kD2OPoc/igCAAbQCTANIBCgEsAUgBYgF0AXABcAFoAUABMgEeAOYAzACUgHIAU8A0QBMf9Y/RT8UPtg+lj5aPjA91D34PYg9kD1gPQA9NDzcPMA87DyAPPA8+D08PWA92j5EPwB/zwCoAXgCHAMIBDAEwAXoBngG8AdQB9AIEAggB9gHsAcABvAGMAVQBLgDrALgAg4BcwBwv44/Cj6QPhw9uD0sPPw8oDywPHg8BDwgO8A7yDuIO3g68DqoOnA6IDnAOYA5WDkYOTA5GDlgOag6GDr4O7A8oD2SPqq/jwDeAcgCzAOQBEgFEAWgBegF2AX4BYAFsAUYBLgD1ANIAugCEAG/APYASkAzv6Q/UD8MPtw+vD5YPmY+MD3APdQ9rD1IPWA9LDzQPMQ8zDz0POQ9JD18Pbo+Gj7SP4eASgEoAcwC9AOABIAFaAXIBpAHKAdQB4gHuAdIB3AG8AZQBegFOAR4A7QC7AImAW8AkQAFP7Y++D5SPgw9xD2YPXA9BD0YPPA8iDyUPFg8EDvIO7g7MDrQOog6cDnoObg5UDlwOTg5KDlIOcg6aDr4O5w8kD2YPqs/mgC0AVQCeAMIBBAEoATQBTAFCAV4BSgE+ARIBBwDrAMUAqwB3AFCAQgAwACQAC2/sj9hP1U/Zj8aPuA+vj5cPlo+CD38PVA9QD1YPTA82Dz0PPQ9BD2MPfI+OD6fP1jAFgDUAaACeAM8A/gEmAVgBdAGWAaIBtAGyAbYBogGaAXgBVAEwARgA6wCwAJmAZgBCAC4P/0/VT8APvg+eD48PdQ97D2MPZg9aD04PMA8wDywPBg7yDuwOxA6yDqwOiA56DmIObA5eDloOZA6GDqAO0A8MDzcPdI+xH/oALwBWAJ0AygD4ARYBIAE8ATABSAE2AS4BBQD/ANQAwQCrgHIAYoBTgE5AIcAev/MP/W/k7+XP00/DD7cPpo+Qj4kPaA9cD0MPRw89DysPIg8xD0gPUA99D46Ppk/T4ALANABnAJoAygD0ASoBSgFiAYABmgGeAZgBmgGEAXoBXgE+ARgA8wDbAKUAhABhgEEAI5AKr+UP0c/BD7OPqA+dj4KPiA98D2EPZQ9VD0APOw8WDwIO+g7eDrQOoA6eDnwObg5WDloOWg5kDoYOrA7MDvoPOw94j75v44ArAFUAmgDCAPwBCgEWAS4BLAEgASgBAAD9ANgAywCpAImAZABZAE4AO8AjQBLQCp/2H/nP6I/YT8uPvo+tD5YPjw9sD18PRw9NDzYPMw87DzwPRQ9iD4MPpk/Oz+1gHoBOgHsAqADWAQwBKgFOAVABfAFyAYABhgF2AWABWAE+ARIBAQDgAM8AngB/AF+AM8AqgAQ/8C/tD8wPvg+hj6WPmI+MD3EPdg9oD1gPRw80DyAPHg74Du4OxA6+DpwOig56DmIOYA5sDmQOhg6qDs4O5g8oD2qPoq/h4BcAQgCLALcA4gEAAR4BHAEiATQBLgEJAPsA6QDeAL0AkACKAGwAXgBJgDGALnAFMAs//O/oD9RPxA+0D6IPmw9zD2APVA9KDzIPPQ8tDyYPOg9ED2MPhQ+tD8n/+MApAFkAhgCwAOoBDgEsAU4BWAFiAXYBcgF2AWYBUgFMASIBFQD2ANcAuQCeAHGAZQBLACUAEXAP7+CP7s/AT8OPuA+oj5kPiw9/D2APbg9LDzgPJQ8TDwIO+g7SDswOoA6gDpwOfg5gDnQOjA6YDrQO1g71DyIPYg+oz9MAAMA7gGEAqADOANEA9AEEARgBHgEJAPUA6gDfAMkAugCSAIOAd4BlAFGATgAuABLAFyAHL/HP6s/GD7KPrA+FD34PWQ9JDz8PLA8qDywPJg87D0kPaw+Nj6PP30/+wC+AXACEALsA0gECASoBOAFCAVoBXAFYAVwBTAE8ASoBFgEOAOQA2wCzAKsAgoB5gFEAS4An4BQgAt/yj+JP0g/Cj7MPo4+UD4gPeg9pD1QPQQ8wDyIPHg76DuYO0A7KDqYOkg6ADn4Obg54DpoOrA68Dt0PBw9PD3MPtu/sQBMAVQCNAKkAwwDuAPABEgEaAQsA/QDuANwAygC0AK4AiwB6AGmAV4BHADgAKoAe8AAwDQ/kD9sPuA+mj5APhg9uD00PNQ8xDz4PIA86DzEPUQ9xj5CPtg/UAASANIBgAJgAvQDSAQIBKAE0AUoBQAFSAVwBQAFOAS4BHAEKAPYA7QDEALAArQCHAH+AWYBGQDWAJqAWMAUv9O/lz9gPxw+2D6aPlo+ED3APaw9GDzAPLA8KDvgO5A7eDrQOpg6EDnwOZA5+DnwOhA6oDs4O5Q8YD0KPjw+6j/yAKABdgHMApwDCAO4A4gD4APUA+QDnANUAxgC4AK0AnwCMAHmAbgBUAFWASMA7QC0AGIAA3/hP3w+1D6uPhQ99D1gPSA8+DykPKQ8kDzgPQA9uD3EPpk/N7+iAFYBCAHoAnwCxAO4A9AESASoBIAE0ATIBNgEoARgBCQD7AOkA1ADAAL4AnQCNgHiAYoBfgDCAMsAiwBKQAv/yb+SP2s/AT8GPvg+dj4APgQ9/D1gPTQ8pDxoPDg72DuIOwA6sDogOgg6ADoQOiA6WDrwO0g8IDyYPUw+Uz9ugBYA5gF+AdQCmAMwA1QDjAO8A3ADVANUAwQCxAKgAnwCGAIkAeABpgFKAXoBGgEMAOwAUgAB/+Y/cj7yPnA90D2IPUg9BDzQPJA8hDzYPTg9aD3oPkc/MT+egEYBJgGAAlgC4ANMA9AEOAQYBHgESAS4BFgEaAQABBwD+AOEA7gDMALAAtgCjAJqAcgBgAF+AP4AsQBHQC6/uT9YP2I/CD7APqg+UD5ePhQ9yD28PQA9FDzYPLQ8MDu4Oxg6+DpwOjg58DnQOhA6eDq4Owg77DxIPXo+KD8AADkAmgF0AdACkAMUA2ADZANkA1QDVAMIAsQClAJ4AiACNgHEAeIBkgGEAaoBeAE8AO8Ak4Brv/E/cj7yPkA+FD24PTw8zDz0PIQ8xD0wPXA9wj6jPwa/7wBYAT4BhAJ8ArADDAOIA9wD5APsA+wD4APEA+gDhAOsA2gDUANYAywC3ALMAtQCvAIoAeIBqgFcATgAuQAP/+Y/iT+uPz4+gD6OPoo+nD5SPgw92D2APYQ9kD1UPMw8YDv4O3g68DpQOig5yDngOeg6CDqwOtA7uDx4PXA+UT9ZgAgA/AF4AhgC6AM4AxADbANgA1wDCALAApQCfAIoAjgB/AGYAZoBngGCAY4BagE2AOIAtsA8v70/OD6+Pgw94D1EPQg88DywPJQ89D08PZA+Xj7yP2AAFQD8AUwCDAK8AtQDTAOkA6wDqAOwA7gDpAOEA6wDZANQA0QDdAMgAwQDHAL0ArACVAI6AbQBagEBAMAAWr/Nv44/VT8YPto+sD54PlY+uD5aPgw9yD3UPew9gD1sPJA8ADuYOyA6qDoIOfg5sDnAOlA6gDswO5A8lD2mPqG/mgB7AOIBgAJAAvwC4AMkAxADOALUAtQCiAJgAigCMAIcAjoB5AHiAdwByAHkAaABfQDTAJgAAT+gPtQ+XD3oPXw89DygPKA8gDzQPRQ9uD4mPsg/oMA4AJQBcAH0AlACzAMEA2wDfANsA2QDZAN0A0ADhAOEA7gDdAN0A2ADQANMAxACxAKcAjABjAFfAPUASUAyv6c/ZD8uPtQ++D6iPqo+vj6+Ppo+qD50Pjw9wD3APZw9ODxoO4A7EDqwOig5wDnYOeg6MDqIO2A7yDyoPXw+Rj+OAE8AwAF0AZgCGAJ0AmwCUAJ0AiACPAHEAeQBtgGmAdACIAIcAgwCLgHWAfQBrgFCAQQAv3/yP1g+yD5MPew9bD0gPSw9CD10PUg90D5yPtO/pIAsAJ4BBgGsAcACQAKsApQC+ALIAwgDDAMcAzQDHANAA5wDqAOgA5QDgAOYA2ADGALsAm4B+AFKARUAlYAnv6o/RT9fPzY+1D7EPtQ++D7IPyY+5j66Pkw+fD3EPYw9IDyYPDg7QDroOgA58DmgOeA6MDpYOsA7hDxYPSw9xj7aP5qAdQDoAWYBiAHyAdwCNAIwAiACAAIsAeYBwAIgAgACYAJwAmwCVAJkAg4B6AFAASAAosAEv5o+/D4EPfA9QD1oPSw9ED1YPaw90D5GPtg/cb/5gG4A0AFcAZgB1AIMAkQCuAKgAvgCyAMcAwQDQAO8A6QDwAQYBBAELAPwA5wDQAMkArACLgGcARwAr0Aaf9O/nT93Pyg/NT8BP3U/HD8XPxc/Az88Ppo+bD38PWQ9BDzMPFA7mDrgOkA6cDo4OiA6eDqAO1g7yDywPRg9xj6PP0JAAQCJAMQBNgEWAXwBZgGAAfoBrAG0AZIB9AHgAhACfAJYApQCvAJ4AgoB1gF0AMgAu3/eP0Q+wD5QPcw9sD14PVQ9hD3SPio+Qj7rPyS/l0A8AFoA4gEIAVgBdAFuAa4B6AIgAlgClALQAyQDeAO4A+gEIARwBFAEQAQkA4ADRAL8AjoBvgE/AJaASwAK/9i/jr+zP5R/0r/Dv/c/pT+BP40/QD8KPoI+ID2UPVw8wDxwO4g7YDrQOqA6aDpAOqg6kDsAO7A71DxkPNA9sj4KPtc/Qn//f8SAbwCQAQgBbgFgAZIB/AHoAhQCdAJIArQClALEAvwCaAIWAfIBRAEZAKtAKz+uPxQ+zD6MPmQ+Kj42PgI+ZD5ePpo+zD8RP3O/i4AOAEkAiwD3AOoBNgFOAdgCIAJAAtgDHANMA4gDyAQoBDAEKAQ0A9gDgANwAswClAI4AbYBdAEvAP4AoQCEALYAfwBKALQARABRgA0/+D9lPxQ+8D54PdA9jD1wPOw8WDvoO2g7CDsIOyg6wDrgOoA6yDsIO0g7uDvMPKw9FD32Png+4T9Mv9AASgDsATQBZgG8AYwB/gHAAnQCVAKwAoQC8AKMApwCXAIMAcIBuAEOAM+AUr/yP18/ID70PpI+vD5wPnI+QD6gPpo+7j8Iv5e/2MAJAGkAVwCWAOQBPAFUAegCLAJ0AoQDGANkA6QD0AQQBDgDzAPMA6gDAALgAlACAAH2AUABTgEdAPcAsgCyAKUAkQCwAHFAFz/DP70/Hj7mPkQ+BD3MPbg9GDzkPGg70Du4O3A7WDtgOwg7EDsYOzg7ODtIO9g8DDywPRg93D5aPtA/ez+eAA0ArwDkAQABaAFkAZQBwAIwAiACeAJ8AnwCaAJwAiYB5gGgAUQBHwCFgGw/zz+LP3Q/Lj8bPwk/Pj7EPxI/Nz89P3U/n//JADyAKgBNAIIAyAEWAWIBsAHEAkgCgALAAxADUAO0A4AD8AOAA7wDMALsAqQCTAIEAdIBqgF+ASABFgEAASQA0gDBAM4AtMAiv92/jT9oPtA+gj5kPdA9mD1oPRA82DxAPBA74Du4O2g7UDtgOwA7IDsgO1g7oDvEPEA8wD1YPfo+QD8aP2s/h0APAE8AmAD0ATQBZAGkAeQCEAJ0AmACgAL0AogCmAJYAjgBkgFGAQEA/4BVgHwAFoAof/8/oT+EP70/Ub+yP7c/rr+4v4j/4f/RwB6AcQC7AMwBWgGaAdQCIAJ8AogDBAN0A0wDsANwAzgCzALcArACTAJUAjwBtAFcAVYBSAF+ATwBHAEVAM0AjAB3/9+/nD9lPxY++j52Pjg93D20PTA88DyYPEw8GDvgO5g7cDsAO3g7IDs4OxA7oDvgPAQ8gD0wPVQ90j5SPt0/AD9AP55/9cASAIYBLAFYAa4BrAH0AhACWAJkAlACWAIaAfIBtgFYARcAygDEAOgAigCrgG0AJf/LP+I/+z/4v/Q/8D/fP9i/yAAQgFMAjwDeAS4BZAGKAfwB/AI4AngCvAL4AwwDfAMgAwADGAL0AqACiAKQAkQCAAHWAaoBQAFoARwBAAEVAOQAnoBNQD+/iD+PP0Y/OD6uPlA+GD2sPRw81DyMPFA8IDvgO6g7WDtoO3A7cDtIO7A7oDvkPAg8qDz8PRg9mD4MPpQ+wz86PzY/e7+jAB4AggE0ARwBVAGKAfAB1AIwAiACMAH8AZQBkgFWATgA+QD/AP8A/gDhAOUAogBHAEiAUIBSgFCAQwByQD6ALgB5ALoA8gEoAV4BhAHqAdQCPAIkAlQCkALEAyQDOAM8AzQDGAMwAtAC5AKcAkgCPgGIAaABRgF8ASYBAgELANgAlIBFQAr/zT+2Pz4+jD5sPdA9gD1APQg8/Dx4PAw8KDvIO/A7oDuQO7A7aDtQO4A78DvsPAw8qDzEPXQ9oj4uPkw+rj6ePtg/Kj9b/8MARwCnAJgA1AEMAUQBuAGeAdwBwgHgAbYBSgFsATIBEAFoAXYBcAFAAXMA9ACcAJsAmgCfAKQAnACIAIUAogCHAOwAzgE8ASQBQgGgAbwBkgHsAeACKAJoApgC+AL8AtgC7AKUAowCgAKoAnwCDAIOAeABiAGAAagBRgFWAREA/gBtwCE/xL+XPyY+gD5oPeQ9tD1MPUg9ODyoPGQ8MDvQO/g7qDuQO4g7mDu4O7A75DwgPGA8pDzkPSw9cD2sPdw+GD5sPos/ND9jP8OAQQCdAIYAwgEAAW4BSgGWAYIBqAFcAWYBbAFqAW4BdAFwAWYBYAFOAV4BKADHAPgAtAC/AJoA7ADrAPEAyAEkAToBDAFaAWYBcgFOAYAB8AHUAjgCGAJ0AlACpAKwAqwClAK4AlgCeAIgAgwCNgHOAdoBqAF8ARYBLAD/AIYAucAbf/c/WD84PqQ+YD4sPfg9vD1IPVQ9GDzYPKQ8SDxwPBA8ODvwO/A7+DvgPBw8WDyYPOA9HD1MPag9lD3KPgw+WD60Pso/TL+MP86AEoBHALcAqgDUAS4BOgE+ATwBOAECAWQBTgGsAbYBqgGIAaABRAFyASIBDAE8APoAxAEUASABKgEuASoBKAEuAT4BCAFAAXoBBgFsAWQBpgHkAgACdAIUAgQCEAIoAjgCKAI+AcAB1AGAAYIBggG+AXYBYAF2AQgBFgDRALxAJH/Xv5o/cT8XPzQ++D6qPm4+AD4MPcw9lD1gPSw8xDzoPJw8mDygPLg8oDzUPTw9GD1YPUw9fD0IPXQ9eD2MPh4+Zj6iPtQ/AD9wP2k/qf/nwBIAbQBEAJsAqwC9AJ0AxgEqAQ4BeAFQAYQBogFKAXwBNAEwATYBOgEwASoBMgE4ATQBLAEqASYBFAEAATwA+QD7AM4BNgEaAXYBSAGMAbwBXgFQAVABVAFWAWIBdgFGAbwBYgFCAWABAgEpAN4A3gDhANwAzwD7AIwAioBJgBZ/6D+zP30/Dz8iPvY+jj62Pm4+Yj5+PgI+BD3QPag9SD1APUg9XD1APbQ9oD3wPfA96D3oPew9+D3IPiQ+CD54PkA+1T8rP3c/qz/HQBCAD0ANQBTAJkAHgHaAbACjANwBDAFoAWwBXAFAAWIBDAEIAQwBDgEQARoBJgEyAT4BCAFAAWgBDAE1AOYA3QDhAPgA2AEqAS4BMAEwASwBIgEgASwBNgE0ASoBJgEiAR4BGgEgASwBJgEEARIA2ACnAEyARQBLgFmAaQBwAF+AZ8ALv98/ej72Pqg+nj73PxE/uT+Iv4Q/Ej5sPYA9bD08PV4+FD7OP2Q/VT8OPow+BD3EPfw9+D4oPlA+uD6gPsY/ID8rPy4/LD8yPws/XT9SP3A/HD89Px2/nwAPAIkAzQDtAIcAqwBogEgAuQCZANYA/gC0AKIAwgFYAZ4BkgFAASoAygEqASgBEgExANMAzADsAOwBNgFgAYoBtAERANwAogC8AIMA9ACkAKcAvQCRAM8AxADBAPwAngCegFQAFv/5P70/kr/pP/5/0cAaABKAOn/Lf8K/tD8BPzY+wT8XPzg/IT96P3k/ZT9CP0s/AD7CPrI+Sj6sPog+6D7NPzQ/Fz9xP30/aD9xPyY+3j6+Pl4+uD7tP12/5YA0wAnACL/Yv4K/tT9vP06/jP/CgBUAHoADgHSATQCPAIUAm4BawBWAOwB4ANoBIgDkALmASIBnAAaASACgAKsAiAE6AWQBfQC5QDLAPwAngBsAYADqANEARIAvgF4A8AD8APIA+gB9/8pAKMA/v6s/cL/rAJsAiIB7AIYBcQCvv7S/iwBQwDI/KD7XP1W/sz9Df+8ArgEkAIp/8T9JP0w+1j5aPpA/dL+pP9gAoAF2ASvAJj8cPkw9mD00PaU/NYBAAXwBjgHgAT3/wD8kPhA9cDzwPX4+ooBuAewC6ALMAfwALD7QPhg9gD3qPos/4QCQAX4BxAJYAdIBHQBwv74+2j6IPvE/FT+xwAgBIgGmAeQCKAI6AQC/lj4gPag98D6hABoB8AK0AhwBRQDGwBk/Mj6+Pu4/Q7/2AAQA3AEaAQYA8sAev60/Yz+g/83AGwBTAJkAXr/7P3w/Bj9M/+CAZYBQAA1AG4BeAHn/7b+Pv4Y/TD8qP1pALQBAgH0/sD8yPyo//QBxwDI/bD7CPs4+8D8HgBcA3QD9AAO/7r+SP7w/Aj8uPzw/iIBrAFqARwC4AKUARr/Mv6b/y4B9wDZ/7T/RABUALQAbAIoBMAD3gEiAbIBeQA0/TT82v4UAeIAcAE4BPAFaAQgAiAB9v5w+vD3WPpk/m4BWAWgCSAKEAb/AHD9gPoQ9yD1EPgk/jQDUAcADFANkAZw+0D10PZI+hT8B/98A3AEqgCK/ooBqASoA4ABwgB+/uj5kPdQ+m3/PAMgBTAFMAOQAFH/Bv7A+zj7tP0EAGn/vP28/mAC+AN0AeD+Lf+YAIwBMALGAeL+6PrI+oH/BAKS/iD98AMAC+AHbP2g91D6SP7N/4wCEAZIBRABzP7a/tT9+PuQ/Pb/VAMIBQgFCAO7/0D9SPwQ/Kz8dP75ACgDWAR4BMQD7AGy/hj7aPkI+2z+LgG4A4AGGAaoAaL+JwBEAUD9UPjw+Lz9bwDDAFQC4AOoAyAEWAWAAvD64PTg9GD4IPvM/pAF0ArwCTgGtALg/ZD3oPPw9bz8egFMApAEMAmACagDnP0I+2D5cPcg+eD/qAWIBdQDqASgA2z+cPvE/RX/jPzY+2YAYAWIBTwDDAPIAxIBgPwg+xD9Sf//AKwCzAPcAl//zPwN/9wDSAV0AkMAiwAh/4D6kPkFAIAFpAKY/TD/UASYBI3/DPxQ/cz+TPzA+Zj8JALABAgEjAJmAav/uPww+7T84P04/a7+vALgBKADHAEV/9z93P3a/2ABeP5Q+nj8NALMAnUAPAP4BwAEePlA9mT8Hf+A+8j8oANQBGX/tQBYBkAEaPyI+jT+tP1Y+vD89AKUA44ADgHgA9AEIAQeAeD6cPag+Q4BgARYA9ADAAZQA6j9dP12AVABzP0e/o4AXP7I/OAEwAyQBpj7mPvbACT+ePly/7AJYAgk/7D9AAKT/yj5wPk4APgEAAa4BBACXP6I+0D7JPy8/UACeAZYBCD/xP31/6gAUP7Y+3T8ZP5e/v7+bAPwB3gG4/+g+0z9OP/Y/Ij7+P4AAej9rP2gBNAIcASL/2L+OPsQ9wj5eP7w/uz83QBQBygHnANYBOgDgPqQ8GDygPszAGgBSAeQDrALy/9Y+Wj81P1Q+PD0oPrcA3AIkAe4BlAH5AMo+3D1cPiE/7wDWANsAmAEoAXkAioAv//E/gT9aP0GAJACMAPMAb4AigGYAmYBHP7M/Cr/w/98/Gj84gGABQgFAAUIBHD9APXA9J7+2AdQB/IBmv/A/Rj6YPqxAIAF7AOPAH8AZAGA/hj6EPqc/Uz+zP3cAgAJGAbA/Qj7+P2W/rj7lPxSAfAABPxE/QQDlgG4+/z8/APgBRABKP5y/0L+8Plg+loAZANqAbv/WQBgAUgC9AIIAon/JPyg+Wj6JP7UAZADMATQBBgFtALE/UD7vPyw/Zz9bQAIBGADAAFMAgAFuAM0AJf/s//w/JD7Lf8AA0gDWAPABHQDGf8+/igCGALw+wj5OP0kAnQDEAQQBsAFIADI+aj5Hv7x/zD+Zv5UAggEpAAS/vIAWAT0Aaj7YPeA+NT9hAIYBNAEwAUkA0j8wPcY+h3/lgAqAFgCbAPq/oD7h/8wA6D/JPyk/ngBLwDu/nwATAEj/6D9V//q/zj9+P1QBBAGGP8w+3wAoAOc/tj7xABoAxD+WPoOALgGqARiADoBiQBg+3D7sgG0AxwAAv+uAUQCOwApALoBYAB0/Yz+OAKkAnYASgBOAcwAwf+m/xwAhAFIAwQCcP24+tT9fAM4BWgCHwDr/4r+APzY++7+UAIoAxwBh/+oAWADlv8o+zz9dgHI/9j64PvcA+AHKAK0/Cv/bAFC/iD9x/8x/5D7kPunAOgEXAMBAMgAogEw/dD5qP3MAsoB2PyY+2oAiATcAlIArwCA/4D7cPp8/cEAaANIBWQD9P3w+0MAUAPW/rD60v5kA9wATP6IAZgDOABY/twBOARBAPD66PoA/8ABpALQBNAG6APU/Xj6JPy/ANQD+gGk/qT+AABCAcgDIAbgBM//OPqA+sYAYAGI+nj78AawCxAEyP06/6wAiP3Q+nD7EPsQ+qf/8AjQCUAE6AOoA0D5IO+g8+b+zAGX/wgEkAtACVD/ePu0/mz90Pag9vz9SAGw/rsAIAhwCVQCJP28/fD9qPuI+1z82Pmo+eABkAkoBwgChAL8Agb+UPng+kT/2v90/TD+wAFoA1gD6AKsAQoBEAGo/pj7dPx4/8UAbgHUA+AF4AOc/jj7HPyY/uD/8QCQA9gFMAVsAej7aPjI+2wDYAbsAtD/kgGIA9T/6PoE/bgCuALA/hv/oAPYBEkA6Pv4/IkAbgFbAH8AugGqAVj/aP36/pYB5f+I+2D6nP2EAtgF2AQMASL/Vv6o+xj6EPxI/mb/4AGABBgEngEbAIH/XPyw9+j4WQDoA6gBPAJgBfQCJP0k/M7+hP5Y+9D7WgGQBYgEbAIMA4ADMf8w+BD2IPvuAFwDYAUACPAGBgFU/Ej7mPo4+lT9lAJQBbAEjANgA1ACh//Y/Yj99PwY/aL+GwDIAnAHkAhQA2z9lPxY/nr+fP2A/QP/RAHYA4AFiAQIAgYAzP04+9j6GPww/ScAsAQoB8gGiAQY/0D4gPaQ+/T/vP4b/0AGEApgAsj5CPvG/gT9yPv7AIAFtALw/db+DALI/tD3WPk4A3gH6AIdAGgChgEY+iD1WPrYA6AGIAKY/o3/kAF+AVwASv8Y/UD7AP0yASADngEqAAYBRgFM/sj74P1MAdQBiAFkAgQBUP0Q/REABAEJAM4BUAWQBKL+gPoQ/UABfAIEA1wDdgFG/1L+mP08/pwBAAUgBF3/sPzy/loAhP1M/fgCKAZsAl//UgGGAQz8sPcY+vj+SAHQA+AIgAoIBDz84PmA+BD1QPZJAGALQA3wBev/3AA4AHj5QPaw+rD9zPwU/6gGAA3QCjwCiPuo+ED3iPiI/J3/pgEwBOgFEAbQBNwCFACA+lD0cPRw+xwD4AgwCwAHmP+s/PT9gP2Q+ij6vP4wA+ABi/8MA1gG8AFE/Z4AtAMM/XD1EPl6AUwCewDgBtAMgASA90D3Tv6o/UD7PAMADFAH1P1Y/dv/NPwo+iQBMAdUAzb+FgHsA3b+YPlM/cAC5gHX/2wCAAWKAUD8iPxK/+D9HPxeAMAFiAS8/0T+Wf/4/bD7EP7YArADmAD8/az9dv9yAQsAyPzo/TgEsAYp/3D34PqQAiwCZv4UATgFfgHY+Uj5jQAIBSACKP/eALgCnf8A+tj5kQD8AyT/PPxYAWgFOgF0/GsAuAaoA2D7QPmI+0j8wP7ABHAH7AKY/gwBqATMAZT8aPtA/Bz98/8YBLgFiAMuAOL+/v9uASoBgv7c/DP/6QAe/uD9CAXQCewD2Ppo+ST+GAHCADIBnAK+Acr+YPzQ/KoA7ANsAvf/tQDb/4D6WPhy/pAEoAL0/XT/+AN8A4IAhwBv/+j5QPew+8D/rf8MAlAIgAiO/xD6OP+AA0r+8PfI+ID8Iv6lABgGYApACRgEsv7I+iD4YPfo+Dj8zQB4BbAI0AlACAQD2Pvg9dDzoPcS/6gEoAY4B1AGWAIs/Xj74P2O/uj7UPykAfgEoAOgAvQCqwBA/Tz+zAH2ADT96P04AlADpAFwAtwDHAFQ/RD+kQD5/4z+kP9qAVwBKAB2ABwCugEa/xz+CP8g/2L+9v7XAHwB3//Q/s8A2AJAAeT9PPxY/CT9Tv9QA5gGOAVj/4j66PoG/kP/vP49AJADgANQ/+j8cv5V/wL+bP6IAeACOQCk/RT+6v4K/wgBEASsA6P/sPwI/QT+3P38/soBsAKWAbABbAJSAR//EP1o++D70v6YAWgCoAIgBJAFmAJs/BD6KPxw/cz9qgB4BJgF8AP6AeUAHf8Y/OD6tPw+/4gB4APgBLgDcgGW/mj8kPye/vcA1AEyAeMAqwBl/xv/DgGoAbr+6Pu0/Lf/ugHQAqgEoAWcA4T/YPvA+DD55Pw4AeADmARoBHwDKAEc/uD8JP2k/Nz8sv/uAU4ALv57/+YBSAEd/+T/PAL0AIT8EPv4/RwArP/E/+EA5ACKALgBGAOsAmYByQCV/2T80PlY+xz/DAFAAtAFYAnIB5IBWPzw+kD7OPsA/Jr+7AFIBNgEeARIBBQDhP9Y+3j5YPqU/Nz+QgFgA0gExAO4Ak4BO/9o/dT86Pws/bT+XgEQA/ACrALUAvIBnP+s/ej9+v7a/mz+xf8sAhAD/AGbAPn/dv9q/pD98P0k/w0AfgDjAHIBuAEaAej/Av+C/gL+yP1M/kj/UADkAMcAmQDJAKoAGwDl/6r/tv7s/Wb+Kv8w/0//mAD+AfYBNgEoARoBkP+U/Qj9rP06/gD/nAAoAqgCZAK+AWoAcv70/PT8Cv4Z//X/+wDGAcABVgHhAAoA4P4m/i7+zP7M/8AAKAEwATIB7ABMANP/v//F/6f/t/9CAMYAwQCiAPcADgEuAPr+dP7W/sT/8wAEAngCDAL4AMD/2P56/rT+Tf/T/xQAhgCGAXgCUALnAEn/Fv5I/TD9MP6n/68AUgEEAlwCegHm/97+Sv58/RT93P1J/2EAHgHcATgCjAEGAIb+yP0A/qj+Gf9H/6P/bwBUAbYBeAHqAEEAuf95/0//A/+6/vT+4/8QAagBkgFSAQwBLADW/iz+mP5r/9X/8v9ZAOMA8wCmAJUAcADY/z7/Mf+B/73/x//r/0YAmQDIAPsALgHvADgAgv/w/pb+4P7U/80AUAF4AWoBAgFTAIz/A//O/uz+d/9OAOoADAH1AN0AlwDj/zH/Gv9z/4X/av+j/zwArQDBAL4AjwASAHf/Ov9h/3b/dv/E/1EApgDEAL8AnAB8AF8AHgDX/9D/AAA9AGsAkwDPAAYBCAHuAOUAzQCdAHMAUQArAPT/vP/C/wwAUQBgAC8A2P+B/2X/df+4//T/0/96/1P/aP9b//D+mP6O/qT+3v5c//b/NAAWAMf/aP/+/rD+qv7c/hL/U//W/34AAgE8Af8AdgDz/5T/cf99/5z/sP/T/wsAPABrAK8A9AD7ALcALQCe/y7/Af8W/zj/dP/y/4MAogA8AMv/lv9f//7+qv6Y/qz+zv4P/4T/9v8nADgAbwCgAJIAUgAWAPX/2v/V/xcAfQDjAFAByAEQAvwBogFqAWgBYgE4AVABtAH+AfwB9gEQAgwC9AHWAZwBJgHGALQAowBgADYAcACiAHMARgA+ABYAsv9R/zj/E//M/sb+F/9N/0X/QP9J/0L/A//o/uj+uP5s/or+Df9j/2z/jP+u/2T/xP5Y/jD+1P1Y/fD8zPyo/IT8cPxo/FT8IPzg+5D7MPvQ+oD6OPoo+lD6iPro+mD78Pt4/Az9vP1i/uj+iP9JABQB0gGkApwDmAR4BWAGYAdACAAJ0AmQCiALkAsADEAMUAxgDFAMIAzQC4ALMAvQClAK4AlQCYAIeAdQBjgFCATMApYBfgCH/4z+vP0Y/WD8cPuQ+tj5IPlA+GD30PZg9vD10PUg9qD2APdw9/D3EPjg98D3cPfA9rD1APXQ9KD0UPQQ9MDzAPNQ8lDyAPPA8zD0QPTg82DzUPPg8wD1kPaA+Jj6TPyw/RH/ggC+AbgC+AOgBWgHQAkgC9AMEA4ADyAQIBEgEgATgBOgE0ATwBKAEmASQBJgEoASABLgEJAPYA4QDZALAAqgCCAHsAVwBHADOAL6AAcAK/9U/oj99PxU/Fj7SPp4+fD4iPho+ND4WPno+Zj6gPtI/JT8yPwI/Qz9AP38/CD9DP3k/Oj8BP0Q/Uz9qP3A/YD96Pw4/Gj7qPro+Uj5mPjQ9yD3gPbg9SD1MPQQ88DxgPAg78DtQOzg6sDpwOgg6EDowOgA6iDsIO/g8uD22PpC/kkA0gHEA4gG8AnwDcAS4BagGUAb4BwgHqAegB5AHsAdIB1gHIAbIBoAGAAWYBSAEiAQEA2ACQgFcwCU/Jj5QPeQ9ZD0APTQ88DzAPQw9GD04PTg9eD28Pcg+XD6oPvo/LL+9QAQA/gE2AZgCHAJgAqQCzAMMAzgC6ALAAsACvAI0Ad4BhAFxAOoAoQBBgC2/jD9QPsY+VD30PVg9BDzQPIQ8vDxIPKQ8iDzkPPw83D0IPXw9dD2sPeA+HD5MPro+mj7wPvo+8D7UPuo+tD50PjQ97D2MPWA8xDy0PDg72DvgO8A8NDxMPWo+bD9YQAsAvgC9AKkAxgGwAnwDCAPABEgE+AUQBbAF0AZIBrgGmAbYBugGeAWIBSgESAPAA3AC6AKwAjABZwCs//E/Cj6YPgg97D1gPSA89DyMPIg8hDzoPRA9rD3GPkw+uD6iPvU/ED+mf9EAVgDQAVQBvgGkAf4BwAIIAiwCOAIoAgACFAHKAbIBMwDUAPMAsgBjABU/wb+nPxg+2D6cPmA+ND3gPdA9wD30Pbw9hD3YPcI+FD5GPpA+mj64PpQ+yD7EPtI+1j78Pqg+qj6cPrI+Qj5ePhw9+D1IPSw8gDxQO8A7gDugO5g7xDxkPOQ9mD5lPzX/3QC5APABJgFQAegCaAMkA/gEaATgBWAF+AYQBlAGWAZIBlAGOAWoBWgE6AQ4A3wCzAKEAjYBYADcwAk/Zj6MPmw9wD28PTA9FD0kPNg87Dz4PNA9LD1wPdg+XD64Pts/az+GwAoAigEqAXwBnAIkAmwCZAJ0AlQCmAKUApwCkAKEAmwB7AG+AUYBRAEQAMUAqgAIf/s/cT8cPtA+qD5WPmw+OD3MPfQ9oD2gPbg9oD38Pcw+LD4IPlw+aj58Pkw+jD6QPpg+nj6GPpw+dD4aPjg92D3oPaw9VD0gPLA8GDvQO6A7UDtwO3g7sDwkPOQ99j7df9QAhgE4ASQBaAHAAvgDZAPQBFgEyAVgBagF8AYIBlgGQAagBqgGYAXIBXAEvAPYA2AC2AJEAZYApf/aP0Q+wD54Pcg9xD2QPUg9fD0APRQ88Dz0PTw9TD3yPgw+lD76PwQ//gAYALwA+gFiAdwCBAJgAmACRAJAAlwCbAJgAkwCaAIuAeYBsAFOAVgBDQDFAIOAaX/AP5s/Bj7CPow+ej4qPgY+HD3APfg9tD2APdg99D3KPhw+Nj4QPmQ+Rj6qPpg+9D7HPwU/Kj7SPvw+oj62Pko+XD4oPeg9rD1sPQw82DxoO9g7mDt4Ozg7GDtgO7w8AD1WPkA/RUA4AK4BOgFgAfwCcAMkA4gEIAR4BLgE2AVIBcgGIAY4BhgGSAZABgAFmATwBBgDpAMUAooB4ADcgD0/aj7sPlA+DD3MPaw9bD1kPXw9FD0cPTw9LD1sPbw9+D4qPnY+sz85v7VANAC6ATQBmAIkAmACrAKkAqgChALEAuwCiAKcAnACPAHMAdYBngFiAS0A7QCXgHD/zT+yPyA+6D6+Plg+XD4sPdA9xD3wPZw9qD2APdw99D3UPig+Nj4CPmQ+Tj60Po4+1D7MPsA+9j6oPoo+oj5+Ph4+ID3cPZg9WD0IPOg8YDwYO8g7iDtAO2g7YDuIPBw89D3+Ps7/6ABmAN4BbgHkApQDVAP4BBAEqAToBSAFcAWoBdAGAAZwBnAGcAYIBdAFUATIBEwD+AMsAkIBqAC7P8w/YD6cPgA9wD2YPUw9dD0EPRw88DzoPRw9SD2APfw94j4kPkY+8j8TP78/wQCQAQoBqgH8AjgCcAKkAswDEAMwAswC+AKYApgCTAI+AbgBcgE/ANgA3QCBAFs/yb+RP1M/Aj72PnY+Cj4kPfw9mD2oPUQ9TD14PWA9tD2IPfg96D4KPmw+Uj6oPrY+ij7kPuA+xj78PrA+lj6oPk4+dj4APgA9xD2QPXA80DyMPGQ8GDvQO7A7QDuQO/w8fD1oPko/HL+lAF4BKAG0AhgC8ANcA8gEaASYBOAE2AUABZAFwAYgBgAGaAYoBfAFuAVQBTgEbAPYA0wClgGqAJc/0j8yPkw+AD3kPVA9LDzoPOA86DzUPQQ9aD1IPbA9nD38Pe4+OD5WPv4/Lj+wQDEAqgEoAaQCDAKUAsgDMAMIA0gDdAMQAxwC2AKQAlACFAHYAZgBYgErAPQAtoB3wDB/3D+IP34+wD78PnY+LD3sPbg9WD1EPUA9SD1cPXw9bD2YPfw91D42PiA+Qj6YPpw+kj64Plw+Wj5ePko+YD4IPjQ9zD3cPbQ9SD1YPSw8zDzQPKg8KDv4O+A8ZDz0PVQ+ND6aP1VADwDaAVAB1AJ0AsADoAPgBBgEQASwBLgEwAV4BVgFqAW4BagFgAWIBUAFOASgBGAD8AMUAn4BRgDkQAw/uD7wPkQ+MD2wPUg9dD0wPTQ9DD10PVQ9oD2gPbA9nD3WPhg+Vj6aPvg/Lz+zQDEApAEOAb4B5AJ4AqwCxAMEAwQDNALIAtAChAJAAhAB5gGwAWwBLwD9AIwAkQBYQBT/0D+IP1M/Ej7APqA+ED3cPag9fD0gPQw9BD0gPRg9RD2UPbQ9pD3iPgg+XD5iPlg+Tj5OPkw+dj4YPjw99D3cPfw9kD2sPVQ9fD0UPRg83Dy0PGg8XDy8PPQ9bD3kPng+2r+yQDQAsAEoAbQCCALMA2wDnAPIBAAESASABOgEyAUgBQAFSAVABWAFMAT4BLgEYAQUA7ACwAJYAbQA1gB0v50/Gj66Pig96D2kPUQ9SD1gPXw9TD2YPag9gD3cPc4+OD4YPno+fj6kPwU/r3/ggF8A1gFOAcQCbAKoAswDMAMEA0ADXAMoAvACtAJAAlgCFAH+AXYBEAEvAPAAoQBewCZ/6j+kP1A/MD6KPnQ97D2kPVA9FDz0PKQ8oDy4PKA8xD00PTQ9dD2YPfw92j40Piw+ID4aPg4+MD3YPdQ9wD3kPYw9jD2APaQ9TD1MPUA9ZD0cPQQ9TD2sPe4+Qz8/P1//wIB7AIABQgHAAmwCjAMgA0AD0AQABFgEeARoBJAE8ATIBQAFGATABPAEmASQBGgDwAOIAwACqgHSAW0AkMARP6s/Bj7cPkI+PD2QPbw9fD1EPYw9qD2QPeQ98D3CPiQ+Cj5uPmY+rj79Pw2/pj/LAHYAqAEWAboB0AJcApwCwAMEAzwC7ALYAvwCkAKYAlACCgHQAZwBaAEvAPYAggCEAEiABf/7P24/Jj7WPrA+DD34PXQ9MDz0PJQ8lDygPLw8pDzEPSQ9DD1IPYg97D30Pfg99D3oPdw92D3QPcQ9+D2wPaQ9kD2IPYA9gD2APYQ9kD2cPbw9vD3mPlw+xD9mv4mAK4BSAMIBdgGgAgQCrALUA2wDsAPYBAAEYARIBKgEuAS4BLAEoASIBKAEQARQBAwD9ANMAxACvgHoAVoA1oBbv+o/RT8cPro+KD3sPYA9tD14PVA9rD2IPeA9+D3SPio+CD5yPm4+qj7nPxs/ab+HAC+AYQDSAXQBhAIgAnACnALsAvwC0AMQAzgC1ALYAowCRAIQAeIBqAFyATwAwAD9AHyABYAGf/o/dj8uPtI+oD48Pag9UD0EPNQ8jDyMPJA8oDy0PIg88DzkPRg9RD2kPbQ9rD2UPbw9dD1wPWQ9XD1YPVA9RD1APUQ9UD1gPXg9SD2YPbw9gj4gPkI+5D8KP6t/zAB0AKIBEgG+AeQCWALAA1QDnAPYBBAEeARgBIAE0ATIBMAE8ASYBLAEQARYBCAD1AO0AwQCwAJ2AbgBPgCAAEP/0z9oPvg+Vj4EPcw9oD1QPVg9aD10PUA9mD20PYw97D3aPgg+eD5wPrQ+/j8Ov64/2wBGAPIBHgGAAgwCRAK4AqgCxAMIAwADOALUAuACrAJ4AgACBgHiAboBfAEzAPEAtIBvgCb/6T+kP3g+zD6mPgg92D1wPOg8gDyoPGQ8eDxAPIA8iDyAPMQ9ND0QPWg9QD2MPYg9gD24PXA9eD1MPZg9lD2QPZw9tD2MPdw98D3MPiw+Fj5WPpw+4z8wP0p/7oANAKMA+gEWAbIB2AJAAuADKANkA6AD2AQABGAEcARABIgEgASwBFgEcAQIBCAD8AOwA2ADPAKIAlAB1gFeAOuAfD/Ov6E/Oj6WPkI+CD3sPaA9mD2YPaA9rD28PYw94D3APig+Ej58Pmg+mj7dPys/fz+YwD2AZwDSAXgBkAIYAlQCjAL4AsgDBAM0AtwC/AKQAqACbAIwAfgBjAGeAWIBIADpALmAfYAx/+O/jz9oPvw+Uj4kPaw9CDzUPLQ8cDxwPHQ8dDx8PGg8qDzQPRw9MD0YPXA9bD1gPWA9ZD1gPXA9QD2EPYQ9mD20PZg97D3GPi4+GD5IPrg+qj7fPyg/QH/XwB6AaAC9ANoBdgGUAjACRALQAxwDZAOUA+wDyAQgBDgEOAQwBCgEEAQwA9AD7AO8A0ADRAM4AqACcgHIAZgBJAC1AAh/4T94Pt4+lD5cPiw9zD34Pbg9uD2EPdA93D3oPfg91D4wPhA+cD5YPow+yz8WP26/jwA5AGkA2AF4AYwCFAJUAoAC2ALkAugC4ALQAvQCmAK0AkwCZAIAAhQB5AG0AUIBSAEMAMoAiQB8P+o/gT94PqY+KD2MPXg88Dy8PGg8aDxoPHQ8QDyQPKQ8iDzsPMA9AD0APQg9BD0IPRQ9KD00PQw9bD1UPbA9jD34Pe4+Hj5KPrI+nD7FPzg/OT99v76/xwBhAIABGAFsAYgCIAJ4ApQDKANkA5QD/APgBDAEOAQABEAEeAQoBBgEAAQcA/gDkAOgA1wDFAL8AlgCJgG2AQEAwIBFv9o/ej7gPpQ+XD4wPcw99D2wPbA9sD2wPbw9iD3QPeQ9/D3aPjY+GD5IPoI+zT8jP0T/5oALALEA1AFmAaYB4AIMAmwCfAJEAoACtAJsAlwCQAJgAgACLAHQAeoBvAFMAVgBHwDkAK0AZ4AOf+I/cD70PnQ9/D1kPSw8yDzoPJA8vDxkPHA8TDykPKg8tDyEPNA8yDz8PLQ8uDyEPOQ8xD0cPTQ9FD1IPbQ9oD3OPgA+cD5cPoo++D7cPxI/Xz+x//1ACwCgAPoBFAG0AdgCeAKQAxwDaAOgA8AEIAQ4BBAEYARgBFgESARoBBAEPAPcA/QDiAOUA0QDJAKEAlwB7AF5AMwAnMAnP7c/GD7GPrw+Bj4kPdA9+D2oPaA9mD2QPZQ9pD20PYQ92D30PdY+AD54Pno+ij8oP06/80ANAKcAwAFQAZABwAIoAgQCXAJsAngCfAJwAmgCYAJMAnACFAIyAc4B4AGyAXYBNwDsAKuAXoA/P5M/Wj7SPkg96D1wPQQ9EDzsPJw8kDyAPLQ8eDxEPJQ8oDygPJg8mDykPLA8uDyQPPw88D0YPUA9rD2gPco+Pj46Pm4+jj7qPtU/Pj8mP1y/o3/xwDoATADgATABfgGYAjgCSALMAwwDRAOoA7wDoAPABBAEIAQwBDgEMAQYBBAEAAQkA8AD2AOUA3AC0AK0AgwB1gFkAMkAqEA9P50/VT8SPs4+oj5KPmg+AD4gPdQ9wD3wPbA9vD2EPcg94D3IPi4+Fj5WPqw+/j8OP6d/xABUAJsA6AEsAWABiAHsAcwCIAI4AhACYAJkAlwCVAJMAnACEAIqAcgB2AGaAVgBFQDIALRAJz/Uv6o/KD6mPjQ9kD1EPQw89DyIPJA8fDwEPEA8aDwUPCA8ODw4PAA8TDxYPGA8RDyIPPw84D0UPWA9oD3EPio+JD5UPrw+qD7fPwU/ZD9eP7V/w4BIAJAA6gE+AUQBzAIYAlQCkALUAxADdANIA6wDkAPwA8gEGAQwBDAEKAQYBAgEIAP4A5QDrANsAxAC9AJcAgIB4gFEASYAiQByf+M/mD9HPzw+gj6gPng+Cj4sPdw9yD3wPaw9uD2IPdA97D3cPgg+bj5kPqo+8z8DP53/9sACAIgA1AEaAU4BgAH8AfQCGAJ8AmgCgALEAvwCvAKsAogCpAJ4AggCEAHgAa4BYgERANcAl4Bt/94/SD7CPkQ94D1cPSw89Dy4PFQ8RDxkPDg76DvoO+g74DvgO+A70DvQO/g78DwcPEg8jDzQPTw9JD1cPZQ9wj44Pjg+bD6KPvo+xj9cP6p/wIBqAIoBGAFkAbgBwAJ4AnQChAMEA2gDUAOAA+wDyAQwBBAEYARgBGAEUARwBAgEJAPIA9wDlANAAzQCpAJEAioBmgFMASsAhQBsv9q/uz8kPu4+vj5IPlg+PD3cPfg9pD2gPZw9lD2YPbQ9iD3YPfg9+D4APrw+uj7PP2s/sn/ywDmAfwC1AOgBKAFkAYwB+AHsAhgCeAJEAogCvAJcAkQCdAIYAioB/gGaAaoBZAEgAOUAlwBff9o/Wj7qPkI+MD2APYw9XD0wPMw85DyoPHg8DDwoO8g7wDvAO8A7+DuQO8g8NDwcPEw8gDzsPMg9LD0YPUQ9tD2sPfQ+Oj56Poc/Jj9Lv+wABgCZAOIBIAFiAawB9AI8AkwC6AM8A3gDpAPQBDgECARQBFgEaARgBFgESAR4BCAEMAPEA9gDnANIAzAClAJ6AdYBvAEjANAAuUAuv+e/lD9+Pvw+lD6kPm4+Aj4sPdA97D2gPaA9oD2kPbw9qD3KPiI+Dj5QPoY+/D7EP1o/ov/cQByAYgCeANABFgFqAbAB3AIEAnACeAJwAnACeAJ0AnACfAJ0AkACfgHWAfYBrAFMAT0Am4BFf+k/CD7OPoY+fD3MPeQ9kD1sPOQ8qDxQPAA78Du4O6g7iDuYO4A7yDv4O5g7zDwgPCg8EDxMPLg8pDzwPQw9kD3QPiw+TD7WPxY/cb+dQDIAfACSASoBcAGAAiwCVALcAyADcAOsA8gEGAQIBGAEcARIBLAEsASYBIgEiASwBHgENAP8A7gDWAM4AqQCSAImAZYBVAEBAOIASYA8P6g/Tj8GPtI+mD5iPjw94D3EPeA9nD2sPaw9pD2wPZA96D38Peg+LD5mPpw+4j87P3q/pr/dQCUAYgCWAOYBOAF6AZoB/gHoAjQCMAI0AgwCYAJoAmgCWAJwAgACGAHoAZQBeQDiAIsAWv/lP1Q/GD7WPoA+eD34PaQ9QD0sPLA8cDw4O+A74DvQO+g7oDugO6A7oDuAO/A7wDwMPDw8ODxkPJA84D0EPZQ90j4mPk4+5T82P1Z/9QA/gEAA1gE0AUYB3AIIArQCwAN4A3ADoAP4A9AEAARoBEAEkASoBLgEoAS4BGAESARYBAQDwAOMA0QDLAKgAmACEAHsAVgBEwD6gFOAAj/Kv4c/dj72Ppo+tD54Pgg+OD3oPcQ97D24PYw9zD3UPfg97D4APlw+YD6kPso/IT8eP2K/hb/lP/OAHgCnAM4BMgEMAUgBRgFoAVoBtAGIAeAB6gHQAeYBjAGsAXQBPQDUAN4AioB/P9T/5r+gP1U/Ij7uPpo+eD3sPbA9fD0YPQA9LDzQPPQ8lDywPEw8fDwIPFQ8WDxgPHA8RDyUPLg8qDzcPQg9eD1sPag97D4+Plo+7D85P34/gEAKAGIAhgEkAXgBjAIcAlwCiAL8AvwDNANkA5QD/APQBBgEKAQ4BDAEIAQIBCwD/AOEA4wDYAMwAsACzAKQAn4B5AGWAVQBDgDGAImAVwAcP9q/oD9xPz4+zD7kPoY+rj5UPkg+Rj5IPkg+Tj5aPmY+bj5+Plo+tD6MPuw+1D89Px0/fD9nv5R/+3/aADtAG4BzgEYAngC+AJIA1QDcAOYA6ADTAPkAswC2AKUAggCkgE8AagA5v9R/wX/iv7Q/SD9qPwM/DD7kPpg+ij6qPko+ej4uPhA+ND3wPfQ98D3cPdw96D3sPew99D3OPho+Kj4EPmY+fj5UPrY+nD7APyM/Ez9Cv68/mb/NwAKAbwBYAIYA+gDkARABfgFmAYYB5AHEAiQCPAIQAmACcAJ0AnACbAJkAlQCRAJ0AigCGAI6AeAByAHmAYIBoAFIAWgBBAEoANAA9QCTALWAYIBGgF/AOn/k/9u/1X/Jv/g/pj+Zv4+/gT+wP2s/bz9zP3E/cD93P0I/hr+Gv4s/k7+bv6U/sr+Av88/2L/iP+//+////8BABMAMgBMAFEATgBfAGoAYgBMADgAFQDe/6P/ev9Q/xP/wv6K/lz+Gv7M/Zj9aP0g/dT8nPx8/FD8EPzY+7j7mPto+0D7IPv4+tj62Prg+tj60PrY+uj6+PoQ+zj7WPuA+6j70PsA/Cz8bPy0/AT9XP2s/ej9KP52/tL+Lv+L//P/ZwDNACYBeAHYATQCjALYAhwDaAO4AwgESASABLAE4AQABRgFMAU4BUgFUAVYBVgFWAVIBTAFEAX4BMgEkARYBDgEGATQA4wDZANMAyAD5AK8AqQChAJMAhAC8AHOAaQBhAFwAU4BFAHnANgAxACqAJYAjgB6AFgAPgAzACUAEQANABkAEwD///f//P/8/+L/zP++/6r/i/9u/13/Qv8f/wL/4v6+/o7+YP4w/vT9vP2U/XT9QP0E/cz8nPxo/DD8+PvQ+6j7gPtY+zj7GPsA++D6yPq4+qj6oPqo+rj60Prw+hD7OPto+5j7yPsI/ET8iPzI/BT9ZP24/Qb+Uv6q/gn/Yv+x/x8AewDRACIBegHcASQCcALIAiADZAOwAwgEQARoBIgEuATwBBgFMAVIBWAFaAVoBWgFaAVgBVAFOAUgBQAF6ATIBKAEeARQBCgE+APIA5gDcANEAxAD3AKwAoQCUAIgAvIBzAGeAWgBNgESAfYAzgCeAG4ARAAcAPP/yf+i/4D/ZP9K/zD/EP/2/ur+3P7E/qT+jP5+/nD+Zv5W/kT+NP4i/hb+Dv4A/uj92P3M/bz9qP2Y/Yj9fP1o/VT9QP0s/Rz9CP3w/Nz8xPyw/KT8lPyI/Hj8ZPxQ/Ej8SPxM/FT8VPxg/HD8hPyU/Kj8wPzg/Aj9OP1k/Zj90P0E/jj+cv6u/ub+HP9U/5D/zv8JAEUAfwC+APcALgFkAZwB2gEcAlwClALMAvwCKANMA2gDjAOkA7gDzAPkA/QD/AMIBBAEIAQYBAgE+AP0A+QDzAOwA5wDiANkA0ADIAP4AsgCoAJ8AlACHALqAcABmAFmATQBDgHsAMIAjABfADkADgDc/6z/jv9l/z7/HP/+/tL+qP6O/nz+Yv5G/jD+Hv4Q/gT+/P3w/ej95P3k/eT94P3c/dj90P3I/cj9zP3Q/dD91P3Y/dz93P3Y/dj91P3Q/dj96P3s/fT99P38/Q7+GP4g/i7+RP5U/l7+bv6I/qb+uP7K/uD+8v7+/hb/PP9h/4H/m/+y/8z/7P8PACwARQBmAJAAvADfAP0AHgFGAWoBigGuAdIB+AEYAjQCSAJcAnAChAKcAqgCsAK4AsQCyAK8ArACqAKkApwCkAJ8AnACWAJAAiACBALmAcIBmgF4AVYBMgEIAeMAwQCbAHMATwAtAAgA3f+1/5T/df9L/yD/+v7W/rL+kv52/lb+OP4k/hj+Cv78/fD95P3g/dz91P3U/dz95P30/QT+FP4g/ir+NP5G/l7+cv6E/p7+vP7W/vD+Bf8f/zn/Uf9o/4L/nP+2/83/3f/s//7/EAAcACQALAA2AD4ARQBLAFUAXQBiAGgAbgB3AHoAfQCDAIwAkACOAJEAmQCiAKkAsAC8AMkA1QDaAN4A5gDzAP0AAgEGAQYBCAEOARwBKAEwATYBPAFAAUIBQgFAAUIBPgE8AToBNgEsASQBHgEUAQgB9gDnANgAxgCzAKEAjwB8AGoAVwBBACgADgD2/9//yv+4/6b/kP95/2X/Vf9H/zb/Jv8a/w//Bv/+/vT+6v7m/uT+4P7c/t7+5P7q/vD+9P76/gb/FP8j/zL/Qf9T/2T/dv+C/5D/nP+q/7X/vf/K/93/6v/v/wAACAAPABEAGAAmACUAJQAxAEAARABEAEgARQA7ADMAMgA2ADIAJAAZABUAEgAGAPn/8v/t/+f/3v/W/9L/z//M/8X/w//F/8j/yf/L/87/0//W/9f/2P/h/+z/8v/4//3/AwAJABEAHAAtAD8ASgBRAFgAYgBtAHQAdwB5AH0AggCHAIoAjQCTAJ4AogCfAJgAlgCYAJUAjQCDAHoAcgBoAF8AVwBLADsALAAgABIAAQDx/+P/1//I/7j/qv+e/5D/gf9y/2X/Xf9X/1H/Sv9D/z7/Of81/zb/PP9C/0f/Tf9Z/2b/dP+A/4r/lv+i/7P/wv/O/9z/7f/+/wwAFwAiACgAKwAtADMANwA4ADoAPAA+ADoANgAyAC8ALwAwADEAMAAxADAALAAnACIAHwAVAAkAAwD9//P/6v/n/+j/5v/f/9j/1P/V/9X/0//Q/9H/1P/T/9D/0v/Y/9z/3//n/+7/9f/6/wMADgAVAB4ALAA8AEMAQgBJAFMAWQBYAFwAawBvAHEAdQB7AHUAcwB4AHwAdgBxAHYAcgBnAGAAZABgAFMATABNAEoAPAAxACsAHwASAAoAAQD4/+v/5P/f/9f/z//G/7n/qf+h/6T/pf+Z/5D/kf+X/5f/k/+X/5//qP+o/6r/s//D/9T/2v/f/+f/6//n/+7//P8GAA0AEQAUAB0AJwAtAC4ALQA0AEEARgBAAD8ARwBNAEUAPwBGAEoARQA9ADkAMQAlAB8AIQAcAA0AAQAEAAUA9//n/+P/3//U/8b/wP/B/73/tP+w/7D/r/+p/6b/ov+h/6H/n/+f/5//nP+d/6L/qv+v/7L/t//A/8j/y//L/87/0P/U/9v/5P/l/+D/4//v//n//f8FABMAGwAZABgAHQAhAB8AHgAoADIANgAyADIANwAyACoAKAAtAC4AKAAmACwAKwAgABgAFwARAAgABQAIAAgAAgD+//7/AAD+//v//P8CAAkADAAJAA4AFgAXABMAGAAqADMAMQA5AE4AUQBDAEYAWABeAFUAVABpAHwAeABsAHUAhgCEAH0AgACCAHUAYgBbAF4AVgBLAEoASwA6ACQAHAAeABUAAAD3//f/6v/R/8b/zf/K/7n/q/+o/6L/kf+F/4v/kv+J/33/fv+D/3//dv91/3n/gf+I/4b/gP+F/5b/m/+Q/5T/rf++/7P/r//G/9z/2P/U/+j//v8CAAUAEgAgACgAJQAjACwARgBdAFYAPwBCAGMAcABUAEgAdQCMAE4AEQA3AHoAUQD6/yMAgwBNALn/yP9VAEkAm/9e/9j/GgDn/83/AwD0/3D/QP+z/wMAvP+C/8b/AACl/z//ff8cAC0Asv+V/wwASwDy/6b/6f9XAEYA+f8QAGkAjgBhADMASgB+AIQAXgBoAKsAygCPADUANQCJALEAgABdAIgAtgCIAB0A/P9IAHgAKQDT/+n/HAD4/7z/yf/a/5z/Z/+a/87/mv9L/1T/bf8s/+r+If91/0f/+P4a/1n/Nf8H/0//nP9W/wb/jP8+AAcAY/96//X/nP/s/lb/cgB0AGj/Cf+y/xEAwf+w/xcASAAgACkAcACXAKQAzADjALwAkwC5APUA4gCyAMwAAgHKAEQAOQC5APQAggAhAE4AZQDy/37/nv/m/5D/MP94/67/Tv8f/4n/vv9A/9z+Xf8dANz/Lf9//yEA1P8v/4j/lADgACAAs/+GACgBWwB6/1wACALGAeX/s/+2AWQCQQBL/3gB2ALeACT/qgBcAlQBmv+GAO4BqwAQ/10AIAKVAKb+1v9YAev/av7g/24BDQAS/uL+bgCv/5r+j/8+APj+cv5z/8b/2P6i/qL/1f/Y/pz+sf/8//b+lv5i/xIAi/+2/lT/fgAnAJr+gv4lAL8AZv+2/iIAvwCE/+j+5/+RAJz/Lv9TAPoA3f9U/3QAzADZ/7b/oACBALr/EwDoAKQAzf/0/7QAdwDQ/1EAAgFaAOn/twCHAGT/uv9mASABA/8J/2gBrgHG/jT+HgEEAiL//P2zACQCt//w/eT/0AFmAE7+SP84AcIAIv87/3oAkwCP/yP/CwDRAFQAe/+y/0EAMgDu//v/MwBMAFIADQD1/0sApwBPAN3/KADAAIwAy//z/9kA3wCX/1P/hgDmAPH/O//r/+MAfQAb/9z+TADBAID/rv6C/8MAQgCs/rT+nADQANb+dP4/AP0Ap/+8/pj/ygAhAOr+cf9+AB0AdP/z/xQAvP/I//v/JwDy/97/KwA1APX/KABSANj/2P+XAFAApP9NAOsAGQCd/6kAxACN/4L/9wBmAe///v5WAEwBMQB8/1IA3ABKAAQA3/8fAOcAcQA6/1r/zAAuAZT/sv5RAKwB3P/c/YT/mAGLAGr+7P5mAesA9P38/cABbgH8/Zj+kgFCAcT9Ev6gAaQBuP1g/uACYAH0/Gz+1AJYAVT96P4QA8QBDP1E/gQD1AFo/Zz+5AJwAYz9wP7sArgBeP1S/nQC+AEI/R7+lANwArD8SP08AugB4P1M/iQCgAFw/cD9LAK+Aaz9Cv4YAXYBmP7M/dX/OALVAFD9Zv6aAFoBff8I/v//LAKOANj8Pf+cAoEAPP2B/0QD6ABY/Aj+EATsAkT8gPy4A6QDLP1s/PwCEAXI/QD7SAHYBN7+MPwwAqAEpv4I+20A0AQ4AUz8Sv+8A3oA1Px7ACQDvP/o/cn/ngEFAHj+VQC8AnMAUPww/gQCMgG+/kX/WAHfAMD92P2EAZYBQP5e/t4BQAJE/mD8yQAYBCr/sPv4AJAEFv+I+9EA+AQlAMj5HP/QBggBEPmQ/6AI2gDA9kz9AAngA/D2YPzgCdgEEPbw+YAIQAbQ+BD5YAbYB8j6YPc0A7AH+P1A+fEAqAV2/2j7AAAwAx3/WP2mARACWP1Q/eADnAOI+8D7AARUA4j7PP1oBVgD0Plw+4gFwAQA+lD68AX4BlD74PecApAHvP0o+RwCgAZo/hD6GAFoBTsAePt/AOADbf/w/JYAOARYAhz+lPxl/wgD7AJF/9z90AFoBLT+MPqa/9AFHAIc/T4AgAJW/nD9pAKgAsT9Sv4YAxwBsPvm/ugFkAIY+cj7KARYA9z8FP6ABLQBWPus/GIB/ACaANQBcv+a/rj/CACX/wb/pQD6AbX/TP0eANgB1P8nAAABAf/4/F3/SAIAAgUAe/+S/xr+aP2uAGADWADc/cAAVgEw/UT+pgE+Aan/I/+s/xkARf9R/3QCUACg+7H/ZAPU/vj8iAJ0A0T9JPxDAPQC3v8M/QAC2AQ4/jj55wDIBfL/EPyGAFAFkwDg+Yj+EAfSAbD5g/9YBxgBuPhY/iAH9AKI+g7+iASJAND7igAwBW//2Pp+AeADDPzg+wAFQAUo/QD7IgBgA0//jPyiAVAExv+U/FD+mAA8AQAAB//HANgBZP/A+5T+MASkAkT8OPxMAvQChv6w+68AMAX6/zj6dP34A5AC4P30/lwDVAHQ+TD8aAbwBVj7wPnQBOgGWPtQ+HADcAiA/nD4zgHAB3D90PcYBMAJgPtQ9FgCQA0yAbDz/P3AC6wCYPNA+8ALWAeA+ND5sAW4BND5+PlwBfAI1P3A9b//UAmAAbD2NP3QCfAEYPfQ9+AGAAm4+7D52AKQA2D70P3IBsQDiPqY+0gEvAMY/Ej8IAXQB/T9kPfE/XAFIAS6/nb+YgFIAEz8qP5gBEYBqPsd/8gEFQDo+Yb+WAWgAiD74PwcAoUAWP5AAqgDGPx4+DIBkAjcAAD36PwwCUAGwPcg9mgE0Akg/ij4vAHoBoz9oPisAtAHDP2Q9ywDwAku/lD2z/8wCUwCMPjw+2gFoAR4/ZT8owBqARL/Nf8aAesAqP74/koBOgH0/Wz8fAGoBXoB0PqI+8wC+ATk/nD79wAgBZL/+PpF/2QDFgC4/RwCeANU/Hj5VALgB8b/GPiS/hgG4ABA+h7/mAVwAcj7Fv4AA4kA8Pu5AKgGTgHg+JT8SAVYBJT8HPx4BLAF2PwA+f7/sAUgA8L+9P3L/6QAn//m/tcAJAPIAWz9+PufAFAEsQDA/eYBkAIo++D5fAPIB8IA6Pr4/XgC1v/g+0L/SAXUAx7+jPxw/TD/OAJAAxwA3P32/qP/a/92/2wBnAL2/kj7Bv54Al4BUf+IAXQC2Pw4+Hj9OAZwBk7/yPtY/v3/hv5a/kwBQATUApz+sPuE/TgCWAN/ADj/iwBN/0j9pwAQBoADqPu4+vQAvAOC/x7+OARYBvD98PfI/AADYAOuAbABBAEw/SD7cP/YA4IB5P2D/8YBtP/c/G7+6AJMA7b+gPs4/WwB/APYAon/Lv5E/gL+4P6yAYgD/gGy/3L/sf8Q/oD9VAEwBcQCMP1w/O3/5gF2AWsAeP9f/97/IwDb/+3/XgGAAv3/NPwk/qQCGALI/44AcAHO/gT8Gf8gBYgDBPwU/LACCANg/aT8aAIgBVr/wPks/dgD8AOe/5T+AgDk/uD8Gv/0A0AEF/9g/Dv/GgHI/nD+qAJYBMH/CPuM/MoBaAPuAAD/qv4Q/tj9NwDcAmgCBv+g/LT9kP8mAO4AWAKUAWz++Pvk/MMAvAPQAoX/jP2E/fz+AAH+AcoBeADC/vj9dv7Y/+AB7AJCART+aPws/qYBQAMAAub/PP44/Sb+/gAYA7QC3QAd/6j9UP18/xADaATMARr+AP1e/tkAAAPsAkYA6P06/ov/iABwARgCnAFa//D87PwTAHwD5AMsAVT9yPvw/aQBcAPaAUv/iv4t/+D+lP74/wwCMAL1/2z9qPzc/iAC/AKDAGj9RP2N/+cAFABq/xYBmgGG/gD8fP4EAwQDXv86/tz/QP8I/sgAGASSAfD8zP2WATIBTv6q/ygD8AGc/UD9mgDWAZAAkQAQATP/TP2d/xQDDAJo/nD+aAH1AND9Fv5QAqADBQB0/RL/OgGCAHv/0gAgAogAeP6G/7oBcAG//+v/egE+AXP/U/8kAbQBZQCG/xoAqwBdAFUAqgCdAAIAgv+u/yIAYgBbADIAu/8y/zD/hv/K/9n/uf+X/0z/9P7+/mD/8v8WAG7/sv7k/pz/i/8K/yb/vf+P/8r+7P65/5D/zP6k/jX/fv87/03/sv+X/9D+fP4N/8v/pv9B/6v/FgDK/2f/k/+9/4L/xf/HAEIBawD9/9oA6QCK/zX/BgF8AuIBmABuAPoAyAB2AFQBIAJiAZgALgHWAVgBkAD0APIBrgFoAE4AyAHAAjQCyADJ/0UAegEMAuoBvgGKAbsAv/+K/7AA7AHMAeEALACC/9T+YP+EAJEAdP9k/lj+5P4B/1r+Ev4U/oz95Pxw/JD8eP0c/kD9uPsw+6D7cPzU/Mj8xPxk/Mj72Puo/BD93PzU/Dz9hP0Q/ez8Ev4d/7D+iP18/cT+t/++/7b/IgBAAML/2f/8APABzgHgAbwCFAOQAoQC5AMwBaAEuAPABGgGUAaYBUgGYAfwBugFiAZgCLAIgAdYBwAIqAeIBrgGEAigCFgHoAVABZgFUAWYBEgEaAT4AyQCNgD+/6kA+/8S/vj89Pxo/AD7UPpA+gj5APcQ9rD2oPbA9eD1MPbg9HDyEPJw85D08PRA9UD18PPA8pDz4PUg9zD30Peg+Gj4GPgw+Uj7uPzM/LD81P1J/wMAcAAsAdoBQAKEAngDQAUoBqgFEAVgBRAGgAZAB3AIEAkwCAgHAAfAB4AIIAmQCYAJ8AigCMAI8AhwCUAKUAqQCVAJAAowCjAJsAjQCUAKwAjwB9AIMAngB3AGeAbABuAFyATQBOgEhAPeAf8AiAD0/x7/Mv6c/UD9GPwg+uj46PgQ+fD3MPbQ9RD28PRQ83DzUPRw89DxwPHQ8pDysPGg8pD08PMA8uDyIPag99D2sPYI+Nj4uPgQ+gD9Hv4o/Tj92P6t/1b/PQCoAvADSAKrAAQCEAQ4BHgD9ANoBBQDSAHuATAEeAQEA3QCuAKqASwAzgD8ApADCAISAbABZAJsApwCHANIAywDcAMwBEgFgAa4BogFyATQBXAHYAjwCMAJwAkgCCgHwAjQCpAKwAlACqAKUAnwB+AIgAqgCWAHyAawB5AHKAYoBfAE/APsAaQAFAFaAdH/3P24/PD7MPpY+GD4SPkY+DD10PPw83DzQPIw8sDywPGg74DvIPGQ8RDxUPIw9DDzEPHA8WD1WPjA+OD4YPlA+ej4kPrI/fT/vQDfAMUAdAB/AKoBpAMYBSAFaATEA7gDaATgBLgEIASkA3wDcAOEA0wD4AJoAsgBJgEqAdQBdAJgAqoBCgGuALgAkgHsAoAD3AJ8AhgDtAMABLAEAAbABlAGCAYAB0AIgAigCHAJEAqwCXAJIAoQC/AKAAoQCtAKIAuACtAJgAlACWAIqAegB4gHUAagBJQD8AIcAvkAIwBd/8j9oPtg+uD5yPhg93D2gPXQ82DyMPIw8vDwQO/g7uDuYO6g7oDwsPGQ8CDv4O8A8ZDxYPPw9lD5kPjw9vD2SPhA+jz9ugDUAX4As/9VABYBPAJYBDgGEAaoBIgEaAVYBdgEiAUYBugEsANIBHgFAAU8A2wCMAKIAUoBtAIgBAgDlwC+/5kA5QDIAMIBWANcA34BmwAoAqwDmAPUAzgF2AXYBKAEiAZQCLgHoAagB0AJYAnwCKAJgArgCRAJgAlgCqAKUAowCuAJgAhIB4gH4Ac4BzgGcAVgBPQCsAHoACEAuv6M/aj8QPto+Tj4gPcg9pD0wPOA82DyMPHA8DDwwO7A7SDvEPHw8ODvcPAg8aDvgO8w86D3aPig9qD2wPdg95D3+PvWADgBwv4s/tz/vQAAAfQCSAUgBYADbAPoBEAFkASgBAgFgAR4A2wDcATwBAgEkAKoAUwBtgHIAowDVAMkAucAegDNAHoBqALEA+wDXAPoAiQDsANIBEgFeAbgBrgGIAcwCNAIcAiwCPAJoApwCuAKkAuAC9AKcApwC0AMkAvQCuAKgApgCTAIsAfAB3AHWAYABawDSAIqAdH/bv54/Xj82Poo+QD4APdQ9VDzcPKA8qDx4O8A70DvgO7A7IDsQO4g8BDw4O7g7oDvwO8A8ZD0OPgY+RD3QPWA9kj5sPu2/vgByAJTANj9HP/EAuAEGAXYBXgG0ATMAsgDsAbQBngEmAOoBMAEYANEA7gEoASuAb7/6QCEAvQCFAMYAxAC8P+k/i0A4AL0A9QDlANcA9wCeAIgAzAFQAfQBwgHwAaIB5AIAAkgCeAJwAoQCwALcAvgC0ALAAvAC1AMwAsACzALYAsgCnAIyAe4BwAHGAZgBSAELAJdAKT/nv6E/Lj6MPqQ+ZD3UPUA9JDzMPJA8KDvAPBg76DtwOzA7ADtAO3g7cDvgPAg7wDugO8A8iD0kPYI+XD5wPcg9vD38PtK/4gBBANwAksA1P/CAWAEUAYoB9gGwAWQBAAFgAaoBqAF2AXwBXAEPAMYBJgFwARkAhwBpgGaAWYBOANoBFQCKf/c/rMAjAGeAfwC0ATMAzwBGgFEA7gEUAWQBpAH2Aa4BdgGAAmQCYAJcApQC7AKMApgC6AMYAzwC4AMkAwgC7AK0AvwCyAKgAhgCCAIgAZIBTAFcAToAZj/0P7k/Qz8aPrY+dj4cPbw89DysPKg8TDwgO8g7+DtIOwA7CDt4O0A7sDugO/g7sDtoO7Q8dD0oPYo+Pj40PdQ9rD3gPsN/2oB5AI4A4QBqP+KAEQDeAXQBoAHkAZQBIAD4AQoBogFUASIBIAEEANsArQDMAQQAvH/BwA6AXYBaAFsApwCdgBm/hH/OgFkAvwC7AM4BOwCzgEUA4gFwAbwBrAHQAjQB7gHQAlAC7ALAAswC9ALoAuQC9AMEA6ADRAMoAvwC6AL4ArACpAKQAlIBzgG2AXwBGwDLAIQAVj/WP2o+4j6SPnA90D20PRg8+DxkPCA78DugO6g7UDsYOvg60DsIOxA7QDvoO+A7iDuMPCA8sDzAPao+bj6iPjA9xD6QP0R/0YBAAXwBfQCcgD4AegEuAYgCCAJQAgwBbgDMAWIBgAGOAVwBRAFQAP0AZACeAOkAvoAzf/G/y4A2ACsAd4BoQCE/vz9jv9yAUACvAKcA8QDpAIIArADQAZoB8AHcAjQCIAIsAiACiAMQAzwC3AMEA3QDMAMoA1gDvANIA2QDOALAAugCsAKMApgCKAGiAV4BPACcAFbAAD/1PyI+kj5QPiQ9sD0kPOQ8pDwYO4g7uDuoO1A68DqoOtA6yDqIOvg7uDv4O0A7pDwYPFg8LDyUPjg+4D6CPng+nD8PPy+/lAEoAZgBHwC3ANgBQAFwAXgCPAJgAfABQAG2AXQBEAFeAawBQQDIAI8A0wDwgGOAFIApP+6/lP/4ABGAXwA2P9O/5L+Zv7Y/1QC/AMwBJADFANAA0gE4AWIB9AIwAkQCrAJsAmgCiAMgA0gDvANwA3ADRAOgA7gDuAOUA5ADUAM4AuwCxALQApgCcgHYAVMA2gC/AHEAI7+UPyA+sj48PYw9fDzMPOw8UDvwO3g7YDtoOvA6SDqoOpg6WDp4Ozg76DuIOwA7cDvQPAA8dD12Pqo+gD4oPgk/Nz9HP6tAHgEKAXMAxgEkAUIBgAG+AZgCFAI+AaABpgGQAaoBRAFOASoA7gDVAMQAjABUAEUAVT/BP62/qb/e/9t/yAAvP8u/sj9O/98AKwA1AHIA+QDaAKQAvAEsAYwByAIwAkgCnAJ8AnAC/AMEA3QDSAPQA+ADjAOEA+wD0APUA6QDTANwAwADBALUAowCTAH8ARsA2gCQgHD//j98Ptg+UD34PVg9KDyMPEw8MDuIO2g7IDsAOug6CDo4Ohg6eDqgO3g7+DuQOxg7IDvsPGA8zD3uPpg+xD66Plo/Bb/6QDYAmgECAV4BTgGgAYgBwAIUAjoB2AH8AcgCBAHmAYoBzAGaANQAswDoATIAgQBagFsAVf/uP2q/vP/y/9A/4//ev9G/gr+n/9cAboBqgGoArgD8APwAxAF8AZACKAIIAkACpAK4AqwC8AMgA2gDfAN0A4QD4AOIA6gDpAOgA1gDDAMIAxQCwAKsAj4BjAF9APYAkQBjP9Q/rj8KPqg92D2YPVA84Dx0PCg74DtYOwg7cDsIOog6KDo4OkA6qDrIO8A8UDvQO3g7UDw8PIQ9tD5BPz4+3j7XPwO/tb/XALgBOAFqAXABeAGEAjACNAIcAioBzAHmAcACPAHeAeABrgEyAL0AUAC5ALgAkgC/gDw/nT9WP0o/q7+/P5c/zz/Wv6Q/Sr+tf/JABABhgGEAnADIARABeAG8AcQCCAIQAnACmALEAyADdAOgA6gDfANEA9wDyAPUA+AD2AO8AyADJAMkAswClAJEAjQBbgD7AL4AQoAOv7Q/Hj6gPfQ9UD10POQ8UDwoO/g7QDs4Otg7ODq4OiA6ODooOiA6UDtYPDg7yDuoO7g73Dw4PKw94D72Pt4+9z8fv7W/ur/bAMwBvgFUAVABsgHQAhgCNAIEAn4B5AGmAZYB5gHOAdABsgE7AJCAeEAngFQAggC9QCH/zj+hP2Q/VT+/v4f/wv/5P60/iD/bQCYAb4BkgFMArgDkASYBcAHkAkwCUAI8AiQCnAL8AuwDVAP8A7QDTAOAA+gDkAO4A4wD/ANgAxgDCAMoAoQCSAIgAZwBFADvAIoAej+ZP0g/LD5wPaA9QD1QPNA8aDwEPAA7mDsYOxg7KDqIOnA6cDq4OlA6sDt0PDA8MDvkPDA8fDxsPMo+AD8fPyc/ND+ewDg/+X/CANYBqAGuAWgBoAIgAjoB6AIYAkQCOgFkAXABgAH4AVgBUAFnAPaAG7/FwDNAFsAsP9s/8r+qP08/aD9+P0W/lL+1v4c/4P/igB6AaIB6AHgAsQDmATYBcgHIAkgCUAJIArgCtAKoAuQDbAOQA6wDVAOwA7wDTAN0A1QDiANkAsgCxAL4AkQCPgGIAZIBPIB7wCGAAP/fPyg+uD5SPiA9aDzgPPQ8oDwAO8g78Du4OzA66DswOzg6gDqIOwg7uDtgO6Q8SD0APRQ87D0QPZg94j5KP3N/yEAigC+AZgC5ALgA5AFmAbIBgAHaAeYB9gHQAioByAG0ARoBEAExAPQA9QD0AI2ASEApP8d/3j+pP4k/8z+6P2k/Ur+pP6Y/rT+Nf/g/0AAxgC+AbwCVAPYA5AEeAWQBpAHkAiQCUAKkArgCmAL8AuQDCANgA3ADcANsA1wDRAN0AyQDOALAAtQCqAJkAh4B8AGwAUABPYBkwBz/+T9dPyw+8D6sPjg9vD10PTA8kDxMPEA8YDvYO7g7kDvQO5g7QDuQO6g7cDtcPAg8yD0MPXw9tD38Pbg9iD5HPwY/pj/fAFoAiQChALoA/AE8AQQBdAFIAbABQgGKAdgBzgGAAU4BEADJALuAXwCeAJ+Ab4AVgCQ/4b+Ov6e/nD+pP2Q/Xj+Af/W/gD/6/9zAAkA9/8gAUACgAIIA4gE0AXoBTAGmAfQCMAIgAiQCbAKwAqgCnALcAxQDOALAAwQDHAL4ArwCuAK4AnQCIAIIAgIB9gFMAVYBKgC3QC7//b+0P28/Oj7wPow+cD3sPaA9UD0cPMg85DysPFg8VDx8PBw8IDwkPAg8MDvsPBw8qDz8PTw9nj4UPiA9wD4wPko+1z8dv55ACoBDgGcAawCAAOoAsACRAN4A4wDOARQBYgFyATkAzwDUAIwAZ8A+AB0AToBwACnAIQA9v9J//r+2P54/lT++P7m/2YAzQB2AQAC8AGyAQgCyAJUA9wD8AQ4BggHkAcwCOAI8AgACVAJsAmwCQAKsAqAC7ALUAsgCwALQApQCfAIwAhACIgH+AagBggGMAUwBPACWAHu/+z+Ev44/YT84Pvw+sD5mPiA90D2EPWA9DD0oPMg81DzoPNw8/DysPKw8mDy4PFQ8uDzkPUA91j4iPnw+WD5EPkg+uD7GP0k/o7/0QBCAUYB7AHMArgC9AHYAWwCnAKQAiQDIATsA5wCqAFoAdkAz/9m/8f/EgCm/2X/r//H/0r/zP6W/mb+QP6A/nD/hQAmAYgB7gFkAqACvAL0AogDYARQBQgGwAagB4AIAAkACRAJUAlgCVAJcAnwCUAKgArACsAKEAowCdAIoAj4ByAHsAZwBtAFCAV4BNADrAJUAWUAev8i/uT8cPxA/HD7SPpI+bj4oPdA9oD1kPVw9cD0YPSQ9MD0YPQw9JD0wPRA9AD04PRw9qD34Phg+lD7MPuw+kD7ZPwk/cz9Df9gAOkAKAHAAUQCGAKaAToBMgEuAWoB7gE4AgQC5AGsAeYA1/8y/wr/sv5S/lT+xP7i/rT++v4n/4D+nP28/Yb+1P7w/uz/fgEQAs4BIAIUA3wDdAMABBgFuAXwBegGUAjwCPAIcAkACsAJIAlwCVAKwAqQCtAKEAtwCqAJcAlwCaAIgAf4BtAGCAYYBbAEeAR4A9gBqADU/77+hP3U/Hz8uPuY+sD5WPl4+DD3cPYw9tD1IPXg9ED1UPXw9PD0UPUw9ZD0kPSQ9ZD2UPeY+Fj6QPsQ+zD72PtI/Ij8SP3C/rb/DQC3AJwBvgEwAekA4gB6AAcARQDaANgAVwBYAIAA2v+4/i7+Cv5Y/YT8hPxM/bD9mP3Y/Uz+AP44/SD9zP1m/tr+1v8iAegBQAIAAxgEmASoBBAF4AVwBugGAAigCbAK8AoQCzAL8ApwClAKwAoQCyALAAvwCsAKQAqQCdAIEAgYB/AFAAWABBgEaAOgAu4BCAGm/z7+QP14/JD7uPpA+uD5QPmA+PD3gPfw9iD2oPWA9WD1MPVw9SD2gPZg9lD2oPbQ9tD2cPcY+bj6gPsI/Mj8cP2I/az9kP59/7b/sf9XADwBqAHSAQwC8AHwANL/lf+6/33/Dv8f/1f/5v7c/TT9KP28/KD7yPrw+lj7gPvo+/z8uP0g/Wz82Py0/dz9RP72/wgC2ALwAugDkAVYBngGIAcwCMAI8AjwCdALIA1gDYAN0A2QDcAMYAzwDEANoAzgC7ALcAuACoAJIAlgCNAGOAVoBMADhAJqAQABSABu/sD8IPyw+2j6WPko+eD4sPew9tD20PbQ9RD1cPXA9fD0YPSA9dD20Pag9lD38Pdg9xD3iPjA+sD7NPxw/ar+ev4C/vL+OwBlANn/KQDeAM8AnQB2AUwCogE5AFX/sP6I/aj8AP2g/Rz9BPyg+4j7uPqQ+Rj5+Phw+CD40Pgg+gD7aPsg/ND80Pyg/Ez9+v6iANoBNAMABagGyAfQCNAJwApwC+ALcAxADUAOcA+gEEARYBHgEEAQ0A9QD7AOoA3ADBAMYAuQCuAJcAlgCHgGcATkAnoB+f/u/kj+RP3I+6D6APog+cD38PbA9iD2wPTg8+Dz4PNw89Dz0PTg9ODzwPPg9JD1sPVg9vD3qPhQ+ND4oPpU/Cj9OP65/1EA/v8zAHQBbAKIAngCdALwASIBHAGuAcgBAgH3/97+lP1c/Lj7iPsY+2D6kPnI+CD4wPeg91D30PZw9mD2wPaw90j54PoA/NT8nP0e/pT+vf/4ATgE+AXgB0AK8AvQDJANwA6wD/APQBAgEUASABMAFAAVQBWgFKATwBJAEXAP0A3ADPALIAsQChAJIAiIBkgECAIEAAj+KPzw+jD6IPmw9+D2wPYg9uD04POQ85Dy4PAA8MDw4PFA8uDyIPSQ9ODzoPMg9aD2EPeA9xj5iPro+qD76P1UAHYBsgFoAhQDMANcAxAEmARABHADsAI0ArQBdAEuAVEA8P58/fj7sPq4+fD4APgA90D2sPXw9ID0gPSQ9BD0gPOg80D0UPXw9lD5oPsc/V7+i/8oAOAAnAKwBcAIIAtgDYAPIBEgEuASYBOgE8ATABTAFIAVABagFgAXgBbgFOASABHwDpAMgApACZAIcAcIBvAE0APWARX/wPwA+xj5QPdQ9iD2kPXA9KD0MPXw9KDzgPKw8aDw4O+w8MDyQPQA9dD1YPYQ9sD1sPZ4+KD5QPow+5j8vP36/uUA+AIYBCgECAQQBDAEiAQoBWgFuARAA/AB0wDk//b+7P3E/Gj78PlY+CD3cPag9RD0gPLg8bDx8PDA8MDxsPJA8hDywPOQ9QD2EPeI+sz9qP6o/5gCuAW4BsgHsAuQD8AQIBGAE2AWIBdAF2AYQBlAGEAXABiAGGAXIBZAFgAW4BPgELAO4AxQCnAHEAWMAwACTAAA/wj+jPwg+vD3sPag9aDzAPJA8hDzwPIA8tDycPRw9DDzkPKg8oDygPJQ9BD3ePiY+Dj5WPqI+nD64Ptk/qP/aP94/6AA2gH0AqAEWAaIBqAFSAWwBagFuATgAzADVAEY/uj7aPvY+mD5UPgw+CD3YPSA8nDyQPFg7iDtoO6g78DuQO/Q8qD0MPPg8vD1ePjg9yD5VP4gA6wDUASwCPAMgA1ADiASwBTAEwATYBbgGcAZABngGgAcoBkAF4AWwBUgE0ARoBFAEYAOIAxgC5AJcAVQAT3/rP1Q++j5WPqI+nD5SPiA9zD2QPRA8+DzQPTA85Dz0PSw9jj4CPl4+VD5sPjg91D3sPdo+Xj7zPw0/ez8wPxE/Xj+wv8yAMD/bv+y/zYAEgGgAoAEkAVoBXgEbAOIAuYBTAEVALz96Prg+PD3QPeA9iD2cPYA9uDzMPGg74DuAO0A7GDt4O/Q8BDxYPPw9aD1oPTA9oD62Pv4+0r/cAQIB/AHMAsAEAASIBFgEWATgBTgFGAWYBigGKAXgBfAF8AWgBSgEiAREA9ADQAM4ArQCSAJIAiwBXgCLABw/sD7UPkw+ZD6APu4+gj78PpQ+eD3KPjQ+ED44PcI+RD66Plg+mz8xP0c/ej7aPuo+qD5APqY+3D8yPtY++D7VPyY/Fz9mv4o/6j+Av4O/rb+7/+kAUADcAQIBfAEeATkAwwDoAFr/9j8cPrw9wD2YPWw9SD2YPbw9TD08PDA7cDroOoA6mDr4O7A8ZDzIPUg95D30PYA+JD7Hv4R/3gB0AVgCXALgA5gE4AW4BUAFAATIBMgFAAWwBdAGKAXYBZgFIASYBEAEHANMAvgCQAIQAWoBJgGGAewA/z/vP5s/Sj68Pco+VD7uPvI+yD9qP0I/OD6oPs4/CD7UPrI++j9jv6A/jj/8/9Z/5z9KPxI+5D6aPrg+ij7mPqo+Zj5KPqI+nj60PqQ++D7ePtw+5j8YP5IAAQCRAOgA9wDuARYBZgEDAOuAar/IPzI+ED3cPYQ9bD0wPXA9WDzYPFA8WDvAOsA6GDpQOzA7XDwYPXQ+GD4oPc4+Xj78Pw9/xwDaAaACAAL0A6AEqAVABjAGMAWABRgE6AUIBZgF0AYYBeAFKARIBDADpAMUAqQCHgG1AMEAsgBQAIoAkgBmv/s/ID6UPkQ+TD5EPrY+3j99P3U/QT+Nv7I/Sj9MP3Q/Qb+0P06/nv/YQD1/wv/zv6U/tD8ePqw+Rj6OPlQ9yD3APlI+vj5OPqY+wz8SPvg+sD7hPxk/ZP/aAIwBOAEEAbABnAG4AVoBZgD3v90/DD6cPdQ9HDzEPWA9dDzkPKA8rDw4OzA6SDoAOdA5wDrUPAw9KD20PnQ+zD7UPrY+yX/RAIQBpAKsA0gD6ARYBYAGgAaABggFmAUoBJgEgAUIBagFiAVYBJAD0AMkAmQBzAG4AToAvUAbQB4AUwClgE6ABj/2P0A/MD6KPt8/Pj9V//HABACnAJYAjoBJADf/9D/Df+e/tT/GAEgAFT+pP6b/8T9ePrA+aj6QPlQ9uD1UPcA98D1sPYw+ej5cPnA+oj8bPzo+4z9LACkAfACAAWQBggH6AdgCUAJGAcQBQgD7v7I+UD2UPTQ8cDv4O+g8MDvgO4g7qDsoOjg5aDmAOgg6CDqQPCg9lD6BP2e/wIAuP6UADgGsArwC8ANYBIgFuAWYBfAGaAbABpgFqATYBJAEeAQABIAEyARUAxQCLgGcAXAAtYAKAFCAR7/9PyA/X//gQCSAIwAu/9O/tz93P4rAH4BlANIBVAFuATABDgEQALUADgBNgEW/4z9WP6M/gT8GPoQ+8j7MPkA9tD1IPZw9EDzEPVQ9wD38PWw93D6YPuo+4z9r/9kABQB2AOQBjAHSAcQCVALUAvgCVAJUAn4BpQCgP64+vD0IO7A6sDqgOoA6YDpIOwg7IDnQOQg5eDmgOYA5wDrIPBw9fj7VAJgBcAFcAdgCgAM8AxwD6AS4BQgF2AaABwgG8AagBsgGSATIA7QDIAM8ArwCfAJQAjYBGACkAFKABb+dP00/uj9NPyo+8j9wQCgAnwDAARABMwDEAMUA/gDOAUwBhgHIAhQCPgGwARQA3wCLAEs/5z9oPxY+9j52Pio+Kj4sPgQ+KD24PQg9DD0MPSw9FD2QPgY+QD6FPx+/ob/MADqARAEKAXQBRAHQAgQCQAK8ApwChAJIAjIBpgDvf+s/Lj40PIg7cDpgOag4qDhIOYg62DrAOnA5yDnwOUA5uDp4O7g8lD3RP2QAugFMAnwDKAPwBBAEaARQBHgESAVwBjgGWAZQBmgGIAVQBEQDuALQAnYBvAFAAXkAvwA/QBsAf3/4P10/Xb+fv6k/aD9O/8mAbgCkASABjAHaAYQBgAHoAe4BuAFsAbwB1AHOAWoA+ACmAGQ/7T9dPwg++j56Piw92D2cPVQ9ZD1kPVw9bD1sPWQ9UD20PdI+ej5CPvU/Gr+Cv8MACACOARwBTAGSAfwBwAI4AcQCKgH6AZ4BtgFWAQgAiwAlP0Y+dDzgO9A66DlIOFg4WDlIOlg64DtYO7g64DoYOlg7tDyUPVw+Dz9rAGABRAKsA6AEaASQBPgEuAQoA8AEaATYBUAFiAW4BQAEmAPgA3wCvgGKASAAwwDJgFf/1L/LAB7AD4AWwBnAD8AHAA5AMEA6AGYA6AFuAcgCVAJcAjAB+gHuAcIB4AGSAaYBeAECATIApUAdv5w/UD8APoA+JD3kPcA9yD2APYQ9vD1gPYw9zD3EPfQ9yj58PnI+sT8kP4//+3/gAF4AkwC1ALQBDAGyAWgBdAG8AeIB5AGEAZYBdgD5AEIAEL+2Pto+GD0UPCA7CDoIOSA4qDjgOYg6gDuUPDA74DtAO1A77DygPaQ+k7+VgH4BLAJIA5gEMARYBMAFGAS8A/QDsAPwBEgE2ATQBKAEHAOAAxACegGoAQ8At0A2gCpADv/Uv6+/8oBxgGrADAB/ALEAxADMAMIBeAG2AeQCLAJIApgCWAIQAgwCOAGwASgA0ADDALi/3L+7P3s/BD7MPnw99D2APaw9YD1EPXg9ID1YPYA98D38PgY+rj6KPsI/Gz9YP78/uz/UAFwAtwCgAPgBMgFkAVIBcAFKAaQBcAEqASQBJADTAKaAbMAL/8A/Vj68PZA84DvQOvA5qDjoONA5kDqgO6g8WDxQO8g78DxUPSg9bD38PtFABwDEAZwCiAPABJgE4ATgBLgD3ANsA2gD8AQIBDwD+AQQBAADYAJIAgIB4gEMAI8ATQAfv5i/lwA0gHIAUACuAMQBEADHAP0A3gEGAUIB5AIMAi4BzAJgApgCYAHuAboBYgDgAE2AfgAQv/Y/Zz94Pxg+gD4cPcw90D2gPUA9qD2oPaw9rD32PhI+cD5qPrQ+4D8AP3Y/QH/8P+0AKoBqAI0A0ADXAOEA3wDSAN8AxAEWAQwBLwDMAOEAgQCkAFzADj+0Psg+nj4kPWg8eDtIOpA5qDjgOTg50DrYO6w8YDzwPGA70DxEPb4+Oj5iPxeAUAFEAgADCAQoBGAESASgBJAEDANMA1QDyAQ0A8AENAPkA3QCoAJ2AdABAYBpwAuAbT/6P2C/oEAfgHiATADSATQAzQDIARoBYAFiAUAB+AIkAmwCVAKoArACVAIAAcoBXQCagDD/z//Dv4Y/ZD8ePvQ+aj4GPgA93D1EPWw9eD1APYw9xD5MPq4+oj7YPyc/Pj8NP52/+b/FgDjAP4BlAK0AvQCWAOoA8QDtAOsA6QDhANoAzgDzAIIAowBbAHxAA7/6Px4+wD6sPfg9NDxwOyg5qDjwOVA6YDqQOxQ8FDzIPJw8ADy0PQQ9uD3ZPwRADIBOAPQCDAOIBBAEOAQ4BAwD/ANcA0QDSAN8A7AEEAQUA7gDEALcAgQBsgENAORADX/HAD9AKUAAgHsAlgEEAR8A7wDAATkA1AEgAWoBngHUAgwCeAJEAqwCaAIUAfwBUgEcAJeAe8AKwAM/3T+Av6g/LD6gPkI+QD4sPZg9rD2oPbA9vD3gPlo+uD60PuE/MD8HP0U/gn/xf+pAJgBGAJsAgQDYAMoA/QCTAOIAzwDBAM4A0gDJAPgAiACCgFpABYA9P4I/dD70Pqg+ND1YPOg78DowOIg48DnAOsg7IDukPEQ8oDw0PBA8+D0EPZY+cj9jAAIAkAFgArADmAQoBCAEPAP4A7wDcANIA6QDlAP8A+wDwAOsAvQCUAIOAbgAzwCMgFlABgApwBKAWABqgGIAhgD1AK8AlAD8AM4BOgESAZ4BzAIwAiACbAJUAmACEAHmAX8A8QCngFxAIT/zv7Y/bD8sPuw+mj5UPjA92D30PZw9tD2YPfA94D46PlA+/D7aPwU/dz9XP72/ggAJgG+AfABZAIQA3ADQAMkA5gDEATgA0gDFAMMA7ACHALgAYIBjQB7/+7+/P3w+yD6oPkY+XD2oPEg7GDnAOVA5iDqgO3g7mDwoPJw8zDyAPIg9HD2wPfw+cT9IAG8A4gHoAywD9APcA+gD1APwA0QDaANcA4wD2AQABHAD6AN8AuAChAIOAVQAzAC4QDt/0EANgGcAaoBTALgAowCzAG0AUQC0AI0AyAEaAU4BqAGQAeACGAJAAmAB9gFYAToAo4B2wCcADEAhf/Y/g7+qPww+0j60PkA+fD3gPeQ9+D3QPgw+WD6UPvQ+1D86Pw0/VD9xP32/iUArQD4ALgBtAIQA8QCkAK4AswCsAKUAoQCPAIsAlwCUALCAWoBNgFwAMD+5Pw4+8D5cPnY+SD4kPJA7ODoIOjg5+DoYOwA8CDxgPHw8rDz8PIQ88D1kPi4+YD7Zv+QA5gGIArgDWAPcA7wDXAOsA0gDIAM4A5gECAQIBBgEOAO8AvQCYAIeAbkAzwCWAFDAL7/ugAkAnACDAI0AjQCRAFmAPsAlAK0A1gEOAUQBlAGwAYQCGAJIAm4B2AGEAUMAxwBewCpAG4A0f9c/1L+YPy4+kD6+PnY+MD3oPfA95D3sPe4+Oj5wPqQ+1z8vPzA/Az9iP0C/vb+HwDaAOoASAHYAcIBgAEQAvgCpALQAe4BuAKAAp4BQgFCAUIBkgHkAdgA1v7U/Xz9CPww+gj6sPmQ9eDuwOqA6aDoQOkA7bDxEPMA8nDygPQA9SD0gPSg9gj5EPt4/XEAIARwCEAMEA4QDqAN8AzAC/AKwAtQDWAOYA/gEGAR0A9ADWALEAoACGAFHAO8Ae8AtwBKAWACTAOgA3QDpAJCASIAEQDxAAQCqAJQAygECAWoBWgGMAeABwAH0AVYBNwCngHzADYB8gFsAs4BSQC2/qT9nPw4+wj6kPl4+fD4kPj4+AD6sPrw+qD7iPzY/GD8CPxU/Cz9FP4K/+3/pgBQAcABpAFGAWQBDAJEAuAB/AHIAsQCGAJgAqgDbANqAcQAIALkAaj+2PsY/BD9TPyw+gD5EPUg70Dq4OjA6UDroO2A8EDyMPLA8bDxIPIw89D0gPY4+KD6FP7IASAFgAiQC1ANMA1wDCAMEAxQDGANUA/gEGARwBEAEgARoA5ADGAKcAgYBkgESANoArgB6AG0ArACkAFjAJ3/Af+K/rT+iP93AE4BPAIcA6wDMAQIBdgFGAbgBYgF6ATIA9QCzAKcAxAEeAM0AtoAov9E/vj8LPyg+9j66Plw+XD5MPnQ+Ej5WPrI+mj6IPpg+oj6sPqQ++j8rP0S/gP/FABvAFYA1ACgAdgB5gFQAsgCuAL8AvgDeASsA8wC6AIQA+ACeAJWAXr+FPyU/Eb+QP2g+ZD2cPOA7qDpIOmA6wDt4O2A8KDyYPFg75DwEPOQ82DzcPWo+OD6aP0UAuAGYAnACnAMUA0wDEALUAxgDuAPYBFgE2AUwBOAEiARIA+ADGAK0AjoBsgEgAMMA+wCzAKMAngBb/+A/Uz8qPtw+xD8gP0H//z/ngAaAZQBRAJIA0gE+AQwBfgEkARgBKgEEAVIBRAFgARMA5gBFwA7/7D+Cv58/ST9jPx4+6j6iPqA+iD6yPn4+UD64PmA+ej5+Pr4++D8nP3w/RD+qP6l/woA9f9+ANwBqALkApQDgARgBKwDAASYBJwDYAJYA9AEjAM5AHb+nP5A/nT9MP3w+9D34PLA7+DtAOxA6+Ds4O6A7+Dv4PCQ8ZDx8PGQ8rDyAPMg9Zj4QPzx/+QDEAewCNAJ4AogC7AKQAtADYAPABGAEiAUoBTAE+ARIBCADsAM0AoQCcgHAAdIBoAF6ARIBPgC0ACm/hj9LPzQ+xD81PzY/cT+R/9J/07/xf+1AJwBcAI4A7ADlANcA6ADSATYBOgEwARYBFgDwAF9AEEAggAoAEL/wP5U/ij9sPtQ+6j7SPtQ+gD6IPpg+Zj4ePk4+8D7gPsI/OD8nPwg/Oj8fv5C/73//gAkAkACLALgArgD4APIA1AECAUIBUgElAMcA3ACUgFaAFgAGABs/fD4QPUw8zDx4O4g7gDvQO/A7sDvsPHQ8eDv4O6A78Dv4O8g8oD2iPpY/UEAAAM4BHAEuAWQB4AIUAmgCwAPoBFAE6AUQBWgFGAT4BFAEGAOEA2ADBAMsApQCYAIuAcYBogD/gDg/jD90Pug+1D8/Pwc/Wz9FP58/cj7+Ppk/Dz+3v5x/w4BOALWAZ4BpAKAAzwDSAMwBAgEbALeASwD9AMsA7wCMAN0Aj0AEP97/0z//P1w/dz9SP2w++D6UPto+wj7QPuo+0D7ePqI+ij7iPv4++T8yP1y/iL/zf/m/wMA4wAMAmACeAIkA4QDrAKWAcQBaAIwAmoBzAAz/6j7APgw9pD18POg8YDw8PDA8UDy8PIQ89Dx4O/A7uDuwO+g8cD0KPi4+oz8Nv5x/38AIAJwBBAGGAcACUAMIA8AEYAS4BNgFKATgBKAEYAQ0A+wD6APAA/QDYAMEAtwCXAH0AQIAjwA0P+L/6L+9P0k/ir+CP14+4D6IPoY+rD60Pu8/CD9aP3k/Uz+nP4O/7X/awAUAZgBugHoAagCxANoBFAE6ANsA+QCcAI0AhQCzgHMAZABcgD2/lT+av4G/mT9dP28/bz8QPtA+yj88Pvg+gD7IPxw/Az8vPwY/mT+FP6u/p3/YP+W/uD+8f9UAHoAWAH2ATQBzf+K/sz8YPqw+Fj4kPew9YD0QPVg9pD2sPbA9nD1gPJQ8EDwkPFA86D1kPiQ+kj7oPt4/Iz9iv7O/14BTAN4BZgHsAkQDIAO8A8AEJAPcA9QD9AO0A6gD0AQABCQD+AOUA1wC7AJUAiwBugEoAPYAiwCkgHpAN3/sv50/Sj86Ppo+qD6APtA++j7SPzg+7j7gPws/bT8dPyQ/br+xP43/yoB8AIsAzwD9APIA0gCsAEAAwgEuAOoA3AEQAScAogBlgEuARsA2P9QAL7/Xv4A/nj+PP5c/Sz9RP18/HD7mPuE/Pj8UP0m/pT+1P3s/Mz8FP1A/dj94P4//67+CP6c/bD8cPuI+rD5YPgA96D2IPfA91D44PiQ+AD3UPWA9BD04PPQ9BD3IPno+XD6sPvE/Lj8jPx0/f7+XAAcAqgE2Ab4B8AIAArgCtAK0AqQC3AM0AwwDcANEA7wDaANMA0wDKAKYAmQCKAHuAZIBiAGkAWIBFgDGAKbAFP/pv5C/qz9MP1E/Xj9FP1Q/ND7sPuA+zD7QPuY++D7QPwE/eD9Vv6Q/tz+Kf8Y//z+PP/R/2IACgHQAVQCVAIEArYBjAFYAUABVgGGAZgBfAFUARYB7QCsACQAev/4/pD+Iv74/Uj+zP7O/mz+IP7o/VT9jPxE/JT8+PwA/ez86Py8/Fj8yPtI+9D6SPrg+bD52PlA+sD6GPso+/j6gPro+ZD50PlY+rj6GPvg+7D8FP0k/WD91P0u/oT+Kv8gAAIBugGUAmgD1AMYBJAECAVABUAFiAUwBsAGCAc4B1AHGAfABnAGSAYoBggGAAYIBuAFiAVABQAFsAQgBIADBAO4AngCRAIUAuIBnAEuAaAADwCX/z//GP8c/xj/4v6Y/nr+jP6G/mb+XP6E/qD+iv5k/mz+jv6e/q7+yv7m/uz+7v70/hX/OP9R/2X/eP94/2z/a/9//6L/tf/C/8z/yP+7/7n/vv+0/6j/q/+w/6b/qv+7/77/l/91/2//Wv8d/+7+7v7u/tj+wv60/ob+RP4m/ir+FP7k/dj99P3o/az9kP2g/ZT9bP1k/YD9iP14/ZD9wP3A/aD9uP38/Rb+EP44/pT+xv7M/ur+S/+d/8H/5f8lAE4AYgCSAOEAGgEuAV4BrAHiAewBCAJAAmACZAJwAoQCfAJwAngCmAKkAqACnAKMAnQCWAI0AgwC+gH8AfQB2AHEAcQBqAF8AWgBagFgAUQBQAFEATQBIAEmASoBEAECAQ4BEgHxANsA6ADpAMcAsACzAJ8AeQBnAGsAVgAtACUALAAcAPb/6P/m/8j/ov+W/4//cv9S/0//QP8Y//T+6P7c/rT+nv6W/pT+gv5s/lj+Pv4i/gb+7P3Q/cD9vP24/aj9oP2s/bD9qP2c/Yz9dP1o/XT9iP2c/aj9yP3s/fT9+P0K/ir+Rv5e/oj+wP78/jH/Zv+i/9f/AAAgAFcAhwCyANwAEgFUAYQBoAG6AdIB5gEAAiwCUAJcAlwCYAJwAoACiAKMApQClAKIAnwCeAJwAmgCWAJIAjgCMAIcAgQC7AHcAc4BuAGeAY4BigF+AWwBWgFQAUABJAESAQgB+QDhAMoAsQCWAIQAeABiADoAEgD4/93/tf+O/3X/X/8+/xr/9v7S/rL+nP6I/m7+Tv4y/iD+FP4O/gj+AP7w/ej97P3w/ej96P3w/fj9/P0A/gL+CP4O/hT+HP4k/jD+RP5W/mD+Zv5y/oL+lP6q/r7+0P7W/t7+9P4R/yv/O/9Q/3D/jv+p/8D/2//6/xgAMQBNAHUAnQC5ANEA8QAUATQBUAFuAZYBtAHOAeQB9gEEAggCCAIAAvIB6AHoAewB6gHoAeQB1gHCAa4BnAGEAWwBYgFgAVYBPgEoARwBFAECAeEAvwCnAJAAcwBbAFEASAA0AB0ACwD0/8//rf+g/5X/fP9e/03/Q/8o/wr//P72/uT+vv6o/qL+nv6K/nz+gP58/nr+gP6M/oT+eP54/oL+iv6O/pr+nv6i/qr+vP7M/tj+5v74/g3/IP86/1P/YP9r/3//mv+0/8z/5f/7/xAAKgBCAFgAZgByAIUAoQC7AM0A1ADdAO4A9QD2AP4AFAEgARwBHgEsAToBOgFAAVABTgEyAR4BIgEwATwBOgEsARgBCAH9AOoAywC0AK0ApgCVAH8AbQBeAEwANwAmABgADAAAAPb/5f/T/8T/wP/F/8D/rf+h/6P/of+R/3//df9x/2r/ZP9l/2n/Zf9c/1b/Vf9V/1H/Sv9I/0v/S/9G/0T/Qv89/zT/Nf9B/0n/RP9F/1T/Zv9s/3D/d/98/3z/g/+T/5r/mP+c/6z/vP/B/8D/wv/H/8j/x//L/9P/3v/q//r/DAAXABYAEAAUAB8AKwA2AEUAVwBlAG4AcgB3AHsAfQB7AHsAgwCSAJ8AoQCjAKgAswC4ALYAtACzALEArACpAKwArACpAKUAowCiAJgAjgCMAI8AhgBxAGEAWABNADsAJwAbABUAEAABAO7/4P/X/9P/0P/N/8T/t/+t/6//tP+4/7r/vv/A/7z/uf+6/73/wf/K/9X/3P/f/+P/7P/0//b/9//5//r/+v/6//z//P/5//b/9f/z/+3/4//Z/9L/z//U/9z/3v/Z/9T/1v/Z/9j/1v/a/+D/4//l/+n/7f/z//n///8AAP7/AQAIAAsABQADAAQABAAFAAkADgAQAA0ADgALAAYAAQABAP7/9v/2///////z//f/9//s/9r/2P/l/+D/1//g//H/9//8/w4AGAAMAP//BgAcACYAIQAgACYAKQAgABcAFQAWABEACAAAAP3/+//1/+3/5v/i/93/1//T/9L/1P/X/9j/2P/g/+r/8P/z//j//v/8//X/9P8DABcAIwAmACgALQA1ADoAPQA8AD4AQABBADwANQA1AD4ARAA8AC4AJAAhAB0AGQAUABAACQD+//j/9//1/+v/4P/a/9X/z//I/8X/xv/E/8D/wP/B/8D/vf+5/7j/uv++/8T/x//G/8D/t/+r/6X/pv+p/6b/n/+e/6H/ov+i/6D/of+h/6T/qf+u/7X/vf/E/8r/0v/a/9//4P/m//T/AwAPAB0ALAA3AD0APgA9ADsAPgBIAFMAXABlAG4AcgBxAHEAdAByAG8AbwBrAGIAVwBTAFMATwBEADUAKAAdABYAEAANABEAFwAXABQAFgAcAB8AIAAoADAANAA0ADkAQABBAEEASABUAFMARAA8AD8AOwAqACAAKAAoAB4AGQAaAA4A/v/7/wAA/P/z//L/7//j/9j/2v/c/9T/yf/H/8j/w/++/7j/rv+m/6X/pv+k/57/mv+a/53/ov+k/5z/j/+L/5n/qv+u/63/r/+z/7P/rv+v/7j/w//G/8P/xv/V/+f/8P/1//r/9P/j/97/6v/4/wAA///9//7/AQAFAAYABgAOABoAIwAmACsANwBCAEgAUABdAGkAcAByAGsAXwBXAFoAYQBkAF4AWABdAGEAWgBNAEcARQA7ACsAIQAkACcAHwAVABMAEwARAAwABgADAAMAAwACAP7/9//x/+7/8v/2//T/7f/t//T/+P/x/+j/5P/k/+P/3//c/9f/0P/K/83/1v/c/9r/1P/N/8X/vv+9/8L/xP/F/8v/1P/T/8r/wf+8/7n/vv/I/9L/2P/f/+n/7f/s/+7/8//1//b//P8HAA4ADgAPABMAHgAmACQAHgAeACYAKQAkACUALAAsACIAHAAkACsAKgAnACgAJAAdABoAGgAVAA8ADwAYACEAJgAqADIANwAxACsALQAxAC0AJAAiACgALQAqACIAGQARAAsACQAMABIAFQASABMAFgASAAcABwAUAB4AEwAGAAQA/v/t/+z/AAAFAO//4v/o/+L/yv/A/83/2P/S/83/zv/M/8P/v//D/8X/w//F/8X/vv+5/8H/zv/U/9P/2f/h/9//1//a/+b/4P/O/9D/6P/y/+L/1v/Z/9f/yP/A/8r/2P/Y/8z/xv/E/8j/0f/u/xkAIwD//9r/5f8IAAMA7P/0/yAARABWAE8APgAoAAEA4v/r/xIALQAsACIAEwDb/5j/jv/K/+3/1//V//v/7/+c/33/zv8bAA8A//8nADkAHgAcAEkAYQBQAF0AiwCbAIYAhgCaAIwAcwCEAJQAfQB8AMAA9QC2AD8AHABRAGIAJwAMAEEAXwAuAP//AgD9/9v/3/8LABAA9/8PAEQAGwCd/23/0P8xAAUAnv+E/5r/if98/7P/y/9h/xn/yP/pAEoB5ABnAJP/Nv7Q/ar/BAIwAmcAAv/Q/tz+1P4m/6f/4//v////KAC3AKQBIAKYAaUAFADy/xoAnQAaAdgA1f+2/uT9oP1Q/r7/4gAOAZYA4/8J/4r+OP+0AJgBfgEsAeoAbwD6/+r/rf/C/hT+nP6L/2T/Xv6A/aj8iPso+3T8ev6Q/2v/xv4W/mj9OP2E/moBEAQwBJQCQAJYAxQDYAFIAnAGYAgwBcYBbAJ4BCgE2AJEA4wDZgGN/+YAjAI0AVD/Ov98/kD8kPxYABQC3v5I+xD7EPx8/FL+7QCrAPj9sPwk/SD9eP25/54BagAw/jD+qP8qALf/YP8W/9L+Iv8lAFoBxAGYAIr+wP0N/5gAAgF2AWQCtgEv/7z9zv5cAJ0AvQCEAXYBHQCA/00AlgCs/z3/6f9oAFsAngDyAEMA3v4Y/kb+4P7R//UAFgG7/1T+BP4w/rT+JABiAZAAuv6i/u7/5P+c/tb+XgBPAOL+MP8eAV4Bh/+W/nn/PAAvAJcAigGWAZ4A+P/8/xkAaQD0AB4BCAFCAUYBbQCi/xYAFgEgAXQAegAeAQgBMADw/4UA0QBfAA8AYAC2AIoAIwDf/63/e/+C/+3/YQBIAKz/S/+n/zgAGgB4/1P/7f8pAID/LP8MAOAASgAd/+j+l//7/+T/8/8hAPv/qv+u/wQAPwAyAPr/zv/O/9n/zf/e/zEAVgAFAMb/AABGAC0AGgBgAGsA7f+8/1gAxgBrABEALQBHABkAHABjAHMAKwASACEA6f/a/1wAgwD9/x8A7gCtAI7/l/+XAIoAwP8EALkACQD2/qT/2QBGAAb/a/9YAL//1v5//4QA///+/kb/3f9T/9r+4//eABUA9v5N/xAAzf9q/xMAuAAKADb/x/+0AEwAc//J/50AaADO/1AATAEGAcb/Pv+v/z0AvQBUAWIBVwDa/ob+7f9QATIBawAjAL3/yv6G/r//EgHbAIP/ov6i/hf/4f+lAHAAQv9E/or+6//hADEAFv8z/3//nv5o/tYA4AIaAdj9mP2O/w4ADgDaAcgCLADo/Yb/jgFxABb/rwB0AgYBwP5p/2YBOgGl/0v/AAB6AOYAUAHVAKP/Ef+M/zEAiwDUAOEAUABt//7+Pf/Y/6oAbAEuAZ7/QP66/lwAFAFPAGL/PP9+/9P/RgA2AFf/tv4K/33/dP+e/1sAdQAC/3j9/P0pAKIBZgFUADT/YP6W/i4AxgHCAakA7f99/+D+MP8KAZQC2AG3/3T+vP7n/zYBqgGTAAD/qP5r/xQAegDeAJAAOP8E/lT+6P9EAUwB3//w/Sj9dP6/APYBQgGs/3r+OP7k/i0AagHQAeAARf+m/qH/zgAeATABMAEWAJT+7v4OATACRAEAAHj/IP9I/5cA4gFKAXn/zv6S/0IAdgASAYwBTgA4/mj+JAGQAvcAXP/o/2EAMP/6/mYBBAO7AMj9hv4gAUIBsv8eAMgB9QAI/lD9w/+qARYBQQBhAOH/jP6I/jQA8gDU/5H/8QAEART/fv5GAFoBOAAe/4b//f+3/9//ewAgABD/zP5D/6T/IQCfAGYAsv9b/wb/mP6B/8oBnAJwANz93P2v/74AoQCpAMAAs/9S/r7+kgBWAWoAhP9a/yL//v4AAIYBIgG4/mz9+P4aAYQBtgDb/xn/kP4n/+QAAAIOAXz/RP/I/5//Yv+HACgCogEL//T92P+UAQABJQB8AGAAO/8j/9YACAIiAYv/Bf9r/xgA/wCuAWIBDgCK/gD+Mf9kAZgCgAEi/4D97P0PAAgC+AEnAFr+mP0K/rf/1AGEAsAA8P2g/KT92//UAVACfwCo/ZT8Zv5iAfwC9AEq/xj9iP3H//AB2AIQArD/GP3I/Ij/vAJoA4gB+P4s/Tz9n/+gAmQDGAHg/cT8nP5OAWgCngEcAMT+FP64/uMA2AJAAnf/YP2Q/UX/XAHsApgC7//g/Hz8SP9IArwCNgHL//z+dP7i/psABAKUAe//tP6o/sX/iAGsArQBNP+0/Yr+iwAcApgCiAEr/2D9AP58AJACdAJOAAD+mP0u//UAtAGsAdoA3P4Q/RL+eAFoA9ABGv/g/RL+Dv/WAHAC7gFa/0j93P1WADQCEAJcAJz++P3S/oYA0AHAASIABv5A/d7+fgF0At8AmP6E/cz97v7OAHwC/AEh/+D8pP0mAMwByAHHAGP/QP5M/r3/egEAAukAUf+4/pf/6gBYAagApP8D/xn/PwDMATwC5wAB/yL+0P58APIBJALwADj/Iv5W/q7/JgFKAdn/cv5W/v7+l/82AIsAoP8a/jD+//8SAUIATv9z/4//Ov/d/4gBBAJrAND+BP8jAK4A5gBUASIBwf+q/lL/7QCkAQIB2v8L/wf/v/+sABYBpwCl/9j+9v7k/7sAzABIAKX/HP8a/xoAcgF4Ae3/rv4R/yQAuQDtAPoAWQAV/3r+Tf+kAEYBEAFbAED/Vv6i/icAYAECAab/6P5a/yMAewBzAEkA5P9k/1n/DwDRALkA6v9C/z7/nf8RAGwAdgAZAK7/nf/Z/xQAFwDl/6v/pf/K/wsAXQBdALL/vv6g/sX/9QDwAP//MP/w/j7/CgDdAPEAQQC8/9L/EwA3AIgA7ACmAO///v/0AFABlADM/5r/dv+V/8EADAJIAa7+NP2A/o8AFgF8AAoApP/g/o7+c/+KAJgACQDN/8v/r/+6/xMAKgCk/yr/ov+rACwBvAC4/77+ov6u//UAVgG6AOP/WP8k/0r/7//UAEwB9gAZAG7/cP/5/2MAZgBrAJ0AlgAyAO//+/8AAPP/NQDDAMQA8P9X/5v/zv9v/4v/pgBoAb8Amv8g/xL/KP/6/0IBlAGOAHL/E/8v/5T/fABWAQQBxf8h/3n/4/8DAFQAvgCPAMD/SP+n/xEA9//k/ygANgDw//b/QQAEADb/8v7L/+sAIgFmAKn/kP/Y/wwADQAWAEEAQwAEAOj////b/5L/lP/Q/8//ov/R/0QADAAH/3j+Lv9JAKQAMACW/x7/5P5W/0sAqADt/0P/gv/2/9v/wP8+AIUAwf/i/lX/qQAwAZIAz/9n/z3/l/+oAIYBLgEIAFj/l/88ALkAxwBrABAAFAA0AC0AUgCYAFcAq/+n/3AAxgAhAKz/GABLAKD/Rf8JANQAhgC9/5n/3f+3/5D/QwA2AQYB0f8U/2P/2P/1/1MABgECAer/8P4a/9X/KQApAEsAWQAMALP/pP+i/4b/rf87ALYAlAAEAIf/Xv93/7P/FgCWANIAXwCA/yD/iP8PAD8AXwCGACwAhf+A/wwALQDG/7X/FQA1AO//p/9e/xz/bf9JAKwAJgCZ/6P/r/9d/2f/KQC9AHYA5/+z/6H/iv/C/0UAgwBHAB8ANQAhANH/wv8YAFkAZwCRALcAgAAUAPf/SACdAMsA+gAAAZEA6/+2/wsAjAD0ACYB4wAaAFb/NP+l/wsAMQBUAFMA6/9V/yT/Wv+D/4//xv8YABsA1f+i/4T/UP9K/8D/XQCEACwAu/9c/yT/bP9FAO8AsgAJAL//wP+Y/33/4P+EAK0ALQCG/0X/ef/f/wkA1v+k/5X/dP9M/5j/DAD9/4j/Z/+t/6L/Vv+F/ycAZgAYAMr/nv90/5P/MQC1AIkA/v/H//D/FgAwAFgAWwAVANT/2P/9/zEAcgB2AAUAgf+N/yQApACUADsA+f+//57/8P+mAAQBpAAHAMz/7P8bAHcA9wASAXQAnP9X/77/WQC9ANoAngD+/2H/X//t/2QAgQB7AHQAJwCi/3z/8f9zAIQAXgBPACoA0P+Z/9v/OQA8AAQA/P8ZAPz/sP+I/47/nf+3/+7/DQDt/63/df8t/wD/V/8UAIIAKQB5//b+yP4A/8D/lQCkANX/7v7E/j7/zP81AGMAQgDi/5//q/8BAFwAbgBHACwAOQBUAHgAmQB5AAsAzP8+AOsABgGaACgA3/+y//n/zgBmAQgBJgCy/6H/s/8kAO0ARgG1APb/s//R/wcAUgCjAJQAMwDq/87/uv/n/0YARgDm/9L/FQD9/4L/dv/m//n/uP/9/2QA6f8F/xj/6v8QAJj/qP8hAOX/LP8l/6z/xP91/6L/QgAuAJL/U/+I/5T/n/8bAKUAigDk/4n/o//2/18AwwDgAI8AIwANAD4AagCNALgA3QDbAKEAXwBSAFUAVQB/ANcA/AC7AHUAdwBtADAAVwD8AFQB+ACPAJEAdAAMAAUAmgD6ALkAiACdAEIAT//I/k3/IgCbAMgAfQBk/xL+qP1q/on/VgChAPj/aP44/XD9gv5f/7D/qv8q/xD+SP20/Yr+xP6y/tT+1P5I/sz9Kv7W/pr+6P0m/jH/iP/u/n7+pv66/p7+HP8RAGsAxv85/1v/r//i/1wALAGaASIBOgAUAOAA0AEcAuwBxgHAAYwBgAEkAtgCsAIYAjwC/AIsA5gChAIQAygDsALMAoADkAOwAhQCfAIAA+ACtALoArgC7AF+Aa4BAALUAbABzgHEASoBkQBrAFYASQBjAIUABAAq/8b+4P6k/gb+5P0e/rD9oPwI/BD82PsQ+7D6oPpI+pD5QPlI+QD5aPgg+Gj4wPjg+Jj4ePjA+GD5yPnY+TD6EPvA+9D7DPzI/Hz96P1e/iv/zP8KAIcAmAGAAmgCNALIAtwDgAS4BEgF+AX4BYgFwAWwBmgHwAcgCDAIoAcYB6AH0AhQCRAJwAigCGAIYAjwCGAJIAngCNAIcAjAB9AHsAjwCBAIOAfYBlgG2AVIBtAG8AUIBNQClAIYAjgB3ACkADT/7Pww+4D6CPo4+Sj48PYw9VDzAPJg8eDwEPDA7qDtAO3g7MDsIOzg6yDsoOwA7QDuAPBA8RDxoPCg8dDzsPXw9zj7QP2E/Aj7NPw2/04BtAJYBagHyAaABHgEYAaoB9AIIAuwDAALAAgYBwAIIAmwCoAMMAyACaAHEAjwCFAJYAqQC/AKYAmACQALUAvgCrAL0AxADIAL0AyQDjAOsAxwDKAMIAxwDOAN8A2QCyAJ0AjwCDAIwAfgB3AGQAPlAEcAq/9K/mT9pPxA+sD24PTw9KD0APMw8eDvQO6A7MDroOvg6sDpQOkg6aDoYOiA6ODoIOkA6gDrwOtA7aDvQPEw8cDx0PTw90j5CPsU/nP/fP40/8wCGAaABvgGcAmwCcAGqAVwCTANIA1ACxAKsAi4BhAHUApADEAKcAe4BuAGWAZYBqgHAAlwCNAG8AWQBoAHIAiQCPAI8AigCFAJAAsQDEALIArgCqAMcA0gDTANcA1wDCAL4AqAC4ALwAoQCoAJUAh4BkgF6ARoBBQDygEOARAALP7A+zD6YPm4+PD3QPcA9vDz4PGw8JDwYPAA8KDv4O5g7SDsIOxg7EDsoOxA7QDtAOxg7EDu4O6A7mDv4PEQ83DzIPaA+vj6iPgo+cD8AP+I/1ADAAi4B5ACxgAABbAIQAnwCoANIAvIBZAEUAlgDHAKkAgACgAKCAe4BVgHAAg4BpAFKAfgB0AGQAUIBiAGiAQIBDAGgAiwCNAHKAeYBlgGOAcgCbAKwApgCkAKsAnACHAIQAlgCtAKcAowCVgH+AWYBcAF8AUABoAF9AOeAdj/df+h/0X/uv7g/QT8sPl4+KD4uPiw91D2gPXA9HDzkPKA8jDyEPEw8ODvgO/g7qDugO7g7UDtAO7g7gDvAO8A8GDwAPBg8bD12PhQ+LD3ePm4+iD6nPwcAygH4ATWAfwCWATIAyAGsAwgEIALuAWYBYAIcAkwCpAMwAzgCFAF2AUQCBAImAa4BmAHcAb4BBAFGAZABigFAARYBMgFKAfAB3AHyAYIBoAFSAagCGAK8AkACSAJQAkQCDAHgAgwCrAJYAhACOgH0AV4BHgFoAaYBfAD4APEA8YBnv+n/14Am/8C/vD8gPyA+xj6SPkQ+Xj4QPcA9mD1UPWg9DDzAPKg8RDxAPBg78Dv4O+g7oDtwO2g7sDuwO5g7xDwYPDw8dD0gPdw+HD4QPgo+Lj5rP3sApAF8ARsAwQC2AC4AnAIgA3gDWAKIAcABhAGoAfgCsAMMAsgCEAGMAUwBWAGeAfwBmAFAAVYBSgFuATIBCgEsAIQA+AF4AfQBhgFsAS4BKAE8AXQCIAKkAnYBzgHIAc4B1AI4AlwClAJsAeQBggG6AUgBlgG6AUIBQgECAP2ARwB0AC2AB4AEP/o/UT9mPyQ+2D6qPmg+TD5IPgw99D2APbQ9CD04PNQ8zDysPGw8fDwoO9g7+Dv4O+A7wDwgPAQ8BDwwPHg81D18PYo+Zj5MPjg97D6wv56AfwDWAW0A28ADgCsA3AIUAuAC8AJ4AbQBDgFcAeQCdAKQAq4BxAFWAQQBZAFuAUYBgAGsASgA3gEiAVgBGgCfAJQBMgFUAaoBkgGsARQA2AEIAcACYAJIAlACPgGcAagB2AJUArQCQAJ4AfQBmAG6AZgB7gG2AWABTAFCASoAhwCEAI6ARYAuf+p/4L+uPy4+1j7ePqo+ZD5cPk4+KD2IPaA9SD0QPPw8/DzIPKg8EDwAPDg7qDuYPAQ8UDvAO6A7zDxcPGg8sD1kPhQ+MD2IPeo+Sj8yP4UAnAEtAMUAWUA2AKYBuAIEApACgAJmAYYBYgGQAmgCtAJQAi4BmgF8AS4BdgGYAaYBKgDOAT4BAgF2ARIBCwDhAKEA/AFkAdIBygGCAVgBBAFaAfgCdAKsAnAB7AGOAfACDAKoArQCZAIMAdIBrAGqAfAB2gGEAVQBKgD4AKwAhQDXAJEAMr+/P4r/wD+8Px8/ND7gPqI+Wj5KPlI+DD3YPag9SD10PTw81Dy0PHw8fDwoO8Q8EDxkPCg7sDuYPCg7yDusPBQ9mD4kPaA9ZD28PaQ9wD8FAIYBIYB0P98ADwBBAJYBRAKkAtACWgGSAVwBYAGwAgAC9AKMAjwBSAFKAVwBegFeAZIBjAFGAQQBLAEmATgAyADSANoBNAFeAaABqgFMAS0AxAFoAdgCTAJkAeIBigGSAZoB3AJkAowCWAGwASIBZgG4AYgBzAHkAW8AmoBaAK4A0gDOAKSAYIA1v7c/RD+JP7I/fD8CPzo+jD6qPnY+CD4IPgo+LD24PTQ9ED1kPNw8dDx4PKQ8eDvAPGQ8sDwAO6g7lDxEPIA8yD3GPpw90DzEPTw+Cj9q/+YAqADYAA4/QH/3AP4BoAIAAowCkAHUATgBBAIQApACvAJkAhIBsAEWAWIBpAG2AVIBSAFmAQIBMQDvANwA2ADqAPwA3gEMAUwBWgEsAMIBGgFmAZIB4gHEAfgBVAFYAYwCPAIkAjIBwgHGAZoBdgFEAd4B5AGGAXcAwgDqALEAvwCIAOUAkYByf/k/qL+RP68/cj9GP7c/DD68PiQ+cD5oPg4+Kj4sPfA9CDzMPRw9GDykPEQ8+DyEPCA7nDwkPGA72DuQPGQ9GD14PWA9zD3gPTA9BD6+v/eAS4BbABr/0L+jv8oBHAIgAlgCPgGKAXMA9gEEAhgCuAJEAiIBnAFkATYBMAF6AVABfgESAXwBAgEbANoA1gDiAOIBJgFuAUoBdAEoARoBNgEcAYACCAI+AZoBtAGQAeIByAIkAjYB7AGgAYoB0gHeAbABXgFAAVIBPwDGATEA8wCtAEaAd8AugBKAFP/Wv64/UD9vPxk/Az84PoI+SD46PhI+fD3sPag9tD1MPPQ8eDy4POQ8jDxwPEw8UDuAO0Q8HDyYPEA8aDzIPZQ9UD0QPaY+DD5uPr8/qABewAU/zAAHALoApgEAAgACsAIuAZQBqgG8AZACDAKgApQCEAGoAXYBagFeAXYBfAFSAVoBDAEGAS4A0QDeAMgBIAEuAQIBVAF2AQYBIAE2AXgBkgHiAdwB8AGgAaIB+AI8Aj4B2AHSAc4BygHoAe4B7AGIAVoBJAEoARYBPwDTAMMArgAJABYAKYAPADK/nT9yPxs/KD7APv4+oj60Pig9/D30PdQ9hD1YPXA9DDy0PBg8yD1kPJg76DuAO8g7qDv8PNw9qDzcPAw8pD1MPYA9xD7zP2A/ND6BP10AFYBNgFgA2AFqARwBOAG4AiQB6gFOAYQCLAIwAgQCYAIOAY4BLAEYAYAB7gGWAZABXgDcAIQA3gEEAXIBKgEkARABCgE0ARwBWgFcAVQBjgHaAcwBxAHIAcwB5gHkAggCYAIgAcQB/gG2AbwBigH4Aa4BXAEKARQBPQDVAPkAiAC6wAtADcAPQCW/3r+WP1g/Lj7ePtA+7D6OPpw+fD3gPag9iD3APbA8xDzgPOw8uDxwPLg8kDvgOvg7IDxkPOw8tDyEPPg8EDv0PIQ+eD74PpY+jj78PoQ+6T+YAMYBcgD+AIYBKgFWAY4BzAI8AcYB4AHAAnQCfAICAeoBXAF+AX4BtAHyAdwBkgEyAIoA7gEuAXoBcAFQAVIBMwD4ARYBlgGoAUgBlAHYAcYB5AHIAiYB8gGaAfQCEAJkAjYBzgHeAYoBnAG6AbgBiAG4ATQA5QDsAM0AyQCogF+AcoAyP+a/4L/SP6Q/MD74PuQ+yD74PoQ+jD4kPaA9sD24PXA9PDz4PLw8XDyEPNQ8WDu4OwA7oDvsPDw8sD0wPJA70DvwPKA9oD5yPts/HD6mPhg+nD+XgH0AlAEWAR8A+ADsAUAB/gGQAfoBwAI+AfgCGAJsAeIBSAFOAYQB6AHEAgQB6AE1AJEA7AEqAUoBjgGcAUQBKwDWARIBfAFWAZwBkAGGAZgBigHkAdQBwgHWAcACDAI0AeYB4AH2Aa4BZgFWAZgBlgFaARIBLwDcALUAXgCWAL6AAUAEAC1/0j+WP1U/cj8ePsw+9D7SPto+Sj4EPhw94D2YPYw9pD00PIg8+DzAPPg8MDvwO8g74Dv0PHg81DzwPEg8ZDxQPMQ9kD5CPvQ+uj56PkA+4D91QDwAigDCAOAAxAEkATIBUgHyAcoBxgHIAigCPgHIAeoBjAG8AWYBogHsAdgBsAEEAT4A3gEOAUIBggGSAWIBCAEgAT4BKgFUAaABjAGCAaABvgGCAcIB4AH8AfYB6gH8AcQCGgHuAbYBhAHgAYgBngGMAbYBMQDwAO4A8wCTAJgArgB6f9J/6z/vP4I/YD8JP1w/Gj6oPlI+pj5gPcA92D3EPbQ81DzcPRQ9EDykPBg8MDvoO4A7zDxkPLg8fDw0PCQ8XDyYPTg9rD4GPnI+HD5EPv4/Jz+HwBSASQC3AKkA8gE6AU4BkgGwAZwB9gHcAjwCJAIaAd4BqAGaAeoB5AHYAdwBkAF8ARYBagFuAXwBRgG0AVgBXAF6AXwBQAGmAb4BvgGMAfAB3gH4AYIB9AHMAjYB+gHQAjAB8AGoAYgB5AGwAXoBQgGOAVABPgDrAPEAgACBALcASwB3ACSAIj+nPw8/ST+wPwQ+0j7iPtQ+XD3WPjI+MD1MPPw9ID2QPTA8QDycPFA7uDs4O/A8rDxIPCw8ODwYO8A8AD04PbQ9qD24PeI+JD4MPqQ/Zn/hP8wAPwB7AIwA1gEuAXgBcAFoAboB3AIIAggCOgH0AZYBpAHgAhACKgH+AYQBjgFUAVYBtAGAAagBSAGEAZgBXgFOAaoBhAGiAVIBjAHCAeoBggHGAdwBkAGGAfwB2gHsAbABuAGQAa4BeAFqAVYBWAFcAWABHwDgANkAzwCegFEAoQCwQAY/2D/CP8I/Yz8GP60/ZD6OPkA+yj7APjQ9eD24PaQ9DD0APbA9EDwQO4A8FDxcPDg8ODyUPJA78DuwPHQ8yD0YPWQ95D3gPag96D6gPyU/AL+NgA0AVoBuAJgBIAEYARQBcgGWAd4B/AHMAhYB5AGIAfIB7gH0AfoBygH+AWQBSAGaAb4BbgFCAboBVAFQAXABdgFmAWIBcgF6AXQBRAGoAbABnAGOAZ4BsgG8AYYB+AGuAbABqAGGAaIBYgFwAWIBeAEqASQBIwDiALgAoADhAImAcgAAAHy/xb+EP4c//D9mPtI+wj8IPtA+fD4SPmQ9/D0MPXw9iD2APOA8XDxUPBA77Dw4PJQ8kDwwO+w8CDxkPGw8xD2MPZQ9TD2APgI+fD5APzY/Sz+qP5YAAwCRAJsAowDsAQYBbgFEAdwB6AGMAaQBsgGyAZgByAI4Ae4BiAGYAZgBhAGYAboBsAGKAYQBmAGSAbABdAFoAb4BrgGwAYQB/gGeAaABhAHaAdIBzgHWAcQB5gGgAa4BpAGKAb4BdgFiAVIBRgFeASQAzgDeANgA4AC2gGMAZ0AYf8b/0v/aP78/HD8hPyg+wj6wPn4+bD4gPYg9rD2APaQ9JDzAPNw8cDvMPCw8dDxsPCA8MDwcPBw8ODxAPTg9MD0cPWw9oD3GPjY+dD7yPx0/bT+eACAAf4BuALMA2gEwATABegGaAcQB9AG4AYABxgHgAcgCAAIaAfQBqgGiAZoBqAG+AbQBmgGOAZQBlAGMAZIBoAGkAaYBtgGCAcIB+AG4AboBhAHOAdYB3AHWAcYB9gGuAawBqgGeAYQBrAFkAUgBZgEQAQYBLwDQAP0AsQC3gHJAHsAcQCb/1L+yP2s/fD8ePsI++D6oPko+OD3QPhA96D1sPRw9CDzcPFQ8UDyEPLQ8NDwMPEA8YDwQPHA8mDzMPPw84D1EPZA9oD3YPlo+hj7aPwa/g3/eP9RAKQBjAL4AugDMAWwBaAF6AVwBrgGuAb4BqAHwAdYByAHOAcQB7gGyAYoBzAH0AawBsAGqAaIBqgG8AboBrAG0AYoBzgHEAcoB0AHEAcABzgHgAeABzAHAAfIBoAGYAagBrAGMAaoBVAF+ASoBIAEQATIAzQD3AJ4AtIBNgHgAF8Aa/+s/lT+5P3w/Ez88Pv4+nj5yPgY+aD4QPcA9nD1YPTA8iDygPJw8lDxoPDA8JDwMPBw8KDxIPLw8VDycPNA9LD0oPXw9hD4yPgA+sD7CP3M/cD+6P/EAIQBjALAA5AE6ARoBegFMAZ4BgAHaAeoB9gH8AfQB5AHgAeoB6gHsAfwBxAIsAdoB5gHqAegB7AH+AcQCNgHyAf4BwAIyAfIB+AHyAfAB8AHuAd4BygH+AbYBrAGsAbABmgG0AVgBRgFuARwBEAECAR8A9gCgAIMAmoB3wB1ANj//P5O/gD+ZP2A/KD70PrY+SD50PhY+HD38PXg9PDzoPKw8cDxoPHQ8DDwEPDg78DvAPCw8CDxYPHg8eDykPMQ9BD1QPYg9yD4kPkg+yz8HP1A/kz/+P/PACwCMAO8A0AE8ARwBbAFIAaoBigHWAeQB9AH2Ae4B7gH6AfoBwAIIAggCCAIAAj4B/gHAAgACBAIMAggCAAIAAgQCAAI2AfoBwAIEAjgB7gHoAdgByAH6AbYBsAGeAYQBsgFaAX4BKAEcAQ4BLADLAPIAlACqAEQAa8ALwBz/7j+SP60/fz8RPyY+8j60PlA+dD4KPgQ9/D1EPUA9ADzcPJA8sDxUPHg8IDwYPCA8MDwEPFg8cDxQPLQ8nDzcPRw9VD2UPd4+Lj5yPrw+yj9Pv4C/8H/zgDaAagCWAMQBKgEAAVgBeAFcAbABvAGUAdwB2gHaAeoB9gH0AfgB/AHEAgQCCAIMAhACCAIMAhACFAIYAhgCHAIcAhQCFAIUAhwCGAIUAgwCBAI2AeoB6gHiAdAB/AGwAaABggGoAVgBSAFgAT8A7QDMAN4At4BcAHHAN3/GP+y/h7+OP1w/Nj7CPsQ+lD5yPgo+CD3APYQ9SD0IPNQ8uDxkPEQ8aDwMPAg8BDwMPBg8NDwQPGw8TDyAPPg87D0kPWg9uD3APkY+lj7jPyU/XT+d/+EAGABUAJMAxgEmAQYBagFOAaQBvgGeAewB7AH0AcACCAIMAhgCJAIgAhwCIAIwAjQCNAIAAkQCQAJ4AgQCSAJAAkACRAJAAnACLAI4AjgCIAIUAhQCAAImAeAB2gH+AZ4BigG6AVoBfAEyASQBPQDSAP0AlwCfgH1AJYAwv++/iz+8P0c/fD7OPvY+vj54Ph4+CD4APeQ9aD0APQA8/DxkPFg8cDwAPDA7+DvwO+g7xDwoPDg8BDxwPGQ8mDzIPRA9XD2YPdo+Mj5KPss/Bz9NP43/x4ADAEMAhgDwANIBOgEiAXwBYgGEAdwB6gHwAcACEAIUAhgCKAIwAjACNAIAAkgCSAJMAlACVAJIAkgCWAJcAkgCRAJIAkQCdAIsAjQCLAIcAhQCDAI8AeYB3gHUAcAB5gGYAYYBqAFUAUIBYAE5AN8AxwDbAKUARYBnwC7/87+Vv7c/dz88PuA++D6wPm4+Fj44PeQ9lD1sPTg87Dy0PGQ8VDxkPAA8ADwEPDA78DvUPDA8ODwQPEw8gDzkPNQ9ID1sPaA97D4IPpg+0z8SP18/ov/awBSAWQCQAPkA3gEUAX4BVAG0AZYB8AH+AcwCIAIoAiwCNAIAAkQCQAJIAlQCWAJQAlACUAJQAkQCRAJMAkgCQAJ8AjwCOAIsAiwCMAIkAhQCDAIIAjwB6gHaAcgB9AGeAYgBsgFYAUQBagEIASgAzADkALoASwBlgDm//r+Mv64/fz8BPxA+6j64PnY+Aj4cPeg9oD1kPTA8/Dy0PEg8fDwcPDg76DvwO+A72DvgO/g72DwwPBg8TDy8PKA84D0sPXA9tD3EPlY+lj7TPx4/bb+of+GAJQBnAJYAwgE2ASIBQAGgAYQB4gH6AdQCMAI8AgACSAJYAmQCbAJ8AkgCiAKEAoAChAKMAowCjAKQAowCgAKAArwCeAJsAmQCXAJQAkQCeAIoAhgCBAIwAdwBxgHyAZwBggGiAUABZAEEAR4A/ACXAKqAdIACwBz/7z+3P0Q/WT8mPu4+vD5SPl4+ID3wPYQ9kD1QPSA8+DyAPJA8bDwYPAg8ODvoO+g76DvgO/g72Dw8PCQ8UDyAPPg87D0sPXg9hD4MPlI+nD7jPyw/cD+3P/eAMYBkAKAA2AEGAWoBUAG0AY4B6AHEAigCOAIAAkwCVAJgAmQCcAJAAoACgAK8AnwCQAKEAogCjAKMAowCiAKEAogCiAKAArwCdAJkAlQCSAJ8AiwCFAIAAi4B1gHAAeQBiAGoAUIBYAEGASQA/ACSAKkAdkACQBL/67++P0c/VT8oPvQ+uD5IPl4+MD30PYg9pD10PTg8xDzkPLg8UDx4PDg8KDwIPDg7xDwQPBQ8LDwUPHw8XDyIPMA9PD0wPXA9vD3APkA+hj7SPxY/Uz+QP9VAF4BQAIMA/ADuARABcgFaAbwBmgH2AdACJAIwAjgCDAJcAmgCbAJ0AnwCfAJ4AkACiAKMAowCjAKMAogCiAKIAoQCgAK8AnACZAJYAkwCfAIkAhQCBAIwAdoBwgHqAYwBpgFCAWYBAgEXAPQAkACdAGqAPz/Vv+k/uT9NP2A/LD76PpI+qD5wPjw90D3wPbw9UD1sPQA9CDzYPIA8pDxIPGw8JDwcPAg8BDwUPDA8BDxgPEw8tDycPNA9FD1UPYw9zD4UPlo+oj7tPzY/eb+zv++AMoBwAKsA3gEMAXABVAG4AZwBxAIgAjwCEAJcAmwCfAJEAowCmAKcApwCnAKoAqwCrAKoArACtAKwArACuAK0AqgCnAKQAoQCtAJgAlACfAIkAggCMgHWAfwBnAG+AVgBdAESAS4AxADbALIARABUACn//r+TP6s/fD8NPx4+8D6GPpg+aj4APhQ94D2wPUg9YD00PMw86DyMPKw8TDx4PCQ8FDwIPAw8HDwoPDw8IDxEPKQ8jDzEPTw9ND10PbQ99D4yPng+hT8KP00/kv/VQA8ARQCAAPkA6AESAXwBYgGEAeQByAIkAjwCFAJoAngCRAKUApwCpAKsArACtAK4ArwCgAL4ArQCtAKwAqwCrAKkApgCiAK4AmgCUAJ8AiwCEAI2Ad4BxgHkAYABnAF4ARABLgDOAOsAv4BQAGKANr/MP+W/gL+WP2k/Oj7KPuA+tj5QPmw+Aj4YPfQ9lD20PVA9cD0QPTQ84DzMPPw8tDyoPKA8mDyYPKA8tDyQPOg8/DzQPTA9HD1MPbg9rD3kPhY+Rj68Prg+9D8wP2s/n//OwD+ANYBqAJcAxAEqARABdgFaAboBmgH6AdACJAI4AhQCbAJ0AkQCmAKgAqACqAK0ArgCtAKwArQCrAKgAqACmAKIArgCaAJUAnwCKAIUAjgB0gH0AZoBtgFSAXABDAEhAPoAlwC1gFAAY4A8f9a/7b+FP6E/ej8SPzQ+zD7iPr4+Yj5CPl4+Aj4sPdA98D2YPZA9uD1cPVQ9WD1IPXw9BD1EPXw9BD1gPXQ9fD1MPbA9mD3oPfw98D4cPnA+XD6cPs8/IT89PwG/gD/Wv/G/w4B/gHqASgCYAM4BCgEoASwBQgGyAVIBlAHYAfgBkgHYAhQCFgH2AcQCbAIgAfoBwAJ0AjIB9gHkAiACIgHOAfIB+gHGAdwBpgGqAYABhgF4AQ4BagEaAMYA4QD5AKgAWQBlAHYALP/Yf+k/wr/3P2Y/bz9/PwA/CD8SPx4+7D6qPqo+gD6aPmw+eD5IPlo+LD4GPlw+ND3cPjg+DD4wPdo+OD4YPgo+Oj4cPkQ+QD5GPq4+jD6WPqY+yD8qPss/Lj9OP6s/Rj+af/V/4T/BgCSATACZAGkASgDiAPQAkADaASQBDAEgAQoBUAFKAV4BbgFmAWQBfgFMAbYBfAFQAboBbAFKAYgBpgF6AVQBpAFyAQoBaAF4AQwBKAE4AS0A7gClAP4A2QCzgHMAlQCkQCoAM4BFgGG/1D/+f+n/2D+Fv70/r7+RP3g/JT9YP2A/HD8aPwg/CT80Ps4+3j76PtQ+8j6+Pow+yj72PrA+iD7OPuI+qj6aPt4+xj7MPuI+/D7EPyo++j7FP1Y/Zz85Pzw/SD+xP0Y/hb/ov8e//r+PwDFAAAAbQDCAbABQAHIATwCnALoAmwCcAKUA9AD0AIoA5gEiAQIA8ACeAQQBYAD+ALYBHAFFAM4AlgEEAX8AngCQAQgBGwCGAIcAwAD7gH+AbwCFALNAHABBALaADUAxwC9AD4A6P93/6j/9/8D/z7+zv4Q/3D+2P0y/sz+qP0M/Jz9b/8s/fj6JP1//7z9APvY+5b+Bv6A+3z8qP5o/fD7VP1o/jT9fPy0/Yj+tP1Y/Vb+fP7E/Tz+9P6Q/pz+ev+S/wP/K/8AAEUA9/8mAHIAYgCnAFYB1wAuAMABfAKyAP//LAJkAzoBCwAQArADZgHf/+gC2AOqACgAOAOEA8MAZADAApADGgHC/1wCoAMQAU8AFAJMAmYBewBZAPgBcAL8/1r/vgEEAqf//P7eAI4Ba/8W/nUA6AG6/hD9XQCoAeT9yPxYABgBBv4E/Sv/TACS/iD9gP4aAL7+OP2K/lj/Vv4m/tb+Cv8P/3z+9P20/uX/cf8q/nr+8P9fAIT+wP0VAIwBjf/w/ab/FAFIAH7/pP89AA4BrgCX/0UARAHuAN0ArACTAIYBJgERAF4BYAKJADgA4AHAAQABkgD9AMIB4QAeAM4BVAI1/yv/oAJQArz+sv60AugCGP6A/fACjAOQ/WD9hAP8Aoj8tP0QBHgCiPzM/UQD2gH4/J7+2ALgAEz9Tv9sATr/0P75AEMAlP14/jgBjAB8/fz9cgFhAMD8EP7KATEA0PxA/swBo/9A+xH/zAON/7D6Yv4EA/j/qPsi/sgChgC4+3z+aAKj/2z9BQCaAKL+df8IAXcA1P4F/zYB/wAq/s7/2AJ8AH7+XQBWAU8AUADEABgBCAEAACMA2gAaAYwBzwAs/58AxAJlALL+wAFoA0v/cP1wAhAExP74/UADtAJo/YT+OASsAtj8xP4gBCwB+PvA/zAFMgGQ+97+sAMKAUj8jv6gA7IBWPx0/fwBoAFK/vT9vf8kAMT/CP/A/qb/WAA6/+T9HP7q/1IBf/8Q/VH/uQCM/Yz90wC/ACz+9P1L/+D/Yv9M/rb+9P+w/5X/xv4W/v4ASALw/Tz8cgGIAnD+uv4oAkgCVv7U/L0A4AO3ACD+1gHcApz+Bv4sAigDVAA6/yABrAIuAQ3/SACQAxgCEP71/5gEfAJ+/isAQANEAhr+pv5oBIAEbP3c/bgEoAKo/Jj++AMkAzL+Bv6uAQwCZv74/bIBdgHM/sD+3//S/+f/+v9Y/kv/IAE+/4z9av++AXP/xPxo/pIBDAHw/JT98AFAAAD8uv7UAhn/oPt9/5AC0v6w+xoA7ALY/Sj7cQD0ArT9IPymAYgCIPxY+/wCiANc/GT8GAJQAmT90PyMAeQC+v7Y/HAAIAJt/77+XAB0AVMAHf/R/xIB6wBCAKQBBgGq/ub/fAKwAWf/MAHQAiAAZv6PAOwDwAHM/bMAmAQMALD71AHwBY7/XPy2AaQDnP5s/TgCxAMx/zj84QD4A0j+uPvEAiAFnPwQ+kQCQASE/ST8VALgArD8yPpkARAFyP3Y+mACbAOo+qD7UAT0AkD80Px8AcYAgP2w/v4BdQCo/Bb+uAHv/5j9cQB2AVb+kP2S/6j/CQDiATwAmP1c/lkAhADI/xkApgGUAGz9H/9QApcALP4EAkQDGP2U/JgDYATM/RD9JAKUAwH/sPvCATgHDAAY+sIASAR+/uj+mATAAvT9MP25AFgEkgEs/fsASAVn/1j7xQCQBBgClv6g/aIAoAJ9/wr/0AImAbj7tv7EA5UAZP0UAWgDSP4A+sr+cAYEAuj55v6gBLz90PnyARgF8P3o+jIAyALi/lj8EQDwAn7+yPqX/+wDDQAs/T7/Yv+E/bf/kgDj/2oBPv9s/Mz9XgCLACwBIP/s/AwC3gHI+Rz82AYwBPj5hPygAxYBrPyLAGAGrACw97D9kAkIBAD4BgDQCh0AgPVo/6AKcATY+rD+CAa4AXj6cv+gCJgEyPrA/eAFzAKw+3b/WAcYBFD7zPzwBHAEVP14/+AFdwCw+RsAkAeeAST8kQCEAhr+BP10AXgDvwCc/eb+XP+4/BoAgARX/0j79ABGAQj7gP0gBIABqPok/CQCxgFE/DT94ALlAOD5YPtsA1QDbP3s/RoBHP3Y+jwAOASSARj81PyQAUgAmPvC/ogEjgHg+5D8vABAAkgAXP6Y/7gA9P4P/2ABQgGy/zoADQCM/iMAHAJAAnABmP7I/dYBOAPU/jEAsAQkAGT8WAFoBIb/Mv4sA0AE4P44+wgC0AciAED6NAJwBvj90Ps4BHAECP4s/UgCwAMq/rj88gFQBNj+kPtt/0gDVAK8/YT80QD+ARj++PyEAdACWP38/O0AmQBU/SL+NgH2AMT+FP38/k0Akv4X/5L/3P0Z/+YBLP5Y+jgAiASW/pD5sv54A0sAHP12/rQAC/9w/bj/VAGN/8T+nABRAH3/zv4E/r4BtAOm/kT8RAJ4BTT/YPr+/ygHWAJQ+gX/gAeoAsj6Ov9YBZQB/PxeAfAE0AC8/Kz/iAW8Axz8bPxQBaAF9P24/IQCMAUHAKj89v+4A7QCgf9v/6cAsQAiAO4AHAM4AJz8V/88A3wCOP5E/ewBEARO/kj6ngBoBToA6PtYALAC3PwY/aACrgGY+1D9+AMYAjj7oPvIAj4B4Pm8/eAEs/94+k3/oAJ8/ID5bAGIBrL+gPfM/8AGZP3w9pABUAh0/uD3TwBwBr3/aPmz/0AGff9A+d8A4AiwAFj4af/IBeT/6PliAOAI8ATI+cD4zAOgBtD90PwoBTgEXPwc/JoBaASKAdD+bQAoAfD+tv90A/oBrv7W/3IAHAA0AZQC+gE7//z9ZAC4Adb+LwAYBtgCaPmw+lAEwAWC/mj7JAHoBa7+wPfBACAJ1v7Q9fr/YAnm/4D2Uf8gCUj/0PLU/hAOtAIA88D8QArk/+DzdP/ADNYBUPTo/MgH9v7g9rIBgAly/iD1tv4wCGAAkPdo/vAF/v9w+eb+CAZ6AeD5+PxQAygAyPuQAVgGZP9o+Q7+SAR+AZT8uAAIBdb/4PqBADAE6P5C/kwDPAKI+x7+EAd4BDD6KPuQBbAE0Pv0/XAG8AR4+xD6jAKABfj/WP6oAgwDNv7Y+yv/MAXwBEz9TPx0A9wD+Ptw+7AFEAhs/OD2MAIgCNj94PlQBBgHKPrw9XQDQArm/rj4SAEYAyD6YPrgBAgGTP0A+zf/hv4k/HABKAUK/4D6fv5bAFj8Zv5YBRAE4PqY+I//pAKN/4P/BANeAXD74Pky/yAFkAQA/tD7oQD0AUD8DPzoBeAIxP0g9m7+GAeKAej84ASwBnD5YPUoBPALtwCg+eQC8Abw+ZD18AXQDUoB6Piy/gABMP11ANgHYAWg+4j6nAHgAmT/SAKgBaP/mPms/KQCqAQIBFgCNv/Q+nD51wCgCOgFKP40/I7+vv7o/DIA4AiQBnD4gPXYAdgFpP7e/3AGPQCw8zj4kAkQCtj6IPmUA1UAYPVc/ZAMIAfQ9pD3dAIYAcD7kAFwCCQBgPUw+EgEaAY2/0D+nAGm/lj50Pv4BCAIVADg+ET8MAKqAJD+bAIABR3/yPjc/NAE8AS1/3z+dgDO/iD9UP9UAxAFqgEw/Gj7vgDUA8kAgP6mAVgEvv5o+b3/cAcIA/j6Ev4oBa4BqPod//AHMAPI+Az8YAXUA9z8JP5wBNAD6Pvw+BgBWAfeAZj7jP1aASgCQ//Y/FkAWAMH/6D72v/QAoYA3v7C/2YAAP74++kA8AUiAeD6UP1kAaYAUv8S/3MA4gHP/9T99P06/3wC1AII/fj60gGoBE//1Pyd/7UABP6c/ewCYATy/iz9OwDg/mD7EgDwBggFhPzY+bUAGATI/lj+KAQcAtD7dv7gBCQCDPzU/TgERAJo+nL+kAnoBWD3gPcYBUAHAv7g/aAF8AKY+AD7yAbwBcj7DP2QBvgCYPfo+pAIOAcI+Rj4MAW4B/T8kPl0ARAEIP2Y+1wC6ATX/4j7sP3LAAMAJ//aAUgD5P4o+7j9mAIIA1b/wP2MAOIBdP74/M4BgAS//4D7NP74AmQCD/8K/woB3v9s/eP/6ANMAmz9sPwRAGIBy/8iAGACZgEM/cD79v9gAyAChv+e/ur+Z//D/28AiAFUAfr+DP2s/pgBvAL6AL7+Fv8cALT+wP6oA8gEWv6w+kD//ALLAKr+ZAFwA6j+MPp4/ngEoAIH/xEA2QD8/fT8owAsAxoBWv+LAIUAWv4+/iQBKAJ7AIr/AgBt/7z+GAF0AjL/8PzT/+gB9v8a/yABkABU/Vj90gDSAZr/qf+2AWb/QPsc/qADpgGA/Iz+6AK3AJj8bv5EAuf/IPxe/0gEhAGY/B3//AK0/jD6AwBwBxADiPoI/AwDmALE/MT+KAV8AtD6wPwgBKQCrPws/2gFgAGA+cT8KAZYBbT8oPuqASQC9P2J/2gELAP0/YD8/P7TAKQBCAPgAvz+XPz4/q4BmAFWAfIAZ/9c/t3/EAIAAez9dP7wAd4AqPyG/rgERAPg+oD56gDQBBAAsPzfAAAD6Pzo+S4BeAUq/xD7hQCUA9T9+Pq2AXAFRv4w+X//uAVcAZD8MQDMAtT9oPtCAYAEhwAO/jQBDAKY/Sz8uAHABDgAYPxF/xQDTgGk/f7+gAJ3AJD8TP9wBGwCKP1w/UQByQA2/rgAOASUAXT8RP1UAYABEwCIARQCCv9c/jQBVgHq/rT/ZALaAID9RP/cA9ACWP0I/T4BSgGk/n0AzANIAdT8DP5kAuABbP3Y/cwCMAMi/uj8agH0As7+CPy//+wDdgFA/VT+IAF5/8z9XgEUAwD+APvo/7QDgf8Y/CkAiAP2/kj6av5IBCgCLP10/Vn/oP6Y/1ADtAN0/sD6Hv44AqkA5P64AogEPv4g+SD9YAP4A8oBtABc/lj7dP2YA3gEIf9s/TABRgG4/AT+GAVoBTj9uPmz/yAE5AGmAOAC9gDg+iD7vAIgBqoB4v7ZALT/iPvM/SAFUAUw/gj76v5EAj4B+v8GAWAA6PzA/C4B7AIOAesAgwBY/ND5xv/YB/AFiPwo+lMAfAFs/en/4AXwAkj7oPtQAVgCOgCUARADqP1o+EL+2AcIBgD9ePuO/zv/7PzRAKAG8AOA+wj51P0EAWwB1AOgBGz+SPho+5ACSASMAa7/K//s/ez88v4wA4gE9wBY/Cj7av5cA+gE/AHw/rz9hP3U/qgB0ANUA9cAgP1w/Cb/UAI4A2gChACk/aj8gv9wA9ADDgBY/dr+iQBE/6P/VAOYAzr+8PpY/rQCmAJ+AE0Az/8U/dz8dgFgBFIBpP0O/lz/uP74/vQBtANuAPj7IPzM/wgCjgGxAA0AsP6k/cj+NAEIAowA6P44/mj+h/9IASAC/QDY/gj9VP1nAGADeALs/mz9qP6b/9H/RgHEAsMAsPx8/FcAaAJOAf0AKgGQ/rj74P0kA3AEhgCI/Wj+ef88/1kAeALeAa7+WP0B/6AABAFqAS4B2P7o/IT+CAJIAzwBBP9k/lr+6P7VALQCXAJKAID+BP7a/kkA4AFAApIAlv5s/sv/wgDLAGcAzP9X/7X/BAFyAQIA7P6l/1sA7f8YAFoBogHc/xj+tP6nAGYB5wB9ACsAlv91/woApwCQALD/e/9hACgBpQCR/2v/1P+8/2X/GQAkAZUAGP+Y/jb/uf8BAJoAzQCN/wr+fv4JAF4A3P/c//7/cP/K/j//QgBkANr/xv/Q/57/2/8nAAQA2P/R/9v/QACXAEEApP+N/ykAnwB7AGoAvQBfAGb/zv/8AKwAzP9nAFgBuQCZ//L/3ACTAM//AgDqAP8AUAALADcA//+9/zMAsQCJAAkAjP+a/1oA1ABHAK3/0P8NANf/kP8hAAYBtQBA/+z+AgCEAEEARwAYAGH/Bf99/1wAuQASAD//Mv+U//r/RABeAAIAb/8A/0L/TADgAJEAx/8Z/yT/+/+nAHIA5/+K/1n/jf9qABQBcwAa/9D+0f9+AFMAZAC3AP3/lv7C/qkAugECAQcAmf9u/4v/WQBqAYYBTQA3/7D/pwCfACEAPgCZADEATv97/9MAAgFp/5b+kf85AJ//sf/dAIYAIP4A/Rn/UgGcAAz/Tv/x/wL/Fv5B/+8AsAA///L+7f9YAKv/ev9MAKEAv/8t/ygAIgFdAAn/UP+IAJcA8P8WAH0A9/8s/1r/KQB8AE4ANwARAJf/g/8cAIoAQwDO/9n/KgA6ABoANABcAC0AuP+0/4EAMAGRALj///9+AEcAFQDXAGoBZwAW/6b/DgEiAXAAkQC9ALT/+P4TAFoBxQCp/8b/FQCG/3n/mgDlAHn/eP5u/3UABQBs/+3/QwAz/1j+PP+MAFEAP/8X/4z/Zv/o/nv/mQA3ALL+PP6H/3EAzP9J//f/PQDy/iT+X///ANsAnP9T/7X/sP+//4gA/gBEAFz/mv+JAMcAegB0AKoAggBBAFcAxgBKAYQBFAFZAEsAQAEcAsYBEAH2AE4BVAEyAWQBvgGqAS4B/gAaATgBQAFgAUgByQCAAMsAHgHiAHMALwD2/+L/BwAbALr/Qv89/0P/3v6k/u7+BP+C/vD98P02/jL+Cv7s/YT9JP1g/cz9jP0Q/Qz9KP3Q/JT8BP18/fT8JPxA/Mj8vPyQ/PD8TP3s/Gz8uPx8/ez9yP3Q/S7+cv5+/rr+iv9YAJIAcgDWAKIB7AHWATgCNAP4A2AE4AQoBfAE6ASgBYAGAAdAB6AHoAcIB9AGkAdQCDAIwAeoB5gHMAfABugGAAd4BpgFEAXoBKAEKASMA7QC3gFIAegAYQDe/1T/Uv78/CT8APy4++j6+PlA+Vj4QPfQ9gD3wPaQ9YD0EPTQ8zDz8PIw8yDzgPLQ8QDyYPKQ8uDyUPOQ89DzkPSA9TD28PYQ+Aj5yPk4+yj9bv4J/xcA2AFEA2AEgAYACbAJYAmQCsAM8A3ADkAQABIgEsAQ4BCAEoATYBOAE0ATABKAEEAQ4BDAEEAP8A0ADcALYApwCdAIAAi4BgAFvAMUA0gC2ADI/yr/Bv5g/Ij7DPzA+8D5CPgo+Bj4cPZg9SD2gPag9NDyAPNw83DyYPEA8rDykPEg8GDwIPHA8DDw0PDA8ZDx8PBQ8UDy0PLw8qDzcPQg9cD1wPaw91j4MPn4+Sj7sPwW/jP/JQDeANQBNAPQBFgGqAewCKAJYApwCxANkA4AD0APYBCgESASoBFAEgATIBIgESASwBPAEiAQsA7QDrANsAsgDJANgAs4B7AFkAbQBewC4AFUA/gC2P9c/gL/5P1Q+1j73P1A/rD7GPoA+wD7CPkA+dj79PyY+sD4kPkg+hj56PiQ+kD7WPkA+Bj54Pl4+HD3WPgI+RD4QPfQ9yj48PbQ9fD1gPaw9sD2wPYw9hD1wPRw9eD1QPbg9tD2APbg9cD2gPfA9zj4aPkY+sj5UPoc/Dj9WP1G/h4ARgHCAeACoATABSAGeAeQCZAKAAtQDLANAA5ADqAP4BCgEIAQYBGAESAQsA8AEeAQkA4wDfANQA2ACsAJcAsQCzAHSASYBAAFqAMUA+ADNAI6/qD8dv7a/+L+hP0Y/Tj8cPpY+mD8bP0g/JD6APoY+nD6IPvI+2j7yPnI+DD5MPrA+oD6ePmY+Gj4ePig+Oj4+Pg4+PD2gPaQ9zj4QPdw9pD2MPZw9fD1oPfg9wD2wPTg9QD30PYg91j4iPiQ92D38Pig+gD7KPsk/PT8XP1m/uL/KAHsAcAC9ANYBaAG4AfQCHAJkAoQDFANIA7QDlAPcA+QD4AQwBHgEeAQ8A9AD9AOgA6QDrAOcA2wCzAK0AjoB8AHQAfwBYAEiAMYAygCPAAc/wX/8P7I/sL+Dv6c/Ij7APtY+zD85PzU/KD7UPrw+UD6qPqA+1j8gPug+Rj5SPrQ+hj6uPkg+gj6CPnI+Hj5aPnw91D3MPjA+Fj4sPdw9wD3EPbw9TD3QPig93D2EPZQ9oD2IPco+ID40PdQ9wD4QPm4+Rj6EPvo++D7HPy4/ZP/RQBHACgBmAK0A+gEqAbwB9gHAAjACdALoAwgDSAOcA6wDeANwA8AEYAQ0A+QDzAOYAzQDHAOcA5QDKAKAAoQCAgGgAboB/gGaAS0AhwCjAHRAJkAagCH/77+lv4y/qD9eP0c/UT8UPx4/bj9YPxg+9D7BPwI+/D6oPwY/fD6aPlY+kj7YPqo+XD64Ppg+Rj44Ph4+WD4YPfg90j4UPdw9rD28Pbw9TD18PWg9iD2YPWA9ZD1IPVg9cD2YPew9kD2QPdY+KD4+PhI+mD7YPvo+3z9rP4w/zMA0AHsAmQD0ATwBuAHuAfgCAAL4AtwDAAOkA8gDyAOIA9AEWARQBCgEGARwA8wDfAMwA5AD1ANYAuACtAIsAZABpgHwAdoBbgCgAFsAeQATAA/AC4A9v4g/bT8kP3g/QD9EPwA/DT8APzQ+0T8OPz4+hD6sPqg+3j74PqQ+hj6SPno+LD5YPqo+bD4oPh4+OD3sPcg+Dj4kPcQ9wD3IPfA9nD2kPZw9jD2kPbQ9rD2cPZw9qD24PaQ91j4cPgA+GD4gPko+kD6KPvE/Cz9AP38/bn/zABiAXwC3AO4BGAFyAZgCDAJ8AlAC/ALcAwQDjAPoA5gDuAPIBEgEFAPwBBgEXAOsAtQDXAP4A2gC5AL4ApIBwAFCAcQCbAGTAPEAswCsgBH/78ArAG0/2T9aP0A/jD9TPzk/Dj9+PtQ+xz8bPx4+7D64PoA+9D6yPoY+/j6+Plg+Xj5gPmY+QD60PkQ+Yj4cPiA+Hj4aPiY+Ij4wPdQ97D3sPdA9zD3kPfQ9zD3oPYw99D3QPfA9sD32Pig+AD4YPho+bD5uPnA+hz8aPxk/Ej9RP70/un/VgFsAhQD8APQBIgFwAawCMAJgAkQCkAMYA2QDNAMwA5QD+ANIA5gEKAQAA6ADOAN8A3AC7AL8A3gDEAIqAX4BhAIiAZ4BdAFGARYAFb/ZgHkAdv/pP4t/4r+rPxQ/Kz91P0M/KD7uPzc/Kj7UPvI+3j7yPoY+xj8BPzg+iD6UPpg+lD6yPoA+1D6qPmg+dD5uPmY+bj5qPkY+dj4MPkY+XD4CPho+Jj4WPg4+Gj4UPig91D34PeQ+Mj4yPjY+MD4sPgo+QD60Pp4++D7HPyE/Fz9Yv5G/ysAfgG4AsgC4AKQBMgGgAe4B9AIYArQCsAKYAxwDhAOwAzQDdAPwA9wDrAOcA/gDXAL8AsgDsANMAvACSAJQAeIBVgG0Ad4BmgDxgGoAQ4BBwA6AJoAVv+g/XD9wP38/Bz8XPzQ/ED8qPvw+yD8KPtA+oD6CPsY+wj7APto+nj5MPng+Uj6GPro+dj5YPnI+Pj4wPnI+TD56Pgo+Sj5uPjA+DD5IPlo+ED4+PhA+aj4WPiw+OD4iPiw+ID54Pl4+Uj52PlY+qj6QPsg/JD8vPxA/RD+2P7M//cAvgEsAggDWAQoBbAFEAegCPAI4AhQCiAMYAwADNAMIA7QDfAMMA6gD4AOUAyADEANEAzACjAL8AsgCvAG6AVwBvgF4ATQBDAE8gHo/7D/XwANAOb+bP5O/nT9aPxg/OT8+PyI/Oj7wPvo++j7mPuw+8j7YPvo+ij70PuI+4j6IPrY+jD7oPpQ+qD6kPq4+Vj52PlQ+ij6mPk4+SD5CPn4+Cj5UPn4+FD4CPh4+PD4kPjw9yD4sPiI+ED4sPhg+Uj5+PiA+Wj6sPrA+qD7qPzI/AD9aP63/wYAWwC6AfwClAN4BOgFoAbQBvgHoAlACkAKUAvgDBANUAxADZAO4A3QDNANMA8wDjAMwAuADKALEAqQCjAL0AiwBXgFkAYgBkgEQAPwAp4B5P8HANMAz/8m/sD9/P2M/Qj9LP2I/QD94PuQ+1D8xPx8/BT84Puo+5D7mPuQ+3j7KPvI+uD6MPsg+5j6GPr4+RD6GPoY+kj6YPq4+bD4aPg4+eD5qPkg+cj4gPgQ+PD3oPhY+eD4KPhY+Lj4ePho+CD58Png+WD52Png+ij7KPsY/Dj9jP3w/ST/IQBDALsAaAIgBJAE8ARQBjgHKAf4ByAKYAvwClAL4AxQDSAMIAwADoAOMA3wDDAOsA0QCxAKUAvQC1AK4AhwCGgHeAW4BIAFCAUgA9ABegHvAA4Akf9s//L+/P2E/ZD9gP1A/ST9uPwk/DT8kPyg/HD8TPw0/MD7kPsI/FT8mPsA+3D7sPsw+/j6YPtg+1j64Pno+oj7wPow+oj6UPpo+TD5OPrY+gj6IPko+VD54Pi4+CD5gPmI+SD5wPjQ+Aj5SPmY+QD6ePqo+nj6sPqI+yT8gPx0/br+WP9W/8j/7wDqAcACKASIBeAFuAVwBsgHcAgwCcAKAAxgC6AKMAtADIAMUAwQDYANUAzwCjALcAuACtAJ4AmACSAIgAbwBcAF8AQYBIADkAKKATgBywDd/y7/EP/Q/kT+Hv4s/rj9+PwU/cD9gP3c/DD9zP08/WT8pPxk/UT9lPyA/Kz8QPzo+1T8mPzI+xD7QPuY+3D7IPsw+zj7sPo4+kD6YPoQ+qj5sPno+cD5OPnQ+Kj4gPhY+MD4YPkw+VD48PdQ+MD4+Pho+TD6UPrY+fj52PqI+/j7CP1W/rr+kv4X/2sAkAFEAngD2AQ4BUAFMAZ4BzAI8AhQClAL8ApQCvAKYAzQDKAMwAywDNALQAtwC4AL4ArwCWAJ0AioB7AGcAYABrgEYAPYAnQCqgHfAFoApP+0/lD+bv52/uT9OP0M/Qz9+PwI/Qz9+Pz8/Pz8vPyY/OD8FP3A/Gj8dPyU/ID8YPx0/Dj8kPtQ+9D7GPy4+1D7KPv4+rD6sPrQ+pj6MPrw+eD5oPmA+ZD5gPkA+aj40PgI+RD5APm4+ED4gPhY+aD5mPnI+SD6CPrg+fD6qPww/az8QP2G/uz+IP+OAGAC1AJ4AlgDQAUYBvgF2AawCJAJcAnQCdAKUAtAC7ALwAwgDUAMcAvQCzAMsAsQC/AKsAqACRAImAegBwAHuAXgBEAENAMgAuAB+gEQAZX/Ff98/zb/TP7w/Ub+/P1A/WD9Cv7Q/Rj9LP3g/dT9/Pww/QL+mP2A/MD81P3E/Zj8IPyU/Fz8sPv4+8j8OPzQ+mj6EPsQ+0D6GPqY+mD6OPmg+PD4MPng+ID4gPiI+Bj40PcY+DD4sPeA9yD4yPjw+PD4GPn4+KD4UPlI+3j8JPxM/Ez9pP28/Un/+AEYAyACJAJIBNAFwAXYBiAJsAmgCDAJoAuQDGALUAtQDRAOoAwADAANMA3AC0ALIAzwCxAKwAjACEAI8AYoBkAGkAWMAzQCUAJEAkIBawAEAGz/vP6q/rz+Mv50/Yj9Ev7A/RD9OP2U/TD97PyE/az9CP2I/MT8DP3Q/KD86PzI/OD7aPvQ+xD8+PvY+2j7sPpY+pj6oPo4+gj6QPoA+gj5gPjQ+Cj5yPhI+Fj4UPjg99D3KPhI+PD3oPcA+ND4OPno+Oj4mPko+jD6oPog/Hz9uP1Q/Sz+z/+7AIgBAAMYBAgEUATgBbgHkAjACGAJQAqQCiALUAwADaAMkAwgDVAN8AygDNAMoAzAC/AK4ApgCgAJIAjQBxAH2AUIBYAEkANAApIBngEYAcn//v70/qr+Fv7k/fz9oP0I/QD9RP0M/aT85PxQ/Sj9yPzM/Nj8bPxU/AT9YP28/Bz8LPwQ/Kj7uPs4/ED8UPuo+sD62Ppo+kj6qPqA+qD5APkQ+Tj5APm4+MD4oPjw94D30PdI+DD40Peg99D30PfQ92j4YPmg+Tj5IPnQ+cj6sPvc/Ar+aP5C/gD/1QBwAiQDiAOABLAFmAaQB7AIYAmQCQAKAAsgDMAM0AzADLAMgAygDCANUA2gDNALMAuQCtAJQAkQCYAIKAf4BXAFwASIA7wCmAIwAioBTADv/43/4P6g/vr+6P4+/uz9FP7g/XT9nP06/mj+1P2M/aT9fP0E/Qz9kP2Y/QD9gPxQ/PD7iPuY++D7yPsg+3j6OPoI+tD5uPm4+YD5GPmo+Ej4IPgw+ED4CPig93D3gPdw92D3sPfw95D3QPew91D4cPi4+Kj5UPr4+bj5EPvI/JD9Mv6F/yYAz/+0ABQDIAVQBSgFiAYgCLAIMAmACmALYAvAC/AM0A2wDXANoA2gDSANIA2wDaANkAwwCzAKoAlgCSAJcAhIB9AFeASYAzwD8AIwAkQBdgDS/wf/bv52/p7+Rv6w/ZD9tP18/UT9YP2M/Yz9nP3Y/eD9fP0k/TD9VP1k/Xz9eP0Y/XD8DPwA/Az86PvA+3j7+Ppo+hj6CPro+aj5UPkA+cj4aPjg96D3wPfQ90D30PYA9zD3sPaQ9jD3gPcA9/D24PeY+FD4aPjg+YD6yPlw+hj9Cf+K/gr+Q/8YAdwBBAOIBdAGqAVgBbgHAApwCmAKsAvwDIAMEAxQDbAOUA6gDcAN8A1gDfAM8AxwDPAKsAmACYAJsAggB+AF6ATYAwgDmAIYAkgBPABj/+r+kv48/hr+9P2k/VT9TP2A/YT9VP0s/UD9lP3s/fj9yP2A/Tz9RP2A/aD9nP1o/dj8SPwU/CT8LPzo+3D7CPug+ij68Png+Zj5KPnY+Jj4OPjw98D3gPdA9yD3IPfg9pD2wPYA97D2UPbg9qD3gPcw9xD4IPnY+ID44Png+4T8zPwq/k3/0v7g/sIBEAW4BfAEeAUYB/AHkAigCsAM4AwgDJAMsA0wDlAO8A6gDzAPEA7ADRAO0A3ADNALIAuACtAJ4AjIB5gGUAVABIwDGAN4AlQBGwB1/yT/kP4S/hj+Cv5o/bj88PyI/VD91PwU/YD9OP38/Hj9AP6o/QD9JP2g/Yz9HP0Q/Rz9xPxY/BT8+PvA+2D76PqA+kD6+PmI+RD56PjA+CD4gPdw93D3EPeQ9mD2cPYw9vD1EPYw9vD10PVA9tD2APeA9xD4MPjw95D4KPrI+xz99P1u/iz+TP5tAIADEAVgBfAFgAbQBqAHcAmgC8AMwAzgDBANIA3QDSAPgA/wDqAOoA5QDqANIA2ADHALgApACuAJYAiQBogFuASMA7ACZALQAX8AF/9a/vz9uP2s/bD9PP18/Fj8kPy8/NT8+Pwk/Tj9QP1k/ZT9hP2A/bT96P3A/Vj9IP0c/Qj9rPw4/Bj8APyI+8j6SPpI+ij6mPkI+cj4YPjg96D3sPeA9+D2oPbA9rD2UPZg9tD20PaA9pD2EPdQ97D3oPhY+SD5wPiA+Qj7gPzM/QP/bf+w/uL+7wB4AwAF2AVIBnAGuAaYBzAJ8AowDMAMsAxQDKAMoA1gDoAOkA5wDuANQA0QDdAMAAzQCkAKEAogCZAHWAaIBYgEaAO0AjgCcAE6ACj/lv4g/vT98P3Y/Vz9zPy4/AD9gP20/cD92P0O/kT+cP6s/sb+1P7q/gj/9P6e/kj+Qv4u/qj9DP3o/MD8APww+8D6WPro+Xj5GPmA+KD3MPdA9/D2IPbg9fD1kPVA9WD1oPVQ9fD0YPXg9ZD1cPXw9oD4UPhw96D3GPm4+jT85P0i/+T+QP42/+wBeATIBaAGMAeIB8AH8AgQCyANAA6wDbANMA7ADlAP0A9AEAAQQA/ADtAOgA5QDUAMsAsAC9AJsAjYB6AGEAXQA0QDpAJcAVsAy//m/tz9jP24/ZT99Px0/HD8oPzU/Bj9UP0Q/fj8iP0S/lD+Uv5g/jL+Hv5u/rr+gv7o/bD9lP34/Dz8PPxo/Hj7UPrw+dD5OPmI+Dj40Pfw9jD2EPYA9nD1APUQ9bD0UPSw9ND0cPRg9AD1UPXg9ID1gPdw+AD3IPYA+Cj6aPv4/OL++v6E/eT9JAFYBHgFMAZgB6AH+AbwBwALUA3QDdANQA5wDkAO8A6AEEARYBDgD8APYA+QDiAO0A0QDdALoArACcAISAf4BeAEzAPcAgACywCs/8z++P1g/Sz9JP3c/ET8oPuQ+/D7RPyY/AT9JP0I/fz8VP0u/qj+bP5I/sb+H/+u/ib+IP5G/tT9MP38/Mz8EPww+7D6EPpQ+dD4sPg4+GD3gPbQ9WD1UPVg9QD1IPTw85D0cPTA8wD08PTw9HD0IPXQ9mD30PZQ99j4MPmA+Tj8pf8UAHD+iv71AGAD8AT4BtAIgAiIB9AIsAswDbAN0A4gEPAPQA/gD2ARABIgEQARIBGgEJAPEA+ADhANoAvwCpAKUAkwB0gFCAQMAywCdAFCAKj+SP10/Az84PvI+5D7APtY+iD6mPoo+5j7+PtY/FT8UPzM/MT9cP5M/gz+ZP7E/sb+jP5o/hj+iP00/Qj90PwM/Cj7qPpA+pD5uPgg+MD3QPdg9jD1sPTg9ND0IPRw8yDzIPMw83DzAPQQ9DDzEPOg9ED2oPag9oD3WPiI+Gj5WPxm/0gAwP8cADIBbALABBAIYAogCiAJkAlgCzANkA5AEEARIBGgEMAQIBFAEeARwBLAEmARoA/gDpAOoA2QDOAL4ApACaAHSAbABEQDZALgAdYAR/8g/mj9xPw4/Az82Pso+7D6EPuo+5j7QPuo+2z8lPx0/PD8zP3k/XD9eP30/RD+0P3Q/cT9CP34+6j78PvA+9D6uPnY+Dj4sPdA99D2IPZA9XD04POQ84DzUPPQ8mDycPKg8pDy4PKg89DzQPNw8zD1MPfg9/D3sPhQ+aj5iPtm/yACFAKQATgC+AN4BWgH0ApADSAN0AvQC/AM0A5gEaATABRgEoAQoBAgEkATgBMAEwASgBBADzAOwA1gDVAMkAoQCbAH4AVgBLwDMANMAQ3/Lv6k/vz9LPxQ+3D7CPs4+nj6YPt4+/D6+PqY+8D7uPuY/OD9IP6Q/Vz9rP0I/kT+kP6e/hb+XP3U/Iz8CPx4+xj7iPqA+Wj4sPcQ94D2sPXg9ED0kPPg8pDykPJg8sDxoPHw8VDyUPKg8oDz8PMA9OD08PZY+GD4oPhw+tj7dPyG/gQCOARcA5AC1ANoBmAIsArgDbAOEAxACoAMABAgEmASwBKAEuAQsA9AEUATABMAEqARwBCADsAMEA2wDTAMkAnwB1AH6AUABAwDRAJzALz+GP7g/fz8mPv4+uj6OPqI+fj50PoI+6j6aPpo+rD6mPvQ/HD9XP0s/Sz9NP1k/Qz+sP6A/rT9EP2E/Jj7IPtQ+yD78PmA+LD3MPdg9qD1QPWg9JDz0PLA8oDyAPLg8fDxkPGA8TDyIPNg82DzYPRw9QD28PYI+Wj6EPoo+qz8sP8+AYgCeARIBQgESARQCOAM8A0ADVANoA0gDfANIBEAFCAUwBIgEuARABGAEaATgBQgE+AQEA/wDXANUA3wDFAL0AjgBsAFiARoA4gC8wDk/nj95PxY/JD7KPuw+mD5SPj4+HD6mPrI+aj5APrg+RD62Puo/Tz98PsY/Bj9GP0c/Tr+Ff/c/eD7aPvg+6j76Pqw+iD6kPgw96D2UPbA9fD0QPSA85DyAPLg8aDxgPGA8VDxEPGg8YDy8PIg89DzIPUQ9gD3WPiQ+Rj64Pog/QgAwAHUAuQDeASQBCgGsAkQDUAOkA1ADUANkA2wDwATgBSgE2ASQBKAEoAS4BJAFKAUABPgEMAP8A5ADtANoAyQCpAIWAdoBtgEHANQAXz/Dv6s/ZD9UPxQ+hj52PiI+JD4KPmo+Vj5UPjg92D4iPnI+uD7UPzY+3D7ePsI/BD93P38/Zz94Pz4+zj7yPrI+uj6oPqQ+RD4wPbg9YD1YPXw9FD0cPNQ8lDx8PBg8eDxAPLg8dDxsPEA8iDzkPTA9ZD20Pfo+Dj5iPlQ+yD+kgBQAggE4ARYBIgEIAfgCnANYA7gDkAOUA3wDQARABRgFIAT4BKAEkASYBOAFIAUIBPAEaAQsA9wD5APkA6gCxAJAAhQBzgGmAW4BNwBWP4A/fz9Rv60/Cj7WPrw+HD3UPh4+rD6EPk4+KD4+PgY+bj6AP34/JD7KPsI/KT8GP1W/vL+6P0k/Jj7APzA+yj78Pp4+vj4gPcA97D2sPXA9JD0QPQA88DxcPGg8VDxAPGw8TDygPFA8VDyoPMA9LD0APew+ED44PcQ+pz8xP2X/7gCyATMAwQDeAUACbAKQAyQDlAPcA2wDCAPwBJgFOATQBPAEkASABPgFAAW4BTgEiARIBCgECARwBCQDuALYAlQB2gGiAbABhgFmgGU/jD9kPxw/OD8YPxI+mj4OPi4+Mj4uPgA+SD5mPiY+Pj5MPvg+nj6CPt4+/D7uPyg/bT9mPxg++j6YPvA+9D7KPtw+dD3EPew9kD24PWw9dD0EPNw8UDxoPEw8cDwEPFA8XDwEPBQ8XDyoPLw8oD0UPbw9jD3QPjw+Xj7UP3F/8AB7ALcA0AEWAUACNAKkAyQDWAOYA6gDVAOYBFgFEAU4BIAE2ATgBLAEiAVIBbgEwARQBBgEIAPMA/AD2AOAAqQBtAGcAcYBoAEiANMASD+jPxQ/Wj9uPvw+pj7CPsI+Yj4iPmQ+Qj50PmI+9j7uPqY+iD76Pro+hT9Bv+c/gT9JPzA+9j64Ppg/ED9OPuo+JD3APeg9RD1QPaA9gD04PBg8DDxkPDg74DwEPFA7+DtYO9g8bDxUPGQ8hD00PSQ9YD3MPno+Uj7uP2j//kAPANYBeAFMAYACMAKoAwQDsAPABDQDqAOABFgE+ATQBTgFOATABIgEmAUYBXgE4AS4BHwD8ANEA7gD/AOwAq4B0AHoAYgBegE8ASEAsz+UP28/aD8QPvQ+xD9APyA+RD5iPlI+TD5IPvU/Cz8yPqo+hD7uPo4+1j9Pv+8/vz84Pso+4D6QPu8/Oj86Pp4+PD2wPXQ9AD1APZg9cDyEPBA7wDvwO5A78DvIO9A7YDsgO0A7+DvgPCA8SDywPJA9CD2CPjA+Vj7pPwo/lkA/AI4BUgGQAdQCIAJgAugDsAQgBCgD8APABFAEqATwBWgFuAU4BIgEyAUQBRgFOAUgBNAEOANcA7AD6AOEAwwCiAI0AX4BJAFaAX8Ai0Aev5k/TD8yPus/BD98PuQ+uD5SPnY+Kj5cPtk/Oj7GPvY+pj6WPo4+wD9Lv7s/QT9IPwg+3D6uPqA+5j7sPow+WD3cPVw9MD0IPVg9MDygPEA8MDugO4g74Dv4O4g7uDt4O0A7iDv0PDA8SDyEPNg9ID1APc4+VD7iPz8/VQAiAIYBJAFeAfACLAJcAvgDaAPABBgEMAQABGgEWATQBXgFSAVgBRAFMATgBMAFGAUgBOAEQAQMA9gDiAN4AsQC4AJMAegBUAFkASsAocA/v4O/iz9qPyo/Dj8APsA+kD6iPpY+nj6GPuI+6D7gPuY+8j7EPyk/Aj9RP1I/WD9UP34/Fj8cPuo+mj6oPpQ+qj48Paw9XD0gPMw81Dz0PJA8YDvgO7A7cDtgO5g74DvgO6A7eDtQO8A8ZDy8PPw9ID1EPbw93j64Pyu/p4AqALcA4AEQAYQCVALMAwQDbAOsA8AEAARgBLAEmASYBOAFUAWYBXgFMAUgBNAEqASIBTAE4ARYA+gDeALkArgClALoAloBjgEhANUAs8AGADZ/5T+wPzw+xz80Pvw+hD7qPtw+3j6ePqg+zj86Pug+wD8YPxo/Jj8BP0k/fD83Py0/Pj7EPsw+oD5UPlA+YD4EPdw9fDz0PIw8hDycPLQ8TDwoO6g7UDt4O0A74DvIO/A7sDugO/g8IDyEPRQ9WD2sPco+Xj6bPxB/4wB0ALgA4AFOAfwCMAKIAwgDRAOYA9gEMAQwBAAEYARgBIAFIAVIBVgE+ARIBHAEIARQBOgEwAR0AwACuAJ8ApAC0ALAAp4BoACFgH4AbQCIAKnAGD/XP0Q+xj7WP14/ij98PuQ+xj7+Ppg/Cb+/P04/ND76PwY/aj8iP2q/pz98Pvg+1z8ePtw+lD6qPlw9/D1wPYQ9wD1YPJw8SDxUPAg8KDwIPBA7gDtAO2A7SDu4O7A73DwsPDg8MDxUPPQ9Qj4OPng+Xj7dP1c/1IBpAOIBdgG+AdQCfAKQAyADSAPwBAAEUAQ4A9AEEARgBLgE+AUgBRgEiAQgA+AEAASQBMAEyAQwAswCVAJ0AoADNALAApoBpACFgEYAlADcAOUAkcAAP0Q+8D7Bv43/2r+uPyY+zj7gPu0/PT98P24/Mj78Pvg/Hj9TP10/Rz9oPuI+gD7APyo+wj6IPig9oD1YPUQ9uD18PNw8eDvIO9A7xDwkPCg76DtgOxA7MDsIO5A8GDx8PBw8DDx0PKw9ED34PkQ+0D7hPzO/g4B4AJQBWgHYAjQCPAJ8AuADaAOABAgEcAQ4A8AEMAQ4BGgEyAVIBXAEmAQwA/AEKARgBLgEgAREA2gCRAJUApACwALEAq4B6wDkQCwAGQC5ALCAe3/nP1Y+6j6+Ptc/Tz9ZPyI++j6cPoI+3T8GP2g/AD8DPwM/Hj8HP1Q/bT8APyY+3D7gPsw+1j6sPhQ96D2YPbw9XD10PQg8wDx4O8Q8JDwkPBQ8EDvgO3A7EDt4O4Q8ODwcPHg8eDxoPKg9AD36PhY+qj78PxC/uH/OAL4BNAGcAdQCPAJsAvwDOANAA/gDwAQ0A+AECARQBEAEmATwBOgEiARwBDgEAARYBGgEYAQAA7QC/AKsApwCoAKEApwCNgFkANoAjACTAIQAvwATf/A/bD8GPwA/Hj8+Pyo/AT80PuY+zD7APu4+xj9qP0k/ZT8cPwE/GD7sPu4/DT9HPzA+sD5qPhg99D2cPeg9xD2MPTg8uDxEPEQ8bDxQPHg7+DuoO4g7sDtwO5A8LDw4PDA8cDyAPPA8zD24PhA+vj6oPxC/jP/jgCQA5AGsAfwB9AIYArACzAN0A4AEMAP4A4AD0AQgBFAEgATQBPgEoARoBAAEeARYBLgEaAQwA7ADKALoAsQDKALMAqACNgGYAUIBBADhAIAAhIB+f+g/mD9hPwU/ND7oPvA+wj8LPyo+7D6aPqY+gD74PsI/UD9gPyg+yj7KPtg+/D7uPx8/Nj6EPlI+KD3YPfQ96D3QPZg9CDzgPJw8mDygPLw8WDwYO8g7wDv4O4A8HDxwPFw8eDx0PJQ8yD0sPbo+Uj7UPvI+wT9GP7k/7ADMAfoBxAHSAewCBAKAAyQDkAQYA9wDXANAA9AEIARQBNgE6AR0A8AECAR4BHgEeARABEwDtALsAuQDGAMsAvACsAIMAa4BIgEcARIA+YBDAHg/4j+vP1k/ZT86PsA/PD7gPso+2j7cPsQ+7j6APtA+4j7RPzE/DT8EPsY+7D7uPtY+2D7EPsA+sj4QPjw93D34PZQ9mD1wPOw8sDyUPNA84DyUPHA7+Du4O4A8FDxMPKA8lDy0PFw8XDyQPWw+BD7sPtg+xD7kPuQ/RABIAVgB3AHAAcgBwAIwAmgDJAPgBAgD2ANUA2QDiAQwBEgEyATgBEAECAQABGgEcARwBEAEfAOgAzwC4AMkAzQC8AKMAkgB5AFGAUQBQgEgAJMAToA9P4A/rD9RP2Q/Pj7gPv4+oj60Ppg+0j7iPog+ij6OPq4+nj70Psw+2D6IPoY+hD6QPpw+hD66Piw9/D2gPZw9nD2EPaw9NDy0PEg8gDzcPPA8tDwgO5A7WDuwPCw8jDz0PKA8QDwcPCg8/D3kPpA+/j6UPrw+Vj7jv84BFgGaAYwBkAGqAZgCLALgA5AD6AOAA6gDbANAA+AEQATgBJgEcAQgBCgEGARgBJgEgARgA+ADqAN8AzgDCANcAygCuAIoAfYBhgGUAVoBCwDtAFtAJX/9v44/oT97Pxw/PD7cPtI+1D7aPsY+5j6WPqI+tj6MPtw+1D70PoQ+sj5QPqA+gj6SPnQ+Aj4wPYQ9hD2YPbg9YD0MPMQ8mDxoPHA8gDzYPEA72DtgO3A7sDwUPKQ8mDxEPAg8ADy8PQA+AD6oPoo+sj5oPqg/VoBKARoBdAFSAbIBsgH0AmgDGAOUA4ADiAOkA7QDuAPoBGAEuAR4BDgEGARYBFgEaARgBGgEHAPwA5ADqAN4AxwDOAL0ApwCWAIaAdgBlAFaARoA1ACVgFUAE7/YP6s/ST9sPxM/CD82Pto+/j6yPqg+oj6wPoo+2D78PpY+hD6QPqA+rj6uPp4+oD5YPjw9wD4IPiA9wD3gPag9SD0EPNw84D0kPRQ88Dx4O+A7mDuQPCQ8lDzMPIg8cDw4PBQ8oD18PhA+sj5OPnQ+TD7WP3KABAESAXABOAESAbIB1AJYAswDYANsAyQDKANoA5gD0AQABHAECAQQBDgECAR4BCgEEAQkA/gDqAOYA6QDaAMAAxACzAKcAkQCUAIuAZABUAEPAM0An4BJgFNAKz+TP2o/FD8APwE/Pj7aPug+gD6sPnQ+TD6qPrI+lj68PnI+cD5+PmI+sj6IPoY+dj4sPgo+LD3GPiA+HD3oPWQ9ID0gPTA9ID1UPUQ8zDw4O6g7xDxYPJw85DzEPKQ8ODw8PKQ9Sj4+PlI+pj5UPnI+rD9lgDQAjAEqASwBHAFIAdACRALEAxQDDAMYAwgDUAOUA8gEEAQ8A+gDwAQ4BBgEQAR4BCAEKAPoA6QDhAPkA5QDUAMsAuwCpAJEAngCOgHCAaQBLwDzALYARwBcgBD/8T9qPwk/Nj7iPto+/j6YPrQ+ZD5cPmQ+dD58PnQ+Wj5UPl4+cD5APow+uj5UPnI+MD4sPiQ+HD4QPiQ93D2gPUQ9UD1kPUA9sD18POA8TDwMPDw8CDyMPOQ88DyQPHw8DDykPQA9xD5CPrI+Vj5wPnY+/7+tgFkAxAEaATwBBgG+AcQCrALMAwQDPALgAyADbAOsA9AEEAQ0A+wDyAQ4BBAEeAQgBAAEFAPkA4wDkAO4A3ADMALAAsQChAJcAgACOgGiAVIBDgD+AHtAFQAyf+i/mj9kPzI+/D6ePqI+nD60Pkg+dj4mPhg+HD4uPjI+Ij4kPjA+Lj4kPi4+AD5yPhI+BD4GPjw9+D3APiQ90D2APUg9fD1YPZA9qD1gPRg8uDwAPEw8mDzIPQg9GDzcPJQ8oDzwPVg+Bj6gPow+lD6gPt0/dr/eAJYBPgE8ASoBUAHIAnACgAMwAygDEAMoAzwDWAPIBBAEAAQwA+AD8APoBAgEQARQBBwD7AOEA7gDcANcA2ADFALQApgCZAI6AdABzAG0ARwA2gCjAGwAN//HP8c/uT8yPsQ+8j6gPpQ+gj6cPnY+HD4aPiI+LD44PjQ+JD4aPiw+AD5+Pgo+XD5YPmo+CD4aPj4+BD5mPgA+DD3QPYA9sD2oPew94D2sPQw82DyYPIA80D0EPWQ9IDzsPJQ86D0cPZo+Cj6yPpo+oD66PsM/h8ALALwA/AEKAWgBRgHAAmQCqALcAyQDGAMsAzgDSAPwA8AEPAPwA9gD7APYBCgEGAQ4A8wD4AOAA7ADbANMA1ADEALcAqQCeAIUAiAB0AG4ATIA7QCvgEGAUwANv/Y/cj8DPxQ+6j6YPpI+qD5wPg4+BD44PfA9wD4MPgY+OD34PcY+FD4gPjg+Nj4mPiY+GD4APgg+Oj4SPlA+PD2oPbQ9tD2EPcI+OD30PWg8+DyIPNw8yD0YPXQ9aD0YPOA8/D0gPZQ+Bj6CPvY+nD6UPtY/bz/vgF4A4gEwAQIBTAGIAgACjALwAsQDAAMIAzgDEAOYA+wD6APgA9QD2APoA9AEIAQIBBAD5AOEA6gDXANMA3ADNALsAqQCcAIIAhoB3gGOAUIBPACtgGaAO7/VP9C/vD84Ps4+5D6GPrI+YD54PgY+MD3oPew99D3APjw9+D30PfA99D3UPgI+UD5yPhw+Kj4qPho+MD4cPlI+TD4oPfQ96D3MPeg95D4CPjg9UD0EPQg9DD0MPVg9kD24PRA9BD1UPaA9yj5+PqQ+xD7MPvE/Jz+WwAsAuwDAAUQBcgFUAfwCCAKIAsgDHAMYAyQDHANkA5QD5AP0A+wD0APQA+wDyAQIBCgD/AOIA5gDQAN4AygDBAMMAsgCtAIkAfYBjgGcAVYBDADDAKyAHT/sv4M/kj9XPyY+9D66PlA+dD4wPh4+OD3UPcQ9xD3IPcw92D3oPfA96D3oPcA+Fj4YPiA+LD4uPhI+PD3WPjw+Lj4MPgo+Cj4sPdA98D3IPhQ99D14PRw9AD0EPRg9aD2cPaA9TD1oPVg9rD3sPlg+wD8+PtU/ED9jv5xANwC2ASoBeAFYAZAB1AI0AlgC3AMgAxgDLAMMA3gDbAOgA/AD5APQA8wD1APcA+gD3APwA7gDUAN8AzADIAM8AsQC8AJYAhYB6gGIAZwBXAETAPmAW0AYP/C/kD+jP2o/MD72Prw+VD5APng+Jj4KPiw92D3MPcw92D3oPfg99D3sPeg9/D3QPho+Hj4uPi4+ED40Pco+LD4qPhg+FD4IPhw9/D2cPfg9xD3sPUA9bD0APQQ9DD1cPaA9rD1YPWw9VD2kPfQ+bj7VPwk/GT8aP3a/ucAYANoBUgGiAbwBsgH4AiACjAMYA2ADVANQA3QDaAOcA8AEGAQIBCwD4APoA/gD9APcA/gDiAOYA3QDKAMYAygC4AKUAkwCDAHcAbYBRgF/AOwAnIBUABW/4j+6P1g/ZD8gPuA+tj5UPnY+KD4ePgA+FD38Pbg9gD3EPdA96D30PeA92D3wPdI+GD4cPjI+Oj4cPgo+Kj4GPnY+JD48PgA+UD4oPdQ+ND44PeA9tD1sPUg9WD1sPbQ90D38PXQ9bD2cPdo+Ij6SPyg/BD8ZPy0/Uv/DgFkA2gF6AWwBRAGSAegCPAJcAvADAANwAywDFANMA7QDnAPABDQDzAP4A4ADzAPIA/ADnAOsA3ADEAMAAywC/AK8AngCMgHwAYABnAFuASwA2ACIAELACL/Zv7E/Qz9LPw4+0D6aPnY+Gj4GPjQ93D3APeQ9kD2UPaA9sD28PYg9zD3EPdA98D3IPh4+MD40PiQ+Gj40Ph4+aD5YPlY+Vj5CPmY+OD4QPmo+HD3wPaQ9vD10PXA9gD44Pew9jD2wPaQ97D4cPoo/JD8FPwo/Ij9Nv/7ABQD6ATABbgFEAYwB8AIIApwC5AM8AzADNAMcA1QDhAPsA8AEPAPkA9gD2APgA+QD1APsA7wDTANsAxQDBAMoAugCjAJ8AcoB4AG2AUgBVAE3AIwAeL/Lf+Y/tj9JP1E/BD7qPnI+HD4MPjw94D3EPdw9vD1sPXA9RD2UPaQ9qD2sPbg9jD3kPcA+HD4sPiw+KD42Pgw+YD5wPnY+aD5QPkI+Sj5UPlg+Qj5QPgA9/D1kPXg9bD2YPfA90D3MPbA9bD2QPjI+Uj7OPxc/DD8nPwy/jEAMAL8A0gFyAX4BdAGEAhwCfAKQAzgDOAMEA2QDTAO0A6gD0AQQBDQD5APoA+QD2APYA8gD2AOcA3QDHAM8AtAC2AKUAkQCPAGEAZgBZgEeAMoAucAvf/E/hL+fP28/LD7qPqw+cD4EPjA95D3MPdw9tD1gPVA9SD1UPXg9SD2EPYA9kD2gPbQ9lD3APhw+FD4UPig+BD5WPm4+Rj6EPqY+Vj5iPmo+bD5kPko+TD48PZw9rD2YPco+LD4sPjA9/D2QPew+GD6APwA/Uj9PP18/YL+SgCEAoAEwAU4BoAGCAf4B1AJAAtwDAAN8AwADXANEA7ADoAPIBAAEIAPIA8QD0APQA8gD8AOEA4ADRAMwAtgC9AKAAoACcAHaAZwBbAE/AMEA+wByQCg/4r+tP0c/WD8gPuY+rj54Pgg+LD3gPcw96D2EPbA9bD1gPWg9RD2QPZQ9mD2kPbw9kD3wPdY+Jj4cPiI+Oj4SPnI+UD6oPpg+uD5uPnY+fj5+Pkg+vD52PiA97D24Paw95D4IPko+WD4gPdQ95D4iPok/Ez9sP3o/fj9sv5VAKQCyAQYBtgGSAewB1AIkAlAC8AMcA2gDdANIA6ADhAP4A9gEGAQABDQD6APYA9ADzAP4A7wDSANcAzACyALoArQCdAImAeYBtAF+AQABPAC3AGTAGj/pv7w/Sz9QPxQ+0j6QPmA+CD4sPcQ93D24PUg9aD0gPTg9AD1APUg9VD1YPWA9fD1gPYA90D3gPeg99D3GPjI+Ej5kPno+dj5iPlg+bj5OPoo+vj52Pkw+cD30PaA98D4cPmY+Zj5EPko+BD4iPmg++T8mP0c/mz+Xv7y/toAQAMgBSgG2AYwB3AHEAigCYALoAwwDWANkA2wDRAOAA/gD0AQQBDgD8APcA8wDzAPIA+gDvANIA1wDMALAAtgCrAJwAiYB4gGeAV4BIwDnAKUAXgAW/9g/mT9XPyI+8D6yPnI+Bj4oPfw9iD2kPUw9bD0UPQw9ID0kPRw9ID0oPTg9DD1wPVA9rD2APcw92D3wPdY+Oj4UPnI+VD6UPr4+Qj6mPro+rj6qPq4+hD6APmI+Bj5oPnI+Vj6+PqQ+oj5iPnQ+lj8XP1O/iP/RP8s//L/1AGQA8gE+AU4B8gHEAjACCAKgAswDBAN4A1ADlAOoA5wD/APQBBgEIAQQBDAD3APgA9QD8AOIA5gDXAMkAvwCmAKkAlgCDAH+AW4BJADnAK2AaMAX/8+/hj98Pvo+jD6oPmw+KD34PYg9nD10PRw9CD0sPNw80DzUPNg84Dz4PNQ9LD08PRA9cD1UPbw9kD3sPc4+Mj4IPmY+Rj6oPrY+tD68PoY++j6wPoI+yD7gPqg+Vj5iPnA+Rj64Ppg+yD7ePqQ+kj7MPxs/er+HQBXAF8A2wDyAVwD4ASYBugHcAigCAAJwAmgCvALYA1gDnAOMA4wDpAOAA+ADyAQQBDgD2APAA+QDiAO4A2ADeAM8AsQC0AKUAlQCFgHUAYQBeAD9AIkAhoBzv+O/mz9WPxo+5j68PkI+fD3APcw9oD18PSg9FD04PNg8xDz8PIQ81DzoPPg8zD0kPTw9FD14PWA9hD3gPfg92j44PhY+eD5kPoI+xD76PoA+yD7GPsw+3j7gPvw+iD62Pno+UD6yPq4+zj8uPs4+zD7APwo/Y7+KAA8AYoBYAHCAdQCiASIBmAIgAmwCZAJ4AnwClAM0A3gDmAPQA8AD+AOQA/gD6AQwBCgEAAQIA9wDjAOIA6wDeAM0AvwCuAJwAi4B7AGoAVgBDgDQAIoAe3/vP6M/Wz8UPtQ+pD50PgA+AD3APYw9ZD0APTA85DzQPPQ8oDycPKQ8sDyQPPA8yD0kPQA9bD1UPbg9nD3EPiA+AD5wPmY+gj7YPu4+/D78Pv4+2T82Pzs/OD82PyA/ND7KPt4+yz8zPxU/Zz9hP28/Ej86Pyq/lkAlgFUAowCPAI4ApQDmAWYB8AIcAngCQAKQAowC6AM0A2wDiAPIA/QDpAO4A6wD0AQQBCwDxAPgA7gDYANMA2gDMALwAqwCaAIkAeQBrAFoARoAzAC/wDu//b+1P2Y/GD7UPpg+YD4wPcA9wD2APUg9JDzEPOw8nDyQPIQ8rDxgPGg8QDyUPLg8pDzMPSw9DD14PWA9gD3sPew+Jj5MPrA+mD7sPvg+1D84PxM/Yz90P0S/tT9NP3U/Lj8tPzE/HD9MP5U/sj9ZP1w/bz9lv4RAK4BTAIQAgwCnAKoAxAF0AZwCEAJkAnQCVAKIAswDIANgA7ADpAOYA6QDhAPoA8AEPAPYA/wDoAOIA7QDXAN0AzgC9AK0AnwCOgHCAdABjAFsANUAjgBOAAm/xj+FP3g+3D6SPmQ+LD3sPbA9TD1QPQw84DyQPIg8uDxwPGw8XDxEPEw8cDxcPJQ8yD08PRw9bD1APaw9rD38Pgw+hD7cPuY+7D7BPys/JD9Yv7q/vz+qv4O/oD9dP20/RD+WP5o/lT+6P2k/bT9Rv78/uT/5gCGAaYBjgEQAhQDUASQBfgG8AdgCKAIQAlACjALEAwgDeANAA7ADdANMA6gDjAPoA+gDxAPcA7wDaANYA0QDaAM0AuwCpAJcAiAB7AG6AXgBKQDUAL9AK//fv5o/VT8SPs4+iD5APjg9vD1IPVA9IDzwPIQ8oDxAPHg8ODwwPCQ8EDwEPBQ8BDxIPJw83D0wPSA9HD0IPWA9kD4APoY+zj76PrQ+nD7YPyg/ez+u/+X/8D+Cv7I/ez9lP6C/xgA4/8v/7L+pP7y/sv/8ADkAVACbAKYAuACYAOABAAGWAcQCKAIIAmwCUAKQAtgDFANwA0QDlAOYA5wDuAOUA+QD6APYA8AD2AO0A1gDRANkAzQCwALAArQCLgHyAbIBZAEaANUAiIBxP9u/iT90Pt4+mj5kPiQ93D2cPWA9HDzgPLg8XDx8PCg8GDwUPAg8ODvAPAQ8EDwsPCg8eDyEPSw9ND00PQg9TD24Pew+Qj7kPt4+0D7ePtU/ID91v7p/0AAqv/g/kz+SP7g/t//0ADiADEAW/8h/0P/0P/qACQC6ALoAtACEAOIA2AEuAVIB3AI0AgACYAJMAoACxAMQA0ADjAOUA6ADqAOwA4QD7AP4A+QDyAP0A4wDpANQA0ADWAMYAtgCnAJUAjwBvAFGAX4A5ACaAFQAAH/dP0w/Dj7CPrY+ND3IPcQ9tD0oPPg8hDyQPHw8NDwwPAQ8KDvYO9g72DvwO/Q8BDy8PJg87DzwPPg84D0UPaA+DD6yPrY+sD6wPpw++T8mP6j/wUA8v+V/97+cv7w/gUA4AAWAfQAhgDD/1z/yf/IALIBVALYAiwDEAMEA7AD+ARYBmgHUAjgCAAJMAkACkALUAwQDbANAA4ADuANQA7gDjAPcA+gD4APoA7QDXANQA0ADYAMIAxgC/AJYAhQB3gGeAWIBKgDdALaACT/sP2M/Fj7UPpo+Vj4IPfg9cD0oPOA8pDx8PBQ8BDwAPDg74DvAO+g7mDugO5g7wDxgPJA85DzcPMw84DzAPWg9wD6WPug+3D7APsY+0j8Ov7+/wwBSAHEANj/+v4K/xQAZgFYAqgCNAIoAUUAGQDZAAQCHAP0AzgE9AOsA9gDuAQYBpAHsAhQCXAJkAkACsAK0AvwDMANEA4wDkAOYA6QDvAOYA+AD0AP4A5QDtANQA3QDIAMAAwwCwAK4AiQB1AGSAVoBGQDMALBAB7/iP0I/ND6wPnI+LD3gPZQ9fDzsPKQ8dDwIPCg70Dv4O6g7kDuAO6g7WDtoO2g7jDwwPGw8hDzoPKA8kDzAPVg97j5QPu4+2j7APtA+4j8Yv56APABPAJkATQAf//A//UAWAJ0A7AD8ALCAcwAuQB8AdgCQAQQBQgFYATYA+wD2ARYBhAIQAnACdAJsAnACUAKUAugDMANcA6wDoAOIA7gDTAOwA4QDzAPEA9wDoANkAwADHAL0AogCkAJIAjIBnAFQAQIA9IBdwAR/5z9NPwQ+/D5mPhA9xD20PSw87Dy4PEw8XDwwO9A76DuIO4g7kDuYO5A7mDuAO8A8EDxcPIw8zDzIPPQ83D1gPeY+Uj7HPzo+6j7DPws/bz+tgBIAvACYAJUAX0AZQBIAbAC9ANQBMwD0ALIAR4BaAGUAhAEGAVoBSgFmAQwBIgE0AWAB/AI4AlQCnAKQApgCgALIAxADTAO8A4AD7AOQA4wDmAOkA7wDvAOsA4ADjANYAyQC8AKAApACUAIKAcQBtAEXAPEAVQAB/+4/Wj8OPv4+Xj44PaA9VD0APPg8QDxQPCA76DuQO7g7WDt4OzA7MDsoOwg7aDucPCg8RDyMPIw8nDywPNA9hD5+Po4/NT87Pzc/ED9ov6mAJwC+AN4BPgD7AIoAiQC6AI4BDgFiAUABSAELAN4ApAChAPgBLgF8AWgBSgF2AQoBWAG4AfwCIAJ8AkACvAJQAowC0AMAA2gDSAOUA4ADvANUA6QDnAOQA4QDpAN0AxADNALMAsQCsAIoAdYBigFKAQ0A9IBEgBm/sT8MPvA+aj4sPdw9vD0cPPg8XDwQO/A7mDu4O2A7UDt4Owg7GDrAOsg60DsIO5w8ADycPIg8qDx4PGw84D2gPng+4j9UP4U/rT9KP62/6IBoANwBUgGsAVwBPADIASQBBAFyAVABtgFAAVQBPwD1AMABMgEeAVwBRAF8AQoBYgFIAZAB1AI0AgACWAJ4AkwCtAK4AvgDFANgA3QDRAOEA4wDnAOkA4gDtANgA0QDWAMoAvgCtAJYAgYBwgGsARIAxQC6gA2/zj9ePv4+Zj4MPdA9jD1sPPQ8VDwIO8A7kDtAO0g7eDsYOwA7GDrwOqA6kDr4OwA7yDxAPOw85DzgPPw81D18Pd4+57+RACuAK4AsAD5AOQBvAN4BaAGWAfQB1gHMAZgBWgF4AX4BQAGAAZ4BbAEeATABKgEIAToA0AEaARgBNgE6AXYBlAH2AeACJAIkAgwCZAKwAtgDBANwA0gDgAOUA7ADuAOwA6wDpAO4A0ADXAMEAxgC3AKUAnYB6gFsAM0AgIBn/8W/pz8yPqw+MD2MPXQ82Dy4PCg70DuwOyg6yDrAOvg6uDqoOoA6mDpIOmg6cDq4OyA79DxgPNw9LD0gPQQ9SD3iPog/rIAYAIMAygDNAPsAwAF4AXgBhAIIAkgCXAIyAdoB9AGOAbgBUgFaATQAzgE0ATQBCgEkAMkA4wCLALAAvQDGAUwBlgHEAjwB5AH8AcACRAKAAtgDJANMA6gDiAPcA8QD7AOwA7gDrAOQA4ADqANsAxwCxAKYAhABjgEzAKGAfH/Pv6Q/LD6mPiQ9sD04PIg8cDvwO6A7eDroOrA6WDpYOnA6QDqoOkg6aDoAOng6eDrwO6Q8cDzUPXw9eD1APbQ9yj7wv6mAYwDmATYBBgFEAYQB8AHMAjgCJAJoAlACeAIgAjAByAHkAaIBQgE8AIMA3gDgAM4A/QCdAKYAR4BUgEMAugCOATwBSAHQAcIB4AHkAjwCXAL8AwQDqAOQA8gEAARABHgEAAR4BBgEKAPEA+ADrANsAxwC7AJOAeoBHQCogC+/uj8IPtI+UD3IPXw8rDwoO7g7KDrwOoA6uDooOcg50DnoOfg58DnwOfA50DoAOqg7KDvgPIQ9QD3EPgo+Kj4ePq8/bABEAVoB1AIcAiQCCAJ8AlwCpAKcApgClAK8AlgCeAIUAioB2gG0ASoAswA+v99ADwBqAHWAboBNAFJANv/QQA4AZwCsATwBkAIcAjACOAJYAvQDDAOgA9AEKAQgBGgEkATABPAEoASwBGAEDAPIA4wDfALkAoQCbgGqAOmADz+CPzI+ZD30PVw9MDykPBg7kDsYOog6WDogOfA5iDmQOZA50DooOiA6CDoAOjA6CDr4O7w8kD2CPnw+pD7aPvY+7T9sABABNgHsArAC2ALUAsADDAMgAvACgAK8AgQCBAIgAgwCAAHuAVIBJABfP6k/Bj8VPwg/Wb+bv+H/y7/Jf9V/zf/zv96AagDmAWAB5AJUAvADHAOIBDAEKAQ4BAAEmATgBSAFUAWoBUgFMASQBEgD9AMYAtACkAIwAVMA9wA4P0A+7D4UPZQ86DwIO/g7eDrAOoA6SDoIOeA5kDmwOVA5eDlAOiA6aDpwOlg6mDrIO1w8MD0aPgg+8j9MgA+ASQBpgHIA3gGIAlwCyAN4A3QDfANIA6wDTAMYApwCMAGMAVIBPAD1AM0AxACPQDE/SD7GPlQ+Dj4yPig+QD7bPyo/Rv/mgDoAdQCEASgBVgH8AjgCmANQBCgEqAUABZgFmAWgBbgFgAXoBbgFQAVABTAEkARUA/wDGAKsAe4BGIBuP1Y+oD38PSg8oDwgO6g7CDrQOoA6WDnwOXA5MDkwOQg5eDlYOeg6eDrwO2A7iDuIO7g7/DyoPaQ+lj+bgG0A7AFCAeoB9AHkAgAClAL8AswDKAMMA3QDcANoAxACjgHQASQAbb/hv7k/Wz9BP1c/DD7YPnw91D3IPcg90D3GPhw+XD7NP5SAegD0AXQB6AJ4ArwCzANIA9AEWATgBVAFyAYgBhAGaAZABmAF6AVoBOAEXAP8A2ADFAKsAfwBOgBMv5Y+rD2kPOw8CDuYOzg6mDpQOjg5wDooOcA52DmIOZg5sDm4OeA6eDr4O6g8UDz0PMA9ID0EPYA+RT9jAAkAzgFMAewCHAJ8AkwCoAK0ArwCsAKIArQCTAK4ArACjAJmAaAA2kAzP0E/Nj6KPrY+fD5EPqY+ZD40Pfg92D4kPiA+Cj5yPpU/aAAWAS4ByAKMAwQDoAPIBDgEGASYBQgFoAXgBgAGeAYYBnAGeAYoBbgEyARQA5QC/AI4AaIBP4BXv+I/Oj4IPWg8eDuoOyg6gDpwOdA5wDnQOdg58DnIOjA6GDpYOqA66DsAO5A8DDzMPUQ9gD2cPYw9xD5LPwCAKADqAUIByAIwAiwCFAIQAigCMAIgAhACAAI4AcgCNAIkAjwBhgEDAEC/kj7oPko+RD5MPno+fD6MPuQ+mj6GPvg+wD8UPxE/b7+DAGIBJAIIAzgDmARoBPAFAAVABVgFUAWQBfgF+AXYBeAF8AXYBeAFkAUQBHQDbAKWAfEA1YA1P0w/BD6UPew9CDyIO+g7MDqIOmA56DmwOag50Do4Ohg6uDrwOzA7UDvQPCw8BDykPTg9uD3UPiA+Ej4GPio+ej8RwC8AngE0AUYBrgFqAUIBtAFSAVoBXgFGAVoBLAEwAVwBoAG0AVABEoBYv5o/ND6iPkQ+ZD5OPqo+kD7aPxM/QD+Lf99AMkAegBuAaADQAbgCPALUA/AEcATgBXAFuAW4BagFyAYYBfgFSAVoBQgFOAToBMgEvAO4AtgCVgGLAJG/oj7GPlA9tDzwPFg7yDt4Otg60Dq4Ogg6KDoAOlg6WDq4Ovg7EDuQPDw8ZDyMPPQ9AD3mPho+Zj5GPlo+Gj4mPlo+7z9YQCAAnAD2ANIBJgEUAQYBFAEMAQsA4ACeALsAlADQARQBXgFQARsAowAZP6I/Dj7mPoI+gD6ePow+wT8AP3m/qsAEAL0AsgDeASIBYAH4AlQDMAOQBGAE0AVgBZAF6AX4BdAGCAYQBegFUAUYBOgEsARYBBgDtAL8AhIBgQDL//A+4j5sPcg9WDyAPDg7QDswOrg6YDp4OhA6YDqAOxA7UDu4O+A8fDy4POA9LD0IPWQ9jj4SPmY+Wj5GPkY+Vj5WPoc/AD+3v8oAeABBAIcAhQCMAKAAowCaALgAaIBsgE0AsACdAMQBEAEmAMIAjUAmP5g/WT82Puo+5D7cPvo+1T9Of8QAZAC+AMYBcAFcAaIB+AIgApwDMAO4BCgEkAUQBXgFUAW4BZAF4AWQBUgFCAT4BFAEKAOIA1ACyAJ6AbgAxAAoPxY+oj4QPaw80Dx4O7A7EDrYOqg6QDpYOkA62DsgO3g7rDwoPJw9AD2gPZQ9mD2YPfA+ID5uPmA+fj4WPjw9yj4yPgg+mD8vP4MAFIAgwD+AGwBkgHSAfYBdAHmAOsAugFcArwC1ANIBfAFKAWcAwACigBd/27+pP2o/ND7mPvo+8D8JP71/4wBsALcA2AFmAaQB+AI4ArgDHAO8A+gEeASoBNgFIAVYBZgFgAWQBUgFOASwBFAEGAOUAzwClAJMAZIAvz+hPwg+rD3wPWw87DwwO1A7IDrIOrA6GDoYOng6kDs4O3A7wDycPSg9uD3IPhQ+OD4OPnA+Uj6kPrQ+eD4YPjg90D3YPco+Yj7WP0+/gf/q/8XAKQAVAF0AfAAyADvAKgASQAIAcACGAQYBegFOAYQBVADoAJkAl4Bs//O/iD+DP18/DT92P5kAPgB6ANgBSAGWAdgCTALUAzQDZAPwBAgEeARIBOgE8ATgBSAFUAVABRAE+ASoBHwD1AO4AzQCnAI0AVsAnb+IPsg+VD3EPXw8gDxoO7g7ADsQOvg6eDowOlA60DsgO0A8MDyoPRw9oj4qPmA+bD52PpY+7D6UPpg+qD5sPdg9jD2UPbQ9nj46PqM/Hj9rv7k/3cAoQBWAQwC8AFsASwBIAEGAawBCAMYBEgEMAQwBOADJAOYAnwCEALNAIf/cv6k/VT9GP5t/9sAJAKIA0gFwAZgCGAKkAxQDqAP4BAAEoASQBJgEmAT4BNgE6AS4BLgEmASABHwD7AOMA2wC/AJmAcwBMcAoP3o+ij4oPUQ86DwwO5g7eDrIOpA6WDpwOkA6sDqoOwg77DxkPQQ95D4WPmQ+oj7YPug+qj6OPsg+zj6SPkg+ID2wPWA9uD3sPiY+Tj79Pzg/cj+IAAqAX4BAAIEAwgD8gFCAcABZAJsAsQCaAPEA2gDwAOgBOgEWASIA/QC2gGsAOD/1//7/2oAXgFsAvgC3APABSAIMAoQDDAOIBBgESASIBPgEwAUoBOgE8ATgBPAEsAR4BAAECAP8A1wDMAK4AjQBggEyQDY/RD7UPiQ9UDz0PAg7qDrYOqg6YDooOeg58DoQOpg7IDvoPJw9fD3gPoc/Hz8bPyI/DD8aPtI+0D7iPoI+Sj4sPfg9jD24PbA+Cj6qPpw+8z86P2u/pn/uABqAd4BTAKUAmACCAIwApQCBAOIAxgEYASABEAFcAaoBoAFEAQ8A8AC4AH9AMsA8QA2AYABPAIcAxAEeAWQB8AJkAsADTAOYA+AEKARIBJAEkASgBKgEmASoBEAEWAQgA/ADrANcAxgChAIoAXkAuL/BP1Y+rD3IPVg8qDvwOxA6qDoYOdg5sDlQOaA56DpwOxg8NDzkPYw+ZD7DP2k/bD9jP0w/dz8lPwg/OD6IPnA9zD3APfA9uD2sPcQ+WD6YPtw/ID9kP69/9wAigGOAZYB9gGAAqgCcAJkApgCAAOkA5gEaAXoBYAGCAfwBvAFqATUAzgDgALSASYBzADcAJYBpAK8A/AEiAaQCMAKkAwgDkAPYBCgEYASwBLgEgATIBPgEiASIBHgD+AOMA5ADcALgAngBmAEBAJi/4j82PmA9yD1EPIA70DsAOoA6GDmYOXg5MDk4OWA6CDs4O+A8zD3SPrA/KL+9f82AKH/Yv+x/zP/sP3g+0j6mPjw9lD2gPZg9uD1kPZI+PD56Poc/Nz9SP9CADYBLAKAAqACGAPQA4wD5ALkArADWASwBJAFiAZIB3AHmAeQB7gGeAWABLgDwAK0ARgB9wAmAaIBUAIMAxAEmAWoB4AJIAsQDTAPABEgEqASABOAE+AT4BNgE0ASIBFAEEAP0A3gC+AJAAgIBsgDLgGS/kD8IPrQ9xD1APIA7wDsoOkA6IDmAOUg5GDkIObg6GDsIPAg9PD3qPuO/j8AQgHmATgCFAK+AeIA/v5c/BD6cPjg9jD1MPQw9FD0sPSw9YD3mPlY+3D9df+pADoBOALMA7AEkAT8A6QDYAMwA3QDAAQYBEAEQAWIBuAGgAawBkgHGAfoBagEpANwAnwBaAGcAQYBhgBGAcQCwAOoBHgG4AgwC0ANoA9AEeARQBJgEyAUwBPgEiASwBGgEDAPgA3QC7AJ6AcYBvgDzAHE/+D9oPtI+fD2UPQg8WDuQOxg6kDoQObA5ODjQOQA5iDpwOyQ8HD0mPgw/Or+7ABkAlgD6AMIBHQD3gGv/5z90Pvo+cD3APbw9ID0gPQg9TD2cPdI+Xj70P2K/9IAZAIgBGAFwAWoBWgFGAXIBJgEqASgBKgEEAXgBZAGoAZwBqAG8AbIBhgGIAUwBFQDcAIMAsYBcgFQAb4BiAJAAzAEuAXYBwAKEAzwDYAPoBCAEaASIBMgE8ASYBKAEUAQsA4QDTALMAlgB3gFYANKAU7/UP0Q+9D4sPZA9JDxIO8g7WDrQOlg5+DlYOTA48DkoOdg60DvIPPg9kj6XP07AIQC1AOIBCAFSAVgBIgCnACG/uj7UPlQ9+D1cPSA8+Dz4PTg9cD2aPjY+iD9M/9aATwDgARgBVgG+AbABlgGUAYwBoAFCAUoBZAFiAV4BdAFKAYQBugFMAYoBpgF4ARwBOADNAO4ArQC0AKYAqACEAP0AyAFsAaACCAKoAswDcAO8A/AEGARABKAEmASwBGAEBAPoA1QDKAKcAggBvQD2AHA/5T98PoA+GD1gPOQ8eDuQOyg6oDpoOeA5eDjQOPg4wDmoOlg7XDwkPOA9zj7Iv5OAHgCOARwBTgGYAYwBQADDAFh/zT9UPrw95D2wPUw9fD0IPWQ9WD2EPhg+pj8iP5TAEACAARoBVAG6AZQB3gHkAdAB8gGcAYoBhgGGAboBbgFoAXYBRgGIAYABugFsAVIBdgEsATABIgEMATwA/wD9AMoBPgEOAZoB4AI0AkwCyAMwAywDfAO0A/wDwAQIBDgD+AOoA1gDLAKkAiwBggFnAKJ//T8QPsg+RD24PKw8MDu4Oyg66DqwOjg5UDkwORA5mDnQOng7PDwcPRw9+j6yP39/yACqAQoBjAGwAXYBSAF5AIyAMz9YPuo+ND2APZA9UD08PPw9BD28PZI+Ij65PzY/tcA9AJ4BHAFqAYACLAIcAgQCAAI0AdoBygHEAfQBlgGMAZoBogGgAaIBnAGAAZwBRAF+AS4BFAE/APgA6wDhAOYA/wDmASABbgGAAgwCVAKgAuQDHANUA5QD/APIBAAEMAPAA/wDdAMgAugCUAHGAUEA5QA7P2A+yj5kPbw88Dx4O+g7aDroOqA6SDnAOWA5MDloOfg6SDtkPCA83D2KPrM/UkALAJgBHAGKAcQB9AG4AXkA4QBY//s/AD6YPfg9cD0gPNw8kDyoPJA89D0APdQ+Wj7yP1+ANQCqASQBnAI0AmQCuAKwAowCpAJcAkwCYAIyAc4B8AGKAbIBaAFEAVABLwDmANYA+wCvAKoAlgC4AHCAfoBUAIIAygEWAVgBoAH4AggCgALAAwgDSAOAA/QD4AQgBBAEOAPMA/gDSAMcAqQCDgGsAMuAYT+oPvg+ID28PNQ8eDuQO0A7KDqAOkA52DlwOSg5aDnAOrg7GDw8PMg9zD6IP3W/yACIAT4BUAHqAeIB+AGcAVQAwYBlv4k/Pj5KPiA9sD0cPPQ8pDy8PLw84D1YPdg+dD7dP7NAOQCKAVwB2AJkApQC5ALcAtACyAL0AogCkAJkAj4B1gHqAb4BTgFaATAA2wDOAMAA9ACxAKsAkgC+gEYAoAC+AJsAxgECAUIBggHEAggCfAJsAqgC7AMgA0QDrAOQA8wD4AOoA2wDIAL8AlgCJAGOASIAS3/EP2I+sD3QPXw8rDwoO4g7YDrgOmA52DmQOYg5gDnQOmA7MDv0PKw9WD46PrE/eoAgAMYBRgGAAe4B7AH4AZABQQDigCa/gT9KPsI+TD30PXQ9BD0APSQ9GD14Pbo+Nj6cPw0/oYAFANIBTAH0AjQCWAK8AqAC2ALoAoACpAJMAmACMAH+AYABuAEAARkA8ACKAL0ASwCSALsAWYBQgF6AeYBaAIQA+ADoAR4BZgGmAdQCNAIkAlgChALsAtgDOAMEA0wDWANAA0gDDALgAqQCRAIWAaYBFgC0v+g/cj7cPmQ9kD0kPKw8KDuwOxA62DpoOcA5yDnYOdg6ADrgO5w8dDzoPZo+cD7Zv6MARAEIAWoBdAGuAdQBwgGyAQwA/UA7P5s/aD7MPkQ9+D1IPVA9MDzUPRQ9YD2MPg4+gD8qP21/1ACmARABrgHMAlQCgALYAuACzALoAowCvAJYAlACCAHMAZIBRgE+AI0AsQBVgEiAUgBcAEIAbEA/AC6AUgC4ALwAyAF8AWYBogHYAiwCDAJEArQChALUAsADGAMEAywC4AL8AoACmAJEAkACEgGmAQgA0oB/v4o/Zj7ePkA9yD1sPOw8WDvoO0g7EDqoOhg6ADpYOlg6gDtUPAg86D1aPgg+zD9Tf8sArAE0AV4BoAHIAhgB8gFcAT0As8Ahv6w/AD7yPjg9tD1QPVw9MDz4PMA9WD2CPgY+ij81P15/5gB8APwBZgHIAlgCiALgAvQCwAMsAsQC4AK0AngCMgHwAagBSAElAJ2AaoALgDh/97/xf9t/x3/Qv/O/2EAMAE8AlQDOAQIBRgGMAfgB1AIEAkQCtAKMAtwC7ALwAuACyAL4AqQCsAJEAlwCHgH2AUABKQCRAFK/zD9oPsQ+gD4APaA9ODyoPCg7kDtAOxg6iDpwOkA6wDsgO0Q8BDz0PVw+Gj7oP0u/x4BxAMQBjAH2AdgCBAI6AaQBRgEAAJ//4T9+Psg+gj4kPaA9YD0wPPA81D0MPWQ9qj4yPqE/Fb+qwAwA0AFKAcQCXAKMAvAC4AMsAxADJALAAtAChAJ0Ae4BnAF0ANMAiYBPQCe/1r/Vv8y//L++P5Q/7n/UQAwATwCGAP0AwAFQAY4B/gHsAiACfAJQAqwCgALwApACgAK4AmwCTAJwAhACEAHCAYIBUAEIAPeAdUA5P9g/pD8KPsA+nD4kPYA9aDzAPJQ8EDvQO7A7GDrwOsg7cDugPAQ87D1oPdo+Yj7mP0j/8wAGAM4BSAGcAaYBlgGUAX8A8ACGgH0/kD9TPwg+yj5QPcw9qD1UPWg9aD2wPeg+Pj54Pu8/Ub/DAFAAzgFmAbIByAJEAqACtAKIAsAC2AKwAlgCdAIgAcQBuAEvANoAmgB/ACvAB0Anf+K/4P/VP9S/6v/OgCyAFYBRAIkA9wDkARgBTgG4AZwByAIoAjQCNAI4AjgCKAIcAhgCFAI2AdIB8AGEAYQBRAEVAOAAnIBRQBY/yj+sPxY+zD6APmQ92D2UPXw8zDy0PAA8ADvAO7g7eDuUPDQ8eDzEPaA92j48PkY/Ab+bv/nAHwCiAMABGgEoATwA7QCtAEGAef/TP7k/Lj7QPqw+LD3QPcA9wD3kPeo+Ij5QPpY+/T8qP5EAPwBvAM4BYgG2AcACbAJ8AkQCiAKIArgCXAJ8AgwCDgHKAYgBTAENANoAtoBbgHgAIcAawBrAFMAKwBPAJAAygAYAcIBkAI8A9wDkARIBcgFSAbgBlgHeAeYB8AH4AfgB/gHIAgACIgHGAeoBvAFEAVIBJgDuAK6AdQABgAJ/+D9sPx4+zD6yPiA93D2MPWw8yDy4PAQ8IDvIO9A7wDwIPGQ8oD0gPY4+Fj5kPoo/OD9bf/dADwCLAOkA9gDCASUA3wCSgFbAHL/Pv74/Mj7wPqo+bj4OPgI+Cj4qPiY+aD6qPuk/Oj9b/8GAZQCCARgBagGyAfACIAJAAowChAK0AmgCWAJAAlQCIgHkAaYBaAE3AMwA2QCoAEsAe8AtwB1AFkASgAwACkAWwC1ABIBkAE8AuQCZAPQA2AEAAWIBfAFSAaABogGiAaQBsAGqAZoBigGCAbwBYAF+ASABPQDPAOAAuYBNgFNAFT/dv6Y/Yz8ePug+sD5uPhw9yD2wPRQ8xDyMPGA8BDwMPAQ8VDyoPPw9AD28PYA+Ij5MPuo/Nj9L/+XALQBTAKEApQCOAK2ASoBtADs/77+tP3Y/OD7uPoI+vD58PnY+RD62Pqo+zz8JP2I/sv/sADUAXAD4ATYBcgG4AeQCNAIIAmgCcAJYAkQCfAIcAiYB+gGgAawBZgEzAN0A/wCYAIQAggCrgEgAdwABAEMAdQA7wBWAbQB/gGUAmQD7AMYBGAEAAVgBYgFuAUIBiAG8AXgBQAG8AWoBYgFgAVQBdAEYAQABHgDsAIMApQBBgFAAIv/9v42/kz9dPzI++D6sPmA+ID3UPbg9JDzkPKg8bDwcPAQ8QDy4PIA9FD1UPYA9xD44Plg+2j8pP1Y/7oAfgEYAqwCsAIAApgBagHWALz/8P5m/mT9CPww+/j6oPow+lD68PpQ+5D7ZPy8/br+X/9pAOIBLAMoBFgFoAZwB+gHgAgwCZAJgAmACXAJEAlgCOgHkAfoBgAGUAXgBEAEeAPwAqgCRAKyAVIBJgHgAJUAnQDqAAwBGgF6ARQCkALMAhADcAOkA8QDAARIBFgESARYBHgEaAQYBOwD7APQA4QDRAMgA9gCZAIgAgQCwgFAAbkAdAAZAIP/2v5m/tT9HP14/Pj7WPs4+gD58PfA9lD1IPSA8+DyYPJQ8iDzAPSQ9ED1cPZw9wD40Pg4+sD7uPyQ/ar+o/8VAIgAKgFQAeAASAAOAM7/J/9U/qD97PxE/Pj7BPwI/OD7DPyQ/Pz8SP3g/cz+qf9xAGQBdAJEA/QD2ATABUgGkAYIB3gHoAeIB5AHgAcgB6AGcAZYBggGmAVYBRAFqAQ4BBgE6AN0AwQDyAKwAnACLAL+AeYBxAG6AdQB2AG8AagBvgHcAfgBJAJwAqACxAL4AkwDgAOIA6wD7AMIBPwD5APcA7ADVAMIA9ACmAJUAgQCnAEaAY8AEgB9/8z+Mv7E/Tz9pPw0/Nj7CPvA+YD4YPcw9vD0QPQw9AD0wPMQ9ND0MPUw9WD1EPbw9tD3MPnQ+gT80PzY/Qj/yP8qAMAAeAG+AbABrgGuASoBTQCe/xz/dv7s/cz91P2Y/Uj9YP2c/cT9Dv7E/pH/IgDNAKYBbALwApwDmASABQgGgAY4B7gHyAe4B7gHgAcQB8AGwAaoBjAGqAVQBfgEeAQABKwDNAOgAjwCGALYAWQBHgEqATIBKgFKAZABngF0AXwB0AH4AdABvgEEAkACQAJAAmACVAIQAgwCTAJkAhgC4gH0AeIBeAEcAQIB5ACjAI8ArQCRADAABQALANj/XP8h/zP/C/+Y/ib+tP24/Gj7SPpA+dD3YPaw9YD1MPXg9AD1EPXA9JD0UPVA9tD2cPfI+FD6aPts/Nj9Dv+U/xoAMgEYAkACPAKcArAC/gEmAcUAYABx/6r+bv4Y/lT93Pwg/Wz9XP1o/fj9pP4h/+D/9wDaAVgCBAMgBEAFAAawBmgH6AcACCAIYAiQCFAIAAjAB3gHEAegBlAG4AU4BYAE7ANoA8gCJAKSAQwBiwAzADAAbACeAM4ABAFQAZ4B4AEwAowCzALoAgwDWAOUA5QDjAOUA5gDPAPUApQCSAKsAQQBpgBOANr/d/9h/yn/gv70/eT9/P3g/cD9uP2I/SD9FP1I/ST9qPx8/Kj8kPwA/GD70PrA+ZD44Peg90D3wPbQ9kD3cPdA90D3gPfQ9xD4qPho+ej5aPo4+zD82PxQ/QD+yP5M/57/EAB6AHYAIwDl/83/lf9H/0P/hf/N/xQAhwAWAXIB0AF0AkADxAMIBHAE8ARIBYAF2AUgBhgG+AUIBjAGAAaYBTAF2ARwBBAE+AP0A9gDtAPIAwgEQARgBKAE6AQIBfAE6AQABQgF4AS4BIgEEARwA/ACdAKoAYgAnv/2/kD+dP30/Kj8JPx4+zD7SPsg+9j6CPuI+8D72PtE/PT8QP1U/aD9Fv5E/mT+Jv8CAGQAaADFAFoBlgGCAa4B/gHKAV4BYgGOASABJQB8/0v/3v78/VT9AP18/Jj70PpY+qD5kPjw9wD4QPhg+Lj4iPlI+qD6GPvY+4T8CP3Q/TH/cAAaAaABbAIMAywDNANoA2QDDAP0AjQDHANoArwBdgEWAXQAIQAkAP3/jf+M////OgAqAGcA6gASAfYALAGuAdgBsAHYAVQClAKUAtQCOAM4A/wCAAMoA/gCnAJ0AoQCYAI0AkgCgAKQAqAC8AJUA5gD2ANABMAEEAUoBTAFMAUIBcgEkARwBEgE5ANYA9ACRAKCAZQAuv/6/kL+pP1Q/Qz9sPxQ/Cz8OPxM/HD8rPzQ/MT8zPwA/RD98Pz0/CT9JP3o/Mj81Pyw/Dj8yPuA+yD7wPq4+vj66PqQ+mj6gPqA+nD6mPrg+uj62Po4+9j7OPxw/OD8YP2Q/dD9gv42/3j/oP8wANoAQgGmAVAC0ALoAgADeAP4AzgEgATwBDgFMAUoBVgFcAVABSAFQAVgBVgFYAWIBXAFCAWoBHAESARABFgEkASgBIAEgASQBKgE0AQ4BagFEAZ4BugGKAf4BoAG8AVgBbAE/ANMA4gCkAFUAPL+gP0M/Jj6SPkg+CD3MPZw9QD1oPRA9AD0EPRQ9LD0UPVA9hD3sPd4+Jj5kPo4++D7wPxY/Yz9yP0Y/hr+1P2k/bj9mP1c/WD9nP2Y/Uj9KP08/UT9RP2E/ez9IP5Y/uj+oP8bAHYA9AB6AcgBJAK8AlADmAPUA0gEyAQIBUgFoAXgBdgFsAWgBWgFEAWwBGAEEAS8A3wDVAMUA7QCOALUAYQBVAFGAUABTgFUAVgBegGuAeoBHAJcAqQC8AI8A3wDmAOIA1ADCAO0AlAC+AGoAUYBygBXAAQAuf9f/xj/1P6K/kT+Kv5I/mb+hP62/gP/Sv+Z//L/QQByAIsAogCuAKsApQChAHwAKADB/3H/JP/S/qL+gP5K/gr+9P34/fT92P3M/cj9wP3Y/Rj+VP5q/nz+pP7G/tD+5P4U/yL/BP/s/uD+xP6c/qD+zv7u/gD/Kv9X/0v/IP/4/tj+lv5U/kr+Wv5S/kD+SP5S/kb+UP6C/q7+xP7w/kX/nP/N/wEATwChAOUARgHAASQCaAKcAtAC4ALQArgCqAJ4AiwC4gGgAVQBAgHCAJ0AbAAxABEAEgAXABsALABKAG8AnQDqAEYBlAHWASACgALcAiQDaAOsA8QDwAPEA+AD4AO0A3wDUAMUA8ACeAJAAuoBYgHbAHAA+v9z//T+lP4y/tz9rP2Q/VD97PyM/DT8yPto+yj7EPvw+tj64Prw+vj6APsg+zD7OPtA+3j7yPsc/Gz8vPwE/Tz9gP3A/ez9CP4g/jL+Mv40/jb+Kv4U/gr+Fv4m/kz+jP7o/jz/hf/r/1YAuAAeAagBNAKgAggDmAMgBIgE4ARIBYgFmAWoBdgF4AWwBYgFaAUgBbAEUAQgBMwDXAMYA/gCvAJgAiQCCALQAYYBaAF6AXgBYAFeAXYBZAE6ASABFgHnAKcAdABAAO//k/9E/97+Sv68/VT98Px4/BD8wPtw+xD70PrI+rj6qPq4+tj6+PoY+2j7yPsI/Dz8mPz8/Ez9hP3Y/RT+Jv44/oj+4P4E/xf/SP+D/5//vv/9/0gAcACXAOUAQAGAAcQBMAKcAuwCNAOgAwgEQARoBKAE0ATQBOAEEAUwBRgFCAUQBQgF2AS4BMgEwASIBGgEaARABOgDrAOQA0ADvAJYAjAC5gFsARIBywBHAJT/E/++/jz+nP00/fz8oPws/Oj7qPtI++D6uPqo+nj6UPpY+nD6aPpI+mD6iPqQ+qD6wPro+uD64Pr4+gj7CPsQ+zj7YPto+5D7yPvg++j7+Ps0/HT8vPw4/cj9UP7Y/on/NAC1ACIBoAEUAmQCrAL8AjwDTANYA4gDoAOUA5ADpAOwA5gDlAOwA7wDxAPkAyAEWASQBPAEYAW4BfgFOAZ4BpAGkAaYBpAGYAYoBvgFyAVwBQgFoAQoBJwDAAN0AuoBSAGvACUAnv8L/4L+Dv6g/Sj9wPxw/DD8APzQ+7D7kPtY+zD7KPs4+1D7cPuw+wD8YPzY/GD95P1M/qD+8P45/3f/rv/i/xAAKQBBAFEATQAvAP3/wv+A/zv/Cv/i/sj+sv6k/pL+gv6Y/s7+CP9A/5r/BQBuAM0ALgGKAcAB5gEsAnQCnAKgApwCkAJYAhAC0AGKASgBxQB8AEEA7/+d/2P/NP/4/sT+tv6u/qD+oP6s/rD+ov6g/rr+1P7e/vL+HP85/0P/Vf99/5v/n/+s/8r/5v/x/wQAIQAqACMAIAAsACoAHwAgAC0ALQAiACMALgA0AC0ANQBKAFQAUwBYAGsAegCIAJsArgC5AMAA0ADeANwA0gDNAMsAwgC7ALoAtACkAJIAjwCHAHsAcABsAF8ARQArABYABADw/9z/vv+e/4D/a/9X/zz/IP8L//z+8P7s/vD+7P7i/tj+1v7e/ub+6v70/gD/CP8J/wj/Dv8V/xb/F/8g/y3/N/9D/1H/U/9M/0H/Q/9N/1j/av+E/5z/q/++/9L/4f/m/+//AgAUACMAMwBJAFwAZgBwAHsAhACFAIYAjwCgAKgAqgCwALkAvwC/ALsAvgDCAMMAxgDOAM8AxwDEAM4A3QDeANsA4QDpAOsA4gDfAN8A2gDSANYA6ADhANYAzQDIALcApgCfAJcAfgBmAGIAXQBQAEQAQAA6ADUAMwA7ADsAKAAaABUACgD///n/9v/x/+f/5v/q/+j/4P/U/9L/zv/J/8r/zv/L/8X/u/+0/7H/pf+V/4f/e/9r/1f/S/9D/zb/GP/2/uL+0v7E/sb+zP7G/rr+tP62/rj+tP64/r7+xv7U/vD+Df8d/yb/Ov9W/2v/gP+d/7//1f/m//7/GAAuAEQAYAB9AI8AmwCxAMYAywDJAM4A2ADjAO8AAAEOARwBKAE6AUgBUgFgAXIBggGQAZ4BqgGuAbQBvgHEAb4BtAGwAawBngGKAXgBXAE4ARQB9wDUAKYAeQBWADEACwDq/87/q/+B/1v/Pf8f//z+3P7I/rj+pv6S/nz+YP5C/ir+Gv4I/vz98P3s/eT94P3Y/dT9xP28/bj9wP3E/cz93P3s/fj9Bv4W/iz+Qv5U/mz+gv6Y/rT+0v7y/hH/Nf9e/4r/tv/m/w8ANgBWAHcAlACrAMEA3AD4ABQBMAFQAW4BjAGmAcIB5AEEAhwCLAJEAlgCbAKEApgCqAKwArACtAKwAqQClAKIAngCYAJIAjQCHAIAAuQBxgGmAYABXgFCASIB/ADXALcAlABvAEcAHgDt/7v/kf9u/0r/If/4/tL+pv58/lb+OP4Y/vj93P3M/bj9rP2k/Zz9mP2Y/Zj9nP2g/aT9rP2w/bD9tP3A/dD94P30/Qz+JP46/lb+eP6S/qj+xP7q/g7/Mv9i/5f/wP/d/wsANQBbAHsApADRAO0ACgE6AWQBeAGCAZQBpgG0AcgB5AH8AQQCCAIYAigCNAI4AkACUAJYAmACbAJwAmgCYAJYAkQCLAIYAgQC6gHGAaIBgAFeATgBFAHzAM4AoQByAEcAHgD3/9H/rv+N/27/T/8y/xb/+v7e/sD+pP6G/m7+WP5C/iz+Fv4I/vz99P3s/eT96P3w/fT99P3w/fj9AP4K/hT+IP4u/jz+UP5o/nz+kv6q/sT+4P74/g//Jv88/1H/av+I/6z/0//+/yUARQBhAH8AnQC4ANAA6QAEASABPAFcAXgBjAGcAaoBuAHGAc4B0gHSAdIB0gHOAcoBygHKAcgByAHIAcYBwAG2AaoBlgGAAWgBUAE8ASwBHgEKAfUA3QDAAKAAfABVACsAAwDb/7T/kf9r/0j/KP8G/+L+wv6i/oj+cv5k/lj+Sv48/jL+LP4g/hT+EP4S/hL+FP4a/ib+LP40/kL+Wv5q/nj+iP6e/rD+uP7G/tz+7v78/hD/Lf8//0r/Wv9z/4j/nv+7/9v/9P8MAC4AUwByAIwAqADHAOQA/wAaATABPAFIAVIBXgFmAWwBcgF2AXgBgAGGAYgBiAGEAYYBiAGIAYoBhgF8AXABYAFUAUgBNgEkARIBAgHzAOIA0AC8AKYAiQBrAFYARwA5ADAAJAATAP3/6P/X/8j/tv+l/5X/if+B/3v/cf9h/07/P/81/yv/Iv8a/xT/DP8D//r+9v72/vb++P76/vj++P78/gL/BP8E/wb/Dv8Z/yX/Mf89/0j/V/9o/3n/if+a/6z/vP/M/9v/6f/1/wEADwAcACQAKgA0AD0ARABHAEsATQBMAEsATgBQAE8ATQBQAFUAXABlAG4AdgB5AH0AhACKAI4AkgCWAJsAmwCWAIwAfwBxAGcAXwBdAFwAXQBeAF4AXQBZAFIASABAADsAOAA2ADMAMgAvACoAJQAhABsAFAALAAAA9f/r/+L/2f/R/8r/xP/A/7z/uf+1/7D/qf+h/5f/jf+C/3n/cv9u/23/bf9x/3b/fP+D/4z/lv+e/6H/o/+l/6v/sv+5/77/wf/B/8P/yP/L/8v/yv/M/8//0f/T/9T/1v/X/9r/3//j/+f/7v/4/wIACgASABoAIQAlACgAKQAoACgALAA1AD0AQgBGAEgARgBFAEQARQBFAEUARgBMAFIAVwBbAF8AYQBhAGEAYABdAFoAVwBSAEkAPwA8ADsAOgA4ADcAOAA4ADkAOwA5ADQAMAAxADAALQAvADQAMQApACkAJgAiABkAFAATAAkA/f/6//b/5v/U/8f/vf+1/7H/sP+y/67/qP+p/7H/t/+5/77/x//R/9n/4P/j/+P/4f/e/9r/1f/Q/8z/xv/B/7v/t/+0/7H/sP+w/7H/sf+x/7P/uP++/8T/y//V/9//5v/t//X//f8EAAoADwATABgAHAAhACMAJQAqAC8AMgA0ADYAPgBFAEoASgBLAE8AVQBZAFoAWgBZAFgAVwBVAFEATQBJAEYAQwA+ADkANAAwAC0AKgApACoALgAyADQANAAzADMAMgAyADIAMgAyADEAMQAxAC4AKQAiABwAFgAQAAoAAgD5//L/6v/i/9r/0//P/8z/y//L/83/zv/P/8//zf/J/8P/vv+7/7r/uv+4/7f/tv+0/7H/rv+p/6P/nf+Z/5X/k/+R/5H/kv+T/5T/lP+U/5b/m/+h/6b/qv+u/7P/uf+//8T/y//U/93/5v/w//r/BAANABkAJwAzADwAQwBLAFAATwBNAE4ATgBKAEcASABHAEMAQQBDAEQARQBHAEoASQBJAEsAUABSAFMAVQBYAFwAXgBfAF0AWABQAEoARAA/ADkANAAwACsAKAAlACEAGwAUAA8ACwAHAAMA/P/z/+r/4v/b/9T/yf+//7n/tP+x/6//rf+q/6j/o/+f/5//n/+h/6b/qP+q/6z/rv+w/7P/tf+3/7r/vf/C/8f/zP/P/9L/2P/e/+T/6f/v//T/+f/9/wEABgAMABIAGAAdACAAJAAnACoALAAtAC4AMAAzADYAOgA+AEMASABOAFMAWQBeAGMAZwBrAG4AcABwAHAAbwBtAGkAYwBdAFcAUABIAEEAOAAuACQAGgAQAAYA/P/0/+7/6v/n/+X/4f/d/9n/1P/R/87/zP/K/8r/yP/G/8T/wf++/7v/uv+7/73/v//B/8P/xP/E/8T/wv/A/77/vP+5/7j/tv+1/7P/s/+z/7T/tf+2/7j/u/++/8P/yP/O/9X/3P/k/+v/8//7/wIACAAMAA4ADwAQAA8ADwAPAA8AEAATABYAGQAdACIAJwAqACwALAAtADAANAA4ADoAOwA7ADwAPQA9ADsANwAzADAALQApACUAIAAcABgAFAAPAAoABAAAAP3/+//6//n/+P/2//X/8//x/+7/7f/t/+7/7v/u/+z/6f/n/+b/5f/k/+L/4f/i/+X/5//q/+3/8v/3//3/AQAGAAsADwATABMAEwAUABcAGAAYABgAGgAaABoAGgAXABMADwAPAA8ADQAOABIAFAAUABcAGwAeAB8AIgAoACkAKAAtAC4AKgAkACAAGwAXABIADAAIAAMA+//2//b/9f/y/+//8f/z//X/9//4//r//P/9//7//////////f/8//v/+f/4//b/9P/y//D/7f/p/+b/5P/i/+H/4P/g/+H/4f/h/+L/5f/n/+n/6v/r/+3/7//y//P/9P/3//v//P/8//3///8CAAIAAAD+////AgADAAMAAwADAAQABAAEAAQABQAFAAcACAAIAAcABgAFAAQAAwACAAIABAAFAAUABQAEAAUABgAHAAkADAAPABMAGAAdACIAJQAnACkAKgAqACkAJwAlACMAIAAcABYAEgANAAkABQACAP///f/8//r/+P/1//L/7v/s/+v/6v/p/+j/6P/o/+f/5f/i/9//2//X/9T/0f/O/8z/yv/J/8f/xv/F/8T/xf/G/8f/x//G/8b/x//H/8j/yf/L/87/0f/U/9j/3P/g/+T/6//y//j//f8DAAoADQAQABQAGQAZABoAHAAdABwAGwAcABwAHAAcABwAGwAaABsAHAAeACAAIgAkACgALAAwADIANAA0ADQANQA1ADUANQA1ADQANQA1ADQAMgAxAC8ALAAqACgAJQAiAB8AHAAaABcAEwAPAAwACAAFAAMAAAD8//j/8//u/+v/6P/k/+L/3//c/9r/2f/X/9f/1//W/9f/2f/b/93/3v/f/+H/4v/k/+X/5v/n/+f/5//n/+f/6P/q/+3/8P/z//b/+P/7//7/AAABAAIAAwADAAQABAAEAAUABgAHAAgACQALAAwADQAQABIAFQAYABsAHgAhACMAJQAmACcAJwAmACYAJAAiAB4AGgAWABEADAAHAAMAAAD+//z/+//5//f/9f/0//P/8//z//P/8//z//L/8f/w/+7/7P/r/+n/6P/n/+b/5f/k/+P/4f/g/9//3v/e/97/3v/f/9//4P/h/+P/5P/k/+X/5f/m/+f/6P/p/+r/7P/t/+7/7//x//L/8//0//T/9P/0//X/9v/2//f/+f/7//3/AAACAAUACAAKAAsADAANAA4AEQATABUAFwAYABoAHQAgACEAIgAiACMAJAAkACQAJAAjACIAIQAeABoAFgASAA4ACgAIAAUAAwABAP///v/9//z//P/+/wAAAgAEAAYABwAJAAsADAANAA0ADQAMAAwADAAJAAcABgAFAAQAAwACAAMAAwAEAAMAAgACAAMAAwACAAIAAgADAAIAAgABAP7//P/7//r/+P/3//f/9f/z//L/8f/x/+//8P/z//P/9P/5//3//P/8//3//P/7//r/9v/0//H/7P/o/+n/6f/o/+f/6v/t//H/9P/3//v///8CAAUABwAKAAsADAAOAA8AEQATABQAFgAYABkAGgAaABoAGgAaABoAGAAXABUAEgAPAAwACgAHAAUAAgAAAP//AAABAAMABQAJAA0AEQASABQAFgAYABgAFQASABAADwAMAAkABQABAP7/+//4//X/8//x//H/8f/x//H/8f/y//L/8v/x//D/8P/v/+7/6//p/+f/5f/j/+L/4f/h/+H/4//m/+n/6//t/+//8f/z//T/9v/3//j/+P/4//j/9v/2//T/8//y//L/8v/y//H/8f/w/+//7f/s/+z/7f/u/+//8P/z//b/+f/7//7///8BAAIAAwAEAAQABAAEAAMAAgAAAP////8AAAEAAgADAAUACAALAA4AEQAVABgAGwAdAB4AHwAgACAAIAAgAB8AHQAdABwAGgAXABcAFwAVABMAFAAUABEAEAAPAA4ADQALAAoABwAEAAIAAAD///7//P/6//r/+f/5//f/9f/y/+//7P/p/+b/4//g/97/3f/d/9z/3P/c/9z/3f/g/+P/5v/p/+z/8P/1//r//P///wMABgAIAAwADQANAAwACAADAP//+v/2//P/7//s/+v/6//s//D/9P/4//3/AgAHAA0AEQAVABcAGQAbABsAGwAaABoAGQAYABgAGQAbAB8AIwAnACsALwAxADMAMQAuACgAIQAaABEACAAAAPn/9P/w/+7/7f/t/+7/8P/z//X/9//5//n/+f/4//b/8//w/+z/6P/k/+L/3//c/9r/2P/Y/9j/2P/Z/9v/3f/f/+H/4f/g/97/2v/X/9X/1P/V/9f/3P/i/+r/8f/6/wIACgAQABYAGgAbABsAGQAVAA8ABwAAAPr/9f/y//H/9P/4////CAATAB4AKQAyADoAQQBFAEYARQBCADwANQAtACUAHQAWABEADAAJAAcABgAHAAsAEAAXAB8AKAAxADgAPgBAAD4AOAAtABwABwDx/9z/yf+5/6z/pP+g/6X/sP/B/9X/6v8AABYAKQA5AEMASABFADsALAAXAP//5v/N/7j/p/+d/5r/nv+o/7f/yv/d//D/AAAOABYAFwASAAcA9//l/9P/w/+2/6z/qf+t/7f/x//b//L/CQAgADMAQgBNAFQAVABPAEcAPAA0AC0AKQAlACQAJgApACoAKgAlABwADQD9/+z/2v/J/7z/sf+q/6z/tf/F/9r/9P8UADAASwBmAHcAeQBwAFwAPgAaAPT/zf+q/43/eP9x/3v/kf+t/8//9v8dAD4AVwBlAGYAWwBDACIA/f/Y/7b/mf+H/4H/iP+a/7f/2/8DACsATgBqAH4AhwCFAHgAYQBDAB8A+f/U/7T/m/+L/4T/iP+V/6z/x//m/wQAHwA1AEUASQBFADkAKAATAPv/4//P/8H/u/+8/8P/z//h//T/CgAgADUARgBSAFoAXABXAEwAPQAqABUA/v/q/9r/0P/L/8v/z//W/+D/7P/4/wIACQANAA4ADQAMAAkABAD+//n/9v/1//b/+P/9/wMACgARABcAHgAkACgAKgAqACgAIwAbABEABQD3/+j/2//S/83/z//T/9v/5P/u//f//f8AAAAA/f/3//H/7P/n/+T/4v/h/+H/4f/j/+f/7v/4/wMADAAVAB4AJgAsADAAMwA0ADQAMwAyADEAMAAuACwAKgAlAB8AFwAQAAkA///3//P/8//0//v/CQAZACgANwBIAFgAYwBoAGYAWwBKADYAHwAHAO7/1f+//7H/q/+u/7b/wP/P/97/8P8BAA0AEAAJAPf/4f/H/6r/i/9v/1n/Tf9O/2H/f/+k/8///f8uAF8AigCsAMAAwgCxAJEAZAAqAOb/mv9O/xL/6v7e/vD+Gv9U/5v/6f83AIEAtwDUANUAvQCUAF4AIQDj/6f/dv9U/0f/Uv91/6f/4/8jAGMAoQDVAP0AEgEQAfwA1gCoAHMAOgAAAMv/of+H/3z/gf+U/7L/1f/5/xsAOABMAFYAVQBLADoAJAAPAAAA9v/y//H/9P/6/wIACAAKAAgA/v/r/9X/v/+r/5n/jf+H/4n/lf+o/8H/3P/1/wkAFwAhACQAHwAVAAMA6//M/6r/if9v/17/Wv9i/3n/m//G//n/LQBbAHsAjACRAIwAgQBvAFcAPgAjAAsA9//q/+P/3//e/+H/7P/+/xcAMgBKAF0AawBzAHcAdwBuAFwARAArABYABQD4/+//6f/n/+z/+P8GABIAFgASAAwABwAFAAIAAAD//wAABwAUACIALAAsACQAFwAKAP//9//y/+//7f/t//H/+v8CAAUAAAD0/+b/3P/Z/9n/1//O/8D/sP+i/5X/h/92/2T/V/9W/2f/hv+q/8z/6P/+/xIAJgA2AD8APQA0ACoAJgArADYAQABDAD8AOQA4AD0AQQA/ADAAGwAIAP3//P/8//n/7//j/9n/1//Y/9j/0v/H/8D/xP/X//X/EQAkADUAQQBSAGYAdwB+AHAAVQA9ACkAEgD1/9P/rv+T/4n/k/+p/8D/zP/R/9r/5f/s/+3/6//k/97/3f/l//X/BAAKAAgABgAIAA8AGgAoADYARABPAFgAXwBfAFAAMwAPAOv/zf+1/6n/qf+2/8n/3//3/w4AHwAkAB0ADQD6/+X/0//J/8j/0v/m/wEAHwA4AEwAWQBfAF4AUQA6ACIADQAAAPz/AAAEAAQA///5//P/6//e/8n/sP+a/5D/lf+m/7v/zv/d/+r/+v8MABgAGgARAAMA+v/8/wsAHgAsADMANQA6AEUAUABXAFcAUQBNAE4ATwBPAEgANQAVAO3/yv+w/5//l/+X/53/qv/A/9//AgAjADMAMQApACYAKgArACIAEQD5/+L/0f/G/7//t/+n/5v/nv+x/8f/2v/v/wcAHgAqAC8AMAAqABMA8f/R/7v/sP+w/8L/6P8VADoAWgB3AIoAhQBnAEMAJgAQAAAA/f8DAAoAEAAZACsAPwBHAEYARABIAE4AUQBRAEsAOgAbAPb/3P/P/8f/vv+8/8T/1v/y/xQAMwBGAEcAPgA4ADQAKQAUAP3/6//c/9b/3v/v/wIAEwAhADAAPABBADsALAATAPD/xv+e/37/aP9V/0b/O/82/zr/R/9X/2b/cP91/4P/of/O/wEAKAA+AEsAVwBhAF4ASQAiAPT/0P+//8T/1v/m/+v/8P8AABoAMgA4AC4AHwAQAA0AGwA5AFMAVABBAC8AKAAnAB0ABgDo/8j/sf+y/9T///8XABkAGQAsAFIAggCvANAA2wDVANAA1gDVALgAdQAbAMX/hv9f/0z/Rv9D/z//SP9q/6X/5P8PACUALwA3AEIASQBFACsA9f+t/2r/QP8v/yz/N/9N/2r/jv+//wAARABxAHwAcQBkAFkAUQBHADMADQDY/6z/pP+7/9f/4P/V/8P/rf+e/57/pv+n/6H/ov/F/w0AXgCXAKgAlQBxAFIAQQA6ADIAIQAUAB0AQQBrAIUAgABkAEYANQAzADwAQwBEAD8APQBDAE4AVABGACAA9f/W/8z/0v/c/+X/7P/6/xcARgBzAIYAcQBBABUA+P/l/9T/wv+4/7f/xP/e//3/DgD7/83/of+H/37/fP+A/47/nv+q/8D/5P8LAB0ADwD4/+7/9v8IABkAJwArACIAFgAZACoALwAZAPT/2v/X/+H/8f/+//7/8P/e/+H///8fACgAGQAIAP///f8CAAcAAADk/8H/uv/Z/wcAKQAzADEAKQAcABcAHgAgAAgA3P++/7z/0f/q//v//f/p/8z/xf/m/xoAOwA7AC4AKwA6AFQAYQBNABgA0v+h/6T/y//x/wAA+//2//z/CgAYABcA/f/R/6r/of+9/+//HQA1ADMAIwAXABIADQD8/9j/qv+J/4v/u/8BADkATQBDADQALAAlABYA/v/g/8f/vv/V////JAAsABsACQD9//L/6//u//b/+P/q/+H/7f/+//3/6P/W/9j/7P8HACYAPgA8ACEACQALABgADgDq/9D/2v/9/yYASgBkAG0AZQBlAH0AlQCHAE4ADADh/8n/vP+6/8H/yf/N/9//FABXAHEATgAOAN3/xf+8/7z/wv/C/7n/vv/m/xkAJQD5/7X/g/9u/2j/df+U/7b/zf/c//P/EQAhAA0A3/+y/5X/l/+3/+3/IgA3ACkAEwAMAA0A/P/U/6j/k/+a/7z/8/8wAFkAXwBQAEgATgBVAEwANAAYAPr/3v/U/+n/DAAdABQABwAYAEgAdwCSAJYAgABaAD4AQgBdAGUAQQAJAOn/6v/6/wUABgD8/+P/x//G/+v/FQAmABwAFQAqAFMAhQC5ANgAywCUAFMAMAAnAA8A2P+g/4f/jf+i/7z/zf/D/5z/eP94/5L/ov+b/5b/ov+3/8f/0P/R/8v/u/+x/8H/5/8OACcAMwA5AEUAVwBbAEUAFwDm/8n/xP/Q/+P/8f/1//z/FwBDAGEAUwAnAAQA8//m/9b/yf/D/7n/p/+i/7v/3v/o/97/3//3/xMALABRAH8AmgCXAJMApAC3AKwAjABvAFYAKwDu/8D/sv+u/5n/f/97/5L/uf/p/x8AQgA0AAEA4P/s/wAA8v/F/6X/qP+7/9D/5P/r/9T/q/+X/67/2P/7/xUALAA6AC8AGgASABQACgDs/8//yP/Z////KQA4AB0A6v/A/6z/pP+b/5L/iv+K/6P/3/8qAFwAYQBMADcAJAAKAOr/zP+5/6n/rP/W/xIAQABOAE0ATABAACQABgD4//f/+v8DACEARwBdAGEAXQBYAEYAJQAFAO3/1P+7/6v/sv/H/9b/4v/4/x8ARgBdAGUAZgBhAFAAOwAuACYAHQAMAPz/8//j/8b/qv+g/6r/tf/D/9//DAA9AFgATwAoAO7/tv+e/6b/u//R/+r/GgBfAKQAzAC5AHgAKADv/93/3//g/9r/2P/s/xYARgBlAGQASQAhAPn/2P/A/7P/p/+b/5T/kP+V/67/3v8WADgANwAmACUANQA4AB8A8//P/8H/yP/i/wYAHgAjACYALgAwAAsAyv+a/43/iv95/2f/d/+r/+n/IwBYAIAAhABsAFwAVQA2APb/u/+s/8L/3f/5/yUAVgBkAEoAKAAZAA4A9P/W/9P/7/8SACwAPwBFACoA7v+8/7H/vv++/7X/xf/6/zcAVwBbAFUARQAlAAIA8//2//P/5P/e/+f/9f8BABEAKQA3ACoADgAAAAkAEQAHAPD/1f++/7n/0f/9/x0AGQD8/+n/8v8JAB8AJwAbAAIA8f8BACkAPQAhAOH/rv+j/7v/3//6////9P/y/w0ANwBOAD8AGQD8//b//f8GAA0AFAAYABIA///v/+3/8//z/97/vP+c/5T/r//i/w8AGgACAO3/+/8mADsAGADX/67/uP/X/+v/8P/q/9L/qP+J/5H/p/+j/5X/rf/n/wwACwAZAFQAhABwADcAIgAvACMA9//c/+D/1/+5/8D/CwBXAF4ARABNAGUASgACANv/7/8HAAIACgA2AFkASwAlABYAEwD1/9D/0//7/x0AKQA9AGQAcgBFAP//2v/d/+n/7//4/wIABAAKACUAQgA6AAQAzf+8/8b/yv/D/8P/zf/W/+X/AAAfAC8ANwBEAFgAYABVAEkASgBNAD8AGQDn/73/pv+j/6f/n/+K/37/iv+l/7v/v/+u/5f/lf/A/xAATQBUADwAMgA5ADMAFQDu/8r/rf+j/9L/OQCSAKUAigB/AI8AiwBdACgAAwDX/6H/lP/R/xsAFwDQ/5r/oP+y/67/s//d//7/7//k/yAAegCQAE4ABQDx//n//P8VAFkAjwB/AE4ATgB/AJQAYQATAOT/0//D/8T/6f8QAAIAxf+Z/6H/tv+l/3//bf91/37/iP+r/+D/+f/f/7v/uP/R//H/GgBTAH4AfQBpAGwAiACHAE0A+/+3/4X/Z/9t/5P/rf+b/4D/lf/X/xsARQBaAFQAJADp/9z/BQAtACEA9P/l/wgAOgBSADkA9P+e/2D/YP+Z/9//DAAmAEoAgQCyAMIApABrADMACwD3//H/9v/6/+r/xf+l/6r/0P/v/+z/4f/t/xEAOQBWAGoAaQBOADYASAB0AHkAOwDp/8f/yv/E/7T/vP/p/w4AFAAeAEIAWAA3AP//6v/t/9r/tv+3/+T/+f/Q/6H/p//M/9r/yv/M/+3/BAADAAsAMgBNADUABgD4/wwAEwD9/+///v8RAA0ADgAsAEsAQAANAO3/+/8UABEA+//w/+7/5v/l//v/DQDy/7v/qv/W/w8AIwAaABsAJwAkACIANQBNAEMAHAADAAgAGAAeABsADwDk/6H/ef+W/93/CQD8/9v/z//n/xMANQAsAPL/pP9//63/AwBBAEoANAAiABwAGwAXAAQA1/+h/4D/kP/R/ygAcwCYAI4AZwA8ABsAAQDg/6//dv9O/1v/qP8NAEsASAAiAAAA8f/s//H//f8JABMAJgBQAH4AigBkACMA6P+4/5b/mv/M/xcATABRAEQARABEAC4A///Q/7L/rP/E/wAAQABKABEAyP+k/6L/nf+G/3r/iP+s/+D/HwBhAIYAdgBSAEYAVQBWACkA6f/D/7j/tv/B/+b/EwAgABMAHwBNAFcAFQC8/5j/qv+//8f/2v/9/wwAAwAMADIAQAATANT/yP/t/wsADwAYADAAOAAdAAIADgAoAB8A9P/Y/+P///8QABwAIwAKAMr/jP97/4j/h/9u/2f/i//H/wAAMgBaAGsAVwAvAA0A/P/y/+n/8v8PACUAJgAiADgAXQBsAFIAKQAXABoAIAAoADAAJQD//9b/yv/X/9z/x/+x/7D/uf/B/9D/9f8nAEIAOwAwAD0AYgCDAIsAdwBSACcADQAQAB0ADQDM/4P/dv+q/+b/AAANADAAXgB7AH8AeABkADoACADq/+j/5f/R/8X/y//Q/7T/ff9a/1//dP98/4z/x/8nAHcAkQCKAJAAmwCCAEEA/P/H/5f/c/92/6X/xv+w/5j/wP8XAEIAHgDz//b/CQADAP3/FgAyAB8A+P8BADMAQAAKAM//w//M/8D/tf/N/+z/6P/X//D/LQBPAEAAMwBGAF8AWQA8AC0ALwArAB0AFQAWABYAFgAoAEcATwAnAOP/uP+v/7D/pv+W/5j/tv/i/w0ALgA6ADEAGAD3/93/1//r/wgAFQARAAgA/f/q/9X/1f/k/+r/3f/i/xIASABPADAAFwAFANj/nP+I/6f/wf+x/6P/yf8GAB4AEAAGAAgA7v/E/7z/4P8DAAcAGQBaAJcAngB7AFsAOQD4/67/jP+L/4b/jv/H/ycAZABhAE8ATABBABkA8v/t/+r/0f/K//z/RgBcADsAHgAoADoANAAlACIAIAATAAsAHAAzAC8AGwAUACMAMQAeAPj/3P/a/+D/2//R/8//3f/2/wsADADv/7//l/+Z/7v/3f/v//f/DwA6AGUAcgBQABMA2f+8/8H/1f/h/+H/5f8BACoAQwBAADAAJQAYAPr/1f+//73/wv/O/+P/8//z/+//AQAkADAAFQDt/+L/7//0/+v/7P8HACQAKgAhACMAMAA4ADgAMwAkAPr/yP/A/+X/AgDq/7z/tf/V//T//v8DAAwAAgDn/+D/8f/0/9v/yP/V/+3/+f8IADcAbwB3AEsAGwAHAAUA/P/s/+j/9/8QACkAPgBAABcA0v+d/5H/ov+x/7v/3f8aAFgAcwBmAEcAJAD4/8b/pP+e/7D/y//o/wMAIQBEAGgAiQCYAIQAUQAbAP7/9v/r/87/pP+F/4v/uf/2/yEAJQAHAOL/zv/P/93/5P/Z/8f/x//t/ywAWQBVACgA+P/i/+b/9f8FAAoAAgD6/wQAIgA5ADUAGQACAP//AQD9//r/BQAXABQA7v/K/8f/3f/v/+r/2//N/8b/0f/3/yEAKQACANj/3f8KACgADwDj/9n///8nADQANgA8ADIAAwDJ/67/q/+Y/4T/of/m/wYA6v/g/x4AYQBMAPn/zf/e/+n/0//P/+7//P/j/+b/NwCQAJUAZgBaAGsASADv/7v/0f/u/+L/4/8ZAFEAUQAuACIAIgAAANL/1P/+/xQABgAHACcAMQD7/7f/pf+8/9T/5/8NAD0AWgBsAIwApwCTAFIAHAATABMA8//H/7f/wf/G/8D/vv/B/8D/v//R//D/AAD3//P/CwAxAEQANQAQAO3/3P/b/9v/zf+2/6r/s//F/9T/3f/Z/8j/wP/f/yUAWgBXADgALgAyAB4A8P/M/7z/rv+h/7//FgBkAGwARgA3AEcAPwAJANf/y//B/57/jv/F/xoAOAATAPn/DwApACEAGwA+AGAARwAYACcAbQCKAFMABwDo/+f/3f/e/w0AQwBCABMAAwApAEMAHwDf/7z/tf+m/5r/uP/0/xAA9P/P/9H/5//j/87/zf/c/93/0P/e/xAAMgAaAOb/x/++/7v/0P8MAEYARwAjAB4ARwBcADUA9v/F/5j/a/9h/5L/xf+4/4j/h//F/wUAIgA0AEQALgDw/9H/+/8+AE0AKwAkAFcAlACiAH0APADt/57/bv91/6P/zv/q/w0ASwCKAKIAhQBSAC4AGAACAO7/8v8NABwACADt//X/GQAnAAgA6v/v/wgAGQAkAD0AUgBGAC0APABoAGgAHAC//53/pP+c/4P/jv/I//n/AAAAAB0ANAAVANn/wv/S/9j/zP/d/x4ASgAoAO7/5v8FAAsA4//F/9T/7P/w//f/HgBCADYACgD5/w4AGQD//+D/4P/v/+z/6v8GACoAIwDr/73/xv/o//b/8f/0/wAAAgAGACMARAA4AP7/2v/y/yEANQAyADgAPQAfAPP/6v8FAA0A7v/V/9v/7P/0/wMAHwAcANv/k/+T/9b/EAARAPn/8/8AABUAMABIAEMAEADY/9n/EQBEAEwAOQApABoA+v/Z/83/zf+//5//kP+s/+v/LQBYAGMATQAhAPX/3f/Z/9L/tP+M/4T/tf8IAEoAXwBVAEIALQAVAAIA/P/8//X/7//9/xoAKQAYAPn/5P/W/7z/p/+z/9//BwAJAPv/AAASABEA+f/l/+r//f8TADEAUwBUACMA6//e//T/9//T/7r/1P8NAEQAaQCBAIAAWwAxACcALwAZANj/nP+M/5v/rv/L//7/MABAADcAPwBaAE0A/v+f/2z/ZP9u/4r/w/8EACQALgBNAHsAfgBDAP3/3P/U/8D/r//E/+//BwAAAPf/+//7/+b/zP+9/6//of+l/8z/BgAjABMA9//u//T/9v/t/+n/8P/5/wMAHABCAFsAVAA3AB4AFAAXACAAMgBGAEMAIwAEAAMAGAAcAPz/z/+6/8r/6f8IACIAIgAFAOb/7v8bAD4AMQAOAAEAEwAtAEIAVQBhAFEAJwAKABEAJAAfAP//5P/i/+v/9/8RADEANwANAM//tf/I/9b/w/+0/8v/+f8YACsAPwBFACUA9f/l//f/9v/O/67/tf/G/7v/nP+P/5j/n/+k/8L/+f8rAEcAVQBfAGUAYQBSADkAFgDr/8v/v//A/8T/v/+z/63/vP/e//z////y//n/GgA9AE0AUQBaAGMAWQBDADYAKQAHANT/sv+p/6H/kf+V/7//7v8CAA4AMQBcAG0AawBxAH4AbwA9ABIAEAAcAAsA4v/D/7n/tv+7/9f/9//w/77/o//M/w0AJwASAAcAIgA/AEQAPwA3ABYA1/+i/5r/rv+4/8D/3/8KABYAAADz/wEAEQAIAPP/6v/z/wkAJQAzAB8A8f/I/7n/uf+5/7r/wf/L/9r//P8uAFIAVgBLAEoATwBHAC8AFgAHAPT/3//b/+f/7v/k/9v/4v/q/+D/z//N/93/8/8JACUAPwBLAEsASgBLAEEAKgAWABAACgAAAPj/AAAOABIADQALABUAHwAhABwAFQAMAPv/5//a/9X/1f/S/87/1P/c/9v/1v/c//L/CAATABsALQBIAFAANwAKANz/vv+//9f/9/8UACsARABhAHUAbAA3AOb/n/+C/5H/sP/L/+L//P8bADcARQA+AB4A9P/U/8P/u/+5/8T/3P/8/xkAKgAtACYAIwAsAC4AGADu/9H/0v/f/97/0v/S/+P/+P8NACcAOwA8AC0AHwATAO//r/+A/4T/pf+0/67/vv/y/ywATgBfAGoAYABDADIAOQA2AAsA1v/H/+D/9P/u/+//CwAmACYAGQAYABwAEQD8//r/DAAWAAgA9v/u/97/uP+U/5H/rf/F/9H/6v8eAFMAaQBfAE4APAAjAAwACQAVABkAEgARABgAGAALAP///v/3/+H/zP/O/+X/9v/3//L/6f/f/9z/7v8KABMA/P/g/9z/6v/x//D/8//8/wQADgAqAFAAYABHABoA/v/5//n/9P/y//T/8f/p/+7/AAAKAPr/2v/K/9L/3v/i/+L/6P/1//z/+P/4/wQAFQAdABUABgD1/+b/4P/q//r//f/r/9r/4f/+/xIAAwDh/9L/6P8NACQALgA0ADEAGgD0/9z/1v/L/7n/vP/d//b/7f/k/wEALgAuAAIA6f8AACIAKAAiACgAKwAWAAgAJgBUAFcAMwAjADcAPwAdAPj/+P8HAAAA8v/5/wkA///f/9D/2P/X/83/3f8MADUANwAnACUAJAAJANv/wv/H/9L/3f/4/yMAPQA8ADgAQwBHADEAEwAOABkAEADx/9v/3f/a/8H/pf+c/6H/pv+x/8v/6P/z//X/DAA4AFsAWgBDADUANwA1ACMABQDi/8D/pv+W/5L/kf+J/4j/n//U/xkAUQBsAHUAggCNAIQAYgA3ABAA8P/U/8P/xv/L/7z/ov+d/7f/2P/r//z/IQBNAGcAcQCDAJsAkQBYABYA8P/f/8n/sP+r/7j/uv+y/8b/+v8eABUA+v/3/w4AIQAqADsAUQBSADsAKwAzADcAGwDq/8j/vf+z/6X/pf+5/8f/wf+5/8z/7/8HABEAHgAvADQALAApAC8AJAD2/8D/ov+a/5X/nP+9/+P/8f/u/wAALABIAD4AKAAhAB0ADgAFABIAHQD//8r/t//T//H/8v/t//r/BQD4/+z/AAAlAC8AHAAXADQAUwBPADIAEgD1/9T/u//A/9z/8v/0//b/CQAdABoAAgDt//D/AwAXACgAPQBTAFsATgA0ABkAAwDs/9L/w//I/9n/7v8FACIAPgBKAEYASABSAEsAHwDh/7r/sP+r/6D/m/+r/8H/zf/Y//D/CQAMAP//BAAjAD4ARQBEAE4ATwAtAPz/4f/e/9r/xv+5/8X/3v/y/wEAFAAhABgABAD+/wgACADy/9j/0P/W/9n/2v/k//L/9//z//z/GQA6AEwAVABcAFwATAA2ACcAFwDz/8D/ov+o/73/zP/X/+n/+v/+/wAAEAAkACEACwD+/wEAAwD4/+7/8P/v/9v/x//T//n/FwAaABMAEQASABQAFQAVAA4A+P/j/+z/EAAtAC0AHAAOAAgA/P/r/9//2v/W/9H/0//l////EQAWABIABwD2/+b/3//l/+3/7P/l/+j/AQAjADkAPAAyACYAHAAVABMAFQAUAA8ADAATABsAGAAGAPH/4//b/9H/yf/M/9j/5f/p/+f/6P/s/+7/8P/4/wgAGwAsADsARwBEAC4AFAAFAAAA9v/l/9r/3//v/wIADwAUAA8ABQAAAAcADgADAOv/1//S/9f/2v/f/+r/9/8AAAcAFQAnACgAFgAFAAEABgAFAAQABwAGAPb/3//X/93/3P/Q/8z/3v/7/xAAHgAvADwANQAdAAAA5//O/7T/pP+l/7D/wP/a//7/JgA8ADcAJwAaABAAAgDw/+P/3//i/+v//P8TACIAJQAjACcAMgA9AEQARwBHAD0AJgAKAPX/5v/T/7v/p/+l/7f/0P/q/wUAGQAmADMARwBfAGoAXQBCACwAHQAOAPr/5P/U/8j/v//C/9T/6v/6/wMADwAkADcAQwBKAFAASgAyAAwA7P/b/8r/sv+f/6D/rP+3/8T/2//z/wMADwAnAEgAXgBcAFAARwA1ABIA4/+3/5f/gP9z/3r/kv+v/8r/5v8GACUAPwBPAFQAUwBKAD4AMgAkABMA/P/h/8v/v/+8/8D/wP/C/9H/7f8MACYAOQBLAFkAXABTAEgAOQAhAAEA5v/U/8T/tf+w/7z/zv/X/97/8P8JAB0AKQA2AEYATwBOAEsAUABUAEgALwAVAAEA6v/P/7n/q/+b/4P/d/+G/6n/yv/h//3/KABRAGsAeAB7AG8AUAArABAA/P/j/8T/rP+h/5b/iP+A/4z/p//G/+b/DAA1AFsAeACFAHwAZABBABsA+P/Z/73/pv+Y/5n/qP/C/93/8/8FABcAKQAyADEAKgAkAB8AGgAYABYAEQAIAP7/9v/u/+L/1//T/9v/6v/6/wgAEwAaAB8AIgAhABwAFgATABYAGgAeACEAJAAnACcAJAAeABgAEgAKAP//8v/j/9L/xP+7/7n/vv/F/8//3//0/wcAFwAkADIAPQBEAEUAQQA6ACsAEwD4/93/x/++/8D/y//b/+7/AwAYACgAMAArAB0ADQADAAEAAQD///n/8v/t/+v/6P/i/9n/1P/X/+H/8P8DABoALQA6AEIAPwAzAB0ABgD2/+j/2f/M/8r/1P/h/+f/6f/t//b///8GAA8AGQAfACAAHwAeABMA+//m/97/3P/W/8v/x//P/93/6P/0/wUAFAAfACsAOwBFAD8AMQAkABwADwD5/+b/3//d/9r/1//b/+T/7//6/wcAFgAfABwAEQAHAP7/7//e/9P/0v/Y/+H/8P8FABoAKQAvADQAOQA7ADkANAAsAB8ADQD8/+z/3P/P/8f/xP/E/8r/2f/v/wUAEwAZABwAHQAaABIACAD9//D/4//c/97/5v/r//D/+/8MABsAKAAzAD0APwA1ACQAFQAJAPr/5f/P/7//tf+y/7f/xv/a//D/BgAhAD8AVQBcAFYASQA1ABoA+f/Y/77/qv+a/5D/kf+e/7P/zv/t/w0AKQA9AEwAVwBZAE8AOwAlABQABwD7/+3/3v/Q/8P/tv+t/6z/s//B/9X/7v8KACIANABAAEcARQA4ACYAGQAUAA8ABgD8//b/8v/u/+v/7P/x//T/+P8AAA4AGQAeACUALgA0ADAAJAAaABAA/v/m/9P/x/+//77/yv/d/+///f8KABsALAA3ADsAOQA2ADIALQAnAB8AEQD+/+z/3v/V/8//y//K/83/1f/j//T/BAASABsAIgAnACcAIwAYAAkA+f/r/+T/3//a/9f/1v/a/+L/6v/y//3/CQAUAB0AIQAjACMAGwAMAP3/8f/o/+b/6v/v//T/9f/1//v/BAALAA4AEAAWAB0AIgAhABwAFQALAP7/8v/r/+j/5v/n/+v/8v/6/wIACwAVABoAGAAUABAACwADAPr/8v/v/+7/7v/w//b//f8CAAYACgAOABAAEQAVABkAGQAVAA8ACgAEAPz/8P/k/9r/0f/L/8j/yf/J/8v/0f/d/+z//P8LABsAKwA5AEAAQAA6AC0AHQAMAPr/6v/c/9L/zf/K/8n/yf/N/9T/4f/0/wgAHAAtADkAQQBBADkAKAASAPz/6P/Z/87/yf/J/87/1v/j//P/AwASAB4AJwAtADAALgApACQAHQAVAAwABQAAAPr/8//s/+b/4v/f/97/4v/q//T//v8JABMAGgAcABwAHAAdABwAGAAVABUAFwAZABoAFwAOAAIA9f/o/9z/z//D/73/vf/D/87/3f/t////EQAhAC0ANQA8AD8APwA6ADIAJQAVAAUA9f/k/9T/yP/D/8f/0f/f/+7//f8LABgAIwArAC0AKwAlAB4AFwAOAAQA+v/x/+r/4v/d/9v/3f/h/+T/5v/s//T//f8FAAoADgAPAA4ACwAIAAQA///+////BQANABcAHAAdAB4AGQARAAYA/P/1/+r/3f/Y/9b/0//O/8z/zv/U/9//7f8AABMAHwAmADAAOgA7ADYALgAnAB8AFAAHAPz/9P/s/+P/4P/h/+T/5//s//T/+/8BAAIABAAGAAcABAD///v/9//0//P/9P/3//z/AAAEAAkADQAQABAADQAJAAUAAQD9//n/9v/1//b/9//3//n//f8EAAoADQAOABAAEQAQAAsABQD9//P/6v/j/9//3f/c/9//5f/t//X//P8EAA0AFAAZAB0AIgAlACQAHwAXAA0AAgD2/+3/6P/l/+X/6f/x//v/BAAKAA4AEQARAA8ACgADAP3/9v/v/+j/4v/d/9v/2//d/+D/5P/o/+//9/8AAAgADgAWAB8AJwAtAC4AKwAkABoADQD///H/5f/c/9b/1P/W/9r/4P/o//H/+f8BAAgAEQAbACIAJgAlACIAHAATAAoA///2/+3/6P/m/+j/7f/z//z/BwASABoAHgAiACQAHwAYABIADAACAPr/9f/x/+v/5f/j/+P/5f/q//H/+P8AAAkAEgAaACEAIwAiACAAHQAZABMADAAEAPv/8//u/+r/6P/n/+f/6v/v//T/+f/9/wAAAwAGAAkACgAJAAcAAwABAAAA/f/7//r/+f/5//v//P/9//7//P/6//r/+//8/wAAAwAEAAQAAgD///7//f/7//r/+f/7//7/AQAEAAYABwAHAAYABgAFAAYABgAFAAUABAAEAAQABAADAAEA/v/7//r/+P/3//b/9f/2//f/+f/7//3//v8AAAEAAwAFAAYABgAIAAoACwAMAAwADAAMAAsACAAFAAEA/f/4//T/8P/s/+n/5v/l/+X/5v/p/+z/8v/4//7/BAAIAAoADAAMAAsACwAKAAgABgAEAAAA/f/6//j/+P/6//3/AQAFAAkACwALAAgABAD///r/9P/x/+7/7v/u/+//8f/0//f/+v/8////AQADAAUABwAKAAwADwAQABEAEQARABEAEQAPAA0ACwAIAAYABAABAP///P/5//f/9f/z//L/8v/1//f/+f/8/wAABQALABEAFAAUABQAEwASAA8ACgADAP3/9//y/+//7P/r/+v/7v/x//X/+v///wUACwAQABMAFAATABAADQAHAAEA/P/4//b/9v/2//b/9f/1//X/9//5//r/+//9/wEABQAIAAoADAANAA0ADAALAAoACgAJAAYAAwABAP///f/7//j/9v/0//H/8P/v/+7/7f/u//H/9P/6/wAABAAIAAsADgAQABAAEAARAA4ACgAJAAcAAQD7//b/8f/u/+3/7P/u//H/8f/x//b/+//+////AgAGAAkACgAKAAoACwAJAAYABAAEAAIAAAD//////////////v////7//f/8//v/+//7//z//f///wEAAgADAAMABAAFAAQAAwABAP///f/8//r/+P/4//n/+f/5//n//P8AAAMABAAFAAYACAAJAAkACAAGAAMAAAD+//v/+P/2//X/9P/0//T/9P/1//f/+f/6//z//v8BAAMAAwADAAIAAAD///7//v/+//3///8BAAQABwAIAAkACgALAAsACQAIAAYAAwAAAPz/+P/1//L/8P/v/+//7//w//L/8//1//b/9v/4//v///8DAAYACgAMAA4ADwAOAAwACAAEAAEA/v/7//r/+f/5//n/+f/5//r//P/+/wAAAQACAAIAAwADAAMAAwADAAIAAQAAAP//////////AQAFAAgACQALAA0ACwAJAAgABwAEAAEAAAAAAP7//P/8//z//P/9//7//v/+////AAACAAMABAAEAAUABgAHAAcABwAFAAIAAQAAAP///v/+//3//f/+//7//v/+//3//f/9//7///////////8AAAEAAAAAAP///////wAAAQABAAAA/v/8//r/+f/5//n/+f/5//n/+v/7//3//v///wAAAQACAAMABAAFAAUABQAGAAUABQAFAAQAAgABAP///v/9//3//f/9//3//f/9//7//v/+//7//v/+////AAAAAAEAAgACAAMAAwACAAEAAQAAAP///////wAAAAABAAIAAwADAAMAAwADAAIAAQD///3/+v/3//T/8v/x//D/8f/z//b/+f/8//7/AAACAAMABAAFAAUABQAEAAIAAAD+//z/+v/5//n/+f/7//z//v8AAAIAAwADAAQAAwADAAIAAQAAAP///v/9//3//f/9//3//P/8//z//P/9//7//v///wAAAgADAAUABwAIAAkACQAIAAgACAAHAAYABQAFAAQABAADAAIAAgACAAEA///9//z//P/9//7///8AAAEAAwAFAAcACAAHAAYABQAFAAQAAwACAAEAAAD+//3//P/6//n/+f/6//z//f/9//7/////////////////AAABAAEAAQABAAEAAQACAAEAAAD//wAAAAD//////////wAA////////AAAAAAAA/v/+////AAAAAAEAAgADAAMABAAEAAIA///+//3/+//6//v/+//6//r/+//8//z//f8AAAAAAAADAAYABQADAAMAAQABAAAA/v/9//3/+v/3//j/+v/5//j/+f/7//z//f/9////AAABAAEAAgADAAMAAgACAAIAAgACAAIAAQABAAEAAAD///7//P/7//v/+//6//v/+//7//v//P/+//////////7//////////v///wEAAQAAAAAAAQACAAMAAQD//////////////v/+//3//P/8//z//P/7//z//f/9//3//f/9//3//f/9//3//f///////////wAAAAAAAAAAAAAAAP////8AAAIAAgACAAIAAgACAAIAAQABAAEAAQABAAEAAAAAAP///v/+//3//f/9//3//f/9//3/+//7//v//P/9//7///8BAAMABQAGAAYABQAEAAIAAAD///3//P/7//r/+f/5//r/+//9////AAABAAEAAgACAAIAAwADAAMAAwACAAIAAgABAAAAAQACAAMAAwAEAAYABgAFAAYABwAFAAQABAAEAAIAAQABAAEAAAABAAEAAAD/////AAAAAAEAAQAAAAEAAgADAAQABQAFAAQABAADAAMAAgABAAAAAQABAAAAAAAAAAAA/////wAA//////7//v///wAAAAD//////v/+////AAAAAP///v/8//z/+//6//r/+v/5//j/+P/4//n/+v/6//v//P/9//7///8AAAEAAQACAAIAAwADAAMAAgABAAAA///+//7//f/9//z//P/8//z//f/9//3//f/9//7///8AAAAAAQACAAMABAAEAAQAAwACAAEAAQAAAAAA//8AAAAAAAABAAEAAQACAAIAAwADAAMAAgABAAAA/v/8//r/+f/4//j/+f/5//r/+//7//z//v///wAAAQACAAMAAwADAAIAAgABAAAA///+//3//f/8//z//P/8//z//P/9//3//v/+////AAABAAEAAgADAAMAAgACAAIAAQABAAEAAAAAAP//////////AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAEAAgADAAQABgAHAAcABwAGAAUABQAFAAQAAwABAAAAAAABAAIAAgABAAEAAQACAAIAAwADAAQABQAFAAUABAACAAEAAAD//////v/9//z//P/8//z/+//7//z//f/9//7//v/+//7///8AAAAAAAAAAAEAAgABAAEAAQABAAAA//////7//v/+//7//P/7//z//P/8//v//P/9//7///8AAP///////////v/+///////+//7///8AAP////8BAAAAAAADAAUABAAEAAQAAwADAAIAAAD///7/+v/2//b/9//1//P/8//1//b/9//3//n//P/+////AgAEAAUABgAGAAcACAAIAAcABwAGAAUAAwABAP///f/7//r/+f/4//j/+P/4//j/+v/8//7//v/+//////8AAP///////wAAAAD///7///8AAAEAAAD+//7///8AAAAAAAABAAEAAQABAAEAAQABAAEAAgACAAEAAQAAAAAA///+//3//P/8//z/+v/5//n/+P/4//j/+P/4//j/+f/7//7/AAACAAMABQAHAAcABwAIAAgACAAIAAcABgAEAAMAAQD///3/+//6//n/+P/4//f/9v/2//f/+f/7//3/AAADAAYACgANAA8AEAAPAA8ADQALAAgABAAAAPz/+P/z//D/7v/t/+3/7f/u/+//8f/1//j//P8AAAUACQAMAA4AEAARABEAEQASABAADQAKAAkABQAAAP7//P/5//b/9v/2//X/9P/2//n/+////wMABQAHAAkADAANAA4ADgAMAAsACgAJAAcABQADAAAA/v/9//v/+v/5//j/+f/6//v//P/+////AAACAAQABAAEAAQABQAGAAgABwAGAAYABQAFAAYABQAFAAUAAwAAAP///P/5//j/9v/z//D/7v/s/+z/7f/t/+7/8P/y//X/+P/6//3///8BAAMABAAGAAcABwAHAAUABAAEAAQABQAFAAYABgAIAAkACwALAAsACwAKAAgABQABAP3/+f/1//H/7f/p/+b/5P/j/+T/5f/o/+3/8v/5/wEACAAQABcAHgAjACgAKwArACkAJgAhABkADwAEAPn/7v/k/9v/1P/O/8v/yf/L/8//1f/d/+j/9P8BAA4AGwAnADIAOgBAAEQARABBADoAMgAnABkACgD5/+n/2f/K/77/tP+t/6n/qv+t/7b/wf/O/97/8P8CABUAJwA4AEYAUQBYAFsAWwBXAFAARQA3ACcAFgADAPH/4P/Q/8P/uP+x/63/rf+w/7f/wf/O/9v/6P/2/wQAEwAgACsAMwA5ADwAPwBAAD8AOwA2AC8AKAAfABYADQAFAP7/+P/y/+3/6f/l/+P/4v/i/+L/4v/j/+X/5//p/+v/7f/v//P/9v/5//z//v8AAAMABgAJAAoADAANAA8AEQARABIAEgASABEADwAOAA4ADgANAAwACgAJAAkACAAGAAQAAwACAAAA/f/6//T/7v/o/+D/1//P/8r/xP+9/7v/uv+9/8D/x//V/+H/7/8FAB0AMQBFAFkAaAB2AIEAhgCGAIAAcQBdAEkAMQASAPH/0P+y/5T/ef9h/07/Qv8+/z//SP9Z/3H/jv+0/93/CQA1AGEAiwCyANMA6wD5AP4A+ADpANAArQCDAFMAHgDo/7P/gf9V/y//Ev8A//j+/v4N/yb/SP9z/6T/1/8JADsAawCVALYAygDUANYAzwC+AKMAgQBaADEABwDf/7n/mf+A/2//Z/9n/27/ff+T/67/y//p/wYAIgA8AFEAXwBlAGYAYQBYAEkANgAgAAkA9P/h/9L/xf+7/7b/t/+9/8T/zv/b/+r/+v8IABQAHQAlACoALAArACcAIAAYABEACgADAPv/9P/v/+//8f/0//n//v8GAA8AGAAfACMAJQAkACIAHAATAAcA+v/u/+L/1f/H/7z/tf+z/7X/uP++/8j/1v/n//n/CwAdAC8APwBNAFcAWwBbAFkAVABLAD0AKwAaAAkA9v/j/9P/xf+3/67/rf+u/6//s/+7/8f/1//p//r/CQAXACgAOQBIAFQAXABhAGYAagBrAGgAXwBVAEkAOwArABYA///n/87/uf+i/4z/dv9k/1b/Tv9L/07/Vv9k/3v/mP+7/+P/DAA4AGgAlgC+AOIA/wAUASIBIgEUAfkA1ACnAHYAPQD+/73/fv9F/xX/7v7Q/rr+tP66/sz+6v4P/zz/cP+o/+H/GABMAH0AqQDNAOYA9gD8APwA9ADkAMwArQCLAGcAQgAcAPb/0/+1/5r/hP91/2z/av9u/3f/hP+W/6v/wv/a//L/BwAZACgANAA9AEEAPgA4AC8AIwAXAAsA/v/w/+X/3v/a/9r/2//f/+b/8f/+/wwAGQAlAC8AOAA+AD8APAA2AC8AJwAdAA8AAQDy/+b/3P/T/8z/xf/A/7//wf/F/8j/zP/Q/9f/3//n/+3/9P/9/wYADwAYACAAKQAxADkAPwBDAEMAQQA9ADgALwAiABIAAQDw/+D/0f/D/7b/r/+s/6//tv/D/9T/6/8GACIAPgBXAG8AhgCXAJ4AmwCPAHsAYgBDABwA7/+//5H/af9G/yb/Df8A//7+Cf8e/z7/Z/+Z/9T/FABUAJIAzAACATIBVgFuAXgBdAFkAUgBHgHpAKcAXgATAMf/ff80//D+tP6G/mL+UP5K/lD+ZP6K/rr+9P44/4D/zv8cAGgArgDsACQBUAFyAYQBhgGAAWwBTgEmAfMAvQCDAEUACQDN/5X/Yf80/w3/7v7a/tL+0P7W/uj+Af8k/0z/eP+r/9n/BwA7AGwAlQC3ANAA4ADqAO8A6wDdAMcApwCFAGUAQwAcAPP/z/+w/5b/gP9r/1v/U/9S/1X/XP9m/3P/hf+f/7r/1P/s/wUAIQA/AFoAbwB9AIgAkQCWAJYAjgCAAG8AWgBCACgADQDw/9T/uv+j/5H/gv93/3D/cv99/4v/nP+v/8f/5v8JACkAQABVAGoAfwCOAJIAjQCCAHQAZABNADAADgDt/8//tP+a/4D/bf9j/2D/ZP9s/3n/jf+r/87/8P8RADEAUQBxAI0AoQCsAK8ArQCnAJwAhwBpAEcAJQADAOD/vP+Z/3z/Zv9V/0r/Q/9E/0z/XP9y/4r/o/+//+D/AwAkAEEAVwBsAIEAlAChAKcAqAClAKEAmgCOAH0AaABRADsAJAAKAO//1v/B/7D/n/+O/4D/eP92/3j/ev99/4H/i/+X/6b/s//B/9H/4//3/wsAHgAwAEMAVwBrAHwAiQCTAJwAnwCfAJgAjQB4AF4ARgApAAUA3f+3/5L/dP9c/0b/M/8n/yj/NP9J/2P/gP+l/9P/BgA8AG8AnADHAO8AEAEqATYBNAEqARYB+QDTAKAAZQAiAOD/nv9c/x3/4v6w/oz+dP5q/nD+gP6g/tT+Ef9Y/6T/8/9HAJ0A6QAoAVwBggGaAagBpgGOAWYBMgH5AL0AewA0AOz/qf9y/0L/Gv/6/uL+2P7Y/uL+7P4A/xb/M/9R/23/hv+h/73/2P/y/wgAGwAuAEMAVwBpAHkAhwCTAJ4ApQCqAKsAqQCjAJkAiwB7AGgAUwA+ACgAEwD//+3/3v/T/8v/xP+//7v/uP+2/7X/sv+q/6H/l/+M/4L/dv9r/2H/Xv9j/27/f/+W/7X/3f8LAD0AcACiANUABAEuAUwBXgFkAV4BSgEsAf8AxQCDADoA8P+m/1v/E//U/p7+dv5a/k7+Tv5g/n7+rP7g/h//Y/+s//f/QQCGAMQA+gAmAUoBYAFoAWIBUAE2ARIB5QCwAHgAPQADAM3/m/9v/0r/MP8i/x7/I/8w/0j/af+Q/7j/3/8EACgASgBnAHwAhwCIAIUAfQBwAFsAQQAkAAgA7P/Q/7f/oP+O/4L/f/9//4H/i/+a/7H/zP/p/wcAJgBIAGoAjACoAL4AzwDdAOgA6gDkANQAvQCgAIAAWwAwAAAA0P+h/3X/Sv8i/wD/5P7S/sb+wP7E/s7+5v4E/yj/Uf9//7P/6v8iAFgAjQC+AOoAEAEuAT4BRAFCATQBGgH4ANAAoABnAC8A8/+8/4f/Vv8x/w7/9P7q/u7++P4K/yb/SP9x/6H/0/8FADMAWwB/AKAAuwDHAMwAyAC9AKsAkQBwAEsAJQAAANr/t/+X/3z/Z/9c/1f/Wf9g/23/g/+g/8L/5P8HACkATABsAIkAoACxALwAvwC8ALAAnwCHAGgARAAcAPT/yf+f/3f/Uv81/x//EP8F/wT/D/8m/0D/X/+A/6j/1/8GADMAWwB/AKAAvQDSAN8A4wDgANgAzAC4AJ4AgQBjAEYAKAAKAO//1//F/7j/rf+l/6D/oP+j/6r/sP+2/7v/wf/I/8//0//U/9T/1f/W/9j/2P/a/97/5f/u//j/BAAQAB4ALAA6AEUATABRAFMAUgBNAEMAMwAiABEAAADw/9//0P/F/77/u/+7/77/wv/J/9P/3f/n//D/+f8CAAsAEQAUABYAGAAcAB8AHwAeAB4AHwAgACEAIgAjACQAJQAmACYAJQAiAB8AGwAXABMADAAGAAEA+v/0//D/7P/m/+H/4f/e/93/2v/a/9n/3P/h/+b/6v/u//X///8IABIAGwAiACoAMQA5AD4APgA9ADkANAAuACMAFwALAPz/8f/n/93/1P/L/8b/xf/F/8j/y//O/9T/2v/i/+z/8v/3//3/BAAKABIAGAAdACYALQAxADgAPABBAEgATgBPAE8ATQBKAEcAQgA5AC4AIAATAAYA9//p/9n/zf/C/7r/s/+w/6//sf+2/7v/wv/M/9b/4v/t//b//f8DAAkADQANAAsABwACAP3/9v/v/+j/4//f/9z/2//a/9v/3f/f/+P/5v/p/+v/7v/w//L/8v/w/+7/6//o/+b/5P/g/93/2//b/9z/3v/h/+b/7v/6/woAGgAsAD4AUABjAHUAhQCSAJwAogClAKMAmwCOAH0AZwBPADUAFwD2/9f/vP+j/43/ev9r/2L/X/9j/2z/ef+I/53/tP/N/+f///8VACgAOQBGAFAAUwBSAE4ASAA8AC0AGwAIAPb/5P/R/77/q/+a/4z/gf94/2//av9q/2z/cv94/4H/jf+e/67/v//O/93/7/8DABgAKAA1AEIAUQBgAGwAdQB5AHwAfwB/AIAAfQB5AHUAdQB0AHAAbQBrAGoAawBtAHAAcQB1AHgAfgCDAIQAgwCBAH8AeQBxAGMAUAA7ACYADgD0/9j/vf+j/47/fv9w/2X/Yv9n/2//ev+J/57/s//K/+H/8f8AAAsAFAAZABUAEAAGAPn/6//a/8f/tP+g/4//f/90/3D/av9l/2v/bv95/3//hv+V/57/p/+0/8T/y//Q/9b/1//X/9j/1//X/9P/yv/D/8H/xv/J/8r/1P/d/+n/+P8JABgAKAA4AEYATwBYAFsAWgBVAE4AQgAyACMADAD5/+f/1P/C/7L/pP+c/5v/oP+s/8D/1f/s/wsAMwBcAIMApgDIAOwADgEqAT4BUAFiAXQBgAGGAYgBjgGWAaABogGiAaABoAGgAZoBjAF6AWABQAEaAe0AswB2ADQA7v+k/1n/Cv+6/mj+IP7c/Zj9VP0U/dz8qPxw/Dz8APzI+5D7YPsg++D6oPpo+jj6EPro+dj5yPnQ+fD5MPpo+tD6UPvg+5T8ZP1Q/k3/XQB+AbQC7AMoBVgGgAegCLAJkApgCxAMoAwgDXANoA2QDXANMA3QDEAMkAvACtAJ8AjgB8AGkAVgBDQDBALPAJj/bv5o/Wj8gPuo+uD5OPm4+FD4APjA95D3gPeQ96D3sPfA99D34Pfg9/D30Pew93D3QPfg9nD2APZw9fD0gPTw83DzEPPA8pDykPLA8iDz0POg9ND1MPfg+Mj69PxL/8YBYAQQB8AJUAzADiARQBMAFYAWoBeAGOAYABngGCAYYBcgFuAUQBOAEaAPsA2wC8AJ0AcABkgEmAIYAaj/dP5U/Vj8kPvI+jj6qPkY+bj4UPjQ98D30PfA98D3wPcA+HD4OPnw+Xj6+PrA+8z8sP1g/uj+cP/v/ywAIgC//xT/Nv4g/cD76PnA97D1sPOw8YDvgO3A62DqgOkA6eDoQOkA6oDrgO3A71DyQPWA+Aj8g//gAigGUAlgDEAPgBFgE+AUQBZAF+AXABjAF2AXoBYAFuAU4BOAEmARIBDwDpANEAywCkAJ+AeQBigFnAMYApkAJf/M/Wz8EPvI+bD40Pcg95D2MPbg9fD1YPbw9rD3iPig+QD7iPwg/pb//ABoArwD6ATIBUAGgAagBlAGmAWIBBQDcAFx/yz9iPqg98D04PEg72DswOmA5+DloOTg44DjAOTg5EDmIOiA6gDtIPCA8xD3wPpW/vYBkAUQCTAMMA/gEQAUIBbAF+AYoBkgGoAagBoAGmAZoBigF2AWQBXgE2ASwBAgD2ANkAvACQAIKAZIBEQCZgCo/vD8SPvY+Yj4QPdA9pD1MPXg9OD0QPWw9UD2QPeA+Oj5KPvA/Hb+CAB+AdwCGAQQBeAFaAaoBmgGAAZoBWgE7AIuAV7/PP2g+uD3APVA8mDvwOwg6sDnoOVg5IDj4OLA4mDj4OSg5qDoIOsg7oDxYPVI+Uz99wDABNAIsAwgEAAToBUgGAAaoBvAHGAdgB1AHeAcQBwgG4AZwBfgFeAT4BHgD4AN8AqgCLgGuAR4AlIAeP74/Fj78PmQ+ED3UPbw9cD1UPXg9PD0sPWQ9lD3GPgA+TD6sPtQ/aj+3v9OAQgDmATABWgGOAfgB3AIsAhgCHAHSAYoBdgDDAKy/xj98Png9rDzwPBg7UDqYOfg5MDiIOEA4IDfAOAA4YDiYOTg5uDpoO3g8SD2YPq8/igDgAfQC7APYBNgFuAY4BqgHMAdYB6AHiAeQB0AHKAaIBlgFyAVABPgEOAOwAxgCjAIMAZoBLwC7QAI/4T9UPww+xD6wPjA9xD3oPZQ9gD2wPXg9XD2IPfw98D42Pkw+6j8Ov7L/1QB9AKgBEAGkAegCHAJAApQCjAKEAoQCZAH2AXwA8IBQv8g/HD4wPQQ8cDtgOog5yDkQOGA3wDeQN0A3cDdAN9A4cDjoOYA6gDukPIg97D7IABwBMAIIA0AEWAUQBfAGcAbIB0gHsAe4B6AHqAdoBxAG+AZIBhAFkAUABLAD5ANUAsACbgGkARgAkoAWP6Y/Nj6SPng99D24PUQ9ZD0UPRA9ID04PSQ9ZD2wPcw+cj6QPz0/dD/0AGwA2gF6AZgCMAJ4AqAC6ALkAtgCxALEAqACHAGcAQ4AqT/nPzw+DD1cPEg7qDqYOdg5MDhwN9A3kDdAN2A3cDe4OBA4wDmQOlg7ZDx8PWY+ib/pAPYB+ALsA9AE6AWIBlAG8AcwB2AHuAeoB4AHgAd4BtgGqAYoBbAFKASQBDQDWAL0Ah4BhgExAFq/zT9OPtY+aD3QPYg9VD0sPNg82DzsPMw9AD1MPaA9wD5uPqM/Db+5v++AagDWAXQBhAIMAkQCsAKMAswC7AKIAqgCaAIMAdQBUwDLgH4/kT8IPmA9aDxYO5g60DoAOVA4gDggN6A3UDdwN3A3oDgIOMg5mDpAO1Q8TD2APt//+gDAAhADEAQABTAFkAZQBvgHAAegB6AHkAe4B0AHeAbQBpgGIAWwBSAEgAQcA2wChAIiAX8AlgA9P2w+5D5oPfw9ZD0oPMQ88DywPIQ87DzoPTw9YD3OPkQ+/D82v7DAJACWAQQBqgHEAkQCsAKUAvQCwAMwAsgC0AKUAlACPAGQAUUA+IAmP44/Hj5wPXg8WDuIOsg6ADlIOKA38DdwNyA3MDcgN1A3+DhQOWg6GDssPCg9cj6sf9ABGAIkAygEEAUIBeAGUAb4BwAHmAeYB4AHoAdwBygGwAaIBhgFoAUYBIAEFANoAroBygFhALX/zD9uPqY+LD24PSQ86DyIPIQ8mDy8PLQ8+D0YPYg+AD6uPuI/WX/LAHYAlAEoAXoBgAIEAnwCWAKgAqwCuAKsAoQCkAJUAhQBxgGiASAAjEA4P2Q+4j4kPRg8IDsQOlA5gDjAOCA3QDcwNsA3MDcQN7g4EDkAOgA7DDw4PTg+fD+tAPYB4AL8A5gEoAV4BeAGcAa4BugHAAdIB3AHGAcwBvgGqAZ4BcAFkAUQBLgD+AMsAmIBnwDngCg/Yj60Pdw9aDzIPLg8EDwcPAA8fDxAPOA9DD2UPig+sT8pP5tADwC/ANwBYAGaAdQCDAJ4AlgCpAKsArACvAK0AogCjAJYAhoBzgGWAQ4As//PP1Y+uD28PIg7gDqwOag44DggN1A20DaQNpA24DcgN5A4QDlQOmg7eDxgPaY+5cAIAXwCFAMgA/AEsAVABhgGaAawBvgHGAdYB1AHUAd4BxAHOAaIBkgFyAVABNAEOAMUAnABVwCHf/g+6j44PWw80DyMPFg8CDwwPAA8mDz8PSg9oD4oPrU/Mr+ZgDQATQDgASQBVAGyAZwB0AI4AiACeAJEApQCqAK4AqQCsAJwAjQB3AGmAQwAn//mPyI+RD2EPJA7aDoIOWA4sDfAN1A2wDaQNqA24DdwN/A4mDmwOog70DzcPcM/MkAOAUACQAM0A6gEeAUYBcgGWAaoBvAHKAdIB5AHiAe4B1AHQAcQBqgFyAVgBJwD+AL6Af4AzMAtPxo+WD24PPw8cDwMPAA8EDwIPGQ8mD0IPbQ96j5kPto/TT/uQAAAhQDGAQwBQgGsAZYB0AIIAkQCtAKQAugC9ALEAzgC+AKgAnQBzAG/ANQAUb+KPvg94D04PCA7ADoYOQA4sDfwN0A3ADbQNtA3ADeYOAA4yDmQOpg7lDyUPaQ+jH/vAPQB0ALcA6AEaAUoBfgGaAbAB0gHgAfYB+AHyAfoB6gHQAc4BlAF4AUwBGQDhALWAd8A9X/ZPxY+ZD2UPSQ8lDxkPBw8KDwMPFg8tDzcPUg99D4kPps/EL+GADQAUADwAQIBmAHYAhACUAKIAsADJAM8AzgDKAMYAzwC7AKAAkgB1AFZAPsAE7+iPvw+ED2EPNA7yDrIOdg5CDiwN9A3YDbANtA20DcAN5A4EDj4OZA66Dv4PN4+HD9aALQBrAKAA4gEQAUoBYAGaAaABzAHKAd4B3gHcAdYB3AHKAbABrgF4AVwBIgEOAMUAmABbIB/P1w+kD3kPRQ8rDwwO9g74DvEPAw8dDysPTA9sj4wPrE/MT+vQCcAigEgAXQBvgHAAmwCTAK8AqwC2AMwAywDJAMQAzwC0AL4An4B/gF8AOwAer+BPw4+WD2cPMw8IDsoOgA5UDiAOAA3kDcgNtA28DbgN3A36Di4OWg6QDucPLQ9ij7w//4A/gHkAuwDmARwBMgFmAYYBrAG+AcwB1AHsAewB5gHmAdIBwgGuAXIBXgEXAO0Ar4BgQDN/+g+0j4cPUw85DxkPAg8CDwwPCw8QDzcPQg9uD3mPlY+xD9rv5XAP4BsANABZgG+AdQCWAKcAtgDCANsA0gDjAO4A0wDVAM8ApQCWAHQAXkAkwAwP04+7j4APYw8yDw4OyA6SDm4OLA34DdQNyA2wDbQNtA3EDeYOEA5eDoAO2A8VD2MPtX/wgD8AZwCgAOABFAE0AVYBegGaAbYB1gHgAfoB8AIOAfwB5AHQAbwBjgFYASkA5ACiAGTAK6/lj7OPig9dDzsPIg8gDycPLw8uDzIPVg9mD3ePjQ+SD7cPy8/U7//gDEArgEoAZgCPAJgAsADRAOgA7ADuAOoA7gDcAMUAuACZgHsAW0A2IB8P7A/Mj6sPhw9gD0cPGA7mDrIOiA5MDgwN3A2wDbwNoA28DbgN1A4CDkoOhA7ZDxEPbg+kb/1AIQBjAJkAxQD8AR4BOgFYAX4BlgHAAeQB/gH4AggCDAH0AeIByAGUAWwBKwDiAKsAX4AXj+ePvo+MD2EPXw84DzoPPw8zD0wPSQ9SD2wPZg9yD4EPlI+tj7pP2I/4wBwAMQBjAIIArQCyAN8A1gDmAOAA5gDaAM0AuQCgAJSAfABVAE0AISAUD/SP04+zj58PYw9BDx4O2A6sDm4OKA38DcQNsA24DbgNwA3sDfAOPg5kDrwO/Q85D3EPuU/ugB6ASwB4AK0A3AECAToBVAGKAaYB2gHwAhQCEAIUAgAB/gHOAZoBaAE9APAAwgCIgESgG6/rT8wPoY+aD3oPbw9aD1UPVQ9SD1IPVA9aD1QPYw94D4MPpY/Jr+9QA4A5AFyAfACWALkAzwDCANIA3gDGAMsAvwCkAKkAmQCIAHcAZABTAE9AIoAeD+iPwo+qD34PTA8YDuAOtA54DjQODA3QDcANzA3EDewN+g4QDkIOcA6yDvAPPw9Yj4SPuM/soBeASgBwALYA7AEeAUoBcAGmAcoB6AIMAgACCAHsAcQBpgF8AUwBGgDpALoAjgBUwDKAFg/9j9FPx4+vj4YPfQ9dD0UPTw8+DzMPTg9OD1UPc4+Zj71P0mAJQCqARoBsAHIAlACvAKQAtwC2ALEAvQCsAKwArACqAKQApgCSAI6AawBSgEygEb/2D8mPnw9nD04PEA7yDsgOkA5wDkIOEA34DeAN/A3wDhIOIg4wDlIOjg62DvkPKQ9Xj4YPu8/hgCSAVACGALAA8gEuAUIBdgGYAbQB1gHsAeAB6gHCAbIBngFmAU4BFQD5AM8AlYB+gElAJmAFr+XPxo+lD4kPYw9SD00PMQ9ID0EPUA9lD34PiQ+nD8ev5oABwCmAP4BCAGOAdwCKAJkApAC6ALEAwgDBAMMAxwDEAMcAtgCsAI8AYoBYQDtgF5/wj94Pq4+GD2APRw8eDuAOwA6eDlgOKA34DdQN0A3kDfoOAA4sDjYObA6WDt0PAQ9OD2gPn4+8T+ogGoBCAIAAywDyATIBbAGEAbYB3AHmAfQB8gHoAcgBoAGMAVYBNgEZAPoA1wCxAJiAb8A3gBMP/8/Kj6cPhw9iD1YPQw9KD0gPVg9nD3uPgY+mj7yPw4/sj/PAGsAjgEgAWgBtgHIAlwCoALMAxQDCAM0AuQC3ALEAtQCkAJsAcoBqAEGAM4AVb/TP0o+9j4cPYg9EDxIO4A6yDoAOXA4UDfwN2A3UDeAODA4SDjYORg5gDpwOvA7uDxsPQw94j5XPzX/6gDoAewC5AP4BIAFuAYABtAHAAdoB3AHWAdQBzAGgAZIBeAFUAUABNAETAPoAyQCSgGCANTAKj9MPsY+VD3MPZQ9TD1cPXw9XD2MPcA+Gj4CPno+Qj7QPzI/Zb/dgEwA7AEWAbAB9AIwAnQCnALcAtQCzALYAswCzALAAsgCsAIKAfQBSAEEALx/7D9UPuo+FD24PPA8EDtAOpg54Dk4OEg4EDfQN/A30DhYOIA4+DjgOXA58DqwO2g8CDzQPUY+OD7BQAYBBAI8AtQD2ASgBVAGCAaQBtgHAAdQB1AHeAc4BuAGiAZABgAF2AVoBNgEUAO0AqoB/AEHAKF/3D9oPsY+sD4CPhw99D2UPYg9iD2APZg9gD3sPeI+ND5uPu8/eP/8AGoA7gEcAVYBiAH4AewCKAJYArQCjALkAuACyALoArQCaAIEAcwBfwCYQAA/iT8oPrg+JD2wPMQ8ADsQOhg5UDjoOFA4YDh4OEg4qDiAONg42DkgOYg6cDrwO3A7/DxsPRQ+Jz8AgH4BJAIsAuQDkAR4BNgFiAYQBlAGgAbgBsAHCAcwBtgG6AawBlAGEAWwBMAEdAN4ApgCCgGCATmAQ4AYP70/Mj7uPpw+Sj44Pbg9XD1gPUA9oD2MPdA+Kj5aPtY/SP/eAA2AZwBDAK0AowDyAQgBjgHIAgACfAJUAoQCqAJ0AiwB2AGGAW8AwgCWQD8/pz9GPxY+mj40PVA8kDu4Oog6IDmAOZg5sDmgOYg5qDloOVA5sDnwOlg68DsYO4w8BDykPSg9xD7fP7MAfgE4AeQCkANwA/gEaATABVgFkAX4BdgGOAY4BjAGIAYIBggF6AV4BPgEZAPQA1AC4AJuAcYBrAEgAMYApkAEv9I/Wj7wPm4+Fj4cPjY+FD5yPko+sj6wPvY/LD9Yv78/lv/n/88ACoBJAIoAzAEIAXgBSAGMAYABpAF0AQoBJwD7AIoAk4BcABV/zT+IP34+3j6cPgg9qDzIPFA70DuIO5g7mDuQO7A7QDtoOyg7ODsIO3A7aDuwO9Q8RDz4PTQ9pD4aPpI/EL+WQBsAnAEKAbQB3AJEAtQDIANcA4gD3AP0A9AEKAQ4BDAEKAQQBCwDwAPMA4wDRAMIAtwCsAJQAmwCPAH6AbQBcAE1AP8AmgCEAKyASYBrwBsAEgAMgBIAFQACQBy/7r+Bv6U/Wj9oP0A/k7+PP4e/gD+zP3A/ez9HP4s/gT+zP2Q/XD9gP3M/Rr+Rv5E/hD+cP2Q/HD7cPq4+VD5OPlo+aD5iPlY+ej4UPjQ93D3QPcg9yD3UPeQ9/D3SPiw+Aj5UPm4+UD60PpQ++j7uPyM/TT+tv46/9n/eAAKAb4BbAIIA5QDMASYBNAE6AQABRgFKAVQBYgFwAXwBSAGUAZwBnAGUAYYBsgFcAVABWAFmAWwBbgFkAUwBcgEWAQQBNQDmANoA0gDFAPMAowCWAIcAtABqgGmAZABdAFoAWwBYAE2ARIBCgHuANoA2QDdAMQApwCkAJwAggBVAC4AGwDa/4D/L//4/sL+jv5g/iT+7P2o/VD9+PyQ/DT82Pt4+yD72Pqg+mj6MPrY+WD56PiY+Ej4EPjw9+D38Pcg+Ej4ePig+Mj48Pg4+ZD58Plg+uD6gPsQ/Jz8MP3Q/Xb+Ef+1/zUAugBCAdIBZALkAlQDxAMwBIgE0AQwBYAFwAXwBRgGQAZYBngGsAbYBugGAAcQBxgHGAcQBxAHAAfoBtAGsAaQBmgGOAYgBhAG8AXgBdgFqAVoBSAF4ASYBFAEKAT4A8QDfAM0A+wClAJIAvYBpAFMAfUApwBTAPX/kP8q/7D+IP6Q/Rz9qPxM/AD8oPtA+9j6iPog+qD5KPnA+Fj48Peg92D3MPfw9tD2oPaA9mD2UPZQ9nD2kPbA9gD3QPeQ9/D3WPjg+Gj5+PmA+hD7iPv4+4j8JP28/VD+4v51/wkAnQAuAbQBOAK8AkADvAMwBKgEIAWIBdgFOAaYBugGOAeAB8gHAAggCFAIYAiACKAIsAiwCLAIoAiQCHAIYAgwCBAI4AegB1AHCAfABnAGIAbABWAF8ASIBCAEvANYA/ACgAIEAoQBBgGZAC4Awv9T/9j+YP7o/Xj9CP2Q/BT8oPtA+9j6gPoo+tj5kPlQ+Rj52PiY+GD4KPgA+ND3wPew97D3sPew98D3wPfQ9wD4OPhw+KD40PgY+XD5wPkI+lj6sPoI+3D74PtI/LT8LP2c/Qr+bv7Q/i//i//m/04AsgAYAYAB5AFQAqwCCANoA8gDMASoBBAFeAXYBTAGgAbIBggHSAeAB7AH4AcQCDAIQAhgCHAIcAhgCEAIEAjgB7AHcAcwB/AGsAZoBhAGsAVABcgEUATkA2QD3AJgAu4BfgEEAZgAOADX/3D/Bf+k/kT+4P18/ST93PyA/DT84PuQ+zD76Pqw+nj6SPoY+vj52Pm4+aD5iPlw+Vj5WPlg+Wj5aPlw+YD5iPmY+cD56PkQ+jj6cPqo+uj6GPtI+4D7uPv4+1j8tPwA/UT9mP38/WL+wP4h/4L/6v9LAKMADAF+AfIBWAKwAvwCQAOEA9wDQASYBNgEGAVYBZAFuAXgBQAGGAZABnAGmAaoBqgGmAaIBoAGaAZYBjgGEAboBcAFiAVABQAFwASABEAE9AO0A3gDHAOsAjwC3AGEASwB0gB/ACwA0/97/x7/vv5a/gT+tP1o/Rj9zPyQ/Ez8CPzI+5j7ePtY+yD78PrQ+rj6mPpw+lD6SPo4+jD6KPoo+hj6GPo4+mD6gPqY+sD68Pog+0j7cPuw+wD8VPy4/Bz9eP3I/RT+Wv6o/gD/Uf+i//f/VACvAAQBSgGKAcwBCAJIAogCxAIAAywDWAOIA7gD4APwAwAEIAQ4BEgEYARwBIAEkASYBLAEuATIBMgEyATIBMAEoAR4BGAESAQoBBAE8APcA7gDjANQAxgD7AK8ApACUAIIArIBZAEkAekApABdABYAzP95/xv/yP6A/jz++P28/YT9TP0Q/eD8tPyI/FT8IPzw+9D7sPuQ+4D7ePtw+2j7aPto+2j7ePuI+7D74PsQ/ED8cPyc/Mj8+Pwk/Vj9lP3Y/RL+TP6E/rz+8v4y/3L/p//T/wcASQCJAL0A4wAQAToBXAGAAaQB1AEEAiwCTAJkAoQCnAKsAqwCrAK4AtAC5ALoAgAD/ALsAtQC1ALgAtACxALQAtwC1ALMAtACsAJ4AkwCOAIsAggC1AGmAX4BUgEiAfYA1QCuAIEAVAAoAP7/zv+Y/1v/Lf8J/+L+wP6g/oL+YP42/g7+6P3Y/cj9vP20/aT9iP1g/UD9MP08/VT9YP1c/Vz9aP2A/ZT9oP2o/bj9xP3Y/eT99P0U/kj+fP6g/rr+4P4L/zH/XP93/4z/ov/D//P/JQBKAFoAawB/AIoAlQCpAMQA3ADvAAIBHAEyAT4BSgFaAWYBcgGKAaABrAG4Ab4BwAG6AbYBuAG6AbgBrgGyAboBvgHEAdIB4AHiAdwByAGwAZoBhAF4AXoBeAFuAVoBOAEKAeEAvACfAIsAeQBlAEgAHQDl/6j/cf9F/yT/Dv8E//T+2v7C/rL+nP52/lj+Tv5E/i7+Gv4Y/iD+Hv4M/gD+/P0C/gz+Hv4y/kj+UP5G/jr+Sv5y/pj+tv7g/gT/DP8L/xT/H/8h/zj/bv+t/9T/7f8GABUADgABAAwANgBhAI8AvQDnAOkA4QDiAOwA9AAEAS4BUgFoAXQBhAF6AV4BWgFyAYYBlgG+AegB8AHmAegB7AHkAcwBuAG2AcYB5gH8Ae4BxgGWAW4BVgFIAT4BMAEqASQBBgHOAI0AWwAXANb/xv/W/8f/p//G/wIAzv8B/2D+Tv56/pL+gP5i/iz+8P20/Zj9sP38/Ub+Nv7w/eD9BP70/az9yP1a/r7+xv7S/gb/7v52/iz+aP7i/jz/if/V/+//0//D/8f/vP+0/+P/MgBcAGcAbgBiADoAFwARAC8ATgB1ALQA4ADnAMcAcAAGANP/8f9RALUA9QAgAUYBPAH3ALYAugDvABwBQAFkAV4BAAF5ACMAIgBMAIcA3wBOAZwBkAEmAYgAEAD+/ykAVAB+ALUA0QCbADUA5//B/73/0v8HADQAJwACANr/d//Y/nz+nv7q/hH/Vv/N/w0A+v/f//D/7/+l/zj/Df8n/zP/8P6Q/m7+pv7Q/pT+pv56/yYA4P/h/zIBnAKQApQB1gA0AEr/yv5q/3UAxgAaADH/qv6+/gf/xv4y/lr+NP94//T+Bf8SAMEAYwA6ADoBVAKAAlQCVAK2Afj/aP6c/o0A/AIQBSgGkAWQA0ABf/9u/mb+1v8YAnADZAPkApAB3P44/MD7WP14/0gBlAK4AuYADP5s/Ej8lPyE/Yf/MgEKAY//Uv7U/Tz9bPyI/DL+BQDCAKAAAADu/hL+Jv7w/nP/gP/C/3oABAHfAJ4AkABKALf/Kv8Z/+3/VgG4AQIBtAClADsAuf+j/9L/6/8PAJEApgEEAhwBNgASAMH/4P7I/uv/5QBDAPz+8v7g/9H/Cv+h/44BCAIyADD/PwB7AIL+4P16AMACogEu/9j+LQCJALz/NACgATgBaf/s/rj/QwBIAJv/ZP7k/Tv/ugFcA5QCPQCu/tD9fPyI/IP/RAI+AfL+iv/pAOb+4Pu4/Kj/8v+q/lQARAOOAbz8lPx0AGAAAP1K/mwDOATy/wT+uAAoAcj8+PtMAigG4gEA/m4AWAJq/oj7SACIBfACAv74/pABkf9E/Z3/7AJQAvb/qv8wACv/PP42/18AngDOAcQDZAKY/fD76P+8AlUAbP5uAUAEdAHE/d3/XAPkAPz8c/8YBHwCgP3c/fgBIALm/gr/TAJYAkD+FPwc/5QCKAKnAMUAGQAg/gr+7P+gAML/5P/AAdgB6P6o/Mj9gAC8AbYAWP+C/8T/uP2Y+4T9kAKwBQgEjf8s/MD6iPqo/VQDSAVAA7QBMv/g+WD48P3sAk4BJ/+YA/gH3AKY+pj6Tv6c/AD6uv5oBgAImAT0AGz92PrA+3T9QP3e/ngD+AVQA4j/qf+aAUoBBf/w/AT8pP2YAaAEcAUQBYgCnPxY+cb+AAbgBMr+4Pxm/0kA1v66AIAFAAXl/1b+gv6o/BT9PwDjAIIAaAOQBogEFP7Y+hj94PxY+aj9QAjwCSwDfgBFABj7UPbo+UwCcAUIAkwA8AG7//j7Cv6yAVsATP2o/dD/q/9c/bD9MAHsAlgB7f9Z/wz9+Pow/UQByAFhABAB5gFy/3D8KP/YBDgCoPm4+RABPAL4/dz+kARwBaD+UPn4+zYAmQAmAN4AJgF8AMb+uPzg/dACmAUMArz9TP50ABf/UPws/sADoAXWAdz/uAJABMMA0Ptg+tj8XgAwA7AF6AYQBWYBzP74/cT99P05/14AxgCKAfIBzACw/zoBUASAAwj+BPzp/0EAqPro+XoBiAakAhf/TAMgBvz+UPdY+sAA6v6w+rX/kAiACJ8AaPuQ/Kj+mPxo+l//KAaABAL+JP1AATYBIPzY+gIBwASQAFD9jf94ALT9wP2YAYADPAKYAPb+GPxw+dD6wAAoBuAGSASjAJD8APrw+nr+3gEUA0gCngGKAe4ATwAcAAP/NP2U/W4A+gHZAJX/OQD2ADwBuAMQB+AE/Pyw+KD7T//c/l7+kALYB4gHwALO/8j+oPvw95j4IP1cAfgDWAYwBxAEhv88/Zj72PiQ+PD8tgHgA5gFqAfYBmgCPP5c/Aj7cPko+hD+iAK4BQAIoAgYBhQB+Pt4+JD38PlM/v4BwAPgBPAFqASUADz9cPzY+2D6YPr0/CQACAKUA1AFwARBAEj7sPnQ+mj8nP56AXADfAP4AbL/tP0A/cT96v50/+3/vgGkA6ACYP+o/WL++P5e/pD+3AD4AkACTgAXAJEAb//g/Vz+kAAQAqoBeAAqALcA5gBbALn/bf9w/5T/GgCIAegCsAJiAY8Awf9K/qj9rv4UANgALgE6AR4BGAE2AQwB/f9K/oT9IP7k/r//UAFkAuIBzQATAFb/Iv4I/Uj9jv5z/zUAuAHcAiACOgDa/oT+Rv7o/aL+gwDiAeQBOAF5ABoAJwD7/3//Ev/I/q7+3P6A/zgAEQD+/nj+Iv/J/2L/sv6A/k7+9P3I/Xb+2P/tAOYApgB6APr/pf/e/1wAAgHYAWgCaAKkAY4AVAAYAboBFAKoAiADEAMIAjgApv78/QL+ov7x/4oBxALEApQBFwCu/hT96PsY/HD92v7j/6YAGAEqAfgAngADACj/qv7Q/jX/yv82AdgCXAOoAgQCygEmAQkAqP+wALgBkgF+ASACAAJ5APT+eP5W/pj9tPz0/LD9qP08/Uz9SP2U/Gj7GPoA+Wj40Pjw+VD7ZPzY/KD82Ps4+wD7YPs0/Aj9rP0s/uj+4//pAOYB1AJkA2gDOANAA8QDWAToBJgFkAagB2AIkAggCHAHoAYQBtAFAAZIBrgG8AYwB5gHAAjwB0gHmAbgBVAFEAVQBfAFeAa4BrAGcAYQBqAFyAR8A1AC1gHwAfgBlgHJAJf/xP14+0j5sPeA9lD1MPQw81DycPEw8MDugO1A7CDrYOoA6gDqYOoA6wDs4O0A8GDxIPIQ8wD0EPXQ9lD5+Pt2/jYBiAS4B/AJMAswDOAMQA2QDTAOYA/AEOAR4BKgE4AT4BIAEuAQIA9ADZALEArQCPAHkAcoBxgGkAQ0A6gCdALIAdEABABY/3r+2P0a/h3/MgCEARQDKAQoBIwDAANAAr4BlALgBBgHYAjgCNAIaAcgBWwD3AKkAiQC9gEMArQBggBQ//L+8P5U/vD8+Ppw+GD1gPLg8DDwwO8g7wDuIOzg6cDnAObA5EDkYOTg5KDlAOcA6UDrYO1g71DxEPPg9AD3aPkw/E7/1ALQBtAKUA7gEGASgBNAFCAVQBbgF4AZQBrgGUAZoBhAGKAXQBagE9APgAvYB2AFAATEA/ADMAMyAXr+qPt4+BD1UPIg8ZDwgPDw8HDy4PPw9CD20Peo+SD7bPxE/eT9UP7D/+wC6AYAC2AOIBEgEoARgBDQD8APgBCAEgAVgBagFSATwA+wCyAI4AaIB2AIAAiIBgAE+P94+2D4QPcw9/D2IPZg9GDx4O1A64DpQOig5yDnYObg5GDjoOJA4gDioOKA5ODmQOng6yDu4O8g8aDyIPU4+Lj7Jv8wAogE2AagCRANIBCgEmAUIBWgFQAWABcgGCAZ4BjgF8AWQBYgFoAVABRgEeANwAkIBlwDsgHmAAcA+P6k/Rj8UPpg+ED2APTA8UDw4O9g8IDx8PIw9ID1MPdg+bD7jP2A/gX/Sv8MAOwBCAVwCEALcA1AD4AQ4BAAESARABHAECAQIBDgDzAPEA5wDJAKoAjoB4AH2AbIBYAEzAIaABD9kPrw+LD3cPcI+Jj4APgA9jDzEPCA7YDr4Olg6ADnAOYg5qDmIOdA50DnYOcA6GDpYOuA7WDvwPCw8nD1mPjY+7D+NAFIAxgFUAcgCgANMA/AEEASABTAFQAX4BcAGAAXoBWgFMAToBJgESAQ8A0wC1AI+AVgA+cA6v6M/ZD8SPsg+hD5gPdA9WDzkPKA8vDykPNw9OD0MPUw9lj4IPuc/d7/ngGEAggD4ANoBTAHAAkQC1ANEA9AECARIBHAEGAQgBDAEIAQsA8gDiAM4AngByAHeAe4BzgHIAbgBEAD4wD8/WD7EPnA9wj4IPnA+fj4cPcA9pD04PLw8ODuwOsg6CDlYORA5aDmQOig6eDpAOmg6CDpoOpg7ODuIPJQ9ZD3ePnQ+yj+CAEoBHgHIAqwC8AM0A3QDrAPABGgEkAUgBWAFoAW4BRAEtAPcA5ADRAM0ApgCRAHQAREAsUAS/+U/Tz8aPuI+rD5APlg+ED3IPbA9QD24PZI+Oj5OPvo+4D86P3k/+4B1ANQBbAFoAV4BXAGIAiwCfAKEAxADaANgA1QDeAMIAxAC8AKgAqgCWAICAcIBtAEeANMA9ADQASMA1QCJAGv/xb+0Pw8/Nj7cPuI+9j7APzI+zD7kPo4+UD3IPSA8CDsgOgg58DnwOlA60DsoOtA6sDowOhA6uDrwO3g7/DxwPPA9dD4GPzU/lwBkATIB8AJcAoAC7ALgAwADqAQYBPAFCAVwBSAE8AR4A+wDnAN4AtgCqAIcAYoBIgC2gEUAcn/mP5I/cD7cPrA+dj5mPk4+ej4SPkY+sj60PvI/Lz9mv7Q/2AB9ALkA2AECAWQBTgGyAbYB8AIMAmgCVAKMAuAC1AL0AogCvAIEAi4B3gHqAagBQgFkATUAwQD5AL0AgwDmAIEAk4BagCf/xv/4v7G/hj/wP/P/67+TP2Q/Jj8oPwY/Ej6MPYQ8GDq4Oeg54DowOkA6yDrQOpA6QDpIOmA6cDqwOwA76DwgPKw9LD2aPlg/TQC0AWwB6AIQAmgCUAK0AtQDkAQgBGAEgAToBJgEUAQsA8ADwAO0AwAC1AIWAVYA7ACjAJAArgBuwBL/7z9tPxw/ED8APzw+zz8bPxQ/GT81PzA/QH/pQBIAhQDGAPkArQC8AKgA9AEwAUIBuAFsAWgBcAFQAawBgAHwAYABhAFGARIA6gCiALoAmADaAM8AwAD1AKQAowC7AJ0A6ADGAOcAsoBOAEYAaQBeALMArACpAELAOz+KP9VAEj/kPsA9kDwgOuA6ODn4OiA6QDpAOkg6cDoAOiA5yDoYOnA62DucPAw8SDycPRI+ND89gCIBLAGuAeACNAJYAvADHAOQBDgEcASwBIAEsAQkA8QDyAPIA8gDgAMIAlIBjgEVAMkA+wCYAJuAVAANP9a/uT9/P0e/nD+XP78/YD9JP0k/Q7+sv94AQwD5AMwBAgEdAPcAuQCbAP0AzgE7AOcA2ADdAPoA3gE2ATwBJAE0APMAugBJAHcACABBAIEA7wDyAOQA1ADbAPkA3AE0ATIBNAEsASABAAEjAOkA4gEcAXwBBgDRAG+AAgBrQDq/lj7sPVA70DqQOcg5sDlAOaA5qDmYOYg5kDmoOaA5wDpIOsg7YDu4O+w8VD08Pew/IIBsAWQCIAK4AsADfANAA9gEOARABNAE6ASwBHAEGAQYBBgENAPUA7wCxAJ+AWYAzwCsgFsAQgBggC6//r+iP6k/sj+3v48/2//YP8A/+b+J/+3/7UAOAL8AzgFeAX4BCgEkAN4A7QDxANcA6AC8gF+ASABEAFMAWoBXAHrAMMALwA3/37+pv6K/zUAyQCAATQCkALYApQDgARgBSgG+AZQB+AGOAZIBqAG2AaYBmAGQAaoBYAEIAPWAfkAVgDu/oj7EPbg70DqYOZg5MDjIORg5MDjYOPg48DkgOVg5gDowOmg6yDtAO9Q8eDzYPck/HwB2AUgCZALMA1QDkAPwBAgEuASIBNgEwATIBJgESARIBFgEGAPAA6wC9AIMAZABHAC6wAuAPD/aP96/uD97P34/QT+hP5c//v/KAA4AEsARgCnAJwBSAO4BJAFAAYwBjgGAAbIBWgF8AQYBCwDjALMAS4BkQCIAIQAYgAlAOr/t/8W/7z+oP76/mz/7P+OAEwBHAIkA2AEWAXQBSgG4AaQBxAIEAggCDAI4AdYBxAHIAcAB1AGIAU8AyIB+P+t/6r+2PoQ9QDv4OnA5SDjoOJg4qDhYOGA4qDjIOSg5MDloOeg6UDs4O6w8NDxgPTw+Mj9QAKABmAKwAxADiAQ4BGAEoAS4BLgE0AUYBPgEUAQ8A4wDhAOsA0ADIAJ6AaABEwCegB9/8L+CP5g/SD9NP00/Yz9Zv6f/3YAKgHuAbACGANQA+QDwASIBSgG6AaIB7gHgAdYB/gGSAZQBXgEeAMgAtsA2/8f/2r+0P1s/fz8ePwA/MD78PtQ/OT8WP3M/ab+pP//AEwCpAOgBEAFGAZQB3AI4AhACcAJYAqACiAKoAnQCBAImAcQB6gFiAO4ARwATv5c/Hj6cPcA8mDrIObA4qDgwN9A4ADh4OAg4aDiIOXg5kDoIOqA7EDvwPHg85D10Pew+/YACAbgCaAMsA4AEAARYBKAE6ATABOAEsARYBBwDtAM0AvwClAKoAlQCAgGXANMAfT/Af8o/qD9FP14/Fz8+PzI/ZT+dv/dABwCJAO8A4AESAUQBvgGuAcwCGAIoAjQCPAI4AiwCAAI4AaQBWgE9AIyAaj/bP6o/WT8WPt4+hj6wPmI+fD5qPpY++j7pPyw/RH/kAAoApQD2AQYBoAHkAhACQAK4AqgC+ALIAwwDGALUAqACfAIkAdQBZQDfAK3APD9sPvI+qj54PaQ8mDtIOcA4oDfQN8A4ADgAODA4ODhoONg5kDpoOvg7aDwoPPg9eD3UPqY/VwB0AVQCtANkA+gEAASQBMgFGAUQBRAE2ARsA8QDhAM0AkwCGgHsAZwBeQDGAIXAHL+yP3Y/Zj97PyE/ID89PzM/Rf/rgBYAuwDYAVgBvAGeAdQCGAJIAqQCrAKcArACVAJYAmgCQAJeAeoBfgDZAKsAOj+TP3Q+2j6QPlI+GD3cPYQ9tD28Peo+Cj54Pko+7D8gv6lAJwCGASQBWgHEAkQCrAKkAtADJAM8AwgDeAMwAuwCgAK8Ag4B5AFeATUApgA/P2o+0j50PdA99D1QPGg6gDlYOFA34DeQN+A4CDhAOJg5CDnAOlA6wDvIPPg9eD30Plw+/D83f+4BFAJQAxQDoAQQBLgEmATIBRAFIATgBIgEVAOgApwB7gFsAS4A8ACgAGK/4j9nPx8/Ij8WPw8/Cz8EPwo/Kz8rP0s/0gBzAMoBrAHoAhQCVAKgAvgDNAN8A1wDYAMkAuwCvAJQAlwCDgHsAXgA8oBjP+Y/Sj88PrQ+bD4gPcg9vD0gPTg9HD1UPZw9/D4OPrA+9T9IAAwAmgE2AYACUAKMAsgDHAMcAygDIANsA3wDBAMUAsQCjAI+AbIBbgDUAGN/5D9gPpQ9yD2YPbQ9dDz0PAA7YDo4OQA4wDiAOEA4cDiAOVA56DpgOxA7xDy4PXg+ZT87P0l/8UAmAK4BFAHAApgDHAOIBCgEEAQwA+QD3APsA4ADXAKAAecAxwBsf8L/3z+4P1A/dj8xPzA/NT8LP3w/c7+gP/y/0UAxAAYAjgEqAbgCIAKoAuQDIANcA4QDwAPcA6gDZAMIAuQCfgHcAYgBeQDhAKwAKD+lPyw+hj5sPeg9qD1oPTA80DzAPMw8wD0cPVg93D5kPug/ZP/ngHIA+gFsAdQCfAKYAwQDRANAA3gDKAMUAxADAAMsAqwCBgH6AVQBHQC+wBG/9D8aPoA+ZD3wPWA9PD0YPUw88DvQOyA6QDngOVA5UDlAOVA5uDpoO3A7wDxcPPg9mD6nP0tALAB6AFMAvADGAbgB1AJIAsADSAOcA4QDiANgAswCjAJ4AdgBSQCV/+c/dz8nPyk/Lz8yPwM/XT94P0I/mL+jP9aAQgDIAQABRAGaAcgCQAL4AxADgAPkA9AEKAQYBCQD4AOYA0ADGAKUAgQBsQDuAEWAL7+WP24+/D5CPhw9nD1APXw9KD0APRg81DzsPOg9CD2GPh4+tD84v66AJQCiASIBoAIMApwCyAMkAwADTAN8AyADBAMgAtgCgAJmAfoBewDOAIOAbf/xP2w+wD6oPhQ96D2gPYg9iD1MPRQ88DxAO+A7MDqwOng6GDowOjg6eDskPEA9gD4gPgI+vz8s/9gAcgClANcAxQDIATwBeAGKAcgCKAJMAqACTAIgAYABdQDLAMUAjAAMP6k/Jj7APs4++D7hPzg/Iz9bv5a/5oAaAJwBEAG6AeACcAKgAtQDMANQA9AEMAQ4BCgEOAP8A7gDYAMwArwCDgHOAX8Aq8Axv4U/Zj7YPpA+QD4cPZQ9dD04PQw9WD1cPVg9WD1APZA9+D4ePrQ+zj96v7mAPAC8AT4BuAIsAoQDAANoA3QDdANgA2gDGAL0AkACBAGgARwA5QCyAH3APX/jv7s/HD7OPoY+Rj4gPfw9jD2YPVw9GDzgPJQ8tDxoO9A7ODpoOng6kDtgPCQ82D1MPbw9xj6wPsQ/fD+qQCqASQCkAK4AngCbAOgBbAHIAioByAHOAYQBXAEcAT8A8gClAF/APb+JP08/Kj8rP2u/s//4wCIAVQC2AMIBgAIoAkQCyAM0AyADUAOwA4AD5APYBCgEAAQAA/ADTAMwArACXAIWAboA6QBR//I/ID60PhA97D1oPQQ9JDzMPOA82D0IPVg9bD1MPbA9oD32Pig+kT80P3P/zwCwAQAByAJAAuADMANkA7wDoAOoA2ADDALYAlgB6AFEAR8AvEAiP9M/jT9TPxw+zj6mPjw9uD1UPXg9HD0EPTw8wD0YPQA9QD10PPw8WDwYO+A7mDuoO/Q8VD0gPYo+KD4mPhA+qz9ogDSAfQBzgFQAbEARAGIAlwDuAOABCAFgAQcA0wCbAKwAjADfAO0AqAAzv5I/kT+Hv6I/qD/mwBIAXgCGARgBbgGIAkgDEAOUA/ADwAQ4A/wD4AQ4BAgEAAP8A2gDNAKQAlgCIAHSAYgBbgDcAFY/sD7IPrY+JD3sPbw9bD0YPMQ88DzoPSg9fD2GPio+ND4cPlo+mj7uPy8/ucAqAIoBNAF0AfACYAL4AyADZANcA3QDIALsAkgCNAGSAV0A8QBVQDa/tj9gP04/WT8EPsA+gj54Pfw9nD28PVQ9TD18PVA9hD20PXQ9cD0APPA8ZDw4O7g7YDv0PIw9fD10PY4+HD5MPvs/YQAvAFMApwCHAJ8ARQCyAOwBJgEwAQABUgECAP8AsgDOARYBJAEQASMAmkAQf/2/q7+eP6m/ur+Tf8IAIABRANoBUAIIAswDVAOIA+wDwAQIBBgEGAQQA/ADdAM8AugClAJsAiACMAHaAa4BDAClv5o+8j56PiQ9+D1sPQQ9IDzsPPw9GD2cPdg+LD5iPpY+jD6APuI/DD+8v/0AbADKAUAB1AJgAsgDRAOYA7QDbAMYAvQCeAH4AUABCACIQBg/tz8iPuQ+kj6cPpQ+rj52PjQ98D2QPYg9uD1kPWg9RD2kPYQ93D3UPdQ9lD1YPTw8mDx4PDA8SDz0PQg9zD5QPnw+AD7wv4SASAB6gBEAfoAXwD0APYBGAL0AWgDIAXIBFADMANIBNAEoASYBPgD9AE3ABEAZACS/4j+8P49ABYBzAH8AqAEYAagCLALUA6ADwAQgBDgEOAQgBDgD5AOAA2gC1AK8AhQBygGwAVoBXAEzAKvAHL+HPzY+Uj4QPeA9nD1gPQw9GD0QPXg9tj4MPrw+rj7fPyw/Kz8nP0w/4sA3AGcA2gFcAaYB8AJ4AuwDHAM8AtgCzAK0AigBwgGxAOwASsAkP6w/Ej7yPqQ+oj6CPtY+4j6GPlI+BD4oPcA9+D20PbA9kD3ePjQ+KD3YPbw9fD0oPJw8MDvUPBQ8SDzQPVg9nD2YPfo+bD8VP5u/34AzwCLAHQA4gASASIBTAIIBLAE6APoAowChAIEAyAEwATYA0QCQgF2AFT/hP7M/nr/6/+cAO4BFAMIBPAFMAmADMAOYBBgEcARYBGgEOAPwA6gDeAM4AsACtAHMAZIBcAEcAQgBAADwADk/Tj7IPmg97D2APZg9dD0UPQg9KD0QPaw+ND6OPzw/AD9wPwM/Wb+RgAIAoQD4AQIBiAHgAggCoALYAzQDMAMwAvgCdgHOAboBHQDtAG6/6z9sPsQ+ij54Pj4+FD5oPm4+UD5SPhQ99D2APeQ9xj4WPiI+Lj4CPlQ+TD5qPjQ96D2MPUA9MDzYPRg9YD2oPeY+Dj50Pno+lj8nP2s/oj/7v+9/47/AgCjAPgAkAGcAkgD6AJEAigCBAKuATAClAPcA2gCwwAXALT/gf+aAMAC0ANoA9wDiAVwB+AIYAswD0ASoBMAFOATABKQD3AO4A4wDvALcAnQB0gGcAQwA9gCWAIiAQ0Asv4Q/Jj4MPaQ9ZD1YPUg9QD1oPSQ9JD1sPfg+cD7ZP18/qj+cv7O/s3/PAEMA0AF8AagB9gHgAigCeAKsAvwCzALYAkYBwgFZAMYAtYAg/8U/oz8MPvY+eD4gPjw+MD5EPrA+RD5ePgo+CD4KPhg+Pj4uPkY+vj5oPlI+dj4QPiw9wD3IPYg9cD0QPVQ9oD3oPiY+YD6gPuI/Ez97P2s/l3/yP/n//T/4f+1/+H/lwBmAbYBsAGAASYB1QD4AHYBlgFYAVoBnAFaAYUAEQByACwBIAJ0A7gEQAXABZAHEAswDwATYBVAFWATwBHgEJAPQA1QC8AKsAkoB2gE+AIkAg4BZwBYAHb/CP1Y+qD4gPeA9rD1oPXg9SD2YPaA9tD28PdI+tT8Yv78/mj/vf8aAAABoAJQBHgFWAY4B8gH8AdgCFAJUAqwCmAKIAkAB2AEUAIkAT4ANv82/jj94PtI+kD5KPl4+cj5GPpw+nD64Plo+Wj52Plo+uD6MPsg+7D6WPoo+sD54PgQ+ID30PYQ9oD1gPUA9sD28PdA+TD6sPpI++D7YPzU/Hz9AP4O/iT+qv5Q/8v/eQB4AVACjAJkAjgC4gFyAWQBkgF+AWYBnAG2AV4BEAFyAcABtgFgAhAEcAWgBZAGgAmADeAQQBMgFeAUABPAEGAPAA4QDDAKwAjwBrgEMAMkAiYBQQA+ABYAfv7Y+8j5qPiw99D2kPaA9gD2YPWQ9VD2EPco+DD6hPwI/sz+SP/M/34A3AGwAwAFkAXwBXAG4AYwB+AHsAgACdAIMAgAB9gEdAK/AMX/6v7w/fT8sPtY+jD5uPio+LD4EPng+YD6qPqY+pD6mPq4+hD7cPtg++D6ePpo+mj6IPqw+SD5WPiQ9xD38Pbw9hD3cPcw+Oj4aPnQ+WD6GPvo+8D8XP2k/bT98P12/jL/8v+KAPoAZAHUARwCBAK8AcQBaAIgA4gDrAOgA3QDHAMAAzADeAOsA2AEcAVYBhAHMAhQCjANgBCAE+AUABRAEuAQkA9ADYAKYAioBrgE6AKAAYQAjf/y/sj+YP5Q/cj7OPoQ+Xj4SPjw91D3APdQ99D3QPgA+VD6DPyw/UT/eAAkAXgBHAIYA/wDkAToBCgFeAUABtAGUAdAB+gGkAbQBWAEsAIyAfv/7P4Y/mz9iPxo+5j6SPog+uj50PkI+lj6qPoo+7j7EPwY/Bz8LPwM/Mj7mPuY+6j7qPto+7j6sPm4+CD4sPdg93D3wPcQ+CD4SPjY+JD5UPpQ+3D8PP04/fz8IP3A/Yb+T/8eAMsAWAHWARAC4gHEAQgClALEAuAC7ALkAoQCWAKoAsQCnAKMAiADxAMQBIgEuAWoB+AJYAzADsAQIBJgEwAUgBMgEoAPIAwgCTgHAAZoBIACHgGOABoAUv8c/qz8UPtA+pD5oPhg9zD2cPWg9YD2gPdA+Dj50Prw/Nr+GwD4AMQBjAJIA9gDEATEA1gDTAPgA+AEyAVgBmAG6AUgBQgEuAJeAU8Alf/s/vD9uPyY++D6oPqw+sj6yPqI+jD6KPqA+gD7ePvY+0D8dPxM/Pj7qPuo++j7QPxI/Nj7+PoA+iD5YPgA+MD3cPcw90D3kPfQ9wD4sPjY+Qj7NPw8/fz9KP42/qr+Wf/d/1IA/gCaAe4BBAIcAvgB0gE4AvACRAMIA9ACnAIkArYBBAJwAigCvgFQAmAD4AOIBEAGoAhgCgAMcA6gEKARIBIAE0ATgBGgDkAMAApIB+gEkAN0AtgA5f9RACYAOP7A+2D64Pkg+XD4CPhQ92D2QPZQ96D4iPmQ+ij84P0Y/7H/CAB1AFQBgAJkA2wDCAPUAgQDpANgBAgFIAW4BDAEiAN4AjgBOwCY/wf/XP6Y/ZD8kPsQ+0D7kPuA+1j7WPuo+/D7GPwg/CT8XPyw/PT89Pys/ED8BPw0/ID8dPzQ+wD7YPrg+Wj56Ph4+BD48PcA+CD4APjQ9/D3wPjY+dj6kPsU/HD82Pyc/WD+AP+D/yUAwAAoAW4B3AE4AnwCIAPMA/QDaAPwAtACpAI4AhwCMAIYAs4BFAIAA8wDiATABXgHIAmwCpAMYA6AD0AQYBEgEsARQBBQDgAM8AgIBtQDHALUAF4AcwD//7z+HP2Q+4D6OPqY+mj6OPnw97D3QPjQ+Gj5WPqQ+7D8zP3U/pX/LAAYAUwCOAN4AzgD5ALIAvwCcAPoAwAEvAOMA3ADIANkAogB/gC5AEoAcP9U/jz9aPz4++j7EPwY/Pj7+PsY/Cz8RPxw/KD8xPzw/Az94Pxw/DT8UPyI/Hj8GPyY+wj7qPpo+ij6uPlI+QD54PjI+LD4uPjw+Ij5aPpQ+wT8bPyo/BT9vP1Y/tD+KP+U/w0AhgASAbABSALQAlADvAPgA3gDzAJMAgQCxgFoATQBQAFmAbIBWAJIAxAE2AToBWAHsAjgCXALIA2QDtAPIBEgEsARIBBwDqAMAAqABsQDHALlAAsAIAB7AGz/WP3g+3D72PoI+mj5GPlI+GD3kPco+FD4ePgA+lT81P06/tT+2P/AAH4BcAJAAxQDdAKEAjQDcANAA2AD8ANABPQDeAPIAqgBfgDg/5j/2v6Q/Xj88Puo+1D7OPtg+3j7kPvo+1j8bPwg/Aj8QPxk/ET8HPwY/Aj8GPxk/ND89Py0/Fj88Ptg+6j64Pkw+cj4qPi4+MD42Pgg+aj5UPoA+7j7ZPwQ/dT9kv4R/0b/Xf+T/+X/RgDCAFAByAEQAlgCuAL0AtQCeAIkAugBkgEsAfEA8wASAVwB8AGsAlQD4AOQBJAFoAbQBzAJ0AogDIAN8A4AECAQUA+ADnANYAtQCFAF+AI8AUMAXwDXAGQA4v5g/XT88Ptw++j6EPo4+eD4EPkQ+dD4SPnI+nD8jP2O/pD/OACdAH4BtAJAA/ACwAL4AggDwAKkAvACTAOQA8ADdAN8AlQBhQDg/+7+7P0Y/Vj8sPuA+8D76PvI++j7YPy0/KD8mPy4/Mj8wPzw/ED9PP34/AT9eP20/Zj9iP2Q/Vj9tPwg/Lj7CPsg+oD5UPk4+QD52PgY+YD54PlI+rj6GPtg+9j7kPxA/aT97P1U/rz+GP+d/1AA9ABcAcQBRAKsAtACwAKMAkAC6AGaATwB0gCbAMsAQgHMAXQCGAOUAwgEwASgBXgGYAfACJAKYAzwDRAPgA9gDzAPkA7QDMAJiAYwBFACDgHSAFABLgEoAGj/PP+c/hD9APyI+yj7UPqQ+Sj56Pgo+Uj6yPuw/FD9UP6b/2EAwAA4AaQBuAHEASQCWAIQAuABUAIQA2QDTAMQA3wCngG+AAQADP/c/fD8cPz4+3D7OPtQ+3j7wPtQ/OT8FP0g/Vz9nP2k/aj99P1M/oD+vv4K/zH/BP/Y/tT+uP5i/gD+mP38/DT8oPso+4D6yPlQ+TD5OPlI+Xj5wPn4+TD6wPqI+zT8tPw4/cT9SP62/jj/y/9VANgAagHqATACWAKEArACvAK4AqQCcAI4AjACXAKAAoQCkALMAjQDtANYBAAFoAVQBngH8AhgCnALcAyQDYAOsA5QDnANsAtgCRgHGAUcA2YBwQDlAOkAiQDv//z+kP1k/ED8WPyA+0D6oPmg+cD5+Pm4+sD7rPy0/cz+dv+O/6P/KgC/ACYBiAHCAawBmgHsAVACWAIUAgAC0gFCAWoAlP+e/oT9pPw8/OD7cPtA+1j7gPvA+0T84Pwo/TD9VP2E/Yj9kP3s/Wj+vP4g/7n/JwAvABcAJgAuAPT/nP8v/3b+aP1s/Kj7+Po4+rD5WPkQ+ej46PgI+RD5OPl4+bj56PlY+hD7wPtY/AT92P2E/tr+Pf/a/3gA9ABcAdgBKAI0AjQCVAJkAkACJAIkAhQC7gEQAmgCrALYAmQDGASgBPgEkAVIBgAHIAigCVALgAxwDWAO0A5ADvAMQAswCeAGyAQsAwgCaAFwAXoB/wAlABL/0P18/Kj7OPug+qD52PiQ+Mj4WPlA+nD7mPzE/fr+4f9iAKQA5gBMAcYBMAJcAjgCHAJkAtQCBAPgAogCAAIuASMAFf8A/uz8APxY+/D6yPrI+uj6QPvI+0D8mPzs/Cj9LP0A/ez8HP1o/dz9nv6B/y8AmgD5AEwBaAFKARgBvAAMACX/Tv6Q/cT8EPyA+xD7qPo4+tj5cPko+SD5UPmQ+cj5GPqI+iD74Pu4/Hz9Pv4Q/+T/nAAyAZwBxAHGAewBKAI8AiQCEAIgAhgCDAIIAuQBrAGeAfwBVAKEAsQCYAPkAzgE6AQQBhAHyAcwCRALYAzADPAMUA3wDKALQAogCXAHcAUQBHQDgAIuAVkA3v/0/oz9kPwI/DD7cPp4+tD6gPrI+bj5WPoQ+8D7pPxg/cT9LP4D/+P/WgCjAAoBiAHwAUACXAIkAt4B/AEUArwB+AAWAEv/cv6s/Sj9mPwQ/Lj7mPuY+4j7qPsE/HT8+PyI/fj9Jv4m/jj+ZP6Y/tD+Bf9c/9z/bwDgADABbgGAAT4BtwAMADj/Rv50/QD9yPyg/HT8PPzg+2D76PqQ+jD6yPmQ+XD5UPlA+Xj5APqQ+ij76Pu0/ED9wP1u/k3/BgCrAFgBBAJgApgCBANUA0wDEAMcAygDCAPkAjgDsAMIBFgEMAUwBqAG2AYwB5gH0AcgCPAI8AmQCgALoAuwC/AKoAlgCCgH2AXIBAgEGAPaAcAADQBs/+z+vv7Q/tD+oP5y/vj9KP1U/Pj74Puw+4j70PuI/GT9Wv5y/30ANAGyAewBugEOAT0Anf8l/9r+5P5B/5r/1v8uAI0AlQAbAGz/xv78/ez80PsY+9D64PpA++j7fPzA/ND8+Pws/Vz9kP3c/QD+5P3Q/ez9Ov6I/ur+X/+q/57/TP/y/oD+EP68/Xz9SP38/MD8mPx4/ED8+PvI+8D7qPtY+/D6sPqg+tj6ePtc/CD9oP0g/pL+1v4O/2z/2/8CABwAZQCbAGkASQC5AGoBvgHmAXACLAPMA5gE4AUoBxAI4AjwCbAK8AoAC0ALYAtwC9ALIAzQC+AK8AlwCaAIYAfoBbgEZAO2ATQAFv8K/rj8sPs4++j6KPpQ+eD4APlA+UD5KPng+LD48Pjw+Xj7/Pw4/oP/xgCeAf4BQAKgAvACDANQA3QDxAJqAUYAr/8x/3j+5P2A/Rj9yPzI/Kj88PsY+7D6kPoQ+oj5UPlQ+Uj5APqQ+xD9/P3M/tL/cgBdACwASQBpAFsAmgAyAXQBDAGUAE8A1f8G/yr+UP0o/Pj6QPog+jD6ePow+xz84Px4/UD+8v5r/87/RwDJAP0A6gDPANsANgEEAhwDaATIBdgGUAdQB0AH+AZQBogFCAWwBFAE6AOYA0wD6AKoAoQCMAJyAYQAcf9e/qD9aP2Q/az97P2Q/jz/nv/e/1MA1AAIAQ4BSgGqAQACmAKMA0gESAQIBBAEGAS8A1wDPAMAA3QCMAKEArACYAIwAmQCVALAAUwBGAGDAJf/G/8T/9D+TP40/oL+pv7E/l//MgCmAN0ARgGEARwBWADS/3n/8P5+/oD+vv6y/nL+Nv7g/UD9YPyQ+/D6mPqY+sj6yPqY+oj6kPq4+jD7HPwc/bj9AP5G/lj+Hv7M/ZT9iP2k/ej9Dv7w/Yz9GP1g/Ej7UPqY+QD5aPgY+DD4gPj4+Gj50Pkg+nj68Ppg+8D7XPwg/eD95P55AFACvAO4BOgFGAfIBzAIsAhACcAJYApwC1AMwAzgDCANMA2wDPALMAuQCtAJMAmwCAAIeAdAB2gHSAewBsgFeATYAlgBUQCF/5L+yP2c/bj9sP2c/aj9kP0s/bD8KPxQ+1D6sPmw+Rj64Prg+6z8+Pz4/Nz8lPw0/AT8MPxQ/FD8WPxo/HT8kPz4/HT9qP1w/QD9YPyA+4j6uPkg+eD48PhQ+QD6yPqI+yT88Pzo/bb+Gf9B/1X/UP9c/+P/EgFsAqQDyATABTAGAAZwBbAEuAO0AvgBcAHrAHAAUgBLAOn/Pv++/lj+0P2A/Yj9nP2Q/dD9zP74//MA3AHcAswDmASIBXAGwAaoBsgGKAdwB3gHoAe4B3gHIAfQBlAGWAWABEAEMAS8A9QCugFjAPz++P18/Rz9rPyM/MD8FP00/TD9CP28/KT88PxQ/WT9bP3U/Z7+U//G/yAAfgDrAFQBpAGoAVYB3gCWAJ8AuwC/AI8AFgBW/27+fP2Q/KD76Pqo+rj6yPqg+pj68PqI+zT83Px8/ez9SP6+/lX/7/+yAO4BTAN4BFgFKAZ4BigG2AUQBjgGoAWgBOQDXAOUAtgBggEAAdb/Zv4s/cD7APpQ+GD3EPcg96D3QPgo+GD3kPZA9hD2APZg9mD3OPgI+RD6IPuw+wz8uPxY/ZT9oP30/ZD+P/9LAK4B9ALAA2AEwASIBNwDUAMUA9wC0AJEA9gDAAQABFgEwAToBNgECAUoBdAEmATIBBgFOAXABagGUAdgB2AHSAfIBvgFkAVgBdAEOAQ4BJAEeAQoBDgEMARwA2gC8gGSAasAz/+f/5b/CP9a/kj+ZP4a/rj94P0O/tj9iP3E/TD+WP5w/tb+NP9C/0b/ZP9T/87+LP6E/Zj8gPuo+kj64Plg+fj4sPhQ+PD3wPfQ99D3sPfA9+D3CPiA+Dj5GPoA+yz8gP2k/jf/r/8wAKEA6gCmAcgCrAPwA/QDOASABIgEcASYBKAESATUA5gDXAPgAoQCpALkAtACrAK0ApgCJALYAQACRAJMAmwCzAIAAxADZAP4A1AEgAQQBdAF6AWIBWgFUAXQBFAEcAS4BFgEsAOkA9wDkAP0AqwCPAIsAQ0Ah/8d/2T+Cv5m/tb+jv4Y/sz9PP1I/MD7APxE/DD8TPzk/GD9XP08/Vz9dP1o/Xz9rP2k/XD9fP3M/Rj+Yv7c/jb/GP++/nr+FP5Q/Zz8ePyg/Lz87Pwc/QD9hPw8/Bj8sPsw+xj7YPuQ+7j7JPyo/ND87Px8/Sb+XP5M/nT+2P4z/8D/qwCQATQCyAJoA7wDqAOsA/gDSARoBKgECAUQBcAEgARYBBgEnAMsA8gCOAKQAfYAYQCy/xD/tP50/gz+mP0o/bD8EPyA+zD7KPso+1D7yPtU/OD8PP18/aD9mP2o/eT9ZP76/pb/PADfAHwBJALQAmADtAPUA/ADCAQgBFgE0ARwBfgFWAaYBogGIAaABegEWATsA+ADCAQgBBAE+AOkA6QCggHSAHkAAQC4//D/RQAdAJX/S//m/iT+pP3I/Qr+0P2Q/bz95P24/Zj9zP3Q/Vj98Pzg/Lj8QPz4+yj8aPyM/OD8RP1Y/Rj9/PwM/fD8zPwg/dj9ev7Y/kD/iP9w/y7/Mf93/5//wf8cAJoACAFsAfIBRAJEAjACQAJUAkQCSAKAArACnAJsAlACJALYAZABYgEsAdMAcQAoAPf/2P/O/7v/gP8z//7+2P6g/mz+Xv5+/rz+Fv+Q/+//HgApAEYAbQCfAOQALgFiAWYBYgFgAWABZAF8AYABUgEGAb8AiQBMAAUAzP+x/5n/ff9s/0b//P6O/hb+wP2Y/ZT9oP28/ez9BP4K/iL+Yv7G/j7/4P+lAGoBKALsApgDEARQBKAECAV4BQgGsAY4B3gHYAcIB4gG2AUABTgEoAMEA3AC+gGqAVQBwgD2/wz/DP4E/SD8qPuo+8D72Pv4+xz8IPzo+8D72Psg/HD89Py0/Vz+wP4T/3f/sf+a/3j/ef+A/1r/Jv8A/8z+eP4I/sj9YP24/Pj7UPuw+hj6sPmI+Uj54PiQ+Ej48PeQ91D3UPdw97D3KPi4+BD5YPnA+Tj6yPpo+zz8PP08/j3/MwAeAfYBoAJUAyAECAXwBdAGqAdwCPAIQAmQCcAJ0AnACcAJEAowCkAKUApQCtAJ8AgACEgHwAZ4BoAGiAY4BqAF6AQIBPgC/gFeAeAAZwAiACcADgCF/9j+TP7I/ST9vPzA/OD83Pzk/Pj87Py0/Iz8nPyw/Kj8wPwI/UD9YP2U/eD9IP5K/nj+ov6y/rj+1v7+/hj/Qv+V/9z/+/8JAAsA6P+s/4//qf/F/8z/4P/7/+f/nf9J/wP/tP5o/lD+YP5c/jj+GP78/cj9lP18/XD9ZP1Y/VT9WP1M/UT9UP10/aT94P0K/h7+Jv44/mD+mv7o/kr/s/8XAG8AsADkAAoBKgFYAaQBDAJ8AtwCKANoA4gDlAOYA6gDxAPgA/gDCAQYBBAECAToA8gDpAOEA1gDNAMQA/QCxAKMAmACKALqAbQBigFoAToBCgHWAKsAhABSADIAIgAEAM//lf9r/0v/Nv88/1H/U/82/xH/8P7G/pD+cP5q/mb+VP5E/jz+Jv78/cz9qP14/Tz9GP0A/ez8yPys/Jj8gPxg/ET8LPwE/OD70Pvg+/D7BPwc/DD8PPw8/ET8XPyA/Kz86Pww/Wz9rP3o/SD+VP6E/rr++P5E/6D/BQBoALsAAAE6AXIBqAHqASgCbAKoAuwCJANIA1wDcAOMA6ADsAPMAwAEGAQoBDgESARIBCgEKAQwBCgEIAQ4BFAEQAQYBOwDxAOYA3QDZANUAzQDCAPgAqwCcAIoAuIBngFSARgB3QCVAD8A9v+0/2T/Df/A/nr+Pv74/bD9bP0s/ej8qPxs/Dz8DPzY+6j7gPtg+0j7OPso+yD7GPsQ+xD7CPsQ+yD7OPtY+3j7mPvA+/D7GPxE/HD8oPzQ/AT9SP2Y/ez9MP5s/q7++v5H/5P/4P8uAHwAzgAiAXIBtgH6AUQCjALQAhADTAOEA7AD2AMABCAEOARQBHAEeASABHgEeAR4BHAEaARgBFgESARABCgEEATsA8gDpAOIA2wDTAMkA/wC2AKoAnACOAIEAs4BmAFiATIB/ADCAIgATgAOAMn/if9N/xv/6v7A/pb+Zv4y/gL+1P2k/Xj9UP0w/RT9+Pzk/OD83PzU/ND8zPzI/Lj8tPzA/Nj85Pzs/Pz8FP0k/Sj9PP1c/Xz9mP28/eT9Av4W/jr+bP6g/sb+5v4a/03/cv+L/7P/5P8DACsAXACQAKkAwgDhAAIBGAE0AVoBcAGAAZQBsgHIAdQB3AHoAfQBAAIQAhgCEAIMAgQC/gHyAegB5AHaAdIBygHAAbABkAFsAVIBPAEmARQB/wDrANMAtQCeAIsAcQBQADAAGAAGAPL/2//K/8H/o/98/1r/Pf8p/xz/Fv8P/wD/7v7e/s7+vP6s/p7+lP6Q/pT+nP6Y/o7+hP6A/oD+fv6A/ob+jv6W/pz+pP6s/rL+vP7Q/uL+8P78/gv/Gv8j/yv/PP9T/2r/ff+P/6H/tv/I/9j/5//8/xIAJwA9AFcAcACHAJ4AugDbAPUACgEgATwBUAFiAXQBhgGOAZYBogGsAbIBsgGwAa4BqgGmAaYBpAGYAYgBdgFkAU4BNgEgAQ4BBAH3AOEAwwCmAIgAawBSADwAKQAWAAUA9//o/9P/uv+i/47/gP91/2v/Yf9W/0z/Qf83/y3/I/8b/xL/Cf8E/wH//v78/vr+/v4D/wL/BP8K/xD/FP8a/yH/J/8r/y//N/9F/1X/ZP9y/4D/jP+X/6X/tv/I/9X/2v/e/+b/8/8EABgALQA8AEgAVwBlAG4AdQB/AI0AmgCjAK0AtAC6AMAAyADNAM0AygDLAM4AzQDKAMkAygDKAMgAxAC8AK8AoQCZAJcAkgCMAIQAegBsAFwATgBDADcAKgAfABYADQABAPX/6f/b/87/wv+2/6r/o/+g/5n/jv+D/4D/ff95/3j/ev93/3f/ef97/3L/Z/9o/2r/Yv9e/2//d/93/3b/gv+O/4b/h/+W/5z/m/+n/8X/2P/Y/9f/3P/j/+X/7P/9/wwADwANABUAIAAiACIAJAAsADUAPQBCAEQARgBLAFAAVQBaAF8AZwBtAHAAcQB0AHUAcwB1AHoAfgB5AG4AYwBbAFUATwBKAEcAQAA2ACsAIAAUAAgA/P/y/+b/2f/S/8z/xf+8/7j/tf+t/6H/mv+b/5z/lv+K/4P/gf+D/4P/gv+D/4P/hv+J/4z/jf+N/5H/mf+i/6r/sP+0/7j/uv+8/8D/x//S/9z/4//l/+f/6f/r/+3/7//0//v/AQAJABAAFwAaABoAGwAgACUAKQAsADAAOAA+AEAAQABBAEIAQQBAAD8APwBAAEMARQBFAEIAPAA3ADUAOAA+AEUASwBPAFUAWgBdAF0AXQBcAFkAVQBTAFMAVQBYAFoAWwBZAFIASgBGAEcARQA/ADcAMQAqAB4AEwAMAAkAAgD6//P/7P/e/87/x//I/8X/vP+8/8L/v/+0/7H/tf+w/6v/r/+4/7f/sP+w/7H/sP+y/7j/vP+4/7X/tv+5/7j/tf+1/7j/vv/I/9H/1f/V/9T/1v/W/9j/3f/h/+b/7v/4/wEAAwACAAMABAAJAA8AFAAXABgAFwAdACYAKwAtACwALAAwADUAOQBBAEoASgBGAEMAPgA7ADwAPwBCAEEAPgA6ADYAMQAsACgAJAAgAB4AHgAaABMADAAHAAQAAQD+//3/+//3//H/6//n/+T/4//m/+f/5//m/+X/5P/g/9v/2f/a/9v/2//b/9n/2P/X/9b/1P/S/9D/zP/J/8b/xP/D/8D/wP/D/8f/yP/K/87/0f/V/9r/4f/n/+z/8P/2//v//f/9//7///8DAAoAEgAZABwAHQAdAB0AHAAcAB8AJQArAC8AMQAxAC4AKgAoACcAKAAoACgAKAAoACYAIwAfABsAGAAXABYAFQAUABIADwAOAA4ADgAOAA0ACwAJAAgABwAHAAgACgANAA4AEAASABUAGQAbAB4AIAAfAB0AGwAZABgAFwAVABQAEgAPAA4AEAATABIADAACAPn/8//w/+//7v/r/+j/5v/m/+b/5f/j/+P/5P/m/+f/5//o/+r/7//0//f/9//3//b/9v/2//f/+P/7////AQACAAEA/v/8//7/AgAGAAkACwALAAoACwANAA4ADQANAA8AEQASABEADwANAAsACgAJAAYABAAEAAEA+v/y/+//7P/o/+X/5v/l/+T/5v/p/+b/4P/g/+H/2v/W/9z/3v/d/9n/3//m/+D/3v/l/+b/4v/l//H/+//9//z//v8EAAYABwAPABgAGgAVABcAHAAdABoAGAAZABwAGwAYABUAEwARAA4ADAALAAsACgAIAAYABQAFAAQAAwAEAAgACwAMAAsACAAGAAUABQAFAAYABwAGAAUABAADAAMAAgAAAPz/+P/2//T/8f/u/+//8v/y/+//7//z//f/+P/1//P/9P/2//j/+f/7//z//f/9//3//P/6//r//P///wIAAwAEAAQAAwACAAEAAQAEAAcACQAIAAgABwAFAAIA///9//r/9//1//X/9f/z//D/7v/s/+r/5//k/+L/4v/i/+L/4f/h/+D/3//d/9z/2//b/9z/3v/g/9//3P/Y/9T/0v/S/9P/1P/X/9r/4P/l/+v/8P/0//f/+f/8/wAABQALABEAFwAcAB8AIwAoAC4ANAA4ADsAPQA/AEAAQABBAEQARQBFAEUARABBADkAMwAzADEAKwAoACkAJwAfABsAHAAYABQAEwAWABQAEAAOAAwACwAKAAwADQAMAAkACAAIAAcAAwAAAP3//P/9//7///////z/+v/3//T/8//w/+3/7P/s/+3/6//p/+f/5P/j/+P/4f/f/9v/1v/V/9b/1f/U/9H/zP/K/8r/yv/O/9P/1P/W/9j/2P/a/97/4v/n/+v/7//z//f/+v/+/wEABAAIAAwAEAATABQAFQAXABkAGwAeACEAJQAmACUAJAAiACEAIQAhACIAIwAkACUAJgAmACUAJAAkACQAIwAiACAAHwAeAB0AHQAdABwAGQAWABIADgAJAAMA/v/5//X/8f/t/+j/4//f/9z/2//b/9r/2v/a/9r/2v/Y/9X/0v/R/9H/1P/X/9n/2//a/9n/2P/X/9b/1//Z/9z/3v/g/+D/4P/g/+D/4f/i/+P/5f/n/+n/6v/s/+3/7v/w//L/8//0//X/9v/3//r//f8AAAIAAwAFAAYABwAIAAsADQAPABEAFAAXABwAIQAnACwAMAA0ADcAOQA7ADwAPQA9AD0APQA8ADsAPQA/AEEAPwA7ADYAMQAuACwAKgAlAB8AGwAXABQAEAALAAYAAQD9//n/9f/y//H/8v/0//b/9v/2//T/8//y//L/8//0//b/9//4//j/9//1//T/9v/4//n/+v/5//j/+f/5//n/+f/5//r//P/9//7//f/9//3//P/7//r/+//+//7//P/5//f/9//1//L/8v/x//D/8f/0//T/8v/y//P/7v/r/+7/8P/x/+7/8P/0/+7/7P/s/+j/4f/g/+T/6P/q/+n/6f/t/+3/7P/x//j/+f/1//b/+//+//z//P8BAAUABwAIAAkADAAMAAsACwAMAAwADAALAAoACgAJAAcABgAHAAoADQAPABAADwAOAA4ADgAQABIAFAAVABUAFgAYABsAHAAbABkAFgAUABAACgAFAAQAAwAAAPv/9//1//X/8v/u/+n/5f/j/+L/5P/l/+b/5//n/+f/5v/k/+P/5P/m/+j/6f/r/+3/7v/t/+3/7//z//f/+v/9////AAAAAP//AAABAP///f/7//v/+//6//r/+f/3//b/9P/x/+3/6//s/+3/7P/u/+//7v/t/+3/7f/v//D/9P/3//r//v/+//3//v8AAP7//P/9//7//v/8/wAABQAHAAYACQANAA4ADwATABkAHgAiACEAHwAfACMAJgAnACkALgAuACsAKgAsACoAKgAqACwAKQAkACMAIwAgABwAHQAjACQAHgAaABsAGQAMAAkACwALAAYACQAMAAcA///8//7/9v/x//P/9f/v/+r/6//p/+H/3P/f/9//3P/c/9z/2//a/9v/3v/b/9j/2P/W/9j/3P/i/+P/3//d/+H/5P/l/+P/4f/i/+X/6v/o/+7/9P/3//P/6f/x//z//v8GABYAGQATABIAFAAdACUAKAAlACEAIwArACoAIQAdACcALAAhABcAHQAfABMACwANABMADwAKAAwACwACAPb/9v/4/+z/4v/m/+7/8P/t//H/9f/2//L/8v/3//n/9//2//n/+v/6//b/8v/0//X/8//z//P/8v/w/+z/6v/p/+f/4//h/+T/6P/p/+j/5//m/+j/6//u//D/8f/0//r///8DAAYACgAMAA4AEgAVABYAFQAUABYAFgAUABYAFwAZABsAHwAjACEAHgAhACQAIwAiACgALAAmAB0AFwATAAwABgABAP///f/7//b/8P/v//P/8P/t//L//f8DAP7/AwAPAA8ABQALABwAIgAhACoAOAA6AC0AHAARAAkA/v/3//j/+P/4//z////+//j/8P/s/+j/4f/i/+3/+P/1/+v/3//V/8b/uf++/8z/0f/K/8j/zv/V/9b/1//e/+T/4f/d/+H/6v/p/+P/4v/o/+z/6f/h/9j/1//f/+r/8/8CABYAJQAsADAAPQBEAD4AMAAmACMAIAAhACUAJAAfABYABwD//wAAAgD4/+//9f/+//z/8P/q/+r/2f+4/7L/4P8TABoACgAaACoA5/+W/6b/8//2/97/QwDsAB4BugA9AK3/FP/G/jv/QgD3ABQB6wCzADYAof93/9z/VwB9AFYARABIABUAx//F/yAAdAB9AGMAXgBCAPD/sv+j/8D/6f8CAAcA/P/v/73/d/9R/2//tP/O/7H/kv9y/zH/4v7I/uz+M/9r/3n/fv+Z/6v/pv+o/7z/wv/B//7/bgCpAJIAfwCbAK8AvQAKAZQB4gGuAVoBNgEWAdcAygAaAXIBggF6AXgB/QCq/z7+uP0S/sb+wf8GAaYB0gBD/1j+Uv6E/uj+p/9YAJUAoACsAGkAt//8/m7+8P2s/Qr+7v7V/24AwQDLAFMAd//c/gr/vv9HAGAAQQATALj/Vf9V/8L/SACwABoBbgE0AXgA4v+5/7///P+zAI4BvAHyAPT/qP/w/0UAxwCQAegBIgGw/8T+3v5d/7b/cwDWAaACfAFV/2L+6v4k/8L+cP8wAYIB7v8O//T/vgAmAGD/Wv8y/0j+OP6//8MA9P8V/6X/CgAl/5b+Lf8v//T9oP1j/14BxAFKAa4APP+A/WT9xP6+/2oAmgFoArgBVgCw/3f/wP4y/g//0QD+ASACnAEMAVwAEv8I/sT+7wAwApIBpwB0APn/+v4J/zcA3gCiALkAXgEYAen/YP+Z/y//fv4a/zAAPwAlAPkANAHM/4j+2v7B//X/BACVAJAAYv/S/nz/sf92/4QA0AEKAUL/T/9xAI3/rP2q/ugBsALEAEUAfgG6APD9cP3d/zABCABi/6MAgAFtAEb/Yf9//wD/Ff8rACIBGAE0AGj/X//F/wsAVgCeAF4AqP87/2v/AQDFABoBpwAUAO3/sv/4/qb+sv8WAecAuf/1/ywBwwA9/zr/iQDJAID/pv5s/4EAewAEAFcA9QDWAO7/5P7U/uT/XgCJ/4f/FgHIAX0AIf9V/woAjv+0/nD/yQCUAPr/jACqAIj/MP8kAH8Avf9v/z4AswArACIAlwDp//L+av8dAPv/qADMAfYAKf8h/97/Nf+0/ksAxAFRAHT+BACcArwBBv+E/mH/D/+K/tH/vAGgAYf/ZP66/2IBRAEJAE7/Lv+u/sz9KP6RAAQD4AJzAEr+sP2k/Xj9R//oAtQDmwAs/mD+Av4I/aD+OAI4AwoBPwBUAaT/hPzU/YwBogEKAFABlAK5/5z8iv5oAjwCNgA8ATAC1P6Q+7D9gAFmAen/2AE4BJoB7PwQ/TEADP/A+zz+SAQABRAB+v8sAfb+ePvs/NUAMwBw/Y3/KAT0A3AAiv+NABv/HPzI+8r+cAH0AXACKAPAAjIB5v6I/AD8lP06/68AiAIwA0IB8P62//gBrwCc/ED8FACOAbf/fwBYBJAE9v4A+/T9lgEiAEj+qQDIAggBqf/qAZgDDQDw+sj6yv6QAZACrAPgAl7/FP3I/UH/awAaAakAyv7g/Dz9bQDEA1gEyAJ7AMT9mPtw+6D9DAGYAxAENAOuAUf/nPxQ+/T8bAAgAoIBygHAAiwBIP5s/br+vv58/QX/zANQBZABIv96/1j9cPqQ/QgE2AR9AJH/gAKXABD7XPzoAhQDqP1s/WQCaAN2/4j+UAJoAy//RPw2/lMAhv/w/ssAcAI8Ao4BtADM/gz9kP1L/1L/Ov4xABgEwAPE/4b+mP9I/nD8sP5wArQBaP6f/xgEnANc/lT8tP5n/0D95P28AqgEPAFb/2ABHgEg/Xj7AP5uANYAgALgBEQDYv6g+4T86P6sAXwDUAJS/7D+9v+q/pD8HQAgBkgF5v4A/FT9cP3k/UACwAVgA0L/+P2A/bj8OP7BAAkAjv7WAVAGOAR6/jz8WPwY+1D7YQAYBQgF3AMQA+j+gPr4+xb/XP4o/dz/vAPAA5QBEAIUA+P/gPtY+kD7lP3wAfAFKAbMAsz+7PxI/TD+SP+ZAK4Azf9NAJIBpAGtACv/wP1s/lYAqAC9/87+VP5D/6EABgEsAhADHgBA/PD7UP1q/uQAcAS4BWgDZ/8g/cz86Puw/KoB8AUwBGgA5f/XABT/0Pvk/OgBIAMKABkAlAKwAMT8lP7gA2ADtP3g+5T+Nv8L/9QCKAb8ApT98PxS/ij9/P3oAhAEgP+g/XcA1AE3AND/KgEOAIj84PuA/vUAIAMIBeQDxf+g/OD7RPzM/Q4BKAMkAhoB/AEQAsD/rP2I/Sz+YP3I/FgAGAaQB1QDxP4s/eD7SPlg+n4BGAYoA5gAGASQBQD/KPnw+20A3P7I/MIA+ARcAtD+8AFgBSoByPt4/RQBtv5w+vz80AMABaABfAL4BaAC6Pmw9ij7Qv9Z/5EAeAVgCDAEEP1I+4z+0P6o+5T8AAI4BEIBVwDUA0AEoP0Y+ej8bAFAAesAaAIaAeT9cP6KATgC3gDAAPcA5P7w+wz87v8wAwAD8QDM/1kAXQAQ/hT8WP2c/08ApgHoA9gCKv6Y+wj9rP7L/1QCGARaAWj9SP3g/pz+8P5EAigEGgHo/YH/EALB/8D6MPr4/9gFGAYYAxIBjv4I+pj4GP6QBJAEZgHKAdQCIf8Y+9T8ZgA5ANj+sgBYA3QCfP+U/ob/8f/o/xMAxP/Y/nT+Dv9TAOQBNAMIA+UAzP1Y+2D7JP7iAVAEtAP3AAf/mv4O/tj9sv/AATQBef+3/woBkAB3/2YAMAGY/tD7xP1QAqQDJAKYASIBmP6s/ND9UP/U/sb+AAKgBVAEnP+I/Y7+VP6k/Fz9rQAYAk0AXQDwAygFzQCo+3D6PPyS/vEAHAMYBJQDzgFM/9D9BP9gAAj+0PrQ/DwCYATEA3gEtANI/mD5ePpm/u//HwAcAigE2AL5/1r/6//e/oD9NP1g/cT+7gEgBGQDXgH3/+r+KP0g/Fz+vgHaAYD/Tf98AUQCSAFMAZgBzv6Y+rD6hP+UA9QD9AK4ApIBB/8M/dD8vP2D/zYBpAHwAVgD0AMmAbT9mPy4/Iz8Rv7MAhgGwAQuAZb/7v44/Dj61PxKATADDAPQAkQCZwAg/nj9RP6O/pb+wP8mAXYBEgGxAE4Azf9k/5j/WwD3AKsA9v7Y/Nj8jf8sAkgD1AOkA1wBzP2o+/j7jP2L/zQCWASsA7AApP6q/hD/af9GAJUAmP/S/nT/iwDTANoAcAHyAGD+2Pxi/tn/wv/aABwDDAPg/yT9eP1K/mT9Vv4EA8gFGAMA/6z98P1M/fj8u/8IBLAExgBY/az9i/9RALkAuAGCAZT+qPuY/CwAKALWAW4B8wAn/zD9FP1s/gX/Yv6w/vIARAPUA2gCnf9g/HD6YPsV/1QDEAW8A0gBv/9g/zb/rP54/kT/JACPAHIB+AKAAzACBwCK/vj9uP30/Tb/JAHoAswDRAOAAXH/1P3M/Hz8iP30/0gCCAP8AnADBAMHAED8uPrA++D9rgDMA4AFWARIAbb+bP3g/Dj9bv6F/y0ACgEoAuQCxAJmAfb+8Pxc/Az9bv4fAHgB+AG8AVoBVAH3AEr/yPxI+zT8sP58AC4BRAKcAxAD//+g/Fj7FPyY/Tz/9wDiAQoBy/8PABIBswAs/x7+NP1s/Nj9pAHYAzwCcgA2AUYBUP50/Hb+sQBwAKAAvAJAA/sAh/+TABoB2f9//+4A1AF8AcoB2AKEAt8AHQCnAKMA1f8BAFIB9AGMAeoBPANAA7kAyP38/PT9LP9+AGAC0AMYA30Adv5G/n7+1P1A/fT9Qf/Z/yEA2gA6AQsA9P14/Pj74Ptw/Br+8f++AHMA1v82/1T+SP2c/JT8GP0y/qj/0wA8AfEANwBe/6r+WP5C/lD+0v7X//MA7gGoAoQCRgHs/27/jP+E/7P/tQDiAUACRAJoAkACQAHn/zH/Z/8ZAOcA2AHIAjQDoAJSAef/sv4S/ob+JgAcAmADeAM4AsX/MP1E/FT9Jf/kAEgCgAIgAVb/kv6e/lb+2P02/kj/tf9s/4r/9v+V/3j+xP3s/Sj+DP4K/nL+1P64/nz+nP4Z/07/iv4g/Uz8wPwG/pn/NgEkAngBUf9Q/RT9Tv6q/9IABALcAuQCpAKYApQC+AECAeAA0gHsAsgDyASwBcAFuARUA0gC4AEcAhADWARIBYAFOAWQBMQD7AI4AroBugFIAggDWAMwA9ACJAIYARYAq//Y/xYAyv84//r+Pv97/zj/gv54/TD86Pqg+lj7GPwE/Fj7uPr4+dD4sPcg9/D2cPYQ9lD28PYw9wD3wPaA9gD2sPWw9WD1EPUA9lD48Pr4/Hr+HP86/nT80PsQ/VP//gEABcgHkAlAClAKAAogCYAI4AhwCpAMYA6AD6AP8A7wDRANQAygCyALoApACsAJUAnQCGAI2AfgBlgFyAOAApIB4ACTAJ8AfwDe/w7/YP6Y/bz8VPyg/Bj9eP3M/QT+kP3U/Hj8jPzc/JT9rP6q/+f/mf+K/5r/XP8T/17///9lAH0AkgClAFEApf/q/lD+sP0E/WT8+Puw+3D7+Pow+jD5GPjg9pD1YPSQ8xDz0PKw8sDysPJg8sDxsPDg76DvoO8Q8GDxAPNg9BD2mPho++D8kPz4+/D7gPx8/uQCkAjQDBAOUA3gC4AKEAqQC8AO4BEgFIAVIBYgFeASwBCgDyAPAA9wD4AQ4BCADyANsAowCOgFcAQABLwDwAIwAcT/qv60/QD9fPyo+yD6SPjw9nD28PYw+ED5iPkw+bj4OPig91D34Pfo+Pj5gPts/eb+Zf9P/yb/AP/6/sv/xAEQBLAFOAbgBSgFgARYBNgEqAU4BoAGiAZQBsAFAAU4BCQDtgF5ACEADgBo/2T+nP14/ID6ePhw99D2oPUg9ADzEPLw8CDwMPCQ8EDwYO+A7gDugO1g7QDuIO8A8DDx4PIw9cD3EPro+/z8LP0M/XD9cv88AyAIgAwgD7APIA+QDpAOUA/gEEATYBVgFqAWABfAFiAVYBNAEoARwBBgEKAQABDwDVALkAn4BwAGeASYA0AC/P8Y/kz9yPzg+wD7OPrY+PD2sPVg9aD1EPaw9iD34PZg9lD2kPag9vD2IPjQ+VD7oPzc/db+6P6A/q7+8P+wAWADKAWgBjgHyAZABkgGgAaABtgGyAdwCJAIMAjgB/AGQAWcA5QC7AE4AaYAEgD4/hz9MPuI+Rj4sPaA9bD0YPOw8RDwIO9g7sDtYO1A7eDs4OtA6yDrIOvg6gDrYOxg7hDxkPQ4+JD60PoY+qD58PnQ+4AAEAdwDBAP0A+AD1AOYA1ADiARABRgFkAY4BngGcAYgBcgFmAUwBKgEoATwBPAEoARcA9wDHAJ0AdQBxAG9AP0AU0Apv5M/dj8fPwI+6D4QPag9KDzkPOQ9KD1sPUQ9WD04PNQ8/DycPOQ9OD1kPeo+ZD7iPyk/ID8kPwo/aj+GgGoA1gFMAagBrgGyAYQB8gHYAigCPAIcAnwCRAKwAnwCJAHyAVIBHgDJAOcArIBfgDU/pz8SPqY+DD3sPUA9JDycPEw8ADvIO4g7cDrYOrA6aDpoOmg6QDq4OmA6QDqoOyg8BD00Pag+Pj40PcQ9+j4QP2EAsgHcAzgDvAOAA4ADuAOQBBAEkAVYBhAGoAb4BtAGyAZ4BagFSAVIBWAFcAVwBSAEsAPUA0gCyAJmAcoBkAECAJIABb/7P1o/OD6UPlA9yD1wPNA80DzYPOw8wD0sPMA81DyAPLw8aDyIPRg9sD4mPqg+xT86Pvg+6z8av7uAIADsAUIB7AHwAe4B/AHcAgwCQAKsAogC4ALgAswCzAKwAggB5AFaAScAyADXAI+AYj/bP0Q+9j44PZA9ZDzIPLQ8KDvYO5g7aDsgOsA6gDpgOgA6KDnoOcA6ADooOiA62DwoPQQ98D3MPew9QD1cPdI/dwDUAkwDSAPwA5wDVANAA9gEcAToBbAGQAcwByAHKAbwBlAF0AWoBZgF6AXYBdAFqATQBCgDRAMoArQCPAGAAXAArsAtv8u/8z9cPsQ+cD2gPQA89DyUPNw81DzQPMA8wDy4PBA8ADwcPDQ8WD0QPc4+RD6KPqw+Vj5GPp4/JH/WAJQBLAFcAaoBvgGmAdQCKAIMAlQCoALMAyADIAMkAuQCWgHOAaYBfAEYAQQBCgDEgF8/lz8YPrw96D1APTQ8oDxYPDA7+DuIO0A66DpoOjA54DnIOig6CDooOdg6KDq4O0A8uD14Pcw98D1wPXA97D7kAEgCOAMsA7QDuAOIA+gD0ARYBRgF4AZoBuAHeAdYBygGkAZIBiAF8AXgBjgF8AVgBOgEYAPIA0wC5AJIAcQBOAB9gAtAOr+iP24++j4sPWQ89DysPKQ8vDyUPPA8oDxoPBA8MDvYO8g8DDygPRQ9tD3GPlY+bD4wPgw+oD81v5wASAE+AWQBsgGaAegB5gHEAiQCUALYAxgDQAOYA1wC6AJcAiIB7gGcAZIBlgFZAMmATP/6Px4+mj44PYg9UDzoPGA8EDvgO3A64DqIOnA58DmoOZg5sDlQOWg5SDngOlA7WDxAPQQ9NDyYPJQ8zD2wPu0AlAIEAvACwAMIAywDJAOIBKAFQAYQBpgHGAdoBygG+Aa4BkAGUAZgBqAGgAZ4BYgFeASgBDwDsANoAtgCMAFUARAAywCUAHn/9D8+PgQ9nD0UPMQ88DzUPSA8/DxsPCg72DuoO1A7qDvMPHg8uD0gPaw9kD2gPaw9zD5QPs4/jQBEAP8A+AE6AV4BrgGsAcQCWAKcAuwDOAN8A0ADeAL8ArQCZAIEAgQCHAH6AVQBMgCdACM/Tj7iPmA90D1wPPQ8lDxQO+g7SDs4Omg5+Dm4OaA5qDlQOVg5YDlIOeg6sDuIPEA8vDxQPEA8UDzqPgV/1AE0AfwCVAK4AmwCpAN4BBgE+AVwBhAGyAcoBwAHYAcIBtAGqAaYBsgG4AagBkAGIAVoBMAEgAQcA3gCtAIIAewBZAEiANyASz+yPoA+PD1oPRg9KD0YPRA87DxcPDg7qDtYO1A7qDv8PBQ8sDzoPTw9ED1IPYg92j4cPpM/QAAFAK8AxgFsAV4BdgFQAfgCEAKoAuADWAO8A0gDZAMgAvACbAIsAiwCPAHCAf4BbgDMwBI/Uj7cPnA98D24PUA9HDxIO8g7SDrgOmg6ADo4Obg5SDlQORg40DkIOeA6qDtMPAw8eDv4O1g7lDyMPg+/rQDWAcACBAHAAcwCUAM0A+gEyAXABmAGaAawBsgHKAbQBtAG0AbgBsAHGAcQBsgGcAWgBSAEoAQ4A4wDYAL4AmACFgHgAWcAgj/yPso+ZD3APdA9yD34PUQ9BDyIPCA7sDtIO6g7kDvQPBw8TDycPIA86Dz4POA9FD24PgY+yT9qf+QAQAC7AHEAjAEaAXQBhAJYAtwDGAMMAwQDDALMArQCeAJoAkgCcAIAAgoBpgDLAEm/0T9WPvo+cj4YPdg9TDzUPGg72DtQOvA6SDpgOjA5yDngObg5aDlYOeg6uDt4O+A8ODv4O6g7xDzYPig/dIByAQgBigGIAegCcAMoA9AEsAUoBYgGMAZABuAGyAbIBsAG6AagBoAGwAb4BmAGEAXoBVAE8AQEA8wDUAL0AngCLAHmAUYA04AQP2g+hj5SPjA9yD3kPZg9YDzoPEw8CDvgO7A7hDwcPFQ8sDy8PLQ8nDywPIQ9ND10PdA+qj8RP4L/5v/TQDnAKgBIANoBZgH8AjQCVAKUAqwCfAIsAjgCNAIgAhwCDAI+AbwBBwDbAGP/3j9GPww+9D5EPiA9iD1wPIQ8ADuoOxg64DqoOpg6gDpAOcg5uDmoOig60DvUPFw8IDuQO4A8CDzIPjg/dAB3AIEAyAE2AXoB8AKQA7AECAS4BOgFmAYABlAGcAZYBmgGOAYgBogG2AaQBnAGGAXQBWgE8ASQBEAD1ANoAzQCzAKYAiIBqADCgBc/Uj8kPu4+jj6yPlA+JD1IPOw8aDwwO/A79DwsPHg8QDyIPLg8TDxMPFg8iD0APYY+Aj6SPvI+0D8BP0G/lv/GgHgAmAEgAVwBnAH8AfoB8AHqAeIB1AHiAcACPgH8AaIBTgEpALfAHv/pP5w/cj7KPoY+YD3cPWg8/DxIPCA7iDuIO4g7UDrAOpA6sDqYOxg7/Dx4PHA78DuwO8w8qD1SPpM/uT/4v+nAHwCcASoBoAJMAzADRAPQBGgEyAVwBVAFoAWYBaAFoAXwBggGaAY4BcAF+AVwBTAE+ASoBFAEPAOwA2QDBALUAkoB9AEdAJ8ABf/LP44/QD8kPrg+OD2APWQ89DyQPIQ8pDy8PKA8uDxkPFg8UDxkPHw8rD0EPYw91j4MPmw+Wj6qPsg/W7+2v9WAZACkAOwBLAFGAYoBkgGeAaQBsAGEAcoB7AGsAWQBHgDaAKEAZcAcv/w/VD8yPqI+WD4wPaw9CDzEPIA8QDwQO+g7uDs4OpA6+DtMPAw8YDxYPEg8ADvMPAQ9BD44Prg/F7+wP7i/nsAjANYBhAIsAmwC4AN8A6AEEASQBMAE+ASgBPAFOAVoBZAF+AWwBVgFMAToBNAE2ASgBGgEHAPUA5QDQAM8AngByAGiAQEA+gBIAHb//j9FPyQ+uj4UPdQ9pD1sPTg86Dz0POA88DyEPLA8aDx4PEQ85D0wPUw9nD2APfQ9+j4SPrg+yT9Hv43/3AAcgEkAiQDAARABEAE2ATQBRgG2AWwBXAFmASsA3gDZAN0Au0A0f8Z/wT+tPzQ+8D6+Pjw9uD1cPWg9JDzsPLg8WDwIO8g72Dw0PEQ85DzMPMw8uDxIPNw9aD38PlI/Mz9Lv7K/sUACAN4BGgFQAdwCdAKQAxwDkAQIBCADwAQYBFAEuASIBTAFAAUwBKAEoAS4BEgEeAQYBAgDwAOoA0ADUALUAnwB5AGAAX4A4wDtALfAPD+nP1Q/Mj6sPko+VD4EPcg9iD2MPaQ9ZD0APSw82DzwPPQ9PD1cPaQ9tD2QPeg91j4uPno+qD7UPyM/cD+X//K/4EAHAE4AYwBcAJIA3gDWANIA9gCBAKWAd4B6gFEAYIA+P8E/6D9qPyA/Pj7YPrY+Ej40Pew9sD1sPVA9aDzMPIg8sDyYPOw9ID2cPYg9KDyQPSw9hj4qPkc/ID9DP0A/e7+FAEIAgwD8ARIBtAGUAgQC8AMYAzgC6AMUA2gDfAOIBEgEiAR0A+gD+APsA+gDyAQIBAgD9ANEA0ADfAMIAyQCrAIUAeoBkgGmAWYBKADLALc/6D94Pw0/eD8ePsw+nj5cPgw9/D2oPeA9yD2QPXQ9XD2kPYA98D38PdQ9zD3GPgY+eD52PrY+wT8sPsc/Gz9jP7k/hT/kv/Q/8D/AADnAIoBIgFcABMAQwBSAEoAeQBCAAH/fP0s/Yz9PP08/Kj7WPtI+iD54PjA+KD34PbA9+D30PXQ9ID3CPpA+ND1kPd4+oD5QPcw+Zz9kP6k/CT9IwDuAHn/LQDQA2gGiAVIBNAF4AggCmAJAAkgCmALoAuwC5AM0A3wDQANcAygDMAM0AwgDWAN0AzACxAL0ApgCpAJ8AiACKgHeAaIBRgFeARMAxgCTgGBAD//CP7g/SD+TP1Y+1D6uPoQ+wj6uPgA+Rj60Plg+BD4MPn4+Yj5MPnQ+Yj6mPqg+lD7GPyU/Lj88PxI/dj9YP6Q/sr+V//w/+X/Uf9F/yMAvwA2AGb/r/+IADYAuv4e/vL+C/9Q/UD8aP34/ZD7gPkA+6D8CPrQ9oD4kPtI+YD0oPVQ+wj8IPdw9Sj5KPv4+ND3SPqI/PD7uPvg/X7/oP78/W3/HAGeASQCyANQBXAF8ARgBVAG2AaQB8AIYAkACeAI0AmQCiAKoAnQCUAKcApQCjAKIAogCtAJIAlQCAAI+AfIB4AHQAe4BmAF/AN8A4QDXAOUAmYBmwA+AM7/Fv9W/rj9WP3w/Cj8gPuo+yD8yPu4+jj6qPrg+kj6GPr4+tD7iPug+lD6+Pr4+4z8pPyE/GD8dPwA/dj9MP7U/cj9fv7W/kL+GP4j/9L/Ev8y/lr+wv6A/mL+5v7Q/qD9sPzM/Cz9AP2k/DT8gPsQ+zD7APvI+Xj58Pp4+0j5CPhw+pT8oPpo+ND68P34+7D4CPvM/9T/GP2w/WEAOwDE/nAAjAOsAyAC+ALYBLAEEATQBbAHoAb4BFAG0AhACHAGMAdACdAIuAbABqAIIAnYBxgHmAeQB8AGkAYQBwAHUAa4BWAFCAWgBIgEgAT4AwQDdAJgAiQCmAFGAQABPABA//T+Sf8V/yb+wP0k/uT9nPwo/FD95P3I/Oj7zPyU/aD8uPvo/Dj+RP3Y+8j8jv4U/nj8DP0k/xD/CP3o/ED/if9I/TT9AABlAAT94Pti/1YBIP5o+5T9HwB0/rD7FPw6/qr+LP2A+/D6HPxM/Tz8gPpQ+0T9QPxA+bD5OP2o/SD6GPmM/I7+SPxI+jj84v5C/jj8lPzs/v//WP8W//L/twCbALcAogFIAjQCnAKkA7wD3AIMA+AE0AWoBOQDQAWABsAF8AToBTAHiAZIBZAF2AYIBwgGoAVoBrAGsAWwBCAFGAboBagE/ANQBHAExAM8AwgDrAJgAkgC5gEoAeQALAG+AIX/Kf8BACcAxP78/fD+e/8K/uz8AP5E/3r+vPzg/Hj+mP4U/aT88P10/kj9ePx0/Xr+pP14/Oz8wP0U/VT8HP28/Yz8oPvc/Lz9JPzw+kj8rP1Q/LD6BPzU/Zj8aPpg+5D9tPwQ+oD6lP3g/dj60Pmc/Fj+8Puo+ej7DP+8/cD6sPsg/zL/PPxg/BsABgHI/RD98gDMArz/PP76AWAEbAFP/6gCkAUYA9gAeAMYBiAE2gHQAzAG4ATkAggE+AXoBFgDYATYBagEOAMgBGgFkARgAygE2AS8A9wC5AO4BLADYALkAggEQAPmAVACOAOoApwBzAGUAjgCCgEGAQgCwgF9AKUAwAFIAdb/OQC+ATwBHv9A/1oBIAHU/qD+4QAaAVj+WP2l/8IAcv7U/Cb+NP/Y/Yj8KP3s/Vz9ePw4/AD80PtA/Dz8SPsQ+8j7kPuw+tj6iPs4+yD6MPqw++j7OPrQ+Vj7APzY+hD6APt8/Ez8wPro+uj8eP0I/LD7hP2y/qT9DP3Q/loAZ/9G/pf/hAFMAUIA+ADAAgwDGAIwApgDYAScA0gDmATQBQgF+APwBHAG+AWQBPgEqAZ4BrgE2ASgBnAGoASgBOgFuAWYBIAEIAXQBOAD+AOoBBAEGAN8A+ADKAOMArwCmAIgAhACUAIMAjYB5gBMAW4BqAALAEAAlQARAB7/B//C/7P/SP6c/YT+9P6M/YD8cP0W/tD8kPsc/Az9cPwY+9j6kPvg+xD7SPpQ+vj6EPsQ+oj5UPoI+2D6sPk4+tj6mPog+mj6APsQ+8D6GPvI+6j7UPvg+7j8zPyk/Bj94P0Q/rD9Lv6H/9n/G/+A/yIBsAHCAK4AYAJ0A4QC/gGAA7gECAR0A5gEiAX4BIgEgAU4BqAFOAXoBXgGAAa4BUAGYAbYBbAFIAYoBqgFcAWgBYAFAAXIBOgEyARQBNADxAPUA3gD2AKkArwCdALCAVIBjgGaAc8AMwBkAHEA0P8U/xb/Xf/m/gz+AP58/ij+NP3k/Ij9YP1I/Aj84Pzk/Ij7KPtk/Jj8KPuo+uD7IPzg+nD6ePsI/Dj7oPow+4D7OPtI+7D7oPtg+7D7DPzw++j7VPzE/Jz8dPz4/IT9jP1w/fD9dv5e/mD+4v57/5n/qf8VAIwAogB4AAoB2gHeAaYBJALEAqACWAK8ArwD+AMsAwwDGASoBAgE5AOYBAgFgAQYBKgEMAWwBCgEuAQQBUAEvAM4BJgE+ANgA1wDaAMUA3wCfAK4AgwCKgFYAaoBBAErABYAbgD9//j+1v57/zz/DP7A/VL+MP44/QT9nP2A/dj8aPzA/Aj9pPw8/Gj8sPxk/ET8fPyg/KD8hPyU/ND87Pzc/PD8AP0A/UD9hP2s/az9pP3Q/Qj+Uv4o/vz9vv5o/9D+Tv5M/wcAff/0/qj/wABPAGr/JABgAe8ABQCyAL4BqgEMARIBpgEcAuwBXAGUAZACmAJ+AX4B9AI0A3QBHgGEA+gDHgHLAPgDYAQCAacA9ANwBCABdQC8AxgE4gBxAGQDmANJACkABAPkAtb/sP8kAvwBiP9M/44BRgGo/tD+DAGCAFj+sv5UANb/HP5M/p3/Dv/g/aL+Wv9E/oj9nv5D/yL+fP2k/j//vP3Y/Jb+DQCQ/rT82P33/zT/HP3Q/R0ACgCk/Vj9BQDBAF7+qP0tAPUAmP7A/TcAbgFI/2T+WgAcAT3/0P4IAVAB+v74/oABYAHu/kX/hAE+AQj/Xv/kAU4BpP6F/0wCRAF+/mb/JALYAQz/3v7WAXACtP/M/hIBHAJTAEn/twD4AdwAY/8fAMoBYgF7/67/igG0AeT/ZP8iAfQBWQAI/3YANAIaAR3/y/+uASwBSP90/xQBJgFo/9r+hwAcAVD/Vv72//YAef9a/ob/jwBL/wb+MP+MAFT/IP43/0IAa/9e/g//DACR/6r+I/8FAK7//v5t/ysAs/8z/8D/PgDr/5z/8v+jAGkAff/Q/+UAsQC2/ywA+gB/AAcAawDMAI4AAwBHANwAtwBdAD8ATACSAOIAEACi/7MAAgEGAKX/QACPAEoAAgD6/ywA+v/f/y0ABQDN/+L/lv9o/xwAawCe/y7/GQCbAJf//P4hAPcA1v8j/xkA3QAmABv/u/8WAbEA8v59/1wBqADA/jr/dAE8Ae7+9P5UAXAB2v7W/pYBwgEd/8z+TgGUAVn/6P4GAboBov/S/qMAiAG6/9L+bgAyAZr/wv4MAAwB9v+u/tb/9gCR/3L+1f/JAJ//Ff/Q////gf9X/6j/IQDg/xP/Fv/N/28A0//Y/n7/9gANAOz9HP9mAcoAdP6o/hwB/gB+/kb+SgGcAV7+/P02AcoBnv7Y/dQAJAI9/0j9EwCEAun/fP2k//gBOACc/Rj/5gH1ABL+yP6SAdcANP7o/rYBSAGc/mr+KgGOAdb+A/+sAd4ANP5R/94BSAHe/jj/dgFqAcT+ZP7MAXwCTP+g/k4BGAKJ/5D+rAEIA6//Bv4qATQDZgC0/UYAiAMMATT9p//AA+kAqPyd/4QDtgB8/KD+qAOKAcj72P24A5oBAPsM/cgDVAJo+/D7dAPoAgj7UPtgAzwDiPuw+0wCvAK8/ND7ugEAA3T9PPx4ATQCWP0Y/SwCFAIs/WT9hAJoAvj8WP0EA0QD+Pxk/HADEAT4/Lz81APAA7D8sPz8A3gEWP04/EADuATo/Uz8QAKYBFP/PPx0AWgEXP9w/IgBcASK/9T8mQC4A77/fP18AZwCYP9U/tsAJAFQ/1IACAIcALz9BQDgAur/uP3UAOwC5P/E/bgAwgGd/+n/iAHV/6D+/QB8AfD+D//qAXYBWP2I/fACWAKo/Tz+IAICAZT81v4wA38AbPxnABwD2P3g/HYBpAKY/pD8ygB8Aiz+ZP0oApABRP1g/iIBMgAM/lX/8AGMAAj9iP6WAREABv42AJQBsv74/eIAHAFe/kr/4wCr/87+yv8GASUAjP7m/ygCAf8w/foBwAIg/jT+TAKuAej9/P5sAvQBGv6A/kwDzgHo/Jz+GAQMAvj8gv4MA9ACRP0c/dQDKARg/Hj8gATAA7j73Pz4BLwDqPvM/HgETAJI+4D+SAV8AcD5Mv4wBnwAKPmgAJgG/P2Q+UoByASC/mD7xAFgBOj8QPsQA6ADYPxI/bQD2AHg+7D9uANwAXT8Bf8AAwEAMPyn/3ADegDI+8L/WATy/jj7/QDIBFT/qPtnAFAEhv/Q+vsA2AVV/4j6QgB4BVoAOPvF/5gE7QAQ/PD+OARuAQz8kP5gBCwCuPu0/SAE8APw/Lj7yAIwBPz9oPuIAvgEVv4M/PAA4AP3/8z8CwBkAwQCWP0c/fgC4APM/jT8LAJ4BKT9fPyyATgFbv4o+8wCuANE/Qj8YATUA8j6WP0oBEACPPxK/kADlgES/pj8mwD0AmP/BP7C/wwBef/4/br+hAEwAtz89PxIA0wC8PrA/NAEqAII++j82ATwAQj7Jv5IBBwCKPwQ/YADwAME/Xz8LAJoBPv/yPrI/dAFtANA+lj9+AUcAkD5mPygB0gEcPhY+xAH1APw95j8sAaMAwD60PvABJACEPuI/TAEUAKY+wT9OAP+AQT9kP18AgQBkP00/lIB8AJY/sD8kQBuAfz/Of90/40A6gG+/1T8QwC8A0UAVP3o/+ADUQAY+3r/QAYkAvD5mP1IBuQCWPr0/SAHnAJg+Rj+yAWoA6D6YPxQB2AESPnQ+sAGEAUI+xj8aASoBFj6KPtYBXgEyPs4/dQDbQBI+7L/eAVAAHj6mgCQBSD9WPmABMAHMPug+AgFYATw+CD9QAnMAlD3gPwgBvgC6PmY/fgF/AJo+pT8IAQFAFz9vAJsAtD7LP24AzwC1P0y/ugCygHQ+0D+uAToAmD8/P2IBHQBOPlO/rAIKASI+YD7CAQcA3j8IP4oBM4BiPzg/hgDQP64/GwDWAPg+9j7CAQgA4D8HP5oBOH/gPni/kgGfAPA+TT9uAfcARD2hP0gCSwD4Prg/SAE5gGo+zT+cAWQAsj7Sv5oA+4Bav42/4ABhgGW/sT+bgCXAPQCYAKg/DD8WAN0AiT8Of/ABSQCSPqY/aAFhAIA+sj9OAcMArD32P1wCDgB4PeUAOgGkP1w+NwBkAgs/oD2GAKwCVD7EPVIBxAKwPew9vAF4An4+1D08AOQDjj6gO7QBcAQaPzA8vgAAAr+/1D0RP3gDNgFEPRQ+FAIwATg99D7UAhYBnD4EPVAAzALDP7Q9cACgAhQ+9D1uAGgChADQPZA+3AHhAEQ+H4AgArcASD3QPqABNgFZP1C/rAFggCw9/b++AZoAcz9MAIYAkz8TPwkAsAFbgHw/YABZAAg+/7+uAakA9T8PP7gAYn/BP1sAaAF8QDI+vD+kAK0/Kj9iAeABTD52PmAAzwCAPzK/3gHrAIA93D6WAe4A4D5bP94Bwn/wPaq/ggHrAOI+2j8xAPZAAD5LP0QCIAE8PlI/OYBS/8g/EgCCAfI/lj4jf9QBpz+UPmoApAIPv+w+A7/4APuAFT+jAJYBPD7UPgEA7AJ8P3A9jgFgAoQ+SDyMAbgELD7QO/oBOAQAPnA7tAIoBKQ9mDu4AlAELD1gPCwC4AQYPWA76AJ8A9w9zDzMAoQDFD1kPQACwALwPZg9rAJwAng9eD18AhgC2D5cPZYBRAHmPvw+TgDSAWS/rj77v/QAo7/vP3WALYBKP5g/GT/ugFtAK7+Df+x/yb/1P1Y/nkAoABqAKf/lP2Q/cYAogG+/qL+BwD7/0X/A/9RAP8ALQCy/rz+IgBMAIIAvgFCAdD9lPwTABQDZgFI/vz/bAO4ALj7mv4gBMYBCv5R/2ACeAFq/n7/DAPSAQD8CP3YA9QDOv7q/mgEMALo+pj7MAMQBXD/dv7IA2gCsPoI/NQDMAMS/kz/sAKGAOD8Nv6wArwCyP0I/bUAmADS/jwB2AKW/5T8LP2w/8wBAAJIARoBi/9Q/Vz9gv9oAlgENAIC/uT9k//W/mX/8ALcA3QAsPzM/HsAHAIdAKn/FgGY/qD7Nv4gAgAD6wCo/Vj87P1a/jD/DANIA8L+WPyU/fT+qv/kABQCtAG+/rD8rP5SAbABfAFwAUr/0Px8/hwDkARkAcD+KP+s/w7/QQB4A1AEIAFA/gb+rv7M//gBkASkA0b+2PpW/vwCxAKcAPn/lwBS/yz91v40A8ADTgBu/oD+LP6w/nQCaAW4AWD7sPsGAewBEABYAawCwf/Q+3D8kgCIApYBoAEKAZT8cPqT//AEQANM/gj9Cv8GACX/zP9gArACRv8g/KT8l/9cAuACagF5/4z9rPzo/tgChAPo/2z9M/9GAaD/Sv6IAUAEUgCg+yT+7AL4AqAAxwA4AQH/mP1fANwDtAJp/8D/HAG2/z7+TwDAAuABav9S/gn/O/+p/58AfgCs/oj9Zv46/wX/qv4c/6T+DP2E/BD+2P+p/xz+KP1U/Xj9iP2A/uT/nv9E/Uj8RP7O/xH//P6DAD4A3P2Q/YYAoALfAAv/bQD6ATQBmwBcApgD6gHX/94AhAOwBKAEMAS0AgYBqgHgA9AEwAQQBZAEeAIkAXwCEAU4BWgDJANYA44BFAEgBNAFRAPe//j/WAKQAucAjAE8AwwBKP3k/HX/awDg/uT9Bv6g/Cj6yPmo+0T8qPrw+ED4GPhY+Jj4SPjA9yD3MPbg9TD3yPhY+HD20PUg97D3cPeQ+Aj7IPuY+Cj42Pqc/ID8zP0MACgACP/Y/4QCEATEA5gE8AaQB+AGcAhgCzAMMAuwCuAL0AxQDYAOIBCQDzANsAzwDXAOYA0QDfANEA0QCoAIkArQC3AJmAaQBogGqASoAzAFsAXUAuX/yf/QANr/Kv7g/QD+iPwY+sD4oPlQ+hj5wPZg9RD18POw8pDyEPMA8gDwIO8g76DuQO3g7EDtIO1g7GDsoO3A7uDuYO5A7kDvAPEA83D1YPew96D38Pgo+0j94/8UA6AFIAawBbgG8AjQCuAMIBAAEiARQBDAEUATABMgE8AUIBXgEkARYBJAEyARgA4gDsANAAzACiALEAuACDAFiANsA0wDHAPwAgwCNQAU/lT9cv7a/5P/LP6o/eT9oP1M/Xr+///r/5r+Yv6I/z4Aj//6/vz+Sv5w/Rz+7v82AD7+oPsY+sD4UPdw9/D4qPlQ9zD0APIw8EDuwO2g75DwYO+g7cDswOug6iDsYO+w8MDvAPDw8RDzoPNA9tj5APuI+pT8wgAwA/wDQAawCLAIwAewCdANgBCgEUAS4BEAEEAPIBGAEwAUYBPgEmAREA8wDjAPkA/wDSAM0ArACSAJkAmACVgHgAQMAxgDfAMIBKgErAPBAFD+QP61/wIBzgEQAvQA2P46/rv/FgEuAUQBqgEOATMA5gAYAjgB7P4A/rj+yP4y/s7+yP5I+/D2EPbw9kD2cPUQ9jD1sPCA6+Dq4Ozg7IDrAOtA6qDnIOYg6CDr4Otg62DsgO1g7cDucPKg9rD4UPnI+rD9UgEYBKgG8AiACkALoAzAD6ATQBUAFYAVoBaAFqAVoBYgGYAZ4BaAFKAUoBTAEoARQBFgEIAN0AqACpAKMAnQBhAFtAPgAZgA/wDYAYIAcP1I+1j7PPyk/MD8AP2w/ID7qPoI/Eb+cP6Y/cj9sv7M/gP/SwCIAVsAAP7M/af/ggDe/yL/Ev4I/Ij5wPhQ+QD5cPfg9eDzoPHg78Du4O0g7ODqYOoA6qDoYOjg6KDogOhg6mDtQO5g7YDtkPBg86D0APgk/SIAtQDaARAEAAYgBzAKcA8AEiARIBKAFWAWABTAE+AWgBhAFyAX4BhgGIAUABKgEgASgA9wD8ARwBAQDHAI6AcQB9AEWAT4BcgF5AIgAKr+RP0I/Nj80v7s/oz9iPyw++j6kPtE/Yr+kP6O/h7/Nf/c/v7/sAHWAOT+Dv+QAPAAjQCWALH/rPzY+TD60PvQ+nj4UPfw9ZDyAPBA8EDwgO2g6gDrQOug6SDo4Ogg6MDlYOZA60DvoO6A7kDwMPAA7+DxMPrfACACwAHMAnwDtAOAB3ANwBAgEeARABRAFSAVYBWAFqAWIBZAF6AYwBjAFyAWQBMgEJAOYA+gEIAQkA8QDcAIyASYAxAEOASABLAEBAP8/rD7sPuo/FD8nPwo/sj9KPtY+vD7PP2k/OD8Dv/Z/9L+Wf/+AbACJgEeAFEAAAE8AXACeAP6AaD+ZPyQ+wj7aPuI+0D6EPew88DxcPBg76DuYO3g6gDpgOgA6ADnwOVA5QDlYOVA6KDsIO+A7oDtoO2A7lDxwPfi/4wD3AIsAgwDaAR4BwANoBLgFAAUIBQgFqAWgBagF4AZABpAGQAZYBkgGSAXYBQAEoAQgBBgEPAPEA/gDNAIsAQEAyQDUAM0AyADrgHk/RD6aPlA+4z8mPww/ND76PoQ+nD66PuU/RD+jP34/aL/7gAmAUwBqgHpAGD/6f+gAkAExAI9ALL+GP0Y+xj7zPyo/ED5sPXA8+Dx4O+g71DwYO6A6gDoAOjg5wDnoOZA5kDloOUg6SDtwO7g7gDvQO4A7vDxKPpEATgEkAQoBLACKAPwCGARABbgFaAVwBUgFWAVwBhgHMAcYBoAGSAZABlgGMAXABbgEoAQYA/QDpAOYA6gDCAIWAMUASgBqgFcApwCQQA4+3D30PfY+Yj6oPqA+0j7KPnw9wj6lPys/HD8aP28/mH/xABkA1gEgAJEAIMAIAKgAygFsAXIA8r/EP2s/Nz8zPyA/FD74Pdw89DwgPAw8IDugOzA6oDoQObg5QDmAOVA40DjwOWA6MDqwO1g7yDtIOuA7aDziPokAAAF0Ab4A4wBaAUgDSATwBYAGeAYABcAFgAZoB0gH4AdIBzAG2AbwBoAGsAYIBeAFCARAA/ADlAP8A3wCoAH+AOtAK7+///QAUkA8Pv4+Jj40PfQ9uD38PnY+eD34PeY+UD6oPnQ+gz9GP1w/BH/HAPAA4gBdwAUAekAFgGQA0AGaAV6Adr+uP04/FD7SPwA/bD6UPag8pDwYO+A7gDuIOwA6SDn4Obg5QDkAONA4yDjQORg6KDtYO+A7WDswOyg7hDzoPuwBEAI0AZIBCgEkAfQDeAUQBrgG6AaYBiAFyAaYB4AIGAeAB0gHeAbgBkAGcAZIBfAEZAOsA5QDgAM8ApQClAG0f+U/Fj+6f+e/pT8+PpI+PD0kPRQ97D4kPcg90j4cPhg90j4KPvo/ET8mPxv/4wBMALwAlwDJAL9AKgCWAWwBrgFMASYAsb/lP2s/Tj+SP0A/Fj6APdQ8mDvYO8g74Ds4Omg6aDogOVg44DjIOMA4aDhQOag6iDsAO2A7oDuAO1g7qD1yv4wBVAIwAhgBxAHIAqQDyAWAByAHgAdQBpAGgAdoB7gHsAfACBAHSAaYBpgG2AYgBNgENAOwAzQCuAL4AvABjcAYP2I/fD8HPyE/Nj78PdA9KD0YPYA9pD1APjg+Rj4kPZo+GD78PtI/Mr+ygAAAbQBwAToBTgEBAOgBIgGOAbYBfAFGAUoAr7//P7Q/TD8kPvY+gD4IPPA72DuwOyA6kDpAOmA56DkYOKg4WDgAN8g4KDjQOeg6aDrwO1A7kDtAO7Q8mD6OAKgB6AJwAmACRAKQA0AFGAbgB/gHiAd4BygHAAdIB/AIYAhAB7AG0AbgBqgFwAV4BIwDyALUArAC4AK2AXrAPD9mPvw+Wj6sPtI+oD2EPRw84DysPGg8zD3mPhQ93D2MPcY+Dj5DPxU/58ABAEMA5gFCAbYBPAEaAZgB9AHgAgQCZAHsASYAlIB4P+Y/ij+WP1Q+qD10PHA7+Dt4Osg6gDpoOeg5cDjIOIA4EDeQN6A4GDkQOhA68DsoOwA7CDsgO9A9pb/gAYACTAJAAlwCXALgBEAGgAgACAAHoAdoB1AHeAeACIAI4AgYB1AHKAbgBngFuAT4A+gCzAKEAuwCpAHBANu/gj60Peo+ID66PlA9/D0MPMw8YDw8PKQ9tD34PbA9uD3wPjw+dD86/+6AH0AaAJ4BqAI+AdoB9gHiAdYB3AIUAoACugG1AM8AsEA1P7A/Rj9uPog9sDxQO8A7iDswOmg54DlYOOA4YDgAOAA34DdAN6A4UDmoOlg66DsQO3g7ODucPVi/sAFoAlgC7ALQAtQDAASABrgH8AhACEAIIAeQB5AIAAjACSAIoAfwBzgGqAZIBhgFeAQYAwwCvAJ4AmgB9wDJf84+pD2sPYQ+bj5sPfA9MDykPDg7qDwYPVo+FD3wPVg9vD3MPmw+3z/kgEwAXwBmAQgCCAJgAhgCJAI+Af4B1AJgApQCYgFSAKqAHf/FP4I/Zj7QPhA86DuYOxA68DpAOhA5kDkAOLA3wDewNyA3ADewOEA5oDpwOvA66DqwOpg7vD1Ov7QBAAJ0AvACxALIA3AEkAZAB4AIUAiQCGAHkAeQCFAI8AhQCCAH6AdYBpAGAAYgBWwDxAKMAgACDAHqAYoBREA2Pgg9ED0oPYA+LD3EPYw8xDwIO/A8KDzcPZY+Kj4APi4+HD7RP7i/0IBoALQA4gFoAjQC3AMQApwCNAIMAkACXAJMApwCEgEYQA8/tz8SPsA+gj4IPQA76DrIOpA6MDlQOQA4wDhQN9A3oDdANyA3KDgIObg6KDqgO0g7sDs4O7g9q7/AAWgCDAN8A/wDtAOoBOAGqAewCAAIwAkwCFgHwAgQCLAIoAgQB6AHIAagBcgFYASwA7QCVgG8AQgBPACJAF6/sD50PRA8vDyIPTw9KD1MPQw8YDvIPEA9AD2gPfQ+cD7+Ptw/Eb/YALQAxAFGAdACaAKUAwgDmAOkAyAChAKUAogCjAJuAcoBRAC/v6Y/Fj64PdQ9UDywO7g6uDn4OUg5IDiAOEA4IDeQNxA20DbQNwA3+DjoOkA7SDtYOzg7SDxwPbm/rAGUAvQDFAOYBDgEoAVwBkAHwAiQCIAIgAiwCFAIQAhwCBAH8AcQBqgGIAXABUgEWAMMAgQBawCMAH3AEAAeP3w+LD0APLw8NDx8PMg9eDzkPFg8ODw0PKg9XD4gPqg+4z8Iv65/4oBGATIBrAIAApgC9AMgA2ADRANoAywC1AKgAnQCEgHgATWAa3/eP04+qD20PMg8eDt4OqA6CDmYONg4aDgIOAA3wDdwNsA20DcwN+g5ODpIO7A74DuYO3A8MD4MAEwCEAN0A/AD4APoBLgF4AcoB9AIsAjACNAIUAhACKAIcAf4B0AHKAZoBeAFoAUABDACfgEfAIOAev/Xf9g/lj7gPZg8pDwEPBQ8NDx0PPQ8/DxEPGA8pD04PXQ93j6vPxi/ucAwAMYBTgFuAawCSAMcA0AD4AQIBAQDpAM8AuwClAJkAj4B5gFtgFe/lj8qPmg9YDxoO6g7CDqQOcA5SDjYOCA3YDcAN2A3EDbANtA3QDhoORA6UDusPBA78DusPKg+nQDgAoAEKAS4BHgEGAT4BiAHkAiACTAJMAjgCGAIEAhgCHgH6AdoBtAGWAWYBSAEiAOEAi8A/4B8wCK/9D+cP2o+ZD0APLQ8aDxgPHQ8nD00PPw8RDygPSQ9rD3UPnY+6D96P50ATAFCAfwBiAHQAlgDOAN0A4AEEAQIA6gCyAKUAlQCMgG8AW4BAIBNPyA+ZD3cPQQ8KDsoOqA6ODlIOTA4iDggN3A3MDcQNvA2YDbwN+g48DmgOsg8PDwIO8w8ID1+PwgBZAN4BMgFGARgBEAFqAaYB5AIgAlwCTAIcAgwCFAIcAewBxgG2AYYBXAFGAUoBAACigEegAk/kT9UP6g/qD7IPeQ8+DwAO9g7+DxQPRw9KDzoPMg9AD1MPcQ+hT8JP0h//wB8ATYBpAIkAngCbAK4AxAD2AQoBBAEOAOQAwACtAImAeoBVAE0ALp/8D7aPgg9vDygO4A6yDpIOfg5IDjoOLA34DcwNuA3IDcwNtA3eDgoOQg6KDsEPHQ8qDyIPSg+E//8AZADsAT4BUgFeAUwBbAGqAfACNAJAAkgCIAIeAfAB/gHQAcgBnAFoAUQBLgD5AMMAgUA+r+gPzI+yT8kPuI+fD1sPKQ8MDvAPBw8ZDzcPRQ9GD0QPXQ9vj4iPsG/qL/ogCUApgFYAhwCgAM4AyADSAOIA8AEIAQYBDgDyAOUAtgCOgF0AM0Am4B9v8c/QD50PQw8YDtYOkA5yDmoOVg5ADigN+A3QDcgNvA3ADeQN9A4aDkQOnA7UDx0POw9RD3uPny/hAGsA1gEyAWoBZgFqAW4BjAHIAgwCLAIoAhACBAHgAcQBogGcAXoBXgEkAQsA1QCuAF6AEI//T8aPuY+vj5ePgQ9qDzYPKQ8QDxUPHw8nD0UPWg9bD2YPgY+kT8sv7OABgCXANIBUgHQAmAC7ANEA9gDyAPsA4gDgAOwA7ADpAMwAj4BAgCGwC5//T/Qv6w+VD0MPCg7EDpgOeg50DnIOXg4QDfgN0A3cDdwN6A3yDggOFg5ADpYO6w8iD1gPYA+JD6qP4YBTAN4BMAF0AXABdAF8AYgBugH8AiACNAIWAfIB5AHOAZYBhAFwAV4BEwD7AMQAkABTIBpv58/Pj6OPqQ+RD4oPWA8xDyUPGQ8aDyoPNA9AD1EPYA9yD44PmQ/Cf/oABMAkAEuAUIBxAJcAsgDdAN8A5AECAQcA4wDhAPYA7gC6AIiAUQAqv/CgAiAd7+ePkQ9ADwQOyg6aDowOgA6IDlwOJg4MDewN1A3sDf4ODA4QDjoOVA6gDv4PIw9VD3SPmQ+2n/UAWQDKASQBaAF2AX4BZgFyAaQB4AIcAhACGAH8AcgBmgFwAXwBXAE8ARcA+wC2AHoASEAr7/wPyg+zj72PkY+BD3oPZQ9RD0QPSQ9AD0QPRA9oj4oPlw+kz8Gv4I/3AA9ALYBGgF2AZwCTALoAvQDNAOEA9wDXAMMA1ADRAMEAtQCSgF3P8s/XD9AP5M/aD6EPbA8ADs4Ohg5yDnwOcA52DkQOHA34DeAN5A30DiwONg4yDlYOrA72DzEPbw+ID6MPt0/ggFYAzgESAW4BigGOAWoBZgGeAcwB7gH4AgYB9gHIAZgBdgFQATgBGAEDAOYApQB0AFaALy/lz88PoQ+eD38Pd4+OD3sPbw9SD1cPOw8rD0wPe4+dD6UPx0/ZD9NP6uAIwDcAQwBbAHMArQCgALUA3QDsAN0AsADAANYAyQC0AL8AkoBYb/EPw4+xD7KPuA+qD3MPMA7kDpAOYA5cDlQOZA5cDjIOJg4IDfQOGA40DkAORA5mDrcPCA9BD4EPso/AT9fAAgBpALoBDAFWAZgBnAFwAYwBlAG0AcIB5gH2AeIBxgGgAYQBTgELAPwA7wCxAJuAdoBrQC8P4o/Pj5sPfA9hj4APlY+PD2gPag9QD0sPPA9Uj44PkI+8j8RP72/hMAVAJABBgFYAbQCBALoAsQDHANMA5QDYAMAA2wDTAN0AtwCvAHWAN2/mD7YPqw+rj6uPkA94DygOwg54DkgOTA5UDmIOag5ODhgN/A3yDioOMg5EDlgOgg7EDw4PRo+XD76Pv0/dABWAbgCqAQwBUAGIAXoBcAGQAagBpAHAAewB0AHMAaQBoAGMAUQBJAECANgAkACKgHAAZUA7kA2P0Q+jD3IPcQ+Dj4kPdw9xD3oPWg9BD1UPYw9wD4WPn4+mz8AP4aAAACSANIBEgFiAYACKAJMAtADNAM4AxgDBAMgAzQDPALoAmoBtAC7v7w++j7eP1E/bD6IPeg8qDsgOcg5qDnQOhA5wDmoOTg4SDgYOGA4+DjwOOA5eDoQOxw8JD1WPlQ+hj7Gv6YAhAH8AuAEUAVIBYgFkAXABkAGkAbIB0AHsAcIBuAGuAZoBeAFAAS4A9ADcAKcAlACMAFbAKg/4T9CPvY+ID4uPjQ94D2wPXA9YD1sPTA9KD1cPZg99D4yPqI/OD9Lf8QAfACOAQYBXAGcAhQCkALQAygDSAOEA1QDAANQA2AC2AIIAbgAuL+4Pzk/Qn/lP0Y+uD10PDA6iDnQOfA6CDpgOeA5SDj4OAA4EDh4OIg5MDkQOYg6SDtYPFQ9cj46Pow/Gb+GAOACAANwBCAFEAWABbgFmAZoBsAHEAcQB0AHSAbQBqgGiAZIBWAEQAQMA6QCxAKwAmoB2ADwf86/tT8yPqQ+bj5UPmQ92D2cPaA9rD1EPXA9fD2YPc4+FD6mPzo/Wz+jf9kAdQCzANIBRgH0AgwCkAL4AvQC5AL0AuQDOALsAmABmQD1ADW/mz+iv8vAJj90Phg82DuwOpg6QDqIOpg6GDmgOWA5MDiQOKg4yDkIOPA40DngOuA79Dz8PeI+UD5wPpg/2gE8AjQDUASQBSAFEAVYBdgGcAa4BsgHGAbwBoAG0AbQBrgF8AUQBFADrAMEAyQCkAI2AVsA3AAuP1s/Mj7ePpg+GD3MPdw9pD1sPUQ9lD1sPSw9cD3yPjg+QD8AP5q/sD+AAFUAwAE0ARQB0AJcAlACmAM4AxgC8AKAAwwCwAHIASIA/ABpf/+/8ABBABg+mD1cPLg7oDrwOoA7EDrwOjA5uDloOSA48DjYOSA5KDkgOYA6kDu0PHA9OD26Ph4+qz8ngDgBeAKYA7gEKASwBPgFEAXoBlgGqAaYBvAGyAbgBpgGmAZgBZAEwARUA9gDSAMIAvgCHgFfAJnAFb+aPxI+9D60Pk4+PD2EPZg9dD00PQg9YD1IPYg95D4uPno+lz83P0P/1cAPAIIBGgFeAYQCBAKsArQCoAL8AugC2AK8AjYBggE9AFUAkwDkAKNAPD9MPpA9XDxAPBg7yDugOxg68DpIOgA5yDnoOag5QDlAOVA5gDp4Oxg8DDzIPVw9lD3UPkQ/aIBaAXgCEAMcA5wD+AQoBPgFWAWIBdAGIAYIBjgGCAaYBkAF+AUIBOgEGAO0A2gDcALAAkYB0AFSAJ4/2r+uP1M/GD6mPkA+aD3YPZQ9mD2wPVw9SD2IPew95j4iPoU/HT8DP2K/jMAMgGoAoAE4AWQBmAHsAjwCPAIMAlgCKAFSAPkApgDuAOkA7wDVAHQ/Jj4sPbw9EDzcPIA8gDwQO0g7ADsAOtg6WDoAOhg5yDnQOng7MDvkPEQ8xD0APWQ9qD5oP0aARgEyAZgCWAL8AzADgAR4BLgE0AUQBWAFiAXoBcAGMAXIBZAFAATwBFAEBAPUA4ADeAK4AhAB0gF8AISAbz/Hv5k/CD7UPpg+Wj4kPfg9jD28PUA9jD24Pbw98D4QPkY+kD7OPz8/HL+gQDUAVwCiAPgBLAFAAZYBkgG+AQMAywC+AIABJgEgAQsA8AAHP34+VD40Pcg9/D1oPRw8/DxUPCA7yDvAO4A7EDroOsg7GDtEPDQ8sDzkPNw9CD2YPcQ+VD8vP+yAVwD8AWQCPAJMAvgDDAOcA4AD+AQoBKgE0AU4BTAFGATwBHgEKAQABAQD1AOgA1wDPAKQAnwB4AGoAS4AlQBCwCI/oT9UP0g/bj72PkY+SD5kPgI+Kj4kPmo+UD5yPkg+/D7aPxs/VD+OP5E/u//GALkAvACXANAA1ABcv/B/z4B1AH8AYgC4AEv/3j8mPsI+0D50PfA9zD3QPVg9CD1UPWA84DxoPDA78DuYO/w8RD00PRg9VD20PYg9zD4CPqw+wj9Hf+sAZQDGAX4BrAIUAmQCVAKQAvgC9AMoA4AEIAQgBCgEOAPQA5ADSAN4AwgDAAMYAywC9AJcAioBxgGCATgAkwC+wC5/8X/GAD2/jz9nPxE/PD6MPrg+qD7GPvA+rj7aPwU/BT8MP2U/dD8BP2G/of/xf+BAFYB3wBs/7j+Jv+a/9v/KQBYAKP/oP6k/az8+PuA++j6yPnQ+ED4APiw98D3kPew9mD1wPSA9GD00PQQ9kD3gPfA93j4SPmw+Xj6oPts/Cj9iv59ANoB6AJABJAFCAZABhgHIAiACAAJ8AmQCsAKAAuAC5AL8ApQChAKwAkwCQAJIAnQCAAISAeoBsAFsAQQBLADEANIAuABnAHLAMz/av9O/+T+TP4u/nz+SP4I/kD+mP58/jb+Rv56/kb+Lv7i/pT/p/+U/63/Z//Y/qT+8P4s/xz/D//y/nT+/P3g/ZT91PxU/DD8qPvw+rD6APvA+hD6qPl4+dj4OPg4+Mj4yPh4+Kj4GPko+QD5kPmA+gj7IPuQ+0z80PxI/UL+ev9DAMYAdAFMAtwCdANABMgE4AQgBdAFcAaoBvgGmAfwB5AHIAc4B3AHYAcoBxAHCAfABlgGGAb4BbgFUAXQBCgElAMMA7wCiAJIAtIBTgH3AK4AZgDt/6X/m/9y//T+yv4l/0T/Av/O/v7+wP4o/vz9fP7I/oL+cv64/p7+JP74/S7+5P08/QT9OP00/cj8lPy8/Kz8APyI+5D7YPu4+lj6wPoQ+9j6wPpA+4D72Pog+lD60PrA+sD6iPs4/Ej8NPzg/Lz94P24/Rj+2v5H/8v/xgC6ATwCfALEAgQDLAM0A5QDKASYBOgEMAWoBegFyAWQBYgFgAVABSgFiAUABsgFSAV4BaAFEAVIBDAEcAQgBIgDXAOEA2QDBAO4AnwC+AE4Ab8AtgDGAKgAYgA7AFgADgAm/57+5P4I/0T+mP1E/uD+Iv5M/ez9fv5k/Uj8yPxY/YT84Puw/ET9XPy4+1j8rPyg++j6aPuI+5j6kPq4+/j7CPuQ+jj7YPug+kD6CPt4+0D7gPtY/OD8uPzo/LD9Hv7w/Tj+Ff+o//D/egBaAeABxgG8AVQCFANAA0gD7AO4BMgEaATIBMgF8AVYBUAF6AUwBqAFgAVIBrAG8AVgBZgFwAVIBQAFQAX4BDAE2AMgBOwD+AKIArgCaAK0AY4BcAG1ABgAIAAZAF7/uP4h/2//WP5w/ez9YP6w/ez88PxM/Sj9gPx0/AT93PwQ/MD7MPyE/Cz8wPv4+zj8yPs4+3j7+PvY+2D7kPss/Bz8cPtI+9j7UPwU/Mj7RPwM/RD9pPwU/Rr+XP7g/R7+Uf/x/33/mv+9AEIB2gBIAWgCfALsAWgCkAPAAygDeAPABOgESAS4BFAFyARABAAFoAUwBcAESAWoBdgEMARwBLgE+AMkAzwDjAM0A4wCTAJEAgwCJgGGAKoA6QAYABb/fv8xAIj/ZP5i/vz+iv6E/Yj9JP4I/lD9RP2U/aD9XP08/WD9WP0c/eD8FP1Q/QT9zPzo/Cz9OP00/Rj98Pz8/PT8CP00/WT9XP1Q/VD9cP28/ZT9dP3s/Wz+Jv70/Xj+DP8t/xL/ZP/h/+r/5P94ABABFgEqAbABCAIIAiACdAKYAowC4AJsA5wDcAOIA+ADuAN8A9gDQATsA4gDwAP4A3gD7AI8A3ADwAIgAlgCeALYAVwBjgGYAdMAXgCqAJIA4//H/xgAvf8Z/zH/q/82/1L+cP5T/wb/FP5I/jX/Hf+0/bz9oP6W/oD9cP3C/qD+VP1E/aj+dP7U/MD8Hv6K/oj9NP0g/nr+eP08/Sj+fv7k/aT9IP5o/nz+fv66/vL++v43/zX/K/9m/9v////a////UgDCAPEA2wAGAVgBmgGGAVYBmgEsAqgCoAJYAkACcAKAAnwCyALUAmgCTAKAAoACOAIAAiACNAK6ARABFgFwATAB/gAgAeAAeQAgACkAagBVAKb/TP+b/2b/Bv83/8P/Y/+E/oz+OP8N/yT+Uv42/wn/DP5w/nj/R/98/pD+BP/G/mb+wP6B/1H/lP6i/l7//v50/r7+DP/s/pL+cP7k/rf/Pv9g/q7+c/8v/1L+jP5u/3P/3P5D/ysAsP/m/r3/TQCI//D+IwAcAW8A7//MAEwBRAAiAEAB/gH3AE8AaAFYAuABuQAGAWAC6AJIAUwA5gHUApoBWgCmATAD+AGo/z8AjAIEAqr/yv80AsIBkP7c/gQCoAFM/nT+3AF4AdT98P1iAfMAmP08/k4BigBs/T7+QgE5AGz9av7nAIf/wP0N/1EACf9Q/aL+4v8G/yD+yv4x/8z+pv5u/uL+AP+W/qz+Jv9n/4H/JP+4/nf/qf++/g3/TwDC/17+M/8AAdEAS/9J/7YAuABf/73/VAEwAeD/aACGAbwAUgBOAdIBAAHw/9MAUAJ2AZgAAAJAAksATQBEAjwCiQCEAFACLAIAAC4AVAIoAhEAfgAgAhIBKP81ACAC/gCY/yEAnQAUACgAgQAQALP/kf/D/4L/Lv/G/0QAwf8c/0z/BP/m/m3/a/8E/wT/CP9A/rb+fP8P/8b+6v6E/sT9NP4//2X/Hv4G/sv/7v82/rr+kgB9/9z9D/96AJ7/BP8kAK8AiP/0/iUAvQB7/wf/fQBEAUAA3v/YAFYBzACe/1//swCEAWYAuP8OAbAB6AC+/9j/6wDKADMAdAA0AcIADABXAAIB8QC6/+v/KgHpAO//TgB0AR4Bsf/j/3gBQAE7/+b/ygHwAI3/2P8iAfMA+P+E/ywAcwD4/xIAp/9I/ywArgA9/+D+ZgD9/7z9NP7oAFsAuP0K/qQAaQDE/Rr+dgAZAMD9fv6EAOL/yv5J/ygAi//u/mD/BQDg//H/vABlADz/Qf+pACgBjQBYAMAAuQD8/+X/2gAmAVQApf8cAKsAUwAQAGgACAFCAcwAYADjAFIBTgAT/9r/dgEKAST/fP+GAboAav7m/jwBpwBo/tb+ywCfAGX/dgCqAaQAOf/X/70AhwD7/97/+P+YAFgBoAC1/8cAsgHW/gD9lf/CAbb/DP7hAJgCBf+I/Mr/1AGk/pz8cf9iASz/Hv4UAXgCEP/0/HL/+wBw/nj93ABcAmr/yP0hAJQBp/96/vT/vAAl/4j+cgB2ATIApP9fAA0AJv+a/54AWwBv/wj/gP8aAFIATQDy/9//OQAbANz+Qv5a/3YArAAgANT/HwB1ACoAx//y/wYAuP9P/8D/rADwAK0AywCLAIX/kf+AAIMAef/m/3wBMAE1/z//aAGkAQEAwP/VACIA9P7N/14BOAEoANoAqAFUAN7+6v8MARYATP8YALoA5f94/1QAhgBo/9T+Sv8S/5T+gf+iALH/Uv5l/9kArf/s/f7+ngBM/3T91P50ASIBQf9U/1YAaf9e/nT/rgDm/9L+BgBkAYEAOv/v/5kAmv/q/sf/5ACtANH/KgDHAAcARP/z/1QAhf9A//H/oABfAO7/PQCPAN//Mf9d/5H/5P8nAD4AGQA8AJ0AoAAxAAYAkQCnAD8ATQDHAOEAYABeAOgA5QApACAA8ADxAEUALACiAHoAKgBOAGUADgALAFsAFgCL/9n/jgAtADH/af+cAJkAm//l/9IAVgBy/+D/mABwAO//OAD5AIoAf//p//QAswDx/xIAgQBMAJ7/q/9NAGQA1v+1/9f/c/8X/1T/z//c/4b/Mv8a/yH/Rv+d/+D/yP9l/wz//P4d/13/t/8eAGEACgBP/z3/5f9GAP7/b/93//z/QgD9/xwAhgBpAL//Sv9+/+7/7f94/3D/s/+6/8H/JgBnABUAl/+A/6v/gP+D/zcA1AC5AJUApwB4AA4ADABOAEkAWADwAHgBFAG0AEgBzAEIATsAwQBkAS4BIgHgAQwCOgHaAGgBggGHAPP/iwDvAHMAbABGAawB/QBLAEAALACi/3n/2f8OALf/vP8pAD0Avf9v/5D/Xv+K/sT92P1a/nb+Uv5c/mD++P1E/Yj8EPyY+yj76Prg+vj6MPtg+1j7MPsg+/j6oPqY+tj6cPts/MD9wv5m/yEAOAHaAeABUAJkAzgEYAS4BMAFmAbABvgGkAf4B9AHuAfoB/AH2AcQCIAIsAhgCBAIAAjYB4AHcAeoB4AH8AZYBrAFEAXABJgEIAQwA3QC9gFKAXcAJQAQACH/TP2Q+yD6iPiA96D3oPeg9nD1EPVg9JDyQPEQ8eDwoO/A7sDuoO5A7uDtwO0A7UDsgOzA7YDuwO9g8tD14Phg++z9BgB0ARgDaAUwCEALAA+AEkAUABUAFuAW4BZAFuAVQBXgE2ASgBHAEJAPMA6QDHAKsAcgBUgDbAGj/2L+zP1E/eD8EP30/cL+rP4g/oz9PP2U/fT+XAHEA6AFGAcgCKAIsAggCcAJMAl4BxAGiAWoBGwD7AKgAmoAcPxw+AD1kPGA7uDswOvA6cDnYOdg52DmgOXg5cDlIOTA4wDmwOlA7XDwkPPw9OD0MPXA9jj5CP28AdgFkAhAC+AO4BHgE0AV4BUgFYAUABVgFkAYoBqAG2AZQBWAEVAOkAqgB3gGGAVoAh8AcP/M/tD88PqI+cD2EPMQ8QDyIPRA9vj4ZPwV/7cA2gH4AvAD+ASIBrAIcAvQDmASQBVAF4AXIBbAE6ARQA+wDHAK8AiQB+gFtAPcADD9sPgQ9EDvwOqA54DlAOQg46DigOIA4qDh4OEg4gDigOPg5gDqQOzg7xD1ePjg+DD5+Prw+lj5SPrI/tADwAhwDiATYBOAEHAPgBDgECAR4BKgFaAWgBYAFyAYYBjAFiATQA0gB7wCpADZAGACZAMIA1gBoP6Y+hD3cPXg9ADz0PGA89D2oPls/IoAyAPAA8QC0APABUgHoAmgDYARoBNAFSAXwBcAFqATYBFgDuAKIAh4BhgFMAPMAJj9ePlQ9XDx4O3g6mDoQOZA5IDioOFA4kDjgOQA5mDnIOiA6GDqwO1g8cDzIPaY+Xz8xP3S/tT/nP9Y/Yj7HPzM/qwD8AngDiAPoAxACqAJ8AkwC4ANUA8gEAARIBLAEqATABXAE7ANgAY4AsAACwD+ANgDMAW0Atb+kPzI+kj4UPdY+Bj4UPag9pD6g/80A1gGkAgwCNAFWAXIBwAL0A0AEYATABSAE8AToBOgERAPwAzgCZgFFAKPAJr/GP3o+XD3UPTg72DsIOtg6oDowOZA5qDlAOVA5oDp4Oug7CDucPAQ8WDx4PSo+XD7mPtg/lABHQAK/mX/hwDI+/D2iPnK/sQAnAMgCsAMIAeIATADYAYYBlgH4AzgEMAPAA/gESAU4BJAEFANMAioAtAAAAMgBcAFmAXIBIYB0PzA+bD5GPpQ+Yj4+Phw+iT8u/+gBBAI4AegBgAHwAdACOAKIBCgE+ATQBOgE2AT4BGAELAPQA1ACegFSAMGAOD8ePtg+kD34PKA72DtQOuA6SDpYOlA6CDmgOXA5oDoQOoA7TDw4PEg8qDzoPZ4+ED5OPuu/n8An/+//xQB7f80/Dj5sPhg+fD7FAKQCLAJoAbQBPgEeARgBAAIAA0QD9AO4A9AEkATIBOAEuAPMApgBBYBVgAsARgDiARkA48AiP1w+rD3QPcg+WD6cPmg+Zj8AQCIAtgF4AkQCyAJEAjgCYAMEA9gEkAVYBWAE0ASgBEAENANAAzQCSgG8gGk/tj7+Pjg9sD10PMw8GDs4OqA6mDpYOgg6QDq4OiA5+DogOyA74DxMPRw9rD2wPbA+Jj7SP3g/r8AvgE+AUwAYP8A/SD6oPfA9RD28Po4AggGQAUoBNQDkAHf/ywDkAlgDYAOgBDAEuASwBLAEyATkA6gCOAEoAKfAGgA0AK4BDADMv+I+4D5wPho+Oj4QPoI+wj78PtO/5QDYAZgCJAKYAvwCXAJ8AyAEYATQBRgFUAVwBKAEOAPoA5gC3AIgAb0ArD9EPpg+DD2EPMg8eDvwOxg6YDoYOlA6WDoQOgg6YDpAOrA6yDvMPPw9WD2cPYw+CD68Pqw/EgBUASAAsP/BQBZ/3j6APWg83D0sPSg94v/QAcwCCgEqwBg/xD/MgB4BVANwBJAFKAUgBYAGMAWgBOgEMAMyAbUARYBfAL8AjQDpANMAVj7kPag9dD1kPVA9/j62Pwg/fj/6AQQCKAIAAoQDGAMAAwgDqASABbgFqAWoBVgE0AQcA3wC+AKoAj4BMgBQP+4+4D2MPIw8aDwoO0g6gDpIOnA6EDpQOsA7ADqQOkA7IDuAO8g8nD4GPzA+pD5ePuU/Aj8Zv74AkQD9P+y/6oBJP4w9mDyAPMA8tDwsPZmAZAHmAYoBN4BbP6o/AwBcAmwD6ASYBVAGEAZYBigF0AWQBJQC+gEHAGy/zMAxgHUAjABSP2g+HD08PHg8SD0MPcI+vz8KwDQAlAF8AiQDNANUA3QDVAPwBDAEgAWwBggGKAV4BKAD5ALQAngCFgHAAQoAf7+YPrA88DvIO9A7kDrgOlg6UDowOZg6MDrAOwg6sDqIO5g8JDxgPUI+1j9SPzA+7T8YPxQ/JH/jANAA2QAtf+k/yz8sPZA84DxQPCw8cD3if8YBdgGIAXPAHT96P2kAfAGUA1AEwAWIBZAF8AZoBlAFkAS0A2QBy4BcP4O/+f/t/+0/vj7APdw8nDw8PDg8hD20Pk4/WAAhAPYBpAJMAzgDuAQYBEAEqATYBVgFkAWgBUgFCASABAwDkAMkAnwBigEtgD4/DD64PdA9ADwYO3g60DqAOng6cDqoOlg6IDpgOog6kDs0PEQ9yj5wPr0/QMAoP68/HT8fPyY/Dr+GAFEAkoBx/8A/uj54PPg7sDsQO6g8xD7NAKwBgAH6AO4/3T90P6oAhAIEA5AE8AV4BYAGQAbQBqgFXAPcAncA8z+IPzw/Af/1v6g+wD44PSQ8QDvcPBA9VD5gPvw/hAEcAegCMAKwA7AECAQwBCAE+AVQBYAFmAV4BKQD/ANwA3wDEALcAloBsABVP3o+lD5EPdQ9EDxwO0A6gDogOiA6SDqgOrg6SDogOfA6qDw0PVo+YD8zv4U/+b+qf+i/yb+uP3q/nn/S/+WAIwChgF8/bj4MPPA7ADpwOsQ81D6AAFYBogHVAMq/qD8SP5UATAG4AygEoAVABcAGkAdIB0AGQATgAwgBWT+iPtg/Mz9VP2g+xj5APUw8IDtgO7A8aD1iPlo/XoBAAZgClAN0A4AEMAQwBBAEaAToBagF2AWwBSAEjAPUAywC4ALoAggBCoBqf+M/Tj7IPow+ADz4OzA6cDooOcA6IDrwO0g62DnYOiA7MDvgPMA+Sj9zP1u/jgBMAMkAu3/cv5g/cD8kP1S/74AegFuAMj7kPTg7qDrYOqg7CD0iP1oA3AFyAXUAxb/DPx6/jAEEAmADYASgBYAGIAZQBzAHIAYABJgC2gDQPug97j5lPxQ/Lj6aPkw9vDwYO4Q8TD1UPg4/JYBUAYgCdALoA8gEoARQBCAECASQBNAFGAVgBWAE2AQkA0QC8AIKAfIBTgDGABg/j7+wP24+0j4QPMA7aDoYOdA6CDqwOzA7mDtYOrg6aDrQO6w8qj4WPzg/Fj/kATIBZ4Bsv5O/9T96Pmw+h4AKAJO/4D9iPzQ9kDuIOrA62DukPLA+mAD0AYoBZwCRQAo/q7+FAPQCNANQBKgFcAWwBYAGCAZQBfgEeAKDAN4+2D3ePhY+zT8QPvQ+QD3oPJQ8JDysPbQ+RD91AEwBmAJ8AwAESATwBEAENAPQBCgEMAR4BOgFIAS0A4gDBALUAlYBkAEQAQ0A9//aP0u/tT+IPxg9wDzoO4A6uDnYOnA6wDsgOtg6wDsoOyA7YDvUPMo+FD83v5mAXgEgAWgAuL+AP0A/Dj7yPynAAACoP8I/dj6kPWA7eDo4OoQ8CD27P3gBJAGZAOyAGMAJgDIALAF8AygEEAQwBDgEyAVgBSAFeAWIBOACc0AEPwQ+UD3IPm8/Pj8EPlw9fD0IPYQ+Mj6Fv5dAGQBBAOoBqALgBBgEwAUwBLgEHAPcA+gEGARABHgD4AO0AyAC7AKgAngBuwDCAKIAKb+yPxY+9D5UPcQ9HDwgO0A7ODqwOjg5mDm4Obg58DqAPDw83D1SPh4/e4A7gAsAbQCVgGU/SD8kP6YAO4AdAIoBI4BkPvg9hDzoO0A6cDqoPGg+Jb+GARwBhQDRP3Y+qz8qwBgBnANoBMAFsAUYBKgEPAPYBCgESARMA3ABnoAyPsA+aj48Pno+TD30PRA9YD3CPqY/VgCuAQ0AxoBLAKoBZAJ0A0gEkAUYBOgEQARYBCADnAMcAvwClAKUAowC+ALMAtACXgG8AJM/1z8OPpg+ED38PZg9rD0IPJg7iDpoOOA4ADgIOIA5yDuYPQg+Mj6AP3s/Yz96P2o/kz+yP01/8YBhAMIBaAGMAYkAoD8QPfg8cDs4OrA7aDzqPn0/kgD0AT2AQj8oPcg+KD8jAJwCQARQBbAFmAUQBLgD2AMsArQDDAOEAtQBuAD3AG8/Uj6CPkA9yDzIPEA9Kj47Py8AUgGYAeoBMYBMAEoAwgH8AuAECAUYBZgFmAT8A8gDlAM8AmQCfALUA0wCyAJwAnACeAGOANrANT8cPcw8/Dy8PQw9oD1cPNg72DoAOBA20DcIOGg5gDt0PRA++z9uP7M/xYAWP4c/cz9TP6C/j4BKAZgCfAJkAlQBqj9gPMA7UDqIOqA7nD38v5cAeoB9ALlAEj7cPcA+VT9+gGQCMAQoBaAF4AVABNAELAMAAogCsALoAuQCKAEzgG8/7D8OPlw9gD0EPKQ8jD3sP0EAygGUAfYBQAC5P7z//AEUAtAEaAVoBeAFiAT4A6wCugHEAjQCqANEA4gDeALEAogBzAEzAKeAfT+iPuw+KD2YPVw9dD14PPg7sDo4OJA3gDcgN4A5CDqkPDw95T98f+TAKkAGv+Q/Kj7/PyU/uAAiAVACqALIAoIB0IAUPUg7KDpAOww8JD2JP4EAsYAR//N//D+uPtg+uD8wv9cAnAIQBHAFmAWIBRAEmAOEAngBjAJQAvQCaAHGAb0AuT9WPqw+Tj4YPQQ8oD0mPkA/jACUAbgB4AFWAJKAVACEAVgCiARgBUgFkAUABFQDGAIkAfgCBAKoAsQDlAOwAvQCFgHaAVMAs//Mv6Y+1j5iPkY+hj4gPTA8QDuAOgg48DhIOGg4EDiIOcA7YDzyPvwAtgEqgFg/QD6wPdY+Oz8YAOgCFAMIA7AC9AERPyA9SDx4O6g73DzsPis/GD+7v6g/wUAJv/E/fz8TP1Y/pABAAhwD8ATABSAEoAQ0AwQCFgGIAlADBAMoAkYBzwDHP1w+FD4aPnw91D2iPis/Az/egCoA0AGUAW0AuwB6AKgBKAI0A4gFGAV4BPgEKAMoAgAB9gHsAkwDHAOgA4ADLAJkAiABgwDhABu/0z9iPoY+gj7yPkw9vDygO/g6YDkoOKg4oDhIODg4QDnAO4g9+UA8AawBRL/APjA89DzmPggAeAJcA+AEDANKAY4/eD1cPJQ8eDwoPIQ94D7CP3c/dH/TgCA/VD6APqY+uD6sv4gB7AOoBFgEsASwA9gCWAFKAZACMAJYAxAD7ANYAdqAej9gPoA90D2ePjI+qD8bP/EAnAEUASoA/AC1AEEAVwCcAYQDAAR4BOgFGAT4A/gCvAG0AUQB2AJEAwADkAOkAxQCnAIgAZ4AwEA0P1U/fD82PtY+5D7cPmQ86DtQOrA5uDhQN9g4IDgQN7A4GDrEPh6/xACJAJk/UD14PDA9Bj9WAXwDOASwBIQDMgDkP1Y+YD2cPUA9hD3wPhI+0j9Tv6O/rj9YPvQ+JD30PcI+sn/2AeADXAPABCQD6AL0AVoAygFyAfACcAMMA9ADRAIWAOn/8D7cPhA+LD6TP2L/xACYAQYBdADwgHo/5z+9v7sASgHgAyAEMASoBLQD/AL4AhAB7gGqAdwCmANoA4QDnANoAyACigHQARgAnsAgP4u/mj/KP/U/Bj64PbA8EDpoOWg5uDlQOHA3YDdwN8g5ODufPyQA2QBWPwI+eD14PNI+LwDIA6AEoAREA7AB///qPro+Cj4YPcg+Fj6XPz0/Iz9wP4P/+D8CPnQ9cD0UPZQ+uAAUAjgDSAQQA+gC0AG1AEcAcwDYAdAC+AOIBCgDQAJQAQKAIz8+Ppg+3j8YP6KAbgEKAagBbwDvQCE/Xz8zv4oA8AHEAxwD6AQcA/wDAAKSAfIBSAGsAcACvAMYA8AEKAO4AwgC3AIKAVEA1gCtgC2/q7+OAAL/xj6cPQA8ODqYOWg4oDiYODA28DaAOHg6GDuQPUC/qABYPyQ9UD1cPlI/hgF4A2gEsAPAArwBaACUP6Q+9j76Pys/Nj7kPvI+/j7SPuY+dD3sPbQ9ZD1kPdI/JgB4AWACbAL0Ap4B/AEsASgBUAHYApgDoAQsA+ADbAKsAaqAQr+vP0t/zkAjgFABAAGEAR0AJb+/P1k/ID7gP4YBLAIkAsQDnAPEA7QCuAHYAYoBggHAAnwCzAPQBEAEVAPgA0wC8AHsASsA6AD8ALuAbYBPgFQ/mD5IPRA76DqIOdA5SDk4OGA3kDcwNxA4GDn8PCg+bL+CP9g/JD44Pa4+uQCoAnQDCAOAA4AC7gF4gFqAP7+XP24/FT8GPtI+gj7UPs4+jD5iPjw9mD1sPYY+lz9fgEAB1AKEAnQBngGeAZoBUgG4AngDMAN8A3gDYAL0AfwBOgC6AD6/zQBqAL4AigDjAPoAv4ABv8G/rD9FP4zAOgDIAgAC+ALsAsAC1AJ2AZYBYAG0AhwCgAMMA6gD/AOEA2gCyAKqAeoBfgEeAQoA4ABgADe/mD7IPcg82DvQOsg6MDmIOWg4cDdwNsA3EDfgObA8Wj74f/C//T8uPhA9aD3HgCQCXAPgBGAEEANIAnoBDQBZv4s/VT8APu4+sj8eP6U/eD76PqA+AD04PHQ9ID51PyeAMgFIAlgCBgGYAVYBfgEeAUQCEALQA3gDbANkAzQCSgGFANKAWwAdwC0AWgDgASABPgDgAKx/8j80Pv8/Cj/pAKoBwAM8AxQC8AJwAjgBmAFGAaQCKAK8AvQDTAPgA7gDCAMcAtwCUgHiAagBagDMAIMAuoAfP0Q+hD3MPIA7ADoIOcA5QDgANxA2wDcwN2g48Dt4Pf0/ID8GPlA9WDzIPZa/iAJ4BCgEkARgA7wCiAGMAKUABcA7P6s/WT+fACQAYkARP4Q++D2APMQ8qD0cPgA/KL/HAOIBJADOAK4AXYBzAHoA4AHsAqgDHAOUA8wDmALcAgwBpAE8AO4BAgGyAbQBhgGcAQQAuz/rP4c/qb+QwB0AqgEuAZACEAI+Ab4BRAGUAZQBiAHgAnAC4AM8AywDZANIAywClAKsAlACDgHoAZYBVQDMAGs/tD6wPdQ9fDwQOzA6gDr4OYA30DbwNsA24DbgOQQ80D7UPtY+qj4EPNg7yD2EANgCyAOABFAElAOsAiIBkAGjAOQAB0ARQBP/5r/mgE8Ai//4Pow94DzYPEQ87D3OPyM/2QChAOwAZ3/PP+v/1gA6AKYB0ALYAyADfAO0A1gCuAHKAeQBZQDGASoBsAHIAfgBngGmAMr/5j8wPxa/nwAdANgBtAHYAfQBVAEqANoBBgG+AeACaAKcAuAC/AKgArACpAKAArQCUAKAApgCCAH4AY4BS4BTP3w+1j6sPWg8RDxcPDg62Dm4OOA4MDZgNbA3ADnAO7g8+j6hPwA9WDtQO5A9TT9gAVQDkASUA+QC4AKsAkYBzgFeAVoBYgD0AKsA+wDhALb/9z8WPgw9DDzcPUg+cD83f9qAY8Adv7w/Cj8CP36/zAEyAfgCXALQAyQCzAKgAkwCYAIkAd4B6gHUAfwBugG4AYYBkAEzAFP/yT+2v5nAFQCgAQABtAF9ANgAlgCYAMgBWgH0AngCkAKUAlACaAJMAnwCFAKIAwQDJAKQArwCtAJWAaYA+IB7P6A+uD3YPcg9UDwIO1g7KDoQOCA2cDYwNrA3SDl8PAQ+fj4IPXA8aDuIO0g86L/EAtgEGARYBBQDVAJGAfgBngGyAXwBWAGiAUoBIgDwALM//j60PZg9KDzsPQI+PD7Nv54/pz9RPyo+jD66PuC/3ADCAfQCTALIAuQCmAKEAqQCRAJUAngCSAK4AnwCfAJoAjQBegCCgGy/yL/ZADgAmgEQAScAxgDLAISAVoBPANoBVgH8AjACXAJcAjgB5gHgAdACOAJQAvgC2AMQAyAChAIeAbgBLQBtv6o/Vj8KPig8xDyUPBA68DlgOJA3oDYANgA4IDpwO2g8CD00PMA7mDq4O7Q9qT9SAUgDbAP4AyQCkALoAr4B5gHsAlACrAIQAhwCDgGXAKl/1D9uPnQ9hD3wPjY+Yj6WPtw+2D6kPlY+bj5UPvM/jACcAQYBngHMAggCGAIIAmgCTAKMAuAC/AKoArgCrAKsAlwCOAGQAS6Af4ArAFUAqwCVAN8A2gC5wCxAGYB/AHoApgEOAYYB6gHUAhwCCAIYAiwCPAI0AlgCzAMsAsAC2AKAAiwBMQCLAFK/nD7ePro+MD08PAg8ODsAOTA20DZwNuA3uDkwO6g9KDxgOyA60DsQOwg8ED7WAXwCHAJoAuQDDAKIAhQCQAKsAggCbALoAyACnAIGAc4BIT/+Pso+ij5MPlY+oj7wPtY+5j62PgQ9xD3wPjY+iz9OgA4AygFWAawB3AI2AdYB2AIIAqAC2AMQA2ADWAMMAtwCpAJ4Ac4BugEdANAAjAC1AL4AsgCyAJsAlIBrgAwAd4BiAIIBBgGIAcoB2AHoAc4BxAHQAjgCfAKwAuADDAM8ApQCTgHUAT2AUkAsP2Y+nD5QPkg9oDwoOvg5QDdANfA2iDkQOoA7CDuoO5g6aDj4OUA7tD0+PmbAFAG0AZ4BRAHAAqgCqAJMArQC2AM4AvwC+ALUAqwB7gEygEg/zT9EPyQ+6D70PsQ+0j58PfA97D3gPd4+Jj6uPsQ/Dr+AAJ4BGAF+AaACJgHKAboB2ALkAxQDKAN4A5ADcAKkAoAC2AJyAZgBVgEsALeAWQCAAP4AsgCLALGAMf/LgAWAcQBaAOoBbAGKAYgBhgHiAdwB6AI0ArQC3ALcAvAC6AKcAioBrgEYAHU/bD7qPpY+UD4QPYA8KDmAN8A3ADcQN/A5iDvUPAA60DmIOWA5WDo4O/o+Bb+SgAEAyAFaAVIBkAJIAvgCnALUA0gDqAN8A0wDYAJuAW4BPQDZgHR/6wAxwD4/XD7uPqo+SD4YPhA+qD6uPkI+oj7iPx0/fr/qAKwA+gD+ARYBigHUAiACnAMoAwgDGAMMA0QDQAMIAuAChAJ8AboBCgEaASgBIgEEASEA5QCZAGVANsAYAHCAWgCcAMoBNQDrANgBBgFOAXgBWgHUAhgCKAIAAkACCAGsATYAnr/YPxU/NT8CPuw92D0gO8g5yDgAN/g4sDnQOwg7wDuQOkA5WDkIOfA7LDz0PlQ/fL+hQDmARQD8ARwB9AIIAmgCpANkA8wD9AN8AsgCSAGCAXYBTAGSAUIBDgCY/+A/JD72PtQ+6D6yPoY+3D6APog+3D81PxY/Un/TgE8AvQCiATwBUgGkAbIB9AJcAsQDBAMAAzQC7AK0AiAB3AHiAcoBygHkAdIB/AFoATYAxQDtAIYA9AD6AMgBIAEAAQsAzADGAQQBMADKAUgB7AG2ATgBCAGYAXUAjoBKABk/bj6APtc/Lj6EPcw8+DtwOYA4gDjAOfA6qDtgO9A7QDo4OSg5sDq4O7w8wD5oPvg+8z8ef8UAtADmAWoB3AJ0AogDAANEA0wDKAKIAkgCNAHqAfwBqgFIAR4AvQAYf8M/iT9aPyo+yD7ePsY/BD8uPv4+9D8ZP34/YT/pAH0AjgDAATIBUAHgAfIB2AJQAugCzALkAvACxAKyAeYB7AI4AhwCAAJkAlQCIAGmAUwBXAEYARwBcgFSAUwBeAE4AISAeAB6ANoBIgE2AUIBowDLAEcAlQDAAIzAL3/dP5A+8j5QPsQ+1D2APHA7WDqIOag5SDqYO7A7gDuQO0g6gDmQOYg7JDxYPRw9+D6iPsw+hD73P7yAbQD2AUACPAIEAnwCcAK0ApwCjAKQAlwCFAIsAegBigGYAb4BAgC7f+D/8r+ZP3c/Ej9KP2E/Ij8vPzY/Cz91P0k/o7+LQBgAsQDsATYBRgGWAWYBdgHMAqwCrAKAAtQChAICAcgCIAJcAkACYAJkAlACJgGAAbYBWAF6ARgBUAGMAYABagDLAPcAkgCkALIA7AE/APYAiADwAO8ApUAGP/8/YT8cPsw/GT8SPmQ9BDxAO7g6aDnAOog7iDvAO7g7EDrYOhg54DqgO5g8QD0wPbg9/D3aPlo/OD+zwBQA1gFYAagB7AJwAoAClAJ0AngCZAJEAqwChAKMAh4BugEKAMcAgQCygHsAH7/VP5o/QT9QP0g/dD8xPzk/BD9sP12/1gB1AGeAeQBqAJoA4gEiAagCFAJoAgwCKAIcAngCfAJEAogCsAJYAnwCdAKsAoQCUgHaAZoBmAGGAeQCKAISAY4AwgCMAL6AdwBRAOgBCgEMANYAxQD/P80/Pj6sPsM/JD8eP1c/JD3gPGg7YDrgOoA7IDvIPEg7yDswOoA6mDpAOuA7lDxUPJg8yD1oPbg99D5IPyw/Rn/WAHMA5AFwAaIB2AHmAa4BjAI4AnACtAK0AngB8gFaAQwBLAEOAX4BMQDAAItAMT+Pv6u/gX/ev60/bT9Ov6y/nv/yABaAZUAwP93ADwC7AOYBUAHqAe4BhgG2AYwCFAJUArgCnAK0AkgCqAKsArQCvAKEAqACFAIEAnwCEAIsAiACFgFyAH8AbQDEANUAuwDqAXoA6wAgv9K/ij7OPnw+nj8IPsQ+fD34PRA78DrQOyg7cDtIO7g7qDtoOqg6YDqoOvA7ODuAPEw8iDz4PSw9uD3qPm4+4D9Z/9QAuAEwAXwBYAGGAcgBwAIIApwCyALcArQCZAICAdgBpgGmAY4BgAGKAVIA1ABMwCm//b+4v5i/47/9v68/jj/W/8O/yf/tf/t/3EACALEA7AEQAWoBagFmAWwBnAIoAkgCsAKoArQCeAJwAoQCwAL8AuADOAK0AjQCZALEAo4B2AGEAZgA0wCcAWgCNAGJANAAogB3P0Q+yT9S/90/UD6aPmQ+CD14PFQ8cDwQO7g7ADuoO4g7cDrgOsg6yDqoOog7YDvsPAw8bDxcPKg87D1QPjY+ij91P7U/9IADAJ8AyAFyAYQCOAIYAngCSAKIAogCgAKYAmwCDAIAAjwB9gHQAeoBZQDGAK+AboBlgFqAS4BcABB/5z+Df/K/+f/wP/T//f/LAAqAcQCnAN8A6wDkARwBTAGkAfwCPAIgAgQCQAKQAoAC1AMcAzACjAKUAtgCzAKMAqQCogHkAPwA7AH0AiwBvAFsAUAAmD9LP3U//f/yP1k/BD7MPew82DzwPPA8UDvYO7g7aDsgOug62DrAOoA6WDpgOog7IDuAPDg76DvYPAg8kD0QPfg+mj9Bv54/sH/AAF8AkgFgAigCRAJcAmwCuAKUApgC/AMAAwgCvAJ0AoQCpAIQAjIB4AFbAO0A4AE0APYAmgCUAGp/2H/agDPAEMAQQCEALn/Uv/RANgCNAPwArADuATIBEAFMAeQCCAI+AdwCaAKgAqQCuALAAywClAKkAsADOAKsAlwCJgGmAVgB0AJYAiABtgF3AOl/0D9ZP5y/9z96Pvg+jD4MPRA8iDyoPBg7mDuoO6g7IDq4Opg68DpoOgA6mDrgOvA7GDvQPBg7xDwoPJA9JD1wPh8/AD+zP2M/lgA/gHUAzAGIAjQCFAJAApgCqAKQAvAC5ALIAsQC1ALQAuwCpAJcAh4B7gGMAb4BdgFUAX4A8wCZAI0ArABVgGOAYQB9gDOAKIBFAKQAWIBLALwAvgCtANIBQAGcAVoBYgGWAdoBzAIkAmQCbAI4AjgCcAJkAhwCEAI6AboBUgHQAmgCFAGeASsAkEAHv+t/wAA5P7U/Fj6YPcw9XD0IPSw8hDxEPCg7uDsYOwA7cDsIOtg6uDqgOtA7ODtoO/g7yDvoO+g8QD0MPag+ID6YPu4++j8Qf9yAUgD4AQgBpAG2AYQCKAJkAqACjAKQApQCnAKEAuQCwALkAlQCLgHiAeIB6AHYAeABkgFaAT0A7gDeANAAxQDnAJcAqgCBAPYAlgCZALkAjADZANwBJgFaAXIBEgFgAboBugGyAfQCEAIOAewBwAJ0Ah4B7AGqAawBtAGaAfoB8gGYAQUArYARQBzAK4A1//s/Uj7wPjQ9uD1gPXg9LDzUPLA8ADvIO4A7iDuYO2g7KDsAO1A7cDt4O5g7wDvYO8Q8dDyMPTw9dD3uPjQ+Oj5gPzG/kAAvAEcA7ADOAS4BaAH0AhQCaAJgAkACWAJ4AoADMAL8ApwCrAJ4AgACQAKYApACfAHeAcQBzAG+AWQBlAG0AQABIgE8ASoBIgEoATwA+gCKANgBAgFOAXIBZAFWAQ4BIAFMAboBZgG0AcoB4gFAAaQB7AGWASwBKAGcAbwBBgFaAUkA0UADwD3AOb/VP5U/sD9gPpw93D3EPiw9sD0MPRg8xDxgO8Q8NDwwO9g7kDuIO7A7YDuMPCg8MDvYO9w8BDyoPOQ9UD3gPdg92j4KPrw+xT+KgAiASgBwAF8A0gFGAaoBmgHwAfgB7AIMApQC3ALkAqwCZAJoAmwCXAKUAvgCvAIiAegB8AHCAfABjAH4AZoBaAE0ASwBPQDyAP0A4ADIAPEA5gEaATYA8wD0AOkA1AEeAXABWgFgAWQBcgEiASIBfgF8AQYBLAE4ASoAyAD7ANcA+MAZP/l/yUA3v7M/WT92PtA+VD4GPnQ+PD24PXA9ZD0wPJg8kDzMPPA8fDwUPGQ8WDxsPGA8rDyoPIw8zD0QPVA9iD30Pdg+Aj5aPr4+zT9RP4k/8T/eQCMAcwC3AOQBCgFwAVIBuAG0AfgCGAJEAmgCJAIAAlgCZAJsAmACeAIMAgQCEAIEAigB2AH4AYABpgFAAaQBkgGSAWwBLgEmARgBIgEsASoBJAEYARgBGAEeAR4BOADQAOAAxgEGATsA8ADEAPoATwBcgHiAawBTgFIAaUA8P7k/Rz+Bv78/BD8GPwE/AD7EPrY+QD5MPcw9jD2QPZg9rD2kPZA9YDzAPPQ85D0UPVQ9jD2APWA9ED1UPZw93j4KPkQ+Qj56PlY+1T89PyA/Yz9kP0A/1wBtAKcAkwCCAIMAuACyATwBvAHqAdgBvAEiAT4BWAIoAkgCcgHsAZABgAHQAiwCEAIiAfgBkAGMAYoB0AIAAhIBqAEWAR4BfAGaAeABiAF/ANEA2QDcASwBbAFSAToAiACrAEIAgAD4AJkAQsA3v8OAJ//Qv9h/4r+pPyQ+/j7sPzo/LD86PtI+oD4WPio+TD6gPnY+HD4sPcQ91D3cPgQ+RD44Pbg9nD3sPcw+BD5aPkA+XD40PiI+fj5iPqI+/j7cPuw+1j9Yv6s/Tz9yP4mAIL/Nf9gAWQD2gHe/64BoARoBNgCAARwBhAGtAP8A+gGIAdYBCgF8AiQCLwDuAKoB3AJoASYAlAIUAqQA5EAoAYgCWgDDAL4BjgGigBEApAI0AXY/Vj/cAeoBWz8lv6ACAAGCPu4+/AESAX0/fz8rAIoA+D8gPuKAcwDLP6Y+mb+LgFU/aj5NP0UAjj+oPaI+JoA8v/g+DD5hP4o/YD3APga/uL+sPnA+Fz8kPso+Oj6a/8c/aj4YPmk/JT8QPt8/UgAxP1o+bD6Tf88/zz9oP84An3/LPy6/vACVAK8/9MAcAP0AcD/9AJ4BhAEegDuATAEnAIgAigGgAhQBBYARgF8A8ACiAKABlAI7AIL/ywCkAQMAmoBGASIBKQBuP9oAcQDyAMYApAA5v9iABwC/AJsAuACYAIO/2z9SgCEArgBUAIYAwUAGPzg/PIAPAIcAAb/SP+A/Yj7MP4IAQX/1P2O/tD7IPl8/RgDvgAQ++D5PPy4/Bj7wPwqAYAA+PrI+ED7GP1s/bL+oP4o/TD8yPuA/M7+XQDw/qD9aP2k/ej+aQA4ARIBv/8A/oz+sgBEAtwC/AFfAO8AEAI1AM7/aATIBlQCOP45AOgDjAOyARwDcAVYAuD9ygAYBTQDKgGkAzAEPAFw/4YAeARoBXUASv4EAhgD7/84AcAFYAQs/Yj6zgDQBOYAEf8QBMAE2PsA+I3/CAVSAFz9cAEaAfj7qPpC/y4BWP6Y/SQAQf8Q+/D9kALQ/5D7MPzA/v7/Iv/g/eP/1gCQ/Oj6XP7h/1v/zv8UAfkAlPwg+eb/OAYq/1j4N/+IBxwDwPlw+jgDUAMo+5D8IAQcA0r+qv8oAsz+gPsb/3gE4ALy/qsAuAIxAAz+KP82AYgCdAJKAZAA3AAsAmQCWgB2/4oADALcAuAC4gCf/9QCpALA/cD8+AL4BlwBXPwl/7QD0/9Q+yQBoATM/iz8xgFsA2z9KPt7ADAEvP6w+dT/OAY2AbD7lP0sAJP/RPwg/DwCIATo/Oj5tP9qAVT8aPtwAWQDLPx4+K0AgAUU/XD4RgFoBWj70PecAiAHQv7I+cb/HAOQ/jz8eAEQBT0AAPxC/3oB8/9wAUADcAGhACIATv4Q/4ADYATc/0z9FgB8A+L/4PwsApgFmv/Y+nP/0ANgAk0AHQAaAFEAtP/E/iYBzAOYAvj/rP0C/2AD/gEk/lYBWAQI/wT9TAI4BMwBdP57/94BFv/s/UgEaAaQ/PD5JAKgA5z8OPyABQAG6Pkg98ADuAa4+pD66AaABOD18PgwCJgF0Pdg+ZAFyALQ97D7CAasAoj5NPw0Abj9lP1UA1wCkPrw+igCHAK4+yD9SAVMA0D6YPuABFgD6PsI/sAFAAGw9q7+QAq0AhD3JP24B/YBYPeA/JAIuATo+Pj84AXKACD7rgBIBBQAgv6aAfACPv8Q/QQC8ATu/lj+CAR8Arr+6/88AjgCngFGABIByAKrAOb/JAIoA2oBB/92/jgCkATo/xj+0AIQBKz8iPpQBCAH/Pyo+twDVAMw+uD7YAboBAj5iPlQBKgCaPls/UgHNALg9rj5kAMkA8j6aPtQBJQDcPnY+EQCKAVm/rD6NP4EAV4AHP7a/rYBHgHk/Nj7vv48AQQClAB0/ar+4v+4/DL+VAIUAsj+FP7c/nn/mQD+/8P/JAC+/2AAAv8m/lQDQAVk/QD6PAKoBMT+Df9gBKAEUP04+en/cAc0Azz9CAJwBOz9iPskAvgF8gHg/TgASASWAfj84v+ABswCcPo4/kAHpAMw/Bn/mAQkAvj5wPuIBmgGAPsI/DgGpgHY+Az90AVwBPj7+PucAv4B4PpI/EgEPAJE/Cj9uQBlAL7+nP9r/4r/Jf/U/Zj+1P/bAHH/pP28/RAATgHQ/dj9SAKrAAz8ov4sA9v/HPzU/8ADIQAo+z4AYAXi/jD6CgG4BSv/qPs0AhgFlP3w+VQDuAag/YD7YAIYBOT94PvWAfAEeQDI+1f/WAMaAcD+pv9sAo4B2P4B/z4BhAKaAfoBKACM/Xz/vAJgAmz/JgH4Avb+PPyq/+AE6gF4/D0AGAXe/vD4wgGgCKb/KPmbAAAGtP5g+gQC8AYN/xD4tf94Bm7+sPhwAgAIsPtA9b4BIAj8/AD4cALABZD74PaSAYAIoP2Q93ACIAao+fj4WAVQBZD70PpkArACzPzI/bQD4gEw+zz9oAMKAUj8MABoA57+qPuH/7YBQABUAP8A+//8/TT+dAEEA1IAzv+MAZsA6/9+ABwBKgEwAygCSP2u/lgEWAM4/TD+GAOIAlr+aPzoASAGf/+Y+q0AjAOs/ej+sAT0AbD9qP24AGwDngAU/VgBGAWs/ij7nAB0AwABXP6E/RUA0gHQ/nj+9AFbAMD7vP4sAnz+pPwuARgDUP1I+WL+gAVMALD4Sv9QBfT9WPm5AFAESv64++UASAPg/mT8WgDQAgb/XPzIACAE+P8o/aT/4gAf//EA9gAh/5gBJAFa/jb+ogD4AXgC2P4w/OQDMAXQ+qj6sAZABtj64PuwBMwDnPzk/cAGnAPw93D7sAlYBqD3eP3gChgD0PWo+/AIMAZo+gT8gAboAzj5wPvQBjAFiPqo+9gEiAOI+hj8MAa4BJj6oPvwA/gCiPtU/qgFcwDo+Ir+cAZrAMj62QDcA8T94Pru/wwDEgB8/GX/TgGI/Ez99AL9AMD8TgCQATT9EP2lAG4BkP6o/VYAugHg/pD9ogCuAYb+oP0oAZAC/f9r/3IBB/9o/QwAuAKIAp7+uv7oAmACOP1E/sgDBAO0/h7+cgEcA4kAOv5pABQCuf9d/+kA1QBFAMQAtwCF/xkAxQBIAYQBGv/i/nwCIAP0/fD9QANyAZj93P8QA63/yP0wAbQC2f9A/D0AMAWt/wD7dAEQBYT9QPuUAqACDv6c/V4BoAJg/Uj8kwBwAsb++Px2/04BUAHU/dT8xQDNAGj9WP2iASQCMP2A/bkAVwAs/eT9TgE8AfT/SP4s/7b/iP5eABYA9P3V/5ACsP5Q++sAGASi/uD6WgCcA5D/gP5AAbgBGv70/ZYB6AHY/zkAxAIQAQn/P/+C/m4BKANY//j9pAIIBFj+QPvJADAGsACo+mUAmAeuARj7WgCYBF0AqPwqAXgEdgEi/kr/YAMUAjj82PyoBDAE/P2o/boBoAOo/vj7pv9sAvEAvv6J/+7/tP8T/zb+swD3/+z8xP7mAb4BCP5w/AgA7AJ1/5j7WwBABDQAXPyFAHQDlP00/YABlAHM/Qb/dAOcAUT9YPxTAI8AwPz9/9gDqv6g+1v/UgFo/XD85AEgBKr+OPqhAJAFoP74+WIBIAa0/qj6AAKABrkAyPqF/1gFogBU/OoBUAgyAcj5sv8oBRIBkPslAPAGoAT4+/j5bAOABgr+yPuoAxgEGv6Y/YYAaANmAdD96v7aAAEAr/+oASMARv7t/zf/G/+iAMQAnABK/+z9V/8UAXr+jP74AzQCKPsA/OACmANY/sj7BgCgBcD/OPiF/6gH/v5g9kH/UAhcAPD2iP2wB40AYPS0/WALKALg9GT98AgrAID1xv5gCq4B4PZs/pgHRv8o+GIBqAf1/xj55/+ABrcAkPqk//AEuQCA/CwAqAQ8Amj9tP6wAowAZP1WAQAFbABY/d7/GALh/4T9oAG8A6f/JP3oAWwClPzE/sADLAHY+qD+IAcwA9D5uPvwBXADoPnE/cgG0ATg+3j66AHcA0r+yPw4AqAD1P5U/NT9HAJMA6D9kPygAsgDtPzI+pwDYAbY/ID3bAGwBoj94PmEA4AHAPyA9kIBQAja/xD7sAH0Avj7EPtEAmQDFP78/VYBPP/4+4wA/AIy/kj9YAHtAPj7vP5IBVgDkPt4+8wBzgEc/ur/AAQgAlD9ePxw/8YBTAJ2ALj/7wBCASD+GPy2AeAFogHg+5z+GATgAOj8SAKoBaT9SPnGATgH7//Q+hwCeAcc/dD1qAFgCc0AsPs8AXYBFPys/cADAASG/g7+pAKaAcz8UP/IAwwB2P22/hEAxADGAdMA/f+i/xj8NP2WAXgCNAAN/yr/qf90/QD7vALwBnD9GPlAAlAEePtM/LgFgAUw+oj42AW4Bhj6aPtwB7QDAPcg/LAHaASw+dT8OAZMAVj5kP1ABYAC0Pss/TgCzgFM/bD+WAMgAlz9GPwqAXAE7wAA/Q0AQARoALD7Av9IBFACWP1d/1gC9ADA/hr/ugGdADn/Zv+i/7gAQAKGAfT9HP4CAVAAiP0B/1AFmAPo+tD7eANEA7D7fP3oBtgEiPro+jAFiASY+7D8eAOwAhj9nP1IAsgClv5w+hD9wAL2ASr+2P2A/6wCjgA4+gz9yAS0Aiz8cv6YAioBEP4G/uoB8AGg/Pj9GARYAqj8+P0QAUcAqf9Q/pT/rAKbAFr/PP/A/fz/mAIs/+D87gHwAm7+lP2i/24BWwDk/WYBbAO0/77+6ADu//T8jf9QA7ADyf9k/PMAaASw/Vj8QAT0A2T9Cv4QBKQCnPzw+xgEsAXY+jT8uAcYBlj54PjIBNAFCPyY+3AFGAV4+RD7qAY0AwD5xP3ACDAE4PfY+hgHcAWA+ND5wAcIBwj7uPneAUAEeP2o+/wA5AKl/0z8bv5KAW0APP5e/3ACDgAY/VL/OAO6Aaj8wPwwApgDFv7I+xQCqARy/uD68P6YA2QBzP0O/5gBwwA4/tn/eALtAGD+aP6hAEIB7/+K/2YAsAA4/+D9wv+YArQCCADI/S7/eAJgAZj9if+YBCAC+Pqs/PACtANc/uD8vALoBOj8OPmsAzgHwPyA+eAC4AQM/YD63AGYBUz9sPjmAPgEdP0M/cgD5gFQ+2D8+AH8AfD9dQCgBbAACPp6/oAEsP/0/OADQAbw/cD4YgEoB07+4PmcA1AGyPtA+mAF+ASQ+dD54AS4BCD6iPuwB6AEYPXw+MgHCASw9jz9MAoAAwD28PogCFgDQPec/WAK2APw9YD88AkYApD04PzwCygEwPUc/BAJWATA9iz88AlgBJD2AP3gCvwCsPR8/OALUASg9cz8wAlIAyD3yPwwCCgCCPjB/+AIcgGQ+tUASASI/fD7GASAB5j9kPl8A2gE+PrY+2gE0AO4+9D7AAX4A/D3kPiIBsAG8Pi4+HAHyAfQ92D2IAXwCJD7MPe4BPAJwPtw9dwDYAnA+7D26AQQCnj84PYIBBAI4Pqg9/AD0Agk/fj4aASoBtD54PggBbgFCPuo+2AGAAUw+qD5/ANYBKj8lPxoAtADPv9Q/BkAOATj/zD6T//oBggDrPzY/CwCgAGU/PP/QAUwA8z8Lv7iAbb/Fv6MAsgE6P4I/iwDDAJg/G7+CAWUAsj7lP2YBMQDPPws/cADZwCo+YL+uAYgAmD65PyABNQCEPmg+VgEKAfc/DD5/gAIBEX/yPqo/ygG+wAA+sj+wAXz/5D5zAIgCGj8cPWOAUALaP9g9Qn/cAkGATD2Iv6wCPQAEPhd/8AEKP34+iAEUAgA/oD1rf9wCeL/4PWIAdALoP/Q9Ez9uAbRAFT8jAPgBHD6cPjABWAHCPkQ+KgHMAmw94D2EAjAClD50PSYBfAJ4PvI+ZgHsAfQ94D3mAZIBwD6MPzQCoAGEPXg90AKsAgA+Sj5kAV4Bgj94Ps4AywDWPt8/OgF1gG4+KYAMAp8ABDxuPnwDOAJYPbw93ALCAbA8rD4cAvQBXD2iP7wCVL/YPSbAIANZP9Q8Iz9MA8YBNDzmv5gCh7/EPMY/tALCAUo+ij+xAO4+qD2YARQDOr/APeWABgF2PuI+ggECAZ4/kj7Av/EAUIBGAIIAoD8mPjD/1AGlgFo/q4BaALg/Mj5jv6ABJAGYgEa/gcAIv4A+0kAYAdEAsj6tPwoAzQDtPxg/HAE0ATY+RD5OAWQCDX/YPseAYgBOPvo+6AGIAlk/Qj4jwCYBIT9PPxoBBgGGv4Q+jD/gATYAdj+kwDVAPD93Pz5ABAEwgFM/nT9pv4s/37/TgFYASQAMv5Q/Bj8UgBwBngCsPnw+gQDDAIA+4D+kAb+AcD3QPu4BtwDePjI/AAI9AGA9XT90AxQBiD2kPjABrgFCPp0/WAJCAQA93j6aAWkAsj6BAGgCNT/oPWY/WAIuAEg+Xr/KAdOAYj5ZP9AB4oB6Prq/mwDZv/4/ZgEUAZw/hD4/P4QBSkAAv5YBBAG3Pzg+Hb/jAOE/9D9aAQQBeD6SPjsAegE6P2Y/cwCNAEw/Gj9UAIQAuz9Cv6hAC3/LP4sA2gE7v7k/Vb/SP3I+wADMAmkAvj50Pt0AtP/bPyQAvgFlP84+ob+dAJW/sj8sAMwBXD7GPmoAtAF3v44+/v/RAM0/gD7zgHQBqsA0PvG/ngBGAE4/5YA2AQYAkD6wPxgBQAEgPxI/cQDxgFw+tz8SAeABcj4YPrABWwCoPgQ/jAIJAM4+XT9+ATmAJD7+P/QBfcA6Pp5/7AFCAFo+wwAuAPMALn/MADI/mH/NAKYAVH/Gf/rAHYB5P0w/awBmAO+/jL+XAKY/zT89QCgBOkAvP0e/sj/NAE2AFP/LgCC/yr+/P4EAVgAxwBfAGj9iP3Y/gwBnAISAZj9TP10/4j/owDgAqgAMPxE/RgCyAI9/4j+ugEUAUz8AP3oAwgGL/8w+w//fgDi/loBaASEAgL+4PuI/a4B4AJPAMcAnALK/0j7PPwcAoAFvQCg+yUABAMo/ND6iAT4BkD7oPbaAUAJKAFI+cz/sAUc/dD2vACACogEgPus/TgCmP5w+m7/kAcoB9D9KPlw/ogDywAw/YoBIAbfAPD4EP1QBkwDQPtE/VADvgCg+yf/OAXAAmj7GPuU//z/8v+IA+AERP8Y+vj75QBQAvEAQAEkApYARPzQ+kMACAYkAnj8Df8EAtz+IPxMAYAGBAHo+Lz8cAR6ART8agHQBhv/QPew/agGSAPE/WoBcAOo+1j4OAJACaQCsPtx/+wCOv44+3oB+AYIAhD85P3gAT4A0P1OAbgECgGQ+RD7wATABrv/8PsQAeACUPtw+OQBEAq0Ayj7NPxU/zj9vPxoBAAH8P2g+AX/kAQiAcD9NAGYA0X/SPsm/gQD3AP8AgIA+Pp4+pYAoAW4Awn/Xv7G/nD8hPwqAeAE9AJZ/wD9EPwA/WoAQATEAl7+kPx8/uP/sv/kALoBr//k/EL+LgHIAM4A+AKCASj7GProAVAGyABU/OD/HAJ4/nj8QgEQBaYAdPx7/zgCR/+Y/hgDUAO8/ej79gDEAw0AwP2qAYADwv5Y/HIAjAP8ADT+1f+KAa7/2P0HAFQD2gCA/Fr+pANcAkz8UP20AxADePsQ+7QCSARo/qj9WANQAvD62PogAugDRf+//zQDQgDg+uz8NAMkA97+If8MAgYAiPwH/2gDVAJ4/Wz8wf+qAccAz/+ZADoAOP40/R7+jgHMA/gB4v70/Vr+AP5k/8ADCAX0/8j7lP5IApkAdP4uAfgD+v/Q+rT9EASgA6r+Wv7tAIj/9PyQ/5AEVAOs/fj8CQAMALb+mgHYBHwBoPtQ/FIBqAKFADoAVgGI/7j8Cv70AZQCkgDE/9r+0Pwk/T4BmASEAvz9sPxo/q7/+//iAZwDUgEo/TT8JP9MAmgDcAJ/AGj+4Pxk/mgCYAT2AeL+wP64/3f/jf8gApQDGgBA/PT8MgAoAoQC2gGJ/zj8WPsL/0wDqAPpAJ7+Iv78/Tj+BwCcAkgDVQBE/Az8DADIAugBegARACz/sP2O/mAC7AN+ACj9Xv6SAKH/VP+oArQDlv4w+nz9+ALgAh4AGgCAAJz9DPwSABAEiAI1/wf/7f+i/mj+tAH4A6sA+PxG/gIBugCn/9UAJgHy/qT9tP/UASQBi/+e//r/Tv7Y/cUAPAPKAcj+wP3S/vv/8f9OAIABUgEv/+D9Rv8IAccAFABlAAYACv6s/ZsAnALCAMz9Fv4eAKz/Yv74/ywCwQBw/fz8nP9GAeUAuQCZAMr+NP2k/lwBIAIqAXAAEwCD//b+qP+GAVQCPgHq/0z/ov9CAWQCiAEMAEn/gf+OAK4B9gGKATcAUP42/uf/WgG4AQwBzv+I/jr+Q/90ALsAOgCA/37+KP6T/0AB4gA9/5b+yP5i/v7+vAHgAj4AkP1a/gEA6P9TAJgCHANx/6z8EP8wAmIB9f/0AAABpP78/WEAAAKDAID+3v7H/y7/Vf8wAXYBNv+Q/Rb+Zf8gAIkAzQCiAEb/MP6u/v3/vAB6ADoA4P9Z/+T+d/+nALgAwP9z//T/lv80/xwAaAGcAJ7+hP4TAAwBgwDG/wQAIwBC/9L+EwDCAWIBrv+u/mT/KAANALgADAKCAQH/av6ZAPYBLgF8AGgB0AF2ALz/PAHoAlACIAFCAX4BDAEGAQACuALiAYcA0ABoApACRgHdAGwBSAE9AGUAzgHUAc3/tv6p//X//P5E/5oAmf8E/bj8kP6w/iT9QP1k/nj9GPs4+1T9HP0g+yD7ZPzY+2j62PoI/Gj7yPkA+pD76PsY++D6aPtg+/D6OPts/Ij9gP3I/Kz8wP3Y/l7/7v/xAGoBKAFwAQADmATgBNAE4AUABygHkAfACLAJIAmgCOAJwAswDKAL8AtgDGALMArgCuALYAuQCvAK0ArwCCAH4AagBugEuANIBPADdAFR/+D+4P2o+7j6iPuA+xj58Pag9hD2QPSA84D00PRQ8+DxcPEw8YDwYPDw8BDxoPBQ8BDx8PHQ8XDxkPFA8vDyAPRw9WD3aPiw9zD3cPi4+pT8TP5ZAKIBIgH0AAwDUAZwCMAJYAsQDOALwAxQD8ARgBKgEiATgBOAE0AUwBVgFiAVgBPAEoASQBLAEeAQQA+wDAAKEAmACZAImAUEA5ABHQBa/qT9sP1A/FD5UPeg9+D38PZA9iD20PTw8mDzoPXg9mD2cPXQ9ED0EPSA9fD3wPiw9zD2gPXA9XD2cPd4+Lj4gPfg9eD1YPdg+LD3cPeQ+BD5OPgQ+Mj5yPqI+XD4KPoE/Mj84P1E/xv/0PyQ++T9WAI4BTgGYAawBaAEoAOIBRAKEA7wDpANgAwgDMALgAzADyAToBKgEGAQgBDQDkANUA4AD/AMIAswDBAMgAj4BGgExANcAeIAVAMoA0r+WPoo+mD6IPmo+RT82Pso+ED2sPeY+ID3EPfA+KD5kPhA+FD6aPtw+ij5APlg+oD7TPzU/Dz88Pkw+Kj4sPp4/PD7CPrA+KD3EPYA9hD4qPnY+PD2YPbw9gD38PZw98D2EPWQ9TD56PuA+2j6APrY+CD3ePlT/2ADzAOoAzQDHgEPAOADwAowDsANsA0wDnAMcAsgD8ATIBUAFCAUABSAEkARYBKgE2AR0A6wDrAOsA2gDOAKIAcgA+4BUAMIBLgC3QAs/vj5EPdw+PD60Pow+VD4UPcQ9ZD00PZg+OD2cPXw9oD4MPg4+Cj6UPqg96D2gPnw+6D7OPuQ+8j5sPZg95j7TP3w+kD5IPlA9wD1IPdY+zD7wPfw9kj4gPcw9uD3qPpA+VD2wPco+8D7QPt4/Kz8cPqA+Zz8VAEYBAAF4ATAA3ACvAMIB5AK8A0AEEAPsAxQDLAOQBGgEkAU4BSgE8ARIBIAEyASIBAgD3AO0AxADIAMYAuoB9QDlAF9AL8AvgHgAQj/2PrQ98D2APcw+Lj5wPng98D1kPRA9OD0cPaQ96D3oPdQ+Nj4cPhY+Dj52Pmo+TD6FPzM/HD7EPrA+WD5EPmg+mD9RP2w+QD3EPeA92D3YPiY+vj6MPhw9uD24PZQ9mD3uPlI+uD4aPhI+mj78Ppg+4z8NP28/aX/WAKYBIAFsAWwBbAFYAdAClANYA/AEKAQEA/QDsAQYBMAFEAUwBTAFMASIBEgESARYA9ADcAMgAwAC9AIIAfgBMQBrf/1/84Aov8c/aj6qPjA9tD1oPbg99D34PbQ9dD00POw8+D0APZg9tD2APiY+ND3cPdo+Pj46Piw+YD7lPzg+6j6APoY+cD48PrI/cD9CPv4+Ej4sPew95j5DPwE/OD5cPjg9zD3kPdg+cj6mPr4+Qj6WPoI+1z8eP1k/bD8OP0E/wgBVAPIBeAG+AUQBSgGoAggC4AN4A/gEPAPgA7gDgARwBLAE0AUwBTAE8ARwBBAEGAPoA2ADFAM4AsQCmgHuATIAYj/7P51/4H/Qv4Q/CD5QPYA9dD18PZA9xD3gPZA9eDzoPPQ9LD1YPUw9uD3cPgg+GD4MPkw+Yj4cPmo+5D8+PtM/ET8QPrQ+JD63P1w/mT84Pow+oj44Pco+sj8EPzQ+dj40PiY+FD4UPl4+hD66PjQ+AD6aPuY/Cj9uPx0/Kz8wP1M/9QBWARoBZAFKAZYBxAI4AjwCrANkA8gEOAQ4BGAEYAQQBEgEwAUgBRgFQAVwBHwDYAMIA3gDEAMsAygC+AGegFz/5f/iv+g/wcA+P7I+kD2QPUQ9jD2kPaQ92D3QPWg8/Dz0PSg9MD0oPUQ9lD28PcQ+sj50Pdw98D4oPmQ+sD8dP4g/Uj6GPng+Qj7rPza/s7+wPv4+CD4uPig+qT8vPxg+pD4QPmw+aj40PgA+/j6EPjQ93D7kP00/ND7XP0A/UD7yPycAfQD4AJAA/gFKAdYBqAHsAoADNALIA3wD6ARwBEgEoASIBEAEKARgBSAFcAUgBJAD9ALQAowC8AMoAyAChgHgAJW/qT9Rv9NAHj/XP1g+hD3oPTA9LD2gPfQ9uD1UPUg9FDzUPQg9nD2wPSQ9BD3UPk4+ej4WPpo+nD40Pf4+l7+3v7I/cT8ePtQ+Yj54PzL/zH/8PwA+0j5mPhw+Qj7CPzY+7j68PiQ9yD4+Pl4+iD5iPjQ+Aj54Plk/Nj9iPzw+rj7Bv4r/yYA4AIgBegE6AQABxAJgAkwCoAMMA5QDqAP4BJAFGAS4BAAEqASQBIgE6AV4BUgElAOoAywCwAKYArAC0AKiAUkAXX/hP7E/cT9MP5Y/ED4cPVQ9bD10PVQ9rD2UPUQ87DygPQQ9hD2EPaQ9kD2kPUg91j6CPwQ+9D5+PmY+oD7NP38/tz+3PyQ+3D7+Psk/X7+nP7Q/JD6APnQ+ND5mPuM/Aj74PjQ97D3sPeY+CD6GPrA+PD38Pjw+Tj6EPvY/Bj9VPyA/fP/RAE+AYwC4ARABuAGEAnQCzAMAAuwC4AOwBAgEoATwBTAE6ARABHgEeASoBOgFGAUYBFADZAKcAlgCBAIcAgwB6QDHwBq/lj9kPso+uj58Piw9iD1cPWg9aD04POw8+DyIPIg82D1cPbw9YD1kPVA9eD1ePgw+yj8uPtg+wj7yPqI+7z9ov9W/yr+wP2s/Xz9lP0Y/uT9qPxo+/D6QPvA+wz8mPuI+iD5EPiw90j4iPl4+lD6WPm4+Kj4IPkQ+mj7zPzY/XD+4v6y/z4A3gCcAqgFgAiACaAJoArQC7AL4AvgDoASoBNgE2ATQBMAEuAQIBLgE4ATIBIgEmAREA4ACugHSAcoBhAFqASgAyIB8P1w+1D5oPcA9xD3MPfg9gD28PNw8oDyIPPQ8vDyMPXw9iD2oPSw9VD38PYw90j6UP2k/Bj74Psg/Zz8MPwG/joAv/8I/uj9kv4e/jD9BP0A/SD8KPsA+zj7QPvg+lj6ePl4+CD4MPgA+Ej4mPk4+oj58PhY+fj5WPoo+zj9Cf+N/6L/iwCcAXQCKAQYB8AJsArQCnALoAzgDTAPwBDgEiAUIBSAE2ATwBOgE2ATQBMgE+ARIBCgDyAPUAyYB5gE5AMABCgDaAKeAe7+UPqw9tD1sPWQ9UD2cPdQ9gDz8PDA8fDyoPLw8iD1cPZg9dD0wPYw+LD3CPh4+kj80PuQ+3D9qP6M/fz8lP7T//j+Kv7Q/hP/EP6E/dT9RP3Y+wD7GPvQ+gj6QPrw+gj6aPg4+Ej4UPfQ9jj4IPpw+oD5UPmw+WD5wPkE/KL+x/8dAKEAVgFcAiAEiAbQCFAKQAvQC1AM0A1AEOARABJgEoATIBRgE+ATQBXgFGAS4BBgEQARAA8QDkAOMAsQBYwBPAIUA/AB3wANAPD8APgQ9TD1EPXA9ND1sPbg9FDy0PGA8qDycPKQ8zD1oPXQ9RD3MPgw+Gj4qPkY+8D7LPxU/Vr+lP5o/o7+3v4z/yP/lv42/lD+wv6O/lz9SPzo+xj7wPmw+QD7KPvQ+dj48Pg4+HD2cPaY+Oj5EPmw+JD5qPnw+Mj5YPxM/qb+OP+zAGYBugHAA6gGkAhgCaAKIAwQDdANkA+AEUASoBKAE2AUoBTgFEAV4BSgE8ASQBKgEaAQIBAAD/AL2Af4BLADNAJUAXoBrADY/QD78Phg9lDzIPLw87D14PSg86DzAPPg8ODvYPGA87D0kPXQ9nD3MPdA92D4+Pno+pD7ZPxs/S7+Yv6I/uj+cf86/4b+Jv56/h7/AP/4/dj8TPyI+3D6APqQ+hj7aPow+dj4iPhQ9wD3aPiQ+SD5ePgQ+dD5yPlY+gD8SP2c/TT+wP/kALgBbAO4BQAHeAfwCNAKQAxQDdAO4A8AEMAQYBKAE4ATIBQgFYAUYBKAESAS4BFgELAPoA8wDVAJAAcwBgAE3gABACQAcv7Q+wj7uPqQ93DzAPKw8vDyYPOw9DD1wPPg8UDxQPEQ8gD0gPZQ90D30PeQ+JD4WPmQ+/T8dPxk/CD+X//G/qj+SADhAAz/sP2a/oH/eP6g/ST+IP4Y/Cj6UPqo+vj5aPno+cD5QPhA95D3KPgA+Aj42Pg4+eD4OPmo+rD7FPzo/HT+bP///2wBnAMYBbAF0AaQCAAKMAvwDMAOUA+AD2AQgBEAEqASQBQAFSAUwBKgEqASQBFgEKAQABBgDbAKkAkgCPgELAIOAQEA4P0k/Lj7SPt4+bD2EPRw8uDxcPJg80D0oPTw84DyYPEA8mDzoPSw9UD3QPgY+Bj4YPko+wT8iPx0/RT+oP18/ZD+xv8WAPD/FACO/yz+iP0W/k7+gP3c/Lz8EPyY+uj5mPro+ij6WPkY+dj4aPhw+Aj5gPnA+Rj6mPrw+oD7aPwc/cD9xP5bALgBtALkAygF4AVYBsgHEArAC4AMgA3gDkAPAA+gDyARIBJAEmASgBIgEmARIBHAELAPcA6QDSAMYApQCUAIEAaYAygCbQBE/RD7oPtI/FD68Pew9zD3QPTg8cDykPSA9AD0wPQg9eDzgPNg9UD3EPfA9uD3EPkw+bD5wPvU/W7+Cv64/VD91PxM/cb+AwBKAPX/if/m/hj+hP1w/Yj9IP1Y/Lj7uPsI/CD8cPuo+gD6UPmw+Lj4ePlQ+tD6+Pow+3j7iPuY+yT8GP0i/gL/AgCQASwD4AMIBOAEIAbIBigHgAiwChAMYAywDGANsA2gDfANsA5QD3APYA8gD5AOEA5wDaAM0AsAC8AJIAgQB4gGEAWoAu8AAQBK/hj8YPvw+3D72Pko+Sj5oPdg9QD1UPaA9rD1UPbw90j4QPcQ9wj4mPiY+Ej5iPoA+0D7cPwK/kj+jP00/Xz9oP1g/fD9Nv8qAAUAX//I/hL+OP2k/Mj8GP0A/bz8BP0o/XT8gPsY+/j6aPrQ+QD6wPo4+6D7TPzI/LD8nPzo/Cj9OP38/Xj/tABUASQCTAPQA6wD6APQBJgFEAYIB3AIQAmACfAJkAqwCpAKwApQC4ALMAsgC3ALsAtwC8AKMArACdAIUAdABtgFmAWIBBQDHAJaAff/uP5o/jT+KP34+7j7sPvg+vD58Pk4+tD5QPmY+VD6UPog+mj6uPpo+hj6aPoY+5j7APyQ/PD85PzI/Mz8uPyQ/Lj8QP2M/VT9GP0k/Tz9BP2o/Gj8QPwA/Lj7mPug+8j7APwA/ND7qPuQ+2j7QPtI+6D7CPxY/LD8OP2w/ez9AP4w/n7+0P41//3/BgG2ARQCjAIcA3ADjAPsA4gE4AQYBagFgAYAB0AHmAf4B/AHoAeYB8gH6AcQCHAIoAiACEAIAAiYBwgHmAY4BpAF6ASoBHgE0AMIA6wCXAJ4AWcA5v+J/9T+KP4s/lT+4P0s/dT8rPwk/Jj7cPuY+4j7UPtI+1j7WPto+5j7qPtw+zj7OPto+6D70PsQ/FD8cPxg/Ej8TPxY/FT8VPyE/MT84Pzs/AT9HP0E/cT8oPzM/Oj83Pzg/BD9VP1k/XD9nP3o/QL+5P3g/R7+cv6c/tL+OP+i/9b/6v8sAH8AmACpAP4AbAGcAa4BCAKgAuAC3AIYA5wD5APIA+ADSASYBJgEuAQQBVAFUAVoBZgFoAVoBWAFgAWQBWgFcAWYBZAFIAXABKAEeAQgBNgDrANcA+QChAJIAvABWAHgAKEAWwAAAK3/W//6/pT+SP4O/sz9eP08/Rj9+PzQ/Mj8yPyk/Gj8XPx4/Iz8cPxU/Fz8YPxc/FT8XPxw/Fz8KPwc/DT8QPxI/Gz8pPyw/JT8hPyY/Kj8tPzY/Az9LP1Q/XD9fP14/YT9nP3I/fz9OP5w/nj+dP6y/gv/Pf9S/33/zv8dAD4AQgCDAOcAIAE2AWoB2AFAAngCqALoAhADIANYA7QDCAQoBGAEyAQIBfAE2AQABVAFaAVQBVgFgAWIBTgF6AToBOgEsARgBDAECASwA0wDFAPoAngCAALSAaYBJgGKADMAEQDK/1v/Df/i/qD+TP4M/sT9dP0o/QT96PzY/ND8uPyI/GD8WPxQ/Cz8+Pvo+/j7EPwU/Az8FPwk/CD8CPwQ/DT8RPwo/Bz8TPx0/Hj8gPyk/MD8yPzY/Az9RP1g/Wj9kP3g/TT+Zv6S/ub+VP+X/7z/8/89AHYArQDwAEQBjAHMAQwCRAJsAogC1AI4A3wDjAOgA8gD+AMQBCgEYASYBKgEqASwBLgEsASgBKgEsASYBGgEOAQYBPADtAN8A1QDIAPYAowCTAIQAtYBmgFYARQB1wCfAFgACQDX/7j/hP87/wP/4v60/nL+RP4q/vT9sP2I/XD9RP0E/eT83PzA/JD8ZPxI/Dj8MPww/DD8IPwY/Bz8EPzw+/D7CPwo/Cz8QPyA/MT84Pzk/CD9SP1c/Xz91P1I/nT+kv7i/jf/UP9e/6P/5P8GADEAiwDnAA4BFgFIAZoB4AEIAigCYAKUArACuALUAgQDJAMoAywDTANsA2gDYANsA3gDZANMA0QDPAMoAwwD8ALQApgCZAI4AhwCAAL0AewBsgFKAfMA3wDWAKwAegBOACkA9//Q/7f/mv9u/0v/K//8/r7+nP6e/pz+fP5E/iD+Iv4w/ir+Ev4C/gL+CP4G/uj90P3c/fT98P3U/bz9rP2I/WT9cP2Q/YD9XP1Q/XD9iP2c/az9uP24/eD9Kv5g/nb+jP7M/gX/HP89/33/qP+0/9j/JABgAIMAnADDAPIAGgFSAZgBxgHWAfYBLAJQAlgCVAKAArgCxAK0ArgC2AL8AvQCzAKsApACeAJkAkQCHAL4AdwBwgGaAWwBUgFcAXABXgEeAecA8gAUAfgAsgCjAMkAsgBeADMAOQAMALD/kf+q/3f/Av/m/i3/N//a/qD+rP6Y/kD+AP4K/hb+3P2Q/Yj9sP2o/Xz9gP2o/Zj9aP1Y/XT9iP2Q/az9zP3U/cj90P3k/Qr+QP5g/k7+TP6a/uj+9P72/kj/y/8mAD8AQwBeAKsAEAFMAWIBjAG8AbQBogHyAXQCqAK4AvACDAPkAugCKAPoAlgCfAI8A5ADlAMwBAgEKgGQ/bz9dAEABEgDtAGEAQgC8gHkAFb/Zv7e/oD/rP60/QL/PgHSAFb+yP1t/5z/2P2k/dv/AAGx/wL/vQBcAqIBFQDc/zQAkP+a/qj+V/+K/3v/3/8eAFD/Hv4E/sL+sP60/WD9ZP6H/6j/R/9C/yf/JP7Y/GD83PyM/dT9uP2w/Qb+Ov6Y/aT8dPwE/Uz9CP1U/ab+4f8nADUA7AC4AcABdAHSAagC3AJAAggCEAOABOgEKAQsA6QCZALwATABngCmAA4BNgHnAJ0AtQDJAEAAY/8A/1X/4/8tACsAIABLAKgA8gDmAK0ApwDGAJIAIwBKABABVgHfAMQAVgFwAY0AEAC8AE4BmgCq/63/9/+f/y7/VP/C//n/5P+N/wX/gv5O/nD+wv7W/nb+FP5i/lH/0f+Q/0//YP8u/6z+rv5O/73/0/8oALoAuwAqAAEAewC2ADMAjP9Z/3X/sP8jAJ8ArwBUABEACAC9/wn/dv5o/rD+B/+K/zAAlQCCADUA3v9b/9D+sv4x/8H/AgApAJkAOgGSAXoBLgHXAHcAOwBTAJYAxQDyAD4BgAGOAYQBmAGEAQwBegAxABMA1/+H/2X/rf9IAMkA3AC4AMoAvAATADz/8P4S/x3/Y/9BABQBHgHxAB4B3gCc/3z+sP6C/5v/Pv9//zoAlgCJAIgAbgDn/y7/rv56/n7+uP4K/1j/tv8FANv/N/+w/qj+rP4+/sT9+P3E/lX/Sv8c/z7/ZP/+/j7+7P1y/k7/0v/m/9j/4/8DAC8AQwAwABUAFgApADQAYQDMADYBRAEQAdQAkABJAEcAtwAsATAB4wDdAFgB2AHGATQBuwC4ANEArACHALoAIAFOATIB+ACmADIAzf+V/4D/if+6/wEARACCAKUAdQD1/6L/vf/V/5P/RP95/w8AgACxAOcALgEkAawAIQDj/9j/qP9i/3H/zP/8/+L/2/8TADAA7/+D/x7/tP5S/iT+LP5Q/qL+N//L/xsAMgAsANn/RP/a/rz+iv4w/ij+nv4l/03/Tv+J/+T/+v+T/+z+aP4+/lT+jP7+/rP/TACGAKMA1QDQAG8AOABrAGcA+//d/20A8gDzAP4AXgF6AQoBpQCrAKUAZgBdAKcA4wDoAAwBOAEOAaIAdwClAN4ACgFAAVoBKgHsAPAACAHUAGYAJAA8AHwAnACpANMAKgGKAbQBigFAAf4A0gDFAOIAEAEiAQoB7QDxABYBNAECAXoAzv86/8j+hP6w/k//9v9AAEAAYACTAGcAz/9H//b+gP7Q/XT9zP2K/hT/UP9z/2j/A/9o/uT9jP1U/Tj9YP3A/QD+CP4s/qj+LP8+/+D+iv5y/kz+/P3Q/fj9TP6o/vj+Lf9m/7X/6//X/4P/Nv8M//z+Jf+e/ykAbgCGALIA5gDlAMwA6QAwAUgBJgEWATIBPgEwAWIB+gGAAoACUAJ8AswCzAKQAowCpAJoAgwCFAJkAlwCFAI0AqgCyAKAAkQCRAI4AvIBugGcAWoBOgFWAZoBogEyAZAAMQA4AEMABgC2/7D/2v/Q/5P/Yv9C/wj/sP5g/ij+Cv4S/jj+Rv5I/kz+Lv7A/UT9+Pys/ED8FPxU/Kj8oPx4/Kz8HP1U/Rz9zPyc/Hj8EPyQ+2D7qPsc/Hz8CP3A/UL+aP5m/oL+nP6a/rD+5v4N/wv/Rf/x/8cAegEQAnQChAJEAhQCDAIAAtwB9gFgAsAC3AIQA8ADoAQQBRAF+ATYBIgEQARABGgEYARgBKAE+AQABdgE8AQgBSgF+ASwBDAEdAP0AtQCuAKEAmwCkAKQAjwC6gHEAZABPgHrAJsAGgB4/wf/9v4R/xn/9v6w/lD+3P1o/fT8oPxs/DT86PuQ+yj72Pqw+tD6+PrI+mj6GPrg+aD5KPnI+Lj4wPig+ID4wPhY+ej5aPoI+6D7mPv4+rD6GPvQ+0j8kPz0/Hj9+P1u/s7+Lf+i/wkADwDS/9H/MACMANsAgAFsAggDOAOMA2AEGAVIBUgFgAXgBSAGSAaQBuAGGAdAB3AHmAfYB0AIYAgwCMAHgAdAB+AGcAYgBuAFiAU4BRgFEAUIBQAF8ASgBAgEZAP0AqACVAIMAsgBegEsAf0AvgBCAJ//GP+m/vj9IP1w/Pj7sPu4+wD8HPz4+8D7kPsg+2j66Pl4+cj4APhw9+D20PUA9RD1kPWA9eD0cPSw9CD1gPUA9qD2MPfQ93D4APmI+WD6YPs8/Oz8gP3Y/fD9Kv7O/oP/3f///10AFAH2AZgC5AIsA9wDyARgBbgFUAYwB9AHMAjQCJAJ4AmQCWAJYAlACeAIcAhACEAIYAhgCEAIEAj4B+AHqAdYBzAHAAeQBhAG8AUQBhAGyAWQBVgF6ARIBLgDTAPoAogCKAKwATYB5gCWACgAwP+N/z7/ov74/Xj94Pwc/Ij7OPvY+lD66Pl4+dj4WPhY+BD44Paw9WD1kPUg9XD0YPRw9LDz8PIA84DzcPMw8xD0gPVQ9qD2EPcI+Aj54Pmg+jj7sPt4/Gj9FP50/gz/4/+nAEYB9gGoAiwDrANIBPAEeAXIBQAGWAbgBnAHuAfQBzAI4AiACcAJ0AngCcAJkAmgCeAJAAqwCUAJ8AjgCPAIAAnwCOAIsAhwCBAIoAdQBygHAAfoBtAGiAboBSgFmAQwBNQDaAPoAlwC2gGWAW4BMAEGAQgB6wBNAE7/cP60/eD8FPxw+7D6qPmw+Bj4oPcg99D2sPYQ9hD1cPQQ9EDzYPJA8nDyoPEw8MDvkPAg8SDxkPHQ8uDzgPRQ9ZD2sPeg+KD50PrA+3z8LP3U/Yz+Tv/x/0AAXwCpABwBbgGcAQgCqAI0A5gDIATgBIgFEAbABnAH4AcgCKAIQAngCXAK8AoQC+AKAAuAC6ALYAtQC5ALYAvACpAK0AqQCuAJkAlwCQAJIAiABzgH2AZ4BjAG8AWYBVgFKAXABFgEQAQwBJQDzAJQAuwBPgGdAFsAJwCD/7D+HP54/bD8CPyY+/j68Pno+AD4MPeQ9kD24PXw9LDzkPJQ8QDw4O5g7uDtYO1A7SDu4O4g7+DvgPFA86D0wPUQ9zD4IPko+kD7BPyo/FD9rP3Q/Tr+/P6R/9v/eAAuAWIBeAEgAiwDxAMQBJgEQAWoBRgGAAfgB2AIsAhgCSAK0ApQC7AL4AsQDEAMcAyADKAMoAyADEAMIAwADLALcAtACyAL4AqACgAKgAkQCYAI2AcIB2AGAAaQBeAEOATkA6QDRAPkAsACiAIMAo4BOAHIABwAhv8V/2b+YP1w/Kj76Pog+oj54PjA97D2QPYA9kD1QPSQ85DywPAA7wDugO2g7ODrIOzg7EDtoO2g7kDwEPLg83D1sPYI+Ij5APsk/AT91P1I/lT+Zv7W/iz/HP8q/6H/KQBoAKcAYgFcAkADGATgBFgFqAVABjAHIAigCBAJoAkQCmAK4ApwC6ALkAvQCzAMUAxADDAMIAzwC7ALcAtACxALAAsACwAL4ApgCsAJUAkgCbAI0AfwBpgGQAagBQAFqARoBOwDiANsAywDvAJMAggCqgE4AdMAMQAw/2r+Mv7Q/cj8yPs4+2D6APng90D3QPbA9KDzIPMw8sDwoO8g7yDuAO1g7ADsYOsg60DsgO1A7uDukPBw8tDzgPWg9zj5yPl4+sj77PxY/az9QP6S/oz+xv4//2L/Z//e/4EAAgGCAVQCHAOwA2gEeAVABogGAAfYB6AI4AgwCdAJcArgCmAL0AsADDAMgAywDMAMwAyQDDAMsAtwCzALsApACjAKAAqgCXAJgAkACUAI2AfoB5AHwAZgBlgG2AUQBcgE0ARYBLADXAM4A7ACHAIMAvwBZAG0AEwAu//o/m7+QP6A/TT8EPsw+vj4gPeQ9gD20PRg83Dy8PHw8KDvwO4g7gDt4OuA68DrgOvA6yDtAO9Q8HDxIPPw9ID2IPgg+rD7ZPz8/Oz9tP6+/oD+lv6o/nj+Nv4u/nr+wP4u/+j/9gDwAaACSANgBMgF8AbIB2AI0AgACSAJkAkAClAKYAqACpAKsAoAC4AL0AvgCwAMIAwQDNALwAuQC/AKEApgCeAIMAiYBzgH6AZYBsgFiAV4BSgFAAVABXgFQAX4BAAFCAWoBDAEGARABAgEdAMAA9ACnAI0ArQBSgHRAAAAH/9K/nT9WPz4+rD5aPjw9oD1cPSA81DyIPFg8IDvIO4A7YDsIOxg6wDrwOvg7GDtIO7g7yDyAPTA9cD3YPm4+iT8sP3I/kv/yf8mAO//f/9p/yr/dv7Q/dz9HP4O/iT+7v7r/78AngG0AsADkASQBagGiAcgCMAIYAnQCQAKYArgCgAL8AoQC3ALoAugC6ALoAugC1AL4ApwChAKkAnQCAAIcAcYB7gGWAYwBiAGAAa4BZgFoAW4BcgFsAWgBZAFqAXABaAFaAVYBUAF8AR4BBAEtAMcA4ACHALKARQBJgBW/4b+dP1Y/Gj7UPoo+RD4MPcg9uD08PNQ82DyIPEg8GDvoO7A7YDtIO2A7ADsoOzg7SDvkPCg8vD04Paw+KD6gPzQ/e7+GQDzACQBGAEIAb4AIgB9/+T+HP44/ez8VP3M/Qj+aP49/z8ASAGEAvwDWAVABiAHAAiwCCAJoAkQCjAKAArgCfAJ8AngCQAKQApQChAKAAowCkAK4AlQCeAIYAiAB6gGKAbQBUgFuARgBCgE4AOgA4QDqAPMA/wDOARgBIgEsATQBOgE6ATgBOAE0ASQBDgE5AOMAwwDjAIUAp4B3gAQAFb/kv6g/ZD8sPvI+sD5kPig95D2cPVg9HDzsPLg8UDx4PBg8MDvYO9A78DuQO5A7iDvcPDQ8aDz0PWg99D4aPpk/BD+/v6w/24A1ADWANgAxQAyAFb/rP5U/tj9QP0I/Sj9NP1Q/dD9sP6p/7kAHAK0A/AEyAWABlAHIAiwCDAJgAmwCdAJ4AnwCfAJ8AnACZAJkAmQCXAJUAlACSAJoAgACHgHwAYQBogFIAWABPADmAN8A0QD8AL0AhQDBAPYAgwDhAPUAwgEUASgBLgE0AQABSgFCAXQBJgEOAS8A3ADOAPAAhgCgAHlAPj/3v7k/fz84Puo+qD5uPiw98D20PUQ9UD0UPOg8kDy0PEw8XDwAPDg76DvQO9g7xDwIPGA8oD0APcQ+Wj6wPtc/cr+1P+0AH4ByAG4AagBogH8AMP/rP74/WT9qPws/AT8LPxs/Nz8pP2Q/qP/AgGcAjAEiAWYBnAHQAgACaAJAAogCkAKMAoACtAJoAlwCQAJgAhQCEAIMAjgB6gHcAcYB3AG2AVwBdgEIAScA0wD5AJQAvQB2gHMAbABsAHQAfYBPALAAlQDvAP0A0gEuAQYBVAFgAWwBZgFSAXYBLAEWAS0AwgDpAJAAnQBhADV/zn/Sv5I/XT8oPuI+nD5mPjA97D2kPXg9GD04PNA89DyUPLQ8VDx4PBQ8ODv4O+Q8ODxoPOA9TD3mPgQ+tj7XP1i/gz/6f/cAIIBpgF2ATYBpgDk/xL/dP7I/eT8TPww/Dz8BPws/BT9OP41/1YA+gF0A2gEYAXIBvAHYAiwCHAJ8AngCbAJ0AmgCSAJwAjACIAI8AeoB6AHWAfQBqAGqAZQBrAFUAUoBZgE6AOUA4gDKAOoAnACiAJ0AjACOAJgAngCkAIMA9ADWASYBPAEgAXQBeAF6AUIBggGyAWIBUgF0AQYBHwDBAOQAvABPgF+AKf/sP7I/ez8CPwI+yD6WPmQ+LD30PYg9nD1oPTg84DzEPOQ8iDy8PFw8XDwwO8A8ADxQPIA9CD24PcI+Vj6WPzA/Sz+mP7D/9oAQAFoAaABTAE2AFH/xP7c/Yz80PvI+4D76Prg+oD7DPyQ/OT9u///AMIBBAPIBPgFgAY4B0AI4AgwCaAJAArgCXAJQAkwCfAIcAgwCBAIqAc4BwAH0AZIBrAFcAVgBfAEIASIAzQD0AJUAhAC7gGkAVwBbgG+AdABygEgArwCUAOwAygEwAQYBVgFqAXoBdAFmAWABXgFIAV4BNADVAPAAigCrAFMAcAA9P9Z//L+eP64/dz8UPzQ+yj7UPqY+dD44PcA93D2EPZQ9bD0QPTg8xDzQPLg8UDxgPBw8JDxEPMw9JD10PfI+ZD6IPuI/Cz+yP4E/8T/jwB8ABkADgDO/+r+rP3s/Ij8CPxg++D6kPqY+iD78PvU/ND9Sf/nADQCPANQBGAFOAYQBwAI0AgwCYAJ0AkACrAJYAlACQAJkAggCAAIyAc4B7AGgAZYBgAGsAW4BZAFKAW4BIAEQATIA2QDPANEAzwDJAMEA/QC7AIEAxgDJANIA4wDyAPwAzAEgATQBNgE6AQQBTgFGAXABIAESAToA3AD/AKMAgACVAGpAP3/T/+c/tT9+Pww/JD74Prw+QD5aPjg99D2wPVg9XD1EPVQ9DD0YPSg83Dy8PEw8uDxcPFg8qD0cPZQ91j4uPmo+hD78Ps0/Qb+ZP4x/ykAbQD//6n/cP/M/g7+sP2E/fz8XPwc/BT88PsM/ND81P3U/u7/VgF0AjADGARABUgGEAcQCBAJoAmwCfAJUApACtAJkAmQCVAJwAhwCEAIwAcAB3AGMAboBXgFKAXoBJgEMATsA6QDQAPoAtAC2AKwAngCXAJYAjgCIAJMAoQCiAJwApgCDANkA3ADbAOgA9AD3APgA+wDyANwAzgDLAP4AmwC9gHKAYgB8wBNAML/D/84/oT9AP1A/ED7gPrw+UD5UPig9yD3gPbg9aD1oPUw9dD04PTg9ODzwPJg8nDygPIw8yD14PaQ9zD42PlQ+4D7qPvo/Fr+1v5D/1EA7QBNALf/9//b/7L+uP3U/dT94PwA/Bj8NPzA++D7IP1e/tb+c//XACwC6AKsA+gEKAYIBwAIEAnACfAJEApACkAKAArgCcAJgAnwCHAI8AdQB6gGMAboBZgFOAXwBKgESATQA3ADJAPcAqQCmAKgApQCcAJgAlwCXAJkAoACqALQAgADKANMA2ADbAN0A4QDrAPQA8QDqAOMA3gDMAPcApwCYAL4AZ4BYgH7AEsAsf9c/+D+Hv5k/dj8EPwo+6D6SPqA+XD4CPjw91D3kPag9uD2oPYA9uD1wPXA9LDzoPMw9ID04PQg9sD34Piw+YD6IPtw+/j77Pzc/XT++v6F/8n/p/90/1P/I//O/m7+CP6U/SD9yPyY/Kj8BP2Q/Tb+AP8OADIBKALwAsQDyATgBeAGyAegCHAJ4AkACvAJAArwCcAJkAlQCQAJgAjgB1AHwAZABtgFiAUgBbAEaAQoBNADcAM0AwQDzAKoApACaAIwAvgB2AG4AagBsAHEAdIB3gH0AfwB9AH8ASwCZAKMAqgCyALcAtwC3ALAAnwCQAIYAuoBiAEeAc4AdwDx/2r/FP+m/uD9DP18/AT8MPtg+uj5iPnI+Aj40Peg9xD3kPbQ9gD3cPag9WD1IPVA9JDz8PPQ9FD18PWA90j56Png+Wj6UPvY+yj8MP2A/hv/Gv9M/8r/tf8A/6D+xP60/i7+uP2I/TT9qPxs/Mj8XP3U/ZD+uP/LAIABLAIUAxgE8ATQBegG8AegCDAJsAnwCQAKAAoACvAJoAlQCQAJcAjAByAHuAZgBugFaAUIBagEQATUA3QDIAPIAnwCUAI8AiAC+gHQAbQBlAGGAZ4ByAHeAdYBzgHAAZ4BigGsAfIBHAIkAjACTAJYAjQCCALoAdABrgGIAWgBTAEkAfIAwACUAE0A4f9r/+7+UP6I/dD8RPyg+8j6EPq4+Uj5uPhY+Ej4MPjA92D3YPcg93D2wPWA9XD1QPWA9WD2YPdo+KD5wPoY+xD7WPsA/Fj8uPzE/d7+B/+m/ub+bP8O/wT+mP3Y/az98Pyc/MT8rPxc/ID8MP3s/YL+TP9LAC4B8gGsAnADOAQgBRAG6Aa4B4AIMAlwCYAJoAmgCYAJQAkgCcAIMAi4B3gHGAd4BtgFeAUoBaAEIATUA4wDEAOUAlACGALKAYgBigGSAXgBdAGcAcwB0AHMAdgB3gHEAbYB1gH8AQAC/AEMAiACIAIUAiQCNAIoAgwC6gHQAbABlAFuATQBAgHjALQATQDV/2r/+P5c/rD9NP28/Az8SPuo+iD6oPko+dj4oPh4+Fj4SPjw94D3IPew9gD2YPWA9SD2sPZw97D46PlA+iD6aPoQ+2j7iPs8/Cz9wP0S/pL+4P6m/jr+Fv4C/pz9VP1Y/Vz9FP0E/Xj9+P1O/t7+1/+8AEIB1gGwApADOAQABfAF8AbAB3AIEAmACcAJ8AkACvAJ0AmwCUAJsAhgCCAIwAcwB+AGoAYgBngFEAXgBGgE2AN4AzADsAIcAsYBhAEkAdIAzwDoANsA2QDzAPgAvwCVAKcAzADkABQBcAGyAcABygHqAf4B9gHwAfAB5gG8AZIBbgEyAecAlABGAAEAt/9o/wD/bv7I/TT9rPws/MD7YPvo+lD6yPlQ+cD4OPjw9/D34Peg93D3YPcg95D28PWg9aD14PVw9mD3YPgA+VD5oPng+QD6YPow+xj8uPxc/Qj+VP4w/ir+cP6E/hj+rP2A/Uz91Px4/Iz85PxU/fj94v7J/44AKAG4AUwCGAMQBBgFKAZIB1AIAAlgCcAJIApwCpAKwArgCrAKQAqgCRAJcAjgB3gHKAfQBnAGEAaoBSAFiAQABHwDBAO8ApgCYAL4AZoBYgEOAaIAZgBpAGQAQQA6AFwAbQBNAFAAlgDnAA4BMgFsAZgBpAGiAaYBtgG6AaIBdgFCAR4B9ACeAEsAKQARAMD/Pf/W/oL+Av5Y/dz8nPxA/Lj7OPvg+nj62PlY+ej4ePgI+OD30Peg91D3IPfQ9lD2APYw9oD2sPZA90D4MPl4+aD5EPqY+tD6KPsY/DD9zP0O/mT+tP7a/tT+yv6y/nT+Cv5k/cT8gPyg/Oj8NP3g/fL+CwDcAIIBLAKsAvgCcANoBKgFyAaYB0AI4AhACUAJUAmACdAJ8AngCdAJsAlACZAI+AewB5AHYAc4BzAHAAeIBvAFYAXQBDAEhAMgAwQD1AJsAvQBhAEIAY8ASABLAFsAWgBoAIUAlgCJAJMAxgD8ACwBZAGoAdQB1AHIAbgBkgFeAToBIAEAAdYAqgB8ADQA2v+B/yv/3P6I/ir+tP00/az8MPzA+2D7EPuw+kD60Plo+fD4gPgg+OD30PfQ98D3cPcw9wD3wPaA9pD2IPew9wD4kPh4+Rj6GPo4+hj74PsI/Ej8QP0K/vT9xP1e/vz+qP4k/kr+cP64/eT86PwU/cz8xPyo/cz+aP8fAIQBuAIAAwwDqAOABPgEoAXIBtgHQAhgCOAIYAmACYAJoAnACbAJcAkwCcAIQAjQB4gHSAcgBwAH6AagBigGqAUgBYAE4ANIA8wCbAIYAsQBZAEeAeYAqABpAEcATQBGACcAFAAeAEAAagCUAMIACgFUAXgBhgGSAZYBbAEYAdwAzADGALoAtACyAIQAKQDG/3H/K//s/rD+gP5C/uD9cP0E/aD8SPz4+7D7YPsI+6D6MPq4+Uj5+Pi4+Ij4cPho+Cj40PeA91D3IPcg92D3APiA+PD4aPno+Uj6kPoQ+8D7TPy0/Dz9sP3M/aD9sP34/fT9uP2M/Vj92Pww/Oj7+PsU/HT8PP1G/lb/awBiAQACWALMAmQD7AOgBLgF+AawB+AHIAhgCHAIYAiACNAI8AjACLAIoAhQCNgHgAdoB1AHMAcwBygH2AZQBrgFKAVwBLgDLAPEAkwCtgEqAbwAXAAFAM3/v//I/8r/zf/S/9L/0//z/y8AaACsAAYBXgGEAYIBegFwAVIBJgEMAf0A+ADxANkAwACcAFoA9v9//x3/1v6E/jz+Av7A/WD96Px0/Bz82PuQ+1D7GPvQ+oD6IPrQ+Yj5UPkg+fD4yPio+Ij4WPgw+DD4WPiI+MD4IPmg+SD6gPrw+nD76PtQ/MD8OP2Q/dT9IP5e/lj+TP5k/lz+8P10/VT9LP2Q/AD8FPyM/PD8oP0a/7oAjgHoAZQCXAOsAwAE4AQQBrgGGAfQB3AIUAj4BzAIkAiACFAIoAgACeAIUAggCEAI8AeAB5AH2AeIB9gGUAboBRgFIASMA1AD3AIsArABagHsAEEA6P/t/+f/xv/Q/wAABADf/+H/EQArAC0AWACQAKEAjwCMAJsAggBhAHgAtwDWAM8AzgDZALkAbAAuAAsA5v+i/2v/RP8U/8z+gv44/tz9bP0A/bz8gPw0/Nj7gPsY+6j6OPrw+cD5kPlw+Vj5SPko+fj44PjI+ND48Pg4+ZD5+Plo+sj6IPt4+9D7KPyA/NT8GP1U/ZT94P0Q/hT+JP5E/ir+xP1o/Vj9KP2k/Cz8MPx4/MT8aP2k/u3/rAAQAXwB+gFsAvQCsANYBAAFwAVoBqAGqAbwBkAHOAcgB5AHEAgACKgHsAfoB6AHKAc4B5gHeAfoBpgGYAbYBfAEQATUA3AD9AKYAlQC7gF0AQ4ByQCmAKoAvwC5AJwAkACBAGEAOQBGAGkAaABvAKIA1gDNALAAtgDdAOoA9AA4AYABggFMATQBJAHjAI4AawBiADAA0v+L/1v/B/+i/k7+GP7M/XD9JP3g/Gz86Pto+wj7uPp4+lD6QPow+gj62Pmg+Wj5MPkA+dD4uPjY+BD5QPmA+dj5OPp4+sj6QPu4+wj8RPyM/ND8/Pwg/Vj9jP2U/YD9WP0I/bj8hPxM/PD7qPv4+7z8eP1Y/pf/1wBaAXwBCALoAmwDoANYBFgF6AUIBlAGyAb4BugGKAewBwAIMAiACNAIwAiQCIAIgAhQCAAI4AegB/AGOAawBSgFWAScAzQD6AJ4AgQCxAF+ARIBsgCaAJQAlQCZAJAAWwALANb/r/+R/6L/3f8GAAoAGQBOAGEAWAB4AMYAAAEYAT4BYgFGAfEAsQCCAEEA/v/l/8//ef8G/67+Wv74/aD9eP1U/fz8lPxE/PD7aPvY+nj6OPr4+cD5uPmw+Xj5GPnQ+KD4ePho+Ij4yPgA+UD5iPnQ+RD6WPqo+gD7WPuo++j7IPxM/IT8rPy4/MT87PwU/Qj94PzM/KT8TPz4+xD8iPwc/cj9wP7B/2QA1QCIAVgC6AJ8A1gECAVgBagFQAbABsgG6AZoBwAIUAiACPAIQAkwCfAI4AjACIAIQAgwCPgHgAcAB4AG6AVABbgESATYA3QDOAPwAogCKAL0AboBdAFAAS4BEAHJAIYAVgAeANz/vP/S//X/GABZAKoA5wD/ABYBMAE2AUIBagGSAYYBUAEQAcAATgDi/7H/nP93/07/M/8G/5j+Gv68/XD9AP2Y/Ez8APyY+wD7gPoQ+rj5iPlo+WD5SPkY+eD4oPho+Ej4SPhg+Ij44Pgw+XD5sPn4+UD6YPqQ+tj6GPto+9D7TPyY/Lj84Pzs/OD8zPz4/PT8jPwo/BD8IPxE/OT8AP4D/3//4/+SACQBggEUAgADzANYBOAEeAUABmAG4AZoB+AHUAjgCHAJsAngCQAKEArgCaAJgAlgCQAJkAhACMgHKAeIBhAGsAU4BdgEoARgBPADdAMIA5gCKALWAZoBSgHvAK0AeQAuAOn/5v/6//3/HQB4AM4AzQDAANsA2QCdAHgAnQC1AIUAWQBhAEwA9/+4/7P/mP9F//7+0v6A/gL+jP1A/dj8TPzo+5j7OPu4+lj6EPqw+Uj5CPno+Lj4ePhA+BD44Pew96D3kPeQ97D34Pcg+GD4uPgY+Xj52PlA+qj6IPuI++j7RPyQ/MD8yPzY/AT9KP0s/SD9EP3s/LD8xPxI/ez9bv4N//H/mwDrAGABOALUAgwDbANIBBgFYAXABYgGKAdIB5gHYAggCVAJoAkwCnAKEArACeAJ4AmACUAJUAkgCZAIAAioBzAHgAboBagFYAXQBFAECASwAzADwAJ4AjwC2gGSAWIBNgH2ALkAmAB/AFsAUQByAJcArAChAJsAjgBmAEwAUwBwAGEARAA5ACoA+v/B/53/b/8c/8r+jP42/qz9LP3Q/Gj80PtY+xD7sPog+qj5aPkQ+ZD4QPgQ+OD3gPcw9xD34PbA9sD28PYQ9zD3gPfg9zj4ePjY+Cj5UPl4+dj5QPqA+sj6GPtg+3D7oPvw+yT8KPw0/Ez8TPxY/Mj8iP1C/uL+g/8vAKoACgGMAUgC8AKIAzgE8ASABdgFWAbwBogHAAigCDAJgAnACfAJEAoACuAJ4AnACaAJcAlQCSAJ0AiACCAIwAdIB/AGmAZABsgFSAXYBGAE5AN8AygD2AJ8AjAC7AGwAXoBSAEQAdwAtwCfAJYAhgB4AF0AJgDn/7T/pv+r/8P/x/+x/47/bv9D/w3/6P7M/or+FP6Q/SD9rPw4/Nj7gPsY+6D6KPrQ+Yj5OPno+Kj4WPgA+LD3gPdA9xD38PYA9wD3APcw93D3wPfg9xj4iPjo+ED5iPng+TD6cPrI+kD7uPv4+zj8aPyY/ND8EP1w/dT9IP5+/vj+bf/e/3QAGgGUAfABXALcAkwDtAM4BNgEUAXIBVAG4AZYB7AHEAhQCJAI0AgACSAJIAkgCSAJEAkACeAIwAiQCGAIMAgACNAHkAdQBwAHqAYwBqgFMAXYBJgEUAQIBNADjAM0A9wClAJMAuwBngGAAVQBBgHFAKYAdgAVAMr/s/+i/3v/Yv9m/0//Dv/U/rL+kv5K/hT+7P2o/Tj92Pyc/Ej82Ptw+zD72Ppo+hD60Plo+fD4kPhY+Bj4wPdw91D3IPcA9xD3QPdg93D3sPfg9wD4IPhY+LD4APlQ+bD5MPqQ+uD6MPug+wj8XPyk/PT8KP00/Uj9lP0Q/qL+LP+o//j/MgCRADQB7gGkAmQDCARgBIgE2ARQBagF2AVIBugGaAfIB1AI0AgQCQAJ8AjwCNAIsAjACAAJIAnwCPAI8AjACFAI6AegB1AH2AZQBtAFYAX4BLAEiARgBDgE/AO8A1wD3AJIAsQBYAEoAf0AwAB9AEcAEgDL/4n/af9P/w3/vP6I/lD+8P2I/VD9PP0Q/dT8rPyE/DT80PuQ+0j72Ppg+vD5kPk4+fD40Pi4+KD4mPiI+GD4IPjQ96D3cPdQ92D3gPew9/D3SPio+PD4EPkY+TD5UPlw+bj5MPrg+oj7APxo/ND8JP1A/Vj9jP3c/Ub+2P6c/2kABAFwAeoBiAIsA5wD7ANABJAEqATIBDAF0AVYBsgGUAfYBzAIYAhQCCAI0AeQB2gHYAdwB6gH+AdQCLAI4AjQCGAIyAcQB1AGuAVwBXAFeAVoBVgFUAUgBcgEaAT8A2gDrAIQArwBiAFmAWgBhAFyARwBvgBvABAAmf82/+D+YP7I/Xj9hP2U/YT9dP10/Uz92PxU/OD7gPsg+8j6mPp4+lj6GPrg+dj58Pno+cD5mPmA+XD5MPkA+RD5SPmA+Zj5kPlo+Tj5MPlw+fj5gPoQ+5D7+PsY/Az8sPs4++j6APuY+5T8+P2E/8QAYgFYAY4A/v5k/cD8iP1x/6wBoAPYBCgF0ARYBAgE0AOYA2gDaAPEA2gEOAX4BXAGqAbIBgAHWAeYB5AHCAdABpgFYAVwBZAFyAUgBmAGSAYIBtgFuAWoBZgFOAVIBBQDXAKUAkgDuAOcAzADtAJMAhAC/AHYAYAB2ADj/+j+YP5+/v7+a/+C/0f/3P54/i7+yP0M/Sz8kPtg+3D7sPsA/ED8bPyM/HT86PsI+zj6sPl4+cD5OPqg+sj6+PpQ+4D7aPtY+6j74Pu4+0j76Pq4+qj6APvQ+8T8YP2g/cD91P28/YT9TP0g/Qz9KP18/fD9ov61/9wAhgF0Ac4A6P8J/5D+6P72/yQBHAL8ArADxAMQA0ACMALEAiwDGAPYApQCSAKAApADyAQIBVgEvAO8A8wDmAOMA8wDxAOMA/wD4ASwBEQDVALwAsQDwAPQA1gEzAMAAlIBXAIkA+wC0AJoAsMAd/8lAPoA8v8o/9wAlAJUAXz/XgB2ATn/fPx4/QwA6f/4/cD9Lv+D/57+2v5qALcAjP74+0D74PtI/HD8iP09/9P/Vv9f/5r/Mv6Q++D5kPng+UD7OP5WAXQCpAEvABL+GPvY+Jj4cPmY+sD8HQBQAxAFMAWEA7f/yPow98D2kPhA++b+FAPgBUAGUAXYAzIBlP3o+lj6EPt0/B//xAIoBXgFQAXwBEQD9wAIAOD/TP4Y/ID8x/8cA1AFiAcQCSgHNAJ+/qD9cP1Y/Rb/OAJ4BDgFaAXwBIQDzAFdAPL+KP5a/+IBhAPQA+ADWANaATL/Rv44/uD+3QD8AiwD+gGCAWoB1P9w/YT80Pzs/OD91ACgA+wDbAJPABT+NP2K/qb/SP4w/Bj8uP02/5QAkAKwA9ABPP4g/Bj8nPzk/Hz90P6xAPABYAHh/x3/rP40/aD7IPyi/qMAjACJ/yn/I//A/rL+lP9jALn/Rv4K/gP/6P6o/RT+nwAUAjYBgQAKAbEA1v4O/if/Uf+c/TT9nf8sAogDAAXQBbgDm/+Q/Kj7yPtA/Pz9CAKgBsAIcAhAByAElP2w9mD1MPr0/4QDmAZQCSAI5ALc/gz/AACu/iz9dP34/QT+Nv/yAZAE6AXQBdQDWABQ/UD8GPyQ/Ob+UAIQBGQDGAK6AdYBdQBs/aj7NP0iAMQB2AF2AXkApP5u/hgBRAIU/wz9BAFgBWQC4Pow+FD8dgCGAWwCQANWASz+WP1W/nL+CP4m/6IBZAMoA98AeP0w+1j7hPyk/Y7/QAJABKAEvAOiAaT+yPvI+bD4WPn4/PwBOAVQBkAGOAMs/Uj5sPrk/ID7MPq4/WADYAVwBPwDuAKX//T9hv4w/VD5QPhw/MwBaAQYBqAIkAjoA3D+6Prw96D14PY0/XgFkAmQCEAHAAfAA+T8kPfw9gD58PtCARAIwApYByQDnAE5/6D6+PhE/In/eQAsAqAFMAfABAYBBf8C/hT8sPpM/AUAjAOYBcAFMARWAWj9mPro++3/zAEsAAv/WABhAHj9OP1oAvgFVAI0/eD9LAEhAOD7CPva/ggCGAFx/xYBvAN0A6oA7P2M/GD8lPz8/bUAKAKKAYwBkAL8AYz/7Pxw+5j7sP06AfwCDABI/BT+aALwAeb+TgCAAwwAkPhI+PD+egEU/ygBQAYQBCD9EP2GAYD/qPlg+pD/YgDi/sIBUAU0A1D/Vf+jACQAof+m/lD7yPnm/vAF4AYUA/oB2AIQ/9j50PsMAsQCXP9vAOADYgHc/SQDkAhsAVD3sPngAcwBqv5IBOALcAfU/Lj6Ov6w/Jj5hP0gBcAJYAp4B8sAsPkg99D4EPuQ/ggGkAswCCYBnv4x/4j9aPoI+kz9awA+AXgCqAVgB7gDOPzQ9+D5uPwU/PT8GALwBCQCfAEoBlAGjv4Q+Yj5uPhg92z8KARgBQADyAWACfAE9PxI+zj7APVA8LD32ASgCtAJYAvgDIAEkPVA77D0QPqA+vT8+AVQDlAOSAd5AJT8MPjQ8kDyAPr4BPAKAAmwBEwDxAHo/DD5wPmw+0D99v/4A8gGCAZcAmX/P/+t/4z9WPqI+1wBEAQ8AeYAwAWYB5QD4f/g/RD5oPPQ9rgD8A1ADOAEqwDI/ZD5+PiE/pQDFAO+AHwB5AI1APD7cPwIAZwCNAFYA1AGigHA+GD3LP2fAKL/vgH4BjgFPP2g+yUA0v6g+Qj8eAToBmQBNP1g/TT8QPnA+m8AvAPsAm4BJgGwATQC+gCY/cD6gPkQ+QD7pwBoBpgHmAVABPACHP7Q9/D2aPtI/nT/0APIB0gFoAC1AEwCY/9Y+/j7qP0g/GD8tgHYBUAFoAQwBYoBsPrA+Q7/ov+Y+uD6eAKgB8AF4AJQAzQCuPtQ9jj5VwD4AnwBRAL4BRAGDgGo/S3/qQBE/qj66Pkm/ngFwAm4B+wDYAL8/uD3MPUM/EAE8AQkA+gF2AZ1/7D5Fv6wAq7+APtc/yAEjAIvAOoBuALa/iD86v4AAQz+/P1oBBAGNv5I+skA+ANQ/Uj6MAFQBBD9QPmYAcAIgAPg/HT+av6g+DD5YAFQBDcAbf9QA4gDQf9A/Ur+bP2g+1z96QDIAdkAxQBFAPr+Ov8zAHv/bv9eASwAAPtQ+Qr/6AWwBtgC3v9m/jj82PpQ/Mf/aAMABXwC/v6AAFgDOP/Y+GD7wAJ0Ajj8KP3gBsAKaAJA+wz+NABI/Bz8fAGQApz+lv7wBFAJsASY/Zz9PgDE/OD4RP3IBDgFdv/M/aQDmAdQA0T+Ev40/aD5YPoTAEgEMAaAB2AEcPx4+Yn/sAPs/Wj5z//gBc4BMv7oAqAFNACQ/HIAuAIU/ZD3mPpAApAFeATQBPAFmgE4+QD1sPiHAGgFfAPR/zYAcgGDABQAngHCAfD8QPZo+HADuAXQ+yD74AhQDUkAcPYo+nb+oPvA+lv/YQDA/QgDsAwACm7+4Puw/UD1oO3A90AIMAuABcgGEAsABHD24PK4+bz8KPrc/ZAHsAlcA5oBqAUABMD7APgw+7z9Nv4SAagCfP7U/SgH4Ay4BLj7wPwy/kj5gPeE/ngF+ATCASACxAKSAPX/EgGW/1j+cwBmABT9NP3+AHgCVgFcAoAEfAIM/RD7MP5gARwCuAJwBFAEiAHQ/TD5MPbI+0AHYAtoBHD9DP9MAqT9kPfA+5gEAAU6/3L+2ALoApj8qPh8/BAC2AIQATYBIAI3ABj8mPr8/dgBKgEa/oD93P+8AzAG1AIA/Nj5BPz4+9D7pv9cA8QDYAQYBc4BVPxQ+2z+pP3g+FD7qAXQCIQCmgCkAwkAEPlI+nEA2wDE/Pz9iATwBqgCWP/dAPIBdP1A9yD4+//QBWAGAAdACBgEQPtQ9+D5qPuQ/OgBwAigCTAFbAETALD9mPoo+/z9b/8QASADxAKUApgFqAVm/uD3CPrN/4ABdwBAAKQAPAEQA5AEqAI4/xz+nP3A++D7Nv7b/2gC0AWABogExgEw/FD14PVR/zgF4gA8/xAIkAsu/yD0sPgRAKD96PoEAoAIoAPw+xj9KALC/rD2qPlIBlAJbwBU/CoBfAGY+ODzoPyACNAJWAIQ/ZD9Lf+Y/uj9cv4m/tj99QBwBVAF6v/o+0r+HgEs/sj7SgFwBxgFhP96/rj9yPlw+mwBoAW8AxwDaAUYAzj6APVo+swBoAMYBDAFGAO4/xr+9Pyc/E7/hAPEA1P/PP39ABQDQf8S/oQDWAU2//D7cQBEAoD80PkGAHgF2ANkA6gHWAaI+5D0IPk8/pD8DP3ABiAQoAwx/zD36Pos/sj5iPioAJAG4ANQATAFgAmgBFD54PPA9yz9KwCEAoAEgAXgBHgCsP9U/ej7VPxI/GD6IPvAAAgHMArIB3n/GPiQ+CT93v7w/b7+kALABJwAvPxIAYgFI/8Q+X3/4AWg/fDz+PqYB7gFQv5YBEAMNgFQ8XD1rAKsAEj5sgGwDXAHEPpw+qIAQP1I+Z4A6AfYAtj74P+wBcIAuPk0/fgDUAJY/UX/mAQUA5z8MPz6AQQDkv7o/lAEgAS4/gj8wv4lAAz+yv58A+AFBAMO/mj7/P3YAqYBePto/MgGkAro/qD0kPvwBugDgPvO/sgGuAMw+rj57AJoBwwBAPvM/eACwwCA+vD74AUACYH/0Pn8AKgFwP0Y+NQAYAhlAKD3rPzCAbD8KP1ACaAMkv5g9VL+gAaT/0j4CPxw/xz9A/8wBiAHuwB8/QX/1P6c/dr+Iv64+xH/GARPAMj6HAFwCkgFYPeQ9ID97AKGASgBrAIcAez9xPzI/SMA2AI4AzwBqf/Q/eD58PjLABAK0AgqAET9tQCoAFz9bP2U/Qj6mPv4BNAIqAKWAbAJ0AdA9iDuSPz4B2oBAPuLADAEsgDyAVAIwAcBAOj7FPxQ+WD2CPsMAwAGQAZACOAIAAWK/tD4EPaA9ZD2hP0QCZAP4AxYBnwAUPrg83D0sP4wBOT9vPxQCHANmAT2/pwBwPyw8KDyuAJ4B+j+/QDgC2AImPug+xwCRPzw8nj4+AP0A3j/DAO4B6gDdP04/rEAgPwQ9yD6/QAAApP/qAIgCtAK7gCQ94j4pPxg+lD44/9ACYAIMAP4A1gGlgDQ9VDxsPYC/wAEMAYwCDAKQAkgApD38PHA9Dj79gCoB1AN0AlL/4j7if/w/ZD3uPuAB9AGsPog+UAEAAgGAfT+oANQAhD78Pl6/zABFPy4+QACkAzACvT+4Pgw/ggERv5Q9BD48AR4B3YBtALACEgGEPzQ9eD3cPvI/MgAaAfQCJgECgFq/oj7YPow+7T9vAEIBYgFXAIs/uj97v6Q/Jz8TAJgBBn/IPvU/VwC0AO0AxgEKAEg+0D4SPhg91D7wAgAE2AMGPxQ9uD8TP3g9Gj4gAjgCtz9oPu4BhAGQPcA9XgE0Amk/fD6+AaIBwj5wPUUA6AId//w+nL/3P2I+TgCsA1QCFj90f9QA8D2YOuA9wALIAqz/5AFwBEACnD2wPB4+AT8EPpo/cAEsAdgBnAE3AIcA2gELgFY+KDxAPQo/agF0AlAChAI+AO1/yj7oPaw92r/6APB//z8NANwCWgF6P1m/oAC+P4w+Jj6WAJcAhT99P6wBvAHggFg/Rz+7PxI+ej6GALABdQD0AK4A0gCrP6A+0j60Ptq/gj/+P70ARAHMAlgBNz8SPvs/LD4sPVR/8AJyAXc/SwB6AZzAAD2KPlQBMADiPvg/fAGmAbm/qD6UPq4+lj9iAJoBRgFWAaABuj9QPMw9ED9UgGQAbgGYAsoBDj4gPgGAUQB4Ptw/YACdAI2AbQCcAEM/aT9ZANYBAf/DP1S/6j8sPif//AJaAfu/okAyAWQALD28PW0/PoAsAIQB2AKUAaE/zD9kPvQ9SD0kP1QBxgG2gGQBcAKeAYI/aD5MPkw8wDwiPxwDSAOEAUgBzAOkAQw8UDt4Pek/AD6C/8wCzAO0AYwA1gFbAKA+IDwUPE4+pAE4AnwCCAFwAIoAfD98Pxs//T9mPiw+fQBwAUXAOD79AIwDAAIUPug9wD9QPyQ9ZD40AZQD9AIav9D/4cAcPjQ8dj5WAVoBeQB4AWQCLoAOPiA+TT9iPtg/JAEcAloBN//oAF2/xD3YPYFALAFZANMA3AGIAPI+SD26PuaAZABrgB4A/AG4ATg/Tj7Xf/c/8D64PvABJgHSwAw+8r+oAKoAQQC8AODAMj5CPl4/cP/TAHwBcgHGAO2/3kA2P0g+AD5//8AA54B9APACKAG+P7I+5D84Pkw+Lb+kAZgBjgDoAR4BVb+cPXw9VT9+wDkAMQDIAeIBGD+kPsE/p0AmP6I+5z9QAKEAjQA1QB8AeT9JPyCAeAFqgHk/Jv/JAKA/GD3KP2YBWAEdv9+ASAFlAIx/1sA4v8Y+YD1qP04B7gFAAE4BBgHgP+w9jD41P4MAuADsAXkAdD6SPtoAngDsP2A/YwDPAMY/Dj7egGQAkb+OQDgBhgFQPxo+nf/aP7w9+D5aARQCcAF0ARgB6ACaPhw9sj7cPvw9tD6KAbQDKAKaAagBJkAqPjg8xD1MPcA+/wDQAuQCZgFIAggCnz/EPAA72D5+PtI+RwC8A/QDzAGCANEA+j7kPJQ86j52PrI+5gFcA+wDNgEYAPIAZj44PFQ91H/0P3A+W7/oAkQDEAJIAlIBpD6QO/A7vD0UPskA1AL0A7ADJgHkgCA+fD1YPbg9/j5jwBQCcALmAcYBSAERP9Y+Yj4UPvE/YIAnAO4BNgCOADu/6gBHAL5/4T9uPzg/Wv/Rf8O/7QBSAQ0Aub+W/9hALT9IPto/f0ArgBl/yQCwARsAdj8jP0AANb+YP0PAEADFAJU/7f/9wDG/tj7/PxYAKABsAGgA9AFzAMW/qD5sPjo+aT8WgGgBZgG4AT0AjQBkv5I+yj5MPpo/qAC9ANUAyADsAJmAAb+Fv7m/iT9wPrg/IQCUAVIBKwDgAPM/zD6+PjU/PP/qv/H/0AC9ANUA3QC8gF+AD7+tPzA+wD7UPwnABADTAMYBJgGeAZGATj7WPm4+mj78Psi/+gDwAY4BowDsACU/gD9ePxw/Qn/9f/0/7//+v/NALQBRAKMAsgCMAIW/6j6sPmI/W4BIALUAbAC2AJKAET9cP0HAF4B3wBoAEsA1/8j/8r+Qf/4//v/RgDiASgDtAEM/sD7zPz+/tz/QwBIAc4BNAFTAN3/e//U/oz+F/88/47+xv5DAD4BJgHkAIgAi/94/qL+1v+RAKwAwwAfAPb+4P6t//v/2/9CACYBZAFNACD/Xv+AAEIBFgFIAHb/kP5c/WT9BQDIAtwCIALIAqACcP8A/Oj71P3O/qL/9gFIBCgEOALFAPH/bv64/Ij8Cv4EAHABJALMAoQDEAPXAHL+TP3s/Kz8RP20//QCSAQYA8YBRAE9AIr+aP0Q/Tj9BP6Z/44BKAPEA1AD8gEiAJz+jP3I/HD8JP0B/0ABxAIcA8gCvgHE/+T9TP1c/TT9hP0k/4wBcAMoBGwDUAHg/pj9oP3Y/Ur+vP96AfwBsgEcArwC7AEPALT+4P0o/UT9rP5kAFwByAFEAlwCRgFG/5j9+Pxs/U7+AP+1/9oAuAGgAVgBdAHqAC//2P0Q/kr+TP0k/c//VAOABMQDGAMYAl//KPwQ+yj83P2w/xQCQASoBBQD9QB2/1L+FP1U/Mz8HP52/+0ArAK4AxwDWgGM/wj+2Px0/DT9nv4xAMAB4AL0AgwC8QDb/4b+RP0M/QT+j//gAMgBWAJgAqQBZwCC/2n/hv8G/3T+5P4FAKIAkwDIAD4B7ADO/y3/hf/1/8z/dv9a/1L/hv81APsAVgF4AXIB3ADV/1//vv/x/67/7f8AAaoBRgGgAJ0AvwAuAE7/Nv/Z/0cATgCAAOAAoQCY/9z+Cv9D//z+9P7E/24AAwBf/3r/gv+U/sT9QP5h/9j/yf/z//z/df/c/sb+uv5u/nL+LP/0/x0ADQAsAEwAEACx/07/5v64/gL/XP9k/4//NAC5AIQAHAAIAPD/bf/w/g3/mv9LAAIBvAEkAjgCJAIQAt4BngG+ATQChAKgAuwCbAOsA8QDGAR4BHAEIAQQBBgErAMkA/AC5AKsAngChAJ4AuYBFAF9AAMAev8f//b+mv74/WD98PyA/Az82PvQ+4j7+PqY+nj6GPp4+RD5APkQ+Sj5QPlw+YD5GPnA+Nj4UPnY+Wj6MPu4+5D7+PrQ+jj7sPt0/ND9Rv/7/w0AHgA5ABMABQCAACgBwgGcAuAD2AQgBVgF6AVoBogG2AaIByAIQAggCHAI4AhACcAJcAowC4ALQAvQCjAK4AnwCTAKQAowChAKoAnwCDAIsAcgB4gG8AVQBZgEzAPkAsIBcAAm/yb+KP0w/Ej7YPow+aD3APZA9JDyEPHA78DuoO3A7ADswOvg6wDsYOzA7ADtQO2A7cDtIO7g7oDwwPJQ9fD3ePpQ/Gz9Rv5U/44A/AG4A6gFgAcACUAKcAugDGANkA2ADUANIA1ADZANsA2QDQANAAzQCrAJ0AjYB7gGuAXgBBgEiANcA2ADKAPEAlQC1AF0AWABcgFsAVgBpAGAAqQDAAVwBpAHAAjwBwAIcAjQCEAJkAlgCcAIEAiwB7AHAAhQCPgHkAZQBMABH/+8/Oj6iPkY+ID2MPXw8wDyoO+g7aDrYOng5mDlwORg5KDkIOaA6MDqAO1g7/DwMPEw8VDycPQQ97D6PP8QA2AFKAcQCYAKUAtwDBAO8A7QDuAOYA9wDyAPMA/gDyAQUA8gDmAMsAmgBngEIAO6AUIAcv8g/4z+4P14/Uj90PxI/BD8MPxo/Mj8WP0u/m3/HAH4AoAE0AXYBmgHqAdwCPAJ4AuwDVAPgBCgEOAPMA/ADkAOwA1gDeAMwAtACuAISAdIBSQDRAFf/0D9CPvY+GD24PPw8UDwYO5g7MDqQOlg5yDlQOMg4qDhAOJA42DlAOgA68DtwO8A8dDxsPIg9KD2SPqS/qgCKAbQCIAKgAugDCAOcA/gDwAQ8A+AD7AOQA6QDqAOIA6ADRANwAtQCYgGEAR0AcD+IP2c/AD8+PpQ+gj6ePnA+Mj4aPm4+dj5sPrY+2z8BP2W/tMAwAKwBAgHIAlQCkALkAxwDaANMA7QD8ARIBMAFGAUIBTAEiARwA+wDoANsAygCzAKgAhgBvADWgEE/+T8mPoY+PD10POQ8UDvYO0A7KDqIOmA5+DlAOQA4oDgIOAA4UDjwObA6gDu4O/Q8HDxQPLg85D2UPpI/s4BqAQYB1AJgAvADfAPwBGAEmASoBGAECAPIA7ADUAOwA7gDnAOIA3wChAIWAX0ArAArP40/ej7QPqg+BD4aPiw+OD4SPmA+Rj5gPgA+Uj6qPss/WH/2AGkAxgF8AYACYAK8AuADcAOYA/gDwARQBJAE+ATQBQgFAATwBGAEAAPYA0wDPAKcAl4B4AFjANQARH/GP0A+2D4wPVw83DxQO9g7eDrQOpg6GDm4OQg4yDhgN9A34DgoOIg5oDq4O1g76DvoO9A8DDyAPaY+mj+XgFABAAH8AjACkAN0A8gEaARQBJgEgARQA9gDkAOIA4wDrAOcA6QDOAJMAeoBEgCswCL//T9uPvo+dj48PdQ98D38Pio+bj52PkY+jj6mPro++T94v/qATAEaAYgCMAJgAtgDeAO4A+gECARoBEgEgATwBMAFOATYBNAEoAQoA7QDBALUAmAB6AFsAOmAbH/sP2I+1j5QPcA9bDy0PBA78Dt4Osg6sDoQOdg5aDjYOJg4SDhoOGA42DmIOqg7UDwYPGw8VDy4POA9jD6AP4uAdQDcAYQCTAL8AyQDgAQ4BBgEUARYBDwDuANcA3wDIAMgAyQDBALUAigBZADlgFp//j9+Pxg+1D50Pcg99D24Paw99j4ePm4+TD6CPvw+wz9yP7VAKgCoAToBiAJwAowDBAO0A/gEMARgBLAEsAS4BKAE8AToBMAEwASoBDADvAMQAtwCZAH0AVABJACsgDg/uj8yPqY+MD2MPWw8xDyUPDg7mDtAOwg6oDowOYA5UDjQOKg4uDj4OWg6KDsYPCQ8gDz8PJw8/D0oPdI++7+xgFoBBgHkAkgC6AMYA7wD2AQQBAAEDAPoA0QDIALgAtACwALoApACagG4APMASMAZv7o/Jj70PmQ9+D1UPWA9UD20Pdo+SD6SPrg+gT8PP2k/rQAEAP4BIgGgAhwCvALgA2wD+ARwBLgEuAS4BKAEmAS4BJAE+ASABIAEXAPIA0wC7AJAAhABsgEhAOgATf/PP2Y++j5SPgw9xD2YPRw8vDwgO+g7SDsQOsA6sDnwOXA5ODjwOLA4gDloOig7BDwsPKg8zDzgPOA9Wj4MPsi/i4BoAOoBegHQArwC0ANsA4AEEAQkA/ADpANIAzgCpAK0ArACiAK4AjYBkAE2gEcAI7+9PxY+7j5sPfg9TD1cPVQ9lD3qPj4+aj6IPs0/Mj9MP/qAFAD6AXAB0AJAAvwDKAOIBDgEUAToBPAE+ATABSgE4ATwBNgE2ASQBHAD7ANYAtgCeAHWAbgBKQDRAJGAAD+DPw4+oj4IPcA9sD0APNQ8QDwoO5A7QDsAOug6aDnoOXA44DiwOEA40DmgOqg7hDysPOw85DzsPQA97D5OPwi/wACWAQYBgAIIApADGAOABDAEEAQ0A5gDQAM8AogCuAJ8AnQCQAJWAc4BeAC4QBT//z9PPwQ+uD30PVg9AD04PQw9nD3sPjw+RD7HPyY/bT/ygG0A+gFMAjgCTALsAxwDiAQABLAE+AUIBXgFGAUwBMAE6ASoBIAEqAQ4A7wDLAKoAj4BqAF4AM0At4ARP80/Qj7iPk4+ND2sPXg9NDzEPJw8EDvIO7g7ADsQOtA6oDooObg5ODiAOLg4wDowOwg8JDyMPQA9YD1wPaY+Nj6kP2iAFADSAUIB+AI4AoQDWAPABEAEeAPoA5gDeALoAogCiAKwAnwCBAIyAawBEwCZwD0/mz9gPtw+TD3MPXA84DzQPRg9eD2WPjA+dD68Puc/bn/GAJYBJgGoAhgCvAL4A3QD2AR4BJAFGAVgBUgFaAUYBTgE0AT4BIgEqAQoA6ADEAKAAgoBqAECANCAa3/PP5w/Ij6EPkA+KD2QPVQ9GDz4PEw8CDvwO7A7WDsQOug6qDpgOcg5UDjAOMg5QDpYO0g8bDzIPXg9eD2ePgo+hT8Zv5KAaADaAUYB/AIwAqgDPAOwBAgEQAQgA4ADaALgAogCgAKcAmACGgH6AXEA6oBMQAB/3j9uPvg+bD3gPXw86DzYPSg9VD3IPmY+rj7HP3q/ucAFAOIBcAHUAmAChAM8A2wD4ARIBNgFKAUoBTAFGAUgBOgEkASgBFgEOAOUA1wCzAJWAfgBVAEdALXAE7/cP14+xD6+PjQ97D2wPXw9KDzkPKg8WDwAO9g7iDuAO0g6yDqoOng5wDl4ONg5UDo4Otw8DD0sPXw9eD2WPiY+ej6YP36//wB5ANIBmAIsAmQCzAOIBBAEMAPsA4gDWALYAowCrAJ8AhQCJgHGAYwBHAC3QAz/+j9vPzo+kj40PVg9KDzYPNQ9CD20Pcg+cj6uPw+/o7/dgEIBFAGIAjgCaALEA2ADmAQYBKgE0AUYBRAFCAUwBMAEwASABEgEEAP8A0ADPAJIAh4BqgEqAIGAYv//P1s/Ej7UPoY+fD3QPeQ9lD14PMA80Dy8PDA70Dv4O6A7WDsgOsg6uDnIOZA5sDngOnA7JDxkPXw9tD2IPcI+Kj5APzW/vgAYAJwBBgHcAngCpAMgA7wD2AQYBBwD4ANcAsQCsAJQAmACKAHmAZABaADVALzAGL/lP3I+5D5QPdA9eDzQPNQ82D08PWQ9/j4qPq0/KT+WwAcAgAE4AWYB2AJcAuADUAP4BBgEqATIBRAFOATgBMAE2ASgBFAECAP8A3gDIAL4AnoB/gFOAS0AjQBcv+Q/TD8YPuA+ij50Pfg9jD2UPVw9JDzgPJA8ZDwEPAA72DtQOyg60DqIOhg5iDmAOcA6eDs8PGw9UD3sPcI+Ej46PgI+zL+9gDwAvgEEAcACQALAA2ADgAPQA9gD4AOQAzgCbAIgAhQCAAIYAcgBnAEvAJgAfz/bv7E/Bj7SPlQ93D1wPPw8iDzgPQw9oD3wPhQ+jj8Iv4DAAQCOARoBoAIYAowDBAOsA8gEWASoBMgFCAUABTgE4ATwBLgEeAQ0A9wDjANsAvwCTAIeAawBMAC+QB+/wr+iPyA+8j64PmY+GD3cPaA9aD0APRQ8xDy8PCA8ADwoO4g7UDsIOsg6YDnwOZg5gDnQOrg72D0APaQ9jD38Pdo+Pj5vPxO/4IBCASwBnAI8AkQDHAOsA9AEIAQABAQDsALUApACUAI0AcQCJgHCAYYBKgCLgGG/+D9IPwQ+vD3MPaQ9EDz0PLA89D00PXg9jD4gPnw+gj9jv8gAogE+AYQCeAKwAzADqAQYBLAE6AUoBQgFEAUoBSgFAAUABPAEUAQwA5ADaALsAmwBwAGeATUAvMA+v44/RT8YPt4+lD58Peg9lD1cPTg83DzkPLQ8YDxQPHQ8HDw4O9A7uDrIOqA6UDoAOdA6IDswPFg9bD3sPho+JD3ePg4+7j9Ev+QAFQDwAWIBxAJMAsQDXAOcA+QDwAOgAvQCeAIIAiwBxAIUAhoB4AFtAMUAm8AAf+w/Sj8CPqg95D10PPw8iDzEPTw9MD1oPaw98D4QPqA/E//HALQBGgHoAlAC8AMoA7gEOASgBRAFUAVwBRAFCAUQBQAFEATABKAEAAPcA2wC8AJmAegBeQDQAJeAE7+lPxw+6D66PlI+Wj48PZQ9TD0wPNQ87DycPJA8vDxkPHA8UDxgO9A7cDrYOqg6KDnIOlA7GDvQPMQ97D4cPdA9rD3QPo0/OT9PQBwAvQDyAUwCGAK8AvQDaAPsA8gDkAMoAogCUAIYAgQCfAIEAgYB6AFfAN2ATsAFv9g/Uj7CPmQ9iD04PIQ88DzUPQw9UD2wPZg9+j4OPuI/RQAUAOIBoAI0AmAC1ANwA6gECATABVgFWAVgBVAFcAUgBSgFOATYBIgEcAPwA1AC1AJsAeYBYgDMAKbADL+FPww+7j6uPmw+OD3kPbg9PDzwPNA80Dy0PHg8aDxEPHg8KDwYO+g7eDrAOoA6GDnQOmg7JDwQPRA9+D38PbA9hj4aPmo+kj9tgA0A7AEgAbQCLAKYAxADjAPYA7gDOALsAoQCUAIkAjgCLAIkAj4B/AFOANQARsAqP4M/YD7ePmg9iD08PLQ8hDz0PPQ9FD1YPUA9nD3WPnQ+zD/yALABTAIMApwCyAMcA3ADyASQBTgFcAWoBbgFUAVgBSgE8ASYBKAEQAQ8A2gCxAJ2AZwBUAEgAIQAMD9YPtA+SD44PeA93D2wPWw9TD14PMA88DyUPKw8YDxoPEA8TDwEPDg74DuwOwA7MDr4OuA7SDxsPQw9hD3OPjY+ID48PgA+6T9+/+wApAFcAdgCLAJcAtADGAMwAzwDBAM0AowCtAJ4AhQCKAIsAhoB5gFEAQcArf/CP5Q/RD8GPqQ+FD3UPVA86DyEPMQ8xDz8POw9OD0gPaQ+ob+tAD4AhgGsAiwCYAKQAywDfAOgBEAFeAWABdAF8AX4BZgFcAUgBTgEuAQwA9gDsALMAkQCBgH0AQMAtv/iP34+gD5KPhw91D2UPWA9KDzAPMQ89DyEPJA8cDwUPCg7wDvgO7g7aDtwO3A7WDtYO2A7kDwEPIg9CD2UPfA94j44PlY++z8W/9IAtgEuAZwCMAJYArACmALIAxwDIAMYAzwC1ALAAugCuAJ4AjQB0gGUASAAioBmP/s/bj8uPto+vD48PeA9oD0EPNw86DzcPJg8fDxMPQQ96j7CgHABGgFiAUgB8AIYAlgClANYBCgEsAUIBcgGKAXYBegF+AWwBQgE+ARABDgDfAMAA1wDLAKsAggBnwCoP7Q+zD6EPlI+PD3EPdw9cDzwPJA8vDx0PHQ8XDxkPDA78DuwO0g7QDtgO0g7mDugO6A7uDu4O+w8YDzIPVg9lD38Pcg+ej6KP1z//wBaARIBoAHcAhQCdAJYApQCxAMcAyQDJAMMAyQCzAL4ArgCXAICAeQBZAD7AHsAOr/PP68/Lj7WPoo+ID2kPVg9FDzYPNA8xDxAO+A8ED1MPoo/gwCgAQ4BAwD0AMYBgAIMArgDcAR4BMgFYAWYBcAF6AW4BaAFqAUYBLgEHAPIA7wDZAOQA4wDEAJmAU8AUz9IPtg+sj5GPm4+OD3APYw9EDzgPKA8RDxEPGg8IDvoO4g7kDtwOxg7UDuQO7A7QDuwO4g7wDwAPIg9GD1cPbA9wD58Pmo+yz+mQDMAjAFUAdACNAIwAnQCjALsAvADJANgA0wDSANsAygC8AKIArQCOAGcAVYBMwCGgHZ/9r+OP1o+8D58Pew9YD0kPRA9BDzkPGA8IDvEPAw9Lj60f84AkgDnAP0AqACEAQgBzAKgA2AEcAUIBaAFgAX4BYgFqAVoBWgFKASIBEgECAPkA4gD0APUA3gCfgF/gH4/Yj70Pqo+kD60PlA+ZD3QPVA8+DxkPCA70DvAO8A7iDtwOyg7IDsoOxA7YDtIO3g7GDtQO6A7yDxAPPQ9ED2sPe4+KD5KPts/cD/3gFIBHgG2AdwCEAJIAqwCmALcAwgDeAMgAyQDFAMcAuwCmAKcAm4B0AGSAXYAygCEAEYAGz+WPwQ+5j5YPeg9YD1APbA9LDyAPFw8EDxoPTY+aD+NgEEAswB+QDKAFgCiAUACYAMIBAgE4AU4BQgFSAVoBRAFIAUgBTAE+ASYBKgEcAQYBAAEGAOQAuIB7QDEABg/aT88Py0/MD7WPpA+DD1MPIw8ADvAO5g7QDtgOyA6+DqwOrA6oDqIOrg6eDpAOrg6mDsYO5w8IDyIPRA9WD2kPcI+fD6NP36/8ACMAUIB0AIQAkQCsAKYAtgDJANMA5wDoAOcA6wDcAMQAzQC7AKEAm4B5gGIAWQA4wCoAHb/9D9+Psw+gD4sPbA9vD24PXw8yDyoPCQ8BDz8PeM/EH/XwBmAJb/6P4CALwCAAZQCcAMABAAEuASgBPgE+ATwBMgFEAU4BNgE2ATQBMgE+ASoBJAETAOYArYBvQDvgG5AJ0AWgAg/xj9oPqw96D0IPKw8MDvAO8A7gDtAOzA6sDpoOnA6eDpYOmg6GDowOjA6aDrYO6w8BDy4PKw87D0APYo+Bj7Cv6NABQDaAUABwAIAAkQCrAKgAsADbAOYA9QDyAPsA6gDbAMoAyADKALAAqwCGgHyAVoBJwDeAJIACL+lPwA++j4gPdA97D28PQQ80DyQPJQ8/D10Pmw/KD9vP3c/aj9kP0Q/0wC6AUgCTAM4A4gEGAQgBAAEYAR4BGAEiATYBNgEwAUoBSgFOATIBKQD3AMoAmIBzgGUAWoBNgDUALr//j86Pnw9lD0YPJw8fDwQPAA72DtoOsg6iDpoOjA6MDogOgA6ADooOjA6eDrQO4A8NDwcPFQ8pDzMPWA95D6xP1mAHACMASYBZgGaAeACOAJgAsQDWAOQA+AD/AOYA7wDaANMA2wDEAMcAswCsAIeAcgBrgEhAOMAv4A1v4A/eD7yPoQ+WD3gPYg9iD2APeg+Pj5oPoQ+6D7+PuY/NT9WP+mACACUASoBoAIEAqAC2AMkAzgDMANcA7ADhAPoA/wD/APQBCAEOAPMA5ADHAKgAjQBvgFmAUABeQDuAJEATf/0Pyo+uD4MPfg9SD1kPTQ87DyYPEQ8MDu4O2A7QDtwOyg7MDsAO2g7cDu4O/g8GDx0PFw8mDzkPRA9lj4iPp0/Pj9Qv9cADABBAJAA9AESAZwB2AIEAlgCXAJ0AlQCrAKsAqwCoAK4AkACVAIAAiIB9AGOAa4BSgFYASAAwQC4v/U/bj8mPwM/fT9Jv+C/2D+sPx4+yD7oPsU/RP/ngAgAfwA4AD1AFQBHAIkAwAEyASoBagGUAeYB6gHgAcYB8gG+AaQByAIYAhACOAHIAcwBmAFuAQQBHAD+AKkAkgC2AE4AVMAKf/s/cj84Psw+6D6KPq4+VD5yPhI+LD38PYQ9lD14PTg9CD1gPUQ9nD2kPZw9iD28PUg9qD2cPdg+Gj5MPqw+gD7aPvQ+2T8IP0E/ur+l/8pAMEAdAEkAsgCUAOsA+wDIARgBKAE4AQgBWgFkAWQBYAFWAUIBZAECASEAxgD3ALMAtQC2AK4AkgCmgHuAF0A8P/G////jQAIAUgBXgFWASoB3wC6AOwAYgHcAVwC9AKIA9gD0AO0A9ADCARIBIAE4ARABWgFcAVwBWgFGAXABIgEaAQYBLgDiAN0AzADtAI4AsoBLgF4APr/rP9a//j+rP5m/uj9SP2w/Bz8kPsQ+/D68Pro+qj6aPoY+sD5cPlY+Vj5QPlY+bD5APog+kD6iPrI+tD66Po4+4j7yPsU/KT8MP2Q/eD9Pv6C/qb+yv4H/1v/s/8BAFoAqgDZAOUA4wD0APoA3ADOAOgADgEWAQAB5wDGAJYAYwBHACMA5/+s/5X/p//t/2MAtAChAFcATwCSAM8AEgGiAWQC5AIsA3gDvAPgA/wDWATQBDAFaAXABSgGUAY4BjAGOAYoBhAG6AXYBdgFuAWABTAF6ASYBEAE9AOgA0gD5AKEAiQC1AGAASIBuwBZAPb/h/8a/8L+dP4e/sj9kP1U/fT8hPws/Nj7gPsg+9j6qPp4+kj6OPoo+vj5yPm4+cj52Pno+QD6EPow+mD6kPq4+uD6IPtg+6D72PsI/DD8UPyA/Mz8KP10/bT99P0q/l7+ev6W/sb+Dv9H/2n/kv/U/w0AHAAsAFEAgACRALAA8gAsAUwBcgG4ARACSAJoAqAC6AI8A4AD0AMgBHgEqATIBPAEKAV4BcAFCAZQBpgGyAbYBsAGuAa4BsAGuAawBogGUAYgBvgFyAWQBVAFAAWgBDAEzAN0AxwDwAJsAhgCrAEqAa0AQADT/1v/6P5+/hT+rP1Q/fT8kPws/Nj7gPsw++D6oPpg+iD6+Png+dD5qPmI+WD5QPkw+TD5QPlY+Wj5gPmQ+aj5uPng+QD6MPpY+oD6uPr4+kD7kPvQ+xT8ZPzE/Bz9bP3A/SD+dv66/gL/U/+j/+f/KAByAMEACgFIAZgBzgH+ATQCdAKkAsgCBANQA4wDsAPkAygESARQBGgEoATgBBAFMAVIBVgFcAWIBZAFmAWwBcgFwAWoBaAFqAWgBXgFWAVIBSgF+ATABJgEaAQwBPgDrANgAxgDzAKAAigCzAFoAQABmgBPABgAy/9h/+j+fv4i/tT9gP0o/dD8iPxI/AT8yPug+3j7SPsI+8j6mPpw+lj6WPpI+iD68PnQ+dD50PnQ+cj5yPnY+eD5APow+lj6iPq4+gD7QPt4+8j7HPxw/MD8IP2U/fj9UP6u/g//Xv+n/w0AiwD7AFIBmAHgASgCaAKsAuwCJANQA4QDvAPkAxgESARwBJAEsATIBNgE2ATYBAAFGAUYBRgFIAUYBfgE0ASwBKgEsAS4BLAEoASQBGgEMAQABOADxAOQA1gDLAP4ArACaAI0AgQCxgF2ASgB2QCOAEUA+/+0/3T/LP/U/oD+Qv4A/qj9YP08/Qz9uPx8/Gj8SPz4+8j7yPvI+5D7WPtQ+0j7KPsY+yj7QPso+yj7QPtI+zj7QPtw+5j7sPvo+zT8YPx0/Kz8DP1Y/Yj92P1A/pT+zv4W/2D/mv/f/0MAlgDIAPwARgGEAbIB9gE4AlACSAJcAqwC9AL4AuAC8AIcAywDGAMYA0ADaANgA0ADTANoA2gDUANEA0ADIAPsAtgC8AIAA/QC0AKsApACgAJsAkACCAL0AfABxgGCAWIBVgEkAdwAvwC6AIcAPAAaAAMAuP9n/1//eP9V//r+xP7Q/sz+jP5K/jD+FP7Y/Zz9kP2Y/YT9TP0k/Rj9EP30/OT85Pzk/OD85Pz8/AT97Pzc/PT8MP1k/XD9eP2Y/cD90P3U/fj9Mv5a/nD+lP7I/ub+/P5B/6v/BQA/AHIAmgCsALwA7gBIAZwB5AEsAlwCeAJ0AnQChAKgAsAC5AIAAwgDCAMIAwQD7ALQAsQCsAKIAmgCbAJ4AlgCEALoAeIB0AGaAW4BYgFOASgBDAEAAe0AtwCAAGsAagBlAFkAXgBoAEwA4f94/1//Zf9I/x//Gf8p/yn/C//e/sL+sv6c/nj+Uv40/hL+7P3s/Rr+PP4u/gr+9P3c/bz9zP0O/j7+Ov42/lL+ZP5O/kT+bv6s/rj+nv6U/qD+mv6S/sL+KP9s/2z/af+G/6T/vv8EAHQArwCZAIcAswDqAPkAAgEmAUABJgEIARgBQAFIAUQBXgGEAYgBZAFYAXwBoAGkAZQBhAF0AVIBKgESAQwBGAE6AVABMgHpAKIAcwBGABIAIgCSAPAA1QCZALEAoAD8/07/Q/+Q/5H/lP8VAJwAegAcAO//d/+K/vj9iv6r/z8AGwDE/z7/av7M/Qj+7P6k/7j/Z/8R/8D+ev52/qT+zP7g/gL/SP+G/37/MP/e/sr+Ff+e/wYAGwD//8X/Xf/2/t7+QP8KAMsACAGJAKn/MP9+/zEAuwD8AAgB0QBkAB8ATgDOAEgBeAFGAc0AbwB5AMoACAEIAeMAugChAKgAxADIAKcAcwA4AAEA5//+/y4AYACPAJIARQDg/6X/jf+f//j/bACTAE4A+//Q/5n/Uf9d/9n/UABvAGYAVgARAKL/gv/b/zwAUAA8ADUAHwD0/+L/BQAhAAMA1f+r/2z/M/9D/5f/9/8wABcAuP8w/8L+qP7k/kX/rP/3//D/kf/6/ob+sv59/zoAbQA/AN7/P//M/iP/DQCHADEA3/8cAFcACADF/xEAVgA8AJgAagFeAQkAMP/0/9sAswDaABgCKAI8AA7/EwAKAbYA0ACcAWIBdwDRAJQBlgBK/1IA/AH6ACL/WQB4AggBRP4x/yQC7gEV/07+FQCQAOD+cP55ANoBlQDa/hD/EgC3/6z+Gv9lABUAqv7i/n4ApQBq/zb/4P9c/yj+iv48AKYApP9h/+f/iv/I/lL/TQDk/6z+WP7k/kr/t/+vABwB7v+A/oj+Rv8n//D+w/9yAML/E//D/3oAy//k/ib/tv+C/3//cQC7AJr/5P5R/3z/ef/oANACPAKB/yj+9P5d/wf/SQDwAmQD6ABk/1MAvQCa/37//QDIARoBnAAWAYgBZAHnADIApP/l/7YAEAHxACYBNgGCANb/sP91/4D/jgBAAT4AMf8SAGYB4ACf/7v/+/+q/tT9kv+eAYQBdAB4/xr+oP2q/wgCmAFd/17+5P4B/8L+8P/iAcYBoP9i/hn/CgDo/2z/kf96AAYBRQBj/83/dwCg/1D+hv4rAHIBSAFaAJb/5v4s/kr+ff+8AOMANAD3/0AAbv/I/SL+lwCUAQIA8P63/xQAKv9x/5oBQAL1/zD++v6d/x7/DQA8ApAC7wABAIkAzQBN/4D9LP6QAKIB0gGYA/gE1AEQ/ED64P1EAYgBHAJABHADWP4A+0j95wCaAXYBaALaAfr+xPxQ/UX/+gAMAvABRgCS/n7+lP4q/uz+zwB8AV0AE/80/6MA4gDU/kD9av6oANwB4AF8AVsAKP54/cv/lABs/cz84AIgCIAENPx4+WD9UwAGABQBQANMAkT/Pv78/ub+Zv5t/0AB0AE2AUsAN//I/nv/CgAAABQA2P8M/97+7f/9ADABHgH0AIX/eP1o/Tb/TADvAFQCxAGE/mT9pADMArT/WPww/vgBjAE+/7j/bgBc/woA4ALcAkr/TP3u/v3/Gv7g/RQCOAVAA4gAVQD9/9T9GPxC/uACiAO6/+T+uAIIBBkAAP1Y/p3/2P3Y/WACwAScAPz8Hf/qANT9SPxYACwDOQAg/ej+0gG8ACD+G//0ARYBYP2A/Nb+wQAUAUwB/gFGAaz96Ppg/UACLANnAOD/8gFtAMD6QPrmAeAGRAKY/IT++ALWAWD9GP1UAbgD7gCA/XT+kAGsAtwB0wBUAAIA/P7O/pMAQAHv/4YA5AK0Ah0AQv4k/mT+K/9cAhAFtAGw+4z8jgHsAPD8VP+wBfADKPvg+UQB/AJE/Yj99APcAnD7RPzMA5QD4Pys/FACTAKw/TT+BALuABD9VP3vAOADGAXMAtT8GPlU/JIBGAIVAHIBxANMACj7LP3kApgCev6w/kgA4PsI+XQCYAtwBND5oPxwA3T+4Pao/NAHOAZ8/Yr+oAR+AbD5YPnG/rQCUARYBDQCpv4E/QD+ev7U/vgCiAbYAtj8BPxu/wwCIAJSAW4BQgFV/xj+jP9QAuwC0f84/RIA4ANUArf/ZQDd/2j7APtMAmAGMAKa/3wBUf8g+9z9HAM1AKD65P0wBAAC5P2gAogHWwAw9uD3CAAkAbz9YAEACagGmPso+JH/pAPo/bj4tPwgBGgF9AAl/yACeAI0/DD32PoAAyAG8AEg/gYAkgGg/mz9//+EABb+AP7oAGwCxwB+/kj+pv9+AOH/gv4k/xQCYAH4+4D6tf/IA1AEcAWQBNz8YPPw8+P/oAqAChAFPAK4/sD4QPdY/YADSARMA9gEqAXqAKD6CPog/gP/QP7sAyALWAfg/CD6tv7Q/6z8gv8wB+AFkPzQ++gCagHY+Qz8gAYQCfoAkPt0/fz9UPtM/RgE8AZkA0b+WPtI+7T9nwBYAlQDYAKa/tD7JP2M/zn/L/+AAggF5AGc/Fz8Tf/s/kD+3ALYBSgAaPqY/dgChgFL/8gCcARG/uj5CP4EAjcAuv9MA+QCCP2E/GADOARA/BD5yP5YA5wB+v/EAvwDdP6g+HD76AJ4BCAAVP4uASYB0PvY+YAA2AfQBl3/KPlY+Qz+UgHeAdQD+AbgA6j60PYU/awDqAL8AAgFyAUQ/eD3PP+YBSgBQP2mAbgEpAC8/YgAKAIE/4T99QD6AZz95P1wBTAGFPzQ90wAUAV5/4T8rAJ4BND7gPaY/rgH0AQM/20AQQAw+gD6NAEIBAYBRQA8AvQAwP3Q/c7/Jv8W/nkA/AL4AXcAYgBQ/tD7nP3aALIAKgEQBXgEUPyg9jj7EANwBCoBbQA8AeD+oPvA+1H/OAMoBCgA8PuY/iQD+f+g+uD+uAZABKD6ePkkA8gHzP/A+Rj/kAMpAFr/oAO4AiT84Pl0/7AEbAJ+/uwAqAPA/pj6z/9QBngDUPvI+cwAiAWUAgYA/gGMAWD8WPr8/UACGAUYBgwCmPog+f3/2ASEALD8kgEgBfH/kPsa/oD/5Pwm/ugEkAeuAZD6oPkw/e7/IAFkA4gF6AJU/Bj4oPpsAiAIKAXU/mj9fP3Y+wj9xAKwBnwDtPwM/XAEoAIg92D36AWgCuD/mPka/0wD5wAaAG4BzPyQ9nj7CAa4BZP/wAOACHj98PDg9qgDXAMQ/YgBQAoQBvD5CPgvAIACCP3w/HADMATU/Zj8ZAJIBH3/DP1LACQDkAIkAQb+ePjY+GgCsAhwBKgAoAMgA4D7oPds/YgE0AQyAS0ARgCW/hL+Wv+GAAQD+AU0A3z8WPrw/Cj+pv4wA4AIKAe7/2j6MPoo++D7Lv+IBcAJYAhsAtj5QPOw9kwCkAiQBOv/SAKoBJT+MPeI+lADCAR6/k7+tAN4BDr++Pko/QwChAKcABQAQAAG/9z85Pz2AFAFMAQ4/qD5SPpB/6ADWAP7ALQBxALg/qj6BPz6/jH/DQDMAngDmgHmAHQBpP6I+Vj6EAEEA4n/wwDwBPIB+PuA/RgDYAK4/KD7zf+cAYD/yf94BLAHEARg/GD4iPr8/cX/lAK4BmgH+AKe/rT82Pog+mj9cAK4BBAE1AIAAmQA7P38/NT9J/9qAFsAIP+bAMgEaAQs/sD6GP5eAQABwQCGAMz9APze/jwClgF9AEgCnAKo/nD7cPvA+0T9ngHYBQgH6ARC/7j40Pes/cwBb/8e/4AGEAr6AJD3KPohAFj/iP3oASgGRAMs/qL+BAJw/4D4SPkEA+gHjAOJADADeALw+TD0kPqoBZAIWANL/zX/f/8D/6z/owDu/tj8yv7YArAD3wAO//wAVALQ/iD7fP1sAlADmgGeAZ4B/v70/OT9yf8MAegCoAR0A03/cPsw+0L+7AJIBigF2gAU/qD8iPpI+1QB+AawBWQARP4z/3z9WPqk/PgCYASFAJT/yAJ8AhD9+PlI/Ir+uP6KAdAGSAf0APj7dPw0/Ej52PokA7AJeAfH/2D7jP3P/xj+kP2nAI4BzP6M/bkAeAWYBdf/8PqQ+1T+R/+L//kAQALcAFz+bf/AAgADTQAE/lD8wPrI+1ABEAiwCMwBYPt4+yz+rv6M/moAYAM4BCoB+P3+/tAA0P5s/awBsAWuAfD6ePt/AKAAPv4kAoAHVANw+rD53P4m/3D9cAJgCLgE1PxI+8j9WP3s/IgBKAZgBNL//v7e/9T9wPsS/tIBGAI6AIUAcAKiAVT+pP2w/5//0P0M/3QC9AJ2APz+fP9P/17+Z/+uARgCtABc/4D+8P7CAOUAmv6S/ggDOAW6/8j5HPzQAewBnP++AZgEAgFg+uD58f+cA4QB0P+kAWwCqP5I+qD7egFkA3z/DP6+AdQCNv6g+0IA+ARIAhz9BP3C/tz9iv5MA9gF1AFA/Uz+YAGJANT9wP1C/xsA8ABMArwCQgHu/rD9sP7JACgB6P7g/VcAqgHw/lb+rANIB6wCcPvQ+QT9X/9lAJgC0AT4A7oA2P0g/Zr+7P9//9j/MAJEAoD+vPxeAKQDkgEm/nT+IgB2/+7+8QDQAW//Vv6TAHABPP8D//4BBAJc/Zj7ZACoBBADxv8i/7b+yPy0/CYAlAOMA24B+/+X/0X/2P6S/p7+Qf9EAEIBNALUAjgCAgAg/YD73PwmAGQCwAKUAtwBk/8U/Wz9IADBALD+cP4gAYwCcAHpABwBgP+A/cT+4gEUAtb/k//gACUAjP6v/84BJgFG/5L/cABD/yD+bv8+Ab4A7P6S/oP/lf8Z/+L/7ABUAAr/Dv8UAPz/hP7o/X//gAH6AUQBSQAa/wL+UP6JAMgCgALa/7D9KP7p/5IAMgDFAOQB6ABY/qD9Dv+C/6T+NP9yASwCTgCU/j7+wP1c/Tr/TAIcA/4AD/8N/4r/O/9V/zEAXwA0AP0ALAJ4AugBygB0/wv/CAAEAZoA6f8KAUADLAPxAAwAqQD0/07+gP5TAHABRgFGAaIB9gB3/wT/gP9c/zD/GwA2AUoBxwD3/xP/9P4CADgBJAEeAOL/IACS/7j/3AEcA/gANP48/pD/Pv+e/m4AxAJAAqf/mP10/Kj7GPwO/tj/AAAr/yz+0PyY+wT8VP1Y/dD8gP30/Uj80PoM/DD+FP7I/Jj9ef+y/vj7wPtS/tL/lf8AALgAtv9O/h7/QgEkAjwCTAMIBGwCpADKATAEQAQkAzAEiAaoBsgEKASABVAGkAXgBFAFUAYIB9gGMAYIBjAG6AU4BQAFeAWYBeAESASIBOAEyAR4BOADtAK6AWQBAAFAAPr/PgDb/67+WP7u/mz+QPwo+nj5SPmI+PD3UPiw+PD3YPZw9VD1wPSw8/Dy8PIA85DygPJw87D0kPUA9iD2YPUQ9GDzMPRw9nj5iPxS/kT+eP0M/Qz9rP2n/2QCWASABQgHgAhgCHgHqAfwCIAJcAmACpAMcA0ADdAM4AwQDFAL4AsADSANQAyAC8AKYAlgCNAIsAlgCQAICAdgBmAFUASkAxQDaAIoApAC3AKUAuYB8QCz/7j+xP6u/3UAqwBgAKT/eP6Y/aT9DP4m/jz+hv5I/iD92Psg+2j6iPlQ+fD5KPo4+ZD3sPWg8/DxkPFA8sDygPLw8aDwIO4g7IDsAO9Q8VDyYPJA8lDygPMA9lj4MPlo+Uj64PvY/eIAyARwB+AHiAfQB5AIcAngCuAMgA5AD8APgBAgEaAQwA5ADKAKUArwCiAMIA0wDWALIAjwBBgDeAJEAv4BegG7ANT/7v46/rD99Pz4+xj7uPoo+zT8iP2O/t7+bv6U/ej8/PwI/uf/AALoA2gFIAYgBsAFWAUQBUgFIAZQB5AI0AmACkAK8AggBzAF6AOMA8ADsAM8A5AChAHV/+T9UPzY+hj5cPfg9kD2gPRw8lDxUPHA8MDv4O4A7gDsoOog6yDtgO4g72DwoPEw8nDyQPNQ9CD1YPaY+Bj7NP3E/8QC2ARwBcgFwAbIB3AIkAmAC8ANsA8gESASQBIAETAPYA3ACwALwAtwDdAOIA8QDqALQAgYBRADWALEAtgDyARQBDACmf+c/WT8sPuw+wT8SPxE/FT8wPwY/cj8FPyo++D7rPwm/gEAlgFIAlgCeAIIA+AD8AQwBgAH+AboBoAHcAgQCTAJIAnQCOAH4AY4BpAFqAT8A+QDkANsAuIACf8k/MD4sPaQ9qD2MPbw9QD1sPGg7CDp4Ojg6aDqYOuA7MDsQOxg7ODs4Oyg7GDtQO+w8aD0APiA+lD7YPtQ/I7+eAGwBKAHQAmgCfAJEAuQDBAOwA9gEQAS4BHgEeARABFwDyAOQA2gDOAM8A0gDmAM0AmIB3gFeAOMAqACJAK+AKD/Qf+Q/lz9bPy4+6D6YPkw+fD5sPo4+5D7iPso+0D7HPxA/UT+f//gAJoB6AHAAkgEmAWQBogHYAiACHAIEAkQCuAKgAsQDJAL0AngB7AGKAb4BTAGUAaIBbwDWgF0/iD7UPgQ9+D2oPZQ9uD10POg7wDrIOhg5yDooOng6iDrgOog6kDqwOrA6wDtAO6g7gDwwPJQ9lj5sPts/Vr+P/9AAUgE0AaACOAJUAuQDPANABDgEYASIBLgEQASABLAEWARYBCwDlANAA1wDbANIA2wC0AJcAYYBMACGAKSATgBMgEOAU0A/v5g/XD7cPkI+Dj4APpk/AL+Nv4w/ZD7WPp4+gD8MP5SAAwCIAOEA7wDgASQBTgGcAbIBogHgAjACRALgAugCoAJEAnQCCAIcAcYB+gFsAP2AbYB/AEKAfT+WPxI+fD14PNA82DzQPNA8sDvAOzg6KDn4OcA6ODnIOig6GDp4Opg7UDvQO9A7uDt4O5w8dD1MPuE/5wBTALAAlQDcASoBpAJIAwQDiAQoBIgFGAUABRAEyASYBEgEqATABTAEqAQUA5ADBALIAtgC6AKgAigBegCrQBF/7L+tP7E/mj+XP3Y+2j6CPnQ9xD3EPdA+PD5mPt8/Fj8qPsI+0D7jPy2/v8AkAI8A7ADkASoBegGgAgACnAK4AmACTAKIAuAC8AL0AtAC0AKgAkgCZAHcAWgA4wCqAHdAMYA5v8Y/cD48PQg8oDwoPDw8TDy4O8A7CDogOVA5IDk4OUA52Dn4OeA6cDroO1g7uDtAO3g7ADvgPM4+Y7+QALUA9gDmAMoBOAFUAgwC0AOQBHgE8AVYBaAFeATIBJgESASwBPgFKAUwBIgECAN8AqgChALcApgCBgGIATQAcP/Fv9S/6L+CP0A/Gj7IPqg+ED4WPjw9+D3GPnQ+oj7gPvA+8j7UPvo+yD+VACSAegCyATYBegFkAYQCBAJIAmgCeAKgAuwC5AMUA2gDEAL4ArACmAJWAdgBuAFYAR8Aq4B6wAt//j80PrA95DzkPAg8NDwsPCg78DtgOpA5kDj4OLg4wDl4OXg5iDogOmA66Dt4O6g7sDt4O1A8AD1GPsSATAFqAboBbAEuASQBgAKEA7gEYAU4BWgFqAWoBXgE8ASYBLgEgAUYBVgFSATYA8QDNAJ4AjwCFAJgAiwBUQC6P+E/kz9rPyk/Cz8aPqo+FD4oPhA+GD3APdw9yj4SPnY+sD7kPsY+8D7fP12/zYB2ALoA3gEKAWQBkAIgAlQCuAKQAswC1ALUAyQDdANoAwwC3AKwAlwCCgHQAZoBdwDaALzABb/LP1Q+2j5cPZg80DxMPCA7wDvoO4A7YDp4OVg5ODj4OOg5IDmAOiA6KDpIOyA7qDvAPBg8KDwsPFw9YD7LgH4BEgHcAgQCCAH4AewCgAOABEAFIAWYBfAFqAVQBTAEsARwBHgEuATwBPgEZAO8ApACDAHSAeQB0gHqAWoAj//zPzQ+8j7wPtY+4j60Pk4+bj4SPgw+AD44Pdo+AD60PvA/BT9VP3U/Zz+QQB4AiAEoAQABTgGoAfwCGAKEAywDAAMgAvQC0AMUAygDNAMAAywCiAKEArACEAGCAR0Ap0AEf+e/pr+SP2g+pD3UPQQ8cDuAO4g7oDtIOxg6gDogOUA5EDkIOWA5eDlQOdA6WDr4O0w8FDxAPHw8CDyAPUg+U7+WAPgBnAI4AgQCZAJkAqgDIAPYBLgFMAW4BegF6AVQBPgEQASgBIAEyATYBIAEKAMwAkwCIgHEAeIBogFgAP/AML+OP0A/Pj6iPqI+nD6KPrI+VD5aPhg92D3UPiI+dD6OPxA/Wj9XP0C/lz/gwCUAfgCYARABSAGyAeACUAKAAogCmAKgArQCrALYAzwC/AKYAqwCYAIUAfwBiAGQAQsArsAaP90/dj7CPvQ+TD3QPTg8QDwQO5A7QDtAOxA6iDooOaA5cDk4OTg5cDmoOeA6cDswO9w8bDxIPHQ8PDxUPXA+ioASATYBiAIgAiwCHAJIAtADUAPYBEAFEAWYBcAF2AVQBOgEQARgBEgEsARQBBADkAMEApwCLAHCAdoBUADhgFxAEf/1P3M/Pj7+Pog+kD60PqA+pj56Piw+Ij4MPnw+qz8NP0A/Xz9mv6Y/9UAVAJIA0wDuANQBTgHkAiQCaAKEAuwClAKwAoQC+AK8ApwC4ALsAqwCcAIQAcoBYADxAIsAuQAQP+Y/bj70Pk4+ND2kPSg8WDvoO5A7gDtQOvg6cDooOfg5oDmQOZg5QDlQOYg6cDsYPAA82Dz4PEw8MDwMPSY+Ub/IARAB0AIIAgQCOAIgAqgDAAPQBEgE8AUQBbAFqAVoBPgESARABFgEeARYBEgD4AMkApwCVAIGAcQBlgE5gEAAKn/r/+G/rT8MPsY+kD5ePl4+uj6IPpI+SD5WPmw+ej6xPy8/Xz9mP0D/9QAQAIwA+AD4AO8A8gEKAdgCWAKsAoAC+AKYApwCvAKEAtwCvAJ4AmwCcAIcAdwBvgEAAMKAfH/Vv98/hT9IPvw+PD2QPWw8/DxIPCg7oDtoOxg60DqIOlg6KDnAOeA5iDmIOZA5yDqIO4Q8pD0IPWg84DxkPEg9QD7qQAwBVAIcAngCLAIQApwDMANsA6AEOASoBQAFuAWIBZgE+AQ8A8gEEAQQBCwDwAOUAtACUAIeAcYBmAEiAJTALL+rv5j/wD/RP1I+8D5kPiA+LD5KPtg+3j6APoo+qD6YPvE/Bj+qv7s/g8ACAJ8AzgEWASIBLgEcAVQB8AJgAvACzALoAqACpAK4AoAC5AK0AkwCfAIkAiYBzAGsAT0AiwBuf/Y/gD+qPzo+iD5YPeA9QD0sPIQ8eDuAO0g7IDrYOpg6QDpwOgg6EDnAOeg5mDmAOgg7NDwAPRg9QD1kPNw8tDz4PdM/VwCuAZgCcAJQAmwCVALkAxwDfAOQBFAE+AUABZAFoAUABJAEJAPEA/ADuAOkA7gDKAK8AjgB1gGQARsAuIAdf+m/tD+F/9C/mj8kPpo+cD42Piw+dj6OPvA+kj6YPoQ+wT8IP0e/sz+d/+LANgBEAPkA4AE2ARIBUAG0AdgCSAKIArwCRAKMApAClAKUArQCdAIIAggCNgHsAYYBXwD7AFbAEH/tP64/fj76PlQ+MD2APWQ82Dy4PDg7oDtwOwA7EDroOog6gDpAOjg50DoIOgg6CDqQO6w8mD1cPbA9SD0UPNA9cD5DP/UA4gHkAnACZAJUArwCyAN8A1ADyARABOAFMAVoBXgE4ARsA/wDnAOIA4gDrANEAzwCUAI+AZ4BaADAAJ7ACz/iP6e/pz+xP0s/JD6SPmQ+Oj4QPpo+8D7WPsg+1D7sPsk/ED9sP7p/8sA1AEsA0AEuATIBAAFiAWgBmAIMAoQCwALkApACgAK8AkwCkAKsAnACDAI2AcwBxgGCAWcA6YBzf/O/iT+2Pwo+7D5ePjQ9kD1APTA8vDw4O6A7cDsIOxg6wDroOrg6QDpoOjA6ODoIOlA6gDtkPBg9DD3APhw9lD0gPTw91z9nAKwBiAJQApgCoAKQAswDEANgA4AEKARgBMgFeAVoBQAEnAPIA7QDQAOEA5wDRAMYAoACagH+AUoBMQCVAGl/17+Sv78/ur+pP3g+0D6GPnQ+Ij5qPpQ+3D7mPvY+8D74Pu0/Mz9ev4p/5oARAJcA+QDUASIBJgEOAXYBqAIkAmwCdAJ0AmQCXAJ8AlQCsAJsAjgB6AHKAdgBnAFUAS4AggB2P8T/+z9PPyw+nD5IPjA9nD1IPRw8qDwYO/A7iDuQO2g7CDsYOug6gDq4OnA6eDpgOog7ODugPJg9kD4kPeQ9dD0UPYA+tb+wANQB/AIkAkQCsAKYAsgDBANMA4wD8AQIBMAFcAUoBJAEKAOkA0wDVANgA2QDNAKUAkgCMgGKAW0A0ACdgD+/rD+B//g/j7+gP10/ND6qPnQ+aj6UPvQ+6D8BP2s/HD8AP3A/Rj+2v54ACwC9AJoAwgEcAQwBCAEOAWwBvgH4AigCcAJMAmQCHAIoAhQCAAI2AegBwgHcAbwBfgERAOMAWUAif+O/oD9iPxg++j5gPhQ9xD2cPTQ8pDxgPCA7wDvoO7g7cDsgOvA6sDq4OoA6wDr4Oog66DswO+w8wD3gPg4+OD20PXg9tD6NACIBCAHoAjQCYAKEAuwC1AMwAxwDfAOABHgEuATIBTAEgAQYA1wDKAMoAwgDIALkAoQCZAHeAZABTQDOgEZAH//2P6S/gD/Lf8y/nj8EPtI+uj5UPp4+3D8rPzI/Cz9WP0A/dT8ZP14/nL/kAAUAmgDCAQ4BDAEEARABCgFsAYACJAIwAjQCLAIYAggCAAIuAdYBxAH0AZoBsAFCAUIBMACNAHv/yX/dP58/UT8IPsA+sj4cPcw9tD0QPPQ8dDwMPCA7+DuYO7A7cDsAOzA68DrgOsg60DrIOxg7vDx4PVg+Hj4cPeQ9pD2OPgs/JwBAAYQCJAIQAkQCtAKgAswDKAMUA0AD4ARYBPAEyATwBHAD5ANQAwwDGAMMAygC5AKMAm4B3gGSAWQA6ABEgBO/x3/Pv9c/w3/GP6o/GD7qPpw+qD6OPv4+3z8vPz0/FD9hP2c/bz9UP43/28AyAEsA/gDCAT0A0gE4ASIBXAGeAdwCLAIsAigCLAIgAgwCOgHkAcgB9AGuAZ4BrgFcAQUA6QBWwBu/77+9P3Y/MD7oPpY+fD3oPaA9TD0sPJA8VDwwO8g78DuIO5g7YDswOuA64DrQOsg66DrQO0Q8IDz8PYQ+ej4EPfQ9QD3ePq4/rgCIAagCOAJQApwCuAKgAtgDJANsA7wD4ARYBNAFEATABGQDvAMQAwQDDAMEAxgCzAKsAgIB2gF+AOYAh4Blf+S/nj+5v4n/6L+TP2g+0D6sPng+UD6sPpA++D7SPxs/Ij8tPzg/Oj8KP3o/Tb/8ACMAngDkANcA3ADGAQABQAG2AZ4B+AHMAiACMAI4AigCCAIkAcoBxAHIAcAB0gGMAUABOQCogFxAJj/Bf8q/tD8cPtQ+kD58Peg9lD10PNg8mDx8PBw8MDv4O5A7oDtwOxg7EDsAOzg64DsoO0g7yDxwPOg9oD4sPjw93D3iPho+3r/eANIBiAIkAmgCiALQAvQC9AM4A3QDiAQ4BFAE6AT4BJAETAPcA3QDNAMkAzgC/AKAArACEAH0AVoBMACBgG2/wH/pv6a/q7+Tv4Y/Xj7YPr4+fD5QPrA+kD7kPvY+0z8oPyY/JD8+Py8/YL+nP8cAYgCMAMwAywDmANQBBgFEAbwBpAH8AdgCNAIwAhQCMgHcAcIB9AG2AYIB8AG4AW4BIADKALhAOz/Gf80/jz9VPxg+yj6yPiA92D2MPXw89Dy0PHg8EDw4O9g74DugO0A7eDsoOyA7IDs4OzA7cDucPCw8lD1kPf4+BD5WPgw+Pj5oP1+AYAE4AbACPAJkArgClAL8AvQDPANQA9gEKARABOAE2ASIBAgDhANgAwQDOALkAvQCrAJkAhYB6AF0ANcAigB7f8P/wn/cv91/6z+WP34+9j6SPpQ+oj6sPoY+8j7UPxU/DD8TPyM/JD8qPxI/XT+6v9UAVQCqAKEApACKAMABLAEYAU4BvAGWAdoB2gHaAc4B/gGsAZoBjgGQAZgBhAGEAWkA0gCQAFjAK7/F/+C/rj9lPxg+yD68PjA95D2YPUw9EDzoPIw8rDxAPEg8EDvoO4A7qDtQO1g7cDtYO4g7wDwkPEA9MD2iPjo+KD4uPho+dj6UP3UALAEYAegCPAIQAnACbAKsAtQDNAM0A2gD6ARoBJAEuAQUA/gDbAM8AugC6AL0AtgCyAKcAj4BugF0ARMA7QBhQD0/+P/AADA/+z+wP2s/Mj7+PqI+sj6aPvw+zT8cPys/Mz8wPyw/Kz84Px8/cT+PwBkAQgCZAKwAuQCEANkAygEOAVIBgAHYAd4B4gHgAdwB0AHAAfQBqAGkAZwBgAGOAUgBAwDAAICAQkAQv+g/uj9zPyA+1D6cPmA+DD3wPWA9MDzIPNg8qDx8PBw8ODvQO/g7mDuAO6g7aDt4O1A7kDvUPHQ89D1MPc4+Aj5KPnY+CD5IPvG/vwCaAZgCBAJIAlgCcAJMArgCkAMEA7ADwARwBFAEiASABEQDxAN0AvAC1AMsAxQDGALIAqwCAAHWAXoA7gCvgH8AFkA7P/E/8P/Zv8i/kT8wPog+jD6oPpA+9j7NPw0/Az8APwI/BT8RPyo/Ej9Kv5R/4AAXgHeASgCSAJQApQCTANwBIgFYAboBgAHqAZQBlgGqAa4BkgG2AXABdgFsAVABYAEhANYAkYBYwCT/9r+Vv7o/Rj9yPtw+nj5sPjQ99D24PXw9BD0UPOw8iDygPEA8YDwoO/g7mDuYO5g7mDu4O7A7xDxsPKg9ID2CPjg+BD5qPiQ+AD6XP1WAXAEeAbQB6AI8AgQCXAJUAqACxANoA6wD2AQABGgEUARoA9wDeALYAtQC2ALcAswC2AKAAl4B9AFMATwAhwCYAGqAEMAOwAaAHT/bP5I/VD8mPtI+3j74PtQ/Kz89PwQ/ez8zPzU/OD88Pww/eD96v4GAPwArgEQAjQCQAJwAuACiANgBDgF4AUgBigGOAZIBigG8AWwBYgFaAVgBWAFQAXYBDAEbAOEAqABzwAvAKP//P4o/lz9kPzQ+/D6CPoY+RD4IPdA9oD10PRQ9AD0oPPQ8sDxMPEQ8SDxIPEg8fDwsPDA8EDxQPKg83D1gPcI+WD5EPkg+Qj6mPtg/R3/1wC0ApgEQAZIB7gHAAhwCOAIUAkACmALAA1ADqAOQA6QDRANsAxADMALUAsAC+AK0AqgCjAKYAlACOAGkAWQBPwDuAOMA0QDqALEAdYAIwCQ/+b+MP6w/YD9gP2c/bD9yP3c/bT9RP24/Gj8jPwo/QD+uv4k/13/iv+x/+H/JQChADYBwAEkAmQCjALYAmAD3AMIBNgDqAOcA6ADjAN8A1QDFAOgAiQCpAEMAYcAPQDv/2L/mv7Q/SD9hPwQ/KD7IPto+qj5GPmA+MD38PZQ9uD1YPXQ9GD0EPTg86DzQPPw8pDykPIw85D0APYA98D3YPjA+Nj4EPno+UD7zPxe/gsAugFQA4AEMAVQBUAFoAWIBqgHwAjgCSALMAyQDAAMMAtwCvAJkAlgCVAJYAmwCeAJcAlgCAAHwAXgBCgEiAMIA9gC0ALEAlQCZgFFAGT/4v5e/sT9VP2A/QD+Wv5a/jj+KP4O/uz9tP2Q/cz9dP5s/zsAmACrAOsAWgHSARgCUAK8AmAD9ANIBGAEiATgBEgFYAXoBEgE+AMQBBgExANEAwAD2AJoAooBiQDG/2L/EP+M/tj9MP3A/HT8+Psg+yD6UPnY+FD4kPew9jD2EPYQ9qD18PRg9PDzsPNw8yDzwPKQ8tDycPMg9OD08PVw96j4GPng+Lj4KPlY+vj7xP13//UAQAJQAygEuARIBegFgAYgB+AH4AjwCQALwAvwC6ALEAtgCuAJgAlgCXAJoAmgCUAJsAjoBygHYAZ4BXgEoAMYA+gC5ALkAqwCIAJaAWcAb/+U/ib+Pv6q/vj+/P7u/vj+Av/e/pb+dP6y/jH/sP8fAI8AHgGqAQgCJAIkAlACuAIwA5QDzAMIBFgEqATIBJgEMATIA5QDcANAA+ACgAI0AvoBigHPABYAi/8Q/3j+wP0s/cz8ePwI/ID76PpY+tD5UPm4+AD4UPcA9+D20Pag9lD24PWA9SD1sPRQ9CD0MPRQ9FD0YPTA9JD1sPbQ97D4OPlg+Wj5yPmw+vj7jP0Z/4AApAGEAlQDGATgBKAFMAa4BkgHEAgACRAK4ApwC6ALcAvwCnAK4AmACXAJcAlQCQAJoAhQCNgHKAdABkgFWASQA/wCsAKQApQCeAIMAkIBTQB5//j+wv6i/pT+pv7m/jT/Xv9X/1r/Xf9O/zz/O/9s/9//mgBQAcIB+gE8ApgC1ALcAugCJAOcAyAEgASoBJgEeARQBCAE0ANwAzwDKAP8AqACGAKSARoBtQA8AJD/3P5K/uz9fP3c/Cj8kPsY+5j6CPpg+bj4GPiA9+D2QPbQ9aD1cPUQ9YD0EPSw82DzMPMQ8wDzEPNA88DzcPRw9ZD2gPcA+Dj4iPgw+UD6qPtA/cL+BQASARACDAMIBPgE6AXABngHAAiQCEAJMAogC7AL0AuQC0ALAAvQCoAKMAoACvAJ0AlwCdAI+AdIB6gG+AUYBUAErANsA0AD5AJMApoB7wA9AI//+v6Y/oz+tv7o/u7+wv6a/qb+yv7I/pb+ev60/jP/vf8kAHQAygAoAWwBfAFsAagBRAL0AmQDgAOAA4ADlAOUA3ADQAMIA+wC4ALAAnQCBAKcATABrwAGAFL/3v6m/mL+2P0o/YD8+Pto++D6cPoQ+pj5GPmg+DD4sPcg98D2gPZg9hD2kPUg9QD18PQA9eD00PSg9JD04PSA9XD2YPcw+Lj4GPlo+cj5cPqI+9z8IP5A/1YAYgFMAgwDwAOQBGgFIAbIBmAHAAjACIAJIAqQCqAKgAowCrAJUAlQCaAJ4AnACUAJkAgACHgH8AZwBvAFiAUwBdgEYAToA6ADdAMMAyACAgFEABQAJgAhAAQAAQAdABAAsf8h/77+tv4G/2b/pP+z/+D/WgDkAAgBsABnAKIAOgGmAcQB5gFQAtgCGAPwAowCSAJAAlQCRAIIAsoBsgGgAVQBwAAkALf/ev8u/7D+IP68/aj9lP0o/Wz8sPso++j6uPp4+hj6qPlo+Uj5EPmI+OD3kPdw92D3MPfw9tD20Pbw9vD20PaA9nD2APfg94D44PhQ+dj5YPrI+jj7yPuY/KD9vP6a/ycAtQCUAaACXAO0AwgEoARgBegFSAawBkAHwAfwB7AHSAcYB0gHiAeoB4AHUAcoB+gGiAb4BYAFUAVQBUAF8ARoBPwD3APQA5AD9AJEAsIBiAFYARYB2ADRAAIBGgHpAIYANgApAEIAWABVAFwAgwC6ANQAzQDXAAwBXgGgAcIB1AHuATQCpAIEAxAD6ALYAvgCIAMkAyADJAMsAxQDwAIwAnIBzgCTAKsAogArAHz/8P6s/l7+sP3E/Oj7cPso++D6cPog+vj5uPko+TD4UPfg9sD2wPag9oD2gPaw9rD2UPbg9bD1EPaA9uD2UPfg96D4SPm4+fj5YPow+yD81PxQ/fz9G/9LABYBfgHsAYgCNAPoA7gEaAXgBUAGyAZQB3gHWAdYB7gHQAiACGAIEAi4B3gHQAfoBnAGIAYABhAG8AWQBRgFsARoBBgEpAMoA9wC2ALgAtQCiAIoAtgBpgF2ATYB9QDqACIBTAEuAdwArACzAMIAnwBQACMASQC8ACYBOAEGAQQBZgHMAbIBTgFGAc4BTAJMAgQCFAKkAigDMAPMAjgCrAFKAUIBnAH+AeIBOAFPAHH/sv4a/sz91P0I/sz9fPyA+ij5IPnA+aj5oPhg94D20PUA9QD0IPOw8uDyUPNQ88DyIPIA8lDyoPKg8hDzIPTQ9WD3UPiY+AD5APpg+6T84P2M/8wBzAPYBDAFgAWABgAIcAkwCpAKAAvAC0AMQAwQDOAL8AvwC7ALEAtgCgAKAAqQCbAIwAcIB3AGmAWQBJgDxAL4AUoB3gCVAAkASP+c/gb+NP1E/Mj7EPyg/KD8NPzw++j7sPsQ++j6kPuI/Cj9cP3M/VT+vP7s/jL/9/8kAWgCMANoA4gD/APgBMAFaAbgBkgHmAewB7gHMAjQCIAJwAmACbAIgAe4BoAGgAZIBiAG8AUQBdACEwCm/vr+pf8e/0z9EPvY+JD2wPSQ9DD20Pcg99DzwO9A7SDtQO5g7yDvYO7g7YDugO8Q8BDwAPBA8MDwoPFg80D2oPkA/Gz8iPsw+5j8RP/8AVAEeAZQCFAJYAkwCYAJkArwC0AN0A2QDTANQA2QDTAN0AtQCtAJ8AmgCeAIMAigB/gG2AV4BCADLALkAQgC5gE4AWMAwP8Y/07+rP2Q/cz9Av4q/kT+HP6w/Wz9pP0w/rb+Ev91/+r/WwCoALYAugAWAQwCTAMwBGAE+AOEA3ADCAQoBSAGuAbgBqgGIAZgBSAFmAVgBsgG2AbQBrAGEAYIBVAE2ANMA6ACkAL8AqwCEgFI/1L+kP1E/Fj70PuI/LD7MPkA9/D1YPUA9TD1gPXQ9DDz4PHQ8ODvgO8g8MDwgO9A7WDs4O2g8ODy4PMA88DwYO8w8VD1UPl4+1j8pPx8/Fj8hP2hAKAE4AdgCVAJ4AhgCRALEA2ADkAP4A9AECAQcA8ADzAPkA9gD5AOgA2ADIALcAqACcAI6AcIBxgGAAWYAxgC6wAxAML/Xf+4/qz9mPzQ+1j76PqQ+rj6UPvI+6j7CPtY+hj6ePo4+0D8RP0m/tT+EP+4/hT+RP7W/zAC/AOwBJgEKATIAxgEaAUgB1AIsAjACKAI8AcwBzgHQAhQCVAJ0AiACDAIKAewBcAEeAQQBJgDpAOkAxACS/88/bj8PPxg+3D7HPxY+2j4gPVA9NDz4PPw9PD1kPQQ8YDuYO7g7sDuoO6A7oDtwOwA7UDuoO8A8SDygPGA7yDvQPLQ9vD5iPs8/KD7sPoU/DYAYAR4BqgHEAmwCUAJ4AmQDEAPIBAgEIAQYBCQD1APIBBgEGAPkA6wDnAO4AwACwAKEAm4B7AGiAYwBsgEEAOsARkAiP4Y/pz+bP4M/cj7QPuw+vj5+PmQ+sD6YPpg+sj6kPrw+QD6GPs8/Pz8wP2c/vr+wv66/j3/PACUATQDYASgBFAEMATABIgFeAZAB7gHuAfQBxAIIAjgB8gHAAgQCNgHeAdQB/gGMAZIBYgEyAMkA8gCeAK6AVgAqP50/dj8XPyY+6D62PnQ+DD38PXA9QD2MPVA8yDyoPHA8HDwoPEw8oDvQOsg6kDtsPAA8gDzUPOg8GDtgO0g8tD2GPnA+oz8kPuY+Cj5Rv5oA0AF+AV4B2AIeAe4BwAL8A1ADjAOwA/gEPAP0A4wD9AP4A7ADaAO4A8AD7AM0ApwCeAH+AZ4B2AIoAcYBbQCEAHJ/+7+FP+b/2n/MP6A/Dj7mPp4+rD6EPsg+/D64PrY+rj6gPqQ+lD7aPxg/fD9PP5O/mD+vP6j/94ABALsApgD+AP8AwAEkASoBbgGcAewB5AHQAcQByAHeAfAB8AHkAc4B7AGIAaoBWgFKAWoBNQD7AIkAmIBrAAbAIT/wP7U/fj8IPwI+/D5WPkA+Tj4QPfA9oD2wPVw9EDzoPJQ8qDycPMg87DwoO3A7ODuAPJA9ND0YPPQ8IDvcPAA86D2SPqE/JD7IPnI+ED7ZP4GARgEiAZoBuAEYAUQCMAJ4AlQCzAOUA/QDYAMAA2QDdAMwAxADmAPQA4QDKAKoAmgCAAIQAigCPAHMAZABNwC+gFGAY8AFQAdANj/mv4U/WT8KPyo+zj7ePsc/PD7GPvg+jD76Ppo+jD77Pzk/YD9FP14/Qz+aP4//8kA4AEUAhgCtAJoA9QDaARgBUgGoAbABiAHWAdABzgHaAeoB/gHQAgwCKgH2AZABvAFwAWYBVgFkAQsA/wBaAH0AEYAy/9t/4L+/Pyg+/j6kPrg+Qj5MPhg9+D2wPYA9oD0MPPA8gDzEPNA86DyMPCg7eDtoPDQ8kDzIPNw8zDywO8g8PDzMPgI+oD6WPqI+bD4YPrO/nACtAP4A6AECAVQBYAG0AjwCgAMwAwwDeAMYAygDEANcA2ADfANYA7QDTAMwArACRAJAAlwCWAJIAgwBlAE8AIkAv4BIALUAfoAy/9q/hj9bPy4/AD9vPxI/Az8wPsw++D6CPtg+3D7uPtw/MT8mPyc/Dj92P02/q7+gf9GAJgA7QCIARgCiAI0AygE0AQYBWAF4AUoBigGUAa4BhgHOAdoB2gHAAdYBvAFyAWgBXAFKAWgBKgDmALaAUgBwwA7AJz/nv5U/Vz8wPsg+0j6mPkA+Rj4EPeQ9hD2APXg88Dz8PNA8yDy4PEA8hDxYO9A75DwoPHQ8lD0kPRQ8kDwgPGA9Wj4sPno+oj7WPow+fj6O//oAoAE+AQYBYAEKAT4BXAJQAwADWAM0AsQDFAMcAwQDRAOgA7gDdAMUAwwDGALMAqgCaAJQAlwCKgH2AYwBUQDcALQAhwDeAI2Ab3/SP5I/ST9lP2o/UT9oPzY+wj7oPrQ+lD7qPvI+9D7iPs4+2j7IPwA/YD9wP3o/UD+1P6G/zsA0gB2ASgCtAI8A9wDgATQBBgFmAVIBrAGsAboBlgHWAcQB/AGKAc4B9AGUAYQBtgFQAXABCAEIAMwAugBxgHyAIX/nP4I/ij9+Puw+3j7SPrA+PD34Pcw9/D1UPVQ9aD0QPPg8kDzIPOA8cDvgO9w8KDx0PIQ9GD08PKg8EDwMPNg9/j5gPoQ+kj5uPjg+Wj9qAH0AxgEyAPkA1gEgAXYB7AKkAyQDMALcAvgC5AM4AwgDcANQA7gDcAMoAvgCmAK4AngCRAKYAngB1gGOAU4BFgD4AIQAxwDCAIvAJr+0P2w/cT95P3k/Wj9XPxY++j6EPt4+/D7SPw4/MD7OPs4+/j75PyI/cT9/P1O/pT+4P5k/0oALAHGAVAC4AI0A0QDsAOQBFAFiAWYBegFCAbYBegFaAagBlAG8AW4BWAF2ASoBNAEeASoA/ACNAJqAfQAwwAXAAH/Qv4M/lj9DPxg+1D7YPrg+MD4gPmI+GD2sPUw9pD14PMA9ID1wPTw8dDwIPJw8qDx8PJw9aD1YPNw8tDz0PQw9bD3qPuw/GD6KPno+nD9jP8IAoAEKAXQA1wDQAXABzAJYAqQCwAMUAugChALcAxADeAMYAxgDEAMkAvACgAKcAnACGAIkAhQCNAG8ATgA2wDAAPEArgCQAL8AGj/eP5M/lT+SP4k/sT9DP1E/Oj7IPx4/IT8WPx0/LT8lPxE/HD8LP2s/eT9RP7E/vD+5v5L/ykA0AD8AGABNALUAuQCAAOQAzgEmATYBEAFiAWQBYgFoAW4BbAFsAXQBaAFQAUABZgEEATMA6wDMANMAnIBNgG6AKr/3P7w/rL+ZP0k/ND7iPtY+mj5aPlo+SD40PbQ9tD2wPWA9ED0YPSw8/DyEPNg88Dy0PHw8fDy8PPA9ID1sPUg9XD0IPWQ96j61PwY/Uj86PvY/N7+YAHoA5gFyAUwBVAFmAYgCHAJ0ArQC6ALoApQCkAL4AuAC0ALsAvAC9AK4AlgCZAIaAfwBogHuAdwBsAExAMUAxACYAGeAfwBXAH0/9D+Bv5s/TT9rP08/vD9+PxI/BT80PuY+zD8WP3c/Tj9fPyE/Mz8CP3k/Uz/3v9U//j+d/8IAFIA9ABAAiQDCAPsAjQDcAOwA2gEMAWIBXAFaAVwBUgFCAUQBUAFSAVoBWAFoASQAwgD9AK8AmgCUAIYAhgBs//o/p7+Nv7g/QD+vP1k/MD6EPoY+tj5aPk4+eD4wPdg9vD18PVw9eD08PRA9ZD0YPMA84DzsPOA85D0QPbA9tD1IPWg9UD2QPfQ+Rz9Jv6E/Cj7TPzM/gQBGAMgBagFsAQwBJgFoAfgCOAJIAuAC1AKUAnwCVALsAtACxALIAvACvAJcAkACUAIUAcQB1gHKAcgBuAE0AMAA1gCLAJAAiwCfAFfABT/JP4i/tD+Jf+S/uT9YP3M/ED8NPwU/cT9gP0E/TT9KP2Q/ND8Iv74/qL+Uv5B/yYAof8b/xQATAF+AbwBwAJQA3wCxgHIAkAEUATkA2gEEAWABKQDxANoBHgEOARoBJAEvAOgAlQCpAKYAhQCygGYAfsA2P/m/pr+sP6g/jr+sP0A/fj72PpA+mj6mPoo+kj5kPgY+HD3sPZA9lD2QPbg9WD1EPXg9JD0QPSg9ND10PZA90D38Pag9qD2sPcw+vj8Av5Y/WT8bPzM/RIAfAJgBBgFoAQYBHAE2AWoBxAJwAnwCbAJEAngCIAJYAqwClAKAAowCsAJoAjAB6gHyAeIB/gGmAYwBhAFtAP0AugC8AKoAjACqAHIAHH/jv6+/k3/Xv/E/ir+0P0w/ZT8sPw8/ZT9gP1w/Tj9xPyA/Pj80P0I/tj9DP6q/h//Fv8I/03/sv8lAOsA3gFMAvoBmgHMAbACbAOcA9QDOAQoBKQDiAMgBLgEoARIBHgEiATQAyADOAOAAzwDoAJYAiQCbgFfANv/6P+//zH/iv7o/TT9YPyI+yD7MPsQ+0j6IPlQ+OD3UPeg9oD2cPbQ9fD0wPTg9HD0sPPQ87D0cPXQ9WD2oPYQ9nD1APYA+CD6yPv4/ED9YPyw+yj9GADAAiAEmASgBGgEOAQwBZAHwAlwCiAK0AlwCRAJQAlwCtAL4AvQCiAK0AnwCBAIQAgQCeAImAdwBgAGSAUgBLAD6AOEA3gCzAGQAdYAjP/I/uT+D//e/o7+BP4g/UT8DPx4/Oz8NP08/cT8+PuI+9j7tPyM/dz9jP0o/Uj92P1C/pT+P//m/9T/pP9WAEQBUgEyAQQCCAMgA7QC9AKYA3ADMAP0A+gEsASwA2ADyAPwA6wDnAOgAzADhAIcAvgBxAFSAdYAWgDX/3b/Af9u/gD+tP0I/QD8ePuA+0D7YPqg+XD5EPkI+DD3QPdQ95D2APYQ9jD2gPWQ9KD0cPXg9QD2sPZw92D3kPag9hj4uPmQ+pj7JP2k/dz8xPza/oIB6AKMA5gEQAVoBCgEaAZQCVAKwAmQCdAJYAkACTAK8AsgDMAKwAmACVAJ8AjgCAAJcAhABzgGwAWYBTAFWARAA5wCiAI8An4BqQAIAFP/gv5m/jH/gP9W/uD8kPzs/BT9NP20/Sr+dP0o/OD74PzE/eT96P00/mT+CP7Y/Zz+h/+p/2f/y/+5ABIB5wAcAdABFAL6AWQCOAN0AwwD2AJUA7wDvAPUAwgExANAA0QDkAOIAwwDpAKMAkgC4gHCAZ4BBAFLAND/pf9s/wj/nv4c/nj96Py4/IT8APxQ+8D6UPoA+sD5aPnY+Cj4oPdQ9xD34Pbg9vD2oPYQ9tD1IPaA9vD2wPeA+KD4GPjQ95D4OPrY+/z8tP3w/dz9JP56/4wBFAOYAwgE4ASABZgFEAZgB5AI4AjwCGAJoAnwCGAIwAhwCXAJcAnQCXAJkAeQBYAF0AZgB7gG4AXoBDQDqgGcAcACKAM8AiYBYQAs/+j9Ev5t/wQACf+c/ej8xPy0/Oj8gP2w/Uz9/Pz0/Mz8tPwI/Xz9yP0C/lr+hv5E/jz+5P53/3T/yv8AAb4BHgGAAD4BTAJYAlgCXANIBLwDwAI8A1AEMAScA0AEKAWYBEgDFAPYA/gDUAMQAygDhAKaAXgBmAH1AAAAxP/s/4L/jP7g/XT93Px8/Ij8KPwg+zj6CPrQ+TD52Pjw+JD4UPeg9tD28PbA9rD24PZg9mD1QPWQ9uD3QPhA+FD4QPgo+Pj40PqQ/Dj9OP1w/SD+Kv95ANoB6AJkA6gDWARwBTgGeAbIBnAHIAiQCMAI8AjgCCAIgAfAB4AIAAnQCAAIoAZYBeAEeAVABhAGCAXQA8QCEAL2ATACOALeAVgBqgDE/wr/FP+F/3T/Hf8J/97+Jv54/Zj9Gv4e/uT9Tv6u/iD+OP1Q/S7+oP6q/hT/l/8r/1D+gP7L/5gAagBfAOcA/ACGAJ4AogFsAjwCEAJ0AqACQAIoArwCMAMAA8QC4ALcAmAC8gHsAdwBrAGuAcIBVgGGAOv/l/9H/yH/WP9v/8j+yP0Y/bj8fPyU/Oj8tPyg+4D6KPo4+iD6IPo4+sD5oPjQ99D3KPhQ+HD4gPgA+BD30PaQ94j4IPl4+Zj5UPkQ+aD5EPtw/DD9lP0A/mr+/v4KAFABYAL8AowDOATYBHAFQAYoB5AHiAeoB1AI4AgQCTAJQAkACWAIUAjACOAIUAigB0gH+AZIBqgFeAVQBcAEGASYAxADOAJ6AUoBOAHbADkAs/9P/+j+hv4y/gT+5P3I/ZD9UP0k/SD9FP38/Az9PP1M/Uj9eP24/aT9fP3M/XL+8P4C/wT/Of9s/6T/IQCxAAYBTgG0AQQCGAIUAmAC9AJYA3QDhAOMA2ADWAOIA7gDpANgAzADIAPwAogCTAI8AhwCtAEYAbwAjgAuAI7/AP/I/q7+Sv68/SD9ePzA+2D7WPtY+/j6MPqg+TD5oPg4+Fj4gPgg+ID3UPdQ9yD30PYw97D34Pcg+KD4+Pio+Ij4YPno+hD80Pyk/fj9xP3s/VH/WgH8AsgD7AO4A3wDKATgBcAH0AjQCCAIcAdQB/gHEAnQCcAJQAmACKgHIAcgB0gHGAeYBigGuAXIBJwD9ALsAuACaALYAWYBuQCt/9b+qv7s/v7+rP48/sz9PP2k/Ij8BP2c/cz9mP2k/bj9UP3k/HT98P4MAAIAhf94/5z/u/9hAKwBoAKIAhwCJAJkAmQCeAJAAyAEIAR0AwADGAMoA+gCxAL4AhADrAL8AXgBFgGjAFEAZQBqANj/9P6C/mz+Av5I/ej8CP3o/FT82PuY+xj7cPow+lD6OPrY+ZD5WPn4+ID4QPhY+Kj4wPio+Ej48PcQ+Hj4uPgI+cD5GPqw+ZD5aPqI+xz8hPyM/YT+Zv46/mP/GgHEARACKAM4BCAE0APQBJAGQAcoB6AHMAjABygHEAiQCdAJ4AhQCFAIIAi4B+AHQAi4B4gGAAYIBpgFqAQYBPgDoAPoAkgCCAKcAcQANgAYAOv/kv9R/yb/rP7M/Vj9sP0i/vT9YP0E/cj8jPyU/Nj8EP3k/Lj8vPyo/Hj8kPwA/UD9NP0k/Tz9aP2g/Qb+ZP5+/qD+GP+Y/73/yP8UAJcAHgGcASQCbAJUAkgCnAIgA4QD8ANYBFgE1ANcA2QD0ANIBHgEOAR8A5gCCAIIAjACMAL2AU4BZgCg/yf/3v6u/oj+PP5w/WD8sPug+3D7yPo4+gD6mPnw+ID4UPgQ+ID3cPfQ98D38PZw9uD2oPcI+Fj4qPiQ+Cj4YPiQ+QD7EPyk/AT9JP08/ej9Vf/uABACpALIAtACPAM4BFgFIAZoBpAGwAbgBhAHSAdwB2gHaAeQB5AHMAe4BlgG6AVYBRAFKAUoBagE5AM0A3wCxgGGAd4BEAKGAaUAAACZ/zX/Kv+0/0sARQDP/1//If8j/7X/xACqAcoBegFcAZQB9gGAAlQDIASABHAEQARABHAEwAQwBZgFmAU4BdgEqARgBNwDcANkA2AD+AI4AkYBNwA+/7T+kv5y/tj92PzI+6j6uPlI+Wj5cPkQ+Uj4cPfA9mD2oPYg91D3IPfQ9rD2wPYg96D3APhg+MD4MPmY+ej5ePoY+3D7sPtg/Hz9UP6O/tr+fP/V/wQAxAAYAgAD7AK8AiADfANkA9QDOAVYBggG+ASQBPgESAWgBYAGIAd4BiAFkAToBCAFCAVQBdAFgAVQBJADrAO8A2wDiAMwBFAEgAOsAoQCmAJkAnQC4AIAA3gC6AGsAVoB9ADsAE4BXAHhAFQA5/94/xH//v4f//7+rv6G/k7+tP0s/Tz9cP1I/fj89PwU/ej8iPxc/GT8XPxs/Nj8EP28/Ej8QPyQ/Mz82Pzs/Bz9DP3Y/PD8PP1M/UD9dP3Y/R7+DP4k/qb+2P6U/rD+gf8uAEEARACwADABTAFsAfgBdAKEAsACeAP0A5wDKANgA/wDUARYBHAEOASQA/wC6AIYAygDFAPAAs4BgADJ/wkAewBbAI//UP4I/VT8hPwY/Sj9gPyY+9D6QPow+qj6EPso+wD7qPpQ+kj66Pqo+/D7APxk/AT9TP10/RD+tP7O/vz+AAAcAWABCAEUAYQBqAHKAcwCAAQQBEQDyAL8AkgDlAM4BAAF2AS0A+gCOAMYBJgEmAQoBHgDxAJsAuQCsAPgAyAD/gE8ARABKAFcAZIBVAFyAIr/L/9M/2b/MP/m/qD+VP5A/m7+lP5y/jL+Fv5q/v7+av9//3j/n//x/1YA3QCEAdgBtgG0ATwC0ALkAuACPAN8AzQD/AJcA8gDgAPUAoQCZAIUArwBsgGEAcEA3f90/4P/Tv+q/uD9QP0I/Qz9BP2s/CD8ePvY+qD6IPv4+yz8kPvY+qD6wPoY+wT8FP2I/TD9yPz8/JT9SP4u/zUA5wASAfIA9QA0AbgBZAIsA+wDSAT4AxwDfAKAAugCVAOcA6wDAAOmAVgA4v8TADcAHgDa/zv/HP7k/FT8cPyE/FT8KPwU/Lj7+Ppg+nj6sPqw+vD6uPtc/CD8gPtY+8D7WPxE/ZT+c/9A/7T+zv6I/2IAYgGMAiQDwAI4AqQCwAOoBGAF0AWQBegE2ATYBegGKAfgBrAGeAZIBpAGMAdgB/AGeAY4BvgF4AUwBmAG4AXoBDgECAT8AxgEKASoA3ACTgHWALsAyADiAMUA2f9C/hz96PwU/RD92Pxc/Gj7aPrQ+Zj5YPkY+Qj5APlY+GD30PbQ9uD2sPag9pD2UPbw9eD1EPYw9kD2oPYw92D3YPeg90j4GPnY+Zj6KPt4++j7wPzk/fL+vP9OANUAZAEcAuACeAMYBPgE4AU4BhgGIAaIBuAGOAfwB7AIsAjoB0AHOAdgB6AHUAjwCIAI4AawBcAFOAZwBngGaAbABagE6AO4A3QDGAMsA4QDdAPAAuoBZgHjAHIAfwDwAC4BFAG2ANv/1v5q/gf/BAB7ADYAnv/q/kr+RP7K/mb/tP/C/4L/1P4m/gD+av7K/uT+4P64/lL+0P2o/aD9eP1g/Yz9vP2Q/UD99Pyg/ED8OPyg/Bj9QP0o/bj8FPzg+1z8JP2o/eD93P2Y/RT9/Pzc/fD+Zv99/57/ff8b/xz/8P/4AEgBOgF0AZIBGgHAAEoBKAJ4AlACVAJYAt4BTAFeAegBKAIIAtgBnAEgAbwA0gAcASIB4ACvAKIAgABFACwALwAcAPr/7v8AAB0AEwDR/4n/ZP9r/57/xP/C/4n/L/8U/3P/0P+a/xP/1P4Z/4H/u//O/9H/j/8Z/w3/n/9IAKgAyAC6AGAA6/8KAPQA4AEYAtwBrgGWAX4BmAH+AWgCmAKQAlAC3gGEAX4BrAGwAYYBVAH9AIkASgA7AOj/Uv8B/zD/TP/m/lb+9P2A/fD83Pxg/bz9dP3w/Jj8NPzA+9D7cPwQ/RD91PyY/ED88Psc/ND8ZP10/Vj9bP1o/TD9JP2M/Qj+Rv5y/qT+uP6I/mj+jv7S/ij/lf8FACkA8v/C/9L/MgC9ADQBigG2AdAB2AHuASwCsAJIA7wDCAQgBAgE8AMwBMAEOAVgBVgFUAVABRgFGAVYBYAFeAVYBSAFyASIBIAEoAR4BCAE1AOgA0AD4AK4AqQCaAIYAtIBigEYAa0AeQBaABcAxf+U/1f/8P6O/j7+7P2Y/XD9ZP1M/fz8lPxI/Pj7wPuo+8D7uPuA+0j7OPsw+yD7IPs4+0D7SPtw+6j7yPu4+7D7yPsM/Hj89PxM/WT9TP1E/Xj93P1W/tj+Rf+S/6v/sv/K/y8AwABIAYYBlgHQARwCUAJgApwC2ALwAvAC9AIIA+wCzAL4AjADCAOAAhAC8gH6Af4B+AHOAVYBugBZAF0AdgBfACsA9f+n/03/I/8y/2D/cP9L/x3/EP8w/2z/pP+6/7n/zv/t/xoAZwDMABIBGAEOASYBXgGcAegBNAI8AgQCyAHSARQCXAKAAmACCAKQAU4BXAF+AXYBRAH3AIEA+f+d/4j/jf9p/xH/ov4w/sT9iP18/XD9NP3g/Kj8kPx4/FD8PPxQ/HD8iPy0/PT8OP14/bj9BP5m/tr+g/9KAOYAIAFEAZ4BQAIEA7wDUASQBHgEWASYBBAFaAV4BVAFCAWoBEgECATcA4QD6AIsApgBGgGRAO7/Qf+C/rD98Pxo/PD7WPuw+hD6ePnw+Jj4gPhQ+OD3YPcQ9xD3QPeQ9wD4UPho+HD4wPhY+QD6kPo4+/j7mPzk/Ez9PP51/zMAaQDLAKIBZALQAlQDMATYBAAFOAXIBUAGOAZQBvAGeAdYBxAHQAeIB1AHAAcgB2gHSAfQBpgGoAZgBvgFwAW4BXgFEAXABIgEOATQA3ADHAPcAqwCYALyAYABJgHJAG0APgA7ACEAv/9C/9j+kv5w/mz+av5M/hD+vP1o/UD9RP08/Rz9FP0I/cD8XPxY/Kj8mPws/CT8bPws/KD76PvQ/PD80PvY+vD6iPtI/Ij9kv7Y/aD70Pn4+fj7rP5pAL//WP2o++j76PzQ/Tr/5QDdALz+LP0O/rf/PAA+ANcAGAE2AKD/mADeAbQBxQDZAMYBIALUAf4BjAKAAtYBigEQAsQCBAMIA/wCnAL+AcoBWAIsA3gD/AJAAugB5gEMAjwCaAJkAggCcgEUASwBYAFYAS4BFgH7AK0ATQAyAFsAfABaAAsAzf+s/5P/iP+b/6n/e/8m//r+Hf9N/zT/3P6W/oz+wv4R/zH/Af+q/nD+XP5k/oz+yP72/uj+rP5q/kj+ZP66/vD+xP6Q/rz+Cf8A/7z+xv4c/0j/K/87/4v/m/9P/zb/jv/k/9j/xf/7/zMA/v+o/8b/QwCFAGMAPQBYAH8AWgAJAAYAbwDXAN0ArgCGAF4AOQBbANYAKAH0AIoAYQBuAHoAqgACASQBzwBmAFAAbgCDALAA9QD2AIwALgBLAJAAmACDAIoAiwBiAEAATgBiAEkAJwAtAEgAUABMADgAAwDD/6z/1/8UADIAKgAHAMT/d/9d/5L/9f84ACIAzv9//2v/mv/u/zAALwD+/8j/vP/a/wIAIwA6ADsAGgDz/wEAPQBmAFUASQBpAHUASAAvAHAAlgBhADgAdAC7AIQAJwA2AHoAbgA3AC4AHADU/7n/IACTAGUAuv9L/03/c/+Y/8z/+v/n/5D/MP/8/gz/T/+L/4n/YP9I/0H/Lv8a/yb/UP9b/0D/P/9p/3//YP9M/3D/oP+k/5j/tf/t/wMA7v/d/+v/FQBJAHAAgAB5AHIAdwCDAJUAtgDgAPEA1wCsAJUAqQDdAAoBCgHgALMAnwCcAKYAyADoANoAogBwAGQAbgB7AIUAhgBtAEkAOwBBAD4ALgAdABMAEwAYAB4AFwD//+T/0//V/+v/BAAJAO//v/+h/6T/u//N/8r/vv+y/5//gP9t/3T/ff9s/1f/W/9j/0r/Jv8n/zz/Ov8k/yL/NP9A/zD/Hv8d/yT/Pf9b/2T/Sf8u/zH/RP9J/1r/h/+a/3f/WP9y/5j/kv+H/7X/8v/e/5z/lP/V/wUABQAJACQAIwD2/+f/JQB1AIgAcgBqAGsAWwBPAG0AqgDNANMA2ADJAJkAegCXAM4A6QDiANoA1QDEALYAvwDPAMwAyQDOAM4AxQC8AL8AvwC4AK4AqAClAKQAmwCEAGsAYwBuAHIAWgBAAD4AQQAsAA0A///8//j/9v/7//b/2v+1/6f/s//G/87/xf+s/5H/hf+E/4r/k/+Y/5H/gv90/3H/cv9m/1r/W/9r/4P/iP9w/1L/Tv9e/2f/bP91/3//g/+A/4H/hv+F/33/f/+Y/7r/yv+9/6n/qv++/9D/2//t/wQABgDy/+r/AwAqAD0ANwAzADsAQABGAF0AegB+AGoAVgBWAGMAdgCMAJwAlgB/AG0AZwBqAHUAfgB1AGMAWwBbAE0ANgAwADwAOQAdAAwAEgASAAAA7v/w//j/9//x/+7/6f/a/87/0v/a/9z/3f/k/+L/z/+8/7z/yv/R/8r/xP/D/8H/v//C/8n/x/+x/5v/oP+6/8n/wv+8/8H/t/+c/5H/pv/C/8z/xf/D/8n/zP/M/8n/yf/S/+D/7P/2///////4//b/AwAPAA8ACwARACEAMQA9AD4ANAAtADcASABNAEkAUABdAFoAUgBZAGoAbgBgAFgAVwBYAFUAXQBoAF4AQAAoACwAOgA+ADUAJwAdABMABwD//wIABAD4/+L/3P/o//D/5v/X/9T/0f+//7P/vf/L/9H/yf++/7b/tP+8/8H/xf/O/9n/3f/Z/9n/3P/e/+H/8f8MABwAHwAZABAACQAMAB4ANgBGAEgAPwA3ADEALwAyADsARABCADUALgA5AEMAPAAvAC8ANgAwACkALwA1ACcAEQASAB8AHgAQAAgABwD7/+f/4f/r//P/7f/f/9P/yv/K/9f/4P/b/9L/zP/F/8v/3v/r/+T/1f/U/93/3P/Y/97/5v/l/+H/4v/k/+X/5//o/+b/4f/p//n/AQD///7////8//v/BQAXACEAHwAZABEACAAGABMAIwApACMAHAAYABAABgAAAAMADwAXABMABAD5//j/AQAFAAIA///+//j/8v/1/wEADQANAAQA/P/5//v/AgAMABMAFAAPAAoACgARACEAKwAmABkAFwAkADYAQAA+ADcAMQAwADcAPwA/ADoAPAA+ADgAMAAxAC8AHwAQABMAHgAZAAoA/v/2/+X/1f/c/+z/5f/M/7v/uf+5/6//p/+m/6T/n/+b/5D/fv9x/3P/e/99/3n/e/+A/37/ef92/3T/dv+D/5b/oP+f/6L/rf+0/7b/wf/W/+P/4//i/+v/+v8KABgAIQAkACYAKgAwADgAQwBOAFMAUABRAFgAWwBZAFoAWwBXAFkAZgBvAGcAVQBNAFQAWgBfAGYAZQBYAEsARwBNAFIAVABTAEkANwAvADUAOgA0AC0ALwAsABcAAgACAAgAAwD//wQAAgDs/9n/2f/f/9n/0//c/+j/3v/G/7//yv/T/9H/y//H/8X/xv/K/9D/0f/L/8n/zf/P/9D/2f/i/+T/3v/Z/97/6v/z//n/+//5//n//v8EAAgABAAAAAkAGAAgABoADwAOABkAHwAdAB4AJgAmABsAFgAeACMAIQAiACoAKQAaABIAGAAcABYAFwAeAB4AEgAJAAsAEgAWABQADgAIAAUABQAFAAQABgAGAPj/7P/x/wAAAQDt/97/5//1//f/9v/3//D/4//g/+7/+v/7//v/AwAFAPn/7v/x//v/AAACAAcABwD8//P/9v/2//D/8v/8////8f/i/+D/5P/g/9n/2//i/+T/3f/S/8z/y//L/8n/xv/K/8z/yv/N/8//y//B/8D/yf/O/8n/xf/K/9L/1//c/+X/5v/g/+D/6//3//v//f8EAAsACwALABIAHAAhAB8AIAAiACQAKQAwADcANwAzAC8ALQAsAC4ANgA6ADQAMAAvACwAIwAdACAAJAAiAB0AHgAiACAAHAAaABUAEQAXACEAIwAeAB0AIwAkAB4AGwAbABgAFAAZACQAJwAfABcAEAANABAAGwAkAB8AEwAMAA4AEQATABcAGQAaABsAGgASAAcAAwAMABYAFQALAAMAAAAAAPz/9P/y//f/9//s/+X/6P/u/+r/4//l/+T/2f/V/+H/7f/p/9n/zf/O/9H/0//a/+P/3//R/9D/3f/g/9X/0f/c/+X/4f/c/+X/8f/u/+j/7P/x//D/8f/5/wMACQAHAAMAAAABAAcACwANAA0ADAAMABAAFwAcAB8AHQATAAoADgAdACoAKwAmACQAJAAlACMAJAArADQANAAnABkAFQAaAB0AHAAYABMADAAGAP//+f/0//L/8v/0//f/9P/r/+X/5v/p/+v/7P/t/+z/5v/f/93/5P/t/+//6f/j/+D/4P/g/+L/6P/v/+3/6P/p/+7/7f/o/+j/7f/w//D/7//y//T/9f/1//P/7v/q/+v/7v/w//H/8P/v/+7/7P/p/+n/6v/l/93/4v/z//7/+v/z/+3/5v/f/+L/7v/0//T/+P/6//D/5P/o//b/+f/z//P/9//4//f//P8BAAEAAQABAAQADgAcAB4AEAAJABAAGgAeACQAKQAoACMAIQAkACcAKQApACQAHAAcACQALQAtACcAHwAWAAkACwAbACkAKgAkACAAFQAHAAQAEgAdABoAGwAeABEA//8AAA0ACwD9////DQAOAPv/6v/u//z/BQADAPf/7P/k/9z/4f/3/w4ABwDz//H/9v/q/9j/3f/u//L/9/8LABIA9//b/9f/y/+o/77/GABgAE8A8P+V/4L/yf8vAF8AQQAKAOT/t/+c/93/WQB/ACMA1f/r/wMA2v/G/wwATAAlAOX/7v8aABYA7//p////BgACAAAA/P/4/wEADAAFAPr/9v/z//X//v8EAAMA+f/6/wgABgD1/+P/2v/p/wwAIAAYAAAA5f/X/+D/+P8KAAUA+/8AAAoA/P/k/+//HwA3ACAACgAAAOP/xP/r/0MATwDu/6L/y/8ZACEA/f/1//z/7P/g//j/AQDR/6n/zf8WACUA9v/m//X/y/+H/7D/KgBAANT/m//L/93/z/8MAF4ALwCy/5L/5f9GAHkAUQDH/4f/PgD9AHIArP9OABYBKAA3/2wA9gEaATf/Mf+GAPkArwDyAEwBtgCC/+j+kv8kASgCLAEx/8b+KwDnACsAPQDEAfgBi/90/VL+cQBIARIBhQDI/lT8LPxk/9AC6AL6/zz8UPk4+Tz9iAJQBBgC3P8//2z+bP2e/i4BrAFUAFUA4gFQAgwBuP/w/lD+3P50AZwDbAJ4/2D+Kv+e/6f/vQBAAtoBhf8C/tD+MQBzACEADQDs/8b/PADTABkAjv5u/hQAYAEaAVAA9f+0/zj//P6p//EAYgH9/4D+Dv9fAFsAsP/S/yAAhv8Z/zoAxgEMAZL+Av4VAFYBRQCd/64A+gBC/0r++v+mAZMArP4X//EACAFd/zb/3wDyAPz+5v6eAcAC3v/0/DD+jgFwAqAAXf9A/8j+7P4IAdwC0AET/0j9VP0A/+4BGASsAib+EPvQ/NoAoAJYAmwCWAFs/SD7wP5UAywCrv6V/ygCbwBg/Sf/ZAI7AIz8bv+YBMYBEPsI/XgE0ANA/Bj7bAEcAzb+QP7wBAAFaPtA9zn/qAWyAZT9xgGwBGj+UPmG/oAEDAJ8/rIArAJ4/8j8Of8wAmYBIABKAYwBN/9M/vb/pP+w/UgACAb4BGz86Pgt/1gERAHA/WUAWAI2/hj8gAEABZD/qPry/lgE/AGQ/c7+tgEAACD9Kf/oA0gENf8Q+0z8TwDYAlQDKAJI/7T8dP3+ADQCS/9M/dz/tAP8A1YADPzY+tj96gGcA+wCBAIeAVT9wPfY+AgDcApoBz0AiPvI+XD7x/9wA+gEqATQAVj8kPlk/tgEvAIo/Ij9YASgBKD+VPyO/44B2P/0/ID7dv5oBVgHlP+Q+WT90gHg/nj8mwAoA17/+Pyo/1QBhAEwBPgDSPuw81j5WAUQCnAHOAM4/HDz4PTgA+ANKAYA+/D6Cv5Y/b7/kASUAiz8cPvP/1wCgAIkA5ABMPuI+Mn/oAUQAtAA+AUcAzD4YPe0ATAGeALcAkgGhv9w9Nj4sAeACTAAhP5cAjb/wPkI/kAH+AWo+xj6tALABGT9ePrY/s4A4//gAhAFhP2Q9Dj5+AWgCEQBJAD4BID+MPGg9vALABK8AgD4EPyw/tj52Pu4B0AMbAPY+uD4cPi4+jQDUAr4B3cA0PpA99D2MP6QCbALhgFo+Vj7cv64/b8AKAf4BVj9wPlk/kQCXAJAA7wDHP/w+ez82APoA1T+7PwYAAgBXACeAUQBMPxI+Dj8/AOQBMD9ePwwA9AD+PrI+LQD0AruAbj4Jf/oBnb+YPR8/dAMEApE/Wj9wAWqATD1oPXYAwAMcAWo/VMAmASF/yD5mP1oBcoBqPhI++AHcAp2/3j4YPt8/VT9qAKoByQCkPmI+WD9EP30/DgCEAfEA1j6APSQ9Sz9eAVACIADIP3Y+y7+tP8dANsAWALAA7QDcALUAtQDRwDA+kT8WARYB2gDdALwBIYAEPeA93wDAAqeAWD46Pz4B2AITPzQ8qD10P08AjgFQAh4A2D3EPPI+9QCgf9I/RQDKAVS/oD7jAGcA/D8CPoeAdgH+AV0AKD9+PyY/igEIAkoBrj9MPnI+7z/WgGAA1gHcAjIApD5UPQg963/qAdQCQgFcv/I+iD30Pfc/rAGMAg4BHz/oPrw9SD3aAFwC8AKhAJI/ID5GPho+zgEMAqgBxACYf/0/AD4sPZG/9AJIApUAtz9Dv4A/Oj4zPx4BVgGBv6Q+dT+YAQ8A+P/9v7c/nz9uPxg/q4BIAT4AgT+OPvv//AFWAPY+7j5aPyW/hQCmAcACAIBcPrw+aD82P6KAYAFWAbVAKD6qPpU/jgBpANoBNYAjPxY/ML+ogCOAfwC2AMCAUD8VPysAagE6AEQ/vT8HP3U/c0AuASQBKr/aPuY+kD7CP3iACgE6APmACb+tPyY/Hj+3gH0A7ACpf+k/Yj+NAJYBRAERP/I+zz8kf/8AigF+AUwBIX/6PoA+Qj6FP70A7gHqAaoAWD8OPro+jj8UP6GAXADaAJmAOD/tgCRADL+yPss/WgCwAZgBogCpv7A+4j67Pw4AjAGgAZ4BIQB/P3w+kj6gPy+/7gBAALGAfcAPP9s/gcAoAEPAIz8IPtU/cUARANYBFADif+4+xD7AP2u/wgCaANAA74BKgBB/zT+7Pw8/Yf/HALcAwgEJAJT/6T8qPo4+zn/5AOABWADsP98/Lj6cPts/8gDeAQAAu7/nv6c/Kj79P2eAQADKAI8AT8Aev6g/Ub/qgEUAvgAzgCGAd4AAf/C/qUAdAGU/8j95P6aAYAC3QD6/pb+sv4M/vT9v/+GAXQBxADbALAACP9I/Xz9Gf8dAGoARgEwAo4BrP+G/qL+yP47/0QBIAMgAs7/W/+KABwBmAA8ADMANP+w/RD+PwBoARwBzQDo/7z9YPxk/er+Kv9T/68A1AHlACv/QP9qABkADv+D/1wA8f+//zwBCAPsAkgBaQCNAPX/6P4l/1gAEgGIAXQCBAO0AQj/eP2g/dj9lP4QAfwC1AEx/7T9MP1A/Sv/LAIkA/kAZP5w/TT9LP3S/gQCtAMwAuf/hP8AAHf/uP6l/7QBaAKUAUoBDAJkAsAB4wA8AHv/1P5O/xABSAKsAQIAXv4c/RT9nP5PAIQAdf8Y/+H/4/9s/qT9Av+9AOsAOAAEAOT/Yv+q/wIBkgGHADn/yP70/k//RAC6AdwBCAB4/tL+//+uAC4BqgFSAeH/ov7M/gcABAFmAXwBrwCk/tD89Pzm/tAAoAHAAbgBJgGL/4z9iPwY/bz+oABIAkgD7AIUAfL+7P0A/qL+qf/5APgBKAK2ASwBpACv/6z+ZP72/gEA6QDzAPj/9v7K/kT/0/85AEoAnP8a/uj8TP0b/98AggEqAXQAi/9o/rT9Lv6I/7kARAGEAbwBwAFgAc4AkgC/AOwA8QDwAO8AzQCqANMAZgHIARwBdP/Q/dz86Pw2/iIANgHFAIL/GP6Q/LD7pPwr/6oBCANMA1wCUABk/jL+kv8gAWACwAOIBLQDsAG0/yz+TP3I/Wb/xQAkAfUAQgC4/gz9jPxM/WD+hf/EAIwBJgHu/8r+GP7s/Yb+9P9GAYIBfQD6/iT+mP7M/6cA4AAYAXABRAGLACMAuAC8ATQCCAKsARgBw//8/UT9gv6SAKQBdAHIAOn/1P78/fD9dv4h/8z/XgB4ACsA+/8JAAcAEAC1AKgB1AHvAN7/RP8B/0T/SQBKASwBGAAo//D+Qf/X/2MAZQDW/zL/1v4C/yEA6gGsAh4BYv7g/Fz9sv7x/yQBEALKASMAUv7Y/dL+BACXAOcANgEsAfUAcAGoAjgDNAKnAPH/PADRABwBqwBH/5T9/Pzs/V//TgB+AMX/FP6c/ED9CwCcAvACJAG0/jD9sP35/4AC6APsA9gCAgEp//D9aP1A/YT9rP6LAJACEAQ4BCACMv6A+nj5CPzAALgE4AVQBGwBtv4Q/dT80P3c/j3/gP9BAP0A8QAmAOL+iP3s/Kj9HP/4/z8A1gC6ARAC5gH0AQQCjgHLAFsASgBqAMgABAGlAND/JP/k/sj+jv5A/uj9bP0E/Tz9ZP75/+4AyQA4AO//pv8G/7j+ff8OAZwCtAMwBKwDCAIEAJD+KP7C/g4AmAEIA/ADdAMGAaz9YPs4++j8gf8YAlQD9gGq/vj7ePug/HT+hAAQAgwCygDn/8f/df/m/jz/xwCcAtgDCATMAi4AaP1Q/KD9DACwARAC5gGWAbMAxP6g/PD72PxC/rT/agHkAvgCJgFy/nD8yPs4/Fj94P5nAIIB4gGSAfgAaQAHAJQAkALoBKgFWARUAvwAMgCS/7P/jQCEAKz+TPwY+2j7zPwL/3IBUAKTAPj8qPkA+ej7JgHwBRAIOAeQBGABiv5E/V7+3gDcAtQDCAT4AgkAnPwo+3z8EP9+AUgDVAO9AAz9UPvk/AAAMAIcAu//QP00/Iz9/P8kAtwDgASsArb+ePsQ+6j8rP5yAVAFIAjYBgQCMP0Q+7j7mP2s/z4BbgHR/2T9cPwa/rsAqgFNAHT+zP2A/sH//wAEApgCWAJGAfj/N/8s/wT/EP4s/aj9GP+1//b+SP7G/t3/zADgATgDgAPGAYb//P5aAOABSAKqAVkAnP4U/Yz8NP1u/qv/pgAwAWoBugEIAvwBigHaADwAOwA0AZACQAO4Aj4BTf8c/VD7OPvo/GD+Wv4C/pT+Nf/4/qb+bP+yABoBEAEQAgAEKAVoBCACa/9g/Xj84Pym/loBZAPQAn7/wPsI+tD6+Pyi/xACCAMAAkIApf8qAJoAuwBOAXQCcANcA9wBmv8Y/k7+lP+0ADwBIAHu/3T9MPsQ+8j86P4KAVwDqARsAyMACP0M/GD9VgDIAzgGUAb4AzEAoPzg+rD7+P29/xsAGgC8AJoB2AE4Adj/vP2o+zD7DP3K/9oBUAOQBJgEYAIv/0z9/PwI/Tj9Jv6y/yYBfALgA0gEWAJ+/hD7QPpk/Pz/9AL4AxQDVAHD/8z+kP78/sP/4AAEAmQCLAHS/jz9vP2G/8oADgHjAC8AUv5A/Bj8RP7pAEQCiAJwAqoBGQAR/9v/tAEcA9ADKATMA1wCRgA+/qz8MPxI/Uj/vgDZAO7/Rv7w+zD6qPok/Q8AoAKwBFgFhANRAPj9aP2o/Sj+af+EAUADVAP+AWkAFv/Y/Wz9B//wAaQDBAOSAS4B3AF0AlQCSgGE/2j9uPsw+xD8/P3j/+UADAGxAJD/4P0Q/TT+igDAAugECAfwB4AGgAOgAFr+lPwI/Cj90P7E/0EArwDo/9j86Pgw94D4UPsu/vMAcAN4BJwDGAJeAdgAX//w/ZL+RgGUA8gDeAKiALb+PP3w/MD9EP8+AN4AvABTAE8AcQC6/wr+rPys/Pz9NwDUAmAEfANyAHD9RPzI/AL+i/8eAcQB5wCR/1n/wwAAA4AEGAQkAqMAqgAoAcEACwAeAC8A4P78/GD82PzI/Hz84P3wADgDeAPcAkgCxQBM/hT9vv7+AXAESAX4BGgDuwD8/QT8mPqI+eD5OPys/3wC6AOIBLgE3AOuAQj/PP3s/Nj9Hf94AFQCaAS4BN4BdP14+oj5IPmI+ZT8fAEoBUAGGAYoBcACIf/4+3D6kPpg/H7/TAJAA5QCBAG6/oT8VPyO/pQAFwBa/iT+4/8UAiAEQAYYBwAFmgCk/CD72Pus/eP/IAKUA2wD2AEVAOb+5P3w/AT9CP/wAfgDmARYBDADGgHa/qD99P1o/woBigFxAJL+HP2Q/Nz80P0r/4UAjgFQAtQC6AKQAvYBEAEFAIn/4/8YAFn/SP7M/Yj9FP0Q/Rb+MP86/9r+Sf9WAAwBcAEEAlgCwgG8ADMAEwBs/zb+VP0s/Yz9Yv4MABgCPAPUAmoB9v/c/j7+bP4y//D/XQCbAH0Ac/+I/eD7wPtg/aT/ngEgAyAEWATIAwgDfAKQAd3/MP7U/cL+4f+MANQAawDS/qD8ePsM/JT91P6t/54AvAG0AkQDdANwAwQD2AH3/0L+fP1g/SD9+Pz4/RgAtgHQAToBGgEGAQ8Azv7U/mQADAJgAnABFgDW/qT93PxE/Q7/JgEEAloBMQCA/zf/R/9aAJQCcAQgBDQCswB/AHEAvP/8/rL+Xv54/Yj8uPw4/hAASAHuAZgCGAN0AnwAbv54/XD9/P1c/2ABiAKeAWn/hP2c/Fz8kPxg/bz+NwA+AYgBjAEYAggDOAMkAssAKgDU/zX/1v47/6z/Jv8A/nz97P2M/tj+Gv+W//j/zv8n/9j+ef+0AMQBVAJwAhwCaAG9AIYAvAAUARgBXAAW/xj+7P0U/kz+Rf8KASACmAFnAL7/T/+a/mj+kf96AbQC1AJYAoYBEgBE/vj8wPxo/Wj+iP8OAeACKAQgBAQDggHI/wD+BP28/Z//DgFgAUwBOAGfAHX/Zv7E/Uz91Py4/HD92P5bAJgBhAI4A5wDaAOAAiIB3/8f/+z+Lv+o/xoALgDw/97/JgBKANH/Bf+i/jf/twB0AmQDMANUAkYB4/9I/lT9TP1Q/cT8mPzU/e3/mAGEAvwC2ALMAVoAa/9R/6f/FACoADwBFAHT/0T+VP0I/ej8EP3c/eT+gP8yAMQBhAMgBOADzANgAwQBTP24+oD6YPts/FD+LAEsA+gCMgGl/4r+hP0w/ZD+JAH0AgADRALaAVgB8P88/lj9HP2w/Hj8pP3z//oBAAN8A7QDOAPOAQIAtv4+/kL+bP7k/tX/6QBYAfAAPwDR/4T/Kv/4/l3/MwDNAM0AqQAUAd4BDAJiAdIA5QDKAPj/RP+m/4sAvwBdAHkASAEEAiwC/AGwAR4BOQAv/2j+YP78/o7/uv8IANMASgGyAOT/DwC4AIwAsv9w//P/BgA2/4T+oP7I/lL++P2a/rH/BgCK/0D/VP/i/sj9BP00/cT9XP6Q/1gBLAICAdz+NP1E/KD7yPtI/W7/9wBsASYBUQDa/kT9cPyo/ED9xP1Q/jL/EwBjACsAHwCXAAIBzABQAEIAggB8AEQAfwA0AbYBngFgAYYB9AE4AkACYAKgAqACKAKSAWABsgE8ArwCOAO8A+QDbAO4AoQC3AIcAxgDUAPMA+QDeAM0A0wDLAOIAtoBoAHOASwClAKwAkwCiAG6AOf/L/8M/3//0f+T/0H/Tf8z/17+TP3Q/Kj8PPyg+5D7EPx4/Hz8ZPyA/JT8UPz4+wT8RPw4/PD78PsY/OD7QPv4+jj7YPv4+jD6gPlQ+dD52Pog/Jj9Ev+i/+b+7P3k/Xj+vP4W/18A8gFsAtgBYgEyAYEAef88/wkAGAHSAXACGAOIA6wDuAPMA+QDAAQQBNgDWAMIAzQDyAN4BBAFeAWoBagFgAVABQgFKAWABagFiAWYBSAGeAYABvAECARMA0gCUgFQARQCSAJ6AdcA+wASAZoAbgA8ASACQAL6AfIB6AFQAVcAZv+G/qz9/PyM/FD8KPwE/PD7FPyA/CT9tP3M/Wz9+PzQ/MT8RPxY+4j6yPl4+OD2EPZQ9jD2QPXQ9ID1EPbg9TD24PcI+pj7sPy4/X7+/P45/8b+8P38/dz+aP5A/CD7jPws/oL+6P/AA9gGSAZYBFAE4AToAq3/vP5hALoBvgFwAsgE0AagBkgF2AQ4BdAEnANIA0AEIAVABaAFqAYYB1AGUAWABFAD3AFCAZgB/AFcAnAD4ASQBZAF4AVQBsAFWAQ8A6QCDAJeATIBygHMApgDxANcA/QCxAJcAmYBqgD+AJoBVAHPAGoBiAJcAgoBRgBiAMH/4P1Q/Bj8NPyo+0j7KPzA/aD+aP4A/hL+Fv50/az8oPzw/Ij8OPvQ+cj4kPfw9XD0wPPQ8/DzcPMQ87DzUPXA9hj4uPpa/iQAAv8y/jYASAJwATsABAIABLIBTP0g/GD9wPw4+0z9KAK4BCAE+APoBPgDDgGp/woBdAJUAkACYANgBNwDyAKkAhQDCAO8AlQDuATABfAFEAawBiAHsAagBQgF+ARwBBAD/AH6AQgCSgHCAFYB3gEQAfj/SAB0Ad4BwgFoApgD/ANUA7gCsAKUAuYBXAGiAVQClAJoAnAC1AIQA8gCNAK0AXgBUAEKAZ0AZAC1AFoB4gEUAgQCjAFcAMD+hP3k/GD86Psk/Bz9xP3Q/Ur+fv87AMv/If/i/jj+uPxg+xD7CPuQ+vD5gPm4+OD2MPSg8UDwIPAQ8eDy0PWQ+dD8xv4QALwBMANUA3wCZALwAuYBfv6A+wj7UPtw+lj6IP22ABgCjAKIBLgGWAY4BMwC5gEmAKz+Sf8GAQQCqALQAygEmAKyAGUAwABlAIwArAJIBUgGaAZoB7AIcAjQBoAFqAQAA30Auv62/rT/swDKATgDKATUA5gCkAESAdYA4wB2AWACNAOcA4gDCAOoApgCcAIIAgQClALcAlwC7gF0AlADrAPMAwgExANgApYAn/+O/7T/NACIAXADoARYBDgDKALyAAr/RP3g/Gj9BP0o/Kz8Sv7a/or+lP94ARYBPv74+4D7EPvY+Uj5yPko+sj5ePgA9kDzgPEQ8IDtgOzA7yD1qPhY+10AWAWABbgCQAKYA1ACAP/E/W7+TP2g+rj56PrA+1D8gP7UARAE2AQwBTAF+AP8AYEAMwCmAEYB+gHAAkwDEAMkAlwBOgFOARwB+wB2AYgC3AM4BYAG2AcACVAJMAhwBggFiANOAVP/1v5b/5f/wf+8APYBaAJMAjQC4gEMAUUAKABrAOQA6gFUAzgEIASEA8QC5AEmAfEAMgGUAQgCyAKIA8wDqAOYA4gD6ALKAfgAzgDpAP8AVAEIApgCiAIMAmABhQCb/+7+bv7Y/XD9hP3s/Sb+fP5M/1IA1wCRAMr/9v4u/gj9iPsI+/D7+PtA+RD20PWw9iD1EPIw8YDxYO/A7GDu4POg+JT8iAKwCAAK+AawBAAEHgFs/LD6YPzU/LD6EPqs/OL+jP7s/mwCqAU4BVADJANwAwACiwCWAdgDaARsA+wCiAKyAFr+2P0a/y8AwgAQAhAEKAUYBaAFUAeACFAImAcAB9gFnANsAUQA0f+Z/9z/owAmARwBHAFYAWYBUAGkAVgCxAK4ArgC7ALkAqQCqAIMAxwDbAKIASgBVAHCAVwCIAPIAxAEGATkA4AD/AJgAqgBCAGgAEcA7//g/zgAlwCrAMwASgGaAUQBvQCOAFQAsf8O/9L+pv46/gb+VP6o/qr+sv7G/mb+vP1M/bT8iPuw+gD78Prg+HD2UPbQ92D3oPTw8ZDwYO+g7iDw0PRo++oBeAZACGAIwAdQBZsAsPw8/OD8aPvQ+aD72v4d/8j9cf84AygE6AG7ALIBpAHo/6f/GAJABPwD5ALUAvQCmAF4/5D+K//n/xcAmgDoAQwDRANsA6AEaAZoB2AHAAeIBiAF5AIkAa4AswBjADkA3gCSASYBNgBUAEgBdAHTABIBZAIMA3QCJALoApwDYAMUA3QDqAMEA1wCkAIgA0gDUAOQA6ADKAOIAkACKAL4Ac4BmAE+AekA6AAUASYBUAHOATQCCAKIATABqwCZ/5D+RP46/rz9VP3M/ar+C/8z/+P/sgCqANX/3v6w/UD8EPuo+tj68PoY+kj4IPfw94j40PVg8WDvwO+A7sDsIPDw+MMAeASYByALQAuwBoABiP5Y/Mj5oPjA+bj7YP3I/vL/zADQAfwCOAMsAhIB7wAYAfoAVgG4AigEiAQABEgDTAK0ABP/XP6K/ub+U/9YAAACpAPQBMAF8AZACMAIAAiIBlgFQASYAhwBDgEYAoQC5gFuAXQBBAEBAJ3/KwCkAI0AwACCAfIByAHYAZQCSAN0A3QDcAMoA2QChgH4AMwA8wBqAQQCiAL4AmwD0APgA7QDcAMMA0gCNAFOAOf/2f/x/zsAmwC8AIAACQCK//L+SP7M/cD9Hv6c/v7+Lv83/yv/5v5y/gb+pP3g/Mj7UPvg+0T8YPs4+lj6wPqI+UD3IPYA9hD1gPNw8uDwgO7g7uDzWPrs/lwDMAlgDIAJMARgAc7/iPyA+ej5IPzE/Dz8NP25/7ABGAIcAsQCjAMQA0wBNgBGARADzAMYBDgFAAaIBJYBrP/w/gL+HP3M/dn/bgE0AlwDSAX4BuAHQAhQCNgH2AZYBXwD2gEgATYBZAFOAUgBTAHfACgA4/9PAMgA1QDOACIBkgGuAZ4B2AFkAsQCsAJIAugBmgEcAXcAOQC8AJIBNALoAhgEOAVYBagEQAQoBGgD1gHOAO0AJAF1AK//DQAIAVQB0wBxAHIAVAD7/6H/Vv9G/4f/iP/u/or+AP8Q/9D9zPx4/S7+JP3w+6D8xP3s/GD7iPtY/ED76Pgo+Oj4qPiA9mD0sPMQ82Dw4OwA7bDyOPrY/2AEYAlADBAKaAU4AjMATP3o+hj7aPyA/Cz8UP2o/6wB9ALkA6AEwASgA3gB4v8wAIgBQAKkAsQDuATkA+ABkQAdAE//XP6i/ggAYgFAAlAD2ARYBmgH+AfQB/gGcAWkAxwCLAHZABgBzgF8AngCygEkAeEAqABJACoAgwDhAOkAtgCRAJwA1wA8AZwBygHOAdQB6gH+ARACHAIsApACVAMYBHAEYAQoBNADPAOMAtIB/wAzALj/gP87/xX/d/8xAL8ACgEsAe8ATADm//r/9f/N/wkASgCd/3L+Ev70/cD8ePs0/LD9KP3I+6j8Zv6I/YD7VPyO/pT9aPro+TD7ePmg9YD0MPUQ82DvIO9Q8UDy4PPI+iAE8AjQCLAIAAnwBZcA0P0k/gj+3Pw8/TP/CgAL/77+egBAAhwCFAEiAegBlgFPAEgAVAJoBPAEAAVwBfgEwAJXAE7/2v7o/XD9Vv6t/64AEAIgBLgFYAYQB+AHeAeQBbQD7AKkAkACEAJ0AvACnAJyAV0A/f/H/0D/+P6U/3AAqgC+AFYB7AHgAfYBtAIkA5ACvAGaAcIBggEmAXgBaAJEA7ADAAQ4BBgEqANMAywD6AJgAvYBzAF4AesAlgCbAH8APABBAEcA8P+c/7T/3v+6/8X/SgAaAMj+vP3I/ZT9cPxA/ND9zP7k/Uz9Mv5c/oT8QPsc/Iz8SPuA+kD7QPs4+VD3wPaA9cDykPBw8ADxQPGA8qD2iP2oBBAJQArACWAIAAXC/6D7yPqo+wT8fPx+/ogAggCN/ycAxAHeAa8AwQAgAkwCCgEAAfACkATYBCAFcAX0A/MAyP4m/oD9rPw4/TX/ywB6AXQCKASgBYAGGAd4B/AGiAXwA6wC4AGqAfwBbAJwAsgB6wBnAAcAa/8T/73/wwDPADUApgDWAfQBVAEQAsQD6ANgApoBBAK6AbQAsQC8AVwCsAKkA2gEIATUA1AEmAT4A1gDDAM8AhYBlgBJAFP/aP6e/jT/IP8q/+n/TQDD/33/6P/V/y7/Uv81ABIAwv4A/j7+CP4M/bD8SP1U/XT8IPzY/Dj9iPwQ/ID8WPyI+qj4KPjA9zD2kPQg9HDzcPFw8HDyUPWA94j7LAMACvAKoAdABewDhgAI/Ij6SPzw/V7+Vf8GAcYBcAFsAcwBcAGTAEcAdABfAKQALAJIBIgFAAZgBgAGnAPR/wj9ePwc/dT9C/8OAegChANkA8gD4ATwBaAG+AbABtAFiARAA/wBWAEsApQDnANQAroBBAJEAWv/zP7n/1EAZ/92//8AgAGXAPoAHAMoBDwDtAI0A5gC+AD5AIQCpAJEAXgBWAOkA9wBVAEkA3AExAMYA1ADvALhALP/EwB5AN7/Lv9B/5//pf9a/xb/Jv+A/6r/XP8F/xb/Q/8//1r/fP/k/rz9PP2U/XT9fPwM/Nz8jP0M/Rj8qPtQ+4D6uPnA+TD6+Png+LD3sPYQ9YDycPDQ8HDzYPa4+Rv/EAYQC6AL0AigBZQCB//I+5j64Pu8/YT+YP7A/iAAOgH8AHcAGgEEAlQB1P/z/7ABxAIIA2gEqAYoByAF3AKCAdb/mP1w/AT9Ev6o/nb/BAG8AhgEUAWgBrgHAAgwB9AFqATEA5wCsgHaAZwCsAIQAowBDgEjAHv/XP+8/qj98P3i/04BhgGEAqAEkAWIBJADXANoAoEAov98AHwBiAFgAdgBwAJ0A3wDOAOwA/AEcAVoBGwDaAPoAgwBpP/s/zAABf/c/TD+Av/y/qr+Of8fAGkAKQD4////9/+l/y3/4v62/iD+AP0Y/Oj7yPsA+2j66Pqw+4j78PoY+4j7MPtI+vj5wPk4+MD10PPA8qDx8PDw8eD0EPk4/sAD8AegCYAJqAdEA2z9OPpA+2z9OP55/6ACoAT8AjIAuv+RANX/3P1s/cz+s/90/y4AFAMoBlAHGAcgB4gGzAMbACz++P2o/Vj9kP7KAAgCdAKUAygFmAVYBdgFUAYIBdgCyAGuAUgBIgFMAuwDaAT0A0wD/AH//3T+wP0k/az8iP2Y/0oBTAJkA1AEKAQ8A4gC6gEcAawArQCbAPkAdALcA8ADTAP4A2AEFAP8AaACGAP4ARgBpgG0AUQAW//t/3UAPgAwAE8A6f98/57/gP/C/pr+ZP+y/z3/Qv/C/1D/9P0o/ST9pPyQ+/j6+Prw+vD6YPvY+xD8kPxs/Wz9APxg+oj5mPhw9jD0QPNA8xDzgPPg9ZD5EP0+ALADeAbABpgEBAJRAAr/4P0Y/nMA5ALYAjQBqADgAE3/HP0i/noBCAJM/3L+2QAgAiYBSAJYBmAIUAZABFgEtAPeAMT+Dv+A/6T+wP3k/Zb+y/+aAUwDqARIBogH+Ab4BLwDcAOgAvoBTAOgBQgGgARQA+QChAFO/1L+1v7+/kz+WP6Y/+oAnAFsApADSAQwBJgDzAL2AXYBfgHmAbgC/AM4BYgF8ATwA+ACugGrAPf/qf+w/+3/NgCsAKwBxALoAhQCegFwAbEA4v7A/UT+9v7A/qT+TP93/0D+uPzw+3j7CPsY+5D76PtI/Az9jP00/dj8BP0I/VD8wPvQ+1j7mPnA9/D2kPYA9rD1APZg9pD2YPeY+Wz8tP52ADACXAMcA9wBvwAyAAkALQCgABIBOAEcAdEAegBlAH8AcABIAGgAewAXAAEADgGcAqADWATYBDgE3AKcAvwCtAFV/8r+XP9c/bj5qPnw/b4BEAMQBaAI8AloB7AEaAR4BOACpAHkAvAECAW8A1gD0AMYAzgBMQA6AIX/0P3s/JD9Yv4I/5IA5AJQBFAExAMMA9YB1QD0AOABzALgA0gFMAYABpgFiAXwBFAD0AFGAacAW//c/ioAkgGiAbAByAL8As0Aav4Q/k7+TP2Y/OD9av9g/+7+IP+e/uT8CPzQ/Cj9OPzw+/z8QP0M/HD7QPyw/OD7ePtE/Hj8APt4+SD54Piw94D2YPaw9pD28PZA+Mj5KPsY/U//fwClAAIBkgFEAaEAFAEsAmwCGAJYAuQCyAI0As4BagGyAPj/bP/U/nz+9P4MAEgBmALUA4AEuATABCAEfAKxAEj/RP1g+mD4mPgg+nz8tQDwBeAIkAiYBwgHGAX+Ab8AOALEA0AEMAWgBpAGwARIA1gCiAA+/hT91PxA/Az8jP3S/zoBYAIwBGgFcAS8AlQCmAI4AhgCeAMwBbgF8AUQB+gHAAdwBbgECAQYAtX/Hv+J/5z/jP+cAFAC6AI0AnAB8gDC//z9HP2Q/UL+kv76/mD/0v5o/XD8FPxw+9j6WPto/GD8oPuQ+/j7ePug+gD76Puw+4j68Pm4+aj4QPfg9iD3APfg9oD3kPhY+Tj6qPvs/JT9XP6Y/2EAZQCdAF4BvgGEAaoBUAKAAhQC4gG8AdAAkf8//87/NgBqABQBHALIAvwCJANgA1AD8AKIAigCYgENAID+EP3I+wD7aPtg/SIAFAPoBdAHgAd4BdADjAOEAxwDlANIBbAGoAb4BXgFqAQwA7oBsQCf/2D+cP00/bz93P5JAKAB0ALkA0AEVAPqAV4BygFkAiADkARgBoAH0AfAB1AHQAboBBAEkAPEAuIBqgHqAc4BYAFIAWIBAgFFANv/nf/Q/tT9qP0m/kD+vP1g/Vz9DP1U/Mj7uPvI+7j7yPvo+9D7aPvw+sj62PrY+sj64Pr4+rj60Pm4+PD3cPfw9vD2sPfA+KD5UPo4+wT8YPyg/GD9iv5w//v/bgC9AMUA0ABOAdAB5gH8AVwCZAKwAewAqQBXANH/+f8GAcABvAEUAgwDcAPQAlgCFALbAI7+tPwY/Aj8bPy8/an/WgG4ArwDKAQ4BFgEaASUA4wCmAKMA0gE0AT4BSgHQAdQBjAF4APkAdr/yP68/if/yv+7ALgBcAKMAgQCHAFzAEYAOQBdADwB+AKwBKgFMAaYBpgG8AVABfgE0ARgBBAEQARwBOQD5AI8AvYBggHbAHYAQQDB/wH/kP5y/iz+rP1U/TT92Pw0/MD7sPuw+6D7sPvg+7j7GPuQ+lD6IPoA+jj6uPr4+qj6EPp4+dD4MPgA+Fj4+Pig+Vj62Prw+sj64Pow+5j7SPxE/TD+qv7e/kD/vP/4/yIAwgCwATACFAIIAjAC7AE2AfMAVgGKAUYBmAGsAiQDWAKKAWIBqwD8/vj9fP76/o7+tv5nAOwB8gHWAcgCiAMEA5gCSAPgA4QDjAOwBIgFWAVYBWAGGAeABnAFqASoAyQCIAEaAVgBWgGMASwCqAJwAtQBVAEWAQoBJgFwAfoB0AKwA0AEkATQBAAF+ASgBDgEzAN0AzQDDAPkArgClAJUAggCygGiATYBjQDt/2L/vP4G/oj9NP3k/Jz8dPwk/Jj7KPsI+9D6WPoQ+hj6APqw+aj5APpI+lj6kPrI+pj68PlY+RD5APkw+dj5uPpo+9j7LPw4/PD7uPvo+zT8ePz0/Mz9oP4p/6b/KQB4AHkAhgCqAJ0AgQC/AD4BjgG6ASQCmAJ4AtYBRAECAaQAOgBNAOAANgEsATABXAFKAeMAsgDoAB4BMAFiAbAB0AHSARgCmAIAA0gDmAPUA9ADpAOMA4QDaANYA3ADhANkAzADFAPoApACQAIwAkACRAJEAnQCsALAArwCzALoAvAC9AIMAxgD/ALgAswCqAJoAjwCJAL4AbABjgGaAYoBQAH3ANQAogA5ANL/l/9j/wT/nv5Y/hr+yP2M/XT9TP3w/Ij8PPz4+6j7cPtY+1j7SPtA+0D7QPsg+wD78Prg+sD6sPrQ+gD7KPtQ+4D7yPsE/ED8dPyg/Mj89Pw8/Zj9/P1a/rT+9P4s/2j/o//Q/+n/DgBUAI8ArADYACgBagFyAWwBfgGCAWABTAFmAYQBggGCAZ4BsAGmAZQBlAGaAZ4BvgHoAf4B7gHaAdgB0AG8AcgB/gEsAkQCbAKkArgCmAKMAqwCzALEArgC3AIYAywDMAM8A0QDKAP4AuwC8ALoAtQC0ALYAsQCmAKAAngCZAJEAjgCPAIQAr4BhAFqAUwBGAHvANwAwgCVAGgANwDx/6P/av87/wX/1P6w/oz+XP4w/gb+0P2Y/WT9NP30/LD8hPxs/FD8MPwU/BT8GPwA/OD7wPug+5j7kPug+7D7yPvg+wT8LPxY/IT8qPzA/Oj8HP1Q/Xz9sP3s/Sb+Xv6U/sj+8P4R/zj/Y/+a/+T/KQBOAGkAmADLAOQA+AAiAVoBigGyAeABCAIYAiACMAJQAmgCfAKIApgCsALEAtAC1ALgAvAC7ALcAtQC2ALcAtwC1ALUAtgC0ALQAtQCzAKsAogCaAJYAkACNAI0AjQCJAIQAgQC8AHOAa4BlgFwAUYBKgEQAeIAqAB7AFwALQDy/8L/mf9o/zb/Ev/4/tr+wP6w/pj+dP5U/j7+MP4Y/gL+/P38/ez9yP2s/aD9kP1w/Vz9WP1g/WT9bP10/Xz9eP1k/VT9WP1w/Xz9gP2M/az9tP2s/az9wP3Q/eD99P0W/jj+Vv56/pb+qP7I/vb+If9F/2//nP/A/9z/AQAlAEUAZQCTAMoABAE2AWABfgGeAcQB4AHkAeIB9AEMAhQCHAI0AkwCWAJYAmACZAJUAkQCRAJIAjgCJAIcAigCLAIkAhgCCAL2AeABxgGqAZQBfAFcAToBKAEiARgB/QDhANAAtQCJAGYAUQA8ACMAEAAFAPX/5P/a/87/u/+v/6f/nf+G/3D/WP8+/yv/Kv81/y//KP8h/xT/Av/2/vz+Bv8J/wz/E/8Y/xT/B//8/vL+6P7a/s7+0P7Y/tj+0P7O/tj+3P7U/tj+4v7k/tr+2v70/gn/Ev8f/zX/Rv9H/0f/U/9j/3D/ev+H/5X/ov+4/9P/4P/k//P/BgATACwAUQBrAHIAegCTAKgAqwCsALsAyADRAN8A7gD0APQA+AD6APEA5gDpAPAA7QDoAOYA3QDKAMAAwwDCALgArwCoAJcAgQB0AHYAeAB0AHMAcwBuAGAATgA3ACIAGQAWAAgA8f/h/97/3v/N/7X/pv+d/5L/h/+B/4D/gP96/3L/a/9k/2H/Yf9h/17/XP9b/1z/Xv9l/3T/fP93/3L/eP+G/5X/oP+n/6//uf/G/9H/1v/W/9z/7v/9/wQADgAdAB4AEgARACIAKgAgABoAHgAbAAkAAgATACAAGAASAB0ALAAyADMAOQBBAEYATwBXAFAAPgAxAC4ALQArACsANAA9AEAAQAA4ACUAGgAeACAAGAARABYAIQAhABoAFwAWAAwA/v/z/+3/6v/u//P/9P/2//j/+v/1/+//7v/u/+r/5P/n/+z/5P/a/9j/0//F/8H/y//M/73/sf+1/73/wP/J/9f/2v/Y/97/6P/v//H/+P8AAPn/7f/x//z//P/3/wIAFAAWAAcAAAAHAAcA/f8DABcAGQAMAAsAGgAdABIAEgAlADQAMQArADQAQQBEAD8AOgA0ADQAOwBGAEwATQBLAE0AUABOAE0ATgBOAEkAQQA6ADkAOwA7ADsAOQA0AC8AKQAhABMAAADz//n/BQAHAPv/7f/s//L/7f/h/93/4P/Z/8v/yP/L/8b/wP/I/9P/zf++/77/wv+4/6r/rP+z/6//p/+p/6//s/+4/7z/u/+6/8P/zP/J/8P/yP/L/73/s/++/8z/wv+s/6v/vP/E/8P/y//T/87/xv/P/97/4f/i//D/BgANAAQA/v8AAAAA//8HABIAFgAUABsAJQAiABkAHgAqAC4AJwAnAC8AMwAvAC0AMwA5ADwAOQAyAC4ALAApACIAHwAnADAAOgBKAFgAWgBXAF8AaQBkAFYAUQBWAFkAWQBdAGEAWABMAEwAUABMAEAAOgA8ADoAMAAqACkAKAAjAB0AFwAPAAkACgALAAgAAQD8//f/7v/m/+H/4//f/9b/1f/W/9L/xv+7/7j/tf+y/7L/t/+8/7z/vv++/7r/tf+5/7//vv++/8b/1f/a/9j/2P/V/83/yv/V/+L/6P/r//L/+P/6//3/BgAKAAIA/P/9/////f8AAAkADwAVAB0AHgATAAQAAAAEAAQAAAD9////AAADAP//8v/q/+z/7//p/+j/8f/8/////v8GAAcA//8CABIAHAAVAAgABAAEAP//+f/7//7/+f/1//7/BwAEAPv///8LABEADwAPABcAIgAkACQAJQAnACkALAAuAC8AMgAzACoAHQAZABwAGQAQAAsADQAPABIAFgAcAB8AGQAOAAcABQAFAAQAAgAAAP3/+v/6//b/8//1//v/+P/q/9//3v/j/+L/3f/X/9X/1v/S/8v/w/+//73/u/+9/8L/w/++/7n/vP++/7//wv/I/83/yv/G/8b/y//S/9j/2P/V/9X/2v/f/+H/5v/u//T/+P///wYABgACAP//AQAFAAYAAwADAAcADQAMAAcAAwAEAAQABAAHAAwADQALAA0AEAAQAAsACAALABEAHgAuADwAQABBAEIAPgAzACwALAArACkAJwApACkAJwAnACwALAAlAB8AIwAuADYAPABBAEgATQBLAEUAQgBDAEAAPQA9ADwAOAAxAC0ALQAqACQAIgAlACQAFQAKAAkACAD+//r/AwAGAPv/7v/o/+P/3P/a/9v/1//O/8z/z//P/8v/zP/R/9P/0f/T/9X/0P/J/8T/xP/H/8r/yv/I/8T/xv/M/9D/zv/I/8L/wv/H/9H/1f/Q/8v/zP/S/9n/2v/b/+H/6P/r/+7/9v8GABEADgADAP3/+f/4/wAADgAYABsAGAAVABQAEgARABEAFAAcACUAKQAoACcAKwAwADAALQArACoAJAAcABMADwAPABEAFAAYABYAEQASABMACwD+//r/AAAGAAUAAwAKABEAEQANAAwADAAIAAEA/f/9//z/+P/0//H/8f/z//b/+f/3//H/6//s//D/7v/k/93/3v/g/9z/1f/R/9L/0//X/+D/5//n/+T/5P/m/+b/5v/u//r/BQANABEAEwANAAIA/P/9/wQACwASABoAIQAlACMAHAAWABYAGQAdACIAJwApACcAJAAlACgAJwAhABkAFwAWABQAEgASABgAHgAhACIAIQAhAB0AGQAaAB0AHQAaABkAFgAQAA0ADwAWABwAHQAYABcAHAAgABwAEwAKAAYAAwD+//3///////n/8v/r/+L/1v/Q/9P/2v/d/9z/3P/e/93/3//h/+H/2f/P/8z/zv/Q/9D/zv/L/83/0v/T/83/yP/J/8z/y//H/8f/zP/V/9v/3v/g/+D/2//W/9P/1f/Z/+D/6v/v/+z/5//m/+r/7f/t/+v/5P/g/+H/5//r/+7/9P/8//7//v/+/wEABQAKAA0AEAATABsAJQAtADEAIAAKAAAACwAdABsAGgAoADUAMAAmACoAMwAxAB8AEQAQAA8ACwAUACQAKgAfABYAFwAdAB8AHQAgACIAHwAaAB8AMABFAE4ASAA7ADAALAAzAEEARwBCADUAJwAfABUACAAAAAYAEwAaABQADwAQAAoA+f/s//H/BAAbAC0AJQD//9X/x//W/+P/5v/r//D/6v/j/+r/9//x/+H/2f/V/8j/uv/C/9v/6//i/9T/z//C/6H/j/+v/+T/+f/t//L/EwAiAAkA8P/3/w0AGgAiADMARQBJAD8AKAD7/8L/of+t/9X/BwA0AEIAHgDa/5T/Y/9V/3X/t/8GAEMAVQA+ABUA9f/m/9z/z//W/xUAgwDUALQAQwD5//f/8P+4/6v/FACSAJYASgBNAJ4AnwAoAOH/KABxADgAAQByAAgBygABAPL/qgCKAAT/Ov4JAMACMANAAcn/2/+r/8L+V//wAUAD5ABE/Sz8Yv6oAQgEkATUAif/mPuY+kz85v4sAdgCFANIAfr+Fv40/gD+GP4AAPQCUATkAsf/ZPwQ+vj5MPxa/1gCaARQBCIB6Pvw9nDz4PGg8nD2JPyUAZgFgAiwCvAK0AfqAcj8oPsu/kQCYAbwCQAMYAugCPgEMgHA/aj7iPuc/BL+SQA0AzAF4ATAAi//cPqg9mD2APmA+9z8sP5YAagCHAE6/oD8fPzw/OT8NP2v/wAEuAbIBdgD/AMYBLUABPzA++P/hAJQAYUATAK8Akf/8PvQ/CX/LP7g+vj5XPyI/rj+sv5u/2T/2P3I/Br+rQDgASQBPgA8AFsARADPABAC1AJ0AhACsAKgA1gDAAI8AXYBPgESAKj/ZgG8AwgEXAL4AJsAsP/Q/Rz99v6GAQACnAD6/+gAXAEGALD+fv92AeoBvQBAACIBVgHi//T+XwBwAnQCxgC6//D/GwDG//P/BgHUAWQBXACz/27/Mv8Q/1D/zP8GANb/s//U/6z/2P4g/kr+kv4Q/oT9Lv5i/33/0P7a/lf/3P7s/Qr+2v7k/mD+2v6SAAgCNAKgAQQBRgA4/37+vv6a/ykAGwAPAFIASACV/8j+Vv7s/UD9zPwg/ST+Pf/f/9D/Dv8I/nT9zP3q/i0A5ADdAF8AyP+K/+L/fADJAOEAIAEyAZYAxv+j//f/6/+//00ALAEcASEAUP8W/yL/gv+LALYBFAJ6AaQA/P9P/9z+Tf9gAPAApgBeAIMARwBi/9b+MP+i/7v/EQC2AOkAvgAMAZABRAFMAOz/egDjAKsAiwD1AFgBHgFRAI//Pv8V/9z+Av/t/w4BYAHmAGkA+P8Y/17+xP6t/6P//v5m/8QATAGTACsAxwAaAVwA4P/DAO4B5gEQAfQAogHIAQwBkwDiACQBxgB8AAQBygGcASYAmP5C/vD+Vf/+/ur+pf8wAJn/zv4j/xMAEgAF/z7+Wv7a/mn/SgB2ASACxAHhADUA2f+w//L/0ADQATACxgEQAXYA5/9E/+L+JP/H/yEAIgAjAOH/zv5Y/dz8xP3u/o7/IgDTALwAr//0/k//5//z/wsAzQCCAWQB6wDOANYAggDq/4//vP9BALAA7AA0AYABSAFIACf/sP7S/hj/Yf/2/8UANAG5AKb/4v68/oL+zP18/YD+HQDRAFkAo/81/+7+7v5n/wMAVwB5AMIASAHUAQgCpAHpAF0A/v9Z/3z+OP7w/uD/MAD9/7n/Tv9+/pD9YP2k/gQB5ALAAgoB1f8RALgACgHWAUADeANuAcT+pP0S/vr+///9AN8APv+8/bT9Qv4u/j7+Xf+NAIIAsf9A/wT/Sv6c/TT+HgAQAvACeAIgAX7/8P3c/Aj90v4IASwCNAIAApABPAB0/nT9oP1e/iD/zP+gANYByAL2ASH/WPzI+zT96P42AGwBMALsAQwBUwDj/4f/cv8JADIBSAKYAvIBygDD//z+RP4I/uj+MgBwAI7/Fv/n/wwBVgEQAQ4BFgGcAC8AiABCAb4BCAI0At4BxgBk/4L+dv4T//3/tgC/ABIABf8O/sD9gP7n/w4BagEqAaoAPAAlAHgA6wAEAYkAwv9A/3D/NQDdAM0AKQBd/37+7P14/iUAmAF8AV4Ayv/7/7H/xv7I/h0A2wCa/+T9/P2N/3QAHADs/1QAEgDI/iD+VP9GATAC+AHCAbgB/gCH/2r+TP66/jn/6P/lALIBvAHwAL//7v78/qL/DwArAMcAHAIoAxgDSAJgAVEAI/+U/hL/tv+R/zX/Yf9a/1j+eP1o/n0AhgEaAdoASgH1AFf/Mv78/o0AFAGxAIgAXQBH/w7+iP6eANQB2QBo/1r/w/9K/yX/6wAcAzADjAEwACz/QP04+2D7sP0qAJYBGAJwATX/ePxY++D8DgAgA9AEkAQ0Asr+ePzg/FD/jgEcAjQBrf8q/kT9hP2q/hcAPgGcAfIArP+g/hz+MP5Z/6wBxAO0A3oBqv5w/CD7iPtE/tABgAO8ArYB8AEAAmMAWP7Q/WT+rP4d/xAB2ANwBfgEHAM7AAT9MPvw+x7+MQAEAugD8ASgAxIATPxI+jD6EPvM/O//SAOwBOQDxALAAWD/GPzo+sT8MP/PAFAD6AbwBzgEkv4A+wD6aPqc/K8AAAT8A6oBov/S/pr+tP4C//j+ev5Y/gL/7f+XAPcA3gAHAA3/4P6O/2AADAHKAYACuAJcAsoBUgGtAFT/tP04/Wz+zP/A/wP/OP/q/y7/MP1c/Pz9ewDgARACHAJkAkgCvgGOAbgB/QDw/lT9AP4mAJwBlAGSALL+DPzw+Zj5SPu2/iwDiAZYBvgCSv9o/Wz9Cf+QAWgDYAMAAhkAaP14+rD5IPxN/44ANgDX/2v/UP6Q/ez+LAJoBQgHmAYwBKUAlP0E/ar/kANIBTwDhf/o/JD7WPpQ+kD9cAHQAt8AUP86AHgBNgEaAbQCcARQBOACOAEz/+T8HPz4/cwAOALQAa8AdP80/lD9SP0Y/ln/twCSAaABoAFQAuwCEALs/xr+bP0o/az80PxE/kgATgG3AIf/9P4C/yX/t/+CAewD8ASYAwgBzv4E/dj7kPyd//ACCAQIA3ABef+A/MD5gPno+w7/fAEsA5AEkAWIBawDXQCU/Yj8WPxk/AL+oAFYBJADzgAU/wz+OPwo+2T9hgEABPADaANkA5QCqQAf/27+XP2g+/j6rPzK/3QC2APkA0ACA/8A/Ij7/P20AZgEoAWYBEAC9v/E/kT+QP2w+7j66PqQ+2j8Qv5AAcwDOATQAg4Bd/8I/rz9qP8EA9gFUAd4ByAFTP+o+PD1qPhs/TYB2ANoBWAEfwCk/Oj7DP6eAHACdAP8ApMAzP0A/Ub+rv8nADgA4v9e/hz8IPuw/PT/8AJQBCgECANGAW3/Zv7u/oEA5AGsAhwDvAK0AOz9oPx4/eL+cf9k/yv/dv6I/fT9kACEA2AE0AJYAAD+PPwA/Cz+8gHwBIAFoANxAAj9qPp4+pj8r//2AWwC8ABY/lj8QPyQ/dL+v/8qAaQCtAI6AaL/yv4+/tj9EP7K/qP/cgAcAS4BjACm/7j+zP1c/eD9Fv9TAJYBJAO4BHAFUATSAd7/p/8XANT/zv98AYwDiAP+AVwBrAH+AIT/Tv+BADoBKAG+ARgDpAPUAuoBxgHuAdQBggFKAWAB4gFkAjQCcAGeAK7/YP5g/dz9nf9WAUwCbAKIAY7/fP2A/KD8LP0M/gb/U/+Q/nD9qPzo++D6SPp4+vD6APsw+yT8UP3Y/fj9Kv4K/gD9mPsg+wT82P3w/6IBFAKMAIj9oPog+fj4qPlY+1b+UgFoAoIBaQDn//T+cP0I/bz+KAGgAlQD+AMwBDQD3gHGASwDmARQBQAG6AYwB2AGuAVQBrAHoAiQCHgHyAUYBBgDDAP0A2AFGAZoBSgEkAN0AxADJAOYBDgGCAZgBDQDwAK6AU8ACADfAAwBAgAD/8T+Pv64/Dj74PpQ+4j7UPvw+hj6YPhQ9kD1cPVw9nD3MPho+LD3kPYw9uD2UPdw9kD14PQQ9TD1cPa4+dT8JP1g+8j5APmY+Fj5OPyL/1ABgAEoAeAA2QBeARACWALUAvwDsAQABDwDGATgBZgGiAYoBxAIwAeQBqAG0AhwC9AMcA0QDpANUAsgCVAJAAtAC6AJcAigCIAIcAf4BlgHCAewBcAEqASIBJAEuAVgB6gHQAZABFQCAACU/ST8NPwQ/cT9Gv4C/gj92PpQ+PD24Paw9rD1QPXQ9aD1IPQw88DzUPMw8GDs4Olg6CDnAOlA74D2ePoo++D62PmQ9yD2GPiM/AkAvwB3ALQAiQC6/vD87P1ZAHUAZv7w/e3/XAHmAWgEcAhgCpAJoAjgBwAGeAS4BXAIUArAC3ANMA3ACmAJQAuQDUAOUA+gEYASIBCADWANkA2QCyAJoAjACDgHuAQIBPAEGAVQBGgE+AQoBDgCugFAA3gEmASgBHgE0AK9/0z9bPz4+zD7mPqw+tD6IPrw+KD3oPVw8uDuIO3A7YDvgPBQ8KDuYOuA52Dk4OIA5MDoQO/A9Cj4+Prw/Gz8wPrY+kT8tPzk/PD+cAHqAfoBpAM4BO0AAP2U/LT9GP0E/WUAuARgBqgGQAjACXAI6AWIBRgHYAgQCcAKYA0QD/AOQA4gDiAOoA3QDPAMkA7gEEASABKAECAOIAvoBzAGKAZgBigGuAZQCOAIOAdgBbAElANMAQ4ACAEAArAB7gE0A9QCRQCY/gf/zP7M/Jj7wPuY+uD3sPbw9gD1MPFA7yDvwO2A6+DrgOzA6CDjgOGA4+Dk4ObA7cD2APug+tD6wPwM/Yj7yPuy/ucAIgBQ/p7+ogAwAbL//P6nAGgB9v6k/Bz+TgEAAwgE+AYACgAKoAfQBVAFIAWgBaAHgAqADBAN4AzQDFANYA6QD8AQgBFgEUAQ0A6gDfAMAA0QDTAMYApACJgGkAVABUAGAAhgCRAJKAeYBKgCMAIIA3gEqAW4BQgEYgHa/rj8MPsQ+3z8iP34/PD7KPso+XD1QPLQ8CDvAOzA6gDsAO3A6yDqYOkA58DiQOAA4mDmIOzg8yz8WAHmAXcAdv/E/nj9YPwE/eT+OAAHAC4AzAEQA7IBGv/0/cj9fPwQ+yD9JALoBdgGsAeACZAJaAbMAxgFMAiACbAJcAvADYANoAtwCzANQA4ADmAOABCAEDAP0A1QDcAMkAtgCqAJkAgwBxAGMAXoBPAFwAdgCCgHuAXgBKwDbALkAtAEeAXkAxACfwAc/iD8lPwu/hL+6Pw8/Vz9yPpQ93D1gPNA74DrYOtg7WDuQO5g7SDrIOfg4sDfgN7A4eDoAPEQ+Gr+SAMIBLgBVQB2AEX/2Px0/HD+uP+9//cAuAPwBPACq/9s/aj74PnQ+SD9bAIABnAHwAjACYAIOAXYAugCEASABdAHQAtwDiAQYBCwD6AOsA3QDBAMoAzQDqAQgBBQD+AOwA3gCQgFgAJQAkwCYAK4BFAI0AmwCAAHuAXQAwwCjAKYBNAFuAWABUgEdgGJ/xcAcwBi/lD8PPzQ+8D5QPko+xj7wPWg7iDqYOjA6GDrgO+w8QDwIOtg5aDgQN8A4iDnoO1Q9dz8sAFcA6gEMAZgBQgCKP9o/oz9APwg/Ev/OAPoBTAHWAZ0Asz8OPgw9mD3XPzkAggHyAcgCLAIaAegBDgEkAZQB6gFsAVQCWANsA9gESAToBIgDxALEAkACUAKUAywDkAQ4A9gDSAJUASqAD7/df/zALQDYAfgCaAJ2AcQBigE/gEmAcACWAX4BigHWAZ4BAQCwf/g/Wj8BPxo/Lj72Pqw+0z8iPmg9HDxAO8g6sDmwOlA7xDwgO0A7SDsYOZA4EDhwOdg7YDyOPowArAF4AWwBjgHmAT+/2D9IP0s/UT9xv6SAUgEQAVQBIgBiP2I+aD2oPZw+owAoAXoB2AI+AcIBnQDaAJkA1AEWASQBQAJYAxQDsAPoBDQD6ANsAvQCnAKgArQCwANEA2QDFAMYAuACEAEKADo/fT9bP/WAdgFgAoQDFAJwAWABMgD5gGcAfgEkAgwCOAF2ASgBEwCiP4g/Ij7SPu4+hj79Pxa/sT8EPjw8gDvAOvg52DoYOwg7+DuIO6g7aDq4OVg5CDngOqg7WDzgPssARgE2AfgC/ALCAd4AWT9CPrA+KD78QC4BFgGEAfABbMAePug+SD6UPp4+/T/yASwBsgGqAcwCEgGdANoAgQD5ANYBUAIgAwgEIARwBAQD2AN0AsACjAJAAqQC6AMsAwgDLAKUAg4BdYBzP6g/Wr+PQB0AkgFAAjQCJAH8AW4BKwD1AJUAzAFcAfgCIAIqAYQBD4BDP5w++j6yPs0/Ez8GP04/dj6YPdA9fDyoO7g6gDrQO2g7UDtIO4A7gDqAOZA5sDoQOpg7IDxYPYo+Ij6IAHACJAM0AyAC4gHRACQ+YD3WPob/7AD8AboB9gFgAEM/VD68Pko+1z8FP3i/nQD0AhQC6AKYAmoB7wDTf9A/8wDIAiACkAN4BAAEuAPgA3gC6AJ2AYABuAH0ApQDaAOsA0wCtAFNAKW/xj+WP5JAIACOAT4BbgHUAggByAFjAN8AjQCoANwBhAJ4AmQCCgG3AIo/+j7IPog+gj7DPzg/FD9yPwA+3j4sPXA8gDwAO4g7UDt4O0g7uDtIO3g6yDpgOag5oDpQOxg7jDyMPcI+iT8JAJAChANAApIB1gFaQCg+eD4Nf/gBKAGoAdwCGAFhv+A/DD9MP3g++D8AACkAsgEEAiQCqAJYAbIAyQCSAGAAkgGkAqADdAOwA7wDRANgAvgCKgG0AaACIAJcAowDOAMkApQBlwD+gHgAKcADAIABFgF8AVABuAFuARQAwQCDgFgAXgDKAbYB2AIoAjAB4AEYADo/QT9EPxg+3T8cP7O/oT9GPy4+lD4APUw8gDxwPAg8GDvgO/A78Du4OzA60DrwOng6KDqwO2g7oDvsPN4+Ij5EPu4AuALYA7wCoAIgAVc/vD3UPosAsgFmARIBYgHMAW2/3T9wP4s/oD70PuA/7ACEAWQCEAL0AmQBXACEgE8APgAkARQCcAMkA4gD7AO8AxgCmAIgAd4BxAIIAlwCoALwAvgCqAIAAW8AQgAwv9lAAgCSASwBZgFOAVIBfAEyAOUAigCnALcA/gFQAhwCeAIuAbEA/4A3v5c/Zz81PyI/dj9jP0Y/Uz8wPqQ+DD2APRQ8jDxkPAg8MDvQO+A7mDtYOwg60Dq4OqA7KDtYO7A8GD0gPYQ+Gj9gAXwCbAJMArQCqAFXPwQ+Rj+bALsAYwCKAaYBtYBSv4v/7H/2Pyw+iT85v7nAAwDGAYgCGgHgATGAYQA6ACIAhgFcAiQC1ANkA0wDdAMAAxwCgAJsAgQCRAJIAkQCvAKwAnQBuwDNAFW/vj8jP4IARwCxAJABAAF8ANYA0AEcAQMA7gC6ASABwAJEArQCqAJSAbEAnYAP/+Y/lT+MP4O/vT9cP1A/Nj60Pmg+KD2kPSg80DzMPLA8BDwAPDg7kDtoOwA7QDtgOxg7YDvIPHA8ZDyQPTA9jD7OAEgBzAMQA/gDcgG9P4Q/KD8xPxy/qADsAfoBbIB3AAAAnEABP0g+wj7wPvY/cQBOAaQCUAKkAeIA4QBDAJoAgwDgAYAC3AMgAswDNANoAwQCWAHAAgQCFAHMAhwCiAL8Aj4BfwDRAIZAI7+6v7iAHwC5AJcA1gEoASQA3QCYAK8AtwCqAOQBagHEAmgCUAJkAcIBfgCegHf/3b+Ev5K/qD9UPxw+/j6wPkw+JD3sPcw90D2APbg9YD0IPJg8EDvIO7g7YDuIO9A7+DvIPEw8XDwEPFA86D0QPZg+1gDkAmwC1AMoAsoB97/2PpA+/b+lAIYBYgGkAYQBZgCTQC4/lj9uPug+tj7BgAwBfAIUAqgCfAG9AJ6/5z+swAQBAgHMAmwCpALwAtQCyAKgAiYBjAF0ASwBdAH8AmwCnAJGAdQBD4B1v4k/iL/ewDCAVAD8AS4BVgFoATYA5gCQgH0AGQC+ARQB4AIoAgQCNgG0AR0AucANwCz//j+nP6K/uj9xPyQ+5j6YPlg+PD3oPcQ99D2MPew9pD0UPLw8KDvAO4A7qDv4PAQ8WDxAPIA8qDx8PFw8jDzAPb4+tz/EAQQCXANIAwgBgYB9v4M/Tj8z/84BYAG/ANMA8gECASbAHb+Tv4Q/Tj7mPyiAXgGQAigBygGGASSAT0APgG0A+gF+AaoBwAJwArgC5AL8AnoBxgGGAVoBSAHIAngCRAJMAfQBIgCzAD8//z/bQAkATQCqAMYBcAFOAUgBBwDKAJwASQCWARIBtAGwAb4BpgG+ARkA7wC5AFTADX/Lv9S/8j+Fv6M/TT8SPrY+HD4gPjI+Hj5sPmQ+ND2cPUQ9CDyoPCA8FDwYO8g73Dw8PEQ8iDyAPMA89DxkPJg9jD6rPyzANgGcAowCgAJIAdEAmj8ePt4/0gC2AL4BLgHYAaaATP/QgDl/wj94PtM/lgBpAIoBCAH0AhoBpYBvP54/0YBzAJ4BSAJEAvQCXAIAAnACZAI2AZgBlgG4AU4BjAIsAnwCMAGeARIAkgApP9SAPcAHAF0ATwCKAMIBOgEAAXQA4wCWAKoAvwCSAQwBvAG0AXgBEgFKAWMAxwC+gEAAusAqP9w/2L/jP40/eD7mPpw+eD4MPlY+UD5GPnY+Bj4cPag9HDzEPJg7wDtQO0A8IDxsPGA8xD2APVg8ADvUPMA94D3GPr5AMgGYAgQCaAKoAjwAoj+uP3A/o0AnAMIBrAFOAQgAxYBWv4g/bz9jP14/Lj9agFoBKAF6AUgBcQCGwCn/wgBGAPIBaAIQAogCpAJgAnwCKgHoAZgBoAGkAYYBzAIwAggCJgGyARUA1ACpgE0AdoAEAEUAhwDkAO8AxgEWASkA8AC9AIgBCgFcAXABVgGmAb4BRAFeAQoBHgDmAIsAiwC3gGiAAH/tP3M/Kj7MPoI+bj4APlI+Xj58Pnw+jj7uPlQ99D1EPVw82DxEPGw8YDwoO4g8ND0EPcQ9TDzoPMw84DxUPPo+Q4AhAIoBOgGYAjIBngENAOsAT3/AP5D/84BYARQBrgGoAQ4Abr+nP0M/WD9Pf+uAfgCZANABDgFuATgAnQB3QCuAFwB/ANgB1AJQAmQCNgHgAYgBfgE6AVoBlgG2AYwCKAIkAdoBpgFIAQUAgIBggFMAmwC0AKsAxAEwANAA8wCUALWAQQC3ALkAyAFGAZoBtAFuASYA7gC8gFyAY4BIAK8AqQC+gHlAIT/tP0Q/PD6OPq4+WD5iPkY+tD6OPsI+wD6yPjw9wD34PVg9ZD1cPQw8YDugO9g8pDzQPRA9uD2EPPg7oDwQPbo+Xj7G/9kA8AECATgBHgG8AQcAdT+Av9XAIwCOAX4BpAGmAQUAmT/wP0S/h7/of9WAAgCAAT4BOAEUATAAl8A6P5h/1IBGAToBtAIAAkwCGAHmAagBVgFAAZABvAFeAYQCAAJkAhgBzAGeAS4AhQCYALoApQD/AO8AxgDrAK4AmAC1gHmASwCGAKIAuQDCAUgBbgEkAT4A/ACiAIIAxgDcAIUAiACkgF8APf/tP+W/vT8HPzw+3j70PqQ+lD6oPnY+Kj4GPkA+pD6+PnQ+Hj40Pcg9eDxQPDA70DuwO3g8UD3YPjg9YD0sPTw8zDzQPbw+7T/SAGAA1AGKAfYBYgE9ANUAg0Aq/8AAhAFgAY4BoAFIAQ+AXj+NP6+/1cA6P8QAbwD0AS8A1gD6AOgArn/8v6kAdAEYAagBwAJAAl4BygGAAY4BhgG2AXwBbAG6AfQCJAIoAdABvQDTAEaADoB6AJkAygDLAMAAywCVgFWAbQBZgHBAPkAeAIoBDgFwAXIBegEiAOsAnQCRAL2ASwCKAJoAa4A0gAQARkAqv7E/Qz92PsY+4D7+PtA+9j5GPkI+Sj5iPlI+tj6uPrY+bj4cPcQ9qD0APOA8aDwkPBA8QDzoPXg96D3IPXw8hDzIPWw91D65P2+AcQDxAMYBKgFsAXQAur/MwDWAWQChANgBhAIwAVQAkIBcAF0AKP/ugDkAbwB9gHAA/gEOAT0AjQCMgFXAF4B+AMQBhAHsAe4B8gGAAZABmgG0AVoBQgG4AYQB3AHEAiwB7AFcANwAowCwAIEA6wDMAS4A6QCYALEAqwCuAFKAfoBxAIEA7wDYAUwBlAF7AOIA3wD2AJAAowC+AKAAr4BZgFYAdIA2/8L/3z+0P3w/Dz8BPwg/Nj74PrQ+UD5APko+ZD58PlI+nj6IPo4+UD4sPdg9qDzcPEA8fDwwPDw8nD3iPnA9mDzcPNA9NDzUPWY+jH/LACpAIwD8AVABcQD/AKCAUb/bv+QAngFuAaIB3gHyARUAYEAfgEUAdD/kwDUAqQDUAMwBFgFGAQoAaz/VQCUAfgC+ATQBkgH2AbQBvgGmAYQBtgFmAUoBXgFAAeACKAIoAdIBpAEbAIgAa4B4AL8AnACiALoAnQCqAGqAdQBPgF1AMcACAIIA+gD4AQwBWAERAPcAuAC2ALkAhwD8AI4AqABWgHeABAAM/96/qj9LP1k/cD9yP1c/aj8iPtg+pj5SPko+Vj5APqQ+iD74PsA/Mj6kPlY+UD4IPWQ8iDzMPQA86DyAPbo+BD3oPNg89D0cPSw9Jj4JP1a/ir+BQD8AkAEdANgAn4BzAD7ADAC9APgBfgG+AWQA/ABHAKMAiAC4gFcAmgC3AEYAkQDtANsAtkAXwClAEABpAKQBLgFeAXIBLAE6AQQBWAFsAWABRAFOAVQBjAHCAfgBagEjAOYAkwC0AK0AxAEnAP0AsQCyAK0AngCNAIIAt4B5gFgAjAD3AMgBKQDBAOcAqQCzALcAhQDSAP4AiwCngHIAQwCigGEALf/XP9M/1b/aP9y/xf/Bv5M/BD7cPtg/AT8wPpQ+pD6sPng+Oj68P2Y/ZD6QPnw+Yj4EPXQ8yD1EPXA81D04Pbg9yD2cPQA9JDzgPNQ9YD4SPsI/Yr+GQAIAWwBkAFiAcsAvQD+AfwDiAVwBugGWAagBNQCTAKIAqQC0AI8A3gDXAOYAwgEtANIAtcA+f+6/10A+gHQA4gEOATkAwAEQARoBHgEsATIBMgEQAVIBkAHeAfoBuAFmARgA9ACKAPMAygEKATkA0ADXAKSASwB9QCTAFIAvQC2AaQCEAMYA7AC5AEuAS4BsAFIAgQDyAMIBIADyAJgAswB1gAdAO7/0v+f/87/YABiAHb/dv7A/RT9RPwM/HT8ePzg+4D7aPuI+oD5yPkw+/D7QPw0/VT98Pow+Aj4qPhQ97D1sPYA+PD2sPXQ9tD3APYA9ID0oPXg9VD3MPt4/hn/9P73/44Asf9M/7kAPAJwAtwCsAR4BpAGuAU4BZgEVANEAnACXAMABCgEKAQIBKwDEAMoAiwBVgDP/8H/XgCmAfQCsAPgA7wDgANoA3QDnAMIBMgEkAUABlAGqAagBsgFoAQIBMgDiAOIA9AD6ANoA9QCaALKAeoARAAOAA8AKQCmAFYB0AH8AQgC8AGmAXYBegG6ASwC4AKgAygEaARIBJQDaAJWAa8AlQACAYABeAEiAQgB2gDp/5r+GP7Q/Zj8iPv4+8z8QPwI++j6IPso+jj5IPqw++D7OPsA+/D6KPpI+Sj56Pg4+LD30PcQ+Cj4aPh4+ND38Paw9gD34Pdo+Tj7iPwo/bj9dP4P/4//UQD5ABABCgG+AQQD8ANYBJAEgATUAwADzAI0A4QDjAOAA4ADXANAA1wDUAPIAu4BRAEQASoBlAFMAtwC/ALMArAC2AIEAxwDOANUA1QDZAPYA6gEKAX4BGAE5AOEAzwDNANsA4QDMAPEAogCdAJIAiAC9AGqATwB3gDSABwBegGWAYYBcgFKARYBEgFgAX4BSgFaAdABDALSAbIByAFaAWwA7P8RAAIAsP+7/xAA9/9j/xn/Kv/y/mD+uP0M/YT8XPxg/ET8HPw4/AT8KPuQ+uD6CPtY+vD5ePqo+rD5CPmg+eD5CPlw+PD4OPmI+FD4GPmY+Tj5QPkY+tD6MPsA/CT9yP3w/Yj+fv8JAEQA3wCUAegBJALUArwDAATUA+AD/AOsAzwDKANAAygD4ALwAjADLAPsAqgCeAI0AuQBwAHsASACIAI4AsgCcANsAyQDUAOoA1AD5AJ0A0gEGAScAyAEAAWwBOQD7APsA+gCAAKgAsAD8APAA/QDkANUAsgBJAL0AQoB9ADCAcwBLAGgAawCNAKrABUAbQA6AL//WwBcAQoB2v+R/+v/p//i/pD+qv5o/uD90P1Q/rL+pv5e/hT+2P2Q/VT9XP10/VT99Pyk/Kz8BP04/fD8ZPww/Fj8XPxc/Lz8MP3E/Mj7gPvY+7D7KPtI+9D7oPsA+0D7+Pv4+4j7yPtg/Gj8aPxA/Tz+gv6O/v7+c/+X//3/6QCGAVwBPgGgAe4BGAJ4AggDHAOsAnQCpAKgAjwC/gHuAboBQAEmAZgBAALAAQ4BjQBlAGMAbADCAFIBugG2Aa4B9AFAAjgC7gHqAVwCyALwAkAD0AMYBIwDyAKwAhQDNAMoA3wD5APEAygDnAI4AsYBPAGuAG0ArwAuAZgBGAK8AuACIAJKATIBRAHzANwAcgHWAYYBWgGmAYgBtwAyADEAvP/m/sL+WP96/wP/5v4H/37+oP1Q/TT9ZPxY+wj7GPuo+kj6mPrw+pD6KPqY+kj7ePuo+2D86PzM/Lj8PP3A/bD9bP1M/RD9rPyw/Bj9WP1I/UT9ZP2E/bz9Uv4J/2H/iP/Z/zUAUwCDABABnAGeAdwB7ALYA8gDfAPAA3gDDAIWAeoBhALEAXYBjALsAlgB9v/r/yv/SP0A/dT+8f+d/+X/FAEKAcr/o/+WALkAjgDAAXwDMASgBPAF0AYQBjgFuAVgBjAGcAawB1AIoAf4BigH+AbIBdAEiAQYBEwD8AIwA0gD3AIkAj4BKABG/9r+nP5K/hr+JP4o/hL+9P3A/VD9sPwU/Jj7cPvA+0T8qPyo/Ez8qPv4+oD6OPro+aj5qPnI+fD5EPow+gj6kPkg+dj4uPjY+FD5APp4+qj64Pog+1D7mPv4+0z8gPzk/KD9ZP76/n//5P////z/MACZAP0AQAGQAeABCAIcAkQCfAKMAmgCOAIwAlACiAK8AvwCMAMwAwgD+AIQAzADTAOEA9QDAAQwBHAEqASQBFgESARIBDgEQASIBNAEyASIBFgEKAS4A0gDHAP0AowCFALQAa4BcAESAbkAXQD0/4z/NP8B/+r+1v64/pL+ev5c/jL+HP4o/iT+BP7w/QL+IP4m/jL+Uv5i/lT+Pv5M/mT+bv5g/lD+VP5E/kj+Yv5y/lj+NP4g/hT+BP4C/hj+HP4a/jT+Wv5q/nz+nv7M/uz+EP9d/6r/2f8JAEgAcACHAKQA3wAUATgBbAGcAboBwAHAAb4BuAGsAaQBiAFsAWQBTgEkAQABBAH3ALkAkgCmALgAnACYAMYA0ACPAGsAjQChAI4AjACvAMAAtAC8AMoArwCPAJYApQCfAJoAqAC3AKYAgwBsAFYAMwAcABYAAgDf/8H/v//I/63/gf96/5L/lf+J/47/mv+Q/3j/d/+B/4P/g/+L/4X/bf9S/zb/D//2/vb+7v7K/rD+rv6e/nT+aP58/m7+Qv5G/nT+gv5k/mj+jP6G/mT+ev6u/qz+lP60/uz+8v7y/hT/PP9B/0D/VP9e/1H/XP+Q/7P/yf/l//7/9P/p//v/DQANABMAPQBnAHwAjACqAL0AtQCmAKMAuQDXAPMADAEoAT4BUAFSAVoBXgFSAUgBTgFWAVwBagF2AX4BcgF4AXgBdgF0AYABjgGCAXgBfAGGAXgBZgFsAXIBbgFUAUQBRgFGAUABQAFEATABDAH0AOcAygCoAJkAlgB9AFYAOwAhAPP/vP+a/3r/SP8d/w3/A//i/rT+lP5w/kT+HP4C/vD90P28/cD9wP2w/Zj9kP2E/XT9dP2Q/bT9yP3Y/fj9FP4g/jD+VP5+/pT+sv7o/iX/Uv+D/8D/8P8DABgASgB+AJgAsADjAA4BJAE6AWQBhgGWAagB0gHkAewBBAIkAiQCDAIQAiQCGAIAAhgCJAIIAuwB9AH8AcwBpgGuAbQBmgGMAZgBhAFOAS4BKgEeAfkA3wDTALYAjQBsAFAAMAAKAOz/y/+b/3X/Xf8+/wv/3v6+/pL+aP5K/jT+HP78/dz9wP20/bT9uP24/bT9tP2s/Zz9nP24/dz98P38/RT+Mv5M/mr+jv6o/sT+6v4X/zr/YP+b/9//CwAjAEMAcwCoANcACgE8AWABggGmAcwB6AH+ARACIAIwAjwCRAJQAlgCYAJcAlACRAI0AiACEALwAcQBoAGQAYgBdAFcAUABGAHmALkAlwBzAEgAGwABAOr/x/+i/37/Xf81/xH/9P7k/tb+xv62/qb+lP58/mj+Vv5M/kT+QP5C/jz+NP4u/iL+Bv7k/cz9wP20/az9tP28/bj9sP20/bD9qP2g/az9uP3A/dD98P0Y/kL+bv6S/qb+wP74/jP/Xv+R/+f/OABqAJYA2wAaAUIBeAHKARACOAJkArQC9AIQAzADZAOQA5wDrAPQA+wD5APUA9QD0AO0A5wDjANwAzwDFAMAA+QCtAKMAmgCNAL6AcwBnAFkATQBEAHkAK0AeQBLABAAz/+Z/2L/Iv/m/rr+kv5e/jD+/P24/Xj9SP0Y/fD82PzY/Mj8oPyE/ID8YPww/Cz8RPw4/CD8TPyk/ND8wPzA/LT8ZPwM/Az8PPxM/FT8ePyc/Jj8oPzI/NT8zPz8/Fz9pP3c/Tr+vP4g/2D/wv9KANEATgHiAYACAANoA+QDaATYBDgFkAX4BVAGkAbIBgAHOAdYB3AHeAdoB0gHKAf4BsAGgAYwBugFqAVoBSAFwARIBOQDhAMkA8ACbAIgAsgBaAEOAbYARQDJ/2D/Bv+g/jL+1P2E/Rz9sPxY/AT8qPtQ+wj7yPqI+lD6GPrg+bj5oPmQ+Xj5aPlQ+UD5OPk4+VD5YPlw+aD54PkQ+kD6cPqo+uD6GPtQ+6D7+Ptc/Lz8EP1k/cT9KP6C/uD+RP+n/wQAYADCACIBegHOASQCfALUAiADcAPAAwgESAR4BLAE4AQABSgFUAV4BaAFwAXIBcgF0AXQBcAFqAWIBWAFKAX4BNgEsAR4BEAEEATMA3wDMAP0ArQCYAIYAtYBkgFGAQQBygCBACkA1v+V/1L/DP/O/pr+YP4m/vT9wP2I/Uj9FP3k/Lz8qPyg/Jz8kPyA/HD8ZPxc/Fz8bPyI/Jj8rPzE/OT8CP0w/VD9bP2I/aT9zP38/Sb+Tv54/qD+yP70/if/W/+O/8L/+P8hAEUAcACaALgA0wD/ACwBUAFuAZ4BugHKAdgB9AEMAgwCGAI8AlgCZAJwAoACeAJoAmQCbAJsAlwCSAJAAjACFAL4AdoBvAGaAXYBUAEgAfUA0QCoAHcASwAkAPj/yf+e/3v/Xv8//yD/CP/0/uD+xP6s/pj+hP5s/lj+Uv5a/mT+ZP5g/lz+WP5a/lz+Xv5g/mr+dv6A/or+mP62/tL+5v7w/vz+Dv8n/0n/Yf9z/4P/lv+p/7v/1v/w/wMAEwAlADgARwBXAGYAcAByAHcAgwCPAJoApgCxALQAtAC7AMAAvACxAKkAnwCXAJoAowCpAKcAogCgAJkAigB9AHMAawBnAGYAYgBeAF0AXABRAEIAOgAwACEAFAAPAAcA9v/i/9f/y/+//6n/k/+A/23/Zv9g/13/Vv9R/1D/Sv89/zj/P/9B/zz/P/9J/0v/Qv9F/1v/cP90/3f/hv+f/7H/v//N/93/4f/c/9v/6v8AAA0AHgAyAEMARQBDAEoAWQBjAHQAkQCmAK4AuQDOAN4A5ADnAO8A+AD9AAgBFAEaARwBIAEeARYBDgEGAQIB+wD1APIA7QDnAOUA4QDVAMIAswCqAJsAhQBzAG0AZgBTADwAKgAXAAAA7v/d/8n/sv+Y/4X/dv9p/1z/Sv8y/x//EP/+/u7+5P7c/tT+zP7G/sT+vP6u/qb+nv6e/qj+rv6u/rL+vv7K/sr+yv7Q/tr+6P74/gz/Hv8u/zz/S/9i/3//lf+g/6v/wP/X/+r/AAAiAEYAXQBuAIIAmQCwAMIAzwDdAOoA+AAKASQBQAFQAVgBXAFiAWQBZgFuAXYBdgF2AXgBeAFyAXABbgFmAVoBUgFOAUIBLgEiARoBBgHmAMwAtQCYAHIATgAwABUA+P/d/8L/o/9//1z/Pf8e//7+6P7c/sr+sP6a/oz+fv5q/lb+Sv5C/j7+QP5G/lD+VP5O/kb+SP5U/mD+av58/pj+qv6w/rr+zP7a/ub+9P4N/yj/Rf9i/3r/jP+k/73/1P/r/woALgBRAHQAmgC6ANEA4QD1AAwBIgE0AUoBXgF2AZQBrAG8AcYB1AHcAdoB2gHgAegB6gHmAeYB5AHgAdoB2AHSAcIBqgGSAYQBcAFYATwBIAEIAe8A1QC6AKEAhQBiADkAFgD6/97/vv+h/4z/c/9S/zf/I/8L//D+1v6+/qL+iv56/mj+Vv5O/kr+SP5C/jz+NP4q/ib+LP46/kb+Vv5k/nD+ev6G/pj+rv7A/tj+8P4M/yj/RP9h/3z/lP+n/7f/zv/q/wYAHQA2AFUAcgCJAKIAvQDUAOIA8QAKASABMAFAAVABYAFkAWIBZgFsAXABbAFoAWQBXgFcAV4BVAFCATIBIAEOAQIB/QD2AOcA2QDQAMQArgCXAIMAbQBWAD8ALAAbAAkA9//i/8f/qv+V/4L/b/9b/0r/N/8j/xL/Cv8F/wH//P72/ur+3P7Q/sr+yv7O/tL+2P7i/uj+8P72/vz+CP8T/xn/Hv8n/zf/TP9d/2r/ef+H/5P/nv+s/7//1P/l//T/AAALABcAJAAxADsARABMAFUAYQBvAIAAigCNAI0AkQCcAKcAsAC3AL0AxADJAM4AzwDOAMsAzADNAMwAywDOAMkAuwCwAKsApwCdAJMAjQCEAHYAagBnAGMAVABCADMAJwAaAAsAAQD8//n/9//1/+r/2f/G/7P/n/+K/3j/cP9s/2f/ZP9f/1P/Sf9C/zr/Lf8f/xr/Gv8Z/xn/Hv8k/yT/If8h/yP/Jv8v/zz/Sv9X/2T/c/+B/47/nf+r/7r/x//a//D/AQAOABsAJQAsADgASQBZAGIAaAByAH8AigCWAKMAqQCsALEAtwDBAMsA1ADcANwA1QDRANAAzQDLAM0A0ADPAMYAvgC8ALcArgCpAKoApgCaAJEAiwCCAHIAZQBdAFUARwA4ADEALQAnABsACwD4/+j/2v/O/8T/uf+s/6L/mv+T/47/i/+F/3z/cf9m/2D/Xv9d/13/Xf9d/2H/ZP9o/2n/Zv9l/2z/dP98/4D/g/+K/5T/mv+d/6T/rv+1/7f/vf/E/8n/zv/Y/+T/6//t//X/AAAHAAwAFwAhACYAKQAvADYAPQBEAEoATgBSAFgAYABkAGQAZgBlAFwAVQBWAFcAUQBFAD4APwBAAD4APQA7ADMAJQAcABYAEAALAAsADAALAAIA+f/y/+v/4//d/9r/1v/T/9P/1v/V/9D/0P/S/9P/0P/O/8//0f/Q/9H/1P/Y/9z/3v/e/+D/4f/h/9//3P/e/+H/4v/o/+3/8P/x//X/+v/5//L/7v/s/+v/7P/t//H/8P/t//D/9P/4//n//P8DAAYABwAJAA0AEgAUABUAFgAWABgAHQAiACYAKAAoACcAJAAhAB8AIAAhAB8AHwAgAB8AGwAXABQAEQAPAA8AEgAXABkAGgAZABMACwAIAAUAAAD9////BgAKAAoACAACAPj/8P/u/+//7//v//H/8//1//j//f/+//r/9f/x/+7/6//t//T/+v///wUABwAEAAAAAAACAAMAAwADAAYACQAOABAADQAKAAwADQALAA4AFQAcAB8AHAAbABUACgAHAAsADQALAAYABQAGAAQAAAD+//7/+v/1//f//P/+//z//v8BAAIAAAD9////AwADAAEA///7//j/9//1//P/8//z//D/7P/r/+v/6v/m/+H/4f/i/+X/6//w//X/9//1//P/9f/3//r//P/8//v//P8AAAQABwALABAAEQAMAAkACwAQABMAEgARABEAEwAUABMAEgASABUAFgAXABsAHQAaABcAFgAVABMAEgATABQAEgAPAA0ADgARABMAEQAOAA0ADQANAA0ADgAQABAAEAARABEAEAANAAsACQAIAAcABQAEAAQABAACAP7//P/8//z/+//6//v/+v/5//j/9//z/+3/5v/i/+D/4v/l/+f/5//j/93/1P/K/8H/u/+2/7L/sP+x/7T/tv+3/7j/tv+x/6z/q/+w/7X/uv++/8H/xf/I/8n/zf/T/9n/3v/j/+r/8f/2//z/BAAMABAAEwAaACIAIwAiACYALAAsAC4ANQA7ADwAPABAAEQARwBKAE0ATQBLAEwATwBUAFcAWABYAFgAVwBVAFIATQBIAEIAPQA8ADsAOgA5ADcANgA0AC8AKwAkAB4AGQAVABMADgAHAAEA+//3//T/7f/k/9z/1P/P/83/yv/J/8j/v/+0/6//q/+r/67/sf+y/7H/rv+s/6z/rf+v/7D/sv+1/7r/v//C/8X/yP/L/83/z//S/9j/3f/i/+X/6f/v//X//P8BAAUABwAJAA0AEAAUABoAIgAqADEANgA8AEEARgBKAE0AUABSAFQAVgBaAF0AXwBfAF4AXQBcAFoAVwBTAFAATABHAEMAPgA5ADIALAAmACEAGwAVABEADgALAAgABQD///f/7//n/+D/2v/X/9b/1f/R/8z/xv+//7f/sv+w/6//sP+x/7P/tP+z/7H/rf+q/6f/p/+o/6v/rv+x/7L/s/+z/7T/tP+1/7b/t/+5/77/w//J/8//0//X/9n/3f/h/+f/7P/x//X/+f/8////BQANABYAHwAoADAANwA9AEIASQBNAE0ASwBJAEsAUABXAFwAXwBeAFsAWABVAFIATgBLAEkARwBGAEUARABCAD8APAA3ADEAKgAmACIAHwAdABsAGQAVABAACQABAPj/8P/s/+n/6P/m/+L/3v/Z/9T/0P/O/8z/yf/I/8r/y//M/83/z//P/8//zf/N/87/0P/T/9T/1P/W/9r/3v/f/+H/5P/n/+n/6//s/+v/6v/t//H/8v/3////AwAFAAkACwAMAAoACAANAAwACwATABoAGgAYABUAFAAVABcAGgAhACUAIwAhACUAKgAqACkAKgAsAC0ALQAsAC0ALgAsACgAJQAiAB8AGwAYABUAEwARAA8ADgANAAwACgAGAAMAAQAAAAEAAwAEAAUABAAAAPz/+v/4//X/8f/t/+r/6P/o/+f/5f/j/+L/3//Z/9X/1P/V/9T/0f/O/83/zv/P/8//0P/R/9H/0f/S/9P/1f/Y/9v/3v/g/+H/4v/k/+X/5//p/+3/8//5//7/AQADAAUACAAKAA4AEwAZAB4AIwAoAC0ALwAwADAAMQAyADMANQA4ADsAPQA+ADwAOwA5ADcANQA0ADQANAA1ADQAMgAuACgAIQAbABgAFgAVABQAEgANAAgAAAD4/+//5v/e/9j/1f/T/9T/1f/V/9L/zv/H/8L/v/+//7//v//A/8D/wP+//7//v//A/8H/wf/B/8P/xP/F/8b/yf/N/8//0P/U/9f/1//W/9r/3v/f/+H/5v/r/+z/7v/z//n//v8EAAoADgAQABQAGQAfACYAKgAvADQAOQA+AEEAQwBCAEEAQQBCAEQARwBKAEwATgBPAE0ASwBHAEUAQgBBAEEAPwA9ADwAOQA4ADcAMgAsACYAIAAdABwAGwAYABMACwACAPz/9//z//P/8P/t/+r/5v/j/+H/3f/a/9b/0//S/9H/0f/Q/8//zf/M/8v/yv/J/8n/yf/I/8f/x//J/8z/z//R/9L/0//U/9X/1//Y/9r/3f/g/+T/5//r/+//8v/2//n//P///wEABAAIAAwAEAAUABcAGwAeAB8AHwAfAB4AHgAeAB8AIAAgAB8AHgAdABsAGQAYABkAGgAcAB8AIQAhAB8AHAAZABcAFgAXABkAGgAbABoAFwATAA4ACQAFAAMAAQABAAEAAAD///z/+P/z/+//6//o/+f/5v/m/+X/5f/k/+P/4v/f/9z/2v/Y/9j/2v/c/97/3//f/97/3v/e/9//4f/j/+T/5f/n/+j/6v/t/+//8v/1//j/+////wMABgAIAAcABQADAAQABwAMABAAEwAUABUAFgAWABUAEwARAA4ADQANAA4ADwAQABEAEQAPAAwACQAHAAYABwAKAA4AEgAVABYAFgAVABIAEQAQABIAFAAWABcAFwAWABMAEQAPAA0ACgAKAAsADQAOAA4ADgAOAA0ADAALAAwADQAOAA0ADAALAAwADAALAAoACQAJAAgABwAFAAEA/P/6//j/9f/1//f/9//2//X/9P/z/+7/6//s/+n/5v/r/+7/7P/q/+j/5v/m/+b/5f/n/+n/5v/l/+n/7P/s/+v/6//s/+z/7P/t/+//8v/0//T/9v/3//j/9//3//j/+P/6//v//f///wEAAAD///3//P/9//7/AQAEAAcACgALAA0ADwARABMAFAAUABUAFwAaABwAHQAfACAAHwAbABgAGAAXABYAEwAQAA8ADwAQABAADwAOAAwACgAJAAkACQAKAAwADQANAAwACQAHAAUAAwABAAAAAQADAAMAAgAAAP7/+//4//f/9v/2//b/9//4//n/+P/1//H/7v/r/+n/6P/p/+v/7P/s/+r/6P/l/+L/3//e/97/4P/i/+X/5v/m/+P/3//c/9v/3P/e/+H/5P/n/+n/6v/p/+f/5P/h/+D/4f/l/+n/7v/y//X/9f/0//T/9f/4//v///8CAAYACgAOABEAFAAYABsAHgAgACMAJgAoACoAKwAuAC4ALAAtAC4ALAApACkAKgAnACUAJQAjACAAHQAdAB0AHgAfAB8AHQAaABcAFAASABAADgALAAsACwAKAAkABwACAPz/+P/0//L/8v/y//H/8v/y/+//7P/p/+X/4v/h/+D/3//f/+D/4P/h/+H/3v/c/9r/2f/a/97/4f/k/+b/5P/i/+L/4f/i/+b/6P/q/+z/7//x//T/9f/2//j/+f/7//7/AgAFAAgACwAOABAAEwAWABkAGwAcAB4AHwAhACQAJgAnACcAJwAmACUAJQAjACIAIAAeAB0AHAAcABwAHAAcABsAGwAaABgAFgAVABMAEgARABAADwANAAoABgABAP3/+f/1//P/8v/w/+7/6//n/+P/4P/d/9v/2v/b/93/3//f/93/2v/X/9T/0v/S/9T/1//Z/9z/3f/d/9z/2//a/9r/3P/f/+T/6P/s/+//8P/x//H/8f/x//P/9v/5//3/AQAEAAcACQAJAAkACQAKAAwAEAATABYAGAAZABgAGAAYABgAGQAbABwAHAAcAB0AHAAcABoAGQAZABkAGgAcAB4AIQAhAB8AGwAXABQAEwAVABYAFwAXABcAFwAWABUAEQAMAAYAAgD///7//v////7//f/5//T/7//r/+j/5//p/+v/7v/w//H/8f/v/+z/6f/o/+n/6//t/+//8P/w/+//7//u/+z/6//s/+//8v/0//f/+f/5//r/+v/7//3/AAADAAUABQAGAAgACQAJAAkACgAMAA4AEAASABEADwAOAA0ADAANABAAEQASABIAEwATAA8ADAAMAAgABAAHAAoACAAHAAUAAgAAAP///P/8//z/+f/3//r//f/+//z//P/7//n/9v/2//f/+f/6//r/+v/6//n/9//2//X/9f/1//X/9//5//v/+v/3//T/8f/v/+7/8P/x//P/9P/1//X/9//5//r/+f/4//j/+f/8////AwAGAAkACQAHAAUABQAGAAYAAwABAAIABAAHAAkACQAIAAYABAACAAMABQAHAAsADQAPAA4ADgAMAAoABwAFAAUABgAKAAwADAALAAgABQACAAAAAAAAAAIABAAHAAkACQAHAAIA/v/6//f/9//5//3/AQACAAAA/P/2//H/7P/p/+n/7P/x//f/+//7//f/8P/p/+T/4v/k/+n/7v/z//b/9f/y/+3/5//h/93/3f/h/+j/7//z//X/8f/r/+b/5P/n/+z/8v/4//z//v/+//3/+//6//v//f8BAAcADgAUABcAGQAZABYAFAAWABoAHQAgACUAKQAnACQAIgAeABkAFQAWABoAHwAlACkAKAAjAB0AFwAUABQAFAAWABkAHQAfACAAHAAUAAoAAQD7//r//P8AAAUACAAIAAMA+//x/+n/5f/m/+v/8f/3//v//P/6//b/7f/j/9z/1//Y/9//6f/y//f/8f/l/9r/0P/M/9H/2P/f/+T/6P/q/+7/8P/t/+n/4//h/+P/6v/z//r//v/8//f/8//z//j//v8DAAUABwAJAA4AEwAXABgAFgAUABMAFgAbACAAIwAjAB8AGgAXABgAGwAeAB8AHwAfAB8AIgAmACgAJgAiAB4AHAAcAB0AHQAbABcAEgAPABAAEgASAA8ACQABAPn/9P/x//D/8f/y//T/9//4//X/7//l/9v/0//S/9j/4v/s//H/8P/p/9//1f/P/8z/zf/P/9X/3v/m/+r/6P/f/9T/y//J/8//3P/q//T/+P/4//X/8f/u/+z/6//u//T//v8IABAAEQAKAP3/8f/r/+///P8NAB0AJgAlAB4AFAALAAcACAAOABYAHwAqADQAOwA6AC8AHAAKAAAABAAVACoAOwBBADwAMQAkABsAFgATABMAEwAXAB4AJwAsACkAGwAIAPb/6//s//X///8FAAYAAwD///z/+v/1/+z/5P/h/+b/8v/9////+P/r/97/2v/e/+f/7//y/+//6v/n/+j/6v/p/+P/3P/b/+T/9P8DAAkAAQDx/+L/2//e/+v//f8NABkAHgAeABUABgD2/+j/4v/q//3/EwAkACsAJgAXAAMA8P/l/9//4//7/x0AOQBIAEAAIgD9/+L/2//p/wIAFgAgACUAJgAhABgACgD1/9//0P/U/+//FQA1AD8AMAARAO//2v/Z/+f/+f8HAA4AEwAYABsAFgAFAOn/zf+8/8D/2//+/xgAHAAKAO7/1//P/9X/4//w//j//P8AAAYACwAKAP7/6P/S/8r/1v/x/w0AHAAUAP3/5P/U/9T/4v/y//z/AAADAAoAFAAaABYABQDt/93/3f/u/wYAGQAdABQACQAEAAYACwAMAAYA/f/8/wgAHgAzADsAMgAhABAABwAIAA0AEAANAAgABgAMABgAIwAkABYABAD2//T/AAASAB4AHgAVAAwACwAQABAABQDx/9//2f/j//f/CAAJAPj/3v/I/8H/zv/i//T//P/7//P/6v/m/+f/5P/X/8r/yP/W//H/DAAXAAkA5v+7/5z/m/+1/9z/AgAeACkAIgANAPj/6//j/+L/6//7/xAAJwA8AEYAPQAeAPT/0//F/9D/8P8ZADkARgA+ACkAFAAIAAUABwAOABcAJAA1AEYAUABKADUAFwD+//X//f8SACsAOwA7AC0AHAAPAAkACQAMABAAEwAWABsAIgAlACEAFQAEAPf/8v/z//j///8BAAEAAAD8//f/7//k/93/3f/i/+n/6//m/+H/4//q/+//7//n/9v/1v/b/+T/6v/j/9D/wf/C/9f/9P8FAAAA5//J/7n/wf/g////CwABAPP/8f8DABsAIwAQAOb/vv+0/9X/DwA8AEIAIADu/83/zP/p/wwAGQANAPz//P8WADwAVABJAB4A7f/T/+D/CwA4AEsAOwAYAPz/9v///wkAAgDu/9//5f8FADIATwBGABsA5//J/9H/+f8lADoALQAPAPv//f8HAAYA8//V/8P/1f8IAEMAYQBHAAAAuf+X/6f/2/8XADsAOwAkAA0AAgD7/+n/yf+s/6j/xv8CAD4AXgBQAB8A4f+y/6H/rv/Q//r/HwA2AD0AMwAbAP3/4P/N/8j/1f/w/xIALgA3ACwAEwD0/9n/zv/a//n/HQA0ADQAHwAAAOr/6P/7/xEAHQAdAB0AIQAlACAADADq/8j/t//G//L/JgBDADwAGwD2/9z/1P/c/+3/+v/9/wIAFAAvAEEAOQAaAO7/y/++/8r/6v8OACQAKgAoACMAFgD9/9//zP/O/+X/DAAvAD4AMQASAPb/6//u//D/6//m/+r//P8bADkAQQAkAO7/wv+6/9X/AAAgACcAGAD///X/AQASAA8A8P/J/7X/xP/z/yoASQA6AAYA1f/J/+H//f8EAPL/2P/T//T/KwBQAEUACAC9/5b/qP/g/xcALQAdAPz/5v/w/w4AJAAbAPf/0v/K/+n/HQBBADoADADa/8f/4f8TADcALQD2/7b/nf+9//7/MwBAACgAAwDt//P/CQAXAAsA7f/Y/+P/CgA2AE8ASgAlAO//w/+3/8n/6v8DABcAKQAzACoADwDw/9n/0v/e//r/FgAhABkADwAUABwAEwDy/9H/xf/Y/wYAOQBTAEIACwDX/8j/3v///xUAGwAYABAADgATABYABADc/7j/vP/p/x0AOQA2AB4AAQDs/+j/6v/f/8X/tv/R/w8ARwBaAD8ABADD/5L/iv+r/9r//f8PAB0ALgA/AD0AHgDk/6L/fv+S/9r/MwBqAGQANgAEAOT/2f/T/8r/vf+4/87/BgBKAHIAYAAfANT/q/+5//H/NABfAFwANQANAAMAFgAnABkA7//P/9b/BQBBAGAARgD8/7X/pv/a/ycAVQBPACgAAwD8/xMAMAAwAAUAxv+r/9T/KQB0AIAAQwDf/4z/ff+8/xsAXQBdACsA+//u//z/CAADAOz/z//E/9//EQA3ADYAFQDr/8r/tP+r/7j/1v/4/xUAJQAkABIA8f/T/8z/2//v//n/8//m/+j/AwAnADsALAD+/83/s/+4/9b/+P8HAAYAAgAJABYAFgAJAPr/7f/m/+r///8cAC8AKwAfAB0AIgAdAAkA8//h/9X/2f/1/x0AMQAkAAcA8v/o/+j/+P8UACYAHgAIAAEAGAA2AD0AIwDy/8L/sP/P/xEARwBCAAgA0P/C/9n/9//9/+3/1//Q/+z/KwBkAGYAJwDK/4b/ff+x/wYASwBVACAA2v+5/8v/9f8PAAUA4v/D/87/BAA8AE4ALwD5/9L/z//w/x0ALwARANz/vv/M//L/EwAhACAAEwAFAP7//v/6/+X/z//W//n/JQBHAFoAWgA6AAMA1P/F/9L/7f8NADAASQBHADIAGAACAO3/3P/b/+j/9/8EABYAMgBHAEAAHQDx/9f/1//y/x8ASQBXADkAAADM/7D/tv/U//z/IAAqABcA/v/z//H/5P/H/6z/rv/e/y0AdACMAGAACwDB/5//o/+5/9D/6/8OADsAXwBZACEA0f+b/57/zf8HACgAIgAFAO//9/8XADMALwADAMP/kf+W/9f/LwBlAFMABQCz/5f/yv8lAF8ATgAFAMb/vv/m/xMAJAATAO//0P/Q//j/KgBFAD0AGADm/63/jf+u/wcAXgB8AFwAIADl/7v/r//G/+f/8//y/wcANABWAE8AIwDn/6n/g/+V/+z/WwCaAJYAZgAsAPT/wf+j/6T/wv/v/yYAXwB/AGgAHwDN/5f/gP+E/6j/7f87AG0AcgBSACEA7P/A/7D/xv/0/x0ALgAlAA8AAAAIAB0AJwAMANL/o/+o/+b/OABqAF4AFQC0/3n/kf/y/1cAdgA9AN7/nP+f/9//JQAyAPj/rv+j/+3/UQCAAFkAAQC6/6z/2f8WAC8AFwDt/93/+P8pAE8ASQASAMT/iv+G/8D/GABgAGQAHQDJ/7b/8P81ADoA9v+e/3P/lf/3/18AgQBAANf/nv+5/+3/AgD4//T/BgAXACIANQBHADoACADY/83/2//k//P/HgBHAD8ACQDl/+j/6P/E/6f/x/8WAFcAawBlAEYAAACy/57/1f8dAD4ASwBlAHAASQAJAOX/3v/J/6v/uP/8/0UAawBvAFsAIADI/5D/oP/V//7/HABCAF8ARwD8/8T/yf/x/wgA/v/j/7//rf/S/ywAdgBoAA4AvP+t/9T/BQAqADYAGgDg/73/0P/+/xsAIAAdAAoA1/+e/5b/yf8FABsADgDw/83/wv/v/0QAbgAxAMP/g/+P/8r/EwBVAG0AQQD8/+b///8IAOT/xP/M/+z/DQA2AGIAYgAhANn/x//Z/97/2//9/zwAZABeAFIARQAJAKX/bP+e/wsAVgBkAFcANwD6/8L/w//q/+f/q/+U/+z/cwC0AJAAOQDb/4n/bf+y/y8AcgBLAAEA5f/0//z/8P/j/8z/o/+Y/+L/VgCCADUAtv9w/4H/yP8gAG4AgwBEAN3/mf+a/7n/0v/m//3/CwADAAYALQBSADMAzP9y/3j/0v83AHIAegBOAPn/t/++/wgAPAAWALz/if+s/woAcQCrAIQA/P9y/13/1f9rAJcARQDN/5f/w/8uAI0AlAAyAKX/Vf+E/xEAnADDAHMA7P+V/6f/AwBWAF8AGQC8/5f/2f9SAI0ARACz/2T/nP8cAIIAmQBkAP7/oP+X//P/WwBoABMAuv+h/7z/7v8kAEIAFQCo/13/gv/2/0gAQQARAPv/BQAWACkAOQApAOj/pf+j/9n/BgALAA8AMwBNADkADwDy/9L/mP9z/6f/KACSAKAAYwAUANj/vf/O/+r/3f+k/37/q/8UAG4AgwBZABMA1f+y/6z/v//l/xYAQQBKADUAHgAUABMABgDp/8X/sP/A//j/OQBMACUA9P/s/wkAGgACAM7/q/+7//v/RABjAEQAAgDG/6//wP/n/wkADgACAAUAHwA5AEIAMwARANr/of+d/97/PwB/AIIAVgARAMv/o/+o/8T/2v/s/xIAQgBPACIA3P+o/5//vP/z/y4AOwAPANz/5/8iAD0AFQDX/8j/9v81AFwAVwAjANL/lP+a/9//NgBpAF0AHQDR/6H/q//q/zMASwAXAMP/mf/A/wwAOAA4AC4AKQATAN3/qv+f/73/+f89AG0AaAAuAPH/2//n//f/+f/3//L/8v8EAC4AWgBbACMAzf+L/4P/vv8UAEIAJQDq/9j/AwAuAA4Asf9t/4j/8f9lAJ8AdgD9/37/U/+Z/xEAZABoADMA5/+r/6f/8/9YAHgAJwCn/3P/tv80AIEAcgApAN3/r/+x/97/CwANAOz/5v8YAEMAIwDj/9j///8KAOv/6v8oAFsASgAmACwAMQAHAN//9v8hAAUAwP/E/yQAdgBsADsAGgDs/6P/gv+7/xIAMAAmADcAVAAtAMr/mP/I/xQAJwACAN7/1//v/y0AdQCGADUAtf9r/4n/5f86AF4ATQAXAMn/hf99/8//UACcAHMA/v+h/4//wv8TAFYAUwD3/5T/kf/k/yAACQDZ/8z/0P/K/9//HwBCABAAz//b/yIAQwAnAAoAAADx/+3/GQBIABEAg/9G/7X/YACfAF0A/f/C/67/1f9BAJcAagDf/47/yf82AGkAZQA6ANH/R/8h/7b/lgDsAHgAwf9j/4j//f9zAIkAGgCH/3L/DgDIAOUATgCL/yn/S/+9/zAAagBeAC8ACQD8////CAAEAOX/sf+L/5r/8f9uAMoAuAAeAEv/zv4E/7n/bwC8AJUAOQDm/8n/5f8LAAIAzf+q/8//JwBuAHkASQDt/4f/Rv9Y/7L/HABoAIkAeQA0ANT/mP+p/+v/IQAxACgAIQAsAEIASAAcAMT/fP9+/8r/IgBUAFUAOAAYAAIA/f8AAAAA//////n/8P/8/yYATgBGAA0Ayf+g/5r/vP8HAE8AXQAvAAUABwAZABUACwAVABEA6//R/wEAVgBwAEQAFQABAND/ev9Z/6D/EgBaAHMAcAA3AMP/Zv93/8f/7P/j/wUAWABzACEAwv+8/+z/+f/u/wUAKQAgAAMAIABWADIAtf91/8//WABxACsA8//e/7r/oP/a/0EATwDz/7z/AABSAC0Azv+4/+j/+f/U/8z//f8kABwAFQAiAAwAu/+H/8v/WQCqAH8AFwDH/6L/k/+m//v/cQCoAGMA3f+F/4H/sf/0/zYARAD2/5X/qv9JAM8AoADx/2f/SP9u/8P/QgCeAIEAEwDj/w8AIADW/5H/rv/3/xwARQCaAMkAcQDV/4n/kf+B/2n/xP99ANUAcgDn/8P/yf+k/4z/3v9LAEMA7f/g/ygAOQDn/7P/5f8fAA4A+f8tAF4AIACj/4D/1v81AF8AdQB8ADcAqf9X/5n/GQBEAAkAyf+8/8n/6v81AIUAfgAGAIn/dP+9/w8AMwAtAA4A5//Y//7/PwBXABsAsv9m/2X/sf8kAI0AxwC4AFgAwv9L/0z/vv82AFgAQQA4ADcAEADZ/8z/1f+u/2//i/8YAJcAqAB4AEkA/f9+/xz/Ov/D/0cAhgCOAGoAGADD/5//tf/a/+H/yP+///z/fADcALwANwC5/3T/W/95/+v/dgCeAEcA4//N/9P/xv/e/zAAVAACAKf/0f9MAGsAGwDf/+7//f/q//r/PwBVABkA8/8iAEYA/f+S/5H/9P9DAFgAaQB6AFAA5/+Z/5v/sP+o/7X/BQBsAI8AXgAUANb/oP+G/7T/GABYADwA+v/g//D/8//o//n/GgAJAMf/tf/z/zIAIQDv//L/EwAOAAAAMAB6AHAACAC4/7v/wv+a/4//6P9XAF8ACwDM/8T/sf+D/5D///91AIIANwDw/9v/3v/n/wwAQgBBAOv/mf+z/yMAawBAAOj/vf/H/+X/HwBwAH4AEQCa/7//agDAAFgAsP9a/1//lf8DAIoAqAAmAJz/rf8KAAUAp/+Y/wUAYwBqAGoAhABPAKn/Lf9q/w8AZQBFABcAEwAWAAgABQADANH/gv9///P/ewCNABoAov+g//P/LAAZAOf/wf+n/5r/x/8vAHcAUgDp/63/yv8jAIgAwAB2AJr/yv7S/sb/3ABMAeoADwA8/97+Nf/t/2cASwDe/5n/qv8KAJAA8gDRAB8AVv8Q/4H/RwDQALUAFwCO/6v/UQDSAJsAvv/a/pT+Ov+CAJQBpgGyAID/3v4F/6j/WQCwAH0A8P+E/5T/DQCNAKIAFwA1/6T+7P7v/wABjAFYAX0Acv/u/lr/NgCdAF8AAwDy/woAJQBVAGwAAQAu/7r+Kf8JAK4A2wCsACAAZP8N/4P/TwCSACMAnv+F/9P/QwCVAIEA3f8Q/9r+jf+aACgB9wBmANT/df90/8z/NABBAPb/vv/a/yQAWwBxAGAAAQBd/+7+Kv/w/7IA+gDHAEsAvf9i/37//v9gADAAl/8u/2L/HADgACoBtAC0/97+1P6e/5sAHgHoADwAoP91/7j/CwAbAPL/y//G/+H/GwBZAFUA6/9u/1T/q/8qAI4AtwCSABEAdv82/4X/EQBiAEwAAQDJ/77/4/8wAHoAfQAUAIn/aP/V/2sArQCYAGcAGACW/yX/L/+w/zcAfQCbAJMAKgBr/+D+Bv+z/2IAxgDcAKgAJQCR/1P/kP/+/zgAIADq/9T/+/9AAHYAcgAeAJ3/R/9w/wUAlwC4AGYA/f++/6L/sP/u/zMAOwABAML/qv+u/87/GwBtAGcAAQCx/8n/EwAiAO7/uf+o/8H/CwBxAJQARQDT/6b/vv/Z/+j/CAAuACUA/f8KAGUAsAB+AN3/Pf8P/3H/HgCgAJsAGwCa/4///P9bAEEA0P9+/4//1v8QADYATgBBAA0A5v/0/woA+//r/wUAHQDt/6v/0v9TAJoAagAeAPz/3v+j/5L/z//+/97/z/8tAKwArAAdAID/OP9i//T/qgDsAG4Ar/9s/7z/IQBUAGYAVwAMAMH/zf8PACYACgAUAEYAOgDk/8n/JgBzACkAk/9e/7H/JQBmAG4AOwDL/2T/ff8PAH4ARgCt/2n/s/8hAE8ATQAzAN3/UP8X/6D/dgC/AGwAHgAQAOz/t//2/5IAqQDr/0//pP9lAKUAWQD//5v/Ef/m/p3/kQCxABYAvP/x/wsAu/+D/7z/BwAoAG4A4wD0AFAAef8Q/xv/WP/G/14AwQCcAD0AHAA1ACwA4v+V/3j/kf/x/5cAJgEsAZgA2f9a/x//Dv8y/6v/SACoAKQAYwARAKb/NP8f/53/SwCsAMAA0wDQAFcAjf8d/0n/mf+9//3/eQCuAE8A4f/e/9v/Y//8/mf/RACWAE4ALABgAFUA9f/b/x0ADwCG/0j/wP86AAMAnP/b/4gAzQB5ABUAyf9Z//L+K/8QANsA6AB7ABwA1v+H/13/lv/0/wcA3v/p/z8AegBeACEABgD7//D/DQBbAIQAQQDP/53/yv8XAE8AXwA0ANn/qP/l/0cASQDe/4H/g//G/x0AgQC7AGgAoP8d/13/9P84ABwABgACANb/uP8cAMUA4gA6AI//jP/r/yIAMwBdAG0ADwCa/6j/HgBIAOf/k/+2//j/7//Y/xAASwAMAJb/oP8sAHwAMgDQ/8P/z/+v/7j/JwB+AEAAy//P/zMAWQAcAPT/CQD5/7H/qf8WAIkAiAAqAL3/av9S/6L/RACsAHgA8P+b/6T/4v8lAE8AQAAJAOn//P8XAAYA2//L/9v//P8mAFEAVgATALX/k//d/1EAfgBBAN//tv/i/zoAgAB0AO//Lf/O/jr/HwC+AMYAbgD3/3n/Kf9g/wIAdABQAPL/2v8EACkAQwBfAEMAyP9g/5f/PwClAIAAKgDu/7X/iP/A/18AzQCPAOv/ef9k/3//zf9SAKQASQCA/x7/hf8xAHwAagBPACsA0/94/33/5P9OAHQAawBRABsA3f/V/xUATQAkALf/c/+Z//n/TgB4AGcAFACq/4P/xP8jADkA+f+q/4f/qP8FAHAAiwAuALD/hf/A/xQARwBNABsAvP98/6b/GwBwAHkAXgA9AP3/qP+M/8r/IgA7AB4AEwAnACkABADd/8//yP/B/+D/LgBXAA0AlP95/+L/XACFAFwADwC3/4H/x/9hAK8AVQDF/5r/w//b/+//PAB3AEAA2P/I//j/5P+b/7L/KABLAOn/sf8HAFQADwCj/5//v/+Q/2b/0v+IAL0AbQA9AEsAEwB9/zb/sv90ANYAxgCHACgAtf9w/5f/9P8QAOL/w//x/0sAfwBxADEA4f+P/1//iP8JAJEAtwBsAP3/uv+4/9b/6P/Y/7//x/8CAEoAaABWADMADgDp/9f/4P/y//7/GQBLAGUANADY/6r/wP/j/+f/5f/z//7/9P/v/wMABwDm/9H/AABLAF0AIADJ/5f/lP/A/xEATwBHAA0A6//4//r/y/+T/5r/6f9DAHUAcgA0AMn/d/+O/wwAiQCWAD0Az/+I/3r/t/9GAM4AwAAPAGL/Wf/c/1MAZAAuANj/fP9n/+P/qQD2AGwAhP8H/zz/2f96AN0AzABDAJ7/af/P/2EAhwArAML/rv/d/w8AMgBLADYA1v9z/3//9v9OADIA6//d//7/DAAOADEATAAOAJT/W/+V//P/LQBJAE0AGAC0/4X/xv8nADYA9//L/97/GgBhAJEAcwDu/1j/NP+W/yEAhgCqAH8A/v9x/0L/iP/o/xcAIQA8AHAAlACFADQAuP9N/z3/nv8sAIkAjgBhADEACwDk/7f/jP97/5z/8v9UAJAAjQBYAAwAuf+C/5X/8v9PAF0AMAAQAB8ANAAiAPT/yP+1/8z/JQCVALUAUQCy/2T/g//G/+v/AwAqADwAHAD5/wcAHADr/4n/Z/+r/wwASABoAH0AVgDb/27/ef/l/z4AQgAjABoAGQAEAOn/8f8OABMABAAOADIALQDg/43/j//p/0kAdQBnACYAu/9Y/13/2f9sAJ4AYwAPANb/vP/I//7/LgAVAMf/s/8HAG0AhABJAPr/tf+J/6j/EwB0AG0AGADX/83/4P8BACgAKgDY/2j/Uv+9/04AjwBcAOX/ev9s/9T/YwCbAE0Awf9x/5z/GACNALAAdAAGAKz/mP/K/xMAPwA1AAIA0//R/wcARgBIAP3/nP91/6L/AQBeAH4AOgCx/0//cv8EAJEAuAB0APr/jf9m/53/CgBgAHUAXQBAACEA9v/K/7n/zf/u/wAACQAbADAANQAXAO3/0v/F/7f/q/+5/+f/HwBGAFEANgDr/4//bv+x/yMAZQBMAAgA4v/z/yoATwA5AOv/nP+W/+3/YgCbAHMAEwDF/6z/v//p/xgANgAoAAQAAgAjACIA1f96/2n/q/8KAF4AhwBfAOn/hP+T//v/SABIACkAFAD+/+H/6f8hAFMARwAMANL/sv+u/8L/5v/7//b/+f8dAEgASgANALf/hf+V/9b/HwBJAEIAFADc/8L/2P8LACsAHQDr/8H/yP8KAF0AiQB2AC8A2/+t/8P/DQBMAEgACwDX/9b/9P8NAAgA3/+n/5j/2v9MAI4AYwDw/5D/g//L/zgAhgCCAC0Awv+W/8z/NgB/AGkACQCv/5L/u/8YAHwAogBfANr/gv+R/9X/BwAmAD8AOwASAOr/4v/X/6z/lP/N/zIAYwBEABEA9P/b/8L/wv/f//T/7//s/wgAMAA+ACgA+//F/6T/vf8HAEkAUAAiAPb/6v/1/wYADAAAAO7/6v/8/wsA+v/X/9X/+f8cAB4ADQACAPn/5P/a//z/MwBEACIA8//U/8b/z/8AAEMAWQApAOj/zP/S/+X/CwBEAGYARAD5/8z/5f8gAD8ALwACANT/v//V/wkAKwALALv/kv/A/xYAQAAfAOX/xf/K//D/LgBZAEIA8P+p/6L/1P8YAFcAeABbAPz/mf99/6///f83AEkANwASAPr/+//6/+L/xP+//9v/AwAmADYAIADm/6//r//k/xwALgAbAAAA7//w/wAAFAAbAAwA/f8FABgAHwAZABUAFQAJAO//3v/l////HQAyADUAGwDx/9f/2f/o//f/CAAeACUAEgD9//n/AwAIAAMA/P/2//P//v8TACYAJAATAPv/5P/W/9n/8/8RAB0AGwAQAAAA7f/h/+P/6P/r//H/BQAiACwAGADw/8v/vv/V//7/HgAmABwAFgAZAB4AFgDy/8P/rP/I/xEAWAByAE8AAwC9/6b/xv/8/x8AIQAQAPz/8P/2/wwAGwAVAP3/3//K/8b/3/8NAC4AKAAHAPH/+v8KAAYA8//r//j/CAASAB0AJAAiABYACAD8/93/tf+2//H/NwBQAC0A+P/S/8D/xP/i/wkAGQANAAYAEAAVAAcA9f/z//j/9f/y/wQAJgA1ACYABgDr/93/3v/v/woAIAAfAAcA7f/m//L/+//7//j/9f/z//f/CQAeACEABQDc/8f/0f/x/xUALgAtABAA7P/b/+P/+P8RACIAHgADAOb/5P///x0AIgAOAPL/4P/f/+//BAAPAAYA9v/y////DwAOAP3/5//Y/9r/9P8bADQAJAD1/87/zv/2/yUAOQAqAAYA6v/q/wYAJwAyAB4A/f/q//H/BAAQAAoA9f/h/9n/4P/y/wQACAD5/+T/3f/q/wEAEQASAAQA8P/l/+7/BAAWABIA+f/i/97/9f8XACkAIAAEAOj/2//g//f/FQAoACYAFgAEAPf/8P/x//r////z/+D/4f/+/x0AJAAUAP3/7P/h/+H/9/8WACgAJQAbABEAAADt/+3/AgAVABEABAABAAcABwAAAP//AQD7//j/CgAhACQADgDz/+f/8f8FABUAFgAHAPX/8P/9/xMAGgALAPT/5//r//z/CwAOAAQA8//u//f/BwANAAAA7f/k/+3/AQAOAA0AAgD1//T//f8GAAYA+//u/+3/8v/7/wMABgD9/+7/5v/w/wcAEwAGAO7/2//c//3/KwBFADQA/v/I/7v/2/8OAC8ALQAWAP3/8P/x//v/BwAKAAEA9//9/xEAIAAeAA0A9v/n/+n/+/8RABcABgDw/+r/8v/9/wMABwAHAAMA/f/+/wgAEQAQAAgAAQD9//3/AQAJAA4ABwD4/+7/7//2//r/+P/1//P/8//3/wAABQD9//D/6//0/wIACgAGAPz/9f/1//v/AgADAP3/9v/2//n//v8EAAsAEQAPAAQA9v/s/+n/8v8CABEAFAALAPz/8f/t/+3/8P/0//n///8FAAsADgALAAIA9v/w//j/BgARABIADQAJAAgACAAIAAsADAAJAAQAAgAHAAwADQAKAAcAAAD3//P/+/8GAAwACwAIAAQA/v/0/+7/9f8DAAsACAD///f/9f/7/wUACgAEAPj/7v/v//j/BAANAA8ADAAEAPz/+f/7/wAABAAFAAIA//8AAAMABAACAP7/+//6//3/AQADAP7/+P/3//7/CAANAAoA/v/x/+v/8v8BAAwADQAIAAEA/P/6//3/AwAGAAMA+//2//f///8FAAQA+//z//L/+P8BAAYABQAAAPv/+//+/wMABgAFAAIAAAADAAoACgADAP3/9//z//P/+v8FAAUA/f/8/wIABQABAPn/8v/v//X/AwAVABwADQD3/+7/8//6////BAAJAAgAAwD+//7/AAD9//n/+P/8////AQACAAIA///7//j/+P/9/wEAAgAAAP7//f/8//3/AAAEAAQA///4//b/+f/+/////v/8//z//f/+////AAABAAIAAQD9//n/+/8CAAcABgD///r/+f/8////AQABAP///P/7//z///8BAAMAAwADAAEA//8AAAIAAgABAAEABQAJAAsACAADAP///P/9/wAABAAGAAMA///8//v/+v/4//b/9v/3//n/+v/7//z//P/7//n/+P/4//r//f8AAAIAAgABAP///v/+//3/+//6//7/AwAIAAkABwACAP7/+//8//7/AQACAAIAAgABAAEAAQACAAEA/f/3//P/9f/9/wUACAAGAAMAAAD+////AwAIAAoACQAIAAYABAACAAEAAwAGAAYABAAFAAUAAQD9//7/AgADAAQACQALAAgAAgAAAAAAAgAFAAYAAwD+//v//f8BAAQAAgD///3//f8AAAIAAwAAAPv/+v/8/wEABAAEAAAA/v/9//3//P/7//n/+P/7/wAAAwABAP3/+v/6//3////+//z/+v/6//7/AgAFAAQA/v/2//P/9f/7/wMACAAHAAIA/P/4//r//v8BAAEAAAD//wEAAwAEAAIAAAD+//7///8BAAMABAABAP7//P/+/wEAAwAEAAIA/v/9//7/AAABAAEAAAABAAEAAQACAAIAAgABAAAAAAAAAAAA/////////v/+//3//f/9//z/+//6//r/+v/7//3///////7//v/+///////+//7//v8AAAIAAwABAP///P/6//v//f8AAAMABAADAAEA///9//v/+//8//7/AAAAAAAA/v/8//r/+f/5//r/+//9////AQABAAEAAAABAAIAAwADAAMAAwADAAQABQAFAAUABQADAAIAAQABAAMABAAEAAQAAgAAAP//AAABAAMAAwADAAIAAAD/////AQADAAIA/v/7//v//v8EAAcABgABAP3/+//9/wAAAQABAAAA//8AAAEAAgACAAIAAgABAAEAAAD/////AAABAAIAAwACAAEAAAD+//z/+//9/wAABAAFAAQAAAD9//z//v8BAAIAAAD//wAAAQABAAAAAAD///7//v/+/wAAAQACAP///P/7//z///////7//v/+//7///8AAP7//P/8//3//v8BAAQABAABAP7//v/9//v//P/+//z/+////wMAAgD+//r/+P/6//3/AQAFAAYAAAD7//z/AQACAAAA//8AAAAAAAD//wAAAAD///3//v///wAA///+//7//v/+//7///8AAAAAAAD///7//v/+////AAABAAIAAAD///7///8BAAEAAQD///7//v///wAAAAABAAEAAAD9//v//P8AAAEA///8//v//P/+/wAAAQAAAP7//P/8//z//f/+////AAABAAAA///////////+////AQAEAAUAAwACAAAA/////wAAAQABAAAA//8AAAEAAQD///3//P/7//v//P/9//7//v/+//3//P/7//v//P/8//3//v///wEAAQABAP7//P/6//z//v8AAAEAAQAAAP///v/+//7//v/9//z//v///wIAAwADAAIA///8//v//f///wEAAgAAAP///v/+/wAAAQADAAQAAwADAAIAAgAAAAAAAQADAAMAAwADAAMAAAD+////AQABAAEAAgADAAIAAQABAAIAAwAEAAUAAwACAAEAAgADAAQAAwABAAAAAQADAAQABAABAP///v///wEAAgACAAEAAQACAAEAAAD///7//f/+/wAAAAD///7//v8AAAEAAQD///z/+//8////AgAEAAMA///8//v//P///wIAAwACAP///v/+////AAAAAP//////////AAAAAP///v/+////AAABAAEAAAD///7//v///wEAAgACAAEAAAD//wAAAQABAAEAAAAAAAAAAQABAAEAAQABAAEAAQABAAEAAAD///////8AAAAAAAD//////v/9//z/+//7//v//P/9//3//f/9//3//f/8//z//f///wAAAQABAP///v/8//v//P/9//7///8AAP///v/9//3//P/8//3//f/+//7//v/+//3//f/8//z//P/8//z//P/9//3//f/+//7////+//7//v/+////AAABAAIAAQABAP///////wAAAgACAAEAAAD/////AAABAAIAAgABAAEAAAABAAIAAwAEAAIAAAD+//7/AAADAAUABAABAP////8BAAMAAgABAP///v/+////AAAAAAEAAQACAAEAAAD+//3//v///wEAAwADAAIAAQAAAP7//f/+/wAAAgADAAIAAQD/////AAABAAAA/////wAAAQABAAEAAQAAAAAAAAAAAAEAAgADAAEA/////wAAAQAAAP////8AAAEAAgACAAAA/v/9//7///8AAAIAAwACAAEAAQABAP////////7//v8AAAMAAgD///3//P/9////AAACAAIA///9//7/AQACAAAA//8AAAEAAAAAAAAAAQAAAAAAAAABAAAA///+//////////////8AAAAAAAAAAP///////wAAAAABAAEAAQAAAP//AAABAAIAAgAAAAAAAAAAAAAAAAABAAIAAQD///7///8BAAIA///9//z//f///wAAAQABAP///v/+//7//v//////AAAAAP///////////v/9//3///8AAAEAAQAAAP//////////AAD//////v8AAAEAAgABAAAA///+//3//f/+////AAAAAP/////+//7//f/8//z//f/+/wAAAQABAP///f/8//3//f/+//7//v/+//7///////7//P/7//r/+//8//7///8AAAAA/v/9//3//v///wAAAAD///7//v/+//7///8AAAEAAQABAAEAAAD///////8BAAEAAQABAAEAAAD/////AAAAAP//AAABAAAA/////wAAAAABAAIAAgABAAAAAQACAAIAAQAAAAAAAQADAAQABAACAAEAAAAAAAEAAQABAAAAAQACAAIAAQABAAAA/////wAA//////7///8AAAEAAQD///7//P/9////AQACAAEA///9//z//f///wAAAAD//////////wAAAAAAAP///////wAAAAAAAP//////////AAAAAAAAAAD///7//v///wAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAABAAEAAQABAAEAAQAAAAAAAAAAAAEAAQABAAEAAQAAAAAA///+//7//v/////////+//7//f/9//z//f/+////AAAAAP/////+//3//f/9//7//v/////////+//7//v/9//3//v/+//7//v/+//7//v/+//7//v/+//7//v/+//7//v/+/////////////v/+//7//////wAAAAAAAP//////////AAABAAAAAAD//wAAAAAAAAAAAAAAAAAAAAABAAIAAwADAAIAAQD/////AAABAAIAAgAAAAAAAQACAAQABAACAAEAAAD///////8AAAAAAQACAAEAAAD///7//v/+/wAAAAABAAEAAQAAAP//////////AAABAAEAAAD/////AAAAAAAA/////wAAAAAAAAAAAAAAAAAA/////wAAAQACAAEAAAAAAAAAAQAAAAAAAAAAAAEAAgACAAAA///+//7//v///wAAAQAAAAAAAQABAAAAAAAAAAAA//8BAAIAAgAAAP7//v//////AAAAAAAA///9//7/AAAAAP////8AAAAAAAD/////AAAAAAAAAAABAAAA////////AAAAAAAA/////wAAAAD//////v/+/////////wAAAAD///7///8AAAEAAQAAAP////8AAAAA//8AAAEAAQAAAP//AAABAAEAAAD+//3//v//////AAD////////+//7/////////AAAAAAAA///////////+//7//v////////////////////////////7//v///wAAAQABAAAAAAD//////v/+////AAAAAAAAAAAAAP/////+//7//v/+////AAAAAAAA///+//7//v/+/////////wAAAAAAAAAA///+//3//f/9//7//v/+//7//v/9//3//v///wAAAAD//////v/+//7//v///wAAAAAAAAAAAAAAAP////8BAAEAAQABAAIAAQAAAAAAAgABAAAAAQACAAEAAAAAAAAAAAABAAEAAQAAAAAAAAABAAEAAQAAAAAAAAABAAIAAgACAAEAAQABAAEAAQAAAAAAAAABAAEAAQABAAEAAAAAAAAAAAD///////8AAAEAAAD///7//v/+////AAABAAAA///+//7//v/+///////+//7//v/+//7//v/+//7//v////////////7//v/+/////////wAAAAD//////v///////////////////wAAAAAAAAAAAAD//////////////////wAAAAAAAAAAAAAAAP////8AAAAAAAABAAEAAQABAAEAAAAAAAAAAAABAAEAAQAAAAAA///+//7//v/+//////8AAAAA//////7//v/+//7////////////////////+//7//////////////////////////////////////////////wAAAAAAAAAA////////AAAAAAAAAAAAAAAA//8AAAAAAAABAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAEAAQACAAIAAgAAAAAAAAABAAEAAQAAAP//AAABAAIAAgACAAEAAQAAAAAAAAAAAAAAAQACAAEAAAD//////v/+/////////////////////v/+//////8AAAAAAAD///7///8AAP///v//////AAAAAP////////7//v/+//7/AAAAAAAA/v/+///////+//7/////////AAABAAAA///+/////f/9////AAD///7///8AAP7//f///////f/+/wEAAQD///7//v/+/////////wEA///8//z/AAAAAP3//f8AAAAA/v/+////AAD///7///8BAAAA/v///wAA/////wAAAAAAAAEAAQABAAAA/////wAAAAD//wAAAAD///7///8AAAEA/////wAA/////wAA///+////AgABAP7///8CAAMAAAD//wAAAAD/////AQABAP///v8AAAAA/v/9/wAAAAD/////AAAAAP////8AAP///v8AAAEA///+/wAAAAD///7///8BAP///P/+/wIAAQD9////AwABAP3//f8CAAIA/P/9/wQAAwD9//7/BAABAPv//v8EAAEA/P8AAAQA///7/wAAAQD9//z/AAABAPz///8EAAEA/f8AAAMA/f/8/wQABAD7//z/BQAEAPn/+P8FAAcA/P/5/wYABwD6//r/BQAGAPv/+v8IAAcA+v/6/wcABwD4//3/CgAGAPr///8JAAMA/P///wcABgD8//3/BgAIAPj/+/8IAAgA+//4/wkACQD7//f/BgAKAPr/9P8FAAwA/P/3/wMACQD+//n/AAAFAPz/+P8CAAIA/v8AAAAA/f/9/wAA///5////AgD///v///8FAPv//P8AAAAA9//6/wsABgD3//7/DgDx//H/CAAGAPr//P8FAPT/8/8FAAsA9//p/wcAGgD3/+D/BAAjAPf/2P8FACMAAwDb////JgAAANn//v8kAAIA3//9/yAAAgDm//7/GwD+/+j/BwAWAP3/7P8CABIA/f/s/wYADwD4//f/BQALAPr/7f8DABYA9v/p/w8AFwDt/+n/EwAUAOv/6/8VABcA8P/s/wwADgDu/+7/DAAJAPX/+/8NAAEA8P8BAAsA8f/r/xEAHQDv/+D/EgAdAOf/3v8YACMA6f/g/xUAHwDp/97/FgAdAOr/5f8VABgA8//u//r/DAAPAPn/5v8DACwABwDH//P/QwAaALb/4f9gACkAmP/Q/3gAKgCL/+r/dAAIAJv/AwBSAPL/uf8gADsA0P/G/0MAPgCz/9z/UgARAKz/8/9iAA4Aqf/u/1YAFACb//P/aAANAKL/9/9gAP//mP/+/3UA/f+M/w4AbgDx/4n/EgBuAOH/kf8gAG8A0f+c/ykASQDH/77/QAAwAML/0v81ABsAw//z/ysAEwDM/+f/KAAOAOj/+/8MAOn/+v8YAAIA8f/5/xYAEgDS/+X/PwAjAKT/2/9yAAgAg/8UAKEA7f8R/x4AGAG9/8D+YgCSAWT/Uv6lALoBUf8u/sUApgFU/1r+tQDIAUn/GP6fANwBcv9g/nsAjAGf/47+GABGAQ8A4P7z//4AGAAk/9n/qgAvAG7/yP+MADEAf//j/3MAAwCe/wIAQwAHANX/BAA7AAgAsv/n/0EACwDa/xEAKADs/93/BAAJAPf//v8aAAoA3v/p/xcAGQDo/+L/KgAWAL3/+P9QABEAuP/w/ywAAQDk//j/IQAMAOz/AAAAAOL/+v8yAPX/1P8eACkA3f/S/x8ANQDi/8D/HwBIAOf/xf8iACcAyv/m/zQABgDg/woAFgDZ/+L/NgAoAMz/vv8/AFMAuf+n/00AaACj/5r/ZwBgAK//lP9HAHUAyf+H/yQAlgD5/1//5f+jADQAYP/I/5gAQABk/6//pgByAHb/a/9qAKUAwP9P/wYAqwA4AH3/hv9dAJ0A1P83//X/9wA3APD+rf9OAVYAWP6x/7wBgwBS/oX/tAFjAE7+av++AcUAfv5Q/zYBwgDW/jP/PgHKANT+N/88AYkAE/+I/8IAbAAY/7b/5gBoAAr/t//wABgA4v7f/0YBIAD8/gAAzADE/z3/IgDXAEUAPv9x/28AkACW/2D/rgDOAF//zv4vAJgBvf9q/lYAzAF9/5T9/gCIAmX/WP0pAKQCef8s/QIBIASg/uD77ACAAv7+nv4oAhQBcP2Q/nQCIgGw/Jb/gAROAND6JP+oBf4AgPoX/wAF9ADI+mL/WAVGASj78P0YBLwBgPyi/oQDogEE/Tb+LAKQAUD+oP6UAaIB+v42/n4AkAG0/+7+uv+rAKkAcP9q/8kAdwD6/q//WQDP/zEAswD8/3X/5f80AOP/ev/o/wQBpgAQ/0X/0gBnAOT+kP/mAJ4Apv+Z/xwAcwAYAFf/yP9VAAkAPABAAK7/JwBUAHL/Y/9BAI8A/f/d/yoAVgCM/xD/eADwAHj/3P7uAGYBIv/U/lIA3gCu/1v/UQBwABoA3//X/w8AAABSAJD/If/vAJYBHf8e/pgBmgHM/fD9AAKQAg//6P00AIQBbf9u/roA2AGp/3z+yP/KAA4Byf+I/tv/KAErAOz+CQBuAZsAsv5U/pEAVgHm/47/lQACAV3/DP5a/zAC6ABG/gAA/AEgADD9MP+IAtkAOP1R/6gDwgBc/Pb+9AJkAMD8tv9wAyQBAP3i/qQCMwDg/KP/pAPDAOD8P/8YA7QAxPwG//QCaAHI/LL+5APMAWj8Nv6UAq8AeP0pAHQDbgBc/GL+FAN4AWT9N/9gAjIBmP30/e8AdAJzAMT9rf/9AFMAI/87//IAbgG6/7j9YQBsAqr/tP1oAMgCvf+I/D3/4AMEAsD8kP3IAqIB4PzU/TAD7APk/RT8yACIAk7+7P3EAhgD+P00/JAAzAJfAFj+eAB4Afj9uP3AAjwDgv4G/mYAOAAo/nT/+AI4A0T/XPzs/gwBV//L/4wCFAKY/rz8e/84AlkAlv5GAJIBIAAU/sj+3AFwAlb+kPzeAOQC1P7M/RwCXAPK/qj6ff/gBGsAQPyCARgGSP5w+LL/EAduATj5yP+wB18AIPds/kAIDAII+Qj9CAZ0A6D6UPzABHwDsPuU/IQDSANc/T7+mAICAWj8Sv78A0gC7PyM/UADQAKw+7D9sAQwAqD7kP6QBAYBePqs/kgGpAKI+WT8OAbsA8D6BPzwBIAEmPoQ+zgFaAVg+8j64AP0Axj9ePzYA0QD4Ps4/P4BgANdAAj/+v68/p//FAE6ANj+EgHwAwf/8Pn4/vgESgHo/AgB8AJ8/WD8zAJwAxT+Tv6EAvD/oPv0/7gGyAIg+RD8jAMAAlj9UQDgBN7/WPuw/ggCIv/T/1AEbACw+9j9VAK8Akv/1P67AMD/QP3u//gBfgBwAUoBnP2A+zv/YAM0A3j/lv6cAO7+2PzAAFgEogAM/ZL/eAHi/vL/tAJ0Acj9cPzj/yQDTAFq/uABhgEQ+7j8oAIcA4kA0P/F/07+XP4u/xwCRAKC/i//8gBd//z84gCcAyAAkPzk/TgDkALA/Ij+KAV/ACj5LP/4B5wCCPrk/dgEdAGI+u//4AZOAHj54P5wBfz/MPsEAtgENPz4+fACqATc/sj9yQASAWj9PP28AoQD3P7a/t0ASv5M/fQANAPKAcL+Qv4V//r/iQCuAToBLv8U/0v/LQDY/oQAEARUAXD7EPzAAiADbv4i/uwDuAN4+bD5AAYYB6j7qPkoBJAFQPsg+hAF6AYI+6D31ANACIj8iPhQBAAIMPtw9qQBUAl0AUj5PgCoBhH/MPcH/yAIrAJ4+/D9aAOqAfj78PygAoAEQ/+Y+vH/6ASeAQj7mP1ABdgBwPr4+1AGoAUA+zz8WAKPAFj7HAFYB2gAUPra/ogDSv7Y+7gCAAbNAHj74P2gAZsAhv8mAfgAZP7u/gQBigHEADb+7P1CABoBrP7tAIgFJAEI+Qj6OAW4BYj7QPwQBpgESPlA+BgDEAgA/zj5wf/ABMwAAP1j/xADvQBA+oT8oAZoB8j8UPiuAdAGnPww92gEsAwp/8D0Gv5QCIYBMPh7/3AJ3AHA9zz9SAXZAOD6KAAABowAwPhm/jAGjAHo+aT8eAWgBBT8CPxoAtADSf+4/Jj/dALmAS7+If/wAgABcPzc/NACKAT4/Qj8TAIgBGj8EPmUAlAIBf+g99X/CAdG/yD6LAFQCAwBwPWo/FAJAAW4+PD88Ae8AqD1gPlgC6AKMPiw9IQDiAes/HD72AQIBkz8QPgs/4gENAMsATQAnPzY+w4BTAKeACQDSAIA+lD55APwBQj+sPywAxgECPoI+LgEQAsF/6D22/8gBfj9iPxQBUgFwPto+YAA0AQa/4z9EAUoBLD4APhIBOgHlf9Y+58ABAKw/MD8TAMwBHz+ZP0AAab/zPycAaAFHgDQ+Lj9yAVoA4j9Uv5AAvoApP0s/fYAYAMMAhAAuf+I/sT8+v9sAjUAZ/8yATABcQDZ/wD91PzM/7gBKARQAmT8oPxYA4wC4Po8/GgEwAac/jj4iv7YBswCMPlU/NgEaANg/Ej9QAXIAwD6oPlQBCgF6PvA/HAHsAaA+HD1eAOgDGsAEPXx/7AKMP7Q8V7/4A4IBiD1EPggBcQD4Pqq/xAKEgFw9ND70AioBeD5IPyYBigDgPYg/CAMcAh4+ED27QBYBC3/S/9gB7AEIPWg9NAFAApw/Pj6MAdABXD1kPOABuAPRACw8ib+0ApF/6D1WAIADYX/APLg/eAMvAJg9Oz/MA5aAADu+PrAEMAJQPSg9jAJAAaA9cD4oAigCGj7EPm2/5ABGP9i/1QDLAMk/bD68P5kAtQDhANh/1j8hP6/ABAALgHkAzADhP14+ZP/4AVxABD9IASwBMj6gPc1AHAIeASw++T87gEQ/XD6mARIB+D8mPqkASwA6PpDABAImAQ4+Qj4aAJgBXj9Uf/wCMYAwPPY/BAKuAOw+Rj9UAawAiD26PqQCxAIIPcQ+lgGYgGI+PX/cAtoBSD1UPhACagFIPa0/ZALoAGQ9OD9UAmN/0D3cwBwCUj/kPVsAdALNP5w8eAAkA4sACDy4P9gDegBUPLY+SANAAgQ9fj4YAmoBHD2qPuwCCAGsPkg+gAG6AQY+QD7QAhgBvD4kPhABdAIgPoA9XAD0AzvAED0uPxQCRgDEPhh/yAI3v7g9jsA8Ai+ATD5BP4IBmn/QPbdAAANOASQ9qD5KAPoASj9uAHwCIgC8PYA+egEYAVI/G//0AdwAdD1APo4B2gHYPvQ9/wAkAWq/mj9WAQAAnj5WPnlAMAE0ALq/1j/Bv/g+0D9nAMYBUoA8P30/gr/BgEAA+gCngDo/JT9jAKABAgBWgA8AcD8oPlo/9AHMAee/mD5GPvI/ZL/EAOwBGoA4PtU/BD+Bv6lAPAEyAKg+6j5fACgBTACYv5zAMYAhPxc/TgFmAdH/2D4pPwIA7kA6v7QBcAHcPog8tz9EAooBfD8KAHQA5D7oPc2AXAImAG4+zcAYAK8/MD9IAYoBXj6aPh0/xgDlAOgBWwDoPlg9hf/MAV6AYAAAAZ8A+D3wPYgAjAHkgE2/tkAmP9M/HT/eAWUAxD7APo5ANgDsAL1ABgAiP6w/fD8OP3lAAAGuAaj/xD3YPg0AjAG4QAq/lAD4ATo+/D1Bv9ACXADuPpM/tADYP8g+7wCYAjQ/mD1DP4gCewDwPr0/RAF/f8Q95D6sAXIByAC0P1A+/j64P6QAwgEBALM/yL+2Pxo/qQCGAPAAFQByAGg+/D31gHgDOAHcPkA9pT/oAUMAln/MAOIBMz9YPcw+4gF8Ag+AeD7Av5M/Xj4aPwQCTAKiPvQ8rj7oAQhAGj96AXIB8D5sPFY/dAJGAfY/1cA/ABg+mD4yAKwCzAITf/Y+mD6sPxcAtAGgAXg/6D6yPjQ/HAEEAjQA6D86Pm4+tj7pwBACeAKGAGQ9nD1eP1ABuAIiAUJAND6SPnw/PgCkAdQBYD9mPio+qz+XALgBlgGWP0g9Qj43AJACCAFKAFc/sD5wPcl/9gH4AfWAWz98PqI+fD9gAZACuwDAPpw98D9QASIBYAEHAKs/VD58PnQAYAIIAVg/Oj5+PyO/rb/qAOoBW//MPfo+BQCAAa4AkUAbwCU/cj5yPukA7AIUARQ/DD60P1DALkAGAJUA8ABOP14+4L/7AIIAh4ABgDs/zr+Cv6aAQgFKALI/Cz8rv5sAO0AigFIAqwBSv6w+rz8ZAIwBBABFv5y/gIBygDW/uMAjAP2ABz9FP74ABQC9gG0Ad4AjP78/Lr/nAMwAwMATP44/lT/9QALAKT+fwAIAtv/WPzQ/OIBdANa/lj7bf9MAtz/zP7jAMIAWP1o/J8AcANAAmIBTgHO/oD7SP1sArgEWAJ//9b+pv5o/m0AhAKiANj+vQA0Ak//jP2fAAgDmv8o+yr+gARABFr+gPwk/wH/gP1xAKQD3gDA/Mz9gADO/sj8lQAwBRACqPts/OQBBAKY/az9XAJ8A97/Mv5ZAKAB1P85/xQBJAIyAaH/7f9UASABmP/h/5YBfAHm/6//egHWAXr/1P2K/4IBvQDT//QABgGC/oj9vv9CAcL/0v4mAI8Aiv5o/fb/VAK0AOj9QP6iACwBDgADANsAUQDC/pL+TwCCAe0Atf/i/pz+AP8NAEgBjAE1AE7+lP3S/m0AGAGOALn/Vf/s/k7++v5sARwCi/+I/Sn/JgHLAOn/jgDpAOz+aP1w/0wCmAGH/5L/LQDW/uT9jf8oAV8AHv+r/4AAzv+y/mf/qAB8AMb//f9/AFUAVwCiAH8AGAA8AJQAngCkAPcAvgAeABoAVgAKAOr/pwBoAdkAtv/I/z0Ao//u/jUAAAKuAfL//v4p/zL/Yv9hAFwB+ADX/1z/bP9U/7T/GgH0AWgALP5K/n4A0gH5ABkABACM/9D+bP++ALsAj/8u/7P/BP80/rf/9gFEAUz+BP1W/r3/5/8dAK4ATgD+/gz+bP6v/9gAAgEZANL+Wv5S/4MA2AAyAOD+Mv4R/78ApgHMAET/sv41/4D/u/8sAQgDaAJB/4j9G/+wAUwCkgGCAVAB0/8X/yoBOANUAjYA7v/FAL0AogAEAtwCzQAW/hL+SwCAAUQBEAFiAGz+MP1s/nwABAE3AHH/3v46/gj+Qv+UABsAfP7U/Wr+Hf9A/4n/8v/S/rT8oPwh/+cASADW/lj+IP60/Yz+jgCmAXwA4v6k/ij/of90AG4BbAF5AH7/af+HAOYBMAJSAX4AmgBUAbQBtAEMAiwCQgFWANsAKAKcAiQCzgHoAX4BmADBABQCxAIAAhwBQAF8Ae8AWABCAXACggGg/37/9QCEAZsAVgCqALr/dv4L/9kACgHN/z3/fP8b/1D+6v5jAEoApP6w/fD9Xv7q/of/tf+0/ij92Py4/Uz+QP6A/n7+ZP0s/Dj8GP2U/Xj9OP2c/ND74Pv8/GD9ZPzA+0z80Px0/KT8zP08/jD9jPyc/eD+8P7q/uf/fgBx/6z+DAAAAlACrgH2AcQCrAKAApwDsARIBGwDAARgBcgFKAVABRAG2AXIBOAEAAZwBhAGuAWABdAEiARgBQgGQAWIBDAFcAVYBNAD+ASABWgE9APQBBAF8AOUA7AEoAS8AuQBMAOEA9QBBgGQARQBD/9A/jP/DP/E/Bj78PoA+sD3APcA+JD3IPVg8yDzYPIg8ZDwAPHg8IDvYO6g7gDvIO8g76DvAPBQ8LDwoPFQ87D0cPVA9oD3KPnA+pT8sP5jAEQBJAK4A7gFgAcACVAKQAuwC0AMoA0gD+APQBBgEGAQoBAgEYARgBFgEeAQQBCgD2APcA8QDwAOEA1wDKALIAsAC5AKMAnoB2AHKAeABqgFYAUIBbADQAIwAsgChAKCAeQAbQBg/3r+4v6V/97+ZP3E/Nj8DPwY+zj7YPso+lD4wPfg92D3oPYQ9hD1cPPg8oDzsPMw8mDwQO8A7kDtgO4A8EDvwOwg66DqYOog6wDuwPCQ8MDuoO7A78Dw8PLQ9mj5ePmg+RT87P4/AMABwATgBgAHIAiwC2AOgA5wDrAPoBBgEIARYBTgFSAU4BGgEcARABEgEcASwBLAD9AMMAxwDHALUApwCsAJGAfgBCAFqAVIBGwCkAEaAQUAN/+u/7z/Lv6o/ED8aPxQ/JT8IP3g/Mj7EPtI+0D8DP18/fD9vP1I/Xz9kP6L/+v/CAA3AIcAdQDjAN4BlAIoAj4BTgHUAdYBkAEcAsYBYQBR/zL/F//Y/QT9PP1w/LD5CPgo+cD4sPWw85D0MPXA8lDwEPAA7+DroOug72DyIPCA7cDtAO4g7aDukPPg9uD1UPQA9gD4WPiw+mH/FAJIARwBGAQoBzAIAAlwC+AMwAzgDSARQBNgEiARQBGAEWARABLAE4AU4BJgEOAOQA7gDSAO4A4QDpAL0AjwBsgGQAYwBbAESAREAhkAyP5c/hj+5PwQ/CD8APwg++j6IPu4+sD5OPnw+Qj7HPzM/Nj8jPx8/Aj9yP2W/ksA8gH0AQQBXgHIAnADcANgBOAFoAUQBPQDUAUABSQDnAJ8A2wDhAEYAKsAeADI/UD72PoQ+6j5UPfg9RD1UPPA8eDxYPFg7iDqoOmA7KDuoO7g7UDtoOtg6aDpIO7w8oD0gPSA9GD0kPTg9kj7uP/pACsAbgGgBOgGUAjQCaALMA3ADQAPoBHgE+ATwBLAEcARoBJAFOAVYBbAFIAR8A4AD2AQABEgELAO8AywCgAI+AbwB5gHQAVwA9ACdgEM/wL+eP6Y/cD6gPkQ+8j7APqg+Oj4gPig9rD2sPnQ+7j6QPnY+dj6kPrQ+sz9LwCh/2T+Nv9UAdYBegG8AmgEMARUA/QDKAXwBMADWAP0AywDogG2ATwCUAHw/hD9PPwA/HD7QPpQ+PD1gPSQ9MDzsPHA7wDuYOzA62DtwO9A8KDtYOsg6yDrIOyg76D0MPZg9ODy8PRo+Bj6RPyNAGADbAIwArgFkAlQCkAKEA3wD/AP0A/gEqAVABSgEaASgBQgFAAUwBXgFcASsA/gD0AQwA5ADmAPQA7wCTgHeAf4BvAEWAQQBXgDmv/c/fT+GP5A+4j6LPzA+/D4WPjI+bj5UPdg9lD4UPlg+ND4WPug+5j5IPm4+8z9gP2k/eH/cAE9ALT/zgH8A9gDOAMwBGgFwAQIBAAF2AVoBJwC0AKgA+QCLgGVACYAOP7w+3j7wPtw+gj4UPbw9CDzYPKg8mDxgO1A6qDqoOyg7UDuYO+g7aDp4OcA6yDvkPHw84D2UPYw80DzePiE/Rr/qABoAzgEfANQBWAKUA1wDMAMIBDgEQARABKAFQAWIBOgEcAToBUgFeAUwBUgFAAQoA5gEEARwA+ADsANUAuwB0gGeAeoB5gFxAOoAnIA8P2Q/UD+LP3I+pD5qPnw+MD3APjw+OD3sPWA9SD3APjw94j4yPmo+aD4OPlo+9T87Px0/f7+ov98/1YAPAIAAywCMALMA6gEGAQQBPgEUARsAvgBCAMMA0wBBgDe/3z+2PsQ+/D7mPpg96D1kPXg9NDycPGg8CDuwOtg7ADvAPBA76DuYO0g60DqoO2w8rD1YPaQ9uD1cPTw9bj7GAFkAhgCdANIBcAFKAdQCwAPcA9wDvAPYBIgE2AT4BTAFSAUoBKgE8AVQBagFCATABIgEKAOIA8gEFAPMA3ACnAIYAZYBcAFCAaIBJgBaP/A/Uz80Ptw/Hz8wPqg+ID3YPdQ96D3ePhw+PD20PXA9kj4UPlI+nj7cPvw+dj5KPx2/kj/1/90Ad4BiACjAEAD+AQwBMgDGAWQBewDMAP4BJgFEAMcAZQB7AGIACz/CP82/nj74PhY+Gj4YPcg9uD0EPOw8IDuIO3g7MDtoO5g7sDt4O2g7SDswOqA7IDwsPMg9aD2kPeQ9uD1aPg4/ekA9AIABSgHIAfQBVgH0AuQDwARgBFAEqASIBLgEiAVQBZAFQAUYBTgFGAU4BOgE8ASYBAgDlAOMA+ADmAMgApgCPgFSARYBMgEnANCAQL/OP2A+7j6CPsI++D5gPhA91D2MPbw9mD30PZw9uD2gPdw9wj4MPpQ+zD6iPlI+1T9FP68/qYAGAIqAREASgGAAwAE9APwBLAFgASwAtQCMAQYBFgCJgFSAe8ACP9k/Qj9bPxY+kD4wPfA9yD2EPTw8kDyEPCg7YDtAO8g7+Dt4O0A7yDvIO7A7cDuEPAw8pD1mPgw+WD4+PgY+1D9QwDgA9AGAAgQCIAIkAmgC7AOgBHAEmASgBIgE4ATABTgFEAVYBSgE8ATwBOgEqARQBFgEDAOQAzgCwAMEAtwCbAHmAVkA+wBmgHYAS4BbP9E/Yj7gPq4+VD5gPnQ+Sj5oPfQ9gD3MPcA9zD3MPjQ+Jj4APmQ+pj7EPvA+uD7kP2K/kX/jQDMAb4BDgFsAdACAARIBFgEqASgBIgDhALMAkQDYALmAI0AnABc/xz90Pto+0j6cPiQ92D30PVw80Dy4PFg8GDuwO3g7YDt4OzA7UDvgO+g7kDuYO6A7kDwgPSA+ND5oPnQ+Wj6gPtc/pwCIAaoB2AIUAngCYAKEA2gEGASQBJAEkAToBOAEyAUYBXgFCATwBLgE+ATYBJgESARgA/ADLALkAygDLAKkAhIBxgFMAI4AXACkAJBALz9pPyQ+5D5YPho+Tj6sPjw9uD2IPcw9qD1sPYI+ND3MPdI+Nj5CPqY+TD6iPtA/AT9eP7K/zYAGwBxAEABygFQAqgDaAToAyQDAAP4AowCaAKQAjQC0ACU/xb/Ov6I/DD74Pog+mD40PYw9gD1MPPg8WDxcPDg7iDuwO4g7wDvoO8A8YDwwO6A7pDwgPPg9ZD4APsQ+3D56PlE/eIAXAPwBVAI4AhACCAJAAygDvAPQBEAE0ATIBKAEkAU4BTgEyATgBOAE8ASYBKgEqARMA9QDeAMgAxwC6AKEApgCHAFDANAAiQCdgFtAFD/oP1g+9j5sPno+aj5EPl4+Aj44PYw9uD20PfQ99D3aPgw+Xj5mPmg+rD70Pu4++j8ov6r/0QADgGEAVgBggGAAowD+AM4BGgE2APAAlwCuAKcAvoBngEmAaD/0P0Q/dj8iPuo+dD4cPjg9vD0APSw83DyUPBA7yDvgO6g7WDuQPAw8UDwIO8g74DvUPDw8mD3iPrY+tj5KPpw+/T89f8gBHgHMAjoB+AIAAtQDGANoA/gEYASQBKAEoATIBTgE4ATgBNAE6ASABNgE4ASwBAAD8AN0AwADFALsAqgCdgHuAW0AzgCtgG2AX4ARv6I/JD7qPqo+Rj5KPmg+FD3sPYA95D28PWw9gD48PcQ96D3YPkg+rj5GPqY+1T8hPzo/fH/eACy/x8AjAEEAq4BbAIwBJgELAMYApACnAK2AVYB5gGoAbj/CP7M/WT9sPs4+vD5gPnA9wD2cPUQ9XDzwPFA8fDwIPCg72DwYPFw8QDx8PAA8dDwkPEg9ED3yPlI+4D7QPuQ+5T9tgDMA+gFqAcACWAJ0AlwC8ANYA9gECARIBJAEsARoBIAFKATwBFgEYASgBJAEYAQwBCQD8AM8AogC+AKMAkwCBAIUAY0A5oB8gGYAdH/hP4e/sD8gPrI+XD6KPrI+HD4sPiw92D2sPYw+Ij48Pc4+HD5ePno+Kj5UPvI+3j7lPxe/iz/5P5l/90ATgG6ABQBkAL8AoQCYALoAogCWgEAAZYBaAEPADP/FP88/oT8WPsI+3D6APnQ90D3YPbg9PDzYPNw8kDxYPBg8IDwkPBQ8WDygPKw8SDxwPEQ8zD1YPg4+2D88Pvw+zz91P6VAJwDCAdwCIAIQAkQC0AM4AxwDmAQ4BBgEAARYBKAEsARABJgEiARoA/wDyARYBCQDtANkA2QCzAJ4AiACVAIOAZQBdgE8AKNABEAYwD0/qj86PsY/AD7aPkg+YD5sPhQ9zD38Pew9/D2gPfY+Nj4OPjI+Pj5SPog+vD6YPw8/Yz9Pv45/27/Xv/5/+4AfgGkAfIBNAIYApwBJgEoATgB/QCUAC4AYv9a/nz9zPwA/AD7SPrw+UD54PfA9jD2YPVA9GDzAPOA8hDykPLA8zD08PPg8/DzgPOg8+D1CPk4+1z8dP3Y/ez8fP2CAKwD+ATwBUAIsAkwCVAJsAuwDcANwA1AD2AQ8A+QD6AQYBFAEAAPAA9gD6AO4A0QDuANYAxwCnAJAAkgCAAHaAbIBYAE5AK2AfYAEAC8/pD9AP1M/Fj7wPrA+oj6sPnQ+Jj4mPhQ+Gj4OPnY+Zj5ePkY+tj6wPoI+xj8yPzs/HD9hv5+/63/2f/DABgBngCwAMoBYALqAYABnAFkAaEARABWAC8Adv/e/jz+LP0I/Ij7MPt4+rj5IPlo+GD3gPYg9oD1kPTw8+Dz0POw80D0UPVA9iD2QPXw9OD1UPcQ+YD7Ev5B/17+0P10/0IBKALQA8AG0AigCDAIsAmgC7ALYAvwDJAOEA5wDZAOwA/QDqAN4A0QDtAMkAsgDAANAAwwCqAJUAngB1AGwAWQBXgEFANgAhAC6AB3/+L+cv44/dD7cPuY+wj7QPoQ+sj5UPkQ+Vj5kPkw+SD54Plw+jD6cPpw+xT8NPxA/MT8dP34/aD+gP8PAA4AHwCnAAIBCgEIAUIBmgGGASYBuABjAAwAxf+H//j+Mv6k/XD9sPyg+wD7CPuY+lj5uPjQ+Hj4MPeQ9iD3EPfQ9VD1gPZg9+D28PYY+MD4OPhI+DD6wPsM/NT8vv4kAFsAAAF4AogD5AOoBBgGeAcQCNAI8AmACpAKAAuAC1ALEAuQC2AMYAyQC0ALkAvwCqAJYAmACeAI4AeQB2AHUAbYBFAEeARUA6QBVgHAAQABhv8g/1n/rP5k/Sj9dP3E/OD7QPzQ/ET8oPsI/JT8KPyA+wj8zPyQ/Gz8RP3o/XD9FP3c/dL+qP46/s7+1v/S/zz/m/9tAF8Akf91/yEAIABG/xX/zP+Q/0r+zP2A/oz+UP2o/Bz92PxI+6D6UPto+zD6iPkg+kD6EPlI+MD48Pgw+OD3qPhQ+Sj56PjI+dD6wPpY+uD6GPyc/AT9WP4LAMEAmQDOAFYBjAE8AtAD+AQ4BfgFIAfgBgAGmAYwCEAI4AYAB8AIIAngB8AHsAgwCLAGeAYYB8gG2AX4BbgGCAaoBGAEoAToA/QC+ALkAiQCiAG0AdQBKAFFAP7/8P9U/9z+4P4I/wv/5v56/jD+QP4e/sj9pP3c/Qb+7P3o/S7+bP4q/uD9Iv50/jb+4P1c/sj+tv6I/lT+gv6a/ib+7P1I/j7+vP3U/WT+MP5I/RT9kP2Q/cT8WPzo/Bz9LPyA+wD8PPyI+yD7KPtg+xj7mPrY+oj7mPso+0j7mPvY+wj8KPyk/Ej9kP2s/Wr+Ef/2/v7+4P+VAEcAtAAMArgCUALsAQQDIAR8A8gCIAR4BZgExAPgBCAGcAVQBBAFKAaoBZAEuATgBdAFuARwBEAFaAWoBPQD2ANoBDgEQAMEA9ADpAMcAoQBvAIYA/oAOgAgAsgCRgBS/14BzgHM/y//1gDrADX/Pf+8AIYA/P7u/owAHQCc/hD/agCj/zT+0P73/3r/HP6y/oT/iv58/RT+qv4S/jj9PP0U/pz9nPy4/AT9ZPzY+yT8aPwU/Hj7YPvw+yD8MPuA+kD78PtA+4D6ePuY/Lj7mPpo+8z8xPyY+wD8uP3I/bT8LP0V/0D/ov4r/+r/q/+Z/90AkgESAfsAsAIoA1oBrAEgBOwD7AGoAsAEoAREAzwD6AQQBQwDSAOABTgFSAOkAxAF+AQoBHQDqAOQBFgEMAMYAyAEUAQoA4QCCANEA5ACGAKYAvgCPAI8AZoBOAKUAYgAtQBIARwBbwDS/xsAhwDj//b+aP/6/z//av66/mL/GP/o/cj97P6S/kj9jP16/nz9nPxs/dj9KP18/Pj8gP20/MD7sPxA/dj7kPvc/AT9qPuw+6j8hPzI++j7pPyw/Dz8BPzY/Gz9FP2g/Pz8vP0U/rj9WP1c/nv/3v7w/Wb/wQDI/zH/VgBqASYBmABOAWwCXALMAf4B8AIAAxgDCAMQA7ADEASoA1QD+APsA6wDEAT8A9gDCAQYBKADyAPkA2gDsAPMAzQD0ALoArQCtAKEAuwBKAJAAmwBBAGUAWoBlwBjAMAAtgD0/5X/9/8SAG7/Hv9g/17/2P62/g3/0v4+/mj+yv5g/gD+Lv5u/gz+pP0k/lz+1P2Q/Rz+SP6g/Wz9BP5O/rT9tP1U/jT+tP3Y/Vz+FP7g/SD+bv4i/vD9lP7i/ij+uP2k/hH/av74/fj+gf/s/lz+5P7Q/1f/hv7y/nQAjf+Y/rH/9gBrAPT+4P9YAZ8ARf+KABwC0QDv/yoBKAJUAZ0AjgEMAiYBTgFQAkgCYgGeAXgCJAJmAdIB0AJAAkYB4AFsAtwBZAGqAfQBgAEqAUwBVAFAAfgA4ACnAJQAjwCbAF0AMgBiABoA5/+1/4D/j//l/9v/Z/8Q/yH/Xv8s//T+8P4E/9j+kv6m/sD+xP7A/tr+2v6E/pD+vP7g/vT++v7U/qT++v45/yf/7v5J/2f/Cv8M/3n/pP9M/3T/pf/Z/4r/Yf/V/9v/qv+f//H/AwC3/8//BAAlAPP/sv/e/wYAFQADACkAOwAqADQADgAzAHUAewBEABoAeQCqAJcAYgChAPUAuQCrALgA+wDIAMoABAE0ARIB8QAUARABBAHjAO4AFAEcAfsA/QDHAM0AngCYAMcAzgCLADEAHwBsAHYA4v+v/10AcAAb/4H/ZgBjAPL+tP5qAJcAxv7s/ZMAtwDE/dz9tgBYAJz9qP6ZAGv/yP0b/+EAPf/A/SP/XgHM/zT9b//qAcX/cP2V/4QBMgCO/kH/qgDnAHr/Ef9DACoBCgDY/uL/NAGXAOz+mf92AdwAoP5l/+wBlgBY/rb/iAFRAAf/yv9UAWwA/v7Q/zYBWwAp/1QAAAEIAJv/MACsAEgA3P8qALQAQQCt//3/EgFwAKv/HQDdAKMAqf/6/+MAvwCx/+f/DgHQAIj/7P/zAIoAvP8HAPAAdQCm//n/pwAIADL/sP9wAFMAUP/G/4gAVP/0/sL/y/9L/3H/wv+i/63/c/8//4r/qv9q/zv/WP+i/9//gf/W/qn/+v8j/w//9v/w/yD/hv8NAMX/Wf9+/xwARQDL/6L/KgArANL/ZgCLAO7/ZAB9APH/5P/hAAQBxP/F/2kAzQBqABcAWwDFAIUA0f8SAHMAgAD9/yQAQABIAFoA9v/f/0kAewDA/+r/TgBIADsAFgAXAA8AKwAxAH4AHQD//3YAmwAUACUAkQBJAPD/SADpAHwArv8JAPsAswCs/8D/7gDKAKn/+f/LAGgA0f84AE0ATgDl/4j/ZgCMAGH/eP96AC4AZv/A/z0Ar//U/lr/YAAKACb/Zv/O/6v/Cf8h/8T/EwBr/1n/DwB0/4X/r/+8/7//CgDT/5z/4/+J/xkA7/+O/8z/EgC9/9n/AgCq/wkAZwDI/5f/KQBFADoAv//V/2oA8/98/3IAnAB//2L/dQDQAPL/7P57/+sAUwBA//r/gwDe/4//0/8HANf/kf/W/zsA2/++/+T/rf+1/xgA3f+Q/w0AKwD//8T/CQApAP7/0P8SAEEA7f8YAIQAfwDa/1wAmQAXAOz/mgD8APn/8P9kABoBZACc/8IA6wAUAN//vQDjAPD/yP9lAOoANgB1/0YA6wDv/4P/zP8AAEgApf9x/3UArgBn/zn/TgBUAFT//v4XAHIAbv8T/0IAdgD2/q7+HABtAMj+yP5xAFwA8v76/h4APgBD/xv/7P9vAKT/Nf8fAGEA1f/J/xMA5/8gAK3/sP8qAIAADgCK/w4AUABKAHb/4f/YAHIAmv+Y/0kAMgD7////AgDI/zoAQgCI/7T/TQBFALf/WP/z/5YAuf9o/4QAngBz/63/kQAvAPb/qf81AI0A5P8ZAMkAewAy/wUAIgGNAKj/+f9eAfgALf/R/84BKgEH/+b/3AHHAMz+PgAIAmkAEf8SAHwBPQA7/3IAFgHX/2T/lgCaAJf/LQCJAKj/Df8sAMgA8/8v/7//uQCk/8r+nv/UAJ3/oP55/6AAof86/nIANAEG//z97v8gAXL/jv4XAEABrf9+/lEA6AB1/xr/KgAIALX/UAAaAMr/lv/p//r/4P9u/0sAlABN/6D/HwAIANb/GgDl/5r//P/R/+7/sP8jAHUAsv8Z/0QABgFv/2D/ZQDHADL/9v5MASwB6P5z/1gBQgAG//7/egEfAM7+bACeAfL/PP/wAGQBbv/0/qEA+QA+AK7/lAAqASAAOv/i/6QAXADK/7H/MgBcAHsA3/+e//7/QQCd/2D/uf9yAH0Alv/o/hoARgAO/5f/SQALAEb/mf8hAOn/uP+l/9j/+v+3/yIAs/86/3QAXQAA/wb/0wBYADP/FQBaAO7/Av9Z/6sAPgH8/xH/bgBeAH7/mv+pAMQAIADE/w4AzgBOAJr/s/8qAYUARP8oAI4BGgDU/uL/aAB8ACr/of9iAeUAkv6F/4IBxv/M/uz//ACWABz/rv+4AEQATf/C/+wAEQCq/+r/NQB0AGIAfgCo/w4AYgCQ/77/YgAeAeD/pP+XANUAWQBB/wsANAEKADD/nQBiAaH/MP+uAAIBff/M/qwA7QDy/ub+5ADyAD7/Nv+6AJEAwP6s/iQBiABM/lr/jgA1ACb/Hv8bAAQAT/+q/uz/gwCS/4r/o/+SADEAUv+e/xgAOABt//z/o/91/zAAhQAHAPb+7/9jADj/Of/7/0oBDADU/ioAIAE+/3j+2QAWAbT+7v7RAM0AS/+H/8YAjABr/+T+iwAgAWf/ZP9gAVYB6v4G/2QB3gBB/1T/HgGQAIb/iP/WANYBUP8D/+4AxgCi/jYA0gFRAJn/KADpAEMA8/9IAKMA8P+o/3kA5AD8/8z/rgAeAIf/1f+OAPv/8P8mAe3/N//F/6QAiwD2/7f/PgAGAMj+DAB8APX/Df9PAFwAdP7m/rAAQQBu/mb/rwAgACD/qP5wAHIBtP7c/WoA0QDU/rT/9QA9/w7/Sf+b/3EA+f/a/rv/wwDc/t7+cgB4ALv/Mv8V/1MA5wCU/7j/twBSAKb+IQB6ATYAbf9sAMgAPP9G//IAjAL4/0r+DgHKAUv/Kf+yAWABcv+L/0wBMgHW/4D/mwCVAJL/p//6ADIBbP9+/zMAYwCu//EASgDS/jIAvf/5/zQAnwA5AKMAdv9S/j4BuQDI/dD+tAI6Afz9T/9sAVIA9v5G/zwBAAD8/eb/8AIwAXj9SwB0Amr+IP2jAHwCMAA+/iIA1gHs/z7+r/+aASEAJv5y/x4BOwDG/hYAhAFTAFT+Y/+YAAgA7P4HAFQBI/9+/pYAAAIl/17+XQAPAL7+1P5aAIEAIQBH//T/ZABQ/1EADAGf/wT/EgFyAMr+5v8kAYcAMv/r/6sASwAK/5b/yQCFAOP/QwBWAZcAYf9w/2YA7v6c/1gBKAGiACH/2f/LAAwA6P7P//kAJQCR//b/nwCnAI7/Ev+b/x0Ay/8VABEA0v80ADcAHADz/3UADQB8/7f/jf99AF4BxQD8/n//9AA+/97+TAAWAX//n//cAHEAxv/2/ikA1gC0/pL+KAFUAaj+/v52Aa7/0v6H/00ANgDG/rz/ogCoAOL/9/9BAA0ATwBR/8D+NQBuAD0A4f8YAJAAAP9o/8D/DgCP/7P/kwD7/3UAo//A/y8AXv86AI7/df8bAG4Agv89/0oB9wB2/97+2wAOAW//+P+DAF8A8P/qAIgBdADX/wYAZgB3/6j/vQCa/0oA4wBPANT/LwA7AAP//P5PANYBXQBN/xYBKAJ3/wj+cgDJAPr/K/+RAKQAzP+4/3z/WAAaAAv/7v5WAcYAnP/7/ycAogAj/zD/LgACAdIAX/9S/+D/SQBdAH//pwAXAEv/LgBdAN8Atf8O/xIAvQCx/3L+kQBOAZf/QP5t/4oA8P3e/uD/SwBi/5H/rgDS/9r+EP7Z/1QA5v4wAGYBOP9U/zwAngCg/2r/gwDNAOb/iP6aAMIBxf/c/ggBtgFq/9T+3gBIAbr/qv6EABQCMQCQ/20AlgHu/qD9KwB8AOj/k/9uARACrwBR/5b+tQA2Aab/Zv9+AdwA0f+YABkAAAFHAM7+0P6V/yUABgCaAEUA+/9ZADr/nv///3j/qf+8/1j/w/+rAD8A0/92AEX/8P0I/2kARgDb/7//eP82ASsALv7A/2IBUf82/o4ALAI/AIj+4//4AQYBGP5aALACHABo/ZL/LAImAJD+TQBMAoL/gP08/yYBl/+g/twALgH//2b+sP/WANz/jv7h/8cARgCo/93/kgAMACf/+P53ADcAqP8mANoAFQCx/xEAQwCZALn/ugDJACoAov+mAIkAJ/+FAGQAIABh/3AAzAEEALT+bP/mAQoB/v5+AC4BMwAV/6z+fQAqAeT/Lf/2/1AAtv9//yv/jgCUAQv/iv6mABwBQP9Q/s4ANAGi/vj8SQCiAQb//v5KAaoBJv7o/SIBLAIG/zT+YADv/77+d/+6Ac4Auv5w/2UAt/8H/0gBcAGA/5P/4QD7AFL/iAAYApsA8P22/ggBEgFCAEwAvgC0/9D+xP7B//P/hwAKAKD/z/8XAML/Dv/1AFIBsf9Q/lH/LAFaAHj/6AAIAWT+Xv4mAZQBmv+R/zwBnAG6/kj+tALMAnf/E//wAMf/Mv+eAagCdgHb/08A7QC7/8D+RQDOAAn/Nv9kADkAwP8TAGL/NP5g/mT9Vf8WAa8AAwC5/+7+9P5k/4L+2AAeAcj94P0QAdEAvv71//AAg/9A/eT9KAJAAdz9u/9MAhUA2P38AFgCQQAc/q3/tAFn/+z+3gCmATkAYv9xALoAZgCa/zcAtgDV/8H/KwBmAVwBYAAa/0f/NgB9/5D+4f/kAD8ATP8iAM7/O/9y/7D+of+j/9r/jABrAI0AOAHWAPD+7v55AIEAXAC0ACwCWgFm/kn/agGKAXP/MgCgAvUAjP48/ywCYgEV/4z/4ACHAB7/2P9HAPr+kv4u/jX/UgHXAIT/9/+L/5UAdABG/pb/DALFAA//pwA4AVsAgP/G/jn/l/+C/lz/6AArAPT+0v8RACz/DQCL/0z/tgAbABUACwBI/x8AjQA7//7+/ABfANb+l/8ZAHEAagDC/0ABqwCw/sj+Tf80/0T/bgH6ASYBef/A/kMA3gCU/jH/CAKIAMb+uv+qASIASP6M/nIBpgH0/TUAvAK1ANT9Dv90ApAB9P5k/2ABzv9I/ToABAMeADD+jgCcAeL+2PyZ/0gCkQAq/nUAaAOnACD+H/+HAJ0Ahf8fAAwBJwCf/13/GADdAD4BkwCx/+b/Ov91/0IAEgFbAB3/VP8+AD0AAP8q//QAjABe/pL+ngBuAQ8AS/9FAI4Az//u/tv/YAC8/hr+8P5JADwA0v/O/1j/0v62/oX/xQDYAKgAkwAXAGH/8/9FAFT/bP+SAEsApv7c/1wB2AFKADv/nABmAe7+7P0UArACCP/o/e4AMAEA/zT+bwDKAez+0P22AOwBVP/h/zYBz/9q/p3/lgFkAUkARAGUAtb/xP0vAGACbQC8/1YBOAGo/hD9iQDYAsz/KP77ADABaP5u/q4B/gA2/ub+zAGYAaD+dP4GARUAXPx0/mgCJgHc/RYA+AFI/zT9aP4eASAANP7x/3gCgwC0/Tv/lgE//4D9ggBEA2wA3P1XAJACZAEu/pf/kgFI/5T8iv/kAlgAlP3s/wwDc/9Y/Or+dgHQ//j9x/9MAnMAGP6/AMACEwBG/on/RwAVAIoAfgHuAU//Yv5QARIBSf86ABgBlwCK/9v/4AH2AEz+Rv9gAmoB/P04/joBeQAE/b7+MAIAAob+xP28ADoBwP14/RgCQAJM/97+zAGWAVj+HP5+ARgBSP6X//ABIAJW/0X/kgG1AOT9n//+AdMAY/+MABQC6f/c/c7+FAHg/+L+NP+s/0EARQCt/7f/fwAl/8D9Jv/KAQQBdf98/j0AUAELAK8AnADy/1L+2v4zALsA+wB0AdoAwP4s/23/aP5a/nUAYgGv//T+TQA6AToA1v6A/5EAHf9H/54BSAI4AKD/QQBuAJn/VP0i/qUAGAEa/0n/jAB9AAcAfv5g/3IBQQAe/tD/lALaAbD/+gAoARD/oP7yADwD6AA+//0AoAIPAJz9CgCAAuz/oP24/ywBqv/G/iIALAHG/gj8Fv+6ASD//PxfAIACqv5o/Ef/pAJEAZn/6QBjAKz9oP2eAQACzv7+/iwCfAF0/Vb+XAL2ARj+qv4gA+wC/v5g/ywC7QAw/Tj+EAJIAp3/AACoArkAFP2E/kQCVwDc/Hz9kQAWAS7/iv6yAOUA2P2A/YsA5P+k/TQADAIlAFT9bwCYBOABwPtA/TADIgDA+/b/QAUkApj9IgCgAqH/lP3gABwD6v6g/J4BcAUEAaj9ngF0Ajj+vPwkAfQDTwAE/cb+TAGx/9z/YAN8A7j+aPwH/8P/Jv9CAewCNgH8/uj+OP8o/6r+3v6y/pT9Jv5mARgCxP/J/0sA9P7M/br+qwCCAUwC1QCa/+D/PP/U/ncAogHD/7D+EP+RAGYB0v9H/2QBfgEk/ir+QgGqAQ3/AP75/78Abf87/xACcALC/nD9CwBEAWT/Iv8uAfAB2v+q/iIAogHX/y7+2P5w/0n/Ff+XAPYBNAGX/yn/Nf/k/vj+UADfAK4AfAC6ACgBWgGGATT/qP16/8IBIgGK/20ASAE+/1D9Nv90Aa3/lP3h/0QCvgD2/kYB8AKx/+D8iv6SAf4A2v5k/5EA+P7c/ZT/IAFvABX/EgA9AF7+9P18ALABEgDa/4YBYAKgAMr+4v+yAS8A/v7r//0A/wDFAJgAhP9m/kz9Df8wAMX/gwC8AesASv5k/hYAiwDL/00ALAJ4AbT+Nv84AjACVgCaAIIAgv6c/fD+CAAZAAAAdwDD/4L+Rv+HADH/kP0a/7L/AP/w/4wDGASm/0z9D/9TAHD+9v7aAWgBTv9I/88AxgCH/08AcALiAKz9JP/8AeUAYf+fAAACSAH8/qb+rgD1ABL/Kv8HAKj/IADf/2r/FACa/2T+HP8xAH3/hP5u/2YBBAF+/xsAyAErABz94P56AZD/1P2+ACgDBgHW/nYA5gB0/jb+GgBCAUkAxv/xAGYBR/9w/uAACAEK/1f/6/9v/x0AjAFCAXEA2//T/+v/5P6N/7QBaAIGAK3/RgFGAHL/9gAUAW7/9v7O/g7/lv93/57/WQACALT/fAACAYf/Bv8k/8j+eP8LADYBOAG9/yT/qgA8AeP/pv9AAGT/wP4UAdACMAEo/7f/sQBZ/1r+vf/wAKn/1P30/oIBagGJAAIB5P9i/tT+W/8L/9//swC8//z/IAGTAPT+bP6o/3AAqv7M/Y8A9gBG/k7/tALUAbT9Uv4cAnABmP1k/TIBSALh/y4AdAOUAyIAZP50/3D/Ev5M/oEASALsAV3/KP6Z/2UA8v7I/Xz/HAGF/+D9rQBsAxoBqv7G/90AYf9K/uD/eAHBAI//sADeAUQBMgFmAV8AzP7e/iwA1QCZAHgA1wBlALb/6P7C/rz/WQC0/jr+2f8RAGv/av+KAB4B2f8S/vz+DQBo/3b/RAEIArf/OP6q/+cAav+A/pD/qf92/hT/6AFoAn8A5/84AdoA0P7q/iQB1AEFAI3/kgCRAF3/a//bAOoA8v8Q/8z/CgFqAJr/kf8KAGz/JP4d/+4B0ALz/5z9rP12/m7+4v6mAZQCywAzAFYBVgG+/6L+j/+aAPT/VP9wANABggHAAD7/DP5m/mz/1v/X//v/6wBkAV4AWwA2AUAB3P8H/x7/uf8mAFUAWAFoAWwAQP8a/9r+cv4U/wUAmgBLAIsAtQCq/4H/YAAUAGD+qv7jAMEAjv4s/54BJgEB/2b+1v9oAO7+9v72AMUAmv6e/k4ANwBL/+P/MAH4AOD/JwCOARABZ/9S/0IAewDc/73/SwBrALn/Uv+I/18A5f/a/mP/1wBPAED+OP/6AWoBQP7G/igCDAL4/qL+EAF5AA7+Qv9YAggCp//A/24AG/8S/rL/WgErANb+KwBUAeT/Af8LAHcAU/9K/jX/5AAKAVMAGQBfADQA///L/3z/dwAaARwAMv9i/zwAkQCBAD4BXAFe/yr+lf9sABz/gP7y/z4B3/86/t//BAK9AHb+Nf+BADT/UP41AMAC8gGr/wwA5wD0/yH/YAAqAZ7/QP7t/8IBCgEjAJ4AuABv/5D+av/eALEA8P8jAPX/M//r/4IBkgG4/x7+Cv6q/jv/g/+SAHIBUQDC/vj+KgCdADQAP//K/mv/3/9JAIoBeAJkAbb/WP9b/7D+cv7x/wwB4f8J/xQAFAGaAI7/Lv8U/4D+vP7aAJgCUAI0AaUAjwDY/+j+AP8HANsAOwDq/or/igG4AVgABwCOAOr/Jv4A/lEAhgE6AIT/FAG8AXD/6P3d/yYBwv4I/Wv/fAHU/3b+JwDWAZYAGf8kAEIBVACH/2gALgEsAHz/iwCQAXMAmP8vAPz/sP6Q/iYA1QAdAE7/l//5/7T/Y//g/28AUv/C/tz/fwC7/+T+LP9hAA4BLAC8/8wATgHv/wH/SABSATYACP+q/4oA+v+///MARAGe/yz+Wf8mAYAAUP98AN4B4gB//yAAygF6AWn/Tv6s/iL/u//PABYBagDS/2//3P6w/tb+UP8MACEA1P8dAHYAhAC/AAMAcv5g/nT/GABhAG8AAQD5/woAaf+z/7cAtwDa/zD/T/+1/8b/lv/C/14ArQBVAKn/ZP+t/8H/3v4s/gj/SQBcAHMAqgGoAbP/lP6y/6IA9//e/5ABdAKrAJT/cAGAAnEA+P76/4IAb/8n/0cAJgHfADwATgA2AEj/Af+3/5D/7v4z/+f/mAA0AXIB6wBJAFD/hv6a/mD/PgBOADoAOQBMABEAIgBqANH/mv5w/mP/q//h//IA8AH0AFD/ev9XAPT/uv6k/u3/lwAkABUA5QB8AZkAW/8J/wIAkgDI/2v/SgCrAJ3/J/8eAJ8A4f8a/4b/FwBu/67+ZP/BAMQA5f+b/9v/zf+G/5H/GABiAPL/3P+NAJgAwv+0/30ArwDE/0//KADSAEMAFwDzANIApf+G/4oAgQCR/6v/mQBlAG7/5f8sAekAav9Z/40AagCM/w0A4wBxAIH/pf+KAMIARgBLAJ8ANACT/63/QAB/AEkA0v+2//T/1/9q/2T/x/+r//T+lv4S/5v/kv9I/4L/5f+p/yj/I/9Q/0b/AP/C/nX/IgAPAPf/bgBtAHH/A/+v/w0AmP+y/8kAVAG+AEcAfABmAMv/qP8gABoAyP8XAGkAQwAnAJcAtAD8/4T/5f+BADoA8/+hACgBxgBJALMARAEiAaAATQBrAG0ANgA6AKMADAHuAJgAOQC3/2T/e//S/wQAzv9r/9P/YwAnAKT/pP+m/wn/Zv6I/lj/uf+q/+D/PwDw/1b/fP/g/+n/qP96/5T/rP/x/2MA0QDUAGAA+f/p/9f/r//R/xUAPwAYAPD/SwCeAEMArv9//zv/pP6u/oH/BgCo/z7/bP+0/5b/LP9t/8r/d/85/+D/yAASATYBQAEkAcoAWQBVANcALgEaAVQBpAGkAVwBYgG2AX4ByQB/APEANgEaAUwBpAGAAc0ApAAuAS4BswCJANUA6ACwAMkALgE4AdIAYQDX/2//hP/m/w4ABwAUAMj/Hv/C/hv/Bf9Y/uD9BP78/UD9AP3Q/QL+EP1c/JT8NPwo+/D6gPuo+yj7SPvQ+/j7uPsA/Hj8YPz4+0z8EP1Y/aD9lP5f/zj/Lf/u/wABcAGYARwCoAKcAtgC5AP4BKgFEAbgBpgH2AcgCOAIYAmwCdAJAAqACvAKcAuwC9ALwAtQC4AKsAkgCVAIOAegBiAG2AQwA/QBLgHk/7T9sPs4+pD4wPag9WD1APUQ9PDycPGg76DuwO7g7oDugO4g76DvoO9g8LDxgPKA8qDyMPPg88D0sPZQ+aj6APs0/OT9Fv/H/7gA8gHQAvACWAMABagGyAegCFAJ4AkQCgAKUAowC0AMcA2wDsAPABFAEkAToBPAE6ATIBPgEkAToBMAE4ASgBJgEsAQ0A5gDdAL4AjABcgDOALZ/3j9DPxw+uD3gPXA82DxQO4A7CDrIOrA6GDoIOmA6cDooOhA6WDpYOkg6sDr4Ozg7cDvEPLg8yD18Pag+Mj5iPrY+8T91v+uAQQDUARwBUAGuAaIB0AIcAiwBygHcAeIBzAHqAaQBoAG6AUoBSAFEAXQBDAEMAToBFAGsAdACUALkAwgDVAN8A1QDlAOoA6AD6AQYBEAEuAS4BMgFIATYBLAEFAOQAyQCuAIIAeABRAETALJ/wD9uPpo+GD1EPJA7wDt4Opg6eDogOmg6SDpoOhA6EDngOYA5yDooOjA6GDqQO1g7/DwUPMw9sD3oPdo+ED6EPzE/dj/+gGAAzgFYAcQCWAJIAkQCYAImAdAB8AHMAjgCCAJ+AdwBvAF8AagBuAElANgA3QCIAIoBPAHwArwCwANsA1QDbAMsA2ADlAOAA6gD+ARABPgEyAVoBWAEwAQYA2gC9AJUAjoBxgH4ASMAvIAOP8A/DD4YPVw8mDuQOug6gDroOrg6eDpoOlg6ADnIOeA5yDnAOdA6ODpYOug7cDwEPMQ9ED10Pbg99j42PpQ/Tr/zwAMAyAFUAaQBzAJYAogChAKMApwCYAI4AjACZAJwAhgCPAHAAZQBCAESAQsAxgCVAE/AO7/igE4BCAGSAewCKAJMAlQCQALgAzgDBANIA5ADwAQwBEAFIAUABNAEaAPEA5gDCALcApgCZAHSAU0A1QBVP/I/Lj5QPbQ8qDvgO2A7CDsYOtA6oDpgOhg5wDnQOeA56DnYOcA6IDpQOug7RDwQPLA88D0APYA+Aj68Pv0/SUAIAKEA/gEQAdQCTAKUAqwCiALAAuQCqAKEAtgCqAJcAmACNgGoAVoBUgFMASoAhwCngFqAM//SABMAngEmAb4B6AIEAkAChALsAtADHANgA5AD0AQYBEAEyAUQBQAEwARkA9wDtAMAAvgCaAIqAYgBAACDQAw/fD58PYg9ODwAO6g7KDrYOoA6UDoAOgg5yDmIObg5mDnQOdg5+DooOrA62DtAPBg8vDzYPXA9/j5ePtM/cD/7AF4A8AEmAbACGAKUAsQDHAMoAyADPALkAsgC2AKgAkgCUAIUAdQBsgFMAVwA/gBGgF3APT+UP7q/u8AsANQBugH8AcACOAI0AnACZAKsAygDiAP8A8AEuATYBQAFGATYBHgDiANgAxwC6AJkAjQB6gFVAKE/wD94PkQ9qDywO9g7aDrwOoA6gDpIOiA56DmYOUg5cDlIOYg5sDmgOhA6uDrAO7Q8ODyUPQQ9nj4UPq4+7j9bQB4AtwD+AWACDAK4ArAC+AMAA2QDMAMMA2gDMALsAtwC8AJYAhgCNgHgAVwAzADKAM2AXz/zf9b/yT+aP+QA1AGgAboBsAIkAlwCPAIcAtwDZANcA5gEOARwBLgE8AUoBMAEeAO4A2gDFALYAqQCdgHSAVYAtD/RP0w+uD2QPPg7wDtgOuA6sDpgOhg58DmoOXA5MDkgOUg5oDmAOcg6MDpoOsA7oDwcPIQ9DD2ePiA+mz8sP7yAKAC8AO4BQAI8AkgC+ALoAwQDRANAA3wDKAM0AsQCzAK8AioBzgH6AaQBXgD+gG6AToBh/8o/nz9WP1Y/p4AuAMABlAHMAjgCNAIwAhACpAMIA6ADtAPwBGgE4AUoBRgFAAToBCADiANEAwwCxAKoAhYBqADLAGe/rj7KPhA9GDwQO1A60DqYOng6GDoQOfg5eDkAOUA5SDlYOVA5kDnoOjg6sDtEPDw8cDzsPVw9xD5QPvA/fT/vAHgA0AGcAhQCtAL4AwQDSANwA1ADhAOsA2ADRANsAtQCrAJ8AigBxgG4AQEA/wATwCWAKH/XP1c/Ez9zv4TAHQCqAUgBwAHIAfgB9AI8AnAC3ANUA5AD0ARIBPgE+AToBNgEmAQUA4gDYAMwAuACqAIUAbQA3gBwv5o+7D3QPQg8SDuwOtg6uDpYOlA6KDmQOVg5IDkwOTg5CDlIOZg58DogOoA7QDwYPIA9KD1kPfI+TT8uP4CAegCwAQAB1AJIAuADKANkA7QDnAOYA7ADqAOsA2QDOALwAogCUAIyAdIBhAEbAKUAdv/7P1Y/Vj96PuA+sT8egDAAugDuAUYB8AGWAbgB/AJIAtwDAAP4BDgEWATwBVgFuAUIBPAEeAPAA5gDRAN0AvgCVAICAbYApD/nPzo+CD0UPDg7eDrAOrg6IDooOdg5kDlQORA4wDjoOMA5ADkAOWA50DqYOyA7kDxsPMg9VD2aPhA++D9UgDQAkAFgAfACQAMgA1ADqAOEA+AD2AP8A5ADzAPQA7wDPALEAuQCTAI2Ab4BGACBgGGABb//PyY/Bj98Pso+hD8kwAYA4AD0ASoBkgGCAYgCCALYAzQDPAOYBEAEsASABUAFmAUYBLgEFAPoA3ADHAMwApACBAGuAOnAKD90PpQ97DyoO4A7MDp4Ocg5+DmAOag5MDjYOMA4+DiYOMA5IDkoOUA6CDrIO6A8NDy4PTQ9nj4iPps/Y0AVAOYBcAHAAoQDOANcA+AEOAQwBDAEKAQgBBgECAQsA7gDFALUArACPgG0AVQBN4BrP/u/iT+MPzY+lj7WPuY+VD6xP4IAyAEUAS4BdgGsAaQB7AKAA0QDpAP4BGAE0AUoBXAFuAVQBMAEYAPMA4ADTAM0AqQCBAGTAPu/5T8cPkg9gDy4O3A6sDoQOdg5uDlAOXA46DiAOLg4QDiwOIA5ADlIOYA6MDqAO6w8MDyEPVw91j5iPuG/ggCuASYBqAIwAqADPAN0A8AEYARIBFgEYARQBHgEGAQgA8wDTAL0AlwCLgGGAXoA0AC7f8Q/hz9+PtY+ij5wPgw+FD4UPtLAGQDyAMgBKAFUAaQBjAIcAvQDbAOYBAAE8AUoBXgFiAXwBRgEZAPAA8ADsAMEAzgCjAIwARwAUT+iPrg9jDzQO/A66DpoOjA5+DmwOVg5IDiQOEA4WDhIOJA4+DkYOYA6MDqAO6A8FDyMPRA9kD4gPq0/W4BgATgBsAIwApwDPANcA+AEOAQwBCgEOAQYBGgEWARQBBgDjAMEApwCMAG2AQ8A/ABngAA/8T9YP2Y/OD6aPl4+AD46PgY/FIA7AIYBLgFQAdYB8gHUAoADdAN8A0AEOASgBSAFcAWwBYAFGAR4A+QDjANcAzgC9AJmAaoA24Bhv7I+uD20PLA7oDrgOkg6IDn4Oag5eDjYOLA4aDh4OGg4oDjgORA5uDowOtA7rDw8PKA9MD14PcY+5b+zgGoBBAH8AjgCvAMcA6QD2AQ4BDgEOAQgBFAEmASABLgENAOYAyACgAJAAcQBbwDrAL6ACn/PP6U/Tz8UPrY+LD3EPfQ90D6cP1+AEADQAUoBqAGiAcwCeAKsAwQDnAPYBEAFGAW4BZAFqAVgBTgEaAPsA5QDiAN4AqgCCgGNAPt/wz9kPlQ9YDwwOyg6kDpAOig5sDlYORA4qDg4OAA4kDiQOKg48DlgOeA6YDsYO+Q8ODxIPSA9qD4IPyeAKQDQAVoB2AKEAzADFAOABAgENAPwBAgEmASIBJgEgASsA8gDdALgAoACLgFyATcAygCoQD9/9T+9PxQ+zD66PhQ9+D2MPhA+tj8hgBQBHAGCAdAB+AHsAgACiAMgA7QD0ARABRgFsAWIBagFUAUQBEgDtAMgAygC1AKkAjgBXQCrP/A/Pj4YPRA8ODswOnA5yDn4OaA5WDkgOPg4SDggOBg4iDjIOPA5ADoYOoA7ODuYPLw8yD0EPZw+Vz8Df/IAsgGAAkQCuALIA5gD+APABEAEuARwBGgEsAT4BMgEyASQBBwDQALQAmgB2AFuAPUAtIBbQBc/4z+xPxQ+pj4sPew9iD2wPcY+2T+KgEQBEgGqAZoBlAH4AjwCYALMA6AEOARwBOAFkAXwBUAFMASgBDgDFALwAvgCrAI4AYoBewBuP1Y+lD34PLg7eDqgOnA50DmoOWA5eDk4OIg4aDgwOCA4SDioOMA5qDoAOvA7XDwoPIA9LD14PcQ+lT8pP/QA/AGMAmACwAOUA/AD4AQQBGgEeARgBIgE2ATYBOgE+ASwBBADiAMsAkwB4AFKAS0AkIBaQCW/xj+cPxo+1j6KPgg9tD1EPew+Fj7h/9cAyAFqAWgBrgHMAgwCYALcA1ADqAP4BLgFYAWwBWAFeATYBBgDUAMkAvACVAIoAewBRgCRv9M/Zj5IPSA74DsAOqg58DmAOdA5sDk4OMg44Di4OEg4mDiAOPA5KDn4OrA7RDxkPPg9PD14Pcw+hj8cP7mASgFiAcgCnAN8A/gEOAQgBGgEQARIBHgEYASgBJgEoASwBHgD7ANgAvwCBAGuANYAloBVQCd/yf/HP58/Bj7gPpo+YD3UPbw9uD4gPsU/wgDkAVgBqAGcAdwCLAJYAvgDOANAA9AEcATQBWAFYAUYBKADyANcAtQCmAJcAiQBmwD7QB+/3j9kPkw9SDxYO3g6eDnoOeA56DmYOVg5GDjwOIA4+DjIOQg5ADl4Odg64DuQPEA9AD2wPYw9wD5+PvI/jAB6APABkAJsAuwDkARwBEAEaAQwBDAEOAQABLgEsASABKgEeAQYA9ADRALgAhABbwCwgFgAQwBkACk/wT+4PuI+sD5sPjQ9qD1APYg+Bj7wP4wAsgE4AVwBWAFeAagCEAKcAsADfAOgBDAEUATgBTAEwARAA4ADOAKwAkgCWAIiAZQA0wAbv6U/FD5IPXg8aDuIOug6IDoIOkg6MDlYOQA5IDjYONg5ODlgObg5uDowOuA7hDxwPPg9bD2gPdo+RT8xP5UAegDEAZACJAKsAygDkAQIBHAEAAQIBDAEAARQBHgESASIBHQD/AO0A3gCwAKEAhYBZQCfgEcAoQB1/+q/lT+NP1Y+9j50Piw9+D2QPho+kD8Hv8gA1gFGAX4BGgG6AcgCBAJYAsgDeANgA/gEaASYBFgELAPgA2gCmAJUAlACBAGSAQwAyYBMP5g+5D4QPWw8cDuoOxA6yDqQOkg6ODmIOag5SDlQOWg5SDmwOZA6IDqAO1A71DxsPNQ9bD2OPhI+gj8lP2D/zACMAWIB2AJgAuADZAOEA/QD4AQgBCwDwAQIBHAESASYBLgEQAQEA7wDGAL0AiABjgGcAVEA0IBJgFsATgAlv58/eD7WPnQ9wj42PjA+YD7Fv4NAE4BuAKABJgFmAXgBYgGeAcACUALoA0gD/APIBAwD5ANMAwgC6AJ0Ad4BnAFeATIAywDagEo/rD6oPdg9ADxAO+A7kDtIOsA6gDqYOlA6MDnwOeg5kDlwOXA54DpYOuA7jDxoPLw8wD2CPgY+eD50Pq4+xD9QwCIBKgHYAngCkAMwAwgDRAOAA+gDhAOkA6gDwAR4BJAFKATIBGgDuAM0AoQCaAIgAjQBpgEoAOsA8gCsgFqAbj/2Pvo+FD5iPqA+qj6yPyq/sj+/v5aAXwD3APUA2AE+ARwBVAHYArQDHANkA1wDdAMAAxQC2AKUAkwCOAGYAW4BOgEgAREAhX/OPxY+RD2oPOg8mDxoO/A7eDsAOzg6iDqwOkg6eDn4OZg5wDpgOrg64DtwO+w8cDyIPRA9jj4EPlg+fD54Po8/CL/PAOYBkAIcAlwCgALYAtQDGANUA0ADQAO8A9gEcASYBSgFCAS8A4gDUAMEAtgCoAK4AkACMAGoAbwBfAD2AEIAGD9sPo4+qj7pPy0/GT9RP4c/uz9Gv9zAKgAogD8AawD0ASABjAJAAvgCjAKEAoQCmAJAAlgCXAJYAhYB9gGAAaIBOQCQAHs/jj8KPrw+GD3cPUA9LDy4PDg7mDtIOyg6oDpgOlA6aDo4Ohg6qDr4OuA7ADuAPAw8YDywPSw9jD4aPmo+ij7iPso/REAHANgBWgHMAlgClALQAzgDAANQA3gDZAOwA+AESAToBMgEwASABCQDXAMcAygCwAKIAmQCfAICAfQBSAF7AIC/5D8KPz4+5D7IPx8/dT9JP1Y/Yr+D/+Q/pL+pv+/AMQB0ANoBhAIoAjgCBAJkAgQCEAIgAj4B5AHwAeIB5AGcAWABOQCbwA0/sj8IPsY+aD38PaA9XDzoPFA8KDuYOwA62DqAOqA6YDpAOrg6mDr4OvA7KDtoO6A75Dx0PPQ9eD2CPjg+fD6kPqY+hj9kQCIA2AFqAewCZAKAAtQDFANEA0ADWAOQBBAEUASoBRAFqAUwBEgELAPYA6gDHAM4AywCwAKsAmQCWgHKATsAQsAVP2I+0T8vP3M/Tj9WP18/cz8uPyI/eD9aP3Q/aj/lAEsAzAFaAe4B3gGGAbIBpgG2AVYBrAHkAc4BsAFEAb4BGgCmwCE/5j9OPsY+sj52PhQ9/D1gPRw8jDwoO5g7QDsIOsA6yDrIOug60DsoOzA7KDtIO5g7mDvEPKQ9HD1gPYI+Tj76Prw+fj6/Py+/hYBqAS4B9AIwAnAC1ANAA0ADTAOIA+AD8AQoBPAFUAWgBXAFOASoBBgDwAPUA4gDXAMMAxwCxAKoAjYBhAEygBY/uT8YPyg/Dj9RP3g/Lj8zPyA/Mj7uPtY/Ij8+Pzw/swBgANIBEgFGAZ4BVgEeARgBXgFAAVwBUAG2AXQBDAEiAOuAWH/tP1o/AD78Plo+Xj4APdw9RD0QPIQ8IDugO2A7IDrQOug6+DrIOyA7MDswOzg7ODtIO9A8LDxMPSQ9vD3CPkY+rD6IPp4+jT8zP7aAXAFUAjACVAKcAsQDYAN8AyADSAPoBAgEkAUoBZgF8AWABVAE0ARwA8gD/AOoA6wDcAMIAxQC4AJuAbMAw4Btv4E/bz8SP3s/fj9ZP2o/Aj8wPtA+7D6qPpQ+3z86P0WAKwCGAQ4BCgEEASMAxQDfANQBKAEwAQoBVgF0ATwA8wCywAw/lj8mPvg+gj6cPnw+JD3sPUg9MDywPDg7sDt4Ozg66DroOyA7WDtIO2A7aDtYO3A7YDvQPFg8hD0oPbg+DD6aPuc/CT8APuY+67+OAKIBCgH8AmAC8ALYAwwDaANwA1wDpAPABFgEyAWoBdgF4AW4BRAEvAPYA+gD/AO4A2gDXAN8AugCRAIUAbQAvD+HP30/OD8vPxw/Rj+bP3A+9D60PpY+uD5IPpI+2z8zP0JAGwCvAN4A/ACmAI8AiACEAOABAAFyATIBPAEOAS0AkgBAAAc/jD8WPto+xj7IPow+fD3sPVw8yDy8PBA7+DtgO1A7cDsAO0g7kDuIO3g7KDtAO4A7sDvwPKw9DD1sPao+aD7uPuY+9j7RPwg/XD/4AJYBrAIIAoQCwAMwAzwDIANYA6wD4AQwBEgFOAWoBeAFmAVIBQAEtAPMA/gD9APoA7gDWAN8AuwCbAHqAWQAnj/Fv78/eD96P1u/pL+TP1I+1j6IPrQ+cj5cPpY+1D80P3f/4YBCALQATwBhQAHAI4A4gEgAxAEQATQA9QCCAJOAef/4P0k/HD7+Ppw+iD6KPqA+WD3IPVg8wDy0PAw8ODvQO+A7oDuAO9A7wDv4O7A7iDuoO5A8KDxoPLA9HD3YPgI+Lj57Pxc/UD7MPsq/g4AAAEoBIAIEApQCVAKoAzgDPALYA3AD0AQIBCAEuAVoBbgFWAVoBRAEgAQoA8gEMAPMA8QDxAOAAwwCvAI2AagA+MAVv9y/k7+xv5D/6z+XP0k/Mj6KPnA+ID5APoI+tj60Pxu/kX/qv8OAGT/Pv4W/jL/ZwBQAXQCXANgAzwC9QA6AIj/Kv6M/LD7oPvI+5D7UPuo+kj5YPeQ9RD0wPIg8vDxsPEA8QDxYPEw8aDwkPCQ8MDvIO9w8MDykPNA9GD2sPjQ+Mj42PrY/BD8EPu8/F7/GgBGAYAFUAlwCYAI8AmwC7ALsAvQDcAPsA9gEGATABbAFcAUoBTgE2ARIBAAEeARQBHQD2APUA4QDOAJcAiYBtQDngGpAHkAFACi/wD/Av4w/Fj6SPnQ+LD40Pg4+cj5oPqI+1j81Pzc/KT8XPxI/LD8yP1M/24AAgECAdAATwBz/5L+6P1A/aj8SPxE/ED8BPyY+5D6KPmQ9yD2MPXg9MD0QPSQ80DzUPMA8/DxcPGw8cDxQPFw8cDyQPTg9ND1cPdo+Cj42PgQ+2z8HPwE/Lz9K/+f/xQBoARIB6AHyAdQCXAKQAoACyAN0A7wDuAPABLgE0AUQBRAFCATQBFgEAARYBGgEPAPoA9gDiAMUArgCAgHgASgAp4BtgDu/5X/Vf80/oD82Pqg+ZD4IPh4+Oj4MPmg+Xj6EPsY+xD7MPsw+xD7YPt4/ND93P6K//v/6P8Z/0z+2P1w/eT8tPz0/Az9vPxU/Aj8OPvw+dD48Pcg95D2gPaQ9iD2gPUg9bD0wPMQ80DzgPNQ81DzQPRQ9aD1IPaQ97D4kPjI+HD60PsA/Gz8KP4d/7z+dP+cAjgFiAUwBtgHQAkgCYAJkAswDZANUA5gEMARABKgEsATgBMAEiARwBEAEoARQBEgEfAP4A0wDOAKMAkYB4gFOAToApgBrQD2/+b+eP2w+zj6GPmY+FD4YPiw+Oj46Piw+MD48PgY+UD5kPng+Wj6SPtY/ED90P0A/sT9OP3U/Mz89Pws/UT9NP30/Kz8XPzg+yD7UPqI+dj4YPhA+Hj4YPjQ9yD3kPaw9QD1APVg9UD1QPWw9WD2cPag9qD3ePiY+Pj4kPr4+3z87PyM/mP/qv6a/lYAoAKAA7gEsAZACAAIEAjQCXALUAtQC1ANMA/wD2AQIBIgE0ASIBFgEYARwBCgEEARQBGwD2AOsA2ADEAKQAjoBpgFAATcAmgCtAFDALL+SP2g+xj6OPng+KD4SPhA+Hj4UPgA+ND3wPew97D3GPjI+HD5MPoY+7j78Pvw++j7yPuY+5D7APyM/Jj8fPx8/Fj80Ps4+9D6aPrQ+WD5iPnA+ZD5QPkQ+Xj4cPfQ9hD3MPcA9yD3oPfg96D3APjA+Pj4wPho+cD6kPvo+wj9aP5o/rz9Pv6H/9j/TQBIApAEGAXIBPgFsAcgCAAIIAnACmAL8AugDYAP8A/gD6AQABGAECAQ4BCAESARQBAAEIAPMA7QDMALYAqQCDAHQAYoBdwD2ALmATkAOv7o/AT80PrI+Wj5KPmY+ED4OPgA+FD3EPdw94D3YPfQ9+j4YPlo+dj5iPqo+mj6oPoQ+yj7KPug+xj8+PvY++D7yPtw+zD7KPv4+rD6yPr4+tD6iPpg+iD6iPkg+TD5WPk4+TD5cPlw+TD5WPm4+dj50Pkw+gD7kPsw/BD92P24/Yz91P0e/lz+Ef+9ABACjAJIA7AEeAWIBSAGYAdACNAI8AmwCwANsA2QDkAPQA8gD+APoBDgEOAQIBEAESAQQA+ADnAN0AuACoAJMAjwBhgGYAX8AywCswB2/wb+vPzw+0j7cPrA+WD58PhA+ND3kPcg99D2EPeg9wj4KPh4+Mj40PjQ+Aj5aPnI+SD6kPrQ+uD68Pr4+vD64PrY+sj6uPrI+tj64PrA+tj62PqY+kD6IPoY+sD5iPnI+fj50Pmw+fD5MPoY+hD6ePqw+sj6QPsM/Lj8DP2c/Sz+Pv4M/lj+LP+5/1cAbAGcAlAD5AOgBHgFAAaYBoAHkAiACaAK8AsADaANEA6QDgAPUA/QD4AQ4BDgEOAQgBDQD/AOIA4QDbALYApQCUAIAAfoBegEgAPUAVwAI//I/Xz8qPvo+uD58PiA+Bj4QPeQ9kD2IPYA9gD2YPag9qD2sPYQ9zD3MPeA9xD4ePig+Pj4iPnI+eD5IPpw+oD6aPqQ+sj62PrI+uj68PoQ+xj7OPs4+yj7KPvw+rj6sPrg+uD68PoQ+zj7UPtQ+4D70Pv4+yj8nPws/bD9Fv6k/iP/Xf92/8X/YwAIAbYBlAKIAzgE0AR4BVgGIAfgB7AIoAmACmALQAwQDcANMA6gDiAPsA8AEGAQoBDAEGAQsA8QD3AOUA0ADNAKsAlwCCAHIAYYBdgDMAL6AN3/bP7g/MD7CPvw+fj4UPgA+ED3YPYA9iD24PVg9YD10PXQ9bD18PVQ9nD2gPbw9nD3gPeQ9xD4kPiQ+Lj4IPmQ+aD5sPn4+TD6GPoQ+mD6uPrQ+jD7sPvg+6j7cPtw+2j7SPtw+8j7EPwo/FD8jPys/Kz84Pws/Vj9mP0m/tr+YP/G/x8AagCSAMcATAEUArwCVAMIBMgEWAX4BbgGiAcwCNAIoAmQCmALIAwADdANQA6wDkAP0A9AEIAQ4BDgEIAQABCAD9AOsA1gDGALUAoACegHEAcABngEAAPaAWMAqv5Q/Yz8kPsw+iD5iPjg9+D2MPbQ9WD14PSw9AD18PTA9MD0APXw9PD0UPXg9UD2UPaw9iD3UPeA9+D3SPhg+Ij4+Phg+XD5gPng+Sj6OPp4+hD7iPug+9D76PvI+6D7wPsY/ET8XPyw/BT9MP1E/Yz9zP3k/QD+bP7u/k7/vP85AI4ApwDNACgBlAEUAqgCTAPgA3AE+ASYBTgG8Aa4B4AIMAnwCdAKkAtgDAANoA0gDrAOUA/QD0AQgBDgEMAQYBDADxAPAA7gDMALoApgCTAIMAcQBrAEIAO+AToAjP4U/SD8KPv4+ej4EPgw93D20PVw9fD0cPRA9DD0IPQQ9ED0cPRg9GD0sPQw9YD14PVg9rD2wPbw9nD30PcQ+Gj44Pgw+Vj5qPkQ+mD6gPrQ+jj7mPvo+1T8sPy4/LD8uPzY/Pj8LP2Q/ez9Jv5O/oz+wv7a/gH/V//G/ycAmAAoAZ4B8AEQAjgCbALEAiwDsANIBNgEUAXIBWAG6AaABzAIAAmwCTAK4AqQC0AM0AxADdANQA6wDkAP0A8AEPAP0A+AD+AO8A1ADVAMAAuACTAIOAcABrAElAN8AuoAWv/k/ZD8SPsg+jj5KPgg90D2wPVA9bD0QPTw86DzYPNg86Dz0PPg8wD0QPRg9JD0IPXQ9UD2oPYQ93D30Pcg+JD4GPlg+aj5KPqg+gD7WPuo++D7CPw8/Jz8EP1w/ZT9qP2k/Zz9oP3I/RT+Yv6a/t7+I/9T/2T/gf/J/yIAWwCrADgBxAEcAmQCsAL4AigDfAMIBIAE8ARgBegFWAbQBngHQAjwCJAJMArACjALwAtwDCANgA3gDWAOAA9AD2APoA+wD1APwA5wDsANwAyQC2AKEAl4B1AGWAVwBCgD+gGnAAv/VP3Y+7j6sPmo+MD3APcw9nD14PRg9ODzUPMA8/Dy8PIg80DzgPOQ84DzoPPw83D0APWA9eD1QPaA9tD2QPew9xD4aPjg+Gj52PlQ+tD6OPto+5D7+Ptk/Mz8PP2k/dT9tP2w/Qr+Tv5k/r7+Wf+1/7X/0/9AAHkAagCmAEABsAHwAWgCCANMA1QDjAP8A0gEeATwBIAFyAUABoAGAAdgB8gHkAhACbAJIArACoALsAsADKAMMA2ADfANcA7ADsAO0A4QD+AOUA6gDRANIAywCnAJMAjYBngFaASIA2gC8ACC/y7+qPwg+wD6KPlA+CD3QPaQ9eD0MPSQ82DzEPPA8pDy0PIA8wDzAPMg80DzUPOw81D0IPWQ9RD2gPbg9iD3cPcI+JD4CPmA+SD6kPro+lj7yPsE/Bj8gPwc/ZT92P08/oL+gP5m/oj+9P5I/5H//f9vAIQAeACuAA4BOAFAAYQBFAKEAsgCHAOEA8QDyAMABGgEyAT4BDgFoAX4BRgGeAYYB7gHIAiQCCAJsAkQCnAKIAugC+ALQAzgDHANoA3QDUAOoA5wDjAO8A1wDXAMYAtQCgAJqAdIBlgFSAQUA+4B0gBl/8T9aPxQ+yj6+Pg4+ID3oPag9RD1oPQQ9IDzYPNg80DzIPNA83DzUPNQ86DzEPRQ9KD0IPXA9QD2MPaQ9vD2UPeg9zj44PhQ+bj5KPqo+gD7OPuQ+wT8dPzg/Ez9xP0S/j7+SP5o/or+vP4T/3z/1/8WAFQAigDHAOQAHAFsAawB4gFEArwCAAM4A3wD3AMYBFgEqAQIBSAFQAWABdgFIAaABigHyAcwCGAI8AiACdAJMArACmALwAtADOAMcA2gDcANEA4wDhAOAA4QDpANoAxwC1AKAAmoB5gGwAXYBMADkAJWAez/cv4k/fD7yPqg+cj4APgg9zD2gPXg9DD0sPOA84DzgPNg81DzMPMA8wDzQPPA8zD0gPQA9WD1wPUA9mD20PYw94D3CPio+Dj5mPkA+oj6yPoA+2j7HPy4/Bz9jP0A/lL+aP6g/vj+R/+G/9z/XgC5AAABPAGEAawBtAHqAUgCrALUAhgDZAOMA5gDxAMwBGgEkASwBAAFCAX4BBgFaAWoBegFWAbwBmgHsAcgCKAI8AgwCbAJYArgCkAL0AtQDLAM4AxADZANoA2wDcANsA0ADfAL4ArACXAIUAd4BrgFsAR4A1gCIgGo/y7+9PzI+5D6WPl4+LD3wPbQ9SD1kPTw85DzgPOQ84DzMPMQ8wDz8PLw8lDz4PNQ9KD0APVw9bD18PVQ9tD2MPeA9wD4mPgg+Yj5APpg+qj6+Ppw+yD8oPz4/Fz93P0O/jj+gP7u/j//Yv+3/ywAlgDLACIBegGWAZIBvAEoAmgCkALQAhQDKAM0A3wD4AMQBDgEeASwBLAEuAQABUgFeAXABVgG6AZYB8AHYAjQCAAJYAnwCZAKIAugC0AM4AwwDXAN0A0wDkAOIA4gDgAOgA2ADIALUArwCKAHuAYIBhgF2AOcAnIB+P9w/vj84Pu4+nj5ePiw9+D2APZA9aD0EPSA81DzUPNA8wDz0PLA8rDysPLw8mDzwPMQ9HD0wPTw9DD1sPUw9oD2wPZQ9/D3ePjw+Hj5APpQ+rD6SPsQ/JT8CP2k/TD+Zv6m/iP/mP+7/+z/ZADYABoBbAHcASgCIAIgAmQCqAK4AuQCQAN8A2QDYAO4AwgEKARABJAE2ATgBOgEGAVgBWgFeAXwBYgG6AZAB9AHYAiQCNAIQAngCWAKsApQC/ALUAxwDOAMUA2QDaANsA2wDVANoAywC5AKMAkACAAHOAYwBTAEEAPSAU0AyP6A/Tj86Pqg+bj40Pfg9gD2cPXQ9BD0gPNw84DzUPMA8wDz8PKw8oDy8PKQ8+DzIPSg9CD1UPVw9QD2kPbA9hD3sPdI+Jj4+Pig+Sj6YPqw+mD7BPxw/Oj8mP0W/kT+lv4j/4n/s//m/2gAywD/AEwB0gE4AjgCRAJ0ArACuALMAiQDbANwA3gDyAMQBDgEUAS4BAAFCAUQBUAFeAV4BXgFyAVABqAG8AZgB9gHEAhQCLAIMAmgCQAKoAowC6AL4AtgDNAMIA1ADXANwA2gDVAN0AwQDNAKYAlACEgHQAZIBXgEiAMYAncANf/w/XD8APsQ+jD5GPgg92D2sPXQ9BD0wPOQ8zDzAPMg8xDzwPKA8qDy0PLg8jDz0PNA9ED0cPTg9ED1cPXQ9XD2EPdg99D3cPgI+Wj50PmA+jD7sPtM/Az9rP0G/lr+4v53/8v/GACXABQBTAF0AdQBTAKIArAC9AIwA0wDWAOMA8wD6AP0AxgEUARoBIgEsAToBAAFAAUYBSAFMAUgBUAFcAWYBcgFEAaIBtAG+AZQB8AHIAiACAAJoAkgCnAK0ApQC7AL0AtADLAM8AzwDOAMsAzwC8AKoAmQCIAHcAbQBfgEyAN0AjYB7v9g/gT9CPwQ+9D5uPjw9yD3APYA9YD0EPSQ80DzQPMw8+DycPJg8nDyYPKQ8hDzkPPA8+DzMPSQ9MD0APWQ9TD2oPYQ95D3IPiQ+Oj4gPkw+rj6SPsI/MD8VP2w/RT+hv7m/j//rv83AJEA2gAUAX4BygEMAmACzAL8AhwDOANoA5ADjAO0AwAEQARABHAEwATwBOgE8AQgBTgFOAVIBYAFmAWwBdgFMAZwBrAGCAdoB8AHEAiACPAIYAnQCVAKwAogC4ALEAyADNAMIA1wDbANoA1ADaAMwAuACjAJEAhIB2gGWAVYBFAD8gFMAO7+0P2g/Ej7KPpA+Tj4APfw9UD1gPTQ82DzYPNQ8/DyoPKQ8mDy8PHg8TDysPLw8jDzkPPg8/DzIPSg9DD1kPUA9qD2IPdw99D3gPgg+aj5OPr4+sj7YPwA/Zj9Cv5U/sr+cf/0/1IAuQBKAY4BpAHeAVgCsALwAjwDjAOcA5QDtAPoAwgECAQoBGgEiASIBKAEuATIBNAE6AQIBRAFIAVIBWAFeAWIBdgFOAaYBugGSAfIByAIUAjACFAJwAkQCoAKIAuQC9ALMAzQDBANAA0gDTAN4AzwCwALMAoQCbgHqAbwBQgF2AO4AqwBPACq/kj9PPwQ+9D5uPjQ98D2wPUQ9aD0EPSA83DzUPMg88DyoPKg8mDyMPKA8hDzUPOA8xD0kPSw9LD0UPUQ9nD2kPYg9+D3KPhI+OD4sPko+nj6OPsI/Gz8uPxw/Sj+bv6Y/jH/3v8nAE0A2wB2Aa4B2gFsAhADUANgA8ADIAQYBNgDEASIBKgEmATIBDgFQAUABQAFYAV4BTgFUAWIBYAFKAUwBYAFmAWgBQAGqAb4BhAHYAfoByAIYAjgCJAJ8AlACtAKYAuwCwAMkAwADSANIA0wDfAMQAxgC3AKQAnIB7AGGAZgBUAEMAMwAq4Apv4c/WD8gPsA+rD4MPgw95D1YPRQ9CD0IPNg8qDy8PJA8qDx0PEA8mDxMPEA8tDy0PKw8lDz0POQ85DzoPSg9bD1sPWQ9nD3gPeg96D46PlQ+oD6kPvc/ED9OP30/Rv/of/S/40AggHWAegBZAIQAzwDTAPoA5gEuASwBAAFQAUYBQAFKAVIBUgFYAWIBWgFGAUwBWgFSAX4BAAF+ATQBLgEwASgBHgEmATgBBgFSAW4BUAGkAbIBhAHeAcACMAIYAnQCUAK0ApAC6ALMAyQDIAMYAzADMAM4AuQCqAJcAiQBnAFoAVoBdADRAJsAUH/WPxg+1z8+PtQ+bD3wPeg9rDz4PKA9ND0kPJQ8YDyIPPQ8dDwgPHg8RDx4PCQ8gD0oPOw8tDywPNA9ID0cPXQ9nD3EPfg9qD34PiY+QD68PoE/FD8gPx0/bD+Dv8B/6b/xQBQAXgBEAKQAngCYAL4ArADAARIBPAECAWYBGgEuATQBMgE4AQABcAEMARwBAAF6ARgBKgEEAWoBBgEMASgBHAEOARwBNAEuATIBHAFKAZQBmgG4AZoB9gHcAggCaAJ8AlwCgALYAvgC4AMIA1QDRANsAywDOAMYAywCvAIeAegBewD/ANQBWAEigDM/Vz9CPx4+Sj5IPvA+lD24PKw87D0kPIQ8aDywPPQ8WDw4PFA89DxIPAg8eDysPKA8lD0MPYg9RDzcPPQ9ZD34Pd4+Fj5SPlA+Hj4ePoQ/Gj87PwE/nD+GP6q/k4AUAFAARgB0AHQAnQD3APwA4wDQAPoA6gEIAVoBXgFOAW4BFgEeATgBCAFMAUIBWgEyAPUA0AEaAQwBNADlAOUA5wDhANkAygDCAMQAzADVAOgAzgEcAQoBBgE6AQABkAGIAawBsAH6AeIB1AIAArACmAKwArQC+ALwArACtAL8AswCsAIIAiQBjAEEAN4A1gD4gH8/yz+8PvI+cj4EPn4+LD3EPZQ9FDygPFQ8hDzkPKg8dDxUPLw8TDx8PEQ87DyMPJw86D1QPbQ9eD1gPag9gD3QPmg+6D7GPrY+eD6kPsc/JD9J/8I/yD+dv6V/w0AWgBuAVACIAK0AUQCLAMcA4wC3AJ8A6gDCATYBAAFEAQ4A6wDoATABEgEaASABLgDCAOAA4gEkATYA5AD7APAAyQDdAMIBKQDpALcAtwDIASsA7QDiATQBMgESAVwBrgGaAaYBngHIAiACIAJgArQCqAKIAsADEAM4AsQDGAM8AsQC4AKgAngBkgEkAMIBNQDGAMwAtn/oPtY+HD4APr4+eD4IPig9XDxoO8A8pD08PMw8vDxEPLw8LDwoPKg8wDyYPGg88D1wPUg9dD18PXg9FD1oPhg+wj7iPn4+PD4KPkA+/D9hP92/iT9kP32/uL/hQCQATgCDAIYAgwDzAOUA2AD1ANoBJAE+ATgBRAG4AQIBLAEsAXwBdAFsAUQBTgEMAQgBXAFkAQgBIAEkATAA2QDjANcA8wCkALgAiQDAAPMAvQC9AL8AqgD0AR4BXAFSAWQBVgGOAcwCCAJwAnQCRAK8AqwC9AL0AtQDCAMYAswC2ALIAooBwgF4ATYBPQD2AMwBAQBsPsg+ZD62PuI+pD5ePmw9mDxAPBg87D18PPQ8eDxkPEQ8CDwcPIA8wDxEPBw8gD18PTw87Dz4PMg9GD1sPdo+UD5CPhQ98D3WPlY++D8bP00/cj8EP1Y/jkAZgFGAb8AJAFUAmwDzAN0AyQDTAPwA7gEaAVoBVAF0ASYBAAFcAVABWAFcAXgBCgEwAOIBGAFAAUABNQD/APQA5ADTAMEA4QCjAIIA0wD2AKUAtwCRAOQAygEuAQABUgFuAUwBoAGEAdgCJAJ0AnACSAKIAsQDJAMgAyADGAM4AsgC9AKIArYB/AEyAMQBcgF+APOAeL/IPxI+Gj44Pts/eD5EPUg86DycPGw8TD0EPVw8sDvEPAg8dDwcPDA8fDyIPJA8dDycPWA9YDz8PKw9ND2MPgA+TD5ePgw96D3MPp4/Bz9RP2Y/aT9ZP0Y/v//uAF4AhgCkAHKAQwDsARABagEOATwBJAFyAVYBqAGGAZ4BeAFgAYoBkAFgAWABigG2ASQBGgFiAXQBFAEYAQgBGQDSAPAA4ADgAIkApgC0AJoArgChAOsAyADQAOQBFgFKAVIBXAGMAcoB7gHQAkgCuAJQAqgCyAMIAvQCpALIAzwCpAJ0AhAB/gE8ANIBBAE8AJsAVj/KPxA+Sj4IPnI+ej4MPdg9MDwYO9w8ZDzcPPA8QDxkPCg7wDv8PAQ82DyMPFA8nD00PRg9PD08PXA9cD1ePh4+0D70Pg4+Kj5OPuY/HT+qP+g/jT9AP4FAPIAWAF8AkQDvAIkAvQCSASYBGgE+AQ4BdgEYAX4BlAHwAWIBGgFsAaABuAFKAYgBsAEKARgBWgGeAU4BHgE0ASsA7QC8APwBIgDhAHKARQDAAOAAjgDIAQwA1wCmANwBWgFiARABegGWAcYB0AI8AlACtAJgArwC3AM4AvwC0AMcAsgCsAJoAmYB9gEmAMgBGAEoAMsAkj/6Prg93D4wPpo+yD6APgg9MDvIO9A88D2kPVA8rDwcPDA73DwIPNA9CDyIPGQ85D1sPSA89D08PUw9ZD1sPjA+ij5MPew9+j4uPnA+7L+bP8I/Yj7SP3L/6AACAHuASQC3AGAArAD9AO4A3gEyAUgBrgFUAYYB4AGaAXgBTAHWAfQBtgG4AaABVAEcAVQB+AGyAQgBMAEYAQgAxQDQAToA9oBJAE0AsgC+AGWAXwCBAOAAnAC3APgBGgEGARoBcAG6AZIB+AI0AlgCYAJAAsgDLALMAugC4ALEAqACRAKwAiwBfQDWAToBDAE+AI0AUT9WPng+Gj7oPxg++j4kPXw8YDw8PIA9gD2gPPQ8ZDw4O4g7xDyUPQA8xDxcPEg82DzUPOA9BD14PNg83D2wPkw+WD2QPUA9xD5IPvE/ID9xPyg+zT8RP75/7wAmAFUAlACHAJsAlADOATQBEgFwAU4BpgGCAeoBrAFkAXQBugHmAeQBrgFQAXgBFAFiAbABmAFyANoA3wDSAM0A8ADeAOWAX8AjAGkAjgCqAGQAjgDWAI0AlAEoAWYBAgE2AV4BzAHaAfQCXALIAqQCWALAA3ADIAMEA2wDPAKcAlQCeAISAf4BTgFkAQQBCwDkgD0/Aj7APvI+pD6GPuQ+rD2oPFQ8PDyMPUQ9eD0MPTw8EDt4O1Q8sD0YPNw8eDxcPIA8pDyUPTQ9BD0QPQA9lD3kPag9XD2EPjg+Fj5kPo0/Cz9LP2g/DD9rP5uAFQCVAMEAxACOAJ4AzgFSAbIBugGsAbABhAHcAdYB4gHuAeABwgHMAdAB2gGsAXwBXgG4AXwBNAEsARcA2wCgAMwBIQCqgAWAQQCnAH9AAACdAPAAhoBmAH0A/AEgAToBFAG2AZgBhgHkAlAC+AKMAowC3AMUAywCzAMsAxQC8AI0AdACGAHaAVYBKgE5AMaAaD+bP0M/Bj6oPmQ+oj6IPgQ9cDycPHg8eDzAPZw9ZDyoO9A7sDu0PHQ9OD0oPIw8QDy0PJw84D0oPXA9XD1cPaA9wD3cPbg95j56PkY+sj7jP1Q/ZD8XP32/jEALgFYAtACLAJQAsgDMAVYBRAFcAWwBpAHqAc4B9gGGAdoB1gHAAcYBzAHqAZgBoAGKAYwBbgEOAWYBZgEVANgA8QDAAOkAUwBCAKEAmQChAIMA7gCzgEEAsADiAWYBfgEcAXoBlAHKAewCBALsAuQCmAKsAtwDMALsAtgDNALoAkwCCAIAAfoBBgE4ARgBEQC6f+U/Qj7cPlI+tD7cPtI+cD28PMw8SDxsPSA93D2UPOg8ODugO4w8fD08PWA81DxwPGw8vDy4PNg9VD1wPRg9bD2kPaQ9VD2qPiQ+VD5iPq8/Fz9ePy0/Jj+TADVANQBDAMUA1wCNAOwBcgGwAVYBegGMAjoB4AHEAhgCHAHoAaAB0AIKAdgBjgHqAcABkAEeATABYgFGATIA8QDqAJYATIBsAGeAZgBNAKUAtIBswDiAHgC1ANwBPAE4ASYBEAF2AYgCKAIUAmAChALYAoQCiAL8AtgC5AKcAqQCaAHKAYgBoAF7ANEA6QDqAIu/+j7sPp4+mj6WPtE/Kj5wPSw8UDyAPQw9YD20PYw8wDuIO3A8PDzMPSQ8zDz4PGA8JDxYPRA9RD0wPNw9UD2gPVw9cD2sPfw9/j42Prg++j7VPyo/XD+nv6h/7ABIAMkAxQDqANoBAgF0AXIBnAHmAfIB0AIUAiwB0AHwAdACAAIMAcAB4AH4AYIBvgF0AWIBAgEqAQYBegDDALiATACLAFaAOgBlAP0AlYBDAGwAeIBvALIBPgFKAVwBFgF4AbwBxAJEAowCuAJkAqgC4ALEAugCwAMgAqwCEAIMAiwBhgFyATIBIADUgGg/wL+OPv4+Oj5hPwM/aD54PRQ8hDy0PLw9LD3MPeA8qDtYO1g8LDy8POg9CD0IPHg7tDwsPRA9ZDzoPPw9BD1gPRg9aD2EPfg9kD4uPqI+yj76Pso/dT9jv6n/zABpALYAzAEwAN8A8gEEAdQCFAIgAjwCEAIqAeQCLAJMAkQCCAI4AgQCAgGGAbwB2AHoAS4A6gEwAS4A1wDQAPEAcr/KwB8AuACSgH1APgBygGmAHwB+AMwBXAE/APoBPAFcAbYByAKcAogCRAJIAuwDMALkAogC5ALQArACIAIIAhIBrgE6ARIBVADfQDc/jz9GPsY+nj7rPwQ+1D3EPRg8mDyQPTQ9vD24PMA8MDtYO7w8DD0sPUg9ODw4O9w8SDzUPRQ9bD1UPRQ84D0EPdg96D1IPYg+cD6IPrA+iD98P24/OT8q/+yAZYBeALYBNgENALgAbAFEAkQCdAH4AfoB1AHkAcQCZAJoAhACIAIyAdYBogGyAeYB/gFwASABDAEKASoBCAEfgGq/+YAHAMEA7IBxgEIAkwBqwBkAtAE4ASUA+QDcAVoBXgF6AfgCqAKUAgACHAKEAxwCzALwAsQCzAJoAhACVAIeAUwBMAFgAb0A1oAQv4s/RD8yPvw/Nz8sPnQ9SD04PPg8wD18PZw9mDyYO4A7mDwoPJg9OD0gPIA78DuAPIw9BD0wPNg9NDzoPKA8+D1EPag9ND10Piw+QD5MPog/ND7MPtw/ekAiAHPAHACYAQEA3AB/AMACMAI+AfgCIAJgAeIBdAHMAvACkAIAAiQCEgHEAYIB1AIUAdABagE6AQ4BEQDbANEA44BOQDqACwCVAKGAekAtQC8AHgBCAPkA4ADFAOcA5AEkAUQB+AIsAmwCOgH0AhwClALcAuwC0ALsAmQCNAI4AhgB/AFaAbABnAETAEcAHP/gP14/ID91P3A+hD3UPaw9lD1cPRw9jD30PMg8EDw8PEw8iDykPMA9BDxQO/Q8GDzcPPg8nDzsPMQ8yDzcPTQ9DD04PRA9xD5wPmQ+tD64Pk4+sT96AEsA3wCIALqASgBTAJgBkAKMAoQCIAHiAc4B4AH0AmACwALMAnIB0gHuAbIBiAIAAlgB+gEQATIBAAFCASYAgAC7AH+AXgCCAPQAeb/w/9eAdQC1AKkAlwD8ANYA2ADQAUgB+gHQAgQCXAJ8AgACWAKUAsAC+AKMAvwCrAJcAioB3AG0AWwBuAGiARmAcz/yv4A/Tz86P1U/qD6sPaQ9iD3oPVQ9ID1EPZA82DwMPFA82DygPAw8YDy8PHw8GDxAPKw8ZDxkPKQ86Dz8PKQ8uDyQPTQ9jj4OPhQ+ED5uPkI+mz8HwBIAggC2AH+AXABVAHgBGAKMAwACmAHmAb4BmAIcAswDvAM4AjQBsAH8AjwCFAI6AcAB8AFGAWQBXAFbAPeAeIBxAKUAqoBgAEMAhoBHP9s//gBwAMoA2ACtAIkA1gDsAQYBzAIgAcwB5AI4AnwCXAJoAmACmALcAsgCsAIMAiwB6AGKAbABogG7AOgAM3/VwB+/8D9YP3o/Kj6GPgA+Pj4kPeQ9ODzQPVQ9UDzoPHg8WDyoPEQ8TDy0PJw8TDwIPGA8pDygPHw8XDzQPMA8pDyEPVQ9nD2kPeg+QD6QPlw+tD9cgBSAeACMASMAigA8AHgBtAKwAuQCrAIGAbIBUAJoA2QDuAL0AjYBrAGIAiACQAJQAcABpgFwATEA7gDyAO8ApgBcgGqATwBwgAwAe4A3P/R/7gBuAOwA0ACvAHkAugEcAYoB1AHWAeIByAIEAkwCmAKEApwCtAKAAogCHgHgAjQCBgHIAV4BMgDeAJcAQoBTgCA/vD8aPzo+1j68Pgo+JD3sPag9fD0sPRw9GDzMPLA8UDysPJg8qDxQPEQ8QDxgPFw8kDy8PCQ8JDxgPKw8oDzAPWw9dD1kPYo+Bj5wPk0/Nn/vAFmAdwAFAE8AcwCOAegCyAMQAngBqAGMAgAC2AOoA+wDMAIgAdQCFAJQAqgCiAJMAbgBNAFAAYIBMgCQAMcA4IB0gCeAXIBwP8b/2wAIgHOAEABxALkAjgBMgH8A7AG8AZgBnAG2AYAB+gHMArAC7AK4AjwCJAJAAkQCLAIgAkQCAAFZAO4A6gD5AJQAl4BDv+U/DT81Pws/Dj6kPgI+KD3wPYg9pD1YPRg85Dz0PNA82DyAPLA8WDxAPGg8VDy8PFQ8fDwoPBw8HDxUPOA9JD0MPWA9vD2kPbQ9zj7Wv5AABAC9ALNAAz+cwDABmALwAvACuAJIAcoBZAIMA9AEQAOgApwCfAIgAgQCgAMAAuYB7gFOAaABiAFxAMkA8QCaAIQAoQB+wCpACwAuP/X/54AVAGcAQQCiAJYAlQC5AM4BlAHkAboBYAGEAjACcAKgApACaAIAAlwCYAJYAnACAgHEAWQBIgE5AM4A+gCdgGo/iD8APxQ/dz8uPrQ+KD3cPbQ9cD1sPXA9EDzoPKw8qDysPHA8KDwYPGw8TDxYPBA8KDwcPAA8FDwsPHw8oDzQPQg9bD18PXw9kj5GPyS/lkAhgGyAZ0Axv/YAVAHsAywDWAKeAd4B6AI4AoADwASABBQCngHgAlgC4AKAAogC8AJaAWYA+gFEAfMAxYBKAJEA34B5v8aAboBUf9Q/Tb/3AHKAfkAxgHcAlACogEoAyAGcAfYBoAG6AaYB2AIkAkwCsAJsAgQCGAI8AiQCBgHaAWABKAEcAR4A2wChgGy/2T9pPwU/Tz9+Pvw+SD4oPbg9VD24PbQ9fDz8PLg8lDysPGQ8cDxkPEg8RDxwPAA8IDvUPAQ8QDxkPBw8VDzkPTQ9BD1YPaQ99j4wPpC/soBvAKgAfsAagGgAgAGcAtAD6ANIAmwBnAIQAtgDqAR4BFwDYAImAdwCRALgAuQCxAKsAbsAzgE8ATAA5wCzAIkAjsAiP86ACUAYP7c/U7/IQBM/+v/QAJoApMAOwDUAjgF0AV4BlgHoAYQBUgGoAnQCgAJ4AegCOAIoAf4BoAHAAdgBfAEMAX4A+AB5QCoADv/bP1c/eD9fPzI+Tj4YPeA9jD20PZw9mD0MPLg8RDygPHQ8CDxsPEQ8eDv4O7g7iDvQO/g74Dw4PDw8CDyEPQA9TD0EPTA9rj6oP2x/5IBrAHA/yD/WAJYB9AKEA0QDvALoAeoBiALYBAgEuAQsA6gC6AIwAiAC3AMoAogCdAIIAdgBPACFAPYAhACXAK0As4AEv68/eD+yP42/o//egFGAXf/S/8cAVACJAMoBQgHYAbABFgF0AcwCRAJUAkACmAJIAhwCHAJsAgAB3AGwAYYBqAECATkAwgCif+Q/gz/1P6Q/ST8ePpI+JD2kPZQ9wD3kPUg9ADzEPJw8WDxoPGQ8SDxkPDA7wDvAO9g74DvQO+g75DwkPGg8tDzgPQg9GD0MPdo+1z+9P9aAXoB1/+a/6wDoAmwDDANAA0wC/AHMAgADiAT4BIgD9AMEAyQCqAK4AyQDSAK6AY4ByAIYAZEAxQC+gGSAY4BNAK0ASL/tPyc/Ab+Wf8vAAQBHAE1ANb+2v5wARgFQAfABqgFCAVgBcgGIAnwCoAKMAnQCGAJIAkQCNgHMAjYB9AGAAZIBfwDnAKEAVcACP+W/tr+NP7A+9D4MPfQ9jD3UPew9uD0wPKQ8VDxUPEA8eDwsPAg8CDvIO4A7uDugO8A74DuIO9w8CDx8PFw80D0QPQA9hj6uP16/qz+NgAqAUgAXALQCKANEA1ACrAJcAlQCVAMABPgFWAQsAnwCLALsAxgDVAOwAxgB7gDYAW4B+AF0AJgAnQC9wCO/wYADQBm/vz8dP1M/sD+5f+aAbIBpP9C/uH/WANIBsAHiAdABlgFCAYQCNAJkArQCuAKIAqQCFAHWAcwCKAIIAiIBrgEdAOYAp4BdwBM/6b+UP50/aD7YPlw94D2gPag9hD2sPQA87DxAPGQ8HDwkPCQ8MDvoO4g7gDuIO7A7kDvAO/A7oDvMPHQ8fDxQPPA9ZD3cPng/Pz/Z/9c/dT+FAMgBqAIMA3QDwAMOAbQBhANoBEgE2AUQBMQDbAGAAigDsARQA/wC4AJOAZ0A6ADuAUQBtQDrAH+ABkAjP6s/Q7+jP5K/sD9Gv7f/0ABuwA7/wj/6QBAAyAF4AbYB7gGQAUABmAIwAmgCSAKMAtACtgHAAfgBxAIUAcgB9gG8ARcAowB8gH2ALL+XP1c/Zz8gPqA+HD38PYQ9iD1gPTw86Dy4PBA8NDwEPHA76DugO6A7qDtQO1g7iDvwO5A7iDvEPBQ8CDxAPOw9AD2iPhk/Pb+r/+y/9H/2v/oAcgHMA6gEAAOsArACDAI4ApAEmAYIBdgEJAKgAhgCSAMIBDAEdANcAdQA2wCBAOwBKAF8AOnAJj+pP5O/qD9pP1s/Sj8IPzS/igBdABm/kr+Pf8QAEACMAagCEgHKAUQBVgGiAdACZALAAxACiAIYAdQBygHgAcQCGAHEAXsAroBFAFJAJT/Av/E/cD72PnI+Ej4QPcA9jD1APVg9LDycPFQ8aDx8PAg8MDvYO/A7mDuwO7g7mDuYO6g73DwcPDg8ADy0PLw82D2cPm4+wT+zAAwAnAAG/+4AWAHoAzwD2ARoA5ACQgHUAsgEkAWgBZgE3AOEAogCaALkA7QD+AOEAugBSACPALYA4AEAARQAjX/cPyw/AP/Qf+s/Lj6uPu8/ST/EACaAND/cv7a/tYBIAXYBngHWAewBggGqAYQCWALIAzgChAJiAdAB/AHoAgwCHgG4AS4A6gCPgEXAJn/1P4E/Rj70PnA+ED3QPYg9nD1oPNw8mDy8PGw8ADwQPCg74DuoO7A7wDvIO0g7eDtAO4A7lDw0PIA8sDvwPCA9OD2iPjU/MoBIAN8AA7/3gAYBBAIEA5gE2AT8A1QCWAK0A4gE4AVYBagFEAQ8AugCrAMoA7ADmAN0ApQB/QDuAKgA0AEUAJF/+j9NP6Y/lD+uP1w/ND6gPpY/EL/6ADXAFQAr/+Q/9cAqAOgBkAIIAgYB4gGQAewCPAJYArwCSAJ+AdoB8AHkAdYBqgExAPYAmgBWgA+AMz/mP3w+pD56Piw93D2kPZg9tD00PKA8fDwQPAg8GDwIPBg7+DuoO6A7cDsQO1g7aDsoO3Q8PDxoO9g7hDxEPNA8kD0CPzgAsQCeQDt/x7/XP6UAwAPgBbgE6ANQAtgC0AMABBAFoAZgBbgEdAO0AxwC3AMIA8AEFANUAkYBqQDuAL4ApwCsgDO/lL+OP7M/UD9QPyI+hD5ePrM/ez/IQBaAC0A9P6q/kYBWAV4B7AHwAcQCDAH6AbwCEALIAtACUAIgAiACKgHSAcoB7AF8ALrALgA9QCTAD3/dP3w+lD4wPaA9qD2gPYw9rD0cPKw8FDwAPCg74DwwPHA8ODt4Owg7uDtgOsA7GDv0PAg72Dv8PGQ8aDuwO/w9fj6FP1qAUAG1AMk/GD6gAKwDAATgBXAFMAO8AfgCKAQIBcAGEAXABYgEuAMEAvwDMAOsA5gDVALEAecA9gCXAMMAk//zP1Y/Wj9lP2I/Qz8wPmw+Mj5kPtI/aP/TgGYAOL+7P79AIAD+AWQCMAJkAgAB7gH4AkAC9AKsApQCiAJmAcwB4AHEAeYBcwD3AERACj/Iv/S/iT9+PqQ+JD2oPXw9UD2EPWg8+Dy8PHA70Du4O/g8VDxQO/A7qDuIO3A60DtYO9g7uDsIO9Q8hDxAO7A7rDy8PQQ90T9iARIBZgAlP14/hgBqAbAEOAYgBfADpAI0AhADQATgBiAGqAWIBAADEALsAvwDOAO0A4gC2AGnANsAqoBEAHRAFX/LP3M/CL+pP7c/Mj6sPmo+QD7WP7oAfwC6gHLAIYAywCIAnAGYArQC+AKcAmwCFAIsAhACrALoAvwCVAIWAcoBrgEwANoA6gCGAFZ//z9vPwY+3D5GPgw90D2MPVA9IDzAPNQ8kDxMPDA76DvoO8A8JDwUPBg7mDswOyA7oDugO3A7mDxsPEA8ODvMPEA8RDyOPnQAsAFKALR/xwAbABoAWAIQBMgGEAVYBBwDRALcAugEaAZgBuAFsAQ0A3QC7AKwAuADeAMAApoB/gENAKq/xL/2v7I/WT88PvY/KD9gP2I+zD5MPjo+VD9DAHAAyAEeALDAD4BlAOABnAJIAwwDRAMIApwCSAKIAuQC1ALcAoQCQAIgAfgBugEUAI/AIH/Fv9u/jD9UPso+UD38PUQ9ZD0UPTg8/DykPFA8BDw4O+A72DvMPCQ8GDvwO3A7WDuwO3g7QDwwPFg8ODuoPAA87DwgO7Q87z9+APoA/gCxQDQ/GD7EAOgD6AV4BOAEcAQEA1gCZAL4BOgGcAYIBXgEVANMAnQCXANwA4ADCAJsAcwBe4AOP46/vT+kv7Q/Yj9vPwI+3D6APv4+kj6yPqw/TAB7AIEA5gC2AHIAbQDKAcwCrALEAywC4AKcAmQCVAKsAqwCjAKwAiwBoAFaAVgBMoBs/8z/8T+dP34+8D62PgQ9oD0IPUA9jD1kPOA8pDxgPBA8CDxsPEg8QDwgO9g70DvAO/g7YDtgO5Q8FDwAO8A74DwEPBA7jDw0PZI/cwAtANIBEz/CPmg+xAIABPgFaAUoBLgDoAKUAvgEQAYgBnAGMAWABJwDHAKoAwAD4AOwAsgCagGYARsAqcApv4U/aT87PxA/cz8CPxY+5D66Pm4+ZD6IP3/AEgEGAWkA7ABDgGcAnAGIAvADUANcAswCjAJIAhwCDAKUAtQCnAI0AYABfwC5AHUASABM/9U/Rj8WPsg+jj4IPbw9BD1gPUw9QD0APPA8bDwcPBQ8eDxMPEg8MDvwO+A7iDtwOxA7UDuAO+g76DvYO4A7UDsYO3g8GD3Gv+IBIAFYAHw+yj5tP1QCQAVYBlgFwAToA7wC8AMwBHgFwAbwBrgF6ASYA0wCzAMIA0QDRAMoAn4BVQDiAJIADj8ePr4+8z8UPvY+kT8FPww+dD3QPnI+vD7Dv/gA+gF6AN8AZwBjAM4BsAJ0AzADZAM8AoACpAJIAkgCVAJ8AjoB2AGuAToAlIBZgCE/8j9oPsY+uD5kPlA+GD2EPWQ9AD0cPMw8yDzsPKg8iDzAPOw8SDwEPDQ8NDwMPCg7+DuAO5A7uDvcPBA74Du4O7A7sDuIPLo+Q4BiARwBIoBsPwA+vD/EAwgFuAYoBZAEjAOYAwgDoASQBfgGYAZwBXAEIANEAygCyAMkAxgCvgFMAOMA0QD1P8I/Nj6wPrI+YD5iPtU/Yj8YPp4+ZD52Plg+5L/iASIBlgFVAPEArwD+AVwCZAMAA5QDQAMwAqACZAIoAgACTAI0AbwBRgFUANeAWUAa/+8/Pj5MPmo+Rj5wPcw92D2QPSA8rDyMPPA8sDyMPRQ9DDyYPCA8HDwAPAg8XDy4PBg7aDsQO8g8GDu4O3g7wDw4O2g7iD0aPvNAGAEoAWoAij9+PsUA7AOABfgGEAXIBSgEOANIA/gE2AYYBmAFwAVwBEgDkAM4AwgDWAKEAa8A5gDRAPiARAAgP0Q+pD3wPdg+aD6wPu4/IT80PpY+UD62PweALgDeAbIBoAF8ATIBUAHIAmwC3ANMA2wC8AK4AmQCBAIQAiYB3AFzAMoAwgCDwDC/jT+UPxA+ZD38Pfw96D2IPYg9hD1cPPQ8kDzQPMQ85DzwPPg8iDy8PGA8ZDwUPEQ8sDvIO2A7kDx4O8A7cDuQPIA8CDrgOzQ83j5yP6oBpAK7ANY+oj6cAMADCASoBjAG6AXoBAADpAPgBGAFIAY4BmAFqARUA7gDOALgAuwCrAH+AM8AvwBNAHJ/5r+jPwo+RD3wPeI+Uj6OPsA/Vz9ePvo+gT9l/9cAawDqAagB5AGCAagB7AI0AgwCuAMAA5ADPAJkAiAB/gFGAWABcAFkARoApQA3P4E/SD7+PlI+cj4WPjQ9+D24PVg9aD0wPOA84D0wPSg86DzUPWg9fDy0PAA8gDzoPAA7wDxIPIg72DtAPCQ8UDuAOzg7tDwgO6A8Ij7iAaACMgEagEK/kT8iAFQDuAYwBqgGKAWoBMQDyAOYBKAF2AZABmgFuARMA1wC1AMYAswCBgFLANuAQ0A3/9g/2j9wPr4+GD3QPbA9pj5ZPw8/fj8uPxM/FT8Rv6mAaAEWAbAB8AIYAgoBxAHoAjQCjAMwAxADNAKwAjQBlAFeARABEgEqAMcAjUASP6U/PD6CPpY+VD4cPdw98D3kPaw9ID0oPWA9cDzcPMA9bD18PQw9eD1UPTw8FDwcPIQ8qDuwO3g8ODxAO9g7WDvwO/g7ODrgO9A9AD5nwAACZAK1ANw/aT9CAMwCqAS4BlgHMAZYBXgEUAPwA7gEaAWYBggFoASYA+ADNAJQAjIBjgENgH+/wgAN/+E/Tj8aPuQ+UD3MPZA9xD5SPuo/Sv/5v68/cD9VP9kAcADyAawCaAKsAnACPAIgAlACqALwAzwC8AJMAhwB1AG0ATsA2QDFAIwAPj+Tv4s/cj7gPpA+bD3oPaQ9tD2sPZQ9vD1gPUg9RD14PRw9ND0cPYw97D14PPg8xD0kPIw8SDxEPCg7eDtoPHQ8sDuAOug7ADvoO6Q8LD3g/8YA2gE2AVYBIMA8gCACOAQIBWgFwAaoBngFaASYBIAE2ATQBUAF4AVgBFwDvAMYAowBtAC0ACH/5r+Wv4o/vD88PqY+KD2QPUw9UD22Pgc/Dz+vP6K/sj+P//X/5oBsASoB6AJ8AqQCwALQAqgCtALQAyAC6AKkAlwCFAHsAagBcADugFxAFj/FP4c/ZT8sPsQ+lD4APcA9sD1gPbw9tD2YPZQ9vD1YPVQ9aD1oPUA9vD2QPbw8/DysPRA9SDywO5A7+Dw4PAg8cDxYO9g6aDnQO0Q9ZD4IPtOAOgD5gGo/mYAsARQCHAM4BIgF4AWoBTAFeAWABUgE8AT4BQgFMASYBKgEXAPEA2gCugGGAIg/mz8iPxI/RL+/P0g/Bj5EPYg9LDzAPXA9xD73P2x/48A4gAgAXYBIAKIA9gFkAjACvALgAyQDEAMoAsQC2AKYAlgCNgHcAeQBkAFvAMEAjUA1v7Y/bT8mPvo+jD64PiQ9yD3QPcg96D2QPZA9oD24PYw9yD3UPeA9wD3APaQ9TD1MPSA81D04PMA8KDsIO8g9KDzQO4g6sDogOeg6JDwGPvK//D+qv7L/4r+/Pz1AOAJwBBgE6AUoBWAFYAUoBRgFiAXABagFOATABPAEQAQAA9wDsAMsAjoAgj+oPtg+/D74Px8/SD8+Pgw9jD18PQA9dD24Plc/Kj9iP/+AfwC5ALUA4AF6AX4BRAIMAuQDIAMwAwQDRAMUApACdAI2AfABtgF4ASQA0ACAgGd/3j+oP2c/BD74PlI+aj44PfA91D4cPjg92D3gPew99D3IPiA+Ij4UPig94D2cPVg9XD1IPRw8eDvYO+g7mDvEPKw82DvoOfg4wDnoOzw8sD6jAEQA4sAqP5O/7cA1ANwCuAR4BVgFiAWIBZgFiAXYBdgFgAV4BRAFAAS8A8AELAPcA1gCiAHcAL4/Gj6WPt0/Nj7+PqI+vj4kPYg9TD10PXw9lj5+PvI/U//RgEMA8gDIATYBAAGOAewCGAK0AuADIAMAAxAC2AKUAnIB2AGmAXoBKQD+AH+AE0AHP9w/WD8mPtw+ij5cPgo+LD3gPfg9wj4UPfA9gD3kPcI+ID42PiA+Dj4iPgA+BD2gPQg9XD1MPMg8CDvgPCQ8WDyIPJA7wDqgOYA6EDtwPNQ+t3/fALyATEAg//VAKAEkAqgEEAUoBVAFuAWIBdgF4AXwBYAFaATABNAEmARwBAAECAOsArgBvAC+v4U/GD7uPsY+wj6ePng+FD30PWg9QD2UPZQ98j5MPyE/c7+DAEsAwgEUAQABQgGEAdACJAJ0ArQC2AMYAygC0AKoAgQB/gFCAVABIQD/AJQAu4AVv/E/VD8sPqQ+Sj5wPgo+PD3gPhQ+PD2APZg9tD2oPbA9mD3gPcg9xD34PYg9VDzUPMQ9IDyAPAg7xDwIPEQ8hDzIPEg7CDoIOkg7XDxIPf0/ZwC9ALYAdYBoAIoBPgHwA1AEqATgBTgFUAXIBjAGKAYABegFKASQBEgEOAPYBDgD3AN0An4BUgC6v4A/Vz8qPtY+ij54Piw+AD4UPeQ92D48PgQ+dD5mPuA/eL+qAA4A1gF4AW4BWAGMAcYB1AHMAlQC8ALEAvQCjAKIAjwBUAFCAXcA+wC9AKYAuwAQ/+U/lj9KPvY+SD6GPpI+Qj5cPmY+LD2APag9uD2gPYA96D3IPcw9lD2UPZw9IDygPJQ8xDyAPCA7xDwQPCg8GDx4O8A7KDpgOtA70DygPYc/VQCXAOYAugCwAPYBBAIkA3gEQAToBOgFaAXABjAF8AXQBcgFYASwBBAEIAQYBCQD3ANQAqABuwCEQDs/Vz8OPuA+uj5KPkw+FD30PYg97D3KPiI+CD5UPqw+yj9TP/sAdgDwAQwBaAFuAWABWAGoAjQClALEAvwCmAKoAjIBhgGAAaIBcgEQARcA8ABJABn/+T+uP0k/FD7IPvg+vD5EPmI+CD4gPfg9sD2sPaA9oD2APeQ9tD0wPOA9BD1MPPQ8FDwEPGw8ODvMPCg8MDvQO/g72DvgO1A7cDwsPVw+kH/UAP4BKgE2ATABdAGMAmgDcARYBMgFOAVYBeAFyAXIBdgFUASQBAAEKAPcA4wDmAOgAygCPAEJAJV/3j8QPtg+yj7YPrA+Zj5APlI+Cj4mPg4+dj5iPpA+zT8xP3l//wBsAPoBEAFyASABDgFqAYQCDAJEApQCrAJgAiIB+gGcAbQBSAFkATwA8wCagFrAN7/Q/9q/rz94PyY+wj6OPng+Ej4cPdg98D3UPdg9gD2APaA9eD0APUA9RD0IPMw8zDzAPKw8NDwQPGg8MDvkPBw8RDxQPAQ8GDwUPGQ9Cj6lP/IAhAEkASgBNAEcAZQCSAMcA7AEAATABRAFMAU4BUAFsAU4BLgEBAP8A3wDRAOQA2gC+AJwAfABHYBEf/c/ST9hPzA+9j6qPnQ+ND4YPmw+ZD5mPko+rD6yPo4++D8S/8WAd4BSAKkAtACNANoBAAGCAeAB8gH4AdYB6AGWAZYBjAGmAX4BDgENAMsArwBpgFUAZkAtP+a/iz9yPvg+mj66Pl4+TD54Ph4+AD4wPdg9/D2UPbQ9RD1UPTw88DzkPMw8yDz4PIw8kDx4PAQ8eDwwPAg8YDxUPFw8UDz8PYQ+3r+/wBkAvACXANwBBgGQAigCiANMA+AEIARgBJgE+AT4BNAEwASwBCwD/AOoA6QDlAOMA1gC0AJ4AZ4BGQCCgH//9L+rP3U/BT8YPsA+yD7KPuQ+tD5mPnY+Sj62Pog/KD9rv48/7X/BABYAAYBJAIcA+gDsASgBRAG0AWgBdgF+AWIBRgFwARIBKQDUANoA2wDFANwApwBWQAA/+z9FP1Y/Lj7KPt4+uD5iPlI+bj48Pcw94D2wPUQ9aD0QPTA84DzQPPw8pDyMPIA8iDyYPKQ8oDyUPJQ8hDyEPKA89D2aPrY/F7+3f9QAVQCdAM4BfgGYAgQChAMcA0ADgAPIBGgEqASwBEgEYAQsA8QD+AOwA4gDnANgAzwCvAISAdQBjAFoAPyAYwAYf9i/qz9IP2o/Ej8BPxw+3D6kPmY+Tj6uPoY+6j7QPyI/Nj8jP1q/vz+if+EAFoBrAHYAWwCQAO4A8wD0APMA6wDiAOYA7wD3APkA8QDcAPoAnAC5AEmATEAVf+u/gz+aP2s/DT8sPvo+gj6cPnw+Bj4IPeA9mD28PVA9fD0IPXw9DD0oPPA8+Dz4PMg9ID0UPSw8wD0MPVA9iD3qPgA+xT9VP4z/y8AQgGUAhAEmAWoBsAHMAnACgAMAA0gDhAPUA/gDqAOgA5QDiAOUA5ADpAN0AwwDFALsAkgCAAH2AVABLQC0gESAen/8P6s/nT+qP3A/FD86PsY+3j6gPrQ+gj7cPsU/Hz8sPw8/Rj+tv7y/kD/xv8xAIIADgGwAQgCPAKcAgADBAPgAvQCMAMcA6QCUAJIAiwCwgE4AdcAewD0/17//v6Y/gD+WP3k/Gz8yPsg+8D6WPqo+fj4sPiQ+Ej4APjg98D3cPcA98D2kPZA9iD2UPaA9qD2sPZA9yj48Pig+XD6YPso/Lj8bP1e/m7/kgCqAYQCHAPQA/AEMAYgBwAIEAmwCdAJ0AkgCmAKYApwCsAK8AqQChAK0AmACcAI6AcYByAGEAUwBJAD3AIgAsIBkgEUAVgA8v/M/2z/zP5i/kL+HP7k/dz9EP5C/mb+oP7i/gL/D/8m/0z/Vf9G/1H/ef+p/8P/3f8GAC4AWACEAJkAhwBgAEQALwAIANT/q/+S/2b/Pv8m/xD/6P6u/nr+PP7s/ZD9QP3w/IT8GPy4+3j7QPsw+zj7OPsA+8D6mPpw+jj68PnQ+cj5sPmo+cj5EPpY+qj6CPt4++D7QPyc/Pj8YP3U/Vz+6P5f/9n/fgBCAfgBoAJkAyAEmATYBAgFSAWABcAFKAaYBvAGGAc4B1AHOAfYBmgGIAbIBUgFuARABAgE/AP4A+ADvAOcA2AD/AKUAjQC2gGEAUIBDgHHAHgAVABkAGQATAAzACgA/f+a/0v/MP8o/wz/8v78/hP/I/84/1n/gv+K/6D/wf/G/5v/dP9s/2j/W/9l/4D/ef9q/3D/cv9J/xL/5v62/nD+JP70/dD9kP1I/ST9BP3U/KT8gPxg/Dj8CPzY+7j7kPtg+zj7OPtQ+2j7kPvA+/j7FPwk/Fj8oPzQ/Pj8QP2c/fD9PP62/k//yP8CAC4AcQDTAFYBzAEYAlQCuAIwA2wDdAOgA/ADKARABGAEiASYBJgEkASQBHAESAQ4BDgEIATgA7ADmAOAA1ADFAPoAtQCuAKUAngCXAI4AhAC9AHgAcoBogFwAT4BEAHaAJcAUgApABAA7f/G/63/lP9i/yv/D//8/tT+mv50/lr+Ov4Q/vT91P2o/Xj9aP1k/UD9HP0U/Rz9JP0s/TT9PP1M/Vj9YP1g/VT9VP1k/Xz9oP28/cj9zP3U/ej9+P0G/h7+RP5u/pz+uP7W/v7+Lf9I/03/Yv+W/9D/8/8aAFMAjgC3AN0AEAE4AUwBXgGAAaYBtgG6AdIB8gEMAhACGAIsAkwCUAJAAjwCPAI0AhwC+gHsAeoB8gHuAeAB0AHCAbYBsAGqAZIBbAFKATIBHAEMAQ4BHgEiARoBEAH+ANsArwCVAIIAXwAyABoAGAASAP//7f/g/8z/sf+W/3z/V/8z/x7/C//2/ub+3P7I/qj+kv6Q/pj+kP6G/oD+fP5u/lj+Sv5I/kj+Tv5Y/lz+Yv5y/oT+kv6S/pD+lP6i/rj+0P7s/gr/Lf9V/3z/nf/D/+//GQAxAEoAaACCAIgAjQCkALwAxQDNAPYADgESARABJAE0ASIBFgEcAQ4B8ADvAAgBBAHcALcAqQCdAIUAbgBhAFEAQwA3ACMADgACAAIA+//m/9v/3P/d/8v/wf/G/8f/vv+1/7b/wf/I/8f/wv/D/8T/u/+1/7z/y//K/7f/pv+o/7f/xP/L/8//1P/d/+n/7f/m/+b/+P8JAAYA+P/y/wAADwAQAAEA8P/i/9j/1f/S/8v/wP+0/7H/s/+w/6L/l/+T/4r/ff91/3H/cf9z/33/jf+d/6//xv/Z/+L/6f/5/wwAGwAwAEYAUQBOAE0AXQByAH4AfwCKAJwAqgCxALcAugC1AK0ApgCkAKcApQCcAJcAmACVAIcAcQBdAE0AOwApABsAEgAPAA8AEAAIAPX/6f/j/+H/2//b/+L/5//p/+z/7v/l/9r/2f/Z/8v/sf+f/5//qv+s/6f/p/+v/7H/qP+f/6T/rP+p/6X/rv+1/6v/p/+7/83/yf/D/9L/4//Z/8r/1P/r/+7/3v/e/+//9P/m/9v/4//h/+D/6v/3/+n/2P/b/+n/6//n//T/AAABAAIADQAYABoAGQAiADMAPwBPAFsAWQBUAFkAYwBoAGYAZwBrAHMAhQCUAJkAjAB4AHQAfwCDAHwAcgBvAHQAbQBgAF0AZgBoAFoATgBNAE8ASgBJAFMATQAtABAABgAFAP//8v/k/9r/2f/a/8//uf+r/6v/r/+u/6f/n/+X/5H/jf+M/43/kf+c/6P/nf+U/5D/lf+a/5T/hv+L/6j/vP+8/7v/xf/P/8r/wf/E/9T/3P/d/9//6P/w//X/9f/2//f/9f/z//b/8v/j/9b/2//s/+3/3f/Y/+T/7f/q/+j/7v/u/+b/6f/y/+r/1v/O/9z/6f/u//X/CAAeACgAKQArACsAKAApADIARABUAFoAWQBdAGMAYQBcAFkAVwBRAEoARwBLAEwARQA7ADYANgA3AC4AHAAOAAoACwAGAPz/+P/3//X/8f/t/+v/6P/h/9z/2v/b/9P/zP/R/9z/2//Q/83/0//R/8X/uv+6/8T/z//T/9P/1//i//P/BwAXABgADgAGAAUABAADAAcAEgAaAB0AIgAoACYAHwAeACEAHAAQAAgACQAMAAoACAAIAAcAAgD7//z//f/6//X/+P8CAAgABAD9//r/+/8CAAoADwARABQAGgAdABoAFwAYABoAGwAcABoAFAAQABIAEQAGAPn/+P8CAAMA+//4//v/+v/1//P/9v/6////CgATABsAKAA4ADsAMgAtADQAMAAgACgANAAxACAAHwAuACYAEwAPABIACQAGABoAJwAYAAAAAQAUABYAAADx//D/7f/b/8n/yP/Q/9H/zf/P/9j/3P/Z/9P/0//U/8//yv/J/8//1v/X/9L/zf/O/9D/z//U/+T/8//1/+j/2v/Y/+H/5v/h/9b/1P/e/+z/9P/7/wgAEwAXABEACAADAAkAFAAcAB8AIwAsADgARwBTAFgAUgBCADoAPQA/ADcALgAuACoAHQAPAAoACQAAAPb/9////wMAAQACAAQAAgD8//r//f8EAAgACQAFAAQACAAMAAYA+f/y/+//7P/q/+7/9v/9/wMACAAJAAUA/v/0/+3/6v/r/+v/5//l/+n/7P/s/+z/6//t//L/9f/s/9z/1P/R/8v/xP/E/8P/vP+7/8r/2//g/+b/+/8KAAEA8P/s/+//6//h/97/4f/j/+X/7P/2/wAAAwD9//L/7f/p/+L/3f/l//D/8f/y//v/AQD1/+j/7f/6//n/8v/+/xQAGAALAAgAFQAZABMAFQAeABwAFgAYABwAGAAWACAAJAAhACYANQA3AC4AMQA+ADsALAAvAD4APwAyAC0AOABGAEwARQAzACQAJwAwACsAGQAOABAAFAASABQAGQAbABMABAD9/wMABgDw/9j/4/////r/1v/W/xEAOQAYAOb/5f8IABUA6/+1/6X/uv+4/47/eP+q/+7/6v+//9P/FQAVAMX/n//M/+b/u/+a/8T//f/6/9v/4P///wUA7v/b/9n/3P/i/+v/7//s//D/AAAMAAkAAAAEAA0ABQDu/+f/8f/4//b/9/8OACkAKQAWABEAJwA8ADMAGAATACwAOQArAB0ALQBFAEUANwA/AFkAWQA5ACEALgBFAD8AIgAZADMATwBNADQALwBIAFYAPQARAPz/AwAAAOX/1//p/wEAAADv/+b/5P/a/8D/of+P/47/kf+I/3//iv+i/6X/jf9//5j/uP+m/2j/W/+q//L/w/9n/3//6//x/3z/cP8SAHUA//+U//7/nQCIABAAFwCZAMIASQDl/z8A3QC5AN3/bf/v/3AABQBi/6r/eQCYAAQA5v+YADgBLAH2ADgBsgHMAYABJgHdAEwAKv/s/ZT9xv6wAAgCoAJAA9wDUAMyAZj+lPzw+lj5WPiw+FD6gPyy/qMAMAJgAzAEKAQYA6ABlgAEAGP/zP70/gEAJgGsAd4BSALQArwC2AHNADEA2P9c/+D+zv4y/9L/dAD5AFQBnAHKAXoBjQB1/7T+JP5U/Yj8fPxE/Sj+pv4z/zIAGAECATUAyv/X/2D/JP5c/cD9ZP5o/nD+Yf+XAOoAogDSAE4BDgEhAKb/3//e/0D/2v5e/0oAtwClANQAeAHaAWoBqAByAL0AngDQ/1L/7v/jAPgAaABtACgBaAGsAAUAagAoAQQBOAAQAO0AvAGQAeQAngCmAC0AKv+G/s7+cf+h/23/iP8yANYA0ABFAOT/6f/U/zz/iv5u/tL+9P6e/mz+4v6Q/7//h/+A/7v/sf84/9r+Fv+m//b/9/8YAIgA6ADPAGEAFQAMAPH/i/8g/yP/gv/T//3/QgC+ACQBNgEWAQgBDAHsAJ4AWABTAIUApQCbAKgA/QBUAU4B+gCnAGoACQB9/w3/6v4B/yT/SP9z/67/3//a/6r/i/+M/27/MP8y/57/GABEAFgAkgC3AHYA8P+H/1z/Rf8i/xf/Uf/M/zgAVgBPAGgAfgBVABQA8P/O/53/pf8GAGEAiwDUAE4BagH4AIUAYwAxAKj/Nf83/1v/QP8g/2P/5f8yAEYAawDEACABPgH6AIYANwAZAOX/cf8Z/y3/cv99/3n/0P9qANEA1QDVABABSgEcAXEAsf9V/0D/8v5q/kr+3P6d/wUAQQC7AEABOAGXAA0AEABBAAQAb/8//6v/EQDz/9H/SADgALwAEADo/3gAzABXALn/kv+p/3//IP8H/1//z//0/8z/lf9t/yz/vP5U/iT+Kv5e/sz+Z/8GAJAAHAGeAc4BlAE4AegAfgDj/0z/Gf9T/5P/ov/b/28A6QCyAO//Q//g/lb+kP0s/ZT9Rv6u/hP//f8iAZ4BZAFOAbABwgEMAU4ASgCkAKsApwBAAUACzALUAvQCRAMsA3QCngEOAYUAvP/y/nz+Vv5M/k7+Zv6M/qD+nP5u/gL+iP1M/Wz9xP0+/vr+/v/4AIYBpgGqAaoBegEEAZAAZQCSANoAEgFMAYoBrAGCARoBuQCOAFYA3v9m/13/nP+k/3f/h//4/0oAFQCt/5r/uf+D/+T+hv7U/ln/Yv8b/z//yP/z/2f/qv5M/h7+uP1A/Tz9uP06/pT+I/8DAMIACAHmAK8AjwCTAKMAnwCHAKcAEgFUARwB7wBaAeABxgFGAUQBwAHeAWwBKgF2AZwBHgF1AD8AaABwAD8AOQCKANwAxQBeABgADgDe/13/8P7s/gT/1P50/kL+av7A/hj/YP+A/1//Dv+8/qr+6v47/2L/kv8GAIcA2AAsAbQBFALEAe8AYgBbAE4A+P/O/ysAgQAsALH/6f9KAI3/Dv54/Tr+3v42/z0AoAHOAdMAfQCqAG//LP3o/GD/tAEcAigCcAOYBLADfgFYAFoAUf8k/Mj4wPeY+MD4kPdQ90j5ePvY+7D7lP2yAAgCHAGBAOYBzANQBDAEeAVgCOAKcAsAC3ALcAzAC4AIeAQEArkA3P6I/OD7sP3r/7gA3AD2AZgDxAOWAYD++Pvo+aD3sPVA9ZD2aPjA+fj63PwO/6QAJAHjAGEAuf/a/ib+VP6G/xwBeAKYA4AEwAQwBEgDMAJlAOD9wPsA+2j7FPzM/Pz9wv+OAZACdAKMAT4AlP6M/Lj60PkA+tj62Psc/dr+1wBAAoQCLAJAAoACvAEXAGP/OgAKAaAA+v9qAJABRAJYApQCMAOMA9gChgHnAHgB6AH3AM7/YwAwArQCZAGmAL4BvAKWAe7/UQDQAX4Bbv/E/mEAbAH4/yb+aP6I//z+VP1I/Tv/0QBeACP/Hv8OAEgAcf/o/r3/PgHKASwB2wDSAQQDlAKFAD7/FgA2AZoAmv+QAMQCTAO+AZIAJAG8AZwAyv5M/i//Wf+U/cD7fPzq/p//7P3g/Db+qv8U/yD+RP9iAbABJwBk/38AtAFOAeb/Jv9h/6z/ZP/w/h//+v/AAMQANwDn/yUAQQCF/4b+aP74/vT+KP4o/tb/qAGuAaAAewAqAfQAuP85/wYAaQBj/4z+P/84AP7/Mf/6/hn/vv4U/tT9Cv42/ij+Ev4m/nL+1P5E/wUAFAHEAdQByAHaAYIBrgA9AJYABAEyAa4BrAKEA7wDoANIA2QCCAEJAOz/LwBEAD8AjQAQASYBjADz/9j/kP9s/gz9mPwQ/Tj9sPxs/Dz9hP5d/+b/0wDUAcIBbQBE/3f/HQDC/+z+Wf8KASACsAH1AEwBEAKWAeD/0P5r/0EAhP/Y/YD93P7O/0X/yv62/+sAwQCx/2//IABUAHP/iv6Y/iL/Rv8d/5n/CAFUAlQCXgH2AHQBpgHLAL7/hf/d//v/EgDKAL4B/AF+ARYB7gB1AKD/H/9C/03/oP7o/TT+OP+L//b+9P4xAD4B3AATAEgAlwB6/+z9LP4DADIB9gDcAOgB8AKsApQBFAF8AaYBtABs/2L/ngCIATABxwBsAQQC9QAD/zD+kP58/rT9tP3m/rX/QP/C/iz/qP8d/wD+cP2Q/Qz+zP7L/8QAfgHgAa4B2ADv/3r/PP/c/rD+Iv/n/3AA2wB0Ac4BbgG0AFoAWQAjAKv/Zf9r/2H/Uf+u/1wAlAAKAKH/KADrAMIAwf8Y/zX/S//a/pr+Wv+aADgBAgHkAHwBDAKOASAAIP85/2j/mv6s/WL+jgD+AbgBUgEoAvwC9gHk/+j+Qv9f/6D+SP5U//cAtAFcAfUAPgGMAdoAbf+y/jz/1v9Z/1T+Bv6G/vr+Gv9a//f/lQCsABIAJv+M/ob+pP6m/t7+gP8TAD4AagDfACABwQAzACcAkADtAAIB4ACgAFcAJQAMAPn/CQBIAGMACwB2/y3/Zf/B/9b/tP/J/wcA5/9c/x3/n/9KAGMAQgB+AMUAZQCJ/zf/2v+2AAIB7gA2AfIBSAKYAXsA9v8DALb/6P54/uz+r/8GAAkAPwCyANYATQBI/1b+zP18/UD9lP2o/pv/gf8H/4P/zQCEASwBsgCfACcA5P7s/V7+q/+EALQALAFAAiQDAAMkAnYB9gAUAMD+3P0e/uT+NP8i/6X/5QDMAWwBWgC+/4b/yP6s/Wz9SP4e/w//zP5K/x4ATwD4//j/bgCvAGgA9//R/+r/DQA6AGsAagBBAGgAFgHKAQQCwgE8AWwAX/+Q/mj+vv44//P/8QCqAcwBsAG0AYgBvACF/2z+rP1g/bT9nv6h/1oAxgAQAUQBZAF2AV4B5gAmAGb/yP5I/i7+3P4xAGgB4gHqARACQALSAc0A7f95/w//jv5S/pb+If/N/5YAFgHxAH0APADx/zH/Zv5Y/vz+iv+t/9f/aQAWAXABhAGgAZgBBAEbAJb/oP+V//z+Zv6Q/j7/sP/b/zUApQCSAPv/qP/O/7v/If+u/tz+PP9T/3z/MwASAToBnAAKAA4AOwDY/+z+Sv5q/ub+Uf/b/7kAhAG2AWYBGgH1AJsAz//s/oT+wv4T/yD/R//l/4gAeQDk/4n/of+x/6D/0/9IAG4AGgDh/z0A1wAaARABEgEkAfsAlABKAE0AVgAgAOH/DACgABoBFAG8AIUAcwA4ALL/O/9G/8T/IgAEALn/vf/6/+7/hP8s/xH/7v6m/o7+3v5O/4T/hf+c/9X/AwAOAPv/5f/f/+b/6v/y/xwAcACsAIgAMwAdAF4AoACtAKEAnwCBAAAAQf/G/u7+cv/I/8H/yP8qAIkAcgD+/5z/U//c/lD+Kv6i/mj/JQC5AP4A2ABsAA8A7P/6/x4AMgAvAB8A+v+7/43/qP8HAF4AmADhACwBKAHuANkA1gCSACUABgAsACwAFgBeAO0AEAGaAD4AewDTAKwAOAAbAFcARwDI/3L/mv/D/4j/XP+p/xUAGwDy/x0AdwB6AAsAlv92/6H/2P/r/+z/DwBUAGUAPABFAJsApAABAFD/KP8//xr/C/+e/20AqgBIAPb/FgBJACYAxv+H/3v/T//u/rr+DP+f/+n/zP+i/7T/5//1/+P/+f9oAOcA8wBmAM//vv/7//T/tv/f/4wADgHxALMA3AAQAasA2f9o/4b/h/8a/8b+Hv/V/z0AQABUAJgAnwAmAJH/Tf9K/z3/O/+Z/0oA9wBcAYgBhgE+Ab4APADg/6H/d/9l/2P/eP+9/0kA6gBGAUQB7QBYAJb/3v50/mj+nP7Y/vz+IP+A/xoAkQCWAF4AQAAQAHn/0v7I/l//6f/x/8f/5/9MAKAAugDMAPkABgGXANP/bv/B/0kAdACIAPIAbgFsARQB/QAOAcAAEAB1/yP/AP8T/2b/wP8IAEYAUADX/yb/6P4c/xb/uv64/kL/vP/X/+v/KQBMABUAxP+N/17/Sf9w/77/BAA+AG4AeQBoAFAAUQBaAFoASgAwABAA/P///yEAYwCqALYAcgAWAOH/1P+//5T/a/9M/z3/Vv+i/xYAhAC6AKIARADF/2b/Pv9K/4n/7P9TAKIAwQDOAOMA/gAEAd8AgQD8/4b/Nv8Q/yH/gf/x/xsA5v+r/5v/cP8a//r+S/+W/3v/Pf9S/6j/3v/x/xEAMAAbAMn/Vv8Q/0v/1/8iAPv/7f85AFAA4/+T/93/LQDn/2L/O/9q/5v/y/8PADAAGgDi/6r/eP97/7X/8/8NACQAYgCIAJAAwwBGAaoBmAFUATgBSgE+AQgBvQCUAL4ANgGOAXIBNAFiAdgB6gF8ARABEAEcAd8AjgB7AIQASgDg/6X/p/+d/3L/Wv9p/1f/E//E/rL+3P72/uL+xP7u/lj/s/+u/6b/5f9lAJkATgDi/6T/jv+F/67/CABqAJUAnwChAKMAqQCkAIcALACy/0b/+P6y/oz+uP7+/tz+MP6U/XD9bP0M/YD8RPxQ/Dz8+Pv4+3j8HP2c/ez9Hv5G/lr+Vv5A/mT+tP7+/jD/Zf/7/6sACgFQAfYB9AKkA6QDdAOMA6ADmAO0AzAEyAQgBWAFsAXIBbAFmAVwBfAEUATQA3QD+AKUAtQCcAOsA3gDUANUAwQDWALEAYABWgEgAQYBBgEoAWIBpgHSAboBlgE6AYAAh/+y/kL+9P28/az90P3c/az9gP1s/Vj9KP3Y/Fz8sPsI+5D6SPoI+uj58PnY+WD54Phw+OD3IPeg9oD2cPYw9tD1wPXg9eD1APZQ9oD20PYw99D3kPhg+Xj6mPuE/GT9ZP62/wwBPAIwAzAEMAXwBVgG2AaoB2AI4AhwCYAKYAvQCzAMsAwQDQANEA0ADVAMQAugCpAKkAqQCsAK0AoQChAJcAggCNAHQAhgCSAKwAlACWAJoAnQCVAKIAvgCrAJMAhABygG2ATcAwwDigE//xD9UPuo+Vj4gPeQ9sD0kPJQ8bDw4O8A7+DuAO+A7qDtQO2A7aDt4O2A7gDvAO8g7+Dv4PCw8YDy4PMA9XD1wPWw9qD3UPgo+aD6GPzw/Kj9vv7d/6wAXAEoArgCBAOMAzAE4AS4BegGAAhgCHAIsAjgCOAIwAigCHAIEAjYB9AHyAfwB/gHsAdoB2gHUAfIBmAGqAYAB5gGEAYwBsAG6AZ4B4AIgAnACdAJcArACqAKwAowC1ALIAuwC7AMsA0wD8ARwBPgEqAQ4A6wDXALoAhIBigEIgEU/uj78PmQ96D1YPRg8gDvYOsA6SDnwOXg5eDmIOfg5mDnwOjA6QDqwOpA7EDtoO0g7mDvoPHA9DD4APvw/Ib+0v9kAIIA1wBSAZoB5AFcApwCyAJUA2AEEAX4BKAEtANUAiYBzABXALL/pP+WAFIB2gCBAC4B+AG+AXYBkgF2AegA1gDMAbgCTAMoBEgF6AUIBlgG0AbIBoAGUAbwBUgFEAWwBXgG0AZgB5AIcAmgCYAJsAnACWAJ4AjwCGAJwAkQCvAKcAxwDQAOwA7QD2AQABDwD8AQ4BDgDsALoAgQBvQDtALcAQEA6Pzo+aD3sPQQ8SDuAO3g64DpIOcg5kDmwOYg6ODpAOvA6iDqYOpA68DrIO2g73Dy8PTw9gj5ePv4/UsA9AFoAmgC0AKAA8ADqAOoBGAGWAc4B+gGuAbQBXgEvAN8AzwCaQCo/8j/fv/G/vD+4/87AOn/pv9i/6L+JP6s/kf/Dv/O/qb/6ABeAYYBhAK8A9wDeAO0AzgEIASgAyAEEAUYBZgE6AQQBoAGOAaIBkAHQAfQBjgHMAhwCDAIgAhwCXAJAAmgCeAKYAtQC0AMIA6gDyAQoBBAESARgA+wDGAJiAb4BHAE4AMcAr3/AP1I+vD24POA8WDvwOzg6SDoIOfg5kDnIOmA6+DroOpg6iDrYOuA64DtsPAA87D0sPco+zj9wv7OAcgEIAUQBGAEqAXwBSgG4AegCdAJkAnwCXAJQAdoBQgFIATKAeH/tv9v/1b+HP7k/rb+KP34+xD8kPtw+kD6iPuE/ET8VPw8/UT+pv4o/yEA2QC3AJAAQgEkAuQCkAPABJgFaAXYBMgEOAUwBRgFkAVgBnAGYAYABxAIYAgwCKAIMAnQCCAIkAigCWAKoArgC2ANYA4wD+AQwBJAE8ASYBLgEAANEAkoB4gGiAXIBJgEoALY/RD54Paw9PDwQO3A64DqQOjg5qDnQOkg6mDrYOyA68Do4OfA6cDrgO2Q8PD04PdI+Xj7qv6gAEIByALoBCgF/ANIBKAG0AiACUAKIAvAChAJgAdoBpAEZAJ6AaAB6gAw/1j+3v4p/0b+VP24/Hj7iPl4+Oj4iPnI+bj6SPwQ/cz8vPyo/VL+fv7y/qn/GgBiAIgBQAOIBEgF8AU4BrAF2ARwBJAEmASwBFgFQAawBqAGyAZYB8gHuAeYB9gHIAggCFAIIAlQCjALMAwQDrAPwBCAEcASoBPAEsAQEA6wCqAHsAYACNgHyAUwA4QAXPxA92D0cPMg8QDt4Org6iDqgOgg6eDrAO2g60DqYOkA6CDnIOkg7aDwEPMw9jD5oPpQ+0D9zf8oAfIBMANwBOAEwAX4ByAKAAvgCnAKUAmIB8AFiASQA+wC9AL0AiwC3ACR/4r+fP2I/Ij7UPrI+CD4IPhw+CD5IPrw+mj7QPvw+rj6sPq4+zz9YP4k/3wAJAJIA9QDQAToBBAF8ATgBOAEsAQIBSAGaAcwCLAI4AjACHAIUAggCPgHMAhACSAKQAogCpAKcAsADOAMMA6wD8AQgBFgEiAT4BKAENAMoAnYB8AGAAYoBugFAAMS/gj6wPdA9YDx4O7g7YDs4Okg6ODoIOrg6qDrIOyA6qDn4Obg6EDrAO0Q8DD0sPcY+SD64PvY/Yv/lgGUA4gE8AT4BfAHkAkwCrAKYAtQC1AKoAjoBlAFWAR4BFgEJANiAV4A2f+i/iD9XPww/Aj7WPlo+AD40Pc4+MD5APuo+rD52Pn4+oD7uPu4/Fz+ev8aAOwA9gGwAmQDgAR4BWAFAAUgBYgFqAXgBRAH+AfwB6gHMAgACZAIEAiwCMAJcAmACNAIwAnwCcAJIAtgDSAO4A3wDuAQwBEAEWAQkA/gDEAJGAdwBsgFGAUoBbAElgGY/LD38PMA8SDvQO4g7QDrwOmA6mDr4OpA6sDqQOpg6IDmYOcA6oDswO9g9DD4QPmY+TD7DP3g/R7/ZAKYBfgGwAegCWAL0AtADFANQA0QC/AIoAhQCPgGIAa4BnAGOATuAacAKf/0/Kj7mPuA+lj4kPeg+BD5KPjw9zj5ePkQ+CD3QPh4+bj56PqA/V//SP9h/+8ALALoAfYByAM4BRAF2AQABggH8AYoB2AIEAkQCKgHwAigCUAJAAnwCYAKoAngCIAJMAogCoAKMAzADTAOoA5gEMARgBFgEJAPEA7ACmgHAAZABsAGUAdQB8gE+v6w+HD0wPHA72DvYPDA7wDtIOvg62DswOpA6SDpwOig5gDmoOiA7IDvEPMw96D4MPdw9oj46PpU/FP/9AP4BmAHIAjwCUAKMAmgCXALYAsgCSAIUAnQCcAIAAiQB6gF+AJkAY4A5v5Y/XD91P1o/Dj6iPlw+Xj4gPcQ+MD44Pcw9yD4gPlo+Uj54Pqs/Nj8jPzk/bn/LwBWAJQBbAPkA2wDCARABdAFqAX4BfAGaAdoB8gHwAhQCUAJkAkwChAKYAlQCWAKEAswCzAMEA5AD3APQBCgEcARYBBQD8AOkAxgCdAHQAgQCQAJcAhQBv4AsPow9jD0EPMA89DzQPNw8GDtYOzg64DqoOkg6qDpAOcA5qDoQOyA7rDwgPOg9CDzkPIQ9SD4KPro/LIBeAXoBSAFWAVwBigHkAggCsAKMArwCZAKkAqgCdAIcAiIB8gFMATYAmgBPgDn/5L/CP74+6j6QPpw+XD4EPgw+PD3MPfg9sD2wPYQ92j4UPpY+3D7oPtc/NT8VP2Q/osA3gEUArQCGAS4BHAE6ATIBjAIIAhQCPAJ8AqACqAKEAxwDHALIAugDKANIA2gDcAPIBFgEQASYBNgE8ARQBAgDyAN4AogCjAKIAoACjAJIAbEAIj7sPdg9KDy4PNA9oD1wPFg7mDsIOog6MDogOrg6aDnoOdA6gDsAO3g7mDx8PHw8JDxAPTA9tD5MP4wApwDuAIcAhwDuARQBvgHsAkAC7AL8AsgC9AJwAhwCMAIUAgwB8AF8AQgBFgDJAKgAMb+2Pyw+wj7ePq4+XD5SPmQ+HD3oPYg9tD1UPbg9yD5OPlY+Uj6CPvI+jD7jP26/xMAFABeAYQCaAKIAqAEMAfgB6AHYAjACfAJ4AkAC6AMAA1wDIAMgA3gDeAN0A6gEOARABJgEiATQBMAEkAQMA8wDiAMUAqwCSAK0An4B3AF1AHw/ND3wPTw84D0IPUQ9RDzIO9A60DpwOjg6EDpwOlA6UDo4Ogg6+Ds4O1A7zDxsPHA8TDzIPaQ+TD9EgEgA4QCxgFUA3AFcAagB0AKkAyADJALoAtQCyAKcAngCcAJ+AfABtgGeAaQBFgCiwDi/iT9SPwI/ID74Ppo+pj54PcQ9jD1EPWg9cD2sPcA+ND3IPjg+BD5WPng+vT8Gv54/jL/QgDaAGIBDAOABdgG4AYoB3AI0AlgCuAKIAyQDbANEA1wDbAOYA+QD6AQQBIAE8ASIBMgFCAUoBJgEYAQkA7wC7AKAAvACqAJUAjIBe8AAPvw9kD1oPQg9ZD2YPaw8mDt4Olg6ODngOgg6mDqwOjg58DoQOpA68Ds4O4A8MDvsPBw8xD22Pic/E0ANAHa/7j/EAJIBKgF0AfACiAMkAsAC0AL4AqQCYAJsArgCnAJYAigCAAIgAXwAtABsAD4/jb+yv6E/lT8MPq4+UD58PYg9dD1gPfA9zD3MPeA9xD3oPbQ95D5iPoQ+wz8JP1c/Xz9ov52AGwCEATgBBAFKAUoBkAI4AnACtALEA1gDeAMMA2gDiAQwBDgEYATYBTgE8AToBSgFAATQBGAEDAPIA0ADDAMIAwgCjAH1APq/lD5QPYw93D4UPgA95D04O/g6QDnoOjg6sDq4OlA6cDnwOXg5cDogOuA7CDtgO6A7xDw8PEA9sD5uPsc/WD+3v5X/6IBeAVACCAJwAkAC2AL0ArACqALUAxQDGAMkAzACxAK4AgQCJgGmAQQA5QCPAJWARAAgP5I/FD6QPlY+KD3wPbg9tD38Pdw9kD1MPWA9cD1QPYA+Ij56Pnw+cj6ePuI+3z8N/8kAlQDhAMgBAgFGAbAB+AJQAvgCwANcA7gDpAOwA8gEqATwBOAFOAVYBbgFcAVABaAFMARYBBgEPAPcA5wDSANwApoBZT/ePuI+RD5IPqQ+0D6EPWg7oDqoOig6ADqQOxg7CDpgOVA5GDlwOag6ADrAO0g7aDs4O1w8ODyYPVo+Nj6APxM/JD9gQDQAxgGoAdQCOAI4AnACjALgAtwDHAN0A1QDdAMQAwQC6AJsAggCKgGCAXQBBAFaAMhANT9SP1E/PD5oPhg+aj5WPhg9/D2cPVA80DzkPXw9mD2wPag+PD4MPfA9hD5+PuI/Tn/XgEAAjIBuAGIBEgHUAhACYALMA0gDQANkA4AEaASYBPAFOAVABYgFuAWIBfgFSAUQBMgEyASABGgELAPQA1wCTgF+wCA/fj7iPw0/dj7IPhA8+DtQOrA6UDroOwg7CDqAOcA5KDigOTg56Dp4OmA6sDrAOwg7EDucPLA9eD2APiQ+nj8VP3B/+wDcAZABogGUAmACxALkAqQDJAOEA4wDRAOwA6ADeALIAvwCQAIOAcwCEAIAAZMA24BZP8A/dD72PtY+4D6UPrg+ZD3sPSg86D0EPXw9JD14Pbg9tD10PWg9jD38PeI+tz9Hf9A/mj+tAB0AlgD4ATgByAKsAowC+AMYA7QDiAQwBLgFAAVQBXAFmAY4BeAFuAVoBXAFMATgBNgE4ASoBAQDgAKuAR4APb+Gf8e/4L+tPw4+JDxoOwg68DrgOxA7SDt4OmA5IDhIOPg5SDnAOig6QDqIOlA6cDrYO4w8NDyUPYo+CD4gPmo/EL/GgFgA9gFqAbgBuAIkAsADBALIAygDhAP8A3gDZAOsA1gC3AK0AogCrAIgAiQCOgF9AHU/6b/wv7M/Cj8sPzY+wj50PYg9hD1kPMg9GD2UPeg9SD0UPQQ9TD10PVQ+ND6yPsI/Iz8aP1Y/i4A5AJQBbAGiAfwCLAKEAyADVAP4BBgEgAUwBWAFmAWwBbAF6AXABbgFGAVwBXAFIATgBIAEKALKAdoBEwC9QAsAZQBaP/Y+eDzoO8g7QDtAO9w8MDtIOmA5cDj4OKA4yDnYOqA6aDmgOag6MDpoOoA7mDyMPQQ9ID1iPhI+mj7Mv5oAngEeAR4BfgH4AlgCmAL8AyQDaANkA4AEKAPYA3gC/ALMAygC1ALAAtwCZgG0AMIAq4Amf9I/17/cv4I/LD58Pdg9lD1MPXA9RD2kPVw9VD1MPTQ8qDzIPYo+PD4wPlg+8j7IPvw+w7/DAKcAygFeAcACTAJ8AlADLAOQBDgEeATYBVAFuAWQBcgF8AWABdAF6AWABaAFkAWoBNAECAN8AkoBiAEqASIBdwDrP8o+5D2YPEg7iDvAPJw8sDuoOng5aDjAOPg5KDoQOpA6KDloOUA5yDoIOqg7QDx4PHg8YDzMPaQ9yD5nPwzAMYBVAL4AygGqAdwCBAKEAzQDDANYA4wD4AOQA1QDDAMsAygDdANMAxgCSgHwAUoBMQC1AI0A1oBlv7o/MD7ePlQ90D3SPiw95D1IPUg9lD1UPMA86D0IPYA91j4ePmA+SD5MPp0/BT+wP+YAkAFGAYYBmgHoAlwC2AN8A9AEiATYBPgFMAWwBagFQAWYBfAF2AWwBWAFqAVQBJwDiAMIArIB7AGeAcAB9wCbP2Q+XD2cPMQ8kDzEPRg8WDsIOjg5eDkAOYA6cDqQOlg5oDkIOVA52DqYO0g74DvUPCw8fDy4PTw9yD74Pxs/q4A+AK8AxAEWAYwCUAKYAoQDEAOUA7gDGAMAA3QDEAMYA3QDnAN0AkwB5gGAAboBKAEsAQwA5EAYv7o/Gj7aPpY+hD6kPjg9qD24PYQ9jD1YPWg9aD1kPaI+MD5EPlo+Ij5oPvk/HT+mAE4BLgEKAQoBaAH4AnQC3AOIBGgEWARgBIAFSAWoBVgFUAWgBbAFcAVgBbAFaASgA+QDcAL0AnwCEAJAAgABBz/WPvI+CD3QPYg9tD0MPHA7IDp4Ofg52Dp4OqA6kDooOUg5MDkQOeA68DuAO8g7WDsIO7A8LDzUPd4+qD7kPuM/P7+3gDcAfQDCAcQCZAJAAqwCvAKAAvAC+AMAA3gDKANIA5QDEAJkAeAB2AHGAdIB9AGWATqAPL+av6g/ZT8iPyc/Oj6GPig9hD3gPcw9wD3IPcA9+D2sPcA+QD5MPiA+Lj6eP1z/6cAgAEUAmQCdAPABcAIwAvgDcAO8A5gD4AQIBIgFEAVIBVgFCAUIBUAFgAV4BIgEVAPIA3QC1ALAAuACSAGZAK+/rD7IPpg+oD6cPgA9GDvoOyg6wDs4Owg7QDswOmA52DmIOag5wDrYO5A72DtwOtg7IDuMPGA9BD4+PmI+Wj5GPtI/bT+owD8A8gGEAdIBkgHcAkwCgAKkAoQDPAM0AygDDAMcAogCGAHYAhQCSAJEAhgBrwD0AAz/17/CwD3/7b+rPxA+pj4cPgQ+VD50PhQ+BD48Pfg9zD4cPhQ+JD4SPq8/Gj+Ff/g/6EAgADgAHgDuAcQC3AM4AywDYANMA0wDwATgBUAFWAUoBTAFIATYBIgE2ATYBHgDtANEA3AC/AJUAhwBRYBzP2w/XL+QP0o+kD2MPIA7yDuYO8g8ODuwOwg60DpAOeg5kDpoOwA7oDtoOzA62DrwOww8ODzAPbQ9mD30PdI+ID5TPzB/zwCOANwA5ADmARwBugHsAhACTAKEAvwCnAKkAqQCnAJYAiwCIAJMAlACIAHOAaIA9kAowA4AqgC1QB4/qD8EPtg+tD6gPs4+zD6YPno+Ij4aPjI+Dj5yPng+iT84PxA/W7+Xf82/13/OAKYBjAJwAkQCsAK0ApAC1AOABJgE2AS4BGgEsASIBIAEsASgBLAEMAOgA3QDDAMQAsgCbgFdALeAFcA2v+W/jT8qPgg9RDzQPIA8sDxMPEQ8MDtIOsA6oDq4Oug7eDuYO7A7ADsgOxA7jDwgPLQ9KD1IPVQ9dD2aPho+iD9yv/KABMA5/+mAUAEGAYwBxAIgAhwCCAIgAiACQAKwAlACSAJMAnACOAHaAcIB7gF3APcAuACHAM4AkgAQP6w/Cj8qPws/QD9APx4+sD4oPcQ+Ij54Pp4+8D7oPvY+oD60Pt6/mYAOAGYAtAEQAawBlgHsAhwCmAMcA6AECARwBCAEMAQoBGgEmATABPAEYAQoA9wDhANgAwADFAKeAcoBbADNAK5AEv/jP3Y+hD4UPZw9TD0wPLQ8QDxwO9A7mDt4Oyg7CDtIO7A7iDu4OwA7WDuAPCQ8RDzEPQg9PDzsPTw9pj54Ptc/fz93P2g/bT+cAFwBCAGUAbgBaAFqAUwBmgHoAggCcAIIAhoB+gGsAaQBjgGiAWoBLADzAIwAtIB3QAQ/7j9cP2g/ZT9iP1w/QT8aPmA9zj4kPpI/Az9GP0E/AD6OPkQ+7T+0AFIA5ADcAOoA7AEwAZQCZALEA2wDcANEA4wD4AQgBEgEkASwBGgECAQYBBgECAPUA3gC8AKYAnoB2AGuAS4Aq4AHv+Y/dj76Pnw9xD2cPRg88DycPKw8VDwoO4g7cDsgO0g7+DvIO8A7qDtYO6g7yDx4PJQ9MD0cPQA9eD2uPgA+nD7KP00/jL+nv6TANwCKARYBLgESAXQBTAGsAaIBxAIAAhIB9gGIAdoBxAHQAaoBdgEXAMoAngCfAPIAkIAPP4y/pz+Uv7U/az9tPyg+kj5yPlY+yD8dPxw/OD7mPrI+Vj7uP7IAeQCfAK8AboBcAOIBuAJAAwQDAALgAqAC+ANwBCgEoASABFQD5AOAA8gECAR4BAQD0AMEAoQCdAIMAjQBuAEwAK0ACz/EP6U/Hj68PcA9nD10PXA9VD0UPKQ8EDvIO5A7kDwAPJg8UDvIO6g7iDvoO+Q8VD0QPVQ9DD0gPWw9iD3SPgI+0j9mP2g/Zj+yP+qAHQBuAJABGAFwAXIBegFCAYwBmgGyAa4B0AIgAdABnAF0ATIA+QCJAPsA4gD5gFKABX/6P1g/UL++v7g/XD76Plg+mj7wPvA+4j7yPo4+tj6ePwm/lj/gwBkAWgBJAGAAgAGYAnQCoAKwAlQCTAK8AzAECATIBLgD5AOYA6wDtAPoBFAEmAQ4AxQCoAJkAmQCeAIOAfIBIQC3gCf/1z+2PzA+qD4sPfQ95D38PXg81Dy8PBg72DvUPHA8qDxYO9A7oDuwO6A76DxsPOQ82DyoPJQ9HD1oPXg9mD5QPuA+5j7pPyw/Xb+6P/AAQQDOANoA1AEEAUIBRAF+AXABvgGCAcIB5gGmAXgBIgE5AP8AjQDYARQBAQCrv/I/gL/UP8v/8b+iP1Q/AT8ePyI/Oj7qPvo+/j7KPzw/Ar+BP/n/9EATAFkAWQCGAXQBwAJAAngCBAJkAmAC3AOgBCgEFAPQA6wDXANcA6AEKARABDgDLAKMAoACqAJIAmACGgGbAOUARwBYABE/vD72PqA+qD5UPhg91D2gPRw8kDxkPGA8gDzcPIg8WDvQO6A7uDv0PEg8wDzAPKg8VDycPOg9GD2UPh4+XD5ePlA+nD7zPyo/psAeAFSAXIBkAKYAwAEsASgBQAGuAWoBQgGQAYoBggGoAU4BHQCJAJgA2AEKATIAr0Ayv7s/Ur+E/8w/17+VP1w/Mj7ePuA+3D7oPtQ/DT9iP2Y/Sr+TP8uAMMAuAFQAxgFmAawB0AIIAgwCLAJMAxQDhAP4A5gDpANwAwwDQAPgBAgEIAOwAxAC8AJIAnwCYAKoAh4BYgDJAMwAi0Anv4C/hz9cPtQ+vj5+PjA9qD0wPOg86Dz0PPw8zDzUPFg78DuoO9A8fDyYPNg8kDxQPEQ8iDzoPSg9hj4OPgA+HD4UPlo+jD8sv5BAAYAYf8qAKABuALEA9gEWAXQBHgEIAXQBdgF8AWQBugF2AN0AhQDcASIBKgDlAI2AYj/xP5e/wEAVf8S/oD9dP0c/XT8GPzw++j7LPw4/YT+RP/D/xQAMwBjAIoB4ANABrAHIAhACCAIQAigCWAM4A6AD5AOkA3wDOAMsA1AD0AQcA+QDRAMQAugCkAKIAogCRgHMAVIBOgDgAKJADr/Av40/BD7KPso+2j5oPbg9GD0EPTw86D00PQw8+DwwO8g8ODw4PHg8iDzIPIQ8ZDx4PIQ9FD1gPbw9uD2kPcI+Wj6KPss/OD9CP8w/47/ygDoAaACfANoBNAEoASwBHAF6AWYBVAFWAUgBWAE8AMIBOQDQAOEAggCEAHr/6P/TAAEAOD9GPxk/MT9Vv7A/YD8IPuw+cj5rPwuAC4B8P+w/kL+vP47ADwD0AaQCJgHOAYwBlgHYAngC/ANoA7gDbAMIAyQDNAN8A4wD2AOQA2ADNALMAvwCoAK0AioBrAF8AXABSAE8gE1AFj+yPyw/Jz9IP14+rD3IPZg9QD1sPVw9qD1MPNg8RDxcPGw8YDygPMQ85DxEPFQ8uDzwPQQ9bD1APYA9hD3UPkA+yD7APsI/Iz9hP5w/7oAwAHqAeYBtAL4A1gEWAQQBaAFGAX0A7gDmAQoBZAEiAMQA8wCKAKYASgB1QCMANH/6v7c/ST93Pxo/Rr+PP70/HD6APlI+oj94f9fAN7/A//Y/Xj93P9IBCgH6AbgBfAFUAaYBnAI8AsgDkANkAugC6AMAA0QDfANcA5gDRAMAAxQDOALkApACSAICAdgBhAGsAWIBKgCZgBi/rT9dv7a/pD9YPtA+ZD3UPZw9pD3CPiA9hD08PLA8qDysPKQ82D0sPMg8uDxQPOQ9OD0APWw9TD2MPbg9uD4uPrY+nD6EPvI/Cb+5P7F/8cAGgEOAa4BzAKMA+ADSASYBGgE0AOkA+gDGAT4A6QDEAM8AuABFAKUAUYAcP93/zD/4P2o/Jz8IP0M/aj8aPwg+yj52Pgo+wL+S//u/sz9wPyc/C7+NAHcAxgFmAVgBWgEYARoBoAJcAvgC9ALsAsQC+AKAAyQDcANEA0gDWANsAxAC6AKsAogCvAIUAhgCKAH6AVwBGwDIAKyAFQA1wCOAIT+4Pto+uj5cPkw+Vj5IPmg95D1QPRA9KD00PTw9PD0YPSA8yDzsPPA9LD14PXA9SD24Pbg97D4QPno+fj6wPtA/CT9VP4p/1X/s//GAMoBBAJAAvgChAMwA8ACEAOUA4ADEAP0ApQC8gGSAYABKgFXAM//pv8G/9z9JP1A/eD8ePzM/CD9BPy4+eD4kPoE/Xj+CP+6/lj9APzQ/Of/EAOwBAAFuAQIBOADMAX4B2AKcAuwC3ALwApwCnALIA0ADtANgA1wDQANEAyQC5ALQAtgCrAJQAmACHAHaAZIBewDpAIcAigCygFqALr+/Pw4+2D6wPpA++j6MPlQ91D2kPXQ9DD1QPaA9mD14POQ8yD0sPQw9eD1UPYg9gD2wPbg97D4OPnA+WD6IPsU/Aj9lP3w/a7+dP+9/xkAKgEwAhACaAGWAUgCPALCAfYBfAL6AfoAvAAaAeQA+f9p/1r/sv6I/Rj9PP30/DD8APxs/DD84Pq4+dj50PpM/AT+Wf+u/mD8aPtE/asAYAOQBKgEWASgA7QDoAVgCHAKYAtgC9AKcAqgCpALEA0wDlAOwA0gDcAMwAxgDHAL8AogCyALQAoACTAIUAfgBVgE2AMoBLgDbAIgAbf/wP0c/OD7lPyU/Bj7YPko+ND20PUQ9sD2kPaA9eD0cPTg84DzUPSQ9bD1APUg9RD2kPbA9pD3wPg4+Uj5IPqY+3j8cPys/Mz9rv4S/67/hgD4ALoAmAAiAZIBfgGEAdgByAE4AbEAkQCyAHIAFQDh/0v/Yv64/aT9vP2I/Qj9jPxY/Cz8uPso+/D68Pvk/Rf/1P64/RD9TP3S/k4BEARYBXAEIANwAzAF+AawCHAKkAvwCmAJQAkAC5AM8AwADXANIA0gDIAL4AsADCALUApACjAKQAkACEAHeAZQBWgE6ANkA9gCHALkAPb+RP3I/PT8vPwE/FD7GPoo+ND28PZw9zD3oPZQ9vD1sPTA8zD0YPXA9WD1kPXw9QD2APbA9vD3iPiw+Gj5qPpA+0j7oPu4/LT9Ov7K/qL/LAAJAOr/aQAeAWgBTgFIAVYBKAHnANMA0QCdAD8A0/9v/xr/oP4c/pD9NP0k/SD9xPw0/Nj7mPv4+qD6qPuI/cL+cP5s/dD88Pz4/YAAsAMABfgDnALMAkgEOAYwCNAJcAoACnAJoAkgChALoAygDTANUAwADBAMwAtAC1ALgAvACuAJwAmgCTAIgAboBQgGkAWABOQDdAMgAjoACf+y/iz+lP1k/ej8QPsA+dD3GPho+AD4YPfw9hD24PRg9OD0kPWw9ZD1oPXA9cD10PWw9sD3WPiQ+Oj4qPmQ+lj7oPvw+8D8tP2M/gr/S/+X//7/GwBZAP4AjAGMARwB8wA2AS4BngBoALYAngDE//j+2P7G/jj+nP2I/Yj9KP2s/ED8yPto+8D70PzY/V7+Xv7Y/cz88PwT//oBsAOkAzwD9ALYAsADYAYgCfAJIAmQCPAIkAkQCiALgAzwDHAM8AvgC6ALQAtgC5ALMAtgCuAJ0AkwCfgHCAeQBggGcAUYBbgElAPEAWgAy/9J/6T+Mv7Y/fT8SPuQ+aD4aPiI+MD4aPhA9wD2UPUw9ZD1wPUQ9lD2APaA9dD1sPZg96D3CPjw+Gj5cPno+UD7NPww/DT8FP0+/tr+Hf9h/63/0v8IAGcArgDHAOYA5ACWAGAAbwBgANb/Z/9u/yz/MP58/cT9AP4w/Uz8OPxw/Nj7wPqo+oj7PPy0/Hz92P0Y/ej7MPx+/iYBvAI4A/AC+gF4AdgC6AVwCBAJsAhQCFAIgAiACTALkAxwDOALAAwgDLALMAtgC+AL0AsQC5AKkAoQCgAJ8Ac4B/AG6AaQBrgFiAQgA6ABiQAqADwA5/+2/jT9EPzw+mD5kPgo+cD54PgA98D1kPWQ9VD1oPVQ9vD1QPVA9dD1MPZw9jD3EPho+Gj4APkY+rD6APu4+4D80Pw8/Vj+Lf8E/6r+Nf9FAJYAPABOANUAsAAgABUAdABgAKr/SP9y/yP/Iv6U/dz9AP5k/Zz8TPwk/JD7QPug+yT8aPyk/DD9YP3M/Fj8GP0R/xgBZALAAjQCmAHsAYgDIAZACAAJUAhgB2gHsAhQCkAL4AtQDBAMIAuwCiAL0AuwCwALAAswC2AKQAkgCTAJQAjQBmAG+AaoBvgEgAP0AjgC3gASADEAFAAH/5D9OPzo+tj5mPn4+fj5KPnw96D2sPWQ9VD2wPZw9iD2UPYw9rD10PXw9hj4SPgw+MD4kPnY+SD6KPsw/Ij8rPyE/Zj+sv4+/pL+qf8pABQAHAB7AHEACAAMAHMAWACm/0r/ZP8d/0T+pP2w/bT9JP2Q/GD8LPyY+/D6kPqo+ij7yPt4/LT8UPyw+4D7NPwA/lYACAI0AngB4gAGAVACsASIByAJYAioBmAG0AdwCdAK8AuADPAL8AqgCiALkAuAC8ALMAzQC/AKUArACUAJ8AjQCIAIsAcYB/AGGAYwBJwCaAKMAuwBCgFTADX/TP2Y+yj7QPvQ+ij62PkI+VD38PXw9cD2IPfg9oD2IPaw9aD1YPZg95D3kPc4+AD5YPmI+SD6CPuw+xT8qPyE/Qr+Uv6c/tz+JP+S/zYAqAC+AHoAHwAYAEAAfAB2APL/Mv/S/rj+Yv7I/Uz9QP0w/ZT8wPtg+zD72Pq4+jj7BPxc/Cz86PvA+6j7OPzo/SUAqgHGAf0ANgB0AEQCCAUgB6gHaAfIBkgGoAZgCAALMAygC/AKAAvQCnAK0AoADKAMIAxQCyAL8AoACkAJcAmwCSAJMAigBxAHCAbQBOgDSAOgAigC4AEcAXT/mP1U/Lj7WPso+wD7YPoY+bD34Pag9qD24PZA90D3oPYA9hD2cPYA95D3GPho+Jj48Pjg+Yj6oPr4+uj7qPwU/Wj9Dv6u/oT+YP4F/+X/8/+s/97/OgD+/27/Vv92/zD/cv70/dj9tP1Q/eT8XPzg+4D7KPuo+jD6OPp4+oj6wPpo+8j7SPuA+uD6PPzs/U//oACCAd0AiP/D/ywCKAUYB5AHUAe4BugFYAbACHALkAwADEAL8ArACsAKkAvgDGANwAwgDMALMAtQCjAKoArACiAKQAmACLgHoAagBRAFaASEA+gCYAJkAdf/Dv6I/OD70PvI+yD78Pmw+KD3oPbw9TD24Pbg9hD2oPWg9XD1YPUA9kD34PeA93D3qPjA+dj5CPq4+qD7SPzM/GD96P08/oD+6v4w/0b/sf8vAD4AGAD6/9j/Yv8G/w3/Df+Q/tj9sP28/Rj98Pto+6j7qPvo+kD6cPrI+rj6wPpY+5j7APuQ+nj7QP2S/kj/GwCaABoAp/+wAFADuAXQBugGeAbIBcgFgAcwChAMUAxgC1AKEApwCpALkAwQDRANgAxwC5AKkArACsAKkApgCgAK8AhoB5AGiAb4BdAEAAS8AxQDqAE0ABL/3P2E/Oj7RPw0/PD6SPkg+HD3wPaA9uD2UPcQ91D2oPVA9WD1IPYA94D3oPfQ91D4uPgo+fj5uPoY+3j7YPxQ/aT9mP0I/tL+Ev/c/i//GACEADoAx/+z/4z/7v6q/vD+Bf9Q/qD9aP0M/Uj8iPtQ+1D78Ppo+kj6OPog+mD64PoA+4j6SPoA+0z8fP2I/kb/aP8e/zv/YgB8AoAE4AVgBvAFSAV4BSAHoAnQC7AM8AtQClAJ0AmgC3ANMA4gDnANAAygCoAKUAswDGAMIAyQCyAKMAjoBugGKAfoBlAGgAUQBDwCsQCc/6T+xP2E/XD9gPzg+nj5ePhQ92D2oPaA95D3sPbA9YD1IPXA9GD1wPag97D3kPcA+JD48Pho+UD6KPvo+5j8SP2w/fz9Xv60/g7/kP8wAK8AzQCpAJIAPQCv/5P/5//p/0H/hv5O/jL+lP2g/CD84Ptg+9j6sPrA+rD6iPqI+oD6KPq4+QD6OPuc/LD9Uv5m/gT+7P3C/mMAWAIYBFgFoAXoBCAEyATYBhAJ4ArQC4ALYApACWAJ4AqADKANMA7QDbAMUAuACqAKcAtgDLAMMAywChAJkAdwBhAGoAYoB3AGgAQsAiIAov60/bz9Fv6Q/ej7OPoI+Qj48PZw9tD2YPdg93D2kPUQ9RD1YPUA9sD2QPeg9xD4sPgQ+Uj5mPk4+ij7MPwk/ej9MP5M/o7+zv74/nf/SwAKASgBogAQAL//fv9j/23/SP/E/iL+lP04/bz8GPx4+9D6QPoY+jD6MPow+jj6+PlI+Yj42PgQ+nj7vPzI/QT+QP1Y/MD8jv6wAKgCmASgBfgExAOQA/gEMAdQCRALQAwgDPAKEAowChALkAwgDhAPIA8QDmAMIAsQCwAMEA2ADRAN0AsACsAHUAZYBggHKAdIBpAELAKp/+z9hP20/Uz9MPwQ++D5aPgg90D24PWw9ZD10PUQ9oD1wPSQ9AD1gPUA9qD2sPeg+Dj5iPnA+ej5SPqg+0T9hP7+/in/Rf9f/2r/zf+2AHQB3AHKAVwBjQDt/8n/3f+7/0T/nP7s/VD9tPwQ/Bj7MPr4+SD6+Pl4+VD5cPkY+Wj4MPiw+Ij5QPpI+6z8JP2c/ET80Pz0/V3/GAEoA5gEsARABGAEGAVIBugH8AmQCxAMkAtAC0ALgAsgDEANsA5gDwAP0A3ADFAMUAzQDHANkA2QDPAK8AhYB4gGcAaQBjgGyARoAgIA2P10/Az8+Ptw+7j6wPmg+DD3cPVg9ED00PSA9QD2APZw9RD18PQg9aD1wPZo+Nj5iPqo+rD62PpI+3T8GP6S/0AAbgCZAJEAfwCVACoB+AFAAuQBbAHtAHkA6v+A/xv/iv7Q/TT9sPzo++D6KPrI+UD5uPhQ+DD4CPig93D3oPfg9wD4aPgg+fD5sPo4+9D7fPwQ/bj9uv4gANoBZANwBBAF2AW4BngHQAhwCfAKMAwgDZAN8A0ADtANUA4wD/APIBDgD5APMA/ADqAOoA5wDrANQAxQCmAIOAcYB1gH0AYoBbQCtP/M/Aj7iPrA+vD6qPrA+eD3MPXQ8tDxcPLQ8zD1wPVw9ZD04POg8wD0QPVA9zj5kPog+0D7OPtQ+zT8GP4zAIAB8AEQAiQCHAIcAnACLAPEA7gDYAO4Au4BOgHPAGYApv90/jj9hPwA/ED7oPr4+Qj54Pfg9mD2EPbQ9cD1UPbA9sD2oPbA9kD34Pe4+Nj5CPsY/PT8rP2k/s3/VAEwA+AEKAYwB+gHUAgACUAKEAzADdAOcA/AD6APYA+gD0AQABEgESARIBHAEPAPMA+QDuAN4AxgC9AJUAgwB7gGOAbYBLwCLQAQ/Vj6yPjA+ID5iPnY+GD3IPWg8vDw0PDw8TDzEPTA9OD0gPQQ9DD0MPXw9sj4ePqI+/j7QPzY/BT+zf9kAaACYAOgA4QDdAOUA/gDeAToBBAFkARYAygCRgG/AB0AJ//Y/VD80Pqw+Rj5ePiQ98D28PXw9NDz0PJg8lDywPLA86D0EPUg9WD1IPYA95D30PiY+jT8hP3w/o4AQALQA3gFMAdQCAAJwAlAC9AMMA6wDyARQBKgEoASABKgEYARABKgEkATQBPgEiASABFwD7ANAAxgCuAIEAiQB8gGkAXAAxgBqP0o+tD3YPfA97D3cPfA9lD1YPNg8XDwUPCQ8GDx8PJA9JD0kPQg9TD2YPeo+FD6sPuQ/Hj94P50ALIB+AJQBGgFoAWABZAFgAWQBSAGuAaQBpgFQAQwAywC9QD4/+D+kP3g+3D6GPmA9yD2cPUQ9VD0MPMw8pDx4PBQ8GDw8PCQ8TDyYPNQ9AD1gPWA9gj4aPmY+vj7sP2f/5QBpANoBRAH0AhwCrALUAwQDWAO4A9gEYASoBMgFAAUwBPgE+ATYBMAE+ASABOgEoARYBBQD6ANUAswCbAHQAbwBOwDmAIqANT8wPmQ91D2QPUA9UD18PTw87DykPFg8KDvAPAg8XDysPOw9MD1gPag93j5WPts/ED9dv7b/ygBXAIYBOgFaAdACOAIwAjIBxAHEAd4B1gH8AZoBlgFwAPuAYwAOP+I/ej7YPqI+GD2cPRQ88DyIPKA8cDwoO9g7sDtoO2g7QDu4O4A8PDwwPEA86D0EPZQ9+j4uPpY/Oj9vP8IAkgEWAZQCFAK8AsADTAOUA+AEIARYBJgE2AUwBSgFKAUgBSAFGAU4BOAE6ASoBGAEGAPAA5gDNAKYAnIBwAGSASgApkAFv6I++j4cPaw9ED0oPQA9cD0QPTA89Dy0PEg8UDxMPIA9ED2IPhw+Yj6+Pug/QL/LgBeAWQCPAM4BNAFcAfwCBAK4AogCzAKsAhIB3gGEAbQBWgFgAQUA4ABx//Q/Zj7ePmw98D1kPPA8aDwAPBg7wDvwO5A7iDtAOzA6wDsoOyA7QDvkPAw8rDzQPXQ9lj4APro+9z9jf9KATgDWAV4B6AJkAsgDVAOMA8AEKAQQBHgEcASgBOgE4ATQBPgEoASIBLgEWARwBBAEHAPMA7ADDALwAkgCGgGAAWMA7gBAgBq/nD8GPqw90D2oPXw9HD0IPRQ9ND0MPVQ9fD0gPSQ9ID18PZo+DD6FPwA/rj/KAFsAlgDEASgBHgFWAZAB0AIgAnQCqALEAuwCYAIOAfABTAE/AIAAt4Aov94/kD9ePtY+VD3EPWw8nDwoO6g7SDtIO1A7UDtIO0A7QDtQO2A7SDuAO8g8LDxcPOA9XD3UPlI+1j9T/8kAeACcAQQBogH8AhACqAL8AwwDiAP0A9AEIAQwBAgESARwBBgECAQsA/gDkAO4A2QDTANYA2wDeAM8ArACKAHaAbwBDADxgGdAPT+bP0g/Jj60PjQ94D3UPew9vD1wPUA9qD2cPcA+OD30Peg+Cj6aPts/Pj9JgBAArADaAS4BPgEgAWABqAHcAggCcAJMAoQCnAJQAjQBlgFCASYAr8AyP5E/UD8UPsI+qj4MPdg9VDzYPHA7yDuQO3A7MDsAO0g7WDtAO7A7oDvUPAg8fDx4PIg9JD1MPfI+Hj6YPxU/hwA0AGIAwAFQAZoB3AIMAmQCRAKEAvgC5AMIA2QDcANsA3gDSAO4A2ADYANkA3gDOALsAtQDAANIA0QDbAMEAsgCegHCAeIBSQDGgGZ/1b+KP1E/GD7gPoQ+hD6kPmA+MD38PeY+Nj4EPlo+dD5ePqo+0j9sP7p/3oBMAOABOgEMAWABQAG0Ab4B7AIAAlACYAJcAmgCGgHOAbQBBgDeAHr/wD+APyg+rj5sPhA96D1QPTQ8mDxIPAA7wDuYO1A7UDtgO3g7aDuYO+Q8NDx4PKw86D0IPaw9wj5EPog+3j8Jv7j/4QBwALQAygFUAYIB1gH2AeQCHAJEAqgCrAKcAqQCiALgAuQC9ALQAywDGAM8AvAC6AL4AvQDNANwA3QDLAL0ArwCaAIAAfYBHwCggAi/9T9aPyo+6D7mPsA+xj6ePno+Jj48Phw+ZD5kPlA+pD73Pzw/Wn/OAHkAjAEEAVoBTgFUAUABvgGkAfIB/gHEAgQCMAHGAcQBqgEWAPiAQkAAP74+0j66PiA9xD2sPRw85Dy8PFA8aDw4O8g72DuAO4g7mDuoO6A78DwIPJg84D0sPXw9lD44PkY+wz8+Pw+/nj/ZwBSAWwCiAOQBJgFOAY4BjAGyAbgB1AIUAhACHAIcAgwCIAIAAmgCTAKAAtQCzAL4AoQC7ALgAwwDWAN0AwQDJALIAsACiAI+AXcA6QBkv/4/eD8PPwQ/Cj8DPxg+4j6GPr4+fj5IPpg+pD66PqQ+5T8vP3w/qsAsAJoBIgF8AUYBjgGsAZ4B/gHAAjYB5AHUAfwBkgGaAVgBEADHAKGAJD+kPzI+iD5kPcg9rD0EPOw8QDxsPBQ8IDv4O7A7sDu4O7g7kDv4O8g8XDyoPOQ9KD1EPdw+Mj5KPtU/Ej9SP6j/7kAJgGOAZQC6AOQBLAE6ARgBbAFUAb4BkgHIAfIBgAH8Aa4BrgGqAcACSAKAAtQC3ALsAtwDIANEA4ADqANYA0ADXAMkAsgCjAIGAYIBNwB8/9c/oD9NP0Y/ej8YPyg+xD7+PoI+wD76PoQ+4j7EPyo/ET9Mv6n/5oBhAPYBLgFMAawBlgHAAiQCIAIUAhACNgH8AbIBfgEMAQQA8IBfwD6/vD8GPvw+cD4APcw9QD0EPMg8lDxsPBA8MDvoO+g76DvYO+g74DwkPGg8tDzAPXQ9bD24Pco+fj5yPoc/Fj9Dv6S/jv/DAC7AJIBgAL0AgwDdAM4BLAEsATwBMgFSAYwBsgFkAWoBUgGkAcACeAJYAogCzAMAA2QDSAO0A4gDyAPoA7QDdAMcAvgCegHkAXcAkYAXP5M/bj8RPwE/ND7oPtY+0j7cPuQ+7j7+PtU/IT8sPwg/ez9B/+YAGgCCARABWAGgAdACLAIMAnACfAJkAngCBAI0AZgBWAEiAM4Ak8Atv5k/RT8iPo4+Tj44PZA9RD0QPNw8nDxkPBQ8FDwQPAA8ADwEPCQ8HDxsPLA89D04PUQ90D4EPnA+Yj6iPt4/Fz9Av50/sT+X/9tAEIBigGSASACFAOYA4wDuAMYBKgEGAUQBZgE4AMYBDgFcAZgBzAIcAmwCqALwAzADTAOkA4wD/APsA+ADjANIAyQCnAI6AVAA5UATP4w/Zj8+Pt4+2j7qPvI+7j7FPyE/Mj8DP1Y/aT9tP3Y/Yr+sv8UAXgC6ANwBcAG2AewCHAJMAqwCuAKsAoQChAJqAcIBmAEvAISAVr/lP3o+3D6SPko+AD3APZA9aD08PNQ88DyIPKA8SDxEPHg8HDwUPCg8DDx8PEg85D0sPXQ9iD4gPlA+rD6gPuE/Bz9RP1w/bD96P1c/jz/9v8HAPr/kABKAaIB/AGoAlQDnAO8A9wDxAOoAwgEMAV4BngHgAiwCeAKEAxQDYAOIA9gD9APQBDwD+AOYA3QC9AJQAeABMwBTv9w/Xj84Ptg++j64PpA+6D7BPx0/AD9cP3Y/Tj+dP6C/rT+cv/FABwCDAMQBFgFyAboB7AIgAkwCrAK0AqgChAK8AhoB8AFEAQMAvn/IP6A/PD6UPnw9/D28PUQ9aD0cPQg9MDzsPOA8yDz0PKg8qDyQPIg8mDy0PJg81D0kPXA9pD3aPiw+dj6iPss/Nj8YP2E/aT94P3s/fD9Xv4f/1P/Jv80/77/WAC3AE4B9AFQAoAC6AJ0A/QDeAR4BcgGEAggCUAKgAuQDJANgA4wD4APwA8gEEAQkA8ADuALoAk4B6gEHALa//j9sPwA/Kj7UPsI+xD7qPto/PD8aP3g/W7+6P5L/8f/VgD6AMgB5AL8A+AEsAWwBuAHsAhwCUAK0ArQCrAKUAqQCRAIEAZABGQCSAAy/oD8wPrg+DD3EPYw9TD0sPOQ84DzYPNQ88Dz4POQ82DzcPNg80DzUPOg8wD0gPRg9XD2EPew97D4APoA+7j7XPzw/Gj9tP0k/pL+nP6M/rT+8P7s/qz+sv44/7//GABRAIsAxwBeAVACWAMYBKgE6AW4B5AJwAqQC2AMYA0gDrAOMA+AD7APwA9gDzAOAAxgCRgHOAVIA1IBp/9U/iz9dPwo/BD84PvI+zj85Pxw/dT9Rv62/g//sf+7AKABPAL8AhgEIAXQBYgGcAcgCJAIIAnQCQAKwAlwCRAJ+AcgBlgExAIIASX/eP3Y+/D5CPiw9rD1wPTw87DzoPNA8wDzUPOw88DzgPNg86Dz4PPw81D04PRQ9dD1sPag92D4APkI+jD7BPxw/NT8YP3k/Uz+tv4h/wD/uP6U/sr+4P6a/mz+mv4V/13/a/+J/+L/pgDiARADKAQYBYAGcAhwCrALYAzQDGANEA6wDmAPoA9QD7AO0A0wDLAJSAdIBWADiAEYAAf/yP2U/CT8ZPxk/PD7BPzA/Fz9oP34/aD+F/+L/6IAAALoApQDmAToBcgGSAcACMAIMAmQCRAKYAogCpAJAAkgCIAGmAToAlABcP+Y/ej7MPpQ+KD2sPXw9DD0kPNg82DzUPNg88DzEPTg86DzsPMA9DD0YPTA9GD18PWA9mD3SPgg+ej50Pq4+1j8oPzo/HD9/P1o/rL+uv5m/vj9uP20/Yj9JP30/Cz9kP24/eD9UP7+/v7/YAHgAjgEkAVwB7AJYAsQDJAMQA3QDVAOAA+gD3APkA6gDVAMUArAB5gFCAScAi4BFQD+/sT9AP30/Bj9vPxk/MD8fP3o/RT+kP4h/4f/QQCOAdgCqANoBJgFuAZYB9gHgAgwCXAJsAkwClAK0AkACUAIOAegBdwDUALVABP/RP2w+yD6aPjg9vD1cPXw9GD0IPQw9ED0YPSw9MD0kPRw9LD08PQg9VD1kPUQ9pD2MPcA+PD4sPlg+ij74Ptk/KD8EP2s/SD+PP5S/kT+7P10/UD9OP3w/JD8jPzw/CT9OP2U/WL+Rv9RAMoBfAMQBbAGkAhQCmALEAzADFANsA0QDvAOUA+gDnANMAywCqAIkAboBIADEALxAEgAkv+e/gD+/P04/jL+MP56/rj+yP4H/5z/IgBlAPEAHAKEA5AEUAUYBuAGgAcgCNAIUAmQCdAJIApACrAJoAiQB0gG0AQsA54BCgBE/pj8IPuw+Sj4oPbQ9WD18PSA9ID0wPTQ9ND08PQw9fD0gPRw9MD04PTg9CD1kPXw9WD2UPdI+BD5oPlg+hD7kPvo+4D8DP1Q/YD9rP2s/VD9+PzQ/Jz8QPwU/Dj8aPyQ/Bj93P2s/on/tABkAjgE6AWYB1AJ4ArwC5AMIA2wDfANMA6QDtAOMA6wDPAKQAlwB7AFUAQoA+4BtgAYAPH/j//C/lT+jP7W/u7+/v4r/zD/Wv/c/5sAFAGIAZgCGAQ4BfAFoAY4B7AHQAggCdAJ4AngCQAK4AkgCegH0AaABcwDPAIEAa7/8P1A/PD6wPlY+BD3YPYA9nD1YPWQ9aD1YPVA9WD1QPXQ9JD0wPTw9AD1MPWw9eD1IPbA9sD3mPgw+eD5mPoI+zD7kPsk/JT8nPyw/PT8EP3Y/Hz8WPww/Oj7uPvw+zz8cPzo/Nj97v7i/9UAUAIoBNAFaAcACVAKIAugC0AMAA1ADUANcA2gDSAN4AtgCpAI6AZwBXAEUAPqAcYAcQB0AB4Amf9E/zT/Gv8x/2X/bv8+/1j/FwDaAFIB6gEIAzgEEAXwBdgGeAfQB3AIcAkACuAJwAnACYAJwAjIB7gGQAWAAygCCAGh//j9lPx4+yj60Pjg91D3sPYw9jD2cPZQ9uD1oPVg9fD0cPRQ9HD0oPSw9AD1gPXg9TD2oPaA93D4KPmo+RD6YPqY+uD6UPuI+3j7ePvA+xT8BPyY+0D7APvI+tj6KPuQ+xj87Pws/nf/cABgAagCQATwBZgHAAkgCtAKYAvgC0AMcAxwDIAMYAzQC+AKoAkwCMgGgAVoBEgDHAJKARgBIAHKAEMA1P+D/zn/Ef89/3f/k//c/6wAqAFwAhwDCAQQBRAGCAcACNAIQAnQCXAKsApwChAK4AmgCbAIiAdIBsAE/AJaAUEAQP/w/YT8YPtY+mj5qPgg+KD3MPdA94D3YPfQ9iD2oPUw9cD0gPSQ9KD00PRQ9fD1UPag9jD3GPj4+Jj5GPqQ+uD6IPt4+9D72Puo+8j7MPxk/CD8oPsw+9j6oPq4+jD72Pug/Kj9/v41ABAB7gE0A7gEKAaIB9AIsAkgCnAK4AogCxALAAtAC0ALkAqACXAIOAfIBYgEoAO8AtoBagE+AQIBewACAJf/Bf+e/rT+Ff89/27/NgBaAUACCAP4A+gEoAV4BsgHEAmgCeAJYAoACwALsApwChAKMAkQCPgGkAXgA0ACLgFGADL/9P3M/Nj7CPtg+uD5YPnQ+Gj4SPg4+OD3MPdA9mD1wPRw9FD0YPRw9MD0cPUQ9pD28PaA92j4SPng+UD6gPrA+gD7KPtA+yj7EPs4+4j7gPsI+5D6OPrQ+aj5CPrA+oD7YPyw/R//FgDWAPQBRANwBLAFOAdwCNAI4AhgCeAJ4AnQCTAKgAowCoAJwAjIB3AGMAVgBJwDxAI0AuYBjgEWAaoAPgCU//r+1P76/gT/Jf/N/7UAmAGIAqQDqARQBQgGMAdgCFAJEAqgCgALEAtAC3AL8ArACaAI2Af4BogF5AOcAqgBtgCs/5j+hP2U/Oj7kPsg+3D6qPkg+ej4cPjA99D2APYg9YD0QPRQ9ED0MPSw9GD1EPZw9vD2sPdo+PD4YPmo+bj50PkA+jj6OPpI+oD6qPqg+pj6ePoA+mj5YPng+YD6CPvY+xD9Qv4r/zAAZgGEAowD2ARYBoAHIAigCDAJgAmACbAJEAogCqAJEAmgCAAIyAZwBYAE3AM0A3QC9gGiAVwBDAHSAIMA9P9t/1n/lP+4/+X/dwCCAaACrAOwBHgF+AWYBsAHAAmgCfAJkApQC6ALYAvQCvAJ0AjYB/AGwAVABPACEAIwAQIA9v44/oD90Pxs/Dj8qPuo+uj5iPn4+Bj4MPeA9tD1IPXQ9KD0gPRg9LD0QPXQ9TD24Pag9zD4gPiw+OD4+Pjw+PD4GPlQ+Wj5kPno+SD6CPrI+YD5cPmA+cD5SPog+wT8zPyM/XD+df+QAKoBsAK8A9gECAbwBnAH6AeQCCAJcAmgCZAJYAnwCJAIAAgwBxgGOAWQBNwDEAN0AgwCqAFeAUgBMgG7ADYAKABLADgACQBPAB4BQAKIA+AE2AVQBvAG6AfQCGAJAArwCsALIAwADJALwAqgCaAIyAfIBogFaARsA2wCcAGEAKr/vP4C/rD9fP3Y/PD7KPtw+nD5UPhw99D2IPZw9SD1APXw9OD0EPVw9cD1QPYA97D3CPgg+Ej4ePho+CD4EPhI+ID4mPjo+FD5gPlg+UD5WPlo+VD5aPkQ+uj6oPs4/NT8nP14/pP/vwDUAdAC3AMQBQgGqAZQByAIwAgwCYAJwAmwCUAJ4AiACNAH2AYABlgFqAT0A1wD8AJkAuQBpgGYATgBsQBrAGMAQwD8/wgAkQBiAXwC1AMoBfgFmAZQBxAIoAhACVAKMAuQC7ALwAuAC7AKgAlwCHgHcAZIBUAEVANEAlYBkwDe/wH/LP6c/Rj9ZPyQ+7D6qPlw+FD3oPYw9pD1EPXg9CD1cPWQ9cD1IPaA9uD2YPfw90D4QPgw+Bj44PeA91D3cPew9yD4qPgg+VD5MPlI+Xj5ePlg+cj5mPpQ+8D7RPwY/bj9Uv5D/6MA1gHMAswD4ASwBVAGGAfgB2AIkAjgCBAJ0AhQCOAHeAfQBhAGgAUQBXgE4ANoA/gCXALkAZoBWAHoAJ4AdAA4AOT/sf8LALsAhAGQAvgDaAWIBjAHwAdwCBAJ0AnQCrALEAzgC6ALYAvACqAJgAhoB1gGSAWQBAAEHAPoAQABkQDa/7D+hP3I/BD8KPsI+vD40PfA9iD2APbQ9YD1gPXg9VD2gPag9tD24Pbw9lD3oPeQ91D3MPcw9/D20PYQ95D3CPiI+Dj50Pno+aj5qPm4+Yj5mPkI+rD6MPu4+4j8QP3Y/bD+7/88AUQCQANABAAFeAXwBbAGOAeAB8gHEAgwCNAHgAdYByAHgAb4BdAFoAUoBXgEAASoAwgDUALOAVoBygBRABoA6P+M/13/5P/xAN4B3AIYBHAFWAbABjAHwAdACNAI0AngCmALYAswC/AKkArACcAIkAdoBpgFKAWgBKQDiAKmAfEA6v+o/oD9ePxw+2D6aPlA+AD3IPbw9QD2sPWQ9eD1YPag9rD24PYA99D2sPYA92D3MPfg9vD2IPcw92D38PeI+Aj5oPlI+nj6OPr4+Qj6CPrY+RD6wPpw+wD8sPyE/Sj+nP5W/1oAQAHOAVgCFAOcAwgEoARwBSAGeAa4BhAHOAf4BsgGqAZoBuAFgAVwBVAFyARIBAAEsAMUA1QCzAFYAdoAZAAjAPX/rf+4/1oAVAFYAmADeASABTgGuAYwB6gHQAgQCQAK4AowC0ALUAtQC9AK4AngCNgH8AZQBjgG+AUABdQD7AIIAqMADf/k/Qz9HPwA+wj6+Pjw9zD3EPcg9/D28PYw92D3MPcQ9yD34PZg9kD2wPYA97D2kPbg9kD3UPeA9yD4uPgI+VD5qPmw+Wj5SPmA+bD5wPlA+kD7MPzE/FD9Hv7C/gn/Zv8pANwAMgGKASwC2AJcA/QD2ASoBRAGQAZwBngGWAYQBtAFaAUQBfAE8ATYBIgEOATsA3gDxAIIAnAB4wBXAOb/sv+m/8H/MwAqATACDAPUA6gEaAXQBRgGmAZoBzAIMAlQCkALwAvQC8ALcAuQCnAJcAiYB+gGwAbABmgGoAXABOADcAK5AGr/jP58/ST8CPtY+qD5uPhA+Dj4IPjQ97D3wPeg9xD3sPag9pD2YPZA9nD2kPaA9pD20Pbg9rD20PZg9xD4UPhg+Jj44Pjw+PD4GPlo+dD5gPpw+0j8zPww/bz9OP6E/uD+XP/Q/y8AnAB6ATACqAJEAzAE2AQABegE+AQoBfAEwATQBPAEoARQBGAEcAQQBGQD+AJ8ArAB7QCwAJ8ASgDq//v/PwB8AN4ArgG4AoADKATgBJgFIAbIBqAHoAigCZAKkAswDFAMIAzwC2ALgArACVAJEAmwCGAIcAhgCGgH0AU4BLACGgGe/8b+Rv5g/SD8MPug+vj5OPnI+Hj40Pcg9/D28PaQ9vD10PUw9kD2APbg9QD2APbw9QD2MPYw9lD28Paw9xj4IPgo+ED4SPh4+Oj4YPnI+Xj6ePtE/Iz82Pxs/fz9UP6o/kb/xf8kALgAuAGIAhADpANABHgEWARQBIAEmAR4BHgEeARQBAAE8AP8A7QDOAO8AjQCcgHFAIAAbgA2APn/EAA/AFwApgCSAcwCnAMQBJgEYAUIBpAGeAfACOAJsApgC/ALIAzQC4ALgAtQC4AK4AnACcAJYAnwCJAI4AeABtgEmANwAjABJwCa//7+/P2o/KD70PoY+pj5OPmY+LD3MPdA90D3wPZg9lD2QPbw9bD1sPWg9ZD1sPUQ9kD2QPaQ9jD3gPeA92D3gPeQ99D3aPgo+aj5APqo+oD7KPyQ/BT9nP3c/QD+aP4B/5//ewCcAZwCHANoA8gD5AOwA4wD3ANQBGgEUAQ4BBAEuANcAzwDGAOMAtYBPgHRAGoAGAD7//z/2v+H/4z/9f+MAE4BPAIoA7AD6ANoBHAFsAbQB/AIAArQCjALUAuAC7AL0AtADJAMkAwgDHALAAugCiAKgAmwCKAHgAZwBYgEoAOgApIBbwAp/8T9mPzw+5j7QPuw+gD6IPk4+JD3QPcQ98D2UPZA9kD2IPYA9hD2IPYQ9gD2APZA9pD24PZQ95D3kPew9/D3MPho+Oj4uPlQ+pD6GPsI/Oj8SP1E/Vz9ZP1w/fT9Gf9JAC4BygEsAlQCUAJcAogCuAL8AmADwAO4A3gDSAM4A/gCcALYAT4BsABPAFQAcwAwAMj/ev9Z/y3/G/+P/3AAbgFAAvwCbAOQA/QD+ASIBvgHAAnQCXAKwArwCkAL0AtwDOAMMA0gDZAM0AtQCxALwAoQCkAJcAh4BzgGEAUoBBwD1AG3AN3/6P60/Zz8APxw+6D6uPnY+Cj4cPcA98D2gPYw9vD14PXQ9eD1APbw9cD1sPXw9UD2gPbg9nD3sPeQ95D3CPiY+ND4+Pho+TD68PrA+5z87PzU/Hj8cPyE/PT85P04/4oAFgHxAJoAhwDXAJABeALsAtgCkAJsAqAC0ALQApgCMAJ8AcoATwATAA4AGgAVAND/J/9a/gr+VP4E/9T/lAAyAYwB0gE0AuACpAOwBCAGcAdwCPAIMAmwCUAKEAsQDLAMAA0wDVAN8AwwDKALkAtgC9AKQArgCfAIeAcQBvgE/APkAgwCkAHrAJH/CP7w/Bz8aPvQ+jD6iPnQ+BD4YPfw9qD2kPag9oD2UPYw9uD14PUg9nD2gPZg9oD2kPaw9tD2QPfQ9yD4QPig+BD5YPkQ+kj7gPzQ/CT8ePt4+yj8XP3U/vX/RwAZAOP/CQBhAP8ACAIYA3QDvAIEAsYBIAJ8ArQChAK6AZ0Azv/i/x8AJADk/5r/5v7s/Tj9aP1O/lz/KQBzAFQAKgCIAGoBgAK4AzAFiAZQB7gHQAjgCIAJcAqwC8AMIA0QDVANcA0gDaAMoAzADHAMsAtAC8AKoAkwCCgHcAZwBUAEkAM0AxwCQwCM/qT9BP1Q/LD7CPvo+aD4kPdA9xD3sPaQ9qD2YPag9RD1MPWQ9bD10PXg9aD1QPVQ9fD1kPag9sD2YPfg9yD4WPgo+WD6QPu4+5D7EPvw+rD7IP1Q/tr+If9P/1z/if8nACQB+gGIAtACuAIUApIB1gGsAjAD1AIcAjABbAAIABwAawBcANL/Pv+Y/vD9nP0W/if/+/80AC0ASACKAOMAtgEMA1AEaAVQBkgHAAhACJAIcAnQCgAMwAwwDYANYA0QDbAMgAywDOAMAA2gDKALYAogCRAIaAcAB4gG2AXYBKQDAAJQAPj+eP5k/gT+DP2g+wj6kPjQ98D30PeA9yD3wPYg9nD1MPVw9dD1sPVA9eD0sPTw9ND18PYQ92D2APZw9mD3kPjA+cj6QPsI+4j6UPq4+uD7nP0H/23/6v4+/jz+G/+rACgC6AK8AjwC6AHYAeIBMALcAlgDEAMMAvUAOwARADsAWQAeAEz/cv74/bj9bP1Q/bj9aP7a/tL+wv78/mL/JwB4AdQCnAMIBOgEOAY4B6AHMAhACZAKgAtADOAMMA0QDfAM8AzwDAANIA2ADVANEAxwCjAJcAggCPAHmAegBggFWAPSAYAAiP9L/zb/hP7w/AD7gPmQ+ED4YPhQ+JD3gPaw9WD1QPUw9UD1YPUg9YD0IPRA9JD0UPUg9lD20PVA9cD1EPeA+JD5MPpI+uD5iPkQ+lj7xPzo/YL+iP4g/g7+/P6uAPwBbAJUAv4B5gEYApgCHAMcA7gCZAIsAp4B+ACFAFoAHwCi/xX/hP7M/Tj9HP08/Vz9ZP2Q/dz92P24/Rb+G/9tAJoBfAIYA5wDIARoBQAHMAgQCfAJsApQC+ALoAyQDfANwA2ADbANwA2wDaANUA1QDOAKsAlACSAJsAjQB4AGwAQMA+oBTAHXAB4AFv/A/UD82PrI+TD52Piw+Fj4cPdA9pD1cPWg9bD1UPUA9bD0YPRw9BD1sPXg9ZD1YPWQ9QD2IPfY+Dj6OPoo+XD4GPnI+rT8Nv5i/nj9iPzo/I7+SwBQAfwBSAK0AcsAmACQAQQD7AOgA6QCXgFdAHQASgGwAQoB6P8B/5r+MP6s/VT9OP0s/fj84PwA/TD9YP1w/XD93P0C/4kA8AGoAtgC8AKQAxAFIAfQCJAJ4AlACtAKgAtQDIANQA5QDgAOsA2QDcANAA7QDRANwAugCkAKAAqACaAIIAdIBYQDbAIIAswBvQAh/3T96Pt4+qD5iPl4+bj4cPdQ9nD1APXw9HD1wPUQ9eDzUPPA86D0UPWA9XD14PSA9DD1sPZI+BD5WPlI+eD4wPho+Qj7PP10/jj+9PwQ/ID8nP4+AeAC6AKkAVoADwAUAagC+ANABHQDJAK2AOn/eQDKAUQCPgGR/2D+/P3g/dz97P2g/eT8gPzs/Hz9cP04/YD9KP7M/of/sQAQAvACUAOIAzgEmAWAB3AJgAqwCoAK0ArgC0ANUA7ADpAOMA4ADvAN4A2wDYANQA1QDCALIAqQCSAJMAjYBkgFwAN8AuABYgFlAKT+7PzI+wD7MPpw+RD5cPhg90D2oPVg9VD1YPWA9UD1YPSw88DzoPSQ9QD24PWg9YD14PUQ95j4oPnA+Wj5IPlo+Zj6OPyU/Rr+jP3U/Lj8xP3v/zQCFAMIAqgAGgDWADgCmANYBOADmAIwAZgAmwD1AJYB7AEeAV7/uP30/CT9rP0A/pD9aPx4+5j7jPwM/fD87Pxg/Rb+6v4CADQB/gFgAuQC6AM4BbAGUAigCRAK0AkACkAL0AzwDTAOEA6ADRANEA3ADRAOoA3ADOALEAsgCmAJEAlwCCAHiAUYBAwDMAJOAV4AHf+g/TD8MPuQ+uD58PgI+ED3cPbQ9ZD1gPUw9cD0MPTw8+DzEPSw9CD1APWg9ND0gPVg9kD38Pdo+Ij4qPgg+QD6+PrI+2j8tPzg/ED92P2m/t7/bAEEAo4BvACtAJIBaAJUAxgE1AMoAnQAEQDvALgBsgEmAQAAVP7k/Mz8uP1K/oj9XPy4+7D7DPx0/OD8CP3g/DD9ZP7c/7QAFgGUAWwCaAOIBPAFcAeACDAJgAnwCbAKAAxgDQAOwA1ADWANwA0wDlAOAA5ADXAM8AvAC/AK0AnwCCAIEAewBXgEuAPoAmgB9f/m/uD9tPzA+/D6APrA+MD3gPdA95D2sPUg9eD0sPRg9HD0YPRQ9ED0YPSg9BD1oPUw9pD2APeg92D4+PhY+dj5gPo4+wD8zPxM/UD9eP22/okAxgGyAf8A2QAIAXYBtAI4BIAEBAPrABcAzACQAdYBoAGsANz+cP1k/dj9lP14/Oj7DPwM/Hj7EPtg+7j76Pss/PD85P3W/s3/eADQAEABYAJQBFgGWAdwB7gHsAgwCnALQAywDCANoA3QDQAOQA5wDpAOYA7ADSANgAwgDAAMYAvQCTAISAfABiAG6ARQA/YB4QDq/9j+uP18/HD7wPrQ+bj44Pdg9wD3gPbQ9SD1gPQw9FD0kPRg9PDz4PNQ9MD04PQA9cD14PZQ91D3YPcI+BD56PnA+nD7oPt4+xT8lP0z/zoArwC7AJoAOwDHAHgCxAPAA8wC+AGIAXoBfgFmASwByAA5AMT/xP6A/dD84PwY/Qz9pPzw+3j7UPuQ+wj8XPy4/JD9jv4e/4v/NwA+ATwCTAOQBMgF2AaYB3AIQAngCdAKIAxwDeANoA2ADfANcA7gDiAP4A5QDpANAA2QDDAMwAtAC0AKkAgYB0gGuAX4BNgDRAKPAC//QP6o/aj8SPvw+Sj5mPjA9+D2MPbA9UD1kPQQ9PDzAPTw89DzwPOQ85DzQPRQ9QD2EPYA9pD2cPcI+Kj4gPkw+oj6EPvw+/D8zP3K/rj/RQBgAJoAdAFoAqwCmAK8AvwCGAO0As4B5wCQANwAUgEqAev/Fv68/FD8tPxk/Wj9hPww+3D6aPoY+/j7uPxA/UT9SP3k/Tv/iQCEAVACGAMIBDAFeAawB4AIAAngCRALAAywDDANkA2wDcANIA7QDhAPkA7ADSANwAxwDDAMwAvACkAJ6AcYB1gGUAUIBPAC6gGvAET//P3w/Oj7+Pog+oD5qPig98D2EPag9TD18PTg9ND0gPQQ9ODzUPTA9ND0APWA9SD2oPYA94D3CPg4+Kj40Png+ij7oPvA/MT9Lv4i/tL+YABwAbYBmAFyAUwBngGcAlgDxAJEAScABgA7AD8A7f9p/1T+yPzo+wz8ePww/Ij74PpY+sj52Pno+hD8MPyg+yD8aP2M/jj/MwB+AWgC6AL4A7gFAAeQB2AIsAngCoAL8AvgDKAN4A0gDsAOUA8gD5AOQA5ADhAOoA0ADWAMYAswCkAJkAiwB2AG4ASYA7gCugGaAGT/Bv6Q/Gj7qPog+mj5gPhw92D2oPVw9TD1sPSQ9ID0cPRA9DD0cPSw9DD0UPTw9VD3cPfg9vD2cPdA+Dj5wPoI/Mj7UPtg/PT9gv6y/mz/vgBmASABCgGQAbIBuAFEAowCwAF5ABgAWwApADj/aP5C/gT+IP1M/Aj8oPvw+rD64PoI+8j6ePrA+mD7wPs0/DT9ZP4n/3T/PgCeARADIAQQBRgGSAdQCEAJkAqACwAMYAwADfAN4A4gDwAPAA/wDtAOoA6QDnAO8A3wDPALUAvACtAJoAhgBygG8AQABCQDHALIACz/1P3g/DD8aPtQ+jD5WPiw99D2APaA9WD10PRQ9JD0QPUg9TD0oPPQ81D00PQg9oD3IPew9VD18PZQ+Yj6yPrg+uj6GPtU/ET+g/+w/6n/EgC3ABgBcAEoApACQAKYAToBIAH6AKYAHABr/67+KP78/aj99Pzo+wj70Pog+0D78Pqg+nD6YPqA+ij7MPwI/UT9hP16/pX/hgC4ARADEASoBIAFCAegCJAJAAqAClALEAzQDJANYA6gDmAOMA5QDrAO0A5gDsANMA2gDAAMkAvQCoAJAAjQBjAGqAWgBFQD0AE1ANL+7P1g/Zj8gPt4+kD58Pcg9/D2oPbw9TD1wPQg9TD18PTA9ED0oPMA9HD1sPYA9yD2UPXA9TD38Pg4+oD6WPpw+uj66PuA/fj+gf9e/23/EgCgAAIByAFkAggCEAHSAEoBRgFXAHr/LP/O/kb++P28/cD8SPt4+sj6UPs4+9j6ePoY+tj5MPpQ+2D8vPzI/Dj9Mv5L/3QA1gHwAnwDIARYBRAHcAgwCfAJ0ApgC7ALcAygDZAOkA5wDpAO0A7gDtAO0A5wDsANMA3ADEAMYAtAChAJ+AcABzAGIAXUA+QC+AFpAJT+fP08/Xz8QPsg+nj5mPgg93D2kPZw9rD1kPXw9fD1APUw9GD0QPUQ9mD2UPbw9YD14PVQ9+D4sPnA+Yj50Pm4+tD7CP0E/qb+4P7q/kz/FgDAABABQAFKASoBDgHaAJoABQAf/6T+xP7Q/lb+ZP1M/ED7qPq4+jD7iPtQ+4j60Pno+aD6WPsQ/Lj8OP2U/Qr+M//GAMYBPAJMA/gEMAbIBqAHIAlQCrAKIAtADFAN0A3wDaAOIA8AD9AO8A5ADyAPgA7gDbANQA0gDNAKEAqgCcAIMAeoBcAECATMAnYBdQBL/5j9XPzo+5D7YPrw+Gj44PfA9oD1gPXg9SD2EPag9dD0APQA9CD1gPbQ9iD2oPWA9fD1QPeg+KD5+Pmo+Yj5cPq4+9z8xP1Q/r7+B/8u/8n/uQAEAb0AswA2AaQBPgFoAM3/Sv+2/n7+xP7A/uT9ZPwI+5D6oPrY+uj60PqY+vD5GPkg+Vj6gPug+6D7kPzs/UD+Yv7U/6wBhAIAA3AEMAYoB2gHUAgACgALIAsADFAN8A3wDeANYA4AD1APIA8AD/AOkA7gDUANwAyADLALcApgCXAIQAfwBUgFwARkA24BNgDU//L+GP2w+2j78PoI+hD5CPiQ9lD1gPXQ9kD3APag9ED0QPSQ9FD1cPaw9vD14PRA9bD20PeY+Fj52PnA+aj5kPpo/Kz9wP0Y/hv/sv+A/5L/ZAAkAUgBMgFYATwBkADX/2L/Av/I/rr+Yv6Y/aj80Pu4+uD5IPrY+rj64Plw+Zj5YPnA+ID5YPtI/Oj7FPxA/TT+dP50/8YBcAN8A8gDeAVIBxAIgAjACfAKcAvwC0ANgA4wDnANEA5AD8APcA8gDxAPgA5wDRANUA2wDGALYAqwCWAIyAboBdAF6ASsAgwBugAoAHD+6Pz4+zj7gPoI+oD54Pcg9qD1cPYg97D20PUQ9XD0oPSA9QD2APYA9iD2APbg9XD20Pfo+Dj5aPnY+Uj6sPrg+0j9+P0k/pD+af/j/5r/tv+sAIgBaAHYAI8ATwC3/wf/0P72/oz+mP0c/cT8yPtg+qj5OPrI+mD6qPmY+ZD5EPnw+OD5QPsM/Ej8pPxI/cz9sP40AMoB8AK4A3gEkAXgBvAHoAhQCWAKgAuADBANoA3wDdANwA2ADnAPoA8gD8AOgA6wDcAMoAywDOALgAqACZAIQAcYBpAFKAWsA74BvAAlANr+hP28/DT8YPtA+kD5aPig9wD3MPdw90D3gPag9SD1YPVA9uD20PZg9kD2cPag9mD3iPhY+Yj5mPk4+ij7sPtI/IT9nP7w/ub+a/9zANgAlQDAAIYByAFIAfMA5wBRAAv/bv4d/5j/Wv6Y/Oj7uPvI+tj5GPq4+jj6APmY+BD5EPmw+FD5sPpA+xD7aPuk/OT9Vv7q/nMA+AHoAvADKAUwBugGuAfwCBAKAAvwC8AMIA1gDcANEA5wDvAOkA+QD7AOAA4wDvANIA2QDDAMcAsgCuAIcAh4B7AFoASABJADogH//07/kv4U/SD8KPyA+4D50Peg99D3YPfw9gD3oPaA9aD0MPVQ9oD24PWw9cD10PVQ9mD3YPiI+DD4iPi4+cj6iPtQ/Nj8OP3E/bL+kf/v/yMAlADQAMcACAF6AWoBbwBu/13/kv87/9L+eP6I/fD7wPrI+lj7wPro+ej5mPlo+OD3wPj4+Qj6aPkA+ij7cPug+yT9xP5D/33/vgCsAtQDgASwBQAHiAfwB2AJIAsQDDAMgAwQDZANEA6wDhAP8A7ADvAO0A5QDtANkA3wDCAMYAvACvAJsAiIB8AGkAUgBEADqAJqAXr/IP70/aD9WPy4+pj5sPgI+DD44PhA+CD2APWQ9XD2gPZA9qD2wPaw9dD08PWQ9xj4MPig+OD4sPiQ+Pj5RPwA/Xz82PwS/p7+cP7K/iMADgHKAIQA+QBIAbsABQDq/8T/Of8d/1f/9v6U/dj7wPqw+iD7YPv4+vD58PhI+ND3EPgo+VD6UPqQ+Zj5WPoI+wD8pP0T/3v/n/+2AIgCuANgBNgFiAcQCCAIYAlgC3AMcAygDLANYA5ADqAOkA/gD9AOUA4ADyAPAA4ADeAMwAxwC8AJIAkACbAHGAZYBVgEqALrAEIAOABa/2T94Ptg+4D6QPmA+GD4ePgY+PD2IPbA9YD1wPWg9kD3APcQ9gD1IPVg9sD3ePjw+DD56Pho+JD4ePr4/MD9GP0k/Qz+WP5K/lX/JgGEAU0AEQBsAcABOQAu/9H/PABl/8r+Av+K/pj86PrQ+kD7IPu4+oj66Pl4+FD3gPe4+ND5SPoQ+pj5sPlw+rD7CP1e/pL/WACzAGAB9AKIBLAFqAbYBwAJYAngCVALwAwADdAMcA2gDvAOcA6QDkAPEA8gDuANYA4wDuAMsAtwCwALkAlQCPgHUAfgBWgEgAOcAhgBjv/4/rj+tP0o/Aj7QPpY+cD4wPig+Bj4cPew9iD20PWA9sD3IPjw9tD18PVg9iD3sPgA+tD50Pio+Kj5sPp4+9D8VP60/hb+AP56/vz+6/9KASQCigGQAF8AjgAsAKz///9CAHH/RP64/SD98Pvo+uj6CPtQ+mj5QPkY+eD3wPYw94D4APng+Cj5kPlo+UD5oPok/Zb+xP5N/4EATAHWAWQD0AVoB5gHyAfwCDAKwAqAC+AM0A2wDYANAA7QDuAOcA6ADsAOUA6wDZANQA0gDMAKAAqgCfAI4AcQBwgGOASYAs4BTgFPAEL/fv5M/aD7gPpA+vD5KPlw+CD4oPfg9pD2sPZw9iD2wPZg99D2QPZw9hD3YPfg93D5iPrQ+eD4iPn4+gz8MP3E/mX/Ov4c/fj9BwAuAVABRAEKAQUARP+//4EAUABI/7D+rP4K/sD8DPwA/FD7MPqw+QD64PnQ+PD3wPeA90D3APhg+bj5wPhY+ID5+PrI+wD9vv6s/4H/6//OAbwDkAToBcgHgAgwCOAI4ApgDFAMQAygDZAOMA4QDhAPYA9gDtANoA4wDzAO4AyADAAMkAqACYAJcAkgCEAG4AT8A+QC4gEsAU8AJP8A/vT8APww+2j6oPkA+bD4ePhQ+KD30PbQ9hD3APcA93D3sPcg92D2MPdo+Uj6SPmw+Gj5OPrA+vj7AP6K/hj9ZPz0/Wz/RP99/zYB9gH4/0r+Jf+rAGgAVP9v/6v/Rv58/LD8ZP0w/Ij6gPoI+zj6oPgI+Jj4WPhA9yD3QPjg+KD4gPio+ND4kPlQ+yz9Jv5K/oL+WP+oAHgCaATIBWAGGAf4B6AIgAkQC4AMEA0ADUAN8A1wDrAO8A4QD7AOUA5gDoAOMA5gDYAMYAtwChAK4AlQCegHMAbgBAAE4ALqAUwBcADY/lD9kPwM/BD70Plg+XD5yPhw9/D2gPdw97D2sPZQ9zD3UPYg9pD3ePgY+Bj4SPnY+fj4uPgo+gD8EP1k/Yj9bP2o/OD8wP6AAPQAvwAZAAf/WP6w/vP/uwBKAFP/fP44/Uj8wPxM/XT8EPuY+rD6GPr4+JD4yPgw+HD3MPio+bD5oPhA+Bj54PmQ+jT8av5i//z+2P7W/34BeAOIBSgHuAdwB6gH4AiACvAL4AwwDVANoA0gDlAOUA6QDtAOsA4ADuANIA6QDTAM8AqQCnAKsAkACYAIWAfoBDgDPAN0AywCWwCA/+b+PP2I+6D7LPxA+3D5uPgA+Xj4UPdQ90D4IPgw9yD34PfQ98D2oPaA+PD5kPkQ+YD5yPl4+TD6cPwo/uT9yPyY/BD9hP3e/vIAnAEHAGj+SP7U/nf/JgDDACcAYv4w/Sj9EP10/Ij8uPyw+xD6cPmo+UD5YPgQ+Fj4GPjQ97D4mPno+ND3iPg4+lj7UPz8/WP/FP9G/mb/FAIoBGAFuAaIB1AHIAdACEAKsAswDNAMQA0ADbAMMA0ADlAOEA7wDeANkA3wDGAM4AvwCkAKMArgCcAIYAcYBgAF4AMgA/ACdALdAPr+1P0E/UT8yPvQ+5D7SPq4+AD48PeQ93D3KPio+PD30PbA9hD3EPdg95D4sPmI+cj48PiI+bD5SPoQ/JD9ZP2Y/Iz8MP3A/Wj+xP+eAOv/vv5E/rD+O//C//P/Zv82/ij95PwE/RT9sPy4+6D6OPpw+jj6WPmY+Gj4aPhY+MD4qPn4+Uj50PiI+RD7fPy8/dj+L/8F/zj/1AAoAzgFMAZgBqgG+AaYByAJEAtADDAMsAvAC3AMEA2ADTAOUA5wDdAM8AwADZAM8AtwC9AK0AkQCQAJgAjQBhgFQASwAxADlAIgAtMAsP4c/bj8pPxk/Fz8IPy4+rj44PdI+ID4qPhQ+Zj5mPhg92D3APjg9wD4uPlQ+6j6YPmo+Xj6iPq4+nj8gP6A/gz9xPzA/Q7+CP4F/0EAKgDc/vD9ZP4g/9D+HP4u/mT+oP10/AD8WPxI/PD6yPkQ+qD6KPpY+RD5qPjg98D3SPno+oj66Pjw+ID6oPtI/KD9If9s/8L+Pf+eAcgDkAQ4BSgGcAZgBmgH0AmwC2ALUArgCiAMQAxwDIANUA5gDfAL8AvwDPAM8AvAC8ALYArACMAIMAmACLgGeAXQBPADAAOYAiwC8gBv/zj+PP20/Oz8DP34+3D6sPlY+cD4gPg4+Qj6UPnw99D3ePgw+OD30Pj4+eD5KPmQ+cD60PoI+rD6dPxI/dz8zPyg/QL+cP1o/br+k//0/lr+uP7Q/hT+iP08/tz+5P1w/GD83Pw4/DD7+PoY+5D64PkI+lj6aPko+Ij44Pko+qj5+PnA+vD6uPqg+4D9pv7Q/iT/DADbALgBQAPgBKgFuAX4BQAHUAhQCRAKkArACrAKEAvAC4AM0AywDHAMAAywC7AL4AvgC0ALYAqQCdAIQAgACMAH4AZoBTAEpAMcA0wCugFOARMAeP60/bj9jP28/Bj82PsQ++j5qPl4+tD6KPqI+YD5qPmQ+bD5QPqI+lD6OPp4+vD6UPuY+9j7HPxQ/HT8tPwk/YT9kP1o/XD91P0e/iD+Kv5I/gr+lP1g/XD9YP0c/ST9TP30/BD8OPvQ+oj6gPoA+4D7EPvY+ej44Pg4+dD5uPpg+0D7uPqg+lD7dPyM/Y7+L/9s/9f/zwDqAdwCrANIBLgEOAVABpgHkAigCHAIgAgACbAJkApgC6ALAAsQCrAJIAqgCuAKwAogCvAIuAcwB2gHsAcQB+gF+AQQBAADbAKgAogCagH4/y3//v6k/hz+5P2k/YT8aPuI+yD8CPxI+8D6uPqg+lD6cPpA+4j7uPro+Tj60PoQ+3D78Pv4+zD7oPpg+5D82Pys/Oj8yPw4/CT8DP0A/vj9aP0s/Qz9mPyo/JT9EP5Y/Yz8ePyI/Cz8wPuo++j7JPzw+2j7aPug+0D7ePp4+tD7DP3I/Dj8yPxQ/dT8KP0z/+sAlQCy/34AJAK4AmgC+AKgBJAFYAV4BYgGcAcwB9gGqAfgCBAJsAggCeAJIAl4B7gH4AlwCoAIcAdQCPAHsAVYBWgHkAcIBcwDyAQwBPoB6gGcA+wCHABi/woBygCg/i7+Jv80/lj87PzY/iz+mPtY+5z8BPzA+vD7Dv50/RD7cPq4++j7ePvA/FL+KP3g+hD7BP2k/fD8+PzM/ZD9IPzY+7D9+v7M/TT8oPyc/Sj9sPzc/cT+DP2Y+tj6zPyg/Zj9zP0U/aj6WPmg+hz8mPwg/j//OPwA+BD5Yv7d/8D8vPwBABX/OPv8/KgCIAPS/jz+YAJoA7oAIAIQB1gGbgCK/wgFgAjwBlgFSAZIBvQDkAMQB8AJEAiIBbgFkAbQBaAFeAeQCIgG3AP0A7AFQAbwBbgFwATQAsgB5AJABFAEiAOUAgQBtv8XAKwBWAIgAYz/Dv/U/nz+xP5L/wb/9P2s/GT8vP2k/rz9mPxI/OD7WPuA+6j84P0c/ej6GPoQ+5D7EPto+2j8PPyY+kj5OPpo/IT8YPoQ+hD8hPxw+tD5XPwg/tj7aPmA+1z++PzQ+sT8zP6o/Gj6uPxpANT/mPyI/Bb/V/+s/Yb+eAEUAiIAkP5+/0gB1AH8AfwCIAOEAbABAASQBHQDzAP4BJgEOARQBRgGSAWQBHgFUAZYBegE8AaYBxAFAAToBZgGMAUYBYgGYAYoBEwD+ATYBZAEvANQBDgE1AIcAuwCuAMAA6ABaAHMAWwBdwAtANIA5ADG/5j+iP4f/yP/gv7I/XT9NP30/Pz8DP24/DT8FPyo+9j6APsQ/Cj86Pqo+kj7oPoo+TD6AP2Y/AD5UPgY/Fj9qPlw+Oz8Iv+Y+qD2oPpJACT+wPjg+rAATv54+Hj72AKwAIj4oPoYBEADaPoI/IAFMAS4+rD6oANIBjgBIQCAAzwCav53AJgFWAVkArQC+AOAAlABvAMABvAE9AKQAiQD8ANQBWAGIAVkAv4A3AIYBtAGMAUABOwD3AJ0AUACOAXYBjgFMAMQAssAvwCYAwAGQAS2AN7/YAHQAVoB4AEwAokA2v4x/+H/1f9PAO8AYP88/ID7wP3F/3n/CP6o/FD74Pr4+0T9FP2Y/FD8SPs4+oj62Pus/Gj86PoQ+pj6cPsc/Ej88PsA+3D66PoY/AD9uPyE/Az93Pyg+5D7HP4OACn/uP3Q/VT+Xv5O/+YAogGuACz/x/+iASQCOgFGAXgCyALgATwB2AJQBCADQgHcAXgDNAMEA2gEwARUArAAtALQBKgDoAKABFAFxgGb/ywDOAbgA/kAZALgBJwDggBAAVgFoATo/jz/cAVQBkr/sPy0A8gGlv4I+hgEQAnY/Rj4DANIB/D7iPlwBCgF0PmY+RAFSASQ97D3qAVIBYD1QPaYBrAFYPUg9XwDUAUY+aD1WABgBSD7kPT0/TgGSv4A9XD7YAWoAJD1KPnYBZgDkPUA90AGaAUw90j4KAUIBKD4mPloBZgFWPoA+tAEWAQw+qD8+AbgBJD7bPw4BEgE/P2i/pAFAAUY/Qz9kAV4Bcj9WP6wBVAF3P24/UAFwAYb/3T8zANoBnb/zP3QBCAG2v7I/BwD2AR2/47+yASABeD9ePsoAhAFG//Y/aQDOAOU/bT9NAJUAr7+9P0qAYwCnv64/FAB8AOP/7D78P3OAbYBcP6s/Z4B1AEQ/Ej7WAFUAhT9KP2gAb8AePv4+pQAuAL0/Xj78P7u/8T8vP2wADr/wP1I/pD90Py7/3ACDAB0/FD8Sv9GAEb+fP6UAToBLP1Y/Lv/1AFCAPr+hv+OAC8A7P65/zgCYAJn/77+zAAAAsQBdgGuASwB7f8pAGQCnAI4AaoBCAIoAPz/UAJgAlcAjAAAA4gCov78/bwCuAQOACz9PgGQA9T/XP50ATwCv/8a/8MAHAJ+AGz+MAFUAwn/nPzQAAwDFwA+/6ABZgGo/az8HgEQA2j/9P1SASACfP3A+00AWANe/6D8LACIAcL+EP0L/6kAqf8Q/tj+KgCy/hb/awAq/5T9Bv5W/5oADwDA/Z7+6QDe/rj8qv7EAIAA6v7q/n0AIf/I/HUAAART/9j6Tf9YBSwDRPws/CADiAM4/bz9aANEAyD/3v6eAVABdP5O/3wDSANj/wD/WAHwAbsAxv+qAEwCuAH2/yIAdgGqAfMAUABoAFAAGADVAPoBsQBS/h0A4AGR/4D9VQBIA0QA+Px4/jgCeQCo/OX/GAMz/4j7eP9sA/b/uPsw/iQD2QAY+1T9bAPQAez8TP24ACoBWP2o/OQBdANk/Xj7aAFEAwz+EPyAAQAEGP7g+nwBaAWo/vD6sAHoBFT9WPqMAvAFYP6w+s4AMATM/pD7vACgBM//cPtW/8gCMwCQ/ngAfAF4AGr+Xv7zALwC2ABs/g//wgBCASP/yv7GAVwCMv/o/RoADAHcACYBGgCY/i8AygEGADv/PgFAAmUA+P2q/1QDGAF4/cIAvAM0//z8eAGMA/QArP0b//ABDwCg/jQCRAMs/Yj8gALIAkj9GP3IA/wDePv4+UwDeAVs/PD6cANgA0D6WPu4BGwD2PpY+7ACqAGo+2z9/AIgAej7iP20AP7+E/8IAo0A2Ptg/VAC0AFo/Q7+HAO+AQD8KP0QBBgD2PzM/bgDHAEI+n7/iAdAAmj58PwgBZgCWPvY/YAFwAK4+rD9aAS+AYD94f/YAej/DP+JACQCxgCW/tH/hgE9/+z/6AIIARX/0/+CAKQATAG9AOgA6gH5/6j+WgDYAsAClP+8/TgBxAOM//D9xAKIBBT+aPsIA7AFKP7E/PgDJAOw+/z8aAVYBHD7KPwwBCwCsPoQ/vgFkAIQ+sD71AKAAiD8mPyMAygDWPto+nYBCATy/sD7fP40AXYA7P1w/noBcAFw/Uz8M/94AXoB6/8Q/nn/BQA4/aj+NAKgAb7+ZP49/73/mADk/0L/5P8IADsA1P5k/ngCjANs/fD6XAE4A9D+Lf+8AiwC4PwI+1kAIAVwASD91wCAAqT9UPzuAZAEUgDI/HX/aAMmATj9X/+YBJIB+PpE/hAGWAOo/ML+ZAO2Acj7pP0IBngF4Ps0/BgF1AKY+wL+KAVoBAj9bPxkAogDDP48/cgCpAI8/qD9rwAQApQAXP/E/pYAIAF8/oz+gAFkAlD+RPxs/4gC/ACo/Dz+wALF//D6/v4YBIf/4Pot/0gDEP+4+h4AqARK/pj58v/ABOD+IPskAUgEUP3Y+WgC2AXc/VD7XgHQA2z+2PtKAZgE8/+I+7z/fAM2AMD9xf9wAoQA+P1X/4IBKAHR/y4BMwCI/Vb/xALCASj+BQCAAjj/vPwbAIAE+wDw++z/2ARl/zj6xAFIBz7/CPoWAdgFif/Q+zgC+AVY/1D6dgH4BoT/gPrMAqgHpP2Q+PACIAgL/zD6FAKABWr+UPrSAUgHAP/Y+eQBOAUg/Fj7SARABKj8ePtyAbgCbP7E/XQB8ADM/Lj9BAL8AKz9Zf8cAaT+LP1O/5AAdQCQAPj+vP1w/pz/MwA/AKb/1f82/5j9dP9kAcb/6P3mAMQBzPzk/OQCOAPk/Fz8kAGwAnb+oPtMATgGCv8Q+QMAEAUe/4j9yAK0Amj+QPwYAEAFAALY+5//oAU2APD6RQBoBYACOP0U/SQChAP8/jb/CAScATD7KP/ABTgCKP2zANAECACY+l3/AAiIA2D6/P6YBaD/8PpUApAGdf+g+vz/wAS2ADT80P/kA8j/4PoU/3AEOgEw/Xb+oP8C/r3/wgDm/8gA2v7Y/Lj9HwAKAT4BUP5s/GQCEAJ4+cD7OAfoBPD4ePoIBCAD0Pvk/XAGFAJg9vj6cAmQBRD3vPzQCfABsPSg++AJWAZI+eD6qAUYA8D4oPyACAgFWPhg+rgFcARw+ij8iAboBOj5ePooBMgEJP1a/rAEDgB4+V7/cAfyAVD7ef8gA2f/1PxuAMADNAL8/YL+QQCK/tUAoAT6APT82ADaAQb+T/+AA6ACAv60/ZoBrAIM/9L+0AIQAqj8hPy4AiAEuf+W/tYAhP58/K//WAOsAlj9tPxOAf0AMPwM/twDMAKs/AD8CwBkAhEA2P24//gAKv68/agAfAGj/0b/wP+w/hz/RABkAW4BdP58/f0ANAK0/bb+3AOIACD8M//0Apz/eP0UASADgP/Y+nf/wAV4AMj6qgAABRr+SPtAArADFv9U/TABMAMQ/kz8mgHQBJv/2Pt8/zQDJAI2/iD+IALeAUz+bv6AAvACgv5S//YBTgAM/h4AvAJuAff/KP80AEQAIv9IAZgBGf+s/4gC0f9I/AIB2ARwAIj7Uv+0AzYBqv7I/7IBx//Y/ez/CAL2AJD/tgCCALn/sP7M/ZgBRAOi/qz8egEkA7z96PocAPgEnf+w+f7+qAViADj6xP5EA3H/cPsBAKwDSgBQ/AD+CAO8AWj7+PsIBCAEZP0g/KYAjAOP/3z8Rv98ApQBFP9Y/1UAkADE/3f/+gFuABD9If/8AuACEP48/McA7APM/3j7//9YBMQAYPzD/zADUv6U/cQB5gFg/Rb+LAO8Agz+KPzOAAgC8P3c/9gDCQDw/GwA0AIF/xj9OAKQBU8A8PqDADgGeAAo+wgBsAWB/3D71AHQBeL/gPpM/8AECQAo+zcAoAZDAOj4Gv7EA2EAmPsn/zAEHAKI+3D6HAJ4BHz9sPsMAjgCdP2I/V4AXAJTABz9SP4iAasAd/+2AAIAsv6N/0P/5/9mAd4AcP+e/rT+IwAoAUb/UP+kAvAAuPtM/ZAD2APW/mT8jv8oBCgBuPtCACAGbf/A+CIA+Ae0ARD6Ff94BpwAQPeL/3ALtAPA9oT8kAfWAcj4w/+QCQQCQPcQ/agGdAFw+sIAqAah/xj4lv4oB7wCsPrI/aQDnAAA/I3/mAXUAoj7OPwUAlgB0P1gARAF8//w+lD9bAIwApr+OwBMAtT+qPtKACQDLv/m/jIBfv84+07+yAUIBMj7wPriAewBZPz2/jAFAARU/HD5j//oA9cAsv6sAWwCGv4g+/D96ATwBdz9MPtCASADvP3s/KAEuAZE/WD3EgBwBkoARP10A3gEiPpg9xQCMAnIAZj7+P/gAGj7RPxoBPgFmf9k/Cj+jP5M/sgC6AQDAHD8pP7J/xD+WgFQBvQD8PuQ+SD/fAP4AgwCoAKEAGj8gPu9/wgFoAUmALz8SP+hAHD9EP6QBfgG7P2g94D98ARMAqz+0AIAA5j5sPf4ApAIkwAQ+6YAJAO4+QD3cATACqEAWPkw/b7+WPwYAHgGGAQQ+5j5PACIAjz/VACMA9//qPrQ+7cAnAOIA5IBBf94++D46P44ByAG4v4o/AL+4P6Y/V//uAY4Brj7oPiuAGQDKP+qAZAG+wCA9kj5KAeACPz9AP10A2L/UPc+/rAJkAZg+4D73gEd/8D7FAJACJACcPkw+rYB+AN5AO8APAPr/3j6cPs0A2AH4ALo/MT9twAh/zL+fAKwBWQBWPtw/AgBkAIuAYEA6QCc/qz8pP3lACgETAOe/qD7zP0vAND/PwDYAggEhP4Y+YD9OAQIAyD+P//YAsD/CPti/oAFeANY/Iz8ewAcAI7+IAGIAywBCPzA+Wb+CAT4Ahj/NP7I/iIABf8o/b8AkARCAYT86P3rAOgB5gFCAVoASv7k/JYAqAR4AsL+Gf+n/+z+/P+DAC4BnALvAKz+PP2M/UAC4AS5/8j7CgC4Aqb/Yv5/ALoBSP8g/XsAqAJSALD/JAEe/6j7ZP7MA6AE8v/Q/LP/VgFs/RL+3AOoAmT9VP5wAiUAJPx6/lgErALA+tD8oAV4BGD7aPtMAywD5PxK/pgEjAJ4+4z9WAQiAYD6kv6gBigD0PlY+/QDTANI+wz8eARABJz8YPuZAAQCNP5q/vgBjgFG/gj91/8MAsoAwP5u/wYBqP9W/hcAwALSASb+QP1cAEgCQQAB/8QBlAJS/kT8UgAABGoBNv6v/6ABzv/k/RQBIATXADT8mP0MAvgBWf8gAAQC7P9w/Hj93gH4Ao4AOf8r/2T+gP5iANgBcgEUALj+3P3c/rsAgALSAU7/wP71/x//cv5cAjgEZP/I+yv/WAJvAGL+9wAEA6T+sPqk/hAEPAIJ//T/gQCo/bj8ugCQA3QBdP+3AI4AsP1s/XIBfAMwAQb/u/8pANr+6P8sAvEAKv7m/hoB2wDA/6gAEgEy/9z9Ef/WADgBPgFKAUT/zPyI/sQBBgGM/h8AQAJNALj9gv7aAGwAFv9VAM4BKQBA/iEADAI2/5z8AABABI4BlPx0/RACpAJO/rT9RAFCAcj9mv5QAg4BDP08/uACZgEg/Ez9bAOgA6T92PtLAKwCRAAt//sAdgHS/5r+SP+rAG4BkAFcARMArP5K/3MAbAGqAcb/Pv6D//ABAAJV/1T9sv6KAfMAXP5E/+gCUAIY/Zj7pP/8AnwBIP9CAEoBZv6w/NgAdAOQ/7D88f94Aoj/PP2xAFgDbf94+zL+8AJAArL/hQDsANz9zPxPAOACdgEKAOQAtAA2/mT9sQAkA1QBsP7y/tQANAHJ/6r/FAEfALD9sP4wAoQCIgDo/mb/nv6k/RMADANAAtj+3P0H/1n/d//6AMgBFgD+/mz/T/8I/28A7AFXALz9DP6tAJYBOwCq/7r/iv7c/ar/jAH9AOf/AADG/y7+OP1V/wQC8gHm/87+N/+h/8r/uP9qAFYBbwDI/uz+vQBiAXEAZwA/AGb+nP1uAEwDrAHa/uz+EgA4/0T+dQAEA7ABov4m/lT/6P/6AIACPAJD/9T8fv7GASwChwC3ADoBIv8o/dj+CAK0AlYBKADM/nz9xP5oAogDeAAM/jX/wAAGAO//1AE4AmL/bP04/14BNAHvAOIB3ABM/XT8YwCkAzwCqv9i/1n/GP6w/qABPAKl//T96P7u/5b/kP/FANYAUv60/Kb+5gAgAeIAQgAs/iD8yP0sAlgDxv/E/cz/8v+E/Xj+hALoAkn/2P1y/wcAY//TAOwCrwCQ/HT9KAIoA0AAaP+OAJL/gP0x/0ADcAPQ/zT+dP9Z/6j+GAEQBGQCEP4Y/Wf/6wACASQBJAHp/37+rP55APABugExAKL+Yv65/xABmAHmAfkAuv6I/bD+1gDaAcABowAg/x7+ZP7u/2IBcgElAAv/vP5b/3UAGAG6AO//Nf+C/gj/CgFAAgoB9v5O/sj+L//C/yABqgG5/5T97P2K/wcA6/86AOH/av6c/e7+7gAAAX//lv60/v7+U/9jAH4BEAE6/xb+wP4fAOkATAESAc3/bv6g/mAAnAFwAW4Ap/9k/43/IgDsAGQB8wD6/3//2P+nAD4BGgGLABsA6f8wADoBDAJwARUAg/8aAPwAPgEsAUIB4gDb/zL/v//VAD4B3gAJAFX/LP+a/zQAPwDP/1j/Pf9p/3T/kf+0/23/3v6K/uL+vf9TAPD/D/+O/oL+4v6n/10AcQCo/9b+xP5G/87/JABsAEsArv8S/wD/uv+AAHIAsP8o/0z/sP/4/xQAIgD+/3P/Kf+8/3MAjgB4AGgAGwC9/87/qwBOASwBvAB3AHkAngAaAZIBigEKAbcA8gBQAaABtgGoAVYBBAEOAVYBuAHQAYIB/gDDANMA+gAwAVwBJgFsABAAdQC+AE8A+/8zABoAl/+L/w4AIgBb/8b+7v4j/wX/Of+l/0P/Uv7Q/QD+dP6K/jD+0P20/az9RP3A/Oj8VP0U/UT8+Pto/GD8yPvg+3z8CPwA+1D7uPwg/Sj88Psc/Zj9KP2I/fz+hP8J/3n/2wB2ATYB/AFkA8ADgAMwBGgF4AV4BdAF2AY4BwgHqAdQCBAISAdwB3AIYAiYB5gHAAh4B5AGYAbYBuAG8AVABQgFWAR8A2gD0AOEA1ACMgH2AMsADQBh/03/I/8O/uT8kPyI/Mj7+Pro+rD6WPkg+Ej4gPhw9xD2sPXA9UD10PQg9RD1sPNQ8hDyMPKA8uDzUPXQ9IDyUPGA8hD0APWw9lD4APgA99D3IPr4+/j8jP7IAJ4BoAGgA9gGgAiQCNAIYAqQDFAOoA/gEEARoBAgEOAQYBJAEwATgBLgEcAQQA+ADqAOoA5ADVAL4AlACWAI6AaABYAEKAOKAd0AQgH2AO7+yPwA/LD7EPs4+yT8LPxo+pD4oPhw+ZD50PnQ+rj6cPkg+RD6qPpg+jD6mPqA+sD5CPpg+7D72PoY+sD5OPkQ+fD58Pqg+gj5wPdw99D3CPgQ+ND3APeQ9UD0QPSA9ZD2QPZw9dD0YPQg9HD1CPig+YD5EPkg+hT8uP0h/+oAjAKkA4gEeAYACfAKwAsQDNAM8A1QD6AQQBLAEsARwBAAEcARIBLAEeAQwA8gDmAMwAvACxALoAkQCDAGMATkAoQCZAJYAXX/BP4U/QD8SPuA+9j7aPuI+hD6APqA+fD4yPlY+/j7cPvI+6z8qPww/Az9F//d/1j/nP/TAEABfgCsALIB2gEIAbgAZgG+AUABmQD2/9z+oP0U/VT91P1o/Wj7+Pig93D3MPeg9oD2QPYQ9PDwwO/w8LDxYPFg8YDxQPBg7gDv8PGg81DzEPRw9oj4QPnY+lj9Yv42/oz/tAPQB9AJwArQC/ALMAtQDMAPwBKgE4ATQBMgEoAQoBBAEuASoBGAELAP0A2gCxALYAsACmAHMAbQBYgE+AJoAvIB6v/A/Uj9kP38/Gj8BP0A/Yj7SPqI+iD78PpA+4j8gP0o/dD8TP10/Tz97P1y/0sAUQBVAJIAhgAsAFUA3wD7ALIAqgCAAOH/NP+s/gz+IP1k/Cj8DPyg++j6sPng90D2EPaQ9iD2IPWg9NDz8PGg8ADxAPLg8YDxMPJA8pDwQPCA85D2MPaQ9VD3gPog/Aj9a/9OASYBmAFQBXAJIAvQCxAN4A3wDBANIBCAE2AUQBNAEoARoBCgEKAR4BEgEAAOkAwADEALIAoACagHqAVMA/4B8AFAAmYBZf9I/cD7MPtQ+9j7DPxI+0D62PkY+oD6+PqA+wT8XPyU/Bz9/P3w/nn/l//U/2EATgEcArQC9ALwAtgC6AIMAygDLAP4AmgChgHIAHMALAA7/zL+WP18/Dj7MPqg+cj4EPfw9dD14PTw8uDxEPKg8eDv4O6w8ADycPDA7qDuAO8g74Dx0PWg+DD3UPUw98D6oPx0/kwCGAUwBdgEOAfACrAMgA1wD6AQ8A9AEOASIBVgFMASYBLAEmASABJAEoAREA8wDNAKcArACfAIUAiABiwDTABf/4P/EP/8/TT9XPwI+7D5UPlw+TD5CPlw+fj5OPpg+sD6SPuw+wj8+PxQ/jj/3P+XACgBjgH+AaQCQAO8AzAEyAQIBagEKATgA4QDAAOYAjwCsAH4AOH/YP4E/Vj84Puw+hD5MPiQ9yD2kPQw9NDzEPLA74DvAPBA78DuoPAQ8kDvAOvg6sDu8PGQ8xD2GPjQ9qD0MPZQ+zX/8AA4AxgGqAYwBkAIMAzADiAPoA9AEeASoBOgFEAVgBTgEmASABPgE+AToBJAEJANMAvwCXAJQAmwCOgG9ANcAcj/jP5k/cT8bPzA+4j68Pnw+Qj5oPeQ95j4EPkw+RD6ePvA+wD7MPvE/Fr+Of9DAIoBDAIMAlgCaANoBNAEIAWoBRgG+AWgBUgFCAVwBKADHAPcAkQCJgHi/3j+/Pyg+/D6gPow+VD34PXw9NDzkPLw8SDxIO/g7MDsIO4A72DvQO9A7qDrgOlg6wDxYPXQ9lD3YPdA9xj42PqF/5gD4AV4B/AIEAqAC+AN4A+AEaASYBOgFCAWgBdgF0AVYBOAEyAU4BOAE+ASABGQDXAKIAlgCDgHIAZwBaADmwDY/YD8sPtg+oD5WPlY+bj40Pcw98D2UPZg9nD3yPjA+VD66Pqg+/D7UPyI/W3/DAGeAfIB0ALAAxgEOAT4BNAFIAb4BTAGYAbgBfgESASwA+wCSAK6AcMAH/90/Sj8CPvw+SD5OPhw9rD0wPPQ8pDxoPCQ8IDvAO1g64DsIO8w8KDvQO6A7ADrQOyg8JD1wPjY+bj5MPmI+ej7mwCYBeAIgApAC8ALAA1QDwASwBOAFAAVwBWgFkAXgBfAFkAVgBOgEkASQBIAEmAQIA1gCZAGGAUgBKwDMAO6AZz+OPsY+Qj4cPcw92D3QPcg9uD0wPSQ9QD20PUg9lD3mPio+dD6dPwS/tj+Lf8LAJAB6AIoBLgF8AZoB0gHeAcQCFAIcAiQCMAIAAgIBygGMAVABEADaALBAHj+rPyo+5D6EPnA94D2sPSA8uDwAPAA70DuIO5g7eDq4OiA6QDsAO5g7uDtIOwg6oDqIO+g9BD48Pk4+5j7MPuE/N4AiAaACoAMMA4gD0APYBAAEwAWwBdAGCAYYBhgGAAYgBfgFsAVYBTgEoARgBAgD+AM8AnwBmAEeAIeAUcAmv/c/eD68Pcw9tD1wPWQ9aD1sPXQ9JDzsPNg9UD3sPeg94D4uPlw+uD7uv5oATQC4gF8AtADyAToBRAI8AkACmAJUAmgCbAJYAlwCRAJ8AfgBmgGiAXgAyQCTQAE/uD7qPoI+ij5gPfA9cDzUPFg78DuQO5A7aDsoOwg7ADqgOhg6YDrwOwg7YDtAO1A7KDtsPHg9Tj4MPo0/Xv/pf9GAMQDgAjwC0AO4BCAEqASwBLAFKAXwBiAGOAYgBmgGAAXgBYAF2AWoBOgEMAOUA2gC+AJEAigBWwCjf/E/Xz8GPuY+fD3QPbQ9ODzcPNQ80DzUPMg8yDzQPQw9pD3QPjI+Lj5uPrY+zL+dgHgA3AEuASoBZAGIAcwCEAKEAxQDLALcAtQC6AKwAmACVAJYAjgBuAFGAUkAwsAnP04/CD7wPlo+HD30PVA8xDx4O+A7gDtwOyg7SDtAOuA6SDqYOsA62DqgOtg7WDuwO+A8ZDyoPKw87D3jPyfAIADkAVwBigGAAfwCXAOABNAFmAXoBaAFaAVwBbgF2AYoBggGAAX4BWgFAATYBAgDgAMgAk4B9AFAAVoAzwAvPwY+kj4IPeg9rD2MPbg9IDzoPKQ8qDy4PIA9KD1MPdg+DD5APog+zj8TP3s/joBwAPQBRAHuAcwCIAI8AgAClALQAyADHAMcAzwC4AKEAmACCAISAcYBtAE6AKOADT+WPyY+uj4wPcg98D1IPPQ8KDvwO7A7UDtAO1A7ODqgOpA62DroOpg6oDrgOwg7aDu8PEg9ODzIPPg85D2CPsiAdgGYAlgCJAGyAYwCUANgBIAF8AYIBigFmAVwBRgFUAX4BhgGEAWgBQgE2ARYA9ADdAK8AeoBegEKAQAAuL+MPwI+rD30PWA9TD2EPYQ9fDzMPNg8uDx0PIg9dD2cPdI+PD5QPuY+zT8/P0tAN4BhAOYBTAH8AdwCDAJsAnQCYAKsAtwDGAM4AtACxAK0AgACMgH4AZABdADbAJQANj9DPzw+qj54Pdw9kD1oPPw8eDwMPAg7wDugO1A7aDsAOxg7ODsoOwg7IDsYO0g7uDv4PIw9cD0sPNA9LD2mPrK/7AFQAnACIgGQAZACMALABCAFEAXYBfgFaAUIBQgFAAVIBagFmAVYBMAEgARcA9wDcAK2AeABTgEkAOIAmgAyP1I+wj5UPeA9oD24PbQ9hD2MPVQ9ODzgPQQ9sD3+PgA+lj7nPxM/fj9If+jADwCwAOoBYAHcAjwCMAJIArQCXAJ0AnwCsALgAuQCqAJYAhQB0AGAAWsA2gCLAGs/8z90Psg+mD4sPZw9WD08PJg8aDwMPBA78DtAO1A7eDsIOwA7ODsQO3g7ADtAO6A7wDx0PIQ9RD2EPVQ9ED28PrzADAGUAnQCQAI8AWgBtAKgBAgFYAXoBdAFgAUoBJAEwAVABbgFQAV4BPgEZAPAA7ADJAKgAe4BDADtALOAUAAHP5A+4D40PZg9sD2IPfw9nD28PVA9cD0APVw9nj4KPog+xT8VP1g/sT+Wv/QALQCaATgBWAHkAggCTAJYAmACUAJUAkACoAKMApgCYAIoAeABoAFkAQQAzwB1//a/lz9cPvQ+dD4cPdw9bDz4PIw8iDxUPDA74DvgO6A7SDtYO1g7QDtYO1A7sDuwO5A70DxsPNA9fD1UPZg9uD2uPk8/0gFcAmQCtAJcAjAB2AJ0A3gEmAWoBcAF4AV4BMgE+ASgBMgFIAUwBPAEXAPIA7ADFAKaAfoBCQDoAGjANr/oP4g/HD5OPiA92D2cPXg9eD24PYQ9uD1cPbg9nD36PjA+vj7/Pxu/sr/TwB5AIQBKAOgBDAG8AcACQAJ8AgwCSAJ0AgACfAJMApACTAIuAcIB+AFuASEA9YBmv8A/iD9dPw4+5j58Pfw9cDzIPKg8bDxgPHA8MDvwO6g7QDtAO2A7eDtAO4A7kDuoO5g74Dx8POA9dD1sPXw9fD2ePla/kAEwAjQCuAKkAnYBxAIcAsgEQAWgBiAGGAWYBOgEeARoBIgE4ATgBNgEuAPMA1QC2AJwAZABKwCTAGm/5D+CP4E/bD6GPig9iD24PVQ9jD3sPeA92D3wPfw9xj4QPmQ+8z9H/8vAEoBvAGQARgCwAOYBRgHoAhACrAK4AnQCIAIoAjgCCAJUAnQCNAH0AboBdAEWAOkAdH/Fv7A/OD7KPs4+uD4APeQ9FDyAPHg8FDxkPFA8XDwQO8g7mDtoO1g7gDvIO9g74Dv4O8w8UDzMPVw9gD3kPcY+PD4MPtv/2gEsAjAC3AMIAswCeAIEAxAEQAWoBiAGGAWwBNAEiASoBJgE+ATwBMgEiAPQAwwCtAIMAcQBRADXAGi/wT+qPx4+7D5wPfA9uD2EPdw9hD2cPaw9kD2IPYQ98D4YPoI/Jz9hv6y/kr/pAAcAlgDiATwBWAHsAjACTAKkAmgCEAIgAgACaAJMAoACoAIUAZYBOwCuAGWAOD/Qf8Y/nj8yPow+WD3QPUg88DxIPHw8EDxwPGA8RDwAO7g7ADtQO2g7YDuoO8A8ADwoPBA8jDzoPNQ9dD3ePmQ+Tj6mPx6AIgEYAhgCyAMAAugClAM0A6gEUAUwBZgFyAWYBQgE0ASQBLAE+AUwBOAECAN0AogCZAHkAa4BfgDTgGa/lz8KPpI+LD34Pfw92D3wPZg9sD14PSA9CD1kPaI+Ij6BPzQ/DT9vP2s/r3/NAH4AogEwAXgBiAIMAmgCWAJIAngCHAIkAigCfAKIAvACVgH2AS0AlYBLgGoAXYBDgDs/aj7aPmA99D1cPQw8zDysPGw8bDxgPGg8CDvwO0g7eDsgOyg7EDuMPBA8UDxYPGA8VDxIPKw9AD4KPpQ+yD9hf+eAXAD2AXwCLALsA3gDpAPQBDAESAUABaAFgAWIBVAFAAUgBRAFaAUwBJAEJAN0AqQCIgHIAcgBjgExgEB//j7cPkY+KD3YPdQ94D3UPeA9oD1wPRg9LD08PXw95D5qPro+0z9HP6c/mb/qAAAAmADGAXIBiAI0AgwCWAJIAkACTAJAArQCiALUAqACDgGcARsAwADBAOUAigB5v5s/Cj6WPgQ99D1YPTA8rDxUPHg8EDw4O9A70DuoOyA6wDrAOvg60Du0PCQ8cDwoO9g7wDw0PFg9cD51Pww/tj+YP8/AFwCIAYgC0APYBGAEeAQoBDgESAUwBXAFgAXABegFgAWgBXgFIATgBGQD1AN0ArQCLAH4AZYBTQDrQDg/Qj7uPhg97D2kPaw9uD2gPag9eD0QPTg8zD0MPXQ9sD4oPpA/GT9AP5c/ub++v+aAUgD0ARQBqgHsAgQCUAJUAlQCWAJ0AmACpAKgAm4ByAGCAWYBJAEAARIAuP/4P1U/KD60Pgw97D1MPQQ86DyYPKQ8bDwAPAA74DtIOyg68DroOxg7mDwYPFw8CDvoO5g7zDxcPRg+AD8Lv7M/nD+jv6OALAEsAngDYAQgBEgEcAQYBEgEwAVQBYgF8AXwBdAF4AWoBUgFCASQBCwDhANgAsQCmAIKAZ0A84AoP64/Bj7qPlI+AD3MPbA9XD1IPWw9ED08PPQ80D0QPWw9kj4yPko+1D8FP3g/fb+bgD8AUwDqAQ4BsgHwAhACXAJoAkQCrAKUAtQC3AKIAnQB8gGQAZIBtAFGAS+Aaj/BP4w/Bj6MPhw9tD00PPA86DzYPJg8MDuoO2A7IDr4OpA6wDsIO1g7kDvIO9g7uDtIO4g8EDz8PYQ+jz8cP0U/vj+3AAwBDAIAAzQDqAQgBHgEYASgBOAFKAV4BYgGOAYABkgGIAWYBSgEkARYBBwD0AOcAzQCdgGKAQcAqkAeP8a/iT82Png94D20PWA9YD1oPUw9VD0oPOQ8yD0IPWQ9iD4WPk4+iD7IPwM/SL+nf80AXgCmAPoBCgGGAfgB6AIMAlwCYAJYAnwCDAIoAdwByAHwAYoBtAEsAKFAML+JP0w+3j5gPjg9xD3MPZA9aDzAPGA7kDtQO2A7WDtIO0A7eDsAO1g7YDtAO0g7aDuEPGA85D1YPcg+cj6tPwg/7oBCARQBuAIgAsADiAQwBGgEuASQBNgFCAWoBfAGOAYIBhgFsAUgBOgEgASABHAD7AN4AogCAAGeAQwA/oBiwB6/tj7ePkA+BD3oPaw9uD2cPZQ9WD0APTg8wD0IPXw9oD4cPkA+pD6EPt4+2j8/P3Y/54BLANQBAgFqAVgBhgHmAfQBwAIEAgQCBAIIAgACJgHmAbgBMACCgHl/7z+gP1k/MD7IPsQ+oj4cPag8xDx4O8w8BDxYPGw8EDvoO2A7CDsgOyA7cDuUPDQ8aDyUPNA9ND1sPcY+uT8lP+uAUwDEAUwB7AJMAwwDlAP0A9AEGARQBMAFYAWABeAFkAVIBRgE+ASgBLAEaAQwA6ADHAKAAnYB6gGQAWoA54BXv9c/fD7APs4+qD5SPnI+BD4EPcg9kD18PSA9aD2CPgY+aD5qPlg+WD5KPqw+1T9uP6W/wkAegBOAWQCKAOYA8AD4APkAwgEsASIBaAF0AScA3ACdgHEAGcA7//u/qD93Pys/Fz8KPtI+RD34PTQ8zD0kPVg9uD1QPRA8kDw4O4A74DwsPLA9DD2oPYA9kD1cPXg9hD5FPww/4ABiAL4AtwDaAVQBzAJwArQC3AMQA1wDuAPABGAEUARYBCwD4APsA+QD/AO8A3ADIALYAqACdAIyAc4BngEAAPcAQYBQABP/zD+GP1A/Lj7YPsQ+4j6sPnY+Hj46Pjw+fj6gPtQ+6j6KPpw+oD71Pzk/Xb+nv60/ur+cf8vAL0A9QD9ABQBMgFyAbIBtgFSAaEAIgDo/73/Qf+O/rD90Pxk/JD8AP3Y/LD78PmA+OD3EPjg+Jj5mPmg+DD3IPbQ9YD2sPfI+Gj5iPmQ+cD5IPrY+tD7/Pwo/kT/SQBeAVACDAO8A5gEqAWYBjgHmAf4B2AI4AhwCQAKcAowCqAJIAngCMAIcAgwCAAIeAdwBmAF0AS4BJAEIAR4A5QCYgFLAKj/iv+G/4//j/9S/6L+tP0o/SD9ZP2w/ST+mv6s/l7+Hv5K/qz+Gf98/9L/JAA9AGYAmACxAKwA3QA6AYYBqAGkAYQBFgGcAGsAaQBNAC0ADwDA/xf/RP7Q/az9lP2Q/az9iP30/DT8qPtw+3D7gPuI+4D7MPvQ+pD6iPqo+sj62Pro+gj7GPtA+5D7BPxM/IT80Pwg/Wj9lP3Y/T7+sP40/wAA3wBqAXoBJgHXAAQB9gFAAzAEgAR4BDgEuANQA3wDIASoBLAEgARgBEAEIAQgBCgE7AN4AwADyALQAvgCGAMcA+gCeAIAAqIBhAGiAdQB2gHAAZgBcgFiAWABbAFqAVQBOAFGAWgBbAFYAVABSAEyARQBDAEGAd4AkgBTAC4AFQD3/+H/zP+r/33/P//y/pz+bP5o/mb+TP4e/uj9qP1o/TD9DP30/OD8yPyg/GD8JPzw+9D7yPvg+wD88PvA+5j7kPuw++D7EPxE/HT8nPy4/Nj8EP1g/aj90P0A/lL+rv72/i//b/+1//X/NACBANQAFAE6AWYBjAG8AeIBEAJAAnQCkAKcArwC6AIIAwgD/AIEAxgDKAMsA0ADaAN4A2wDUAM8AygDJAM8A2QDbANQAyAD+ALQAsQC2ALwAuwC0AKsAoACTAIoAigCLAIYAvABxgGmAYoBcAFcAUIBGAHmALsAkQBtAE8AMQAFANL/pP97/0P//P6+/pL+bP5K/iL+8P28/XT9MP3s/Kz8fPxc/DD8+PvI+5j7gPtg+1D7OPsY+wD7+PoA+wj7GPso+0D7UPto+4j7uPv4+zD8bPyw/PT8MP1w/cz9FP5c/qz+Cv9q/7P//f9QAJcA0AAOAVoBmgHWASQCfALIAvwCHANAA3ADnAPUAwgEMARYBHAEeASABIgEoASwBLAEsAS4BKAEgARgBEgEOAQYBPQD0AOsA4ADUAMkA/wC2AKoAnACOAIMAtoBngFYARQB3QCsAHYAPAD+/8T/if9M/wj/vv6A/kz+GP7g/aj9eP1I/Rz97Py0/Hz8TPwg/AT86PvI+6D7ePtg+0j7OPsw+zD7KPsY+yD7KPtA+1D7cPuI+6j70PsI/ET8hPzI/BD9XP2o/QT+YP62/gX/Tv+f//f/UwCxAAgBXgG0AQQCQAJ8AsACBAM8A3QDsAPkAwAEIARABGAEcAR4BIgEkASgBKAEmASQBIAEgARwBFgEMAT8A9ADoAN0A0gDKAP0ArACfAJQAhwC1AGYAXABTAEQAc4AmQBsADcA///M/5n/Xv8g//D+0v6y/n7+SP4U/uD9rP2E/Wz9WP08/ST9FP30/MD8mPyE/ID8gPx0/HD8bPxk/GT8bPx0/Hj8jPyo/MT86PwQ/Tz9YP2Q/cT98P0g/lb+jv6+/u7+Jf9p/6v/3/8SAFMAkAC/AOgAFgFIAXYBqgHYAQACJAI8AlQCdAKMAqQCtAK4ArwCxALIAsgCxALAArQCoAKMAngCYAJAAhwCBALwAeQBygGcAWwBSgEuAQwB8ADXAL4AoACDAGcASQAkAP//5f/X/9D/vv+f/33/bP9i/1P/Pf8x/yP/C//w/tr+zv7E/rj+qv6c/o7+gv58/nz+eP5m/lD+QP46/jr+Pv5I/lL+Tv5I/kz+VP5g/mz+ev6E/oz+pv7C/tD+2v7u/g//KP86/1P/c/+R/6z/z//3/yAARgBrAI4AqwDGAOsAFgE8AVwBfgGiAboBxAHOAeAB8gH8AQQCDAIUAhQCDAIMAgAC8AHUAboBtAG0AagBigFsAVIBKAH3ANIAugCiAIMAYwBFACUAAwDm/8b/pP+P/4P/dv9j/1X/RP8u/xn/EP8I//r+7P7o/uz+8v72/vj+8v7y/vr+Av8D/wH/CP8S/xj/Iv8w/z3/Q/9G/07/Uv9U/1f/Yf9s/2v/Zv9k/3D/e/+C/4L/gf+D/4j/j/+V/5//qv+v/7L/wv/e//n/CAAUACsAPwBKAF0AeQCTAKoAuwDLANkA6QD/ABABIAEwAUABSAFEAUQBPgE4ATQBOAE+ATQBJAEOAfEA1ADAALgAqgCXAHwAYQBFACQAAwDm/8v/r/+O/27/Wf9L/zr/JP8P/wT/+v7q/uT+6P7o/uD+3v7s/vr+Av8I/xL/HP8f/yT/Mv9G/1n/Zv9w/3r/hP+U/6r/uP++/8j/1f/f//T/DwAhACEAHwApADYAOgA8AEMARwBJAEoASgBHAEMAPwA6ADEAKgAuADMAMQAuAC4ALQArAC4AOQBGAEwATwBNAEcARwBRAGcAewCJAJEAlwCaAJoAmgCaAJ4AqQCzALIAqgCiAJ4AngCUAIMAcwBlAFUASAA9ADQAKgAWAP3/5v/S/8D/sP+g/47/e/9l/1T/RP84/zL/KP8X/wf/Av8J/xf/IP8j/yb/Kv80/0H/UP9e/27/g/+X/6f/uP/O/9z/5P/0/w8AJQAuADQAPQBDAEEARQBWAGUAYwBbAFoAXgBkAGUAZwBoAGYAZQBfAFAAOwAtACgAJwAmACAAHwAdABcAEAAGAPr/9/8AAAoADgAQABcAIgAoAC0ANgBCAEgASwBRAF4AbgCAAI4AkwCXAJwAogCmAKsAsQC3ALoAtgC0ALIAqACbAI8AggBxAGcAYQBUADoAHAAFAPf/5//a/83/t/+e/4n/ev9w/2b/Wv9M/zn/Jf8e/x7/Hv8a/xr/Hv8d/xT/EP8Y/yP/Kf82/0f/Tv9J/0//X/9u/3f/hv+f/7b/vv/D/9L/5v/2/wEACAAMABQAIQAvADgAPAA7AD0AQABAAEAARQBGAEAAOgA1ADcAOwA9AD8APQA4ADQAMQAvACwAJQAiAC0AOgA/ADsANQA5AEUATgBRAFcAYABiAGAAZABuAHYAewCFAI8AjQCFAIQAiQCGAH8AgACAAHYAaABgAFwAWQBUAEkAOgAuACYAHgASAAQA+P/r/9H/vf+0/63/mv9//23/a/9p/2H/WP9N/zz/L/8w/zn/P/9D/03/Wf9f/17/X/9p/3j/h/+Y/6n/tf+8/8j/2f/j/+v/+/8OABkAGwAdACYALQAyADUAPgBIAE0ASgBCADwANwAzAC4AKAArAC0AMAA2ADcALwAkACEAIQAbABEADQAPABQAGQAeACEAHgAaAB4AKAAyADcAPABHAFAAVgBdAGUAbABwAHAAcgB0AHgAfgCEAIcAhwCEAH0AdwBzAHEAdAByAGgAYgBbAFAAPgAuACEAFAAGAPn/7f/i/9L/w/+z/6H/kP+L/4n/gv98/3r/fv98/3X/cP9q/2X/Zf9t/3f/e/96/3r/ef96/4H/jP+S/5D/jf+N/5H/lv+e/6j/r/+2/7//wv+9/7j/vf/M/9f/3f/e/+H/5P/o/+r/5v/l/+r/7//t//H/+f8CAAYABgAOABIAEgAcAC0AOgA9ADoAOQA8AEAARwBSAF0AYABiAG0AeAB6AHYAeQCBAIUAgwCAAIQAigCIAIQAgQB7AHYAdQB1AHUAdgBxAGYAWABQAEsAQQAzACcAHQAWABAADAAGAPz/6//X/8X/vf+6/7b/rf+j/5r/lf+T/5H/kP+V/5z/nP+U/5D/lP+f/6j/rf+v/7H/sv+z/7H/rv+q/6f/pv+n/6v/q/+m/6T/p/+q/6z/sP+0/7b/s/+y/7b/vv/H/83/z//N/8v/zv/U/9v/5f/y//z/BAAOABkAIAAkACgALgA2AEAASQBUAGEAbgB4AHwAgACEAIoAjgCRAJcAmgCbAJ0AnACXAIwAgAB3AHEAcgB3AHoAdQBsAGIAVQBHAD4AOQAxACcAIAAaABEABwACAPz/7//e/9P/zP/I/8P/v/+4/7H/rf+t/6z/q/+t/6r/ov+d/5//ov+l/6f/r/+1/7n/vv/F/8n/xv/H/8z/0//Z/+P/7//y/+3/5//n/+T/5v/s//P/8//v//H/8P/r/+b/6v/t/+7/8v/6//3/+f/6////AQACAAkAEQAVABMAFAAcACYALgAwACoAJAAjACQAJgApAC0ALwAyADYAOQA5ADcAOwBDAEoAUwBdAFwATQA+ADUAKgAbAB4AMAA4AC4AGgANAAwAFwAeABYAAQDx/+z/4v/W/9r/7//2/+f/3//m/+H/zP+//8T/y//H/8j/1P/e/9r/0v/O/8z/yP/G/8b/yf/O/9n/4v/f/9b/zP/D/8H/w//H/9P/4f/o/+f/3v/V/8r/wf/H/9r/5f/m/+n/8P/1//P/6//c/8b/tv+0/73/yv/Z//D/CQAZAB4AGAAJAPb/7//+/xMAHwApADMANwA4ADwARQBLAFMAYwB0AHYAbABgAFcAVABfAGoAXABOAFcAWQA/AC4AOwA8ABoABAAVACIAEAD6//H/6//j/+P/7/8DABQABwDi/9j/BAAiAOv/r//H/+v/xP+t/+n/EADR/5L/tf8PAFoAhgCJAGEALgADAO3/EAB5AMwApABQAFcAkwCEAEgAUwCHAG8AEwDn/wgAIwAcAC8AZwDFAJAB2AL0AwAEnAIlADT9oPp4+SD6wPtQ/bT+7v9iAJj/Iv7I/Kj7CPuI+zD9Cf9rAGIB2AGSAd4AbQBzAGUAEQAKALYApAFMArQC9AL0AoACxAE+ASoBUgF6AZQBnAGMAWgBGgGMAOL/eP90/6//9f8tAE0ASgAuAP3/oP82/xX/Kf8V/xT/h//v/+X/wf+7/4z/LP8P/0b/e/9x/0v/VP+S/77/qv+D/4X/qf+p/23/UP+Y/93/uf+j/xEAUwDU/4L/HQCpAEQA1P81AHoAw/8T/3v/QABOAOz/3/8hAE0AcQCSAGkAGgAGAPz/z/8BAK8A2wALAC7/Nv8KANQAGAFKAaABFgFz/6T+vv+hAK7/Ef+SANoByAB6/y8AAAGm/yj+T/88AasAPP8nALABjABA/lD+MQCrAJ7/z/9UASQBAv9a/gsA6QCv/yP/ggAQAbD/Qf/BAEQBCACZ/y8Atf+Y/vj+WwCsADgAsgCKAecAPf+w/lb/Jf8w/vL+XgEUAkIALf9BAN4Adf9A/g3/9P85/8b+TACKAWUAEP/0/zABdgAW/w3/zv/7/7//MwBWAaABXAAK/xb/0v9wADYB6gF+AeP/AP8sAFQBHQCA/on/zAGIART/Xv5cAIQBfgCqAKwCZAL2/gz84Pv8/eEAzALEA2wD+f/g+xj8Nv8vANn/0gHYA6gB5P30/c//Mv7A+0z+8ALEA7QCAAOKAQD9iPqY+3z88P1oAvAFIAT0ACYBdgEc/vD64PtO/qL/owBKAaQBRAN4BIwBePxA+xr+kv9w/1IBdAKm/uj6Iv5QBGgEwv8a/vT+AP14+8z+ngF1AN4AhAPoAcT9Qv4qAVv/EPtw/HACGASCARAD2AVqALD46PkK/3v/uf+IBCAHTAKs/QcAEAJw/fD6KgBsA8z/Zv5IA6gFvgDI/Oj/HAPY/xT8hv5AAhIBVP/UAbgDhAAA/X7+MAIcApj+wP1nAAMAfPzk/eQDQAVsABT9FP7k/tz9Yv4mAXACfAGcAGb/gP0g/oABRAKQ/wr/HAE1ALj8EP3yATAE1wAu/tv/6QCM/rz8dP1+/hr/GQBKAZQCKATwAyAAJPwA/BL+dP7w/Ub/tgG4AmwCqALYAlgB+v6E/ZT9uv7W/lD9vP2QAYQD+QC1/1wDIAWd/1D6dPyE/3D8GPocAAAHQAX8AOgCAAXa/6j5iPp9/wwCiAE8AaACBAN7ADb+df+2ARgBB/+Y/0QC+AFe/mj9BwAeATIADAE8AmsA5P2Y/Tz+nP75/1wCHAOFAMD8KPtM/OD+8AEABJADBAFI/tj8GP0I/mL+pP6m/2kAPgDdAEwCcgFk/mz97f+gAVgACv/q/sT9nPwm//ADmAXwAkgAogBmAQn/kPuQ+5L+iQAeAQADEAXAAy0Atv52/gj8QPp8/eIBFAIYASgDoAR0AXj9MP1c/tT9UP3K/qoAogGkAowD/AI+AaP/wP2I+zD7nP2tAMACiASABcADWwCu/gz/iv74/FT9rv+0APz/SgAIAvACNAIMAcT/vP0A/KT8PP/EAGgABgAoANr/k/9JADQBRAEcAWwBIAE8/yj9LP3w/hIAPQBuAcQDsATcAhQAwP6E/oj9kPzQ/aUAUAJAAvYB4AH5AOb+SP2Q/fL+mP8q/77+dv/iAGYB2wCzALAAY//c/Sb+Uf9w/1L/UAA4AcsACwAgAI0ATAB3/9L+iP6Q/pb/TgHwATIBnAA2ADn/kv4o/x8AUAAfAI0ANgECAUkAAADW/1b/IP/R/+MAVgEEAa4AnwBDAIz/V//u/7QADgHAABUAp//h/0wASAANAAoABgDA/5//xP+M/8z+mv6Y/8UAGgHsAPMAygC//3r+Nv7K/lz/GgAQAYIBWAEKAaQAEQCO/4D/AABjAPP/IP+m/qz+E/+0/14AIgHwAUwCwgFxAOb+uP34/LD8XP3o/pwA+gHMArgCygGFAFv/dv7c/cT9SP4C/6T/dwCeAXgCgAIQAnYBjgBl/6z+2P5p/8D/PQA+AeYBmgE+AVwBDgH4/xz/DP8P/5r+ev5c/z8ALADK/9b/4P+G/wr/vv7Y/jf/Zv8j/9D+xP7g/hb/r/+jACIBzQA5ANb/dP83/5L/RwCvALEAtgDAAI8ARwAuACQA///2/xsARwBPACcA1f+W/8D/PgCPAG0AKwAWAP7/yv+0/9L/3v+5/7P/AAA5ADEAQgB2AG8AJwDv/8P/eP9M/27/q//j/zsAsQDuAMEAVQAWAA0A6f+e/5L/6P84AFYAWgBiAFwAMgALABUAQgBKADoALAAdACkAOAAXANj/vP/B/8T/3f8TACQA/f/L/6b/ff9t/4z/tP+o/5H/v/9BALkA1AClAHUAVgAZALb/bv9d/5j/+/9YAIsAiQBhACIA6//W/9j/xv+V/3H/iv/g/0IAcQA3AMf/eP8e/47+Hv4s/nb+mv66/hn/a/97/33/j/9U/8r+av5g/jr+9P0U/pz+Bv9G/7n/XwC0AKUAkQCgAH4AIwALAH8ALgGgASQCGAMoBMgE+ATwBLAEIAR4AxwDNAOIA/ADUATABDgFgAVwBRAFkATsAwwDHAJ0AQoBqABgADkABgCi/yr/zP5i/sT9EP2E/Dz8APzI+5j7UPvo+kD6kPnY+Cj4kPcQ95D2QPYg9tD1cPUQ9YD0EPTw82D0IPUg9iD3IPjI+Fj5EPog+zD8SP2s/ksACAK8A2gF8AZQCIAJwAogDJANsA5gD7APwA/ADwAQ4BAgEkATIBSgFEAUwBLgENAO4AwgC9AJ8AgACLgGcAUoBKwC7QBQ/+z9ZPyY+gj54Pfg9gD2wPUg9oD2oPaw9sD2cPbA9fD0QPTA85DzkPOA8zDzwPIQ8iDxUPAA8CDwQPBA8CDwEPAA8ODvMPCw8KDx4PKA9FD2OPhY+oD8bv4wAPAB/ANQBgAJ4AuwDgARwBLgEwAVABbgFqAXIBgAGIAXwBYAFgAVABQgE0ASQBHwD3AOAA0wCwAJ0AYIBWQD0AFrAAb/VP1o+/D5KPm4+ID4oPgw+Yj5mPmw+dD5qPlo+WD5sPko+tj66Pvw/HT9TP2w/ND7uPqo+cD4EPhw99D2APZA9VD0MPOw8SDwgO4g7QDsgOvA6wDsoOyA7cDuIPDA8ZDzoPXA99D5HPzK/v4BIAXIBxAKkAyAD6ASoBXgF6AZABrgGYAZYBlgGWAZIBmAGCAXQBUgEyARwA6ADKAKsAjgBhAFaAOAAUv/HP1A+6D5aPiw90D3oPbg9bD1QPZw9+j4mPok/Pj8CP3g/Bj9uP2O/rb/IAF0ApgDGAT0A/ACIAH6/gj9YPsI+hD5QPhw9zD2sPQg85DxgO/g7CDqoOfA5YDkYORA5cDmoOjg6mDtwO8w8gD1EPgg+xb+MAFYBDAHwAnADEAQIBQAGGAbwB2AHgAeAB0AHAAb4BlAGaAYgBfAFaATQBHwDoAMMArwB4AFJAPlAJT+MPwg+kj44PYA9gD2oPYg9yD3IPdA9+D3aPmA+8T9Xf9NAJsAwQD/AAwCwAMYBcgFMAawBngGMAU8AxYB3P6w/Ej7YPow+WD3YPVA89DwoO4g7aDrQOlA5sDjIOLA4GDgoOFg5GDnoOpg7vDxAPWA9zD6JP2IAJgEAAkQDWAQoBPAFgAawByAH0AhgCHAICAfYB1gG2AZgBfAFeAT4BGgD/AM4AngBhAEYAHK/sT8CPso+TD3gPVA9LDz4PMQ9YD2gPdY+Dj5YPrQ+6T93//4AeADMAUABpAGAAeoB4AIIAlgCVAJ4AigB7AFVAPrAJb+WPxA+hj4APbA84DxAO/g7CDroOkA6ADmwOOA4YDfgN6A3gDgYOJA5iDrUPDw9Lj4yPv8/SsAWAPQB3AMgBAgFEAX4BkgHGAeQCBAIUAhQCDgHqAcgBmAFoAToBBQDmAMgAoQCIAFlAKF/8T80Pp4+SD4oPYw9QD0YPPQ8yD14Pao+HD6SPzE/Tn/xwB0AgAEsAW4B2AJcArACsAKQArgCbAJwAlACRAI8AU8A1cAfP0Q+9D4kPZQ9FDyIPAA7iDsIOqA6ODmgOXg40Di4OAA4ADfQN8A4UDkoOgA7gD0oPnM/XkAlAIQBVAIcAxgEcAV4BggGyAdwB7AH4AgACFAIKAeIByAGUAWIBJQDiALcAhIBpgE5AKTALj9CPv4+FD3UPaQ9QD1cPRA9OD0APag98D5QPyc/qEApAKQBBgGCAf4BzAJ8ApgDGANkA0ADcALUAoQCfgHiAaQBCACMf8M/CD5wPZw9BDy4O+g7cDrAOpg6CDnAOYg5UDkYOOA4kDiIOLA4QDi4OPg5wDtwPIY+TX/9APwBvAIIAvADcAQYBQAGOAaAB2gHoAf4B/AH2AfAB4AG4AXIBSAEFAMMAgoBTADggH7/5D+3Py4+lj4kPag9RD1UPXQ9UD24PYg+AD6HPxu/hIB4ANIBhAIYAlgCgALYAsADEANQA7ADkAOMA1gCxAJ6AbIBKACOgCI/Xj6QPdA9NDxwO/A7UDswOqg6YDooOfg5iDmAOYA5gDmAOZA5oDmAOaA5QDngOtw8WD3OP3QAjAHsAmQC6ANoA+AEeATwBZgGUAbgBwgHeAcQByAG+AZgBaAEoAOAAuAB2AEaAIiAcz/nv6w/bT8YPsQ+gD5EPiA9xD4OPlY+oj7UP2Z/5ABpANABuAIoApwC7ALsAtgCyALMAtgC6ALgAsQC9AJyAc4BXgCW/88/HD58PZw9BDyMPAA76DtoOzg64DroOoA6qDpYOkA6aDoAOnA6cDqYOtA6wDqwOiA6YDtEPO4+E7+oAOIB7AJQAsQDaAOsA9AEeAToBYgGMAYABkAGeAYoBjAFyAVQBEADUAJqAXcAmgBygBCAKb/bP8a/xr+sPy4+zD7qPq4+qj7VP3+/pgASAIoBCAGMAhACsALkAywDGAMgAtwCuAJsAlwCZAIkAdQBogENAJn/4z8sPnw9pD0UPIw8KDuoO0A7eDsAO1g7UDtgOxA7MDsAO1g7ADsAO2A7gDvIO6g7CDr4OpA7RDy0Peg/fQC6AbwCEAK0AsgDYANQA6AEEATIBXAFWAWQBegF6AXABcAFSARkAxACJAE7gHuAAQBSAFOAXQBggGxACj/DP50/Qz9jPzU/BL+9//wAdAD6AXYB1AJMArQCjALIAtgCiAJEAhwB0gHIAewBugFsAT8ArcALv6g+wj5YPbA86DxMPBA76DuYO5g7uDuoO+g70DvAO+g7xDwoO8A76DvMPHw8YDx4O+A7QDrwOpA7jD0yPq0AEgFAAiACYAKIAtgCxAMMA4gEWATwBSAFSAWABbAFWAVIBQgEZAM4AcYBEABgf9Q/wMA4AAoAeUAYgBo/yj+LP3w/HT9Vv5z/wQB6AIQBQgHwAggChALsAvAC1ALYApgCVAIWAe4BmgGEAYYBXgDWAEo/xj9CPvQ+HD2EPQw8pDwYO/g7iDvwO8Q8HDw8PAw8SDxQPGg8aDxEPEQ8dDxsPLA8hDy4O/A7EDrAO0w8aD2pPyEArAGsAgACmAL0AuwC5AM4A6AEQATIBRgFeAVoBUAFeAToBHQDdAIEASIAKT+GP6u/gUAQAHIAYoB6QAUAPT+Ov5G/uL+6f84ASADWAVwB1AJ4ArQCwAMcAuACnAJMAgQBxgGmAVgBRAFgASUA9YBXP+4/Fj6QPjw9fDzkPKg8XDwwO8A8KDwEPGw8UDysPJg8gDyEPKw8TDxkPEg8zD1APbw9HDyIO9A7MDrgO3Q8VD31P38A0AIgAqAC/AL4AvQC9AMsA6AEOARoBLgE4AVABbgFAATQBAgDFgGKAGA/sD9Lv5D/w4BjAJYAkIBiQBXAD0ADgAjAFcAZwAcAQwD8AWwCMAKQAwADcAMgAsACtAIwAd4BnAF6ASwBEAEmAPgAqgBZP9w/GD5oPaQ9PDyIPLQ8dDx0PHQ8fDxEPJQ8rDyIPNw8zDzYPKw8bDxwPLQ9MD20PYg9ADwYOyg6uDqwO3w8TD3wP3ABAAKwAtQC/AKEAtAC5AMMA/AEeASoBMgFYAWgBbAFCASIA4ACYADB/98/DD86P10AGgC5AIkApIAI/+G/uj+uv+OAD4BHAJQAygF8AfwCvAMYA3QDNALUApACLAGSAZgBigG+AXwBYAFGAQYAhUAcP0w+kD38PTg8kDx8PCQ8dDxcPGA8dDxsPGg8WDysPNw9ID0cPTg8zDz8POg9qD4kPeQ9FDxIO7g6mDqgO2w8eD1sPvMA3AKsAzQC8AKUAowCkAL4A0AEeASQBSAFSAWgBVgE0AQEAwYBxwCVv4c/Bz8LP5sAdADaASYA2wCKgH5/5z/6/9tAAQBkAIoBQAIUApADPANUA4gDUALcAmoBzAGwAU4BpgGqAZwBvgFoAQsAk//NPwI+RD20PNQ8kDxoPDg8NDxcPJA8tDxEPJA8iDycPJg8wD0wPPA89D0QPYQ97D3oPdw9YDx4O3g62DrQOzA70D1sPusAlAJgA2ADSALMAkQCRAKYAzwD0ATIBVAFUAVgBSgEoAPUAvABigCav74+7D70P2QATgE0AQ4BFwDBAL2/1z+GP7m/l4ADAPgBpAKkAwwDWANMA3QC1AJ8AagBXgFGAYgB8gHEAjYB5gGCASUAPz8iPkQ9sDzgPMQ9KDzgPKQ8oDzEPNg8dDwoPFA8hDy4PKg9LD14PWg9gj4mPjw9+D2kPVw88DwQO6g7ADsIO2A7wDzKPhV/wAH0AzQDlANEApYB5AHkApADsARYBSgFWAVABQgEmAPMAvQBhADIAAo/rT9F/+qAZAEgAZgBsgEBANoAV3/tP0M/kcApAMYByAK4AswDLALMAswCsAIeAdoBqAFYAUABugGaAegB0AHIAVCAWD9GPpQ94D1YPXA9cD0EPOQ8uDyIPLw8ODwkPHA8cDxoPIQ9ND0QPWA9jD4sPiw93D2kPUw9KDx4O6g7WDtgO1g7sDxoPcI/qAEgAsgEEAPUAqYBtAGIAkwDEAQYBRgFiAWIBVgE2AQIAyQB6ADIgHf/yf/N/9SAVAFEAgQCIAGqARwAnP/aP28/cz/0AKABgAKMAyADPALEAsACjAJMAiYBnAFyAXYBjgHmAfACAAJOAbKAaT9uPnQ9SDz8PKw85DzAPOw8lDygPFg8IDvYO8Q8ADx4PHw8nD0APZA94D4wPnI+XD4IPfw9bDzUPAg7uDtgO3A7XDx4PeS/nAEsApADxAOYAjwA+wDAAdAC2AQgBVgF4AWABXgE2AR4AywB8wDdgHl/w3/8P8IA+AG4AgwCOAFxAKK/xD9XPxk/cv/KAPoBrAJEAvgCsAJwAjQCPAI0AdoBpAG4AcwCNgHIAhgCNgGKAS2AUb/4PtA+ED2YPXg9GD08PMg8+DxgPDA7mDtYO0g77DwsPFA82D1YPaQ9uD3cPkw+ZD3IPcw9zD1EPKw8LDw4O8g77DxgPec/eQCsAhgDWANsAjcAxQDUAYwC4AQQBWAF8AWIBQAEsAQ8A1QCdgEDALMAEUAOgH0A/AGYAjAB5AFWAIg/7z8FPxw/TYAcAOQBvAIEAqQCUAIyAfYB7AHQAfIBhgHwAdQCAAJYAkQCcAHaAU8Arb+WPuQ+LD24PXg9ZD1kPSA8zDyQPBA7oDtQO6A75DwQPJw9ND1EPbg9mD4QPno+Ej40Pfw9kD1gPMQ8uDwIPAg8ODxAPYs/EwCOAfwCkAMAAkkA6sAKATACWAOoBJAFqAVoBHgDrAO8AzwB6gDOAIgAoABTAIYBaAHQAhwB6AFcAK4/uj7iPuo/YYBGAWAB1AJUApACaAGGAXQBfgGgAdwCKAJ8AmQCYAJkAlQCPAFuAO8ARP/JPz4+ZD40Pdw9yD34PXA81DxIO9A7QDtAO7A79DxwPNg9fD18PXw9oD4SPlY+RD5IPjQ9nD1UPQQ87DxIPFA8UDysPWo++IB+AUQCGAI4AW0AUUAWARQC+AQwBMgFSAUABFADkAN0AsQCGAEdAMwBKAEGAW4BjAISAeoBP4B0v/c/cj81P2UAGwDUAW4BhAIgAhIB6gFMAUwBpgH0AhACsALcAzwC3AK4AgwBwAFpALuAPn/zP4M/BD5gPfw9mD1wPLw8MDvIO7g7GDtYO8Q8QDyQPMw9ED0MPTw9CD3ePm4+kj66PgY+DD38PQw8kDx0PFg8jD0aPllANAEOAYABwAHSASyANEA2AXAC8APYBLAEwATwBCQDnAMcAm4BQADOAJYA7AFMAiACUAJWAd4BGABgP7k/Ej9dP98AhgFUAcgCZAJwAjYBkgFmATYBGgG4AhAC9AMUA3ADAALcAjoBbwDtAE0AGX/Tv5w/ID6QPnA9yD1cPKQ8CDv4O1g7WDu4O/Q8KDxsPLg86D0gPSg9MD1wPfQ+CD54Pkw+hj4kPNQ8ODv0PDA8sD34P4kAzgDBAN4BMAEWAIuAcAD0AcgC4AO4BHAEyATQBHgDlALwAb8AqoBHAOgBtAJ4ApQCsAISAasAo7/3v6A/xwAFgF4AzAGsAdQCOAIYAjwBTgD5AIYBQAI0AoQDTAOkA1gC6AIgAYYBWgDbgHa/0f/lP4U/QD7yPjg9TDywO7g7KDsIO0g7mDvoPBA8RDxcPGA8lDzEPPQ8vDzIPYw+HD6gPyA+3D2cPBg7aDtAPCg9ZT9CAP0A5gDYAQIBKoBoQAQA3gGwAiwC8APoBLgEkASABHwDeAIIAQgAhQDYAYgCoAMUAxwCrAHUAQ4Acj/XgB+AQgCsAJYBCgGUAcwCMAI2AfQBOQBIAKQBZAJIAzADYAOsA0ACyAIkAagBSAEGAJxABT/tP0Q/Hj6oPiQ9ZDxwO3A66DrAOyg7GDusPCQ8dDwUPDg8TDzkPIQ8rDzIPYQ+JD6HP2g+xD14O6g7RDwIPTA+QIAwAPIBPAEcAS4AoQB/AKwBaAHsAnwDNAPQBEgEqASYBBQC4AGOAQgBJAFgAigC9AMkAvgCPAFHANQAVgBfAJAA0gDUAMoBMgFeAeACDAIeAb0AywC/AIwBrAJIAxADfAM8AoACPAFUAUABdwD7AGb/5z9GPwY+xj6SPhQ9WDx4O0A7IDrAOxA7WDvEPEw8cDw0PFA8/DykPHw8eDz4PXo+AD9fv6A+cDxoO3A7iDyAPcY/RQCEATAAzgDcAJ0AYgBXAMQBuAIcAvADcAPgBFAEiAQQAuYBpgEOAUABwAJIAugDAAMEAmoBVADTAKyAaABzALMA1gDrAIoBBAHEAhgBqgE/ANQA7gCeASQCBAMMA1wDDALQAlIBxAG2AVgBXwDqgB8/oT94Pyg+5j5APdg8+DugOug6qDrAO1A7hDwIPGQ8EDwwPEQ83DyEPFw8bDzIPcg+1D9OPuw9SDxEPAg8mD2yPtSAKAC+ALkAqACWALIAhgESAaACFAK4AvwDWAQgBHAD/AL8AgYB3gGWAegCZALUAvgCeAIEAdIBLQC/AJYA7wCdAI0A7AD2AM4BfAG0AYoBVAEiAR4BHAEgAbgCcALcAuQCvAJsAiIBugEkAS4A1YBdv5o/Xz9kPzQ+XD3cPUA8kDtYOpg6yDt4O3A7oDwQPHA8NDw4PFA8uDwwO9g8dD1uPrY/PD64Pbw8uDwsPGg9cj7kQC0AiwD7AJUAvYB1AIIBTAHoAhAClAMgA6gEIARoA/gC7AIaAdgB0AIwAowDeAMYAqwCNAH2AVwA5wCKAMcA1wCAAMIBVgGMAZ4BegEKARAA/QC6AOQBfgGMAiwCUALcAvwCRAI4AZwBaQDXALSAeYARP8y/rT9qPsA+AD1wPJQ8GDtgOyg7YDuYO5A76Dw0PBw8NDwwPHA8CDv8PBg9uD6kPuI+YD2MPMA8YDyoPfY/BgAnAH6AXABmgDzAOgCQAXABvgHUAlwCxAOoBAgEYAOYArgB3gHYAhwCkANoA6ADPAI2AZYBngFoARABKQDfAK2AdQCyARwBqAGOAXIApwBYAJMAzAEAAZwCPAIAAhQCOAJcAkAB1AG8AbIBfgCFALsAqIBSv50/Nj7CPnA9NDy8PLA8cDuQO1g7eDsQOyA7QDw8PEA8hDxgO+A7jDwcPQo+Hj5WPjw9QD0gPOg9Yj5CP3y/vX/kwDgAHgBnALIBKgGgAfgB/AIIAsgDkAQIBAgDlALcAnACGAJgAtADRANYAtwCUAIwAaIBSgFAAXkA2gCIAIwA+gECAYwBggFAAOsAegB8AJABOgFgAcQCLAHiAcwCMAIQAhwB4gGeAXgA3gCgAHLAHr/ZP3g+kj4UPaw9IDzsPKQ8eDuYOvg6aDr4O5g8XDzsPRw8sDtwOsg7xD0wPaw90j4MPeA9NDzIPZI+cD66PsM/lkAugHcAiAEQAUABjAGqAZACIALUA4AD1AOYA0gDHAKsAmgCrALgAsgCyALgAoQCaAHyAZwBdgD+AIMAwwDaAOwBLAFWAUYBOQC4gFOAc4B6ANQBrgHAAiQB3AHgAeABzAH6Aa4BsgF7AN0Au4B2wAL/xT9IPsA+JD0YPNA9KDzcPAA7eDq4Olg6uDtsPLg9IDywO6A7EDsoO6Q8zD4WPlg95D1gPXQ9RD3wPko/PT8qP1IALwDmAXwBRgG8AVQBdgF4AgADQAQgBDwDqAM0ArwCRAK8ApQDOAM0AswCqAJsAlgCIgFqAPgA0gEsAN0A5AEyAW4BAQDpALoAjQCkAFUAygG+AYgBlgGIAfIBiAG8Ab4B6AHsAaIBcADPAGR/wv/Fv6Q/MD6aPhw9dDzoPNQ8oDuAOtA6iDr4OxA8CD0gPTA8KDsoOsg7UDwsPRw+BD5APdQ9TD1UPZw+Ej7NP2M/YD+xAEoBXAGIAY4BrAGaAZAB9AKIA/AEDAPIA3wC5AKIAowCyANgA3gC1AK4AmwCaAIGAewBegEcARwBNAEKAUoBfAESASAA/AC8AJkAzAEQAUwBsgG4AbQBrgGoAbYBigHCAfYBrgGiAUIA0gAGv9a/vT8ePt4+gj5IPbQ88DycPCA6yDoQOrA7lDxoPGg8TDwAOxA6UDrQPCg8wD14PVA9mD1YPQw9eD3UPpY+9j7dP3EANgDGAVQBcgFeAaYBmgHsAogDmAPgA4QDqANQAxAC1AMAA6gDRAMcAtgC3AKUAmwCPAHMAbIBJgEMAUwBZAEOASsA+wCLAKIAlwD1AP8A9gEyAW4BeAEAAVABsgGyAbYBigHwAZYBaAD4gEeAPL+QP74/CD7kPnw9+D1oPPg8ADt4OhA6aDu0PKQ8uDvwO0A68DoYOoA8CD0MPTQ86D0kPTQ8wD1GPhI+nD6kPvC/uQB/AOgBVAGMAVQBBAGwAnADBAO4A7ADhANcAvwC4ANoA3ADIAM8AyADFALgAogCuAIyAZIBWgFkAY4B1gGcATsAlgCKAJUAkgDiARABOwCCANoBDAFcARoBAgG6AbQBZAFEAeABzAFNAKEATQBj/9q/vb+0P1g+dD10PXA9cDxIO0A7ADt4O2g7wDyQPEg7QDqYOpg7MDuMPJA9dD0YPLg8aDzkPVw9yD6OPzg/Kz9WwA4A7gEKAWoBWAG0AcQCmAMoA3gDQAO0A1ADUANUA6gDmAN8AvgC1AMIAxwC6AKoAmYB0AFiAQwBXgF2AQIBHwDlAJqAfgAbAF4AWgBHAJAA5ADEAMgA3ADcAOMA6gEwAWwBSgFiAQEA8MADwB/AO//eP0A/Lj7KPow94D0kPJA74DsQO0Q8eDyUPGA7uDrIOpA6mDtoPHw88DzoPJQ8YDxkPMA94j5cPo4+xD9Ev/MAJgCSARABXgFsAaQCVAMEA3ADBANoA1wDSANgA4gEJAPIA2wCxAMcAwQDAAM0AvACcgGOAVwBZgFUAX4BKgEdAMwAqIBNAFvACkAFAFQAhQDeAN4A6wCqgGGAXwC9AN4BYAG0AVMAxIBZgBpAC4Ax/+W/jT86Pn4+ED4gPVQ8SDugO3A7gDxoPKQ8SDuoOoA6WDqwO3A8SD0APSA8uDwIPHA87D3QPoY+/D76P0sAMoBuAMoBXgFoAXIB1ALoA1wDsAOQA6gDEAMQA7gEGARoBAQD7AMYAqgCvAMkA1wC9AIWAcIBpgEaARABeAECAOcAY4B4AGGAc0AWQAqAGEACAGMArwDhAPwAfYApAFIA6gEEAXYBCADugA1/2//GAC9/wr+0PsY+gj54PZA82Dw4O+g8ODwAPEg8cDvYOwg6mDrAO4A8KDxEPPg8nDxAPEw80D2aPiA+nj84P3q/qIAfAKAA0gEaAZgCbALAA3gDdANEA1gDSAPwBCAEaARIBHQD/AN4AzwDEANIA1ADNAK8AgwB7gFqAT8A4wDbAMsA4QCWAHk/+D+5v5C/6v/ZwAUAfQA6/84/57/bgAyAaQCqAP0AhgBbwD9AFkAjv7U/Tj+9P3A/Aj7CPlA9VDxMPCg8TDzkPMA85DwAO2g6kDr4O3g7/Dw0PHA8cDwkPAQ8jD0EPaQ99D5MPwS/m3/xQDSAWAC6AOQB6ALcA3wDKAMQA0QDjAP4BBgEkASQBHAEIAQIBBADzAOwAxQDMAMkAxACngHCAaYBBADDAP4BMgE3AFS/07/EP/0/dj+SAFOAbD+/P0FAPMA0/8nACwCTAJUACQA/gGAAoYAuv4G/hD9GPyA/Cj9CPtg9pDyMPFg8aDyIPTQ8xDxgO2g62Ds4O1A70DwsPBA8BDw0PAQ8oDzgPSw9TD3cPmY/HH/ZwA3AK4AaAJQBRAJkAwADgANYAxwDWAP4BAAEkATIBOgEcAQQBGAEUAQ0A4ADsANwAwQDFALcAloBngEaASwBFgEgAOIAqQAZP6o/eL+CgADAGD/7v6m/oT+6v4EAK4AcAAHADAADAE+AUgA7P4+/nz9WPwc/Bz9vPyA+DDzUPFQ8lDzoPMg9ODyAO+g68DrAO4g74Dv4O8w8EDvAO+A8HDycPMg9LD1MPhI+4T9dP50/jj/KgHkAzgHkApgDOALIAtADJAOYBAAEgATwBKAESAR4BFgEmARIBBgD5AOsA0wDYAMoArYB7gFWAX4BbgFeATAAgwBTf8y/t7+UACLAE3/Nv4+/m7+VP7g/gEA6P8d/0j/gwDHAI3/ov48/hD9iPuo+9z8OPzY+BD1oPLA8RDykPOA9NDyYO8A7cDsYO2A7uDv8PBA8EDvoO8w8YDykPOg9AD20PdA+uD8eP4W/6n/HgFQA1gGYAlQC9ALMAzgDPANUA8gEaASoBLAEaARQBJgEiAR0A+AD3APkA5gDVAMQAvgCIAGCAa4BlgGWASsApgBLgDq/o//wgA6AJL+Iv5k/g7+JP7U/mP/D//g/j//+P6g/uz+Pf/0/Tz80Pso/Jj7cPog+XD2MPPA8RDzQPSw8wDykPCg7gDtYO2A7/DwcPDg7+DvIPDQ8HDyYPRg9cD1YPdQ+sD81P2O/t3/KgH0AuAFUAkwCwAL0AowDPANgA/gEEASoBKgEQARYBEAEsAR4BAAEFAPoA4QDlANoAtwCRAIoAcwB1gGqAWgBLwCtADR/1gA9gDWAB4AQv+k/n7+av5c/rT+Rf+K/xD/0v7I/qb+Nv6Y/RD9EPyA++j78PuA+bD1gPMw81DzUPOg81Dz0PDA7aDswO0A76DvEPAQ8MDvwO9A8KDxMPOA9ND1YPeo+aj7hPwc/aD+7QAsA3AFIAjACfAJIArgC/ANQA9gEMARQBKAEQARwBFgEsARIBHgEIAQkA/QDrANMAzACpAJsAjQBxgHKAbwBDgDjgGoAIAA1gDKAPX//P5U/sz9yP0q/oL+tv7M/rr+RP7g/Sz+cP6g/Wz8FPzo+yD7UPrg+SD4MPSg8cDyoPQw9FDy8PAg7yDt4OwA74DwoO8g78DvEPAA8DDxQPNg9LD0gPaw+cD7VPww/eb+egBIAhgF0AdACaAJgArQCxANYA5AEIARIBGgEAAR4BHgEUARoBBgECAQkA/gDrANcAxgC2AKMAlwCBAIMAdYBWADlAI4AogBFAHvAKEASf8C/iz+8P6c/uT9Ov7E/n7+qP0E/oL+pP2U/Pz8PP1w+9j5aPp4+mD38PNg8yD0sPPw8iDz8PEg76DtwO7g76Dv4O/A8GDwgO9Q8HDygPPg82D1sPdw+cj6nPwO/vz+OQCUAlAFcAfgCNAJgApAC9AM0A5gEAARABHgEAARIBEgEUARQBHAENAPUA8AD9ANUAwwC2AKYAlQCKgHyAYwBWwDdAKsAdoApgDkAC8AlP68/dj9zP1g/Xj96P20/Sj9NP1U/cT8pPwE/bT8OPuQ+ij70Pro+LD2sPVg9CDzAPMA9IDzYPFg74DuoO5A72Dw8PBw8ODvMPAA8eDxAPOw9HD2sPcY+RD7yPzw/QH/pwAgA5gFaAegCIAJIAowCyANMA8gEOAPABDAEEARwBDAEGARIBHADyAPgA/wDmANEAyQC6AKYAmQCDAI6AYoBfQDCAPmASwBOAH/APH/zv4y/sT9XP1A/Xj9jP1o/Tz96Pxs/IT8+Pyc/LD7OPvw+iD6KPmg+KD3YPUw84DyIPNg8+DygPGg72DuoO6A7xDwMPBg8JDwwPCA8XDysPMQ9dD2QPiw+aj70P0s/9r/lgHoA9gFQAcQCcAKUAvgC5ANIA9wD7APwBCAESARwBAAEeAQ0A+wD0AQwA8gDgANoAygC/AJ8AigCMgHWAb4BOgD7ALoAQQBVwDi/5D/6P5C/qD9HP2g/LT8HP0g/aT8PPyE/Ej8oPtw+6j7OPso+oj5QPlw+PD2wPTQ8nDygPMg9NDyoPCA72DvQO+A77DwcPFA8QDxgPFw8mDzsPSw9kD4cPlY+3T9uv6G/zIBdAMoBZgGsAiwCnALwAvgDEAOMA9AEGARoBFAEUARgBFAEaAQQBCAEEAQIA/wDSANIAzgCqAJ0AgwCCgH2AWIBFADIAIIAWoAMQCF/3z+xP1U/ZD8qPuY+zz8QPyo+8D76PtI+3D66Pq4++j6aPlQ+dj5MPlg93D1QPRw80Dz4PPA83Dy8PBA8IDvQO8w8JDxEPJg8SDxEPIg8xD0MPXA9nj4YPoI/ED9ZP4hABACyAOABVgHQAnQCqALIAwADaAOYBAAEeAQwBBAEaARwBGAEeAQgBAgELAP0A4gDoANYAxwChAJAAlgCJgG8ARgBEQDlAGXALoA7/8o/oT96P1Q/cj7gPtQ/Aj8+Pog+wT8kPtQ+oD6gPso+4j54Pg4+QD5wPdg9lD1APTw8uDyMPPA8uDx4PDA70DvoO+w8KDxkPEw8bDx4PLw8+D0APaA93D5GPuc/Pz9jP9QARwDmAQYBjAIMApwCwAM8AxADlAPYBAAEUARQBEgEcAR4BFgEaAQgBBgEJAPsA4ADnANAAyQCrAJ8AiYB0AGWAVABMgCgAHhADQAC/8a/sD9TP2I/Nj7gPtI+xj78Pog+xj72Pqw+qD6sPpA+nj5IPlY+QD5kPcQ9kD1kPQQ80DycPMg9LDygPDg7zDwYPDg8ODxQPLA8UDyYPNg9PD0YPag+Fj6iPsw/QD/PgCwAWADIAXYBgAJsApgC+ALQA3gDoAP4A/gEIARIBHgEGARgBEgEcAQgBDgD6AOAA7QDdAMMAvwCSAJIAjABpgFoAR8A+4BowDc/1z/mP6I/dj8VPyw+wD7kPqo+nj6APrw+XD6aPrw+aj5uPlo+aD4ePh4+KD3cPaw9RD1kPMQ8kDyUPNg8wDywPAw8CDwkPCw8ZDykPKQ8mDzoPRA9VD2QPgo+nj7zPx6/joAtgFEAxgF2AaACCAKcAtADEANsA7QD2AQABFAEUARQBFgEUARABHAEIAQ4A/gDvANUA3ADMALQArACMAHQAcgBlAE8AI8AkgB0P/w/qb++P2k/Oj7mPvY+gj6MPpY+qj5UPmY+eD5YPno+BD5APm4+Jj4SPhA91D2QPYA9mD0sPKg8kDzYPMA84DycPFg8IDwEPIw8zDzIPPQ87D0MPVQ9ij4CPpI+4j8OP4CAHIB/ALYBJAG6AdwCXALwAxQDfANUA/AECARABGgEcARYBHAEOAQIBGAEIAP4A5wDmANQAyAC7AKYAn4ByAHIAaoBGgDgAJgAe//Cf+W/rj9kPzw+8D7GPsQ+nD5aPlY+TD5GPkQ+SD5GPno+GD4SPiY+MD4MPhQ9wD3oPbA9bD08PNg83DzUPSA9CDzUPEg8VDyIPNg8+DzwPQQ9WD1MPag90j5+Ppk/Mj9Tf/IACwCfANoBaAHYAnACvALEA3QDbAOQBCAEcARgBHgEeARQBEAESARQBFgEJAPMA9wDgAN4AswC1AKMAkgCLgGIAXsA/AC2gGbAKX/tP6M/Vj8wPuI++D64Pnw+FD4SPiY+ID4MPjg98D3wPfQ9+D3oPdg93D3cPew9uD14PXA9YD0EPMw8zD0EPRQ80Dz0PKA8TDxIPPg9LD08PPA9ED28PYA+OD5ePuA/DT+ewAQAsQCMATQBgAJIApwCzANUA7gDuAPQBFAEmASYBIgEsARgBGAEWARgBDQD5APEA/ADTAMMAuwCgAKwAhwBygG8ASUAyAC4gAoAIr/kv4o/ej7aPsg+0j6KPlo+Hj4YPjQ94D3oPdw9/D2APdw93D3sPbQ9lD3wPaA9WD18PUQ9dDz4PNQ9HDz0PLQ82D00PKA8dDygPSw9HD0QPUQ9jD2YPd4+cD6cPs4/bP/BgGiAXQDAAbAB9AIkAqADPAN0A7AD8AQoBFgEgATQBPAEkASABLAEQARgBBAEEAQYA+QDeAL8ApQClAJkAjgBzgG8ANMAo4B2gDf/wT/IP7M/HD78Pqg+qj5qPhw+Cj4kPcw9zD3APdw9nD24PbQ9nD2oPYA94D28PXg9eD1UPXg9AD1gPSg82DzUPRg9GDzsPJw8xD0MPSQ9ED14PVA9hD3UPig+fD6lPwk/o3/9wC8AqAEKAaYB3AJcAtADWAOAA/QD+AQoBFAEuASIBOgEqARABHAEEAQoA+QD2AP8A0gDPAK4AlwCJgH0AdYBzAFfAImAZgA3/9R/97+lP2o+8D62PpY+jj5ePhQ+PD3QPcg90D38Pag9uD2EPew9nD24PYw98D2MPbA9ZD1kPWQ9QD1QPTw8xD0QPTQ83DzkPPw80D0cPSw9HD1gPYA93D3uPiY+gT82PxE/l8AHAJsA0AFKAeQCAAKQAzgDXAOQA+gEMARIBKAEiAT4BJAEsARYBFgELAP0A+gD0AO4AxADOAK0AiQB6gHaAcIBiAEgAKhACH/Iv+T/4D+NPzw+tj6iPqI+bj4iPg4+ID3UPdQ9+D2QPZw9gD3wPZQ9oD2MPcQ99D1MPWw9QD2kPXw9KD0MPSw87DzAPQg9JDzcPPw83D0gPTw9AD20PZA9wj4ePkY+2D8/P3C/wwBQAIIBEAG+AdwCUALIA1wDlAPIBBAEUASIBOAE4ATgBNgE6ASYBGAEGAQIBCAD9AO0A3QC8AJoAj4BzAHcAb4BbgEwAEn/6z+Yv/0/oD9+Pvo+hD6SPmg+Cj4CPjg97D3IPeQ9hD20PUg9tD2MPfA9mD2kPZg9sD1sPVw9qD2wPUQ9RD18PRQ9DD0sPSw9CD0EPSA9MD00PSA9WD2MPfw97D4yPkQ+7j8YP7V/xwBrAKIBEgGEAgACqALIA1wDoAPwBDAEaASIBNgE4ATgBNAE+ASoBEgEGAPsA+QD0AOsAyQC+AJOAcIBrgGsAbIBIwCJgFS/4D9UP1O/tD9QPuQ+YD5aPmg+ED4IPiA98D2APdw97D2kPXQ9QD3YPew9lD2QPYw9vD1APYw9vD1sPXA9VD1cPQw9KD0APXg9MD04PQA9SD1cPUA9tD2wPe4+Ij5WPqo+2z93P7v/4QB1AOYBbAGQAhQClAMYA1gDiAQwBEgEkASABOAE2ATABNAE8ASABFgD2APkA8wDuAMcAwwC1AIMAYoBiAGoAQsA4wCjQCU/Uz8IP14/SD8yPrg+cD4APhY+Jj4oPeg9jD30Pcg9xD2IPaQ9vD2MPeA91D34Paw9rD2kPZw9sD2UPcQ9xD2UPUw9ZD14PUA9gD2APbQ9dD1cPZA96D3UPhw+YD6KPsc/Lj9eP/JACgC/AOwBRgHwAjACkAMQA2wDmAQgBEAEsASYBNgEyATgBNgE0AS4BDgD/AO4A2QDWAN0AtgCUgHUAYIBcADgAN0A3wBav5k/MD7wPug+3D7iPrQ+ID3UPdQ9wD3wPYg91D3kPbw9dD10PXQ9UD2EPeQ9yD3UPYA9jD2cPbA9kD3YPfA9rD1cPXQ9QD24PUw9sD2cPbg9WD2kPcI+PD3sPhQ+oj7HPz8/Hj++P+OAXADEAU4BqgHwAnACyANYA7QDyARIBIAE4AToBPAEwAU4BMAEwASQBHgD0AOcA3wDPALcArwCDAHyATkAmwCiAKUAcL/wP3Y+3j6EPo4+jD6YPk4+BD3cPaA9qD2oPaA9mD2MPbw9QD2MPYw9iD2APfA90D3QPaA9oD3sPcQ9/D2IPfA9rD2EPcA9yD20PWQ9hD3kPaQ9oD3APjQ9yD4cPnA+rD7yPzc/Zj+zf8YApgEKAbwBvAHwAkQDCAOYA9gEGARgBIgE4ATABRgFGAU4BMgE+ARgBAwD0AOMA3gC9AK4AlQCBAGTANWAQoBhAECAbr+JPxw+mj5mPjA+Lj5YPmA9/D1sPUA9gD2APaQ9rD2IPYQ9mD2UPYA9pD2wPcg+MD3sPcQ+CD44Pfw9wj4GPhA+JD4MPhQ98D28PaA98D38PcQ+AD4GPi4+Ij5SPo4+1z8dP1k/mj/wwBQAhAE2AVYB6AIIAoQDPANcA+AEGARQBJgE2AUoBQgFAAUIBSgE2ASABHAD+ANYAwQDMALYAoQCKAFZAPwALX/dgDuAP7+sPso+dD3gPco+Mj4IPgw9gD1IPUw9aD0sPSQ9SD28PWA9YD1wPUA9lD28Paw9/D3EPg4+BD4kPeg93D4WPkw+WD48Pfg96D3oPc4+LD4mPgY+AD4ePiI+YD6APsg+xD87P0w/8f/4gAQA7AEuAVoB+AJYAsADNANQBCAEaAR4BLgFAAV4BMgFEAVwBQAE0ASABIAECANsAugCxALUAl4B3AFcAKa/87+Z/8u/7D9YPvA+ND2MPaw9mD34Pag9ZD0IPTw81D0gPSg9AD1UPWQ9ZD1sPUQ9nD2sPZQ90D4iPhA+Fj4uPio+Fj4yPiw+ej5IPlA+Ej4ePi4+Cj5oPlQ+aj42Pj4+QD7IPuY+/D8Vv7U/mn/DAEcA9gESAbIBxAJMArwC3AOYBBAEeARQBNgFKAUgBTgFGAVIBUgFOASwBEgECAOcAyAC9AKsAlQCGgGcAOX/2T9Rv6F/0b+aPso+TD3IPVw9PD1cPdw9pD0cPNg8xDzUPNg9DD1APXg9ED1kPWg9aD1MPZA90j4qPiA+Hj44Pjo+ID42PhI+iD7cPp4+QD5+PgA+dD52PrA+uj50Pm4+ij7GPvg+4j9vP4p/6//8wCYAhgE4AW4BzAJQAqQC7ANwA/gEMARIBOgFEAV4BSgFCAVIBVAFGATgBLgEJAOoAxQC7AJ6AdQBwAHcATd/1T8iPsw/FT8sPsY+gD3oPOA8oDzoPQQ9fD0YPSw8kDxwPFg86D0QPWA9XD1IPVQ9WD2QPeg90D4EPlY+Wj5oPm4+Yj5wPmQ+hD72PqQ+nj6APpw+aD5qPoY+7D6iPoQ+2j7WPvQ+yz9wv5f/8P/AgG8AgAE6ASoBgAJkAqACyANUA+gEEARwBJgFAAVIBVgFaAVQBWAFAAU4BJgEZAPwA2QC5AJQAg4B7AFCATWAVL+qPpQ+WD68PpY+aD2kPTA8pDx8PFw8/DzMPOg8lDycPEA8YDyAPUg9nD1UPUg9qD28Pbw9xj5WPl4+XD6kPtI+xD68PkI+6D7mPuA+6D7KPtg+vD5GPqY+vD6QPtA+xj74PpQ+2z8pP12/gD/vv8wAdACcAToBVAHoAgQCrALkA1wDyARYBJgE0AUgBQgFQAWYBbgFcAUQBSAE+ARgA9gDXALAAkwBwgHyAYQBNb/VPzY+Tj4YPg4+oD6oPag8cDv0PDw8aDycPNw8wDycPBQ8GDxsPIw9PD1kPbw9bD1YPaA92D4OPkA+qD6ePvo+1j7aPqw+gD8uPxw/Fj8gPzY++j6EPu4+2j7CPug+1z8sPvw+qj7SP0U/i7+Cf9YAFIBTAIoBCgGaAdgCCAKQAwADlAPQBFAE0AUoBRAFYAWQBcgF4AW4BUgFYAUgBNgEVAOMAvACDAHmAaABigF8wCg++D3YPaA9gj4OPng9nDxIO1g7eDvAPEw8ZDxQPHA7yDvYPBA8iDzMPTw9cD2cPbQ9nD4cPlY+cD5ePsQ/Rz9jPwg/MD7qPus/AT+/P3M/MD7WPsw+xj7mPtY/ET8OPso+hj6GPuQ/ND9WP5m/rD+dP/FAMwCYAWAB6AIgAnACoAMYA6AEAATABWAFcAVoBZgFyAXgBbgFiAXABZAFCATIBFADTAJUAfYBtgFwAS4A0oAsPlQ9ODzMPZw96D2IPQw8EDsgOvA7cDvEPBw8ADxEPCA7gDvcPHQ8yD1EPbA9lD3GPho+TD6MPrw+sz8av6q/iT+nP0E/dj86P1J/6L/tv6M/WD8aPtI+1z8vP2M/dj7IPqg+Vj6BPzo/Qb/Ev9y/lz+i//sAfgEsAdgCeAJUAqQC+ANoBAAEwAVIBaAFiAX4BcAGIAXQBcgF2AWwBSgEyAScA7gCSAGeASMA1ADfAOKATD7kPPg7+Dw4POg9QD1gPGA7IDpIOqg7ADvoPCQ8QDxQO8A7xDx4PMw9vD3APlI+ZD5+Pq4/HT9RP3A/fD+KQCoAHIA0v/a/jb+WP4h/7j/K/+g/fj7IPso+2j7qPuI+7j6iPnw+Jj5EPts/Fj96P0e/o7++P90AkgFuAdwCbAKEAzQDSAQoBIgFcAWwBdAGAAZwBmAGcAYQBhAF6AVQBQAE+AQkAyoB/wD3AHYACIBrwC4/BD2YPCg7eDtEPCw8nDyIO5A6YDnwOgg6wDuwPCw8WDwIO9Q8LDy8PQw96D5SPvg+4D8tP3Q/i//Pv/9/54B/AIUA+QBggCZ//b+yv5h//r/Sf9A/XD7UPqQ+WD5CPrI+oj6KPlI+Mj40PkI+4D8MP50/zQAMAFQA/AFQAhACnAMsA6AECASQBSgFgAYgBiAGaAaABsAGsAYQBjAFgAVABTgEtAPwApQBTABNf/M/ov/yP5I+nDzQO2g6mDrIO5g8FDwQO0g6UDmQOZA6aDtMPEg8kDxcPAw8ZDzcPao+Hj6WPx6/sn/8P///zEAdQDxAEwCOATIBHgDVAGI/zD+kP1I/q//y/+k/cj6KPmo+Ij4iPgQ+YD5EPkw+GD4kPlA+sj6SPyg/lIASgE8AzAGYAhwCSALEA5AEYATQBUgF4AYABmAGeAaIBwAHOAa4BmgGMAWYBSgEqAQIA0gCCwDgf8U/Tz8NPwA+2D2APBg6qDnoOjg6+DuwO6g66DnIOVA5SDpIO9A81Dz4PEg8rDzgPXw92j7Nv7I/wwBUAJ0AnoBYAG0AogDbAPgA8AEUATmAQr/KP2Y/CT9Ov5s/pj8wPng9yD30PYw90D4KPkA+YD4CPkg+hD7TPxY/iYAYAHoAgAGMAkAC+ALYA1wD6ARYBRgF6AZQBpgGsAaABvgGiAbYBsgGqAXYBWgEwAR0A3gCsgGrwBQ+2D5yPkY+fD2kPTg74DoIOOg5ADqoO3g7SDs4OjA5EDkQOkQ8LDzQPRw9ED14PUA9/j5hP07AIABcAI0A/ADaASoBDAEAAP0AWAC+AOwBCADiP/Y+8j58Pkw+yD8mPvY+cD3sPVg9JD0YPY4+Aj54PjA+GD56PoE/QP/iQDgARAEKAcgCmAM8A1gDwARIBOgFSAYgBoAHIAcIBygG4AbwBvgGwAboBiAFcASQBCQDaAKEAf4Afj7APew9HD0UPQA9ODxQOzg5KDgQOKA50DsAO4A7cDp4OZg52DrgPAw9CD3cPmI+nj6yPoc/UwAqAJoAyAEgAU4B6gHmAZoBMQBFgAYAPwBfAOoAjf/UPtY+ND2sPYY+Bj6YPpg+JD1EPRA9JD1cPdI+Wj64PrY+5T9UP+gANoBzANQBuAIwAuQDuAQ4BFgEkAT4BRAF0Aa4BygHYAc4BqAGaAYYBhgGOAXABUAEXANUAoIB3ADHwCw++D1MPEg8FDxoPGQ8ODtwOhg4oDfQONA6iDvAPDg7cDqIOkA68DvIPUY+ZD7pPxo/FD89P3XAHgD0AQwBTAFmAWwBnAHeAZ8A0AAiv7o/nsAuAH1AKz9QPnA9TD00PQA93D5aPq4+JD14PIg8vDz0Pfg+9z9wP1Q/Rr+6//aAUgECAdgCRALAA2wD0AS4BPAFGAV4BWgFoAYoBsgHgAewBsgGaAW4BRAFMAUQBRAERANIAmoBG7/APtA+ND0sPCA7sDvgPHA7+DrIOfg4QDfAOLg6VDwYPHg7uDr4OkA6wDwcPYI+yz9Qv46/nj9SP6MAbAEwAWQBVAFiAXoBQgH8AYIBK3/RP24/eL+h//s/tz8QPnw9WD0cPSg9bD3SPm4+KD2MPWg9RD3EPlo+3T9Vv7Y/pUAMAMABRAGcAeQCaALYA1gD8ARwBPAFAAVQBXgFUAXABlgGsAagBlAGAAXgBXAEwASIBCwDWALgAnoBogCpP1o+aD0AO8A7MDtAPGA8aDvYOwg5wDhgN/g5eDtMPKQ8iDxwO7g7KDuUPS4+Zz8Gv4U/1X/5/++AfgDQAVYBfgEIAT4A7AF0AdIB4AD0v7Y+wD7JPwo/pD+VPyQ+ND1sPSw9AD28Pfw+Dj4APcQ94D4gPoo/Dz9kP20/fr+1AE4BXAHEAgwCOAIgAqwDCAPYBHgEqATwBPgE4AUABbAFwAZwBigF0AW4BTgEyATABJAD8ALoAnACNAG/AIG/5D6MPSA7SDroO1A8CDxEPHA7gDowOCA34DlAO0A8ZDyMPJw8EDvAPGw9Ej4OPvA/Yz/YQBuARgDgAT4BKAErAPQApwDKAbYB9AGkAPo/7D8uPrQ+oD8vP0Q/cj6wPcQ9SD0sPVA+LD5MPlI+FD4QPmw+mD83P2w/gH/+//+ARAEyAUYB3AIQAmwCXAKUAxwDvAPABGAEUASwBKgE8AUoBUgFiAWQBaAFYAUoBPAEsAQMA7gCyAKEAiABdQDsgHc/KD1gO9A7GDrIO1g8eDzkPCA6cDkQOQA5gDp4O1w8sDzsPJg8lDz4PTA91D7yP0+/vb+ZgFIBLgFoAWoBOgCtgFMAkAEeAVYBRgEhgH8/dj6kPmQ+SD6aPpA+uj4QPdg9oD20Pbg9mD3IPjA+ID5QPug/WH/DwBUAL8AKAE8AlgEKAeQCbAKIAtQC6ALMAyQDUAPwBBgEaARQBIgEyAUoBRgFOATYBNAEyATQBKgECAPQA1ACrgGQARIA1wCGgFe/vj4APFA6qDowOsA8JDywPJg74DpoOUA5oDpYO0g8WD0oPXw9PD0EPeo+Wj7ZPz0/LD9HgAwBGgHeAdgBRwDCgGf/yUApALwBCAFRAMcADT86Phg99D3qPgY+TD5gPl4+Yj4sPeA97D3oPcA+Nj5gPza/noAsgHoAQABcgB4AXQDCAUIB8AJkAuAC3AKAApQCiALMA2QD2AQABBAEEARoBGAEcAR4BJAE6ASYBKgESAQAA/gDaALuAcoBFgDQATEA0QAqPlQ8oDsQOpg66DuQPJA80DwAOug50DnQOmg7ADxAPTw8wDzoPRI+Pj6iPt4+xT8zPyg/rACKAegCJgGqAOWATAArP9mASgEuARQAkH/hP10/BD7yPkQ+Tj4IPew9tD30PkQ+1D72PrY+Zj4APgg+Qj8ev+0AWQCPAIgAogCRAOwBHAGYAdgBwAIwAmQC3AM4AwwDbAM0AswDJAO4BDAEaARwBGAEWARIBLgEkASwBCAEEAQUA6AClgHiAWgBNwDZAJQ/2j6gPWQ8aDtoOrA66DvkPFg8ODt4Ovg6SDp4OsA8LDx8PHw8/D24Pew96j5lPxI/ej8cv6CAaQDgASIBfAFCASaARAB3gEMAj4BoAB7ALj/Ov7M/Jj7YPoY+cD3UPfA98j4CPpo+4z8xPzI+0j6sPkQ+nD7oP2JAPgC2AOQA1ADxAOIBPAEGAVoBcgFqAbgCOALwA1QDXALAApgCWAKAA1gECASIBLgEYARYBAAD2AQgBOAFKARkA1gCjAIoAYoBjgGOARdAGD8YPjg8+DvQO5A7oDuAO7A7cDtQO0g7aDtIO4A7sDuoPCg8vDz0PW4+DD7JPx8/Bj9EP5K//UAeAJIA+ADuATIBKwDZAKqARABaQBOAHQAeP/Y/SD9fPzQ+qj4QPjg+Mj4uPg4+mz8HP2Y/Nj7yPqg+SD67Pz8/7gBhAIIA4gCsAFwAmAEiAVIBRAFUAXIBfgGoAkADOALMArgCOAI8AlwDPAPgBIAE0ASQBHgD3APoBHgFKAVIBMgEMANMAsQCSAIgAbYAsT/vv6U/aj58PTQ8SDvQOsg6YDqIO0A7qDtoO3A7aDtIO6g74DwYPAA8YDzYPdA+wz+l/8YAI3/VP4u/iEATAMgBRgFqARQBEwDvgEeAf4AMQCO/pD9NP14/Hj7UPuA+6j60Pjw91D5gPvY/Az9oPzA+6D6wPrw/Oz/5gGcAnQCjAExACYAfAKoBSgHeAYIBSgEiAQQBvgH4AiACMgHSAeAB+AI0AvQDkAQ4A9gD4APIBAgEcASABSgE4ASwBEAEYAPgA3QC6AIcAPo/sD9uv5k/vj70PcA8qDrIOhg6CDqwOsA7aDtwOwA7ODswO5A78DuoO5A77Dw4PRQ+0sAXAEiALD+WP20/Lj+DAMoBnAG4AUIBtAFWAQMA5ACrgFe/0j9NP3I/eT9tP2g/VD8oPnA90j46PlY+mj6IPuA+9D6wPqA/Fr+4P76/rn/wf8M/9n/BAPIBXAGYAZ4BvgF2ARABTAHYAigCDAJ8AnQCfAJ8AsgDqAOcA5gD2AQYBDAEYAUoBUAFMAS4BIgErAPQA7QDUALGAasAbP/5v5a/uj90PuA9qDvgOoA6MDnIOmA6wDt4OxA7ODrwOvA66DsgO3g7eDusPHQ9dj5cP3L/xEAmv6A/dT9Lf+OAeAEuAdACNAGkAX4BMwDbAKqAeAAKf84/cj8sP0y/tT91Pwg+wD5kPfg9zj5yPrQ+wj8uPuY+5D8Ev4f/6b/uP+R/67/IAG4A9AFiAZ4BkAGwAVgBSAG+AdwCYAJMAkwCWAJIAqgCyANcA0gDdANQA9AEIARoBMAFQAUYBLgEUARwA9wD4AQEA/ACSAFYAMeASz9mPtI/Wj84PZQ8UDuQOtg6CDpAOxg7EDqQOpA7IDsYOuA7CDvoO/A7qDvoPLg9ZD5yP1sAPf/bP5c/lj/mgCUAvgEaAZYBgAGAAbwBbgFyARwAvz+mPyU/OD9tP5A/2j/2P3Y+rD4qPhQ+Yj5EPow+6D7UPuw+3T9xP52/pz9YP3U/Z7+TADwAoAFiAYoBngFIAVYBSgGqAcACYAJoAkACoAK0AqgC+AMoA1QDUANUA7AD0ARIBOgFAAU4BHAEOAQ8A8wDqANYA2QCkgG6APQAkUAvP1U/cj8sPhw8/DwwO+g7MDpgOqg7KDsgOsA7MDsQOxA7ODtoO5A7cDs4O9w9ED3gPk8/OT9nP2Q/Bj9lP5pAFQCOARABYgFIAbYBvgGmAVQA0QBZABTAFcAmQAiAVABRwBC/nz8ePvw+uD6aPvQ+8j7NPxQ/Rz+3P2E/Xj9OP2g/Pj8sv6OABgCnAPABNAEWASYBIgFEAZQBugGyAdwCCAJMApAC9ALEAxQDJAMEA0gDjAPQBBgESASwBEgESARYBGgEPAO0A2wDEAKkAcgBsAECAI4/yz+fP0Q+/D38PWg8wDwoOwg7ODswOzg7ADu4O7A7YDsoOxA7SDtYO0g73DxIPMQ9dD3IPoA+4j7rPyM/YD98P2x/+gBhAOwBLgFCAaABegEiATEA7ACFAL4AdwB3AFIArwCWAImAef/ov5I/ZD8CP3Y/RT+BP5S/pL+Qv7I/dz9EP6M/RT9hP2G/oT/ygB4AowDbAMUA3AD6APgAygEGAUQBogGOAeACJAJ8AmQClALgAtQC9AL4AyQDQAO4A7AD5APsA4wDpANAAxQCpAJ0AgoBzAFEATsAvQAA//s/Xj8wPkA92D1UPTw8gDy4PHQ8RDxEPCg72DvIO9g7yDwsPDA8DDxgPIw9JD1kPaw98j4gPkw+jD7kPzg/QH/CgAWAeoBjAJUA/AD6ANcA+wC3AL4AigDmAP8A+wDlAP4AjACZAHqALQALABj/yP/ev+z/7P/2/8KAH7/Yv6w/YD9SP1o/Uz+Wv+z/77/UAAmAUYBBAEoAYgBggFgAewB5AKYAzAECAWwBcAFsAUYBogGoAaQBvgGkAcgCJAIYAkQCjAKwAlACdAIIAh4B0AHEAeIBvAFsAVoBbgElAOoArgBfABH/2z+wP3w/DT8wPtI+5D60PlI+dj4OPig91D3MPcg9yD3UPeg9+D38PcY+FD4iPi4+BD5aPnI+Sj6cPrg+nj7EPyE/OD8CP0M/Sj9ZP28/Q7+iv4P/0j/O/9f/6f/vf+j/5v/tv/c/w4AbgDOAPIAAgE4AVgBOgEgATYBXgGEAbQB1gH2ARACNAJMAigCAALyAc4BjAFcAWgBjgGyAegBMAJcAnACjALQAgQDFAM8A5gDCARgBLgEGAVwBZgFsAXQBdgFuAWoBcAF2AXIBaAFgAVgBQgFuAR4BAgEdAP4ApACKAK8AWQBEgGfABMAmf8j/4D+7P2I/Tj90PyE/FT8FPy4+3D7UPsY+9D6ePpQ+jj6MPpA+jj6KPow+mD6ePqA+pD6wPro+hj7WPug+/D7LPyA/NT8DP00/XT9uP30/QL+JP5a/qj+3v76/hf/Pv9X/1T/T/9D/zn/S/9i/3L/fv+L/5v/rf++/8X/4f8RADUAOAA5AE8AgwC7APgAQAF4AaQB2AEcAlQCeAKoAuwCMANkA6AD+ANQBJgE4AQgBUAFWAWABbAFyAXABdAFCAYwBjgGMAY4BhgG6AXIBbAFiAVQBSAF8ASoBFAEAASwA0ADyAJgAu4BdgEEAaIAOgDO/1//4v5o/vD9iP0g/aD8IPzA+2D7CPuw+nD6QPoQ+uj50Pm4+aj5mPmQ+bj50Pnw+Sj6aPqg+tD6EPtY+3j7iPuo++D7BPwo/HD8uPzc/OT89PwM/SD9PP1c/Wz9aP18/bD94P34/SD+ZP6S/q7+2v4Z/0n/c/+n/+L/GABGAIoA2gAsAXoBtgHqASACcALIAiADdAPEAxAEUASQBNgEKAVwBcAFAAYgBkgGeAa4BtgG6AYABxgHIAcYBxgHGAcYBwAH4AawBngGQAYQBtAFeAUQBaAEOATcA2QD5AJcAs4BRgG+ACsAhf/i/kz+wP0w/Zj8FPyQ+wj7ePoA+qD5UPkA+cj4oPho+Dj4EPgI+BD4EPgg+Dj4cPio+PD4KPlg+Zj54PkY+lj6mPrY+iD7aPu4+wT8RPyA/Lz88Pww/XD9uP0E/kz+nP7o/h7/SP9+/7n/7/8iAGEAqADjAB4BZAGuAe4BIAJcApgCyALwAiQDZAOwA/wDOAR4BLgE8AQgBVgFiAWwBdgFEAZABlgGaAaIBsAG2AbQBsgG0AbIBqgGiAZwBlAGIAbwBcAFgAUgBdAEeAQYBKQDQAPsAoQC+gF2AQ4BnAAiALX/Q/++/jr+zP1g/eT8XPz4+6j7UPsA+8D6ePoo+uj5wPmI+Vj5IPkA+fj4APkI+SD5MPk4+Uj5aPmg+eD5EPpA+oD6yPoQ+1D7mPvo+yz8WPyQ/NT8HP1g/az98P0g/kb+dP6y/u7+JP9g/5r/0/8TAFgAiwC5AOsALAF8AcwBFAJIAnQCpALkAiQDXAOQA8gDCARABHAEiASwBOAEAAUQBTAFYAWYBbgFwAXABcgF0AXQBdAFwAWwBagFmAWIBWAFMAUIBegEwASIBEgECATMA3QDEAPIAnwCIAKwAUwB8gCJABYAr/9S/+L+eP4o/tT9ZP3s/Iz8RPwA/LD7aPs4+wj70PqY+mD6KPoA+uj54Png+eD52PnQ+eD58PkA+gj6IPpA+nD6oPrY+gj7QPuI+8j7CPxI/Jj85Pwc/Vj9qP34/UL+hv7I/gz/Sf+B/8D/9/8qAFEAgwC7APMAHgFOAZIB3gEcAlACiALAAuwCHANQA4gDxAMABDgEaASIBLAE6AQgBUAFUAVYBWgFeAWABYAFiAWQBYgFeAVgBUAFGAXwBNAEoARoBCgE7AO0A3ADJAPYApACQALwAZoBPgHgAI4ARQD5/6r/Xf8S/8T+cv4u/vj9wP2E/VD9IP3s/LT8jPxo/Dj8DPzw+9D7qPuA+2j7WPtA+yj7EPsA+wD7CPsY+yj7KPs4+0j7WPto+4D7oPvQ+/D7HPxM/Iz8vPzo/Cj9WP2M/cz9JP56/rT+8v5E/4f/tP/f/x0ATQB4ALgAAAE4AVYBcgGgAd4BEAJAAmgClALEAugCCAMoA1ADdAOUA6wDzAPsA/wDCAQYBBgEEAQABPgD7APYA8ADnAN0A0gDJAMEA+ACvAKcAoACTAIQAtgBugGaAW4BPgEOAesAygCuAJcAfQBkAE4ALgAFAOD/x/+4/53/ef9W/zb/Hf8G//D+yv6c/nL+VP48/hL+8P3c/cj9rP2I/XT9XP08/SD9HP0Y/QD98Pzo/OT82PzU/Nz84PzY/OT8AP0Q/RT9JP1M/Wz9eP2Q/bj93P3o/QD+KP5K/mL+gv6s/tL+8v4b/1P/gP+c/8X//P8uAEsAawCjANkA9wAWAVYBngHSAfYBHAJEAlgCbAKUAqwCpAKUAqQCyALcAtgC3ALwAvgC7ALUArwCtALEAtQC1ALQAtQC4ALgAtwC1ALEAqgClAKIAmgCNAIMAgQC9AHIAZgBcAFCAQABxACfAH8ATQAfABAAEADy/9b/y/+8/4T/T/86/yv/Cf/o/tj+rv50/kj+KP78/cD9kP1w/Tj99PzI/MD8xPy4/KT8nPyg/KT8qPzA/Nz83PzM/OT8DP0M/QD9MP2U/bT9jP2M/dT9/P0E/iz+Xv5G/iz+jP4e/2T/ZP98/0j/hv7s/Yb+2f/XAEwBSgH9AMAAMgHeAegBgAGwAVgCcAIsApQCXANkA7wCmAL0AtwCgAKwAjQDBAN8ArwCfAOcAwQDvAL8AvgCmAKUAgQDNAMQAzwDsAPEA3ADTAOIA6QDbANYA6QD6APsA+wD6AOoAzADzAKoAnACBAK2AYoBKgF+AOn/a/+6/sj97PxU/Mj7MPvQ+qj6cPoI+qj5kPl4+SD5uPiI+Ej40Pdw95D3QPjw+Ej5UPkQ+dj4+Ph4+QD6YPqo+hj7qPsM/Fz8uPw0/Zz96P1G/vb+/v8iAfQBYAK8AjADvAMIBBAEIARIBHAEWAQQBKAD0AK4Ad0AbgA/AAUACwA1ACUAj//6/uj+PP+y/3MA5AHQA6gFIAdACCAJwAkACjAKoAowC9ALsAwgDsAP4BBgESARQBCgDrAMMAsgChAJ8AcQB2gGgAUwBLwCIgH+/lj80PnA9wD2sPQQ9ODzsPMw88DyYPKw8dDwIPDg78DvAPCA8IDxsPLQ88D0kPUg9lD2cPbA9kD3sPdI+Gj5APtY/FD9RP4X/4H/cP+z/20AJAHCAbAC9APgBDAFiAUYBgAGEAUoBAAE9ANoAwgDlAN4BKgEYARQBFgEuAP4ArwCgAK+AQwBNgF+AQABhACCAMn/TP1I+nD4KPgg+Uj7xP3y/tr+Ev/J/wYANwDWAYAEmAbQB9AJoAwQD8AQ4BEgEuAQsA+wD0AQYBBgECARYBEAEMANgAswCTgGOAPnANT+1PyY+2D7APt4+XD3oPUA9BDyUPCA72DvwO+Q8KDxgPIg8+DzoPSw9CD0IPRA9ZD2YPdo+OD5KPvg+5z8fP2Y/fz8rPzk/Jz8EPxc/Fj98P28/Zz9rP1g/QD9+Pz8/MD80PzM/TP/UgA6AUgCJAN0A4AD1AOYBIAFIAagBgAHkAcQCFAIYAhACMAHGAfQBngGsAW4BGAEYARkA6oB+/9W/hD8EPoI+ZD3APUw88Dz4PQQ9YD2uPom/vT9bPzQ/ID+h/9iATAF8AiwCoAMIBBgE6AUYBRgFCAUoBLAEKAP0A+gECARwBAgD5AM0AnQBoADVQCY/Uj7kPlo+LD3IPfg9sD2UPYA9TDz4PGA8eDx0PIg9KD1IPdg+Ij5iPpA+6j76Pso/BT8wPto+wz8OP0q/k7+8P2c/fj8yPtY+lD5mPgI+HD3UPew9yj4oPgg+cj5UPpw+jj6yPog/Pj9o/86ATADAAUYBpgGgAfQCNAJ4AlgCfAIwAjwCEAJMAmwCAAIEAdwBdgDKAO4Ah4BE//0/Sz9CPvg+Nj4KPnQ9vDysPGg8mDyoPFg9AD6Nv7p/xwBMAKOAbcA3AJAB8AKMA2gEGAUgBbgFqAXgBhgF4AUYBEQD4ANEA3gDYAOYA0AC0AICAUUASj9aPpo+ND2sPVA9UD14PUw9/D3UPfA9cD0kPTA9JD1UPd4+SD7dPy4/cj+B/+i/uj9OP1w/Kj7MPv4+hD7CPvA+gD6EPkg+BD3wPVg9GDz0PKg8rDygPOw9ND1UPaA9hD3MPio+Rj7sPx8/mcAQAJoBBAHcAngCqALYAzgDMAMoAwgDXAN4AzQC/AKAArACKAHMAdwBtAEMAPaAYYA8v4a/rD9gPy4+mD5cPiA9oD08PMQ9BDzQPJw86D14PcE/GgCcAZQBbQCHAOgBFAFsAdgDaASYBQAFcAWgBfAFYAUoBQAEzAO8AkgCYAJAAnACDAJ4AesA/D+ePuQ+MD1gPQQ9bD1oPXg9TD3YPiw+ID4WPgo+MD3wPeA+DD6aPy0/sMAMAJkAnAB+//M/qj9hPy4+1j7+Po4+nD50PgI+ND2cPUA9JDyQPGQ8MDwsPHw8mD0oPVg9uD2UPfw97j4wPlQ+4D9n/9sAZQDUAbgCGAKUAsQDEAMkAswC/ALsAxgDOAL8AuwCzAKgAggB5AF/AP8AkQCtgBd/3b/2v/W/mD9WP3k/Ij6iPjY+Aj5IPeA9ZD2YPfg9ZD1oPlG/3gC1AMQBXgFWAToA1gFWAdgCUAM0A8gEgATYBNgE2ASYBAQDjALQAhIBpgFQAWgBAgEoAO8AgIBov6w+6j4gPYA9oD2oPcQ+Zj6wPts/HD8DPy4++D7PPwQ/Lj7KPyc/Vr/2wDcAdwBkwB4/jT8UPoQ+Xj4SPgY+OD3UPdw9oD10PQQ9PDycPFg8CDw0PAg8iD0YPZg+AD6wPrI+sj6UPtg/Lz9kv8oAvAEMAcACYAKkAvwC8ALgAsAC0AKoAlgCZAJ0AnACVAJUAigBuAEmANkAiIBeACeAKYAHQAjAAgB8AAL/5D9tP0o/QD76Pno+qj6APgw9pD3+Pjo+Ej7gAAYBCQDcAFcAtwDjAOAA9AF0AgwC8ANgBHAE8ASIBBQDrANQAzQCcgH4AYwBsgEWAPkAuwCOAKWAJb+NPxo+TD38PYo+Jj5oPqg+7T8QP0Q/bz83PxQ/YD9XP1Q/aT9QP4A/+b/zQAwAY8A5v7k/CD7+Pko+WD4oPcQ97D2QPaQ9dD0APTQ8nDxsPAA8eDx0PIw9GD2ePjo+fj6CPzM/Aj9HP2I/YT+UgAYAwgGQAhACXAJcAlgCXAJcAlQCTAJ4AhgCBAIIAhACOAHGAcoBpgEcALsALUA9wAaAZQBmAL0AmAC/AH0ARABg//K/r7+nP1w+0D6WPoY+oD5OPoA/Fj9dv5ZABgCmAKsAoAD5AP0AjADcAX4BwAKkA0gEiAT4A7ACrAKEAugCKAFOAVwBVgD8QA4AeQCzAL1AFL/9P3Q+9D4APdw93D5MPt4+3j7rPxK/m7+eP1g/XD+gP4w/VD81PzI/cD+WADmAcoB+//0/Wj8qPq4+FD3gPYA9hD2sPYw99D24PUQ9QD0YPIQ8VDx0PKg9JD2yPgI+8D8sP06/lL++P2Q/Zz9Uv6v/6IB6AMQBvgHgAmACqAK8AnwCNgH2AZYBsgGAAjgCLAI8AcIB9gFUAQQA8ACqALuASQBNgHkAWACsAIIAygD1AIgAswA2P5U/fT8tPyQ+7j66PqI+jD5cPms/Lb/VADtADADQATMAWX/cQBUA3gFaAdgCkAMMAwgDAANAA2wC0AKsAggBpQDCANUAwAD3AIYBJgEeAJ4/wb+TP2I+7j5mPlo+sD6APso/LT9yv5H/2T/Df8M/sj8kPvY+iD7VPxg/dj9oP7p/ykAmv6w/ID7yPkg94D1IPZA95D38PfY+HD4QPZQ9LDzAPMA8nDy8PSw95j5wPpI+wD78PqQ+yT8QPzU/Nj9RP6m/gAB2ASQB7AIAAqgC0ALAAmYB1AIYAlwCXAJIArACmAK8AhYB/gFqAQ8AwwCtAH8Ac4B5gAzAF8A0wDDAB8ARf9M/jT9FPxQ+2j7RPy8/AD8EPsg+9j7uPxa/vsAFANUA6gChALMAlwDuATABiAIcAjgCLAJEArwCQAKEApACWgHQAUoA4IBHAHQAbAC/ALAAvYBdQDg/vT9UP1g/Oj7nPyY/dD9oP0+/k7/yP+v/3r/AP/s/dT8XPw0/Aj8JPy0/Pj8nPwU/Kj7CPs4+rj5SPlY+GD3gPdA+Ij4gPjQ+Aj5kPjw96D3QPfw9mD3gPj4+Cj5YPqo+zD7APpI+kD7IPv4+nz8wP2k/Dj8hP/QBOgHUAlAC7AMMAuACCAIMAmQCdAJAAwgDmANoApQCaAJAAkIB0gFCAQgAh4ARv86/+L+mP5d/0MAl/+Q/aD7QPoQ+bD4oPng+lj7iPtg/Iz9XP5j/yIB8AKgA2wDPANAA2wDMATgBcAHwAjgCLAIgAgwCNAHYAfIBsAFaAQMAwQCwgEcArACIANwA1wDaALQAGr/tP5o/kD+MP5e/sr+aP/m/9//Zf/S/i7+QP1I/JD7+PpY+ij6iPro+tj6qPqo+oD6EPq4+ZD5gPmw+TD6oPqo+rD6EPtY+2D7YPtY+8D6CPr4+Tj6KPpA+lD7RPzo+yj7YPuI+0D6iPgw+Kj4uPjQ+PD5sPtQ/bb/dANwB3AKkAtAClAHkAXwBmAJcApwCyAO8A8gDsAKkAnQCQAIyAQUA4wCgACY/ez8yv5oACEAVP/g/vj96Ptg+dD3GPig+RD7uPs0/FT9yv7t/x4BtALgA7ADqAJAAqQCIAPkA5AFsAcACdAI6AfoBuAF+ASYBJAESASsAzQD/ALEAqgCEAOYA4QDrAKYAb8AAQCh/+3/ywCKAbQBcgEMAZgAOQD9/8n/H/8M/gD9JPxo+9j6yPr4+tj6YPoQ+rD5+PhQ+FD4wPjo+Pj4aPm4+aD50Pno+hT8iPyk/PT83Pzw+zD7QPuo+xT8kPzE/Hj8JPwA/Kj7KPtQ+yD7GPmA9iD2kPc4+Jj4cPteAOwDaAVQBzAJ4AjwBmAGqAfwCNAJQAvgDJANoA1wDcAMMAvgCXAI2AV8An4AcQCuAJAAHAEEAp4Bn/+4/YT8MPuA+cD4SPkY+pj6KPtE/KT9H/9/AEwBYgEwAf0ArQCUAK4BuAOIBagGiAcQCFgH4AXoBMgEmAQQBNgD7AO0A/wCdAJUAhwCoAE8AQoBpgATALD/rP/d/xUAaQCyAKYATAD0/87/p/+A/1//Hf9m/lj9hPwU/Lj7OPvY+qj6WPrI+VD5KPko+SD5QPmA+ZD5aPmQ+Tj6CPuQ+8j7uPt4+zD7+Pq4+mj6gPow++D7LPxE/FT8DPyA+1j7ePsw+5j6oPoI+/j6mPoA+yj83P2pAFAEwAYwB1AHcAhwCTAJQAmQCtAL0AtwC5ALoAvwCiAKgAmgCOAGkARoAgABbgAuAKz/Rv+q/w8ASf+w/Yj8BPxY+6j64Prg+7j8RP0S/i//JQDNAGQB7gFAAlwCWAJ4AgQDGAQgBXAFOAXwBJAErAOYAjQCgAKwAowCZAI8AroB8wClAOYA/gCcADkASACOAKAArwDgACABSgFiAWwBaAFqAWYBNAG9ACYAa/9e/lz9+PwI/dD8APxA++D6WPqY+Tj5sPko+vD5QPnQ+LD4oPjw+JD5QPrw+rj7TPxc/Fz8yPzc/GD8BPxw/Hj8iPsQ+8j7rPx4/ET85Pxc/XT8+PpQ+jj6OPpQ+gD7bPxM/ngA2AKoBZAIMAqgCUAI+AeACMAIEAmgCqAMsA3QDZANEA2gC5AJsAcABiAEFAJIAGj/kP/v/5r/qv7g/RD9ePuY+aj42Phg+ej5CPug/Pj99v76//IAfAHKAUwC+AJ4A8QD7AMYBJAEWAU4BogGUAa4BRAFSAR8A9gChAJwAlgCCAKMAQwBqQBVADEALAAJAJL/4v5o/i7+KP5I/pD+2v72/tr+gP4G/qz9lP2A/Tz99PzA/Fj8oPsI+8D6mPpQ+mD60Pr4+pj6SPpY+mj6cPrA+oj7PPzQ/Dz9QP3g/Ij8YPwc/Nj7+Ps8/ND7aPvY+4T8MPyg+yj85PxQ/ED7iPs4/ND7UPuU/Ir+Qf/f/ywC+AQIBlAGqAcwCVAJEAnQCWAKoAlACeAKwAzQDJALUArwCNAG2AS8A+QCoAFgAML/ev/8/mr+KP5I/mr+9P2k/ED7sPog+8j7jPzM/Rn/5P9CAL0AUAGqARACzAJUA0gDCAMEAzwDjAMwBMgEmATAA+ACEALZAHH/hv5I/lj+lv70/mT/1/8wAGUAZABTACUAp/8Q//r+p/+DAEwBIAIEA2gDFAOAAhQCtgEeAZIASwAYAJ3/Hv/i/r7+Yv7Q/Rj9DPzA+pD5wPgY+ND3APho+HD4MPgY+AD4wPeg9wD4cPiw+Aj54PmA+sj6OPsY/Lz8wPy0/Nj8qPxA/Iz8SP2U/Wz9Cv5A/5D/Df/S/jz/vP97AGwCEAVQB+AIIAqgCkAKkAkQCQAJYAkAChAKQAngCLAJUApwCdAHaAbQBIQCagBn/wD/jP5K/oj+iP6s/WD8mPto+zj7yPpo+oj6GPvg+8z84P3+/uL/kQAqAXwBWgE2AbYBvAK8A3AEKAXYBSgGEAbQBYgFSAUIBcAEUATcA5wDbAMoA9gCgALiAegA6v9E/+D+nP5q/j7+GP7Y/WD9zPxw/Iz8zPzY/Mz83PzE/Fj88PsI/Ij8GP1g/WT9OP3Q/ED8sPtg+zD78PqI+kD6MPo4+lD6YPqY+uD6+PrI+nD6YPqY+tj6+Pow+5j72PvY+9j7FPxA/FD8kPzk/BT9aP0g/tb+Nv/1/4YB9ALAA/AEGAfgCPAJYAsgDWANYAuQCaAJIAoQCoAKkAvQC1AKoAiwBzgG8AN0AmgC7gEyAJ7+Zv6O/ij+uP2k/RT9iPsQ+pj5sPmo+Tj6+Psu/rv/cgAGAYoBqgGMAbABPALMAjwD2AOYBCAFKAUgBTgFGAVgBDgD+AHRAM//OP8t/5f/FgBlAHcAKACE/7b+6P0Y/Wj8BPwk/LT8fP14/p7/rwAwARQBkgDk/xP/QP7Q/ej9Tv7Y/oj/NgBSAIT/Gv6Y/GD7ePrQ+ZD5oPnw+UD6iPrY+gj7sPr4+WD58Ph4+BD4cPiA+XD6EPuo+zz8YPws/DD8WPxg/HT83PxQ/Zj9Ov5S/yIAbgAAASgC3AIEA/AD6AWgB6AIEArgCxAMQAqQCFAI4AhACaAJ4AlgCXAIaAc4BrAEnAMUA/IBBQCs/lr+wP3E/AD9av6M/sD8YPuA+4j7oPqA+lT8hv58/8v/kgB2AcoB3gFgAjQDtAOwA5wD+AO4BEAFSAVIBXgFaAWABFQDsAKIAjgC2gEQApACbAKkAQ4B5QCGAJH/tv5W/uj9OP0A/az9eP6e/or+zP7o/k7+dP0w/XD9iP2A/aD95P3U/Yz9cP1s/SD9lPws/Aj8+Pvg+8j7oPtw+yj70PpY+uj5oPlw+VD5WPmo+fj5CPog+lj6WPrY+XD5gPmg+Xj5kPlA+hj7gPvg+5D8MP2I/QL+tv5q/2QACALQA1gFOAcQCnAMQA1wDZANcAzgCcAIYApwDLAMYAxQDWANMAtgCPAGsAWcA6oB4wA9AP7+Vv6c/rz+wP08/KD62Phw9wD3kPeA+OD52Pt8/SD+HP5C/pT+6v5X/xUA9QDSAfgCUASABXAGGAcIBxAG6ARQBOgDeAOsA5gEAAVIBIQDSAOcAhQBAwDq/4H/Mv5Q/Yz9yP18/Yj9OP5U/pD9/Pz4/Kj8APz4+7T8TP2A/cj9Iv7w/WD9GP0A/az8KPwQ/Dj8JPzQ+5D7ePsY+3D6yPlQ+QD50PjQ+Oj4IPlo+aD5oPl4+UD5+Piw+LD4GPmo+Tj6APsI/PT8WP1k/cD9iv5h/xcABAFwAvgDeAV4ByAKUAxQDbAN0A3gDOAK8AkwC9AMUA2ADbANkAxQCsAIQAjYBkAEuAJ4AqQB1f/Q/hr/FP8O/rj8UPuQ+SD4wPdA+Aj5+PkA+8j7WPzc/Az93PxI/bD+CQBrAOwAZAIQBMgEKAX4BXgGIAaQBZgFqAVQBUgFIAbgBpgGyAUoBXgENAPQAfEAbwDr/6f/pv9T/3b+wP2E/VD9zPxs/Gz8SPzw+8D7yPuw+5D7+Pu0/Oj8gPxM/Fz8QPzo+7j74Pvw+wD8GPz4+4j7GPsA+/j60Pqg+nD6EPrA+eD5MPoY+tD5yPmw+QD5MPg4+LD4EPmw+cD6YPsA+9D6cPvI+9j73Pz6/jkArgBcAmAF4AeQCdALgA2gDFAKoAnQCgAMQA2AD4ARABHwDgANkAtQCjAJYAgQB1gFKARsA6QC7gGkAb4Ajv4I/CD6iPgQ9+D2QPjQ+Vj6WPqg+sD6WPrw+Xj6kPuY/IT9ev6o/wgBfAKgA0gEkASwBKAEgAToBNgFwAYwB6AHEAjQB4AGKAWoBGAEhAOcAngCkALqAeAAYAAiADr/zP3A/Cj8cPuo+oD62PoA+7j6aPpg+jj6yPlo+Vj5gPmg+cD58Pkw+mj6mPrQ+vD66PrI+rD62PoQ+yj7KPtI+4j7sPuo+6D7qPuA+xj7uPqQ+oj6gPqQ+uD6OPtg+zj7MPuY+yz8jPz8/Pz9Fv/X//cAaAM4BtAHUAjwCFAJgAj4B3AJ0AugDHAMgA3gDkAOcAwADIAMkAuACaAI0Aj4B2gGMAa4BogF4AIUAWgAHP80/TT8VPww/Hj7EPsY+8j6MPoI+nD6wPqo+rj6cPts/CD9mP0+/iP/uf/x/ykA0gCcAUgCDAPcA1AEWARwBMAE4ASgBGgEUAQABKQDhAOMA1ADAAPQAmQCfgF2AM3/Uv/W/oj+YP4M/oj9NP30/GT8yPuQ+2D7wPoQ+vj5IPoQ+gD6YPqo+kj6wPmI+XD5IPkA+XD56Pno+cj56PkI+vD5APpI+kD62Pmo+fj5aPqw+kj78PtE/Cj8MPx0/LD8CP3I/ar+Ov/P//AAXAJcA/wDmAQwBUgFSAXIBbAGaAfwB8AIgAmgCUAJEAkwCSAJ4AiwCJAIQAjAB3AHWAcwB9gGQAZgBVgEaAOwAiQCtgF6AVIB6AA7AKj/UP/u/mb+/P3c/aj9TP0k/WT9vP3M/dT9Av4W/uj9yP3w/TL+bP6+/i7/cv+H/7H/7P/v/9H/7P8nACIA5//p/ygAMwD4/9f/1f+O/wD/ov6O/mL+Fv78/Rz+/P2Q/Tj9GP3o/Jj8dPyA/Hz8XPxg/Hz8jPyY/Kz8xPzA/LT8zPwI/VD9nP3c/Rz+WP6Q/sT+5v4C/yX/R/9q/6P/8P8yAFoAbgCJAKAArAC4AMsA3gDyAPwA/wAWAUABYAFcAVYBaAFyAWABYAGMAbwB0AHcAQQCKAIsAiACMAJAAkQCUAJ0ApQCkAKAAowClAKAAnQChAKIAmwCZAJ4AnQCRAIcAiACHALYAZABegF4AVgBMgEqAR4B4QCSAGMATAAsAAMA9f/w/9f/rv+S/4H/dP9g/2H/a/9Z/zf/Jv8r/zL/L/8p/yf/Jv8g/x//If8f/xr/HP8Z/wr/+v7o/tz+zP6+/qj+lP6I/nj+YP5C/iz+HP4Y/hL+BP7w/fD9Av4M/gr+CP4I/hD+Fv4o/kD+Vv5i/nz+nv7C/t7+9P4J/yL/Ov9P/2j/hf+h/8L/6v8OAC4ARwBeAHEAfACUAMYA8wACAQoBKgFMAVgBXgF2AZIBpAGwAcgB3gHgAdoB2gHmAewB6AHWAdAB0gHKAbYBpgGmAagBkgFyAWABVgFIATgBKAEaAQgB7wDgAN4A1wC9AJ4AhABzAF8ATgBHAEcANgAeAAwA+P/d/8X/sP+R/2//W/9L/y7/Df/+/vj+5v7K/rz+sv6c/oj+gP6A/n7+fv6E/oT+ev5y/nT+dP5u/mj+cP6A/oT+gP6A/or+lP6S/pD+mP6i/qr+uv7O/uT+9v70/u7+9v4P/yH/J/88/2T/e/+A/5P/uP/X/+7/CwAyAFgAeQCjAMQA2gDzABYBNAFKAWYBhAGaAaoBwAHUAd4B3gHkAfIB/AEAAgAC9gHuAewB6gHSAbIBpAGaAX4BZAFaAVIBQgEoARYBAAHeALgApQCXAHwAWAA5ADEAKgAeAA0A/P/v/93/x/+0/6z/p/+U/3z/cv92/3T/Zv9c/13/Uv80/yH/Hv8Y/w7/Cf8M/wr/CP8N/w3/Cf8L/xT/HP8f/yX/K/8q/y3/QP9g/3P/h/+b/6n/rv+z/8f/2//p//T/AAAKABEAFQAZAB4AJAAjABwAHwAuADUAMAAwADoAPAAtACgALAAlAAsA+P/8//3/8f/q/+7/7//h/9H/zP/M/8v/y//N/83/zf/Y/+v/+P/7/wEABQAAAAoAIQAxAC8ALQA5AEMAQAA8AEEAQgA+AEEARwBIAEUARgBEADgALAAtADAAKwArADAALwAiABoAHQAfAB4AIAAiABYABgABAAoAEQARABQAGAAaABYADgABAPX/9P/6//f/6f/f/+H/6f/m/9v/0//L/73/r/+p/6r/q/+n/6P/oP+a/5T/kv+S/5L/lP+W/5f/mP+j/7v/z//U/9T/2P/m//f/BQAQABkAIAArADcAPwA/AD4ARgBKAEgASQBQAEsANwAsADEAMgAkABsAHAAVAPz/7P/2/wMA+//t/+z/8P/u/+b/4//g/9v/2//h/97/0//L/8v/z//S/9b/5P/y//3/BwAMAAUAAQAKABQAFwAVAB0ALAA0ADcAPwBLAE0ASABCAEEAQABGAE0AUABSAFMAUwBMAEIAPQA5ADEAJgAjACQAGwASABEADAD8//X//f8EAPv/8P/u//H/7v/y//v/+//y/+3/7P/r/+r/7//1/+3/3f/c/+P/3//U/9b/4f/f/83/wP+//7f/p/+n/7b/tf+k/6D/rP+w/6T/o/+2/8f/xv/A/8n/1//g/+f/6//r/+v/8v8AAA4AGQAgACkAMAAzADgAQwBNAFIAUgBQAFEAVgBbAGMAZwBjAF4AXQBfAFoASwA6ADsARgBLAEQANwAxADEAKwAeABsAHAATAAEA+//9//j/7//z//3/+P/p/+X/6//l/9n/2//l/+X/3//f/+P/5v/q/+3/6//m/+X/5v/f/9n/3v/i/9D/v//F/9P/0P+8/7X/vv/B/8D/yv/U/87/wf/C/87/0f/O/9X/5v/v/+v/6P/q/+n/6P/v//n//P/5//3/BQABAPf/+v8FAAcA/P/3//v//P/1/+//8f/0//b/9v/y/+//7//v/+z/6P/s/+7/8f/+/wsADgAFAAUADQANAAUAAgAGAAoAEQAgADEANgAxADYAQABEAEEAQQBHAEkARwBJAE8AUwBUAFMAUgBMAEcASABLAEwASwBLAEcAPQA1ADAAMQAsACEAHAAcABcACwABAP3/9//u/+j/6P/p/+f/6f/r/+f/3//i/+n/6P/l/+f/8f/0//L/9P/0/+z/4v/k/+3/8v/0//f/9//z//L/+v8CAAAA+v/2//b/9f/2//z//f8AAAgAEAAMAP7/9//6//z/+v/3//f/9v/3//b/7v/p/+r/6//j/9//4v/o/+b/5f/u/+7/3//V/9z/5P/i/9n/0f/L/8P/wP/H/9H/0P/L/9P/4f/l/9//4v/t//T/8//z//z/BgAIAAsAFAAZABkAGwAeACMAKgAwAC8AKQAmACYAIgAdABwAGwAYABMAFAAaACEAIAAYAA4ACQAJAA0AEAASABIAEgAUABIADgAQABkAHgAUAAgAAQAAAP7//f/9//r/9f/w/+z/6v/m/9//2P/X/9v/3f/b/9r/3//g/9z/3P/i/+b/4v/c/9f/1//c/+T/5//m/+P/5P/k/+T/6//4//3/+//9/wUABwADAP///v/9//z/+v/5//n/+//+//7/+v/1//L/7//t/+7/7v/s/+z/7P/s/+3/7f/p/+P/5P/t//b//P8BAAMA/v/2//T/+f/5//f/+v/9//f/8f/4/wUACAAEAAMACQAOABAAFwAeACQAJwAoACkAMQA8AEEAOwA4ADsAPAA9AEEASwBPAEsARwBFAEMAQABAAEAAOgAxAC4ANwA4AC8AJQAhABgAEQASABUAEAAHAAYAAQD3//L/+//7/+z/4//m/+T/1f/Q/9n/1//H/8H/yv/S/83/xv/E/8n/0v/a/9n/1P/W/9//4P/a/9//7P/z//P/9v/5//P/7v/v//P/9v/5//v/8//p/+3/9v/u/+P/6P/5/wAA9f/r//L/AQAHAAMAAAAJABgAFwAFAPz/CQAXABIAEQAiACoAFQD5//f/CwATAA0AEwAjACIAEAAGAAwAFAAXABMABwD3//H//P8MABEABAD2//j////+/wQADAAMAAAA9f/v/+n/5v/z/wIA///3//n/9//s/+v/9v/t/8z/vP/X//f/+//v/+L/zv+7/8b/7v8CAPD/1//M/8L/uv/G/97/5P/X/8j/y//f////GwAZAP3/5f/n//r/DwAkACIA+//Y//H/MwBbAFoAUwBAABIA/f8vAIEAsgCqAIUAZABMAD4AYQC2AOYAogAzADAAnwDZAI0AXACLAFsApP+W/3wADgGpAA4Aqv9A/yb/0v+kAMkAfgABAAv/Kv7O/mkApQBz/yb/BgD4/8r+pv7e/04AQv+K/gT/Xf8+/7j/YgC7/xz+fP2I/kgA5AHUAtYBxP4o/FD8QP7h/0IB1AIsA2gBlP/O/+sAGgH9AIQB4gGeAbIB4AGoAGT+gP3A/isArAA4ASwCKALCAHf/of8KAYAC8AJEAogBRgGzAF//Hv7A/SD+cv4e/iD9JPzA+/D7LPzw+9j7kPx8/bz9VP1s/dL+GQBo/1j+if90AYAB/wA4ApQDhAIQAVwC2ASQBKQC9AKQBOwDHAK0AoAEEAQQAsoB0AJUAqwAeACYAbIBXgAh/8r+yP6k/pT+7v5Y/x7/GP6w/Pj7GP3W/sr+FP0Q/JT8XP1k/Wj9UP74/rz90PsQ/Lr+GAHeAJ7+zPzA/Lz99v7BAHwCVALo/8j9NP79/xoBwgGEAkQCtgDi/xQBgAIYAhIBlAGMAu4BGgFMAuQD1AL6/9b+CQAMAVoBrAL0AzgCnP5w/Uz/pAB/AFgB8ALyAcr+yP2G/5kAFAAfAPMAxACp/3n/SwCMAOf/a/+Z//n/OgB8AKcAJgAS/7r+4/9GATABHQDc/1kABQBV/9H/wABzAJX/zf9mALj/5P7U//4ADwCY/iP/rQCiACr/nv7E/68ALQBg/wv/wP7W/uX/CAHzAAkAwP88ALz//P2s/WUAKANYAkv/VP7E/9z//P1e/uoBsAOcAT7/uP5C/pz9Nv/wAhAEwADw/cb+mP+M/nz/mAJ0AkT+OPzy/qIB4wBk/0n/Rv5g/LT9JAIYBMABqv7E/MD7lPwJANQDSAREAej9LPwo/PD92QAMA+wCzv/w+8j70P8kA7QCVgBk/rj88PuY/ngD2AREAYD9LPw0/Oz9MAKgBawD/P3I+hT8wv6oAbgEkASH/wj78Pv8/6wCWAMUAzIBkP3g+wT/rAPoBPgCKAB0/aD8Yf+sA2AFTAO7/1z98PyM/ggC4AQABG4AkP0U/WT+rgDMAjADXgGE/sz8wP1mACQC3gFkANz+8P3I/cj+KgHsApwBkv4M/ZT9H/8oAfACFAPkAOz9BP3c/kwBkALIAiACNQDo/Vz9av9QAlgDyAGj/8D+8P52/ywA2QAAAUcABf96/jv/VQDJAIwAwf+6/jj+qP7R/wABYAGVAP7+oP24/Zj/ZAFoAWUAm//Q/iT+DP9eAXAC4ACm/jT+/P6k/8cASALCAbz+qPwY/igBvAJEAgQBiP8g/vT9m//yAfACugGa/6T+Sv8eAGIA2wCIAeIAGf/y/jQBgAKmALL+Z/+mAB8A8P+IAdgB/v60/Dz+5gAyASMACgD4/6j+2P0P/6EAkQCo/3D/w//7/wgAyv8A/1z+/v6LAHQBDAHZ/2z+iP1q/tYAkALUAY7//P0A/kD/MgHMAlwCqP8I/fz8dv8oAvgCeAEP/6T9FP7Z/9YBnAISART+fPzo/dQAoAJMAnoAYv58/cj+QgGEAngBY/+8/YD9gf9wAlQDHAE8/kT9OP4HAAAC9AJ6AaT+KP0A/uP/2AEUA9YBTv4w/Pj95ACmARYBOgHEAC7+aPzU/rwC4ALQ/zT+Ef/a//j/zwCmAagAyv6W/gMA+QDQAGYAy//C/pb+OQDkAXABa/8W/qb+XgB6ASYBSQD4/97/Pf/Q/tr/fgGqAWcAdv85/yP/nf+3APwAyP/K/pT/EgEeAb3/tP7A/jb/zP/PAN4B6gFmAC7+JP1G/n0AFAJsAnABUf+U/bj9Sv+kADQBbgEsAfv/sP6W/n3/LgAiAAoAeQDsALAAzf/s/vT+DADeAH8ABwCGADQB2ACZ/9L+T/9+AGwBnAECASIAaf+K/uz9Q/9IApQDpgH2/sT9cP0C/rgAAASoA0b/2PvQ/K7/KAGUAcYBjwD0/aj8kv6sAbgCGAHM/qz9Pv4nACACeAKpAEb+eP3W/voAfALcAlIBJv5k/G7++gE0A+IBjwDV/4D+pP2k/8wC4AIFAGj+Qv8MAOL/WAB4AQgB2v7s/YP/CAGaABIACgGQAfj/Mv6q/mcA/ACHAIwArAC7/97+mv+vAHMA3P80AEcAA/8m/jb/pACtADQAJACI/zb+FP7N/ywBpgCc/3T/jf9d/8X/vgC0AGj/vv7K/wwBqQA6/9r+hf9y/wb/+/9qAQIBSP+M/hb/WP+f/0YBgAJ0ACj9AP1y/5kA+/82AFQBpwAC/qz8lv6SAXACAAFv/+D+AP+j/+AA8AF8AW//Gv6C/xACnALRABn/4P5U/+H/VAEMA2AC+v6c/CT+wgGIA2wCdAAd/yb+8P2s/6ACpAP8AFD9tPxC/7ABPAKEAf//Iv6Y/Xr/5gEYAk0Auv40/qL+YABoAjwClv94/fD9p//NAJIBCALwAKD+xP1f/wgB/QCSABIB9wAm/9T9H/9WAYgB7f/2/lH/f/8U/1r/hAAIARsABP8a/+T/WACTAKkA6f/W/ij/wgBMAQYADf+p/1kA9f+p/0sAvgArAJP/2/8nAMX/vf/AAFgBRgDQ/tb+EADEAKwAwADJAM7/iv6C/pj/jwC8AIYARwDI/xf/H/8ZALEAJwCL/wMABAEQAc//0P5f/4sAwgAfAOP/OQA2AL7/wv9zAMIAXQAJANv/af8q/9f/9wB6AecAvP8t/67/MADI/0T/1P/cAKsAdv8W/6b/a/+Y/gj/ZACHAGD/8P5u/0//qv5C/+UADAFA/1D+sP8MAVYAI//A/1QBbgEeAKj/jwDqACkAIQBKAaABRwA4/97/3gC8ABIAAABAAEIAQABHAN3/Sf9o/+f/7v/d/ykAzP9Y/rz9K//gAPkATgAaAJD/Qv7g/ZD/pgEMAsoASv+U/tT+rf+mAD4BDgE2AIH/lv8uAI0AgwBlAFAALwBPAOUAFgHM/wr+Lv5bAOYBJAGX/0D/hP/m/iz+Jf8cAXQB0v/I/pf/TgB8/7z+3f+SAXQB5/9I/+//FABx/87/agEIAq0AX//C/4IAGwB//xoA6wBUAFT/tf/CAI8AX/8a//n/eQAgAAoAgwBhAGb/1v56/3AAugB0AB4AwP9C/wb/eP9fAO8AfQBA/2T+2v4bAMkAjQAoAO3/iP/o/sj+u/8UAWYBUwAa//7+tf8PAMz/4f+aAOMAIwCA/+z/jgBHALv/AQCXAGcA5v8FAGcAQwDz/wwANgAqAFEAngBOAKH/yf+VAIsA3P8rAC4B6QBm/7r+hv9KAEcAcgDcAEMAzv5C/kn/hQChAPH/mP++/5z/Tv/B/8sAAgH9/yb/nv92AGUA2f/T/wEAxv+s/1QAAAF7ACn/jP5B/4IAQAEgAWIAeP/M/sr+rv/8ALYBMAH+/0L/Tf+2/zIAmACsAFEA7f8CAEwAIQCb/4T/CACPAKAAZQAcALD/IP8K/9n/0ADvAFsA9//M/2X/Gf/H/wYBTgFuALr/yv/i/63/tf9GAN8AzgAHAED/NP/G/y0AKQBJAKEAYwB8/w3/kP8kADIANwBdABYAbP8a/3P/9f8yADAADwDN/4P/ZP9p/6r/HQBSAPD/e/+j/xQAAQB1/0b/o//8/zwAoQCLAGj/PP6E/u7/vAA5AIv/pv/Y/2n//P5r/0gAggAaAPn/QwAzAK7/gP/q/08AYAB5AKIAWgCn/1P/1P+ZANgAhAAAALH/4P9aAHwAIADt/zMAlAC8ALcAiAAcAKn/vv9qAA4BKgHLACcAff9M//n/IAGoAQoB8f8s/+r+Of8tAEABcgFrAAX/fv4C/87/WACfAIgA6/8n/+T+Wf8OAHIAaAAiAND/r//l/yEA/P+p/57/3/8vAJYA7QCLAEn/XP7k/lEAXgGGAewAoP8+/g7+bP//AHgB6wDy/9z+LP6y/jgAVAEgATsAi/8g/+b+U/9eAAABcgB9/1//1v/a/47/sf8EANj/iP/m/5QAfAC5/2P/rv/0/zsA0gBAAcoAyv9I/7P/jQA2AWoBDgE8AID/Z//3/9AAPgHpAC4Aq/+Q/7L/HACdAJUA8P+U//v/ZgAmAMX/7/85ABgA8P9IAKgAZwC9/3n/vv8VAEMAOQACALn/if+B/5r/2P8WABMA3P+e/1X/Dv8o/8P/SgAnAJ3/Ov8I/+7+Mv/W/y4A3P9g/0X/Yv95/6v/9P/6/7n/sP8NAEUAGAD1/xgAKwAVACsAfAC2AI0AKwDs//j/NwB5AJIAiABtABkAiv9E/7n/mgD5AIUA4/99/yH/6v5q/4UAMAG7AMX/MP8H/yL/tv++AHgBPgFSAIn/Tf+F/xwA5gBsAU4BmwDI/2n/sP8/AKUAxwCsAGwAEgC7/6P/x//o////IgA2AA4Au/9s/zL/Hv9C/5T/+/8lANH/H/+S/pz+Ov/x/08AOQC7/yL/8P4//7n/KAB9AKMAVgCb/yD/dv86AJ0AhgBlAFIACwC7/8//IQA+ACoANABGAC8AEAAmAFYAQQAPAC8AjwDHAMEAfgAYANv/HQCgAAABBgG4AEIA0/+9/zAAyADnAJYAOwALAO3/7/9BAM8A8wBbALv/2f9cAGwAJwBhAOAAuADv/7D/KwBYAAMAAgBoAF4Ax/+O/+7/4v8x/9L+U//S/6P/G//E/n7+/P3Y/Yr+Vf8q/zz+oP2c/aj9sP1E/hv/Bv8M/oD97P1k/nj+zv5x/3b/0v6u/lX/x/+y/9D/VQCMAGUAlwAiAVoBCAHkAEYB8AGYAvACpAL2AcoBMAKcAhADwAMYBGADMAIQAtgCPANkAxgEeARIA7wB2AE0A5wDyAKsAlAD2AJOAcoApAE4AroBaAHeAdgBhwCA/+//vACyAE8AXwBOADn/Av4c/gH/Jv9W/tD9rP0c/Sz8+PuM/ID8cPuQ+oD6WPrQ+aD5+PnY+ej4SPiI+OD4oPho+Mj4IPko+TD5YPmA+aD5CPrY+rj7KPxs/ID8zPys/ar+T//3/wwBGAJsAlwCHAOABFgFkAVwBrgHIAigB9AH4AhQCdAIAAkwCsAK4AkgCVAJcAngCFAIwAhgCQAJAAgoB8gGaAYoBkAGcAYgBugEzAOMA8ADnAMQA9gC8AJwAjwBewDKADQB2wAVAGP/4P4u/qj9uP2w/cD8aPt4+gj6mPng+Cj4kPeg9kD1MPSw83Dz8PIw8nDxsPDA70DvoO8g8BDwwO/g77DwUPEA8jDzgPRw9eD14PbI+OD6hPwU/qb/nAAMASQCmAQwB4AI8AigCVAKoApAC5AMAA6ADkAO4A2gDVANMA2QDYANwAwADFALsAowCvAJoAmgCIAHUAeQB3gHCAfgBmgGWAWIBMgEwAVYBmgG0AWIBEgDPAMoBBgFqAWYBUgEPAKAAZwCjAMsA9QCTAO4AnMAJv8dAJgA3v5E/dD9av6s/ED6OPkQ+ED1IPNw9OD2EPaA8qDvIO5g7CDrwOwA8MDwIO6A68DqgOrg6kDt8PCA84DzkPIA8kDygPRg+Az8Zv5x/5n/Hf9l//oBoAXAB1AIIAnQCRAJcAjgCUAMAA1ADMALkAvwCrAKgAvgC7AKgAmACWAJYAgACIAIQAjoBjAGyAboBjAGMAawBvAFsAQgBfgGqAeABpgFmAWYBZAFoAbgB7AHQAY4BdgEeARoBGAFIAZYBegD/AJYAsIB9gHAAoQCYAE4AZQBLACw/fT82P3g/ez86PxM/Kj40PTw9LD2kPXA8xD0kPRQ8aDsAOxg7gDvQO4g78DvYO2g6oDroO4A8GDwYPLg9AD14PPg9OD3oPqk/IT+TQD6ACIBDAIwBEAGYAcQCCAJMAogCqAJ8AlAC/ALkAswC2ALYAtQClAJQAlwCUAJ4AhQCMAHwAbABYAFQAbgBngGYAXABJgEaASABEAFCAbABfgEuAQABTAFUAXQBUAG8AVgBVgFaAUIBcAECAXABPwD3ANoBPwDwAJkAuwCcAKYATwCHAMQAjEA1v/d/4b+rP0hANYBQv7Q+ND2oPdQ92D3ePk4+lD1AO8A7pDw8PAA8PDxcPNQ8EDroOog7jDw4O8w8TDzwPKQ8SDzYPbQ9wD4uPnw/LL+F/9FADQCEAMEAyAEmAaACEAJwAkACkAJUAigCFAKcAtgCyALwApwCagH8AaYB3AIsAiQCJgHwAUgBLQDkASgBSAG+AUIBaQD9AKgA5gEMAWQBbgFQAWABGgEWAUIBtAFqAXgBagF+ATgBDAF0ATsA6QD4APYA3wDTAPAAqoBhAGAAuACRAJQApQC6gA0/mr+TgFEAokAYv82/qj5IPXg9tT8Ov5w+YD1UPRg8cDtQO8A9cD2cPJA7oDtoOwA6+DssPHw88DxgO9w8MDyoPOw9GD34PnY+pj7UP1K/0cAgQCEAXADOAWQBpgHkAjwCEAIYAfgB3AJYApgCmAKcApACWgH8AbYBxAIWAeoB2AI8AZABHAD2ASgBfgE6ATABWgFqAMAAxgESAWABUAFWAWQBVgFAAU4BfAFaAboBQAFAAWYBXgFiAQ4BHAEMARMAwADqAOsA7gCBAJAAtACQAN4AxQDnAEZANP/tADQAQgD6ALA/xD7EPiA+ED6UPtI/Dz8wPfQ8IDtoO8Q88D0kPQQ84DvYOtA6qDsoO+Q8aDyQPIg8cDwIPJA9ED2gPho+jD7EPxs/qAAzAB6AOABYAToBeAGoAiwCfAIkAe4B9AIsAlgCjALIAuACagHCAdQB5gHyAfYB1gHOAb4BIgEoASwBNgESAVoBagEuAPUA8gEYAUABdAEYAXQBYgFIAWgBVAGKAaABYgFqAUwBZgEqATgBCgELAPkAvACkAIwAhQCtgEsAYIBTAIsAo4BjgEwAbH/rv5YAGQCCALy/0z+jPwQ+QD3OPn4/GT9OPoA9mDywO+g72DygPXg9eDyAO9A7IDrIO0A8HDyUPPA8qDxQPGg8mD14Pcw+RD6mPuE/UX/1gAAAiQCGAJgA+AFYAiwCRAKcAm4B7AG+AdwCrALMAtACtAI4AawBaAGkAjACOgGOAWYBBAEhAMYBKgF8AUYBFACqAL8A2gEMATABHAFwATEA1AEwAUwBrgFmAXgBXAFCAVwBeAFCAUoBCgECAR8AzwDpAMwA7IBDgHAAc4BVgEMAjwDbAIlACT/1/8WAAYAJAEAAhEAHP1g+yD6OPjQ96D6iPwY+pD14PLw8EDvYPAw9OD1sPKA7gDtQO0A7QDuUPGw8wDzwPGA8lD0YPVA9jD46PrQ/Cr+HwDKAf4BZAGsAcAD2AZQCYAKIAqACOAGqAYgCHAKIAwADEAKyAc4BmAGkAeACLAIIAioBpgEzAPYBCgG6AXwBPgEMAUYBCgDaAQQBogFAARoBMAFkAXQBKgFsAbABYgE8AQYBuAF+AT4BMAEhAPsAowDiAOgAkwCWAKkAaUAzACsAb4BUAHiARQCXADO/mz/oABhABcAjwCn/0T8aPk4+YD5ePiQ+Lj6OPpg9eDwQPAQ8RDxAPJQ9MDzAO/A6+DswO7A7sDvcPPA9YD0sPLA80D2gPcY+Zj8SQBWAaIAbgB4AZQCqANYBuAJUAuQCaAHsAfQCEAJsAnQCoALkArwCCAIuAcoBwgHYAeIBwgHcAbYBQAFQAT8A/QDWAQgBYgFAAWUA/ACsAOYBKAE+ASYBYgFuARABOAEgAUgBZAE0ATwBEgEfAOAA7ADLAM0Av4BdAI4Aj4B1AAGASYB3QAmAVgCkALXAFz/y/9rAAIA4v/+AP0ABv7Q+vj5yPko+PD3sPro+wD44PIA8RDxsPAw8dDz0PQg8qDuYO1A7WDtgO/A85D2IPag9AD0wPSg9uD5iP3R/6MABAEaAUoBWAJwBNAGIAiACEAIAAhwCFAJoAkQCUAIUAgQCdAJoAmACBAH4AWABQAG4AaYB1AHsAXsAwQDdAPIBAAGGAYwBbwDrAIEA6AEQAZABtAEyAMQBKAEyAR4BUAG6AUYBPQCkAOQBEAEnAOYAwwDrgEYATACwAJsAeb/VgCOAdoB6gGEAkQCGACi/r//aAEoAW8A0gBKABj9yPlY+Qj6ePk4+Zj6UPoQ9mDxwPDA8WDxkPGg83D0IPEg7SDsYO3A7jDxAPXQ9uD04PKg8+D1UPhA+4L+IwDL/6P/3wBEAngDUAXgBjAH8Aa4B0AJQArQCaAIgAcABxAIIApQC1AK2AeYBdgEcAWgBtgHQAg4B7gEfAKcAoAEwAXIBVAFSAScAv4BtAMQBhAGKARYA9ADAAQgBAgFAAZoBawDyAIcA5ADoAOsA6AD3AKsATYBqAEAAnQBhQBSABYB6gEcAvABRgFnANj/JgAKAXYBLgE9ABv/iP0Y/AD7uPrQ+oj6sPmA+CD3QPUQ84DxIPKw83DzUPIw8YDvIO2A7GDvUPOA9KDzwPMA9DDzAPTw9yj8ZP3c/JT9PP/b/6UA7AJQBbAFCAWwBXgH0AgwCSAJoAigB/AGsAfgCTALUAogCEAGqAXgBbgGAAiQCEAHEAUABDAEuARYBRgGSAbABOgCOAMYBeAFYAXIBKgEAASgA8gEQAboBYAE5AMwBPwDNAPcAwAFOARwAlwCOAPwArwBegEwAtQBWgFwArwDsAKiADQANgF0AeEAbgE4Av0ASv60/HT8OPxY+8j6uPoA+hD4MPYg9eDzYPLw8TDz4POw8nDwgO4A7WDsgO6w8sD0cPMw8lDyMPIQ8+D2JPzo/fj7oPtM/sf/0f9gAvAFuAV0A6AEoAigCaAHqAeACcAIaAZ4BwALwAsQCXAHqAfABlgFsAZQCQAJOAZ4BBgFiAXIBCAFmAZIBjAEbANgBEAFQAVgBXgFcARIAwAEwAXYBfAEqARwBHQDLANQBIAENAOAAhwDRANgAgACgAI0AvgA8gAsApQCXAJ8AugBegDv/wYB3AFwARgB+QB3/+z8BPyM/FD8yPoI+jD68Phw9gD1sPRw8yDyMPJQ81DzcPEA78Dt4O3A7oDwsPJw9ED0APMw8vDzIPfA+dj7eP3w/WD9Pv7CABQD1APoA3AEgAVgBrgHMAkgCaAHCAfIB6AIcAlACpAKQAkQBxgG8AboBzAIgAgACFgG6ARABXgGuAbgBXAFYAWoBPwDyAQoBuAFoAT4A/wDrAPMAwgFuAVoBNgC9AJ0AxgDxAJUA2QDPAL4ATADYAPUASgBDAJMAq4BJAJ8A2QDdAGtAGABkAEEAVQBKAIiAcb+ZP1g/eT8oPu4+mD6oPkg+OD2MPbw9CDz8PEA8pDygPKA8VDwAO/A7WDtAO/g8eDzAPSg8+DzMPQA9bD3ePuM/Zz9rP0w/8kAcAFMAqwDeATABPgFAAggCWAIEAeoBuAGSAegCGAKoArQCMAGAAYgBpAGsAcQCbAIeAb4BGgFAAa4BbgFSAbYBYAEUASQBSAGMAVwBIgEKASQA1AE0AXABUAERANQA0wD7AJ0AzgE6APEAlgCxAK8AjQCBAJAAiQCBAJUAqwCeAK0ARYB3QDsAAoBJAG2AML/iP5Y/WD8sPs4+5D6cPlA+JD38Paw9RD0EPOA8sDxQPHQ8eDxQPCA7kDu4O5g75DwkPNw9ZD0kPMg9fD28PdY+sT9pf/K/mL+uAC4ApQCDANYBaAGqAaQB1AJUAmAB9gGEAjgCAAJAAoAC/AJeAdIBtAGwAdgCCAJ4Ah4BwAGkAX4BXAGeAb4BXgFQAVgBVgFQAUoBbAE0ANgAxgEIAUgBYgEAAREA4ACmAKgAzgExAMMA+gC1AKAAowC+ALsAjAC6gFgAtAClAI8AhACngHrAL4ALgE6AXgANf8C/ij9aPx4+8j6OPow+ZD3cPYg9qD1IPTg8qDyIPLg8GDwAPHw8EDvQO7g73DxkPHg8jD18PVg9HD0kPfw+vj7sPze/sf/jP4A/2wCoARoBFAEQAbABygH2AaACCAJsAdQBwAJMAqwCSAJMAlwCNgG0AaACJAJ4AiYBxgHiAaQBYAFgAbIBhAGYAVABTgFyAR4BLAEkAT8A+ADYASgBCAEgAM8AwwD7AIwA5ADnAM4A7AClAKoApwCnALAApACRAJMApACqAJYAuwBvgGSAU4BPgEwAYEAUv9k/rT94Pwk/Kj72Ppw+Sj4gPfA9qD14PRg9FDz0PFQ8YDx4PCA72DvAPCg74DvcPGw85DzwPLA87D1cPaA9+D6eP30/AD8kP0LAAYBxAHwA8gFSAXwBIAG2AfIB7AHgAggCdAIwAjgCWAKUAlACFAIgAiwCCAJgAkACdgH+AbABqAGqAYoBygHaAbIBZgFOAXABMgECAXABDAEYATIBBgEHAM4A5gDEAPAAmgD3AMcA1gCmALcAnQCUAL4AiwDmAJsAqwCmAIYAvwBNAL2AaIBrgFmAUsAT//a/jL+NP2Y/DT8OPuo+YD4APgA99D1QPWw9HDzMPLg8aDxgPCg74DvoO9g7yDw8PHQ8rDywPLw8+D0gPXA99j6sPtY+1D83P2c/mD/UgGYAzAEKARIBYAGaAagBuAHYAgACGAIsAkQCkAJ8AggCaAIMAjwCMAJUAmACDAI2AfoBngGCAdIB7gGMAYoBrAF6AS4BOAEiAQIBDgEUATYA2QDXANIA+ACrAL4AjQD+ALIAsQCjAI4AhgCRAJoAmgCcAJMAiAC/AHeAbABigG6AbABDAFDAOP/Wv+A/sj9eP3s/LD7qPog+jj54Pcg99D28PWA9KDzYPOQ8mDxAPHw8GDwAPDQ8PDxUPJg8iDzAPQQ9OD0APfg+KD5cPqQ+3z8LP1e/g8AaAFAAkQDWATIBEAFMAbwBhAHSAcACKAIwAjwCEAJEAmQCIAIAAkwCfAI4AjQCGAIkAdIB2gHWAcIB9gG2AZQBsgFgAVoBQgFsASwBKAEYAQABOADyAOMA1ADTANYA0gDQANEAzAD+ALEArwC2ALkAsQCsAK8AqgCSAIQAiQCEAKsAUIB6gBaAHT/2v54/sT9mPzY+2j7cPo4+Vj44Pfg9oD1oPQw9EDzEPKg8YDxoPDg7wDw0PBQ8WDx8PHQ8kDzkPOg9ED2oPd4+Jj5wPrQ+6j86P1F/3MAcAFgAnQDcAQoBcgFUAbQBkgHuAdACOAIQAlQCUAJQAlACUAJcAmQCYAJUAkACcAIgAgwCBAIEAjQB4gHaAcoB9AGgAZQBggGoAVQBTAF8ASABFAEWAQYBLQDhAOYA3QDOAM4A0wDCAOsArgC4AKcAkgCZAKQAiwC2gH8AfIBYAHdAJEA+f8M/2T+Ev5c/UT8ePv4+tD5kPgQ+ID3QPYg9cD0QPTA8pDxcPEg8cDvIO8w8ADxsPDA8NDxgPJQ8uDywPQw9pD2cPcw+Vj6oPqo+5T95v6C/5EAMAI0A6ADYASQBRgGIAbIBtAHQAhwCAAJkAmACUAJgAnwCQAKwAngCfAJYAngCPAI0AiACEAIMAgQCKAHSAcwB/gGUAbgBcgFmAUoBegE2ASoBCgEyAPcA9wDhANcA5wDqAM4A+QCCAMgA8wCnALEAtQChAJMAlwCFAKYAUQBFgF5AKb/MP+6/tz98PxY/LD7iPp4+RD5WPjw9vD1oPXA9DDzMPIA8lDxAPCA7zDwUPDg72DwkPHg8YDxQPLg8wD1YPWA9jD4IPmQ+cj6pPy4/V7+wf+QAYACAAMABDgFwAXQBagGuAcwCGAI4AiACYAJcAnACSAKIArwCQAKIArQCXAJUAkgCbAIcAhgCEAI+AewB3gHKAe4BlAGGAbgBaAFaAVIBRAFwARoBFAEUAQoBAAEAAQABOADlANwA1wDIAPsAsgC0AK8AowCbAI8AuQBZAHeAHEA8f9P/4D+vP0Y/Uz8OPtI+nj5uPjA97D24PUg9eDzoPLw8TDxQPBg70DvYO8g7yDvwO9w8KDw0PDA8eDygPNw9OD1QPcA+ND4KPqA+4D8oP0d/34AZAE8AlgDMASwBGAFYAYgB3gH8AewCCAJIAlgCdAJEAoQCkAKkAqACkAKIAoQCsAJgAmACZAJYAkACdAIkAgQCLAHkAeABzgH2AaYBmgGEAa4BYAFcAU4BegEyAS4BIgESAQgBAAEvAN0A1QDRAMQA9QClAJAAt4BaAEGAYgA4P85/5T+zP3k/Bz8YPt4+lj5cPiw97D2oPXA9BD04PKw8fDwcPCg78DuoO7A7oDuYO4g7+DvIPCA8GDxkPJg8zD0oPUw90j4GPlg+sD76PwW/o3/7wDiAbACzAPYBIAFIAboBqAHIAiQCBAJkAngCSAKMApgCpAKoArACuAK4AqgCkAKEAogCvAJsAmQCXAJEAmQCGAIUAgQCMgHoAdwBxgHwAaoBogGOAbYBagFgAVIBQgF8AToBKgEUAQYBPgDuANoAzQDCAOoAjAC0AF0AfwASgCQ/+z+Qv5U/Xz80PsI++j50Pjw9yD3APbw9ED0kPNg8kDxwPBQ8GDvoO6g7uDugO6A7mDvMPBQ8IDwcPHQ8qDzcPQQ9rD3gPgg+aj6QPw8/QT+if8YAfQBmALYAxAFgAXwBegG0AcwCHAIMAngCeAJwAkgCpAKoAqQCtAKEAvQCnAKcApwCiAK4AngCeAJcAkACQAJ8AigCEAIEAj4B6AHWAcwBwAHoAZIBggGwAVwBUAFQAUYBcAEgARYBPwDnANwA0AD2AJgAgwCvgEuAY0AEwCP/7r+7P1g/bz8uPvI+gD6CPng9+D2MPZQ9SD0QPOg8rDxkPDg74Dv4O4g7gDugO6A7oDuIO8A8FDwsPDg8XDzcPQw9aD2MPgQ+dj5SPvo/Aj+/P5ZAMABkAJYA5gEmAUYBpAGaAcwCJAI8AiQCQAKEApACrAKAAsgC1ALgAtwCyALEAsgC/AKoAqgCpAKQArwCfAJ0AlwCRAJAAngCFAIAAgACKgH8AaIBoAGIAagBXgFkAU4BagEeARgBAgEdANEAygDpAIgAswBgAHdADkAx/8t/1z+pP0Q/Tz8QPto+pD5ePhg94D2sPWg9KDz0PLg8dDwAPBg78DuIO7g7QDuAO4A7mDu4O5g7+DvAPEg8iDzEPSA9dD2sPew+Cj6gPuA/Lz9MP95AFYBQAKEA5AEQAUABvAGgAfwB5AIMAmQCdAJMAqgCtAKAAtwC6ALkAuAC4ALYAsgCwALAAvACoAKUApAChAK0AmQCVAJAAmwCGAIEAjIB4AHGAegBlgGCAaoBWAFIAXYBGAEEATQA2QD6AKQAjQCrgEyAd4AigDj/zn/uv4g/kT9ePzo+0j7SPpA+YD4sPeg9rD1APVA9EDzYPLA8QDxIPCA72DvAO+g7qDuAO9A74DvAPDA8FDxAPIw83D0gPWA9rD38PjQ+ej6SPyk/az+2v8EARAC7ALoA+AEkAVABgAHsAcgCJAIIAmgCeAJEApwCtAKAAswC3ALgAtgC0ALQAswCwAL4ArQCrAKcApACiAK4AmQCUAJIAnACGAIIAjgB4gHGAfQBngGGAbABYgFUAXwBIAEIATIA1AD0AJ4AhAClAEQAZUAEgB7/77+Dv5k/bT86PsQ+2D6iPmY+LD34PYQ9jD1YPSw8wDzEPJg8eDwYPDA74DvYO9g70DvgO8A8IDw8PCg8ZDycPNg9ID1wPbg9+j44PkQ+0j8eP2Y/rr/4ADaAdgCsAOgBIgFUAbwBpgHQAjACBAJgAkACkAKgArAChALMAtAC1ALcAtgC0ALUAtACxAL8ArgCsAKgApgCkAKAAqQCVAJIAmgCCAI0AeABxAHkAYwBtAFQAXABHgEKAS0AzgD3AJsAtIBNgHZAHcA4/9M/9z+UP6U/fD8dPzg+yD7aPrY+Rj5SPiQ9/D2IPZQ9aD0EPRw8+DycPIA8oDxIPEA8eDwsPDQ8DDxcPGQ8SDy8PKQ8yD0APUw9hD34Pf4+ED6KPvo+/D8KP4p//D/6QAEAuACmANgBEgF8AV4BjAH2AdQCKAIEAmgCQAKMApwCtAK8AogC2ALgAuAC2ALYAtQCzALEAvwCuAKkAowCuAJoAkwCeAIgAggCLgHOAfYBnAG8AVgBQAFoAQgBKgDUAPwAmACygFYAe0AVwDE/2P/+P5M/qz9OP2s/Pj7SPvY+lj6qPn4+HD48PdA96D2IPaw9UD10PRg9AD0sPNw8zDzAPPw8vDy8PIQ82DzsPMA9HD0IPXA9VD2APfg97j4aPkw+jD7GPzQ/Jz9lv5s/x0A9ADwAcgCaAMYBPAEuAVIBtgGkAcQCIAI8AhwCdAJAApQCqAK8ArwCgALMAtACyALAAsAC9AKkApQChAK0AlgCRAJ0AiACPgHiAc4B9AGQAbABWAF4ARQBMwDXAPkAlQCyAFaAd4APwC5/0D/rP4Q/oj9GP2Y/AD8kPsQ+5D6CPqQ+Sj5oPgw+MD3YPfw9oD2MPbw9aD1YPUg9fD00PTA9MD0wPTQ9AD1IPVA9YD18PVg9rD2IPfA93D4APmY+WD6KPvI+3T8SP0a/sz+h/9JABABnAFEAgADtANQBOAEiAUgBpgGAAd4B+gHQAigCBAJYAmQCdAJAAoQCiAKUApwCkAKIAowCiAK0AmACWAJIAmwCFAIEAi4BzAHuAZQBsgFMAWwBEgExAMkA5gCDAJsAckANgCx/zf/rv4S/oT9AP18/Pj7kPso+8D6UPrY+YD5QPn4+Jj4SPgY+OD3sPdw93D3gPdg9zD3QPdw92D3YPeg9/D3CPgY+Fj4wPgQ+Uj5qPkg+nj6wPpQ++j7UPy4/Ej97P1u/uD+gP81AL4AGAGYATgCtAIkA5wDGAR4BMgEIAWABeAFIAZYBqAGyAbgBggHOAdQB1AHSAdIB1gHQAcYBwgH+Aa4BogGcAZIBvgFoAVoBSAFwARgBBAEzAOAAwQDeAIwAuwBeAH5AJ4AcAAIAGv/EP/+/rD+GP7E/bz9gP0A/aT8hPxw/DD82Puw+7D7oPtY+xD7KPtY+/j6mPoI+2j74Pp4+gj7iPsI+6j6YPv4+4j7KPvg+3j8JPwA/MD8WP0Q/RD95P1w/hj+NP4P/4z/UP9s/0QApQBPAHUAUAGcAT4BeAFUAowCDAJIAhwDLAPIAiQDxAOkA0QDmAMoBAgEpAPQAzgECASMA7gDQAQYBHADMAOIA6wDLAOsAsgCHAOYArgBxgFIAhACRAH6AEIBBAEzACkAqwBGAI//oP+z//j+ov5J/2P/OP68/cL+CP+c/RT9Uv6y/jD9nPz8/Vz+6PyI/Nz9BP6c/Gj8wP0Q/uD8gPyc/RD+KP3U/Kz9Dv6Y/ZD9Ev4y/hj+PP5q/oz+vv7i/vb+Bf9H/6P/pv+I/9X/KwAeAB4AeADOANAAvwDYACQBXAFqAX4ByAEMAgwCCAIsAlwCdAJ8ApwCzALAAqwCxALQAqwCpALEAqACfAKQAnwCTAIgAggC9gHGAYABfAGOAT4B3gDnAO8AhAAiADQATgD0/4X/fP+3/3z/5P7Q/h7/A/+G/nD+pv6Q/kz+OP44/iL+CP4S/vj96P08/iz+kP2o/Yb+Tv5s/eT92v6C/sD9BP6+/tD+aP5w/tz+6v7O/hz/O/8V/2v/lv8t/2L/QABMAI//q/+GAJkA1v/h//UAKAFbAEAACAFcAc4AgAA8AQACTAGfAJQBSAJgAawArgGQAr4ByACaAaAChAFeAHIBfAJeAVoAVAEAAuUA/P/aAKgBngC4/4oAOAEiAE3/KgDLANX/AP+L/0MA0//e/jH/HABs/0L+6P7b/y3/bP4K/2L/qP5G/s7+YP8J/3D+cv60/gf/DP+O/lz+Wf+Y/xL+2P1v/w8Atv7w/T//NAAA/9D9d/8AATb/wP23/1QBnf8k/tb/rgFdAFD+eP/cARgBFv+8/7QBbgFz/5P/rgH6AQsA0P+gAcYBEgDW/4gBFAKnALL//wAQAqkA///IAQQC+v/c/6oB9gGaAEoAYAHQAWwAUv/mAEgCtQB2/7IAdgH1/97+ZwC4AQIASv6k/0YBEgAo/vb+GAFzAMj9KP40Ac0AiP0K/hgBoQCU/WD91gCqAeT9yPzHABACmP08/MkArAJw/uD7RwAkA6T+oPtLADgD0v5s/CAAZAJX/wz9rf8EApz/iP0PAM4BJv+w/ZUA0gEE/9z90wBEAh7/hP21AOACsv8I/ZQAlAPU/wD9DgH0A8b/wPwEAUgElgAE/VQAKARCAXj9j/+MAzQCHP45/yADFAIu/mf/RAMcApj+L/+8AtgBkv7r/8gCoAEW//n/jAFzAL//WAHYAZD/uv5QAboB1P6u/tQBlgFk/sb+xAAVAFj/UAD6/6b+Sv+XALf/jv74/3oBNf/Y/KH/5gGS//D9NwAuAdD9SP0yAVYBPP1a/hgCXv84/PT+GAIZAMT8SP4YASj/6Pzt/4gBUP5c/bn/6f/s/Xj+6QDYAA7+rP08AF0Abv6m/6IBdP+g/VUArgFP/3X/SAGbAB//l/9WAd4BMACE/+4BTgFE/owAoAMUAQv/gAEUAqT/9/8UAngCigBX/54BjAK7/yD/lAKYAl7/JP8eASQCrACi/jwAsAL8/1D9dwAQA7v/MP0zAHACiv9s/X4AJALw/qD9DAGMAmD+8PwwArACnPxw/aAD2AF8/ET+PALBACT9iv6QAqUAgPzQ/iwCQP/Q/BoA5gG2/jD92/+kAKr+cP5RAEMAAv4A/n4A+ADw/SD+egF/AOT88P32AVQByP0Q/rQBfgHw/Jz9CAOcAkz9oP2IAiwC/P1+/kwCUAK2/hD+OAJQA+7+GP6kAlgD2P7k/eYBUAQAAaT9qwCkA6MAaP3eAKAEOgHI/S4A0AKqAKD+lQDwAWwB3f+a/kkA6gEQAbr+T/+2AcIAiP6a/ogCYAJ4/Sz+CALtAED9fgAQBBH/6Pt1AKQCXP64/cQB3gFe/vz8wv9IAeb+gv46AVIA9Px+/mwBVgC8/oT+CP///yYARP6s/o4BTwBA/Oj8WAKWATT8vP2QAqoAuPug/MABgAKs/cD8YQCxALz+Ev9j/2f/ggAm/x7+xgBAAoz/BP30/1ADDABs/AgBYAUOABD8eAD0A9UACP6MAewDFgAQ/pABQAMEAEH/oAIEA0P/Rv6MAnwDwP/2/moBlAJyAOL+PAEwAhAAk/8+Ac0AMv+mAHQBZgDk/9z/GQD8/0wA0QA0AA7/i/9aAQ4AnP3U/4gCjf9s/L7/NALq/mD9of+4AQb/IPt0/pgDsgDI+mj9zAJCANj69Pz4A0gCsPqA+2gCAAKI/Pj9+AFTAOj8JP4sATsAov4zAL8A6PxA/SQD1AGY/Gj/FAM0/tj7/gHcAyf/qP08AagCxv68/MYBwAUXALj7rgFgBN7+fP7cA7QCTP5U/4wC8AKn/zj/YAPMAjz9Hv4QBHADK/9X/9QBygBa/rL/jALaAQn/jf+2AZz/iP24AOQCDQBo/d3/DAI3AGz+Of+tAJwAzv+W/h3/TAGoASv/Wv6k/2H/r/8QAPP/+gCUAAr+Tv6hACL/SP5+APcAuQBE/5D82P1gAjIBtPxQ/nwByAAg/pz94f+gAUAAKP1W/jYBKAEt/6T+JAEoAZT9OP3qAQwDCP/I/QoBCAJk/oD8gQBABUIBgPpa/rgFZAGA+un/4AYoApD6fP1IBGgDav7B/2AEZgAE/P7/oAToAkj+3v70AhwCzPwR/0gFhALs/Mz9ggHOARgAkv8YAhwC4PuA++gDYAVk/XD83AJYAhz8SPskAmAGlwAY+YT9eAV+AMD5ef/ABuoAMPjo/IgGuAIg+Vj9EAe6AYD2BPwwCKAEqPiY+jgFZAJ4+SD9OAVcArD75P0mAdj+dv5IAfoBPf8Y/er+5wB3/3//PAKnAFj8QP22ASQCuv6Y/kwCJAEw+4D92ARYAtT8n//8Avn/LPyy/igFSASc/Bj92AMeAYj8mAJoBTr+8PzIAiAC+P3l//QDDANw/dj7CALQBEL+0P2wBfwBCPmM/mAGKALI/Gr+wAOsAwj84PuwBXAFSPtw/GgEFAJI/Ir+6ASUAxj6gPqwBVgE+Pio/bgHrQCQ9/D+gAbM/qj5hgA4BhL/8Pdc/yAHef8A97j/+Adk/9D3qv8oBq0AcPlw/GgG+AOY+TT8YAUkAhj7YP5QA+QBmP1A/bQBYALk/Vj9XALUAjz+cPxMALAEbwAI+/j++AXkAsD5XPw4BswDePrg/cAFOgHA+lr/SAWkAUD7uP04BUgCOPoG//gG+AEg+mD9QATUAsD9L//YBIwC6PpU/JAFIAUw/Ez+YAbwAnj6mPwgBSgFhP0w/NQCQAQc/cT88AJUAaT8AP6wAfQA+v68/oX/7v/A/Qj+7wDVAFL+H/90ADD+Uv73/2EAdP/8/Sn/jAGFAOD8nv5gAn7/dPwMAPwDIAFA/KT9rgHUACr+eAAIAz7/nPxNAHwCnP5I/cYBRAPE/uj7hQBYBL7/uPsgAMwD4P8Q/TAB4AOt/6D7xv+YBbAB6PvUAEAGbv64+PoBoAhlAND5UgGwBRL+OPqIAsgG7P3I+owDCAWI+7D7oAX8A7D5bPzgBSwD2PvD/8AEfP3w+PABcAcb/7D6uAIwBXj7SPkgA1AG0v7g+3YBPAJQ/Wz9tAJUAhT8qPyyAUgCiP98/vb+6P6s/zr/zP6OAMwBigEr/6j7qPycAjAEPv80/fMA1AI0/nD6YQD4BhIBaPpb/2gEMP+A+1wCwAVw/YD4kgGgB+L/KPq3AGAFuP0Q+UQBQAe5AJT8cQDg/6j7Cv+ABcgCfPyo/TwC6/98/JYBOAWT/+j7sgBkAqz9lf94BoAE2PpQ+RgCeAa0AQD+2wDcAjP/uPty/uAEMAZh/8D7EwCkAlr+XP34BAgHuP2w937/AAdKASD8XAIwBSD7APc4AkAJXAE4+jr/yAI4+wj5/AOACOL/kPqs/cT9NPxQATgGqAHA+gD8IAARANv/uAJEApj8MPsr/yYBIgFQA1wDMP6I+UD6FAGYBvAEXv/o+yD8iP7r/6gAmAQIBNj76Pjp/4QDQAAYARgEff+g99j6IAfwB4z94PssArH/aPkaAEAJ8ARA+wj8gAHM/2r+mAMIB+kAaPmQ+xwDAAUWAQMAEgFh/4j8AP0EAyAHNAIQ+5z8HAKCAcL+KgGgBOwAuPoA/XgDnANs//j+GAEn/4j8Qv5YAugDCAEc/TT8nP5/AGAA4f+cACACTv/A+sz8lAI8A3j+YP1YARoBRPxo/WAEiAM4/Hj7dAAoAqX/TP/4AUgCUP1w+Uj+4ARoA0r+GP0D/2YBr/94/OP/OASlAOj7XP4EAvQBgQAJAD8ArP6E/XgBUAUsAuz91v45AAUAUgGeAdUAaAGKAWwA6P2U/egCmAU9/0j7WgHwBO3/7PxEACgCmP48/eQCuARf/0j99f9o/6z84P9oBaAEyP04+zUASALs/Rb/uAS+AbD7Xv44BBABKPug/UgEQAJw+gD+SAe8AzD4OPkwBOgEiP2i/rAEmwCA+MD8+AX0Aij7UP6wBVYBQPjo+yAG+APg+TD7wARoBGz8ePu3AHgBaP00/swCxAKm/gj84P22ACQBFACUAHoBTf/s/HL+iAJEA3z/aP1gAHwCf//8/VgCMATw/qj7//+IBAACHv6Y/zAC8P9M/QoBKAXiAVz8BP1+AQAClf9FAJAC4ACk/KT8BAHwAvAAWf8o/9r+LP8gAM4A9ABEAKr+qP0e/1ABaAKnABb+pP5uAAD/RP7wAogEZv6w+mX/VAPSAPz9lABAA9T+cPq0/igE1gGI/t7/jADs/TT9bwBsAqEAlf/aACAAwP02/jABuAE7ABkAjAAP/+T9uwC8An///PzR//oBBAAf/zgB1wCQ/VT9pwDWAQcAIgD4AcD/yPsY/uwCfAGU/b7/KAO4ABT9hv64ASEAoP1cALADHAGQ/bz/XALy/vD7uQAYBiwCwPtE/ZgCMAK8/Sf/oAOUAUD8FP5wA74B2Pzu/mAEgAEI+3T9qAQIBFj9XPz2ALgBtP6//0wDVAJe/vz8wv6sALgBbALsATP/fP0L/2QA5QC0AewAEv/k/tAACAL8/0T9qP5MAlwByP0G/2QD5gGo+xD7lQCYA2sAuP07ALoBYP0g+6gA9AM8/xD8OwDsAtD+FPxfADQDfv4g+77/iASIAdT9BAByAeD9EP3EAfQD7QBO/1IBbgE8/oz9zgH4A9YA3P00//gBmgHQ/tb+kAGdAEz9/v7IAxwDTP7Q/Mv/7gBm/9sAwANQAnz9sPz3/5oBHAGEAaYBov/o/jEAXgCX/3QAmgHT/9T9ov/EAuYBRP7E/c//nP+y/roAqAJtAJz9hv4CAaoAOP66/pgBsAHM/kb+ugBkAS//eP2A/1AC7ADU/VT+ogDg/2L+igD4Aaj+LPxD/1wC5f9s/ez/RAI4/+j7Cf+IA6oBbP3I/br/JP92/4QCrANw/xj7cP0UAogBXv8UAggEGf9w+kT9kAJ4AwACXAFa/zz8UP2kAjgEBQDU/WcANgFe/gD/gAOcAzr+CPzh/4gCXAFuAVgDGgF4+0j7qAFIBVwCmf8hADn/wPya/pQDxANX/yT99v7DAIMAagCQAcwAZP24/FQASAJKAQoBNwCs/Gj60P6ABdgE2P3Q++//t/94/M7/mAUQA0j88PsoAEIBFQCqAVwDBf8A+rD9MAXoBD3/+P2J/zL+yPz7AFgGWAQ4/WD6JP0i/0YApAMgBSoASPro+l//IAKoAsABy//o/UT9XP46AZwDtAKu/oj7MP3kAZwDqAGbAOP/aP2M/NT/qAPQA4oB4P6Q/Rz+yf8gArgDgALy/hj9eP5OAfgC9gH2/2b/dP+S/mP/pAKoA1gAMP3s/ToACgECAbIBIgEE/oD8Y/+IAvAB+P9y//7+uP3s/dgAdAMQAnT+/Pwo/pT/VABMAdABVwDs/Yj9lP9gAUIBaQCF/4j+Nv6L/6IBMAJnAKT90Pzw/owBygFAAEX/uv7U/RT+lwC8AnIBMP4s/Zr+l/8pAPgBsAKh/xj8AP0GAegCZAH3/+7/OP86/l3/4gF4Ap0AI/8S/1P//f+aAUQCOADY/Sj+cgDkAWYBkgAXAPj+AP76/jwBdALYAUAA2P52/gv/oQAMAtYBawBr/4b/5P8kAEoANADw/wsAvQCvAHT/7v7R/z8Alv+g/8oAVAE1AMr+xv7C/0wAXABkADcA4f/b/+//4/+//0P/Rf8wAC4B7ACT/+r+bP/U/33/2/8IAQgBrP+g/sT+W//W/3gA6wAZAI7+dv6f//3/n/+x/wAAsP8C/xb/0/8UAMT/n/+F/3//DwBqACAAv/98/3v/LwAOAfsABgBk/8j/RABAAKMAkAFEAbP/if+0AK8A/f+0ALwB9wCO/wEAWAEeAe3/y/+7APEAcACYAB4BmACd/8f/lwDlAKkAOAD5/xAAJAD2/w4AeQB3AL3/6v5P/5gA2QCP/97+Yf+F/1b/7v93ANj/sv5O/hT/4P+5/0j/Of/o/nD+ov6L//r/dv+K/ir+tv5j/+z/7/85/5z+8v6l//T/EgD+/3P/Ef+9/8wA7ABJABoAVQADAMT/0wA0AtoBLwCk/5MAUgGcARACEAIyAXQA0gDeAXwCPALYAQACCAJwASgB5gHYAqgCbgEEARACcAJWAe0AqAFcAez/BQAEAngCJgBi/lj/ZABD/27+tf+hABP/LP14/aD+YP5c/XD9Nv7o/XT88Pvs/Iz9qPzQ+4T8QP1c/DD70Pv8/KD8uPso/BD94PxA/Hz8CP38/Nz8fP0c/vz9Av6u/ir/D/8t/9//hwDHABoBzgFsApgChALAArADqATABKAEMAXIBbgFoAWYBtAHiAdgBmAGQAdwBzAHyAdACCgHsAXgBbAGUAaABVAF6ASAA7QCUANsA+wBjwB/ADAA3v4a/pb+kP7o/GD7UPuI+9D6+Pno+bj5ePgw93D3iPhY+BD3IPYg9vD1IPUw9bD2cPfw9UD0gPTg9XD2YPYA98D3cPdA94j4QPrY+sj6oPsk/fD9dP6+/2YBIAJUAhQDeAQIBmAHQAhwCFAIIAmQCqALQAzQDFANIA3ADAAN4A2ADmAOEA6QDeAMgAzADLAMsAuwChAKgAmgCBAIoAeABvgE9AN8A5QCjgEkAXsAyv4g/cj87Pxs/GD7uPoY+hD5iPjo+Pj4OPiw96D3UPew9uD2kPdw94D2MPaw9rD2QPZg9tD2YPZQ9TD1APZA9qD1EPUA9eD0YPRw9KD1kPZQ9rD1EPYA91D3cPew+Nj6IPyA/Cz9Jv6c/kT/TAHMA0AF6AWQBgAHWAeQCMAKQAyADKAMUA2wDZANIA5gD7AP4A5gDtAOEA+QDgAOgA2ADHALMAtgC/AK0AmwCGgH2AUIBUgFUAVoBCQDIALPAI//dP8PALH/WP5c/QD9VPyA+7D7UPzo+8D6cPrA+pj6QPp4+tD6WPqo+eD5ePpo+hj6IPro+Tj5GPnA+dD56PhA+Cj4sPcA9+D2IPeA9kD1EPUA9dDz0PLQ8+D0EPTQ8uDyAPSA9MD0APYw9xD38Paw+PD6TPxg/e7+PACiAHgBmAPwBYAHsAjQCYAK0ArgC4ANwA5AD5AP0A8gEGAQgBCgEIAQQBDAD3APIA/wDlAOEA3AC9AKQAqgCeAIAAiwBiAFuAO0AjwC5AE0AR8ACf8o/mT9sPw0/Oj7iPsg+9j60PqI+hD6sPnI+SD6cPqw+vD6MPsA+9D66Ppg+wD8fPx8/Dz8HPwU/Nj7sPvw+yT8mPsA+9D6UPpQ+dj4WPkw+YD34PWQ9lD3QPbg9GD04POg8gDzcPVg9yD2MPSQ9PD1YPZg97D6TP08/VT8NP1G/8AAMALIBNAG0Ab4BtAI0ApgC5ALwAwgDqAOEA8gEMAQIBAQD/AOgA/AD+AP8A8gD0ANkAvQCtAKkArgCSAJ+AdIBqgEoAMEA2ACxAFaAaQAdv9Q/mD90PyI/Hj8hPxE/Hj72PrY+tD6wPrw+kj7YPtA+1D72Psw/CT8UPzA/Oj8BP2U/Tj+Jv6g/VD9WP2Q/bT9zP1w/YT84PuY+xD7UPoI+sj5wPhA95D2cPag9bD0wPRw9EDyYPCA8UD0APXA80DzgPMQ8zDz4PXA+Vj7yPrY+iT8BP06/kIBoAQYBvAFWAboB6AJsArwC0AN4A1QDjAPIBCAEEAQoA9wD7APIBCAEEAQQA8QDqAMUAsQC1ALEAvgCZAIWAfwBXgEwAOcA9gCmAESAdsAg/+8/fD8GP3Y/CD8APws/Ij7UPr4+Wj6qPrQ+iD7cPtY+yj7WPvw+4D86Pw8/Uj9gP34/Vz+VP4+/lT+Wv4i/gD+Ov4S/kj9bPzQ+1D7uPpQ+gD62Pgw9xD2wPWA9VD1oPQg83DxUPDw8FDyIPPQ83D0sPMg8kDy0PQw+Kj6sPs8/HT82PyG/mIBCATwBVgHMAjwCCAKgAvQDMAN0A6wD0AQoBCAEeARABHwD/APwBAgEcAQYBBQD4AN0AsgCyAL8AowCjAJyAfgBSgEDAOMAjQCogHDALf/ov6E/aD8APyg+3D7YPtA+8D6EPqo+bD56Png+QD6oPpI+2D7MPuI+wD8WPyc/GD9GP4w/h7+ZP6i/mT+PP6A/qj+UP4C/vT9fP10/MD7ePvI+vD5ePnY+JD3IPaw9WD1cPRQ8wDz0PJg8VDwEPHw8iD0QPTQ8xDz8PJQ9FD3kPqc/DT9PP1o/W7++wBQBAAHoAiACeAJIAowC0ANgA+gEMAQABFAEYAR4BFAEgASQBHAEMAQoBBAEJAPgA6wDOAK4AmwCVAJcAhoB7AFcANmAZIAeQAnAFf/VP4k/ZD7MPrY+WD6wPpI+lD5mPhw+Ij4qPgw+fD5OPoI+ij6qPpg+9D7cPxQ/dz9Kv50/vz+M/9h/8v/MgBPACMAKgDl/0r/5v7i/oT+eP2I/BD8cPtI+jD5WPgw9xD2gPUw9SD0APNg8rDxMPAg7xDw4PEg84DzsPPA8lDxIPLA9dj5CPzY/Gj9wP3E/S3/HAM4B3AJUArQCiALkAvwDCAPYBGgEsASoBKgEqASwBKgEkASIBIAEqAR4BDgD8AOQA2QC2AK0AlACVAIKAewBdQDzAE1AHv/aP8g/wz+pPxo+2D6MPmY+CD58PmQ+Yj4APgI+ND3wPfQ+Dj6kPpI+qj6UPt4+9D76Pw6/tL+A/+2/zoAFQAYAKgA5ACoAPEAhgFQAVQAlf86/4T+cP0c/Sz9WPzo+tD5sPgA99D1wPWg9TD0kPIQ8uDxsPCA78DvkPAg8VDyIPSg9DDzUPIQ9BD3cPnw+/D+oQAEAD3/2gAwBHAHIApwDNANQA1wDHANABBAEiATgBPAE2ATQBLgEaASQBOAEiARABBQD4AOoA3QDJALkAmwB6AGGAZ4BYAE8ALvAO7+wP1M/QT9oPzg+3D60PjQ9/D3gPig+HD4IPiA98D28PYw+ID58Pnw+UD6uPoQ+5D7oPzU/cT+Z//+/3gArgC9ACwB6AFcAlQCgALMAqgCugGhAEMAHAB5/9b+vP7s/fj7SPqY+bD44Paw9RD2QPYQ9FDxYPCA8ODvgO9g8CDxEPEw8YDycPMw8zDz4PSA9+D5UPyc/uz/YwAsAZwCoARoB8AKYA0wDtANAA7QDiAQwBGgE2AU4BNAEwATYBKgEWARoBGAEWAQEA/wDZAM4AqACcAI0AeYBlgFMATsAhwBS/8q/rT9VP2Y/HD7OPpI+Yj4EPgI+FD4mPhw+PD3sPfQ91j48Pi4+Xj6GPto++D7vPzo/aL+7v6R/7YAtgEwAoQCyALgAsQCFAPIAyAE1ANcA8ACrgGjAEoAdAAMAO7+pP0M/Ej6KPnw+FD4gPZg9GDzAPNA8lDxEPFA8GDuIO3A7YDv8PAw8lDzgPOQ8hDysPPw9nj6qP3o/2sA+f9wALQC6AXwCKALoA1QDjAOgA7gD4AR4BLgE4AUQBSAE2AToBNAEyASABFgEMAP0A7wDfAMMAvgCPgG+AVABTAEDAMUAp8ARP4w/HD7ePsQ+zD6aPmQ+GD3YPZg9hD3cPdw93D3gPdg93D3IPgo+Tj6APuw+2D88Px4/Yj+n/9jABoBHAL8AkwDdAPQA0gEUARYBLAE+ASQBKgDCANwArgB3wB1ALj/Yv70/LD7gPog+Rj4UPcA9iD0sPJQ8uDxIPGA8MDvQO6A7IDswO5g8bDyIPMw84DyAPJg8/D22Pq4/Zj/qgDTAOgAbALQBXAJEAzgDfAOIA/wDsAPoBFAE0AUoBTgFGAUgBPgEsASQBJAEQAQMA9ADhANwAtgCrAIyAYYBQgESAMoAqsAHP9w/fD76Ppo+lD6yPng+BD4UPdg9iD2wPbQ90D4EPgw+JD4wPjg+ND5SPts/Dj9Gv72/mL/zP+sANwBzAK4A6AEEAXoBOgEKAU4BSgFeAXYBVgFIAQkA5QCkAFIAI7/QP88/oz8IPso+uj4EPeA9bD0sPNQ8jDxwPBg8IDvoO4A7oDt4Oyg7ODtIPBg8qDzUPRg9BD0wPRw91j7wP70AGwC2AOgBFgFMAcgCgANEA9gEEARoBHAEWASoBPAFOAU4BSgFAAUABMgEkARgBCwD6AOUA2gCyAKsAgYB2AFGARYAyQCXQCw/mj9HPzY+iD6EPq4+aD4oPdg9/D2UPZQ9hD3kPew9wD4qPgY+UD50PkA++j7hPx8/eD+1P80ANgA2gGoAhgD4AMQBagFcAUoBZAFwAVoBRAFKAUgBSgE2AIUAnABSQAZ/3T+0P18/Mj6cPmQ+FD30PXQ9PDz4PLg8VDx8PBA8GDvwO6A7iDuAO6A7qDvcPGQ8wD1cPVg9QD2oPcQ+rT8tf9sAgAE4AQABtAHkAlgC5ANwA8AEQARYBGAEoATgBPAE4AUYBRAEyASwBFgESAQ8A5gDnANQAswCRAI8AZABcAD5ALIAR8AsP7I/ZT8GPtg+kj60Pno+KD4wPhg+LD30PdY+GD4WPgI+UD6uPq4+lD7dPz8/Az93P0z/ysAnABcAXwCGAMkA4gDeATYBMgEuAQABfAEeARIBGgEMARIA1QCrAHAAHD/Xv7E/Sj9GPzo+vj52Phw90D2gPWw9KDzkPLg8WDxsPAw8DDwIPDA7yDvAO8g70DvkPDQ8iD1kPZQ9wj4oPhY+SD7Rv4qASgD4ATgBlAIIAlQCjAMEA5ADyAQQBHAEcARgBKgEwAUQBOgEkASQBHADwAP4A4gDsAMoAugCrAIUAbIBBgEOAPKAbQA///M/iT9+Pto+6D6yPlw+XD5EPlY+Cj4oPjg+Mj42Pg4+XD5mPlQ+nD7ZPz8/JT9RP7K/i//zP/HAKIBRALUAlgDuAPsAygEYARgBDgE7AO4A4ADQAPwAowC3gHzAPr/Gf84/kj9cPzQ+yD7KPog+TD4MPcg9iD1cPTQ8xDzgPJQ8iDy4PGg8YDxQPHg8BDxwPHg8kD0IPbg96D4IPkg+rD7NP3a/gwBPAPIBAAGsAdwCcAKsAvgDCAO8A5AD8APgBAAEWARwBEAEoARYBBwD5AOoA2wDOALIAswCuAIgAcgBtAEhANkAnYBjABx/0D+UP2Q/PD7aPsA+7j6YPoA+rD5kPmY+dD5QPrI+iD7cPvQ+3D8FP3I/YL+H/+W/xMAlQAmAbQBPAL8ApgD0APMA+gD/APkA7ADkAN4AzgD2AJwAhACcgG7AO3/Fv8u/jj9WPyI++j6QPqY+eD4IPhQ93D2gPXA9DD00POQ83DzcPNw84DzcPNQ8zDzIPNg8yD0oPWA9/j46PnY+uj7wPys/ST/DAGcArAD8ASYBvAH0AjwCVALMAyADNAMUA2ADXAN0A1wDqAOIA6wDVANkAxwC5AKAApgCYAIqAfgBuAFwATMAxADQAJeAbEAIwBy/6D+BP6o/Vj9CP3g/KT8RPwI/DT8hPyk/LD85Pwo/TT9QP2U/QD+aP7K/jb/mP/L//f/UQC/AP4AAgEUATIBTAFMAUQBPAEqARIB6gC6AFwA4v9r//T+ev70/ZT9HP2E/PD7kPso+4D64PmI+VD5uPgA+KD3kPdA9/D28PYg9wD3wPbg9jD3QPcg94D3IPiQ+Pj4wPnA+pD7ZPyM/cT+jP8RAMEAvAGkAoQDiASYBYgGeAdwCCAJcAmACeAJMApACjAKYAqgCpAKcApgCjAK0AlgCfAIUAhgB4gGEAagBQgFiAQ4BMgDCANYAuwBfAHVAEsACgC8/0H/+P4D/wz/8v7k/uz+0P6I/m7+fP56/m7+pP74/hX/Af8H/zr/R/8x/zD/Vf9V/x3/Af8c/zP/H/8D//r+2P56/hz+AP7k/aD9SP0M/dT8fPw0/CT8EPzA+1D7APuw+lD6CPrw+fD52PnA+cj5wPmQ+XD5YPlY+WD5YPmQ+dj5IPpw+tj6SPuY+9j7MPy0/Fj9AP6u/lz/6f9gANgAWgH0AbgCiAMQBGAEwARgBeAFIAZQBqgG+AYIBxgHaAewB8AHwAe4B5gHSAf4BtgGkAYgBsAFgAVQBSAFEAUQBdAESATEA2ADAAOkAmwCVAIcAsYBeAFQATwBHAHhAJAALgDK/37/R/8s/yj/Jv8Q/+T+tP6K/mj+WP5E/hT+wP10/Vj9XP1c/TT9DP30/Mz8mPxs/Ej8DPzY+8D7uPuY+3j7gPuI+2D7IPsQ+zD7SPs4+zD7KPsQ+wj7MPt4+7D7oPuQ+5j7wPv4+zT8ePy4/PT8JP1U/Zj99P1i/tz+Vf/C/yUAbACeAMIA/ABmAewBhAIkA7wDGAQYBAAECARABGgEgASwBPgEOAVoBaAF0AXIBZAFUAUgBdgEkARYBGAEkATIBMgEgAQ4BAgEuANQAwgD5AKsAmQCUAJIAu4BggFwAZIBTgGvAGAAXAAhAKD/Wv9p/1//KP8Z/zj/Qf8P//D+2v6s/nz+hv6a/nb+JP7w/eD90P3k/Rj+Iv7g/Zz9iP14/UT9FP0Q/SD9GP38/ND8kPx8/LD85PzM/JD8gPyU/KD8mPys/ND8vPxg/Bz8WPzs/Gj9oP3Y/SL+Ov4S/ir+tP4O/8T+PP5M/vr+1f+oAHgB9gHWAW4BHgEgAVoBsgHwAQACMAK4AkADXANEA1gDZAM8AxgDTAOYA4ADPAMoAxwD4ALYAjwDmANoA+QCrALcAtACOAKqAaoB8AH6AdABxgHWAbABYAE+AUIBGAHHALsA4wC/ACYAm/+O/7v/v/+3/93//P+z/yz/5v7o/sD+aP5O/oz+sP6A/lz+kP7I/q7+gP6I/oT+Mv7I/ZD9kP2o/dT9HP5c/mD+Pv4C/qz9YP1E/Vj9lP3c/Rj+Iv4c/jb+VP44/uT9lP2Y/dz9Kv50/s7+J/9I/xj/2v70/k//h/+L/7P/EQBUAGwAlADXAPcA4gAAAXwB6AHuAbwBwgHmAeoBxgHeAUgCkAKIAngCmAK8AqACXAIkAhwCJAIoAiACGAIEAvoBLAJsAlACzAFQASoBLAEUARABWAGQAVABzgCEAGwASQA0AGYAoABvAPn/zP8DACgABwDj/9f/qv9J//L+xv7C/tr+Av8V//z+zP6u/rD+tv6q/oT+dP6U/rj+ov5g/jD+Nv5e/qL+/P4m/+b+dv42/iL+Iv5I/pb+vv6S/mT+kv76/l3/sP/c/5b/7v6I/uT+e/+a/4P/6P+cANoAuQDVAPsAWABj/1T/PgAEASwBaAG8AWYBfgAMAFAAjgCdAOQAWAFsAQYBowCbALEAnwB0AGcAlADbAPIAzwDJAOwAwAAgAKr/0f8tAEIAPABeAHgAXgBWAJMAqgBDALD/bf96/6b/7P84AF8AaACQALgAigAmACQAkgCuACcAnP+b/+L/7P/G/9f/NQB8AFoA/P+y/5P/kv+s/8n/m/8c/9r+Hv98/5j/tP/+/w8Anv8W/+r+8P7y/gz/O/89/xD/Ff9w/+D/FgD//7T/bf9a/4z/2//8/8z/jv+z/zAAlACjAIIAPgDb/4n/iP/E/wQAXwC8AKAAEADj/1sAngAyANL/9f8UAPz/PgDjACABogDs/4H/b//C/14AyACnAFYANwANAM7/0f8pAEgA8f+4/xEAcwAOAGD/cf8SADYAyf/Y/4IAvgAwAOj/dAD1AKgAIwAaAC0A6v+6/yQAzwAGAcwAnQCDAFAAIQAUAAUA1/+6//X/LQAMAP3/XAB8AN7/N/9c/wgAXABEACgADgDM/5L/cf9G/1n/2P8oAN3/kP+5/7X/Uf9T//T/QADC/1P/nf8NAAkA3v/w//f/nP9Q/6n/WwCgAFMA8P+8/5f/gP+2/yEAKQC5/53/OgC3AG0AEQBmANYAXgB5/2r//P/z/5X/HAAkASQBFQCd/yYAYADe/93/jACNAML/oP9iAKMAAQCh//7/JAC3/4T/5/9NAFMALQANAAIA2/9v/yj/dP///xsA7P8TAF0AIgCj/7T/LQA6AMr/oP8WAKcA1wC3AGsA//+7/7v/7P8pAEIAHQDy//T/AAD1/9n/3//w/8//l/+s/xYASADc/xj/vv4o////mgCrAGoA9f9a//L+8v4a/yv/T/+Z//n/RABAAPH/nv9+/3P/Sf9L//3/4QDeAAUAj//y/2QATwARACsAXwBVAEAAYQCIAIEAdwB3AEoA/f/m/x4AfQDWAMUANwDD/w8A1QBAAewASADp/8r/vv/d/zoAoADAAHYA+v/Z/y0AYAAxACkAgQB7AOz/1f+OAMsAq/+U/jP/pgD1AE0AGwBLANb/GP8+/xQAUADg/6X/2f/z/+P//f8lABsA3/+T/yn/Dv/G/6gAiwDL/97/rwC7ANr/ff/l/87/E/8W/+X/DgBq/5X/wgAEAdD/5v4s/2f/9P7+/gEA5QDXAGwAJgC4/xr/8P5f/4z/Hf/O/hj/rP8cAHUArQBkAK//UP+S/9L/oP97/+3/iwCbAG8ArgDlAH8A7/8aANYAGgG7AJAA1gC6AC8ABQBqAKMAagBQAF8ARwA+AJwA1gBQALj/4f8ZAG7/0P6O/54ASgBz/9n/4wDHAMP/a//O/8T/Ov86/97/XABZACEA6/+w/3v/QP8U/0n/5P9bAF8ALgDj/33/X//O/0QAMgAiAMoAPAGBAIX/uv+ZAMYAXgA/AH8AmwCOAHkAIAB1/xP/av8HAGgAmgCpAEcAn/87/y//Tf+X//z/HACt/+j+ev7e/p//8v/F/6//1v+i/+r+gv7g/nv/4P8kAF8APgC7/17/aP+Z/+H/OwBQACwAUwCtAIYA/v/P/ycAWQANAMb/AABtAKIAqQCSAHcAwwBAAdMAkv/6/qn/fwC7ALwArgAfACL/9P4UACYBFgGTAIMAYgCy/xf/fP9qALMAHACd/9v/VgCMAFkA7/+e/3z/ev+W/9b/JABgAC4AxP8LAOEA9wAbAJH//f9mAPP/g/9BACYBsQCi/6//bgBOAHH/R/8bAH8A0P9H/9L/WQDk/4H/AAAbACL/kP6A/70AqgDo//j/ZwDW/wH/PP/m/+X/nf+3/83/gP+A/04A3ABHAFD/Bv82/13/uv+AAOoAZACe/3r/uv/S//f/igD7AHAAUf/g/lX/wP/i/3UAQAEEAQoA5f+aAJ0AwP+D/1AAqADu/5D/FQBRAO//HQDSAMkACwD0/58AogDM/4n/egA8AYYATP9Q/1YA6ACbACAA8v/e/6X/0f+6AEwBtQDO/8//dQCBAMX/dv/c/8n/H/8x/1IAHgGsALf/SP9a/4z/7/+HAOAAmQDm/5T/OAAUAd4Ajf90/oL+T//6/1gAYwD0/2z/U/99/3n/gf+S/0v/sP5+/hX/vf/H/5v/v/+l/wv/nv78/sT/PAAzACAAJADZ/3H/ef/+/1sANQDu/wkAVgBnAFAAPgACAHP/Av9i/2wAKgEcAY0A//+t/4z/oP/4/3YA9AAsAcgAFwDl/0UAkABYANX/tv8eAJAA0AAWATgB9wCgAJMAxACuAGEAbQC2AHUA3f/g/28AwQBxAPn/zP/b/9b/6v9kAMsAqQAxABEASABLAOT/vf89AHEAsP/u/mL/gQDjAFYA3v/t/7b/Bv/E/jv/1P89AGwAKwCm/zf/A/8q/6v/DQD//8f/4P8WAIT/dv5s/of/FQCq/5//PAAhAAH/jP5p/w4Ag/8M/9X/sAAwAF//vv9nANv/5P5B/54A8QDX/0//WQAeAUcAVv+t/2EAUgAbAJ0AIgHbAEEAQQCOAHUAOAA9AEoAPACHAMQAOgBr/2P/CQBpAKYAaAEcAl4Bsf/s/kn/rP/N/0YA3gCyALL//v57/2cAeADb/5f/wP+0/3L/kf8dAGIADADB//L/GADP/5//5P8NAN///P+QALUA9P9Q/8j/cwDy/w3/dP+5APMA5f9D/8X/GwCP/zf/+f/VAGIAJf/G/pf/PAAKANv/RQB+ANb/Gv9L/8z/i//c/uj+tf8TAPn/MACKACIAF/+o/kD/BgAMALr/vf/c/7P/gf/Z/34AtABIANX/0P8JAEQAjADeAO0AqABQAEUAlADOAJ4AaACBAJEAhgCjAPAAJgEIAZsAAwB6/3v/dQCSAXABggBDAG0AmP9k/qr+EABdAGT/Rf9mALcA4P+a/wUAsf+y/nL+BP94/6H/FwBeANn/Xf+o/7X/Lf9I/xkALQBJ/xD/OgA4AbYA5P/j/+D/Yf8c/57/SABBAJn/Yf/v/zMABABAAAYBFAH4//j+Tf8BAN3/iv8DAKkAhgATACkAkwBaAM3/x/8aAAMAbf8E/zv/zf86AHgAkQBuACsA1v+Q/4D/tf8SAGwAgQCWANsA7wCQABkA+P8pAHIAoADCAIUACADk/1EAlwCNANIASgEwAV8ACwBuAJAACQDK/z4AXwD0/9z/XwCMABYAnP9+/4v/af8T//T+lv+qAAwBUwCi/7//3/9L//j+kv8oAM3/Jf8G/zj/gP/R/ycAHQDj/8H/pv9w/1//y/8CAMX/iv/R/yEAGAAaADkABwBw/3j/QwCqAAwARP/w/v7+Y/8rAPsA+QAyAKn/DABeAMv/8P4T/xoAdgDK/2b/AQBfAKL/2P5L/2sA5QCeAFEAPwA4AEgAWgAvAKj/WP93/6v/+P9lAFgAvv/U/84AYgGjAIv/bv/5/wEA1/9PAPgA/wCLAHEAtwDgAMgAwgBfAGH/zv5m/5kAWAFsARABfwC3/xD/Uv8lAH4AIADr/zcAVQD0/7L/DwA8AJ7/5P7e/j7/gv/m/0EA/P91/7T/gwCJALT/K/8q/wT/FP8hAFgBQgHo/97+1v4T/1v/DwDAAKcAFADG/83/5f8CAEEAMQB7/8b+C/8GAJEAnQDDANEACAAT/2n/lACzAN3/vv9WADUAaP93/0QAQgBM/wz/zv85ACIAQQB3AAgAUP8y/+b/oACzAEIA0f/N/y0AfAB7AHoAXwDi/4H/HgA6AVgBrABRAD4Awf+E/0MAKAHrACQAPAC9AHsA2v8dALUAWgBK/wv/xv9RAF0AUgBaAC4A4f+W/4b/3P9sAIcA3f8W/+z+cP8pAMsAzQD+/xP//v6u/1UAogCeABMALv/O/j3/sf/J//f/OwARAI3/hv8XACEAef9D/8X/+//K/97/CwDJ/yj/3v4P/2f/1P9aAG8AAQDB/+P/2v+q/xsAEAEIAbP/Bv/P/5EALgDI/0oAowDG/+j+gv/DAEYBLAE+ASwBRgAI/5r+LP/s/6IARAFwARIBhAADAK//yP9SAOEA2gBEAO//KwA/AA4ALQB2AEUAr/9x/8f/SgBYAPH/v//q/xMAEQD+//P/3v+1/4b/if+Z/5H/0v9vALoALwBu/zr/iv+o/3//YP9R/2z/CQDYAM8ACQCy/wwAHwCa/1//w/85AEIABADK//D/dQC3ACMAGf/O/pH/RwBDAB8AAgCa/2T/+v+PAGcAuP85/yH/Kv8p/3n/AAAbAPf//v8vABoA1v+Y/7v/AQDA/3j/GwAYAfwACQDN/5AAzwC5//r+2P/7AM0AFgAkAMQA0AA+AOH/uP+1/yUAKAGAAagAjv9t//7/GAAHAHIAxgAPAEf/k/9JAC0Alv/S/7UAuACv/zr/7v+FAAkAWf9z/wkAQgAUABUAFQDF/33/yP9XAKQAfAD7/43/f//k/zQAFgD7/yMApv/g/mn/6gAiAe7/i/9xAIgAE//a/osAMgGr/9b+9v/jAHYA+/9yADsAuv4i/rT/GgF9AGf/gv9HAA0AJ/8d/wsAWgDm//j/nQCmAMH/G/8d/zT/If+w/7IAHAGnAGcAqQCgACgA1//e/4z/F/9W/10A+ADPAHoAJgDZ/5z/l/+l/+r/dQAUAQYBPwDk/9X/Tf/g/rz/GgFwAbUAcgDxAIEACP+U/oD/9v+n//z/KAFkAVEA2P/MABABxP/m/nn/3/8S/4b+SP9PACIAsP9KABIBmQBC/6D+BP+U/2n/Jf/x/04BwAHtAA0Atv94/+j+jv5v/94ASgGiABcA9f+N/0T/zP+JACEAE/8a/xIAZAC8/6P/ggC+AN3/af/+/0sAvP89/3L/+v80AFIAmABlAI3/K//N/2IAIACh/5r/yf+k/6n/eQBUAdgAc//m/rr/hwAiAF7/tP+WAFcAiP8JAHIBmgFhAH7/2f9iAGoAeQDRANAAKQDI//H/SwBhACQAKACdAOYAHQAn/0v/HgAnAHb/rP/TADgBGgAs/3T/xf8e/+T+5P+EAM3/Kv/T/5gAJgBG/4H/YQBXALr/wf83AD8ADQAmAA4Aff8o/8H/nACUANz/ef9s/x3/Iv8iAAgBzQA6AF8AogAqAHj/kv8nAPL/ZP+Y/20AuwAlACv/iP7q/ur/vwD5AMkAdwAbAOf/BgAvAMr/F/8D/83/swAGAfQA4QC0AA0ATf9Q/z0A+ACTAMD/oP8RAAYAov/h/3YAOwBt/2X/MgB2AMf/X/+9/8j/Tf+U/9QAgAHUAPD/2//Q/wr/2P4sAIwBHgFo/37+D//v/w0AHgCKANUApAAIAE3/4v4+//v/XwAoAPT/UwCmAHMAMQD2/2L/0v4S/67/FwBdAJMAggAlAAsAVAB4AD8AHwDS/+D+TP5o/yYBiAGeAAUA/v+M/wr/c/9uAIQAyf+P//T/JQDh/+X/WQC3AHwA1v9D/zz/y/8FAJX/Wv/l/14AEgB7/6H/dADtAMsAtQC6AFkAvf9n/9D/kQDBAE8AJwBJAP//lP/D/2YAhQAUAAcAagAoAH//s/82ANr/av8MALYACwDa/uT+1P8fAOT/LQDSAJ0Apf8X/0v/fv9o/4n/7v9IAGMAKQAEADIAQwC4/wj/6v5f//L/RQCyAAIBrADh/83/VABHALv/kv/l/xQA1/9+/5j/AQASAOL/4P/3/xcAEgDY/6L/6P9vAK0AcQDb/47/tf8XAG0AZgC0/+7+MP9RABoB/QCOABgAof9///L/ewBkAAEADABGAAsA1v9wADAB6QDp/2v/sv83AGIANgAvAIQAwgCXAGEAMADR/33/q/81AEUAt/+a/1wAuAAdAMv/PABnAPH/w//1/4P/iP6E/tL/uQBKAOP/ZQCMAHX/TP6E/rH/igCgAI4AiQAlAG//Yv8nAJkA8/8S/z3/AAAVAJn/uv9FACYAnv+N/9j/yf9a/yf/cP/V/x0AYgCFAGYAOwAUAO//7/8nAFwATwALAOH/9/8JAAcAFwB1AO0A5QAlAKT/4f8VANP/n/8GAF8A6v9E/7P/pQC/ACIA5/8nACUA6v/w/x8ACAD7/08AjQBdAD8AYAApAJ//hf8EAD0A+P/0/2oAewC//0n/vP9RADwA1f/b/yMABgCH/4H/FAA9ALn/YP/2/9oAFgHVAI8A5v+8/jr+/P7y/xYA8/99AAoBmQCo/0P/T/9L/07/uv9CAFkAOgA0AP7/Yf/s/v7+cv/h/wcA1P+h/9f/WQCEACgAEgB2ALIAVwANAFkA0QDVAG4AJwDw/6L/Qf8l/27/CgCyAOIAkgA4ACwAJgAAACsAnQCfAPz/kf/L/+v/nf+N/+r/9/+Z/4T/EwCWAGkAAwDw/+z/x//e/zgAcABpAF8AfACTAGsAFQDS/6v/q//c/yQAVgBdAFcAcgCZAF0A3v+x/wQAEQC8/77/LQArAH//P/+4//H/pv/h/5kAYwAy/7z+sv+oAJsANAAnABkAw/+N/5T/t//l/yQALADZ/6r/8f8oAMT/Uf9q/73/1v/c/ywAhgBFAJb/SP+l/wgA9f+3/8D/FgAMAIr/XP8CANcA7gBbAPH/9v/o/8b/6v8iAAQA1P/4/zEACgDN/ygAnAA7AGf/SP/q/2QAiwC0AMoAYADc/wQAawA9AKv/mf8BADkAJwAzADgA4P+I/6T/+/8aACUAUwBYAPT/tP8cAMMA5gCLAA8Anf8+/1H/7/+AAHkA+//I/woANgAUAP//HQAQAL//i//R/zkAFgCX/2n/kf+d/5r/3/9KAGYANAAmADoAGQDp/9j/r/9R/yD/i/9NAL8AswB+ACwAn/8f/xb/e//f/x8AcQDBALYANQDJ//r/YAApAH7/Nv+G/8X/jv91/+7/UgANALf/5f8EAJP/Sv/l/3kA/f81/1z//v/s/4b/2/+XAJgA+v/S/zMATwAAAOb/PAB3AIMAkwCYADYAxf+8//X/GAApAFMARAAFAAoAcACnAHEAPwB8AM0AjAAJANz/+P8dAEoAhQCvAJcAMwDf/+T/BQAEAPf/7v/E/3X/WP+Z/9D/kf8z/zj/bf+W/9z/XgCbADEAv/8CAJwAtQB0AFYAQADQ/2X/oP9bANAAmgAMAIP/PP9G/2f/bv+J/8//EQAuABYA1v+U/2r/cv+7//f/AAAfAD0A+/94/zT/ff8QAEAA2P+Y/+L/LwASANH/2f8WADYAUgCqAAQB8ACNAD4AHQD4/8P/u/8SAIEAiQATAKP/lv+l/57/3P96ANIAkwBdAJgAtAA3ALn/2/8bANv/r/8gAIEANgDK/9D/AwDt/6r/uP8OAEQAWgCCAJoAogDLAO4AxwA/AJT/MP9S/6X/xP+r/4j/c/9T/zT/Mf9d/5H/sP+s/5b/rP8EAFEAMQDr/+P/+//O/4n/kP+o/3b/Qf+N/yUATgDo/7T/IAClAJYARABFAIsAXgCd/xz/V//A/8X/uv8JAGAAWAAKAOb//f8PABwAWQCfAIMAHgDm/wgAOwA/ACAACwD1/7v/if+U/8L/8P8yAHUAdwA5ACQAbwCsAHcAJQAwAGQAYQA9AC0ADwDh//X/UAB3AEAADgAeADUALQBEAHwAcAAZAN//3v/Z/9b/BgBJAD4A8v/N/+b/+P/t/+3/+f/j/67/k/+k/6f/e/9Q/1L/f/+v/8//7v8TACEADwDo/9n/6v/3/+L/2v8BACYAGgDp/+L/1/+p/4n/t////wEA9v8sAGYAUAAnAC0AIQDZ/6///f99AKQAXAAMAO3/8f8EABEAHgA4AFkAUwAeAPf/AQANAN3/n/+f/8f/2v/Y/+3/GAAYAOj/0P/9/zsARAAvACsAMAAEAMj/yv8PAE0AVAAsAPj/2P/Z/wMAIwAKAOf/9/8XAAoA6f/0/ygANgD7/7D/nP+//+v/DAAMAOv/yf/I//L/HgAlAAAA4P/i/+v/7P/0//v/9v/k/9v/3v/f/9r/3//i/9T/3f8aAGEAZQA0AAQA4v/G/8v///8rACAA5P/I/93/6P/V/8T/zv/Z/9//5P/6/xwAHwABAPb/DQAdABUAEAAgADQAMQAhABUABADs/9j/yf+3/7P/4P8pAGEAcQBxAGYATwA2ADMAQQA/ADQAOwBHAD0AIAAdAEkAdABaABUA6v/v//j/7//5/yQAOAATAOf/3//Z/7n/qv/U/+v/uP96/4n/vv+7/5v/ov/F/8P/mf+K/5//nv97/2r/iv+g/6T/o/+c/3n/X/96/7X/1f/M/8H/tv+x/8T/9v8iADcAPgBPAFwARAAkABkAHAAsAEwAagB5AHgAdwB9AIYAiQB+AG8AYABZAGMAeAB8AF8AKAACAAUAEgAeADIAUgBgAFAASwB0AKcAqgCPAIEAfQBsAGoAkAC7ALcAfQA+ACAAHwApACkAHAAeAC8ANQApAAkA4P/I/8v/4//8//X/0f+1/6D/fP9d/2H/hf+s/6v/hf9x/3z/dv9S/y//LP9E/13/cP+G/5b/i/9u/1v/YP9w/33/j/+w/8n/v/+f/5D/lv+Z/5v/t//i/+r/zP/A/9r/7//e/9D/5f/9//3/BgAqADoALAAxAFoAfAB6AGQAYwBxAHAAZABpAH8AmACzAMEAvQCkAIEAbgCHAKkArACcAJAAjgCCAHAAYwBhAFwASgA2ACkALwBBAEgANgAmACkALgAgAAoAAQD///b/7v/w//X/7f/a/9f/5P/5//P/4//f/+f/1/+m/4b/kf+l/6H/nf+3/9D/1P/D/73/zv/e/+n/8P/t/8z/rf+u/8n/2f/Y/8v/v/+o/4r/ev+B/4r/iv+S/5r/kv+E/4v/pf+u/5r/j/+g/7T/t/+y/7b/t/+4/8X/3P/m/9v/0//U/93/6P/7/wwABwD2//D/+v8IABYAJgA1ADYALAAsADUAPgBHAFQAWgBWAEoATQBcAGIAWABbAGcAegCQAKMAuADOANsA5gDmAOUA6QD0APgA/AASASoBMgEqATYBMAEcAQoBFgEmARIB/QAGARIB/gDkANAApgBrAEwAVABiAFIALAANAPL/2v/C/63/p/+j/5r/ff9M/yr/HP8N/+j+wP6o/oz+Zv5I/jb+Iv78/dD9sP2g/ZT9fP1o/VD9OP0Y/QD9/PwU/Tj9TP1M/Uz9VP1w/ZT9tP3I/ej9Fv5E/nD+ov7k/jD/bf+Y/7//+v9FAJkA4gAcAVIBkAHSARgCZAKoAuQCGANQA4gDuAPsAxgEQARYBHAEgASIBIgEiASABGgEUARABCgEAATIA4QDQAMEA9gCsAJ8AkACBALQAZoBXgEgAdwAnQBhACcA5v+o/3b/R/8R/9r+pv52/kj+IP4I/uj9xP20/aj9kP14/Vz9SP00/RT9BP34/OT8wPyQ/GD8JPzY+5D7QPvo+nj6EPrY+Zj5UPkQ+ej44PjA+Lj4yPj4+Dj5kPkA+oj6APuA+xz83Pyo/XL+RP8fAPAApgFcAiQD5AOIBCgF2AWABvgGWAewBwAIQAhgCIAIoAigCKAIoAiACFAIIAjoB7AHWAfwBogGEAaQBRAFkAQYBJwDIAOcAhQChAEAAYYAAwCG/x7/1v6Q/kz+Cv7U/az9gP1o/Vz9ZP1c/WT9fP2k/cT94P0G/jz+aP6U/sT+9v4j/1f/iP+q/7z/x//a/+n/4P/K/8H/uf+i/3b/Pv8B/8j+kv5e/h7+0P2M/VT9GP3Q/Hz8PPwQ/OD7sPt4+0j7KPsQ+/j66Pro+uD64PrY+tj64Prw+gD7IPs4+zj7QPuI+wT8dPzI/CT9qP1A/ub+nv9ZABIBwAGEAlADCAS4BGAF+AV4BvAGWAegB7AHwAfQB9AHmAdQBxAHwAZQBtgFaAXwBHgE+AOQAzADuAI8AtYBfAEcAbIAVwAXAOT/pP9j/zL/Bv/U/rD+mP6M/oD+dP5y/oj+lv6Y/qL+tP7a/v7+HP9C/23/l/+6/93//P8bADkAYgB/AJgArwDJAO4A/QAOAR4BMAE8AUoBVgFuAXQBdAFmAWYBXgFMAToBJgEKAdoApAB6AFQAKgDs/6L/Y/8c/8z+eP4q/tT9iP04/fj8xPyU/GD8LPzo+6j7YPsQ+8D6ePow+uD5gPkw+fD4uPiI+GD4QPgw+DD4SPiQ+Pj4gPkQ+sD6gPtk/Fz9TP5N/1gAZAF0AngDaARQBSAG4AaIByAIkAjgCDAJYAlwCWAJMAkACbAIUAjoB2gH6AZgBtgFQAWgBPwDbAPcAlQC0AFQAcoATQDk/4D/Lv/e/qL+av5A/ir+Hv4Q/hr+KP40/j7+TP5u/oD+lP62/tj+8v4Y/0L/Zf+D/6L/yP/4/yMAWwCcANwAEgFEAXYBpgHOAQACPAJgAnQCgAKQAowCdAJYAigC7AGgAU4B/wCmADcAwP9I/8r+Rv7I/VD92Pxk/PD7iPso+9D6gPo4+vj5yPmA+TD56Piw+Ij4UPgI+ND3kPeA92D3QPcw9zD3UPdw97D3CPiQ+DD58PnQ+rj7sPzM/f7+OACGAdQC+AMIBRgGKAcQCMAIYAnwCWAKwArgCtAKwAqgCmAKEAqQCRAJkAgQCIAH4AZABrAFKAWoBCAEmAMUA5QCLAKyAUAB0QBzABgAxf9w/yD/1P6W/mj+QP4U/uD9xP28/bj9sP2w/bz91P34/Rb+OP5Y/o7+1v4h/1//nP/e/ycAcAC4AAQBWgGmAfQBRAKMArwC5AIUAzADPAM4AygDFAP4AsgCiAI8AuYBkgEuAcMAWADh/2L/4v5m/uD9WP3U/Fj88PuI+xj7qPo4+uD5ePkQ+aj4QPjg94D3MPfg9pD2YPYg9hD28PUA9vD1EPZA9qD2EPeg92j4SPlA+jj7RPyA/dL+JAB2AcgCCARIBXAGiAeQCHAJMArQCkALkAvAC+ALwAugC1ALAAuQCgAKcAnQCCAIcAewBgAGSAWgBPQDZAPMAkACvAFKAeAAcQAPAMD/iP9M/w//zv6i/n7+ZP5G/ij+Ev4C/vz9AP4K/gT+/P0A/iD+Nv5E/l7+jv7I/vj+LP9w/8H/CgBcALIABAFKAY4B1AEQAkQCaAKMAqwCsAKoApACcAJIAhQCzgF6ARoBuABOANn/Vf/O/kr+yP1I/cT8RPzI+0j76PqA+hj6uPlg+Rj5yPiA+DD48Peg92D3IPfw9sD2kPZw9mD2UPZQ9mD2kPbQ9jD3wPdo+Cj5APro+gz8NP1u/rr/GgFwArQD8AQ4BmgHcAhQCSAK8AqAC/ALQAxwDIAMcAwwDOALYAvgClAKsAkQCUAIiAfQBhgGYAWoBOgDRAOoAhwCmgEQAZUANQDi/5P/SP/8/sT+kv50/kT+Gv78/ej93P3Q/cD9wP3M/eT9/P0M/ij+SP50/qj+4P4g/1f/nP/u/0UAmADnADwBkAHiASgCaAKkAtAC/AIoA0ADTANEA0ADKAP4ArgCcAIgArgBUgHdAGQA2v9J/7j+JP6U/QT9fPzw+3D7+PqA+hD6oPk4+cD4UPjg93D3EPeg9kD24PWQ9UD1APXQ9KD0gPRw9ID0oPTw9HD1IPbw9tD30PgA+lD7xPw4/s3/VgHoAngE8AVYB5AIwAngCtALkAwwDaAN4A0QDhAO4A2QDSANoAwADFALkArQCfAIMAhgB5AGwAXwBEAEjAPkAjgCmAEOAY4AEgCh/zb/2P50/iL+1P2M/Uj9FP3g/LD8lPx8/Gz8ZPxw/ID8kPyo/ND8DP1Q/aD96P1E/qL+Ev+A/+r/WgDQAEIBnAH0AUgCkALQAggDKANEA0wDRAM0AxwD7AK0AnQCIALOAWgB/ACMAAsAj/8J/3r+7P1c/dj8UPy4+yj7qPoo+rD5KPmo+Cj4sPdA9+D2cPYQ9sD1YPUg9fD00PSw9LD0wPTw9ED1oPUg9tD2sPeQ+Ij5sPrw+0T9pv4TAIQB6AJgBMAFCAdACFAJUAogC/ALkAwADVANcA1wDWANEA2gDCAMkAvwCkAKgAnACBAISAeIBtAFEAVgBLADCAN4AuoBWAHbAGgA+P+a/zr/3v6K/jz+/P3E/YD9SP0U/fD81Py0/KD8mPyc/KT8uPzY/AD9MP10/cD9KP58/ub+VP/T/0gAvgA0Aa4BHAKAAuACKANoA6gD2APoA/AD5APIA6QDYAMUA7wCUALaAWAB3gBUALr/Iv+M/uz9TP2k/Az8ePvo+lD6yPlA+cD4QPjA91D34PZg9gD2oPVQ9QD1wPSQ9HD0YPRQ9FD0cPTQ9FD14PWQ9nD3cPiY+cj6HPyU/Q7/hAAMApQDGAWIBvAHMAlQClALQAwQDaANEA5QDnAOcA4wDtANUA3QDDAMgAuwCvAJEAkwCFAHcAaYBdAEEARIA5QC6AFWAc8ASgDH/1r/+P6q/mD+Cv7E/Yj9XP0w/fz81Py4/Jz8iPyI/HT8dPx4/JD8uPzo/BD9UP2k/QT+bP7a/kv/v/9GAMkARgG6ASgCkAL4AlQDnAPYA/gDGAQYBBAE4AOoA2QDFAOwAjACqAESAX8A0v8r/3b+zP0Y/XD8yPsw+5j6CPqA+fD4gPgA+JD3IPew9mD2APaw9XD1IPXw9ND0sPSw9KD0wPTg9DD1oPUg9sD2kPeQ+Jj50PoM/Gj94P5eANwBWAPYBEgGqAfwCCAKIAsQDOAMkA0gDmAOkA6QDnAOMA7ADTANgAzQCwALMApACVAIaAeABpgFqATMA/gCOAKAAdsAOACv/z7/1P5s/hT+2P2U/WT9NP0U/fj82PzE/LT8qPys/KD8rPy8/NT86PwE/TD9bP20/fj9Sv6m/hT/hP/y/2sA5QBeAdYBVALAAiADeAPQAwAEMARABDgEKAT8A8ADbAMUA6ACKAKcARYBagDA/w//Yv64/QT9WPzA+yD7iPoA+nj56Phg+PD3gPcQ97D2QPbg9ZD1UPUA9cD0kPRg9FD0UPRQ9GD0oPQA9XD1APbA9rD3qPjI+RD7YPzE/Tf/vQBMAtgDUAW4BhAIUAmACpALYAwgDcANMA5wDoAOcA5ADvANgA3gDEAMcAuwCuAJEAlACGgHkAa4BegEGARoA7ACCAJgAdEAUQDU/2n/BP+m/kr+/P28/XT9OP0E/dj8sPyU/Hz8YPxQ/Ej8UPxc/Gz8kPy8/Pz8PP2I/eT9Pv6s/iP/nf8XAJYAFgGcARwCkAL8AlgDtAP4AzAEQARQBFAEOAQIBMQDcAMMA5QCDAJ6AdgAJQB9/8L+Cv5M/ZD82Ps4+4j66PlQ+cD4MPiw90D30PZw9hD2wPVw9TD18PTA9LD0oPSA9JD00PTw9FD1sPVA9vD2wPeo+MD52PoI/GD9vv42AKYBJAOQBPgFUAeQCNAJ8ArQC6AMUA3gDUAOcA6ADmAOMA7QDVANsAwADFALgAqwCdAI8AcYB0AGaAWIBMAD+AJMAqABBgF1APX/iv8j/8T+aP4g/tz9nP1c/Sj9AP3Y/Lj8jPxw/Fz8RPw8/Dj8PPxA/GT8kPzM/Az9XP2w/Rr+iP4B/33/BQCPABoBrAEoApwCDAN4A8wDEAQ4BFgEaARgBEAEEATIA3gDGAOkAiACigHwAFMAqf8A/0j+lP3o/Dz8mPvo+kD6qPkg+Yj4APiA9wD3oPYw9tD1gPUw9fD0sPSQ9GD0UPRQ9ID0oPTw9ED10PWQ9mD3UPhI+Xj6qPsE/W7+0v9OAbgCMASQBfgGQAhgCWAKUAswDNAMQA2gDdAN4A3ADYANIA2gDBAMcAuwCvAJIAlACHAHoAbABegEGARUA6gC+AFOAbQALwC2/03/5P6I/jj+9P20/Yj9VP0g/QD92PzI/LD8lPyI/Iz8mPyc/LT81PwA/Tj9hP3M/Sb+iP70/nj/7P9wAO8AfAEEAogCAAN4A9wDOASABMAE8AT4BAgF+ATYBKAEWAQABJgDKAOgAgQCaAG8AAUARf+C/rj9/PxA/Ij72Poo+nj52PhI+LD3IPeg9iD2sPVQ9fD0oPRg9DD0IPQA9PDz8PMQ9FD0kPQQ9aD1UPYg9wj4GPlI+pj73PxK/rv/NgGwAigEiAXoBjAIYAmACnALQAzwDJAN8A0wDkAOMA4ADrANQA2wDBAMYAugCtAJ8AgQCCAHSAZgBYAEpAPUAgwCRgGcAPL/XP/O/lL+4P2A/Sz96Pyg/HT8TPww/Bj8APwE/AD8APwQ/CT8PPxg/JD8vPzw/DD9gP3Y/TD+mv4M/4X///9/AAABigEIAogCBANwA9QDKAR4BLAE0AToBOAEyASgBGAECASoAzADoAIIAmABqgDp/yP/Vv6M/cD8+Ps4+4D6yPkY+Xj44PdQ97D2MPbA9WD1EPWw9ID0UPQg9BD0APQQ9DD0YPSg9AD1gPUg9tD2oPeQ+KD5wPoE/GT9vP4rAKYBEAN4BOAFQAeQCJAJsAqgC3AMIA2gDfANMA5QDkAOAA6gDUANwAwgDHALoArgCRAJQAhoB4gGqAXYBAgERAN8AsIBEAF6AN//WP/U/l7++P2c/Uj9AP28/ID8VPw4/Bz8APz4+/D7APwQ/CD8PPxg/JT80PwU/Vj9rP0K/nT+4v5W/9P/WADfAGgB7gF4AvACYAPUAzAEgATABPAECAUQBQAF2ASgBFgE+AOEA/QCXAKuAfkANABq/5z+yP38/Cz8cPug+uj5MPmA+OD3QPew9jD2wPVQ9fD0oPRg9DD0EPTw8wD0APQw9GD0oPQQ9YD1IPbQ9qD3kPig+bj68PtI/aL+BABqAdwCSASoBQAHQAhwCYAKcAtADAANgA3wDTAOQA4wDgAOwA1gDdAMMAyQC8AKAAogCTAIUAdwBoAFqATMA/wCNAJ+AdYAMgCi/x7/tP5K/vD9nP1c/ST9/PzU/Kz8nPyI/Ij8gPyA/IT8iPyU/Lj8zPzk/Az9RP2E/cT9EP5s/tL+OP+q/x8AnAAUAZQBEAKEAvgCWAO0AwgEQARwBIgEiASABFgEIATQA2wD+AJsAtABIgFpAK7/5v4Y/kj9ePyw+/D6OPqA+dD4OPig9yD3oPZA9tD1gPUw9QD10PSw9KD0kPSQ9KD00PTw9ED1kPUQ9qD2UPcQ+PD48PkA+0D8hP3U/jkAogEIA3AEyAUgB2AIgAmQCoALYAwQDZAN8A0wDlAOQA4QDsANUA3ADDAMcAuwCsAJ8AgQCDAHQAZYBXAEoAPUAhQCXgGtABQAlv8b/6r+Rv7o/az9YP04/fz8yPyw/JT8hPx4/Gj8bPx4/Ij8nPys/NT8BP08/YD9wP0U/mr+1P5H/7n/LgCoACgBqAEoApgCCAN4A9QDIARwBKAEwATQBNAEuASABDgE4AN4A/ACYAK4AQYBQgB5/6b+0P0A/Sz8aPuY+tj5KPl4+OD3QPew9iD2oPVA9dD0cPQg9ODzoPOQ83DzYPNw84DzsPPw81D00PRw9UD2MPcw+Fj5kPr4+3D9+P50ABQCmAMoBagGAAhgCYAKoAugDHANEA6ADtAOAA8AD+AOkA4wDqANEA1QDJALsArQCfAIEAgoBzgGUAVwBKAD0AIQAlIBqQATAIL/+v58/gz+tP1U/Qj9wPx8/Ej8JPwA/OD72PvI+8j70Pvo+wD8IPxQ/Iz82Pwg/Xj90P1A/rD+L/+s/yQAowAsAbIBJAKcAhADdAPQAyAEUASIBKAEsASoBJAEUAQIBLwDUAPYAkQCpAH+AEAAgv+4/uj9IP1Q/JD70PoI+lj5uPgY+ID38PZw9gD2kPVA9fD0sPSA9GD0UPRQ9GD0cPSg9PD0UPXA9WD2IPfw9+D4+PkY+1D8qP0O/3YA3gFQA7gEEAZwB6AIwAnQCrALgAwgDbANEA5ADlAOQA4ADqANIA2QDOALMAtgCpAJsAjYBwAHIAZIBXgEoAPkAiwCfAHiAE0Au/9D/9T+YP4G/qj9WP0Q/dD8mPxw/Dz8JPwM/AD8+Pvw+wD8GPw8/GT8mPzU/CT9eP3k/Ur+zv47/8b/SgDfAGQB6gFwAvgCbAPUA0AEgATABPgEEAUIBfgE0ASQBEAEyANEA7gCFAJiAaMA1v8J/zD+XP2M/Lj78Pog+mj5uPgI+HD30PZQ9tD1UPXw9JD0QPTw89DzoPOQ85DzoPPA8wD0YPTQ9GD1IPYA9wD4CPlA+pj7/Px6/vP/dAEIA4gE+AVwB9AIEAogCzAM8AygDTAOgA7ADtAOwA6ADiAOsA0QDVAMkAuwCuAJAAkACCAHMAZIBWAEjAO4AvoBSgGcAAIAbf/w/nr+Cv6g/VD9/Py8/Hz8PPwQ/Oj70Pu4+5j7kPuY+6D7uPvg+/j7NPx4/Mj8JP2M/fT9dP4C/5L/HgCyAEYB1gF0AvwCeAPsA1AEsAT4BCgFSAVIBTAFCAXABGgE6ANkA8QCFAJUAXkAn/+4/tj96PwI/CD7UPqI+cD4EPhg99D2QPbA9TD14PRw9DD08POw87DzoPOw89DzAPRQ9MD0QPXw9ZD2gPd4+Jj5yPoQ/Gz94P5pAOYBcAPoBFgGwAcQCUAKUAtQDBANwA1QDqAO0A7gDsAOkA4wDqANAA1QDIALsArACdAI4AfoBvAFAAUIBCADSAJ6AbQA+v9V/8L+PP7E/Vz98Pyg/GT8LPzw+8D7sPuY+4j7iPuI+5j7qPvY+wj8OPyM/NT8OP2k/RT+jv4W/6T/OwDSAGQBBAKUAjADvAM4BLAEEAVoBbAF4AXwBeAFyAWgBUAF2ARIBLADAAM4AmQBewCT/6D+rP2s/Mj70Pr4+SD5WPiw9/D2UPbQ9UD1wPRg9PDzsPNg80DzMPMg8zDzQPOA89DzQPTA9FD1EPbg9uD3APko+nD72PxQ/s3/VgHgAmgE8AVgB7AI8AkQCxAMAA2gDTAOkA6wDsAOsA5wDgAOgA3gDDAMYAuQCqAJwAjQB/AGAAYYBTgEaAOkAuIBLAGEAOr/Xf/c/mD+6P2I/TD92PyI/ET8DPzY+7D7kPuA+3D7ePuI+6D7yPsE/Dz8jPzw/FT9wP00/rz+Sv/R/1sA9QCAARQClAIcA5QDAARoBMAEAAUoBUgFQAU4BQgFyARwBPADbAPMAiACTgF8AJT/vP7I/dT86Pv4+hj6QPl4+LD38PZQ9rD1IPWg9DD00POA81DzIPMQ8xDzIPNQ86DzAPRw9AD1sPWA9nD3ePiQ+dD6JPyQ/QL/hAAEAoQDAAWABtgHEAlAClALQAwADaANIA5wDpAOoA6ADiAOwA0wDaAMAAwwC1AKcAmQCKAHsAbIBdgE9AMkA0wCnAHVADoAnv8f/6D+OP7U/YD9NP30/Mj8hPxo/Ej8OPwc/CD8HPwo/ED8TPx8/Kj85Pws/Yz98P1c/tj+Z//x/4kAKAHAAVwCBAOQAyAEoAQQBXAFwAX4BQgGEAYABsAFcAX4BHAE0AMIAzACOgE/ADL/JP4c/RD8CPsI+iD5OPhw97D28PVw9dD0YPQA9LDzYPMw8xDzAPMg8zDzYPOg8/DzUPTg9ID1MPYA9/D3+PgY+mD7lPz4/Wv/5gBoAtQDUAW4BhAIYAmACpALcAxADdANUA6gDsAOwA6wDmAO4A1gDbAMEAxAC3AKgAmgCKgHsAbYBdgEAAQkA1gCngHpADoAmv8c/5z+LP7Q/Wz9FP3g/KD8YPww/AT84PvQ+7j7sPuw+7D70Pvo+yD8WPyo/Pz8YP3Y/Vj+5P51/xsAuABeAQQCrAJIA9QDWATIBDAFcAWoBagFwAWABUgF6ARgBMwDEANAAloBYgBc/1j+SP1M/DD7QPpI+WD4kPfA9vD1UPXA9DD00PNg8yDz8PLw8uDy8PIQ81DzoPMQ9ID0IPXQ9aD2gPeA+Jj5yPoY/HD93P5OAMQBQAO4BCgGiAfACPAJAAvwC9AMcA3wDUAOcA6ADmAOIA6wDTANoAzgCxALQApQCXAIgAeQBqAFqATUA/ACLAJuAboAGACX/xT/pv5G/uz9qP10/Tj9EP3s/Mz8sPyY/JD8gPx4/Hj8hPyQ/Kz8yPz4/DD9eP3I/Sj+mP4I/4n/HACyAFIB9AGMAkQD1ANoBOgEYAXIBQAGOAZIBjgGAAawBUgFqAToAxQDKAImARMA+P7M/ZD8iPto+lj5UPhg95D2wPUQ9YD08POA8zDz4PLA8qDykPKw8uDyIPNg88DzMPTA9GD1MPYA9/D3+Pgg+mj7rPwY/ob/DgGUAhAEiAX4BmAIsAnQCuALwAyADRAOkA7QDgAP4A6gDlAO0A0wDXAMsAvQCuAJAAkACBAHGAYoBUgEeAOwAvYBSgG8ACsAsP9I/+z+kv5C/vz9wP18/UT9GP3k/LT8jPx0/FD8PPws/DT8QPxU/Ij8uPwI/Vj9yP1E/sj+Yf/9/64AUgEMArQCaAMABJAEIAWQBeAFGAY4BkgGGAbwBYgFAAVgBJwDyALMAcIAs/+W/nT9YPw4+zD6MPk4+FD3gPbA9QD1YPTQ83DzAPOg8nDyUPJA8kDyUPKA8tDyQPPQ82D0APXg9dD28PcY+Vj6uPs0/aj+PAC+AUwD0ARIBrgHAAlAClALUAwgDcANQA6QDrAOsA5wDkAOwA0wDYAMwAvgCgAKAAn4BwgH+AUIBRgERANoArIBCAFyAO//c/8b/8T+ev4u/gD+xP2c/WT9QP0Y/fT81Pyk/Jj8hPxs/Gz8ePyM/LD84Pwk/XT92P1Q/tr+cf8PAL8AgAE0AvACpANQBPAEeAXoBUgGgAagBrAGiAZABsgFKAWIBLwDwAKyAaEAbP9E/hz94Pu4+pD5iPiQ96D2sPXw9ED0oPMg87DyYPIg8gDy4PHg8fDxIPJw8tDyUPPQ83D0QPUg9hD3MPhY+aj6CPyA/Qn/fwAgAqwDOAW4BiAIgAmwCuAL0AywDVAOwA4gD1APQA8wD+AOcA7gDTANYAyAC5AKkAmgCKAHmAagBagEyAP0AiwCcAHVADoAuP9O/97+jP4u/uz9pP1k/TD98PzA/JD8YPw8/CD8APzo++D76Pv4+yD8TPyY/Pj8ZP3w/Xj+MP/W/58AagEwAvgCrANgBAgFkAX4BVAGgAaoBogGWAbwBXAF0AQQBBwDGAIAAcr/nv5g/Rz86PrI+Zj4gPeQ9pD1wPQA9GDzwPJQ8gDysPGA8XDxgPGw8eDxQPKw8kDz4POg9ID1gPaQ98D4EPpw+9z8Wv7q/3IB/AKIBAgGeAfQCAAKMAswDAANsA1ADqAO0A7gDtAOgA4wDrANAA1QDJALsArACdAI6AcABwAGIAVIBGwDsAL8AVYBuAAxAL//RP/k/oL+Lv7c/ZD9UP0I/cz8jPxc/Cj8CPzg+8D7wPvA+9D7APwo/Hz83PxU/dz9fv4p/97/rgCCAWACLAP8A9AEkAUwBsAGMAeIB7AHyAegB0AHyAYgBlAFaARYAygC6QCi/1L+AP3A+2D6KPkQ+PD24PUA9TD0kPPg8mDy8PGg8XDxYPFg8XDxoPHw8VDywPJg8xD04PTA9cD24PcY+WD60PtE/cr+VgDoAXwDAAWABvgHQAmACpALkAxgDQAOgA7QDgAP8A7QDoAOAA5wDcAMAAwgC1AKYAlwCIAHkAawBcgE+AM4A3ACzAEkAZMAEQCO/xj/rv5O/uT9iP0s/dz8gPw4/Pj7sPtw+0j7KPsY+yD7OPtg+6j7CPx4/Az9rP1U/if//f/SALgBkAJ8A1AECAXIBVgG2AYwB3gHgAdgByAHuAYQBlgFcARoA1QCHAHm/5L+VP0Q/OD6sPl4+HD3YPaA9bD00PNA85DyIPKw8WDxMPEg8TDxMPFw8bDxMPKw8mDzMPQg9SD2UPeo+PD5cPvw/Ir+IwDEAWAD+ASIBvgHUAmgCrALsAyQDUAOsA4QDzAPMA8AD7AOMA6QDeAMAAwQCyAKIAkQCBAHEAYYBSgETAOAAsIBHgF0APj/bP/6/pb+OP7Y/ZT9RP0A/bz8iPxE/Bz88PvQ+7j7qPuo+9D76Pso/ID83Pxc/fD9lP5F/xAA3ACyAZgCYAMwBAAFsAVYBuAGWAeYB8AHyAeYB0AHsAbwBTAFOAQcA+YBnABW//j9rPxQ+/j5yPiQ93D2cPVw9JDz4PJA8rDxQPHg8MDwsPDA8ODwIPGA8fDxgPJA8xD0APUA9jD3cPjA+Tj7vPxO/tb/fgEIA6AEGAaYBwAJMApQC1AMQA3gDYAO0A4QDyAPEA/QDnAO4A0wDYAMsAvQCuAJ8AjoB+gG+AUQBSAEQAOAAroBEAF3ANb/X//m/n7+Dv64/WT9GP3U/JD8VPwo/Pj74PvI+8D7wPvI+/j7MPx0/Mz8QP3M/WD+/v6+/3EARgEQAtgCjANIBOgEgAX4BUgGkAaoBqgGeAYoBqAFAAU4BFQDUAIkAe//pP50/RT80PqY+VD4MPcQ9iD1IPRA85Dy8PFw8SDx0PCg8KDwwPAg8XDx4PGA8kDzIPQQ9SD2YPeo+Bj6mPsc/bT+TAD0AZADGAWYBhAIYAmgCrALoAxwDQAOgA7gDgAP8A7QDpAOEA6QDfAMIAxQC4AKkAmwCLgH2Ab4BSAFUASEA9ACIAKIAfsAbQD4/5H/Hf/O/mL+Ev7M/Xz9OP30/MD8gPxU/DT8IPwM/Az8LPxU/Iz85Pw4/bz9Qv7a/n3/KwDtAJgBaAIcA9gDeAQIBaAFCAZIBngGgAZwBigGwAUYBUgEaANoAj4BBQC+/mz9FPzQ+oD5QPgQ9+D10PTg8/DyIPKA8fDwkPBA8CDwAPAg8GDw0PBA8eDxkPJw83D0kPXQ9hD4gPn4+oz8IP66/2oBDAOgBDAGmAfwCDAKYAtgDEAN8A1wDuAOEA8gDwAPwA5gDuANYA2gDOALEAswClAJcAiAB6gGyAUABTAEdAPEAiACiAH3AHAA/P+A/w//tv5A/uz9kP08/eT8jPxI/Aj82Puo+5D7iPuQ+7D78PtA/KT8IP2w/Vz+Av/O/44AXgEcAuACoANIBNgEUAW4BQgGCAYgBvAFmAUoBXgEuAO8ArgBpwBy/yr+6PyY+2D6IPnw98D2oPWw9LDz4PIQ8mDxwPBg8BDw4O/g7+DvEPBw8ADxoPFw8nDzcPSw9RD3iPgI+qj7ZP0i/9EAjAI4BNgFaAfQCDAKYAtwDGANMA7QDjAPgA+QD4APUA/gDoAO0A0wDXAMoAuwCuAJ4AjwByAHKAZYBYgE4AMYA3gC5AFUAdoAWwDw/4D/Ff+u/lT+8P2U/TD96PyM/Ej8BPzQ+6j7oPuY+8D7+PtM/Lj8PP3M/XD+Lf/k/8AAjAFgAjgDCATABHAFAAZ4BtgGAAcIB/AGoAYoBpAFsASsA6ACbAEuANr+dP0M/KD6SPnw97D2cPVQ9DDzcPKQ8dDwMPDA72DvIO8g70DvgO/g71Dw4PCg8YDygPPA9AD2cPfo+ID6MPzg/Zj/SgH8ArAEUAbQB0AJkArQC+AMwA2ADgAPgA/QD/APwA+QDzAPsA4gDoANsAzgCxALMApACVAIWAdoBogFsATYAxQDSAKeAfwAagDU/0j/zP5Y/uT9hP0c/bj8cPwU/OD7oPt4+2D7UPtg+4D7sPsA/GT84Pxw/Qz+xv6A/1sAIgEEAtwCmANoBAgFsAUoBpAG2AbwBuAGoAY4BqgF2AToA9wCpgF7ABn/wP1E/Oj6ePkg+MD2cPUw9CDzIPIw8XDwwO9g7wDvwO7A7uDuIO+g7zDw4PCw8cDy0PMQ9WD24PeA+TD77Pyu/noAPAL4A6gFUAfACCAKcAuQDKANcA4gD5AP4A8AEAAQ4A+QDxAPkA7wDSANYAyAC7AKwAngCPgHAAcwBlgFiATQAwQDWAKuARIBhQDw/2f/7v58/gL+oP04/eD8gPw4/Pj7sPuI+2j7aPtw+5D7yPsk/JD8EP2c/U7+/v62/40AZAE0AggD2AOQBFAF2AVgBsAGCAcYBwAH0AZoBtAFCAUQBPQCuAFdAAH/kP0U/Ij6EPmQ9yD28PSg84DyYPFw8MDvIO/A7kDuQO4g7kDugO4A74DvMPAQ8RDyQPOA9PD1cPcY+dj6nPxu/jQABALQA4gFMAewCCAKgAugDKANkA5AD8APIBBgEGAQQBDwD4APAA9wDrAN8AwgDEALUApwCYAIoAe4BtgFCAU4BGgDqALwATgBlgD6/1r/yv5C/rz9OP3M/GD88PuY+0j7EPvY+rD6uPqw+tj6GPt4++j7ZPwU/cz9jP5o/z4AJgEQAuwCzAOQBEAF2AVYBrgG2AbwBsgGgAbwBVAFeARkA0wCAgG6/1T+3Px4+/j5kPgg99D1kPRg81DyUPGA8MDvIO/A7oDuYO5g7oDuwO5A7+DvcPBA8VDygPPQ9ED20Peg+WD7UP0i/woB8AKwBIgGIAjQCTALkAygDaAOcA8gEIAQwBDgEMAQoBBAELAPEA9wDqAN0AzwCxALIAowCTAIWAdYBoAFmATQA/wCPAKEAcoAJwCN//L+Yv7k/XD9+PyQ/Cz84PuQ+1j7MPsY+xD7IPsw+4D7wPss/Lj8WP0E/tD+mv91AFABNAIYA+wDuARwBRgGkAb4BjgHSAdAB/gGgAbwBTAFSAQ0AwQCqQBK/9j9SPzI+kD5wPdA9tD0kPNA8jDxQPBg76DuIO7A7YDtYO1g7aDtAO6g7kDvEPAQ8UDyoPMQ9bD2aPg4+ij8HP4EAO4BzAOoBXgHIAmgChAMQA1gDlAPABCgEAARQBFAESARwBBAENAPMA+ADrAN4AzwCxALIApQCWAIaAeIBqgF2ATsAyADVAKMAcAAAABN/4z+5P1E/aj8GPyI+xj7wPpw+jD6EPoI+gj6MPp4+tD6SPvY+4T8WP0o/gT/8//nANgByAK4A4AESAUIBpAGEAdgB4gHkAdgBwgHeAa4BeAE1AOwAmQB8P+Y/vj8ePvg+Vj44PZw9RD00PKQ8YDwoO/A7iDuoO1g7SDtIO1A7YDt4O2A7kDvQPBw8bDyMPTw9bD3sPmg+7j9xf/YAfAD2AW4B4AJMAvADBAOMA9AEAARoBEAEiASIBLgEYARABFgEJAPsA7ADeAM8AvgCuAJ4Aj4BwgHEAY4BVgElAPIAgwCYAGxAAAAb//S/kL+pP0Y/ZT8BPyg+zD72PqQ+kj6KPoY+ij6WPqo+hj7qPs8/AT9zP28/rn/rACwAaACrAOYBHAFOAbwBngH4AcgCDAIEAiwByAHaAaQBYAEUAP8AaIAE/98/eD7OPqg+AD3gPUA9KDyYPEw8CDvQO5g7cDsQOwA7ODr4Osg7GDsAO3A7aDuoO8A8ZDyQPQg9iD4MPpQ/Hr+rADYAvAEAAfwCLAKUAzQDSAPQBAgEeARYBKgEsASgBJAEuARQBGAELAP8A4ADgANEAwACxAKEAkgCCgHKAY4BVgEgAOwAt4BFgFQAJr/3v4m/oz93Pw8/Jj7IPug+ij62PmI+WD5OPlA+WD5sPkg+pj6QPsA/Oz82P3a/v//GgEkAjgDUAQwBSgG6AaQBxAIUAiQCGAIMAi4ByAHQAZABRgE1AJwAd7/TP6g/AD7OPmw9wD2cPQA86DxYPAg70DuYO2g7CDswOug66DrwOsg7IDsQO0g7kDvgPAQ8qDzcPVw94j5sPvk/R0ASAJ4BJAGkAhwCjAMsA0wD4AQYBFgEgATYBOgE6ATYBPgEmASoBEAEQAQAA/wDeAM0AuwCpAJgAhoB1gGWAVQBFgDfAKoAdEACgBI/4z+4P0s/Yj8APxQ++j6aPoI+rj5iPlI+Uj5UPl4+dD5MPrI+nD7QPwU/Qb+If86AFwBgAKkA7AEsAWgBngHIAiwCBAJMAkwCfAIkAjwBxAHEAboBJQDIAKPAPb+PP2A+7D5APgw9qD0EPOg8VDwAO/g7QDtQOyA6yDrwOqg6qDq4Opg6+DroOyg7eDuQPAA8tDz0PUA+CD6gPzQ/i4BdAO4BeAHEAoADMANYA/AEAASABPAEyAUgBSAFGAUABRgE6AS4BEAEfAP4A6wDaAMcAtACiAJ+AfoBtgFyATMA9gC6gEqAVkAhv/G/gD+VP2g/PD7QPuo+hj6kPkw+dD4iPhY+Ej4WPh4+Nj4UPnw+bj6kPuM/KD90v4UAGIBsALsAyAFSAZABzAI8AiACeAJAArwCbAJIAlwCHAHUAYIBYwD5gFCAH7+pPzQ+vj4MPdg9dDzMPLg8IDvYO5g7WDswOtA6+DqwOqg6uDqIOug62DsIO0g7oDv4PCw8oD0kPa4+BD7WP3T/zACkATwBjAJYAtgDUAP4BBgEoATgBRgFcAV4BXgFYAV4BQgFEATQBIgEfAPsA5wDRAM0AqACUAI+AbABZgEhANoAnABlQDF/wf/Rv6k/QD9YPzY+1D7yPpI+uD5iPkw+fD40Pi4+Lj44PgQ+YD56PmQ+kD7HPwU/Qb+Of9eAKgB7AIYBFAFeAaAB2AIMAmwCTAKUApQCvAJcAmwCLgHkAY4BbQDGAJXAHT+jPyQ+qD4wPbg9DDzoPEg8MDugO1g7KDr4Opg6gDqwOnA6QDqYOrg6oDrYOyA7aDuQPDw8fDzEPY4+JD6DP17/+4BgATgBjAJcAuQDXAPIBGgEuAT4BTAFSAWYBZgFgAWgBXAFMAToBJgEUAQAA+gDUAM4AqACTAI6AbIBZAEfAN8AoIBpgDQ/wz/XP6w/fz8SPyo+wj7ePrg+Vj50PhQ+AD4wPeQ94D3gPfA9xj4gPgw+fD54Prw+xT9Vv6z/ygBlAIABFgFqAbQB9AIwAlwCvAKIAsgC/AKcAqwCcAIqAdABsgEGANaAXn/iP2Y+6j5wPfw9TD0kPIQ8aDvYO5A7UDsgOvg6oDqIOog6iDqYOrA6kDrIOzg7CDugO8w8RDz8PRQ93j56Ptw/vUAiAPwBXAIwArwDAAP4BBgEsAT4BTAFWAWoBagFmAWABZgFYAUYBNAEgARoA9QDvAMcAsgCsAIaAcoBvAEzAO4ArwB1ADs/x7/aP6s/ez8TPyg+/D6WPrI+UD5yPhY+PD3sPeQ94D3kPfQ9xj4sPhI+Sj6APsM/Ej9ev7K/0IBmAIABHAFoAbgB/AI4AmQCiALgAuQC2ALAAtgCoAJgAg4B9AFMASMAr0A2P7k/PD6APkQ91D1kPPw8YDwQO8A7gDtAOxA66DqQOrg6cDp4Okg6qDqIOvg68Ds4O1g7wDx8PIg9VD3sPlE/Nz+dgEoBMAGUAnAC/ANABDgEYAT4BTgFeAWQBeAF2AXIBeAFqAVoBRgEwASgBAAD3AN8AtgCuAIiAcwBvAEwAOgApABpQC3//D+Jv50/dT8LPyQ+/D6SPq4+Sj5kPgQ+ID3IPfg9rD2oPaQ9sD2MPfA92j4OPlQ+mj7vPwk/pL/GgGwAlAE2AVAB6AI0AnQCrALUAygDMAMoAxADLALwAqgCVAI2AYwBWgDhAGI/5z9kPug+aD30PUQ9HDyAPGg74DuYO2A7MDrIOug6mDqQOpg6qDqAOuA6yDsAO3g7SDvoPAw8iD0QPaQ+Pj6iP0rANACaAUgCJAKEA1AD0ARIBPAFAAWIBfAFyAYQBgAGGAXgBaAFSAUoBIgEWAPsA0ADFAKsAgwB8AFSAQQA9oB1ADY/+z+Iv58/eT8WPzQ+1j78PqA+iD6sPlQ+ej4mPhY+Bj48Pfg9+D3EPhY+Mj4UPkA+uD64Pv8/Bz+X/++ACgCiAPwBEAGkAfACMAJoAowC8ALAAzwC8ALQAuQCpAJgAggB6gFAARMAoMAqP7I/PD6EPlA95D18PNw8hDx4O/A7uDtIO2A7ADsoOtg60DrQOtg68DrIOzA7IDtYO5g76DwEPLA87D14Pco+pz8Mv+uAUgE0AZQCbALEA4AEOARoBPgFAAWwBZAF0AXIBeAFuAV4BSgEyASgBDwDjANgAvQCSAImAYoBdgDmAJoAWwAk//W/ir+lP0c/bD8TPwE/LD7WPsA+7D6WPr4+Zj5OPnw+Kj4ePhI+Ej4YPiY+AD5ePkY+vD64PsE/TD+cf/RADQCpAMQBWgGqAfgCPAJwApwC9ALEAwADMALQAuACpAJcAggB6gFEARcAqIA6v4o/Wj7wPko+JD2MPXQ87DyoPHA8ADwQO/A7kDu4O2g7YDtYO1g7YDtoO0A7oDuAO/A76DwwPEQ86D0UPZY+ID6yPxL/74BUATQBlAJoAvQDeAPoBFAE4AUgBUAFmAWYBYAFmAVoBSAEwASoBDwDlANgAvgCTAImAYwBeADsAKwAbcA6P9M/7z+Sv7k/ZT9TP0Q/dD8kPxI/Pj7sPtg+wD7kPoo+tj5kPlY+TD5IPlA+YD54Plw+hD78PvY/Pj9FP9UAI4B2AIgBHAFkAagB6AIcAkgCrAK8AoAC/AKoAogCnAJgAiAB1gGGAWgAzACmAAj/4z9FPyQ+iD50Pdw9lD1IPQg80DygPHQ8DDwoO9A7+DugO5A7iDuIO5A7oDu4O5g7wDw0PDA8eDyMPTA9YD3ePmg+/z9VADYAjgFsAcACkAMQA4gEMARIBNAFOAUQBVgFSAVoBQAFAAT4BGAEAAPUA2gC/AJQAioBkAF5AO4AqoBvwDt/z7/yP5c/gb+vP2E/VT9OP0E/dD8lPxY/CD80PuI+yD7yPp4+ij66Pmw+Zj5qPno+TD6oPo4++D7yPy8/bj+1P/tABQCOANIBFAFMAYQB9AHcAjgCCAJQAkgCeAIgAjwBzgHcAaYBZgEjANkAjQBAADW/qT9dPxI+zD6GPkI+AD3APYQ9UD0cPPA8iDygPEA8YDwIPDA74DvgO9g74DvwO8g8LDwYPEw8jDzYPTA9XD3MPlA+1z9v/8UAogE4AYwCWALcA1AD+AQQBJAEwAUoBTAFIAUIBSAE6ASgBEgEKAO8AxQC6AJ+AdgBtgEeAM8AiIBKgBr/87+UP7w/bD9jP1o/WT9ZP1c/Vj9SP04/SD9+PzQ/KD8aPww/AD80Pug+4j7iPuI+7D76PtE/MD8SP3s/Zj+VP8lAP4A3gG4AogDUAQQBagFQAawBggHSAdgB2AHQAf4BpgGEAZ4BcgEAAQoA0wCaAGEAJL/oP6o/bT8wPvQ+uD58PgQ+ED3gPaw9QD1UPSw8xDzgPIQ8rDxcPFA8TDxQPFg8ZDx8PFg8gDz4PPQ9AD2UPfQ+FD6APy0/YH/fAF8A3AFaAcwCeAKcAzADeAOwA+AEOAQQBEgEcAQQBCAD6AOoA1wDCAL0AmQCEAH8AWwBIQDfAKkAewAUgDc/4f/Tv82/yP/GP8e/yn/SP9I/0H/KP8O/+b+pv5W/vj9pP1U/QT9rPxk/BT84PvA+7D7yPvo+zj8nPwY/aD9Nv7i/p7/WwAiAd4BiAI0A8QDOASQBLgE4ATwBOgEuASABDAExANIA7QCGAJyAc4AHwB5/8D+BP5Q/Zj88PtA+5j6+Plw+eD4aPjg91D30PZQ9uD1kPUw9fD00PTA9MD0sPTA9OD0IPVg9bD1MPaw9nD3QPhA+Vj6oPsE/ZD+RQD+AcADiAVIB/AIgArwC0ANYA5AD/APYBCgEIAQIBCAD8AOsA2ADBALoAkQCIgGAAWMAyAC2AC1/6r+0P0E/YT8LPz4++D74PsE/Dz8hPzU/BD9eP20/Qb+SP6A/pj+uv7O/ur++v4B/x3/Iv9A/2H/kf/H/yAAjAAEAaQBPALsAqQDUAQABaAFMAawBhAHYAeAB3gHYAcIB6AGAAZIBXAEhAN8AnYBVAAm/wL+0Py4+6D6qPnA+PD3QPew9lD28PWg9XD1QPUg9QD18PTg9OD04PTg9OD04PQA9SD1UPWg9eD1QPbA9lD3APi4+JD5ePqY+8j8Fv5w/9kAQAK0AyAFgAbQByAJUApwC2AMMA3QDWAO0A4wD2APcA9gD1APIA/gDnAOAA6ADQANcAzACwALMApQCWAIYAc4BgAFvANoAggBlv8Y/qT8QPvg+Yj4UPcw9jD1cPTA8zDz0PKw8sDyAPNw8xD00PSw9cD20PcA+Tj6gPvQ/Bb+Wv+FAJwBlAJ8A0AE8ASABegFMAZYBmgGSAYQBrgFSAXABBgEYAOYAsYB3gD0/wT/Gv4w/VD8ePu4+gj6YPnQ+Fj48Peg94D3cPeA96D3APho+Oj4gPko+uj6uPuQ/HD9Vv5L/zoALgEYAgAD6APIBJgFWAYAB5gHEAiACNAIAAkwCUAJQAkgCeAIoAhQCOAHYAfQBigGeAW4BPQDHANEAnQBnwDR/wT/PP58/dD8KPyQ+xD7mPow+uj5wPmY+Yj5kPmw+fD5QPqY+vj6cPvw+3j8BP2Y/Sz+xv5g//D/ggASAZYBGAKYAgwDcAPIAyAEWASQBLAEwATIBMAEsASYBHAESAQQBNgDlANMAwADrAJgAhQCyAFyATYB6QCoAGcAJADw/6//ef9P/yP/9v7S/rr+oP6M/nr+bP5o/mr+cv6A/oz+mv6q/rT+zv7a/ub++P4A/wj/Cf8B/+r+1P66/pT+av46/gD+zP2Q/VT9EP3Q/Jj8XPww/Aj86PvI+7D7qPuo+6j7wPvY+wD8LPxg/Jz84Pws/YD94P1E/q7+Hf+U/xAAjwAKAYYBAAJ4AuACRAOgA/QDOARoBIgEoASoBKgEmAR4BEgEEATUA4gDPAPoApQCRAL4AbABbgE0AQAB2wC+AKkAmACYAKAAqACzALsAwgDNANAAzADDALIAmQB6AFIAJADs/7L/dP82//r+vv6C/lL+Jv4E/uj91P3M/cz91P3o/fz9FP42/lT+dP6Q/qT+tP6+/sj+yv7M/sr+yP7E/sD+wv7C/sj+0P7e/vL+C/8m/0f/b/+Z/8H/6v8SADIAUABpAH4AjgCUAJQAkACGAHgAZQBUAD8ALAAbAAoA/v/w/+z/8P/4/woAGwA1AFMAdgCXALMA4QD9ACYBSAFuAYgBpAG4AdAB3AHmAfQB9gH2AfQB8gHoAeYB3AHUAdAByAHKAcoBxAHEAb4BuAGyAaYBnAGKAXgBZAFIAS4BDgHkAL8AlQBpAEEAFgDo/8P/mP90/1b/PP8h/xD/Af/2/vb++P72/gP/Dv8Q/xj/Hf8c/yH/If8d/xL/Af/s/tT+tv6W/m7+RP4a/vD9yP2g/Xj9VP00/Rj9AP3w/OD81PzY/Nj83Pzk/PD8BP0g/UD9YP2I/bT96P0g/lj+lv7a/ib/df/F/xYAawDFACIBeAHOASACcAK4AvwCOANoA5ADrAPEA9AD0APIA7wDqAOQA3QDVAMsAwQD3AK0AogCXAIwAgQC2AGuAYIBWAEsAQIB1QCnAHsATQAgAPT/zf+n/4P/Xv88/xz//v7i/sr+tv6i/pL+hv56/nD+Zv5c/lL+SP5A/jj+MP4m/h7+Fv4O/gj+AP78/fj9+P30/fD97P3s/ez97P3s/fD9+P0A/gz+Gv4o/jr+UP5m/n7+lv6y/tL+8v4W/zr/YP+K/7b/4/8UAEcAdgCnANgACAE6AWoBmgHGAe4BGAJAAmQChAKgArgC0ALkAvQCAAMIAxADFAMYAxQDEAMIAwAD9ALkAtACuAKgAogCbAJMAigCAALcAbYBjgFoAUABGAHwAMcAnwB4AFEAKwAGAN//uf+W/3L/T/8t/w3/7P7K/qz+jP5w/lD+Mv4U/vT92P3A/aj9lP2A/XT9aP1k/WT9YP1k/Wz9dP14/ZD9mP2w/cT91P3s/QD+Ev4s/kL+Vv5u/oz+qP7G/ub+A/8l/0v/cf+c/8j/9P8bAEUAcgCaAL4A4QD/AB4BOgFOAV4BbAF2AXwBfgF8AXYBcAFqAWQBXgFUAUwBRgFCAT4BPgE+ATwBPgE8AT4BPgE+AT4BQAE+AToBOAE0ATABKgEkARwBEgEMAQQB+wDwAOcA3QDVAMkAvQCzAKoAoACRAH8AbgBbAEcAMAAVAPf/2f+5/5j/dv9Q/yv/Cf/q/sr+rv6U/n7+av5a/kz+RP5A/kL+Rv5I/lD+Wv5k/m7+eP6E/o7+lv6g/qz+tv6+/sj+1P7e/ur++P4G/xT/Jf84/0r/XP9v/4P/l/+r/8D/0v/l//n/DAAdACwAOQBCAEoAUQBWAFoAXQBfAGAAZABmAGkAbABwAHQAdgB6AH4AgwCJAI4AlACbAKAApQCrALMAvADFAM0A1gDeAOgA8QD6AAIBDAEUARwBIgEkASYBJAEiASIBHAEYARIBDgEGAfwA9wDsAOYA3gDZAM8AxgC9ALMAqACcAJEAhABzAGIATwA5ACYADQD0/9z/wv+t/5f/gv9w/1z/Tf8//zD/Jv8b/xH/CP8A//r+9P7u/ur+5v7i/uL+4P7g/uL+4v7m/uz+9P76/gL/Cf8Q/x3/KP8z/0D/Tv9Z/2X/b/93/4L/jP+W/6D/qP+x/7n/wv/L/9T/3f/m//D/+/8FABAAGQAkAC4AOQBEAE8AWQBkAG0AdQB8AIQAjACVAJ0ApACrALQAvQDGAM4A1gDdAOUA7QDzAPcA+gD9AP4A/gD7APYA7wDlANsAzgC/AK4AmwCHAHIAWwBEACwAFQD9/+b/0f+8/6j/l/+G/3f/af9c/0//RP86/zL/LP8n/yT/If8g/yD/If8j/yj/Lv82/z//Sv9U/1//av9z/37/iP+S/5v/o/+s/7T/vP/D/8r/0v/a/+L/6//0//7/CAASABwAKAAzAD0ARwBPAFYAXABfAGEAYQBgAFsAVgBQAEoARQBAADwAOQA3ADYANgA4ADoAPQBBAEQASQBMAFAAUwBYAFwAXgBeAF0AWwBZAFcAVQBQAEsARQBBAD0AOAA0AC8ALAAqACcAJAAiACAAHwAfAB4AHQAbABkAFQARAAwABQD///f/8P/o/97/0//I/7//tv+v/6n/pf+i/6D/oP+j/6f/rP+x/7j/wP/I/9D/1//e/+T/6v/v//P/9v/6//7/AAABAAEAAwAFAAYACAAKAA4AEwAbACEAJwAuADgAPwBDAE0AUABYAFkAWgBfAFoAVQBTAEwAQQA3AC8AJgAcABMABwD9//b/7v/o/+X/4v/c/9j/1//U/9H/zv/K/8f/xf/B/7z/t/+z/6//qv+m/6P/oP+d/5v/mv+Z/5r/m/+e/6L/qP+v/7f/v//H/9H/2//k/+7/+f8DAAwAFQAdACYALgA1ADsAQABEAEkASwBLAEsATABMAEkARgBDAEIAQQA+ADkANgAzADEALwAsACkAJgAkACIAHgAaABUAEgAOAAsABgACAP///P/5//b/8//y//P/9P/1//b/+f/8////AwAGAAgACQAKAAsACwALAAkABwAFAAMAAQD9//n/9v/z//D/7P/n/+P/3//a/9X/z//K/8X/wP+9/7n/tf+v/6v/pv+j/57/mv+X/5P/kf+P/4//jv+P/5D/kv+V/5j/nP+g/6b/q/+x/7f/vP/D/8r/0//b/+T/7v/4/wMADgAZACQAMAA8AEcAUgBbAGMAaABtAHIAcwBzAHQAcwBwAGwAagBmAGEAXgBcAFkAVgBUAFIAUABPAFAAUQBQAFEAUQBRAFMAUwBSAFEATwBPAE0ATABMAEkASABGAEMAQgA/ADsANwAzAC8AKwAmACIAGwAWABMADQAJAAUA/f/5//X/8f/t/+r/5P/f/9v/1v/R/8//y//H/8X/wf+9/7v/uf+3/7X/s/+y/7D/r/+u/63/q/+q/6r/qf+q/6r/q/+t/6//sv+2/7v/wP/H/83/0//Y/93/4v/m/+n/7P/u//D/8v/z//T/9v/3//r//f8AAAMABgALAA8AFAAaAB8AJAAoACwAMAAyADMAMwAyADAALQAqACUAIAAbABUAEAAMAAcABAABAAAA//////////8AAAEAAgAEAAYABwAJAAoACwAMAAwADQAPABAAEgAUABYAFwAZABoAGwAcABsAGwAZABgAFgATABAADAAJAAUAAAD8//j/8//u/+r/5f/h/97/2v/X/9T/0P/N/8v/yP/G/8T/wf+//73/vf+8/73/vf+//8D/wv/E/8f/yf/N/9D/1P/Y/9v/4P/m/+3/9P/7/wEABwANABQAGwAgACMAJQAoACoAKwAqACkAJwAlACIAHgAaABUAEgAQAA8ADgANAA0ADgAPABAAEgAUABcAGgAdACAAIwAlACcAKQArAC0ALwAwADEAMQAyADMANAA0ADQANAA1ADYANgA3ADgAOQA6ADoAOgA7AD0APAA7ADgANwA0ADAAKwAkAB0AFgAQAAkAAQD6//X/7v/o/+T/4P/e/9r/2P/Z/9X/0f/R/8z/xP+9/7f/r/+o/6H/mf+T/4//i/+K/4z/kP+S/5f/nv+m/67/tf+8/8X/zf/U/9r/4P/n/+3/8//5/wAABwAOABUAHAAjACoALwA0ADkAPQBBAEMAQwBCAEEAPwA9ADoAOAA3ADUANQA1ADgAOwA/AEQASABMAFAAUgBSAFEATwBLAEUAPAAzACsAJAAaAA8ABQD9//f/8f/s/+n/5//m/+b/5f/k/+P/4//i/+D/3v/b/9n/1//V/9P/0f/R/9L/1P/W/9n/3P/f/+P/5v/q/+3/7//w//H/8//0//X/9f/2//b/9v/1//P/8P/u/+r/5v/i/93/2f/V/9H/zv/M/8r/y//N/9H/1v/a/9//5P/p/+3/8P/x//H/8f/w/+//7v/u/+7/8P/y//T/+P/8/wIABwAMABAAEwAVABgAGQAbABsAGwAcAB0AHwAgACIAJQAoACsALgAxADIAMQAyADEALgArACkAJwAjAB8AHQAaABYAFAASAA8ADAAJAAQA///6//b/8f/t/+n/5f/k/+T/5v/o/+z/8P/2//v/AQAHAAoADAANAAwADAAJAAUAAQD+//3//v8AAAYADAAUAB8AKgA1AD8ARABIAEoARwBAADYAJwAVAAIA7f/Z/8r/vf+0/7D/rv+v/7X/vf/H/9L/3P/j/+r/7//z//X/9P/z//D/7f/q/+j/5f/l/+X/5v/o/+3/8v/6/wIACAANABIAFQAYABkAGAAXABUAFAATABMAEgASABIAEwAUABMAEwAUABQAFgAYABsAHgAiACcAKwAtAC0AKgAmAB8AFQAKAP3/8P/j/9j/0f/M/8r/y//Q/9f/4P/q//P/+f/9///////9//n/9f/v/+r/5f/g/93/3P/d/+D/5f/q/+//8//2//j/+P/1/+7/5v/e/9f/0f/N/8z/zv/S/9n/5P/x//7/CgAUABsAIQAkACQAIQAbABQACwABAPj/8P/q/+X/4f/f/9//4f/l/+v/8//7/wIACAAMABAAEwAUABMAEQAOAAsACwAOABMAGgAjACsAMwA8AEUATQBSAFUAVABSAFAATgBLAEgARgBDAEAAPgA8ADsAOAAzAC4AJwAeABQABwD5/+n/2f/J/73/tP+u/6z/rv+z/7v/xv/T/+H/7f/3//3/AAACAAIAAAD6//H/6P/f/9f/0//R/9L/1v/c/+f/9f8FABUAIQAoACkAKAAhABQABAD0/+X/2v/V/9b/3f/p//n/BgASACAALAA3ADwAPAA7ADUALgArACAACwDz/9z/yP+8/7T/rf+r/67/t//K/+L/+P8GAA4AEQAOAAUA9v/n/9r/0P/L/8n/z//f//b/EAApADoARgBNAFEAUgBNAEEAMAAfABIACgAFAAAA+f/y/+v/5v/j/+H/4v/m/+z/9f8BAA8AHgAsADkAQgBDAD0AMgAnABwAEQADAPH/3v/O/8P/vP+z/6r/pf+n/7D/wP/W//D/DQApAD8ATABOAEgAOwAnAAsA6//O/7r/sP+v/7H/tf+8/8n/2//s//r/AwALABMAHgAqADMAOAA6ADkANgAsAB8AEQAGAP//+v/2//X//P8JABgAJAAnACMAHAAUAAoA/f/v/+H/2//d/+X/7P/v/+//6//j/9X/wv+v/6L/nf+h/6v/uv/O/+n/BQAdACkAKAAhABoAFAAMAP7/7f/h/93/3f/d/9v/2v/g/+r/9v8AAAgAEwAlAD0AUwBcAFoAVABOAEkAPgAvAB0ADQAEAAUAEAAYABwAIgAqADMANwAyACYAGwAYABsAGwAXABAADQAUACAAJQAeAA0A/v/7//7//P/v/9n/xf++/8L/zP/R/9X/4v/6/xwAPABXAG0AfACBAHgAYgBMAEQASABPAEUAJAD2/9X/x/+1/4j/Nv/e/rT+yP4M/2P/q//h/xQATwCLALIArwCBADcA7f+x/4j/d/99/5H/oP+e/5D/i/+f/8H/2v/X/8X/wf/m/zEAgQCxALMAkQBpAEgAKgAFANn/rP+I/3r/if+3//r/PQBrAHsAdABqAG0AfACHAHsAVwAzACQALwBEAEoAMgAEAM//pv+T/4//k/+W/6H/uf/f/xEASAB5AJYAlAB1AEoAJAALAP3/7//a/8D/sP+2/8z/3//Z/7f/jv92/3//pf/X/wcALgBRAHQAkwCkAJoAdwBFABEA5f/K/8b/2P/w//7/+f/s/+H/3//e/9X/w/+u/6v/xP/5/zIAUwBSADwAIgAKAOr/wv+Y/3n/bf9y/4v/tv/r/yMATgBbAEYAGQDv/+T/8v/9//L/4P/k/xAAUwCJAJQAcwA/ABQAAwALAB4ANQBOAGgAfgCJAI4AjwCHAGUAIQDM/4z/hP+y//H/FwAXAP//6//q/+3/2f+g/1r/Mv9G/5D/8v9MAIwAqwCrAJgAfwBlADwA/f+y/3X/YP+C/87/HQBCACcA5f+u/53/qP+w/6P/jP+E/6L/7f9QAJ0ApABYAOD/ef9G/0b/Vv9b/1P/XP+V/wEAcACoAJEARgAFAOz/6v/m/8//vf+//8r/xf+p/4H/Yv9l/4j/tP/V/+f/+v8fAEYAVABDAC0AJwAqACYAIAAxAGQAngC0AJIASgADAOP/9v8oAFEAXQBfAIEAywAWASwB+QCXACcAyf+W/53/1P8XAEQAWQBrAIwAtwDRAL4AdgAHAKH/ef+o/xUAggC8ALQAgQBMACsAFwDy/6D/Kv+8/pT+xP45/8D/KABQADUA7/+u/4//if94/0H/9P6+/tb+Rv/k/1cAWADy/3b/Pv9X/4X/h/9Q/xz/L/+b/zMAqQDGAI8AMwDq/8j/xf/V//D/DwAfABUAEQBBAKQA7QDLAEEAtP+H/9X/XwDCAMEAbAAdAC4AngAGAfQAcQDt/8H/5P8MAB0AJQAuADIANABIAHEAkwCOAHMAVQAvAAsAFgBwAN0A9QCiAEMANgBiAGYAEwCb/0T/NP9x/+r/bACyAKkAigCCAHwARwDo/5n/ev9s/13/Zv+g//X/JgALALv/af85/zn/XP+G/6T/vf/k/x0ASgBFABwA8f/J/4n/J//S/sD+Bv90/7z/uf+C/1b/aP+q/+L/4f+y/47/o//w/1EAnQC4AKcAfgBIAAoA1P+4/73/zP/K/7T/pP+x/9v/EQAzACMA3v+P/3T/of/t/yIAKgAXAAkAFQBFAIMApACPAF8ARgBKAFEARAAnAAkA8//t/wcAOwBrAIQAjwCVAIUAUQALAN7/0v/H/8T/6/9MAKsAxwChAGQALgD9/9b/wv+x/5P/iP/Q/2gA5gDqAIsAKAD8//b/+v8BAP3/3f+8/9b/MgCJAIwAPQDV/33/R/9D/3b/p/+V/03/Nf+J/xYAcwBuACQAwP9j/zH/Qf97/53/mf+Y/8L/CgBCAF4AYgA7ANz/gP+G/wwAsAD9AOUAsgCXAIgAcABIAAoAo/8q//b+Rv/t/3UAlABYAPj/pv+O/8r/JgA+AOL/cf96/yAA4gAqAdsASQDW/6T/tv/7/0YAXwA8AB4ARwCzAB4BQgEWAaIABwCG/2z/vP8HANn/Vv8W/33/OACmAIIABQCK/0L/Q/+T////MwAdAAYANACJAK4AhwAyAMb/NP+k/n7+8P6i/xAAJgAzAGsAnACDABsAkf8I/6b+nv7+/of/6/8lAGcAswC7AFkAv/9A//z+7v4s/8L/hQAWAUIBJAH0ANIApABOAM3/SP8I/0D/6P+fAPwA3gB+AC8AEgAEANb/lf98/6r/AwBJAGYAawBnAFQAKwD4/9f/2v/9/y0ASQAyAPP/vP+2/9P/2f+4/5//1P9SAMAAzQB0APf/k/9X/z3/Qf9Y/3f/nv/m/1AAngCRADUAzP+H/2D/Uv95/97/XAC2ANgA0QCsAGkAEgC9/3r/Tf9J/33/2f8nAEYARgBHAEsAPAAOAND/jv9p/4r//f95AKAAbwA/AFgAkgCLACgAqP9W/0f/d//a/1kAvwDhALgAbAAjAOr/xf+4/7H/kf9a/0j/lf8kAIgAdAAUAMD/mf96/07/Tv+k/zUAvAACAQYB2wCdAGAALAD5/77/iv97/5//7P88AGUAVgARALf/a/9O/2z/sP/h/87/lv+a/wIAeQB5AOD/Lf/0/kv/zf8XAAsAwv96/3f/2f9sAMAApABDAPP/0P/M/+T/GwA7AAQAgv81/4b/OQCmAGsA1P9x/3P/sf/9/0MAZABSAEIAeQDfAPIAfgDz/9X/CQAkACEAWwDWABwB6gCUAGcAPQDj/5X/ov/m/woAHwB3AP4ANAHeAFIA7/+d/zb/8P4N/3b/2v8pAIMAxACeAB4Aw//M/+n/tf9L/yv/lf9PAPEAMgH7AF8Aqv9H/1z/n/+v/4D/Yv+M/+L/NwCLAN4A8wCBAK3/Cf/8/lj/sf/L/67/cf8w/yz/ev/C/6T/Pv8Q/1n/0P8oAGcAoACuAIMAWgBpAH8AUADs/6b/nv+///H/IwAdALn/T/93/ywAswB/AOP/mP/h/3MA+QBGASABggDR/5v/4f8SANP/af8x/zH/bv8XACIB3gGYAX0AhP9d/9b/TgBiABoAyf/X/3MAPgFsAZMALv84/jb+2v6A/9T/+P8jAF4AhwCHAGIAHwC6/z7/5v7w/mH/AwCJALEAYwDB/zn/OP+4/zcARwDz/6j/qP/f/yEAUQBXACIA0P+p/9D/FQArAAYAzv+d/4D/iP/P/zkAgQCBAFAAEgDQ/5r/k//M/xkAOgApABgANwB7AKYAiAAhAKT/Xf97/+r/XACSAIYAYgBKADQACgDS/6n/nv+m/7r/9f9iAMwA5QCXAB8Avf+P/5T/zv8lAFkASwAqADoAaQBtADIA9P/d/8v/tf/S/0UAwADgALIAhABiAA8Akf9P/3H/rP+6/7L/uv++/6r/qf/d/wQA0f+A/3//wP/U/6L/nv8IAIIAlwBtAFsAWAAuAPz/DQA3ABYAzv/t/44ABAHPAE4AFgAaAPD/n/+L/63/nP9Z/2T/5/9OABoAtP+z//z/+P+I/zP/Tv+d/9j/EABkAJwAggBXAH0A0QDIAC0Ad/8u/07/j//n/3wAEAESAVoAdf8L/yD/UP9h/2T/Yf9X/4b/LAD5ACgBagBi/+T+Ef99/+L/SQCcALAAmgCfALMAfwD+/6H/sP/x/yEAXwDBAPcAuQBDAPv/zf9u/xj/T//u/0QAEADn/zAAiAB8AD0AKAAPAJP/Bf8N/6v/LgBAAEUAiAC/AJgAUQA2ABIAnf8j/0L//f+wAPQA5QCsADYAnv9V/4b/wv+U/zD/If+I/w0AcQCzALoAUgCe/yr/Uv/Q/yQAIAD3/9v/0f/Y//L/CwD8/8X/pf/U/0EArgDhANMAnwBDALf/Kf8G/4X/VADYANUAlQBdABIAlf8i/wf/J/85/1X/0/+pAEYBTgHnAF8Ar//e/lD+ev5G/x4AlgC3ALoAqwB4AB8Au/9a//L+nv64/nD/bgAIAe8AfQAeAN3/nf96/5r/yv+7/4X/kf8CAH4AxwDzAAIBrgD//4P/nP/n/9H/ef96//T/cQCdAKgAtwCdAEkAAQDp/77/V/8a/3z/QAC7AL0AoQCdAH0AGACt/4D/d/9v/47///+TAOIA1QCmAHwASwAYAAcACQDc/3L/Kv9P/7r/EAA9AGIAbgA9AO3/2v8BAAsA0f+q/+P/QwB0AIEApAC4AHEA5v+H/3D/Uv8R/xL/k/8wAFgAEQDc/+v//f/m/+P/GwBFAAkAl/9l/5n/6P8DAPz/9v/j/7f/rP/0/08ASQDT/3H/hv/x/1MAhACHAE4A9f/j/00AugBuAID/yP7U/m//EgB7AJUAUgDv/+z/XwCkAD0AnP+V/zcAygDiAL8AmAA0AJL/Qf+l/0kAZQD2/7T/DAClAO8AvAA7AKD/Nf9N/9z/VAAvAKf/ff8IALYAxgApAGv//P7m/hH/hv8nAJYAlwBWADoAZgCyAMkAXgBn/2T+LP4e/6IAlgFmAWUAWv/U/u7+Xf+l/4j/OP8u/6D/WwACAUoBEgFPAE7/pP7K/rH/owDvAHUAzf+1/0kA2wChAIz/Wv7w/ab+GwB4AewBRgETADX/Hv+N/wEAKQAKANL/t//f/1YA5QAcAaYAmv+w/p7+f/+0AHgBggH8AD4Awf/h/38A5ACGAMv/d//A/zMAcAB6AEkAwv8l/wz/rv99ANsArQA4ALf/Z/+R/zMAqwBfAIv/Cv9W/xEAjQBxANj/If/S/kj/SgAcASIBiwD9/9L/7v8aADkANgD2/57/hv/P/zwAewB4ADkAv/8w/wX/g/9SAMsApQAxANH/oP+f/9//SABoAO3/MP/u/n//fwAsARQBSwBc/wL/kf+gAFIBJAFUAJH/V/+h/wsAMAD3/57/af92/7b/CQA9ABoAqf9P/2r/4v9aAIwAZAD8/4D/P/9+/xsAmQCTABkAlP9d/37/0/83AHoAcwAcAMv/8v9/AOAAqAATAKT/df9T/07/o/9DALoAwQCHADcAuf8Y/8T+H//r/5cA1gDNAKIARwDV/6f/5P84ACoAvv9n/4D/+/9+AMAAnwAeAIb/SP+h/0AAmwB2ABQA3v/q/xEAQABrAGcADgCF/x7/Df9J/8b/WgCpAGoA6//M/ysAeAAxAJP/OP9h/+X/fwDnANkAZwAAAO3/9//T/6L/sP/o//r//f9UAP0AUAG+AJ7/0v7k/pn/QQBTAND/Pv9B//j/xgDdACYAVv8Y/2r/zP/1/wUAGwAjABQACQARAAcA4P/B/67/f/82/0H/4f+WALEARADz//n/AADS/7L/y//S/7D/0/9rAO4AtgDk/zn/KP+p/2IA1wCUAMf/Rv+c/1gApABlABQA8v/U/8b//v9WAHEATQA7ADoA+P+c/8D/bwDNAEgAg/+A/0AA5ADUAFEA1f+T/6b/IgCzAMAAIgB8/3z/+/9PADcABADg/5z/Q/9f/ycA6ADQABkApf+6//n/OwC0AA4BowCq/1v/JgD9AM4A4P8s//7+If+g/3AA1QA+AFT/G/+E/53/M/8F/3f/CQBVAJkA4wC5AOT/Af+y/ur+U//e/3cAuwB0ABwAMwB9AGQA1/9g/2H/zP9uABABRgHKAOz/V/9I/2D/Wv95/wkAuQDzAJoAAABp/9T+dP6y/pD/dADoABYBSAFAAZsArv85/13/jf+W/+b/nQAmASYB9ADQAFMAYf/S/kf/CwATAJv/ov9GALAAkgBrAFsA7P82//7+aP+R/wD/pP5o/60ALAGrAAEAm/9G/xj/hv95ABQB1gBIABEAJgA7AFIAcAA5AIb/7v4e/9f/RAAUAL7/qv/E//j/XAC7AJUA3v9D/1X/5v9bAHIAQgDn/4//jv/1/zwA3/8k/9D+NP/5/7YANgE6AZQAt/+T/2IAOAEqAWoA0P+f/5T/wf9hAPUApgCQ/+b+Xv9AAJkAZQAwAA4Axv+k/xEAswC9ACQAwP/1/zgADgDV//H/BgCr/1z/yP+YANIATgDd//L/HwAJAPr/HAACAIr/XP/n/4sAdgDZ/3//hv9o/yD/Qv/u/3YASwC3/0z/Uv/B/3AA8AC9AOz/Uv+D/zEApACaAE0AAQDU/9z/CAAcAOX/jf9s/5P/3v8qAGIAWwDr/1r/Mf+u/0MAQADA/3r/2v+PAAYB/wB0AIz/wv7I/rL/tQAEAbYAWAATALz/iv/i/4MAmgDz/13/f/8MAF4ATQAMAKz/Tf9k/xgAxgCyABAAqv+v/6f/d/+j/1QA3wC3ACcA0//c/xoAlAAaAe8Av/96/nr+v//zACoB2QCgAFoAvP81/1z/7f8lANn/jv+Y/8v/GgCiACwBGgE8AD//3v4p/6f/FwBvAIEALgDY/wgAoQDnAHIAnP8D//D+Zv8rALoAhwC+/zn/fP8ZAGYAOQDZ/3n/Q/90//X/PAD1/5P/ov/w/+T/h/96/+j/SQA5ABEALQBGAP7/p//D/zgAfwCAAJYAsQBPAH3/Fv+d/2QAdADU/0X/NP99/wYAywAwAZEAVf+y/in/9/9VAGoAjAB+ACMAAgBbAHsA2P8l/1b/GQBrAEAAWQC0AJIA+//J/wwA1/8C/7L+j/+5ACAB7QCaAPT/5P5Q/hn/oABUAbkAuv9L/4n/JwDYAC4BuQCr//r+V/9wAGABjgEYAVQAlf8q/1j/AwCTAH8A2v9C/zj/vf9WAGoA2P8r/xz/zP+VAMIATQC4/23/iv8LALEA4gBPAID/T//U/z8AAgB7/0X/dv/g/3wALAFYAZQAbP/a/in/tP8VAHAAxACaAOD/R/9Z/9H/+v+1/1v/GP8B/1X/MAAEARABRwB7/1f/wP8yAGIAOgC5/zD/Rv89AGQBpgG3AGn/sP7S/pj/qgByAVIBVgCE/8b/sgAKAV4Aef8q/2P/1P96ACIBFgEJAMz+dP4X/+b/WQCHAIYAOwDb/+L/XwC2AG8A1/+S/9L/QgB/AGcAFADG/8D/FAB4AIoAHABo/wP/Z/9kACIB9QAgAIP/dv+a/5v/j/+a/5j/cf9T/2v/l/+g/4n/dP9m/2n/pv83AN8ALAHgACEAev9M/4r/3P8YAHUA8wAWAX8AkP8Q/yj/Wv9Q/0z/nf8+AO8AYgFAAVwAOP+4/jD/BwBtAFsAWQCXAKkARwC7/3D/ev+z/w0AgADZAPAA0QCWAC0Amv9C/4//SgC6AIoAOgBaALwApgDT/+D+lP4j/yQA/gA8AcQA9v91/5n/+/8RANj/w//+/y0AIgAeAE4AYQAOAKX/mf/b/w4AGwAwADUA5P9d/yf/fP/2/yUACwD4//n/5P+8/77/+f8XAOT/mf+V/9v/FwAaAP3/5v/T/8L/4v8nADsA6f+D/5r/NgC/AMAAaQAeAPb/6f8EADUALgDd/8P/NwCzAGwAgv/4/m3/VAC+AHYA7/+V/4P/s/8cAIMApgBqAPX/jP9x/9P/kgAYAcoAtP+q/pT+mP/sAH4B1gCB/6b+/v4QALQAQgBT/+j+Yf9ZADABbgHPAI//kP6o/qH/hwCqACUAiP9K/7H/qwCaAawBqgA5/zj+KP78/kUAUgGIAfUAPQDy/wYACACd/+b+bv7I/u3/KgGsAUoBdwC3/zX//P4V/4D/EACLANEA2gCrAGgALQDu/5b/Pv8x/6P/dgAoATwBjwCE/7j+mP4r/x4A5AAKAZYA+/+h/5j/tv/S/8X/jP+A/wUA7wBuAfgA5/8E/6L+xv5s/1oA/wD6AKUAhgB4APf/Ov8S/7f/awCFAEcAQABSAAUAhP9p/7z/4/+Z/2f/uf8wAEQAEQD4/+T/nf9i/67/TgB/AAUAiv+p/yoAeABQAPP/qv+Z/9v/TgCSAF0AxP8i/+L+J//I/2IAnwCEAEoABACk/0v/Rv+x/zoAhQB7ADEA1v+q/+3/cgCvAF8A7P/n/zgAZABMAEIAdwCpAJEATwA5AFQAbABeACgA1P+D/23/tP8WACUAy/98/6z/SgC/AJAA6f9p/3T/9/+MANUApgAjAMH/0f8NAPP/lv+N/xQAnAB/AOX/e/+R/9X/5f/G/9D/JwCZAMwAiQDr/1n/Mf91/6z/d/8W/zb//P+vAJMA3v9q/5H/1//A/4T/of8MAFkAWgA5AA0Aw/+P/8r/RABpAAcAsv/a/yMADQDU//r/awCkAIEAYwB3AG8AEQCQ/0j/Z//k/4oA6gCqAPH/Xv9k/9r/SABZABMAvP+p/woAogDkAJYAEwDO/9D/1//R/+D/BwAtAFcAggB5ABEAov+l/wMAIgDM/5X/+P+gAOsAuQBBAIL/iP4G/sr+bgB8AQwBy//u/sD+2P4Y/77/kwDxAKIAJAD2//n/5P/T/woAXQBaAP7/y//8/ycA6P94/1P/gP+0/+P/PQCcAIoAAgCT/53/3v/6//T/CQA8AGsAlACkAGMA2/+B/5f/vv+K/1D/tf+VACoBCgGRAB4Apf8//0j/1/9hAHgAaQCLAJgAHgBi/xr/df8KAH8AvACeAAoAa/9r/wcAlQCKAB0AyP+9//7/cwDEAJYA//+B/1b/TP9M/6T/cQAoASABXgCB//r+1P4F/4D/FwB7AJIAigB0ADoA8P/U/+n/4v+y/6f/8/9MAFwALwD2/7//qv8FAKwA4AA7AGD/PP/Y/28AgQBKABQA8f/r/xgAVgBYABMAxv+b/3f/Tf9W/8H/WQCiAFMAwf+a/ykA5wACATUAG/+I/tD+qv+UABgBAgFvAMP/X/9T/3//sv/W/9n/yf/Z/yEAeACdAHcACwB1/wP/JP/r/70A6ABeAM3/sf/f//f/2/+//8j//f9gANYABAGgAM3/Hf/4/kn/zP9SALwA2gCPAAYAj/9i/4b/zf/1/+//8v8zAIcAfwAHAJD/k//9/2MAiwBwABEAi/9S/8L/mQAMAasAxP8E//L+rf/JAGoB8gCt/7D+wP6i/5QA6ABtAHv/1v4i/y4AEAEWAWcArv9c/37/7/9iAG8ABQCK/4H/+P+QAOYAxgA0AGz/3v7+/s7/yAAsAbEA0v9x/9//kgC/ACgARf/C/vj+yf+wAAwBmAC1/yf/T//c/ysABADH/83/+/8DAPb/EwBHADwA4/+X/5X/s//F/+3/PABnAC8Ayf+h/7T/uP+i/7z/EQBLADgADgAQABUA3/+O/3//zf80AHgAowC6AJYAOgDm/7j/jf9l/5r/UwAUATwBvQAMAJP/a/+T/wEAagB0ADEADAAlACAAwP9X/2n/6f9VAFsAHQDW/5//rv8fAKUAswA2AL7/0f9PALsAwwBpANv/Xf9B/6H/MAB5AFIA9v+t/43/jv+y//j/OQA4APT/sv+4/wIAYQCwAMsAcgCP/6j+dv4a//n/eAB+ADkA0/+W/73/HgApALf/Uv+H/z4A5AAUAdQAWADa/5T/kP+j/6v/yP8TAGAAdABPACEA3P9m/xH/X/9KACABSgHhAEwAyf98/5b//v8wANj/Yv9//ysArQCUAB8Ao/8p/9b+IP8tAEwBlgH2ABUAlP+c//v/XwBmAPz/mf/E/1sAnQAjAFT/3P70/nD/FACqAPYAwwAfAF3/3P7k/nb/PQCzAJEADQCj/6r/AAAoAMv/K//y/n3/ZwAEARIBugAlAH3/Nf+q/5EA/ABxAHz/A/9U/wwArADLADkAQP+2/jj/ZgAkAcAAvf8Y/07/FQDeADYB6wAOAA7/nP4m/08ANgEoAUUATf/+/nr/SwDTALkAFwB1/2n/GgDmAPQAJQBJ/z3/7f+UALkAfQAeAK3/W/+J/zYAwwCoAA4Alv+M/83/LQB/AHwA+P9N/yD/pf9XAIgAIQCf/3z/v/8YAEkASAAWALL/Sf81/6D/TwDUAP8A2ABtAOb/kf+V/7P/n/+O/+//rQAaAcUAAwCC/4T/zf8GAPz/r/9h/23/+f+pAPgAvQBBANr/nv97/3T/q/8XAGgAWADy/6P/wf8uAIUAbwD2/3T/SP+V/yoAmgB/APb/if+g/w0ARwASALH/hf+m/+f/IgA8ACcA5/+k/5P/xP8NADgALgAYACAAQQBVAEoAIwDj/5P/YP+J/woAlwDRAJ8AJgCj/1H/Uv+n/xoAawCDAHMATQAUAM3/lf+I/67/9v9GAHcAUQDd/3//mP///zMAEgD//0sAtAC4AEUAwv+E/5T/2P81AIoAowBqAPL/dv8y/0b/rP8yAIMAXQDP/0j/OP+l/ycAZABwAHYAZgAGAGr/Ff9g/w4AnQC7AHYACACv/6L/4f8uAD4ACADI/7X/5P8+AJoAwQCGAPD/Wf8p/4X/JACDAFkA4/+i/9j/QABUANn/OP8c/7j/mAAWAegAPAB//xj/QP/g/4kA0QCSAP7/ZP8Z/1H/9/+HAHsA2P9A/1H/9f+PAJ8AQADl/8n/1f/i/+r/7P/h/9T/4P8IABUA6P/F//H/PQA+APX/1P8eAH8AmAB6AGEAPwD5/8H/0P8FAAgA3//d/x0AUwA6APP/u/+V/3r/hv/L/yMAXQCAAJgAfwANAIX/a//Y/1YAYgD+/6//3v91AAIBCgFxAJ3/IP9S/woAyQAQAcEAEQBl/wH/DP+E/0MA2QDNABYARP/6/lX/7P9QAFcAFgDB/6z///9wAIIAHwCs/4T/m//A//L/KgAxAPb/xP/o/z4AYgAtAN7/t//Y/zEAgQBrANX/N/88/+r/iAB2AOD/bf98/+T/UgCHAFUAyf9S/2f/FADRABIBxQAWAFH/5P44/zQACgHxAAIAJP8Q/7X/ZwCTACcAlv94/wYA4gBMAd4A7/9C/0n/y/89AFIALgAaACQAHgDy/8D/s/+w/5H/aP9t/73/QwDFAPkAnwC5/9D+kP40/zcA5QDlAGoA3v+I/4L/uP/t//D/2P/r/0kAuADYAIcA9P9q/yb/Q/+3/0wAsQC5AGMA2/9T/wX/Hf+a/zUAjQB6ACUA6P/1/yYANQAEAMH/s//y/1AAhgBzAC8A7//e//X/FgAkAB4ADQD2/9z/2f8CAEAAXwBEAAoA1//C/8v/8P8oAEwAPQANAPP/BAAfACMAFAAGAO3/zf/X/ykAjgClAGQADADH/3v/M/9C/83/hwDuAM8ATACl/yH//P5I/8T/IQBYAIcAnABbAMj/T/9O/6T/9P8mAFsAiwCJAEsAAwDD/37/V/+X/z8AygC6ADUAuf+A/3T/jP/d/0EAXwAyABkASgBmABIAlv91/7r///8HAAgAMABXAEUA//+y/3z/bf+m/y8AuwDbAGoAw/9m/3T/s//0/0UAnQCrADkAk/9I/3r/2P8VACkAHgDz/83/8/9hAKAATgCz/2X/kP/p/yoASgBPADMACgAAABAAAQDB/5P/tP8SAG8AqQCxAHEA+/+T/3H/ff+J/7T/LgC6ANIAVAC2/2//ev+k/+P/OwB4AF0AEQDv/wkAGwD+/+T//P8tAD8ALAASAOz/sP9+/5f/AgBuAJEAZgASALX/cP9u/7f/DwApAP3/zf/L/+//GAA2AD8AIgDe/6L/pv/p/ywANgAQAPH/+v8dAD8ATQAxAN3/fP9W/5L/CwBwAJwAlwBfAOr/Z/83/4r/FgBnAFwANAAgAAoA3P+8/8r/4v/S/7n/4v9HAIgAbQAfANn/of97/4z/6P9fAJgAcgAaAMr/o/+q/8z/8v8FAPH/x//B/wkAbwCNADQAsv9v/4H/wv8NAE0AYAAzAOv/zv/0/yUAOwBAADwAGwDo/93/FwBbAFUAFgDw/wcALQAqAP//0f+2/8P/+v82ADgA7P+U/4n/2f8/AHwAgABdACQA4P+w/6v/y//6/y8AYQCBAHAALADZ/6T/pf/b/yUAVwBQAB4A8v/j/+n/6//p//D/9P/q/9r/3f/k/9T/tv+2/+b/EQASAAYAFwA0ADAABADV/7r/qP+l/9r/QQCKAGgA9P+Q/3b/j/+6//3/VACBAFIA7/+z/8j/CAA1AEMAPAAcAOf/y//q/yIALgDz/7j/u//4/zoAVQA9APv/vv/M/zoAqwCbAAoAf/9o/7v/IQBZAFUAJADy/+7/FAAdAOT/rP/O/0IAmgCWAFwAIQDj/6H/jv/U/z0AXwAfAMz/s//M/9r/wP+T/33/nP/v/00AbQAtAL7/jf/Q/z8AZQAqANj/t//H/+D/+v8XACEA+/+3/5f/xP8lAG8AYADt/2D/Mv+h/2kA8ADXADkAjv8+/2L/z/81AFYALQDq/8X/1P8JAEEAXQBBAPX/sP+6/yIAlgClADcAsv+W//z/eQCQACQAhP8o/1f/BQDHAAwBnwDW/0//Yf/d/2UAqwCVADkA0v+n/93/SgCSAG8A7f9s/0z/p/87AKAAmgAyAK7/Yv+B//H/SwA6AOP/qP+7//v/MQBBABwAxv9z/2//0f9TAJoAggAmAML/lf++/x8AYABCAOL/m/+o//r/SABSAA0Ar/+J/8L/MAB5AGIACAC5/6P/yv8RAEYARQAMAM3/vv/e/woAJwAvACEA9v++/7P/6/86AGEATAAcAPb/4f/i//v/IQAmAO3/n/+Q/+L/YgCpAH0A+f91/0//mf8aAHEAZwAVAMj/uv/k/w0ACADf/8P/zv/7/zEAWABZACUA1v+u/9H/GwBWAGoAVwAmANv/nv+f/+H/JgA1AA4A3P/F/8r/5v8TADIAHgDU/5P/o//2/0kAZwBXADMA+f+y/4v/rP8FAF4AjQCHAEkA3/95/1v/ov8fAIEAkwBZAAEAsv+Q/6P/3f8YADEAJQALAPz/AQAFAPv/4f/H/8X/6v8qAFoAVQAbANL/sf/O/wYAMAA0AB8ACwAEAAEA+f/z//3/FAAiABUA/f/4/wUADAD1/9D/wv/f/xwATABFAAEAt/+q/9j/BwAKAOz/0P/H/87/6/8aAEAANADq/5L/cv+s/x4AeAB9ADYA4P+9/9//HAAtAAMAy/+6/9r/BgAXAAwA8//b/9D/2//6/xIAFQAJAP7/9//x//r/IwBQAFIAJQDw/9n/3//s//3/FQAlACcALQBEAFwASAD7/6v/nP/r/14AnAB1AAkAqP+F/6X/5/8jADgAHgDt/9X/5v8CABMAGAAcABwAEwATACoAQAAtAO//uf+///r/OwBMACQA2/+f/5v/1/8lAEMAGADR/6//y/8FADEALgD6/7T/kP+3/xUAXQBPAAEAt/+Y/6j/3f8nAFEAMADf/7X/3P8mAEwAOAAAAMv/tv/c/yQASQAkAOT/0f/3/yQAKQAPAPj/8v8CACcARgA+AAoAzf+4/9r/GwBNAE4AIADj/8b/3v8TADQAIgDq/7n/uP/t/zkAaQBeACQA4/+//77/0v/u/w8ALQA9ADkAHwD7/9v/yf/W//r/IAA0ADUAJAACANH/o/+Y/7n/7/8ZACMADADi/8L/wf/U/9//3//x/x0APgAzAA8A8//s//H/AQAeAC8AGADt/9b/4f/0//T/9/8QAC4AMgAXAPn/3//J/8L/3P8VAEMAQQAYAOv/z//F/8r/4P/8/xEAHgAoACcAEgDz/+X/+v8gADUAMAAaAAEA7f/m//b/GgA7ADoAFADk/9D/5v8QACgAGgDz/9X/2f/7/ycAOwAjAOr/u/+8/+j/HAAyACIA/f/Z/8n/4P8VADkAJgDs/8H/x//v/x0ANwA2ABkA8P/d/+//DwAfABcACgAFAAIA//8EABAADwDz/9f/3P///xwAGAD//+n/4//q/wEAHwAqABYA+//z////CwAIAAIAAQD8//H/8f8HACIAJAAGANv/xP/W/wIALAAzABAA3P+9/8X/5/8LABoADwD6/+3/7v/1//n/+f/6//7/CQAZACMAFwD6/+X/6P8IACYAIAD2/8f/vv/l/x8AQQAxAPb/uP+l/9D/GQBOAFIAKADx/83/0P/0/yEANgAkAP//6P/v/wwAJQAhAP3/0f/H/+z/IgA9ACsA/P/Q/8L/3f8WAEQAPgAGAMf/s//R/wQAMABAACgA8//G/8T/7f8YAB8ACADw/+r/7v/5/wgAFAAUAAUA9P/y/wAAFAAcABIA/v/u/+z/+v8NABMABwD1/+z/8v/+/wUABgADAPz/9v/1//3/CQAQAAoA+v/r/+v//v8XACQAGQACAO7/6//7/xMAIwAhABIAAgD9//3//f/6//b/8//w/+7/8f/2//X/6//b/9L/2f/v/wYAEAAJAPb/6P/s/wAAFAAYAAQA6v/e/+j/AgAYABwAEwADAPf/8//2////CwAMAAMA+P/1//3/CQATABMAAwDq/9n/4P/8/xAADwABAPX/8P/r/+3//f8UACMAIwAbAAwA+v/v//f/DwAeABwAEAALAAwACgAEAPz/9P/r/+7/BgAfACQAEQD3/+v/9v8KABUADQD9//H/7//5/woAEwAMAP//9f/4/wQACgAGAPr/7f/u//z/DgAXAA0A+//s/+n/8f/3//v//v8DAAkACQABAPf/7//v//b//v8DAAYAAQDz/+n/7v8CABcAGAD9/93/yv/U/wAAMQBFAC4A+//T/9H/7/8SACMAHgAOAPv/8P/0/wMAEAAOAPz/7v/0/w0AIQAfAAcA6v/g/+7/CwAkACYADgDx/+L/5P/x/wAACwANAAQA9//z//z/CgARAAwAAgD9////CQAUABgACwD2/+v/8v8BAAkABAD4/+7/6v/w//v/AgD6/+v/5P/r//v/BgAEAP3/+f/5//v///8CAAEA+//z/+//8v/+/wwAFgAUAAcA+P/t/+z/+P8HABEADwAHAP//+//5//f/9P/y//H/8v/4/wAABQABAPf/7//x//7/DAASAA0ABQD+//z//v8EAAwADwAMAAYABAAIAA4AEAAQAA0ABQD6//X/+P8AAAgADQAOAAoA/v/y//H//v8MAA4AAQDy/+z/8/8CAA8AEgAIAPj/7f/t//T//v8GAAgABQD9//n/+/8CAAkACgAFAP7//f8BAAcACQAGAAAA/P/+/wUACgAHAPz/8//z//7/DQAUAA8AAQD0//D/9/8DAAkABwABAPv/+P/7/wEACgAMAAYA/f/6/wEACwAPAAYA9//v//L/+/8EAAYAAgD6//T/8//1//n/+//6//r/+/8BAAkACgAEAAAA+//6//z///8CAPr/8v/5/wgADgAGAPX/5f/h/+3/AgAWABkABwDy/+z/9P/9/wIABwAKAAkABAD//wEABgAGAAEA/v8AAAQABwAIAAUAAAD6//b/+v8DAAsACgABAPj/8v/y//f/AQAKAA0ABwD+//r//f8CAAMAAQD+//3//f/+/wAAAwAGAAYAAQD5//b//P8GAAsABgD8//b/+P/+/wIAAwABAP3/+f/4//n//P/+/wAAAQAAAP7//f/9//3/+v/4//j//v8GAAoABwABAPv/+f/8/wMACQAMAAsACAAHAAgABwADAAAA//8AAAAA///9//3//P/4//T/8f/y//X/+P/6//v/+//8//7/AQAAAPv/9P/x//X//P8DAAUABAABAP3//P/9////AAD///3/+v/6//7/BAAJAAoABAD6//T/9v/9/wMABAAAAPr/9v/1//f//P8CAAUABQADAAEA///+////AwAHAAgACAAJAAoABQD///3//f/9/wAABQAIAAQA/v/8//7/BAAKAAsABwABAP7/AAAEAAUAAwAAAAEABQAKAAwACgADAPz/+v/9/wIABgAGAAQAAwAEAAMAAQD9//r/+v/+/wMABAAAAPz/+f/8/wIAAwD///r/9v/3//3/AwAHAAcA///1//H/8v/5/wMACAAFAP//+v/4//z/AQADAAEA/v/9////AQACAAAA/v/8//3//v8CAAQABAAAAPr/+P/6////BAAGAAQAAQD+//7//////////v//////AAAAAAEAAAAAAAAAAgADAAMAAwADAAQAAwADAAMAAwAEAAQAAgAAAP7//f/9//3//f/8//v/+f/5//r/+f/4//j/+v/+/wEAAwACAAAA/P/6//n/+//9/wAAAwADAAEA///9//v/+//9////AgACAAIAAQAAAP7//P/7//v/+v/7//v//P/7//n/+P/6//3///8AAP///f/9//3//v8AAAEAAgABAAAA//8BAAQABgAHAAYABAACAAEAAQACAAMABAADAAIAAQABAAMABwAJAAYAAAD7//r///8FAAkACAADAP////8CAAQAAwABAP///v/+////AAAAAAEAAQACAAEA///+//3//v///wEAAgADAAMAAwABAP7//P/8/wAABAAGAAQAAAD+//7/AAACAAEA///+////AAD///7//v/+//////8AAAMABQAFAAEA/f/9////AgACAAEAAAABAAIAAgABAP7/+v/5//v//P/+/wEAAQD///////8AAP///v////3//P8AAAUAAwD///r/9//4//z///8BAAEA+//3//n//v////7//v///wEAAAD/////AAAAAP////8BAAIAAQD//////v/+//7///8BAAEAAQD///3//P/8//z//v8AAAEAAQD/////AAACAAQAAwACAAEAAAABAAEAAQADAAQAAwAAAP7///8DAAQAAQD8//r//P///wAAAAD///7//P/8//z//P/9//7/AAAAAAAA/////////v/8//z//v8BAAIAAQD///3//f/9//7///////7//v8AAAIAAwACAAAAAAD//////////wAAAAAAAP7//f/9//3//P/7//v//P/+/wAAAgACAAAA/P/7//z//v///wAA//////////8AAP///v/8//v/+v/7//z//f///////f/7//v//f8AAAIAAgAAAP7//f/9//3///8AAAIAAgACAAIAAQAAAP//AAADAAQABAAEAAUAAwAAAAAAAgABAAEAAQACAAAA/v/+//7/AAACAAMAAgABAAEAAgADAAMAAgAAAAAAAwAGAAcABwAFAAIAAQACAAMAAwADAAIAAwAEAAMAAgABAAAAAAABAAEAAAD+//3//f///wIAAQD///3/+v/7////AQADAAIA///7//v//P/9////AAD+//3//P/8//7//v/+//7//v///wAAAAD///7//f/9//7/AAABAAEAAQD///7//f/9//7/AAAAAAAA////////AAAAAP//////////AAAAAP///////wAAAQABAAEAAQAAAAAAAAABAAEAAQACAAIAAgACAAEAAAAAAAAAAAAAAAAA///+//3//P/7//r/+v/7//3//////////v/8//z//P/9//7////////////+//7//f/9//3//v/+//////////7//v/+//7//v/+//7//v/9//3//f/+////AAAAAP/////+//////8AAAAAAAAAAP///////wEAAgACAAEAAAAAAAAAAQABAAEAAQABAAEAAQABAAMABQAHAAYABAABAAAAAQAEAAUABAACAAEAAQADAAUABQAEAAIAAQAAAAEAAQABAAEAAgACAAEAAAD+//3//f/+////AAAAAAEAAQAAAP///v///wAAAgADAAMAAQAAAAAAAQACAAEAAAAAAAAAAAAAAP///v/+//3//f/9////AQACAAAA/v/9////AAAAAP////8AAAEAAgADAAEA///9//z//P/9////AAD///3//f////7//f/+//3//P///wIAAQD///3/+//7//7///8AAAAA/f/5//r//f////7//f/////////+//7///8AAP//AAABAAEAAAAAAP//////////AAABAAIAAQAAAP///f/9//7//////wAA///9//z//v8AAAEAAQAAAP//////////AAABAAIAAwABAP//AAADAAQAAgD///3//f/+////AAD///7//P/8//z//P/8//3///////7//v///wAA///+//3//v8AAAEAAAD///7//f/9//7///////7//P/9////AAAAAAAA//////7//v///wAAAAAAAAAAAAD//////v/9//3//f/9//7///8AAP///f/8//z//f/+//7//v/+//////8AAAAAAAD///7//f/+//7//v/+///////9//v/+////wIAAgD/////AAD///7///8BAAEAAQADAAMAAQD//wEAAwACAAIABQAHAAUAAwADAAQABAADAAQABgAFAAIAAgADAP////8DAAUAAQD+/wIABAABAP//AgACAP7//f8DAAcABAAAAAEAAwACAAIAAwACAP////8DAAQABAADAAEA/f/8/wAABAACAP7//f/9//7/AAACAAIA///5//X/9/8AAAkACgACAPv/9f/x//n/BwAKAAUA/P/z//D/+v8GAAcA/f/3//z/AAD9//z/BQAHAPr/8P/6/woACwACAP/////6//f/AQAMAAcA+//5/wEAAgD+/wAABAACAP3//f///wEA/////wEAAAD7//v///8CAAMAAAD9//3/+v/9/wMAAwAAAAEAAQD8//z/AgAFAAEA/P/+/wQAAgD9//z//f/6//X/9//+/wQAAgD///3/+f/y//L/+/8FAAkABQD7//T/9f/8/wEAAwADAAIA/P/2//z/BwAIAP//+v/7//v//f8GAA0ABgD1/+///f8KAAQA//8JAAwA+f/q//3/FwARAPz/+/8HAP//8P/+/xwAFAD1//L/BAAEAP3/AwALAAgA///2//P/+/8QABwADQD4//b/+f/3/wYAHAAWAPr/8P/9/wMA/f8CABUAEgD2/+//BgAOAPz/9v8JAA0A9//1/w0ADwDy/+f//v8LAPv/9/8LAAwA8P/l//v/DAAIAAMAAQD5//T//f8HAAgABgADAPf/8P/5/woAEAALAAAA8P/k//H/EgAdAAYA8P/w//f/+v8FABYAEADu/9j/8P8TABQAEAAaAP7/vf/B/ycAUwD9/8b/CAAfAL//vP9eAIcAyf9W/9X/UQAvAAsAPwAsAIj/RP8AALkAbgDM/8f/BADS/5f/AQCfAHQArf9t/+f/PgAjABMAKAACAKr/qf8XAGAAOgAAAOb/y/+8/+z/OgBcADMA6f++/8X/6f8ZAEIAOQD8/8b/yf/0/xYAHwAYAAUA5v/R/+D/CgApACYABwDa/8T/6f8dACgAGgAQAPT/z//W/wsAMgAgAPL/6P/9//v/6//9/x8AEwDj/9b//v8dAAsA+/8GAP3/3P/e/w4ALAAYAPr/7P/h/+D/AQAwACYA6//a//n/AQDv/wkANAAVAMn/xv8YAD4AAADT/wMAIQDm/9X/IwA+AOz/u//4/ywAAgDd/w8AOQD4/63/3v9FADgA0//I/xYAJgDn/93/HwAvAOf/xf8JAEEABwDB/+z/QgAwAMX/qf8jAHsABAB0/9X/kwBPAH//r/+FAEYAWP+w/8kAfABP/4L/oQBmAFD/m//RAKYAYv9K/2QApwC//4b/ZQCEAJL/eP9rAIUAs/+g/1QASgCP/63/dwBlAKf/uf9WABYAc//e/6wAVgCL/7L/PgAPALX/DACCAC4AgP+M/zMAYQDr/9L/TABIAIb/S/81AO4ALABE/8//ggC9/zD/jgB4Aev/Zv5i/9oANwB4//AAnAEA/2j9wf+6AaMA0f+fAA8AQv7g/lIBTgFK/57/QAHP/3z9dv/wAqIB2P0w/ioB8gCw/pv/LAIYAdj9FP4sAaQBWv8h/yQBBAGg/lL+uQDCAQ8A3v7c/7YAzv8l/zsAHAExAA//Vv9KAIAABgADAFwA7P9F/5//TABdAEYAQwDf/3j/s/8tADoAAwAUAEIA//+P/7n/RQBHANn/zP8OABAA5v/q/yAASAAQAJr/kf8RAGUARAAGAOn/5//R/8D/9v9SAFsA/v+//9P/9f8FABYAKQAWAM3/pP8QAIwAOgCY/6D/IwBLAPH/uf8jAJcAEQA//6f/nQB1AJT/pP+RAHMARf9q/+YAqAAC/1n/AAG5AF7/af8pADcABAAhAB8A0//Q/xIA8//T/3kAowB//xv/OgCuAMz/sf+iAI8APv/q/kgAEgEoAHb/GAB/AJ3/Bv8MADIBdwAt/57/ogAMABH/+f8uATUA2P6y/w4BOQD4/tD/+gAVAPr+7//5ACMAOv/n/58A5v9C/wcA3wAdABz/zP/QADMANP+q/54AWgB7/7T/oQBiAGP/lP9eAD8A7f8wAA8Akv/Q/zAAEQA8AIcAzP/e/sX/JAE0ANL+QwDIAYj/hP3y/3ACZwAM/sT/ogHb/yL+TABgAv//cP2j/0QCTAAC/vj/RAJeAIj9uP7QAYAB5v4N/yYBtgCW/tz+AAFKAY7/MP+MAHAA6P5d/y4B8AB1/1b/EgDs/4L/agB6AUcAaP4i/8QATQCG/5kASAHM/2z+FP+aAPMAMgD1/0QA2P/w/jz/ygBqASQA5P5D/2sAswC//2z/qQD6AAv/RP6LAO4BCgCK/vz/TgGo/wj+GwBwAl8AyP2b//4BGQDU/dr/XAJwAKD9c/8wAnIAGv7a/6ABx/9q/iUAegEwAOD+uf+1ANP/H/9uAFYB2/+M/sj/RAFLAKb+o/+6AdAAJv6s/rwBngF0/mz+bAFeAYr+zv6uATQBNP7G/owBCAG4/hv/FgEMAVn/zP4mANcA3f/S/6MABwAD/57/lACWADIAsf+v//b//v+h/4z/zgDUAfn/YP2o/vABXAHO/r7/yAElAIz94P7yAZYBrv5L/yQCIwB4/E3/CAScAeT8RP4gAiQB+P12/9wCDgHs/Dr+5AEgAQz/kACuAbb+eP2hAAQCqf8Z/wwBoAC4/hr/xwDRAB4A/f9M/03/vgC8ABL/pv+wAZMAnP1I/hAC9AFy/iL/CALm/+z8rP8sAwIBpP0S//IBQgDA/VkAoAKb/6j9eACcAU3/0v4cAcAB1P5Y/aMA4AKK/6T9AgGwAU7+iv5+ATAB9v4T/+kA4wD8/ub+BgHJAAr/oP/xAGMATP+U/yEADgD3/0oAcQArAIn/J//2/8EAXAAaADEAq/85/5v/iAA8AUQA3v7A/3MASf+O/zYB2gCp/4j/J/9M/8IAcAEVANT+2/8MAcn/OP7o/3QC0wDI/fz+ugFtAEj+1P+4AX4AhP4j//oA2wBF/2f/6QB2AMb+S/8wAfsASf9A/3UAaAAh/3//WgEUAbz+fP7WADwBZf8l/5oA2QA3/8D+zgB6AU7/oP6tAFQBOP9E/lYAHAKEAFD+Dv8MAQgBFP/u/gQBYgFh/7L+GwAQATYAyP5t/9ABTgHE/Qr+EAI8Agr+4P04AgQC1P3E/TQCRALo/Sr++gGUAbz9xP6QAiwB1P2w/joBvwBP/9n/8ACYAPj+oP4jAEoBlAB5//b/rAC9/5L+5v/sAXYALP6w/wQCJADY/fr/HALA/5j9hgC8AsD/iP31/+gB2v8A/jcAdAIFADj9GP9UAoIBgv5S/tkAHAGu/hX/4AFqAVL+Vv4yATABsv5K/9oBIgFS/rD+ygACASEAz//Y/7v/6P8OAOL/LgC7APb/nP6A/3oBpQCq/lj/eAFJALT9p//wAjgBbP1Q/sABLAEI/jX/JAOyAaz8sP1IAkYBGv76//QCLgAc/I7+eAP0AUj9tv6cAnoA3Pw+/xwDRAHQ/fj+YAGOABr+J/+YAt4BEv7E/QgBgAEx/+b+AgHQAWr/HP4BANoAbv8fAAACAACI/XD/zgFKAGT+hQB8AmT/bPza/3wDFADQ/aAB6AGs/DD9ZAOgAqj9lv5gAvQAAP1i/vgBhAFN/zIAAgH0/fD9XAKMAhb+7P3OAW4BIv50/mwCUAKI/Yj9hAGEAbb+yf+IAr0AmPxA/RgC1AJ2/wb/2wCa/9z9BgAIAg8A2P7PAFYBLP6s/TQCSANG/mT8FAGcAqT+ev74AswBqPw8/bAB0ALs/rD9QAIsAxz9OPwYApQCxv7+/lABvgCo/gr/RAEYAcj+Iv8OASEAHP85AOEAZQBO/0T/sP9w/1kA8gGXAMD9j//mAYr/zP29AJAC6v6Q/ZABoAJg/jz91gHQAqT97Pz8AmgDqPx8/cQDWgHw+7j+OAREAZD7tP5ABUIBgPl1/+gGEQC4+Zr/gAVUASj7pP3QBXgDqPls/EgFnAIE/Pj+6AOcATT8TPwUAtgDPv+0/bQB3AGs/FT85AEQBOsAKv58/j4AHwBc/oQA7ANUAfD8UP1ZAJAC8QCi/rgABALs/fj7CgEoBJoBjP2k/fsAQwAO/hYB9AMm/xz8sf+qAbH/Jv+SAeIBB//0/Pr+bgHRAJwAJAHG/wj+3P5+AOgAsABPACoAff/Q/nL/2gAwAaIAYACe/mD9JwDMAjYBSv/e/7r/mP6a/nwAEAO8Adj9XP67AKz/Jv+SAegBgv8S/pz+lgA8AUAARwCjABD/uP3s/4gBPwApAEgBwv84/Qb/RAIWAWz+vP+YAoEA3PxQ/kgCwgF3/20AYgBc/hj+3QBcA24BgP2s/ZwBdgHA/Hr+MAVsA7j64PowBKAEIPuQ+xgG4ASA+Rj7qAboA+j4VP2wB+AB8Pe0/nAI9AGQ94z94AeeASD4Rf/ACPwAsPcR/4gGJgAA+rgAKAfF/6j47P5ABpUAyPp2AKAEEv+I+xEA8AIcAF7+ngD8AJz9vP2IAmgDL//Q/YIA1ABa/pD+MAJwA38A6P2O/iUA2/8+AAgC1gHG/nz9DACqAakAi/8VAHAA6P70/ar/sALQAtT+6PsI/kYBEgFEADQBOgGs/tz8IP/6AQoBAP8EAegCMv/I+yf/8AQAAwj88PuoA4AEbPys/FgFaARw+dj5UAS4BAT89PwQB0gE8PZI+DAGeAUQ+nz9QAisA8D3CPrgBAgFVP2k/YADSAGI+yT/kAU4AiT88P1WAbb/ev7SAYgEtAFk/Bj7AP90AfMAjgFsApEA7PyA+5D+/AJUAjv/cQB+AbD9kPtc/5AEcASM/mD7VP/eAUb/XAAYBDAC7PyA+2D/9ALWAef/XAJ0Atj7EPoeAYAFbAGo/XMAcALU/Zj6dQAgBnYBQPsq/tgCPP9w/JACEAaQ/vD31P3IBVQCgPwQAaAFfv5I+Dz+qATQAiUABAKuAZD7sPnwARAIxgFI+1D+4gGS/5T9rQBABDgCWPzw+i//SAIIAugBQAL+/vj5kPt0A4AFZv+c/QACJAGA+zD8nAMIBsb/cPs8/jkA2v5SAVgFTAJg+6j6XAAYA5IAu/9QAnQCLv6o+uj89ALoBZACIP0s/Ir/1gBn/8oA1AOWATD8qPzYASQCcP1G//gFNAM4+fD5yATYBWj9cPxMAzQD0PtY+4AC8ASv/3D9EAEgADj7iP04BZAEfP1E/HQAiAD0/BX/KAQsA6T9QPxW/zgBhgC9AIgC6gCA/Sb+SAHWAS4A/P/OARgCqv7A+8L+GAS0A37+TP3pANQA0Pxc/eQCcANe/nj9uQDI/9D79P7gBaQDsPro+TgC6ASH/67+MAQkA/j6SPn+/5gEkATIBKQCYPvA97j9UAQYBLYBCALWAfz8YPk6/rgEuAM4AG3/PP0Y+9z+YAUgBqL/cPnQ+pL/egD7AKAESAWw//j50Pki/mwCgASYBCwCWP2w+lD9WAHUAswC/QCk/bz8T/+6AUgC4AGNAPT9ePvo/EwCMAV4AoL/Lf+4/Vj7rP2cAwgFKAG0/qb+vP0U/Vv/0AJAAz4A/P3U/tf/vf+2AJoBTQA0/vT9TgDkAsgCUgCu/gz+3P0y/wwCiAPiAaf/4P6S/rT9F//EAjQD4P7U/BwAwgGj//7+7QBjAFj9dP0qAfAC3QBS/10AIQDQ/Vj9AQDkAnwCDQCa/mv/ugCMAMj/zv9ZACEAxv9KANUA7QCvACAAZP/2/lP/dQDqASQCOACw/Wj9e//qAHEAFQCyAAcAGP64/SH/OgCBAMwAswBD/3D9Bv4aAVACewA6/5H/mv9U/yQAVAFqAUEAR/9H/3X/7P9oAVQCmQCE/ur+aADCAHQAlADAAPb/rv4B/5cACAFhAPn/m//6/tD+tP82AcIBOADi/qX/qQCCAGcA7wD2ACUAVv99/5kAigFiAbwAKQBn/9T+Iv/0/8IA8wAYAIb/lP9F/87+XP8WAG7/ZP7Y/icAZwARAGsAjgAY/3z9Hv45AHQBpgG0Aa8Amv7Q/ej+YADjAOMA7ABiAGX/M/9OALsA9f+T/5v/cP+o/9oA1AFqAdn/Tv4I/hr/iQBoAaYBXAE7AMr+GP7Y/msAVgEcAYcA1v/c/vT+RADcANH/wP76/qX/ov+P/4wAJAHT/zb+YP5X/8T/XwBGATYBy/9s/rT+9f+mAMoAJgEUAf7/Rf/D/58A8gDPAJgAjwCVAJEA0QD1AHMAz//O/0kAkwCyANoArADJ/+j+5P6a/0sAKgDM/8X/sP9s/3P/zP/S/33/Kv9C/8D/CwAkAEcAHwBt/wj/SP+z/+r/9f8sAEoA6v98/4j/vv+f/3r/k/+6/93/EwBHAAQAcv8X/2j/LwCrAJAAMADr/9r/3v+//+j/lgAAAZEA1v+4/xAANQA9AKsA2AA5ALz/LwDYAKkAQgDLAFABqgDC/zUAIgEKAYQApgDnAF0A3P9QANUAbQDk/xIAZwDk/4L/BQB7AOD/M/9M/3j/Vf90/wsADwAw/4j+6v5k/1X/W/+q/6D/G/8A/3r/of9B/yP/Qf8q/+b+1v4Z/0H/I/8T/xv/+v7A/q7+7P5e/8r/+f/9//j/wP+f/+T/hAAYAQ4BpwCxACgBZgFuAaIB0gGCAfkA3QBOAcwBHAJEAhACegH1ABIBfgG2AbYBrAGiAWwBFgH/AB4BPgFcAVAB6gCxANkAIgEoAbYAMgA5AIcAbQBrAMMA6ACJAO7/ev8y/9b+uP4s/6j/ef/S/j7+9P3U/aT9gP2M/Wz97PxE/Az8QPwc/Kj7kPvg+4D7sPpY+vj6MPvI+tj6wPs4/Mj72PuY/Aj9wPwU/RD+3P43/xcAXgH4AcoB6AHoAsQDYAR4BdAG4AdwCMAIwAigCJAI0AhACVAJUAlgCXAJQAnQCCAIgAfYBigGoAWoBfAF4AVYBYgEuAOgAroBqgH4Ae4BgAEQAeIAPAC+/jD9RPwM/Kj7QPvQ+kj6yPhw9mD0wPIA8cDuIO0A7IDqoOjA5yDogOiA6IDoIOng6SDqYOsg7qDx8PRo+AD8wv6XAJwC4AWgCcAMYA8AEsAToBRgFeAWgBigGYAa4BqAGuAYYBcAF8AWYBVgE2ARAA8wDPAJEAlACHAGiARIA6wBKv+M/bT9NP4K/sD9wP1k/eD81Pw4/cj9XP8AAugD4AOIAh4Bzf+0/yYBMAIoAZL+DPw4+MDyAO+g7xDx4O8A7WDqIOeA4kDfwN5A3sDcgN0g4uDn4Org7EDvoO9g7iDvYPSY+4wCsAnAEKAUQBQAE0AT4BPAFCAXoBrAGwAaYBjgF0AWABMAENANUApABrgEcAV4BRAE7AK+Adj+qPsI+8z8iv7Z/44BzAIIA5gDmAVQB3AHcAeACKAJMArwC6AOYBBgEAAP8AzACQAIAAlwCpAJSAfQBMQBEP6o+4j6gPdA8mDtgOoA6IDmIOiA6sDp4OXA4YDewNzA3aDhgORA5QDmYOjA6oDsoO9Q9LD3MPmY+3H/iANQB7AL8A/AEYAR4BGgEwAV4BRAFAAUoBMgEnAP0AzACtAIGAcgBqgFyAQ4A2QCBAIUAX7/vv7G/8ABRAOYBEAGqAcgCCAIwAiwCXAK0AqwC7AMsAzwC9ALUAwgDJAKQAkgCZAI0AYABngGIAaQA0UAqP6k/LD5mPhQ+tj70Pqw92DzgO0g56DlIOpg73Dx4O9g7WDpgOWg4+DkAOeA6CDpAOnA6EDpYOzg8FD18Peo+HD5TPyzAGAF0AmADuARABMgEyATgBLgECAQgBGAEoARIBAwD/AMYAiABCADsALqAdoB2AI8A6wCvAKIAyADMgE3AAgCSAX4B8AJ4ApAC4AKsAnQCfAK4AtQDGAMEAxACyAKkAngCeAJMAjIBXgEOASEA7YBIACx/4r/wv5I/uT9TP08/FD7YPlA9KDtgOmA6uDtYPKw9QD28PHg6mDkgODA3+DhAObg6KDpYOpg7ODtwO6A8KDysPMQ9UD5zv9gBiAMgBGgFeAV4BNgEiARQA8ADvAOIBFAEiASABEwDjAJxAOt/0T9hPwY/uoA0AKUAzgEgASAAzwCVAJsA6gEOAdgC+AOQA/QDSAN4AzwC0ALwAvQC4AKYAlwCTAJiAcwBtAFiAS8AdP/9P+w/1j+Fv4a/6z+5PzY/Ar+LP04+1j6oPjQ8cDpoOjg7dDyoPVw+ND3sPCg56DjQONg4WDgwOMA6SDrwOtg7tDxwPIw8sDysPPA9bD68ALQCmAQIBTAFqAXgBbAE0AQoAwACwAM8A1AD8APoA8gDSAIygGQ/Hj6SPvg/eIAvAOQBWAGiAZwBggG6AUAB4AJUAzwDbAOIA8wDwAP0A4gDrAMwApQCXAIsAdoB0gH6AZYBQgD3wBE/wr+bP3k/XL+bv7Q/eT9dv7I/Zz8ZPyM/DD6wPPg7GDpoOmA7QD0qPko+hD1IO5g6ODigN7A3UDhAOaA6eDsAPAA8rDyIPOw89Dz4PSA+Az/WAaQDUATABcAGUAZYBcgE3AOAAsQCdgHkAhAC1ANoAxACiAHvALo/ZD7hPww/pL/fAKgBlAJEAqgCnALAAugCiAMMA5QDjANUA3wDZANcAxQDLALAAn4BaAE4AOIAsYB4ALEAywCbP/Y/Sz9VPxM/LD9jv6Q/Xz8RP1Q/gj+qP1s/bj6wPNA7GDooOnA7mD1gPpY+sD1wO/g6UDkQOAA30Dg4OKA50Dt0PAw8lDzUPUQ9vD1UPfg+vb/cAbADeAToBegGcAawBhgE5ANYAlwBggFgAbACVALQAqQCIgG9ALE/gz9Nv65/64A4AJ4BpAJ8ArwCyAN4A3QDcANcA6wDgAOYA2gDYANwAswCegHaAdwBngEtALCAUAB6wAKAeEAmf94/TD8bPww/eT9mv5r/z3/EP4U/Rj9MP2Y+7D3kPKg7YDq4OrA7zD2OPlA98DyYO4A6UDjQN/A3gDgQOLg5sDsAPCA78Dv4PLQ9rD5gPwaAZgFkAmwDYASoBZgGUAaYBjgE8ANcAiQBagFUAeQCFAI2AaIBCQCgwA/AIkAIAFAAuwDWAWABjAJ0AwwD8APQBBAESAR0A9wDwAQQA/wDFALUApgCDAG2AWABjAF1gFb/+T+9P4F/5T/2P+6/sz8KPz8/BD+2P6+/yYALP9k/bj7gPoQ+dD2YPOg76DtIO+g8vD0wPTw8lDwgOxg6GDlQONA4qDjAOeA6sDrIOvg6sDrAO+g9Pj7EANgCCAMgA7wDyAR4BKAFOAUABRgEVANwAnwCEAK8AqgCXgHgARqAKj8GPy6/oYBnAMgBkAIoAgwCIAJwAwADzAPQA+AEGARYBFAEUARgA8wDPAIAAcABmAFSAUQBfgD3AG8/yr+mP1K/mX/qP++/kr++v7a/zAAlACMAEX/qPxI+uD4kPfg9RD0oPIw8YDwcPEA8yDzgPEg76DsYOrA6ADnQOUA5QDogOyg7UDrgOng6IDo4Org8mD9CAXgCUAPABRAFCASwBFAE+ARQA4QC+AJwAmACmAMgA1gDKAIrAMD/xz8EPsk/C3/3AMACOAJgAoADGAOABBAEEAQIBBAD/AOgA+gD6AOAA2ACwAK4AhACCAIOAdwBTwD6QB4/gz9gP3s/v3/SwCCABABBALQAvACDAInADz9KPrQ95D2IPZQ9ZD0IPSQ86DyQPLw8nDyQO8A6+DogOiA5yDmgOYA6SDs4O2g7kDtIOnA5GDkoOkw8ij7MASwDIASoBTgFGAUQBOgEMANMAuwCLAG2AawCaAMgA0wDIAJIAUSADj8APvg+yj+pAGABQAJAAwQD+ARgBPgE8ASwBDgDsANUA2gDPALwAuwCwALcAogChAJ0AYgBKIB2v5M/ID7xPx0/l//SgC4AcQC+ALgAlACZAC8/ZD7GPpo+ID2oPXA9bD1IPXQ9ID0gPNA8hDx4O5A64DogOgg6UDoIOfA6CDsIO4g7sDsQOmA5MDioOfw8ID6GAMgC6ARQBVgFmAWoBQAEfAMcAmYBsAESAUwCLALsA1gDbAKgAbgAVr+mPx0/KT9EQCEA0gHQAtQDyAToBUgFqAUQBKwD5ANQAxQC3AKsAlQCcAJgAoQC6AKsAhYBUQBrP1Y+9D60PuQ/UH//gAIAwAFGAbIBWAEEAL8/tD7UPmQ9zD2UPWg9SD20PUg9dD0QPRw8gDwoO3A6uDnAOdg6ODowOcA6EDrgO4g7gDsAOlg5YDjYOeQ8BD6ZAFACBAPoBOAFcAV4BRgEaAMAAmABpAEqAR4B/AKcAzACyAKoAcIBCQByf92/1v/cwCIA1gH8AqQDoAS4BVAF0AWABRAEdAO8AxgCzAKgAlwCcAJQArgCuAKIAnoBbgCKAAA/nD8UPyQ/er+DgCUAZQD+AQIBTgE4AK/AMj9uPpI+HD2EPWQ9BD1kPWA9TD1UPSw8uDwIO+g7MDpYOhA6cDp4Ofg5kDpoOxg7SDsQOoA56DjIOVA7pj4tv84BXALABFgE0AUABWAEyAPcApYB0AFMARYBWAIkApwCvAIGAcwBZgDsAJEAswBcgFwAsgEQAgwDEAQ4BPgFUAWABWgEiAQ8A0gDFAK0AgwCJAIYAnQCcAJEAlIB7gEZALkALj/jP4O/mr+Ev+K/2oACAKYAyAEaAP+AQoAmP0I+6D4UPaw9ODz4PMQ9FD0cPTA84DyQPFg70DsYOlA6SDqwOgg5iDmwOlA7ADswOoA6UDm4OWA66D1Bv7QAkgHUAwgEKARoBKAEkAQcAxQCYAHaAZABnAH4AggCSAIuAYwBfADkAPQA+wDbAMoA/QDEAYwCfAMoBAgE0AUQBSAE4ASYBHgD/ANgAuACbAI4AgwCTAJwAigB6AFtAOcAqoBhAB6/1f/gf+B/+P/QgHUAoADZAOIAkQBRf9Y/Vj74Pig9vD0cPQg9ODz8PMQ9KDzoPIg8cDuAOyA6qDqQOpA6IDmwOcg6uDqoOlA6KDmYOXg56DvsPj6/jAD2AdgDOAOABAAEYAQQA3QCVAI0AcAB8AGkAfoB7gGWAXYBKAEgATQBJgFcAU4BHQDIARABiAJUAxADwAR4BGAEkATYBOAEmAQoA3wCkAJsAigCEAIgAeABlgFgAQgBOwDSAMwAiwBhQAcAPT/ZgBOARQCSAL+AW4BrAB9/7z9cPvI+GD2wPQQ9ODz0PMA9CD0wPPA8gDxwO7g7ADsoOuA6sDoIOgg6QDqYOog6mDpwOcg58DqYPKw+fD+gAP4BzAL4AyQDpAPIA7wCrAIMAiQB/gGEAdgB5gGQAVwBEgEeARoBfAGqAeoBigFuASgBXAHAAqwDIAOEA+QDyARABNgEyAS8A9wDRALkAlQCTAJIAgoBsgEiASYBHgEWAQIBAgDiAF0AD0AegDsAHgB+AEgAtABOgGTALT/Jv6w+wj5YPeA9sD10PSQ9PD0kPRg8/DxYPCA7sDsAOzg6wDroOnA6MDoAOng6KDoYOgA6KDooOtg8Yj4Sv+QBCAI4ArQDPAN4A0QDcALEAogCAAH+AaQBhgG4AXwBWgFiATQBNgG0AjQCJAHKAaABagFOAcgCmAMUA3QDXAPwBGAE8AToBIgEIANgAvQCmAKEAmIB0AGWAWgBOgEWAWgBAADAAK4AeQADAA3ADoBkAF+ARQCiAKqAREADv/4/ZD70Phw99D2wPXA9ND0MPWQ9EDzIPKw8KDu4OxA7CDsQOtg6iDq4Omg6YDp4Ong6UDpoOkg7IDwYPZo/RgEIAigCeAK4AyQDXAMkAsAC1AJsAaoBZgGKAcIBhAF+ASIBDAEuAWACFAJoAdoBegEuAU4B1AJUAuADCANUA5AEAASoBJgEfAO8AwQDJALsAqACVAI0AYoBUgEmATQBOgDvAIwAswB/wBEAHUAKAGkAQQCVAIcAtEAQP82/kj9qPug+QD4APdw9lD2cPYg9iD1sPMw8rDwQO9A7iDtAOwg6wDrAOuA6gDqIOqg6mDqQOrg6qDswO8A9bD7GAJgBrAIIAoQC9ALYAxwDCALMAmgB7gGkAb4BkAHWAZYBKQDGAWwBmgHAAhgCPgGgAQQBJgGQAkgCqAKAAzADcAOIBDgEcARcA8QDZAMoAzgC4AKcAkACCAG2AQQBSAFEASsAgACkAHTAJkAOgHKAdoBQAK0AkQCtwCI/wP/1P3w+4j6mPlA+BD3EPdw95D28PTg80DzwPEA8ADvIO6A7ADrAOug64DrwOrA6iDr4Opg6sDqQOxA7mDx4PZ8/RQDuAYQCTAKcArgCvAL4AsACoAHYAbABiAH8AaIBjgFdANMAzAFQAegB/gGYAa4BfgEqAXIB4AJwAngCaAL0A1wD4AQ4BAgEGAOIA0ADcAM0AsgCkAIoAaoBSgFyAQwBGwDiAKsAVgBogHyAeIBlgGSAawBfgEKAWgAb/8Y/sz8yPvI+nj5QPiA9yD3wPYw9lD1IPTg8rDxoPBA78DtQOyA60DrgOsA7CDsgOsg60Dr4OuA7EDtYO9g85D4gP4gBMAHkAiQCNAJcAuACwAKkAhYB2AGWAagB/AHCAacAxADkAQoBpgHMAjAB6gGSAYIB/gHkAhQCUAKAAswDNANYA/AD2APgA6QDcAMMAzgCyALwAkwCPAGIAaQBRgFmATYA9QC2gFoAX4BxgHOAc4B9AEcAhQCpAHVAIL/Hv7Y/Lj7gPpA+Xj44Pdg9+D2MPYw9dDzsPLA8XDw4O5g7WDsoOtg66DroOsg64DqQOrA6iDrgOvA7EDvUPPY+OL+EARAB6AIUAlACmALoAuQCuAImAf4BhAHaAdIByAGcATgA3AFuAeQCHAI4AeABxgH8AaIB3AIIAnACfAKcAzgDeAOgA/wD2APMA4ADZAMYAygC1AK4AigB6gGAAboBUgFxAMwAioBzQCNAP4AiAGGASQBagEIAsIBswCs/6r+7Pw4+2j6+PnQ+HD34Pag9rD1gPTg81DzAPKA8GDvIO6g7IDroOvg64DrAOsg62DrYOuA6wDs4OyA7gDykPeU/WQC0AXgB9AIYAlACvAKUAqgCGAHYAeYB6AHwAcwB4AFIATYBOAGEAjQB3AHMAfIBpAGKAdACPAIsAmwChAMEA3wDdAO4A4QDvAMMAzQC/AL8AsACzAJuAcQB4gGoAXABBAE4AJgAbYAEgFaASYBRAHAAeQBqgFkARIB/v9G/tz88PsQ+wj6MPlw+KD34PaA9uD1oPRA80DyYPEA8IDuQO1A7KDroOsA7ADsoOtA62DrgOvA66DsoO7A8RD2kPsIAdAEoAaAB1AI8AiACdAJcAkgCDgHmAdgCFAImAe4BqAFGAUYBgAI4AjQB/AG6AagBmgGOAfACKAJ4AngCoAMgA3ADSAOcA7ADUAM0AtADHAMYAvwCeAI+AcYB0gGuAWwBDgDwgEeAc4AzgAIAY4BvAGSAY4BsgF0AWIAFf/Y/cj8oPvg+mD6iPlw+LD3QPdg9kD1QPRA8wDycPBA70DuIO1g7EDsIOzA64DrwOvg64DrIOuA66DsgO7g8dD2TPzHANAD4AUAB4AHMAggCWAJcAhoB2gH+AdQCFAIyAfIBpAFaAX4BkAIIAiIBxgHyAZQBrAGEAjwCBAJwAlAC3AM4AxgDTAO8A3ADCAMUAxwDNAL4ArgCbAIgAfgBmgGmAWABGwDgAKqAVQBWAFiAVgBVAFcAUwBBgGyAPf/1P68/ej8KPww+yj6YPmg+OD3UPeg9qD1cPSQ86DygPEQ8KDuoO3A7IDswOwA7eDsYOxA7EDsYOyg7IDtgO+g8uD2+PtpACADUAQ4BWgGWAfwBzAIwAf4BtAGyAeACCAI8AYIBqAF6AUIB1AIEAmgCBAIoAewB0AIMAngCUAK4ArgC7AMEA2QDeANgA2ADBAMIAwQDMALMAswCtAI0Ad4BzAHYAYgBQgE8AKwAd4AuwDlANUAyQD8AD4BFgGFAMv/2v7Y/dz8IPxY+3D6mPng+Gj4oPeg9rD10PTg87DycPFQ8ADv4O1A7SDtIO3A7GDsAOyA6yDrAOuA62Ds4O0A8XD1YPqy/toB3AMIBcgFyAbwB7AIgAgACOgHgAjgCLAIQAioB1gHcAdQCIAJIAqQCdAIMAjYB+gHUAhACTAKEAuwC0AM4AyQDRAOAA6wDRANcAwADOAL0AsAC7AJwAggCIAHgAagBYgE2AJOAXAAHgC0/8T/UgCiAEMABQAMAGz/Dv74/IT8uPt4+pD5SPmo+KD34PaQ9uD1sPTg81DzMPKw8GDvgO7g7UDtIO0A7cDsQOwA7ODrgOsg60DrgOwg7xDz0Pdc/NH/NAKwA8AE4AXoBmgHcAdwB8gHkAggCXAJQAmACJAHcAdACCAJgAlwCfAIMAiwB9AHcAgQCbAJwAqQCxAMgAxgDSAO8A1QDQAN4AygDHAMQAxgCxAKEAmQCPAHAAdABqgFeATEAn4B1QBiABQAdQDTAMoAdAD4/0v/PP5I/aD80Pug+sD5YPn4+Hj4IPiw95D2MPVw9DD0UPOw8UDwIO8g7qDtAO4g7mDtgOwg7ADsoOtA64DrQOzA7eDwoPVw+rT92f+QAfQCCARoBeAGaAcoB1AHQAgQCUAJMAkACUAIsAcwCGAJIArgCXAJ4AjYB0AHkAdACOAIcAlQChAL0AvADKAN0A2gDWANYA1ADQANsAzwC9AK8AmACeAI+AdAB6gGeAXsA5QC2AEqAYsAWQB/AKMAiQCCAPb/9P64/dz8+Pv4+hj6YPng+HD4GPiQ99D24PUA9TD0MPNA8iDx4O/A7kDu4O2g7UDtAO2g7ADsgOtA6yDr4OrA60DuQPLA9uD6Lv4yAEoBjAJQBNAFWAaQBhgHsAdQCBAJwAnQCQAJMAiQCFAJ0AkgCjAKoAlQCFgHWAfABxAIwAigCUAK0ArACxANoA1gDQAN0AzADLAMkAwgDDALMAqwCTAJsAhQCLgHsAZIBUAEZANkAnoBJgEeAQoB5gD4AKoApP+I/sT9EP34++D6KPqA+bj4UPhA+MD3sPag9eD0IPQg8wDyIPHg78DuIO5A7kDuwO1A7eDsgOwg7MDrAOxg7KDtUPBg9HD4ePuk/Vz/vgAkAsgDMAXgBRgGsAagB6AIQAmACUAJkAhQCMAI8AnACiALsArACdAIgAiwCBAJoAlQCtAKAAvAC+AMsA2QDTANwAxQDEAMcAxgDLALoArgCWAJEAmwCGAIwAdwBgAFxAO4AqQB6QCMAIAAiwCMAG4Ayf/o/vj9LP1A/FD7gPrA+TD5qPg4+MD3APcg9jD1EPQg80DyUPFA8GDvoO4g7uDtoO0g7YDs4Otg60DrIOuA64DswO4g8vD1gPlg/Eb+m/8OAeACmATQBagGiAcwCLAIYAkQCmAKEArgCWAKQAvQC0AMIAwgC9AJ4AiwCAAJoAlwCiALYAuwC4AMQA3ADZANIA1ADLALsAvgC5ALAAuACiAKcAngCJAI6AfABlAF+ANkAg4BWAAoAMv/pv/y/xMAZ/9W/qj9/PzQ+7D6IPqA+Yj40Pew93D3kPbA9UD1cPQg8wDyMPFA8ADvYO5g7iDugO0g7QDtwOwg7KDrYOsg64DrQO1Q8ODzYPdo+qj8Iv6E/zAB7AJYBHgFuAaoB4AIkAmgCvAKsAqQCsAKUAvwC6AMsAzQC4AKoAlACTAJ0AmQCiALMAugC6AMkA3QDcANUA2ADBAMMAxwDBAMgAsQC5AKwAkgCQAJwAiwB0AG8ASUA/oB8gB7AEAAIgA2AE4Av/+e/qj9DP1M/Ej7YPpg+Uj4gPeA94D3EPcw9oD1sPRw83DysPHQ8IDvwO6g7oDu4O1g7UDt4OwA7MDrwOuA64DrwOyA73DyYPVg+OD6VPyY/bb/FAK8AwgFkAagB/AHgAjQCcAKsAqwClALAAxADOAMsA0gDYALMArACXAJcAkgCvAKIAsgC9AL8AyQDZANgA0QDYAMMAxADDAM0AuACxALcArgCeAJoAnACEgH2AVQBPgC6AE8AcQAVABSAEcA8v8v/4D+tP20/KD7gPp4+XD4wPdA9/D2kPYg9oD1kPRw83DygPGg8MDvAO9g7uDtwO2A7SDt4OyA7EDsoOvg6qDqQOtA7TDwoPOg9sj4UPro+7z9ov+iAaQDQAUoBuAGyAcACfAJYAoQC5AL0AtADCAN0A1wDXAMgAugCsAJwAmAChALEAsgC/AL0AxQDYANgA0ADSAMwAvwCwAMwAuQCyALcArwCRAKMAqQCXAICAdwBcwDxAI4AtgBNgHxANMAXAC+/zf/2P7g/Zj8YPtI+vj44Pdw90D3wPYw9sD1MPVA9CDzcPKQ8WDwQO/g7qDuIO7g7eDt4O1g7QDtwOyA7ODrIOzA7SDwkPIQ9WD3APlI+vj7Kv41APABqAMIBegFiAa4B+AIcAmwCSAK4AqQC5AMYA2QDQANMAyAC/AK4AqACzAMIAzwC0AM8AxwDaANsA0wDXAM8AvQC9ALsAuQC0AL0ApgCmAKoApgCmAJ2AcwBpgEUANsAgQCzAF4ARABkwAaAIj/2P4A/uT8oPto+oj54PgY+ID3EPfg9nD2oPUA9TD0MPMg8kDxcPDA70DvIO/A7kDuwO1g7UDtoOwg7MDrwOuA7CDucPAQ80D1IPeQ+Pj5mPug/dT/6gGkA9AEsAVoBmAHYAhQCUAKUAtADCAN8A1gDlAOgA2QDNAL0AtADNAMUA1gDXANgA3gDVAOcA4QDkANcAygCxALMAugC/AL0AtwC0ALwAowCmAJMAiIBsgEgAO0AgwCuAG0AZwBAAE0AJD/yP6w/WT8UPtI+kD5cPjw92D38PaA9kD24PUw9YD0cPNg8iDxQPCg72DvQO8A78DuoO6A7iDuoO3g7EDswOvg6+DsAO+A8dDzwPVA93j4oPlI+yj9Jv/rAKQCMARoBVgGYAeACGAJMAoACyAMEA3QDSAO0A0gDWAMUAyADOAMMA2gDfAN8A3gDfANIA4ADoANwAwADHALYAuwC9ALsAtAC9AKUArACUAJkAhoB8AFQAQkA3wCZAKUApAC7gHzAOz/9P7w/ez8APzo+sD5+PjA+HD40Pcw98D2QPaQ9QD1gPSg83DycPHg8IDwUPBA8EDwwO9A7wDvwO5A7oDtIO1g7cDtwO5w8HDyIPSA9eD2MPiA+TD7NP0b/6kAHAKMA7gEqAXQBgAIEAnwCeAKEAwADaANAA7wDXAN8AzQDOAMMA2wDTAOUA4wDhAOMA4gDuANkA0ADTAMgAtQC1ALIAsgCyAL0AogClAJkAioB5AGcAVYBHQDvAKAAkgC8gF+AfkAQQAt/xj+/PzY+5j6uPkw+cD4WPgY+KD3wPbQ9SD1oPQA9HDz0PIQ8kDxsPCA8HDwYPCQ8MDwkPDg7wDvYO7g7cDtYO6g7xDxsPJg9OD18PbQ9wj5WPqw+zT9/v7AADgCjAPgBBgGEAf4B/AI0AmQCnALQAzADPAMAA0ADeAM0AwQDZAN8A0wDkAOIA7QDYANQA3gDFAMwAtQC9AKcApQCiAK4AlwCfAIUAigB+gGMAZgBYAEnAPcAlQC5AGEAQwBlgAPAGz/oP60/Zj8YPtQ+pD5GPnY+JD4OPiw9+D2MPag9SD1kPQA9JDzEPOw8mDyMPIw8iDyEPIA8sDxkPFw8WDxYPFw8dDxoPLA8wD1MPYw9xD40Piw+fD6gPxg/ikAkAGAAjADEAQQBSAGCAegBzAI4AjQCdAKsAtQDKAMUAzgC7AL8AuADBANcA1wDUANMA0wDUANEA2QDMAL8ApACtAJwAngCfAJsAlACZAIkAdoBkgFWARwA6wCCAKuAVYB3ABIAIv/zP78/XT9DP2Q/PD7MPuA+tj5OPnY+JD4KPig9zD3wPZg9gD2kPUg9ZD04PNw81DzYPOA86DzwPPA83DzEPPg8tDyAPOA83D0gPWA9lD3MPjw+Jj5cPqY+8z8vP18/mT/gwDeAYADKAVYBugGKAeAB9gHQAjQCJAJQArgCsALgAzQDIAMQAxgDGAMIAwADEAMMAzAC7ALIAwwDKAL8ApACjAJUAgQCPgHUAeoBnAGIAbwBJADAAOUAloBLAAkAF8Ayf+w/gr+wP0s/Wz8KPw4/PD7MPto+tj5UPmo+Bj40PfA93D3MPdQ96D3QPdg9sD1MPWA9DD0oPSA9QD2IPZQ9mD24PVA9TD1UPVQ9cD14PZg+Nj5MPs0/Fj8uPtY+7D7dPxY/cb+wQB0AqwD0AT4BVgG8AVwBUAFKAVYBUAGyAfwCKAJUAogC2ALYAtwCzAL8AlACIgHAAjgCAAKcAuQDGAM0ApACSAI4AaYBfAE2ATIBOAEOAVwBQgFMAQUA6oBOgB7/2v/Rv+0/jb+0P1I/aT8JPzw+wT8PPz4+yj7kPqQ+lj6gPmI+ED4IPjQ9xj4QPkY+rD54Pgo+HD3QPcQ+PD4mPhw9/D2oPeg+ID5kPpg+wD7sPkY+bD5kPrw+mD7YPyo/Zz+Ev99/wgAQwDq/8P/gQAIAnwDSASYBLgEyATgBFgFKAaoBmgGIAZQBqAGcAZYBoAHEAmACcAIMAgACJAH+AYYB4AHyAZgBegEoAVABpAGOAeQB2gGUASgArQBxwCh/yr/QAAUAkQDxAMABMQC7v5g+nj4sPlY+xz8EP1e/kL+ePxo+yT83PwU/Mj60PmA+AD30PZo+ND6xPyQ/Qj9uPt4+tD5EPlw+Nj4EPro+ij7uPvI/KD9XP1I/Lj7PPwA/Wj9eP00/Uz8YPsA/Fj+AwDc/3QAZANIBbQC9P0c/AL+SACqAZgDqAXoBcAEMAQgBIwD4AJMA5gEsAUQBsAF+ARgBCgEGAQoBNAEyAUwBgAG2AWoBeAEeAMMAjQBYAGsAkgEOAWIBTgFXAOlAJH/fwDFACL/IP6J/1QBHgFAAGsAPAA0/xn/lv8Q/rj6EPkw+pj7+Pug/UIBGAMCAfD9+PvY+UD3cPbg+Kz8ev6Q/sT/igG2AGj9mPpg+cj4uPiQ+gz+MwDI/0v/2f8z/wD9SPyg/Rr+DP00/bz/CALQAaIApQDQAFT/kP3g/bD/RgFsAqADSARQAx4BPwDeAcgDfAPUAWABLALiAVYAGgEIBTgHoAREAcoBEASMA6kAkf9QAawCxgEmAeACyAS4BGwD+gGoAMj/YP+Y/2YA7gAoAd4BbAL+AT4BLgCo/uD92P6uAAQB5v4Q/Xj+mwDz/7r+OADSATX/uPqA+hT+X/8E/hn/zAHUAPD98v64ARIA8PuQ+yj+Zv4Q/W7+CAHKAA7/QP9/ANsAfACu/gD7uPgI+z7/xwCRABgClAMGAWT9xP2x/xz+oPsI/Yb/tv72/gAF8AhkAxD8dPx6/2j9OPv3/0gGMAVsAGcAfAJhABT9kP0CAOgBoAMgBNQBrv5K/sr/s/+J//gCCAYgA07+2P0VAEcA6v40/zQBEAJqAeABfAO0A4IBTv64/BL+BgBaALgAAALAAXr/Xv+IArQDEgFu/9X/Qv4Y/Nj99wApAFb+DAHIBGwDmwAQArACSPyA9XD3Uv4AAcYAGARACCgF4PyQ+WT8WP3w+ZD44Pz4AoAF/AMQAloBlP+A+6D4gPqe/5AC/gAd/5EAFAKcAFL/4/9//1j9dPxo/goBigFGAAMAQAHcAaUA7v4p/+oAPgA8/Yj9CAK4BNgDJAOAAnL+OPlQ+kgCEAhABiQC3wBm/4j8GP0QAjAFeANkARgCUAJJ/2z8dP1DAL4A/QAYBdAIiAXS/pz8Gv7A/SD8ev44AxQDPf/6/7ADygH0/OT90AJEA/L+0PwK/pT9SPtY/G0ABAKAAD//Pf9x/5v/ef9q/vD8kPvY+vD7Ov+MAmADeALaAQYB8P0Q+rj53PwC//f/lAJgBOQBuP5y/zAByf/Q/ar+RP9M/Tz99wAcA6IBaAE0A64BUP1Y/bgBrgHA/Pj78QAgBNwCQAJQBOwD6P4A+wj9IgG4AQcAYwDoAmwDBgHo//YBiAOCAaz9SPuo/BQBgASYBJQDHAPkAHz8uPoy/iQCtgFIANYBNAI6/jT8JgDEAn7/HP2B/yoBaf/M/qsApwDY/cj87P6q//D9H/9cA9wC1PzQ+k3/KAG0/dz8qwBKAez8yPs+AfgEiAEC/iv/vv4g+yj8uAEUA8T/zv4WAYoBuf9+/7sA6P/8/bL+GgHOASQB0gAVAC3/4P9KAX4B6gFAA7QByPyQ+qr+IATwBIQCiAGgAar/IP2I/Y8AOAOgA2QBTf8SAbADXAEI/eD9oAHeAMT8aP30A+gGogEc/TH/rAA6/o7+sAGCAET8aPyYAegEdAJ//7UANgHw/Fj6SP64AmQB7Pzw+93/MAMgAiQArf8q/qD7wPv0/bH/xgGcA1oB+PsY+5sAqAPS/tj63P6cAmb/3PxKAHgCm/9o/tYBaANz/1j7QPzh/8gBUAL8AyAFEALM/ID6AP22AfwDxAFD//j/ngAZAKoBuARgBGz/cPqg+yoBKAEs/Kb+QAhACmACcP0U/4T/mPzw+/D9iP0I/ZQDEAzACngDmAGPAOD3MPHg9wwDqAWgA5AGkAp4Bhz+ePtk/cD78PfI+eX/tAJEAmAEkAe4Bdr/hPx4/Bj8oPsE/Rz9QPqA+xAE8AmIBuQB9AFhADD6gPaQ+dz9VP5k/Xj/rALEAygExAOkAFj9TPy4+tD44Pq6/7wClAPYBHAFYALo/Lj5YPpY/Dz+2QAABIgFyAQkAlj9QPmg+7ACKAW/ACz9vP/oAlUA1PzT/+AEjAPY/qj+HAJoAnL+HPzw/ggDEAQgA7QCTAKRAPj94Pzu/toBugGM/x//JgFQBFAGOAQy/5D81PyQ/Lj8Jf+wAfQCUASwBAQCUv5I/fj9CPy4+FD74AJgBUwCeAKQBIgA+PnI+eT9Vv64+zT9yAIwBVgCzP9iAH0AwPyg92D3AP1UAqwDSATABegDyP2w+Uj6YPvg+xr/EASQBfgCmwCmACYA0P3U/LD9Nv6i/pP/ZgB8AhgGUAYcAWj8CP2O/33/Kv4u/mX/MAH8A3gG8AU4A+AAgP64+0j7dP0BACADQAaIB+gGcATa/vD42PiI/iwCNAB0APgGYAk+Adj5oPwUAfr+7PxsAVgF7gE8/az+5AG6/ij58PvIBNgGjAFr/4IBQf/Q9yD1aPxgBdAGsAIEANz/QP/E/Wz96P3o/AD8ov4MA9ADKwBg/ab+5v+U/fj7hP+cA5QCM/9G/tj92Pts/GwAMAPwAvQCfAPyAED7GPhI+yYAYAKQAyAEWAL4/3j+CP34/Ln/vAJAAjr/kv6SAbAC+f/n/wgEuAQHAMD9cAAQAQj9EPv6/mwDaATABbAIIAfa/jj4qPhg+uD5CP2YBkAOoAvOAcj7bP0G/kD5YPfE/IYBjgGEArgHwAs4B4z8wPUQ9sj4+PtHAMwDKAXgBMADkAKnAOD9wPvA+aD3uPhq/vgE0AigB2AB8Pss/Ej+eP1o+9j7/P4WAZz/N//MA1gGSgEU/XUAfAJY+9D0wPloAqQCKwAABrALKATQ+FD5cf+g/UD61QDACAgFWP1S/pgCYABU/RQByATdAAT8iv6kAkMAsPym/5AEGATsABABwAKOAAT80Puv/yoBMgA8AvgFIAVYAJz9VP6S/jz9Mv7YAdwDaAL1//z+KAB8AU//uPtM/dQDmAVS/mj45PyEAz4BkPyp/6gEqgH4+kD7FAKwBJH/gPvQ/fcAN//A+2D9UANwBIb+wPs1AIQCAP4A/HgC+AbEAGD5CPtq/oT8hP04BTAIigDA+iEAKAbIAcD64PpM/eD8Nv6kAxgH2AS8AKb+TP7e/ub/Ov/4/aT/ggFj/4z+0ARQCmgFwPtw+Rr+xgBJAIIB8AMsA9P/0P0h/8QCaAVABC4BNP/g/Bj5MPnrALAIeAcWAZb/SAKyAQv/HP8+/nj5QPiW/twDTANYBOAISAZQ+uD0WP1oBLj/wPkI+1T9aP2XAKAGwAgIBRcABPwA+PD1wPjE/dIACAPgBXAHgAZYAz7+yPjw9GD0cPlgAgAJEAo4B5QCNP2w+Lj4xP0jAPz8UP0wBIAH2AOgAWQCyv44+FD5fAGkAwL/2P+gBdAEHv9Q/7wCIwBo+8j9UAPYAk//1f+QAiQCGwDaAPACtgEw/nT99P7q/iT+RQDIBGAGhAIA/hD+c/80/eD69P0YAyAEkAJ8AyAFEAJI+5D32PnE/bH/6QCkA6gGQAZCASj7OPjY+Ej7Qf9oBGAHgAR0/sj76Pws/Sj94wDoBDQC2Psw+wAAjAHy/uD+ugFkAssAiABUAdz/YPto+Oj7lAKABIQBZQBwA0AFGQCo+BD5+P5NAJr++gGIB1AHyAGU/Yz9Av7k/OT9dgEEA5ACGANIA2oB9v5I/Yz9z//8AdQCCAJ/AD8AMwDE/hT/GAJoAor+APzY/XoBpAOIBFgFzAMO/5j6QPjw9wD8cAQACogH7wAc/pb/eP6I+ij8TAJUAqj91P5YBAwD2Pug+rUAhALQ/QT+8AOYA0T8mPr4APQD3f8U/Tz+oP2U/BgBeAbIBKoA8wBbACj50PN4+XwC6AINAPAEsAuYBzz8wPYQ+bD7RPya/qwCkASEA6QBJgGsAggE5AG4/Oj4WPmE/UwCCAUABYgDQAI4AS//+PwE/n4BNAGM/Fj7pgAgBTADAQBsAeADfAFk/Rb+qACw/gj71PyIAgAFNAPEAYIBG/9Y+zj7xP7PAIUAbAFgA0wDNgEm/wD+jP0o/aT8KP2y/yQDIAXMA6QAG/88/iD7+PlO/0gE+gE+/jcA7ALG/3D7sP2IAvYAkPy+/mgEMASE/0D9jP1A/Qz9/v7KAbADKAXwBGcAWPrw+ET8cP9yAVgECAa8AoT9KP06AAMAVP2g/QIA6wBCAVAC6AG5/wP/2wAMAqgAPf9I/2T+HP08/9ACqAKnALwBoAPAAcT98PuM/ID9K//EAjgGCAbUArn/LP2g+qj6dP58AXAAXf9gAmAGOAaQAnD/aPyg94D1GPu8AhAEdALQBfAJSAWI+zD4UPsg/DD6aPysAoAF6AP0A0AGyATg/XD30PZQ+0UA2AJEA1ACzwDS/+//LAGEAeD+FPxA/UcAHwAQ/WD8gwAgBeAEwAHpAAYBYP3A+DD6wwDIBPwCnwD4ARgDo/9g/Lr+BALrAGT/mAFAA3YAbP1y/lgAn/+I/6gC4ATUAkwAEgCa/ij7QPvg/1gDtAMwBNgEgAIA/uj7aP3G/lj+YP5eANwChAM4AlYBNAHo/jj7UPtk/3ABgf8+/ksAgAKcAkgCcgFU/pD6EPp0/OT+RAE4BDAFyAI0APT+1PyQ+qD78P55AHcA2AG8A8ACjf/E/Vz9OPwc/PD+2gEUAqwBiAJ4Ann/APzA+yL+IwA2AWQC7AK0AcP/mv4J/zIAFQDs/jT/SAFoArgB2wDJ/8z9FP2I/2wCsAIEAoQCJAL8/mD89P3XAFQAeP6Z/zwC+AKsAvACAAJw/oj7EP1PAJ8Azv/GAbADMAFw/cz95ABYAuABFAFK/7z8ePwS/7UA6P8SAEQClALH/xL+Ff9d//D9av5qAaQCzQDO/8MA2P+Y/Mj7xv4cAc4AGgHUAlACOf8M/i3/Jv4Y+yj7SP/8AnQDxAJcA0ADNACk/JD70PtU/Cr+qAD6ARAD0AWwB/wD7Pwo+kT8ePyg+oD97AMYBswDYAPQBBADgv4Y/Cj8QPuY+iD+dAP4BNADOAR4BEoByP1O/sj/IP0o+Uj6lv9IA+AEWAcwCJQDtPyQ+Qj66Pp4/LH/FAPIBMgEzAM0AjkANP6M/MD7zPwm/4oAngBuAaQCQAKxAM7/q/+Q/57/hv/o/iD+6P3O/qEALAJIAi4B7v9Y/xn/ZP7o/ej+IQCv/yH/ewDQAdoARv9y/wsADP/Y/cD+UADj/9T+pP/5AIYAk/8SAMgA6f+Q/rT+nf9B/yD+Rv6Z/3IAvgC2AQwD4AK+AEr+/Pzg/KD9Qf8cAVAC1AIgA+gCngF6/5z9IP02/tv/BAG2AVQCeALcAUYBJAGeAPj+UP2E/Wj/FAH8AfQCZAPqAWH/GP6M/vr+VP7Y/ab+9//TAFYBwgHCARAB6/+c/nz9JP24/XD+Df9xAIACfAOAArsAt/8g/+T9sPwQ/ej+sgB+AYABRgEMAYwA9/+9/8z/n//w/ib+5P1i/k3/WwCKAZQCpAIIAZr+YP3g/bL+HP/P/9MAJAFkAKr/AwD2AE4B3gA5AI3/4v5a/hL+Pv78/vv/PgGsAmwDdAIMAPz9VP2E/dj9tP4sAFIBwAHkAeYBYAFoAL//of9I/6r+4v4LABgBsgFEApgCIAISAVsAMwAJAOv/LgB3AJYA+ABeAUwB8wCuAGcA2v8Z/6T+3P6X/3cABgH4AHAArP+k/tT9FP72/nn/BAAwAeoBEAGE/9D+sP5E/hz+8v4uAJUAWABqAJAA2v+W/vD9AP4u/l7+wP5z/z8AmwBCAH7/oP6s/dT8kPxQ/br+tf/U/woAogDFACsAcv/S/lb+RP7I/uP/LAEwAtwCNAMsA+wCgALUAf0AngAqAVgCjANgBPAEEAV4BNADbAP0AhACcgHMAcgCyAOYBLgE4AOEAoYB9AA1AIb/gf/M/5z/Qv+U/zcAEAAn/yr+KP0k/Ij7gPuw+9D7GPx4/KD8IPww+2D68PnY+eD54PkA+nj6APtA+5j7EPwQ/Fj7wPqg+kj6kPmY+Rj76Pzc/Uj+6v4Q/xj+zPx0/Oz8yP0r/zwBSANgBIgEcASQBLgEwAQIBdgF6AYACFAJ8ApADJAMIAygC0AL8ArQChALgAsADIAMoAxQDIALgApwCfAHSAYABUgE3AOAAyQDlAJ8AdL/4P00/PD64PmI+ED3gPYA9mD1kPRQ9GD0MPTQ89DzUPTA9KD0cPQg9NDzwPMg9OD0gPUw9tD2EPfA9qD2sPaQ9lD2oPbA99j4oPl4+nD78Puo+zj7OPuI+wD82PxU/hIAiAG0AvgDYAWABoAH0AigCoAM8A1QD8AQgBGAEcARwBIgFCAVwBVgFmAWgBUAFGASYBDwDfAL0AoQCiAJUAiYB0AG4APvAPD9CPuI+PD2UPYg9kD20PZg90D3sPZA9rD1sPSw82Dz4PPQ9PD1gPcQ+Vj6SPtA/NT8+PwU/Vz9lP2Y/QT+Kf9xAKIBwAJ8A2ADsAIIAjwB9f+2/sz99PwY/ID7cPtA+1j60PgQ9wD1EPPg8aDxoPHw8ZDygPMw9LD0MPWg9WD18PTw9LD14PaA+LD6RP2//zwC6ARQBxAJwAkACjAK4ApwDBAPwBJAFqAYYBkAGYAXQBUgE+ARgBHAEUASoBKAEkARMA+ADEAJ+AWEAzwCegHNAEgAjf8G/rD7iPkA+OD2EPbQ9fD18PXg9dD10PUA9lD20PYQ9yD3gPdI+CD5yPm4+gD8EP3U/aT+i//m/8P/pf+v/9T/agCiAewCiAOMA2ADwAKGAT0Aa//G/tz9/Pw8/Fj7+Pl4+BD3kPXA8zDyUPGQ8MDvgO8A8JDw8PCw8XDysPKQ8rDyYPMQ9GD1kPcQ+nz8CP8wAigFUAdgCSALcAwQDdANoA9AEkAVABggGqAaIBpAGYAYoBfgFoAWQBaAFYAUYBPgEXAPkAzgCYAHiAUwBIADVAJMAHT9cPqw98D18PTw9CD1IPUQ9ZD0sPOw8vDxYPHw8BDxIPIA9DD2SPi4+VD6OPr4+Sj6APuQ/HT+NwBwARACZAK8AkwDQARQBTgGmAaIBhgGcAWABGwDYAJwAcsAWgD0/1j/MP74+wj50PXQ8lDwwO4A7gDuIO6g7oDvQPCA8GDwIPCA78DuoO4g8DDysPTg95D7Cv9MAXQD2AVQCDAK8AvwDaAPwBCgEsAV4BhgG8AcgB3gHGAboBmAGGAXQBYAFgAWgBUAFEASABCwDMAIoAVkA74BmADH/5L+RPwo+SD2gPOQ8eDwgPGg8iDzEPOA8pDxQPCA76DvUPCQ8VDzgPWA9wD5SPoo+1D7GPtg+1z8AP4HAPwBaAMIBBAEOATQBMgF0AagB+gHeAeoBsgFEAVgBJADuALmAQQB7f/E/lD9EPsA+KD0kPFA74DtAO1g7QDugO5A7wDwIPBg74DuoO0A7eDsoO7w8WD10Phs/If/cgHEAugEiAegCWALQA2QD+ARQBQgF6AZQBtAHOAc4BzgG6AaYBkgGMAWoBVgFSAVABRgEgAQwAwgCfAFdANCAWr/LP4Y/Uj74PiA9kD08PFw8EDw4PCQ8UDyoPIw8hDxMPBA8MDwoPFA82D1QPe4+BD6MPug+8D7SPw8/ZD+OwAsAswDiATABOgEMAW4BbAG2AeACJAIMAiAB2AGOAV4BOADKANsAqgBtQAr/xz9mPpg9/Dz4PBg7oDsYOug64DswO3A7oDvoO/A7oDtgOzA6yDsAO6g8bD1YPno/BsAWALwA+gFYAiwCqAMgA6gEMASQBVAGAAbwBzAHWAeIB4gHeAbwBpAGWAXwBXAFAAUQBNgEsAQsA0QCogGeAOmAHD+0PxI+2D5YPeg9eDzEPKQ8MDvYO9g7wDw0PBA8TDxwPBw8IDwMPHQ8iD1QPc4+bD6sPsw/Gz88PzA/ej+YwD6AZwD+ATYBSAGAAYIBnAGEAe4B0AIQAigB5gGmAWIBJwDBAOIApoBNgC2/iz9OPuo+OD1APMA8KDtIOxA6+DqAOsA7CDtAO7g7mDvgO9g7mDtoO1A78DxYPWA+Tj9GACgAugECAdgCQAMcA4gEKARgBMAFmAYYBpAHIAdwB3AHcAdgB1gHMAa4BiAFmAUABNAEmARsA9QDWAKAAeYA7wAiv5U/Cj6OPhw9sD0MPPA8WDwAO8A7uDtgO6A73Dw0PCw8DDwAPCA8PDx4PMA9gj4yPk4+0D8CP3g/fz+AQDwAAACJAMwBOgEeAXwBVAG+AbIB6AI0AigCPgH0AZgBTAEsAM8A5wC8AEKAZr/wP0Q/Ij6ePjQ9RDzsPBA7iDs4Oqg6uDqoOsg7eDuAPBA8ADwQO9g7iDugO8Q8mD1MPns/AMASAJYBIgG4AgwC3ANoA+AEQAT4BQAFwAZYBqAGwAcQBxAHCAcoBuAGuAYABcAFUAT4BGgEDAPAA1gCqgHIAXYAqUAiv5s/FD6QPhg9uD0kPMg8tDw4O+A76DvgPCw8ZDykPIA8tDxIPKQ8oDzQPVA99D4+PlI+5D8eP1E/mP/hwBmAVACRAPwAxgEGASIBBgFsAWIBmAHsAdIB8AGKAY4BTAEiAP8AhgC0QDa/x7/7P1k/ND6GPnw9nD0MPLg70DtYOvg6kDr4Ovg7GDugO8A8ADwAPAQ8EDwMPEw87D1UPj4+rz9UACQAvAE4AfgCpANwA+gEUAToBTAFUAXwBgAGuAagBvgG+AbYBvAGsAZYBiAFoAUoBLgEAAPAA3gCnAI0AVkAzoBM/9A/YD7oPnA9/D1gPQw88DxkPAA8ODvIPDQ8LDxgPKg8pDyoPLw8oDzoPQw9sD3+PgA+jj7gPxo/Sr+Ef8uADIBCALcAoAD5AMgBIgEIAWgBeAFQAZ4BlgGAAaoBWgF+ARABIADxALCAZAAiP9i/vD8KPuI+bD3QPVA8oDvoO1g7ODrQOwg7QDuoO5g7xDwMPAw8JDwMPEw8sDzEPaA+Kj60PxV/9QBYAQgB1AKEA0QD8AQYBLAEwAVYBYAGGAZABqAGsAagBogGoAZ4BjgF0AWwBRAE4ARoA+gDZALEAmQBlAEUAJ5AHj+kPzg+jD5oPcw9sD0cPMw8lDx8PAQ8aDxQPLQ8gDzEPMg86DzQPQQ9RD2MPdo+HD5ePqg+6D8ZP06/jz/PgD5ALQBWALsAkQD0AOABBgFWAWYBeAF2AWABSgFIAXgBFAEvAM4A4gCnAGhAGD/zP0Q/LD6WPmQ90D14PKA8EDu4Oyg7EDtAO7A7mDv4O8A8CDwYPDw8KDxwPJw9DD2APjY+eD77P0uANAC8AXgCIALwA2gD0ARoBIAFIAVIBdAGCAZoBnAGWAZIBnAGEAYgBdgFiAVoBMAEiAQIA7wC7AJeAeABYwDkAGJ/7j9APw4+pD4QPcg9uD0kPOQ8gDywPHQ8fDxIPIw8lDygPLw8oDzQPQg9QD2APfA99D40Pmw+oj7aPxg/Tr+IP/7/88AbAEMArACaAMIBIgEEAVgBYAFWAVoBUAFIAXwBMAEcAToAzQDeAJeASEAzP6s/WD84PoY+eD2cPTw8UDwgO+A74Dv4O8g8GDwgPDA8DDxoPFQ8kDzcPSw9RD3YPjg+YD7ZP22/1wCGAWwBxAKMAzwDbAPgBFgEwAVYBZgF+AXIBgAGOAXoBdgF+AWQBZgFUAU4BKAEeAPMA5QDFAKQAhABkgEVAJIAGD+hPzg+mj5EPiw9mD1UPSA89DycPJg8nDycPJA8kDycPLA8kDz8PPA9ID1UPYw90D4IPkI+vj68PvM/KT9gv5Q/wwA1wCmAXACKAPkA5AEAAVIBWgFiAWIBZAFkAWYBXgFKAWgBPwDNANEAh4Byf94/hT9oPsg+nD4cPZg9LDysPFw8VDxYPFg8VDxUPGQ8QDycPIA89DzAPUw9lD3iPjw+XD7CP3a/uoAJANQBWgHUAkQC9AMoA6AECASYBOAFEAVwBXgFQAW4BXAFYAVABVAFEATIBIgEfAPkA4QDZALIAqQCOAGEAU8A1gBh//s/VD8uPow+dD3gPZQ9VD0sPNA8/DysPKQ8nDycPKQ8uDyQPPA81D08PSQ9UD2IPfw99j4sPmA+nj7aPxE/RT+6v7I/5YAYAE8AgQDlAMQBHgE2AQABQAFCAUgBRAF2ASYBEAE2ANYA+ACQAJcAUYANf8O/qz8+Po4+bD3cPag9QD1gPQg9NDzwPPQ8+DzIPSg9ED18PWw9qD3oPio+bD64Psw/Yr+AwCGAfgCSASwBVAHAAmQCiAMoA3wDvAP4BCgEUASgBKgEsASgBIAEmARwBAAEDAPQA5QDUAMIAsACtAIeAcYBtAEmANIAucAnf9M/vj8uPuw+sj54PgQ+GD34PaA9hD20PXA9bD1wPXg9SD2cPbQ9iD3kPfw92D4yPhA+bj5IPqI+gD7iPsc/LD8XP0Q/rD+R//h/3sA9wBeAcQBJAJ8ArgC6AIQAzQDMAMwAyAD9AKcAiwCtgEoAYcA2f8Y/yL+/PzQ+8j68PlI+cj4QPjQ93D3YPdQ90D3QPeA9/D3aPjo+Hj5GPqw+lj7JPzs/Kj9ev5t/2UAWgFIAkADQARIBWAGeAdgCDAJEArgCpALEAyADPAMMA0wDRAN4AyQDDAMsAsQC3AKsAkACUAIgAfABvgFMAVgBIADsAL0ATIBcgCy//r+UP6s/RT9iPzw+3D7APuw+lD6CPrQ+aj5kPmQ+Zj5oPmw+cj54Pno+ej5APog+lD6gPq4+vD6MPuI+wD8fPz8/HD95P1q/vb+ev/p/0gAowD5AEYBegGmAcQBzgHAAbQBlAFoATIB9gC6AHMAHADA/1j/4P5k/tz9UP3I/Ej86PuY+0D7APvQ+rD6kPqA+oj6qPrI+gD7UPuw+xj8gPwE/aD9Nv6q/hP/jv8VAJYAFAGWASQCuAJMA9wDaATwBIAFEAagBggHWAegB+AHIAggCCAIIAgQCOgHuAeABzgH4AaABhgGyAVgBQAFoAQ4BLgDTAP4AqACQALgAYoBLAHVAIcANADX/4P/RP8K/8j+fv5G/g7+yP2Q/XD9TP0s/Qj9+Pzo/Nj8xPys/Kj8pPyg/Kj8vPzI/NT83Pzw/Az9LP1M/XD9lP2w/cj96P0Q/jD+Pv5G/kb+Qv46/kr+ZP50/nz+cP5U/jb+Hv4G/tD9mP1w/WD9RP0g/QD98Pzw/Oz87PwA/RT9MP1Q/XD9jP2s/dT9Cv5E/nj+qP7m/jL/ev+y/+j/LAB+AM0AGAFiAbAB/gFIApQC5AIkA2wDsAP8A0AEaASABKgEyATgBPAEAAUIBQgFCAUQBQgF+ATgBNAEuASgBIAEWAQwBAAE1AOoA3wDRAMEA8ACfAI0AuQBkgFGAQIBwQCCAEAA9v+s/2L/G//g/q7+ev5E/hz+/P3g/cD9lP10/VT9NP0U/fD82PzA/Kj8hPxg/Ez8QPww/Bz8EPwM/BD8DPwU/CD8LPw4/FD8bPyQ/Kj8yPzs/BT9MP1I/WD9hP2s/dT9/P0k/kz+dP6W/rb+2P7+/h7/Nv9G/1b/av+J/6v/x//g//v/GgAzAEcAXQB2AI4AogC5ANQA6gD9ABwBPgFaAXQBlAG+AegBEAI8AmgClALEAvwCKANMA2wDkAO4A+ADCAQwBFgEaASABJAEoASgBKgEqASgBJgEgARwBFgEQAQgBPgDzAOYA2QDMAP8ArwCcAIoAt4BlgFKAfsAqABSAPj/nP82/9L+cv4S/rT9WP0M/cj8hPxA/BT84Puo+4D7WPs4+xD7+Pr4+vD68Prw+vj6+PoA+xj7SPt4+5j7uPvo+xT8QPxs/Jz80PwI/Uj9hP3A/fz9QP5+/rb+7v4q/2P/mf/P/wYAOwBpAJQAwgDzACIBRAFiAXwBmAGuAcYB4gEEAiQCOAJMAmACeAKUAqwCwALMAtgC6AL4AgQDDAMYAywDMAMsAygDKAMwAywDHAMMA/wC8ALkAtACvAKkAogCcAJYAjgCEALoAbwBkgFiASwB9gDBAIgASwAMAND/nf9s/zj//P7A/ob+Tv4c/vD9zP2o/Yj9aP1Q/UD9JP0M/fT86Pzg/Nj81PzQ/ND81PzU/Nj83Pzo/PT8BP0Y/TD9TP1o/Yz9sP3U/fT9FP44/mL+kv7C/vL+I/9R/37/qv/S//3/KQBQAHUAnADGAPMAHgFMAXYBnAGyAb4BzgHiAe4B7AHmAeQB4AHYAc4BzgHOAc4BzAHMAcYBtgGmAaIBpAGYAYgBggGCAXgBZAFWAUwBPgEqARgBFgEGAfMA4ADSAL4AsQCtAKgAlgCAAHQAZwBXAEUANAAjABYACgAAAPD/1f/A/6v/lP+B/3T/Z/9Y/0r/Qv84/yz/HP8I//j+5v7a/tb+0v7G/rz+tP60/rj+tP6s/qr+rP6s/rD+tv7C/sz+zP7I/s7+3P7s/gb/Jv8//1P/Y/92/4//qv/C/9X/6v8FACMAPABNAGAAegCWAK0AwwDbAPMACAEUAR4BJAEsATgBQgFKAUoBRgFAAToBLAEaAQgB/AD1AOkA1wDCALMAowCSAH0AaQBXAEUAMQAkABkADAD///f/9P/v/+X/2v/Q/8f/uv+x/6v/pP+Z/4//iv+H/4L/gP+A/4D/hP+O/5j/n/+g/57/nv+d/5r/l/+a/6P/rP+x/7H/sf+v/6v/qv+t/7H/sf+u/6//sv+x/63/p/+k/5//mf+U/4//if+D/3v/dP9x/3T/ef99/4H/h/+S/5//q/+3/8j/2P/n//b/CAAdAC4APwBTAGYAcgB6AIUAlACjAK8AuwDIANUA3QDgAOMA6gDqAOAAzQC6AKoAngCWAJAAhQB2AGgAXABMADcAHwAHAPD/1/+//6n/lv+G/33/dv9u/2L/Wv9V/1H/Tf9K/0z/Uv9a/2T/bv92/33/iP+Y/6f/tv/F/9P/3f/m//P/BwAZACcANgBIAFkAZgBwAHoAgwCMAJMAmQCfAKUAqwCtAKgAnwCcAJoAlQCOAIUAfABxAGQAVwBCACwAGAAJAPf/5v/e/9z/0//G/8j/wv+5/6z/pf+l/5f/jf+U/5v/lP+J/4X/g/+B/4T/jf+Z/5z/mf+d/6n/tv+8/8T/0//k//P///8JABUAIgArAC8ANQA8AEIAQwBBAD4AOwA4ADQAMQAzADQALwAmABwAFAANAAYAAQD///3/9v/u/+n/6f/o/+T/4P/c/9z/3v/j/+b/6f/y//7/BQAGAAoAFgAkACkAJwAnAC4AOwBFAEwAVQBfAGcAbwB0AHkAfAB/AIQAigCLAIkAhQCBAHoAcABlAF8AXABZAFIARwA8ADIAKAAcABAABgD9//L/6P/h/9n/zf+//7L/qP+e/5L/hv98/3X/bf9j/1r/U/9P/0v/R/9H/0j/TP9R/1f/Xv9m/2z/dP+B/5L/p/+7/87/3v/r//X//f8CAAYACQAJAAsADgATABsAIwArADAAMQAsACgAJQAlACEAGgASAAwABwABAPr/9//2//P/7//r/+j/5f/i/+L/6//z//n//v8KABMAEAASABsAJgApAC4APABHAEsASwBTAFsAYQBpAHIAdgB2AHoAggCHAIgAhwCIAIoAigCJAIUAfAByAGUAWQBPAEQAOgAvACMAGQANAP7/7v/d/83/v/+0/6z/oP+R/4b/f/99/3z/df9v/2z/av9s/3H/dP94/3v/d/90/3j/fv+H/5b/ov+s/7b/wP/L/9f/4v/s//f/AwAPABsAJAAqAC8ANQA7AEAAQwBGAEkASABFAEEAPgA+AEAAQQA/ADwANwA0ADAAKQAiAB0AGgAYABYAEgAPAA0ADAALAAoACgAJAAgACAAJAAwAEAAVABsAIwArADIANgA6AD4AQQBDAEYASABHAEQAQQA/ADsANwAzADAALwAwADEAMAArACQAGwASAAkAAwD+//v/9v/w/+f/3f/R/8X/uv+x/6r/o/+d/5j/k/+N/4b/f/96/3b/cv9x/3H/cf9y/3P/eP99/4X/jP+T/5n/n/+n/7H/u//H/9T/4P/r//X//v8IABEAGAAcAB8AIQAkACgALgAzADkAPgBDAEYASABIAEkASwBJAEEANwAuACkAJwAlACQAHwAZABUAFAATAA8ACgAHAAYABgAGAAgACQALAA8AEQASABIAEQASABUAGAAeACUALgA1ADoAPwBDAEUASABNAFUAWgBdAFwAWQBVAFIATwBLAEQAPgA6ADcAMgAqACIAHQAXABEACgADAP///P/4//H/6v/o/+r/6v/n/+T/5f/k/+H/3//Y/9D/yP/H/8T/v/++/8L/wf+8/7//vf++/7n/uf/A/7//wP/K/9H/zf/F/8T/xP/E/8P/xP/J/8j/wf/A/8f/z//P/9H/2v/l/+z/7//0//z/AwAJAA4AFgAfACYALAAyADcAPABAAEQASABLAEwASABCAD0AOgA4ADYANgA1ADQALwApACUAIwAgABwAFwARABAAEAASABMAFAAYABwAHQAaABgAGQAaABYADQAFAAIAAQD+//r/9f/x/+z/6P/l/+L/4P/g/+T/6v/u//L/9f/6//7/AAAEAAoAEQAWABgAFwAVABUAFAAUABMAEgASABEAEAAPAAwABQD9//X/7//o/+H/2v/V/9H/y//E/73/t/+w/6n/ov+d/5r/mP+W/5T/k/+S/5H/kf+U/5v/pv+x/7v/w//N/9f/4P/n/+z/8P/z//X/+f/7////BAAJAA4AEQATABgAHwAoAC8ANAA4AD8ARgBMAFEAVwBfAGQAZgBnAGUAZABiAGEAYQBeAFwAWQBWAFAARAA7ADYAMgAoACEAHwAYAA8ABgACAP3/+v/6//f/8f/s/+v/6v/n/+T/4//l/+j/6v/q/+r/5//n/+T/4v/i/+L/4//l/+X/6f/s/+z/6//o/+j/6v/v//P/8//y//T/+f/+/wIA///+////AQAAAP///v/7//b/6f/c/9X/z//J/8j/xf/C/8D/vf+9/8H/xv/M/9L/2f/i/+n/7v/y//j/AQAMABUAHQAlAC4ANQA6AD4ARABOAFoAZABrAG8AcwB2AHYAbwBmAF4AVwBQAEUAOAAuACcAIAAYABEACwAHAAIA/P/3//P/7v/q/+f/5P/f/9n/0f/J/7//tP+p/6H/lv+J/37/dv9v/2n/Zf9k/2n/c/+C/5P/o/+x/7//zv/f//D/AgAZADEARwBXAGEAaABrAGsAaABkAF0AUgBFADYAJQARAPz/6P/X/8j/vf+0/67/q/+q/6v/sP+7/8j/1//l//P/BAATACAAKAAvADYAPABAAEMARABHAEkASQBIAEYAQgA+AD8AQQBFAEoAUwBdAGYAbgByAHgAfgB+AHYAawBhAFoAVABMAEIANQAqACEAFwAKAPv/7//k/9j/yP+6/7P/sP+u/6v/q/+r/6v/qP+l/6P/pv+t/7T/uP+9/8T/zf/R/9D/0P/V/93/4v/i/97/3P/f/+P/5P/h/+H/5//v//D/6v/n/+n/7f/r/+L/3f/e/+H/3v/R/8P/vP++/7z/tP+u/7T/w//Q/9D/0f/Z/+j/8//5/wEAEwAxAE0AWQBeAG0AeAB/AHUAaQBqAGoAaABeAEcAKAANAPD/wv+U/3b/Z/9X/zn/F/8M/xn/Lf84/0n/cv+u/+z/HQBJAIIAyQAQAUYBcgGeAc4B9AH+AfAB3AHGAaoBeAE0AecAmgBMAPP/kv81/+b+qv5y/jr+Cv7s/ej98P0A/hT+Pv58/sr+GP9k/7f/EwByAMUABAE6AXABnAGyAa4BlgF4AVQBIgHcAIoAOADn/5L/N//c/or+SP4W/uz9zP24/bz90P3s/Rb+UP6i/gj/ev/x/3AA9QB8AQACgAL4AmADvAMIBDgEWARYBEAEAASoAzQDsAIQAlwBmgDU/w3/RP58/cj8JPyg+zD72Pqo+pD6oPrQ+hD7cPv4+5j8RP38/bz+iv9WABABuAFMAtQCRAOUA8AD3APkA9gDxAOQA1ADFAPQAoQCIAK+AWgBHgHUAIMAMQDx/8D/kP9Z/yP/Af/u/uL+zP62/q7+uv7M/tj+5P74/hn/Pf9S/1v/Z/+A/57/sv+7/8v/7v8PACYAMQBDAF8AhQCeAKkArAC2AMIAugCfAHkAVwAzAAcAx/9+/zv//P6+/nr+Pv4W/gb+AP74/fz9Fv5C/nb+pv7a/hn/ZP+x//L/KABZAI0AuADUAOAA5ADoAOMA1gC5AJkAegBZADIAAgDV/7b/pP+W/47/jf+V/6j/wP/b//7/KABVAIMArwDdAAgBLAFIAWABdgGCAYQBfgFyAWQBSgEoAf8A1wCzAI0AYQAzAAcA4//C/6D/fv9k/1f/VP9T/1H/VP9i/3n/j/+i/7b/0f/x/w4AIQAyAEQAVQBfAGIAXQBXAFEARAAtAA4A8f/W/7z/nP93/1j/Rf82/yb/F/8S/xr/Lf9B/1T/a/+L/7D/0//x/w8ANABdAIMAnACtALsAyQDRAMsAvgCyAKcAlwB8AFsAPAAgAAMA4P+8/57/h/91/2L/T/9D/0D/RP9I/0//Wf9p/37/k/+n/73/1v/z/w8AKAA9AFMAaQB7AIUAiwCQAJUAlgCQAIgAgQB6AHAAYwBWAEkAPgAyACUAGgAQAAUA+//0//D/8P/z//f/+P/6//3/AgAEAAQABAAEAAMA///4//H/6v/j/9n/zf+//7H/pP+Y/4z/gf94/3T/b/9s/2n/av9t/3L/e/+G/5T/pP+0/8L/0f/g//H/AAANABcAIwAtADUAOgA9AD4AQAA+ADgAMQAsACkAIwAbABMADQAMAAwACwAKAAsAEAAVABUAFgAWABoAHQAiACUAKwA2AEMASwBOAFgAXABiAGMAYABhAFsAVQBPAEMAMAAdAA0A+f/n/9f/yP+6/6z/nv+X/5T/l/+Z/57/qv+4/8j/2P/n//r/DQAgAC0AOgBFAE4AUwBUAFEATQBHAD8ANAAnABkACAD3/+b/1//K/7//t/+x/6z/qf+o/6v/s/+8/8T/z//e//L/BQAYACwAQgBZAG4AfgCKAJYAoQCoAKUAnQCTAIoAfQBpAFAANgAdAAEA5f/H/6v/k/9+/2v/W/9N/0X/Qv9D/0f/UP9f/3X/jf+n/8H/3f/8/xwAOgBWAHEAiwChALIAvgDHAMoAxwC/ALEAogCOAHcAXQBBACYACwDv/9P/uf+j/5D/gv94/3H/b/9x/3j/f/+K/5b/pf+2/8f/2P/o//b/AQAJAA4AEAAPAAsABwAAAP3/+v/5//r//f8EAAsAFAAdACkANgBEAE8AWABhAGoAcgB4AHsAfQB+AHwAdwBtAGAAVABFADcAKAAYAAkA/P/w/+T/1//Q/8v/yf/I/8f/zf/Q/9f/3P/l/+3/9////wQABQAFAAUAAgD7//L/5//b/9H/wv+0/6P/kv+F/3b/aP9c/1L/S/9F/z//Pf87/zr/Ov86/z3/Q/9J/1P/Wv9i/23/eP+E/4//mP+h/6z/uf/E/8//2v/k/+//9////w0AHAAsAEEAUwBmAHsAkgCoAMEA1wDrAP8AEAEgASwBNAE4ATwBPgE6ATQBLAEgARIBAgHvANsAxwC3AKQAkgCAAG4AYABRAEQAMwAmABoAEAAGAPr/7f/j/9r/0P/G/7r/rv+k/5n/jf+B/3b/bf9j/1v/Uf9J/0H/Ov80/y3/J/8i/x7/Gv8U/w//DP8M/wz/Df8P/xX/Hv8p/zP/PP9F/1D/W/9o/3b/hf+X/6r/vf/N/97/7v/9/wsAGQAlAC8AOQA+AEQASwBNAFAAUwBVAFkAXQBiAGgAbgB2AIAAjQCeAK4AwwDWAOwABAEcATQBSAFcAXQBiAGWAaQBrAG2AboBuAGuAagBmAGEAXABVgE6ARgB+ADVAK0AiABbAC8ABwDb/6v/ff9X/y7/Dv/q/sz+qv6O/nb+YP5K/jL+Gv4G/vT95P3Q/cT9uP20/az9qP2o/aT9qP20/cD92P3w/Q7+Mv5c/oz+wv78/jj/fv/C/wgATgCUANQAFAFOAYIBsAHWAfIBBAIQAhQCEAIAAuoB0gG2AZQBcAFKASoBBgHlAMgApwCZAIYAegB0AGsAbQBzAHMAdwB5AH8AhgCKAI8AkQCWAJwAlgCHAIQAagBbAD0AHQAGANn/tv+S/2//Of8I/+j+vv6e/oT+av5S/kD+Mv40/jb+Qv5K/lz+dv6Y/rr+3P4G/y//Z/+a/8//AwBCAIIAxQAEAUQBhgHKARQCVAKQAswC/AIsA1gDeAOYA6wDuAPAA7gDqAOIA2ADNAP0AqwCVAL4AaABOgHIAFYA5f91/wj/nP4y/sz9eP00/fD8vPyY/Ij8jPyc/MT89Pw4/YD91P0w/oj+4v5H/5b/4v8WAEMAZQBzAHIAXgA5AAcAyv9x/wr/iP4G/nD90Pwk/HD7uPrw+UD5gPjQ9zD3gPYA9qD1UPUg9SD1QPWA9QD2sPaA94j4yPkw+8z8kv5yAHACeASgBrAIwArgDNAOoBBgEgAUYBWAFoAXQBigGMAYoBggGIAXoBaAFSAUoBLgEBAPAA3gCqAIOAbIA1YB5P50/Pj5oPeA9WDzgPHA7yDu4OzA6yDrgOpA6iDqgOog6+Dr4Owg7qDvUPEQ8/D08PbY+ND61Py2/mIAEAJgA7AEoAVoBuAGIAcgB+gGaAbIBRgFCAQkAwgC8QDH/7r+rP2s/Mj78PpQ+rD5OPnQ+Ij4WPgw+CD4GPjw9/D38PfQ99D3sPeA94D3cPeA95D3sPcI+ID4OPkg+lD71Pxc/moAsALoBKgHIAoQDQAQABPAFYAY4BrgHKAeACAAIYAhgCHAIKAfIB5AHOAZIBcgFCAR4A2gCjgHxAOtAJz9yPoY+LD1UPOg8SDw4O7A7cDsQOwA7ADsAOwg7GDsAO2A7SDuoO5A7xDw0PCg8XDyMPMg9CD1EPYw90D4WPnA+hD8gP3Y/kgAygFMA9AEMAZoB5AIkAlwChALcAuQC2ALIAuQCtAJ0AiYB0AG2ARoA9YBRQDK/lT9HPzw+uD58Pgw+JD3MPfg9sD2oPaQ9qD2oPbA9tD2wPbA9tD2sPag9oD2cPZw9pD28PZQ9/D3sPjY+Sj74PyG/qQA3AJYBRAIsApwDUAQABPAFSAYIBoAHEAdYB7AHuAeYB6AHUAcwBrAGGAW4BMgEUAOYAtQCFAFWAKI/8z8SPoA+PD1QPSw8nDxUPCg7+DuoO5g7kDuQO5g7qDu4O4g76DvEPCg8EDx0PFw8gDzsPOA9ED1IPYQ9wj4KPlg+qD74Pwy/p3/DgF4AtADCAU4BlAHMAgACYAJ4AkQChAKwAlQCaAI8AcAB/gF2AR8AzQCBAHS/6D+eP10/Jj70Po4+rD5QPng+MD4kPh4+Dj4EPjg98D3sPdg9xD3sPZQ9gD24PWA9WD1QPWA9RD2wPbQ9/j4kPqQ/Nz+XAHoA7AGoAkADWAQgBNgFsAYIBtAHQAfQCCAIEAg4B8gH8AdwBtAGYAWwBMAEeANkAowB9wD+QA6/pD7CPmw9tD0UPMw8jDxYPDg76DvwO8Q8FDwkPAA8XDxAPJw8tDyIPNg87Dz8PMw9FD0gPSg9PD0UPXA9UD24Pag97D46PlA+5D85P13/yQB5AJoBMAF6AYQCDAJEAqQCrAKsAqQCkAKwAnQCLAHmAZwBVgEJAPCAXoAWv9u/oz9wPz4+1D78Pqo+nj6KPrA+YD5MPkY+bj4OPiQ9+D2UPaw9QD1QPSg8yDz8PLw8kDzwPOg9AD2sPfo+Tj8yv60AdAEMAiwCzAPoBLAFeAYoBvAHaAfwCCAIQAigCGAIMAe4ByAGgAYQBUAEuAOgAtwCFgFOAIg/0D82PnQ9+D1IPSw8pDx8PCg8GDwIPAg8FDwwPBA8ZDx0PEA8mDysPIA8zDzQPNQ84DzsPPg8xD0UPTA9GD1QPYg9zD4SPmw+jT82P2E/zwByAJQBOgFOAdwCGAJEAqACtAK0AqQChAKQAlQCEAHMAb4BKgDPAICAcn/zv6o/bT80PsY+8D6YPoI+sD5gPlo+Wj5SPkg+cj4iPgg+LD3IPeA9sD1EPWA9BD0wPOQ86DzIPQA9VD20Peo+cj7QP44AUAEmAfQChAOYBHAFAAYoBrAHGAeoB/AIAAhwCCAHwAeIBwAGqAXwBSAEVAOMAswCCgFFAIr/5T8aPp4+LD2MPXg8xDzkPJA8gDyAPIQ8kDyoPLg8iDzUPOQ86DzwPPA88DzwPOg84DzYPNg80DzcPOg8+DzYPQA9eD18PYY+HD58PqU/Gj+LADwAZADIAWQBuAHAAnACVAKsArgCsAKcArQCfAIAAgAB/AF0ASIAzwCCAHz/wX/JP5A/YD84Pt4+zj76Pp4+iD66PnY+Zj5QPmo+BD4oPcg95D2wPUA9YD0MPQg9DD0YPQA9SD2kPdg+Uj7lP0dABwDOAZgCZAMwA/gEgAW4BhAGyAdgB6AH+AfACBAHwAeIBwAGqAX4BQAEvAOwAuwCJgFtALg/zT9wPqo+OD2cPUw9EDzkPIg8gDyIPJQ8oDy0PIw86DzEPRg9JD0sPTw9BD1MPUg9QD18PTQ9ND0wPTQ9PD0IPWA9QD2wPag96j4yPkQ+3j8/P2I/xQBiALsAzgFcAZwB0AI0AhQCZAJkAlQCeAIQAh4B6gGsAWoBIQDYAJSAVAAXv98/rT9DP18/Pj7mPsw+/j6mPpY+vj5kPkg+Zj48PdA94D20PUg9XD0wPMg8wDzMPPA86D0sPUQ97j4MPvY/YwAdAOABrAJIA1gEIATQBYAGUAbQB3AHoAfoB9gH4AeQB2AG0AZoBbAE+AQ8A3QCpgHaASIAer+iPxQ+lj4oPZQ9WD00PNw8yDzAPNA87DzUPTQ9CD1cPXQ9TD2gPaA9kD2IPYQ9vD1kPUQ9XD0IPQA9PDz4PPQ8/DzUPQg9QD28PYY+FD58Pqo/FL+8P9yAQwDoAQABigHEAjQCGAJ0AnwCbAJUAnACBAISAdgBlgFKAQsAyQCRgFuAJb/7P5U/tz9eP0c/cT8dPwY/Lj7WPvI+ij6WPmI+KD3sPbQ9dD04PMQ83DyMPJQ8tDy0PMA9YD2aPi4+pz9gwCYA6AG4AkQDWAQoBNgFuAYABvgHEAeIB9AH6Ae4B3AHAAbwBgAFiATYBCADZAKeAdgBHoB9v60/Jj6sPgQ99D18PRw9BD00PPQ8yD0gPQA9YD10PUg9nD2sPbA9sD2kPZw9jD24PVw9SD1sPRw9ED0IPQg9DD0cPTA9GD1IPYg90j4oPkI+4T8Ev60/2gB5AJwBKgF6Ab4B9AIgAnQCQAK8AmwCUAJkAi4B9AGwAXABKQDmAKMAZwAyf8j/4z+9P1s/fj8rPx4/Az8mPv4+nD66Pk4+WD4UPdQ9mD1oPTg8+DyEPLQ8QDysPKw89D0MPYw+Lj6iP2ZAIADeAawCRANQBBAE+AVIBhAGkAcgB0gHkAewB0AHcAbABrgF0AVgBLQDwANMApAB2AEsgFA/wz9EPtY+eD3wPbw9WD1EPXw9PD0IPWQ9eD1QPag9tD28PYA99D2sPZw9hD2sPUw9cD0MPTQ83DzIPPw8uDy8PIw84DzAPTA9KD14PZA+Lj5QPvM/Ib+YwAsAsADKAWABsAH8AjQCVAKkAqgCqAKcAoACiAJIAgoBygGKAX0A8QCrgHEABMAbv/I/g7+iP0w/fT8jPwU/Ij74Ppg+qD56Pjg9+D24PUQ9UD0cPPQ8mDygPIQ8zD0cPXw9rj4GPvc/dIA2APIBsAJwAzQD8ASYBWgF4AZIBtAHOAcAB2AHIAbQBqAGGAW4BMgEUAOgAvQCCgGaAPEAF7+SPyI+gj5oPeQ9tD1cPVg9XD1oPXQ9TD2wPZQ99D3EPgw+Dj4OPg4+Aj4oPcg96D2IPag9RD1gPQA9KDzcPNQ81DzYPOQ8yD08PTQ9eD2OPiI+SD70Px+/jMAwAFYA9AEMAZYB1AIAAmQCfAJEAoACsAJMAmACLAH4AbYBdgE1APYAvYBGAFvAM3/Hf9i/tD9TP3c/Fz8uPsI+yD6WPmQ+LD3oPaQ9aD0APRg8+DyoPKg8hDzEPSQ9SD36PgQ+6z9ngCwA6gGkAlgDDAP4BGAFKAWYBjAGeAagBugG0AbQBoAGUAXgBVAE6AQ4A0wC7AISAbcA3ABK/9E/bD7YPo4+SD4YPcQ9wD3EPcw90D3gPfg91D4wPj4+Aj5APkA+eD4kPgY+KD3MPew9jD2gPXg9FD0APTA84DzYPNA83Dz0PNg9BD10PXg9jj4sPlA+9D8YP4XAMQBZAPIBAAGIAcQCOAIcAnQCfAJ4AmQCTAJkAjIB/AGCAYIBRAEEAMoAlwBnQD5/0v/qP4Y/oD9BP1k/MD7CPsw+jj5OPhQ90D2YPWA9MDzIPPA8sDyIPPQ8/D0QPYo+Dj6tPxf/zgCOAVACFALMA7gEEAToBWAF0AZYBogGyAbwBogGgAZoBeAFSAT4BBADrALAAlABrwDfgGT/7T9EPxg+jD5cPgQ+ND3sPeg99D3MPjI+ED5mPn4+Uj6mPrY+uD6oPpA+sD5SPno+GD4kPfA9hD2YPXg9ID0EPTA85DzcPOA87DzAPSg9JD1oPbw9zj5wPpY/Az+uf9WAcwCGARYBVgGQAcACJAI8AgACdAIgAgwCMgHGAdIBlgFmATgAzgDeAK4ASoBzwB4ABIAgf+w/hj+jP30/AD8sPpI+Rj4EPcA9uD0oPOw8jDyQPJw8tDykPOw9HD2wPg4++D9mgCUA9AGEApQDQAQYBKAFKAWYBigGWAagBoAGmAZYBjgFgAVwBJgEPANYAvACDAGsANoAVz/rP0k/Mj6oPnQ+Fj4GPgo+Ej4gPi4+CD5oPk4+pj64PoI+xj7GPv4+qD6GPqA+dD4SPig9+D2APYw9ZD0APSg81Dz8PKw8pDywPIg87DzYPRA9XD2APiY+WD7+PyY/lMAFALUAzAFSAYwBzAIIAngCSAKEArACZAJYAnwCCAIEAf4BSgFqAToAyQDWAK2AVwBBgGSALT/yP74/SD9SPwY+4j5APiQ9nD1cPRg84DyoPFA8XDxEPIg80D00PUA+Hj6aP1sAHwDoAbACQAN0A9gEoAUYBYAGCAZwBkgGsAZ4BjAF2AWoBSAEiAQsA1AC7AIcAYwBCQCLwCI/ij9FPxA+4D6APrA+bj56Pkw+mD6qPrw+lD7uPvY+9j7oPtI+wD7gPoA+jD5YPiQ98D2APYw9WD0cPOw8kDy8PGg8VDxQPFg8eDxgPIw8zD0UPXg9uD44PrM/IT+SAA4AiAE0AUoBzAIIAkACuAKYAtwCzAL8AqgClAKsAnACIAHaAaQBegEIAQsAzgCdAHRABcAN/8g/vD82PvI+oj5APhA9rD0cPOA8qDx4PBA8ADwYPBQ8ZDyMPQQ9nj4SPtK/nIBuAQACFALcA5gEcATwBVgF8AYwBkgGiAaYBlAGOAWQBVAEwARgA7wC5AJSAcABdQC0QAx/9j91PwA/FD70Pqo+rj68Po4+3j70Psw/Jj83Pzo/NT8vPx4/Bz8ePvA+uj5GPlY+HD3cPZg9ZD0sPMA81DykPHw8KDwkPCg8MDw8PBg8RDyMPNg9OD1oPeY+aD7tP24/6YBfANwBRAHkAjACaAKYAvQC0AMQAwADIAL0ArwCfAIuAdYBhAF+AMAAwwCEAH7/wj/Nv6A/az8oPtw+lD5OPgg99D1cPRw85DyAPLA8XDxcPHQ8eDygPRA9ij4cPoQ/REARANYBmAJUAwwD+ARQBQAFkAXYBggGWAZABkgGAAXgBXgE+ARwA9gDfAKoAhoBlgEMAKGAA7/6P34/Ez8yPtw+2D7iPvw+0j8rPwM/XT9zP0M/iL+GP7M/Vz90Pwg/FD7YPpg+Uj4QPcQ9vD0wPOg8qDx0PAQ8IDvAO/A7sDuAO+A7yDwAPEw8tDz8PVY+Lj69Pw8/5QB2AMoBkAI4AkwCxAMwAxwDcANwA1ADYAMoAugCnAJ6AdABpgEVANQAkgBDQDa/uD9PP2o/AT8KPsw+lj5iPig95D2gPWA9NDzYPMA89Dy0PJA8yD0UPXw9tj4CPt4/R0A3ALwBQAJMAzgDmARgBNgFQAXIBjAGMAYYBigF6AWIBUgEwAR0A6gDGAKAAiIBUgDSAHM/2D+KP0Y/Gj7KPsg+1D7gPvg+2z8LP3U/Xb+yv4E/zn/ZP9q//7+Zv6k/ez8DPwQ++D5gPjw9pD1QPTw8qDxMPAg7yDuoO0g7QDt4Owg7eDt4O5A8NDx4PNg9kD58Pt4/rAAPAPIBVAIUAqgC5AMgA1QDuAO0A4gDmANgAywC0AKoAiwBugEjANYAiwByf+I/oj9wPwM/Ej7aPqg+bD40Pfg9tD10PTg82DzEPPg8uDyIPOw85D08PXA98j5HPyi/lgBSARgB4AKgA1AEKASwBSgFgAYwBhAGUAZoBjAF2AWoBSAEkAQAA6ACyAJsAZ4BFwCcwDG/mD9fPzQ+3D7SPtw+8j7aPwQ/dj9jP40/+b/XwCsALcAkwBEAM7/OP9m/nD9VPwI+6j5MPiQ9vD0QPOw8TDw4O6g7aDs4Otg60DroOsg7MDswO1A74DxQPQg99j5gPwx/xwCWAUQCCAKwAtADaAOkA/QD6APAA9wDsANsAwQCwAJEAeABSAEpAL6AH7/Rv5k/cT8DPwg+0j6uPlo+dD48Pfg9vD1YPXw9ID0EPTA87DzIPQA9SD2UPcA+QD7XP34/7gCcAUwCCAL4A2AEMASYBTAFcAWoBcAGMAX4BagFSAUgBKgEHAO8AtwCSAHEAUEAwIBK//A/dz8YPwQ/Pj7GPyA/Dz9JP4B/7f/cgAgAbwBJAI8AgQCgAEIAVkAgv9O/sT8MPuI+fD3EPYw9CDyQPCg7iDt4OvA6uDpYOmA6QDqoOqA62DsAO6A8JDzsPaI+VD8XP+QApAFMAggCvALcA3QDpAPoA8QD3AOQA6gDZAMsArgCEgHCAbQBFQDuAFZAHz/1P4g/vD8yPvo+mD60Pnw+LD3UPZA9ZD0MPSQ8/DyoPLQ8nDzcPSQ9QD3yPgQ+7j9hABUAwgG4AiwC5AO4BAAE4AUwBWgFmAXgBcAF0AWABWAE+ARABCgDUAL8AjIBsgEzAIIAW3/aP60/XD9WP14/bT9Uv78/sr/gwAWAbYBIAJ8AogCUALKASgBVQBs/0D+5PxI+4D5sPfQ9eDz8PEA8EDuwOyA64DqoOkA6QDpIOkA6gDrAOxg7YDvgPIA9lD5JPzm/uoBMAVgCOAKgAywDfAOIBDAEGAQgA+gDhAOUA3wC+AJ0AcABsgEoANEAqYASv90/rT9HP08/Gj7qPoo+pD56Pjg99D24PVQ9QD1kPRg9FD0gPQw9UD2wPdI+Rj7NP3C/1wC+ASQBwAKYAzADuAQgBLAE2AUABVAFSAVgBRgEwASYBCwDsAMsAqACGgGkATsAnABIwAh/3z+Mv40/oT+6v5X/9r/hwBUAf4BdALEAvgCCAPkAowC7gEAAef/wP6E/QD8APrw98D14PPg8eDv4O0A7GDqYOnA6CDowOfg56DowOlg6+DsAO/A8VD1MPnQ/ML/jAKgBfAI8AsQDlAPIBDgEGARgBEAEcAPgA5QDSAMcApwCEgGaATsAqABbQAa/8j9oPzg+zj7kPrQ+Rj5cPig9+D2QPaA9cD0UPRA9HD0wPQg9cD1wPZQ+Ej6kPzO/hYBnANQBhAJkAvQDdAPgBEgEyAU4BQAFcAUYBSgE6ASABEgDyANIAsQCfAGCAVIA8QBhgCW//D+lP6a/gT/qP9EAAQBwAGAAjwD+AOQBPAEAAXIBIAE6AMIA+QBnAAZ/4T9uPuo+WD38PSg8pDwgO6A7IDq4OjA5wDnoOaA5sDmoOfg6KDqgOwg72DyYPZA+qj9uQDQAxAHUArwDMAO4A/AEGARoBGAEYAQQA8QDtAMUAtQCTAHIAVkAxQC2QB9/wz+5Pwo/JD74PpA+pj5IPmY+AD4UPeg9uD1gPVg9WD1gPXA9TD24PYI+JD5YPtA/UD/dgHUAzgGcAigCrAMkA5AEIARYBKgEuASwBJgEoARQBDADiANUAtwCYgH0AVABMACigGGAOv/qP+m/+H/UAAAAcQBpAJwAyAEwARwBfgFMAYIBqAFAAUoBCQD3gEwAD7+GPzo+aD3EPVw8uDvYO1A64DpwOdA5iDlwOQg5aDlgOag52Dp4Osg77DyUPbg+Wz9CAFwBJgHQAqgDHAO8A+gEOAQwBBgEOAPEA/gDUAMkAowCZgHCAZQBOQCxgHcAPb/yv68/cD8PPyg+/D6CPoI+Rj4YPew9uD1MPXQ9MD0EPVg9eD1kPbA92D5SPto/W//mgHIAygGgAigCpAMEA6AD+AQwBFAEiAS4BGAEQARABCQDsAMAAtgCfAHiAb4BJADnAIMAtABogGuAewBaAIkA/QDmAQQBYAFEAZ4BpgGWAbQBSgFQAQ8A9oBDQAW/vj70PmA9wD1UPKg70Dt4OoA6UDn4OUA5YDkgOTg5ODlQOcA6WDrQO6w8WD1OPn8/GQAkAOYBqAJQAxADnAPIBCAEKAQoBDgD9AOgA0wDAALgAmoB9AFSAQ0A2ACSgH6/7T++P2g/Uz9nPyw+8j6OPq4+TD5UPhQ98D2kPbQ9gD3MPdg9wD4GPmw+lj82P1u/zIBUANoBXgHEAmACvALcA2wDmAPkA9gD2APMA+QDqANUAzQCoAJYAg4B+AFoAS0AwwDqAJcAlACeALgAmgD/AOgBAAFeAXoBVAGiAaIBlAG0AUQBTgEIAPMATYASP44/Pj5oPcQ9YDy4O+A7SDrIOlg5yDmQOXg5ODkYOVg5uDn4Okg7ODuAPKw9Yj5JP1sAFADKAbgCHALUA1gDsAOQA+AD2AP4A7ADbAMkAuAClAJsAcQBqAEnAPIAsYBpgC1/+D+TP6w/RD9VPx4+7j6EPpQ+aj4EPiw94D3cPew9xj4wPiY+aD64Pt0/Sf/BAHYApgEYAYwCOAJUAuQDIANMA7ADiAPEA+wDhAOQA1QDFALIAqwCFgHOAZABXgEuAMIA6QCqAIEA2wDxAMQBGgE8ASIBfgFKAYoBhgG6AWoBfgE+AOoAlgB9P9g/mT8IPrA92D1EPPA8GDuAOwA6mDoQOdg5uDl4OVg5mDn4Oig6sDsQO9A8sD1aPmo/Fr/3gFYBMAGAAmgCoAL0AsgDGAMcAwQDEALcArACSAJUAggB8gFyAQoBNADNANYAnQB6ACEAAsAbf+i/tT9GP10/Lj78PoY+qD5cPl4+YD5oPkI+qj6iPuU/Mj9AP9nANgBRAOQBNAFAAdACFAJEAqgChALcAuAC3ALEAugChAKYAmwCOgHKAeABugFkAU4BQgFAAUYBVAFeAWQBagFyAXgBfAF4AW4BXgFIAW4BPQDHAMgAvcAhf/U/fj78Png97D1cPMg8eDuwOwg66DpYOiA5yDnQOfA58DoAOqg68DtUPBg83D2kPmE/Dz/rAHMA9gFkAfQCJAJAAoAChAK4AmwCTAJkAjgB0AHyAY4BqgFCAWgBGgEWARQBBgErANIA/wCqAIoAlIBQAA3/0z+fP2c/Lj7+Pp4+kj6aPqI+qj6APu4+8j8/P0c/yQAQAF8AswDGAUoBgAH0AeACDAJkAnACcAJoAlgCUAJ0AhQCOAHYAdAByAHGAcQB0AHcAewB/gHMAhgCGAIUAgwCBAIuAdgB8AG8AXwBNADkAL9ADf/MP0Y+/D4sPZQ9PDxgO9g7WDroOkg6CDngOaA5uDmgOeg6EDqIOxg7vDwwPOg9qj5jPw1/24BJAO4BDgGgAdwCOAI4AjACJAIcAgwCNAHQAewBkgGCAbIBXAFMAUABQAFGAUoBfAEiATwA3wDCANwAooBfQBy/47+/P1Q/aD8+Pug+8D78Psk/Ej8kPw4/TT+Qv8yAOAAqAGgAqgDiAQYBZAFCAaIBtgG+AYIB+gG4AboBvAG8AYAByAHUAegByAIsAhQCeAJMApwCqAKwAqgCmAK8AlgCdAIAAj4BogFAARcArwAxP6U/DD6wPdA9cDyYPAg7gDsQOrA6KDn4OaA5sDmoOfg6IDqQOxA7oDwMPMQ9iD58PtU/nEATALYA/gEyAVoBtgGEAcoB9AGYAbYBZgFmAWYBWAFEAXIBLAE2AQYBVgFaAWABZAFuAWYBQgFYAScAwADaAKuAb0Aq//a/mz+OP4A/rz9pP3M/Q7+XP6U/uL+bf8OAMkAUAGSAcQBDAJsAswCJANcA3gDhAOQA7AD6AMYBHAE6ARgBeAFkAZoB2AIQAlQCjALAAyADNAM8AzwDOAMoAwwDHALgApQCeAHQAZQBDgC/P+Q/fD6IPhA9WDyoO9A7SDrIOlg5yDmYOVA5aDlgObA50DpIOtg7eDvwPKw9cj4iPv8/QoAugE0A2gESAXQBRAGKAYoBgAGsAUoBdAEoAS4BMAEoAR4BHAEsAQIBXgFuAXQBdgFwAWABRgFeAS4AxQDhALoASwBVwCt/1L/Qv9N/0T/Kv8Z/zT/gP/m/z4AmgDmAC4BVAF4AX4BcgF0AaYB3gHwAdoBxgHYASwCpAI8A9ADcARYBXAGoAfACOAJ8AoADPAMgA3QDfAN4A3QDZANEA1ADDAL8AlwCMgG4ASoAh8AWP1w+pD3kPSQ8aDuAOzA6eDnYOZA5aDkwOSA5aDmAOjg6QDsgO5w8ZD0sPdg+rD8sv6jAFgCuAOIBOgEEAVIBWAFWAXwBHgESARYBIAEiAR4BIgE2ARgBfgFSAaIBsgGIAdIBzAHwAYABnAF6ARgBJADtALsAW4BKgHzAK4AaQAzADUAUQBRAEIAMQA6AFYAWAAzAPn/qf+I/4v/sf/N/87/yf/X/z0A0QCMAVQCSAN4BNgFcAfgCFAKkAvQDPAN4A5gD5APkA+ADzAPkA7ADcAMYAsACoAIeAb0A0YBfv6o+8D4kPWA8mDvoOxg6kDogObg5CDkQORA5UDmgOcg6WDrQO5g8ZD0APc4+WD7wP29/x4BxAE4AqACBAMkA8QCGAKUAaIBBAJkAogCvAI8AxAEEAXQBXAGGAfQB4AI8AgACbAIQAjABzAHcAaYBcAE8ANEA7gCQALaAZQBXAE8AR4BCgHgAJQASQAMANL/jf9A/97+iP5E/hz+Fv4W/ib+VP6o/iH/xP+YALQBIAO4BGgGEAiwCUALoAzgDeAOoA8AEEAQQBDwD1APkA6wDbAMcAvQCcgHSAWIArz/3PzI+aD2oPPg8ADuQOvA6MDmYOUA5SDlgOVA5kDnIOnA66DuUPHQ82D24PhQ+zz9ev4v/8r/aADFAL4ANwCg/zn/Hf9I/47/8/+SAIQBvAIABEAFgAbIBxAJQApAC+ALAAzwC8ALcAvQCgAKAAkQCCAHUAaABZgEtAMMA5wCJAKeAd8AHABi/8j+UP7M/Uj9uPxY/BD82PvI+8D78PtI/Nj8jP1k/nD/uQBMAhgEIAYwCBAK0AtgDcAO0A+AEOAQABGgEEAQoA/gDtANwAyAC/AJ2AdIBTgC5P6Y+5D4wPXw8iDwIO1g6iDogObA5cDlIObA5gDo4Okg7IDuAPGw81D22PjY+hj81PxE/aT9oP1Q/dj8SPyw+xD72Pr4+nj7ePzw/ZL/IgHYArAEoAaACFAKAAxADQAOMA5ADvANgA0ADWAMkAugCtAJ4AiwB5gGyAUwBagE9AP0AsoBpACv/8z+4P30/Oj7CPtA+pD5MPkA+UD5yPl4+jj7JPx0/Qr/xAB8AmAESAZACCAKoAvADKANgA4wD4APUA/ADjAOsA0QDXAMgAsQCnAIcAb0A9oAOP3Y+dD2QPTw8WDvwOwg6oDoIOhA6MDogOnA6sDsQO/g8UD0cPbA+Aj76Pzg/ez9hP3U/DD8YPs4+sj4UPdQ9gD2IPaw9qD3QPlw+/D9iwAEA2gFuAcgCmAMUA6ADwAQQBBgEGAQABCgDwAPQA6gDdAM4AvACpAJYAhwBzgGuATsAvcA+v4c/Yj7APpw+BD3EPZw9VD1kPVA9lD3gPgI+iD8WP6nAOQCMAWQB8AJsAvwDLANAA6QDiAPMA+wDgAOYA3ADEAMoAuwCnAJMAj4BggF3AHw/SD6EPeg9GDy4O8g7cDqQOmg6ODooOnA6sDsIO8g8vD0oPfg+Uz86P7iALABJAG+//j9OPxg+lD44PVg85DxgPAQ8CDw4PDA8nD1+PiM/Nb/4AIABkAJYAzADoAQoBEgEoASoBJgEiAS4BHgEeARoBHgEMAPcA4gDQAMsAqwCPAF4ALm/xT9cPoI+PD1IPTw8nDycPKw8mDz0PQQ95j5YPxQ/xgCoAQwB8AJ0AsgDQAOsA4ADwAPoA4ADvAM4AtQC8AKAArgCNgH+AbIBRgEiAH8/fD5YPYQ9PDxgO/g7ADrAOrg6UDqIOvA7ODuAPJw9ZD4MPu0/ZcAMAPYBAgFrANSAZr+sPuo+ED1oPGA7gDsYOqg6YDpoOrg7FDwcPS4+OD8tABoBCAIsAuwDgARoBLgE8AUIBWAFaAV4BXgFSAWwBXgFKATABJAEDAO0AvQCEAFTgF4/Qj68PZg9KDywPGA8ZDxQPKA80D1oPd4+pD9bADEAuAEyAawCFAKgAtADIAMgAxgDMAL0ArgCUAJEAnQCHAIqAfIBhAGSAUQBOIBG/8M/Lj4UPUw8oDvoO2g7KDsQO3A7aDuYPAg83D2YPkA/Iz+DAF8AzAF6AUoBVwDpABU/VD5UPWQ8SDuAOtA6IDmwOVA5iDoIOvg7oDzSPjs/EYBOAXwCFAMgA8AEqAToBRgFSAWABeAF+AXIBggGAAYIBegFWATwBAQDhALaAdAA8j+cPrA9iD0wPLw8dDxwPJQ9DD2EPhY+gz9z/9wAogE4AVoBsAGQAfoB2AIwAjwCAAJsAggCKgHUAdoB9gHEAjIB6gGQAW4A+wBDAAI/nD7aPhg9ZDyQPCA7uDtYO7A72DxcPNw9UD3wPiY+vT8Mf8wAdACKATQBIgEdANCAZz94PiA9PDw4O2g6oDnwOQA4wDj4OQA6EDrIO8Q9Nj5Cf94A6AHoAsgD0ASwBRAFqAW4BaAF2AYoBhgGCAYgBdgFsAUYBIQD2ALQAhoBf4B3P0Y+nD3wPXg9CD1QPaQ9zD5ePsC/v//pgGEA6AFMAfwByAIyAdABwAHKAdoB3gHUAcYB6gGyAXoBGAE7ANkA9QCOAIyAaz/EP6w/ED7uPkw+KD28PRg85DyYPKg8mDz0PSQ9ij4kPn4+gT8vPwK/oj/GgEIAkQCQAJwAXn/0PvA9jDxgOxg6WDnoOWg44DioOKA5CDo4Ozg8RD3uPy0AsAHgAtwDkARwBMAFoAX4BdAF6AWwBbgFqAW4BVgFWAUABIQD7AL8AfMA3IAPP40/Lj5oPcA99D3GPkY+6j9FQA0AhAEkAVQBoAGEAf4B2AIIAiQBwgHIAZQBUgFsAWgBTAF0AQgBNgCcAHCAJEATQDl/6P/Gf/U/Uz8OPso+uD4oPfA9hD2IPWQ9LD0YPUg9lD3EPkQ+3j8fP2o/gIAwgEkA2gE6ARoBJAC0P44+VDyYOvA5QDjAOKA4eDgwOBg4mDmwOtw8TD31PyEAsAH4AtQDsAPYBGgE6AVoBYAF+AWgBYAFqAVYBVAFCAS0A8QDWAJ8AThACj+bPxQ+7j6ePqg+nD7KP2a//ABEATYBQAHOAcYBwgH8AbQBvgGqAfwBzAHIAZwBeAEMATQA8gDPAPSATwAIf9M/rT98P3Y/l//Ef9w/oz9HPyA+nD5uPjw9wD3sPag9nD2kPaQ9yj5yPps/Bj+VP/c/4QApAGYAhgDTANcA6gByP3w9/DwIOmg4kDfAN/A34DgwOHA5ADpAO7A8+D5gP+oBHAJAA3QDnAPgBBgEqAUQBYgFyAXABYAFeATwBLgEJAOQAxwCdgF7gHI/vD8UPys/HT9av5m/6gANAL0A6AFKAcgCFAIEAiIB9AGEAb4BbgGkAfoB7AH8AaQBeQDiAKIAacApP/C/uT96Pxc/LD83P0t/zUAjQDI//j92PsQ+nj4MPdw9pD2IPew9zj4IPlg+tD7fP3Q/l3/J//6/ij/k/8CALkAmgHEAXIA3PyA9sDtQOWA34DdwN0A3wDh4ONg5yDs4PEA+Pz92AOQCcANYA9wD5APQBBAEeASYBQgFeAUABTgEoARcA9gDYALgAmABuACs/+k/eT8mP1H/zQB7AJIBIgFaAboBlAH2AdACEAIAAggB/gFKAVgBSgGqAagBjAG8ATUAv4Azv/g/uD9aP2Q/ZD9WP2c/ar+4P+LAIEAu//I/Xj7YPnQ91D2QPWg9QD3YPiA+YD6WPtA/FD9aP7W/lj+Hv6M/hX/cP8kAEgB4AHBAGj9EPcA7sDkgN6A3EDdQN9A4uDlwOmA7kD0SPqT/+gEcAqADuAPkA8QD1APgBCAEoAUgBVgFYAUgBKwD5AMEAogCCgGKAT4Abb//P3o/dT/aAKgBGAGwAdgCBAIUAe4BpAGcAbABmAH2AegBygHKAdwB3gH8AbIBQgE2AHF/xj+8Pwc/Nj7DPyA/Az9zP3O/qT/KAARABT/GP3g+hD5sPeA9jD2QPdY+Xj7yPyI/QD+XP74/qH/eP9o/oz90P12/ur+5v+6AaQCkwCA+5DzYOmA3wDaANrA3IDfYOOA6CDuEPNg+AT+JANoBwALgA1wDkAOUA5wD+ARoBRgFkAWwBSAEnAPUAuQB5AFoASEA0gCbgHmAK4AAALoBNgHUAmgCYAJ0AiIB5gGmAbIBtAGWAdQCIAIkAcIBzgH0AYIBUAD+gFbAEL+FP1Q/YD9NP00/dD9fP68/vz+Sf8g/3T+QP1Y+xj5UPdw9gD2APYQ9xj56PoI/BD9MP7m/i//mv8ZAMH/ov7M/RT+Kf9oANwB2AIYAhT+EPYg60DgQNnA1wDaAN4g42DoQO1w8rj45P4QAyAGoAnQDLANEA2gDaAPoBGgE8AVgBaAFAARoA2gClgH2ASkAxADXALSAQQCmAKsA8AFgAiACiALYAogCaAHOAaIBYAFCAaoBlgH+AdQCBAImAfgBsAFKAQoAgwANv4o/Sz9NP0M/Tz9QP5o/woAMgAdADL/OP0g+3j54Pcw9qD1oPZY+Mj56Po4/ED9oP3c/WL+E/8Y/+r+5P4m/xb/4v47/zwA1AGIAiIByPzg9aDsgOLA2QDWANhA3cDjgOrw8GD24Pp1/7ADAAbIBjAI8ApgDaAO8A8gEgAUoBVAFgAVIBEQDAAISAXsAmwBxAEgAxgEsAS4BQAHsAdACHAJUAqwCRAIIAf4BpgGeAZYB7AIMAmgCPgHMAf4BWAEGAOmARAA5v6c/q7+jP7K/hT/F//K/sb+7v6g/qz9DP1c/CD7oPmY+ED4IPgw+OD4APpA+2j8bP1C/vT+qP8wABwAl/8M/67+Mv7g/Qj+gv64/sL+oP5g/MD1gOtg4QDagNZA14Dc4OQg7eDzkPmY/bD/BAEwA8AFgAdgCRAM4A7gEGASYBTAFWAVwBMAEfALcAV0ADD/AQA0AaACiATwBUAGiAaYB/AIEAoQC+ALoAsACjAIsAeACMAJsAqgCkAJGAfoBAwDcAEzANj/BgDj/53/qP/+/wgAvf+7/97/d/+K/pT9tPyw+6D6yPkY+QD4EPeg9uD2wPco+Qj7AP3e/rUAIAJkAo4BRwAn/1r+5P28/UT9nPyM/PD9bf/e/kD74PQA7ADiwNlA1kDYwN7g5yDx0Pcg+8D8Lv55/wgBZANABgAJsAvQDqARYBPgFKAW4BYgFJAO6AfKAZT9xPwX/7QCkAVgB4AIkAiIB5gGYAeQCTALMAuACgAKoAngCfAKUAwgDPAJCAdQBMABk//y/vz/LgGmAa4BdAEIAZgAegBwANv/tP5k/Tj8gPsA+6j6iPqQ+vj5KPgg9nD1YPYQ+FD6mP0iAUQDGASgBHAErAIpAKz+Sv4g/Tj76Pmw+XD6OPya/oj/OPwA9EDpQN8A2QDXgNrA4oDssPTI+Rj81PwE/Yj9Z/+8ArgGEArQDHAPABKAFKAWwBdgFgAS8AtoBRn/yPp4+tT9ZAIABmAIUAlQCMAGSAfwCYAMEA2wDLAMgAzgC+AL0AwwDfALMAnwBUACwv4s/S7++v/YADQBEAI0A2wD+ALMAnAC7QBC/qj7yPm4+Ij4ePmY+kj6EPig9aD0QPWw9hD5iPwnALQCIARQBYgFiATUAnoB+P+A/fD6WPm4+Hj4ePkY/Kz+dv6o+XDwgOXA3ADZANrA3qDmgO/w9gj7dPyI/Mj76Puy/mgDsAfwCiAOYBFAFCAWQBfAFqATkA6wCIwCVP2Y+iD7Yv7UApAGUAgACBAHyAbYB9AJ8AtgDRAO8A0wDcAM4AwQDRAMwAlgBmQCoP7E/JT9U/9+AFQBiAJcA3QDrAP0AzwDcgGo/9j9cPuQ+cD5KPs4+5j5kPdw9YDzIPMQ9dD3YPq4/ewB8ASYBYgFSAboBcQDsgGKAHj+2PoA+ED3wPe4+Mj6CP2g/JD3YO+A5oDfQNtA20DfYOYA71D2iPsg/o7+lP04/d7+UALoBVAJEA3gEAAUIBYAF2AWgBOQDsAIKAPe/sz86Pzg/gACeAXwB9AIkAjwB+AHIAkwC8AMEA3QDAANYA2wDWAN4AvQCOgEjgEk/5j9lP1P/6wBaAMgBDAEIAQgBCAEmAMoAh4AIv6w/OD7OPvg+Qj4gPZg9YD0oPPQ8/D0kPYI+Wz8OQBoAyAGQAjACPAGCASuAc//uP1I+1D5MPhQ+MD5cPv4+yj6APag74DoAOLA3QDcQN7g5CDusPYc/U4BBAL2/jD7iPps/TwC4AdADsAToBYgF8AWIBWAEXAMwAfYAxYAQP28/Fj+NgEABeAI4AoACmAIMAggCSAKYAtgDdAO8A7QDiAPIA7ACngGNAOcAAT+gPwY/dr+igDsAQwDKAOEAkwCrAKYApQBhACq/77+XP24+4D58Pbg9IDzsPIw8sDyEPRw9XD3SPsIAEgEuAcgCgAKkAaEAsD/Cv6Y/IT8sP38/eD84PtY+9D54PaQ86DvQOqA5IDgAN8A4GDkoOyQ9l7+EAJoAXD9sPiA9lj5EgDIB1AOYBPAFgAYQBYgE8APMAwACPgDJAH4/zgAUALoBQAJwAlQCFgGeAQ8A6ADIAYwClAOQBGAEiASYBBQDYAJqAUgAnj/eP6V/54B3AJoAxgEYARIAzgB0f8z/6L+4v6iAEwC+AHr/2z9MPpw9RDxYO/A78DwsPFg87D1EPgg+/H/MAXACNAJkAgYBqgCUf90/cz9xv9cAQoBL//I/Fj6YPeA9EDygO+g66DnoOSg4QDgoOIg6kDzSPsqAeQCCv94+DD1oPdY/WgEoAzgE8AXIBiAF0AWYBKQDKAHcAS4Adj/kwAABKAH8AkAC0AKGAcwA1YBbAJoBQAJQA2AEeAToBNgETAOsAp4BhAC+v5G/nH/YAGcA4AFCAaoBKwCNAH6/2z+vP0I/+wAgAHEAOD/cv44+xD30POg8YDvQO4A79Dw0PKw9WD6LgBQBYAIgAmgCLgGgAQQAvL/Sf9zAPABkALCAVv/gPtw9xD0EPEg7oDrgOlg5yDlwONg5GDnYO2w9ST9zwAgAKT8oPjA9oj5wADgCPAOoBLgFOAV4BSgEZANcAlABY4Bx/+zAAADwAWwCFALEAuoB9gDPAI4AvACwAWwCrAP4BKgFMAUQBKwDYAJGAZIAgD/nP7NADgDYAVIB8AHyAU0A04B9P7Y+9j6SP31/3sA5/9E/wD90Pgw9VDzQPHA7sDtwO5A8ADyQPUw+g4AeAUQCWAKcAlwB+AETALWAGwBsAKUA7gDqAJ4/5j6wPUg8sDvIO5A7WDs4OpA6MDlAOWg5wDtwPM4+pj+Z//g/KD5MPmY/GQCoAiADQAQwBAgEaARABGwDpALYAg4BWwCOAEIAjgEAAdwCSAKcAjIBQgECAQgBUgHwArwDoAS4BMgE+AQAA4gC9AI+AbYBBgC0f8PANYBSANIBGAFyAXwA7cA/P0o/ND6CPvM/C7+eP1I+1j5kPew9bDzcPHA7qDsAOxg7cDwwPas/vAF8AqgDQANAAmYAy0AaP/a/7ABcAWgCDAI+AOk/vj4kPIg7eDqAOsA60DqwOlg6cDoIOlg7KDxwPag+tz83PxQ+6j73P+wBfAJkAxwDsAOQA1ADCANkA2wCyAJyAcoBhQDnQBOAcgDYAXQBWgG2AaQBngGaAfwCIAKwAxADwARIBFgEFAPMA4QDVALgAiIBHQBxf87/xIAbAKIBPAE9ANcAqj/4PvA+QD6APtY+9D7VPxQ+xD5QPfA9QDzQO+A7ODqYOrA7ODyMPs4AwAKcA5wDqAJMANq/qD8xP1iAXgGkApQCyAIaALI+8D0IO7g6SDpAOqg6iDrAOwg7cDtAO4A74DwMPJA9AD3IPrA/WgCmAfgC9ANcA2QC/AJoAmgCgAMYA1QDiAOcAygCRAGZAIgAC0A5gGYA9gEiAZACMAI0AjgCYALgAwADfANEA8ADwAPQBDgEOAOIAoYBQQBFP4A/aL+sAH8A4gEqAPgAcL+EPto+PD30PhI+SD5uPno+gD7IPmQ9pDzAO8A6mDnIOgg63DxHPz4B1AP4BBwDnAI+v/I+TD6a//oBIAJgA0wDtAJWAJA+3D0IO0g6EDnIOlA6gDrAO2A7yDwwO/g75Dw0PDQ8ZD1YPsWAdAFYAoADrAOsAxQClAJkAlACgAMQA7AD2AP0AzgCHgE6gDk/rj+dgB8A/gFaAdQCOAIwAhwCLAJkAzgDgAQABHAEYARoBCAD3ANoAlQBVQClwBr/2T/9QDoAqQD0AJ4AEj9GPpY+PD3QPi4+Gj5aPo4+8D6yPhA9hDzAO8g6gDnoOfg65DzWv6gCWAQQBBAC2AEeP1Q+Rj7sAH4BxALAAywC+AI6AJ4++D0AO/g6eDmQOfg6WDsgO6A8MDx4PDg7mDuwO/g8fD0YPpcATAH4AowDQAOgAwQClAJoAlQCXAJsAtgDgAOQAtwCJgFwAHY/nj+Q/8CAJwCSAdACtAJgAjwCNAJYAowDEAPwBHgEmATwBKAEBAN4AnIBpAEbAOcAqABsgFIA9ADvAH4/mj9OPso+FD28Pbw9yD4qPi4+fj50PhQ92D14PHA7GDoQOdg6nDxSPvQBaANgA9gC3gEpP4U/FT9DAKAB6AKMAugChAJ0AQH/5j5wPRA74DqwOig6SDrAO2g7xDxAPDg7SDtIO6g74DyGPh7/8gFMAmgCjALoApwCUAJkAowDKAMkAxgDYANEAuYB2gFQARwApoAaQCcAcQCcAQIBzAJoAkgCXAJcAqwC6ANIBBgEoATgBPgEYAOsArwByAGEAW4BKgEKAQMA0QC0gF7ADz+VPzA+ij5kPdA9+D3EPgA+OD3oPdQ9kD0gPKA8CDtgOlA6GDrIPPo/aAIUA6wDLAGpwAk/PD5TPzMAhAJcAtgC6AKsAeoAcj74Pew8+DtQOog60DtgO7A76DxUPFg7iDsgOtg6yDt4PLQ+jABOAXgCBALQApgCEAIcAkACgALcA3AD/APoA4QDdAKQAdIA6gAx/8XADgBOAMQBpAIsAlgCcAIMAjoB8AIUAugDmARIBMgFIAToBDADIAJSAfIBbgEQAQgBAgEcANEApEAXP5Y+yD4cPaA9pD2EPZg9oD38Pdw9mD0EPOw8aDvQO3A62DrAO6w9Hj+CAdQC6AKeAb9ACT9ePzA/vwC0AeAC1AMgArIBtgBWPyw97DzwO8A7WDtwO/A8DDwcPAg8QDvQOsA6oDroO2w8DD3Mf9YBDgGUAcwCJgHWAb4BqAJMAzADeAOkA8gD3ANYAsACcAFtAIkAWQBYAIIBGAGgAgACYAIEAh4BwgH6AdwCoAN4A+gEWASYBEgD9AM0ArACBAHMAbQBUgFuATABIgEKANwAGD9wPoI+QD4sPc4+LD4aPjw9hD2cPXA8+DwoO7A7WDsIOqA6rDwOPpsA4AJoAuQCAQCgPxI+4D9bAHIBmAMcA/ADUAJmATJ/8j5MPRQ8XDwwO/A7/Dx4POw8sDvwO2A7CDqYOiA6sDvQPUA+z4B4AXwBrgFeASYA5AD8AWQCsAO4BDAEWARUA8gDJAJ4Ae4BZgDJAMIBIAE4ASABoAIsAgIB5AFAAX4BDgGsAkADgARABIAEoAQsA0ACzAJEAhwB6AHMAj4B9gG2AVoBPwBLv8I/Uj7oPno+Hj5WPmg9xD2sPVQ9NDwgO7g7oDvYO2A6gDq4OsQ8LD3xAGwCCAJ0AWQAhcArP6JAIgFYAoADcAN4AxQCVgEsv+4+zD3APPg8CDx8PEg8sDxkPCA7kDsoOog6sDqwOww8JD0YPkI/rgBsAOABCgFAAbwBsAIEAxQD+AQABEAEWAQ0A2gCsAIqAfIBfgD7AMABYAFgAXYBegF0ASsA9gDaAXAB9AKAA4gEOAQgBBwD5ANwAugCvAJYAkwCWAJMAkwCLgGKAXQAvX/bP3I+5j6uPkw+dD4YPcQ9SDzMPJQ8TDwgO+g7qDsIOnA5qDnAOxA9M7+EAeACegG2AK7/xL+Mv8gBHAKwA7QD2AOMAvQBrAC7v4w+yD3cPNg8UDxgPIA87DxgO9A7SDrIOnA6ODqoO7A8nD3DPxm/zIBFALwAuADiAUgCHALoA7AEEARgBBwD5AOMA0gC5AJkAhoB3AGUAZwBuAFEAV4BJgD5AJ8A1AFKAewCLAK0AyQDWANEA2gDFAL8AngCUAKwAkACbAIAAhABkgE9AJ8AWb/5P1k/dz8OPto+RD4MPZg8xDxYPBw8IDw8PAQ8eDtQOjA5MDmIO3w9JT9IAVACGgGwAIcAIz/pAEYBgALQA5gD4AO0AvACDAGkALI/CD3IPTA8pDxcPEA81DzcPCA7ADqwOhg6MDpoO1w8oD26PlA/RQAFAJAA1gEEAZQCPAKwA2gEEASIBLgEHAPsA1wC5AJkAjgB0AHiAdQCLgHyAUYBFQDTAKQAdgCGAYACdAKcAywDWANEAxAC9AK8AlACcAJYArgCRAJsAiAB1AFdANEAlIA1P0A/Vj9OPyQ+eD3QPfw9ADxgO4A73DwoPBg72DsIOjg5KDlgOuQ9Dj95ALYBEgEQALp//z/kAPQCFAM4A3QDuAOEA0gCpAHiATF/3j6APdw9aD0QPRw9ODzMPFA7QDqYOgA6IDpAO3w8DD0IPco+gz9P//VALACuAQIByAK0A0AEQATwBMgE6ARYA9wDWAMwAvwChAKYAmgCNgHkAboBBgDuAFAAdoBLAMQBTgH8AigCWAJEAkwCTAJYAkACrAKwAqACnAKEAqACLAGgAVgBOwCZgEhAHL+HP0M/Lj5MPbw8xDz0PBA7SDtsPDA8SDuAOrg5yDlgOQg6wD3v//cAlgE0AT6AZD+KACABbAJAAxADtAPgA5QDDALYAnwBGb/qPow9/D0APWw9iD3APUg8cDs4Ojg5qDngOrg7WDxsPRQ9yj5IPuM/ZD/1wDYAvgFMAlwDCAQQBNAFCATIBEQD5AM0ArgCiAMoAwgDDALYAnoBlAEMALrAN0AGALUA2AFsAbQBzAI4AeIB5AH+AfACNAJwApACzALcApgCVAIMAeoBXgEaARABGgCsv8k/uj8+PmQ9gD1wPOw8EDuQO9A8QDwIO3g6yDqoOWA40DpoPME/BoBSATAA+T/NP2O/zgEoAfAClAOQBBAD6ANsAzwCugGTAKg/sD70Pk4+Rj6wPng9mDyAO5g6gDo4Odg6mDuwPHg8xD14PXA9vD3OPok/VEAlAPoBjAKMA2ADwARYBGgEEAPAA4wDeAMIA0ADmAOcA1gCwAJqAZYBMACqAKgA7gEcAX4BSgG2AWwBSAGKAfQBwAIQAggCQAKAApQCQAJ8AgwCKAGgAVgBRAFxAOMAnwBXv/o+1D5MPhg9oDy4O9g8CDx4O8A7iDtgOpg5YDioOVA7HDzwPo2AQADUP+Y+/D7Qv88A/gHsAxAD2AP8A7gDoANUArIBpgDBQC0/Ej78PtQ/Nj6APgQ9CDvYOog6ODoAOtA7aDv8PFg8yD0EPXA9pj4yPqU/bkA/AOQB4AL0A6AEIAQwA/ADtANgA1wDiAQQBEAEaAPwA3wCuAHwAUgBSgFYAUABtAGAAd4BggGsAUIBZAEAAUQBvAGoAdgCNAIMAgwB2AGkAXgBOgEaAUQBSgElAPQAoYAlP24+zj6kPfA9JDzoPIA8WDwQPHA7yDqAOWA5CDnYOog8Bj4vP3g/bj74PoA+wD86P8gBlAKkAuwDMAOQA+gDbALAAroBiADGgH2AMQA2v+w/iz8cPfw8UDugOxA7MDsIO5g7xDwcPDQ8JDxAPPw9MD24Piw+wf/jAIABhAJEAvACwAMYAzQDJANEA/gEMAR4BHAEQARQA/QDAALwAnQCHAIAAmgCZAJwAgQCEAH+AXQBJAE0AQQBYgFOAaYBnAGOAaYBagEwAOYA5gDdANwA5gD/AKaAQ8A4P0o+xD5mPjQ95D1sPMw9ID0IPKA7kDrwOjg5uDoQO8Q9oD5APtE/MD7MPlw+HD8dAGIBIgGgAnACxAMEAyQDEALmAdoBPAC2AG+ADIBbAK6ART+oPlw9dDxAO8g7sDuwO+g8JDxEPLw8QDygPJA8zD0oPUI+GD7PP8MAyAGEAjgCBAJMAnQCVALUA1QD8AQwBEAEoARoBBwD/ANMAwQC8AKwArgCjALYAvQCpAJQAj4BngFUAQoBKAEAAV4BRAG+AXoBKgD2AJEAtQB4AEQAtoBmAFIAUQASv6c/ID76Pmw91D2APYQ9fDzcPMg8uDtgOlg6aDs4O/Q8uD2APpo+QD34PYI+Tj7pP0eATAEKAXgBSAIUAqwCqAJYAiQBiAEdAK4ArgDAARQA4IBUv5o+jD3APVg81DyMPKA8mDyEPKQ8lDzgPNg87DzAPSw9ND2YPoC/u0AlAOYBRAGyAWwBqAIMAqwC8ANcA/QD+APgBCgEMAPwA4wDoANgAxQDMAM8AyADEAMoAvwCSAIQAewBqgFGAWIBdgF+AQIBMQDdAOAAtwB9gGsAbMAEgD3/0n/Fv6A/Uj94PuY+fD3MPeA9hD24PVA9CDxIO4A7eDsoO3w8PD1qPgo+ED3QPdw9yD4gPqk/Vr/YwCMAtgEAAb4BsAIUAmQB3AFkARgBCAEwASgBRAFBAP9ANT+2Psg+RD44PcA9xD2wPWw9UD1APUg9fD0gPSg9GD1UPbA9zj6uPxI/jn/MgA6AUgC1APgBbgHAAlgCrALkAwADYANEA5gDnAOgA5ADsANoA3QDbAN8AxwDAAMEAugCdAIcAioB7AGIAaQBSAErAIMAqYBxAA8AIcAiwB3/1D+0P0Y/ej7IPvI+vj50Pig+Oj4aPhg99D2EPbQ83DxsPCQ8QDz8PRA97j4yPhI+Dj4WPjI+Oj5uPsw/Ub+u/+aATQDQATgBNgE/AMAA7AC/AKIA1gEOAU4BSgEqAI2Abr/MP4A/ST8WPug+mD6aPoo+uD5mPn4+ND34Paw9iD3CPhI+cD62Pto/PD8oP0y/s7+7/9mAbgC5ANQBcgG4AfQCLAJMApACnAK0ApAC6ALMAzQDAANwAxQDNALUAuwCjAKcAmQCAAIkAcABzgGgAW4BIQDaAK6AUIBqwAUAMX/Sf9K/kT9oPz4+zD7kPp4+lD66Pl4+RD5YPhg94D2APbg9SD24PaQ9wj4WPiY+Kj4oPi4+Oj4MPmI+Tj6OPtQ/GT9eP5Q/7j/zP/K/7n/yv8XAK4ATgHOASgCYAJIAuABXAHRAEMAqf8w//T+7v4N/zf/Nv8K/7j+RP64/UD9KP1E/YT9zP00/pL+wv7u/i3/Wv9q/6r/PADYAF4B8AGcAiADXAOgA/ADQASYBPgEYAW4BRgGiAbgBggHEAcYBxAH6AbgBuAGwAaQBmgGQAbYBVgFEAX4BMgEUAT8A9wDtANYA/ACjAIQAooBKAHZAG8A2v9c/w3/pv4C/mj96Pxg/Nj7kPuA+2j7OPsI+8j6aPoI+tD5oPl4+WD5ePm4+Rj6aPqw+gD7OPto+4D7wPsU/ID89Px8/QL+Xv6Y/r7+0P7G/tL++P4V/w7/CP8h/yn/EP/0/uL+tv6A/m7+dP5g/kz+aP6e/p7+ev6G/rD+uv6e/qT+6P4q/2L/sP8SAGIAlwDTAAgBLgFUAZgB/AFUApQC1AIwA5QD3AMIBEAEgASoBMAE6AQoBVgFkAXABegF6AXQBbgFyAXQBcgFyAXABbAFmAV4BVAFGAXQBKAEaAQIBJwDOAPYAlgC5AF6AQYBgADu/3T/+v6M/ib+xP1M/dj8cPwQ/LD7aPtI+yD7+Prg+tD6yPrA+rj6sPqg+qD6qPq4+tD6+Pog+0D7WPtw+4D7aPto+4D7mPuo++D7JPxg/ID8rPzQ/PD8CP0w/WD9hP24/QD+Sv6C/rT+8P4f/y//LP9D/27/oP/a/xMARAB2AKsAzADlAPIAGgFUAYQBtgH+AUwCkALQAhgDaAOgA9QDCARQBIgEwAQABVAFeAWoBfAFQAZ4BqAG4AYIB/gG4AboBggHGAcYBwgH0AaIBkgGAAagBSAFsARIBLwDLAO4AkwC0gFEAccAUADQ/0f/1P5s/gD+kP0o/cT8fPw8/AD8uPto+yD72PqQ+mD6OPoY+vD5wPmI+WD5WPlQ+Uj5QPlI+Vj5aPmA+aD52PkI+jj6YPqQ+sj6EPtw+9j7MPyE/Nj8MP2E/dD9Gv5c/qT+8v46/3v/tP/s/x0AUwCMALcA0wDyABoBPAFgAZABxgH0ARACMAJMAmACdAKwAvQCKANUA3wDuAPsAygEWASIBMAE+ARIBYgFyAUABjAGUAZYBmAGaAZYBlAGSAZABigGCAbQBZAFOAXoBIgEKATIA3QDIAPAAlQC7AF4Af0AggAbALf/Uv/2/qz+YP4A/qD9UP0A/aj8QPzY+4D7OPsA+9D6oPqA+mD6OPoQ+vD50Pm4+bD5wPnQ+cj50PkA+ij6QPpg+qD62Prw+hj7WPuY+9j7GPxs/LT8+Pw8/Xz9tP3Q/Qb+TP6S/rj+4v4Y/03/d/+l/+j/FQA5AGIAmADDAOYADgFAAXgBrgH0ATQCaAKcAtwCHANUA5ADxAP4AzAEgATQBCAFUAVwBYgFuAXgBfgFCAYgBjgGOAY4BjgGQAYoBgAG0AWgBWgFKAUABeAEqARQBOgDhAMcA7gCVALuAYYBLAHZAH0ACwCd/zz/4P6Q/kb+9P2Y/UT99Pyk/FD8CPzQ+6D7YPsg++j6wPqo+nj6OPoY+hj6IPog+iD6OPpI+lD6YPqA+qD6wPr4+jj7cPuo++j7LPxs/KD82Pwc/WT9nP3A/eT9KP5+/rz+6P4a/1f/hf+s/9z/EQA5AF8AogDpABQBLAFWAYwBvgHyATgChALQAhQDVAOQA7QD0AP0AxgESASIBLAEyAToBAAFEAUQBQgFAAX4BOgE2ATQBMgEuASYBGgEQAQgBPADrANwAzgDEAPcAqgCdAI0Au4BqAFoASIB0AB+ADIA3/+L/yn/0P6I/kb+8P2Y/VD9FP3M/Hj8NPwE/Nj7uPuo+5D7aPtI+0j7UPto+2D7YPto+3D7ePuI+7D74PsQ/Dj8YPyQ/LD82PwQ/UD9ZP2E/bD95P0K/jL+YP6Q/q7+zP7o/gz/Jf9A/2L/iv+v/9X/AgAvAFsAiQDAAPUAJAFUAYoBwAHyASgCYAKYAsgC9AIoA1ADcAOQA7ADzAPYA9wD3APkA+gD4APYA9ADwAOsA5ADdANkA0gDNAMcAwwDDAMIA+gCvAKUAmQCKAL0AfIB5gHEAZoBfgFkASQB5gC0AIEARgAnACUAAgC8/2r/I//m/qD+YP4m/vD9vP2U/Wj9UP1A/TD9HP0M/QT9BP0I/QT9BP0M/RD9EP0U/Rz9LP00/TD9IP0g/SD9FP0M/RT9KP0g/QD94Pzc/PD8DP0o/Tj9VP14/aD9wP3k/R7+Zv6i/tD+BP9N/6j/AABUAJkA2QAUAVYBngHcAQwCLAJMAmwCiAKkAtACCANEA2QDeAOIA4gDgAOIA6ADsAOoA6ADqAOcA2QDIAPkAqQCdAJgAlgCPAIcAhACFAIEAuoByAGoAXwBWgFSAVwBYgFQATABBgHkAMgAngBiAC0ACQDl/7f/if9q/1L/NP8T/+j+xv66/rD+jP5G/vj9tP14/Uz9OP00/TD9LP00/Sz9+Pyw/Gz8OPz4+7j7iPuQ+9j7NPxw/Ij8rPzc/OD8rPyM/LD82Pzs/CT9jP3Y/ez9Fv58/q7+lP6C/qr+wP6o/tL+Vf/J//D/DABFAHAAbgByAJkAzwDzAEYB0AFYArACBANoA6wDyAPkAxAEGAQQBDAEWARgBFAEaAR4BGAEMAQIBNgDnAOAA5ADnAOcA7QD8AM4BGgEeARYBCAEzANYA+wCvALAAsACwALoAvgCpAI4AvYBpgHFALz/I//o/t7+JP/5/4YA5/9W/uj8FPzA++j7PPxI/Bj8KPxY/AT8UPvY+mD6KPmw9yD3kPcg+FD4qPgY+Qj5mPh4+Kj4mPh4+MD4ePk4+tj6oPuE/Bj9MP0c/Sz9aP3E/Xr+kP+0AJYBOALEAkgDoAPIA+gDEARQBLgEOAXABVAGsAbIBqgGcAY4BvgFsAWIBYgFeAVQBSgFGAUQBfgE6ATwBOgE2ATgBBAFWAWABZgFsAW4BYgFMAXIBGAE/AO0A5QDlAOQA2ADLAMMA+ACnAJQAvwBjgEEAXEA5/92/yT/1v5w/tz9VP3Y/Dz8SPtQ+nD5sPjw90D3wPZw9kD24PVQ9bD0wPNg8gDx4O8g7+DuYO+w8GDy8PNQ9ZD2sPdY+Nj4wPkY+6D8aP6ZAAwDeAV4BxAJMApwCgAKQAnACJAIsAggCdAJYApgCtAJAAn4B3AGgASkAjQBBgBK/0b/0P9RAHwAjABoANH/Jv/m/g3/Sf+n/3YAlAGkApQDeAQQBTAFGAUQBSAFSAXABbAGyAewCBAJMAkACaAIyAfgBjgG4AWoBYgFoAXABcgFgAUIBTgEDAPWAc0AEwB+/yr/H/9O/0n/9v5q/tD9DP3w+7D6uPkY+YD44Pdg9/D2YPaw9SD1MPTg8mDxIPAg7yDuoO3g7WDuYO5g7sDu4O8A8jD1sPhY+wj9lv4PACgBRAJABLgGoAgQCrALMA0QDpAO8A6ADpAMUAqwCLgH2AZwBqAGaAbwBPgCOgFJ/wj9cPvQ+iD6MPkQ+UD6qPts/Aj9tP3U/XD9oP2u/tv/CgHAAtAEKAbQBpgHkAjwCKAIYAhwCFAIAAhACOAIEAngCKAIMAgoB8gF2ARYBOwDnAOEA3ADaANgA2ADPAMMA/gCsAIoAqoBjgGeAcwB/gEQAswBTgHKAAwAMP9Y/rz97Pz4+xD7CPrI+ED3APaQ9CDzwPHQ8MDvgO6A7UDt4OxA7MDrQOug6qDqoOxg8FD0ePjI/NP/MgCk/+wAgANwBcAG4AgACzAMIA3gDkAQkA/ADdALUAnoBWwDGAPgAxgEtAMEA2wB8v6A/Jj6+Pig9/D2APeQ97D4mPrw/Pz+RQCcAFcAPQDYABwCzAPgBQAIwAnQCqALQAwgDGALkAqwCWAISAcoB8gHIAhQCGAIsAcoBqAEiANgAhABWAC9AEIBxAGsAvwDuAS4BIAEEARUA6gC0AJcA+gDYAQIBVAFEAWQBNADkALMAEr/Av6s/GD7yPqo+lD6MPmQ93D1EPOw8MDuIO1g7ADsoOug6wDsYOxg7ADs4OsA7EDsYO6w82j6a/88AoAEYAbABmAGGAcACXAKMAtADHANsA2wDUAOkA5wDFAIYATCAQAAmP5M/u7+Zv+Y/gT9mPtQ+ij5YPhA+Dj4KPjQ+BD7Cv5WAPoBiAPgBFgFSAWgBZgGsAfwCBAKwArQCtAK8AqgCqAJMAjoBmAFyAOYAugBjgGGAegBGAKgAcgAPAD//7L/h//k/9IA1AHcAggEWAVoBggHSAcwB8AGYAZgBoAGeAZQBngGUAZ4BUgEKAP4ATEAbP4U/cj7KPrA+BD4UPfQ9dDzQPLw8IDvIO6A7UDtAO3A7ADtAO3A7MDsgO2A7mDvoPCQ81D41P3EAugFGAfwBsAGCAeIBzAIcAlAC6AM4AygDMAMgAzgChAIEAXSAaj++Pwk/fD9CP5G/gf/8v5I/Vj7kPoo+oD5gPnI+nj8NP6zAMwD4AWABsgGMAcQB3AGYAYYB9AHYAhACeAJoAnQCEAIkAf4BdwDMAI0AT0Agf+N/3AASAGqAbgBpAEyAXwAYwDnAIQB4AHYArAEgAaAByAI8AgACUAIGAeoBjgGgAUQBTAFMAWABMwDSANUAncAdP7s/JD7APqY+MD3cPdA9wD3YPYg9ZDzMPJA8VDwQO/A7gDvQO9A70Dv4O9w8GDwIPBA8ADxAPPQ94z+8APwBTAGsAbABtgFiAX4BpAIIAlgCUAKoApACkAKIAogCAAEOQAQ/rj88Pus/HD+Z/9m/3z/Uv/Y/QD8kPs8/Dz8BPw4/br/CALwAyAGEAiwCEAIqAfwBvAFWAUABhgHkAdgB0gHCAcIBqgEiAOgAj4Bl/9k/sT9eP3M/S//5gDAAcIByAHuAcoBtAFkApQDqAR4BXAGcAcgCMAIQAlACWAIEAf4BRAFQASoA3ADMAOQAqwBsgCv/6z+eP08/AD7EPpo+dD4oPiY+Hj44PdQ96D2gPXw8/DysPKA8jDy0PGQ8RDx8PCQ8bDxgPBg7zDwQPKg9Gj4dv70AxgGuAUwBQAFOAQgBIAFAAfwBpgGoAcwCfAJMAnYBxgGyAPpAPz96Puw+yT92P7h/14A2QDKAPT/6P4s/oz9CP1I/Zb+XQDsAbQDAAYgCOAIUAhAB0AGQAVgBPgDGASABPgEWAWABTAFeATwA0ADGAJ4ACr/lv6s/jr/OACUAdgCuAMQBBAEzAOAA1gDnAMwBPAEeAUABvgGIAgACeAIQAh4B1gG4ARwA7ACWALuAWAB9wC5AGQAmv+K/lT9OPww+yj6MPmw+MD46Pio+DD48PeQ91D2sPTg86DzwPKA8WDxAPKg8YDwoPDQ8cDxMPDg75Dy4PaA+/j/0AOYBTgFYARYBOAEiAWIBsAHgAiACHAIkAjACLAIsAeIBZgC4P/4/fT8zPys/Tr/ZgDJAKQAZQDT/xL/pv6G/kr+MP4b//MA4AJwBAgGgAcQCLAH0Ab4BfAEEATYAyAESAQYBPQDGAQgBMQDEAMgAiABJABm//T+2v5N/1gApgGkAjgDkAPEA5ADNANMA+gDgASYBKgEOAUYBrAGEAeQB6AHwAZwBXgEwAPEAtQBkAGeATQBbwDw/5L/1v7s/VD9pPyQ+3D62Pmg+UD5EPkI+eD4IPhQ93D2YPVg9AD00PPA8lDxsPDw8PDw4PAA8XDwIO+g79DzaPnE/fYAcARwBrAFOARoBJgFGAawBiAI8AgACHAHoAjwCUAJEAfYBEQCDf+Q/Bz8zPyY/bb+GwCuAOn/6v6Q/nb+Hv7c/QD+XP4A/1gAWAJ4BGgG4AeQCDAIAAeQBXgEAAQgBFAEMATgA6QDfANUAxQD0AKAAt4BuwBD/xD+sP06/mH/5ABQAjgDgAOQA8QDIASABOgEWAWgBZgFmAUABrgGYAeQB1AHsAbQBcAEvAPoAkQCsAEwAbsAPQCH/9r+WP74/Yj96PwY/BD7UPow+lj68Pko+dD4sPgQ+BD3wPaw9tD1cPSg8xDzMPLA8bDyoPOQ8mDwgO+Q8NDyMPa4+v7+ugFoA8gEYAU4BRAFiAX4BcgFgAWwBXgGmAfACAAJEAg4BvQDiAFE/7T9CP0Y/bz9B/9VAPIAwgCBAKAAzwCUAAIAw/8wAOEAjgGkAoAEiAaQB6AHOAeIBnAFKARcAwQDrAJIAugBugHSARgCeAKsAqQCHAL7AIT/Zv4u/tD++f8+AXACVAPkAwAECARoBBAFaAVYBUAFUAUoBQAFiAVwBtAGaAYYBqAFiAQsA5ACgAL8ATIBzgBNAC7/Rv5s/sT+Mv5A/bj8VPxw+7j6wPrQ+mj66Pmw+Tj5UPhg9wD3oPaw9WD0UPMA89DyMPJQ8YDwwO8g7wDwUPPg92D7AP4IARAEUAX4BMAE4AS4BJgEgAXIBigHKAfoB7AIMAhwBqgE4AKjAGD+AP1o/HT8WP3o/gsAHQDD/7L//f8jACMA/P/O/+n/qQDaATQDcATYBSAHiAfQBpAFuARABLgD9AKYAmgC7AFGAUQB4gEYAuwB/gEsAmIB2/8z/93/pwAKAeQBJAPUA9gDGASoBMgE0ASQBTAGmAV4BGgEMAVgBfgECAVYBcgEqAMIA+QCeALuAaoBbAGfAJr/1P5W/gz+9P28/ST9mPyI/Jj8PPzY+6j7YPuY+tD5KPlQ+CD3QPbw9VD1cPTw8wD0gPMQ8oDwwO9g70DvUPDQ8iD2qPnY/agCWAZ4B5AGeAUIBQAFSAXIBUgGeAagBugGCAfABkgGYAWwA2wBE/8Q/XD7IPtA/OD9yv4R/5T/XADkAPcA4QDOAM0A9ABEAeQBDAOQBOAFoAYQBxgHgAawBTgFyASgA/AB6wDaANUAewCMAGoBaAKoAvIB4AD7/5v/sv80AAgBCALcAnAD7AOABOgEMAWgBRAGCAY4BUgE8ANQBPAEUAUoBZgE3ANQA5wCugFIAYwBmAGYAGv/CP8b/8z+cv7C/vr+QP5Y/Wj9zP18/dT80PwA/XT8YPto+mj5QPig94D3YPew9uD1EPXA8xDyAPGQ8BDwgO/g70DxEPPQ9UD6q/8IBDgGqAYYBtgE4AMYBDAFIAaABrAGwAagBmgGIAaABTAEOALE/yT9QPuQ+hD7YPxC/hwAFgFCAV4BbgHuAPr/pP8XAJ4AEgH+AYwDGAVIBvgGEAeABqgF0AQoBIwD4AL2AQ4BrADCAP0AZgE4AugCzAIMAmgBzAAyAB8ApgAeAXQBfALwA7AEwARQBWAGuAYIBlgF2ATwAywDiAOQBBAF+ATQBHgEWAP+AVgBOAEuAUoBXAHdANb/a//j/1MARgAdAAEAQf8G/kj9YP1w/Rz9rPwI/Nj6cPmo+Fj4EPjA92D3kPZA9UD0wPMQ88Dx0PCQ8KDw8PAQ8hD0oPbo+Sj+bAJIBXgGuAZYBngFwAToBLgFYAaQBpgGYAa4BdgEQAQgBJQDogGc/uj7gPpo+ij7yPy0/hYAtQACATwBDgGdALUAggEgAiQCKALYAhAEWAVQBsAGgAboBWgFyATEA7gC7gEAAfP/c/+6/zgAwQDGAdQCrAJyAacAqwByAJn/O/+3/3wAWgGoAvADcASYBPAEAAU4BIwDqAPwA+gDGATABPAEaATkA+gDqAOkAroBfAFqAf4AcAAnAAYA0v9r//D+zv7+/vD+Xv7U/cT9yP1I/cz8+Pwk/WT8GPtg+kj64Png+DD4IPjQ97D28PRg8yDyMPHg8ADxcPEA8gDzwPTA9+j7MAA8A/AE+AVIBlAFEAQoBGgFKAYYBmAGuAYwBhgFkAQwBPACLgGy/wT+6Pug+hD7MPxc/Tv/WAH8AQYBkgCWAdQCdAMoBOAEuATgA5QDYASYBZAGMAdAB7gGyAWoBHwDvAJAAkwBov9u/nD+5v4k/8T/XAGoAnACLgEEAPL+zP10/Wr+5P/cAOYBkAM4BbgFYAX4BNAEYASUA7gCCAKsAbYBNALwAqAD6APIA2QDwAK2AZoAIgBmAKoAewBsALsA/wDiAL8A0QDPAIoAFABr/3b+ZP1c/Kj7YPuI+3D72PpY+lD6CPrY+HD3gPaQ9SD08PKQ8mDyMPKw8vDz4PRA9SD2QPgI+6D9IAB4AvgDiAQQBSgG2AaoBjgGeAawBrgFOASMA8gDuAMcA7ACZAJEAXz/fP6M/nL+sP1E/aT9MP68/uv/iAGgAiwD7AOIBOADgALkAXgCPAPEA2gEGAUwBfgEGAVYBdgEbAPCASgAhv7k/Nj7yPu8/DT+lv9fAIkAhQCzAM0AbQCw/zn/ZP++//D/mQA8AjAEmAVgBtgGkAZYBVAEQASgBGgEAAQwBIgEaAQoBCgExAPIAtYBCgG9/zT+yP2G/g//9v4h/6P/i/8T/1v/KwBZANn/zf8IAKX/pP7c/XD96PyA/Ez80PvQ+hj6EPoY+rD5MPmY+DD3IPWg8yDzMPOQ88D0YPbQ9/D4WPqo+4D8bP3u/l8A/gB8AZACxANIBGAEqATIBFAExAPAA9gDQAN8AkACPALsAYABugGEAkADqAO8A1ADgALmAdIB8AHiAboBigFiAV4BfAGQAYgBrgH6AeQBRAGwALAA9gBCAZoBLAKgAuQCTAPcAygECASwA1QDtALGAbAAkf94/pD9CP3Q/Mj8DP2Y/Rj+Ov4y/mj+6v6R/1EAJgHmAZACVANYBEgFAAZ4BqgGSAZ4BbgESAQIBJAD+AI8AkQBLwBo/wD/lv4G/nT9BP2I/Oj7aPtI+3D7sPvo+wD8APwU/FD8mPy0/Lj89PxY/bD9uP2M/Wj9cP2s/fT9DP7A/RT9PPyo+3j7UPsQ+9j68Pow+1D7kPs0/BT9yP1K/sr+O/+n/2QAggF8AhwDjAPMA4wD5AJUAvIBbAHeALAArQBWAOL/3/8bAP3/uf/H/+L/nP9f/7L/PACDAOMAsAFkApACqAIEA0QDVAOsAzAEOATEA4gDgAMEA0ACFAJoAmQC9AHIAcwBbAHUAMEAEAEAAYQAZADBAAQB5ADHANEAqABBAAcAKwASAG3/qP5c/nb+gv6O/uz+cP+l/6T/6v9uAJkAeACpABwBJAG8AJ0A4QAOAT4B0gFkAjgCtgGkAawBEAFMADYAhwB9AHAA7gCGAaIBlAGsAUgBHwDe/gT+LP1w/KT8jP1O/gP/dwDKAXYB1//A/jb+5Pwg+4j68Pq4+vj5KPpQ+9j7uPtE/ID9AP6I/WT9+P1i/nb+/v4bAN8AHgGoAZQC7AJsAuABlgHuAMD/sv4c/rT9gP3U/Xz+3P7i/gn/Z/+k/7H/zv/r//z/BAADAOH/8v/BABgCLAOQA6wDxAO8A4wDWAMwA/ACkAIcAqoBVgFAATwBOgFmAbwBlAGiALX/mP/k/8z/pf8GAIsAbQD+//n/YQCCAC0A4v/c/8n/Sv+i/kr+QP4S/sD9zP1K/pb+VP5C/tz+gf+E/0X/Vf+B/1r/Kv9k/+H/PABlAJcAxgDMALAAtwDgAO8AyAC2AAoBkAHUAd4BDAJMAkwCEAIgAngCvALYAhADWANMAwADzALQAsACTAK2AUYBDgHlAMsA6gA2AV4BQgEmATQBPgEIAa8AdAA/ANP/P/+w/kr+EP74/ej90P3k/fj90P1k/SD9DP2o/Pj7iPto+wj7gPpY+oj6ePog+hj6SPpQ+nD66Pp4+9D7PPzY/Dj9WP3A/X7+GP+R/zMAmQApAFf/8P6s/tj98Pzs/KT9dv6o/xACYAVgCHAKgAtQC8AJwAdwBtAFIAX8A9wCDAJwAToBWAFQAcEA3P/m/pj98PvI+uD6qPuQ/Lz9LP9WACYBZAIYBCgFSAVIBYgFWAWIBOgD2AOkAyAD7ALcAjgCNgHLANQAWQBS/4z+Ev5Y/ZD8XPy4/Bj9kP10/lb/q/+z/xUAxwAoASYBGAESAccAVAA1AJMA6wDhAK8AnQB5APX/O/+U/uj9CP0k/Hj7APuQ+kD6IPr4+cD5wPkQ+mD6yPqQ+6D8dP3o/Vj+7P6b/1AACAGcASgCzAIwAyADyAJ8AgACKgFzADkA/P9Y/8j+1v4R/wn/Bf9b/8X/6f/x/wUACQARAE4AnQDDANcACAE6AUQBXAGqAe4B5gHSAdwB2gGoAXIBZAFwAZQBtAG0AZoBqAH2ARACugFSAUQBTAECAbsA3gA+AVwBXAG2AUQChAJwAoACpAJ8AvwBkAFoAVIBJAEEAQQBGAEaAQQB1QCGABcAlv8i/8z+jv5q/nL+lP60/sT+5v4W/wj/rv40/tD9gP1k/aj9Jv6a/u7+W/+8//P/BgAdADAAMgA2ACkA2/9n/zv/XP9l/0n/TP9v/2j/O/9T/7r/HwA8ADEAAQCy/4b/mv+t/4D/Qv8d/+r+nv6G/q7+3P7+/kX/jP95/0b/bf/W/wUA/v8kAHcAkgBqADgA7/9y/+L+ev4w/tD9ZP0w/Wz9+P2S/vj+Tv/S/2sA0QASAWgBxgHgAdAB7AEcAhACzAGuAcABugGWAaQB3gH+AQgCJAIsAvQBtAGqAbABjAFeAWQBhgGcAbgB1AGqATIBuQBvADkA9P+p/1r/E//o/uD+yv6W/n7+oP6+/qL+fv6M/rL+xv7I/r7+mP5Y/h7+7P28/Yz9hP2Q/ZD9eP1Q/Sz9OP2U/Qb+Uv6g/hn/df9s/1n/g/9H/yT+kPwY+1D5QPdA9oD36PnI+0D9Uv9qAUACYAJEA6gEIAXIBPgEsAXQBYAFIAaoB7AIkAgQCNAHWAdgBnAFsATEA6QCvgFCAewAwgAMAdABgAKkAjwCggGgANj/df9q/2H/Pf9T/97/owA2AXgBlgGiAX4B+wBHAKr/L/+8/lT+JP4c/gL+3P3g/fz9yP0Y/Vj8APwc/ED8RPx0/PD8dP3c/Wj+Mv/Z/wsAFQBOAGkAFQC0/8X/BADv/67/ov+W/zb/tv5+/lL+9P2c/Zj9kP1E/Rj9ZP3Y/RD+SP68/iX/Sv92/+b/XwCeAMgAFAFoAY4BiAGOAbYB3AHmAeIB2AG2AV4BBgH3ABwBMgEyAVwBlAGWAWQBVAF2AV4BAAGuAIkAagA6AC0ARwBFAB4ACwAtAFAASwAqAAwA6f/F/7X/yP/7/0EAeQCQAJYAiwBsADgAEwDv/5P/Cv+w/q7+zv7k/vb+Dv8M//r+/P4I/+r+rP6W/sL+CP9K/5T/8P9JAI8AvgDOALAAdwBPAEgASwBDADcALAAbAO//pf9b/y7/IP8e/xb/Dv8R/y//bP/E/yQAbgCYALsA5wAMARoBGAEeASQBEAHlAMUAswCsAKUAnwCMAGQAQgAyACMAGwA3AFQAOAAHAAIAGwD9/8P/yP8CAAwA1P+4/9v/5/+2/3n/T/8g/+j+1v7u/vj+5P7a/ur+2P6m/pz+wv7I/qT+tP4R/z3/Gf8i/5D/1P+Y/1z/gv+R/yX/sP6w/tz+xv6m/ub+UP93/3H/j//Z/wgAAwAEAFIA3ABKAYwBAAKcAqACsgFyAIb/qv7A/Yj9Tv4i/3D/FwCeARQDuAM4BPAEKAWIBPwDGAQwBOgD9AN4BJAE/ANsAzgD1AIIAkYBtwAJACz/jP5O/jz+MP5A/oD+yv76/g3/Mf+E/9P/3/+8/6v/kP9C//7+GP9O/zP/5v7S/uL+xv6Q/oL+iP5c/vD9gP0o/dz8pPyU/LT8/PxI/Yj91P0u/nL+gP6A/rD+8v4f/0H/jP/+/3cA4wA+AXoBkgGUAXgBQAECAdQArACGAH0AmQCoAKIAtQD6AC4BGAHiAMQArgB1AD4AOgBSAEsAMQBFAHsAigBrAGcAjwCaAHUAXgBtAGUALgAQACMAMgAfAAkA7P+1/37/hf+6/9L/u/+W/3j/Rf/+/sD+nv6c/sL+Ef9w/7L/yP/T/wIAUQB/AHgAdgCuAPQAGAEyAX4B4gEIAt4BigEcAYoA9P+W/3b/UP/+/rz+1P4g/0r/V/+H/9X/4P+i/5L/zf/y/+T/CgBvAJYAYABGAGoAXwAVAPX/EQAJANz/5v8hADwAKwAmACIA/P/Q/9H/2//L/7j/rf+S/1//OP8q/yf/Kv8+/1j/af92/4b/jf+f/9L/EAAnACUARgBxAGgASABiAJoApACJAKEA5QD7ANkAxgDTAMsAkwBTACQA7f+h/2L/ZP+p/wAAUwCyAAYBIAEKAQ4BQgFiAWIBcAGMAWoBCAHUANoAvwBqAEIAcQCHAFoAPwBvAKQAlAB3AHwAiQB7AGgAaABhADkABwDm/9H/uP+V/2r/Tv9G/0X/P/88/1D/b/+Q/7n/6/8YAFYAowC9AF8A3P+2/7P/P/9G/lj9uPw4/Oj7MPwE/cD9Av4Q/ir+Hv60/UT9LP1Y/XT9VP08/Wj94P14/vr+a//U/xQABADP/8X/1P+9/5f/rv/l/+X/zf8FAH8A0QDbAOEA/gAKAQQBCgEqAVgBjAHOARACTAKEArQC6AIcA0wDPAPkAoQCTAIwAhQCCAIgAkwCdAJ0AmQCSAIoAugBigE+ATQBUgFgAXgBxAEMAgACvgGgAX4B9gA2AMD/fv8I/3j+NP4O/pz9EP3g/Oz8sPxI/DD8SPwQ/LD7wPso/Fj8SPx4/PD8NP1E/Zj9Ov6u/sj+9P5m/8j/4f/p/xMANAAnAA4ABwD9/9T/qf+m/8j/8/8jAEsAVwBLAEcAXgB9AK8ACgGGAe4BMAJ4AtQCFAMsA0QDaANoAywD6ALQArQCdAIsAgAC1AGIAUYBJgH1AI4ALQD8/8X/b/9A/0z/TP8x/1j/yf8DAOj/+f9ZAHkALQATAGMAigBKAEIAqQDaAJcAegDAANcAhgBcAIIAawADANX/8//O/1b/K/9f/2T/H/8W/1b/U//6/tr+EP8R/7b+fP6a/pz+UP4o/mb+mv5u/kL+gv7m/hP/IP9Z/5P/dv8x/y//U/8j/6z+fP6u/rj+gv6S/gf/Zv+I/9b/XgCmAL4AJAG6AeoBzAH6AVQCRALkAaABWAG2ADcAPwBZABYA7v8pAEEA+f/O/8H/Tf/M/gj/dP8A/2D++v4HALf/XP6U/ej88Prw+HD52Pt0/fz9lf8oAkADeAIcAvACCAN+AfT/o/9y/4T+FP4y/8AARAE0AZwBHAK6AdAAVwBVACYA4/8CAFQAhgDtAN4BzAIYAwgD/AKkAroBwAA8AAAAzf/q/3UA8AAUAVAB7gGMArgCmAJkAv4BagEUAS4BaAF+AawBDAIoAqYB4QCAAHMAGgBi/+L+yP6k/lb+gv5s/2UAzQDxAEwBsgGaAQIBZgAkAPP/W/+E/hL+DP6w/eT8iPzs/Az9QPyA+7D7IPzg+5j7SPxw/ez93P00/vb+Yv9Q/2n/2/8UALP/Pf8//4n/hv80/yT/bP+N/1f/Q/+T/9//1P/V/zEApADLANMAFAFiAXgBcAGWAeYBFAIcAjgCaAJsAkACPAKAArwCuAKoArQCsAJoAiwCOAJUAiACrAE0AcoAYAAPAPX///8RABgABwDv//n/FgD5/6L/c/+G/3D/Cf+2/rb+uP56/kr+UP5I/vz9qP2U/aj9wP3g/Rr+ZP6Q/oj+Yv5e/p7+5v4H/yP/av+i/4v/Vv9R/17/M//0/vr+O/9b/1T/a/+z/+v//v8nAIMA1QDwAPYADAEUAe4AqgBcAAIAtv+v/9r/DQBZAOAAXgGUAawB0gHWAZIBdAGyAcwBhAE+AUwBPAHXAJQAoQB1AMn/O/81/0H/Dv8B/1L/nf+U/4r/u//t//f///8YAAoA4f/U/+f/7f/t/xIATABUAEkAgQD5AEIBMgEgASAB7ABnAAQA/v/y/5n/Qf9K/2n/Tv8w/1f/c/8r/9j+yv64/mD+RP7O/n3/rP+3/zAAygDlAK8AsACxADsAq/+h/+3/3P98/3D/zf8DAN3/yv/o/9T/jP9x/5r/uv/N/xcAaABXAA0AHgCKAMIAtQDPAP0A2QCJAKcAIgFQASoBSgHYATQCHAIYAmwCoAIoAloBsQApAHz/xP6E/sz+Dv8V/yv/YP9R/+L+qP4E/4//0f/V/6j/Kf98/gz+8P3g/dT9BP5a/or+qP7m/hv/CP++/mD+0P0o/bT8mPzc/KD9pv5K/2z/nf8IAAQAff9Z/7z/rv8h/zP/AgBmAFMACgFgAtACSAJYAhQD8ALyAawBJAL0AR4BIAH0ASQCnAGWATwCjAJ4AswCYANwAygDYAMYBLAEIAW4BSgG6AU4BZgE1AOsAnQBoQAbAHb/nP7c/Xz9nP38/U7+gv60/vL+H/9L/5n/3P+s//D+6P3s/Cz8sPt4+4D76Pt8/Nj87Pw0/aj9iP2U/Lj7uPsQ/BT8TPxI/UT+PP6Y/UD9CP1Q/KD72Pvk/NT9jv6f/xgBXAIMA3gDuAOUA8ACeAFUAJ3/Pv9O/xUAjAHsApQDmANUA7wClAH8/1D++PxM/Gz8HP0i/mz/zgDiAXQCwALEAiAC2wC0/xL/cP6E/Rz97P1w/74A9gGoA0AFuAVABRAFAAX4AygCKgFSAQwBBADW/zgBYAIgArIB/AGqAbL/kP3U/MD8LPzw+0D9Sv+CAOsAgAE8AlACuAEyAeIATQAe//D9kP38/V7+Vv52/g//jP95/2v/4/9kAFAA7v/V/+P/s/9d/zP/Ov87/w3/qP4I/kT9ZPyI+xj7gPuc/MD9lv5e/1AAKAGYAcoBRAIQA6QDmANAA+gCLALPAKH/Y/+E/xb/dv6I/iz/if/Q/6cAmgGAAVQAO/+S/rj9zPzg/B7+Tv+g/8H/WgDmAOAA6ACEAeQBHgHt/4r/sf9w/zD/GADEAcQC8AI0A4gDNAOUAqwCSANkAwgDDAOMA/QDOASwBPAEYAQUA2wBlP8O/oz9AP6q/k//WQCsAbACdAOABJAF0AU4BXAEgAMwAosAO/+G/gD+HP3Y+7j6IPoA+hD6iPqQ+8D8OP3k/JT8gPwU/Fj7UPto/JT9/P2a/hEALAGIAPz+Cv5U/eD7ePqI+mj7iPs4+9D7EP1o/bz8NPwM/Jj78PrI+vD6OPvY+xD9OP4J/xkAggGAAswCJAOwA7gDNAM8AzgECAUYBRAFcAWoBUgF2ATYBKgEvAOcAhQCLAKEAjQDYASQBRAG+AXgBdAFWAWIBOQDYANYAtoAyv+v/xIAYQCrADwB4gEcAuABbgHWAMT/SP4Q/ZD8PPyo+1j78PvI/LT8+PtQ+3j6GPnw9wD42PjY+Uj7QP3I/m//KwCGAWwCAAIaAWUATP/A/Rz91P10/i7+Cv7i/qj/jf91/zsAOgGEAUgBEgHeAIoAWACrAGIBCAJIAjQC3AEYAR4Ag/+q/0MAEgFoAvADsASwBBAF2AWYBSgEMANIA/ACogEWASQCEAOcAvIB/AFmASr/5Pyk/OT9oP6Y/jT/kwAeAUIAnv8fAFAABv+8/fz9iP68/Qj9gv7LABoBEAAPAJoAcf9E/aD8LP20/KD7+Ps8/Tj9NPwg/Mz82Px4/Nj8NP18/Jj7uPs0/Ej86Pys/jkAqwA8AVgCaAL5AAsAfQCRAIL/5P5g/zb/7P1g/Qz+Hv4E/az86P1Q/zkAsAHAA9AEIAT4AlwCvgGHAGf/Mf9t/xz/eP6o/pr/7f9K/yf/LQA2AcIB/AJQBdAGOAbYBBgEYAM8AtIBxAIQBPgEKAZoB5AHiAbIBcgFOAW4A1gCxgFsAUwBMAIABKAFUAaIBmAGYAVQAwABKv+4/RT8QPoA+dj4SPnI+eD6+PwN/+f/BACSACYBqADk/1wAUgG2AAH/pP7i/2gAg//m/ur+1P2Y+1j6uPrQ+mj6UPuI/f7+Xf+aAJwCcAPwAoAClAF0/mj6EPhg98D2oPaw+AD8jv4rALwB0AKkArwB8QD8/4L+/Py4+6j6KPq4+uD7pPzI/LT8TPxQ+0j62Pkw+iD7pPyC/l4AJALEA7gE2AS4BIAEbAM2ASL/AP4g/Sz8aPxi/mMAGAGGAcgCxAN4A9ACOAMQBDgEIAToBFAGYAcQCMAIcAmACdAIoAeABugF4AU4BhAHYAhQCdAIOAdYBUAD6wD8/uz9ZP0U/Vj9QP46/18A4gHMAs4BO/90/MD5cPeg9vD36PkA+5j7NPzg+0j68Pjw+ED5+Pjw+Nj5qPqw+gD7qPzU/kcAuQCRAOf/nP4A/Zj70Pqo+nj6+PkQ+nD7lP2T/6YBKATIBYAFQASEA4QCSAAu/qz95P1M/ZT8DP3M/ZD9NP1M/iYAEAHnAN4AIgEYAQwBIAKIBLgGkAfAB5AIcAkwCTAIEAiACPgHuAZABogGIAb4BGAESARMA3wBMwCX/8D++P1+/isA3gEgA0AEAAUQBeAEuAQoBEgDqAIoAhwBwP/0/q7+gv7a/t7/IwDs/uj9ZP76/kb+TP3Y/Oj60PZQ88DykPMQ9JD1IPmM/KD9lP0w/gL/Tv92/7b/Zf/Q/t7+ZP+Y/5n/9P8CAEX/mP6k/pT+rP3c/PT8LP2M/KD7gPss/Oj8gP0y/tL+Bf/M/kj+eP1o/HD70Ppg+kj62PoA/Cj9aP6DACgD6ARQBZAFIAawBcADKAJgAjwDiANYBJgGgAggCJgGWAZwBmgE+QBu/1gABgEIAawCcAaACXAK0ApgC3AKaAdABMgCGAJqAVIBJAIAA4wDMAS4BMgEaATAA1gCoQDb//7/1v9P/3H/tf/K/kj9UPwA+zj4cPWw86DxwO6A7rDyIPjY+wr/3AJQBDACQADQACYBAf/w/CD9nP1s/Ej7IPyI/Xz9ePzg+5D7qPqY+fD5SPwX/6oABAFGAToB1f+c/Zj8WP0C/oT9qPws/Fj7IPrQ+QD7jPww/Vj9+P0M/wgAzADGATADcASIBDADsgE8AXQBsAH8AjAGYAkQCjAJgAlQCjAJ2AZwBkAHQAbsA5gDKAW4BWAFkAbACNAI6AbYBfAFaAUwBJwDbAOQAqQBwAFgAtwCgAOABBgFwARQBIQDogGV/7r+mv4e/gj+A/9r/xL+zPyg/Nj6sPUw8GDtYOwA7GDuUPTA+YD8D/+kAjgEjAIEAVQBeADw/Pj5EPoQ+/D6OPtY/Yj/Uf/w/Qj+lf/t/2L+IP1o/Sj9EPvQ+Yj7Iv6+/sT+NgBMAZf/yPyQ+zD78Pnw+KD56PqA+yD8WP2U/tv/8AEABMAEoASIBNQDXAIgAvQDmAW4BWgGsAjwCdAI4AfACMAISAYoBFgESAToAUQANAKABRAHuAdwCaAKoAngB0gHEAeQBdQDkAPMAzwDmAIUAxgEIARgAwwD3AJmAUT/pv7v/9oAkgBCARwDrAJk/mD6YPkI+ADzYO0A68DqIOtA7nD1+PzCAYgEGAZgBZQCJAB0/nD86PoA+1j7GPvQ+1T+egCnADUA6/9+/iz88Pow+9D7qPxG/nz/Lf96/o7+iP50/Sj8wPtw+1D6IPno+ND5APsE/Aj9Fv7e/rj+/P0S/qX/kgGMAgQD7APwBBgFwARQBeAGIAiQCOAIoAkwCrAJYAgwByAG+ASkA6wCbAIEAyAEqAWIBzAJIArgCfAIyAfoBigGiAUABbAEqASgBAgEHAMEA6gDqAOMAiwCKANAA6oB9AAsAkQC1v8G/nb+iP1o+ZD1APTw8ADrIOcg6QDu8PK4+Cz/WAP4A4gDEAN+AQ//bP04/GD6SPko+qD7dPz8/csA9gHa/xz9OPzg+8j6uPrI/OL+QP8M/6T/zf+2/tD9QP6a/jD9APv4+ej5QPlw+CD5QPtk/Pj7SPxM/tP/5//fANQD4AUQBegDyAT4BagFeAUoByAJkAlgCZAJUAnwB3AGOAW8A0QCvAEsAhADeAS4BuAIwAnQCaAJIAnYB1AGUAWwBAgEpAPQA2AE0AQ4BZgFgAW4BOQDYAOwAnABuAASARQB6P/m/if/pv7Y+9D4QPdg9ADuQOjg5yDrgO5w84D7ZAK0A0QCpAIcA5wADP3I+8j7wPrQ+YD6yPvE/Bz+a/9P/9z9nPy4++j6KPsU/fb+aP9R/3j/DP/I/QD9ZP3g/bT9KP0w/Lj6ePkQ+Rj5UPko+oj7pPxg/az+gAAEAkQDuASoBVgFyAT4BFgFcAWABrAIMApgCpAKkAoQCZgGIAUQBXAEEAPIAiAEmAWwBiAIsAmQCqAKMAogCZAHIAZABXAE5AMQBFgE+APIA7gEiAXYBLADqAOkA/4B4v9Q/6f/N/9C/hD+UP6Y/Sj7QPfg8mDuIOpg58DoAO+A9nj7OP4OAcwCfAFd/3r/3f80/Vj5mPg4+sj68PqI/RoB2AE3AFr/O/9k/cj6iPpM/PT86Pug+8j8gP0E/Tj91P7x/xb/iP2w/Kj7cPmA99D3gPlw+tj6WPym/igA7QBIAigEKAUABXAEYATwBPAFCAdQCFAKMAzQDOALgAoACbgGUAToAlgCvAFyAVACCATwBQAI0AmgCrAKsAowClAIOAZYBTgFYAQ4AzwDMASgBFAEiARIBWAF/AP+AZIAs/+Q/hj9oPxs/QL+HP2g+0j6gPcQ8mDsQOng6GDqwO4Q9gj9gQB2AVwC5ALcASsAvP7s/Kj6aPng+Uj7OP2e/0QBUgGVAOX/Sv54+6D5cPr4+9j7QPtQ/B7+Sv68/aD+NQDs/zL+WP3M/Kj6KPgI+Jj5KPo4+gD8Zv4F/xD/9ACUA1AEIAQwBXgGMAbwBbgHwAnwCfAJ0ArACqAIgAbQBcgE5AJUAoQD+ANAA/gDeAYgCHAIMAmwCvAKwAnACCAIsAboBBAEIAQIBMwDKAQIBZAFcAXoBGAElAMgAk8A6P4E/hj9ePwM/R7+oP0g+7D3cPPA7UDowOag6aDuMPSY+isAUALWAegBoAKSAbr+ePxY+xD6GPkY+oz8xP6NABQCGAIqAPD9iPwg+5D5ePnY+mj7mPqY+nD8Bv4a/mb+3P9zAHr+oPso+oD5gPgQ+CD5oPpY+wj8lP1Q/4sAKAJgBLgFoAWoBbAGkAfQB8AIoArwC8ALAAtQCuAIqAagBIgD0AIgAuoBaAJ0AxAFGAfwCGAKUAugC+AKQAmAB/AFYARQAxwDcAOcA9ADaAQIBRAFgAToA1QDPAKOAA3/TP7w/ZT9lP3A/bj8iPlA9eDwQOxA6ADoIOyw8UD2wPpP/5ABKAFMAZgCFAKE/lD7sPqY+uj5cPoI/XX/nACGASwCDgGW/uj8RPxI+wD6qPlI+qj6yPqw+2z9I/8pAFkAqv8i/rj7KPnw94j40Pk4+oD66PuA/Qr+rv7CACgDSATIBNgF2AYQB6AHQAmgCjALoAswDGALMAkQB+gFsAQkA0wCfALQAhADSASoBtAI8AmgCkAL4AoACegGsAUwBdAEyARgBTgGaAbYBUgF0AT0A3wCFAH8/9j+AP5g/qf/XQBIABcAxP6Y+rD0IPBA7UDqoOgA7IDyMPfA+Aj70P74AKoA0wDoAZQAiPz4+fD6aPyc/FD9f/8IAcUAAgCj/7r+VP18/PD7uPpI+fj4iPlA+mD7UP13/wIBiAGfAFL+gPtI+fD3UPeg9/j4MPq4+lj7mPwe/oT/PgFwA1AFYAY4B1AIMAnwCfAKMAywDPALkArwCBgHQAUwBMADFANAAiQC6ALsA0gFeAfACQALIAvACtAJEAggBhgFAAVYBcgFSAa4BogG0AXQBLgDbALnAIH/mP4i/mz+5//qAYgCzQAA/pD6MPWA7mDqoOqA7ODt0PAQ9rj5kPmo+Vz9PgEqAeb+Cv7g/Vz8CPtY/Cz/zAD/AAgBBgE+ALT+UP2g/FD8mPso+uj4wPho+VD6uPse/rYA2gFCAeT/HP6g+xj54Pcg+ID4mPgw+WD6OPvo+5T9+P/SAXQD2AUQCOAIIAmACtALgAvQClALkAugCRgHCAawBVgExAKQAkwDpAPYA+gE0AagCNAJUApQCgAKEAlwB8gFMAVoBcAFMAYQB8gHcAcoBgAFCASMAosA9P4w/gr+cP6D/9QAaAFoAED9EPhQ8gDugOug6gDsAPCA9PD2GPhY+ij9NP74/cD+wf9w/tD7MPvw/Jr+ff+uAOYB9AH1AOH/4P6s/WT8CPuo+fj4KPlg+ZD5+PqM/ZD/SQDsAFYBEwBE/QD7EPpg+bj4+PjI+aD5wPiw+Lj5+Pq8/AMAEAR4ByAKcAygDRANwAvwCoAKoAmgCCAIiAdYBvgEIASYA/gCsAIgA/gDuARYBUgGmAfwCOAJIAqwCbAI8AYwBYAE8ASQBcAF+AVABsgFcAQEAyQCYAGGAAAA4P/J/87/z//k/nj8QPnw9QDyIO5g7MDtYPBg8sD08PdI+pj6sPr4+zD9IP24/Ez9Nv6m/i3/bwCaAcoBSgHEADIAQ/8C/qj8UPtQ+uj5+PlY+gj76Pu8/Iz9iP5J/0//8v6c/sD9GPzI+nj6QPqY+Zj5IPoY+cD2kPbQ+az9sAAoBUALUA9wD3AOEA6ADEAJaAcQCFAI4AbQBQAG0AXYBNgE2AUQBmgFQAV4BRAF2AQoBlAIcAlQCeAIIAgIB/gFYAVgBZgFeAWwBLwDPAPsAkACtgEIAnwCFAIGAQ0Atv5s/OD5oPcg9TDy4O/A7sDuwO9Q8oD10Pfg+JD5IPoo+ij6CPuY/OT90v7u/wQBXAEWAcgAiwAbAHv/0v4k/oj96Pwo/Kj70PtM/GT8PPxc/LD8rPzM/HT93P3M/Tj+Df9o/mT8mPuo/Dz8GPlg9sD1kPWg9bj5BAJwCQANUA8gEkAS8A2ACVAIIAioBmAFMAYwB4AG0AXIBsAHCAfABQAFGAScAjACxANIBnAIQApwCzALgAlgBwAGaAX4BGAE1ANsAwgDbALYAeABjAJIA6QDfAOoArQApP1w+vD3EPYw9DDysPAA8ADw0PDw8pD1oPdQ+Dj4CPgQ+Fj4UPkw+4z9lf/3ANgBUAIIAhoBLgCZ/+z+Av5M/QD9pPw4/GT8EP2A/WT9IP3k/Jz8mPzg/CD9cP1C/tj+Pv44/Qz96PyI+xD6gPng9zD0gPJQ9gz9ZAIIBxANgBHgELANIAyQC3AJ+Aa4BoAHyAZwBbgFQAcwCEAIIAhwB3AFEAO+AdwBMAN4BTAIYAoQC2AK4Ag4B+AFCAVwBPADjANcAyQD8AJAAwgEsAToBPAEcARYAhb/JPzY+XD3MPUw9JDzIPKg8MDwQPJg8yD0oPUQ9zD3oPYg99D4wPqs/NT+9ABoAtgCaAJmAVwATv8k/jz9NP2s/cT9jP3k/aL+vP4A/lT9CP2E/Mj7qPtQ/BD9kP0A/lb+Dv5I/Xj84Pso++D5gPcw9CDysPOY+Jz+AAXwC2ARYBIAEGANcAsgCdgGSAYQB1AHAAdgB0AIsAjwCPAI0AeIBWQDvAFwAKQAaAMQB0AJEAqQCuAJgAc4BZgEsAQgBJwD8ANABAgEGAT4BMAF8AXABdgEmAJZ/zD8gPlQ9+D18PQg9BDzIPLw8XDyMPNA9HD1cPbA9oD2sPbA94D5UPsI/eD+ggBeAWgB/gBIADn/Jv6w/cz92P28/cz9Iv5Q/gj+xP2w/WD9xPxY/ED8DPzY+1T8OP2E/UD9IP0A/Uz8gPv4+kj58PWA84D0cPgw/eACkAkAD8AQkA+QDWAL4AgAB4gGGAfgB4AI4AhwCVAKwAqQCVgHWAW4A5gB2/9zADADyAVgB8AI0AkQCeAGKAWgBFgEqANAA5QDKASABNgEgAUQBiAGeAU4BEgCt//w/Hj6mPgA94D1UPRg88DycPLA8mDz0PNQ9CD1wPXA9SD20Pc4+kD82P3I/6IBeAJEAtYBHAHU/5T+5P2k/Yz91P1C/pL+7v5f//D+VP08/Fz8NPzI+hj6uPuk/bz9FP2Y/fj9jPyw+jD6uPkQ95DzoPIQ9WD5eP6QBOAKIA/gD2AOMAwQCvAHeAaoBjAIoAkwCsAKkAugCzAKIAhIBlAECAJxAHgArAF8A+AFYAjQCYAJUAg4B9gFQAQwAxADZAOoAzgEOAUwBpgGiAYgBlAFwAN0AfT+yPwg+8D5oPjg9zD3EPaA9DDzsPJQ8gDyQPJQ85D0YPWQ9uD4YPsA/Rr+xv9kAYwBqwBTAHoA3f/e/v7+AABVANf/vv8LAJ3/EP5U/Bj7wPr4+rD6CPrA+gz9Zv5I/TT84Pzw/AD7oPkI+oD44PPA8IDyoPaA+gAAqAdwDcAOAA4wDVALUAigBmAHYAjACNAJoAvADMAMUAxAC6AI4ATqAR0APP+n/9QB6ASIBzAJwAkACYAHAAbYBPwDvAM4BLgE0ARABVAG8AbABnAGMAawBCACx/9S/rT8sPo4+YD4sPdg9gD18PNQ89DyMPKg8ZDxQPIw80D0UPZo+Uj8PP7A/xwBmgEgAbkAuQCUAAkAwf8CAEkANgDc/4X/M/9u/uD8IPtI+kj6+PnY+Sj7EP14/ej8hP1U/rD82Pk4+Qj6SPhA9BDyIPMg9Tj4ZP4gBmALIA2QDTAN0ArIB5gGaAeQCBAKMAwADhAOQA2wDLALYAlgBjgEnAIOAYEA9AHABDAHoAgwCdAImAf4BXAElAOIAxgE4ASoBcAG2AcQCHAHkAawBTAEygFg/5j9KPyg+jD5IPhw93D2APWg88DyUPKQ8RDxcPFg8nDz4PQw9+D58Ptw/f7+QwBPAID/Df9P/5P/kP/o/8kAXgEmAX8A5f/w/jD9SPtY+lD6GPqQ+eD5cPuw/JT8ZPwg/Sj9KPvY+DD40PfA9UDzoPKw82D1uPgG/yAGsApADIAMsAtgCQgHeAYQCNAK0A1AEAARQBAQD8ANYAsQCCgFRAO2AYsAJgGcA2gGMAgwCYAJUAiYBdwCfAF6AYgCcATABvAIgAoAC+AJwAfYBbgEdAOcAf3/6P6U/Zj78PlQ+dj4gPdg9aDzYPIQ8eDv4O8Q8XDykPPw9BD3UPn4+jT8dP2W/hz/Pv98//T/WAC9ADQBgAFiAdsABwDu/pz9TPww+3j6WPpo+jD68Pkw+qD6qPqI+qD6EPqI+HD3cPfg9rD0EPPw8yD2EPhw+0IBMAcwCrAKUAowCbAHoAfwCQANYA8gEYASgBIgESAP8AxgCgAIQAa4BFQDDANYBDAGkAcQCKgHaAboBGQDvgHXAPYBoAToBmAI8AkACxAKqAf4BSAF7ANMAkIBZgDC/tT8ePuY+qj5mPgw90D1IPOw8eDwIPBQ8JDxEPMQ9ED1IPcg+YD6uPss/Tb+ev6U/gn/of8oAMwAagHKAfABxgHSADD/nP10/Gj7iPoo+jj6UPqA+tD6iPq4+Tj5KPko+GD2gPXA9RD1gPNw86D1aPhQ+yIA2AXwCDAI0AY4ByAIoAhQCsANIBHgEiAToBIAEYAOUAyQCsAI4AbQBagF+AWIBlAH6AfIB7gGyASQAsAA1/8YALABWATwBqAIgAlwCWAIeAbYBBAEoAMUA5QC+gH/AJn/HP6E/Mj6+PgQ9wD1MPMQ8nDxIPGA8TDysPLw8rDzYPVA97D4OPrA+9T8SP2s/Ub+zv5M/xEA+ACYAdoB3AFwAXUASv88/ij9CPxQ+xj72Ppw+lj6qPpo+mj5ePjw9/D2QPVA9CD0oPPA8gD0gPh8/WUAgAIYBYgGuAUABdAG8AmADCAPABKgEwATgBFAEBAPwA2ADFALEAqACaAJYAmACPAHkAdABhgEZAJ6AckAkgCoAZgDQAWABmgHeAdoBggFMATIA5gD3ANQBBgEHAP8AekAS/8A/eD6ePkg+FD2wPRA9ODzwPLA8dDxgPLQ8iDzgPQw9lD3CPj4+Pj5uPp4+1D8FP30/Sb/NwDAAC4BqAGaAaoAr/8L/zr+LP2s/Nz81Pws/JD7KPtQ+vj40PfQ9qD1QPRw80DzcPPA9ID3wPpE/fD+MgDSADABdAIQBfAHsApADqARoBIgEZAPQA/wDiAOAA7ADuAOIA6ADfAMsAswChAJcAcoBUADdAIUAhgCOAOwBCAF8AQYBfgElAMYAugBaAJ0AogCAAMoA2wCdgGkAHX/9P18/AD7aPkg+GD3sPbw9aD1UPWw9ED0QPSQ9MD0APWQ9TD20PbA98D4cPko+hD7wPsg/AD9YP5F/0r/Qf9x/yf/gv5W/qj+ov5g/mD+PP5Q/TD8oPtA+yj66Pgg+GD3UPbA9XD2sPf4+KD6hPyY/dT9dP7W//4ARAIIBQAJUAzwDaAOsA7QDdAM8AzgDdAOsA+AEGAQcA+ADqANIAxwClAJUAioBhgF+ASQBZAFIAUABcgEvANkApYBLgHSANMAWAG0AXwB/gB7AM3/Av8e/iz9JPwg+3D6wPnw+ED44PeA9/D2YPbw9eD14PXw9UD2oPbw9jD3kPcA+Hj44Phw+Tj6IPv4+8D8ZP20/bD9mP2g/dj9Iv6I/vr+LP8B/6b+Uv7A/ej8GPyg+wj7EPpI+Rj5UPmA+eD5yPqg+/D7IPzU/Oj92v7c/5gBIATYBhAJcAowC0ALAAvACkALkAzwDdAOgA8AENAPwA6gDQANYAxQCzAKYAnACPgHWAcQB7AG+AUwBUgEGAPeAQwBtQB0AFwAggBvANT/C/90/tz9GP1g/Pj7kPv4+mD60Pk4+bD4UPgA+ID3MPcQ99D2MPbw9WD28PYQ9yD3YPeQ93D3UPfA98D4qPlQ+uj6YPuY+7D7CPys/Ez9uP0M/mr+rP62/nj+Hv7Q/bT9qP18/WT9cP2U/WD9DP0Q/VD9lP30/aj+Wf/K/2oAiAGIAhQD0ANQBcgGeAe4B0AI4AhACZAJMArQCiALcAvAC+ALoAtACyAL4ApQCpAJ4AhQCLgHSAcIB8gGWAbABegE8AMAA0gCvgE8AbwAQgDb/37/Ev+C/sz9DP1U/Kj7APug+mD6OPoA+rj5aPkI+Zj4KPiw93D3kPfQ9/D3CPg4+Ej4IPgA+Cj4aPiw+Dj5+PmA+pj6yPpA+5D7oPvg+4z8OP2Q/cj9Gv5o/qz+7P4i/0//h/+1/7v/u//d/wUAFAA6AIEAsADCAP8AbgG6AeABQALQAjQDjAMgBLAE+AQgBagFOAZYBjgGYAbIBhgHOAdgB6AH0AfYB7AHaAcIB9AGkAZYBiAG+AXIBYgFQAXYBGgE+AOIAwgDkAI4AtoBXgHhAHcA+P9M/6j+RP7k/Wz9BP3A/Gj88PuI+zj76PqA+jj6CPrY+bD5sPmw+ZD5aPl4+YD5UPko+Uj5iPmo+dD5MPqY+tj6+PoY+0j7cPuw+wT8YPzA/Bj9bP2w/fD9Ov6G/sL+9P4g/0H/eP/Z/0YAiACyAOEADAEaASoBagHAAQgCWALEAigDYAOIA8AD9AMQBCgEYASgBOAECAUgBTgFQAVIBUAFSAVIBTAFEAXwBMgEkARQBCAECATwA8gDkANAA/QCsAJ0AigC5gGwAYYBTAH7ALQAewA8AOz/p/9u/zD/4P6S/lD+HP7k/az9fP1Q/ST99Py8/ID8TPwk/AT84PvQ+9D70Puw+4j7iPuY+5j7oPvA++D7+PsQ/DT8UPx0/KT86Pwg/VD9hP3E/Qr+VP6W/sb+4v4L/0T/gf+6//j/OABmAI0AvQDuABIBNAFqAZ4BvAHcARACQAJUAmgCjAK0AsgC2AL4AggD+AL0AgQDHAMkAygDLAMsAyADEAMAA+gCyAK4AqgCfAJYAjgCEALQAZIBcAFMARoB8ADbAMMAngB5AFwAOAAcAAUA6f+//5X/iP96/13/OP8g/wT/1v6m/pb+mv6G/mr+Zv50/nL+TP4u/jT+PP4k/gj+Av4Q/hT+Fv4s/kz+Tv46/jb+UP5s/nb+jv62/s7+1P7e/vr+Ff8g/zz/cv+W/5P/jf+a/67/uv/L/+j/BAAZADYAVgBrAHMAhgCZAKYAtADCANAA1gDkAPUA/QACAQwBGAEUAQgBAAEIARABDAEGAQwBGAEWAQgB+ADqANoAygDCAMAAvQCrAKAAnQCeAJoAjwB/AG8AXQBIADUAKgAjABwAEwAHAP7/9P/e/8b/qP+b/6b/sP+m/5T/j/+L/3r/bf9v/3T/dP92/4P/i/+E/3T/Zv9o/3X/gv97/3T/dv94/27/ZP9t/3z/ev9x/3D/bv9q/2z/d/+A/4D/f/+F/5L/nv+j/6T/pP+n/67/u//S/+//BwAZACsAOQBCAE8AXQBdAFsAZgB5AH0AeACAAJQAnACcAKUArQCrAKcArQC2ALwAxwDcAOkA5gDcANkA1gDKALwAvQDLAM0AwACwAKkAnACBAGcAWQBRAEEANgA1ADkAMgAUAO7/1f/M/77/pf+b/6L/mf98/2T/Xf9X/03/SP9P/1j/Xv9p/23/Z/9m/2z/b/9y/3//jf+P/4v/kf+b/5z/lf+T/5b/nP+n/63/pv+h/6j/r/+p/5z/nf+j/5//ov+0/8n/1f/g//L//v/+//n/BAATABoAGQAZACUAMwBDAE8AWABgAGYAZgBlAGwAdgB3AHAAcwCCAJEAlACWAKEAowCRAIIAfAB2AHAAagBqAGQAXQBdAFcATABEAEAAOQAsACEAEAD5/+P/2//e/93/4P/g/9X/v/+r/6L/nP+V/5H/kP+M/4L/df9s/2f/Z/9j/1z/X/9s/3X/eP+C/5b/of+g/6j/vP/F/7v/tf/C/87/0P/V/+H/7P/p/+D/3v/e/97/4P/m/+f/5P/p//b/AAAFABAAFwATABoAMgBHAEwATABXAGEAXwBcAGAAYQBhAGYAbABuAG0AcABvAGUAWgBcAGAAYABjAGoAbABkAFwAWgBYAFMAVABVAEsAOAAqACcAJwAmACUAJAAhABgACgD2/+D/1f/U/9D/yP/A/77/wf+//7j/s/+t/6L/lf+O/4//lP+X/5f/mf+Z/5j/mP+a/53/ov+l/6r/q/+x/8L/1P/c/9r/2f/f/+n/8v/5////AQADAAYACQAIAAUACAAJAAUABwAOAAsA/f/1//r//f/2//b///8CAPX/7f/8/xEAGgAfACsAOQBDAEsAVQBcAF8AaAB0AHcAbgBlAGEAXgBdAGAAawB2AH4AiACLAIAAdABxAHEAbABjAGIAZABgAFgAVABUAE0AQAAxACMAFwASABAADAAKAAcAAgD4/+3/5P/d/9T/yv/G/8T/uv+w/6z/o/+R/4b/iP+M/4b/f/99/3v/dv96/4X/i/+J/4j/iv+K/4z/lv+h/6H/mf+b/6H/ov+g/6j/uP/A/73/uv++/7v/s/+4/8r/0f/L/83/1//b/9X/1//o//r/AQADAAsAFQAdACYALAAtACwAMAA6AEUATgBVAF0AYwBkAGUAawBzAHcAeAB3AHcAeQB+AIgAjwCOAIsAiQCKAIYAdwBmAGIAZwBqAGUAWwBTAE8ARgA6ADQAMQAnABYADQAGAPv/7//u//P/7f/f/9n/1f/G/7T/rv+t/6b/nf+Y/5b/lf+Y/5v/m/+Y/5n/mv+V/5H/l/+c/5H/hf+K/5b/l/+O/43/lf+a/5//sP/B/8P/vv/B/8v/0P/S/97/8P/9/wAAAQABAP7//P8CAA0AEgAUABwAIwAhABoAHwAqADAAMAAzADsAQQBDAEUATQBXAGIAagBsAG4AcABwAG4AbQBxAHMAdwCEAJQAmACSAI8AkACJAHwAcQBnAFwAVgBYAF0AWQBOAEgARAA7AC0AIgAbABEABgD+//j/8v/q/+L/2P/K/73/tP+u/6v/qf+p/6X/nf+U/47/jf+K/4X/hP+G/4X/f/95/3X/cf9u/27/cv93/33/hf+O/5D/j/+W/5//o/+n/6//vP/E/8j/0f/V/9D/yv/L/9H/1v/b/+H/4v/e/97/5f/u//L/8//1//f/+f8AAAwAFQAhADUASABQAE0ATgBWAF0AYwBpAHAAdQB7AIAAfwB+AIMAhgCCAIAAhACIAIcAhwCPAI8AgwB4AHgAegB2AGwAYgBUAEIAMwAvAC0AIwAYABYAFwAQAAMA+//5//P/6P/e/9v/2f/T/87/zv/K/8H/uP+x/6v/qf+o/6L/lv+N/4b/ff90/2//bP9o/2T/Zf9r/3X/e/95/3P/b/9w/3f/gP+I/5H/m/+l/6n/rf+3/8n/2f/e/93/3v/i/+b/7f/2////BgALAA4AEgAWABkAHQAnADYARABMAFYAZABvAHcAgACMAJcAnACcAJgAmACbAKAAowCjAKEAmwCTAIkAhgCIAIUAfwB7AHoAdQBrAF8AVQBMAEQAOAAsACIAHQAYABAACAAAAPb/6P/d/9b/zv/H/8T/wf/A/73/uf+x/6X/nv+e/6H/pf+u/7T/sP+o/6P/oP+c/5r/nv+g/5r/lv+a/6L/o/+j/6b/q/+u/7T/vv/F/8n/y//N/9D/2f/l/+r/6P/q/+7/7//v//f/BwAPABAAFQAeACAAGwAfACoALgArADIARgBTAFQAUwBWAFQAUwBXAFwAWABVAFoAWwBXAFoAZgBnAFsAVQBYAFUASQBFAEoARwA6ADEAMAAyAC0AIgAXABQAGQAaABAABgAFAAUA+//s/+X/5f/m/+f/5//l/93/0f/D/7n/vP/D/8P/t/+w/7b/tv+k/5n/oP+u/7P/qv+g/57/pv+t/6z/qv+2/8T/vf+n/6L/s/+9/7T/tv/L/9X/x/+5/7//yf/E/77/yf/d/+r/7//1//z/AQALABQAFQAOAA8AGAAgACMAKgA9AFMAXQBbAF4AYQBcAFcAXQBqAGwAYABVAFEATgBMAEsASwBNAFUAWwBOADIAIQAlACwAKQAkACMAIwAhACMALAAyADEALgAuADIANgAyAB8ACwALABwAKgAsACsALQApABsADQALABkAJwAkAAMA0/+3/8P/5P8EABgAEADZ/4T/Vf91/8L/+f/8/93/qv9k/yj/PP+t/wsA4P9d/x3/R/93/4b/0f9FADEAbv/q/k//FABuAEUA6/+I/0D/Xf8DAPAAgAEEAa//yP5H/28AzQBhADsAXgDc//r+Lv+fAKwBMgHr/w3/0P4f/yYAeAHIAT8AsP0w/DT9gQD0AzAFkAN4AIj9wPuw+8z9AgEsAzADLAJeAZgAjv/8/o3/0wAUAgwDKAPcAcD/iv4d/5UAsgHsATIBjf/M/Uz9wP5AAfwCyAICAQz/CP4K/pL+EP9A/yj/wP7w/dT8HPxM/AT9nP0K/sL+nP+4//7+jP5+/1ABXAL2AVoBYAEeAV4AlQBEAiQDiAGY/+b/bAF4AWIAaAAmAWYArv6m/lYAEAETAIT/XADUAOr/V/+MADQCKAKVAHn/h//O/8n/WADsARgDGAJx/7z9tP7AACoBwP98/iL+pP3s/Iz92v8yAUj/6Pvw+lD9KwD7ABMA5P64/Xj8dPwF/7QCKAR0AigAuP+AAAIBiAGoAnAD4AIIAiQCqAJgAroBxgEYAsIBUgHYAZwCIAKWAHD/A/+i/qD+wv8MAaMAxP58/Vj9FP2g/FD9Cf/M//L+8P2w/ZT9ZP3U/ez+sv+Z/yr//P4R/0L/jv8MALUAXAGwAUQBMQBc/77/JgFMAoACUAI0ArABfADN/5kA0gEEAnQBPgEyAWwAX/9b/1EA7gCyAF8AbgBSAJf/7v5Q/38AIgFpAN7+uP20/Zr+pf86AHIAoACIAH3/8P24/aT/xAGwAUMAEwDeACgAJv4a/rMAlALQAWUA1P/o/mz9vP2pAPgCJALX/1D+YP0E/aT+TgGoASz/XP0A/ub+hv5m/lL/hv9o/iD+zf98AUYByP+c/qj+uf/PACAB8QAEASoBmQBm/7L+QP+GADABMgCM/pT+gQDmAYYB1gCPAF//dP2E/TUARAKCAcr/Qf+E/6r/DADNAC4B5QBEAGz//v47AFACWALs/4j+AQCkAQwB6f9SAPAA/f/2/goAJAKQAiIBnP8y/+f/DgG8AaQBRAHEAMT/yv5X/1oBSALRACH/Vv9VAPz/2P7i/g4AawBZ/2D+pv4s/67+7P12/tj//f9+/nD9QP6A/5H/Tv/f/yMACf8g/kP/YAHwAdsAKgCLAIoAyv/z/6oB4AK+AaD/Ov+eAF4BjgAwAIABbAL1AMj+0v6rAGYBYQDn/9gAHgGj/4L+lv9GAeEAxP7A/QL/swDHAK//Lf+F/4D/qv5i/qP/7QBtABH/N/+hANgAkv8O/wcAdACP/3L/5gBmAX7/vP3K/h4BpgFrALT/+v+5/9z+GP/XAOwB6wCb/x8AVgHRADf/S/8MAW4By/9G/yQBNAJRAGT+M//JAG8Alf9yAGwBBgDc/Qz+//+/AMP/Lf+x/+P/EP9a/r7+lf/F/2L/WP/u/zkAfv+A/pz+2P/CAJcAHwAQAOX/SP85/2IAmgFCAc7/K//0/wgBbgFeARABSAAm/6r+oP84AcwB2QC1/6r/NgA8AOr/CQA2AIr/ov7a/hYAtQD2/wn/Mv8qAK0ARwC4/5P/fv8M/w7/ggAwAtgBnP8u/vL+VgCkAFcAhADGAFgAbf8N/6//ywBIAYgAgv+j/30ARwAl/1n/SAEMAgEA+P3g/vIAyAAX//b+TQBfAO7+jP78/wYBSwAq/wv/e/9//yn/S/8zAE4BcgEVAFL+1P38/rMAzgHGAb4AhP8P/3H/6v84ALIAGgHwAHMAPwAZAKD/cv8UALUAcwABAIMAYAH/AFr/Jv56/qj/pgBEAZ4BVAEaAJz+Ev7K/v3/7QCCAYIBewDi/uj9QP5j/2QA5QDyAJYA7P8z/7D+qP4X/9n/wQBkASYB5/+O/mL+Yf8cAOT/3f/FAGQBfwDu/ob+dv94AOQAIAFOAesAyf+m/qD+DADUAWACtAHVAO3/jP7g/av/nAI0A7oAXP5y/n3/m/+T/3wAIgEbAHj+Yv7M/6EA3//Y/gL/6v9OAPb/vf/q/7z//P64/r7/RAG6AZEADv/S/sn/awBEAIAAigHSAVoAzv47/6sA7QA3AG0AVgEKAZH/8v7o/8sAbQDQ/+j///+L/6H/9gAAAiIBL/8+/tL+zv+OACwBPgFKABf/yv5V/+z/cADpALAAeP9O/mD+c/+gAG4BegFSAJT+0P2o/hEA4QAKAdUAMwBl/yD/gP/j/xoApQBgAUAB5f+k/tr+5/9GAP7/IwCIAB0ALv/u/ln/dP92/0MAFgFsAOT+fv5D/5v/U/+4/9cADgHQ/6L+zv6w/w4A7/8gAJUAegDA/2v/9v9sAOr/Sf/o/z4BfAFRAFv/mf8dAP7/6f+LAPIAMwA9/4n/uwASASQAa//W/2gAIAC//1gALgGiAA//oP4HAGQBLAEpAK7/uP+c/5P/GwDCAKYAzP88/8X/9wB0AbUA0f/U/zAA2v9Y/+j/LgFyAWsAnv+z/5z/7v7m/jIAUAG5AFn/Av+q/8v/Hv/W/mr/1P91/y3/x/+DADMAGP96/uT+q/8zAHkAkwB8ACoArf85/zf/9v/8AFgB1wAsAOP/4f/3/zwAlgCVAD4AJACJANUAfADW/4r/vv8vALoAOgFAAY8Apf8e/wD/PP/0//4AigECAd7/Gf/8/hT/S//1/+kATAGpAJn/Jf98/+X/7f/P/9r/5v/U//n/gADtAKkA8P9v/0f/SP+U/2MAXgHUAWIBXQCR/3X/s//I/97/ZgAUARABYwDk/77/R/+2/vb+8P94AC0A8v8GAKD/vP5w/ij/y/+Y/2v//P9sAMX/wP7A/pj/7/+M/4D/JQBwAN//c//T/0EA+f+S/+X/hQCUAB8A7P9BAKkApAA3AN//DACeANYAfQAsACYA0v8S/wL/DwASAfMAUQAgAPf/N/+Y/ir/kQBuATgBhQDx/4n/Ov9L/+n/tQAMAcEAKgCq/2P/Zv+3/y8AiQCwAJ8AJQA1/37+3v4DALkAkwBKAFwALABI/4j+6v77/5QAgQCKAMsAagBL/57+TP+OAAIBkgA9AEUA7f8Z/9L+qf+vANcAdgBfAFYAvP/i/sb+gP8jAFoAhQC/AIcAuv8D//b+df8MAIcA2QDRAFgAp/88/1//5f9iAJsAuADJAJwAJADL/9j//v/c/9L/ZAAwAVABtgAjAN//jf8L//r+1P/5AFABkACK//7+yP6A/nj+Nf9WALoAHAB9/3P/bf/0/qz+MP/q/wkA1v/w/yoA/f+X/3T/m//b/yEAUgAyAPT/CQBVAF8AWwDOAFoBJgFhAOv/AAAxAG4ADgG+AbgBAgFOAPX/xP+j/8H/KQCiANAAqQBaAAYApf9B/wz/Nv+a/+z/GAAqABIAxv96/1f/VP9J/0//m/8gAKEA1wCWAO7/Mv/K/uz+if9YABABRgHbABAASf/W/tz+T//5/4sAyQCmADAAk/8v/1H/zP9BAH4AkQBoAPj/g/9///n/bQCLAIkAngB8AAUAsf/9/6oA/ADaAKUAgwBEAO3/zP8OAIcAvQB2AAUA7v8dABQAzf/S/zAARwDu/8z/KwB0ADgA0/+u/6H/iP+Q/+j/VQCBAE0A3v9r/yH/Df8X/2T/9P9zAGUA6/+O/2T/I//Q/uj+iP82AJMApwBWAIf/uv6i/j7/0P/6/xAAUgBXANn/Pf8N/03/of/w/0wAhwBWANL/bf9b/3r/r/8DAGoAlgBaAOn/qf/K/xsAVQBZAEwAZAB6AFgAEAAVAHkA5AAWAQoB1wCJAEUASwCkAP0AGgECAdgArgCUAKkA4gD9AMoAbgAcAOD/x/8JAIkAvgBXAKL/Rv9U/2r/bP+N/8b/vv9i//D+xP7Q/v7+Of91/5n/kP9d/wn/yv7a/jH/fv+3/wIAPgD6/0T/2P4s/8r/KQBJAFgAJgCl/1D/ef/H/9n/0v/j/+f/1f/b/wkAEwDx/8//wf+Y/2X/of9AALkAswB8AGoAUgACANL/FgCTAOkAEgEyASgB3QB9AFsAfwC2AOwAGAEmARIB/gDxAPYACgEgARwB7QCoAIMAoADUAAQBDAHuALYAbAAoAPr//P8tAFIAVgBZAGcAQwDf/4P/e/+r/87/4v8HADEAJwDS/3P/If/y/tz+1P7s/ir/gf+o/3L/D//A/oL+Sv4q/jT+ZP6g/tT+6P7c/r7+aP78/aT9lP3U/Rz+dv7u/k//QP/U/mL+CP7c/QD+kv5l//n/HQADANf/qf9+/4T/5f93AAIBWgGSAboB2gHkAdIB3gEIAiQCKAJQAswCTANwA1ADJAMEA9wCsALMAhQDTANEAxgD+ALoAtgCvAKcAngCWAIcAu4B0gG+AZ4BegFWASoB8wC1AH4ALADZ/4z/X/9C/zP/Kv/Y/kD+kP3s/ID8MPwM/ND7aPvg+lj68PmY+VD5OPlI+SD5sPhQ+Dj4YPiA+MD4KPmI+cj5CPpg+rj6CPt4+zT89PyA/QT+iv4l/83/pQCOAUwC1AJMA9wDUATQBJAFcAYQB2gHwAf4ByAIUAjACFAJwAkQCiAKIAoACuAJ0AngCSAKUAqQCoAKYAogCuAJkAkwCeAIgAjoBygHiAbABegEAAQoA1ACNgHB//j9QPzY+qj5kPhg9yD2gPTQ8lDxMPBA72DuwO2A7cDsoOvA6qDqAOug64DsgO0A7iDugO5g75Dw4PGw86D1YPfY+GD6EPyU/Tn/WgFsA+AE+AUwB6AI0AkAC7AMkA6gDwAQIBAgECAQABCAECARgBHAEaARQBFgEMAPMA+wDuANQA3wDIAM0AtQC0ALYAtAC+AKcAoACkAJUAiwB2gHQAfoBlgG8AVQBRgEIAK8/zD9yPq4+HD3wPYw9qD1YPRg8uDv4O1A7IDqAOkg6ADoAOgg6KDoIOkg6eDoAOmg6eDpYOpA7ODuAPHg8uD04PZY+HD5CPsU/fT+3QBMA5AFQAeQCOAJIAvwC3AM4AxADYANEA7ADlAPcA+AD2APkA4QDeALcAtAC1ALkAvAC0ALQAqACfAIEAgoBwgHaAewB9AHMAjACAAJUAngCWAKIArgCfAJMAowChAKQAoQClAJcAioBzgGQARIAoIAfP5k/LD6MPlg92D1APTA8gDxoO6A7ODqAOlg52DmYOaA5sDmwOZA54DnwOdA6GDpAOtg7MDtIO9A8TDzEPUA94D5HPyu/sYAuAJ4BEAG0AcwCYAKwAsADeAN4A6wD0AQgBBAEMAPEA8QDsAMsAvgClAKEAoQCiAKAAqACXAICAeYBVgEqAOIA+gDoASIBVAG0AY4B8AHcAggCWAJYAmgCSAKEAtQDHANIA5wDjAOUA2QC4AJ2AeQBmAFSAQwA4oB2v7w+0j5kPYA9ODxoPBA72DtIOsA6SDnAObA5aDlQOWA5EDkoORg5cDmgOig6oDsQO6g78Dw8PHw85D2SPkA/Kj+HAEcA0AFgAeQCfAKYAywDcAO8A4gD7APYBAAEUARQBGgEFAP4A2QDCALoAnACIAIQAjQB0AHeAZQBSAEWAOoApgBlwBjAAYBrgFIAlQDmATQBagGqAdwCIAIcAggCYAKoAuQDIANMA5ADsAN4AyAC5AJ4AfIBrgF+AMEAikADP5o+3D4EPbw8wDyUPCg7oDsYOpg6ADnAOZg5UDlIOXA5MDkgOXA5iDooOmg62DtAO9w8PDx4PMg9qD4QPvA/TUApAIABRgH8AjACjAMQA3gDZAOUA/gD2AQwBBgEYARwBCwD4AOEA2ACzAKUAmACIgHwAY4BrgF4AT4AwwD6gHBAN3/V//i/g3/CABgAZgCiAOQBNgF2AbIB8AIwAmQCpAL0AzwDZAO4A7gDuAOQA4wDcALUArACDgHYAUEA4oA4P0Q+zD44PXA8+DxIPCA7sDsQOpg5yDl4OMg48DioOIA46DjQOSg5WDnYOlA6wDtwO5Q8JDx8PIQ9aD3mPqc/b0AjAMABkAIUArwCxANQA6QD0AQgBAgEeARYBKgEsASwBIAEoAQ4A4wDYAL0AmACHAHcAaIBdgEQARoA3gCgAGGAGv/jP74/cj9FP7k/jIAigEMA1gEkAXQBjAIYAlQCkALYAygDWAOsA4QDzAP4A5gDnANQAyACrAIOAdYBdAC2/8M/QD68PZQ9GDyoPAA74Dt4OuA6cDmoOSg4+DigOKg4kDjAOTg5EDmQOhg6qDs4O7A8PDxMPNQ9aD3+Plw/Hf/rAKABSAIgAqADNANEA9AECARgBHAEeARoBHAEQASABJgEWAQgA8gDhAM0AlgCBgHeAXEA5AC2AEGAVMAx/8B/x7+bP04/bj8ePzQ/PT9CP8lAM4BuAM4BWgGIAgACnALIAwgDWAOQA+QD9AP4A+QDyAPwA7gDUAMcArACLAG3AMMASL+APuA95D0UPJQ8EDugOwA62DpIOcA5WDjQOLA4SDioOIA4wDkgOVg54Dp4Otg7qDwQPJA9HD2ePhQ+tj82f8MA+AFsAhQC4ANQA/AEOARgBIgE4ATYBPAEiASoBEgEWAQgA+gDkANgAugCbgHyAUIBKwCcAFRAE//Yv5k/YD88PuY+2D7OPuY+zj83Pyw/SD//gDsAtAEsAZQCNAJQAvgDDAOQA9gEKARYBJAEuARYBHAELAPYA4QDWAL4AhgBtAD5QC0/YD6gPew9BDyoO9g7UDrgOlA6KDmoOQA4+DhwOEA4oDiYOOg5CDmIOgg6mDsgO7w8FDzkPXA98j50Pvo/X0AbANoBvAIcAuwDYAPwBCgEWASABMgE8ASABIgEQAQMA+ADrANsAxwC/AJUAiQBtgEMAPCAYIAj/96/mj9TPxQ+8D6YPpY+qj6SPsA/JT8cP3Y/pUAZAJIBEgGMAjQCTALsAwADmAPwBAAEqASoBKAEgASIBFAEFAPMA5wDBAKwAdABWACM//g+6j4kPWg8uDvIO3A6iDpAOjA5gDlgONg4uDh4OFg4iDjIOSg5WDnYOmA66DtMPDw8pD14PcQ+gD80P0kANAC2AVgCJAKAA0QD6AQoBGgEoATIBRAFMATwBJgEQAQ0A7ADYAMIAuQCeAHMAaQBAADVAG//5r+wP2I/BD70PkY+dD4iPiQ+Aj5mPl4+nj7wPxA/ikAgALYBOAGoAiQClAMsA1ADwARgBJAE4AT4BPAEwATIBKAEaAQIA8QDfAKoAgoBlQDLgDU/FD5EPbg8qDvoOyA6uDoQOfg5aDkgOMg4oDhwOFg4iDjIOSg5UDn4Ojg6mDtAPCA8lD1CPhA+vj7DP6lAEgD8AXQCHALcA0gD+AQQBIAE8AToBQAFWAU4BKgEWAQ4A6gDXAMEAtACWgH4AUoBFgCBAH8/9z+hP1c/Fj7KPoQ+cj4wPiQ+JD4UPlA+ij7RPwS/jgAaALIBEgHYAnwCpAMYA7wD0ARoBLAEyAUIBQgFOATABMgEoARQBBQDhAMAApwB3AERAE0/qD6oPYw82DwYO1A6gDooOZg5QDkwOLg4QDhoOBg4WDiIONA5CDmQOjg6aDrAO7Q8KDzUPYI+Wj7fP3r/7QCmAUwCOAKUA0gD6AQABJgE2AUABVgFUAVYBTAEoARIBCgDhANoAsACjAIOAZABIQC7wDA/7D+gP0g/Nj68Pko+Uj4oPdw96D34Pc4+OD4MPqw+1z9bP/8AaAECAdACXALgA1wD0ARgBLgE+AUYBVgFeAUYBQgFEAT4BEgEHAOgAxACrgHCAXqAZT+OPug98DzAPDg7CDqoOeg5SDk4OKg4aDggOCg4ODgoOFA4wDlgOYA6ODpIOzA7nDxIPSg9gD5qPti/oAArAJoBWAIEAsQDfAOoBAgEiATYBRAFUAV4BQAFAATwBFgEPAOgA3QCyAKgAigBqgEBAPGAYoAMP/s/cj8oPto+nD54Phg+AD4wPfw92D4EPno+Sj79Pz0/kwBtAP4BUAIYAqgDKAOYBAgEoATYBTAFCAVIBXAFAAUQBMgEqAQ0A7wDOAKgAgQBogDSQDQ/Cj50PVg8uDuoOsA6cDmwORg40DiQOFg4GDg4OCA4aDiAOTA5YDnIOlA64DtwO8w8uD0kPfg+RD8XP7bAHwDIAbQCFALoA3QD6ARABMAFAAVwBXAFSAVABTgEqARIBCADuAMMAtgCaAHGAaABOQCZAEQANj+tP10/Cj76PkA+WD4wPcg97D28PZw9zj4OPl4+iD8LP6QAPACSAVwB9AJIAwwDgAQoBHgEsATQBSAFIAU4BNAE6ASgBEgEJAO0AzACnAIAAZEAysAuPxI+eD1UPIA7wDsYOkg52Dl4OPA4sDhIOEA4YDhgOLA40Dl4Oag6GDqYOzA7hDxYPOQ9fD3UPp0/I7+wAA8A9AFQAiACoAMUA4gEOARIBMAFIAUwBSAFMAToBJAEcAPMA6gDNAKAAkoB4gF9AN8AhQBuf+I/oD9jPyo+4j6kPn4+HD4GPjQ99D3GPjA+Nj5GPuM/GT+wAAkA4AFqAfgCSAMYA5gECASYBMgFMAUwBSgFEAUYBNgEiAR0A9ADjAM8AmoB5AF8ALi/6j8SPkA9qDyYO9A7IDpYOfA5SDkwOKA4cDgoODg4ADioONA5aDmgOig6uDsQO/A8SD0YPaQ+Lj6zPys/qwA7AJgBaAHwAnQC9ANgA9AEeASIBQAFQAVABWgFKATQBLAEDAPgA2gC5AJaAeABeADYALhAHn/av6k/dz8EPxo+7j6MPq4+XD5GPn4+Cj5qPlY+iD7OPy4/WH/UgF4A7AF4AcQClAMgA5gEOARABPgE2AUoBRAFGATYBJAESAQkA5wDEAKEAjQBXQDqgDI/cj6wPfA9KDxwO5A7CDqIOiA5gDloOOA4uDhwOFg4mDjoOQA5oDnQOmA6wDucPCg8uD0UPeI+Wj7OP1E/1wBlAOgBaAHcAkwCwAN4A6AEMAR4BLAE0AUQBTgEyATIBLgEKAPEA4QDNAJ6AdQBogEtAIeAcn/mv6s/dj8APwg+5D6ePoo+qD5MPlA+Zj5+Pl4+jj7JPww/bT+WgAoAgAEIAZQCHAKsAygDkAQgBHAEsATIBTAE2AToBKgEUAQkA6QDJAKUAjYBWADsgDQ/eD68Pfg9PDxQO8A7eDqAOlg5wDmoOSg4yDjQOMA5MDkoOWg5gDowOkA7EDucPDA8hD1cPeo+aj7sP3B//YBIAQwBhAIwAmQC1ANIA/AEOAR4BKgE0AUIBSgEwATQBJAEQAQYA6ADIAKYAi4BiAFaAOgASYABf/k/bz8wPsI+2D6+Pmw+XD5MPkY+Wj58PmQ+lD7NPw8/YD+JwD8AcgDkAWoB8AJwAtwDfAOYBCAEWASABMAE6ASABJAESAQgA6gDJAKUAjgBTwDiQCk/YD6cPeQ9NDxAO+A7MDqQOng54DmYOWA5ADkYOQg5aDlQOYg56DoIOqg64DtoO+Q8ZDzsPXQ95j5ePu0/SkAWAJYBGAGcAhgCnAMUA7gDyARYBKAEyAUIBTgE4AT4BIAEsAQQA9wDaAL4AkwCHgGsAQYA5YBKwDe/sT9wPzg+zD7uPpg+gD62PnI+QD6aPoA+7j7hPyY/ez+hgA4AuQDsAWgB5AJcAsQDYAOwA/gEKARIBJAEuARgBHAEJAPAA5QDGAKEAjQBUgDigCI/WD6YPeA9LDx4O5g7EDqoOhA5yDmAOUg5ADkYOTg5IDlQOZg56DoQOog7ODtoO+g8eDz0PXQ95j5kPu8/fr/SAJABBgG+AcQCgAMsA1AD8AQIBIgE6ATABQAFMATQBOgEoARABBADnAMwAoACUAHeAWwA/wBewAZ/7D9cPxo+9D6OPq4+Vj5SPlY+Yj5EPqw+nD7UPxw/cz+QwC0AWADOAUQB9AIkAogDKAN4A4AEAARoBHgEeARgBHgEAAQwA4wDXALcAk4B6gE+gHg/uj76Pgg9mDzsPBA7mDs4Opg6UDoIOeA5iDmQOag5kDnwOeA6IDpAOuA7ODtYO/w8KDyYPQg9sD3ePmI+9D9+f/aAcAD6AUQCDAKMAwADqAPIBFAEkAToBPAE8ATgBPgEuARYBDQDiANcAvACRAIQAZ4BNACNAGk/yj+AP0I/Cj7YPrw+Xj5IPkA+Tj5kPkI+qj6mPuw/Nz9OP/HAHACKAQIBugHkAkQC5AM8A0wDyAQ4BBgEWARIBHAEAAQAA+QDQAMIArQB2gF2AITADD9QPqQ97D0APKg78DtIOyg6mDpQOiA5+Dm4OZA58DnIOig6KDp4Oog7IDt4O4w8MDxcPMA9ZD2MPgo+lT8aP5lAHQCqATYBhAJMAsgDeAOgBDgEeASoBMAFCAU4BOAE6ASYBHwD1AOwAwgC2AJiAfIBQgESAKeAED/5P20/LD78PpY+sD5cPlY+YD5yPlQ+vD6qPuc/MT9Hf+FAPgBmANQBQgHsAhACsALEA1QDmAPIBCgEMAQwBCAEPAPIA/QDUAMcApwCBgGgAO4AOT9+PoQ+CD1cPIg8CDuYOzA6mDpAOgg58DmoObA5iDngOcg6ADpIOpA64Ds4O1g7wDxoPIw9MD1kPeQ+cD7vP3E/+QBGARgBpAIsAqgDIAOQBCgEcASgBMAFEAUQBTgEwATABKgECAPoA3wC/AJAAgYBlAEmALtAHn/Dv7E/Oj7OPuQ+hj68PkI+jD6iPoQ+7D7bPxs/Y7+z/8WAWwC+AN4BfgGcAjQCRALMAxQDUAOwA4AD0APQA8AD1AOYA0wDKAK8AgAB6gEBAJf/8T8EPow93D0EPLg7wDuQOzA6kDpIOig54DngOeg5wDooOhA6UDqYOug7MDtIO+g8CDykPMA9aD2WPhI+iz8FP7m//ABIARQBlAIUApADCAOwA8gEWASIBPAEyAUQBQAFEATQBJAEfAPUA6QDJAKoAioBrgE9AIQAWT/2P2c/ID7mPrw+Xj5YPlw+cj5QPrY+qj7oPzU/Rj/ZQDGAUADwARABqgHAAlACmALcAwwDdANMA5wDpAOcA4ADkANYAxAC+AJUAhoBjgEzgFm/wT9aPrg93D1UPNA8SDvQO3A60DqYOmg6EDo4OfA5wDogOhA6SDqIOsg7GDtwO4g8HDx8PKg9HD2KPgQ+uj78P34/ywCcASQBqAIoAqgDHAOABBAEYASgBNAFIAUoBRAFIATwBLAEYAQwA4ADTALMAlQB2AFiAOqAf7/pv5I/QD86PpQ+uj5sPm4+eD5SPrY+qj7uPzc/Rv/hgAEAoQD6ARgBtAHIAlgCnALUAzwDFANsA3gDdANYA3QDAAM8ArACVAIgAZwBCgC4f+E/Rj7uPhw9lD0IPJA8GDuwOyA64DqwOkg6aDooOjA6CDpoOlg6iDrAOwg7WDugO+w8BDysPNw9SD3uPiA+mj8fv6fAMAC0ATQBuAI8ArADGAO8A8gEWASIBPAEwAUwBNgE8ASABLgEIAP4A0wDGAKkAioBtgECANSAcn/Yv4Q/QD8GPuQ+jD6EPoI+lD6wPp4+3D8hP20/gUAegEAA3AE2AVAB7AI4AnwCuALkAwQDWANsA2gDVANsAwADAAL0AlwCMAG4AS8AooAPP4I/Mj5oPeA9YDzsPEA8GDuAO3g6wDrYOrA6YDpgOnA6QDqoOpA6wDswOwA7iDvMPBg8eDykPRQ9gD4yPmg+5D9tv/mAQAE8AXYB+AJ0AtwDeAOQBBgEWASABNgE0AT4BJgEqARwBBwDwAOcAzQCiAJcAfIBSAEgAIGAa7/YP5U/Wj8yPtY+xD7CPs4+5D7LPwI/QL+F/9HAJAB6AI4BJAF4AYgCFAJUAowC+ALYAzADOAM0AyADAAMUAtQCjAJuAcwBmAEVAJYAEb+PPwo+kD4YPZw9LDyMPHg74DugO2A7ODrYOsA6+DqwOrg6gDrgOsA7IDsIO0A7gDvAPAw8aDyMPTQ9bD3mPmI+6j98f9EApAEoAbACMAKsAxQDsAPIBEgEuASYBOAE0ATwBIgEkARABCwDkANoAvgCUAIoAYIBWAD3AF6AEL/IP4o/Xz88PuY+1j7cPu4+yT8uPyQ/Xr+gP+OAK4B0AL8AzgFYAZYBzAIAAnACVAKwAoQC0ALMAvwCnAK4AnwCOgHoAYoBYADzgEOADb+YPyY+uD4EPdg9cDzUPIA8eDv4O7g7QDtgOwg7ODrwOvA68DrAOxg7ODsgO1A7iDvQPCw8SDzsPRQ9ij4KPow/Fr+jQDUAggFGAcwCRAL4AyADuAPIBEAEoASwBLgEqASIBJgEWAQEA+gDTAMoArwCGAH0AVQBNQCdAEyABL/Iv54/dj8bPw4/ET8hPzw/Hz9Kv4D//L/+QAUAhwDIAQwBSgGEAfYB4AIEAmACeAJMAowCgAKwAlQCcAI6AfgBqAFUATkAmYB1/84/qz8CPuA+QD4gPYA9bDzkPKA8WDwgO+g7gDugO0g7cDsoOxg7GDsoOzg7CDtoO1g7mDvsPAA8qDzUPUg9yj5YPu8/QcAaAKwBAAHEAkgCxANwA5AEGARYBIAE0ATQBMAE4ASwBHAEIAPEA6gDCALgAnoB0AGsARAA9ABfwBW/2r+uP0k/bj8fPx4/LT8EP2Q/TT+8v7O/7UArgGwAqQDmASABVgGAAeIBxAIgAjgCBAJEAnwCKAIQAiwB/gGCAb4BOgDwAKIATUAzv50/SD86Pqg+Uj48PbA9bD0oPOg8rDx4PAg8IDvwO5A7sDtYO1A7QDtAO0A7UDtwO2g7qDv0PAg8rDzYPVA91D5kPvk/SoAcAK4BPAGIAkgC/AMkA7wDwARwBFAEoASgBIgEqAR4BDQD6AOYA0ADHAK4AhwB/AFcAQIA6wBfgB2/57+/P1k/fT81Pz0/CD9dP3c/Xz+Jf/7/98AwAGgAnADaARABfAFiAYIB4gH8AcwCFAIQAgQCNgHYAfoBigGaAV4BIQDjAJwAUkAEP/0/cj8mPtQ+ij58Pfg9rD1sPSw87Dy0PHw8CDwYO/g7kDu4O2A7UDtIO1A7aDtIO7g7gDwMPGw8kD0EPYg+Fj6pPzo/jQBdAO4BfgHEAoADLANQA+gEIARIBKAEqASYBLgESARQBAAD7ANUAzgClAJwAcwBsAETAPcAZsAh/+K/tD9RP3g/Kz8hPy4/BD9jP0c/sj+nv93AFABPAIgA+QDqARoBRgGmAb4BlgHkAfAB9AHmAdYB+gGaAbYBRgFSARoA2wCbgFkAET/MP4Q/fj76PrQ+bj4sPeQ9qD1oPSw88Dy0PHw8DDwYO/A7iDuoO1A7QDt4OwA7WDtIO4g71DwoPEg8+D04PYY+Vj7kP3Z/zQCeASoBtAIwAqADBAOcA+AEEARoBHgEcARYBHAEAAQEA/gDcAMcAsQCqAIQAfoBbgEfANgAmgBkQDb/1H/9v6s/o7+kv7E/hv/ff/7/4IAEgG4AWQCAAOgAzAEuARABbAFEAZYBpgGuAbIBrgGgAYoBsAFUAXIBBgESANwAogBjwCL/3j+VP0s/Pj62Pm4+JD3gPZg9WD0UPNg8nDxgPDA7yDvgO4A7mDtAO3g7ODsAO1g7QDuAO8w8JDxMPPg9MD24PgQ+1T9lP/SARAESAZwCHAKMAzADUAPYBBAEcAR4BHgEaARQBFgEHAPUA4gDdALYArwCIAHMAbgBKQDkAKCAaQA8v9o/wz/xP6e/pz+wP4Y/4L//v+LABwBxAFoAgQDmAMgBLAEKAWQBfAFQAZwBpgGuAaoBogGQAbwBYAFAAVYBKQD3AIQAiwBPwBI/0j+PP04/Dj7MPow+Rj4IPcg9jD1IPRA81DycPGg8ODvQO+A7gDugO1g7WDtgO3g7aDuoO/A8DDywPOA9UD3QPlo+7D93/8MAjAEUAZgCEAK4AtQDYAOgA9AEKAQwBCAEEAQ0A8ADwAOAA3QC6AKYAkgCOgGsAWQBJADlAK2AQABdQAQALz/gf9v/3L/nP/f/zgAoAAUAY4BBAKAAuwCZAPcA0AEoAQABTgFaAWQBbAFsAWgBXgFSAUABZgEKASoAxQDbALAARABPwBn/4T+lP2s/Lj7yPrY+cj40PfA9tD1wPTA88Dy0PHQ8ADwQO+g7gDuoO2A7WDtoO0A7uDu4O8Q8ZDyMPTw9cD3wPkA/EL+cACIAqAEqAagCGAK4AsgDTAOAA+gD/AP4A/AD3AP8A5QDnANkAyAC4AKYAlQCEAHKAYoBUAEWAOYAvIBaAH4AKUAYABAADgARABvAKYA6ABAAZgB5gE8ArACBANkA7ADCARIBIgEwATgBAAFCAUIBfgEwASABCgE1ANYA8wCOAKWAeQAIQBb/3b+lP2o/Lj7wPq4+Zj4kPeQ9oD1gPRw83DycPGA8KDv4O5A7sDtYO1A7SDtgO0g7gDvIPBg8eDycPRA9kD4UPp0/Kj+xQDgAvAE4AawCFAKoAvwDPANwA4wD3APgA9QDxAPkA7wDTANUAxwC3AKYAlgCGAHcAaIBagE1AMYA3QC8gF+ASYB4wC0AKEAnwC4AM4A/gA6AYQB0gEkAoAC2AIcA3gDzAMIBEgEgASgBKgEoASYBGgEKATcA3wDEAOUAgACbAG1AAAAPP9s/pT9qPzI++j64PnQ+OD34Pbw9eD08PPw8vDxAPEg8GDvoO4g7sDtwO2g7eDtgO5A71DwkPEA86D0UPZI+HD6iPyk/sMA7ALYBLgGkAggCnALsAygDXAO0A4ADwAP0A6QDiAOcA2gDNALAAsQCiAJMAg4B2gGmAXQBBgEcAPoAnQCFALGAYQBWAE+AToBNAFAAUoBYAGKAbIB9gEcAlwCnALkAigDYAOsA9QDGARABFgEaARoBFAEIATwA6QDPAPMAkQCqAEEAUwAgv+y/tD96Pzw+/D66PnY+OD30PbA9bD0oPOg8pDxoPDA7wDvQO7g7aDtgO2g7QDuwO7A79DwMPKw82D1UPdY+YD7hP2m/8oB3APYBagHUAnQChAMIA3wDYAO4A7wDvAOsA5gDuANQA2ADLAL4AoAChAJIAhQB3gGsAXgBEAEpAMgA6QCQALiAYoBVAEuAQgB+QDrAPkABAEyAVwBmgHgASwCjALUAhADUAOQA8gD7AMQBBAECATsA7gDeAMoA8wCZALiAVwBqgD9/0b/fv60/dj88Pv4+vj5+Pjw9/D24PXQ9MDzsPKg8ZDwoO/A7gDugO1A7UDtYO3g7aDuoO/A8CDywPOw9aD3wPnQ++z9GQA4AkgEMAbwB5AJ4AogDCAN4A1QDqAO0A7ADoAOEA6QDQANYAyQC8AK8AkQCTAIWAeABrAF8AQwBJgD+AJwAvgBjAE4AfMAyACoAJIAmACoAMsA9QAoAYIB1gEoAoAC5AIsA4QDzAMIBDgEWARQBFAEMAT4A8QDaAMIA4gCDAJwAbwAAgA2/3b+mP24/ND72Prg+dj44PfA9rD1kPSA82DyQPFA8EDvgO7A7WDtIO1A7aDtQO4g7zDwkPEg89D0wPbA+PD6EP0r/0IBSANIBQgHoAgQCkALMAwgDbANAA4wDjAOIA7gDYANAA1gDNALIAtgCqAJwAjoBxgHWAaIBdAEGAR8A+QCTALgAVQB+wCvAH4AYwBIAFwAeQDDAAABXAHGAUACuAIsA5gD8ANQBJgE2AQIBRgFGAUgBeAEqARIBOADWAO4AhwCYgGIALD/yv7s/QT9+Pvw+tj5wPiQ92D2MPXw87DygPFA8CDvAO4g7WDs4OvA6+DrQOwA7eDtIO+A8CDyAPQg9kD4aPqU/Mz+7wAIAwgFwAZgCNAJEAsgDOAMcA3wDTAOQA4wDvANoA0wDcAMMAyQC+AKIApwCcAI6AcoB1gGqAXwBDgEjAPgAkwCwAFIAd0AewA6ABUACwAfAEEAiwDiAEYBygFIAtACVAPYA2AEwAQYBVgFgAWgBYgFaAUwBeAEYATYA0ADhALMAfkAKQA+/1D+XP1U/Dj7GPrg+KD3UPbw9LDzUPIA8aDvYO5A7WDsoOsg6wDrIOug62DsQO1g7uDvsPGg86D1wPfo+ST8dv6eALQCqAR4BjAIkAngCuALwAxgDfANQA5wDmAOQA4gDtANYA3gDFAMsAsAC0AKYAmgCLAH2AYABiAFQARQA5gC5gFGAcAARwAIANv/0P/v/ycAewDeAG4BBAKQAiwDxANYBOgEaAXQBSAGUAaABoAGcAZABvAFmAUoBZgE7AM0A3gCmAG6ALP/rP6U/WD8CPuQ+SD4kPYA9TDzgPHA7yDuoOxg6yDqYOng6KDowOgg6eDp4OpA7CDu4O8A8jD0cPbY+Ej7pP34/yACMAQYBugHcAmwCuAL0AzADWAOAA9QD4APkA+gD3APEA+wDkAOoA3wDCAMMAswCjAJMAgYBxAG+AT0A/wCNAJsAdkAaQAdAAMAAAAmAGcAugAgAagBKAKsAjADpAMoBJgE8ARABYgFwAXYBfAF4AW4BYAFOAXwBJgEGASQA+ACNAJuAY0AjP9e/hz9qPso+mD4oPaw9MDysPCg7sDsIOvg6cDo4OeA52DnwOdg6GDpgOoA7ODt4O8w8lD0gPbg+ED7fP26/9QB1AOwBXAHAAlgCsAL4AwQDvAOoA9AEKAQ4BDgEMAQYBDQDzAPUA5QDSAMAAuwCZAIWAcoBvAE2APgAhACZgHEAEcA///j/+j/CABCAIoA8wBkAeIBVALIAjADnAMgBHgE0AQgBXAFsAX4BSAGOAY4BiAGEAboBZAFGAWABMAD5AL2AeAAh/8S/nD8yPr4+OD2wPSQ8mDwQO5g7KDqAOnA5wDnoOaA5sDmYOdg6KDpIOvg7MDuwPDw8kD1cPfA+fj7UP5/AMACwATIBpAIcAoQDKANAA9AEEARIBKgEuAS4BKgEiASYBFgEDAPAA6wDFAL8AmgCGAHOAYgBQgEGAM8AooB5ABiAPr/uP+f/4j/if+c/8f/FgCFAPwAdAEEApwCUAMQBNAEiAVABugGcAfQBwAIEAjwB7gHeAcAB3AGmAWwBNQDsAKAAS0Atv40/Zj7wPmg91D18PKg8GDuQOxA6mDoIOcA5mDlQOVg5QDmIOdg6ODpwOug7aDv0PEg9GD2iPiw+vT8Pf9kAYQDmAWoB6AJgAswDcAOABBAEUASABNgE2ATIBOgEuAR4BDAD4AOIA3QC5AKMAn4B8gGuAWwBLADyALqARoBcQD5/63/Wf8R//z+A/89/2v/xf9QAO8AlAFUAigD+APYBLgFmAZIB+AHYAigCKAIkAhwCEAI0Ac4B4gGoAWwBGgDNAK6ADX/mP3Q+6j5YPfg9GDywO9A7SDrIOlg5+DlIOWg5IDk4OSA5YDm4OdA6eDqoOyg7qDw0PIQ9UD3iPnw+17+xgBQA6gFIAiACsAM4A6AEAASQBNgFOAUABXAFCAUQBNAEiARsA9ADvAMoAtgCiAJ6AfIBsAFyAS8A7wCvgHFAAYAZ//Q/lj+9P3M/cj96P1I/rj+a/85ADIBOAJEA1gEWAVYBkgHEAiwCAAJMAlACUAJEAnQCHAI6AdIB1gGgAVQBPgChgHw/wj+wPso+UD2UPNg8KDtQOsg6WDn4OXg5EDkIORg5CDlAOZA54Do4Okg66DsYO5Q8HDywPQQ94j5JPzK/pABWARIBwAKYAygDoAQIBJAEwAUgBSgFEAUwBPgEuARwBCwD9AO8A0ADQAMAAvwCcAImAd4BjgF/APEArABsgDB/xj/ov5U/kL+Sv6S/vr+ff8bAOEAwgG8AqgDgARIBRAGwAZYB7gHAAhgCLAI8AgACQAJ0AiwCCAIcAdIBugEiAP8AS0A5P1Q+1D4UPVQ8oDv4Oyg6uDooOeg5sDlYOVA5WDlwOVg5uDmgOdg6IDp4Oqg7ODuYPFA9ED3KPpA/UEAQANIBgAJcAtwDTAPwBAAEuASgBPAE+ATABTAE0ATgBLAEQARIBAwDwAOwAxQC8AJQAjIBjAFsANUAj4BXQCQ/wv/uv6O/n7+mP7S/uz+Jf+K/xEAkQA0AdYBnAJwA1AEWAU4BugGmAdQCOAIMAlwCYAJQAkACXAIqAegBjAF2AOQAtkAwP5c/MD54PbQ8+DwYO4A7EDqwOig56Dm4OWA5YDloOXg5WDm4ObA58DoIOrg6wDugPBw84D2mPmg/KL/lAJwBTAIoArQDJAOIBBgEYASYBPgEyAUQBQgFMATQBNgEmARgBBwDzAO4AxQC7AJAAhYBsgEXAMIAu8ALQCY/yT/sP5a/ir+Hv5I/mr+jv7M/i7/4f+qAI4BbAJ8A7AE8AXoBoAH+AdgCOAIQAmQCcAJkAlgCRAJYAhIByAGAAWsAyQCIACQ/Xj6IPfw8yDxoO6A7ADrwOnA6ADoYOfg5qDmgOaA5qDmoOYA5wDogOlg6wDuAPEQ9ED3WPpI/dL/UALABCAHIAnwCqAMUA7gD4AR4BIAFKAU4BTgFIAUoBOAEmARIBDwDtANgAzgClAJ+AfABmAF3AOIAnwBhQCk//T+Sv7M/WD9RP1U/WD9hP38/bj+kv9/AHoBbAJEAzAEQAUYBpgGCAeQB0AIwAggCZAJwAnACUAJoAhgB/AFiAQUA0wBTf/M/OD5oPaA8xDxAO9g7eDrAOvg6eDooOeg5uDlYOVg5cDlQOZA54DoYOrA7KDvoPKA9UD40PpY/Xr/lAHsA4gGMAmgCwAOABAAEoAToBRgFWAVABWAFKAToBLAEcAQABAgDzAOEA2QC9AJIAhwBsgEFANyATkAYP/C/lj+BP6s/VD9DP0Q/Rj9MP1o/QD+zP7B/8MAxgHYAvwDMAU4BtgGMAegB0AIsAgQCWAJkAlwCfAIcAhQB8AFEASgAgABtv6Q+xj44PQQ8gDwoO6g7cDsoOuA6uDoQOeg5cDkgOTA5GDlYOaA5yDpYOtA7lDx8PNQ9qD4wPqA/Gr+5AAYBGAHcApwDeAPoBHgEuATYBSAFEAU4BOAEwAToBJAEiASoBEAEQAQUA4QDMAJwAfoBSgE9AJMAvIBngEkAagA3v/g/gL+VP3M/Jj8wPxc/WT+nP8CASwCBAOgA1AEyAT4BBAFoAWQBngHQAjwCHAJYAkACRAIuAbwBCwD9AHEAOT+GPwI+eD1QPMw8aDvYO5A7eDrgOrA6ADngOXA5KDk4OTA5aDmoOdA6WDr4O1Q8MDyQPWg98D50Ps6/vwAGASAB8AKgA3AD4ARoBJgE6ATwBPAE8AT4BMAFAAUwBNAE8ASwBEAENANwAugCcAHUAZQBXgE0AM8A8QCAALwAND/yv7Q/Rz98Pwo/Yj9Nv5U/4wARAGuAfgBYALAAhgDzAOgBHgFeAaIB1AIkAiQCEAIcAdIBvAEtANcAgoB7f+s/hj8iPgw9ZDygPDA7uDtQO0g7KDqwOgg56DloOSA5EDlQOZA58DoQOog7ADucPAA82D1cPeg+eD7aP5iAQgF0AjwC2AOQBBAEaARwBEgEsASYBPgE4AU4BTAFAAUQBNAEqAQ0A4gDWALkAkQCBgHWAaIBbAEGAREA/wBnABT/17+oP2c/TL+8P6Q/+X/XgCzAPIAOgGGAe4BXAI0AzgEMAUIBvAG+AdgCDAIYAdwBnAFWASMAxADjALUAbcAlP4I+9D2APOg8IDvIO8A76DugO2A62DpgOcA5kDlwOXA5uDnAOkg6sDroO3g71DyYPQg9uD32PkA/NT+fAKIBvAJcAwADsAOAA9QDwAQIBFAEkATYBQAFaAUwBOgEqARoBCwD3AOwAwQC+AJAAkwCEgHeAaIBWAE4AJWAeH/wv5u/gD/x/8PANb/cv88/yz/Q/+f/xsAugCwAbQCZAPAA1gEaAVYBnAGCAZgBcgEEASkA2gDLAPgAjQCGAGE/tj60PZg80DxsPBA8ZDx8PBg70DtgOrA58DlwOWg5uDnAOkg6iDrIOyA7UDvMPEg8wD14PbI+Cj7Tv4YAvAFUAnQCwANUA2QDUAOUA+AEAASwBNAFYAVwBRgEyASIBFgEKAPgA5ADRAMEAsgCiAJAAjgBrgFaATYAkwBBABx/4v/7v8jAAcAqP8S/3b+AP4Q/oz+hP/FAAgCzAL0AvgCZAMgBNAEEAX4BLgEiARABOgDjAN0A1QDgAJ6AHj9KPqA9pDzAPIw8uDyEPNQ8mDwQO2A6cDm4OXA5iDoYOmA6kDrwOsg7MDsIO4g8JDy0PTA9qj4OPty/gwCiAVgCCAK8ApAC/ALMA3wDsAQoBKAFEAVoBQgEwASgBFAEUARABFgEDAPoA1ADBAL0AnACBAIQAcIBqAEaANgAn4BAAH7APAAXgCh/zr/6v6a/pT+R/9UACYBSgEmARIBWgFAAmgDWASYBEgElAPoAmwCSAJQAjwC+gE+AXP/SPyI+DD1QPOQ8gDzsPPA84DywO9g7MDooOaA5uDnAOqA60DsoOzA7ADtwO0A79DwYPMw9qD42Pqw/fQAEARoBiAIQAnQCaAKYAzwDgARIBIgE+AT4BPgEsARYBFgEWARQBHAEIAPAA6gDJALcApgCVAIWAdIBkAFOAQQAygCxgGcARgBRQCV/yr/6v7S/hT/l//6/0AAeABwACoAVgBoAcwCsAPMA2AD1AJQAvQB3gHEAZYBdAH4AEb/kPxw+YD2QPRQ83Dz8POQ83DyAPGA7sDqYOeg5kDoYOrg6wDtoO1g7cDswOwA7uDvgPKw9UD5IPwG/rH/mAEQBDgG2AcQCdAKEA1AD6AQQBGgEUASwBIAE8ASIBKAEUARABGgEMAPwA6gDaAMkAsQClAICAdwBgAGOAU4BGADwALIAZcAo/8Z/wv/ff8cAFsAEQCO/2r/w/85AJcAGAEIAvACVAPoAmQCSAKYAtQCrAJkAtIB1gCJ/x7+XPzw+ZD38PUw9aD00PMw84DyEPFg7gDrYOig58DoYOvA7aDuIO4g7SDs4OvA7GDvQPNQ9/D6XP1i/oz+Vf9UATAEKAcQCoAMUA4gDzAP8A4AD/APoBFAE8ATABPgEYAQYA/gDvAOAA+QDoANAAwQCgAI0AZoBkAGAAaABXAEsALjAJ//Cv8P/7r/3QA8AVMAyv4A/iT+vP7J/y4BRAJ4AvYBagECAc8AQAFoAlgDJAPiAUcAvv50/XD8gPsI+hD4YPYw9TD0QPOw8hDyoPAA7uDqoOhg6EDqAO3g7uDuwO2A7MDrwOtg7bDwEPVg+ZD8Kv4S/oj9Pv7IALgE0AgQDBAO4A6wDvANUA0ADoAQoBNgFeAUABPgECAPcA4QDyAQYBCAD6ANQAuwCKAGAAbQBrgHWAeQBSAD5QBT/57+B/9EAGABegFnAMb+UP3w/PT9qP80AdgBsgFAAeAApQCzAEABKAL4AvgC4gErAM7+Ev6E/YD84PoY+XD3APbg9DD0APRg88DxIO9A7ODp4Ojg6YDsAO9g7+DtAOwg60DrgOxA76DzWPjA+0T9NP2Y/MD8ov7IArgH8AsQDnAO4A3wDEAM4AygD2ATwBWgFYATwBDwDmAOUA+AEEARwBAgD1AMcAnIB4gHQAjgCPAIgAfABOwBYgBeABIBvgE4AiQCKAF//yz+DP70/i8A7wAQAdcAlAB/AKYA5gAwAUwBJgHiADAAcf+w/iL+OP24+7D50Pew9vD1gPUg9VD0oPJg8CDuIOzA6qDqIOxA7iDvQO5g7ADrwOrg62DusPHQ9JD30PmI+wz8YPxs/ez/hANYB7AK0AzQDaAN8AyQDKANYBAAE0AUQBRgE6ARwA/ADoAPgBDAEPAPsA7wDGAKgAgwCKAIkAiwB2AG0AQAA4wBBgE8AUABDAGXAPn/c/87/wP/wP7C/hz/lP/K/yYAzABEAfsAewAyAOj/W/8M/5r/BAAg/+z8kPqQ+CD3gPaw9gD3cPbQ9FDygO8A7cDrAOwg7UDuIO+A7sDsIOvA6sDroO0g8BDzsPXw9hD4ePrU/AT+4P7WAMwD6AbACUAM4A0ADmANoA0AD4AQwBHgEsAT4BOAEoAQYA+gD0AQQBBgD3AOUA3wC0AK4AjoBzAHmAYYBlAF+AOcApwBFgFyAOn/nP/K/0YAVQCV/0r+iP3c/Qb/FwC0AB4BWgHxAPX/DP/Y/mj/GQBVAND/cv4o/MD5aPgo+DD40PcA9/D1IPRA8WDuIO1A7cDtAO4g7gDuAO2A6+DqgOvA7EDuYPCw8pD0EPZQ+PD64Pzg/ZL+JwDgAmgGIArwDNANMA3ADBANIA7ADwASABSgFKAToBHwD/AOAA/QD4AQgBCQD8ANgAtgCQAIYAc4B0gHGAdABqgEzAIoAQwAYf+T/5IAXAE0Afj/fP5A/dz8jP0R/3cAOgEyAWYACv/k/bD9iv5o/9P/y/+q/kj8sPlo+Ij4sPgo+JD30PYA9SDywO+g7kDuYO6g7uDuQO7A7MDrAOzA7IDtYO6A7/Dw0PIA9cD3qPoA/TD+cP6E/ur/nANwCJAMcA7QDUAMoAuADMAOgBHgE+AUYBTAEqAQIA/ADsAPIBHgESAR8A4gDOAJ0AiACCAI+AcQCHgH6AVYAwIBp/9z/ykAOAGgAfkAsP8K/pz8APzU/NT+tgB6AewAc//c/WT9Dv4X/7n/7/+Q/yj+6Pso+oD5WPkw+eD4IPiQ9lD0YPIQ8RDwIO/g7iDvoO5g7UDsQOzg7GDtoO1A7gDvAPCg8ZD0CPjY+qz8rP0W/uT9rv44AvAHoAxQDnANwAvQCsALQA5gEQAU4BRAFIASoBAgD9AOsA+AEQATYBJwD2AMUAqACfAIoAgACWAJwAioBsgDLAHX/y4AdgGEAqwCogHc//z95PzQ/Jj9Zf9YARgCswBm/vj8BP0A/u7+kf+N/47+zPzQ+lD5oPio+Mj4cPhQ91D1IPNg8WDwwO8g76DugO4A7gDtgOyA7ADtQO3A7YDuAO/g73DyMPZg+QD7UPxo/Xj9jP3l/+gEYAqQDcANkAzgCkAKYAxgEOATIBVgFOASYBHgD8AOQA8gEQATABPAEHANwAqgCVAJQAkwCTAJ0AiAB/AELAI0AIj/dgAwAvgC4gHz/2L+eP2Y/GD8tP0GAGABGgGV/8D9mPyc/Nz9EP+T/xf/FP5Q/FD62PhQ+JD46PjA+CD3sPSg8rDxEPEw8KDvgO/g7uDtQO1A7WDtgO0g7iDvYO8g77DwMPTg90D6yPv8/HD9KP0o/hQCcAewC6ANYA3AC1AKwArwDUAS4BTgFKATABKAEEAPEA9AEAAS4BLAETAPMAwwClAJQAkgCRAJsAjYB0AG3AM0Aar/BQBwAXgCTALUAD//3P3Q/Kj8cP0V/7gAaAFZAE7+sPxY/ID95P6p/13/YP4E/YD7+Pn4+AD5gPlQ+Qj4QPZg9PDy4PFg8RDxcPCg7wDvYO7g7YDtoO1g7iDvwO/g73DwYPKQ9ZD4qPo8/ED9XP0o/fL+hANwCGALYAwgDHAK8AggCjAOQBLAE0ATABLAEMAOoA1gDiAQYBFgEQAQgA3wCgAJUAiACOAIsAgQCAgHWAUQA7kAxP/gAHQCEAN0Au4ADf98/fT8qP0S/6EAvAG+AUEAEP7A/Pz8av7T/2cAsv9K/pz8CPu4+UD5WPlo+fD4kPfQ9dDzQPKQ8XDx4PDg7yDvgO7A7UDtQO3A7WDuAO+g70DwkPHg86D22Pio+jj89PwI/Qb+hAFoBjAKgAtACyAKIAnQCRAN4BDAEsASwBGgEDAPEA5gDvAP4BCAEEAPsA3gC2AKgAkgCaAIAAiIBzAHcAa4BNACkgFgAdoBiALIAjwCFAGT/1j+HP4I/4MAtAEoApgBNAAm/vD8sP19/3wABwD8/pD9sPvI+RD5UPlI+Zj4kPcg9hD0IPLA8JDwoPAQ8ADv4O0g7cDsoOyA7EDtoO6g72DwsPHQ86D1EPcI+YD7EP2s/dz+EALYBWAIoAlACmAKYApgC7ANQBCgEYAR4BBgEOAPgA+gDyAQQBCQD5AOcA1ADCALQArACRAJMAigBwAHMAbQBJADzAKAApQCvAKoAiACVAFkAIT/Mf/k/ywB+AEQAtQB+AB1/0b+lv6u/0wANADH/7z+tPyQ+qD5qPlQ+Wj4gPew9nD1IPPQ8IDvgO+g72DvIO9g7gDtQOuA6sDroO1g7zDxcPNg9MDzsPMA9sj5yPzG/qAAeALIAygF8AbACEAKgAvwDGAOMA9gD3AP8A/gEEARABFgECAQABAwD0AO8A2gDYAM4AoACoAJ0AgACIgHAAeQBbwDAAN4A8gDfAPYAkACVAElAET/sv8QAdYBmgH3AKgATwC8/zP/Nf9i/zn/wv5+/gr+7Pxw+yj6WPl4+DD3cPZw9hD20PPA8KDu4O0g7uDu4O9g78DsoOmg6CDqgOxA72DyQPSw8zDyUPKQ9Aj44Pu4/2AC7ALoAuADuAW4BwAKgAywDuAP0A9wDzAPsA8gEWASYBLAEUARgBCQD6AOQA7wDfAMkAvAChAKwAjYB7gHcAfgBawDwAJwAygEtAPcAiwCQAEAAF//+f8qAcwBpAE0AWYAnv8w/1n/vf+k/zn/lP4Y/qT91Pxo+zD6oPnw+MD3YPYg9tD1EPRg8UDvQO7g7cDuYPBA8CDtgOlg6CDq4OzA77DyAPSA84DyoPJg9HD3yPvh/0gC3AIAA8gDMAVwB2AKAA2QDoAPIBAgEKAP0A8gEYASoBIgEuARYBEgEPAOkA5ADiAN4AsAC2AKMAnYB0gHGAcABgAE1ALgAiAD3AJ8AgAC9ABl/3z+DP8WAMQAEgHeABAA8v5a/o7+Lv+A/xr/bv68/Uz9qPyY+3D6qPnY+ND3UPcA9xD2MPQw8mDwwO5A7mDvkPFQ8QDuIOpg6IDp4OwA8cDzUPQg8yDyUPJA9LD34Pux/yQCCAPsAvQCYARgB5AKkAygDYAOYA+wD6AP0A+gEEARQBEgESARABHgD4AOsA0ADcALkApQCnAKcAloBxAGsAUIBbgD/AIgAxQDbAK4AUYBsADa/2H/rv9BAKkAzACaADQAwP9k/3b/tP+z/zv/gv4e/uj9hP2c/Jj7YPrY+MD3kPdw95D20PSw8nDwwO6A7oDvwPBw8GDuIOvA6CDpoOyw8EDz0PMg8xDy0PHg8yj4gPxo/0gBYAK0AtACUAS4BxAL4AyQDTAO8A6AD9APQBAAEYARQBEAESARABFAEPAO4A3gDLAL4ArACsAKoAmgBwAGMAWwBEgE/AO0AyQDJAJCAeEApQB1AE0AcQClAH0AJgAoAHYAbgAEAMT/3f+r//r+fP5I/tz9FP1w/ND7wPpA+QD4gPfg9uD1cPSQ8uDwAPDg7wDw4O8g78DtwOsg6kDqgOwQ8ODyEPRw8+DxYPFw88D3OPxY/zQBBAIYAiQCRANABhAKAA0wDlAOMA5QDqAOYA/AEKARwBFgEQARoBCQD2AOsA1QDbAMcAuQClAK0AkwCDgGMAXYBIgEOARABDAEIAOMAb4AxQCfAIMAEgH8Ad4BrQDo/yEAhQCKAKAA3wC9AN7/Jf/m/nz+lP3Y/Ij8APzA+jj5KPhw91D2wPRg8zDycPHQ8DDwgO+g7qDtgOwg62DqYOvg7eDwMPOg8yDyUPAQ8fD06Pmg/QcAsgEYAj4BSgHUA/AHwAsgDiAPkA5gDUANwA6gEKARABJAEuARoBBwD7AOYA4ADlANUAwwC0AK8AlgCdAH6AXABGAEOAQ4BHAEEASEAuAARQBGAD0AsgDaAXACYAHF/3L/6P8QACgArgDLANz/1v5y/vz9+Pw8/Ez8HPwA+6D5qPhw9/D1wPTg88Dy4PHA8YDxAPBA7sDt4O2A7ADrYOtg7YDvoPGw8/DzEPLA8ADzkPd4+y7+xwDIAowCkgFoArgFgAlgDFAOAA9QDnANUA4gEGARYBFAEWAR4BDwD5APgA/QDpANEAywCrAJoAkACpAJmAdIBRAEwAPAAwgEcAT8A4QCEgFtAGAAsABuAUwCRAIKAQUABgCKANEA9QAEAYwAkf/I/qL+Zv6g/dD8dPzY+3j6CPko+HD3EPaQ9IDzoPKw8fDwkPDA74DuoO1A7aDsoOug62DtEPBg8pDzoPPw8tDygPQI+ND72P5QAeQCSAMYAyAEqAbACVAMsA1wDrAO8A6ADyAQgBCAEEAQIBAgEEAQABAwD8ANAAxACgAJ0AhQCYAJgAjABggFkAOMAjAC0AJsAzADSAJeAX8Amv9O/+7/wgD4AJ0AUwD2/3T/aP/g/xwAhv/S/pL+SP6I/eT8yPyk/Nj7uPqQ+Tj4EPeA9kD2kPVA9ADz8PEA8TDwEPAg8MDvIO9A7qDt4O3A75Dy4PSA9SD1EPUQ9gj4wPrM/YMAbAJkA/gDsAQIBgAI8AmQC6AMgA1ADuAOMA8gD9AOkA6ADrAOEA8gD5AOUA2wCyAKEAmwCMAI0AhwCGAH4AVYBFwDEAMIA+wCvAJYAqYBywA8APP/xf+z//n/QgD9/33/Wv+V/33/Df/I/sD+hv4Q/sj9hP0k/aj8RPyo+5D6SPlw+Cj4oPfg9gD2UPVw9DDzUPIg8kDyIPKw8SDxkPBQ8ODwoPKg9AD2kPbg9mD3IPho+Yj7Lv40AIABZAJUA1gEUAVwBtAHUAmQCmAL8AswDFAMQAxgDJAMsAzQDPAM4AxQDDALIAqACUAJAAmgCGAIuAfIBtgFQAXYBIAESAQQBHwD2AJMAhAC1gGSAV4BPgHvAGoADgAFACgACAC8/1r/5P5C/uD90P3M/Yz9BP2Q/OD7CPs4+sD5aPn4+Gj44Pdw9+D2QPbA9XD1EPWw9ID0gPSw9ND0IPWw9WD28PZQ9+D3mPiA+cD6NPy0/dL+ev8OAKgAYgFAAoQD0ATIBWAGoAbQBvgGSAeQB6gHkAewB/gHAAjYB6AHeAcIB2AG4AWwBYgFiAWoBZgFEAVYBOQDtAOUA4QDjAOYA1gD9AK0ApQCjAKUAoACQALuAb4BuAG+AaIBbgEuAdIAbAA3AA8A3P+q/4T/Q//I/kD+5P2s/Wj9HP3Y/IT8DPyY+1D7IPvY+oj6QPrY+Wj5KPlA+Vj5cPmQ+aD5iPlQ+Uj5iPnw+XD6GPug+8j72PsM/HD82PxM/dz9Zv7I/hT/iP/9/04AjQDTABIBQgGEAeIBWALIAgQDBAP8AgADJANMA4wD4AMwBFAEUARgBGgEcASQBNgECAUoBRgFMAVQBXgFgAV4BWgFUAVIBTgFOAU4BTAFGAXoBLAEiARYBBgE3AOEAyADxAKAAjgC1AFwAQgBkAAJAJj/Of/e/nb+Dv6g/Rj9iPwo/PD7sPtI++j6mPpA+tj5kPlg+Tj5APng+OD4wPiI+HD4iPiY+KD4wPgA+TD5QPlw+cj5IPpw+sD6MPuY++D7RPzI/FT90P1Q/sb+Kf+N/w4AowAuAagBGAKQAgwDhAP0A2gE2ARQBbgFIAZwBrgGAAc4B2AHiAewB9AH8Af4BwAI8AfQB7AHiAdYBxAH2AawBmgGCAagBUAFwARIBOgDiAMcA5QCDAKUARABmAAjAKn/JP+i/jj+0P1U/eD8iPww/Lj7UPv4+qj6UPoI+sj5kPlA+fD4uPiY+ID4aPhQ+Cj4EPgA+AD4GPhA+HD4kPiw+ND4EPlg+bj5GPpw+tD6SPvA+zj8tPxU/QL+lP4Y/6f/UQAAAaABPALIAlQD7AOABBgFkAUABmgG0AYwB3gHwAcACEAIcAiQCKAIsAigCJAIgAhgCCAI8AfQB5AHKAfIBmAGAAaQBSAFwARIBMADPAPUAmwC6AFmAeEAZQDe/2T/7v5+/hb+sP1I/dj8ZPzw+4j7IPvI+mj6EPrA+XD5IPnY+Ij4SPgI+ND3wPew96D3oPew98D34PcA+Dj4gPi4+Pj4SPmg+Qj6cPr4+pD7GPyE/AT9lP06/tb+cf8NALMATgHaAXACDAOsA0AE2ARwBeAFSAaoBjAHqAf4B0AIkAjgCAAJIAlACUAJQAlACSAJEAnQCKAIQAjoB3gHGAfABlgG0AU4BbgEMAScAwQDdALUAUIBvQA6ALL/E/+E/vz9cP3o/Gz8+Pt4+wj7sPpY+vj5kPko+dj4kPhI+CD4APjQ96D3gPdw94D3gPeQ96D3wPfw9yD4YPjQ+ED5kPno+Uj6sPoo+7D7TPzg/Gz98P2A/hL/of8uALwAUAHyAZwCLAOoAxgEkAQQBYgFAAZwBtgGMAeAB8AH6AcQCDAIUAhgCGAIYAhgCFAIIAjIB3AHOAf4BqgGSAbgBXgFCAWQBBAEkAMMA4wCEAKaARYBhQD3/37/Af+E/gr+oP00/bz8SPzw+6D7SPvo+pD6WPoY+tD5mPlo+Sj5+Pjo+Oj44PjQ+Nj46Pjw+PD4CPkw+Wj5sPn4+UD6iPrQ+ij7kPv4+2z83PxM/cT9Sv7I/kn/xP9JANAAUAHMAUQCwAI8A6gDEAR4BOAEQAWIBcgFEAZYBogGsAbQBvAG+Ab4BgAHAAf4BtAGsAaIBmAGGAbIBYAFQAXoBIgEKATQA2QD+AKIAigC0gF2ARIBowAxALX/Tv/6/qj+SP7s/Zj9SP30/Jj8SPwM/Nj7mPtg+zD7APvY+sj6wPqo+oj6gPqA+oD6ePqA+pD6qPrA+uj6CPso+0j7ePu4+/j7OPyA/Mz8GP1k/bT9DP5k/rz+Hf+A/9z/OgCgAAIBWAGwAQgCXAKsAgADVAOkA+ADCARABHgEoATABOAEAAUYBSgFMAU4BTgFKAUQBfAEyASoBJAEaAQoBPgDuAN0AygD5AKgAkgC+AG4AXYBHgHDAHUAIQDO/4H/Ov/0/pz+Qv78/bz9fP00/fT8wPyU/GT8PPwU/PD70Puw+5j7iPuA+4D7iPuQ+5j7qPu4+8j74PsU/Ez8gPys/ND8/Pw0/XT9vP0E/kL+dv6w/vT+Rf+X/9//HwBQAIcAwgD/ADwBfAHAAQQCLAJMAnwCvAL8AiQDRANUA2wDkAO4A9gD6APwA/AD8APsA+AD0APAA6gDkANwA1ADLAMIA9wCqAJsAjACBALYAaIBXgEgAdsAlgBSABcA4f+f/1n/E//e/qb+bP5C/hr++P3E/Zj9aP1A/SD9DP38/PD84PzY/Mz8vPy0/LT8uPzA/Mz83Pzs/Pj8CP0g/Tz9XP14/ZD9rP3M/ez9Ev5E/oD+tP7Y/gH/Mf9g/4z/w/8GAEMAbgCMALAA2wAOAUIBcAGUAcAB6gEMAiQCSAJ0ApgCuALcAuwC7AL0AgwDJAMkAzADSANUAzwDLAMsAyQDAAPoAtgCzAKgAoACaAJEAhAC6AHIAZIBUgEmAQIBvgB1AEsALADo/6L/fP9a/yD/2v6y/pj+cv5U/jz+Cv7Q/aT9kP14/WT9UP00/Qz98Pz4/Az9AP3o/Oj8/PwI/Qj9FP0w/VD9bP14/Yj9sP3g/Qz+LP5Q/oL+sP7Y/hL/UP91/47/q//W/xAASwB3AJ0AxwAEATwBWAF0AaYB1AHgAeYBEAJQAnQCiAKgArQCsAK4AsgCzAKsApACmAKsAqAChAJsAlgCMAL6AdgByAGwAYgBWgEuAfwAwACAAFcAOAAUAN7/n/90/1f/Mv8I/+r+1P6u/nz+Wv5W/kb+IP78/fT9/P0G/g7+Gv4Q/uj90P3o/Rb+Ov5Q/l7+Wv5O/lb+fv6u/sr+4P72/g7/Kf9N/4T/t//L/83/zv/V/+n/DgA6AF4AbQB3AHwAewB6AJAArgC0AKgArADPAPUABAH5APEA+gAOASABMgE4ATIBJAEsAVIBbgFqAUYBIgHyALoAjwCuAP0ALgEgAe4ArwBoACkADwAoAF0AbwA5AO7/x//K/8j/tv+q/6D/dP9G/1r/q//1/xsALgArAAUA6v8NAFEAdgCTAOcATgFsATgB8wC6AIEAegDhAHwBvAFqAdsAdwBXAGoAiAB4ABgAgf/q/oj+dv6g/rL+Xv6o/ej8fPyM/Oj8QP1A/fD8mPxg/ET8XPy4/CT9WP18/Qj+/v7d/2cA9gDIAZwCPAPQA4AEAAXoBFgEuANgA+QDUAVYBvgE1QDA+zD40PcI/JgDgAkwCFUAMPiw9FD20PoMAIwCagBA/Ij6JPz0/fT90PxI+1D5cPgI+18AWAQ4BBgB7P18/Bz9P//AAWQD0AOsA8wDkAR4BXgF2AN+AXgA7AGwBNgGwAfAB/gGkAVQBOAD5AOsA0QDTAPwA5gEqAT8A9QCeAEAAHb+KP28/HT9xP60/6b/iv6s/Lj6WPno+BD5qPlo+ij7qPvY+8D7MPsg+hD50Pio+SD7xPwe/qj+Ov50/Rj9PP2Q/fj9dP7G/hL/1f8YAfABiAFOAEr/D/+a/7sA9gG8AtQCiAIoAt4BzAEAAkQCXAJcApwC/AJEA2ADaANoA1QDKAPUApwCrAIAA3QDyAPQA3gDAAO4AqwCnAJ0AmQCRAL+AcIB2AH+AbIBEgGZAFMA5v+E/43/z//D/2j/Ef/Q/oj+LP7c/ZT9aP2A/bT90P3M/bz9aP3c/Jz84PwQ/QT9NP3M/QT+wP2Y/bT9lP1U/cj9jP7A/mj+jv4s/4D/aP9v/3j/Lv/+/qD/hQDMAJIAZgBVACUAQAC6AAYB0gDCADIBmgGEAWYBkgHOAfQBTALsAmADbANgA3ADjAO4A+QDAAQQBBgEIAQIBNwDeAPoAnACWAJsAmgCZAJsAu4B0AAIAEQAxQCOAOb/ZP+4/vD99P04/1UA4P86/rj86Pug+wD8oPzw/Nj81PzQ/GD8qPtg+1j7CPuQ+lj6gPqQ+pD6sPrw+vj6yPp4+uj5MPno+Ej5APqA+oj6QPrw+aD5cPmQ+RD6sPoY+0D7mPtQ/DD9HP5D/7sAHAL8ApgDuASABnAIIArAC0ANQA6gDiAPQBCAEYASYBMAFGAUABRgEwATQBIgEQAQQA8wDqAMwArwCCAHAAXUAsMAwv7M/PD6IPlg99D1gPRg8zDy8PCA70DuQO3A7ADtoO1A7sDuAO8A70DvwO/A8FDyQPQg9rD3EPl4+pD7RPz8/Az+PP9HAEIBQAIMAwgEUAXIBogHCAdgBRwDzgAh/5j+mP9mASQD0ANEA5QBxv4w++D3UPbQ9sj4IPv0/JD9AP34+6j7pPyO/rwA5ALwBPgGUAmADEAQABQAF+AYoBmgGWAZYBkgGiAbwBvgG2AbABqgF+AUwBGQDiALsAeQBGgBEP7Y+gj4YPWA8qDv4OzA6aDmYOQg4wDjYOOA5ODl4OaA5wDoAOmA6mDswO4g8UDzEPUA92D5+Pu6/pIBCAToBfgGWAdQBwAHGAfYB0AJIAuwDNAMEAsQCAAFZAJ8AJX/bv9V/67+8P1w/cz8YPuA+dD3EPbA9FD08PTA9TD2MPcg+Tj7gPzU/Mj7SPnQ9sD22PmY/rADcAjQCjAJEAXwAbYBgARwCqASwBmgHMAboBmAFwAWQBZAGIAaYBugG+AbABvAGAAWABMADyAKQAb8A+oBdv9s/eD7oPlg9gDzQO+g6iDmoOOg4wDlIOdA6SDqAOkg52Dm4OZg6ODqgO5Q8uD1APkU/Ib+zv8YADAAqACKARQDOAUACIAKIAyADIALoAlIB1gFEASUA8wDaATgBKAESAMQAYL+8PvA+Vj4CPhI+OD4oPlo+qD6uPlo+FD3cPYg9vD2CPlo+2T9IP+zADYBdwBD/0L+hP1E/Vb+mwD4AvgEwAZACFAIOAdgBeQCOwCZ/3ADsAogEsAXoBrgGUAWIBKwDzAPwA/AESAVQBiAGUAZgBfAE/AOAAtwCMAFoAI3ANT+1P38/Fz84PqA97DywO2g6aDmYOUg5uDnwOlg62DsgOyg68DqoOpg66DtAPFg9CD3gPlw++T8OP7o/2wB+gGAApgDwASQBRAHAAkQCqAJ0AgwCMAGoAQ4A/gCeAKyAWABRAEbAAz+hPxw+0D6gPl4+Xj5wPgY+FD4YPgI+BD4APm4+Rj60Pr4+8D88PyE/Xr+Rv/P/8UA5gGQAtgC9AIQAyQDZAPcA2gE4ARABVgFuAXIBtAHYAiACbAMgBFgFqAZQBrgF4ATIBCgD4ARwBMgFsAXoBcAFWARoA2QCVAF7gELAI7+3Pzg+tj4gPYA9ODxAPCA7UDqYOdg5YDk4OTg5mDp4Ovg7WDvoO8g78DuwO8Q8jD16Pic/IP/XAGYAswDwARIBZAFAAZIBmgGqAZgBwAIIAj4B7AH0AYABbQCmQDU/nj9+PxY/dD9wP0k/TD8yPoA+cD3oPdQ+PD4iPmQ+vD7wPwM/Xz9AP5E/l7+Yf/+ACwC0AKoA6gE+AS4BKAEgAS0A5wCEAIcAvgBNALsAqADcAPIAlgCxAG1AJD/YP8AATAFoAtgEmAWgBbAEwAQoAwwC3AMoA8gE+AVYBeAF6AV4BEADWAIAAV8Ao0AOP/E/aD7QPnQ9xD3UPVQ8uDugOvA54DkwOOA5eDngOqA7QDwMPAg78DuIO+g71DxIPWA+Zj8Nv8QAtQDAARYBOgFOAdABzgHuAeoB8gG0AYQCOAIIAgQB7AFTAM5ABL+GP0I/Aj7+Pqg+6j72Pr4+UD5WPhg9yD3gPco+Pj4WPrg+wj9wP16/lD/+v+TADAB3gFwAuQCkAOABGAFyAXABYAF8AToA9gCHALQAXoBPAEOAcMALAC5/xcAvgCmACAAZwAIAlgFkAoAEaAVgBZgFAASIBBwDkAOQBBAE6AVgBfAGMAXYBPADbAIWASlAJb+7P2I/AD6IPhQ97D1oPKA78DsYOmA5WDjYOPg4yDlYOgA7ZDwAPJw8mDysPGQ8UDzkPYo+tz99AGQBagHkAgQCSAJQAhgBzAHSAf4BmgGSAZoBmgGWAYwBjAFqAJn/4T8gPoY+VD4mPh4+Uj60PoA+5D6YPkY+JD3sPdQ+ID5SPsc/ar+DwBaAUgCoALMAgwDYAPEAzgEoAQQBaAFOAZwBgAGOAUYBLwCYgFvAHL/Yv7E/fT9oP7e/s7+Nv5A/VD8nPxW/rsAOAQwCcAOABNgFaAW4BXAEkAPQA4AECATQBYAGcAZ4BeAFCARcA2ACKAD3v+M/ej78PrI+bD3IPVg8/DxgO8g7IDogOVg4wDj4OQg6EDrQO5A8ZDzgPSA9GD0oPTA9WD4hPzGAPADEAagB6AIIAlQCVAJsAioB8gGKAZoBUAERAPQAsACdALCAV4AAP44+6D40PbQ9bD1YPaQ95D4UPnQ+eD5ePkI+Wj5aPqA+2j85P1r/5wAcAGAAtQDiATIBAAFSAXoBDgE1AMABCgEUASQBEgEVAMoAkoBQQDE/qD9XP0o/bT8AP0w/if/Bf/8/o3/3P8eABwCkAZgC5AP4BNgGMAaoBmAFkAToBDgD0ASgBYgGQAZYBeAFEAQMAu4BtQCsP4I+yD5GPhg9hD0MPKg8MDuAO3A6+DpwOYA5EDjYOSg5gDqYO4A8oD0cPbw9yj4oPcw+Kj66P34ANgDGAZAB3gHIAjwCDAJQAj4BrgFWATMAmIBMwAX/4L+kv7g/lr+1PzA+pD4kPZA9QD1kPWQ9pD3EPmQ+nD7ePto+yz8bP1c/uT+cf8lAOcACALQA4gFaAawBjAHYAeYBjAFUAQIBMADyANYBKAEAAQoA9ACWALoAE3/Xv6A/XD8EPwo/UT+gv7E/pj/MQAVAM8AyAIwBdAHUAxAEoAXoBqgG2AaABbgENAOYBCgEqAUgBZAF0AVQBFgDfAIYAMe/jj7qPlw99D04PKA8YDvIO4A7mDtAOsA6EDmQOWA5ADl4Oeg60DvUPNw9wD6aPow+qj6yPtU/aj/ZAKgBCgGmAcgCfAJ0AkgCUAICAeQBewD5gGa/4z9cPxU/Jj8xPyU/AD8+PqQ+fD3gPaQ9VD18PVQ9xD5qPrY+8T8fP0M/m7+2v5Y/9H/cQBkAbwCCAQgBfgFsAYIB+gGaAa4BdgE/ANYAzwDQAMsA+ACmAIcAkwBiACu/5z+VP2Q/ID8kPyY/Dj9tv4GANYAzAHkAkwDdAOYBKAHsAuAEMAVABogG+AYgBVgEvAPsA4QDyAQoBDgEAAR0A9gDHAHuAKo/hD7EPjg9dDzkPHg7yDvIO8A78DuQO4g7WDrwOng6MDowOlA7CDwUPTQ94j6fPyY/fT9LP7Y/rL/kgCUASwD+ARIBvAGAAeoBuAF4AS8AzACQwBg/pz8CPvg+bj5YPpg+yz8gPwU/PD6iPlQ+LD3wPe4+Hj6hPxW/qr/OwBzALgAHgFsAX4BzgFMAswCVAMYBJAEsAS4BAgFOAWQBMQDQAOkAuIBjgG2AaYBGgH7AFYBXgGvAA0Awv8j/2b+MP6o/gD/MP+7/7EAhAEIAqQCXAMYBFgFIAiQDIARgBWAF2AXYBVgEjAPAA0gDBAMwAxQDgAQYBBwDoAKqAWMABT8OPmQ9/D1UPRg81DzAPMA8vDw4O+g7kDtgOxg7EDsgOzA7QDwkPIg9Sj4GPso/Ur+Iv/a/zAASADqAP4BAAMQBHAF0AboBvAFuATkA7gCEAGc/5z+iP0c/HD7mPvQ+6j7uPsc/Oj78Pog+vD5uPmA+VD6EPyk/Xr+N//4/w8AxP8VAM8A7gCoACgBZAIYAwQDFANcA1ADCAMMA/gCWAKoAaIB4AHKAdYBRAJsAugBWgEsAeMASgAfAEYAJQC3/9f/bgCcAIAA8gDmAUQCUAKwAmwDCAQwBeAHgAvwDuAR4BRgFkAVwBHwDeAK0AigCDAKMAzwDLAM4AvwCXgGEAK8/bj5oPZQ9YD1kPWQ9HDz4PJg8rDxIPGA8CDvwO2A7YDuoO/A8IDyIPUA+Nj6ZP3A/rb+TP6a/pb/tQD2ARgDrAPYAygEeAQwBEgDXAKwAfwASwCU/2j+rPwI+2D6wPqg+3D80Py4/Gj8LPzI+yj7yPoY+yj8jP0V/3gAQgFgAVYBYAEuAdMAxAAsAcYBWAIYA3gDSAPkAtACxAJoAjQCNALeARABuAA6AaABfAF8AQQCXAI0Av4B2AE0AVYAQADgADQBKAGEATAClAKsAugC/AJ4AiwC4AIwBLAF0AcgC7AOQBFgEkASQBDADKAJMAgACFAI8AjACSAK0AnQCBAH6APz/1D8uPng96D20PUw9bD00PRw9dD1YPUg9HDycPDA7gDuYO6g78Dx4PRY+Ej7NP0S/g7+eP0s/aD95P5eANYB7AKcA/gDEATAAyADgALuAWgB9wCLALH/Yv4w/Yj8BPyo+9D7bPzE/ND8AP0o/dD8YPys/Ej9mP30/Rv/fwBCAaABHAI0ApYBDgEkAVYBQAGSAYQCKAMUA/gC5AJgAmIB4ADEAEYAsv/X/3MArQCuAAYBZgEiAdcAHgFcAeEANgD8/8f/g//p/xwBFAJkAsgCbAOMAwADuALcAjADGASABuAJAA1QD6AQgBDADpAMwApwCUAI0AcgCJAIgAjoB+gGYAWEA5QBff8s/Zj6QPhg9jD1oPSQ9ND0MPWg9aD10PRw8/Dx0PBA8PDwsPKw9OD2GPkI+zz86PyM/Sb+iv4f/xkA8wAsATIBagF+AWwBsAFwAsgCiAIYAqQBmwAR/8D9uPzA+0D7yPvQ/HD9rP38/Sj+3P2U/aT90P3g/Wj+hf92AN4ALgGYAa4BcAFKAVYBOAEEASQBhAGmAZIBfAFyATQB9QDWAKsAfgBfAD4AIAA2AKIANAGQAQACoAIMAwQDvAKAAhwCkAE2AVQBpgHUASgCoAIAAwgD2AJ4AtABYAG8ASQD+AQYB1AJIAvwC+ALQAswCoAIGAfQBlAHwAcQCKAIsAjIB2gGMAWkA2gBKv9w/dD7OPpo+XD5MPl4+BD4wPfg9oD1gPTg8wDzUPKg8uDzAPUg9qD3MPko+vj6GPw8/ej9bP4Z/4X/dv9c/3X/d/9p/9H/uABsAb4BAALsARABm/9o/pD9sPwA/CD8+PzY/Zz+U//H/3H/vP5g/l7+Nv4K/lb+D//G/20AMAHIAdwBmAFwAUoB5gBrAEwAdACZAMoALgGcAbwBngGWAagBogGMAZwBsAG0Ac4BLAKUAtAC+AJQA7QD1AO4A3AD5AIkAoYBWAFeAWwBmgEEAnQCnAKMAmwCYAJoAugCCASABcgGwAeQCCAJEAlwCMgHOAeYBhgGIAaABmAGuAU4BdgExAMMAoUAWP/k/TT8GPuI+qD5aPjA97D3cPfQ9rD20PZw9rD1cPWQ9WD1MPUA9nD3iPho+aD6+Pu8/DT93P1g/lL+Kv5w/tT+3v7s/nf/LACvAC4BvgHiAWIBogABADj/PP6M/Xj9wP0e/rT+mv94ANAAugB7AC8Avv9Z/0b/e//G/yIAzwCWAf4BAALqAcYBTAGiADkAFADm/9f/SwD+AFIBVgGGAcABfgECAeUABgEGARABngFEAoQCoAL4AlQDRAMgAzQDOAMEAwQDZAOsA4gDYANkAywDxAKYAtwCIANgAxAE+ASwBQAGMAY4BsAFKAXoBOAEsASIBKgEyARwBNgDVAPUAgQCFAFSAKT/uv7M/Sj9oPwQ/Jj7ePto++j6OPqA+bD4wPcA96D2kPaQ9gD3wPeI+BD5ePng+TD6cPrY+nj7KPzU/Kj9iv46/63/IwCsAAABJAEsASoB/gChAE0A9P+D/wn/uv6S/nj+fP6y/ub+6v7Q/rz+qP6I/ob+uv78/kH/mv8hAMcAWAHWATACXAJoAmwCaAJgAmgCgAKoArACrAKkAowCQALaAXABDgGsAF0AMQAeAAcA+f8EAAwACwABAAcAFQAZAB8ARgCMAOwAbAH0AXACvAIIA3wD+ANYBJAE2AQgBVgFeAWgBbAFiAVABRAFEAXoBJgESAQABIAD0AIoApgB6AAeAHn/8P5A/mz9rPz4+yD7OPq4+YD5UPk4+XD50Png+eD5GPpQ+kD6SPrQ+mj70PtE/Bj94P1E/qj+Rv+5/8H/6v96AOUA7gAOAWYBagH2AKQAhgAcAGP/C/8a/+D+TP7s/dT9gP30/Lj8xPyo/HT8rPws/WD9UP10/eD9Iv5A/pD+HP9q/6T/LQAOAdYBYALwAqADCAQgBDgEaAR4BFgEWATABEAFcAWIBdgFCAbABVgFIAXgBDgEtAO4A/AD4APoA3gEEAUgBSAFYAVgBcAEIAToA4ADvAJgAqgCtAJQAjwClAJIAhgBBgAI/1T9KPvg+bD5OPl4+HD48PjA+PD3sPfw95D3APeA97D4YPnA+cj6BPxs/IT8UP1O/oj+hv4z//z/4v97/6v/3/9Y/87+B/9d/w//wv4N/zb/oP4e/j7+VP7g/aj9MP6w/sz+IP/9/6sA8gB+AWwC7ALcAhQDxANIBHgE0ARgBbAFwAX4BTAG+AWIBVAFOAXoBIgEWAQoBMQDdAN0A1gD6AJ0AkgCGAKwAUQBJAEaAeUAwADhABAB7wCgAHcAfwBkADUAIwAsAAYAqf93/2L/Gv+U/ib+5P2k/Uz9CP3E/Fj82Ptw+yD7uPpY+hj6APrg+dj58Pkg+lD6aPqI+sD6CPtg+9D7RPzQ/FD90P1K/qr+7v4h/2n/uv/8/z0AiQDQAAIBRAGKAawBqgGwAcQBwAGyAbwBzgHQAcIBwgHOAcABtgG6AcIB6AEwAoACpAK8AuAC9AK8AmgCNAL4AZwBXAFeAVQBJAEKAQoB4ACIAEUABwCa/yH/0P56/vD9gP1Y/Sj91Py4/OD85Py0/KT8uPyg/Hj84PzU/cz+AgDkASgEKAbYB3AJoArAChAKYAmwCOgHYAeIB9gHwAdQB/AGQAa4BNQCDAFF/2j9APxg++j6MPqw+dD5+PnQ+dj5SPqY+pD64PrA+1T8kPww/Vb+L/+X/0QANgGgAYoBzAFMAjQCrAGCAYwBCAEvAM//rv8Z/1z+Fv4A/oD93PyU/Ez8mPsA+/j6MPsY+yD7oPtM/LT8GP3I/W7+yP4i/8f/bADNABoBjgEEAlACpAIoA5wDwAPEA+gD/APUA6ADqAPMA8wDzAMIBDgEEATIA6ADeAMwAwAD/ALcAnwCKALcAUoBdwDW/3r/F/+2/pb+jv5E/tj9pP2M/TT92PzI/OD83PzQ/Pz8GP0I/QT9LP1U/WT9iP3Y/Rj+Nv5g/qj+zv7Q/tz+Av8X/x3/Kf82/zf/Hv8C/+L+rv6A/k7+Fv7k/dj97P34/Qz+Nv6E/sT+/v5L/5f/yv/x/ywAcgC4AAQBfAH8AXAC3AJEA4wDrAO0A6wDiANQAxwD9ALUAqgCiAJcAhgCtAE6AbkAKwCa/xH/ov5e/lL+av6c/tT+AP8a/yT/Pf9K/1r/e//D/yYAkAD/AGQBqAHMAfgBJAIwAigCIAIgAhAC6AG6AWgB5gA/AK//I/+K/gD+jP0U/YD8EPzY+7D7cPtY+2D7ePuI+7j7APwY/Cz8ePzk/DT9dP3g/WL+rP7U/hv/Zf+X/8z/MQCcAOcAMgGaAfYBKAJIAlgCXAJUAnACjAKEAmQCZAJcAiwC7gHKAaYBcAFcAYoBxgHeAfgBJAI0AiQCKAI8AjwCQAJ8AtQCHANUA7ADAAQgBDAESAQ4BBgEEAQwBEAEKAQgBCAEAATMA6QDdAMcA9ACsAKcAlwCFALgAaIBRAHsAKQARwDb/4//YP8Q/67+av4q/rz9QP38/MD8ZPzw+6j7KPto+pD52PjQ94D2YPWA9IDzkPJQ8rDyYPNA9LD1QPdY+OD4iPlY+sj6KPsk/MT9Tf/PAJwCYAR4BQgGuAZYB3AHWAeYB+AHwAdgBzAH6AYwBnAFCAWYBOADKAOkAggCEAEMAFL/uP42/hj+cP7q/lP/z/9uANwA9AD8ABIBNgFkAdoBfAIUA4QD5AM4BFAEKAToA5gDJAOgAiwCxgFOAcsAVwAAAJz/Gv+i/kr+6P1s/fz8sPx4/Cj8+PsE/CT8LPw0/HD8qPyw/Lj85PwI/Qj9JP18/dj9IP5y/tr+J/9C/2f/o/+3/6H/n//E/9//3v/z/xMAFgAEAAYACwDp/7z/qP+o/57/lv+v/8v/3/8DADsAggDAAPgANgFeAXgBjAGmAbIBrgG+AdQB8AEgAkgCdAKEAnQCWAJEAjwCQAJMAlgCbAJ4AogClAKgApwChAJoAlACLALmAZ4BVAEKAasAXwArAPL/t/+V/4j/YP8c/9b+ov5w/kD+KP4W/gr+FP5G/ob+tv7O/tr+2P7M/r7+qv6W/oT+jv6y/tb+8v4C//b+zP6e/n7+Xv48/jL+UP56/p7+zv4F/zH/Pf9D/1H/Yv9p/3j/l/+1/8v/5v8UAEEAZQCKAMgABAE8AWoBngHWAfgBGAJMAoACnALEAgADKAMoAygDQAM8AxwDBAMEAwAD1AKoAqAChAJEAgwC9gHkAbwBlAGEAVQBDgHYAMIAmgBTAB4AHQAWAPb/3//j/87/nv+B/4H/a/8t//D+2v66/oL+WP4+/iL+9P3M/aj9aP0E/Zz8KPzA+2j7OPsY+wD7+PrY+lD6iPmo+JD3cPbQ9fD1sPbA9zj5GPvc/C7+Uv9XAN4A4wAiAeIBwAKMA6AE6AXIBkgHwAcgCNgHIAeQBjAGiAXABEgE6AM8A3gCCAKmAfkAQQDb/5D/Df+Q/lz+Kv7M/Yj9rP3o/Sr+lv5C/+X/XwDWAFYBoAG8AdoBEAI8AlgChALEAuwC9AL4AvgC4AKoAnQCNALgAWwB5wBYAMP/PP/G/nD+Lv4Q/gD+7P3Q/cT9pP1o/Sj9HP0o/TT9VP2k/RD+av7C/iv/gP+o/8n//v8qADMANwBZAIEAlwClAMEA0QDBAKQAjwB1AEUADgDp/9T/v/+n/4z/bv9F/xr/+v76/vL+4v7Y/uz+Af8X/zL/WP9i/0v/OP85/zL/Ev8D/xz/R/94/7L/6//9/+n/3//3/xMAKQBPAJQA5AA4AY4BzAHSAaoBgAFMAfoAjgA7ABYA///n/+H//v8OAA0AIgBQAGEAUwBbAJMAxQDSAPIAOgFwAX4BlAG4AbABeAFSAUgBIgHyAOwADAEMAf0ACAESAeEAlgBrAEUACwDX/8z/sf90/zv/HP/w/qz+hP6C/ob+gv6Y/r7+zv7G/tj+/P4Z/zL/aP+x/+H/DABCAHQAhgCSAKsAygDPAM0A0gDHAJkAWwAiAOT/mf9J/w3/7v7g/tb+2P7m/uj+0v7E/sT+xv7C/tr+F/9V/4j/vf/7/xgADwAWAC8AQABAAFkAkAClAJgAjwCOAHMAQwA5AEkAVABlAJ0A5wAWAToBcgGwAdQB+AFIApwC3AIgA3gDwAPcA/wDMARYBGgEgASQBHgEGASgAwwDNAIuASIAI/8w/oD9OP0g/fT8oPw4/Jj7sPqY+Yj4kPfQ9pD2wPZQ9wD4yPiQ+Tj60PpQ+8j7MPyk/ED97P2K/hr/mP8BAFgAswAQAWABnAHOAeoB3gG2AXoBKAHCAHIATgBKAF8AjQDEANsA2gDQAL4AhgA9ABEACAAcAFoAxwBIAbwBKAKcAggDSANoA4gDqAPEA/gDSASgBPAEQAWIBcgF6AXoBdgFqAVgBRgFwARQBNwDXAPQAjAClgEAAWAAvP8i/5T+AP5w/ez8gPwY/Lj7aPs4+wj72PrI+tD64PoA+zD7cPu4+wD8WPyo/Oz8KP1o/aD90P38/Sz+VP54/qj+2P76/gn/Bf/2/uD+yv7A/s7+9P4v/3n/yv8bAF4AhACUAJ0ApQCtALgA0wAAASgBTgF0AYwBkAGEAXoBegFyAWwBcgF8AXoBcAFyAXABaAFuAZYBzgEAAkQClALUAvgCEAM0A0gDRANMA3ADiAN8A3ADZAM0A9QCcAIcArYBQAHnAK4AXgD8/6r/Z/8J/5b+RP4Q/tj9nP2I/Yj9fP1g/Vj9ZP1Y/Uj9XP2M/az9yP0E/lb+mP7Q/hj/cv+x/+H/GABZAIAAjQCYAKYAngCEAHAAbgBvAGMAVwBdAGIATgAxACgAIwAIAPT/DAA0AEkAZwCqAOkA/wAaAVQBjAGWAaQB1AHuAcoBqAGUAUoBwABQABIAtP8p/8L+fv74/TT9jPzo+wD7+PmI+bD5APp4+lj7WPzw/DT9fP2g/UD9vPzA/Dj90P2u/vr/WAFUAiAD/AOQBKAEeASIBKgEmASQBMgE6ASgBEgEEATAAxwDeAIQApYB6gBSAPj/if/o/mz+Qv42/i7+YP7S/jL/Y/+c/9//5/+0/5L/nf+x/8r/EAB3AMAA4AD8AAgB2QB/ADUA+f+z/3H/T/8z//7+vv6Q/l7+Ev7A/Yj9XP0g/eT8vPyc/Gj8NPwg/Cj8LPw4/Gj8vPwI/VT9sP0Y/nL+uv4d/5v/EAB1AOwAdAHyAVgCuAIUA1ADdAOcA8ADzAPEA8ADvAOcA2QDNAMEA8ACeAI8AgQCwgGAAVIBJgH0AMIApwCZAI8AkwCpAMsA5QD+ACABPAFGAUIBTgFgAXIBkAG+AeIB9AEIAhgCIAIMAuoBwAGKAUwBEAHbAJsAVgAWANv/mP9O/wX/uP5c/vz9pP1Y/Qj9wPyU/Hz8bPxk/HD8fPyI/JD8mPyw/ND8AP08/Xz9xP0M/lT+lv7Q/gf/PP9y/6n/3v8PADgAXgB/AJEAmgChAKoAtQDFAN0A9AAAAQQBAAH9APEA2QDAAKYAjAB1AGcAZQBhAFwAYwB2AIYAkgCnALcAtQCoALQAwgDQAOcAEgFMAXYBoAHMAdwBvgGYAX4BZAFGATgBPgFEAT4BPAE6ARYBzABzACEAzf95/z3/HP8D//b+Av8X/xn/Cv/6/ub+xP6e/oj+hv6C/oD+kv6u/sD+xv7U/ub+8P74/gf/F/8Z/xX/GP8m/zT/SP9x/6D/zP/4/zAAYQB7AIUAigCKAH8AdgB8AIwAmwCtAL4AyQDIAL4ArACEAE0AGgDw/8n/qv+X/4n/fv95/3r/ev9x/2b/Yf9f/1//Z/97/4//pP+9/9j/6v8CACQASABpAIgApwDEANMA2QDaANEAuQCnAJsAlgCKAIEAdwBnAEwALQAHANr/qP96/1T/NP8a/wf//P72/vD+7P72/gT/F/8y/1L/cv+J/6L/uP/L/9r/8P8TADsAaACWAMMA5QD2APkA6wDLAKMAgABjAEwAPwA6ACwADgDo/8P/lP9b/yf/Cf/6/vb+AP8c/zT/Q/9W/3P/i/+W/6f/yf/x/xUAQwB/ALoA6gAcAVQBhAGeAbgBzgHgAd4B4AHgAdgBwgGwAaYBkgF2AVoBPgEUAeQAtgCKAFoALQARAP//8f/p/+j/4//V/8b/tv+k/5P/iP+E/4v/mf+n/7L/tf+x/6H/if92/2z/W/9E/zH/JP8G/97+uP6O/lT+Fv78/QL+Cv4Q/iD+IP74/cj9qP2M/WT9XP2E/cD9Bv5g/sb+CP8a/yz/Uv9u/3n/nP/o/zcAhQDmAFQBpAHKAfYBKAJIAmACgAKsAswC3AL0AhQDIAMYAxQDGAMQAwwDEAMUAwQD8ALgAtgCwAKoApwCkAKIAogCjAJ0AkAC+AGsAVIB7wCQAEIAAADP/7b/q/+P/17/IP/M/lb+wP0c/Wz8uPsg+6D6SPoQ+gD6CPoo+kD6WPpY+lD6SPpI+lj6gPq4+gj7aPvI+zD8mPzs/Dz9jP3s/Vr+0v5R/9L/TQDGADoBqgEUAnwC7AJUA7wDIAR4BKgEuASoBIAEQAT0A6QDUAMAA7QCeAJEAhAC2AGgAXABQgEgAQgB9gDrAOcA9gASAUQBjAHoAUgCuAIwA6gDAARABGAEUAQoBPQDwAOMA1QDLAMQA+gCqAJQAtoBQAGIAMn/FP9o/sz9VP0I/dD8oPx4/FT8JPzw+8j7qPuY+5j7wPvw+yz8bPyw/PD8LP1g/aD95P0s/m7+sv7s/hH/Kv8+/0v/Uv9b/2z/h/+l/8T/2//h/9X/uP+b/37/Zf9Z/1z/bv+P/7j/6v8ZAEMAbACWAMAA7AAiAVgBhgGsAdwBAAIcAjgCVAJsAnACfAKIAoQCcAJQAjgCHAL8AeIBygGoAXwBTgEgAecApABhACQA7v+//6D/jP9y/1n/R/8z/xf/+P7e/sj+tv6u/rD+uP68/rz+vP68/rj+rv6o/qD+nP6c/p7+ov6i/p7+mP6W/pj+ov60/sr+3v7w/gD/EP8c/yP/Kv84/0z/aP+L/7b/4f8GACEAMAA9AEkAVgBiAHEAiQClAMQA5gAEARgBIAEiAR4BFAEEAfUA6wDiAN0A3QDfAN4A2gDWAM0AugCoAJoAjQB8AGwAXgBRAEQAOQAyAC0AJQAjACQAJgAjABwAEAAAAO//3v/N/7//s/+s/6f/o/+g/5z/l/+T/5H/kf+V/5r/o/+s/7P/uf+4/7T/rP+m/6P/pP+q/7b/w//P/9j/3v/f/97/2f/R/8v/yf/L/8//2P/k/+n/6P/k/+L/4f/g/+H/6//7/wkAGAAoADUAOwBAAEsAVgBaAF4AaAB1AH8AgwCKAJEAjwCJAIQAhQB6AG4AaABpAGYAZgBrAG4AZgBgAGMAYwBbAFIATQBEADwAOAA5ADUAKwAqADAAMwA2ADgAOAAzACoAKAAlAB0AFQAPABEAEwAUABYAEgAGAPn/7P/g/9T/wv+w/6H/lP+J/33/cP9i/1P/Qv80/zD/LP8l/x//GP8N/wT/Af8D/wf/Dv8b/yv/O/9L/1v/Z/9u/3X/gv+T/6T/tv/J/93/6//4/wIACwAOABIAFgAcACIAJwAxADkAPQBAAEQASQBMAEwATQBRAFgAZABzAIIAkACgALUAyADbAO0A+wAGARIBIAEqASwBKgEoASYBHgEWAQ4BAgHwAOAA0gDBAKkAkQB6AGAARwAvABgA/P/g/8b/sP+b/4X/cP9c/0f/M/8e/w3//P7u/uj+5P7i/uD+3v7a/tb+1P7Q/tD+0P7W/uD+6v70/vz+A/8G/wj/Df8U/x//Lv9A/1b/bf+G/5//s//C/8//2//n//T/AwAWACgAPQBUAG4AhQCZAK0AwADRAOEA7gD6AAYBEgEgAS4BQgFSAWABbAF8AYgBkAGUAZIBjAGCAXoBdAFsAWQBWgFUAUoBPgEuARwBBAHpAM8AtwCfAIYAcABeAEoANAAdAAUA6f/K/6z/j/9y/1b/Pv8p/xL/+v7k/tD+uv6o/pr+kP6I/oD+eP50/mz+ZP5g/lz+XP5e/mj+dP6G/pj+rP68/sz+2v7q/vr+Cf8Z/yz/P/9V/27/if+i/7r/1P/y/w4AJwBDAF4AcwCDAJsAsADDANIA5AD4AAIBCgEYASABHgEaARwBHgEgASQBJgEoASIBHgEcARwBGAEOAQgBAgH9APgA8wDoANwA0QDGALkAqgCbAIkAdQBiAE4AOgAlAA8A+f/l/9P/wP+v/53/jf99/23/Xf9L/zr/KP8Y/w3/Bf8A//r++P72/vT+9v74/vj++P76/gD/CP8R/x3/K/85/0X/UP9c/2n/eP+F/5H/nf+p/7b/w//P/9j/4P/o//H/+f8AAAYADQAUABsAIwAsADMAOgBCAEgATgBWAGAAbAB2AH8AiACRAJcAmwCeAJ8AnwCgAKIApQCoAKoAqgCpAKgApgChAJkAkwCMAIQAfQB2AHAAaQBiAF0AWABTAE0ARwBBADkALwAhABEAAADv/9//0v/I/8D/uf+0/67/qP+g/5X/iv99/3H/aP9i/1//Xv9f/2D/X/9e/13/XP9c/13/Yf9o/3D/ef+E/4//mP+h/6n/sv+6/7//xP/L/9T/2//j/+//+f8AAAgAEgAaAB8AJgAwADoARABPAFsAZABsAHcAgQCIAIwAjwCRAJQAlQCYAJgAmACYAJsAngChAKAAngCaAJQAjwCJAIEAeQBxAGwAaQBkAGAAWQBPAEYAPQA1ACwAIQAWAAwAAgD7//P/6P/d/9L/yP/A/73/uf+z/67/qP+h/5v/lv+R/47/i/+J/4r/jP+M/4z/i/+J/4f/h/+I/4n/i/+N/5H/lf+Z/5z/nv+g/6L/pP+l/6b/qf+u/7T/u//C/8r/0v/b/+L/6f/w//b//f8FAAwAFAAcACQALAA0ADwAQgBGAEkASwBMAEwASQBHAEQAQgA+ADwAOQA1ADIALwAuACwAKgAnACUAIwAgAB0AGAAUAA8ADAALAAoACQAHAAUAAwAAAP3/+//6//v//P///wIABAAEAAQAAwABAAAA/////wEAAwAFAAYABgAFAAIAAAD9//z/+v/6//v//P///wIAAwADAAEA/v/6//b/8v/v/+3/6//r/+z/7//y//b/+f/8////AQACAAMAAwADAAMABQAGAAcACQAMABEAFAAWABUAEwAQAA8ADgAMAAoACAAIAAgACgALAAsACgAJAAkACgAKAAsACwANAA8AEQARABEADwAMAAoACAAHAAYABgAGAAYABQADAAEA/v/8//v//P/+////AAACAAQABAADAAEAAAD+//3//v///wAAAwAFAAYABwAIAAoACgAHAAYABQAEAAMAAwAEAAMABAAIAAoACgAKAAsACAADAAEA///8//j/9f/2//P/7//w/+//6v/m/+b/5//p/+r/6//t/+//7//y//b/+f/4//j/+f/7//v/+v/4//b/9P/z//H/8P/u/+z/6v/p/+j/6P/n/+b/5v/n/+n/7P/u//L/9f/5//3/AAACAAMAAwACAAMABAAGAAgACgAMAA4AEgAUABUAFQAUABQAEwARABAAEAAQAA8ADgAOAA4ADwAPAA4ADAAKAAkACAAGAAQAAgAAAP7//f/7//n/+P/3//f/+P/4//n/+v/6//r/+f/4//j/+f/5//n/+v/6//r/+f/4//f/9f/z//L/8//0//X/9v/3//j/+v/6//r/+v/6//r/+v/6//n/+P/2//T/8v/v/+3/6//r/+r/6f/m/+L/3f/X/9H/zP/I/8b/xv/H/8v/z//T/9f/2f/b/9z/3P/d/9//4v/n/+v/8P/1//r/AAAFAAkADQARABUAGAAbAB4AIgAlACgALAAvADAALwAwADAAMAAvADEAMwA0ADYAOQA8AD0APgBAAEEAQQBBAEAAPwA9AD0APQA8ADoANwA0ADEALQApACQAIAAbABkAGAAXABYAFQASAA8ADAAIAAMA/f/3//L/7v/r/+j/5P/f/9z/2f/W/9P/z//K/8j/xv/F/8X/xP/C/8H/wf/C/8b/yf/M/8//0f/U/9f/2v/c/97/4P/j/+b/6f/s/+//8f/y//T/9v/3//j/+f/6//v//P///wEAAwAGAAkACwANAA8AEQATABYAGQAdACEAJAAoACsALgAvADAAMAAwAC4ALQArACkAKAAmACUAIwAhAB0AGgAWABEADAAIAAMA///7//j/9v/0//L/8f/x//D/8P/w/+//7v/s/+r/5v/j/+D/3f/c/9v/2//c/9z/3P/b/9v/2//b/9v/3f/f/+H/5P/m/+f/6P/o/+j/5//n/+b/5v/m/+f/5//o/+n/6f/q/+v/6//s/+7/7//y//X/+P/7//7/AQADAAYACQALAA8AEgAVABkAHgAjACkALwA0ADgAOwA9AD4APQA7ADgANQAyAC4ALAArACoAKwAqACkAJgAiAB8AGwAYABQAEAAOAA0ADQAOAA4ADQAMAAsACQAHAAQAAQD+//3/+//6//j/9f/y/+//7P/q/+j/5//n/+j/6f/r/+z/7f/u/+//8f/z//X/9//6//z///8BAAIAAwADAAQABAAFAAUABgAHAAcACAAJAAoACgAJAAcABgAFAAMAAQD///3//P/9//7//f/9//z/+v/3//X/8//w/+3/7P/t/+z/7f/v//H/8f/x//P/9f/3//n/+f/6//v/+v/6//z//P/6//j/+P/3//f/9f/z//L/8f/w/+//7//w//H/8v/1//j/+//+/wAAAgAEAAYACAAJAAoACwAMAA0ADgANAAwACgAHAAUAAwACAAAA/v/9//3//f/9//3/+//6//n/9//0//L/8f/w/+//7f/s/+3/7v/v/+//7v/t/+3/7f/t/+3/7v/u//D/8f/z//T/9v/5//v//v8AAAMABQAHAAcACAAIAAkACQAKAAsADAANAA4ADwAPABAAEAAQABAAEQATABQAFQAWABcAGAAXABYAFQAUABMAEQAPAAwACgAHAAMA///8//j/9f/z//H/7//t/+r/5//k/+H/3v/c/9v/3P/e/+H/5f/p/+z/7f/u/+3/6//q/+j/6P/o/+j/6f/q/+v/7f/u/+//7//v/+7/7v/t/+3/7f/t/+7/8P/y//P/9P/1//f/+f/6//7/AQAEAAgADAARABQAFwAbAB4AIAAiACMAJAAlACYAKAApACoAKwArACwALQAuAC4ALgAuAC8AMQAzADUANQA1ADQAMgAwACwAKAAkACAAHQAaABgAFQASAA8ADQALAAkABQACAP///P/7//r/+P/2//T/8//y//P/8//z//L/8f/w/+7/7P/q/+j/5v/k/+L/4f/h/+D/3//e/93/3P/c/9v/2//b/9z/3f/f/+H/5P/n/+r/7f/v//L/9P/3//n//P///wIABAAHAAkACwAMAA0ADgAOAA0ADQANAAwADAANAA4ADgAOAA4ADgAOAA0ADAAMAAsADAAMAA0ADwAQABEAEgASABIAEgARABAADwANAAsACAAGAAMAAQD///7//f/9//z/+//6//j/9v/1//P/8v/w//D/7//t/+z/6f/n/+T/4f/e/9z/2v/Z/9j/2P/Z/9n/2v/a/9v/2//c/93/3v/g/+P/5v/o/+v/7f/v//H/9P/2//j/+//9////AgAFAAgACwANAA4ADwAPAA8ADQAMAAoACAAHAAYABQAGAAgACgAMAAwADAAMAAsACwALAAoACgAKAAsADQAQABEAEwATABQAEwASABEAEAAPAA4ADwAPAA8ADgANAAwADAALAAsACwALAAwADQANAA0ADQANAAwADAALAAsACgAKAAoACgAJAAcABgAFAAMAAgABAAAAAAAAAP///v/+//7//f/8//n/9//1//P/8f/v/+3/7P/t/+3/7f/t/+3/7f/r/+v/6v/q/+r/6//s/+7/8f/0//f/+f/6//z//v8AAAEAAQABAAEAAAAAAAAAAAD///7//v/+//7/////////AAABAAMABQAHAAkACwANABAAEwAVABcAGAAZABoAGgAaABoAGgAbABsAGwAbABoAGQAYABYAFgAVABQAFAATABMAEwATABMAEQAQAA8ADQALAAgABwAGAAUABAADAAMABAAFAAQABAADAAMABAAEAAQABAAEAAUABgAGAAYABgAGAAYABQAEAAMAAwABAP///f/6//n/9//1//T/8//y//H/8P/v/+7/7f/s/+v/6//r/+v/6//r/+v/6//q/+j/5//l/+T/4v/h/+H/4P/f/9//3v/d/9z/3P/d/97/4P/h/+L/4//l/+b/5//o/+r/7P/w//T/+P/9/wAAAwAGAAcACAAIAAgACQALAAwADgAPABIAFAAWABgAGAAZABgAGAAWABUAFAATABMAEwAUABQAFAATABMAEwASABIAEgASABMAEwATABMAEwASABIAEQAPAA0ACgAHAAUABAADAAEAAAD///7//f/8//r/+P/2//X/9P/z//P/8v/w/+7/7P/q/+f/4//g/93/2//Z/9j/1//X/9f/2P/Z/9r/2v/a/9v/3P/f/+H/5P/m/+j/6v/t//H/9f/4//v//v8AAAIABAAGAAcACAAKAAwADQAPABEAEwAUABUAFwAYABkAGQAaABsAHAAdAB4AHwAgACIAIwAjACMAIwAkACQAJAAkACQAJAAkACQAIwAiACAAHgAcABkAFQASAA8ADAAKAAcABQADAAAA/f/7//j/9f/y//D/7f/s/+v/6v/p/+j/5v/l/+T/4//i/+H/4P/e/93/2//a/9n/2f/Z/9r/3P/e/+D/4v/j/+X/5v/n/+n/6v/s/+3/7//w//H/8v/y//L/8v/y//L/8//0//X/9v/4//r//P/+/wAAAQADAAUABwAJAAsADgAQABMAFQAXABkAGwAdAB8AIQAiACQAJQAnACgAKgAqACsAKgAqACkAJwAkACIAHwAcABkAFwAVABQAFAATABIAEAANAAsACAAGAAMAAQD+//3//f/9//7//v/+//7//f/8//r/+P/2//X/9f/1//X/9f/0//P/8v/y//H/8v/y//P/9P/1//b/9//4//n/+//8//z//f/9//7///8AAAAA/////////////////////////////wAAAAAAAAAAAAAAAAAA//////7//v///wAAAAABAAEAAQAAAP/////+//7//v/+////AQADAAUABgAHAAgACgALAAwADQAMAAwACwALAAoACQAIAAYABAACAAEA///9//v/+v/4//f/9v/1//T/9P/0//X/9v/2//b/9//3//f/9//3//b/9v/2//b/9v/1//T/8//x//D/7//u/+7/7f/s/+z/7f/t/+7/7f/u/+7/7v/t/+3/7v/u/+//7//w//H/8//1//b/9v/2//f/+P/5//n/+v/8//7/AAABAAMABQAHAAkACwANAA8AEQASABMAEwATABMAFAAUABQAFAAUABQAFQAVABUAFAATABMAEgASABIAEgASABEAEQAPAA0ACwAJAAcABQADAAEA/v/8//r/9//0//H/7v/s/+r/6P/n/+X/4//h/+D/3v/d/9z/3P/c/97/4P/i/+T/5f/m/+f/5//n/+j/6P/q/+v/7f/u//D/8v/0//X/9v/3//f/9//3//f/9//4//n/+v/8//3//v///wAAAQADAAUABgAIAAoADAAOABAAEgATABUAFgAXABgAGAAYABkAGgAbAB0AHQAeAB8AIQAiACMAIwAjACMAIwAkACUAJQAlACQAIgAhAB4AGwAYABYAFAASABAADgAMAAoACQAIAAYABAABAP///f/9//z/+//6//j/9//3//f/9//3//f/9//2//b/9f/1//T/8//z//L/8v/y//H/8f/w/+//7v/t/+z/6//r/+r/6v/r/+v/7P/u//D/8f/z//T/9v/4//r/+//9////AQACAAQABQAGAAcABwAIAAgACAAHAAcACAAIAAgACQAJAAkACQAJAAgACAAHAAYABQAFAAUABQAFAAUABAAEAAMAAgACAAEAAAD///7//f/8//v/+v/6//r/+v/7//z//P/9//3//f/8//z//P/9//3//f/9//3//P/8//v/+v/4//f/9v/1//T/9P/z//P/8v/y//H/8P/v/+7/7v/u/+7/7v/v/+//8P/w//H/8v/0//X/9//5//r//P/+/wAAAgAEAAUABgAGAAYABgAFAAUABAADAAIAAQACAAMABAAFAAYABQAFAAQABAAEAAQAAwACAAIAAgADAAQABAAEAAQAAwABAAAA/f/8//v/+//7//r/+v/5//n/+P/4//f/9//4//n/+v/7//v/+//8//3//f/+//7//v///wAAAQACAAIAAgADAAMAAwAEAAQABQAGAAYABgAHAAgACQAJAAkACQAJAAkACQAIAAcABwAHAAcABgAGAAUABAADAAIAAAD///7//v/9//7///8AAAEAAQABAAEAAgADAAMABAADAAIAAQABAAEAAAD///7//f/8//v/+v/5//j/+P/3//f/9//3//f/9//4//n/+v/7//z//f/+//////8AAAAAAQACAAMABAAFAAUABQAFAAUABQAGAAcABwAHAAcACAAJAAkACQAJAAkACQAIAAgACAAJAAkACAAIAAgACQAKAAsACgAJAAgACAAHAAYABgAFAAUABQAFAAUABAAFAAUABQAFAAUABgAGAAYABQAFAAQABAAEAAQABAAEAAQABAAEAAQABAADAAIAAgADAAMABAAEAAUABQAGAAYABQAFAAQABAAEAAQAAwADAAIAAQD///3/+//6//n/+P/3//X/9P/y//H/8P/u/+3/7P/s/+z/7f/t/+7/7//v/+//7v/u/+7/7//w//H/8//0//X/9//5//r//P/9//3//f/9//3//P/8//3//v/+//////8AAAAAAAABAAIAAwADAAQABQAGAAYABwAIAAgACQAJAAkACAAIAAcABwAIAAcABwAHAAcABwAHAAcABwAGAAUABQAGAAcABwAHAAcABwAHAAYABQAEAAMAAgABAAEAAAD///7//v/9//z/+//4//f/9v/1//X/9f/0//P/8//z//P/9f/2//f/9//3//j/+P/5//n/+v/6//v/+//8//3//v/+//7//v///////////////////////////wAAAQABAAEAAQACAAMABAAEAAUABgAIAAkACgALAAwADAANAA0ADQANAAwADAAMAAwACwALAAsACgAJAAgABwAGAAUABAAEAAQABAADAAMAAgACAAEAAAD///7//f/8//v/+f/4//b/9f/0//P/8//z//P/8//z//P/8v/y//L/8v/y//P/8//0//T/9f/2//b/9//3//f/+P/4//n/+f/5//n/+v/6//r/+v/5//n/+f/5//n/+v/7//v/+//8//z//f/+////AAABAAIAAwAEAAUABwAIAAkACgAKAAsACwAMAAwADAAMAAwACwAMAAwADgAPAA8ADgANAAwADAALAAsACQAIAAcABwAIAAgACQAJAAkACQAIAAcABQAEAAMAAwACAAIAAQAAAP///v/9//z/+//7//v/+//7//v/+//7//v//P/8//z//P/9//3//v//////////////AAAAAAAAAQABAAEAAgACAAMAAwAEAAQABAAEAAUABQAEAAQAAwADAAQABAAEAAMAAwABAAAA///+//7//f/8//z//P/9//3//f/9//3//f/+//7//v/+//7//v/+//7///////////////////////////////7//v/+//3//f/9//3//f/9//3//f/9//7//v//////AAABAAIAAwADAAMAAwADAAMAAwADAAMAAgABAAEAAQABAAEAAAAAAAAA///+//7//v/+//7//v/9//3//v///////v/9//z//P/7//r/+f/5//n/+f/5//n/+f/5//r/+v/7//v/+//8//z//P/8//z//P/8//3//P/8//z//f/9//3//f/9//z//P/9//3//f/+///////////////////////////////////////+//3//P/7//v/+v/6//n/+P/4//f/9v/1//T/9P/z//T/9f/2//b/9//3//j/+P/4//j/+f/6//z//f/+////AAACAAMABAAFAAUABAAEAAMAAwADAAMABAAEAAUABgAGAAcABwAIAAkACQAKAAoACwALAAsACwALAAsADAAMAAsACgAJAAkACQAJAAkACQAJAAkACQAJAAkACAAHAAcABgAHAAcABgAGAAUABQAEAAQAAwACAAEAAAD///7//v/9//z//P/7//v/+f/3//X/9P/0//T/9P/z//L/8f/x//H/8v/z//P/8//z//T/9P/0//X/9f/2//b/9//3//j/+f/5//r/+v/7//v//P/8//z//P/8//3//f/+////AAABAAEAAgADAAUABgAHAAgACQALAAwADQANAA4ADgAOAA4ADgANAAwADAALAAsACwAKAAoACgAJAAgACAAHAAYABQAFAAUABQAFAAQABAADAAIAAQAAAP///v/9//3//P/6//n/+P/4//j/+P/5//n/+f/5//n/+f/4//j/9//3//f/9//3//j/+P/4//j/+f/5//n/+f/6//r/+v/7//v/+//8//z//P/8//z//P/8//z//f/+//////8AAAAAAQADAAQABQAHAAcACAAJAAsADAANAA4ADgAOAA4ADgAOAA4ADgANAAwACwALAAsADAANAAwACwAKAAkACAAIAAcABQAEAAMAAgACAAIAAwADAAMAAwACAAAA/v/9//z//P/8//v/+//6//r/+f/5//j/+P/4//j/+f/5//n/+P/4//n/+f/6//n/+f/5//n/+v/6//r/+v/6//r/+v/6//v/+//7//v/+//7//z//P/8//z//P/9//3//v/9//3//f/9//3//f/+//3//f/8//v/+//6//n/+f/5//n/+v/7//z//P/8//z//f/+////AAD/////////////AAAAAP/////////////+//7//v/+//7//v/+//3//f/+//7//////wAAAAAAAAAAAQABAAEAAQABAAIAAgACAAIAAgABAAEAAQABAAEAAAAAAAAAAAAAAAAA/////////v/+//3//f/+//7//f/9//3//f/+/////v/+//3//f/9//3//f/9//3//v/+//7//////wAAAQABAAIAAwADAAQABAADAAMABAAEAAQABAADAAMAAwADAAMAAwACAAIAAQABAAAAAAABAAEAAQABAAEAAAD//////v/+//7//v/+//3//f/8//r/+f/4//j/+P/3//f/9v/2//b/9v/2//b/9v/2//b/9//5//r/+//7//v/+//7//v/+//8//3//v/+////AAACAAMABAAGAAYABgAGAAUABAAEAAQABQAGAAYABgAGAAYABgAHAAcACAAIAAkACQAJAAoACgALAAwADQANAA0ADAAMAAsADAAMAAsACwALAAoACgALAAoACQAIAAcABwAHAAYABgAGAAUABAAEAAMAAgABAAAA///+//3//P/7//v/+//7//r/+f/4//b/9f/1//b/9v/2//X/9P/0//T/9f/2//f/9//3//f/9//3//j/+P/4//j/+f/6//r/+//7//v//P/8//3//f/+//7//v/+//7//////wAAAQABAAEAAQACAAIAAwADAAQABAAFAAUABgAGAAcABwAIAAgACAAIAAcABwAHAAYABgAGAAUABQAEAAMAAgABAAAA/////////////////v/+//7//f/9//z//P/8//z/+//7//r/+f/4//j/+P/5//n/+f/5//n/+P/4//j/9//3//f/+P/4//j/+P/4//j/+P/4//j/+P/4//j/+P/5//n/+f/6//r/+//7//v/+v/7//v//P/9//3//f/+//7//v///wAAAQACAAIAAwADAAQABQAFAAYABgAHAAcABwAIAAgACAAIAAcABgAGAAcACAAIAAgACAAGAAUABQAFAAUABAACAAEAAAAAAAAAAQACAAIAAwADAAIAAQAAAAAAAAABAAEAAQABAAEAAAAAAP//////////////////////////AAAAAAAAAAAAAAAAAAABAAEAAQABAAIAAgABAAEAAQABAAEAAQABAAEAAQAAAAAAAAAAAAAAAAAAAAAA/////wAAAAABAAEAAQABAAAA//////7//f/9//3//f/9//7//v/9//3//f/+////AAAAAP////8AAAAAAQABAAEAAgACAAIAAgABAAEAAQACAAIAAQABAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAEAAgACAAIAAgACAAIAAgACAAMAAgACAAEAAQABAAEAAQABAAEAAAD////////////////+//7///8AAAAAAAAAAAAAAAD/////////////AAD/////////////AAAAAAAAAQABAAEAAQABAAEAAgACAAMAAgACAAIAAgADAAMAAwADAAIAAQABAAEAAAABAAEAAQABAAEAAQAAAP///////////////wAAAAD///7//f/9//z//P/7//r/+v/5//n/+f/4//j/9//2//b/9v/3//j/+P/4//j/+P/3//f/9//3//j/+P/4//j/+P/5//r//P/9//7//v/+//7//f/9//7//v///wAAAAAAAAAAAAAAAAAAAAABAAEAAQABAAEAAQABAAIAAwAEAAQABAAEAAQABAAFAAUABQAFAAUABgAHAAcABwAGAAYABQAFAAYABgAGAAYABQAFAAUABQAFAAQABAADAAMAAgACAAIAAgADAAMAAgAAAP///v/+//7//v/+//z/+//6//r/+v/7//v/+//7//r/+v/6//r/+v/5//n/+v/6//r/+v/6//r/+v/7//v//P/8//z//P/8//z//P/9//7//v/+//7//v/+////////////AAAAAAAAAAABAAEAAgADAAMABAAEAAQABQAFAAUABgAGAAcABwAHAAcABwAGAAUABQAEAAQABAAEAAMAAwADAAIAAgACAAEAAQABAAEAAQABAAAA///+//7//v/+//7//v/+//7//f/9//3//P/8//z//P/8//v/+//7//v/+//7//v/+//7//v/+v/6//r/+//7//v/+//7//r/+v/6//r/+v/7//v/+//7//r/+//7//z//f/9//3//f/9//3//v//////////////AAABAAIAAgACAAIAAQACAAMABAAGAAcABwAGAAYABgAHAAcABwAGAAUABAADAAIAAwADAAQABQAFAAQAAwACAAEAAQACAAMAAwADAAMAAwACAAEAAQACAAIAAgACAAEAAAAAAAAAAAABAAAAAAAAAP///////wAAAAAAAAAAAAAAAAAAAAAAAAEAAQABAAEAAQABAAAAAAAAAAEAAQABAAAAAAAAAAAAAAABAAEAAgACAAEAAQABAAAA///////////////////+//3//f/+//7//v/+//3//P/8//3//f/9//7//v/9//3//f/+//7//v////////////////////////////////////7//v/9//3//f/9//7//v/+//7//v/+//7///8AAAAAAAAAAAAAAAABAAIAAgACAAIAAQABAAEAAQACAAEAAQAAAP//AAABAAEAAgABAAEAAAAAAAAAAAAAAAAAAAAAAP///////////////wAAAAAAAAAAAAD/////AAAAAAAAAAD///////8AAAAAAQABAAAA//////7//v/+///////////////+//3//f/9//3//f/9//7//v/+//3//f/9//3//f/9//z//P/8//z//f/9//z/+//6//n/+f/6//v//P/8//v/+v/5//j/+f/5//r/+v/5//n/+P/5//r//P/9/////////////////wAAAQACAAIAAwADAAIAAgACAAMAAwAEAAQABAAEAAMAAwAEAAUABgAGAAYABQAFAAQABQAFAAUABQAEAAQABAAFAAUABQAEAAMAAwADAAMABAAEAAQAAwADAAIAAgADAAMAAwACAAEAAAD/////AQACAAIAAQD///3//P/9//7///8AAP7//f/7//v/+//9//7//v/9//z/+//7//v//P/8//z/+//7//v/+//7//v/+//8//z//f/+//7//v/9//7//v///wAAAQABAAAAAAAAAAAAAQABAAEAAQAAAAAAAAAAAAEAAQACAAIAAgACAAIAAgACAAMAAwADAAQABAAEAAQABAADAAMAAgACAAEAAQABAAEAAQABAAEAAAAAAP///////wAAAAAAAP///v/8//z//P/8//3//f/9//z//P/7//v/+//7//z//P/8//v/+//7//z//P/9//3//f/9//3//P/8//3//v////////////7//v/+////AAABAAEAAQAAAP////8AAAIAAwADAAIAAAAAAAAAAgADAAQAAwABAAAAAAABAAMABQAFAAMAAQD//wAAAwAGAAkACAAGAAQAAwAEAAcACQAJAAcABAACAAAAAQADAAUABwAGAAQAAgD///7///8BAAIAAwACAAEA///+//3//v///wAAAQAAAP///f/9//3//v/////////+//3//P/8//3//f/9//7//f/9//3//P/8//z//f/+//7//v/9//z//P/8//3//////////v/9//3//f/9//7/AAABAAEAAAD///3//P/7//z///8BAAEAAAD9//r/+v/8////AQABAP///P/5//n/+//+/wAAAAD+//z/+v/6//z///8AAAEAAAD///////8AAAEAAQACAAIAAgACAAIAAgAAAP////8AAAIAAwACAAEA///9//7/AAADAAQAAwAAAP7//f///wIABQAFAAMAAAD9//3/AAADAAUAAwAAAP3/+//9////AgAEAAMAAAD9//v/+//9////AQAAAP7//P/6//n/+v/9////AAAAAP7/+//5//r//P///wEAAAD+//v/+f/6//3/AAACAAEA///8//r/+//9/wAAAQABAAAA/v/9//3//f/+///////////////+//3//f/+////AAAAAP///f/8//3/AAADAAQAAwD///v/+v/8/wAABgAIAAYAAAD6//j/+f///wUACAAGAAAA+v/3//r/AAAHAAsACwAGAAAA/P/9/wEABgAKAAsACAAEAAAA//8AAAQACAAKAAkABgACAP////8BAAUACAAJAAcAAgD///7/AAADAAUABAACAP///v/+////AQABAAAA/f/8//z//f8AAAEAAAD9//r/+f/7////AwAEAAAA+f/0//T/+v8DAAoACgABAPb/7v/v//j/BQAOAA0AAgD0/+v/7f/4/wcADwANAAIA9f/u//D/+v8FAAsACAAAAPj/9P/2//z/AgAFAAUAAgAAAP7//////wAAAQADAAQABgAGAAQAAQD+//7/AAAEAAcABwAEAP//+//7//7/AwAHAAcAAwD+//v/+////wMABQAFAAEA/f/7//z///8CAAMAAQD+//r/+P/6//3/AAABAAAA/f/6//f/+P/6//7/AQACAP//+//3//X/9//7////AgABAP7/+v/3//f/+v///wIAAwAAAPz/+v/6//z/AAAEAAUABAABAP///f/+/wAAAwAGAAcABwAEAAEA/////wEABgAKAAsACAADAP7//P8AAAYADAANAAkAAgD8//v/AAAIAA0ADAAFAPz/9//6/wIADAAQAAsAAQD3//T/+/8HABEAEwALAP//9v/0//v/BgAOAA4ABwD7//L/8P/2/wAACAALAAYA/f/1//D/8v/4/wAABQAFAAEA+f/z//H/9P/7/wEABAADAP3/9//0//X/+v///wIAAQD+//v/+f/5//v//v8AAAAAAAD//////v/9//3//v8AAAIAAwADAAEA///9//3///8CAAQABQAEAAEA/v/7//r//f8CAAgACgAIAAAA9//x//P//P8IABAADgADAPX/7P/u//n/BwAQAA8AAwD1/+3/7//4/wQACwALAAMA+v/1//b//P8CAAYABwAEAAEA///+//7//v///wAAAwAGAAYAAwD+//n/+P/7/wEABgAIAAQA/v/4//j//P8DAAgACAADAP3/+f/6////BQAHAAUA///5//f/+/8BAAYABQAAAPr/9v/2//v/AgAFAAUAAAD6//b/9f/5//7/AwAEAAIA/f/4//b/9//7/wAABQAGAAMA/P/3//X/+f8AAAYACAAFAP7/+P/2//r/AQAHAAkABgAAAPv/+f/8/wAABAAGAAQAAgD///7//f/9//7///8CAAMAAwABAP3/+v/7//7/AgAFAAMA///6//n//P8CAAcABwACAPr/9P/1//z/BgAMAAsAAgD3//H/8//8/wgADwANAAUA+v/0//X//v8JABEAEgAMAAMA/P/6//3/BAALAA8ADgAJAAMA/v/9/wAABgALAA0ACwAGAAAA/P/9/wEABwAKAAkABQD///z//f8AAAMABAACAAAA/v/+/wAAAAAAAP7//f/8//7///8AAP///f/6//n/+f/8////AgABAP3/9//y//H/9/8AAAgACAABAPT/6v/p//L/AQANAA4ABADz/+f/5f/w/wEADgAPAAUA9v/s/+v/9P8AAAkACgAEAPz/9//3//v/AAAEAAUABQAFAAUABAACAP////8BAAUACQAKAAgAAwD+//3///8EAAgACQAHAAMA///+/wAAAwAFAAYABQADAAEAAQABAAEAAgABAAEAAAAAAAAAAAAAAP///v/9//z/+//8//3//v////7//P/5//f/9v/4//z///8AAP7/+v/1//P/9P/4//3/AQABAP7/+v/2//b/+P/9/wEAAwABAP7/+v/5//r//f8BAAQABAACAAAA/f/9//7/AQAEAAYABwAFAAIA///+/wAABAAJAAsACgAGAAAA/v///wUACwAOAAwABQD///3/AAAHAA4ADgAJAAEA+//9/wQADgASAA4ABAD6//f//P8HABEAEgALAP//9v/0//r/BAALAAsABAD6//L/8P/0//z/BAAHAAUA/v/3//L/8f/1//z/AgAFAAMA/P/1//H/8v/4////BAAEAP//+f/1//b/+v8AAAIAAQD+//z/+//9////AAD///7//f///wAAAgABAP///f/9////AQACAAEA///9//z//v8AAAIAAgAAAP7//P/8//z//f///wIABAAEAAAA+v/1//T/+f8CAAoACwAEAPn/8P/w//j/BAAMAA0ABAD5//L/8//6/wMACQAJAAQA/v/6//r//f8BAAQABAAEAAMAAgAAAP7//f/9//7/AQAEAAUAAwD+//r/+f/7/wAABAAGAAQA///7//r//f8BAAUABQACAP7/+//8////AwAFAAMA///6//n//P8BAAUABAAAAPv/+P/5//3/AgAGAAUAAQD8//n/+f/8/wAAAwAEAAMAAAD9//v/+//9/wEABQAIAAYAAQD8//r//P8BAAcACQAGAAEA+//6//3/AgAGAAcABAD///v/+v/8////AgACAAAA///9//3//P/7//v/+//9////AAD+//v/+P/4//r//v8AAP//+//3//b/+f/+/wMAAwD+//f/8//1//v/AwAIAAcAAAD4//P/9f/9/wYACwAKAAQA/P/4//n///8HAA0ADgALAAUAAAD+////AwAIAAsACwAJAAUAAQD//wAABAAJAAsACgAHAAIAAAAAAAMABwAKAAkABgADAAIAAgAFAAYABgAEAAMAAgAEAAUABgAFAAIAAAD//wEAAwAEAAMAAQD+//z//P/9/wAAAgACAP//+//2//X/+P/9/wMABAAAAPj/8f/v//T//f8FAAYAAAD2/+7/7v/0//7/BQAGAAAA+P/z//P/+P///wMAAwAAAPz/+v/7//z//v8AAAEAAQACAAIAAgAAAP7//v8AAAIABQAFAAMAAAD+//7/AAACAAMAAwACAAAAAAAAAAEAAQACAAIAAgACAAIAAgABAAEAAAAAAAEAAQABAAEAAAAAAP/////+//3//P/8//z//v/+//7//f/7//n/+f/6//z///8AAP7//P/5//f/9//6//3///////7/+//5//n/+v/8//7/AAD///3/+//6//r//P/+/wAAAAD///3//P/7//z//v8AAAEAAgABAP///f/8//3/AAADAAUABAABAP7//f///wMABwAIAAYAAwD///7/AQAGAAoACgAGAAEA/v///wQACgAMAAoAAwD9//v///8FAAsADAAIAAEA/P/8////BQAIAAgABAD///r/+P/7////BAAGAAUAAgD9//r/+v/8/wEABQAHAAYAAgD+//v//P///wQABgAGAAMAAAD9//3///8CAAQAAwACAAAA/////wAAAAAAAAAAAAAAAAAAAAD///7//v/+////AAAAAP7//f/8//3//v///wAA///9//z//P/8//3//v///wAAAAAAAP///P/6//r//P8AAAMAAwAAAPz/+f/5//3/AgAFAAUAAQD8//r/+//+/wEAAwADAAEA/v/9//3//v8AAAEAAgACAAEAAAD///7//v///wAAAQACAAIAAQD///3//f/+/wAAAgACAAEA///9//3///8BAAQABAACAP///v/+/wEAAwAFAAQAAgD///3///8CAAQABAABAP3/+//8//7/AgADAAMAAQD+//z//f/+/wEAAgACAAEAAAD+//3//f/+/wAAAgADAAIAAAD+//3//v8AAAMAAwACAP///P/7//3/AAACAAIAAAD+//v/+v/7//3//v////7//f/8//v/+v/6//r/+//8//z//P/7//r/+f/5//r//P/9//3/+//5//n/+//9/wAA///9//n/9//4//z/AAADAAMAAAD8//n/+v/+/wIABQAEAAEA/f/7//v//v8CAAYABwAGAAMAAQD//wAAAgAFAAcABwAFAAMAAAD//wAAAgAEAAUABQADAAEA/////wAAAwAEAAUAAwABAAAAAAACAAMAAwACAAEAAQABAAMAAwADAAEAAAD//wAAAQACAAMAAgAAAP///v///wEAAgADAAEA/v/7//r/+////wMABAACAP3/+f/3//r///8DAAQAAQD8//f/9v/5//7/AwAEAAIA/v/7//v//f8AAAMABAADAAIAAAD/////AAABAAMAAwAEAAQAAwABAAAAAAABAAMABQAFAAQAAgAAAAAAAAABAAIAAgABAAAA///+//////8AAAAAAAAAAP///////////////wAAAAAAAAAA///////////+//3//P/8//z//f/9//3//P/7//n/+f/6//v//f/+//3//P/6//j/+P/5//v//f/9//3/+//6//n/+v/8//3///////7//P/8//z//f///wAAAQAAAP///v/+//7///8BAAIAAwACAAAA///+////AAACAAMAAwABAP///v/+/wAAAwAEAAMAAAD+//7///8CAAUABQAEAAEA//8AAAMABwAJAAgABAAAAP7///8DAAcACQAHAAMAAAD//wEABQAIAAgABgABAP3/+//8////AgAEAAQAAQD9//r/+f/7//7/AQADAAIAAAD9//v/+//+/wEABAAEAAMAAAD+//3//v8BAAMAAwACAAEAAAD/////AAABAAEAAQABAAAAAAAAAP////8AAAEAAQABAP///v/+////AAABAAEAAAD+//3//P/8//3//v///wAAAAD///7//f/9//3//v8AAAIAAgAAAP3/+//7//3/AAACAAIAAAD+//z//f///wEAAwADAAIAAAD///7///8AAAEAAgACAAIAAAD///////8AAAEAAgACAAIAAAD///3//f/+////AAABAAAA///9//z//f///wEAAgAAAP///f/9////AQACAAMAAgAAAP7///8CAAMAAwABAP7//f/8//7/AAABAAEA///9//v/+//8//3//////////f/8//v/+//8//7///8AAP///f/7//v//P/9////AAD///3//P/7//3///8BAAIAAQD///3//P/8//7/AAABAAEAAAD///7//f/9//7//v///////v/9//z/+//7//z//f/+//7//f/8//v//f/+/wAAAAD+//z/+v/6//z///8BAAIAAQD+//z//f///wIABQAFAAQAAQD+//7/AAADAAYABwAGAAUAAgABAAEAAwAFAAcABwAHAAUAAwABAAEAAgAEAAQABAADAAEA/////wAAAQADAAMAAgABAP////8AAAEAAQABAAAAAAAAAAEAAQABAAAA////////AAAAAAAAAAD///7//v/+////AAAAAP///f/7//r/+//9/wAAAQAAAP3/+f/4//n//f8AAAIAAAD8//j/9//4//z///8BAAEA/v/8//v//P///wIABAAEAAQAAgABAAAAAAABAAMAAwADAAIAAQD///7//f/+/wAAAQABAAAA///+//7//v8AAAEAAQAAAP/////+////AAABAAIAAgACAAEAAAAAAAAAAAABAAEAAQABAAEAAAAAAAAA//////7//f/9//3//f/9//z//P/6//n/+f/5//v//f/+//7//f/7//r/+v/7//3///8AAAAA/v/9//3//f///wAAAQABAAAAAAD/////AAACAAIAAwADAAIAAQABAAEAAgADAAUABQAFAAQAAgABAAIAAwAEAAUABAADAAEAAAAAAAEAAwAEAAMAAgAAAP////8BAAMABAAEAAMAAQABAAIABAAGAAYAAwAAAP7//v8AAAIAAwACAAAA/f/8//z//v8BAAIAAAD+//v/+v/7//3/AAABAAEA///8//n/+P/5//v//v8AAP///v/8//r/+f/7//3/AAABAAAA/v/7//r/+//9//7////+//3//P/7//v//P/9//7//v/+//7//v/+//7//////wAAAQABAAAAAAAAAAEAAgAEAAQAAwACAAAA/////wAAAQACAAIAAgABAP///v/9//7///8CAAQABAACAP///P/7//v//f8AAAAA/v/6//j/+P/7//7/AQAEAAMAAQD/////AAACAAQABgAGAAQAAgAAAP////8AAAAAAAAAAP///f/7//n/+f/5//r/+//8//z/+//6//r/+//9/wAAAQACAAEAAQACAAMABQAHAAkACQAHAAUABQAGAAcABwAFAAMAAAD/////AAABAAAA/v/7//n/9//3//j/+v/7//v/+f/4//f/9//4//r//P/9//3/+//6//r/+//9/wAAAgADAAIAAQAAAAIABQAHAAgACAAHAAUAAwADAAQABgAHAAcABgAEAAIAAAAAAAAAAQACAAEAAQAAAP///v/9//7//v//////////////AAABAAIAAgAAAP//////////AQACAAMAAgAAAP////8AAAIABAAEAAQAAgABAAAAAgAEAAYABgAGAAQAAgAAAP//AAABAAEAAAD///7//P/6//r//P/8//z//v////7//v/9//3//v/+////AAD//wAA////////AAAAAAAAAAABAAIAAgABAAAA////////AAAAAAAAAAAAAAAAAgADAAMAAgABAAAA///+//3//v8AAAIAAwACAP//+//2//X/9//9/wMABAAAAPn/8f/s/+7/9v///wUABAD9//b/9P/4////CAAOAA8ACgABAPr/+v8AAAcADAANAAoAAwD6//b/9//8/wIABgAHAAQA/v/6//r//v8CAAUABgADAP///P/7//3/AQAFAAgABwAEAAAA//8BAAQABwAHAAYAAgD+//v/+//9//7//P/3//L/7P/n/+b/6P/s/+3/6//n/+P/4P/i/+j/8v/7/wEAAAD6//T/8P/y//r/CAAVABwAHAAWAA4ACgAMABQAHgAjACIAHAAVABAAEAAUABoAHgAbABIACQAEAAMABAAHAAoACQADAPn/8f/t/+3/7v/x//T/9v/1//L/8P/x//P/9f/7/wUADgATABYAGQAeACMAKQAxADwARQBKAEwAUgBZAFsAVABGADUAJAAWABAAEQAPAAMA7P/P/7L/nf+Q/4z/if9//23/Uv87/zP/Pv9V/23/f/+H/4L/fP+C/6D/0P8IAD4AaAB8AHoAcABxAH8AlQCtALsAtQCTAGAAMAARAAIAAQAFAAIA8P/T/7j/rv+1/8b/2P/m/+r/5//j/+b/8P8AABIAIAAlACIAIgAsADgAQwBSAGAAZQBWADwAKwAqAC4AMAA5AEgASgAxABIABgAIAAAA9P/8/xAAEwAGAPv/8//a/7H/mf+q/8n/1v/S/87/x/+u/5X/nf/I//T/AgD3/+j/1v/C/7f/yv/x/woABADt/9n/zf/A/7v/yv/p//z/9v/m/9//3P/V/9P/5f8LACwAOQA3ADIALAAjACIAMABHAFcAWABOAD8AMQAnACUAJwAlABoACgD7//H/7v/v/+7/5//d/9b/1f/Z/+H/7//9////9//w//X/AwAUACcAOQBBADcAJwAaABYAGgAnADwATABKADYAHAAHAP3/BAAVACMAHwAJAOz/0//F/8b/1f/j/+D/y/+w/6L/ov+r/73/0//f/9r/y//D/8v/3//2/wsAGwAhABoACQD7//r/CQAdAC0ANwA3ACoADQDv/+T/7f/0//H/7v/u/+f/0//J/+L/CAATAAAA8P/1//b/6//4/ygAUABGACQAGgAgABYADwA3AHIAewBNACoAKwAnAA4AEwBEAF0ALwDr/9H/0v+//6z/yv/3//P/xP+n/7D/u/+6/9L/CQAwACUABwABABAAFgAZADEAUQBTADQAFQAMAAcA+P/0/wcAFgAHAOn/3P/c/9b/zv/a/+//6f/E/6n/sv/H/9D/1//s//f/3v+9/8X/8v8LAP7/8/8AABAADQAMACEAJwDz/67/ov/g/zMAYgBiAEcAFADQ/6D/s/8LAGUAeQBKABEA8f/c/8z/4v8kAFcASAAXAAYACwDz/8n/0f8UAD8AIwD//woAFgDw/8v/7f82AEsAIwAQACcALQAMAAgAOwBdADgAAAABACYAJQAEAAIAGgAOANn/vv/a//X/3/+9/7v/wv+q/4n/j/+z/8T/v//F/+L/9f/u/+r/AQAjADYAPwBMAFMAQwAkABMAHAAzAEUASwBBACAA8f/O/8n/3f/2/wYABADx/9H/tP+o/7D/wv/P/9D/zf/R/9j/2//e/+r//P8IAAwAFgAoADUANQA0AEMAVABUAEgAQwBEADgAIwAfADAAOAAiAAQA9//1/+r/4f/w/w0AFQD9/+H/2P/a/9v/5v/+/wwA/f/g/9X/3P/q//j/BgALAPn/3P/N/9L/5P/4/wsADwD+/+j/4v/t//j/AAAOABsAFwAGAPz///8EAAQACgAZABwABgDm/9T/2P/o////GQAlABYA8P/S/9L/7v8UAC8ANAAiAAIA7P/y/w4AKwAxABsA/f/s/+7/+v8HABAADgD7/+H/2f/u/wsAFAAJAAMABAD8/+3/8/8PAB8AEgAKACUAPgAtAAoAAwAPAP7/2v/c/wMAFAD6/+T/5f/T/6H/h/+0//v/FQAKAAcABwDj/7H/t//+/0IATgA5ACoAGwD4/9n/6P8VACsAGQAAAP3////x/9//5f/7/wIA9v/0/wkAGgAMAO//6P/+/xkAKAAyADgALQANAPL/9/8TACcAJQAWAAUA8v/p//f/GAArABcA7v/S/9P/5f/8/w8AFAD8/9L/uf/G/+n/BwAPAAQA7v/X/8z/1v/t////BAACAAMACgAQABEADgANABEAHgAuADsAOAAmAAwA/v8HAB0ALQAqABUA9v/W/8L/xP/a/+7/7P/b/8z/x//F/8X/zP/a/+T/5v/o//T/BAAIAP///P8SADQARgA7ACoAJAAgABUAFgA2AFYAQgACANv/6P/6//H/8/8UACEA7f+y/8L/BwAeAPz/6v/+//f/x//B/wwATQAtAOH/z//s//H/7P8eAG0AcgAeANT/1f/t//D/AgA6AFgAJgDV/7r/1P/l/+L/9P8VABYA7//X/+z/CwAOAAUADAAWAAwA/f8GABkAFgAAAPr/BgAJAPn/7f/y//T/5f/a/+r/AQABAPH/6f/n/+H/3f/v/w8AHwATAP7/7v/h/9//8/8YADIAMgAfAAYA7P/c/+j/DQArADAAJQAWAP3/2//O/+z/FwAjABQADgATAAgA6v/a/+n/+v/3//f/FQAzACEA5//D/9P/9v8IABYALAAsAPn/vP+9//7/NgAwAA8AAAD+//D/7P8SAEQAOAD0/83/8f8tAEMANgAoAA8A2P+q/8T/FQBGACoA8P/T/8//w/+7/9b/AQACANb/u//V//X/6//N/9H/9P8JAAwAHQA4ADAAAgDs/xQASgBUAD8ANAApAAIA4P/1/ysAOAAKAOX/7P/6/+z/4v/x//L/yv+r/9H/GAAuAAUA3P/Q/8P/tv/W/yYAWwBAAAEA5P/t//f/AAAcAD8ARQAtABoAHAAeAA4A+f/z//n/AAAEAAgACQADAPf/5//X/9L/4f/3/wEAAAAEAA8ADAD4/+z/+f8JAAEA8P/1/w0AFAAFAP7/CAACAN//zf/w/yMAKwALAPb/9v/q/83/z////ykAHAD6//3/GgAXAPH/3//0/wMA9v/z/xsAQAAnAOj/yv/d//X//v8PADIAPwAZAOT/2P/x/wUACQAYADgAQQAZAOP/y//T/9//8f8YAEAAOQD9/8L/uP/Q/+n/AAAiADAADgDa/87/7/8IAP7/9P8CAA8ABQD//xUAJAAEANj/2v8CABYACgADAAgA+P/V/9L//v8hAA8A6//q/wYAFwAaACIAJAAJAOb/6P8XAEEAPQAVAOz/0v/L/9//CAApACQA+f/M/7v/yf/m//7/BAD7//X//v8QABkAFAAHAPj/7////ysAVABOABkA4P/K/9j/+/8rAFAARQAFAL7/qP/G//L/EAAhACIACADb/8D/0f/3/wgA/v/0//b/+f/y//T/CQAcABEA9P/n//T/BAAJABAAIQAmAA0A7P/o////EgASAA8AEwAQAAIA/f8LABYABgDn/93/7v8BAAUABwAOAAcA5f/H/9D/9v8OAAsADAAdACAAAgDm/+v//f///wEAHwBDADcA///Y/9//8f/2/wIAIAApAP7/xf+0/83/6P/1/wAACQD9/9//z//c//L/+/8AABAAKAAyACYAFgAMAAcAAwAIABsAMAAvABYA+//1/wQAEgAVAA0A///u/97/4f/4/w4ACADo/8z/yf/X/+f/8////wQA+P/o/+7/BQARAAcAAAAPACoANQArAB4ADwD8//H/AwAsAEMAKADx/8z/z//r/wcAHwApABEA1/+p/7j/+P8uADIAGQD+/9//u/+7//D/KAAtAAwA+P/4/+v/0//a/wMAGgAMAP3/CAAVAAcA8v/x//7/AQD9/wcAFwAZAA8ACQAFAP3/9/8AABAAFgAQAAkAAgDy/+b/7f/9/wMA//8DAAsA/v/g/9X/6f////7/+P8DAA4A///m/+z/CwAYAA4ADAAaABkA/v/y/w0AKwAlAA0ACQAPAAEA7P/2/xgAIQABAOP/5P/w/+7/7P///xAA///b/9L/7f8DAPr/7P/1/woADAACAAMADAABAOj/5/8KAC0ALAASAPT/2f/D/8j/9/8uAEEAJQD7/9v/zf/Y//z/IgAvACUAFwALAPz/8v/6/wgABgD7/wEAFgAYAP//5//l/+r/7P/1/wsAFgADAOX/3P/n//D/9P///wkAAwDw/+z//f8OAA8ACQAHAAUAAgALACMANAAuABsADgAHAAAAAAAOABwAFgD+/+r/5f/n/+v/8//7//n/7v/k/+H/5v/v//n/AAD9//b/9P/2//j//v8MABgAFwANAAUABAABAPz///8MABgAFwANAAEA9v/u/+n/6//z//3/BAAIAAsACwADAPP/4v/a/+H/9f8PACQAJQAPAO//2//e//T/EgAsADEAHAD9/+z/7f/8/xMAKgAvABcA8//k//L/AgADAP//AQD9/+3/4//y/wYA///k/9j/4v/s/+3/+f8RABQA9P/X/+P/BwAaABsAJAAvACEAAAD3/w4AHgAQAAIADAAXAAcA8P/w//3/9P/a/9T/6/////r/8f/1//j/6//c/+P///8UABYAEQASABAAAQD0//r/DQAWAA8ACQAMABMADwAFAP///f/2//L//P8PABoAFAAGAPb/6P/l//b/EAAdAA4A8v/f/9v/4v/z/wsAGQANAPL/4f/m//X/AQAIAA4ACwD+//T/+f8GAAkAAgAAAAkAEwASAAoABQABAPj/8v/4/wUACwABAPP/7f/w//X/9v/4//n/+P/z//L//P8MABYAEQAGAAEABAAIAAoADgAWABgAEQAIAAcACAADAPj/8v/8/wwAEAACAO//4//d/9r/4v/8/xcAFQD0/9j/2v/o/+//+/8XACkAFADv/+r/BgAVAAYA+v8GAA4A///4/xMALwAgAPb/5f/2/wMAAAALACMAIgD5/9L/0//o//L/9/8JABgACQDq/+L/8/////r//P8MABMACAAAAAkAFAAKAPj/8v/4//r/+P8BABAAEQAAAPT/+P////3//P8HABQAEwAIAAcAEQATAAcA/P/9/wMAAwABAAYACwADAPL/5f/m//D/+/8CAAcABwD9/+z/3v/c/+j/+v8IAAwACwAEAPX/5P/j//n/EgAbABUAFAAVAA0A/P/z//v/CAALAAsAFgAgABEA7v/Y/9//8//+/wIACAAIAPL/1v/V//L/DAAKAPv/9//8//v/+f8FABgAFwD///L/AgAcACQAGQALAAAA8//q//f/FQApAB4ABQD1//P/8//y//n/BgALAAIA+P/8/wUAAQDy/+z/9/8GAAwADAAKAP//7P/i/+3/AwALAAYAAAD4/+r/4f/v/wgAEAADAPj/AAAIAAIA/P8BAAQA+f/x/wQAIQAkAAoA8//v//D/7//7/xkALQAdAPv/6f/u//X/9f/5/wcADQACAPL/7P/v/+//6f/n/+//+f///wEABgAMAAwAAwD4//n/CAAXAB0AHgAeABsADwAAAPr/AgAIAAMA+//9/wYACQACAPv/+v/1/+j/5f/4/w8AEAD+//D/8P/x/+3/8f8FABYADwD9//v/BgAGAPb/7v/4/wUABgAGABEAGwAMAPD/4//u////BwANABQAEgAAAOr/4//s//b/+/8BAAkACQD6/+f/4P/n//T/AwATAB0AFwACAO//7f/5/wgAFQAgACEAFAACAPz/BAAJAAQA//8DAAcABAAAAAEAAADx/+D/4P/v//j/9P/x//X/8//q/+r/+v8KAAgA/v8CABAAFwASAA0ADAAJAAQABwAUAB8AFwABAPD/7//2//7/BgALAAcA9//m/+H/6//3//z/+//7//7/AAD+//v/9//z//H/9f8BABEAGQARAP7/8P/v//r/CwAaACMAGwAGAPP/8P/7/wkAEgAVABIABgD1/+n/7P/4/////P/3//b/9v/1//b//P8BAP3/8v/s//L//v8HAAsADQAKAAAA9//4/wQADgAPAAsACQAIAAcACQALAAcA/P/w/+//+P8CAAUABAD+//P/5v/g/+n/+v8FAAYABAAGAAMA+P/y//j/BAAMABEAGgAhABcAAgD2//z/BwAMABAAFwAUAAEA6//m//H/+////wAA/v/2/+v/5f/q//H/9v/5/wAABgAFAP3/9P/x//P/9v/8/wYADwAPAAcAAQAEAAoADQAMAAkABgAEAAMABQALAAsAAwD4//P/9f/5//r/+//8//3//P/8////AgD+//n/+/8GAA8ADwAHAP//+P/2//v/BgAPAAwA/P/t/+r/9f8GABEAEgAKAPv/7v/r//v/FAAjAB0ACgD7//L/7f/z/wYAFwAWAAcA/f/7//b/7//x////BwACAPv//f////j/7v/r//D/9P/2//z/BAAGAAAA+f/1//T/9//+/wgADQAKAAQA/v/6//r/AAAIAA0ADQALAAUA/P/z//P//P8FAAYAAgD///3/9//x//P//f8DAAEA//8AAP7/+P/4/wMADQALAAMAAgAEAAIAAAAHABAADwADAPr//f8FAAcABQAGAAYA///2//X//v8FAAEA+////wgACwAFAP///f/7//j//P8LABUADgD7/+n/4v/k/+//AQARABAA///s/+L/5P/u//z/CAAMAAkABAD///r/9//7/wEABAAFAAkADgALAAAA+f/7/wEABgAKAA0ADAAFAPv/+P/7//7//v/+//7/+v/0//P/9//6//f/8v/x//T/+v8CAAoADgAJAAMAAQAEAAgADAAQABIADwAHAAQABgAJAAsACgAHAAMA/v/8//3/AAABAAAA/f/3//H/8f/1//j/+////wMAAgD9//n/+f/5//r//f8DAAoADAAJAAMA/f/5//j/+f/9/wUADAAOAAoAAwD7//L/6//u//n/BgAMAAoAAADy/+f/5f/u//3/CQAMAAUA+v/x//D/9/8CAA4AFAARAAYA/P/7/wEABwAKAAsADQAOAAwACAAIAAgAAAD1//L/+f8BAAQAAwABAPf/5f/b/+T/9/8DAAUABAACAPr/7//v//7/DAANAAoADQAQAAsABAAEAAoACAAAAP3/BQAMAAkAAQD7//f/8v/u//L//v8GAAMA+v/1//X/9v/3//n//v8BAAAA//8CAAcABgD///j/9//8/wUADgAUABEABgD8//b/+f8DABAAFgAQAAAA9P/y//b//P8CAAcABwAAAPf/8//2//j/+f/7/wEABAABAPz/+P/3//b/+P///wkADgAIAP7/+v/9/wIABgAJAAoACAABAPz//f8CAAMAAAD7//r/+//7//v//f/9//v/9f/0//j///8CAAEA//8AAAEAAAABAAQABwAGAAYACgAPABEACwADAP3/+//+/wMACQAMAAcA+//v/+z/8f/4//3/AAABAP//+v/4//v////7//L/7v/0//3/AgAGAAgABQD5/+7/8f/+/wkADQAOAA8ACQD9//b/+/8EAAYABAAIAAwABwD6//T/9//5//n/AAALAA8ABwD8//n/+////wQACQAKAAYAAAD+/wEAAwACAAAA/f/7//v//v8BAAIAAQD///z//P/+/wMACAAIAAUAAgABAP////8CAAcACAAFAP///f8AAAQABwAFAAEA+P/w/+3/9P8CAAwACwD//+//4//h/+z/AAARABQACQD3/+n/5//u//z/CQAQAA4ABQD8//f/+P/7////AwAHAAoACgAGAAAA+v/2//b//P8FAAoACAABAPr/9f/z//b//f8FAAcABAAAAP7//f/9//7/AQAFAAYABgAHAAkACAAFAAIAAgADAAQABQAGAAUAAgD+//z//P/9////AQADAAYABgADAP7//P/8////AwAIAAoABgD+//X/7//w//f///8GAAYAAAD2/+3/6//w//j/AQAHAAcABAD+//n/9//4//r///8DAAYABwAFAAEA/P/6//v/AQAGAAkACAAFAAAA/P/9/wAABAAEAAAA+v/2//f/+v/+/wEAAAD6//X/9P/6/wMACQAKAAYAAAD6//r/AgAMABIADgAGAP7//f8CAAoAEgAUAA0AAgD5//j//P8DAAcACAADAPz/9v/0//j//f8BAAIAAQD+//v/+P/4//v/AAAEAAYABgACAPz/9v/2//z/AwAIAAkABQD///j/9f/4//3/AAAAAP///v/8//r/+f/6//v/+v/5//v///8DAAIA/f/6//v//P/+////AgADAAIAAAAAAAIAAwACAAIAAwAGAAgACAAIAAoACgAFAP7//P/9//v/+f///wkACgD///L/7P/s/+3/9f8FABIADAD7//H/8v/2//r/BAARABYADQAAAP3/AAABAP//AQAHAAkABQABAP7//P/4//T/9////wUABgACAPz/9//z//T/+/8EAAkABgD///n/9//6/wAABQAGAAQAAgABAAEAAwAFAAcABQD///v//P8CAAgABwACAP3/+f/3//r/AAAHAAgABAD9//n/9//3//r/AQAFAAUAAQD9//r/+P/2//n///8GAAkABgABAPz/+v/6//7/BAAJAAgAAwD///7//////wAAAAD///3/+//7//3///////z/+//7//z//P/9////AQACAAMABQAIAAcAAwD/////AwAGAAgABwAEAP//+v/6//3/AAAAAPz/+f/5//v//v8DAAUAAgD5//H/7//1//3/AwAFAAMA/P/0//D/9P/9/wQABwAIAAcAAQD7//j//P8DAAYACQAMAAwABQD7//j//P///wIABwALAAgAAAD6//r//v8CAAUABwAGAAMAAAABAAMAAwACAAAAAAABAAMABQAFAAIA/f/6//r//P8AAAQABgAEAP//+//6//v//v8CAAYABgACAP7//f8BAAYACAAGAAEA+v/1//f//v8HAAkAAwD5/+//6v/u//n/BQAKAAUA+//y/+3/8P/4/wAABQAFAAEA/P/5//j/+f/8////AgAFAAYABQACAP3/+f/6////BgALAAsABwAAAPv/+f/8/wAABAAFAAQAAAD9//z//P/9////AQADAAMABAAEAAQAAwADAAQABQAHAAgABwAGAAQAAQD///7///8BAAIAAwACAAEA///8//r/+v/8/wAABAAFAAQAAAD5//X/9P/4//7/AwAFAAMA/f/2//L/8//2//v///8BAAAA/f/5//f/+P/6//z//v8BAAIAAQAAAP///v///wAAAwAFAAUAAgD///3//v8AAAMABQADAP7/+v/5//z/AAAEAAUAAgD9//r/+////wUACAAGAAIA/f/7//7/BAAJAAoABQD+//v//v8FAA0AEAAOAAcA///8////BAAIAAkABgAAAPr/9//4//z/AAACAAEA///7//f/9f/3//z/AQAFAAUABAD///r/9v/4//3/AwAGAAYAAgD9//j/9v/4//z//v/+///////+//z/+v/5//v//P/9/wAAAwAEAAEA/f/8//3///8AAAIAAwADAAIAAgABAAEAAAD+//7/AAADAAUABAAEAAQAAwD///v//P/9//z//P8BAAgABwD///f/9f/3//j//v8IAA0ABgD5//T/9//7//3/AgAJAAoAAgD7//v/AAABAAAAAgAHAAgABAABAAAA///8//r//f8DAAUAAgD+//n/9v/0//f//f8DAAQAAQD9//r/+v/+/wMABwAHAAQAAQABAAIABAAFAAYABAD///v//P8BAAQAAgD+//r/+P/4//v/AQAFAAUAAAD7//n/+f/6//7/AwAFAAQAAAD+//z/+//6//3/AgAGAAcABAD///z/+//8////AwAFAAMA///9//3///8BAAIAAQD///3//P/9/wAAAwADAAEA/////////v/+//7///8AAAEABAAFAAMA/v/6//r//f8AAAIAAwACAP//+//7//7////9//n/+P/5//z///8CAAMA/v/2//D/8f/4/wAABQAGAAQA/v/4//b//P8FAAsADAAMAAoABQD+//v///8DAAUABgAJAAkAAgD6//j/+//+/wEABQAIAAYAAAD7//z/AAADAAQABQAFAAIAAAABAAMAAwAAAP7//v8BAAMABgAGAAMA/v/6//r//f8BAAUABwAEAP//+//6//v//v8BAAMAAQD8//j/+f/9/wEAAgAAAPr/9P/w//T//f8FAAcAAgD5//D/7f/y//z/BwAMAAcA/v/2//L/9P/7/wIABgAGAAMAAAD9//z//P/9/wAABQAJAAsACgAFAP//+v/7////BgAKAAoABQD+//n/+f/7/wAAAwAFAAQAAgAAAAEAAgAEAAUABgAHAAcABwAHAAcABQADAAEAAgADAAMAAwABAP7/+//5//j/+f/7//3//v///////f/6//b/9v/4//3/AgAFAAUA///4//L/8f/1//z/AwAGAAUAAAD4//T/9P/3//z/AQAEAAMAAAD8//v/+//8//3/AAADAAQAAwAAAP///f/9////AwAEAAMAAAD9//z//v8BAAUABwAFAP//+//8/wAABgAKAAoABQD///v//f8DAAkACwAIAAIA/f/8/wEACQAPAA4ABgD+//n//P8EAA0AEAAMAAIA+P/0//f//f8CAAQAAAD6//T/8P/y//j///8EAAQAAgD9//j/9f/3//z/AwAHAAkABgAAAPj/9P/1//r/AQAFAAUAAQD8//f/9v/4//v//f/+////AQACAAAA/v/8//v/+//+/wIABwAJAAcAAQD+//3//v8AAAEABAAGAAYABAACAAEA///9//z//v8BAAIAAgACAAMABAAAAPv/+P/4//f/+f8DAA8AEAAFAPj/8f/x//X/AAAPABcADgD8//P/8//3//3/BQAOAA4ABQD7//r//f/+//3///8EAAYAAwD///3/+f/0//L/9/8AAAYABQAAAPr/9P/z//j/AgAKAAwACAACAP3//P8AAAUACAAHAAIA/v/+/wAAAgACAAAA/P/2//T/+f8AAAUAAwD9//b/8//0//n/AgAJAAoABQD+//n/9//4//3/BAAKAAsACAADAP7/+f/4//v/BAAMAA4ACgACAPv/+P/5////BQAIAAYAAAD8//z///8CAAQAAwABAP3/+//8/wAABAAEAAIA///+//7//P/7//z//f///wEAAwAEAAEA+v/2//b/+/8AAAIAAQD+//r/9v/3//z////8//b/8v/y//f///8GAAkAAwD3/+3/7v/4/wYAEAATAA8ABAD4//T/+v8GAA8AEgAQAAoAAAD2//P/+P///wMABgAJAAgAAAD3//b/+v8AAAUACwAPAAwAAwD9//3/AQAFAAgACgAIAAQAAQACAAQABAABAP////8AAAQABwAIAAQA/v/4//b/+P/9/wQABwAGAP//+P/0//X/+P/+/wIAAgD8//f/9v/6/wAAAwAAAPr/8f/t//H//P8JAA0ABgD4/+v/5v/s//v/CwATAA0A///x/+v/8P/6/wUADAAMAAcAAQD9//z//v8AAAMABgAKAAwACgAFAP3/9//1//r/AgAJAAsABgD+//j/9//7/wIACQAMAAoABgADAAMABgAIAAkACAAHAAUABAAEAAQAAgD///z/+//9////AQAAAP7/+v/3//b/+P/8/wAAAgADAAIA/v/6//b/9f/4//3/AwAHAAYAAAD3//D/7v/z//v/BAAKAAkAAgD4//H/8P/1//3/AwAGAAQAAAD7//j/+f/7//7/AQADAAQAAwABAP///v/+/wAABAAFAAQAAQD+//3//v8CAAYACAAFAP//+v/6//7/BAAJAAkABQD+//n/+/8CAAkADQAKAAQA/f/8/wAACgARABAACAD+//f/+f8AAAkADgAKAAAA9f/w//L/+f8AAAMAAQD7//T/8f/0//r/AgAGAAcABAD///r/9//4//3/AwAHAAkABwAAAPn/8//0//r/AgAHAAgABQD///n/9v/4//z/AAACAAMAAwACAAAA/f/8//z//P/9/wAABAAGAAQAAAD9//z//P/9////AgAFAAUABAACAAAA/v/8//z//v8CAAMAAgACAAIAAgD+//n/+P/4//f/+f8CAAsACwABAPf/8//z//b/AAANABMADAD9//b/9v/5//7/BQAOAA4ABgD+//3///////7/AAAEAAUAAgD///7/+//1//P/9////wQABAABAPz/9v/0//j/AAAIAAsACAACAP3//P/+/wMABgAGAAIA/v/9////AAABAAAA/f/4//b/+v8BAAUABAD+//n/9v/2//v/AwAIAAkABAD+//r/+P/5//3/AwAHAAcABQACAP7/+//5//z/AgAIAAsACAADAP7/+//8////BAAHAAUAAQD+//7/AAACAAMAAgAAAP3/+//8////AgACAAAA///+//7//f/8//z//P/+/wEABAAFAAIA/f/4//j/+////wEAAgAAAPz/+v/6//3////9//j/9f/1//n//v8EAAUAAAD3/+//8P/4/wIACQAMAAkAAQD5//b/+/8FAAwADgAOAAoAAwD7//j/+v///wEABAAHAAcAAQD6//f/+f/9/wEABwALAAkAAwD9//z///8CAAUABwAHAAQAAgACAAIAAgD///7///8CAAUABwAHAAQA/v/6//n//P8AAAUABwAFAAAA+//5//r//f8BAAMAAQD9//n/+v/+/wMABAABAPv/9P/x//b//v8HAAkAAwD5//D/7f/y//3/BwAKAAYA/v/2//L/9P/6/wAAAwAEAAIAAAD+//3//f/9////AgAHAAoACgAGAAAA+//5//3/AwAIAAgABQD///r/+P/6//7/AgAEAAMAAQD/////AQACAAQABQAFAAUABgAGAAUABAACAAAAAQADAAQABAADAAAA/P/5//n/+//+/wAAAgACAAEA/v/7//n/+f/7////AwAGAAUAAQD6//X/9P/3//z/AwAGAAYAAQD7//b/9v/5//3/AQADAAMAAAD9//v/+//7//3///8BAAEAAQAAAP7//f/9////AQADAAIAAAD+//3//f8AAAMABAADAP//+//7//7/AgAFAAUAAgD9//v//P8AAAUABgADAP//+//7////BgALAAoABAD9//v//f8FAAwADgALAAQA/f/7//3/AgAGAAYAAwD9//f/9P/1//r/AAADAAMAAQD9//n/9v/4//z/AgAGAAgABwACAPv/9//3//v/AQAGAAgABgABAPv/+P/5//v//v8BAAMABAADAAAA/f/7//v/+//+/wEABQAFAAMAAAD9//z//P/9//7/AAACAAMAAwACAAAA/f/8//z//f8AAAIABAAEAAUABAAAAPz/+v/6//r//f8DAAkACAAAAPj/9P/0//f///8IAAwABgD8//b/9v/3//v/AQAHAAgAAwD+//3//v/+////AgAHAAgABgAEAAIA///7//r//f8CAAUABAAAAPv/9//1//f//f8CAAMAAgD+//v/+//9/wEABAAFAAMAAgACAAMABAAEAAQAAQD+//z///8EAAYABAD+//n/9//3//v/AgAGAAYAAgD9//n/+P/5//3/AgAFAAQAAgD///z/+v/5//v/AAAEAAYABAABAP7//P/9////AgAEAAIAAAD+////AAACAAMAAwABAP///f/9////AQACAAIAAQAAAP///f/8//v//P/9/wAAAwAEAAIA/v/7//r//P///wEAAQABAAAA/////wEAAAD+//r/+f/6//7/AgAFAAQA///3//L/8v/4////AwAFAAEA+//1//T/9//+/wUACQAKAAkABAD///z//f8BAAQABwAJAAkABAD9//n/+v/8////BAAHAAYAAQD8//v//f///wIABAAFAAQAAwACAAIAAAD+//7///8BAAQABwAHAAQA///8//z//v8CAAUABwAFAAIA/v/9//7/AQADAAMAAQD9//v//P8AAAQABQACAPz/9//1//n///8GAAcAAgD7//T/8v/1//z/AwAGAAQA///6//f/9//6//3/AAABAAEA///9//r/+f/5//v///8DAAYABgADAP7/+//7////BAAHAAgABgABAP7//P/9////AgACAAEAAAD+//z//P/9//7/AAABAAMAAwADAAIAAQABAAIABAAGAAgACAAHAAQAAQD///3//v8AAAIAAwADAAEA/v/7//n/+P/6//7/AgAFAAUAAQD8//j/9v/4//z/AQAEAAQAAQD8//n/+P/5//z///8BAAEA///9//z/+//7//z//v///wAA///+//z//P/8//7/AAABAAEA///9//z//f8AAAIABAACAP///P/8//7/AQAEAAQAAgD///3//v8BAAQABQADAP///P/8////BAAGAAUAAAD8//r//P8CAAgACgAIAAQAAAAAAAMABwALAAwACQAEAP7/+//7//7/AgAFAAUAAgD9//j/9f/1//n//v8CAAQAAwAAAPv/9//3//v/AAAEAAcABgACAP7/+//7//z//v8BAAMABAACAAAA/f/7//r/+//9/wAAAgADAAEA///9//z//P/8//3///8AAAEAAgABAP///f/8//v//P/+/wAAAgADAAQABAACAP7//P/8//3///8EAAkACAACAPv/+P/3//r///8GAAkABQD9//j/9//4//v///8EAAQAAAD8//v/+//7//z///8DAAUABAADAAIAAAD+//7/AQAFAAgACAAFAAAA/P/5//v///8CAAMAAAD8//j/9//5//z///////7//f/+/wAAAQADAAQAAgAAAP//AgAHAAkABwACAP3/+//6//3/AgAGAAYAAgD+//v/+f/6//3/AQAEAAQAAgD///3/+v/6//v///8CAAMAAgD///z/+//8//7/AQACAAEA///9//3///8CAAMAAwACAAAA/v/9////AQACAAMAAwADAAEA///8//v/+//8////AQADAAEA/f/6//n/+v/8//7///////7//v/+/wAAAAD9//v/+v/7////AwAHAAcAAwD8//f/9//7/wEABgAHAAMA/P/1//L/8//5////AwAFAAQAAAD8//n/+////wMABwALAAwACAACAP7//v///wIABwAKAAkABAD///3//v///wIABAAFAAQAAwADAAMAAgD///7//v8AAAMABgAGAAQA///7//n/+//+/wIABAADAAAA/P/7//3/AAADAAMAAQD9//v//P8CAAcACQAGAAAA+f/1//j/AAAHAAoABgD8//P/7v/v//b///8EAAMA/v/3//P/8v/2//v///8CAAMAAgAAAP3/+v/5//r///8EAAgACQAGAAAA+v/5//z/AgAIAAsACQAEAP///P/9/wAAAwAFAAUAAgAAAP7//f/9//3//v///wAAAQACAAEAAAD/////AAADAAcACgALAAkABgACAAAA//8BAAMABQAGAAQAAQD7//b/9P/0//j//v8DAAUAAgD8//b/8//0//n/AAAGAAgABgAAAPv/+P/4//z/AAADAAQAAgD+//v/+P/3//j/+v/8//7//v/8//r/+P/4//r//v8BAAIAAQD///7//v8BAAUACAAHAAQAAAD+////AwAGAAcABAAAAPz//P///wMABQAEAAAA+//5//z/AgAHAAcAAgD7//b/9v/8/wQACgAKAAUA/v/7//3/AwALABEAEQAMAAUA/v/9////BQAKAAsACQADAPv/9f/z//T/+P/9/wEAAgD///n/9P/y//T/+f8AAAUABwAFAAAA/f/7//v//v8BAAUACAAIAAUAAQD+//v/+v/7////AgAFAAQAAQD+//z/+v/5//r//f8AAAIAAgACAAAA/f/7//n/+f/7//3///8CAAUABwAFAAEA/P/4//b/+v8EAA8AEgAMAAEA9v/w//D/+v8IABIAEAAFAPr/8v/w//P//P8FAAkABgD///r/9//1//X/+P/9/wIABQAGAAUAAAD7//f/+v8CAAsAEQAQAAoAAQD6//n//v8FAAoACQADAPz/9v/1//j//P/8//v/+P/4//n//P///wAA/v/6//n//f8FAAwADgAJAAIA+//3//r/AgAKAA4ACwAEAPz/9v/0//f//v8FAAkACAAEAP7/9//0//b//f8FAAkACAADAPz/9//2//v/AQAFAAUAAQD8//n/+v/+/wIABQAFAAEA/f/7//3/AAADAAYABwAHAAQAAQD9//v/+//9/wAABAAGAAMA/f/3//T/9f/4//z///8AAP3/+//6//3////+//v/9//2//n/AAAJAA4ADAACAPb/7//z//3/CwAUABQACQD4/+v/6f/x//7/CgAQAA4AAwD2/+7/7//1//7/CAAPABAACQD///j/9v/3//3/BgAOABAACgACAPz/+v/7/wAABgAKAAsACQAHAAYABAABAAAAAAABAAMABwAKAAkABAD7//T/8f/y//j/AAADAAEA+v/0//L/9P/6/wEAAwAAAPv/+v8AAAsAFQAWAA0A/v/x/+//+/8QACEAIgARAPb/3v/W/+H/+v8SABsAEgD7/+T/2P/c/+z///8OABEACwD///T/7v/u//P//P8IABIAFgATAAkA/P/z//T//f8MABkAHAAUAAUA+P/w//L/+/8EAAgABAD9//b/8v/y//X/+P/7//3///8CAAYABwAFAAEA/v8AAAUADQAUABUAEAAFAPv/9f/2//z/BQAMAA0ABgD7/+7/5v/l/+7//P8KABIADwADAPP/5v/k/+7/AQAUAB0AGQALAPr/7v/t//b/AwAOABIADgAFAPr/8//x//P/9//8/wAAAQD///v/9v/0//X/+v///wMAAwAAAP3//P8AAAYACwAKAAUA/P/4//r/AgANABQAEQAGAPn/8//3/wMADwATAA0A///y/+//9/8EAA0ACwD9/+z/4v/m//b/CAATAA8AAADw/+n/8P8CABUAIAAdAA4A/f/y//T/AAAPABkAGgAQAAEA9P/t/+//+f8EAAwADQAHAPz/8f/r/+z/9P/+/wYACQAFAPz/8//v/+//9P/6/wEABgAHAAYAAwD///z//P/+/wIACQAPABMAEQANAAYA///6//n//P8BAAYABwADAP3/9v/w/+z/7f/u/+//8f/1////CgAOAAoA/v/v/+P/5////yAAOAA4ACAA/f/e/9L/4/8IACsANgAlAAQA5P/R/9H/5f8AABEAEQAGAPn/7v/m/+P/5//x//3/CQAUABgAEQABAPH/7f/3/wwAIAAqACMADwD4/+v/7v/9/wwAEgAMAP//8v/t//H/+f/9//v/9f/y//b//v8HAAsABgD6//H/8/8AABAAGgAYAAsA+P/r/+r/9v8IABUAFwANAPz/7P/j/+f/9f8HABQAGAARAAMA8//p/+v/+P8KABcAGQAOAP7/8P/q//D//f8IAAoAAwD4//H/8v/5/wMACAAGAP3/8//w//X///8JAA4ADgAJAAEA+v/3//f/+/8BAAgADwARAAwAAQD2//D/8v/7/wYADgAPAAcA/P/2//j///8DAAAA+P/w/+3/9P8DABEAEwAFAO//3//d/+3/BwAfACkAHAAAAOb/3P/m//z/FAAlACUAFAD8/+v/5//u//n/BwATABYACwD7/+//6P/n/+3/+/8KAA4ABgD7//P/8P/z//3/CQAQAA4ACgAJAAwADgAPAA8ADAAHAAUACQASABcAEwAHAPj/6v/j/+b/8//+/wAA+P/s/+P/4f/p//X//v/+//j/9v8AABQAJwAvACQACQDs/+H/8v8aAEEATgA3AAQAzv+w/7r/5f8ZADgAMgALANv/uv+2/87/8/8TACAAGQAGAPP/5//j/+f/8v8CABQAIgAlABwACAD0/+n/7v8BABcAJAAiABIA/v/v/+v/8//+/wMAAQD7//b/9v/5//z//P/4//P/8v/4/wIACQAJAAIA+v/1//j/AQAOABQAEQAHAP3/+P/5/wEADQAXABoAFAAGAPf/6v/l/+z//v8SAB8AHAAKAO7/1f/M/9n/+P8YACoAJwAQAPP/3v/b/+r/AAATABkAFAAIAPz/9P/w//H/8//2//v/AQAHAAkABgD///r/+P/6////AwAGAAcABwAHAAkACQADAPj/7f/p/+///f8NABYAEgABAO3/5P/q//3/EgAeABoACgD3//D/+f8MABoAGAAIAPH/4f/h//P/CwAYABIA/f/l/9f/3P/y/w4AIAAfAA4A+f/t//D/AAAVACUAKAAeAA4AAAD7//3/BAAMAA8ACwACAPb/7v/q/+r/7v/y//T/8v/u/+z/7P/v//L/9v/6//3/AQAHAA4AEgARAA0ACAAHAAoAEgAcACEAHgAUAAcA/P/y/+3/7//1//v//f/7//X/6//d/9H/zP/Q/9v/6P/5/w0AGgAaAA0A+f/l/9f/3v8FAD0AZQBpAEcADgDU/7f/y/8IAEkAZABOABsA4v+5/7H/zf/2/w8ACwD4/+f/3f/Z/9j/3P/i/+j/8/8JACAAKAAbAAYA+f/+/xIAKwA8ADgAHAD5/+b/7/8IAB4AIgASAPP/2P/R/+P//v8QAA0A/f/s/+T/6v/8/wwADAD8/+v/5v/y/wcAFgAXAAYA6//V/9b/7f8OACcALgAhAAUA6f/d/+X//P8XACsAMgApABIA9v/h/9v/5P/4/w4AGgAUAAAA6f/Z/9j/4//y//r/+f/y//D/9f8AAAsADgAFAPT/5v/o//v/FgAsADMAKgATAPn/6v/s//n/DQAeACgAJwAdAAsA9v/m/97/5P/1/wgAGAAdABUAAgDw/+b/5f/q/+//9f/7////AwAJABAADQD5/+D/0f/T/+T//v8dADMALQAJAOH/y//L/9z//f8lADwALgAJAO3/5P/j/+n//P8TABcABAD1//j////7//b//v8EAPz/9P/9/xIAHAAcACEALQAuACIAGQAdACAAGAASABoAJQAfAAsA+P/p/9T/wP+8/8f/zf/E/7z/xP/T/9z/4v/t//f/+P/8/xUAPABYAFwAVwBdAG4AewB9AGgALgDX/5b/o/8EAHkArwB3ANn/E/+C/ob+Kv8TALoAxQA9AHn/4v7G/iz/1v9kAJEAZAAcAPb//v8ZACgAJAAVABMANAB5AL0AyACDABsAzv+//+L/HgBTAGAANADu/8T/yP/a/9f/wv+2/73/1P/9/zAARgAeANH/oP+w/+r/JwBTAGMARwAMAOT/8v8eADYAKwAXAAgA/v/+/xcAOgA6AAsA0P+x/63/t//Q//X/FAARAPX/2P/E/6r/kf+V/8X/CQBBAFoAUQAgANb/nP+b/9H/FgBGAFMAQwAcAPH/2P/b/+n/7f/o/+3/AgAfADIAMwAkAAUA4P/K/9L/8/8VACcAKwApACEAEAD6/+n/4f/h/+//EQA/AF8AWQAxAP//2v/O/+P/FABFAFUAOgAJAOX/2v/l//v/DQALAPD/1v/Z//z/KABAADgAEQDb/7L/tv/o/yYASgBDABkA4f+0/6z/zf/7/xUAEQD9/+X/0f/N/97/9/8HAAgAAQD3/+b/0//N/9z/+P8TACMAIAAFAN7/xv/R//r/KgBFAD0AGADt/9n/6P8NACsALQASAO//4P/0/xwANQAoAP3/zv+0/8D/8P8qAEYAMwAKAPT/9f/8//z/+P/w/+T/7v8nAHcAnABwABIAtf98/3f/v/9CALEAvQBrAPv/nv9j/2L/rP8dAGcAYwA1AAgA2v+p/5D/qP/R/+X/6f/8/x0AJwASAPv/8//p/9X/0v/1/yQAPQA/AD8AOgAhAPv/4P/Y/9P/zf/W//r/JAA2ACQA9v+6/4f/f/+0/xEAYgB4AEwA9/+p/4//vP8XAGkAgABVAAgA0P/S/wcARwBiAEUAAwDJ/8H/9v9DAHEAXgAVAMf/n/+w/+z/JgA2ABQA3f+6/7v/1P/t//X/6//j//H/FAAwACcA9v+9/6D/uv8IAGUAlwB7ACYAz/+j/67/4v8eAD4AMQAQAAUAGwAtABkA4f+k/4P/lP/d/0UAjgB9ABkAp/9q/3D/p//2/0UAbABTABcA7v/n/+b/2//e/wAAJAAqACAAJwA1ACQA/f/v//r/7//B/6j/zf8OADYAQwBJAC0A1P92/2v/u/8bAFUAcwB9AFcACADT/+D/AgD//+r/9P8aADQAPQBFADoA9v+T/2X/kv/u/z8AbQBtAC4Awv9z/4D/2f8yAFsAUgAnAOb/t//I/w4ARQA5AAYA4f/d//L/HABNAFoAIADG/5j/sv/s/x0APgBEABsA1P+u/8v//v8RAAQA9v/m/9D/0f8IAE4AWAAbANX/r/+f/6X/3v86AG4AUgAYAPn/6P/J/7j/1/8JABcADAAbAD0APAANAOb/3//S/7L/sv/1/0oAbwBiAEsAIwDX/43/jP/Y/yUAPwA9AEAAOAAPAOP/1v/T/7X/kv+s/wsAaQCGAGcAKwDg/5X/ff+6/yIAYgBiAFAASQA7ABAA2v+4/6r/rf/a/z0AoACoAEIAsf9M/zr/df/m/2EAngB2ABIAwf+q/7L/uP/A/9n///8kAEUAYQBZABMAsf99/5//9v8+AFgASQAeAOv/1v/1/yMAIQDh/57/lv/Q/yQAaAB4AD0A0P9+/4j/4v8/AGIAQwAFANf/2/8TAE0ATQAKALb/i/+o/wAAYwCRAGYAAwC0/6T/wv/r/xAAJgAjABQAGQAxAC4A7v+c/4L/tv8PAFwAhgB0AB4AtP+M/8n/LgBlAFgAKAD3/9L/z//7/zYAQQAIAMD/pP+2/9T/7P8DABQACwDv/+T/+/8UAA0A9f/r/+3/5P/X/+v/JQBZAGQATQAjAOL/lP9t/5b/9/9LAGwAYQA6AAAAyv+7/9H/5//k/9j/4P/+/yMAPgBIADQABADN/63/s//W/wMAKwBEAEkAPAAjAAMA6P/Z/9z/8f8RAC4AOwAvABIA+P/s/+v/7f/p/9z/0P/V//D/FgAxAC8AEADi/7v/sf/K//H/DwAaAB4AIwApACsAJQANAN7/rf+f/8X/EABcAI0AjgBVAPb/n/98/5D/yP8NAE0AawBTABIAzv+j/5f/pv/N/wEAJgAnABQABQD9//H/4v/h//b/FgA2AE8AVQA4AP7/yf+9/+H/GwBJAFAAJwDk/6//rf/f/yQATQA6APP/of93/5L/6P9OAJAAigA9AM//ev9o/5v/9v9NAH0AdwBFAAYA2P/G/8v/4P/7/xMAIQAlACEAFgAFAPb/8//5//r/7//g/9n/4v/+/ygASwBGAAcAsP96/4r/1P81AH4AhwBBANT/h/+O/9b/KgBbAFwANQD9/9n/4f8GAB8AEADq/9L/1//x/w4AJAAmAA4A5f/H/8n/3//t/+r/6v/7/w8AFgAVABIA///R/6r/tf/y/zIAUQBWAEsAKAD1/9v/8f8RAA4A8v/q/wMAIwA6AE4ATQAWALT/cP99/8b/FABLAGQATwAKAMP/tP/c/wkAEgACAPT/9P8GADEAYgBtADQA1P+Q/5L/1P8wAHcAfwBAANX/ff9r/6n/CgBTAF8AOAD7/8f/tv/R/wYALQApAAwA+f/6//3//f8GABEABgDn/9f/5f/2//b/+P8NABsABgDl/+H/9v8DAAQADgAaAAMA0v+//+D/CQAMAPv/+v8CAP//AwAhADYAFQDU/77/7/80AFwAZABNAAoAsP+H/7b/DAA7ADMAGQAAAOX/0//c/+//6v/T/9r/FABaAHUAWgAbANH/mv+Z/9b/JgBUAFAAMgAVAAkADAANAPT/wP+R/5P/1/9DAKAAtQBoANj/VP8o/17/0f9BAH8AdwA6APb/0//T/9f/z//K/9//DgBJAHkAhABPAOX/gP9a/4D/1P8sAGMAYQAqAOD/tP+0/8v/3//s//j/CQAkAEoAaABlADMA6v+x/6L/vf/1/y8AUQBNADEAEADz/9z/y//B/8H/0v/6/zQAYgBnAD0A+P+x/4H/g/+//xQAUgBeAEYAHwDz/9H/z//q/wIAAgABABoARwBmAGoAWQAsANv/hf9o/5r/8f88AG0AegBMAOT/f/9d/33/tP/u/zAAYwBhACoA9P/g/9z/z//Q//n/LwBGAD4ANwAuAAUAyf+y/9X/BwAfACQAKgAfAPL/wv+9/9z/7v/n/+f/AAAXABYAEQAaABcA8f/A/7b/3f8RADgATwBPACgA4f+v/73//v9BAF8AUgAlAOn/t/+y/+T/KwBQAD0ADADi/8r/w//Q/+7////x/9j/3f8JADMAOgAmAAcA3P+u/6P/0f8VAD4ARgBFAD4AFwDb/7L/r/+9/9P/CABdAJsAjgBFAPT/rv91/2r/sP8lAHMAcwBDAAsAzf+S/4b/uv/9/xcAEAASAB0AEwD3/+7/AwASAA4AEAAoADQAGQDv/+X/+/8RABwAKgAyABwA7//W/+f/BAAHAO7/0P+7/7H/xf/+/0IAXgA+AAEAzf+2/7z/2/8DACEAKgApADAAQQBIADAA9v+y/4X/jf/K/yMAbwCLAGQACgCw/4b/mf/N/wIAKAA5ADIAGgAGAP7/8f/Q/63/q//V/xcAVAB4AHIANwDc/5H/fv+n/+3/MgBhAHEAYAA7AA8A5v/B/5//i/+a/9r/OgCMAKMAewAkALz/bP9c/5f/8/84AE4ARAArAAQA3v/T/+D/5//a/9L/6f8PACUAKQAsACUAAgDX/8v/6v8VADIASABVAD0A+f+v/5H/o//N/wUARwB4AHAAMADl/6//j/+D/57/5v82AGQAagBZADcAAgDS/8j/5v8GABEAEwAaAB8AGQAVAB8AIgAGANX/tv+7/9L/6f8CABkAFQDz/9b/5P8TAD0ASgBBACMA8P+9/7H/2/8aAEAAQgAuABEA7//T/9T/7v8CAPr/5v/j//b/CwAYAB8AHgAGANv/vf/D/9z/6f/l/+j/9/8CAAEAAwALAAUA7//t/xoAVgBqAEsAGQDq/8P/tf/Y/x4ATQBCABkA9f/S/6f/i/+g/9f/BAAdADMAQwAyAAMA3//g/+//9f/8/xQAMAA4ACwAJAAiABUA/v/0//3/BQD9//P//v8aAC4AKwAUAO//xP+o/7H/3/8OABgA+//V/8X/2v8NAEUAXQA4AOf/pf+m/+v/SQCKAI0ATQDy/7L/sf/d/wYABwDj/7n/q//K/wcAOQA7AA4A1P+y/7j/2v/9/wsABwAKACoAWQBsAEUA5/+D/1H/e//3/4YA0wCyAEIAyf+O/6L/6P8pADsAGgDs/+H/CQBFAFUAGACn/0T/Lf9z//X/eAC4AJUALwDT/7f/0P/2/xIAJQAuADcATgBzAH0AQwDX/33/aP+U/+H/MwBnAF4AIADk/9P/3f/d/83/x//c/wEALQBWAF4AKADH/33/fP+4/wMAPwBbAE8AIADy/+P/6v/k/8r/vP/W/xAAUAB/AIQASADZ/3X/Wf+N/+b/NABdAFoANgALAPj/+f/s/73/hf91/6b/CgB1ALIAmQAvALD/Z/94/8z/LQBqAG0ARAATAPr/+v////j/6P/d/+X/BgA1AFAAOgD7/77/p/+///X/LQBIADAA8/++/7f/2f/9/wQA7//U/8f/2v8VAF0AfgBYAP//sv+h/87/IAB0AJ4AeQAQAKD/bv+K/9X/JQBaAFoAHADA/4P/iP/A/wEAMQBHAD8AHgD8//P/AwAMAP3/4v/U/9j/7f8QADYARAApAPT/zP/F/9f/8/8PACMAKAAhABsAIQAnABoA+f/Z/8n/zP/d//v/GgAiAA8A8v/l/+j/7f/t/+3/8P/x//X/CgAnADUAKAASAAYAAAD4/+//7P/s/+r/8/8TADoARgApAPX/yv+5/8T/6P8TACkAHwAHAP7/CwAYABUAAQDm/8//xP/Q//L/FgAlAB0AEAALAAkAAwD8//f/8P/m/+b//f8eADIALwAhAAsA7f/J/6//qv+2/9D//f80AFgAUwApAPX/z//K/+z/IgBHAEAAHgD9/+v/6v/3/wYAAgDi/8H/wP/c//z/EgAiACoAHgAHAAMAFQAhABQABAALAB8AKAAjAB0AEgD2/9v/4v8FABoACADo/97/7f8EAB4ANQAvAPf/q/+H/6T/3v8LACYANQAtAAkA5//l//H/5//P/9v/FQBTAHAAcABYABkAv/+G/5r/2/8RADIASgBLABkAyv+T/4j/lP+v/+v/OQBlAFMAHgDq/7z/k/+H/6n/4f8TAEMAegCgAI0AQgDk/5P/Zf9z/8//WADCAN8AswBVANn/ZP8s/0r/nv/4/0MAdQB6AEIA6v+p/5D/k/+u//D/SgCKAJMAcwBKABUA0v+h/6X/1f8FACoAUwB4AG0AKADY/6b/iP9z/4D/y/8uAGwAfQB9AGUAFgCk/1L/Q/9c/4n/3/9dAMAAywCJACsAxv9k/zH/X//U/0YAhQCfAJsAaAAQAMT/of+U/4v/mf/R/xMAOgBFAEIALwD//8n/sP+3/8P/0P/z/yYARQBBACwAFAD0/9b/2/8KADwARAAtABsAFAALAAoAHgAzACQA+P/j//n/EQAKAO7/1v/A/6j/sf/0/0UAYQA9AAwA7v/Y/8n/2f8IACcAGAABAAwAJwAoABEABAAEAPv/6v/2/x8ANQAjAAoADAAZABQABAD///z/4v+9/7X/yf/V/8n/wf/Q/+T/7P/z/wEABgDy/9z/6P8OAC0AMAAiABAA//8BACQAVgBrAEkABQDL/7L/v//q/xoALAAVAPD/3//o//b/9//p/83/sf+w/9r/HgBRAFcAOgAOAOD/vf+8/+P/GwBKAGUAbABVABkA0f+n/63/0/8FADoAYwBlAD0ACADi/8T/o/+J/5D/uP/p/xgAQwBbAEUABgDP/8H/zv/b/+v/CAApAD0ATABlAG8AQADb/4D/af+W/+j/QQB6AGMA+/+J/2n/rP8WAGQAfQBdAA4AvP+m/9n/HAArAP3/wf+h/6z/6P9DAIUAcgAOAJ7/Z/97/8H/FgBaAG8AWQA9AEEAVQBOABUAwP95/2L/jf/w/1UAfwBeABsA6v/h//L/AwD7/9D/nv+Y/9j/QACTAKYAcAAHAJ3/Z/9//8X///8TABAADwAaADAARQA/AAsAwv+h/8v/IwBuAIYAagAlAM//lv+b/83/+P8GABEAJwAwABMA5P/B/6j/jf+N/8r/KABgAF0ASwBAAB8A2v+e/5P/oP+o/8r/KgCbAL0AfwAlAN//oP90/4v/6/9CAFcATgBeAHEAUAACAL//lP9r/1j/j/8BAFwAaABAABIA4/+0/63/5f80AFwAWABMAEEALQAbACkATQBVAC0A9//c/9n/4f/2/w0AAQDK/5n/pf/k/x8ANgAqAAEAvP+F/5L/3v8nAEEAPQA1AB4A9//o/wUAIwAPAOL/2P/4/xoANwBgAHkASgDd/4//lf/E/+X/AwAtADYA/f+2/6b/uP+s/4z/mv/c/xAAHgAzAFgAUgAHAL3/tP/S/+T///9OAKgAuQB3ACkA8P+x/3L/c//I/yQAQwA9AEoAXABAAPz/x/+t/43/df+g/xQAegCDAEYACgDp/9X/1f/9/y8AMAADAPD/GwBTAFQAJAD0/93/2P/v/ycAUwAxAMX/aP9m/7X/FgBeAH4AbQAoANv/uf/G/9D/uv+k/7v/+/86AFoAVQAlAM3/e/9v/7n/GgBNAEgAMgAjABwAHwAoABcA1P97/13/oP8aAHYAiABRAO//mP+G/8n/JQBKACMA5v/O/+3/MABpAGQADwCe/2f/kf/3/1sAjAB4AC4A5v/g/xoATgBGABUA7f/h/+3/DAAoAA0Arf9P/1L/uv8zAHIAdABOAAwAzv/L/woAQwAyAPb/3/8IAEkAdwCKAHMAGgCX/z7/R/+V/+L/GABPAIkAoACHAFYAHgDP/2n/Hf8e/1//rP/z/0EAjACfAGIA9f+N/z//Gf9D/8X/aQDbAPwA6AC9AH0AKwDe/6P/ef9l/4D/1v89AHwAdgA7AOT/kf9c/1f/ff+4//T/KQBPAF4AVAAzAAMA0v+3/8P/9P80AGoAhQB9AFYAJAD4/9r/wv+0/73/6v8yAHMAjQBxACcAxP9o/zb/Pv9z/7X/8v8nAFIAYgBNABwA4v+q/37/ev+0/x4AiQDKAN4AwwB7ABYAwf+d/6L/uf/c/xAAPQBCAB0A7//O/7T/nf+Z/7H/0P/j//L/CQAaAAkA4//S/+z/HQBFAFYASgAbANn/rf+9//v/PABeAFoAPAAYAAMADAApADQAEQDL/4v/ev+p/wAAWACGAHQAJgC9/2b/RP9h/6X/9P82AFwAYgBQADcAHwABAN3/w//H/+v/IwBaAHwAegBSABsA8//k/9//1P/J/8r/2//6/yAANQAZAMn/dv9i/6H/BQBXAHAASQD5/7T/rv/t/zwAWgA9AAwA8P/1/xIANAA9ABYAzP+X/6b/8P87AFQAOwAOAOL/v/+1/8v/6f/s/9n/2v8AACQAHAD8/+f/2f/A/7P/4P88AHsAewBjAFMAMwDy/8H/yf/k/9v/yf/t/0EAeABwAE8ALQDp/4n/Wv+P//X/NwBMAFkAWgAzAP3/9v8YAB0A5v+r/6n/3/8jAGAAhwB0ABkAqv95/57/5v8VABQA8P++/5j/nf/b/zcAdwB0ADoAAQDt//r/EgApADMAHgDo/7z/xP/r//r/5f/U/9z/3P/J/8b/6P8DAPf/6v8FACkAIAD9/wIAKgAwAAYA4P/U/7z/mf+w/xQAZQBTAA8A9v8NAB0AJQBHAF4ALADX/8n/FgBOACcA0f+T/2r/WP+P/x0AmACUADAA5//h/+3/7//9/xUAFAAPAEUAsQDpAJ4ABQCA/z3/Of91/+L/QwBeAEYANQA0ACgAAQDO/5v/cf9w/7f/NACYAKgAYQDm/23/OP9q/+D/SABtAGAARQAtAB0AHQAhAAsA3P/B/+D/IQBOAE0AIADL/2H/Gv8q/4f/8f83AFEARQAYAOT/0v/s/wsAEQARACUATQB3AJIAjwBdAAAApv+A/5r/0v8MADUAQgA1ACEAFgAMAPH/zP+z/7H/y/8EAEsAdQBcAA8Av/+O/37/lf/Y/ygATwBEADcAQABDACsAEQAMAAQA5v/d/xUAaQCLAG0APQAIALT/Vf8//4X/2v/+/w4ALwA7AAoAzP/J/+3/7f/P/9r/EwAtABAAAwAvAFAALAD3//b/DAD2/8n/z//8//7/1P/S/xUARwApAPL/6f/y/9f/uP/W/xYAIQD0/+H/BwAnABQAAAAWACkAAwDF/7v/4/8CAAAAAgAVABgAAAACAEAAjACWAFAA7P+d/3H/cf+x/yUAigCXAFEA+v/K/7j/q/+o/7z/0f/W/+n/NQCZALgAaQDt/5P/aP9d/4f/7/9TAGcAPgAoAC8AEwDL/6D/uP/i//f/JACCAMIAkwAaAMH/lP9k/0f/hf8DAEwAMwAQACUAOgAaAPT/AwAVAOP/oP+y/wgAOgAtAC8AWQBjACwA/P8BAP7/u/92/43/7v87AFwAeACHAFIA5f+d/6P/tP+Z/3j/jv/Q/xUAWwCoAM8AmAAdALf/mf+t/9P/AAAmACoAEQD//wYADAD3/8j/lv90/3z/w/8uAH4AjABgABMAuv9+/47/5f8+AF4AVwBPADwACgDP/7T/rP+Z/5H/0P9QAMAA4QC+AHIA+f9o/wX/D/9z/+T/OwB6AKMAogB2ADQA7P+h/1T/Jf9G/8T/bQDqAAQBywBnAPP/j/9m/4z/yv/c/8r/1f8SAEYAUQBSAFgAMgDP/33/iP/F/9n/x//Z/xEAJQAQAB0AXAB2ADwA9//n/9z/n/9p/5T//P86AEUAYwCWAIkAKgDS/7j/pf96/3v/3v9bAI0AfQB3AHwAUQAEAOH/6//S/4L/Uf95/8f/9/8YAE0AbAA8AOT/v//X/+n/2f/b/wwAOgBEAFEAiAC1AJcAOgDp/7v/j/9m/3D/vP8PACsAHgAUABEA+f/W/9H/8v8FAOj/vv+7/9r/7//r/+//BAAGAOr/4f8OAEIAOAD4/9H/4/8BAA8AKwBaAGcAOQARACgARQAJAIj/M/80/1j/hv/c/00AggBVABcADwAPANr/nf+y/wwAUABmAIAAngB8ABYAxP+9/8r/uP+u/+f/RAB8AIUAggByADAA0P+b/6L/tf+v/7X/7v9CAHEAYwAnAM//cf86/1T/s/8ZAFMAZgB0AJEAtADHAKwATAC0/yv/Af9Z/wAAmQDVAJoAEgCM/0X/RP9d/2n/Y/9r/6P/EQCVAOgA0gBXAL7/XP9Y/5////9JAGIAWwBgAIYAoQBpANT/Kv/S/gT/r/+HACIBLAGkAOr/cP9g/4//uv/D/7n/u//i/zoApQDWAIsA1P8f/+D+Mf/d/5EAEgEuAdoAXAATABgAIgDw/6b/j/+2//X/PQCCAIsAIwCF/zb/a//Q/xIAMABDADwAFgANAEUAcgA6AL//ff+h/+7/JgBFADwA7f97/1X/sf83AHMAXAAyAA8A5//M/9z/8//P/3r/V/+Z/w4AZgCHAHIAHACb/0b/Z//e/0YAZgBUADcAHwAXAC0AQgAYAKD/KP8R/3H/CwCMALYAfAAHAKz/r/8EAF8AegBKAPz/y//Y/xIAQwA+AAcAzf+3/8//BwBBAFAAHwDV/7j/4f8pAFkAWAAtAOP/mv+J/8r/JwBJABcAyv+f/6H/xv8MAFsAfABQAAYA8v8hAFcAXwBBAA4AwP9j/zv/ef/4/18AgQByAEEA4P9r/zD/Xv/G/x0AUQB3AIoAbQAxAA4ADAD3/7P/cf9s/6T/9P9IAJMArQBwAPr/o/+Y/7f/0//r/wkAJQAuADIASQBbADwA6v+a/3P/dP+S/9j/NwB9AIYAaABUAEIAEgDH/4v/ef+J/7j/DQBsAJgAdwA0AP//1/+p/4X/if+u/9//IQCDANsA5gCKAAQAmP9g/1j/fP+8/+//AwAaAFMAlQCcAFYA8v+m/4L/hP+x/wEATQBrAGIAUwBCABQAzP+O/3P/b/94/6b/BABkAIkAeABWADEA+v+5/5D/i/+Y/7b/+v9XAIcAYwANAMP/oP+m/9j/HgA+ACEA+v8DACsAPgA0AB4A9v+y/4b/q////zMALgAkACQACgDZ/9X/DwA2ABcA8v8VAGAAfQBmAFMAQQAIAMj/0v8iAE0AGwDd/+7/JwA1ABgAAQDi/5H/OP9E/7//LwA9AB0AGAAcAAIA8/8mAGMASgD3/+3/RgCNAHMALgD8/8T/eP9k/7//LAA0APT/0//V/63/Xv9J/47/4P8UAFYApwCvAD8Ar/9e/0X/O/9X/7n/LQBmAHYAlACqAHYAAgCm/43/n//U/0EAtwDWAIYAFAC9/3P/Lv8r/4z/CgBNAFoAVgAzANT/cP9l/7D/AQA/AJgACgEwAd4AWQD1/6L/Pf8B/0L/2v9YAKAA5AAaAeAALACB/0D/NP8b/y7/vP95ANoA1QDFAK0AMwBs/+b+5v4K/xb/Zv84ABIBVAEMAa4ARwCr/x3/H/+k/xIAIwAuAGoAhwBIAPD/wP+G/xf/wP7u/nv/8f82AHYArQCkAGUAPAAuAAEAs/+X/9D/IQBKAFcAWgA1AOj/tv/G/9r/s/99/4z/3/8yAHAArgDIAIUADADW/wEALAAOANX/wv++/6b/rf8DAF4ATwDx/8f/+f8wADUAOwBfAFsACgDG/+j/MwA3AAAA8/8aAB4A6v/S//X/AgDK/6b/6P9RAHIAVgBQAF8ANwDc/6j/tP+v/3X/Wv+d/wEAKQAgACAAGgDc/4//kv/r/zUAMwAVAA4AEwATACoAXgBuACgAxP+h/8z/CwA4AFQAVgApAOT/vf+//7//q/+l/8H/5f/2/wEADQACANf/uP/M//T//v/+/ykAfQDEAN4A0ACPAAQAZv8j/2f/3/8vAFAAXwBRABcA5v/x/w4A6P+K/1n/ff+8/+n/GABDAC4Azf+J/7X/FwA/ACYADgABANj/t//0/3sAxgCSADoAIAAxADUAPwBaADYAk//W/rD+Q/8DAH8AvQDGAHMA1f9o/3n/vP+8/4L/cf+k/+3/QgC5ACIBCgFkAKf/T/9e/5b/3v8zAHEAdQBqAI4AxACzADsAnv8u/wX/Jf+F//b/KgAIANP/1v8GAC0ANAAiAPn/wP+m/9f/LwBfAFAALwAYAPr/3v/1/0AAcwBXABsA///2/9f/vf/f/yAAOQAsADgAVAArALP/Vv9V/2//Yf9a/5b/7/8hAEwApADiAJcA7P+D/5X/yv/v/zwAtADfAIoAJgAMAPT/iP8c/yv/if+1/8D/FwCdALYASADd/7L/bf/8/vL+nv9yAMUAtgCoAH8A+v92/4X/AwA8AAMA3f8TAFYAbgCHAKkAcQC5/xX/Gv+i/ykAdgCcAIgAJgC7/6//8v8VAOz/tf+q/8P//v9mAMcAxABZAOz/yf/Q/9T/6f8cAD8AOQA/AHMAigA9AL//dv9g/zr/FP9B/8D/LABgAJQA0AC4ACkAkv9h/3r/lP/K/0sA1QDpAI4ANQAJAMv/Xv8P/xD/Nf9e/7//cAAIAQgBfwDv/6P/hv+A/57/1//w/+P/+P9dAMUAuwArAHv/Dv8B/1D/6f+OANgAnQAvAAYAMgBZADQA4P+l/5r/wf8oALQA+gCeAM//LP8V/2H/v/8bAHAAjwBjADAAQwB3AGEA8f+K/3n/o//U/xMAZQCPAGEAAwDK/7z/nv9r/2r/v/8vAHQAiwCTAIQARwD5/9H/0P/K/6//n/+q/7n/uf+5/8//5v/o/+P/9/8jAE4AZgBdACYA0f+L/4L/tP/+/0IAagBWAAEAn/9w/3b/gf+E/6f/9v9VAKoA+AAkAe8AXQDN/5r/qv+x/6r/u//d/9n/tP+s/83/3v/N/9n/IwBvAHsAYwBiAGoARwARAA4APABPADAAHgA2ADwA9v+N/1L/Uf9x/7H/IACLAJ8AXQAdAB0ALgAQANT/r/+t/67/vP/5/08AdQBMAA4A+v8FAAgACgAjAD0AKADq/8r/5v8OAAoA4v/B/6z/kP9+/5v/3/8LAPz/3P/e//n/AgD9/wsALgA/ADIAMwBTAGIAMwDp/8r/3//5/wUAIwBUAGQAOwADAOz/4f/B/6P/rf/J/8L/of+o//D/PABMACcA7v+z/4v/pv8UAJYA1gC/AHgAMwAIAAMAHQAmAPD/kP9V/3v/8/94ALsAiwD4/2D/KP9a/6T/wP+4/8L/+v9eANUAFgHQAAIAJP++/ub+V//T/0IAjAChAKsA4AAeAf4AVABx/87+qP4H/9X/xgBaAT4BqwAQAKD/RP/s/rb+uv76/nX/LQDxAGIBQgG2AAwAgf83/0P/ov8dAHgAoACpAKQAjABQAPT/iv86/zT/iv8SAIIAoABnAP7/p/+a/9P/EgAaAO7/v/+r/7P/zv/y//f/wf+A/43/9/9tAKIAnAB6AD0A7v/S/xMAdACUAHMAVwBLABcAwf+X/6z/s/97/0X/Xf+k/8//6v8jAFkAPQDm/7//7/8pADAALABJAF8AQQAXABoAJADo/3v/RP9x/87/JABsAJ4AlgBSABYAEgAcAPb/oP9S/zb/VP+m/xIAaQB6AEEA6P+a/3j/kv/h/zgAcACFAIoAiACEAIcAjQBwABQApP9m/2r/jf+2/+n/GwArABcADgAxAFcAUAAlAP//6f/Y/9v/CQBCAEQABgDP/9f/BQAcAAoA7P/a/9T/6P8fAFkAXAAeANP/uP/K/+L/8/8NACkAJAD1/7//q/+x/7X/t//T/xEAUwB+AJMAlQBsAA4Anv9a/0v/Tv9V/4j/8f9VAHMAUwAwABgA7P+u/5D/qf/R/+7/HgBvAKsAlQBMABwACQDb/4z/X/9//7r/6P8cAGkAoQCQAFkAPQA1AAkAuf+I/57/2/8fAGkApACZADkAyf+V/5v/qv+x/77/2P/6/y0AcwCiAIsANwDg/6j/kv+l/+n/QgB2AHUAWgA4AAQAyP+w/77/vf+R/3n/sP8WAF4AbABQAAUAh/8f/zX/wv9IAGgAQgAZAPL/wv+3//b/PwAwANb/nv+7//f/IABKAHoAcgAPAJ7/iv/G/+7/5P/g/wMAJgAwAE4AjwCpAFcA0/+G/4H/hv+M/8L/JABmAGIAUQBZAEsA+f+a/3v/kf+j/8L/KwDBABoBCAHGAIQALAC8/3b/gf+p/7f/yf8PAF8AZQAmAPH/5f/d/8n/w//K/7f/kv+g//X/UQBuAFcAPQAjAAMA9f8JABgA+f/C/6r/wP/r/ykAfAC6AKAAMgC0/1v/Jv8Z/0P/jv/H/+L/CgBQAIMAfQBPABwA2v+P/2n/jv/Z/wcAGAA1AGQAhQCXAKcAmgBCAMH/dv+N/9H//v8TACIAJAAWABsAQQBQAA0Ai/8Y/+b++P5L/9z/egDVANEApwCXAJ8AmgBoAAsAl/87/zP/m/89ALQAwwB0AAIAof9w/3n/pv/R/+H/4//2/yYAXgB5AF4ACwCg/1H/TP+X/wIATABRACMA7//T/9j/8/8VADUAUABrAIgAmACCAD8A5f+S/1z/T/9w/7b/BAA3AEAAJAD1/8X/pv+i/7f/2P/+/x8AMAAyADMAQQBXAF0AQwANANL/tP/O/xUAVwBUAAMAmf9f/4D/7f9sALAAiwAaALb/nv/I//j/9//A/3r/Zv+x/0gA0wD4AKAABwCE/0n/X/+m/+//FgAjAEMAkQDuABQB0gAyAHr/+P7s/lb/9f9sAIIATQAUAAEABADs/6b/Sv8U/zP/r/9gAPcALAHuAHEA/v+6/53/mf+t/87/6P/v//r/GAAwABcAz/+H/2X/cP+o/w8AhQDAAJwARAD//97/w/+p/63/zv/o/+7/AAAqAD0AGADg/8//5v///xwAWwCnALwAiQBCAAsAzf9//1X/fP/F//L/BAAmAE4ASQAZAPr/AQAEAPX/AwA8AGoAYgBRAGwAiwBkAPn/k/9b/0X/X/+//zoAcABHAA8AEgAvACgA+v/J/5n/af9o/8v/ZQDJAMIAfgAqAMj/av9H/3j/vP/X/93/BABIAHkAiAB8AD4Atv8Y/9D+Cf+H//z/VgCOAIkASQANAPz/7v+1/3j/fP/A/xMAXgCmAMUAiAAKAKv/k/+W/5b/uv8SAGIAdQBmAF4APADd/3//gf/a/ywAUABwAJYAjQBMABMA/v/S/3L/Lf9f/+b/VwCHAJAAdQAoAM//uf/t/xcA/f/T/+P/KABuAJoAogByAAQAj/9f/3//r/+6/6n/q//W/x4AagCYAIkAMwCy/0L/HP9N/6j/9P8cAC8AOQA2AC0AJgAOAMX/ZP8+/43/HQCRAL8AtwB/AB8Ay/+7/9r/1P+U/2v/nf8MAHIArgCxAGIA1f9o/27/xf8CAPP/yP+2/8z/BQBWAIsAZADs/4L/eP/L/0MAqADPAKgAXgBEAHQArQCiAFEA5/+I/1H/Yf+o/9n/wf+R/6H/9f9DAGIAYgBEAPb/m/+E/8T/DAAeABsAPABvAIEAbwBVABsAo/8b/+z+OP+9/zUAmgDvABQB5wCFABYApf8k/7D+jP7M/lD/6v98AO0AFAHYAEoApv8i/9z+4v4//+b/ogAsAWIBUgEUAbQAKwCR/w7/xv7K/iT/yv+CAPgA+wCmADMAxv9v/z3/Qf9v/6z/6f8wAIAAugC+AIgALADH/33/cv+t/wcASwBdAEsANAAkABgABgDo/8v/x//t/y8AZgB1AFEACACz/3P/Xv9w/5P/vP/p/xsAPgBIAEAAJwD7/8D/mP+p/+3/PQB6AJwAnQB1ADUA/f/c/8H/oP+N/5//yv/s//r/BQASABIA/v/n/93/1//O/9P/8/8XAB4ADAAFABcALQAqABEA8f/Q/7X/tf/h/yoAaACCAHkAWwA2ABUAAwD///T/z/+Z/3f/hv/F/w0AOwBCAB8A3v+a/3f/j//Z/y0AbQCRAJkAiQBwAFsASAAdANH/iP9x/5v/8P9KAIUAhgBJAPD/tf+x/8n/1//P/8P/yf/q/yIAUwBTAA4ArP91/4v/0f8RACoAGgD3/+P//f9AAH4AgQBDAO7/tv+x/9T/AQAVAPf/tf+B/4v/0P8aADUAHQDz/9P/yf/b/wQAKwAxABYA/v///wwADgARAB8AIwAGAN//3/8OADkAPAAmAAoA5v/A/8D/9v80AEYAOQA/AF4AawBUAC4ABgDJ/3//YP+N/+b/LgBTAGAAUwAlAPf/9/8YACIA9v+9/7L/5v85AIMAoQB5ABUAqP9y/4b/uf/X/8//vf+9/97/IwB/ANAA5AChACcAv/+W/53/sP+5/7L/l/93/3n/sf/2/wgA4/+//8L/3f/+/zEAbgCMAHUAVABSAFQALwDw/8//zf/A/5r/gP+D/4r/lP/O/zUAewBqADAAHwA+AFsAZQBnAE8ABwC4/63/6P8TAPH/qf94/27/j//s/3MAyQCpAEAA+P/4/xQAIgAdAAgA6f/j/xoAdQCYAE8AzP9h/zb/Rv+H/+P/MwBXAF4AYgBjAFEAKgD4/7v/fv9j/4r/6v9JAHQAWwARAMT/p//N/w8ALAAMANX/tv/A/+n/HQA7ACoA9v/M/8//8f8OABUABADf/7X/qv/X/ygAagB7AFcAEwDK/5//qv/a/wEABQD5//r/EgA6AFsAWgAoANb/mP+U/8X/BgA7AFIARQAiAAYAAQADAPj/5P/X/9j/6f8SAE4AdgBpAC4A7f/C/63/sv/V/wEAEAD///P/AwAZABgACQACAPr/5v/k/xMAWQB6AGkARwAmAPP/tv+f/7v/2f/S/8L/0P/u//j/+P8LACAADADa/8b/3P/v/+X/6f8WAEQARgAxADEAOgAkAPn/6P/w/+z/3P/x/zgAcgBrAD0AGgAAANP/pf+a/63/t/+z/8f///8sAC4AHwAdABcA7/+1/5v/sv/f/wwAOQBlAHwAdwBtAHIAcgBJAPH/mf9r/3T/o//r/zwAdABqACIAzv+d/4z/gP92/37/mf+///r/VgCwAMEAcQD9/7L/pP+6/+z/MwBrAG8AUQBDAEkAOAABANH/yf/S/9b/7f8kAE0ANgDr/6f/ff9c/1f/jv/t/ysALgArAEkAagBjAD4AFwDm/6T/ff+j/wIAUQBvAHoAhgB6AE0AHAD7/8//if9U/2n/wf8hAGMAgwB2ADEAzv+G/3P/dP9r/2f/iv/X/zQAkADYAOoAsABCAN7/rv+s/8D/2f/v//r/AgAUADUAUQBOACcA7//C/7b/0P8AACkAMQAXAOn/wv+7/9z/EAAvACMA+f/R/7n/s/+7/8z/2f/j//v/OACPANEA2gChADoAv/9b/zH/VP+s/wsAUAByAHoAbgBRABoAx/9m/w3/4v4J/4T/JwCpANgAvQB6ACwA4v+u/5b/i/+B/4v/yv88AKsA6gDxAMUAYwDi/3r/UP9S/1v/bf+m/wMAWwCVALYAtwB9ABAApP9h/0P/Pf9c/7b/KQB9AKcAugC5AI4ANgDb/5z/dv9s/5f//f9vALIAuwCnAIIAQQDt/6T/b/8+/xX/HP9j/8z/KABqAJYAowCDAEYAFQD9/+r/1v/V//f/KABNAGcAewB4AEcA8f+e/2b/Qv81/1D/l//t/ysATQBgAGoAYABBAB0AAADc/63/jP+U/7//8P8SACkANwAzACAAFwAiACkADQDc/8L/1v8EADIAVwBmAFAAGwDw/+f/4f+3/3f/WP9w/6j/6f8rAGMAdABcAEEAOQAwAA4A7P/x/xQAKQAjABkAFQAEAOP/zv/R/9n/2P/m/xwAXwB+AGgANAD9/8n/qP+o/77/xf+2/7P/3v8pAF4AWAAeAM3/if94/6v/DABiAIMAewBvAHUAgAB4AEYA4P9d//r+8v5U/+P/TgBnADcA6/+2/7H/z//l/9f/tv+1//P/YwDQAP4AzQBPAMX/d/+A/8P/AQATAPz/4//u/yIAVABJAO7/df8v/1L/0v9oAMMAtwBaAO//tv+//+T/8f/V/6r/n//N/y0AkgDBAJMAGQCe/2//of8IAGMAhgBtADEABgAOADkARgAKAKT/WP9R/4v/5P80AE4AIwDh/83/+/86AFQAPAAKANv/yv/r/y8AXAA/AO3/rf+o/8//+/8TAAoA5P/E/9n/KwCBAJgAaQAfAOD/vv++/9b/6v/a/7X/q//V/xsAUABbADwA/f+3/5v/w/8SAEsATgAqAAMA8P/5/xQAJAAFALv/f/+K/+D/TACSAJMAWgASAPD/CQA+AFIAJQDP/4j/df+W/8//9v/z/9P/uf/E//P/LABQAE4AJgD3/+f/AwA1AFoAVAAnAOj/tf+s/9D/AQAWAAEA3P/M/9//CwA9AFwAWAAxAAUA9P8AAAsA/P/X/63/iv94/4n/xP8PAEUAVQBKADAACgDm/93/9v8cADgARQBNAFAARAAqABAA9P/L/5n/ev+F/7b/9P8sAFEAVQA0AAYA7P/r//D/6//l/+n/+P8KAB4ALgAsAAgA0P+k/5b/pf/H//v/NABeAGwAagBmAFMAIADX/5r/g/+U/8b/CwBKAGEATAAlAAYA6//L/6r/m/+n/8z/BwBTAI4AkwBUAPf/qf+A/3v/kP+z/9b/+v8rAG0ApgCsAHkAKQDk/7z/sf+//93//v8UACAAJgAfAAMA0/+j/4X/ff+L/7f//v9HAHEAdgBhAD8AFgDq/8P/pv+V/57/zv8XAFQAZQBNACkADwAHAA4AFQAHAOv/3v/1/yEAPgA8AB8A8P++/5//pf/A/9P/2f/h//X/CwAhAD0AWQBYADEABgD+/xkANAA8ADMAGgD5/+X/9f8XABwA9f/F/7v/0//x/wIAAwDx/83/tP/I/wQANQA6ACcAGwAaABwAJwA9AEIAGwDi/8v/4f/8//7/8P/m/9//2v/s/xUALAAOANj/vP/B/8r/0P/m/xMAPABTAGQAaQBDAO3/kv9f/1f/av+Y/+b/OQBvAIgAkwCLAF8AFwDY/7r/uP/H/+v/FgAuACQADAD6/+v/1//L/9f/7P/z/+v/4//h/97/4f/9/ywAVABnAHAAcwBcACEA2f+m/47/iP+b/9P/IABdAH0AjACHAFgAAQCv/4b/e/97/5L/0f8hAFYAZQBgAEkADgC//4j/fP+B/4v/tf8TAHwAuQC9AKAAagAaAM7/q/+v/7X/rf+2/9//CQATAAQA7P/H/5T/cv+E/73/+f8sAGAAlACtAKQAiQBfAB0Azv+X/5L/rv/M/+P/9f////3/+f////3/4f+7/7X/4P8kAGMAjACVAHQANwADAOv/2P+y/4T/cv+F/7D/6/8yAGsAdABVADoAOgBEAD4ALgAiABQA/f/v//v/DAD8/8//qv+j/6j/sP/F/+f/AQAIABQAPABmAG0AUAAqAAoA6v/O/8r/2v/h/9P/zf/j/wYAGgAbABcADADy/9z/6f8TADIAMAAaAAQA8//o/+3//P///+f/zv/U//T/EQAbABYACAD1/+j/7v/9/wEA9v/z/wUAHgAoAB4ACADt/9j/2f/3/xsAKAAgAB0ALQBDAEoAOAAHALz/c/9c/4f/1f8VADQAOgAyACUAIQApACoABgDG/5b/l//C////NwBWAEkAFgDr/+v/CgAdABEA9P/Z/8v/2v8SAFoAfQBgABwA4//H/8D/xv/P/8f/pP+H/57/8P9NAIIAhQBjACkA6v/G/8v/4P/l/9f/1P/q/xUARwBzAIUAYwASAL7/k/+Y/7f/1//w//7/BgAYAD0AYQBgACwA3P+Z/3z/h/+x/+T/CAAXACIAPABeAG8AYAA3AAAAyv+p/6r/xf/j//T//f8HAA8AEgAVABkAEwD+/+j/6P/7/xEAHgAlACkAJQAbABMACwDw/8L/nP+b/7j/2P/u/wAAEAAaACYAPgBRAEQAGADv/+P/6//0/wAAEwAYAAAA4P/R/9P/1P/Y/+3/DwAjACQAKgA+AEEAHQDp/8H/qf+a/6P/0/8RADIAMAAjABMA9v/S/8X/4v8KACMAMQBDAFQAUgBBAC0AEwDn/7v/tv/g/xkAPABBACwABADS/7D/sf/E/9D/1f/l/wYAKwBIAFYAUAAxAAcA7f/w/wQAGAAnADIAMgAhAAcA7v/X/8H/sP+v/7z/0P/s/xMAOwBQAEgALwASAPf/4f/W/9r/4v/q//j/DgAcABMA9//b/8v/xf/I/9n/9/8ZADkAVgBnAFkAKADq/8D/tf+5/77/w//I/9D/4v8GADAAQgAoAPT/zv/N/+3/HgBJAFkAPgANAO//+v8YAB8AAADR/6//r//c/ygAZQBkACcA4P/G/+H/EgA1ADoAHwD1/97/7f8TAB8A+f+3/4j/if+z//T/MwBWAFEAMgAgACwAQgBFADAAFQABAPv/BQAcACoAEwDU/5D/bP9u/4b/pv/F/9f/3v/u/xoAWQCEAIIAYwBCACsAHwAZAA4A6/+v/3z/d/+i/97/CwAgABwAAwDo/+P/8v8AAAQACQAiAEkAagB3AGgAOADu/6T/df9n/3T/k//G/wMAOABaAG0AdABtAFkAQAApABMA+f/n/+P/5//n/+H/3P/W/83/x//P/+P/8//4//7/EQAzAFgAdwCEAHEAPwACANf/wv+1/6j/ov+x/9L//P8oAE0AWwBGAB8AAwD6//r/+P/1//P/7P/d/9L/0v/U/83/wf/C/9f/9v8TACwAPwBIAEQAOwA1ACsAEwDx/9r/2//s//j/+P/s/9b/v/+1/8f/7P8JABQAGQAoAD0ATQBNADkADQDU/6r/qf/P//r/EQARAAgA///7/wIADwAPAPn/4P/l/w0AQQBlAGcAQwADAMX/q/+7/9X/3v/T/83/3f8DADEATQBBAA0A0P+z/8f/+f8oAD4AOwAnABIACQAIAPv/1v+k/37/fv+q//X/QwB0AHkAXwBDADcANQAsABAA5f+8/6z/xP/1/x8AJQAEANH/qf+a/6j/yv/w/wsAGwAqAD0ATABOADwAHAD1/9T/y//e/wUAKQA4AC8AFgD2/9n/yP/J/9n/8P8FABcAJQArACkAHwAOAPP/zf+q/5//sv/X//z/FAAdAB4AHwAqADwARAAzAA0A6f/Y/9r/5v/1/wIADAATAB8ALwA2ACEA8//D/6b/o/+3/9r/BQAoAD4ATABVAFIANgAEAMz/nv+F/4f/p//a/wsAKwA6AD8AOwAsABMA9v/c/8//2v/9/ysATABSAD4AHQD6/9z/xP+y/6X/ov+w/9L/AQAtAEYARQAyABoADAALAA8ACwD6/+H/zv/L/9j/6//4//r//f8OADEAWwB4AHsAZABCACUAFwARAAEA3/+0/5T/j/+j/8P/3P/j/9z/1v/l/woANQBRAFYASwBBAEQAUwBiAFsANADy/6//gv93/4T/nP+3/9T/8f8QADIAUABdAFQAPAAkABIABgD//wAA///w/9P/sv+X/4j/if+d/8D/5v8IACgATABrAH4AfwBuAE0AIAD3/97/0f/F/7b/q/+p/7D/vf/R/+T/7//0/wAAFwAxAEMATABOAEoAPAAtACQAGwAIAO3/2f/P/83/0v/h//f/BAADAAIADQAdACkALgAqABkA/f/k/97/6f/v/+b/2P/U/+D/+P8XAC8AMAAXAPn/8v8EABwAKQApACEAGAASABMAFQAGANz/qP+F/4H/nP/K//v/HQAjABQABgAHABAAEgALAAEA+/8CABkAOgBMADwAEgDk/8L/sf+w/7r/yP/U/+L//P8gAEAATgBLADoAIAAEAO//6P/r/+3/7v/y//n///8EAAwADgACAOz/3f/h//T/EAAtAEMASgBCADUALAAhAA4A8//a/8f/vP+9/8z/4f/w//X/9v/7/wQADwAbACYALAApACYAKAAvADUANwAxACEACQDu/9X/wv+3/7H/tf/G/+H/AQAZAB8ADwDx/9L/v/++/8v/4f///yUATwB0AIMAcgA/APz/wf+g/53/sf/P/+v/AgAVACgANwA7AC4AEwD1/97/1//k////GAAfABAA9v/e/9H/0f/b/+X/5f/h/+P/9f8QACkANgA5ADUALgAsADEAOgA5ACUAAgDb/7j/pP+l/7z/2P/r//X/AgAWACwAOQA7AC4AEQDu/9n/1//f/+P/4//k/+j/7f/1/wQAEwAVAAkA+f/v//L/BAAjAEoAZwBuAF4AQAAdAPX/zP+m/4r/fP+C/6P/3f8dAEwAWgBJACMA+f/Y/8n/yv/P/9L/1//p/wgALwBPAF4AUwA0ABEAAAAFABQAGQAOAPf/4v/c/+r/BAAUAA0A7//O/7v/vP/H/9L/1v/U/9n/8P8aAEYAXABUADMADwD1/+7/8//8//7/+v/5/wMAFQAlACcAGQAAAOn/3//o//3/EQAZABUACwAFAAUABgAAAO3/0P+5/7P/w//d//L/+//+/wAACQAXACUAJgAZAAgABAAPACIAMQAzACYACQDp/9X/1v/f/+P/4v/i/+b/7/8BABsAKgAeAPz/3f/Q/9P/3f/n/+3/6v/k/+v/CQAuAEIAQAAxAB4ACgD+/wMAFQAjACMAHwAeAB0AFQALAAIA9//k/9f/3f/0/woAFAASAAEA4/+//6f/pv+2/8z/6P8OADYAVABnAHIAcABbADoAGwAHAPr/8P/q/+n/4v/R/73/sf+v/7X/w//b//b/DAAfADQASQBUAE8APQAlAA0A+P/p/+H/1//H/7b/q/+p/6v/tP/F/+P/CAAxAFgAdQB/AHcAYwBFAB0A6/+9/57/lv+h/7f/zf/b/93/3P/k//b/CgAXAB4AJwA4AFMAcwCNAI4AawAvAO//w/+u/6f/pP+e/5f/mf+v/9z/DQAnACEACgD5/wAAHwBKAGsAcQBaADsAKQAnACUAEwDv/8P/of+X/6n/y//o/+7/4v/Y/+L/AQAmAEIASgA8ACYAFQATABQABgDh/7P/kf+M/6P/zv/5/xIAEgAMABUALgBIAFEARQAtABQABwAMABcAEgDx/8L/oP+a/6r/w//a/+X/4f/e/+//FAA+AFsAZwBnAF8AUwBCACoABQDS/57/f/9+/5f/wf/x/xwANQA6ADUALQAlABwAFQASABEAEQAUABkAFwAHAOn/x/+s/53/pP/C//H/IgBKAGcAfQCKAIkAeABVACEA4P+k/3//df9+/4//o/+7/9b/8/8RACwANwAuABoACwALABgAKQA2ADoAMAAbAAUA9v/r/93/z//G/8z/3v/5/xYALAAyACkAGQALAP//8f/g/9H/y//O/9j/5f/v//H/7P/p//P/CAAfAC8ANgA4ADcANgA0AC8AHgACAOb/2f/e/+z/+P/6//P/5v/c/97/7P/6//3/9//2////EQAhACgAHQAAAOD/zv/W/+n/9v/0/+v/4//n//j/DgAbABgADAAKAB8ARABlAHAAXwA2AAcA4P/K/7//s/+j/5f/nv+8/+v/GwA4ADcAHQAAAPD/8f/7////9//o/+D/6v8GACUANAAsABUA///6/wgAIQA1ADoAMgAkABoAFgASAAUA7P/M/63/nP+e/7H/yP/Z/+H/4//n//T/CAAhADcARABFAD8ANgAsACAAEgABAPD/4P/Z/+D/9f8NAB4AIgAZAAoA/P/3//r//f/4/+z/4f/g/+f/8f/4//j/8v/r/+r/9P8CAAgAAwD5//X/+/8JABwAKwAwACgAGgAQAAoAAQD0/+f/3//d/+X/+f8RACEAIAAPAPn/5f/X/9L/0//Z/+L/8f8IACAALQAmAAsA5//G/7L/rf+5/8//6v8KAC4AVAByAH8AdwBgAEAAJAAQAAQA+f/o/9P/wP+3/7j/v//F/8j/y//W/+//EAAuAD8AQAA5ADMANAA4ADQAIgADAOP/zv/I/87/1//b/9z/4//4/xwAQgBbAF8ATgA1ACEAFQAPAAQA6//H/6P/jf+N/53/sP/C/9L/4//9/yIATABuAH4AewBtAF0ASwA3AB0A+//O/53/dP9e/13/bf+M/7b/4/8PADoAYwCCAI0AhQBqAEYAHQD6/+H/z//A/6//ov+e/6b/tf/K/+P//P8UADAAUQBvAIMAhwB7AGQAQQAYAPL/zv+s/43/d/9w/3n/jv+y/93/BQAlAD4AVgBqAHcAeQBwAFsAPQAfAAoA///1/+P/zP+3/6r/qf+y/7//yf/M/8//3v/8/yAAPgBNAE8ASAA9ADYAMQAlAA0A7P/Q/8P/yP/X/+j/8f/s/93/0f/S/97/7P/2//z/AgAMAB4ANABDAD8AKQAMAPT/6P/m/+r/7f/s/+j/6P/x//3/BQAHAAIA/P/6//7/CgAaACYAKgAoACIAGgARAAYA9f/d/8H/rP+l/67/wv/b//P/BwAZACsAQABRAFgAVgBMAD8AMwAoACAAFQAEAO7/2f/M/8f/y//S/9r/3v/g/+H/5f/s//T/+v/+/wEABQALABQAGwAeABwAFwATABEAFAAXABYADgACAPb/7//v//P/+f/+/wQACgAPABAACgD5/+P/z//G/8r/2P/q//j/AQAEAAUABQAEAP//+v/5//7/DQAlAD8AUwBXAEkALAALAO3/2P/N/8n/x//H/83/2v/r//r/AwAGAAUABQAJABQAIwAtACoAGwADAOn/1P/M/9H/2v/g/+L/5//0/wUAFwAlACsAKAAhACEAKgA0ADUAKQASAPb/3P/L/8n/0f/Z/9z/3v/k/+7//f8MABUAEgAEAPT/6v/t//f/AAACAAAA/f8AAA4AIwA0ADgALgAaAAkAAAD//wIAAgD5/+z/4//k/+//+/8AAPr/7f/h/97/6f/7/wgABwD7/+//6//w//z/BwAKAAgABgANAB0ALgA2ADAAIAANAAAA/f8AAAEA+P/o/9n/1P/Y/+H/6P/o/+X/5f/u/wEAFwAnACsAJwAfABoAGQAXABEAAwDx/+H/2P/X/9z/4f/j/+P/5v/w/wMAFwAnAC0AKgAiABsAFwAUAA0AAQD0/+v/6f/t//H/7v/h/87/vP+0/7r/zv/o/wIAGgAvAEMAUgBZAFQAQAAgAP//5//f/+D/5P/l/+L/3v/d/+L/8f8DABEAGQAhACoAMwA4ADkALgAXAPb/2P/F/73/uf+3/7v/w//R/+v/DwA1AFAAXQBhAGEAXABRAD8AIwAAANz/wv+3/7b/uP+6/7z/wv/N/93/8/8KABsAKAAzAD0AQwBEADwALQAYAP7/5v/U/8n/x//L/9T/4P/r//X/AAAMABgAIQAlACMAHAATAAkAAAD2/+v/2v/K/8D/wv/R/+n/AgATABgAFwAWABkAIAAlACQAHQAUAA8AEQAWABYADQD7/+X/1v/U/9//7v/5//3/+//4//r///8CAP//9P/o/+L/5//1/wkAGgAjACUAJQAoAC4AMwAyACcAFQABAPL/6//p/+j/4v/a/9T/0//a/+T/7P/u/+z/6P/q//L//v8IAA8AFAAZAB4AJgAuADEALQAhABEAAQDy/+b/3f/W/9D/zv/R/9v/6f/0//r//P/9/wEACgAYACYALwAwACsAIQATAAIA7f/W/8P/t/+4/8b/3P/1/wsAHAApADMAPABBAEAAOgAuACAAEQADAPb/5//V/8T/tv+w/7P/vv/N/93/7f/8/w8AJwBCAFoAagBvAGgAWABAACYACwDt/8//tf+l/6T/sv/K/+P/9f/+/wAAAQAFAAoADwARABAADgANABAAEwATAA0AAQD0/+v/6//0/wIADgAVABYAFAARAA0ACAD+//D/5P/e/+H/6//3/wAAAwACAAEABAAKAA8ADwAKAAMA/P/4//b/8//v/+f/4f/h/+n/9/8HABUAHQAjACcAKgAsACgAHwASAAEA8P/i/9j/0//S/9P/2f/k//H//P8FAAwAEAARABAADgAMAAgABAADAAMA/v/2/+z/5f/k/+r/9/8HABUAHAAfACMAJwAmAB8AFAAHAPn/7v/q/+v/6//n/97/1//T/9b/4P/v//7/CAAPABUAGgAgACIAHwAWAAoAAAD7//3/AwAHAAYAAAD6//b/+P/+/wQACAAHAAUABAAFAAYAAwD7/+//4v/Y/9b/2//m//D/9v/7/wEACgAVACAAJgAmACEAGwAWABIADgAFAPr/7P/g/9n/2P/e/+b/7//5/wQAEAAdACYAJwAiABcACQD9//T/7v/q/+f/5P/k/+f/6//v//P/9v/5//z/AQAIABAAFQAWABQADwALAAgABgADAAEA/v/8//7/AQAFAAYABgADAAAA/f/5//L/5//Z/8v/wf/A/8f/1v/r/wEAGQAwAEQAUgBXAFMARQAxABsACgD9//P/6P/e/9L/yf/E/8X/zf/Z/+j/+P8KAB4ALwA8AEEAPgAxAB0ACQD4/+r/3//W/9P/1P/Z/+P/8f8AAAwAFQAeACYALgAzADQALgAkABYACAD8//H/5P/X/8z/xP/B/8P/yv/T/97/6//8/w4AIQAxAD0AQwBEAD4ANAAmABYABgD3/+n/3f/R/8j/xP/G/83/1//i/+//+/8IABUAIQAoACoAIwAZAA0ABAD+//r/9f/t/+P/3P/a/+D/7P/6/wgAFgAkADMAQABIAEcAOwAmAA0A9f/i/9T/yf+//7f/s/+2/7//z//h//P/BQAXACsAPwBPAFkAWQBQAD8AKQATAP//7P/b/83/w/++/8D/yP/V/+T/8v///wsAFwAgACUAJAAeABMABQD4/+7/6P/j/+H/4//n/+//+P8CAAwAEwAXABgAGAAVABEADAAGAAAA+f/0//H/7//u/+7/7v/v//H/9v/8/wIABgAHAAYABAD///v/9v/y//L/9P/7/wUAEQAbACMAJwAoACUAIAAYAA4ABAD6//L/6v/k/+D/3P/a/9j/2f/e/+b/8f/+/woAFQAeACUAKwAuAC8ALAAlABsAEQAGAP3/9f/u/+f/4P/d/9//5f/u//b//P///wAAAgAFAAgACQAJAAgABwAGAAYABwAFAAIA/P/3//L/8f/y//X/+P/6//z//f///wEAAwAEAAUABgAKAA8AFAAXABYAEgAKAAIA/P/3//L/7//s/+v/6//t/+//8P/x//H/8v/2//3/BgAOABQAGAAZABkAFwAUAA4ACAABAPz/9//0//L/8f/y//P/9f/5//3/AQACAAQABAACAP///P/4//T/8v/y//T/9v/3//n//f8DAAkAEAAWABkAGAAVABMAEAALAAMA+v/y/+v/5//m/+n/7P/v//P/+f8AAAgAEAAXABsAGwAYABQADgAHAP7/9P/r/+P/3v/d/+D/5//u//X//P8EAAsAEwAaAB4AHwAcABkAFAAOAAcA/v/2/+//6P/k/+P/5v/s//L/9//7/wAABQAJAAwADQALAAgABQACAP///P/5//f/9P/y//L/8//2//r///8DAAgADQASABUAFgAWABMADwALAAcAAwD+//j/8//u/+r/5//l/+T/5f/o/+3/9P/8/wMACgAQABQAFwAYABgAFwAUAA8ACgAEAP//+v/1//D/7f/s/+7/8f/2//v//v////////////7//f/9//z//f///wIABAAFAAQAAQD///7//v8AAAMABQAGAAcACAAIAAkACAAHAAUAAwABAAEAAQAAAAAA///9//v/+v/5//f/9v/2//b/+P/7//7/AgAGAAkACwANABAAEQASABAADgAKAAYAAwABAP3/+f/1//L/8P/v/+//8P/x//L/9f/6/wEABwAMABAAEgATABEADwALAAYAAgD+//v/9//0//L/8f/x//P/9P/1//f/+v/9/wEABQAHAAYAAwAAAP7//P/8//v/+//5//j/+P/5//v//f/+/wAAAgAFAAkADQAQABEADwANAAkABgACAP//+//3//T/8f/w//H/8v/0//T/9v/4//z/AQAFAAkADAAOAA8ADwAPAA4ADAAIAAQAAQD9//v/+v/6//r/+//8//3///8BAAIAAgABAAAA/v/9//v/+v/5//f/9v/2//f/+P/6//3/AAADAAUABgAHAAYABQADAAIAAAD///7//f/8//z/+//6//r/+//8//7/AAABAAMAAwADAAIAAAD+//z/+v/5//n/+v/7//3///8AAAIAAwAEAAUABQAFAAYABgAHAAcABgAFAAMAAQD///7//v/9//3//P/8//z//v///wEAAgADAAMABAAFAAYABwAGAAQAAgABAAAAAQADAAMAAgABAP///v/+//7//f/7//r/+v/8//7/AAACAAMAAwADAAIAAQAAAAAA///+//7//f/8//r/+f/4//b/9v/3//r//f8AAAIAAwAEAAUABgAGAAUAAwACAAIAAgACAAEAAAD+//3//P/7//v/+//8//z//P/9//7///////////////////////7//v/+/wAAAQADAAUABwAHAAcABgAFAAMAAQD///z/+v/5//j/9//2//X/9f/2//n/+//+/wEAAgAEAAYACAAJAAgABgAFAAMAAQAAAP///v/8//v/+//7//v//P/9//7///8AAAEAAgACAAIAAQAAAP///v/+//7///////////////7//v///////v/+//3//v/+////AAABAAEAAgABAAIAAwAEAAQAAwACAAEAAAAAAAAA///+//z/+//7//v/+//8//z//f/9//7//v//////////////AAABAAIAAgACAAIAAQACAAIAAwADAAQABAAEAAUABAACAAAA/v/8//r/+f/4//j/+P/5//n/+v/7//z//f///wAAAgAEAAYABwAGAAUAAwABAAAA//////7//f/9//z/+//6//n/+P/3//j/+f/7//7/AQADAAQAAwADAAIAAQAAAP7//f/8//v/+//8//3///8BAAIABAAFAAYABwAIAAgACQAIAAgABgAEAAIAAAD+//z/+//6//r/+//8//3///8BAAMABgAHAAgACAAIAAcABwAGAAUAAwABAAAA/////////v/9//z/+//8//3///8AAAEAAwADAAQAAwACAAEAAQAAAP///v/9//3//f/+//7//v/9//z//P/9//7//v/+//3//P/6//r/+v/6//r/+//7//v//P/+////AAAAAP////8AAAAAAQABAAEAAQABAAEAAQABAAAAAAD///////8AAAEAAQABAAEAAAAAAAAAAAD//////v/+//////8AAAAAAQACAAIAAwADAAQABAAEAAQABAAFAAUABAAEAAMAAgAAAP7//f/7//r/+v/5//n/+f/6//r/+//8//7///8BAAIAAwADAAIAAQD///7//f/8//v/+//6//r/+v/6//r/+v/7//v//P/9//7///8AAAAAAAAAAP///v/9//z//P/8//z//P/9//7///8AAAAAAQABAAIAAwAEAAQABAADAAMAAgABAAAAAAD///7//f/8//z//f/+////AAABAAIABAAFAAYABwAHAAYABAADAAMAAwADAAMAAwADAAMABAAEAAQAAwABAAAA/v/+//7//v/+/////////////v/+//7//////wAAAQACAAIAAgABAAAA///+//7//v/+//7//v/+/////////////v/+//7///8AAAAAAAAAAP////////////////////8AAAAAAAAAAAAAAAAAAAAA///+//3//P/8//z//f/+////AAACAAMABAAEAAQABAADAAMAAgACAAEA///+//z/+//7//r/+v/6//r/+v/7//3//v///wAAAQABAAIAAwAEAAQABAAEAAQAAwACAAEAAAD//////v/+//3//f/9//3//f/9//3//f/9//7//////wAAAAAAAAAAAAABAAEAAQAAAAAAAAAAAAEAAQABAAEAAAAAAAAAAAAAAAAA///+//7//v//////AAAAAAAAAAAAAAEAAQABAAEAAQABAAAAAAAAAP///v/+//7//v/+////////////////////AAAAAAAAAQACAAIAAwADAAIAAgABAAAAAAAAAAAA//////7//v/9//z/+//6//r/+v/7//z//f/+//7/////////AAABAAEAAQABAAEAAQAAAP///f/7//n/+f/5//n/+v/7//z//f/+//7////////////+//3//f/8//3//f/9//7//v////////8AAAEAAgADAAQABAAFAAUABQAEAAQAAwACAAIAAQD//////v/+//7///8AAAAAAQABAAIAAgADAAMAAwADAAMAAwAEAAQAAwACAAEAAAAAAP//////////AAAAAAAAAQABAAEAAAAAAP/////+//7///8AAAAAAAD///////8AAAAAAQABAAAA///+//7//v/+//7//f/9//3//f/9//3//f/9//3//f/9//7//v/+//7//////wAAAAABAAEAAQAAAAAAAAABAAEAAQABAAEAAQABAAIAAgACAAEAAQABAAAAAAAAAAAA/////////////////v/+//7///8AAAEAAgADAAQABAAEAAQABAADAAIAAgABAAAA///+//3//P/7//v/+//8//3//v/+/////////////////////////////v/+//7//f/8//z//P/8//z//f/9//7//v///////////////v/+//7//v/+//7//v/+//3//f/+//7///8AAAAAAQABAAEAAgACAAIAAgACAAEAAAD//////v/+//7//v/9//7//v///wAAAQABAAEAAAAAAAAAAAABAAEAAQABAAIAAwAEAAUABQAEAAMAAgABAAEAAQABAAEAAQABAAAAAAD///7//v/+//7//////wAAAAAAAAAAAAAAAAAAAQABAAEAAAABAAEAAQABAAAAAAAAAP//AAAAAP//////////////////////////AAAAAAAAAQABAAEAAgACAAIAAgACAAEA///+//7//f/9//3//f/9//3//v/+//////8AAAAAAQACAAIAAgACAAIAAQABAAEAAAD///7//f/8//z//P/8//v/+//7//v//P/9//3//v///wAAAQABAAEAAQACAAIAAgACAAIAAgABAAEAAQAAAAAA///////////////////////////////////+//7//v/+//////8AAAAAAAABAAEAAgACAAEAAQAAAP/////////////+//7//v/+//7///////////8AAAAAAAAAAAAAAAAAAP/////////////+//7//v/+//3//f/8//z//f/+//////8AAAAAAAAAAAEAAQABAAIAAgACAAMAAwACAAEAAAD///7//v/9//3//f/8//z//P/8//z//P/9//7///8AAAEAAgACAAIAAgABAAAA//////7//v/+//3//f/9//7//v/+//7//v/+//3//f/9//3//f/9//3//f/9//3//f/9//3//f/+////AAAAAAEAAQACAAMAAwADAAQAAwADAAIAAgACAAEAAQABAAEAAQAAAAAAAAAAAAAAAAAAAAAAAQACAAIAAgACAAIAAQABAAEAAQABAAEAAQABAAIAAgACAAIAAgACAAEAAAAAAP//AAAAAAAAAAD///////8AAAAAAQABAAEAAQABAAEAAQABAAAAAAD//////v/+//7//f/9//3//f/9//3//f/9//3//f/9//3//v/+//7//v/+//7//v/+//7//v//////////////AAAAAAAAAAAAAAAAAAAAAAAAAQABAAEAAAAAAP/////+//3//f/9//3//v/+////AAAAAAEAAQACAAIAAwADAAMAAwADAAIAAQAAAAAA/////////////////////////v/+//7////////////////////+//7//v/+//7//v/+//7//////////////////v/+//7//v/+//7//v/+//7//v/+//7//v//////AAAAAAAAAAABAAEAAQABAAEAAAAAAP////////7//v/+//7//v///wAAAQABAAEAAQABAAEAAQABAAEAAAAAAAAAAAABAAIAAgACAAIAAQABAAIAAgADAAQABAAFAAUABAADAAMAAgACAAIAAQABAAEAAAAAAP////////////////////////////8AAP///////////////////v/+//7//f/9//3//f/9//3//P/9//3//f/9//7//v///wAAAAAAAAAA//////7//v/9//z//P/7//v/+//7//v/+//7//z//P/+//////8AAAEAAgADAAMAAwADAAIAAgACAAEAAQABAAAAAAD///7//v/9//3//P/8//z//P/7//v/+//7//z//f/9//7///8AAAEAAgADAAMAAwAEAAQABQAFAAUABQAEAAQABAAEAAMAAgABAAAA///+//7//v/9//3//f/+//7//////wAAAAD/////AAAAAAAAAAAAAP////////7//v/+//7//v/+//7//v/+////////////AAAAAAAAAAAAAAAAAAD//////v/9//3//f/9//7//v/+//7//v/+//7//v/+////AAAAAAEAAgACAAIAAgACAAIAAgACAAIAAgABAAEAAAD///////////////8AAAEAAgACAAMAAwADAAMAAwADAAMAAwADAAMAAgACAAEAAQABAAEAAAD///7//f/9//z//P/8//v/+//7//r/+v/6//v/+//8//3//v/+////AAAAAAEAAgACAAIAAgACAAIAAgACAAIAAwADAAQABAAEAAQABQAFAAUABgAGAAYABwAIAAgACAAHAAcABgAFAAQAAwACAAEAAQAAAAAA///+//3//f/8//v/+v/6//r/+v/6//v/+//7//v//P/+////AQACAAIAAgACAAIAAgACAAEAAAD///3//P/7//r/+f/5//j/9//3//f/9//3//f/+P/4//n/+v/7//z//P/8//3//f/+////AAABAAIAAwAEAAYABwAIAAkACQAJAAoACQAJAAkACQAIAAgABwAGAAUABAADAAIAAQAAAAAAAAAAAAAAAAAAAP/////////////+//3//P/7//n/9//1//T/8//y//L/8v/y//L/8v/y//L/8//0//X/9v/3//n/+f/6//v/+//8//z//P/8//z//P/8//z//P/8//z/+//7//v/+//7//z//P/9//7///8AAAEAAgADAAQABQAHAAgACQALAAwADQAOAA8AEAAQABAAEAAPAA8ADgAOAA0ADAALAAsACgAKAAoACgAJAAgABwAGAAUABAAEAAMAAgACAAIAAwAEAAUABQAFAAUABQAGAAcACAAJAAoACwALAAsACgAJAAcABgAEAAMAAQD+//z/+v/3//T/8v/w/+7/7P/q/+j/5//l/+T/5P/j/+P/4v/j/+P/4//k/+X/5v/n/+j/6v/s/+7/8P/y//T/9f/3//n/+//8//7///8BAAMABQAFAAUABQAFAAUABQAFAAQABAADAAQABAAEAAQABQAHAAoADQASABYAGQAbAB4AIAAiACQAJAAiACAAHQAbABgAFgATAA8ADAAJAAYAAwABAP///v/9//z/+//7//v/+//7//z//P/9//7//v///wAAAAD//////////////v/9//3/+//6//j/9v/0//H/7f/p/+b/4v/f/9v/1//U/9D/zf/K/8f/xf/E/8P/wf/B/8H/xP/G/8n/zP/Q/9T/2P/d/+H/5v/r//D/9v/6//7/AgAGAAkADAAOABAAEgATABQAEwATABQAFAAVABYAFwAZABwAIAAmACwAMgA4AEAARwBPAFYAXQBkAGoAcAB1AHcAegB6AHoAeAB0AG8AaQBiAFoAUABFADkALAAeABEABAD2/+n/2//Q/8T/uf+t/6P/mP+N/4b/ff92/27/aP9j/17/Wv9W/1b/VP9W/1j/W/9f/2X/bv93/4H/jf+b/6n/uP/J/9b/5//3/wcAFwAmADIAPgBMAFcAXgBmAG4AdAB6AHwAggCDAIYAhgCJAIgAigCLAI0AjACMAJAAkQCRAJUAmACaAJ0AoACkAKYApwCoAKoAqACoAKYAogCgAJoAlgCQAIUAfABuAGAAUQA/AC0AGQACAO//2f/D/67/l/+A/2n/Wf9E/zX/J/8Y/w///P7u/ub+3P7S/s7+yv7C/sD+vv7A/sT+yv7Q/tj+4P7u/vz+Cf8W/yT/Of9M/13/bv+B/5L/p/+0/8f/2P/q//r/DAAdACsAOQBGAFUAXQBlAGwAcwB6AHwAfwCDAIkAjQCQAJgAnQCjAKsAtAC+AMsA0gDeAPAA/wAQASIBMAFEAVYBZgFyAX4BjAGSAZoBoAGiAZ4BmgGWAZABjAGAAXoBbgFiAVQBRAEwAR4BCAH1AOEAyQCzAJcAfwBiAEcAKAALAOz/zP+p/4f/af9G/x//9v7Q/qb+ev5O/hz+8P28/ZD9YP0w/QD91Pyk/Hz8VPw0/Bj8APzo++D70PvI+9D70Pvo+/j7HPxE/HD8pPzc/CD9bP3E/Rr+fP7m/kz/vf8tAJsACgF6AdoBPAKgAvQCTAOYA+gDKARgBKAE0AT4BBgFQAVgBXAFgAWIBZAFmAWQBYgFgAV4BWgFUAVABSgFCAX4BOgE0ATABKgEoASIBHAEWARABBgE6AO0A3ADGAPAAlAC1gFMAbQADwBl/6r+8P00/Wz8sPvo+ij6cPnI+Bj4cPfQ9kD2sPUw9cD0UPTw85DzQPMQ8+DywPLA8tDyEPNQ87DzQPQA9eD14Pbw90D5oPog/Lj9Wv8UAcQCeAQwBsgHMAlwCqALkAxQDeANMA5ADiAOwA1ADZAMsAvACqAJgAhIBxAG2ASgA4ACcgGMALH//v50/gr+xP2k/az91P0Q/nT+8P6H/ywA0wCMAUQCAAO4A2gE+ASIBQAGYAaoBsAG0Aa4BogGOAbIBUAFqATwAyADSAJgAWcAZP9e/lT9TPxI+0j6UPlg+ID3sPbw9VD10PRg9PDzoPOA82DzYPOQ88DzAPRg9ND0UPXg9XD2IPfA94D4WPko+gj78Pvk/OT97P4EABgBOAJIA2gEeAWQBpAHcAhACeAJYArACgALAAvwCrAKYArQCSAJcAiYB7gG0AXgBPgDBAMsAlABgQDT/yv/rP5O/hT+8P3s/fj9Iv5u/rr+If+T/wgAkgAUAagBRALQAmAD4ANYBMgEIAVoBZAFwAXoBegF2AWwBZgFaAUwBegEkAQoBKQDIAOcAtQBHAFLAJH/tv64/dj80Pvg+tj58PgA+AD3MPZg9aD0IPSA8yDz4PKw8rDy0PIQ81DzsPMw9OD0cPUw9vD2wPeI+HD5YPpI+0j8NP1g/nn/lwDKAQgDOARwBbAG8AcQCRAKEAvgC5AMEA1wDZANgA1ADfAMQAyQC5AKgAlQCPgGwAVIBNgCfAEJAMD+VP0k/DD7gPrw+bj5oPnI+Tj62PrI+8D8+P1J/58A9gF0A/AEKAZYB2AIQAngCVAKgAqACkAK0AlACZAIwAfQBvgFEAUoBEQDSAJsAYoApv/E/tj9BP04/Gj7iPqo+dD48Pcg92D2kPXQ9ED0kPMw88DygPJg8nDykPKw8vDyYPPQ81D04PRw9RD2oPZQ9+D3oPhA+eD5qPqI+2z8aP2K/qX/zAAQAmADqAQIBlAHsAgACiALMAwQDZAN8A0wDkAO4A1gDbAMwAuwCnAJIAiwBjgFmAMUAo8AH//I/Yz8gPvA+jj62PnI+QD6oPpI+1T8gP3C/ioAhgEMA3gE2AUwB4AIgAmACgALYAtwC2ALIAuQCvAJIAlQCEgHUAZYBWgEpAPcAiQCegHOACQAkv/+/l7+zP1M/aj82Pv4+hj6KPkw+CD3EPYQ9QD0EPNA8qDxAPGg8GDwQPAg8BDwQPCQ8BDxsPFQ8hDzwPOg9JD1gPZw94D42PkY+2j82P1Y/+8AeAIwBPAFoAdQCRALsAwwDoAPoBCAEQASQBIgEqAR4BDQD6AOIA1wC4AJcAdgBTwDJgEP/yT9aPsA+qj4oPfw9qD20PZQ9zj4cPn4+tT88P4CARgDAAXwBuAIwApgDIANYA7wDiAP0A4QDiAN0AtgCgAJYAeoBcwDLALGAJr/rv7A/QD9UPzY+5j7OPu4+kD6+Pm4+Tj5iPjQ9wD3MPZQ9aD00PPw8jDysPFw8VDxUPFg8YDx0PFQ8uDyUPPw86D0cPUg9sD2UPfg93j4MPnw+dj6wPvU/BT+bP/uAIgCOATwBcgHwAnAC5ANMA+AEOAR4BKAE8ATgBPAEsARoBAQDyAN8ArgCKgGYAQQArb/XP1A+4j5KPjA9qD1IPUQ9WD1APYw95D4EPpM/Mb+SAF4A2AFmAfgCfALoA3gDoAP4A8AENAP4A6ADQAMoArwCAAHAAX8AgoBbv9A/hz9EPw4++D6mPqI+jj66PmI+Vj5SPn4+Gj4oPcA9zD2YPWQ9LDz0PIQ8pDxYPEw8TDxUPGA8QDykPIw89DzUPTw9MD1kPZg9+D3SPjQ+Ij5YPow+zz8QP1+/u3/mgFEA+gEyAbACPAK8AzQDoAQIBJAEwAUgBSAFOATwBLAEUAQEA6gC3AJKAfABHgCPwDY/YD7YPlA+AD3sPXw9BD14PWA9pD38Pi4+rD8Iv/2AaAEoAagCDALcA1QD2AQYBGgEcARYBHAEBAP8AwgC3AJYAfwBJgCaABc/pz8UPso+ij5gPhY+Gj4aPhA+ED4SPhA+Fj4cPhI+PD3kPdA99D2MPag9SD1oPRQ9AD00POA8zDzMPNg84DzYPNw81DzUPOA88DzAPRg9JD0IPXw9fD2GPiY+Wj7dP2n/+4BWAS4BiAJwAtwDuAQwBKAFAAWIBeAF2AXABcgFoAUwBKAENAN4AowCOAFcAOPAOz9ePsg+dD2gPWg9MDzUPPw80D1UPZg91D5+PvI/pIBcAQ4B6AJAAxgDmAQYBEAEoASgBLAEWAQwA5wDBAKoAdgBcwCDQCM/Yj70Plo+JD38Pag9rD2MPfg91D4uPhg+fD5IPow+jD64Plo+Qj5qPjw9/D2MPaw9RD1MPSg8zDzoPJQ8mDykPJw8kDycPKg8qDy0PIw87DzQPQw9WD2oPcY+RD7WP3S/2ACMAUACHAK8AyAD+ARABQAFsAX4BhAGWAZIBngF0AWgBRgEpAPUAwQCeAFwAIFAKD9UPuo+GD2wPRQ83DyQPIQ8zD0cPUg94D5qPv0/cwA7APQBpAJ4AvQDTAPYBAgEWARABFgEMAPMA7gC4AJOAeoBOwBx/+s/fD6WPjA9rD1kPTQ89DzMPRA9MD0wPWg9kD30PfY+Hj5kPl4+Yj5QPmg+FD4KPjA9zD30PaQ9iD2oPVw9ZD1kPWA9ZD1sPWw9XD1YPVQ9TD1IPVQ9QD24PZA+PD56Psu/vgAAAQQBwAK0AygDyASQBTAFeAWwBdAGEAYgBcAFgAUoBEAD3AM4AnIBrQDNAFX/5D9mPt4+qD5sPjQ99D3ePig+Aj5WPo4/KT97v5mAGQCcASIBoAIEAqAC8AM0A1QDlAO0A3ADDALsAkgCNAFyAL0/7D9WPvA+ID28PSw84DyEPJA8oDy8PIQ9PD10Pcg+XD60Pu4/ED9vP20/fj80PvQ+sj5YPjQ9lD1EPTg8tDxIPHw8DDxoPFw8sDzQPWw9gD4mPl4+/j8sP1W/nb/lwCOAYAClAPQBCAGSAdgCIAJAAsgDMAMQA1QDhAPYA5wDWANsA2wDFALwAowCiAI0AUABfAEoAPWAYoBUAJsAgwCdAJMAyQD1AJUA/QDkAMIA5QDMAQwBNgDCATsA5gDvAM4BPgD3AIkAtgBfgGwAPD/Dv/o/RD9kPzY+8D6IPoo+kD6mPoY+7D7yPsI/Oz8Gv50/mj+5P5p/xT/yP18/GD78Plg+OD2YPVQ8yDx4O9A7+Du4O5A7wDwoPCQ8eDyMPTw9cj46PsM/pH/ggFEA9ADOASwBfgGmAa4BbgFyAXIBNADSARABVgF4ATgBPAEyAQABXAF8AVQBoAGmAbQBrAH0AhgCSAKoAsQDVANEA3gDSAPQA8AD3APwA9wDoAMAAvwCEgF4gECACT+oPow99D1EPXQ83Dz0PQQ9mD2sPfI+kz9Rv7S/3ACUASYBMAEGAUwBIgCvAGiAcUA/P7w/YD9zPzo+6j7gPsw+wj7SPtY+5j6qPnw+CD4oPbQ9DDzwPFA8ODuoO4A7wDvwO7g70Dy4PPg9OD2QPqE/Dz9eP65AHACHAOIBIgGYAdoBoAFWAXQBIQD3AIEA9QCQAI0AuwCnAM4BMgFEAgACmALkAzwDRAPYBCgESASIBIAEmARIBAgDpAMQAtQCZAHkAYQBZgCuADTAHABzwAZADQA3f9Y/kT9QP2Y/AD7wPrw+4j7qPmg+Ij5YPqQ+rj7RP34/dj9gP7w/8UA1QDPAM4AOwA6/8T9bPxg++j60PpI+kD5kPhY+Ij4mPi4+CD5OPmo+ND3QPfw9jD2UPUg9fD0EPTQ8oDyQPMw9JD1oPeI+XD6wPpo+wD8KPy4/BL+lv9qAOwA4gF8A1gF0AfwCuAN8A/gEKARoBIAFAAVoBSAEyASQBBQDdAJcAdQBsAEzAKwAQIBjv8G/r7+EgGEAsgC0AOIBegFIAVQBUgGUAbYBSAGQAaYBMQCnALwArQB6P8Y//T9kPuY+WD56PgQ9xD28PYw99D14PRQ9jD46Pjo+dD7KP0M/TD9av4d/y7+yPzo+8j6APlQ94D2QPYg9kD2oPaw9tD2gPfA+HD6KPxw/ZT94Pzw+5D6YPgw9qD14PVA9ZD0QPXw9lD4kPpF/4gEAAigCuANYBBAEWASQBTgFEATYBHAD+AMQAmQB1gHGAYQBKADYAQYBEwDYAToBhAIuAeoBxAISAdgBUAEgAR4BCgDrAFiAWYBXwBX/xgA2gFMAogBWgGsARQBEACKAKYBGgEo/zD+7P38/LD7wPvQ/AT9GPxw+0j7oPqw+Wj5wPk4+XD34PWQ9XD1kPTw88D0EPYw9sD10Pao+AD54PiA+lz8OPsI+DD2sPWQ8wDxMPGQ8/D0IPXQ9hD61PxN/2wD0AhQDcAPYBCgEOAQoBBgD7ANYAxACmgGdAKEAIf/Kv78/UcAWAKsArAD6AZQCUAKQAxAD0APsAwQDOAMAAtwB/AGgAhYB3gEeAQABuAEbALkAsgEsAPDANr/UQDe/lz8qPtI/Hj7mPnw+PD5CPuo+wz9b//AAbQC+AKoA2gEyAPwAQ8Aov6c/Kj5UPdg9rD1QPQA8/DyUPNw84DzYPSQ9UD2gPag9pD1wPIg7wDtIOzg66DsIO/w8eDzMPZA+iP/mANgCIANoBBAEWARABJgEQAPQA0ADBAJ4ATSAe3/qP0c/Oz87P7c/4IAjAIgBegGoAigCoALYAsACyAK4AgQCFAIQAiQB9AHIAkwCQAIMAiwCZAJqAcYB6AH2AXQAcr/fABMADj+NP3g/az9ZPyY/O7+bABOALIAKAIsAj8AqP4y/jj9QPvo+SD5sPcg9oD2APgA+JD3UPmQ+1j7aPqo++D8sPrA96D3EPeA8eDq4OjA6ADnYObA6nDw0PJA9Nj4Nf8oBCAIIAzQD0ARYBDADSALIAoACQAGpAJkARAAdPyw+Vj7Ev5+/vL+bAKgBagFeAW4BwAKwAkQCfAI+AfwBYgFaAbQBpAHsAmwC7ALYAvAC9ALoAqQCQAJsAfoBEQCrQD2/5r/SP8o/9z/IgGQAXoB/ALoBVgHoAZQBtgGaAWiAQ7/pv5E/eD5gPeg95D38PVQ9aD3IPoA+tj4OPlo+tj5kPew9uD2EPXg8EDtIOvg5+DjAOQA6QDukPAg9PD5tP5oAdgFMAxAEMAQQBAgEOAN8AkwB2gGKAWIAk7/hPzI+iD6SPoI+xD9V/8CAI//SwAIAqgCyALABPgGOAb0AwAEmAXIBUAGkAnADHAMUAugDGAN0AqACEAJMAlYBaoBegGMAXr/9v48AiAFWARsA4AF+AcACKgHUAmQCtAIiAVkA+gBMv80/OD62PrI+dD3UPfY+Ij6aPtc/BD+wv58/Vj78Pk4+aD38PQg8uDvoOzA52DjYOJg5KDmoOlA72D1sPhI+00AaAYQCmAMMA9AEFAN0AmACEAHIATEAaABhQDU/DD66Ppo/Kj8sP2yANACqAJ8AigEAAYwBpgF4AVABggF6AIcAoADSAU4BiAHkAgwCTAIEAdIB7AH0AaIBfgEQASMAigBqgFwA9gEgAUoBvAGIAdQB4AIMAqgCqAJoAiYB2AFTAKYAIgAqv98/Yj8dP2M/Rj8ZPxC/40Agv7k/Hj9XPzw93D0UPQA8wDuIOkg5yDlQOEA3+DhoOfA7KDxUPcE/RoBfANIBmAKUA4wDwANcApwCPgEkgC0/k3/gP6I++j5MPro+Zj5PPwtADAC3AK4BAgG+ARYBEgGuAdQBhgFCAZABjgE0APABkAJMAmQCXALcAtgCOAF4AWoBaQDwAFWAdEAlf8x/5kAjAL4AyAFaAbYB9AIQAmgCVAK8ApgClAIQAYoBbwDUgGA/4j//v+P/z7/XQCqAaABKAFKAa4ADP4w+1D5MPeg83DwoO5g7GDoQOQA4kDhgOLA5oDtAPQA+QD9TADwApAFUAgQCkAK4AlQCLgE3ABZ/zv/8P0M/JD7iPvo+SD4GPkA/OD95P7iAOQCJANkAtwC0AQwBkAG6AUQBlgGqAYoB0AIsAnwClALcArACCgHmAW8A1QCKAJYAk4Bwf/a/6oBbAOYBMgGcAlgCrAJoAlACiAKIAkgCAAH0AR8AtYARv/8/bD+sADgAPP/mAG4BLgE7AIYBEAGZAP4/aD8NP1Q+MDwAO9w8IDsgORg4aDiYOLg4WDnIPFo+AT8Q/9IA+gFGAcwCPAJYAtgCpgGGAK1/4L+QPww+rD6iPvQ+WD34PfY+fj6kPwBALQCvAJkAjADrAMkA+gDiAWIBVAEQARIBagFUAYwCEAKUAoACWAH+AVABJwChgF+AUQCcAJyAVQBhAMIBtgGyAdACuAL8AoACkAL8AugCdAGUAYQBkADyv88/7cAAgEPAKcAzAKUA+QCdAOQBVAFTgEy/vj9MPzA9oDycPKg8aDsAOhg5+DlgOHg4CDoAPGQ9bD57gBABvAF8AQQCHAL0Ar4B2AG0AQgAej8IPsA/Lj8OPuY+ND3yPj4+Ij4oPor/4QBeAAUAPYByALKAegCcAbQBwgGOAU4BlAGwAVIB3AJ8AgIB3gGgAUAAg7/4/96AUEAqv79/yACCAJcAiAGYAoAC8AJgApADHAL0AggCBAJwAcQBKgBlAH/ADH/Rf8QAiAEpAMMA3gE6AVwBbgDRAIkAfr+iPuQ9/D0gPMA8WDtIOsg6iDnQOJA4SDmYOzQ8aD4WABABHAEYAX4ByAJAAmgCbAJ0AbcAmwAkv6U/Ej8SP1U/HD5KPgg+XD5kPlY/F0AsgHIACIB6AJMA8QCQATwBngHSAW4A1AE+ASIBJgEIAbYBvAERAJuAagBAAFtAN4B8APsA7wCWAPoBfAHgAhQCcAK8ApQCRAIsAhgCfgHiAWQBLAERAOiAFkAOAM4BSAEOAMIBQAGTAPvAPwBeAJA/oD5UPmw+WD14O/g7oDvQOzA5mDkQORA4yDkgOqA9JD8IgE4BFgG+AagBqAGmAeACAAIkAXwAbT+sPw0/Lj8qPyY+7j6EPpw+FD3mPme/pwB4AFsAyAG0AUAAzwDQAcQCbAGMAVABvAF+ALaAagEYAfQBtgEOATYA+QBp/8BAJgCUAR8A6wCUASYBugGcAZgCCALoAqgBwAH8AjwCAAG6ARoBzAI2ARgAlgEYAa4BDgDyAUQCGAF/AEMA3AEVwAo+wj7dPw4+JDxEPCQ8aDuwOhA5sDlYOLA3gDioOug9GD6t//4BEAHGAbQBLgFuAcgCEgG2ANEAnUAmP2g+0T8GP0Q+9D3wPag97D38PdQ+yUAhAKAAiQDAAXgBcgFmAYQCOAHKAYIBfAEwATIBDAGmAdAByAGiAVgBOYBrwBQAhAEqAMcA7gEmAZwBsgGcAmwC8AKsAhQCOAIyAfABVgFYAawBkAFoAOIA6AEUAUIBZAFsAdQCEAFrAL0A8AE7//A+sD73P1Q+MDvoO4g8UDsIOOg4cDkAOIA3UDj4PHI+pj8GgGgCFAJjAO+AYgGQAlIBrgDKATgArT96PmY+uD70Png9iD2QPZQ9cD1ePkY/g4BDAPABMgEnAO8A3gFMAa4BfgFKAZIBGgCyAMwBoAGKAZwB8gHEAU8AmwClANcA4wDoAXwBlAGiAbwCOAK0AqACtAKQArgCEAIcAjIB3gGSAbgBmgGOAWwBSgHQAcgBjgG0AZABegCIANYBMoBsPwY+yD8yPgQ8qDvkPEg70Dn4OKg44DhwNwg4GDt4Pjw/EAB4AiwC7gGJANwBqAJMAeUA1wDOAOp/6j7IPtk/Fj7sPcQ9LDyAPNg87D04Pjo/nwCZAIkAjgESAYwBhgGoAdwCEAGRAOoAgAECAVIBfgFGAfgBmAEJgEDACABGAIYAtgC+ASQBsgGoAdgCpAMAAwwCpAJcAnAB3gFgAXQB+AIMAfoBTgHQAiIBkgFkAcACgAIqASQBKAF/ALQ/tj9pP6E/LD3UPSA8mDwQO3g6eDmIORg4YDfYOHA6SD1kP38AtgHYAp4B0gDeAMwBiAGWARoBIAElgHE/bD87Pxg+2D4kPVA86Dx8PFw9Bj4tPxwARgEYASYBMAFIAb4BFgEOAUwBeQCKAGoAkAFoAWgBDAFSAZwBMcAAgCMAtQDmAIoA/gGYAlgCIAI8AvQDRALyAcACLAIeAaABGAGcAkwCRgHQAcwCVAJWAeoBnAIQAmoBhgDlAIABKQCfP7Q/Db+zPxw9rDx4PHg8ODqAOYA5kDlwN9A3YDkkPAo+WL/YAYQCxAJnANOAYgCyAMABLAEeAVQBC4BSv7k/Dj8yPrQ9+DzcPCg74DxwPT4+G//IAbACLAGCAX4BWAFeAIEAhgF0AWkAuABiAVoB1gFyAQgB7gGLAKI/68A5QBj/6QAAAUwCEAJ8ArQDEAMsAmwB6gG0AUoBrAHsAgwCbAKQAyAC5AJgAmQCtAIQAXIBFgHSAcIBGADSAaYBUP/wPpw+/D5gPKA7eDv0PGA7GDmAOZg5SDgwN6g6LD1fPwO/6ADOAfQBIkA9wAABegG2AXgBKgEVANbAFz9APxA+1j4IPNA72Dv0PHg8/D2IP2QA7AFgASwBEgG6AWoAwADcASwBDADXANwBpAIiAfQBdgFUAUYAtz+uv6fAJwBeAJQBTAJAAvwCmAL4AtgCqgHaAYQBxAIUAiwCIAJMApAChAKoAkQCZAIsAdgBngFGAZYB7AHSAfYBtgFuAJs/TD4cPUQ9GDxIO6g7SDvwOxg5cDgAONg5qDngO2A+qADEAL0/tACoAZAA08ACAUAClAGWwC0APgCM/9Q+YD4IPnQ9IDuAO5Q8mD1QPdQ/KwC0ARIAywDoATsA9QB/AGYA3ADGANYBUAIIAjIBvgG4AXEAQj/SAD4AHj/uQC4BRAIsAboB7AMcA0ACVgHcArQClgHaAcQDHANsAkwCFALUAwgCYgHsAngCSgG0APgBRAIoAeAB5AICAdYAZD7APhw9LDw4O+w8eDxAO8g7KDpAOUA4eDiAOrA8FD2pP2IBAAGSASYBcAIwAd4AywCOAN+Afj90P1BAKH/MPtQ9wD1wPFg7qDuQPP4+CT9tP+gAWwDSASgA9wCmAOABHQDAAIYA+AF8AZgBvgGuAeoBdABIABpALn/fP5z/4QCGAXIBpAIQAqACoAJYAj4B4AIgAkwCkAKIAoACoAJ8AiQCSALoAvgCbgH+AYQB6gGaAbwB8AJYAj4AxEAXP3g+ODyYPAA8sDyQPAA7iDtQOoA5YDigOUg6+DxePmSANAEkAYYB2AGAAV4BAAEtAGj/+X/cgCm/gj9pP2c/HD3MPKA8EDwIPAw87j5rv45AOQBwASwBSAEaANIBLwDjAHbAIwCgARgBTgGQAeoBtgDwgBF/8r+LP5O/uEAsAQYB0AI8AlQC6AKIAlQCTAKQAkACFAJQAvQClAJEApwCyAKEAhQCIAJwAhwBzAIUAnQB2gFyASQBPYB2P3o+hD5APYw8kDwwPCg8EDtQOmg56DmQOQg5CDrMPZo/TgBaAbgCqAIqAJuAYgEWASZANj/eAFPAKj82PsM/mD94Pgg9FDx4O/A77DxcPbE/GwCaAXoBZgFwAQQA4YBGAFQAfoBVAMABdAFmAaoB9AGkANIAZABdABY/Zz93AKoBjAGAAcgC3AM8AhwBxAKcArYBuAFkAmwCyAK0AkADAAMEAkACNAJ8ApQCmAJwAgAB7AEfANUAxADUAKHAOT8WPhA9PDw4O0g7GDsIO2A7IDqAOkA6YDqIO7g9AT9WANABpAGaAX8A0QDMAOcAiABDgAz/wb+hP2i/mL/AP2w+AD1QPFg7cDtAPRY+zz/QAIgBoAGDAIA//8ApAKMAOb/4APABvgEUAQwCKAKKAdwAl4BJgFM/oz84f9oBVAIgAlQC8AMIAu4B+gFqAYQCKAIgAmgC6ANQA3gCkAJUAkACeAHAAiACYAJMAdoBYAFYAXMA4gCtAFw/yj7APdA9LDx4O4g7UDtoO3g7ADs4OuA6+DqIO2w84D6xv4gA/AIIAv4BgQDTAO0AfD76Pko/wADxf/0/N7/qwCo+QDysPDw8dDwEPEg90L/IAPUAtwCcAR4BMoAQP1K/uABQAKrACADAAngCvgHgAbwBnwDaP2g/EIBGAQ4BJAHsAxADdAJgAfYBvgE7AOIBnAKsAvQC8AMAA1AC+AJ0ArwC8ALkApQCSAIUAcIB0gHuAdIB1gETv/o+jD4UPXQ8dDwIPIw8eDsYOrg66DsQOqA6YDtYPFw8uD10v6IB1AKkAmACdgGxP6Q9yj4Yv7MAggEoAUgBjYB8PiA86Dx4O8g7sDwIPcc/Ej+TgAIA8QDwgEn/5z94Pzs/Mz9HADgA5gHcAmwCfAJsAj8A4T+LP14/zQBpAIYB1AM4AzQCXAIMAgwBeQBiAOwB9AIkAjwCnANwAtACQALEA4wDbAK4AogCwAIQAVIB6AKoAlABqAEnAJw/FD1wPKA86DygPAg8MDvwOzA6UDqwOwg7eDsYO/Q8wD42P1IBgANsA2QCcwDoP04+GD3jPyIA9AHkAcYBFL/2PnQ82DuQOyA7oDy4PVY+tX/uAKcAXQAEgGt//j6kPiI+3v/QAEgBCAKgA7wDJAIiAU4AhD9KPqs/cAEIAkACnAL0AzACSgDvf80AiAFEAVQBiAL4A2QC9AJcAxgDtALQApADdAOYAtACcALYA2ACoAIsAkwCCQC9P28/Oj4gPJw8BDzwPLg7QDrwOvg6qDnAOdg62DvEPFg9Aj8IATgB1AIwAjgB0ACqPqw+Oz99AKsA/ADIAbYBPj8cPRA8aDwIO6A7dDz4PwjACb+2P2HAKgAmPzI+rT9mv+I/SD9VAIwCEAJ8AgAC9AKWAQg/RT87v65AEQDAAmADTAMIAigBXADzgASAUgFIAkQCnAKsAsQDLALgAzQDYANMAywC7ALcAsADCAN8AxwCzAKYAiQBMgAsv4A/CD3YPMw88DzMPJg8IDvwOwA6EDlAObA6MDtUPVQ/UgC6ATwBfwDMwCm/kD/Qv/F/wgEAAmwB6QC2wAwAAD6QPFA7jDwkPAg8XD3av95AJz8WPtI/Pj5MPbA93D9agHoAoAFoAjwCPAGAAZoBfgCXABXAMwB1AKQBHAIkAvQClAI8AVkAsD9PP0IAxAK4AyQDMAM4AsACRgH4AjwC2ANYA2QDUAOAA8QDyANcApwCeAIKAb4AhgDJAOA/fD1QPSg9RDyAO0A7qDwQOug4sDigOmA7ODtYPYSAawCFP5C/hgCtACA/KL+EAU4B1gF2AVQCKAGCAGg/BD60PXA8MDu4PHw9kD7dv6xALYAqPxw9tDyQPSw99j6nP9oBgAKcAfwA2AE6AQqAQr+wgD4BEgFUAUQCvAO4AyAB3AFsATDABz9iABgCOAMYAxwCyALEAnQBSgF8AcwCwANkA6gEKARIBCADYALIArQB3AFuATQBEgDEQBY/bD60PZA80DyoPGg7SDo4OXg5mDn4OiA8Gj68P04+5D67Pxg+4D3ePqEA0AH5AOQA5AI4AjoAfz9FAAU/xD3kPHg8xD3QPYQ93T96ALfAFD6UPag9WD0QPNQ9ywAaAbYBTAD4APIBHwBJP49AAgEtAO0AgAH8AxADeAJ0AhACHQDtP6vALAGgAkgCRAKIAugCMgEQAUgCRALAApwCrANYA+gDUAMEA5wD2AMUAjwB7AIyAUeAc//YwDo/OD2sPSg9UDzYO0g6sDpoOfA5MDnEPAw9sD3kPlk/PD7GPno+Ur+GgH+AcgEQAjYB5gFeAW4BWACvP3A+2D6kPaQ8/D0gPjQ+tT8Kv/C/gD6MPQw8bDx4PRI+QL+CAKIBHgEUAL2AKwBNAL+AM4AIARgCIAKYAsgDaAN0AlUA9X/VgHYBJAHIAogDRANUAiEA8wDaAdwCeAJ8AtwDgAOEAxQDGAOYA6wCxAJwAeABtgE1APYA2gDeADg+jD1EPLQ8CDvIO3g7GDtAOyg6iDtgPKA9QD2APig+1T8yPqQ/HYBoAPAAjAEcAfYBtwCxAHkAp4AyPvY+sD7QPgQ8/Dz0Pm4/AD8dPyw/Aj4gPFg8ND06Pg4+2j+UAK0AwACHgDv/9oAMgFoAUQDWAcQC0AM0AuwC3AK8AaAA8AD2AYwCSAK4ArACoAIuAVYBWAHsAmACyANcA1QDFALAAzwDMAMAAxwC9AJmAagBBAFaAU4A0AAqP1A+ZDywO1A7pDw0PAA8BDwwO8g7cDroO4g81D2WPkg/dr+SP0Y/Iz9dP9OAegEoAjoB+QDxgFAAaT++Pus/Iz9APrw9QD3oPqo+6j72PzY+9D2QPKw8uD1kPmk/XwAegBp/xL/Qv7E/D7+FAMABtgFEAdQCkAKWAaABGAGAAdwBYgGgAtwDtALcAfQBSgGQAYYB5AKAA9gEHAOAAyQC2AMQAyACzALgApACHAFsASgBuAHsAWsATD+GPpQ8yDtgOyQ8JDzUPNA8zDz4O8A66DqQO9Q8/D0EPnQ/zQCqv6I/FX/TAElAFgBQAaQBxwDpQAYA/QCUP0A+qD72PqQ9RD0mPmg/QD8aPo4++D4sPJg8LD1WPzM/kb/aADqAOb+mPxk/XgB0AWgBxAIAAlQCYAHMAVQBUgHAAiYB9AIIAtAC7AIMAYgBogGaAaAB+AKYA7wDhAOAA6wDaALMApQCxAMkAkIByAIAAlwBtADwAMIAmD7MPVA84DxYO7A7rDz0PVQ8kDvwO9g7yDsIOxg8TD3EPqw/Pz/cADA/ST8nP4wAggECAVABjAGKATGAaAAxP9M/sz8iPu4+VD4EPkg+9D7kPoA+QD3IPSg8jD1gPnA+yj8vPwY/Qj8iPsg/ngC4AXwB3AIEAewBKQDiASABgAJsAvwDAAMsApwCXAH6ATgBLgHMArgC4AOoBGAERAOkAswC+AJMAigCdAM0AxQCTgH0AYQBHb/kP2w/cD6UPWg8gDzQPKg8IDxgPOQ8qDvIO8g8BDwEPBA82D40PtY/VD+PP64/CT8cP7YASgEWAX4BfAEBAKX/xD/6P4I/qj9OP6M/TD7EPo4+2D7IPlg93D38PbA9YD3SPye/qz8yPoQ+wj70Pr4/WAE4AhgCcAHiAWUAkABLAO4BmAJ8AqQC8AKcAmwCLAHeAVYBGgG8AmQDFAPIBJgEmAPIAxQChAJsAiwChANQAxACVAHOAakA3IAnv6g/ED4APQQ8wD0oPOA8hDzkPMQ8WDtAO2g70Dx4PGA9GD5BPwg+5j6MPwc/Vj8uP3MAqgG4AUwBAgFMAXOATr+2v4qAcMA+v4w/8L/ZP3Q+ej4sPlQ+ID1EPWA9zj5APlo+RD7KPvA+KD36Pr0/ygDEAVYB+gHgASkAG4BoAWgB/AHIApQDfAMcAmAB4gHKAZABPgGwA1gEmASwBAAEPANoApACbALkA5wDhAMIAqwCFgG/ANYA9wCMf9Y+bD1YPUw9UD0UPQA9RDzYO/g7eDuYO8g70DxsPTw9dD18Pfg+hD70Png+rD9XP+wAMQDoAY4BtwDaAKiARUAFP9cAKgCEANcAcj+TPw4+sD4MPhQ+Mj48PiY+ED4uPh4+QD5IPjA+AD71Pxo/qgBgAUYBigDgAEsAxAFUAWoBtAJsAvQCvAJAAowCOgEQAToB3AMwA/AEWASQBBADHAJIAkgCxAO4A+ADrALkAmQB+AERAM8A1ABDPyw9yD3YPew9aD0wPXA9MDvQOyA7aDvYO/A7xDzwPXg9GD0UPdg+hD6MPn4+tD9Jv+kABgE4AYABiQDhgEQAawA+ADAAkgExAPGAYb/EP2Q+nD5iPmg+Tj5KPlQ+QD5qPi4+Ij40PdY+JD6PP1x/8YBpANgAzQCvAJgBMAEWAUACIAKcAowCtALkAu4BoADMAewDKAO4A9AE6AT4A3ACEAKsA1ADTAMMA6QD7ALAAdABkgH6ASb/8D7OPoQ+QD3UPZg92D34PPA74DuIO9A7gDtwO5A8oDzoPLw8wD3KPgg94D3kPlQ+/z8MwD0A5AFGAUABNACVgHLAO4B5AMoBSAFrAMsAaD+oPxA+5j6wPqQ+pj5wPjQ+Nj4CPiA9/D3SPiw95D4DPxf/yEAIQCmAcAChAHBALQDgAdgCDAIkArwDLAKEAbABWAJ8AuwDcARwBXgE1AO0AsADSANIAzQDQARgBDADIAK4AmQB1QDEQBO/iT8CPpI+Uj5KPjg9QDzcPDg7oDugO5g7gDvMPBw8FDwMPJg9ZD28PXw9oj5wPpI+1z+uAJIBEQDhAOIBHQD5gE0A9gF6AWABHAEGATgABj9cPwY/eD7SPrg+nD7cPkw92D3APjA9gD2SPjg+vj6APt8/en/3f+S/zABlAJUAiADqAbACUAKIApgCvAIIAYgBnAKsA8AE0AUwBPgEJANIAwQDZAOwA8gEIAPMA7wDGALoAiwBdACwv+U/DD7kPtI+4j5UPfA9DDxYO5g7qDvQO9g7qDuoO/g75DwAPOA9eD1UPUQ9gj4UPog/bwAiAPkA5ACogEQAjgDWASIBQgHuAdIBqAD1gEYAdX/9P0o/UD9dPwI+7j6sPrw+ED2YPVg9uD24Pao+FD78PsQ+4D7XP0Y/vD9W/9MAhAEwATIBqAJsAkQB/gFcAiAC+ANYBGgFcAWQBOQD4AP4BCAEIAQYBJgE6AR8A6gDeALIAjcA1YB9/+a/hD9iPtI+kD4IPVA8SDvoO8g8IDuAO3A7YDuAO5g7qDx4PPg8hDyIPRg9qD3oPqP/xQCDAFxAHgBsAF4AfwDkAcwCIAGAAb4BcwDRAE+AaQBfv8s/YD9SP7A/MD6QPpY+YD2oPTQ9Rj4EPmY+YD6oPq4+Xj52Pqo/Ij+kgBQAgwD1ANIBRgG+AWQBpAIsArQDCAQoBMgFOAR4BDAEeAR4BDAEeATYBSAEuAQsA8ADWAJsAaQBOoBNgDj/+7+APzQ+BD24PIA8IDvEPAA74DtAO6g7iDtYOxA7/DxAPHg7yDy8PRw9TD3hPy6AO7/iv7l/zwByAAcArgGkAnoB9AFWAZoBkgECAOcA+wCNADc/rf/wv/U/UD8SPvY+AD2sPWw9wj5ePk4+lD60PiQ9+D4OPus/A7+GgAwARwB6AH0AygFkAVQBwAKwAtQDYAQABNgEiARQBKgE2AS4BFgFCAWIBQgEqASYBHgC1gHEAeABhADqwBQAUUAMPtg9vD0oPOQ8KDuAO8A70Dt4Otg7KDtAO6g7YDtAO6A79DwQPIg9Tj56Pto/Mz8Iv7U/hz/UgH4BOAGcAaQBqAHOAdoBegEaAVwBGwCtgFwAjAC2QCc/zz+kPvg+ED4QPkw+lD6OPro+ej4sPfA96D5KPxg/Tz9KP0W/ib/9//QAfgEUAeoB0AI8ArgDcAOUA9gEcASYBEgEEASQBVgFUAU4BQgFWARAAwwCrAKIAmQBhgG+AV8AjT9UPoY+TD2APNg8nDyYPDA7YDtYO7A7UDsQOzA7KDsAO0A73DxIPPg9MD2CPjw+Ij6vPx0/hQA7AFYA9wDsAQQBpAGCAYQBsgGQAaoBDgECAWIBIwCoAGQAev/LP1I/DT9AP3Q+/D7jPz4+lj4ePiQ+jj74PpY/Gr++P10/Fj91f/2AMQByAQwCOAI4AjgCpANEA7QDSAPQBDQD9AP4BEAFAAUABMAEnAPgAvgCOAIcAnQCJgHEAY4A4j/TPww+oj4EPeQ9eDzYPLQ8aDxEPFA8IDvgO5A7QDtgO6A8DDysPMQ9bD1wPWA9kj4MPqo+xT90v47AB4BDAJkA2gEcATsA9gDUASwBNAEMAVYBZAEDAPgAUwBiQDX//D/YgC6/07+cP1k/fD8IPwc/LD8xPx8/Pj81P0W/gb+vP7v/8kArAFoA4AFoAYYBwAIUAkAChAKsAoADCANoA1ADhAPEA/QDUAMUAugCvAJoAnACYAJEAjoBfQDPAInAPj9TPxY+6j6mPlo+HD3kPZg9cDzcPIQ8sDxYPGw8dDysPOw8wD0MPUg9iD2YPbA9xj5yPnA+rj8Ov6K/qr+Rv+u/67/PQBsASQCIAIwAoACJAJaARYBbgFkAeUAugD2APkAjwCDAK0AUQB5/xH/Xv/C/wkAhgBSAZIBRgE8AcYBXAK0AigD+APABEAFsAVgBgAHMAcAB+AGGAeAB7gH0AcwCHAIEAhQB9AGmAbwBRAFwATQBGAEcAPcAnQCTgGt/7L+UP6w/dz8ZPwg/JD78PqQ+gj6QPnQ+Nj4sPhI+Gj4EPmA+Yj52PlQ+lj6IPp4+hj7gPvQ+3D8IP1M/VD9jP0A/hj+Av4M/iL+MP5a/q7+Ef9E/0f/Nv8m/yH/Nv9n/53/1/8hAFUAVwBMAHIAsQDSAPEAMgGAAZwBngHiAVAChAKEAqQC2ALwAgwDUAOUA6ADnAO0A8QDuAO8A+gDGAQgBCAECATcA8gD8AMQBPAD2APcA7ADXAM4AzgDDAOgAkQCHALYAXoBNgEUAdYAcgAHAKD/Xv80//7+ov5o/lL+KP7Q/Zj9jP1o/Rj97PwE/fD8pPyE/Kz8sPyA/FT8ZPxg/ED8JPwo/Cz8JPwc/BT8GPws/ED8SPxI/Fj8dPyM/LD86PwE/fD89Pww/Wz9hP28/RT+TP5K/mr+wP7+/h3/a//U//z/+f88AMUAJgFWAaoBHAJUAlgCkAL0AjQDVAOkAxgEUARoBKAE+AQQBQAFIAVoBYAFWAVgBZgFoAVwBWAFYAVABfgEwASoBIAEQAQIBNwDhAMEA5gCTAL4AYoBGgG9AF8A9f+C/yD/wP5g/vT9lP08/ez8pPxY/BD80PuQ+1D7GPvo+uD6yPqw+qj6oPqY+nj6ePqY+rj60PoI+0j7WPtY+4j72Psc/Dj8aPyw/Nz8CP1U/aD90P34/T7+fP6S/rb+D/9l/5b/x/8ZAF0AjADGACQBggG4Ae4BNAKMAtwCIANsA7wDAAQwBGAEmATYBCAFWAWABZgFsAXIBeAF8AXYBdAF0AXIBZgFaAVYBVAFEAW4BHAEMATgA4gDOAPgAngCCAKmAUoB4QBtAPX/gv8Q/5D+Gv60/VT9+Pyg/FT8EPzA+3j7QPsA+8D6iPqA+oD6cPpY+lD6UPpA+kj6aPqI+pj6qPrY+iD7UPtw+6j74PsQ/ED8ePzA/BD9WP2o/fz9SP6M/tL+IP9w/77/DwBkALgACgFiAbgB/AE4AnwC1AIoA3gDzAMgBHAEqATYBBgFUAVgBXAFmAW4BbgFqAW4BdAFwAWQBVAFMAUABcAEgARIBBgE1AN8AywD4AKEAhwC0AGSATABrAA9APr/sP9E/+T+rP5q/gb+oP1g/TD95PyU/GD8SPwU/OD7wPuY+1j7MPsw+yj7EPv4+gD7EPsQ+yD7OPtY+2j7kPvQ+wD8KPxg/KD82PwI/VD9lP3M/Qr+WP6m/vD+Nv99/77/8v8tAHoAzAASAVIBjgHYASgCaAKcAtQCHANMA2QDmAPkAyAEMARABFgEYARIBEAEaAR4BGgEQAQoBBAE6AO4A4QDTAMgAwADzAKMAkgCDALKAYABPgH7ALYAcwA7AAAAuP92/0L/Ff/g/pz+Wv42/iD++P24/Xz9ZP1Q/Sz9CP38/Pz86PzQ/Mz81PzQ/MT8yPzg/PD88PwA/SD9QP1Y/XD9nP3I/dz98P0c/lr+hv6e/sj+A/8t/0j/cf+j/8P/3/8YAGIAlACyAOAAHgFOAWgBhgGyAeQBGAJQAoACpAK4AsQCzALYAugC7ALsAugC5ALYAsQCrAKQAnACSAIgAvgB2AG8AZgBYgEyARAB6wCwAHIARgAfAO7/vf+b/4H/XP8w/xT/BP/y/sz+sP6m/pz+gP5i/lj+XP5U/jz+Nv5A/kb+OP4s/jD+PP5I/lD+Wv5e/lj+Wv5w/o7+nv6o/r7+1v7g/uL+8v4P/yL/Mf9K/2X/cv9//6D/yP/e/+n/AQAiADcARQBeAIMAoAC5ANwAAAEUARwBLAFIAWABcgGMAaQBqgGoAbIBvgG+AbQBsAG0Aa4BoAGWAY4BfgFmAVIBPAEeAQAB7wDgAL8AkgBxAFoAPQAZAPn/4v/K/7H/m/99/13/QP8n/wr/6v7e/tj+xP6o/qz+qP6U/oD+gv6M/nr+dP6W/rr+vP68/tT+4P7Y/t7+C/80/zf/Mf9H/2b/eP+D/5P/qP+4/8X/0P/a//D/DAAiACcAMABIAGAAcAB/AJYArAC3ALwAyADhAPYA/QD+AAABAgH/AP8ADAEiAS4BJAEaARYBGgEaARYBEAECAfIA5wDcAMoAtwCxALMAoQB8AF0AUgBJADMAFwD//+3/3P/L/8D/tP+e/4D/aP9Y/0P/Lf8c/xP/DP8D//r++P7w/ub+3v7a/t7+6v76/gf/CP8I/w7/F/8c/yj/P/9T/13/Z/+F/6b/tv+8/8r/3f/p//H//f8PACAALQA5AEcATwBQAE8AUABXAGIAagBvAHcAfAB8AHgAcwBvAG8AfACOAJgAnQCpALsAwgDDAM0A3gDeANcA2QDdANUAzADSANsA1QDAAK8ApgCaAIkAeABvAGsAXwBOAD4AOQA0ACUAFgARAAQA6//V/8//y/+2/6X/qP+q/5T/c/9t/3H/ZP9N/03/YP9a/0v/R/9J/zn/L/89/03/Rf86/0f/UP9F/z7/Tv9g/2D/Yv90/4T/gf+A/4n/kv+a/6b/rf+t/63/wP/W/+H/5P/o/+r/6v/5/xwANwA3ADQAQQBXAGIAYgBsAIIAkgCQAJAApwDEAM8AxgDBAMIAuQCrALEAwgDCALIApACbAI8AfQBxAGoAZQBkAGIAWABJADsANQAuACgAJgAnACIAFQAKAP//8P/k/97/2f/R/8H/t/+9/8H/r/+U/4z/kv+P/3//d/+D/43/hP98/4P/jP+L/4b/h/+K/4b/g/+G/4n/hf+E/5H/pv+p/5j/j/+g/7b/uP+x/7v/z//U/8n/yf/U/9j/2v/t/wsAGgAZAB8AKwAtACgALwBGAFkAZQB2AIgAlQCSAIoAiQCOAJAAkACRAJEAjgCMAIsAhgB+AHYAcABtAGoAZQBeAFUASQBDAEQARQA7ACwAIQAaABAAAADy//H/7//l/9r/2f/b/9L/yP/K/8v/wf+7/8L/w/+3/67/tP+9/7z/s/+s/7D/uf++/77/uP+0/6//rv+1/8P/zv/Q/9D/0P/M/8T/xP/N/9X/1//a/+D/5P/j/+j//f8TABoAFwAcACUAIwAgAC0APgA4ACcAKQA4ADcAJwAlADEALAATAAEACAAWABIABgAEAAoAAwD0/+7/9P/3//T/9f/5//f/9f/7/wEA//8BAAkABQD1/+z/8v/6//n//P8MABMADAABAAUAEgAUAAUAAAATACkAJAAYACMAHQD3/9X/6v8RAAcA6P/y/w8A/P/P/8z/5v/h/7z/vv/r//P/x/+2/9f/5v+//6j/zf/0/9//uP/A/9z/0f+z/73/6f/8/+//6//+/w0ACwAJABQAIQAwADsAQgBNAFUATwA+ADsATgBjAGEAWQBYAFIAQQAxADEAOgBCAEQAMAAPAAEAFQA2ADwAIQAHAAIACQAAAOT/1f/g//L/7f/i/+//AwD6/+D/2v/g/9T/w//G/9L/1v/W/97/4v/O/6//nP+U/5D/j/+e/7T/tv+W/3P/dP+S/6D/mf+k/8j/3//g/+//IwBcAHAAZgBiAGoAbgB5AJUAtgDIAMIAsQCpAL0A2wDPAJQAXwBZAFYALQAYAEgAcgBBAOj/2f/2/9f/mv+h/8//sf9k/23/y//k/4H/M/9Z/3L/C/+a/sb+O/8G/2T+av72/oj+OP0w/fD+7f+8/gb+BgBUAiwClAF4A4AFnAOo/9L+YAEMA6ACyALUA9QC2f+o/v3/ZgDO/kD+o/8vAFH/i//WAEEA7P1E/cD+av+2/v7+MwD5/6D+kP6x/yIA5P85AMsAlQA3AMkA0AE0Au4BsAGSAUIBzgC/ADwBXgFdAEn/mv+GACsAFf8m/8P/8P6c/TD+0//7/xH/Uv8PAEv/Iv7K/hcAy//y/lj/+f+N/1j/DwAVAPj+mv5i/4X/2v4k/ywAAgAE//b+O/+G/kj+sP90ABz/hP6KALwBpP/0/QUARAKoAFD+sv9kAtABxf/qANADhAN5AJP/sgHQAnABlwDkAdwCsgE/AKoA6AG0ASMAJP9k/8X/s//D/x4AHgCD/+L+uv7w/i7/Qf8h//z+Ev89/zj/O/+j/wcAnv+2/nL+8v42/wL/Q/88ALsA//8h/1L/7P+Q/5r+rv71/7kANgDH/2oA9QAcAN7+AP8VAFQAjv9S/zgA5QBoAML/EgChADQATP9Y/1QA1ABsAFUAGgGeASoBtwAGAUoBuQAwALEAegFeAdIA1QAuAd4ACgCv/+n/2/9e/xj/Uv+F/1f/Fv8x/3H/Q/+8/qT+Ev87//D+Ev+7//H/i/+N/zwAdAD2/9j/VwBUALH/tv+LAN8AYQBCAM0A2QAzABgA5gBwATQBDgFyAYIB9ACtABwBcgEqAecANgF4AR4BsQC3ALEAJgCX/4f/nf9P/9b+sP6q/mr+KP5I/ob+bP4S/hD+ev6s/nL+Zv7I/gz/6v72/n7/1v+n/3z/tP/X/6H/pP8tAJYAaQAnAGAAwgCQANr/ff/K/wQAr/99/x8AuABOAJD/n/8KAMn/cP/9/9wA9QDQAFQB4gGWAQoBMAGeAZABVAGSAfIB5AG2AcgBwgFeAe8AqABWAPH/yP/Q/7P/iP+D/13/5P5u/lT+YP4s/vD9GP50/o7+hP7E/hf/EP/I/rT+5P4n/4r/FABxAGMATwB2AJYAaQBHAIIAzgC7AI0AxwA2AVABEAHPAIkADACe/5//4//l/7T/qf+r/3T/Kf8b/xb/1v6E/lr+WP5q/qb+Jf+c/7P/hP9s/3n/if9//5z/BQB/AMsABgFMAVIB+gCZAH8AewBVAFkAmADNAM0A4gAGAdYARwDG/4n/Uf9A/7P/WQCYAH0AgwCNAFkADgAQAE4AjgDuAFQBsgEIAmwCqAKcArAC/AJcA2wDjAPkAyAE+AO4A5gDVAOkAtYBWAEmAcwA5v/q/mT+/P3c/FD7ePpQ+rj5qPhg+Mj4ePhg9zD38PfQ93D2EPZw9zj40Pc4+DD6qPuw+yD8rP2U/jb+pP5qAJ4BkgEcAtwDKAVABaAFyAYQBygG0AVwBrAGYAboBiAIEAjwBsgGgAc4B9gFOAVwBeAElAOAA6gEGAWYBKgEQAXQBGwDLAOABEgFuASYBNAFwAZYBkgGcAcQCAAHGAZgBggGOARQAzAEGASIAV//Qf9O/hj70PfQ9TDzwO+g7hDwkPBA74DuQO3g6IDjIONA5oDnwOYA6eDsgO2g7MDv4PSw9dDzkPVI+ij8AP3oAqALgA+QDjAPABJgEoAQoBGAFUAXABagFoAZQBrAF4AVoBSgEQAMoAfgBkAHmAbwBbgFoAN5/9j72PkQ+CD2sPUg9wj4sPew94j4OPkw+Uj5YPnY+Kj4sPp4/rYBGARIBiAIoAggCDAIcAngCtALYAzQDBANUA3QDVAOIA7ADNAJSAYAA88AxP/B/zQA6/+s/YD5YPUA87DxQO8A7IDpIOhA5mDkoOTA5mDnQOVA48DjAOWA5oDqsPAQ9aD1UPXQ93j7VP6mASAHkAxAD6APYBCgEcASIBOgEwAUQBPAEeAQwBEgE2ATABIgD1AL4AZ8Aqv/eP+7AOQBLAIoApIB+f+k/Uj7gPlo+AD4yPho+jD8wP0Z/xgAhwBYAJD/mP5A/rb+pf+NAPQBgATABtAGOAUoBOwDUAO0AmgDIAWwBSgFyAWAB1AISAeYBggH6AaABWgEkAWIBzAIYAcYB6AHMAf4BPACdAKIAcL+oPyM/Qb+mPpQ9qD1UPbg8sDtgOzA7aDqIOXg4yDmQOVg4mDkYOrg7ADsIO9w9XD3EPTA8yD5uP0GAMAEQA0gEyATIBKgEoAR4A3QDNAPABMAFOAUwBXAE2APQAxQCogGngHC/oj9WPsA+pT8zf/C/pD6APgQ9hDy4O4g8WD2kPkA+2z9qP+Z/3D/ogGoAzQDoAJ4BAAHsAiAC8APQBIAEXAOMAwwCaAGWAdgCmAL8AkQCVAJyAeIBKwCbAI8Af7+dv6X//7/W//A//0AbgDw/Tj8WPyw/Gj8cPwU/ZD9nP18/cz8kPuA+kj5APdw9CDzwPLw8VDxIPLg8WDuQOqg6WDqQOlA6QDu0PQg9xD2oPaA+Jj4iPgw/G4B1AP4BBAJkA7AEPAPQBCgEGAO4AqwCsANIBBgEKAQABHQDhAKKAbIBLQCUv7A+ij7rP04/tD9+v4cAOT8APfw80D1EPfg9yD63P25/y3/rf9YAlAEqAPAArgDYAU4BigHgAlADIANcAwwCugHgAboBUAGOAcgCPgHkAYoBUgEWAOgAQMAgv/d/3oASgFcAigDoAKTACr+5Pzc/Dj9nP32/r8ArwDi/gj+fP5g/WD6uPiQ+Vj4UPMA8GDxcPPw8XDwIPHg76DpAOUg58DrQO1g7tDz4Pio+JD2CPgA+6j7vPy2ARAHsAjQCfANABLgEcAPUA8gDxANAAxADgARgBGAEGAQgA9QC6AFeAEw/1z9RPzo/Hj+Bf8W/oD8yPrA+GD24PRg9XD3+PnY+0D9sv4pADAB9AHUApwDKASYBHgFOAdgCfAKUAtQC2ALYAoACLAFAAWABagFqAVQBtgGoAVAA4IBZwDk/lT9fP2t/7oBVAI4AlgCLAJ3ACD+lP0s/2QAJQA+ABwCGAMWASX/NwAqAdj9QPmw97D2wPFg7CDtoPFw8iDvQO3g7ADqYOZg5yDsYO5A7oDwYPV4+JD5GPze/9wBOAIQBDAHcAlgC1AOABGAEaAQYBAgEIAPQA/gD9APgA7wDFALcAjYBDQCjQA6/6D+9P6A/mT8UPq4+eD44PYA9nD3GPmY+dj6oP1m/7j+GP6x/9oBcAKkAkgEkAZ4B0AH+AfQCfAKIAqwCAAImAcoBoAEsAQwBsAG+AXABQAGuASYATr/Iv+b/9D/0ADQAtADHAPuAUYBcgDg/04AFgHjADIA3P9a/5L+qP40ANoAVP9s/Rz82Pjw8sDtAOwg7ODsIO6A7wDvwOzg6kDqgOoA6+DrIO0g77DyoPc8/N7/kAOgBigHWAYoB4AJAAsADMAOQBJgE2ASQBLgEmARIA5QDAAMsArYB3gFKASAApsAzv/7/2z/dP0Q+/D4MPcQ9jD2QPfY+ND6DP3W/nH/RP8I/xj/g/+BAJwCqAWQCCAKUAogCqAJ0AggCEAIsAiQCPAHYAfgBhAGSAXoBKgECATwAkABI//Q/RD+2P6s/rT+MQBiAXcAzv7u/mr/UP5M/QH/2AHkAfn/Tf/v/zj/uP28/Uf/0/8o/lD7oPcg8+DugOwg7CDtQO7A7oDugO5g7wDwAO+g7WDtQO5Q8CD0MPpoALgEYAdQCfAJ8AgQCLAI0AogDbAPYBIgFAAUIBPgEdAPQA1wCyAKQAjABVgDlAE6AFz/cP/k/xH/PPzQ+JD2UPVw9FD0IPaA+Tz8OP24/bL+Bf8c/vT9BAAAA9gEMAYwCAAKMApgCVAJ4AkgCvAJwAmQCcAIkAdABjgFEAWwBagFIAREAk4BcgD0/hb+0P6A/7z+AP7W/mb/Tv4k/eD9UP+t//n/vwDcAEP/yP10/XD9NP3U/aD/gwAJ/8j7kPeQ8gDu4OtA7EDtoO1g7uDvkPFQ8gDyIPGA78DtgO3g77D0gPohACAF8AiwCkAKwAjQByAIMAkQC+AN4BDAEgATQBIgEZAPQA2wCrAIGAcQBeQBAv9A/iH/Yf+a/kz+8P0g+5D2IPTw9PD1EPZA+Aj9UwASAFf/IgBcACH/Xf+4AkAGmAdwCPAJsAoACmAJkAlwCbAIUAggCDgHGAa4BYgFqAT4A7ADxAIUATYAbgDh/5T+dv7a/0kAef9F/+H/o//U/pX/FAE2AXEA3wD0AUgBU/9W/kj+yP2k/Sb/fAD+/gj7MPfA86DvoOsA6sDqwOvA7IDuIPFQ8lDx4O+A74DvAO/A77Dz2PnZ/+AEEAmAC0ALwAlACQAKMAtQDAAO4A9gESAS4BFAEFAO8AygC3AJwAaIBOwBhv40/Jz86P1k/Sj8ZPx4/Lj58PXA9PD1cPaw9mj5kP2c/5//ngCgAggDEALUAngFMAdAB8gHgAlgCvAJQAoQC6AKsAhYB/gG+AVYBOADuARoBHwCYAH4AfQBMgDW/mj/JgCV/yT/zP/M/xj+SP3E/oEAzQCsAIIB+AF4AQQBkQDe/rT8rPyK/pH/Rf8T/0b+APtA9oDygO+A68DooOmA7KDu4O8Q8pDzgPLA8IDwsPDg77DwgPVY/NQBIAZACqAMwAvgCQAKUAvAC9ALUA3wD4ARIBFAEJAPMA4QDAAKYAgABnwC0v5o/HD7KPtA+8j7ZPww/Nj60PjA9kD1APUw9oj4MPvc/fv/QgH0AagCWAPoA/AEoAYQCJAI0AiwCTAK4AmgCTAKQArwCIgHAAcYBjgEFANoA4gDeALGARgC0AE0AAn/P/9f/+D+Vv/zAHoBXABE/zH/P/81//3/bgFAAkACPALoAXMAqv7s/Qb+AP7o/ez9yPy4+eD1oPKA7yDsAOog6qDrYO2A77DxkPKA8TDw4O9A8PDwUPPw90z95gEABtAJ0AsAC4AJwAkwCzAM4AywDgARYBFgEMAPYA+QDYAKgAigB+AFjAJy/5j9LPwA++j60PsY/DD7EPrw+FD3sPVw9SD3cPnw++L+QgEEAvYBkAKYAwAEqASYBuAI0AnQCVAKoArACYAIcAjACPAHoAYwBqgF5AMYAqIBpAHYAEsAEgGGATYAiP5A/ib+QP0k/Qr/FAE+Ae0AmgEQAv4AAwCbAJwBbgEaAbwBHAL6AJn/m//Y/wr/kP00/AD6EPbg8cDuYOxg6kDqYOxA7/DwkPGg8YDwYO4A7eDtUPCQ8xj43P1QAwgHUAmQCnAKQAnACPAJwAtADfAOQBHAEqASoBHgEFAPAAyACGAGyARIAtH/lv4G/uT8wPvI+9D7WPoY+ND2IPYA9XD04PWw+Pj6HP28/9IBPAIQAtACzAPwA3gEcAbACNAJgApgC2ALAArACLAIYAjwBpgFYAXwBKgDoAJ8AjACRgHsAFwBMgHg/wb/6v6G/qT96P2l/+QA7QAeAUQCoAKMAaUA0wDQAM//av9+AFABXQAk//r+Sv9U/sz8OPuo+AD04O7g6+DqAOsg7MDusPFQ8xDz0PHg76DtYOyg7XDxgPbw+1QBwAVwCNAJMAqwCbAIkAgAChAM0A1wDyAR4BFgEcAQYBCwDjALmAdIBUwD+ABQ/9D+Ev6s/Fz8UP00/eD6gPhQ9yD2oPTQ9DD3oPkg+2T9yQDQAnQC8AHQAngDPAOwA/AFMAhACVAK0AsQDFAKsAiACEAImAbgBFAE6AO4AuYBWAIIA3gCSgHcAK8AyP9e/oj9OP00/bj9+v5+AHgBvgGcATgBwACBACsAvf9W/83/bgB2AMj/ZP9d//D+OP6g/ZD8KPnA8+DuIOzg6kDqwOuA76DyUPMg8zDzAPLg7uDsYO5Q8kD28Po6AagGEAnACdAKcAtgCpAJ0ArQDBAOIA/gEOARgBHgEIAQAA/gC7AIOAaQA8oA/v74/YD8KPsw+xz82Ptg+vj4wPfQ9QD0UPRA9gD4mPmQ/F0AqALsAgADiANQA5wCDANwBQAIoAkQC5AM0AxwC8AJ0AggCMAGeAXgBIgEvAMoAzQDJANMAlQBwgDf/3D+MP3Y/KD8WPz8/Nb+cwC1AJMAygBoAAL/Tv5M/4oAqADIAPIBsAKWAcT/5P48/jT9fPxw/BD7YPcA84DvoOzA6mDr4O1Q8LDxAPPg85DywO9A7uDu4PDw81j5xP9QBJgGYAjwCbAJkAjACGAK0AsADTAPgBHgEcAQQBAgENAOEAzgCWAIKAb8ArMAnv80/jD8IPvA+0j8cPvY+Xj4APdQ9YD0UPUg9zj5qPt2/tEAKALIAuACjAJgAkgDIAXoBlAI8AlAC2ALgAqwCYAJ0AiAB4AGIAZgBbQDbAI8AiwCagHAALMAVwAJ/7T9DP14/MD74Pss/WT+B//Q/60AbwBA/wb/9/9RANz/IQBsAY4BYQC//xMAlv8C/oj9PP54/fj5sPXw8WDugOuA6+DtQPDw8ZDzwPTw85DxoO9A76DvkPFA9lD8GAEQBLgGAAmACcAIwAgACiALEAzwDUAQgBEgEeAQ4BAgELAOIA0wCzAI8ASwAgQB6P7g/Dz8hPxI/KD7SPt4+lD4oPVQ9MD0gPVg9oj4wPuE/gsADAH0ASgCxAHsATQD6ASIBmAIMAogCxALwAowCgAJ0AegB8AH6AaABfgE2ATUA0gCygHUAdMAH/+U/sL+6P1w/FT8gP0G/vz9lP6d/3v/eP5E/sb+tv5w/mP/3gBAAa8AxwAwAU8AYP40/UD9lPzg+vD44PaA82DvIO1g7eDuUPAQ8rDzYPRw89DxYPCA7wDwkPJA95j8tgHYBUAIwAiQCKAIwAiwCIAJ4AuwDmAQQBEAEuARQBBgDmANYAwQCggH4AR4A3IBJv/E/SD9NPxY+2j7kPtA+vD3gPYw9rD1oPVA9/D58Ptk/cP/JAKMAq4B6gFIAwgEcAQoBqAIwAmQCeAJcArACTAImAcACKgHSAYwBZgEhAM4As4B6AFOATQAs/+r/9r+WP18/HT8aPxc/Bz9Uv4k/zv/N/82/97+fP6a/hH/V/+S//v/KgDd/67/r/9A/wz++PwU/AD6MPYw8sDvoO5A7kDvEPKw9BD1EPQw81DyUPDA7uDvYPPQ92D8agEgBpAIoAhgCOAIQAlACTAKcAyADuAPABEAEqARQBBgD8AOMA2gCkAIEAZEA3YAAv9I/uj8gPt4++D72Pro+KD3kPbg9MDz4PQQ97D4SPoA/cj/1AD0AKoBmALUAkQDUAXQB1AJ8AngCqAL0AowCWAIUAjoB1AHKAcoBzgGmARQA2wCTgH5/y7/1P5+/vz9qP1M/cD8PPxE/Hz8mPzU/ID9FP4W/iL+rv5a/2n/X//e/3AASADd/wcAUwCQ/xz+aP0U/ZD7ePgw9YDyAPBA7qDu4PDQ8rDzEPQw9ADz8PDg71Dw4PEQ9Wj6PQAwBEAGEAjwCAAIwAZoB4AJIAvQDNAPoBIAE4ARoBDgD9ANUAvwCfAIyAYoBNACygGH/wj9EPz4+wj70PmY+Wj5wPew9WD1YPYg99D38Pn0/Af//v8MASQCZAIYArACQATYBVgHEAmACtAKUAqwCdAIoAfQBvgGEAdIBlgF2AQgBIQC6gA7AOj/5v7M/Zj9tP30/MD7YPvQ+wj8+Pug/MT9YP5O/mr+4v4b/xv/e/8kAE4AVwDDAAYBbAB7/zv/5P5k/YD7EPoA+AD0QPBA71DwIPHQ8bDzQPVw9CDyEPHw8EDwgPAQ9Mj5lv4QAlgFoAdIB/gFAAYYB8AH8AhADAAQABJgEqASgBKAEAAOwAzQC8AJQAfwBSgFcAM6Acr/xP4w/Xj7uPoY+qj4APcA9oD1MPWg9YD3sPk4+5z8bP6n/6f/Vv8mAJABlAK8AzAG4AhgCsAK4ArQCrAJAAgoB2gHgAcwBwgH6AYoBsgEhAM0AqcAXf/i/qL++P1k/Yz9cP2E/OD7ZPzI/DT86Pvw/OT9fP0k/Tz+lv+X/1P/JgAQAZQAjv9z/37/Sv7I/Dz8FPyQ+rD3APXQ8gDxMPDw8JDycPNw80DzIPNg8kDxYPFg89D24PpS/zwDsAUwBsgFYAVQBeAFaAcgCoANwBAAE8ATABNAESAPwAyQCiAJQAgwB+AF+ASABDADuABU/vz8yPv4+Xj4APiA9zD2YPVQ9gD4APn4+QT8Jv7y/vb+kv9mAHUAtABMAoAEGAaQB5AJ4ApgCkAJwAgQCNAGEAaQBtgG2AXYBOgEqAQcA4IBIgHqALH/Vv74/dD9pPxw+5D7dPzY/Oj8nP2O/oj+jP3Y/MD8xPz4/Oz9Z/+DAM0A2ADfAEAA3v5Q/TD8MPsI+oj4oPaw9HDzQPOg8wD0UPSA9LDzEPKw8GDwsPCg8YD0mPnk/mACeATwBSAGmARYAyAEQAZACNAK4A7AEkAUoBPAEmAR4A7gC0AKkAkgCFAGqAWgBYgEiALjAJT/iP1A+8j5oPiw9tD0gPQQ9XD1UPao+Dj7dPw0/Y7+cv/Q/jj+bP9yAbwCKAT4BtAJwAqgCuAK0ApQCYAHUAfoB6gHuAZwBmgGSAWIA4ACDAIEAeD/oP+0/8b+NP0o/Kj78Ppg+gj7QPzw/ED97P1u/uj99PzQ/Ez9mP3w/ST/rwB2AXIBOAGHAOz+GP3Y++D6MPkQ92D1MPRQ80DzUPQw9bD0YPNQ8mDx4O8g74Dw4PPg9zD85QCwBLgFsATQA6ADXAO4AzgGcAowDgARoBPgFIATYBAQDsAM8ArQCCAIUAhgB4AFUASUA4wBvP4g/Zz8aPto+SD4YPcw9hD1kPUg94j4EPp4/Jb+R/9L/5T/if/k/iz/OAGsA1AFMAfACTALkApQCdAI6AcABtAEaAUYBoAFyAQABQgFnAPSAeQARgDy/pD9GP3g/Bz8SPtI++D7RPyQ/Dj94P3o/aj9yP0C/sT9rP18/qf/NgCTAIABRALEAYkArP/U/vz8wPpY+UD4UPZQ9NDzUPSw9ND0APWA9LDywPDA72DvAPCg8uD2GPt+/tgBuAQYBZgD6ALcA6AEWAUwCNAMIBAAEeARYBMAEyAQcA2gDMALsAkACLgHQAdoBYQDgAKSAbn/qP3o+2D6uPhA9xD2QPVA9TD20Pdg+QD7pPyk/ZD9QP2I/TD+zP7//0gC+AToBjAIMAkACsAJsAjAB0AH2AagBvgGeAc4B0gGSAVQBMwCIAEjAMr/Iv8w/gD+Ov58/Qz8ePvw++D7QPuo+yT9vP0o/UD9RP58/sD9BP6U/4YANQBOAAoBDAEIACn/xv60/dD78Plo+OD2YPWA9CD0YPQw9aD1kPSw8lDxkPAA8BDxsPRg+cT8UP9YAogEEARQAhQCdAPIBJAGIApADqAQYBEAEoASIBGADqAM8AtACwAKEAkgCLAG0AREAxgCswAF/3D9BPyI+uD4UPfw9TD1UPWQ9nD4EPpw+5T8YP14/TT9IP2Y/XT++/9kAvgE2AbQB4AIsAhACHgH8AZ4BugF6AWgBggHYAZwBegE7AMsAu8A7ACcADP/DP4M/sT9SPwg+7j7tPyk/Ij8bP0s/nT9aPx8/CD9GP0E/Tj+AgDUALkAsgDgAEQA9P78/ZT9zPwo+3j5ePjA95D2cPUw9cD18PWg9QD1EPSg8mDxsPGw87D2MPrU/QgBQAOIBOAEKAQcA0ADEAWoB3AKsA2gECASQBLAEcAQcA7QCyAKYAmQCLgHWAe4BhgFVAMkAqoANv7I+1D6APkw9/D18PVA9kD24Pag+Ej6APtw+yD8oPy0/AD97P1T/w4BPAOYBZAH8AhwCfAI6AcgB5gGCAboBcAGwAcQCLgHGAewBVwDLAEmALv/+v5q/qb+4v4k/gD9fPxM/Mj7YPvg+7j85Pxs/FD8yPxM/YT9/P0U/zkAtACdAKEAiADI/5D+zP14/cT8cPtA+nj5aPgA9/D1YPUw9SD1QPXw9PDzwPJQ8sDyQPQg9xD7jv7hAMACMAQQBJwC5AEIAxAFaAfQCtAOgBEAEsARIBEwD0AMIAqACRAJUAgQCEAIUAcgBSADwgGs/9D8sPqo+aD4QPeg9vD2MPcg97D3CPkQ+pD6MPvg+yD8RPwA/Sb+P//dAFgD4AV4B2AI8AjQCJgHGAagBcgF0AUgBkgHgAhgCPAGeAUYBCgC///a/tD+nv7w/cj9Rv4S/uT8KPxY/Fj8sPt4+yj8hPxA/KT8Bv7w/u7+Zv+OAP4AXQACADMApv9u/tz96P0Y/Wj7GPpY+SD4kPbg9QD20PVw9YD1QPUg9MDycPJg8xD1APjY+z//NgFMAuQCdAJaAVABEAOIBSAIYAsQD2ARQBEgEDAPEA7AC8AJoAkwCqAJUAjoB8gHGAYEA8kAwP8A/gj76PiY+Fj4MPeg9qD3uPi4+KD4iPl4+lj6KPq4+tD71Pwi/gIADAIABOAFSAewB3gHWAcoB5AGWAYwByAIQAhgCCAJEAlIBxAFjAM8AowAk//w/zYAj//4/h7/kv7I/ID7mPuY+8j6oPro+9T8dPyA/Nj9tv4W/rD9uv7O/4P/1v7w/jD/gP6M/Sj96Py4+7D5EPhw9zD3kPYQ9nD2EPeg9jD1QPQQ9NDzEPSA9rD6Yv5aALIBzAKUAioBiQDWAfgDSAZgCRANoA8gEHAPoA6QDSAM4AowCvAJsAlQCbAIsAdQBnAEUAKYAG3/+P3I+8D50PiA+BD4wPcw+Pj4UPlI+cD5gPq4+pD6APtk/Nz9+P4hAPQB2AMQBbAFQAbABrAGSAZgBgAHSAcwB2gHEAgACOAGsAXABIwDJAJ8AYYBCgHU/wv/5v46/tT8CPxE/GT8+PvA+yj8OPyA+xj70PvY/Ej9hP04/hT/Rf/O/nT+Sv7c/Rj9gPxM/MD7kPo4+VD40PeQ94D3sPfA93D3wPbA9fD0wPSw9YD3GPpY/XUAUAKAAhwC4gGoAagB/ALQBdAIQAtwDXAP4A+gDjANUAwQC4AJ4AgQCdAIIAjIB2AHuAVEA2QB0f98/Rj76Pmg+fD4aPjw+LD5cPnI+PD4YPlI+WD5aPrA+6T8mP0c/5wAtAHsAmgEgAUABlgGsAagBmAGmAZIB9gHMAiQCKAIwAcoBpAERAMgAkwBEgE2Af0AMgA5/1j+TP0g/HD7cPt4+xj78Ppg+6j7UPtQ+0T8QP1c/Wj9Hv6O/uD9HP14/ej9UP2E/Jj8gPwg+3D5uPhg+KD3MPfw97D4QPhw9wD3YPZg9ZD1sPe4+oj9QgCUAiQD2gGvAN0ApAGIArAEQAiQC4ANkA5AD2AOAAwACnAJYAnQCLAIUAlgCXAIWAcYBrgDhAAw/hT90PtQ+vj5wPrI+vj56Plg+pj58PfA9yj5GPpA+nD7cP1U/jz+T/9uAWwCZAJoA0AFyAUYBUgFYAZ4BugFwAaQCNAIQAcgBuAFwAS8AvgBqALYAsYB4QCeAKv/1P2M/Gj8aPwA/MD76PvY+3j7YPuY+7j7+Pu8/LD98P3Q/QL+MP6k/ez8IP2c/RT9yPso+wD78PlQ+OD3qPjg+Gj4gPj4+Bj4EPYQ9dD1EPfg+Ez8GADgAaIBOgH0ANz/UP8wAWgEwAbACBAM4A7gDhANEAyAC/AJkAhACZAKUApgCZAJ8AkwCEgFDAMaAVz+CPyI+8D7SPvo+pD78Pu4+uj4CPiw90D3gPc4+Sj78PtY/Hz90P5f/8H/9QB4AkgDtAOQBIAF0AXYBZgG2AegCLAIkAgwCNAG4ATwAwgE/AOUA8QD+APQAnMAtP4K/gD9wPug+5T8yPz4+7D7CPyw+8j6uPp4+/D7LPzk/Hj9IP2w/AD9MP2I/DD8hPwc/HD6WPmA+VD5OPg4+MD5gPpA+QD4wPcA92D1UPVg+FD83v58ANIB2AH5/z7+uv7SALwCwAToB3ALUA1gDQANYAzQChAJ0AgACtAKcApgCgAL8AowCfAGAAWIAn7/UP30/Cz9+Pyo/NT8wPyY+8D5KPgw9/D2kPew+Nj58Prg+1D8iPxg/dL+uP/h/6wAeAKwA4wDwAM4BYgGkAbQBlAIEAmgB8gFkAXYBQgFcARYBRgG4AQEAxwCFAH+/nD9rP0i/nD90Pww/RT9sPug+uj6GPto+mj60PvU/Dz8qPss/LT8DPxY+8j7KPw4++D5oPno+YD54Pho+YD6aPow+WD4KPiA96D2YPfw+Zj8Yv7F/9EAhAAX/2r+Uf/5AIQCaATYBkAJEAtADJAM8AvACuAJUAlACfAJ0ArwCoAKYApQCtAIkAWMAtMAVf+M/eD8+P2k/mT94Puo+zD7yPig9iD3yPgA+Zj40Pmo+9D7SPtk/Gb+6v6u/tH/uAGEAtQCAAR4BegFQAZ4B1AI4AcoBxgHyAbYBbgFoAa4BnAFaAQwBCgD8wCY/4//H/+s/dz8XP1M/QD8EPto+4j7iPrg+ZD6SPvI+kj68PrQ+5D7APto+/D7QPsI+rD58PmQ+eD4KPkQ+lj6wPlA+SD5uPgQ+Bj4CPlo+vD7WP1s/vr+R/+Q/9L/RgAyAVwCQANQBLgGEApQDJAM8AtQCxAKMAiYB0AJ8AoQCyALAAzAC7AI6ATYAp4Bzf+w/oz/cwB1/+T9WP10/CD6aPig+CD5cPhg+PD5APtw+lj6+Pv8/ED8IPzk/WD/Wf8HAIwCaAQwBBAEkAWwBggGkAWQBkgHiAYIBhgH4AfQBlAF8ASgBBgDlAF6AagBowA5/8r+sP7U/aT8RPxY/Oj7UPtQ+5D7YPvg+rj64PoI+xD7KPsg+8D6UPr4+bD5SPko+Yj54Pm4+WD5SPkQ+Wj4APiQ+Ij5KPrY+kD8kP3g/fD91v74/0EAaQBUAXgCSAPoBAAIsAqQC6ALoAtgCiAIuAegCSAL8ApgCwANkAxACagGIAaoBGYB6v+WAYACgwC2/hb/0P4E/Kj54PlY+gD58Pc4+cD6WPqQ+WD6mPtY+5j6SPvs/Nz9gv4bABgC3AKgAgQDOATgBOAEYAWgBjAHyAbIBngHeAdgBpgFmAUYBcwDJANkA9gCIgEfAAsAWf/w/ZT9FP6c/Sj8wPtU/Mj7cPpA+hD7yPqo+bj5kPpY+kD5+Pg4+bD44PcA+ID4ePhI+KD4uPhI+Dj4qPjo+CD5SPrI+3T8yPz8/WP/uv+R/2YAxAFQAogCIAQoB7AJ0AowC2ALwArQCFgHcAggC3AM8AvQC2AMAAuIB3gFsAXoBAACsgBoAjgD7wD8/mX/6v6o+0j5IPro+kj5QPgo+sD7uPp4+XD6ePuA+pj52PrI/KD9WP7t/0YBSAH2AGoBWAIwA/gDuARABcgFYAZoBugF2AVABvAFsAQgBMAEyASAA2wCdAIQApgAoP/Z/8X/kv6g/bT9iP2Q/ND70PuQ+7D6EPoA+rj5OPko+Sj5ePhw90D3oPdw9wD3UPco+Dj4cPdg94j4aPk4+aj5iPsc/QT96Pye/p0AmwDu/yQBXAMQBDgEkAYQCiAL8AmQCXAK8AlgCOAIgAvgDBAMUAuAC7AKgAjoBogG0AX8A6gClAKwAhgCJAEBAHL+3PzQ+xj7MPrI+fj5+PmA+ZD5YPpo+lD56PjY+XD6KPoI+5j9JP+I/kz+4P8MAZQAxADUAlgE4APEA1AFYAagBSgFAAZIBgAFUAQYBVgFQARwA5ADCAOQAewAOgGxADD/iv7Y/lD+4PxM/KD8EPyA+tD5YPpg+kj5sPgY+fD4oPfg9nD3APiA9wD3sPd4+Dj44Peg+ND5EPrY+Yj64Puw/Pj88P2d/7YAvQDhAPgBWANgBHAFGAeQCNAIYAiQCFAJwAmwCfAJkAqACrAJYAnQCeAJ8AiQB1AGGAXoAzQDGAMQA8gC/gGcABv/Gv5o/XD8ePs4+2j7IPvI+hj7aPvI+uj56PlY+ij6WPrA+zD9VP08/Sj+Kf8Z/xX/QABYATgBPAGUAtADmAMwA+gDgAS8A+ACZAMoBLgD+AIoA3wD0ALqAeQB/gE4AUIAJABEALj/A//s/ub+PP5o/RD91PxM/Nj7wPuI+/D6oPrA+pj6EPrQ+fD54Pmg+cD5MPpY+lj6sPo4+3D7sPt4/GT9xP3k/XL+Pf+8/z0ARAFwAhwDfAMgBMgE+AQIBYAFIAZQBjAGeAYIBygH6AbgBugGYAZIBaAEoASIBBAE5AMYBMQDpAKoAWIBAAH9/zP/P/9m/+b+Vv5o/o7+/P0s/QT9TP04/fj8PP3k/Tr+HP42/rj+DP/s/tD+Kf++/yMAYADIAEQBcgFEASABQAFuAXABgAHCAfwB5AGkAaYBxgGiATYB8gD0AOUApgB3AHIATwDi/3v/LP/Y/nL+Kv70/aT9VP0s/fz8kPws/PD7uPtY+yD7KPso+wD7APtA+1D7KPsg+3j7yPvg+xj8nPwc/XD9vP1I/uD+NP90/+v/hgD7AFIBzgFsAsQC4AIcA5AD3APUA+QDMARQBCAEGARgBIgESAQQBAAE4AOQA2ADaANIA/ACtAKYAlgCBALiAdIBggEoARYBGgHSAHQAYgBrADsA9//5/xUAAgDf/+z/AQDo/8P/1v8IAA8A+v/8/w4A/f/O/6//s/+4/6n/jv96/2X/Rf8a//b+3P7E/qL+kP6Y/pz+gv5k/lj+VP4w/gj+BP4O/gb+AP4S/ir+Iv4Q/hr+LP4m/hr+KP5A/kD+Rv5o/oT+iP6M/pr+pP6i/qj+vP7K/tz+CP8z/0X/T/9v/5X/qf+7/+H/DAAsAE4AegCiALkAzgDlAPcADAEqAUYBUAFgAXgBigGGAYoBogG0Aa4BqAG6Ac4B0AHOAdoB4AHgAdYB4gHsAfQB+gEIAhwCKAIoAiQCIAIkAiACHAIUAgwCDAL+AfAB5AHcAcwBtAGUAWwBSAEsARIB6QC5AJMAcAA+AAMA1P+t/3//Sf8a//L+xv6W/nL+Uv4s/gD+2P24/Zz9eP1Y/UD9LP0c/Rj9EP0E/fT86PzY/NT82Pzg/Oj88Pz8/Aj9FP0o/UD9XP10/Yj9qP3I/eT9Cv48/nD+mP68/u7+If9R/3z/p//O/+3/DQA1AF0AfwCgAMwA9QAQASQBRAFqAYIBjgGmAc4B4AHyARACNAJAAkACWAJ4AnwCeAKQArwCzALMAtQC5ALgAtgC6AL8AgQDAAMEAwgDAAPwAuQCzAKsApQChAJgAiwCCALoAbgBfAFEARAB1gCUAFcAHgDl/6n/bf82//7+zP6a/mT+LP74/cT9lP1o/UD9IP34/NT8tPyY/IT8cPxg/FD8QPw0/Cz8KPwo/DD8QPxQ/Fz8cPyQ/MD88PwY/UD9eP2w/eT9Iv5k/p7+2P4f/2n/qP/h/ygAbwClANUADgFMAXoBoAHKAfABDAIwAlgCdAKIApQCoAKsArACsAK0ArwCvAK4ArACrAKkApACeAJsAmQCUAIwAiACIAIQAvQB5gHeAcwBsAGiAaABjAF0AWgBZAFQATQBIAEEAdkAqACQAHoASAAQAPT/4v+y/3j/Xv9P/yj/8v7a/tb+tv6E/nD+dv5o/jz+IP4m/i7+Hv4S/hz+Iv4O/vD98P0A/vz99P0A/hz+JP4U/hj+Lv40/jD+Pv5e/nD+dP6E/qr+yP7W/u7+Df8n/z7/Yf+F/6P/wf/q/xUAMwBUAHsAmwCxAM4A8AAKARwBOgFgAXgBfgGOAawBtgGuAbIByAHSAcgBwgHGAcYBvgG4AbYBqgGYAYoBgAF0AWYBWAFGATABGgEIAfEA2ADAAKwAmwCMAH4AbABYAEYALQAVAAYAAADy/9r/y//G/7//qf+Q/4D/dv9m/1T/RP82/yT/C//6/vb+9P7m/tL+xv7E/rz+rP6i/qL+ov6c/pb+nP6q/rD+rv6q/qr+pP6c/p7+rv68/r7+wP7M/tj+2v7k/vb+Bv8S/yT/O/9N/1//e/+V/6T/t//Z//v/DQAhAEsAdgCSAKwA1gAAARgBKAFIAWgBeAGGAagBzAHYAdYB5AH0Ae4B2gHYAd4B1gHAAbIBrAGkAYgBZAFKATQBHAEAAe0A4wDPAKgAgQBsAFoANwAUAAcAAADq/83/vf+x/5n/fP9q/1z/Tf9D/zn/LP8e/xX/DP/+/vD+6P7g/tr+3P7k/uj+5v7q/vT++v7+/gT/B/8G/wr/Gv8o/yz/Nf9J/1z/Y/9t/4b/nv+n/63/vv/O/9H/2P/s/wQADAARACAANABDAEoATgBTAGAAbQB1AH0AjwCiAKkAqACxAMQAyADDAMkA0gDRAMkAxwDOANAAywDLAMsAxQC8ALQAqwChAJ4AnwCeAJsAlgCKAHUAZQBbAFMASAA9ADYAKgAWAP//7v/g/8v/sf+d/5H/hf9z/2P/X/9c/07/Pv89/0f/Q/8y/zD/Ov87/zD/L/9A/0T/OP80/0H/Tf9K/07/Yv9z/3b/fP+O/6L/rP+5/8n/1v/l/wEAHQAtADsATABXAFsAZAB2AIAAfwCGAJgAogCiAKUArQCuAKwAsAC1ALIArwC2ALgArgCpAK4AsQCrAKYApQCZAIIAcQBqAF8AUgBLAEcAOQAiABEAAgDv/9n/yv+9/63/nv+U/4n/fv95/3j/dP9l/17/Zv9v/3L/dP99/4T/hP+B/4f/kP+T/5T/mf+e/5//oP+l/67/rf+m/6X/qf+u/7P/vP/F/8f/xP/F/8r/zf/P/9P/1f/X/9v/4//i/9j/1v/g/+P/3f/h//H/9//s/+7/BAATAA4AEAAkADAAKwAuAEcAXABgAGUAegCIAIIAeQB5AHkAdAB1AH8AhQCCAIMAjACLAIMAgQCEAIMAggCGAIUAfQB2AHkAegBsAF0AWABTAEUANwAxACoAHAAOAAEA8//m/9v/0v/D/7f/sf+q/5z/kf+N/4P/c/9u/3T/df9s/2z/dP9z/2z/dP+I/5H/jv+W/6f/r/+z/8L/0v/T/8z/0v/e/93/2P/l//L/7P/f/+P/7P/k/9j/5P/5//j/6//w//7/+f/q//H/BQAHAP3/AgAVABoAEQASAB8AIgAXABMAGwAjACUAJwAvADQANgA+AEwAVQBXAFoAYwBqAG4AcwB9AIYAiACHAIoAiwCHAIIAfQB5AHQAcABqAGQAWwBOAEIAOwA7ADYAJQAXABYAEwACAPH/8P/w/+L/0//R/87/u/+r/6//sf+f/43/i/+J/3v/cP9y/3L/av9m/2r/a/9p/27/c/9t/2f/cv9+/3r/eP+H/5b/lv+Z/7T/zf/K/8T/1f/q/+3/7/8HAB8AIQAfACwAOAAwACYAMQBAAD0ANgA9AEYAQgA8AEQATABHAEEASABPAEgAPwBBAEkASQBEAEUASQBFAD0ANQAvACkAIwAcABgAGAAbABgAFgAZABoAFgASABcAGgATAA8AGQAjAB4AFgAZACEAHwAcACUALQAoACAAIgAmAB4AEwARABIADQACAP//AAD9//f/8//v/+T/2P/V/9X/0f/L/8r/zf/G/7r/tP+z/6z/ov+i/6v/r/+u/7L/uf+5/7P/tv/A/8b/yf/W/+f/8P/2/wMADwANAAkAEAAbACAAIgArADIALQArADMAOQA0AC8AMQAvACUAIgApAC4ALAAvADYANQAuACoALQAuACsALgAwACwAJAAfABwAGAASAAoAAwADAAcABAD6//j/+//4/+3/6P/z//j/8//2//7//f/v/+v/9/////f/8f/6/wMA/P/1//3/BQAAAPr/AQAKAAYA/v/+/wMAAAD1//L/8//0//L/8v/x/+r/5f/g/9r/0v/O/8z/yP/C/8D/xf/I/8b/w//C/8P/wv/E/8v/0//X/9n/3//m/+v/8/8AAAoADgATABwAIwAmACsANQA7ADgAMgAyADYANgAyAC4ALwAzADMALwAsACsAKQAkACQAKAAoACYAJAAkACMAHgAdAB4AHgAaABMADQAKAAgABwAEAP///v/+//3/+f/3//b/9v/1//X/9f/1//T/8f/v/+7/7v/q/+f/6f/u/+7/6f/o/+n/5//h/93/2//Y/9T/2P/g/+X/5v/n/+X/3v/X/9T/0v/N/8n/yf/I/8L/vf+9/73/tv+w/7D/sv+w/7H/uP/A/8H/v//C/8r/0P/S/9f/4P/r/+//8v/6/wUADgATAB0ALQA4ADkAPgBLAFMATgBPAF8AawBnAGQAbABxAGoAZQBsAHEAaQBgAGAAXwBXAFQAWABXAE8ASQBJAEYAPQA2ADIALQAmACEAHQAYABAACQAEAP3/9//w/+n/4v/d/9z/2v/V/8//yv/F/8P/w//G/8b/wv/A/8X/yv/N/8z/yv/K/8b/v/+9/8P/yv/L/8r/yf/G/8P/w//I/87/0v/V/9v/3//g/+L/5//r/+7/8//5//v/+f/4//n/+P/0//T/+P/7//n/9//3//b/8v/y//b/9v/1//f//v8DAAIAAgALABQAGQAcACIAKQAvADMANwA7AD8AQgBFAEoATwBSAFIAUQBUAFYAUwBQAE4ASQBAADkANwA0ACwAJQAjACQAHwAXABIADgAEAPv/+P/6//j/8//w//D/6f/b/9D/zf/L/8T/wv/G/8f/wv+9/77/vv+5/7b/uP+7/73/wP/H/8n/yP/L/9P/1//Z/93/5P/l/+T/6P/y//j/+P/6////AQD//wIACAALAAgABAAFAAMA/f/6////BQAFAAUACAALAAkACgAQABIADQAIAAoADAALAAwAEwAUAAsAAwAGAAkABQACAAYADAALAAwAEwAZABkAGAAfACcAKQAnACgALQAwAC8ALgAvADEAMQAuACoAKQAnACIAHgAcABsAGQAUABEAFAAXABYAFAAVABUAEAALAA4AEwARAA0ADwAPAAUA+//7//3/8v/i/9r/1v/R/8//0//S/8r/xf/E/7//uv+//8n/yv/G/8j/0P/U/9b/2//g/9//2f/d/+r/8//5//z/AwAIAAQAAAAIABQAEwANAA8AFQATAAUA+P/2//n/+P/y//P//P8BAPj/7f/r/+//6//i/+L/6//s/+P/4f/r/+7/4f/a/+n/+P/v/+D/6P/4//D/3f/o/wgADQD6//7/GQAaAAAA/v8fAC0AGAAOACkAPQAzACkAOABKAEQAMgAuADEAKwAiACQAKQAhABQADgAMAAMA+/8EABMAFQALAAUACwAYACEAHwAXABAADgAOAA0ACgAEAPf/5P/W/9n/5f/n/9X/v/+3/7r/uv+4/7//zv/T/8X/uv/M//H/AwD1/+r//P8OAAAA7/8JADAAIQDs/+f/FgAjAAAA+P8aABQA2f/D//T/DgDo/9b/AwAgAAIA9v8oAE4AMAAGAAMA///b/8n/6v8GAPD/0f/Y/+P/yf+p/6//zv/i//T/FwAqAAwA5f/s/wYABgACACgASwAvAP7/CwBAAEMAIQAxAF8ATQARABAAQwBEAAIA1v/g//D/9f8MAC4AIgDe/6X/uf/9/y0AOAA5AC0A/P/N/+z/TACCAGQAOAAiAAIA6f8cAIIAowBlADIARgBcAEsATwCNALgAjgA/ACYAJgDl/4v/qP8iACUAkP9W/8b/+P+R/3n/7v/t/3D/7P98ASgCLAHw/xz/+P1I/eL+yAHAAgYB1v68/aT9WP5h/6j/PP81/yX/yP2U/OT92//G/kD89Pz2/ycA2P06/koBjAF+/vT9cgGcAzACjgHkAygFHAOcAWADOAVQBPACjAM4BNwCQAFuAdQBiAAA/y//+P+e/8D+bP4I/hT95Pwy/mL/af99/xgAtv9W/jb+ov8IAL7+Rv5b/3//3P08/dL+xv9g/kz96v4iATYBHQD0/9P//P0c/HT9igEoBNwCrP94/fD8dP3Y/vcAnAKQAiQB1/+M/w0AwwAkAdoARQBNAC4BAALYAcoAg/+W/pD+mv/CAAAB4QAAAUEARP6E/Vz/2AC9/+r+nQBwAcj+5Pw6/5QByv+0/Vz/LgFn/8D9CgC4AqABUv+Q/6YA8/8+/6EAJAJeAbb/bv8LAD8AXQAYAaoBIAEFAJ//IwDbAGgB1AHMAfEAuf9I/xQAUgH+AeIBCgGy/5b+xv5EAKABoAGqAMf/H/+K/p7+w//pAKUAWv+o/vT+Uf+L/x0AhgC//2T+Nv6M/84A/gCpAEcAbv9O/jr+uv9YAX4BawBr/+L+iv7K/ggAIgHBAIP/A/9O/2P/cv9DAPgAHQB4/i7+Zf9VAEQAEgD8/0//Yv58/q7/nwCNABwA4f+u/4D/zf+fACYBvQDT/3f/8/+WAMoAsQCPAEQAyP+P//3/swDoAGsA3v/K//X/9v/6/1YAqABTALz/yv9YAIUAPAApAFoAQADi/9P/HAA9ACEAHwAvABgAAQAkAEsAOAAeACcAFgDU/8n/EQA9ABYAAQAdAP7/nf+Y/w0ARgAKAPf/QABNAP3/8v9VAIAAOQAUAFgAhwBhADoARgBCAAEAxP/W/yIAUgA3APP/sP91/0v/WP+U/7j/mf9X/xX/1v6k/rL+4v7w/uj+/P4K/9r+ov7A/gP/DP/+/jP/hf+L/2T/eP+3/8P/lP+N/87/DAAXACQATQBMAAYA2f8SAFgAWgBXAJsA1ACoAIYA1wA2ASIB6gAYAV4BUgE4AXYBpAFQAfUAFAFmAWgBMAEkAUYBQAH/AM8A5AAWAQgBtgCSAMkA2ABsABsAVQB3APf/hf/c/yEAi//m/jf/vv9e/7L+wv4R/6T+DP5K/tD+kP7s/ez9TP4g/rj90P0i/gD+sP3g/VL+av4u/ir+XP56/pb+5v4+/z3/Af/w/iv/c/+l/9b/HgBJADsAJQBPAJYAuQDtAFABigFoAVwBsgHyAdwB8gFkApACTAJUAtwCHAPoAugCQAMoA7QC4AKYA8gDLAO0ArgCrAJ4ArACMAMcA2wCuAFGAQoBMAHKARwCjAGrADsAAQCu/5z/8/8GAE//lP6C/oj+9P1w/Yj9gP20/PD7MPy8/Ez8IPuo+tj6iPrg+fj5uPrQ+uj5WPmg+bj5MPkw+Uj6GPu4+jj6wPqY+7j7qPuM/ND9Vv5g/gD/IwCgAHMA0gAQAvACAANMA2AEIAXwBLgEaAVIBnAGkAZQB/gHsAcoB2AH8AcACPgHYAiwCEAIkAdwB4gHSAfoBtAG2AaoBjAGwAVYBbAEMAQQBBgE3ANUA9ACVAKwAe0AfABxAFIAsv/o/kz+yP0M/Uz80Pto+8D6uPnI+DD4kPew9gD20PVg9fDzMPJg8XDxYPEA8SDxsPFQ8SDwwO+g8JDxIPIw89D04PUA9mD28Pcg+rj7LP1r/+YBaAMQBFgFiAdwCaAKMAxgDtAP8A9AEEAR4BGAEWARABJAEkARABBgD2AOwAyAC8AKoAnwB3AGIAVAAx4BxP/0/sj9ePyw+yj7APrQ+GD4iPiA+ED4wPjA+XD6cPrI+uj7KP2o/Q7+nf96ARwCsAF8AlgE4AQABEgESAbIBtAExAOIBXAGMARAApADsARcAuL/JgH4AqAAJP2k/REArP5w+8D7wP0o/JD48PiI+3D6gPaA9SD3kPbw9CD2UPjA9sDyQPFg8oDzgPWg+MD5IPdw9KD0QPbg97D6Mv7g/iz98Py8/q//XAD4AtgF8AX4BHgGAAkwCUAIMAmACgAKwAkgDCAOkAzwCZAJAAoACXAIQApQCzAJKAYoBcAEXAPMAkAEsAQUAm3/ZP/S/z7+wPyQ/VL+0PxQ+0z8gP1A/Jj6GPts/Dj88PuY/V7/5v5w/WD9rv65/4MAlAFwAmACsgFEAZABeAJYA8ADoAOgA6ADHANoAoACEAPYAiACDALcAugCkAFKACEANwB7/w3/s/8cAET+yPtg+wz8APsA+Wj5MPsQ+qD20PWQ9yD2UPKw8oD3MPnw9ZD00Pbw9YDxUPKo+eT9+PqY+Nj6yPtY+WD6GAFwBWgDVAHMAwAGqAR4BDAIIAsgCvAIoAoQDLAKEAnACZAKwAkQCfAJUApQCIgFSAQIBJwDZAOoAyAD4gAs/tT8nPxk/Hz8RP10/RD8UPrI+Vj6kPow+/D8SP7I/Vz9YP6C/2r/oP/aAfQDCATIAxAFAAZoBUAFsAbwB6AHiAdgCDAIwAY4BuAGuAa4BcAFOAb4BOwCrAIwAwQCLgBhAFQB+f+I/TD9OP5k/SD7WPoY+3j6APiw9pD3wPfg9WD0QPUw9kD0MPEg8VDzEPSQ8xD1UPcA9tDx8PDw9Nj48PkQ+1T96Pyo+QD5uP2IAnADWANQBdgGQAXQA0AGQAoAC4AJIApADBAMsAnwCIAK4ArACPgHIAoAC/AHQAS0A5gEiAPwAdgCWASIAjL++Pvw/Lj9AP34/Fr+UP6o+4j5wPoI/QD9MPyE/az/m/8o/sz+CgGoAeIA3gF4BGAFeARwBLAF6AXQBDAFOAdACCgH+AXoBdAF6ARIBPgEeAV4BMAC+gEEAl4BIQDD/yoAwf82/hz9PP0s/QD8wPqw+sj6APrg+Dj4GPhw93D24PVQ9sD20PUA9BDz4PMw9eD18PZI+ID3kPRQ80D2ePpQ/Gz8nP1k/qT8QPsY/kQDWAWYBOAE0AaoBogEiAXACZALUAlwCAALIAwQCcAGwAgwCuAHEAYQCCAJiAX+AWQCXANmAdL/cgFgAoX/VPww/Lz86PvY+3T99P1E/ED7HPyA/OD7qPzQ/rz/S//l/4oBxAEAAboB7APoBLAEkAUoBzAHoAVgBeAGuAcQB/AGyAc4BzAFAATABBAF7AMgA1gDwAK4AJD/+P8OAP7+VP56/vj9mPwg/Kz8bPxo+zj7ePuo+pj5qPng+YD40PZg98j4IPiA9pD2wPaQ9HDyoPTI+Ij5gPdg90j48PUg84D27P1aAFz9LPw8/rj9QPsQ/kAF2AdYBCQDUAboBrwDOARwCWALEAiwBqAJQApoBqgEMAcQCFgFiAQgBxgHqAKg/9MA1AFOANz/iAFEAeD9mPtc/Bj9cPzI/Ir+uv7Y/Aj8LP34/cj9hv5FAOUAnABaAbgC4AJsAjADuARoBbgFsAZAB1AGUAWgBUAGYAaoBjgHmAbABIQDdANcAwQDXAOwA2ACNwB+/wAAy//u/jb/DQBI/0j9xPwE/gz+bPwQ/JT9oP04+zD66Ps8/OD44PZQ+UD72Pig9nD4yPjg88Dw0PWg+5j5oPVA90j50PQA8dD2Nv8A/1D6ePui/vD7UPgw/ZgFiAYMAtoBgAVYBXwCnAMwCKAJeAfoBrAI4AhYBoAEQAWYBoAGsAVoBVgF+AM+AVz///+QAawBogDs/2P/0P0Q/Bj8tP2s/mz+KP5u/pT++P2U/YD+VwBkAXABtAEoAyAEbAPQAkAE+AUIBgAGeAewCFAHYAXQBTgH4AYYBggH0AcoBrwDPAOUA+wCOAL0AlgD2gHv/1f/QP+y/oT+Pf+b/7z+tP10/XT9GP3A/Pj8cP0U/cj74Po4+0j7mPkQ+ND46Pmg+ND2cPfQ92D0APEQ9Oj5ePrQ9sD14Pag9JDxcPXM/UYACPwY+nD8dPyw+fj7CARQCPgEtgHMA9AFuAPgAlAHkAvACTgGIAeACXAHuAOQBBAIwAc4BLwDAAbwBG8Ahv6lAMIBDQB0/xYB6wCY/TD7ZPxe/nT+Jv5N/2gAcP/M/cD9jv8OAVIB1AEsAwgEhAPoAqgD4AQYBfgEIAawB6gHYAaIBYAFSAXoBFAFKAYgBtgEhAOoAuwBQgEcAawBAAJ0AU4AO/9s/tj95P2y/pL/c/+W/gD+wP1c/RD9hP0O/uD9YP1E/dT8iPtY+kj6IPog+fj4MPpo+gD4YPVQ9AD0IPSw9pj6MPsQ93DzsPMQ9QD2SPmA/i0AWPz4+Hj6JP0a/jsAIAVoB5AE3gFwAwgGuAV4BSAIkApwCTAHWAfQB1gGsARwBeAGaAboBFgEwAOiAWr/Gv8YAKkAgQAUAB3/cP0c/DT8PP0Y/tD+hP+F/8z+Wv4M/z8ABgGiAcACxAPoA/QD0ASQBWAFKAUoBrgHAAh4B2AHYAc4BvgEcAWoBsAGcAVwBNADqAJEAf4AtgHQAecAwv83/8r+AP5s/cD9hv62/hL+YP1Y/bj9vP1s/Wz92P0e/oT9nPyg/CT9UPxA+mD5aPq4+kj56Pgw+gj5IPSg8QD1KPkI+dD3SPnA+IDzYPBA9dj74Pyo+3z9ev6A+sD3ZPz4AgAEvAKoBJgGKATMAZAEYAggCKgGYAhACkAIeAXgBQgHqAUABPgEUAYgBeACygEAAXv/0v7v/9wAPABN/67+hP1A/LT8oP54/xX/Wf8cAIn/iP6p/xgCxALSAWgCWASYBJADSARYBogGKAWIBUgHiAdABjgGEAcgBjgEIARABQAFoAMwA/gCgAHs/wcA6gB9AGn//v7K/vj9LP2w/Zj+xv42/vT9cP6o/jb+4P3M/p3/2P6Y/Rb+N/8M/kD88PwI/mj70PcQ+Yz8SPvw9uD2GPng9ZDwEPPA+hj84PYg9dD3APYA8YDzPP1MAYj8OPkM/PT9SPtw+94BQAfYBbgCmAPIBQAFYAM4BRAJEArYB2AGKAdYBwAF5AKoA5gFeAWEA3wCZAIKAW7+kP0//44Anv9Q/ob+rP40/Qj8XP2Q/97/7P6a/0oBcgFKANsA3AKYAwgDtAPIBYAGWAUYBXAG0AbgBegFcAf4B+gGEAYABmAF6AO8A4AEkARYA3wCFAL6ALv/kP89ACEANP+c/qz+oP48/tz95P1y/vz+qv4o/vT+SgCp/5D9rP36/93/IP30/AgAof+Q+qD4NPwo/Rj48PXQ+vD8cPYA8eDzQPeg9JDz2PkA/sD3EPDA8WD3KPhw+D7+KANK/4D40PgG/osAdAGgBZAJmAfoAlQCMAWYBpAGQAhwCqAJ2AZwBYgFKAVABAAEIATIAwADVAJiARcA+v4q/qz9Hv5m/+z/+P7Y/az93P2g/dj9jf9aAbYBaAHEAVgCLAIEAhQD+AQABvAFCAZ4BlAGmAWoBXgG2AZYBhgGsAagBiAFsANYAwgDPAIUAswCnALaAGv/Rf/w/uj9zP0B/37/hP64/cT9lP0s/eD9Jf+V/1z/if+c/yL/X/9HAEcAVv+p/34AIf/0/KD9XP8M/QD5APko+zj5MPZg+Ej7cPYA73DwQPc4+CD1GPiI/GD3gO5g8ED6dP24+sz9IATcALD3KPjwAagGQASoBTALEApUAp4AOAfwCiAIEAdwCrAKIAVwAagD4AXIA34BlAKQA/AApP1s/cj+WP6k/Lz8Xv6M/tD8+Ptw/fT+uv5A/nn/VAG8AUYBCALMA6AEMAQ4BHgFWAbwBbgF6AZACOAHeAb4BWgGOAYwBTAFQAZQBnAEgALyAcoB6gBSAAYBdAEbAFj+Jv68/kz+gP02/nf/F//c/Tr+Yf8N/0D+kP9sAW4AmP7i/5gCuAH+/o//uAH8/3T85P3IAVsACPvg+eD7sPkQ9dD23Pyo/ND1APKQ81DzIPEA9ED7LP3g99Dz0PRQ9gD2cPhs/gACJAAs/Xj9gP/CAPgBqARoB9gHeAbQBagGaAfwBkAG4AbwB8AHQAYABZgE8ANcAg4BNgHqAWIBtP+4/sb+dv5A/eD8IP4E/1L+2P0E/xsAov9p/94AVAIsAvQBZAPQBLgEmATIBVAG8ATsAzgF2AaoBiAGyAboBoAEKALkAuAEyASsAzgEoAToATr+YP4SAVoBnv85AO4BKQA8/Cz8hv8yABj+yv6wAcIA1PzE/L0AvAEG/+T+RAJsAtD+RP7GAZwCAP90/VUAigHw/aj7AP4P/6D6gPZA+Jj7EPqQ9iD34Pgg9eDvoPGI+MD6YPfA9ij6kPlg9DD0sPrG/rj8kPyMAZwDP//E/OIA0ASgAwQD+AbgCQgHxAPgBMgGiAU4BBgGuAewBYQCCAKMAoYBIABGAKQAfv8I/hT+Uv7M/aD9Wv5O/vz86Py2/jkACwCrAFwCQAIdAAcAFAPoBFAE6ASwB7gH/ANQAggF2AZwBbAFwAjgCHAEAAIwBBgFcAJcAjgG4AYkAlT/kAGAAkP/QP7sAVwDfP/8/H3/DAEi/lT8Zf/KAWD/yPyE/vwAw/+g/dT+RgHnABT/cv9qASQBzv7s/Yv/eQAW/4T9wP0C/vD7cPlY+cD6aPpg+FD3kPfQ9vD0kPTw9bD2EPag9ij52Pow+sD4KPjw94j4oPsSAKQCEALYABkAAv+a/lYB6AUQCGgHuAaQBqgEJALEAggGUAegBYgEyASEA6kAkP+uAPgAh//C/pD/6f/+/lD+Xv4K/lz9cP2Q/i0AsgGUAkACFAGQACIB8AHYApgEwAaIBygGWASUA6AD3AP4BBAHgAiYBzAFoANMAwQDsAKsA2gFqAXgAxQCXgGrAPT/cADGAewBlAAHAEUAV/8A/sL+rgBkAKb+tv4yAJz/sP12/r4AQADs/ZL+UAFQAdD+qv6/AHUAJv4O/sv/bv9I/eT8/P0s/fj6QPpA+sD4YPcI+PD48PfA9gD3sPbw9CD1wPio+xD7uPnI+Sj5IPeg92z8JAHoAbgAdAA3AMT+JP6vAMAE2AaABrgFaAWQBNwC/AFwA7gF+AVwBKADkAMkAlf/WP66/5AAuP9h/4gAyAAt/7j97P1C/gD+dv6AAJwCLAOMAtIBigFkAboBGANIBdAGqAaABeAEiAT4AzAE2AUQB0gG+AToBPAEwAMgA5AE0AWwBCADCAPYAi4BbwAYAnADcAL/APMArgAl/4L+0P8CAeAAqAC5ANX/gv6E/of/5f/h/5sA2QCT/5D+ef9/AOv/P//B/4f/mP14/JD9mv64/WD8oPtA+ij4UPdY+Pj4kPjg9/D2YPWA9ID1IPfw99D4WPqY+rj4wPdg+UD7aPsU/CT/wAEaAdP/ywD8Ab4Ad/8EAjgGYAewBSAFgAW4A6UArgAIBOgFuASwAxgE4AIP/5D82P3s/xMACgBUAbgBnP9M/Tz9Zv4a/wkA9gGIA6wDLAO8AkgCHALgAiAEGAUQBugGgAbQBMQDCARQBDAEyASwBRAFZAPsAmwD6AJEAjADMASIAhwAIgB8AUQBsgBEApADfAFO/lj+dwDTACcAWAEcA/oB9P4c/pL/bQDd//H/6wDBABT/+P2W/pD/5v+Y/zv/nv6w/dz8rPwk/bT90P2c/Jj6+Phw+Lj4wPio+MD4SPiA9rD0APUw9+j48Pgg+Vj6WPpo+KD3QPos/TD9tPzw/k4BPwBo/h4A6AJgAtQA1AIYBogFPAM4BIAGEAUsAtwCEAU4BHACGARIBgAEw//i/uj/5v4S/rkA0AO4Alb/Pv7k/lj+pP3n/4QDwARAA/QBQAKMAvgBAAIQBGgGUAY4BDwDQASYBEgDGAMIBcgFaANYAYACOARgAzwChAPgBCwDUADk/0wBrAE4ARgCWAOMAj0AEf+Y/0wAfQAaATQCPALLAF//Df9B/3v/CADmAO4A5f8K//L+xP6C/iT/IgDa/5T+Iv4w/mz9gPwo/dT9cPyQ+oj60Pog+dD36PjA+cD3EPYw9yD44PYA94j6nPww+gD4cPmY+gj5sPmi/uIB4P/w/fD/IAGW/qz99AGoBUAEXAJQBCAGsANMASADWAV8AwgBpAJIBWgE5AG2AQQCiP+k/IT9qwDCAfUAHAGiAdT/5Pxs/Lb+5QAIAnAD8ARoBPwBiwB+ASgD/AOwBNgFSAboBHgDfAMoBPwDfAMIBKAEzAOoAigDeARABAAD5AJkA2gC5wByAUwDoAOIAmQCwAJSATD/Tv86AeABVAGsASQCrgCO/or+tP+1/1H/SwD0AEv/ZP3M/fr+kP78/Qr/rv8K/jz8pPys/Qz9RPzE/FD9APwo+pD5oPlQ+cD42PgQ+bD44Pdw9wj4iPnI+uD6mPqI+jD6OPmA+Sz8sv4U/+r+KQCzANj+sP3p/6gCiAIQAhgE2AVIBFQCfAPoBCgDIAGcAigFqAQYA5wDIASCATb+IP7n/2QAhgBEApQDzgG+/qz9Xv7+/hoAkAKQBGAEBANcAiQCzgEoAqgD6AQABbgEsARQBIgDTAOsA6gDIAMQA4wDvAOUA9wDOASoA2wCzAHaAbQBlAE0AhwD6AK0AeQArAAiAG3/tf/SAFwB3gBnAFoAyP+e/jD+BP/O/5v/Pv9e/yD/AP5Q/fT91P6g/vT95P3M/eD8DPyI/GT96PyI+8j6mPrI+aD4qPig+YD5GPhQ9+D3SPgA+Hj4IPoY+5D6GPrA+kj7+PpI+2D9mP9IAEgAkQCGALX/h//1ALACWAOEAwAEEARYA7ACyAIAA8wCtAL0AjQDMAMQA4wChAGDAOn/rv/u/+AA7AHkAeEAFQDV/3n/Zf+mAKwCsANIA+gCJAP4AkACdALkA+gEiAQQBIgE4AT0A9gC9AKMAygDeAIAAygECAQQA/ACiAMsA9wBmAGMAtgCMAIoAtgCgALzACkAogCtAAYAdwDaAeoBaABn/3T/Cf8U/qL+WACcADP/oP4l/67+RP04/Y7+kv4w/QD9OP5G/vD8nPyM/UT9aPuQ+iD70PpY+Rj5WPqo+lD5gPjo+Nj44Pcg+PD5MPvo+sD6gPuY+8D64PqQ/Pj9YP4e/2kApACr/3L/YADiAAgBXAIgBAgErAKgAowDEAPyAcgCcATMA+YBDAJ8A8AClwDJAGACpAF2//f/ZAJwAkMAEQDoAcwB/v+lALADuAQIA3wC4APsA0ACVALABOAFoATUA4AEYATIAkgCkANABJADLAOwA7QD/AK0AvwC3AJ8AowCkAIsAhgCcAIIAgAB0QBIAagAgf8FAHoBUAHV/6P/YACH/7j90P1n/43/kv7m/gMAXv+A/RT9DP4S/jj9XP0e/tT9CP1s/WD+FP6w/AD80PvY+tj5UPpo+0D7APqQ+QD6aPkw+GD4+PmQ+uj5IPqY+xD8+PrQ+mT8jP0k/UD9zv7P/0j//v4yAGYBcAFWAQwCrAKEAlwC+AKQA8gD6AMQBJgDoAIMAvYB1AG+AWgCBANMAt8AdADRAFoAkv9TAOIBwAFkAIsAJAJkAl4B4AGwA5gDwgG+AdQDoASMA5gD+ASYBFgClAEAA9QDTAN8A6AEiAQgA2wCyALQAoQC/ALYA9gDPAP4ArwC5gE8AXIBngEgAcQAOAGKAd0AIwA9AFcAZP9W/oL+Sf83/6T+7v6U/wH/jP0o/eT95P3Y/Lj8xP34/dz8cPyE/QT+7Pzw+0D8IPyw+tj5wPqQ+7D6mPnI+Rj6IPlg+GD5oPpw+tj5UPrw+oj6SPqI+yj9mP2U/Sz+fP4A/hz+iP/JABwBxAHQArACiAF+AbgCEAOQAmAD+ATABAgDjAIsA3QC1AAQAcgC/AKqAVQB6AEaAVf/KP+EAAYBggDaABACRAJqAVIBNAKEAv4BEAIIA9gD/AMoBIgEMAQMAygCNAK4AjQD6AO4BNAE5APcAmgCUAI4AoQCWAPkA5gD+AKcAkAChgHdANIAKAEeAb0AqgDxAOIANQCO/2n/Pf+Y/iz+nP5H/07/7P7q/vr+VP50/WT96P0K/sD9tP38/eT9YP0o/Uj9HP2A/Oj7ePsw++D6oPqI+nD6MPqg+Rj5GPmo+fD58Plo+iD7IPtg+pD66Pug/Fj8/PzQ/nD/Rv4i/gUAHAE0AFcAwALIA+4B4gDUAjAElAKkAfwDyAX0AygCdAOgBEwCAACKAdgD3AIAAQwCjAPAAfT+af+KAVQB6v/0AFQDNAMmAfIAfAKYAkwBogG4A4gEhAMcA/wD4ANIAnIBTAIMA8QCzALEA0gEhAOoApACdALwAeABkAIoAzADIAMMA4QCoAEOAdYAiQBcAKcABAHrAKUAdwAMAD//sv7M/uj+zv7w/lP/Kf9u/hj+UP44/qj9iP0C/gr+cP1Q/Qb+av7k/WT9eP1c/ZD88Pss/Hj8CPxg+0D7MPuY+gD6CPp4+pj6iPqg+tj6APsg+1D7qPsw/MD8DP0k/Yj9SP7Y/iT/xf+1ABIBxgDJAGwB2AHEARAC4AIsA8gCsAIkAzADuAKEAlwCggHEAFwBZAIwAqIB+gEIAk4AuP6o/zYBvgDu/4IBVAM8AjkAAgH0AlQCtgDsAWgEIAQoAnQCQATAA6ABggEcA0ADBAJEAvgDaARQA7QC/ALAAvoB7AG4AmgDjANwAwwDaALmAXYB4ACdACoBsgFqAf0AIAEkATAAOv9T/6P/Kf/A/lz/6/9d/5b+rP7I/gL+RP2Y/TL+DP7Q/Uz+sv4k/lT9NP1o/Rz9wPzg/Bj9sPzY+1D7KPv4+qD6gPqw+uD64PrI+tj6EPtQ+2j7kPvw+0z8cPyA/Oj8qP1A/qz+Rv/s/zIAKwBSAMAAEAE+AagBHAIsAjQCwAJMA0wDBAMEA7ACjAHAAEQBJAIkAgwCnALAAoABIwA1AJwAKwDy/xIBMALeAToBsAFAAqQBEAHCAbQCkAJIAuQCbAPYAhQCMAJkAuIBkAEoAtgC2ALAAvAC4AJQAgACSAKUArgC9AI0AxgDxAKEAiAClgFSAWABPAHzAB4BaAESAVoAFQAMAHD/yP72/m//PP/U/g//Sf+m/sz9vP3c/Wj9GP2s/Ur+Ev6g/bT9mP3c/FT8pPz8/LD8ZPx8/GD8uPs4+0j7QPvo+tj6GPsw+wj7GPtI+0D7KPto+9D7+Pss/Kz8HP1M/aD9UP7i/ir/n/9RALUAvwD/AI4B1AHGAQwCxAJMA4QD4AM4BNwD4AJAAiwCEALkAWwCWANgA1gCbgEmAYYAlv+2//sAtgFIARYBuAHcAfkArQCyAZgCbAJYAiADmAPoAkQCmAL4ApwCRALAAkgDHAPEAtAC6AKcAlQCbAKkArgCsAKYAmgCJALoAZYBTAE+AVIBJgHVAMkAygBrAN7/t//J/5X/TP9k/4j/N//K/rz+wP5i/iD+aP6u/nD+Jv5G/kz+2P18/bj9AP7A/Xz9tP3s/ZT9CP3Y/ND8dPzw+9D7IPxU/CT8+Pv4+/D7oPsw+zj7sPsA/Az8QPy8/AD92PzA/DD9xP0K/lj+Bv+z//L/CwB+AO0AAAEQAYIB9gE4AqQCXAOoA2wDRANQA8QC3AG0AUQCfAJAApACEAOMAioBcQCNAFcA9v9pAFQBcAHyAPEATgFGARoBnAFQAlQCEAJQAqACVAIIAlQCtAKIAlgCwAIkA9gCdAKkAvQCxAJ0ArACRANQA+ACmAKYAlQCogEmAVwBzAHAAWYBUAFiAesA7/9z/8j/BwCZ/1P/1P84AID/Yv4o/mL+8P00/Xj9Xv5y/qT9VP28/Zz9wPx8/Dz9wP1s/Sj9jP28/Rz9bPyA/ND8nPxI/Hj81PzA/Ez8FPwk/BD80PvQ+yj8fPyE/HD8nPzk/AT9BP1A/bD9FP5I/qD+Qv/R/w0ANwCZAA4BPAE8AYoBLAKsAtgCDAN8A6ADCANUAlACgAIYApQBDALgApACcgE2AawBFgHA/8n/HAFaAUsARACcAd4BnQB0AP4BoAKQAXAB/AKMAzwCrAHcAkwDBAJ+AdQCpAPMAmACXAO4A5AC4gGwAjgDiAIoAuACLANIApgB3gH2AVYBDAGGAbQBFAGVAJcAZQCx/07/iv+h/z3/9v4O/+7+Xv7s/eD9zP2A/Vz9iP2k/Wj9NP00/Rz96Pzg/BT9JP0I/QT9EP3c/Ij8kPzE/MT8uPz0/Dz9DP2o/KT8xPyQ/Fz8tPws/TD9BP0s/WT9NP0A/Uz90P0E/iz+rv44/2T/fP/c/zUAQgBaALUABgEoAXwB/AFQAmACmALUAoQC8gHIAeQBsgFsAcABUAI4AqYBYgFSAb8ABAANAKwA3AC1APoAbgFIAbUAswAyAWYBbAHUAVQCQALSAbQBwAGYAYIB3gFIAnACmALgAuACgAJYAoQClAJ8AsgCYAOEAywD+AL8AqQCFAL4AUACPALaAbgBxAFgAaYAQwA8APz/j/+D/8j/pf8V/8D+sP5c/sz9sP0U/kL+/P3Q/fT92P1c/SD9aP2w/Yz9bP2Y/Zj9JP3E/Nz8BP3k/Mz8DP1A/fz8nPyM/Jj8bPxU/JD87PwE/fD8CP0w/Sz9FP0w/Yj91P0O/mb+3v47/3b/q//u/yUAVACdAP4AYAG2AQgCTAJ4ApACmAKMAmwCTAI4AiQCDAIIAhgCEALcAZ4BcAEqAcoAlgCrALwAogCrAO8ACAHQAL0AFgFYATIBNgG2AQQCqgFyAeQBNALIAXwBAAJgAuwBpgFoAhgDtAJEAtACQAOUAgACnAJQA+ACXALwAnADiAJsAZAB7AE0AWsA4gB8AcgAsv+x//r/O/9K/pD+Pf/e/gz+FP5s/uj9IP1Y/RT+Ev6Y/bj9KP7g/Tj9OP24/cz9jP20/Qz+3P1Y/TT9YP1U/SD9PP2A/Wz9EP3g/OD8wPyY/LD8BP1A/VD9XP1w/Xj9bP1w/aD98P1I/pr+9P5f/7j/6P8KAEIAfwCvAOkASgGyAfYBFAIYAggC4AG4AagBsgHGAdoB4gHWAbgBhgFCAQYB7QDoAN4A0QDYANoAywC7AMAAzwDUAOUAAAEMAQYBEAEgARwBFgE2AWIBagFoAYYBoAGAAVwBcgGYAaABwAEkAoQClAKEAoQCcAJYAoACwAK4ApACnAKcAhgClAGmAcwBYAHqABwBQgGIAKT/m//O/z//ov7q/mL/6v4o/j7+oP5I/rj9/P2W/nD+9P0M/mb+Lv7A/dz9Qv5C/gz+IP48/gL+sP2o/bz9sP2k/cD9wP2Q/XD9ZP08/Qz9FP1Q/Wj9ZP2Y/dD9wP2U/bD9+P0a/jz+pv4q/2X/cv+k/+//AgAGAFAAwwAGAR4BTgF6AWIBJAESASwBMgEyAVwBigF+AUoBJAEAAcQAjwB/AHsAaABjAHgAgQBwAHQAnAC0ALgA0gD2APQA1wDRAOAA5wD2ACoBWgFqAXoBkgGCAWABcgGeAZwBkAHoAVwCbAJoAtACOAP8ApQCvAIMA8QCUAKIAuACjAIAAgQCIAKOAd4A3gAGAYoA8//1/wkAf//k/uL++P6O/iL+RP5o/g7+wP3k/QD+tP14/aT9uP10/Uj9dP2A/Uj9PP14/ZD9bP1s/Yz9gP1Y/WT9jP2I/Xz9lP2k/Xz9VP1s/YT9eP2I/dD9Av78/Qj+OP5S/lL+iv78/lT/iP/Y/zgAXQBbAIYA2QASATgBfgHQAdwBvAGwAcABrAGKAZoByAHMAa4BnAGIAVAB/wDWAM8AyADHANoA7gDnANUAzQDHAMIA0gDyAAgBFAEiAS4BJgEeAT4BZgFyAX4BsgHiAdQBrgHAAdoBxgHEARwCjAKoAqwC7AIEA6gCTAJwAqQCcAJEAngCeALUATQBIAESAY4AMABnAIYABABu/0v/If+Y/kL+dv6m/m7+OP5K/kD+4P2o/cz97P3c/dz9/P3w/bT9kP2U/ZD9iP2c/bz9tP2c/ZT9hP1o/WT9cP14/Wz9eP2Q/ZD9hP2Y/bD9sP20/dT9AP4K/ib+cP6w/sL+3v4l/2T/hf/G/zwAnwDJAPEANAFaAUgBSgGEAbgBxgHSAfIBAALiAbYBpgGkAZoBjAF8AWoBUgEqAfoA2ADXAOMA4ADgAPoAEAH5ANgA2ADhAMwAvQDkAAoB+wDxABwBOAEeARQBSAFgAT4BOAFyAXYBNgFEAbQB+AH0ATACkAJ8AgAC1AEQAhQC5AEEAlACLAKwAWgBSAHyAJIAhwCYAFsAAADO/5n/Jf/E/rL+tP6G/l7+Vv4y/uD9pP2k/aT9kP2Y/cD90P24/aT9pP2g/Zz9qP3A/dj98P0A/vD9zP3E/dD9xP2w/cj99P3s/cD9zP30/dT9jP2U/eT9+P3k/RD+fP6m/or+rv4c/1v/WP+N/wcAUQBRAHAAxwD9APwAHgF0AawBqAGsAc4B1AG0AaYBuAG6AaQBlAGQAXwBUgEwASIBGAEUARoBIgEiASIBIAEeARoBJAEyAT4BRgFQAVwBYAFQAUYBVgFuAXABagGEAaQBlAFoAXIBngGgAYoBzAFEAlgCDAIQAlgCPALGAcQBNAIwAqIBdAHIAaQB4wCLANYAxAAWAMr/FgD1/y7/wP72/uD+Nv7w/VD+av7s/aT93P3c/WT9JP1o/Yz9VP1A/Yj9rP10/Uz9eP2c/YT9gP2w/dj9xP2w/bz9zP3M/cT94P0K/hT+Cv4Q/ij+KP4S/hr+Qv5e/mb+iv7K/vL+Bv8y/3X/of+///v/QgBpAIoAxAD4AAQBGgFYAYABgAGKAbYBvAGWAZABsAG2AZIBkgGwAZ4BXgE+AUgBMgESASIBTAE+ARQBDgEOAegAxgDaAOsA0AC+ANkA6ADMAMoA8wAIAfAA+wAsAS4BCgEcAV4BeAF0AbABFAIwAgQCBAIsAhwC5gHyATACJALcAcABwAGAAQ4B4QDtAMcAcwBKADUA3/9m/yr/H//2/rr+rP60/o7+UP4w/iL+/P3U/dz98P3k/cz91P3U/bj9oP2w/cT9xP3E/dz98P3o/dz95P30/fT9+P0Q/iL+IP4o/kL+UP5G/kr+aP54/m7+gP64/ub+7P78/jf/Zf9r/3z/u//4/wgAHABUAIIAhgCaAN8AGgEiASoBTgFoAVYBTAFoAYIBegFyAYQBkAF+AWwBdAF6AXABbAF+AYwBfgFoAWQBbAFsAW4BeAGGAYQBdgF0AXgBdAFwAXgBfAF0AXQBggGIAXgBdAGIAZIBegFyAYQBiAFiAUYBVAFQASYBCgEUAQgBzwCgAJcAdgAxAPv/6f++/2//Sf9J/yb/1v6s/rD+kP5C/ij+Tv5O/hL+Av4y/j7+/P3c/RD+Lv74/dT9AP4w/hb++P0m/lj+PP4M/iL+Wv5c/j7+WP6O/oj+Xv5o/pz+qv6U/rb+A/8e/wf/E/9K/2b/Y/+B/8L/6f/y/xQARwBdAF4AegCfAKoArgDJAOYA5wDqAP8ACgH9AP8AFgEYAQABAgEgASoBFAEUATIBOgEkASABMAEwARwBIAE6ATwBKAEkAS4BKgEgASgBNAEqARQBDAEMAQAB8gD1AAIBBgECAfwA+ADuANsAyADJAOEA7gDeAMYAwQC3AJMAcQBwAHoAbABSAEkAQgAZAOH/wP+4/63/k/97/2b/Tf8p/wP/4v7S/sr+uv6e/oj+gv54/mD+Uv5W/l7+Vv5Y/nD+gP50/mj+cv58/nr+iP6u/sr+0P7c/vD+9P7w/gP/Hv8f/x3/Pv9j/1z/S/9k/4v/jP+E/6X/zP/G/7P/yP/n/+T/3v8CACkAJQAXAC8AUQBPAEcAaQCeALMAswDIAOgA9wDyAPgADgEmATIBPgFUAWoBbAFWATwBQAFOAVABTgFeAXABaAFOAUQBSAFEAT4BRgFSAVQBVAFUAUgBLAEcARwBGAEMAQYBBgH3AN4AyACyAJoAggBsAFcASgBGADUACgDm/9z/x/+V/2v/Zv9c/zH/Dv8Q/w7/6P7C/sD+tv6Q/nD+cv54/mD+Rv5C/kb+RP5G/lD+VP5a/mz+eP5w/nT+jv6Y/oz+lP6+/t7+3P7g/gD/FP8I/wb/Jf9C/07/XP93/43/mP+o/7z/z//m/wUAHwAvAEAAUQBYAFwAdACbALYAygDfAPAA7gDkAO4ABgEWARoBJgE+AUYBOgEuATgBRgE+AS4BPAFYAVgBPAE0AUIBOAESAQYBGgEWAewA0gDfAN4AvAClALAAswCUAHoAewB3AGIAUwBQAEQALgAqAC8AIgAKAAIA+f/e/83/1v/b/8L/qf+l/5z/fP9j/2D/Wv9L/0j/T/9E/zD/LP8m/wn/9P4E/xT/B//+/hH/F//6/ur+/v4P/wb/C/8p/zD/Fv8L/yL/Mf8v/z3/XP9q/2b/bf91/2z/av+J/6f/qf+s/87/8f/v/+X/+v8XABgAEgAnAEoAXABfAGsAfACDAIQAjwCjALMAvwDMANgA4QDnAPEA/AAAAfcA7gDzAP4AAgH6APAA6ADhANkAyQC3AK0AsgCsAJMAgwCNAIcAWgA4AEgAXAA/ACAAMQBAABQA4//0/xcAAADW/97/+f/j/7r/u//J/7X/nv+t/7v/n/9//4T/i/94/2v/gP+S/4n/gf+E/3b/XP9a/2n/Zf9Y/2b/gP+A/3L/e/+O/4v/g/+L/5X/k/+d/7X/uv+y/7z/z//H/7j/yf/k/93/z//o/wMA9//s/wYAGgAHAAQALwBMADoAMwBUAGIASwBOAHUAfABeAGAAfwB6AF0AcQCcAIkAVABgAI4AegBEAFUAkACGAEYARABxAGAAHwAiAGAAYQAkABoASgBGAAMA7f8fADYACwDx/w8AHgD6/+D/7v/y/9L/xv/i//H/2P/I/9v/4v/B/63/w//U/7z/pv+z/7//rP+d/63/wP+2/6j/sv/B/7v/p/+c/6T/uv/H/7//tf/F/9f/x/+v/8P/5f/Z/7v/0P/3/+b/v//X/wgA+P/N/+X/FwACANP/6/8dAAwA4P/y/xsADgD0/woAIQAKAPz/FwAcAPz/AgAvACoA+v8IAEkASAALAA4ATABSACkAPgB5AGoALQA1AGcAVgAmAEQAhwB5AD8ARgBtAE4AFQAoAF0ATwAkADgAYgBDAAIABwAzACkA/P8CACsAKQD+//H/BQAIAPT/8f8BAAYA+//y//X/9//w/+f/6v/7/wMA9f/l/+7/+P/m/8z/1v/t/+P/zP/d//7/8f/I/8n/6P/k/8P/xP/n/+j/x//A/9v/4P/I/8f/4//p/9H/zf/o/+7/1f/R/+r/7f/N/8P/4P/r/87/xv/q//v/3P/J/+X/9v/d/9T/+P8RAAAA+f8PABAA7v/q/w4AFQD5////KQAvAAwACAAgABUA7//3/yEAJQAQAB0AOAAlAAEADgAxACcACgAVAC4AHgACAAsAHQASAAQAEgAeAAgA7P/v//3/9//n/+n/+f8CAPv/7v/w//z/+//n/+b/AgAOAPP/4//9/wkA5P/L/+//FAD8/+D///8fAP7/1//1/x8ABwDj/wUAOgAsAAAADAAzACkABQAPADQAMwAcACQAOQAtABYAGwAqACEAGAApADgAJgATABoAHwAMAP//EAAgABUACQAVACEAFAD+//v////3//D/9//9//T/6//v/+//4f/X/93/5P/Y/8L/vP/C/8L/u/+8/8f/zP/E/77/xP/M/8v/yv/R/9j/1//U/9b/2P/W/9b/3P/k/+v/7//u/+j/5v/r/+//8P/0//3/AgABAAMACgAMAAoACQAKAAoADAASABAACAAPAB4AGAAGAAoAHgAbAAcADgApACUACgANACkAKAAPABYAMwAyAB0AJQA5ACcADAAfAEAAMgAWACwARwAnAPz/EQA6ACcAAwAhAFMAPgAKABYASAA/AAoACwA+AEYAGQANADYAQgARAPP/FgA2ABkA+f8UADMAEgDg/+r/DQD6/8//4P8NAP7/yf/G/+n/3f+u/67/2P/d/7n/tv/X/9j/uf+2/8//0P+5/7z/1f/c/8//0P/e/9//1//Z/93/2f/a/+X/5//e/+D/7v/w/+X/5f/w//H/6//w//r/+P/z//f//f/9/wUAFQAaABIAEgAcABsAEQAVACUAKgAjACUAMAAtAB4AFwAfACoAMAAxAC8ALQAuACwAIQAZACEALQAqAB8AJAAuACEABQABABMAFwAGAAAADQAOAPr/8P/8/wUA/P/z//b/+P/w/+f/5f/m/+f/5//o/+z/8v/0//D/6v/n/+P/4v/m/+z/7//y//n/+v/x//D/+f/4/+v/7P///wEA6P/g//b//f/j/9j/9P8DAOv/2//x////6P/e//z/DgD0/+L/+/8KAOz/2f/5/xUAAADn//j/DwD9/+L/6/8CAPz/6//z/wsADQD2/+f/7v/3//D/6//6/w4ADQD+//z/BAAEAP3/AgAPABMAFQAfACMAFwAOABgAIAAZABoAKgAyACgAJAAvADIAJAAdACgAMAAvADUAPwA+ADkAPQA+ADAAJQAsAC8AIAAYACcALwAdABAAGwAgAA0AAQASABwACgD0//j////0/+T/5f/w//H/5//g/+P/5//f/8//y//a/+T/3P/X/+f/8v/k/9X/3P/o/+L/2f/g/+f/3v/U/9b/2f/V/9P/2f/c/9b/0v/R/8v/xv/L/9X/2//d/+H/4//c/9T/2P/h/+P/4v/q//T/8v/n/+b/8P/x/+P/3f/u//v/8v/p//n/CwACAPL/AQAaABMA/v8JACMAIAAKABEALQAtABcAGAAvADIAIwAlADUAMwAoAC8APgA8ADQANwA6ADEAMQA+AEIANwA0ADwANwAlACAAJwAkABgAGgAhABoADgAOAA0A/f/y//n//f/y/+v/8//0/+X/3//s//P/6v/p//L/7f/b/9X/4f/l/97/4v/w//T/6f/g/97/2v/V/9b/1//R/9D/2f/d/9T/0v/c/+D/1v/S/+D/7P/q/+n/9P/8//X/7//4/wAA/P/6/wQACgAEAAQAEAAUAAcA/v8GABAADwAOABUAGQATABAAEwAPAAcADQAWABAABgAOABgACwD4/wAAFAANAPv/BQAZAA0A8f/1/w8ADQD1//f/EAASAP7///8UABgACwAQAB8AFwAAAPz/BgABAPP/9/8IAA0ACQAPABMACgADAAoADgAHAAYAFAAbABIAEAAdACMAGQARABUAFgAQAA8AFAATAA0ACgAIAAEA/f8AAP//+P/2//v/+P/w//H/9f/t/+T/7f/7//b/6v/v//j/7v/j/+3/+v/y/+f/8f/8//P/7f/7/wQA8v/o//j/AwDy/+r/AwAUAP//7f/+/wsA9f/n/wAAFgADAO////8QAPr/5P/2/xEACQD2////EwANAPr/+/8DAPv/7P/u//j/9f/r//D/+v/4//H/9/8DAAQA/P/7/wAA/v/6//7/BgAJAAYABgAKAAoAAgD4//X/+/////n/8P/0/////P/v//L/AQABAPH/7//+//z/6v/q/wAABgD2//b/CgALAPn/+f8OABIAAQD9/wkADQADAAEACAAHAAEAAQACAP3//v8HAAIA8f/x/wQABwDz/+3/AAAJAPz//P8SABkABAD8/wwAEgACAP//FwAjABUADAAYAB0ADQAIABsAJQAaABgAJwArABoAEwAiACgAGgAQABoAHwATAAYACgARABAADQANAA8ADQAHAAAA+//5//X/7//x//r/+v/w/+7/9v/y/+D/1//e/9//1P/U/+X/7f/i/97/7f/2/+r/5P/w//j/6//h/+v/8//r/+T/7f/z/+r/4//r//L/6//n//D/9f/r/+T/7v/3//H/7P/5/wQA///2//r/AAD5/+7/8f/6//3///8GAAgAAQD9/wAA/v/6/wAADgASAA8AFwAiAB0AEQATAB0AGgATABwAKQAgABIAGwArACMADwAQABwAEgD8//r/CAAIAAAABgAVABcADwATABwAGAANAAkADgAQAA0ACgANABAADwAKAAUABQAGAAAA9//3//z/+P/v/+7/9v/5//L/6//r/+X/2P/T/9v/3f/V/9b/4//p/9//2//m//D/7P/o//P//f/4//L/+P////v/+P8EABEAEwATAB8AJgAaAAoACwASAAoAAAAKABwAFwAFAAcAGAARAPb/7f/7////7v/l//X/BQABAPr/AQAMAAsABwAKAAsA///y//L/9v/w//D/AwAaABwAEQAOABAABgD0//H/+v/9//z/BQAWABwAEgAHAP//8P/d/9X/3f/i/+L/8v8SACQAHwAeAC0AMQAZAAgAHAA3ADMAIwAwAFAAUgA7ADUASABJACQAAQD//wIA5//K/9n/+v/1/9j/2//5//P/xf+1/9b/5//R/87/+/8cAAkA8P/4//7/5v/S/97/7v/f/8f/w//G/7X/nf+i/8f/7/8KACAANgBAADYAKQAoACoAIwAYABEACQD8//j/AQAGAPv/8//4//L/3v/e//v/CwD+//j/DgAbAAkA+P8DAAgA8P/i/xUAaACNAH8AgwCSAGoACwDW/+T/4P+m/37/j/+M/07/I/83/0L/H/8a/2D/qP+1/8v/IgBtAFcAIQAwAF4AUwAzAHAA5AD1AJQAZQCgAK4AVAAmAFwAXAD3/9v/KgAbAJj/mP82AFgA/P9zAIABBAGG/lT84Ps0/Gz8VP2P/xgCmAOwAwADbAIQAuYAcP6Y/Fj9SP/A/7n/AAIwBTgFSALsAM4B2ABE/aj70P2W/6b+XP7rAPQCtAHb/0AA5ABH/0z9jP2Y/gL+6PyQ/SL/Yf+g/rb+k//p/8b/LAAEAVIB4AAqAIj/Uv/q/88AGAE+AVACfAMQA5gBOgGqAYwA/P0U/db+iAB+AOwAlAMgBugFQAQwBPAERAME/5j7CPuo+wz8LP3Q/ygCGAI/AJb+cP34+4j6SPog+xj8RP1o/7QBdAKQAaUAdQArAGX/H//1/wIBOgHYAAYBRAJMA4QCoQAnAEAB4wBU/jz9If/t/xT9APtA/d//jP6k/GT+xQBV/6T8NP1+/7//Jv+8ADgDsAO0ApAC7AJAAhwBzAASAUgBwgG8ApgD1AOYA+ACcAGr/0b+ZP0Y/cT98P56/x//zv7E/mT+AP5o/vb+Uv5E/ZT96P6b/xAAYAFYAloB0f8CAP0AugA7AFQBvAKEAhACQANoBFADRgHTACABPwBP/zkAmgEGAW//Lv+0/w//9P0i/qT+sP2E/FT9wv5w/qD9oP7O/2z+YPxE/dT//v9E/mr+bQCjAND+pP4IAYACWgFDAFYBnALEAUsAogDYAWoBz//P/5oBIAIxAKT+bP88AOj+mP30/ggBbwBi/qj+9wBqAWf/ev78/9YAPv/8/Xz/gAH7AEL/WP+rAJIAPP8F/x0AogBEAGsAHAHpANr/Vv9w/w//gP4Z/14AjADG//P/LgGMAYcA1P86AGEAof9R/z8AWgGeAZQB2gEUAtABXgEaAbwA+P9A/x//Zf96/17/hP/J/37/1v7i/qD/1f8g/5L+mP56/jj+yv77/2wA///z/4sA0AChANsAbAFqAfcABgGMAawBhAHSAVACNAKuAZoBugEgAeT/Fv/i/oT+Av4s/uT+AP9k/hr+Tv4k/qD9jP3Y/ez9Lv4p/zMAlQDKACQB4gAdAF0AvAE8AnQBjAH0AhQDHgEVAGoBNAKYAIL/DgFAAkoA5P2i/o4A5//g/Sb+CADv/wz+zP2J/ygAzv7I/fz9vP3Q/Cj9JP+sAO4AUgEsAtgB/v/g/oL/6f/E/uT93P4iAAIAnP9OAOQA8P+E/jT+lv7A/hX/7f+dAN0A9QCMAJL/XP9qAOAArf+o/iX/iv/K/rj+ZACoAfsABQBWAMgAWABNAEgBngGmAFwA3gEYA1QCGAFSAd4BxgAZ/1H/9gBKARgA7f9GAXwBt//E/jEAWAEGAJD+Z/+aAMP/4v6KAJACngFc/4b/DgGXAEP/XgB8AuoBv//Y/4wBJgH+/qL+OQCfAD7/pv7X//MAowCl/wj/rv70/eT8kPyo/Tv/xv9R/wD/9P5w/qz9mP0k/k7+Hv6U/vL/WAEUAhwCrAEcAbgAbgA5AHYAOgHiAfQB7AFQAqQC+gGsANr/w/+r/2P/hP/l/4v/cv4I/gr/NQA2AIr/S/9b/wL/Rv7g/Vb+ev9EAA8Ax/+PAHgBtQD4/sb+SgA0AQQBmAEYAzADdAFEAKUA1wD+/5D/PwDTAK0AmQC4AEcAav/M/hr+AP2U/NT9X/+N//D++P5s/yn/qP5C/2cATAAI/7b+BAAKAYMABgA8AZwC5AF5AFYBhANAA8MADgDMARwC6f/a/kIAigA0/hD9S/9sAZ0A9P6c/jj+tPwA/DT9wv6r/5IALgGeAAsA6wDKAboARf+g/1IAZP/a/iIB3AO0A1gC4AKIAxwBqP1Q/fb+yP54/Wr+vgDtAHz/rv8KAWYAEP4Q/Yz9bP0Q/Zj+UgGMAhwCwgFmAeD/MP48/kz/aP8D/9j/SgFSAWYAsQDsAbwBLgDM/9wAxAD8/nb+WwC0AYgAEP87/3D/Yv4Y/g4AHAIwAnABOgF0AN7+fP6+/zYAdP8DAAwCbALIAIoALALOAZ7+uPzM/Wb+GP00/RkANAJ6AYEAGgFeASAAP/+1//z/lv8EAIABQAK4AUoBdAEKAYP/2P08/dj93P5O/x//Nf/F/9T/Kf8S/wEAfgDV/17/2v8LAEj/A/8ZABwBxwAUAFAA6QCsAMz/Qv8x/yv/eP+UAPQBhAJIAhACogFOAM7+xv78/4QAEAAFAFAAd//0/dD96P5B/6b+sP54/6T/FP/W/mT/dgCcASACpgEEAegAhwBN/3z+Gv9CAC4BJAKEAjYBjf+l/2cAiP9Y/mL/4gC//+T9Ef+qAZoB5/8DALEAqv7I+1z8gf/CAKD/P/8kAAYA6P4z/xYBKAKiAUQBzgHoARYBxwBqAVQBBgCe//YAvgG2ACUAMgEgAcz++P2FAAQCbv8w/Rn/BgHm/tz8ev9kAjwA2PxM/pABsgBE/vP/CAN+AdT9Yv5aAbkAPP74/wgErAMAAI7/5AHlAPj8BPzw/YD9YPsA/ZwBCAPhAFcA0AHDAHT94Pw3/97/bP7e/lQBFAIwAQQCvANYAmz+jPx0/fD92P2r/zgC8AHU/9L/SgGrACb/sgCcA4gCZv4U/bj+Pv4o/Az+zAJIA47/2v6IAX8A8PtU/IACGAX9AEb+0gA8AiT/iP3XALQD5AH8/gX/QwAUAKT/rgDsAVgBNf9w/Zz9h/9QAYIBFAGwAYQClAFs/7D+zf9xAKz/Of++/y//1Pyw+yr+wAF8AggBrgDhAKD+cPsc/GMA7AIkArABdAJ2AXL/WgDQAnwBNP3Y+6j93P0M/Yz/dANEA68AYgGcA5gBbP10/T0Atf8Y/V7+XAKYAg7/oP0f/9D+VPyA/Pn/sAHG/6z+BgFYA8ACAALAAxAFnAL8/nz+MADNAKwAbAEsAU7+NPzo/T0Ahf+c/t8AtAL3/4D8kP1mAPP/nP7nANgDPALG/j3/rAFNAKj89PziADwC8P8F/xgBMAKWAKL/RAGcAkYBLv/Q/lv/Jv/6/lAA3AH+APz9+PtQ/DD9XP1e/i4BqANgAzoBtP9d/xf/vv4m/zsA8gDhAKMAxgAQAdkA+v8u/xD/9v4o/uD9qP/yAZoBQ/+i/uD/a/9E/bj9EgFQAjwAkf9kAd0AVP3k/CABnAOgAagAJANQA8T+QPzk/4ADbgFA/uH/DAO6ASz+UP7bAN3/CPy4+5n/rgEbAPT/AAPUA7T/8Pug/KL+uv4V/yABvgHN/wD/wAC8AQoBzAHsA5QD/wAfAG4AQP4Y+6D7ov68/6f/mAFQA/IA/PxQ/DT+MP+s/0wBYAI+Aef/OAAuAdIBvAJUAxACvP9m/gr+wP1G/v3/2QDp/3P/cwBhAHj+YP7OAXgE3AIhAGkAVAHm/qD71PzIAD4BUv5Q/vwBoAJe/lT8OQBEAxAASPwy/kwBSv9c/In/+ARgBMj/TP8AArIAjPwo/bYB1AEg/QD8RwBsAvL/Pv+kAtAD7P/8/Ob+AgFy/+j9w/+GAaj/gP1K/6gCuALk/2j+Sv/M/+T+0v6qABQCOgECAKMAegEXAEr+PP/4ALX/2P01ACgE2ALA/bj81v/n/xD96v4YBWAGWgGM/m0AAADY+0j73f88ArD/EP7k/ywBtAAoAcYBBwAm/tb+Yf8c/oX/0ATABhwCTP7F//3/WPsg+Sz9JgDQ/TT9bAI4BjQDgv8AAXADegE6/tD+agE6Aab+MP7vAPQCrAHR/3YAQAGo/mj7kPxdAMsAZP4V/9gCoAOVAFr/kAHAAiQB1v/G/0T+QPsw+oj86/9QApgDyAOQAiUAgP0g/AT96v6H/zD/SABEAtwBOv+O/psAVgHV/xwAtAKMAnr+PPzK/nIBpgDu//4B4AJf/4j7EPzg/pn/nv68/sn/CACh/7f/rQCMAnAEGAQCAYb+hv5Q/pj8IP06AZQDXAGG/z4B8AEd//j9EgG0AtX/5P3m/zoBmP9Y/8ABNAK8/67+h/94/mz8rP3IAMAAiP66/nwAJgAr//UAeAM0A2wCMARYBewBSP0g/dT/8f/U/SD+tAAGAY7+iP0N/4n/9P3c/VgAiAG9/4r+zv9jALz+HP79/zwBeABbAFoBqAC+/gb/qwDB/5D9tP7eAeYBjv8OADwDeAR0A3gDnAObAAD8QPqQ+9D8SP0c/ob+kP3k/DT+MQAGAVwBKAIkApUA2v8cAkAFoAWgA2wCYALrADT+fP0L/2n/1P2w/bv/awD6/t7+lQCNANT+Y//EAUgBlP7e/ooBKAGc/pj/wAJoAZj8cPtk/uT/8/+QAngFaAPG/tz91//9/zD/pgBQAiQBqv+8AMABTwAm/yMA4P+c/ID6bPzw/qL+5P2s/94BUAGJ/8n/PAHoAKj/7AAgBKgEXgGY/hn/3f8u/qj8RP6rACYABP7o/av/UACC/5j/5AAGAW//1P6iAFwCXAEn/6T+S//a/jz+y//SAdcAOv5Y/qoA+QCE/3kAeAPAAxIBaQDMApwDCgHy/ln/Uv9I/Rz8oP16/3n/Hv9SANwBvgG5ANEA1gHYAYkAsv8SAEAAhf8R/zb/Tv5Q/Aj8lP4WASYBVgBaAOn/Rv7A/ZH/RgEmAewA1gEwAvwA6P/v/83/KP8z/8r/1f8LAGABOAJEAZ8A3AE4Arr/xP0f/zoAwP2g+wD+CgG8/3j9eP9IAkAABP1l/2gEcATWAJAAxAJgAeT97v6MA+AEUAIEATQBrv5w+tD5FP2b/9j/GgCpAOD/nP4Y/9sA7AEoAjgCVAEu/2j9XP1G/iH/6v85AC3/eP0I/Sr+ev9xANIBVANwA/oBlwAwABwAHgDLAIgBxgDO/hT+c/+TALH/aP6g/iP/9P1A/MD8HP+yAAIBxAHwApAC3wBgAJABIAJGAagA4QCrAAYATAAsAUIBzwDXAJMAS/+2/gMAKAFWACT/M/9S/5r+oP73/3IAGv8S/qD+IP+I/mb+3/+kASACygG4Ac4BEAGK/9T+zv/kACoAqv7Q/h8A6P8k/oT9dv6y/vz9tP7wAPgBSgFAASwCrgG8/yD/YQDvACkAKADLAI7/MP2g/ecATAKBANT//gHIAjUAuP7oAHQCKgDo/Sz/iACE/pD8jv5iAaoAfv7+/rIACgA8/or+HQBMALz/cgCaAXgBxgDOACQBYAHyAeYBAAAk/tT+RwCS/8T+6wDwApYAEP20/db/GP5Q+zD9kABC/4D8QP+4BOAEEAHDAJQD2ALY/ib+EgFQAcD9GPw4/kz/GP3A++z9aABzACwArAHIAnYBx/86AGwBJgFUAJkA7gAJAET/CgD6AFYA6P7w/Rz9YPwY/Uz//QBkAcoBgAJoAtQBJALMAlwChgGGAQIBtP7Q/Iz9H/9H/4f/WgFAAn4AEf9IADYBhf+I/rIAQALu/4j9Dv+QARAB9v/CAZwDcgHE/UT92P6g/mT9iv5IAegBMQA5/xAAvwAQABj/If/l/0MAxP8z/6j/ygAMAfz/AP/g/pj+sP3I/Yn/sQDI/x7/uwBYAkgBiv8rAJwBzAA4/xAABAKwARQAXgCIAWMA9P2g/cD+RP7Q/GT9Wf+M/2T+5v7XAGgBrwA+AbACLAL2/3H/OAE0AgQB6/9jAK8AX/8u/iT/GAF2AU0AAgAoAcgBLAEgATwCWAJ8AAT/m/9uAKr/jv60/if/lP7I/Qb+Lv9uAFgBmAGIAegBWAKmAWAAfwCAAcsAtv5K/l7/rv5s/Hj82v5J/zT91Pwf/yQA7v4u/54BZAJ6AG//WgA8AHj+FP6W/9v/Rv7M/Tn/GwDf/5wANAIIAhEAOf8MABoA9v76/mIAnAAk/3z+f/8ZAG//RP9RABIBuQBCACMAxv9j/8r/wwBgAZABvAG+AZYBBAL0AiADBALrAKUAWgCC/1H/dwB+AQIBEwBMAPYAhACT/7z/YwC8/0T+Gv44/3n/jv54/sf/mQAXANn/pQDsAM//9P7N/yIBUgHrABoBTAFNAML+cv5x/w0AV/8e/kz9zPyA/PD8UP67/1IAOgDy/4f/Df8P/7b/RwAjAJP/H//i/vb+nf+RACIBDAGXAAYAnf+V/9D/MADnAOIBRALCAWQBvAF+AQIA7P5n/9r/Bf9u/mz/VwDu/wAA0AFQA8ACugHwARACCAE5AL4AOgG1AC8AMADU/0f/5P9UAc4BUgFWAbIBIAEgAGEAjAHAAeEAbQB4AKT/AP5E/fj9kP70/Sj9PP1g/bz8ePzE/Vz/ef/W/hD/e/+i/qj9XP6K/xv/Ev5u/gj/9P2c/FT92P60/uj9nP7u/9j/Uv9RAN4B5gHxALoA8QB8AOv/WwB+AVgCwALcArACcAJ4AowChALQAiQDqAKgAYoBgAL0AowCoAJ0A4wDpAJQAvwCQAPMAuwCpAOkA6QC2gGmAUYBsQB5AFcAmv+i/iz+AP64/Zz9kP3E/Ij7MPuo+8j7cPvA+2D8BPxY++D7rPwE/Mj64Pp4+8D6sPkw+nD7UPuI+gD7NPyA/Cz84PyA/k7/Fv9G/1EA0AAjALv/rgCMAcQAq/9cAPQBKALeAagDiAZYB7AGsAfQCYAJEAeYBnAIcAjABYAE8AVYBjgE9AKABPgFEAUoBJAFWAfQBngFGAa4BxgHKATkATYB4v8U/RD7IPs4+9D5mPgw+Tj6APqg+XD6kPtw+5D6KPoQ+qD5CPmo+ED4cPeg9mD2cPZg9nD24PaA99D3IPg4+fD6GPyg/MD9n/96ANf/c/8uAC4AlP6s/dj+6/9o/2//ggFkA3gD8ANABgAImAeAB0AJgAqgCTAJkAogC7AJMAmwCmALIArQCaALcAzQCpAJsAowC1AJyAdACFAIyAX4AjgCnAG+/nj7qPpI+5j6MPl4+ej6wPoo+ej4IPow+nD4cPcg+Gj4UPfQ9qD3KPiw91D3oPfA91D3QPfA9xD4APgQ+OD3UPcw99D3EPiQ97D34PhY+YD4UPjo+ZD7DPzo/E3/qAF0AhQDKAVoByAIMAggCYAK4AqgCuAKsAtwDKAMoAzgDGANYA2QDAAMsAygDcAMIAsgC7ALAArYB2AI0AkwCPgEkARwBQgDLP/C/rH/tPzw91D38Pgg9wD0QPXY+Hj48PVw91j7UPtY+MD4mPv4+pD3QPfo+fD5oPZQ9QD3sPaA81DywPQw9rD0APRQ9pD38PWA9Vj4QPoQ+ej4qPs4/Uz8dP2KAWQD7AF8AhAGAAfABGgFsAkgC9AI8AiADJANUAtgC7AOgA/gDLALUA3QDSAMEAuAC4ALQAogCXAIIAgQCLAHwAaQBmgHMAdABVAE4ARwA23/8PzU/OD6QPbQ8/D0MPVQ8/DzAPhA+hD5SPmk/I7+5PwA/AL+nv6A+9D4YPlA+ZD1sPJw8wD0kPFA8ADzQPWw89DyEPZw+AD3oPZg+sj88Pqo+rT++wC4/iL+fAGAAlv//P5cA6AF3AOIBAAJ4AogCdAJ8A2AD5ANkA0gECAQUA0QDGANQA2gCgAJkAnACSAIoAYwBxAIGAeYBSAG6AcgCKgGGAbgBgAGyALX/5D+ePw4+ODz4PHg8VDy8PLw9Hj4aPsA/BD8zv6UAuACLACI//gAwv5I+RD3kPhA9yDyAPAQ8oDx4O3A7eDxwPNg8qDzsPdI+bj4ePq0/Ur+rP1B/88Aaf/g/SP/PgAR/+D+kAGQA/wCtANgBzAKIArQCkAOoBDwD2APIBEAErAPIA0gDfAMwAmIBrgGqAfYBUAEiAZQCVAIwAYwCQAMEApYB8AI4AlYBdv/Vf8g/1D5EPOQ8lDzEPBg7pDzwPmA+nj6yP6cAnwBFwBEAmQDNgDo/Gz8IPsQ91D0YPSA84DwAO/g7zDwoO/g8AD0YPXw9KD18PcA+Vj4MPkE/Fz9aPxE/AT+B/84/nr+rAD4ASQBHgE0A2AFqAYQCNAJAAtQDBAO8A7ADrAPIBGgD9AMAA2ADqAL8AaAB9AKwAhoBLAG0AsgCiAFkAdADTALGAWoBmALQAeW/qT9oQDw+2DzoPJw9iD0oO9A83D7wP0I/OD+IAQ4BFwBKAKoBLQCFv4Y/Lj7qPiw9FDz4PJw8CDuQO5A70Dv4O9A8uDz0POA9JD2wPfQ9zD5UPu4+0D7rPy6/oD+tP1H/1QBowCL/6YBGAS4A5QD+AZACtAJYAmQDJAPcA4QDQAPYBDgDXALMAxgDJAJmAfgCOAJUAiYB2AJcAowCZAIIArwCmAJEAhgCJgHIARDAFL+qPyY+AD0UPKw8sDxkPDg8/D6Kf8L/6UAWAWYBgADugHwBJAEAv5o+aj6UPqA9HDwAPIA8yDvgOzg7sDxUPGw8BDzIPbg9gD2sPYQ+TD7EPt4+ij8Cf9A/0z9GP5+ASgCy/9kADAEGAWMAlQDQAhQCnAIIAnADYAPEA3ADOAPIBDgC3AJEAtAC4AHiAXYB1AJ6AaABXAI0ArgCBAHUAnQC6AJkAYwB7gHQAOI/fD7cPvw9uDx4PGw8xDyAPEQ9kj9+v+NABgEeAcoBqwDKAWgBvwCpP3Q+8D6oPaw8lDygPKA7+DsIO7g7+DvUPBg8yD2QPbw9XD3KPnA+SD6QPtI/MD83Pwk/Qj+e/9YAEgAtACUAhgE0AP4A3gGQAmACRAJAAvQDQAOcAzwDMAO8A1ACpAI4AnQCcAG2ARwBqAHCAZwBSAIQAowCSAIoAnACoAJ4AcQB5AFzAIOAEj9uPkQ99D1APRg8cDxUPVI+GD6Pf9YBfAGyARABVAI6AeoA0oBAAGI/cD3YPUA9iD04O/A7uDvIO+g7YDvEPMA9HDzQPWQ9/D24PVI+ED7WPqA+ID6+P3U/Qj80P1UATQBUP+zAGAE8AQgA0gEMAjACcAIsAnwDDAO0AyQDAAO4A2ACzAKMApQCSAHQAbABnAGaAWwBTgH6AewB1AIwAlgCqAJ4AjQCNgH8ASgATz/OP2o+aD10POg87DygPEg9Ij6XP/QACADaAfQCGgGiAUACJgHWAEA/ID7yPrA9YDxwPEg8sDuwOtA7YDwUPEg8ZDz0Pag95D2wPYA+aD6aPoA+hj7qPys/Dj8UP1f//X/kP+6AAQD4AOkAxAFoAegCGAIoAmgCwAMkAtwDIAN4AxwC0ALUAuwCcgHMAcYBwgG+AR4BdAGcAfAB7AI0AkQCrAJsAlgCSAIOAbgA9QAaP24+pD4sPXg8jDyEPNg8/D0uPqeAUAE/AOQBiAKAAloBbAFQAdwAlD6APjo+QD3UPDA7nDxIPDg66Ds0PFg81DxoPIA94D38PSA9Rj58PlI+AD5sPsg/BD7hPxO/7n/5v53AEgDvAPcAuQDiAawB4AHgAjgCjAMoAtwC4AMUA0QDAAKUAngCfAISAbQBMgFWAbABOADeAZACeAI0AcQCiANEAzQCAAJsArQB9ABYf8XAMD84PWA88D10PSQ8MDxcPlu/p7+wAGQCJAK6AZgBvAJsAgQAkr+Vv5w+6D10PPw9JDyIO4g7hDx0PAg7zDxMPWQ9eDzIPXw9zD48PYg+Ij62Pr4+dD6AP0A/uj9iP4DAC4BwgFYAggDjANABEgFgAagB8AIAArgCkALoAsADMALoAqACfAIQAjQBngFAAXwBKgEmARgBbgG+AcACRAKQAvwC+AL8AqwCWAIsAWQASj+fPwY+gD2EPMw86DzAPMw9aD7hAEwA7gE8AiQC8AJ6AfQCHgHrgGI/Fj76PmQ9UDy0PGA8IDt4Ozg74Dx8PBA8sD14PZg9eD10Pio+dD38PeY+lj7cPnA+Wz9hf8A/nD9jQAYAyQCLAGIAwAGGAVABAgHUArgCSAIoAkwDHALEAlgCdAKcAlwBhAGUAcoBnwDUANABZgFqAQoBtAJoAvgCtAKgAywDNAJIAcABuQDAf+Y+mD5iPgw9SDy4PJA9QD2EPhe/rAEcAagBsAJMAwgCkAHaAcgBsX/wPkI+dD4MPSg7+DvsPAg7oDswO+g8zDzMPLg9AD4cPeA9RD3GPog+hD4aPg4+4z8wPuQ/K7/FgFl/wT/ZAIQBYQD2gE4BEgHyAaYBRAIMAsgCqgHAAkQDEALUAiwCBAL0An4BRgFAAcwBpgC4gHoBHAGcAXQBjAL8AyACpAJ0AuQC4gGlAJcAmYAePpg9kD3cPeg88DxUPVA+Vj6EP3kAyAJAAnwByAKoAvgCFgFqANiAfD7APdg9bD0sPEg7mDt4O6A72DvYPEA9aD2gPVw9Qj4YPlQ9zD2EPlA+9j4MPdQ+9H/hv7w+8b+iALBAEL+DAIIB3AF1AGIBMAJAAmoBZgHgAvgCdAFMAdQC5AKCAfQB+AKIAnoBPgEgAcYBmgCMANIB0AI0AawCJAM0AwQCnAJwAqwCJwDuAA2AIz90Pig9lD3sPYw9ED0CPh4+2j9IAGQBjAJIAgwCMAKAAsoB6wDUALw/vj4oPUw9tD0oO8A7UDvsPAg7+DvYPQw9nDzsPKQ9pD4QPag9RD58PoA+cj4oPxR/zj+oP14/1QAOf+M/xgCnAMoA4QDUAVYBogGiAfACMAIcAhgCUAK8AmwCYAKkAqwCAgHoAboBTAEaAPcA/QDzANYBdAH8AiwCZALwAxwCyAK8AnIB7wCWf8P/6z8UPdQ9cD3oPfQ87D0UPuU/jD9RgBACGAKAAZoBnAMIAzwAxUAaAJu/4D2UPPw9oD1AO7g6wDxsPIA7wDvAPQg9dDxAPJw9uD3sPVQ9ij6aPtY+uj7wP95AEr+9P3F/47/zP2w/soBjAL9ANQBgAVYBzgGWAbgCDAKMAlACbALsAzACiAJsAlgCcAGeARYBHgEhAMUA1gECAZIB8AIcAqgC1AMAA0QDZALMAmoBmQDJ/+w+/j5kPgA9iD08PTg9vD3UPlI/dwBzAOIBGgH4AqwCjAISAcoB3QDmP3o+mD6UPeA8uDw8PEg8SDvEPAA80DzcPGw8QD08PRQ9MD0cPZw98D3+PiA+/D9I//y/sL+af/o/zL/J/9MASQDVAKEAdADmAZ4BmAFsAYACAAH6AZACtAMIAsQCfAJUAowB6AEMAXIBJwBmQDMA7AFEARwBOAIwAtQCkAK8A2ADxAMsAiACFgGt/9w+gD6ePlA9QDyEPQw91D3CPi0/IIBwAKwA7AHQAugCpAIkAggCFgElP8g/WD7sPfA8+DxcPFw8GDvIPDg8fDykPIw8lDzMPWg9aD0oPRg9qD38PcA+nD9Hv9K/mD+xv/U/wT/JQAsAiQCRAGgApgEeASABLgG2AewBagE4AfwCgAKwAhgChALEAhwBXgGSAdABCQBIAJ4BFAEYANQBaAIwAlwCfAKAA4gD1ANMAsgCugHOANC/pD7+Pkg9zD0oPNw9QD3sPfg+Q7+tAFwA0AFkAgQC4AKcAiQB6gGRAOi/uj7gPpA9wDzgPEw8kDxIO8A8CDz4PNQ8uDywPXw9dDz8PNA9mD2oPRA9hD7ZP1s/BD9hf/N/0L+9P4sAgQDVAEKATgDqAQYBCAEkAVQBrgFuAWwB9AJMAqwCQAKMAqQCHAG6AU4BsAEWAL8AUwDrAMwA9AEAAggCcAIkApQDsAP0A0wDAAMsAlYBPb/UP7o+xD3gPMA9JD1YPWQ9ej4KP0x/90A0ARQCaAK4AkgCpAKYAhYBEoBP/8c/MD30PTA88DyUPHg8ADyAPNA88DzAPWg9eD08PMQ9HD0YPSQ9LD1UPf4+Dj7QP0m/gb+oP7R/94ABAJYA9wDSAOoAzgFiAU4BDgE8AVIBiAFcAbgCaAKkAhwCIAKgAm4BZgEcAaIBYwBtgB8AxgEGAIMAzgHIAkwCIAJkA1AD2ANMAxQDCAKaAXSAcz/nPyg+GD28PWA9YD1MPd4+TD7nP0YAcwDMAUwB5AJoAmYB2AGwAXMAqj+fPwo+7D3EPTQ84D0oPIQ8SDzcPUQ9ADzcPVg9tDyMPHg9FD28PHg8ED3cPt4+ID41/9wAlz80PogA0AHAgHo/fAEAAkAA83/EAawCYAD5f8QBgALeAfIBMAJgA3ACRAGYAggCpAGQANgBLAEfgEkAAgDuATsAvwCoAYACcAIsAqADpAO8ArACTALsAggAnT+aP6w+3D2QPUg+Kj4cPaw98z8pv+t/2ACeAdACbAH8AfwCdAI4ASMAqoBXv6Y+XD3YPcg9bDxcPFA8wDzsPFQ8zD2cPWg8iDz0PUg9UDy4PIw9tD2gPWQ+Oz9ZP5A++D7VAB6ASr/EABABOAECAKcApAG8AY4A6QCAAY4BxgFSAXwCGAKQAggB7AI4AiIBugEYAUYBdQCMgHiAUgDeANIA1AEYAYwCHAJAAvgDHANQAygCpAJEAjwBHwB5P5g/Dj58Pbw9qD3kPfw9wD6sPzK/kgB4ASABwAIEAgQCUAJGAeYBCgD7QDI/Gj5cPgA95DzcPGg8lDzkPFA8TD04PXA83DywPTQ9TDz0PGQ9OD24PVw9uj6Vv5g/Sj8eP7qAJgA0f9IAfgC4AKoAhAEeAUIBcADiAN4BDAFWAXQBbgGYAdoB0gHaAdYB5AGeAW4BEgEvAMQA+gCsAOgBAAFcAU4B8AJQAuwC6AMwA0gDbAK4AjwB2gFEgHA/VD8SPpA9wD2MPcA+JD3oPjo+xv/9gBkA6AGwAggCVAJsAnQCEgG/AMEAkv/8Ps4+YD3oPVw8zDyMPKA8mDygPLQ8/D0QPTA8tDyEPRA8/DwYPFg9QD4APiA+dT9qP90/Tj9gAG4A7cA4v60AlgGYAQQAmgEsAbAA6cATAMYB8AFsAK4BNAIEAgABRgGcAmACHgE/AOoBhAGhAIIAvAEaAVQA2gE8AgwC3AKkAvwDrAPMA0ADGAM8AkQBRQC5gC4/fD44PZw98D2EPXw9fj4qPpY+4L+cAMgBoAG0AdgCsAKsAj4BlAG4AOg/+T8NPxw+oD2APRg9DD04PFQ8cDzwPTA8iDy8PSg9RDyYPBQ8zD0oPCg8FD3CPzY+TD5AP/UAmP/uP0gA1AGhgHC/pAE4AhYBCQAwAPgBqQCTP/wA2AIUAVUAhAGoAmgBnwDUAYQCZAFsgFcA8AFyAOsAcgDCAaYBBgEAAgADNALQAtwDTAPkA3ACzAMUAvoBoACywDo/sj6gPfw9pD2APUg9RD4CPt0/CD+SgEwBBAGuAcwCaAJ8AjoB0AGMAR0AlwAPP1g+pD5yPgQ9rDzQPSA9SD0cPKw80D14PNQ8mDzMPQA8gDwcPGw8xD08PRQ+BD7aPu4/CkAAAIwAYoBEATQBCQDMAM4BfgEIAIyAbACsAISAZQBOAQIBSAEsASoBhAHGAYwBtAG+AWgBLAE+AT4AxADuAPgBPgEyAUwCHAKsAqgCiAMYA2gDCAL0AqQClAIMAU8AwQCDv/Q+gD4YPew9nD10PWQ+GD75Pwj/+gC6AXIBpgHUAnQCUAICAcIB4gF7gFd/5D+mPw4+dD3aPig9gDzYPLQ9LD04PHg8YD0APTA8CDxQPTQ83DwIPGQ9SD3wPWg91j8yP1I/Iz9kAEUA/gBlALwBCAFZANEA2gExAOaAaAAUgH4ASgC3ALoA2AEgATwBNgFaAaABggGeAU4BSgF8ARYBPgDQATQBDgFMAYwCDAK4ArgCqALoAwwDMAKIArACdgHIAWkA8QCFwDw+7j4QPcg9lD1IPYY+Aj6SPxz/+ACcAUYByAIIAjoBzAIQAioBjgEoAIUAUL+gPto+tD5EPhQ9kD2cPZQ9VD04PRQ9TD0IPNA8zDzMPIg8iDzMPOA8oDz4PVw92D4qPoc/dj9iP5mAUgEiAQgBKgF4AZYBUQDNAMkA64Afv4V/30A//+Q/5oB3AMQBLwDSAUgB0gH6AaYB/gH4AYoBqgGqAYwBYgEmAVABuAFsAbQCEAJQAgACRALwAqgCDAI0AkgCZAFiAM0A9gA6Pu4+HD4YPfg9MD0IPg4+1D8EP5AAvgFsAaQBiAI4AkQCdgGGAbYBVQDav+8/bz9uPsI+ND2KPhw94D0APSg9uD2APRw8xD2YPYA89DxUPTg9LDxgPDQ8zD2APVQ9dD5NP3M/Fz9wAEoBZgEAAQgBkgHOAV4A0gEQAR0AWD/CQClAJX/YP8OAUgCHAL8AqAFOAfQBggHgAjACDAHuAa4B0AH0ATkA0gFqAVYBNAEmAegCFgHAAhgC1AMkAlACCAKMApQBjgEWAUoBH7+mPp4++j64PXA8hD2ePm4+Bj5yv7QAzADlALgBnAKAAgoBVgHMAkoBZkAcgGgAgz+APn4+Rz84PgA9UD3gPqQ92DzYPX4+HD24PEw82D24PPA78Dx4PVQ9LDwAPNI+MD4UPf4+loAnwAE/zgCEAegBuwDSAWwB2gF/AHwAngEfAEK/nT/tgGt/3T9BgAkA/YBpgDEAyAHIAaQBKgG8AhoBzAFWAYwCOgG0ARwBRgH+AYIBsAGgAhACfAI0AhgCfAJQAl4B2gGgAagBXAC9P/z/wz/kPpw9pD2sPfw9fD0UPhg/Nj8eP0sAtAGuAawBfAHMArACLgGgAeYB0AEvgAtAHX/RPy4+cj5aPkA96D1sPYg95D1oPSQ9cD1UPTw8xD1APVg89DyoPMg9DD0YPVw98j4CPp0/DX/+QBkAigEMAU4BZgFiAZQBqAEPAPQAswB5v+w/ob+/P3g/KD82P1z/4kAdAHYApAEEAboBoAHgAhQCfAI+AfQB2AI4AdYBugFwAawBsAFOAZACCAJQAj4B+AIgAjABjgG4AboBYADZAI0AiUAcPxQ+iD5cPbg8+D0oPdA+GD4mPsvABACgAKABVAJ0AkwCLAIsArACWAGWAQYBCQCIv6w+8j7SPtY+ND1APbQ9tD1sPRQ9XD2sPVA9MD0MPbw9WD0wPNw9MD0oPQw9aD24Peo+Pj5CPyA/qcA/AH0AiAEQAVwBQAF4ATIBJgD3gEOAe4AIADA/hj+LP7E/Xz9jP5RADwBuAFEA0AFSAbYBgAI4AjQCKAIMAlQCVAImAeIBxgHKAYgBtAG0AaQBqAHwAgACNgGMAdwB7AF9AOgBPAEoAI5AAcAPv9I++D3sPcQ+FD2UPWQ93D6iPvg/BYA0AKYA4gEuAZQCEAIAAjgB8gG8ATAA4ACDgCk/Zz8sPuI+cD3oPdw9xD2cPVw9vD24PVw9XD2oPZA9bD0kPWQ9bD0APWA9gD3sPbg90D6kPsA/OT92QBkApAClAMoBSAF1AOYA2gECAQoAjABzAHUAWgAXf/k/3kA5v/L/14B7AIgA1QD+ASoBtgG0AbYB8AIMAjAB2AIYAgQBygGiAZgBjAFGAVoBtgGGAZwBrgHYAeQBSAFsAWYBJgCdAIcA64BqP9k/wb/CPwg+Rj5aPmw9+D2QPlo+wj7uPuV/4AC+gEUAigFQAfYBbgESAbQBhAEqgEIAhwClv8s/QT9+Pz4+gD56Pgo+UD4IPcA90D3EPew9pD2cPYw9uD1sPXA9UD24PZA95D3ePjY+Tj7dPzI/WX/+AAwAuACdAMoBGAEuAPwAhADRANcAigBGgFsAYIAV//E/94AuAAoABYBlALoAuwCGARgBXgFiAWwBpgHaAdYB9gHiAdABtgFSAaoBYgE6AT4BZAFsASwBRgHMAaYBAgFuAUoBIgCdAMwBOYBxP+iABAB0P2g+tD60Prw90D20PgI+7j5ePlc/ZgAzP+T/xwD6AWgBHgD4AWoB2gFrAIgA8QDCAHg/dD90P4w/Yj6KPow+2D6KPjQ9yD5SPnA90D3cPjQ+HD3oPZg99D3EPfA9vD3CPko+XD50Pos/Pz8MP4UAI4BWAJMA0AEcAQYBCAEGAQsAygCBAIEAgoBJABHAHkAsf8n/xQAHgH7ALsAzAEkA3gDeAOABKgFqAVYBfgF+AbIBsgFuAU4BrgFYAQgBBAFEAXcA+gDqAVABtgEQASABYAFBAPSAWwD2AMQAUD/uQBQAVz+2Ptc/FT8aPmQ90j5wPqg+TD5sPv4/Qj+nv4qAQwDFAOQAzgFAAZIBfAEOAWIBPwCNALYAcIAW/+O/tT9ePxw+zD7qPqw+UD5ePkw+Wj4YPjA+FD4oPfg96D4kPhQ+CD5SPqA+mj6aPvI/Gz9Av55//QAggHcAdQCjANMA+QCEAMAAxwCVAFEAQoBFQBU/2z/jf8W/+T+cf/w/7T/sP+dAJoBzAEAAgAD7AMIBAgE8ASoBUAFyARIBZAFiASAA7QD2AOcAqwBkAKQAxQDyAIQBKgEJAPgAcQCeAMEAuwAGALoAmIB5/9YAD8A4P3g+zz8sPx4+8j6PPyY/VT9dP1a/wgBPgG0AXQDmARABBgE+AQoBfwDKANUAwADlgGYAIoA/f+C/pD9lP0s/QD8ePvY+7j7yPpY+sj6qPrA+WD58PkI+kj5GPnw+Uj6uPmo+bD6cPtg++D7WP18/p7+8P4RANkAvAC9AGYBzAFaAfgAJAEcAXUA2f/O/9T/gP9L/6v/FAASAAUAZgDrACIBTgHKAVgCiAKgAgQDcAOYA6gD7AMoBBAE7AP0A6wDHAPEAswCyALMAngDaAR4BOQD2AM4BMgD6AL0AqQDXANsApACTAOoAt0A7P/c/xD/qP1U/ez9xP30/BT9GP6o/rj+Uf+HAFoBxgF8AlADtAO0A7QDoANQAwADvAJAAooB+gBsAJ7/3v58/g7+UP2s/HD8MPyI+xD76PqI+uD5qPng+dD5cPmA+eD52PmA+cD5UPpw+lj64PrA+1D8qPx4/Vb+jv6W/iD/xv/g/8//GAB0AFkAGQA2AFMADACq/6j/3P/q/+r/JgCAALcAzgAGAXwB6AEQAigCXAKsAuwCLAOQA/QDQARwBJAEiARQBPwDZAO8AqwCVAPgAwAEWAQgBTgFeAQwBMAEwASoAzgDEARoBEgDUAKEAjACXQD0/jf/UP/w/dz8gP04/nD95Pwc/pv/nf+A/+MAhAKUAiAC2ALQA1gDRAJUAugCWAIaAcIA6QAgAMb+Ov46/oz9aPzg+9D7WPvI+qj6qPo4+tj56PnY+Wj5QPmI+YD5IPlQ+fD5IPrY+Sj6KPuo+6D7JPw8/eD92P0u/gf/g/9g/4f/MQCDADsADwBYAF0A9v/X/y4AYwBGAKAAVgGoAY4B4AGgAswCdAKoAmgDkAMoA2wDWASYBCAESAQwBVgFgAQoBJAEcARoAwQDlAPcA3wDuAPIBFAF0ASABNAEuAT8A4ADlANcA8ACmALIAlQCUAG5AHEAkv9y/ir+Nv6I/aj82PyA/Uj9+PzU/fr++v7O/ub/LAECAWwAGgHuAVABaADsAKQB3QDF/wIAfgCO/0r+Uv6I/nj9OPxA/Jj84Pvw+hj7aPvI+jD6qPog+6j6KPpw+sj6SPrQ+VD6yPp4+kD6IPsw/GD8hPx8/XD+bv5K/g//9v/r/6D/QAAcAQ4BrAAYAbIBYgHHABQByAGyAToBfgEgAgwCpAEEAtAC3AJoAqQCZAOAAwgDIAPAA9ADUANwAxgEEARAA8gC4AKUAgQCQAIgA3ADOAOIAzAEIASwA+gDSATMA0QDyANQBKQDnAKEAmgCCgGl/6T/z/+y/pT96P1k/pT9yPxs/Tr+2P2A/Zb+wf+5/6j/rgCGARYBrwBmAfIBSgG8AEYBoAHMAAAAOwBLAD7/Qv5W/mD+dP2g/MT85Pwo/Hj7uPvo+0D7uPoQ+3D7GPvA+hj7UPvg+qD6CPto+0j7cPs4/Nj8AP1U/Qb+ZP5G/mr+AP9i/1//hv/0/yIA+f8CAGcAoABzAFkAnQDdAM0AygAkAXYBYAFkAf4BqAK8ApQC8AJYAyAD0AJEA+wD3AOkAzAE4ASYBAgESASgBAgEZAPwA7AEWAT0A5AECAUgBCQDmAMIBAQDzAEgAqwCoAFIAIEAEAH//5z++P4EAIz/TP5u/l//D//c/dD91P4T/3j+tP7t/3IAy/9g/9b/AgBY//j+ov9XADkADgCGANYAPwB9/3r/if/s/kr+XP5+/gj+lP2k/Yj95Pxw/Kj8vPxU/Cj8dPx4/BD8IPyg/Kz8RPxc/Nj8zPx0/Kz8RP04/dj8IP3Q/ej9nP3g/YD+ov56/uL+mP/D/53/4P9cAG0AQwBxANkABAEsAaQBNAJ4AoQCpALEAqgCXAIcAhgCQAJEAjwCZAKgAngC/AHQAQQC5AFeAToBtgEIAt4B7gF4AswCoAKgAiADcAM0A+gC6AL4AtACmAJsAjwCCALKAXQBFAHkAMEAVgDW/8D//f/3/7j/0/8sAB0Awf/k/3oAoABKAEcAoQCxAHsApQD9ANsAfACLALcAdwA8AGMARQCJ/w3/L//m/tT9JP00/dT84PuQ+zD8KPwo+6j6CPvo+hD64Pmo+hD7yPoI+xD8oPxo/Gz89PxE/ST9VP3s/Uz+UP5O/l7+VP5e/qD+8P48/7L/LAA0APr/AAAnAPv/wP8aANwAYAG0AUACuAK4AnwCgAKwAtQCBANoA8QDCARABHAEgARwBFgEKAQQBDAEOAQIBAAEIAT8A6gDvAMYBOgDJAPcAgwDqAK2AWgByAGKAbsAqQBKAUQBfAAxAH8AQgCA/0b/pv+s/zz/HP9J/0r/H/8t/y3/3v6i/qr+nP5k/nr+zv66/mb+nv5A/2//Jf8u/4T/Zv/g/sb+DP/2/ob+WP56/m7+JP7g/aD9QP3k/KD8cPxU/Ez8IPyw+2D7cPuY+4D7mPsA/Gj8jPy8/ET9tP3A/aj95P1U/qz+6v5N/9P/NABWAIgABgF6AYwBfAG+ASQCPAI4AogC3AKsAiwCAAIEAqYBHAHeANMAiQAzADsAXgAvAOD/1//p/+L/EQCoAEIBlgH0AYwC9AIMA0ADmAOkA2gDaAOcA4wDRAMYA/ACgAIcAgwC+gGUATgBIgHjAHQAYQDAAO4A4QA2Ac4B7AGWAYoBrAFcAd4A5QA6AR4BzwDWAPAAmwAoABwAKQDy/8D/1v/R/3v/Nv8a/8L+NP7w/Qb+Bv7M/bz9zP2Y/Sz99Pz8/ND8gPxg/Hj8ePxc/HD8vPzo/PD8FP1M/XD9bP1g/Vz9MP3s/Mj8vPyg/JD8lPyU/HT8aPyg/Nz82PzQ/Cj9oP3g/Sj+5P63/xAAOwDsAOgBaAKMAhADzAMIBPADYARABbAFoAX4BbAG+AbIBrAGsAY4BogFMAU4BRgF0ATABKgEWAT8A8ADgAP0AnACMAL+AbABkgGwAaABVAEgARwBDgHmAMIAmgBUABIA6v+p/1H/Ef/c/nb+EP4G/hz+0P1U/TD9LP28/Dj8LPxU/AT8oPvQ+xz8+Puw++j7IPzQ+5D76Psg/Nj72Ptc/JD8PPxk/CD9YP0U/Wj9WP6u/l7+rv6L/6H/Dv87/xsAPwDA/97/jgCQAOz/5/93AIAABAAQAK8A6wC8AN0AUAFmASoBNAGIAbABvAH8AUQCVAJUAngCnAKkAqwCyALIArQCsAK0ApwCdAJQAhwCzAGMAWgBFgGKABMAzP90/wb/zv7Y/rL+OP70/SL+VP4q/gj+Sv6k/qb+ov4T/6L/tf+P/97/cQCUAGQAjgDxAOgAlwC5ACwBOgH8ABgBZgFaATQBbgGoAXYBUAGOAaIBPAEMAUgBJgGIAGMAzgC5ABgADgCRAGwAo/96//T/0P8g/yz/4f/p/1b/Xv/b/5P/tv6G/uL+sP4g/jj+qP58/vD99P0+/uz9WP1U/aD9bP0E/RT9YP08/fT8JP2Q/aj9mP3c/TL+OP4q/mL+sv7g/jL/xv9WAL8ALgGeAdAB5gEUAjACHAIYAlwCfAJYAkwCgAKEAkQCRAKMApQCRAI8AoQCjAJQAlgCrALMArgC+AJwA6ADpAPYAxAEAATMA8wD3AOkA1wDUANIAwADsAKQAmQC/AGUAWABMgHZAIIASwAPAK3/Q//2/qz+Sv7s/aj9cP0o/dj8lPxY/AD8kPtA+xD76PrI+tD68Pr4+uj6+PoY+yD7+Prg+uD60PrQ+gj7aPuw++j7QPys/Oj8DP1Q/aj92P0W/p7+Q//A/yQAnAAQAVgBigHOASQCfALEAvQCGANQA2gDPAP0AuwC9ALMAqACvALcAogCGAIQAjgCFALWAQwCdAKMAoACwAIMA+gCiAJ8ApwCdAIoAhgCGALKAV4BLgEGAbIAXwA4AAMAmf81//r+pv4o/sz9uP2I/Tj9HP00/ST93Py8/MT8tPyA/Iz8yPzk/Nj8+Pw4/VT9VP2I/eT9LP5c/qz+Gf9i/4n/yf8mAG0AjwC4APoANAFeAYIBsgHiAQgCOAJ0ArAC4AL8AhgDOANgA4gDqAPEA9QD3APYA8gDuAOYA2gDKAPcAoQCOAL6AbIBVAEEAcoAmABdACcA+v/A/3j/Nv8T//z+2P62/pr+iv6E/oT+fv6A/o7+lP6K/ob+kP6M/mb+Pv42/iz+GP4c/kL+VP48/h7+Ev7s/aj9gP18/XT9ZP2I/cj97P3w/RD+SP5m/nb+qP7+/kL/bP+p//v/MwA/AEcAagCUAJsAlgC2AO8ABgHzAPgAKgFAASIBIgFgAXwBUAE8AXYBnAFuAVIBkAHKAbABmgHOAfQBwgGWAcIB/gHiAdABBAIwAhAC+AEkAkACFAL4ASACNAIQAvIB9AHcAZoBagFiAUQB/QDGAKoAdwAuAPD/v/94/x//5P7A/or+Pv4E/uT9tP10/VT9YP1Y/TD9GP0w/Uj9KP0E/RT9KP0E/eD8FP1o/Xz9XP1s/ZT9dP00/Tz9ZP1U/Sz9SP2E/Yj9cP2A/ZD9gP2A/cT9Cv4k/kr+pv78/iv/d/8DAH4AvAAOAZoBCAIkAkACmALcAuAC7AJQA6wDrAOQA6wDzAOkA2QDXANoA0QDDAMAAwgD9ALEArQCuAKwApwCiAJ8AnQCXAI0AggC8AHiAcIBmgGYAaIBgAFEASwBKgH3AJgAXABCAAYAsP9//2z/NP/W/pT+bP4m/sD9dP1M/Sj9BP34/Pz8+Pzk/Nz83PzQ/Mj81Pzs/Aj9MP10/bT91P3s/Sb+YP5+/pb+1v4e/z7/Tf+E/8//9P/6/x8AWgB9AIYAnAC8AMUAtQCrALsAywDYAOIA/AAaATQBQAFIAVYBYAFgAWYBdgGOAZwBoAGeAaABsgG+AbwBuAG2AawBkgGAAXwBcAFQATIBJAEQAecAxACzAJ0AawBDADkANwAdAAAA+P/r/8H/m/+X/5f/fP9d/1//af9Y/z//PP82/xL/7v7q/vD+4v7Q/s7+xv6q/pL+jv6K/nj+bv54/n7+fP6K/qj+sv60/sL+4P7y/vz+Hf9B/07/TP9g/3T/d/93/43/nv+k/7r/6//+//b/CAAvACsAIABcALQAwgCwAPQAOgEwAQQBOgGSAXgBVgGqARQC/gHAAeABFALsAaoBzAEQAu4BqAGyAdABogFSAUIBTAEeAd8AzADDAI4ATQApAAoA2P+o/5H/f/9X/zL/JP8K/9b+qv6c/o7+YP4w/hL+9P3A/Yz9dP1o/Uz9JP0M/QT9+Pzk/Nz86Pz4/Aj9HP04/Vj9eP2g/cT98P00/oD+0v4d/2f/qf/d/xsAaQCtAOIAIgFkAYwBngG6AdwB5AHoARQCXAKQAsgCFANMA0QDJAMwA0ADPANEA3ADkAOUA5wDsAOoA3gDTAM0AxwDCAMAA/ACvAJ4AkACBAK+AYwBdAFcAS4BAgHQAH8ACwCc/zr/1v5+/k7+Qv42/hz+BP7w/bj9bP0s/ej8mPxE/Az86PvQ+7j7wPvQ+8j7uPuo+2j7APuI+kD68PmY+XD5mPnI+cj52PlY+uD6CPs4+/D70Pww/Xz9gP7L/38AxACeAdACSANIA+gDCAVoBTgFcAU4BmAG8AX4BXAGaAbQBdAFUAZQBsgFmAXIBYAFAAUABWAFOAXABMAE8ASYBBgECAQABJgDMANIA3QDJAOwAogCUALCAUABIAEEAZIAHgDe/5T/Bv9u/gj+pP0g/az8cPxI/AT8sPtw+zj7+PrI+sD60Prg+uj68PoI+xj7GPso+0j7aPuA+7j78PsQ/CT8SPxo/HD8gPzE/Az9MP1M/Zj94P34/Q7+aP7E/tr+AP9+////JQBHALwANgFgAYYB+gF0AqACxAIsA4QDjAOQA8wD+APsA+wDEAQQBOQD3APwA8wDjAN8A4ADRAP4AuwC7AKkAlACRAJIAgACrAGgAZ4BWAEMAQgBCAHGAIYAfgBuACUA3//K/6n/Yf8r/xv/+v62/ob+cv5K/gT+2P3M/bD9hP10/Xz9bP1E/TT9RP08/ST9IP04/Uj9RP1Q/YD9oP2s/bz96P0Q/iL+Ov5k/or+nv60/uL+Ef8v/0z/cf+V/6//yf/r/wkAIAA3AFgAdgCcAMcA8gAQATQBZgGQAaYBvgHmAQgCEAIYAjwCXAJcAlwCfAKUAoQCaAJsAnACTAIkAiACHAL4AdABwgG0AYoBYAFOAToBCAHWAL0AowB2AE4AOwAkAPr/2P/K/7f/jf9o/1b/QP8a//j+6P7U/rD+kP6G/oD+cP5c/lj+Vv5I/jj+OP5C/kL+OP46/kT+Sv5S/mD+eP6K/pL+pv7I/uj+A/8d/zz/T/9h/3X/kv+s/8P/4P8EACIARABkAIEAlAClALIAwQDaAPUACgEQASYBNAE+AUIBTAFeAVoBWAFwAY4BlAGQAZYBmgGWAZIBlgGcAZABdgFkAVYBQAEeAQAB6QDJAKQAhwBtAFAAMAARAPL/1v+8/6b/lf9+/2T/VP9E/zD/Hf8V/xP/A//s/t7+1v7I/rL+qP6m/p7+lP6Q/pr+nv6a/pr+pP6o/qj+rv7C/s7+1P7k/vz+Df8V/yb/Rv9j/3L/hP+e/7v/1f/v/w0ALABIAF0AeACTAKkAuQDNAOIA9gAGARgBKgE4AUABRAFIAUwBVAFgAWYBYgFiAWQBYgFaAVQBTgFEATgBMAEyAS4BIgEYARABBgH6APMA6gDdAMoAuQClAIcAZwBKACsABQDg/8T/qv+I/2X/Rf8j//b+xv6i/oD+Xv48/ij+GP4I/vj99P3s/ej94P3g/eD93P3c/ez9+P38/Qr+IP4u/jj+SP5q/or+mv6w/tr+Av8X/y7/YP+S/67/xf/z/yIAOABIAHIAqADDANUAAgE8AWABcAGUAcYB4gHuAQwCPAJQAlQCZAKAAogChAKIApQCiAJwAmwCaAJUAkACMAIgAgwC+AHuAeABwgGkAYoBaAFCARwB9QDJAJYAagBDABQA3v+p/3n/R/8V/+z+yv6k/nb+TP4s/hD+7P3I/az9mP2E/XD9ZP1o/WD9TP04/Tj9OP04/UD9VP1o/XD9hP2g/bz92P30/RT+NP5a/ob+tP7e/gP/MP9e/4j/s//o/x0ARwBsAJgAyADzABoBSAF4AaIByAH0ASACQAJUAmgCgAKUAqQCrAK4ArwCwALAArwCuAK0AqwCnAKQAoQCcAJUAkACLAIQAu4BygGsAYoBYAE2ARAB5QCvAHsASwAXANr/nv9p/zP//P7M/qL+dv5I/hr+9P3Q/az9kP14/Wj9WP1M/UT9OP0s/ST9JP0k/Sj9LP04/Uj9YP10/Yz9pP28/dz9/P0e/kT+av6S/rb+3v4H/zP/X/+H/67/1f/9/yUASgBuAJUAvgDlAA4BPAFsAZgBwAHmAQwCMAJEAlgCbAJ8AoQCjAKUApgCmAKUApAClAKMAoACbAJgAkwCOAIkAhAC+gHcAb4BpAGEAV4BOAEUAewAvgCSAGwARgAcAPT/0P+p/37/V/80/xH/6v7G/qr+kP50/lr+RP4q/hD+/P3w/ej93P3U/dT90P3Q/dD92P3k/ez99P0E/hT+Jv4+/lb+bv6G/qT+wv7i/gP/J/9H/2L/fv+f/8D/3/8AACQARwBpAIwAsQDNAOMA+QASASIBMAFMAWQBbgFyAYYBlgGYAZQBoAGuAaYBoAGwAb4BtAGgAZoBlAGCAW4BZAFaAUIBIAEIAfYA3wC+AKEAiwBzAFoARAAyACAACwD1/9//zf+8/6v/l/+E/3L/Yf9P/z3/Lf8e/xH/AP/w/uD+1v7K/sD+uv64/rj+tv62/r7+xP7I/sz+1v7c/uL+7P78/gn/E/8h/zP/Rf9T/2T/fP+U/6b/tf/I/9z/8f8BABEAIQAuADkARQBTAF8AagB0AIEAjwCbAKUAsAC5AL4AwgDIAM8A1gDeAOQA5QDkAOUA5QDhANsA1QDRAMsAxgDEAMIAvQC2AK4AqQCkAJwAkgCIAH0AbwBfAE4APwAwAB8AEAADAPb/6v/d/8//wf+w/5//jv+C/3j/cv9s/2j/Zf9i/13/WP9R/0r/Qv85/zD/Kf8k/yH/Hf8Z/xb/FP8S/xD/FP8d/yX/Kv8z/0D/Tf9W/1//b/9//4j/kf+g/7L/v//I/9v/9P8IABcALABIAFwAZQBzAIkAmACdAKYAuQDDAMEAwwDNANEAzgDOANQA0wDOAM8A1gDZANcA1wDZANwA3ADcANsA1QDLAMAAtACpAJwAjgB+AHAAZQBaAE0APwAyACUAGQAPAAgA///z/+T/1//L/8D/sf+h/5P/hv97/3L/a/9l/1v/Tf9C/z7/Pf89/0D/RP9G/0b/SP9N/1L/VP9V/1j/XP9i/2r/c/96/37/hP+N/5f/ov+v/73/yP/T/+D/7////w0AGgAnADEAOABBAEkATgBOAE0ATgBRAFMAVABXAFoAXQBhAGUAawBxAHUAeAB9AIEAgwCDAIMAhACBAHsAdABvAGgAXgBVAEwAQwA3ACsAIgAYAA0AAwD8//b/8f/u/+v/5//h/9r/1P/O/8n/xP/A/73/uf+0/67/qP+h/5z/mP+Y/5r/nv+j/6r/sf+4/73/wP/E/8f/y//O/9H/1f/W/9f/2P/a/9z/3//h/+L/5f/p/+//9f/8/wQACwASABkAIQAoACwALgAtACsAJwAhABwAGAAUABIAEAAQABMAFgAaACAAKAAuADEANAA4ADwAQABCAEMAQgA/ADwAOgA4ADQALwArACcAJQAkACMAIgAgAB4AHAAZABYAFAASABAADgANAA0ADQAKAAgABAAAAPv/+v/7//z//f/9//7//f/9//v/+//5//b/8//x//H/8f/w/+7/7P/q/+n/6P/n/+f/6P/n/+T/4v/l/+f/6P/p/+z/7//w//L/9P/z/+7/6v/r/+n/5v/o/+z/6v/l/+n/7v/t/+j/7P/z/+//6//x//j/8f/l/+L/5P/h/9z/3P/h/+D/2P/Z/+L/6P/n/+j/8P/5//7/AwALABMAFQAVABcAGwAdABsAGgAZABgAFwAWABYAFgAVABQAEwATABMAFAAVABYAGAAaAB0AHwAgACEAIwAkACQAJgAmACYAJwApACsALAAtAC8AMAAuAC0ALgAuACoAIwAdABkAFQAOAAcAAgD8//X/8P/t/+v/6f/m/+X/5f/k/+L/3//d/9r/1f/R/8//zv/M/8n/xf/C/8D/vv+8/7z/vP+9/7//wf/E/8b/x//H/8f/yP/J/8r/y//L/8v/yv/J/8j/yP/I/8r/zP/Q/9X/2//i/+j/7f/y//b/+f/9/wQACwAQABYAGwAfACIAJAAkACMAIgAgAB8AHwAiACQAJwArAC4AMwA3ADsAQQBHAEsATQBPAFIAVABVAFYAWQBcAF0AXgBfAGEAYQBfAGAAYgBjAF8AXABbAFYATABCADwAMwAmABoAEwAKAP7/9P/w/+z/5f/g/93/2P/S/87/zP/J/8L/vP+4/7P/r/+q/6T/nv+X/5D/jP+J/4j/h/+H/4r/j/+U/5j/m/+e/6L/pf+p/67/sv+z/7X/uf+9/8L/xv/K/9D/2P/h/+3/+P8DAAwAEwAcACYAMAA5AEIASQBOAFMAWQBeAGIAZQBnAGkAbABvAHMAdwB6AHwAfgCBAIQAhwCIAIgAhgCCAH0AeQBzAGsAYgBYAE0AQgA3ACwAIAATAAgA/v/2/+//6P/j/97/2f/V/9H/zf/I/8L/vP+1/67/p/+g/5j/j/+H/3//ef9z/27/af9n/2X/Zv9m/2f/av9t/3L/d/9+/4X/jf+V/53/pP+q/6//tP+5/77/xP/L/9P/2//k/+7/9/8BAAwAGAAkADEAPgBKAFUAXwBoAG4AcwB3AHkAewB8AHwAewB7AHoAegB7AHwAfgB/AH8AgQCDAIMAggCBAH4AegB0AG0AZgBeAFQASgA/ADQAKQAeABUADQAHAAIA/v/8//r/+v/5//n/9//0/+//6f/j/93/1//R/8r/wv+7/7b/sf+t/6j/ov+d/5n/l/+W/5X/lf+V/5b/mP+Z/5v/nf+g/6T/qP+u/7T/uv+//8X/yf/N/9H/1v/c/+H/5v/q/+//9P/4//z/AgAHAAsADwAUABoAIAAlACoALwA0ADgAPQBCAEYASgBMAE0ATgBQAFMAVABUAFUAVgBXAFcAVgBUAFAATABLAEkARQBFAEQAPwA6ADgANgAvACcAIQAdABQACgAGAAIA+P/t/+f/5P/g/9v/2f/a/9n/1f/U/9f/2f/W/9P/0//T/9D/zP/K/8j/xP+//7v/uf+3/7P/r/+u/63/rf+t/67/sP+x/7T/tv+4/7v/vv/C/8b/y//Q/9X/2//g/+b/7f/z//n///8FAAoAEAAWABsAHgAjACcAKQAqACsALQAvAC4ALAArACwALgAvADAAMQAzADYAOAA7AD4AQQBDAEUARwBHAEYARQBDAEEAPQA6ADcANgA0ADEALQAqACcAJAAhAB0AGgAWABIADgALAAcAAgD8//b/8P/r/+X/4P/b/9f/0//O/8r/xv/C/77/u/+4/7X/tP+z/7L/sP+u/6z/qv+q/6r/q/+s/63/rv+w/7L/s/+0/7T/tf+1/7f/uf+9/8L/x//N/9P/2f/g/+j/8f/6/wIACgASABwAJQAuADcAQQBLAFMAWwBhAGgAbABuAHAAcwB0AHIAcABvAG0AaQBmAGUAZABhAGAAYABhAGAAYABhAGIAYABeAFsAVgBQAEkAQQA4AC4AJAAaABEACQABAPn/8v/s/+b/4f/e/9v/2P/U/9H/zv/K/8X/v/+4/7H/qf+i/5z/lf+P/4r/h/+G/4b/hf+G/4j/jP+R/5b/m/+f/6P/pf+o/6v/r/+y/7X/t/+6/73/wv/I/83/0//a/+H/6v/0//3/BwARABsAJQAuADgAQABHAE4AUgBWAFgAWwBcAFwAXABbAFkAWABXAFYAVABTAFIAUQBSAFMAUwBUAFUAVQBVAFUAUwBRAE0ASQBEAD4AOAAxACoAIgAaABMACwADAPz/9f/u/+n/5P/f/9r/1v/T/8//zP/J/8b/xP/B/7//vP+4/7T/r/+r/6f/pP+i/6H/oP+g/6L/o/+m/6j/rP+x/7X/uv+//8X/yf/O/9L/1v/Z/9z/4P/k/+f/7P/w//X/+/8CAAkADwAWAB0AIwApAC8ANAA4ADwAPgA/AEAAQABBAEEAQAA/AD8APgA+AD8AQQBCAEQARgBIAEoATABOAE8AUABOAEwASQBGAEMAQQA9ADkANQAxAC0AKQAlAB8AGAARAAoAAgD7//P/7P/l/9//2f/U/87/yf/G/8P/wf/B/8H/wf/C/8L/wv/D/8P/w//E/8X/xf/F/8X/xf/F/8X/xv/H/8f/yP/K/8z/z//S/9X/2f/d/+L/5//s//L/+P/+/wIABwAMABEAFQAYABoAHQAgACEAIgAjACIAIQAiACMAIwAlACcAKAAoACoAKwArACkAKQAoACUAIgAhAB8AGwAWABMAEgAQAA4ADAAMAAwACgAKAAsADQALAAkACQAJAAgABgAEAAMAAgD///z/+v/4//X/8f/u/+z/6f/m/+P/4f/f/9z/2f/X/9T/0//S/9H/0f/R/9L/0//V/9f/2v/e/+H/5P/n/+r/7f/x//P/9f/3//n/+f/5//j/+P/4//b/9P/y//L/8//0//X/9v/4//v//v8CAAYACQAMABAAFAAWABgAGQAbABwAHAAcAB0AHgAgACEAIQAhACMAJAAlACUAJQAmACcAJwAoACgAKAAnACYAJQAkACMAIgAhACAAHwAdABsAGQAXABQAEQANAAoABwAEAAEA/v/6//X/8f/t/+r/5v/i/9//2//Y/9X/0v/P/8v/yP/E/8L/wP+//77/vv++/73/vf+9/77/v//A/8H/wf/D/8X/yP/M/9H/1//e/+X/7P/z//v/AQAHAAwAEQAWABgAGgAcABwAHAAcAB0AHgAeAB8AIgAmACkALQAzADkAQABFAEsATwBSAFUAVwBYAFgAVgBTAFEATwBMAEgARABAADwAOQA3ADUAMgAwAC8ALQArACkAJgAiAB4AGQAUAA8ACAACAPv/9v/w/+r/5P/e/9j/0//P/8z/yP/E/8D/vP+4/7b/tP+y/7D/rv+t/6v/q/+q/6r/qf+p/6n/qv+r/63/r/+y/7X/uv+//8X/y//S/9j/3v/k/+r/8P/2//v///8CAAUABwAJAAsADAANAA8AEAATABYAGQAdACIAKAAuADQAOgBAAEYASwBQAFUAWABaAFwAXQBdAFsAWABUAFAASwBFAEAAOgA1ADAAKwAmACIAHgAaABgAFQATABAADQAJAAUAAAD6//T/7v/o/+L/3f/X/9L/zP/I/8T/wP++/7v/uv+4/7j/t/+3/7b/tf+0/7T/s/+z/7P/sv+z/7T/tv+4/7v/v//C/8f/y//Q/9X/2//g/+T/6f/s//D/8//2//r//f///wIABQAIAAwAEAAUABgAHAAhACYAKwAwADUAOgA+AEEARABHAEoATgBRAFQAVgBYAFoAXABdAF0AXABZAFYAUQBNAEcAQQA8ADYAMAAqACMAHQAXABIADQAJAAYAAwAAAP3/+//4//X/8v/w/+7/7P/p/+b/4//g/93/2v/X/9T/0P/N/8v/yP/G/8T/w//C/8L/wv/E/8X/yP/L/83/0P/U/9j/2//e/+H/5P/n/+r/7P/t/+7/7//x//L/9P/2//n//P/+/wEABQAHAAkACwAOAA8AEQATABUAFgAVABYAGAAaABsAHAAdAB4AHgAfACEAIwAjACMAIwAkACQAIwAjACMAIwAjACIAIQAhACAAHwAdABwAGwAZABgAFgAUABEADgAKAAYAAgD+//r/9v/x/+7/6v/n/+T/4v/h/+H/4P/g/+D/4v/k/+X/5v/o/+n/6v/p/+j/6P/n/+T/4f/d/9r/2P/W/9T/0v/R/9D/0P/R/9L/0//V/9f/2v/c/97/4f/k/+b/6f/r/+7/8v/1//j/+v/9/wAABAAGAAkACwAOABAAEwAWABkAHAAeACAAIwAlACcAKAArAC0ALwAxADIAMwA0ADQANAA0ADMAMwAzADIAMQAvACwAKQAmACQAIQAdABkAFgASAA4ACgAGAAIA/f/5//X/8v/w/+3/6//p/+b/4//g/93/2v/X/9P/z//L/8f/w//B/7//vv+//8D/wf/E/8f/y//O/9L/1v/a/97/4f/k/+b/5//o/+n/6f/p/+n/6v/q/+v/7P/u//H/9f/5//3/AgAHAAwAEgAXABwAIAAlACkALgAyADUANwA5ADsAPAA9AD8APwA/AD8APwA/AD8APgA9ADwAOwA6ADgANgA0ADIAMQAwAC4AKwAoACQAIQAfABwAGAAUABAACwAGAAMAAAD8//n/9v/z//H/7//t/+v/6P/m/+P/4P/e/9v/2P/V/9L/0P/O/8z/y//L/8v/zP/M/87/0P/S/9X/2P/a/93/3//h/+P/5P/l/+X/5f/l/+T/5P/k/+T/5P/l/+f/6f/r/+7/8v/2//v/AAAGAAwAEgAXABwAIAAjACYAKAAoACkAKAAnACUAIwAgAB0AGgAXABQAEgARABAADwANAAwACwAKAAkACAAIAAgACAAIAAcABwAGAAYABQAEAAMAAQAAAP7//f/7//n/9//1//P/8f/v/+3/6//q/+j/6P/o/+j/6P/o/+n/6f/p/+r/6//s/+3/7f/t/+3/7v/v//D/8f/x//L/8//0//b/9//5//r/+//8//3//f/+//7////+//3//P/8//3//v8AAAIABAAGAAoADwATABcAGgAcAB0AHgAeAB0AHAAbABkAFwAUABAADAAIAAUAAQD///3/+//6//n/+f/5//n/+v/7//3///8AAAIABAAFAAcACAAJAAoACgAKAAoACQAIAAcABgAFAAMAAgABAAEAAQAAAAAA//8AAAAAAQABAAIAAwAEAAUABgAGAAYABgAHAAcABwAIAAgACQAJAAkACQAIAAcABgAFAAMAAQAAAP///f/6//n/+P/4//j/9//4//j/9//3//j/+f/5//j/9//3//f/9f/0//T/8//z//L/8v/y//P/8//0//b/+f/7//3/AAADAAUABwAIAAkACgAKAAkACAAHAAUAAwAAAP7//P/6//n/+P/2//b/9//4//r//P///wIABQAHAAoADQAQABEAEQAQABAAEQARAA8ADgAMAAsACQAHAAUAAwABAAAA///9//z/+//6//r/+f/5//n/+//8//3//v///wEAAgADAAQABAAFAAUABQAFAAUABAADAAIAAQAAAP7//f/8//z//P/7//v/+//6//r/+f/5//j/+P/5//n/+f/5//j/9v/2//X/9P/y//D/7//t/+z/6v/p/+f/5f/k/+P/4//k/+b/5//q/+z/7v/w//L/9f/3//j/+P/4//f/9v/1//T/9P/0//T/9P/1//f/+P/6//3/AQAFAAgADAAQABQAFwAaAB0AIQAiACMAJAAlACQAIwAjACIAIQAgAB8AHQAbABoAGQAXABYAFAASABIAEQARABEAEAAPAA4ADQANAAwACwAJAAgABgAFAAMAAQD+//z/+v/4//b/9P/y//H/8P/x//H/8f/w//D/8f/x//L/8v/x/+//7f/r/+n/5//l/+P/4f/f/97/3f/d/97/3//g/+H/4//m/+n/6//u//H/9P/3//v//v8BAAQABwAKAAwADgARABQAFgAYABkAGwAcAB0AHgAeAB4AHQAcABsAGQAXABUAEwASABAADwANAAwADAAMAAwADQAOABAAEwAVABcAGQAaABsAGwAaABkAFwAUABAADAAHAAEA+//1/+//6v/l/+H/3v/b/9n/1//W/9b/1//Z/9v/3v/h/+X/6P/r/+3/8P/x//P/8//z//L/8P/u/+v/6P/l/+H/3v/b/9j/1v/V/9X/1v/Y/9z/4P/l/+r/8f/3////BgANABQAGQAeACIAJQAnACgAKQAoACYAJAAhAB8AHAAYABUAEgAOAAwACQAIAAYABgAFAAQAAwADAAQABgAJAAwADgASABYAGwAgACUAKAAqACsAKwAqACgAJQAiAB0AGAASAAsAAwD8//X/7v/o/+P/3//c/9n/2P/Y/9j/2v/c/9//4//n/+v/7//z//b/+v/9//7///8AAAEAAAD///3/+//5//b/9P/y//H/8f/x//H/8f/z//X/+P/6//3/AQAFAAkADAAOAA8AEAARABIAEQARABAADwAOAA0ADAAKAAgABwAGAAUABAAEAAQABAACAAIABAAFAAYABwAIAAkACQAIAAoACwAKAAkACAAHAAYAAwABAAAA/v/8//v/+f/5//j/9//3//j/+v/7//3///8CAAQABgAIAAkACgAKAAoACQAIAAYAAwD///v/+P/0//H/7f/p/+b/5f/k/+P/4//k/+f/6f/r/+3/8f/1//j/+P/5//v//f////////////7//v/9//z/+//7//v/+v/6//n/+f/6//v/+//7//3///8BAAIABAAGAAgACgALAA0ADgAOAA8ADwARABEAEgASABEAEQARABAADwAPAA8ADwAPAA8ADgANAAwACwAJAAgABgAFAAQAAwACAAAA/v/8//v/+v/5//j/9v/2//X/9P/y//D/7v/s/+r/6P/n/+X/5f/k/+P/4//i/+L/4//k/+T/5P/k/+T/5P/l/+b/5//p/+z/7//y//X/+f/9/wAABQAKAA0AEAATABUAFgAWABYAFgAVABIAEQAPAAsACAAHAAYABgAGAAYACAAKAAwAEAAUABgAGwAfACMAJgApACsALAArACoAJwAlACEAHAAXABIADQAHAAIA/f/5//X/8//x//D/7//w//H/9f/5//3/AQAFAAkADQARABQAFwAXABYAEwAPAAoABAD+//f/7//n/+D/2f/S/83/yP/F/8P/wv/D/8X/yP/M/9H/1v/d/+T/7P/z//v/AgAIAA0AEgAWABoAHAAdAB0AHAAbABgAFQARAA0ACAADAP7/+f/0//H/7f/r/+r/6v/q/+z/7//y//f//P8CAAkAEAAXAB0AIwAnACsALQAtAC0AKwAoACQAHwAZABIACwAEAP3/9//z/+//7P/q/+n/6f/p/+v/7f/v//L/9v/5//v//v8AAAEAAgACAAEAAAD///3/+v/4//b/8//x/+//7v/t/+z/7P/t/+7/8P/y//X/+P/6//3///8BAAMABAAFAAUABAACAAAA/v/7//n/9v/0//H/7//u/+7/7//w//P/9v/5//7/AgAHAAwAEQAVABgAGgAbABwAHQAcABsAGQAWABQAEgAQAA4ADAAJAAYAAwABAP7//P/7//v/+//7//v/+//8//3///8BAAQABgAJAAsADgAPABAAEQARABEAEAAOAAsACAAEAAEA/f/6//b/8v/v/+3/7P/r/+v/7P/u//H/9P/5//7/BAAKAA8AFAAZAB0AIAAhACAAIAAeABoAFgAPAAcA///3/+//5v/f/9r/1f/R/8//z//R/9P/1//d/+P/6f/y//r/AQAGAAsAEQAVABcAGAAYABYAEgAOAAoABwAAAPr/9P/w/+z/5//k/+P/4v/j/+T/6P/s//H/9v/8/wIACQAPABUAGgAfACMAJQAlACQAIwAgABwAFwASAAwABgAAAPr/9f/x/+3/6v/o/+f/6P/q/+z/7//0//r///8DAAgADgATABYAFgAWABcAFwAVABIADwALAAgABAAAAPz/+f/2//T/8v/x/+//7//v//D/8P/x//L/9P/2//f/+P/5//r/+//8//z//P/8//z//P/9//7//////wAAAAABAAEAAgACAAMAAwADAAIAAQD///3/+v/3//T/8v/v/+3/7P/q/+n/6f/p/+v/7f/w//P/9//7/wAABAAHAAoADAANAA0ADAALAAkABwAEAAEA/v/6//f/9f/1//T/8//z//T/9v/5//3/AgAIAA8AFgAcACMAKgAuADMANwA5ADkANgA0ADAAKAAfABgAEAAFAPr/8v/q/+H/2f/W/9T/0//V/9n/3v/k/+z/9v8AAAkAEQAYACAAJgApACsAKwAoACQAHQAWAAwAAgD3/+z/4v/Y/9D/yf/E/8H/wP/B/8X/y//S/9r/5f/x//3/CAASABsAIwAqAC8AMgAyADAAKwAkABwAFAAKAAEA+P/u/+X/3v/Z/9X/0//T/9T/1//b/+D/5v/t//T//P8DAAsAEgAZACAAJQAqAC0AMAAyADMAMgAxAC4AKwAmACEAGwAUAA0ABgD///j/8f/r/+b/4v/g/9//3//g/+L/5P/o/+z/8P/1//n//f8BAAMABQAFAAQAAwAAAP3/+v/2//L/7v/r/+j/5v/k/+T/5v/p/+z/8f/2//v///8EAAgACwANAA8ADwAPAAwACQAFAP//+v/0/+7/6P/j/9//3P/a/9r/2//d/+L/6P/w//j/AgAMABYAHwApADEANwA8AD4APwA9ADkANAAsACQAGQAOAAMA+P/v/+b/4P/b/9j/1//Y/9z/4f/o//D/+f8DAAwAFQAdACUALAAvADAALwAtACkAJAAdABUADAADAPv/9P/u/+j/4v/e/9z/2v/Z/9r/3P/g/+X/6//y//n/AAAIABAAFwAeACQAKAArACwAKwAnACIAGgARAAcA/P/v/+L/1f/J/77/tv+w/6v/qf+s/7L/uv/F/9L/4v/0/wYAGAArAD0ATgBcAGYAbQByAHMAbwBnAFsATgA+ACsAFwABAOv/1v/D/7L/o/+Z/5T/kf+Q/5b/oP+t/7r/y//e//D/AgAWACgANQA/AEgATgBRAE8ASwBEADsALgAfABMABwD4/+n/3v/V/83/xv/C/8L/xP/I/87/1v/g/+r/9f8BAAwAFgAfACcALQAyADQAMwAxAC0AJwAhABkAEQAIAAEA+f/x/+v/6P/l/+P/4v/i/+T/5//q/+3/7//z//f/+v/6//r//P/9//z/+f/1//T/9P/0//P/8//2//n//f8BAAYACwARABcAHAAfACEAIgAjACEAHAAWAA8ACQABAPj/7//m/9//2f/T/8//zf/N/8//0v/Z/+D/6f/y//z/BwARABoAIQApAC4AMgAzADMAMQAtACcAIAAXAA8ABgD+//f/8f/r/+b/4//i/+L/5P/n/+r/7//0//n//f8BAAMABAAEAAIA///7//f/8v/t/+f/4v/d/9n/2P/Y/9r/3P/g/+b/7//4/wMADwAdACsANwBCAEwAVABYAFoAWgBXAE8ARAA4ACoAGAAEAPT/5P/S/8P/uv+z/63/rP+x/7r/xv/V/+f/+v8MACAANABGAFQAXQBkAGcAZgBfAFUARgA0AB8ACQDy/9v/xf+x/6D/k/+J/4T/g/+G/47/mv+q/73/0f/m//z/EwAqAD8ATwBdAGcAbgBwAG8AagBhAFQAQgAvABoABADu/9n/xf+y/6H/lP+K/4T/gf+C/4b/jf+Z/6b/tv/I/9v/7/8EABgALABAAFIAYgBuAHcAfgCDAIQAgQB6AHEAZABVAEMALwAYAAEA6//V/7//q/+a/4z/g/99/3v/ff+E/5D/n/+x/8f/3v/3/xEAKgBCAFgAagB5AIQAigCKAIgAgABzAGQAUQA8ACUADgD2/+D/zP+6/6z/oP+X/5H/jv+O/5D/lf+c/6b/sf+8/8j/1P/g/+z/9/8CAAwAFQAeACYALQAzADgAPAA/AEIARABEAEMAQgA/ADoANAAuACcAHwAVAAkA/v/y/+b/2v/P/8X/vP+1/7D/rf+t/7D/t//A/8r/1//m//f/CAAaACwAPQBNAFkAZABrAG8AcABtAGQAWABJADoAKQAWAAMA8P/e/8//w/+7/7X/sf+x/7X/vP/E/9D/3f/s//z/CwAaACcAMgA7AEIARQBFAEMAPQA1ACoAHAANAPz/6v/Z/8r/vf+x/6f/oP+e/6D/pv+u/7n/x//Y/+v//v8QACIAMwBCAEwAUgBVAFUAUgBJADsAKQAYAAUA8P/a/8X/tP+l/5r/k/+P/4//lf+i/7D/wv/Z//X/EAApAEQAXwB2AIcAlgChAKQAoQCdAJMAgABnAE0AMQATAPP/0/+3/5v/gP9p/1z/VP9N/0v/Uv9e/27/gf+Z/7T/0f/v/w4AKwBHAF8AdgCIAJUAmwCeAJ0AlgCLAHoAZABMADMAGQD9/+L/yv+1/6T/lP+H/4H/gf+G/43/lv+j/7T/yf/d//D/AgAWACkAOQBDAEoAUQBXAFgAUQBHAD8AOAAvACIAFQAJAAAA+f/z/+v/5f/k/+b/6v/r/+z/8f/4////AwAHAAoAEAAWABgAFgATABAADgAJAAEA9v/r/+L/2P/N/8H/tv+t/6f/ov+f/53/oP+n/7L/vv/L/9z/8P8HAB0AMgBGAFsAbgB/AIwAlACYAJkAlACKAHwAagBWAD4AIwAGAOn/zf+y/5n/gf9u/1//Vf9R/1P/Wv9m/3j/jv+n/8P/4f8DACMAQABZAHEAhgCWAJ4AowCjAJ0AkAB/AGsAUQA0ABgA/P/g/8P/qv+Y/4r/ff93/3z/hf+Q/6L/vf/b//b/EwAzAFIAbQCEAJYAngCfAJsAkwCBAGYARQAkAAIA3f+3/5T/d/9g/03/Qv9A/0f/WP9v/47/sv/c/wsAOwBpAJIAuQDeAPsADAEQAQ4BBAHyANYArgB/AEsAFwDh/6n/cv9A/xb/8v7Q/rr+rv6u/rr+zv7m/gP/K/9a/43/vv/s/xoASAByAJcAsgDGANYA4QDmAOEA1wDKAL4ArQCVAHkAXgBHADIAGgD//+T/zf+6/6n/lf+A/3D/Zv9e/1b/Tv9M/1L/Xv9r/3r/jP+n/8j/6/8OADAAVQB9AKQAxwDjAPsADgEcASABHAEMAfsA4QC/AJMAYwAwAPv/xv+P/1n/KP8B/+D+xv6y/qj+qv64/s7+6v4Q/0D/d/+w/+r/JABfAJgAywD3ABoBMgFCAUgBQgEyARQB8ADEAJMAWwAgAOX/rP92/0P/F//w/tj+xv68/r7+xv7a/vj+HP9G/3T/pf/Y/wwAPQBrAJcAvQDbAPMAAgEIAQgBAAHwANoAvQCdAHkAVAAuAAoA6v/N/7L/mv+L/4T/hP+K/5b/pf+5/9P/7/8NACgAQQBYAGoAdgB8AHwAeQBvAF8ASwA0ABsAAADl/8v/tP+f/47/gv95/3f/ef+A/4r/l/+p/8D/2P/u/wIAFgAqAD0ATQBWAFsAXABbAFcATQA9ACsAGgAHAPH/2f/D/7T/qP+b/5D/iP+J/5H/nP+n/7T/x//g//v/FAApAD0AUgBmAHQAegB+AIEAfQBzAGQAUgA8ACMACgDy/9T/t/+i/5X/hf92/27/bf90/4D/kf+n/77/0//v/xMANABLAGAAeACOAJoAnQCcAJgAkQCDAG4AUwA1ABkA///i/8D/n/+G/3P/Zf9X/0z/Sf9P/1r/af95/47/q//P//L/DgAoAEgAbACMAJ4AqACxALsAwAC5AKgAkwCBAHAAVgAxAAwA8f/e/8j/qf+L/3z/e/9+/3v/eP9//5H/qv/A/8//3//2/xQALAA3AD0ARgBUAFsAVABHADoANAAvACEACQDz/+X/3//Z/83/wf+8/8L/zP/T/9n/4v/z/wcAGQAmADAAPQBOAFoAXgBaAFUAVABPAEMALwAZAAUA8//g/8j/sP+c/4z/gP90/2n/Zv9q/3P/fP+H/5f/rf/H/+H/+v8SACsARQBfAHUAhwCUAJ4ApACiAJoAjgB/AGwAUAAvAA4A7f/L/6r/i/9w/1j/RP83/zL/M/84/0P/Wf90/5L/tv/f/wgAMQBcAIgArgDMAOcAAgEWARgBEAEGAfcA4QC/AJYAZQAyAAQA1v+n/3X/Sv8u/xv/DP8B/wT/GP82/1b/e/+o/+D/HQBYAIsAugDpABQBOAFGAUYBQAE2ASIB+QDAAIIARgAKAMn/fv8z//b+xv6e/nr+Wv5Q/lr+cP6I/qb+1P4S/13/pP/h/xsAWwCfANwABAEcASoBOgFAATgBHgH6ANoAuwCWAGUAMgALAPH/2f+6/5n/gv9//4T/hv9//3n/f/+Q/6D/pP+h/6b/tf/F/8r/x//I/9b/6f/1//f/+/8KACIAOQBGAE4AXAB0AI0AngClAKsAtgDCAMUAugCqAJ8AkwB9AFwANAANAOr/xf+Z/2j/O/8Z//7+5v7M/rj+tP6+/s7+4v78/iX/XP+V/8z/AgA9AHsAtwDpABABKgFCAVIBVgFKAS4BDAHmALoAgwBEAAUAy/+T/1z/KP/8/t7+yv6+/rj+uv7M/ur+Ef89/2r/nf/V/w8ARwB4AKcA0gD1ABABHgEiASABGAEGAeoAxwCfAHYATAAgAPf/0v+z/5j/gv90/3D/dv+D/5X/qf/A/9z//P8aADIARQBVAGAAZABiAFkATAA6ACUADADx/9X/u/+k/4//ff9u/2X/Y/9m/23/ef+I/5r/sP/L/+r/CAAkAD4AWAByAIwAoQCvALoAwgDHAMkAxAC4AKsAngCLAHEAUgAzABgA/P/a/7T/kP9z/1v/Rf8r/xX/Bv8C/wP/B/8L/xf/Lv9O/23/jf+z/+H/EAA8AGYAjQCzANQA8gAGAQ4BDAEOAQoB+ADYALMAjgBpAEMAGADr/73/kf9w/1f/P/8k/xH/Df8R/xb/Hf8s/0X/Zf+I/6j/yv/v/xoARgBrAIYAnAC1AM8A3gDgANgAzgDCALEAlwBzAFAAMgAYAPj/0v+t/5f/jP+C/3L/Y/9h/27/gP+O/5f/pv/C/+T//v8LABgALwBLAFwAWQBQAE8AVQBWAEYAKgATAAcA/v/u/9P/uf+u/7D/r/+m/5z/of+z/8f/0v/Z/+j/BQAmADwARQBNAF4AdQCGAIUAfAB3AHcAdgBoAFAANwAkABQA/v/g/8L/rP+f/5T/gv9v/2b/af9y/3j/e/+E/5f/sv/N/+L/9v8OACkAQQBRAFsAZABsAHAAagBbAEoAOgApABMA+f/e/8f/tv+q/57/lv+U/5j/of+s/7n/yf/e//T/BwAWACUANQBCAEsAUgBUAFQAUABLAEQAOAArAB8AFgAMAAIA+v/2//X/9P/3////BwANABcAJgAzADcAOQA+AEMARQA/ADMAIwATAAQA9P/g/8b/sP+i/5j/jf+A/3v/gf+M/5X/n/+w/8v/6v8HACAAOABWAHYAkgCjAKoAsQC8AMEAtgCdAIIAawBTADIABADS/6f/hf9l/0L/Hv8H/wH/A/8D/wr/G/8//3D/nf/D/+n/GABOAH8AoACyAL8AzgDYANUAvwCiAIkAcwBZADQADQDx/+H/1f/D/6//pf+u/7//zf/Q/9X/5v///xUAHQAbAB4AKAAxACwAGgAIAAAA/P/w/9r/w/+4/7j/uP+y/6v/r//B/9r/7v/+/xEALQBOAGoAegCFAJMAoQCmAJwAiQBzAF0AQwAdAPD/xP+f/3//Xv86/xr/B/8C/wP/CP8S/yn/Tv92/5//xf/v/x4ATAB0AJIAqAC9AM4A2QDZAM4AwgC2AKgAlAB6AF4ARwAxABgA/f/j/87/u/+o/5P/ff9r/1//V/9P/0X/Qf9D/03/Wf9p/37/mf+6/93/AAAkAEkAcACUALQAzADeAOsA8wDyAOoA3QDIAKwAjABpAEYAIwABAOL/wv+m/47/fv9y/2n/Y/9i/2X/bP94/4j/m/+v/8X/3f/1/wsAHgAvAD8ASwBTAFgAVwBUAE8ARwA7ACsAGQAMAAIA9v/n/9f/y//H/8b/xv/D/8L/yP/T/9//5//t//n/CgAaACQAKQAxAD4ASgBOAEoARABDAEQAQQAzACEAFAANAAYA+P/k/9P/yv/J/8X/vf+6/7//yf/T/9z/4//s//j/BwASABQAFAAcACYAJwAeABIACwAKAAsABgD7/+7/5f/k/+f/5P/Y/9D/0//Y/9f/0P/L/8//2f/i/+X/6P/w/wIAFgAjACcALQA8AFAAXABcAFcAVABXAFUASQA1ACMAGgATAAIA5//M/77/u/+0/6P/kP+J/5L/n/+k/6T/rv/H/+f//f8JABYAMQBSAGkAbABpAHEAgwCOAIQAbwBdAFUATgA6ABcA9f/h/9f/xv+p/4v/fP97/3v/cv9m/2b/d/+M/5r/nv+m/7v/2v/0/wIACgAbADUATgBbAF4AYgBtAHoAfwB4AG0AZwBnAGMAUwA9ACsAIQAYAAcA8P/c/9H/zf/I/77/s/+x/7X/vP/B/8P/yv/X/+T/7P/v//H/9//9/wAA/f/4//b/+P/8//z/+v/5//r//P/5//X/8f/x//H/7v/q/+j/6v/v//b//v8HABEAGwAlAC4ANAA5AD4AQwBEAD8ANwAvACYAGQAMAAAA9P/n/9//2//X/9H/z//U/9//6//1//3/BwATACEALAAzADUANwA6ADoAMgAkABcADAAAAPD/3f/O/8b/wv+9/7f/t//A/8//3//s//r/DwAsAEcAWQBkAHAAgACOAI8AgQBtAFkARgArAAcA3f+2/5X/dP9Q/zL/IP8g/y3/O/9K/2D/hv+3/+r/FAA2AFoAggCkALkAvAC3ALMArQCbAHsAVAAwABQA9v/R/6r/jf+E/4T/g/99/3z/i/+n/8H/0f/d/+//CgAjAC0AKQAnACwANAAzACUAFQAQABMAFAAOAAUABQARACEAKQArAC0ANgBEAEwASABBAD8AQQA+ADIAIgAUAAwABAD4/+f/2P/Q/8v/wf+x/5//lP+Q/43/iP+E/4f/kf+e/6j/s//B/9b/7/8HABsALAA/AFUAaAB0AHkAfAB/AH8AeABpAFYARAAyAB0ABgDw/97/z//B/7P/p/+g/6H/pv+r/6//t//B/87/2//l//D/+/8HABEAGQAeACUALAAyADYANwA2ADUAMgAtACUAHQATAAgA/f/1//H/8f/y//P/9f/4//7/BgANABEAFQAZAB4AIQAjACcAKwAwADQANQAzAC8AKwAnACIAGgARAAkAAQD3/+z/4f/W/8z/xP++/7n/tf+w/6z/q/+u/7T/vP/D/8r/1P/h/+3/9//+/wcAEgAaAB4AHgAfACQAJwAmACAAHAAbAB0AGwASAAgAAQD9//f/7f/g/9b/0v/S/9L/0P/T/9z/5//x//v/AwAOABoAKAAzADkAPQBEAEoASAA+ADIAKAAfABYABgDz/9//zv/E/77/t/+u/6n/rv+3/77/xP/N/93/8f8DABEAHQAqADoARwBOAE8ATgBQAFIATQBAADAAIQAUAAYA9f/j/9T/yv/C/7j/q/+h/5//pf+q/63/sf+8/9D/5f/4/wgAHAAzAEoAWQBgAGUAbQB0AHQAaABaAFEASwBBAC4AFwAEAPb/6v/c/8v/v/+8/77/wP+//8D/xv/T/97/5v/r//L/+/8CAAQAAAD8//v//f/7//b/8P/s/+v/7P/s/+r/6//u//b//f8DAAcADwAWAB4AIAAfABwAGQATAA0ABQD8//f/9P/z//L/9P/4/wAACgAVACIALgA6AEIASABKAEoARwBAADcAKwAeABMACAD8//H/5//g/9n/0//N/8v/zP/Q/9T/1//c/+L/7f/2//7/BwAOABQAFwAaABcAFwAVABQAEwANAAYA///6//P/6v/k/9//3f/a/9n/3v/f/+b/7v/7/wcAFQAiAC8ANwBAAEsAUQBUAFIATwBFAD0ALQAdAAoA9f/j/9L/w/+1/63/qP+m/6b/rf+1/8H/zv/d/+//AwAZAC4APgBMAFkAZABrAGwAZQBaAE4AQgAvABkAAgDo/9T/u/+l/5f/jP+G/4b/h/+I/43/mP+m/7j/x//W/+X/9f8EABEAFwAbAB0AHwAaABMAAwD3/+n/3v/O/8H/t/+2/7b/t/+8/7//y//Z/+7//f8MACAANwBMAFsAZABtAHUAewB6AHUAawBlAFsAUwBJAD0AMwArACYAHQATAAcA/P/z/+f/2//M/8X/vf+0/63/qf+q/6n/sP+1/77/yP/V/+X/8f/8/wsAGwAuAEMATwBdAGsAcwB7AHkAdQBtAGcAXgBTAEMALgAdAAsA/f/s/9T/wf+y/6f/m/+N/37/df9y/3D/bP9n/2X/aP9s/3L/dP97/4X/kf+i/67/v//M/+j/+/8UACQAOgBOAGYAewCJAJcAoQCqAKYAngCRAHQAXQA6ABMA7P/C/5b/bf9R/y3/Gv8B//T+5P7g/t7+6P7y/gD/Ff8t/0v/aP+L/6//1v/2/x0ARABqAJEAvQDyACQBXAGWAdgBGAJcAqAC7AIwA3ADtAP0AzAEWASABJgEoASgBJAEaAQoBNgDdAP8AnQC2gEyAXkAvf/0/ib+XP2c/Nj7KPtw+tj5SPnY+Hj4KPjg98D3oPew98D34PcQ+Fj4uPgg+ZD5APqI+hD7mPsI/Jj8DP2M/Qb+av7c/ij/d//H/xAAQAB0AMMABAFeAcQBMAKsAjwD6AOwBIgFcAZgB2AIgAmQCqALoAyQDYAOUA8AEIAQwBDgEMAQgBDAD+AOwA2ADBALcAmoB8AFtAO4Aa//sP2w+8D58PdA9rD0QPMQ8gDxUPDA72DvIO8g72Dv4O9g8PDwkPFA8hDz4POw9GD1MPbg9pD3IPig+Aj5ePnQ+Rj6UPp4+pj6uPoA+yD7WPuo+xD8jPw4/fD90v7Y/wgBcALgA4AFKAcACeAKsAyQDmAQQBLgE0AVoBaAF0AYoBjAGIAYwBfAFkAVoBOgEVAP0AwgCmAHoATOARD/aPzw+bD3wPUQ9LDykPHg8IDwYPCA8ODwcPEg8gDz0PPA9KD1kPag97D4yPno+vj7JP1W/pX/1QDcAeQC3APABJAFGAZoBpgGsAaYBhgGMAUIBMgCRAGO/3T9MPvg+MD2kPSQ8nDwwO5g7YDswOtA62Dr4OsA7WDuUPBg8uD0wPcI+0D+qAHYBDAIgAugDkARwBPAFaAXABngGaAagBpAGqAZ4BiAFwAWQBRAEmAQMA4wDBAK8AcIBkAEiALbAEb/5P2k/ID7ePqA+bj4APhQ9/D2YPbg9YD1IPUA9dD0gPRg9FD0kPTA9DD1wPVQ9mD3cPjI+UD71PxU/hYAwgEgA3AEgAWwBogHEAgQCJAH6AYwBhgFUAMaAbL+YPwg+oD3kPTw8aDvwO1g7ODqgOkg6WDpQOog6yDsoO0Q8ADzAPbo+MD7Gf/AAlAGYAkADKAOQBHgE+AVIBcAGAAZwBlAGgAaIBlAGIAXwBZgFYAToBHQD1AOkAyQClAIWAagBDQDmAHD/+T9gPx4+2D6KPnw9+D2MPbQ9VD1sPQw9PDzEPRA9ED0MPRg9OD0sPWA9kD3MPho+eD6dPwG/mT/5ABsAgAEUAVoBjgH0AdQCHAIQAioB6gGOAW4A9IBsv8Q/WD6oPfg9GDywO9g7UDrgOlg6MDnIOdA58DnIOng6iDtgO9A8qD1UPkc/Z4AMATAB2AL0A6gESAUYBZgGCAagBsgHGAcYBxgHMAbwBpAGaAX4BUgFCAS8A+QDVALUAlIBwAFuAKkAOr+TP2Q+8j5MPgg90D2cPWQ9NDzMPMQ8xDz8PLA8tDyQPPg82D0wPQw9RD2IPeY+PD5KPuc/FD+OgD4AVgDoAQYBqAH4AiQCaAJkAmQCaAJ8AiAB4gFcAN2ATf/ePwg+dD14PJg8MDtAOuA6MDmAOag5YDloOVg5gDoYOog7QDw8PJw9oD6pP5sAsAFIAmwDAAQ4BIAFaAWABiAGcAaQBsgG4AaQBrAGeAYgBfgFSAUoBIgEYAPYA0gC0AJkAcQBuwD1gHe/yj+rPw4+6j5CPig9rD14PQg9CDzcPIw8kDyUPJw8qDyEPPw8/D04PXg9vD3qPmQ+4D9O//hALACmARgBtAHAAkgCjALcAtgC+AKQApQCSAIaAb4AzwBhv7I+7j4YPXw8cDuAOyg6SDnIOXA4+DiwOJg4yDkQOUA56Dp4OwQ8HDzAPfw+iT/LAPYBjAKYA2gEKATIBbgF0AZoBoAHOAcQB3gHGAc4BtAG2AawBjAFgAVoBMAEuAPQA3gCtAI4AaoBBgCgv84/YD74PkY+BD2UPQw84Dy0PEA8TDw4O8w8LDwEPFQ8fDx8PJA9JD14PYY+OD5IPxi/ngASAIIBMgFuAdACaAKcAsADGAMIAygC8AKoAkQCBgGnAPIAMD9kPpg9/DzkPBA7YDqAOjg5QDk4OIg4kDi4OIA5KDlwOeA6sDtcPEQ9fD49PwkASAF8AhADGAPQBIAFWAXIBlAGmAbQBwgHUAdwBwgHIAbwBrgGYAYoBbAFCATgBGgDzANsAqACHgGOASkAQT/nPyo+uj4MPcw9VDz4PEw8bDwEPBg7wDvQO8Q8ODwcPEg8iDzwPRg9tD3QPn4+mj9+/9AAtADcAU4BzAJwArgC4AM8AwwDfAMQAwAC4AJ+AcgBlwD//+w/HD5QPaw8iDvwOvg6GDmQOSg4iDhoOAA4QDiQOPg5CDnQOrg7ZDxcPVw+aD90AHoBaAJAA0gEEAT4BUAGKAZ4BoAHAAdoB3gHaAd4BwgHEAbQBqgGAAXABUgEyARAA+QDPAJaAcABaQCAQAo/Zj6cPig9tD08PIw8cDvAO/A7qDuYO4g7sDuAPBA8TDyUPOg9FD2aPhI+sj7cP2i/1ACqARoBrgHIAnQClAMUA3QDdANwA1wDcAMgAugCcgHqAVAAysAoPzY+GD14PGA7uDqwOfg5MDiIOEA4EDfQN9A4MDh4ONA5kDpoOyg8AD1OPl0/YIByAWwCXANgBBgEwAWgBhgGuAb4BygHWAeAB/gHkAegB3AHKAbQBqAGGAWQBQAEsAPUA1wCmgHcATEAfT+8PsI+YD2gPSg8hDxgO8g7mDtYO2A7eDtAO7A7jDw0PGA88D0UPYw+GD6cPxQ/sz/igHsA1gGUAiQCYAKkAvwDAAOcA5ADsANYA2gDGALcAkwB9gEbALK/zj8WPgg9JDwYO0A6qDmgOMg4cDfwN5A3kDeAN8A4aDjYOZA6YDsYPDw9KD58P0IAtgFwAlwDaAQoBPgFeAXwBlgG4AcQB3AHUAegB5AHsAdwBzAG2Aa4BggFwAVYBKwDxANUAooB8wDlwBk/Tj6UPeQ9DDyEPCg7mDtYOyg66DrYOwg7eDtAO+g8JDyoPSg9kj4+PkM/FT+EwBsAcgCkATIBtAIMAowC+ALAA0gDgAPEA/ADmAOEA4gDYALUAkIB6AEIAIJ/yD7cPYQ8kDuwOog50DjIOAA3oDcwNtA28DbQN3A3yDjgObA6WDt8PEw90z81wDIBKAIcAxAEGAToBWgF2AZIBuAHEAdoB0AHoAeAB8AH0AeIB0AHOAagBlgF6AUwBEQD0AMwAgABTIBkP0w+uD2oPPA8GDu4Ozg6+DqQOog6mDroOzg7UDv4PAg86D14Pf4+YD7CP36/ggBkAJcA1gE0AXYB4AJ0AqQC3AMkA2QDlAPcA8gD9AOcA5wDbALEAlgBrgD+wB0/fj4IPSA70DrYOeg4wDgAN1A24DaQNpA2gDbgN1g4UDlIOkg7UDx0PUA++v/QAToB2AL4A7gESAU4BWgF2AZwBrgG8AcIB3AHYAeQB+gHyAfQB5AHeAbABqgF6AUQBGgDQAKWAYYArT9ePng9bDyoO8g7QDrwOmg6eDpIOrg6kDsQO5g8HDycPRA9mD4wPrY/B7+uP6z/14BuAKAAzAEYAXgBqAIgApADHANgA7QDyAR4BGAESARwBBwDzANgApYB+wD0f+w+2D3gPJg7cDogOTA4IDdwNuA2sDZgNlA2oDcAN9A4gDmQOpg7qDyoPbI+oz+iAJwBgAKkAywDgARYBOgFWAXIBngGiAcgB2gHuAfgCDAIEAhwCAgH+AcwBoAGIAUoBCwDDAIYAPQ/vj6gPfg86DwAO6A7GDrAOsg66DrgOwg7gDw0PHw8kD0APbw95j5wPqI+2D8pP0G/w8ApgC8AVQDUAUwB+AIoAqwDAAPYBHAEuAS4BLgEgAT4BGAD8AMsAlIBsAC8v7Q+oD2gPJA74DrYOeg4+DgQN8A3kDdQN2A3cDdQN/A4eDkwOfg6qDuMPKw9Tj5RP1CAfAEsAhwDGAP4BFAFCAX4BngG4Ad4B7AH0AggCAAIcAggB9AHqAcQBrgFoATQBCwDKAIwAQEATT9OPkw9sDzsPEA8KDu4O2g7cDtoO7g7+Dw4PFg8/D0UPZA90D4gPnw+mj8bP1Q/g3/SADyAXQDmAQABoAHQAkAC2AMsA2QDpAPIBBAEIAPUA4ADYALcAkAByAEyQBs/Uj6kPfA9IDxIO5A64DooOXA4oDgQN/A3gDfwN8A4IDggOLA5WDpoOzg72DzIPdA+4v/dAPYBjAKEA6AEcATgBVgF4AZgBsAHSAeYB5gHsAeQB/gHoAd4BtgGmAYoBWAEjAPcAu4B1gEGgFA/VD5QPZA9JDyIPFA8MDvgO/g7+DwMPIQ8+DzEPWg9tD3mPho+Vj6ePuY/MD9lP5L/2QALAL4A2AFkAboB2AJ4AowDDANoA3QDcANYA1gDLAKAAlIB1AFCAPDAAb+CPug+KD2EPUA81DwwO0g68DoYOYA5ODhoOBA4IDgoODg4ODhAOSA56DrYO/A8nD2+PrU//wD0AeACzAPIBLgFOAWABjgGGAaYBxgHUAdAB2AHaAdIB1gHIAbIBqgF2AVQBMAENALAAgQBeYBAP5Y+oD3sPQw8uDwoPBg8KDvwO8g8VDyEPMQ9ND1IPfw9+j4IPrQ+kD7gPwo/j7/xv/bAKwCUARwBdgGgAiwCYAKgAuADKAMEAzgC/ALQAvACTAI+AZgBWwDsgFaAHj+BPwI+pD4IPew9HDyUPDA7WDqIOfA5IDiYOAA38Df4OCA4WDioOQA6MDr4O+g9Pj4WPzB//QD+AegCtAM0A/AEiAUwBQAFsAXABkAGqAbAB0gHaAcAB0gHeAbABqAGKAWYBNQD9ALQAgABAMANP3Q+rD38PRg84DysPGA8WDyUPPA8zD0UPVQ9qD2APdI+Dj5cPm4+Zj6ePsk/DT9Df/OACQCtAOYBRgHEAhACaAKcAuQC2ALEAtwCoAJwAjwB9AGsAWYBGADCALqABMA7P5Y/eD7SPo4+BD2EPTQ8YDuAOsg6IDloOJA4IDfYOCA4aDigOTA5kDpwOyg8WD2wPmQ/OP/KAOwBfAHsAowDTAPwBCgEkAUgBUgF2AZoBvgHIAd4B3AHeAcwBtAGiAYIBXAEVAOgApwBsQC0f90/WD7iPnw92D2UPUg9WD1kPWg9dD10PWg9ZD14PUw9oD2MPcg+Oj4kPnA+oD8YP5cAGQCWATYBQgHAAjACDAJgAnACXAJ0Aj4BzgHgAYABuAF0AWABfgEgAS4A9wCFAJqAS8ATv4g/BD6wPdA9fDysPAA7sDqoOfg5ADjYOGA4cDiQOTA5YDngOmg60Du4PEA9oj50Pvc/TAAuAIgBcgH8AoQDsAQ4BLgFOAWoBiAGsAcQB6AHqAdYBxAG0AZwBagFGASsA9QDDAJQAZUA84AN/9M/tz84Prg+FD3APYA9ZD0cPQg9MDzgPOw81D0APVA9jD4UPrY++z8Rv7T//wADAKMA9gEKAUABXgFOAYQBrgFMAYYBxAHmAagBrAG6AUwBagF8AXgBDQDcALGAR8AdP7I/QD9APv4+PD3wPaA9JDykPEw8EDtIOrg58DlIOQg5ADmoOfg58DoAOuA7eDvIPPw9hj6nPyF/1gCMAQQBiAJwAyAD8ARwBNgFUAWoBfgGaAbIBwAHOAb4BrAGOAWgBXgE2ARIA8gDVAKkAagA/4BnwCo/tT8aPtA+bD24PRg9NDzEPPg8oDzwPNA86DzUPUg95j4cPqI/JT9uP18/jAAXgHYAcACKAS4BHgEyATQBWgGWAYQByAI2AeIBgAGMAa4BbgEuATwBNgD+AEeAdkAhf8A/oD9XP3A+4D5SPhA9yD1wPKQ8UDwAO0A6YDmgOXg5EDlIOdA6UDqAOvg7MDvUPLg9Ej4qPsQ/qH/2AFwBOAGYAlwDLAPABKgE0AVIBdgGKAZwBrgGwAcABugGQAYIBYAFEASwBCgDsAL8AhwBtQDcgGg/2b+yPyw+vD4kPfg9WD04PMw9FD0QPTA9HD14PVg9sD3oPn4+jz8nP2s/hT/uP/9ACQCvAJcA0AEqASIBMgEgAXgBcAFIAZ4BgAGQAVQBVgFkAS8A7gDeAP8AbcAYwDs/x7++PwY/Tj84Plo+DD44PbQ8xDyoPGA7wDrAOhg54DmgOVg56DqAOyA6wDtMPBA8jDzMPYo+jT87PxZ/9wC0ARwBgAKcA7gEGASoBQAF8AXABjAGUAb4BqgGQAZIBjgFaATwBLAEeAPoA3wC6AJYAZ4A8wB+v/M/dD7SPpY+CD2kPQg9NDzkPPQ84D08PQw9QD2QPdY+Gj5sPos/PT8RP3s/Q3/KQA+AZwC4AOgBAAFoAU4BngG2AZwB6AHAAd4BjAGuAXwBKgEuAQQBOgCZAI4AiwBm//6/tb+gP2Y+8D6KPoI+FD1IPSQ8xDx4O3A6wDqQOeA5SDnIOpg66Dr4Owg7mDuIO9A8pD1IPdw+FD7cv41AGACUAagCmANABBAE4AVABYgFqAXABkgGSAZgBkgGYAXABagFSAVwBNAEuAQ4A6QCxAISAWUAs7/oP0g/HD6aPiw9qD18PRw9HD04PTQ9GD0EPRg9PD0wPUQ98j4QPpA+yD8QP1S/pf/IAGgAsADcAQYBWAFsAUwBgAHkAe4B8gHkAfoBmgGaAaABsgFqAQIBGwDLAIcAb0AbwAx/9j9VP2Y/Hj6WPhg91D2MPTw8ZDwgO7A6mDngObg5qDnYOkg7MDt4Owg7EDtIO+Q8MDyAPbQ+ID6ePzT/0gD8AUQCSANYBCgEYASABQgFYAVoBagGAAawBkgGQAZQBjAFqAVQBXgE2ARsA5QDHAJKAa8AzwChgAy/lj8CPs4+RD38PWw9VD1cPQw9FD08PNw8wD0kPXA9rD3OPnA+lj7sPvQ/GT+ef91ABgCjAMIBFgEYAVgBsgGGAfwB0AIoAcQBzgHGAdQBtAFuAX4BIwDrAJ4ArYBfwDw/77/ev6E/Bj7GPpQ+DD2APWg8wDxwO2A6+DpwOfA5uDn4Okg68DrgOzg7GDsYOxA7rDw4PIw9Vj4iPse/voA0ARgCBALcA3QD6ARwBIAFMAVoBegGMAZoBpAG8AaIBqgGQAZoBegFaATIBEwDlALMAlgB1gFhAOyAXr/uPwY+ij4gPbw9AD0oPNQ88DygPLQ8iDzgPNQ9JD1kPZg92D4iPlI+gj7OPzU/Xb/GgHoApAEcAXwBYAGCAcgB1AH2AdACGAIcAiwCGAImAfABigGSAVYBMwDcAOEAvwAdf/o/VD8+PrI+sD6oPkw90D0EPGA7eDqwOkA6iDqYOpA6yDsQOzg6yDswOwA7aDtQO/A8TD0wPb4+WT9QwAIAxAGoAgwCnALQA2QD8ARABSAFoAYgBmAGYAZgBlAGeAYoBjgFyAW4BNgESAPwAzACmAJIAhgBigEpgH6/iz8yPko+AD3APYQ9VD0oPMQ88Dy8PJw8+DzUPQA9bD1QPbw9rD3mPig+SD7KP1Q/yABjAKsA0gEmAQoBfAFqAZQBxAI0AggCTAJEAmwCBAIWAcIB9gGYAagBaAEEAPgABn/TP4Q/sz9QP0E/Cj5UPXA8YDvAO4g7SDtgO2A7eDsgOyA7GDsAOxg7EDtQO6A71DxoPOg9ZD3+PnQ/H3/xAEIBPgFOAdgCCAKgAzADuAQwBIAFIAUoBQAFSAVABXAFIAUABQgEwASwBBgD+ANcAwgC7AJEAh4BrAEvALhAHr/RP5A/Uj8WPtI+iD5OPig91D3MPdg95D3sPfQ9/D3APgY+Hj4GPnw+QD7RPxw/UL+3P5q/9b/KgCrAFQBDAKgAkwD6AMQBOgD1APgA9QDxAPQA5wDvAKeAa8ADwCe/63/EgAIAA7/VP1o+0j5UPcw9jD2kPbA9hD3YPcg93D2wPVg9QD14PRQ9TD2APfQ99D46PnY+sD74Pz8/bb+Uv8PAM0AeAFYAowDoASgBYgGcAdACKAI4AgQCQAJ0AjACPAIMAlgCaAJwAmgCVAJwAgACCAHKAZQBbAEYARIBEgEWAQYBGwDXAJMAWkAy/+a/6v/7f/p/5v/C/9O/nT9xPx8/ID8uPzc/Aj9CP3Q/ID8QPwM/Nj76PtI/Lj8DP1M/Yz9uP20/cz9Kv6s/ir/lv/x/yUAOgByAMsALgGCAdABBALcAYABOAEQAeMAxwC2ALQAjQBGAOn/eP/u/mr+GP7s/cz9tP2I/TT9yPxU/Oj7kPtg+3D7mPu4+9D74PvY+8D7uPvI++j7DPxk/Nz8RP2Y/QD+Zv6m/tr+I/9u/6H/3f9NAMsANAGcAQwCXAKAApwCvALQAuACBANUA6QD5AMoBFAEWARQBEgEQAQwBEgEgASwBNAE0ATIBKAEYAQoBPADuAOQA3wDaAM4AwADyAJ8AigC2gGgAWwBOAEaARIBAgHXAKsAnACIAG0ASQAvACUAJQAzAEgAawCLAI8AhABeADcA/f/H/6v/p/+b/3j/Uv8s/9z+bP4E/qz9TP3U/ID8RPwM/Lj7cPsw++j6mPpY+ij6APrA+aj5uPnQ+cj52Pnw+QD6EPpA+pD60PoQ+3D74Ps8/Jj8CP2E/fD9Uv7Y/mL/zf8tAJ8ACgFaAZgB5gE4AnwCwAIIA1wDmAOwA8gD4APsA/AD/AMgBEgEYAR4BJAEsAS4BLgE0ATQBLAEkASYBLgEuASoBJAEaAQgBOQDtAOEA0QDFAP4AtAChAI8AgQCwAF0ATwBIAEGAeYA0ADCAKUAdwBeAFkATAA3ACgALQA1ACoAEgACAPL/0/+w/5D/cf9B/wP/yv6Y/mD+HP7Y/Zj9VP0I/bT8YPwM/LD7aPso+/j6yPqQ+lj6QPow+hj6APr4+QD6CPoQ+ij6SPpY+nD6sPrw+iD7UPuY++D7KPx8/Nz8QP2k/RL+iv4A/2T/x/8wAJoAEgGWARgCiAL0AlgDqAPwAzAEeATABAAFQAWABcAF8AUYBigGMAY4BkAGOAY4BjgGOAYgBgAG6AW4BXAFKAXoBKgEaAQgBPADuAN8AzQD7AKkAmgCIALWAZYBWAEaAdoAmgBlADcAEgDs/8n/pP9u/zv/Fv/4/s7+nP5y/kj+DP7U/aj9hP1Y/Sz9BP3Q/JD8TPwY/OD7oPto+0D7IPv4+tD6sPqQ+mj6SPoo+hD68Png+eD58PkI+jD6YPqQ+rD62PoQ+1D7mPvo+0j8sPwU/Xj94P1M/rD+GP+K//r/ZgDUAEoBvgEgAngC1AIsA3gDvAMIBEgEiATABPAEIAVIBXAFkAWYBagFsAXABbAFoAWYBYgFaAVABTgFGAXoBMAEqASIBEgEEATkA6QDWAMkAwwD3AKcAlwCIALaAY4BTgEYAdgAlwBcAB8A3f+c/2T/K//o/q7+fP5K/hD+3P2w/Xz9SP0Y/ez8zPyo/IT8WPw0/BD86PvI+7D7qPuQ+3D7UPtA+zj7OPs4+0D7SPtY+3D7gPuQ+6j70PsA/CT8SPx8/MD8EP1Y/aD96P0w/nj+yv4a/2v/uP8EAFUApgDwADQBfAHAAfwBOAJ0AqgC2AIEAzQDYAOIA6wD1AP0AwgEGAQoBDgEOARIBFgEWARIBEAEOAQoBBAEAAT0A+QD0AO8A6QDhANgAzgDDAPgArgCjAJYAiwCAALSAZoBXgEgAeAAmgBVABYA1v+Z/17/JP/k/pz+XP4a/tz9pP18/Vj9MP0I/ej8yPyg/Hz8ZPxI/Cz8DPz4+/D78Pvw+/D7APwQ/Bj8JPw4/Fj8cPyI/LD85PwQ/TT9ZP2k/eD9FP5Q/pr+2P4F/zb/eP+8//P/JQBrALEA5QAOAUABcgGSAboB6gEcAjQCSAJsAowCmAKkAsAC2ALcAuAC8AL4AvQC6ALoAuwC4ALcAtQCwAKoApQCgAJoAkgCKAIMAvYB4AHOAbQBiAFWATQBFgHxAMcApQCHAGUANQAMAPD/0v+p/4D/Xv9A/x//AP/s/tz+tv6K/mj+TP4q/gz++P3k/dD9xP24/aj9kP2A/Xz9fP18/YT9kP2c/aD9rP24/cz93P30/Q7+Iv42/k7+bv6K/qD+tv7g/hH/Ov9b/4D/q//M/+T/AwAvAFcAeACdAMgA8AAOATABUAFqAX4BlgGsAb4ByAHIAdIB4AHsAe4B7AHuAfIB6AHaAdABxgG0AZ4BlgGMAXYBWgFIAT4BLAEaARQBEgEKAfcA5wDaAMUArACZAI8AiwCFAHsAbwBgAE0AOQAmABYABwD1/+r/4P/W/8X/sv+d/4n/df9i/03/NP8c/wv//P7q/tj+yv68/qz+mP6K/oL+dv5s/mr+av5o/mL+ZP5s/nD+cP52/oT+kP6U/pz+qv68/tL+6v4F/x7/N/9V/3n/mf+3/87/5f/5/xAAKwBLAGsAigCjALoAzgDbAOYA8QD/AAwBGgEkASwBLgEyATgBPgFCAUIBQAE8ATgBMgEmARYBCgEAAfEA4ADUAMsAvwCvAJwAhQBuAFcARAA2ACsAHwAUAAgA/P/s/9n/zP/I/8L/t/+s/6b/nP+P/4L/ev9x/2T/Wv9V/1H/Sv9G/0P/QP83/zT/N/89/z7/Pv9C/0X/Qf9B/1L/Wf9b/1v/Zf9y/3H/dP+E/47/jf+X/7L/wP+8/77/0//u//n///8RACUALAAoAC8AQwBWAGMAdQCNAJ8ApQCmAKwAtAC0AK8AswDCAMYAvQC5AL4AvQCwAKUApgCsAKcAoACeAJMAdABYAFAATQA/ADEAMwAyABsA/v/t/+j/3f/U/9T/0//N/8r/y//H/7j/s/+9/8v/z//S/97/5f/Z/8T/uf+1/63/qv+0/7//uf+k/47/ff9y/2//eP+G/4//lf+W/5P/iv98/3H/cf+B/5P/n/+m/6v/rv+n/5n/lf+o/8H/z//e//7/GgAYAAsAHABIAF8AXgB4AK0AuQCTAI0AtgDAAJ8ArQD0AAwB1wC8ANsA0QCAAFQAfACSAGYAUgB9AIgASAAaAC8AOQALAPL/JwBcAEYAFwAXACsAFADn/+D//P8FAOv/2f/u/wYA9v/Z/+D/AQAEAPP/BAA1AD8AJAAoAEMANAAPACAAUABIABIA//8JAOj/sv+p/7v/qf+A/4f/sP+m/3L/cv+a/5H/Yf9q/6D/mf9a/1T/hf92/yT/FP9J/zT/xv6U/sL+zv6U/p7+Ev9i/1b/V/+N/6T/kP+t/w4ATAA7ADUAbACMAGUAaADoAGoBcAFUAYQBhgG9AMz/hv+G/03/+P+UAmgFsAVYA3EA1P1I+7j5YPq8/GL/ygGEA7wDnAJGAer/Iv4k/aL+dAEEA1gDQAToBCQDLABv/94AVgF6APwA3AL8At4Aa/+e/0T/3P28/X7/sQAoAIf/o/8N/0j98Pss/Bz9tP0q/sD+9v6G/tT9UP1E/aj9Jv5m/oT++v6w/8T/Bv+u/m//IADF/4P/fwBuAdAA2/9rAI4BTgFfAKoAkgFaAYMAsQC0AUwCQALmASABVQBjAOIAsQBxAIoBxAL+AVEARwD/AB4A3P7Q/6QBagErAL0A2AFrAAD+SP5AAEQAGP/P/3QB6gDy/sD+BgDv/5r+tP6CAIgBtwCl/+z/8ACbAK7+Gv5MAMoB3P8Y/jMA5AK0ATD/kf+IAGD+KPxG/vgBeALnAI4AmwCF/6r+vP5+/nD++f88Ad//iv5UAAgCpP+c/OD9VgD2/gz96/+cA0IBLPxM/ML/iv+A/cP/ZAPwAfj9/P3H/xL+DPwR/xQDcALSADwCFAJ4/ej6YP6WAXUAowDYBLgFGABc/PL+ywA6/hz+UAPIBXgBRP4kAagCpP0A+oj+CATsAgMAWgFAAij++Pr4/YoBKwCi/rgBcASwAeT9kv7ZAJX/gPz0/EoBIARUAiUAyAFwAxwAcPuo/JoBjgGY/Yz/qAZgBgr+uPsEAtgCiPpw+BgCaAfU/2D6eAHoBqz+MPbo+0gFdAIA+1r+EAZgAnj4QPm4AugEfv7Y+8P/ogE3/+j+OAKQAxoBsv7I/VD9nP4+AQQBIP4a/sIBsAMYAuQALAFV/+D6QPmI/egCEARcAjQCeAMAAkD9gPrw/IwAAAGWALADiAfIBAT9sPpd/8cAOPxA/FAEkAiAAvz8RwAoAtD6sPYz/wAHcAKI/SgDkAbQ/MD0nPwgBtABYPsAAWAHKgH4+Mj8WAQQAtj7SP7QBIADdP2A/ZwC/ANmAbwAQgGk/uD7ov6MA2wDcAB0ASAESAHo+yj8j/+c/kj8IgAABkgEpP2s/C0AEv/Q+ij8OALQAz7/bPxd/yQCqgAZ//n/x/+A/XD8eP1y/jT/gAGoBHgEv/+w+5T8BwCbACL+Xv4AA4gEtP5I+g//qAXABAQByAGSAaj5APQQ/fAKcAv0AzgDbAOw+QDySPqIBsgFTgBABYALmAPQ9pD2jPyQ+tD3SgGQDgAQkAdBAFD7MPWA8UD1GP6wBuAMUA9gC5ABIPhA9bD4kPvA+qz8IAWADLALyAY0Azj9wPKg7iD5KAbIB7ADWAQwBZb+gPc4+kgBsgFs/j3/JADw/Oj73f8EAlwAMgFABZgEQP0g+PD40PjA99L+QAsgD1AJWAPU/bD0AO7Q8oX/cAhACtAK8AlUA/D6cPeQ98D32PpgAhAJYAloBdACAAGg/JD42Pmc/Xb+G/9ABJAJ0AcoAVT9EP34+mj40PxwBbAGugDI/iQCYAKo/oD+QAPwBJL/YPrA+7z/UgE0AtgEAAdwBagAJPzA+iz8WP6n/2oAxgGoA/QDngGc/z0ATADE/Nj5zPw0ApQCdv50/eQApAIEAV8AVAEeADT9XPw8/Sj9aP0xAMwCdAJoAVIBxP/M/Dz93AC2ANT8wP1gAxgDNPzo+iAC0AX4AHD+QAOwBGD9YPho/RADkAA4/QgC4AjgBlL+IPos/Tj/0Ptg+koBcAjABc7+sP4oApL+wPdA+kQDuAQu/4n/+ARoA7D7YPpAAFQCGv80/0QDCAMg/kj9QAIgBWwCOP/s/tD+WP10/cQAxANkA6IBZAFsAbT/xP1c/Uj97Pxs/iwCSAT4AlQBZgFkAJD95PzY/qD+uPtE/OQBEAZwBLgBMAIEAnz9WPm4+kb+Gf8i/xgCqAWYBeACHgGC/9D7aPgI+Yz81v+IAjAFmAaYBcgCIv9I+5D4SPgo+iD96QDwBCgHuAYgBQQDA/+w+cD2APg4+4z+HANgCFAKEAf+ARz+oPpw92D3YPtaAHADAAXQBSAFfAJ9/6j9nPy4+6D7WP1hAFwDUAXYBRgFDAPE/1z80PrY+y7+eQCgArAE+AVwBaQCmP6A+8j6yPtg/Xr/ZAKoBFAE9gHk/4r+yPxA++j7oP65AOUAugBqAbgBhAD0/nL+hv48/mL+1v9uAZYB+AAcAWgBVwDO/tT+5P81APv/WgDQAKUArgB2AbABdgAO/9j+8P5i/kb+lP/OALgAXACXACgARv60/DT9iv4e/8z/jgGgAkYB5P60/bD9vP1M/jUAVAL8AmgCjgGCAHP/6v78/kX/wP+6ABQCCAMIAzQC+ADg/2X/mv8FADgAQABnAMgATgG4AfgB7gE4Aer/2P4+/vz9QP4Y/yMAIAHyARwCQgGW/xT+lP3o/Xr+Y/9aALcAagCC/1L+lP3U/az+bv/p/zQAFQAP/7D9+PzM/Lz8PP3M/o0AQgEAAVcAT//0/Qj9JP3c/cj+JQCQARACwAGsAXIBPgDi/tT+sv8lAIsAAAK4A8QDeAK4AWwBQwAP/6f/eAGIApQC7AKQAxADtAFGAd4BxgHqAK8ATgGwAa4BeALkA1AEMAPQAQoBbwDz/2IA6AFAA5ADRAMIA5ACfgFKALn/0f8KAE4AxQBAAUoBiwB8/37+oP20/AD8wPug+zj7wPr4+lD72PqY+Xj4wPfA9iD2gPaw9zj4KPhA+MD4EPn4+Dj5uPnQ+bD5UPrY+5D91P7X/98AtgE0ApAC7AJgAxAE8AToBSAHgAhwCZAJMAngCLAIQAjgB0AIAAkwCRAJAAmQCFgH6AVIBUgFKAW4BIgEmASIBBAEnAMwA6wC7AFeAWQBxAHWAZQBZgF4AVoBMAFsAfIBIALwAeQB9AFcAVwACQB5AI4ADQDF/7H/+v60/bz8IPzw+mD5MPhg91D2APUg9GDzEPKg8MDvIO+A7gDuAO4A7kDt4OsA62DrwOzA7rDxsPVA+SD7yPtA/MT8aP0j/9QCmAfgC0APQBIAFCAUYBMgE2AToBMgFAAV4BXAFSAVoBTgEyASYBDgDrAMcAlABswDjAFd/yb+CP6o/Uz80PpQ+SD3oPQQ8+DyMPPQ83D1gPe4+Dj5yPlo+oD6uPrQ+7j9X//bAMQC2ARQBlAHYAhACVAJwAiQCMAI4AgQCeAJ4AogC7AK0AnQCBAH0AToApgBqwDU/0H/0P4S/pT8uPro+ED3sPUg9ADzIPJg8bDwYPBQ8FDwEPAA8EDwUPAw8CDwEPDg7+Dv0PDA8sD0UPZQ95D3APcg97j5Yv40A0gHUApAC6AJgAcgB7AIAAtQDqASQBZgF6AWABVgErAO4AtAC/AL0AzQDaAOgA1ACrAGUARgAlEACv+C/hT9iPq4+JD4wPiI+ND4kPk4+bD3oPaw9oD2MPYA9wj50Poc/Nj9rP85AJf/dv9nAGIBPALIA4gFSAYwBpAGoAdgCLAIAAkgCYAIkAcYBxAH+AaoBogGUAbIBSAFiATQA6ACSAEjAGT/zv5i/gD+SP0E/Jj6sPkw+cD4EPhw96D2YPUQ9GDzMPPQ8mDyYPKw8pDyUPJw8oDy0PFA8SDyYPPA84DzAPTg9ED1QPdE/AwCWAVABqAG+AUIBDQDAAZACnAN8A8gE0AVYBQAEkAQ0A5wDOAKwAtADSANwAuwChAJcAYYBEgDyAIGAVT++Pvg+eD30PZw99D4sPkA+jD66Pmw+ED3oPbg9rD3cPkE/Lz+nQCGAfgBKAJAAqQC7AN4BagGOAf4B+AIcAnQCbAKcAtgC5AKgAmwCIAHeAYoBoAGiAY4BuAFUAUQBFwC7QCX/1L+kP2s/QD+3P1k/cz8mPvA+TD4cPfw9lD2wPWg9VD1gPSw82DzIPNg8qDxUPFw8ZDxUPFQ8cDxEPIw8tDyQPQg9VD0APOw85D2kPqV/2gF4AmQCmAIgAYgBngGQAhgDMARABWgFaAVQBXgEkAPEA3QDMAMAAzgCwAMgAoIBwAE1AIMAt0ACACN/5T94Plw9hD1APUw9VD2UPjA+eD5ePlg+ej40PeA96D4qPrE/Pz+NgGIAtACCAMIBDgFQAYgB7gHmAfoBrAGaAewCOAJsAoQC3AK8AgwB/gFAAUgBIwDlAPUA9QDjAP0Au4BiwB6//L+rv5g/mr+Rv6Y/az8OPwM/Hj72PqQ+ij66PiA9+D2cPag9aD0UPQA9DDzgPKQ8pDyEPJw8bDxEPLg8dDxgPIg8/Dy0PKA80D18Pd8/BQCsAbQCBAJYAgABwgGWAcgC2APoBJAFWAXQBcAFUASYBBgDvALAAugC6ALoAlYB/AFSAQUAtsAEAEOANz8YPkg9wD1EPMQ83D1kPdY+CD5SPoY+mD4YPfQ92j4EPlA+7D+LgEYAhwDwASgBdAF4AbACEAJEAhYB8gHIAhACGAJQAvQC5AKUAlwCNgGSASgAmwCOAKKAbIBwAKgAggBjP8g/3j+cP08/fj99P3g/ID8/PwU/Wj8MPyE/PD7gPp4+fj4wPcg9qD1EPbg9RD1sPSg9IDzsPEg8fDxEPJw8ZDxgPKA8sDxMPKw8xD00PMA9hD7WQAwBMAHoAowCkgHIAZACCALkA0gEYAVQBcAFqAU4BNgEYANcAugCzALYAmACDAI8AU8AokA8wBgAB7+RPzY+sD3EPTQ8kD0oPVg9hD4IPp4+nD5OPm4+XD5KPnI+qT9nf/SAKQCgATwBOAEMAYgCNAIkAjgCAAJuAc4BoAG+AegCKAIIAlQCbAHOAWwA7QCNAHP/+X/rwCdAB4AJwAXABD/8P3o/X7+nv5+/tr+LP+m/vj9HP6+/t7+av4y/tD9tPwQ+8j5GPkQ+LD24PXg9YD1UPRA89DyEPKg8GDwYPHw8dDwMPBg8QDy8PCQ8PDy0PWw93D7kALACKAKEArwCWAJMAdQB/ALwBFAFAAVYBbAFsAUgBGgDyAO0AuwCQAJcAiABuQD4AF4AFD/Cf8A/9z9aPuw+DD28PPg8tDz8PWQ9/j4yPoQ/OD7UPu4+6T8KP0U/jsASAIMA4gD4ARoBjgHMAggCnAL8AqACZAIiAcQBoAFkAbYByAI6Ad4BygGjANMASgAYf+U/pz+Sv9H/5j+Wv7Q/pb+Qv7Q/iEAjgAAAOv/HgDB/yL/nP+sABQBegC+/6L+6PxQ+zj6+PhQ9zD2kPVQ9IDy4PEA8sDwAO8g75DwUPDA7kDvEPGg8IDuAO9A8gD0UPTA95T+MARgB9AKEA4wDQAJeAeACjAO4BCAFGAYABlAFgAUABPAEAANoArQCWAIAAaIBHAD9AAW/jD9pP1s/Rz80Pq4+ID1EPMQ82D0gPUg96D5qPtE/Mj8+P28/pr+Hf8iAdwCcAMABGAFYAaABiAH8AiQCrAKcAogCgAJqAbIBGgEkARwBKgEYAUQBVwDkgGUACv/SP1o/Dz97P1g/dD8QP1w/eT8VP07/9UA6gDrAOwBZAJ2AdAAlgF4AjwC2gEIAm4Bff+I/Uz82PrQ+DD3QPbw9CDz4PHw8MDvwO5A7yDw4O9g78DvoO/g7QDtgO6A8BDxsPIg95j7QP4YAqAIUA0wDcALAA3ADZAMcA2AEsAWQBYAFaAWYBfAE9AP8A6QDdAIeAQwBBAEeADI/Nj8yP0c/Cj6cPow+rD2QPMA8zD0IPRA9KD2SPlA+jD7xP1OAAQBHAEkAlQDiAPcA1gFEAcACNAIMApgC4ALIAvQChAKUAiwBvAFWAVIBGQDRAPoAswBswBNAMX/gP48/dT8vPw4/AT8hPws/UD9UP0g/k7/PwAoAVQCPAOQA7wDIAQwBKAD8AK0AkgCUgFMAJX/BP5o+yD5MPhA9xD1MPNg8vDwoO2A68DsIO+g76DvkPFA8oDvoOzg7RDwEPDQ8AD2QPwj/04BGAaQCsAKEAqQDLAPoA9QDyASIBWgFMASIBPAE8ARcA8wD9AOoAtAB0AE8AH8/rz8ZPxw/Ij7wPq4+hj6UPjg9qD2cPYw9iD3YPnI+rD6aPvU/ToAcAEQA3AFeAYIBcQDkAToBVAGCAcQCYAK8AnwCKAIAAgABjAE/AMIBEwDbAIQAmQB7P/Q/pb+av68/Uj9bP1I/bD8lPxQ/R7+Ov6E/m3/QACTAEAB7AJoBMAE2ATgBaAGGAZABTgFsARYAkEABABx/6D80PlA+Wj4QPWA8nDy4PHg7QDqoOrA7ODswO2A8XD0kPKA7+DvkPHw8EDwEPPQ91D7YP4oA7AHgAnACRALYA3gDoAPIBDgEEARQBHgEKAQQBDgD7AOQA0QDAAKKAaiAZb+EP3A+7j6CPvA+yj70Pmw+ZD6UPro+GD4SPng+dj5iPps/AD+Cv/MAMQDKAbgBsAGiAb4BRAF4ASwBfgG2AdQCFAIuAfoBkAGmAWIBJAD9AI0AswAtv9o/1P/yv54/vL+Hv80/lz9XP18/UT90P10/3YAIAD4/7QADgEwAdgCoAWYBqAFmAXABkAGkATIBCgGaAQjAGT+K/94/UD5sPcA+aD3QPNQ8dDx4O7A6KDmAOrA7ADtYO/Q86D0MPHg7wDy0PJw8bDykPeg+8z9HgHIBTAIgAgwCoANsA8gEMAQIBFgEDAPQA9wD7AOYA4AD6AOIAxQCagG6AKQ/oj83Pxs/Kj6+Pmo+jj6uPjw+Mj6qPsA+0j76Pxs/Xz8XPzU/Wj/pgDsAggGEAhgCBAI8AdIB0gGEAYAB6AHOAdoBtAFOAVYBOwDMARIBHQDZAK8AaoAsP78/Mj8QP1Q/Yj9bv7W/uj9+Pxg/SD+ZP4Y/5IARAF5APP/sQC0AXQCEAQQBtAGYAZ4BvAGIAbYBNAEIAWAAzQB+P9+/sj6oPfw9xj5MPfg81DyMPBA60DngOjg68DsQO0g8eD08POQ8XDyMPTQ8tDxoPXw+tz80P34AZAGiAewBxALAA+AD7AO8A8gETAPkAzQDPANMA0QDJAMoAzwCVgGEAToAbz+WPzw+yD8WPt4+lj6CPow+RD5ePoc/AD9uP3M/mX/LP8n/y0ApAG0AtADkAVAB8AHWAdAB2gHAAdoBpAGKAewBigFEATQAzgDGALCAaACHANgAnwBGgElADL++Pxg/S7+8P30/QP/0P82/8b+sf+qALEA+QAYAiwC2gBRAIoBWAJYAoADkAXYBWgEYARoBYAEWAJgAqADLAKs/ij9BP2A+gD3gPbA91D24PIQ8RDwIO3A6eDpYOxA7uDv4PKQ9aD1gPRg9BD1UPVQ9qj4QPsk/Tb/+AGIBJAGsAjACkAMYA1gDvAOgA5wDXAMkAvgCtAKMAswC2AKsAigBkgEBAIbALj+xP0k/aT8CPxg+9D6mPr4+tD7DP1Q/kv/4/8lAF4AvQAQAXgBRAJsA1gE0AQ4BYgFaAUYBSAFkAWQBfgEaATMA7QCbgHvADIBXAFkAeYBbAIkAiYBVACl/7z+Nv6k/mH/pf/C/wwA3P9K/2//cwAMAe4AZgE0ArwBfACiAPYBIAKcAewCIAXoBAQDJAOQBJQDMgFqAeQC8gCc/FD7ZPxQ+jD2UPVA9+D1YPGA7zDwAO7A6UDqQO9g8uDxAPOA9jD3oPQg9CD3+PhA+Hj50P0EATYBBAI4BcgHUAigCfAMAA9ADvAMAA3ADPAKsAlACvAKEAoQCQAJQAjYBVADGAIEAS3/xP2o/Yj9aPx4+9j7pPz4/IT9+v4lACcA1v83AM0AyQDOAIQBmAI0A5QDMATABMAEWAQoBDgEUAQ4BBgE0AMYAwwCWAFGAYgBxAEEAjwCHAJ8Ab8AOAC0/y3/Bf9h/8H/zv/M//n/BwDc/+b/fQA0AXIBXAFmAWIBBAGoAPkAxAE4AmACAAPcA/QDUAMQAzADnAJOAY4AOADg/rz8gPsA+1j50Paw9ZD14PPg8GDv4O5A7cDrAO7A8hD1sPTQ9TD44Pdw9fD1WPmY+rD5oPuMAPAC/AG4AngG0AiQCMAJAA0wDvALQArgCiALgAmACCAJMAnAB5gGgAawBaADoAGOAKv/pv78/aj9LP20/Nj8ZP3I/Uj+Bf+n//H/FQBqAKUAtwD9AIgBEAKMAiQDnAPkA/wDGAQIBMQDxAPkA9ADSAPIAmgC+gGIAYQB6AEMAqoBPAEGAdQAdAAkABcA9f+6/6H/0P/6//b/AQBRAKsA8QBUAcYB0gF4ASYBBAHBAGgAngBKAeQBZAIgA8gDzANwAzwD3ALUAcEAMABE/7T9iPyw+wj6kPdg9pD2cPWg8oDwoO8A7mDswO2A8eDzQPTQ9SD4QPiA9sD2uPiQ+aj5MPwZAJYBfAEUA+gF8AZQB8AJsAzgDKALAAzADEALQAlwCTAK8AgwBzgHcAegBVgD2ALMAkABY/8N/xP/+P3I/ND8RP00/VD9Tv5U/8T/DACAAPYASAHSAVwCtAL4AkgDbAN0A6gD4AO0A1QDSANUA/ACaAIgAtIBIgGoANMACAG9AFYATwAqAIz/GP9L/5b/W/8n/2//zP+6/6T//v9hAHAAigA0AeoBGALsAdgBnAECAZMAxwBOAaYB6gFIAogCiAJ8AnwCKAJuAcUALwA8//j91Pyg++D5MPhg97D2QPVg8zDyAPEA74DtQO4Q8KDxkPOA9pj4APgg9yD4gPmo+WD6JP3Z/0sArADcAggFWAXYBWAI8AqAC1ALEAxADLAKMAlACaAJ4AjoB4AH4AaIBVgExAMgAxwCQgHBABoAR/+c/hj+sP2I/fj9gv76/of/HwCRAPcAjAEUAkwCeALwAkADOANcA9QD+AN8AyQDRAMIAzQCygEgAiACSgGjAMcAvQACAKD/DABIAJj/G/97/9r/dP8O/1T/rf+F/1v/1/9ZAEAAGAB7ACwBfgGCAagBvAGEASgBGgFGAUgBPgFoAfABZAJkAjQCIAIkAsYBCgGRACcA/v40/QT8iPsY+sD3EPaw9WD0APJw8EDwgO8g7gDvcPJA9dD1YPbw92j4cPeA97D5oPtY/Kj96f+UATQCUAMgBaAG8AfACYALAAzgC+ALkAuwChAKMArwCZAIWAfgBjAG0ASwA1QD/AL8ARQBpwAjAEz/hP4i/uz98P1I/rz+Lv/h/68AAAEMAaoBrALcAnQC0ALIA9gDFAMgA9wDWAPoAbwBzALgAuIB0gHEAnwCBAGiAEABzgBh/yz/GADw/9j+1v7K/8z/9P4m/xQABABH/4r/igClAAoAKADlAPgAigCKANAAkAD6/+P/LwBvAIUAswDwACoBZgGAAWYBRgEqAc8AEAAS/wD+vPxQ++D5iPhg9yD2gPTQ8uDxUPEw8GDvQPCQ8lD0UPUQ9xj50Pgw9/D3sPrQ+zj7jPz3/2IBnAD0AZAFKAd4BhAIAAxgDTALkApgDEAMYAlACAAK4AnwBpAF8AbYBhgExAIQBAAEdgEJABwBNgHi/oj9qP5G/wD+iP0Y/zMAUP8J/4cAqgEiAcsAJAJYA/ACeAJIA/gDWAOIAuQCTAOIAugBhAJQA+gCGAIMAhACTAGbAMwA5QAtAKL///8qAGv/+v5s/6H/L/85/ycAiwABAPn/xQAAAWAAVAAKASwBkwBqAL0AhQD7/y8A7gAgAQoBggEAAuYBtgHgAawBxAAEAIr/aP6k/Hj7oPoQ+TD3EPYw9SDz8PAw8BDwAO+g7sDwwPMw9QD2oPfI+BD4oPdo+aj7NPyI/Ij+ggDuADwBOAN4BXAGkAcACuALwAsgC5ALsAuQCsAJAAqwCQAIoAZYBrgFMARoA8ADkANgArgB3AFSAfL/Rv+K/0r/dv5k/gb/If+y/g//DABvAHEARgF8AuACwAIsA8gDcAOoApQC2AJQAmoBXgHkAeYBTAE4AX4BNAFmADwAwQDLAAcAlf/Q/5r/uP5a/tr+8v5g/mb+c/8jAOX/EgBAAfYBjAF0AUQCgAKAAboAKgFWAVoAr/9PAAgBvQCIAGABBAKIARoBdgGGAVAA5P42/mj90PtA+kj58Pfg9SD0MPNA8vDwMPCA8CDx0PFQ83D1EPew90D4APlw+dD54Po8/Aj9lP3u/qoA5AH8AsAEuAb4ByAJ0AoQDOALMAswC0ALYAoACVAI2AeYBjgFwASoBPQD7AKoAtwCdAJyAcIAnABvAOb/d/9o/z3/vv5u/qz+NP9Z/1P/+v9OAVQCxAJAAxAEaAT0A8ADMAQYBCgDkALoAugC5gEkAWoBtAEoAe0AiAHmATIBlwDTAOsAJwB//6P/l//a/kL+dP6U/k7+bv4//+f//P9PAPEAIgHPAOMAagFqAe0A1QAiAe4AeAC8AIoB4AHEARgCdALeAe0AoQBzAD//yP0U/TD86Plg9wD2oPRA8nDwoPDw8MDv4O6w8CDzoPMg9KD2yPhI+HD3KPlo+zj7mPqk/IT/MgA0AIwCgAUgBugFAAgwCxAMkAtwDBAOoA3ACyALQAvgCagH2AboBtAF2AMUAyQDiAKAAV4BlgHyADQAPABQAJX/7v4C/97+KP4q/g7/NP/A/mD/HgHiAYwBFAJwA4gDsAIcA2gEMASoAmQCVAMkA7oBUAEEAvABBAEAAcABdgFNAAYAvwDIAPj/of/y/67/7v7Q/jj/Kf+o/gD/yf/d/1//jv9EAEcAwv/h/4kAdQD4/y0ADgE6AQIBigGIAqwCBALQAaoB8wDN/z3/vv5s/ej72PqY+YD3cPVQ9FDz4PEw8ZDx8PFg8XDxEPPA9DD1oPVg99j48PjY+Ej6yPv4+yz8OP7TAMwBTAJQBNAGsAcgCCAKoAwwDaAMQA0ADgANQAvwCjALwAnABzAHCAdwBWAD3ALwAuIBkAB6AK8A0//e/hH/QP9g/pD9yP3w/ST9sPxU/QT++P1O/qn/pACIAJoAygHkAtgC2AK8A3gE8ANAA6ADMASwA/ACQAPkA5QDyALUAjwDvALIAbgBLAK2AYsA9/8fAKz/sP5O/rr+wP44/ir+xP70/mj+WP4X/7X/a/9Z/wkAqACjAMoAmgEcAsIBgAHKAaABnADA/6b/WP9o/pz96PxQ+/j4cPeQ9jD1UPOQ8sDyUPKA8dDx8PIw8zDzcPRw9jD3APfQ93j5MPpI+oD7jP3S/n3/BAEAA/QDWATgBSAIkAkgCkALkAzADEAMUAywDCAMAAtwCiAK4Ag4BzgGsAWgBEQDpAJkApABqgCSALkAIwBE/w3/B/9a/qD9oP3A/WD9HP2k/TL+Iv4o/uL+tf8FAFoAIAG6AcYB5gF8AsgClAJ0AtAC7AJ4AigCPAJIAv4B9gFEAkQCuAF6Ac4B4gFiAfQAGAEiAacAOgBNAC4AhP/0/h3/L/+m/i7+fP4A//b+6v6J/0UAWgBUAMYAOgHfADUAJgAzAHD/Hv5Q/dD8uPsI+tD4KPgQ95D1wPTg9MD08POQ81D0MPUg9TD1EPZA98D38PfQ+Nj5MPpg+nj7NP1y/iz/bAA8ApgDYAR4BRAHUAgACdAJ8AqQC2ALMAtwC2AL0ApACuAJQAlACFAHkAaoBYgEyAN4AwwDgAIIAswBQgGzAGAAKgCh//b+tP6O/ib+mP2M/cD9uP2g/fT9hv6y/sL+Mv/4/3sAyQBwAUACqAKgAswCKAM4A+gCvALIApQCEALKAdABnAEaAekAJAEcAaUAZgCjAMAAcgBKAI4AiQD1/3L/W/8l/4r+Lv5s/qT+dv5e/sT+Lf9A/1j/zf9TAHIAawBcAEQA1/8m/1r+dP1s/ED7EPrw+PD3EPdA9qD1cPVw9WD1gPUQ9tD2UPfA91j4EPmo+Sj60PpY+7j7QPw4/T7+9P7H/+UABAL4AiAEeAWABigH+AcQCcAJwAnQCSAKIAqQCRAJ0AggCBgHUAbYBTAFOASIA0QD7AJgAgQC4AGgAToB7gCrACgAiP8Y/8T+Uv7s/cD9pP1o/Uz9hP3A/dz9JP7c/pX//P9WAPAAggG2Ac4BDAJAAiwCFAIsAiwC3gGSAZoBtgGeAXwBoAHWAeIB3AEUAjwCJAL4ARgCNALYAU4B+wDMAE8AqP9W/0n/HP/S/tL+Fv85/zT/af/C/+X/yf+x/6L/Uv/A/hb+cP2w/OD7GPtA+mD5iPjg91D3wPZw9nD2oPbQ9jD3sPc4+KD4OPnw+Yj64Pow+6j7JPyQ/Bj9yP2E/j3/CgD8AOYBwAKcA4gEeAVgBigHwAdACKAI8AgACfAI0AiQCBAIkAcIB3AGwAUoBbgEOAS4AzwD3AKEAigC0AGEATAB3ACRAEsABwC3/3H/Nv8K/+D+sv6A/nD+ZP5e/mb+gP6w/tT+/v4s/1b/dv+c/8r/8f8JACAAOwBJAEwASwBJAEEAOQBKAG8AhwCcAMsAAgEaASQBOgFYAVgBSAFEAToBFgHhALwAkQBHAPP/sf93/zb/AP/Y/qb+ZP4y/gT+xP18/UD9CP20/FD8BPy4+0j74PqQ+mD6KPro+cj5wPnI+dj5GPpY+qj6CPuI+wz8dPzc/Fj92P0+/qb+JP+h/w0AeADwAFYBpAH0AWgC4AJAA5QD8ANIBIgEyAQIBUAFWAVwBYgFiAVoBTAF+ATIBIAEMATcA4ADJAPMAnQCIALQAYYBUAEaAekAvgCVAGwATAA/ADoAJwANAAAAAwD8/+v/7f///wwA///8/wcADQANAAoAFAATABQAGQAgABQA///2//f/+f/1/+L/z/+r/4f/Z/9G/x7//v7u/t7+0P7C/r7+wP7O/tj+4v70/g//Mv9D/1T/a/+E/4n/hv+M/5P/hv9v/2f/bv9r/17/VP9Y/1b/Rv9D/0f/Q/8z/yv/LP8j/wr/9v7c/sD+mv58/lL+Hv78/eT9yP2o/Zj9oP2s/bD9yP0A/jb+WP6K/tL+Dv8y/1v/ov/o/w8AMABqAKUAxgDfABQBTAFoAXQBkgG+AdYB4AHyAQwCGAIYAhwCJAIsAiwCLAIwAigCGAIQAgwCDAIMAggCDAIQAhQCGAIYAiQCMAI0AjQCPAI4AiwCIAIgAhQC+gHiAd4B1gGoAWoBOgEgAfgAxACVAG0APQABAMz/pv91/zT//P7U/qr+bv44/hL+7P3A/Zj9fP1o/Uz9MP0U/fj85PzU/MT8rPyg/Jj8lPyE/IT8kPyU/JT8qPzQ/Oj89PwM/Tz9aP2A/aD92P0G/iD+TP6M/sT+5P4M/0f/fP+h/8z/CABGAHQArQDxACoBTgF4AbQB6AEIAiQCUAJ4ApACoALAAtgC4ALkAvAC/AIAA/wC+AL4AvQC9AL0AvQC9ALwAugC4ALYAsACqAKQAoACdAJcAkgCOAIkAggC7gHSAbABhAFeAUYBIgHxAMEAmwB3AEoAIQD9/9P/pf97/1P/I//w/sj+nv5s/jb+CP7g/bD9gP1c/Tj9EP3s/NT8vPyk/JD8iPyI/ID8iPyU/KT8tPzM/Oz8CP0k/Uz9eP2k/cz9AP44/mr+nP7O/gf/Qf90/67/7v8tAGEAkgDEAPcAJAFQAYABrgHQAfABFAI4AlgCbAKEApACkAKQApAChAJ0AmACVAJMAjwCKAIQAvoB4gHGAaQBgAFsAVgBOAEUAfgA2QCuAH4AWAA5AAsA3v/F/6//hf9V/zT/If8J/+7+3v7U/sL+rP6e/pr+jv5+/nb+ev56/nj+ev58/oD+hP6K/pD+lP6c/qb+rv60/rr+yv7U/tj+5P76/g//Gf8l/zf/TP9c/2z/gf+T/6L/tP/L/+P/+v8RACoAQQBRAGQAegCQAJ8AsADDANgA5gDvAP0AEgEoATQBOgFCAVABXgFmAWgBbgFyAXYBdgF2AXIBaAFeAVYBUgFIAToBKgEeAQ4B+gDmANUAyQC+AK0AlQCCAHIAZABSAD0AKQAWAAAA5//Q/7r/oP+H/3L/Y/9V/0T/Mf8i/xf/C//+/vD+6P7k/tz+1P7Q/sz+zP7K/sr+yP7K/sz+zv7S/tL+1P7W/tL+0P7U/tz+5v7y/gP/Gf8t/z3/Tv9m/3v/if+a/7L/yf/Z/+r/BwAqAEIAUQBnAIUAoQC1AMsA6wAKAR4BMAFIAVoBXgFgAW4BfAF2AWYBZAFmAV4BSAE+AUABOAEiARYBFgEGAesA2QDVAMkAtACmAJ4AiwBwAGEAVwBGACsAFwAJAPr/5//Z/83/vP+u/6j/of+Y/4v/f/90/2X/Wv9Q/0b/Ov8t/yj/I/8d/xj/FP8Q/wz/Cv8N/xD/DP8G/wj/Ev8X/xn/Hf8o/zD/Mf84/0r/Xv9u/3//kf+d/6X/sP/C/9X/5f/1/wMAEgAfACwANQA4AD4ATABbAGIAZQBtAHMAdgBzAHMAdwB3AHMAcwByAGsAYwBjAGgAZwBgAF8AZwBrAGUAXQBaAFsAWQBXAFUAUwBQAE0ASwBIAEIAOQAwACkAIwAYAAkA+//x/+f/2v/Q/8v/xv+9/7f/uf+6/7b/s/+1/7j/uP+6/73/vv+7/7v/wf/K/8//0//c/+j/8f/2//z/BgATACEALwA/AEsAUgBWAFgAXABcAFsAWQBaAFsAWgBVAE4ASQBDADsAMwAvACwAKAAiABoAFgASAA0ABQD9//X/7P/i/9j/0P/K/8T/wP/A/8P/xv/J/87/1//g/+T/5v/q/+//8v/z//b//f8CAAIAAgAGAA0AEgAUABQAEAAKAAYABgAFAAEA/P/7//z/+v/3//X/9f/2//n/+//9//3///8DAAcACQAKAAwADQAMAAoACAAGAAUABgAKAAoABwADAAAA/f/6//r//f////3/+v/6//r/+P/z//D/7//v/+7/7f/s/+3/8P/y//L/8f/2//v//P/7//r/+//9////BAAGAAcADAAWABkAGAAcACMAHwAVABUAFgAOAAEA//8CAPb/5f/k/+f/2v/H/8T/zP/N/8b/x//P/8v/vv+9/8j/zf/F/8D/xv/K/8b/wf/A/8P/xP/G/8r/0P/U/9f/3P/j/+n/8v/8/wUADgAYACIAKQAwADgAQwBNAFMAWABcAF0AWgBZAFoAXgBfAF4AXwBfAGAAYABfAFwAWABVAFQATgBFADwAOQA2AC4AIgAZABYAEwALAAEA+P/w/+f/3//X/8//x/+//7r/tv+v/6f/ov+h/6H/n/+e/6D/o/+k/6L/oP+i/6b/q/+v/7T/uP+8/7//wf/F/8j/yv/N/9L/2f/g/+f/7P/y//v/AgAIAAwAEQAWABoAHAAeACAAIQAgAB8AHwAfAB0AGwAbAB0AGwAWABAACQADAP3/+f/1//L/8f/x//P/9v/5//z//v///wAAAgADAAQACQAQABUAFgAZACAAKQAvADUAPgBJAFAAVABZAGAAYgBhAGMAaQBoAF0AVABRAEsAPgA2ADgAOAAvACkALAAsACQAHQAgACMAHwAZABkAFgAOAAgACAAGAP//9v/y/+//6f/h/9v/1v/S/8//0f/T/9L/0f/O/8v/yf/G/8L/vf+5/7f/tP+z/7L/sP+t/6z/r/+z/7b/tf+2/7v/v//F/8r/z//S/9X/2f/f/+j/8f/6/wMACwAQABUAGwAjACoALwAzADgAPAA9AEAAQAA/AD4APwBBAD8AOwA4ADQALwAoACMAHgAZABMACwADAPr/8v/s/+r/5//j/+L/4//k/+T/5P/l/+f/6f/s//D/8//2//n//f8CAAYACQALAA0ADQANAAoABwADAP//+//3//T/8f/t/+r/6P/o/+j/6P/p/+v/7f/v/+//7f/q/+j/5//n/+f/6P/o/+j/5//m/+b/5v/n/+r/7//z//f/+f/7//v/+v/5//j/9//1//P/8v/v/+z/6v/o/+f/5v/m/+j/6f/q/+z/7//0//n//v8DAAgACwANABAAEwAWABkAHAAgACQAKQAwADgAPwBGAE0AUwBYAFsAXABcAFsAWQBWAFEASwBHAEQAQQA9ADUALAAjABoAEwAKAAAA9f/r/+P/3P/V/8//yf/G/8X/xP/C/8H/wv/F/8r/0P/W/9v/3//j/+f/6//w//X/+/8BAAcACwANAA0ADgAQABMAFgAYABgAGQAaABsAHAAaABkAGQAaABoAGAAWABUAFQAVABIAEAASABMAEgAOAAsACAAEAAAA/f/4//L/8P/y//H/7v/u//D/7f/n/+f/5//i/9r/2f/a/9P/yf/I/8r/wv+2/7X/vP++/7r/vP/F/8n/xv/K/9j/4//l/+j/9P8AAAQABwAOABgAHgAhACcALQAwADAAMQA0ADUANQA1ADUANAAyAC8ALAApACYAJAAiAB8AHAAXABMADQAHAAMA///8//n/9v/z//L/8//1//X/9f/2//n/+v/4//f/+v/8//v/+P/4//v//v/+//3//f/9//3//P/8//v/+f/4//f/9//0//D/7v/u/+7/7v/v//H/9P/1//X/9v/4//v//v8BAAQACAAKAA0ADwARABEAEQAPAA4ADQALAAgABQADAAEA///8//j/9f/y/+//7P/o/+X/4//g/9z/2f/W/9T/0v/S/9P/1P/U/9P/0v/S/9H/0P/P/8//0P/S/9b/3P/j/+n/8P/3//7/BAAKABAAFwAdACEAIwAlACgAKwAtAC8AMgA1ADYANgA2ADcAOAA2ADYAOAA4ADMALQAqACYAHgAYABcAFQAPAAoACQAIAAQAAAACAAQABAADAAQABQAEAAMABgAJAAkACAAKAAwADAAKAAgABgAEAAEAAQABAAEA///+//7//v/9//v/+f/4//f/9v/1//b/9f/0//T/9v/4//j/9//2//f/9//4//j/9//1//H/7v/t/+3/7P/s/+z/6//q/+r/6//s/+3/7f/u//D/8P/w//D/7//u/+7/7v/v/+//7v/t/+3/7f/u/+//8v/1//j/+//9////AQAEAAgACwAOABEAFQAZAB0AIAAjACYAKAAqACwALQAtACwALAAsACwALAAsACsAKgAnACQAHwAaABQADgAHAAAA+P/w/+n/4v/b/9b/0v/Q/8//z//Q/9H/0f/R/9D/0f/S/9P/1f/W/9f/1//X/9j/2P/Z/9r/3f/g/+P/5v/q/+3/7//y//X/+P/6//z///8BAAMABQAHAAkACgAMAA0ADgAOAA4ADwAQABIAEwAVABcAGQAaABsAHAAcAB0AHQAdABwAHAAdAB4AHwAgACEAIgAjACIAIgAhAB8AHAAYABQADwALAAkABwAFAAMAAAD+//3//v/+//3//P/8//3//v/+//////8AAAEAAQABAAEAAgADAAYACAALAA4AEAARABIAEgATABMAEwATABIAEQAOAAoABwADAAEA/v/7//f/8//w/+7/6//o/+X/4//i/+H/4P/e/9//3//f/93/3P/e/+H/4f/i/+P/5f/n/+j/6f/q/+v/7f/x//T/9//7////AQACAAUACQALAAoADQARABAADgAPAA8ACgADAAAAAAD+//n/9//5//j/9f/2//7/BAAEAAYADAASABMAEwAVABkAGgAaABoAGwAbABgAFQAUABIADwAKAAUAAQD7//T/7f/n/+L/3v/a/9j/1v/U/9P/0v/S/9P/1v/Z/9z/3v/i/+j/7//2//z/AwALABMAGQAdACIAJwArAC0ALgAvADEAMwAzADEAMAAuACwAKQAmACMAHgAZABUAEQAKAAQA/f/3//H/6//l/+D/3f/Z/9b/0//R/9H/0v/U/9X/2P/a/93/4P/i/+T/5P/k/+P/4v/h/+D/3//e/93/3P/b/9z/3f/e/+H/5v/r//D/9v/9/wQACgARABgAHgAkACoAMAA1ADgAOwA9AD0APAA4ADUALwAoACEAGwAWAA8ABwABAPz/9//x/+3/6//q/+f/5f/k/+P/5P/l/+j/6v/s/+//8//3//v///8EAAoAEQAWABsAHwAkACUAJgAmACYAJgAlACMAIQAdABoAFgARAAwABwACAPv/8//r/+X/3v/V/83/yP/D/77/u/+6/7n/uv+9/8H/yf/S/9//6//4/wcAFwAqADkARwBVAGQAcQB7AIMAigCRAJMAkACNAIoAhQB7AGsAXABNAD0AKwAVAPz/5P/O/7v/qP+U/4f/f/91/2n/Xf9Z/17/Yv9d/1T/Vv9j/23/bP9s/3v/j/+Z/5z/qP/A/9L/2P/e//D/BAAOABQAHgApADEANgA+AEYASwBQAFgAYQBnAG0AeACEAIwAkACXAKMAqwCwALMAuAC8AMAAvwDBAMUAygDOANAAzADJAMkAxgC+ALUAqgCgAJYAjgCGAHsAcQBoAGMAVgA/ACEAAgDX/5n/Sv/4/qj+VP78/aT9WP0Q/dD8jPxY/Dz8OPw0/DD8QPxo/Kj87Pw0/Yz9+P14/gL/k/8uANYAhgE0AtgCfAMwBNAEYAXQBSAGaAaQBpAGWAYABpgFAAU4BFQDZAJiAUMAH/8K/gD9BPwg+2D60Plw+TD5KPlY+bD5MPrQ+pj7dPxg/VD+S/9FADQBFALoAqQDQATABCAFWAVwBWAFOAXoBIAEAARkA8ACFAJoAb0AFgB5/+b+Zv78/az9bP1E/TT9OP1M/XD9rP3w/Tz+iv7g/jn/kP/j/ykAYwCUAL4A3gDsAOoA3wDMAKsAeQA/AAYAz/+N/0T/Af/K/pz+dv5S/jz+Nv4+/lL+bv6Q/sL+Af9D/37/vf8JAFsAowDeABYBVAGOAbYBzAHcAeYB5gHOAaoBhgFcASwB7gCtAGwALwD3/8H/i/9d/zz/Kf8Z/wf//P4G/xn/Kf83/0v/a/+L/6T/uv/R/+3/CAAaACkAOQBLAFcAWwBbAF0AYgBeAFIARAA5ACwAGAACAO//3//O/73/sP+o/6H/mv+V/5T/l/+d/6b/sf++/87/4P/y/wEAEwAnADoARQBLAFMAXABiAGAAWQBVAFMATQBEADwAOAAyACcAHAAXABUAEgAPAAwADQAOAA0ADQAOAA8ADwAPAA4AEAARABIAEQAQAA4ADQAMAAwACgAHAAEA+//1/+//5P/a/9H/yv/D/7v/tP+w/6//r/+u/6//sv+4/7//xf/M/9T/3f/n//D/9/8AAAoAFAAdACYALwA4AD8AQwBFAEYARQBBADwANwAvACgAIgAdABgAEgANAAsACQACAPr/9//4//X/7v/p/+f/5v/k/+D/4P/l/+j/6v/s//H/9//+/wYADwAWAB0AJQAsADAALwAyADYANgAxACwALAApACIAGQATAA8ACwAHAAQAAAD8//v//f/+//7//v///wAA///9//n/9f/v/+j/4f/d/9r/2P/V/9T/1v/Z/97/4f/l/+v/8f/4////BgAJAAwADwATABcAFgAVABUAFQARAAsABwAEAP7/9P/q/+T/4P/a/9X/0f/O/8r/xf/D/8T/xf/G/8X/x//M/9L/2P/d/+T/7v/4/wAACAAQABkAIAAlACcAKAAqACsAKQAjABwAFAAMAAUA+v/w/+f/4v/e/9j/1P/S/9X/2P/b/9//5v/v//j/AAAKABYAIgAsADYAQQBKAFEAVgBZAFkAVgBTAE4ARgA7ADAAJwAeABQACgADAP7//P/7//v//P/+/wEAAwAHAAoADgASABQAFAATABAADAAGAP3/9f/t/+b/3P/R/8n/wv+7/7T/r/+r/6r/qv+q/63/sf+3/7//xv/P/9n/5f/w//r/BAAQAB0AKAAxADoAQwBJAE0ATwBOAEsARQA9ADMAKAAcABAABQD7//H/6f/j/+D/3P/b/9z/4P/k/+j/7P/z//z/BgAQABsAJQAuADcAQABHAE4AUwBXAFkAWgBZAFgAVgBSAE0ARgA9ADQAKgAgABUACQD+//T/6v/g/9f/zv/G/7//uv+1/7L/r/+t/6v/qv+p/6r/rf+x/7P/tv+7/8H/xv/L/9D/1//d/+H/4//m/+r/7f/t/+v/6f/o/+f/5P/f/9r/1f/Q/8n/wv+6/7T/r/+q/6b/pP+n/6z/sP+z/7//yf/X/+X/9P8HABYAJQA4AEoAVQBfAGkAcQB3AHoAfQB+AHsAdABvAG0AawBjAFsAVgBQAEkAQQA6ADQALwAoACEAHAAYABMADgAKAAcABAAAAP3/+v/4//X/8P/s/+n/6P/n/+b/5v/n/+n/6f/o/+j/6v/r/+r/6P/m/+b/5v/l/+P/4//j/+T/5P/h/+D/4v/l/+T/4//j/+b/6//t/+//8f/1//f/+v/9//7/AAACAAQABQADAAMAAAD+//n/9P/t/+f/4P/Z/9H/yf/C/77/u/+6/7z/wP/E/8z/1f/j//D//P8JABYAJQAyAD4ASgBVAF8AZwBvAHQAeAB5AHoAegB4AHgAcwByAGwAaABjAF0AWABRAE8ASgBGAEEAOgA2AC0AJgAbABAAAgDz/+X/1v/I/7j/q/+f/5X/jP+C/33/ev97/3r/fP9//4T/jf+U/53/pv+y/7//yP/W/93/6P/y//3/BwAOABUAGwAkACcAKgAuADMANgA6ADsAQwBDAEkASwBQAFMAWABdAGIAYgBiAGcAaQBpAGsAawBqAGsAaQBpAGQAXwBaAFYATwBHAEIAOQAyACsAJAAeABQADQABAPf/7v/j/9v/zv/B/7X/qv+e/5P/hv94/23/Yv9X/0z/Rf86/zT/Jf8Y/xT/Dv8G/wb/Bv8C/wP/Bv8J/xH/F/8f/yP/K/84/0L/UP9W/2P/d/+I/53/qv/F/9n/8v8IAB8AOQBWAHEAjACoAL0A1QDoAP8ACgEQARoBIAEoASQBIgEiASQBIgEgASQBJgEsATABNgFAAUYBTAFQAVwBZAFmAW4BZgFmAVwBUgE4ASoBCAHpAMMAngB5AEgAJAD2/9b/s/+W/3f/Yf9I/zX/IP8Q/wD/9P7u/ub+5P7e/tz+3P7W/tT+0v7Q/sj+xP62/rD+ov6Q/nz+YP5E/iT+Av7g/bz9lP10/VT9NP0Y/QT9/Pzs/Oj88Pz8/BT9LP1Q/Xz9rP3k/Sr+aP64/gD/Wf+s/woAZAC/ACIBjAHwAVQCvAIoA4wD9ANQBKAEAAVQBYgFwAX4BRgGOAZYBnAGaAZ4BnAGaAZQBjAGEAbgBbAFcAUgBdgEgAQoBMQDXAPsAnAC8gF4AesAWQDI/zP/lv70/Vj9tPwM/Gj7yPow+oj5CPmA+Bj4sPdg9zD3IPcw90D3gPfg91D42PiA+Tj6CPvQ+5T8XP0a/r7+S/+z/wQAGwAfAPH/mv8j/3r+vP3s/AD8CPsQ+iD5SPhw99D2UPYQ9vD1IPZg9iD38PcA+Vj6yPuU/VX/UgFsA4gFkAeQCaALgA1AD+AQYBKgE6AUgBUAFmAWgBaAFiAWwBUAFSAUIBPAEYAQ8A6ADbALAApQCIAGsATkAhoBWf+g/ej7UPrA+ED3wPVg9BDz4PHA8MDv4O5A7qDtQO0A7cDs4Owg7YDtAO7A7oDvsPDQ8SDzcPTw9YD3IPnI+mz8FP6s/zwBpAL8A0AFYAZYB0AI4AhgCcAJ8AkACuAJkAkwCaAIAAhIB3AGmAWoBLwD1ALmAQwBPgCC/9T+KP6g/ST9yPxw/Dz8HPz4+wD8APwg/ET8WPx0/Jj8uPzM/Oz8BP0U/TD9YP18/bj9/P1U/rT+Hv+p/zIAxgB4ASQC0AKcA2AEMAUABuAGuAeACEAJ4AlwCvAKQAuAC5ALkAtgCyAL4ApgCuAJQAmACLgH0AbgBdgE1APcAtQBwgDA/87+2P34/BT8QPuA+sD5EPmI+OD3cPcA97D2cPYw9iD2APYQ9hD2IPZQ9nD2wPYg94D3IPiQ+DD52PmQ+jj7+Puw/Hj9JP7W/qT/QgD0AKYBRALAAlQDvAMYBHAEkATABOAE4ATgBNAEsASABEgEEATEA2wDJAOsAmACAAKOASQBsgA8AM3/Q//G/j7+sP0k/Yj8APxY+8D6IPpw+eD4MPig9zD34Pag9qD2oPbg9lD30Peo+ID5mPrw+0j9uP5pABQCyAOIBTgH0AiACgAMYA2wDtAPwBBgEQASQBJgEkAS4BFgEcAQ4A/gDsANgAwgC6AJMAi4BkAFxAM8AtEAaf8c/tz8qPuA+oD5ePig97D24PUw9YD0APSA8xDzwPKQ8mDyUPJg8nDyoPLw8lDz4POA9DD1EPYA9wj4CPkw+lD7bPyY/bL+xv/eANgB0ALAA5AESAXoBVAGsAboBhAHCAfwBsAGeAYgBqgFMAWgBBgEfAP4AmwC+AGIARwBtQBiABMAsP9j/wX/yP5c/gb+qP0w/dT8TPzI+zj7kPoA+nj54Ph4+PD3wPeA94D3oPfw93D4MPk4+lD7qPwS/qD/VAH8ArgEgAZQCPAJkAswDZAO0A8AEeARgBIAEyATABPAEiASYBGAEGAPIA7ADEALsAkACFAGmATYAiIBef/s/Xz8KPvo+dj40Pfw9iD2YPWw9CD0sPNA8wDzwPKQ8pDykPKg8tDyEPNw89DzUPTQ9HD1MPbw9tD3yPjI+dD64Pv4/BT+I/8mADABJAIYA/QDwAR4BQAGeAbYBgAHIAcQB/gGwAZ4BiAGsAVABbgEOASsAzwDqAI4AswBbgEYAbYAVwD8/4z/GP+Y/hz+kP0A/YT8+PtY+7D6APpQ+aD4EPhw9/D2kPZQ9jD2UPZw9uD2kPd4+JD52PpM/OD9mf9iATgDCAXYBrAIcAogDLANEA9gEGARQBLgEiATQBMgE8ASIBJgEWAQQA8QDtAMcAsACoAI8AZoBdgDTALUAGP/CP7I/Jj7iPqI+aD4sPfQ9gD2QPWg9AD0gPMQ87DyYPJA8iDyIPJA8nDysPIg86DzMPTQ9JD1cPZQ90D4WPlo+oD7kPyk/b7+vf/UANQBwAKUA1gE+ASYBQgGYAaYBqgGuAaoBogGQAb4BaAFUAXQBGAE9AN8AxQDtAJUAvYBjAE4AdAAUgDq/1n/4v5S/sT9NP2U/PD7MPt4+rj5APlA+KD3EPeg9kD2EPYA9jD2kPYw9xD4OPlg+tj7bP0y//YAwAKYBHAGQAgQCvALgA0AD0AQYBFgEuASQBNAEyAT4BIgEmARYBBQDxAO0AxgC/AJYAjYBkgFwAM8AsMAav8Q/uD8yPvI+sD52Pjw9zD3YPaw9RD1cPTw84DzMPPw8sDykPKQ8sDy8PJA88DzUPTw9LD1gPZw92D4WPlg+nj7iPyY/bD+tf+7ALIBgAJUAwgEoAQwBYgF2AX4BQgGAAbQBZAFQAXgBHgECASEAyADtAJIAuABigFAAQ4B3ACoAHwATAAWAN7/jv88/9T+ZP74/WT9yPwQ/GD7oPrw+SD5WPjA9zD30PaA9lD2UPaQ9gD30PfY+BD6iPs0/QL/yQCYAogEcAZgCEAKAAywDUAPoBDgEeASYBOgE8AToBMgE4ASgBFgEEAP8A2QDBALkAkACHAG8ARgA+IBfAAu//z95Pzo+/j6GPpI+YD40PcQ94D24PVg9eD0cPTw86DzYPMQ8+Dy0PLw8iDzYPPQ82D0APXA9YD2cPdo+Hj5ePqQ+6j8xP3U/ub/1gC6AYwCTAP0A3AE4AQwBWgFeAVYBTAF6ASIBDgEsANAA8QCUALkAZQBRgH4ANMAuwC0AK8AqwC5AL0AwQCuAJEAaQAwAND/Zv/g/kD+jP3k/Cj8SPtw+qD56PhI+KD3QPfw9uD2APdg9xD4+Pgo+pj7MP3m/p4AeAJYBDAGIAgACsALcA3wDmAQgBFAEuASIBMgE+ASQBKAEaAQgA9QDgANoAtACtAIWAfQBWgE9AKUAUkAHP8M/gT9KPxY+5j60PkI+WD4sPcA92D24PVA9dD0QPTg83DzIPPg8sDy0PLg8iDzkPMQ9MD0kPVg9mD3aPhw+ZD6wPvo/Ab+G/82ACQBBALMAmwD7ANIBKAE4ATwBOAEsARwBCAEyANIA+gCiAIUAsYBiAFSASABBgEcASgBOgFUAWYBiAGaAaABkgFkARwByQBXAMT/Df9G/mj9gPyQ+5D6kPmg+MD3APdQ9tD1gPVw9aD1IPbg9uD3KPnA+nz8Xv5gAGQCcAR4BoAIkAqADEAO0A8gEWASQBOgE+ATwBOAE+ASIBIgEeAPkA5ADeALgAoQCZAHKAbQBGwDKALYALL/sP68/ej8FPxA+3j6sPno+Dj4cPeg9vD1QPWg9AD0cPPw8pDyYPIw8jDyUPKg8hDzsPNw9FD1MPYg90D4UPlo+oD7qPzQ/eL+3f/IAKIBTALgAlwDxAP0AzAEQAQ4BAgE3AOoA1wDIAPMAoACXAI4AiwCKAI4AlACbAKwAtgCCAM0A1ADZANsA1ADEAPAAkgCygEGATEAQv9Q/jj9LPwg+/j5+Pjw9yD3cPbA9WD1MPVQ9bD1YPZQ92D44Plw+0D9LP82ATQDSAVQB2AJUAsgDcAOIBBgEWASIBNgE4ATQBPgEiASIBEAENAOcA0gDNAKYAn4B7AGWAUABLQCaAFLAED/QP5M/Wz8iPuo+sj5+Pgo+FD3YPaA9cD08PNQ87DyIPKw8XDxUPFQ8YDx0PFg8hDz8PPw9AD2MPdg+Jj50PoM/FD9gP6P/6YAlgFUAvgCbAPUAwgEOAQwBDAEEAS4A3gDQAP8AqgCZAIgAgQCCAIEAhwCSAJ8AsgCGANcA6ADzAP0AxAECATcA5QDMAOgAvIBFgELAPT+8P3I/KD7WPo4+Sj4MPdQ9oD18PSA9GD0kPQA9bD1oPbw92D5CPvU/MT+1wDsAhAFOAdQCTALAA3ADkAQYBFAEgATYBNgEyAToBIAEgAR0A+gDnANEAywCkAJAAjQBngFOAT8AsoBuAC7/8T+5P3k/AD8KPtI+mD5YPiA96D2wPXw9DD0YPPA8iDy0PGQ8YDxkPHQ8UDyAPPg88D04PUA91j4uPkY+3T8oP3g/ggAGgEQArACRAOwA/ADKAQoBPwDwAOEAzwD1AJgAuoBjgFGAQIB0QDCAKsAxAAKAVgBrgH0AVwCtAIIA0wDgAOgA6QDkANkAxQDdAK6AfQAAgD8/uD9yPzA+5j6sPmw+OD3APdQ9uD1oPWg9bD1EPbg9uD3IPmQ+hj8xP2K/2QBXANABTgHAAnACpAMAA5QD2AQIBHAEQASIBIAEoAR4BAAECAPAA7QDIALYApQCTAIAAfABaAEcANcAk4BMgAh/wz+EP0o/Bj7+PnQ+ND30PbQ9dD08PMA80DysPFA8fDwwPDQ8BDxoPFQ8iDzAPQQ9VD2oPfo+Bj6YPuc/Mz97P7j/68AVgHUAUACeAKIAnACTAIcAuYBtgFwARoB4QCoAJUAlQCSAKgA4gAsAZQBBAKEAgwDpAM4BJgE+ARABWgFcAVoBUAF6ARQBJwDwALIAbAAjv9c/jD9DPz4+gj6GPlQ+KD3EPfA9nD2UPaQ9uD2kPdw+Ij54PpM/Oz9sP90ATAD6ATABqAIUArwC0ANgA6AD4AQIBGAEaARYBEgEaAQ4A/wDuANsAyAC1AKMAngB6AGcAVIBDADBALnANr/4P4E/hD9DPwY+zD6aPmQ+LD3wPbg9RD1UPSw8xDzkPIw8hDyMPJw8tDyYPMg9AD1APbw9hD4KPlQ+oD7uPzc/b7+m/9dAB4BhgG6Ab4BsgGWAVIBBAGvAC8AyP94/07/Mv/4/vj+Hf9k/6n/EgCFABQB1AGoAnQDOATABGAF6AVYBngGiAZgBhAGoAXwBDgEMAP8AcgAoP9U/hD92Pu4+sD52PhI+MD3QPfw9tD28PYw96D3YPhI+XD6sPso/a7+RgDSAYQDMAXYBlAIsAkgC1AMYA1ADuAOUA+gD7APsA9AD7AOEA5QDYAMkAuACoAJYAhIB1AGSAU4BAwDBAIiASgAIP9C/mT9ZPxg+3D6mPnQ+OD3APdQ9pD1wPRA9NDzgPNg83DzwPMw9KD0MPUA9vD20Peg+Ij5mPqY+4T8aP06/vr+dv/Y/xMAHQDw/7v/Y//+/nz+8P2c/Vj9EP3M/Mz8BP1Y/bj9Ov70/qr/lQCcAcAC1AO4BLAFsAZ4B/gHQAhwCGAIEAiQB9gG4AW4BIQDSALrAGH/4P2I/Ej7OPpA+Yj48Pdw9zD3IPcw91D3kPcA+MD4mPmY+tD7KP2S/gYAlAEkA6AE+AV4B/AIcAqgC8AM0A2gDlAPwA/wDwAQ8A+gD1APoA7gDdAM8AvgCtAJoAhgB0AGEAXcA4QCSgEFANL+sP2U/HD7WPpY+XD4kPfA9vD1QPWg9AD0gPMg8xDzIPNg88DzQPTg9JD1cPZg91D4MPkg+gj74Puk/Gz9OP7u/l3/pv/M/7T/bv8N/6r+Hv6E/Rj9zPyg/HT8YPyI/Oz8WP38/cr+v//JANIB8AIIBCgFIAb4BsgHUAiwCNAIwAiACPAHEAcQBhAFyANkAvsAm/8o/sT8gPt4+nj5sPgI+MD3gPdQ90D3YPeg99D3KPiY+Gj5OPpA+3z8wP0I/08AxgFMA7AECAaQBzAJwAowDJANkA5gD/APgBDAEMAQYBDwD3APsA6QDXAMIAvACVAIAAe4BTgEuAJqAUEAG//Y/az8sPvI+hD6cPnY+Dj4kPcQ97D2YPbw9ZD1YPVw9ZD1wPUA9mD28Pag91j4IPnA+Wj6GPvg+4D87PxU/cj9Pv6G/qL+kv40/oz95Pxc/Oj7SPuo+mD6UPpo+oD6wPpY+wz8CP04/pT/6AA0ApgDIAWABpgHkAhwCTAKwArQCqAK8AkQCRAI2AaIBeQDFAJcAOD+cP3o+2j6KPlA+KD3MPfg9rD2sPbg9kD3wPcw+Kj4UPlY+pD7uPz4/Ur/sQAkApgDEAV4BtgHUAnwCnAMoA1wDmAPIBCAEMAQ4BDAECAQcA+wDuANsAwwC6AJUAj4BoAFEATYAoABNQAH/wb+EP0A/BD7aPoQ+pD5APl4+CD44PeQ90D3IPfw9sD24PYQ91D3cPfQ94D4MPng+Yj6IPuY+wT8oPwg/Vj9UP1k/ZD9jP0o/aj8EPxI+1j6qPkg+WD4oPdg97D3CPhQ+Nj44Pko+2z8/P3C/3oB4AJwBBAGYAdgCFAJYAogC0AL8AqACsAJkAhYBxgGsAQIA2IBDQDm/pj9NPwo+2D6uPk4+QD5CPnw+OD4CPmA+cj50PkI+qj6kPtc/Cz9YP6+//0AHAKIAzAFoAbgB3AJMAuwDJANUA4gD9AP4A/QD8APYA9wDlANUAxAC9AJMAjIBqAFYAQUA/AB4gDQ/9b++P08/XT8sPsg+9D6ePoI+qD5MPno+Lj4ePgg+OD34PcI+Bj4OPiI+Pj4kPlA+jj76PtU/Kz8RP20/aT9cP1Y/UT93PxQ/OD7QPsw+iD5iPjw9/D2APag9dD1APYw9gD3QPho+cD6pPzW/rQANAL0A+AFgAeACFAJgApgC8ALwAuQC/AKsAlgCEAHIAawBCAD7gEQAe3/oP6A/aD8sPvw+oD6aPoI+oD5OPlI+WD5OPkY+Tj5mPkY+vj6BPwc/ST+cv80AegCeAQgBhAIIArQC0ANYA4gD4AP0A8gEOAPMA9QDpANoAxAC9AJgAhAB/AF2AT4A/AC0gH5AIYA9P8R/zj+rP0Y/Wj84PuI+/j6IPqg+Xj5MPmQ+CD4QPho+DD4SPiw+FD5uPlg+mj7VPzY/Aj9kP34/dD9MP2w/FT8wPvw+jD6mPmo+ID3sPYw9rD10PRA9GD08PRw9VD2oPdA+dD6lPzk/i4B9AJYBAAGmAewCDAJ0AmACuAK4AqwCjAKMAn4B+gGEAYQBcwDyAIUAnIBfwBq/07+SP2I/AD8ePug+sj5KPnY+ID4QPgA+ND34PeI+Lj54Prg+yT91P6gAEQCGAQABtAHgAlgCzANQA6QDuAOcA+QDwAPUA6gDbAMcAtwCrAJoAgQB9AFQAWwBKQDeALOATQBSwBX/67+9P3c/Nj7aPsg+2j6mPlg+Yj5aPlA+Xj58PkY+kj6APvw+2j8iPwY/fz9lP66/tr+Bf+8/gj+bP3c/Az8yPqw+SD5gPiQ96D2EPaQ9QD1cPQg9BD0EPSA9GD1gPbA90D5EPs0/WH/WAHkAlAE2AWIB+AIwAlQCsAKEAsAC+AKkAqgCWAIYAeYBmgFAATkAhgCCAGT/2r+oP2g/HD7sPpg+qj5sPgw+Gj4aPgQ+CD44Pi4+Uj6OPvQ/Fz+mf8cATQDMAWYBhAIIArQC8AMgA2QDlAPMA+wDoAOIA7QDIALAAugCnAJ4AcYB6AGkAVABKQDUANIAu8AWwAeAAn/gP2I/FT8oPuA+vD5EPoA+pj50PmY+vD6uPoY+xj81Pzo/Cj9yP0q/gb+Dv54/nT+4P1k/ST9ePxA+yD6UPlg+GD3sPZQ9sD1IPWw9ID0IPTA88Dz8PMw9ND0MPbw97j5oPsg/nEAEAKIA5AFqAcgCUAKgAtADNALEAsgCzALIApwCFgHuAZwBaADdALQAXMAzv4C/uD9+PyA+7D6sPpY+jj5mPjI+MD4OPhY+Fj5OPqI+iD7tPx2/sX/IAEgA0AF6AZACNAJQAsADHAMIA3wDSAOkA3ADBAMQAsQCuAIEAiIB6gGsAUABbAEIARAA5wCdAIgAiYBVwDk/1j/Nv4c/aj8SPyA+9D6+Ppw+4j7qPtM/Mz80Pzg/LD9lP6e/kj+av66/mz+3P2M/Wz9qPy4+zj72Pq4+Tj4UPcQ96D20PVg9XD1QPXA9JD0sPRw9BD0EPTw9PD1EPew+Dj7rP23/7YBnAM4BbAGgAhAClALoAvAC7ALQAtwCuAJ8Ah4B/gFIAVQBLgC9gDX/1z/fP5c/aT8KPww+xj6yPno+UD5IPjQ94D48Pjg+JD5GPto/CD9cP6dAIACxANwBdgH0AmgCjALMAzgDBANEA1wDUANUAxgC8AKAArgCPAHWAfABvAFQAXQBCgENAOQAjwCmgGdALH/Ff9Y/mT9xPx0/AD8YPtY+wT8wPwk/bT9nv4u/zP/Of+m/+D/g/8a/wX/wP7w/TT91Px8/Mj7KPvo+pj62Pno+ED4kPfQ9jD2wPVA9cD0UPQQ9JDz8PLQ8iDzgPMw9OD1OPiY+hT9FgD8AsAEsAVQB2AJoAoQC7ALUAyQCwAKUAlgCYAIgAZQBTAFWASUAo4BYAFxALT+2P3A/Yz8WPo4+Xj5CPmQ9wD3sPcA+LD3oPjQ+kz8zPw4/toA5ALAAwAFQAcACaAJMAowC3ALAAvwCrAL8AsgC7AKkAoQCuAIIAj4B2AHMAaABWAFoAQ4A0QC+gFcATEAaf8g/4r+qP1E/WD9QP3Y/Nj8dP34/Yj+Wf8bAEsAPgBrAH8A9/9e/0T/Jv9i/qT9kP1w/ZD8wPsQ/Ej8WPsg+uj5uPkY+FD24PXA9WD04PIQ88Dz0PKA8UDyoPNg89Dy4PRA+OD5CPt8/sQCIASsA2gFgAgACcAHcAigCqAKQAiQB9AIgAg4BmgFeAYIBpwDFAJ0AggC4P8s/sz99PwI+6j5UPnY+OD3oPdI+LD4uPhg+dD6NPyM/T//5wDoAewCgAQQBugGqAfACKAJwAngCYAKAAsACxALYAtAC3AKgAlACcAI0AcYB9gGKAb4BBgEmAP4As4B8QCLAPn/AP9c/jj+5P1Q/Rz9jP3Y/fj9cP5l//H/AgAfAGQAJQBP/9z+1P6k/uD9QP0g/Qz9qPxU/HD8sPxs/Hj7iPro+fj4MPdg9cD0oPSQ8yDyQPKQ8+Dz0PLw8qD0cPUw9cD28Poc/nL+P/+IAhgFuARYBFgGQAjABygH0AgQCqAI+AbIB+AIsAfABXgFWAVUAxwBjQA1AFb+XPzo+7D7SPoA+WD5KPrw+bD5ePpI+1j7sPsQ/YD+Kf/Y/xoBZAJEA2gEMAbAB7AIUAkACmAKkArQChALAAuQCgAKcAmgCOgHaAcIB6gGYAYIBmAFeAS0AyQDdAKGAcQAJgBr/57+Qv4q/uD9hP20/ZT+Ov9f/6r/ZQDUAHsA+P+s/yj/MP6g/dj98P1E/Zz8xPww/ST9/Pz0/Hz8aPs4+lD54PcQ9uD0YPSw8+Dy8PLg81D0IPSQ9ED1MPXg9GD2OPko+xD8GP4YAcQC4ALAA8gFkAb4BXgGcAgQCagH+AboBzAIwAbIBQAGQAXMAgAB0gAXAOT9ZPyU/Dz8YPoo+fD5oPrw+bj5APvY+xD70Ppg/AT+Sv6a/lsAOALoAqADsAXgB8AIEAkACgAL0ApACoAKAAvACuAJYAlACcAIEAjAB6gHOAeIBvgFSAUYBNAC8gE2AVsAmP9R/x//mv4m/k7+tv7O/vD+f/9HAKcArwDjAAABlADj/4v/ZP/w/mD+Kv4Y/sz9mP3s/SD+uP1E/SD9UPxo+qj48PcA9+D0IPMg81DzoPLA8qD04PVw9ADzcPSA9sD2MPdA+qD9dv6q/iAB3AMIBMAD2AVQCPAHsAaoB1AJkAgYB5gHUAiIBigEAARQBEACiv8n/4j/0P1Y+8D6MPtg+lD56PkA+5D6sPlA+mj7qPvo+0z9tP47/xQADAK4A1gEaAWQB/AIoAhwCGAJ8AlgCWAJcAqgCnAJwAhACUAJIAhIB2AH+AaYBagEUAR0A/oBTAFmAeUA1P+E/9j/j//W/vL+pP+H/xb/rP/qADIBpADNAGQBJAEvAPb/OACZ/4r+ev4v/8r+0P0C/gT/sP7w/CD8GPxg+iD3oPVA9jD14PGA8ADzMPUQ9ADz8PRQ9iD0EPIw9ND3kPiY+Pj7YwA4Afv/kgFYBegGqAWIBTgHyAeoBmgG4AdwCAgHsAXQBcgFKAT8ARIBHgFbAGD+qPwc/KD7ePqg+TD6EPtw+kD5mPn4+kj74Prg+0b+mv+D/00AoAJIBKgEeAVwB5AIMAjgB/AIAArwCeAJYAqgCjAKoAlQCSAJkAjwB3AHqAa4BdgE5APMAgwCugEwATEAi/93/0L/jP46/r7+LP8P/yT/0P9nAHYAXQBYAA0Av//Q/67/7P6Q/kT/tv/W/nL+0f+iAML+mPyo/Jj8QPmQ9dD1QPcA9WDxIPIQ9qD2APTQ8+D1oPTg8ADxcPXg9wD3mPjI/bMAhf/5//gDSAbABBAEcAaIB6AFEAXoB8AJEAioBsgHUAggBuQDzAOcA2QBE/86/rz9fPyI+6j78Pvw+9j7cPug+lj68PpQ+0D7CPwI/jP/Pf9oAAgDwAS4BFAFOAcQCAgH0AaQCMAJEAngCFAK8AqgCaAIYAmwCSAIqAawBmAGkAQcAzQDRAPkAbEA7QAOAcv/pv7g/jf/fv78/dr+nf8k/9b+6f/EAPn/9P5h/xQAgP+u/u7+hP9H/xr/3/9xAMT/xP40/kz9iPvA+WD40PaA9WD1sPUA9XD04PWw93D2gPOA8kDzAPOA8iD1oPnI+6j7lP1OAYgCRAG8AVAE0AQcA1gDGAaAB+gGuAfQCaAJ+AbgBYAGQAU4AgwB3AH0AEL+eP3Q/tr+IP2U/HT9/PzY+sj5cPrI+oD6cPtk/Yz+B/8zANoBqAIIAxAEIAUoBSAFSAaoB/gHIAhwCZAKEAowCXAJ0AnACHgHqAfwB6gG8ATYBDgF4AP0AboBYAJeAX3/N/8ZAJ7/NP58/ioAXgD0/rj+GgCMAGP/4v7K/ysAOf/w/u3/ZwC6/5L/ggDpABYAUv/i/qT94PvI+tj58PdQ9rD2YPcw9uD0QPbA9+D1QPKg8fDysPJA8kD14PkY+1D6RPzu/0MAVP4a/xgCsAJaAaQCMAaIB/AGEAgQChAJIAaIBaAGgAWkAswBxAIoAkIA4f+nAAYAcP4O/gD+cPyY+pD6OPvI+oj6EPzE/eT9EP6//wgBcgAWAKIB/AJ0AkQCIAQQBigGGAaQB9AIMAhwB/gHcAhgB3AG2AY4B1AGcAWwBcAFsASYA4QDSAMQAv4ADAEiAX0AGQCtADoB0wBxAMUA9wBgANf/CgAzAM3/lf8OAE4AHgBTAPIA5AARAMH/v/94/jj8KPtw+3j6SPiA97D42Pgw93D2gPcg9yD0YPKg8+D0UPSQ9JD3QPog+sj5oPt8/RD9OPyo/bL/EAAgAOgBMATYBLAEeAVoBvAFyARwBIgE/AMsA+wC8AKkAkgCKAK0AeAAGwBp/0z+JP2g/Jj8cPxs/Dj9JP5K/jT+1v5s/y7/sv5F/10AwgDNAOgBkANgBJAEOAV4BggH0AboBrgHIAjYB9AHUAiQCCAIwAe4B4gH6AZoBhAGiAXABEgEGASYA/wCzAK4AggCEAHEANkASwBt/1P/wf92/4j+TP7C/q7+1P2E/Tj+Yv58/aT8yPzM/Kj7OPrY+fj5WPlg+HD4KPnw+ID3YPYw9uD1QPWA9RD3SPhQ+Ej4OPkI+sD5gPmQ+gj8jPzI/OD9ZP8SAD8AAAEUAmgCOAJsAggDVAMUA/wCVAOoA7ADjAOEA7ADqAMcA0QCxAHCAYIB2wC7AGAB1AFwASgBjgHKARIBfAAIAZ4BTgHyAKABjAKUAnACFAPoA+wDtAMgBKgEgARQBMAESAUQBcAEEAVwBRgFqATIBNgEMARoA3ADnAMgA4ACoAL8AoAClAFUAYQBFAFBABIAgQBsAMr/oP8bABgAa/8z/4f/if/i/oT+mv5E/mD9zPzc/LT8CPyg+6D7aPuY+rD58PgY+HD3YPew98D34PdI+Hj4KPjg9yD4YPhY+KD4qPmA+qD6CPtU/FD9RP2M/ej+6P+b/2X/awBCAdIAnADYAQQDwAJsAlgDGARQA2QCyAJEA5gC+AGUAjgDvAJAAsgCJANoAswBUAK8AjAC4gGUAhwDtAKEAkwD6AOkA5ADaAQIBagEgAQ4BdAFiAVIBdgFUAbYBWAFuAX4BXAF2AQIBSgFmAQQBDgEaATUAzQDMAM0A5wCFAIsAlwC7AFkAWgBXgHVAGAAeQCRAC0AuP+p/2v/jP7A/Wz9CP0w/Ij7YPsI+yD6aPkI+TD4oPag9aD1oPUw9VD1UPaA9nD1wPRA9aD1QPWQ9QD3EPjg9xj4WPlQ+lD6+PrA/Oj90P0G/kj/BQC4/xcAsgHEApwC4AIgBLgECATAA5AEAAVYBBAE6ARgBdgEkAQYBUAFeAQIBIgE2ARgBCgEoATIBCAEuAMwBIgEUARIBOAEMAXQBJgEAAVQBQAF6ARIBVgF4ASgBNgE8ASQBFAEaARQBOgDrAPEA5gDDAOcAoACOALAAaQB8gH8AY4BRgE8Ae0AQAAEADAACwB3/xj/I//E/uT9QP0Y/Xj8cPvY+qj6APrY+Dj44Pfw9oD18PRQ9SD1sPQg9fD1sPWQ9GD0MPVw9TD1MPYA+ND4iPj4+Fj6GPsg+9j7fP16/pz++P4jAAIBKAGcAbwCsAPsAxgEsAQwBRgF+ARIBagFsAWYBdgFOAYgBqgFaAU4BfAEkAR4BKgEsARwBEgESAT8A4wDdAO0A8wDtAO0AxAEMAQoBFgEuATABIgEgATIBNAEcASABOgE4ARYBEgEoASYBAgEyAMIBMQDCAO0AgwDGAOoAoAC0AKoAt4BWgFeATABjAAvADcA4f8P/3z+PP6Y/Xz8uPtY+5j6cPnQ+JD4gPfw9SD18PRQ9IDz4PMA9fD00POA80D0MPRw8/DzAPYg99D2cPdw+Wj64PmA+qz88P2M/ez94f/mAGUAuQCoAsQDRAN0A/gEsAXgBLgEuAXwBQAF6AQABlAGqAWQBUAGAAbYBIgEAAXYBCAEQATgBJAEuAPcA2gECARkA8QDgAQoBJwDIAT4BLgEKASoBDgF0AQ4BKgESAXgBDgEgAT4BIAE/ANgBMgEUASoA6wDsAMEA5ACBANYA8wCSAJwAkQCYAG0ABIBFgEgAGD/lv+I/z7+IP0Q/dD8SPvQ+bj5qPlQ+OD2sPZw9vD0gPPA83D0MPSw83D0EPUw9FDz8PMA9SD1kPUw98D48PgQ+Uj6iPu4+yj8vP34/vr+Wf/UAOwB4AEkApQDeAQoBDgEYAXQBfgEuASQBegFKAUwBVAGoAagBSAFuAWIBVAE7APYBCAFSAQQBOgECAX8A6ADYARwBKQDnAOQBNAEIAQYBOAE4AQgBDAECAUIBUgEUAToBLgE3APUA5AEgATMA7gDOAT8AxQD+AKMA4gD0AK0AigD/AIUApoB5AGqAckATQCCAEMAOP9u/jz+nP0w/CD7yPo4+uj40Pdw96D2IPXw8+Dz4PNg81Dz4PMA9FDzsPIA84DzkPNA9ND1IPew90j4YPk4+oj6KPt0/JT9HP7i/ikACAFAAcoB7AKYA6gDAAToBEAFwASgBDgFaAUABRAF0AX4BWgFOAWYBVAFcAQoBKAEuARABGgEGAUYBVgEIASABHgE/ANQBDgFgAUYBRgFeAVQBdgE+ASABYAFEAUQBUgFCAWIBJgE4ASoBDAEGAQoBMQDRAM8A2QDEAOsArwCyAJUAsoBvAGUAd0APAAhAP3/Sv+m/mr+zP2c/Ij7APs4+vj4IPig99D2YPVw9ED04PNQ82Dz8PPw8yDz0PIg82DzYPMg9ID1oPYg9/D3MPkI+lj6KPuE/ID9+P3Q/isAHgFYAcYBzAKEA7QDCAQABZgFWAUQBWAFoAVIBTAFyAVYBiAGwAXIBbgFKAWQBLgEIAUABcgEAAVABfgEeAR4BNAEwASYBOgEgAWoBWgFWAWYBYgFMAUwBagF2AWQBWAFkAVwBeAEoATgBAAFoARoBKAEsAQYBLQD3APsA1wD6AL4AtwC7gEgASIBDgE6AIj/lf9e/zD+tPwg/HD70PlQ+AD48PfA9lD10PSw9JDzcPKQ8jDzwPLw8VDyAPPQ8oDycPPg9HD1oPXQ9jj4kPi4+PD5iPss/Jz88P1x/9z//f/gAAACWAJwAmQDgASwBIgE8ARYBQAFoAQIBcAFyAWgBdgFCAaYBQgFEAVYBVgFQAWIBcAFkAVIBVgFiAWABYAF0AUYBiAGKAZIBlAGGAb4BQgGCAYABhAGMAYYBtAFmAVoBSAF2AToBPgE4ATIBMgEoAQ4BPAD9APUA1wDCAPYAkwCfgEeAS4B7gAqALL/Yv9W/pT8WPvA+qj5SPiA91D3cPbg9PDzsPMg8+DxcPHA8aDxAPEQ8dDxIPIQ8rDy4POw9BD1APZQ9zD4mPiQ+fD60Ptw/JD99P6w/wsA1QDIATwCiAJoA0gEiASIBOAEKAUIBQAFcAXwBQAGAAZABlAGCAYABlAGeAZQBlgGiAaIBkgGUAagBsAGqAawBvgG6AawBqAGyAbQBpAGgAagBqgGeAZoBmgGSAbwBaAFgAVgBTgFIAVABTgF+ATABKgEiARABAAE4AOMA+gCRALiAZIBIgHXAJ8AGAD2/rz9pPx4+zD6GPmI+OD38Pbw9UD1gPSA88DyUPLw8XDxIPFA8WDxgPHg8XDy8PJw8zD0EPXQ9ZD2gPd4+Dj58Png+uD7rPx8/Yr+b/8QAKQAWgEEAnQC5AJ0A/ADKARgBLAE6AQIBSAFOAU4BTgFWAWQBcgF6AUQBggG8AXYBfAFIAZYBrAG+AYoBzgHKAcQB/AG6Ab4BhgHMAc4BzAHCAfQBqAGgAZABgAGwAWQBWgFMAUIBeAEwASwBJAEYAQwBPgDtANUA+ACaALsAY4BRAHyAIYA7/9A/1r+QP0g/DD7aPqg+bj44PcA9xD2IPVA9JDzEPOg8kDy8PHg8eDxAPJA8rDyMPOQ8yD0APUA9sD2cPeA+Kj5ePog+xT8LP3w/YT+ZP9uACABnAF4AnQD/AMQBFgEyATYBJgEuAQYBRgF2AQYBYAFYAUABegEKAX4BJgEmATwBPAEwAQABZAFwAWYBagFuAV4BTgFiAUoBpAG2AYwB4gHeAcYB+gGAAcYB/AGyAbwBhgHAAcABzgHIAdgBpAFQAUwBdgEeASQBJgE2ANwAlABsAALAEX/ev6o/aj8oPvA+uj58PjQ95D2YPWA9AD0YPOw8mDygPIw8nDxIPHQ8VDyIPIw8gDz8PNA9AD10PaI+Dj5uPno+vj7EPwg/CT9jv4+/9f/PAGcAtQCuAIoA6ADUAMMA8ADSATwA5gDQATgBKAEWATQBCAFiAQQBHAE+AQQBYAFwAaoB7AH2AfACEAJ0AhACIAIsAgwCEAIYAlQChAK0AlwClAKkAgoB4AH6AeQBjAFyAXABlAGUAVQBQAF1ALz/4j+TP6o/lsASALqATj/fP1Y/Vj8WPo4+pD7sPpY+ID46Pr4+kj4EPdQ9xD1EPGQ8IDzcPSQ8jDy8POw8wDxMPAA8nDyoPCg8KDzAPZQ9rD32PrY/Ij8YPy8/QX/gf+6AAADkARQBeAG0AhgCcAIgAjgCJAI+AdQCDAJ8AjIB0gHEAfYBSAEZAN0A+AC3gG6ATACEAJkAUABuAH4Ae4BLALIAgwDCAM8A5QD6ANQBAAF0AUoBtAFOAXoBBgFsAU4BmgGgAbQBugGaAa4BYgFsAUwBRAEeAOwA8wDTAMgAyADYAJ9ANr+MP6A/UT8cPvY+0D8OPto+Sj4MPfQ9RD0APNA8lDxMPDA7xDwoPDw8KDwAPBA7wDvoO/g8WD10PjQ+qD7jPwI/sD/4AHYBOAHcAnACQAKgArACuAKoAswDHALEApwCVAJoAhgB1AGwAQYAoH/Rv7Q/SD9AP28/QL+9Pwk/Jj8HP30/Kz9wf9qAfQBTAP4BeAH6AfQB5AIoAi4B9gHsAkwCxALcAogClAJwAewBsAGwAaYBeADvAJwAlAC3AFAAYoAYv9c/Yj7gPs0/WT+Iv6E/fT8aPso+eD4OPss/bj82PsA/Hj7KPnA97D4mPiw9QDzkPMA9eD00PQg9kD1IPBg60DroO6g8pD3mPyI/aD5wPaI+Bj86P5cAogGEAgYBwAIgAtQDfALgArwCTAIgAaACOAMsA6QDCAJYAUaAVb+uv4pAPL/Qv+v/+j/4P5s/hb/hv5c/MD7zP01ADgCaAXACOAIOAb4BCgG+AbYBiAIYArgCrAJcAlQCuAJ6AeQBhgGwAQAA+ACAAQ4BAQDlAHw/7z94PuQ+xD8WPyg/PT8WPzA+pD5UPlQ+VD5EPrw+pj6oPm4+SD6EPlA9yD24PUA9fDzcPTg9aD24PVg9ODx4O4g7cDukPMA+Wj8CP2w+wD6KPkQ+pj9gAIwBogHUAjACaAKAAoACvAKIAowB1gGsAmgDPALEAqACbAGwABI/XX/BAJ4AKj+DwAGAVb+QPw2/isAPv6E/Ab/wALgA3gECAeQCLgG2ARQBqAIMAmACQALoAsgCvAIUAkwCdAHQAd4B2AGMASYAzgEdANaAZQAoQAw/wz92PyM/YD8cPpg+rD7MPuA+Xj5APu4+uj4iPhA+tj6YPmY+Aj5oPgw9jD1gPZw9+D1cPRA9XD1QPIA7uDt4PAQ9ND2gPqg/Dj6EPYQ9jD6wP1kAHgEoAiACLAF2AUwCTAKgAhwCHAKkArACMAJ4AwADHAGYAL8AX4B2v+nAMwD2AO7/8D8CP1I/Vj8OP1LAPABjAFgAqgEMAU4BKAEUAYIB1gHsAlwDGAMwApwCkAKEAiABmAI4AogCuAHSAeYBmADgAAiAbACiAGJ/33/uP+4/UD7+Pqg+9D6uPkg+vj6+Ppo+jj68Plg+ej44PjY+BD5IPng9yD2kPXg9QD18PPA9CD2APQg76Ds4O1w8JDzsPjw/KD7gPYg9HD20Pl0/QgDQAjwCDgGSAX4BkAIYAiwCTALoApgCUAKUAwADOAIQAWgAoMAyP+cAWgEOAU0A9z/AP1g+3D7FP3F/3QCIARIBLgD3AO4BDgFcAXIBgAJMAqgCuALgA0wDbAK0AiQCHAIEAjwCIAKIApIB0gEhAIkASYAXABGAfIAIv9I/Qz8WPvY+rj6gPoA+nj5ePmw+eD5UPpA+lD5GPiA90D3APfw9nD38PbA9CDzEPSQ9fD0cPKA7+DsIOtg7SD0kPoM/Kj5sPYA9MDy4PUa/ggGcAhABzAGiAWQBEAF0AjQCzALQAkACkAMoAwwC1AJuAakAoL/XwDoAzAGuAWAA0IA2PzI+rD7nP6SAVgDsAMEA7ACxAM4BRgG2AbwB3AIMAhQCYAMkA5QDSALYAqQCdAHkAfgCXALoAmgBgAFqAOgAaQAZAEKAWz++PvY+2D88PtQ+6j68PjA9jD2gPco+fj5SPrA+eD3EPaw9TD2oPZQ98D3cPZQ9AD0oPUA9sDz4PBg7sDs4O2w85D6yPz4+TD2kPNw8iD1wPw4BdAIoAf4BAwDUAIABBAIYAsADDAL0ArQCuAK4ArACWAGxALQAWgDIAUQBlgGYASZ/0j7KPsa/r0AbAIIBIAEmALRANwB0ATQBrgHAAnwCcAJgAmgCvAL4AtQCxAL8ApQCgAKEApgCagHIAZABTAEVAN0A4ADkgGI/tj8pPw0/JD7sPuw+xD6GPgo+Pj4YPiw96D4UPmg98D1cPaA9zD2gPQg9XD1kPMA86D18Paw8gDtwOug7eDv8PNA+kj9OPkQ82DxcPTo+Fj+sASgCGgHjAO0AWwDqAZACbAKsAswDKALkApgCtAKMAlgBQADIAQoBjAGkAVYBUwD1v4g/CT+PgHOAcIBeANYBIgCqAEgBHAGoAVIBUAIMAuQCpAJIAsADMAJ6AcACoAM8AtQCiAKgAlABogDEASABegENAP+AVUA0P04/Dz8PPww+zj6uPng+Bj4MPiQ+Aj4IPfw9uD2IPaQ9SD24PYg9lD0kPJw8jD0EPbw9fDyAO/g6yDrQO6g9Tz8dPxg9zDzQPKw8hD2pv6QB+AIGAReAWwCBAOAA9gHEA0gDYAJ0AhQC6ALcAlACNAHYAXQAhgEeAcwCNgFDAN7AOj9FP2s/0ADqAQgBHwD/AJAAoACQAR4BuAHwAigCRAKQAqwCvAKYArQCaAKkAtQC7AKoAqwCfAGsAQwBTAGqARkAugBkgHI/uj7CPxg/Tj8mPkY+Zj5KPgQ9qD24Piw+HD2cPVQ9nD2UPWg9KD0gPTg8+DzcPQg9QD1EPMA7wDsAO3Q8JD1WPo8/bj6wPOA78Dy0PkAAPgEkAhgBxgCHf+0AWgFeAdACmAN4AwQCQAIUAoQCoAG0AT4BZAF4AOABQAJUAcCAaD96v6f/+z+rAHoBoAHEAOMAHAC6AOYA8AFMArwC7AJoAggCuAKsAnQCcALYAxgCwALcAtwClAICAd4BgAFsAO4AzAEJAO0AID+0Pxg+4j6kPrA+lj6APlg91D2QPaA9lD2YPYA97D2IPQA8uDy0PRg9NDy0PPA9WD0gPCA7mDuoO2A7lD0OPsU/BD3UPMA89DzoPbk/cAFcAc4BKwBegEGAfwBCAegDAANAApQCUAKQAkIB2AHMAg4BqwDAAX4B0gHrAO6ATwBU/+s/QQAqARIBoAEOAM4A1gCrAFABLAIwAogCsAJAAowCSAIYAnAC7AMEAwQDPALAArYB6gHMAgYB1gFKAWABegDNgHe/1b/sP2w+yj7uPsY+2j5mPhw+HD34PWA9aD2wPdg9wD2oPTg80DzoPKA8jD0gPaw9iD04PAg7iDsYOyA8QD5SPxQ+UD0YPHw8HDzKPr0AYgFwAOfAAL/5P7rAJAFQApgC8AJoAigCLAIEAngCRAJ8AXkA6AFcAigCNAG6ARQAqr+dP3FAPgEmAUQBJgDIAP/ACMAlAMACKAISAcgCDAK0AlgCKAJwAtAC+AJcAsQDpANcAoACTAJ8AfgBRAG2AdoBzAEQgE7AF//qP1g/GD8NPyI+mD48PfA+Ej4MPYA9eD1QPYA9RD0kPUw9sDz4PBQ8fDzAPVA9CDzAPHg7IDqAO5A9UD6wPkg9lDyAPDw8OD28v5oBIAE/wDk/RT9Bv+4A3AJgAyQC8AIiAfgB5AIkAmwCrAJwAbIBQAIwAnYB8gE/AJMAWn/ugBYBcgHGAVSAZwALAEaAQwD4AfgCgAJ8AVQBqAIYAmgCeALoA1gDGAKQAuADZAMUAkwCFAJ4AgQB8gGgAfQBagBIP9e/yL/kP3w/Bj9UPvw95D2sPcI+MD2YPag9xD3wPTQ8+D0sPSw8sDyIPUg9qD0QPRg9NDwIOug6oDwMPZ4+ID56Pgg8yDsIO2Q9qT+QAG8AmgDQ/84+Wj60AIACXAJkAkwC8AJAAZoBmAKAAtAB6gFUAggCtAIiAf4BrQDCv86/vIBUAXYBTgF7APSANj9nv5oAsgFiAegCIAI0AbABTAHYAngCUAKwAsgDUANMA0ADRALIAgYB6AIwAlwCcAIMAecAwAA1P7Q/sD9DP3U/Rj9cPmw9hD3MPcw9bD0QPfg98D0kPMA9vD1kPHA71DzcPaQ9dD0IPbw80DtwOkA7rD0WPiw+SD60PZA8GDtYPII++QAHAMUA8kAdPy4+mj+8AQwCaAKAAsgCuAHWAaoBzAJsAiYB6AIEApQCbAHSAbcA0YANv/kAfgEUAVYBIADegGU/jr+agHgBHgGUAcACDAHcAVwBdgHEArQCnALkAxADcAM8AswC1AKkAnwCcAKcAqwCMAGMAVsA7QBugAFALD+1Pyg+/D6IPlQ9xD3kPfg9nD1QPXw9ZD1UPRA9ID08PJw8ZDykPXQ9nD1IPMA8WDuIO0w8ED20Pq4+nD3gPNA8cDxEPb8/OQCcARoAZz9NPyw/dAAGAWgCfALsAr4B9gGIAfoBogG0AcACpAKUAm4BzAGvANgARIBAAPwBDAFWAQgA4AB+v+U/9kAPAN4BeAGKAeYBsgFeAU4BrAHkAlgC5AMIA0QDfAL4AlACOAIUAugDHALMAnwBmAEJAIkAmQDrAJ2/5j8ePsw+lj4APgY+bj4kPbA9HD0oPTg9MD1EPag9FDyYPFg8pD0APfA97D1kPFg7uDt4O/A88D4wPvA+YD00PBA8aD0mPmc/7gDyAJS/lD7hPyb/7QCwAbQCgAM4AlwB/AGGAfwBrgHYApwDPALsAkIBzAEsAEwAfgCOAXwBegEnAIvAML+2v6z/zgBTAMoBaAFqAQ4BMAEEAWIBXAHAAogCzALEAzADBALIAiACLALIA0ADMAKkAlIBggDkAMgBiAF4wD4/Wj9wPtA+ej4MPpo+UD2UPSw9AD1cPSA9DD1cPQQ8oDwUPGw8yD1kPUg9eDzYPHA7mDuUPFw9UD4QPmQ+AD20PLw8aD1ePuJ/zwB8AHfAHj9KPu8/WgDiAfQCcAL8AsQCHADtANwB+AJwArgDLANUAn4Ap4AjAI4BCAFSAcgCHgEbf8K/tT/LAEMAgAEiAXABLgDWATwBHgEIAWYB1AJgAmwCtAMoAwgCrAIkAmACpALsA2wDqALUAZgA6gDAAVIBiAGNAMG/+D7+Pl4+KD42PrY+uD2wPPA9JD1YPOQ8vD08PTA8KDvEPSg9sDzsPEA9FD0QPCg7kDyMPVQ9LD0GPjo+MD1IPRw9qj4IPmw+5MA8AI+ARb/nv7E/l8ACAWgCuAMMAswCIgFzAPQBDAJcA3wDcALYAg4BNkAXAE4BRAISAcoBYADpwCk/Rj+9AH8A5ACBAIgBOAEXAKgARgFkAfgBegE8AiwDMALkAmACiALgAigBxAMoBAgD3AK0AfgBrgEsAOwBZgHEAbSAaj9wPpQ+WD52Pl4+UD4gPZg9GDzsPRw9TDzMPDA8PDy8PIw8sDzQPUQ8yDwAPHA8mDxkPAQ9PD3QPdQ9aD2wPcw9RD0IPn2/r3//v4OAZABwP3I+6AAuAYgCIAI0AoQC/AFlAKwBXAKkAtAC2AM4Aq4BRAC/AP4BsAGqAXgBZgEwAB8/lIAvAJYAm4BMAKYAkgBUgFABMAGwAU4BIgFMAhgCfAJYAsQDKAKYAngCoANQA4wDeALcArACGgHaAdwCKAI6AVWAfz9KP0Q/Sz8uPs4+zD4YPPg8dD0kPbw9FDzsPNA8uDuoO7w8hD1oPKw8SD0wPRQ8RDw0PIQ9EDykPNI+TD86PhA9VD1IPbQ9tj65AE4BVgCRv4A/Vz9vP48A2AJgAwQC0AICAYIBDgEYAhADRAOQAuwCAgH0AT4A4gGEAmwB2AELAMYA5gBLQB2ASADFAL3/xUA9AHgArgCAAOYA6QD6ANYBYgHQAmQCbAIEAgQCQALkAzgDLAMkAvQCMAGIAggC7ALYAn4BUQCBv7g+7T9OACL/2D8APkw9aDxYPGg9DD3IPYA9GDy4O/A7SDvoPLQ84DywPLg9HD08PBA7wDxAPPw88D2KPss/Bj4APRg9BD3YPkY/RQDIAYcAhj8QPsK/0QC4ASACRANsApABfwD0AZQCGAIsArQDYAMiAfgBBAGuAZwBfAESAZgBuQDdAFeAagB9v8y/kb/MAJQA+QBcgHkArAChgAAAbgF8AkQCpAI4AjQCEgHEAjADAARABDgCyAJkAgACDAI0AqADeALKAXA/oz8FP2s/Yb+jf9g/eD24PAg8MDyMPSg9LD1oPQA8GDsAO4w8YDxUPGg8xD1MPPQ8UDzMPMQ8CDwMPYo+1j60PiY+Yj4UPRQ9Bj7YAG+AbgAHAKQAXz9LPzGAegH0AjIB3AJsAroBygFmAYgCsAK4AnwCkAMQAooBkgEGAXIBYgF0AW4BsAFTALM/sj91v5UAFYBSAJAAwADiAEZAAgAegHUA6gGcAnACrAJiAegBvAHwAoADQAOQA7ADbALgAhQByAJEAsgCqAHqAXYArD+HPxU/WL+DPxo+ID2APWg8vDx4PNA9TDzQPBA72DvwO+w8EDy4PLQ8hDzMPNg8rDxIPIQ8yD0wPbo+Vj6APhQ9uD2MPhg+dj8dgFUAtz+sPy8/lABRALMAyAHQAjwBUgFgAiACpAIkAfgCeAKoAhwCNALcAywBzAEKAV4BcQDIAXwCDAHJgDY/Cj/xP/w/ev/oAQYBP7+FP4qAWwBhP9gAvAHoAiYBdAFIAmQCeAH0AgwDBAN0AtQCwAM8AuwChAK0AnQCOgG6ARwA9QCvAGf/zD9MPu4+HD1gPNA9ED2oPbw9DDyYO/g7IDs4O4Q8rDzkPPQ8rDxAPAg73DwEPMg9UD2gPdg+KD34PXw9dD3oPlo+zr+NgESATb+HP1a//gBCAPIBKgH0AggBwgG+AcACoAJoAiACtAMAAygCbAJ8ApgCSAGoAX4B3AIwAVYBPgEhAOd/zj+mwD8AUQA8P43AMsARP+u/q4AmAKMAmwCzAOwBbAGIAegB1AIQAngCUAKQAvQDMAM4ArwCcAK8AogCQAIcAgYB6wCtf9CAMUAYv6I+7j5YPaw8SDwoPNw92D3QPRg8ADswOhg6mDwoPXA9gD14PEA7uDroO5A9LD3IPhI+ED4IPZQ9LD28Ppc/Jj7IP0RAAMAVP6b/4QCcALnAPgCcAfQCIAHAAiQCVAIAAZQB3ALIA0gDIALIAvQCDgGkAaQCAAJ4AcYBwgGwANYAbUAVAE8AZAA+/+g/wT/lv7c/nn/7P/7/3oAmgHgAsQDcASwBRAHgAcQB6AHAAogDDAMsAtQDEAMIAoACTALwAzwCTgGWAawBlgC9P2f/wwCRP3w9RD0UPXw8pDwkPSo+ODz4Oqg6IDrAOwg7KDxYPeg9GDtQOtA7iDwUPHA9Yj6sPmg9bD0cPdg+fj5wPua/p7/sv7o/hIB+AKAAowBdALwBLAGuAdgCaAKYAloBrgFUAjwCtALQAyQDNAKUAegBfgGkAhwCBAIAAh4BlADUAHqAZQCnAFlAEsAz/+O/lL+pP81ABn/jP6k/6EAqACmAWgEUAZwBXAEuAWYB/AHsAhwCzANQAtACaAK8AvgCVAIEAvQDGAIhAJ4AmAE5gHi/vn/r/+Q96DvwPBA9hD2IPOA9ED1AO4g5QDnwO6w8VDwcPLw9IDwAOrg6zDzkPVA9ID2ePr4+DD18PZU/GD9WPvo/N8AmAHp/zYBKASYAygBWAIoBpgHGAdACEAK4AiwBaAFgAgwCkAKIAsQDEAK+AY4BsgHgAjwB7AHgAfYBcQDSAO8A+gCKAFYAB4Aav/A/jL/zf8v/wT+BP7O/j3/3/9wAeQCIAMoAzAEqAWQBhgH+AdgCdAK0AvQC1ALgAvACxALQAowC/ALsAkYBigFYAVoApD+uv66/5j6MPMQ8gD2IPaQ8pDyIPRg74DnQOcA7gDxYO9A8HDzIPFA62DrcPEg9YD0kPUQ+bD58PbQ9nj61Pxo/PT8hf8YAdcAPAEMA8QDzAKAAsgDiAUoB5AIQAnQCKAHeAYoBmgH8AmwC3ALkAqQCbAHkAXwBYAIQAlAB7AFiAVIBOgBSgFUAqgB7P6g/XD+xP4Y/iL+3v5u/gD9dPyU/Uf/7gBgAuQCIAPQA+gEcAVYBnAIgArgCrAK4AvwDEAMgAuQDEANsAuwCaAJUAnYBoAEaAToA64AbPzo+OD1YPMA9KD2EPdA9CDx4O2g6SDnYOmA7qDxcPFQ8MDugOzg6yDusPFg9OD1kPYQ99D3CPk4+hD7wPxK/lb+ev4mAYAEAAWkA9QDgAVQBTgEEAbwCWALsAmQCBAJ0Ah4BzAIIAtwDJAKkAiQCOAIiAeABpAHcAiYBigE5AOIBHwDzgGSAUIB/P7w/Kj9Sf+u/lz9AP7+/pz9DPyg/SwAgwApACwCQASgA/gCWAUACJAH+AZwCdAL8ArwCQAMkA3ACzAKgAvwCzAJMAfIB0gH0AO+AcABcv/w+UD2kPZA9kD00PNQ9eDz4O6A6mDpAOoA66DtsPBw8eDuYOzg6yDtgO8A8lD08PXg9mD34Pd4+ej7eP2Q/QT+NABwAoAD0ATYBogHCAZgBSgHUAkACvAKwAywDJAKMAkACrAKYArwCjAM0AuwCVAIEAgwB8AFwAWABugFMARAAxQDzAGw/4D+av7k/Qj9HP3k/eT9rPzY+xz8LPwg/PD8+v50AI0ArwC0AawC0AKoA+AFwAcgCGAIsAmwCoAKgAqQC+AL4AogCpAKgArgCEgHuAaIBSQD+AB9/8z8kPmg9xD3QPYQ9dD0APRA8aDtAOyg66DrYOzA7mDwYO/A7YDtgO4g73Dw8PJA9QD2UPag94D5GPtU/Iz94v7u/8sA9AGsA5AFyAYQBygHsAcwCIAIYAnwCvALgAuwCoAKUAqwCcAJsAoQCyAK8AggCCAH2AVgBZgFWAVwBKwD5AKKASkAfv/Q/rz9EP1g/bT9SP3o/PD8kPzI+7j7pPyk/YD+nf+wAAgBJAHwAfQCgANIBKAFiAYABxAIoAkQCmAJIAmwCXAJYAiACKAJQAlQB+gFYAWkA9QAS/+w/sD8yPmQ+AD5QPjw9eD04PRg83Dw4O5g78DvgO+A8IDy0PJg8bDwgPFw8rDy0PMw9ij4ePiw+FD6KPz0/Dz9Rv5y/9j/FgCsARgEcAXABRgGkAY4BqAFIAbQBwAJMAlQCYAJMAmQCIAI4AgACdAIgAgQCGAH+AYIB8gG8AVQBeAEKAQQA1ACHAJ+AVgAoP9+/wr/Rv7s/RL+0P3o/Gz82PxE/ST9NP0G/gb/L/8L/5r/kADlAPcA6gFsAwAE/AOYBLAFwAUQBVAFcAaABoAFYAUABrAFQASMA4ADaAJkAG//af9s/rz8PPy0/Pj7OPoo+QD5UPgQ97D2EPcQ95D2sPZQ94D3QPcw94D3kPeg9/D30PjY+Zj6EPuI++D7HPxA/Jz8SP0A/pL+J//e/3wAzwAsAb4BKAJYApwCKAOgA9gDKASwBAgFCAUABRgFGAXwBAAFIAUoBfAEyASoBGAEAATkA+gDlAMQA6wCXALkAWABLAEyAfwAdgAZAOf/r/9a/z//Y/91/0D/GP8y/1T/Q/9C/6b/IABdAHEAxwAuAWoBcAHeAYwC3AL0AjwDyAP8A9wD+ANIBDgEvAOAA4gDZAMIA9gCyAJQAnoB/QDWAIcAFADC/4z/IP96/uz9sP14/Rj9yPyY/FT88PuQ+2D7UPso++j6uPqY+mj6QPo4+jj6KPoo+lD6cPqI+qj66PoY+zD7aPvA+xT8ZPzQ/Ej9oP3o/Uz+tP7+/kj/uv86AJYA5wBWAcwBBAIsAnQCyALsAhADYAOwA9QD1APsAwgEAATcA8ADtAOgA3gDUAM0AxQD4AKsAogCbAI0AvQBvgGiAYYBaAFqAYQBoAGaAaIBsAHIAeYBFAJYAogCrALgAiQDUANgA3QDiAOYA5QDlAOQA4QDZAM0A/ACqAJkAggCmAE+AfUArQBXAAsAz/9z//j+gP4i/sT9VP30/LT8hPww/ND7iPtI+wj7sPpo+kD6KPr4+cj5sPm4+bj5qPmw+cD5wPmw+dD5GPpI+mj6oPoQ+2D7iPvI+zj8rPzw/Ej9yP02/nz+5P56//D/QgCkACIBlAHKARgCiALoAhADUAOoA/AD/AMABDAEOAQoBDgEUAQ4BBAE8APgA7gDcANEAygD/ALMArQCpAKAAlwCVAJYAlgCVAJsApgCwALYAvQCJANQA2wDiAPAA/wDEAQoBEAEYARIBCgEIAQQBNgDiANEA/wCoAJUAiQC2gFcAd0AagDy/3b/I//4/qr+Gv6g/VT99Px0/BT80PuI+yj74Pqo+mD68Pmg+YD5WPkY+eD44Pjg+MD4mPiY+Lj4yPjo+Bj5aPmo+ej5OPqQ+uD6MPug+yT8oPwM/YD9+P12/u7+YP/U/1oA6ABgAdABPAKwAggDUAOkAwAEOARgBJgE2AT4BAAFEAUgBSAFCAUABQAF4AS4BJAEcARYBDgEGAT4A9QDsAOUA3ADTAM0AzADMAM4A0QDTANIA0ADQANMA1wDZANoA3QDhAOIA3QDXANQAzQD9AK0AngCQALqAZQBTAH+AJ0ALwDR/3L/AP+G/h7+vP1g/ej8ePwQ/LD7SPvo+pD6UPoQ+sj5iPlI+RD56PjI+LD4qPig+KD4qPjA+Nj4+Pg4+Yj50PkI+lD6qPoQ+3j74Ptg/Nz8UP3E/UL+vP4r/6H/IQCZAAABZgHWATwCnAL0AlADnAPkAygEaASYBMAE8AQYBTgFSAVQBVAFSAU4BTAFIAUQBfgE4ATABKAEgARgBEAEGAT4A8wDsAOYA4ADbANgA0wDMAMkAxgDGAMUAwgD9ALoAtgCyAKwApgChAJsAkACFALuAcABeAEqAfMApQBHAPH/p/9a//T+mv5K/uj9bP34/KD8PPzY+5D7UPsI+7D6WPoY+uj5wPmg+YD5aPlQ+Uj5QPlI+VD5cPmI+aD5yPkA+jD6aPqg+uj6MPt4+9D7KPyI/Oj8RP2g/fz9bv7m/mj/4P9TALsAGgF6AeABTAKwAhADZAOoA/QDQASQBMgE8AQYBUAFWAVgBXgFkAWgBZgFiAV4BVgFQAUoBRgF8AS4BIAEWAQwBAAE0AOsA3wDSAMcA/QCxAKUAnACUAIsAvwB3gG8AYYBRgEcAfYAyQCcAHkAVAAVAM7/jv9a/xv/2P6Y/lL+CP68/YT9SP0I/cz8mPxg/CD84Puw+5D7YPtI+zj7KPsQ+/j68Prg+tj62Pro+vj6GPsw+zj7UPtw+5j7uPvY+xD8SPx0/KD86Pw4/Xz9uP0G/lr+ov7i/jL/k//w/0AAigDQAB4BZAGkAewBPAKEArQC7AIwA1wDbAOMA9ADAAQIBBAEOARYBEgESARoBIAEeAR4BIAEcARABCgEKAQIBMwDvAO8A5QDUAM4AzAD8AKkApQClAJYAhQCCAIAAsoBiAF4AWYBJgHzAOMAwAB7AE4ARAAXAMb/i/9s/y7/1P6e/oz+VP7w/aj9lP1s/ST95PzE/Kj8cPw4/BT8+PvY+8D7oPuI+3D7YPtg+2D7aPto+3j7iPuQ+6j72PsA/BT8NPx4/MT86PwI/Vz9tP3k/Qr+Xv7A/vb+Gf9o/8j/BgA8AJYA+gA2AVgBnAH6AUACYAKMAtACEANAA3QDsAPcAwAEGARABGgEiASYBLAEwATQBNAEuASoBLAEqASABGAEUAQwBOQDmANgAywD1AKQAmACLALeAZABVgEKAbEAbwBKABMAyP+G/1H/Cv+4/oT+Yv4m/tj9rP2Y/Wz9KP38/PT84Pys/JD8oPyY/Hz8bPx4/Hz8WPxE/Fj8bPxc/Fz8iPyo/Jz8kPyk/MT80Pzg/Az9MP1E/Vz9hP2w/dj9CP48/nb+rP7a/vr+Mf+I/9f/+P8dAG8AxwD1ABoBaAHOARQCOAJgAqAC2ALsAgQDQAOAA5gDsAPoAyAEGAQQBDAEaARIBCAESASIBHAEIAQgBDgE6ANgAzQDTAMEA1wCAAIIAsYBJgHDAL8AhwDt/3r/Yf84/9b+lP6Y/oL+OP4A/gD+/P3U/aj9pP24/cD9wP3U/fT9HP4i/hj+Lv5Q/kr+JP4g/jj+Kv7s/cD9tP2I/UD9NP1Q/VD9JP0o/Vz9XP00/XD99P3w/Xj96P09/6//6P4W/8gAJgFi/5b+HQCmAMb+iv6+AQAEUAJRAIQA+v90/Qj9gQAIA14BUf+TAIgCCAIKATwCwAMsA9gBNALgA/gEKAUIBcgEcARoBJgEcAQQBBAEKATQA5ADIAToBJAEcAPMAsQCWAJqAd0A6ADCAAkAT//+/rr+FP4E/ej7MPv4+vj60Pqo+rj62Pqo+jj6APoA+vD54Pkg+oj6wPrI+gj7gPvY+yD8cPy8/OT8KP2o/Qj+WP7+/tn/VgCMACgB6gHuAXABlgFkAtwC7AJgAwgE8ANMAzgDxAMABLwDjAN8A0gDQAOwAwgE0ANcAywDDAOwAoACzAI0AyQDzAKYAqQCmAJMAiACSAJQAv4BqAGeAWYB0gB4AKkAqgAIAIz/uP+4/+j+KP40/ir+RP1Y/GD8rPxA/Jj7mPvQ+1j7cPpQ+tD62PoQ+pj5APqA+jj6yPlQ+jj7IPtw+rj6+PtU/Lj7APyc/U7+uP0u/k8AggHDAIoA+AHYAhAC+gGYA5gE7AO4AxAF4AUIBZAEYAW4BaAEEATgBEAFWATEA1gEeASIA/wCSAMYAywC4AFsAnQCsgGIATwCiAIcAhQCmAK8AjQC8AFkAqwCZAJsAjwD0ANsA/QCZAPEAwADGAKAAiADcAJmAY4BAAIOAb7/wv/p/1z+GPw4+zj7aPqA+dj5KPro+CD3YPYg9mD1IPXg9SD2MPXA9JD1MPbQ9QD2YPdQ+DD4oPh4+uD7SPxQ/Vb/mACKAPYAyAJwBLgE8ARgBtgH0AdYB+gH4AjACAAI8AdgCPgHCAegBrgGQAYIBewDVAOYAlgBDwB9/3//Tv+e/hb+Fv70/Tj9sPwE/ZD9hP2w/eL+SADDAOQA0AHYAvgCyAKAA6AEKAVgBTAGMAd4BzgHUAeQB0gHqAZABuAFQAWgBIAEsASQBNwDCAM0AjABDgBQ/xr/zv4o/oT9GP1Q/Pj66PmQ+TD5CPjQ9kD2wPXA9NDzcPMw80Dy0PAA8ADwYPAw8dDy0PQA9rD1APVA9UD2QPfI+Lj7IP9AAWwCMARgBqAHMAgACRAKUAogChALMA0gDyAQoBAAEfAPsA0wC6AJwAi4B6gGGAa4BagEFAPcAeMAH/+g/JD6UPko+ED3kPfg+Lj54PkI+iD6iPno+Fj5cPog+/j74P0nAMABFAPwBIAGsAYYBigGsAbYBigH0AgACyAM0AtgCzALEArwB4gGgAYgBrAEpAMoBJAElAOcArwCiAJcAOD9KP10/cT82Ptk/LD9fP3o+wj7CPsg+hD4wPbA9kD2UPTA8uDyEPMA8sDwUPCg78Dt4OyA7lDx0PMw9ij4APgw9pD18PZQ+ZT8bAF4BXAGUAYwCGAKYAoQCtALIA2wC5AK4AzADyAQoBAgEuAQcAtwBmgF2ARwAqgByAMgBN0AnP74/rD92Pnw9+D40PdA9ODzcPfI+Vj5kPq8/dT94Pow+qz8xP1U/eD/AAUwB/gFgAbACeAK8AhwCCAKAAq4B1gHsAkACwAKsAlQCgAJeAX4ArQCuAKqAc8AwQCkAAUAb/9V/2r/PP+E/rT9NP0w/Xj9BP4O/wkAPgCE/7D+8P0g/Qz8IPvI+pj6yPkA+GD2YPVQ9PDxYO9A7kDtgOuA64DvEPQQ9TD0IPUg9SDxAO9A9Pj7Xv6w/ngDQAigBggEkAhADmAMwAegCVAOUA0wC9APQBYAFWAPoA1QDSAI7gEEAjAFSATfAG4AjAGY//j76Pog++D4YPUQ9AD1sPVQ9sD4YPxS/gL+ZP2Q/dT97P34/tAB2ASIBugHMAowDFAM8AtwDJAMoAqgCJAIEAnQCAAJAArwCeAHoAVoBHwC3v+s/u7+fv6U/dz9zP64/lr+Qv+l/zj+DP3k/bT+Kv6e/iIBzAIgAvABCAN0Akz/LP1M/aD82Pkg+Kj4cPhw9UDy8PDA72DsQOjg5mDoAOpg6wDvoPQA99DzQPCQ8WD0APWA92T/uAYQB2AFMAmwDpAOQAzQDqASQBCQCwANgBKgE0ARgBIAFaAREAlQBPgEKASs/3j9r/8sACz8+PhI+oD7kPhg9XD2CPig9QDzoPXo+gD91Pw4/7AClAJcAN0AEATwBVAG8AcgCnAKgAkwCvALsAzQC3AK4AjABsgE0AOoA8wDAAS0AyACtf/Y/SD9uPwU/Mj7MPyE/HT85Pw+/on/FwDIAN4BUAKwAcABzALQA1AESAVgBtAFAASgAogBVf/0/Bz8oPuA+XD2kPQQ8yDwAO1g6+DpQOcg5eDlgOiA6yDvIPNQ9dD0kPNA8yD0oPb4+5wCwAfQCkANEA+gDyAQYBJAFCATIBAQD6AQQBHAEOARgBRAE5AN0Ah4BswCKP0w+6T9xP2o+YD36Plg+rD2MPUg+Pj4UPWQ82D2SPjQ92D6nwDkA8wC6AKgBUAGuASYBbAIkAlwCGAJoAuAC2AKkAswDdAKUAYgBLQDygGb/0UAbALgAVn/mP4b/5D9cPrI+aD7IPyY+vj6Nv4lAKz/PQBoAxAFeANUApwDUATcArwCOAXgBrgFcASIBGQDNABc/eD7qPmg9rD0sPOg8SDvoO1A7CDp4OVA5aDlAOVg5gDscPKw9PD0IPfQ+ND20PWo+zAE4AfQCKANABMAEtAOwBHAF+AWABGQDwASYBBgDAAO4BJgEdAK6Af4BzQDePsY+Uj7KPow9iD2CPlg+LD1EPeY+sj5oPZg95D6qPp4+ZD86AEIBBgEeAZgCcAIAAdACHAKcAlIB7gHAAnoB6gGAAhwCcgHGAXUAxwCpv58/ED9AP7Y/Cj8LP08/cD7sPtY/dD9wPzs/Gj+zv6a/n0AoAP4BPgEIAaIB/AGqAVwBvgHeAfwBQAGmAbYBOoB5wAOAc7+sPqI+Bj4gPXA8KDugO/g7SDpgObg5wDnoOJA4uDogO4g76Dx6Pgk/DD30PRo+/4BcAFEAtAKoBGQD2AN4BJgF2AUYBCgEuATIA6QCFAKEA5ADRAL8ArwCUAFWQCY/UD7sPjA99D3APfA9hj4cPmA+aj6jP1W/sj7aPqk/Ob+Cf83AJgEUAhgCKgHIAnQCvAJIAggCBAJ6AcgBRgEiAVQBiAFKAQABYAE0wAo/aD89Pxo+zD6wPuk/Yz8EPts/Kz+0P6k/nAAEAJiAYgAIAJIBEgFOAYQCPAIIAiQB9AHoAe4BmgGUAZgBagDRALoACH/HP0g+xD5UPdg9aDyAPBg7wDvQOwA6aDoYOhA5IDgoOMg6mDt4O/A9xL/vPxw9vD3O/+CAXIAqAVQDrAP4AswDoAVIBdgEoARABUgE9AKKAawCMAKYAgQB3AJoAkoBKD+hP00/ej54PbA93D5WPjA9pj48Pt8/Q7+xP8sAXcAfv8rAKIBvAJ4BOgGgAjACAAJsAmgCTAJ4AgwCBAGvANIAj4BQQAXAAYBfgGXABD/nP34+3D64PlA+sj6MPuY+wT8iPxc/ab+JQDCATAD/AP4A+ADOATwBAAGaAeQCNAIUAjAB/AGEAaABTgFUAT0AuQBqABi/sj7WPpg+eD3IPYA9SDzQPBg7oDuQO5A7KDq4Ong5+DkIOUA6sDvQPSQ+Vb+XP4w+3D7sP9IAowCiAXwChANAAzQDaASIBTAEWARwBIAENAJyAagB0gH8ARIBagHKAd4AxABVgAA/oD6UPko+mj5kPfw94j6NPwA/UD/LALkAqIBXAFYApQCIAJMA+AFSAfYBhgH0AjQCfAIEAhQCFgH8AOwAPT/LwCJ/yD/awBYAeX/wP0s/RT9sPuY+nj7xPxo/LD7yPyo/rL/bgBcAkgEmAT4A/wDkATwBCgF6AUQB5AHIAdgBvgFwAUIBagDgAIQAoQBBwD0/Xz8mPuI+rD44Pbg9dD0kPLg7wDvgO/g7qDsoOsA7ADqYOYg58DtMPTA9oD5tv62AOT9+Pw+AXgEvAPABDAKkA3wC8AL4A9AEiAQsA7wD3AO4AiABWAGSAa4A3QDCAbwBSwC3v8dALL+WPtw+hT8+Pv4+Rj6lPws/tD+MAFYBNAEZAOMA/AE0AQABDgFgAeQBxgGSAaIByAH2AVABvAG2AQiAWj/Kf+w/RT8AP3m/pr+CP3k/CT96Pvo+jT89P2k/fT8+P0w/xz/d//MAQAEcASIBHAF2AXYBFgEUAVQBkgG2AW4BTAFMARgAzgDRAPIAsABiwCz/7T+FP1w+8D6CPo4+ND20PZA9iDzgPBA8TDy4O9A7QDuQO5A6iDnIOsQ8mD1YPeU/E4B0/+I/ED+xAJ8AwgC8ANQCDAKcAlQCnANoA9gDzAOIA0wC/gHkAQIA5QDqASABMQD8ANIBKwCx/9O/p7+PP5E/AD7oPtM/DD8PP2DAKQDcAQYBHgEqAR0A1wCIAOQBIAEoAP4A+gE8ARwBDAFMAaQBYwDygF+AMT+UP1k/Yr+GP/q/qb+bv4E/uT9VP6s/qr+vv4O/+b+vP5S/7gA1gGcAtwDGAVIBZAEQASwBBgFIAUoBdAE/ANcAyQDrAIUAmgCOANgAi0ASv+l/xb+APsY+kj78Pnw9dD08PYg9oDxwO/g8rDzYO/A6yDsgOuA6CDpYPBw95D5oPrM/bb//P34/Ln/TAN4BBgFQAdQCQAKwArgDOAOYA/wDrANIAsQCCgGaAXYBIgEIAVIBQAEpAJEApIBnP8e/iL+AP5k/Bj7mPus/ET9xP6yAcgDpAMgA+gDuAQwBIADGATIBCAEZAP4AwAFCAXoBMgFkAZgBdQC5wDS/7b+6P12/lT/0v6A/WT9Vv5u/qz93P3a/tD+wP2I/UL+Wv4s/qL/FAIQA5wC3AL8A1gEEASYBJAFcAWgBFgEKARoA+QCVAOkAywD4AJoAvkAS/8h/xn/7PxY+kj60PqQ+PD1MPZw9vDyIPCg8rD0IPBA6qDqoOxg6mDpgPAQ+Qj6qPgI/cIB5P7o+gX/yAWYBbQC0AVACyALwAjwCyARoBCgDPALAA3gCcAEpAOoBaAFnANQAwgEjAKw/5r+E/+c/hT9LPzY+xj7aPro+sz8FP/7AFQCJAOQA9ADAARYBAAFuAXgBVAF2AQABYgF+AWoBqgH4AdIBpwDjgFiAC7/LP5Q/h//7v6s/TD90P0u/sj91P3O/lD/jP64/fT9pP4I/7b/SgHQAjQDDAOEA2AEyATYBFAFiAXQBAAEKAQoBOwC+gHEAoQDFAJ4APEANgGs/vj7hPw8/ZD60Pco+aD6QPfg8nDzEPbw9EDygPIQ80DvwOpA68DuUPBQ8YD10Poc/RT9EP7O/2sAkACuAVADeASIBeAGYAgACrALwAzQDKAMYAywCogH+ARgBJgEIAR4A5wDvAOIAqQADwDiAPkAX//Y/cT9zP2U/ND7WP3k/yQBegGMAsADqAMEA2ADeATQBEAEkAMYA/ACRAMIBLgEUAXABWAFkANQARkA1v9p/5r+cv74/sb+aP3E/Br+l/9N/5D+dP9SALL+gPw8/aX/EwBI/7QAKAP0AnQBvAJoBUgFdAPcA2gFOATCAeABiAPMAvcAkgEUA/oBgP+D/98Aq/90/Hj7wPxI/Ej5kPd4+Dj4IPVw87D1QPew8wDvYO6g74Dt4Org7cDzAPYA9sj5Vf/7/9z8XP2AAcgCCAEgAmAGYAiIB5AIwAswDRAM0AuQDDALIAhIBiAGoAXQBLAEqARoAzACIAIUAtYAvv/r/+z/OP64/CT9DP60/Zj97/+QAqACdgGEAqAEgAQ0AxgE8AXABPQBCAJgBGAEqAKwA3gG6AWoAr4BtAIiAUD+zP4WAZ3/FPxg/DL/uP5E/Gz9qAAaABT9ZP3u/zr/jPxg/bsAIgEH/13/KAIgAxgCgAKQBFgFMARIA1ADHANcAsgBxgFcAtgClAK2AYgBCAJ8Aa7/tP4J/wj+GPsQ+XD5sPnw95D2APfQ9pD0oPKg8gDyAO9A7ODsgO8A8iD1WPlY/AT9dP3g/tb/s/91AFQCiAMYBOAFIAiQCGAIUArQDHAM8AngCNAI8AZABOAD2AQoBGwCfAK8A2QDcgEzAEcAMABG/2T+Kv5Q/lr+Qv6s/hIAoAE4AkgCLAPQBHgFqATAA5QDcAPQAoACNANABJgESAQwBFAExANEAvgAxADMANT/Vv6o/bz9uP2g/TT+/v4C/4z+fv6q/oD+cv43/7T/DP+i/q7/uQBPACgAzAFsAwgDgAL8AyAFdANyAVQC5APUAtIAUgHYAkACBgHqATgDJALp/+7+VP5o/LD6wPro+uj5IPnY+HD3APVQ9BD18PPQ8ODuoO7A7QDtwO8w9cj4oPkw++z9tP44/fT8G/80ARQCXAPIBbgHQAiwCDAK8AuQDJAL8AnQCPAHWAbABMgEGAagBugFkAV4BSAEogEgAO3/YP86/uD9rP41/zr/dv80ANEADgF0AUACEAM0A8QCiALkAiAD5AIAA8gDCAR8A5gDeAQwBIACwAFIAq4Bi/9c/o7+AP7c/Hj9Yf+y/4b+Wv7e/gj+rPwE/UD+XP4s/gr/if+W/jj+v/8aAfgAcgFIA8gDXAIQAtQDaATIAggCOANIA3AB5wCgAnQDGAJEAdABWgEB/xj9kPzg+5D66PkI+pD5QPjQ9nD1QPSw82DzAPIA8KDuYO4g7qDukPEw9sD5cPvw/Jj+uP54/cz97gAoBAgFKAXwBjAJkAlwCVALwA1gDdAKsAmwCdAH2ARQBDAG8AbgBWAFsAWIBBgC2QDiAFgAPf8L/4n/fv9q/wMAfAAzAIgA7gHMApQCrAJ8A3QDoALcAigEKATgAqQCrAMQBIgDnAPsAxQDngH6AFkAlP4o/Vz9+P2o/ez9X//G/zb+OP00/r7+fP3Y/E7+ev+M/sT9AP9tABwAov8OARgDnAPsAswCaANoA6wCeAIsA8ADdAPAAqACBAMQA4gC7AGOARoB+P8u/nT8cPv4+rD6QPrw+aD5mPiw9vD0QPQA9ODy4PCA72DvQO+g7mDv4PIA9/D4EPqM/KL++P20/GD+UAFQAqACEAUACKAI0AjwChANoAzwC1AMQAvwB+AF6AawB8gGCAeQCJAH2AMcAjADEAN4ABb/EAAIAPD98Py4/kQAuv8Y/14APAJMAjYBLAGcAoQD7AJ0AmQDWASEA2ACUANgBZgF+ANcAxgEaAOZAL7+Lv+v/6j+DP5v/8YA7v9Q/h7+av50/QT8BPz4/Az9gPzk/BD+mP6G/g//MQDoAA4BNgFUASYBOgHyAZgCwAIQA8QDAASIA1gDdAO4AngBIAFoAYIAnP64/cz9IP0A/Az8cPwA+5D4gPcw91D1sPIA8pDy4PGA8JDwoPGA8RDxEPPw9kD5kPnA+qz9k/9z/9T/MALoA1gDdAPIBpAKEAuAClAMkA4gDdAJQAlgCgAJqAagBxAK0AgYBTgEwAXYBPABlgEUA6wBEv4E/V7+/P2A/MD97QCEAeb/EQDAAZoBQQAGARQD8AIqAVIB5AL8AmwC8ANABvAF0ANQA8wDSAKK//D+NgAiAMz+Gv+oAE4AUv7o/TP/5P58/DD74PsU/Cj7qPvU/c7+Ev5M/h4AvQC1/6//LgGKAYMAygB4AsgC3gGoAvgEcAUABIwDIAQ0AwYBdQAaAX0A5v6+/o//3P78/Nj7WPvw+Qj4wPaQ9dDzYPLg8aDxUPEw8QDxYPBA8LDxMPPg83D1IPlo/Hj9dv7NANwBMwBz/yACUAWgBrAIwAwwD6ANkAsADHAMoApgCXAKIAtwCeAHIAgQCIAGyAWgBnAGEASmAQoAAP4M/Fz8Sv4M/6b+If8LAH7/Xv7a/gEAr//e/qb/5gChABgAbAGUA3AEuASIBcAFOAR0AgwC9gEYAYsAJgGCAdkAcgDmAOcA5/8w/x3/Uv58/Cj7EPs4+3D7aPzo/ZL+UP4m/oz+6v4i/5L/OwCiALYA9AC2AcQC2AO4BGgFyAVwBUgE7AIsAsgBQAHqADoBeAGmACv/Pv6A/dj7sPlA+FD3sPXg8/DygPJg8VDwkPBQ8UDxwPAA8fDxIPMQ9Uj4MPuU/FD9aP5D/0j/xv/MAXAE2AagCaAMMA6wDYAM4AtQC+AKYAsgDMALgAqwCVAJkAggCJAIYAgoBkgDegEvAD7+AP3k/XT/kv/u/kz/5P/q/jj9FP1A/qz+OP6s/i4A+QDoAKYBjAPABFgEzAMIBOwDrALCATAC6AK4AkgCjAK0AuwBPgFoAXIBQQDA/gb+cP1Y/Nj7sPyo/aT9gP34/fT98PxE/DD9Qv5o/qj+5v/IAH4AlAAQAoADdAM4A9QDCATsAvoBYALoAogCOALEArgCFgEb//D96PxY+wj6aPlw+JD24PTw8wDzoPGg8HDwEPAg7yDvkPBg8sDzsPVg+Dj6gPrI+uD7SPzw+1j9jgHwBXAIYAqgDPAMwAqQCWALQA3wDHAMoA0wDnAMQAugDJANoAtQCfAIIAjoBMABNgFYARsAb/+/AJ4B7v/M/Vj9TP04/Jj7kPxQ/dD8mPzM/e7+Kf+o//kAqAE+ASgBkAFGAX0A6wA4ApQCLAKoAoQDAAMYAoQCKAPMAdr/vP9JACr/zP2A/p7/0P5o/cj9gv50/Tj8/Pwu/rz9HP0u/oD/Zf87/2QAjAFQAQoBzAE0AloB0QCyAagCtAK8AlQD5ALVANT+TP4S/tz8ePvo+lD6ePiQ9sD1cPUQ9CDyUPFQ8RDx0PDg8cDzMPUg9sD3cPnQ+Qj5YPjA+Cj6CP08AVAFyAfQCBAJ0AhQCKAIAApgCwAMsAzgDaAOIA6QDfANQA4gDXALgApACXAGxANUAyAE4AP4AvAC6AIeAbr+9P0G/uT8YPtw+1T8NPzQ+6T86P38/bD9RP7o/pj+LP6C/sr+lP72/lMAZgG8AWQCbAOgA+wClAKgAuYBlQA8APgATgH9AAwBiAE4Aez/D/8d/w//SP64/Q7+qP7A/tr+pv9kADoAn/+u/ysAHQCc/7T/cADwACgByAGUAkgC3ACS/xH/kP6w/Rz90PzY+xj68PjY+Ij4MPfg9SD1APSA8iDyUPNw9OD00PXA9wD50Phg+CD4IPdA9vD3UPy2ALwDGAZQByAGGAQIBAAGsAfgCCALYA2gDdAMUA1QDgAO4AzADNAMUAtACaAIgAhgBygGWAagBmAFkAOoAr4Bs//U/ZT95P1k/eT8aP3I/ez8+PtA/Lz8ePw8/Oj8hP0k/eT8uP2q/tD+Gf87ADYBPAE4Ac4B9gEcAVwAnAAOARABUgEUAmQCxAEMAboARQCJ/zn/if/E/8L/8/9ZAF8AIwASACkA7P+j/7H/v/9f/xL/iv9NALQAygD6ALMAfv8e/oD9SP2Y/LD7QPvo+hD6IPnI+ID4UPew9bD0MPSw83DzMPSQ9WD2wPZQ9+D3oPfQ9qD2YPe4+KD6XP1KADACvALIAuQCIAOcA+AE4AbwCHAKgAtQDNAMAA0ADfAM8AzADGAM8AugC4ALQAvQCkAKsAnACJAHUAZABTgEEAMYAnAB5AAqAIX/Ff+i/uz9EP1k/Mj7KPug+nD6gPqI+sD6SPvQ+xj8SPxo/Fz8PPxg/Mj8HP1o/dz9cv7a/iX/i//l/+z/pv92/1P/EP/c/g3/mf81ALkAJgFgAS4BmwD6/6D/iv+U/8n/PQC9AAoBHAEcAf4AjQD4/4n/Qv/4/sT+yv7a/rb+av4y/tj9LP1o/Nj7ePtI+5D7JPxs/Dz88PvQ+6D7ePvI+3D80PzQ/PD8YP3A/fz9fv41/6f/vf/9/4QA9wBAAaQBLAKMAsgCDANkA5QDpAO8A9wD3APwAyAEWARoBGgEcARQBAAE0APEA6wDeANoA3wDaAMoA/QC0AKAAhgC+AEMAggC4AHGAagBXAH4AMYAsQCLAGYAdACSAIoAbQBaAEIAEwDt/9z/yv+q/5H/if+I/4f/lP+q/6j/i/9S//7+nv5c/kj+Zv6a/s7+7P7k/rb+ZP4I/sT9qP2k/aj9yP0E/jz+Pv4g/vz91P2U/Wj9bP2Q/aj9tP3M/ej96P3Q/cD9tP2s/Zj9lP2g/bz91P3Q/dD92P3c/dj92P3o/fz9EP4a/ib+MP46/kb+av6i/s7+5P4B/zT/bf+v/wUAYwCqANYADgFMAYwB0gE0AqAC9AIwA3gDwAP8AzAEYASYBLgE0AT4BCgFSAVgBXgFkAWIBXgFaAVIBRgF6ATYBMgEoARwBDgE9AOcA0QD/AK0AmQCGALGAWgBCAGuAFQA+v+h/0v/9P6g/lr+GP7Y/ZD9UP0Y/dz8nPxo/Dj8CPzQ+6j7mPuA+2j7YPtg+2j7YPtY+3D7ePt4+4j7sPvY+/j7HPxY/IT8oPzQ/Bz9UP1k/YT9vP34/Sr+av6y/ub+Bv8q/1P/eP+a/8j/9v8YAD0AbACSAKgAxwDzABQBJAE+AWoBkgGoAbwB3AH6AQgCFAIwAlACaAJ4ApACqAK8AtAC6AL8AgQDCAMQAyQDMAMwAzQDPANEA0ADOAM0AywDHAMAA9wCuAKYAnACTAIkAvoBxAGIAU4BGAHeAJsAXAAnAO3/sv96/0X/E//e/qr+ev5M/h7++P3Q/aj9gP1g/Uj9MP0c/Qz9+Pzg/ND81Pzc/OT85Pzs/Pz8BP0M/RT9KP04/Uj9XP18/Zz9uP3Q/ej9Bv4g/jj+UP5u/pT+uP7e/gr/N/9j/4v/s//Y//j/HABIAHgApgDTAAABJAE6AVABbgGCAZABqgHMAegB8AH+ARwCOAI8AjACLAIwAiQCDAIIAhQCFAIEAvoBAAL4AdwB0AHcAd4BxAGsAa4BsgGYAYABigGWAYABXAFSAUwBKgH9AOkA5ADCAKMAmQCPAGEALgAUAAAA3P+3/5//ff9S/y7/G/8B/9r+wP6y/qD+hP50/mL+Qv4e/hL+EP4I/vz9AP4C/vz99P3w/fD96P3c/eT9/P0S/iL+Mv5I/mT+ev6Q/rL+3P7y/gH/HP9H/27/iP+t/9r/9f/8/xAAOwBnAIoAqQDFANgA6AD+ABABGAEmAT4BVAFeAWYBcAF0AW4BagFyAXQBcAFsAWoBZAFQAT4BOgE+ATQBIAESAQoB/ADgAMYAswCkAJAAgQB5AHAAXQBEADEAJAAUAP//6//j/97/0v/D/73/u/+x/6L/n/+i/5r/g/92/3T/b/9e/1T/Uv9K/zv/OP8+/zn/K/8m/y7/NP8z/zH/Nf82/zD/LP8w/zj/QP9K/1z/b/93/3T/cf91/3//h/+R/6H/sv++/8j/0P/c/+T/6f/u//b/AgATACEAKgAzAEMAVQBlAHEAgQCPAJgAnwCsAL8AzQDTAN0A6QD0APIA8QD1AP0A+gDtAOUA4QDYAMgAvQC6ALcAqwCXAIEAbQBWAEAALgAbAP7/3f/F/7v/sv+n/57/mf+O/33/b/9l/1v/Uf9P/1L/Uf9N/1D/Wf9f/2H/af9z/3v/gP+K/5n/pf+x/8T/3P/u//j/AwAOABcAHgAvAEQATwBRAFQAWwBfAF0AXgBkAGcAZQBjAGMAYABbAFkAWABTAE4ATgBQAEsAQgA8ADgAMgAvAC8ALQAnACEAHAAPAAAA9//x/9//z//S/9j/zv/C/87/0f/A/6//uP/A/6n/lf+f/6v/of+c/63/s/+b/4T/jf+h/6L/m/+k/7H/s/+x/7n/yP/Q/9b/3//p//L/+/8DAAcADQAXACAAJQApAC4ANAAzACwAJwAqACwAKAAlACcAJgAaAAsACAAPABQAEwARABAACwAGAAYACQAGAAIABQANAA0ACQAOAB8AKwAqACcALAAyADQANAA3ADoAOQA3ADoAQwBHAEUARABGAEcAQwA9ADwAPQA5ADQAMgAxACwAIgAXAA0ABgADAAQAAgD+//b/7P/h/9n/2P/X/9L/y//L/8//zf/G/7//uv+y/6n/ov+e/5v/lv+Q/43/iv+H/4D/d/9x/27/bP9q/2z/cf94/37/gv+F/4j/kP+e/7D/wf/T/+X/8v/7/wUAEgAaAB8AJwAxADcAOwBGAFkAawBzAHUAeQB9AHsAdgB1AHgAeQByAGsAaQBoAGAAWABZAFoAUQBBADoAOwAyACMAIgAwADEAIAAZACEAHwALAAIADQARAAYABQAOAAoA/f///w8AFQAPABEAGAAWAA8AEgAZABkAFwAdACYAJwAlACIAGgAQAAsACQAFAP3/+f/4//X/8f/u/+X/1f/H/8b/yf/F/7z/tf+y/7L/sP+x/7b/t/+z/63/rv+4/8D/wf/D/8X/wP+2/7X/vf/F/8j/yf/M/8//0f/T/9b/2f/g/+j/8P/1//f/+/8AAAcAEAAaACYAMAA2ADkAOQA3ADgAPwBIAE4AUABVAF4AYgBdAFgAWABXAFMATwBQAFEATABFAEAAPwA8ADQAKgAhABgADgADAPz/9v/w/+r/6P/q/+b/2//S/9H/0v/L/8X/xf/D/7v/tv+3/7b/sP+v/7n/xv/P/9b/3//l/+P/4v/n/+//+P8CAA8AHAAiACEAHgAdABwAGgAYABcAFgASAA4ACwAIAAQA/P/1/+//6//m/9//2P/U/9T/1v/Y/9j/2P/Y/9f/1v/V/9j/3P/d/+D/5P/p/+3/8v/5////AAD9//z//P/8//r//P8DAA0AFAAWABgAHgAmACwALwAuACgAIAAdACMALAAxADQANwA3ADUAMwAzADIALwAtAC4ALgAtACsALAAvAC8ALAAmACAAGAAQAA0ADgAOAAoACQAKAAcAAAD5//f/+P/6//3//v/7//f/9v/2//T/8v/z//L/7//r/+j/5v/l/+b/5//n/+j/8P/5//z/+P/4//v/+//6/wAACgAQABUAHQAjACEAHwAfABYABwACAAgABQD7////BwD9/+n/5v/t/+H/zP/P/9//4P/a/+P/7f/h/8r/yv/d/+H/0P/F/8n/y/+//7r/xf/T/9P/z//X/+L/5P/f/+D/5//q/+n/6//y//f/9//2//n//v8DAAYACwARABMAEQALAAYABAAJABUAIgAnACkAMAA6AEMARgBJAEwASwBGAEEAPgBAAEcATgBRAE8ATgBOAEwARQA8ADQAKgAeABUAEQAMAAEA9P/q/+D/0//H/8L/w//D/8T/yv/R/9P/0f/R/9P/1P/X/9r/3v/h/+L/4//i/+H/5P/n/+b/4f/j/+n/7v/x//j/AAADAAIAAAD9//f/8P/t/+3/7P/q/+z/7P/r/+v/7//1//b/9v/6/////f/0/+z/6v/m/9//4P/s//X/+P/+/wsAFAARAAwADgANAAAA9P/z//f/9//y//D/8f/y//D/7//y//b/9P/q/+P/6f/1//z/AwAOABYAFQASABQAFwAWABYAHQAnAC4AMgA2ADYAMAAkABsAHAAhACcAKQAtAC4ALAAlAB4AGQAYABoAGAAXAB4AJgAgABYAGAAgABwAEQAUACIAJAAcAB0AJQAiAA8AAAD9//3//P/9/wIACAAHAPr/7f/p/+X/1//J/87/2v/Z/87/yf/C/7L/rP+8/9L/5v8KADMAMAD7/8n/sv+o/6j/sv+0/6X/p//G/+T/9P8WAEAAMwD0/9f/6//k/7f/wP8MADYAJAAsAGQAbAAhAOf/8P/1/9D/x//9/ysAKQAqAEoATwAhAPr/+P/z/9n/zf/m/wIABAABAA4AGgAXABgALwBNAFQARAA8AEcAUgBaAGcAdwCBAIEAfAB1AGsAXABHACwAEQDw/8L/jv9s/2f/cf96/4L/jf+Q/4r/hf99/2b/U/9d/3X/fP+F/7f/8/8AAPn/EAAgAPj/1f/8/yEA7v+8//P/MQAHANL//v8rAO//qf+9/+b/3f/c/w0AMAAeAPr/4v/u/zIAaAA8AAkAWAC+AJAAUwC9ABoBiADe/zAA1QDGAGUASwANAH7/Vf/N/0wAoADdAKUACAAGALwAxADh/6v/gwC3ANr/y/8cAfABcAEeAaABhgFbAJj/pv8j/7T94Px4/bj+QQAsAnADpAJbACb+IPzY+Zj4mPnI+3z9TP/wAawD/AJaAZcAGwAy/yT/kwC4AXgBOAH8AXQCpgG1AHcAFQA0/+z+3P8SAZoBlgF8AUwB+gC4AKIAgQAzAAgANwBWAN7/Af84/qD9MP0E/TT9xP2Y/jL/Af+0/n7/ngBJACn/YP9BAJ//eP5d/zQB3ABA/8b/9AEoAl0AAgBwAXoBgf+g/v3/HgFlAJf/gAD8AdoBeQBPAOIBoAIOAZv/dACWAYoAXf8mAQAE4ANiAaAAXAI8AwACNAH2AfwB//8q/mD+iP+n/6L+uP2g/Tb+8v7w/pz9wPt4+nD5SPgY+cT8r//A/lj9kP8AAtX/jPwC/hgBm/+Y/Bz/YAQABK//PwBQBRAG3gFwASgGMAfmAQ//kAIgBHr/FP0YArAFeAHo/bIBKAQk/uD46Py4AZr+2Pqc/gADPwCQ/F//PAMGARD9PP6aAQoBpP7M//wCCAOKAMD/MQBW/rj7+PwCARwCGAAXAEgCbAGE/ZT8Wf/8/3T9pP2YAeACof9M/loByAK8/zT+ZAEsA0r/wPt6/vwCAAPIAM4AoAAI/SD6kPyhAKMA9P4mAXAEgAHI+oD6GAHMAmz8sPoQA2gHB/+w+N8AAArIBID81gC4Btz9YPMM/PALAAoA/sP/oAhEAtD1APtwCAgFYPgA+2gGoAN4+Lj53AEA/zD4Ev5gCXAJ1AEJ/3n/FPxA+CD6Xf/wAtAEsAbYBxgGEgFE/HD7yPug+KD23PzgBTgHQASQBQAGCv4Q99D7dAKq/kj5zP00Awv/YPvuAZAHXAKc/Nr+JwDg+7j7/QA9AED6APz0AzAENP7c/ggD0P4w+GD8aASUAmD9WQB8A0D9kPht/xgGMALM/rgE6AepAID88AJ4BXD8wPf8ALAI7AIg/bwDgArEA0j6LP1oBMwAaPjw+rAEkAVY/cD6xAD4AoT92Pt8ArgFJf84+SD8qQAk/3j8Gf8IA0ACcv///3QCbAI7AMj+1v6j/3cAbgDL/5AA5AJ4A9UApv7k/3ABy//s/ff/HAMMAlT+rP02AMgA/P1U/I7+oAH6AVoAlP9TANoAdv/8/Gj8eP65//z9OP0SAegE1AK6/iMAyAP0AMj6yPssAt4BGPuo+mACkAUYAFD9NAK4BEj/yPro/W4Blv4A++z9lAMQBAYAnP7+ASAEugAM/Y7/5AOWAQD8LP1AAzgD/P3Q/lgFqAU2/7j9SAL+AbD7SPq1/1QCqP9R//wCqAPO/wL+WwCQATT/+PwA/Vz9aP0M/zwCAAQEA0QBcgCh/zz+2P3a/hn/7P0M/n8AGAIoAW4AmAHyAVoA6P9iAc4AFP0w+5T9+P9U/0n/ZAJgBPYBT/9IAHwBIv9Q/OT8jP5K/mL+EgFAAyQCdQDQABoBff8+/hP//v+i/3X/UQDeAIwATwA9AOj/3/+HAN0AmADSAG4BxQAX/6r+hP9j/1z+Mv/GAcQCjAEgASQCnAEC/4D9ZP5G/5z+Ev72/hwASwBRACQB8AFCAWn/Av7Y/Sr+TP7C/uH/uQBXAIz/1//fAAoBNQDF/wgAOQBCAHUAWwC0/4P/JwBtAOP/BwBsASACHgEZAGkAlwCB/7z+pf+yACoAYf8xAIIBQAEkAC8A7gBvACP/M/9ZAGAAdv/M//YAhwAA/yz/ygD6AKb/Xv8sAM3/fv6w/jQAgwB5/2r/ZgAtAMD+mv77/4gAvv+h/5MAnQBt/+r+ff+h/yX/av95AOcAaQAEABYACwC7/6D///+OAL4APwCY/7L/TwBkAOv/0P8SAOn/hv/A/zUA9P90/6z/QABGAAAACwAUAKH/Q/+a/1IAvgDhAO4AuAAuANf/+v8UAOP///+tACwBEAHZAOwA3wBtAAEA8//3/+H/BgBHAEMAFQBLALcAtQBQACIAMQDf/0X/CP8S/9z+lP7e/oP/0//b/wsAQQALAKb/Zv8s/+b+7P4q/0j/hP8oAJgAYgA6AKUAxwAIAIP/CwCeADYA1f99ACoBtgAJAE4AuABRAMf/HwCxAF8Atf/e/4MAgwAQAAsAUAAeAIv/cv/k/zMAEwDs//X/2v+M/3f/2P9FAEAA+f/y/yQAGwDg/9T/9f/o/5j/Yv9v/5j/xP8DAEEAQwAGAN//6f/r/7j/iv/A/ygATwBDAFwAcgAcAJz/iv/n/wsAy/+Q/6f/wv+m/63/BABCABgA0v/M/9H/jv88/zD/Tv9U/2D/iP+v/7D/nP+A/3n/uf8ZADoAEwAkAIIAmwBUAEUAowDWALgA1wAwASgBswCGAMoAzgBcACEAZACDAD0AKwCVANgAlQBOAGUAgABOAC0AUgByAD8AHgA5AEcAEAD5/zYAUgD//6L/tf/p/9T/uP/w/zYAMwAoAFoAhABPAAAA8v/r/7T/mP/A/+3/4v/K/73/kP88//T+6v76/gr/8v7k/vz+Av+q/kT+RP5i/hj+mP2A/ZT9SP3c/AD9hP28/cD9MP7i/hf/Bf9S/9H/AQD4/zwAiwCKAJIAAgGAAaQBygE0AnQCWAJcArgC+ALoAhQDfAOgA4QDpAMABPwDsAOYA6QDXAMIAxgDVANMAzwDfAO8A4wDVANcA2ADDAOoApQCdAIMAoYBIgGnABwAyf+//5f/Pf/0/tb+sP5o/gz+nP34/Bj8EPv4+Qj5UPig9+D2MPaw9VD10PRg9DD0MPQQ9BD0kPRA9dD1QPbQ9qD3cPhY+bj6RPyk/cL+4/8YARQCEANYBOAFQAeACLAJcAqgCqAK0ArgCuAKMAuwC/ALoAtgC1AL4AogCsAJ4AmwCfAIgAhQCOAH+AZYBjAG+AWQBXAFkAVwBRAF0ATYBLAEgAR4BIgEEAREA5QC2gH9ANf/0v6M/ej76PnA96D1wPPw8VDw4O7A7eDsAOyg64DrgOuA66DrIOzA7KDt4O5g8MDxAPOg9HD2MPgA+iT8bP5xAFQCaASQBjAIgAngChAMwAwQDZANAA7wDSANcAzwC1ALYAqgCQAJAAjABrAF6AQQBBQDUALgAXYBEAH2AD4BWAFOAYQB8AFQAuQC6AMABcgFaAYoB7gHEAiQCDAJsAkQCoAK0ArQCpAKcAowCmAJoAgwCIgHCAY4BIwCegC8/eD6mPhA9mDzgPAg7uDrwOmA6IDoAOlA6WDpwOmA6iDr4Osg7cDucPDQ8VDzAPXg9pD4iPrk/G7/lgGYA9gFyAdACYAKEAxgDQAOQA5wDtANQAzACqAJYAiwBkAFgASEAxACHgEEAQoBigBKAIEAaAC3/1r/v/8LAOz/IQAeAfoBVALUAvgD6ARwBVAGuAcQCcAJgApwCyAMMAxgDNAM0AxQDLALMAuwCiAKsAlgCbAI0AfoBsgFUASEArsApP5g/AD68Pew9SDzQPBg7eDqIOmA6IDoAOlA6WDpwOlg6kDrQOyA7UDvEPGA8vDz0PXQ90j5yPr8/FL/PAEMAzAFCAcgCDAJkArwC1AMUAyADDAMMAvwCdAIiAfgBXgEmAPUAsoBFgHKAIEA8/+h/6D/a/8j/1v/BwBPAGIACgEAAogC/AIQBGAFEAZwBpAH4AhgCaAJkAqAC5ALkAtQDOAMYAzgCxAMAAwQC2AKkAowCtAIwAdoBxgGyAM4AlwBQf8s/PD5ePjQ9UDy4O9A7gDsoOlA6SDq4Okg6YDpwOoA6yDrgOzg7mDwYPEQ82D18PYQ+Aj6UPwM/nr/oAHkA4AFgAYACHAJYArACoALAAyQC7AK4AkACWAH0AW4BNADfAJSAdQAdACw/+L+vv60/nL+YP7i/mf/pf/4/9YAvgF4AlwDqATgBZgGOAcgCBAJwAlgCjALwAvwCyAMgAzQDKAMQAwgDAAMcAvACmAK4AnwCOgHSAdIBogEnAIiAZb/RP0Q+1D5MPeA9NDxwO+g7UDrIOpA6oDqQOpg6iDr4Otg7IDtgO8w8YDyAPTw9aD3KPno+tT8cv7p/4YBKAOYBMgF2AaoB3AIIAmwCdAJwAlgCdAI0Ae4BqgFaAQAA7IByADw/yX/mP5I/gL+uP3A/QT+QP6c/kj/KADwALIBsAK8A6gEiAWgBpgHIAhwCCAJ0AkgCkAKwApAC1ALIAtAC1AL8AqACnAKUAqQCcAIYAjYB7AGiAWYBIgDxgELAKr+EP0o+wj5QPcg9cDygPCg7iDtYOxA7IDsYOyg7ADtoO1g7qDvYPGw8gD0kPUQ92j48Pmg+wD9Hv6D/xYBXAJMA3gEqAVgBugGqAdwCHAIIAgQCMgHwAZwBYgEpANUAuwANgDF/xv/dP4+/k7+Fv4G/qL+fv8tANUA9AEoAwAEuASwBcAGcAfoB5AIEAkgCTAJgAnQCdAJwAkQCjAKAAoACjAKEArACZAJYAnQCBAIoAcoBwgGuATQA8gC+AAD/6T9KPzY+VD3sPXg81Dx4O6g7eDsIOzA64DsAO3g7ODs4O1A72DwYPEQ88D0APZA9+j4oPr4+0j95P5lAJQBkAK4A9gEkAU4BhgH6AcgCAAIAAjYBwAH6AUoBWgEMAPyATwB0gArAIH/e/+b/4X/af/f/48AGgG4AbwC4AO4BIgFgAaIBzAIoAgACWAJcAlgCWAJYAlgCWAJgAmQCZAJcAlgCVAJAAngCLAIUAjwB6gHOAdoBlgFYARcA9YBHACS/iD9KPsA+RD3QPXw8oDwwO6g7cDsYOyA7MDswOzA7EDtgO7A78Dw4PFQ8xD1oPYQ+ID5KPuY/Mz9D/+iAO4B0AKsA9AEsAUYBogGIAeABzgH4AbYBmAGUAVIBIwDxALaAUwBHgHEADEACwBAAEwALACCAEoB5AF8ApAD0ASABRAGKAdQCOAIIAnQCWAKQArQCQAKQArQCWAJkAmwCSAJoAjQCOAIQAjYByAIEAg4B4gGiAbgBUgEJAOMAhoB1P5A/TT8CPoQ9xD14POA8cDuoO2g7eDs4Otg7IDtQO2g7ODtAPDg8FDx8PJg9ZD2MPfY+Aj7DPyQ/Dj+KQAcAYgB5AJYBPAECAX4BfgG8AZgBogGoAbABaAEKAS8A4gCkAFyAXgBtQAOAEcAkAA1AAYA0wCeAc4BMAJgA2AE4ASIBfAGEAhwCOAI0AlwCkAKMAqwCvAKkApACnAKcArwCaAJsAmQCeAIUAhQCDAIiAf4BrgGMAYQBcwD4AKIAbr/BP64/CD7wPiQ9sD0wPJw8KDuAO5g7aDsoOxA7YDtgO0g7qDvAPHg8SDz8PRQ9nD32PiI+tD7wPz0/Vn/dgBOAUACLAPkA2gECAWABcgF2AXQBZAFQAXYBGAElAPIAjQCyAFOAdsAngB5AEgAPAB4AMUA/wBkARQC1AKUA2AESAUgBtAGiAdACNAIIAlgCZAJkAlwCXAJgAlgCQAJAAkACcAIYAgwCDAI4Ad4B1gHKAeQBtAFQAWABBwDsAF5AEL/cP2Q+/j5OPgg9vDzMPKQ8EDvYO4g7gDuIO5A7oDu4O7A79Dw4PEA8zD0gPWw9vD3aPm4+rD7yPwY/kr/QQBcAYgCdAMIBMAEoAUQBhgGGAY4BuAFMAWoBBgETANQAswBfgEOAWsALAAwAAcAyv/i/2wA5ABIAQQC8AK4A1AEKAUoBuAGUAfoB6AI4AjgCAAJYAlwCVAJcAmQCXAJMAlACVAJMAnwCOAIsAhACNgHcAfYBgAGIAU4BNQCRgHc/17+YPwo+lj4kPZQ9BDykPBg70DuYO2A7eDtAO7g7WDuQO8Q8PDwQPLQ8wD18PVQ9+D4OPpA+3T89P1L/z8AMgE8AkQD6AOIBGAF8AUYBhAGMAboBVAFoARABJgDwAIYAtABfAHwAJMApACvAH4AlAD7AHABrAEwAhAD6ANwBCgFMAYYB6AHEAjACDAJQAlQCbAJ8AngCdAJAAowCvAJsAnACbAJUAnwCNAIoAgwCKgHMAeYBqAFeARQA/4BdgDE/gj9OPtQ+XD3cPVw84Dx4O/A7iDuwO3A7eDt4O0A7mDuYO+g8LDxwPIg9JD1wPYI+JD5APv4++j8dv77/74ARAFwApwDEARABAAFqAWYBTgFSAVoBcAEzANgAwQDLAJqAVQBWAHMAC4ANgBtAEEALgCgADYBbgHuAfwC8ANgBAgFMAYoB6gHUAgwCbAJoAnQCWAKkApQCnAK8ArgCnAKcAqwCnAK4AnQCfAJYAmgCEAIyAeIBiAFMAQQAzABb/8y/pT8OPog+KD20PSQ8uDwIPAg7+DtoO0g7gDuYO2A7aDuYO/g7/DwwPIA9ND0MPYw+Jj5cPqo+3T9zP50/4EA0AHAAhwDuAOABAAF4ATwBBgF6AQ4BMwDmAMYA1wCAAIMAsoBaAEqAS4B+QCjAKQA8wAgASYBmAFAArQCFAPcA/AE2AWABlgHQAjQCDAJ0AmACuAKEAtgC8ALwAuAC4ALsAtwCwALoAqAChAKcAkACbAI4AfQBtAFyAREA4QBFwCy/gj9IPtw+cD3kPWQ8yDy8PDA7+DuoO6A7iDu4O1A7sDuQO8A8CDxMPLg8uDzUPWQ9rD32Pg4+mD7XPx0/Zb+k/9WAA4BwAFYAsgCRAOUA8AD0APsA9wDqANUAzwD4AKUAnQCgAJcAvYBxgHSAcQBlAG2AQQCEAIQAmwC+AJ0A8gDYAQQBZgFGAbIBngH6AdQCPAIkAnQCRAKgArgCuAKAAtAC1ALEAvgCtAKkAoQCpAJIAlwCGAHSAYgBbQDHAKcACr/dP2o++j5EPgg9jD0wPKg8aDw4O9A7+DuwO7A7uDuQO/g76DwYPEg8gDzMPRA9XD2sPf4+Aj6MPto/LD9zv7B/6MAfgEwAsACQAOoA+AD7AP0A+ADlAMsA8ACgAI0AuYBqAGQAWIBGgHhAMcAwACuANIAIAFeAYIBpgEMAnQC1AJAA+wDiAQYBbgFaAYIB5gHQAjgCGAJ0AkwCpAK0AoQC1ALgAuQC5ALgAtgCxALoAoQCmAJoAigB4gGOAXgA3gC3wAe/0z9ePuI+bD3IPbQ9MDz0PIg8rDxUPHg8MDw0PAw8ZDxEPLQ8pDzQPTw9ND18Pbg96D4ePmI+kj72PuU/Hz9Jv6K/i7/0f8nAEgAcwC3AM0AwgDXAPIAEgH+ABgBNgFmAVIBcAGaAaoBnAGKAb4B1gEIAjgCgAK8AvgCOAOcAxAEeATwBFgFyAVYBuAGYAfoB3AI8AhACZAJ4AkAChAKMApgCnAKcApQChAKgAnwCGAImAe4BtAFGAUABMwCugGaAHD/8P2g/FD74Pl4+MD3cPfg9oD2EPaw9VD1MPWw9QD2IPaw9pD3KPiI+Pj4yPmo+jD78Pvs/Kj9zP3w/VL+hv6W/uD+TP9n/yr/Av8X/+j+Wv74/cD9aP0E/dT89Pzk/LT8xPzg/PD8EP08/Yz9tP3k/VD+wP4g/5P/PQDvAJQBRALoApwDGASIBDAFyAUYBnAG+AZ4B9gHQAjACAAJEAkQCUAJIAnQCHAI8AdgB3gGoAX4BDgEdAPUAjQCcAGVANf/DP9K/pT9+PyQ/Cj84PuY+0j7APu4+pj6iPqg+tj6EPtw+9j7IPyU/BD9uP0+/rb+X//g/zwAdgC1AOsA8AD5APoAyACKACkA4f+I/yL/rP5A/tT9dP0g/cj8oPyA/FT8NPwk/Bj8KPxE/Hj8mPzM/PD8LP2E/dj9aP7O/k3/4f96APMAXAHOAVQCgAK8AgQDQANsA2gDxAPUA9AD1APEA9gDtAOgA5wDgANkAzgD7ALEAnQCPAIAAs4BsgFeAUgBAAHZAKYAeACaAI8AgwB4AGMALgD4/73/v/+T/3r/Uf8x//D+iv6G/lT+dP5o/mb+ZP5E/ib+Mv5A/l7+ev6U/qz+kv6c/n7+tv64/rj+0P7O/sr+tv6s/tL+4P7g/vT+DP8r//j+Gv8m/0T/af97/7T/8v/w//j/8f8NADQAZwDHAAIBQgE2AUQBhAGUAcQBKAJQAnwCUAI4AjgCJAIMAiQCRAIQAr4BfAFGASIB5wC4AOcApwA/AN3/gf9C//b+pv6g/pj+Sv7c/Yz9SP0c/QD91PwM/fj8rPxs/GD8bPyA/Jz88PxE/Tj9HP0s/Vj9hP3k/RD+gP7M/tL+9v4d/3D/0/8pAKAAEAFCAVoBlAHiAQQCVALAAvwCNAMcAxgD9ALoAhwDbAOUA6wDkANUAxwD2AK0AqACuAKYAjAClgFqAV4BYgF4AaABsgFMAQQBhwBSACYA1v+d/2f//v6Y/vj9zP3w/cD9kP1c/bj9vP20/bz9nP3c/bT9gP2s/Zz9wP3I/dD9MP6I/g//c/8dAEgA/f8AAMb/CgB9AIEA/AAaAVgBpAHMAawCPAMQABIADwAXABoAHAAZABsAHAAjAB8AHwArACQAJQAqACkAKQApAB8ALAAlACEAJQAiAB4AIQAeACQAHwAgACQAJQAcAB0AIwAYABgAIwAgABoAJAApACUAJgAiABEAFAATABAADQATAAsACgAHAAcADQAQAPv////4/wEABwACAA4ABgAQAPf/CwALAPL/GwARABQADQAFABAADwAFAA0ACgACAAkAAAAIAP//+f/7//v/9P/4////+v/y//T/8f/0/wAA+v/+/wcACwD8/wAADAAFAP//CQAKAAwAEgASAA8AFgAaABkAGgARABQAFAAHABEAEgAGAAMAAwADAAgACgAEAAEA/v/5//L/9f/3//T/8v/y//b/9v/6/wAA///7/////P////3/9f/y//b/8//7////+//9//z/8v/y//3/+f/1/wAAAgABAAIABAAGAP7/+//7//3/AgACAP7///8BAAIA///9/wEABQAAAAAABAD+//z/AAADAP7///8BAPv/+//+/wIA/v/+//z//P/9/wEAAQAFAAcACQAHABAABgAHAAQAAQD//wQABgAEAAMACwAMAAsADQALAAIABQABAAEABwD9//7/+/8AAPr//v//////BAD5//n/+f/x//3/AQAIAAUAAAABAAAA+f/4//v/9P/2//j/9//5//P/8//x/+7/8v/0/+//7f/u/+r/4//k/+j/6P/l/+j/4f/v/+T/7v/1/+7/+v/6//7/BgAJAAgABwD//wEA/v8EAAMABAAKAAkACAAQAPn//v8CAO7/7v/y/+z//f/s//H/+//f//j/5//5/+j/5P/5//H/7v/p/wsA5P/n//f/5v/8//T/5f/t/+f/3//o/+j/8P/l/+v/7f/o/+X/6f/w//X/8v/3/+//7f/4//P/8v/1//b/+v//////AQD+/wAA8v/u//D/7P/t/+//7f/u/+n/5//m/+z/8//x/+n/5//o/+j/6f/r/+z/7f/r/+3/7P/s//H/8v/n/+H/4//h/+X/6P/j/+T/4P/i/9//3f/h/+X/5f/i/+H/4//j/+P/3//i/+H/4P/j/+f/5v/k/+H/3//g/9//5//j/+H/4P/i/+L/3f/g/97/3//h/+D/5f/i/+H/5f/i/+P/4v/g/+T/5//v/+//8f/3//b/8//x//H/7//r//D/8P/w//T/9f/5//b/8v/3/+//6f/r/+v/5//k/+X/5v/l/+r/6f/p/+X/6P/o/+n/6f/v/+z/6//q//L/9v/z//P//v/7//b/9P/6//j/+//8/wUABAACAAYAAgAIAAcA+f8HAAYACAD9/wMAFgD1/woABQAVAAcADAAUAAgACAALABYADAAOABQADwAQABQACwAPAAkAAgATAAoADgAYAAgAEAARAAoAFQAKAAoADQAHABcAFAAVABsADwAOABYACwAYABwADgAVABgAGwAZAB4AFwATABUA/v8KABgACwALABQABgABAAwADAAQAA4AEwAOAAcADgASAAwAFQAYABYAHgAkAB4AFwAfABwAGAAdABsAJAApACAAHgAgABkAFQAgABoAGAAcABwAHQAbABkAFgAcACAAHAAiAB0AHwAkACIAHwAmACUAIgAmACsAKgAnACIAIwAmACYAJQAmACYAHwAdABsAGwAaABgAGwAeACAAHwAeABwAGgAWABQAHwAdAB4AJAAmACMAIAAaABcAHQAaACEAIAAiACEAIgAjACIAJgAgAB8AIAAlACMAJQAmACMAJwAoACoALgAuAC4ALgApACsAKwAwAC8ALgAwADMAMQA0ADIALAAzACgALQAsACwAJgApACsAKwAuADMALwAuADAAMwAsADQANgAtAC0ALAAyADUANQA2ADYAMQAzADUANwA0ADYANQA0ADMAMgAxADEAMgAsACgAKQAkACgAKgAuACkAJwAoACYAJAAlACEAHwAhAB8AJQAnACcAJQAiACMAHwAkACYAJwAnACIAKAAqACkAMAAxADAALwApACcAJwAqACcAKQAlACQAJQAuACsAKAArACYAIQAbABgAIAANABoAGQAdAB0AFwAkACAAEQARACMADAAhAA8AGwAkAAAAGwAYAAoACQANABIACwAXABIABwAQAAYACAAPABAADgAGABAADgAMAA4ADwASABQAEwAOAAkADwAKAAsADgAPABQAEgASAA4ADgAPAAcACAAFAAYADAAJAA4AEQAPAAwACQAKAAwADgAJAAQABAAEAAQABAAFAAgACgAHAAIAAwACAAYABAD9//z/9P/5/wQA/v8CAAEAAQABAPn/BAACAAQAAAD7//v/+f/7//v//P/3//r/+v/7//n//P/3//L/8//2//n/+/8AAP7//P/5//3/+f8BAPv//P8FAPz/AQAGAP3/AQAEAAEAAwD7/wIABgD8/wMAAAADAPr//f/+//z/9//8/+7/+v/9//f/BQDv/wAA8f/v//j/6//q//H/8v/r/+//8//0//X/8v/8//f/+P/z//z/+f/9//r/8v/2//3/AQD8/wUACgADAPj/AQD9//r/+//+/wQABwD5/wcAAgD6/wEAAAD9//7/9v/5/wMA+v/+/wMAAQACAAAABQD+//3/BwD7////+v////z//f8AAPr/+f/9//f/9v/9//j/9v/7/wAA9//2//7//v/4//b/9f/1//T/9v/7////9//7//H/8P/v//P/9//q//b/8f/q//P/5v/m/+v/4f/q//D/6P/v/+7/5f/s//H/9f/r//D/+//u//j/+P/v//f/8v/5//v/9//7//X/7v/q//L/9//x//X/9f/2/+//6//0/+v/7v/u/+v/7P/2//3/9P/9//n/7//y//D/9v/5//P/+P/2//L/8f/1//r/7//w//H/7f/m/+r/6//p/+f/6f/t/+b/6f/m/+b/6P/h/+P/5v/v//X/6f/t/+//6f/l/+r/8P/s/+7/9P/t/+n/7//s//D/6//k//L/8P/w//n/9P/r/+7/8v/s//f/AQD6//T/8v/6//f/6v/7//f/9P/6//X/+//7//X/8f/z/+j/9P/0/+//8f/x//f/8f/1//L/7f/s/+7/6//1//L/9P/1//f/+//5//z/+f/x//P/9v/s//H/8f/s//D/8P/o//n/9P/2/+7/7v/l/9//5//g/+3/3f/p/+X/5P/p/9//5f/a/+H/4f/b/+P/5f/j/+X/2f/p/+z/3f/p//D/4v/i/+T/3v/k/+r/7P/w/+n/8P/v/+f/6P/j/+v/4//r/+3/7P/q/+D/6P/X/97/5v/e/+X/3v/n/9n/4f/k/9j/4//Y/9b/3P/S/97/3f/Z/93/2P/c/+T/4v/Y/97/3P/R/87/2f/a/9X/3//R/9j/2v/N/9z/2v/X/9f/0v/f/+H/3P/n/9r/1P/a/+f/3P/m//H/3v/k/93/4v/m/9n/5P/j/+P/3v/k/+b/3//p/97/5P/i/+D/5//l/93/3//f/9//6v/m/+z/6//m/+H/3P/g/9f/4//e/+P/5v/l/+T/5v/i/9v/5//b/+D/5f/T/+L/4f/h/+L/5f/X/+X/3//d/+P/4//k/+P/5P/W/+L/4f/g/+X/3f/m/+L/4//q//L/5P/t/+r/3v/x//D/8v/4/+n/7v/r//X/7v/z//T/9f/0/+3//f/r//P/8//6/+r/9v////T/9f/z//H/+P/4/+///P/5/+n/7f/t//H/8f/z/+//AQDz/+7/8v/n/+P/7f/m/+v/6P/z/+7/CwDl////8//u////8v/6//b/8f/4/wIA+f/7/wgA+v/7//P//P/8/wAA+/////T//P////7/BAADAP7//f///wIA9v8VAPf/+P8GAPr/BAAFAAUA/P/7//X//v8FAPn/9P8DAO3/8P/+//H//P/2/+v/7f/w/+//+P/7//r//f/z//b/AQDo//b/AAABAPP/+/8GAPj/+v/z/wMA8P/0//n/9//4//X/7//2//z/6//s//H/6f/1//L/5v/z/+7/8P/2/wIA+f/5/woA9f/2/wAA9/8BAAUA+v8DAAQA/v8DAAcA9v8IAP3/AAAMAPv///8EAP7/AgAKAAMAAAABAAkAAwD4//3/CAAAAAMAAwAFAAIA9v8GAAUAAgD3/wgAAgDw/wEABgAEAAEAAAD4//3/AAD//wUABAD4/wAACQD6/wIAEAD3/wQA+P///yAACAD9/wIA/f/7//z/AAALAAUAAwAJAPv////3//v/BAAJAPj/BwAHAA4AAwAEABkAAQANABEAFAALAAYADQALAAwAEAAQABoAHAATABYADAARABEABwATAAAAGgAeAAAAJgAMAAgAHQD//xkAAQACABEACQAMAAkABQALAA8ABAAMAA8ABgAIAPv/DAAIAPj/CgAEAAgABgD8/xAADAAIAB4ABgASAAcADwAGAAQAFgD9/xMAFAD3/xQABwD///z/8/8JAPr///8LAP3/CQACAOb/DQD4//v/EAAJAAIADAAZAA4AGADw/xwADQANACMAEAAvAAsAGAAmABcALQAgABoAIQAEABAADQAdABQADwAxABgAGAAhAAUAFAAHABgAGwAPAA4AJwAQACEAFQAWABMABQAyAAkAFwAQAC0ABgAaAPT/EQAsAO7/OwAUAAQAFgD8/xcAEQAZABMAEQAqABwAFgArACgAHQASADMAJwAkACgAIwAxAC8AHAAWAC4AKgAkADcANwAqADMALwAhACMAKgA0ACgAHwAuAC0ANQAqADQAKQAeADQAEwAlADkAJAAeABcAGwAYAB8AKwAnACIAJAAcABUAFAAaAC4AIgAZABMAHAAhACQAHgATAB4AGgAsAB0AIwAnAB4AFwAVACAAKwAcAC0AHgAgABkAIgAvACQAMAAdABsAHgAoACkALgAgACQALwAmACkAKQA0AB0AIgAxABoALwAtAC4ALAAzAC8AJgAmADAAMgAwACYAMAAwACAAKwAjACUAFwAZAB0AKAAeACkAKwATABcACQAZAAkACQAZABEAFwAKABsAFwAaABwAEQAeAA0AEgAdAB0AIgAYABIAGQATAB8AGgAUABgAKgAPABEAHQAZABgAHQAnAB4AHAAkAB4AJAAcABMAEgAuACIAIQAeACcALADw/z4ABAApABAAEwAXAPn/GwAIABcAAAAJAAwABgATAAUA/v8OAPT/AwASAAAAFwANAAEAFQAMAA4AGQD9/w8ABQD//yYA/v8WABIA+f8TAA0ACgASAAYA//8PAAsADQALAAsACwAGAPb/7f8fABsACwAfABQAAwARABoAFgAdABsAIwAUABQAJQAaABAAHgAXABwAJwAdABEAGwAdAAsAGwAaABYALAAkABcAIwAeAA8AGQAjAAgAEQAjAB4AHQAKABQAGgAcABgACwAgABMAIgAUABEAHAAaABcAHQAhACEAHwAhABgAGAAfABcAJAAeABIAEgAbABoAFgAOABAAHQAYABoAEAASAA4ACgAKAAkAFgAIABUAHgAcABIAEAANABUAIAAVACkAHgAnACAAIgAnACAAIwAfACMAHAAsACEAKAAfABsAIwAgACAAJgAjAB4AFwAZACoAGAAjAB4AGgAmACEAHQAgABgAHgAhAAUAJQAVABoAEgAfAB8ADwAdABoAEQASAA0AEgAHAB4ACwAAAA4ACgAhABMAGwAXABMADwAVABcAFwAUACAAGwAXABUAFwAbABYAHgAOABQAEQANABkADwAXABUAFAAYABsAGQAcABoAIwAeACIAKwAnACcAJwAoACgALQAvAC4ALwArAC0ALgAqACUAMAAsAC4AJwAjACkAJgAuACMAKAAmACIAMwA0ADAAOAA2ADMAMwAuAC0APgAoAEcAMQA/AEMANQBOAC8AMgA5AEUAMQBMADUATgA4ACMATQAqACgAKAArACoAIQA3ABoAKAAlABcALwAtADUALgAnADsAJgAwAC0ANgA2ADEAOQAzADwAQQA4AEQAQwBGAEUAQgBFAEQAQQBEADgAPQA9ADoARAA+AEIAPgAyADAALgAyADYANgAqADEANQA2ADwANgBMAEMARQBAADgAOgA7AEMAPAA6ADcAPQA2AEkAPAA5AD0ANwA7ADAAOgAuADAALwAkACgAIgAdACIAJQAfACUAKAAnAC0AKQAqACwAMgA1AC8AOgA5ADsAPAA1ADwAQAA7ADYANQA3ADoAPQA9AEMAQQBHAEIAQABLAE0ATwBPAEcASwBOAEIAPwA7ADgAOgAvACwAMAAnADQAJwAkABsADwAKAAsA//8BAPn//v8GAAoACgAGAA4ADAARAAkACQAGABEAFgASABEADwAOABUAHwAkAB8AIAAZACYAHwArAB0ALgAwACsAKgAuAC8AJQA0ACIALwAnADYAJwApACwALQAlACAAEwAbABIAGAABAAIAAAD///n///8BAP///f/+/wQA/P/t/+3/9f/2//r/8/////f/+/8FAPT/+/8HAAUAGgALAAoAEAAdADAALQAIAAEAMgA4ACQABwD7/yUALwD8/wcA2v/n/y4Aw/8DAHr///+3AGYA2v/K//D/KwB7AP3/KQDN/0sAJADp/xwALQCCAEoAFQAWAF4ASQAPACgAXABNAFgAs/99AHEANABKAPr/ZgAqACQANQDp/xMAAwAGAEIA4P/x/0kA7P8yAPT/8/8yAOf/6f/r/67/wf8RAHX/AgDg/53/0v+v/5r/tf8KAKT/xf+1/yAASgAHANoAfACaAM4AoQDvALQAIwBHAF4AgQA5AKf/9P+RAA4BhgC2//j/SgDkANgADwBHAJAAtwCBAC4AZACeAPgA1gA4AC0A0ACyAH8AUADG/xoAmwDC/9n/+v+u/9z/YP9r/57/tP+I/yj/nP6M/z3/Yv/o/qj+NAD4/iT/Rv98ACz/7/8mAA8AcAADAGcAUQCMAHsAZwCQACABowDDANEApwCQAeAAswCmAGoAwwBgAI8ACAA8AIIA3v8eADEAVv9MAMn/AQDh/wv/fv/B/9n/y//u/3L/ef8OANf/x//n/9f/QwArAK////9ZAEAAYgBYACgAnABJAPwAYQB9ADUACAGeAHkAGQA0AHIBcgA0AMf/igDnANEA+P/s/3UAPgDXACcAu//h/0wAEAH0/5D/2f+tALYAFwBz/1sAaAAbAHUAeP9vAHIA//9PAFcAEgAkAI4A3P9ZAK3/bABWABsAJwDl/3kAUgBeAPP/ZABbAHwAz/8XAF0ASAAcABIAEQA7AFwAwf8lAEsANAAIAOT/9/8zADoA5f+y/93/fQAwAOD//P/w/2YADgDC/9n/EQAmAMn/rP/g/wIAAAAgALD/4P/9/+j/DwC8/8L/9v+y/9f/of/D/xEA3P/D/6H/yf/d/7j/1P/J/4b/4f/G/5D/wf/L/9H/y/+N/6H/1P+0/6//p/+h/8L/wv9d/+n/m/+a/+v/sv+//7X/tf/P/8T/kv/F/5v/6f/I/43/5f+i/wkAq/+w/9n/f//v/9v/e/+//6P/FQDG/6n/nP+w//7/sP9V/7X/3v+D/8b/Z/9d/6f/f/+T/z7/i/9+/yv/kP+B/43/hP9v/6T/l/+4/1P/bf+9/43/ZP91/1v/ef+p/1v/aP9r/4X/gf9M/7b/e/8P/4r/vf+E/0n/Q//3/1r/of97/43/mP+w/7//V//K/6L/yP+A/7z/bv/a/9L/U/+U/8L/3v9t/3f/q//E/9D/oP9N/7b/ov+N/3b/uP/I/27/j/+8/8r/4f92/13/lv/k/9L/uv8s/5j/8v/S/73/S/+T/93/rf9x/63/vP+S/6D/xv+O/3L/1P+A/8j/vv+Z/3H/5f8PAHP/2P/o/9r/jP+h/87/PACQ/7f/t/+w/9n/7f9//9L/6v+y/5D/rf/m/5f/tv94/47/SwDh/7P/cf+o/wEAJgCO/1b/1/8oAML/l/+f/wYA6//J/8f/iP+m/9D/RAB+/6f/cP+9/2MAqv9s/5P/EQAHALP/HP+Z/woAqf9R/2r/tP/n/3T/Xv/C/3r/5v+w/5T/df/G/4D/bf/V/zP/uf/E/9z/mf+Y/83/pv/f/47/qv/R/7b/gP/0/8r/pv/9/6b/jP8PANf/ov8AAHX/6//0/7z/6f/E/8b/7f/1/9j/0P/q//v/of/u/w8A0f8SAPT/7//0/+L/FAARANv/TQDn//n//P9VACUA+f8hAEUA5/9SAAcA/P8SAD4AKAD2/0IAOQAZACkAcQDW/30AUQDY/zgAUQA0AEYAXgACAFQARQA4ACIAXgAlAFsALQDl/2AAJQBSAEUASQBHACsAIQBLACoALwA+AE0ASgAwAPr/PQD1/0kAQgAlAAQA7v/o/wEACQDx/xsA1//y/xQAEgC8/7//EwAVAPX/4v/5/wQAFQBWAO7/3//+/20AJwDK/7T/8//s/zYA6P8KAEcA3f9KAJP/cQDx/+3/BAAAACwAPACz//n/WwBU////wv9MALf/qv/5/3f/9f+d/2//sf/c/8//rf9f/8D/lv97/4n/vf+a/8T/Qf9z/9X/g/8e//v//P+f/6P/Ef/m/yAAUv+r/4r/V/9GABUAi/+I/yoALADt/9n/g//m/6cAs//0/woAx/+xADoA0wCUAC8ArAB1AJgAogBcAKwAcwDOALwAmAC9AMQAagBaAXQBDgH0AD8A8gAsAe8A3QA6ASwBbgH6AUIBzAF4AVACiANwAfoBZALGAWQDBANsAkADMAJgA9wCAAPUAuACRAKkAlwCSAK4AvABeAKmASwCpAGqAdABNwCwAVgBwv/PAGP/NgBE/1n/jP8g/tz+2P1J/8j9Nv7Q/fj8WP1s/Db+LP3U/ET9PP0g/Vz96P2o/GL+bP2Y/Vj/eP3k/pz8NP42/iT+sP7U/TD++P7U/aD9WP6i/nT/Cv64/Xz9WP18/Wb+kPzw/Vj+Fv6E/UT9OP2A/ib+tv6E/YT9yP28/YL+kP0w/9T9Av4u/j7+KP4q/vT91P7k/gb/eP4M/kT96wA7/yMAWgDg/sUAmf82AJ0A7wDYAWgBuADPAAIBfAGKAXwCHgGUAVABfgG+ASACyAK4AfgCVgF4ArgCcAIAApgCLALMAxADdAIQA9AD8APEA/AEGASwBGADaAW4BDAGsAUwBZgFiAUQBlAGqAboBWgG8AUoBuAEgATkA6gE4AN8AxwC2AG2AVQCQAKYAN0A0gDu/ub+rP7Y/Yj+xP3o/Xz8GP00/Nj7PP3A+2z8uPsI+2D78PuI+0D8wPuo+4z8YPtc/AD9DPwo/Tz9XP3s/bT9cP7U/er+sP7M/pYA2v4xAAb/0P28/7j/cP86/7X/1P2S/xT+dP2i/tz9xP5w/QD90Pwc/Yz9qPzg+4j7ePyA/Gz8IP1Y/PD7GPwM/AD9RPxo/JD7YPzg+1j9ZP34+0j9EP6o/mT9xP3M/XT+oP53/9T+tP2O/uz/5P6jABsAwf86AGoAfAG1ABwAzv+GAckAegHV/04BAwDsAGQCAgEcATAB1wA8AqgBiAB/AFYAUAJMAqACfgHQAWgA8ALeASwCIAOYAlgDHAOgA3AD9AMwBTgF2AXgBUAEOAQwBQAGMAaYBWAEMAa4BAAFIAVcAyAE7AOYA2AExAIwAkQC1AGQApYB3gFaAMz+B/+I/qr+3P5a/lb+xP14/UT8KPxQ/BT8mPzo+zj7sPqQ+nj7ZPxA/Oz8iPtY/Oj8EP1c/JT9NPy4/Zz9jP3M/nT8Av58/Qr/OgAFAM3/eP7I/lz+FgDG/uD+Gf8Y/kr+vP3Q/RL+i/90/lT+yP08/az8JP0M/aj9kP20/Jz8jPy0/Gz9OP2M/Kz8JP28/Gz9APzI+zz9vPxe/uj9gPww/Qj9rP4i/4b+S/+W/iT+L/8A/1n/JwCq/4UA8v/j/zsAlP/aAHIABgFaAYMAQgHgAMkA1gG/ACoBKAL5ALgCmgGQASQCigHwAsQBSAKYAt4BEAMQA+ACzAK4AjQDmAN4A1gEqARoBMgFcATgBIgFAAZYBlAGUAa4BWgGuAXoBWgFSAWYBSAGOAYoBdgEYAQABHgEIASMA0QDAAJeASwBPgH5AN4AAAEUATEAJv9I/zj+cv/K/tL+6P3k/OT8FPx4/SD9nP2c/cj80P2E/Pz8AP3k/Ij9mP3k/ZD92PzM/Sz+E/+r/57+n/9H/9j+GQBv/0D/1/9y/tsA+P/x/53/Xv4iADv/Q/+X/2T9lP4U/pz9uP7U/Dz9aP1A/ZT+8PyY/Cz9bPy4/Tj98PtQ/Mj6hPyY/Fz8MP0E/GT9VP3c/GD9YPyg/ED9WP0g/uT8kP2k/aL+yP89/0T/Fv/2/sX/j//a/5b/xv4eAAkAyP9NAOf/KAHuAdgBDAI+AGQBigDfACgC7ACCAZgBkgFUAvQBrAFYA6wCuAOQA6wCSAMgAgQDOAOQA7AEKAQQBPADWAQoBQAFsAXIBZgFYAX4BFgEoAWgBZAFGAYIBUAFCAWQBGAFCAVwBCgExAOoAxADtAIkArgCsAJwAnACFAL0AKIACQCy/7cAbAA1/9r+pP18/Tr+pP60/kr+ZP3U/HD8qPyE/aD9IP1c/MD8vPxY/dT9vP3k/cT99P20/Ub+Av5A/gj+eP6a/kr+dP7K/gH/D/+I/2P/uv/4/j7/uv4n/8r/C/8G/wj+HP5a/oL+Tf8+/kT+MP60/TT9xP10/Sb+HP2I/KD8+PuI/IT8IP3s/Gz8jPwU/Mz8RP3M/Cj9PP2E/Wz9KP2g/bD9Dv5a/pj+Ov/E/iD/uv54/lT/3P8BAEcAAgDD/9H/yQC7AN4AUADZAJoAxAH0AWwB6gE+AfQBVgGSARwC3AEkAjACTAKMArgCgAMwAzwDFANkA3wDuASwBHgEUARgBEAEOAQQBRgFeAVoBQAFaAVYBVgFSAX4BNAEMAXYBOAF4AQ4BMgE5ANwBbAEGATcA+ACIAQkAxQDsAJOAXABAgEYAV4BZwBEAEwAsf93AKL/9P4r/0T+Df+M/uj9rv6I/bL+QP46/mr+Bv7q/mb+/P7m/qj9yP2o/fj9NP7w/VD+XP5A/tj+Kv7c/eD97P12/gz+LP7o/aD8LP0w/bT9av6I/cz9QP2g/fD98PyQ/bD85PxA/dz8FP34+0j8ZPys/Bj90Pxo/HD8VPzQ++D7YPxo/JT8jPxQ/RT9cP1U/Tj+pv60/ob+JP6C/qD+0v64/iz/U/9A/yEALgCUAKcANAA2AKUAXQCaAPkA5AA2AVgBUgFYAawB+AEgAogCSAKcAjACLAKAAkwCDAMwA6gDvAOUA6ADUAQYBKgEkAR4BKgEwARoBAgFeAVIBUAGyAUwBYAFMAUIBtAF2AWwBegE0AS8AzAEgASwBMgEWATAA8wD+AIUA9wCHAOUAnACGAJUAXQBWAF6ATQBZAGGAG8AQP+P/zAAzACOAMn/iwCT/37/6f9k/8z/Y//8/k7/gP8T/4QA9/8sAD0ALf9D/5L+tP8b/w//Qv68/mr+hv6w/qz+RP5Y/aD91PyE/Sj82Pt4+xD7yPsA+3D7qPqI+nj6IPo4+sj5aPk4+ED40PdQ+ZD4MPlA+Tj4wPi4+Jj46PjA+KD4kPlA+Uj60Plo+qj6IPsM/ID8QP08/Uj9cP3I/Rz+Nv9TACoAFgHk/6YAgQAgAvABugE8Al4BOALmAVQCzAIkAwgEUAPcAtQCOAPoAuwCqAOEA4ADQAOwA8QD9ANwBCAEgAQ8A4QDEAP4AogDkAMIBPQD7ANIBEgEuAO0A1gEaARYBGgDMANsAvwCEANIAzADpAKcAmwDwAMwAwgDpgFoAlQChAJoAiAC7gGyAZwBnAEgAsABZgH/ANEAPAGOAGIBJwB//4H/Q/8lAG4A2wAFAK7/8v9wADYBnQBKAFwA8P+jAJP//v+Y/07/0f/H/0oA6/+e/s7+Kv7s/aj+xP1E/Vz9uPtA+8D7UPsg/Pj76Prw+Xj4qPjQ+Wj5wPkA+AD3YPcg93j44PeQ94D3sPYw92D3YPdg97D3UPfw93j4iPgY+VD5+Plg+tj6APsc/Gz9UP7k/Xz93P1W/m8ArAEoArgB3ABmATQDlAMQBIAETAOIA/gDYASgBMgEGAWYBYAFOAXQBEgE8ATIBIAE0APYAnwDrAPEA5QDxAK0AvAC7ANQBHwDTAL0AaQCmAN8A+ADXAPMAqwDNAOcA/ADmAMoBMwDvAOMA4QCJAPgA1gE2AQABIQDCARsA1gEcAS4A9AD5AMoBIgDPANAAoQCOAL2ASQCyAFMApgCbAJ0AiQCugH6AeIBpAGuAZABOAI4AtwCCAIYARQBcAEcAoYBagFFANb/ZwCsAIEAKP9s/Qz91P1c/Sz9APyA+nD6WPsI/DD70PkI+GD3sPfg92j40PeQ9iD2YPQw9PDz0PQA9vD1YPUg9AD0APQQ9fD20Pag9hD2oPVw99j4ePlY+pj6GPuo+6j7iPx0/bD+5f8KAVgBigCJACwBAAKoAygFSAUoBmAFgAX4BdgFiAYgB3gHeAdABxAHuAYYB1AHUAdIB+AGGAY4BnAG0Aa4BogGGAZ4BTAF4ATQBBgFgAUoBWgFmAUoBbAEAATABNAEWAWYBVgFAAXABHAEWAUgBYgEAAXsA/gDEASIBKAEqAQwBCQDIAMEA6QD1AMIBJQDGAPkAtwCJAPwAxAEcAOsA9QC8ALcArACaAP8AjQDsAOAA6wD4AL8AlADhAPYA2wD/AJsAqoBuAHCAZgB4QDY/5r/9v42/gz91PzA/GT86Prw+hD3IPaQ9ZD1qPmw9+D20PNg8dDxsPHw8gDzgPHg8KDvcPBw8ODwIPGA8XDxgPGg8ZDyoPOg81D1UPXw9cD24Peo+WD64PmI+tD6PP0k/wUA8wD//zUACALYAigEQATQA5AE8ATABigHEAiwB2AGWAewB1AIUAioB4gHaAe4B3gHEAhoB5gGaAYQB/AGcAYAB0AGEAZoBVAESAUwBUAF0ASgBIAEMARoBdAF0AWIBCADqAMwBZgGIAcwBigFeAQoBdAGMAf4BhgGaAWgBWgGeAb4BugGQAbABeAFyAUABjgGCAbIBVAF4ARQBJAEaAQIBNwDvAOQBBAFOAWABIwDOAM4A7wDuANIA0gCMAKoAXQBIgHKAFcAjQBMAfD9pPwA+rD3MPrw+mD6GPlQ9vDzMPRQ9PD0sPSQ8pDy8PAw8SDxYPDA7wDv4O8A76DvIPDA76DwkPCw8CDx4PFA86DzQPXg9YD1UPco+ED5MPqA+UD64PpA/ej+kv97AIr/ZADwACQCqAN8A0gE5AP4BIAG0AVQBrAF8ATIBSAG0AbABiAG+AUgBVgFSAWABagFMAV4BRAFOAVABbAEuARIA0ADKANkA7gEwATIBLADcAL8AmgDkAQABYgEUATgA7gEYAXgBYAFiASgBKgEiAUABxgHKAfIBlgGaAbYBtgH+AeQB9AHWAdwB7gHiAdIB3gHwAbgBkgHcAeoB/AGSAcIB+gGqAdoB+AH4Ad4B4AHaAdYB9AG6AcIBxAGGAUAAvH/qf/n/5AB2ALLANj8UPpQ+UD4YPiI+WD24PRQ82DywPIg8/DxYO/g7uDtwOwg7qDt4Oyg7MDrwOzA7KDt4Oxg7SDuQO5Q8FDxIPIw8qDxAPLA8wD2cPc4+aj5kPng+fj6tPw6/kX/3/9cAAIBdAKAAzgEKAXoBEAGIAd4BrAHIAcIB1AIwAdwCLAH2AZYBggGoAaQBjAH2AXABAAE3AMABLgDKATQAjwCwAGyAeYBcgEyAVwBRgF6ANkAowBkACwBQAE8AmQCfAKgAtACqAIsA6wDQAOIBEAEsAT4BDgE8AQgBYAFGAYgBjgGCAaYBhAH6AeABwgHYAfwBrgH+Ad4B0AIaAfIB9AH2AeQCHAH0AgACbAIYAkACBAJ+AcACNAHSAbABvgFUAWYBbAFmAWoBPADCAPM/rD7IPjw93j7IPuY/Gj7oPUg8rDw4PDA8SDyIPAg7mDt4Oxg7KDswOoA6cDoIOmg6uDrYOyg6yDrIOug66DtoO6g72DwAPDA8cDyUPVw9xD3QPZA9+j4YPsw//gAZgDc//L/ZwBIA8AFYAX4BfAFOAbgB3AIkAiwBxgHgAbAB0AJsAnACQAJ4Af4BmAG2AXABaAFeAUQBcgE2ANgA9AC/AFgAVUACgDCAAoB5AAgAf//DQABANv/fQBm/yv/mv4r/+f/ggCwAcIB5gFEAoQCXALcAqACIANsAxAEoASABOAEcASwBDAF0ARQBpgFeAZgBjAGSAa4BggHgAfwB6AIwAjgCAAJUAmACYAJQAkQCkAKgAogCyALEAtACqAJcAlwCVAJ0AhgCCAI+AeACGAH+AXaAKj70PpQ+sD+dP+4/dz8EPbA8hDxYPGg8qDwgO9A7iDtoO1A7QDtQOsA6GDogOng6kDtoOvg6cDoYOgg6kDs4O0A70Du4O4w8ODxgPTw9ED2gPYw9+j6VPxK/tH/OABGAAkA4gHcA/AEYAYIB5gHoAdwB1AIkAjgCBAIQAhwCRAKwApgCvAJQAngBxAI8AdACSAJIAigCPAGQAVYBZgE2APQA2QDLANMAhACxgA3AHQAs//o/3v/yv7I/s7+lP80/2f/hv5a/gD+fP5+/jL/sf8i/+v/s/9FABoAagB4AXgB+AJQAsQC4AI4A9ADwANIBAwDcARQBEgFqAUIBQgFIARwBTgFQAaABugF0AbABvAHQAgACQAJ8AhACQAJAAqACQAK0ArwCaAJIApwCPAJsAsQCWAKCAfQB1AIoAhQCiAFxAO2/nD7gv5o/Cj//P9s/FD6sPZw9NDz0PGg8TDxgPDA72Dv4O/g7cDrwOnA6EDqIOsA7aDtQOug6aDoIOpg7GDtoO7g7iDvYPCg8RDzEPQg9AD1cPYY+Oj6HPyA/Sj+MP5X//v/GAK4BAAGIAcYB0AHQAdACKAJYArACsAK4ApgCwAMsAuACzALMAsgC+AKUAsgCjAKYAnACMAJ0AhQCGAHIAZIBXAEcASABMAEmARoAwACxQDM/8//XwApAGYAfP/Q/nD+BP7o/XD9gP2c/Uz9xP2U/ez9sP0C/hz+Bv5i/ij+PP5Y/uD+Tf+6/1wAqAACATYBYAHcAeIBYAL4AnQDUATABNAEKAUQBcgFYAboBtAHgAjgCEAJsAnACSAKcArQCjALcAugDEAMkAwgDDAMEAzQC4AMEAzwDHALkArQCXAKMAqQCSAMkAagAkgB/P1+/yAAmABa/8z9ePug9oD3APbA87DxQPEg8HDwgPDA74DuIOsg6cDoQOkA6yDsQOxA6qDowOnA6KDqIOwg7CDtAO1g7sDwEPGQ8bDxUPPQ9ND20PhY+gj70PoM/Ij9N///ABgD5AMwBNgEQAVABkgH8AjgCVAKUAvgCjAM8AsgDBAMoAvACxAMwAwwDRANgAyAC9AKQAoACgAKsAkACaAI2Ae4BogGWAUIBTgEuAMgA/ACbALqAfcANwAi/1r+KP4E/vj95P1M/cj8DPyI+zD7UPtw+8D7yPv4+xj84PsA/OD7UPyA/Bj9vP1I/o7+0v7M/vT+pP+2AI4BbAL6ATQC2AHgAmgDCATwBDAF+AVABpAG8Ab4BkAHQAfIB5AIkAgACUAJQAkQCeAIMAlwCbAJ4AnwCRAKEArACdAJkAlgCdAI8AiACUAKIAkACQAHWAcABpADeAPiASoALP6b/5wC5P+k/nj70Pgg9pD14Pag9/D2QPQg9FDyQPLQ8CDwwO9A7aDuoO4A78DvoO3A7QDs4OxA7mDvkPBA8DDwwO8Q8EDxwPJw8/D04PXQ9tD3IPi4+GD5WPr4+2D9Gf8bAIMAIgFaARQCMAMwBLAFgAZgB5gHcAfABwAIsAhACeAJUAqQCuAKkAqQCmAKUAoQCmAKgAqAClAKoAnwCCAIiAeQB2gHWAe4BmAG4AVwBXAEbAOYAswBoAGEAbIBCgFZAFn/ov5y/gj+Av7c/Zj9UP0k/Rz97PzU/Jj8lPwE/XD9hP18/Uz9OP2E/ej9uP4V/3r/sf/P/3gAkADRADoBtgFcAlgC4ALMAzAEQARIBGgE0AQ4BfgFgAbYBsgGQAbgBsgG4AZIB3gHgAf4ByAIyAdgCPAHsAdgB5AHwAdgCKAH0AYACSAJOAcgCqAJgAiIBQgELANQBPgE0ATwBZwDeQBY/8j//P4s/mD9mPsg+2D5wPng+Vj40PYA9KD0YPOA9OD0kPJQ8sDvIO9g71Dw8PDg74DvQO7g7mDvYO9A8FDwUPDg8PDxMPPQ87DzQPMg9ID1YPcY+UD6qPp4+tD6mPtA/Qn/8v/XAGwBMAJQAzgEOAXABSgGuAaYB8AIQAnwCQAKIAowCrAKoAtgDLAMcAwQDNAL4AvgCxAMYAzwC5ALsApgCmAKIArACdAIAAgQB9AG2AawBjAGEAXYA9gCKAIoAuwBtgG7ALn/5v7A/oz+Sv7E/Uz9AP24/Mz8uPys/PD7yPvw+2D87Pxg/Uz9DP0s/UT9oP2c/kX/g/+1/7X/HQD9AA4BCAKYAkQCzAIkA8gDSAQABKAEuAT4BLgFwAVgBhAG0AUABqAFaAZAB1AG6AYIBwgHsAYgBhgH2AaoBbgE0AWwCMgHsAigCaAEQAW0AqADsAUoBJgEmAQUA8QCgAH4ASEA+P6U/gD91P7k/Rz9gPuQ+QD5cPhg+Hj5YPgg91D0kPNw9HDzsPNA9ADzEPIQ8rDxYPLw8JDwsPBA8dDxMPOA80DzQPIw8vDyAPRw9TD2sPYA96D3gPhw+WD6MPu4+1z8WP2e/of/MwDqAJIBFAIsA/wDQAWIBbgFQAaQBtAGEAgACXAJcAlQCaAJwAkACoAKcApwClAKgAqwCmAKUArgCUAJoAiwCMAIwAhACLAHAAcwBpgFKAWwBLgEsAQgBEQD6AJkAowB+wArAE8AJwDj/6D/Lf+W/uT95P0A/jD+NP7E/ZT9UP08/Xj9jP3o/fD9Sv5s/qj+Af/e/tr+Wv+V/08AuwA6AYwBSAGsAQwCsAL0AjwD/AO0A8wDSAR4BKgEsATgBCAFcAW4BagFgAUABigG+AXYBSgGYAWYBIgF4AXgBfAFyATgBXgGIAZoBRgFcATcAlAC5AIIAygE0AKhAF4BfgCK/27+6v5i/lT8fPyA+/D7IPv4+dD5mPgI+CD3APcA9+D1MPVA9BD0wPSQ9DD0kPNQ84DyYPJw84Dz0PNw87DzgPTQ9HD1wPUA9vD1QPZA9yj4UPmY+fD5yPo4+xD86PzY/Yz+kP5g/+j/yAC4ATwC+AJ8A5gDQAS4BFgFsAWYBegFIAYYB0AHoAfoB5gHOAdYB4AHAAhACDAIEAiwB5AHWAdoB2gH6AbIBuAGkAZYBiAGGAZoBdAEgAToBMgE6AOkA5QDzAJEAhgCcAL6AbABRgEeAb0AUAAsADAA8//0/7X/df/B/7P/Y/9L/3//ff/S/4D/BQDs//b/uP/n/0sAoQB0ANIA9AD2AFYBlgGMAcQB2gEwAogChALYAtgCCANAA1wDmANsA+ADyAP0A+ADzAP4A/gDAAQ4BDAEgATEAzAEIAQABLgEKARYBOwDbAMAA5wCjAMkA1QDEAN4AlQChAFUAZYBEAFZADsADgCu/5r/aP/E/uT9cP2U/Uz9TP3U/Dj80PsY+0D7EPug+sD6YPoo+rj5gPm4+Wj5QPnw+OD4SPmo+MD40PjI+PD4uPjY+Dj5ePk4+ZD54Pno+TD6kPr4+iD7KPuI+/j7WPy4/Bj9mP3U/Qj+UP6Y/h//Vv+Y/+f/PgCaAN8AOAGyARQCJAJgAqgC5AJEA0wDcAPYA+ADSARoBIgEmASYBNgE0ATABAAFMAUwBVAF8AQgBRgF2AQYBdgE0ASYBHgEkAQ4BGAECAQABNwDxAOUA1ADUAPUAsACQAJUAkQCJAIEAn4BlgGGATgBEAHrACIB0QCMAF0AWgB5AEIAJwAYAA4A9//u/xUAGwDC/7T/8v8IAEUAHgBTACYAgAAbAJIAaAB4AH0AwgCwAN0A+ADfAAYB3wAwAWABRgFqASgBXAESAZQB1AH+AQAC1gH4AYABxAHkAfQBIAL8AQgCwgH8AQQCxAHMAbYBhgG8AcIBqgFoAVQB7QDvAOYA1gDVAK0AaAAkABAAHgAJAJL/Sv8Y/9z+7v4g/8b+gv4+/tD93P3w/fD9ZP00/Sz9FP0E/cD8uPzY/Iz8SPxk/Fz8RPwc/BD88Pvo+wD8APwM/AT8BPwI/Cz8bPw4/ED8aPyQ/MD8tPzg/Oj8NP08/YT9rP2w/S7+Bv5Y/oD+nv7g/vj+L/9p/7v/BgD6/zQAVgCuANgALAFmAa4BtgHIASgCQAJoAoAChAK8AtgC/AIcAygDJAMkAxgDGAM0AywDFAM0AywDJAP8AvAC7ALEAtgCzAJsAmgCMAJgAmAC9AEQAswBzgHwAZoBmAFOAUoBcgE+AVwBOAEOARQBLgH+AEQB6QDdAN0AxADsANAA0QD6ABoB9QDyAOoABAHgABYBIAHfADQB7ADgAF4BzgAKATYBPgFEATYB9ABMAQABCgEgAQwBNgHkABQBPgEOATIB9gD9AOAAtQDcAOIA4AC6AMMAvgCqAKYAkwCeAGsAbQBIAEkATQAOAP///P/c/8//m/+o/4H/TP9Q/0D/N/8i/y3/H//Y/u7+yP7K/qb+zP7E/pb+hv5k/nz+hv54/mj+fP5y/mz+bv5W/kT+Zv5U/lL+Vv52/qb+mv66/n7+uv6g/uL+wv4C//7+Jf8U/yX/Z/8q/z7/Zv+I/43/uf/u/8b/7v/l/yAAPQBYAH0AcwChANsAlQC4AN4A6wDnAO4ADgEYAS4BKAEcAVQBMgFEAUIBRAFYAWgBeAGIAWABaAFMAYwBtAHWAdQBgAGkAYYBpgHMAdABxgGcAYYBlAHCAQgC4AH4AdABzAHOAdoBzgHQAQACoAG4AZ4BbAGUAcIBlAGqAYoBdAHCAY4BBALCAeYB8AG6AeIBygG2AdIBtgGCAaQBlAGGAbIBoAFEAXQBYAFYAWYBZAFoAUwBbAEoATQBLgE2AekAvgCmAJkAkQBwAJcAbQCQAFUAMwA9AAMAIAAsALP///8PALX/uv/K/37/i/+q/5r/wP+L/7j/e/9R/1D/SP8b/xj/SP8Q/9T+uv7S/jz/3P4X/07/3P7Q/qL+4v7M/rz+qv6U/pD+sP7U/vj+lv7S/uL+nP5U/sD+2P6U/nz+zv7+/uL+yv6k/vr+gP7y/uL+2v7u/u7+B/8t/6L+Nv8V/0//Yf9O/3D/x/9o/7r/JACh/7r/8P8qAEYAIgAmAKgAXQBVAO8AkgCvANUAuAAwAYcAjAAsAfEAwgGCAeAAtgDeAJYB3AEsAcAAOgE4AWYBQgH3AGgBigHmAAwBmwA6AUoBOwB8AFYBvgB3AIL/vQAIAmQA9P/g/64A+QAGATAAOwDv/1YA7v95/5v/cwCVAIn/mv8eAKUAj/85/0cAbwDh/7H/BABoAKr/v/89AEIAdgDi/6UAYQC3/0wAkAAWAa4AQAC6AN8AmADYAJ8AlADsADIBGgH9AIEARAF2AXUARAFkAWwBDAG4AFoBCAJWAb0A3wBAAZABSgGmAEoB6QBkAKgA+QBAAawAKwA4AFMAdwAgAHcAAgBLAHsAAQCN/97/EwAvAE//xv72/8H/Cv8+/yL/UP+w/jr/gP9R/5L+Z/+C/3n/Gv+U/mv//v6I/lX/qP/W/tr+nv4tALb/kv7o/v3/xv9s/+f/cf8A/1H/MAEr/4j/RAHgAbT9R/95ALQBlgB7/3wBtwAe/+7+DAHiAQACmP91/yL/HAK8Aj0Az/9HALwCogBW/5j/wwCaAar/oP83AOT/gP1c/4YAiAJ0/sD71Px8/+8APALwBBAD/AK+AewA/P9d/4gBUAJv/1j92v+uALD+QPxQ/Dj9Rf/uAHQCQABC/nz9YAH5APr/AgAYAvQC5/98/rb/oAMYBOYBPv6qAegE8ATAA3IA5gA0AVgEkAcIBYgC0AEQA0gC6AKwAqAFJAPEARIBowC4ApQCOv/w/eL/uP4EAQ4BtP4s/gj61P3E/vQAoP3g+4j9zP5c/kD7EP6s/fz9gPps/Hn/MgA4/XT8oPuM/VL/WP0gAi0AEP10/Kj9GAIcAu//zPzO/kYBvAOcAM0AtgG0/vn/G/+OARAG6ATj/+z9/P24A6gEEAT0AzYBcAJAAqEAvgGsATgCUgGKADgDvAJaADr/Xf+j/zoBBAFoAkQC5v9Q/UL+egFfAGL+Df9GAE4BsP8q/qL+wP7Y/Bj+dv9YAZT+GP59/6j98PvA/H4BwgF4/Tz97P86AKD8UP24/poB4P8k/R7+Lv5//yb+VP3W/hcAm/8r/8T9jP08/tb+t//M/UD+Gv4eANT+Tv4e/1j+xP3M/uYB0v+g/ET8hf+YASr/iPzi/rH/mP6o/fj9IAIwAnz+oPwOABn/DgBj/6gBJ//Q/j7/AANjACz9xP1cAAAD8gFwAeD+j//u/70AP//6/4QCMAVvAIj8/P5qASoB3v6yAYgC2QAQ/2D+Jv/H/ywDfAFw/3T+2gFIA9H/pP5yAQ4BIwAzAJ8AvAEcAFwBYwDi/iz+CAMwBDD+PP7o/yoBtAF+/zACwAF6ABf/bP2N/xwBmAQEAnMAmP+I/yQAYgGQAdAB9gCCABn/QwDwAdAAuQBy/lz/JgGwArQBNv5o/nD+Qv/zAB4BUAFiAPz+wPws/vT+8QBcAkcA+P0U/Rr+av/U/Zr/wP5MAbL+MP0c/fT9Bv8BAIz+fP1//0j/ev6I/jb/EP2I/Df/qAJ+AJD9TP2k/x0AO/8sApQB/P5O/zj+6gCt/+wBKAQlACD8jP2UAtIBRgFSADUAyv8z/2IA4wD6/qIAggFd/7H/4v6VAIT/+wA4AJb+K/8IAbAC2v4O/gf/3gG4/hz/rP8FALABI//0/mn/rv9m/03/xP8YAjIB7Py6/qoBMAEi/gr+CgG6AFD/z/8eAVf/Iv78/jQC4AEcAOb/wP9O/9j9X/+MAVwC6v+U/dMAdALSAEz+bf+4APP/K/8+AFACKAGF/+D+Wf9EAegAqP/e/4r/U/9a/kQA8AMwAmT+EPqj/0QD2AFsAnT9tP6w/UgBMAPO/nYBvgFVACj9PP3wASgCWALM/5T+zP4nAKwD2AGQ/ZT9vP5YAwwC9AJeAFj9Ev7k/nQCSALsA/YAEv4U/fYAcgGB/ygBiAIfAB7+Qf90A4QC/P0c/Vj+IAFQBBwDTQA4/cT9Ov7aAEQDzAIEAHT8hv56AZj/MQA8AcQCsv5M/Zz+GAKEARf/OP7N//IBfAH7AKz86P3Y/3oBLAJWAUr/zABm/ir/pv7tAAgDQAHW/3b/zv6E/wwByALeAez+nf9y/4MAUAGaABQB+P8IAYoBHQCi/28AIgEuAY8A5gAwAuP/vv96AFj/8P5+AfwCAANHAPD8B/+m/xgB+QA6AaQBgP9I/Xj+LANEA2QAqP1x/xABwv+sAFABSgEnADT+T/+cAPwC1AJo/kD8Gv9wAxADZADXAJn/Sv7S/swCnAIkAND+RwDEAZ0ABwA2AaoBygC4/gYAXgE2AQwCgABq/6P/ZAEmAZYBsP9V/2gBhQB7APH/1QAoATYA/f/uAGsArf9L/5gAigGw/woBFQBP/1X/VgGcAZ0ATv5JAGQBov/9/0b/vAFaAd0ACv9s/hsAIAKOAWMAKQCB/wYBMgBx/9n/GQD3ABQC1gHh/xb+av7h/wQCjABq/goAwAEiAUb+Gv4eAIEAqwAz/73/RwAUAR3/BP4w/1IA3AHM/w4Baf9o/ur+JAAdABD/8v7T//cAGwCX/8D+SgBfAEP/wAAkAY//dPz0/WoBYAIkATv/Wf8i/w3/kv/UAWgArgBcAEH/ygC0/0cAuP/W/tX/MgH4AqEAFwDs/or+Nv8EAfgCVALEAPz9vv58ABABjgHyAYwBYAC8/pf/IgFIAjQB/v62/+ACXgFoAQ3/4f8gAFsAtgGUAsIAmv4T//gAJAEQAFAAmAEYAcz9ev6+AfQCWgGE/qj9IQAeAYwCcP8N/2cA2f/1/xIBsQC6/8z98v5AAcABfQAE/2r/wf9T/8P//f82AZoAAP8w/7b/JgBRAPYA4wBu/yz+CP+1ALQBOACv/0cASP9z/80Aof8j/38A6gBKAPr+mwD0AJQAlv5H/7MApQAFAD//7ABT/4z+igHSAZkAVP+Y/TkAzwCd/+X/vf8oAREAAgDH//T+uv4t/4UAiAGu/nn/7ABO/wT+Cf9kAar/WAAdAIAA4Pzq/p8AXgGN/87+dAL//7j+XP2JAEgC5/+u/jEAlgCtAP7+3v5QArYAY/9B/3z/gwDC/0AAdACrAKYAQf9C/9v/vQCGAcv/Qv/B/wQBiQBIAZD+jv46AIwBOALc/hD/pf+fAH4AHgDsAG7//P7O/7b/4wCSAL8ATwAV/6D+qQAIAcUAEwD2/rb/P//P/6UAogArAAz/pP4IANf/zv4gAK0AhADA/qL+9/97AF//Fv4q/s//egCNAIIA5P5N/3j+dv6x/6UAzACE/gn/cP8FAGEAn/8NABv/If86/6YA3wAUAAcA2P70/9oAGgFyAOD/NwDo/ir/6f+WAXgC+QBO/yL/Vf+XAL4A4ABQAEoAegDw/yMAPADCANn/BgDY/y4ARgCY/9P/BQDa//7/KABkAEYAa/9Q/jb+q/9PAEQAGgBG/3r+cP1C/8T/c//S/ob/2v/2/qT+QP5R/5L+uP+8/9r/Vv4U//3/4/8y/or+Df9E/5f/HQDt/zL+yv6p/7n/zP4a/94A4v8p/+r+9v/J/yv/Yf+Y/77/IwCDAD0AZv9k/n//yP+TACYB8v98/7b+UgCKAEL/q//G/30AXAAx/0r/s/+X/0P/a/+uAHQB8v8A/jD+lf+3/07/m/9a/2v/ev5h/2z/Mf+4/pX/wf/Y/ub+fP6s/yP/yv7I/iL/Yv+O/6H/Mv6u/jL/IgBH/37+2P5m/1X/+P6a/1P/R/+L/8n/oP5E/cr+yQDcAD3/dv7q/n7/i//2/kj/Tv/l/1X/5P4U/77/JP99/9H/p//G/sT9R/+//zz/rP52/pf/Jf/I/jP/Zv/+/kz+8v74/lD/qv4//7b/tv4a/pz+Qv/o/7X/Z/+A/jz+kv9P//r+pv4h/w7/+P6q/9z/n/8g/y//Sf9C/oj+fv9wAOv/w/9e/pb+CP9m/8r/fP9R/3L/Tv/g/m//5f9Y//z+Qf91/0f/XP+V/1v/9v7q/vr/IQBL/3X/af8//+D+aP/s/9H/z/+a/5D/1P5P/7////9aAGD/J/9H/23/1f+t/xUA3v+1/+L+hv8MAN3/yv4Y/7//bgAaAHf/F//q/tL+gf8WAB0AGwD+/h7/NP9p/6T/K/+u/6n/Lf8z/0T/a/9Q/9r+lv5x/8j/Jv/s/oL+xv7Q/ob+kv+K/x//Uv7C/vr+I/8e/5z+7P7E/tT+Kv8R/8f/qv6s/ib/6v4j/6L+fP6Z/9T/Af8C/2v/h/81/8r+kv5q/5v/cv9H/yL/I/8r/03/ev87/1f/6v4M/3r/8P6k/hf/Nf/V/13/mv70/in/wv5C/jH/oP+B/9r+hP7G/ob+Bv7I/iL/qv/m/+7+ov78/Yb+tP4H/yr/8P4m//D+nv5u/vj+gv6i/lf/g/8e/2r+UP6k/uT+QP4X/5H/xv+w/tj9lP7M/iv/ev9w/wr/QP6Q/vL+3P7e/nD/CAC1/+T+6P5N/1j/tP7i/r//GADM/x7/+P4Y/2D/tP/U/7j/CACK/xb/Lv+A/xEA+f/r/4r/f/9g/5T/r/+L/3P/j/+y/1P/Kf+D/8v/mP93/9P/DQCQ/zX/Xf9w/5L/SP/S/yQAyv+A/+r+Yf9t/6L/yf+y/7v/Uf/6/ib/BP9d/3n/U/86/zz/dP9b/3T/iv+d/yv/df9r/9v/1P9W/4H/xf/W/3T/9v88AMf/MP+X/yUAUAD6/9b/YgDe/13/n/8zAFYATQAbAB4A2P+k/53/pP/k/+L/KwAnAOX/ff9h/5f/tf/P/9P/xv9B/37/iP9n/0z/g/+b/5L/MP+R/zz//v4a/zz/n/9W/zf/Zv9u/xT/Bv8c/0v/3P4s/7r/Yf+e//7++v4C/wX/Nv9k/3X/O/8J/yz/E/8x/27/kf9n/7D+zP7G/ln/Pf9M/1T/DP8I/8L+3P7S/pD+iv5e/wT/0v7o/gv/DP/e/sD+7P7a/tL+BP9p/0//J/9H//z+Av+O/zb/yv92/zn/4v9+/5X/0/94/wUAMQAZAK0A8v/k//L/SwDzAGgAbAD6ALAAYQBtAHUA5QAKAY8AzQDoAN0AVQAGAeYAygCDAIAA7wDPAGAA7gCbAJgAbQA2APcAbwALAF8AkAApAOP/BgAmAIP/oP/8/2H/zP8T/6z/LP8r/yf/1v4N/zH/D/9i/t7+pP5o/jD+pP6c/nb++P3c/az+Bv52/uz9JP40/uj9Xv4Y/tz97P0S/vD9hv5m/vT9qP0K/nD+WP42/lz+uv5+/jb+Qv78/lz+fP5G/kr+5P6W/tj+Hf9Q/4j+IP7S/iT/2P4H/+z+rv6N/7T+Wv+X/wf/iP5S/m//AQBk/7b/i/9A/7f/UP/6/7z/2v9CADgAvwBMALoAdAHmAOMA6wAoAaoBsAK4ArAC+AIYAtACPAOEA3gD2ANoBNwD6AMQBJAE8ASYBBgF2ASYBGAEGAVYBYAEuAQYBYAFaARIBPgD+APgAzgDEATQA0ADZAJMAowCTAEIASoBEAH7APj/IAALADb/sv4J/3D+IP7I/ez9nP1c/Yz8LPzY/MD8KPwM/Kj7cPtg+yj7sPvg+pD6MPsg+5D6GPo4+xj7aPqI+tD6KPuQ+gj76PoI+8j6aPpg+zD7qPqw+gD7UPtY+sj6ePoQ+yD7APsA/Pj7QPtQ+tD6cPsQ++D6LPw0/KD7WPsw+wj7yPqA+vj6SPuo+6j64Prw+kD6CPrA+YD66PtA++D6WPuw+uj5QPrA+lD7SPvo+yD8wPyU/WT96P7b/0gAcgHMAesAyAHeATADGAaQCBAKEAnQB8AFwAWIByAJUA2gDqANYAuwCaAKYArgCRAMwAwgDIALcAtQDMAKkAhYBzAJYAgAB7AJ8AgQB+gEiARgBHgEKAOQArgCRgHO/0T/pQB+/+L+1P2U/dD8sPvY+yj7hPxo+/j6+PoQ+4D6EPkA+mD5cPlw+qD6IPv4+SD6sPlg+aD6+PlA+pj6SPqw+8D72Po4+1j7QPtI+tj7FP1E/HT9QP3I/JD8iPvg/Pj8MP7s/UL+9P0U/Mj8dP4u/uT96P3Y/aj9iP2k/R7+TP4s/hb+qP6E/RD9IP20/fD8OP1g/rT9BP1I/LD7UPt4+3D83Pzw/Gj7aPog++j5UPqg+pj6wPpA+xj6cPqw+RD44PmY+Tj6yPqw+bD5IPkQ+dj4iPlY+5D6oPoo+/j54Pv4+RD8DP2I+wL+pPyn/4z9HP0c/DD+OAVQAhAJIAgyAHwBxQDIBSAKsA2AC7AKAA1wB4AIoAsADpAMUA3wDBAOMA2wDuAOcA2wC6AJYAvAC2AN0AzgDNAIkAggCoAHgAhQB7gG0AUoBHgFeAVQBCwDPAMqAYUAZP7q/ooAtP++/qD+wP1o+8D8zPxM/PD6gPrA+yj76Psw/Cj7UPuo+Tj64Po4++j62Psw+xD7CPsA/KD72PuI+0D7WPtY+/T8AP1g/ZD8dPxw/Kj8EP1Q/fz97P3M/Zr+fP1U/mz+dP/y/lb/Nf/u/jT/rf+WAMsAjQBxAG0ARQD9/5wA4QCUALMApQCDAAoA0P/i/6P/DP8i//L+Av68/GT9GP3Y/cj9vP0k/Zj7OPqw+zT8QPxY+0D7OPuI+rj6cPkg+vD5UPmQ+rD5qPow+cD4ePn4+Nj5APmg+tD6EPpI+mj5IPvA+xj7OPu4+5j8YPzg+ob+PP0N/1T+uAIwCYgFxAINALAD3AF4A0APABHgDogHAAkgCFAJYAtwDoATkA1QDsANMA7QDFALUA8ADmANEA2gDOAMsAogCxAKYAngCEAJIAiIBwgF5AOwBKAE+AXQA+QC1ACm/8D+iP2g/mj/wP/I/uz8MPvg+dj5iPsg/ID74PpY+pD66Pkw+rD5iPmY+Rj6MPuA+gj6uPn4+ZD6qPpo+wj7SPsA+/j6MPuQ+6T8wP2s/bj8iPwE/bD8IP0W/lb++P50/+D/fv/W/oj+f/+uAEYBVgEkAYQA2AD2AGwBnAHiATQCnAHWAcYBkAGoAYYBNAEOARgBOAEqAVQA1v+//0r/lv5a/sj9jP4M/pT9nP20/PD7OPv8/Mj8iPuI+5j7QPso+6D6ePpw+rD6IPtw+qj6CPro+Zj6UPp4+vD6wPpI+ij80PvY+pj7YPyc/HT80Psk/Wf/oPtY+1UA5P38/rAD0AgQBiAEC/+IAeAEqAawDGAOgA7wB+AIEApgCjAN4AwAEtAOcA3ADiAOoA/AC/ANsA1wDKAO0A2wDlAMEAnACLAJAAuwCVAJ2Ad4BVAF8ASoBcAFxANoAxAC5wAqAEz/Yf9c/yb/rP7I/QD9QPzA+7j7+Pow+xD7IPuY+/j6MPow+Qj5cPnQ+Yj6wPpg+zj6APlg+Rj5ePoA+8j7mPv4+rj6oPoM/FD8uPxg/Xz8ZP0g/Q7+Qv5U/Rb+nP6K/+H/4f9//+L+Rf8MAMQAlgFYAQYBlQADADcATAFIAlACEAL8ASABWgEaAUgBjgFWASwB8wA+AT8AQADw/8n/V/8e/43/Tf/8/pz+dv4S/kr+cv6g/ir+bP2I/Sj97P0O/qj9XP1A/Qj9AP1U/dj8JP34/GD9uP20/Ez8/Pwg/Wj9oPyu/hj/jPxU/az94P4w/mj9FgHa/3j9nPx0ArAFKAMgCRgEeAIYAnQC0AlgDCAKIAyAC1AJ0AgwC7AMAA7wDtAMIBDgDsAN4A7ADFAMYA0QDcAPYBCQDsAKQAhgCfAKYAugC4ALUAjoBcgFWAfoBqgFeAQ4BmQDqAKAAogBSAGF/7T/7AB4ANz+VP5I/Uz88PsE/ez9oP1g/OD64PpQ+hj7wPtg+4D7oPqo+jj6yPrI+jj6gPrQ+0D7QPsA/ID7GPu4+uj72Pxk/Yj9PP28/BD8AP1W/iT/2v6Q/hn/Hv6y/gb/qP92APj/+f87AEcAhgBUAN4AUAHEAY4BGgFAAtgBigHYADQByAGsAWQCGAIgAVQAfgBCAcIBWgF8ACEAuP+b/2YAhwCdAJj/Hv8Q/yD/FP9l/xn/GP/E/gr+Pv6g/qT+IP6w/az9GP70/Zz96P30/Xj8pPwS/gL+EP6Y/eT9sP0g/YD+uP1W/ov/1P5E/Zj9DABt/+IBkAVYBHgE6gE4AMgE8AhgCRAK8AoQCgAHsAhQCdAMkA/wCzAOkA0gDjAMYAyAD1AMwAywDNAOEA+wDIAM8AnQCfAJEApgDMAK4Ag4BwAGgAeIBnAGgAV4BKADHALYA9gCLgE1AMz/qwAGAHz/6v5w/Wz8+Pto/Oj82PxI/Ij6OPqo+lD66PrI+pj6oPnY+ID5APog+pD5iPn4+dD5aPrQ+hD6yPnA+Vj6EPsg/GD86PsA+wj7gPsM/YD9xP08/oj99Pxs/Wj+4v58//L/1f8a/4f/0wDRANz/2AA4AuYBIAEQAggDhgG5/wgCmANcApoBDAOIAlgBVAFcAngCuAFOAYYB7ABOAGgBQgH8AFABcwC0/z3/mP8AAW0AUP9s/nP/mP4C/mz+zv64/SD93P3k/WT9UP3I/KT8SPyw/Jj9wPwk/cj87Pzs/Hz8hP30/JT9LP3I/JD93PzM/s8AyAEUA5IBTAISATgCOAUIBjAKQAogCFAGsAbQBzgH8AywDjAOAAwAClAM8AsQC5AMkA4QDVALAA4ADqALcAkQCaAKUAqgCnALQApwB5AF4AVQBpgGsAaQBRAESALOAfIBkAH1AOIAQgCe/tD9hv5c/bD7UPsI+6j7oPvA+vD56PhA96D3gPkI+jj5cPeg9pD2EPbw9jj4WPiw90D3MPew99D3MPfQ96D5UPnY+Hj5mPng+RD52PkY/Ej8qPuw+wD8qPtY+9j8qP5m/7j9zPwI/ur+Sv4Z/3UApgAs/wD/igEEAigBfP9CADQCTgFgAdoBzAJKAf//jAJsAoQC2QCIASgBYAA+AeUA0gFeAcMAGwCF/9b/rQA4AlMA+P44/4L/tP4O/kL/Uv9K/hT9BP7O/nT9XPyQ/HT9DP2w/AD96Pw4/Dj7TP0I/Qj9hPyI/Gj8EPzo+kz8+PyU/pL+BAC5/5P/Q/+J/+gCkANABfgG4AXQBXgDCAWYBdAIkAuQC4ALMAggCtAI0AhwDCAMgAywCjAMsAuwCjAKYAhgCmAKQArQCmAJQAjgBXAGqAYAByAHiAU4BNQCLAP0AkQCVAK8Ac7/pv7G/j//SP5c/fD7sPsM/Cj7oPog+zj64PdA90D5+PkI+UD3MPeQ91D2QPZg96D4IPfg9YD3YPfg9tD2ePjw+DD3KPho+HD4wPjo+Pj5mPlI+sD6EPsY+/j5EPv4+1T9YP3U/Ej9yPw4/fD9+P7O//7+0v70/p3/5gDNAAYBewACAdoBYAEuAaoBrAKyAa4BUAJAA1wC1AAEAkgC3AG0ATACSAPWARQBLgCuAawCcAHOAUQCyAA4/w4ASgG8AKb+JP/u/yEAG//o/T//7P2I/S7+2P6k/tD7vPwg/cD9Av7E/Mz9OP2E/Bj8iPyw+wj8yP1W/rD+kP00/R7+nv+YAAwDGAPAAuwCtAMYBFAEYAR4BQAIAAjIBVAJ0AgQCCAJoAkgCuAIkAfwCxAM4AmACTAIoAkQCHAIYArQCBAI8AVACJAHsARoBcAEaAVQBNQDuANMAtoB4QBuAbn/p//e/5b+UP88/XD8fPxI+9D7OPsY+0D6ePig+VD5EPmo+KD3mPhQ91D3APjg9uD2oPbA9lD3wPeg95D3kPfw91j4wPeg9nj4MPr4+Fj4OPro+nD5+PhY+5T84Prw+hz9rP2g+yz8nP1W/uT9qP6v/7j/1P5w/ngAkAH2AO4AOAF8AqYBvgHkAjQD9gHmAbADzAMMAyADbANgA/ACwAIABEgEoAIwApAD+AMgAuACzAPYAgAC7gEIAxwC/QDEAU4BJQAtAOoBRgF+/7f/I/+U/tz+rv53/7b+8PyQ/Yj+cP2Y/RL+hv7g/GT8LP3A/Dj8PPw4/vD9lP0G/rD+Hv83/9cAZAKQArACyAMIBRwDyANQBdgFmAYQB9AIkAngB/gHMAkwCdAI8AlgCyAL8AnwCcAJ0AnwCaAJcArQCQAJEAkgCaAIAAigBzgGuAYAB5gFEAUIBYgE1AK8AqgCuAFGAcsAXQAYAOz+2P1k/WD9/Pxg+4j7wPuQ+hj6MPqg+Uj5iPjg+PD4qPhg+JD3cPfQ93D3EPfQ9wj5iPhY+MD4EPjw91j4wPh4+fD58PnY+Tj60PrI+uD6SPuE/IT81PyI/DD9kP1c/dj9F//o/4r/BP++APoAQwCdALwBYAK6ARADKAPgAiwDlAJAA3AEvANoBIgESAScA9gDgAQYBFAE4ANwBMQDXAMgBCgEwAPcA4wDQAO0A0gDPAIIAgAC7AFaAeQBkAEKAfH/xf8PAN3/zP6i/nr/jP5A/UT+/v70/XD8QP3k/eT8PPwc/Q7+4Pyg+yj91P1Y/fz9bP8DAGn/TgAsAjADHAL0AlgEoAQoA/gEEAdQBlgGcAhwCaAI+AfQCEAJsAmgCHAJoAugCjAJkAkgCtAJgAjgCAAK4AkACUAIsAhgB7gGKAagBYgGWAVIBJgEZAOkAsABKAJiAboAYgCs/+D+DP54/nT9oPs8/Jj8WPrg+ej6yPmw+AD4qPjY+Cj4sPZQ90D4oPbQ9eD2gPcQ9vD1kPeQ9yD2IPYg92D3gPYw9zj4kPeg95j4KPno+FD58Pig+VD6gPrg+tD7fPyQ+7z8mPy8/ez9VP4C/yz/egDq/w4AVgFUAmwBMgFIA+gDTAI8A2gEEARABOwDOAXIBNAEUARoBFAEIAU4BKgEuAT4BJAEAATwBAgE7AMQBIQDgAOsAjACrgGWAbQBMgEwAecAiACq/xr/R/8s/uj+sP7U/dz9uP2Q/Lj7uPxg/Oj7GPwo/FT8WPv4+qD70Pu4+4D8Fv6k/Sb+Vf+z/+v/3P9cAYoB4gFMAmwCCARIA4gD4AXgBVgFUAbIBpAGwAa4BpgHwAegB9AHoAeQBzAH6Ad4BzgHAAiIByAH2AbIBrgGEAX4BGAF2AQgBFgDnAP4AsgBPAF0Ae8Apf/H/5P/DP+I/Tz9uPzw+wj7APuo+lj60PkA+Rj5WPjA98D3oPeA96D2sPbw9kD2EPYA9pD2APaA9XD2QPbw9UD14PVQ9iD2MPbQ9iD3cPfw9oD3cPjg90D4OPnw+ej5MPpA+xD7MPvQ+7D8XP0w/VD+uv7g/jP/u/+dANAAfAEQAnQCeAIwA6QD8APwAwgECAXoBLAESAWABVgFAAWIBTgGgAWwBUgGgAYIBpgF6AXgBTAFuASQBOAEMAScAwgExAMkAyAC/AEgAmQBiAB/AG0AAgDI/qj+I//o/WT9lP2I/Qj9gPzw+4z8zPyY++j7rPx8/LD8PP2U/aD+YP7Y/iUAAAAdAMEAewBQAbIBggFEAuACAARgAyAEcAQYBcAEmARwBUgGUAWoBXgG0AboBqAFuAZIB+AGIAaABmAH6Ab4BVAGEAYQBmgE0AMQBWgESANEA+AC5AK0AesAmgESAf7/Q/8I/3z+hP2o/HD8bPwI/DD7KPtQ+1j6QPlI+dj4uPhQ+ID4cPgo+LD3YPew90D34Pag91D38PaA9+D2EPfg9rD2EPdQ91D3EPgo+Ej4mPio+FD5ePlQ+gj6CPsw+yD7PPyA/AT9oP0W/lj+XP8h/4n/FwCiAOIAFAKIAtwC+AM8A9QD8ARIBLAE4AUIBmgGKAZQBrAGkAaABqAGaAeYB0gHiAeABzgHwAZwBpAGUAYYBngFIAUIBVgE1ANYAwwDBAM4AowBYAGWACEASP/G/vT+PP5w/UT9eP1o/Aj8YPt4+4j7IPsg+8j7yPtQ+5j7KPyM/IT8VP0K/ib+MP6I/lb/hP9E/+P/uQB8AW4BNAI8A7ACfALEAggE3APQA4gESAUIBRAFkAXYBdgFaAVQBkgGWAZoBhAGeAYABjAFgAUgBdAE2AQ4BeADtAOIBKwDLANMA8wChALeAegAJAFCAMT/ff9E/0b/av4M/sT9IP1I/MD7JPyA+4D6GPvA+jj66PmA+aD5UPnQ+Jj48Phw+LD30Pfg92D3IPdQ9+D2kPdQ92D30PeQ9wD4CPgg+Lj4+Pj4+Fj5APoQ+pD66PqY+wz8lPzE/Fz9Yv4Q/u7+zf/s/9kAdgFwAvwCnAJgA0gEGASIBIgFWAbQBmgG4AY4ByAHCAf4BlAIEAgACEAIkAjQCLAHAAgwCGAHgAdoB5AGGAcoBmgFYAVYBfAEeAS0A1ADFANYAhABDAESAQoAd//o/hP/gv4k/UT9nP2A/HD8ZPzw/GD8IPxE/Nj8+Pzw/Iz9Lv7g/dD9XP5u/gf/Av91/8X/FAB0AG8AnQAwASwBOAFgARgCeALaAQwC0AKUAmQC2AKAA8gDYAN8AyAEvANgA2QDCAS0A2QDFAOYA4wDuAIMAyQDJAOAAuwCFAMcAvABsAGEAe4ATgC0ALcAHAAZAOn/X//U/mT+YP4o/nj92P0o/Wj9XPxY/Nj8ePuY+9j7YPvY+uj6uPoQ+oj5yPnA+TD54Pj4+ND5CPmw+Gj5UPlI+Rj5kPlA+vD5OPqg+gj7SPug+/j7yPxs/QD+GP7S/ov/pf89AP4AlgEsAsQC7ALcA5AEWAQIBcAFcAZ4BtgGgAd4B3gHgAfwByAI+AdgCKAIwAhgCIAIsAgwCOgHQAgQCCgHAAcAB4AG0AWwBVgFCAVQBDgE8AO8AigCyAHEAZ0AXgCPAEwAY/96/iz/pv6g/dj9Nv7U/Wj9eP0k/uD94P3E/Ur+3v54/qr+h/+w/lz/JP+2/77/Mf+BAOn/AQCV/6IAcgCj/7QAyADQAJkAwQAmATwBAgFoAVQCygEQAmwCiAJ8AmgC2AIYAkQDuALgAiADqAIgAxwD9AIsA2ADYAMEA/gC0AKIAiQC/gH2AWgCNAFWAZQB2ACEAOz/UACMAC//Wf97//j+3P3E/Rr+mP3I/Oj83PyQ/Kj7MPuI+8D6KPrY+aj50Pkg+fj4IPkA+fD44Piw+MD4WPmQ+QD5gPl4+lD6CPrQ+tj74Pv4+5D8oP1w/uD9eP7i/0IACwChAKoBQAKoArQCxAOYBJgE4AQoBqAGyAVwBtgGCAeQBxgHcAcACOAHMAiQCFAIcAhQCLgH8AcwCMgHsAZ4B8gGEAYYBigFqAVYBBAErANgA7QCpgGgAWUARwDg/0P/DP+8/jj+0P08/eD8NP1c/Nj7+Pto/AT8OPsg/Cz8uPsg+xD80PwI/Pj7SPzw/HD8IPxs/AD9+Pwk/Az9vP1M/Vz91P0m/lr+Ov52/oX/B/84/wUAMgD5AMsAdgEIAfABVALOAXACIAPgAnwDbAPQA1gEaAQYBDgF+AQQBeAEuARwBeAEaATYBEgF8AQYBCgFsARwA7wDQARMA0wDQAI0AoACwAAiAZMAMABf//r+Hf/o/ZD95Pzw+8j70Pow+kD6aPm4+KD4UPjg96D3wPZA9+D2MPZg9nD20PYA9mD2APfw9hD3MPcA+HD4IPjg+LD5KPoY+hD7uPsc/Dz8PP0W/vD9Gf+b/9gAFAGMAaAChAL4AlADKAR4BKgEgAXwBeAF+AUgB1gHMAfQBkAIwAjgBwAIoAigCMAHqAdQCGAIUAdIB6AHQAcgBpgF+AVoBSgEWARABPADGANcAugCvgHzACIBYACsAK3/Jv9M/8L+ev5G/qj+Ev7s/Nj9VP3o/LT8CPyU/OD7uPu4+8j7UPtw+oD7iPpo+sj6UPrQ+mj6UPrw+rD6sPqI+pD7gPuA+6D8WPy4/CT9yPyw/dz92P1U/rj+dv4v/6v/8P/9/3cAxgC/APsAZAHMAXQBvgFIApACIAKYAkQD2AIoA/wCWAO8A0ACZAMwA6wCjAI0ApQCWAKyAe0ATAHnANH/zf9m/xj/hv4A/mj9UP3I/OD7GPzg+3D7mPrA+uD6GPqI+kj52PmI+aD4mPlA+eD5mPiI+QD6aPng+dD5gPpg+nj6QPto+9j7QPxI/Lz81P3M/VT+U/9z/8cAaQD4AAgChAKMAuACKAQoBLAE2ASgBaAGGAaQBuAHuAdgB+AH2AcgCBAIQAjACHAIIAjQB7gHwAdIB3AGoAbYBfgFAAboBGAEwARwBMwDBAPQA+AC0AH2AeABngEFAD4BLgG8/6f/wP+0/xP/xP3C/oD+0P3o/Jz9jP0c/Dz8FPzY/Aj7KPvQ+0j7qPqg+uj6UPqY+gD64Pro+mD66PrA+mj7WPsA+1D76PuY+wz8+PtA/BD90PyE/Gz9HP6k/Yj9bv7W/pr+Lv9f/3AAzgAxAOwAPAGeAVQB7AIkA7QCjANsA0AExAPUAyAEOAVgA5QDUAUYBKQDwANMA7ACWAK4AiAC+AGIAH8AqAExACL/L/9U/7D+AP5G/lj9gP0E/fj7QPyQ+xT82PsY+6j74PqQ+nj66Pp4+rD5mPpY+kD7cPpw+lD7uPog+4D7KPxg/Nz8oPwg/Qz+Lv5w/r7+Av/H/40AYQAEAbQB+gG2AQwDbANkA5wDgASwBBAEQAVABfAFUAWQBagGgAYYBhAG+AaIBngGUAZYB6gGUAbIBmgHoAaoBcAG8AVgBigF+AWYBSgFIAWoBGgEpAM4BBgD7ALMAkQDGAKmATwCNgEOAeD/NgBaAFD/tv7S/uj95P2M/KT9CPwk/Bj8UPuw+5D6sPoA+ij6mPnw+Ij56Pjw+Hj4aPhA+Gj4wPhQ+Ij4gPho+PD48PhY+SD5GPr4+TD6UPs4++j7LPyE/HD9lP3Y/Yz+S/+3/zwAPAFQAf4BfALQAmgDHANoBJgEoAQQBTAFyAWgBXAF6AWQBoAFCAaoBtgFGAaoBSgGkAVYBXAFOAVABTgEkARoBLgDTANAA9gCLALeAfQBYAHPAMIAVAA+AOL+ev8O/9L+qP0S/gr+SP2Q/QD9DP18/Mz8HPyc/BT8mPxY/MD7bPzg+8D70PvA+8D7kPuY+wD8OPwM/Pj7NPxE/HT8/Pyk/Aj9dP2Q/YD9+P1K/nD+WP7S/mD/7/9//xoAzQDCAAgBVAHeARQCJAKcAtwCIANIA7wDwAPMA4AEcATIBNAECAU4BXAFyAXwBRAGeAUQBjAGWAYwBpgF2AXIBVgF8AQ4BWAFwARYBEAECASkA1QDBAPkApACDALmAYoBSAG4AJoAWAABAKv/Wv8r//D+yP5G/iL+3P3Y/UT9LP3s/AD9yPxQ/ET8EPxs/OD7sPuo+9D7cPu4+yj7sPtI+2D7aPtg+/D7qPuw+7j7cPxI/Nj7ePxQ/UD9CPyk/Z7+/P1A/Pj9IwAP/+D94P57AD8ABP8cAOMAkwBHAMYB3gEiAWQAPAKAAjwCTgEIArAC+AIQAkgCoAKkAnQCeALIAiwCOAIQArAC6AFuAVQCCAKuAaAAqAGAAQwCwP2oArgAZv+V/30AxQCc/sP/eP+A/9T+PP7W/77+dP3S/kUAIP7A/Bz+HgBC/pj8AP62/yL+4PwW/mz+3P6E/Yz9Hv6M/nb+gP3Q/WT+VP/I/Xz91v63/27+Yv4U//n/2v5Q/kYAigA1/w3/ygC8AHwAc/+/AMgBUgEIAcsAWAKsAWoBzgFIAlQC2AGcAnACwAIMAtQC9AK0AvABkALgAqQCBAO+ATQD2gFAAwQCOALcAVQCQAKoAcoBTAFQAkIBNAHmADQB6ACBAOYAnwA3AET/jAAAAbj/3P10/2oBGACE/Wj9XgHMAHj9wPtGAWEANPzW/sj+sP7s/ZT96P7u/lj7l/+E/jT9RP10/UL+xP34++T+fP0c/Bj+4v5s/fD6Pv4L/1z+UPv0/Mr/6v4A+9T8CgFC/hj7BP4YAfj95PwK/nEAcP00/d4Blv+0/Eb+2QDDAJj+gP0sAWgBYv7o/14Buv+q/tABcgEOAHH/BAHYAeIABgAGAbYBYgFZAN8A0gFEASABOAHYAQQBUQCAAYIBCgEsAfUA4gAYAcwA7QAgAa0ApwDNAAIBUQD2AHMApwBmANIAMQBlALb/SwAOAO//JABFAOL/6f/n/2X/5v+k/5L/oP9q/00AVv8f/8T/xv8t/87+DP9iAIj/Xv7L/4MAdv9k/noAoP6Q/hAAbABy/8D+b/+w/un/qP9O/1b/lf9C/oABMP/s/L4BiAEc/fT+IALI/sn/D/+8/5H/x/++/kYAggEP/6L+9/9tAMwAwP7M/t4B0QAw/rz+QgEqAVD/ZP6IAHIBMf/K/mgBy/8u/7UALwCY//z/7//g/zwAPQCq/kgBPAGg/1b+u/8MAU0AuQCC/uIAJgGu/iD+eARA/1r+xv54AkwC3Pxu/xAC0ANA+sD+iAN4ArD9uP5kAO8Ae/+V/1QBfP3BAD0AOgFg/dEA1ABh/63/x/8gAVT9dwCYAXwCzPwo/nQBDALC/gT+rgGWAHsAkPxuALYBlAEA/U7/hAG+AIT+h/+SARsA0P6b/2wBvv+j/0UA4f83/wQAQwBaAEoAjACg/l7/9ACkAi3/MP0mASwDc/9I/TABQAT0/mT9DAAEAzIAzP+7/1YBGwBfAJT/FAJmAI4ACQBe/5wCWQAiAbT+MgFAAecAwf/vANQCyf8+/04AwAHUA+L+NP4YAnAGGPwg/agCcAZOAXD6Wf/YBjQCBPxXADYBrAIWAWr+Nv6YBBQCOPxAAHwBoABSARX/6ALH/9D7ewDIBrz+MPaYBVAINPyQ+JABQAUWARj57P4wCFj7vPybADgGOPko/OgDvv76AVj93PzIAI4ByP1B/3r+yP2QBVj8APrMA2QCoPnw/hAHMPd2AQj93AEoBPj5IPpYBRAE8PeM/+ADtP2AABL/oP78Ai//MPvQBJwC4PjoApgCRAIw/EEAmAC+AAgDEv7SAN4BOwBm/2oA5v+EAk8AaPyQA+gEXP44+gQCKAYSAZD2CAT4B5D8IPhYBwAEEPtQ/YUAwAkI+nD6oAPYBMD7OP4QA2QBYP6o/TACOgBM/rf/KAOY/QT/sAI8/IABWwC8AJ7/UP33/9ADsgC4+8YAXgEEArD7xgH2/zgCAP14AgYAbv8YAXX/mALQ/qb/cP1QBqP/pv4E/8oASAT4/VoBAAAUAPL/pAMwAQ3//v+QANQB8AJEAaT8pwCsAxgFcPvo+hAI+AVY+7D7AATwBsD7EPxoBQAFEPto/ZAHUAIo+Lr+EAkS/oz94wBIBGz8zP3wBN7/HP38/fAGIACA+NT+IApW/tD2mALgBc7+kPnZAFwC2AGA+ogAiAMg/EP/ogEDABT9mP8mAMgBKP1E/xv/5wA4/1wCIP3o+YAFkAPY+nr+uQAsAib/0PzIA+YBiPkAAZgFrP0u/hf/nAKqAez+ePwwBCwD6PpIAAwC6AE9/3n/cACuAWz9EAKQA9j9qPuwBBgCHP10AZr+zgFn/zACsP3MAJf/2AFT/4gBZP5Y/qAENP1g/0ABjAHc/nP/TAInALb+Iv8O//AE7wA6/xj++PrgCBQCGPvE/YACGAaw+6b+sgHYAzj46AXgAnT8YP4oBCAFQPgIAnT+wAY0/AwBMgH4/ToBEAQp/zj6KgG4BQgBAPpvAHgESQDE/Qz+oAOuAJv/QQCeABj+dP8gAmAFtP3Q+rIAQAZYBJD0fAO4AagEEPum/iQDMAOE/Uj6aAdm/50AEP1QAyUADAEA/j//uAN4ADz+SADEA3IBmPom/mAG7gF4/cT8fAOoB6j44PvwBBgEuPxQ+tgH0AMg+aD8uAbqAVD7wPoQCCwDbPxI+UAFgAT4+iv/ZAIIAf7/UP42AaABfP3pAJwCEP6c/6ADFv7w+6QDOgAiAaD9uP54BcD8pP0AAvADFP0xAMz/AANc/UYAHAPPACT/5PxABvz8WAIV/1wCgv5UAjgDqPwW/vgEYAhQ99j78AVgCTz8YPXQCZAFmPyY+xgH3gA0/bv/MAQQBEj5zgF4BUj9BPyACKb+3P7s/oAAPAPE/TQBrAICAJj6qAMwBnD40P3QB50AePm0/fwDYAZI/TD3dALEAvABdv4W/iT9XgFkAjACUPpA/MgDcAcQ+hD62AEoAxgD4Pa9ACgHhv6A+WAChf8tAIT9YAKoAmL+CPiQApAGyPlE/dAEUP+6/3j8FP04BZEA8PyG/p//jgGIBDD82Pn1AKgGrv7Y+hQBwAPk/UL+kP8oAdz9nAKe/7IBiP3U/WAIKPtg+QwCOAc0AuD6BP1mARQCU/96/lwDGP5GAIcAdAKo+tz9EAaAAsD7oP18AtYB1v+k/Dz96AQx/00AwADA+1YBowAcAXj6sAHEAiwCMPuw+oAIvQBq/lj6tAL8AiD86ANQ/ggEYPmJACQDiAVo+oD7YAcK/7b/+PyEA7H/yATo+rj9mAMMAqD+gv4wAmEAyv9V/7//MAPJ/5D7BgEYBO7+vwCr/5T92AS0Asj4nAJKAZIA6v9A+7gG5v48/Oj7gAvUAbD1zv4LAPAI7Pww+SgErAKw/gj7pgHcAqz88wAU/08AZP7u/1ABtP5O/5D9TQDQAor+oAAk/ED98AQf/zP/PPzoAjIBoP4o+5H/oAVY/cD8f/84Bfz8NP74/IABTAJg/CQBxgH9/4D6xAJS/hYBdgETAJL+kPgoBkACrv7Q+4wBbP32AHADKP+M/Qj7eAK4BTD9oPf4BvABzv6w+/4AAAWU/Pj+av98A3j+vAG+AMD7ZAJA/pgCbgFQ/GMAzAAI/4b+SAMi/mz9NAIY/LwC/v7MAG8AIPfA/jgG7AJQ+pD6HwAwA+oAAPlEAHQBZgFw/Yj6VAJpAGT/Lv7r//j6WAJgBcz9bP2w9GAHIAqw+XD3uANIBRj88PviAVAHEP2Q98gD6AU0/Dj+igAwBKj5mP5ABoQDdP0Q+DADjAMYAdj6igHcAlABsPww/QgE0QD9AID9hACWAGYBOADs/KwC3AAsAHj9nALUAYz8TgD4/WAEigEE/KT8wAFYBND9PP0g/ggEuv/g/KL/YgBEApj+qPrV/1gFcPuw/TQCwgCr/0D6ePsYB0AGgPPI/TgF2gCT/9D6aQCy/6kAsP3gA3j7jPywBhcAiPnv/+YBfwCUAUb+4gH4+tz96AWIBsD0yPigC1AGiPvA9gAAKAZMAsf/NP4w+IwDIAmeAXDzHP8gCef/RgDw9vwCiAQ5/+YBMAIQ9fj6gBC4A1DzWP6IBCAD4f/4+Xr+lQD4BpQAIf8A+Xj8EAlABMD5gPUQCvACBPxwAlQCePjc/CAKU/94+dD/QAXAA/j7UPZIBkAIEPh4+8AIEQCQ9oAGdANM/aD7RAPg/z//WAQs/E//w/8oA63/ePxl/1gE2ASw9kD8OAVgB5j5BPxABej/4PsYBXgDgPeoAgT+WAb8/Sj9MARsAlj8mPvQBZj+gAXY+3QBjP5G/t4B4AUY+kj8gArw+Hn/lAJcAqD4sANMAFgCEAHQ+ngDrAFQ/ID3EA5k/pD7rP5gCJj7EPdgBn4AMAOw+mj72AOQCpDzyPsIBOAEYPq+/7D+SAQ8/uD3gAUM/pn/VPzACMj+8PbA+cANgAMw9kj7QALwCaD6BgBw/NwDfPyoASAC3P1w/nQBaAWI/CD62ARTAPz9nAMHALj7rPzIBMAGnPw4+wT9kAqY+d4AhAGAA7j6jgDAAn//iv6Q/UgFIP+e/tD+7ALQ+8gBkAOw+pgBiP20A/D9Sv/g/EABzwAE/ggEQPpA/VAEsAXA99D67QCQCnb+oPmY/HQCyAY4+pz9XPzgBxn/3v8a/7D5+/+IBIQBhPxI/CD9wAp6ATD4gPiEA7AE6gEc/TT8eAKbAA0Af//Y+ssA2Ab/APj9uPs2/hgE2AYI+vD7cAQSAWgET//A+1T9HAPcArABRgBW/oUAZgHGAeD7bPyQBrAGSPkGAZAAJv/GAcz9IAIYBYT+APegCswAEPjgArAE1/8e/gL+tf8oBSj7OP1kAigBMv94ATj9EP7yAbYBFv74+TgC2AVAA6D3oPoqASgEqARY+ob+mP3oA24ASP3E/Yj+MAVT/68AuPgr/6AEIAjA+pD2YPzwCcAG+Pko+Lz9cAk4AkT8JPzQAgQB1AAR/2j7agGsA8QBCv4s/lT9gAOE/kADwP2I/Wj98ALABeL+iPgxAHADsgDA/O7+TAHQAgz8APqgBYoAdwAmACj8AP2sAGb+rv7gAyb+xv4W/xD9XQBQBJD8VPzwAIb+2v7iAFIBQwA5/yj9oPuIA2gEdP2E/r7+MQBEArj6LQDQB3ACwPQw+7AFqAVM/bD5OANIBOD7CPtp/0QDNAKE/Jn/4v7AAfr+V/8A/QQCX//xAK8AEP2Y+x4BUAbkAij4aPiwBnAHNAGw+XD5rACwBqADAP8I/fj7kAipAID65PwYA8ADuAao+vD4sAQsA3gEyPp4+nkAoAts/Tj9uAJA+2r/KAIABQwAYPzo+sAIdgEo+vj8CAV0Aev/nPzY/LAFLv4I/OQCFP54AFQCIQAQ+e7+1P7kA7gCgPsI+2gFPv64/fT8NAKoBbT88Plr/9QCMQBgBaH/KPhAAa7++ARwBoD4kPZwB/AGJPzg//T9YwBsAiD7uf8oB1gBWPiCAf4AaP0uAXgFZv/4+qr/QAWMAaD58/+QBFkAbP3a/xACXAEM/ZEAFAEa/mr+iAYeAMj7MP6gAdsAFwAY/5H/+AbW/6D69f9IAZH/lv68/eAGaAWg/ID3AAK4BDr+JADmADT+3AEqAKz87P0AB1b+rPxQ/iwBMAbw+OD5iAfQBOj4mPnQBnAESP2Y+tb+gAR+AID+9gG+/lj8bP6IBWQDxP3M/tD7mAWi/x7+yv5ABcUA8PybAIT9CAC8A2wD1P2o+kD+0AeYAcj73PxsAkwDGPteAB4BYAb8/Mj5qP88A0AGKPsg+EgE+Af4+lD4iATgCIj6cPht/4AJm/9g89AIgAXg+MD2iAdQCdj5yPl4/cAJiP84+0gCLAKA/bj7kAGYA5ADqPvk/WQDxv70/ewBYf93ADAB+PyGAdACAPz8ADQDUPskAFQDHAJ2/zb/YPjABE4BdgBP/+v//AMU/RL+lQBMAsj+hP2wAVgF9Pwq/j4AZAK1AID72ASa/tj9CAIcA1gAAPlhAHgFtAIs/S3/EAAY/lIARgA1AJACTAJrAKz9tPxK/w7/VAKwBcoBXPy4+IkAEAqK/lj7UPzeASAIPf84/Uz93AHMAhT96PvXAPgEYAV0/AD7HP2qABgGhAMe/pD7CwDm/x8ALAEK/gAFWwCI/RL+sPkgBlAGzv6A+Kz9YAqxAHD7kP0sA3oB+PsCALAGDAE8/OD94AJWAVD5UgFwB+AHUPRg92AFUAeW/pD6JAJ4B3z9YPM0ARAJWgAA+tgD+AKA+/D68gFIBSAAAPgc/nAHiABg/dD8dgCOABz/SP21AMgD+/9b/2j7O/8I/oQAcAOIBHv/SPmE/moBpAL6/oYAxgD0AX7/kP50AfQCBP0E/doB0AY+AZz8RP14AzwDCPuk/oAEqAU0/CD9FAI8AUwC+/9PAF7++P30A2gGtP40/JkAqAUiAdj8sP2cAEgGSgHi/jL+RP3IBPADzP2I+uD+2ASQBOj86Pj3AOAI7P/4+Zj7LAP4BOL+5P2g/BD+ugGoBRgCwPqY+wwDVAPj/wD5Iv/QBvgErP1I+fj+FAPQBaL/UPuE/d4BTAIIBSz80PstANAECP+w/CIBUAKQA2j+mP3i/sj/aAPgBET+6Pl3AGQDoASQAFz9dwDFAJL/3AF8AVD8kAIQBrj9sPvy/2wCKAQU/6T9qgHVAPz9kgAo/3b+qAFkAmQBcPzI/agBUAMC/5j8sP9AA68AVv6U/iABkAL+/lz/Ev4dANQCVAKA/Zj7mP7oBP4BeP3k/WQBOQAU/If/eAAoAeH/FAG7AAD+7Pwo/xQDigFQ/PL+RgH0AMT9Jv5yAMwCKQDo/bj7kP5gAqQCNP0Y/YQAWgG6AND+7P/e/sT9KACXABz/1P58AugEuP6w+Uz+6AQoAxj+hPzj/0wBkgHKAfoARP0e/toBggGk/mD7rgHABMQCtPxU/BP/DAFIA7H/Rv/E/NAAnAOOAUT8UPz+/5ADqAOk/ej7yf/MA5L/IPsE/bADAAfo/rD7Tv4NABQA3v5EAewBw/+QAKv/q/8O/mz99gE4AQwBNwAo/3r/2gEH/wP/oP64AMACxP2Y/mgBqAQw/VD8VAHIAxj/yPsi/74B6ALGAAL/Bf+M/ToB7AIK/9z8XAB4Arv/sP4jANQDeP3o/IABpACE/GwCeAQy/jj8KPuQA6gFYf8Y/Zb+VP38/UAFXgAkAN0A9Py8/Bn/vgHKAXMANP3SAXD9VP2E/4AF6gHg+kD65P5QCJ7+Tv+X/1z/PP4I/nQBTwA0A8z8LP0/AEwDpf8K/+X/Vf8C/mz8fAL8AlACkPqW/p7+xP90AhQA6gDw+wj99AJgAhz+tP2AAo4Bdv6k/iQCQALW//D9sv4c/2QBmAQoAmT9MPuYAbAE7P6U/TD9fAJ8A74AHP7Y/dIAUwC5AKD8RP4gBDAE6v7g+kD+3f+kAj0A9QDs/B7+YAIwBG7+iPpN/9IBqgFc/ZL/UATuAHj7uPxlABwBuAGQAaL/Vv5s/VD+rAGYAxoA0P1Y/fIBpgGHAN7/BP+h/0X/QwDkAsQCRACc/iz/AP50/9wCIAQIAjT90PyUALQDNgEqABf/c/8H/4UAfAIcAvL/QP6wAOr/8v5aAGQBrAHg/u7+QAFaAQgB4v/m/mb+NAD8ASwCKwCU/lQAmP9k/kb+9AHoAX0AJf+k/VL+zf9cAnAAvv8c/+D+M//a/iIB7AG0/0j9HgDIAgoANv5x/xIBJgC2/iT/+gHjAO7+Yf8u//7+6v9yAWYBfgDC/vj+XACMAEQBiP8Z/5//DgHsACkAuQCWAGn/gQDiAGMA1P/F/3oAYQAyAMn/TAGKAcv/x//6/h3/LQD2AOQBU//o/sP/qwAWAVr/jP+d/0QA2/8UAQoBzv9H/3H/NABnAIcASwB2AcH/Vf/I//4AiADYAC8A7v7O/pUAqgG5AI4AWP/1/3r/DQAiAEoBNv9y/mwAqQBsADL/swDY/+D/DP5//1sAeQDSAKr/C/+m/hgBcQD9/3b+Hv8VAM7/AAAZADgA/P6O/wz/tv5q/2wAhgD1/y7/VP5X/+z/6P/7/+j+wv9wACEAvP8aANf/aP/U/+f/lgDh/8z/IQACAe7+Qv/9ABwBJgF7/0f/JwBGATIBwgAdANr/2QBqATwA8//cAZsAQAFOAeYAcAHh/8r/qgHkAjIAVgBEAtgBhQBm/mQAbAKAAtoAGgB5AFkA/f/b/2IBjAHaAIj/pv99ADwAGwCV/4wAjP/o/gr/rgC6APL+xP2+/j8Arv+3/+L+kv5+/t7+WP9a/0//h/+F/1L+sv4e//D/wP84/yX/YP5N/yEAfwC6/zX/Ev/a/y4Acf+U/2H/nf83AC4ARwDK/xEA6v9A/5H/RQBDAMIA5v/Y/3cA7P8dAJ8AZwCh/8v/RgH2AN4AaQAmABEACgB6AP4AmQD9/wsACACu/z0AYQBrAIf/d//o//X/Nv8OACn/Ov98/9L+KgBo/3P/OP9w/3f/9P0M/lL/HgDO/zz/ev7H/xYAOQC//77+UACVAGwARAAkALcAcgGcAf4BPACIAGgCWAIOAT0AkAK8A2ACWAFkAlQCsgHOAbgCyAK2AcwBWAIEAkgBngEkAgwCrQA0ACIBaAGuAA0ATwD//03/L//e/hb+3P20/WL+OP5M/Uz8QPwo/ID7UPtA+wD8yPuw+gD6KPrY+mj6QPrA+kj64Plg+Uj6uPqI+jD6oPoo+9j6UPoA+/D7GPyA+7D7GP0c/Rz9YP0Y/nj+DP7g/if/1v8zADsAAAFwAWgCcAPAA+QDmAMwA8gD6ATwBRgGaAbgBrgGuAYYBqAHAAgwB2AHYAjQCIAIkAiQCEAIWAdgB2AIwAnACTAJ8AgwCCAHuAaABwAI2AcACBAIyAdABsgEKARABJwDGAMUA2QCXAH1/43/yP64/UD94PtQ+6j54PgY+ej4KPjQ9jD2MPUA9IDzAPMQ88DyAPIQ8vDx4PEw8pDxEPEw8MDwEPGQ8dDykPNQ9FD0IPSw9MD1sPZg94j5YPno+Sj7NPwc/mH/KwD9AAgBUAGYAmAEAAa4B6AJ4AhgCfAJQAkwCzAMMA3gDUAN0A6gD5APAA/wDuAOAA/QDqAOoA9AD5ANEA2gDDAMsAuACiAKEAkgB+AFkAU4BvwDGAKzADP/dP44/YT9iP3g+yj54PdQ+GD34PVA9sD18PTg85DzoPRQ9FDzgPIA83Dz8PKA80D0cPXQ9HD0MPYA96D3UPcA+PD5ePqA+nz8Zv5q/uj9rP3e/rkAiQBqAbAFgAX4BOAFiARIBZgFwAWgCbAMEAzgCgALoAqACmAKwAywDeANkAxgDMAM8AvgDMAM8AywDPAJYAmwCVAJ8AcIB4AIOAegBBAE+ALDAH7+YP49/9//hP5w+2j7EPnA9lD2wPa4+ED2gPRA9HDzoPLw8TDzkPKQ8QDwgO+Q8uDy8PGA8uDy8PLQ8eDy0PVg9lD2EPZY+Fj52PnQ+oD7jP30/HT9Zf8AAd4BmgH+AdgD+AU4BgAHiAcgBsAFoAaIB2AK4AoACvAL4AtAC4ALwAxQCkAKAAogCrANQA/wDqAMQAogCUAJsApQCvAKwAroB7gG8AZwBwAH6AV4BMIB/AAl/zL/0ACG/vD9xPzw+wj7CPnQ93D2QPZg9TD1sPbg9QD1sPLg8SDy8PCQ8VDy4PJg8wDzAPMw80D0IPSw9ID1sPTg9WD36PgA+2j7cPxE/Hj8BP0A/ucAyAKIA/wCEAS4BOAE4AbAB5AIcAhQB6AIkAqQCvAKgAswC4AKYApgC/AP8A9QCzAMIAxgCiAKsAzQDtANQAvwCHAK8ApgCdAI8AiQB3AFnAOYBQAHeAT0ApgBlABE/sj9sP24/ST8oPlA+fD6cPkg92D2kPRA8+Dx0PJQ9LDz0PJA8lDxYO+A71DwIPBg8ODwQPHQ8sDzQPPg8hDzoPNA9HD24PcQ+Zj54PkA+yT80P1i/tz+//8cABoByALQBGgGUAaoBpAGwAbgB5gHkAggCjAKMApwCjALMAswCmAJYAwgD5ANsA1QDGAJwAkQCfALEA/wDtAMwAoQCvAHSAfQCNAJcAmYB9AFQAYABjAEgAJ2AZYB4/+6/rD+tP6g/Dj5wPgg+vD5MPiQ9oD1kPQA8rDxwPMg9TDzkPGw8KDwIPAA7wDxYPJQ8eDw8PHA8wD0kPPA8zD0QPXw9Tj4mPr4+nD7iPoU/OD9af/+AJQBiAKcAugDUAXQBVAH6AcwCNgHMAhwCaAJ0ArwCuALUAvQCWALsApQClALMA2wD6AO8AyQCSAJoAggCPAMgAyADGALYAjwB8AFEAd4BogFaAVoA0gFfAOgAmgCrv7y/hT9SPyA/XT8cPsA+CD48PdA9/j44PZw9cDyIPFw8eDx0PPg8iDzMPKg7yDwgO4Q8DDxMPFA8lDyAPOA8yD04PPA8+D1gPUQ95j52Pmw+hD70Pzk/Xj/KAC//5ABPgEsArAE+AWIB4gHeAeoB8gHaAeACPAKAAqQCqALcAqwCnAKsAlgCkAMIAwwDVAPUAtQC4AJ2AeACiALQAswCzAL4AkgCcAIsAcwCJgGsAUABhAG0AVYBKQD2AF8ARUA9P9xAAUAKP5I+xD5wPmw+ej6cPqY+DD3kPRw89DzEPUA9XD0sPJA8kDzMPGA8bDyoPJQ8tDxEPLA8/D0cPOg9ID2QPbQ90D5OPlQ+kD5uPjU/Kv/6QCEAlgClAF2ADEAyAMACAAHcAjQCTAJsAjAB7AIsAngCZAIAAzwDcALsAsACqAJgAlwCMAMcA4wDWALEAqgCegHUAlgCLAJUAmoBRAIkAigCOgGzAP4A6wCPAL4ALwDPAPK/xP/IP1C/hb+9Pw8/TD7QPgQ9bD1uPh4+Oj4oPbg9FD0APFg8SDzcPNA8RDxoPKQ8iDz8PAQ8iDzcPAg8MDxwPMQ9ND0gPaw9wj4APcg+HD52PgY+XD7NP+oAQwCcAOYAgwB/ACkAdAEOAfgCHAJwAqwCRAJQAlQCJAKcAlQCUAL8AoQDUANoAuACsAKUArgCGALMAxAC9ALEArgClAKYAkgCcAHcAeQBSAJIAnAB5AJEAaIBNwD2gEYAqACnAKLACQBeAFZ/6n/TP1g/Cj6wPZ4+ND4ePn4+aD38PeA9aDzYPLg8rDzkPGQ8jDygPLQ8iDxYPOw8rDxAPLQ8CDzsPPQ9ND2oPaA+LD2cPfg+Kj56PrM/JP/nf+IAVgBpgGYA5ACiAOgBTgH4AggCcAJEAqwCmAJ0AlADGALUApwCdAIcAqACgALYA6gDWAJYAgoB9AGoAeACMAJoAwgCoAGaAe4BSADvAOgAiAEAAaQBAgGUAacA3P/R/+y/gz+CQCE/qX/CgB4/FD9/Pxs/Oj5wPeQ93D30Pfw9oD4IPoA9nD1EPTA8yD04PGQ8jDz4PNA8lDzcPYQ9GDz0PLA8qD0MPQQ9fD2ePjQ9+D3EPpo+kj6CPsA/Kj/gf/J/3wCnAJQAiwDoAQQBngGsAdoB5AJwAjQB7AKwAugCmALcAtwCSAJEAegCZAM8AyQDdAMAAtoBwgHwAYQCCALkAogC+AKsAhYB7gFgAXcA6AE4ANQBdgH6AcwBmAD1gH//7j96v51APEAIABc/nj+HP0c/Nj6APkg+ID3gPbw9hj4wPfg9RD14PTw8uDyUPNw83Dy8PCg8eDxUPIg8+DzUPQg88DygPOw9MD04PSw9XD20PiY+Bj7HP0g+xz9iP1K/hwAeAEsAgAE2AXYAzAHWAboBhAK2AeACqAKEAlQC0ALoAtwCRAKMAigCIAJYAmAC8AMoAkgCNAGcAVoBqgEYAgQCpAIsAaQBRgFFANMAsIBrADMA2gDXAPwBlAFLAKy/6D9tP0Q/lT+nP8YApT/hP4j/1j9nP0Q+sD46Pno+Aj5cPoI/Aj7iPkg+CD3IPfg9SD1gPVA9XD1oPXQ9sD3YPYA9iD2MPXA9hD3kPdQ+LD3QPlY+bj6VPwg+xz9WP4c/2kAkAFgApABqAPQAzgFOAYgBsgH4AggCtAIAAvgCQALgAowCsAKYApgCYAIgAsgCZAJoA4wC2AJ0AmYBvAFQAZIBpAJMApACJAIsAeQBtAD+gEUAqgCnAKoA6AGkAYABeQC9//I/rT8kPwO/qz+gv+S/lD+Pv4w/SD7uPiw90D2oPVQ9ZD30Pjg9vD3gPXw9PDzcPJQ8rDxoPEA8LDxcPKw9MD0IPRA9bDzgPRQ9GD0MPUw9QD2cPdA+yD8OPwc/Q7+pP0U/84BogEQBJQDOAZwBhAHUAggCaAMgAkgDCAKIAvADNAI0AxwDWAK4AqwCqAKwAmwC2AJ8AgQCtgGSAbIBjgFCAcYB1AFkAZYBFAEMAMAAUQB/ACSAJAA9AJMA1ACzAKVACH/4P6s/Zj9xP0R//j+Cv/c/ij+Tv5A/YD8SPvI+hD6aPnw+eD56Prw+Rj6OPoY+SD5iPhw91D2IPbg9CD08PXA9vD3uPhQ+bD5IPrY+RD4cPjQ91D3ePng+8j9uv/kABoBngGIAVACAANIA0AESAVIBkgGmAcQCTAKsAtgClALcAtwCtAIUAoACwAHAAgQCVAIAAgACmAIYAlwCAAFyAVYBcADAAXAA3gDcAQwA/wC0AMEA98A1AHd/0oAxAK1ADgAygGW/zH/Z//W/1z/rv5k/Wz+ZP4s/SD90P04/PD6YPpw+bj6cPm4+Jj4SPjw9dD1IPag9nD2IPYw9gD2gPYQ81DyIPOA8jDzIPTA9sD3sPdw94j5mPiw9rD3oPcY+Mj6uPwb/4ABvAGAAtADtANQBDgGgAiYByAJsAkQCoALIAuwDEAOAA3ADSAOYA0QDUAMIAsACrAIwAeYB1AJ0AfABxAIEAVoBAAE7ALIAq4B9QCwAP7+8v4P/1L+6P3s/S7+pP2a/pr+VP50/oz9iPwU/fT8oP1E/uj96v60/iD/aP/A/vD9IP2I/Rz9pP2S/jz+xP1M/Rz9vPwk/CD89Pzs/OD7qPtg+1D6uPlY+fj4iPnI+aj5WPvA/GD81PwQ/fz8mPuA+4j88Pzw/c//SgGWAeoB/AKUA8AEUAVIBhgHQAcQCCAI0AhQCSAJEAlwCuAJEArgCUAK4AkACRAJgAegB2AHSAaQBqgFAAVABIADTANQA9wC2AIIA2gCXAIIAc0ASACS/4L+PP6A/lz/6P8lAGUA4P81/7L+Nv4f/wD+xP0A/vT87Pwc/CD98PtY+ij74Ppw+rD6+PnI+YD3kPZg9jD2sPaA9lD2QPYw9uDz4PPA9NDzkPMw9BD1gPVA9gD3oPgQ+PD3aPh4+Gj5KPlY+qj7vP14/kkAEAMYBCgEWAVQBvgHUAjgCGAKUAuACkAKoAsAC1AMIAxwDBAN0AvwC8AKQAowCNAGOAdoBRAFtAOkA4gDQAOkAdIBYAGf/y//5P7U/mD9AP3w/PD8QPzY+nD8LP1Y/dD9a/97/6b+Tv7Y/SX/xv7c/qb/KQDt/0MAZADVAFgBmv9UAEwA6P/DANUApAA0/zn/2P1s/ab+qP0a/pj9ZPxQ/LD72Prg+mj6IPqQ+TD6+PoA+9j7YPv4+wj8cPtE/Ez8jPwg/az9Iv95/8IAaALwAgAE+APoBAAGkAZoByAIYAiAB1gHuAcgCPgHAAggCNAIYAjAB2AI0AeABzgG4AWQBRAE+AN8A2gDVAJAAsYBgAGgAX4BEgEaAccAawAOANL+H/9M/pT+hP7M/h3/YP8R/0T/oP6S/or+wP14/pD9ZP3I/Gz81Pxw+8j76PqA+gD6sPlQ+eD4ePjg91D3EPeA9vD1EPag9VD1kPQw9DD00PNw87DzMPQA9DD1UPYA97D3wPeo+DD52Pmg+gj7gPtk/ET8xP3w/zcAaAKkA7AEkAa4BuAIoArgC8ALgAyADCALIAuQCgAKkAkgCRAJoAkACWAIMAggB2AGkAWoBTAFjAPEAsABpgBZ/6z+Zv6U/SD9OP1E/cj9fP18/Wz9wPww/Yj9qP4t/zv/av+J/4v/l//+/58A5gDVAKgBzgEUAmQCGAKoAigCBAIoAggCOAJsAVQB5gDv/7b/4v4v/6T+Rv5W/qT9PP2g/Cj88Pv4+sD6uPrw+fj5uPkw+nD6APro+sj6YPss/Iz8QP04/Qj+fP5e/wAA0gDCAXgCtAJ4A0gEmARgBQAGEAcIB0gHuAfAB1AH0AbgBpgGmAaABmAGAAYYBaAEiARABCAEZAM4A+ACNAIUAqIBVgHAANz/0P9v/2n/Kv8L/xX/nv74/QL+RP5Y/mz+zv6Q/uz9Qv5I/gj+AP5I/UT93Pzg/JD8APwY/HD7wPoo+hj6MPqo+WD5MPkY+OD3IPew9pD20PXw9eD0oPUg9TD0APXg9JD08PQg9cD2YPYg9zj4aPig+XD5UPrg+5D70Pus/F7+cf8G/+sAYAIwBOADeARgCAAIQAgwDBAMcA0ADfAMYA1ADcALoAvAC0ALEAmgCJAJUAfQBmAGaAboBYAEaAQgBTADuAKIAfkASwC6/lf/qP1E/nj9DPxE/ej88PsA/Zj9jv68/j//igChAPgAagHAAVAC8AFgApwC6AJ8AmQCvAIUA8gC6AKsA3ADuANkA9gDnAPQAswCDALsASgBYwA9AGP/1P7s/Yj9JP3E/Fj8lPwg/Nj7gPuY+/j7ePu4+6j7IPyc/AD9+Pw8/ZT9RP0s/uj+a//o/8EA/gFMAggDaANwBAAFoAX4BWgGMAcIB2gHwAbgBoAGQAYIBhAGkAXYBNgEcARgBEAEpAMQAwADjAJkAmQCdAG+APX/CQCf//b+nv74/fj9UP1A/fz8fP00/Zj9OP1o/Zz9CP24/cj9vP0Q/fT8HP2c/FD8BPzw+2j7QPso+4j6wPog+tD5qPlA+aj4oPhA+ND3YPfw9vD2APag9fD1wPSw9FD0kPWA9PD0wPWQ9TD24PYw92j42Pl4+Yj6UPvY/Ez8iP00/vD9HwCU//IB1AFcA4gECAZwB6gHkAqQClAMIAyADhAPoA4gDyAPUA6gDFAMcAvACkAJsAngBxAHoAbgBRgFGARQBFwC4AI8AlAB7wBAAP3/bP68/kT+WP2M/HD8KPyw+9D7WPzE/ND8+P0q/gL/nP9YAPQAUAFMAigCpAIsA8QCAAMkA/wCmALAAsgC4ALYAswCqAKAAlgC6gHuAaQBegEOAasAWwCm//D+qP4W/nz91PyE/DD84PuA+2j7YPuY+2D70Puo+2D8PPzM/FT9dP3Q/Yr+fv43/2//dQDZAIwBXALAAtQD6AMQBQgF0AUQBpgGiAbIBjAGSAYIBngFmAXABHgEOAQoBNgCIAI4At4BHAKSAawB4ADZ/z8Agv8E/oj+LP5M/Wz9wPxc/Ej8cPso+2D7APzI+hT8MPxc/AT9HPy8/Pz8mPxY/Rz9EP08/Zj8pPyo+4j7UPvY+uj6oPpw+lj6qPmY+WD5OPiY+Ej4APgI+ED38PZw9pD1sPUA9RD1wPTw9OD0UPWw9eD1cPaw99D3+PhY+oD6iPxI/Oz9Sv4a/5X/zwDyATwCbAP4A4AFcAaoB2AJIAtwC1ANAA4QDnAPwA8AEcAQYBEAD5AO0A0gDDAL4AmACTgHoAXYBYgExAKMAtIBogCE/+D/wP7g/vj9UP0Q/Uj8APyo+6j7wPqI+qD5UPrA+Wj60Ppg+8j7fPws/q7+wf9DAKoB2gHMAmwDkASYBIgEAAWgBKgEvAOABNQDeAMYA5wCnAKgAcYBdAHrALQAFAB/APX/MP8s/1r+3P2o/Iz8UPyo+4j78Pqw+vD5wPnQ+Sj62PlQ+lj7+Pvg+1D8VP0A/mT+EP8GADoBqgEMAugC6AKAA6wD8ARIBaAFuAXIBSAGIAYoBiAGKAYABqgFMAWYBPADhAPQAiQC3gFcAbQA/v+D/wD/XP6Q/Sj96Pxs/Cz80PtI+wD78PoA+/D60Pog+zD76Prg+kj7cPss/OD7aPyk/PD86PwQ/aT9rP2k/Wj98P0g/pT9UP38/Lj8nPwg/BD8wPsA++j5WPrY+Vj5EPiA+JD3QPig9nD2gPeg9XD24PYA9pD2APdA9wj4EPiY+BD5WPqw+mD7UPxM/dz98v65/yIBDAEMAjAEMASwBegGQAjACDAKcAtADPANYA+gD2AQQBEAEIARQBCgEdAPoA8ADyALEAzQCfgHqAcABpgEdAOYAogBvv9DADT+UP3E/ej7uPz4+4D7APsA+rj64Pmw+Tj6+Png+fj4IPpg+kD6wPvY+0T9/P2y/moArwBAAZACsAIgBAAEsASgBdgESAWoBLgEgAQoBOwDgAOoAkwCOAFaAVMAAgD5/xv/2P4G/iz+UP3U/GT8KPx4+xj7MPtY+4D6IPpI+hD6OPro+ZD6CPvQ+oj74Puo/JT9mP30/pX/9f9QAe4B+AIoA+gDmATQBFgF6AWIBpgGUAZgBkAGGAYQBlAFSAVQBMgDgANsArAB1AB8AOT/Df/c/lD+bP00/fj7mPu4+1D74PqI+nj6EPpg+eD5IPpI+iD68Pkw+wj6mPrg+kj72PuY+wT84Pwg/bj9jP0i/jz+NP7s/mr+a/+2/sj+hP78/Tb+pP10/ez8wPzY+3D7ePpA+vD5oPn4+KD4sPig98D3kPeQ91D3gPfA97D3gPfg94j4SPmg+TD6GPuY+2j8MP1i/in/0P/TALYBYAJsA1AEQAUIBvgGAAgACTAKEAtgDGANoA6gD8AQQBFgEeAR4BEAEWARoBGAEAAQYA5ADHAK0Ah4B2gFUASIAgwBFQBa/rz9kPyI+9D62Pnw+Sj56Pho+cD4iPjY+LD4qPjQ+HD5iPnY+XD6aPr4+tD7VPxo/Vj+Rf9RAIIBWAIEA4wDgAQIBWgFSAagBjgGcAYIBqAFMAV4BIgDPAOcAgwCHAFjAIH/H/9u/sz9GP28/LD8sPuQ+2D7oPpo+ij6iPqQ+tj6KPvQ+gj7UPto+2z8hPwk/Q7+hv7e/q//MgF4AboBxAKwA3AESAT4BJAFAAYABjgGmAcoB2gHEAcoB7gGCAYIBmgFYASMAxQDWAIEAUEAHwC6/sj9TP2w/DD8QPug+pD6SPpI+aD5EPrA+ZD5yPmY+bD54PlQ+qj6cPpQ+hD70Prw+gD7EPy0/Ez80PyQ/YT9ZP0e/oL+fv7M/vD+L/9O/xf/2v42/4L+QP44/hr+XP2E/Hz8wPvA+mj6UPrY+aj46PjQ+GD4gPg4+Ej4GPjw9/D3ePjw+JD5MPrg+vj6sPvc/FD9yP0q/+P/SADGAEACqAL0AigEEAUQBggGmAYAB+gH6AdQCBAKMAsADPAM8A2ADoAO4A7AEGARIBEAEaAQ4A9gDsANwAwgC9AJwAegBpAEGAPyAbL/XP7c/FT8UPu4+kD6EPqo+ZD5IPr4+VD6APo4+tj6yPpA+2D7EPwQ/Nj8mP0W/nr+YP9nAPUAegG8AoADIASwBKAFGAZoBhgH2AdAB+gGiAbQBTgFeARoBGQDgAKEAX0AFgCc/qD9MP14/Nj7gPvA+hD6MPog+kD6OPoA+lD64Plw+gj7kPu4+/j7GP10/Sz94v41/1kA7gCMAcAC3AIEAxgEyAQIBdgEcAXIBcgFMAU4BUgF2AS4BIgEQAT4ArwC0AIkAqwBPAFXABX/lP4I/rD91PxY/Oj7QPvw+gD6cPrA+ej5+PlY+fj5qPk4+oj6MPuY+yT8jPz4/Lz9lP30/RL+5P64/oz+Kf/6/jT/Tv4A/zT/NP5I/uz9Ov4w/TD9vPzE/HD84Pto/Bj8LPy4+xj8cPu4+pj6sPqo+kD6APpY+mD6qPng+fD5cPkA+rj5kPo4+oD6CPtg+zz8iPw0/Tr+DP6W/mj/tf8FAHAAsAGAAmwC0AJ4A5wDFAO0A3AEcASoBHAFcAYABrgF8AVgBrgGQAZQB2AIQAggCbAKkAvgC7AMsA0wDgAOYA6gDlAOAA4ADWAMAAtwCWAICAfQBRgEKALEAEj/pP0A/dD7GPvo+oj6WPpg+rj6APvQ+oj78Pvo+3D8VP1K/jj+Ev7U/vj+F/+h/7oAhgGaAawBmAKcA2wD/ANQBbAFQAVQBegFOAawBUAFoAUQBYAD7AJ0AswBIgBe/wX/Sv60/CD8UPxg+5D6mPoQ+yD7iPrg+tD7qPug+8j76Px8/TT9SP7A/jP/8P7P/xIBHAGiAewB+AIYA1QD7AOgBOAEoASgBDAFKAWABKgE8ASsA+QC8AI8AkIBpQBeAA0AKf+0/pr+Yv74/Yz9kP1k/ST9jPy8/Lz8XPyI/KD8qPww/GD8yPyQ/Nj8bPy0/DD9gP3o/VT9bv5s/qL+Rv6u/h7/Ov6G/qL+qv70/Uj9eP0k/Yz88Pt8/Aj8ePvQ+vD6uPpA+jj6YPo4+sD5CPrQ+UD6IPow+hD6APrY+rj6IPvw+vD6aPvQ+/j7QPx4/GD8ePw8/Vj9jP0M/qz+LP7M/gX/bv+W/rj+wf/2/ycAwgD1APQARAHiAcgBNAIgAnACEAMYAwQDGASYBNAEKAUABmgGMAYABggGIAbgBSgGOAcQCXAKkAvwCyAMoAzgDNANYA+QD4AOYA7ADrAN4AvgCgAKAAigBdQD7AICAbr+ZP24/AD7mPmo+TD6KPrY+Pj5GPvY+rj7kPyQ/fD9FP4c/9v/UAAFAB4BngB9ALoAXAEwAggClAI8A8AD3ALgAsgDmAPcA3wDtANMA4QCrAG8AcUAl/+y/oD9CP0k/ND7mPvA+jD6UPrY+uD6uPqA+0j8jPzk/C7+EP8L/4L/EAAUAfQAsQA6AVAC+AHaAYQCpAKgAjACsAIcA7wCKAJoAkgC+gEsAmAChALOASoBsAAcAOX/Pf/6/uz+tv5Q/lD+eP5G/gT+lv7i/jv/XP+f/7n/8v+w/5f/PQAgAKf/t//v/0z/xP2E/hj+bP2w/Ez9Fv7c/HT84PxI/cD8wPws/bD9OP0E/QT9nP30/HT8wPxQ/Bj8SPvQ+2j7+Pr4+ij7SPuI+gD7aPtg+0j72PrY+wD8WPvA+0T8lPwY/Bj8qPzs/Ij8SPws/VD9/Py4/KD9KP48/UT97P1e/lT+Uv4Y/xD/jv44/r7+Ef9Q/nL+pv78/jH/gP9qAAgBNgFOARgCNAIsAogCvAJUA+wDsAPABIgFuAXoBdgFyAb4BQgFYAX4BZgFqAT4BsAIgAngCFAJgAtgCtAJcAwADxAOAA2ADVAOAA2QCnAKAAkYBqQD0ALQAQT/pPxo/JD7+Pgo+Gj56Pm4+FD5QPsI/Jj7zPx7/6YAzv+NAHACCANwAkQChAMIA9wB7gG0ApgChgHeAWwCPALvAP4A+gGaARwB+gBYAXgAOP9T/9b+wP3s/GT8KPxY+4j68PoA+8j6wPpw+1j85PyI/Yz+oP/5/wABZAIcA2ADiAOMA6ADUANAA1QDDAOwApQCQALMAY4BPAFAAQIB6AAQAewA2ADTAMIAzQCcAGgAPgA3ALP/ZP8g/+T+jP4u/kD+qP4F/2T/if/L/y8AewCxACgBmgHSAfgBDALQAWIBNAFZABYAbf/M/uT9LP2s/Pj7sPs4+wD7IPvw+vj6YPsU/Fj8EPx8/NT88Pz4/Az9CP3A/KT8lPyE/IT8APyI++D6GPsQ+wD78Pow+5j70PvQ+1D8yPyo/Ej8jPx0/Fj8cPxs/MT8YPx8/HD8WPzI+7j72PsI/Dj8jPzQ/Mj8IP1c/aT94P0A/kT+Lv4A/lT+7P7g/pL++P45/+T+/v5a/0UALQAoAMgBbAIMAoQCyAMwBGQD0APgBKgE0AN4BGAGmAU4BTAGuAZwBvgEMAWYBqAE+ALIBMAG2AXgBJgHwAtACiAJsAqQCvAKQAqwDNANkAywChAKAApQBqAFrAMoAQkAzP2w/ZD7yPkQ+vj4gPig+Cj6cPuw+0j80P3i//H/0gCAAkwC/AF0AlQD6AKAAmgCJAJ/APj/RgAGALv/3v7A/0IAXf9s/zEAugC//y7/cP9h/0r+IP2A/Qj9gPuo+sD6uPow+tj58PoU/JD8JP3G/sEAxgGEArgD+ARYBaAF6AXoBXAFIAQoA3QCoAGyAGP/sP4E/nj9vPy0/ET9vP0G/qb+v/9xAJcANgGGAYwBagG8AaIBUgHSAIUABgBx/8L+uv7+/kz/jf9CANMALAHYATgC5ALcAjADHAP0AngC1AEIASgAYf+o/pT9TPwg+5D6kPkI+TD5gPlY+aj5GPrQ+oj7PPww/dT9NP6Y/gz/Fv+o/ob+lv5g/gD+zP2E/cz8SPzw+6D7ePu4+wD8MPwc/Ij8qPyE/Fj8TPxM/AT80Pvg++j7oPtg+0j7WPtQ+3D76Pug/CD9FP3k/XT+AP8s/6H/hgCtALAAqAClAI8A2v9R/8T+9P3U/ez9cv4w/sz92P1+/pj+9P5FAI4BRAJEAigD/ANYBPgD6APoBLAEAARQA1ADyAO8AgwDrAP4BNgEwANwBTAFKAUIBKgEUAbgBGgEMAVwB0AIYAjgCGAIgAcIB1AIQAkgCZAKMAsACnAIkAf4B9gFmAP4AtQCZwAA/Uj89Py4+xj5GPlg+nj6oPkY+7j9PP4g/pT/3gFQAvwBNAMoBAAEKAMYA5wDhALsAA8AN//c/dj8OP2k/dT8GPxI/JD8TPwk/Tz+2v4m/sD9Vv5Y/uD9dP20/Vz9bPzw+6D87Px4/NT85P3K/u7+TgDWAcwCEAPgAwAFCAWoBFgEMATYAqABswBKACf/2P2I/Qz9ZPzY+1T8EP18/fT9G/9HAHMA2ADEAcQC4ALAAtgC5AIYAnoBXgGCAfwAVwCPALMAXAAwALwAeAEsARQBeAH0Ac4BKAECAdwAJQAP/5b+VP7A/eD8cPxM/GT88Pvw+yz8kPz4/AD9AP0M/QD94PyY/Gz8XPwk/Ij7EPsY+xD7OPtY+wT8lPzI/BD9pP2C/vb+Jv9P/3r/nf8R/5z+IP6A/Wj8IPtQ+sj5SPmY+Ij48PhI+Wj5GPoY+8D7qPtc/MT96P5d/zcAsAFWARUAqv8iAHr/DP7a/jEAUP80/ZT8oP7u/iz9HP3G/+n/WP7g/fgADAEy/+D+PAAkAXv/bADaAYgCYAESAUwCLAIkAmQCMASsAzQDXAMwBCgEgANIBJAE4ANUAwgEoAQ4BKgD4ATABCwDoAFsArwDJAN0A1gFmAewBoAFQAeACUAJAAmACiAKoAgwCLAIYAowCHAFYAUYA04AyP2A/Vj9MPqQ+Oj4mPkg+XD5UPuI/HD85PyH/xQBEAGOAZACuAMAA7ACmAP8AnwB6f+o/7z/AP58/Xz9kP2k/Cz8RP2Y/Zz9/P0F/5X/1v6A/rT+pv7I/XD9/P2c/bz8lPzY/Mj8PPyU/ID9LP6y/tX/ZAHCATQCFAMABCgEGARwBPwDxALMASABSgDE/h7+Qv4U/jD98Pyo/Qr+KP78/p8AtgHkAUQC9AKAA1wDOANcAzAD6gEuATABOAGTADwAUgAPAN7/VgBWAdABsgFUAvACtALAAdABNAI0Acn/sP+//6T+UP3g/Bz9oPtA+yj85Py8/PT82P1E/oT9+PzE/cD96Pxk/KD8sPtw+iD6sPpo+hj5MPn4+Sj6KPqY+7D9ZP4i/gT+wP6x/23/k/8RAKH/WP4A/cT89PxQ/Lj74Ppo+iD6mPmw+Sj6mPrg+gD7UPvg+0D8FP2k/ez9Pv6G/rj+Bv8o/2P/f/+V/4T/bf9d/2T//P4X/3P/zv+x/y3/nf+r/zv/Av8y/4L/Uf++/vD+Lf8t/0r/DgDdAEYBlgFgAiQDPAPMA4AEoARgBGAECAXwBHAEcARwBEAEeAM4A3ADlANgAxgDiAPUAwgEMASABFAFaAVgBRAGkAbYBnAG0AZABwAHSAboBUgGuAbQBqgH4AgACSgHEAbwBGwDEANkAmgB9f/I/QD9OPyA+1D7mPuA+9D6YPrg+tj7JP10/goARgH0AcQCGANIA+ACfAKAAXcAwv9k/nT91PyI/Bj8sPvY+zD8XPwE/RL+G/+o/zMAKgE2AfYAFwDu/8r/qP5G/gD+KP0o/Lj7uPvo+1D8uP1Z/wEAqgDwAQwDKANgA0AEyATEA1gC4gHwAU4AsP7y/ur+Tv6M/aj9tP6o/lH/sgDkAYgCZAIoA5ADfANAA4wDkANYAgYBuQAuAMX/Vf+I/6r/Rf9D/3f/UgAoAcABXAKoArACdAJQAggCmgEAAToAjf9W/sT9LP2I/BT8UPtg+7D7KPtw+9j7WPyI/GT8FP2s/Vj9lPx0/ID84PsY+6D66Pmw+SD5ePnI+Vj6kPrI+zj8kPzY/dj++v/6/yUAqgDaAEYAsf8V/zb+kPxY+2j6qPkQ+Vj4oPio+Jj4QPkg+pj7VPyE/fz9SP8JAMYAqgHgAUACKAL2AdIBigEaAbgAeQBDAOv/1P+H/4r/l/9a/2T/Bv8i/2j/FP8e/1j/GABbAN8AHgGaAUgCQAKkAhADzAMYBDAESARwBOgEIAVoBeAF8AXYBaAFWAWABUAFOAX4BBgFKAXYBMgEYARgBFAEUASIBHgEcARwBIAEsAR4BNgEaAXgBQAGKAbgBmgH4AdQCHAIyAfwBZgEMAQwAyACyAGMAcoA/Pxw+qj6SPs4+pD5gPvA/Hj7APus/QwBNAKGAPgBnAPEAm8Alf8QAiIA3P0s/Fj8dPyA+nj7bPxg/Xj9cP3Y/nb/0/+8AAYB3gEwAa4AYQA8/kb+6Pzg/HD8UPug+3D62Pts/Lj9ZP+cAHQC3ALAA2gESAXIBZAE4AOQAzAC6gCt/xsA1v9Y/vz91P2c/qj+6v7S/+cArAE2AYwBZALAAkACFgFgAUABUQBq/0L/HgCe/8T+VP9oAJMALQDQANIBBAL2ATwCAAOcAvQBogH8AEwAGf80/oj9aPzg+4j7WPuw+pj6OPtg+9D7UPyE/DT8IPxo/FT8iPyE/Ej8cPto+tj5APrQ+dD5sPlg+QD58Phg+gD8jP2C/lX/5v+V/6P/KwCrAL8AcADz/4f/Fv4s/WT8ePs4+gj5WPnI+Cj4GPj4+WD7uPuo/Pj9YP9H/9X/MAI4A9wCmAKkAigCxgBdAG4BCAL3ADIAPQAkAPP/NAByATQCsAGYAaIBbAGOASQC7AJEArIBbgGsAUYB4wDmAdQCrAJIAtwCOAQIBVAFUAYIBzAH8AbYBrgHkAcgB5AGAAZIBVgEOAQIBMwDDAP0AhADLAOsAygE0AQYBTgFwAVIBqAGQAdAB9AGcAbwBdgFKAVYBNADwAPIArIBTAEUAcsAEgCA/0j/2v5u/kL+Cv7E/XD9WP1M/fz8DP1k/ZD9cP24/RL+aP6Y/sz+Tv91/13/Wf+K/5D/X/8k/yj/1v68/pr+cP4E/vD9AP4g/tD9vP20/cT9fP18/fj9Vv6I/rz+s//3//X/LwDjAHYBbgFiAQACIAKwATQBkAHIAVwB9wDZAOgARAD0/3UAyACbADUAawCsALYApwDxABYBEAHGAHwAzACoANgArgC1AKQAmACLAJEAtgC0AKoAtQCPAJAAkQBxAJUAWgCBAEIAJQDa/8H/gP8+/67+dP4G/nj9HP2E/Az8ePs4+/j60PqQ+rD6+PoY+xD7kPvY+3j7IPuw+nD6kPkI+Vj5cPlo+GD4UPk4+ij6wPqY/PT8UPy8/CX/lADmAEQC/AI0Au7/gP7+/+L+MPwA+xj74PkA9+D26PnQ+cj40Pmg+1D+8P1l/5QB6AK4AlACfAO0AhADcAKiAcYBHAEEAXoA3f/FAPIAYgHIAXQCkAM0AywDuANoBEgEmAOsAxgD4gFMATwBKgEWAQwBmAFwAfoB1AIYBCAFSAWYBrgH+AfQB/gHkAhACBAHCAbQBRgF0AM4AwwDgAK0AdQBUAK0AqwC+AIgBPAE2AT4BMgFIAZ4BQAF6AR4BLgDxAJcAhgCIgFwAFAAVQBQALf/mP+h/17/zv5o/nz+PP6s/dz8aPzw+2D7QPtg+2j7iPvY+wz80Px8/Wj+tP6G//T/dABWAEEABQDw/3r/1v6a/rz9RP24/OT8oPxo/GT88PxY/WT9zP2k/kH/i//X/2kAlgB8AH8AwgCjALMAmADCAMYAjwCDAIsAvgDxACIBPAEeAXIBqAHCAZYBkAHGAVoBJAHLALAAggAeAO3/xv96/5v/kv+y/8//6v9LAHwA5QDzADwBVgFiAS4BDgEgAfcAewD6//X/ef9E/9D+I//q/nD+Gv7k/cT9GP28/Kz8bPy4+zD7APsQ+5j6cPqY+sD60Pq4+qj6YPrY+dD5qPko+YD4WPiA+Cj44Pf4+Fj6iPoA+jD62Ps8/Nz8ev5WARACMQC/ACoBygHg/yD//v/8/QD7ePlo+mj6IPnQ+Oj5IPow+nj7wP1B/xUAWAE0AoACZALgA2gESAOAAsQCuAIwAYwAnAFwAmoB+AAIAogDSAM0A3gEWAU4BdAEUAUgBVAEvAM4AwADNAJ2AZ4BsgGOAa4BkAI8A6wDmAS4BXgG6AaABzAIUAgQCMAHeAfwBggGmAX4BBgEgAPwAsQChAJ8AsgCUAOIA9ADQASIBNAEOAUgBdAEKATkA5gDzAIcApgBKAF6AOr/n/+F/1v/Ff8T/xT/6P7A/ob+cv4o/qz9HP3A/Gj8MPzA+4j7ePuo+9D7FPxw/CD9jP30/Wz+Cv9t/4H/hP9//1//A/+O/kL+WP7U/TT92PwI/Qz99Pwk/Yj9+P1E/sD+rP9bAJkArgAMAYgBUAFmAYQBeAEqAa8AswDNAOEAsgCgAMsA8QAkATgBvAHQAdYBqgG8Ac4BtAFkAVwBIgHCAHsAgQBoACAAJAATAA8Az/8RAEkAiABLAIEAyADvALsA9QAkAfMA0wCCAGMAJgC//47/c//u/qL+pP56/tz9hP1o/fj8kPxI/DT8oPvw+vj6YPvA+mj6+PoI++j5KPnY+Qj62Pgw+Ej5aPng99D3gPm4+jD6qPkE/LT88PoY+0j+ygAHACj/7gEgAikAvf9gAOAB7v6Y/Ij88Pzg+3j6gPtI+3j7YPvw+wj+wv6m/48ABgH4ASwC5AJMAzADmANMAxgDTAOEA6gDNANYA8QDIASoBPgE0ATQBCgFyAVoBUAFQAUIBWAEzAK8AiQDzAL+AZQBRAJ8AlQC6AJwBIAFUAWgBfgG2AeoB/AHMAggCDAHYAYwBvgF8AT8A/wDjAPMApQC/AJkA2gDWAPoA4gEkASABMAE8ASwBPgDpANgA9QCzgEqAQoBmQC7/03/nf/Q/4X/Yv+f/7//qv+r/4b/Lv9k/uD9EP2A/Mj7cPvw+pj6WPqg+hD7QPvw+5j8bP3A/Yb+Rf+8/4X/g/+k/4P/4v5a/gT+aP2Y/BD8yPug+4D7qPvw+4T86Pyc/Yr+cv8iAI8A/QBeAW4BUgEeAQ4B4gBnAOf/tP/K/5z/fP+f//v/MQB+ANwAegGoAfABzgHAAZoBUgEEAagAPACl/yv/1v7m/tL+Ev9B/5X/2P8yAOcAXAHiAQwCPAIMAtoBtAFwATABrgDv/3D/Df+c/mz+Lv5Q/uj9sP2U/Zj9hP1o/SD96Px8/Cj8JPyw+zD7sPrY+tD6QPo4+pD6oPoY+tD5iPqQ+jD6oPlY+sj62Pl4+gj76PsQ+7D64PuI/AD9lP0Q/+D/j/+z/4sA6QDlAL4AwgDL//7+2P60/kT+bP3Y/fj9XP08/XT+BgBFAEwAgAHAAuAC9ALsAzgF0ARIBJAEKAUQBZAEIAVwBQgFeAR4BOgEsAR4BNgECAWQBCAEkAToBJAEIAQ4BEAEiAMEAzwDiAMkA/wCkAMQBBgEOARQBWAGaAaABugGWAcYB4gGyAbABjAGWAUgBegESATgA7ADvANIA+ACKANgAzgDLANgA6ADWAMsA0ADQAO8AuoBwAFOAaAAHABIABcAd/+K/+j/UQDg/8P/dQBYAJv/Ov+g/73/YP6s/fz9hP1w/KD7TPwI/Nj6cPo4+5j7UPto+9z8cP1M/Lj8qP2A/oT90Pzw/UD+1PwU/FD9EP6g/OD72Pwq/kz9XPzI/WP/3v4Q/rD+RAAWAMz+e/+lAJkANP/m/rj/j/8Q/hr+Fv8r/4j+jv6D/ysAjf/4/y4BZgHEAL4APgE2AawAjwDxAGAAVf81/6T/Yf8R/2H/BADF//L/ggBmAWIBagHqAaoBLgHTAN8AvQDb/zv/Df/2/kT+hP0U/iT+jP2A/fj9Yv4E/tT9Sv5m/gL+KP0M/aj8sPvA+mD6cPqA+SD5CPlI+bD5WPkg+lD7uPss/Mj8uP1o/gj+5P1M/lD+bP1g/Lj8mPz4+2j7kPv4+7j7wPuI/LD9KP5U/vT+tP8rAH4A2AAeAfIAegBgACAAAQDp/9L/BwC9/9D/oAC6AWwC0AKwA0gEeAT4BLAFWAaIBuAF0AWwBYgFEAWgBJAE2AM0A4wCmAIwA0wDOANgAygE8AQIBZAFiAbgBogGWAbgBhAHsAYYBvAFkAWoBCAE3AOsA2gD3ALUAhADKAMsA2wDuAN0A7wDoAOkA/gDtAOMA/ACjAL2AXoB8QA8ACoAq/8G/6T+mv4D/7T+fP4l/3H/q//b/yoAjQCmAEgAzv/q/5H/Lf+q/lb+TP6g/YD9ZP20/YT9KP3A/Rj+XP6E/ur+sP8t/xL/mP+4/z3/aP5g/lj+iP3M/Aj9SP20/Ej8lPz0/Bz9wPxI/ZT9cP00/WD9CP78/QD+pP3M/YT9XP14/QT98Pys/LT8gPxg/BT9iP18/Xz92P28/sz+qv4g/8L/tP9O/5P/BQAtAPX/z/80AGIAQAD6//r/LAC7/57/qv8QAB0Ayv++/5T/lP8s/wn/EP+W/mj+CP4Y/hj+YP6u/pz+1P5E/9z/QQByAEoBlAFeATYBZAHeAVYBjABSAAIAOf8s/hj+Kv5U/Vj8DPwc/Mj7aPtw+9j7wPtY+4j7HPxg/GT8bPzE/Kz8lPzg/Ez9XP2Y/bj9lP3o/ST+VP6E/nr+tv6O/qT+4v4B/+r+tv7G/sT+lv5q/rj+D//Q/p7+MP+K/7n/DQCiAGABaAGgARgCkALIAtQCXAOYA9gD3AMABEAEGAQYBAAE+APIA9QD2AOIA8QD+AMQBAAE1AP8AygE8AP4AxAEMAT4A5wDxAO0A9ADpAOwA9QDlAN4A4ADyAPsA+ADvAPkA+QDlAPkA+wD5APAA3gDgANMAygDIAP4ApACMAIYAvYBogH6AP4A1QA+AJ///f8XAH3/2v4e/3D/Lf/e/hz/rP9I/5j+8P5Y/0j/gv6I/rj+lP7w/Rj+QP7U/XT9kP2o/ej95P06/lj+gv4I/oz+YP40/kr+MP78/Zz9sP3k/eD9hP1s/Yj9HP0A/ej8CP3k/AT9FP0s/TD9oP3o/cT93P0q/lb+OP4o/pr+kP62/hr+nv4J/4D+oP7S/hP/eP5Q/pz+uv5i/jj+kv56/vj9Yv7C/qL+Wv5i/sL+aP7Q/Rj+rv5G/lT9xP0m/rD9OP1o/VD+Mv6k/Qj+Lf9j/7L+Vv8vAHYArf/N/6sAegDF/6//8P///zr/2P5E/1j/D/9L/wEATgBXAKYAVAEEAhwCWALAAvQCpAJoAqACjAJIAuQBhgGqATwBIAE+AUgBQgGUAX4B7gGUArgCiAKoAugC+AKkAhQCCALmASQBWAA2AH8A6P86/3b/yP+S/yz/rv9kAC0A//9FAAYBzQB7AMkA4gB/AP//EgC+/1r/Ov9g/0f/2v4e/9D/2/+o/3MASgEUAecAYAFgAjACXAGoARACZgFuAMsASgG+APn/TQAQAbMAVAD3APwB/AHkAZQCjANsAxwDhAPgA2QDYAJkAlgChgFyACsANQCI//7+8v4+/3j/P/+p/yYAbgCwAMgAGgFMAS4BXgEAAb8ApgDZ/0T/F//S/pb+8P1U/vD+FP9g/0sAIgGIAd4BaAIwAzwD4ALoAgQDrALEAXIBdAGjAN3/h/9m/yj/zv70/kz/IP9B/3j/EwD///z/VgAwAB4Aov9X/2D/nv4I/sD9jP1Q/ej8IP10/Uj9dP3A/eT9Gv7o/TL+Sv4E/rT9uP2k/RT9pPwo/DT8iPs4+5j7YPtg+/j6cPvA+4D7sPu4+6j7QPvw+ij7CPvo+qD6yPro+nj6kPoI+wj7IPtY+yz80PwQ/dj9mP49/5v/7P82AFMAjgCaAEkAUQBZAF0AvP+c/6f/t/+R/2f/SACGACUAZgAiASgCIAJ0AnwD/AMABPgD0ARoBQgFsATgBGAFEAXYBGgFuAWYBVgFgAW4BbgFsAXQBeAFiAVIBVgFIAXABLAEkAQoBIgDZAOIA0ADBAP8AhgDvAJYApwC1ALwAsQC3AIMA8QCkAKUAsAChALmAX4BUgHJAC0A7P/B/4//5v6a/oz+lv6G/pD+tP7K/tT+4v47/5T/1//V/9f/6P/6/w8AGQAaABcA+P/L/8P/+f8ZAC8APgAtAEgAYACjAMYA0ADKAJUAhwBwAGYATgAgANX/pf+d/3v/mf+x/53/iv+X/5P/mf+o/7z/sP+5/5r/pv/R/8D/vv/B/4r/dP+F/4T/lv9y/5b/fv8j/x//L/8f/9D+vP7Y/tL+nv50/uD+7v6W/n7+qP7c/qT+jP7s/jT/F//u/g3/Yf81/yL/Mv9G/0D/KP8X/13/fv+G/3b/sP/o/9//5v/p/xQA7P/C/57/pv+v/5z/af94/z7/N//+/gb/FP8a/wD/E//2/h//Lv8h/zH/MP9K/xH/KP9C/1D/Ov/6/ij/Qf86/0X/W/+d/3n/X/+a/63/tv+d/3f/lP+I/6D/kv+c/6L/fP9S/2b/nv+n/2//av+Q/5f/dv9y/8X/v/9W/0L/U/+o/37/O/+i/17/+v4n/1z/YP9a/3D/n/8g/zn/zf89AOr/cP8qAH8ACACL/14AMgEsALT/cgAmAc0Aw//HAGwBzgBBAJ8A8gGGAZIAFAG0AagBtwAYAd4BiAHkAOYAhgFoAc4AAAFeAWoB5wBQAbYBkAHOAawBLAIUAqIBIAJcAiAC6gEcAjgCuAGGAYAB0AFIARQBcgFkAVQBFAEmAYwBXgEkARoBYAFyASgBbgF2AUIB/QCSALgAswCzAL0AkACHAFwApQDhANcA3gDjANsAqADyABoBMAHWAIcAzACnADsAPwB0AFUAnP/c/n3/sP8Y/4b+1P5B/47+7P2e/k//tv4q/hT+e/8f/0r+fv7B/y3/Pv6C/gj/Ef9O/g7+OP46/jT+0P3o/Wb+FP64/cz9qP3c/VT9UPwo/Nj7YPuY+kj6YPrg+UD5mPjQ+Bj5ePgI+UD5gPnA+Uj64Pvw/KD9ZP6u/sT+Zv4A/2P/E//C/m7+sv5u/ij+1v4d/8r+rv40/xMAdADFALQBMAIUAsABkAIYAxgDuAJwArQCMALEAdgB/gHiAVQBbAHYASQCTAKcAjADQAMkA0QDyAPYA3wDZANMAwwDhAL+AQgCqAEOAdcAkACTAFsAQgBWAFkAcgBuAJgAnQC6AMUAngB6AE0AKADT/2P/Pf8U/9T+fP5U/lr+RP5C/lj+qv7a/t7+Bv9B/4H/l/+C/6D/wP+n/37/av90/2P/Lf8C//r+K/9D/yr/XP+c/8f/0/8OAFgAiwCdAKEA2gD1APoA8wD1AO8A3QDMAOgACAEGAQABHgEyAVQBcgGoAc4B0AHkARQCHAI4AjgCQAI4AgwCDAIMAhgC+AHeAeAB0gHGAcwB7AH2AfoB8AH+AQQCCAIMAhACCAL6AeQB5AHkAcoBvgGoAZABbgF8AWgBWAFSAS4BQAEiAfMA/AD4ANQApACFAKEAgABKAFoAVgBaABQAGgAzABkA9P/u/+H/8/+y/7v/1P+G/5P/S/96/1v/Gf8q/0X/L/8A/w7/Rf8f/+j+5P4b/w3/uP6i/uT+yP6Y/mL+kP6y/mT+Uv52/qr+hv5Q/mT+ov52/mT+fv64/qz+gv6M/sT+jv5m/oD+pP6M/nT+eP6k/qj+lv7G/vL+4v7Y/gX/Jf8O/wf/P/8p/zr/Gf9J/0j/Nv9E/zj/Uf9E/y3/Uf9r/1z/Tf+M/6//f/+V/7j/zf/T/83/5/8CAAMA+f8YAEYAMQA6ACkAPwBMADwATQA7AFUARQA3AF8AUwBqAHwAcwCgAL0AvgD3APwA4wAEARQBKAEIARgBKgEaARQBAgECAQQB6QDZAOUA9ADqAMwA2wDtAAgBAAH7ABQBFAEYAfAA9wAGAd8A4gDQALkAtgC9AL8ApgCtAKAAgACIAI0AmwCpAIYAjgCJAH4AawBYAFQAGgD8/9D/oP+M/4b/bv9O/0f/b/96/2j/gf+r/8D/yP/q/xsATABTAFwAXABrAFsAPwBEAEkANgAeACMAOAAnABcAMwAsAFkAQwBUAJ8AqQDDAMUA7wDgAOQA6gDWAAoBCgHgANMAzADnAM0ArQDoAO0A6QACAQYBGAEmAR4B+AD8AN4A6gDVALEAowCJAIAALQA9AC8A+//q/9P/3v/f/7//1f/F/73/uf+y/7H/hf9f/2D/TP8O/wT/+v7g/rb+lv6C/oT+RP40/hb+IP70/dj9+P0A/iL+4P0I/gr+FP4g/uz9EP4A/vT94P3U/QT+Dv7w/fT98P0m/iD+Dv40/lz+UP5U/nj+jP6s/r7+2P7g/u7+Dv8U/wv/Fv8W/zr/LP9b/4P/oP+o/5v/3v/Z//7/IAApAFcAOABeAFcAfQCUAHMAhwCQAKEArgCfAOQA6QDbAOIA5wAmARYB/AAEARgB/QDOAOMAEAH1ALYAxgDDALYArACWAMIAtgCdAJoAsQDUAL4AwQDWALUApACsANgArAC6AMwAhwCBAGsAfgCEAEcAXgBOAFkAXgBYAHYAWwBcAFUAUgBdAFgAbwBiADYARABBAEMARwBFAGcATgA0ADkAPwBIADwAYQBnAIMAdwCFAKgAnQCYAHsAiABzAHMAgQBWAFoAUQBDAEAAGAD6/wUA3v/J/63/sP+l/33/av9Q/1r/N/8e/xv/A//a/rr+tv6i/qL+bv5u/lr+HP4q/hz+EP74/cT9wP2g/ZD9fP1s/Uj9GP0E/fD88Pyo/Kj8qPyA/FT8fPyo/Jz8cPyU/LT8wPzI/Nj8JP0k/fz8GP1g/ZD9nP3A/fD9QP5C/pj+6P4k/2b/w/8iAJwABgF6AcwBSAJIAqwC1ALoAiADNANEAzADVAN0A4gDiAN8A6gDkAOQA6ADvAPEA9QD2AP0A9QD8AP4A+wD5AO8A8ADoAN4A3gDSAN0AxQDAAMgA+gC4ALAAswClAJcAkACLAIIAs4BlAFwAQgB0wCmAGIAHwDN/5j/W/8e/+b+/P7w/pj+kv6E/n7+YP4u/k7+WP40/vj9Iv4+/vT95P3U/fj9wP2k/cD91P3M/bz9yP0I/iD+Iv5G/nr+kv62/vb+Hf9C/1n/ef+g/8P/3f/x/xsACgAIAC0AOwBbAGwAcACPAJIAogDAANcAxQDrANMA4QD+AA4B/gD1APYA/AAOAfEA6gD3APYAxwCtAMoAzQCqAJwAoACdAHsAYwB6AGoASAAnADEAIAD7//L/9v/d/7//tv+Y/4X/bf9p/1X/MP8Z/x3/Gf/k/ur+Dv/u/tz+vv7k/v7+wP64/rr+uv6I/oT+qP6o/pD+fP6W/pL+hP6A/pz+tv6u/rD+6P7s/gD/A/8g/0L/Gf84/1b/bv9h/2X/iP+W/5n/pv+9/+L/5f/q/wEAEAArADgARgBkAGMAlQCiAJcAywC7ALYAxgC8AOUAwgDPAOcA5ADlAOgA7gDrANsAygDWANsAvQC3ALIAvQCpAIsAsACfAJMAiQByAIgAaABgAGgARABIACEAJwAZAPn/CgDg/+z/4f+0/9z/w/+8/7b/rv/K/7D/s//B/6f/rv+i/4//p/+T/6L/rP+v/6D/rv+//7b/u/+W/7//q/+j/9T/y//z/8//4f/+/+3/DQARAB8ALQATADAAQgBgAF8AZwCIAHsAdwCNAIYAjACJAJcAqQCpALQAxgDKAOAA4gDeAOgA6AAEAe4A8QD2AAIB6QDhAM8A1gDbAKoAxgDLALQArQCSALEArgCXAKAAlgCqAJYAhACiAJYAfABvAHcAewBpAFsAVgBKAEQALQAaACQADQAIAAUA+v/5//P/8f/a/8r/1f/Q/8T/wv/O/83/yP+8/8n/yv+7/73/qv+0/73/sf/A/7j/xf++/7//1P/N/8z/3P/Q/8v/zP/O/+n/7v/5//v/8/8KABYAFgAoACkAMwAxACkAQABEAFQATgBSAGIAYwBtAH4AfwCFAIAAgQCSAI8AogCbAJUAlACQAJAAhwCCAHsAawBdAFYATgBRAD8AMAAvABIAFAAOAPH/8f/x/+H/2f/F/8//z/+1/7r/r/+z/57/mv+b/5v/if+K/3b/h/+B/3n/jv9n/3X/WP9d/2j/UP9h/3L/cf9n/23/fP97/3L/bf9//3v/df9s/4j/l/+Z/5X/nP+w/8D/w//P/+3//f/7//H/EwAcABgAGAAlADcANgAmAEEAQgA6AEEATQBiAG8AbgCDAJgAlgCfAKkArQCxAK8ArwCpAK0AuwCjAKgAmQCUAIUAfAB+AHMAbgBoAFwAYgBiAFQATwBSAFIANwAtADEALQAhABEACQACAP7/9f/0//j/6f/o/9b/0v/R/87/zf+3/77/tf+s/7D/nf+d/5j/h/+Q/5X/kP+V/4z/fP+C/4n/kP+F/4v/mf+T/6D/pP+g/67/o/+q/6z/tP/I/8D/wP+7/8r/0f/I/9P/1P/a/8//zP/h/+P/8//1//f/AgAOABoAEwAoACcAFwAaABYAIwAoACMAKwAhAB8AGAATAB4ADQASAAwACQAGAAsAEgAJAAQACgAPAAcABQANABYAFgANAA8AGQAeAB8AEgAWABAA///5////AQD3//X//P/y/+n/6//u//X/5P/Y/+X/5v/q/+z/7P/h/93/1v/O/+D/6f/j/9X/1//l/+P/3P/y//X/9v/3//f/BgAMAAYA+v/5/+///P/+//n/+v/5//7/8f/6//3//f/9/wAACgAfACMAKgAoACYAIgAaABgAEQAIAAMABQD4//3/AQD///7/9f/t//r/8//2/+//+P/t/+X/9f/0/wgA9/8CAP7///8GAPr/BQD9/wcAAgD8/wwAEQAMAAYA9f8BAPr/6P/w//3/9//x//P/7v/3//T/9f/1/+7/9f/x//D/9P/u//f/6v/z//H/8v/z/+L/6//X/9r/4f/c/+r/4f/n/9v/3v/i/9T/3P/T/87/0f/I/9n/3v/f/9v/0v/W/9r/0//N/9f/2f/M/8f/1f/c/9f/3f/W/+D/4v/V/+X/6f/p/93/1//g/+D/3f/h/9T/yP/F/8n/u//C/8r/tf+y/6r/sf+3/6n/sv+y/7j/s/+5/8L/wf/G/7v/uv+6/7n/vP++/7X/sP+t/6r/rv+s/7D/tP+u/7D/sf+4/7f/v//A/8X/w//G/8j/yf/F/7v/w/++/8H/yP+//8r/y//R/9j/3v/Z/+X/5v/n//H/+f8CAAYABgD//wgACwANABQAFgAaABgAGwAfACkAIwAmACEAFAAbABsAHQAfABMAEAAKAA4ADQAPABAADAAKAAcAEQAFAAkABwAIAPv/AAAKAAYAAQD5//T/8f/t/+L/7P/s/97/3P/d/+L/4v/f/9v/5P/a/9j/2P/Y/9b/4P/h/+j/7P/1//v/DQD9/wkABQADAAsADQAWABUAFwAeACMAJAAiACoAKAAkAB4AJQApAC8ALQAvACkAKgApACkAMAAyADIAMwA3AD8AQQBVAE4AUABYAFgAWgBhAGYAXwBcAFUAWQBdAFYAUABSAEYAPwBBAD4ARQBEADwAQABCAEQATQBTAFIATgBIAEgARgA3ADUANgAyACIAIgAjABkAEAAIAA0ABgAEAAYACwANAAgAAwAKAA4ABwAAAP///f///wEA/f8EAAEA/f/8/wMA/v/9/wUA/v/7//////8EAAkABAAGAAYAAgAAAAAA9f/1/+3/7P/v/+3/7f/v/+7/8v/7//r//f8BAAkACgAJAA8AFwAWABYAGQAaABcADgATABQAEAAKAA4ADgAHAAoADgARABEAEQANAA4AEAARABQAFAASABQAFwARABUAHwAYABoAFAAUACUAHgAWABcAFQASAA8AFAAaABkAFgAYABgAGwAXABsAJAApACQAKgAvADQALwAsADEAJAAiACEAIQAcABYAFAAUABIADwANABEAEQANAA0ADAAQAA8ADAAMAAcACgALAP//CAABAPr/AQD7/wcABAAHABEAFwAeACIAJgAqACwAJwAnACkAJQAiABkAGgAaAA0AEQARABMAEwANABUAFQAXAB4AGwAiACAAIAAfAB4AIwAcACAAIgAVAB4AGwAaABkAFwAfAB4AHQAjAB8AIgAeABQAIAAZABsAIAAfABkAFgAYABUAEgAEAAgAAwD//wYAAQALAAEA/P/+//b/9//z/+7/8P/i/9//3f/e/9n/0v/W/9D/yf/H/73/vP+5/7f/uf+z/7L/s/+u/7X/sf+v/63/p/+u/6f/qP+n/6v/qP+q/6b/qv+y/63/uf+//8D/yv/F/9H/2f/W/9r/1//i/+P/3P/m/+X/4f/f/+H/6P/o/+j/5//r//L/7//v//n/+f///wQACAAPAA8AEwAPAAoADwANAAwADAAMAA0ADAAIAAoACAAFAAYA+v/9/wEA+v/8//f/+f/y/+z/7//m/9//3//V/9D/yf/E/8j/xf/F/8D/uv+//73/uv+8/7n/vP+5/7T/t/+3/7v/t/+5/7z/u/++/8L/wP/D/8L/wv/I/8b/z//O/87/0v/V/9r/2v/c/+H/4v/j/+f/6//x//L/9P/6//j//v8BAP7/BAAKAAoADgAJAA8AEwAMABIAEAASAA0ADQALAA0ACAAJAAEABgAIAAUAEAAIABEACgAQABgAFAAdACYAKAAmACkAKgApACQAIAAkABsAFwARABYAFgAVABUAEwATABgAGAAXABwAHQAaABEAFgASAA0ACQAIAAkACAD//wUABAD//wEAAwAHAAwACQAQABUAEgATABIAEQAPAAsABgABAAEABAD8//7/+v/6//b/+P/6//r//f8AAP//BQAHAAQABAAGAAYA/v/4//n/+P/y//D/7f/s/+v/6v/t//H/8P/z//L/8v/1//n/+v/4//7//v///wMA//8BAAIA/v8EAAYABAAIAAUA/v8AAAEAAQD7//3/AAD6//7//f/6//z/9//4//j/+P/8//v/+v/5//7/AAD9/wAA//8AAPz/+f/+//r//P/8//n/+v/7//v/9//8//j/8//x/+3/7//u/+3/7f/q/+f/4//g/+H/2//b/9r/2f/X/9n/3f/c/9//4v/l/+b/5//o/+3/7f/q/+n/6f/s/+3/5f/p/+j/5f/l/+v/8f/y//n/AAACAAQACAAQABYAFAASABkAGAAZABwAGQAWABUAEAAOABQAGAAYABQAFgAcABsAGQAiACMAJAAmACMAKQApACUAIwAiAB0AIgAiACAAIQAhACMAIQAjACIAIQAeAB8AHQAiACAAHQAZABUAEQALAAYAAgD8//r/+f/0//b/9f/z//T/8P/q//D/6//s/+n/6v/m/+H/5v/k/+r/4//n/+X/4//k/9//4v/e/+H/3//c/+L/5f/m/+b/4f/p/+n/4v/p/+//7f/u/+7/7f/w/+//8f/x/+7/8f/w//D/8v/x//X/8v/3//b/+P/5//T/+P/u//D/8v/t//L/7f/u/+b/5v/m/9//5P/f/9z/3v/Z/9//4P/g/+D/2//b/9z/2f/V/9r/2v/W/9P/2P/c/9n/3//b/+L/5P/d/+f/6f/r/+f/5P/r/+r/5//s/+f/4v/i/+b/4P/m/+z/5P/n/+X/6v/v/+v/8//1//v/+////wMAAwAIAAQABQAFAAQABgAHAAUAAwAEAAIABQADAAQABwAEAAUAAwAGAAQACAAHAAkACAAHAAcABwAFAAEABQABAAQABgAAAAYABQAHAAkACwAEAAsACgAIAA0ADgASABQAFQARABUAFgAXABoAGgAdABwAHQAeACIAIAAjACIAHAAiACMAJgArACcAKAAnACwAKgAsAC4ALgAtACsAMQAqAC4ALQAwACoALwA0ADMANAAyADEAMQAxACsAMQAwACgAKAAnACcAKAAlACIAKgAlACYAKQApACoAMwAzADoAOgA+AD8ASQA+AEQAPQA6ADsAOQA6ADcANgA3ADoAOAA4AD4APAA8ADcAOwA7AD4AOwA6ADUAMwAvACsALAAqACYAIwAiACIAHgAnAB8AHwAiAB4AHgAhACMAHgAeABcAGQAZABMADgAPAAUAAQABAP3////9//f/9//3//X/+P/5//n/+P/1//X/9//t/+//8P/w/+n/6v/r/+X/4v/f/+P/3//g/+D/5P/m/+X/4//o/+z/6v/p/+v/7P/w//P/8v/5//n/+f/7/////P/9/wIA/v/9/wAA/v8CAAUAAQADAAMAAQABAAMA/f////v//f8AAP3//f/+//3//v8CAP///v/+/wEA///8//3/AAD9//3///8AAP7/+v///wAA/v/8/////v/4//n/+P/3//b/8//u/+3/7f/r/+3/7f/s/+7/8P/u//L/+v/3//z/+f/7/wYAAgD//wAA/v/7//v//f8BAAEAAgAFAAYACgAIAAwAEgAXABUAGgAcACEAHgAfACQAHQAfAB8AIAAfABwAHQAeAB4AHQAdACAAIAAeAB4AHQAfAB4AGwAcABcAGgAZABEAGAARAAwAEQAKABAACgAKAA0ADQAPAA4ADQANAAwACAAIAAcAAwABAPr//P/7//H/9P/x//H/7v/o/+r/5//l/+b/4f/j/+D/3v/c/9z/3//a/9//4P/Y/+D/3P/c/9v/2v/f/97/3v/i/9//4v/g/9n/4v/d/9//5P/j/+H/4P/j/+H/4f/Z/97/2v/Y/93/2f/h/9v/2//e/9v/3v/d/9z/4P/Y/9j/2P/Z/9X/0//X/9L/0P/Q/8n/yv/J/8r/zP/K/8r/zP/K/9D/zv/P/83/yf/P/8n/yv/H/8n/xf/H/8L/xf/I/8P/zf/N/87/1P/Q/9j/3P/c/97/3f/l/+T/4f/o/+b/4//h/+L/5P/j/+L/3v/g/+P/3v/d/+L/3//h/+T/5f/o/+j/6//n/+X/6f/o/+j/6P/p/+r/6v/o/+r/6f/o/+n/4f/m/+n/5f/o/+b/6v/m/+b/6v/l/+X/6P/k/+P/4f/h/+f/5//q/+r/6P/v//D/8P/0//T/+P/4//b/+f/5//3/+//+/wAAAAAEAAcABgAJAAkACgAOAA0AFAATABMAFwAYABsAGQAbABwAGgAYABgAGAAaABcAFwAaABUAGQAZABQAGAAbABsAHQAZAB4AIAAbACAAHgAgABsAGwAYABoAFAAUAAsADgAOAAoAEAAIAA8ABwAMABAACwASABcAGgAYABwAHgAeAB0AHAAhABwAHAAYAB8AHwAgACAAHwAgACQAJQAkACcAKQAmACAAJAAgAB0AGgAZABoAGQASABcAEwAOAA8ADgAPAA8ACwAOABAADQAMAAwACgAJAAcABAABAAIABQD//wIA/v/+//n/+v/5//b/9v/1//P/9f/0//D/8P/x//L/7f/r/+7/7//s/+z/6//s/+z/7P/u//H/7v/w/+3/7P/t/+7/7f/r/+//7//w//T/8f/1//f/9v/+/wIAAwAJAAkABgALAA4ADwAMAA8AEwAQABQAEwASABQAEQATABMAEwAWABQAEwARABUAFQARABMAEQARAA0ACgANAAkACwAKAAgACgALAAwACgAPAA0ACgAKAAgACgAKAAoACwAKAAgABQADAAQA/v/+//v/+v/2//f/9//0//X/9v/4//f/9v/3//r/+v/4//f/+P/8//3/9//6//r/+P/3//v//v/9/wEABQAEAAQABgALAA0ACwAJAA8ADwAQABQAEgAQABEADwAPABUAGAAYABUAFwAbABgAFQAaABgAFwAXABIAFgAUABAADQALAAcACgAIAAYABgAGAAcABQAHAAUABQACAAMAAQAGAAMAAgAAAP3//P/4//b/8//w//D/8P/s/+//7v/t/+3/6v/m/+r/5f/l/+L/4f/d/9j/2//Y/93/1v/a/9r/2f/c/9n/3f/b/9//3//f/+X/6P/p/+r/5v/t/+3/5//t//D/7f/u/+7/7f/w//D/8v/z//H/9f/1//X/9//2//v/+f/+//7/AAACAP7/AgD7//7/AAD9/wEA/f8AAPv//f/+//r/AAD+//7/AQD//wcABwAJAAoACAAKAAsACQAGAAoACQAGAAUACQALAAoADwAMABMAFQARABoAHQAhACAAIAAoACkAKgAvAC0ALAAuADMALwA1ADkAMwA2ADQAOAA5ADQAOQA4ADsAOQA6ADsAOQA8ADgAOgA5ADoAOwA9ADwAOwA9ADwAPwA9AD8AQAA+AD4APAA+ADsAPQA7ADwAOgA4ADgANgAzAC8AMgAuAC8AMAAqAC8ALgAwADEAMgAsADIAMAAtADAALwAxADEAMAArAC0AKwArACsAKQArACkAKgAqAC0AKgAsACoAJQAqACkAKgArACUAJAAiACQAHwAeAB4AHAAaABcAGgATABUAEwAUAA0AEQATABEAEAAPAA4ADwAOAAsADwAPAAgACAAGAAYABAABAP3/AQD7//n/+P/1//P/9//1//n/9//7//v/BAD6/wIA/f/9/wAA//8BAP//AAACAAYABQAFAAsACAAKAAYACwAMAA4ADQAOAAsADQALAAoADAAKAAgABwAHAAgABAAMAAQABAAHAAIABAAFAAUAAAAAAPz//v/+//r/9v/5//P/8//1//L/9P/z/+7/7v/u/+3/7//w/+//7//s/+z/7f/l/+f/6f/p/+X/5//p/+X/5f/j/+f/4//l/+X/5//n/+b/4v/m/+f/4//h/+L/4f/l/+b/5P/q/+r/6//u//T/8//2//v/+P/6//3//f8BAAQAAgAFAAYABgAHAAgABAAIAAUACAALAAkACQAKAAoACwAPAAwACwALAA4ACwAJAAoACwAJAAkACQAJAAcAAwAHAAYABAABAAUABAD//wIAAgACAAIAAAD8//v//P/5//n/9//0//T/8v/u/+//8v/s/+7/6v/s//X/7//s/+z/6//p/+j/6f/q/+n/5//o/+f/6P/k/+X/6P/r/+j/6//t//D/7v/v//X/8f/0//b/+P/3//b/+P/5//r/+//8////AAAAAAEAAAACAAIAAQABAP7/BAAEAP7/BQAAAP7/AgD8/wMA/P/+/wEAAwAFAAUABgAHAAkABwAJAAoACAAIAAQACAAIAAIABgADAAQAAwAAAAMAAQABAAQA//8BAP///v/8//v//v/5//3//f/2//z/+P/2//T/8//2//X/9f/4//b/+v/4//T/+//3//v///8AAAAAAQAGAAcACQAEAAsACwAMABIADwAWABEAFAAZABgAHQAeACAAIwAgACUAJgArACsALQA0ADMANAA3ADIANQA1ADcAOQA4ADcAPAA5AD4AOwA9ADsAOQBCADoAPQA8AD8AOgA7ADMANgA2AC0ANQAwACsALAAmACoAKgAqACgAKgAwAC0AKwAwAC4AKwApAC0ALAAqACkAJQAoACgAIgAeACIAHgAeAB4AHQAcABoAGgAVABQAFwAXABMAEgAWABYAGAAWABcAFgAUABYADwATABUAEQAQAA4ADgAMAAwADAAKAAYABgACAP//+//7//7/+f/4//P/9P/0//T/8v/u//D/8P/y//D/7//w/+//7f/t/+7/7v/r/+3/6f/p/+f/5//p/+r/6//o/+r/6//w//H/8//z//X/+v/4//v//f/+//3///8CAAIABQAGAAYACAAKAAoACAAIAAoACgALAAoADAAPAA0ADgAOAA0ADAAKAAsADgAKAA4ACgAGAAQA//8AAPf/9v/1//L/8v/s//H/7P/t/+r/6f/q/+T/5P/k/+X/4//f/9v/2v/X/9j/1P/Q/9H/0//N/8z/zf/M/8n/zP/M/83/y//M/87/zv/R/8r/zP/Y/9L/1P/U/9j/3f/K/+P/1P/f/9f/3P/d/9f/4v/d/+j/3//l/+f/5//t/+3/7v/y/+//8v/8//X//P/8//b/AQD6//3/AgD0//3/9v/y/wAA8v/9//j/8v/5//P/9P/0//D/7v/y//H/8//w//n/8P/x/+7/4f/9//b/9f8BAP3/+P/6//7/+f/+//7/+//7//v///////v///8AAAYADAAKAA4AFAAYABUAGAAcACQAJgAoACkAKAArACQAJwArACAAIgAnACgAKAAiACUAJwApACgAIwAoACYAJQAlACEAIAAfABQAFwAaABMAEgAOAAkACgAGAAEAAwABAP7/+v/+//3//P/3//j//P/4//3/9//3//T/7P/q/+b/5v/k/+T/6//r/+f/5v/h/+X/5v/j/+3/6P/v/+7/7//1//L/9P/x//P/9v/7//r//P/5//f/+v/2//b//P/5//r/+v/2/wAA+v////v//P8DAAQABgAKAAoACQAQAPz/CQD///z/8v/1//D/4//i/9j/0P/G/7v/tf+i/67/l/+N/5H/iP+Q/4T/iv+F/4H/gP+C/4P/gP93/3f/df9w/2z/av9r/2b/YP9c/1b/V/9Q/07/Vv9S/1X/Xf9d/2f/Zv9u/3P/fv+A/4z/lv+Y/6X/pv+0/7z/xP/U/9P/4//k/+//AgAHABUAJwAuAEUAUABgAHsAjQCrALsA1gD8AAwBOAFeAXIBpAG8AeIBEAIcAjgCWAJcAogCjAKsAsQCxALgAsQCzALQAsACsAK8AqACtAKgAnQCkAJQAiwCEAIAAuYBzAHKAYYBbgE0AQIB7AC1AIoAQwAEANv/fv9F/+z+nv5a/gD+xP1w/ST97PyI/Ej8APy4+5D7YPsw+wj70Pq4+oj6cPpw+mD6aPpo+mj6gPqA+pD6sPrA+vD6IPtA+4j7uPsE/Ej8fPzY/CD9eP3U/TT+mv78/mb/w/8kAJMA/wBwAeoBSAKwAhgDcAPMAxgEgATABBAFcAWgBeAFEAYoBlAGaAaABqgGwAbQBtAGyAawBpgGcAZQBiAG4AWoBVAFCAWoBFAE4ANoA9wCfAIYAq4BWAHrAJIAMADe/5T/Qv8I/8j+eP5O/gz+0P2c/Uz9DP3E/Hz8WPwg/Pj74Puo+4j7UPs4+yD7EPsY+wD7IPsw+1j7mPvI+yD8TPyQ/OD8GP14/bz9EP5u/rz+Cf9O/5z/9/86AIMAvgAEAU4BmgHIAQgCOAJ4AqgCDANUA4wDvAMIBDAESASgBLgEAAUgBTgFWAVIBWgFUAUYBVAF8AToBLgEeAQoBMwDdAMAA6wCMALoAXgBBAGlACUAsP9c/wD/rv6W/g7+8P20/Uz9TP3k/LT8aPz4++D7cPtA+xj7oPqA+hj66Pm4+WD5UPn4+ND4uPiY+ND40PjY+Bj5mPjQ+Pj4+PgI+hD6mPoI+xj7ePu4+1D8iPwA/Uj9uP0c/pb+I/8u/1v/tP8MAJ4AOAGgARACaAKYAugCdAMQBKgEMAXABfgFcAboBiAHqAfAB+AHQAhwCNAI4AjACKAIUAgwCBAI6Af4B4gHQAfgBkgG8AWQBQgF0ARwBMgDaAP8AogCJAKaARoBngBLAAQArP9v/+z+gP4S/tj9rP1c/Sz9wPxM/ND7YPv4+qD6aPoQ+tD5oPk4+QD5wPhg+Fj4OPgo+GD4YPiw+LD40PgA+QD5ePnA+TD6wPog+3j72Psk/Ij8/PxA/bT9Gv50/tL+EP9b/7//0/9CAIoA6wCEAbQBHAKEAqQCBAOYA9gDuAQQBbgFIAbABiAHWAe4BwAIUAhwCNAI4AiwCMAIQAggCBAIwAe4B1AHCAdoBsAFUAXQBFAE1AM8A8wCZALIAV4B1wBJANT/Qv/8/qD+TP74/YD9TP3c/Mj80Pyk/IT8JPzA+0D7APuo+mD6EPqI+TD5yPh4+Dj44PfA91D3MPcQ9xD3QPdQ92D3gPeA98D3CPhw+PD4aPno+Tj60PpQ+9D7dPzc/Ez9xP0Y/rb+A/9W/5H/2/8mAJkA/gCWASACbALcAvACdAPEA0AEsARoBfAFuAaIB/AHoAigCLAIEAmgCUAKwApgCwAL8AqQCmAKgAogCiAKoAkgCQAJYAjwBzAHeAbIBRgFmAQYBLwDTANAAngBuAAAALn/Tv/4/mz+sP0k/aT8aPw0/PD7qPsY+8j6aPoY+sD5SPng+HD4MPjg99D3gPdg9xD3oPaA9mD2cPZw9oD2oPag9sD28PZA98D3IPig+Cj5mPkw+uD6ePsM/Jj8HP2o/T7+9v55/73/JABqALsASgG+AWQCxAI4A5AD0AMwBLAEUAWwBSgGwAZoBxAI8AhgCdAJMAoQCnAK8AqAC7AL0AuQC3ALAAsQC9AKUAoQCqAJEAnACCAIqAfwBugFiAWQBGgE9AOAA9ACFAI+AZcADQC2/2n/7P5E/qT9ZP3c/KD8LPz4+6D7KPvY+nD6+Pmo+UD5uPiQ+GD44PeA9yD38Pag9nD2MPYg9uD14PXg9fD1EPYQ9lD2oPbQ9kD3cPco+LD46PjQ+RD62Poo++D7TPyg/Dz9nP0E/qL+6P56/9n/TwDZABgBpgHgAXgCyAJkA7wDMASQBOAEeAUgBjAHsAdwCIAIMAlwCaAJEApQCpAKcAqQClAKUArwCYAJQAnACFAIEAhYB+AGUAaQBdAEKARkA7QCKAJ4AesA4v/V/1z/Dv8H/yz+zP1I/bz8pPxY/DT8BPzY+3D7KPvA+rj6qPpI+gD60Pmo+WD5IPm4+Hj4kPgw+Ej4IPjw9+D34PfA9+D3WPgw+Jj42Pgw+Xj5EPpo+uj6gPvA+5z8MP2k/SL+rv50/6v/cQDrAH4BHAJsAgwDkAMYBCgEiAT4BIAFOAaQBvgGAAcwB+AHoAgwCfAJYArACuAKsArwCvAK0ArACnAKkAowCvAJ0AkwCeAI4AeAB9gGcAZgBpgFAAUwBFgDdAK8ASYBeQDY/zb/nv4k/rT9GP2E/Mj7GPuI+jj66PlI+Qj5qPhQ+Bj48PfQ99D3gPdA9wD3oPaQ9gD2MPbw9aD1kPXA9aD1APbw9fD1EPZA9mD2YPbA9tD2QPdA99D3UPio+Lj58Pmw+kj7uPsg/HT8KP18/SD+2P5X/0MA1wCaAVAC0AKkAyAEqAQIBaAFCAZYBsgGkAdwCIAJcAoQC+ALQAzQDFANoA3ADYANcA0gDaAM8AtQC6AKAAoQCVAIoAf4BuAFSAU4BEQDOALcAL7/nv58/Yz88PtA+wD7mPrw+Wj5MPkg+WD5iPnw+eD58Pn4+Xj62Po4++D7RPys/OT8MP2c/ZT9fP10/Sj9eP2U/az9rP2A/QT9qPxs/Ej8oPxY/JT8tPzQ/AD9LP2A/Wz9vP0a/sD+Mv+h/w4ARQB2AOQAKgG0AeYBPAKEAowC3AL4AlQDhANcA8AD6APsA0gEUASwBOgEEAWYBegFeAbQBgAHGAcQB0AHUAd4B6AHkAeQB1AH+AaQBkAGsAUgBYgExAMUA0ACrAGzANb/DP8g/kz9VPyw+yD7cPq4+Rj5UPjg95D3QPdA9wD34PbA9rD20Pbw9jD3kPfg90D4qPgI+Tj5ePmo+ej5GPog+nj62Pro+sj64PqY+mj6qPpw+rD6qPpw+pj6sPro+gj7IPtA+4j7yPtw/Pj8fP0U/o7+/v6g/zYA+ADOAUwCNAOsA4AEcAUoBtAGeAfoB6AIEAngCbAKMAvQC0AMEA2QDSAOgA6gDrAOYA5QDiAOsA1gDXAMoAvgCnAJQAhoBwgGQAUABLQCigH7/5z+bP1g/Ij7mPoA+pj58Pi4+FD4CPgg+Dj4gPhI+bD5aPrg+nD7EPyg/ID9/P3O/kv/gP8JABYAEQAyAAUA3//D/3f/c/8G/2b+CP4o/cT8jPxI/GT8QPwY/AD88PsE/Az8HPxI/HD81PxI/cz9cv6c/g//af+j/yUAqgAcAWQB+AEIAmgC0AIUA3ADtAPkAyAEgAQABXAFuAUYBmgGqAYwB5gH+AdQCGAIcAhwCHAIYAggCMgHaAfIBjAGsAXoBCAEOAMUAiIBPQAz/1T+MP1I/FD7QPqo+SD5iPjg94D38PbQ9vD28PYg9zD3IPdg98D3QPiw+AD5cPnI+Tj62Pow+4D7ePtY+3j7ePug+5D7cPtg+xD7wPqQ+lD6APrQ+bj52Pmo+cD5EPoQ+ij6QPpg+qj6WPvw+4z8VP3Y/Uj+9P67/z8A1gCcAQgCyALAA3AEIAX4BVAG6AYgB7gHgAjQCKAJAApwCgALgAsADIAMMA2QDcANIA5ADkAOIA7ADVANkAwADFALgArQCaAIwAdYBggF3AOYAlgBIAAm/+j9CP0o/Hj74Pog+uD5cPlg+ZD5sPno+Qj6WPqY+jD7wPtk/Mj8QP2c/dD9KP5a/pD+ev5Y/jb+8P24/YD9FP2Q/Aj8WPvo+pj6OPrw+XD5UPlQ+Vj5mPmw+bj5qPm4+QD6kPpo+9D7WPzQ/Bj9wP1o/sz+V/+F/8r/SQDKAF4B8gEwAnwCwALkAmwD5ANoBOgEIAWYBUAG6AZoB/AHYAigCAAJQAngCeAJ0AlwCQAJgAgQCMAHIAdYBnAFYARUA1gCGgE0AOb+8P0Q/ST8YPuY+sD5+Pho+BD4KPgA+Fj4ePho+ID4kPjA+Aj5YPm4+Tj6mPoI+1D7aPtY+1D7QPtI+yD7GPvo+qj6gPrY+bD5UPnA+Nj4gPhY+CD44Pco+Cj4iPjg+BD5aPnA+RD64Pp4+xj84PxA/Ur+6v6d/7AA4QBEAfwBSAIMA/QDkARoBbgFKAZ4BsgGeAf4B6AIEAlgCUAKEAvQC4AM8AxwDaANQA7gDhAPYA/wDkAOwA0QDXAMwAsACwAK4AiIB1AG2AREAxQCowB1/3r+hP2w/Lj7EPsY+oD5gPmA+cD5MPpI+mD6iPrI+iD7wPtE/LT8UP3Y/R7+Xv5I/jL+8P3w/cD9oP2o/Tj9+PxI/ND7OPuw+oD6IPro+YD5YPkw+Uj5UPmA+dj52Pko+lj6yPow+7D7MPx4/Nj8dP30/YL+Lf9M/3n/7/8HAOoAIAHuAXwCjAI0A3AD+AOIBBgFOAW4BXAG6AbQB4AIAAlwCZAJ4AlQCnAKoApQCgAKkAnwCHAI2AfgBiAGCAXoAwgDPAIEAer/mv6Q/XT8yPtI+6j6APpo+fD4mPiY+Lj4wPjo+ND4CPkY+Uj5oPnw+cD5aPrQ+gD7ePuA+4j7SPsI+zj7IPtA+1D7IPug+mj6GPrg+eD54Pmw+Zj5oPmI+cD52PkI+gD6MPq4+sD6YPtA/Jz89PyA/Qr+IP4C/4j/GwDpAFIBGAKAAmADpAMIBMgEeAUIBrAGUAcwCMAIoAhwCfAJQAqAC5AMYA0ADlAOoA5ADzAPoA+AD8AO8A5ADsANUA0QDAALYAlgCEgHWAZIBcwDUAJ9AJ7/Sv5w/az84Pso+3D6UPro+RD68PnQ+ej5IPpw+sj6QPuA+9D7yPs8/AD9GP2Y/ZT9bP3o/Mz8yPx8/ID8FPzo+2j7GPuw+jD64Pko+eD44Pi4+Oj4+Pjg+Pj4APnQ+FD5WPkA+oj6kPp4+3D7GPxs/LD8UP04/cz9fv6s/mr/c//a/yYAigAmAfABVAI0A7QDCATABNAEaAUABtAGyAcgCPAIgAmQCRAKYArQCSAK0AmACaAJoAgwCPgGyAUIBfwDcAOYAm4BgwAe/yD+OP08/LD7APtg+hD66PnA+cj5iPmA+Wj5cPng+Rj6uPrY+uj6MPsw+4j70Psk/ET8PPxI/ED8aPwg/ED80Pu4+zj7KPsw+9j66Pow+hj60Pmo+eD5yPkg+gj6MPqQ+oj6APto++D7dPz8/HT9NP6C/oD/+v84ABIBcgFAAvwCWAMQBIAE0ASIBQAGwAZgB6AHYAjwCAAJ0AlgCgALEAygDJANYA7QDmAPgA/AD8APcA+wD/APoA/ADpANAAzACtAJwAjgB4AGOAXQAzwCEAFj/yr+yPxg+xj7WPpY+jD6qPmY+Rj52Pg4+YD5KPq4+vj6SPtY+8D7QPyE/Oz83Pzs/AT98Pz0/OD8YPwY/Jj7QPsg++j6oPpA+qD5YPkY+ej48Pjo+PD4CPkg+Uj5WPlw+bj5APpo+qj6KPt4+9D7PPyI/KT86Pwk/XT95P1e/pr+3v43/6//JgCXAEYBxAFEArQCUAP4A1gEMAXIBVAGIAegBxAIkAgQCdAIwAjACOAIgAigCDAIIAdQBmAFSARwA5gC/AHhABMATP9s/kz9YPyw+7j6YPow+gj60PnY+Yj5aPkw+Tj5aPnA+UD6YPqo+sD6uPoA+wD7SPto+1j7qPvY+9D72PvI+2D7ePs4+yj7OPsI+wD7wPqY+oD6GPog+jj6YPpY+nD6gPrI+tj6KPto+6D7KPyQ/Gj9Bv6G/jX/nf8xAM0AOgEcAoQCeAMgBJgEWAXoBVAGyAZIB6AHMAiwCCAJ4AlQChALkAsADPAMUA3QDYAOoA7wDjAPAA9AD8AOcA4ADjANsAwgC4AJoAgIB7AGeAVIBBwDJAHH/0T+dP04/Ij7iPoo+hD6qPnw+Qj5WPkQ+SD5OPog+lD7WPug+9D7wPv4+zD8sPzc/CT9CP3w/Jz8RPwc/Jj7UPvQ+qj6ePpI+iD66Plo+fD42PjI+GD5UPmQ+bj5kPn4+TD6UPqw+jD7IPu4+0T8XPyw/PD8QP0c/XT9bP2w/YT+xP4//1L/mf/y/0EAAgG6ATQCeAIEA8wDeAQoBdgFYAbYBlAHmAcACHAIgAhwCDAIEAioB2gHEAd4BtAFkASQA6QCCAKOAe8AOwBX/6r+5P1s/QT9ePwc/ND7uPug+8D7mPt4+1D7KPtI+1j7mPuo++j72PvY+6j7ePuo+7j78Ps0/Bz8OPwc/CD8OPzw++j7sPvI+9D70Pu4+4D7UPsg+/D68PoA++D66Pro+gD7GPsI+5D7oPss/Ij8BP24/TL+zP5l/wEAwAAgAdIBsAIsA/gDeAQIBYAFCAZ4BvAGeAdwB+AHIAigCCAJkAlwCrAKUAsgDHAMQA2wDeANcA6QDsAOYA8QDzAPwA4wDTAMsArQCZAIEAg4B3AFUASoAloBFQDc/nz9aPyY+xD76PqI+lD6yPmY+cj50Pmw+kD7qPsE/AT8KPwo/Ij80PwM/SD9LP1c/UD9PP30/Fz8yPsw+yD7EPv4+sj6MPrg+Yj5WPlo+Yj5iPlo+Yj5iPnI+Qj6SPqY+qD6yPrg+kD7kPvA+wD80PsE/Pj7PPyg/MT8JP0I/Tz9hP3U/Yr+Fv+j/xEAhAACAZQBPAIEA5wDOATYBFAF0AVABrAGuAbABrAGkAaYBngGSAYYBqgF+AQoBHgD+AJcAtoBfgHhAEUA+f+r/0v/+v6o/nj+WP5O/kj+Kv78/eT9wP2s/Zj9cP1s/Vj9WP0k/eT8tPyI/Jz8hPyI/JD8jPyw/Oj8EP0E/ez8HP0o/UD9aP1E/Rj97PzU/OT8uPxs/Cz80Pug+3D7UPtI+0j7cPuA+7j7HPxg/Pz8kP0g/rz+MP8EAKsApgFYAtwCoAP4A3gEIAWIBUgGeAbIBiAHYAeYB4gH0AdQCPAIgAkwChALwAsgDNAMcA0gDjAOsA5gEGAQYBCgEFAPsA6QDWAMsAtgCoAIMAcIBtAEYAPKAacA7P6Q/aT8wPuY+/j6iPqI+tD54PnQ+Tj64Pog+1j7EPtg+4D7cPvA++D7kPuA+1j7aPuA+yj7+PrY+nj6KPoI+hj6GPoY+vD54Pmw+aD5yPkI+jD6SPog+vj5EPrg+QD64Pmw+bj5qPnQ+fD5CPoQ+gD6MPpQ+oj6wPoo+3j76Ps8/Jz8AP1k/QD+hv48/7P/LQCMAPwAXAHEAVACmAIAA1gDnAPoAygESARYBFAEMAQwBAgEEATkA6gDZAPQAnQC0gGeAUIBwgA7AOT/qP+L/3b/I//I/n7+WP5y/rj+kv58/l7+UP5q/m7+cv42/vT9xP2o/aD9eP1Q/ST9OP3w/AT9zPwI/Xj9aP2g/Yj9hP2I/cT9Gv4q/gz+zP3U/bD9rP1w/RT9/Pxw/Cj86PvQ+7j7wPvY++j7EPxE/Nz8WP3s/aL+L//c/58AnAEcAuACaAP4A5AEKAVYBdAFSAZYBsgG6AZAB+AGWAeoBxAI0AjQCOAJYApwC0AMMA2gDbAN4A5AD2AQgBAAEaAQgA/ADqANUAzQCqAJQAi4BhAF5AOUAlABTwAM/5T9dPzw+5D7wPuQ+2j7GPvY+jD7OPuY+6j7kPtY+yj7GPvA+pD6aPpQ+hD66Pm4+bD50Pn4+Sj6CPr4+fj5QPrI+hD7aPtA+wD74Prg+vj68PrI+mj6APqQ+Tj5APng+Mj4qPiA+Hj4oPjo+FD54PlA+pj68PqI+0T87Pxs/dT9Dv5O/oz+Cf96/wMAPgB2AKgApgDOACgBegHsASwCrAIAA3AD/ANYBLgEsAToBOAECAUYBQAFyARoBOADVAOoAhgCuAE0AbUASACn/xD/F/9V/3L/Uf/+/vb+1v7c/j//bf8Y/zP/ZP85/0j/Av/y/ub+bP4w/gT+7P2M/fT9Cv7w/dj9VP2Y/dD9AP5k/kT+Tv5Q/lL+eP5Y/lL+JP70/bD9gP1A/fD8tPxs/CT8sPuw+7D76Ptg/LT8FP1o/Zz9Sv7w/o3/QQDqAJgBSALsAlADuANABEAEuAQYBUAFwAW4BTgGeAa4BsgGMAegByAIAAnQCeAKoAtgDEANEA5ADtAOIA+wD6AQwBAgESAQAA8wDTAMUAvgCaAI6AbQBRgE0AKYAqwBnwC6/wr/JP58/YD9ZP14/cj8XPzg+1D7MPs4+yD7iPrw+UD5KPnQ+ND48Pj4+AD5OPnQ+Sj6kPr4+rD7+Ps4/Hj8uPy0/Jj8sPw0/Kj7qPpY+uD5OPnY+Dj4CPhg91D3kPeg9xj4SPgQ+Uj5iPkQ+nD6GPto+yD8dPyc/MT80Pwo/RD9GP0M/UT9VP2U/WT+zv4Y/4j/SADyAF4BHALwAuQDSASYBPAEAAVABUgFyAVwBQAFmARgBGAEEATcA2gDCAOgAlACNAL8AfIB8gHuAdoBwgG0AZYBsAG2AXwBKAGaACMA9P+G/2b/Kv/W/qT+iv7C/tz+3v4R/yD/KP9x/+L/SACvAK4AuwCkAI8ALwDc/5z/N//4/mz+XP4m/rD9dP1E/Vj9TP0w/TD9WP1o/SD9mP2w/ZD9bP3Q/dD9Kv7M/Qr+vv5Q/pz+0P72/nD/7/+jAFIBvAEMAtQCgAPUA0gEwARoBagF+AUoBngGYAawBkgHiAe4BxAIoAjwCMAJcApACwAMgAzADAANkA2wDaAOwA7wDvANsAygC3AJAAmgB1AGYAXAA4QCgAEGAXgA//+w/2b+zP1k/cD8AP3Y/ED8gPuI+gj6SPno+MD4cPgY+ED3cPeA95D3UPjw+Oj5OPrA+qD78Pts/Aj9CP30/Ej8yPuA+7j6MPqA+eD4GPhg9xD38PYA91D3sPdA+Gj46PiI+Qj6iPrA+jD76Pqo+pD6mPqg+pD6wPrY+pj6oPoA+7D7PPzU/MT9dP7W/qH/YwA8AcAB8gFkAmwCbALAAvwCQAMQAyADUAOAA8gDSATIBOAE+AQQBSgFMAUIBfAE0ARYBOwDdAPEAkgC2AGwAaYBegFyAYYBmgHKAeYBDAJoAlAC8gG4AYQBYAEIAQoB8QCiAEAA4/9MAAgATQCyAO8AOAEWAXQB2AHiAQgCrgGsAToBxQCJAPj/3P8l/+b+pv5g/lj+PP5q/kz+XP4y/k7+Vv5w/r7+2v7M/sL+1v6+/tL+6v74/gr/IP9B/2b/kP8lANIAcAHuAWACEAOAAxgEuAQoBWAFYAWgBbAFwAXwBSAGaAZ4BtAGOAe4B0AIEAkQCuAKsAtQDAANIA1gDZANgA0gDRAN4AzAC4AKsAjYBoAFaATQA/ACUAKcARQBygASALP/0v70/Qz9DPxo+0D6qPkY+RD4QPeA9sD1YPWg9UD20PZg98D3IPi4+Fj5CPqw+ij7UPtQ+zj7uPpg+uj5yPmI+SD54PiI+Fj4oPio+Oj40PiY+LD4KPlo+aD5kPmI+Xj5WPk4+Tj5CPko+WD5cPnI+ej5EPqY+hj7wPs4/Kj8BP0k/Yz9Av5E/u7+5v46/7P/+P9gAO8AtgHOASwCsAL8AogDmAMgBHAEqASYBIAE8ARwBHAEQAQwBOQDlAOAAyQDyAKMAnQCcAIgAggCFALaAeYBEAIoAjwC/AHQAcwBrAFIAWwBYAEcAfgA/wAEAU4BbAGmAcwBsgGOAb4BsgHMAbABFALqAU4BKgEQAa4AhgCcAFkAUQArAAYAMgAQAND/kP+w/y7/5v7G/rr+VP7c/cz9mP1s/YD9/P1s/p7+JP9L/3v/ev9F/1X/O/83/zf/uP/S/zcAgADfAEgB2AG0AiQDrANoBKgEEAVABaAFeAWgBfgFCAZoBnAGqAYgB0AI4AjwCRAL4AtgDKAMkAyQDHAMEAwgDEALcAnABygGMAUgBKgDHANIArQBLAFMAdYApADF/0b+PP14+4D6KPlA+FD3kPYA9pD1gPUw9fD1YPZg91D4uPhg+XD50PnQ+SD6EPrA+XD5SPlQ+Sj5UPnI+fD5KPpA+tj6APtA+3j7kPvg+iD6uPkw+QD5yPgA+fD42PjI+Aj5gPmA+dj5KPpo+qj6uPrA+tD6OPtA+2D7aPtI+6D74Puw/GT9xP0k/n7+Rf/C/zAATAGiATgCfALUAiQDJANMA9QDKAQYBBAEWASABJgEaASwBKgEUARQBDgEIAR8A1wDVAPkAkgC+gGoAVIBmAG6ATgCOAIoAkgCYAKQAkAClAIoAkAC0gF8AcQBdgGmAaIBLAJEAnQCpALkAkwD8AIIA6gCsAL0AZYBxAE8AUYByAA2AS4BpQC7AH0AqgDb/xIAvf+X/wr/mP6u/jj+BP60/RD+4P3g/T7+jP68/qr+zP5V/1P/3v4A/yr/Av9Y/3f/OABYAOoAsAE0ArgCmAIAA4ADSAOgAxAEiAT4BEAFGAZoBigGKAa4BkAH6AdACYAKgAuQCzALAAvgCWAJYAlwCVAJIAiAByAHeAbwBYgFyATIAyADSAKgAbYAZv9m/iD9uPtQ+mj54Pi4+LD4GPjA9+D2APbg9fD14PUQ9vD1UPag9sD2IPdw99D3GPhI+ND4GPlY+bD5GPpI+gD64PlA+nj6qPr4+kD7GPuo+jD6CPoA+qD5uPkI+vD5+PnI+QD6GPrg+dj5CPoI+tD56PkQ+kD6OPow+lj6ePpY+sj6YPsY/HD8zPwo/Xj9oP30/bz+cf/a/14ANAG0AeYBPAKsAlQDnAP8A4AE0ATQBJgEsAT4BNAEOARQBHAEsAPQA5AEYAQABHgDZAPMAoQC/gFsAgwCrAHWAdoBEAIAAgQCKAI4AnABJAEmAQIB0wBCAYoB5AHSAQACrAIAAwgDIAP4AowCTAIwAiACPAIUAhgCcAJgAlACHAIYAsoBdAEQAcEARAD9//f/9f+j/2P/SP83/wn/Dv+u/nr+KP44/lD+Yv50/lz+lv6G/p7+lP4l/2v/6v+FAKcANgFYAaQBEAI4AmwCxAJQA+ADgAT4BIAFwAXYBRgGkAYABxAIIAlQCgAL0AqACgAKwAkwCtAKUAvgCuAIgAj4BiAHsAZwBhAH4AXgBVgEZAPOAaD/WP70/LT8yPuw+zD74Poo+rD4MPhQ9qD1APUw9VD1UPVQ9XD10PWQ9bD14PUg9mD28PbA91D4UPhA+Hj4mPi4+Dj56PlI+pj6GPtY+8j7OPv4+hD7uPqg+tj6APsg+5j7kPvI+7j7CPvA+uj62Pp4+nD6OPog+lj6iPq4+qD6sPrw+vD6APtg+5j76Ptc/Nz8MP2M/Qr+uv5t/+X/GgB8AFYBCAKsAkwDAARQBJAEKAWIBcgF8AUoBlgGUAaABkgGSAZwBogGiAZQBggGqAWYBWAFGAWgBCgEyAO0A7gDnANgA+gCjAIYAtwBwgGeATgBDAHzAOsAyADVAMYAFAE8AUgBkAFmAWwBgAHiAdgB1gGKAYYBxgG+AcABvgGsAYABYgFkATgBDgF/AKwAdQBKAAwAAwDD/7n/V/8C/77+gP4W/uj9SP4c/lD+8P0U/hL+2P0Y/hz+ZP46/o7+KP/P/0wAkgAqATIBMgHUARwCEANgA5ADUAQABcAFwAcQCQAKcAowCVAJ0AiACfAJkAvADFAMsAxADKALgAqACUAJIAkACXAJYAkACPgFSARMA6ACdgEMAY4AZv+M/ZT8aPsY+tj4APiw9/D2gPaA9kD24PTg8wDzYPNw87DzMPSg9KD0EPSg9ND0MPUg9cD1oPag9iD3oPdg+Kj48PiA+RD6KPoY+pj6KPso+1D7yPuQ/Oz8GP08/Rz92Pys/Oj8SP08/Vz9kP2g/aD9ZP1c/YD9KP1U/Yz9wP0K/vD9Fv4c/mr+Yv6c/tL+9P5q/7L/EgCKAA4BWgG+ARwCWAKoAuACcAPcAzAEoAQoBTgFQAWoBdgF6AX4BRgGSAaQBrgGsAa4BmAGQAY4BkgGSAYQBsgF0AXABYgFKAW4BIgEWAQgBOgDgAMYA9AC2ALMAmQCGALSAZwBfAFmAXwBIgH/ANIA4gDnAJ8AdgAYABcA0//j/5j/aP9q/3P/bf9a/1b/I/8x/+7+8P7M/oL+hv6A/mb+ev4+/or+Uv4i/lb+Ov5y/jT+Fv6U/sL+gP66/h//5v7E/gP/hv8fAC8APQDQAVQBSQDnAJkA7AGAAkQDKAS4BCgEuAQwBfgE6ARABVAGwAY4B3gHAAiQB0gHsAY4BwgHAAfwBsgGiAboBXgFuARYBLQD+AKoAsABswAuAFL/wP4c/iz9tPxo/Fj7uPoI+lD5uPgo+ND3oPcw96D2cPbw9ZD1QPVA9TD1IPUQ9SD1cPVg9XD1oPXA9fD1IPaw9vD2UPeA99D3IPio+Aj5oPkQ+mj6sPoI+6D7DPxc/Lj8JP1w/ez9Pv6u/gD/DP9Q/4//u//5/zMAhQCRAI0AygAsATYBPgE+AWQBvgHGAeYBCAJMAngCaAJ4AsAC8AIAAxQDAAMIA2QDiAOoA6QDZAOUA9QD7AMABBgEIAQ4BDgEQARYBHgEYARgBEgEcAQoBEAEOARIBHgEQARQBDAEGATwA9wD4AO8A6ADhAOoA3gDOAP0AsQCsAJwAkwCPAL8AbYBjAFgARwB9gDZALUAawAcAC4A7f+8/27/hv8X/+T+9P7y/sL+fv5Y/oL+nv4U/hj+Qv6M/ij+Jv5U/gb+TP7Y/V7+Ov4+/lL+Ov40/uj9aP50/pz+gP7S/iz/If8G/wX/D/9A/2T/aP/R/87/MABFAGsAfgC4ANsAMgFcAXQBxAH2ARgCTAJsAqgC3AL8AhgDMANgA2wDXANYA2ADhAOIA3QDZANYAyADGAP0ArgCfAJEAiQC3gG4AXABJgHaAKkAVgAYAL//cf8h/87+hv4s/tj9cP0o/dT8iPw0/Oj7wPuI+0D7GPsA+8j6iPpo+mj6UPog+gj6KPow+hD6EPog+jD6OPpw+oD6sPq4+gD7IPtA+1j7qPvA+wz8KPxY/LD8yPwk/Rz9dP2c/ej9+P1Y/oT+vv4B/zP/h/+D/7j/4P8QABoAVACmAL8A0ADNAPQAHAFCAVQBegFwAcYB5AH0AQACFAJUAmgCaAKMArAC/ALwAhADMAMwA0wDRANwA5ADmAPQA8AD4APoAwAEOARABGgEaARwBHgEeASIBIAEkARwBGgEWARgBFgEQAQoBPwDAATIA6gDlANoA2gDLAP4AswClAJ0AkQCJALsAbQBcAF0AQgBBgHHAH4AhgAwAAoAAQCz/3H/U/80//b+3P6s/pT+dv4a/hb+BP7s/dT9vP3M/az9lP2M/Zz9dP2M/Vj9dP2E/Wj9rP2I/bz9pP3A/eD91P0A/h7+Gv5U/kj+nv6e/qb+rv6+/uj+Av8f/zj/nv+J//D/9P/7/1cAZgCXAIwA2gD1ABwBMgE8AYIBhgGUAcIByAH2AdoB8AEEAggCBAIEAv4B6gHuAbQBqgGOAWQBTAH8ABQB0QCBAEsAaAAuANn/if++/3b/HP/g/uj+yP50/lj+PP4+/tT98P2c/dj9OP2Q/YD9YP1I/Sz9bP04/VT9MP10/XT9UP2A/Zj9fP2k/Zj9qP3s/cT9EP4c/gL+Nv5e/mL+Zv5g/or+vv6K/sD+0v72/uD+vv7w/jr/WP8V/zL/eP+W/47/lf+9/9//+//A/wgA/P9OACYAeACxAGgAqQCmANIA1gAYAQgBXgEyAWABugG6AXwByAHqAQQCMAJEAlwCVAJgAlQCwAKUAmgCxALoAuQCsALkAuACDAPQAnwC2AIIA/AC3AK0AugCwAKcAoQCfAKYAkACfAI0AlQCDALmARQC8AG4AZIB0AG+AagBTgE2AWYBUAH8AMMA2ADfAKsAXgBrAFAATgAHAB0A9//r/6X/nf/M/2X/lP9c/4z/cP9C/1X/Rf8l/wX/F//o/iP/1P4D/97+vv7u/sL+xP60/sb+oP72/p7+yP7O/sz+vv6+/sz+2v7i/sr+zv7e/iD/1P4U/yD/GP9D/0f/X/95/33/W/+y/1v/r/9t/5z/fv/h/67/pP+8/8n/uP+//6j/w/+Y/8D/lf99/3D/Wv9p/0L/ef8f/yz/Hv8F/w//+v7w/vb+E/++/tz+8P74/sT+0P6+/tz+2v6o/sz+2v7g/tT+4v7q/gH/8P72/iD/L/8t/zf/Uf9V/1z/Rv9g/3v/ef+P/2r/tP+Y/5j/l/+v/7L/rP+y/8P/6//Q/8H/7P/w/+H/0f8CAOv/EQAVAA8AMgABABwANwAvAOb/SgAiAHsAJAA4AIUAcQCKABwAmAB3AKUALgDbALwAtQCgAJAAAAGRAJYAxQD3ALcAgAACAdoACgGXAKQA+QDbAMoA7wC0AAwBvADTAKwA7QDnANkA4QDFAAIB+ADVAAQB7gD9AOsA8gAgAQwB6QD5AMcABgHZAOgA1wD3ANoA8ADZAJEAqwB/ANQAyQB5AG4AYACYAJUAYgBhAEsAVQA5AAcA+//t/yEA5v/S/6n/pv+H/6v/Zf97/0z/Pf9V/0L/TP8V/0r/Hv8d/wD/Af88//z+Gf8A/yn/F/8g//b+Gf8O/yD/Sf82/1L/YP9q/5j/d/+F/4j/mP+1/7z/0f/F/97/5v/W//P/0v/+//L/7P8KAPP/HgDp/wYAAQD5//X/xf/+/7r/7v/Y//D/6//R/+P/3f/s/8f/6P/Z/wsA4f/j/9H/4P/O//v/3/83ANn/3P/Y/wEAHADT/+//3v8fAMz/4/8BAEcAif/g//f/WADy/2//RAATAPD/Mf83AHsAp/+R/+H/OwCh/77/LwDH/3b/yv9gAN7/Mv+u/38AVwC8/sH/ggBlADT/pP84AKgAuP/Y/xEAsgD9/93/AwB5AGMA3/8+AIMAcQAUABEA3QCWAB4Ay/8WAYoAVwAnALkAuQB9APD/wACAAHoASACXAJMANwCTAIkAdACXADcAtQA0AHwAWwC8AHkAawBUAM0AZwBlAF8ApQC0AB4AlQBeAJkASwA2AJ0AegBHAH8ApgBcAGcAQQCHAC8ABgBpAKoAZgBMAF8ATgBOAL7/GgB6ANL/8P8TABYA7f+4/83/1f/T/6H/jP+t/9P/of+Q/0n/o/+f/6j/LP+Q/7P/df+D/3b/i/8k/3b/f/+O/1f/Sv9j/4H/cf94/8r/pv94/6f/r/+S/wYADgCo/3j/vv+LAO7/HgC6/z4AbgC0//T/+P+hAPH/BwD//2cALQD5/wMAFQCIAOH/5/8ZAIUA9//+//T/6f9NAMD/MADt/xgAk/8fAAMAHgC5/7f/BgBZACIAn//r/xUAUgDU/8D/JAAfADAAw////ygAOwDc/zkAEQDO//T/KAAGAB0A8f+y/2gARAC6/+X/HQD0/33/0/9dAJYAqf+d//j/YQBu/9v/+v+TABUAUf8YAAAADwBc/2UAuv+yAPj/kv8+AB4AkADC/2UAzP/7AOH/AQBxAHsAHwBVAIAA7v9gAEcAfQAqACUAwP+6AEIAJgCQAND/xf/UACgBnv/k/qn/SgEuAWb/Ev+lAKQAwv/K/xcAMgAZANr/WQBNANP/vP8oACIAVQDk/7j/egCLAP3/ev90AJoAPAB1/+3/sQBMAO//uv/uAP7/UADC/+T/+//UAJUARf/L/xcA+wDd/9z/pP/1AMj/Pf9KAbz/cv/d/5MA4QAx/9n/MwB4AbL/cv6kAOsAX//W/+T/ewAcAcD+TP/nAMkAJf8k/18AXgCUAEP/XQCnAGv/Tf+SAEwBbv9X/2AAxgGQ//D+TgA0AXYAHv9U/zIBiwCe/0f/+QCxAHT/egCM//gAiP+3/2wA/gC3/zX/UADHAM8Aev67/wQBRAKu/vz9eAC6ATYBiP3h/3wBVgEZ/x3/TwDgAaj/BP8MAUEARP8JAD4BMgA5AOb+4f/aAY3/4P5tAIcAKv+nAM//EgArADD+gwDmAPH/EP4ZANMA9v+0/sD+OAEKAdj9mf89AFoBIv6o/hQCSwCc/pL+nAETABIAMP6UAWMALP8N/8AAxgBXALr/7v7o/vQBQgFF/3T+YgBwAo//WP5L/6QD9P6E/lMAYAH6/1T+nwD4AoP/0PqeATADqv8o/bL+FAPmAMT8iP7YAVACmPwu/xsAHAGQAOj+d/9E/tQB8P6EAH7+JQDUAAsAbP3H/6ABsv5XACb/sP/Z/x//nf/9/xYBFP7v/47+ZwCaAUb+oP6mAAABOP30/wQAsAIM/pj87AI5ADL+cP5cAuD/cP78/WgDFAB0/eD/LAIgACz8XQDEAtEARP08ACACJgHg/Ij+eANOAcb+lP1gATwC4ADI/TH/6QCoAkb/Kv4CACADmAA5/5j9TgFgAh8ABP7GAfcA5P7u/+//RALW/oX/nv8IAg4BeP70/qwALALn/xD/VP38A6YBeP6w/WQC9gFA/CsAowDIBLb+jPyLAPgBagDA/CgDYAAdAEb+EQCcAiD/2P7M/oADP//tAPz8XANAAQT9H/8kAkIBQP24Aar+eAQ4/Gj9UAPoAWD8lv5EA2UA2/+g+/AAyAIu/vj99AAYAY3/Hv5P/3ABVAC+/uT+wgAzAMj+Vv/a//QCXP1B/6L+oANB/8j96f/t/xgDmP3q/ngCp//S/vYAjgFB/2z+wwDwATIA+PtAAnQD8P1Y/VwC3wBO//T88gHgAyz9+PpIBAQDCP1Y/ZIAvAOd/+D6AQBIBBkAsPss/xwCBAKG/uj7JAEgBCT9sf8Y/bQCfACB/37+CAB+AWD/eP5o/owCMAJo+yAB1v5QBMD8NPxkAmAEPP3o+mACKANo/vj7gAFoAtz+aPsuAYACmv+w+yIB3AOw/Fj8OAE8A8n/oPkoAz4Bdf9I+wAC5AJI/8j8XPyIB7j7bP4GAaAChP2C/tsAAgBAA4j78gEA/1gBCQDMAET+v//gAqL+OgAw/bQDvADO/pr+HAKm/8T8eAQG/hwDzP1w/gQDjv/O/5T+2APE/eQDOPuQAQsAuALa/zT80v+IBJQCqPgxADACOAR6/sD5FACIBrb/GPscA7L/Zv4g/pwDAACWAZD7Ev9IBqz9FPw0/3gGT/90/cj7rgFwBiL+HPye/iQDyP+X/6T+zALA/WgAKgEA/N4A5wBwBGj9ZP3c/DgGWwC4+vwDKgHk/gz9IANAAk0AqPo+AQgEiwAY/UAAbAMUAAf/oPoIBYIBngEe/zj+UP8IArYAhPwgBwL+3v7g/WIBLAPNABj8aPsgCpkAMPs4++gFrALk/Sj8cAJAAKD+UAA4BToA0PjH/4AGwAJw9eEAsAg5ALT80PooBvQCaPvc/JgExAKk/KT8iAMIA/j7rv4kAkgG0PpY/fn/CAXm/9T8uAAsAMYBqv4gA/z9pv7F/0QDTv7k/HgCu/+EAaD9eP/3/8IAh//X/9YB2PseAXIAEP8P//wBIf+Y/boBw//UASj8/v9pAIABuP2QAHQCCf/+APj7fgHU/sf/MAM8A3j7EP3oARgC/AJw+nv/dAMUAdz8l/+oA1oAZP6U/cUAGAPc/sz+BAHAAAz/ZP5pALYB2AFP/1z9kP8WAVQCdQA5/wr/6v6IAVkA0v+2/7wCKP3q/nABeAF2/oX/yAF2AMr+GPwkA0AFXP3I+6QBYAK6/kv/DAN+/l//uPxUAsgEYPyG/nMAXAP6/oD8kv4kA1AEGP3w/A4BUAJ+AND9dP7kA/j8DgEaAfgAZABg/IAB2v+0Atz8CQBkA8z9RALI+sUASATgAKz9yPvEAgQD6P80/ez+cAFX/3IBKAHc/tgAGf9GAcP/sPxYAaACIgEy/hIBTP7YAuoASPtCALABwAP0/Qb+fgCwBNr/4PiuAJgEPALY+wsArAHgAOD7/gDIAwH/gPzQ+5AHAARA+tj6AAQQBED9SPuy/gAJ7AAg+7D7qAI4AhwAaf8Q/0UA3P7+/qAEof/4+2f/wABYBIz9iPt4AjAEZAGA+hD9vALQAVwBJPzcAsD9XAIwABr+mv/M/VwBTwDkARj++f8jAGz+aAHI/hz8oANUAuQAmPsg/UAElgEA/hj8eARQAzT9rPwYAegDdv60/OQCwALI/qD+XAEgBAD9yPz4/pAFKQCQ/GgDxAI+Adj5uPzgA6QDOAII+owBbANo/kz+pgCIA0QBvP3w+gwDqAQb/yD+pADiAHQA/P33/7gCZAJ4+8D+HgG8ATYAdv80ArIAXP3A+1gBiAU4Apj6GP5QAkQDCP/k/Q7/0APG/tj7DALgBG7/oPsN//wCdgFA/ccACAXvADD4Gv54BbQDmv4k/egDTAAQ/XT9BAMQA1z+wP85ALAA4P2vALQBJAHQ+yv/qAIAAwz/Dv73/60AeP+o/RACLAJOAGj+OgAVAJL+EwCdAAACNv+O/uj/4AJJ/4r+Yv5Q//oBOgEy/yj9VAMeARD+oPpk/+AGVgEk/Fz8GAROAcj72P7sAXwD7P0I/MAC+ALU/TT8ZgDAA3YBOP3g/NgD7ANQ+0j8xAJABG4A8PiwABAF4ACI+ysAYATE/ZT92v7wBfkAePq8/iwCqAGc/bAAgwBwAQD+lP3D/7kAJALW/hD+3v4kA4r/4PwZAGADWAGg+Sj90AKABJr+MP2VAEsAyv4c/cYBjAGZAKj9bP9xAEsAGP6k/jQD1AIk/jj6UwDoAzQCzP0Y/f4Bmv8+/hIBrAL8/rz9xQB+AF7+HP34AnAFLf8Q+VL+WgG8AvsABgBv/+D9XgDF/2MAPf89AL8AEf+S/i0AIAJuAQYAO//g+6D9+gFABNIBOP84/OT/XACN/0QAWgF+Acf/PP0Q/dACAASN/0b+VP9S/w7/GAE4A8QB2Pzg+0QCtAI8/4IAGAJUAJz8nP1AAlwD3P/2/p0Awv4c/+AA0AHUAeT9oP0sAB4BOABNAIIBLAA+//j8ZQC8ArIBcP1Q/ooA6AHH/8X/xABOAGb+5P1uALABGgH4/UAADwB8AG3/vP2aAFgBrv9+/rEAaAGu/9T9ev5YAooBDP7U/ygBeAAC/nj9WAK4AXj/aP1xAMQB8f9M/8r+EQAf/+z+fQB8AYwCLP20/TYB/wAAAMD9UP5cAwQC4Pxc/nwCLAKS/vT9wP6IAkABHf9QALkA+v7E/tIAeAFjADgAwv4GAOQBE//W/hIBhwBYAb7+bP54AsgCPP5k/JUAAAIkAqb/MP+QAdr/IP16/38ArgFQAkoAxv8M/b7/egDCAXEA/P1tALoAcAC3/80Axv5o/jwAGgEsAU8A1f/CAMb/FPy2/7gCKATP/xD9H/+s/7QA6wDKAWgAXP6p/6gA+P/a/kMAaAKAAID9cf8EA8AC3P14/en/aAHSATMA4wA4AA3/T/9DAMQANALkAHn/1v4h/9sANgGgASwADgCW/v7/sAEAASgAr/9eAHj/X/+9ANAB2QD6/kf/dgBeAAUAtwB0ALT/Dv6f/7QBdgE8AH7+kv+P//X/VwDSAFoB3f+U/kb/8f9KAZ4A7v9Z/2T/z/+N/84A3wBhAFz+tP6f/z4BrwAN/6v/CgB7/xb+xgBeAUYA+P3k/moAZwB9/67/5gH3/zb+Lv76APsAgwC5/xUASQC4/1MAjv+3/5n/2ACKAB0A8/8/ACQAfP+v/1sAtwBq/7QAZAC5/yf/EQBNACkAq/+LAHgAdf8s/0v/2f+4/3wAdADT/6D+qP+zALr/IP4P/34APwAZAIb/GwCg/xj/5v5N/7r/OwCQAIEAwv4c/o//3QDzAGn/K//c/jQAa/8OAMEASQAVAKP/NACc/2n/BwCYARwA1P5N/xQBqgFdAD7/2/83ALH/gv9qAPEAegFSANL+5P4zAPQAkgEyAIz/4P9d/zkAlgFiAFz/LP9WAOYBZgBF/7f/6gBHAMr+bP/MAYgC2v/q/hX/mQBCASIAvABEAYUADv9yANcAXgExABsAqwCHABQA2wA2AecATgBZ/04AZgAcAWwBnACg/8v/pQBmAOT/TwAyATgAi/9C/9EApQAhAIv/m/8PAN//1P/E/9QAif+2/pb+wP86ABQA/P7W/hT/DP5u/1b/wv/o/hL+mv54/gz/0v7e/gb+hP6i/mT+QP6s/gz/OP54/fz9Hv/Y/oL+Yv6u/gT+7P2u/g3/wP7s/d7+Xv+M/6j+tv5n//D+wv58/y4ARQAsAPj+mP9rAIIARwAKAGEAvADIAHwBkgEaAS4BAgHCARoBbAEgApgChAI+AawBbAJMAiwC7AEAAsABXAKoAswCwALEAWwCgAIcAgQCzAKYA+wCQALuASwCoAIAA6ADlALwAfYBhAK8AqwB+gHEApgCoAF6AQgC3gEcAbMAZAGeAQgBxAACAQ4B1P+B/9X/KgDx/xj/Fv/m/ij+GP6y/m7+6P0c/Sj9NP34/PD7+PuM/Pj76Pv4+7j7kPuo+7j6gPqY+Vj6yPuY+2D6GPqA+/D6+PkY+tj6SPuY+uj6cPt4+/j64Pr4+2j7uPqY+5T8lPyY+/j7oPzE/Dz8XPwS/gL+fP2E/Sb+WP6g/R7+R/+J/4j/vv87ALr/wf+H/34AagFMAngCTAIsAgACLAIEAkgCiAPcAyAEEAUwBnAGCAbABJgEsAR4BvgHgAkgCkAJ4AjQCMAJwAqAC/AKUAowClAKoAvQDBAOkA0ADMAKgApQCiAK4ApwC2ALkArwCZAJIAiwBWAEMARIBDAE5AOQA/IBDv/U/GD8BPyA+yj7YPq4+Qj4YPbg9UD2gPWw9AD0sPNA89Dy0PLg8mDzEPOA86DzsPMg8zDzEPSg9ID1UPYw9wD44Pfg9yj4KPlQ+vD6+Pvo/Nj9uv4X/5z/qv9fAHUAXAG8AqwDgASoBOAE8ARYBJgEUAXoBSAGGAZABkAGAAagBYgFMAWwBHAEMATMAzwDoAMwA7QC/gE2AegAFgDm/sL+Nv+Y/mL+1P0M/ez8NPzA+xj7yPp4+sD68PrQ+jD7UPq4+eD54PmA+rD6qPow+zD7UPvw+5j8XP1Q/SD9pP3w/Yr+0f+qABYBvgGOAbACWAOAA6QDzAPIBHAFcAcACSAJYAhIBsAGwAdACWALsAtwC8AJyAeoBwAJ8ApwC2ALYAswCXgHiAawBnAI2AcgB8AHAAc4BeQDLAPEAlgCRAHfACgBigBb/xH/JP4w/Tz8ePuA+3D7UPu4+hD6kPlw+Sj6KPpA+mD6yPgQ+AD4CPnA+uD7iPvw+uj6SPq4+uj7+PtE/Lj8gPyo/bD+vv6s/ir+oP3g/ZT+mv+iALoAhv9W/1n/DwDsANgAhQDR/1L/of/tALQBggH5AMf/uP6s/tD+YP/m/yD/VP4I/vD9mP1g/Tz8YPsQ+5D6sPsc/BT8gPsw+hD5APn4+Ej5kPlo+QD54Pgo+XD5uPkY+dD4KPmo+VD62Pow+8D7wPuE/OD8sP0i/lD+gv5r/zAAJAH2ARQDfAOUA8ADQAR4BXAGGAdACNAI8AjwCJAJgAogC4ALEAygDIAMwAtQCyALEAuQC3AM8A5wDkAL4AhQBtAGaAdwCLALkAtgCDAECAIIApwCXAPAAxgDxwA0/ij+f//s/pD9oPuo+sD6WPr4+Tj68Pm4+CD4KPjY+Nj48Pfw9mD2oPZQ9yD5gPpg+sD5WPjg97D4MPqI+/j7iPwI/Uz9XP24/bb+A//e/i//JQB4AaoBngHwAWACUAJsAjQDmANEA5wCBALEAsQDKASYBCAERAI+AQQB5ADsAVAClAL4AQwBo/+u/mz+Pv78/jL/tv7o/Vz8QPwA/Lj7qPuw+9D6kPr4+aj5EPoo+ij6CPpo+jj58Pgo+Rj5OPq4+WD6CPsQ+zj7APug+1D7SPyY/Jj9lv5o/vD+Lv+1/2YALAFEAqwCJAN0A+QDgATABFAFcAZgB4AHMAiQCBAIsAigCNAJ8AuAC+AKAAvACHAI6AcQCpAMAA1QDPAI4AY4BcAEgAewB6AHSAcwBUgEVAMoApIBGQDI/ir/LQCZ/9T+RP6I/AD7wPlQ+qD7EPtY+fD4APkw+bD5qPpI++j5sPdg94j4oPq4+zT8rPxo/Jj76Pus/MD9MP7g/Vj+g/+fAPIALgEyASoB/QDxAPQB6AIwA+AC5AIYA3wDVAPAArgCWAK+AcQBiAIcA4ACQgEqAOj/yf99/3n/SP90/pT93PzA/MT8UPx4+5D6UPrQ+fD5uPmA+XD50PgI+KD3sPcg+Bj4IPgg+Ij4sPjI+Kj48PjQ+DD5oPm4+oj76Psw/IT80PyA/UT+5P7t/8IAHgEMAkACLAOgBFgEWAVQBqgG2AbYB/gHkAhQCVAJwAqQC6AK4ArQCoAKIAuwC8AMAA4wDmAMgAvQCqAIoAhACrAMkA0gDLAIqAaQBcwDaAVAB5AHgAUMAqwBCAGZAD0Alf9t/yj9GPvY+uj7CP0Y+2D5UPjA+BD4wPc4+Gj44PYQ9oD26PiY+Zj4UPdg9/D34Pe4+KD7XPx8/Oj6UPtc/ET96P0e/mv/sP98/0YA1AFsAgwCywAKAQgClALsAjgDZAPsArQCdAIQA4wDWAHjAHgAlgD1AIYBiAHjAJv/kP3c/DT9lP3M/WD9JPzY+4j7IPv4+kj6sPkY+YD4KPhg+ZD5GPkw+aD4iPgo+Hj4+PhY+dj5kPkI+ij7kPtY+/D70Pt4+2j8ZP0q/n3/4/9rAIwAJQDn/8gACAL8AqAEiAUQBUgEGASABDAGwAbQB3AIuAfgBpAG6Af4B5AIsAkACbAIOAfoB8gHeAe4BTgH0ApwCvgHIAYIBBAChAF4BKAIkAlYBawCCgHE/8D++P8wAnQDWQDc/fb+If9Z/1b+vPxw+1j7EPus/PT+oP0g/HD64PkY+yz8EPxw/ID8qPrw+tD7iP3O/2r/AP7w/OT8vP0GABgC1AKUAjQCaALIAngDQAQgBFAE4ASgBWgGSAdoBvgFoAVYBLAEyAXIBegFSAXIA7wDmAMMA8gC3AG5AGsAjf9F/wz/4P4w/cT8JPwo+zD6WPmA+fD4UPjg96D3sPeg9rD1EPUw9TD18PWg9aD1cPUA9ZD04PRg9XD1oPYQ9mD3cPdg90D3mPg4+SD6uPq4+nj7iPug+1z81P1B/wkAZQCs/zsAEAAuATgCiAPsA/wDMASoBPgEeAVoBSAFEAYwBrgGgAeABwAHsAYIBggFsAaoBrAGeAdgBkAGOAcYBhAFMAXgA/QDMAW4BQAGEAW8A1ACHAMQAnwC0AJQASoBsQBuAQACdALEAk0AWP6I/OT86P7iANoBYgHu/1T+cP3Y/dj96P0D/4j/bABUAfoApv9q/mL+R/+iAHwCsAN0A6QBHgDhAEgDIAXoBTAFqAM4AlgCeASgBvAG0AUYBNQDzAMwBNAEgASAA/gCpAJEAwgEvANEAsv/hv5k/rT/1QBdAHP/9PyQ++j6+PvQ/BD8APvg+RD5MPmY+Sj6YPpA+UD4wPdQ+FD5uPlw+pD5qPmY+Tj66Prw+gD7+PrY+7j8/P2K/l7+lP2E/SD+Dv+DANgA8ABFAPD/2AC4AUwCHALcARAB2ABsAcwC4AKAArQBNgEsARIBXAHWAVIBQQBZ/7r/GACzAOv/QP/s/dD8sPxM/fD9OP6I/Qz97Pwk/KD7CPu4+uj60PuI/Gz8gPy4+zj7kPpI+kD7JPzE/Oj8DP3U/Ij8FP2s/bT+Ff+q/nP/3P/8/7kAxQCkAoQDEATgA+ACuAPgA9AEUAZAByAJ6AfYBqAGmAZgB2AH8AhwC4ALAAqgCVAKwAl4B8AHoAmADAAMwApADHAK6AYoBggGMAjACEAIEAkQCdgE9gHoAYADWARABBQDYAHc/7j9jP10/83/iv5Q/UD7wPrA+Qj6aPuw+zD74PjY+Bj5yPhg+ZD5YPlA+SD5+PlI+6D6SPqw+pj60PqY+7j8RP2c/cz8nP1s/pT+Sf+F/z3/5v4C/6b/TAGUAW4BywDp//3/7v/PAM4AswApAAn/rf8eAFYAif9w/tj8lPzc/PT9rP4A/sj8QPsA+0D7IPxs/ND7UPo4+ej5iPp0/Cz9RPwg+9D52Pnw+hT8vPxM/Yz8GP2Q/Tb+4v4S/ir+OP3E/TH//AAUAvoB2gC//wkAbgDgAQQDFAOMArwCoALgAnwDtALwAhgDiAOwAzAD0AJ8AhwD4AIMA/QCTAM8AnoBlQDaALIBFAE0AggCMAGC/1D+r/9TAAIA4v4U/0v/Qf8A/8T+MP/A/fT80PxC/sr+bv/o/vD99P08/eT9bv6e/+z/uv4y/lL+QAFiAaIBPAFwAWwBAAGUAYwD+AQIBFAE8ARQBmgFkAVgBTAFOAagBXAIQAmACjAJ0AfgBogF6AdQCNAKYAswC0AJiAYgBqAGyAcwCKAIeAcoBhAE+ANIBHgEiARcA/wBq//q/tj9ev44/uD9/P0U/GD76Pkw+dD30Pag9vD2KPgQ+HD34PWQ9MDzQPTg9MD1MPag9RD1wPTA9UD24Pag9/D3kPgA+DD46PhI+ij7EPzI/Aj9RP30/Aj9lP3I/s7/uAAUARgB5ABKAFkAUgE0AlwCEAL0AfYB9AFUAc4BAAKUAYUAbgBoAMkAHwDP//L/D/9e/kj+Xv6Y/uz91P2Y/YT96Pyw/Fj9VP2U/Uz9WP1A/fD8SPy0/Pz8AP6a/t7+DP8s/oT9iP0M/tT+hP8wALEAngGGAeEAQwDq/7YALAIMAiADQAQgBPQDIANYA7ADiAPwA+AEMAYwBTAF2AUYBhgGwASABNgE6AQ4BUAFyAXQBVAFwATkAwgE9APEA7wDkAOYAzADCAMwA4QDKAL9AIUAgQAmASABHAFWAY4AVP+0/tz+9P4m/xb/xv6+/nj+Av40/+b+Iv4K/jD9Sv6u/n3/ef/T/wn/0v5L/+D+pf8tALIAdgHEAQAClAJAAsABNAJoAkwD4AQIBxgHoAb0AxgDSAQIBYAHsAhACDAG3APkAygFoAaIBqAGCAWUArQBRgEMA6gDoAIqAd7/wv5u/vD98Pzo/Bj7UPpY+lj7+PoA+fD24PWw9jD2UPYA95D2gPRQ86DzcPVA9mD1IPVw9AD0gPMw9QD3kPfg95D2gPeA9zD48PjQ+FD68PoE/Hj87Px8/ez8ePyA/BD/vgDmAJ4BNgEGASgAdwBAAhAErAOsAiQDZAMYA2wDGAQoBQgF5AOMAxAESAQQBNwDKATABIgE0AR4BIgEAAPoAWACyAN4BfgEOAScA8ACBAIEAjADMARwBKgDcANYA2gCDAKoAigDwAOoAzADYANUAr4BEAKIAtACFAMsA1QDbAKAAYYB3AG4AfYBxALsA0QDBAJgAeABdAHMAPwBXAN0A3gBMgEwAswB+ADnAFQC8AJiAS4B4AHsARgAWQDkAQQCUgEOAZ8AIAFT/w7/AgEQAZ8AmQDS/5L+ev4C/+3/WQDq/ob+4v5M/jb+kv56/sj9+P3c/dT91P1Q/ZD9Fv4k/mT+2P0A/eD87Pxw/az9l/8fAET/OP6I/Eb+/P1bALQBBAIYAib/yP9+AHgBdAKMAowCVAEwAaIBOALMAwgDqAEkAan/iQDkAXwBGgHp/0v/eP4U/zv/JP94/oD7YPtY+2D7BPxg++j66PmY+CD4qPgg+AD4QPfg9mD34Pcg+ED3EPfg9cD1EPag9/j4QPmA+Mj4yPjo+ID58PoQ/ND70Pvs/Er+Av9M/38A4QCJAKgAvAF4A2wD/APoBKAFCAboBVAG0AaYBggHmAeQCPAI4AjQCCAI8AfACDAJIArwCZAJUAhIBxgHIAhACbAIkAgQCEgHeAb4BTAGSAYgBrAFcAZIBlAFaAS4A7wDmAO8A1gEYASMA5wBzwCCAQgC1AJkAu4BEAFB/+b+xv/3AA4Bwf9eANT/df8m/tT96v6G/vz9iP7w/3YACv4U/eD8SP10/cz8YP/c/1D+fPxM/Sj+RP0o/ND7Ev6Q/QD9/v6O/4j9CPvA+hD8Ev7A/U7+2v44/Mj6PPw8/Rz+1P1w/Cj8WPvQ+sz8GP4E/Wj8ZPwo+6D78PsI/Oj8ePuw+jD8sPzI/Oz8UPxo+yj7YPto/JT9vP1E/Vz9vPwY/RT+yv7m/rD+oP7e/rH/5gDiAYACOAIwAkACfALAAmADIASgBCAFiAWwBYgF8AT4BMAEiARQBbgFKAZ4BUgEuANsAwQDUAOkA1QDCAL8AEwAFQCt/z//sf9+/37+GP2A/Mj7SPtw+7D7BPwY+xD6wPmY+UD5SPnQ+dD5mPmQ+Rj6sPpo+kj6yPr4+oj7JPxc/fT9kP2I/VT+av8HANUA1gFMAuYBFALkAmgEGAVgBQgGeAaYBtgGaAcwCIAIYAhgCCAJ4AkgCkAKMAqQCmAKkAmACdAJMAqwCTAJsAnQCVAJUAgwCMgH6AYYBsAGMAfIBlgF4AS4BMwDJAMQA3AD3AKeAQYBBgGWABEA4/+k/yL/xv70/XD+gP0M/dz8mPys/KT8ZPwM/HD7gPrQ+pD6ePoo+0D74PqQ+iD6wPkQ+sD5KPrI+pj6uPqw+oj6uPqY+mj6gPr4+nD7APsY+0j7qPt4+4D7VPyE/Oj7aPso/Ez82PvA+3D9Ev5s/YT99Pw8/QD7CPsM/Rz+8P5w/or+KP0Y/ND78Pxg/Yj8nP0U/lD9GP08/ZD9FP0E/Ez8KP1g/Rj9hP3A/ez8iPxo/U7+wP4+/qD9IP6W/rb+k/9qAOkAywCMAOMAygEEAhQClAIgA3QDoANABBgFQAXQBJgEyARIBYAF6AVoBlAGAAaoBfgFSAYgBrAFSAUABfAEIAVQBWAFIAUwBHgDWAMUA/gC2AJQAu4BsgFIAQIB5gB6AA8AoP9N/zP/Mv+w/pr+mP5m/hL+IP5a/jj+AP68/dD93P0e/kr+qv6Y/qD+6v7s/vD+Df+J/8n/7/8tAJUAuQCyANkAAgFQAXYByAEsAlgCLAKgAogCHAMIAzwDTANcA8QDzAPsA/QDKARQBBAEQAT4AzgECAToAxAE9APQA5wDqAOwA1ADHAMUA/QClAI0AiACNALqAaIBjgFcAdoAcQBbAE0A+f+A/0T/Tf8C/5L+ev4+/vz9kP1o/Vj9DP3U/Iz8fPxc/Cz8JPwQ/Nj7iPto+1D7SPtI+yj7KPs4+/j68Pr4+vD6CPvw+uD68Pr4+hD7QPto+2D7aPuI+6j76PsI/Dz8cPyA/Kj84Pz0/GT9aP2I/bz95P1O/lT+iv6y/tD+mv7A/gj/E/80/yj/gP+W/3j/nf/A/5X/aP+f/+n/EADx//f/FgD8/+H/CQAhADQARABUAGkAVwBXAH0ApwCpAKwA6ADzAAgBJgFGAWYBegGSAcIB5AEMAhgCLAJQAnQClAKoAtwCFANAAzgDRANkA5wDvAPQA/ADCAQoBEAEWAR4BHgEkASoBLAEkAR4BJAEoASgBIgEaARQBDgECATwA+QDwAOUA1QDLAP4AsQCnAJ0AjgC6AG6AZQBZgEwAfwAzgCtAGcASwAtAAUAzf+k/33/Zv9h/0X/OP8b/+r+xP68/rD+nv6Y/ob+mP6S/nz+gP6Q/pb+gP5y/pj+pv6W/qj+wv7g/sD+zv7u/gn//P4J/wD/HP8a/yf/a/9O/1v/Qv9e/3P/Z/9t/5T/n/+C/6L/yv/Q/8L/uv/q//L/2/++//P////7/+T/7f/8/9v/xP/G/+X/6f/I/7P/vf+V/2j/Tv9E/zz/Jf8E/xv/9v6s/pD+jP58/l7+Qv42/i7+EP4C/gL+7P3U/cj9yP24/aj9sP2g/Zz9hP2Q/Yz9jP2k/aT9lP2U/Zz9tP3E/cz93P34/Rr+Fv4u/k7+XP50/pD+sP6+/sz+5P78/iH/Mf9Z/23/ef+F/5n/tf+5/9//8v8AACQAMQBGAFoAVABnAJEArgDcAP0A+gAKASQBRgFSAW4BkgGkAcQB2gHwAQwCEAIcAjQCUAJwAngCgAKEApwCrAKwAsgC4AL4AuwC4ALwAvgCCAMMAwgDAAMIAxADFAMsAygDCAPwAuAC0ALQAsACvAKkAoACZAJQAkACHAL8AdABoAF6AWwBTgEcAekAywC3AIgAYgBJAC8AAgDO/7T/ov+O/3r/WP87/xH/8P7S/sb+tP6U/ob+gv5y/lb+Uv48/jz+Lv4U/iL+KP40/jr+SP48/jb+MP4o/kj+Zv50/nb+gv6U/pb+gP6e/rD+tv7C/tL+5v74/gb/Av8K//z+DP8n/zT/RP9L/1r/Tv9n/3r/gv+D/4f/lP+r/7P/zP/T/9H/2f/g/+n/5v/a/9//4v/K/8f/z//K/8P/uv+g/5//h/+L/4D/e/9c/zj/M/8e/zH/Df8N//b+7v70/t7+5v7Y/tb+vP6q/r7+1v7U/tb+zP7a/t7+zv7k/gX/Cv8K/xX/G/8u/0P/Xv90/4D/pf/G/9n/8v8AABkAHAA9AGgAmAC6AMIA4wDbAO0ADAEmAVABVAFwAXABhgGeAaQBvgHCAcwB1AHOAe4BCAIMAggC/gEMAhQCDAIQAhQCBALiAdAB4gHgAcYBwAGqAZgBggFoAXABagFYAUABJgEYAQ4BBAEEAekAxACnAKEAfgCBAIkAXAA/ABwADwAFANv/0f+7/6T/iP+E/37/bP9g/0f/N/8c/xX/Jv8q/xL/B//+/vD+8v7y/gb/Df8A//z+8v7u/uT+9v72/v7+AP8F/xP/F/8S/wP/Cf8B/xL/Iv8V/xz/IP8m/y7/Mf8o/zv/Nf8v/zT/Pv9F/0j/R/83/z3/Nf83/0L/Pf86/zL/MP8y/0H/Pv9N/0r/MP89/0T/Wf9w/2j/bv9r/23/c/+E/4n/i/+R/5b/sv+p/7j/w//I/7D/x//j//L/9P/4//z//f/+/wYAMwBBACoALAAwADoAPgBFAEYAWABKAFQAXABKADgAPQAzADQAMAA+AEYAaABDAFYARQA4AEsAVwBeAFYAUwBZAG4AaABxAI4AhwCLAHsAhwCTAKQArgDAALEAswC+AL0AxgDKANIA0gDSANgA0QD0ANQA0ADdAM4A2ADsAAQB9wDqANkA6ADwAPEA+AAGAecA2wDlAOIA8ADsAN8A1wC+AKsAvwDKALgAtQCrAKoApgCHAIkAjwCCAGsAdwCCAGsAXgBNAFkANwAnADAAOgAvABgA+/8BAAEA5P/Y/8v/sP+o/6X/m/+W/4P/cv9r/23/Xf9b/2j/Wv9K/z3/M/8+/0j/Qv9K/0X/PP9B/0j/Of9E/zD/Mf9I/0z/Q/9A/zz/RP9Z/07/WP9o/3P/aP9h/3H/hP+H/5P/qf+1/7P/sf/L/9f/2v/U//b//P/u//r/CAASABcAHwAXABwAGgAgACYAIQAVABsAFgD+/wMAIQAOAP//5v/w/xEACAALABAAAwDh/+H/7//+//n/8v8HAP7/6v/Y/9n/3f/Z/8r/3f/Z/9n/zv/L/9L/uf/F/9j/6//e/9T/1//W/9b/1f/d//P//f/5//X/7//1//L/6//w/+P/9f/5//D/EwAIAPP/+//0/wsA9v/y////BwAGAA4AGwAjACgAHQAwAD8AOQA9AEAAVgBSAE8AYQBjAGQAXABVAF8AXwBZAG0AYgBpAFYAWABIAEMAUwBFAFEAUAA6AE4ARQAwACwAJwAuAB8AHQAnACYALwArABYAGwACAAIAFwAWABAAFQAgABkAHgAAABMAAwD4/woACQAbAAgACAAFAP7/DgAYACUAHgADAAQAAQATAAoACAAcABEAFAAcAAEA+//x/+z/8//r/9//7P/i/+H/1P/K/8P/wv/W/77/vf+3/9H/tP+3/57/qf+s/4H/sP+4/6L/jv93/3n/d/98/3n/iv+N/3v/fv+c/6T/j/+H/6j/rv+v/7T/w//U/8v/w/+//9r/z//G/97/4f/f/+H/5f/b/9v/2//p/+b/7f/3//T/BQARACMAJQAgABsAAwACAB4AJgAfABEAEwAEAAgA//8LABMAHQAXAAYA+//s////9v/0/+P/3//S/93/z/+//6//pv++/7D/x/+3/7X/qv+f/6b/pP+g/6r/q/+T/4v/jP+U/6H/nv+R/5r/m/+c/5n/q/+v/7f/yv/M/9f/5v/v/+v/7P/w/+3/AQAFAAYA/v8XABQADgAPAA8AFgAqACcAMQBHADkAQABGADwAPQBFADwASwBIAGgAdwBsAFoAUQA8ADMANAA7ADcANAAxAEAAKgAiACoANQA8ABwAHQAiADcAOAAyACsALQAdADEAMAA4ADsANwATABgAIgAzABoAHwAsABwAIQAVADEAIAAtAAsAHAAOABsAHwA1ACwAMwALABQADAAWABYAJQAIAAMAEwADAAYA8/8FAPn/BAD1/wQADwD2/wMA8v/e/9z/8P8SAAUA6v/6//T/9//1/+T/4v/W/+f/8P/5/wQAFQDk/77/yv/5/9z/1//V/wMACADg//r/3f+b/9z/pP+t/x7/Q/9PAKAA8/9n/17/iP8dAOn/OgDX/9r/uP+u/6H/vv9CACgA1P+K/97/DACE/17/5//4/yUAk/8gAFMAAADO/5L/FgAVADsAMAD9/9r/x//r/w8A4P/Z/xAA9v8YAPX/6/8iADQAOQBwACEADQBIAP3/ggCRAFgAEADv/6j/8P84AOn/3v/E/9z/9f9M/6r/BwDn/+T/5f9mAJEA9f++//7/EQC5/53/pv9hAAIBswCk/x3/Hv8vAIIABwBMAI4AnQBQAB8AQgA9AFUAdgB9AB4AmAAuASIBTgA9/5b/mgCAALwAVAGsAGwA8f/sAMwBugF0ARwBwgD2AGgBngGvAAoA0wAhAHn/S/8MAUX/WP5q/iwAfAHRAOUAQAFiAHH/BADcAKABlAAaAHv/oP9iACkAdv8u/hr+vP3g/Nz8KP38/bz90Pyo/PD82Psw/Rz+kf+y/sT8NPwQ/dz9oP4SAa8ABgAN/37/6f9h/1j/5wA0AkoBjgFwAnACQAFZADsAfgFgAtADvAPQAngALAE2AWwBNAE4AhgEXAPxAHf/QAEYAjgCIP9+/zoBmAF0AeT/Fv9g/nr+6//x/3r+4P0L/2X/sP64/L7+HACS/yj+fP3S/mQAIv/A/Uv/v/+3AGsAbv6o/4L+Z/9T/0EAbQDv/ywAWwCgAOb+EwCFAF4Bzv8//6gADAKbALb/ev9dAFYBff8kARQCOgHm/1f/RgEwAsoBZwAxABgARgGIAbwBzgFXAJwAbwD0/+EAOAKqATcA/P3Y/sQA5AEcAn8Avv+4/1b/8v9FAKwAuAAvAAAAqP+V/9X/EgBK/3T+pP4xAAgBigC0/nz+EQDP/6r+Ff+9AOIBcACO/u7+WQCC/5n/VwCuAYkAr/+YANIA2v+y/uAAaALlALP/eQDEAbwAgP+J//wBfAKnAMD/oP+oAJUA+f/r/9wAPAFWASkAFf86/+D/xwBGADkA6v8KAVQAH/8L/1z/xP88AFYBSAFe/yD9PP6xAFgBeP8y/7b/UP8K/qj9FQCkAR8Aev41/8L+f/8k/xUAFP8H/9L+OAHKACn/uP3U/Xn/SgA1AIv/OAD7/yv/vPwG/qkADAMCAb7+dP7m/sb+L/9UAXgBTQAq/9z+Vv40/ywBPgGl/8D9df+oAVoB1v/j/07/qv4y/1MAEAKOAY8A4v6U/bz94wBQAhEAmv7s/YD+jP97/1QBlgFcAHD+SPw4/Xr/RAIgApgAuv5i/mb+dP+3AHQBCgCU/oj+ff9EAaQB/wDS/rT9eP7OATQD2AGMAK7+Bv4a/3ABkAOoAxoBTv7I/bT+JgEABDgEfAHI/lb+0P/UAHgCJALEAsQAYv81/zIBTAK6ARwA1P5NAM0AngHKAVoB5v50/aT+nAGMAooBp/+y/vz9JP7lAFgC7gEcAKj9lP0q/pkA5AKAAaD+bP0w/lf/0wB5AOn/Cf8y/mb+Uf87AFoBmAAU/sD9ev5EAOUAlgGVAOT+jP3o/qwBngHNALT/CQDm/vb+xv9kATQCjABU/x3/gf/1/zIArQBKATsAlP68/+4BLALs/9T9AP/y/yUAvQBUAXYAYP7E/QIAxAHmADoAawCx//D9Cv5XAGACOgHe/pX/ZAA9AA7/P/9cAFsAUP89/9UAUgFrAAz/b/+mAIcAbf8kAOsAzf90/kj/XAI4Aqr/nP1s/6kANwCQAK//SgAm/2v/NgC9/1kALgDW/wP/oP6E/yUAKAFJAPj+QP4e/0QBFAFo/6T+kv4SAE8AUAGyAFf/hP4k/pz/ygDkAagATv9O/mb/b/9r/48ALAFHAG7+Uv68AOYBEQAQ/rD9jf9yAbIB/gDa/6z+lP3W/hwBSAIQAfz+qP5x/w3/9v8mAfYB6f92/qL+hQA6AVcA2//7/6YApwCyAHn/Xv9r/w4AlQAqASoBUgFb/4T+NP5+/0YB6gFAAZn/RP6i/iYALgEkATgAuP/4/ob/TABwAFsAhv/6/wEAkv+k/xIAMQDB/4L/xv+4AFEAAgCN/3r+Jv62/3wB+gF4AB7+hP7e/oP//v/9AFgBZ//A/V7+KAHoAV4A3P7a/nT/Rv/e/9QAGgEcABT+8P2I/3QBNAEC/5z9OP7j/7kA3wDdAF3/4P0G/i0AEAFiAIj/kf+S/zr/aP+jAA4BDwB4/sD+1f+uAGABgQCk/zj/vv8cAM0AcQBgAK8Axf/T/yUA6ADfAKUAhABVANr/wP9DAMIA0wAnAG8A/P/X/+L/0ACsAC0AY/8aANoAVADz/1L/cwCvAGUAof9p/yIAqwAxALT/HAA5AIEAzP9M/6f/2v8cACQBigGkAOb+hv5v/9gAcQCW/xwArQCOAFz/Sf87AI4ANgBK/yEA5ADUAHn/Bf/T/0MA2AAiAO0ATwCG/wD/uP+GANv/YP9//1sAEgC//7H/NwDv/2X/WwDSAPL/HP5u/jEAdAEoAdP/iP8b/9L+Cv9GAGIAbwAYAHL/MQDX//b/av/q/k3/9f84AeQAvgCB/67+ov7E/5QBygH4ABX/tv52/1cAFgF6AVgB8P+2/vz+bACyAfQAv//G/xoBnAB4AJz/5f/m/7v/qACOARABZP8F/5b/8v/t/2UAVgGwAH7+yP2M/5YBeAGO/zr+Mv/N/3AAm/+n/wUAif90//j/MQCg/2z+mv4QAMwABQAg/13/ev8U//L+bv9zAGMAkf88/0//SP+//50A2wAJAOT+vv6i/58AowBQACgAvP+J/9b/l/+n/2kAmQBXAKT/OQCaALUA1P+q/w8AWQB7AHEADAHV/1z/ngBsAU4BNgA0/y8AyQANAPz/jQA+AcgAbQDr/23/cv/X/5MAEAEJABMAMQDa/3//e/87ANv/vwCuAIoAmv76/tH/nQA0AJ//HgFWAFr/CP6+/zIBYQCJ/53/KwAmADj/Q/8OAQIBCgBv/4r/GwC2/5b/JwDeAKAAdf9Y/8T/TQBwAMr/zf/L/4YArwDOAFH/2v6o/+YAggHm/3L/kf/q//j/KgCkABsAiP80/1H/AQA/AKgAfwCA/7b+eP9MALQAZQCq/6n/MP+L/1sAuABAAEb/AP/A/+b/TP/n/1sARQBM//z+4f+zAPT/vv6m/qr/WwCYALAAGQDn/+7+6P7z/8cAAAGu/3v/m/84AKIAYABrAOD/a/8F/wcA6gD4AGQAV/+P/xEAgQB7AFwAQwAg/8b+Uv/BAL4B3ACE/wD/Ef/V/xoAgABBADMALgDD/9v/7/8+AOX/0f+s//j/MADY/+n/BQD6//X/EQCsAL8ACgA1/zH/MwDiAC4B+gA7AFP/wP7i/7oA3QBkAHcAhwAZAKH/U/8OABEAzACLAEwAnv8OAHsAjwDo/9f/w//s/0gAiQCIALD/9P8yABMAYv9A/2IAZQAHAJ7/EwBAAN//dv9+/9L/QQCdAJgASgCB/4f/xf+bABgBXgDZ/3r/dQChAPz/PQB+AA4BfgCQ/83/RgAqAKD/KQA+AZ4BWADo/i3/JABPACsAjQCQAFAANf+k//n/NwD5/zMAWQDN/7n/i/9vAEwA2v+H/7H/LAByAE4AWv/G/ywApAAtAMX/3//i//f/CwCkAJAAnwDRAIcAj/+U/sz/cgG+AaIApP8BAGQAZQDo/2YAsgC8AAYAxP8JAIoARwCvAAgBnACS/87+IgDuAK4A7/+s/0MAuP9m/7T/NwD4/2H/o/+k//D/m//N//7/Sv+q/hj/6v+iAGsArf8e/xn/2v/s/xMAwP+I/1n/a/8HAEQAbAD9/7X/eP+4/gz/6//+AMUAXAAO/yD/rP8EAEoAGAAYAAoAEwD5/6EAvAD5/7v/1v8kAE4AlACvAD4Aq/9s/1EAnwBQAFQAGwAJAJ//EwCCALsAhwAgAC4AmP/v/1EA2gD+ABAAnf/K/ysASwAvAEUAIgAiAIj/MACOACMAH/82/+z/ugCHAA0A1v+C/yf/iv8vAJQAigCu/77/s//f/wYAtP8sAGUAFgDe/wMARQATAJ7/aP+FAN0ASwAOAKz/zv+2/5H/qACtAFIAiP/H/yMARQAaANX/KwD+//L/EwAgAKgA4v/X/zkAPAAqALH/X/9HAHQA0/8YAG4AiwDj/2L/Pf8eAFMAIQAgAPz/6v/L/9L/8v/z//n/zv/y/4MAHAB1/6P/zf+CACYAqP8WADcAoP8d/9H/VACiADoA7//8/4T/1P5x/xcAzAAaAUcAGABP/6L/r/8WAFsAYgCdAFwAAwC9/9P/Vf+U/yQAtgCiAPz/oP9+/4r/+v4TAMYA2ADf/9j+NP9p//z/cQCOAB4ALP8k/1//dv+d/xoArQBZALz/hP+3/6r/PP+l/50ADAHYABEAo/+r/8b/NADVACwBPAFYAMP/zv8vALUAxgAKAZgARgDo/zMAmAB0AG0AmQCbAA8Ax/8hAHQAWwA8AJYA0AA7AKj/sv/e/w0A5f+UAAoBiADd/yv/jv+4/wQAVQB9AIcA+v+S/4v/qP8OABYACQDo/9j/9P/O/+L/HwA0ALH/5//k/1kAIwDN/w4ARwA2AMP/YAB4APj/ff/M/2wApwBIADoAogALAHL/k/8zAGIAdwBwAH8ATADA/6T/tv/y/xkAkQCFACwA2P+u/8n/1v8jAEEAMwDT/w4AIADu/8b/9f8PACcA6v9HAAUArf+Z/8X/DQDv//X/AgABAI3/dP/Z/+r/jf/Q/xgABgA2AL3/9P/z/6f/x/84AHIAQAAJAA0A3v/2/z0ApwCZANb/sf+7/0cAIABgAJUAXQAgALj/AAAlAP7/AACtACwA7f/t/yIAbgBNANv/AwDx/5T/0f8zACEAJQDN/2X/j/+z/5H/HQCT/4D/5v+A/5z/l/8r/4X/dv+T/z0AyP+I/xT/M/+V/23/gP87ACwAgf9H/xT/vv/u/1X/z//n/5T/Jf+1/7//+f95/2v/6f+8/4f/AgDW/9r/q/93/yMA5P/L/w4A/v/a/77//P8PAN7/AwD8/wsARgDB/00ACwAJAAEA8f83AFoAJQDV/2cAGAD7/+7/WgCHAHEAxv/O/1AA6f9uACkAgABiAND/JQAUADkAFQA8ABwApwBlAPX/GQAXADkAIwATAEgApQBkAO3/9P9RAC8ALgD4//r/LwDF/+r/cgDTABsAbv+q/+X/IAAbACYAWwBgAEH/t/9FAPD/jf8M/8T/EACV/8j/4f+y/0j/1v5v/3b/fv+W/4X/3v8y/2D/+/+S/2X/Hf8q/zr/4f/Q/yYAKwAD/1H/S/9X/2L/7f9bAN7/nP86/4r/h/9j/wYABgDI/4v/0f8JAG7/Y//B/2wA8v/Z//r/EADu/3T/LAChAHcAGQBvAOMAGgAJADkAuwAMAT0AgAAmAZ4AjwAEAcoA2ACBALsAQgGUAeUA/wCIAfMA7gAkAS4BRgFcASwBlAEIAcYARAFAAfQApwBsAZABwgDiAOsAGgGDAOgANAFsAecARgBoAVgBwgDYAFYBggGlAMQA0gA0AZkAeQCCAVYBygASAFEAVQCd/5H/RABCAK3/df8K/4b+yP4W/rD+pP5y/sz9sP08/Qz9ZP3Q/Nj8SP2k/HD8cPwk/Cj8OPzY+4D8GPyE/FT8YPxU/BD8pPyQ/Az97PwA/fT88Pww/ZD9yP2Q/QD+pP2g/eD9AP4U/iL+gP5o/pL+Gv5U/pr+jv5o/u7+OP8d/yr/Cv83/z3/M/+p/5sApgBLAGcApAA8AcQASAHmAaQCZAI0AugCjAN8A0gD0AQoBXAEYARQBSAGgAb4BZAGcAiwB7AHsAhACMgHUAewCGAKoAswC8AKwAqgCKAIIAnQCQAMsAvQClAJ4AfoBngGaAZABtgGiAWgA2gDaAKvAET/Xv7m/rr+7Pwc/Mj7WPqY+Fj46PiI+HD3kPaA9jD28PTw9AD20PXA9FD0kPTw9PD08PSg9SD20PVQ9rD2MPcw9zD3sPd4+ID5GPpw+pD6mPqA+pD6mPuc/Cz9TP10/Tj9fP14/dT95P5E/hD+Tf9a/zX/mf+o/4L/PP8k/6r/WwBGABcAKAG7ANz/0QCOAO4AOAFSAVYB6gFcArACyAKUAuACjANAA2gDQAS4BGAEaARgBYAFmASYBIgF8AVYBVgFeAZIB4gG6AVgBpAGEAb4BZgH0AcYB6gGEAf4B0gH2AYQCPAI4AjwB2AIcAnwCIAIoAngCvAKIAlgCjAJmAcwBRgEUAnACJAIwAYgBLoBdP5m//4BAAMGAcz+WP6g+0D6mPko+wj8QPpw+PD3kPdg9gD3wPaA9uD1sPWQ9mD3oPXg9MDzQPSg9YD2MPgA+KD2gPbg9UD28PZA+AD68Pm4+Zj4EPrg+hj6WPsg/PD7UPvA+2D9zP1g/TT8cv4F/3j94Pym/tD+NP2Q/XL+6/+6/zD+4P9o/0z9nPzy/uQADwC+//P/jgB5/47+sP+tAH8ARwAsAf4B/gB7ABQB1AHGAZ4BogE8AuACOAIcAv4BfAK4AuACyAKAAmACuAFIAoADYASUAwADdAPYA9QDKANQBAgFiAU4BQgFyAXYBagFyAWIB1AH4AcACEAHgAggCPgHwAkQDeALAAsgCHgEOAZwBxAJkAuwCqgG5ANIAS8AjAJ0ApgDzAIAARD/CP2o+9j6ZPww+6j6sPo4+kj6APgg9lD24Pbg9jD3OPiQ9+D10PTA9ED2kPeQ9jD3MPew9mD2IPbQ9+j4oPlI+HD4SPnA+KD5ePmg+gD8iPqo+xT82PvQ+5j7JPzY/Cj95P0u/oz+xP1g/TT97Pyo/r7/AAAsALb+Pv/I/mT/QwD7/38AHgAKAWoB1QBwAcMAZwBTACABRALYAfgBfgHQAVoB7wAUApwCMAJ8AUIBigHWAUQC9AFIAigCPAHlABwCFALoAtgCJALAApwDQAO4A3gEYASYBCAE0AR4BjgGEAaIBjAHUAewB3AIIAmACfgHcAlgCpALAA1wDdALcAn4BgAHcAnACjALEAsgCQgFmgFUAuwBYANAA0AC5AHv/zz94Pro+2D7IPp4+rD6qPpA+WD28PWA9qD20PVQ9xD4UPaw9ED0APUQ9sD1IPZw9xD3UPWg9XD2QPfQ9+D36PhA+aD4EPk4+WD5SPoA+wj74PsM/FD8qPzI+5z8cP0M/Rb+3P6I/+T+eP5o/or+Cv+J/8gBXAFhAE8AnwCeAB4AIAKIAjgC1gGAAkgD2AKsASAC4AJEAvQCLANsA1gDSAIgAlQCtAK0AlwDTAJ8ArACKgFAAoQCxAKUAmIBcAFwAnwCBAKYAjgD4AJkAiQDaAR4BOAD2APQBLgFcAUIBZAGmAagBggHAAigCUAJoAiACHAJ4AnwCkANkA0gDrAKuAcwCPAIcAmQCjAMoApYB5wDMAOIA3QDGAJEA2gE2P8A/jT9DP14/ND6kPpY+/D6sPfg9xD4APeA9hD2YPbQ9+D2YPWA9cD0cPXg9WD2gPcI+AD38PTw9TD3APiY+Bj4EPl4+WD44Pcg+lj7IPoI+oD6mPvg/ED8gPtU/Yz8wPvg+/z9lP84/2D9HP1y/sD+iv4DAOgA4QBe/jr+pgDaAVwBFgGUATIBywDfANQBrAIsAhIBTAL2AaoBkAIkAvgBNAGiAfABsAJUAowBPAIXAOcAygFIAowCigHcACgBPgE6AagCZAKgAnQCxAIMA8gDAAToA6AEkAQgBeAFeAVgBvgFaAfoBrAHIAiQCTAKIAnwCOAJQApwC/AMwA0ADVAKYAewB/AIAAqAClAKUAm4BmQDOgGwAmQD1AIMArIBogDQ/Tz8cPzY+5D6CPpw+hD8SPlA91D3YPbA9lD3yPgQ+dD3QPWg9MD1MPYA+AD5UPmw9yD2wPSg9rD4OPl4+Uj50PhI+CD5ePmI+oD6MPp4+gj7LPz4+6z8yPuA+5T8lPws/fD9/P74/Qj9pPxS/sH/nf9V/0L/2P/K/tj+swBUApgAkv+qAKYBbgEnAAIBXAL8AYQAowCkAq4BDAE6AW4BzQAMAXoB9gGkAkMAZQDC/5cAdgEsAu4BNwBWADEAOgGWAewB0AMcAiACBALkAzAEYATQBEAFOAaQBMgFIAcQCIAGOAdQCKAI8AmgCJALAApwCIAJQAtgDrANQA6ACrAJYAeYB3AKQApgC/AISAeYBPQC2AIUAgwDFALOAX7/MP/w/ZD8wPug+RD6mPrQ+uD6uPkw94D1UPaA9vj52PhA+XD2QPVw9WD1gPiY+Bj5uPiA9rD2kPZw9yD4GPnw+Ej5wPhQ+CD5mPkI+UD5MPq4+tD70PpY+4D7aPqI+kD86P3Y/cj8qPyU/Rj9BP1W/u3/IQDe/kj+pv8RAFv/AwDvAEwB7QDg/0QBKAKaAdUAnAEYAuQBPAIoAogCbAKEAXIBAAIEAkgC2AJkAaYBogGYAdQBxAEAAp4BOgGzADACiAM4AtgCxAKgArQCKAOwBIAFKAWwBMAFUAbgBVgGGAdgB+AGQAeACOAJQAlgCdAJMAlQCAAKcAxQDXAMUAsQCrAIGAd4B9AIUAnwCOAHMAZ4A2ABLACuAMYBcgGjABv/XP2g+9D52Pnw+Yj5iPm4+Tj5MPgQ9qD1kPYg9qD2gPdw9yD3kPUg9dD1QPaQ9mD3wPdg9xD2sPWA9lD3OPh4+AD4YPg4+ED4iPjA+Mj5oPmo+XD6SPtQ+2j62Ppo+9j7MPz4+/D9Iv6U/Cz9bP1+/mj+Fv+R/+f/KP/A/jEAwQBdAPAAdAFgAZgBjgGCARgCTgHaAcQCWAJAAt4BiAKuAZQBfgHmAUgCrAGsAeIBlAE6AYwA1QAgAcgBUgHEAXQBnAH6AcABPAJUAxgDbAPgA2AEcAUwBUAFCAaQBsAFaAbAB8gHwAcwCOAIEAowCaAJAArACmAJ0AuQDAAMMAsQCNAIuAegBmAI4AlACYAFQARoAcYA0QA+AFwC3QD+/pT9aPvY+mD6YPkA+ej5mPnQ+JD38PZQ9sD1MPXg9UD3cPdw9iD2oPVw9ZD1sPUA99D34PbA9gD2MPYQ99D2oPdQ+GD4WPgA+KD3QPj4+HD5YPoo+3j6cPpY+qj6APyk/Jj8sPws/cj9xP3Q/eD92v64/g3/OgB+AKEALQAWANIA8wBwAUACQAIsAsgBxAG+AYQCSAPUAlgCGAJIAswCJAJYAtQCcALgAVACvAIQAmYBXAH2AUgC1gFQAsQCDAKmARACAANsA2wD3AOABAAEGAR4BbgFiAbgBkAGwAbYBoAHwAdwCGAIkAlQCYAIwAmgChAKMAkwCkAMUAvwCRAKMAqwCGgFOAYwCKAHcAVgBAgGiAJC/mf/Xf/FAD7+wP0y/wD8MPhQ95j52PkA+DD50PgI+LD1kPRA9sD2sPUg9iD3YPfA9VD1YPXA9eD1APZA97D3cPdA9tD1oPag9tD3QPiI+Oj4UPeg95D4wPno+aD5cPoI+3j6sPpA+3z8cPx4/FD9AP4W/rT90P2M/i//Zv/P/+wAJAFYADYAtgC0ATACGAIwAvACKAL4AewCKAMkAwADiAIUAxQD4AKwAiwDNAPkAtwCtAKMAsACMAJwAlQC2AKMAogCrAJ4ApACpAIcA/ADeARIBEAE8AS4BdAFUAZoBnAHmAe4B9AHgAjACGAI0AgACkAKEArACcAKkAuACsAKAAzgC/ALkApwCgAKcAegB8AHMAhQB4AG+AUYA3ACrgAqAJ0A2v9+ALz+OPzI+lD6WPrw+LD5oPng+AD4MPfA9+D2kPWw9dD24Peg9pD20PYw9lD10PTA9uD3UPfg9vD2IPfw9fD1QPeQ+JD4UPfw97D4oPh4+Pj4SPpo+kD6mPpA+5j7MPvY+8z8eP3o/aD9CP40/mD+gP5C/3UAdwBiAFwAsAAWAcgATAEgApgC6gEQAsACtAKEAogC+AKkAwAD7AIEA/wC/AK8AoQDuANYA6ACnAKsAowCpALoAnQDkAOAAnwC9AIsA5ADuANYBMgEwATIBFAFEAZIBjgG6AaQB/gHqAdgBzAIkAigCAAJoAnAClAKIAlwClAL8AqwCmALgAugCmAI2AdgCtAIkAZwBwAHoARoBFgCuANQA6b/ov+CACr/RPzA/HD8sPto+rD44PlQ+vD3IPcA+MD3cPYw9mD3sPdg9xD2MPYw99D1wPXg9oD3UPeQ9rD2MPcQ95D28PYY+Bj4oPfg91j4uPio+Pj4YPm4+SD6KPqQ+ij7APtI+9j7WPzc/Hz9kP2w/fT97P14/iL/l//s/yoA0/9zAKgApAAGAUwBcgGuAZQBrgEIAhgCHAJUAqACfAIoAjwCcAKsArgC5AL4ArACVAIgAkgCXAKAAtwCAAPIArQCoAL8AhQDIAOUA8AD6ANIBAAFUAVYBRAGgAaQBhgHIAdIB7AHUAcACPAIwAjwCMAJsAlQCbAJ8AngCjAL4AkACkAJwAeACDAJsAdIB8AFeAWIBEQDVAN8A5ACKwD9/2n/ov6M/Xj8bP0o/Fj6APuQ+hj6yPgo+DD4sPjw9zD4yPgg+ED3wPbg9iD3UPcw95D3QPcw90D3EPfw9nD3kPeg98D3OPiQ+FD4APjY+ED5UPlI+Zj5sPp4+pD6KPsA/DD8qPuE/ED9cP1Y/ZT9Sv6E/sb+7P6c/+X/of/N/5MAzAD4ABQBGgGUAUgBSAHaAQQCCALaAdwBJAI8AhQCPAJcAngCZAKIAnQCgAJIAuQBRAJIApgCuAKUAugC+AKwAvACgAOMA7QD1AOQBDgFaAXwBcAGKAcwByAHqAdACFgHkAegCMAI8AhQCSAKUArACfAIEAowC0AJsAqgCVAJAAngByAI8AfABrgF4AWgBOwDcAPwAjQCWAG0/1j/xP7M/YT9lPzQ+5j7iPog+tD5WPnI+Fj48Pfw90j44PeA91D3MPfQ9rD2wPYw9/D2UPag9hD3kPbA9vD2MPdA98D2YPcw+CD4CPiA+Oj42Pgw+Wj5SPqo+oj6UPsA/Cj8hPzk/DT9kP2w/fT91v4u/1b/vP/o/yUAYACQABQBegGIAYIB0AEkAiACPAJ8AsQCuAK0AugCJAMoA+wC6AI0AzQDHAM8A0wDTAPoAtwCKAMUA9gC2AJEA4ADWANQA8gDEARABFAEwARoBeAFCAaoBoAHqAe4B6gH2AdACGgHEAhwCUAJsAnwCeAJAAoQCeAIYArwCYAJoAkwCcAIEAhgB+gGkAbgBUgFAAUwBFQDgAJyAb4ASQCP/77+bv68/dT8BPwo+xD7iPrQ+YD5WPng+GD4APjw98D3UPdQ92D3QPfQ9qD2kPaA9lD2gPag9qD2cPZg9nD2kPag9tD2UPeA97D34PcQ+HD4mPj4+Ij58Plw+qj6UPuA+8j7OPxo/Oz8aP28/TD+kP7s/ir/OP9h/xAAKQCYAMEABAGSAToBXgGuAZQB9gHqATwClAKkAqACqALoAowCjALEAggDxALEAswCCAOsArQCeAIcA1wCvALwApQCSAOsAmADyAPMAxAEyAR4BUAFUAZwBuAGQAfIBjAH+AZIBxAIIAjwCLAJwAlgCTAJMAkwCQAJcAlQCQAJkAgQCKgH6AYYBugFUAXoBKAEsAPsAhACCgFrAI//1P6g/vT9NP2g/Mj7OPvI+hD6qPlg+Qj5qPiA+OD3sPeg9zD3IPcw9xD30Paw9pD2oPaw9oD2wPbA9nD2gPaQ9qD24PYA91D3oPfA9wD4GPho+Lj4IPmA+fD5kPrQ+jD7WPuI+wz8NPyc/DD9mP3s/Uz+lv7W/if/N/+R/xMASQCOAAIBBAFQAW4BhAH0AQACMAJ8AsQCuAIIA+AC5AJAAxADOAMsA3wDRANsAyADeAOcA0ADKAOEA5QDQAMwA6AD/APUAxAEwARgBVAFsAVIBugGIAd4BogHwAcQB/AHuAfACOAI0AigCZAJoAkQCUAJsAkQCWAJAAmACIAIyAdABzAHcAbQBRgFyAQoBGADYAKsARQBIQBr/3r+Kv5c/WT8EPwo++D6MPpo+Vj5qPgw+ND3gPdg9/D2kPbA9lD2MPbw9dD14PWw9cD10PXg9fD10PWw9bD14PXw9QD2UPag9sD2APdA96D38PcA+JD4+PhY+dD5SPqo+gj7YPuw+yj8nPzw/GT98P0+/rL++P4l/5T/qv9CAHIA4AAkAXIBqgHkAf4BOAJsAoAC+AIQA1QDUAOQA4wDxAO4A8wDxAP0A8gDtAPAA9ADvAO8A8wD8APIA3wD1AOwA5gDKARIBEgFsAX4BegGmAa4BtAGOAeIB9AHoAhgCNAIIAkQCXAJUAnwCVAKYAowChAKAAqACRAJ0AigCGAIEAiwBzAHOAZwBagECAR4A+QCbAKwAdIAsP/I/gj+LP2I/AD8uPso+3D64Pkw+bj4KPjw97D3gPdQ9/D2wPaA9kD2IPYg9gD2APYQ9gD2APbw9fD1APYg9jD2UPZw9qD24PYw92D3oPcQ+Fj4oPjo+HD50Pk4+rD6IPuI++j7PPzI/Aj9kP38/UD+pP4N/07/gf8BADUAjADxAEoBmgHkAfABSAKQAqwC3AIQA2gDmAO0A8QD+AMwBCAEQAR4BFAEYAQwBCgEYAQIBCgEcARABHAEEAT8A2AEGARQBMgEyAUABogGuAbwBlAHqAYQB2AIQAigCKAJwAjQCVAJYAkACkAKcAqQCkALkAowCpAJYAkwCQAJUAiQCFAIUAd4BoAF+ATgA3gDAAN0AugBnwDg//r+2P0I/aD8OPy4+wD7cPro+UD5gPgA+Bj4wPeA92D3IPfg9mD2IPYA9gD2APbw9RD2EPYA9gD2EPYQ9iD2MPaA9rD2wPbg9jD3oPfA9xj4aPjQ+DD5ePnQ+Vj6wPoo+6D7DPxk/Kj8FP1w/dD9RP6K/uT+Q/+G/9j/OQCMAN8AIgF8Ab4B3gEIAkQCmALIAugCMANIA1gDcAN4A5QDwAPoA9QDAATkA6AD1AOoA6wD1APQA+gDzAOAA4wDtAP8A4gECAVoBfgFAAbYBWgGiAaQBlgHYAewB6AIkAgACaAIEAlQCYAJwAnwCTAK4AmwCTAJ0AjgCFAIEAhQCHAH+AZwBpgF+ARABFwDNANoAuYBIgEwAGb/Zv6s/fT8mPwQ/Ij7CPtQ+rD5SPmo+GD4KPgI+ND3cPdQ9yD3wPaQ9oD2cPbA9oD2gPag9pD2gPZg9tD2wPbw9gD3QPeA94D3wPcI+GD4qPgQ+TD5yPno+Vj6yPog+5D72Ptc/Lz8DP1g/bT9GP5q/rr+LP9k/8n/KQBWAKoA6QAmAVYBhAHKAfIBMAJsAqQC5ALwAiADWANIA1wDeANsA7ADlAOUA7gDcAOIA7ADoAO8A7QDUAN0A4QDQAP4A4gE8AQwBaAFsAWABjAGsAVoB7gGgAfoBxAIcAjwCLAIAAlgCUAJAAoQCjAK4AnQCUAJYAkQCYAI4AhACNgHoAewBkgGiAXABCgEnAMIA2ACrAHAAO7//P5K/oD9BP1Q/Nj7EPtg+gj6QPnQ+KD4IPjg94D3EPcQ95D2QPZQ9hD2EPbg9QD24PXQ9bD1sPXw9dD1EPZw9nD2gPaw9uD2QPeA98D3UPiw+AD5YPnI+TD6mPoQ+5D7GPyQ/Oz8UP24/QT+UP6+/i//pf/z/1sAnwDrADoBcAHAAQwCXAKYAsgCEAMgAzwDeAOsA/QD5AMIBEgEWARYBFgESARYBEAEMAQ4BFAEaARQBEgEKAQgBDAE8APABFgFUAUoBngGSAaoBrAGMAfoB2gHYAggCQAJUAlgCYAJ4AkgCjAKsArQCqAKgApQCvAJsAmQCWAJQAkQCWAIEAg4B3gGEAYoBcgEOASoA+wCJAIwAW4Aev/E/k7+lP3s/ET8kPvY+jD6ePkY+aj4QPjw96D3EPfQ9lD2MPYQ9sD1wPWw9ZD1cPVg9XD1cPVg9aD1sPUQ9vD1QPZw9pD28PZA96D3OPiQ+Nj4SPmI+Qj6oPrI+qD7HPyQ/Dz9RP3I/T7+Uv70/lH/zf83AIUAwQAAAYABbAHsAUACOAJ8AtAC5AIMAwwDTANsA9wDSAM4BMwDpAMwBIwDAATEA7gDsAMgBJgDaANABGQDhAOQAzQDrAOwAyAEuAT4BFgFwAWABbAFeAaABhAHcAf4BxAIgAjwCPAIQAlwCcAJQAoQClAKUArQCbAJgAkwCSAJwAhwCEAIaAfwBmAGsAUgBXAEwANEA7AC3AEGAVEAV/+s/hD+QP3A/Bz8KPuY+hj6YPnw+FD48Peg9xD3sPaQ9iD20PXQ9ZD1kPVw9UD1YPVA9TD1UPVw9aD1wPXw9QD2UPZw9rD2EPdA98D3QPiA+Pj4cPmo+Sj6sPoI+7D7LPx4/BD9gP2s/VT+qv7o/pP/zv8mAK4AzAAKAaQBkAEYAowCUAK8AgADDAMoA4gDbAP8A9QD1AM4BFAE+AMQBFgEaARIBBAEWARgBPwDxANIBPwD/APsA6ADqAT0A9gDGAWoBDAFaAWIBRgGAAYoBrAGaAdgB1gHMAhQCGAI8AjgCBAJgAnwCGAJgAkwCQAJ0AiwCIAI+AewB3AHyAaABsAFOAXwBPQDgAPYAgACgAGtAPv/b/+Y/uT9PP2Y/Pj7CPug+gD6UPng+Fj4APiQ9xD3wPZg9gD28PWw9ZD1gPWA9XD1cPWA9XD1gPWg9bD1APYQ9kD2kPaw9uD2QPeA98D3KPiA+Pj4UPm4+RD6mPoQ+4j7FPyY/CD9ZP30/X7+0P4k/7X/4/+QALsAAAGiAbIBBAJkArwCvAIMAyADYAOEA7QDiAMwBEAEYARgBJgEiARYBHgEaATgBGAEcATwBGAEoAQoBCgEKAS4AwgEEARABAgEMARwBCAEsASwBAAFYAWQBdgF+AUYBmgG0Ab4BigHqAfQBxAIQAhQCGAIUAhACIAIUAhgCEAIAAiYB2gH4AagBkgGuAWABRAFkAQABEADvAI4AowB6wBKAJX/Cf9i/rj9GP2I/Nj7OPuw+gj6qPkw+cD4YPjg95D3UPcQ99D2sPaA9nD2cPZA9mD2YPZw9qD2oPbA9gD3IPcQ95D3oPfg9zj4cPjQ+Aj5WPm4+Qj6aPrI+kj7sPsc/Jz8+Pxg/bz9Qv6k/hj/Z//R/zsAbADjADoBjAHQAf4BUAKYAsgC7AIoA3ADcAPUA8ADAAQgBCgEUARgBHAEgASQBIgEuASIBHAEkASIBFgEaAQIBCgE+APgAxgEEAQIBOgD7AMYBCAESARQBJAE4ASIBDgFMAVwBXAFeAUYBjAGgAYgBuAG4AZgBngG2AYYB1gGeAaIBkgG0AWoBbAF+ASoBCgEMATkA6ACpAKQAuABzwC8AHoA4v/4/oj+Jv7g/ez8lPwc/Mj7OPt4+jj66PlQ+cj4iPhg+PD3oPdA97D3MPeg9vD2EPeg9tD2gPYQ9wD38PYg94D3sPeA9wj4aPhY+Mj4+PiA+eD5EPp4+vj6GPt4+7j7mPyk/AT9jP0C/pj+jv4r/5//9/9MAKoAMAGWAZQBBAJgAngCwALwAmADiAOsA9ADEATwA9wDMAQgBIAEYARoBOAEcARwBKgEaARoBFgEeARYBFgEUAQgBCgEGATkA9QD0APQA7QDxANYA4wDmANsA2gDfAOMA3ADpAO0A5ADiAOUA8QD0APIA7ADxAPIA4QDwAPoA4QDqANsA2QDRAM4A1wDtAKcAlwCPAIcAtIBhgFqAUgBlgCJABkAHwB+/yz//P6k/mL+AP60/Uj9MP18/Fz8KPy4+6D7QPvw+pD6mPoo+jj62Pmo+Yj5kPlo+WD5MPkA+Uj5UPlY+UD5WPmg+aj5uPnY+Rj6SPqY+qD62Poo+3j7wPtE/DD8lPwo/Rj9lP0O/gj+Uv7q/lj/h//m/zIAaABwAK8AYAHWAawBIAJMAqgCeAK4AuQCaANcAywDGARIA6QDqAPIA7QDCAQgBMADQAScAzAE7APIA+wDIASIA4gD4AOIA1wDcANsAwgDEAPgAmAD+AJMApQCzAJYAmQCjAIIAuoBOAKMAkQCWgEQARgCBAKEAYgBqAFmAUgBYAE+AQoB0AAOASoBrwCmAJ8AWABQAGQAOwDP/ysANgDP/2P/h//p/63/B/8S/0v/2v6s/qD+B/8m/qT+Ov7c/bj9xP1a/hj9aP3c/JD9ZP0M/ED9zPww/Gz83Px4/ND7HPws/JD8HPyg+2D8QP3A+xT83PwY/Jz8XPxE/Pz8sP2E/Nz8zP2g/cz9aP3U/SD+sv5U/uz+tP/E/hn/m/+FANH/xv/YACIB6wCrAAAB+gHSAZIBVgFwAlgCuAFYAmgCfAKYAgADgAIUAxQC2AIoA9gCzAJYAlADfAL4AtABMAL8AvwCeAJSASgCdAJAAk4BigG4ATQCuAHdAIgBrgHmAKoBrgFzAOAA/gAcARwBOAEYAAYByAHn/xABkgBEAPAAZwCHAL0AHAFe/0QA7wB7ABgAov+jAPQAdv+G/30AEgFB/3L/1wDWAJj+Y/9oAc3/g/+2/goB9P/G/kX/zACV/5j+aP8xAOb+f//k/yn/xP36/jIAif8E/uj91gDs/qD9Iv6sAHb+ZP5s/k//c//4+wcACgE2/tj8+P52ANL+lP2A/l8AEQBQ/Tr/OACU/8D+wP9j/+z+EgEsANT/9P5hAB0AGgHI/m0ALAJi/xMAtADGAJ3/TgEOAZ4A1QBX/5ABwwBhAJYAcAGm/48ADAIW//AAtwBkAaX/0P7cAXgCov7W/pwCowBo/9L+dAIAAXz+Sf90AnYARP5QAJgCmABc/ZcAVgF1AHz+AABEAuwAMP62//QBDQDI/4L/IAGq/+QAWwAdABIAigCXAE4APP85AIwBmgH8/ZUAQgFb/1IAiQC/AEH/PACkANwAof9C/5//uAHZ/4D/ZgDw/lgBnwCq/zj9ogEQAZL+DwAyAFIBvP1O/of/NAKi/9z9DgGx/5L+9P04AQkAVP9k/rT/bgF0/tT/sP3XAGEAT//A/VgCAgFc/UMAyP7iAR//gP5EAKADcP0k/hQD/f/4/gP/QAFAAr//MP4oAcwAov9Q/xIBigCrAKj/2P6UAH4ANgEd/8L/xAEQ/1D/tv4MA3//xP0PALgB6wCQ/Xr+9gF6APD8uv/IArT+PP3s/9wBCABM/A4AoALI/uD7DAGQAcT+qP2HAIABsP4w/HwClAII/PD9tAGeAcr+qP2qAPYBsf94/DIBLAK+/pf/bv/1ABQBzv7n/90AWgGo/sABHgDA/7X/vgAYAov/2v/AASz/zgAb/+QBSwBu/6D/EAPs/kT9pAGYApT+SP2YAdIBvv4M/agBcAFp/+j8lv+0Apz9/PyWATgC8P1g+4wBeAGu/qj7rAJ1AKj9RP3u/kgEJP6w/Ob/KARw+qL+kAJZAKj+jP26Acv/VgDw/VACYv6B/zwAoABsALT+KAFPALz/Wv6+Aev/iv7MA+T/MP3H/0wCJQCA/z//BgH0Aoj7ugHA/5QBfP1uAZIBtv48/coBoAPI+hf/GAKMAeb+tPzC/ggFXwBw+t0AxgHY/T3/SARs/ZL+6/+r/zwCmf8w/VwAQAUM/dT8/QA4AnQB2P5s/Uv/qAQE/1P/CgC4Aiz9SP8UAzsAUv8YATwDwP3I/pT9CAecApD6mv/wBPD/lPzcAogBzQCk/JgC1AGbAKD9VgEMAuD97P7SAKAEkP7s/R3/QAIo/bQBMAII/YQCtP2S/pz+iAOi/sIAEf+I++gEWgGg++j5kAeYAnj7DPzIAysAgv/0/UwDef/w+tj+uAZYAyD2zf9wCgr+CPjX/xgG3ALA+iT9QAb7AND8FP68A9wBWPxm/5ADMALA+UMAiAO4A2D7jv6wAnwCYP0o/dAEvP/o/Aj9kAYnAEj7RAFAAoz+tPxMAl7+TAFN/+7+yAFM/Lb+4APqAKj5SARcAqj66P54A0AB8PrY/8ACMASA+uD9SAQtACj9rPzIBBQDkv7k/FAFmPv4+ygFsAG0AZT8cP68AnAD0Po5AAwDPAEo/sr+LgFgAiQBLP34/yoBNgFwAMr/IgEz/2f/OQBmADoB1gGk//T/LP6c/lgBAAU6/pz8EASq/vD+dP/gA7D8T/8wAloAbgAM/NcA4AWI/bD3JAMQB0T+OPnIBG7+q//4/rr+MAaY/Dz9iv5ABXT94P1uAP8AKAQ0/ZD6yAJcAwD/tP08/sAGcP2M/XoBgANY/RD8yAJqARgDYPtw/qgFCP3w/rz/OADcAWYB2Pwo/NQDwAJLAIj6of/YA93/tP89/3T/zv8W/+j/NAI4/y7+9AL1AKD7PAMk/MYBSARI/UT9fAK4BID9aP2Y/KgGCANw+bT9uAegA9D41v7rAOAFCPuIAfwCoP/g/cT9yAWKAZT9wPcACgADyPrA/jv/sAhk/Ej7cv5wBgYBUP22/0z/MP/cAEb/AAUC/tD46AJEAvAAdPx4/NADKAT8/OD3OALUA2gA8PwM/DgHiPlLAHj/VAEY+8r//AKXANn/iPj6AbQDmPug+1AIOPt6AJ0A9wCo/Bj9YAR0A3sAgPaIBbgGXP0A9xAEIAkE/sD4SAOwBlD9HPws/0AIUP0k/bD/wAlB/6D27APsA4YAWPg2AGAJPANY/GD2qAQoBub+QPegBTgF8Pvk/nD7cAUIAzD9uPwoAsv//P0kA/v/1PwMAsj9ugHEAL//Zf8zAFD//v+q/iD/4gGYBaYAQPc8/agGAAX4+Yr/Lv+wBnoAwPjB/8AJXP2Y+JQCCAcEAXD6Wf/IA7gEIPUsAaAMfgGg9bz8wApFAAj6sPygC3QCYPeY/CgHBAJI+KwC2APIAwD3WADwBFAEoPb2/nAEMAME/tD8aAOoAEH/ePrQA8YBav7W/mgDYf/w+18Aqv+wBWj6dP/9AHADTPwU/7gEiPnAA4j+zAKI+27/sAb1AAD70PcwCeAFePks/bgEjAIc/bD6wAIYB1j9UPsUA1wDJP2U/gAATAFYBmj5lPzIB1AB2PxA+ZgGeAUs/7D0uATgCfj4CPrsAgAKgPvA9xgBQAvE/ND3oATgAS3/yPoYBWwCdP0a/kgBVAJI+lgFGAJ0/cD92gGwBMD5y//4BcAFUPks/MgEWAIo/b7+sAZOARb+KPuQBWkAWAHc/NAB/ANsAfr+0Pf4BagGXgCY+pD9AAb4AaD7GAGQB9D6wPjQBEAG4PxI+zQC8Aec/VDwSAWQCQwBaPpN/07+0PzYAgwB4AEU/Ab/4AFxALD60f8gBTD+cPsFAJj/RP8gBMQC6Ppi/uj5KAMgBC4AlP0IAsD9GP2wAYD7SAXABUj7aPhYA4wCOP0IA+wBXQCA+1j5QAg4BwD4aPtACMoA4PZGAZgHyASw92j6EAmeAaD5MgHgBqQAmPmU/VAFqAXA+/j9CAVR/xz+zPzIBJAEt//4+eP/iAX8AqD61P0YBHgEiPn0/oQD7gH0APD32ANcAgT+7PwKAIQB/AGK/zD7cgHEAmD7ZP0oAZAGyALw9HL+SAbEAmj5oPsQCpQDsPi4+KgHKAWw+vj67AOQBBT8OPwwBowDWP3w93z9AAsABED4Yf8KACgEtAKI+Iz9gAj8ArD4Xv90AZgCcAFs/nj/1AKQ+37+AAaIA/j5mP34AxABHALY+3D7gAj0AJj76P7l/8wDcAM4+dD52AdIBJD82P6w/qT+kALA+qQDoATw/Lz/uv5h/8D4IAS4BKAC7P2I+m7+IAWW/6D8qANg/R7/MALQBDj76v5T/2MA4ASQ92gEUAhMAjD2ePm4BpgFMwAS/1gD6f+4+Jb+EAk0A+D5Qf+oBvgBgPUQ/lAIiAZQ9wD4sAkQBvz8GPm6/3AEtP6s/XgEXAJhAMD6DP0oAqQCegFuAMgDTPxY/fj9yAOABeD+cPs0AcgEkv6I+5YBuAah/7j6UP3oBDAEdPz0/NL/UAO8/nL+jAMXAJD96Pk+AHADQAHC/gv/pgA0/QD7eP/YBJgCkPuc/db+rgEy/wr+aAAYAmEAWPlIAXkAqALg/Yz9QABoAvf/WPrgA8gBUv5w+RAEHALl//j8JP6sA+T+KP2A/YgF/P1EAHoByv44/ij/SgGh/0EAPAGABcT96Psd/wQDL/+IAWgEtABm/jD63ALwBZ7+mPxQBBgCuv4q/tgCXgGC/o7+OAJGAaAArAL6AGT+WPngAHgGuAE4+oQC3APo++D78f/wBCz/uPqdAIAF6Pwo+hABkAjw+2D0Cf/QDDACwPQg/VgCwAXg+Fj9YAYgAwD3IPxABun/qPt0/VAKYgEQ9pj56AYoBir++Pme/5AEzP2g/WgDCAJEALj9QPyc/UgFZAKcAjz9kPoMAscAzv5gBMIAmPzM/fn/6AQkAbD5Wv7wBtP/2PpQ/WgGwAeg9oD4RANQCCX/aPv6/4gFEP6w9sgEcAUqAMD4PALMA/L+cPjkAhAG6PsY/Jz+yAXq/5T83v8UAxj79P0QA2QB/P24/SgFdgAY+6D6sAZ0Azj9YPuTAAgElf/M/BoB2AUw/Xj57P+wCcb/LP2o+0ACEATQ+8YBuAQ4BNj40PuuAaQDogFbAGADYPzG/4AAQgE4/mwBZALy/qT8tgCwBbIBGPsw/JgELP+I+wQD2AdE/ZD3yf+4BegESPgA/CAEkAWQ+hj7wATEA77+wPrs/igECgHQ/EoAEAJI/4D6KAV4BZD7sPkOAFAJhP0Y+uT+IAjkARD5gPvYBDwD8PzNAIEAAPs2//gFoAPw/Zj4MgHgBOn/gPrgAIgH+P8A+0D7fgDUAYAEEAWo+yD4MP14BjAEPPxs/MwDSARw+WD7kAVABXj7yPrsAjgDlP0tAJgErgEw+Pj5sARYB+b+VP00A8gAsPks/GAIQAXg/PD5hACMAyQCvP6J/3gBe/92/ugCy//4+0AGnANY/OD17gFwCVgHaPoQ92gE0AGM/Or+qAUOAXD6MQAwA5T90PuAArgHYP1Q8wD8gAuwB4D3EPsUAQn/tPyT/9gGHAKg++D5JP/6/nL/8AToBgD/QPZ4+9AEUAOAAXz+jP67/34ASP7EAZwDaAIU/Ej7DP2ABWAHu//U/Lz9x/+l/3EAMAQIAP0AKP/y/vr/wv8i/3wBEAUw/Zj7kP/IBEAEqPy4+coAUAaY/gD8MgEIBe7+yPpyAMgC1//A/FgCAAQC/gD6/QBgBu3/EPuK/sgEnwDY/Lj9iAQwArz8JP5C/zACS/8G/34BmAG0/hz+PACcAdz+MP+V/3oB9P/M/R4BsAEgBPj80Pl4/+AE6AM4/sD9RQDiADj+Bf/QA9AC2Pso/XIBlALA/fn/qAWDAAj62PlgA3AI1AEI+nz9cgCv//j/PgFsApb+1P01/+YAuP3x/4wCzP8M/Vj8wAHgBI4BIPs0/tz9y//sAagB8f+Q/eoAwP7iAKj7w/9IAjYAlP9Y/lwBXP6g/1T/iv4O/lMAeAQIAwD8EPk7/yAEzAJaAAj/C/+O/jT/BP96AewASgEAAIb+EP+JAMACtP+JAHD7DP1BAOAFSAac/cD5CPu0AiwCwADKAdn/GP7k/Yj+wP9UAhgCogGo/oj7tP0QBLACav/4/gT9NwAIAgwC1/8F/0r+4f98Agb/zgHsAFD+Vv81AJ3/OAIAA5UAqP34++z/kAJ4A1QBPQCU/rj7vf8oBJwCNP2y/jIBnAEG/0UANALu/l7+pv5EAZAB7gHZAEkAUP0A+/8A+ASAAqMA+Pyg+i7/wAS8Ao3/Nv7E/vL/ZP1m/0AC2AQa//D7cv4uAJr/xAKIA7T9hPzY/MgBmASYAQD9XP1A/wYBzACgAu3/h//0/qD7bP9cAmgFpABA/eD7eP5cAiwDuAKo/0j8YPsYArAG7AIs/VT9WgDUAC8A7AEQBAQCoPxg+uMA6AWkAzQC/v6Q/LT89QAoBJAEfAEY+vz87AKAA3D/O/8PANz/Nv4O/mgDRAM4/ZD8qQBQAhj9HP6ABWAEkPtI+Pr++ATgAaz9kf9EAnAAgPwJ/6ABYwBg/T//3ALgA5r+4Ppd/5AElAHE/Lr+CAT4AsD7vPxwA+AC6v6a/tIBTAJy/kr+lwDMAub+Xv7XABQCeALT/67+6P2NAFQCBAEfANb+3gC8/7wAkAARAPb+QAJ2AGz+7P/4/x4BUf/e/77/7AHg/Qj/bQC+/nb+9f8wBGIA+Ptw/I4AkAFhAKYAXv40/qL+2gFuAU//EP6rAA4BaP4I/vgA7ANTAFz/Nv7e/14AwgAYAtz/gP88/jcAYAS4Acr+9PxcAMwBpP7A/fIBIAccAuj7YPpM/jADYAEwAtgBDv60/dQADALIAfz85P2kABgC2f8Y/lYBvgEkAqT8UPu4/wgF8AMW/kD7Iv7gAvwBkAAiAM0A6P2a/oX/4AC0ATD/bgFmAHf/hP2GAPYBMwC6/hD9fAHcAo4BrP80/ar+ggAmAV3/jv9aAToBqP14/fABXALZALz9fP1c/2MAbwCsAo4BtP34/CP/TwBnANkAywDW/jb+1P4gAj4Bx/+I/vT9mP5+/3gB8AHXAPj8CP6k/oYB/gC+/2r/sf/m/qT8nP+wAuwCbP2M/IsAdAEgAF7+TACT/4j9tv7sAogD1v9s/tz9Sv4p/6YB+AKoAPD94v4WAan/3v8oAZEAgv58/dj/1AKgAkMApP3Q/W//LAEkAkoAtv/j/3j+N/94AHoBrwDW/u//5gC0/sj9igHkAib/+Pwu/mAC/gES/oz+wwDsALT+sP9YASH/ZP6E/soBLAIA/6z+wv+PAKv/4//O//8Ahf/S/2YA8P9LALgARgBY/9f/kv8eASQBvP+g/77+mv6WATgDVAHQ/Qj97P5oAFABiQDJAPcA/P5A/WL+NgEMAk4Bxv7Q/Ez+LgGwAuwBnP88/ZD9XgD0AfgAk/9N/xIALf9p/8oAoAFCARb/CP3E/XUAYALAA5oBWP1Y/G7+1AGcAiEAL/+j/64AiQDg/u//dALmAZz+KP7s/6gB4AH2/2oAg/8x/z8AmAJMAub+RP0UAGQCEgFl/w4BbAKa/+z9fP4+AbQCZAFlAA3/oP6T/8kAqAGz/2X/Nf+LANP/5/+WAIb/4v4C/5sAdwBzAGD/Sv9+/uz+XAAQAcIBqv7E/UT/pgA9AM//pP/T/+QAp/+J/xUAkwCy/6r+u//zALUA4f+q/4b/UP/e/4YBJAGk/+D96P5qAW4Bc//M/9sAvP/W/gD/ywDuAUUAJP4i/tn/CAHsAdgA2v7Y/Zr+i/9MAb0Apf+C/2T/I/8h/+X/AgCHANz/tP2a/q8A0gHUAC3/gP0K/pwA3wB4AR4Bef+c/rr+DQD+APUAhACw/4j/FQDUABYBCgFQADP/mv7q/5IB6AK0AV7/0f/z/9L/egAgAvQBRACs/wgAWgFyAEgAiAGeAT3/jP6EAEgCagH9/zv/O/+pANIANgG/AJb/zP5h/9D/MwAsAboAEwD+/jX/Cf9DAEUAvv9S/x3/UAAYAHkAWf8e/9T+lf8JADcA2/92/9//6P5w/7f/xADp/4r+cv8CABsAWf8N/+r/kwCA/+D+Bv92ALb/SP8m/zIA5QBT/7T+O/8nAND/yf8WAX8Ab//G/qz/1gBHAL7/x/+8AJoAtP/2/0UAVwCRAIUAUgBAAGAANwB+AFAAh/9nACwBLAERAKH/5P9kAHsAYADgAH0A4f/J/4kANwCs/0wA8QA3AAr/vv+fAIwAjf8s/0wAKABs/9v/AQBP//7+lP8jAGMAYf8b/07/U/9R/13/7P/T/7v/E//m/on/AQC7/3v/oP/G/4z/bv8wAD8A3/9D/37/+f8kAKP/x//a/6D/HgAYAM4AggAdAK3/lP/K/y0A1QA8AQIBSADz/xQAQgBJAIwAowB6AOwA2wDTAFUAMwCqAJIAfQB0AEwBEAEaADUApwACAXcAhwDaANMAOQDk/7cAEgGdAIMAWACDAEUAgQC3AEMAiAApAFUAuwBrAHoACAHVAPb/OgDv/6cAMAGKABoANQAeAAwAZgCnAIwA9/+q/5X/8f/g/9b/dwCQ/0f/Fv/Q/pL/Qv/F/8f/yP6u/in/Q/9k/+j+C//k/4j/R/9M/5T/iv9L/2r/wf8KAOj/2P9XAEoAhv/6/kAA3ABnAGgAzv/t/9X/AwBJAPMAngAV/5f/ff9h/9H/PQDz/1j/8v6c/gX/5v7S/hT+Bv5c/vj9Ov7s/XD9GP24/MD8HP3U/fT8DP3k/Aj8HPyI/Cz9mP34/Aj8MP1U/TT9Tv6u/jn/sf9a/3T/MwBcADQBeALEA2AEfAPABCAF2AWwBugGcAgQCTAJQAlQCWAKEArgCvALwAuAC9AKYAsgC0AK0ApwC5AKIApQCfAIcAjwBhgGEAcoBpAE4AMkA1QCGgC8/vz+3v7Y/PD7cPtA+jD5YPcw9xD3kPVA9LD0oPSQ84Dy0PFg8iDx4PBg8WDxAPGA8HDwsPCg8WDx0PHg8lDyoPGw8jDzwPPQ9GD0QPWg9qD3oPgA+SD4IPhQ+Vj7bP3q//YB+wAKAcD/egEgBVgGwAegCbAJAAmACsAMcA3gDaANUA4gEHAPAA+gEaASwBDgD2AQgBDAEFAPQA9gEIAOkA3gDWAN4AyQCoAJAApQCdAH6AbABmgFIASoAkwC9gGgAGD/3P7s/UT8sPug+iD74PoQ+bD3oPZg9gD2APZA9SD1gPTQ81DzYPOQ87DysPJA8yDzkPLA84DzoPLw8tDyQPNQ8yDzQPSw9QD1wPSQ9QD2IPXA9YD3oPmA+ej4MPu4/JD95Pze/ocAdQBmANYB2AR4BtAGwAbgCCAJ0AigCEALgA3ADFANoA0wDyAPsA2QDcAOkA6gDrAOgA+QDvAMQAwgDOALUAtAC4AKUAqgCEgHuAYABpAFkARQBIwCsgHqAEv/9P48/gr+JP5I/aj7iPrA+aD4IPh4+Mj4WPiQ90D2cPVQ9bD04PQA9lD10PNg88DyMPOQ8xD0MPQg9JDzwPHQ8bDy8PLQ8mDzAPQw9eD1sPOQ9JD10PQA9hD40PrQ+7j7KPvE/PD90P0fAIAC6AOoAwgEoAVQCCAJgAhwCWAKwAtgC5AM4A6AD9ANQA0ADrAPABAQDgAPsA8wDuAMYA0wDvANgAsgCtAKcAogCbAHyAfAB8AFkARABOwDGAKnAJT/kf9O/7j9mP1k/Rz8sPqw+Tj5QPm4+GD3gPeQ9zD3kPYA9uD08PTA9KDzgPQw9cD0cPRg82Dz4POQ8xD0EPUw9ZDzcPLA86DzsPSA9UD2EPjA9bDzYPVg9jD3CPnQ+dD6wPuw+4j8fP2w/vb+IABCAQQCWARIBbgFGAeYB9AH4AfwCMAKAAwwDPALAA1ADUAM8AxQDoAOQA6ADeAMMA5gDQAM8AwgDHALoAqQCmAKMApACaAHCAeABWgFCAWwBDAEpAK6Adr/HP8E/zb/Pv4M/Vz8gPvg+kD6oPnw+cD54Pfg99D3EPfg98D24PbA9rD1sPUA9iD2IPVQ9mD1wPQQ9nD1EPbA9PDzcPRQ9cD0APWQ9mD2QPSQ9LD1QPcg+dD3wPfA92D2OPlA+77+v//2/oj+WP2Y/gYA2APQBGAGGAfoBigHSAfwCBAKUAsgCwAMUA1QDRAOMA0gDUAN8A2wDtAOYA/wDqAMcAsADDANQA4gDCALAAsQCUAHmAcQCeAISAcYBVgDcANYARoBPAImAZEAwP5k/Yj9bPzQ+6D6mPpY+rD6EPrQ+Kj4IPgw9yD20PZ4+Cj48PZA9jD20PXA9BD1IPYA9yD28PSA9cD1gPSQ9BD0oPTg9SD1YPWA9cD1YPUw86D0oPYg+KD3oPbg+Pj4YPg4+YT8nP5c/jT9FP4XAFf/iAF0A3gGGAZgBKgG6AdQCFAI4AgQCvALQAtwDBAOcAxgDNALkA2ADVANgA2wDCANYAvQCzANoAzgCpAJ0AjoB7AIwAeQCKAIIAaIBOgDfANoAjwCSAGMAQoBMwAQ/+j+cv5k/OD7wPro+/D8WPyY+4j6YPpw+FD3gPiY+oD6GPlw+PD3oPcw9rD2GPgA+WD3wPag9lD2oPaw9WD20PbQ9fD08PSA9UD2cPVQ9WD1oPaA9pD1IPeg95D2UPdI+Dj7PPz4+/z8HP6M/Bj9fv/uASgEBAMgBLgFCAbwBuAI4AkwCYAIIAqQDbAMAA7QDQAOEA6wCzAOYA7wDrANIA4QD3ANQA2gDHAMEAtACjAJ8AqQCqAI4AjABtAFQAUgBBAEXAPyAboBvwAGADD/OP5U/uj8+PuI/Kj7+PoI+qj5CPqY+aD4EPlg+aj40PZQ98D3gPew9/D2wPcw9zD2wPUA9yD34PWw9aD1UPYQ9oD0MPUw9kD10POQ9PD04PXA9ED0MPUg9sD0UPUA+BD4IPcQ9ij4EPvY+6D8fP4t/+z9hPwE/pgBoANABRAHIAiwBjgGyAboB2AK8AoADDANIA3wDTAOUA3QDFANwA5wDmAOcA6QDlAOUAzgDDANcAwQC1AKMAvwCbAI8AdACOAHcAaABXAFGAUAA/gB5gEgAawAeABwAA8A1v4s/fj8uPzg+/D76Pt4+0D7+PoA+6j6kPkQ+dj4OPgI+KD4WPkI+SD4APdQ9jD2MPag9tD2gPbg9WD1MPUw9eD0IPSQ86DzcPTA9BD0MPRQ9ODz0PIw9FD2sPZQ9nD18PZw+Ij4CPoW/1T+CPvI/AT9lwAEAhwC0Ab4BuAFuAX4B5AIsAjgCTAMcA6QDLANEA/QDkAOYA2gDkAPkA+wD4AQoBAQDiAOQA3gDRANAAwwDIALQAvACQAJIAiACLgGgAV4BdwDwAN8AiQCRAIyAev/df/U/kT+tP0Q/ej8LPzQ+6j7WPuA+3j7sPrY+RD5UPmA+QD6qPmo+WD5aPjg99D3SPgg+ND3wPfA91D3APcg9kD2gPbw9aD1gPWw9UD2UPSw9GD1APVQ9CD28PYg9yD2APSw93D3wPZY+vj9bf/A+9j7yPsW/pj+5gBABrAHMAQQA4AHmAcwCEAIgArgDMALYAugDoAPcA2wDYAOwA8wD5AOIBBAEAAOYA2ADsAOAA8ADsAM0AugCRAJMArQCoAJ8AiYB5gGEAXQAxAEpAO0AtABSAIMAgIBkP/s/jb+cP1s/dj9RP6I/fD7ePuQ+1D7iPvw+4D7mPrQ+ej5KPoY+tD5CPp4+cj4gPhw+Lj4GPig9+D3oPfw9pD2kPYw9tD1UPUA9WD1gPWg9NDzoPOw9KD0wPTA9ED2oPXA84DzcPag+Qj5wPpo/CD9+Pmg90j9WAEcAqgC2AMgBSgEBAPYBDAKMAngCAALUAyADBAM4AsgDXAOcA2wDqAPwA9gD4AN8AwwDTAOUA6ADrANkAxQC0AJMAkgCgAKoAjYB4AHaAZQBZAE7AMsA+QBrgFYAsIBUgDT/0L/vP1g/fD9/P6y/jz9iPx0/KD7MPss/CT9/Px0/Jj7WPtg+/D6wPoQ+5D7uPs4+4j6aPog+qj5OPlg+dD5aPng+ED4GPhw9+D20Paw9oD2QPaA9UD1APXQ9XD20PZQ9XD2APbg85D28Peg+1j9OPsg+9z82Prw+kX/QAIQBFAE9AIYBagFYAWgBrAIoAmgCvALEAyQDVANEAzQDNAMMA8AEIAOoA4gDyAOkAxADXAOIA+gDOAKcAugCtAJ8AhgCVAJgAe4BZgF+AX0A1ADDAI4AkgCQgEQAZAApv8k/pD9ZP0W/qD9YP28/bT8OPyg+4D78Ps4+2j7IPx0/Ij7yPoQ+7j6aPoo+uD6EPtQ+pD56PmI+Xj4uPjg+AD58Pfw9wD4gPdA9iD28PbA9VD1kPXw9TD1EPQw9oD1QPYA9fD0UPdg9UD2GPmg++D7uPtQ+0D7LPxM/SsATAIgBCAEUAQoBYgFyAYACOAI4AkwC0AMkAxwDaAN8A0wDVANcA4gD1APIA+QDsANQA0wDfAMMA2gDHAL4ApwCRAJwAigB9AGEAa4BagEtAP4AqwCOgFdAEUArv9b/3b+DP4O/nz9AP2k/Dj8yPsc/AD8sPvg+9D7sPtQ+zD7gPsY/CD7QPvQ+9j6KPv4+pj7KPtw+iD6UPpI+hD5yPmY+fj4IPh4+DD4gPew9tD2cPYg9mD1cPVg9XD0UPTw9RD0QPUA9RD10PQQ82D1QPfI+Nj4kPtI+8j4yPjo+sT9MP+HAIACuAMQA5oBeASwBsgGeAdwCeAKIAtgC0ALAA3wDBAMkA3ADvAO4A4ADsAN4A1QDVANMA6QDYAM0AsQC4AKkApQCSAJoAjwBngGOAZwBVgElAMQA0AChAHeADoBtQAP/zr+Dv9w/lj9QP2w/cj9VPzg++z8LP2Q+/D7uPwU/BD8WPuw+1j88PoQ+xD8yPsY+xD7uPrI+ZD58PnI+fD5mPlg+Rj5QPdg96D3IPcQ9yD3EPeg9bD0MPUg9nD0sPSw9FD2kPUw8+D1wPWQ9GD2+Pgg+3j6uPjI+Wj7ePmo+5f/vAGcAtEAhAKcA0wDoAP4BcAIAAkgCSAKwAvAC0ALUAuQDNANwAxQDaAOAA+gDbAMUA2gDaAM4AtADHAM0AowCmAK8AmgCIAHCAcYByAFyASIBQgEqAKMArYB+gANAIP/EwBj/8D9Zv6w/uT8+PzI/BD9yPwQ+2T8HP1U/ND7PPzQ+8D7+Prg+xz8yPuQ+3D74Pvo+zj6+Pq4+qj6OPro+Rj6oPoA+Uj4+PjY+PD3IPcg+ND3kPWQ9JD1kPcA9vDzgPWg9pDz0PPw9ND1gPUA9GD4kPnI+KD4APm4+bj40Plw/YX/XP/SACwBZAH6AOIB6AR4BUAG+AfgCCAJYAnQCRALgAowC5AMoAwQDTAN0AxgDWAM4AwwDQANQAwgDMALMAuwCsAKEApgCfAIsAcgB3AG8AW4BSgFKATMAxwD5AF+Ac4AqQCpAMX/pf+b/zb/eP5Q/sD9zP1c/WD9kP1G/tT9EP3s/AT94PxE/Aj9KP38/Bj8KPyc/Fz8IPuY+5T8IPsw+kD6APvA+uD4QPlQ+rD4APeo+ND4IPcA9fD0cPYw9tDzgPaw94D0wPJw86D0MPQw9ND2+Pg4+CD2aPgI+YD3UPgI+wz9mP2U/fX/WAGe/4D/dAJwAzAEGAVoB2AI0AewB0AJQAqQCYAKEAygDPALsAugDMAMIAywC8AMsAygC/AKMAvwCiAKIAkwCXAJ+AewBsAGgAYgBfQD0APoAxQDlgFGAVoBDQBU/w7/f/+y/iz+yP3E/Vj9lPys/OD8CP04/ID8lPxw/OD74Ps0/Oj7SPzw+3T8MPz4+9j7sPuo+2D7qPtA+4j7wPpY+6j6KPog+tj5aPng+Kj4EPmw+ID3wPZw96D2MPbQ9nD3gPdw9WD0sPXg9YD1UPd4+CD5UPjg9zD58Plw+bD6bPw8/Sr+kP70/9wAQQD5ALwCgAOYBOAFcAZwB0AHeAfACCAJAAqQCtAK0AogCwALUAswCzALkAswCyALAAvQCvAJ0AmACdAIgAjgB6AHOAfoBeAFaAWYBPADEASwAtQC0gE8AZYBhwArAG4AWgA6/2H//P7e/qj+VP6o/nD+dP4w/oL+Av4+/ib+Ev7g/fT9Tv6k/cz9sP3Q/ZD9LP1s/WT9oPyA/KT8LPyg+2D7ePvw+qj6wPog+tj5IPnw+KD4wPeQ92j4cPcA91j4CPiQ9zD2EPaw99D3sPdw+aD62PlQ+Qj6OPt4+/j6iP2w/tb+Gf8aAJwBeAHvAOAB7AMoBMAE0AXABqgGOAb4BtAHgAhACNAIYAkwCaAIAAlgCYAJEAnACFAJwAhQCCAI+AdwB8AGoAZwBjgGUAVQBcgE6AN4AwQD7AKgAtQBgAE+AccAXwAFADcAvP9Z/x7/Ef/+/pb+hv6G/r7+Ev4g/kT+TP4Y/tD9OP64/eT9tP0m/vj9jP20/cz9nP1o/aD9qP1Q/dz8NP1Y/RT9OPyw/NT8IPwI/PD7KPyA+0D7cPug+/j6sPr4+hj7cPog+mD6SPq4+mD6CPtQ+1j72Pqw+2D7iPsM/Gz8IP0s/bz9Lv4R/4D+/v7e/7b/ZwDOAKgBwAG4AUQC2AIUAwwD1ANYBEAExAOABAgFyATIBDgFoAVoBQgFaAXgBVgF8AR4BYgFMAUoBTgFaAUIBWgE0AToBIAEUARoBHAEGATAAwgEGATQA2QDgAOUAzgDDAMgAygD5AJ4AogCtAKAAiACVAI4AuwBhAGCAZwBWAH9AAoB8gCbAEMAXgBAAOT/k/9Z/3z/8P6q/pD+bP4O/sj93P2A/Yz94Pzg/MD8VPwU/BD8BPyw+4D7YPt4+zD7APvI+sj6iPqI+uj6CPvY+pD6CPvo+tD60Ppg+6D7oPug+xz8ZPw8/FT80PxA/Sj9XP3w/U7+WP5o/vr+QP9J/3v/BgBFAEYAcQDpADYBIgFYAcIBKAIUAigCdALAAtAC5AIgA2ADbANcA5QDwAPEA8wD+AMgBPQD6AP8AyAEIAT8AxAEEAQABNQD5APsA9ADvAO8A7ADcANgA1wDSAMEA+QC2ALUApACYAJoAiQC8AG4AbQBfgFMASIB/ADTAIMAcgB0AFIA///k/8j/lP9k/zD/H//8/r7+kv5+/mT+KP74/cz9sP14/Uj9LP0s/ej8xPy4/Kj8YPxc/ET8RPw4/Nj7BPwE/Oj72PvY+9j70Puw+8D78PvQ+7D72Pv4+wT86PsQ/DD8bPxQ/ID8qPzM/Nz8CP1A/WT9lP2o/cz98P04/nD+tv7w/hr/XP+A/57/4v8GAD8AjADSAPYAHAFAAXQBrAHKAfQBJAJQAoACsALgAvQCIANUA2ADmAOoA9wD6AMABBAEIAQwBFAEaARgBHAEYARYBGAEWAQoBDAEIAQIBPAD1AOsA4gDZAM4AxQD9AKkAoACPAIUAtoBrgF0ATgBBgG9AIQAVQAYANb/qv9n/zf/Ev/A/o7+Uv4S/vz93P24/YD9YP1A/RT9+Pzc/MD8sPyc/Jj8iPx8/Gz8UPxU/Fz8aPxg/GD8aPxs/Hj8cPyU/Lj8yPzQ/Oj8/PwU/TT9SP1g/Xj9kP2s/eT9FP4w/lz+dP6c/rr+5P4R/0v/bf+P/8P/8v8jAFMAjACjAM4A/gA4AVwBcgGeAcwB8AEEAjQCWAJ4AowCoAKwAswC6AIIAxwDMAMwAzgDRANIA0ADOANQAzwDQAMsAxgDEAP0AtwCtAKoAngCZAJIAiQCAALIAYgBVAEuAfwAygCSAH0APgD4/8L/j/9R/yX/8v6+/qT+bP5S/iD+7P3E/Zj9gP1Y/VD9NP0Y/QD9+Pzo/Nz8xPzE/Lz8wPzQ/Nz84Pzo/Pz8FP0w/Tj9WP14/YD9oP24/dT9+P0K/jz+SP5y/oL+sP7c/vD+FP8S/0j/Uv95/5D/p//F/9z/+v8QADYAVABpAGUAhACcAL4A1ADnAAoBKgEsAUQBZAFwAZABnAGwAbwBxgHiAeYB8AH+AQwCJAIkAkACPAI8AjACLAJEAjwCUAJQAkgCPAIoAigCFAIYAggC+AHqAdgBxgGyAZoBigFwAUgBMgEiAQwB8ADMALkApwCEAHQAZwBaADMACAAFAOn/0P/C/6z/o/+D/2j/U/9K/zv/Kv8d/xL//v72/vr+Av/u/vT+8v7Y/uT+8v78/vz+9v4C/wf/B/8I/xT/D/8W/x3/J/8u/zb/Rv9J/0z/RP9b/2r/cv+D/4r/mP+a/6H/s//G/9z/8P8NAA0AGQAeADMAQABNAGEAcwCTAJwAqQCwALEAvwDRANYA3ADjAOMA9gDvAPAA9AD2AOoA5ADeANcA3QDQAMUAtwCoAJUAjAB/AGwAZABGADgAIgAKAA4A/P/m/87/tv+p/6P/m/+Q/4r/d/9x/2r/ZP9f/03/Uf9L/0v/RP9Z/1j/S/9E/1P/V/9e/27/dv+E/3n/dv+P/6b/qv+w/7z/wP/T/8//3//n/+r/+v8TABYAFgAYABkADwAYAPv/FAAWABwAIwAlABUAEwAaABgAHgAWABsAIwAYABgAHAAqACkALAAiACkAHgArADEALQA0ADIAOAA0ADUAOQA2AEMAMQA3AEMAQAA8AEIANgAlAC0AMgA+ADYALgAlACQAEAARABkADQAFAP3/7//s/+v/5P/q/97/xP/H/8P/vP+1/7H/uf++/7T/qv+3/6//ov+p/7X/vv+1/8H/zP/O/7//yP/V/+v/7v/p//f/BwAIABQAHAAYABsAHgAmACwAMwAuADMAOQAvADIAQgBLAFAAUgBHAEoATQBJAE8ATwBBAEgAQQBFAEAAMgAbAB4AGgATABEA/f/8//X/7P/d/+D/5f/h/9H/zv/J/7//tv+0/7z/tv+w/6//t/+q/6P/qv+x/6z/qP+s/6j/rv+u/63/rf+s/6v/r/+y/6//uv/B/6f/p/+t/7r/vf+q/6P/pv+m/6L/tP+4/7H/qP+l/6n/of+a/6D/rf+w/63/pf+y/6r/qf+q/7T/wf/D/9H/2v/Z/9L/4//z/wAABgAVACEAJgAmACMAMAA7AEcATwBWAGUAaQByAHAAZwBxAG0AbQB+AHsAeQB2AHUAegBwAGIAYgBXAE8ASQBBAEEAOQAsACkAJwAkABsAEQAVAAcA9//z/+//8f/o/9r/3f/O/8n/wv/E/8T/xv/G/8T/xP/G/7f/wf/C/7v/x//I/83/yv/B/8P/u/+8/7D/p/+u/7L/t/+0/63/oP+n/6P/nv+q/6X/sP+o/67/wf+7/7v/s//B/8f/yP/P/9v/1//P/83/3P/q/+X/3v/i//P/5//Z/+T/4//r/+3/8P/6//7/+P8FAAUADQAJAA4AFgAbABsACgATABEAGwAFAAcABAAOAAsA/v8QAAwA+//7/wQADQASAA0AAgAFAPT/6v/k/+v/3P/M/87/1P/J/7//vP/A/73/u//A/8L/xP+8/7z/yf/A/7T/sf+//8L/wv/G/9T/0v/P/8//z//d/9v/2f/e/+X/5P/a/+v//P/y/9z/6f/5//P/6//m////+f/1/+n/+/8NAAoADQAYACwAHQAVAA8AIQASAAkAFgArACgAEAAeACIAMAAeAC8AMQAxACEAGgAoABgACQD+/wcABgD7//L/6v/r/+T/5P/2//j/8v8AAA0ADAAPAAsAFAAXABEAFgArADsAMAAkAC4APAAuADQALwAvADEAMAAnADEAQgBBAEgASABRAFwASABOAGUAgQByAGsAcQB7AHUAagBsAHsAegB+AHUAdwBSADwAMQAoABsA/v8DABkAOgBDADAAIQAXAAsAIAAwADcAMgAgABoAFAAaABEA7//v/+f/5P/j/97/6v/q/wIA7//1//b/BQDz/wsAEAAjAPn/+P8LACYAQAA0ADoAQAAtACUAHQBGADcAMQAkACUAMgAgAB0AFQAfABwADQAkADUAQAAbAAoAEgA4ACgAFQALAA0AIAD7/wUA+//t/6r/rP/M/9j/ov+e/83/5v/P/+X/5v8IAKL/j/+P/6v/3P9sALIAVgDY/vb+Nf+B/9//df/8/7X/RQDM/+T/HgBRAFkAqP+w/zIAPwCw/3P/ngCEAVcAx/93/90AdADW/ysAKAH3AA4ABAC/ACoBRgAZAIcA2QANAMT/lAC4AFQA0/8uAMcAWABV/6n/bP9M/y8Asv9LAKD/pf+F/8L/YP/a/wgBkP9b/0T/ZP+a/pD9gv5Y/oz9rPwQ/RD9UP28/CD+0//2/rj+BgBsA3AFWAS0AND97P5cAP4AUgEQAZIBowCq/pb+u/+B/wL/rv8uASgBcwAYAqQCOAJpAMIA4AKIA/YBLAEsAzgCGgEgAvgBvAL0AU4APAAiAOgC5gF2AEn/VgD4Afz9RP06/7QBlPy8/f///AG0/Zj7UP2P/yD+qPrE/b7+2P0g/Cj9wP8g/kT95Pzs/LT9FP2a/mT/QAB8AMsAEAHd/3f/sQCT/8AB3AGUARAAH/+g/+YBqAK+AXoBaADQ/7f/cf/F/yoBhAGqAIAA2v8lANj/gv6c/xoAMP9k/hb/VQCl/+L/4v5mARH/Zv7G/nAAZgHy/sr+EP/2AIv/a/+H/2kAHwAe/wYAOQBl/7b/AAEIAisAvv4EAHACwAB//9j/wgHXAG7+f/+8AWoBOP9a/0YB3AGK/zz/5QAdACH/mv4oAZYBHgB4/pH/ngAA/yD+1v6TALH/Yv4o/p7/YADL//L+k//R/4D/8P7c/iAAwACV/yb/cQDxAHwAl/+x/3IAMgDL//P/ewAAAF3/Nv+y/9z/oP+h/4f/3P/e/0QAWAAcAEEAzP+i/9n/BwBwAFYAt//v/yEABQCC/08AqQBrADsAPADhAOoAdwCeACQBRgE+AV4BHgFmAaIBFgHGAMgA0QDzAM4A9ABMAQYBwwCxAJUAeQASAEcAqQBvAAUA8v8cAEcASQAIAC4AVQBwAOL/2f8WAP3/8v+p/9P/7//K/9f/QgAkAMn/uv/0/zwA4P+Z/zoAcgA8AAYAcAD1AJIAcABaAJgAYgAXAGwAxgDSABAANwC3APkAiQAhAGwAxwBTAP3/BgA3AGIACwCu//7/JwBXAMf/m/++/woAu/9m/97/HwCS/yn/n/88AJv/GP9h/+D/Qf/Q/vL+M/8h/9T+6P4P/z//Gv9O//z+ZP95/woAzv/T/73/CgCc/3f/QQCNAJsAOgBdAKoAbgDa/0IAaAAyAAYArv9xAJIA0//N/+D/LQBSAMP/qv/9/5//X/9J/6f/q//k/gH/fP93//r+Pf+K/yv/9P5j/+//FABo/w0A3gBTAHwA8ACiAXgB2ABSAbwBTgEsAVgCLALQAVQB/AFIAm4BHAHSAcQBFgEaAY4BoAFMAb4AJgGmAawAvgAeAaoANgDx/1wAjQBTAIn/5v90APX/Xf/A/0QA4v94/9X/ugAIAVgAEQDMAJ8AZgBUAOMAIgECAZwAwwA4AWgAFgDZ/ycAPQCK/xD/9P5E/mD9sPxA/VT9tPz4+6D7gPuY+qD5WPmo+VD56Pgw+ej4YPiw94D38Pfg93D3ePhQ+XD5mPmQ+dD6sPrY+rD7wPyw/Sb+1P73/+IAqAC8AeACGARoBNAEaAZAB6gHmAdQCFAJoAmACVAKIAsgC1AL4AoAC7AKAAmIB/gGuAWoBRAE5AO0A9QD/gHoAdoBtgFwAUgAagF0AmwDoAOoA7AE6ASoA4ADEATEA2QCWAH8AVQDcARwBWgGAAeABfwDfALVABYAu/9VAIgALwBCAND/Uv9H/xv/3v5g/GD4oPbA9dD10PbA+Jj6cPto++D6WPpI+GD10PRg9PDzAPQA9cD0sPSA9FD2wPjw+FD4cPdQ9vDzAPPQ8pDzYPSw9HD2IPgg+hj6OPoI+/D68PqA+fj6+Pwg/uT9zP8IAoAEwAO4AygGaAdgB4gF6AfAClAMgAkwC5ANgA0QDKAJMA0ADdAJoAhwCtAK2AaIBKACEAP4ASYBYAOEA2wCdAHi/iL+7Px8/Vb+Rf90AcAD/AOwApQC8AU4BqAFOAcQCHAIeAaQBaAHMAioBggGKAeoB/AGsAXgBGADjAJ2AToBMAH7/yUAW/9I/eD8wPy4+3D7APx8/Jz8GPvQ+iD7gPqw+Xj5QPpo+Qj5ePqA+/D80PtQ+5D70Ppw+qD58Pr0/LT88PpI+vj52Png+KD4uPr4+dj4sPfQ9mD2IPRQ8wD08PUQ93D3sPeg9/D3MPjA+Mj5CPvg+5j7gPzk/Wv/2//2AMwDkAVoB/gHIApQCrAJgAmACuALQAuQC5ALUAwQC6AKoAowCnAIYAegB6gGgAVQAxADbALXABwBUAHYAIr/AP8I/4T/8v4V/4YAWAE0AowB5AJ0A1wCpAJIApAEQAaABigHgAfAB1gG8ATIA6AFKAU4BJADaAM8A1QBNwCx/0sA/f8M/1X/zv7K/oz96PyU/Tz+7P6s/lz+cP6L/yYA3/+E/tD/lP4e/pD6gPtE/dT8/Pzc/L4A8QBW/1j80Py0/dj6OPso+jD76Pmw+ND3cPgw+xj6QPlQ9/D2IPbQ8/DywPMQ9uD1cPZg94D6RPyI+oD5sPoI+9j5CPmI+Vj8wP0g/cr+/gF4BdgFMAYgCLAKIAsQCdAJMApACkAIoAeQCSAL8AmAB3AIEAlACbgGmAWABSgEfgFyAPAB/AGdAGT/+f/hAJ0ACwDzAMABhgFAAQQCoALQAlQCPAIwBGgFcAboBqAHMAjQB9gGsAWoBZgEaAMoAuACYANYAskAvADuAGj/yP3o/JT9MPy4+lj7cPwk/cj7MPx0/Sz+FP5U/b7+hv6e/rz++v8cAIb+PP2w/LD9JPzU/OT9Jv+I/vj8oP3E/cD8YPlQ+sD7APsY+ZD3WPl4+AD3oPeI+Tj6UPgg9zD5mPiA9jD2wPZw+ID3qPiY+tj72Pvg+8j8zPx4+/D6iPsU/Pj8uP1m/skAEAI4BHAGoAhACgALQAvACoAKIAqQCSAIUAjYB0AIoAjYB/AH+AfABxAHCAaABSAFLANMASwBigGGASgAMwD5ALYB2AGIAuwDcATIA5gCMAJwAowC6AKEA7gEiAawBogG8AVYBiAGQAQwA1gCCAOgAeYAEgGIAY4BKgDE/+L+6P5U/bT8sPzQ/DT9KPyY/Bj9+P2w/XT9lP6p/+j/mv55/yIAcwAu/hj9GP7E/Xj8OPuU/Fj9nPwI+1D76PtI+yD5APlI+kj6+PiA93D3EPdw9uD14PZQ+GD4iPgQ+ID4APhg9pD1sPUA+FD5sPn4+Uj7IPwg+hj6QPt4/Hj7YPrQ+1D+Tv/E/tYAIARYBggH0AggCyAMwAoACeAIkAhwCLAHYAcoB2AHyAaQBpgGsAboBugFyATYA8ADGAPIAVoBUAG4AS4BFAH8AQQD3ANIBIgECAW4BHADtAIEA/ADcATABCgFgAWoBWAFYAVYBeAE1AMEA0gC5gEsAU4AOADd/9T/Hf9s/uT9UP3g/Jj81Pxc/az9UP2k/bj9Av4A/uT9tv6A/9b/jf/z/zAARAC6//L+sv6c/sj9/Py8/Lz8vPz4+wD7ePpI+pj54Pi4+Aj52PgY+CD3MPfQ98D30PeQ95j4cPng+PD3GPiY+Wj5UPiA+HD7HP0g+6j6uPv4/Oj6OPks/Jr/uP0A+xT+y/9cAoQBqASwCfAKgAmQCdAMAAuQCCgHMAmACfgHoAagB8AIQAZwBlAH6AcIBwgGqAX4BMwDBAI0Ar4BCgGUAcwCnAL0AggECAWYBSgF6AQABXgEGANYAzgEcATUAzgE6AQ4BQgFsAQwBQAF/AP4AhwCVAETAD7/5v4l/9D+NP6s/Xj9kP2A/bz9YP3U/Qj+zP2w/dD9NP5A/gr+sP0i/gD/ev9P/3H/eP+Q/mD9rPzM/Kj8sPs4+1j7SPuw+hj6QPp4+vD5IPk4+Xj5SPmg+Dj4ePhw+Fj4QPhY+JD4oPiI+Jj4gPmI+WD5QPm4+ZD62PoA+wD7sPuI+xD7sPqA+pj7aPsA/GD9Xv88AfQCMATIBiAMAAxgCjAIsAnQCfAG6AWAB0AKMAdABAgFcAiACMgEUAWACJAIAAUsA1gEwAQAA9D/xAFQA9ADdAIYArgEsAXABcAEcAWABUgFOAR4A9AEeAVoBCgDqAO4BAAFkARgBIAFyATgA5QC3AHKAef/Ff/Y/gD/jv5Y/s7+Yv40/jb+4P4y/xn/yP7G/g7/iP56/oL+Hv+k/kz+wv7U/iT/4v6G/tT9KP24/BD8QPsI+wD7APtQ+gD6mPqw+jD6mPnQ+fj5IPnw9xD4kPgg+JD3kPdo+Kj4wPjg+LD5SPrY+eD5sPmY+vD6aPog+tD6YPuI+nj6APu0/JD7wPkI+5T9pf/n/9gCOAbQCPgH0AcwC8AJMAlQB9AHyAfQB8gGYAawBsAFEAc4BpgGoAZQCAAIMAbABegFGAbYAnAB/AKkA5QCJgGcAlgEMASkAngDwAUIBpgEfAOABIgEjAMMAjgCbAOIA+ACJAJIA5gEiAM8ApwCUAOoAkoAgv8hAMP/Iv7g/MT9MP5I/Zj8yP3I/pL+BP5k/jz/H//i/rL+Sv8d/1D+4P3E/QL+tP2E/UT9MP0U/cz8FPyI+0D7IPv4+sj6wPrI+kD6qPlo+aD5sPlI+Tj5YPm4+WD5EPlI+aj5sPlI+aj5OPqQ+lD6OPo4+/D7uPtA+8j7vPzA/Cj8fPyA/Tz9RPwY/Jb+IgGoAsAEcAewCWAI+AewCpAL0AmgCGAJAAroBwAFyAawB2AG2AQABpAIEAhwBmAGIAhgBxgFMATIBLgEVAMQA1QDYAQwBGwD5AOgBOgFsAV4BdgF4AVYBewDhAOIA4QDnAKYAjwDPAMYA5AC2AKcAuIBgAFQAYoAtf95/zr/gP44/dj8JP3U/Lz8JP0O/vz9hP18/QL+9P30/Qj+JP40/lT9kP0U/ZD8YPxE/Az8uPu4+6j7WPvA+mj6gPoo+rj5iPmg+Tj5uPjY+BD58Pi4+KD48PgA+QD52PjY+CD5APkI+aD46PjY+Yj5KPkQ+nj7wPsw+sD6yPv0/ID6WPqM/Dz8iPpw+jb/cAJsAnwC2AWgCOgGqAYQCCAKoAlQB1gHyAcQCBAGSAXYBYgG2AbQBUgGEAcgCEAHIAZIBngGuAV4A8gCGATwAxADugGsAvgDAASMA9AEcAbQBgAGEAWQBZAFeASMA2ADyAPIA+QCPAJ8AjQD7AIMAsoBMAIUAgwBAwBzANz/5P30/MD83PyI/ED8FP2o/UT9yP1y/nz+oP5+/rr+Pv4s/fT8wPwo/Fj7OPuA++D6iPqo+kD7ePsQ+xD7WPsQ+6D6UPr4+aD5SPnQ+Kj4yPgY+Qj5APk4+cD58PnY+TD6oPrI+rj6uPrQ+uj6uPoI+yD7SPuY+0D7UPvQ+3z86Pto+1j83P1R/2gAuALwBXgG0ATYBsAJUAmwB5gHwAmQCVgGMAZgCGAIgAWQBEAIEAlwBjgGkAggCkgHEAWYBlgHyAT4AkgE+AUABFwCxAMIBWAE0AO4BFgHgAYIBQAG0AaoBVgEuARABVAE1AJwA5ADSAPsAdABJAMIAsQASAGoASgB/f+U//j/3P4U/Uz91P0C/tz88Py4/YT9ZP18/dT9zP1U/TT9PP1Y/PD7+PsQ+2j6GPpY+nD6OPmY+cD6oPqw+Yj5kPqY+lD5WPnI+ZD5gPjg95j42Pjw98D3cPjA+MD4kPgQ+Xj5ePmI+QD5SPmA+YD5OPlw+QD6gPq4+Sj5ePoA+5j5cPlg+5z9xv7i/3ACqARYBbAEgAaACDAIWAe4B5AIAAgIBzAGwAagBpAFEAaQBkAHYAfoB2AI+AfQB3gH6AYgBggGGAY4BVAE/ANoBPwDnAMoBEAFqAVgBeAFiAZABoAFWAVgBRAFIAScA/gDPANUAjgCkALGAVABfgHWAYIBywCvAPUAKQCs/kj+lP4k/pD97Py4/Wj96PyU/Cz92P1o/RT9ZP2s/cD8KPxA/AD88Po4+lj6YPqo+Xj5YPro+lj6WPoo+8j7+Pp4+vj6cPvo+ej4UPlo+bj4sPcw+PD4SPgI+CD5+Pnw+Zj5KPrI+pj6SPro+kj7oPpI+rD6+PqI+ij62Ppo+4D7gPyW/n0ATAIkA6AEEAZ4BvgGuAfwB3AHSAdQB4AGmAZ4BnAGaAYoBhgHwAe4B+AH0AhACbAIyAe4B9gH8AYABtAFMAaIBWAEuAS4BbAFeAUABpgGEAf4BrAGOAdAB0AGwAXQBTAFkAS0A2wDiAPsAlgCaAKQAlQC0AGmAfABbgFnAA8ADQCT/3b+7P0G/sz9RP3g/Gz9WP10/UD9WP2c/WT9BP3U/Lz8BPyo+zD7qPpg+lD60PnA+ej5GPpY+kj6cPrI+rj6uPpI+nj6MPqY+Qj5uPiI+Dj48PcQ+Hj4gPiA+Bj5WPl4+aD5KPqA+oD6EPrI+sD6wPnA+Vj6uPrY+bD56Pqs/CT9Bv4oAUgDlANYBPAFeAdgB3gG4AbQB8gG+AVIBngHyAbIBegF+AYgB5gGKAegCBAJUAgACHAIIAjQBkgGcAYQBkgFeAS4BPAEwASABDgFsAWoBSAGSAbIBsgGgAbQBRgFCAWgBLwD9AIYAwgDXAIoAWYB5gHwADIAsABAAYIAhf8g/33/Df+o/VT9hP1Y/bz81Pz8/Aj94PyQ/KT82PyE/Fz8VPzI+6j7UPug+nD6MPoQ+lD66PnI+Rj6mPpY+gj6UPpo+ij6kPmo+YD5OPlw+JD44PjA+MD4APlI+Qj5SPlo+dj5ePm4+dj6kPpY+lD6EPvY+gD6UPqA+1j7+Poo+zT9xP5P/xwAtALIBAAFQAWQBiAIgAdoBtgGIAiwB4gG6AbAB3gHQAZIBsAHMAigBxAIQAlQCWAIMAhgCKgHuAZwBmgG8AVgBXgFgAUoBfgEUAXABYgF6AXgBhgHgAZIBrAGWAYgBcAEIAWoBJQD/AJEAygDyAE6AZgBDAISAVAAMgFUAYIAMv85/7z/tv6U/cD9hv4A/iD9DP2o/Wz9VPwc/DD9BP3Q+6j7+Pvg+8D6IPpY+pD6yPlg+fD5ePog+nj5GPpo+gD6QPmY+bD5SPmo+Jj4KPnI+HD4yPjI+Ij4QPhY+KD4sPg4+dD50Plo+ej5yPrg+XD5IPrQ+mj6uPmo+jT8YPxk/CT+3AAYAlgC9AMoBmgGkAW4BdgGAAdoBqgGYAcQBwAGwAUgBiAG8AVABkAHuAegB9AHQAi4BwgHqAZ4BvgFaAWYBZgFQAWoBHgEmARQBFgECAW4BbAFgAWIBbAFMAW4BIAEaATkAzAD4AJwAqABJgHOAGwAMAAHAP3/1P+P/3r/JP+k/gz+7P3k/aT9OP0s/fz8fPwI/ND70PvA+6D7oPvo+4j7KPsA+/j6sPqI+lD6UPog+gD6+PkQ+uD5kPmo+aj5mPlo+Tj5MPk4+eD40PgQ+Uj5QPnY+ND4IPkI+aD4yPjY+Vj66PnQ+cj6KPsw+hj6+PrA+0j7cPrQ+0j9mPxs/ML+HwCgAQgCEARwBqAGsAUYBrgHGAeABjAHQAgQCCgHqAZ4B5gHKAaoBgAIIAjwByAIoAiACMgH8AZYBzAHMAZQBsgGQAaABTAFCAUIBegE4ASIBfgFmAXQBSAGwAVIBTgFCAXIBDAEiAMwA6QCrAE+AQgBtABZAAcA7f/0/6D/Cf/i/rT+ev4o/ir+AP7s/XD9wPxc/Bz8qPt4+6D7sPuA+zj7CPvw+uj62PrI+tD6uPqg+qD6iPpo+kD6IPoQ+uj56Pn4+eD5uPmg+aj5oPmA+YD54PnI+Xj5YPlg+Xj5gPmA+dD5WPpI+lj6qPq4+qj6iPrQ+hD7OPtQ+7D7MPx0/DT9Mv6A/wgBkAJABIgFWAUoBXgGeAZABvgFQAe4B8AGSAbABngHOAZQBQAGaAdoB3AGKAeQCNgHuAaQBigH6AYgBqAFcAboBfgEcAR4BNAEWARwBNgEQAVIBWAFcAUYBfgEKAXYBHgEIATcAygDcALoAbwBFgGmAGAAZwCKANT/qv/A/4r/Kf/6/iT/zv6I/jr+3P1U/dT8oPx0/ET8CPz4+8D7mPtI+2j7cPsw+yD7SPtY+yD7+Pog+/j6oPqQ+oj6kPo4+hj6EPq4+ZD5ePnI+fD58PkI+jD6KPrQ+ej58Pno+cj58PkY+kD6aPpg+pD6YPqY+vj6CPs4+9j7SPws/Gz8TP0R/yQAKgEUA6gE4ASYBEAFAAZIBrgFCAbABygHIAcwB1AH0AZYBlAGAAdgB0gHIAhgCCAIcAeYB2AH6AaABpAGsAawBcgE+AS4BCgEkAP4A2AEQAT4AygEiAQYBKgDuAMIBJgDQAMAA6gCEAKMAUAByQBfAE0A+f+n/0T/G/8d/4r+Rv5A/iT+7P1g/Wj9NP3A/FT8UPxs/BD82Puo+2j7APu4+sD60Pq4+qD6wPq4+pD6kPrQ+sj6mPqI+rD6qPpo+ij6KPro+Zj5ePnI+SD6OPpI+kj6SPog+vj5GPpA+nD6ePqQ+rj64Pr4+ij7UPuI+8D76PtY/Mj8BP0g/WD9+P3k/vT/VAGwAsgDcASwBBgFWAXABVAGCAfgB8gHuAcwCNgHkAd4B7gHAAj4BxAI8AggCeAIgAhgCHAIIAjoB+gHAAiQB8AGUAYIBpgFSAVoBWAFaAVABQgFCAXgBNAEqAR4BGgEMAQYBLADUAPUAnQCBAK2AWIBHgEKAaEAagAQAMb/ev8f/9D+wv6i/lj+Nv4Y/vz9qP04/ST9+PyQ/Bj86PvQ+4j7QPsg+yj7+Pqo+pD66Pr4+uD64PrI+qj6YPog+hj6CPrw+dj5yPnI+fD58Pnw+ej56Pn4+dD5uPnQ+fD5APr4+Rj6UPqA+qj6sPoI+wD7MPtg+4D7yPsw/Iz8+PxY/Vz+HP9lAMgAxAGIApwC6AJUA3gEKAWIBegFkAbQBlgGsAYABzgHYAeAB/gHQAjQCNAI4AjQCIAIgAggCAAI4AfwB3gH+AaQBoAGcAYIBvAFOAYIBtAFcAV4BVgF8AR4BHgEaAQYBKgDOAMIA6QCKALCAbgBjgFMAQIBqQBxABsAh/8S/+j+uv6w/o7+cv6G/hz+WP0I/cD8ZPwI/ND74Puw+xj74PrQ+qD6UPo4+mD6WPow+hD6GPoQ+qj5cPmA+XD5cPlo+ZD5mPl4+YD5oPnA+fD5APoo+iD6MPow+kD6ePrA+gD7IPs4+3D7gPuA+5D7wPsI/ED8gPzg/Gz9vP00/sb+iv9XAPAAwAGUAjADQAN0A+wDUAS4BDgF4AWoBrgGYAbgBmgHUAdYB7gHoAjwCLAIEAlgCTAJYAjwB6AIUAjYB9gH8AfQB7gGSAaIBmgG6AXQBTAGQAZgBRAFAAWgBPQDcAM0A0QDpAI4AkQC1AEqAdoA2gCpAD0A8v/n/0f/Af+e/ob+fP7o/ej9Bv54/ST9xPyk/Fz8yPuI+5j7YPsQ+9D62PqI+hD6GPog+iD66PnA+dj5qPlA+Sj5UPkw+fD4APlA+WD5+PgA+VD5YPlA+SD5oPmY+Xj5kPmo+dD5wPnI+SD6YPp4+pj68Pow+1j7mPvo+1j8tPwU/Xj9Mv7I/nj/SABoAUQC7AIUA0AD8ANABIAEWAV4BiAHUAeQB+gHAAj4B9gHsAhwCbAJ4AlACkAKAAqwCXAJsAmwCWAJcAlACfAIYAj4B8AHeAdoB0AHMAcIB9AGeAaYBfgEoARoBAgExAOoA0wDuAIgAuoB1gFiARAB5ACRACcAr/9h/0T/uv5O/iL+/P2Y/Xj9bP0o/az8JPzQ+9D7aPtA+zj7CPuo+mj6KPpA+hD66PnA+bD5kPl4+Wj5aPlo+TD5GPlI+Tj5KPlQ+WD5SPkQ+Rj5QPlg+TD5OPlw+YD5WPlw+dD5OPoo+kD6oPrw+jD7OPu4+0T8WPyE/PT8nP1I/uD+yf+9AHgB/AGgAjADcAP0A2AE+ASgBSgG8AZQB3gHiAeQB7AHIAiQCEAJsAmgCaAJgAlQCRAJQAkwCdAI4AigCIAIIAiQB8gHWAcIB+gGCAfwBnAG0AVIBeAEOASwA7ADvANIA7ACVAIwAsoBQAEAAd4AoQAWAJL/f/8Y/4D+EP7s/aj9eP00/TT9KP2U/CD86PuI+zj74PrY+tD6YPoA+vj50PlY+Sj5OPkw+QD58Pjg+Bj5sPiY+JD4yPjA+JD4sPjg+MD4cPio+Kj4mPig+MD42Pjo+Mj44PgI+Qj5UPmQ+bD5+PkY+nj6oPrA+ij7kPvY+zz8+PzI/YL+Ov8UAAoBqAEwAsgCbAPsA1AE+AQIBogG4AZYB5gHmAeIB+gHwAhgCWAJwAlQCvAJcAlwCYAJkAkACaAI8AjgCDAI8AfgB8AHIAfoBgAHMAeIBrgFeAUQBUgEuAOYA7QDUAO0AmgCRALuAVoB+gDxAMgATgC8/7D/XP+2/kj+9P0S/sT9jP2E/Wz9PP2U/Cz8GPwI/Kj7WPtA+0D70PpI+iD6SPog+rD50PnY+cD5ePko+Wj5UPkg+Sj5cPmY+XD5ePl4+Vj5UPlA+Wj5gPlo+cD50PnA+cD50PkA+jj6KPp4+tD6+Prw+jD7qPvY+yT8cPw8/fz9fv4S/+//wwBKAdABZAIkA4wDGASYBJAFIAagBjgHSAeoB9gHMAhwCPAIkAnQCcAJ4AmwCfAJYAkgCSAJUAnwCJAIkAiACEAIiAc4B2AHYAfABkAGGAaoBcgE/APUA9wDTAPQArgCxAJAAoABVgFIAdEAOQDp/9j/hv/w/ob+Pv4S/rT9fP14/VT9PP3k/Hz8OPwM/Nj7ePtA+zj7APuY+ij6GPoQ+tD5iPmA+ZD5iPkg+fD4GPn4+MD4kPjQ+BD5wPiY+LD46Pio+ID4oPjw+Pj4uPjY+CD5GPno+CD5SPmY+Zj5yPkQ+lD6WPqA+uj6YPvw+3T8KP3s/aD+Lf/2/3QAJAG0ATQC/ALIA6AEYAXYBVAGqAbwBggHcAcwCMAI8AgQCYAJ0AlACVAJkAmwCVAJAAlQCXAJ8AhwCFAIUAjQB3AHmAeIBwAHWAYABsgF4ARYBDAE9AN0A+QCsAKAAvQBfAE6ARIBoAAkAO//sv8v/6T+Mv4I/qj9cP1Q/TD9/Pyg/HD8JPzY+6D7ePtY+wD7uPqI+kj6APrQ+cj5uPmo+ZD5oPmI+VD5KPkY+QD5APn4+BD5APn4+Nj4uPi4+Mj44Pjg+PD4CPkI+fj4+Pjw+AD5EPk4+Wj5mPn4+QD6QPp4+tD6SPuY+0T86Pyc/RD+zP5//yIApAA+ARQCyAJcAyAEQAXwBfgFeAbgBmAHaAeoB9AIcAmACbAJQApwClAK4AlACqAKcAoAChAKUArgCXAJAAlACRAJgAhQCEAIEAgwB3gGMAbYBVAF0ASABEgE5ANUA+gClAI0AqIBSAHxAMMARADK/2P/GP/I/lr+KP4A/vz9rP1Y/ST9/Pyc/Gj8EPwE/Kj7aPsI+/D6oPpw+kj6EPpA+gj68Png+fj5uPmQ+WD5aPmA+UD5QPk4+VD5KPkY+SD5UPk4+UD5SPlA+XD5IPlI+Uj5YPmA+Zj52PkI+kD6mPrY+jj7oPtI/Mj8SP3k/dL+af/g/2kAQgH6AWgCDANoBFgFmAUQBngGQAdABzgHIAgQCUAJUAngCWAKYArwCdAJYApQCiAKIAqAClAKsAlQCUAJIAmgCHAIcAhQCKAHEAeYBhAGiAXIBJAEOATIA1wDCAOIAvQBfAEQAa4AQwD2/3D/Gf+Y/iL+tP1E/SD97Pzo/ID8fPw0/Nj7oPs4+wj70Ppw+lD6MPrw+cD5gPmA+Uj5QPk4+SD5KPnw+PD40PjA+Kj4sPi4+Lj42PjI+Oj42Pjo+PD4EPkY+RD5MPlA+Uj5IPk4+WD5ePmQ+dj5MPqI+rj6EPuI++j7ZPyo/HD9+P2S/j7/4v+LABIBxgGAAkwDCATwBJAFWAaIBigHiAfgB0AI4AhQCbAJEApgCtAKwAqgCqAK8ArACrAK0AqgCoAKAArQCaAJUAkQCdAIsAgQCIgHKAe4BiAGgAUYBegEaATQA6ADRAO0AhwCxAGEARIBnwBBABQAoP8L/7T+eP4a/sz9kP1w/Uj98Pys/Hz8LPzQ+3D7SPsg+9j6qPqA+lj6IPrw+ej54PnQ+bj5qPmQ+XD5SPlA+UD5KPko+TD5QPlA+VD5WPlw+XD5gPmI+aD5sPmo+cD5wPnw+RD6SPpw+tj68Ppg+6j7+Ptw/Lz8TP3Y/Wj+AP+j/zMAsgA+AcABYAIoA9ADcAToBEgF2AXwBVAG4AZgB7AHAAhgCOAI8AgACQAJMAlACSAJQAlgCUAJAAnACLAIUAgACMgHoAdgB+AGcAYIBogF6ARwBAgEpAMoA6wCVALmAW4B4gB2ABkAuP9O//b+oP5G/tT9ZP0Q/bD8fPw0/PD70PuI+0D7+Pqo+nj6OPoI+uj5yPmo+XD5WPlQ+Sj5EPkQ+SD5KPkw+Sj5MPkw+Sj5SPlY+Xj5gPmo+bj5yPnA+eD5APoY+jj6SPqI+qD6uPro+hD7SPtw+7D7+PtM/Jj86Pws/Yj93P1C/r7+Lv+t/xkAnQAWAXoB3gFYAqwCGANoA9gDWASgBBAFeAXgBUAGgAbIBiAHaAd4B6AH2AfwBwAIEAggCFAIQAggCCAIAAjYB4gHWAcwB/AGoAZIBvgFuAUwBeAEgAQ4BMgDYAMMA6wCOAKsAXABEAG1AFUA9v/B/2D/F/+y/nD+XP7M/dD9dP1c/QT9yPyM/Dz8DPzQ+8D7ePtg+0j7GPsA+wD70PrQ+tD6qPrg+rj6kPqg+pD6kPqY+qD6yPrA+uD66Prg+hj7APsQ+yj7SPto+3j7kPuw+8D7yPsI/CT8dPyI/ND8FP1I/aj9yP0y/nT+sv72/lD/sv8QAIoA2gA8AYYB5AE4AnwC3AJAA3gDuAMQBFgEmATIBOgEGAVoBZAFsAXwBQAGEAYgBhgGIAYgBiAGEAYgBgAG0AWoBXgFSAUIBcgEmARwBEAE9AOsA2ADGAO4AnACHALgAY4BOAHuAJwARADh/5f/U/8N/8b+hP5S/gr+yP2E/Uz9EP3U/KT8iPxg/Dj8DPzw+8j7sPuw+5D7iPt4+2D7WPtY+1D7UPtY+2j7iPuQ+6j7sPvQ+9j78PsI/CD8RPxU/Hj8gPys/Lj82Pz0/Bj9SP10/aT9yP34/Sj+UP5w/qb+2v4I/z3/b/+s/+//HwBdAKgA4AA+AWIBvgHyATwCaAKcAuwCGANUA4wD0AMIBCgEYARwBJgEuATABNgE8AQABQAFAAUABfAE8AT4BOAE0ASoBIAEYAQwBAAEzAOkA3QDSAMUA+gCuAJ8AkgCEALWAZgBWgEgAewAqQBsAC8A8v+6/3//SP8O/9b+pP5y/j7+CP7Y/aD9dP1M/SD9AP3k/MD8pPyI/HD8ZPxU/ET8OPw0/Cj8HPwc/BT8FPwY/BD8FPwg/Cj8PPxM/FT8cPxs/JT8oPy0/ND83PwA/RD9KP04/Wz9ZP2I/ZT9rP3I/dD9AP4c/jT+VP6A/rD+uP7g/vz+IP9N/2v/nP/J/+n/DQAsAF4AiwCvANQAAgEkAUoBbAGKAaABzgHqAQQCLAJEAmgCgAKMAqgCsALIAtQC5AL8AgQDDAMMAwwDCAMMAxADDAMMA/wC9ALgAtACtAKgAogCYAJEAigCEAL2AdYBqAF6AVQBJAH2AMoAqgB/AFsAKwD6/9n/sf+R/2n/Rv8b/+z+zP6m/n7+Wv48/iD+CP70/dz90P28/az9qP2c/Zz9mP2c/Zj9mP2Q/ZD9nP2k/bT9vP3U/eD98P0C/hj+MP46/lD+YP56/pj+ov66/t7++v4X/yf/SP9s/37/lP+x/9P/7v8CABwANwBJAGQAdwCOAKkAwwDcAO8AEAEkAToBVgFgAYQBlgGgAb4B0gHoAQACGAIoAjgCSAJUAlQCXAJkAnACbAJkAmACZAJYAlgCVAJQAkACPAIwAiACDAL0AegBzAG0AZYBegFUAS4BCgHsANMAwQCRAIQATgA5ABYA7v+9/5j/iP9i/zL/Ev8P//D+tv6c/pr+dv5W/kL+Nv4m/vz98P3w/dD90P3M/bz9vP2w/cD9wP2s/bj9vP24/bD9uP3E/dD91P3Y/eD98P30/RD+Fv4c/kL+UP5m/oL+hP60/sj+2v4C/yH/Ov9W/3L/fv+j/7X/0P/k//j/DwAvAEIAZgB/AJAAsADGAOMABAEIARwBOAE8AUoBagF0AXABcgGGAawBuAHEAdYB6gHoAegB9AH2Ae4B6gHyAfoB8AHuAeAB1gHIAboBpAGUAX4BZgFMAT4BMgEeAf4A4QDPALYAnQCFAHIAUwAxAB0AEQDs/8X/rv+l/6r/lf+I/4D/f/+B/2z/Yv9a/1H/Tf9B/zf/Of8t/yL/F/8b/zH/Lv8r/zf/UP9s/2D/bf+G/47/fP9n/2r/a/9c/0H/Lf83/zj/Lv8u/zj/Pf8u/x//OP9u/3v/eP9//7L/3P/p/+v/CwA5AEMAVgBdAHkAcgB/AHcAgQB9AIEAbgBiAGcAcQCLAK0AxACvALUAwwDZANIAqAB+AH8AdgBPADoAVgBcABUA2P/D/8T/t/+z/9b/FQAVAOz/CAAxADQAFAAeADMACwDX/8//4/+u/33/cf9z/3D/Yv9g/2P/Wf9H/3//wP/s/+T/IwBTAE8ABgDl/8D/zP9o/yb/CP8P/wP/8P4B/9j+sP7Q/gX/B/8J/0T/fP+W/7X/ov+i/6//CABpAE0A2/8bAKIAugD7/97/bQDDAGEA8v9uAewBZQDq/i4ABALN/6D9LP10/j7//gH8ApgDUgFS/t3/7QAIAXP/9gDMAYgB7//Z/xIByAI8AucAHAGuAcABSgBm/1QAOgEAAHT/lQCqACACJgHXAMgBiAFIAeP/IwCn/6MAeQA2/4v/+wAoAnwBNwCxAO4BYAKL/yj+PgBOAeb/vP3Q/kwBUwAG/2T/WwDg/zT+Uv+QAKv/mP3U/AT+TP0E/Nj8EP90/qz8hPyE/az9fPy8/Hz9FP3c/a4B4AVQB7AFoAW4BL4B7gHABrALQAkcA3gBMAM4BKACxv+e/hT/W//2/oj/MAKwBGAESAKWASIBBf+0/Ij9FgBJABj/qP6o/mz9SPwo/UT+NP6g/fz94P24/Pj7/PwI/kD+C//aAAgCVgGkAAgBQgHq/yX/VQCcAIX/g/9MAbgC5AJQAkADVAMwAmYBygGMAXcA2P5jAKoBGAHL/34BOAL2ATD8JPwSAI7+zPzY+uT+3P4S/rj7m/8qAWL+NP6GAdwCcv+Y/UUAuAFz/67+sgEkAycACf+CAOwBoP9i/rb/Tv+Q/ST9wv7a/uj9xP1f/27/Cv5C/mD/oP4E/QT8uPxg/fz8dP0o/7j/AP+Q/u7++/92/9L+/v4q/8r+lP47/+b/4v+i/uz+EQCFAM7/kv+z/+3/2v4+/nf/N/9u/hj+2v4p//D+Kv6e/rD+DP7Q/RT+eP2E/Vj+7v4X/xD/lv/X/8r/7//dACIBpAACAWQCPAMQA6wD6ASIBWAFuAW4BlAH+AbwBnAHMAegBiAGAAZYBfgEuARwBOADQAOUAsgB7ACiAEAAc/+4/qT+wP6i/nr++v5+/13/6P4Z/9b+lv5i/rT+zP6W/tL+e/8cAEoA0ABSAYQBPAFGASgBmwDI/6r/JwAhACUAPABLALv/xP74/Uj9iPxQ+1D6cPn4+Gj40Pdw95D3kPeA9qD1oPWA9ZD0gPOQ84D0gPTw9JD2+PhI+vj6iPxC/sr+aP6B/9IAIALsAmAEuAbIB3AIsAigCZAJcAkwCZAJQAmgCIAIgAgACWAJoAlQCUAJkAhIB9AFEAVgBKQDDAP8AqQDqAOMA1gEwATYBFAEOAQoBMgDLAOYAogCaALAAqgC+ALIAggDvALYARgBvgD0/9z+uP1g/fz82PtY+xD7wPuQ+6D7+Ppg++D6oPog+Sj4APjg9iD2YPUg9hD2YPVQ9QD2QPZQ9RD10PRQ9GDyIPJw8hDyEPKQ8pD1wPVA9kD3YPlY+dD3gPe4+Bj58PZQ9wj5lPwo/fT+HAO4B9AIAAlgDMAPoBHQDyAQABFAD/ALoAqgDGAOsA/QD6APEA1gC+AIWAYoBRgG4AQUApz/lgGgAxACCgEoA3AHUAbcAqgDGAW8AxQCwANIB3AH0AXYBsAIYAlQCEAIkAhIB5AFoAQIA34BqQCwASgCPAFaAboBlgDw/h7+qP7M/Pj6WPrA+nj5QPho+dD6yPvY+oj7pPwY/Jj6CPpA+ij6cPko+Xj5sPmI+eD50Pnw+RD6yPkA+ID3wPdQ9zD18PQQ9oD2UPXQ9DD2gPYw9tD14Pag97D2UPag9hD34Pbg97D4ePqQ+4D9z/9+AXAEIAaQCZALIA3wDfAOsA/wDcAKoAlQCwAMIAogCqANYA6wCNAGQAlAC8gGigGYBZAGyAIK/iQB6AR4BGgCUANgBrgE3AKoAngEaAS8AzgE4AQABpAG2AZYBYgGAAkwCcAGwAQgBYAEtAKOAYgCYALnAJYA0wBCAdAAAgAvAAMAdv8M/4L+LP0w/eT96PwI/Jj7xPzk/Lj8tPwc/VT8qPyg+yj6ePn4+QD6IPnQ+MD4yPnA9+D2wPfo+MD3IPZQ9gD3EPYg9PD0IPaA9iD2YPaw9iD3MPcA91D3oPfg9/D3MPhw+Hj5kPp4+0T8dP5sALACEASABmAJIA0gD/AOwA4wD6AN4Ag4BqAHEAtQCIAGsAmACrgGbAKYAwAJkAd4Ai4BmAOIAhz+GP1uAcgC1AHaAUAGsAaABIgCGAUACHAGiARIBHgFGASwAzAFiAYYB2gFAAY4BuAEdAHzABIBLgBm/kj9AP5Q/Rz9AP3A/Sv/EP/c/az9Wv4i/nj9BP2U/rT+RP6c/fj+lAAkADv/Jv9HAHT+2Ptg+6D7ePsw+jD6MPqo+QD5SPiI+Nj4SPjg94D3UPfg9vD18PWw9fD1UPZA9yD3MPdg9+D3UPiI+Cj5ePnY+ej5yPnQ+lD7LPy0/MT+rQBQAswD4AWgCPAKkAwgDyAPEA4QDYAKsAhIB5gHoAfgB9gHEAhYBzAG5ANoBhAIaAbcAY4BVANMAmP/dP4wA3AE2ALAAgAH0AfwBBgE8AWwCMgFUATgBLgF2AXcA6AFmAVoBggGoAVIBNgCWAN4AvD/tv5v//7+8PyI/Jj+Wv+G/oD+SP82AAL/nP1k/nz/jv5Q/oD9NP7A/Qj+av40/+L/AAAt/8z9EP0U/Jj7wPqQ+nj5OPlw+ZD4wPfg9rj4gPi4+LD3WPgw+CD2APYg9oD3IPfQ9gD3yPgI+bj4APmY+dD6aPoQ+uD56PpQ+5D6YPr4+wD+Rv/E/rUAwAS4ByAI8AiQDYAQIA8gCzAKkApIByADoATgCUAKYASmAbAH8AcoBUADAAbwBxAFmAJ8AuQCdgH1/74BGARwBPAEMAWgBGAFUAcwCJgFWAVIB5gHeAQYAnAEgAYABewCXAPoBCQDmADnADgCOgHo/qj9LP7Y/fD8uPwc/az9qP3Y/WT+LP6U/mb/b/9L/5j/DABX//T9rP24/gP/Nv5c/SL+rP1k/Aj7YPtY+6D6EPoY+lD5CPhw94D3sPfQ96D34Pfw9yj44Pfg9wD4QPi4+CD56PiY+Sj5GPmA+Kj5SPqg+Sj6gPmA+jD6WPpw+mj6mPsA/Lj8SP1w/1AC8ANQBBgHMA1QD7AMoApgDbAM+AXIAtAFMAmwBhgC5AJIB/gEWAKYBCAJ4AhoBIwCIAOIBWgCIf/s/wQDUAWUA+wCUATwBpAHGAaABmAJIAkABfAC+ASgBjgElAJMA8gEPANyAPj/mAHMAaX/J/9Z/3H/iP78/aj97P1q/mL+YP5Y/pL+2v98/6D/M/9kADMAOv+8/rD+DP8o/oz9SP28/fj8BPwI+5D7GPxo+1j7GPu4+oj50Pmw+Cj5oPiY+Mj4sPdQ+PD3ePgI+JD3gPig+eD5iPng+Aj50PkY+lD5kPlo+nD7EPmQ97D5OPwo+9D5aPpQ/hj9ePkc/PgCcAZEA7AFwA1gELAMMAkAC2AMUAp4BugHgAo4BlwC/gGwBJgFCAX4BOgFcAaYBWgECAMYA2gD8AM8AvwAzAL4A/wCxAFoBNAHEAi4BZAGMAjoB5gGWAVABlgG0ATcAigDSAOQAjABCwBkAPUA7AAB/zr+1v5a/7j+zP2s/db+PP6Y/Dz96P6a/27+lv6CAIgBQABW/vT+lP9a/wz+NP66/uD90PtA+xz8KPxQ+7D6QPss/AD8+PpI+rD5QPqI+hD6APkI+Vj5wPjg9wj46Ph4+AD4WPgA+rD6uPnI+UD6ePrY+fD5gPk4+dj4sPno+Rj4CPnQ+9T90PoA+tj7sP6c/Sz/mAZADLAK4AYwC/APQA1QCHAK0AwwCoAF3AMIBjgDCAFcAogFAAaMA1AEUAXQBIgDEAUABggEPAKwA4AEygHPAEgD0AVIBbgEEAbAB+AH6AbgB9AIwAiwBygG4AQwBHgDHALrAGwAGAEkAFz+5P0A//7/ev6Q/eT+XABR/wT9bPys/fz97PxE/Tj/mABW/2b+Zv82ARwB2//R/7AAagBo/uD85Pyw/ED7iPp4+iD7sPro+UD6CPs4+9D6YPrQ+qj6YPoI+eD4iPh4+Bj4oPdI+OD4uPiA97D3qPmQ+3D60PiY+Xj7WPrg9oD50PuA+TD3EPlQ/bD9WPkY+Tj8bP1E/Fj9yAL4BdAGcAigCtAL8AowC3ALwAvQCtAIAAa4A1wDPAPMAlwCXANQBBAEuAMgBFgF6AS4BJgFcAWIBBgDQAO4AwwDwANQBBgFeAUwBQgGsAYQBzgHAAfoBqAGgAUwBNACCAKiAbwAPQC5/0P/uP4u/nT+pP64/uj+zP7M/oj+Bv7A/Yz9pP1I/mr+dv4q/nj+8v4g/1n/Lv9l/2L/Hv+o/vz9gP00/ZD84Pug+8j7kPvg+pj6+PpY++j6QPrI+jD7sPoY+jD6QPoA+jj5EPmw+MD4yPjQ+ND4EPmw+mj6qPi4+Oj6iPtA+SD58Prg+oD3wPbQ+37+WPow+Ej8WP3A+8j5uv7wAzgDeAIIB5AMEAogB3AJ8A3gDDAJQAjQCWAISAPwAhAFmARMAhQCwARoBfgDLAMgBXgGoAWYBUgGMAW4A3QDSAT4BLgE4ASYBaAFMAUIBjgHMAeABkAH0AfQBmgFyASABEAD1gGmAV4BFwBO/jb+N/9S/9z+2v5q/zn/J/9+/+j/M/+8/r7+E//w/pj+0v4Q/77+Pv58/kj/BP8o/lb+4P4s/sT8WPyc/Ej8CPuA+tD6yPog+hj66Ppg+zD7IPu4+9j7iPs4+0j7CPtQ+sj5wPl4+QD5oPiA+Pj4iPmI+aD54PkA+rD5sPlI+oj6sPp4+tD68Ppg+kj6sPqI+9j7mPvQ+/D74Pv+/ggFmAYQBmgGYArQC2AJ8AhgC8AMAAhoBPgFwAcQBAL/DgFQBTgE3QCCAUgFWAawBMAD6AYgCNAG0ASoBAgGOAVoBOQDgAToBNgECAQABMAFOAfwBngGEAeAB5AGuATAAwAEJAPIAQ0Acv+Q/3b+IP5E/sD+6v43/6L/lv/t/1kAcAA7AO//p/9//wr/Uv5a/tb+Bf86/gz+rv7Q/qL+bP6S/nz+3P0g/WD82Pt4+8j6SPqo+bj5QPpI+lj6APsY/FD8qPu4+5T8bPwo+0j6WPoY+gD5ePio+Bj5CPnI+GD52Pmw+uj6ePp4+mD7sPt4+uD5EPts/Ij6kPjo+Sj8kPtI+cD6fP2S/i7+3gCIBmgHkAfwB/AJwApQCrAJcAmQCOAG+AUgBAQDVAJUA/QC0AGEAkAE2AS0A5gEeAfgB1gGeAWYBvgGUAXQA1AEGAUoBEADfANgBFgEwARgBfgFwAYIB6gGMAWwBCgFGAQsAhIBJgHPALj+qP2g/nb/hv7U/Uj/cQAGAE//7/+IAMn/bP5i/rz+NP6E/Uz92P3w/aj9/P2I/tL+zv70/vb+iP5K/uj9LP1U/Hj76PqA+vD5sPn4+TD6WPrQ+pD7BPw4/JT82Pzk/GT84Pto+9j6UPqw+Rj5oPig+OD4CPlQ+cD5YPqw+gj7wPtw/FD8+Ps4/GT86PsY+4j7EPzo++j7ePx4/Uj9Iv5sAQgEqARYBYgHcAlQCaAIMArQCjAJSAfQBjAHwAXAA0gD5APYA8QCoALYA8AE+ARoBdgFoAYIB6gGgAaQBsgGUAYwBcAE8AQgBYgEOATYBJAFiAVgBcgFaAZIBlgF8ATQBDgEAAPqASIBhwCr//L+fv5M/lb+iv7G/jf/4P84ACoA//8gAEAA7P9C/8L+hv5S/pj9UP1I/Zz9pP14/aT9Tv60/mz+Av4e/lb+eP0Q/Jj7sPtg+0D60PmA+rD6KPpQ+mj7nPzQ/Lj8RP2s/XD9sPxo/Nj7CPuA+gD6OPnY+Aj5gPno+Ej5MPqQ+yD7KPt4/CD9CP0c/Oz85P2I/TD8KPxM/QD9zPwI/UT+hP8DAPsAUAKoBGgGCAdIByAIAAlgCKgHOAdwB5gGMAUwBCAEQARYA7QCRAMwBHgE/ANYBIAFAAaQBTgFcAWwBQgFAAQABHgESASYA3AD9AOABHgEkAQoBagFaAUgBQAF6ASYBIADXALGARABEgBa//b+1P6Q/lD+kv4T/z3/ff/j/ywASwA1ABAA4/+H/yr/vP52/hj+zP2Y/WT9iP2Q/Zz9nP2w/bT9eP1E/Uj94Pw8/Mj7mPsw+6D6UPpQ+jj6EPpQ+hD7YPt4+/j7kPzY/OT84Pzk/Kj8JPxA/OD7+PrQ+tD6cPrQ+TD6sPrA+lD6KPuQ/Mj86Puc/Ez+Bv4Q/bT9Ov/Y/lT9pP1s/1//Gv7c/k4BSAJmAbACeAUIBtgFqAbgCOAIAAfIBgAIyAeoBbAESAV4BLwChAJUA4wD+AKAAhAEAAW4BMAEmAVABgAGwAXABaAFAAV4BOADzANkA8wC3AKoArQCDAMwA4ADhAOUA9ADrAMUA5ACDAKIAWgAiv8Y/3D+0P1o/Vj9ZP1c/bT9Nv56/u7+g//q/9X/yP8HAOT/Bv9q/jD+xP3g/HD8vPzA/ET8LPyM/Oz83Pzg/FD9mP1k/Tj9aP1g/RD98Pzw/KT8MPxE/DD8LPwk/Hj83Pzg/LT8LP1w/QT90PwA/dz8CPyg++D7MPxY+xj7kPtk/Pj7BPxA/RL+nP1U/XL+Ef9g/nj9Pv7o/iL+mP0C/rL+MP6w/cj+w/85AKUAzgEYA+ADkAQoBdgFQAaoBsgGQAbYBegF8AUYBWgEqATgBGgEEATQBMAFyAVgBfgFyAaoBvgF6AUwBsAFyARoBGgEAASAA4ADlAM8A+wCKAOIA2gDKANoA4QD+AJgAnACjAL8ATQBDAHqADoAsv/e/z4A6/+I/93/JQAcANf/AABFAOH/KP/E/rr+Mv6U/ST9BP24/Cz8KPyA/Mj8iPyQ/Mj8CP3w/PD8IP0I/aD8UPxo/DD8APz4+yj82PvA+wT8TPxM/Dj81PxY/fD8iPwQ/Xz9KP1Y/Hj8nPzo+0j7cPsM/KD7OPto+wD8DPxM/JD8+PwI/SD9Kv4g/lr+bv4c/17/pP6i/qb/CQAh/y7/agAiAXAABwCeARAD4AIAAigDgASABLQDEAR4BTgF6AOYA8AEKAVABLQDoAToBDgE2ANgBNAEiAQwBNgEEAWQBGgEqASQBBAE6APcA4AD5ALsAkADxAIEAvQBDAKaAeIADgH1AHAAqv/M/7T/Gv/g/vj+5P5M/iT+aP6a/ij+5P1U/qz+Nv4A/pL+oP4Q/sj94P3o/Uz96Py0/MD8KPzY++D7wPtw+yD7UPsY+wj70PrY+jD7CPvQ+gj7YPtI+2j7kPtc/Aj94PwY/ez95v7Q/tz+ff8YAAcAy/8XAIYARwCJ/zr/Nv8u/6D+OP4A/vj9+P3E/dT9Hv7g/j//Lv9t/yEA0AD3APcAagEAAr4BRgGuAWwCUAKiAZABxAHmAX4BqAE4AmwCNAIoApwC2AIQAwwD6AKAAmwCOAK0ATQBIgEkAYMAFwBRAN8A7QDPAGoBUAKUAtACgANwBMgEmARwBMAEoAT0A7gDzAOwAwADrAKoAhADFAPYAjgDoAPoA9QDMASABKAEKARYAwwDzAJEAnAB7ACvAFIAa/8N/xj/F/8v/yz/OP+E/wMAHQAxAB0AQAAsAJX/Qf84/0f/mP4c/gD+6P2I/TD9JP1U/Uz9cP2Q/XD9iP3o/Qr+rP1A/XT9gP2w/Bj8QPxc/KD7+PoQ+7j7YPvw+iD78PsI/HD7iPvw+5D8LPxA/ID82PwM/eT8IP1c/cT9sP1w/YD9Jv52/mr+XP7s/qb/k/95/xEAwQDsAMEA5QByAb4BogGaAf4BbAKEAnQCzAIwA2gDLAM0A3gDtAPIA7QDEAQYBAAE5APYAwgE4APUA4gDbANMAxQDzAKcAnwCUALWAZoBtgGqAWgBEgEOAQYBnQAtACUABAB5/8r+gv5m/tj9YP0U/fj8tPw0/BD8HPws/AT8+Pv4+/j76Pv4+/j76PvQ+7D7aPtA+4D7ePtg+0j7YPuI+4D7oPvQ+wz8KPxk/KT82Pwg/Wj9sP20/eD9Ov6M/pT+1P5d/6D/uP/M/2IA6gAUAVYBxAEgAgwCLAJgArQCuAKoAtgCAAMUAwgDLAMYAxgDKAMUA/QC4ALoAvAC1AKMAqACmAJsAkACVAKAAmgCWAJYApQCnAKEAqQC1ALgAtAC3ALcAtwCpAKgAqgCWAIoAgQC7gHSAagBngGKAV4BMgE8ASgB/ADYAMAAzQB7AFsAZABxAP3/yv/m////wf+c/8X/4/+4/3b/uv8OAOn/vP/O/wkA8P+//6T/1P+m/3H/ZP9W/xb/9P7E/rL+iP6M/nL+uv6S/tL+Af/0/ur+D/9G/y//G/8P/zr/J//0/gX/FP8h/+b+7v7u/gb/9P4P/xH/If9A/zL/M/8+/1v/bf9R/1z/SP+N/2X/S/97/4X/a/9d/53/uv/K/6X/zf/Y/8//yP/3/+f/xP/X/83/vf+9/8X/3f/J/43/pf/n/7//qv/k/x4AHgDr/wAAUgBeABEAKQCOAH4AQwA5AJ4AlwBbAEoAlgCnAIoAbwCaAL8AkQB8AJUAfgBeAFoAZABpAGMAYwB1AH0AcgB7ALMAuACoAMMA0QDOAM4A0ADqAO0AzgDNAPUA0ADhAMsAvAC7AN4A3QDfAOMA4gAOAQIB7wD7ADABFAHjAOIAAgHdAKUAngC5AK0AXQBQAFUARwD+//T/9//e/7r/qP+h/5b/pP+Y/4P/cv96/4D/aP9I/1j/bv8q/+z+I/87/yn/4v7s/i7/H//y/hP/Vv8q//T++v4z/yD/8P7+/iP/I//g/uz++P74/sT+7P4M/wv/Bv8a/23/YP9a/33/xv/P/8f/8v8mADEAJQA0AF0AdQBzAIcAkgCXAJ4AngCtAJYApQDMALoA5QAMARgBMAEeAVIBUAFEAT4BQgEyASwBHgEQAQgB2gDRANYAxACoAJUApACVAGgAdwB8AG8AagBdAGoAYAA3AEEAJQAJANL/u/+a/0v/L/8A/+D+zP6I/pL+kP5q/lL+VP5c/j7+HP4o/hj+6P3c/az9rP1c/Sj9IP0Y/fD81Pz4/Pz8IP38/ED9ZP1Y/XT9kP3g/dT95P38/Qj++P38/Qb+FP4I/gD+Iv44/lL+eP7W/g//MP+Y/9z/HAAtAGIApwDtAOIAGgFCAYYBpgGqAdIB4gFAAiwCVAJ4AugC6AL8AjQDcAOoA0wDiAPsAwgE6APQAwAEAATIA6gD2APsA8ADjAOoA8wDoANkA2ADaANEAxQD+ALYAsQCnAJQAhACzgGUAWABEgG4AJMAZgDs/4X/YP9U/wD/kP52/mT+LP7M/aT9qP1Y/fT8pPx8/FD8BPzI+7D7gPs4+xD7CPsI+/D68PoA+/j68Pro+gD7EPsQ+wD7CPsQ+xD7KPtA+2j7iPvA+wj8bPzk/FD9xP08/q7+Pf+//1kA3QBiAdQBNAKQAuQCVAOcA8wD1AMIBDAEWARwBJgEyATYBOgE+ARIBWgFWAVYBVAFUAVABSAFCAUYBQAF0ASgBKgEmASIBFgEUARIBBgE/APkA+ADtAOIA0ADIAPsArwCkAI0At4BdAEYAaQAOQDx/7n/bv8H/97+uv6I/kL+Bv74/cz9dP0w/SD9GP3o/JD8cPxs/FT8DPz4+/j7FPzo+9j7EPxM/ET8LPxs/LD8wPy4/PD8RP1g/Wz9gP3c/Qj+Iv5I/oz+8P7C/hv/KP9l/3P/rv/i//D/EgAwAHsAcgCcALsA3ADsAAoBOgFqAXYBZgGWAagBpAG6AcwB2AHSAcgB5gHoAeQB3AHYAfwBzAHMAeQB5gG8AZgBkAGWAXoBNAFAATIBCgG5AJkAtACYAGsAHgAqACYA9f/n/wgAFQDm/8D/kv+T/3n/Xf9B/xD/CP8D/97+tP6k/qL+kP5s/lL+dP6W/mb+RP5q/nr+UP4+/lL+iv6E/kT+Qv6U/pD+WP5i/pj+wv6y/q7+5P4Y/x7/Bv8l/0f/WP9V/2j/jv+7/7D/qP/J//n/GQAdADAAUgB2AHAAeACeAMIAuAC0ANEA/gAYARABLgFCAVgBYgFyAYgBoAGmAZwBsgGwAa4BqgGwAbABtgGoAYABgAFwAXgBYAFeAVYBUAFEASQBJAEUAfwAwgC+ALcArwCLAG4AcABaACcA//8GAAYA7v+8/8P/xv+7/6L/kP+d/5T/b/9W/17/Vv9W/xn/Jv8f/x//Af/4/hf/G/8Y/w3/Gf8r/yb/If8J/yn/P/87/zn/Pv9d/2H/Y/91/5v/q/+x/7P/0//j/+P/9f8HAB4AJQAwADYATwBgAHUAgwCJAKAAvgDZANwA7AD8AAoBAgEOARoBIAEeARABHgEuATIBKgEoASYBFAEMAQQBCAEMAf4A9QDvANwA1QDIALwAswCgAIUAawBhAFYAVQBFACwAHAATAAAA8//p/9z/xf+x/5b/kf9t/3H/ZP9S/0r/Rv9Z/0z/Pv80/1D/Gv8Z/xj/Lv8y//T+FP8q/x7//v4E/yn/Jf8p/zb/Xf90/1//Xf+E/6T/p/+k/8j/6//4//T/9v8CABMAGQAcACAAQABLAEcATQBiAH0AhQB2AHkAkACgAJIAhgCdAKoAowCTAKUAxADDAK0AoQClAKYAnQCQAJAAkwCEAHYAawBoAGEAVQBHADIAGQD8/+3/6//j/9P/tv+c/6L/mP+Q/4r/hv94/1f/R/8+/z7/L/8e/xP/EP8M/wv/E/8T/xL/Cv8J/wz/Hf8g/yH/G/8e/x7/H/8v/zj/QP8//z3/N/9L/1P/V/9h/2T/eP+C/33/gP+U/6L/n/+V/6r/w//B/8n/2P/2//H/8//6/xkAIQAxACQANgBIAE8AbgBZAGkAXQBiAGUAXABfAHkAhwBxAHwAmgCqAJwAjwCtAMEArgB8AIgAnwCcAHMAZQB4AHgAWQBHAGgAhABsAEEASwBTAEIAHQAXAC0AMwAKAAcABgD2/9//1P/Z/9z/0P/B/8n/zf/K/8j/wP+5/7f/u/+x/6b/tP+t/6v/mv+j/6H/mv+U/5L/kv+N/4f/iv+a/5f/jf+V/67/rP+h/63/vv/E/8P/xv/S/9r/2v/e//f/AQANAAsACwAQABkAIwAdACgALgAyADsANwA5AEkASQBLAF8AawB7AIEAbgBrAHQAfwBwAGUAcQBzAHUAcQBpAHEAaQBZAFEAXABtAGIATgA9AEUASgA5ADAAMQA6ACUABwAFABIAGAAJAPz/AAAOAAwA//8MABsACwDr/9//6P/1/+n/4f/j/+P/1v/J/9L/1f/Y/8r/vv+6/8f/x/+6/7H/uP/F/7v/tv/C/9f/2f/N/9X/7P/6//3//v8NABIACAD6/woAGgAUAA8AGgAmABwAFgAYACkAKgAZAB8AMAA9ADoAPgBAAEIANgAjAC4AQgBEADAAKAAxADIAFwAXACMAKwAqACEAKgA4ADsAKQAjABwAJAAjABsAHQAgACUAEwAPABMAGAAPAAkADQAkACsALAAsADAANgAwACkAJAAhAB0AGgAOAAwAFQAVAA8ADQALABgAEQARAAoAFQAMAPb/9v/7/xQABwAJAAsAGQAhABYAGQAcACYAHAASABsAMQAvACYAGgAjACsAFwAQAB8AJgAdABMADgAWABcAEgASABQAHAAcABMAFAARABMAAwAFAAwAEwAVAAQACAD+//v/+P/3/wIA/v/+//L/9P/2/+3/5v/h/9//2v/O/8//2v/c/9T/zf/N/9T/zv/D/8X/yv/B/67/sP+6/7X/sf+q/7D/uP+t/67/uP/C/7v/sP+y/7z/vf/B/7//vP+8/8H/u/+//87/yf+//7X/t/+8/7P/r/+y/7z/vP/A/8b/zv/X/9b/1//Y/97/4v/p/+f/5v/p/+X/5//p//L/+//4//b/9P/6//X/+v/9/wcACgAKAAwADgAQAAcACQAJAAsAEAALAAsADgATABQAFwAOABMAFAAQABAAEwAXABYAEgAHAAgABwADAAQABQAIAAQAAgACAAoACQAIAAcA/v/+//z//P////r/8v/p/+f/5P/m/+P/4P/g/9//5v/f/9//3//i/9f/1v/h/+f/5P/e/9//4f/j/9v/4v/t/+j/4f/h/+n/7f/r/+b/8f/z//H/7v/u/+z/8v/0//z/AwAOABIAJgAiACoAKwAnACcAKwAvAC4AKgArADMANgAyADcAOgA7ADAAMQAyADcANAAyACoAJwAjABsAGQAZABUADwAJAAkABAAMAAYAAAAEAAYABQAHABAAEAAOAAQABgANAA4ABgAGAAEA+f/4//X/9//5//L/7//u/+z/8P/5//z//f/+/wAAAwD6//j///8GAP3//P8GAAcAAAD5/wMABQADAP//BwAPAA4AAwAFAA8ADQAFAAUABwAMABEAEAAWABkAFwAUABsAHAAZAB0AGgAUABMAEgASABcAFQAWABcAFQATABUADAALAAQAAAABAAAA+f/2//L/8P/1//T/8v/y//n/+f/2//j/AAADAAQACAAPABMACwALABEAFAAOAA4AEQAOAAsACwANAA8AEQAJAAQABQAGAAYAAwD+//7/AwD+//z/CQAMAAwABwAHABkAHwAWABMAFwAUAA0ADAAWABsAFwAVABcAGwAUAA8AEwAcABkAGAAaACAAHwAYAB0AGQAUABEAFQAUAA8ACgALAAwACgAIAAwAEQAPAA0ADAAOAA8ACwALAAgACQAOAAUACQAJAAAAAAD7/wAA/v/8/wAACQAQABQAFwAaAB8AHAAcAB8AHgAaABIAEQATAAoABwAIAAoACgAFAAYACAAFAAYABAADAP7/+//5//X/+P/1//f//v/3//n//v/+//7//P///wMAAQAFAAQABAAEAPn//P/5//f/+v/+//z/+P/8//v//P/u/+z/7P/m/+f/5v/t/+j/3v/c/9v/2v/Y/9T/1P/O/8j/xv/K/8r/yP/M/87/x//H/8L/wP+8/7j/u/+9/7n/vP+7/8P/wv/B/77/u//E/8H/v/+9/8b/wv/B/7v/v//K/8T/zP/c/+P/5//k/+3/+/8AAP//AgAQABYADgARABsAHAAUABIAGgAfAB4AGAAbACUAJQAcACEAIwAnACcAKQAsAC0ALgAoACMAIwAkACIAGgAYABkAGQATAA8ADQAGAAMA+v/3//z/+v/1//H/8P/q/+X/5f/n/+L/3f/Y/9X/0f/L/87/0v/U/8//y//P/9T/1f/T/9L/1//Z/9j/2P/c/+D/3P/b/+H/6f/s//D/8v/3//n/+P/8/wEABwAIAAQAAwAHAAsADgANAA8AEwAVABYAGAAdACEAIAAiACMAKAAsACwALAAxADMAMgAuAC8AMwAzAC8ALAAtACwAKgAnACcAJAAhABsAHAAeAB4AHQAZABYAEgARABIAEgAWABwAIQAhACMAJgAoACYAIQAfAB4AGgAUABUAGwAcABcAFAAVABkAGQAWABYAGgAXABAACwAMAAoAAwD9//3/AAD6//T/8//5//n/7f/y//v////5//j/AgD4//j/8f/4//b/8//w/+3/7v/t/+//7//v/+z/6v/r//D/7//x//D/8P/z//P/9//5//X/9v/y/+//8f/t/+z/6v/m/+r/6P/r/+z/6P/o/+n/5v/p/+n/4v/k/+b/5v/q/+z/6//v//D/6//x//r//P///wIA///+//7//f8AAAIAAgACAAEAAQABAAAA///9//3//f/9//z/+//8//v/+f/3//j/+//+//3///8BAAEAAwAHAAwADQAOABEAFAAUABIAEQARABIAEAAPAA8AEQARABEAEQASABEADwAOAA0ADQAMAAoACAAIAAgABwAHAAgACAAIAAkACgALAAoACAAIAAgABwAFAAMAAAD8//r/+v/7//z//v8AAAEAAAAAAAAAAgADAAUACAALAAoACgAJAAkACAAHAAcABwAJAAsADQAOAA4ADwAQABEAEwAVABcAFwAYABcAGQAbABsAGwAbAB0AHQAdAB4AIAAjACMAJQAnACoALAAuADAAMQAxAC8AKwAoACUAIgAeABwAGgAWABEADwAPABAADgAKAAUA///7//j/9v/0//L/7//t/+3/7P/s/+v/6v/r/+n/6P/l/+T/5P/j/+L/4f/g/9//3f/c/9v/2v/a/9v/3v/h/+L/4v/h/+H/4//k/+X/6P/p/+j/6P/r/+3/7v/u/+7/8P/x//L/8v/1//f/+f/4//f/+P/7//z/+v/4//f/+f/4//b/+v/3//v/+f8AAP///v8BAAEA/P/4////9//9//T/+v8BAPb/+v8CAAAA/P/7/wEABAAHAAUAAwAJAAUA/v8AAAYACAD/////AQABAP7/+f/5//z/+//4//f/+f/7//j/+P/6//z//f/8//z//f/+//3/+//6//v/+//6//n/+f/3//X/8v/x//L/8v/x//H/8P/w//H/8f/y//H/7//v/+//7f/r/+z/7//w/+7/7P/t//L/9P/z//P/9P/0//T/9P/1//X/9f/1//X/9v/2//X/9f/3//j/+P/5//r//P/7//n/9//4//r/+v/6//v//P/8//v//P/+//7//v/9////AQACAAMAAwAEAAQABAADAAIAAgACAAEAAAAAAAAAAAD///7//v/+//3//P/+/////v/8//r/+v/6//v//P/+/wEABAAHAAsADwASABMAEwATABIAEgARABIAFAAWABUAFAAVABcAGgAaABsAHQAeAB4AHQAeAB4AHwAdAB0AIAAfABwAGAAaABsAFQAWABgAGwAWABMAGQAUABUADwAVABIAEQAOAA0ACwAJAAkACQAHAAYAAwACAAQAAwADAAIAAQACAAEABAAFAAIAAwD///z//P/4//T/8v/v/+//7P/r/+v/5//m/+X/4v/k/+P/3v/e/9//3v/h/+P/4v/j/+X/5P/o/+7/7//x//T/8v/z//T/9f/3//j/9//3//j/+P/5//r/+//7//z//v///wAAAQACAAMAAwAEAAUABwAJAAoACgAJAAoACwAMAA4ADgAOAA8ADwAPAA8ADgANAAwACwAJAAgACAAHAAYABQAFAAUABAADAAIAAQAAAP7//f/8//v/+v/6//r/+f/4//j/9//3//b/9v/1//T/8//y//D/7f/r/+n/6f/o/+n/6v/r/+v/6//s/+7/7//y//T/9//6//z//f///wAAAAAAAAEAAQABAAEAAQABAAEAAQABAAIAAwAFAAYABwAJAAoACwANAA8AEAARABEAEgASABMAFAAWABcAGQAaAB0AHwAiACQAJgAmACYAJQAkACMAIgAgAB8AHgAdABsAGwAcAB0AHgAdABsAGQAYABcAFwAWABQAEgAQAA8AEAAPAA4ADAALAAoACAAGAAQAAwACAAEAAQD///7/+//5//j/9//2//X/9v/2//f/9v/2//X/9v/2//f/+P/5//j/9//4//n/+f/3//f/9v/3//f/9f/2//b/9//2//b/9f/3//j/9//0//P/9P/z//D/8//w//L/7//1//T/8//z//X/8v/u//P/7v/1/+z/8P/2/+7/8P/2//X/9P/z//f/+f/8//z/+v/+/////P/9/wEABAD///7///8AAP///P/8//7////9//z//f////7//f///wEAAgADAAIAAwADAAMAAgACAAMAAgACAAEAAAD+//7//f/8//z//f/9//3//P/8//3//v////7//P/8//z/+v/4//f/+P/5//b/9P/z//X/9//2//T/8//y//H/8f/x//D/7//v/+//7//v/+7/7v/v//D/8P/w//D/8f/x/+//7v/u/+//7//u/+3/7v/t/+3/7f/u/+//7//v//D/8v/0//X/9v/3//j/+P/3//f/9//3//b/9v/1//X/9f/1//T/8//z//L/8v/y//P/8//y//H/8v/y//T/9f/3//n/+//+/wEABAAHAAgACQAKAAoACgAKAAsADAAOAA4ADQAOABAAEwAUABUAFgAXABgAFwAYABgAGQAZABgAGgAbABkAFwAXABoAFgAXABcAGwAYABUAGgAWABgAEwAXABQAEwARAA8ADQALAAoACQAIAAYABAADAAUAAwAEAAMAAgADAAIABAAFAAMABAABAP//AAD9//v/+v/3//j/9v/1//b/8v/y//P/8f/y//L/7//v//H/8P/y//T/8v/z//X/8//2//r/+v/7//3/+//7//3//f/+/////v/+/////////wAAAAAAAAEAAgADAAQABAAFAAYABgAHAAgACgALAAwADAANAA4ADwARABIAEwATABMAFAAUABQAEwASABAADwAOAAwACwAKAAgABwAGAAYABQADAAEAAAD+//3//P/6//r/+f/4//j/+P/3//f/9v/1//T/8//y//H/8P/v/+3/6//p/+j/6P/p/+r/6//s/+3/7f/u/+//8f/y//P/9f/2//b/9//3//f/9//3//f/9//3//j/+P/5//r/+//8//7///8AAAIAAgADAAQABQAGAAcABwAIAAkACQAKAAwADgAQABIAFAAWABcAGgAcAB4AHwAfAB4AHQAdABwAGwAbABoAGgAZABgAGAAZABsAHAAbABoAGAAXABYAFwAWABQAEgARABAAEAAQABAADgANAAwACwAJAAcABgAFAAQABAADAAIAAQD///7//v/+//7//v////////////7//v////////////3//P/8//3//f/7//v//P/9//3//f/+//7//////////v///wAA///+//z//f/9//v//f/6//v/+P/9//v/+v/4//r/+P/0//j/8v/5//L/9P/6//X/9f/7//n/+P/4//r/+v/8//v/9//5//n/9f/0//X/9v/x//D/8P/w//D/7v/u/+//8f/x//D/8f/z//P/8//1//b/9v/3//X/9v/1//b/9f/0//T/9f/1//X/9f/0//X/9f/1//b/9//4//j/+P/3//j/+f/6//n/9//3//j/9v/1//X/9v/3//b/9f/0//b/+P/4//f/9v/2//b/9//3//j/+P/5//r/+//7//v//P/8//3//f/8//z//f/8//v/+f/5//r/+v/6//r/+v/7//r/+//8//z//P/8//v//P/9//3//P/8//v/+v/5//j/9//2//X/9P/z//L/8v/x//D/7v/t/+z/7P/s/+3/7f/s/+z/7f/u/+//8P/y//P/9P/2//j/+f/6//r/+v/6//r/+v/7//z//v8AAAEAAgADAAUACAAJAAoACgALAAsACgALAAsADQANAA4AEAASABMAEgAUABgAFgAZABoAHgAdABsAHwAcAB4AGgAeABsAGwAaABkAGAAYABkAGQAZABkAGQAYABsAGgAaABoAGAAYABYAFwAWABMAEwAPAAwADAAJAAcABgADAAQAAgAAAAEA/f/9//3/+v/6//n/9f/1//X/8//0//X/8v/y//L/8P/w//P/8f/x//L/7//u/+//7v/v/+//7v/u/+7/7v/v/+//7//v/+//8P/w//H/8v/y//P/9P/1//b/+P/6//v//P/9//7///8AAAEAAgACAAIAAwADAAMAAwADAAMAAwADAAMAAwADAAMAAwADAAMAAwADAAMAAgACAAIAAgADAAMAAwADAAQAAwADAAIAAQAAAP///v/+//3//P/8//v/+//6//r/+//8//3//f/+//7//f/9//z/+//7//r/+v/6//n/+P/4//j/9//3//f/+P/4//j/+f/5//n/+v/6//r/+v/6//r/+v/6//r/+v/7//3//v///wAAAQACAAQABgAHAAgACQAKAAoACgALAAsACwAKAAkACQAIAAgACAAIAAkACQAJAAkACgALAAwADAAMAAsACQAJAAkACgAKAAoACQAJAAkACgAKAAsACgAKAAkACQAIAAcABwAHAAgACQAJAAkACQAJAAkACQAKAAoACwALAAwADAALAAoACgAJAAkACgAKAAkACAAJAAoACgAJAAkACgAKAAoACgAKAAoACgAJAAgABgAHAAgABwAFAAQABQAFAAMABQACAAMAAAAEAAIAAgAAAAIAAAD9/wEA/P8EAP7/AAAGAAEAAgAGAAUAAwACAAMAAgADAAIA/v/+//7//P/7//3////8//z//f/+/////v/+/wAAAQABAAAAAAABAAAA//8AAAAAAAAAAP//AAAAAAAAAAAAAAAAAAABAAEAAQAAAAAAAAAAAP//AAAAAAAA//////////8AAP///f/9//7//f/8//v//P/9//z/+//7//z//v/+//3//P/8//3//f/9//3//f/9//3//f/9//z//P/8//z/+//6//r/+v/6//n/+P/4//j/+P/3//f/9//3//b/9v/2//b/9f/0//T/9P/0//T/8//z//L/8f/w/+//7v/u/+3/7f/t/+3/7f/t/+3/7P/s/+z/7f/u/+//7//w//D/8P/x//L/8v/z//T/9P/1//b/9//4//j/+P/4//n/+f/6//v//f/+//7//v/+////AAAAAAAAAAAAAAAAAAAAAAAAAgACAAMABQAGAAYABQAGAAkABgAHAAcACgAIAAUACQAGAAcAAwAHAAUABQAFAAUABAAEAAUABQAFAAUABQAEAAUABAAEAAMAAQABAP//AAAAAP3//v/8//v//P/7//r/+//5//v/+v/6//v/+v/6//v/+f/6//v/+P/5//r/+f/7//3/+//7//3//P/9/wAA/////wAA/v/+//////8AAAAAAAAAAAEAAQABAAIAAgACAAMAAwAEAAQABQAFAAYABgAGAAcACAAIAAgACAAIAAgACAAIAAgACAAHAAcABgAGAAYABQAEAAQAAwADAAMAAgACAAEAAQABAAEAAQABAAAAAAD//////v/+//7//v/+//7//f/9//z//P/7//v/+//7//v/+//7//v/+//7//v/+//8//3//f/9//3//f/8//z//P/8//z//P/9//3//f/+//7//v///wAAAAABAAIAAgACAAMABAAEAAQABQAFAAYABgAGAAcABwAIAAkACgALAAsADAAMAA0ADgAOAA8ADgAOAA0ADQANAA0ADQAMAAsACgAKAAoACgAKAAoACgAKAAoACgAKAAsACwAKAAkACAAIAAgACAAIAAgABwAGAAcABwAIAAgACAAHAAcABwAGAAUABQAFAAUABgAGAAYABQAFAAUABQAFAAUABQAFAAUABAAEAAMAAgACAAIAAgACAAEAAAABAAEAAQAAAAAAAAAAAAAA///////////+//3//P/8//3//P/7//r/+//7//r/+//5//r/+P/7//r/+v/5//v/+v/3//v/9//9//j/+f/+//r/+v/+//z/+//6//v/+v/7//r/9//4//n/9//3//n/+//4//j/+f/6//v/+v/6//v//P/8//v/+//7//v/+v/7//v/+//7//r/+v/6//r/+v/5//r/+v/6//r/+v/5//n/+f/5//j/+f/5//n/+P/4//j/+P/5//j/9//4//n/+P/4//f/+f/6//n/+P/4//r/+//7//r/+f/6//r/+v/6//r/+v/6//v/+//7//r/+v/6//r/+v/5//n/+f/5//j/+P/4//j/+P/3//f/9//4//f/9//4//j/9//2//b/9v/3//f/9v/3//b/9v/2//X/9f/2//b/9v/2//f/9//4//j/+P/4//n/+f/6//z//P/9//3//v//////AAAAAAEAAQACAAMAAwAEAAQAAwAEAAQABAAFAAUABgAHAAcABwAHAAgACQAJAAkACQAJAAgACAAIAAcACAAJAAgACgALAAsACgAKAAwACgALAAoADAAKAAgACwAIAAkABgAJAAcABgAGAAUABQAEAAUABQAEAAQAAwACAAQAAwACAAIAAAAAAP7///8AAP7////9//z//v/9//3//f/8//3//f/9//7//f/+/////f///////f/9//7//f///wAA/////////v///wEAAAAAAAEA//////////8AAAAA//8AAAAAAAAAAAEAAAAAAAEAAQABAAEAAQABAAEAAQABAAEAAQABAAEAAQAAAAAAAAAAAP////////7//v/+//3//f/8//z//P/7//v/+//6//r/+v/6//r/+v/6//r/+v/6//n/+v/6//r/+v/6//v/+//7//v/+v/6//r/+v/6//r/+v/7//v/+//7//v/+//8//3//v/+//7//v/+/////////////////wAAAAAAAAEAAQACAAIAAwADAAQABQAFAAYABgAHAAcACAAIAAgACAAIAAgACQAJAAkACgAKAAoACgAKAAoACwALAAsACwAKAAoACQAJAAkACQAIAAgABwAHAAcABwAHAAcABwAGAAYABgAHAAcACAAHAAcABgAGAAYABwAHAAYABQAFAAYABgAHAAcABwAHAAcABgAFAAUABAAEAAQABQAFAAUABQAEAAQABAAEAAQABAAEAAQABAADAAMAAwACAAIAAgACAAEAAQABAAEAAQAAAAAAAAAAAAAA////////AAD///7//v/+///////+//7///////7////+/////f8AAP/////+/wAA///9/////P8BAPz//v8CAP7///8CAAAAAAD//wAAAAABAAAA/f///////f/9//7////9//3//f/+//7//f/9//3//v/+//3//f/+//3//f/9//3//f/9//z//P/7//v/+v/6//r/+f/5//n/+f/4//j/+P/4//f/+P/4//j/9//3//f/9//4//f/9v/3//j/9//2//b/+P/4//j/9v/2//j/+f/5//j/9//3//f/9//3//f/9//3//j/+P/4//f/+P/4//j/+P/3//f/+P/4//f/9v/2//f/9//2//b/9v/3//b/9//3//f/9//2//b/9//3//f/+P/4//j/+P/4//j/+P/4//j/+f/5//n/+v/6//v/+//7//v/+//8//3//v/+//7///8AAAEAAQABAAIAAgADAAMABAAEAAQAAwADAAMAAwADAAMABAAEAAQABAAEAAQABQAFAAUABQAFAAUABAADAAMABAADAAMABAAFAAQAAwAEAAYAAwAEAAQABgAEAAIABQADAAQAAQAEAAIAAgACAAEAAQAAAAEAAQAAAAAAAAD//wEAAAAAAAAA//////7///8AAP7/AAD+//7////+//7////+/////v///wAA/v8AAAEAAAABAAEA//8AAAEAAAACAAMAAgACAAMAAQADAAUAAwAEAAQAAgADAAMAAgADAAMAAgACAAMAAwADAAMAAwACAAMAAwADAAMAAwADAAMAAgACAAIAAgADAAMAAgACAAIAAgACAAEAAQABAAEAAAAAAAAAAAAAAP/////////////+//7//v/+//7//v/+//7//f/9//3//f/9//3//v/+////////////////////AAAAAAAAAAAAAAAAAAAAAAAAAAABAAIAAgADAAMAAwAEAAQABAAEAAQABAAEAAUABQAFAAUABQAFAAUABgAGAAYABgAGAAYABwAHAAcABwAHAAgACAAIAAcACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAHAAcABwAHAAcABgAFAAUABAAEAAMAAwADAAMAAgACAAEAAQABAAIAAgACAAEAAAAAAAAAAAAAAP/////+//7///8AAAAAAAABAAEAAAAAAP///////////////////v/+//7//v/+//7//f/+//7//v/+//3//f/9//3//v/+//3//P/9//3//f/7//z/+//8//v/+//7//v/+//6//r/+f/6//v/+v/5//n/+v/6//n/+//5//r/+P/8//r/+v/6//v/+v/4//v/+P/8//f/+f/8//f/+v/8//v/+//6//z//P/9//z/+v/8//v/+v/6//z//P/6//r/+v/7//v/+v/6//r/+//6//r/+v/7//r/+v/7//v/+//8//v/+//7//v/+//7//v/+//7//v/+v/6//r/+v/6//r/+v/6//r/+f/5//r/+v/7//r/+v/6//v/+v/5//r/+//8//v/+v/6//z//f/9//z//P/8//z//P/8//z//P/8//z//P/8//z//f/9//7//f/9//7//v/+//7//f/+//7//v/9//3//f/9//3//v/+//7//f/9//3//v/+//7//v///////////////////////////wAAAAAAAAAAAQAAAAAAAAAAAAEAAQABAAEAAgADAAMABAAEAAQABAAFAAYABwAHAAcABwAHAAcABgAGAAcABwAHAAYABgAGAAcABwAHAAgACAAIAAcABgAGAAYABgAFAAUABgAGAAUABAAFAAYAAwAFAAQABgADAAMABgACAAQAAQAFAAMAAwADAAIAAgABAAIAAQABAAEA/////wEAAAABAAAA//////7/AAD///7/AAD9//7////+//7//v/9//7//f/9//7//f/+//7//f////7//f/+//7//f///////v///////v8AAAEAAAABAAIAAAABAAEAAQACAAIAAQABAAEAAQABAAEAAQABAAEAAQABAAEAAQABAAEAAQABAAEAAQABAAEAAQABAAEAAQABAAEAAQAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA/////////////////////////v/+//7//f/9//3//f/9//7//v/+//7//////////////wAAAAAAAAAAAAAAAP////8AAAAAAQABAAEAAgACAAIAAgACAAMAAwADAAMAAwAEAAQABAAEAAQABAAEAAQABAAEAAQABAAEAAQABQAFAAUABQAFAAQABAAFAAUABQAFAAQABAAEAAQABQAFAAUABQAEAAQABAAFAAUABQAEAAQAAwADAAMAAwACAAIAAQABAAAAAAAAAAEAAQABAAAA/////wAAAAAAAP7//f/8//z//f/9//7//v/+//7//v/+//3//f/9//7//v/+//7//v/9//3//f/9//3//P/9//3//P/8//z//P/8//z//f/8//z//P/8//3//P/7//z//P/8//z/+//8//v/+//6//r/+f/6//v/+f/5//n/+v/6//n/+//4//r/+P/8//r/+//7//z/+v/5//z/+P/+//b/+//8//b//P/8//r/+v/6//z/+//9//z/+//9//z/+//8//7////7//z//P/9//3/+//8//z//f/8//v//P/8//v/+v/7//z//P/8//v//P/8//z//P/8//z//P/9//3//P/8//3//P/8//z//f/9//z/+//8//z//f/9//z//P/9//3/+//7//z//f/9//v/+v/7//7////+//7//v/+//7//v/+//7//v/+//7//v/+//3//v/+//7//v/+////AAAAAP////8AAAAAAAD//wAAAAD/////AAABAAAA///+//7///////////8AAAAAAAD/////AAAAAAAAAAAAAAEAAQABAAIAAgABAAEAAQABAAIAAQABAAEAAQACAAIAAgACAAIAAgACAAMABAAFAAUABQAGAAUABQAFAAYABgAGAAUABAAEAAUABgAGAAcABwAHAAcABgAGAAUABgAFAAUABwAFAAUAAwAFAAYAAQAFAAMABgABAAIABgD//wQA//8GAAEAAwAEAAEAAgABAAMAAgABAAEAAAABAAIAAQACAAAA//8AAP7/AQAAAP//AQD+////AQD//wAA///+/////f///////f///////v8BAP///f/+//7//v8AAAAA/f/+//7/+////wAA/v8AAAAA/v///wAAAAABAAEAAQABAAAAAAABAAEAAQABAAEAAQABAAEAAQABAAEAAAAAAAAAAQABAAEAAQAAAAAAAAABAAEAAQAAAAAAAAAAAAAAAAABAAEAAQAAAAAAAAAAAAAAAAAAAAEAAAABAAEAAQABAAAA/////////////////////////////////////wAAAQABAAEAAAAAAAAA//8AAAAAAQABAAEAAQABAAEAAQABAAEAAQABAAEAAQACAAIAAgACAAIAAwACAAIAAgADAAMAAwADAAMAAwADAAMAAgACAAIAAgACAAMAAwACAAIAAQABAAEAAQACAAEAAQABAAEAAQABAAIAAgACAAEAAQABAAEAAgABAAIAAQD///7//v///wAAAAAAAP7//f/+////AAAAAP7//P/7//v/+//8//z//P/8//z/+//6//r/+v/7//v/+//8//z/+//8//z//P/8//v//P/8//z//P/7//r/+v/7//z//P/8//r/+//8//z//P/6//v/+//7//z//P/9//3//f/7//r/+//9//3/+//6//r//f/7//r//P/4//r/9//9//r/+//9//3/+//6////+v8AAPb//v/9//b////+//r/+f/5//z/+/////z/+//+//r/+v/9/wAAAAD7//7//f////7//P/+///////+//3///////3//f/+/////v/+//3//v////7//f/9//7//v/+//7//v/+//7//f/9//7/AAD///3//P/9//7//v////7//v////7//f/9////AAD///v/+v/8///////+//7//v/+//3//f/+/////////////////////////////v///wAAAAD///////8AAAEAAQAAAAEAAQABAAEAAgADAAMAAQAAAAEAAgABAAEAAgADAAMAAgABAAEAAgACAAEAAQACAAIAAgACAAMAAwACAAEAAgADAAQAAwADAAIAAgACAAIAAgACAAEAAAAAAAIAAwADAAMAAwADAAIAAgADAAQABQAFAAMAAgACAAIAAwADAAQABQAEAAMAAgADAAIAAwACAAMABAADAAIAAgAEAAIA//8DAAIAAgD//wEABAD9/wEA/f8DAP//AQAAAP3////+/wEA//////7//P/+//////8AAP3//P/8//z////+//7////8//7////+/////v/9//7//f////7//P/+//////8CAP7//P/9//3//v8CAAEA/v/+//v/+f/+/wAA//8BAP///P/9//7///8BAAEAAAAAAAAAAAABAAEAAQABAAEAAQABAAEAAgACAAEAAAAAAAAAAQACAAIAAQAAAAAAAAABAAEAAQABAAAAAAAAAAAAAAABAAEAAAAAAP////////////8AAAAA/////wAAAAAAAP/////+//7//v/////////+//7//v/+//7//v/+////AAABAAEAAAD+//7//v///wAAAQABAAEAAAD//////////wAAAAAAAAAAAAAAAAAAAQABAAEAAQABAAEAAQACAAEAAQABAAEAAgACAAIAAQAAAAAAAQABAAIAAgABAAAA////////AAABAP///v/9//3//f//////AAD//////f/9//7///8AAAAA///8//r/+v/9/wAAAAD+//v/+f/6//3/AAAAAP7/+//6//r//P/+/////v/9//v/+v/5//n/+v/6//v//P/8//z/+v/6//v//P/8//z//P/9/////v/9//3//v/+///////+////AAABAAEAAQAAAAAAAAAAAAEAAwAFAAQAAgAAAP//AQAFAAQAAgABAAIABAADAAMABAD//wEA/f8DAAMABQAHAAIAAAAAAAUAAAAGAP3/BwAEAAAADAAHAAEA/P/9/wEABAAJAAQAAwAAAPn//v8FAAsABwAAAAIAAQAEAAIAAwAGAAUAAwABAAMABwAFAAMAAgAEAAUABAACAAMABgAFAAIAAAAAAAEAAwAFAAYABQACAP///v8BAAUABwAEAAEA//8BAAIAAwAFAAUABAACAP///v8CAAYABwACAP3//P/+/wMABQAEAAMAAAD+//z///8CAAQABAACAAIAAQABAAIAAgACAAEAAQACAAUABAAAAP////8DAAQABQAEAAIAAgAAAAQACAAJAAYAAgABAAMABQAFAAYABgAGAAQAAwADAAMAAwADAAMABQAFAAMAAQACAAIAAgAAAP//AQACAAQAAgAAAAEAAAAAAP7/AAABAP///f/8/wAAAAAAAAEA//////n/+v8AAAQABgACAP7//f/9/////f8AAAQABQAAAP3//P/8//n//v8CAAUA///7//3//P/8//r//v8FAP7/+v/8/wMAAwD0//7/+f8BAPz/AQD+//r//P/7/wAA+P/7//r/+v/8//7/AQD8//X/9f/6//r//v/9//j/+v/8/wEABAD7//r/9f/0//7/AQAKAAMA+f/3//v/AQADAP//+v/7//j/+v///xIADwAAAOv/3f/5/wUADwAXABMA///s/+z/+f8XABwADwAAAP3/BQAIAAQABgALAA4ABAD8/wUADwAOAAAA/v8EAAsABgAEAAYACAAKAAUABwAFAPn/+P8BAAsACwACAPz//P8BAAAA//8DAAAA+//5////BwAIAPv/9f/7/wAAAwAEAAAAAAD5//P/+f8AAAIA+//7//3//v/6//j/+P/9/wMABAADAAIA/f/5//f/9//9/wEABQAFAAIA/v/3//f/+P/7/wUABgAEAP///P8AAAIAAgABAP///f/+//7/AwAGAAYA///5//j//v8DAAMAAAD//wMAAQD+//z///8BAAAA+/8AAAMABAADAPn/AQD+//3/+v8GAAUAAQABAAMABQACAPn/+P///w4ABAD3//T/9/8BAAAABQAGAAAA8//z//v/BgAGAAYA///5//T/9f/+/wQABAACAP3/+P/x//L//P/+/wIAAgAEAAMA+f/6//3/BQADAAgACwALAAYA/v8EAAwADgALAAcACgAKAA0ACwANAA0ADgAKAA8ABwACAAoADwAbABQACwADAPv/AgAHAAsAGAAXABUABgD+/wEADQABAAAA+v8GABEAFgAZAAYA///3//X/6v8LABIAGwD9//f/JgAUAPf/1//Z/9X//P8uADUAKgDZ/7T/0v8AABQAEwAYABQA7f/c/+P/EwAYAPP/5//s/woADwD/////AQD2/+z/8f/7/wgACAABAP3/AgD6/+j/7P/7/wwAEgD//+z/5f/p//f/AAD//wIA/P/x/+z/8/8NABMACADy/+n/8/8EABMAFAAKAPr/9P/6/w4AEAANAA4ADgAJAAMACQAIAA4ACwAHABMAEwAGAPj/9//+/wcACAAFAAoAAQD5//7/BQAIAAYACwAKAAAA+//5/wUACgD9//z//f/3/+//7//6////9v/y//P/+//6//b/8f/1//f/9v/6//X/7//r/+3/9P/w/+j/6v/w//b/8P/t/+//8v/s/+3/6f/v//T/AwAPABEAAwD9/wUACwALAP7/AAANAB4AFgANAAUAAgD1/+//9/8PAAgA///0/wMA+f/u/+D/+v/5/+z/7f8EAAUA6P/o/+b//v/1//P/9v8LAP7//P/1/w0A+//2//T/BQAEAAUAAwD8//H/7v8CAAEADgAHAAYAAQDq//n/DwAZABcAEwALAAoAFAAYABgADAAIAAkAFgAWACIACAAJAB4AGwAFAPD//f/2/+D/8P8fAB8A8v/4/zYAAwDL/9b/uv/V/1v/JABAASoB8P8N/xf/gv88AEUApgB0ADsAmf9B/5L/PACbAO3/R/+q/3gATQCj/7v/WQDm/0L/AP9HAJEA3/+g/+X/TwCO/zX/jv8RAB4Asv8IAF4AGgDC/5z/7v81APL/8f9MAH0AZQAMALj/CgBWAPf/MwBdAIMAYgDf/83/RwCQAC0AAQBOAKYAhgAPAD8AmgCbACUA7P9nAJEACAB9/6P/EQDk/3X/nv9KAIoAzf/e/tT+RP++//L/AQBMAB0Anv87/03/v//f/9L/x//Z//3/SgBGACcAtP89/2z/+v9VAFsAMAAGAAYAkf9f/4z/IgD9/zH/HP8AAEIA3P+V/6r/BgAH/wP/p/++ABEAt/8CAFgARgDA/4j/ef/k/z4AVQBkAEcACQDv/9L/JACVACYAjf/Q/00AaQAkAFEAeAA1AJb/Rf/n/y0AHgCxAKMAOwCA/1L/vP8RAIsA4ADEAPX/c//C/x8AJgBLALcAswACAK7/KgCgAHUAJwAoAAoAIAApAM8ArgAkALL/3/8YAEsAVgBLAGUAy/+Q/9X/XABgAB0AuP+Y/8X//f9mAKwAMACt/47/sf+X/+r/SgDHAMwA9P+c//b/RgAYAJ3/Wf9sAKsALADm/1IAowCv/zb/bv88AMv/7f/iADABWwDc/jD/OgBPANP/EgCeAHsAov+M/yEAuwBJAJX/g//Z/1QAKAAhAF4AegANAIz/vP9PAHIA5/+K/wIAigBwANb/z/8cADQA8v+8//f/TQA2APb/tP/a/yIAIwDp/6H/w/8CACoACQDI/+X/AgC3/5//t/8SADUA1f/I/+v/3v8NAFIAbgARAJD/ff/H/xAAPACLAH8A5v+H/4//+P9OAIgAYAD//8b/2v8RACIACAATADUAKgAdAAYAJwAfAAkAwf+0/6r/AAA6AEUAOgDV/77/z////+z/xP/u/wsA5/8VAE4AXwAEAHb/kv/L/zMARwBgADgA9f+8/5n/uv+//yMAFgAgAPv/+P/7/67/rf/w/2MANACa/6H/9f9GAMr/x/8gAGoA7v9r/6r/IQAIAKr/7/9ZAG4A5/+P/+H/IQDO/7H/p//S//P/9P8QADMA3v/g/9//rf+J//7/XgBbABsA2/8uACEA3f/E/+f/+v8yAGsAPADN/57/qf/p/woAiQBoAOX/Y/+b/0wAeAAvAOf/3P/X/6j/4P+TAKQAFAB0/4//BwBEACAAGwAqABEAyv/F/xEAMgAMACYAWgAtAMz/Rf+y/yAARQBiAG4AQQCv/4n/tP8yAA0AAwAlADAA5//R/00ASwD4/5r/uP/k//3/+f9QAGcAKQDt/7r/m/+g/7//xf8RAGYAVAAFALH/qv+4/6n/yf8FADYA+P/X//D/TgBvAPv/qv+D/5z/6/9GAFEAhAAiALr/lf+c/9b/7v8QAOn/EADy/wIAHQAJAMX/df+M//r/kgCaAGwAGQDI/5r/lv/e/zcAPAAxAD4AMgATAP3/2P/Y//z/5//q/woAVwCIADwAk/98//z/MwAVAOf//v8XAAMArv+9//7/JgArAO3/0v+s/9n/GwA9ACYA0P+G/2D/9/9zAG0ACwCW/3//kv+2/wgAbgBuAAkAlv99/5//+f9LAEwADQDa/7f/zf/U/zQAIgCm/4D/yP91AHsAy/+P/8P/z//V/+H/YgBQAN7/a/+q/93/HQAcAA4AEADQ/93/2P8lAEMAXwAxAMb/2v86AHYAIwDr/xQAOgDm/8f/BABdAE8AMQBBAGMA5P9v/6//CgBDADoAWQCRADkA3P+y/9b/GQAXACcA/v/S/77/IgB6AFYAJwDg/9f/zf/P/xgAPQAPAO//DQAjAC0A8f/7/ykAFQDp//3/5P8DAPn/9P80ABwA/P/F/wIAFgDs/+H/5v86ACkAKwAfAAAA9f/c/woAEgAQABQAMQAyAPH/GwBoADUA4v+x/+r/FAD9/xMAVgB4ACkA6/+t/53/zv/j/y0AJQAmADcAJgDz/8v/vf/X/wMAMQBbAEoAJADy/9j/sP8MAE8ATgDq/9T/DgAmAC4Axf+z/7H/1/8uAEoAYQAjAAEA0v+T/7D/KQB7AIIAKgDl/6H/qP/x/0QAeQBXAPP/AADl/9j/xP/O/0UAjgBoADwA9//m//X/6v8hADAAJAAUAOX/9/8LAEAASwAMAN//wv+9/+b/CgBRAEkAGADM/8r/9v8YAAYA5P/I/9P/TQB+AEkA2f+Y/5v/4f8vAFkAgAAzANX/pv+e//T/+v9aAEcAAACg/4T/9P9NAGEAFgDf/7f/2v/5/wAACQALACkABQALAOj/DQARANz/AQA7ABgA6P+q/wcAMQAmAMb/xv/l/7z/lf+0//v/EADv/8//BgAJAPv/r/+k/93/wv/h/zMAPAAtANj/x//r/9b/wv/D/zIAIgDm/9n/1P8fAEwANQASAL//ef/m/xAAZwBHACoA9f+r/3//u/8SAGUAcwBfAP//oP9x/7b/NwB8AEsAKQD2/9f/zv/v/2IAYQAHAM//0P8YAAoAFQAvAFEA+f/P/97/LAAoABsAFQARAAUA7f8QAOr/vf+6/wsAkQB9AO7/j/+i/+X/NAA5AAQA3/+p/6X/+v8wAFUAFACk/2z/cv+w/0AArQCNAPH/YP9a/8L/QABlADMA5v+7//P/RwBTACUAuP9f/4H/zf9XAFoAHQDb/+L/AQDz/9b/xP/Y/+//EAD6/zgARgBEADIA3P+//5f/uv/y/2YAngCBACYAvv+O/7v/AgAnAGcARQAnABIACQAmABEA7P/I/7z/2f8IAEAAWABWAAYAxP+b/63/4P8KADIAQgA/APP/yv/B/9X/DgABANj/1P/Z/+z/FQAKAAIAAQACAOT/3P/m/9v/CADy/wMA9//d//P/CQAVAM3/vP+u/93/CAAYAB8ACgD8/7n/yf/f//v//v/p/+7/6f/q/9L/DgA0AAIArv92/6f/2f/4/wwAYwCEAC0A6/+X/5v/zP8qAGAAaABSABEA+//a/8H/yv/t/x8AXgBKAPH/zv/v/xAABwDh/+f/FQD8/xsASABmAC4Ajv+K/9n/EQA2ADsAWQA1AN7/x//6/z8ABACu/+T/OQAyAAUA7P8QAC8A6P/l/73/5v8OACYAZgAsAAYAsf+N/4r/2v9XAIUAeAAiAAcAqf99/7z/TwCUADIA///l/w0AJgA0AGAARQDd/1n/kP8yAHgAfABAACAA/P/K/8j/5P8OABcACwAhADoALAD2/9n/yP+o/77/5/8JAB4A+v82AGMAIQCz/3//1P8tAEUAPQBQAC8A6P+O/5n/9v8rAEUAGgAXAA4A8//Y/7f/v//I/+v/GwBJAGsAHgDS/7z/sv/t/xIAOgA3APX/1//X/z4AfQBwAEIA8f/e/8j/3P8OADMAQQAcAAoAAQAoADIAHAD0/+L/0//F/+v/OQBTAFkAPAD//8n/gP+M/9v/UQCPAGkAHgC+/6z/5P/x/+D/9P8+ADUA///r/08AVwD1/6D/w//X/73/6v9OAI4AXAAgANT/0f+V/7z/HAAuABEAJAAhAAcAAwAeAD4AAQCX/7v/CgAgADMAXABLABYAu/+u//D/PgBiAEIAYADx/7b/m//v/ywANAD9/+f/9f/i/+v/8v8OAAwA1/+j/7j/sf/M//v/LQBFAB4A6//K/8H/y//Y/9//0P8EAA8AMwAhAP//7v/e/7X/zf/8/ywAKADk/87/q//M/9D/LQA2ADgADQD5/+v/vP/e/wEANADw/97/9v8bADUAFgAxAPv/wf+O/7b/8P8XAD4ARgBQACsA/f/O/9D/8P8zAC4AJwAkAD4A8/+3/7X/9/9QAEoAOwDW/+P/yP8JAEAAQQAwANf/zv/B/z0AVgBTAPT/q//T/+X/NgAlAAcAev9r/9r/RgB6AFMA+//G/8H/1P8nABkACQDU/wwAPABHAPv/qf/c/8D/1v/t/0wAfwAmAKz/bf/X/zoAPwAGALb/rv/f/xkARQDu/7r/vv/h/xsASgA5AMD/xv/W/yYAJADv/wsALAAgAPT/CABIAHAA+v+c/1f/df/1/58ADgGbAOj/YP9b/7r/MABoAGcAPwDH/8L/6P83AHgAawA5ALr/X/9m/+b/bwCWAEUA4v/H/9X/MwBIAOb/jv90/wMAkgC0AI8AIACH/y//Zv/v/30AdgA2AAQAsf+R/8z/NQBdABUAuv9x/3P/2f92AOIApgDI/yj/GP9G/9z/XQCwAFUAjv9P/43/6f/6/xoADwDK/4L/u/86AJ0AaQD9/67/Yf+f/xAAfQBwABEAqv+w//b/KwBPAAAAqP+e/+r/RwB0AHIAMwCw/27/vv/g/yoALgApABYA6v/x/yMAPgAjABoA2P/I/5b/3f9pAK0AYwD+/7X/i/+7/+//SwBHAB8At/9w/7X/RQDIAJUA2/83/yL/if9vANYArgAFAFv/Sv+Q/wgAegCXAE4A9/++/9X//f8dADIAFwDj/8f/KABmAFYAFwDh/7L/lv/v/zgAmQB0ABoAzv+v/8T/MgBfAGEAHAC9/5v/m//4/40AqAAWAJf/Uf+b/9r/KwChAMsAfwDW/2b/ZP+Y/wAAWwCeAIQAKgDS/5L/f/+8//b/KwA7ACEA7v+e/6X/2/88AFsAAQCr/6L/w/8QAEwAXAAwAN3/p/+W/9//TABiAGIAQgDp/6D/g//X/z4AjgB1ADgA6P+a/8T/CQA/ABsA2//I/wwALAA6ADcAGQDz/9f/4P/N/9b/IQBJAEUAEAD9/yQANwAJALX/gP+8/0QAoQCIAOX/g/+2/zEAWAA7APv/v/+l//3/CwA5AC0A//8aAAEA6f/W/w0APABOABQA2f+2/+X/FwBOAHYANQDb/8P/3f/0//P/8v8yAJAAPgAGAAMAEwAeAOP/3f8tAGQATQAVAJX/l/+r/y4AXgAlAOL/rP/V/8//3f8IAFEAPAAPANf/qf/K/+P/KgBeACUAtv99/8v/UQBpABMApf+A/83/CABCACUA8v/d/+H/5v/x/wcA5P/j/7b/xP/u/wUAIgBaAAAAcf9d/8z/UgBJABcA+v8HAKH/xP9IAHcA8v9C/3P/6/91AGcAdABPALv/bf+E/+P/3/8RAFUAtgCZABoA2P/a/73/j//A/+v/VQBpAIUAXgANAND/1v/x//D/zP/J/wQANwCLAHcATQDd/47/gf+x/9X/+P9YAHMAnABSANn/Z/8w/2H/5v91AHQArwCKAD8A1/+Z/7D/y/+5/7b/PgBuAE8AFQAxACEAs/9F/1//tf/v/xQAZAB1AN//g/+//y8AQgAWAOn/GADi/7L/5v/z/wMA6f8WAGYAfAAaAJH/bv+p/y8AbQCKAEMAGQDa/2j/nv8UAIkAjQAiAMz/kP+c/wIAaQBjAPT/yf/u/0QATgA4AEgAAACZ/4//+/9eAGEAOAAIAPf/7P/i//v/7P/B/9P/JABuAGEARwABAMv/l/+v/xcAbQBlAOL/i/+V//P/TwBCACsAFQC1/37/mf8iAIYAZwDk/5z/mv+4/8T/5f8TABAA7/+s/63/5P/Z//P/8P8WAAgA1P/s/xEANwDy//X/BgAqAOf/tf/N/wkACgAOAEEAOQDp/5X/nf/n/xsACgAUAEMADQCr/33/tP8rAHMAlgAWAJb/Sv+e/0sAfQBSAAsA5P/R/7n///8pABgA9f/n////BQAFABcAIwDh/7f/uP/u/xEAHAAFAM3/+v9WAHEAMwCP/1j/e//a/0gAsQDMAE8AvP+L/63/1v8GAEkAfQBEANb/l//t/2AAWQAMAND/zP/i/wUAVgBjADoA1v+e/6D/2f8iAHMArgBUALr/T/+D/xQAkACBACUAjf8J/z//JgDpABQBWwCg/3D/f/+f/+P/cAC/AIYA1/9j/5f/IgCNAIMAGACL/0n/Uf+1/00AfABbAN//vf+z/9//NwBZADsAuP9z/5X/DgBrAHUATQDi/43/u/82AHkAPADW/7z/t//a/xsAbwBuAAcA5v/k//P/xP/O/x4AagBIAOj/wv++//n/+f/s/w4AOQBGAB4A1f/Y//H/+P8cAC0AYADs/5v/rf89AL0AfwAWAML/k/9e/73/LQCbAHcAAgASAA8A3v/P/w0ANQDo/87/DABjAEEA+/8pAGkAGgCk/3P/xP/n/+f/awAEAfMAFwBs/1z/kf/o/30A7gDcAB4Acf9S/9z/VwCyAF8At/9L/0//2v9hALgAewD3/0H/D/+T/wwAaAB+AF4AFgCk/6H/4P80ABsA4v+s/8T/RQBqADkA1f+W/7T/+/8MAAgA/P/4/9X/8P9BAEgA8/9t/0r/x/8/AJIAbQAZAKn/Zf9M/7n/XwCTAIEA+//k/7j/pP/0/1EAfAAsAJ3/WP+2/w8AcQCaAD4Avv9r/5//+/9QAFEA+v+6/7z/AwCYANQAjwDj/0j/K/+I/0QAoQCmAEgAxP+J/7b/KgB2ABcAlP9u/+r/ewCaAFwAGQCv/x7/Kv+y/1wAewBCAPb/4v/B/8T/+P8uACoA9P/l/wUANgA8AEgA///f/+D/9P/y/7z/jv+L/+//IQB6AJcAPgCb/x7/gv8eAFYACQAEADcAMgAVAPD/7//3/87/t//e/xwASQB/AJgAXgDt/47/aP+I/wsAbgCcAJMAYwBKAPv/Uf8i/4r/JQBsAB4ATQB5AJgAggALALL/NP9O/8H/awCYAH4AUQAiABgAtv9v/0j/p/82AIYAcwBEABkACADV/7H/qv+8/+n/EQBbAFQAIgAVABoA7/+V/z//Yv8eANMA3wB4ANH/eP+V/8f/EgADAO//uf/b//T/FwAOAP7/FADX/5v/cP/A/yoARgA0AAsA2/+9/7D/EwBYAFgAGgDZ/8r/2P8OABgACQAbAPv/2f+x/+n/GgAjAAoAy//L/+//DAAaACgA7P+i/8//EgBeAHoA/v+m/4f/sf/a/wYAMgA9ABsA5f/f//H/pv+6//v/ZgCiABcAi/+B/+r/OQBSACMA6P/P/5v/pf/N/1IAlwBfAPP/Xv9M/5X/UQDOAK4AAgBt/23/AACDAHsABgBv/2X/CQDHAOgAagC+/2f/fP+X/1MAwABxAN3/d/+5/0IAzgC8AFgAcP+s/tj+gP9fAOUA5wB4APT/hv9+/+j/yP+v/5f/wf8lAL8AJAHpADcAVP83/0j/iP/S/0cAlQCoAHcA8v/V/4b/e/+o/7L/t/8CAIUAuQC6AEwAx/8y//L+bf8qALoAvACeAC0Awf+Y/6z/AgDb/8P/vf8RAF8A0QDfAGMAv//4/jD/of8bAJcA5ACWACoA4f+m/8D/lv98/9b/TwBiAC0AFADo/yoACADQ/9v//P8aAPL//P81AJMAOgDt/9j/xf/U/77/+v8iAEYA/P8NAF4AbQBDAM3/mv+l/xQAPwBpAC8Azf/D/6P/yf84AG8AVQAcAMX/vP8AAPr/NgBiAIwAbwAIAM7/tf/c/xIAewBPACAAtv+G/9P/IQATALv/9//t/xkAGADw/xIAIgAQALv/sf+c/8n/OwBSADwA4v/A//b/GwAbAPf/q/97/9L/OgB7AFcAEgDU/97/sP+r//P/2v/9/xkAewAgAMr/eP+q/xgA7/8VAPT/EABUAFAAFgDF/4j/j//n/+z/5P/s/xEAdAB+ADwAu/9q/7X/GQArAOf/5f8TAHwAXQAXAL7/zv8BAPD/DAAMAA8A2v8NABIAZQDy/9T/GAAkAEEA7v/4//3/8f+p/6j//v8uAF4ASgD+/5X/iP/V/x4ANwD1/+f/6f/5/0wASgBmABUAvP+i/+3/+v8eABsAJgA5AAYABwDA/9b/n//O/+3/IgAGANn/EwBUAJwAEQCW/0T/Yf+0/yQA4AAiAaEAj//4/jz/4/9kAI4AswB+APz/pf+X/9v/GQBYACYAGgDe/wQABQD//zkADwD1/53/0/8cAIQAYgBUADAA9f+P/0X/1v8rAFsASAAhAB4ABADy/+z/5v+z/7P/yv8GABkAKwCgAMAAZQCp/yv/XP+A/83/FACaAK8AbADh/7z/rf9b/3H/4v/HAIwASADg/6j/o/+I/wIAVAAcAIT/Yf+i/x0AQgBWAEEAof9F/07/yf8iAGUAwwDQAGQAkv8Q/yD/sP8+AGUAlgBQAC4A7//T/9H/2P/O/8P/5P+3/9b/AAChAJoAKQCy/4P/xf/D/xUAQgBCAK//qf8vAGUAQwC2/7j/5P/r////QABmAAcA1f/H/87/tP/H/y0AYQBVAAUADgD0////JwD9/4D/7v4p/+D/7wAAAd0AWADD/1b/FP+F//f/WQBtAG0APAA1ABkANQBBAMf/fP9R/5z/BwBtAAYB3wBXAIf/Vv+b/9r/2P/4/1UAUgB6ACsAFAC7/1H/Sv9a//j/MwCYAKIAjQAsAMb/fv+G/8n/4v9DAEQAPgBMAFsAUgDx/6j/h//P/w4A8/+c/6b/AQAbAHEAcgBhAL3/DP8T/5//ZwDSAPMAVQCo/yD/df9YAJ8AUQC6/57/a//s/44ALgHmAOL/Wf8n/5L/7v9ZAJMAYwD0/8n/LwBRAD4A2/+j/1//PP/g/3kA+wC1ADoAwP9m/5z/EgBBAM7/lP/E/1oAoAC+AIsADgCZ/z3/mP/l/zMAPABNAEgAIQAfAO//7v/r/xoA3/+v/7L//v94AH0AdQBEAOX/g/9a/67/9f9hAFMAWQBCAAsA9//u/yQAEwAWAOr/CAAoAG8AeAAjAAcAw/+M/2v/sv/4/zcAZABhAEQAu/9n/2v/x/8NAEIALwA1AA8Avf/Z/+T/7P/y/+//IQBBAB0Avf+n/+z/HgAgABUALAC9/5//uv9OAGkACgC9/3L/df+T/yMAhACbACMA2f+q/4f/of/l/z8AGgDz//P/BADy/xQAbABqAOD/SP87/3L/mP8zAPIAMAGSAML/jv+Z/6v/p/8ZADEAAgD5/3YAuwCDAAAAhv+P/3D/qP/5/24AgwCEAGcAKwDo/5b/e/+T/8v/5v9uANEApgAPAGj/Tf+l/+b/EwA0ADcAAAADADMAfABrALn/ff+e/9L/+f9YALIAzAAHADv/Rf+o/wsAKQBCAAUA1/+7/xAATgDv/4n/mf8MAEEARgA6AFUAGACk/3X/iv/R/zQAtADdAGQA0/+I/97/IwASAP3/z//M//L/VQCvAHEA3v+k/6b/jP+o/yQAlAB0APf/m/8HAIMAeQA3AOP/hv9c/8//dwDLAFsAyv+M/63/KgBOAEEA8v+F/37/z/87ALMA8QB8AKb/Fv9C/+D/dwCWAEgA3/+0/6//BAA8ADEAz/94/6f/+v90AIQAEgDp/+f/uP+k/5T/8P8IANX/tv/x/ykANwAFANH/o/9k/6P/GACIAHcALQAPAPv/CwAaAAgAsv97/5T/7P8JAEYAiQC/AGAAs/9I/0b/UP+F/wkAXgB4AEwAXQB0ABQAkP9t/7P/9//b/8//6/8uAHAAsgCxAEcAuP80/0r/if/G/ysAewCEAGoAIgDS/8//0v/7//v/u/+F/5//5f+IALgAeAAZAKP/cf91/+n/NwBYAEMANQBQAD4ADwDY/8//1P/M/+3/GgBMAF8ARgAnAOP/0//f/8z/v//E//D/LABOAGYAaAAVAKj/bP9m/6z/HgA6AFsAPwArAA8A3//F/7L/uP/G/wEASgCEAF8AKAAIAOH/sf/S/wcA/P/J//H/PwBKAP3/dv+K/9P/+P8HAAcAEQDh/9r/4P/l/w4AQwBHABMAof94/6j/KwCkAMQAlgAKAID/hf+Y/8D/4/8nAKoAugA0AL//gv+s/9T/3v8LAAMA5//m//n/RABfAFgAIQC4/3X/Zf+x/04ApwCkADYAzf+e/87/GwAkAPr/4P/p/yMAggByABAAv/+g/8T/DAA8AEEAOQD//8n/v//Z/zkASgBfAAEAqf+T/+P/eQCwAHIA8v+r/6T/4v8NABkAKAAzAEgAKAAQAOn/FAApAAsAFQAdAOv/3v/p/0wAYAAcAKj/nP+4/67/wf8aAGMATQD9/83/5f/g/87/rf/f/x8ADgAcAEEAOwAnAPT/7f/3/9f/yf/x/08ALgD1/9//6/82ADcA5f+d/2v/f/8NAD8AYgAQAM3/qP+d/8P/IwBoAHsAQgDw/5P/df+p/zgArgCQAPr/ov+Y/9D/BgA3AG0ALQDF/6b/3v87ADMAJwAZAA0Awv/M/xkAbQBEAOj/t//C/93/5f////v/DwAwAGQAlwA2AJj/av+9/ykAZQA1APT/2v/E/+P/JgAwABEAqv9Q/2z/z/9UAN8A4QBDAF3/7v5V/xwAsACgADEAzP/B/xAARQAcALj/W/9c/8z/MgCHAG0ALwDw/9L/xv+o/6D/u//+/zoARQAjAEEAOAAXAN7/j/+L/6j/AwBqAMEArABJAN3/lv+e/+P/FwAsAEoAJwAKAAUABAALAN3/pv+R/6z//v9RAIoAkQBkAP//tf+Y/8D/DQBIAGgAVgApAOn/3//q/wEAEQDa/6//zP8FAEUAcABbADUADwDm/7r/vP/a//T/KAAsAD0AJwD9//b/7v/Z/6r/u//r/zcAWABCABkA/f/s/7v/yf/l/wIACQD7/wIA/v/y/9T/7v/7/8//ov+b/+r/KwA1ADwAawBiAAkAwv+X/8P/BAA/AE8ARQAmAPH/4//b/9H/0f/d/wMAKgABAL3/w//8/x4ABwDT/9H/8f/0/w4AHAAdAOb/kf/K/zAAWwBMABoACgDl/7b/wv8JAEIA//+5/+r/JgATAOv/6P8QABoA3//Y/9T/BAAoAC8ANgDs/7b/kP+u/+r/NwB1AGkAKQDh/8n/nP+d//j/dwCGACMA7//0/yUANQAVAP//1/+U/2//5f+DAJcAUgAAAOD/xv+p/7n/6P8IAAwADQAuAEwAIQDQ/6r/of+g/8r/BgBGAGYASgBaAE0A+f+i/5H/6f81AEEAMQAqAAsA3v+0/9D/EgAiAAkA3//Y/9//2f/Y/9z/5f/q//7/JgBMAEsA9/+4/6v/u//x/x0AQwBAAB0AEAAaAEgASQAVAN7/q/+m/7L/3f8bAEEAQwAkAAIA4v/c/9f/zP+//8//5f/8/ycATQBIADAA9/+3/5v/k//A/xMAZAByADkA8f++/8b/7//0/+n/+f8mACUAEgAVAEUAKADR/5j/tv/Y/+3/JwBgAGoAKADi/7b/xf+7/9//GQAkABQAKAA7AEkAQQAkAPv/rf98/8v/NABjAGkAWwA1AA4A3v/g/xUANgAZAOL/9//n/+b/+f8zADgABwDG/9D/+f/+//L/4//3/w8ADwAOACEADQALABoAMQA/ACAA8f/d/9X/3//u//j/CgA1AC8AKwAOAPH/5P/a/9D/7v8IABQABQDe/9z/3/8GABcAMwAXAPL/y//R/+j/7f8HABkAKwAHAP3/FAArACAA7f/g/8T/tf+4/+n/IAA5ADgAIgAZAAAA2f+7/8r/9/8sADIAOAAzACcA7v/L/9n//f8jABkA/f/S//D//f8fADMAGwD0/8L/y//2/0MAQwAfAOD/yf/j/+3/AADp/8r/k//H/zsAdwBfABwA4//f//b/AAAXAAIA+P/5/ysASwAwANX/mf+4/8L/2v/0/yAAJQDs/7L/uf8HADgAHQDb/7v/2/8nAGIAZQAOAMz/0P/y/xsAIADj/5b/sv/o/y0AOQAgACUAFwDt/8z/4f8gAEIAAgDO/7v/5v9CAJUAmAATAIT/TP+A/+n/PABPAEYALQD5//z/DwAyAEMAIQDr/6b/l//X/0QAhgBsAAQAs/+u/9T/FAAVAND/sP/U/0kAoACXAFsA+v+c/4T/wv8sAIIAbQA4AAcA0v/T//z/JQAaAMr/k/+S/9f/QgCKAIsAMwCn/2P/if/M/x0ARgBQABYAxf/V/yIATwAkAO7/x/+5/8v/HQB9AJYAQQDc/7D/r//h/wkAHQACAM7/t//3/0MAUQArANr/of+s/+v/MQBJADEA+v+//8P/AQAOAB4ACwDw/+b/6/8KACwAJwADAOf/wf/L/9D/BwBRAFkAFgDa/7v/u//a/+3/CgADAPT/4f/m/yIAVABSAP3/kf9m/5b/+/9oAGsAIwDO/6v/2P8RADEALgAHAOL/6f8KADUAPAAeAPz/3v/X/+v/KwA7AAcAyf+u/7f/2P8SAB0AJwADANj/zv/l/wgALQAgAAsA8v/k//L/CgAxAFMAMwDo/8j/x//y/wEAFAA2AD0AGQDc/7r/vv/M//D/GgA/ADYAEADn/8T/tv/N/+z/EAAdABAA/f/p//X/BgAhACEA9P/U/9z/9P8cADQAMAANAOf/2f/V//L/EgAHAP7//v/x//P/9/8LABkAHQAJAPH/1//H/+v/EwAiAAQA5v/t/xYAIAAHAOT/zf/Q/+3/FAAPAP//DAAXACIAGAALAAcA+//b/73/u//0/0MAawBNAOf/qv+3/+7/AADy/9n/y//c/xwAMgA4ABwA8//5//T/6P/k/wMAKgA4ACEAEQAKABYAEQAJAAYA5P/G/93/DAAoACoAIgAuAD4ACADp/+X/6f/r/+D/7P8XADYAMwAYANT/wv/H/wQALQAtABsACgAWABUAGgAmAC4AEQD4/+r/4//3/woAHgAfAPr/1P/L/+//HAAZAPf/2f/g/xQAMwBDACsABgDq/+b/9v8SAB0AAQDz/+T/8/8RACQAIAASAM//nP+3//7/MgAoABUABgD//9X/5/8ZAB0A4/+r/8f/+/8yADMALwAUANf/zf/4/y4AIwALAP3/GgAlAAcA7P/i/87/xP/k/w0AOQA1ACQA+//X/8n/0//l/+7/4v/j/wEAKwBbAE4AJgDp/77/tv/Q/+7/CwAwADYAQwAwAAoA3//G/8n/5v8NAA0AJgAZAP//5f/T/9L/1v/Z/+b/GAAtACkAEwAMAPz/4f/O/+X/AQAPABcANQBAABEA6//s//b/5f/I/7//5P/w//f/GwAqADEAFAABAAkACQDq/8P/0f/5/yQANQBGADEAFgDu/7//zv/q/wQAFAAWABwAHQAaACIAHQD5/9T/0f/o/woAEAAFAA0ABQD5//z/CQAMAPv/6f/g//b/GgA2AEQALwAFAPf/DQApACUAEADz/+P/4//5/x0AMQAlAPr/3P/Z//D/CQAIAAkACQDx/+f/9/8bACcAEwDt/97/4//4/wYAFAAUAAcA///4/wIACgD6//f/+P8EAAIA9/8GABEADwDt/+T/7f8JAA4ABwAGAAcA8f/u/wIACAD5/+b/4P/x//////8JACEAGQD4/93/2v/1/xEAKwAWAPb/1//g/wwAIQAVAP3/7//t/+f//P8IAAEA9v/x//7////+//3//v/s/+D/5v/6/wQA+//v/9r/6v8SACoAJwDx/9T/3f8HADAASAA/AAsA1P/F/9n/9P8GAA4ADwAEAPb/6f/9/w8A/v/f/83/2P/y/w4ALgAvABIA8P/s//f/BgAHAAEAAgD0/+r/8f8LACIAIwAKAPj/6v/f/+3/CgAaABsA+f/j/+z/AQAIAAAAAgAHAAYA+P/o/+f/8f/5//n/8P/m/+7//P8JABYADwAFAO//8P/w//D/+P/4////+//8/wYAGAAbAAkA8//h/+H/8P8IABMACADw/+n/8/8CAAsADgAFAOj/3v/h//T///8AAAEAAgD+//v/AwADAAcAAQD6//r/BQASAB0ADQD5//D/6v/x//j/CgD+//D/4P/m//z/CAAAAPX/7v/f//b/AwAeACEACQAJAAwA/f/1/wEADQALAAQACAASAAkA/v/9/w0ABwD2/+r/AQAbACEAHgAfABwA/f/Z/83/2v/l//v/FQAtAC0ADwDy//L/7//8/wcACAALABIAIQAxADEAFwD9/+j/2f/h//X/CQAUABwAGwADAPj/8P/7//n/8v/u//T/CwAbAB4AFAAHAPz/+v/9//T/6f/3/w4AGgAZAAsA+//0//L/9//5//v/8v/1//n/AwAHAAQA///4//j/8P/2//r/9f/6////CQAdACIAFwAHAPD/5v/z//z/AQAAAAoAEgANAAoA+v/t/+7/7//4/wIABwADAPj/9v/8/wgACgAHAP//8P/n/+T/+f8WABsADQD3//P/BgAZAB4AFQAGAOr/3v/v/wwAHgAbAAUA7f/d/9z/7f/+//7/8P/q/+n/8/8EABAACgD6/+//8//6/wEADgAVABEA///0//r/AwACAPT/6P/u//T//v8NABsAGgALAP7/8v/t//X/BAALAAgA+//1/wIACwAJAPr/5v/b/+b//v8aADAAJQALAPX/7v/x//f/CAAdABoAEQALAAsAEAAHAPb/5//q//n/FgAlACQAHQAQAAcA+//3//D/8v/8/w0AHQAjABgADgAEAP7/+v/3//n//P8BAAcABgAEAAsADAAHAPv/9f/8/w8AEgAPAP//9f/w//n/DQAPAAwA+v/8////BgAGAPr/9v/s/+7/8f///xcAGwAPAP//9f/8//7/AgAOAAwA/f/2//j/AwAMAAoABQD9//v/AAD+//j/9v/1//z/AQALAAwABADz/+X/6P/t////DAAOAAwA///6//f/AgAFAP7/+//1//v/BQAPABkADwD8/+r/5v/x//n/+v/8/////P/4////CgAGAPr/9//x//n///8IABkAFAADAPL/8v/9/wAA///7//D/8P8BABIAFQASAAIA8P/u//P/AAAHAAUACgAGAAQAAQAEAAUAAQD5/+7/8P/4/wYAEAAMAP7/9P/0//f/AAAEAAgAAQD2//P/9P/+/wQADQALAAUA/f/5//r/+v/5//j//v/8//z/+f/1//v/+//7//b/8f/t//f//P8DAAkABwACAPj/8P/v//n/AQAGAAgAAQD+//3/AQAIAAkA///3//D/8v8FAA0ACgD9/+z/6P/q//L/9f/3//b/9v/5//7/AQD3//f/9P/0//b/BAANAAkA///1//P/9v/6//v//v/2/+//9v8CAAkABwADAAEAAgD4//X/9P/2//3/BQAFAAgABAAFAAMA///u//H/8//5/wQABgAIAAgACgAKAAcAAAD9/wAA//8AAAIACgAMAAsAAwD6//T/9v/7/wAABQAGAAUABwAIAAkABgAIAPz//P8EAAcADgAQAAoA/v/4//j/AQAEAAAA/f/9//r/AAAHAAcABQD8//P/9f/5////CgALAAQA/v/5//r//P/6/wIACAAEAP7/AQACAP3/+v/6/wAA/v8AAAIABQABAPz/+/8BAP7/9v/z//r/AgAKAAkABAACAPz/+////wQAAgABAAEA+v/7/wAABQAKAAcA///9////AgAFAAMA/v8BAAAABgAIAAMA/P/6//z///8CAP7//v8AAAEA/P/9/wMACAAHAAQAAQD+//z//f8FAAUA///8//z/+//3//n//P/8//r/9//1//n//f//////+v/3//n//P/+/wMABQD+//3/+/8CAAcA/v/3//T/9f/5//7/BQAHAAMA/v/7//j/+P/3//7/AgADAP////8AAAEA+//5//n/9P/5//7/AQABAAAAAQAEAAQAAwAEAAcABgADAAEAAQAEAAQAAwADAAQACAAHAAIABQABAAAAAgAAAAQA//8DAAgACQAHAAMAAAAAAAAAAgAGAAcABQAEAAIABAACAAAABAADAAIA///+/wQABQAGAAUAAAD+//z//v8CAAUACAAGAAcABAD//wMAAgABAP//AAAEAAQABgAFAAIAAQD9//r/AQABAAYACAAGAAUABAAGAAMA///4//3///8EAAsACgAJAAAA/v///wAAAgABAP///f/6//7/AgAGAAMAAQAAAPv/+f/7//v/AAACAAUABAACAAEAAwABAAMA///+//3///8GAAAAAQAAAAAA/P/5//b//f8BAAAACAAEAP/////9/wMABAACAAEAAgAFAAIAAQAEAAIA/v/9/wEAAQAAAAAAAAADAAIA/f/9/wAAAAACAAMAAgABAAAAAAD+//7/AQACAAEAAAACAAQABAADAAAA/v/8//3//P8CAAQAAAD///z//f/+/wAAAgAAAP7//v/+//3///8CAAQAAQD9//r/+////wAA///+//7/AAAAAAAA/v////7//P/+/wAAAQAAAAAA/v/9//z//v8CAAEAAAD8//v//f8AAAEA///9//3//P/8//v/+//6//n/+P/6//r//P/8//z//P/9//z/+//7//7////9//z//P/9//z//P/7//v/+v/6//z/AAAAAP///f/7//n/+f/7//7///8BAAEAAQAAAAAA//////7//P/8//z//v8CAAUABAABAP7//v///wEAAgACAAMAAwABAAAAAAAAAAAA/////////v/9//7/AAD///3//P8EAAMAAgABAAIAAwD9/wQAAQAGAAAAAAAAAP//AgACAAMAAAD+//3//f8AAAAA/v/+//z//v///wAAAgD///7//v/8/////v/8//7//f///wEAAAAAAP3//f8AAAAAAAAAAPz//f8BAAEAAgADAP///f/9//v//f8EAAQAAwACAP7/+//9////AAABAAAA////////AQABAAAA///+////AAAAAAEAAQABAAAA/////wAAAQAAAP7//v/+//7///8AAP////8AAAAAAAD///////8AAP/////+//7//////////v/9//z//P/8//z//P/7//v//P/9//3//f/+//3//f/+//////////////8AAAAA///+//z/+//8//3///8AAAAAAAD///3//P/8//3//////wAAAQAAAP///v/9//3//f/9//7///8AAAEAAQAAAAAAAAAAAAAAAQABAAEAAQABAAIAAgACAAEAAQAAAAAAAAAAAAEAAgABAAAAAAD//wAAAQACAAMAAgACAAEAAAAAAAAAAQABAAEA/v/9//7/AQAEAAQAAQD+//z//f///wAAAQD//////////wAAAAABAAAAAAD///////8AAAEAAgACAAEAAAAAAP///v/+//7//v///wEAAgABAAAA/v/9//7///8AAAAAAAD+//7///8AAP///v/9//3//f/9//7///////7//f/7//z//v////7//P/8//3//f/8//z//f/6/////v8CAP7///8AAPz/+//8//7//P/+//r/AgD9//v/AgD8//n/+v/8/wAAAQACAP7//v////v//v8CAAEA/v/8/wAA//////7//f////7//f/8//3//v/9//3//v/+//7//v/9//3//v/+//3//f/+//////////7//v/9//3//P/9/////v/9//z//P/+//7//v/+//3//f/9//z//P/9///////8//v//P///wAA///9//3//f/9//3//v///////v/+//3//f/9//3//v/+//7///8AAAAA///9//z//f/+//7//v/+//7//v/9//7//v/9//v/+//8//3//v/9//7//v/9//z//P/8//3//f/+//7//v/////////+//3//P/8//3///8AAAAA/v/9//3//f/9//3//f/+//7///8BAAIAAgACAAEA//////7/AAABAAIAAgAAAP////8AAAEAAQABAAIAAgABAAAAAAABAAEAAQABAAEAAgAAAP7///////7//f8BAAAAAAD+/wEAAgD+/wIAAAAEAAAAAQAAAP//AQABAAIAAQAAAP////8BAAEA//////z//v/+////AgD//wAAAAD9/wAA/v/9//7//v///////v////7//f8AAP7///////v//P/+//7/AAABAP7//P/9//v//v8BAAEAAAAAAP7//f//////AAAAAP7//v/+//7//////////v/+//7//////////v/+//3//f/+//////////7//v/9//7//v////7//v/+///////////////////////////////+///////////////+//7//f/9//z//f/9//3//v/+//7//f/9//7//v/+////AAAAAAEAAQAAAP///v/9//7//v///wAAAAAAAP///v/+//7//v///wAAAAAAAAAAAAAAAAAAAAD//////////wAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAQABAAEAAQAAAAAA//8AAAAAAQABAAAA////////AAABAAEAAQABAAEAAQABAAEAAQABAP///v/9//7///8BAAEAAAD+//3//f/////////9//z//P/9//7//////////v/+//3//f/9//3//v///wAAAAD///7//v/9//3//f/9//7///////7//f/9//3//v/+//7//v/9//3//v////7//f/9//7//v/+//7//v////7//f/8//3//v////7//P/9//7//v/9//z//f/6//3//f8AAP3//v8AAP3//P/8//7//P/+//r/AgD9//z/AQD8//v/+//8//////8AAP3//v////z///8BAAEA/v/9/wAA//8AAP7//v8AAP///v/9//7//v/9//3//v///////v/+//7////+//7//v/+//////8AAP/////+//7//v/+///////+//3//f/+//////////7///////3//f/+///////9//v//P///wEA///+//7//v/+//7//////////////////v/+//7///////////8AAAEAAAD///7///8AAAAAAAAAAAAAAAAAAAEAAQAAAP///v/+/////////wAAAAAAAAAA/////////////wAAAAABAAEAAQABAAAA////////AQABAAEAAQAAAAAAAAAAAP/////+//////8BAAIAAgACAAIAAQABAAEAAgACAAMAAgABAAAAAAABAAEAAgACAAIAAgABAAAAAAABAAEAAQABAAIAAgABAP//AAAAAP///v8BAAAA///9/wAAAAD8/wAA/v8CAP7/AQD///7/AAD//wEAAAD///////8BAAAA//////3//f/9//7/AAD+///////9/wAA///+/////v/+/////v////7//v8AAP////////z//f/+//7/AAAAAP7//f/9//z//f8AAP////8AAP7//v//////AAABAP////8AAAAAAAAAAAAA/////wAAAAAAAAAAAAD//////////wAAAAAAAAAA////////AAAAAP//////////AAAAAAAAAAAAAAAAAAAAAAAAAAD//wAAAAABAAEAAQABAAAAAAAAAP////////////8AAP//////////////////AAABAAEAAQABAAAAAAD/////AAAAAAEAAQABAAAAAAAAAAAAAAAAAAAAAAABAAEAAQABAAEAAQABAAEAAQABAAEAAQABAAEAAQABAAEAAQAAAAAAAAAAAAAAAQABAAEAAAAAAAAAAAAAAAAAAAAAAP//////////AAAAAAAAAAAAAAAAAAABAAEAAQAAAAAA///+//7///8AAAAAAAD+//7//v8AAAAAAAD+//3//f/9//7///////7//v/+//3//f/8//3//v/+/////////////v//////////////AAAAAAAA///+//7//////wAA///+////AAAAAP///////wAAAAAAAAAAAAABAAEAAAD/////AQABAAAA//8AAAEAAQAAAP/////9/wAA//8DAAAAAQADAAAAAAAAAAMAAAACAP7/BQAAAP//BAAAAP7//v8AAAEAAQABAP7/AAABAP7/AQAEAAQAAQD//wMAAgACAAEAAQADAAIAAQAAAAEAAgAAAAAAAQACAAEAAQABAAAAAQAAAAAAAAABAAEAAQACAAEAAQABAAEAAQACAAIAAgAAAAAAAAABAAIAAQACAAEAAgACAAEA//8BAAIAAgD///7/AAACAAMAAQAAAAAAAAAAAAAAAQABAAEAAQABAAIAAQAAAAEAAQABAAAAAQABAAIAAgD//wEAAQACAAEAAgACAAIAAgABAAMAAwACAAAAAQABAAEAAQABAAIAAgACAAAAAQAAAAEAAAABAAEAAQACAAIAAQACAAEAAQABAAAAAgABAAMAAgAAAAEAAQABAP////8AAP///////wIAAQAAAP//AAABAP//AAABAAMAAgABAP7/AAABAAEAAAAAAAEAAgD/////AAABAP7/AAABAAIA/v/+/wIAAAD///3/AAADAP7//f///wAAAQD4/wUA/P8BAPv/AwD+//z//v///wIA+f8BAP//AAD9//7/AgD9//z//f8BAP3//v////7/AAD+/wAAAQD8///////9/wIA/v8BAP7//v8AAAAA/v8AAP7//v8AAAAAAgD8/wQA///+//z/9v8JAP///v8BAAIA/f/8/wAA//8GAAEAAAD+////AwAFAP7//f8BAAgAAQD6/wAABgADAPn///8BAAcA+v8AAAQAAQD///3/BQADAPz//f8CAAQAAAD+/wEAAAACAAAA/v8DAP3//v8AAAAAAQD///7///8EAP//AQABAP3/AgAAAP3/AAABAAEA/f/+/wAAAAD8//7/AAABAAIAAAAAAAAA///+//////8AAAAAAQACAP//AAD9//7//////wQA///+/wAAAAD//wAAAAABAP///f8CAAMA///9/wMAAQAAAPz/AQADAAMA/P/7/wYAAgAAAPj/AgAGAP//+P///wcA/v/9//f/CAAAAPb/9v8NAP//+f8AAAAAAQD///7////8/wQAAQD6//b//f8LAPz/+////wQA9v/7/wEABQD9//z//f8DAP//9v8EAAMA//8BAPj/AwD6//f/AwD+/////P8AAP///f/5////BgD2/wQA/f8DAP7//P8BAP3/AQADAP//AgD2/w4A9/8BAPz/CQD4/wcA/f/8/wgA9v8RAAIA9v/6/wcAAgD///v/BgAKAPz/+/8DAAIACADm/xQA/P/9//b/DwAbAOj/5v8RADAAx//2/wsARwDW/8T/QQAgAO3/tv85AP3/CQDZ/wUAUwDC/9T/BQBDAPb/1//0/zUAAgDi/9f/KwAjANT/+/8AABgABADi/wIAFQAAAOT/FgD4/wAABADv/wQABAAAAOf/CgANAPT/AwD6//v////y/wQAEQD4/+v/AwAOAP3/5/8FAAwAEADj//T/DAD//wAA7/8LAAUA8P/p/xkACQDu//L/AgARAOf////y/xYA+v/0/wkA///3//f/CQDy/wIA/v///wIA9//3/wUA///x//v/DwAEAO7/BAD3/wEADwDy//3/CQD+/+z/AwACAA8A/P/t//n/FQD8/+7/9f8XAAQA5////xAA///s/+7/GQAJAN7//v8KABoA7//j/wcAGAD3/+H/BAAWAOz/7//6/xwAAADj/+z/FwAYAOD/4P/8/zAACADb/9r/JgAZAPD/yf8TACsACQCt/xcANQDy/6L/JgBIAOf/uv8DAE4A4v/E/+v/VgD7/8X/8v8vAAgA5f+5/2cA3v/r/9//RADt/9//AgACABsAvv8kAAAADADT/w0AIwDg/9T/DQAwAM7/9f8fAAMA7v/x/wwAHwDq/+f/6v8FADsAzP8BAAwAOgDJ/9D/HQBLAMr/qv86AHwAwP9S/8MAMwCi/8b/mP82AVH/Xf/GAOsAOf9O/3EA5P+CAK7/VwDC/9X/JwCAAIf/bf++ANcAN/8P/64AHAF3/7j+6AC0AAMAhP62ACABgf86/9T/YgGv/1L/8/95AFQAWP/r/5cA6v/I//P/7v9uANL/wv/9/z4ADQAgAIf/9f/SAIT/7v8ZABgAEwD8/57/GABzAMv/zf/r/yQAUQCT/8n/SQBWAA0AfP8eAGkA6f9//xsAYQDp/wMA2P8nADkA5v+u/0sArf8TAGYAuf/N/0cAOQDA/9X/+/9RAPn/p/85AD8A8v+B/3oARwCM/5b/pwBSAKX/1f/4/50AlP/n/xIAOgDr//7/8//+/wkAQwDI/4P/uwAaAKr/Ev9+Afr/Rf9u/70A6gBx/zf/NwDDAK7/XP92AHYAcv8XAKP/YQCCANn/gf/n/18ADwDk/57/NQDSAKT/Rv/7/9IAmv87AEX/7gAtAOb+hf8uAUIA/P6BADAAowDA/of/DAFsAAT/qv+aAdr/7P7X/6gAWgA3/7X/JgEzAFb/bP9iAWb/1P93/xQBTAAq/wQAqwA8AEz/3P84ADQBWP74/zABcgAK/5X//wC//7//wf+CAIsAwP7w/9cAAAGi/mYAzv9eAG0Ayv7s/z4B1wCo/l8Ap/8SAQoABP7/AIUA5wDQ/dIASAGI/9L+pP/oAdz/K/+y/vYB1gBk/uL+pgHNACT/rv4/AJgCrv74/ggAhgGD/3T+NAF/ADAAKP4tAJgAXgGk/j//xAGu/gEAgAAsAIb/UwAf/zIAz/8dAO3/AgEHAGT+bQDv/7z/4wBZ/zcAcgDC/gEA2AC//4n/DQDd/yQBpf8S/6v/tgG5/xD+gAHDAGj/Nf/w/5QBmgCI/er+QAPs/qb+ev+UA2D/NP2Z//wB7AHg+3T/mAPdADj9dP7kAoEAlP8U/aoBYALE/cr+xP80Arz/JP+x/+8AzP+7/0j/x/+QAN//AgFC/zkAVv4EAigALP48AMQA5wBO/jAABgGxAJT9+v6QAqQBMP1+/kAB5AFh/6T9gQBIA3j+NP0cAi8AJQBU/fQBJwB6AfD8hgE1AA3/FgCW/3QB1v8GAW7+/v6W/8ACR//g/rz+SARa/1D9av7EAnYBNP0+AT8AEP9Y/swBrwCu/rr/jwAQArj8TP8wA0IBiPuX/3QB5QDS/4D9QANx/7z+4P8SAej9g//oAhD+3v8NADIAkAIw/UMAggCz/zf/cv/cAUb+dALr/y4AmP1Q/8QBlgBx/4YAmwCy/+b+CQA8Amr+2v6zAAQCRP0AAYoBtP67AAz+MAGgAbj+gP4gAuIAvPxMAXgBWf9LANr/igDq/vr/aQAUAOQCEPxMAwD/aADY/WAB6wCh/04BePwkA7kA/P2u/qAC1v+A/hP/WgFUAdD+RP3UAdQCYP0SAFoAaP9MAIb+rAL1/1D+4wCuADT+Zv/OAXj/8ACk/h3/KgGQ/1r/kAEs/7UAaAFs/dr/8f9wAoT+FAF5/6IBvP5A/SQD+v/F/6j9ZAKM/3cAzP0jAKADmP7G/nL+4QB3ALr/Uv6SAbACvP1i/kIB0AHx/9D6hgF4A6j/2P0r/3QDrACw/EAAWAQL/7j7AgFcA67+0P0U/2gFvgGI+jUAnAIuAej67v94AhwChP5Q/SQDxgBD/yz9ZgAIAggBfPwy/9AC1ABA/zz9jANOAez9aPs4AxgDrPw3APb+WASg/j7+jALJ/wH/fP1uASABmP///77/zAK8/pz9rP/kACwCQP+4/QYBdwBaAcz9WAFxACv/z/+F/94B0v6oAFL/2QCc/rsAFAIOAHQA3v7xAF//O/+nAMgBUgD4/RH/kAIIA2r+oPyq/3wB6/9X/ykADAKB/1r+TP/iAdD+TP95ANIBYv6b/7j/NAJiATj/c/+yAIwBcv4MALr+2gGAAYkAh/+pAEwAgP+e/on/EgHkAPwANADb/13/vP6nAFQBQQCJ/0IAPAF0/g3/Ff/GANgAGP9kAK3/Pv/I/sABtQBF/37+Of/6AD7/c/+FAOAAYP83AKcAp/9G/3z9zgAUAev/FP+PAJABCgDI/qz+GAFhAAD/8P6YAI4BrQA+AM3/2f9o/6D/Vv8jADIAYgDy/13/qQA2Af0AyP6D/yL//P4dAJIBqgDg//f/GAAZADcA7P7l/3gAaACq/0QAVwDv/4YBBgBt/4D/TQCh/1YA2v8mACoBc/9S/zYAzADc/57/Tv/D/0H/iP9dACABPwDG/vb/g/8JAHv/o/+W/1AA2v/n/8b/K//jAE7/dP/G/j8AYADJ/8H/YwDJ/8z+EACN/8kAt//q/rMAaAEy/6P/KAC1/z8A1P9AADsAAgBj/0QAagA0/ywAcAA7AD//cv+J/xgAaf/o/uf/Uv+LAK0ArgAs/23/9v/A/yz/G/9gAEIAYQDj/xcAZgAlAKH/CQArAB7/OQCs/+f/aAC1AOr/6//n/3D/hf9o/ycALAFlAMD++v9sAAH/J/9h/2IA3AAK/x3/lABrAHz+tv+UAJ4AFQAe/+3/kAD3/4D/+v/eAM4AlP9p/6r/OQAaAD0ATQCNACAAe//M/7AAMwCSAC0AZAB+ACIAwf9bADsA2v/i/6H/XQBVAP3/tf/u/8//W/8YAN3/MADR/7T/BgBNAKAA4P+6/5X/4/+J//n/8P8/AG4ABQBRAO7/DAAAAMD/uf/t/0EAUACEAHgAWQAzALv/Y//E/87/Wf9Z/9r/KgDi/4v/d/9a/7L/df/O/x0ABwAbADAAHAAVAD0AGwCx/6n/4f/+/yMAkwB+AHUAIQCjACYALgAXAOL/tQC2AJoAGAHVAFIBPQBuAKIAqwDz/03/rv86ACMAHwDA/1b/ff9b/57/Xv/u/s7+QP9O/wcAFv8JACIAmf8O/+z+BwDN/zz/Tf9xAF4AWAC0AHoBFgGWANsA9QC2ADwA6gBKAQ4BfwBxALAA2QBkAEkAzQClACYA3f/0/yQAAgB3/zoA4P9d/9T+qv89ANL/bP88/7T/Hv9W/jD+MP+9/3//dP/U/3H/vP5W/gD/Lf/C/gb+KP70/qb+cP4M/2T/vP60/eD9cv5s/oT+3P52/+D+HP4Y/nj99Py4+8D7IPxQ/Lj8XP2A/Rb+9P3U/WD+yv5M/0T/EACGAWQCHAMUA0gF4AXQBcAGgAnACcAIcAfIB/AIMAggCZAKAA3QC6AJQAhoB2AFCATABNgF6AaoBVAFSAUgBFYBFwB6AN//DP9U/cz8kPy8/OD8VPzY+7j6YPig97D2oPfA+ND3QPeg9hD3UPZg9CD1QPWg9GDzIPOw9ED18PTA9ZD1wPNw8ZDxMPNQ9ED2gPhY+cD5oPmQ+x7+6f+eAOQD8AJ4BFgGUAhACyANAA+ADjAM0AsgDZAPgBAAEaASwBDAD9AOMA1gDmAOIA3wC3AJoAmIBwgG+AWYBwgH6AQcA/ACUAKo/oj9Ov9AAP//4P5S/8H/hv9M/sb+tQC+ARkA3v5G/wgA/QD3AMQBYAOwAR7+1Pyw/Xz+AP2w/fj8iPuI+JD1APVg9MDzYPOA8+DxEPCg7cDsQOzA6mDpwOlA6sDqgOsg70D0YPmY/IABzAMkAvb+5P0IAqAGcAkgDWAUoBKgD2AOMA8gE4ASYBHgEBAO0ArwCKALsA7gEOANQAx4BgQDNP7I/Iz+SAB4AjwAr/95ABT+/P1m/l7/5/+u/o4AFQCp/9wBOAMsAvIBYAOwBKwCsP6w/swCgAOcA9wDyAWoBTwCMAJAA4QDHgE2/yr/pP34+4D5wPmA+8D6kPeQ9CD00PKA8IDtAO2A7ADsgOsg62DrgOzg66DsAO0g7KDr4O1w9LD8ZANIB+AJ4AjwA54BqALYB0ANIBJgEyATYBCADgASIBKAEZAN8AqQBQAGaAbwCBAMoAvwCdgFpAGQ/rz8WP08/2gCLAILAOoA/AOoA9YBhAKoBHAEcAKsAaAFsAgQB2gHWAcoBtgDZAIsA5wCDAJcAkQDuASgA1wCAgAcAGgAXQCW/8j+5f9BAPz9gPlQ+qD7KPqA+JD3cPeg9XDyEPEw8lDwAO5A7uDvgO/g68DqgOtA7ADsgOzg7pDyUPiu/7gEEAQEA1AEqAQEAbwBcAjADSAPoBAAEyAVAA2QCFAOoA5gCAQDiAewCrgGoAR4BzALAAewAXb/QwDA/VT8fP3mAaAEGAP8A8wCGAVQBFgDxAJgBUAGmAaABRAIEAkQCdAGWATYA4gCLALbACABHAPoBCQDZAARABv/mP0A/ggAywBdAPD+qP48/vz8IPvQ+kD6IPng9mD0wPOw86D1MPRQ8YDv4O6A7gDsoOtA7MDtYO7g7ODsIOzA7RDyWPpYA7AH0Ae4BbQDeAIcAjgFgAzgEGAPoA/QDpANkA6ADaAO8AnABDgCtAKMAxQD+AVQCNAGJAJcAdgAbf/w/Cz94ABIAnADeAQoB6gHaAZYBBAE2AVoBugFiAVgCeAK0AiQBCgE+ASUAzsAIwB6AToAbP7L/2gCSAFy/lT9FP4k/qT+8/+5AL0AKgG7/6j72Plg+wD+oPuI+DD30Pdg9aDyMPPQ89DxoO6A7aDuQO0A7CDtUPAw8CDsIOhg6rDwUPg6APgG0AogCMQDwP6N/6AEkAogDyAQABHQDXAMoAmgDvAOwAl8A2D/tgE2ANAAmAZAC7AIeAMgAjQD+P9Q/58AiAHEAsQD6AX4BugFQAiwCPAGjAOIBVAI8AeYBjAIoAqQCGgEPANUA+ABAv+I/Vz+hv/6/oj+Qv5c/hr+ePz4/ID/YAIIAk4A7f8/AGD+pPwI/JD91P2I+wj4IPeg9dDyAPFA8eDxIPGA76DsgOyg60DsYOzA66DqAOqg6QDsIPNK/vAHgAzwCmAIYATV/7b+yAUAEaAUoBHQD2AT4A0wCTAJcAtQC4wCRP24/8wC5AM4BfAIEAvQCGgClgGGAIgEEATgAoAFoAlgCrAGsAcQC5AKGAcIBRAI4An4BxAJ8AeIBygGQATkAUb/DwA7AFT9MPq0/HkAKP5A+6D7A/9s/ej7CP8wBLgDOACaAC4Bnf8U/Nj7VP18/GD64PfA9uD1MPPg8ODvAPBA7yDuIOxA6+DrIO0A7cDtwOtA6QDoIOsA9Hz/AAkQDvAPsAvsA5b+OQBQByAOABRgFEARcA2ADGAN8AqACGAFoAO0/Nj9iv64A8gG8AYgCmAIoAMcATAC9APYBBAImAcgBrgF4AhgC9AJgAhgCnAJQAUwAtAGIAsgCEgGcATsAzgBsP5c/sb+7P2k/Lz8KP7w/aD90PoY+zj9h//M/rD9qgDEA+IBUP0k/TP/1v4o+/D4QPk4+aD1sPJA84DygO+g7eDv0PGg7wDsoOuA7sDtwOrA6UDqoOrg7WD0yPxIBrAOwBGADKgEKAH0AjAFwAigEAAZABGwCaANUA9QCpQDkAVYB14B+Psa/tQDWAXQBHgGcAjoB4gF9AK8AtAFIAmQCYgDyAbQCaAK6AcQCpAMoAlkA/AEcAiQCaAGaAVwBtwDtAKqAaD/6v4aAeMA2Pwo/Rb+nP6o/Fj8kv7//9z+bv/UAjwCBQAI/47+AP7A/ND6EPmw9pj48PeQ87DwUPHA8mDvAOwg7UDvAO8g7CDugO8A7uDqwOng6kDsoO6Q9rQCAA7AEQANwAmABjgBcAI4BmAOgBPgEEAPgAwwCvgHAAloB8QC+//O/lv/jv52AYAG8AeoBpAGiAeQBaQCaAMwCUALIApAB9gF0AcgCuAKMAiQB3gHKAasArADMAggCWgEZAM4BVgD4Pz4+ugA6AJS/7j9jf8Z/xT8IPsY/Xz+EP82AWwCuwB+/lv/6P7Q/cT9rP1Q++D3sPag9+D1MPOg8MDwoPGA72DtQO2A78DvQO2A7CDvcPDg7IDqYO0Q8CDzMPioAxAPIBFQDPgGKAVwAkgEoAbwD8AUoBKADPAH0ArQCQgEPAPgBkgE4P1c/NQCsAZgBUAGkAlQCogHMAWgBqAHgAhACeAKIAh4BcgH0AjQCPgH0AaYBgAFwAMABvAGqAYgBvAEgAXcA1kAbP0p/zgBegGC/3T/9ACM/Qj7HPzS/zT/cf9kAXAENALY/Zz/NwCu/jz8YPtY+rD2QPTg9eDzMPAg7mDwYPCg78Dt4O/A7uDsQOsA7MDr4OtA7EDtUPKY+Bj9bALwDQAT4A60A2wCOAMgBEAH8A9AGeAV4AxACTAKIAb2ATgCKAQwBWr+V//IAjgHYAi4BiAHgAhACVgFMAaACFAJYAoQCyALoAlAB2AIAAl4BDwDkAW4BigEkAXQCFAItAFCAMgEWAS0/WT8UAAgAYr+MP0OAbQBGPzY+uD8JP+Y/ST8SAA8AzQCdv4j/y//Cf8Q/Gj4OPoA9iD0sPLQ8mDxoO4g7WDuoPCg7SDtwO4g7aDqYOuA7KDsoOmg6+DygPdo+8QDgA/AE8AMqAUwBEwAXP2ABqATYBogE+AO0A2QCVQCTABUA4gE+wAY/cAACARYBNAHoAmQCDgFaARIBuAI6AbwBrAKQAxQC9AIcAkACCAG9APgBGgFlAPgBKgGUAhQBogESAVkAz4BnQCY//j+JP+wAMQClgHL/1L+sPwE/ID8HP3Q/VAAgALMAJb/0P3k/03/ePwc/DD6sPfg8yDzMPNQ8iDuwO2A8LDwgO5g7+DvAO/g6wDrAO0g7UDrQOww80j4mPtIAbAN4BFwDXAI8AVbALz+GAVAEIAXgBVgEfAN4AngBTgDSAKoAkwC9gCH/zEAGAOACFAH2AYgCMAHyATgBFgGcAmgCJAJEAtAC4AK6AcQBowDsAOoA7wDzAOQBOgFmAU4BRAEoATAA3ACCAF8ASwAiP5SAOn/rQAvAO7+fP/6/jj9NPxA/d7+iACCAIv/NP4M/Jj7APzg+Vj54Pdw9QDygPBA7+DswOyg7gDwQO7g7qDuUPCg7qDsAOxg7YDrQO6A9LD69AFgB5AOwBBQDCgE8P/I/b4AAAkgEEAVgBXQDYAJgAdYBXQCngCBACgDKABS/tj/eAUgCHgHkAfQBzAJeAToA2gHgAvQC+AIoAnAC8AJ5AOdAJAE4Aa4AwYBSASQBoAFyAKQBIgGzANgAJ4BgARwA5gA9P4a/57/eP1Q/v3/dQBRAOj9dPxw+9j9xgCHAH7/gv50/Uj74PkY+jj7ePjA9MDxAO8g7UDtgO/w8cDwwO/g7sDvgO7A7rDwgO3g6sDsYPCQ9GD6MASQCxAPwA6gC+QC0PuU/DQDgAyAEeAUABXADtAJOAb4BjQDxQBAA0wDIQDg+7T+CAVQCIAIgAgQCtAHTAO8ApAIkAsQCnALYAwADcAHiAPAAiAEWAWoAuwBPAIYBOgFWAUABtgESATSAQcAsgEIA8wB8v/S/1ABHgGSADr/yv8CANT82Pto/QYAZAKsArgBrv/I+/D6aPwA/BD48Pfw96DxIO2A7NDycPGg7cDvEPMg78DrIO6w9KDwwO0g66DtYPFg89D5/gDQCLAPIBAQDFADAP5o/cr+wAjAEKAXQBJQD8AM4AdABDACCAWIBFACSwBU/ET90P2IBeAKsAvACbAIQAhsA/QC4AiwDrAOMAvAC3ALGAWk/wADQAhgBhwB+AEYBCgEHANkAigHGAYwAxwCAAIoAtEASwCcAYX//v+B/2wA0v4g/jr+7Pz4+17+BANIBQgCJf8s/kD8cPcA92D6gPhQ9pDykPIg72DsIPCg7gDtoO1g78DugO3Q8eDy4O0A6iDuIPLA8eD0xwCACZAIgAngDnAMB/84+aIA+AYwCtAOABgAFRAMMAWwBPwDEP8GATgE6APl/0z8hP3WAJAE4AiQCxAJaAfABaAF6AVwC+AQEA8wC/gH0AegBWQDAAUgByAFigAgA0gEYANEAsAEwAcQBZgCQAJwBI8AyABEAwgEkP+U/SgBcALdAGj8ePsw/g7/Fv7g/PAEAAaoAdD7WPtU/ND34Pbg9gD6cPUA8MDukPBg8GDsAOtg64DuIO8A8KDxEPJw8aDuQOzg78DzsPd4+8gGUA9wD9AKMAm0Ayj+/PyYA/AM4BHAE4AUsA7wBiQCyAN4BQADDAK0A3QBoPtI+4IA8AR8A3AH0A4ADPAC2/84B/AOoAswDOAL8AzIBiAFcAmgCZAI8AMsA2IBzAFAA7AEuAfIBqAG1AO5ACgCHAEsAQAAQv/rALb/OAGt/8D+9P30/Ez8mPoQ/TIBWAI2AID9Fv7Q/GD6SPlo+nj6uPiA9BDxUPDg7oDrwOmA7cDuQO1g7KDw8PPg70DtIO9g7oDtIO9g+OT9EAN4BzAPQBD4B2IBYwAA/2r+iAZAEoAX4BLgDnAMYAeF/z7+BANYB+AEFAHM/+T+WP0Q/VwBkAewC9ALyAcwBvAFoAfACaAK8AwQDQAKKAQgBOAJAAogBuAB2ALcA/MADgHgBHAIUAaiAbQCqAPEA8EAoQBqAboBev/I/Xz9iP+PAEb++Pqo+5b+1P7o/Or+kP+e/nj6kPus/Q3/wPkw99D4wPUg8CDtQO6A7wDtIO4A8ODu4O2A7qDvYO2A7EDuoO5g7yDzAPrqAPgC4AowD7ALvAOw/mL/L/8EAkALoBbAGIASEA1ACRgGygHkAOQDYAdgBSIBeABeAd8A7P0yAGgFIAjQBUQDKAawCdAJgArwDCAOwAlwB9AGEAcgB5AG8AfYB+AFCAR4A0AE6ASQA4wDdALUAsgCOATABEwCAgAo/wIAbACY/ID8zP4r/yD8mPrw/kwCUADU/KD+bP3g+Gj51PxwAZ7+kPgA9yD1MPJA7WDtQO/w8ODuYO6g7uDuoO0g7QDuIO/g7gDtgO1Q9Ej4GP1gBXAM0A+gC8gHeADw+Kj6YAWgEKAVIBfgFyASgAf0AbAFkAeMA+gC8ASIBs0APv7AAqgDoAF8/+AEaAdQBdgDGAaACoALYAowCoAKYAhgB4AGYAkwCQgHuAaYBoAGGAQoAQwDuAKAA5ACYAOABRAF2ASIAv8A0P5c/DD89v7N/+v/NABo/+D8qPoA+uj+zf8K/rz8Mv4s/Lj6mPtQ/tz9kPrA9QD0APFA7mDtAO+Q8DDxoO7g7IDrIO1g7mDuQO6A7iDuAO4A81j5uALQCJAOkA1QB34AUPoI+ln/gAqAFUAXwBSAEDANAAa4ApgHEArQBlIBEQDMAxAF+AGsApgFmAREAH//OAKIBOgGYAZQCnAMcAkwB3AHkApACUgHMAiwCQAIIASIAwAFvANIA+AECAXGAZL/GAOABFgC+gCYA/AChv7o++z9AP7Q+8H/oARwA4D7qPjY/Ij9YP38/R0A0f8W/8D92Pzg/Kj9yPvg9rD0gPKw8GDs4O5w80DyoOvg6sDtIO9A7KDu8PDg74DsgOvA8AD4/f/wCWAPEA3IBSf/wPrA+2wDAA0gFAAWYBSwD9AJgAfQBmAKcA2QCuAEHAPQBHADmAL0AagFYAZeAXb/BAIABfwDiAXgCWALgAkYBLgFIAgwCCgHsAiADUAM+AUkAtABcATIAvQBYAWwCDgErAHoAiAEHgF0/bb/agEwAPD85P2a/4D/3P9IAND/BP0Q+kD6gPus/Ib+Fv9o/qj+FP34+vD3SPnA+ZD38PSQ8uDxIO4A7ODugPBA7SDrQOvg7GDsIOyg7WDuYO7g7FDwwPcaAdAKEA4AC7wCkPso+Kj62ATgEYAZ4BYAEIANQAsoBkgDqAZADbALQAbgBRAI8AZiAYwBMAboA2L+aP4YBCAGuAOoBUAKYAo4B6AFuAXIBDgG4AkgDaAKQAiwCCAH2AMMAqAEkAS0AygE0AVwBRwCZgG0AXwBiP+O/tz+BgDO/yr+vP1u/koAg/9Y/aD8mPzw+zD74Px8/oj9wPtQ+3j7YPnA9vD1MPcw9oDzoO+g7iDugO4A7ADrYO3g64DpgOtA7oDtQO0g7JDwgPZQ9+z9cARQCTgGywAa/mT8EwC4BwASwBWgE6AQ8AxwC2AK4AlAC+AK0AugCZAJIAjQBwgGwARoBbwCQf98/FgA4ARABBQDWAcQCyAH1gEuAfAFQAfAB1AL4A0gDHAGgAPQBfgGwAZ4BiAIMAkQBogDxALABLgFoARqAUgARwAaAZEAGQB1AHEAmP0w+0D8oP10/LD7wPxu/r7+MPso+3j7mPuQ+gD6MPl4+GD10PKQ8WDxIPFg8ADwgO6A7EDpwOlg7cDsQOzA6sDuQO5w8qD4fgDIBToBSQAa//j6kPVA/HAI4BQgF6AUIBFACtQDMAUQDJAPwA4gDYAOIA2IBvQCGAZwCNAE7gCWABgCYwCa/jgEIAfABRADcASwBUAC8P5MApAIsAoAC9ALcAsYByQDyAOoBVgHsAngCgAKCAewBCAECAWEA4ADMAR4ASj/GwC8Ab0Aqv5n/6v/Ov4g+oj5wPug/Pj8gP3S/mj9MPu4+ej5MPtY+qj4YPeA9hD1wPJg8ADygPGA72DsgOzg7ADsgOlg66DuoO2g6oDs0PWw+WD71P3ABNAEwPmg9Dj4hf8wCHAOQBdgFiAO+AVYB5AJoArwDcAQoBFgD1AMYAmQCAgH2AbABTgDoAIMA4gE7AMwAyQCVAJkAlwDkATYBKgDWAQwBVgGIAhwCRAJEAiABxAH4AaYBYgGUAnQChAISAbIBygHCAS9AHgCSASIAqQAEAIYBNABWP74/Mj9kP1I+7j5MPvQ/Bj8APtY+6z8DP0A+pj4oPhg+CD2YPQg9RD2APVA8fDwkPBg7+DrQOsg7cDvwO2A68DpYOlg6cDsQPRQ/L4B4/+3/2D4EPXQ9XD4M/8AC4ATgBTQDgAJ2AZwCMAHwAsgEkAUIBEQDfALoAqwCnAJUAmwCMgEMAMuAfgEIAnIBuwCVwCGAQwB8f+NACgFOAYABUgEcAWYBigEFAPwBJAIUAmAB2AIsAggCcgGCAVoB5AJwAaABPADAAUwBQgEEAVAA54AWv6k/aT+GP8s/8j+EPxQ+fD4KPl4+nD6mPuw+xj54PYg9nD34PUg9TD0YPXw8+DxYPFA8EDuQOwA7sDvoO9A70DvgO0A6oDqgPAI+bz8HANAAyH/kPYA8XD6awB4BmALQBHAERANEAmgBiAJwAvgDiARABKAEHAOIAugCxAOcA1gCYgFkAYgB8AEKASwBqAIAAXBAPn//AFcAVYB8AJ4BWAFoAMoAmgDgAR4A2AEyARAB9gHAAhQB/gGAAgoB1AIcAf4B7gGOAXYBFgFCAcgB1gFsAIoARIAiP9K/g//uP4s/vD7UPr4+jj6sPnw+UD6KPkY+LD3EPgA9lD04POg84DxMPGg83DxIO+A60Du4O4g7UDsYO7A8CDsgOpA8KD2oP4j/5P/sPzA93Dz0PcBAFAK4AwgDYAO4ArwCGgFYAogDsARIBEAEIARIA/QDTANoA0QDJAJsAgACSAI0AVoBSgFsATwARgCaAKsAVsA7AHcAmACTgEqAYwDRAJcAqADWAW4BEgEcAVIBjAGiAa4B0AI4AYIBjAHIAeQBYgGuAbIBggEKASIAt4Blv+v/9kAYP/o/ej89P1A+0j4SPm4+UD5oPgI+DD4wPXg9BD1kPRg9DDywPHg8UDvsPGA7wDtwOwg7yDvQOwA7HDx4O/A6QDpMPGQ+gD7d/8CAWD7MPIw8Gj7CASQCLAKoA+wDAAHYANAB3AMwA2gEYASIBFgDbAMgA2gDqANMAzgDGAJwAjwB+gHwAcABigFbANsAggCrgFwAmQCYAJkAlQBjgBsAvYBigHkAhAEUAR8A/gDpANABdgEUAb4BwAJ8AeABkgF+AQQBoAGMAcgCBAI2AV4AnABcAGkAmYBkAHEAbr//PwI+1D6qPlQ+sj5gPqA+aD3UPWg84D1APWw8yDxUPEQ8pDwwO3A7qDvIO5g68DtYPFg70Dr4Oxg71DwYO+w+KgC2wBI+DD0gPRQ9gD+EAZAEPAOEAi4BvgFOAewCFAP4BRgFSAQUA9QDfAM8A6AD6ASQA3wC6AKQAsAC8AIsAloB2gG+AJ0An4B1AKYAhADJAOJACYA8P7w/z4AZgHGAcQCqAJQAggCkAFgAkQD0AXIB6gHIAewBSAGOAXABFAFcAjwCGAIcAb4BMQDGAI0A3AD9AOyAcj/8P3c/CD7qPmo+mD7WPuo+GD1gPVQ9QD0MPPA87DxUPCA7YDugO/A7ODpAO0g76DsAOug66DuwOzA6qDt8PNA9wj6IP2c/ND2kPDQ9Dj92AXwCSAOIAyIB8AEkASQCfAMQBFgFOATkA+gDCANwA/gDxAPEA9QDUAMoAkQC1AKkAjwBigFCAZgA+wCbAKoAjwC7AAYAHH/BP+O/sn/kgC/AAQBlgHKAaEACgCjAEgDWARoBWAGKAZgBIgDEAV4BlgHWAegCIAIqAYYBcAEIAXABMAESAQYA/UASv9+/qz9nPyo+yj7iPoQ+QD4QPbQ9ID0MPQg87DwEPAA8KDuYOyA68DrgOog6qDr4O0g7ADpQOlg7wDvoOwg8lD1GPnA+MD2APkw95D4xP3gBRAJ4AhgCaAJAAlAB5AK8A8AEiATYBPgEdAP4A4gEGARABHgDYAOMA7QDRAMcAoQCQAHSAYwBDAENAPQAxwCSAFuAMz9YP3g/CD+Pv6+/tj+8f89/xb/XP4V//j/PgGIA7ADJAPAArwDQASgBVgGeAdIBwAHyAYoB2AHwAb4BrAGCAZQBNQC3ALuAX4BFgHu/mj9APww+8j5iPig91D3sPQA9IDz4PHA78Dv4O9g7eDqwOiA7kDuoOrA6YDooOkg6EDvkPPA9TDxAO+g8pD14PXA94P/Xv/s/2b/OAPABbgHgAmwDOAMgApwDUAQABMgEiASIBOAE2ASQBLgEQAQYA8QD8AOEA8ADiAMoApwCGAFYAS4AxgE5APsAjACigD6/hT9sPzM/ED9bP22/kb/tP6U/TD9PP5d/x0AJAF0AlQCSAJUA7AEGAUoBdgF2AZoBxAHEAiACLgHwAYIBrAFoARIBDAEUAS8AtcAPP8A/vj80Psw++D5SPlg92D1wPPQ85DyMPHA7qDuQO2A68DrwO4g74DnQOMA5QDroO7A70D0IPMg7SDq4OwQ9OD4APwA/nAA9Px4+0X/aARQCAAL4AtADGANwAywDkAQwBFAE0AT4BOAEyATQBEAELAPQBDgEEAP4A3ADHAKMAgoB5gGKAXYAyADMAJCAfv/gv/2/uT8ePtI/Bz9hPzg/KT9wP3E/FD8qP1X/1QArQB+Ad4BcAEMApQChAM4BVgGCAf4BhAH4AaoBhgGUAZoBtAFQAUYBcAEtAOUArYAvP9W/qT9OP0s/Fj64Pjg9pD1MPSQ9HDyAPBg7IDtAO9A7aDuIOwg6oDlIOLA5nDwYPPg8qDx4O2g6gDsgPBw+Cz9Yv72/uD9tPxq/mwD6AYAC3ANQA1wDUANQBAAEiARABIAFWAVwBOgE4ATgBMAEoARYBIgEaAO4AwgDRAMgAqwCAgHAAbcA3gDDAIuAWYAV/86/kD99Pyc/Nz8rPzo/ID8OPwE/QD9mP0K/jb/tAB3ALwAegEUAvABMALgBFgGyAZgBoAGSAZ4BVAFMAZgBmAFcAVIBTAExAEgAa4AOgBi/qT9nP2o+kD5gPgA9zD1wPIQ9ZDyIPAA7eDroO8A7oDtoOsA6QDm4OZg6wDwwPIA8+DwAO2g7EDusPOo+Sj+YgBR/2D9CP0/AAAF8AiwC+AMsA1wDfAOwBBAEmATYBSgFIAUQBTAFGAUQBTgE6ASgBFQD9AOIA+ADhANkArwCIgGwATkA+gD7AKYAVAAxv7A/dj8FPy4+2j7uPu4+8j72PvA/Az9QPwg/Pz8tv6a/1wA+gD2AY4BRAI4BJAE+AWABRAGmAWwBSAG8AWoBugEiAUABSQD2AGUAdsAngCm/sD90Pvo+dD4gPcg9tD0kPNw9eDwoO/g7ADsgO1g7MDuQOwA6MDjwOag6+DtUPGQ86DxAO2A6qDs8PIY+Sj8yv+t/7T8cPuI/rADEAiAC0AMQA2QDUANgA5gEGASwBTAFKAUgBSgE8AToBOAE+ASIBJgEHAO8A6wDUANUAzQCXAIIAZABBQDeANcA4oBDgCG/iD+QP3o+9j7/PxY/Oj78Ptc/Mz86Puw/Dj+L/8O/lr/IAGSALwBaAKYAzgFwAToBJAF4ATQBDgGKAdoBggFQAX4A2QCzgEYARQCygApAEH/+Pt4+Rj5MPkQ+CD2YPRQ9ZDywPFA7wDugOzg6SDugO4A64Do4Odg6YDpYOyQ8SD1QPEA7oDtgO4Q8gD2xP2qAbAAbP3A/N3/GAIwBrAKAA7QDhAOkA2gDmARIBJgEyAU4BQgFIATwBNAFGAT4BGgEIAPEA4wDYAMQAwgC3AJ2AaABcwCygHSAe8AfwB0AEb/UP3Y+zj70PoQ+8j6uPyg/rT8QPzQ+/D8qv4q/tn/lgDFACgBKAP4A8AEAAQIBXgFwAWIBZgFuAaoB2gGSAa4BGwDYAJ0AkACTAL//+7+b/8c/kj68PYg+LD5SPgw9TDzIPNQ8YDuIO/Q8CDswOqg68DsAOyA56DpQOoA7GDvEPIA9ODxoPBg8NDw0PKo+QYAUAN8AjIBFAE7AAADkAggDbAOwA9gEAARgA+AD+ARoBJAEwAUABQgFIAR4BCgEEAQgA4wDRANUAzACqAJAAjQBkAGSAR4AigBMwC9/2r/6P4l/8r+CP3I+1D7mPsk/Dz8wP0o/1r/Wv5+/gT/XQAYAe4BHALcAgAEsATgBdAGuAYwBvgFGAZYBpAGsAZwBvAFkAQUAyQCUgFCAQIB+v+E/XD7ePs4+6j5YPdA9+D1APQg8xDz0PEA8MDrIO1g7gDtAO3A7MDsgOng56DoIOrg7iDyoPag9qDyUPDA8KDyQPdU/N4BqASkAywDFAPYAogEEAiwDWAPQBBgEIARoBGAD2AQYBGAEQASoBKAE0ASgA+QDUAOEA1AC8AJ0AkwCZgH+AWwBGgERAJVAJH/vf8G//j9zP0S/oz9iPsg+8j7EPyI/KD8Jv7M/a7+GP9e/5z/qADdAMYBIAOwAlgE8AQwBVAFwAWYBkAFGAWQBegFcAUQBagECAMwAp4A4QD2/5n/OP1A/ZD7qPkg+bj4OPiQ9oD1gPRQ8nDxcPBg8iDwgO1A7ADtYO8g76Dt4OxA6sDmAOmA7SDzEPZw9wD4cPQA8YDx4PTw+Uf/OAPoBXAF6AL8AqAEoAZQCNAMwBBgEQARgBDgEMAPUA9AEMAR4BFAEeAQABHgDwANAAzQCnAKMAnwB2gH0AaQBVAE3AMAAs4AT//I/eL+JP4M/fj9EADg/RD9oPzg/Hj9DP14/jYAJgH3AAwCUAIcAnoB4AG4AygEEAVABlAGAAawBSAGcAUQBUAFIAbgBEgDwAIEA4wBCwCA/wf/+P0I/Gj60Pr4+Aj4EPfw9uD1gPSQ81DzUPNA8cDvoO6g7qDtQO3g7ADvYO9A7wDvgOvg6aDoYO2w9YD4YPuw+kj4EPXg9JD1bPxIAdgEmAfgCDAIcAYoB7AI8AoADaANQBAAEyAT4BGgECAQYBCgDmAOYA/QDwAPQA0gDGAMsAqQCFgHeAZIBYgDYALYA2gEiALoANn/qP5c/TT8tPyk/vr+WP6i/lz/wv4U/fz9uP40//7/zgF4A4QDqAKEApwCyAIoAzgEyAUABqAF2AQgBbgE+ATcA3AE7AOYApYBHAGOARAAmP0I/WD8YPvQ+dD5mPhw+MD3kPYA9lD0EPMg89DykPJQ8jDxQPCg74DwYO8g7mDv4PDA8QDuIOuA7ADu4PGQ9vj8+PxI++D20PZI+Aj6hP3oApAIEAjACNAHcAmgCmAJIAvQDGAP4A8gEMASgBKAEIAOUA8wDyAO8AxADUAN4AvwCsAKAAoQB/AFWAUIA1gCGALYAugBVwAkAb0AxP48/bD96v4e/sj9AgAgAff/K//G/oYAh/+QADQC8AToBAADGARkA/QCZAL0AkAEKAVwBMAECAbAA1AD1AE8AhgBmP9I/4T/TP98/QD9BPwo+2D5GPhQ90D3QPYg9qD2EPaQ9dD0QPRA8wDz4PJA8wDzcPKg8rDxoPBw8ODwgPIQ8qDwUPGg8IDu4O3g8Rj5FP40/vz83P1o+fD38PnI/0ADmATwBxALcAuQCZAJAAtgDJAL4AxQDxAPABDgEEASQBAgDoANcA0gDGAKAAqACwAKcAkgCZAIqAasA+gCiAMUAt8AMgGQAvoBoACw/1wAKv+o/Vj+N/8WAFgAxwAIArgBWQBsAAgBFgHAAfQCvAPgA5wDyAOwAzADcAIoA3wCWAJUArQCfgE0Ad4ARwBh/zb+Sv7o/Gj8uPs4+0D6QPnA+KD4CPgg95D3gPeQ9zD3wPZQ9jD2QPaQ9XD1QPUA9sD0UPUg9ZD0wPLw8QD14PUA9HDwQPCQ8rDw4PKQ+E7+bP8M/eD96P0A+xj5yv4kA6AFaAXIB3AKQAtQC9AL8AywC+AMQA2QDqAO8A4gEMAPABAAEEAPoAxACxALcArQCJgHYAhQCAgHCAZYBWAEgAOUAuQBgAH6ADUAGQDZ/73/1P8N/5j/tQBIAUYBLAEiAWgBCAC/APAB6AKMAhAEoAQgBCAD6gFQArIBpAGOAYwCcgH+AMcAjAAyABn/5P74/SD9yPuY+3j6MPpw+oj6sPlw+FD40Peg97D24PYQ91D3oPfw9yD44Pfw9yD4EPeA93D28PUg9eD18PbQ9ODzYPTg9iD1EPBg77DxsPLw9hD7t/9nAFT9LPyE/Xj9EP3q/nQDqAbYB3AH4AngCpAMAA1ADlAPQA8ADsANMA8gDkAOEA7gDyAQwA4ADpAMMAwQCRAIkAd4BigF2ARIBZgEkANAA9ACkAFsAYcAKgBC/3r+WP4a/mz/jf8CAbwALgFeAf8AtwDV/4sAyQAgAcIBgAI8AsoBhAE4AeAAsQD1AEsALwBv/5z+zP08/TT9CP3c/ET8MPwY+9j6yPmQ+Tj58PjQ+CD48PeA9+D3MPjw9wD4GPj4+Cj5iPk4+QD5gPi4+FD4UPgw94D3YPhw9yD3kPaA9WD14PVA9SDzUPCw8ODy4Peo+hj9LP9//1j9lP1o/qr/0P/qAEAEQAZ4BzAHoAtwDTAOcA9gD+AQMA/ADpAOAA7ADQAOQA+AD5APoA5wDmAMQAuwCfAI6Aa4BMAEOASUA6gCEAMcA1wC4gG8AUYBwQAR/wj+zv50/vb+yP4QACgBFAI0AmgCdAI4Ap4B9gFMAmwC0AEuAbIBKgHQAJgAFAFMAYcAMAAH/4z+BP2Q/Az84PsQ++D6sPpY+qj6aPmA+bD5OPlY+KD3sPcQ+KD3YPdQ9yj4mPjQ+Ej6OPrQ+oj6QPrY+Xj5qPgo+ED4qPhA+FD28PWw9mj4IPYw9NDyEPLQ8vDyMPig+zT8qPwN/2b/Y/8C/0wBJAKkAjgEiAWoB/AHwAnQDAAOoA7QDyASgBEAELAP4A/wDvANwA2gDjAOMA3QDHAM0AtgCpAJ4AjYBngFKASAA7AC+AEIAtQB1AHOAVoBjgEUAaAAogBZAHb/F/++/5EAOAEsAWwB2gHWAc4BLAJwAkwCcgHCATwBigBC/xz/R/8E/+D+mv4I/kj94Pxk/KD7SPvo+lj6MPrY+dj5kPmw+AD5yPho+aD48Pho+aj40Pjw+Bj6KPpg+oj6OPvI+wz8HPww+8D6gPrg+oj6ePmI+bD5OPgw9kD2sPcQ9jDz8PIw8pDxgPJg9ej60PwU/Xz95P91AFgASgHnABACaAPgBLgFKAfQCJAKcAzgDkARwBGAESAQIBDAD0AOgAxgDDANgAzQC2ALkAuwCgAKwAgwCIAHkAVIBBADiAIuAeAAzACdAOoAgQB/AMUAhACCAAIALgB7/8z/AgBUAFQAuwDnADwBhgGqAfwBIAJoAroBVAE2ALf/rv4K/kL+SP3s/aD8ZPzY+7j7mPvA+oj6WPqQ+oD6SPpw+XD5KPlA+WD5oPmA+dD5aPk4+Xj52PlY+mj64Pp0/MD7sPtI+4D8sPyw+pj5gPqY+zj6UPhw+ED40PaQ9nD3MPYA9IDxYPAQ8nD0oPZg+QD8NP2u/k3/YgBgAYQCdAMwBJAFeAaABxAIEAmwCiAN8A5gEMARQBKAEiARoBAgEKAOUA3ADDAMgAsQC6AJAAlQCAAIyAdYB4AGKAUgBLgCqgEKAbIA7f8tAAIA+f88AOD/BgAiAFAATABhAIEAcQBUAEUAoABfABcArv9aAOgAjgFUAaYANwC5//b+lv4o/lT9dPyg+6j7QPtI+nj5kPmQ+aj5qPkQ+tD5aPlw+YD5iPkw+VD5UPmA+WD5gPmw+YD5QPq4+nj7MPuY+7D8cP18/fD8PP0U/AT8bPx0/XD74PjA9wj50Phg9xD3kPaA9IDwwPGg84DzkPTQ9wz8JP1U/b7+5wByAXwCWAQoBkgGsAUYB2AIUAmQCaALcA4gEEARYBLAEsARYBEgEWAQAA+gDWAM8AqQCVAI4AfwBtAGGAfQBmAGkAUwBVAESAN0AugB7QAcAH//Uv9j//z+Pf9Y//r/hADcAGQBtAEcAqoBSAGdAB0AqP9h/3P/mv+E/3D/kf+o////df9K//T+fP7I/ST9iPyw+3j6sPlA+Tj5CPlY+aj5wPng+YD62PoA+0D6iPrw+pD6WPqw+UD6APqg+WD6YPs8/Ij7VPxW/vj9iPxc/WL+Bf9c/UT8mPvg+aD44PgA+iD5MPfg9cD1sPSA87DzEPQg9eD2uPkA/Ez9pv4IAKYBnAL8AxgFqAWIBggHQAdgB9AHAApQDOANkA9AEEARgBGgEcARABFAEOAO4AzAC3AKIAkACPAGQAdAByAHOAcgBwAHaAbABTgFCAQYA9QBlAAHAHD/B/9G/gj+fP4v/4P/PwDdAGwBagEkAQ4BHADq/5v/PP8f/+T+lv4M/tz9Cv4k/tD9vP0u/oD+fP38/AD8APsI+lj5APpQ+Tj4iPiQ+bj5qPkY+nj76PrY+ij7SPz4+2j6wPr4+pD6GPpY+hD74PvQ+8z8hP34/bj9xP0H/2n/dP5Q/Mj6iPuw+uD5OPmA+CD3UPUg9ED08POQ8tDz8PWo+KD5IPt0/Rf/fv+nAGwCfAOAA5AEoAUgBtAFSAbAB6AJ0AoQDKANwA4gEIAQgBEAEQAQEA8gDrAMIAtQCYAICAfgBcgFuAXIBSAFMAWQBQAG+ARIBOADCAM4AWQAogCd/xb+FP3Q/eD9OP18/bT+yf+x/48AwAFEAW0ARAA+AW4Bw/87/9j/Of8A/rj9Zv5m/oT95P12/or+uP0M/RD9YPyA+2D6APrQ+VD56Ph4+HD44PhY+aD5KPqo+gD7UPqo+vD6sPrI+dD5oPoI++j6+PqA/OT8wPxU/bL+4v6o/hj+ZP70/Sj8yPpw+gD7OPr4+AD48PXw8xDzUPRg9UD20PcQ+Tj7DP0J/7AAFAIIAiADUAXIBdAFyAWwBuAGSAeQCDAKwAuQDPANQA9AEMAQIBHgEMAQoA8wDjANoAvQCfAHcAZYBSgFoAWwBGgE0ATQBNgEWATgA2wDvAJUAl4BTgCT/y7+JP2M/NT8IP1E/fz9xv7K/3gAGgCBAGABPgEiAdwAWwDJ/xv/mv7Y/bj9kP38/ED9AP1o/fD9+P34/Iz8cPx4+5j6GPoY+nj5MPjg9xD4QPgw+LD4aPko+jD6gPog+xj7ePqA+gj7APtw+9j7GPxI/BD8CP28/Xj9MP4N/3T/yP7M/Vj97PxY/BD82PsI+4j48PXQ9KD0sPQQ9VD24Pfo+OD6AP2U/k8AggGUAggEAAWwBeAFSAbQBigH0AeQCFAK4AugDKANkA6gD0AQwBCAEWARwBDgDxAPUA1ACwAJ6AdgBqAFAAXQBIgEGAQgBLADnANkA2gD9AK8AsYB0gBu/9r+OP78/Cz8PPzE/Nj8SP10/iP/Z//t/1IBGAKwAZABVAHsAM7/U/8k/zj+jP0A/fD8DP3c/Fz9CP7I/Xz9IP0g/TD8SPug+wj7yPkA+eD4CPm4+Kj4SPmg+QD6gPoo+5j7QPvI+zT8QPzw+yT8nPyw/HD84Pws/bj8RP0Q/lD+1P0o/dT8WPw8/Fj88Pvo+pD4sPbA9cD0cPRw9FD10PbA9zD5kPpE/Jb+UgAsAugDEAVgBQgGwAZYBxgHmAfgCBAKQAswDDAN8A2wDnAPwBBAEUARABHgEAAQAA5ADJAK8AhYBwAGqAW4BOQDnAM4A9QCWALsAhgD8AIsAqgBwgCI/5T+uP3c/GD72PqQ+uj6MPsA/Az9kP2a/sD/GgFSATIBagFgAUkAL/8B//j9DP1A/CD8aPw8/Iz85PyY/bT9MP0o/cj8VPzA+xj7UPrw+YD5APlQ+KD3ePig+BD5YPlQ+uj6+PpA+5j7+Pvw+7D7LPxY/Ij8VPw0/LD85Pxw/bT9wP1U/ST99PzE/HD82PzI+3D6WPhw93D2QPXg9FD1cPbw9ij4YPk4+5z8HP5xALYB6AJYBKgFkAVIBYAGWAfIB6AI8AnwCnALYAzgDXAP0A+AEOAQoBFgEaAQoA9gDvAMwAoACVAHgAbwBcgE7AMIA/gCiALIAkgDUAPMAr4BogH/ANz/JP7Y/Lj72Pr4+Xj5APrY+ZD6kPso/Tb+9v6l/2IAFAG4AIkAMABl/1j+gP0Y/ZD8KPzo+2j89PwA/WD9gP2k/aD9MP2s/ET8APxw++D6KPpg+cj4kPiQ+Kj4EPlg+Rj6iPpo+4j7UPuY+/j7WPw0/DD8QPww/HD87PxU/Yz9lP2Q/bj9vP1Q/Qz90PzE/AD8OPvw+XD4YPdw9rD2IPfQ9wj4GPkA+8T8VP7G/uAABAP4A1gFMAbIBpgGsAYgCBAJgAkQCvAKMA0ADpAOIBCAEOAQ4BDAEcARgBAAD0AO0AzgCrAIgAdwBjgFaAQIBCgDvAJYAlAC4AKIAvgBwAH1AMr/eP5I/QD8EPqA+fj4aPhg+Hj4aPnY+rD75PxA/mf/NwBTAF4AYgCc/yD/iP42/kz9UPxk/KD8AP10/Qj+dP5g/mj+lP6a/uT9YP0w/bz80PvI+oD60PkI+cj48Pho+VD5GPro+lj7WPuA+4j7MPtI+5j70Pt4+3D7sPtY/Jj83Pxg/Rz9FP08/bT9tP3g/AT9xPxM/LD6qPkg+Tj4YPew9+j4YPkw+tD7uP00/zsAuAF4A6gE2AWoBqgHgAc4B/gHoAhQCSAKUAvQDLANkA6QD2AQwBAAEaAR4BFAESAQ8A5wDUALsAmgCEAHGAZwBQAFcASAA0gDUANEA/wCiAJIAlAB/P+W/uz8MPuo+fj4qPhQ+Aj4iPjg+LD56Ppg/MD9lP4//1z/Q//8/m7+Nv7Y/TD9wPxU/Cj8OPy8/GD9rP38/TD+Jv4Q/hD+5P1Y/aT8+PtQ+6j6MPqw+TD54PjA+DD5uPlI+qj6+PpY+4D7SPsw+yD7KPsw+yD7aPug+xD8lPzo/JD9fP2U/bz9wP24/Yz9QP2I/BT8UPto+mj5ePgA+FD4mPhQ+Zj68PtE/Wz+0f8UAUgCYAOABIgFCAZQBtgGIAd4B1AIUAnACrALwAwgDgAPYA/gD8AQABFgECAQwA9wDqAM4ArgCdAIOAegBkgG+AVwBHgDeARkAywDrAKQAuABogAA/9T9BPyY+WD4KPho+ED3sPfA91j4GPmo+Uj7ePzQ/CT9yP2Y/dD8dPxw/FD86PvA+/j7gPxY/Mz8oP3c/fz9VP6K/nL+FP6M/RT9ePy4+xj7CPtw+sD5YPlo+YD5wPkA+pD66PoI+zD7UPtw+zj74Prg+hj7OPtY+6D7KPyM/Dz96P1i/rD+tP6S/mz+Cv6U/TT92PxI/DD7YPr4+aD5qPkY+gD72PvM/Pz9MP9QACwBBALsAqgDKASwBDgFoAUIBnAGGAcgCFAJoArQC+AM0A2wDlAPkA8AEMAPMA+gDuAN0AyAC1AKoAmwCAAIaAcAB7AGAAbABYgFAAWABKADcAM8AjwAEf9g/Fj62Pgg+Qj5KPjw93D4EPlQ+bD5wPrw+9D7+Ps4/Lz88Psg+4D7kPsw+4D7mPus/Pz8fP3k/Tz+1P4n/2v/Hv9+/vD9yP0M/aT8CPzQ+zD7qPoI+wD7APv4+iD7uPto+2D7aPsY+/j6aPpQ+mj6OPpQ+tD6SPt4+/j7/PzA/RT+qv7I/rr+TP7I/aT96PxY/KD7OPsQ+6D6gPro+jD7oPtg/Gz9bv4T/wUArgBOAbgBGAK0AvQCZAMABIAEGAXgBSAHkAjQCfAKQAxADfANYA7gDtAOYA4ADqANQA2ADNALcAvACvAJsAlQCeAIcAgQCKgHOAaABWgFOAVIBIACeAGS/2z9ePso+vj5ePgo+JD46Pho+AD5+PiA+Xj52PmY+jj6aPrg+Xj64PmI+QD62Pp4+8j7jPyM/fz9HP7w/p//of9f/xb/U//s/lT++P2w/cD9XP2k/cT9pP2k/Zz9aP0Q/dj8/Px0/Mj7mPso+9D6YPqY+iD7OPug+xz86Pxw/dT9Yv7e/sD+qv6Y/l7+/P1o/Sz9pPww/Pj7GPxc/IT89Px8/fz9Sv7i/oL/MgBmALwAVgHqAXQC9AKQAygEwASQBYgGmAeQCKAJsAqACzAMwAxADZANwA3QDbANgA1QDSAN8AyADOALcAvQClAK0AkgCYAIQAdIBqgFqAQgBDwDtAIYAmgAmP6c/Oj6gPmQ+Jj4APjA9iD3QPcA9wD34PYI+BD4OPio+PD4wPiA+JD4OPmY+dj56Pqg+4j81Pxs/Qj+9P1+/g3/Cf/i/rL+5v6k/kD+NP5U/lb+NP5K/lj+UP7A/aD9XP30/IT8JPzg+2j7WPtI+2D7SPuI+wz8RPxQ/MD8SP3M/cz9/P1G/uD9oP2g/YT9lP3w/Cz9PP3s/PD84PyA/Xz9jP0q/sj+6v5F/6P/LwCQANwAjAE8AgwDxANoBCAFwAWYBpgHUAgACeAJwApwC5ALQAyQDMAM4AzgDGANMA3gDOAMUAzwCzAL0AowCgAJ0AioB2gHwAVABaAE0APgApwCbAI7AMT9mPvQ+ij5cPdQ9zD3wPYQ9hD2APbg9SD2IPZg9jD2kPag9oD2YPZw9mD3wPdA+Gj5uPpI+7D7aPzI/fj9Bv5G/sL+CP/6/qj+J/84/zb/K/9a/4b/q/+2/2P/+P5s/hr+SP2g/DT8OPzQ+4D7ePvw+yz8IPww/IT8wPyE/Oz8hP1g/Tz9eP1g/Xj9MP2Y/Rr+pP3U/Ub+ev52/lT+Bf9i/yv/Yf/g/3kAlwDsANQBaAK0AkwDCATIBDAFsAWABvgGcAdACAAJoAlACgALgAuwCyAMsAzgDNAMwAzwDKAMQAwQDJALMAuQClAK0AkgCYAI0AcAB2AGqAWoBCAEMAPUAsIBKABQ/gD8YPoo+OD3YPjg9kD2cPZw9qD2kPWA9dD1APUQ9dD0oPVA9RD0gPWA9uD2YPc4+BD6yPqw+uD7MPxw/Dj8sPy4/YD9aP2e/jj/9/+r/+j/ZABrAKD/z/93/5D+9P2U/dz9BP0E/RT9JP08/Tj97Pwk/bD8KPyA/Bj8+PvY+yT8GP0M/UD9KP1s/XT9jP2U/cD9cP1Q/eD9JP52/lj+8v65/9L/MAACAW4B1AHqAaACqAPIA/QD6AQQBqgGEAcACOAIMAkACsAKYAvQC/ALoAwgDUANoA3gDQAOwA3QDeANcA0ADbAMkAzQC3ALoAoAChAJUAggCJAHAAaYBUgFYASMAoQAKP6g+6j5cPjQ+FD4wPfg9jD3kPZA9eD0IPQA9JDzQPOQ84DzYPOw88D0gPUg9gD3GPhw+Ij4QPno+fj5aPpg+2j85Pxw/YD+tv/+/18ArwD0ALsAUQCrAIYARADs/9X/GgABAMn/yP+b/+T+Df98/jr+OP0k/VD9DP0o/fD8jP3Y/aD9sP0k/SD9jPx0/Fz81PzI/ND8uPw0/bj9sP04/ob+8v7c/l7/5P9MAMAAeAEoArACRAPkAwAFeAXABcgGgAeACKAIQAlQCvAKYAsADLAMQA1ADUAN0A1wDTANwAwQDSANwAyADBAMgAuQClAKEApACVAI6AcoB1AGCAUIBHQDVAGS/wD9yPvA+pD5sPk4+aD4kPew9lD20PRw9NDzwPKA8oDyAPNQ8xDzkPOA9LD0QPVg9fD1QPZA9hD3APjo+CD50Pn4+vj7pPwo/cz9Zv7u/lP/SP9G/z3/bv+//3kAOwB2AFoAjADCAJYA2v+C//r+tv5u/iD+ZP5S/oz+A/8v/3L+sP14/Vj9+Py0/Hj80PyU/Kj8aPwA/bT87Pw8/bD9oP08/dz9Nv7w/iz/nAASAZABOAKcArgDzANwBJAFeAboBmgHMAhACeAJUArgC1AM4AzQDNAMMA2wDNAMMA3gDRAOwA3gDXANwAywC4AL8AqACiAKMApQCZgHwAYQBjAFnAM4AlwBGf/I+/D6GPsI+wj6uPjI+Aj4wPWQ9FD0YPPA8ZDxQPLw8kDycPIw8wD0IPNg8tDyMPNw8xD0wPVw9hD3wPf4+Mj5wPm4+oj7wPzM/DD9Lv7A/h3/u/+qALwAuwCmAOQBugFAAYIBegHYAfoAQAEgAQoB6ABeAcIBDAGaABEAQgDj/zj/+P7u/sT+bv6e/kr+7P18/dj9yP3c/fD9kP3g/eD9QP4G/w3/vv8jAGYAYAFOAdwBtAJ0AwAEmARoBRAGSAb4BlAIIAnQCZAJgAoAC1AL8AoQC+ALsAuwDGAMQA1wDKALsAswC9AKEArACYAJwAlACcAI+AYgBvgESAT0AoQBAQBe/yj+9Pxc/LD7QPvQ+Qj5QPig9zD2IPUg9bD0MPTA8zD0kPQg9LDzkPOA82DzgPNw9AD1APWg9ZD28PZA98D36Piw+Qj6sPqA+xz8RPwg/Rb+fv50/vT+jv/6/xYAqwB0AYABvAGsAc4BrgEqAc4BLAKAAmwCUAKAAjACkgFiAWgBTgEWAdYA8wDxAIYAXgAdAEUAyf+E/6P/t/+m/5X//v9LAEcAPwCyAN0AEAHWAG4BDAKMApgC3AKoA7gDYAQwBHgFeAWoBUgGsAZIB9AGEAeIBxAIsAe4B3AI4AjwCNAIkAjAB1AHUAcQCAAI2AfYB1gHsAbgBVAF8AT4A2wDSANEA0gCEgHUAKsAAQAf/4r+Xv6w/eT8kPw4/Lj7QPsQ+yD7yPpg+gj6mPkw+cD44PgA+aD4gPhw+KD4QPgA+BD4OPg4+CD4YPiA+JD4oPgo+Wj5ePmI+Yj5APog+pj6CPtY+5j72PtE/GT8kPzY/GT9yP1E/rb+FP9S/5L//P9tALEAyAA2AXABvgHcATQCfALAAvwCRANYA0QDTAN8A/wDEAQgBGgEeASABFgEeASQBIAEaASIBLgE2ASwBLgE4ATYBNAEyATYBMAEmASwBMAEkAR4BGgEeARYBDAEKAQYBCAE8AMIBAAE1AOYA2QDeANIA+QCuAKcAngCNALUAZIBhAE6AQIBrAB3AB0AvP9f/yr/9P6s/kr+CP7A/Wz96Py8/Iz8XPwU/Mj7wPtg+yD7+PrY+tj6mPp4+mD6QPow+uD5GPrY+dj5yPkA+uD52PnQ+eD5+Pnw+TD6SPpo+nD6wPrg+hj7SPtg+9D78Psk/Iz8yPz0/ED9lP38/VD+uv4K/2z/x/8DAE8AsQDjABgBgAHIASgCXAKIAuwCCANAA2ADsAPcA/QDGAQ4BHgEcASABKAEyASwBIgEiASIBKgEqASgBIAEYARYBFAEIAQABPwD2APIA7ADjANkA0gDEAP4AgAD0AK0AsACoAKIAmwCSAI0AjgCDALqAeoB0gG2AZYBdAFoAUYBIgEIAQYB8ADQAI8AawA3AA8Ax/+e/3f/VP8e//L+2P6e/mD+KP4S/vj9xP2M/Wz9TP0g/fT8zPyo/GT8RPww/Bj82PvA+6j7kPuI+3j7YPtQ+1D7QPtQ+1D7SPtY+2j7kPuY+7j7qPvA++D7BPw0/Fj8nPzA/Az9KP1s/aD94P0a/lD+kP7Q/h//U/+Q/8X/BwA7AGcAqADdAA4BSgF+AcAB/gEkAmwCfALEAtwCAAMMAzgDYANgA2wDhAOkA8QDyAPoA/QDEAQIBPgD+AP8A/AD6APsA9wDyAOgA6ADmAOUA4gDfANoA0wDMAMUAwAD1ALEArQCnAJ0AkgCKAIIAswBlAFqATIBBAHOAKgAegBAAA0A5P+u/3T/Of8E/87+lv5m/k7+HP7o/bj9jP1o/Uj9IP0M/ez8xPys/JD8cPxc/ED8NPwg/BD8CPwI/Bz8FPwg/DD8PPxc/Hj8iPyw/Lz86Pz0/Az9KP1M/WT9hP2s/dz9MP4o/oj+qv7g/hH/Of+R/7f/4P8pAHAAoADEABgBRAFcAXYBogHgARACLAJUAngClAK4AswC6AIAAxADJAMYAygDLANEAzgDMANEA0QDSANEA0ADRAM0AywDCAP8AvQC5ALYAsACtAKMAnACUAJEAjwCNAIcAuoB1AGqAZQBfAFUATABFAH7ANcAugCWAIEAaQBCABYA5v/Q/6D/j/9w/0b/K//2/uL+vv6u/oL+Tv5A/iL+CP78/eD90P3I/cD9tP2w/Zz9mP2E/Wz9bP1g/Wj9VP1U/Uz9UP04/Tj9WP1c/YD9fP2Y/bj9yP3g/fD9EP4g/jz+Xv54/pz+vv7Y/gD/Jf9O/3H/jf+p/9j/+f8fAEIAXgCJAJYAswDIANQA8gAQATABPgFYAWYBdAF8AXwBkgGSAZIBkgGYAZgBigGKAYoBmAGOAYYBfgF2AXIBYgFUAVYBVgFOAUABNgE0ARwBAAEIAfcA5ADLAMsAzQC5AKkArwCyALoAlQCZAI4AgQB4AFcAdwBKAFkAQwBVACsAGQAQAA4ABgDm/+n/3//I/6//r/+p/6H/iv98/37/av9S/0j/Mf8e/yX/Hv8g/xn/EP8Y/xT/GP8L/wD/8P7a/tz++P7q/tT+yv7A/sz+vv7E/s7+3P7q/uT+8v4A/xX/GP8l/zX/P/83/0X/Yf9v/4T/if+c/7H/vv/P/+z/9/8VADMASwBhAHYAeQCDAJoAqADIAN8A3gDvAPoA9wD0AAQBDAEaAS4BGAEkATwBNAEiAQ4BEAEKAQgB/QD8AAQB7QDhAMsAxgCuAKAAlQCRAG0AWQBRAEcALAAOAPr///8JAPX/1f/P/9D/w/+2/6f/of+i/43/jf+M/4P/Z/9o/3z/e/9x/2r/bf9o/1//TP9g/2X/Zf9w/27/g/98/3P/ZP9o/3D/fv+D/47/n/+Y/6//rP+5/8L/yf/L/9v/3v/p/+7/4f/j/+j/AAD5/+7/+v/2//D//f/5/wkACgAEACEAIAAvACoAMQAsAEEAMAAbACAAKQAqACgAKgA5AEIAWwBKAFQAWgBrAH8AfgCCAG0AdwBzAIYAiACaAI8AlgCJAIQAhACGAJIAhQCSAIkAjQCFAHoAdwBxAHAAYgBZAEwAQwA3ADIALAAjAA4AEAAGAAIA6v/j/+f/6f/c/8j/wP/B/7X/tv+u/7//sv+7/7D/uv+3/6z/sP+4/7//sv+s/7T/wP+8/7n/sf+y/7X/q/+z/77/tv/N/73/vP+u/7z/sv+3/4//nP+l/63/vf99/8n/ov+u/3v/fv+2/6L/mP+L/8r/mf+R/67/pf+Z/23/df+t/8f/jf9+/4n/t/+N/5P/rP/S/8j/l/+s/9T/zf+7/6//x//g/9X/x//y//X/7f/m/wkAEwAfAB0AJwBTAFIAPQA1AFgASABVAHoAmQCkAGsAawCGAJYAiABoAIgAhQB7AFMAXwBfAG0AbwBwAFwANgBAADsAagA8ACcALQA9ADYADAAmABUAHwD///X/+v/z/+v/2f/z/9L/3v/g/9j/zP+4/8X/2//U/67/tf/M/8r/qP+t/7r/vP+5/7X/xP/J/7z/t//Z/9P/xf+o/8D/xP/A/77/vf/A/8n/x//C/9X/yP+0/7v/1f/f/+//v//Q/9v/9v/D/6b/sv/m/+n/vf/S/8v/3v/Z/+H/6P/M/9T/6f8ZAOX/yP/z/ycAKADl//L/HQBeAA8ABgAZAG8AZwBCAC0AWgByAGMAUwCXAIQAbwB/AI4AgwBSAJwAugC6AHAAjgCpAK4AdQCSAHcAqwBgAIQAXwCOACgAYABgAEkAHQD7/08AFwATAM7/8f/m/7L/pf/v//f/uP+t/6D/kP9//6X/lP+U/3v/iv/D/4r/f/+N/7f/m/8//wv/pv/k/8n/DP9n/7j/s/91/3X/6f+S/0r/NAAeAIz/xP4/AJIB7ADA/Sb+TwBGAfAABf+i/7b/xQCj/2T/wv/bADgBuv/g/hwAOAGDABb/4//qAWYAXP8s/7ABMgF+/y//ywCgAeP/1P9AAAYBIQA8AGYAyQAWAM7/owBdAFIA4/8ZAFoAmgDV/xcA2v82AHwAnf/o/1QAcQB0/3f/r//WAMwAdf9C/1gA9AADABb/8P8OAVsAQ/97/44ACwAN/1j//QDEADn/Ff/o/+YA9/8z/4b+EAB2AIwAXP/k/sb/+ADO/0z+9v5CAM8Aof8r/5b/6/+8/93/EQCQ/yz/6f8SAQkAIP+M/xUAMgA2/8H/TgBhAIL/xP9zAFoAbP9Q/1YAMgGdAKr+JP8gAVwCxv4Y/kwAVAJbAL7+WP+SAK7/Pf8+ASACEADQ/db/SAHQAbAAbP/s/lkAkAHNABD/2v6iARwCtP/c/ev/sAEVAMn/JgAYAon/HP4B/9gCTAEA/9T/7f8cAaj+nP/u//EAuP+cALMAbP7Z/04AXgCg/mAA9gF6ATD+VP6sAFQCuP5C/yIAnAGa/1sAOQC5/8T9jf9cA4ABRP4g+5YBMARUAWT8cP0uANUALgHV/zn/jP1z/yQCNAFA/Zj7wgFgAp0AQPts/SAB+AOp/+j68f8HAKoB5P0o/gACbP8PALT9AASA/mD95v74A64B2PqO/7gDWAWo+pT82AHYB5z9sPtLAHgFoALI+swAXAK8Arj79f9oBCACbv50/HQC7gG4A7L+Wv9IAbsAbAFZ/7j+SAGQBs7+0Pvk/UgFkATu/rj8F/+AA6j/dP1cARwDiAEQ/ST9lQAMAx//hP6wAIkAFgDU/VAATAEYAJD7nf9gBZQBGPtQ+4gD2ASoAFj5Rv/IBHsA5/9i/zwD5P1GADAC/AH4+4T8OAa4BVT9OPm0AdQD6P6Q/Pr/qASM/vD6tP5gBH4BUPzw+8UAKAS//4T9APvY/mQByAOeAcj7GPy8/qAEOP+U/MD+6AIFANj9Pf80AZz/KPykAZwC6v7o+o8AKAVAAaD6mPqcA+AGzv64+qj9xAD4AtP/kP7I/VADmgHiAdD6FPx6AaAElAL8/sD6XP8cA0AEyPwY+voBKAb4BJD5IP50/qgEdP4YBBAFtP4Q+5r+KAbe/swAGAPQBLT9+PjgAMgE9gEY+sgCnAIU/8D7x//gBrX/kP1I+9gAuQBUAAgBhv4wApoAfQAY/bD6W/9WARgE4AGw+pD6kwCQBdQCA/+o+qD88P45AIAF4ASQ/JD74v5AAhv/9PzPADgG8gEQ+BL+hABQAiQCHgDA/lz8dP2cADgErv9Y/AAAb/8c/jb+2AFIAlT9bv78/Pr+oAE8AXADMv4Q/sj5gAFrALQDwAMI/hL+UP63AMv/0AGgAKACpgGU/wT+egE4AfYBVAKyARQALv4zAMYB/AIIAgABwP8sAUj+3P1QA6QCSAGk/yT/SgAEAvT+2P0UAnYBcAHw/nj99QCQAcz/BP7OAAkARgGo/iP/m/95/9sAvP8wAsUAnAB4+/T8vgFUA8wBsPtc/2wCygG0/Sj+iABP/yIAagDL//r+GP2cAuACtP6o/Vb+vADk/ycAoAFz/wj+UP+0A2f/kPv8/jgC9AJ4/Ar+CAIQAdz9QP1sAvr/nP2I+4gC8APDALj82Pt6AdYBRAAQ+2wABAJNAEL+mf+UA9r+sPwI/2AF7//g+tb++ALoA8L+Af/OAUQBxv7a/qH/nf9J/7QCxAO2AUD9RPwN/4YBoALQAF7/kv8w/8P/rP+oADMAqQBB/wD/nP4y/yYBYwB/AOb+wgCCAHj/Zf/G/oz+YP3VACwDgAMk/3z8bP7BAHz/C/8EAa4Btv/I/Rj/SAFsAhcAwP+w/lT+XP6bAKoBuAHNAGYA7v+0APj/Xv86/rr+aACiABACBgH6Aen/0v74/Uj/8f88/1IAngBIAgIBzgB/ABkABv58/e3/0wBkAc4AVAG8ANP/SP/e/uX/a/+J/2cAVwBtAFMAzgBMAAcAUf8W/0b/CP/r/30ABALUAXsAxv4+/sL/HACMAOr/HgCjAL8AeAAbAGIAugDA/7T+dP57AN4BGAKzABIADgDY/rr+vf8sAeMAWgAEAIsAtQAnAFAASgDI/h7+8P4MARwCIAFnAML/cv96/kz+fP/Q/9EAvACJAKb/jf+4/43/V/9g/gX/kv+eAGEAzgDj/zL/2v7a/sT/wf/a/zX/i//9/0IAAgEEAVUAyv5O/kD/WQB2ACgBDAKgAZ4AX/89/6b/PwCkAAgBTAEIAYgAsQCsADcAs//1/3MA4ADgAFsA1QB2AdgAlQAPANb/+P8LAPT/FgAKAQYBNAFrAAUAa/89/x//cf9TAKAABgHcABkAz/+B/x3/w/+2AFsAKgBPAHIAvP+C/yoAegChAHr/S//q/y8AWABUAJEAMwB3/+r/IgAsALH/4v/J/wQAaQDKANIA4f8U/1f/HgDd/zQAEQA1ABAAaf8pAB4AW/9R/1j/wf+0/27/U/+x/8//2/97/0//H/9e/sj+Xf9c/zX/pP/G/+b+iP6c/tb+Hf+Q/nT+T/9I/7z+Av+N/2//hv7s/Rr+lv5c/8L/1f+7/+r+Sf9E/xf/Bv9u/83/AQAkAAQAGABRAOT/VwCoACYAiABsAQAB0gC1AOkAmgHgAWIBYAFAAv4B4gEMAlQCgALWAdwBOAJ0AogCVAK4AogCiAL+AQgCPAJQAjACMAJcAjwC/gFwATwCuAKQAtgBrgGwAQIBsAAIAaABQgF/AFMAYQCP/9j+fP4u/2j/R/82/2r+Dv5k/ez8SP0Y/YT8qPzM/Lj82PzY+9D72PqI+lj6WPqI+mD6wPqg+gj7cPrA+pD68PlY+XD5gPro+hD7GPtg+1j7KPsQ+yT8EPxg+yT8sPzU/QL+5P1u/jn/nP82ALr/jADmAK4B0gEgA3AEAAXwBBgFAAYQBsAGEAgQCVAKQApACtAKwApQCuAJwAqAC7ALQAxADNALUAtQClAKgArQCXAJQAngCMgHQAf4BrAGGAZIBZgElAM8Ag4BCAE1AEr/3v7E/vT9KP3A/LT8yPt4+gD60Pkg+Xj4UPeA91D2EPZA9kD2UPZg9RD1QPSQ80DzYPNQ8/DywPKA8iDygPGQ8RDxMPFQ8UDxcPEw8HDwYPDg8ADxoPLg84D18PVw9SD1YPSQ9Tj4ZP1oAdgESAYwB3gG2ASwBaAG0AoQDoARQBVAF+AVwBPgFIAV4BagFuAWgBXgFAAWYBcgGAAY4BUgFMAQMA3gC5AKsAmwCNAIQAloBigEYAL4/9T9EPtg+sj6ePqA+mj62PmI+KD3sPdw9wD3APeQ9+D3gPiQ+RD74PtA+7D7wPvA+4D78PvI/Iz8iPyU/Hj9vP1c/Yz8sPtg+tj48PdQ92D3gPbA9nD28PXg9AD0APNQ8WDw4O/A7xDw4PBA8cDx8PGg8oDzoPNA9HD0IPUQ9YD3DPza/qYBCAagCOAIYAiwBoAIIAuQDcARIBSAFgAWQBYgF4AWYBagFgAXABaAFaAUABSAE8ATgBOgEsAPwA1wChAJkAYwBfwDGAMUA5oBUgCc/Uj8yPqw+Wj5UPoA+pj44PeA91j4sPeY+LD5GPoY+3D78Pt4/GD8+Px4/bT9Yv50/iv/U/+l/9//OADv/zr/Mv7A/YT8+Ppw+lD6oPm4+Ij44Pcg9+D1UPRw89DyQPFw8CDwsPAA8ADwgPCg8TDxgPHw8mDzsPOw80D1kPYw9jD2cPu6AJQDOAeACAAL0AeACLAJoAxgDgAOYBJAFWAW4BRgFmAVABbgFKAUIBTAEaAQYBAAESAQoA9QD8AN8AqAB+gEPAJSAF3/Y/9r/3r+GP34+6D78Pl4+Tj5UPko+Qj5CPlo+RD5QPnQ+jT8fP3A/Tz+ZP5s/g3/HwBcAL8ASAFCAXwBpgGEAYgB5QADAFr/Bv+8/Yz8WPtA+vD4UPjQ9yD34PXQ9PDz4PIQ8tDw4PAg8EDv4O7A7sDuwO6A74Dw4PBg8YDzUPSg9SD1MPYQ9yD4+PnI/eQC4AXIB1AKwAygC/AK8AuQDyAR4BBgEiATQBTgFAAVwBaAFQAVIBMgEwAR4A5ADqAM4AuwC0ALkAnYB7gFKAT2ATwAXP8o/pz9LPzg+2D7CPv4+hD7EPxQ/Dz8uPy8/Gj8uPyo/CT97P1k//IA/AEYAkACAANoA+ACpALYAhACgAEAAYgBSAEPAGT//P4W/oD8+PqA+cD3cPYA9RD0cPPw8jDyUPGA8MDvgO9g7gDugO0g7QDtIO2g7aDuQO8w8NDx8PLA9FD14PZQ9zj42Pjw+jz9YgFABTAJEAxgDUAOMA3QDrANIBCAEcAQIBEgEwAUYBQgFEAUABSAE+ARoBBgDuALgAkACVAIWAfAB2gG+ARIA/4BFAFu/nz9eP0s/AD7KPr4+gj7MPtk/Pz9kP7G/tr+Dv8r/2b+C//L/6gA5AHEAkAE0AO4BDAFyASIBIQDeAKGAWwArv8p/0D+qP1M/Dz8qPso+rj4APeA9QD0APJQ8dDwIPDA7+DuQO8A7+DuAO8g7wDvgO7A7sDu4O+g7zDx0PKg9JD2wPco+tj6EPtA/GT9jf/QAZgF0AkQDfANgA8gD9APgA9AEEATgBEAEoARIBJAEiASgBKgEaARYBHwD+ANkAtQCUAIMAbQBdAFiAQMA/ABzgHiACz/qv5w/gL+vPz4++j72Puw+xj9GP58/1QA0gBsAdgB3AGUAUQCQAIcA6QDMASIBMAEaAUwBYgFYASkA3ACXAFJABf/Zv48/Rj8GPvA+gD60Pjw9uD1sPRA88DxAPGA8IDvIO9A74DvIO9A76Dv4O9g76DvwPAQ8fDwEPJg8yD0gPWw9pD58Plg+rD7/P2w/98AoAQQCbALoA4wDqAPgA+gD4AQABLAEsASgBHAEYASABKgEkARIBIAEaAQEA+gDEALsAioB/AG2AUIBagDtALeAa4Auf8W/2z+MP6w/ez9TP08/Fz8AP0M/sz+YP9nAJABhAEcAnwCmAKMAhADwAP8A+wD3AOoA6QDVAN0A/wC3gGaACgA9P4O/nz86Pto+nD5MPiA95D2APXQ81DzoPIg8WDwkPBg70DvQO/g7iDvgO5A74Dv4O8Q8JDwwPHA8QDysPSQ9ND1kPcY+ej5kPmw+4r+qP6sAMAEEAqgDLAMcA+AD7AOEA+gEMASIBEgEKAQgBHgEKAQIBGAEcAQIBCgELAOIAzQCdAI0Ae4BoAFwASsA4ABmAEeAWYAhv8K/53/+v6q/gz+EP1U/RD9iP54/4f/fwCqAZwBHALgAtgCDAPQApADxAMgBDQDbANsAwwDiAIgAkIBiQDe/+D+IP5Y/ej7kPow+Xj4wPew9mD1kPTw8+DyEPJA8XDwUPBQ8MDv4O+g7+DvwO/g7xDx8PCQ8ZDxoPKg89DzYPSA9mD38PeQ+Kj6+Psg/Lj9kgF4BEgHAApwDlAPsA0ADuAP4BAAEWAR4BAgEbAPIBCgEeAQwBAgEEAR4BAAD5ANsAtACeAHCAdIBjAF6gEMAhYBZgAhAFL/AQDk/kX/7v5A/pT97Pzg/Nz9HP58/lz/Uv8yAAwB7AFMAlQCtAJAA1wDUAMYAywD/AKgAhwCzgGxADgAB/+c/lb+kP1I/BD78PkQ+fD3APcQ9tD0UPQQ84DysPHw8GDw4O8A8DDwEPDg78Dv8PDA8ADxUPHA8QDykPLg8nD0IPUA9WD2ePjg+BD5oPrA/Pr+/QDQBDAJ4AugDIANoA6QDnAOoA9gEeAQ8A+ADyAQoA/AD5APoA/QDwAPAA/wDfALAArgCHAIEAdQBRAEnAIUAf//WP/2/w7/QP/Q/9//8P+e/r7+YP7E/kz/cv/a/63/8P/XAGoB6gF4AjAD/ANoBIgEyARoBPADJAPwAogCTAEvAGD/7P4y/mz9vPw8/Cj7YPqQ+ZD4cPcw9kD1MPRQ82DykPGw8EDwYPCA8FDwUPDg8EDxgPEQ8pDy4PKQ8vDyMPQw9PDzoPTw9UD3kPe4+Cj6GPvA+/j+AATYBuAHQAuQDfANkA5QDiAQwBCQDyARABGgEDAPwA/gEEAQIBAgEGAQQA/QDRANgAtwCQAIOAc4BiAEVAIAAYwAYP+G/5j/pf/2/6v/3f9b/4T/Wf9x/4r/8v/3/8b/OgBjAFgBsAH4AugDgATwBHgFqAWYBRgFAAVIBLQCuAHaAAwA9P5Y/qj9YP1s/Az8SPu4+mD5QPhg90D2EPXQ89Dy4PEw8fDwkPAw8KDwsPDg8ADxIPKg8oDyoPLQ88DzwPNw9CD1gPWQ9bD2CPmg+Sj48PnE/N7+hAKIBfAJYAqwC9AMYA9AEGAOQA+gEKAQIA/QD/AOEA9wDhAPQBDAD2AOUA4wDqAMUAsQCjAJqAcIBpgEwAKzAGj/P/9P/2X/lP/+/i//Q/+i/+b/y//U/xwAKgBVAIIAaAB1AIoAjgGEAnQDMASoBBAFMAVQBXAFYAVwBIwDjAIYAdr/1v4A/kj9pPwo/OD7WPuA+rD52Piw99D2wPWA9HDzYPKA8bDwMPAw8BDwMPCQ8DDxgPHA8WDyIPPQ8kDzkPNQ9MDzAPTg9AD2IPbQ9kD4+Pg4+ZD7qwAgBAgGsAegCsAMsAxwDuAPABDADyAPYBDwD9AOAA5gD8APgA9gEAAQcA+wDrAN4AzgCxAK8AjQB9gF/APcAWIAkv/T/8P/sP9d/x7/uf/m/yIAoACHABcASAD8AEYB0wC3AAQBtgHwAaACIASIBGgE2ATgBeAFWAXYBMgECASAAkIBTAAb//j9dP0w/YD8HPyY+/j6QPow+VD44Paw9bD04PPA8sDxAPFQ8CDwIPCw8ODwEPFA8eDxEPJA8oDyAPPw8jDzcPNA9FD0MPVg9mD3UPcw+Dj6FPwAAGACcAawCSAKMAvgDRAPgA8AEEAQ8A/QDzAPgA8wD2AOwA7QD+APcA9wD3AOIA1QDFALkAowCPAG6AWkA5IBRwDB/wP/pP7W/u7+dP5I/hX/mP+I/0n/mv/D/23/xf/s/zQArP8pACIB5AGAAggD2ANQBHgEiAToBKAE2APQAtoB5wB//z7+NP2Y/Fz8sPsg+5j6GPq4+aj4EPjw9uD1sPTg8xDz8PHQ8BDwQPDg7zDwUPDw8BDxkPGA8iDzEPNA8/DzIPQw9KD0UPXw9dD1gPcg+GD50Pno+rX/FALQBUAIMApgC0AMwA6QDyAQIBDgD+AP0A9gDwAPwA4wDvAOkA9wD9AO0A1gDXAMwAtwCiAJQAewBUgEvALRAEX/lP4G/vT9FP7U/dD9gP0C/kT/Yv8j//j+If90/z7/xP+4/7b/EwCfAK4BWAKcAgQDGATwBGgFOAWABBAEKAMQAq4Am/+c/nT9EP2A/Oj74PoI+rD5EPlo+ID3wPYw9UD0UPOQ8kDxIPDg74DvAPAg7yDwMPAw8ADxAPLg8tDywPLQ81D0IPUw9aD2EPew99D4sPp4+lD7MP3bACAFiAYwCoAL4AywDWAQoBJgEYAR4BBAESARABDwD3APcA8wD8AQgBDwDgAOEA3gDAAMAAsgCZAHkAUYBCQD/QB7/7D+eP6c/lz++P3Y/UD+vv7t/2sAMACJ//v/vv8jACUAbv8jAGUAGAGEAdgBnAKoAtQDQASABUgFIASgA7AC6gE0ACb/dP74/bz8+PvQ+4j6QPkY+fj40PdA9/D1IPVA9KDy8PHw8ODv4O5A76DvAO8g74Dv4O+g8FDxMPIA86DygPOw9AD1oPXA9SD3YPdQ+Fj5uPqo+xz9NACgBKAHsAigC0ANwA6AEMARQBOgESARYBHgEUARkA+AD7APYBDwD2AQsA9gDnAN8AyQDYAL0AmgB8gFiAQgAroALP+g/qD9WP1Q/WD9NP0k/Vj+Hv91/7D/o/+v/13/t/+e/woAEQBOAEYB6gEcApwCYAOQA3gEMAVYBQgFQARMA9QCogEYAGf/qv5o/bj8qPsY+zj6qPi4+Cj4sPcg9mD1cPRA8/DxQPEw8ODvIO8A76DvQO8A78DvMPCQ8fDxUPIg8zD0kPQg9eD1cPbg9hD3sPjo+Zj6MPs4/aABrANoBTAIAAuwDNAOQBGgEoASIBGAEsARQBGgEOAPgBDwDpAPwA8ADxAOgA2wDQANwAvwChAKeAeABcgDMAJwAKr+Lv6c/WD8tPzw/CT9gP0K/hf/QQC8/xQA1P9DANr/1/9pAO//FwC1AAQBDAKMAsAChAMABIAE+ATIBCgEpAP4AiAC2gBi/0T+VP0Y/DD7aPrA+dD4ePjw94D3kPaA9VD0oPMw8sDwEPCg7yDv4O4A7wDvAO8A7wDwAPFg8QDy8PIQ9FD0kPRQ9UD2YPbA9gD46Piw+bj6hP2x//QBxAOIBnAJMAsADUAQYBIAEyATABOAEkARYBGAEeAQoBAgD0AQwA/QDsAOEA7QDeAMMAygC4AJCAcIBfwDUAJHABT/bP5I/fj8pPzY/AD97Pxo/kv/if9E/8L+m/+l/97/zf89ABQAKQDYAGgBKAJAArACYAOIBGAEOARABDgEvAPAAvgBVgHf/47+zP38/HD7sPoY+gj6sPiA+OD38PYA9qD00PPg8tDxsPCw8LDwAPAA8GDw4PDA8HDxMPLw8lDzoPOw9PD0wPXQ9SD3kPcA+Lj4KPoo+zT8Ov6GAMACqATABiAJ0AqwDPAOYBKgEiATgBIgEkASwBCAEYAR4BDgD0AQQBCQD4AOIA7gDdAMcAygCxAKAAjwBXgEbAOgAQIARf9Y/qT9LP1E/Rj9gP08/gD/pf8f/zH/Sf9F/63/tf/5/y8AdwCyAEQBpgHcAQgCyAIsA1QDiANwA2gD0AIwAoIBUAAVAAL+AP0A/AD7yPnI+fj4cPgY+KD2QPYg9RD0wPLw8QDxkPBA8IDvoO9A78DvIPCA8LDwkPFw8tDyoPMg9PD0MPVA9jD3EPio+FD5wPos/Gj9uv4YAVwDEAUwB7AIsArgDEAP4BGAE+AT4BKAEkAR4BEAEkARQBHgEAAQABDwDuAOIA7gDKAM4AvgCoAJmAZ4BWgDFAJ+AGoAGv8o/oz9IP1I/QD9QP2I/aD+vv62/gr/Wv5+/uz+l/8UAGYAKACuAFABrgEkAjACkAK0AkQDmANUA8ACUAKqASQBTQAF/2b+1Pyw+/D6SPqQ+Qj52Pjg96D3kPaw9XD0QPOA8rDxAPFA8EDw4O/g7wDwsPDw8EDxcPGA8nDzgPOQ9MD0APZg9mD3wPcI+Sj6+Po8/LT9mv/eADQDSAUwB0AJYAqgDBAPYBGgEsATwBOgEsARgBFAEYARYBBgEEAQgA/wDoAO4A1wDAAMgAtwCuAIcAfYBOQDBAISAUcAi//c/WD9iP3M/Lz8SPwI/Zj9Uv70/Xb+KP5I/YL+pv6R//D+Nv94AGIAXgHXAL4BPAIYAswCJAOsAgAClAHQAUABEQCt//7+1P3A/Bz8yPug+tj5mPnw+ND3gPbw9YD10PPQ8gDygPHw8HDwcPDQ8DDwgPCg8FDxsPEA8iDzYPNQ9MD0UPVg9iD3EPig+BD66Pos/IT9Tv8oAcQCoASoBmAIAAowDLAOABGAEkATIBTgE+ASABLgEYARIBFgEaAR4BDQD0AOIA7ADbAMYAxwC9AJ4AfIBgAFMAN+AWsA+P98/17+xP2k/SD92PxQ/Xj+LP5u/jT+wv6y/sz9XP7A/j3/w/95ABYBEAEmAf4BvAK8AqgCtALkAjgCiAGEAQ4BOQAr/5z+7P2c/Hj7CPuY+rj52PhA+HD3UPaw9eD00POw8rDxUPGw8HDwcPBw8JDwsPAQ8cDxIPLQ8pDzMPQQ9WD1cPZA99D3qPhA+XD6oPuQ/BT+EQCMAYgDcAVABwAJkAqwDGAOYBBAEaASABSgEyATABPgEWARABKgEUASgBGwD1APQA5ADrANsAzAC+AJIAigBhgF+AKcAdMAr/8O/x7+QP0g/XD8mPzQ+6z81Pw4/Tz9QP3o/DT8wPuM/ND9CP4F/4r/igCZAMMAaAFsAdABmAHUAcQBjABcAM7/F//c/vD9ZP0A/aD7QPuQ+uj5+PjA9yD38PXA9BD0MPPA8uDxEPHw8KDwIPAg8FDwMPCQ8KDwMPEg8vDysPOA9DD1MPaQ9oD3cPiQ+bD5uPqs/KD9kf9kARwDOAXYBgAI8AoADPAM0A4AEKASoBKAE+ASoBKAEqARgBKgEsARIBFAEcAPwA9wDgAOoA0wDDALwAnYB3gFMAQkAywC8QDq/yj/Yv6A/eD8iPys/Nj8+Pyk/az93Py4/BT8FPw4/Nj86P3K/iv/s/+u/8X/9f8gAKYAvgCvAF4AHwA4/6b+kv4Q/gT+oP28/GT80Pu4+vj5aPnw9wD3IPZw9dD0EPSQ87DyIPKQ8QDx4PAA8aDw0PAg8fDwwPFA8hDzoPMg9BD1QPUw9uD2YPd4+Aj5qPpQ/Oj9af8QAfQCuAToBSAIQAqgC0ANYA5gECARgBEAEwATgBOgE+ASgBPAEgATYBIAEuAQwA/QDxAPMA6wDXAMAAswCVgHkAbYBNgD3AKKAdwAN/96/gj+SP1U/ej8bP1U/Yz89Pxs/Kj7oPuI+/D7SPyw/Gj9rP38/fD9fP4I/6L+pv7o/mj+TP4C/tj93P08/UD96Pxg/Pj7QPuY+qj56Piw9xD3MPaw9QD1gPSw8yDzsPKw8ZDxIPGg8ODw0PAQ8ZDxYPEw8tDyIPNA9ND0wPUw9mD2YPeI+HD5ePvs/IL+Yv/eAIACyANYBkAHoAmQCwAMsA1AD9APQBHgEcASYBOAE2ATIBNgEgASwBFgEcAQYBBAEEAPcA4gDRAMYAuACYAImAfwBfAEsANIA/gBDgFtAL//Kv/g/nr+Wv7s/Wz9VP3Y/Mj8WPxA/DT8CPyI/OT8VP3o/Qb+HP78/cD9uP1g/XT9oP04/Uz9UP0M/dT8cPzw+5j7yPpg+vj5ePnA+MD3APdg9sD1UPUQ9cD0QPSQ80DzEPNQ8hDzQPNg89DzsPNw9ND08PTg9XD24PZg90j4kPmI+nD7AP2I/fD+ef/cAEwDAAQQBuAH4AgQCjALIAxADTAOcA8AEGAQwBDAEGAR4BCAEKAQABDwD5APQA8AD7AN4AwADMAKMAowCYAI0AdoBqgFSARcA6wC5AGAASIBiQDo/3L/pv5m/gD+tP1U/Vz9jP0U/fT8+Pzg/Nj8JP10/cj9Cv70/bz9mP1E/TT9SP0Y/QT9LP2k/Bz8mPuQ+0j7kPpQ+oD5SPlY+ND3UPdw9hD2sPWA9RD14PRQ9CD0QPPg8pDzwPMg9ND0MPVQ9VD1oPVw9vD2gPfQ9/D4UPoQ+yD8jP3w/ZD/CQBUAdgC1APABSAGQAcgCHAJQAoQC4AMcA3gDVAOoA7ADtAOgA6QDoAOMA4gDtANsA1ADcAMUAxQC0ALQAqACYAIoAfQBigGGAVQBJgDRANgAooBJAF/AAgAiP8b/6j+FP7Q/YD9QP3Q/KD8zPz0/Cz8jPyo/GD8XPx4/KT8fPzo+wD86PvQ+9D7JPxI/Mj7UPvI+lj6IPrA+Zj5iPnw+JD4KPiQ94D3sPeA9/D2kPZQ9vD1MPVQ9fD18PUg9hD2gPYw92D2YPYw9+D34PdI+HD5wPqA+9D7hPy8/cD+a/8AAdIB+gH4AjAEMAVYBvAGyAcACWAJIAogC0ALoAsADPALYAxgDKAMgAxgDJALUAtwCwALAAsgCgAKMAlQCLgHEAdYBjgF4ASwBIgEyAN4A1QD0ALaAVoBdAF5AOH/Nf9K/4D/mP7I/gz/gP74/SD+hP48/rD9gP30/dD9UP0w/fz9FP7Q/ej94P3A/VT9KP18/Az8kPtA+5j7yPq4+gj7mPow+hj5uPiQ+GD4IPgo+CD4aPig9wD4wPdQ90D3UPfg90D4APgA+FD4UPgY+Rj60Pr4+0T84Pws/bj9QP7G/sD/lwB/AIoBRALgAkAEoASABRAGUAaIBnAGyAZIB6gH4AeYB1AIAAmgCMAI0AjQCFAIoAc4B5AHWAeYBlgGkAbYBngGAAbIBUAF8ATsA8ADEATEAzwDmAKAAhACtgEcAZoBQAGEALn/+P8KAFv/wP+q/5v/4v6C/p7+PP4k/Yz8gP1I/sj9GP0o/YT8JPx4/Gz8VPy4+gD7YPso++D5CPv4+zD7iPiw99j5SPv4+oj58PkA+rj4EPco+Zj6QPto+qj5aPsY+mD4aPgA+ij6qPmI+y7+h//Y/XD8zPyc/Vb+kv78/sL/NQB/ANcA+gGUAhwCsgHIAWQDsATABKAFCAb4BAAEpAN4BPAEeASgBGAFSAboBlAHuAeAB1gGIAUABEgDDAPAA7gFuAZIBtgExANQBNgEMAWoBHgDnALKAbkA1ABIApADZAPaAcAArgAQASgB8wCZAJv/Yv5k/hD/Mv/s/sT+9P7C/iD+0P0q/m7+4P34/Jj8lPxI/Bj8YPzE/LD8KPxg/OT8NP0o/fj8EP28/Hj8DPxQ/LD7uPso+9D6qPsE/Wj+yP2E/bD9hP14++D65Pxk/nz93PxQAGwBGv6w+hz+7AJkARj+0v58AeIA3P2+/pYB4ALMAqAEuASGAZT+dgD0AvQB8P+8AagEAAUwA5ADYAUYBXQDpAL4AUwASACYAUADRAPQA+gF+AVYA74B+AIAA2YBiPy8AboBKAHEAbADgAV4A1gD5AF0ALD+KP7//5b/0f/gAhgF/wDw/IT/cAPSAT7+lv/oAp//KPv4+wUAhAL4/gT97P5kAVwAsP2e/vX//P7A+kD6xP2UAAAAUf+J/2j/uPzA+/L+4v+4/Cj7zPy4/LD7kPt1/+oBYQCw/hX/av90/BD7YP0q/5z9iPxo/+8AjQAz/8UAlgEM//j7gP2jAHYBogC//0gCUgH6AEv/GgBNAAEAev/s/3QBsAHcAkACOAJ+AVgA0/8qAEoBKgERALgAeATwBE4AYP2EATgFugGk/An/wAWABPj9rPxgBPgEAv80/9gAxgHg/wT+uP/TAMj+fAIcA24BZgABADcAiv4s/c4AcgCh/7YByAIZAMD8lAAQBAgC8Pys/gwDKAE8/Jz9JAK9/7D72P4cA1wBrv5K/sz/Ev4hAFgFRAI4+/j5sP36/lT8cPwIAwAFDgAc/jz/8P14/Hz/mQAW/rj70P1WAbABmQDeAXQCx/+o+2j82P/WABIBbAEQAY7+AP22/rABsAKoAjgBDAAQAAUAVAA8AGT/4P5S/9cAJAKsAmwCSALAAV0Axv6s/mL+BP4i/qwArAKEAsoBEAK5AJj9WPyA/W3/8v+KANgC6AJWAY4AGQAw/gD8WPx+/yQB4gEABJAFzAIA/YD7APvs/A8AYAPoBHwCoP8S/7oBXgGC/qT9rP2w/Fb+Nf+IARgFGAT6/wUAhAKTAF7+uPoA+nD7RP36/qwDEAdcA4j+Ov4a/6L/fP3s/bsAZv8c/ID8rgGcA9oA6P3u/hgBTACg/fz9Of9ZAK3/NP3E/RsAFQDM/fz+XAKQAwADEADE/ND5mPrg/cQBPANqAVgA6/9U/t//0AS0AGz9IPyZABQCov9gAWQCuADg+JT8EAUwB2oBbP3c/V//Gv7A/tgBtgD/ALL/tgBcAEADWAQQAgD+2PoY/PD8iAKwB/gHiP9w+37+OAJ7ABr/3AKsA4T+YPp6AJAF6APY/UT+TgE6Adb+jwC4A2gCQP9w/pIA0gHzAPT9dPzw/Dj/rgFoA/ACVwCY/OD9LAFAAuz+HP0x/47/sP7H/8AEgAXw/oD7YP2a/67+8P5BAPT/tPxk/Y4B+AWEAuL/Lv///+//sP28/mT9Gv4q/gYABgGAAogDoQCg/fj88ADoAzkApP30/v0AyPrA+qgCUAoQBoj64PloAngEiP3Q+8n/sAQOAKD68P14BKgC6PrI/HYBaAT4BEAEsAO4/bD50PrW/8z9BP14B9AK9gBw+Wf/0AToApD6iPyABQgCvP7E/pgE/v4g+5L/jAPIB8YBEP36/poByv6E/UT/QAFYBdD/nPyYAIQDWgC8/p8ASPqY/nj/PANQBEj9qPoC/5wBPPyI/lgDBAJwAPr+fP8fAEz+MPvS/rb+gPtkAQgEMAQA/qj8oP1t/2wCmgGEAe4B7P5g+wz8Dv+UASwCjAIIBawD+Psg+Gj9HAKA/1j7kAK4BBUAPP7QBWAFmPwQ+hD+uAMw+hD3FP9oBmgEjgHgA9QD8P5w+pj88P6g/5QAMAMkAXr+Tf9k/0gCPAJaAZT/5Py8/twDaAVGAcH/SAEAAZz8pP1hANwDZAFeAVAB4AEIAdr/pADK/lD92PzYAXgB1P7A/VwAuATEArAA1P1U/Vj+GADk/lD95Pzq/oQDwAQKAWz8EgC4AmEAUPoU/BAECAKw+3D8nAIoBPz+nP+QBXAE8Pto+hkA4f94+Wz8IAbABgAF+gGyAez9OPuI/AT9nP2c/nQCSAEd/3gCIAnQBOj7aP0HADT8IPbo+WQDYAdYAUUAkARQA23/QP3I/vT9oPsM/In//wDbAJYByAagBoQB6PpI+pgBIAIc/FD8JwBwA0ADTAKABKgCGP0e/uX/ZP7I/ID9pAKQAyQByv+cA2gCZPy0/EUAUgEq/mj+BAHWAZ4AoALkA+L++PpQ/nAAcP7Q+zj80gHIA6ACBf+nAA4Bg/+0/aL+SP20/CEA7P8sAPsA0AKcAj8AmP7c/Nj7BPx6/mAGCAaI/uj5nPyYBeACBP2K/qgBZgH4/Nj8tv+8AB7+kAJYAvcApQCeALT+2PmM/NT9+gGIAdQCvALKAdoBIAHs/Qj7CP28AEMACv5iAUgF/APx/4b+QAG/AND9UP3k/Tb+vgHgBhAITv+Y+WL+sARYA6D6kv/MA1wDRPw8/MIBlAOM/mj7zgHEApgAsP1sAcgCEgCw+9T8PAEKAfP/fAJQA0T9IPc8/OAEYAOeAMAA+ANUAZD3+PmM/5r+MPzRALAJOAQA+uT86AN6/6j4aPtIB3gGvPzI+mACsANM/RD8YgAoAVz/8P3lAFQCiABoAUQCIwDe/pz/4Pyo+9r/sAIgBDMALP6hALT+GP6x/yQCEgGO/7j+fQD6/uQAeANoA+//SPr0/Nb+4gBf/wgC0AQ4Bdj+qPqqAFgGkgGA9vj6cAXwBXz9PPywB0AIYP6w+tr/cP5w+nj8MARQBxwBkQBkA3wBgv5i/6T9Av4Y+wT8uQBUAiAFeAQcAuEAoAGfABD6qPns/9r+oPod/wAIoAuUA6D5RPwzADL/KPt4+5b+RAKcA64BJv5+APgFwAWI+8D39PxbAKj9kPuYBTAKdAEw+m7+AgGo/ij8hAMIBsL+oPcU/qAFYgER/3gD1AJ8/cD3mPpYA6QCEP83AJAE8AQ4AdD8lPzQ/mkAvP6k/poBnAJAAZIAMf/w/WD9wgHAAvQCrgB8/xAB0PvY+2wCMAcQBOz8QPuU/Kz9nf8oA9AGkAJvAGIAOf8I+YD6eAJABHUAgP74ASQCL/9k/dr/IAQa/4L+JwCO/ub+RP4tAK8AGANYAmkAQP0v//AEdgF4/Cj5MP2X/w7/+AQABvwDmPvg+7H/uQC4+sj7IARQA00AjP7gAgQCYv8Q+XD59P5+AcwC+AOgAywCBQAb/3r+eP2Y+tD3YPt8ApgFCAcYB7AH2Ab4/DDzEPi0/TD9oPvq/mAIGAfYA2gFQAviAZDxoPDg+bQBwP7VAJAJ4AoYBG7+EgEfABj5qPnM/Zf/av6UAUgGeAXQAYMA2AJUAsj82Prw+4D9xAA8AtAEWATwA0QBCv4A+3z8b/8v/1wA9AE4Bf8ARf+U/Uz+mACV/84AjgAM/tD7NAAYA+gE2ALC/gz8UPpE/8cArAC7/xcAwf9QBIAFoQDQ+9j6KP/j/8j78PtABQAGcALa/r8APAFw+iD6wP0kA7QC1gB8AZoBlgEy/tz+u/+E/Tj9fv/SAbQBkgFU/if/uAI2ASgCbP9l/0T9KPkw/dwDyAXpACD+LAF0A8YAyPxC//gB/ACk/dD9fgFzAI4AdQCPAOz92gFIBlT/yPkQ+iAGEAZI+Zj4oAKABLT8BP3IBmAJnPyA9zwCGAXQ+1D3HP5wBJT9zP1ABoAIRAEg+tD+cAEY/ND37v8QBQQCTP2p/7gFQAPvAO3/8/9A/aj5KPzN/9AClAIcAhABsgHaAO7+sQCj/4T/5PzA+kz9lAI4BS4B3P3M/zgE7AGs/FT8zgC0Ajj9yPqGAOgG0gD4+yoB7AOk/2j5oPtABPQDcPuH/ygGCARs/mD7Xf+m/gT9RP2gAZwCQAP4A9H/3Pw0/44Buv/Q//D/oQCw/cD8ZAL4BZkAOgCQBUAD+PoQ9kD7eAGsAnwBxwBzAPgEEAWGAOj6sPyfANj7APpk/PAESAewAkIAV/+Q+vj7EAQkA4z9DP9qAAD+aPvg+1kAJANoBvgE1AKk/Kj6bv83/3D6YPpYBYAGfAO4AhwCEP3Q+m7+MP5q/pwC2AWsAnz8+PrkAtACAPoo+0AE9ANM/ToBiAUIBDj8kPpg/JEAzgHY/p4BGAQ0A8z9dP1+AKgCv/9Y+TT9OATIBWMAPf9cArMAEP0TAEwBAv5N/+P/XAO2AXgC2ATIACD6wPgU/mgCSASLAAADtAKyAO3/BgEM/6j9Nv4w+nj9gQCcAowBwAUABqgC1P0w+sj7gPoI+QD8kAdQBiAEEASABYT9kPQ4+sn/OAHQ/PT+sAbgB7D8LP4wBZADyPlI+ZD+UAJA/OD8QAZQBZABiQBABZD9sPUg+eAE7gFQ+oD92AcQCxABLv9d/+D8kPaA+RX/OgFOAeAEmAdYBBMAGABs/DD66PtQ/aD8QP7oBfAJ2AR8/TT8qv80/IT+EgFEAyT+7P4IAdgCsAEwAB4Blv7Q/Hj90QD9/8QASAPkA1QDeP6s/Rr+wv4o/Xj8mv5AAjAFHAGyALgCqAKI+1j6IQCoBNb+mPk0/UAEuASM/bX/jAOABVv/0PyY/GD6IPsT/6wCyAJcA7AEMAc8/2D5GPrg/U3/Yv+sAcgCfAFbAM4AJgAc/bD9bgHQAb7+5PxR/+wCdAMK/zgAlAMwAvP/uPzg+uD7iv6CAWgE8AR8A/oBnwCE/Yj5KPu2AOQB0v7uAQAEdALn/1cAWASYAfD5IPdeAOgBXP/0AjAHMAauAPz80P3e/qj60PuQ/zIB1gHoApgCoAKcA2QDef8A+yT8dP9H/wj62PoAA0AI4AgoBOMA0Pyo+yD6YPr0/LL/eASABMAEYwDuAfgEWARQ+7D0kPZq/ggCBQD6ASAGMAj+AXz9+P16/nD6yPkw/SUA7APQBJgEHAOnAID8OPpQ+Qj+ov/G/8AASAXACFgEWP1w/eD9sPt4+LD7iAGYA7sALAIwCEgH1AIo/HD54Pho+Zj6r/9ABkgHCAZwA0IBPwBs/lj5YPhw+7D+MgHcA8AHMAgUA4T82Plm/nYBUP0E/ZIAGAPwATj/3ANgCEoBIPaQ92oAKAQCAX0ACAU0A+D7GPrx/1ADgABM/uoAUgDO/iD9kgAYA3gDvf9P/3T9EPpA+5QBOAaQA/D9bP2UAQgDVwBQ/Oj5wPtiAeAEEATtADn/cAKu/nD62Pqb/zACHAIe/6P/gALSAOD/rP28/l8A1AFJ/w0AqgAk/ej7a//4BFQDzv6s/GAC6AGA/bz8/gB0ApAASP47//cA+P59/+wD+AJYALT+OP4Q/AT9YQDwBIgDFP/Q/aoBOADo/Lj99ALoA17+4PuL/0gCfAKkA5wCNP4U/ED7ygHQBDX/JPx+AcADJADw/wD/fv8M/93/KATwAxj+2Pgy/v0Amf/vAIgERAPu/i//IALPAPj62PuQAGYBJf90/kABOANGAYUAjAA9AC7/WgDu/lz8aPss/hgAXgF8A6AGcAjwAKD5EPrQ+2j6gPuiAGAJYAkUAVT83f88Arj+FPzg/Lz92f+c/zX/SAOAB5ACJP5Y/fT+UP6Q+Bj7YAWIBpr/PP0EA7gEZf9w/H7/LgEk/SD7rP5LAOr+UALACKAHVgD4+wj7gPxY+07+qAOoBlwC6/88Afr+lP3DAOADef9o+iD7lgEgAzEAcACkA5QDwP1g/Gz/KAJg/lD7xP7YBDAEHP34+4wCEAT8/ID6uQAwBCz9CPvuAVgGqwB4+4wDTAO4+aD2ewAoB5MA1P3YAqAHLgCw+/z+wgCI+/D3HgDYBWAFOAC4AeQDIP+s/Hz9Zv7Q/Hz9DwCIAvQC8v90AiAERP9i/t//KAD8/MD5+PlYAtwD0AOwAqwDlAMs/YD7xP2I/qD91P10AogGgAI6AfEA3v+k/hT8Gf/g/Xz94gHQBIgDIf/9ACgFZAK4+pD6IP3M/bT+TgDgBeAHiANZ/2T9JP24+xD7MwD4BNgDHgA0/J7+5ANkAMD9GP3D/5gEqAE3/zD+Yv5S/9z9mPxIAEwCIARSAVz9yv6O/xAB7QAn/6EAGgHg/bT9gP82AaQCtv6c/Xj+sv54A2wDuQBc/Sz+DAON/4z8nP48AkgBuv4eALgEfAHY+rj7YAEMA8D8iv5wBbAFSPtI+SoBoATY/sD8SALIBAD9EPeN/8gGlALw/fwBAAPg+0j5DgCwBPoB+PuK/vQDqgCQ/VD/0AKrADD+Ef8oAkgCrv/AAH3/IP0g+tj9GAQgBjADyP68/n7+6P3Q/TgBfALIACz//P4uAWgCyP1M/Y4B8AQ4AQj8YPul/8UAPP4IAKADKAQH/4L/JAJ3AMz90Pte/ur+9v68A6AHQAT4/jT9pv6M/CD6oPygAYAFKATYAuABYv6o/cD+GP7M/AD+wADAAtEAUQAIBEgFGP8Y+pj75P+j/wL+RQBgAkACWAFEA4QD5P5Y+/z8Af+u/rT8SgCABRAF8QAo/+j/qv70/Qj+T/+e/ykAkAEoBHYBfv7Q/dL+8Pxu/qQDgAWcAxEAO/8i/6D9fP09/+j+UP1m/iQBSAVYBUwDiAFC/ij89PwS/nT8EP4wAtQBFAGmAZQC0AOSAfr+Bv7A+4D5yPuJ/5QDMAWABZAEJgAe/pj9oP3M/JT8dv+QAugBOAKEA6QDlAG8/Uz8HPwa/uIAWAJgAacA1AEgBGgBoP2M/ej9MPwI+5D/EAT4BHADZAM8A5b/8Pqw+Yz8qP7m/u8A3AI8A1gCuAIMAqAAhP04+zD6aPtG/7wCaANIBFgEVAJi/7T9eP3k/MD7sPyo/rEAgAM4BrAGugGE/KT82P3I+yD7XP4UA8QDQALAAhgDvP8o/Yz9Cv4k/cj7CwBwBBgFxAEUAD3/Mv4K/p7+kACm/rz+wQCgAoABrv7F/+ACcANH//D7fP32/8j+fP2AANAEcAbEAbX/0/9I/jT8APsl/7wCqAK8Ad0AHgHX/9j9Cf8AARQC5wBg/nj+NgHfAF8A3v5q/4oAdP5f/wQCxAMVAGD9vP4yATL/iP0V/1IBrAJ0Ae3/Tv8e/sL+SABqALD/VQDNAMr/ZP/w/6wB+P70/cv/aACG/0YBKAIaAJD9oPy+/+IBvwAYAI8AvP6M/tQBHALeARMALP1g/Lj93/9EAngDUAKwAi//vPzM/KwAcAJt/0z9O/+MA/wA1ADWAegBWv4o+4D8Iv/wATMA5wBIA1gErgCY/cT9GP5O/sb+CAHKAWoBmP+LANf/2/8CASIBGADY/ND80gBYAlMAKwBkAvoBsv8M/7AAnv9w/dz8VP6n/8oA1AKMA/QBJv/E/0oAqP34/Gz9iwAgAngBJwDP//T/jf/U/27+6P5WAfwB0P+c/VL+aP7z/3IAEAL/AFIAMgFUAV7+JPwg/ocADgE7ADgCyAScAcD8GP3w/00ATf82AKwBgAGf/x3/CgFMAh8AVP5y/qEAdAA0AKYAaQDJ/yH/RABkAlACnf/0/Sb+nP1W/hgBIASsA1IA6v4HACkAfP2o/Zn/4gDb/9EASAMYAyIA0P1n/63/TP4Q/jX/yQAKAcYBhAJ8Ab//MP7c/TL+BACIAYYBDQAr/2EA2f9s/kT+OgHkAvgBwf/s/RD+NP/TAMYAJgHZADT/Rv5q/pMA6gGbAOT+7v9eAcz/jv5n/8sARgCY/nT+AQA3AF7/9/91AB4AEgDjALwBkAEXABL/9v5U/g7+DP4y/4YA4AGIAnQCAAJhAHz+ev5w/tT9xP0L/9wA6AH2AUwBmAE0AZv/If92/jb+aP5W/w4B2AD4AEQBTgEOAbn/bf9T/4f/rP8QAd8ASv+m/hb/NgCSAPAAhAFMAv8AzP+0/6X/lP6E/rr+2P53/w4B/AHaAWQBfgAsAA7/VP4M/vT+YP68/qoAwAHqAfAArQBu/67+nP06/gH/iv9RAJsAWAAKANwASQA0/0b+E/+6/4H/jv8iAMYA5v9C//7+Rv8lAM0ACAHaANr/hv4y/nj+B/89AAIB7AGuAZUA8/+2/xP/7P0o/gT/EgB0AO4AkgGYAbL/Tf8sAB8Aw/8U//7+1/9fAGQAXQAeADQAcQBIAEv/jv9CAbcAawCCAI8A4//Q/eT96ADQAqkAEwA4ARABLP9o/Zn/IAJcAgoBhgCMADL/zP2W/iYBDAI6AQ0AFgDxAG4A4P9I/wH/Jv4i/hL/yQDaAdYB7wB1ADsAnP9o/6b+dv4A//T/ZQCLANEAPAH0ALf/rf+c/zz/bP5E/i7/fv8eANoAWAEMASAAJ//O/oz+Fv6W/hr/4f/PACgBNAE4AJf/E/+A/oL+7v4H/8n/NwAMAcwBGgFSAOb/RP96/k7+Wv9IAAgBIgHcAEwAMgAtAHcAHwB3/1z/Rf+V/6YAWgGSAfoA8QACAQIATP5K/nb+fv9LAL0AZAJQArQB1wAtAIz/kP0I/Yj+yQBgAtQCWAJwAqoBVwBw/3j+JP+A/+H/1ABeAQQCuALIAkQCAAA//8f/mP84/8r/6gGcAiYBWgBWAcgAQf8U/2gA9QDh//j/8QDxADAAKgDxAJkAE//6/kgAjABl/wP/fP9Y/57+xP5K/7r+MP4o/jz/FP/w/Uj9rP2A/bj8yPxU/eD9aP3Q/ND88Pzw/LD8JP1k/eT8XPzw+zz8TPwA/ez96P5G/x3/EP/4/sr+ev5K/pr+YP8hABgBxAFcArwCnAI0AlQBPAG8ARQCaALMAowDEAT8A7QDuAOEA1QDtAM4BEgEWATYBDAFgAUQBbAFwAVABVgFuAXQBcAFoAXQBUAGqAXABeAFEAYABmgFAAWABLgDEAPwApACRAKEAkwCFAKhAAT/yP3Y/PD7kPsk/ID8PPxo+8D6YPnQ98D24PWw9VD1EPWQ9eD1gPXQ9ED0APRQ8+DyMPPg85D08PRg9eD1MPZA9yj4kPj4+Cj5mPkw+sj6GP3I/kAACAG6AK4BpgFgAbgCKARgBTAHEAkQCmAKEAoQCpAJ0AhwCMAI0AnACnAMcA1ADUAM0AowCmAJwAjgCEAJgAlgCUAJcAkgCXAIIAjQB3gH4AYQBgAG4AVgBVAFmAXABXAFSAUQBYAETAMUAoYB7ABiAMj/mP+y/+z+Rv6Q/Rz8cPro+Bj4YPfw9RD1MPTw8wDzMPIQ8oDxIPEA8SDxgPGA8fDxAPNg84DzIPRg9ZD1gPbQ99D4uPmI+Yj6MPt4+yD8Rv4MATgC+AIQBcgFUAagBZgEKASEA5wDiAVoB6AJMAogCrAJEAcgBYADbAKUAaQC0AN4BCAF2AQwBLwCOAFeAAcA6f9RAEAB0AFoAoQCSAMQBEAE8AQABfgESAWwBYgG+AZQBxAIkAigCJAIoAiACGAIQAioB+gGQAYABdgEOASAA3ADhAKkAW0A6v78/Yj82Pvg+gj6sPhA92D2kPVw9JDzMPNg8hDx0PCg8DDwQPAw8GDwcPDA8BDxoPGA8tDykPOQ9ND0UPbA96D4mPmA+nj7WPuY+6z9Gf9SAOoBcAQABwgHqAZABmAF+AToBFgGIAjwCLAJIAvwCsAJuAe4BlgG6ATwBKgFIAbIBmgHgAcYB0AFjAM8A2gCMAK0ArADUARIBLgEEAVYBTAF+AQgBagEAAXQBTAHkAdwCLAIQAgwCGgHEAfwBvAGwAbYB1AIkAggCKgHqAaQBDQDxgGUAcgBmAH4AeQBxgAa/uj7IPpQ+PD2YPaw9hD2MPXw88DyYPFg8GDvQO+g7sDugO/g74DwIPDA7+Dv4O/w8HDywPOQ9eD2IPgA+Bj4MPkQ+kj7uP04ACADkARYBqAHeAaABEgEyASgBhAJcApQDOAM4AuQCxAKsAhgB/gG+AcACEgHQAjIB+AGuAVkA4QCoABXAFQBUAI4AzgDTAOcAmQBYwBEAFkAigEUAkADoAToBCAGIAdgB1gHaAZABjAG6AXYBuAHAAnwCRAKgAqAClAJcAgwB0AGIAXMA7wDgAR4BKAEAATYAioAjP2o+2D58Pfw9oD2oPXA9LDzoPKg8TDwAO8A7mDsgOxA7eDtwO4g7yDvwO/g7uDuMPAA8YDxsPOQ9WD2MPcA+Aj6wPrI+w7+PgHcA1AFmAXQBXgEiAKwA1gFMAcgCbALsAyADGALwAjYBqAEmAOQBAgGSAeYB2AIoAiQBdgCoABp/wP/5P7hAHQCWAMgBNQD8ANUAh4BJgFYATwCPAOYBBAGwAaYBwAJUAnACKAIYAgwCLAHEAggCVAKEAsgC0ALYArwCCAIUAdIBvgEMARQBAgEnANoA3QCtgBo/gD82PnA92D2sPXQ9PDzwPLA8dDwYO/g7eDswOsA60DrIOxg7SDuAO/g78DvwO6g7iDvEPCA8bDzsPa4+ED5SPpQ/YD8pPw3AOgBWAV4BjgGkAc4BtAGqAcgCQAKQApgC4AMEAwgCvAJIAngBlAGYAaoBuAGqAbIBnAFkAMWAb0AJgD5AIoAwAD5AG4AAAESAYgBngFsAhgCeALsAvACGASABJgFmAZQB7AIAAqgCrAL8AqgCvAJQAmwCdAJoApwC9ALgAvACjAJAAiIBgAG0ATsA1wDxALIAYYAMf/c/JD6mPig9sD1IPVw8wDzwPEg8ADuYOxg66DqAOoA66DsYO0g7uDvIPBg70DuYO3A74DvcPDg8+D2kPoI+xT+vP3s/Uj9kP7yAVgEUAUQB0AKkAlwChAKwAowCvAJcApwC5AKMAoQCyALcAoQCZAIcAhQB8gFYAUABHQC4AEIAoQCAANsAmgCUAF0/0j+MP6u/jMA1AGEA7gEcARIBJwDaAOUA4AEsAVAB5AIkAoADKAMoAwADFAKYAlQCYAJoAqAC9ALYAuQCoAJkAh4B3AGWAVABDwDEALGAMr/Iv6A/ID6gPiw9lD1IPQw8/DxYPDA7sDsoOtg6oDpwOnA6gDs4O3A7hDwYO9A7oDsgOwA7UDt4PDg9Bj5qPoQ+wT92PyY/Jj9Wv68APAC6AWQCCALsArACrAKoAnACBAJoAlQCuAKEAvAC9AKIApwCdgHqAYoBZAEIAQsA2wCWAJkAsoBmAHiAVYB4v+i/vT9UP34/bb/ogEMA4wDOASgBFAEwAMIBKgEGAVwBlAIkArAC3AMAA2QDJALkApwCsAK8ApwC6ALoAtwC5AKoAlwCDgHEAYoBbwDwAJkAfr/gP4I/Sj7qPkQ+CD2APUQ8wDysPBg70DtoOvg6eDogOig6eDqQO1A7oDwgPCg7iDuAOzA7KDtoO/g8zD5WPtM/W7+Pv4A/pb+Av/2ALACkAXwCHALAA2gDbANAAywCsAJwAnACuAKUAzADLALUAvgCtAJEAiwBngFkARMA/gCEAPEAkwCrgHOAUQBiQDu/0L/3P4o/lL/eQD6AYgDkARIBWgFSAVYBYAFkAWABqgHsAmgC6AM0A2gDdAMAAyACmAKkApQC9ALgAuwC9AK8AmgCFAH0AWQBGADdAI+Aab/hv7c/GD7CPnA9wD2wPTw8vDxwPCA7mDtYOwA6+DpYOiA6eDoQOqg66DtwPAQ8IDw4O8g7wDuwO7w8GD0QPgk/OD+lf+GAF8A5ABGATQC1AMwBhAJgAvgDQAPYA5ADcAL0ArwCXAKYAvwC0AMAAxQCxAKsAiwB8gFmARoAzACXAKqAXIBWAGvAEIApv+k/z//yP4u/hD+IP46/9wAOALcAwAFmAW4BbgF6AXoBWAGkAeQCYALkAywDTAOUA5ADRAMcAtAC+AKEAtwC8AKoAqACfAIkAdgBugEFAO4AVr/ev64/CD7IPrg+ED3kPUw83DyYPAA76DtgOyg64DqQOnA6eDnoOhg6ADqgOwA7SDwYPAQ8SDvIO+g7uDu8PHQ9Vj6wP3p/9kAwgDKAAkAKAGMAmgEwAbQCZAM8A3gDmANUAxQCiAJ0AggCXAKcAugC2ALgAowCbAHAAZQBOgCNALeAa4BgALaAZYB6QCs/8H/BP/2/tj+uv5C/0n/egDaAZgDqAQwBTgGwAaQBpAGyAYQCFAJ4AngC1ANQA7gDRAOoA3wC8ALIAsQC4ALcAqQCiAK4AjIB4gGeAW0A0ACjAHx/2r+/PxA+/j5UPcg9uD0MPNQ8hDx4O+g7oDtIOzA62DpoOiA50DoIOmg6QDtoO4w8KDxIPLA8QDwYO/A72DyEPVg+Zj9FwAUAjAB5AFUAbgBdAIYBEgH8AiQCzANQA7QDXAMsApACfAIUAiACYAKcAuwCmAJMAhYBpAEaAOUAvwBngF6AVAB3wApAKD/1P4E/0z+9P5t/0L/dv/V/zYAoQDEAXgDKAVYBsgGgAcQCFgHUAgQCVAKgAvAC6AN4A6ADuANEA0QDKALoApgC8AKQApQCZAIAAjYBrAEQATAAoYBEADQ/sT9VPyA+hD5gPdw9XDzQPLg8aDwIO9g7qDtAO1g6yDpYOhg6MDnAOoA7EDu0PCQ8VD0QPNg8rDxcPDA8WDzQPeg+9r+bAFgA1gD0AKOAfIBYANoBMAGoAmwC9AMUA3wDFAM0AmwCDAIgAfAB0AIsAhgCfAHMAfYBYgEAAPcAaoBPgEwAPL/Vf8//0f/nv4J/2//tf/d/8v/sv/z/xcAvwA8AuQD6AWAB4AIAAkACfAI0AigCSAKYAuADNANUA4QD/AO0A3wDAAMYAugCjAKgAkQCRAImAeYBtgFgAQcA+ABJQBc/sD8+Puw+nD5YPjg9jD1EPMw8qDwQO/g7SDtoOzg7GDrgOuA6gDpwOhg6SDsQO5A8bDzQPRg9KDy4PFA8bDxcPQo+KD7Ef9AAUwDkAOMAuwBSAKoAnAEoAbACUALcAyQDPALwApgCCAIiAdIB3gHWAcwCNgHMAcYBmAFdAPgAcgAwQB9AOv/sP9k/7D/5P6+/vr+Y/9U/9b+C/9c/8H/BQBwAdgCCARgBTgGqAdQB9gH0AfwB4AI0AnwCgAM4AxADPAMUAyQC/AKcAqwClAJIAnACDAI2AbQBUAFEAQ4A7YBNgG4/8r+ePwU/LD6APkI+ND2oPXg83Dy8PFw8MDvIO6A7kDtwOxA7EDrwOrg6ADpIOtA7qDw8PMg9TD1gPMA8uDxsPFQ83D2APpg/TgANALQA/gDtAI4AqACrAMABbgHUAqAC/ALgAtQC8AJgAi4B4gHQAfABqAGEAcQB+gFiAVgBDgDmAG/AI8AUgCa/0L/QP+C/mz+5P4S/z4A9v/y/1YAEAEpADIBSAKcAxAFAAbYB/AIgAlACVAJIAlgCSAKUAsQDWANkA2wDQANUAygC1ALcApgCdAIYAigB4AGCAZYBfQDoAKWAagAJv+Q/dj7ePuQ+YD4sPcg9/D1MPTA8qDxUPCA7kDuoO1g7WDsYOwA7MDroOpA6uDrYO3w8EDz8PXw9kD0oPOg8kDzMPSA9+j5gP4CARwDmATQBOgDoAKkAgQDqASIB/AJAAzADAAMQAvgCaAI+Ae4BngGKAaoBvAGCAd4BkgGyAQgA6ABoQCNADoAov/j/7H//v7+/j//dv+H/4//s/+UAH0AgQBaAUgCHANkA6gFKAdACLAIIAlACdAIoAigCfAKAAxgDBANYA2ADOALQAtgC2AKgAlQCIAIiAdgBpAFWAR8AwwCEAHkANf/RP7E/OD7KPro+OD3wPYw9tD0sPNQ8xDyEPEA8GDvoO6g7UDtoOzg64DrAOsA7CDt4O/g8yD2UPcg9uD1oPPw88DzkPaY+VD8qv9cAmgFuAToBLADEAOkAnQCUAXgByAK8ArwCpALIArgCJgHUAcQBggF+ARgBZgF8ASYBCgELAOaAQIB+wDV/57/Yf+x/27/B/+4/woADgAIAN8AqgGEAXABTALUAvQC7ANQBeAHUAhwCfAJkAoACsAI0AnwCfAKkAuwDJANMA0QDBAL4ArgCFAIQAdQB1gGaAUABVAEJANaAYEAp/+g/oz9oPzI+/D6iPng+BD44Pag9eD0MPQg81DyoPEA8cDvwO5A7uDtgO1g7cDsoOwg7GDsIO/A8eD04PYQ+ND3EPaA9CD0IPbg9tj53Pz7AEwDgASYBZAETAOeASACcAMwBQgHgAkwC5AK0AkQCWAIaAbwBLgE6AS4BKAEeAX4BUAEhAPgAsACoAF1AJIA0gApANT/UwDxAFYA4f+LAHIBdAGCAZQCBAP4AtQCdAPwBJgFeAYACIAJ4AkAClAKQArgCZAJMArgCkALIAtgC5AKwAmwCEAIgAfYBlgGeAXYBKAD+AKwAS4B8v8R/9T+Tv60/bz8+Pvg+uj5yPg4+HD3kPaw9RD1gPRw85Dy8PGQ8WDwMPDg78DvgO6g7YDtgO3g7sDxsPUA+YD4yPhw98D1cPRg9ND36PlY/KD+0AIABBgEUAPQAkQCDAGAAtAEcAdQCHAJQAoQCrAIYAcQBwAG8ASoBCgFmAVoBXgFaAXABKgDJAP0AkgCmAHfAMIAGAEMAX4BEAIcAnoBoAEkAowCxALMAqQD5AOQBCAFYAY4B0AIQAhQCcAJYAlACfAJ8AnQCSAKgApQC8AKIApwCbAIeAfYBogGQAaoBbAEmATIA8QCZAHZAKH/rP4m/jj+rP30/GT8wPsI+8D5APl4+KD3QPYw9dD0UPQw8+DyEPLg8bDwIPAA8IDvoO7g7MDtAO9g8lD1GPgA+0D6oPcA9gD1kPVQ9qD4cPzs/ygC+AOwBNgEPAMMAgACYAPwAwAGEAjACZAJ0AgQCGAHwAY4BSAF6ASwBLgEgATYBBgEqAOoArgCbAKqAZQBOgEWAa0ATgDPALwAAgFuATYBjgGiARQCuAL8ApADlANYBJgEaAUIBtAGoAfwB4AIcAhwCHAI0AjwCAAJ4AiQCEAIAAhoB5gGQAbQBWAFAAWoBEAESANkAkwBkQCK/6L/zv6y/mT+Qv7s/az8QPxo+7D6uPnA+Ej4YPfA9gD28PVQ9WD0wPMw83Dy8PGw8HDwgO/A7iDvQPAw8tD00Pew+UD6EPlw9yD1IPXw9YD4ePtw/rwAvAO4BNAEqAPcAngCBAJ4A4gEsAeQCDAJ0AngCIAI2AbgBoAGeAUQBVAEOAWwBJAESAQwBGwD0ALgAtQCPAI4AQ4B+wCZAPUAlgFAAugBOAKgAtwCOAMMA5wDIASoA4AEaAUAB1gH2AdgCMAIUAgQCCAIwAiACHAI0AgACUAJgAgwCIgHeAYABVAEqATkA9QD+AIUAwwC4QAYAI7/JP8A/jT+fP2k/ez8SPzY+/D6SPqw+Yj52PgQ+HD3sPbg9YD1oPRw9GDzgPJQ8gDyoPHg8GDwcPDA8GDyUPWI+Mj62PpI+hj40PXQ9OD1yPmA+3z+NAHMA5AESAR0A5gC9QDFAFACqAToBgAIoAmwCSAI4AYgBmAGuAQwBEgEaARABEgE2AToBLwD+ALgAiQDpAL+ARQCtAFIAW4B1AGIAiQCMAJIAmQCcAKMAigDXAM4A5gDeAQQBUgFkAUoBmgGiAbgBkAHOAfYBrgGIAcoB/AGqAbYBiAGoAW4BHAEuAMcA5wCcAIoAtwBuAFAAVwAd/+g/mL+aP5U/jr+AP6Y/RD9YPxQ/Ij78PoA+kD5+PgQ+PD3IPfg9rD1APWA9AD0cPNw8mDyoPEg8dDwkPFg86D0APcg+bD6GPrQ97D24PVw9aD2sPkU/XwAdAHEAtQChAIiAecAWgEqAQwDaAQAB0AIgAgACJAGmAXYBKgEWAQIBJwDCAT0A5gDjAPoA9ADMAMIA/gCsALsAcIBrgHGAYABrAF0AsQCzAKYAnADlAPUA/ADEAQQBAgEQAQoBXAFSAY4BjAH6AbIBsgGYAYoBpAFqAWYBQAGCAYIBrAF+ARgBMwDXAPgAoQCAAIYAuwA8wAYAPn/Uf+S/gb/dv6s/ir+Fv6k/UT9tPxM/Nj7CPtI+pj5uPiI+OD3oPew9hD24PVw9bD0cPSQ8xDzcPEg8TDygPPg9XD34Png+uD5aPjg90D3wPYw+HD66P0mAbQC0AM0AwACzgD5AJ4B5AIgBBAGMAeQB/AHaAcoB/AFIAXQBFgEgAR4BKAEOASAA9gCNAMcAwADBAPoAkgC3AGyAXgByAGiASgCgAKoAsAClALsAowCvAIgA1gDvAMQBGAEGAU4BVAFeAWABZgFcAWgBZAFcAVQBVAFcAUABQAFwASQBMQDMAOEAiQCnAFCASAB1AA9AHT/H//Y/qT+Rv44/lD+Cv7M/bz9lP0E/Vz8MPwk/KD7KPvA+oD6EPpw+dD4QPiA9wD3IPfg9qD24PVw9fD04PPQ88DzAPWg9TD3aPio+cj5GPrQ+Xj50Pjo+HD6ZPx0/nIA2ALMAngCNALgAWgCVAKYA6AEoAVYBjgH+AeYB8AG2AWQBbAEOAQYBMAE8ARwBKgEAAXQBFgE3AOoA/wCaAIMAmgChAKMAtQCTANwA5wDrAOwA5ADHAMgA2QDxAMoBGAEyATQBOgE0AT4BPgE8ATIBMAEgARgBIgEwATwBPAEyAR4BPgDMAN8AsgBFgF8AAgAuP93/27/If/+/nD+9P1w/fj8gPwM/Kj7YPvQ+qj6IPrQ+WD5+PiY+FD4wPdg9+D2gPaQ9sD2MPeA9+D3kPdg9wD34PaA98D3OPnI+QD6iPrg+sj64Prw+rD7TPwk/SL+XP8oAAwA3P+r/4X/gP8IAEABEALcAjADjANoA1QDUANgA4gDiAMABKAEOAWgBcAFCAbIBbgFqAWwBQAGKAZIBkgGIAYQBugFwAWgBUAFEAXIBFAECATcA7gDuAOEA2wDKAPIAkwC1gF2AQwBywDxANsA6gDlAMQAfQA1APz/zv+a/3H/Vv85/yL/Af8W/x//Tv9q/5b/rP+Y/4f/Uf8n/87+fP4s/gD+6P20/aD9OP3Y/Gj8BPyg+1j7CPuw+oD6SPow+jD6OPpQ+nD6cPrQ+rD62Pqg+mj6MPoA+iD6oPpY+zD88Pyw/fj9PP48/l7+hv6q/hX/pv+BAFABEAJ4AuACJANAAzwDTAN8A9QDIASYBBgFiAWgBcAFmAV4BQgF+AQIBWgFkAW4BRAGEAYYBtgFwAWQBWAFMAU4BTAFUAXoBOgEmARwBAgE8AO4A4QDKAPUArACOAI4AhQCCAIIAtIBxAFiAQQBYADe/37/Ef/Y/tD+4P7e/rD+ev4q/oD93PwQ/Mj7QPvI+vj6KPsw+wj74PrI+ij6SPno+JD4UPiQ9zj4uPhI+ED5GPmQ+vD68PpA+wD70Pl4+PD4UPnw+hj8Xv5J/+D+3P74/sT+FP6M/q3/IAEcAhwD6ASIBQgF4AQgBfAFsAW4BjAIgAiQCGAI4AgwCZAIgAjQCPAIwAjQCHAJcAnQCNAIsAiwCDAIoAdYB4AGIAVQBPgD8AJsArIBwQDH//z9+PwY/Pj6APpg+eD4QPig9yD34PbQ9eD0gPRA9AD0EPSA9PD0YPXg9bD2sPeY+FD5KPoY+4j7LPzs/Mz95P6V/68AQgFEAcIA9f+B/wL/pv7O/jz/ev+4/4f/Rf92/oz96PyI/Ez8dPwo/cj9Rv4s/or+uv7y/lH/s/9UANwAEgHeAeACOAM4BIgEkAXQBaAG+AaoBxAI+AcQCPAHEAj4BxAIMAjAB+AHwAdIB5gGAAYQBTgEeAPsApQCwgFWAecAtgBWAM//pv8i/4L+4P2o/cT9sP3s/Tb+WP5a/jz+oP78/uT+Df8u/3L/sv8iAMMANAF6AbAB4gH6AdYBsAGuAaIBtgEMAnQCyAKwAnAC/AGAAfYA2gDZAPcAKAEQAQQB1AC0AGMAEQC8/3D/Tf9n/5D/0P/k/93/2//l/+X/GQAOAE8AKgD4//X/3v/d/6n/nf9m/4f/5v76/uz+ov6G/uD99P2k/Wj9ZP2g/Zz9OP1g/Tj98Pyc/FT8hPyo/LD8FP1I/WD9RP1E/Wz9YP1s/bj9GP44/kL+rP7G/rr+zP7i/h//Iv8W/1r/ff+L/3z/ov/z//X/8f/7/wEA8P/p//T/IQA2AFsAsAC+ALkAnACXAKEAkQCcANQA/gAWAQ4BDgEaARABGAH+APcAvACfANQAwwDOAL4AnwB4ADYAQAApADEA/v/d/7b/hv9y/1r/cP9c/0v/Qv8//yn/K/8k/x3/D/8I/wT/Bf8M/+D+xv6m/qL+kv7a/uj+3P7W/pD+fP5I/gj+Cv4Y/ij+Iv4g/mj+Yv40/jz+SP5k/jL+YP6G/rL+jv7W/uT+O/87/0P/tf9G/27/P/+k/87/0v8UAHAApgB1ALMA4QDhALUAogAEARwBFAEQAZoBugG6AaYB1AEQAvgBGAJgApACgAJkAmwCxAK4AugCQAN4A3QDRAMIAxgDzAKsAvgCWANcA0gDTAMwA/wCoAKMApgCYAJEAlwCgAJEAu4B8AGgAXABAgEEAdYAeQBHABwA/v/X/7L/rP+b/z3/1P6w/pr+Pv4i/k7+TP48/hj+AP7U/Zj9cP1c/Xz9UP1c/VD9YP1Y/VD9cP1E/WT9UP1E/Vj9QP1M/YD9qP3Q/Rz+GP4s/hD+2P3w/R7+dv6c/ur+P/9e/2r/av9s/4D/iv+9/xEAXQCZAJ4AxQDWAAQBJgFEAWwBdAGeAZ4BtAHqARQCTAJoAngCgAKYApACbAJUAkQCIAJAAogCqALIApQCaAIMAr4BigFuAW4BPAE2AQoB0QB/AFcAGwDK/4b/cv9t/yr/Av/e/sL+kP5w/nT+cP5O/hr+6P3A/ZD9lP2k/dj93P3Q/dD9uP2I/VD9cP1g/Zz9wP3k/ST+Hv4W/tT90P2g/bj9Bv40/pD+pv6O/lz+OP5M/nb+jv4A/0v/dv+K/4H/b/92/4n/lf/u/y4AjQDAAMgA0gC7ANMAxQAEATwBWgF6AaIBzAHwAe4BFAIQAvwBBAL+AQQC6AHgAQQCNAI0AjQCSAIkAuYBuAGOAaABagGCAWoBfAFQASwBVgE8AU4B8AD3ALwAlACBAE4AUAAnADUANAAuACIAAgC3/3X/Lv8s/zn/Nf88/0v/K//8/ur+2P7i/ub+6v7e/rz+qv6O/nD+fP6A/r7+1v4B/wL/3v60/m7+iP6e/u7+P/9s/4z/Yf9V/y7/Pv9W/3n/rf/Z/wUAHQAdAC4ANQArAC0APABfAHEAZwBnAHsAjACYALYA7QDyAMIAvQCwALcAzQDpACYBSgFUAUIBQgE0ARgBAgEKARABHAFEAXYBZgFOASgB1QCoAI8AnwC7ALgAzgDDAMUAngCBAFoANAAlABkAJwAhACoAIwATAOX/1v/Z/9n/6f/h/9n/uP+C/3j/f/+l/8L//P8LAAUA2f+t/5n/ff+F/5b/0//t//3//P/W/7T/mP+W/5v/pP+e/7//vv+2/6n/qP+i/5f/mv+a/6z/rf+p/7X/tf+1/8P/4//y//v/6v/l/93/y//r/w0AJAApABgAFwASABIAGwAzADwAPQBGAEgATQAtACwAMABDAEQAYwCBAHMATgA5ADwAQQBPAFMAbgBeADQAJwAtADoANgAyACMAGQDr/9D/wP+1/7z/5P8CABkADAD1/8T/qf9n/2j/cv+B/6X/tP+0/5r/hv96/3X/a/9h/23/aP9u/2z/g/+M/5v/mf+a/4b/e/9y/2b/bP9z/4f/lf+d/6P/lf+e/4H/gv+a/6//xf/b//P/6P/j/97/8/8AAAAABwATAA8AEgAkACwAMAAwAC4APgBFAEsAZwB5AG4AagBwAHgAgQB9AI8ApACkAI8AlgCcAIcAfgCBAJoAlgCWAJsAogCSAHkAZwBsAGsAXQBeAGoAcQB8AIAAdQBkAEwAOgA0ADkAMQAtADAAIQAUABQAEQARAAwA+P/u/+D/1P/P/87/wv/L/8T/yP/O/8T/q/+Y/47/jf+c/5f/mP+d/6D/lP+R/5v/pv+o/63/tv+6/7v/uv/P/9r/3P/c/+v/8P/s//H/+v/+//z////9//3//v/9//z/9f/y//z/CAAIAA8AIAAZABQACQAPABwACQD6//b/+f/3/wEAEAAWAAoA+P/u/+D/1//Q/+L/+f8LAA0AFQAMAAAA7v/n/+7/5v/x////CQAAAPX/7//t/+f/4f/h/+f/5v/f/9v/2//f/+T/6P/u/+7/9P/u/9j/1v/J/7//x//K/9v/1f/Z/+D/4//h/93/3P/d/93/3f/r//P/7v/r/+v/8v/z/+v/+P/6//b/7//m/+z/6v/q//P/7f/s/+b/6f/q/+n/7v/q//D/7f/h/+7/8//3//3/CAAVABQADgALAPz/9v/y/+3/AwAGABMAGwAWAAYA+f/1/+n/5f/a/+//+f8DABgAFgAYAAIA+P/4//T/+/8BAAgAEQAMABYAIQAtACwAKwAwACYAHwAgABsAJAAuADwASABLAEwAUQBQAFkAVwBVAFkAXQBwAGkAawBlAGQAVwBPAEYASQBPAEEASgBHADcALAAeACUAKAAhACEAHwAnAB4AEgAUAAoA+v/y//j/+f/y/+z/5v/k/+L/2f/U/9v/2v/g/+X/5P/i/97/4P/d/+D/8v8BAAsAEgAcACAAHwAYABoAHQAdACUAJgA1AEIAQgBEAD0APAA1ADIAMwArACYAJgAeABcAFAAVAB0AGAASAAMA9//4//f/9f/3//X/9P/v/+f/6P/m/+j/4f/h/+P/4v/h/+L/3P/b/93/4v/v//b/AgACAAIABgAKAA4AEAATABYAFwAZABwAHwAlACAAHwAiABsAHwAdABQAFwAcABcAEwAKAA4AEAAGAAYAAgADAPf/9//0//f/7P/r/+T/6v/o/97/3P/E/8L/tf++/8X/w//P/9r/2v/P/87/zv/L/8r/y//X/9L/0v/P/9v/3f/X/9D/zf/S/9j/2f/Y/93/2f/P/8b/z//Q/9H/0v/a/9z/1P/C/8L/uv+z/7f/wP/K/8//y//S/9b/0P/O/9L/2P/e/+X/7//5/wYAEgAPABQAEQAWABQAHgAmACsANAA7AEIASwBQAE0ATwBWAFgAUABRAFoAYABeAF0AXABeAF4AXQBeAFwAUQBIAD4AOAA2ADQALwAmACMAGAAPAAgA+v/3//f/9v/+/wAA+P/y/+b/2v/e/+L/4v/c/93/4P/X/9P/x/+8/7v/t/+8/8D/xP/I/8L/v/+//8f/yP/E/8P/wf/C/7z/vv/L/9D/1//Y/9j/3P/g/+D/3f/j/9//3P/l/+///f8EAAYABwACAP7//P/+/wIA//8DAAUABgACAAYACAAEAAMABgAKAAkACQAOABkAHQAdACEAKAAtACgAHgAgACAAHwAiAC0AMgAtACwAKQAfABYAFwAeACIAHgAbACYAJwAhABgADQAFAAEAAQAHABMAEwAGAPX/7v/s/+X/4f/s/+z/6v/m/97/3//W/87/yv/O/9P/4P/k/+L/4P/g/+P/4v/o/+v/9P/+/w4AFwAjACAAGAAPAAsACgAJAAwADwAUAB0AJAAiACYAJQAhABsAFgASAB4AHAAcABgAFgAQAAsAFQAYAB4ADwAQAAkACAAJAAIADAARAB4AIQAoADUANgAtACQAGwAhAB0AGAAnADEALgArACgAKQAtAC4AMQAxAC4ALwArACgALAAtADUANQA6ADYALwAjABYAGAARABoAIAAfACIAFQAQAAMAAwD9//P/9P/v//L/8//y//z/+P/v/+b/3//i/+H/2//X/93/1v/K/8f/zP/I/7v/uf+y/7f/tv+2/8T/x//E/7r/uv/D/8L/vP+7/7H/rP+0/77/vP/D/73/qv+n/6T/rP+y/7D/uv++/8H/vf+9/7r/tv+2/7P/uv+9/8f/0P/S/87/zv/V/9r/4f/g/+T/3v/Q/87/1P/k/+z/9v/2//X/6//h/9v/1v/T/9L/3v/n//b//P/4/wIAAQD+//j/8//x////BQAQACIALQAwACUAGAALAA8ADgAUAB8AIwAmACQAKwA1ADcAKQAiABkAFQAiACoANQAzAB4AEQAIAAsACgAJAAYAAAD5/+//7P/j/+r/6f/j/9z/6P/q/93/0f/O/9H/1f/a/+D/7f/k/9P/2v/n//P/8f/w/+//7//c/9b/2f/g/+v///8KABoAHAAiAB4AHAD+/wIA/P8KACQAMgA5ADMAMgAyADIAJgAhACAAEAANABQALwBAAEkAPgAtABYAEQAUAB8ALgAzAC8AKAAjACkAMQA/ACgAJgAqACoANQA8AD0AKAAZABUAJgA1ADcAMwArABcAFgAgACYALgAeAAwAAQD//woAJgAxACMAEAD1/+f/5P/n/wcAGAAIAO//6//l/9X/1P/d/+v/4f/d/+T/7f/l/9r/2f/m/+L/0//d/+//AgAUAB4AIAAgABcAEQAUABUADAAHAAAA7//v//z/DAAfACEAEQAHAPX/6P/l/+j/6/8AAAUAGQAkABoADQAFAAMA///2/+T/5//w//L/7//9/xAAEwAFAPr/8v/h/9L/2P/4/wgADgALABAA/f/k/+L/5v/n/93/z//H/9H/4f/v//j/7v/a/9X/2v/p/wsAHQAKAAIAAQAXACYACgDz/93/xv+9/9r/BgAhABkAAgDs/9H/z//l/xQALwAnAA8ACAADAAQABAARAAwA6f/i/+T/7P/l/+X/8//6//v//f8OABsABADf/8v/0v/g/+b/+f8OABQAGQALAAUAEAD3/+L/6//3/w4AEQAyAFYAWQA1AAkA6f/V/8L/wP/e//D/7v/v//n/CgD9/+v/6v/d/9D/w//I/9v/4v/n/+X/2P/N/8P/wv+9/8X/0f/Q/9j/0P/N/+X/5P/y/wUAEwAIAPP/8//6//L/4v/P/8D/0P/j/xYAQgA8ABsA+//m/83/xf/L/+v/8P/7/xQAGAAMAOb/4//w//n/BwADAPr/5f/P/+T/EwBFAFMAVgA8AAcA5//r/wgANwBFADkAHgAVADEAXQCJAJcAdQBHADkAOgBFADMAMQAmABYABwAdAEYAdgB5AGEAXwAmAPL/9f80AIQApgCmAJcAegBMAB4AIgA5AB0A+v/4/xQAIwAtAEQASwAuAO7/wP/F/+z//P8bAEQATgA/ABIA2/+o/4b/if+t/+z/GwAzACYABwDm/8f/p/+Z/6j/vP/h//P/6f/m/97/2v/S/9T/2f/M/7X/j/9h/2D/nP/s/0QAXgBIAA0A2f/c/wIANwBhAFoAJQDj/8D/8f9QAJUAjwBeACUA7//3/x8ATwBbADwANgBOAHYAkACIAHgAWAAxACcAMQAzAB4AAADz/+r/8P8kAEkAaABPABUA8P/P/9f/CQAnAAoA3//e/xcAPwBDAB4A0v+G/0j/af+q/+X/7v/Y/8f/vv+8/7z/xP+4/73/nf+W/5//uP/x//7/6f+7/4//bP9Z/3n/nf/H/67/qP+s/8b/vP+e/5//rv/G/8P/2f/x/wAA4/+y/7b/wf+n/6n/4f8hAEMARABIAGAAKADt/9L/4/8HADAAVQB9AGsAIwAEAPz/9f/w//P/+v8LABQA+f/u/xcAUgBzAGIARwD5/93/4v8fAGUAdQBNABAA/P8TAC4ANQBIACEA2/+Z/4v/u//5/ywATwBdAEIAAQDZ/wMAPQBCAB8A7f/X/9f/5v9aALsArABHAOv/v/+i/5v/vP8cAC8ADAD7/yQAHwDo/8v/vf+1/4D/hf/B//z/9v/8/w8AAwDN/4z/lv/Z/xIAGwBMAGkALADN/4f/mP/J/+n/BAAVAB4A/f8DADAAYQBVAN7/oP+y//b/PQByAHsAXADr/47/kv/F//H/7//2/+j/9P/+/zIAbgBhAB8A9/8hAGwApwCOAE4A+f+t/53/yf8gAG8AlgCQAFYAGgDd/93/6P/0/wMA6f/1/ykAZgCCADsAtf9r/3b/jf+3/+///v/t/9f/yv8QAFMAQADs/5D/Zf9u/8//SAB8ACwAs/9y/5j/IABhAEYA7f+J/23/rv8YAHQAhAAeAIX/IP8w/37/2f8DAM//bv9M/2n/z/8jAEcAGADZ/+L/AQBWAHgAMgD+//3/BAAiACkAWQBEAPn/wP/a/xgAUwBYAFQAUQAnACgAZADKANQAkgBEAAYABgAbADAAKAAiACUAPgBLAIsAvQDSAJgAOgDz/87/m/+s/ykAjgCzAJIAggBeANn/Wf8t/1//kv+H/5b/vf/w/yoAkgDSAIYA3/8z/wH/I/9f/8v/OgBiAFcALwDz/8n/hv9t/2j/P/8s/1n/lv8dAGQAXgAvANP/jv9u/6z/zf/Y/+r//v8bAA0A9v/I/6D/kv+a/9n/BwAWAB8ANABCAAsA9P8CANv/pv+X/9L/IQBDAFEAZQA3AMb/dP9g/6D/7v8JAEgAZABhAEUAJAAaAPv/1//a/wkANgBDABEA8P/2//f/2P/9/yEAAQCw/63/3f/p/9L/ff+Q/+D/JgBaAF4ARwDT/37/YP9b/53/CQBCADQA1P+W/43/4f9iALEAngAKAEP/L/9f/8H/IgB3ANoAugAGAH//M/9J/4j/wf8eAB0A3P/H/97/JgA4ADAAHQDY/5n/ev+Z/xYAbACJAFAAAQDF/9b/DgArAA4A8f/f//X/agCVAEQA2/+i/7X/DgBZAIAAhQA3ANj/r//Y/1MAgwC/AIwALwDz/wYAfwDVAMAAQADC/5j/5/9BAGgAZwBIAC4A9//w/+f/JAAuAPr/CgA0ABgABAAFAF4AYgAIAI3/nP/y////+P87AHUATwDq/7X/1v/B/5f/af+o/wYA5P/o/zUATwA3AN//yv/i/8P/m/+u/yoAOAAJAAoAKACEAJ0ATAD7/6L/fP/6/14A0QC3AGgACgDI/8v/KABkAGkAHQC+/0j/EP9R/xoA6QAOAYAAFADw/w0ARwCqACIB+wBsABkALABtAEYALgBMAG4AEwDk/xwAeABQAAAA6f8JABAABwA+AGIAbwBOAEgAbwAYAFj/9v5F/8f/IAAGAMH/k/9k/3b/5f8pACcAuf9E/1n/rv8UAJcAsQAVAPD+Iv5Y/kr/RACXAEIAqf8t/z3/mf/I/5z/Jf/6/m7/7v9nAFsA/P+A/yL/D/8m/2b/ov/R//T/+P/Z/xcAXwCBAFgAxP93/3f/4/9qAN0AzABCAKP/R/9v//f/WwBuAIEAPwAIAPr/EABIAD4ADwD0/wMATACWAMUAugBvANz/gv96/87/QgCRAK4AggAwAM7/yf/5/y4AXgApANr/zv/x/zQAegBuADsABwDO/5H/lv/H/+j/FQARACkAIgDy/+f/+v/8/7z/tP/o/1QAhgBZABIA6v/b/6v/4v82AFcAFwC5/6P/sP+1/6L/6v8pAOv/fv9J/5f/5f/v/wMAbwCXADIA3//A//D/GgA6AFcAdgBWAPv/8f8pAFMAVgBcAIgAswBWALb/nv8BAFQAWwA9AEsATADw/9P/8v8VANn/V/+i/zoAZgBJACoATwA8AO3/5v86AJMARgDW/xIAWAAsAPb/CABmAIMAMgAYAO//9v/1//b/MwALAMr/jv+o/wMAdwDTANIAcADg/5f/Tv9b//H/zAAKAYgAGQDk//r/FQAeADcAEQCT/yT/qv+YAM0AgQAmAP//xf+F/7H/HQBhADAA5v8GADkAEgDK/+n/EADU/6X/yP8rAGEAHgAhADoA4v9V/yz/w/9NAD4A8v/Y/7r/ev9J/7b/cAC1AIIAJAACANf/kP+C/7n/AwAVACoAcwC9ALIADACC/1//Uv95/8X/QgB9ADwA9P/m/ywALQDT/4T/Sf83/zX/kP8/ALEAsQBgACAA6v/a/97/CQAoADAAIAAXADsASAATAPr/2v+X/3L/g//i/0YAjgCMACUAkP8O/xX/sf8TACgAQgBvADcAwv+O/+3/9v+T/1L/lv/T/93/OgDGAPoAhwDn/3b/e/9e/5r/HwBIABkAIAA8AFgATgA6ACIAs/8u/23//v8+AEQASwAwAPP/mP+p/zoAngBYALb/of9K/xH/Sv8qAMwAswAYAOD/6v/F/47/gf+3/7L/Vf88/7T///8iADsAXwA9AML/SP88/3n/sv/J/9b/6v8vAB8AIQAGANT/rP+J/23/tf8CAB4A/v/R//X/AgAzAGQAzwC1AD8AuP+b/6r/lP+u/wcAXwAcAN//CABcAGYADQD0/9f/r/+Q/+v/gwDZANsAuwC/AIsAIgDI/83/9f8qADAAQwBlAH0AOgAUAB0ASQCGAIUAWgDs/+H/0P8DAEsAaABWAPX/0v/x/1wAVQAeAM3/tP/W/93/LQBaAEEAoP+Y/zkAoACNAC0A0P+Y/2f/Y//S/wEA7v+r/9j/JgAkALr/kP/1//7/5f/j/x4ALADW/3//gv8BAE8AKQDO/3//b/+o/xAAbAA5AAAACgAkAFwAhgAyAJD/nv/o/1MAXQAyAE4ATgD+/6j/tv8QACcArf+D/6H/9P+RAGIBwgHmAJn/3v4Z/+//tAD7AO8AmAD0/+H/IwBaAD8A0/9y/wD/9v6R/4YAHAHqABoAav80/1j/5P8nAMf/Xv9j/zQA7wDmAFsAgP+s/nD+Cf8HAM4AsAAxAMf/Xv9N/7n/PgBCAK7/M/8H/0X/6f+TANEALQD0/mb+xv5o/xkAggCaAPP/+P70/rz/XwA/AAQA3/+a/1T/nv9SAK4ADgBH/x//TP/R/1EAyADGACEAb/+c/08AswCnAC8A0//a/y0AoADeALUAEgBA/yL/2/9WALwAxgCXAEwA8P/m/zIAYgA7APf/qP++/8L/FwClAL4ALgCO/0z/hf8eAJAAxwB/ACAAs/+Q/xMAsgD2AGoAdf/o/hD/uf+0APEAdwCK/9b+F//d/5oA8gCwABMAkP9o/7j/GABBAD0ADQDI/6n/BABRADQA3f+Z/4z/zf93AMoA9wCFANP/Zv90/+L/iwCqAGkA6v94/4X/v/8uALgAmwDr/3r/gP8lAJEAyQDjAKwAKgB//zz/kP/t/08AjgDDALMAXAAGAL//oP/U/wUASgCHAIwAVQDt/+3/MgCRAJUADwCq/6z/v//6/0wAiQBfAPb/xP/D////OQAYABcADwC6/4D/u/9eAL8AvQBfAAUArP9V/5L/EQBaACcAzf/h/2MAhABiADQA9/+c/1f/hv/C//n/QgBJAEQAGgDf/97/6P+7/2D/Iv+E/0sA0gDLABYAnv+u/wAACwDs/7L/WP9C/+b/SwCCAEYA5v8CAPP/t/+M/9n/JwAoAAAABAASAD0ATgB4AIgAAQBh/3T/8v9GAEMAPAB7AMEARQD//xcAAQDG/4H/vv9MAGoANwAhAMv/s/+Q/xUAdAAjAK3/fv/n/x0ABQAeAGQALgDD/2//bP/C/9n/BwBHABgAlf8x/5P/PQA2AKL/I/82/8T/+f8SAPT/pv9V/zf/fP/5/y8A3//W/9///f/4/9//BgBNAND/GP83//n/fAA0ANX/tf+Z/wP/IP8BAHAAx/8S/4b/VgDJAHIASwAhAFn/6v51/4YAxwCTAHMApgBxALH/Xf+8/+//zv8bAKMAQAEqAewAkwATAJP/gP/p/2IAXQAwAEgAdACzAHsAKwDF/2P/Sv+q/yMAkQDlAL4AoQBGALT/S/9K/8T/cwDqAMgA7QDFAEAAnv9Q/23/hv+D/8P/oAD1AJYAJgA5AAsASf+s/vz+qP/x/wkAlwD/AF4Alv+j/xoABABk/wr/jf+//7P/HwCbAN0AcQATADgAVQDT/yT/N//c/2UAZgBxAEkAMADo/4H/5f9XAFsADQDB/8v/0v/5/4oAFAHuACcArf+9/wkA8v+7/9X/vf9x/4z/PwC9AIYAEwDK/9j/6v/y/zwAeQA/AAoATAC7AKkANwC2/43/av9p/7v/QQB/AP//hf+f/y8AlgBSABAADQCx/2//n/9aAM4AWgB9/zz/fP/B/8L/8/81AAoAq/+M/wIAgQA2AOX/0/8KAP3/sf/t/z4ALACC/17/s/8bAOf/pP/V/yUA+//W/x8AWQAHAKX/sP8nAHUARgA3AGgARQDU/6T/6P9HADUADQCo/3n/e//t/6gAywBAAIv/Q/91/6//IQBWACcAz/+i/9z/LABEACgA/v+a/23/fv/p/0kAZgBBANz/5P8xAD4A/f9k/zn/bP/o/2cA0wDXABsARf8Y/4P/4P8LACYAPwAHALj/uf9PALsATwCo/3T/t//v/wsAYwB4ACMAq//N/zkAZwAgANb/5P/Z/6//yf9UAJQAPQB1/xz/RP+P/ywA3gAGAYoAeP/0/l7/DABXAEkAUABGAAIAxf/b/0YAjgBBAND/W/8R/zH/o/9eAO4AvgBTANv/0P+9/6P/3f/4/8P/S/83/77/dgDRAKwASACh/wv/IP/L/1wATwDn/9v/DgBEAHoApwCFAOv/h/9n/6X/8P9CAGwAbAAGAJH/j//B/y8AOgDf/5T/mf8VAIgAhwBGAM//X/9X/8b/igCrAH0AMAAQAPX/tP+r/9H/yP+B/9//WgDFAKQAPwA7AAYAgP9K/9v/SAD3/7b/BQCpAKAATwApACQAqf8R/0n/YAAsAfcAjQBoAGsAMQAOAFQAegD//4T/h/8nAMgAzQBrABwAqv9+/3z/yf9DAIgAOADI/7v/2P8UAAUA5P/8/yIAFQAmAE8ACQCM/4H/8v9eADkA6/+U/6b/+P9PAHIADgBs/xP/Yv8XAG4AcgB8ABQAbP8c/2r/7f8dAPP/4f/p/93/tv/8/3sAaQC1/0D/Wv+X/8n/BwDFAPgAYACi/1z/dv9s/4n/5v91AFEAIgBXAKkAmAAcAM3/qv+u/7n/FQCMANsAsgB7ACwAxv9u/yT/If+H/xoAbQDEAOgAqwA5ALn/r//0/zwANwDq/+X/+P8zAGwAmQBrAJL/+v4b/8f/cACiAFIAIQDe/7L/9P9eAIQAFgCL/0X/lP/q/yAA//+Z/xz//v6T/3YA/wB5AKL/Jf8z/6P/EgBTAFIAEgDk//D/IwA1ABcAu/9v/2//k/8RAKAA3wCpAAoAff+W/zQAaQA0ANz/pv/D/xMAWgCeAJQADABr/zX/oP8uAL4A+gCwAPj/af+V/z4ADAHpAAgASf8o/6b/WwDHAKwAMQCZ/1//nv9HANEA9wCsAPv/ev+w/ycAhQBVAAsAoP97/xYA0AAmAXQALP+2/j3/6v9aAFsAXgD8/5T/rv9NAKIAgQDS/yT/8v4g/9P/iwAWAeIAQwC//4f/4v8hANH/GP/w/or/MgB1AKsAygCPAPf/i/+D/5X/Jv/6/qT/WwC8AMkA5wDBANz/GP/8/of/HgA2ACEAAwATAFwA9gAsAYcAk//m/vD+Z//x/2gAfgAwAOv/4f/P/7n/ev+O/8//xP/I/yQAaQCoAGMA8/+5/37/h/+3/y8ARwAbACcAWQCPAEEA0P9J//7+I/+W/zMAdgB0AFwAUAAZAKj/nf/L/5r/Yv+B//7/VwBlAHIAiAA8AJP/N/9O/7L//v8TAG8AkAB0ADYA/v/W/5n/a/+M//b/QQA6APD/2f/Z/9T/w////xoA5f+h//L/ZwCAAEEApf+D/63/9v9cAIkAkQAxAOz/xf+s/97/NQBBAA8ArP+Q/7P/MADGAPMAnADq/zD/SP9//8v/FgBnAOkA8wBvAPv/jf98/6r/0P8bACkAGgAoADcAawByAGEALwDO/5z/l/+9/zIAeQCMADAAxv+T/7f/2/+2/2L/Rv9q/9v/lQC1AB8AZ/8s/3f/GwCMAJ0AbADT/1r/W/+//0oAPgAtAL3/XP9b/9z/rwD+AJIAwP9F/1z/7/9RAFIAJgDz//n/8/8YAAwAGQDu/6//9f90AIgAegBjALIApQA8AMf/7v9AABkA7v83AJUAfgAXAOT/EQDn/5P/V/+6/0MAKwAuAIMAlwBdAN//y//8/+v/zf/s/20AXwAEAAEAPACkAJwAGQCs/2H/Zv8UAHEAswBGAMf/aP9L/4D/BABQAFgACQC9/2L/PP9+/ygAsQCEANH/jf+p/+7/FgA+AHYAGQB//2H/rf8HANr/yv///zQA4//L/xQAcAAhAL7/t//t//r/0P/h//L//////zcAlwBHAHP/GP+R/zwAkABQAPn/0/+x/9L/TACKAFsAr/8x/2//+/9yAN0A2AAqABb/jv4V/yQA6QDQAD8Az//D/y0AkQByANv/I//6/rD/iAAiAegAQwCh/1//c/+a/73/wv/B/83/8f8NAHIAlABaAOD/Sv8+/4v/LgDIACQB5QA4AKT/ef+3/xIAMgAuAFsAVABJAEoARAAmAL3/Yf9V/4v/6/89AH0AhgBDALT/X/9a/5r/7f8vAG0AfABjACoAJwAqABkAAwC5/4v/t/8IAG0AswCOAD0A7f+v/33/kf/M//H/KQA5AGgAYQAlAAAA6/++/27/e//c/2gApACCAEIACgDK/3j/pP8EAEoATABAAGQAbgBEAAIAFgAiAMj/Y/9g/9n/NAA9AEcAjABwAND/av9b/7L//v9EAHwAnABwAAAA3//8//r/0f/E/wcAaQBIAN//3/8tADQA4/+k/87/BwDc/+P/FwAzAM7/Mv+A/x4APAACAOL/GgALAK7/pf8EAEsAzf9A/4f/7f/X/6j/wf8WABMAoP+I/5H/0f/x/wIAPwAdAN7/jv+Z/97/MQBlAEYA/f+2/5j/U/9K/8L/bACEABUA8v8NAEIARwA2AEEAEgCc/0v/4f+3AL8AWQAFAO//wv+N/8L/MgBuAFAANQCAALYAbgDy/87/wP94/3H/0/9fAJgASwBBAEsA+P94/1f/3/9SAD8AFwA5AE8AGwDB/9v/NwAzAOP/p//K/+D/rf+R/7j/7//i/9T/FgBuAHIA3/9v/2n/cP+L/7P/CQAtAPr/2v8GAHoAmwBEAOH/iv9n/1v/nv8rAIoAjABCAAsA7f/n/9r/yP+v/6v/sP/Z/0QAqACxAIEAFACh/3n/hv/O/ykAfACOAEUA5f+r/8j/EgALAOv/AQBJAE4AOQBFAIgAUgDC/23/p//x/xwAbwDIANQAYADa/4r/oP+Y/7//DQA3AD0AbgCRAJkAcgAoAMf/SP8D/4b/PwCWAKIAmABpACEAx//C/xoASgASAMz/HQAzAB8AEgBUAGQAEACb/6r/AQATAN3/tv/W/+f/u/+q/+7/BAAEABcAWgCNAGIA/v/H/8D/yP/I/+D/GABxAGoAVQAwAAAA0f+i/4n/wv/5/wwAAgD2/woA9v/8/wEALgANAM3/mf+x/9L/y//f/w8AOgAHAOb/DgBKAEIA9v/u/+H/vv+U/7j/FgBNAEwAPABSADkA2/98/3z/u//8//7/DwApADUA+v/d//T/FwAfAPH/zf+t/93/8P8dAEwARgANALn/vf8FAGYAUgAVAOD/2//t/9z/8P/l/7H/Rv9t/xoAfwBkABkA4//X/8L/vf8JADIAJAD1/ycAawBdAOj/nP/F/8L/t//O/yIATAALALP/ov/t/xwA/P/R/8n/5P8UAE8AewBIAAgA7P/4/y8AUwAZALj/1/8XAFEARgAZACEAHADr/9H///9WAGkABwDL/7v/3P80ALgA9gByALD/TP95//v/WABZADYABQDD/+n/PQB7AHsAOgD1/6f/nv/0/3oAyQClADEA2f/I/9v/EQAJAJ7/Uf9x/yEAuADBAG0A4f9b/y//g/8cAJQAewA6AA0A3f/a/wMAJAABAI3/RP9H/6j/RwDBAM4ASwB+/yP/WP+p/wMAOwBWAAsAmf+0/xsAPQDf/4//i/+h/7//MADGAPoAcQDP/53/pP/O/+j/GAAgAOL/p//s/1cAWQABAJH/Y/+M/+j/VACVAIQAJACw/6L/7P/1/wIA/f/z//H/9/8jAFYASAD3/63/gP+r/9T/LACXAKsARADb/5z/mf+//87/5P/h/+z/8/8KAFMAfQBdAOb/Zv9B/4L/9/+DAJ4AWwDi/4//o//c/wYAFQD8/+P/6P8OAEAAQwAcAPH/2f/K/9H/IABVADQA5P+n/5j/sP/u/wIAJgAWANz/uP/Q/wgAPQAdAPP/y/+5/8j/5/8pAHAAUwDk/6n/pP/g/+7/CABCAGMAQQDq/7b/uf+//9j/CQBRAFkAFgDN/57/l/+9/9z/CQAiABcA9f/R/+z/GwBHAEIA/v/O/9v/+f8tAFkAYQAoANv/vf/D//X/IgAVABcAGwD9/+7//v8xAEIALwADAOX/z/+5/+n/JQA+ABAA2v/f/x8ANAAiAAoA9P/k/+//IwAzACEAHQAVACYAKgAdABQACQDs/8b/uv/5/1oAmgCOAB4A0v/a/xQALgAsAA0A1f+2//f/LQBSADEA7v/1//r/5P/Q//v/NgBCAB4AFgAeADgAMgA1AEAAAgCm/6f/8/8tACcACwAcAEQACgDh/+D/2//D/6b/x/8UADEAFQD6/8P/sv+n//T/OAA5AAsA5P/5/wUABgAaADMAEwDn/9D/0//r/+z/8/8JAP3/1v+8/+j/LgAqAOr/qv+w//b/FQAjABQA+v/X/7//2v8WACQA3f+4/8r/AQAjAC8ATABtABQAmP+V//v/QwArABIAJAAuANz/3f8/AGMA7P9p/4j/+P9OAEEATABTAPT/nf+z/xsALwACAOz/MQBkAC0A6P/i/9X/q/+w//H/XAB5AGYAMwADAND/pf+f/7P/pv+W/7P/CgCEAJoAZwAEAKz/e/+I/7v/CQBVAGIAcwByAEQA8P+n/5X/sf/V/9L/EQA3ACEA5/++/73/vf+z/8z/NQBlAEsALwBPAFYACgCx/7b/5f/z//H/PQCNAF8A/f/o/w8AAwCv/3//z/8MABsAUACUAL4AdQAPAPj/BQDN/23/fP/l/z0ATQBdAFkAPQDg/3P/kP/l/x0AOQBXAIAAcgBEADgARwAlANH/o/+4//b/BwD3/wgABADd/8v/6P8MAAYA6v/d/wMALgA9AEQALgDt/7b/xP8IACoAGQDn/8z/v/++/9j/CgAkAPf/w//F/wUAPgAvABsADwDM/4z/i//k/zIAKwDo/9T/8P8CAPL/AgAhABkA9v/h/xIARgAlAPr/8v8MAPf/v//Q/wUAGQDW/7n/4P8hABAA6f/z/xMA8v/U//j/JAAQANn/wv/q/wYA7f/u/yUANQACAM//0v8EACUAOwAhAP//zf/C////OgBBAB8A+//z/+j//f8MAAkAAgD2//7////9/wEACQDz/+D/2v/r//v/AQD8/9v/5P8aAEUASgD9/8b/xv/4/zcAbgB+ADcAyP+Z/7H/2v/1/wkAIwAeAPb/z//3/y4AHQDa/6r/qv/A/97/KQBWADYA4v/C/+L/DwAOAPn/AAD2/9X/zf8EAEoAWQAiAPP/2P/A/8f/+v8xAEAA+P+0/7n/6P/8//L/AAAfACcABgDg/93/7P/u/+z/7f/k/9//5P8DADgAPAAYAOL/3f/f/9n/5f/2/xUAFAALABkAPgBHACcAAQDd/8L/wf/q/xoAHwDx/9L/2v/1/wgAFgAXAO//yf+3/9X/+P8HAAwAGwAfAA0AAAABABYAFgD5/+3/BAAmAD0AMwAnABsA/v/2/woAOQAmAPX/1P/q/xcAKQAeABkABwDO/9f//v8/AEUADQAFABMA9f/U/+7/IgAoAAsADQA6AEUAIQAMAC0AKQDt/7n/6P82AEEAKgAxAEQADgCx/4n/pv+5/8f/9P9JAHUAOwDr/+H/5P/n/9z/3P/v//r/AgAiAEsAPAAGAM//s//C/+b/CwAyAFQATwAWAPL/4v/y/+j/0P+9/7r/3P8DABwAGQD7/9T/x//Y/+P/5v8HADEASwBPADUADADq/9X/1//j//H/7f/6/woAGQASAP//9P/w//n/+/8SACIAGwAdACIAKgA4AC0AEgD8/9r/xf/Z//P/AwD8////CQAMAA4A/P/w//n/AAAPACIALAAaAPP/2P/Z//H/AgAEAPz/5f/K/7P/zf8JACYAFADn/9v/BAA6AFUAUgA0AO7/s/+5//P/KgAwAAEAzf+y/7H/yP/p//j/4//C/7H/0/8VAEYAPAATAPL/6//r//n/HAAxACAA9f/m/wMAIAAYAPb/4v/n/+n/+v8oAFoAVgAnAAYA+P/z//H/+v8KAAoA6f/X//z/IQAeAPb/0f+//8//9v8yAGsAYgAmAPT/5//x//b/CgAwADUAKAAhACwAPAAoAPP/xv/F/9//EgA+AE4APQAXAP//8P/r/9L/wP/K/+r/FAA0ADoAMQATAPP/3f/X/97/6f/4/wgACAACAA8AGgARAO//0f/S//j/FAAkABgAAwDl/+D//P8RABUA8//u//z/FAAaAAQA+v/j/9D/wf/c/xYANAApAA8A+//5//D/7/8GAAoA7P/W/97/BAAmACUAEgD///b/9P/w/+3/8P/s//D/+/8bACsAHADx/8r/xv/K/+P/AQAYABsA/P/m/+b/BwATAAUA+f/t/+//+/8WADkAMgAFANj/z//n//n//P8AAAQA9v/q//n/FgAVAPf/5f/Z/+T/9f8OADQAMwAMAOH/3P/1/wcACgAEAO//5v/8/yIANgA0AA4A3v/Q/9j/8P8FAAoADQD///f/9v8BAAkABQD3/9//3f/t/w4AJwAiAAIA5v/b/+D/+f8OABoACwDx/+j/7f///woAFQAUAA0AAgD//wcACQABAPT/8v/t/+//7//v//v////+//j/7//o/+//8P/4/wUACgAJAP7/8v/p/+//9////wYAAAD6//r/BgAZACMAFQABAO3/7P8IABsAHgAOAPD/3v/Z/+L/6v/r/+L/3f/m//X////1//L/6v/i/+L//v8bAB4ADgD8//f/+/8CAAYACwD7/+P/5v/+/xYAGwATAA8ADQD9//f/9//+/wYADgAOABgAGAAXABAABgDn/9//3v/r/wEACwANAAwADwAVABgAFQAPABEADgAQABQAIQAmACQAFgACAO//6//v//f/AQAEAAEAAAACAAkACgAMAPv/+P8DAA4AHQAlAB8ACQD3/+7/+P8AAP//+v/3//L/+/8IAA4ADgAAAO//7P/x/wAAGAAgABUABgD5//P/8P/t//b////4//D/+f8CAPr/8v/w//f/9//5/wIADwANAAIA/f8IAAYA9v/r//H//f8IAAsACwAKAP7/9f/5/wYABwAFAAQA/v/+/wQADQAZABUAAwD6//r/AAAGAAQA/f/8//f///8JAAcA/P/1//X//P8FAAMABQAHAAMA+P/4/wMADwAQAAwABgAAAPn/+f8GAAwABQD6//r//P/6//v//f/+//r/8f/r/+//9//5//j/8v/u/+//8//6/wUACAD9//f/9v8DAA4ABAD5//X/8//1//3/CwASAAwAAgD9//r/+P/0//3/BwAIAAAA//8CAAUA/v/4//b/7v/y//r/AwAEAAAA//8CAAQAAwAFAAoACQAEAAEAAwAHAAkACAAJAAkADgAOAAsAEAAJAAQABgAFAAgAAAADAAoADgANAAgAAwACAP//AAAHAAoABwAGAAYACQAGAAIABwAHAAUA/v/8/wIABQAGAAcAAQD7//f/+f/+/wQACAAGAAkABgD+/wMAAgD+//z/+/8AAAMABwAIAAQAAQD5//P/+//+/wUACQAHAAUABQAIAAUA///z//T/9f/8/woADQAOAAIA/P/7//v///8AAP///f/3//v/AgAJAAYAAwAAAPj/8//z//X//P///wEAAgD///3/AAD//wEA/P/6//n//v8GAP///v/8//z/9v/y/+3/9f/6//r/BQAGAP3/+f/1//7/AwABAP//AQAIAAQAAAAEAAIA/P/3//r//v/9//3//f8CAAIA+v/1//r/+//9//7///8AAP///v/7//v///////3//f8BAAQABQAEAAMA///6//r/+f8AAAUAAgABAP///v/8//7/AQAAAPz/+//6//n/+v/9/wIAAAD6//P/8//4//z/+//6//v//v/+//////////z/+P/6//3////+/////P/6//f/+f///wIAAQD7//j/+v///wEAAQD+//z/+v/5//n/+f/4//X/8//1//X/+P/5//j/+f/7//r/+//8/wAAAgAAAP3//P/8//v/+//6//n/9v/1//f//P/+//z/+f/1//P/8v/1//r//f8BAAMAAwABAAEAAAABAP///P/7//v//f8CAAgACgAGAAAA//8BAAUABgAHAAkADAAJAAYABQAHAAUAAgABAAIAAAD9//3/AQACAP3/+f8DAAcABgAEAAcACQAAAAYABgAOAAgABQADAAMABgAHAAoACAAEAP///v8CAAQAAQABAP//AQADAAUACQAGAAEAAAD9/wAAAQD+//7//f/+/wIAAQACAP7/+f/7//3//v8AAPz/+f/+////AQADAAAA/f/8//n/+f8EAAkACAAIAAIA+//8//7/AQAEAAMAAAD//wAAAgACAAEA///9//7/AQABAAIABAAEAAIAAAAAAAIABAADAAAA///+//7/AQADAAIAAQACAAQABQADAAIAAgAEAAQAAwACAAIAAgACAAEAAQD///z/+//6//r/+f/4//f/+P/5//n/+v/7//v/+v/7//7//////////v///////f/7//n/9//2//j/+v/8//3//v/9//v/+P/3//n//P///wEAAwACAAAA/v/8//v/+v/5//r//P///wEAAQAAAP///v/+////AQABAAEAAQACAAMABAAEAAMAAQABAAAAAAAAAAIABAAEAAMAAwADAAQABQAHAAoACwALAAoACAAHAAYABwAIAAkABgADAAMABgALAAwACgAFAAEA//8BAAMABQAFAAMAAwADAAQAAwADAAMAAwADAAIAAgADAAUABgAGAAUABAAEAAMAAgACAAEAAQACAAUACAAIAAYAAgD/////AQADAAQABAACAAEAAgADAAMAAwABAAIAAgABAAIABAAGAAUAAwAAAAEAAwAFAAQAAQD/////AAAAAP7/AAD8/wEAAQAGAAMAAwAFAAAA/P/8/wAA+/////n/AQAAAPn/AQD///n/9v/4////AgAFAAIAAQACAPz//f8EAAYAAgD9/wEAAgABAP///f///////f/7//z//v/8//v//f/+//7//v/9//3//v/+//3//f/+////AQABAAEAAAD+//3//f/+/wAAAAD///7//v///wAAAAAAAP7//f/9//v/+v/7//7////8//n/+P/8/////v/8//v/+//7//v//P/9//3//f/8//z//P/7//r/+//8//z//f/+/wAA///8//r/+v/8//3//v/+//7//v/9//z//f/8//r/+P/4//r/+//7//v/+//7//r/+f/4//n/+//8//3//f/+//7//v/9//v/+v/5//n/+//9//3/+//5//f/9v/2//X/9v/2//f/+P/7//3//v////7//P/6//n/+f/7//7///////3//P/8////AAAAAAEAAgACAAIAAQACAAMAAwADAAQABQADAAAAAAABAAAA/P8BAAIAAwAAAAEABQD//wMAAQAIAAUABQADAAIAAwADAAUABQAFAAMAAgAEAAUAAwACAP////8AAAIABgAFAAUABQACAAQABAABAAEAAQABAAMAAgAEAAMAAAABAAEAAQACAP7/+//+//7/AAADAAEA/f/8//r/+f/+/wEAAAACAAAA/f/+////AAABAAAA////////AAAAAAAAAAD/////AAAAAAAAAAD///7//v///wAAAgACAAEA///+//7//////wAA////////AAAAAAAAAAAAAAAAAAAAAAEAAQAAAAEAAQACAAIAAgABAAAA///+//3//P/8//z//P/8//z/+//7//v//P/8//3//v//////AAD///7//P/6//r/+v/7//z//f/9//z/+v/5//n/+f/6//v//f/+//7////+//7//v/9//3//f/9//3//v/+//7//v/+//7//////////v/+////AAABAAEAAQABAAAA///+////AAAAAAAAAAD/////AAABAAMAAwAEAAQABQAFAAUABgAGAAYABAADAAIAAwAGAAgACQAHAAUAAwAEAAUABgAFAAMAAgACAAMABAAFAAQABAAEAAMAAgABAAEAAgADAAQABQAFAAUABAACAAIAAQABAAIABAAFAAUAAwACAAEAAgACAAMAAwACAAEAAgADAAMAAgABAAIAAgACAAIAAgADAAMAAwABAAEAAwAFAAUAAwACAAMAAwADAAEAAgD+/wEAAAAFAAMAAwAFAAQAAgABAAQAAAAEAPz/AwADAP3/AwACAP7//P/8//7///8BAP///v8BAP7//f8BAAQAAwD//wEAAgADAAIAAAACAAMAAgABAAAAAQAAAP7///8AAAAAAAAAAP//AAD/////////////AAABAAEAAQAAAAAAAAAAAAAAAQABAAAA/////wAAAQACAAEAAQABAAAA///+/wAAAQAAAP3//P/+/wAAAQD///7//v/9//3//v/+//7//v/+//7//v/9//z//P/8//z//P/9//7////+//z//P/9//3//v/9//7//v/+//7///////7//P/8//z//P/9//3//f/9//3//P/7//v/+//7//v//P/8//3//v/+//7//f/8//z//f/+///////+//7//f/9//z/+//6//n/+f/6//v//P/9//3//f/9//z//P/8//3//v/+//3//P/8//3//v/+////////////////////AQABAAEAAwADAAIAAQACAAMA//8CAAEAAwAAAAAAAwD//wIA//8EAAIAAwADAAIAAgACAAMAAwADAAMAAgADAAQAAwADAAEAAAAAAP//AQACAAEAAwAAAAEAAwABAAEAAQAAAAEAAAABAAEA//8BAAEAAQADAAAA/v////////8CAAEA/v/+//3/+//9/////f/+//7/+//8//3//f/+//7//f/9//3//f/+//7//f/9//3//v/////////+//7//f/+//7///8AAAAA//////7///////////////////////////////////////////////7///8AAAAAAQABAAEAAQABAAAAAAAAAP/////////////+//3//f/9//3//f/9//7////////////+//3//f/9//7//v/+//7//f/9//z//P/7//v//P/8//z//f/9//3//f/+//7//v/+//7//v/+//7//v/+//7///////////////////8AAAEAAQABAAEAAQAAAAAAAQABAAEAAQAAAP////8AAAAAAAAAAAEAAQACAAIAAwADAAQAAwACAAEAAQACAAQABQAEAAMAAwADAAUABgAFAAQAAwACAAIAAgADAAMAAwADAAMAAgABAAAA/////wAAAQABAAEAAQAAAAAA//////7//////wAA///+//3//f/+//7//v/+//3//f/9//7//f/8//3//f/9//3//f/9//3//f/8//z//P/9//7//f/9//3//v/+//3//v/7//z/+v/+//z//P/9/////f/8/////P8BAPr///8AAPv///8AAP3//P/7//z//P/+//z/+v/8//v/+f/7//3//f/6//z//P/9//3//P/9//7//v/+//3//v/+//3//P/+//7//v/+//3//v/9//3//f/8//3//f/9//7//v/9//7//f/9//7////+//7//f/8//3//f/+//7//v///////v/9//7///////3//P/8//7///////7//f/9//3//f/+//7//v/+//7//v/+//3//f/9//3//P/8//3//v/9//z//P/8//3//f/9//3//f/9//3//////////v/+//7//v/+//7//v////////////7//v/+//7//v/+//7///////////////7//v///wAAAQABAAEAAQACAAEAAQAAAP///v/+/////////////////////////wAAAQABAAAA////////AAAAAAAAAAABAAAAAAAAAP//AAAAAAAAAgADAAIAAQADAAQAAQADAAMABQACAAIABQABAAMAAAAFAAIABAAEAAMAAwACAAMAAwADAAMAAgADAAUABAAEAAMAAgACAAAAAgACAAAAAgAAAAAAAgAAAAEAAQD//wAA/////wAA/v////////8BAAAA/v/+//7//f8AAAAA/v////3/+//9//7//P/9//3/+//7//v/+//8//v/+//7//v/+//7//v/+//7//v//P/8//z//f/8//z//P/8//z//f/9//7//v/9//7//v/+/////////////////wAAAAAAAAAAAQABAAEAAQABAAAAAAAAAAEAAQACAAIAAgADAAMAAgACAAMAAwADAAMAAwADAAIAAgABAAEAAAAAAAAAAQABAAIAAQABAAAAAAAAAAAAAAABAAEAAAAAAP////////7//v/+//7//f/9//3//f/9//3//f/9//3//f/9//3//f/9//7//v/+//7//v/+//7//v//////AAAAAAAAAAAAAAAAAQABAAEAAQABAAEAAAABAAEAAQABAAEAAQABAAIAAgADAAMAAwADAAIAAgACAAIAAwADAAMAAgACAAMABAAFAAQAAwADAAIAAwADAAMABAAFAAUABAAEAAMAAgABAAEAAQABAAEAAAAAAP/////+//7//v/+//7//v/9//z/+//7//v//P/7//r/+v/6//r/+v/5//n/+f/5//n/+P/5//n/+v/5//j/+P/5//r/+f/5//n/+//7//r//f/6//v/+P/8//r/+//8//3//P/7////+v8BAPr//v8BAPz/AAADAAEAAQAAAAIAAQADAAIAAQACAAEA//8AAAIAAwAAAAEAAgACAAIAAQACAAMAAwADAAMABAAEAAMAAgAEAAQABAAFAAQABQAFAAUABAAEAAQABAAEAAQABAAEAAQABAADAAMABQAFAAQAAwADAAMAAgADAAMAAwAEAAQAAwACAAIAAwAEAAIAAQAAAAIAAwACAAIAAQABAAAAAAAAAAAAAAD//wAAAAD///////8AAP/////+//////////7//f/+//3//v/9//3//f/8//z//f/+///////+//7//v/+//7//v///wAAAAABAAEAAAABAAEAAQABAAIAAgADAAMABAADAAMAAwADAAQABQAFAAUABgAHAAcACAAIAAgACAAHAAgACAAIAAgABwAIAAcABgAGAAYABwAIAAcABwAGAAYABgAGAAYABwAHAAcABQAGAAQABQAEAAQABgAEAAQAAgAEAAQA//8DAAEAAwAAAP//BgD9/wIA/P8DAP7/AQABAAAAAQD+/wEA//8AAP/////+/wAA//8AAAAA/f/+//z//f/+//v//f/8//r//v/7//z//f/5//z/+//7//3/+//7//3/+//+//7//P/8//z/+//7/////v///wEA+v/7//z/+f/6//3/+v/5//n/9v/4//r/+f/6//r/+f/7//r/+v/5//j/+v/6//r/+v/6//r/+f/4//f/9//4//j/+P/4//j/9v/4//j/+P/4//j/+f/5//j/9//3//f/+P/4//j/+f/4//j/+P/5//n/+P/4//j/+P/5//j/+P/4//f/9//3//n/+P/4//f/+P/4//f/9//2//b/9v/3//n/+v/6//r/+f/6//r/+v/8//3//////wAAAQAAAAIAAwAGAAYACAAHAAoADAAMAA4ADwARABIAEwAUABYAFgAYABgAGQAbABwAHgAfAB8AIAAhACIAJAAkACUAJQAkACUAIgAmACMAJQAjACUAIwAiACIAIAAfAB4AHgAeABsAHQAZABkAGAAVABMADwALAAcABwABAAIA+//3//L/7//r/+j/5f/h/93/1f/Q/83/yP/H/8L/v/+8/7P/r/+r/6b/o/+f/57/mv+Z/5P/lP+Q/4//kf+Q/5T/lP+X/5j/m/+g/6P/q/+u/7X/uf/B/8X/zv/R/9v/4//o//D/9f8AAAgADwAXAB4AHwArAC0ANwA8AEEASwBTAFUAYABiAGoAbABwAHIAdAB8AIMAhgCFAJUAhgCXAIkAjwCdAIkAkwCaAKEAlwCcAJcAiQCNAIQAiQCNAIEAcQBpAGMAXQBLAEkAPQA2ACcAGgAWAAcA+f/v/+H/2f/M/7r/sP+j/5L/iv9+/3X/aP9g/1f/Sv9B/zP/Jv8e/xH/Cv8J/wL//P70/uz+8P7q/uj+6P7m/u7+7P7w/vT++P7+/gb/D/8X/yP/Mf9B/07/Xf9n/3f/jf+d/7b/zP/n//7/GAAzAEkAYwCEAKIAwQDiAPsAFgEyAUQBZAF4AZIBrAHEAdoB6AH6AQgCEAIoAjgCRAJQAlQCXAJkAmQCaAJsAmQCVAJEAjwCJAIMAvQB2gG4AZQBbAE+ARIB2QCgAG8ANwAIAM3/kv9f/xn/1v6M/k7+Ev7Q/ZD9WP0s/fj8yPys/Ij8YPw8/DD8JPwY/Az8CPwk/DD8SPxY/ID8oPzQ/PD8IP1M/XD9lP3A/fD9Iv5E/nb+oP7i/vD+I/9O/4b/sf/h/y4AVQCQALQA+QA6AW4BuAH0ASwCfAKMAuQCCAM8A1QDsAPUAxAEMARQBJAEgASoBMAE4AToBPAEGAUYBSgFEAUoBSAFCAUIBfgE6ATYBLgEoASIBFAEMATUA6QDSAPUAoACFAKwAVAB1QB2APv/bP/k/kj+Cv4o/fz8oPwY/Fj8qPuA+wj7gPoI+jj6CPrg+QD6aPlw+TD5iPlw+Vj5WPlw+aj5ePm4+cj56Pnw+QD6cPrA+tD6APtI+5j7iPvo+1j8nPzw/Pj8OP2c/bz9AP5G/oT+vP7k/lb/sf/l/zgARACmAPkALAGaAQACRAK0AgwDGAOcA9ADEASIBMgECAVABYAFmAXoBRAGMAZ4BqAG0AbwBvAG4AbYBtgG+AYYByAHMAcoBygHGAcoB/AGyAaYBkAGKAbQBVgF+ARIBOgDYAPwAoAC2gFQAbIADwCT//L+bP7s/VD92Pxc/Pj7qPtI+9j6ePoQ+uj5qPlo+WD5GPkY+SD5GPkw+Uj5CPkY+UD5MPmQ+ZD56Pno+Tj6OPqA+rj64Poo+0D7iPuw+wT8QPxM/KD82PwY/Wz90P0I/hT+Pv56/uL+G/9x/7D/CwAyAGgA5wA0AbIBEAJwAsQC6AIsA3QD4ANABJAE4AQYBUgFgAXYBQgGKAaIBsgG8AZQB1gHWAdgB0AHqAcACEAIMAhACFAIIAhQCFAIkAiACBAIwAdoBwgHiAYYBnAFKAVABIwDKAOQArABhgDQ/y7/wP60/WT9zPzo+zj74PqY+mD6qPkA+eD4WPgA+ND34Pfg99D3YPeg98D3cPeA92D3gPeQ96D3OPig+Jj4MPhg+LD4+Phg+aj5KPpg+ij6qPog+2D7mPvI+1D8wPz0/Cz9fP2Q/aj9Lv6g/hP/Rf9c/7T/BgBaAPwAcgHIAVwC1AI0A3wDwAN4BFAE+AQ4BdgFcAYoBsgGAAc4ByAHmAcACBAIYAhwCHAIMAhwCJAI8AgQCdAI4AjgCBAJQAlQCeAIcAjwB6gHYAfABigGcAXIBBgEhAOcApwB4QAHACz/gP6s/QT9fPxw+8j6QPqg+Uj52PjQ+Aj4YPfA9pD2sPaw9qD2YPag9mD2UPZw9nD2gPZQ9pD2MPfA98D3YPeg9wD4MPh4+Pj4iPnY+Zj5GPqg+qj6CPso+yD8UPxo/GT8yPxY/Rj9wP3g/YL+8v4y/4f/p//1/2EACAHiAUQCvALUArQDWATgBKAEkAXwBbgGCAc4B4AI+AdgCGAIcAnwCAAJMAqQCuAKAArQCRAKIAqQCuAKoAvAClAKoAoQC0ALwApACnAJUAmwCDAIoAdwBtAF+ARABMAD2AJyAVgAcv+g/vj9FP2I/Lj70Ppg+Qj5sPgo+FD4cPfg9hD2gPWg9XD1sPWQ9cD1QPUA9XD1gPVQ9RD1sPVQ9lD2MPag9tD2cPaQ9oD3CPhI+Ij4yPiA+YD5UPkg+qD6+PpY+7j7yPv4+5j8BP1k/dz97P1O/uD+HP8BAMj/NwAsAaIBRAJUAogDIASABFgEUAXgBUgGgAZAB2AIiAcwCCAJwAmACcAIkAmACgAL0ApwCyALIAoACpAKAAzQC6ALAAswC6ALIAvQC1ALAAvwCRAJ4AiACJgHEAbIBRgFMASYApIB9gCv/57+zP1k/UD8OPtw+rD5mPjA94D3UPdA92D2QPYg9UD0cPSg9ND00PQA9cD0gPTg83D0EPXw9OD04PUQ9gD2oPUA9iD3IPcg9+D3ePig+Pj4iPko+qD5oPlA+sj7dPwU/OD7aPxs/ET9wP1a/pz+kP7W/pf/WwBGAHwANgGIArQCzAKUA6gEiAXABGAFiAYQBygHYAjQCMAIoAgQCRALUApQCgAKkAqgC4ALgAzwCwAL0AowCxAMsAywDIAM4AvQC0AMkAxgDCAMcAtwCnAJgAigCHgHKAaABWgEkAM0AucAIACu/tD9CP1Y/Kj7OPo4+UD4UPdg99D2gPaA9uD1QPUg9LDzAPRw9HD0YPTQ9JD08POQ8/DzgPTA9ND0QPXA9fD0MPVg9WD2kPaw9gD3wPd4+Fj4iPjY+Dj5OPko+hD7DPyI+/j6QPsI/ND81PzM/Wb+jP4A/nD+2v+k/wYAvQBsAkACSAIwA4AEOAXIBCAFmAa4BuAGUAgQCRAJwAiwCVAKUAqQClAKQAsQC/ALwAzAC8AKsAqwC+AMAA0QDfAMIAygC+AMsA1ADXAL4ArACkAK4AioB8AHQAbIBBgEWAOgAvv/iv5w/iz+NPzI+rD6GPpA+GD2QPbQ9oD2EPXg9OD00PMg8oDy4POw8+DysPKw87DzsPKg8jDzUPSA8/DzgPTA9AD1gPQg9QD24PXw9VD30Pdo+AD4OPjI+Aj5MPqI+tj6wPqo+1T82Psw/GT87P3s/VL+9P62/4T+zv4CAZABrAEwAcgCWAS4A9wDCAX4BpAFUAbgB9AIcAhAB7AJwApQCvAJEAtQCyAL0ApwDBANEAwQDIAMIA1gDJAMgA0ADrAN4AwgDgAOMA4QDrANkAywCrAKoAoAC+AISAc4BrgE0AOoAngCXAHi/iD9KP10/Cj7iPlw+FD4oPYw9rD20PbQ9ADzIPOg8/DzAPKA87D08PJQ8YDyEPTA8yDz8PLQ9AD0wPIw9AD2MPUQ9AD1kPbQ9uD10PZY+BD48Pc4+Mj5WPnI+fD6kPsw+7j64PuI/Pj8TP2I/Tb+HP7M/v3/HwDG/hcAigGAAvACyAIABGAEmAS4BJAGGAdgB7gHcAmgCaAI0AgQC6AMEAuQClALcA1QDfALAA6wDDAMIAzQDuAP4A4QDEAMYA6wDrAO8A8AEHAN4AvACtALkAygCmAJwAiIBwgFjAN0AowC6wAh/yb/zP08/KD5YPjI+Aj44PZg9mD2UPWQ9FDz0PLg8uDy4PKw8kDzIPOg8tDw0PHg8pDzQPNQ89D08PLw8RDzMPYQ9oD0MPWQ9qD24PVw9ij5aPmQ91j4SPqQ+oj5SPro+zj9aPuw+pT8LP4q/jj9fv6F/4D+vv7iAJwBzwAGAGAB6APQBCwD7AOYBWgFKAbABsgHgAgQCaAJsAmACgAKoArgCwAMEA2ADDALAA0ADcAN8AvQDIANQA4QDhANoA2QDAANYA3wD6AQMA4wCzAJ4ApgC4AKYAkACTgH2AKMAcQCQAMeANz9Fv64/Uj6IPgA+Rj5APYw9CD2cPbQ9BDz4PLA8lDxAPIQ86Dz8PLA8fDxsPGw8fDywPOA86DzQPSw8/DysPIQ9cD14PXQ9eD1wPZQ9aD24Pdg+ej4sPdA+bj6qPpI+bj62Pu4/Aj7mPtk/bD9NP1A/T7/tv6K/g7/IAEQAoUAAgDWAfwDaASYBCgFaAXQBdgGAAgACdAIQAkgCvAKQAvACgAMwAyADPAMUA3QDHAMUA1ADnAOEA3QDNAOwA9gDVANQA3ADXAOQBBAEYANkAqwCfAKIAvgCZAKEAkQBXgCNAO8Ao8A8v7o/wT/SPsQ+eD5yPlg9kD04PZg9yD1APOw8wD00PBA8EDzQPXA81DwoPFg84DyEPGg8mD1oPTw8iDz0PQg9QDzwPNQ9yD4EPZQ9eD28PeA92D3iPnw+vD5UPmg+kD7kPtI+9z8EP2w/ZT9RP2C/tz+LP9q/wUANwBGAeoB3AH+AXwCyAP8A0gFSAbwBjgGAAbYBxAJ0AkQCVAKQAsQC6AKUAwQDUAMgAzADYAO4AwQDDAOcA9gDrALQA4QD8AO0A1gDeAO0AtgDGAQYBIwDuAJYAlwCoAJcAlgC5AJsAQUARwC/AIAAez+pP8q/8j6kPjA+cD5cPZw9CD2QPaw9ADzAPRg81DwgO9w8gD1EPPw8HDxEPJA8aDxAPOw9JDzIPJw88D08POg8iD04PXw9rD1oPTw96D3EPYw9oj50Plg+SD5CPqw+9D5gPpM/Iz9lPzA+zT9XP5m/lb++v6u/n7/mAD/ABgBqAH0AowCBAKgA2gGgAbIBPgFsAhgCDgHYAhgC4AL4AjgCeANoA3wC1ALAA7ADgANkAzQDWAPYA1ADeANgA9QDjANkA7gDwAOQAsQDWAQYBKADdAKgArYB6AJkAmwC0AJ0ATPANYBlAKqALf/dP4U/UD7APoo+CD4kPcg9WD0cPSg9VD18PIA8ZDxcPGA8RDykPRg9DDxwO/A8bDzgPPQ8hD0YPUA9EDyIPTg9fD0cPRQ9bD38Peg9ZD1gPj4+AD3EPhg+5j70PhI+fD7+Pw4+yj7NP7y/mj84Px2/4IAIP4U/n8AiAFYAUcAJAI0A2gC8gHYA5AFKAaQBUAF8AbIB6gH8AjQCdAJoAmACoALsAxADBALgAwADcANsA2QDLAMgA2ADuAMYAzwDSAP8A0QDBAMQA7wDMAMgBAAEGAM6AUQCNAKoAugCCgH6AcUA9j/GgBUA2ABqP0o++D7cPxI+ND2oPYw9zD18PLw9QD2kPTw8KDwUPJA8tDysPOw9IDyQPAA8pDz8PMw9AD1cPTw8yD0EPbA9eDzMPVQ99D30PVQ9xD5IPeg9VD3EPuo+rj44PgI/Aj7sPhI+tj94P2w+nD8AP7k/kD9tPySADgAYP5A/gwCCAO2ACUALAJABMADeAPgBRAHYAUABWgHkAmACaAIYAngCrAKAAvQCxANwAwwDLAMUA2wDUANcA1ADaANYA1wDRAOoA6QDiAOsAxQCwAOYBCgERAP8AuQCkAJAAkgCnANIApgBdQC6ANkA04Ayv9sAGr/+PrQ+QD8MPrA9ZD0IPcQ9+D0gPQw9pD0EPCg7wD08PXg80DzYPTA8qDxEPKA9cD2EPRA9ID10PWg9AD1UPbA9SD2IPc4+OD38PZw94D3KPjg+BD6GPsQ+uD5QPpI++D6wPto/Q7+SP0k/Fz9zv4F/1b+Iv9iAKkAgQCJAFwC5AG8AbQCeAQgBhgFyAQgBtAGYAdwB0AJQAqgCUAJwArQC6AKEAsgDTANMAxADHAN4A1ADCAMgA4gDsALcA3gDyAPoAzAC3ANgA4wDtAPYBGADUAKEAlgChAKQArACtAIsAVQAbAB5AAUAEkAmwAo/lj5GPio+ej4oPaA9HD2UPaA9MDzIPSw8hDwoO/A8wD2wPOw8pDxcPIg8cDywPSg9eD1UPMg9ED04PPA9PD0wPYQ9vD2oPaQ9oD2oPVA96D3+PiQ+XD6EPpw+Jj4KPmY+zD81Pzs/Mj7mPu4+zD+tP4I/7T+/v4HABMA9/8QAjgC1gF0AngEAAYQBYgE8AawB8gGqAbwCvALwAmQCEALkA1ACzALoA4AEHAMUAvADbAPMA5ADDAOkA+QDtAM0A0gD2AO8A3ADKAOIBAgELAOkAwgDQAL6AbABxAL4AyQCGwCVgGTAI//zP73AAAC4PuQ9/D2cPkA+LD0QPTw9tD1oPIQ83DyEPIw8LDwAPQw9IDzsPFQ8uDxsPEQ80D0IPZA9bD0UPMQ9CD0EPSA9pD2sPfg9QD2oPaQ9jD3UPfo+Mj4YPng+YD6oPlw+VD68PpY/Pj9/P2Q/MD7RP24/kj++P5QAZgBnP7k/cgCIARoApABgAQoBmgDlAPIBhAKIAdIBWAIYAtACmAIoAqADVAMAAogDBAPIA9gDOALYA4gD6ANAA1ADtAPoA0wDJAN0A/ADgANgAwgD3AO4AzgDVAPQA2QB/AFUAigCXAIkAd4BVgAaPxc/ZwB+v/U/FD7YPkw9mD1EPcQ99D04PLQ9GDz4PIw8oDy8PEA78Dy0PNQ9JDzsPKA8kDwQPJw9UD3wPUw9GD0wPOQ9DD1MPdw9wD2oPYQ9qD30PdA99D2sPdo+bD5+PjA+Tj7uPrQ+OD5LP24/Yj7nPyo/oD+5Pxg/T4B4gE3/7L+9gH8A8wC7AHoA3AFcATgA7AGQAlQCBgHyAeQCdAK8AnwCiAMkA0wDMAL0A0QD/AO4AzQDTAPMA9wDpAOUA9QDoANIA4gELAPsA6ADuAN0AzgDaAQQBDQDjAMYArIBhAFQAggDDAKTAO3/63/IP2M/HT/GAGw/DD2UPbQ95D2EPQw9MD2IPOQ8TDzkPSg8gDv4O+w8jDzUPOw9ND1EPJg7zDxMPUQ9+D1YPUQ9tDzYPKw9HD3kPcw9SD1qPhw+GD2QPbQ+ID48PZI+FD7pPzA+ZD4ePtI/Lj6sPuG/n7/ZP3A/Nz+ZgDw/pr+1gA0AsQBMALoAsQDZAIwA1AEcAbQBzAHcAdQB7gH0AfACcAKUAvAC4AL4AvQC+AMYA1wDWAN4A2gDoANsA3ADTAPgA2wDGAOIBDADmANUA5QDhAMgAuwD2ATIA8QCbgH0AhQBTAGQAqADLgFKPtU/Nz+fv44/Ob+g/+Q+KDyAPSI+GD2cPLg8hD1APSA8QDyQPOQ8IDtYO9w89D1gPQQ84Dx4O/g7zDysPaQ90D2wPNg8vDygPPA9TD3APfg9WD1MPeQ99D2cPag9yj4GPio+UD7yPvg+fD4WPp4/LD6wPyj/wb/cP34/JT+bP88/43/2AL0AuIBSAK4AnQCmAIgBUAHmAegBoAH+AfwBtgHsArgCzAK8AogDZANEAwADHAOAA9wDTANIA8gEEAOcA2ADoAPEA6gDTAOIBGgEOAMwAsQDeAPgA4wDwAQwA+wB1ABUAYAC3AK0AbIBGgDDPwo+Cj8OAG9/7D6sPfo+ED1YPJg8tD24PXA8qDxUPLQ9DDywO5A71DyEPOw8lD1wPbg9ODugO5w9Bj4gPZw9gD4cPaQ8iDxwPUY+Uj4EPfg9oD3oPbA9XD3KPlY+SD4oPcw+gz8cPso+QD6aPyw+4D7lPz6/xsAdP1I/Uz+hf/c/rMAQAPIA3QC4QCYAegDwARoBRgG6AaYB9gFwAZACLAJ0AgwCfAKEAyQCzALoAzADKAMYAxQDdAOIA7QDdANEA6wDNAMYA1gDsAPsA6wDDAM0AvADJANcA5gD+ANUAqwBhgHIAbQBHgGQAiABeIAmPqQ+uD7cPxo+1j8QPsw9uDyAPIA9XD1cPMA88D1sPQA8ODwIPNA9NDwsPAA9oD3oPUw8nD1kPSQ8tD0SPlw+yD3IPUg9rD28PUA9xD6kPnA95D3SPhQ95D3mPi4+eD48Pcw+jz8+PpI+mD6KPtI+jj77P1xADj/FP1k/V7/XP9H/8gBlANYBH4B1gGwBEAFUARwBFAIMAiIB6AGUAmACugH0AhACwANIAuwCxANkA0QDKALYA4QD5ANMA1ADoANcAwgDWAOMA7wDBANsA5gDXALkAsgDVANYAygDgAPQArIBHwDeAUYBXAE0AbIB7L/0PbQ9jT8mPsQ+/j7VPyg9aDu0PHQ9sD1UPFw81D3kPPg7yDx8PTQ8kDvUPIQ+DD3cPTw9ED28PMw8dD0qPrQ+jD3YPXA9kD1IPRg9jj5CPmg9rD2WPkw+DD2kPYA+Sj5APjg+Qz8WPyg+ZD5kPsg+0j79P2IANH/nP3c/Rv/ff8z/7wB5AOkA6gCjANMA8ADMAQoBhAH2AfYB6gH8AfwB+AIEAngCaAK4AvgCwAL8ApACwAMUAxwDMAMUA2wDLALIAwADRAOsAsADBAOkA5gC9AJ8AwQDtALIAtgD8APCAfIAYgF0AgABFADUAeAB6z8cPT4+oD+mPt4+Gj9zPzw8+Du0PMQ+bD0sPGQ9HD34PMQ8VDy4PNQ8YDwYPRg91D3gPTw8zD04PMw9KD14Pco+GD3sPUQ9RD1MPUg9lD3wPZw9vD2aPgQ+HD2cPZg9/D3MPgQ+7j8wPu4+QD6uPto+wD6Yv7oAfMAmP42/y4Acf+R/3gCaAbQBHwDcARgBTAEvAO4BhAJoAi4BzAJ4AiAB9AHYAowC1AKIAuwDKAM4ArwCnAM0AzgCxAMcA2ADcAMUAzADEANgAwADLALEA7ADWALUAogDJAOgAwgC4AL4AvAA7X/GAUACSAHPAIxAG7/CPnQ9WD6qf9s/cD3sPbA9/DzEPFw8kD4EPeQ9PDyQPRw9VDy4PGQ8wD2sPSA9CD3WPig9qDy0PPg9qD38PXQ98D5APiw9NDzIPYg9nD24Pdg+LD3sPag9sD38PcY+JD48Pio+uj73Pxo+wT8mPxw/Gj9dP7aAZgCJAKmAdYAtgC9ANADQAbgBrgGYAWgBEAFGAbIBxAIwAhgCaAI8AjwCPAJwAlQChALgAtgC9AL8AwwDIALgAuQDKAMMAxwDUAOMA3gCvALYAwQDDAMMA2wDSAL4AjgCnAL0AnQCbAK8AngBTAE3ALoARoB2AHsAg4BoPoQ+Uj5+Piw98j4sPlg9+DzUPLw9HD0gPJw8zD2oPSQ8fDyIPWQ9dDxUPJg9bD14PTQ9Cj4cPXQ8jDzgPbw9wD1kPWw97D2oPMA9PD20Pbg9XD20PdQ9/D1UPbY+LD48PYo+BD7aPtA+wj7nPyI/BT84PzI/wgBlgAiAYQCsAKuAdQBGARYBggF0ASQBmgHeAYABpAI0AggCFAHUApgDGAKQAoQC5AL4AlgCvAM8A6gDRAMEA3ADCALAAuQDRAOEA1QDAANAA3wCkAKoAzgDCALwAnACgAL0AhQCaAKkAkABbgC9ANQAtD/zQDYBEACCPvQ9xj6aPjw9mD5bP0o+vDy0PIg9rD1YPKg9AD5UPbA8ZDyUPbw9ODxMPPg9gD1QPMQ9VD4sPbg8gDzEPXQ9YD18PYo+GD2cPSw8yD1MPZA99D3kPjQ9yD3MPcw+DD6yPqw+tD6+Ptw/Bz9TP5x/43/wf9IABoBHALsAsgD+ARIBIAEEAXwBaAGGAfYBpgHEAgwCRAJIAlQCeAIYAlwCiAMAAyQC0ALcAtAC+AKgAvgDDAN0AxwDFALUAvwCkALIAzwC4AMAAtQC4AKcAoACiAJ8AkQCnAJ2AcQCHAIQAWYAugCAASsAewAMAKIAqL+mPnA+mj7QPpY+aj7JPw4+LD0QPaw+PD2QPUA9tD2YPUg9QD2cPbw9MDzAPRw9CD1cPWA9bD1kPbQ9WD0sPMA9aD2cPUg9dD2MPgQ9vD0QPYw92D1APZQ+VD6SPjA93j6GPvw+TD6mPyk/YD9rP1MAP//PQCbAOgBlgGOAIACSAVgBuAEOAWoBIQDWASQBmAIsAgQCJAIwAggB4gGkAfACSALEAsgCyALsAqACWAKsAowCyALMAswDJAM4AoQCRAKsAswCnAJQApAC9AJMAkgCaAH0ASYBNAHgArACIgGyAXkAFD8UP1wA5gFSAOT/97+8Pqw9SD4yP06/oD6UPlQ+4D4IPUQ9ZD50Pgg9KDz0Pf4+bD2kPWg9pD1wPLA8kD3iPgQ99D1QPdo+ID1kPJg9DD3sPdA99j4YPnw9lD2APbQ9rD2kPeg+Zj7MP0Q/ID6MPio+ZD8Wv4Y/8MAIAIuAHL+Bv/qAQQDnANgBWgGWARkAtQDcAZgBvAFQAd4B6AHOAZoB6gHgAdQCBAIgAgACMAIMAkgCvAJgAmQCUAJcApQCpAJUAnwCkAKgAlQCpAL0AlYB6gHcAjYB7AGcAiQCdgGFAMwBHgFWAPyAaACsAQEAzYB1AB0AOT9yPss/Bf/6P18/Xj8IPyA+QD3cPdA+fj58Pfg90D4IPdg9jD38Pdg9jD2IPfQ92D3sPVg9pD2MPaA9kj4UPhg9VD1gPZA9yD2MPe4+uj6UPjg9gj4UPjY+LD7Kv4c/Rj6mPnw+hD7KPuA/b7/pP+M/oT96P1k/qAAIAMIBEwDnALMAZgC8APABLAFuAWgByAIeAZgBRgFOAWgBGgHsApQC+AIGAdoB+gFmAXwCHANsA2gCugHAAfYBYAGQAlgDAALEAjQB3AIcAmAB3gHuAaoBfgE4AcQC9AKUAioA0wBP/+HAGgEIAjQCLgF9AIL/0D7GPoE/TYAEgHXANIA4P3w+fD3ePkA+qD4qPko/Az8uPjw9/D5ePgQ9aD0gPfo+JD4cPmY+kD3wPJg8+D2cPdA9oD36PlI+QD3wPbw9wj4APcA+Fj5OPiA94D4QPvA+9j6mPqg+vj6GPtw+8z8XP5i/xb/+v7q/oz+/P1jAMQDYARsAsUAdAHCATAC2AMYBugFOATYA5gDPAPgA0AIkAugCbgFfANwA4AFEAgwCkAKCAfoBVAGEAhwCGAIuAe4BrAEQAQYBwAKoArACGAHSAbgBIAE6AVQCEgH0ATgBfgGEAb0AygEQAQmAAD+x/9EA7wDyAMYBHsAWPog97D7Hf/0/if/iP+c/Yj56PiI+uj68PeQ95j7xPw4/Ej60PqI+ED1EPUY+GD64PkY+LD2EPbw9aj4sPqQ+lD3wPSQ9ND1IPdo+tD8uPxA+rD30PVQ90j69P0m/vD72Pk4+cj7XP4oAcAAKf8w/Gj6WPuO/s4BaAQQBSgERwBg/Ej7Bv+YAWAEKAcACHAGSAJKAJIBEAMoBmAI8AgwByAF6AVwCKAKEAmoBkgEMAQgBdAGYAngC7ALcAd4BbgGeAcQBegEUAeACQAH4AXIB8gHAAQIAhgGKAfkA7H/NAEcA1gDZAN4BdgEn/84+7D7B/+VAHQBoAIwAlT+YPsw+yj9NP58/Vj7qPkg+Wj6kPsg/Hj8CPyA+KD1gPXA9hj5UPss/Zj7kPhw9pD3wPqI+yz88PpY+aD3gPhA+qD7MPu4+tD5APhY+Kj6WP2W/j7+YPzw+6D85P1k/oD+LP6s/vQBEASgBaACUP3A+sD6Qv6UAkAHmAdABnACqv/4/rAA4ASQBhAGmAVAB0AJ8AlgCOgEMgDc/VYB0AewC8ALsAr4BtACVgE4A8AEEAX4BaAIAAl4BoAGIAioByAEyAGYAdACeAUgCVAJQAXS/4T8UPwqAFgEoAUcA9IAhACo/6T9GP4+ASIBIv6I+wD+pP3E/JD9BP4Y+0D3IPj8/Iz+KPuw+MD3wPdo+Jz8Vv9k/pj6EPpo+VD3MPcQ+sj8sPpQ90D2cPeA+Ij5gP26/sD60Pao+Pj7sPs4+ij78v4m/oj8MP04/tj8IPs0/Ez+SPxg+Rj7Wv5bALAAUAPABPoBUv5E/Oj8cP4mASgFCAdoBT4BTf/W/84BkAPIBDAFAARwAuAC0AVgCAAJeAaABcgEgASQBNAHwAjoB7gGMAdgCIgFNAPQAH//CACMAwAK8AtACXgE2AJFADj/YAL4BsgHnAOyAWwCSARMAzgEYAWAA2T+ZPxu/kYBEAP4AngCkP/Y/Nz8Rv6J/6j+gP2o/IT8EPzo+rj5uPmA+1T86Po4+UD4YPjA+Kj6Bv5U/vD7IPr4+cj5GPrA+2L+kv7g+wD50PdY+Aj5yPos/ED8APto+rj6ePvA+uD5yPrY+8j9Gv4U//z/zP7M/YT8PP24/Vr+ggGIBGAESAGq/jT+tv7W/9QCOAb4B+gHCAR2AKj+Hv96AXgEYAbgBgAHMAa4BZgDNgDc/VYAsARgB9AIkAkgCMgE0AJgA0AGOAbABXgFWAWYA9wCoAUgCJAHEASEAQ7/MgBgAhAHgAqQCXAFiwAp/9r+uf8sAkAEcAUQAzIB5wCdADD/hv5R/1H/+PzI/Oz/2AJ8AgIAmf9Q/mD7QPs2/t//kP5o+uD6uPzc/LD7kPrw+bD2wPTg96j7Kv42/qb+iP+w+6D2cPXw99D6oPsA/cj+kP04/CT9iP0I/MD3cPeY+dj7Jv6CAEADlAKr/8D9lPzo+7T8Tf/kAUIAOP14++j8R/+OASAD0AJCAGz+9P8wBKAG8AU4BtAFWAP3AOIACASQB1AIcAiYBwgFcv8Q/h4BTAOwBMgGQAngB+gCHP7y/hABaAQwCMAKEArgBZwCuwC8ANQCCAaQBkgEzgEuAGT/cgBYAgAFGAQUANj8pP3w/4wBrAPcAzACTP5Y+hD6ePtU/TL/KAEIAq//EPow9VD1cPfQ+ob/YAQ4BVoBMPsQ9wD3WPl4/XgB/P4w+BD0cPWw+gkAOAM0ARD5MPHg8MD2uP14ASADXgEA/cj5SPoA/YT9uPwA/BD9zPxe/lkAlAJ8Atv/Rv7I/Qr+SP7CAJgDqAaQBnAF9AKnANb/DgAkAt4BUwD9/+wCIAaoBRAECAN6ASz+qP7QAnAJ0AuQCyALMAjcArb+cgD8A9AF2AW4BpAIyAcYBHoB1wA6AFQAvAGABBAGsAUoBKACoALwAiAEPAOhAMT9CPw4/bIBUAb4B4AFCALo/Tj7MPmw+uz9qAGsA8ACBgG4/Qj7oPho+FD5IPsg/cz9pP3Y/FD7APvA+8T8yPqo+LD3aPok/Xr+BgDz/1z88Pag9cD3wPpY/OT9t//S/tz80Ps8/Ij6cPgY+Vz+TAKAAdz+wPpA+ZD5CPyj/zABegBw/YD9igDIAhgDdAHf/3b+mPxA/CX/vAJABcAFcARwAUz9oPxfAGAEAAgQCGgG8gEw/mT+rgGABTAHAAmwCEAFdAIYArACSAL2AfQCIAQABdgGcAiIB1AEugEeAeABGAQgCFAJQAakAan/GgFwAjgE0AUYBvgD/ACqAZwCvAK0AogD+AQ0A3UAhv6G/jz/kv/TAEgD4AOFABD95PzE/KD76PnA+/j93P3w+/j80P4Q/rD7WPus/Dj8ePoI+vj7VPwg+zD8uP2c/Cj5IPdo+LD7mP2C/kj+oPvw9+D2UPkU/Zr/UAEIAVr/2Ptg+dD51Pzl/8cAAQDQ/Xj8BP06/9ABOATYAnf/nPx0/Mz+fAIQBSgG6ASMAG7+Gv+r/4gAWgEQBAAGoAZYB3AHgAbYAkD/3P2i/jAB+AUQCpALYAmIBWgAyP0C/r4AZAPABIgGwAjQCHgGaAbABlgFwv/g+/D7gP5gAZgF4AvwC0gGWgBk/vT9uP3w/o4BgAT8A1gEGASQA/4BCAAy/jD84PsY/HT9dP3X/5//lP04+2j7tPxg+3D72PtM/4r+KP1E/PD6GPnw9jD4wPk0/KD87P3G/rD+iP1w+mj44PUw99j4yP2IAvgDhAAs/Bj6sPjg+Jj4pPzk/az+XP5kABIBvP2A+8D6ZPzo/C7/AAIwA1sAfPy4/JT9cgHEAmgEMAK6AZQCUATYBVAFoAXwAj7/CP1y/8QD8AUIB6gHkAZsAfj95P6aAE8ASAGYBKAHkAdAB4AIQAlABxAGAAZwBAAD7AO4BmAIuAawBegE3AGI/WD8QP32/ygDqAcgCPQD3P0Q+xD8kP3M/i0A2gH2ATAC1gE6Acb/BP24+aD4ePlA+xz9Ov76/oz+IPy4+gD6YPrA+dD6lPys/Q7+EP2o+uD2UPWw9QD3EPgI+nz83PzY+3j8FP3E/Oj6QPro+qD6IPqA+8b+MAJMA3wDewAg+yD3gPag+ED9egFsApQB4v54/ej+igF0A4ADeAA6/gL+GgHABVAJEAvgCEAF+wDN/0oB3AP4BQAGYAWABLgEcASIBAgGyAcgCHAH0AaIBrgGmAZgCKAJcAmAB6gGqAWsAUT+6P0iAfgEwAjACmAKIAZcAswCmANUA2gD4ASwA6YBrQC2AXQCWAFXALD9WPog99D3oPtE/6wBDAKpAIr+FP0w+/j4gPfY+Bj7sPsc/Oz8lPxo+bD2cPZg9jD2wPbI+KD7sPwg/PD7fPwY/KD6gPlY+fj4sPkw+zz9jP44/Fj5mPjA+aj6+Pt6/s7/UP/0/ET9cv/l/yj/cP5Y/jz+Gv4RANgDAAWgA9QB+ADDABYA8QCwAnAEQAXwBQAGyASAAygDsARQBpAGgAX4BBgFEAYwB3AH8AboBLgDSARAB2AJ0AmgCNgF4AK8AJABqANgBegFcAYYBhgFwAMIBJwCrv+K/jAAdgFuAXgCoAQYBEoBEgBaAWABCP7w+zj9IP34+Yj5fPyg/gz9+Ppw+8D6APjg9xz85v48/Wj6+Pgw95D1QPXY+BD8dP3Y/WD9oPkA9SD0cPYY+mT99P7E/fD6oPjA+ID6OPug/KT9hPxI+XD36PhM/Iz/3wA+AaL+CPtQ+sj8dP80AbACyARIBigEBAOwAqAD0AJkAiwD+AOwA9QDQAZQCNAI8AbYBFwDzAKUA4AFAAjACpALcApwCcgH+AUgBQAGEAfwBlAGCAVoBLwCsAJgBCgGOAVsA8wCLAIgApgEWAbABogEgAFe/iT9Cv6NANAC1AEP/wD7oPeg9ij56PrY+zz87P2Q/Vj70PrY+iD66Pho+ZD7YPvY+RD62PoA+lD3IPUQ9YD0EPXA+Kj70PwI/Mj7KPvo+PD1gPag+Vj7uPvk/JT9SPtg9zD3UPvI/BD8yPvs/Y7+dP6VALAEgAU4A9wBKAKmAZcAgAJYBdAGYAbwBZAEzALSAagCLANAA+gEgAiACwALAAvADLALwAhACIAKsAqoByAGYAjACfgGkAYwCvAKAAYMA4AEyAWQA2ACUAXgBqwDQAKQBFgH2AaABBQD3gEVAOz/IAHoAiQCdQDs/jT+Qv4U/fD7SPto/Jj8DP10/fD8oPuY+Vj4CPhQ+ND3uPjA+HD4oPiI+Uj6IPpg+eD2MPSg8xD22Pg4+qD68PlA+WD3YPfQ94D30PaQ98D4GPjA9rD2UPjQ+Kj5NPxc/hr+zP2Y/UT/Yv5o/VT/3AFoAiAA//+sARADrAPgBfgHsAeoBkgFOAT0ArQDCAYQCZAKIAzwDaAM0AmQBwgGeAOwAhgGgAnAClAKAAqACjAKwAhAByAI+AZwBTgGcAiQCaAHEAa4BnAH4AWIA+wDiAMuAeH/kwC8AvQB/ACPADgAGv4k/BT9bv6I/bT8UPxM/cD7APmg+Oj5IPr4+Uj7HPxg+6j5SPhY+JD34Pfw92D3mPiA94D3gPdw+Qj6qPmQ97D2kPZw9RD1sPWQ9pD1kPUw9fD00PaQ+Ij5IPmo+qD7KPt4+sj71v/SAWwB2AG4AwACZf8x/4wC3ANgA2gEcAaYBbADoARYBugG+AaACeALIAtQCiAMgAwgCpAJ4AwwDcAJQAigCbAJMAaoBbAIEAsACXAHQApgDBAKgAeYB+AIcAdoBaAG0AmwCcAGqAQYBVAE9QCS/zkAUwAG/2r+VP/f/4f/7v4c/rD8uPsI+yD6mPjY+Oj6oPuQ+jD7mPxw+nD20PVY+Pj4cPcQ+CD6CPmw9fD0IPdg99D1APYQ97D1wPNA9HD2QPZw9RD2gPYQ9HDxAPIg9QD1gPXw93j7VP3A/NT9mP7E/YT8Xv7FAGwCYAToBKwDBAEOARwCuALwA3AGkAhAB6AEYAVgCIAJkAlQC0ANYA1wCyAL8AygDQAMQAowCrAJUAhQB6gHAAngCNgH8AcwCEAI8AeQBwAI8AeIB5gGgAYoBvgFOAaABkgGGAVwBcADDQBA/Sz+zP9q/pD8gv6aAGD+iPpo/Jn/nP1A+gD7LP1I+6D3ePio+/D6aPnw+cj7oPkA99D1APbQ9eD1OPhY+KD30PfY+MD34PVQ9TD2UPSQ8kDy8PJQ8XDwEPJg9FDzwPOQ9RD3EPZA9rj6IPyw+8D7JgB0AK7+Q/+sAXACCQB2/zMAmf8y/vr+CAQQB+AHQAgwCIgHiAbYBsAHEAvgDNAMUAyADIANYA2wDEAMEAyQCaAGoAWYBtAHMAhACdAKIAwwCsAI8AdgB3AHcAZQBmAIYAmgCJAFaAQYBSAG/AMIAygFiAVQAej8JP4UAdf/IP1RALgDywAY+0j7kP1o/Gj6APxWAKL/SPro+FD5kPew9tD4APvA+rD6MPpY+HD2IPaA9wD40PZo+ID50PfA9wj6UPow9qDyYPLw8QDtQOwA8GDz0PIQ9FD5ePkA9tD1MPpc/ED7FP2yAZwCOf83AKgDPAPO/y7+BQC8/vj8nP0MAoAGGAfYBxAJUAqwCNgGWAcgC1ANUAtwCwAOwA9wDEAKkAtwC0gH0ASIBpAIAAjAByAJoAkwCLgHwAdYB4gGoAjwCCgHWAdwCfAIoAVgBYAHWAcoA5wCIAYwBaD+HP3VAPABYP50/EkAXgEk/Sj7sP3o/Qj7YPkM/WL+YP0I/LT9Ev7A+5D5APtw+vj4gPgw+RD5kPeg9jD4iPkY+KD2OPgU/KD8APqA+eD6CPkg8iDtgO3g60DnwOmA8cD2MPew96D7GPmw9eD2uPq4/LT9SAPABwAGMATABtgFFQDw+6j8PPzY+Mj6ogEQBbAFUAgADNALsAfwCNALkAuACgAMIA5QDiAM4AyQDRAMQAiIBZAFiAaQBlAGcAYwCWAK8Ae4BrAIwAqwCWgHwAewCVAI6ASQBHAGGAdABqgGEAhoB7AEggEXACL/TABcAeYBlAGkAkQCV//M/Nz8jP3Q+yj6APuw/MD7MPus/Kb+AP6k/DT8IPtA+Yj4uPiQ93D3KPqA+4D6APkg+yj74Phw90D6gPuI+FD1EPdw9UDvAOqg6CDo4OdA7BD0cPnw+wD9OP2I+JD04PZg/Nj/9APwCCALIAe0Abv/fv4w+tj4OPvk/UD9AP9QBBAJwAmwCdAMAA3gCaAIIAtADuAM8AsQDqAQ4A2gCYAHgAf4BRQDSAPABnAJgAd4BbAG8AgQCLAGEAjACiAKUAe4BnAHGAcwBuAFCAfoBfAFAAXMAo8AFwDe//f/mv//ABAEiAKc/0D+bP4g/Rj6APtg/cz82PlQ+bD6cPrY+TD6fPwA/AD7sPro++D58Phg+hj7+PjA9/j40Pq4+BD3yPjY/GD7EPn4+GD5kPbw8GDugO2A6eDkYOcg7gD1GPkY/h4AWPtQ9dDzsPUo+Xb+4AWAC7AKmAaABJQBvPxw+cD6PPzo+mD7rv/gBBAHQAlQDYAPAA0gCjAK4AoACnAKwA3wDiAO8AyADNAKmAZcA0gEwAUQBWgF+AbwBxAI2AV4BkAJYArQB9AHkAjIB8gF+AQwBzAIiAcQBzgHqAVMA5oBeAD2/jD+ewCYAvQBdAJ4AygCSP1Q+rj7cPzo+dj40Psw/Yj60Pmk/FL+LPyQ+vD7JP1I+sj4KPr4+iD5KPiA+Zj60Plg+YD7aPu4+fD3uPnY+SD2EPLg8uDzgO9A6iDo4OlA6wDsAPao/lgBPP0g+nD2APUg9Bj6QAOACsAMUAzgCJQDBv9w+9D3wPcA+2D9uv6bAAAGoAsADNALAA3gDQALoAcwCZANUA7QDYAPwBFgEDAKsAW4BXgEnAGgApAGUAm4BpgEWAZACIAFQAQgCMAKsAfQBNAHUAlQBjgEIAfwCFAFEALgA6AESAEg/qX/VAE3AB8AbgHQArAArP08/OD8LPzQ+9j7kPvo+qD5+PgY+gD6MPos/Mz99Pyg+3j7kPvA+sj4qPgw+XD4kPnI+/D7MPqo+uz8YPvA99D2QPeA9ADvAO6g7+DrgOdA6SDykPbA+eD8cACA/JDzwO9Q9Ij7BADoBlANgBBQDLgEeABE/3D88PjA+ID9Jv9k//wBUAgQDMAMgAzADBALcAjQCMALAA1wDgASYBLgDQAL8AmwBrgBtwCwBGgG8AMoBKgHCAeEArACGAdQCLAFoAWwCJAJ0AVQBUAIkAnIBggFYAf4BSACsP+uABoBXP60/QYBtAMEAaL/kP+i/2z8ePpo+zj8EPvg+dj6aPvA+sD6iPuI+/j60PrI+1D7oPr4+lj7qPng93j4uPkI+hD5kPpY/ID7cPnQ+Jj5mPhA9DDxEPKA8cDsYOiA6EDsQO/A8zj7UgGk/fD38PPA82D0KPowBYAN8A/ADlAMoAVg/Fj42PkI+jD4SPs6AWgEIARoB4ANoA5gCiAJMAvwCsAHUAsAEiAUABDgDdAO0ArwApkA1ANQBVQCUAOYB6AHeALLAFgEAAb4A7wDAAfwCMAGOAVYBzAJqAf4BagFEAXIA2gCRAK+Ab0ALQASAHj+pP6k/9IAfP7M/Fz9AP1o+/D5iPrY+3D72PjQ+Ij6uPoI+QD5UPx0/YD7WPpk/Pz8SPqI+LD58PoQ+cD4oPro++D5MPr4+3D7oPeg9SD1EPMg7kDswOzA6yDooOxQ9pT9Lv6g+7j70PZQ8FDxDPyoBYAL0A/gEtANfAPs/XD8CPpA93j5av4qADT/KARQC/AMAAuADPAOEAxAB8AJkA/AEWAQ4BEgE+AOAAjQBNgEmANmAYQCoAUgBggFSARoBOADRAMgBFgGkAZQBtgGAAigCOgHGAZwCJAIAAUwAoAEEAWMAuP/dwDUAQP/NP5/ADACBgBo/cT8sPsY+XD4+PoY+zj6qPsg/fj6EPjI+Wz8iPrY+Mj7ov7Q+3j4yPoc/bj6UPdw+Zz82PpA9yD5QPvQ+nj4WPj4+MD2UPIw8ODvgOyA6MDmgOsw8tD3XP3qAcr+sPWg7xDyMPk0/wAI4BPAFUAQeAYAAUj8OPgg9lj6cv4JAPYB4AUwCdAKcAyQDIAL8AogCtAJAAvwDiAUQBVAEiAQkA2ACeACdQAMA7AFwARoBLgFOAbIAkH/aAEgBQAFMARwBnAJoAjoBMgFYAkwCKADCAQYBygF4AC8AQgFigEc/SL+ygGWAPT8IP5JAPz8EPmo+Sz9APxQ+Xj6fPxg/Pj4uPiQ+pj7sPnI+YD7iPz4+jj5+PpA/Cj6OPn4+hD8sPoA+iD7sPsA+oj4QPq4+VD1MPJQ8IDuwOpg6YDqwOyg8oD6ZP/0/Sj5kPXw8YDv4PWuAXANYBAAEiAQ8AqlAFD6wPrg+xj7APt8APgECAfQBpAJYA7wDZAJ8AeQCjAMgAlQDKASIBZAErAOUA4QC0AEBAGwAxgFyAIIA0AFWAOC/wEAkALUAqACuAUgCSgHkAQgBlAIgAb4BBAIcAlYBtwCsAMgBG8A4PyL/2gC/gA0/hv/lAAo/MD44Pg4+1j6EPiI+hD9hPzI+Uj7cPzo+pD3KPi4+sj66PhY+dj7FPzI+uj6sPuQ+7D5uPjw+RD6gPlA+bj5CPlQ90D1IPPQ8GDtQOpg6ODoAO2A9Kj8xP/I/Aj4oPIA7eDtQPjYBqAPQBHAEkAR+Aco/Fj6rPxo/Jj6/P5gBFgE/AOIBzAMQAsACRALYAzQCeAIEA4AE0AT4BIgFKARUAk8A7gDCAVcA0wDSAdgB1AC+P2M/3gB4v9EARgHQArQBswD4AZgCMgFQATgBxAKQAakAqwDuAXQAij/5QDgAl8ARP1a/tP/oP3Y+oD6yPvQ+ij6uPo8/ET8NP34/Cj8wPlA+ZD4kPiY+Sj6UPuY+6D7wPrY+xD9+Ps4+jD6FPxw+8j50Pqo/Nj6cPYA9dD0cPFA6yDqgOsg7MDtUPU4/ED9ePnA9VDxIO2g73D7IAeADSARABWgD8AEmP22/vj+6Phw+6ACsAVMAWQC8AiQC9AIIAkwDWAMsAigCWAPYBNAE6ATYBXAEVALCAeQBpgF8APwBMAGIAWbABr+wv7K/zoBfAP4BlAIKAbUA5AEoAVwBVAGEAnQClAIGAWYBFgFIAMgAQAC2AOMAej9Tf/sAUT8IPiA+nD92Plw9yj7hv+M/PD3kPuk/Qj6kPXQ94D6UPgw9+j6LP4Q/Ej7tPzY/GD5iPgw+qD5wPgQ+4T9UPs4+OD2oPVg8ODroOtA7eDswO0A86j4uPkg+bD14PHg7oDtYPLc/SAMgBOgEoANwAlcAQD5OPpAAUQDmgDkAcgHqAbgAsAFQAsgC+AIkAkQD8ANIAvADWAVQBWgEcAQ8A9QCzgFMATYBAgGmAWwBIgEQAJ3AGz+tP8sAxAG2AWQBFAEMAU4BJAD6AWQCXAKwAjIBYgEYAQYA+QCrANwBMgDRQAw/Vj82Ptg+ej4EPtk/ND7KPsE/Ij7cPko+RD5IPqY+mD7QPvA+Sj5WPqI+9D7yPqg+9j7wPnw9xj4EPt4+xD7MPrA+8j5EPSg70DwIPLg7sDt8PAw8zDzQPMw92j4IPXg7sDu4PLA9jD+YAkgEqASYAv4BO7+QPto+4D/wATABYAEbAL8ARgE0AhACzAOcA4gDwANkAuwCaAMABEgFcAWIBWAEoAKUAJc/UAARAN4AsgDOAa4BZL+2PvKAcgFgASEAvgGGAfsAXYBEAdQC4AIkAZwCMAGMAL/AFgFqAZ4BKgDcAPS/6j6EPoA+7j6YPnY+qD9KPt4+bD4iPrw+HD32Pgg+6j6KPng+bj6EPpo+OD5cPuA/Ej7OPsM/cj7CPpg+Ij6OPmA91D2sPdw9tDx4O9w8XDyIO8g7vDwsPMA80DyYPWQ9uDzIPNY+Nr+IASgCDAMMAyoB5ACygBrABkAkgH4AmgC//9wAhAIwAsQD8ATABZAEGAGdAOQCYAN4BBgGYAiQByQDWADpAHs/tD72ADQB4AJQAS8AmgFnAKM/vD/qAQgBOQB0ARACWAISAbgCLALcAi0A4AEcAdYBdACOAQ4B4AEVP6U/Oz8YPuY+GD5HP24++D44PcI+2D78PhY+Bj6SPsQ+LD3qPoo/ID6qPrA/HD92PrA+sj9zf8Y/Rj8mPsQ+hD38Pbw9gD3IPVw9EDzwPFg7wDugO/A8EDxAPJA9MD0oPPw8zD36Puk/nIBiAXgCGgHcAX4BEAEPAJ9ACwCbAJsAgwDEAbgB5AK4A8AFIARgAywCRAImASoByAWgCMAIWAYQBFgCYj74PJg/UAHYAhoBeAIsAkABLj9rv6yAbYA/AA4A0gGmAfQCfAKgAswCcAHyASAAVQCcAWoBoAFGAWoBFYBJPzo+fD5OPnw+LD5yPn4+AD5GPkQ+dj4WPlA+TD3oPaI+BD66Phw+qj9BP7o+mj6JPwo/Lj5iPuE/Ij6gPZQ97j4EPfg8kDyQPUA8qDuwO0w8IDv4O6A8HDyYPJg8VD0wPZg+sD8qgAgAtgD4AWgBhgGiAQ4BXAECAOeAdQDIAZgB7AIsAtwDyARIBCADQAJ8AZAB5ALYBMgHkAjwBqQDRAFhAJ4++D6oAXADRALwASIA4gHgAHw+tj94ASwBP7/LALgCGAIeAW4BbAKEAjgA3QB+ARgCEAGcAXwBugGzwCA+uD40PnY+CD3+Pns/JD7wPbA9zD6OPhQ9YD2SPmQ9xD2oPjA+wT9BPzI+/D7APoI+lj7hPwo/eD68Pl4+AD4YPYQ9ZD14PSQ9ODyIPIQ8jDwIO9A8EDxAPBQ8MDzcPeQ99j5AP7mAWoBMgGoBEgFQAR8ArgE2ATgAwQDGAVQB8AI4AsADyASoBEAEfAMmAcQByAKYBEgGUAgYB+gFqAJIADQ+hD6Gv7wBxAKaAeQBSwDxf+8/Nr+NAHqAaMAdALoA9gFKAbgCpAMYAhMA9gCyATQBIgFYAeQCcgFXgCI/dD8mPgw91D5WPrY+hj4uPlA+tD3oPbA9YD3MPbg9eD30Pqo+zD7WPyO/oj8cPoA+xz93PzQ+9j8ePx4+lj4gPew9sDzAPJA8nDycPAg8aDwUPGg74DvIO9g75DwkPS4+LD7Yv7MAH4ByAAAAUwC2AOYBCAF2AUYBWgFKAbACaANABHgEiAS8A8ADHAIUAcQC2ATgBxAIWAfQBgACwz/+Pmc/QQDeAYgCfAIWAVqAKT+bwDh/3b+yf8JAMEAcAIACOAKkAvgCbAIwAbsAhgDqAfACyAKcAjQB1AGPP9A+kj6jPy4+gD4MPqQ+1j5IPbg9lD4EPfA9OD1YPew9lD2QPms/OD8jPys/DT8CPuA+jz8aP3k/OD6cPoo+WD4sPcQ98D1gPSQ8oDw4O+g8IDxEPGg8LDwkPAA8aDzcPgw/Ib+vv9AAfsA9v9+AAwCGARQBSgGSAbgBsAIcAsQD+ARoBPgEeAO0AtQCoAKsA7AGMAfgB+gGIAQYAQI+FD3pwDQBrgHYAcQBwgFQP3w+Gj9mv4o/WT8MAH4AygDoAXQCcAKMAaIBNAEQAWYBZAH4AnwC5AJCAfIAtT+cPpw+fD5qPtI/Uj7kPgg9oD2YPTw8zD1QPcA9lD0oPWw98D5MPo4/Kj8QPuo+Zj5ePoY+8j6yPuI+/j6qPqA+ZD3APWg87DxkPCg77Dw0PEA8sDwAPHA8cDxoPKQ9aD5YPug/Db+Bv+A/93/tgAQA7AEeAZIBwAKgAyADuAOIBGgEqAQkA2ADDAPgBHgE8AbQCQgH2APhANI+wD5sPcsAtAMABBgCFP/qP6Y+QD1sPW+/qACGAO0ARgFyAYIBigG8AcwB1AEyAOQBXAI4AnAC7AMUArwBH8APPww+mj6qPwE/jj+gPtg+QD3sPQw8wDzsPMg9KD0kPaw+MD4sPjQ+Fj5qPhQ+Bj5cPoA+8j7qPxs/Tj9+Pv4+Sj40PUg9JDzsPOw8zDzMPJQ8TDx8PAw8WDygPQw9tD3yPnw+3D8WP2M/h0AQAFcAlAEOAYQCKAJMAwADwASoBGAEfAPQBAQD4APoBMgHEAiwB5gF1AP+ARA+cD4DANADUAMgAdQBWsA0Pdw8yD2YP3U/eD9Xv8MAzQC9AGQBBgGmAYABSAEYAUgCCAKgAsQC+AJ4AYkAqD+uPzY/dD+/P7k/ZD8kPog91D1kPWw9HDzsPJw87D0APZw98D3MPfA9eD10PYw91j4MPtc/QD86Ppo+yz8gPoY+Sj5EPkQ99D0cPTA9ODz4PGw8GDxQPNg9JD1sPZQ+ID48Pfg9wD6iPyW/lMAYAIYBbgGQAfACLAMwA/AESASwBNAE+AR4A+AEiAYAB8AIoAg4BhADTwC2PpI/UADoA2ADlAJMAQs/2D2sPEQ9HD7iP80AGEAbAJUAooAZAF0A8gE6ARIBdAFUAgACzAMIAvgCOgHPANo/MD7Nf9wAiIBLACA/0z8kPaw8pDzEPXg9GD0UPbg90D3sPVw9JD0MPQw9XD2+Pi4+9D7OPt4+nD6KPpo+Uj5kPmA+ZD5ePig9+D2UPXw83DyAPJA8yD1EPdo+Fj4IPnY+Cj5SPlA+vD7WP3f/3QC6AWwB+AJ4AtQDaAOgA/AEMAQwBDAEmAVQBmAHMAgYB/gFjALrAON/4kAeAWwDuATcAuoA0j7EPcw9FD1wPo6/wwC8QBa/xX/hf8LAD4B7AGgBKgFeAWABiAKkAwACpgFMASUAi0AMv60ALwDnAMOAVz+iPvw92D0oPKw80D1kPXg9QD3sPXQ9ODywPHg8QDz4PVQ96D46PiI+bD5oPh4+Pj4YPkY+GD38PfQ+MD3kPZQ9kD2kPQg86DzAPaA9wD5KPo4+kj5WPjg+HD5qPuc/mADQAUgBeAG4AmwClALAA9AESASoA/AEIAUYBjgGuAeACEgG0AQAAj1AFADYAjAD+ARkA6gB7D9oPUg82D2UPuuAHABUAJE/Rj5QPfg+uX/ZAJoBQAFNAOMApgDsAUABZgEAAUQBDACQAE0A6AExAKmAAn/gPyY+aD3oPcQ+BD3gPWw9YD1YPTg8lDxwO/A8ADzUPSw9aD2APeA9mD1APag9+D44Pco+Cj4QPiQ97D48Plg+nD4cPZQ9sD3OPgo+ED6mPvQ+eD4aPnw+kz8XP0AAfgCKATQAjgEwAZwCPALwA+QD6AQ4BBgEUASwBWAHKAeABsgFyAT0AyAB3AJABHgEMAMMAg4BA//sPjA+nT+DAE2AIP/pPwA97DzgPbA/UQCwAUwBrQDmgCw/Qj+oP9UASwDUAboB2AIOAZEA2oBvv5M/Rz8DP1g//z9IP1w+uj4APjQ9YDz0PLQ8rDxoPIg9JD2QPbg9GDygPKA8gDyQPOQ9oj4kPgQ9xD2UPaQ9vD1sPY4+AD5YPhY+Oj5qPpQ+gj6IPv4+nj6gPrg/BL/vAFQA7AEIAQYBMAE4AXgCNALgA/gEAASYBOAFIAToBRAF0AZIBaAE2AT4BFADbAKEAugC3gG2AN4BHQCav/y/iwCkAIo/xj5APdw9mD3+Px4AsAFhAKw/zL+0PoY+Zj6cf+cAygG4AUgB7ADBgFE/wb+/P7s/QUADv/O/lj+wPzA+8j6EPmg9iDzgPDA8mD1YPcQ+FD3kPWg8UDuYO6A76DycPXQ9nD3MPYw9DDzUPJg9ED2UPfw9zj5KPrg+bj5qPq4+9D6gPto+yD9cP6xALQDMAaIB6gHgAbgBAAFkAYQCYAPgBTAF0AWwBOAEWARwBDAEsAXABlAFYASoBDQC7gHGAawCMAHAAZABZAGYAXwANj9+Psg+dD2aPpI/9YBggHQAQgAFPwo+Tj4oPu8/X4BKAXABcQDMwC1/wcAQwB7ACQBEgGj/8T9SP1c/dz9qP4M/WD6cPXg83DzAPSw9pD4uPjg9eDxAPAg78DugO+w8pD1APVw87DywPEg8nDyoPSA9vD2UPYA9zj42PjQ+YD7iPzo/Ez9YP5i/4gAQAOABmAIwAjwCIAIKAeIBxALoA+AE6AVQBcgFYAR4A+gEGATQBVAFqAWwBQAEPALMAlwCPAHQAhgCfAJQAlYBaoB0P4A/ED6+PrM/ZgAJAFIAOT+MP34+rD4KPmY+vj8oP98AoACTgDw/Tj9VP2a/hIAxwAbAKT+gP08/Lj8OP0e/kD9KPvQ97D0MPPw9OD3wPmg+PD2cPRA8WDv4O7w8WD00PTQ9PDzAPLQ8IDxkPMg9tD2UPbA9dD1EPeQ93j5wPuw/Wz9xP0G/nD/XgFsA1AGwAiACLAH0AdACUAKsAzgEOATwBVAFQAVgBJgEIAR4BOgFUAW4BTgEkAOAArACGAJQArwCTAKcAgwBjgCpP/Y/iz9qPwE/Qz/BADz/8D9LP04+0D5qPjQ+Gj79Pya/kP/g/+U/XT8pPys/Hz9YP0g/UT9uPyE/IT8oP20/dT8uPpw91D1wPMA9Sj42PoY+yj5wPUQ8kDvYO+g8eD0YPZg90D2EPSg8FDxIPMg9LD1IPfQ9wD3kPYQ94D4APp4+xb+1P42/sr+9AFsA0gFGAdYByAIQAjwCVALIA7gEGAUIBVAE6ASQBHgEMARIBRgFuAUoBIgEHANoAqQCRALgAsQC7AI0AU4BOAC0gChAKz/pv4Q/vz94v50/jT+VPz4+xj7SPkI+pj77Pw8/dT9+P0I/YD8eP1e/iD+tPyk/Bj9NPwg/LT9V/8E/kT8kPpg+OD2YPbA98j5IPo4+RD5wPZA9GDyQPJA89D0kPaw9RD1wPOA85Dy4PJA9ID1sPUQ9iD3APew94D30PoI/Dz8fPy6/gsAFAKAA0AFGAbABvgHEAjgCZALcA6gEEASYBIgEQARABBgEWAS4BLAEgASYBCgDVAM4AvAC2AM4AvACRgHKAUIBDwDnAKiAYgBwgDs/gz+6P2g/YD99Pys/Oj7wPrw+bj6wPvY+6j7NPyE/dj80Pto+zj7BPyw+/j7PP1Q/Qz8bPwU/DD7cPoI+kD6EPq4+Wj5WPnA+FD4CPhw9iD1sPRQ9cD10PUw9qD18PRA9BD1YPWw9UD2cPfw9+D3CPjI+OD56PlA+/D7NP04/g4AGgFgAtwCxAOgBPgEQAbwBjAJQAuwDJANwA0gDUAMMAxwDOANgA/wDyAQ8A7wDHAMQAwwDMALoAsQC/AJcAhYB+AGeAYIBbAEGASIAoIBngB5ADsANP+s/rz99Pyc/CD88PtQ+5D7YPtQ+/D6iPqw+mj6aPoI+lj6+PmA+oD6KPpw+lD6gPpA+lj6OPqI+lj6WPqQ+oD6gPp4+qj6WPo4+jj6OPqQ+mj6cPog+iD6QPpg+oD6mPoQ+2D7yPvQ+yT8MPxo/PD8fP30/bD+iP8QAHIA0gBWAWoBGAK4AnADGARoBMAEYAXgBeAFUAaABtgGMAegB6AH4AcwCEAIYAhgCEAIEAjoB5gHeAcYB/AGmAY4BqgFOAWoBDgE+AOgA4QDLAOwAiwCsgE6AdAAZgA4ACgAof9P/wf/yP6e/lz+IP4u/gz+mP04/RD9EP0k/Uj9RP1s/Sj9CP24/ND8rPy4/NT8CP0I/bj8qPyo/OD87PwA/Qz99PzY/Lz8xPzU/Oz8AP3c/Cz9vPzA/HD8YPwo/BD8SPxc/Gj8WPyU/HD8fPyU/Kz83PwQ/Uj91P0s/jr+nv7c/hX/U//Y/1QAzgAUAYgB3AEwAmwCkAIMAzgDlAPQAyAEYASABJgEqATwBOgEGAUQBUAFUAU4BUgFSAVoBRgF4ATABJgEeARoBHAEUAQQBLQDTAPkApgCfAIwAtQBrAF4ATYB5gCCADUA//+y/2b/Rv8j/+D+wP6U/lT+Nv74/dD9zP2w/Xj9bP1g/UT9HP3k/Mj8zPzA/Lz8nPyM/Gz8QPwc/AT88Pvg+7j7uPu4+5j7ePtw+4j7kPuY+7D70Pvw+xD8VPyQ/ND89Pww/Xz9xP0K/nL+0P4U/23/0/8tAHsA2QAoAYwB5AE0ApQC5AJEA5wD/AMoBFgEcASQBKAEyAQABRAFIAUgBTAFIAUQBegEyASoBJAEiARwBFgEQAQgBOADoANoA0AD8AK8AnwCTAIYAtIBogFWARoBxgCRADwAHQDG/43/Rv8R/+L+kP5q/kL+IP78/dD9uP2M/Xz9SP0k/Rz9DP0I/ez82PzA/Kj8oPyo/Kj8qPyk/Kj8lPyM/JD8nPy4/MD84Pzs/AD9EP00/WD9fP2c/cD97P0e/kz+gv66/ur+KP9u/6D/yf/u/yEAVQCHALwA+QAuAUQBZgGEAaIBzgHsARgCSAJUAmwChAKQAqQCsAK0AqgClAKMAogChAKAAmgCXAJAAigCHAIQAv4B7AHQAcoBlgF2AWQBRgE6AQAB+wDsANQAoQCUAF0AKwDw/8D/vv+F/3D/bf9g/0D/Df/6/sr+pP6W/pT+nv6M/n7+cv5e/lD+OP4u/iL+Hv4k/iT+Dv4E/gT+CP74/fj9Bv4Q/hr+Iv42/kr+XP5w/nz+mP64/tL+7v4E/y7/T/9z/53/x//y/w8AJAA6AFgAeACYALUAxgDXAOkA+gAGAQoBHAE0AUABNAEoASYBLAE4AUIBMAEmARwBGAEWARQBHgEEAf0A7QDdAM8AwgC/ALQApgCZAJcAiwCBAHAAZABTAEsATABSAEkAPAA0AB4AFAAIAAcABQAFAO//5P/X/7r/qv+N/37/ff98/2//ZP9n/2//Yv9T/1z/Vf9T/0P/V/9W/1f/TP9R/0v/S/8//zH/MP8V/zL/Mf9K/0r/Qv9b/2X/Yv9g/33/i/+L/5j/rv/T/9L/3//1/yAAIwAhACsATABrAH0AkwCjAK8ApwCmALkA2QDhAPAA+wD/APQA3QDJANUAxQDOAOAA5ADaAMoAwwDIAMQAtQC1ALUArACrAK8AqQCaAJcAlgCDAIAAbQBrAFUASwBCADAAJgAeABkAEwADAOr/4v/f/8r/r/+x/7f/q/+c/5b/lP+U/47/jP+E/3b/Xf9a/1T/WP9d/2D/Wv9K/1D/RP8+/z3/Nv9H/07/Uv9g/2H/V/9S/0z/Uf9r/33/gP9//4//m/+V/5r/mf+k/7n/xv/a/+b/7P/2//n/CgAjADoAQQA/AE8AWwBpAGkAeQCPAJEAkgCQAJcAoQCnAKIAlQCUAIYAggCQAJsAngCaAI4AiAB5AG8AaABhAFYAQQBBADEAJQAcABwAEgD///r//f/0/9v/2f/j/+3/6//q//L/8f/m/9r/zv/T/9D/1//g/+r/5f/Y/9v/1f/J/8f/1v/i/+r/6f/x/wgA/v/0/+n/4f/e/+j/8v/7/wUA9f/e/83/1P/c/9n/3v/6////+//4//L/9v/u/+z/8f///wUAFgARAAQAAQABAAMA+v8HAAsAFwAjADYAQABIAD0AQgBFAE0AVQBYAF4AYQBoAHUAdQBpAGsAZQBdAFIATABDAEYALwAlABQADgACAPz/CgD7//j/3P/j/9z/2//V/8b/0P/S/+P/4//o//X/8P/j/97/3//z/+//6v/9/wIA9f/z//f/+v/9///////3/+//7//q/9//5//v/wMAAAAFAAEA+P/x/+3/AAAAAA8AEAAHAAYA9P/4/+3/9v/w/+b/6v/k/+j/6P/m//X/8f/r/+v/7//7//T/7P/v//v/+f/0/wEADAACAPP/+f/5/wEA/P/7/w4ACwAJAAoAFgAjACIAHgAiABkAHwAvADQAJAAkABoA/P/3//D/8//m/87/1P/M/8T/sv+s/6T/m/+h/6H/rv+t/7b/vv+6/7T/v//Q/9j/4v/j/+f/3//V/93/5f/1//v/CgAFAP//8f/o/+X/3//e/97/6P/k/+j/5f/Z/+P/4//k/9v/0//S/+f/6P/s//T/9f/0/+7/7//w//3//f8AAAQA//8FAAcADQAOAA0ABAAKAAgACgAfACIAIgAdABQAIAAlAC4ALwA1ADgAOAA+ADsAPQAqADYAOAA3ACkAMAApABMABwAKABEADwAIAAEACAD0/97/5v/m/+L/0//K/8D/uf+d/5P/jP+G/4z/nv+e/6T/mv+j/6D/qP+T/6z/q/+5/83/0P/V/9T/4//x//f/7P/p//T/7v/3//v/EgAUABYAEAANAAkAEgAZABoAIAAiACMAIwAhACUAHwAvAB0AMQBBAD0AQQBDAEYAOQBDAEwAYABbAFAAUABWAE8AVwBhAFgAVABGAEYATQBMAFEAXgBbAEkARAA+AD0AOgAyAEgATwBCAC8AMQArABUAFwAfAC4AGgAVABQAEQAAAPD/5//q/9j/wf+8/7v/tv+z/6j/l/+R/4j/h/+I/4j/ff99/4L/eP9+/4b/jv+a/6D/nP+k/6L/pP+p/63/q/+9/7n/wv/K/8T/xf/O/9z/5v/p/9n/3f/o//D/7//5/wwAFgASABMAFQASAA8AFQArACoAJgAlADYANgA2AEcAUABTAFAAUABMAFIAWABZAFMASABCAEoAQgA0ADgAQQAyADUAOQBKAEsAKwAjACwANgA2AEUAUwBVAEgAPwBDADgAMAArADgAOwAyAB4AHAAOAAcA/f///wEA6//r/+H/1P+9/7P/uP+3/7X/rv+u/63/pP+Y/5H/j/+R/5H/k/+b/6P/tf+z/67/uv+u/6b/rf+r/7n/r//A/9b/4P/i/+D/5P/o/+r/6//4//z/+/8GABAAIQAcABkAJQAiACIAIQApADgAPABCAEgAPAA+ADcAQABAAEgAUgBMAFMARwA8AEcAOwA0ADMANgA8ADQAOgA7ADUAMQArACYAMwAvAD8ASgBFAEQARgBIADkAMgAnADkAMQAwADUAIwAaAAIACAAJAP//9f/f/8//vP+t/7L/tv+//7P/sv+w/5v/kv+J/3z/g/+D/4j/fv9z/3D/dP9x/3T/bv9v/3P/ev+L/4H/kv+Y/6r/of+r/7X/zv/Z/9H/5//W/8f/yf/M/9//4v/n/+n/8//7//T/+/8HAAIAAAAOACcAKgAsADgAQwBPAEoASQBSAGIAXgBlAHYAdABwAGgAZABfAF8AYQBhAF8AZQBwAHAAcQBoAF0ATwBFAEcAPABBAEMANgArACYANAA6AEYARABBAD0AOAAmABcAGQAcAB0ABgD3/+b/3f/K/7//tv+t/6r/pP+r/6H/qf+g/6T/pP+r/67/of+c/6T/p/+l/67/wP/I/8n/vv+6/8X/x//L/9r/7v/y//n/AwAKABUAEgALABAAHwAkACEALgBDAEsARABHAEUAQwBAADwARwBPAEIARgBDAD4AOgAzAC4AMgBAAE4AYQBrAHkAdQBpAFwAVgBYAFgAUwBTAFoAXgBcAGAAXwBiAFIAPAA3ADoAOQAxADMAMQAqACQAIQArADAAJwAbABQADAACAAAABQAIAP7/BgACAPn//P/q/+T/0P/W/9H/3P/X/93/3f/U/8X/vf+9/8r/yv/S/9z/2//H/8T/yP/J/8b/zf/l/+7/8P/x//r/AwD3//b/8f/v/+v/8//+/wQADQAXACgAMwAhAAQA9P/0////+//1/wQAGQAiAC0ANwBDAEEAQAA3AEsASQA3ABgA5//H/8z/wv/S/8z/8P8aAA4AAwAPADIASQAyAN7/pf+H/6D/wf/l/w8AOABYACkABQAAAAEAwP95/4X/q//C/7//2P8nADIAEQDk/9T/0f+1/5j/if+c/8T/wf/Z/9r/0//L/7b/wP/W/8n/7f8PAPv/8v/1/+f/2//T/+H/CwDm/7//8v8SACMAKAADAAYAAgANABcAKwBDAI8AnQCbAJEAiACBAGcAIwAFACAAFwAEAPD/LQC/AL4AUwBKAMQA2wC6AHQAjQCsAFIAQwChAMcAKADQ/y4AQwDv/9P/SQCRACQA0f8dAGgA0v9F/7n/3v+l/9r/FwBtAHEAdQC2/zT/sf+TAPT/xP6C/kcA6wAM/u7+RgG0AXL+vP4ZANIAxv4I/W7/oQCX/+7+BQDrAHwB1f/U/oD+Lf8BAEz+TP1Q/sX/lv5Y/aX/fAK0A/YBDANABlgF5AH1APz9cPnA8uDvYPMg+KD9dAP4B/gG8AZwBxAGeAL8/iz+9P3o/Eb+ZAMoBiAGEAcQCEgGIAP5AFoBWP7Q+vj5GP53/9v/9QC4AxAFagEXACoAkwDo/ZD7OPuU/MD8gPyo/u//jwAqAO7/1wDU/vD96P2a/lb+Cv7+/soBgAFkAQgDpAO4A8wAHf9XAC0ArP0A/Iz9ZP4V/xz94//qAZwCDgG1/+4BYgF+/2D9yP5r/97+SP1Q/14BuwAv/x//QgAfAAL+sPzO/iL/jP6W/iIASAKQAnwCkAL4AuQCAAJZAIr/cf82/5L/Z//EADgCZALUAegBCAOEA3QCbAEWAfj/E//s/s7/FgEyATYBhAGCAV4BlgAnAKr/TP/8/vj+OP/N/zoA4ACwACIBmgHoAJ4ABgFmAfwAxv9o/7L/v/9N/y4A9QBQAXcAYgAuAbgA9/88/9H/2v/6/hX/2v+SAJUAdwBqAHgAsP/c/uD+zP66/nT+Cf8PAH8AfgDYAPAAawCu/1//af8B/2T+Rv4i//r+4P6H/40A9ABaADIAdQD1/+7+5P6W/5v/HP+w/jv/QADsAOQAAgEQAWsA2v9Q/3j+sP6w/gL/uv6X/+P//AB2ANgAcACxANAAGAAs/7L+kv7g/tr+Ff//ALsAEAGKABwBPgFhAFL/1v/U/4z+Fv4e/x4AkP+n/0QAhABKAFj/XQBdAEj/Vv4G/nr+ov5M/xQADAHYADwBjwCa/+b+cv56/uj9VP5Q/44AzwCRAP0AfgB+AF7/Mv7i/vT+Df/0/lD/qf8cAN7/mQDhAGQAk/8UAJMArQCEAHAAfgAfAGUAxwCqAaAAgwD8AN0ARgDK/4sAFQBR/+7+YP9hAH8ANQBIAXIBfwD8/0MAsQAXACoAz/8yAYsAsQDVADoB4QCwAOYA1QAuATAAdAAWAAoAAgAMAD0ACwCu/6//o/8DAMr/GQD3/0D/iv+R/2wA1gAtACwALwCY/+7+9v5L/+L/ZP+i/vr+hf/i/4z/mv/s/wEAC/8W/oT+vv4w/wD/Vf/2/77/QP8S/yb/Q/8//+r+ev++/xUAagCBAOAAVQCa/13/yv7i/s7+pf9uAMoARgG6AdwBBAHR/+z+zP7o/fT9Zv5q/vj+nP/9ADQC3gEWAR4BpwCw/7r+1P7g/4oAWQCkAKABigFGAc7/v//R/43/xP5H/1UAfgA7AMX/ZAEgAkwBFgBJAJMAg/+4/iH/GgA+/6r+5P4tAPX/pP9bAFEAlwCc/6IARAGTAD4Ahf/6/pr+aP5j/+b/ewAoANn//v8DAEgA+//m/7f/qf8iAOz/fgBFAEwANgB2/3n/pv/I/+r+Yv46/nT/e//O/64AOAGDALT/Z/8KAGEAlf9M//X/cAGYAYAB4wAGAZ8AA/9B/wMAiQBEABwAiwD7AH3/YQBjAJABBQD2/wMAPQA9AAkA3wDiALUAcf9mABUAUgDv//X/VgF0AScA1f9U/woABv9+/nr/xgBgADr/Df9BADEAhv94/7QAGAEp/1j+4P4z//L+av5r/xgA5v8zAJQBXAK8ARYBJwBqAID/n/86ALEA1QCaAQwCtAHUAHn/MABL/+b+VP72/iIAr/+M/8r/SgFEAbMAyf/m/7IAwwAwAaMALAFSAXQABQBIAJIBfgEcAA7/uf9/AN4AZQDpAGsAi/9a/yb/rv6A/tD+j/8+/0//lP/7/0j/Lv+g/nr/TP/u/hQAfgAxAHD/y/+n/9T//P9fAFYB6f/B/1T/OQBmALUAgAGAAacA6//D/8//owDg/y0AMP8f/xL/Y/9K/zQAnf8w/0z+dv53AN3/zv/6/rL/bf+M/gj/3wChACH/8P6G/j8Azv6k/vz/SgGSAXgBIAJUAvwANv/s/n3/yP8u/0v/jgAgARQBLgGgArQC9AFCANr/Sv+Q/qz93P3p/3oAlAHqAWgD6AIqAQ//MP5E/Rj8wPvM/Br+Dv+yAFACOAQoBKwCWAFEADj/jv4P/yj/6f94ANYANgGOAbAC9APwA5wCdAJoAkMAjP7g/Fj9KP2k/KT9R/9YADL/iv7g/ZD9ZPw8/Az9wP2k/nr+PP/rAAgCUAIsAigC9gAQ/6D9KP1s/bz8oPtI/IL+7P4bABsAQAGqAC4AyP9SAMz/bP6s/vD+zv+A/68A5AEEA3wClAGgATgBvAHCAFEAFwA8AEYBHgG0AawCIANoAoIBzQBeAOn/8P7e/nz/6v9c/0r/yf9hAEABfwB+AGkAMADg//L+Rf+V/8T/Hv8R//b/2ABGASACKANcAhQBd/9M/3f/C//Q/rb/lACjAA4BogEMAgQCfAG5AFD/6v4G/yD/Cf8R/4j/nQBbAMz/JAEyAVAA4v6W/hcA//+4/8b/bgF6AYoAlwDOAawBowDm/9sAqAECAGP/DAAMAV0AiwC+ADYBuP43/1cAXgGLAAYAmgFGATkAbP6U/1IAhf9u/iP/2/9nAIwACgDjAIEAEwC3/w//cP8nAIYAwv87//3/uACGAHT/vP8YAaYAr//s/i4A+P+M/8T9bP5l/2v/PP/A/pT/ZQA4AMH/5P/e/z3/pv6G/rr+JP9d/7D/3v+a/0L/Pf8p/0r/7/8HANj/s//T/ysAp/+Q/6T/lv+J/7f/zf/7/8T/NABtADkAIv8J/zr/+P4y/mb+mP8qACsALf+9/wIAq/9t/1H/JgDK/6L/Vf/8/4MASAAHAA4ALgCd/4r/yf9uAJwANwBnALwAwQCqAH8AtACgABwAHQBEAIsAlwBbACkAxv/K/4v/rP98/9f/TAA9AAMAKABTAPX/WP/+/pL//P9e/y7/zv8zAJEAJgB/ALkAOAB3/0f/zf89AFUAXAB7AIMAQwBlAJ4AUQAmADAAvv9R/zX/8P5a/1n/1v/R/yEA0/8bABUAgv8F/xH/Hv8n/2b/6f9bADAABgDs/yYA6P/1/0oAGwDj/4D/MP8s/0D/kv/l/+r/JwCDAJAAVQDW/6H/Pf/y/l3/rP8wAGcA7wAmAdMAvACjALYATwCz/yb/9v6s/i3/LADVAJQBwgHIAcQBsgFUAQQBTADN/9n/yf/1/+j/tgD4ACgBmAB8AEYB6wB/ANz/GgDO/43/VP8dAAgBjgA6AML/dgAsAB4Ay/8gAC8AMQA1ADEAlwBjAPT/lf8o/1r/2f9yAA4BCAHDAGMAhwDV/3D/Cv8K/67+cv7K/tb/gwDDACABGgGzAIn/gP+g/4v/2v74/XL+Df/O/xMApwBKAQYBbgDc/xMAAAALADf//P68/gj/qP+/AJoBzgHOAUYBWAHlAJ8A2//G/wr/ov4E/1n/lAD3ACIB2ACIAFEAAwAYAHn/hP/0/pz+rv5F/1r/V/+9/0YAHAGNAIEAcwACAKb/Ov9o/z3/4P7k/qb/CgDm//v/SwCBAI0AIAANALb/ef8y/zj/aP/2/7kAtgAUARoBSAFMAfUA0wCLAOz/M/8B/1X/jv8TAIYAFAHeAKkAJwBuAG4A7/9s//7+4P7y/gL/Sv8oAIYAqwBFACcA9P+E/1j//P4e/xz/R/+a/04AkwCVAM0AtACZAEQAKAALAOD/e/9c/1D/Zf+Q/7//9f9qAFsAQgAMAHL/e/+T/17/Yv9p/x4AWwCIAJ4AFAHzALAASgA/AEwAEgAwAGoAmwA/AOgAIAE6AecAxwC2AHIAhAD6AAoBVwBmAI8APgH5APYAjAE+Ab4AKwCNAOcAjQA3AGwAtgA5ACUAZwDiAPEAsQB9AGUAnP9R/0b/Zv/M/2P/qv/6/zIA7f/w/wQAPQDp/1f/+P4A/yH/0P7K/sT+Vv9N/2X/Zv94/3f/tP5I/nj+4P62/mL+gv4z/zv/K/+I//7/wf/6/lj+HP7k/ZT99P2S/t7+cv6E/vD+ZP+D/7v/KQAQALD/Z/+u/ysAEgAWADIAywCaAFQAoQBwAYYBCAHMAOUAcAECASgBbgHIAY4BegGgAbgBsgGoAbwBxAF4AZwBtgF4ASYBWgFaAWgBCAEmAZIBhgHEAVIBxAGgAW4BWgFGAWABTgGUAXQBrgGkAXwBSAH+AHoA7f/+/8//HgDU/7f/SP8P/w7/+v6y/pL+ZP5i/sT9NP1c/Xz9hP0M/RT9NP2w/Fj8TPzc/Nz8ZPxE/BD8KPzo+xj8QPw0/Nj74Pvo+zz8pPw4/aj9lP10/Yj9+P08/ur+Lf+P/6n/z/9rAJgAYgHuAUwCiAKQAsACTAOwAzAEgAT4BFAFWAVQBpAGIAdgB+AHYAhwCLAI4AhgCTAJoAmACZAJcAlACWAJoAhQCBAIQAhAB5AGSAbABVAEAATQBFgEYASYAjACaAKaACcAC/8c/gz88PkY+Sj4QPcw9mD2APaQ9PDzMPMw8yDzsPLw8iDyYPJw8VDysPKQ8wDzEPMQ9BD1wPVw9fD2WPiI+cD3UPhw+Qj6MPqQ+pT8TP0I/Uj9yP4eAKAAGQB0AfQB8gEsAhwD8ARwBVAGYAfACEAJ0AlwCqALsAvQCxAM8AzQDVAOoA6wDyARYBGgEUASABOgEgASgBHgEeAQwA/wDoAPkA6QDcAMcAxgDEAK8Ai4B1AGCATMAsIAXwDU/uD8APwQ+Uj4oPQA8xDwQO6g7GDqIOqA6uDr4Opg64DqYOyA7KDtAO+A7wDvAO/A8GDxUPLg8vD0kPZg9rD1IPfA+fj5kPnY+aD60PnA9xj5KPqg+pj5APo4/KT8yPtA/OT9MP6I/ZT9Iv/w/woACgEUA3AEIAWYBsAIsAowC4ALQA0ADsAOgBCAEQATYBTgFMAVYBaAFsAWQBfAFkAWYBXgE4ASABIgEaAPYA6QDWAMUAoACcgHMAfwBFwDKAIhAE7++Pv4+yD72Pk4+PD30PWw8yDyYPEA8MDswOzA68DrYOrg7IDxsPJw8xDzIPQQ9aD0MPaw9xD4UPYA97D3aPhY+XD75Pwg/Xj8QPvo+8j6gPqI+kD6APlA98D3SPgY+dD4CPmg+WD5sPhA+Cj4uPhA+eD5GPto/Lz9IP8IAUgDkAUwB9gHcAnACuAK8ApgDUAPABEAEUASIBTgE+AT4BTAFkAWQBXgFIAUwBMAEiARABHgDwAO8AwQDAAKgAhwBxgH8AV4BGgDVAKJAC7/SP5g/Uz9MPyo+6D6wPlA+cj4APgg96D0gPKg7qDswOwA7hDwEPHw9CD1sPUQ94D3EPfw98D3QPk4+TD3UPbw+PD5qPoo/Bj+ov5Y/Zj7CPrY+lD58Pfg9/D2sPbQ9CD1cPeg+GD4IPcA+FD3UPbg9OD2APcA9+D26Pjg+4T8JP73/3QDEATIBLgGQAlgCtAKkAtwDXAP0A4gECAR4BJAE8ASgBTgE8ASgBHgEcARoBBgD2AP0A7ADCALkAogC1AJ6AdoBjgFKAPUATwCQAKoAZT/y//G/qz9Hv7Y/dz98PsQ++D6OPnQ97D2APbQ87DwAO/A72DvYPMQ9lj5OPmw9Tj4MPjo+JD46Pkw+nj5cPng+Kj6iPwo/pb+3v4w/ej72Pmg+Ej5gPkw+OD1UPWQ9YD18PTg9fD2UPYg9fDzEPRQ80Dz4PNg9fD1MPZw9uD4kPvE/Ev/pwB8AiwDMAXIBzAJQAvwC5AO0A9gEAARgBKAEwATYBPAE6ATYBKgEiATIBOAEQAQsA8AD1ANkAtACwAKUAgQB9gF2AR0AzQDxAO4AoQBuQA5AG7+Rv6r/+T+WP54/Bz9yPzw+RD48Peg97DzUPAQ8ODvcPJQ9PD3OPr4+TD4kPgQ+fD6kPqA+lD7ePlA+oD5TPyU/UD/6v8U/tj9ePto+lD60Pnw+HD3QPbg9ZD1UPUQ9jD2APYw9KDz4PPg8hDykPIA9ID0EPSg9FD3MPkI+0z9nf/5AJ4BYAPwBRAIwAlgCyANsA1ADvAPgBFgEoATYBPAE4ASYBJgEsASoBIgEoAR0A9ADmANcA2wDNAKsApACXgHcAYwBRgFxANAA4wC3AEuAa7/XP/X//D+aAAY/zT9IP1g/aT82Pkg+Hj54PbA8uDvAPHQ85Dz0PfI+5z8oPqA+Pj62Ptg+wD7KPyY+2D6EPro/EX/lf86ATQBIAAU/dD6MPpo+kj5sPdw95D18PRg9DD1IPZg9WD0sPJQ8oDxEPCw8CDxEPLA8pDyoPNA9hD4QPr0/OD+vf+MALgC0ASoByAJMAsgDbAOQA+AEMAR4BLAEyAToBJgEqASYBIAEkAS4BHgEBAPEA6ADcAMsAugCiAJQAc4BugEiATgA9wD3AJ4AcABCAGTAIf/+/+nABAAGv5u/lL+aP3A+wz8kPxY+VD1gPRQ9JDzIPKw9pj8nP0M/Oj7cPxQ+3j7CPzK/lj9aPog+9D8+P5p/+oBdAPyAQr/zP0s/LD6MPlo+HD5sPVg9FDzMPRQ9SD0QPWg81DyYPAA7+DuQO8g7zDwMPGw8UDzcPTA9ij5yPug/cr+OABEAsgESAdQCXAL0A2AD4AQABKgEiAU4BPAE6ATYBPgEoASQBIAEkARABAgD5ANwAwQCwAKAAnoB3AGaASsA3gDBAMQArMATgHtAPj/o/98AFQABAAq/+X/OgD4/Wz8Hv6A/rD7EPng95D24PPw8iD2sPo0/ED94v4Y/2z8CPoA/C7+HP5Q/IT8uPtE/Cb+nADgAsYB+P/M/bD7+PiQ9+D3IPiw9oD1cPSA80DzsPIg9EDz0PEA8GDuYO4A7gDvgO8Q8GDxUPKQ87D0gPYA+Qj7ePwM/tv/hALwBBAIAAtADTAPIBBAEUAS4BLAEuASYBNgEwATYBKgEoASQBIgEfAPcA4QDEAKsAioB6gGiAVQBIADcALWASIB5QCCAND/6P6M/tr+QP8J/xv/oQDHAIv/5P4d/8X/NP70/NT8OPvQ9tDzgPY4+8j74P1uAawBlACE/KD8Af9Y/pz+jv42/0z9zPzY/+ACzAOoAvgA5P44++j4WPjQ9wD3wPXg9dD0APSw8iDzkPPw8sDwQO5g7YDs4OwA7aDuMPCQ8aDxAPPg9OD1EPdg+ED74PzY/oQBEAWgCNALwA3gDyAR4BHAEoASYBIgEoASYBMgFEAUIBTAE0ATYBHQDwAOQAsQCSgHmAbABeAEsAQABLADDAKjAOcA/f/q/oT9hv6a/pD+5v7uAIIBrQDmAJACiAI9ACr/YgDWAHj6YPeo+Dj6sPwS/jgE4ASwAgD/tP7FAGz+CP3E/rYAsP0U/UT9OgHkAhADxALdAFz88PdA97D2oPbA9bD2QPcA9iD0sPIQ83DyMPGA70Du4OyA6gDrwOyA7yDxkPFw8sDzYPPQ83D1kPdQ+gj8ov68AWAFwAggDNAOwBBAEeAQwBCgEOAQYBFAEmATwBTAFAAUIBMgEqAQwA6ADCAK4AfgBRAFsAQIBeAEQAQAAxoB/v+a/zb/kP5U/rj9rP1u/iUAwgFsATgC6AJcA5gBhgDaAPAAmv5g+9j6IPuA+5z84ALoBbAEdgBg/9oA7P54/mn/fQA5AMz9Qv6A/44BzAFsA8ACnv5g+uD3kPaA9vD28PaQ99D1oPRA80Dy4PEw8fDwgO/g7WDrYOog6yDtgO8g8YDxAPKg8uDyMPSA9sD4cPrI+9D+KAMoB9AKMA6gEKAQEA+gDtAOwA/AEKASwBRAFcAUoBTgEyAT4BEAEFANsAowCEAG0ASgBKAFWAZYBYADqgGW/4j9/PyQ/cj9qP1s/f7+SADxANABpAIEA+gB3gCAAAwAEv88/3b+Vv4g/dz9h/9CARgE2APABNwBVAAiAVIBbf+v/+UAaAGjAEQA+ADkAeIAnf8A/uj7aPig9sD2UPYw9vD1cPUw9KDysPHA8IDv4O9g7wDuAOzg6sDrAO2g7qDwoPGQ8dDwAPEw87D0kPbQ+BD7rP2jANAFIAtADsAPsA7gDOALUAtgDqARoBRAFgAWgBVAFKASYBGgELAPwA3QCdAHkAUABuAHYAlACbAGQAOk/8D8KPuI/HD+4v9VAN4ADAI+AUABzAKkA1wDMgGbACoADwCEAN4BoAIwAowBqgHoAZ8ASgEsAjgDrAJ2AagCwgEcAfIAvgFAAlIBJAHtAKP/HP6Q/CT82PvY+ej4cPcQ9hD1cPQg9GDzEPKQ8WDwQO+g7gDuoO0g7WDt4O1A7sDuoPCA8SDxUPGg8hD10PVA99j5hPzQ/VIBIAnwDbANIA5QDrAMgAuACrAPwBWgFsAXwBZAFmASABGAEiASsA+wCxAKkAhQB6AHwAigCbAIuAQgAaz8KPtY+hT98v9+AZcAk/+RAKkA5QDN/6gBnAKMAbD+DAAQAnAC2AK0A4AFGANMAToBdAIkA8gCcANwBcgECATIArgCnALuAdACmALwAXUAV//8/cT82PpY+hD58PfA9sD18PSg89DzAPPg8VDwYO7A7cDtAO1A7WDtgO4g70Dv4O/Q8MDwYPCQ8oD0kPVw9YD3WPvQ/nUAIAYgDVAOAA1QCSALoAgACqANgBQAGcAUoBOgFIAU4A8gD9AOwA/QCzAJcAmACZAIMAjwCRAIxALA/fj7GPwQ++j7yv/IASIBFv/4/l7/dP6k/S0AXAHpABUAjgHoA+wDEANIA7wDPAKeAegBhAMYBDAFoAYoBwAG6ATYA+wCgAKYAqwDAAQEA9wB1QDs/Sj7UPrg+Uj4kPbA9aD1MPXQ8wDzAPJg8KDuQO0A7eDr4Osg7ODsIO6g7+DvwO9A73DwMPGw8DDzkPVQ+Ij4GPv6/yAFsAeACmAN4AwQCDgGcAuADyASIBMAGGAZwBNgECAQYBEAEeAOYBDwDkALoAewCJAJEAd4BfwC0v88/Sz8cPw0/vT+rACDAH7+qPxg+yj8lPyo/hwBfAIQA6QC+ALwAbsAFAJYA2ADoAOgBHgFmAU4BqgHMAgQBngDlAO4BDAErAOABSAG+ANkAAH/PP7A+9D5OPmY+RD4APaw9PDzoPPA8eDvAO/g7cDsgOug6qDqAOwA7EDtAO6g7sDtgO2g7qDwEPKg8vD0IPbY+ED7kQCoBUAKcAtQC/AJQAiACKAMgBIAF4AYYBYAFkASoBHAEwAUQBMgEvAPEA4AC7AJoAlAC6AI8ATCAVL/kP0M/dj+HwAOAej+SP1Y+6D60Pvo+6b+wAE0AqMAwv4w/wYADAGUApgEmAVgBTgEiAQYBkgG4AYIB5AI8AfgBpgGGAbYBpAGaAS8A9wCYABc/gj9VP3Y++D5gPhg9gD1EPPQ8WDxoPBA7yDuIOwA6+DpYOrA6yDr4Oug64DsoOzA7aDvMPHA8kDzQPVw9bD3NPyIASgHQArwC9ALEAlwCBALUA9AE4AVQBcAGMAU4BRgFCAV4BNgEQAToA8gDiANYA1ADAAKwAboAwwBaf9T/+r+6v/S/kf/mP3I+hj6gPoI+5j7bP1N/2D/mP0w/m7/OAAiAdIBAARgBOgDbAPQBIgGsAYwB6AIQAkgCBAIsAYYB4AGkAXQBLQDnAM8Afv/FP7g/ED7WPjQ9rD10PTw8nDxkPAQ8MDtoOtA6qDpIOlA6ODooOkg6uDpgOog7IDtAO6g7yDxUPKw8tD08PocAAQDEAjgCsAJCAfQBAAKsA2gEeAWoBpgGaAUgBKAFAAUQBWgFIAUwBNgEBAOMA2wDPALQAlQBvADoAGzALz+XwDrACQAePzg+nj6OPnQ+AD6WP2M/Tj9OPzg+5T8GPx0/vYAOAJYAa4BkANMA/ADOAXYB8AIUAcYB/gHwAb4BFAFmAYgBkADPAP4AV4AZv5A+1j7kPlw94D24PSA8wDyEPGg70Dt4Otg6kDpwOgg6cDpoOqg6WDqQOsA7EDtoO3g7hDx8PFQ9HD5PP6oBGAGYAa4BPgCuAWIByAOABYgGYAXQBMgE2AToBIgFIAYABqAFgASoBFAETAOcAygDdANkAj4BJAESARsA2IBBAINAKz9GPvw+VD7KPug/ET9oPwA/Fj62Pmw+8j8bv7f/1oAQAGpANoAQAE8A+gEeAWwBvgG2AbwBVgFoAX4BUgFMAMgBHgDpAEp/w7+Ov6k/Cj5cPfg9+D1cPNA8oDywPDg7WDsAOwg7ODpwOhA6mDrQOug6QDswO0A7sDtAO8A8bDyAPcg+yQBAAQQBOoB3QBgARAG8AsAEcAVABdAE9AO4A3gEIAUQBbAGMAXoBRwD4AO8A5gDeAL0A0wDZAJ8AZgBYgFAAM2AYwC4wC8/ej7rP3V/8D9lPzQ/cz9EPz4+cD7fP6a/qD+1QDrAIoAm/9yAXAErANQBDgEaAaABXAF6AR4BMwDrAP4BNAC/AIEATsAvP7Y+zD7QPqw+PD3YPZQ9fDycPDA8EDvIO7g7GDrwOog6sDqIOvg6uDrQO0g7gDtQO1g7+DxYPSQ+CD+lgE2AWb+N//RAKYBcAZgD+AUIBSgDxANIA5ADaARABfAGWAX4BIgEnAP0A2gDPAPYBHADnAL4AoQCeAFCAa4BgAHRAMwAvABLAKjAAz/fQDhAKj/Qv5o/gP/ov6Q/r//hwAfAOL/VAGAA0gDsAJsAgwD2ANgA1AEsATsAwgEIANAA9QBIgBpALX/wP4E/aD7MPuA+bD34PYA9jD0IPIg8dDwIO/g7GDsoOwg7CDrwOrA6+DsoO3A7eDtwO0A7oDvEPRQ+Db+9v5M/dT8yPvM/P//eAdgEMAR8A2gCjAJAApwDMASABjgFiAUoBCADrANgA1gEKARoBHgDhANEAsACaAIQAlwCEAGYAVwBaAFjAPMAlwCeAHZAE0A6gGqAT0Abv/FABgB7f8KABACuAOIAggCpAK4A5QCQALgAxgEsALOARwDtAPuAdX/Bv88/0z+4PxU/AD8KPrw98D2UPZw9eDyEPIQ8WDwQO5g7GDsQO1g7MDqoOng6sDsAOxA7UDuoO9A7UDvsPRA+Tz8UPyQ/Mj7KPog+iwCsAmQDuAOoArgCNAF8AiQDkAUQBbgFGARgA3gDBANIA/AEcASgBCADhAMMAsACtAJ0ApwCXgHEAewCIgHcAU0A/gCsAKYAfgCSAVIBOwA3P+//6YAVABmASgErANIAhgAnQDWAbYBagGAAkwD0QA/AHMAhgFaAMj8CP0i/hD9GPso+9j6gPig9SD1IPbw9DDykPGg8SDvAO2A7IDtYO2g64DrAOyA6yDrIO0A7wDvYOzA7TDzgPbI+bD6Uv7w+vD2uPj6/ugE4AkgDtANsAmYAkAEgAxgESATYBQAFHAOMAoACwAQQBGgEPAP4BDgDgAKkAoQDOALYAkQCNAJAAqQCCgHuAbwBMQBmAKABbAGgAWMA6wCbgEzADoBNAPUA4gEfAO0AuQBngH+AcAC5AKmAewBrgBuAdAB3wAY/zz99PyY/Mj8ZPxI/OD5EPfw9QD2UPWg8/DysPIA8YDugO2A7iDuwOyA7ADtwOxA6uDrEPGg8CDtIO7g8GDzwPXY+Rr+OP0A+dD3YPtLAOAE0ApADQAM2AZIBFAHYAvgEAAUQBTAEFANkArADMAOABGAEMAQQBAgDZAL0ArAC1AK4AlACkAL0AmQCHAIAAbAA/wCaAWgBigHMAXoA7ACqwCuAawDeASYBHAEhAM4A9wBsAFQAjgD/AJ8AgQCZgEoARAAd/++/vD95Pw4/dT8GPuQ+eD3oPZw9rD2YPXA87Dx4O+A7+Du4OwA7qDt4Ozg7CDrgOuA60Ds4O0g8CDvQO4w8ADyAPbI+HD6QPvQ+qD4GPro/rQDgAigCdAJAAcwBegEcAlwD+ARABJwDtAMcAuQCzAM4A7gEEAQ4A6ADXAMAAvACYAJYAuwC7AKkAqACYAH4AToAygFMAfIBwAHiAVYA3oBzAG4AkgE+ARoBCAErAOsAvAB0gEEAgwCyAIoA+IBngFTAC3/YP7c/Jz9TP6c/fz8APuQ90D1gPXw9wD44PUw88DwwO9g7QDu4O/g7gDuoO1g7KDqIOqg6yDugO6A74DvgO6g7+DxcPao+Lj5kPr4+fj5OPqQ/WwD6AawCNAIKAeABVgF0AgwDgARYBAwDhANkAyQCmALIA6wDyAQoA6ADpAM8AnACEAJoAtADEAMYAugCUgH0ASIBOAFwAeACWAIeAWAA1QCmALMA0AFcAVABZAE3AMwBBwDGAKwAjQDsANoA9wCgAJKAT3/5P1i/1L+MP7G/1D+oPtQ9kD1QPgo+Uj4QPcA9XDxoO1g70DwkPBg8GDuIO4A7YDrAOyg7KDuYO9A7+DuQO+A8aDyYPXw9oD5QPo4+vj64Ptc/YX/qATAB3AI4AcQBkgGwAegCqANIBDAD9ANkAyAC2AKEAswDgARgBGADqAMUAsgCdAIEAuQDtANMAywCuAHaAagBPAGgApQCgAJyAaoBGADVANYBaAGWAZ4BbAFaAWQBKgD3ANUA8ACaAM4BHAE/AIiASEAzv4I/Wz+1v+vAJL+APtY+PD0IPbw+Jj5YPig9TDyYO6A7WDwAPIQ8KDuoO4A7iDrwOog7sDvIO6g7ODvgPHw8HDywPTg9vD14Pcg+7D8NPyg+8b+sAHsA4gG+AfIB0AHmAV4BxAKAAzQDuAOAA6gCtAIkAiQCtAOABDQD/AMEApgCCAIQAmgC5AO4AwQCmgHGAaQBfAGQAmgCtAJqAVABegEIAXYBAAGmAdwBqAFqARwBmgGaARAA/gD8AWAA1ADwARgBaYBQP5g/gv/iQADAIgAIP5I+nD2kPZ4+Bj5kPmA98D0YPEA7+Du4O8g8ZDxoO/A7IDrwOxA7QDuIO+A76DtYO4w8bDyEPNw87D10PgY+fj5sPv4+4D8FP7OAQgFMAXABQAHyAZQBYgFIApQDXAM8AwwDJAKmAeQBpAKIA2wDkANYA0wClgG4AVwCIAMsAxwDGAJGAfwBBAFkAgwCsAJoAigBngF4ARIBbgH2AfQBmAFgAWIBkgGeAZYBkgFoAPQAqgE6AVoBUwD7gBc/9T+Ov/hAEwAAv+k/KD5kPcw97D48Phw+OD2QPRw8CDu4O8Q8YDwYO+A7kDtoOsA7IDs4O0g7aDtIO8Q8EDvwO8Q8gDzgPTg9UD5CPoQ+oj6KPyM/fb+6AEoBYAGSAVYBJgE+AbgB8AJgAswDGAMEArwCEAHKAdQCRANkA/wDYALoAhYBVAGoAngDHANwApwCTgHqAU4BuAIkAvwCdgHWAe4BkgGgAdQCbAIcAbwBcAHwAgACAAI8Aa4BNQDOAU4BwgHOAWQA6YB6P+U/nsA0AE9APT9SPvQ+Tj4APjo+Ej4APew9HDyoPAA8ODvoO9g7yDvQO7g7ODrgOuA7KDsYO2g7qDv4O/g7wDwMPGQ8xD10PeY+Uj62Pn4+UT8cf9kAQgCeAQ4BqgE2ATABuAHwAmgCZAKwAxgC8AK8AnQCeAIsAjQC6AOsA9gDMAJuAcQB7AJ0AvwDUANAAuwCCgHsAgwCZAKgAoQC0AKIAjYB/AIQAowCFgHQAiwClAJUAggCXgHoATEAlAG0AjIB4gFAANqAZv/Tv5ZAIgBhABM/YD6ePnw91D38Pew91D28POQ8TDx4O8g70Dv4O5g7gDu4O2A7ODrIOzA7ADuwO4Q8EDxYPBQ8NDxQPQw9vD3mPnY+qj6APuY/R4AwgHYArgDsATQBZgFIAfgCDAJwAmQCLAKMArgCmAKgAngCYgHyAeQCoAOoA2gC1gHWAZgBgAIcAtADYAMUAlQB3AGUAcgCHAJ0AuQCxAI6AbgB9AIcAiwBzAJIAq4ByAIQAnACJAFjAOYBYgHIAf4BTAFsAKa/2T+wv/yAEMA4P7c/Aj6UPfA9oD3OPhA99D0sPMg8eDuYO9g8IDvoO6g7kDu4Oxg68DrgO1A7mDuoO9w8IDwUPCQ8dDzoPXQ9hj4mPmA+jD7xPxk/kkADAIwApwDYATABbgGSAfQB9AIYAhgCEAJkArQCsAIIAlgCCAImAYwCUAOEA1QCgAHwAWYBvgGoAowDbAMYAjIBtgGaAbQB1AKwAuwCpAICAdgCAAIIAhQCaAJcAmgCBAJYAkwCMgF0ARgBlgH4Af4BpAEaAJMACz/KQB0AdUAZf9Q/DD5CPjQ93D3oPcA+ND18PEQ8MDvMPAg7+DuoO+A7kDs4OpA7CDtoOwg7aDuIO8g7oDusPAQ8tDycPRA9iD3kPfY+Fj7AP2M/ab+igDCAWgCgAOQBOgFMAYIB/AHEAgQCKAIYAiACKAIQAngB6AG6AZgCOAJ8AgwCxAKuAYQBWAFMAegCQAL0AtACugFyAMAB3AJAApgCjALAApQB7gGMAhgCmAJYAkACsAJcAnYB5gH6AdwBrgFuAaYB8AGYATeAYMAYf/Y/9oAKAAm/jD7GPmw93D30PdA91D24PMA8mDxYO/g7sDv4O7A7cDsAO1A7WDsgOxg7GDsYO3A7lDwoPCg8JDxsPJg9MD1kPfI+QD6QPto/Jz9Cf/lAOACgAPgA0AE8AWIBhAHwAhACZAIeAcwCNAJsAnQCMAI0AjAB1AG4AfwCuAK4AoQCagHAAWcA4AJgAzADKAKkAjIBgAG6AdgCjAM4AtwCnAJoAhACNAJYApQCqAKkAqwCbAI0AhgCegH0AU4BsgHsAeQBaQDXAKPAHf/mP/HAMr/pPy4+Tj5oPiQ9mD2MPbw9VDzoPHg8MDvIO9g7kDvwO6A7eDsQO1A7aDsYO2g7mDvwO8A8TDyYPKA8lD0wPbQ99j4kPpQ/Pj8vP1X/30AzAFAAzgFAAb4BOgFuAeQCIAHkAjACRAIsAcgCHAKkAmoBvgFKAcYB1AGEAmgCyAKqAdIBKgDMAWQCLAL0AzwCTAHsAQ4BaAIAAuwDMAKIArgCMAIkAgwCZALQAvACnAKgAqwCUAIMAiACLAHyAaAB7AHMAYcA8wBjgGeAAMAQQDL/0D9KPoQ+XD5wPdg9iD24PUg9PDxoPDg72DvAO9g72DvwO1g7IDswOxA7WDuwO5A78Du4O+w8ODx8PKg9JD20PaQ99D4EPuQ/DD9av/n/1AAggFEAzAFUAWwBQgG0AZoB4AHMAgACBAH0AiACMgHyAeoB8gGkAQQBQAJoAlACFAI4Ag4BqgBiASgCUAM4AqwCHAIcAXIBLAHoAzwDMAKYAlACbAIuAdQCkAMsAwgCyAKgAngCIAIwAjQCVAIgAeABkAGsAXcA4QCFgHNAF4AnP/Q/sz8QPuA+YD3APew97D2sPRg8+DxYPBg7+DvwPCg8ADuQOyg7EDtYO1A7iDvYO9A74DugO/A8RDz8PMw9bD2QPeA95D4GPv4/Lj9/v4eANUAnAE4A8wDsAR4BcAGQAfYBoAHgAdABwAHIAjwCMgHqAZoBwgH6AS8A4gGEAlACDgHIAjQBqADGALIBlAKEAmQCLAJUAigBIAEqAdQDIAMAAugCjAIsAa4B2AMAA7QC0AJMAlQCcAIEAnACWAKGAeoBnAGSAZgBfgCxALhAJoAtP/S/zn/9PyY+TD3YPfA94j44PZw9MDxwO+g72DwQPHQ8GDvoO1g7ADsAO0g7gDvgO/A7gDvAO8A8LDxkPPA9ED1EPZw98D42PnI+gD8MP5c/3EAhAG0AgQDFANoBDgGSAfoBigHsAiwB4AGqAYwCMAIIAgYB4gH+AaQBGgE+AaIB+gGEAhwCYAISATEAiAFAAgwCbAK0AuQCcgFsATgB4AKwAtwDAANQAoACEAI8AmQDMAMsAwwC6AJEAmQCVAKkAnQB0AHcAd4B8AGeAQoA/AARQB3ACkA+v/g/fD7+Piw93D3QPdQ9wD2cPRQ8qDwEPCA8ODwgPBA7+DtQO3A7YDuwO4g76Dv4O8g8ODwIPIQ8+Dz8PSA9oD3oPgA+hj78Pus/Oj9f/8+AbACYANsA4gDaAToBbAGYAcQCBAIEAfABmgHmAfQBmAG6AfIB8gFeATYBFgFOAQ4BTAIAAqgBiADEAR4BFgDyAaADDAM0AjQA1gEIAhACOAK8AwgDXAJ2AdwCeAKcAsQC+AMEAywCcAJkArwCsAJEAioB5gH0AdIBzAHMASmASEAAQAkAdgAhP8E/Oj5KPhw93D24Pbg9iD1APOg8DDwoO+g7+DvwO+g7sDtQO2g7cDtIO7g7oDvQPAg8ZDxkPHA8tDzoPXg9lj4EPkg+uD66Puc/eL+SQBQAXACtALUAgAECAWwBbgGMAf4BgAGeAZgB1gHKAYgBxgH6AU4BWAFeAXIA1ADIAXwB7gFwAVoB5AF4ALHAAgGQAkgC5AI6AdQB7QDeATQCSAOUAvACZAI0AnwCMAIYAtwDZAL0AmQCvAJgAlQCPAI8AhABygGaAd4B9gEKALO/5j/gAAgAOv/iP44+xj4wPaQ9kD34Pbw9YD0IPJQ8GDv4O8A8ADwYO+g7uDtgO2A7eDtoO7g7qDv8PCg8eDxMPKw8rDzwPWg9xj52Pk4+gD7JPxw/Tz/9QDYAXQCwAJYAwAE4AQ4BhgHAAfgBgAHCAeABuAGkAewBigG8AWYBigF4AN4A9gEMARUA7AFEAjABiADVAPwA7gD4AOACFANkAnoBLQD2AWQCGAJ4AuADRAMcAfoBwAK0AoQDJAM4AwQDCAK8AhQCvAJEAlACBAIwAgQCIgGcATUAscALAD5AIoBbAFm/oj6qPgw+PD3kPfw90D3gPTg8YDw8PCw8ADwgPDg8GDvYO0A7qDuwO5g7mDvMPHg8YDxIPJA89DzoPRA9gj4sPmg+hD7+PsU/az+1f8QAWACsAPwAxAE4ASQBVgG8AaoBwAIiAfoBkAHUAegBlAGuAZABqAFkAT4BPADlAIwAsADMAS4BIAGwAXwBOAAUwCYBBAHUAdwCaAJQAY4A+QDuAfgCyAMcAuQClAIIAigCVAL0AuADAAM8ApQCpAJoArwCPAHAAmQCEAHmAbQBpAEUgFp/3cAaAH5/9L+CP1g+iD3MPZQ95D3MPYw9HDzgPEA8EDvYO/g72Dv4O5g7gDuQO0A7cDtAO+g78DvwPDA8VDykPIg83D1IPfg95D4UPoM/AT8CP1i/kAA2gCsAVADcARgBHAEuAVABnAG8AYACAAI2AaYBkAHyAaoBUgGcAZoBbAEMASwBFgCYAJsAigE8ASYA3AG0AR8Al4A5gEwBWAHwAnACJgGUARgBIgGcAlwC/ALQAtwCWAI8AiQCvALkAygDMALcApwCQAKwAkQCWAI+AdYB/AGcAagBDACSgC4/xEAkP/s/az8aPoA+HD28PUQ9pD0sPOw8jDxgO9g7kDuQO6g7iDu4O1g7YDsYOxA7IDt4O5A8IDw0PDA8QDyAPMA9GD2CPgQ+bD5GPtc/KD8zP6W/3IB+AFYA4AEyAQoBfgEEAewBkAHUAhQCNgHKAeIB3gH+Aa4BngGoAZIBUAFAAU4BMwBOAPoAnADtAPoBNAHEAToAaYAIAOgAzgGQAvwCfAGrAOoBKgHcAkgC8AM0A3QCRAIsAlAC8AMEA3ADQANAAwwClAK8AqgCTAJsAhwCKAIEAe4BPQCNAFKAJ4AiQAm/zT92PoQ+JD3kPbA9SD2cPTQ8gDxMPAg72DuoO5A7uDuYO3g7GDtwOxA7KDsgO6g7+DvAPBw8UDyAPJQ8+D1oPaQ91D5UPrA+1T8TP1J/w0AhwD6AcgD6AOQBLAF+AWYBWAGYAe4B9AHSAegCDgHKAaYBqAGQAYoBQgGgAVABAACJAPcAxQDnAF0A9AGkASgBGgEDANcAXABgAfwCkAKaAd4B8AGCAVAB9AKYA/QDXALUAowCoAKkApwDiAPQA4gDFAKwArAClAKIAnACfAIqAcIBhAFYATaAT8Azf/5/8T++PyQ+1D5gPeA9XD18PUQ9aDygPHg70DuQO5A7oDuoO7A7cDsIOzA60DswO1A7qDu4O9g70DwwPCA8uD0IPUA9gD3wPiY+Xj73Pw2/gz/KwAoAXQCYAPUA/gEuAa4BggH6AbIB2AIIAjIB9AIEAloB5AG+AZwB3gF4ATwBZgGEAQpABgCUAQEAywBwAPgBCAEaAOAA3gEeABAAigGcAnQCcgHUAj4BXAFSAdgC5ANMA3QDBAM8AnQCKALQA7QDiAOIA1wC9AJkAngCkAKsAiQCGAIWAcgBSQDyALzAPH/Wf9y//z9KPuQ+cD3EPaA9SD1wPTg8xDyIPCA7qDtwO3A7oDuoO0g7YDswOxg7ODsQO4g70DvYO9Q8NDwcPLQ86D1sPYw92D3iPgY+2j8uP0G/9r/EgD/AHACQATIBOgEkAVQBjAGOAYACJAIEAhoBlgGSAeoBoAG2AZQBvQCMAJ4AzgFkAQAAlIApQDU/of/rANIBZAEwAGOAZsARwBkAogFcAmQB9AGYAZwBdAFwAdQC9AM0AugCnALwAuwCtALMA3gDeAMEA3gDCAMgArACcAK8AggCPgHQAhYBxgEFAKQAFwA3P47//z+vPyo+RD3YPYg9oD14POw89DysPCA7qDtQO4g7qDtQO0A7gDt4Oug7ADtgO0g7QDv4O+w8DDxgPEA80D0UPWQ9gD5UPkQ+qD7UP1+/s7+EAHkAdQCOAPQBKAFiAVoBqAGEAiYBwAIMAjACDgH4AYACHAHQAdIBjAGEAUwA7gDkASoBdgCuAECAPr+nP8uAVAG6AZQA9P/HP+V//wBCAZwCUAJ6AVABKgEqAW4B8AKAA0gDeAKoAkQC8ALsAvADCAO0A3QDDANIA3QC4AJIAmwCQAKYAmgCMgHiAV4AtkA+gCtAKwAh/8+/pD7UPgw9uD1YPYQ9uD1oPMA8qDwgO0A7iDvIO9A7mDvYO6g7aDsQOyg7gDvQO8w8MDxMPJA8qDy0PNw9YD2GPnA+tj6UPuY/Gz9YP5CAIACYANcAzAEOAUgBcAESAawB7AHQAeIB4AI+AcwBsgGOAfwBugFcAUgBXAE8AJcAmQDJAOkAp4AyP8l/9D+W/+YAmAFaAQgAnj+KP/W//wC0AjwCfAI2AR4A2gEkAgQClAMQA5QDLAKAAoQC4AMMA4ADrAN0A3ADAAN4AxwCyAKsAhACBAKYAoQCTAGFAMMAXYACQC9AAYBmv9Q/Hj4IPYQ9vD1QPaA9pD0MPKg72Du4O4A78DtAO5A70DuQO0g7SDuYO0g7WDuYPDQ8bDxsPKQ8zDzgPMg9dj44Ppg+6j7NPwA/UT9Zv/kAVAEqAOIAxAECAX4BbgFEAfoBzAH6Ab4B6AIcAfIBvAFOAaYBtAFIAa4BWwDHAIIAmACtAKgAqIBeP+E/Xj9Lf9oAoQDCAVsAoT9rPzI/pAEKAcgCRAHGAaQA/gCeAewCiANoAvwC5AKwAqgCjALkA5gDcAM0AuADcAOwAtwChAJcAkACLAIQAowCQgG3gFCAZ4Ayf/2/4QAOv84+9j4MPew9iD1UPUw9nD0YPLA8LDwwO5A7cDtQO9A72DuAO/g7iDu4OuA7QDwAPHg8EDycPTQ8jDzAPQA9wD5sPjA+pz8NP3A+9j9CwAuAYwBtAIIBdgEsANABGAGeAbABZAGqAcgCOAGIAbgBlgGeAWYBTgG8AWIBEQDGAOEAjABSgH2ATgCoACs/mD9pP3g/WgA4APwA3wCMf9s/t7+3gA4BZAJQArABQgFSAWoBjAIIAtADnANkAuQCmAMcAyQC3ANQA9gDgAMwAzQDWAMcAkACWAKgAkgCJAIwAgQBQoBLAFGAeEAUv+6/vD+cPvA96D24Paw9QD1oPXA9FDy4O+g72DvYO6g7iDvwO8A7yDuYO4A78Du4O4A8bDxIPIA85D0cPXw9HD1kPf4+ZD6uPsg/Sb+lP4W/hoAbAJMA+QDuASABUgFyAToBWgH2AcoB3gHUAjYB0AGWAaAB9AGOAXABUAGAAWMA/gCLAM8Ao4AoAFMA/0Afv4m/lL+pP6wADADKAWgAuj+Sf9W/8IBOAWwCdAJKAfYBGgEmAawB9ALoA7gDfAKAAowC9ALQAwgDuAO4A2gCxAMgA2gDMAJ0AjgCHAJAAjIByAIwAQ0AggAfgBp/43/N/98/Yj7oPfw9XD10PWQ9QD1YPSw8SDw4O7A7qDugO6A7yDvQO/g7SDu4O4g78DvEPDQ8SDyAPMw9BD1IPYw9tD3APlA+pD71PxC/uz+aP6l/+4BzAJAA1AEMAVIBRgECAXgBjAH8AWoBrgH6AYoBYgFIAeoBoAEcATIBfADwAJ4AogCJALXACABHAE7AGL+nP3o/QL+dABUAggDRALYAML/3P1X/0gF4AiQCWAIsAawBSAEaAZwC4APAA+ADGAM8AtQC0ALQA7QD1APAA3ADWAOMAugCpAKsAqgCeAHIAggCHgGaAPgAVAAHv8t/9z+tP6w+2j5sPbQ9WD1IPTw9IDzAPOg8GDvoO6A7mDuAO7A7uDtYO4g7sDuwO7g7jDwAPFQ8WDy4POQ9GD1YPZI+Aj54Pgw+vT8OP6I/Wz/ugFkAloBOAKIBDgFIAUgBSgHcAeABggGYAfIB9AG6AXYBpAHQAYwBWAFWAV4BOwClAJIA4QCegEsABYB6gDO/oT96P3I/WD+1v7WAUwDIAE4/5L+T/+xAMgDkAewCagHcAUwBQAGUAiwCjAOcA5QDJAL8AzwCyAM0A2wDgAPQA2ADgAN8AvwClAKQAqQBzAIgAiYB4gEjAKcAfP/dv7c/Xj+QPzg+fj4cPcQ9uDzoPMw9KDywPGg8ODvYO/g7iDuIO7A7UDuQO9A70Dv4O/A76DvYPCA8mDzIPSw9aD2wPew97D4ePrQ+6j8qP2V/wQBggF0AbwCIAQ4BFgE2AVAB4gHQAewBqAHMAfIBkAG4AdwCPgGIAYgBkAGGATsA0gEoATsAngBrgGqAbcAmf9UADz/cP2U/Mb+pwASAbgCeAIUATz+dv5+AYgE6AbgCAAKWAcQBMgF8AgQC1AM4A3QDpAMoAtgDIANAA4ADcAOcA+wDeAM4AyADKAKQAigCOAIMAj4BpgG4ATqAVP/oP7c/gD+iPyI+9D6sPeA9WD00POg8wDyEPLQ8bDwwO6A7kDugO0g7UDtwO5g78DuIO8Q8IDvoO+g8JDyIPQA9RD2QPdw94D3CPkA+1j8vP3e/kAAmQCUAXwCVAMYBAAF+AWIBlAHeAf4B/gHeAd4B9gH6AfgBxAIoAcwB9AFQAVABagESAQcAyADZAJ+Ab8A6QA5AGz+eP3s/R7/0v/eAEgCQAJ5/1D9lf9QAUADwAQgB8AIsAXkA0gFaAcQCOAJwAsgDbALgApQC+ALkAtgCxANwA3ADVAMwAuwCiAJwAggCOgHcAfABnAF2AMgAs0AXv+4/TT9iPxg+9j5yPiA98D1wPOw8mDyEPJw8TDxsPBA72DuoO2A7eDtgO5A7+DvYO8A8GDvoO/Q8JDywPPg9LD1cPbA96D36Pig+iz8GP1i/qn/mgAwAeoBQAPYA8AESAVIBsgGUAegB5AHcAdoB7gH4AcQCAAIuAcYBzgGqAUABXgEgATgAzgDfAJYAn4BbADK/1f/Mv6E/fz+3gAgAtwAKgE+AWT+sP0sAFQD+AWIBfAF0AYoBawD0ASQB2AJsAkwCwAMYAswCaAJcApQCxALIAuwDJAMQAtwCTAJgAh4B7AGsAagBlgFaATMAiQC4/8u/qD9HP0Q/Ij6APrw+DD30PWg9DDzoPKQ8pDyAPLg8IDwgO8A72DuYO8Q8DDw0PDQ8DDxwPBw8eDyEPQA9aD1sPaA9/D3GPlA+qD79PyE/c7+uv+yAJQBNAI8A8ADkARABTgGYAboBigHqAeQBxAHsAcQCFAI2AfYB6AH2AYoBvAFOAZgBaAEeARYBGgDvAIoAogCBgFIAOUA7ABgAagBzALcAgwCPgFAAbYB6ALYAxgGeAbIBXgFUAZgBngGgAfQCPAJMAkACZAJ4AmQCBAJEAqwCYAJwAjACZAI6AagBkgGOAZYBOwDtAOwAt4AHgDC/7L+AP0o/BT8mPow+ZD4WPgg9/D1oPXg9HD0gPNQ84DzwPLw8TDyMPIw8vDxgPIQ8zDzIPOA8yD00PQg9fD18Paw91D4oPiw+VD62Ppo+2T8lP30/dT+aP93AKwA9QDmAZQCFANUA/ADMASwBJAEAAVYBYgFqAXIBRgGoAWIBTgFEAUABcAEOASABMADkAOAA0QDAAMcAtABfgGSAaYBoAJYAyQD2AKAAvwBkgEoAtQDKAWwBCgFYAUoBVAEmATQBWAGKAagBkgHSAeYBoAGcAcoB1gGUAaIBogGqAXwBRgGgAWABMgDjAOoArQBWAF0AdkA7f8j/2T+hP1o/PD7cPsQ+2D66PlI+YD44PeA91D34PZw9jD2APZw9VD1gPWQ9YD1cPWw9cD1YPWw9VD24PYA90D38Pdo+DD4qPhQ+cj5CPqg+nj7DPxA/Mj8lP3Y/UD+vP6V/w0AaADxAHYBzAH2AWQCzAIwAywDaAOgA8QD/AMIBEAEIAQQBPgDzAPwA/QD4APcA9gDkAMsA/QC9AK8ApQC5AJQA0gDMAMIA0QDIAPAAgwDhAO8A+ADGASABJgEYARoBMAE4ASwBNgEAAU4BUAFGAUYBUAFQAU4BQgF4ATgBMgEiASABFgEOASsA3ADHAPEAhwCyAGoAWgBtwAmAOP/Uv/M/jj+AP6w/Sz9zPx4/Cz82Psg+zD7kPpo+hD6KPro+YD5gPlw+XD5EPlo+Vj5GPkQ+Vj5cPlw+Wj5ePkQ+rD54PlI+nD6ePp4+tD6OPtQ+6D78Ptc/MD8uPww/Yz97P02/p7+Kv+o/9j//v+EAKkAEgEkAbABGAIUAkwCUALgAuQCGANQA1gDOAMIAzwDMANcA4AD1AOwA0wDhAPEA5wDgAOwA+gDCAQIBAgEQARABAgEKARoBEgEOARoBGgEaARIBDgEQARwBDgEKAQwBDAEOAQoBAgE7APIA7gDnAOAA2wDVAMIA9ACmAJ0AiACzgG0AZgBSAHZAJIAVQDj/3j/TP8R/6r+TP4O/uD9gP0U/dD8pPww/Oj7yPuY+zD7APvw+rD6qPp4+mj6SPog+gD6APrY+bj56Pnw+fj5APoY+gD6EPoY+kD6ePqQ+sj62Po4+2D7sPvY+yj8jPzY/CD9bP3w/U7+pP7a/mD/u/8EAGYAsQAQAUgBiAHUASwCTAKYApQC+AIAA0QDWAOEA8wD0APgA+AD+AMABPwDIAQIBCgEKAQgBBgEGAQoBBgEMAQwBBAE8APsA+gD7APYA9gD9APYA7gDqAOwA5QDhAOEA5QDhANcA1wDWANIAxwDEAMEA+wCwAKsAowCTAIkAhAC8AGuAWABKAHkAJQAQQAdAM7/ef8o/8j+gP4i/sT9iP0g/cT8dPwg/ND7gPs4+/D6qPpo+ij6+PnY+aD5iPlI+Sj5IPkQ+Qj5GPkI+UD5WPlw+aD5uPkA+hD6SPp4+uD68PpQ+6j76Psw/HT8+Pw4/Wz90P1C/qz+4P5i/8T/CABEAJEADAFeAaoBDAJAAoQCyAIYA1gDgAOsA/gDIARABGAEuATQBNgEAAUIBSgFOAVABXgFaAV4BWgFaAV4BXAFiAV4BYAFWAU4BTAFEAUIBegE2ASgBIgESAQoBBAE3AOYA1ADKAPkAqQCWAIYAuQBlAFEAfUAqwBXABUA3/+A/zr/2P6m/k7+Gv7c/XT9UP0M/cz8rPxo/ET8CPz4++D7wPug+6D7oPto+3D7aPuQ+5D7mPuw+8D7yPvA+wD8BPxE/ET8YPyU/Kz87PwE/Uz9YP2U/dj9AP5A/oD+sv78/jX/i//O/wgAOwB3AK4A7AAwAWYBvgHWARwCTAJUAoACqALgAugCEAMwA0wDbANcA5ADnAOoA6wDrAPEA6ADmAOAA5QDiAN8A2QDTANUAygDEAMEA/gC4AKoApgCjAJgAhACFAIEAuABfgF0AWgBMAHbAMUAuQCKAEYAKwAlAN7/xf9s/63/MP8q/wr/CP/O/oL+fP5W/lL+Av4O/vz9uP2k/ZD9hP1c/UD9NP1Q/ST9GP00/ST9EP0Q/ST9MP0c/Sj9UP1Q/XD9aP2U/bD9pP24/fD9KP4w/j7+WP6Q/qD+xP7k/hL/Sv86/23/fv/M/+T/DABcAGwAdwCQAMkA1wAMARwBSgFcAVwBggGyAZgBmAG8Ad4B3gHoAeoB8gHqAbYB5gH2Ac4BvgHOAdABsAGaAXgBfgGCAS4BEgEqASQBFAHaANEAuwCUAHYAYQBrADoALgADABEA5P+6/6L/r/+b/27/YP9Z/0//Nv8D/+7+C/8D/9T+yP7U/tj+uv6u/rL+0v6u/rj+wv7i/qb+kv7A/rb+yP6m/sz+4v7i/tT+7v7y/uD+Dv8H/zf/Mv9W/2H/Xf+E/5T/tf+8/+H/3f8mACIAPwBYAHgAigCnALwA4AAIARQBHgEcAXQBXgFyAZABmgGyAaoBwgHQAeYBwgHsAb4B3gHEAb4BngHEAcABjAGGAYIBZgFOARgBMAHwAPsAxACtAIoAZwBkAEAAcAAkACQA5//x/9D/2v+p/5z/u/+R/3v/Zf97/1P/WP9G/07/V/8p/zT/R/9P/y3/N/9R/2v/TP9I/1v/fv9b/2//eP+T/4b/c/+F/47/m/+j/4z/yv+f/8P/r//L/8n/0f+6/9j/7P/k/+r/7v8IAAMA6f8KAPb/HQATACIALAAiABsALwBIAAIASgANAGYAJQAnAFMASwCFAPv/WQA4AI0A9f9ZAEkAZgBAAOf/lwA2ACYA6P9mAC8A+f8hABMAaADi/9n/+/9iAPX/8f/U/x8A9P/F/8P/9P///5b/0P/W/83/zv+3/9b/zP+d/63/1f/C/8L/sf/L/7T/qP+d/6j/qf+s/9//o/+x/63/oP++/7f/2/+i/8//ov+w//j/qv/v/7z/BQCo/93/2v+0//f/p//X/9r/y/+F//H/CACt/9//nv8IAKf/BgDa/+v////L//3/DAAKANL/GAAEAOb/AwAAABMAKADm/wIA7v8KAPD/7v8nAMT/IgDO/xMAt//+/+H/0f/P/4T/+P+P/93/kf/B/8n/mv/C/7z/fv+0/1n/yP/Y/8P/h/+2/+z/n/+b/4j/NwCX/wIA6P+2/wIA5P83ALH/TQAIABAALgDK/2AANwD1/xQAgwBaAAoAVAAxAFAAOgBcACoAKwB5AFEAHgAdAE0ApwC4/0oAkQCEAHD/UAACAfb/vf8rAAgBPgBc/ywA1gBYAET/XgDxALz/8/+k/5wBTf/5/xwA2wAwAHL/swBsAEoAYP+JANUA0P/J/9oAYQDc/7b/YACNAHn/xv+sACUAG/8YAFoAHACG/47/fgBf/3f/Zf+yAO//A/9i/9z/bQA3/wv/EgAJAK7/Hv8K/5gAKACG/gwAi/9QAKj+YP9DAEkAU/8T/74ALP/8/8P/kwB3/5b/IQAMAWb/Iv+UAAYBcP9i/6cA1AAbAHz+lAGSAGr/Ov8cAVQB5P7N/zsA0gGA/wT/3QChAOn/ZP9bANYAvf/E/zUAHAA/AMD/WwCV/4cAnv9gAO7/sf+aAGj/TQC1/5AA1P+w/wUA9v9cAJP/4/9SAMz/RABS/wEAVgB6/1sAlP/CAOr/7/8EANb/cQBT/0sACgA7ANP/QACz/zcAMwA//5cA4f/B/93/CQANAMj/vf/a//7/b////6D/FwCB/0UA0//d/yD/EgBKAIz/vf++/+IAL/9IAOX/JgCZ/wIAEAA9AP//u/+gAJX/xQDW/20ADP/EAeX/3P/W/+EAeAAwACsANwC7AFEA+f+yAKgAf/+wAJL/XABjAIAA4/+w/6YAw//6/6n/lgBKAM7/0f/T/7kA8v6CADf/wwD9/1r/iv+KAPH/yv4+AAUAigD2/oP/twAGAFz/bP88AUEAIv/B/6YAIgAU/6//rQA5AJX/U/9gAVH/CwD+/scAIADY/vT/qQAqADr/8//E/wIBEv6G/28A/v9G/wr/eAHU/nH/6v/7/ykASP7o/3r/+gA6/mkA7P/R/+//uP7n/2P/FAFs/qUAbv9IABkAGf9vABT/ZAEU/qsAFAD2/2X/ov/5AIb/agC8/lcA/ADM/7b+8wBlAMb/NACg/gQCo/+H//P/8gA2AB//nABlAEgBZP4EASz/9gGn/7D+UAJi/h0AUQDSAIv/CgEs/8kAKP9LAI7/4//+AWD+pACRANL+LAG7/9f/wgH0/rb//gDn/2IAZP90/7QBZv/q/xz/WAFzAMD9QACOAcr+Nf8JAF8AJAGE/gP/SALi/l///P00A+L/Nv5dAKAA5gH4/bT+MAJWATT+FP4kA1D/rQDM/fkA0AIu/pz/qv/KAfb+mv+IAEABkP4+AGYBjv+r//L+eAIx/1sANv4cAvwAcP33AI4AIAHM/PUAtgEbAEz+Gv8cAjYB/P18/mgCdgDA/tv/Wf8IA3T/3Px8Ax4AvQBs/JADMf+eAXj9wAGEAgj+OgCn/1wC2P1kAmsAbwDo/XgBtAHd/2j8MANYAkD+VP6XAFwDgP1I/1AC4ADs/TkAugFe/lsAnP+2AUD+eP5aAawDyPvS/0gCov7W/yz91APC/o7+wP+0A0T+kPtQBRf/Hv65/57+KAQI/Zj/jAEuAZT9Zv7oA0T8sQCC/9gCuv6K/kP/eAL+/tz9wgHhAL7+pP4wA+L+t/+e/hQC9P5M/vgBBP8WAaz9WQCEAUf/Xv4AACwDQPzx/24BgP93AMr+3AEq/y4AfwDU/fgE2PpwA6b+XAI8/joA2wC7/wwCiPs4A44BzP70/DADcgE0/lz9rAIQA9D9WP3fAEAEYPs7/7gEPv4kAND7iAROAbD7xgDwA4X/CPs0A+X/AAGY/v//xAFO/6j8UAJYADz9ZgGCACYBMPwgAjj+KAJY/bYAWgFI/SIBwv4wA2j7SAOy/uYB3v5A/GAElf93/6z+aAOT/3X/Ov6ZAJgE2PuG/pwCPAHyAFj8xgGkAiT/6P20ATQB7//I/CIAyAMNANj8KACABXL+iP4G/gwCwAL4+yv/nAIQA2D8ZQD/ACkAKf+M/ewAuADF/9j+8v9///AC7P1i/soB4AD+/1D7dAPo/4ADMPrxADAF0PmwA9j8uAN4/Pz8eAXQ/ff//P3gA3AAxPzs/yD+kAO+/kT/TAH8/YkArf/2/ogB1P0YAmD9VAJTAA7+sf/6/ywCSPwYAuj+hAOw/HD/TALk/B0AY/90An4BZP3M/ggCqAOy/mr+4P3EAsQClP2NAHQDCQAY/Uv/PAJgAuD9kP6QBZD+gP1M/SAIsP2VAEz8lAOoAQz9p/8qANgE8PtEA8z+9gAx/3EAMwBQATD+oAKyAcMAjv/8/UkAIAEIAKoBzP4XAN3/DAHK/nj91AI+/g0AJv/n/7oB0P0YANwBfQDI+vgAiQDMAZEAHv4wBNr/KP7M/qAEdP01AKf/1//gBMD7mgGoABQD7PzK/goBTADsAPD5IATfAMoBQP72/v7/qv56APj+xAGg/fQCqgDS/gz+BAP8AoT9HP1s/igDIPuzALwCbgHo+zL+6AEe/+j9EP38As4AvP20/gABnANw/CYBbQCY/t7+jgEMAbD9ggGq/1gDzP4Q/fwBMAIA/xj9RgEYAeP/2v6IA4QB3f88/RsAaAJk/R0ADgCMArL/7QBe/7wB+v7W/3QBePy4ASgAGAPk/v//0f8kAHz8DP8EAlr+oQDc/HYALgB4/Gz9KAL8/nT9q/8g/s8AyP30/hgACADC/uz/eAFN//L/+v4AAtj+3/8GAJQC+gHrAOQCDgAVAMT+QgHF//f/OgFkArwBff/gAMH/oP/8/TH/Rf/A/oj9pv5iAOj83P9G/2r+WP2w/V//ZP9M/0kAsAGHAFT+gf8qAar+xP6MAggBsQBW//7/BAIY/xT+cACUAxX/9P7+/x8AZAD+/s//JALaAKP/Zv6Y/iEAggAcASAB0gH5/yb/cP8iASQCggHDANQBAACq/zwAOAF8AbsA7P7W/0f/CgBqARQC0ACp/7j+xP7Z/5IB+gCmAYcAYgBEAYEAggAYAE4Bxf/r/9L/WgFCAWYBDgFnAHwAzP6x/zX/Hf9TAMoAswB4AFYAlv8N/xj+kP4i/8D+NP4Q/80ASgC0/x3/4f9q/qT9vP7U/6oABwD3/yoAv/9E/zYAAAC+/qL+Df/g/4H/PgCXAAoBjAAl/23/bv9iAKb/wv5i/6z/PAGwAYkAlQBq/ggBO/+0/uj9GQDeAf4AXgAPACoBvgDJAOv/AgDk/2z/QwBoAPYACAJMApACtP7Y/ub/VAGo/xr+oADiAQYBBf+4AD4Aaf8Q/o7/3P6Q/ab+pQAgAdz+D/+IAIH/Lv4g/p//EwBH/0YAxgAMAe//YQC1ALX/sP6s/r0AjABpAFsA0gDFAE//GP+8/pr/fv+a/2n/xf+aAIsAiQB9APj/KwDU/mv/rf+w/yQAjAAMAXQAr/+a/wwA3//u/93/9/8yAIsAZACGAH8AXQCQACwAPf/r////hQBfAIcAMgEmAQYBcQA5ALP/0v93AHoA6QD/ABwB+AA6AGYAaQAUAOj/cgBdACMATgBwAMUADQCx/9//2/9+/2X/PwBZAC8Ap//h/zYAc//C/1IADAFsAC8AIwA9AKb/VP8LAMYAUwDE/w4ACgDS/x8A/P+cAG8AyP/5/+H/EwDb/0oAUwAWANj/mP+2/y8A8f9HAPT/BQAGAPT/FgAeAGEAEQCx/5b/wv8rAHEAfwB0AGMAEQCV/93/CQAqAHwAzQC7AJAAjACaAMkAXAHzAOIAPAEWAXYBUAFcAc4BXAGMAVoBsAF6AagB3gHWAfwB8AFEAsgBmAF+AX4BPgEUAaQBHgFQABUAVQCu/zL/Jf+S/3r+gP0S/vj8Mv68/YD9Ev5w/Ij8QPyg/Oj7mPuA+6D6OPpI+ej5oPno+Jj5QPmQ+AD48Pfo+Bj4APkA+Vj5sPkI+3j7aPvA++z8bv5k/nr/8AGgBBgEEAXYBtgGQAYYBugHQAlwCZAK0AtgDCAMgAtQDAAMUAtACzALQAugCuAKMAsAC0AK8AlQCSAIiAbgBRgFMATIA/gDTANcApAC9gH3AEcAeADD/7j+TP2o/Sj9TPxw+8D7UPtg+uj5sPm4+aD48Pfw97D2YPXQ9ZD0sPTw84DzEPQg8sDyUPEA8GDt4Ovg6+DqIOoA66DuYPBg8vDxcPJQ8dDwUPLA9Uj4OPvi/rkAOAKEAiAEMAdwCcAJsAowDfAOIBAgEsAVYBcgFUAUABOgEQAPIA6gEEASgBGgEAARMA8QDHAJgAj4B3gGKAa4BngGiAXwBPgEyAQABKgChAJCAX0AsgGEArwD+AVIB3gHyAawBagEtAO0AgADCATgAwAD2AJEAlUAHP5o/dj86PqA+dD44Pig9+D2gPcw9zD1APJg8CDvYO2A7GDugO7A7cDsYO1g7GDoAOmA6WDqoOcA6MDscPBA9cD5wP3C/tD7+Pok/Af/XAHIBoALMA1wDRAOQA7gDpAPoA8AEDAOYA3ADQAP0A9QD0APgA3QChAHgAQYBOQDWATYBMgEaARIA2ACvgHQAVgC7AIgAzQDSARgBZAF+AZQCaAJYAeoBmAGYAe4BhAIMAtAC3AJUAdwB8gFcAQIBagFoAVQAywCigHt/wb+WP0w/Rj7ePmg+KD44PfQ9xj5wPlA+KD24PXQ8wDz8PGg8uDyIPIg8qDxwPAw8GDwgPFA7wDsQOkg52DmgOag7IDxAPYQ+8j9JPy4+WD3MPks/Jb+tAEACBAK8AkACnALgAwgDLAMYAswC2AJkAjACuAMoA8gDuAL4An4BggECAHgApAEIAVUA+AEqAQgA2gB/gHAA4wDfAPkA2gG+AVwBRgGEAhACSAJkAhQCLAJIAgwCEAIEAlgCMgFmAbIBeAEWAO4A5QDjAGq/47/CwCW/rD9KP30/Nj6oPko+iD7QPqY+Tj6oPnI+LD34Pio+ND20Pag9rD18PIg8gDz4PFQ8CDwkPCA7yDtAOuA6sDkoORA50DvkPXw9pD9nP7U/PD4kPmY+3T+fANABrAJQAuQDMAMMA0gDsAO8AuwB/gGYAggCYAJYAxgD5ANQAiQBNAC7wCu/6gAZAN4BDAELAOsA0AEGAWEA2wDoAQgBOgE2AToB1AJQArQCmAKoArYBxAIIAigCAAJ8AmACgAIgAYYBpgF7AIYAvwCzAPKAXAA8gA6AdX/zP0w/hD9uPpo+qj64Ppo+sj66PsY+pD5uPmQ+cD1EPSg9uD0wPIQ8EDzoPQg8UDuoO4g8MDrYOgg6IDlgOTA5MDq0PKA+mD9sP8c/jb+iPuY+pj/rAMQCnAKYA0wDlAP0A7gDJAOQAxACTAHkAegCEAJ4ArADCANoAnYBggECAK0/9D/hAIABBAEGAWQBhAH+AWgBKgFaAUABRgG0AjQCqALMAywDNALYAoACYAIEAjABhAHAAd4BhgH6AWQBSADgAJbAI3/kv6k/l4AJwBw/4L+bf+w/tD78Psc/Fj7mPqQ+mT8PPwo+5D6yPqI+hD4wPXA9SDzIPRQ80DwYO8Q8WDxgO0g6UDtQO6g6eDkQOVA5wDi4OWA8QD9jgA0ADgEOAPa/nD7MAEgBqAJkAvgDkARgA4gDzAPQA8wDJAJQAZgBEAECAVgCbAJEAugCXAGMAM4AOL/Ef/qAMADUAWABsgGcAhACfgHaAYwCBAIOAfwCCAMAA4wDaAN8AzQC9AH8AWoBegF4AQIBZAFGAXABCwDNAFz/97+rP6w/bT9+v5dAJL/Df+O/6b/RP6I/ZT98PxQ/OD6oPtQ/Lz8BPxY+rj6+PkI+ED1MPRA9DDzwO8g8ODwYO+g68DrIO+A7WDoIOiA6aDngOBA4wDukPZw/BgEsAmABnACeP4YAkgEqAXACrAO4BAADyAQYBAAELAMsAtwCBgEpAK2ARAHsAYACcAIqAegBZ8AeAD8/rYBFANoBcAGwAgACVAIcAngCBAKIAnQCGAJkApgC7ALkAyADJALEAmIBqADPAJYAlQCIAOMAhgEIAMWAbT+hv7o/Tj9QP2c/qT/wP6i/w4A0gFEAOz+TP46/pD9UPto+1D8VP2U/KD66PrA+UD3UPUw9vD0gPNQ8MDwUPKA76DqYOvA7QDswOkA6kDsoOhA48DigOhg7aDzcP6ACRANUAhIBVwDLAPoAoAIMAzADqAQQBDgEOAOMA7wDGAKQAVwAZ///v/lAPADkAgwCrAJ4AQkA50A3v5v/6sAiAUwCGALQAzADOAMwAuwCkAJMAnwCOAJwArwC7AMMAwgC9AIcAbYA8AC5AGEAUQClANwA0wCgAHJAA0AVP46/ur+uv9UAPwAQAKIAmAC3AFkAf//mP6g/YD92Pw8/Oj7+Pvw+xj7iPnw99D2sPUg9NDxEPJA8sDwQO/g7iDvIOvA56Dp4O5g7GDlgOMg6ODmoOag8iH/MAmQCeAIUAvIBQoBaAFACdAM8AygDgARABHgDUAO0A3wCdgFYAOgAcP/k/+8AnAGwAiQB+gHOAX8AnoB3wBwAoAEoAgQChAMIA2wDqAMQAtAC2AK4AlgCJAJMApgCnAJQAkACPgGCAVwA4QBnAD0AewCdAPoA9QD0gH+/3r+pv6k/uT/3wAEA9AD9AKUAmwCvAHt/1b+tP1U/LD7gPwg/FT8+PsY/MD6yPiQ9gD1IPOg80DzsPDA7oDwMPKg74DrgOoA8KDswOgg68DqoObA3oDlAPD4+kv/gAfgEIAPEAadAFAFYAT4BTAIAA9AEPANkAzQDlANIAj4BTwD6QDM/AT9IgA0A+AF4AhwCsAIqAXkAa//DAHoAggGYAlgDKAN8A2QDMALcArwCFAIYAcACAAJIAoQCpAJcAggB1AFxAPQAkYBdQC4APoBTAPUA7ADIAN8AU7/NP4E/vT+VQAMAkwDkARQBBQDLAKJAG7+6PtY+wD8UPxw+3j7OPwM/Gj6kPiQ92D2MPWw8rDx4PBg8UDvIO5A7hDwIO2g6ODpAO9A7oDj4OBA5YDpQOog8mgEUA1QC3AI4Aj4B8oBrgBYBrAN4AuQCkAM8AywCwAKEAmwB+AEHv/8/ED8mP1eANgDoAgQC2AKcAaoA9IBBALwA8gFQAkQDAANYA0gDnAOAA1wC6AKUAmYB1gH8AlAC5AJ+AdgCCAHoALVAAgCzAJEAFD/7gHAA0QCBAHeAUwCGgFXAFkAVgHIAqgDyASIBWAGqAUgA9D/Ov48/Wj84Puw/Pz9QP1A+8j5yPnQ+DD34PUw9aDzYPFA74DvwO9g8MDtYOxg6+DtgO5A68DqQOhg54DiYOKA7sb+iAVACoAP0A8wCTAC3QB4BWAH4AdQClAMEAzACkALMAogCsAHOAJk/cD6TP10/aD+yAXwDMAM8AjQB+gGSAQ4AXAEoAkgCyALwAxwDyAPcA2ADKALgAloBuAF8AXABmgHyAeIB0gGEASAAqwCmAGLAIgAIAK0AkIBlgCkAeoBngDI/gMAagEwAQYBKALQBOAEIATYAiQC8/9A/YD7YPsQ/Lj7+Pt4+5D6GPmA+GD3YPbw9fD1IPQQ8XDx4PEQ8ADuYO1Q8SDuIOzA60Dv4PAA6GDlIOXg6MDtGPhoBLAM0A6QC0gH2AN0A4gC+ATACGALsAvQCSAJMApAC6AJwAVQApD+2Pvo+tz9eAIYB1AKkAsAC8AIAAYIBCADIAV4B6AJIAvgCqAMwA2ADcALAAoQCQgGsAMIA6AEuAVABkAGkAbIBUwClP9M/0IBSAIQAkQCsAPEA4ABYf/B/68APwDy/44BXAMIBKgDzAPQA4ABmQCE/qj9mPuo+0D86PvI+zD6SPsw+dD2sPYQ96D1APRA88DzkPFA8GDvIO/A7aDtQO6A7oDrgO8w8aDuIOig4wDoYOjA7pD7AAvQDdAJUAqQCegEUwCwAjAIIAnQBvAG4ApwCjAJ4ArwCwAJcAL8/OD5oPuk/vACIAiwC6ANAAwQCOgFEAVABdgGQAjgCZAKkApQCwANMA/ADWAMoAmIBjAFtAKMAmgECAfQB4AGWAZ4BJgCVv9P/74BCANoAjwCpAP0AooAFP5ZABgClAHIAaAEwAW4A2QDDAIQAsMA8P3E/VT9cPwA/Gj8YPu4+Sj5CPiA9rD2wPdg95D2QPQw9FDywO/A71Dw4PAg72DvEPCg72DsoOyA7ADqQOQg5CDtEPMI+7AFMA0gDcgHeAdQCMAEXACQAyAJcAlIB9gHcA3gDKAJIAggCLgEQPyQ+dD7HAHYBPgHgAwAD3AM8AUIBDAFIAZoBfgGcAowC+AJQAoADFAN8AuQCsAI2AbIA1QCNAOgBJgFaAfoB3AGMAUAAyAAhv4m/24AnAFEAXACsATYAx4AqACcAfoBJQBOALgE0AREAs0A0AJYAkEAjv5i/xT+nPwA+7D62PlI+HD4APpA+fj4SPhg9/D1cPPw8PDwcPGg8MDvgPAw8+DwYOzg6wDvYO1g5SDloO2Q8rDxYPh4ARgGeAawCAAQUA3wCYAH6AW0AygBcAawClAMIA0QD5ALWAXCAF7/eP3g+mz+IAPQBQAIYArACsAIKAagBoAFqAMYBbgH8AlQC5ALkA5gD7AOkAuQCQAIuAXwA1QD7AO4BkgHoAW4BUAG+AQAAoL/TP+cAAcAvv/SAYAEuAUYBAACHALwAa4AOADcAaAD8AOkAtgCIAOoAgcAyv7u/rz8aPnw9zj44PfA+FD6wPuw+gj5aPjg9qDzQPEw89DzIPKQ8IDyEPNA72DtoO5g7sDo4OVg6UDuwO7A7/D1EP1I/Iz8IASwDAARYBDAEHAMgASI/7b+yAQQCLALMA/QDSAJ6AT2AVj/EP38/UYBlAFgASgEgAgACtAIkApQCsAHyAR4BPAGQAbQBmAKoA6ADyAM8AmgCEAHeAOwAuwDOAWIBAwD+AOgBYAE6wAcAZgC+gAE/dz8iQDAAlYBzgEIBAwDcgAiANsA7QAsACACSAKUAd4A6gB3AI3/Iv5I/QD9yPlw9zj4GPkA+TD5APt4+7j6qPgQ9+D1cPTw8wDzoPLg8NDwcPAw8EDuAO6g7UDroOhA6WDtQO8Q8BDz8Peo+pj5agFwDOATIBPQDtAMUAY8/bD7XAOACFAL0AwwDvALSAawAn4AQv4m/hz/w/9uAeQDEAkwDPALAAxgCxAIxAPkArwD0ASgBvAJQA4AD4AN8AugCUAHgAVQBMADYAQABWAFmAVgBmAGEAX4AnwBsgDA/sT9p//oArgD2gFQA3AEPALU/goADwA8AKH/0wC8A/QCBAEdAG4AOv60/ND68PnY+aD50PnI+ED5YPpw+4D5GPjA9wD2IPPw8TD0oPNg8eDvQPEw8SDuQOzA7MDtIOuA6UDsQO+A8XDxoPKg9cD64QBwCCASgBegFRALbgGU/xP/ff/wBiAPYBOgD6AKkAmYBjIBnv5q/1AB9P48/iACIAiACEAK8AtgDOAI1AN8AmAESAaoBTAI4AyADnAM0AngCSAJyAUoA2gFQAc4BYwDUAWIB9AFKAOoAkwCuQAw/3P/BALMA1gE4AP8AVYBrQDK/qT9J/8tABcADAEwAvgC5gH3ALQAKv8s/OD6WPrw+Lj4GPpI+9D5kPkQ+sD68PdA9bD0cPPA8sDx0PJw8nDzAPJw8CDvoO4A7oDrQOuA6yDtYO5A7wDzkPUg9kD4Yv/IB4AOwBNgFeAQUAiC/9D9gv/IA1AKgA/gD1AOEAvQBUQBBABxAC7+Hv7r/5ADcAWoB3AK4A9ADpAIAAXsA1wDCALwBJAIAA7wDOALEA3wCTgHuAN4BbAGaAS0A7gEAAeQBRAEYAVgBsgC7P8sALUA2v/4/zwD2AQ4AwQC6AFtADD+D/92AYQBiAHwAtADhgFi/rX/TQB8/fj6KPtY+7D5sPcQ+uD6IPpw+Kj4uPhw9hD1QPQA9XD0QPOQ8vDycPNg8cDvwO6A7kDsgOog68DsQO2g7YDwwPKQ8lDzYPkwA5AJIA/AFAAVEA3gAqT+TP58/1gFUA2AE2ARAAwgCOACkv4m/rT/qv70/c0AWAXoBiAI0ArADXAKjAMqAaQCPAPyAfgGwAyAD8AMAApQCjAIcAQ0A1gFgAZABsAGyAdIB8gFyAWgBawDDAE7AM8ASwCfAKAD4AUABkAEaAOMAmP/3PyQ/UEAFAGUATQCSAKGAef/JP+K/uT84PoA+ZD4GPmY+Xj5yPkY+qD50PcQ9lD2IPZw9WD1sPVQ9eDz4PIQ8iDx4O/A7oDtQO0A7SDsoOug7UDwwPEQ8kD0gPo8/uIBIAqAFCAVQBDwDIAHUAIE/RcAQAtAEAARMA+gDbgHyACZABADKALY/ngBEATgA0AFEAkADQAMyAcgBbwD+AL9ALQDsAdgDHAMwAvAC5ALUAmEA+ACuATABRgEyAXwCVAJuAUoA4ADFAIP/83/fAJsA8QDyAM4BXAEHAKWAdwANv9C/iT/9f9EALIBaARgBNQB6P4i/lD8aPm4+FD6cPtA+zz8jP3o+xD58PYw9WD04PNQ9SD3aPjY+HD3kPTQ87DxAO4g7KDucPDA7kDtgO7w8UDtYOrg8BD3sPfw9Lj96AZgDOAMABEgFQAOOAPcAGAFYAToBSALABKgEKAK+AfYBjwD7gAgA9ADPAFN/7ACAAdQCOAIYAugC8gHoAMUAV8AZgDCATAHQAywDgAOgAzACdgG6ANkA8AEiAaQCOAIoAj4BtgERALKADIALAHyAWgCRAOEA8wCVALqAZAAiwArAJr/iv7K/owAggGCAagBSAIGAbT9ePtA++j6qPjA+HD7NP0A/Pj6KPvA+dD10PMA9VD2YPdw9yD4GPjw9QDxYO2A64DtwO0g7UDvoPMA8sDpwOeA6+DuoO7Q824AgAUoBJgGUA3gEaANwAjQBigFPgEgA0AJ4A0ADwAPIA3ACDAEPgHkAND/mQCAAtQCaAMQBZAIYApQCbAI4Ah4BooBqf/KAdADsAUgCsAOcA7wC6AJEAiABdADKAUAB4gGOAXwBsgHKAWYAqAC5ALCAK3/HgGIAsQCPALYAlQDGAPwAYsANQBVAMX/zP7k//oB/AIgARz/k/8Q/yT94Ppo+kD6yPkQ+uD71P0I/HD5IPfA9TD0APVA94j5qPjA99D08PDg7IDtoO7A7tDwsPJg9XDwAOqA6aDrYOog7SD2uP7SAUwDEAegDAAO4A3ADBAJuAT8ArgEsAeADQATwBOgDyAKQAcAAiT8Hv44A0gEOAI4BaAJMAl4BbgGMAqgCGgEkAOIBQgE4gG4BFAKQA1wDGAMgAsACfgFEAXIBdgFgAXQBagGOAe4BogF6ASsApT/rP5l/6YBpANIBEAFwASQAmb/9P1J//n/tf/i/8kAlQCP/+j+yP7c/Xj8ZPwo+xj6gPho+ZD5MPkI+jD8ePuA94D3qPiA9qDzwPSI+sD4MPXg8tDzYPKA6+DsUPEg81DwIPBw8EDt4Okg6kDugPKo+Ij9tgEIBQAJsA3gD0AOkAoYB2ADXgFABeALYBHgE+ATYBAQCTQCrv7o/aX/CAMYBtgGSAdgBwAHEAegBRgGIAfQBVAEnAOwBPgEaAaACdALsAsQCtAHsAUgBXgEKAQoBfAGMAhYBxgG+AXoBZwDPABUAEQC8AKoAQgDEAYIBjgCHgDNAG4Ar/+U/u//uf8K/ij9rP1y/lD9IP4E/Rj7oPng+OD3APfA97j6CPr4+OD4KPp4+ED1EPUA92D1APZg9kD3wPOA7oDvgO1A7EDs0PLw8xDxQO/g7EDqIOgA7ODzwPmM/Ef/YAbACpAMwA3QDYAKwARiAUgBkAYQDEARoBQgFAAQIAh0AEz9BP5jAMgDKAdwCcAJ0AfYBUAFiAWIBJAF8AV4BRAGSAUoBoAIUAtwDCAKsAjYB/gGYASwBJAI0ArQCHAGmAfIB6ADxf/IAhAFbAIBACgDwAVABJgC4AJIBMwBWP2A/n4A4P7Y/YX/EgGJ/1L+JP70/Aj7gPqw+8D7gPnw+oD7+PnY+Hj5CPsI+VD34Pf4+ED1kPSg9hD4MPWA80D2UPJA7QDsIO4A78DuEPPA9VDxIOng6GDsIO0A8PD1c/9cAnAEAAmgDoAQIAyQCRgGhAMcAkAEYAsgE0AXYBOQDUAH8QDQ+yj8FALoBkAIAAjgBzAHCAUQBNAEqAXwBWgGWAboBXgF6AfgCIAIoAmAChAI7APMA4AG0AfwBSAHAAuQCSADugFYBIAFyAGoAKgF+AUCAZoAUAWQBVQBnP7eAegBp//a/goBrwCA/XT9FAGG/4D8uPvo/FD8MPrg+aD7VPwI+wj6cPr4+mD4sPVw9tj5UPpw9lD2oPoo+gD0YPPg9MDzoO8g7TDw4O3A7sDyoPTw8WDswOzg7ODqAO5g9nD7kP38AkAMkA/ADHAM0A2gCcwCugEQBuAJgAxgE8AWQBEACUQDtAAs/gD9mAJACNAIuAX4BBAG0AQMAzAEkAbwB5gGgAR4BeAGaAeQB/AIkAtwDAAJyAWoBUgHaAcYB3AIEAogCIAEQALcAiACjAKwArgDMATYBPADTAI4AmgCLgH8/wYBZALwAfj+oP6x/5P/Ev6U/rAA7v4s/AT8yPyo+oj4kPro+5j6CPkg+8j7uPlQ+Hj56PhA9RDzkPdg+dD2APbw9qD14O8A7iDvYO+A78DvoPKQ8CDtwOxA71Dx4PKQ9sj7N/9cAhAJEA8QD3ANYAtwCagE9AJ4BiAM0A+AEcATgBAwCTQDWAG0AiACOAIQBVAIIAdwBFgEEAbIBfwD/AMABrgGJANIAgAGMArACHAG4AiwCnAIGAWoBegHQAcABogGgAg4BkAEkAPUA/ACMAHnAIQC7AKUAlgEHAPkAH//HACi/3T9Ov5wAJUAJv7M/Zr/OP+s/Rz9yv4I/RD6YPk0/SD9GPvw+5j8QPtA+PD3oPrA+Tj4APko/KD4IPRg9MD2YPYA8gDyoPMQ8QDtAO4g8eDx4O4g71DwgO5A7EDtQPHg9DD4VP1gBIAJwAvQDbAMAAlgBRgEoAWgCBANgBCAEqAQAA5AC0gHZANaAdABFANIA3wD4AXgBtAGiAbABXgFWAMwAf4A3AL0A9gE6AYACiAMcAjYBtAIQAigBGgF4AjACRgHcAVACJAIaATqAdADZAN1AOj/+AIoBBACZAFkAt4ArP5G/nYAtP9m/vb+3f+k/oD95P65/2b+OP2Y/cz9KPvw+Ej6IP2I/Dj8iPzg+yj6MPcA9/D3sPeQ9pD3cPjQ98D0EPRw9NDygO+g73DxYPCA7yDwAPKw8MDssPBA84DywO5g8LD0OPo0/jAGoA6gEHAM0AiwBlgDJAPgBtANABSAFKAQgA3gCpAHQAUwBIAFiAVgA9QC3APABSAHAAegBxAH+ARkA7wCOALgA+gFQAcgCIAJUAqYBxgFyAUwCIAGsAVQB2AJ0Aa4AugE0AYYBUQCKARIBTgCsP8YAkgEJAP5/+8AGAIc/wD96P7MAagA2P34+xb+bP2Q+3T8/P4r/2z8wPuw/bT82PlI+gz8PPyY+iD6qPrI+uD3MPcA+fD3cPcg+CD5QPeQ9GDz0PGw8eDx0PEA8pDw8PAw8uDvgO+g7xDyEPFw8dDwYPOw93z9YAaADWARQA6wCXgGgAWQBcAG8AxAE6ATQA9gDcAOIAsgBlgFcAgYBkcAOQDQBdAGxAPIBCAJyAc4AmIB+AJkApoAyALwBqgH+AagBzAIAAdIBQgGoAeYByAIQAngB1gE8ANABUAGEARABCgF+AMkAQwAUAOkAgoB/P8sAtgCXv/g/RMAvABs/PD66Psm/lj8qPuM/Rz/0Pzg+RD7yPvo+pj4qPiA+tD6WPmo+Sj7APto+Xj44Pfw9uD1cPWw9sD2YPVg9AD0gPNw8YDwgPCA7mDtgO9w8TDxUPBg8vD08PKQ8CD0OPyyACAGsAwAETANWAdwBpgGSAYQCLANYBLAEWAPYA6gC0gHsAa4B+AGAAM0AnAEEAXMAyAFUAjoB3wDjAIIA2ABpv6RAHgGAAjwBQgG4AdgB2ADKANwBiAIwAYgBtgHIAcwBNACSARgBpgEmAKsAhAD+gG/AFIBXAJAAh4AIf/u/r7+fv6U/vz9Dv7Q/FD8GPtY+4j8LPzA+xj7UPtw+xD7wPnA+Uj7wPsA+7j68PuA+4j5cPh4+ZD50Pcg91j40PiQ9hD1IPUg9UDyIPGg8bDxsPAQ8RDz8POA8iDyYPMw9HDxQPPA9zD92AGwBgAPABBwC5AHQAfYBqAGMAmwDkARgBDQDyAPkAzQCYAJ8AmgCOgEEASYBNQDOAQQB9AISAeYBEAE2AKAADT/ggEYBJAEyATABdgGKAYYBfAF4AaABmAGYAYoBiAFIAQABKAFaAbYBQgFaAQIBFACxP/0AbgC+wDi/9wBtAGs//z9hv5P/wD8CPrI+gD8kPtg+1j8RPyA+rD5oPro+Vj5CPq4+uj5oPkA++D7SPrA+Qj7wPrw9zD28PeA+OD20PUw97D3MPWg8kDzIPLA8MDvYPAA8iDyoPGQ8QDzcPPA81D0sPeE/CAA6ASgCwAPgA3ACXgHWAfoBZAIoA9gEuASYBDgDyAO4AqgB5AIMAnwBoAFCAWwBEgE6AVAB6AHaAYQBOoBEwBV//P/SAGAAlAFIAdYB0AFeARgBcAFsARYBcgGOAdoBagDWARgBQAF4ATABaAFpAPMAKcANAJ6Acr/+gA8AnkABv4m/kX/NP2o++D78PwY/Lj6cPuY/Aj7qPl4+cj6aPqg+Vj68PoQ+zj6gPpA+8j76Pkw+VD5yPkw+YD4yPn4+WD4YPcw95D1UPOw8sDy0PJQ8vDxgPOA82Dy4PLA8sDyQPKg9JD3kPoK/8AEUAmQC+ALcAugCLgEcAYQChAPABDgESASgBEwDuALYAyQC6AJ8AYwBvgE5ANEAgAEAAhQCPgFyAO8AwgC/PyI/Pr+TgGqAOgBMAWoBawDIANYBbgF8AMgBBAFOATIAuQDqAVIBsAGUAjwB7AEyAJ0AlQCfgBnAIgCIAIMAMD+sP+s/vD7SPqQ+2D7QPlI+Fj6iPtw+XD54PnA+oj5sPcY+Wj5qPgQ+HD62Pvg+gD6mPoI++D5ePjo+Mj5mPjA9/D3QPhw92D18POw8wDzMPIg8nDykPLw8WDx8PGg86DzEPTg9SD5/PzvACAGUArACzALgAnwBtgGQAnADcAQ4BEAE8ASMA/wC0ANYA2gCwAJ0AhwCCgF+AIQBIAG4AaABlgH0AUGAQT98Pyg/ZT9uv5kAkgEgAPMAgAEwASEA7wDIAaIBVADfAEQA4AFKAVoBtAIIAmQBpgEwAN0AjgB/gCIAUoBPwBu/7r+SP7Q/Qj9aPwI+7D6QPow+RD4sPgQ+iD62Pno+WD6qPm4+ID4ePkg+mj6kPqQ+hD70Pq4+jj7+PvI+/D6WPkQ+Vj48PYw9dD0MPVQ9MDzIPQA9BDykPFg8tDyUPLQ8oD0UPZg9+D6zgAYBugHQAqQCzAKyAd4ByAKQA1ADyARABMAEkAR0A9QD1AOoA0QDcAKYAiwBaAFqAQQBXAHIArwCcAGNAOsAJT8+PpA+7z+mADaAAoBbAJQA6wDqAOwBKAE3AKEApAACgGCAYAEgAYgCEAJ8AcQBwAG6ASQA3AC7AEyAeQAcAAsAJ4AKf/c/lj+pP0o+6D58Pgg+ID3MPcg+AD5+Pi4+ID40Phg+ND38Pfg+Bj5qPjA+ED5OPnI+gD7CPvY+iD64PhQ90D1EPbA9ZD1oPWw9uD14PIw8SDyMPMg8nDycPWA9lD18PbQ+m7//AGABJgHQAmwCOAHwAkQCwAMUA4gEAARYBFAEaAQcA/gD2AQkA7QDCALcAkoB+gEAAeACaAKwAkACPAFowCw/Mj7SP3Q/UT+jf8aAYAANgBoAkQDxAKgAekA1QDp/5//AAHsAsAEIAfACGAI0AegBiAGeATQA9ACVAHcAcIBTAKNACcATwC0/xb+iPwQ/AD6WPiw99D4APiA93D4oPnw+Ej48PdY+AD4CPiA+BD4MPdQ+Kj5wPk4+Zj6EPtA+eD3kPeA9/D1IPVQ9rD3EPZg9JD0YPTA8gDyMPMA9SD1MPVQ99D5mPug/bUA7AMgBjAGKAf4B2AJcAlQCvALEA4QDyAQwA+AEGAQIBAAEGAPEA6AC3AJ+AfYB0AI8AlwCxAL0AhgBawCnP5w/FT9AP7E/HT9EP+gANMAVgAQAgQBwwBAAJH/+P58/Xr/tgGwAkAE0AaQCDAIcAeoB2AGCASQA0AExAPAAtIBQAIcAuwAJAGlAGf/zP0Q/Fj6oPjw9kD3EPeA92D3MPfQ9jD34PeQ96D2APeg99D20PYg90D48PdA9zD4QPko+dD3wPcw+Dj4IPdA9qD2QPaQ9XD0UPTw8/D0wPXg9uD3uPlY+3T8Pv4PADQCAANwBDAGIAhgCGAI0AnAC6AMIA1QDgAPIA9AD+APgA9gDyAP4A0wDAAKsAkwCuAKQAvwC/AKSAckAxQCigBT/5T+7P60/1v/jf8l/yf/bP+D/28AsP/E/or+IP4+/jr/1AAsAxgEuAXABhAH6AUQBSAFUAUwBXAEyAMsA5gC7AEYAsYBkgE6Afr/Gv+k/KD6WPlA+Rj5mPiw90D30PfA91D3sPco+LD3cPdQ95D3EPdg9mD2gPeg90D3MPfw9/D3sPcg9zD3IPdg9/D28PWg9eD0oPUw9vD20Pd4+cj6ePv4/Fr+FgAoATQDyARoBqgGMAcgCAAJEAqACiAMwAyADaANAA4ADrAOIA8QD/AN4AyQC8AKgAqgCpALEAwQCuAHWAWcA2QCVwDPAPsAMQAs/3j+rP7M/p7+3v7U/gz/YP5c/ej8xPyc/Z7+OwCCAXgCkAO0A8ADAATEAxgEEAQwBFwDyAIEAvQB7AFEAlgC7gEUAer/nv4w/QD8+Pqg+iD6aPlA+OD3sPew9+D30Pew90D3wPYw95D1sPXQ9bD1kPWg9dD1IPaQ9tD1oPbg9pD2APaA9oD20PWw9eD14PaA99D48PlA+2j87P00/34AfgE8A6AEeAVgBkAHUAigCKAJ4ApwC2ALIAzADGANEA3QDTAOgA7ADtANEA0wDHALYAsAC3AKgAoACXAGyASMA3ACzgFkAZYBJgGb/9L+sP6S/lj+ZP3I/bD8MPwM/CD8qPso/Mj96P7//1kA7wAgAeAB4gE0AmQC9AFwApgC9AE6AZQBlAFIAggC1gH5AMT/Qv+G/qz9dPyw+5D7WPtA+mD5KPlY+cD5UPmA+CD4KPhg9xD3oPYA9vD1IPYg9gD2EPZA9lD24Pbw9sD2wPaA9tD2APew9vD2gPf4+OD5gPqw+5z8XP6z/90AEAKgA9AEyAVgBngHcAjQCLAJoAqQC5AL4AuADDANgA1ADYAN8A1wDbAMYAzAC8AL8ApAC6AKwAmACPgGqAUYBHQDnALkAW4B/wBV/03/av4E/3L+vP3I/Ez8XPw4+xj7oPoo+wD8zPzU/JT9FP5U/hr/jf8DANb/JwCQAF0AJACa/1AA8AC0AMsAqQAzANj/b/9X/6T+/P2c/UD9nPyY+zj7CPug+oj6aPrw+XD5APkw+fD4OPgY+Bj4YPjw97D34PcI+BD4QPig+OD4sPio+AD56Phg+WD5kPlI+qj6MPtw+0D8JP1O/hL/0v+cAJIBaAJUAzgE6ATIBXgGSAegB/AHMAjACCAJcAnwCdAJUApACoAKkAqwCmAKkApwCuAJkAkQCfAIMAiIB4AGqAXYBDAElAMsA5wCJAIAAkYBmgD9/xEANf/M/i7+Cv6s/Tj99Pzg/BD9/Pwk/YD9qP3g/VD+Zv6C/o7+sP7c/pz+hP5s/k7+9P20/dj90P2o/Yz9gP2U/Yj9WP1A/VD9HP0A/cj8fPxw/Ej8KPz4+/j7+PsA/BD8IPwo/Fz8hPyE/Kz8rPyw/MD8yPzM/Lz8vPy8/ND81Py4/LT8EP0o/Vz9kP3I/SD+Tv6W/tj+Mv9x/9P/LgB6AJQA/ABwAcoBLAJYArgCGANgA5wD7AMwBHAEuAT4BDAFaAXABegFMAZgBmgGcAZgBjgGEAbYBbgFiAVYBTAF6ASQBFAECATAA4wDRAMYAwADwAJ0AjgCBALeAY4BTgEQAdAAdwA4ABYA8v/W/7D/p/+Y/3v/OP8e/xL/GP/6/sj+lv6K/mb+QP74/fj96P3U/az9mP14/Uj9MP1A/UD9GP38/PT89Pzg/MD8sPzA/KD8rPyM/Lj8XPx8/HD8ePx0/GT8nPyQ/JD8iPzA/Lj8vPzY/Oj8BP0o/Uz9iP2g/Zj95P0I/ir+VP6Q/tb+B/8x/3T/mv/U//D/FQB9AJwA5AAgAVgBmAG4Ae4BKAJ8ApgCyALwAjQDXAOAA8QD5AMYBPQD/AMQBBgEMARABFgEWARgBFgEUAQ4BCgEKAT0A8gDxAOcA2gDLAPsAtACuAKEAkgCOAIIAsoBmgFiASIB7QCtAHgAUgANAMP/mf9z/yv/8P62/pb+dv4+/gr+xP2k/Wj9QP0E/dz8uPyg/HD8WPxA/Bj8+Pvo++j72PvQ+8j74Pvw+/j7CPwg/DD8OPxY/HT8lPyc/Mj86PwM/Tz9eP2w/eD9IP5G/oL+tv7k/jH/ef/P/xkAbACVAOIAHAFgAZgB1AEUAkQCiAKwAvACFAM8A0wDdAOMA6ADsAOoA7QDuAPIA7ADrAOoA6gDjAN4A1wDUAM4AwwD9ALIAqwCeAJgAjQCJALiAcoBnAF6AU4BDgHrAL8AlwBvAEQAJgD4/+P/tf+W/4H/Zf9H/xf/+P7Y/sD+sP6a/o7+ev5k/lj+RP4u/iT+Gv4S/vz97P3g/dj90P3M/cz9wP28/bj9xP3I/cj92P3o/fz9EP4m/jL+Qv5O/mL+fv6Q/q7+zP7u/vz+Gv8y/0z/c/+Q/7T/zf/c//z/HwA+AGcAjACtALwA1ADwAAwBHAEoATABQAFEAVYBZgF+AYgBlAGUAaQBhAF4AXYBYgFcASYBNAEwAR4BAAEIAe0A1wC4AKYAswCBAHEAdgBsAE4AIwAdAAAA5v/Y/8r/wv+g/4b/bf9P/zr/FP8B/+j+3P7S/sT+qv6i/qb+qv6W/pT+lv6Y/pj+kv6Y/p7+pv6s/rD+wP7K/sz+zP7K/tL+1v7Y/ub+9P4G/xX/Iv8y/0v/af+E/53/r//H/93/8v8KACIARQBnAIIAkwCmAMQA5QAEARYBFgEoAToBSgFUAWABegF8AZIBnAGqAbABtAG8AbgBsAGoAagBngGUAYABdAFiAVYBTgE+AR4B/ADhALkAnAB+AGkAUgA8AB0ACQDy/9P/w/+p/5X/jP+D/2//Yf9j/2n/Wv9I/0v/Qv88/x7/Jf8W/w7//P76/vT+7P7c/sz+0P68/tb+1P7s/u7+7v4R/yb/KP8t/07/YP9f/2X/df+U/5D/lv+o/83/yf/D/8z/7/8JAA4AFAAeACoAIwAhADMAVABgAHIAgwCZAJ4AlgCVALQAswC+AM0A1wDbANoA5ADyAPgA8ADzAPYA7wDrAOkA4wDZAN4A5ADXANYAyQDMALsAswCtAKIAmQCSAJIAjAB6AGIAWwBWAD0AHQAYABEA+P/d/8//x/++/67/o/+T/4L/bP9q/2D/XP9b/1n/VP9K/1f/U/9U/1f/Vv9p/23/bP9z/3L/a/9r/2j/af94/37/ff97/4v/mf+Y/53/oP+t/8H/x//S/9n/5P/w//b/BAATACAAGwAUABwAIQAjABYAGAAjAB8AHQAZACAAJQAjABIABQAIAAEAAQARACAAJQAjAB4AJgAmACMAIgAiAB4AEwAbABUAEwASABoAGQAQABIAGgAbAAwADwAeACgAIwAjAC0AMgAoACAAGwAkAB8AJAAqADEAKAAcACEAHQARAAgADgAPAA0ABQAEABIACAD7/+//7P/u//T/9f/2/wEA+//w/+//AQAPAAwADwAoAC8ALAAoACcALgAmACEAHgAmACQAKgAlABwAHQAfAB8AEwAbAB4AJQArADgAQABHAEAARwBKAEoARAA4ADIAKgAnACoAJAAWABYAEwALAP7/+f/x//H/2//V/8//0//R/9b/7v/t//f/7v8BAAQABwAEAPr/BAAHABYAEQATAB0AHAAQAAsACwAZAA8AAQAMABAABgAFAAwAFwAdAB4AIAAfAB0AHgAcABcAHwAjADEAKwAsACUAGwATAAsAFgANAA8ACQD///r/6f/p/97/4P/X/8v/zf/H/8v/yv/G/9H/zv/G/8L/wP/D/7X/o/+d/6P/nf+Q/5L/m/+U/4X/iv+N/5f/k/+Q/6P/p/+q/6//wP/U/9n/2//o/+z/+P8GAAsAAAACAAEA8//1//X/+//3/+z/+f/8//z/8f/0//T/8v/2//b//v/9/wUADAAPAAsAFQAiACQAJQAfAB8AFwAOABUAGQAfABsAJAAgABoAEAAKAAgAAQD8//j/+//0//b/+f/0//7///8BAPr/9f/0/wUABAD//wAA/v/7//T/8v/v//X/7//q/+n/4v/k/+P/5P/g/9r/0P/S/9H/z//Z/9X/0f/M/8X/yv/J/8r/w//B/8D/vP+7/7X/s/+m/7H/tv+4/7H/u//A/7v/vP/H/9n/4f/k/+r///8EAAEAEwAjAC4ALQAsAC4AMQAhAB8AIAAjACkANwA3AD4AOQA/ADoAPAAnADAAKwAqADEALQAuACwANgBAAEEANQAvADgAMgAyAC4AOwA5ADkANQA1ADMANQA1ADEALQAoACUAIwAeAB0AGAAfABIAHAAnACEAIAAhACUAHQAgACQALQAlABgAFwAdABQAEQARAAYA/f/y/+7/8v/s/+f/7P/n/9n/0f/Q/9H/zv/G/9P/2f/N/8D/x//L/73/vP/B/8z/wP+7/7//xv/C/7r/uv/F/8H/t/+7/8b/zP/T/9b/2P/j/+n/8//7/wEA+//+/wQAAQAFAAkADAASABMADwAUABMAEgATABIADQAVABAAEwATABAAEAAVABoAHgAeABAAEAAVABcADgANABUAGQARAAsADAAJAAMAAAALAAYA+//3/wEAAQD6//7/AgADAP7//P/7//7////9//n/8f/v//j/9v/r/+3/9f/v//D/7//5//r/4//d/+X/6v/l/+T/7P/s/+L/2//f/9z/1//T/9//5f/i/9v/4//n/+n/6P/u//X/6v/t/+//7//n/+X/7//3//f/9P/4//3//P/6//7/AwANABMAHQAoADEAPwBAAD4ASABCAD0AQQA9AEQAOgBBAEsATABGAD8AQQBDAEAAOQA7ADgAMQAvADAANQAuACYALAArACkAIQAgACUAIQAbABgADgAKAAQABQABAP///v/4//r/8f/l/+v/4//d/9z/4P/o/+T/5v/o/+j/6f/n/+n/9P/u//P/+f/2//L/7v/y/+r/4f/W/+D/3P/W/9X/zv/P/8L/xv/K/8T/vf+2/7b/tv+0/77/yP/S/9H/1//c/9T/0//V/9P/2P/Y/93/3P/X/9n/4P/f/+D/2v/a/9r/3P/n/93/4//m//H/7P/v//D//P/9//H/+//0/+z/7f/w//z//P/5//n/AQAGAP3//f8GAAUAAQAEAA8AEAANABAAFQAeABwAFgAaACcAJgAnACcAIwAgAB0AGgAUABUAGAAWABEAEgAZABgAEwALAAcABAAAAAIAAAAHAAgAAwAEAAYADgAPABUAFQASAAsADAAIAAQAAgADAAUA/P/0/+7/7//s/+j/4//h/+L/5P/m/+T/5v/o/+z/7//4//7/+//6////AgAFAAYADQARABIAEQAPABUAGwAiACMAIwAiACMAJAAfAB0AHgAdABwAIAAlACYAKQArACsAKQArACYAIgAiACYAJwAnACMAKAAqACYAKAAqACoAKwAzADgAPgA8AD0AOwA1ADcANwA4ADUAOAA5ADcANAAxADQALAAoACIAIQAeABkAGgAcAB4AFwASABEAEwAPABEADQAKAAkACQAFAAUABwAKAAkADAANAAsACQADAAcAAwACAP7/BQAGAAIA+//5//T/8v/r//T/7v/v/+v/7v/o/+b/7P/r/+3/5v/w//D/8v/v//H/9f/u//P/9f/4//X/+P/7//n/+v/6//3//f/1//D/8v/0//r/9v/1//T/8f/x//D/8P/r/+X/5v/o/+j/5//j/+j/5v/l/+X/5//0/+//8//9//3/+f/9/wQABwAMAAMA/P/5/wMADAALAP7/+f8JAAUA9v/o//b/AQD1//H/9f/9//j/6P/u//H/7f/k/+P/7P/q/9r/2v/d/+P/2//a/9v/2v/c/9v/3P/i/9r/4f/n/+f/6//u//P/+v8FAAIADQANAAgAFQAeACAAJgAgACMAIQAnACEAJAAaACEAIgAeABoADgAYABYAGQASABsAJQAvAC8AMQA8ADsARgA/AEcATgBeAGMAWQBSAFUAaABnAF8AUABVAFQAVQBQAD4AOwA2ADgALwAhABgAJAAbABAA/P/z/wkA+f/y/9j/7P/f/9P/vP/J/77/pv+s/5z/3v+j/7D/sP8BAOf/6/8EACIAUQA5AEsAQwBsAHgAZQBaAHAAaABUAEIAIwAqAOj/of9+/1P/GP+0/oD+Qv4A/rj9VP04/RT9wPzE/JD8sPzk/Dz95P2U/lj/CACKAOgAdgEsArwC/AIsA2wDxAPYA6QDZAMcA+QCqAJUAsgBaAECAdkAPwCv/zr/MP8I/57+Qv78/UT+OP4s/hL+Ov6a/tT+C/80/7H/JwCcAOcADgFwAbwBNAIUAiACHAJEAkAC3gF0AT4BHgGsAFsAuP+o/2H/EP+8/mb+eP4+/mL+Pv6A/oD+zv4V/0H/iv+d/wcATQCBAI4AvQDrAAQB5gDqAPAA3wC5AH0AXwA4AAwAx/+O/2b/UP8x/w//+v76/hP/G/8n/z7/fv+u/8b//P82AH4AnwDJAPMAKAE+AUgBUgFgAWQBQgEYAecAxgCWAGgAHwDc/6D/cf9B/wz/5P7M/sL+rv6e/qr+vP7q/gD/HP9K/4X/zf/8/zMAYACZAMUA3gD5ABABMAE6AT4BKgEgAQoB+ADWAK0AhABVADIACADf/6v/hP9j/0//Nv8s/xn/HP8h/yP/Pv9I/1v/cf+K/6H/t//J//b/BwAeADsATwBwAGMAfQB3AIwAfwCHAG4AdgBbAEsAOgD1//r/uf+7/4n/bf9V/0n/Nv8i/yb/DP8O/wb/Ef8i/x//Jf81/23/YP9+/3b/o/+//8D/zf/l/wgAGgAMAAcAKQAtAD8AOwBNAE8ATgA6AEAAHAAJAAoACwD0/9f/uP+6/7L/m/+B/4H/cv9n/1//TP9F/z3/Uv9A/1X/Sf9v/23/d/+E/4//rP+//9b/5P/9/wYAFQAoACIAEgAOABEAAgDv/97/0f/O/7j/sv+w/7r/qf+s/6f/uv/N/9j/7f/3/x4AKwA5AFsAWAB2AIgAiQCnALcAvADQAMwAwADTANYA4wDUANsA5QDkAOUA3QDXAM4AwwC8ALcArQCbAIIAfgBwAHEAYABVAFIASgBWAD8ATQBUAFwAaQBpAHIAdgCHAIUAgwB6AGUAUABFADUAGQAEANr/zf+h/3r/V/86/x//7P7Y/rj+qv6a/p7+nP6g/qz+yP7o/vL+Df8z/2D/fv+g/8n/8f8PACkANQBOAFcAbgB3AIwAlQCdALYAugDBALkAzQDTAOYA4QDvABIBGAEqASIBOgEsATgBNgE2AU4BPAEuARwBDgH8ANcApQCbAGgANQD6/7b/ef8t/+D+hv5Q/gD+1P2k/Xj9aP1k/Xz9hP3I/QL+Yv66/if/nP8aAIsA/QBaAbYBDAJAAmQCaAJcAlQCMALgAZgBPgHgAGsA+v95/xv/mv5G/uD9nP1c/TT9MP0g/Tz9NP18/az98P08/nj+4P4o/3z/vv8OAF0AmQCzAM0A2gD0AO4AzwDBAKwAgwBdADAADADn/8f/rf+N/3n/cP9t/13/Z/9s/5H/p//T//X/FgAzAEgAewCCAKgAugDLANkAxADUAL8AwgCoAJIAgQBuAFYARwAmACkAFQD+//r/5v/y/9v/1f/R/9z/1v/b/+z//v8HAPj/FQAWAB4AIQAgADUAMQAvACgALQAtAB0AEQAJAPr/6v/l/+n/1v/c/97/yv/M/9D/5P/y/+n/AwATADIAQgBOAF0AYgB1AH4AiQCKAI4AlwCWAIQAfgB8AHUAdwBlAGYAWQBJAEoAOAA6ADIARAA+AD4ALwAvADYALQApABcAJAAgACsAJgAaACEAJgAqACAAFwAGABoADQAJAP3/9//2/+f/4P/M/9H/xv++/7P/pf+h/6D/ov+c/6D/mP+i/6D/l/+p/6//uv+//7f/wP/F/9H/0f/V/9X/2v/l/+T/8P/c/+r/6P/v/+b/+P////v/9P/+/wsAEgAbAB4ANgA0ACkALwA7AEMAPgA9ADkASAA7AD8ANgAqACYANgAzAD8ANgA8ADUARwAjADAAIgAdACYAHwAdABEAHgAgACkAHQAVACUAGgAjABYAJgAnADEALgAzACkALwAxACYAJQAaABwAFwAMAAcA8f8CAOT/4v/k/9T/1v/N/8//uv+2/7H/vP+3/7D/qv+0/6z/s/+8/7f/v/++/8D/yv/N/9H/5//x/+f/7v/u/+//7//h/+f/7v/q/9v/4P/g/83/yf/E/9H/v/+7/77/yf/F/8P/v//T/9r/1f/c/+v/+P8KABgAGwAlACwANgBAAEoASABHAFAARgBFAEcARABMAEkAQABAAD0APAA8AD8ANABFAD0ATABZAFwAVQBaAGMAbQB5AGwAbQBuAHEAZABeAF8AXQBSAEgAPwA0ACcAFwAcAA8ABgD5/wEA/v/x/+3/7v/u/+j/5//f/+D/4v/g/9v/1f/P/9f/1v/J/8j/0f/C/7z/rP+w/7P/l/+H/3r/cv9i/2L/Yv9k/13/W/9o/2r/bf9v/4X/mf+u/7T/z//Z/+7/+v8GAB8AHAAtADYAPgA3ADYAOwBAAD0AOQA3ADoANwAtACgAIAAkACAAIAAjACIAMQA0ACsAOQAyAC4AOgA2AEgAOgBFAFIAVgBXAFYAUwBRAE0AQgBHAD4AMQAqACMAKAAcABEAFQALAAkAAQD6////9//0//T/4f/g/9b/2P/P/8j/zv/E/8b/wf+0/7z/tf+v/6v/q/+z/7D/sf+y/6r/qv+p/5n/o/+X/53/pP+i/6D/of+o/6f/rP+f/7X/tv+9/9L/0f/k/97/8v8BAAgAFQAaACMAKAAoADgAQABOAFIAVABhAFkAWABiAFMAXQBcAGUAbgBpAGkAdQBuAHcAcABsAGwAZgB9AGkAbgBsAHgAbgByAGkAdgCBAG0AgwB7AHIAbQBqAHUAbgBnAFwAVQBMADwALQApABgABAD1//b/7v/c/9b/zv/Q/8z/w/+6/8f/xv/J/8z/y//I/8//1f/O/9r/4P/t/+n/8P8BAAcAEwANABYAFwAXACkAIwA2ADwAQwBAAEEAQwBDAEgAQQA+ADQAMAAfABsADwAHAA0A+//0/+L/4v/Y/87/xv+0/7X/qv+r/5//m/+W/4z/kv+U/5f/o/+Z/6T/ov+m/6z/r/+z/7j/u/+x/7b/sP/A/7n/t/+1/6j/tP+k/6f/n/+i/5f/kf+h/5X/oP+Y/5f/k/+T/5n/iv+S/5v/lv+i/6L/qP+y/7P/vf/G/8n/3//m//n/GwAZAD8APQBQAGUAcgCWAI8AugDJANQA9QDyABoBEAEkATIBMAFKAUABVAFeAWoBegF8AYABhAGMAZQBjgGMAYABjAFyAVoBUgE8AQYBAgHVALoAdgBJACYA4/+9/3D/Sf8a/97+tv56/k7+Jv7I/eD9gP1w/UT9HP0E/cj8yPyc/JT8YPxc/Dz8IPwU/AD88Pvo++D72PsE/Oj7APwk/BT8WPxs/Iz80Pzg/DT9cP2U/Qj+JP54/s7+Bf9n/6L/AwBKAIkA3AAsAYQB1AEIAnQCrALgAkQDXAP4AzAEaATQBAgFUAWYBQAGOAaYBuAGMAdwB6gH+AcgCEAIUAhwCHAIgAhgCCAIEAjIB2gHKAfABkgG2AVIBbAEAARcA5gC6AE+AUYAf/+4/uz9JP04/Hj7sPr4+Uj5kPgI+HD38PaA9hD2wPWA9UD1MPVA9SD1MPUw9VD1kPWw9eD1IPZw9rD2APdw97D3KPh4+Oj4iPnY+YD68PqI+xz8rPxo/fD9rv5R/+L/ogAeAZYBMAKAAgQDgAO4A0gEYATQBBgFUAXIBegFUAaQBvAGUAfIByAIkAgACYAJEAqACgALcAsADHAM0AwgDZANoA3gDdANsA2gDUAN4AxQDJALwArgCbAIyAdoBmAF6APMApwBJQD4/qD9nPxY+1D6aPlQ+ND34PZA9tD1YPUg9bD0sPRw9FD0UPRQ9HD0wPTg9DD1oPUA9oD24PZw9/D3YPjo+FD5wPkw+oj6GPt4++D7cPzI/Ej9qP0Y/nj+zP4r/4z/0//4/ysAUQBTAGMAMgA2ANj/sf9i/+7+zP5K/vT9qP1I/RT94Pyw/LT8xPzc/CD9SP3o/Sb+wP5d/83/lQAAAeIBgAJQA9gDsARABTAGoAZIBxAIYAhACWAJIAqwCiALYAsgDFAM0AwwDfAMoA1ADUANEA0ADcAMEAwgDBALgAqgCbAIMAjwBigGMAWoAyAD2gHkAO7/rP7w/eD8VPxY+3j6WPpA+eD4mPjw9/D3gPdw92D3APdQ9yD3QPeQ95D38PcI+ED4iPi4+DD5WPmY+TD6WPrA+jj7gPsY/GD84Pw0/ZT9+P1a/rD+8P4//1v/sP/A/9T/4//l/97/lv9r/zX/2P6i/jL+9P2M/SD9AP2c/Ej8LPzo+9j7uPvY++j76Psg/Ej8kPzU/Cz9mP0G/nj+6P5r//n/cQAeAdYBTAI8A6gDeAQ4BegF6AZYB1AI8AjQCZAKUAvwC5AMIA2ADcAN8A0ADqANwA1QDcAMoAzAC1ALMApQCbAIUAdwBmgFcARcA1gCUgFWAIf/sP7A/Rj9SPxw+/j6OPrI+Sj5sPhg+Aj4CPiw93D3cPdg92D3YPdw93D3kPeg9+D3IPhA+Jj46PhA+bD54Plg+sD6MPug+xD8kPzI/FD9qP3Y/RL+Pv5I/l7+NP5i/vz97P2o/Wz9FP3M/Gj86PvY+zD72Pqg+kj68PnA+Yj5gPlg+UD5cPlg+Zj5wPn4+WD6uPoY+6D7DPyg/Dj92P2Q/iv/AADaAJIBcAJkAygEKAUIBvgG8AcACfAJAAsQDBANAA7wDrAPQBDAEKAQABFAEcAQwBBAEJAPIA/gDfAMMAwAC/AJsAiYB2AGIAUoBMACzAGJAKv/zP7w/Sj9NPyg++j6UPqw+Tj5wPhY+Bj4sPdQ9yD3EPeg9tD2gPaA9pD2kPbA9rD2IPcw93D3APhQ+Kj4QPng+WD66Ppw+xj8lPxQ/aD9VP6Y/tD+W/9S/7z/nf+T/6r/Pv8z/9L+eP4i/pj9dP3s/Ij8QPzA+6D7OPv4+uj6qPqo+qD6uPrY+gD7GPtg+7D7HPxs/Mz8VP24/Uz+sP5d//T/fQA+AeYBxAJ4AyAECAXgBcAGyAdwCNAJgAqQC8AMcA2ADiAP8A9gEKAQABHAEMAQwBAAEOAPAA8wDlANcAxACwAKwAhwB0gG8AS0A3ACaAEQACz/Sv5A/aT8qPso+3D6wPlo+cj4qPgg+OD3oPdg90D3EPfw9gD30Pbg9gD38PYw90D3cPeg9+D3YPiQ+Aj5gPnQ+Xj6yPpA++j7TPzo/Dj9qP0M/kr+jP7E/sj+Af/c/tD+pv5Y/iz+oP1k/fT8fPwg/KD7aPvY+pD6MPr4+dD5kPmY+Zj5kPmo+eD5+Plo+pj6GPt4+/D7hPwE/Zz9IP6+/lf/AgDHAIIBIAIYA6gDmARgBSgGIAfwB/AI0AngCtALwAzADZAOIA/ADwAQYBBgEIAQ4BDwD9APQA+ADsANsAzAC6AKcAlgCBAH8AWwBFQDWAIiAfn/+P4c/kT9NPyQ+9j6IPqI+RD5wPhQ+PD3sPdw90D3EPfQ9tD2sPag9rD2oPbA9sD28PYg90D3gPfA9xj4gPjQ+ED5wPko+rD6KPvA+0T8yPxA/aj9Cv5U/pT+zP7i/tz+2v7E/n7+SP7k/ZD9KP3E/Gz88PuI+zD70Ppw+jD6APrI+bj5wPnA+ej5CPpA+qD62Ppo+6j7UPyk/CT94P0u/ur+UP8BAJ8ASgEAAqgCfAMgBOAEoAWABkAHIAgQCdAJ4ArAC/AMsA1ADkAPwA/wD2AQYBCAEKAQ4A+gDwAPcA6ADbAM4AuACrAJQAhABygG2ASwA3QCjAGCAJL/vv7g/Qj9bPy4+xD7gPoY+qj5SPkI+bD4iPhQ+CD48PfQ97D3kPeg95D3kPeg99D34PcI+FD4kPjo+DD5gPkY+lD68PpI+/j7WPzc/Fz9uP0q/m7+sv7Q/g//Bf8X/+r+zP6S/jz+4P2M/Tj9uPyE/ND7sPsg++D6kPoY+ij62PnY+dD50Pn4+RD6OPqQ+uj6SPu4+yD8jPww/Zj9Nv62/lD//f99ABQB7gF0AnAD9APABJAFMAYwB8AH8AjgCYAKsAvADLANcA5AD5APIBCgEKAQ4BDgEKAQQBDQDyAPYA6ADZAMgAtQCkAJ+AfoBpgFWAQoAwACBgEKACj/PP5o/ZD8EPxA+7j6YPrI+XD5IPnY+Hj4SPgI+PD3wPeg94D3cPeA91D3cPeA93D3sPfQ9/D3YPiQ+Oj4UPmg+Tj6mPow+5j7HPyw/Cz9qP3w/Vr+nv7c/gD/Kf8p/xj/7P6w/oD+LP7I/WT9AP2g/FD84PuI+zD70PqY+nj6SPow+ij6QPpo+mj6qPrI+hj7ePvA+zz8lPwE/XT9/P1k/vb+YP8GAJ0AHgHaAVgCMAOsA5gEOAUIBqgGiAdQCGAJYApQC3AMUA3wDaAOsA/QD0AQoBCAEMAQQBAgEIAP0A4wDjANUAwgCxAK8AjQB4gGSAUIBAgD8gG1APf/A/8S/lD9lPz4+2D78Ppw+iD6wPl4+Uj5EPnI+KD4ePhA+DD4APgA+OD30PfQ98D30Pfg9wj4KPho+Jj44Pgw+Zj58PlY+tD6OPvA+zT8tPwg/Yz93P0g/mr+pP6+/tj+vP62/oL+NP74/Yj9MP3E/Fj8APyQ+zD74PqA+lj6CPoA+tD52PnQ+eD5APoo+lD6mPro+kD7kPvA+1T8mPwY/YD9AP6I/qz+qf8HAF8APgG8AWwCOAPAA7AEWAUQBuAGsAfACIAJkAqgC4AMUA0QDsAOMA+wDwAQIBAgEPAPsA8wD6AO4A0QDTAMMAswCuAI2AeQBmgFWAQQAxQC+AAIACn/Rv6k/dD8KPyg+/j6mPow+sD5ePkQ+cj4kPgw+BD40Peg95D3UPdQ90D3QPdA90D3YPeQ98D38Pc4+JD48PhI+cj5OPq4+lD7uPtc/MD8PP20/RD+ev64/vz+Gf9J/0v/Pf8Y/+j+ov5a/gz+qP1E/dz8fPwM/Lj7YPsA+9D6oPqA+mj6WPpo+mj6ePqg+sD6GPtI+5D78Psw/LD8+Pxg/dj9QP60/iX/vv8dAKkAQgHoAZwCSAPAA+AEcAXoBWAHqAfgCMAJsAqwC7AMkA0gDgAPcA/gD0AQoBBgEIAQABCAD1APYA6QDdAMwAvQCsAJoAhwB1AGGAX0A/gC4gHhACcAS/92/tD9HP2I/CD8kPsg+9D6UPoI+sD5ePkY+fj4yPiA+Fj4MPgY+Aj40PfQ99D38PcQ+DD4aPio+PD4QPmo+Rj6iPr4+oD78PuI/AT9hP30/VT+pv7y/ib/Y/90/4D/f/9I/xr/2v6U/jj+1P1o/fz8mPw0/Mj7ePsg+9j6sPqI+nD6YPpo+mD6gPqY+qj62PoY+0D7gPuw++j7RPyY/Mz8LP2I/ej9Wv7M/lz/0/9vAAwBrgFgAvgCrAOABFAFKAbwBuAH8AigCeAK4AtgDIAN4A2gDuAOUA+gD2APgA8gD/AOcA6wDfAMAAxQC0AKEAlQCCAH8AX4BPADyAIQAvwATgB3/8b+KP5c/Qj9cPzw+4j7IPu4+oD6OPro+Zj5aPkw+ej44Pi4+JD4gPhY+Ij4aPiA+LD4mPgI+SD5YPnQ+TD6kPro+nj72PtQ/NT8TP2w/SL+ev7O/h//Qv95/23/h/9n/0T/KP/k/pD+OP7U/Wj9+PyQ/Cz8wPtw+wj72Pqg+mj6YPo4+jj6MPow+kj6WPpw+pj6wPrw+ij7ePu4+/j7UPyU/OT8WP2k/Sb+ov4T/67/RQDiAJIBUAIAA9QDeARoBSgGAAcACBAJIArgCvALoAyQDVAOUA5QD1APgA+gD4APIA/QDjAOgA3ADNALEAvgCRAJ0AfYBsAFmASoA4QCsAHAAMf/If9O/qj9BP14/OD7ePsA+5D6SPrg+ZD5MPkQ+cD4mPh4+Dj4IPgA+Aj4APjw9yj4OPhY+JD4uPgg+Vj5uPko+oD6APtg++j7WPy8/DT9rP0Y/nz+3v49/4P/pv/L/9z/3P/K/6r/h/9E//D+pP5M/uT9eP0U/bT8VPz4+8D7iPtY+yj7+Prw+uj66PoA+xD7MPtQ+4j7uPv4+zj8hPzQ/CT9hP3Q/TL+ov4Z/6H/EgClAEoB7AGoAlwDCATYBIAFUAYwB+AHAAngCdAKsAuADHAN4A2wDkAPgA8AEEAQABAAEMAPYA/gDvANYA2ADKALsAqACXAIWAdIBjAFIAQcAywCMAFqAIf/rP4e/mT9xPxI/Lj7QPu4+mD6EPqY+WD5CPnQ+Ij4YPgY+Aj44PfA99D3wPfQ99D3APgw+Gj4qPgI+Vj5uPkg+oD6+PpY+9D7WPzA/DD9qP0A/lj+rP7s/jv/U/98/5X/g/+U/z3/Jv/2/pj+UP78/Zz9PP3s/IT8MPzg+6j7cPsw+yD7APv4+vD68PoQ+yD7OPto+5D74PsA/FD8iPzQ/DT9YP3Y/Sz+iP4D/3z/EgCYACoB7AFsAmwDzAPYBGAFIAYIB9AH4AiwCbAKgAtgDPAMoA2ADsAOMA+AD6APgA9wDzAPkA4wDnANsAzQC+AK8AnQCNgHkAaQBXgEgAN8AngBngCz/87+NP5k/cj8LPyg+yj70PpQ+gD6sPlo+SD52Pig+Hj4WPgg+BD44Pfg9+D34Pfg9/D3EPgw+Hj4sPj4+FD5iPnY+Vj6mPoA+4D74Ptc/MD8JP2s/fT9PP6W/sj+9v4E/xX/DP/q/sr+jv5a/hD+qP1o/QT9oPxQ/Pj7uPtw+zj7GPsA++j62Prg+uD6CPso+1D7gPu4++j7SPx4/Mj8JP1s/cD9JP6I/uL+XP+0/z4AtABIAc4BXAIMA7ADWAT4BMgFaAY4BxAI8AjQCcAKgAswDEANsA1QDgAPMA+AD5APgA+QDyAPsA4QDlANwAyQC9AK4AmgCMAHkAaQBYAERANsAnoBfgC8/8L+Mv5w/cz8SPyo+xj74PpI+gj6wPlI+Qj56Pig+HD4UPgY+Aj40PcI+MD30PcA+OD3KPhI+GD4yPj4+FD5sPno+Vj6wPoY+6j7+PuI/Nj8SP24/fz9Wv6O/sD+7v72/v7+9P7Y/pD+cP4y/tz9nP0o/fz8lPww/PD7qPt4+yD7EPsA+9j64Prg+tj68PoQ+zD7aPuQ+8D7CPw8/JD8xPwk/WD9qP0K/lb+xv4c/6z/EQC4ADgB5AG0AjAD9APQBHAFOAYwByAIIAkQCgAL0AvQDJANYA4QD6AP8A9gEIAQgBCAEAAQoA8wD3AOwA3gDBAMAAvwCfAI4AfQBsgF0ATYA9QCBAIiAUwAiv/a/jD+iP34/HD88PuA+/D6iPoo+rj5aPkQ+dD4qPhQ+Cj4APjg99D30PfA99D3APgo+FD4mPjg+DD5iPnQ+Tj6sPoA+5j74Ptk/MT8SP20/fz9Vv6u/uz++v4r/zb/If8Z//j+wP6M/kb++P2o/WD99Py0/Gz8GPzg+7D7gPt4+zj7SPtA+zD7QPtA+3D7iPuI+8D74PsM/Ez8cPy4/OD8LP1o/dj9KP5o/gP/RP/Q/2QA7wCYATQC2AKMA0AEAAXgBagGwAeACGAJYApACwAMwAxwDQAOUA7wDgAPQA9AD/AOwA4gDsANIA1gDJALwAqwCdAI0AfABsAF0ATMA9QC/gEoAV8Alf/0/kb+qP0o/Yj8CPyY+yD7oPpI+vD5cPlA+dj4iPhY+PD30PfA94D3gPdg93D3gPeA98D34Pcg+FD4qPgI+Uj5wPkg+nj6IPto+/j7XPzs/ED9pP0C/lb+jP62/vj+4P7o/ur+zP6C/mj+Ev7E/Yz9HP3g/Ij8KPzw+5j7gPtI+xj7GPsA++j6+Prw+gD7IPsg+0D7YPuI+6j7yPv4+yz8WPyU/AD9KP2I/eD9Nv6+/kD/4/9tAAgBjgE8AhQDqAOYBJgFYAaAB2AIUAmACkALAAzgDJANMA7ADlAPYA+gD4APYA8wD9AOMA6QDfAMEAwgCzAKQAkwCEgHKAYwBUAERANoAmYBswC5/wH/Yv6Q/Qj9UPz4+2D74Ppw+vj5kPlQ+QD5oPhw+Cj4GPjQ98D3oPew96D3oPfw9+D3IPhA+HD40PgY+Wj50Pk4+qj6GPug+wz8fPwY/XT9/P1i/rr+G/9M/37/tv+1/7P/xv+A/2//JP/g/oT+SP7s/YT9SP3k/Lz8WPw4/Oj72Pug+4j7cPuI+5D7iPuw+6D7BPzg+yj8UPxE/KT8vPwQ/VT9lP3k/Sj+jP4t/13/DwByABgBpAFQAugCrAN4BDAFMAbwBvAH4AjACaAKcAtQDAANsA0wDqAO8A4QDzAPMA8QD8AOUA7gDTANgAzQC+AKAAoQCQAIGAcIBhAFEAQoA0ACSAGBAKH/2P4U/mT9rPwM/Ij7+Pp4+gj6oPkw+dj4gPgw+Aj4sPeg93D3UPdg9zD3YPdg95D3oPfQ9xD4UPig+OD4QPmg+RD6ePrg+mD70Ps0/Kz8JP2A/ej9Ov6K/rz+/P4I/yb/Jf8V//j+vv6S/kL+AP6M/Wz97PzA/HD8KPwI/KD7cPtQ+yj7EPsA+xj7CPv4+hj7KPs4+zj7UPto+2D7qPvQ+/D7NPxk/Lz8CP1M/bz9Mv7K/i//wf9zABYByAGYAnQDSAQoBSAGEAcQCAAJ0AmwCoALQAzwDIANAA5QDpAOsA6wDoAOUA7wDYAN8AxQDJALwArgCfAIEAgwB0AGUAVoBHgDkALGAd0AHQBE/4z+4P0o/Yj88Ptg+9j6UPrw+XD5EPnA+Gj4GPjg98D3kPeA92D3YPdw93D3oPew9wD4KPho+Lj4+PhQ+bj5GPqA+vD6UPvI+zz8rPwY/Xz96P1A/pL+0v4M/zn/Wv9r/2X/Yf9C/x7/6P60/mr+GP7g/ZT9RP0Q/cT8hPxg/Bz8GPzw+/D78PvY+/j7DPwc/Cj8UPxQ/Fz8aPyM/LD88Pzo/ED9pP2U/Vj+XP7g/l7/yf9hAAgBtAFEAiQD7APABJAFmAZgB3AIUAkQChAL4AuADDAN0A1QDrAOAA8gDzAPEA/QDoAOEA6ADfAMQAyAC6AK0AngCAAIIAcgBkgFWARwA5wCzgH6ADcAjP/c/kD+qP0Q/Yz8CPyI+xD7sPpQ+gD6oPlg+Sj54Piw+Ij4cPhQ+FD4UPhg+ID4qPjQ+Bj5SPmY+eD5SPqw+gj7gPvg+0z8tPwk/Xz94P0y/nr+xv4F/zL/WP9y/37/ef9y/1L/KP8C/8D+gP4+/uz9pP1o/SD93Pys/GD8PPwo/Pj76Pvo++D78Pvo+/j7DPwg/Cz8OPxM/Ez8RPxs/Jz8vPzQ/Oz8UP1w/dD9SP5q/hf/bP8hAK4AUgEcAsQCsANwBGAFSAYwBxAI4AjQCZAKMAvwC5AMAA1wDcANwA0ADuANwA1wDSANsAwQDJAL4AoQClAJcAiQB9AG8AUYBTgEYAOcAtQBEAFnALf/GP9s/vT9ZP3U/Hj82PuI+yj7sPpo+ij64PmQ+XD5QPkg+QD5APn4+BD5GPkw+XD5kPno+RD6aPqw+gD7YPvA+xj8fPzI/DD9fP3M/SD+Yv6u/t7+Fv9D/1v/f/99/23/Xv84/w3/0P6C/jb+5P2Q/Tj96Pyg/Ej8EPzI+4j7cPs4+yj7GPsI+xD7EPsY+zD7UPtI+4D7aPuI+5j7qPvQ++j7OPw4/KD8zPww/cT9zP2S/vD+iv83AOgAhAFsAigD/APoBLgFqAZoB3AIIAkACqAKUAvwC2AMwAwgDTANYA1QDUANAA2wDEAM0AtAC5AK8AkwCWAIiAfIBtgFCAUoBEgDfAKeAd4ALABZ/8D+Ev50/eT8QPzY+1j74PqA+ij62PmI+Vj5EPng+LD4mPiI+Ij4gPiY+LD4yPjo+BD5QPl4+bj5+PlQ+pD64Po4+4j70Pss/Hj8yPwY/WD9rP3w/Sb+VP56/p7+sv62/sD+qv6U/m7+QP4Q/tT9lP1U/Qj9zPyQ/Dz8FPzY+8D7oPuI+4j7gPuA+5j7mPuw+8j70Pv4+/j7JPw4/Ez8bPx4/Lz81PwM/Wz9nP38/Xb+zP4+/9H/UgAaAZoBWAIgA9wDwASABUgGGAfoB7AIYAkQCsAKQAvQCzAMcAzADNAM4AzgDLAMgAwgDLALUAuwCiAKcAngCCAIcAeoBvAFMAVwBLgDAANQApQB+wBKAMH/If+S/hT+lP0o/az8VPzw+5D7UPsI+7j6iPpI+iD6+Pno+dj50PnI+eD56PkQ+ij6SPqI+rD68Pow+2j7wPsM/Ej8mPzc/CD9gP2o/fT9NP5k/qT+tv7q/v7+D/8m/xb/Kf8G//j+0v6g/o7+SP4m/vD9xP2M/WD9PP0g/fD87Py4/NT8oPzE/LT8sPzE/MT82PzQ/PT84PwI/QT9/Pw0/Uz9bP2M/dT99P1I/p7+4v5W/77/NwCtADoB2AF0AjQDzAOYBDgFAAbABmgHEAjACEAJ0AlQCrAKEAtAC1ALgAtgC1ALIAvQCoAKIAqwCSAJoAj4B2gHuAYIBmAFuAQIBGgDzAIgApgB9wBxAOr/Zf/e/n7+Gv6g/UT97PyY/Ez8BPy4+3j7QPsA+9D6sPqA+nD6WPpA+lD6QPpQ+mD6cPqQ+rj62PoQ+0j7gPvA+/D7OPx0/LD85Pwc/VT9iP24/dz9Av4k/ir+Tv5U/lz+ZP5c/lL+Rv42/hj+Fv7s/dz9xP28/aj9nP2M/Yz9mP2A/aT9lP24/bj91P3g/ez9BP74/Rj+Jv4k/jj+QP5S/mj+ZP6W/rD+2v4U/zD/pv/a/zAArwD6AIYBAAJ8AhwDmAM4BNAEWAUABnAGAAd4B+AHUAiwCNAIIAkwCVAJYAlQCTAJEAnQCJAIQAjYB3AH4AaABvAFaAX4BFgE3ANYA8QCUALMAU4B5wBhAPT/iP8a/7r+RP74/ZD9LP3g/Ij8QPz4+7j7gPtI+xj78Prg+tD6uPrA+sD60PrY+vj6EPso+1D7cPuo+7j76PsQ/DD8WPxw/JT8rPzY/Oz8CP0g/TD9SP1U/Wz9cP2A/YT9iP2M/ZD9nP2M/Zz9gP2I/Xz9bP1s/VT9TP1I/Tz9OP00/TT9QP08/VD9QP1c/Wj9gP10/aD9pP20/dj91P0K/hL+Kv5g/ob+tP7g/hr/Wv+X/+r/PwCZAPIAVAG2ARwCjAL0AlgDyAMwBJAE8ARABZAF2AUgBlAGgAaoBsAG0AbYBsAGuAaQBnAGSAYQBtgFmAVIBQAFsARoBBAEvANoAxgDxAJsAhgCzgF8ATQB5ACZAFQADgDQ/4//T/8Y/+L+rv56/lb+LP4U/vj92P3I/bj9sP2s/aT9qP2k/aj9rP20/bD9sP24/bT9uP2w/bT9qP2o/Zz9kP2I/XT9cP1g/Vz9RP08/TD9JP0g/Rj9GP0Q/RT9EP0U/SD9IP0s/UD9TP1o/YT9oP3A/eD9Dv4w/lj+hP6y/tz+Cv8y/1//gf+p/8//4P8IABcAKgA/AEgAWABfAGQAbgBwAH0AiwCYAKsAywDkAAYBMgFeAYwBvgHyASgCZAKUAswCAANAA3QDnAPEA+wDEAQoBDAESARIBEgEOAQwBBgE9APUA7ADmANgAzQDEAPYArgCgAJkAjQCGAL8AcIBzgGQAYgBYgFYATQBJAEOAfwA4gDCALsAmgCHAG0AWQA0ACQACADq/93/s/+g/4//bf9d/0n/LP8j//z+8P7Y/rr+sP6E/nL+Vv40/hj+/P3M/bD9hP1U/Tj9/PzY/KD8iPxY/DT8HPzw+/D70PvI+8j70PvY++j7CPwU/Dz8XPyA/Kz81PwE/TT9WP2Q/cD96P0a/kD+bv6e/sj+8P4e/0v/df+c/87/8v8iAFAAfACnANQA+AAkAVABdAGYAboB3gEAAiACPAJQAnAChAKcArACxALUAuwC+AIEAxgDHAMgAywDNAM4A0ADPAM8A0ADPAM8AzQDNAMsAyQDIAMYAwQD9ALkAswCuAKcAoQCYAJAAhgC8AHKAaIBdgFOASQB+wDRAKAAdwBKACIA8f/M/57/cf9C/xH/5v6w/oL+Rv4a/uT9tP2A/VT9JP34/NT8rPyM/Gz8WPxA/DD8JPwc/Bz8JPwk/Dj8RPxU/HD8gPyo/MD86PwI/TT9XP2A/bD93P0I/jj+ZP6Y/r7+8v4g/0r/fP+o/9P//f8lAFIAeACfAMYA4QAEAR4BPAFWAWoBhAGaAbIBxgHaAewBAAIQAiQCNAJIAlQCaAJ4AoQClAKcArACuALEAtAC2ALcAuQC6ALwAvQC+AL8AvwC+AL0AvQC7ALkAtwC0ALEArgCqAKYAoACbAJUAjgCHAL6AdwBuAGSAWwBOgEQAeEAsQB+AEoAEwDi/6T/d/82/wb/zP6Y/mT+LP74/cj9lP1Q/TD98PzI/Jj8YPxE/BT86PvQ+7D7kPt4+2j7WPtI+0j7SPtQ+1D7WPtw+4D7mPuw+9D78PsQ/DT8YPyI/LD84PwM/Tz9bP2k/dT9Cv5E/nz+uP7y/jD/a/+q/+z/JwBmAKIA4AAcAVYBjgHGAfoBLAJcAogCtALcAgQDKANEA2QDfAOUA6gDvAPMA9wD4APkA+QD4APcA9ADwAOsA5gDhANoA0QDIAP0AsgCnAJsAjgCBALQAZgBYgEqAfMAuwCHAFIAHwDt/77/k/9o/z//E//u/sr+pv6E/mT+Rv4q/gz+8P3Y/cD9qP2U/YD9dP1k/Vj9UP1M/UT9RP1I/Uz9VP1c/Wz9fP2M/aT9vP3U/fD9DP4q/kz+av6M/rD+0v72/hf/PP9f/4P/qf/M//D/FwA7AF8AhACoAMsA7AAMASoBRgFiAXgBkgGsAcAB1AHkAfYBCAIYAiQCMAI4AkQCRAJMAkwCSAJEAkACQAI0AigCGAIIAgAC5gHWAb4BrgGWAXoBcAFMAT4BHgEQAfIA3QDGALAAlgB8AGcATwA5ACAACgDw/93/xf+w/53/hP90/1//TP8//yz/IP8S/wH/+v7u/uL+2v7M/sr+wv68/rz+uv62/rr+uP68/sT+xP7I/tD+2P7e/uz+8v76/gr/EP8X/yX/Mv85/0n/U/9b/2j/cf98/4b/kv+c/6b/sf+8/8j/0//e/+f/8//9/wgAEQAaACQALAA0ADoAQABIAE4AUwBYAFwAXwBjAGYAagBsAG4AcABzAHUAdgB1AHYAdgB1AHIAcABtAGkAZABfAFkAUgBKAEIAOQAwACcAHAARAAgA/P/z/+v/4f/Z/9D/yv/D/7z/t/+x/6z/qP+l/6L/nv+b/5f/lf+U/5P/k/+U/5b/mf+b/57/ov+l/6r/rv+0/7n/vv/C/8b/y//P/9L/1P/Y/9v/3v/h/+X/6P/t//D/9v/7/wIACAAPABUAHQAkACsAMgA5AD8ARQBKAE4AUQBXAFgAXABeAGAAYwBlAGgAawBuAHEAcwB2AHcAegB7AHwAfgB/AH8AfQB8AHwAfAB7AHsAdwB1AHEAbwBqAGYAYQBcAFcAUgBNAEcAQgA9ADkANAAvACkAJAAfABoAFQARAAwABwADAP3/+P/y/+z/6P/k/+D/2//Y/9T/0P/N/8r/yf/J/8f/xv/H/8j/yv/K/8z/zv/S/9X/1//b/93/4//l/+r/6v/v//T/9//6//z/AAAGAAYADwAOABcAFQAhACQAKAAsADUAOwA1AEcAOgBIAEEAPgBIAD0AOQA+ADoANAAuAC0AJgAjACIAHAAbABkAEgAQAA8AEgALAAkACgAHAAYABQABAAAA///9//n/9//3//T/8f/w/+7/7v/u/+z/7f/t//D/8P/x//P/9v/5//3/AQAEAAkADgARABUAGgAfACQAKQAtADIANgA8AEAAQgBHAEsATQBNAE0ATgBRAE8ATQBKAEkASQBGAEIAPgA7ADYAMQAsACYAHwAYABEACgACAPr/8f/q/+L/2f/S/8v/xf+//7r/s/+u/6r/pv+i/57/nP+a/5b/lP+S/5H/jv+M/4r/if+I/4f/hv+G/4b/h/+I/4n/iv+L/47/kP+T/5b/mv+e/6P/p/+r/6//sv+3/7v/wP/E/8f/y//O/9H/1f/X/9r/3f/g/+T/6f/t//L/9//8/wAABAAIAAwADwAVABgAGwAeACEAJgApAC0AMQA1ADoAPABBAEMARwBJAEoATgBPAFEAUABPAFQATABOAEoATQBJAEMASQBBAEUAPABCAD0APgA9AD0AOgA3ADcANQAzADAALQAnACYAIAAdABkAEQAOAAUAAAD9//X/8v/t/+X/5P/e/9n/1v/P/83/yP/E/8T/v/+7/7z/t/+3/7j/tP+z/7T/sf+y/7X/s/+0/7j/tv+2/7v/vP++/8b/yP/L/9H/1f/a/+D/5v/r//L/9//+/wQACgAQABYAHAAiACgALgAzADkAPQBCAEYASQBNAFAAUwBUAFUAVgBXAFcAVgBVAFMAUgBRAE8ATQBLAEkARwBFAEIAQAA+ADoAOAA1ADIALwArACcAIgAdABgAEgALAAQA/f/1/+7/5//g/9n/0//N/8f/wv++/7r/tv+0/7L/sP+v/6z/q/+p/6j/qP+n/6j/qP+p/6n/qv+r/63/r/+x/7T/tv+5/7z/wP/D/8X/yP/L/87/0f/T/9b/2P/a/93/3//i/+T/5//q/+z/7//x//T/9//6//z//v8AAAEAAgAEAAUABgAGAAYABgAHAAgACQAKAAwADQAQABIAFAAXABoAHQAgACIAIwAlACgAKwAuADEAMwA1ADcAOQA7ADwAPAA8ADwAOwA7ADkAOAA3ADYANQAzADEALwAtACwAKgAqACkAKQAoACgAJwAmACUAJAAjACMAIgAgAB4AHAAaABgAFgAVABIADwANAAwACwAIAAcABQAFAAUAAwADAAMABQAFAAYABAAGAAgACQAJAAkACgAMAAoADQAKAAwABgAMAAkACgAIAA0ADgAJABQACgAWABAADwAXABIAEAAVABQAEgAQABAADQAMAA0ACAAIAAgABAABAAEABAD///7////////////+//7///////////8BAAEAAAABAAEAAgADAAIAAwAEAAUABQAFAAYABgAHAAkACgALAA0ADgAPABAAEgAUABYAFwAYABoAGwAdAB8AHwAhACMAJAAjACMAJAAlACUAIwAhACAAIQAgAB8AHgAdABwAHAAbABoAGgAZABgAGAAWABUAEgARAA8ADAAJAAYABAACAAAA/P/5//f/9f/z//H/8P/u/+3/7P/r/+z/6//q/+j/6P/n/+b/5P/j/+L/4f/g/97/3P/b/9n/1//V/9P/0f/Q/8//zv/N/8z/yv/K/8n/yf/J/8j/yP/I/8f/x//G/8b/xP/E/8P/wv/C/8L/wv/D/8T/xf/G/8j/yf/M/83/z//R/9L/1f/X/9r/3f/h/+X/6f/u//H/9//7////BQALABEAFAAZACIAIgAoACkAMAAyADEAOAA1ADoANQA7ADgAOgA6ADsAOgA4ADgANwA3ADYANQAxADIAMAAvAC4AKgApACQAIQAgABoAGQAVABAADwALAAcABQD///3/+f/0//P/7f/p/+f/4v/g/+D/2//Z/9n/1f/U/9X/0v/R/9L/0P/O/9D/zv/N/9D/z//P/9H/0f/S/9T/1f/W/9n/2v/d/9//4f/j/+X/6P/r/+7/8f/z//f/+f/8//7/AQAEAAcACgANABAAEgAUABYAGAAZABsAGwAcABwAHAAbABsAGgAaABkAGQAYABcAFgAVABQAFAAUABQAFAAVABUAFgAWABYAFgAXABcAFwAWABYAFQAUABMAEQAQAA4ADQAMAAwACwAKAAkACAAHAAYABQAEAAQAAwADAAIAAQAAAAAA///+//7//f/9//3//P/8//z//P/7//v/+v/6//n/+f/4//f/9v/1//X/9P/z//P/8v/x//H/8P/w//D/8f/w//D/8P/x//H/8f/x//H/8f/x//H/8f/x//H/8f/y//P/9P/1//b/+P/6//v//P/8//3///8BAAMABAAFAAYACQALAA4ADwARABMAFAAWABcAGAAaABsAHAAdAB0AHQAcABsAGwAaABkAGQAYABcAFwAWABUAFAAUABQAFAAUABMAEgASABEAEQARABAADgAOAA0ADQALAAoACQAIAAcABgAFAAQABAAEAAQAAQABAAIAAQABAP7///////z//v/7//z/9v/4//X/9P/w//H/8P/p/+//5P/s/+T/4v/m/+D/3f/h/9//3f/b/9v/2P/X/9f/1P/T/9P/zv/M/8v/zf/J/8f/x//H/8f/xv/F/8X/xf/G/8X/xf/H/8f/x//I/8r/zP/O/8//0f/T/9b/2P/a/9z/3v/g/+L/5P/m/+j/6f/q/+v/7f/v//D/8f/y//P/9P/2//f/+P/6//3///8AAAAAAwAGAAcACAAHAAgACgALAAsACwAMAAwADAAMAAwADAALAAwADQAMAA0ADAAOAA4ADwAOAA8ADwAPABAADgAOAA0ADQAMAAsACwAKAAgACAAIAAgACQAJAAgACQAJAAgACAAHAAcABwAHAAYABQAEAAMAAgAAAP///f/8//r/+f/4//b/9f/y//H/8P/u/+3/7P/r/+v/6v/r/+v/6//r/+r/6v/p/+r/6f/p/+n/6P/o/+j/6P/q/+n/6//r/+z/7//v//H/8v/0//j/+P/8//v/AAABAAMACAAJAA4ADgASABgAFgAaABsAIAAgAB0AJwAjACkAIwArACYAKQAoACgAKAAkACYAIwAkACAAIgAeAB4AHAAZABsAFwAWABQAEAARAAwACgAKAAIAAwABAPz//v/5//f/9v/y//T/8v/u/+//7P/u/+//7f/u/+3/7//s/+//7//v//b/8//z//X/9f/x//X/9f/0//X/8//x//L/9P/y//P/8v/1//T/9f/0//P/9f/3//b/9v/3//n/+v/6//r/+v/6//z//P/9//////8DAAYACAAJAAsADQAOAA8ADQAMAAsACQAHAAQAAwAAAP7/+//7//r/+P/2//f/9f/2//f/+P/5//r/+//8//////8AAP7///8AAP///f/6//j/9v/z//L/8v/y//L/8f/x//P/8v/y//L/9P/2//b/+P/3//r/+v/6//v//v/9//3//f/+/wAAAQD//wAAAgADAAIAAQACAAMAAgABAAEAAwAEAAIABAAHAAYACAAGAAoADAAMAA8ADgAUABMAFQAVABoAFwAXABcAGAATABEADQANAAoACQAFAAQABwAIAAsACgALAAkACwAGAAkABgAGAAIAAQD+//v//P/5//r/9//1//X/8//1//X/+f/8/wAA//8AAAEA///+//v/+//3//D/7v/p/+X/4P/c/9r/4P/g/+D/4f/n/+r/7v/r/+//7P/x/+f/5f/h/+D/4f/c/9z/3P/g/+P/6f/t//3//P8DAAEACQAIAAMAAwAFAAMABAACAAQABgAGAP7/+//0//r////v/wcA/f8IAO3/7/8DAPD/4P/U//D/4f/1//b/+v8LAAcADAAbACkAGQAVAA4AGAD3//P/7v/+/wAA6v/y//7/BQD+//n/BAAUABQACwARABEAGwAWAA0AEgAQABwACgAMABUAFQAQAAMA/f8JAAoAAgAAAAsAGgAdABAAEgATACgAGQACAPj/9v/8//T/3//n/+//7//l/9//7f/o/+D/2f/i/+D/3f/X/+j//f/+//P//v8KAAkA///5/wkAFAD4//n///8RAPj/8f/4/wgACgD4/wIADAAZAAcADgAZABkADgD8/wIABADw//D/5f/y//j/7f/h//H/BgALAAEACAAVABIAGAALABYAFgAMAAAA9P8OACAA+P8EAAQAKgAgAPP/+v8wAEoANgBJAKgA7gD8APIAAAE6AeAAeAAxAD4AGwCW/2H/mv8dALn/Of9c/zIAOQC9/97+AwCHAPcAzwAMAvQDUATsA7gDQAS8A3gD4gHKAdsA7P8h/7b+9v5E/lL+Hv9P/8v/UgAEAQYBxQAoAOv/T/9+/lz93Pww/Dj7iPsQ+0D7yPs4/Ez95P2o/rD/cgDsALAA/QCmAB0Alf+2/r7+OP7I/Xz9Dv6q/g3/ov8TAGYBWAHKATgCGAKMAnYB0AEsAesAQwDA/24ABwB2AHsAcgEkAdYBcAJkAjgC6AGkAVIB+gC0/4T/Hf9c/8L+qP7w/aj+bf88/9z+0P7QAJ8AZgAD/6IAEAEQAIr+nv6m//j+hP2U/Sn/q/9p/6j+ZwB4AXQBwAAeAcoBlgHNANH/IwBRAML/rv68/kf/Vf87/xH/yv9UAHkA//9pAO4AvwApAPf/MwAvAJP/Yv/X/10AYwDl/2gA3gDKAEcA9P+bAAYBbQARAGIAHgHhABEACgClAA4BZAApAJUAaAEYAUcAbQDiAN0A6f8//5r/wP+O/8j+Bv+6/8X/jP+W/z4ApwBqAEAAmwACAZ4AbgBiAIQARwBo/6H/q/9q/zn/AP+v/4P/rP9i/4kARQBPAGUAAAHgAI0A9v/Y/x8AxP9k/wT/uP+u/4D/w/8MANcAmAD5/ykAagB/ANT/yf9AAEUALQDQ/8b/oQAQAAUAUv/U/nj+6P2o/cz9MP6g/uD+yv5J/8z/FgCr/07/Yf9F/8z+EP5E/lD+Mv7k/Ur+EP++/8b/PwBVAJsA1v9pAPn/+/+A/7T+LP9E/zH/Mv/k/xEAbwBvALEAXgG0AZIBmgEiAQYBuQDLAPX/pf/0/6EAfgDcAFUAjgGgAZAAcQCg/54Afv/q/uz9kP66/rD9qP2U/Uv/SP68/s7/MgFqAbUA/AAsAnwChABdAIUAHAFd/5z++v79/+b/Gf91/90AegHiAI4ADAEQAoIBkgBkANYA+AD6/zr/o/+9AKcAkf/E/+gA0gFUAZUA3gDiAXQBVwAgAMgAZAF8ALD/3/+BAKAACgD//20AmgA0AOb/GwCyAGgACADe/+H/HwDH/4z/pP+0/67/gP++//7/KgAsACoAJwA+ABAAAAAcABIABQD2/+T/6/8IANT/zP/h/9f/2//5/+D/IADk/9v/AQD9/zQA8P/4/xgACQD5/9n/+P8MAOX/xv+q//P/KQDU/9//MgBYAFoAEQADAFcAMAASAAcAJACKAFoAQgA9AGsAhABOACoA+P9DACUA2f/T/zUATwAXAN//IABzAEQA1P+n/8//EgCX/3b/rv/y/8D/f/9V/8P/2/+v/2D/qP+9/6b/Pf+v/+z/z/99/7f/GQDk/8T/xf8zAF0A/v/v/y8AWwBPAMv/NQABAFkAKABNACMANgBLACUAOQAxAFcAKAANAMX/HQAIAMv/rP9+/wAA2/+//w8AFgAlABkA6/8FAB0A4f+O/4j/xP/X/7r/nv+K/6T/4f+2/+D///8hAD8Atv/q/+f/+v+5/zz/RP+F/4v/Gv9A/8r/DADD/3j/wP8iACAAif+Q/9f/3/+K/0b/M/+J/zz/C/88/6j/p/+E/7H/+v9IAB8Azv9QAKoAaAAEACcAaQCEAF8Azv9FAMMArACBAIkAAgEqAdMAgQCoABIB3QCYAHEA1gDfAJsAVgC5AN0AqAB8AHoAyACCAAIABwBnAE4A5f/K/yMASgARAOP/LwCDADIAFwAHAEAA8/+y/5v/tf/a/5P/pf/C/wcA+//5/97/2P/u/7T/0v+u/8L/ff+T/3b/bv+A/1z/n/9L/33/Yv+Q/53/gv9y/2T/Zf9p/2//J/87/0P/kP+E/3D/1/8JAAoAIwAuAJYArQBDAFkAMQCTADIAFQATAHgAlAAuADYAjgDTAJwARQB4AKEAogAjAPP/JwAuACIA8/9AAEwASgAfACcAQABhAFAAIwAeADAAHwD//+z/zv8OAOf/uf+K/7r/6v/e/8P/u/8GAOz/vf+V/8r/yv+e/2n/dP+d/2P/Q/9C/0H/Yf8x/1f/YP9g/2v/Rv9O/23/Zv9N/0D/JP8//y3/A/8i/zf/V/8k/xb/QP9a/4j/Tv9e/5v/iv95/0b/Pv+Y/2L/Y/9j/6P/3P/q/9P//v8VAAMAIQDj/2AATwBWAD8AVQCnAFoASABhAJEApwCGANEABgEKAfIACgE8AYgBYgFsAWYBmgGwAYABmgGSAcYBqgFgAXQBhAG2AV4BMgFoAXABWgEeASIBZAEmAQABpgDFAMEAhABjACMAKgDf/2T/F//m/tb+sv5u/g7+KP4E/hr+AP4G/gL+BP70/Zz9lP1k/WT9MP0E/cD8hPx8/ED8gPxw/Ij8wPyc/BD9CP1g/Zz9eP28/ej9xP34/dz9+P1g/oT+5P5C/8r/fgDTAFABvAFoAvQCLAPYAxgEqATABDAF4AUIBtgGoAYYB4gHwAcwCEAI4AjQCAAJ0AigCHAIgAjQB2AHOAeIBigGEAWgBAgEGAPgAtYBeAEYATkA3v/y/pT+uP0Q/WT8cPsI+zD6qPmA+XD5aPlA+Sj5SPkY+cj4kPgQ+PD3wPcQ93D28PWQ9SD18PSw9AD1oPTQ9AD1IPWw9bD1QPYw92D3MPgo+GD5CPo4+qj7JPxo/Uz+cv/0AOYBfAMgBfAF4AewCDAKgAtwDEANQA4AD6APQBDAEGARYBHAEeARYBLgEaARYBGAEIAQIA9gDoAN8AvQCoAJ2AcgBpgECAPMAe7/7P7E/YT8kPso+pj5sPjw93D3gPag9jD2oPUA9gD2QPZQ9gD2cPaw9pD3IPgQ+Uj6+PoI+3j7oPvY+6j88PuY/Oj74PtI/LD72PvA+wT8sPuA+2D7cPoQ+pD5uPhg+MD3gPag9kD20PWA9RD2YPbw9oD3UPd4+BD5CPr4+nD72PxA/RL+Cf8TAHwBhAIYBHgF8AYgCGAJgAowDBAN4A2wDrAOcA/QDhAPIA/wDvAOYA6ADjAO8A3ADXANUA3ADLALIAvwCbAIEAd4BSAETAIoAaf/Tv6Y/bT8+PuI+7D6gPqA+vD5OPqg+eD5WPlA+VD5EPko+bD4UPkw+fj5GPoA+xj83Py8/QD+qP4U/4f/Nf/H/1D/1P8z/+T+R/9C/mj+kP1s/RT9yPug+qD5UPjA9yD24PXw9MD0QPSg88DzAPTA9OD04PWA9rD2kPcQ+AD5CPpY+4T87P2c/6gA9gHMA3gFOAdACcAKAAyADXAOgA+gEEARABKAEmASQBIAEuARoBGgEYARQBHgEAAQcA+wDtANUAxAC8AJAAgQBtwDdAKUABr/Hv6k/Dz8ePr4+XD5yPjQ+KD4kPiA+Aj44Pfg93D34Pcw+MD4OPlQ+SD6wPrY+/z86P0L/23/IABeAFcATgDJAGMAdgATALH/i/8Q/+D+dP78/VT8QPtY+ZD4gPaA9fD00POg8xDysPGw8NDw4PBA8RDzUPPw84D0YPWw9rD3GPlo+hj7GP0I/mD/NgHIAsAFQAcQCeAKMAxQDgAPgBAgEkASIBMgE0ATYBOgEsASoBKAEmAS4BFAEaAQwA8AD7ANIAzwCgAJYAc4BfwCngG7/2j+LP3w+6j6aPnA+Gj40Peg92D3MPdg99D28PYg90D3GPhY+Mj4UPm4+Yj6gPt4/Ij9Mv4h/7D/7v9SAAoANgBDABsACABt/wb/xP5m/pT9KP1E/PD66PhA+HD2UPQQ9DDycPKw8QDwgO+A7kDvIO8Q8BDx4PHQ8tDzQPUQ9qD3QPmg+kT80P0N/8AAvAJIBRgHoAkgC0ANoA7gEAAS4BLgE4AUYBUAFSAVQBTAFCAUgBNgE6ASgBIgEWAQMA/ADXAMwArACEAHEAUkAzABeP8c/mD8IPv4+QD5IPhg97D2wPZg9rD2gPaA9tD28PYw96D3mPgo+bD5qPpY+2z8qP00/pb/SADrAFQBmgGkAbwBbAF2AUoBwwAfAMv/Tv9m/sT9JPwI/Dj6SPgA99D0MPQQ8kDyEPGA8CDvIO5A7uDuQO9g76DxIPJA9KD0EPZg9+D4gPoM/Jj9mv6IACQCYASQBrAIEAtwDRAPoBAgEiATYBQAFYAVwBUgFcAUYBSgEwATgBLgEaARgBCAD6AOUA3QC2AK4AjwBvAEBAMsAez+NP3g+5D6ePmQ+GD34PZQ9rD1APaA9pD2oPbg9kD3gPcY+Kj4kPkY+sj6oPtg/JD9Sv5k/1cAIgHMASgCHAJQAjwCSALYAS4BLAEnAGP/eP6k/Yz8gPvQ+dD4kPbQ9PDyMPLw8eDvYO8g7kDugO3g7EDuAO+A8ADy4PKA9JD14PZg+Lj6CPyM/RP/rABkAvAEKAcgCfALwA0AEEARgBIgFAAVwBXgFSAW4BWgFeAUQBQAFEATYBIgEiAR0A/wDmAN8AuwChAJKAcwBeQC4gAt/3z9yPuo+tj5WPhw96D2oPZA9gD2cPbQ9uD2APdQ98D3WPgg+eD5ePqA+0z8FP0c/uz++v8yAbIBQAJsAqQCmAKwApwCoALwAQYBoQBo/5b+TP0A/Jj6GPkA92D1YPMw8qDwEPDg7uDt4OzA64DswOvA7EDuYO8A8VDz4PPw9LD2OPh4+nD8YP01/+sAEAPYBIAHMApQDBAPgBBAEmATgBTgFUAW4BbgFgAWwBVgFcAUABRgE4ASIBLAELAPIA6ADKALsAlgCGgGaATuAaL/FP4c/Nj6iPkQ+JD30Pag9aD1kPXw9SD2MPaw9pD2MPew9wj4yPho+QD6CPuQ+7j8pP2q/vT/eQB6AfwBQAJUAnwCcAIoAugBLgGaAHj/vv6w/Tz82PqY+QD4UPYw9MDygPHg72DvIO6g7QDtgOuA7IDrwOzA7YDvsPKQ8nD00PWA90j5kPso/Q//ugCUAmAESAZgCSALIA4AEAASgBMAFCAVQBYgF0AXoBaAFuAVIBVAFKATQBNAEiARIBCwDhANUAsACpAIWAcIBaQC9QBM/qz8+Pqo+UD4EPeQ9pD1IPXg9BD1oPUw9pD2APeQ99D3WPj4+PD5gPpY+yz8PP1I/i7//f8cARgC7AJIA2gDdAPAA2wDBAN4AuABXAEEAKT+9PxI/Cj6GPhA9xD10PNQ8RDwYO+g7kDtYOxg7EDsQOvA60DsIO7Q8FDy0POg9aD2EPlo+lj9UP+nAOwC2APYBmAIIAvwDOAPYBLAEwAVoBWgFmAXIBggGIAXgBagFQAVwBMAE0ASwBGgEPAOgA3gC3AK0AhwB1gGiASwAYH/vP34+4D6CPnw9zD3YPaA9ZD0MPVA9eD1UPaw9sD3MPh4+CD58PkQ+1j7dPw4/Yj+Qf+r/84A1gG4AugCQAPAA2ADPAMoA+ACjAJqAWcAJv+s/QD8IPrI+HD3MPUQ9HDxwO8A74DtIO1g7MDrwOvg6sDrgOyg7SDvAPHg8wD1UPaQ9/j5dPyC/qUAUAJwBMAFgAiQCjANUA9AEQAUQBUgFsAWYBfgF4AYoBcgFyAWYBQAFOASoBJgEUAQkA+wDeALAAqQCLgHwAX4A6gBmf9A/fj78Pm4+AD4UPbQ9SD1wPSw9DD1UPVw9iD38PcI+PD4KPqo+oD72Pv8/ET+qv6L/24A1gFMAsgCnAMoBBgEtAPoA8ADsAO0AvABmgCb/wr+iPyA+sD4MPcw9WDzcPGg7yDuIO1A7ADsoOqg6iDqAOvA64DswO6w8FDyUPTA9RD4iPnY++j+QgE4AhgEOAawCNALIA1wD6ARwBOAFeAWABiAGOAYQBmAGSAXoBZgFUAUABTgESAS8A8AD7ANQAzQCsAIeAeoBfwDmgGu/xD9LPyI+pj4sPfA9RD18PRg9KD08PSg9aD2gPaQ91D4GPko+pD6kPuQ/Jj8aP0a/ir/nQAKAZoB6AIwA4wDaAPAAwAEgAOoA0ACdAElACr/hP0M/Ej6APhQ9gD0IPJQ8MDtAO0A7KDrYOrg6cDoYOmg6WDqgOyg7sDv8PFw9KD1gPfI+eT8XP/9AJACeATABmAJkAugDmAQIBIgFOAVwBcAGCAZQBkAGeAYQBcAFqAUoBNAE+ARoBDwDrANAA1QC8AJQAhQBrAE/gE0ABj+RPzA+vD4OPhw9lD1IPTQ81D0EPVw9TD2sPbQ97j4OPkI+uD6OPyc/AD92P0O/gz/4f92AUACVAMwA+wDoAR4BKAEqAT4A3gDWAJOAcf/vP3M/CD7GPnA9sD0MPPQ8IDvwO1A7KDrYOqg6qDpgOjg6EDpwOrA7GDu0PDg8nD00Pbw+Fj7kP3g/5QC0ASYBvAHYAqwDSAQoBFAE0AVwBZAGAAZQBmAGWAZwBggGMAWABUAE6ASgBFgEPAOEA2gC9AKgAnAB2gF1AOoAuD/iv7A+zD6uPiQ97D24PQg9LDz4PPw9DD1MPbw9sD36Pjo+dD6aPsw/CD9yP5k/pL+/f9zAIwCEANoAwAEAASQBOgEOAW4BGAEJAM4A1QBl//E/Qz86Ppw+BD24PNw8YDwIO4g7UDsYOpg6oDp4Okg6eDogOoA7CDuwPDg8jD1APf4+Aj7qP3N/5gCeAWgBrAIIArgDNAPwBHAEyAVABfgF8AYYBnAGQAZgBjgF+AWYBUgE6ASIBGAELAO8AxADDAKwAjgBiAFKASIARoAJP4Q/HD6mPhg9zD2QPVw9KDzwPOg9KD00PUA9xD4EPnw+Uj64Puk/Lj9wP6P/3P/rABSAfgBzAJUA9ADiASYBLgEOAQQBPQDqANsAg4BL//E/dj76PlA94D1QPNg8YDvAO1A7GDqgOpg6QDpAOlA6ODoAOpg68DtAPBQ80D24PfI+Bj7iv7cAJADuAX4BhAJQAvQDCAQgBLgE2AVIBcAGOAXwBhgGIAZYBiAFmAVwBNAE2ARQBDQDmAN8AuwCiAJcAcwBYAEYAOEAcb/UP3w+yj6SPnw97D2UPVQ9WD1UPUg9UD1QPdw+Cj6UPpg+0j8nPxU/gf/9P9rAAIBWgGAAowC6AIMA0AEQAWgBGAE2ANoBKwD0AKWAdkAuv4o/aj62PhQ9hD0cPIg8KDuYOzA6gDq4OmA6cDo4Ojg6GDp4Ong6mDtQPDg8+D10PcQ+qj7Jf9sAqAEkAaQCAAKYAswDuAPYBJAFMAVQBegF6AXwBegGKAYoBeAFkAUwBMgEqAQsA9ADkANUAsACuAIsAYABZwDjAK4Ac3/3Pwc/Ej6yPjQ99D2sPaQ9VD1gPXg9YD2QPdw+MD5yPqQ+xj83PzU/b7+u/8aAGYA7gAMAc4BHAIUA0gDuANABAgEKAQcA6wCGAJwAQ4A0v4Q/ND5kPfg9aDzYPGA7wDtQOyA6oDpwOhA6ADpAOkg6cDoIOkA6yDuwPFw9ID2APl4+sD85f+oAlgF6AYwCTALkAwQDgAQYBNAFgAX4BegGOAYQBmAGYAZoBgAFwAWoBTgEmARIBDADgAOgAxwC9AJ0AeQBngFiAQgArQAov7A/ID6yPjg9zD3cPZg9RD14PSw9TD2cPfg+Aj6+PoA/KT8kP08/gH/3f9nAHMAegChAF4BNALoAkwDcAMQBNgDGARIA5QCvAH0ADr/rP1w+yj4kPZg9WDyAPCA7uDr4Oug6kDpYOmg6KDpYOkA6uDpIOpg7KDvMPNw9eD3yPnA+2X/BAJgBNgG4AhgC6AMwA7AD0ASYBTgFgAYABhAGEAYQBnAGGAYQBfgFgAVIBNgEoAQMA+QDVANoAywCjAJUAdwBtgFzANsAn0ApP4Y/Oj56PiQ98D2YPaw9VD10PXQ9VD3IPhY+cj6mPtM/DD9TP6Y/uz+sv9AALsAjwBrANABPAKcAgwDuANIBDAEnAN8A6gCmAGXAA7/XP1w+pD3MPXA8+DwQO7A7ODqoOrg6EDp4OfA6ODoAOkA6sDpgOrA7DDxsPPg9qD3GPpw/F7/XALABMAGsAjwCtAM0A5AEEASABUgFyAXgBfAF8AXABhAFwAXYBYgFEATABIgEYAPAA7QDYANIAxwCiAJuAfIBiAF0AMkAt//ZP0Y+1j5wPcQ9yD2wPWw9TD14PWA9hD3uPhY+gj7yPsE/dz9KP6I/uD+3v9ZADcAtwBYAfIBRAIUA9ADeAS4BGgE/ANUA0ACMgG6/wD+APyg+DD2oPPQ8aDvgO2A66DqYOkA6SDooOiA6eDoQOpA6qDrQOzA7pDzIPZw+OD5QPvq/j4B+AMIBrAI4AkgDEAOkA9gEaAToBXAFsAX4BZgF+AWwBagFoAVYBQAEwASIBHgD3AOwA2QDZAMEAvQCSAI+AbQBTgE0AIqAXj+CPw4+mD4YPfQ9uD1IPVQ9aD1kPXQ9tD3UPlA+vj6YPwM/Xj91P3W/qX/8/8fADYA7ABkAZoBOALoAjADfAPIAzgDxAKQAQYB7v9s/uD7GPmA9rDz0PFg78DtYOsA6gDpwOhA6IDoAOnA6UDqAOtA62Ds4O6w8tD2APio+iz8HP5CAWAEMAbACIAKgAywDmAQ4BCgE+AVIBegF8AXoBfgFiAXgBZAFsAUYBNgEiARgBDADtANwA3gDJALEArgCGgHaAbABMgDZAH4/uj8wPp4+VD4gPcg9sD1gPXg9cD2kPeY+Dj66PqI+zj9+P1s/nj+g/9UAOf/TQAiAG4ACAEuAZ4BWAKMAjADIAMkA1QCFAHgAGb/yP0g+yj4YPXg8uDwAO/A7ODqQOpA6eDo4Ohg6SDqIOvA68DsYO1A7gDxkPQg+Aj6QPuE/VP/oAIgBUAIUAoAC3AOABBAEYASYBTAFYAXwBcgFyAWABYgFkAVwBTgEgASQBEgEGAPwA7QDWANcAwQDNAKkAiQB2AGWAXUA/oAov54/AD7EPlA+GD3UPYw9UD14PUQ9nD3EPjA+ej6+Pvc/ET9jP6+/q//GgB5AFEAVADoAP8AuAHeAUACjAIkAxwDiALYARgBpQCW/zT9IPpg98D00PLw8IDuQOxA6iDpQOmg6GDogOmg6oDqQOsA7MDs4O5Q8QD2mPhQ+aD6mP02AAgDMAVQCGAJkAsADdAOQBHAEgAU4BXgFuAW4BVAFSAVIBVAFYATYBLAEMAQYA/gDqAOsA1ADTAMkAuwCVAIoAYYBegEaAI9AKT9wPuA+Uj44Pdg9oD14PRg9aD1wPVw9sj4WPoY+0D8VP3w/az9wv5N/+3/NAAT/9L/9/8mAAYBYgEUArACGANkA3QC0AEcASwAcP4A/CD5APaQ8pDwoO7g7IDqgOjg56DooOig6CDqYOoA7MDroOwg7gDwoPSQ9sD4aPoU/Ez+JgEoBcgHAAlQChANoA9gEQASYBPAFWAWIBbAFaAVQBTgEyAUwBMAE8AQIBDwDnAP0A7wDSAOUAwADJAKQAn4B0gG8ATcA6wBKf9I/Qj7+PlY+OD34PYA9vD1kPWQ9hD3MPig+QD7GPzw/Oz9iP0g/5z/awBsAOj/1P/s////HwDOARgCOAKAAgQDGAM4AoYBHgBQ/wD9EPqQ94D0MPJA7qDtAOwA6gDoQOfg54DoYOoA6uDqoOvg7ODtoO8Q8kD1YPjY+Rz88P0KAPwC8AXQCKAKcAuQDfAPoBIgEwAUABWgFWAVABagFGATYBPgEkATABJAELAPwA6wDiAOwA0wDdALQArACWAIoAaYBLwDJAOEAOT9oPzI+oD5CPjg9iD30PUg9vD1cPfA9wj5+PpA/Fj97P3C/pj+3v/c/ywANABB/1P/pP+I/y8AYgA+AfwBZAFoAY0AiwBl/zL+ZPzw+VD3UPSw8WDvQO0A62DpoOhA6ODnIOhg6cDqoOzg7MDsIO7A8HDzYPUA+BD66PvA/RgAMAOABCAHsAmwC3ANgA4AEeARIBQgFAAV4BRAFOATIBRgE4ARoBGgEeARABDAD2APIA/wDlAOkA5gDZALoAlwCCAHuAT0AjABmv+w/cj7sPlQ+LD3MPdA9yD38PaA97D4oPnY+sD8cP3s/Rz+hv5p/yT/Pf9E/6L/Vv/g/mv/tv8KAXoBdAKIAlgCmgE+AcwAIv+s/bD76PiA9dDyAPCA7YDs4Oog6sDoAOkA6UDrwOvA7CDuoO7A7/Dw8PKA9UD3mPm4+wT9hv4EAdQDMAaQCAALAAzADaAPgBGAEwATQBQgFOATQBMgEoAR4BDAEKAQwBEgESAQ0A8gEKAQwA8wD3AO4A0ADIAJkAf4BVAEPALqALb+6PsI+sD4wPhg+ID34PZA98D38PeA+Vj6yPsI/Sz+6v5M/tT+Xf89AMYAqACH/4T/HgCZAO4AkgHWAdoB2gFWAdEApv/s/ez8iPuw+GD1wPGg72DuQOxg6kDqAOmA6GDqIOsA7aDtYO4w8FDxkPLg8/D1YPjA+nD7MP1I/r8A+AKgBbgHEAkAC+AMAA5AEIARQBIgEwATgBJAEWARQBDgDqAOMA+gD/APIBBAEIAQQBBgEIARQBFgD2ANAAvwCRAHWATcAqwAVv4o+6j5MPgg94D2sPYw95D2gPZQ9wj5aPpo+/j7gP20/VT9oP10/S7+1v7y/qb/9v4c/7H/2QAkAoQC3AJAAv4BQAHc/+L+oP2Q+8D4MPbQ8sDvoO3A6wDsAOsA6mDpgOpg6wDtQO4g73Dw4PEA84D00PWA9yD56Po8/MD9B//oAKQCeAV4B1AJwAogDLANEA+gECARoBGAEEAQsA/wDsAOcA2QDZAOwBCAESAR4BAAEcAS4BLAEgASkA9gDXAL0AhoBogEVgEs/zz9qPoY+LD2wPYQ96D3QPYw9gD3APhY+Vj6ePuY+/j7hPy0/Ej8hPyc/br+Gf/c/i//XP/aAJQCCARQA9QCbAKAApwB7/9K/hj9GPsQ9xD1QPLg72DtoOzg7MDr4OrA6iDsQO3A7iDv8PDw8YDz8PNA9WD3IPho+gj7BP2Y/Tr/9wCkA5gFkAeACKAK4AvwDHAOAA8gEIAQ4A8gD5AOwA2QDWAN0A0gD2AQwBHgEQASYBIAE6AToBNAEaAOIAyACcAGwASMAuL+6PwY+nj48PZg9aD1IPag9hD2oPUw9oD3WPlg+jj7IPsA+0D7wPvs/Pz8DP08/tD+0/8eAIoArAHcA3wDWATsA1QC5AGxAIQA0P24+vD3sPWA8+DwwO4g7cDsAOwg7GDswOwA7WDukPDw8TDzkPOw9AD20PfA+Kj5aPus/JL+NP8WAegCgAWYB9AJUAsgDMAM4A3QD4AQ4BDQD3APYA+gDtANEA3gDVAPgBFAE8ATQBOgE8AUIBVgFAATABDQDHAJaAdIBe4BCv+w/Gj7IPnA9tD1gPYQ90D3UPcw9zD3oPeQ+ej62PqQ+pD60Pqw+pj78Pv4/Ej9Kv4C/43/JgD2ANgCMANIA7gCVAJyAQgA2v4Q/cj6KPiw9VDzkPGg72DuoO1A7UDtAO1g7UDuQO/w8ADysPPg9LD1gPag9zj5CPtI/DT9sv49/zwBGAMIBkAIAAogC9AMwA5QDoAPIBHgEeARABEwDwAPoA4gDqAP4A8gEcARABOAFKAUQBSgFIAUwBKAECANgAkYB+AEFAKl/wz88Pkw9xD34PUg9ZD0APVQ9oD28PbQ9qj44Pm4+sD6aPsI++j6iPvY/Pj9bP28/Y7+/f8sAYABjgHQApwC1AIAAnIBNgAG/rD8MPrw98D0IPIg8EDvwO3g7ODr4Ovg7EDtAO4g77Dw0PGA87D0wPVQ9nD3sPgI++j7+Pzc/Tj/WgFMA7AF6AfwCaAKgAxgDcAOYA+gD0AQoBBgEKAOYA4gDVAOQA5AEOAQwBHAEgATwBVgFsAVYBMAEnAPEA5QClAHqAR6AQv/YPzg+dD3gPaw9QD2oPWg9HD1MPdQ+BD5EPkQ+qj6wPoo+xj8SPtw+3j7tPzU/XD9FP5m/9QAogE0AogCtAIwAuYBwgGkAJr+MPyg+ZD3QPVw8qDwYO/g7cDtIO2A7ADtQO5A74DwkPHA8uDzQPUw9nD3UPjI+DD6qPsA/cj94v4+AIQC6AQIB8AIIApgCwANwA0wDkAPUA/gDwAPgA7QDRAOIA5gD8AQQBGgESATIBXAFUAWwBWAFeASIA/QDNAK4AigBV4BDv94+xD5MPcw9/D10PTQ9PD08PWQ9pD3oPgQ+uD5ePrY+sj6KPvA+jj7UPtw+wT8rPy4/Vj+3//bAKgBdAJIAjACEAJkASQA7v6U/AD6gPeA9GDyEPHg7wDuIO1A7eDsoO2A7kDwoPFA8pDzQPWA9hD38PdA+VD6GPtY+7T8Mv4Y/6oAgAIwBBAGIAigCaALMAwwDcAOgA8gENAPMA/gDsAOYA4wD6APIBCgEAASABMgFUAW4BbAFmAVIBNAEGANkAvgCbgFyAKm/gj7APnw98D2UPbg9HD0UPWg9rD28Pco+VD60Pro+mD72PrA+nD66PpQ+6D7mPug+0z9pv6P//0AygFoAngCcAI8Al4Btf88/gz8sPnw9uDz8PFw8GDvwO3g7IDswOxA7uDu4O/Q8dDy4PMw9bD20PcQ+GD5IPvY+9j8OP2q/q8ARALkA6AFOAfgCFAKAAzwDHANkA5wDyAQYA9wDtAN8A2wDoAPwA+gDwARgBIAFGAVABaAFoAVgBNAEYAOwAuQCLgGSARkAEj7cPgA97D2IPag9WD1cPPw9JD2oPgw+WD52Pk4+yD8SPso+oj5kPpQ+wD8IPuQ+nj7EP3q/i8A1gDzAAgBIAKIAkABj//E/Yz8KPvQ93D04PHA8KDvgO4A7iDtwOyA7cDvAPHQ8VDyAPTg9XD3GPgQ+Ej5gPqg+1D8qPxk/ZL+xQBIAhAEWAWABlAIQArwC6AMYA1ADiAPkA+wDuANoA3wDbAO8A4QD6AP4BCAEiAVQBbgFeAVgBVgE0AQ4AxACgAJKAUYAsz9wPmg9nD24PZQ9vDzQPOA81D2wPcA+LD4sPkQ+4j78Prg+Uj5mPmw+uD6EPuQ+RD6ePuQ/uf/9v99AFIBEAOwAkgBtf+0/vD9QPtA+eD14PLg8EDwMPCA7qDtoO0g7wDwsPAQ8mDz8PRw9vD3oPjA+KD5OPtI/PT8AP28/dT/CgHIAuQDOAV4B0AJ4ArQC7AM4A3QDoAPkA8gD3AO4A0QDgAP4A7QDkAPIBGgE2AUQBWgFmAXIBbgE6AQ8A3gCjAIIAbkAdT9IPlQ9vD14PVQ9WDzEPNA9CD2APeA99j4uPqw+3D7QPtw+jj5aPmo+mD7OPrA+Mj4QPsM/TD+dP70/6AB3AH+AQABMwDu/oT9kPyY+cD1IPNw8ZDwgO8A7uDtAO7g7uDvQPGg8kD0oPZY+PD4aPn4+Tj7IPyM/TD9sP34/fr+wwB8AfQC4ATYBjAIgAnwCqAMIA7ADnAPgA8ADwAOEA7QDkAOwA3QDfAPoBCgESAT4BTAFoAWABagE8AR8A1QCxAJAAY0AoT9QPkQ9/D1gPQA87DygPNw9KD0APVA9zD5OPuI+zj8GPsg+pD6ePuQ+zj6iPiQ+Cj64Ppo+xD8PP20/xYBzgEcAaH/j/+1/9L++Pt4+AD2APSw8jDxwO8A7uDtYO6g71DwEPCw8uD00Pdw+Hj5KPpY+xj96P1o/pz9EP5s/iAAyACEATQDkASABjAIkAlwC4AMUA4AEGAQQBCQDwAQgBBgENAPkA8AEKAQgBEAE2AUgBXAFUAWgBUgE0AQIA2wClAIkAWNABz8MPkw93D1sPMA81Dz0PPQ89D0oPVw99D5iPug/Fj76PqY+nT8RPzw+vj5MPm4+Wj6OPvo+lj70Pwz/2MA5P+s/oz+Fv+y/gT9QPqQ94D1IPSQ87DxwO/A7mDvUPCA8NDw4PEg9JD2iPiw+Rj60Ppk/A7+eP5S/rj9pv6e/1wAgAEYApQDCAWoBnAIkAmgCvALEA5QD7APMA9gD0AQYBCgEEAQABCAECARQBKAE8AUABXAFUAVABQgEZAOoAtgCsAHUAMM/0D7YPnw9uD0MPTw86DzEPOw86D0sPUQ+BD6MPtQ+9j6uPrY+yj8EPyo+uj5MPnw+XD6ePqQ+mj7UP0+/nj+Rv4o/lD+Pv7A/eD7cPnw9qD1EPWA8zDxgO9g7+DvUPCA8DDxYPJw9KD22PgY+mj6uPu0/bT+J/+u/v7+1P+jADIBxgF8AngDGAWwBkAIIAlACkAMcA5wD8APsA9AEEAR4BHAEcARIBKAEiATABRgFcAVQBVgFOAT4BAADqALQAlQB2ADUP/o+0j5wPbg9PDzkPNg85DyYPNw8wD18PbY+Fj6+PrY+pD64PqA+7D7GPso+kD5SPlw+Uj6GPqA+tD7qPwE/QT9jP1k/Xj9lPyY+zj6sPcw9iD1gPSw8pDwoO8A8JDw8PDA8aDyUPRA9jD4UPqY+2T8hP38/hMAPgD1/zgAWAHWASACmAJYA2AEuAUoB6AIkAmgCoAMcA6QD/APIBCAEMARgBKgEmASQBKAE6AUwBWAFeAUwBMgEoAQgA0gC6AI4Ab8AjMAFPwo+bD3MPYg9aDzsPLg8vDzYPSg9KD2uPhg+rj6APvg+vj62PuM/Hj8aPuQ+bD50Pog+1j7OPv4+7T8BP0A/TT9aP1A/ZD8ePvQ+SD4YPaw9dD0cPMA8rDwwPBw8fDxEPIA83D0EPYI+HD5APtc/Hz9hv7F/5IA/AA6AbYBsAIcA9ADQAQ4BTAGkAeQCKAJ8AoQDLANkA4wD7APIBDAEMARwBIAEyATQBNgFMAWIBZAFEATwBFwD7AMgAoACJAEswBo/WD7uPjg9fDz0PPg83DzoPJg86D08PUo+Fj5APsY+4j7iPto/Cj8yPsQ+yj7WPqw+dj5OPpA+7D7fPzI/Aj9LP3g/cj93PyQ/GD76PkI+HD2MPUw9PDycPHA8FDwcPBw8SDyEPOQ9CD2UPjQ+Uj7YPyU/QH/9/+zAIUA1QCCARwCCAOIA1AE6ARABmgH4AhACkALcAzwDTAPABBgEIAQoBHAEsASQBMgE6ATIBWAFaAVwBNAERAPIA6QDFAJ2AU4Anf/tPxg+mj4YPaw9NDzMPTw8/DzMPSw9dD3sPlI+mD6cPtI/Az9DP3o/DT8oPvo+rj6mPpQ+hj62Pqo+yT8wPvg+3z8HP04/cT8sPtA+mD5uPjg93D2QPUA9CDzkPJQ8oDykPIQ80D0EPZw92j42PmA+1z9pv5j/1EACAGQAUAC9AJ0AxAEOARQBSgGuAawB/AIsApgC8AMoA0QDyAQwBDAEWASQBMAE0AU4BNAFQAWoBUAFAARwA9ADjAMkAnoBiADpf/k/CD78Pgg97D1MPTg87DzkPNA9AD1wPYg+GD5sPlY+gj7BPyI/Ij8ePxQ+8j6uPrw+gD7qPq4+jj7wPvw+8D72Ptw/LT8vPwM/Nj60Pkg+cj4CPiw9jD1IPTg87DzUPOg87DzoPQg9oD3oPiQ+eD6oPxw/nv/WgCxAH4BcAJEA+gDaASYBBAF8AUIByAIEAmgCRALoAwADpAOIA9gEAASIBNAE2AUABTgFEAWwBZAFkATYBDgDtANwAtwCOAEngE5/zz8gPoA+JD2wPVA9bD04PPg86D08PUY+Lj4KPmw+fD5EPtw+/D7CPso+kD6MPqQ+eD4CPkw+dD5CPrw+Uj6MPrI+kj7kPtI+2D6+PmQ+UD5kPhQ95D2sPVA9aD04PPw82D0APUA9kD3gPiw+aD6hPw4/mD/LAAMAawBuAI4A/QDuAQIBRgFgAW4BngHIAiACNAJkAuADFANQA6AD6AQYBIAE6ATgBMAFGAWABcAFiATQBFwD/AOUAwgCeAFbAI3ABD+aPvw+CD3MPaQ9SD1IPRg80D04PWA9xj4GPi4+Jj58Poo++j6+Pog+vj52PmI+fD4cPjI+ED5gPlI+dD4QPnQ+YD6gPow+tj5kPnA+XD56PgQ+ID34PZw9jD2oPVg9WD10PXw9hD4mPig+dD6TPz0/Uj/mABEAVQCTAN4BFgFsAXoBUgGGAfgB4AIgAjgCCAKkAtQDJAMYA3QDkAQ4BFgEsATwBMAFKAWwBcgFiATgBHgEFAPgAwACfAFyALp/zT9GPuI+KD2cPVw9dD0cPOw8+D0wPaw94D4cPig+Sj6EPs4+wD7APrg+Zj50PgY+HD3gPdw97D3oPfg98D3oPfg+Kj50PmI+Yj5sPmY+aD5aPnI+BD4cPcw97D24PWw9fD1wPYQ99D3iPhg+aD6VPxC/kL/MQAwAWgC0APIBPgFcAb4BjgHEAiwCOAI4AiQCQAL0AtQDHAMkA1wDyAQwBFgEoASABQgFcAWABbgEyASABEgEHANIArYBuADkAAG/rD7OPkA94D1EPUQ9IDzQPMQ9LD1APeQ99D3wPjg+fD66PoY+6j6KPqA+cj4CPhQ95D2UPaQ9kD24PWg9XD2cPc4+KD4qPgQ+cD5sPo4+xD72Ppg+iD6+PmI+fj4UPgY+ED4uPjY+Nj4mPko+5z8vP1I/m7/BAG8AkgEcAUgBsgGgAfwCGAJYAlgCTAKUAsgC7AL8AsgDRAOEA8AEIAQgBFAEmAUABWAFaAUgBNgEgAR4A+wDYAKSAeYBH4B0v4o/Dj68Pdg9hD10POQ87DzkPSA9RD2wPZg96j4iPkg+oD6mPpI+pD5IPk4+KD3MPfQ9nD2oPUw9WD18PVg9rD2QPcQ+MD4gPko+vD6KPuY+6j7qPsA+2D6gPpQ+tj5KPkw+TD5ePko+iD72PuA/Ij9CP/FAO4BRAM4BMAF8AbgB7AIYAkACsAKcAsQDFAMoAzwDDAOMA/QDyAQoBBAEsATQBSAFOAU4BSAFEATQBFAD+AMsApgCIgFNALM/oT80PpA+fD2kPWA9GD0UPRQ9KD0YPVQ9jD3APiw+Ij4qPgI+dD4mPiA9/D2sPVQ9UD10PQg9HDzoPMw9MD0EPWw9ZD2kPeI+ID5QPrw+ij76Ptw/GD8+Pug+5D7cPso+5j6APvo+jD7yPtw/Gz9HP44/4EANAIQAzgEaAXQBhAIEAkQCqAKQAvQC3AMUA2gDdANcA4QDyAQwBAgEWAR4BGgEmASgBIAEqARgBDQDuAMoAowCTgHEAXaAYD/YP2o+2D60PiQ92D2oPVw9YD1kPWQ9UD2APcA9/D2APcg90D3IPfg9mD2oPXA9HD0sPRQ9CD00PPA82D0wPRw9SD28Pbg97j4oPkg+tj6oPs0/Iz8bPxQ/Ej8SPxg/GD8IPwI/Bj8pPxQ/QT+0v7B//QACAKEA+AEIAZYB8AIEAoQC8ALYAwADeANgA7QDvAO8A6AD0AQgBBgEEAQQBAgEEAQ8A9QD3AOMA0gDEALQAk4B8gFIAR4AoIAzP44/ej76PrY+RD5APgw97D24PbQ9oD2EPYA9jD2EPYQ9nD1gPVA9SD1wPRw9CD0MPRA9LD0cPSw9PD0UPUQ9oD2EPdw9/D3UPjw+JD5yPlg+qD66Pow+4j7CPyM/Nj8JP14/fD9iP5R/w4A2gCuAWgCYANABIAFkAagB6AIYAlQCiALAAzwDMANUA6wDiAPUA+wD8APoA+gDyAPkA4wDqANAA3wC/AKEAoACagHgAZQBSgEGAPWAdgAtv+i/sz97PwM/CD7ePrw+VD5uPgw+MD3YPfw9pD2UPYA9tD1oPVw9WD1cPVw9YD1sPXg9TD2YPag9sD2EPdA96D3wPcg+GD40Pgw+aD5EPp4+iD7oPsg/Lj8gP1q/hz/zf9YAPMAwgF0AiADlAPYA2gE2ARYBcAFQAbIBjgHqAcwCOAIgAngCZAKUAuwCwAMIAyADOAM0AywDCAMoAsQC3AK0AnACOgHyAbgBdgE1AMQA0gCrgHlAFsAt/9c/+z+jv5E/sj9WP2w/Bz8qPtA+6j6+PlY+aj4CPig91D38PaQ9nD2MPZQ9mD2oPbQ9iD3gPfQ90j4qPgA+Xj58Plo+qj68PpQ+8D7HPxM/JD8xPwc/WT92P1Y/pj+9P5Y/wEAfgAKAWAB6gFwAuQCiAP4A4gE2ARoBcgFIAaYBtAGMAeAB8gHEAggCEAIUAhwCIAIYAgwCAAI4AeQB0AHsAYoBrgFKAWgBBAEhAP0AnQCEAKuAToBpgBSAAUApf8v/4r+JP7Y/ZT9JP2g/CT8uPtw+xD7yPpw+hj6+PnQ+cj5iPlw+Xj5qPmY+YD5cPmg+Zj5qPnQ+Qj6MPpA+nD6uPog+2j7wPvg+1T8gPw8/Zz9CP5W/rL+OP+I//3/TwC/AOwAPgGgAeIBLAJQApAC9AJEA3wDyAP0AzgEoATwBBAFGAVIBXgFmAWYBaAFoAW4BWgFKAUABeAEmAQ4BAAEyAOAA+QCjAJQAjgC/AFmASAB1gDdAKgAlAB0ABgA8f+W/3H/Qf8o/9b+iv48/iL+GP7I/WT9QP0s/Sz9BP3I/LD82Pz0/PD82PyY/LD8GP0w/dz8jPyQ/OD8HP3I/GD8lPzw/CT9LP0g/Wj9rP0A/kj+cv7W/gr/fv/E/xkATQBvAKgAvgDqAB4BRgE2ARYBGgFeAawBtgF4AZwBCAJoAoQCeAKoAvACNAMkAzgDIAMEA+wCzAKUAkwCKALGAaYBZgE8ASIBzwCGAGUAiAB3AHYAOQA0ADgAWABWAA8A9v/Y/wIA5P+7/2v/d/+a/4b/SP/u/vz+CP8H/9j+sP6y/rr+nP62/qj+lP56/mD+hv56/nL+PP5Y/kj+gP5U/nD+bv6M/oD+cP6Q/p7+jP6E/nL+mP6u/uT+zv7a/gT/Lf+F/5z/0P/R/yMAawCBAKAAowDdAB4BQgEiARwBJgFOAWgBfgFaAUIBMAFAAX4BbgFYASgBOAFIAUYBMgESARIBJgE+ASgBAAEAAf0ABgHtANIAvgClAIsAnACIAGwAOgAfACYAOwAoAAgA3//I/+b//v/p/8D/tv/B/9j/uv+f/5f/tf/A/63/b/9X/2D/nv+f/53/Wv9v/6H/if9+/zT/Zv8o//r+xP4L/yL/D//W/qz+Bf/w/iH/Af/+/in/jf/m/6n/q//S/1EAlwBfADwAZgC2AOgAqgCZAKAA3QDjAJ4AfQCLAMEApgBYAGIAdAB/AEwAJABAAFoARwAsAFEAkgC7AKMAngDlAEgBUgEQAe8ALAGAAYQBBgHCAPQAOAEKAX8AIwBJAG0AJQCG/yT/Wf+P/43/Iv8L/zn/fP+T/4L/ff/b/w0A9v/N/83/HwA3ACYA5//q/woA9f/N/5n/wf/Q/53/KP/c/gz/Xf9F/+L+iv6s/hX/UP8i/7j+7v4u/4X/Xf9R/17/wv8IAO//5//F//v/KgA7ABcAAwAjACkALABnALAAsAB6AEsAwgASAWIBEAHpAAYBSgGEAUYBIAHRADABIAEWAckAfwCzAKEApQBgAEkAGwDu/zUAHAAoAJT/pP/Q/w0A2/+G/5v/xv/j/7r/yf/P/9b/o/96/4D/hf9E/xn/5v4K/yz/GP/K/tT+9v57/2j/Cf/e/mD/3v/M/3j/Nv+i/9//zP9s/zb/Rf9m/1v/9P6s/tL+5v7q/qT+2v7U/tb+xP4K/5D/xf+8/8P/LwDGAAoBDAE0AVYBigGkAagBigGSAY4BfgE8AQIB1ADUAKgAUgAdAC0ASgAKAP3/4/91ALkAtgCyANoAUAFgAXIBLgFiAVYBWgEiAdIAnACFAIsACwC2/3j/qf+Y/2H/IP9a/4b/ef9R/0D/df+m/6P/Yv9x/7D/sf+P/1D/Wf95/1v/Ov8R/0//Uv9M/yf/PP93/2D/Uv8i/0b/c/+f/17/V/9E/3L/nf9z/1//U/+r/47/p/+S/9b/GgAXAAkA/v9YAH4AmwBkAGMAbwBsAFcASABpAIgAaQBeAIMAzgDpAPEA5gAQAWwBXAFMAUYBfgGkAXYB/ADJAAIB4wCNAPv/yP/K/9r/dv8h/xj/Pv9t/yj/D//+/nL/z//b/7X/qf8OAEMAjQBvAFIAVgBYAFsASwA/ACkAEADN/5D/gP+B/1D/C//i/ur+wP6U/jj+TP52/qj+YP4K/kb+uP47/yr/2P4D/5X/8v8PAOD/MwBOAIAATABpAF4AfwBxADwASAAcADcAAAAcACAAOgAsAOT/AQBEAI4AYAA4AFkAsADfAP0A3ADxAPEALgEyARoBvQCUAN0A3AC2AGQATgBiADgAIwDk/7P/qf+h/9D/vP+n/5b/3/8mABcAFQDt/w8AIwA0AE0ALwAhABwATgBaAFsAIAAJAPb/7//g/+z/hf9X/0n/Wv9//yn/+v7a/kX/av9G/y//Mv+s/9n/9P/H/7v//v8eAEAAFAAKABoALwAmAO//BQAsAO7/s/+W/9L/9v/F/5T/mv/x/w0A/v/E/77/OABrAIAAJgBFAK0A+QDeAJYAowDwAC4BCgHiAOIAGAEgAQQBswDtABYB/AB+AEkAgACYAIoA8v/K/+r/HQAXALb/nv+e/93/zv+K/2b/q//Y/+X/rv+n/6j/5f/8/wsA+P/r/8X/9//1//j/z/++/93/9f/R/7P/lf+U/5//fP9y/17/UP9W/0n/XP9M/1n/Tf8+/1H/ev+J/5H/hP/A/+3/FwDn/+X/EQBXAGsAPQAVABAAigCzAJwATABLAIUAzQDnAKQAlACYALsA4QCaAKEAZgDOAMsAwQCUAI4A4QAGAR4B6ADeANYA/AAKAeUA3wCmAKEAWgBpAD4AMQDf/4H/gP+4/4f/V//8/kv/Yv94/xX/Dv86/2v/if+H/4P/eP+t/8b/4f+t/5n/df91/3D/O/8x/0f/Ff/u/sr+2v76/sz+oP6I/vb+E/8P/wX/Bf9v/8L/3/+s/6D/s/9MAEoAWgD9/zUAbgCsAIMAawBgAJYAqQCgAEYAJQAeAEIAKQD2/7r/yf/O/7z/qf/C/w4ADADy/x8AfgACAfIADgEqAcoB7AEEAsAB3AEEAigC4AFGAeYA3gAOAZwA6f9f/2v/0f+d/wP/mv7G/jD/Uf8K/7z+5v48/2H/bf86/1z/ef+V/5P/kv+J/7b/3f/a/8D/qP+0/7P/tv+5/8L/q/9n/0T/Yf+S/4v/Of/G/vD+Pv+s/2z/J/8f/5r/+v/a/5L/fP/n/zUAOQDa/+r/MQB3AI0ARQBKAFkAnACiAMMAzwDtAO8AygDJAAIBQAEiAfcAxADxACoBHgHmALEAywDvANYAngBvAKQAyADUAHsAVQB3AKIArwBqAEgAVQB3AFEAHQD5//r/CwDQ/33/X/9v/3v/ef89/yv/Of9g/0z/Nf89/0L/gP9Z/2v/b/+T/7D/of+s/4X/q/+H/4P/eP94/3P/Q/8u/wH/Kv8m/xn/Av8K/0X/V/9a/0P/iP/R/87/ov9+/8//DAASAM3/x//6//3/AwCo/53/tv/7//f/x//D/+b/SQBdAEMAPwCAAMEA8gDiAN0AEgFUAWQBSAFYAXYBlAFaAUQBQAFAASIBrQCSAIMAWgAbANL/sf95/zv/Cv/6/vb+sP54/pT+zv7Y/s7+2P4K/27/jP/R/83/AABKAIUA0QCeAMAAuwDwAOQAyQDCAIgAgwA4ACYAwP95/0b/Mv8U/77+zP6y/qj+mP6q/vb+/v7y/sb+JP+q/8z/yP+5/wUAWQBwAFwAQgBuALAAwQCmAIwAnQC4ALAAfQA2AEcAZABNACUA6/8wAGcATQAKAAAAcACfAIQAPwBrALAA3gCxAI0AtQDfAPIAtQCLAIgAjACFAEcAHQAQABsAHAD1/+v/zf/J/8T/lP+U/5H/tv+7/5j/m/+s//z/HQAXACQAJABNAEMANAArACQANAAQAAAAw/+w/6L/m/9w/z3/E/8G/yT/Q/8p/yP/OP9X/3X/Wv9Z/4P/0f/1/9r/z//n/yAASwAnAA4AFQBgAE8AQwAxAIMAjwBqADMAUQBsAFgATwBKAHEAbAB/AFgAcQBiAJQAqACMAGMAmgDFANIAtgC3AMsAzgCYAJoAuQC3AKAAmQCGAJ0AlwCRAIMAbwB+AFAAcQAOAA0A8P8gAO//uf+H/5//wP+q/33/Yf9v/3v/dP9Y/27/V/9j/1v/aP97/4L/bv9q/2X/hP99/4H/WP+X/6n/1/++/67/xf8GAAsAAQDW/9L/8P/f/9L/hf+d/3//sf93/27/Wf97/5P/d/+F/5P/5v/x/xAAMwBaAJMAhQC4AKMAvgC1AMcAugCOAI8AfgCPAGIANgABAAcAEAAbAOr/4//h/yUAFQADAPj/EgBKAEAATwALAEwAOQBbAFUARABZACwATgAaAGAARQBKAC0ADAAzAAcAFgDI/8v/h/99/3v/YP9I/0H/Mv8o/yf/HP9S/z3/Tv84/4f/l/+Y/3z/df/t/+j/5v+8//7/XABlADsAAQA1AHIAdQA1AOT/5/8bACUADwCm/5v/u//Y/8//pf+d/2T/qP+t/9v/0f/Q/w4AXACSAI8AnQCzAAIBEAEsAfsA2ADhACoBYgEMAaUAWABoAHcAUgD8/6T/of+M/7L/q/+R/4//qP/s//T/7//Z/wEAVQCYAJwAYQBRAGgAtQDQAGYAEQDa/xcAOAAVANn/mf+A/3f/l/+F/3n/Uv9k/6D/qv+d/5H/o//Q/+j/9//S/6r/v/8RAFwAVAAAAM//DgA1AE8AHAD///D/3//8//L/0/+L/5H/nf+b/13/SP9a/5j/rv+2/7z/mf/C//X/QwA8AB0A/v8kAG8AfAB7AFUARQBhAIYAjwB2AGsAdgB1AFUAZgAoADEAGAAYAA0A/P/r/9f/2v/E/+T/tP+e/1f/dP+z/9z/l/9l/3b/k/+8/3D/S/83/3L/hf9h/1L/av/D/+r/3v+4/9b/BgBfAGgAUgBBAEwAbwBmAEsARABIACoABgDm/+3/6//S/7X/p/+6/6n/v/+w/6H/tv/P/83/kP+p/7X/BgD//+n/3v8IACEARQAwAEYAVQBlAFsARQBSAH0AmQBNAEIALABhAEoAHQAZADIATQAnAO3/1//f/wUADgAMAPL/9f8MACAADAAXAB8APQA/ADgAOwA1AEEANgA/AEMAJwAAAAMABgAaAA0A/P/i/9//+P/0//L/+P/h/9z/6P/g/+n/4//y/+3/AQAGABQAFgDl//P/AgAhAP3/2P/B/wAALAAjAPT/y//c/wIAJADx/7j/2P8WAEYAJgD9/wkAPwBRACYA4P/Q/wAAIwApAOL/yv/h/x8AFwAIAPT/AADq/xsADQAuADkAGQAsADQAVAA2ADIAGAAzAEgAYABGAFEAZgClAN0AwQCMAI8AzgDnAMcAlgCLANAApgB8AGEAXgBlADcA/P/l//X/4f/W/2z/Z/9T/4X/bP80/yT/LP9s/03/N/89/4j/sP+4/8H/zP/6/yAAKAA7AEAASABEAEAATQBJAEQAFwDf/9//0//k/6//dv9a/2b/bv9L/zb/EP8//0T/S/9B/17/hf/d/+L/0P/u/zcAfgCIAKwAxgAWAeMA5QAAAR4BCAGtAIkASQBXABgA4/+a/y//JP8h/zD/2v7c/gn/gP+1/6j/sP8FAGAAgQClAKQA9gAiAWoBXgFQATABNAEcAfMApgBoAD4AAQD9/7z/qv9o/0X/KP8z/zT/Hv88/yr/ZP90/4H/df9w/4f/nv/m/7//7P/d/+//9P/4//b/5v/r/+D/HwArADQAIwBDAFoAbQBLAEQALgAzACcALwAkAPT/8f8OADIADAD6/9r/BQDw/73/0//K/+j/xP+6/8L/5P/j/6T/pv+p/+b/3//1/+3/HABqAGcAfQCKAL4A+gACAf4A6AD4ABYBFAHoAKEAoQCTAHQAIwC//7r/pP9x/zP/Ef8t/zf/L//y/u7+E/84/0b/Iv8a/0z/kf/C/6//0/8CAEMASAA5AFwAigC5AJkAewB0AIMAkwBXACwAKgAKAO//tP+t/6D/r/+J/2//V/9m/3n/d/9v/13/h/+h/6L/pP+Q/8H/3f/4/+n/zP/9/w0ALQD1//b/9v8iABYA/f/3/x4AHQAeACYAMwA+AEoAXAB1AJUAmACfAMUA2wDsAO4A1wDqANkABAHbAMEAgwBsAHUAWwAvAPv/4f/g/7P/pf98/2f/Xf9N/1T/OP9A/0D/bf9p/3T/gP+r/9f/+v8sAC4AWQCMAKcA0gC5AMQAvADNAM4A0QDRAK0AhwBlAEcAHgD0/9D/yv+l/4//W/9h/3L/fv+C/3P/jf+q/7n/5P/3/xYAHQA4AD8AVwBsAHIAhwBsAFEAPwBFAEAANQAbABUAFwDv/9n/6v/5/xYA8f/X/8//6v/x//H/6v/1/x0AKwAsACgAOgBlAHMAaAAzACgAMwAVABMA6f/a/7L/rv+O/27/aP9N/1b/Mv8m/yn/Rv9m/3L/lP+y/8n/9v8aAFAAZwB7AJ8ApQDDAMQA4ADmAMcAygCmAK8AgQBiAEYAMgAYAOz/zf+d/6L/lf+D/3H/Zf91/4P/e/95/4T/jf+c/6T/tv+n/7z/sP+7/8j/0//i/+X/9P/v/w0ADQAcACMAGwAXACQAGwDy//7/5v/T/8b/uv+7/7H/oP+f/6r/l/+b/3H/if+K/4f/kf+c/73/v//L/9T/yv/k/9b/7//6/wYAFwARACQAHAA3AC4ANQAoACkAEAAbAB8AEQD7////3f/s/+v/zf/E/7r/0v+3/87/uv/l/+X/7v/w//P/CgAMADUA/P8RAAsAEQA1AA8AEgDs/+f/9f/k/9j/xP+//8b/vf+7/8L/wP/H/8T/zf/W/8z/3P/6/wUAFQAXABsAKwAxAEEALwA2ADwANQBNADQAHgAiACgANAAwABgAHQAqADQALAAgACYANwBBAE0AYABPAF0ASABVAFsANQBCACkARAA8AB0AJwASACEAHAASAAYA9//q//D///8KAA4AAQASABgAJwAmAB0AIQAHABAACgD2/+7/2v/b/9X/3f/R/9b/2//b/wIACgATABEAFQArADoAQwBBAFIASwBfAFgARABGAE0AJwAiABQA/v8SAPT//P/m/+z/0v/J/8T/xv+7/7v/wf+1/8D/vv+8/7r/t/+3/73/tP+z/77/vf/M/63/0P+6/8z/xf/O/93/zv/G/8X/xf+9/7r/q/+0/7n/q/+6/9b/vf/e/6X/tP+7/7//yv/e/+T/8P8KADEAVwBwAH4AtgDXAAoBIAEsAVYBbgGOAZQBqAGMAZoBnAGWAYIBdAFWAVgBTAE0AQoB+QDfAM8AxACKAHsARAAxABoA3/+6/3z/aP8g/+z+rv6A/kj+Bv7M/ZT9aP00/QT95Pys/KD8bPxw/ET8NPxA/Az8MPwU/Bj8MPw8/ET8WPxY/IT81PwE/UT9mP3w/V7+yv5k/9b/gQAOAbYBXAL4AqQDeAQgBfAFiAYwB/gHYAgACUAJoAnQCdAJ0AkACsAJ4AmACQAJAAlQCOgHQAfABvAFSAXwBOADQAMkAnoByQDm/1X/VP6M/eT8KPyI++j6OPq4+Uj5uPg4+KD3cPfg9oD2QPbA9YD1EPXQ9JD0UPTg85DzcPNA8xDzMPMg83Dz4PMw9KD0QPUg9kD3gPiQ+QD7XPwi/hoAngGoA2gFSAdACdAKcAwADmAPwBCAEYAS4BJAE8ATwBPAE2ATwBIAEmARoBBwD3AOcA0wDCAL8AnQCLAHkAaIBaAEgANUAkgBUwAs/+T9zPzI+9j6+Pkg+Tj4sPcQ96D2kPbg9WD1IPXw9LD0YPQA9LDzYPOQ8lDykPHA8KDwwO+A7wDvoO6g7mDu4O7g7qDvQPBQ8WDyAPQA9hD4CPp0/KL+RAGsA/gFIAggCjAMoA1wD2AQYBEAEgATIBNAEyATABIAEsARABEAEJAOwA2gDHAMAAuQCiAJcAjAB1AG6AWwBBgEjAMMAywCGgH6AIAA0f/0/57+RP5I/bz8VPzA+2j70Pqg+iD68PkQ+uj54PmY+RD5EPmw+Hj4CPiw91D3YPaQ9QD1sPPg8qDxUPDg7yDuoO3g7KDsoOzA7CDtoO0g7zDwUPKw88D1KPiw+oD95f9IAggEgAfgCXALAA7QDqAQoBIgEwAUoBMgFCAU4BOAEwASgBEAEWAQIA+gDYAMwAuAC7AKoAkgCEAHAAdgBsAFmATcA3QDPANsAkoB2AA9ANL/g/9U/jj90PwY/Cz8APwY++D6ePrA+tj6SPvY+iD7ePsI+zD7sPp4+mj6QPpw+Wj4EPfg9TD1IPTQ8uDwYO+A7uDtIO2A7EDsQOwA7eDtQO+w8BDygPSA9vj4WPus/YgABAO4BVAIkAqgDCAOABDAEcASYBOAEyAUwBPgE0AT4BGAEYAQkA/QDnAN8AsACxAKkAkwCEgHMAaIBRAFaATAA+gCyAJsAgQCwAH3ALwAegBSABgAH/+G/ir+8P1k/Sj9PPwE/PD7wPsk/Lj7gPuo+3D7yPs4+wD7KPoo+sD5sPgY+HD24PWw9GDzIPIA8EDvoO0A7QDsQOsA6yDrAOzA7ODtIO8A8UDzkPUw+Ij6AP2g/5ACYAXQB2AKYAzADmAQoBGAEiAT4BPgEwAUYBNgEiARgBAgEDAP8A1gDEALMArACXAIqAeIBrgFMAX4BOADWAP0AtwCsALyAXAB0gASAf4A2QDH//T+3v60/l7+3P3o/FT8IPxA/Oj7DPx4+wz8CPz4+5D7YPto+zD7IPsQ+pD5YPjQ99D2YPXA8xDygPBg7wDuYOyg68DqoOrA6uDqoOvg7GDuIPCg8uD0gPdQ+hz96/+4AqgFkAjgClANQA9AEaASYBMAFEAU4BSAFKATwBKAEWAQ0A+QDlANsAswCpAJYAh4B5AGcAUIBWAEmANMA8wCBAOgApwC+gFEAWYBXAFIAfwAnwDG/1H/FP/C/lT+7P1I/XT8FPwQ/BD8OPzQ+9D76Puo+6j7SPsQ+zj7sPoA+sD4oPfQ9sD1gPTQ8hDxQO8A7sDsoOuA6gDqIOoA6iDroOsg7UDvsPFw9KD28PmU/Pn/IAPwBfAIkAsADtAPABJgE0AUABUgFeAUwBTgEwAT4BHgEGAPAA5QDdALwAqACVAI2AfoBgAGSAWYBEgExAOwAxAD1AL8ApACoAKWAT4BUgEaAQwBwACR/5j/MP9L//z+pP7w/Xj9lP2U/ZD9SP2E/Wz9MP1E/cD8SPwg/Hj7APuQ+bD48PbQ9aD0APNQ8WDvgO3g6wDrAOoA6YDoYOhg6YDqwOsA7UDvUPIg9Yj42PpS/lgBkATYB6AK0AzgDoARIBOAFEAVQBUgFsAVgBUgFGATYBJgEfAPYA5ADVAMIAuAChAJ4AcgB0gG4AXgBCgE8ANcA+QCXAKoAdgBdAFMAXMAuv/E/9f/sf9v/67+jP5g/i7+Rv6k/XT9PP2U/UT9QP3o/LD85PzA/FT8UPv4+vD5qPnY+JD3MPaA9DDzwPEw8GDuYOwg6+DpwOiA52DnAOdg6ODpwOqA7EDuYPHQ9HD4WPuq/soB8ARQCfALAA6AEIASwBTgFaAWoBagFuAWABagFeATABOAEaAQkA/ADXAMgAvwCuAJgAhoB6gG2AWQBbAE7ANIA3wCOALcAUgBAgHCAG8A6f9y/0X/l/9D/3b/I//I/rL+xP7c/nT+Mv7Q/fz9tP08/cD8ePxY/Aj8cPvI+Xj5aPig9yD3MPXg81DyIPHA78DtYOyg6sDpYOjg56Dm4Oag5yDp4Oog7EDuAPFw9Gj42PsM//IBkAUgCcAMwA4gEQATIBUAF4AX4BdgF2AXwBfgFqAV4BPAEkAS4BDwD+ANEA3QCyALIAqwCLgHmAYwBhAFWAQIAyQC6gEaAXwADwA7/zf/Qv5i/hz+Bv78/bT9SP64/Qj+7P0s/iz+4P0K/rj9tP1A/dD8rPxE/MD7+Pp4+jj5WPig91D2cPUA9KDyUPEQ8GDuAO1A6+DpQOkg6IDnAOdA5yDowOng60DtYPBw8oD2cPqU/YgAGAT4B1ALYA4gEEASoBTAFiAYYBjgF4AXgBegF4AWABVgEyASQBFAEIAO4AxwC3AKYAkwCNgGiAUABegDPAPQAToBzgACALH/Iv8N/4z+Uv46/k7+Sv5E/kz+kP6A/rL+8P4C/w//0P66/tL+bv7o/WT92Px4/CT8sPuQ+uD5IPk4+ID34PXA9EDzkPKw8KDvYO2g66DqIOmg6IDnYOZg5mDmgOfA6cDrQO6g8JD0wPdo+5z/8AK4BtAKoA1AEAASQBTAFoAYIBngGAAY4BfgFwAXwBVgFGASYBEgEMAOQA0ADOAK8AmwCDgH4AWIBegEoAOEAjQBtQAkAJ3/+P4+/vD9sP24/dT9QP3E/QT+eP6y/tr+Ev+3/yQAOgAuAML/1f+S/yr/TP6Y/YT8APxg+1D6MPkg+OD2IPbA9GDzEPLQ8IDvQO6g7EDrYOpA6KDo4Ofg5iDnwObg52DqoOwg7yDywPQI+CT8l/94BNgG8AoADoAQwBJgFIAWABigGcAZgBhgGIAXIBegFiAVoBOAEcAQgA/wDXAMcAtACvAI0AcQBkgFsARUA4wC6QACAFn/zv66/hr+tP1w/bD99P0A/nb+gv4g/6r/uv9hALwAFAH7ADIB+ADJABoAv/9j/1j+YP14/Jj7+PoQ+vD4wPeQ9lD1EPQQ8+DxMPAA74DtQOwA62DpIOig5+Dm4Oag5iDnwOiA6gDugPAQ9ED22Prk/TgCaAagCZANABBgEiAUABYAGCAZ4BkAGWAYABhAF2AWIBUAFKASIBHQD9AN0AwADKAK4AnYB1gGOAVoBJADQALMAJX/yv5C/lj9+Py0/NT81Pzo/BD9oP2C/kD//v9JAPwAmAEcAlgCTALMAVAB4AAbAE7/Av60/Ij7ePpw+Tj4UPdw9pD1cPSA81DycPHg8KDvwO5A7QDs4OrA6cDoAOhg5wDnoOcA6ADpQOxA7nDywPZo+CT8XwAwBWAJMA3wDwASwBSAFqAYYBkgGoAZgBnAGKAX4BWAFKAUIBMAElAP8A2gDKAMoAtgCoAIKAeABVgFUARUAiQB4/8z/xz+HP0k/GT8mPwM/Uj9wPxw/dT+EAD5AIABDALkAvADOATgA6ADGAPMAhgCtwAn/4T9cPwo++D5QPgA9wD2YPVQ9ADz8PEQ8bDwIPDA7qDtAOxg62DqQOng5wDnoOaA5oDngOdA6UDrYO4Q9LD2wPmY/RYBEAdAC+AOABGgEwAW4BegGWAZgBkgGaAZQBhgFqAUIBNgEyAS4BBQDjANgAxQDFAL8AlQCJAG4AVgBFgDQAErAO7+MP7g/Kj72PpA+8D7MPyI/Lj82P0D/4QAjAFoAuACvAOABFAE8AMwA2ACtgGdACz/oP34+4j6YPlo+DD3MPag9SD10PTw8+DycPLA8TDxYPBA76DtwOvg6sDpIOgA58DlwOUg5sDmQOhA6mDtAPIg99j6yv6qAagG0AzQDwAToBSgFcAXoBhAGYAYABhgF6AWYBWAE0ASwBFgEYAR4A+wDqANMA3QDHAMAAugCPAGOAXwAwgCAQAU/pD82PvQ+uj5ePmA+SD7oPyA/UL+Fv+qAMgCiAQ4BYgFeAXoBcgFyARIA1ACDAHw/w7+VPyA+nj56PhY+HD3cPaw9bD1gPXg9ODzoPLw8bDwoO8g7gDsIOrA6KDnQOag5CDkQOTA5cDmAOmA6yDwoPSQ+Eb/4gDwBJAJEA5gEkAUIBUAFiAXwBigGCAYIBegFsAVoBUAFMASwBKgEiAT4BGAECAPgA7wDZANoAqgCNAFMASAAhMA7P3A+xj7oPpA+tD58Pmo+oz8nP4cACgBHALQAzgFiAawBlAGkAVwBegEmAO2Aej/7v7c/ZD8CPtw+dD4qPho+OD3IPfQ9oD2MPaA9SD0kPKg8RDwAO8A7eDq4OiA54DmoOUA5WDkIOUg5mDoIOqA7XDxEPaA+tL/fAOwBeAIwA0gEmATQBVgFMAUoBYAFoAWIBbAFOAUYBTAE8ASQBIgEiATgBLAEDAPIA3QDAAMEAqYB1gExgEcABT+lPxo+sj52PmY+aD6kPqw+6T9wf8sAiADCAQIBUAGAAcAB2AGOAVQBJgDaAIQAUn/Hv6I/dz8JPy4+jD6APrw+ej5CPmI+ED34Pbg9UD0sPKQ8ODuQO0A7ODpQOjA5iDmQOYA5kDmQOag56Dp4OtA7hDyUPY4+UD/mAK4BGgHwAoAD6ASgBOgE6AU4BTgFuAWABegFoAWABbAFaAUYBMAEyATgBLgEAAPoAwwCyAKoAhoBkAEuAHj/wz+0PyQ+9j6WPtg+6D7KPz0/Gz+NwA4AoAD5AOgBOAEWAWgBUgFAAUoBFAD1ALSAZgAVAAu/33/iv58/YT80PtI+2j6IPpA+OD3wPUw9XDzwPHw8GDuYO5A7ODrYOrg6ODoQOjA6IDoIOhA6ODo4Olg64DtYPAw9CD4QPzJ/64BUAUQCoAOYBFAE6ATQBXAFiAXgBeAF8AWABbAFcAToBKAEYARgBGgEPAOUA3QC+AKIApACFAH4AT0AmABQv8Y/hj80Pt4+2j7cPvw+yz87P2F/0YBCAO4AwAFcAVABnAGaAbwBUAFyATgA7wCTgFHAJb/Uf+o/pj9pPyA+9j6aPqo+XD4gPcA9jD1wPNQ8nDw4O7g7eDsoOtg6sDoIOhg6IDo4OjA6ODoIOrg6gDsIO4A8PDzCPgk/Or/SAIABQAJAA1AEAAToBTAFIAV4BXAFoAXYBYgFgAVIBUgE8ASABLAEUASQBHgD7ANwAtACxAKoAhABngDWgFf/wj+vPxQ+4D7IPtw+5j86Px+/qn/9AE4A6gEWAWABfAFyAWgBYAFYATAAyADVALqAQgBcwD+/6D/v/8C/yb+AP24+yD7IPp4+ND2QPXA80Dy0PCg7+DtIO1g7ODroOug6oDqIOoA6oDqQOpA6iDqIOrA6wDtYO+w8WD1uPl6/jwCcAWACBAMkA/AEyAVYBYgFiAWoBaAFuAWYBUAFSAVIBVAE2ATYBKAEoATABKgEEAOYAxgCjAJ+AY4BKIBxP5u/kD8HPzY+gj7UPzg/OD+gP98AYQCWAMgBRAF6ASABKQDzANQAjACUAHxAMYAGgFiAf8A0QDnACgBgwCd/xT+qPzo+jj5IPcQ9XDzQPEA8EDvQO6g7eDsoOyg7EDsYOzg66Dr4OoA6wDqAOqg6eDoQOqA6oDsoO5A8rD2EPwyAYAEcAgAC/ANABJgFEAV4BUgFQAVQBUgFYAUgBQgFWAVIBVgFOATYBMgFOATQBKAENAM0AtgCKgGSAQSAdX/5P1k/Nj7mPtw+/z8VP5d/wIA+wDGAVQCeAO0AhgDHAJ6AXAB/QAmAbf/RgH9ABgCQAOQAkwDtAKkAsgBywCU/3j9APy4+XD3oPVg9ODykPKw8VDxQPBg76Dv4O4g7+DtIO1g7EDrAOvA6QDpQOhA6CDpIOpg6+DsgO+g80j48Px6AbgEEAdwCdAMMA9AEcAS4BKAE+AT4BPAFGAVYBZAF6AXoBjgFcAVABagFEAUQBIgD2AMAApIBxgFQAOgAUQAef+S/nz9bP1c/dj+gP9N/ywADf8zAJj/y/9LADUAFgBiABwAoACpAJYBDAIUAygE3AOoBLADfAO4AiQC7ABL/y7+6PtI+sD4cPcQ9rD1oPQQ9IDzMPKQ8YDw4O9g7yDu4OyA60DqwOng6KDoYOjA6CDpwOnA6oDroO1g8CD0KPls/YYADAOABSAI0ArADfAPABEgEmASYBOAFCAVgBUgGEAY4BhgGMAWYBYgFYAUQBOgEVAO4AuwCQgHUAV4A6gCBAI2AWoAyP/m/qL+Yv8v/xQAbf8e/xz+Nv6q/qz+xP/L/xQBVgH+AVwCPAMQBMgEMAXYBTgFeATIA2gC4gHXAAoA6P7M/WD8SPpw+Wj48PfA96D2kPXA8+DxMPHg7wDvoO1A7GDrIOqg6QDpoOjg6ADp4OoA7ODrgOzg7ADwMPMw99j7gv60AJwCYAVgCJALUA4AEAARwBHAEkATwBRgFSAWIBigFyAYIBdgFmAVgBQAFMAR4A9ADtALQAl4B5AFQATQAhACSAE+ADv/Qv5Q/XT9eP3M/Vz9CP28/Jj8mP1S/lj/1f/5AHQBQAJ0AvQCuAMQBGgE4ASoBGAEkAMkA7wCsgGyAUcAEgCK/nj8gPsA+nD5APiw95D10PPA8rDwsPCA7kDtAO1A66DrgOoA6cDooOeg6CDpAOrA6UDqQOtg7hDxMPZA+eD8pf8EATgEEAawCRAM4A2ADwARQBFgEkATYBVgFkAYABmAGGAZoBcAF6AVQBQgEkAQEA7AC2AKgAe4BvgEnANYA2wC+AF0AF7+EP1E/Aj84Puw++j7cPvQ+1z8LP0O/rz+gf+MAA4BvgHSAUQCgAKEAuQDAARQBFgEWAMEAzACpAGUAUQAqv/o/VD8IPv4+Tj5wPfw9sD0oPPQ8cDwAO+g7aDsgOsg7ADqoOkA6MDnwOdA6IDogOig6SDqIOwg8ODygPb4+qD8Iv9gAUwDyAYwCdALgA7QD6ARgBIAFAAWQBfAGEAaoBrAGkAaYBngF4AWwBQgE8ARQBBADlAMoAqACHgHUAawBWAEiALCANj90Pxw+6D6SPuY+vj6gPo4+yD7APzo/Lj8tP2g/Vr+gP5M/wUAgQCIAUgCSAPIA4wDBAOEAhgCtgFYAeYAmgAy/qT9uPxo+5j7mPlw+aD2cPVQ8+DwMPCg7aDuYO2g7GDrAOng6CDogOeA6GDoQOig6GDqYOwg7+DywPUI+Ej7oPz6/iQC5ANIB6AJ4AvwDXAPwBFgEyAVgBcAGYAaIBtgG8AagBmgGEAXQBaAFaAU4BKAEUAPgA0gDJAKkAnQB4gG0ANcAdD/YP28/Gj7MPuw+iD68Pm4+bj5kPk4+gj6MPpo+gj6qPoY+3z8mP1D/3gA/gCyASoBaAAfALz/jv/Q/4r/o//I/uz9qP1U/Bj8aPtY+nD5UPdw9fDyAPEw8EDvIPCA78DuAO2g6yDqoOjg6CDpAOng6UDsAO0A8DDyAPSw9sD4CPrU/OD+TAF8A7gF+AcQChAN4A6AEUATABUgF0AYQBlAGqAZIBmAGMAXQBeAFwAX4BZgFQAUIBKgEJAOkAwQC4AIkAaIBNQCXAFFALT+Mv58/Dz8KPtI+ij6QPmo+ej4sPjQ+Bj4EPiA+HD50PqA/MD9qv5w/uj9XP1I/ej8bP2Y/Tj+zP5g/vD+hP4O/lD9VPzo+2D6mPmw+OD20PWA9MDzQPSA86DzsPIQ8YDvYO3A7IDsoOwg7qDuEPAA8XDyMPTg9ED2APiI+TD7YP3w/gQBqAKIBGgGEAhQCmAMkA6AEAASgBMgFGAUwBSgFAAVABUAFWAVABWAFMATwBKgEcAQsA9wDiANIAtwCbAHoAZQBYAEEAT8AlQC5ADF/3r+ZP38/GT8LPzo+3D7QPsw+yj7iPsA/JT8jPzg/Lz8HPwA/ID7kPug+7j7CPww/JD8NPz4+5j72Ppo+pD5MPmA+AD4cPcA97D2UPag9pD2QPaw9dD04PMw85Dy0PIQ83DzcPTw9AD2EPZw9tD28Paw93D4cPko+yz81P28/p3/swBmAdAC3AOABbAGQAgACRAK8AqgCyAMoAxQDbANQA5wDqAOoA7gDuAOEA8wD+AOkA4wDjAN0AwADIAL4AqACvAJgAnACCAIYAeoBqgF4ATkAwAD/gE8Aa0AFwCx/yH/jP7Y/Qj9TPyI+zD7SPoA+rj5MPkQ+fj46Pgg+fj4+Piw+Hj4SPgw+Cj4GPg4+Fj4gPjY+Oj4+PgI+cj4ePg4+BD44Pcw+Fj4gPj4+Cj5ePmY+bj50PnA+Qj6SPqg+hD7UPu4+yT8cPys/Mz8PP28/Rz+pv7e/mX/w//w/3QAygAiAYIBNAKgAjwDqAPwA2AEgATQBDgFeAXoBWAGmAYIB2gHsAf4B0AIUAhQCGAIYAhgCHAIgAhQCFAI+AfIB3gHAAegBkAG+AWQBWgFEAXIBFgE8AOsAyADyAJcAhwC5AGGATQB+gCFADEA4v+O/zn/3P6e/lL+EP68/Wj9YP0A/bj8ZPwg/Nj7ePtA++j6wPqI+jD6EPrI+bD5gPlI+SD54Pio+Ij4gPho+FD4QPhg+Dj4UPhI+FD4UPiI+Kj4CPlI+aD5+PlI+qD6APtI+6D7GPx8/PT8XP3g/W7+5v6x/w0AxABCAboBaALgAngDEASgBCgFsAU4BsAGQAewBzAIkAjwCCAJgAnACeAJEApACmAKcApwCoAKcApQCiAK8AmwCWAJEAmwCHAI+AewB2gHCAegBjAGuAUwBYAEEARkA/ACXALUAWYBuwBcAL7/Sv/A/jD+qP0Y/ZT8GPyw+0j7yPpQ+uj5YPkA+aj4MPjw94D3YPcQ99D2oPZw9lD2IPYA9vD18PXw9QD2EPZQ9mD2kPag9hD3MPeA9+D3MPio+Pj4WPnI+Tj6wPo4+9j7RPyk/Cj9qP0u/rr+S//Y/20AEgG0AUQC3AJsAwAEmAQYBbgFUAboBmAH+AdwCOAIQAmgCeAJQApwCqAKwArgCvAK8ArwCuAKwAqQCmAKEArACXAJIAmwCDAIuAc4B7gGMAaYBRAFcATUAzADiAL0AWYBzwAxAJr/+P5u/uD9aP3g/FT82PtY+/j6iPog+rj5UPkA+aj4YPgo+OD3sPeA92D3QPcw9xD3EPcA9+D28Pbw9hD3MPdg95D3sPfg9xj4cPig+PD4KPl4+eD5KPqQ+uD6QPuQ+/j7UPyw/BT9gP3g/VL+vP4r/5T/+/9rANsASAG8ATQCnAIoA5ADCAR4BOAEaAXYBVgGwAYwB4AH2AcgCGAIsAjACPAIIAlACUAJQAlACTAJIAnwCMAIgAhACPgHqAdQBwAHoAZIBtAFaAXoBGAE2ANwA9wCVALMAVQB4ABSAOf/ef8A/5L+Ev60/UT94Px4/AD84Ptg+zD72Pqg+jj6+PnI+Zj5cPlA+UD5IPkg+SD5GPkI+RD5CPkY+TD5MPlI+WD5aPmA+aj50Pn4+SD6WPqQ+sD6CPsw+4D7wPv4+1T8tPwA/Vz9sP0O/nz+yP4z/47///9aAKoAEAFuAeYBPAKcAvgCQAN8A9gDOASQBOAEIAVwBagF4AUYBkAGWAaABqgGyAboBugG4AbgBtAGsAaoBogGYAZQBigG8AW4BXgFOAX4BLgEUAQIBMADXAP4AowCLALMAWoBDAGuAFYA8f+V/zP/2v54/iL+zP2E/Tj98Pyw/HD8LPzo+6j7ePtI+xD74PrA+qD6gPpg+kj6QPo4+jD6OPpA+kD6SPpw+oj6qPrQ+vD6IPtY+4j7sPvo+xz8ZPyw/PD8OP1s/aj93P0i/mT+pP7o/iv/ff+//xMASwCUANUAGAFaAZwB3AEgAlwCkALIAgADPANgA4wDvAPkAwgEOARYBIgEqATIBPAE+AQYBRAFGAUQBRAF+ATYBMgEsASQBHAESAQoBOwDxAN8AzwDBAPIApACTAIIArIBZAEaAdgAiAA+AO3/qP9Z/wf/uv52/jj+9P3E/Yj9WP0o/QD95Py4/JT8cPxc/ET8OPwk/CT8GPwg/Cj8MPw0/Dj8RPxQ/GT8ePyY/LT8yPzk/Pz8HP08/Vz9fP2s/dD9+P0o/lD+eP6m/s7++P4h/0r/fv+v/93///8xAGAAjAC9AOUAEAFEAWIBnAG2AeQBBAIkAkQCXAJ8ApwCuAK0AuQC1ALoAuAC4ALsAsgCwALEArQCmAJ4AmQCKAL6AdIBrAGMAVgBJAH8AM4AqgB3AEcAIQD3/8v/pP90/1P/Mf8T/+T+yv64/pr+iP5w/l7+UP44/ij+Ev4W/hr+GP4c/hr+Hv4e/ij+OP5O/mT+av52/n7+lP6e/rD+uv7A/tb+6P7+/g7/JP88/17/cP94/4T/nf+5/8f/4f/m//n/EAAgADsASwBcAF8AcgCMAJUAqAC/ANMA7gAGASABOAFOAVgBaAF0AXwBjAGaAagBogGoAaQBpAGcAZ4BpAGaAZgBgAGEAXoBZAFQATYBHgH9AOMAxwClAI8AcwBZAEQAJAAKAOr/y/+2/6f/lf+H/37/c/9n/07/RP80/yv/MP8t/yv/Jv8n/x7/F/8R/wv/D/8C//7+/v76/vj++v4G/xD/Fv8Z/yD/J/8v/zj/RP9M/17/Y/9q/2v/eP+B/4H/i/+f/6L/q/+3/8v/2v/m/wIAIAA5AEcASQBoAHQAgwCSAKMA0gDLAPEA7wAGAfgACAEWASIBJgEoAT4BOAEyATABPgEwASoBIgEiASABAgH2AOMAxwDAALIAlgCHAG8AawBoAFYARgAnABYAAwD+/wIA+P/e/9T/zf/A/7L/nv+c/5X/kP96/3D/cf9r/2n/Uf9B/zn/Jf8V/x7/H/8W/xn/Ev8Y/xX/EP8K/wf/Bf8O/xP/Fv8Y/xj/Gf8c/x3/IP8u/y//Mv9A/0H/Sf9i/3n/jf+i/7b/xv/u/wEAAQAOAB0AMQA9AE4AYwCDAJsAnwCyAMIA0gDRANgA3ADkAOgA8ADrAOQA2wDaANwA4QDWAMMAvgC8ALIAlwCKAIAAgwB8AHEAcABkAFoATABOAE4ARQA/ADwAMgAfAA8ABQAIAPv//P/+//v/AADq/97/2f/T/83/yv/D/8b/yv/D/8n/uP+x/6P/l/+X/5r/mP+e/6D/n/+h/6X/qP+b/5//pP+j/6r/sf+w/77/vf/F/9L/z//j/+b/8f/6/wkA//8TACgALwA3AEYAVQBoAHAAdABqAHQAegB2AHMAYwBbAE8ATABJAFwAXgBfAFYAVgBJAD4ANwAzADcALgA1ADgANQArACQAJAAcABIAAQD5//T/6v/m//D/8v/u/+j/5f/W/87/y//a/+H/3//a/+D/2v/P/8n/0f/W/9r/0f/b/9L/0v/H/9X/5v/b/9L/0P/U/8v/uf+t/8L/sv+l/6H/s//D/8f/yP/j/9z/4f/R/9P/0v/U/9z/8/8KACcAQQA/AFgALQARAOH/+/8SAPn/EgBNAIwAfQCMAC8A1f+t/5X/yv/4/w4A/v8UAAoA6P+r/8P/0v/1/+z/7P8bAA8A3P+z/5v/nv+f/6D/zf/1/9b/1f/k/9D/p/+I/5f/r//M/7H/p/+//5n/gP+h/8X/2v/J/7n/1f/X/8T/3/8SAEIANgAwADgAWQBaAEIARABHAEoAVgBUAEkANgAHAAcAFQATAAEAFgBCAC8AFwAEAA8ADADx/wgANwBeADMAGwDs/8P/kf94/6n/3//7//b/GQATANr/r/+u/83/8/8DAAkAQABJACgACQACAPL/3P/F/9z/9P/o/7D/nv+y/9b/sv+s/wAAGQD///j//P/X/5//f//F/8D/iv9w/73/+P/i/8f/9v8JANX/kv+Z/5z/hf9+/7f/7f/M/7L/xf8YAA4A5P/M/xMAKwARAAoANwBgAEIAGgBMAIIAjgBoAHIAiACFABkAIQBMAGYAWwCiAO0AtQClAH8AbwApACsASgBqAD8AmQCVALsAeQBvAE8AbABKAGMArADHAJMAXwBrAD0AHgD3/+D/KgBdABEACQBJACcA6//A/8H/JwBCACIARgA/APn/AQCx//f/zf9p/7T/HwAGAHP/Pf+z/3v/wP5q/sr+YP/O/l7/CADx//YASQB3ABT9KPno+CL+zwBAAngDjAJYAub+mP0A/GD9fP7z//cAHAF4ApgCrgDU/XT9Pf9f/2L+OAGUA8gEFgEFAJoBugFP/xT+DgHAAqgCsgG4AkgDIgHg/XL+RQBx/8j/9QC4A8wDbACh/44AKAD7/+z/SACUAZP/ev4N//r//f+zAHP/XP30/r7/8v6A/cb+bgEIAIz8QP3d/0r/gPxg/eABYAI2/7b+UgHSAGD9iPuY/DT/EAJUAoQCXADe/qj/yPwo+vj8wAHcAcX/TgE4A2YAXPzE/CX/Lv5o/MQBcAgwBkn/pf9uAZz9uPzg/9AEuATEAZACuAO4AmEAsv7o/QT97gDoAgwA/AHQBbQDwPp0/MUALAHg+hD6qAFQBowCOAK4BuwCCPtg9zz8PP8cADgCEASQBXgDiAHy/uz8AP6O/3j+8PvE/UAEyAQ8AUQDgAEE/dD16PjuAbAGdAKKAfACsPsg+Wj6XwC+ATQCBAKAAvb+yPqW/mz+sPug/QQDpAO3ACb+yP6A/Wj6mPoYA0QD7gEDAMgB3/9w+iD6FgFYBZT93PxGATAIBAII+lj9QAIhAHT9LAK4BEwAvPy4AbAEiP3I+Kz+wAYhAOT8EANgCPAC+PnY+VQB1AP4+/z+QARoBMwCqP5YA/AB9Pyw9jD8rAKsArr/WQAQCGgFZP1g+FEAiAL4/KD38f+wCJgGIf+M/RgECv4Q99D6+AQgBiv/8P0sA9AFVQDc/Nj72Pvo+kD80gGIBDAGkAZSAZD4yPhM/ogAKP0E/CABwANQAloBcANsAwj98Pho+7T+aP9GARAF+AUoApT+6v5a/mz8ePxR/0QBeARYBRgDKwAE/nj+RP2o+zz9KAMYBcQCIAPsAhAB6Pyg/Hz9jP4CAPADIAb1AET+7f9YAAj/EP6x/5QC1AEg/0YApAJqAa7+BP6bAPQCJAEg/sz/QAEbAKv/SAHwAr8AXP0I/owBCgEDAAoB6gEuAVH/Vv6V/wQAKwBMAU4B2gBiAC8AIf/c/dj9kv7r//j/+f9w//b+5f8wAkgBHP70/AL+4P1w/IT8JgFwBIAE0gEv/5T9Jv5I/KT85Pz6AUgFLAJ1AE0AmAEw/6b+1v/IAj3/2Pps/bACtANEArAEsARIAKD7BPwWAHkAkv8/AHwDWAQ4A4gDugGQ/ZD6cPv8/VgBCARABUgEogEm/8j8MPtY+27+oAFcA6QDCAMgAjgBlP0A+xj7YPxI/2oBmAMABZQDzv9s/Vz8aPuA/Fr+TgFgAsQBRgEwAZD/ZP3Y/Az9qP3o/Qz/3gB8AagAhwD7/2v/DP5k/Vj9kP3c/VD/1AG8ArwDOAOWAIz9EPzg+4z8wv4cArAFcAW0As8A6v8S/jj8OP3T/0oBgAFoAmADTANgAVQArv8D/3L+wP62/6oA5AKIA6wCeAHNAEAAFP+m/oH/YQAFAHUAVAIwA6ACYAGnAFb/PP3c/Kz+ugDMAawCpALgAW0AYv9W/lj9XP0R/7QAwAAUAVQBxgBe//z9av7E/jj+WP61/1wA4/9y/2L/ev8R//r+7P4H/5v/RQBlAHT/C/8p/0z/7v4e/2QA4wBHACoA8f+d/8z+zv7B/0sANQCm/38AgwA+AMf/i/8uALj/8v6+/sn/bgBXAEwAOAFwASoAGf8v/97/sP99/y0AegEaAXkAtwAsAYAAqP/v/4MAlwA6ALYAfAEEAUoAIgCHAEMAyP/r/6AA8wDcAAIBNAEUAS0Ayf+M/zf/lv8HAPIA7QCpAJAAUACf/57+qv4Q/0X/X//E/5sAewB2/yr/kf9j//b+8P6n/+D/if9s/9b/aADG/1L/Y/81/xr/vP5o//P/BQAdABsA9v+m/5T/rv/s/7L/CwAkAF0ASAB0AIUAWAAiACQAlwCUAM0AhgD2APAA2ADqANgA/ACKAHEAnABiAAcAuv9zANoAJgEWAUAB3gDq/zX/Wv/W/4AA6ABkAXoB7wBhAJX/nv+b/3P/AAAOABQAZQBtAJgAPQBT/wn/rP6q/sr+/P5s/0D//v7A/kL+uv52/qL+Uv7A/UL+Qv6Q/tz+sv6C/+r+6v78/kH/5f8SAJwAbwDHAEIBOgF2AVYBggGaAYoB0AEkAgADJAMQA/ACvAK8AogC4AJ0AywDwAMwA2AD6ALsAlgDFAM0A8gCzALUAtQCgAKEAnQCfAJMAjQCVAL6ARgCmAHgARwCMAIkAooBmAG4AOv/hf9B/67+zv7c/bD9aP24/DD8SPu4+tj4APcg9pDz4POw8/D00PaQ9nD3MPUw88DxUPHg8fDyEPSA9cD20Pf4+GD5QPqo+oD70PxG/pj/NAEMA3gEUAYQCJAJgApQC9ALwAugDNAMQA5wDwAQABFgEGAQwA+wDoAOsA0wDdAMIAxwC9AKEAoACfAHcAeIBlAFWARAAwAD+wCEAf8AcwBkAHIAdf/I/j7++Pyo/fz8oPzY/CT99Pzo/Aj97Pzc/CD84PuQ+/j6yPpQ+gD6sPmA+Uj5CPnA+Fj4YPdQ9uD0APRw83DzQPOg87Dz0PKA8ZDwoO7g7YDtQO0g7mDvgPBQ8YDzIPTA9JD0YPSA92D6yv64BDAH6AfABfACRAO4BJAIgA6AEaAUwBMAE6ARQBDAD8AQoBIgE4ATQBNgEmAQoA7QC3AKgAqwCGAI8AZABDwCeABB/zgAY/9j/5j+WPzA+mD4oPeA+Ej54PrQ+wz8bPxk/Fj8YPxo/Br+jv9qAewCGAQABVgECAWYBXgGqAcQCFAJ8AhwCLgHMAcIB7gGqAb4BfgE4APGAZYAlf8g/uj9nPyY+0j6GPhg9sD18PPQ8+Dz4PNg87DxgPFw8EDvwO6A7kDugO7A7qDvUPDw8ADxUPLA88Dz0PRA9CD14PWI+CD98AFgB4AK8AvQCuAH+AVIBRgHoAxgEMAUgBVgFaATYBLgECAQQBBgD3APEA6ADQAMIAwgC/AJsAm4B8AFSAMoAfz+XPzg+9j7/Pyo/Gj8JPzI+gj5EPgI+Kj4+PgA+mj7yPvc/IT9MP9lAKABQAPIAxgE0ARYBYgGIAhACaAL4AtgDMALAAsQCjAJMAjgCKAIEAlgCOAGKAboAhACo/+a/vD92PsA+6j5aPhg9vD1cPSA9NDyYPKQ8bDwcPAA78DvgO4A7+DuwO/g76DvgO/g72DwEPBw8aDxMPMw9PD10PYQ+PD30Pcg+cj6Pv84BCAKEA4gDkAMcAi4BcgFcAjwDCAR4BIgE2AS4BCADsAPgA5QDRALsAlwCQAIEAj4BrAGmAY4BcAEMAN4/+z8WPpI+ZD5qPkg/HT8PPxw+3D62PqA+hj7SPxY/DT9gP2y/lUAfwC+AZwDgAWYB8AHUAhgB6gGmAawBxAJAApwC5AL0AtwCuAIEAg4B3gG2AVABWgEMAPaAQwAuv5Q/Zz8FPwo+0D5SPiQ9qD18PSw9AD0gPOA8zDzAPOA8uDyYPKA8oDyYPJw8jDyUPLg8ZDxYPFQ8rDyoPMA9MD00PXQ9fD2APfA9mD2kPdA+ub+CAQACVALkArIB8gE7ANoBIgHcAxgDXAOgA0QDQAOMAywDYANcAywCYAIaAe4BkAG6AWgBlgGoAYwBqgEPAEC/uD7+PsM/ej9B/8c/mj98Pyc/Wj+Ev+9/5L/Y//U/n//XQBKAQADMARgBdgGyAcQCCAI8AegBwAIoAiACWAKwAmwCeAIkAjgB+gG0AXoBSgEnAMYA8oB///8/vz9+Pxk/MD6YPoQ+Qj4UPdQ9yD30PYw9iD1gPRQ8zDzcPPQ8+DzkPSA9JD0gPSw9ED0wPMQ84DyUPJQ8sDykPPw9PD1EPdQ95D3EPfA9jD2IPfI+Tr+5APgCCAMUAvgCIgEWASwBSAHsAvADYANwAzwCnAMUA3wDTAOIA2gC6AJCAfIBRAECAQoBBgGQAbwBXgErAGS/wD+WP10/Yj+RP6s/az8MPyQ/fj+pwBaASQCGgHgAJ8AlwBeAfABEAR4BVgGoAeQB5gHEAjgBxAI0AfAB9AH6AbwBugFAAaQBSgFAAXwA5gDMAJuASoAiv5w/az8ePyw+zj7qPqw+Yj5cPko+TD52PhQ+JD3gPYQ9kD1cPWQ9QD2QPbw9hD3wPYQ9rD10PXg9DD0MPPA8uDy4PIA9ND0sPXg9XD2sPZg9gD28PWA9mj5cPzyATgHwAmgCuAIiAa4BGAFeAcwCiAM4AywCzAMEAyQDQAPcA+gDbAL4AnoB2gGcATEAzgEWAVgBZgGaAUIAzIB0P4b/wj+Nv5i/vT84PyY+4D9Yv/wAEgCeAKIAtABcAEoAmgCoAKwA0gF6AZwBzAIkAgQCHAIcAiACKAIiAe4BngGSAUgBVAEmAToA2QDWAKiAcAAsP9o/mz9jPzY+zj74PnQ+fD4yPjY+Cj5QPlw+MD4kPew92D2MPZA9tD18PXQ9VD2MPbA9oD28PaQ9gD2QPUg9BDz8PGA8pDy8PKQ8wD0wPSg9WD1MPbQ9RD2kPdo+kn/3AN4BwAJEAkYB4gFeAXYBsAIYArQC5AMsAtQCsAMYA1gDpANYAwAC0AICAeQBUgEnAM8A1gEQAUIBPwCbgHm/+D+CP5S/2j+sP0E/Vz8cP30/Y//hgE0AvQCuAIUA1gDCAMcA1QD3ANoBUgG0AcgCBAIEAgACHAI2AfAB+AGAAYQBXgEOAT4A0ADJAOkAiQCdAGLAJ//Jv60/PD7mPsw+0j6MPrA+cD5wPko+hD66Pk4+dD4IPhQ9xD34Pbg9uD2UPdQ97D3cPcA95D20PWA9VD0gPNw8vDxwPEQ8dDx4PGw8rDzAPWg9aD1QPWQ9YD36PoUACAFwAiwCLAHEAjABkAHaAcQCZALMAsQDJAMoAxgDNANoA7ADsAM8AowCRgHWAUgBMAE6APABFAE3APkAjwBJAFkAI//0P6e/vT9eP1w/U7+av8RAGQB0ALQA2AEmARQBMAEGAQ4BPgE+AVYBxAIsAjgCHAJAAkgCbAIQAi4B5gGmAUoBdwDCANsApwCGALgAbABlgDO/5z9aPzI+zD7oPqg+lj6QPrg+cj5IPr4+SD6oPk4+QD4QPfA9nD2kPbA9gD3cPeA90D34PZA9pD1gPRw81DyoPHw8NDw0PCA8aDxgPLA83D1wPUQ9QD1MPXg93D7ZAJgCDAJcAnQCLgHEAlwCJAJwArgCqALUAwADfAMYA0wDoAOAA8ADbALoAgoBjAE6AIwA6wD3APEAkwCTAE8AQoBqQD//xn/iP5Y/dT9DP1A/fD9Vv/xAMACIAWgBcAF4AVQBcAEEAVABSgGqAZAByAIwAfgCDAI4AhgCNAHkAdIBmAFZAN0AsABHgEWAXwBnAHdAAEALv+k/Zz8yPsg+9j6CPro+RD6KPow+ij6uPrQ+rD60Pn4+ND3APfA9rD2MPcg93D3QPdQ90D3oPYA9sD0sPNg8rDxAPGg8DDwMPBg8KDyoPMQ9eD2wPUw9eD0MPfI+5wBmAZACYAJMAkgCKAJUApACvAK0AswDKAMoAwwDQAOEA6QDtAOUA6AC4AJWAbMAyAD+gGEA6QC5AFoATcAbAA9AG8ADwB6/2L+zP1I/Tj9jPzw/U3/EgFMA6gEIAYABhgG+AUwBmgGgAbABlgHoAeQB2AIYAjwCFAIYAgACLAHwAZoBaADdAJCAb0AUgDd/9n/Jf8I/wb+ZP1c/Hj7KPvw+bD5GPlg+VD5kPno+Rj6OPog+rD5yPiQ+ID3cPcg9xD38PbA9jD3MPdA90D3UPZA9fDzMPLg8aDwEPDA78DvcPAQ8cDyYPRg9VD1MPUQ9lj4RPxEAlAGIAngCDAIYAogCZAKYAsADFAMcAwQDTANgAxADQAOgA4ADzANkAzgCeAGIAW0A9wDSAJkAugB1wD5/5r/HQCvAKsA8QCRALr/Mv9A/n7+pP7p/xwCWAMIBYgFgAbQBqgGQAdoB8AHwAdYB4AHUAcgB8AHcAeAB1AHIAcQB4gGqAWIBAwD8gEqAWcAsP9h/6z+nv7U/bj9zPyY/BD8WPsg+/j62PrA+qD6wPrA+rD6uPpQ+jD6mPk4+SD5cPio+OD34PeQ9xD3QPdQ9tD1IPSQ8/DxYPEw8MDvoO9A73Dw0PAg8kDzYPRQ9rD1MPYA+FT8/AFgBXAIoAqwCZAJUAqQCoAL0ArgC9ALsAzQC+ALsAzADDAP0A6QDnAM4AnYBxAFrAMIA3QCnAE6ARgABQCO/27/NwBWAbABagGeANb/I/9e/r7/wgD0AiAE4AQYBngGgAd4B9gHMAgwCIAIQAi4B2AHqAYAB6gGYAe4BvAGqAbwBagFUASAAwQCDAGr/0P/qv5E/tT9YP0M/bT8fPxQ/Cz8yPv4+yj7ePu4+tj6cPqI+TD68PhI+Xj4cPgo+PD38Pdw9zD3EPfQ9sD2MPVg9KDysPFg8ADvgO+g7mDuIO/g78DxIPGw8mD1QPVw9hD20PjA/cwC6AbQCeAKkAkgCvAKcAtQDNALQAzAC0AMsAtwC4ALoAxwDZAO0A2QC4AJ4AVYBGwCIAIEAm0A1//S/rD+G/8uAKYALAJMAhwCZgGXACX/av4DAAYBSAM4BNAFOAYwBoAHoAcACTAIQAgwCDgHMAaoBVgFUAU4BVgFAAbgBaAF0ASYBMgDrAKMAXcA8P+q/jb+xP2k/ej8yPzw/OT8/PzU/NT8cPwY/Mj7qPto+9j6EPrY+Zj5UPno+ID4qPhw+Ej40PeQ93D30PZQ9kD1oPPw8bDwQPBA70DugO6A7mDvMPBw8TDzAPQA9jD2UPeA9/j5Bf+ABDAIsApQC6ALUAswDAANoA1wDWAL0AwwDGALAAzAC/AMsAywDWANEAvoB/gERAMAAjIBkgBdAMr+Iv7I/Rj/hQBOATgCLAPUAnQBvQDW/9f/ggAsAhgEiAU4BqAG4AdACGAJAAqgCmAKoAlwCEAHUAb4BXgFoAVgBZgFwAVoBTAFYATYAwADZALkAG3/eP5M/ez8hPyk/Ij8fPyk/DD9SP38/Cj9xPyk/DD8ePvQ+iD6WPkY+dD4wPhg+ED4SPig97D3YPdw9wD34PUQ9IDy4PDg76DuIO5g7eDs4O3g7sDwEPHg8kD0kPWw9jD2KPq0/fgBsAZACgALgAogChAM8AxwDaANQAyADEALsAsADOAL0AsgDKANoAwAC5AIQAbEA4gCTAH0APP/qP40/rz9hP5J/8UAUAKgAiQDYAKYAe8AqwAqAaACmAPIBLAFOAYAB3gHMAigCEAJIAngCCAIIAc4BlAFCAXABHgEaARwBIgEAAT0A2wDNANIAtoBnwBm/2T+ZP28/Fj8RPxc/Gj8nPwA/bD8TP3c/Nj8wPwQ/Kj7YPoQ+vj4kPhI+Aj4IPhQ+Gj4oPfQ94D2kPbQ9VD0YPJA8KDvwO7g7WDsIOvA7KDtoO8Q8kDzkPRw9ID1EPho+sD8rAGgBRAJsAlwCsAKQAsgDNAMsA0QDGALcAoAC0ALQAuwC+ALEAxgC6AKQAggBjAE/AIcAtUA9f8K/xr++P2O/hT/ogAwAdABGAJkAjwC9gFkAlwC6AIwAwAEAAWwBVgGOAeAB/AI0AgQCVAJYAkgCKgHIAfgBSAF4APQA8QDQATkA1gEsAM0A7wC1AGEASYAHf/c/Rj9CPzo++D7GPxg/DT9NP0I/Tz9AP38/GT8sPtY+mD5WPig90D3QPfg9nD3UPfg98D3APeA9gD2sPUQ86DwQO6A7YDtoOvA6mDsIO0w8IDzMPXg9VD1MPaI+Qz9vwAQBOAGsAggCtAKMAxADAANUA2QDbAMIAyAC5AKUAtQCwAM4AvgC+AKgAn4B2AFiAT0AvYB9wAFAPr+RP4g/qj+aP/YABAC1gFwAlwCjAK4AvAC1ANsA5gEmATABWAGyAaQB9gHYAgwCMAIsAhwCIAH2AYABsgE9APkApgCIALYAsACkAIUAmABWgEQAYcAgv+m/qT9JP1U/HT8QPz4+yz8kPxk/Wj9RP00/Qz9uPzA+7D6iPl4+MD3UPdQ9xD3oPZA9zD3oPew9sD1IPUw9GDygPCA7sDsIOwg7GDsIOyg7qDwQPRw9vD2gPfo+JD6kP5EA4gGcAiQCbAKYAswDaAMwA0QDuAM0AzwC9ALAAvgChALEAsQC+AKAAoQCKAFVAOcAqABVgExABT/MP4U/aD9vv7E/5wAqAGAAowCXALUAhQDuANgBLAE6AUABigGcAZwBzAI4AhACQAK8AmwCcAIAAgYB4AFoASYA0gDmAL+AfwBRAIwAggCDAJcAZsAZP/e/iD+kP3o/NT8AP0Q/GT8rPxI/cD9jP5u/hr+RP00/Jj7ePrw+Ej4EPiQ97D3oPZw9nD2sPYA94D2UPXA8wDyQPBg7oDsIOuA6qDq4OpA7IDuYPEw9ED1MPco+Kj5EP34AdgFUAgACeAJsApgC1AMkAzgDAAM0AswDJALEAsQCrAKAAugCrAKoAmwBwgFqAIsAh4BWgADAO7+Wv54/ZD9mP7O/xABfAKUA0wD9AIkA8gDmANoBIgF+AVoBogGUAcwB7AHcAhgCRAKgAnwCOgHkAcQBgAFeATUA0gDFALYAXIBLgGkAWABogGUAWcA4f85/2D+wP0o/RD94PwU/dj87Pwo/cD9Ev60/r7+xP2c/OD7GPvI+Rj5UPhw9/D2sPaw9qD20PVA9ZD1gPSg8gDxoO6A7SDsIOvg6qDpYOog7MDv4PGA9ED2QPcg+UD7UP/UAgAGYAhgCtAKwApwCgAMgAxADPALQAtgC8AKMAqgCgAK8ApgCoAKkAnQBqgEkAIQAsAAOAEZANT+3P18/ej9wP5dAKgB+AK4A+wDOAQQBFgEmATQBeAGKAdYBxAHaAeYB1AIMAmwCaAKsAowCvAIcAdYBqgFYAWgBJQDuAJ4AgQCAAPMAuAC9ALqAVwBxQDx/+7+wP3w/fz97P1Q/dz9+P3s/Rb+3P4g/7D+kP2g/AD8ePl4+Aj4IPeA9hD2MPZw9VD1IPXA9GD08PIg8nDwIO6g7CDrIOpg6aDpIOyg7eDvYPNQ9gD4iPio+jj+aAJABkAJsArgCqAKQAuwDGAMkAygC0AMQAzACqAKEArgCWAKIAtgCsAIuAaIBCQDpgEiARkACP9e/mD94P1o/Vb+wf9UAUwD6AOoBNQD/AMwBJgFgAYYB6gHYAcACBAI4AiwCBAJoAlwCmAKQArwCAAH6AUQBagEuAO0ArQBWAEAAYAAyAEsAtQB3wDIAJYAnv8v/47+aP7M/Yj9GP18/XT90P16/ir/bv+o/j7+mP1E/CD7uPmY+PD38PaA9tD1kPWQ9RD1sPTg9GDzoPJQ8CDvoO3A68DqoOrg6mDrAO1g7zDzIPaA+ED6MPvM/aQB2AXgCDAKMAuwDPALwAwwDdAMkAywC8AMYAugChAKwAkACpAJ8AnQCLgG1AOsAgQB1//s/mr+ev4A/Vz86Pww/TT+yP94ARQDTAPsAzgESATgBAAGaAZ4B/gHkAjgCNAIAAnwCZAKwAqwCuAKAAqgCLgH+AVwBDADhAIIAjgBhwCQAPgAOAE2ARABsAAnAEH/Af8X/zz+bP1E/QD9hP18/TL+Fv60/hn/sv5I/pz9nPzw+gD6IPlQ+PD2QPaQ9aD1cPXA9MD0wPMQ87Dx8PDg7qDsoOtA6gDqYOkg6mDrwO1w8UD1GPhI+RD6QP3yAMAEMAiQCrALUAvgCxAMoAtQCyALoAuAC6AKIArACSAJgAnACRAKcAhQBgAERAIzAHL+vP2s/XD9JP2U/Fz8CP2c/d7/8AEEAzgESATIBLgEiAS4BOAFwAbAB6AI8AjQCPAIQAkQChALkAogCoAJcAgoB9gFaAR0A5QCeAFMAcIAbwCXAK4AZAEOASQBtQAgAID/Df8q/lj9dP34/MD9+P0A/gD+gv72/sr+uv4+/oz9JPxY+1j6APkA+KD2cPbw9ZD1MPQQ9IDz8PIQ8pDwwO7g7ADsAOtg6sDpoOmA7KDucPJg9UD3MPlI+lD9mgGABbgHQAogC7ALYAtQC4ALAAsAC2ALUAuACsAJYAnwCXAKQApgCmAJmAfwBPwCGAF+/9r+aP6C/qT9HP3w/DT9iP4iAMwBZANoBNAEIAUgBSAFcAUABggH0AdwCHAIYAjQCNAJ8ArgCgAMYAtgCtAJoAigBtAF2ATcA2gDGALGAbYBuAGYAdAB6gGkAUgBoAD4/7T+5P2g/XD9XP2Y/Yj9YP1U/dj9Fv7g/Uz98Pwk/Dj7MPoo+Sj4IPdw9sD1gPUg9NDzcPMw87DyMPHA78Dt4Owg64DqwOkA6gDrQOzA76DzgPUg9/D4aPvY/gwCwAXgCMAJEAtQC7ALIAsAC8AK8AtgC4AK8AmwCXAJ8AmgCmAKAArwCBAHGAX0AgwB1P8h/2z+KP4s/dz8+PyQ/dz+RADSAZADYATwBOgEkAQwBaAFOAbwBmAH8AfgB1AI4AjgCTAKoAowC9AK4AmwCBAIMAcQBggFAARcA5ACXAIsAggC0gHUAYQBvAFYAdQAKwAT/1z+uP28/Vj9PP2Y/Cj9TP1k/Tz9CP1A/VT8sPs4+2D6+PgI+KD38PZA9kD1sPSA9NDz8PJQ8qDwQO/g7SDtQOwA68DqQOsg7SDvoPEg9PD1KPjg+uz8rP84AqgFEAjACvAKMAsQCxALIAswC4ALkAqwCmAJsAkwCqAJIArQCeAJAAjoBYAEhAL9ACz/A/82/jz9SPxQ/Kj8+PwU/tj/cAE0AtwCmAOQA9gDaARwBbgFEAbwBoAHwAcwCOAIMApwCtAKUAtwC6AKYAlwCNAHYAZwBUAE6AMsAygCWALoAQACTgE8AdMAlQCY/4b+jP4g/fj88PvI+6D7ePvA+7D7+PtI+8D7uPuA++D6IPp4+fD4GPhQ9wD3MPaA9QD1kPSA8/DygPHQ8ADwYO6A7UDsQOyA7EDtIO8A8UDzsPXA98D5QPtc/VgAGAQYBwAJAAsgCpAJUAlACsAKgAogCvAJAAoQClAKsApACxALIAvwCvAIyAZIBFgDrgFRAJH/jP5g/Xz8dPxY/fD9/v6SAEACGAPMAtgCcAOMAwAEiAQgBRgFOAWgBSgGuAY4B3AIgAkwClAKAArACRAJgAgQCLAHkAaYBQgFOASkAzAD6AK8AnAC1gHGAeMARQBw/7z+4P1A/bT8HPyI+/D62PqQ+tD60PoY+wj74PqQ+hj6yPlQ+SD5QPjA9xD3QPZw9WD04PMQ80DyEPFg8EDvoO5A7sDu4O8g8eDyoPSw9gD4WPlg+9z8qP/YAqAFcAeIB9gHIAggCIAIgAmgCcAJQAmQCRAKcAqwChAL8AvwC5ALUArwCBAHSAVABCQDBAL0AKv/wv4A/uT9Uv4j/yIAEgGmAegB3AHyAQACvAL8AnADiANIA0wDWAPUA1gEkAWIBlgHMAhQCDAIIAgQCJAIMAgwCHgHyAbABZgFwARoBCgELAMkA3AClAGUAFoAyf8d/8D+Lv6M/YD8wPsY+7j6SPo4+tj5yPlI+fD4yPgg+Cj40Peg9zD3kPYg9iD1QPTg80DzwPLw8VDxsPAA8BDwIPDA8BDykPOw9VD30PgA+ij7QPzY/qIBeANABWgF6AXoBbgFQAZAB7AH2AdgCDAJkAngCUAKEAtAC7ALoAvgCuAJIAj4BugF+ATkAzADbAJsAY4ACgDO/9j/rADxAEoBJAH1AAoBEAEoASoBVAF8AYYBQAFoASwBVgEcAugCuAPsA3gEwARIBVgFuAUgBggGAAbgBZAFMAWQBFAE9AOUAzQDgAIwAm4B8ACHAOn/of8f/97+MP6I/ej8aPwI/Lj7mPsQ+9j6QPoA+qj5aPlA+eD42Pig+HD44Pdw9yD3APew9lD28PXw9YD1QPWA9ZD1APYg9hD30Pdg+AD5iPmg+sD7RP3E/tL/egAOAVQBJAJUArgCCAOcAwAEyAQ4BYgF+AVwBlgH6AdACAAIMAjoB0gHGAeYBnAG0AVgBeAECAR4AwgDAAPYAqQCkAKQAmACMAI0AlgCUAIoAiQCMALsAZABeAGGAXABnAHSAQACLAIgAkgCgAKYAsQCCAMYAwQDyAK0ApwCXAJUAiACHALWAYgBXgEoAQ4B4QCxAIoAQADY/3//Sf/i/qj+Vv4g/gD+2P3E/bT9oP2M/Xj9gP1k/VD9OP0A/dj8pPyM/Fj8DPzQ+5D7UPv4+vj6mPqw+rD6uPro+uj6APsI+xD7IPtg+6j72PsA/Cz8DPzY+7j7yPvY+/j7UPxQ/IT8wPwc/WD9oP3s/W7+yP4E/yP/Zf+X/6T/3/8jAE4AdgCgAAABKAFyAcoBJAKEAtwCSAOQA8gD2AMQBDAEQARIBFAEYARYBFgEWARoBIAEkASYBKgEuAS4BLgEqASYBIAEcARABAgE1AOkA3wDVAMgA+ACtAKAAmACQAIgAuwBuAGiAXYBPAEMAeQAqQBpACgA+f/N/5n/fv9J/zD//v7o/tD+pv56/kD+Fv7g/aj9dP1M/Rz98Pzc/MT8wPy0/Kj8kPyI/Iz8gPx4/HD8fPx0/Gj8YPxo/Fz8ZPxc/GT8RPxU/Ez8bPyU/JT80PzM/OD8AP0o/WD9iP2g/dz9Iv5E/mr+oP7S/vz+Hf9W/3z/rf+0//b/MQBoAIIAnwDVABgBWgGSAcwB+gEoAjwCZAKAApgCvALcAgQDPAM8A1gDbAOEA5QDuAPMA9wD5AP0AxAEIAQgBCgEKAQoBCAEIAQgBPgD9APYA+QDxAO0A6QDiANwA1gDOAMUA/QC1AK8AqQCcAI8AhwC3gGaAV4BMgH6ALwAdAAvAPT/wf+D/13/Ff/Y/pT+WP4c/uT9rP1k/Sz9+PzA/JD8WPwY/Pj72Pu4+7j7oPuI+4D7YPtQ+zj7QPs4+yj7OPtQ+2j7ePuQ+6j7yPv4+yz8VPyE/Kj82PwE/UT9hP3A/fz9LP56/sD+/P5F/5b/5/8wAHgAvgASAWgBsgHuASgCVAKAAsQC+AI0A1gDhAOsA9gD+AMQBDAEMAQ4BEAESAQ4BDgEMAQoBBgECAQIBPgD3AO8A7ADmAN8A1wDPAMMA9wCnAJcAhQC0AGIAVABEAHQAIwATAAUAML/hv88//z+uv5s/jD+9P3E/XT9OP3w/LT8jPxY/DT8FPz4+9D7sPuQ+5D7cPto+3D7ePt4+4j7mPuo+8j72PsA/CT8VPyQ/Mj8AP0w/Xj9sP3s/Sb+aP6i/ub+J/93/7n///9GAI0A1gAaAVgBjAG8AewBNAJsApQCyAL4AiQDTANkA4wDnAO8A7wDzAPMA8wD3APYA/AD2APUA8ADtAOsA4wDaAM4AxgD+ALQAqQChAJcAjAC+AHGAaIBcAE0AQwB3ACkAHIAPQATAOT/u/+b/2z/RP8i//T+zP6U/nj+Vv5E/jD+HP4M/uj93P3Q/cj9yP28/cD9uP24/bD9tP24/bz9wP3I/dj98P0G/h7+RP5g/nr+kv6u/tD+5P7u/gf/H/89/1H/bv+e/7L/z//w/xMAPQBbAIEApgDKAOYA/gAeAT4BUgFoAXoBiAGSAbYB0AHWAeoB8AH0AfYB+AEAAvYB8AHqAfAB7AHmAdgBygG2AagBmgGGAXQBYAFWAT4BHgEIAe4A3ADEAKwAkwBrAEIAGgD+/9f/wf+n/5X/e/9f/0j/Kv8T//L+3v7I/rD+ov6O/nz+cP5s/mD+Xv5G/kL+SP5O/lD+Uv5W/lb+ZP5o/nT+gv6Q/qL+tP7G/tb+9v4Q/zX/TP9i/3//kv+s/83/6v8CABQAJQA4AFIAYwB3AIMAkACiAK4AxADGAMkAyQDZAN4A5QD0AAABAAH+AAIBCAESAQ4BDgESAQgB+gD0AO4A4QDXAMMAvwCvAJ8AigB2AFoATwBGAEAAMgAuABgAGwD9/+r/1P+9/6b/lv+G/2//XP9P/03/R/81/yv/Hf8W/wf/A//6/vr+8v70/u7+5v7m/uT+5v7m/ur+8v70/v7++v4H/wv/Df8a/y3/PP9H/1v/aP93/4T/nv+5/8//1//o//j/AgAZAC4APABLAFMAYABzAH0AiwCkALQAvwDJANEA2gDaANwA5QD1APQA8gD4APkA9QDqAPEA7gDqAN8A3gDXAM8AvgCxAKcAlgB/AHIAaABhAGAAWABMAD4ANQArACgAHgAKAP7/8P/g/9f/0P/G/8T/u/+z/67/pv+d/5z/jv+O/4z/jf+P/5L/if+D/4D/f/+H/4b/gv98/4H/g/+C/4H/if+P/5L/mP+c/6D/nP+i/63/tv+1/7v/xf/J/83/1P/d/97/5P/n/+b/5//m/+j/5v/f/93/6P/u/+v/9v/6/wAABQALAB4AJwAfABgAGAAWABUAFwAgACUAJAAmACgAKAAgAB4AIAAqACgAKQAnACYAIwAbAB4AGQARAA0AEQANAAcA/////wEAAAD+//r/+v/1//L/7f/o/+j/5f/p/+r/7f/7//b/+f/9//j/+//1//n/9v/z//f/BAAOABMAEwAVABwAHQAhACYAJAAgAB0AHAAiABsAGwAeACAAIgAfAB4AIQAdACEAHgAYABAACwAMAAcABwAEAAAABgD///3/AAD+//7//v8DAAsADAATABUAFAAYABAAFAARAA8AEAAXABgAFwAeAB0AIwAVABQAGgAaACUAKAAvACwAJwApAC8AMgA0ADMANgA1ADYAPABFAEsATgBVAFoAUgBRAEkAQQA9ADkAOwA6ADMANgAzADcAMgAxAC4AJQAtACsAKQAdACEAGAAWAAcA/P8CAPv/+v////j/8f/o/+f/7f/v/+v/5//r//H/7v/w//T/8//w//P/+v/7//v/+//9/wMABQD+/////v///wIAAQD9//b/9v/0/+7/6//t/+//6//u//L/+v/7//r/+f/y//T/8v/y//n//P/9//z/+//3//f/9//4//D/6v/j/9v/1P/O/9D/0f/Q/8r/x//I/87/0f/R/9L/1v/d/+D/3//d/93/3f/d/+H/6P/n/+z/7v/x//T/9v/9/wMACQALAAoACQANABIAGAAXABYAGQAcABwAGQAXABYAEwAUABMAEAAOAAoABAADAAAA/P/0//D/8P/w/+v/5//n/+f/5//j/+P/3v/d/9z/4P/i/+D/2//U/83/w/+9/7r/uP+4/7v/v/+//8D/wP/B/8H/vP+4/7P/sP+v/7L/t/+6/7f/uP+6/7//xP/G/8f/z//U/9f/1//b/+D/5f/p/+7/9P/z//L/9P/5//z/8//8/wUADQAMAA4AHAASAB0AHAAuAC4AMQA2ADsAQgBGAFEAVQBXAFMAVwBbAF4AWwBcAFwAWwBhAGQAaABoAGIAYgBfAFoAWABQAEoARQA9AD8AOAAyAC0AJAAfAB0AFAAPAAYA9//w/+3/5//h/9n/zP/E/73/sP+v/7f/tv+0/7L/qf+k/6T/pP+n/6n/qP+q/6r/rP+s/6v/qv+q/6z/sf+z/7P/tP+3/7n/uf+7/73/wP/E/8P/w//F/8f/yv/S/9n/3f/k/+3/9v/6//z///8GAA0AEgAVABgAHgAlAC0AMgA3ADkAOwA+AEAAQAA/ADwAOQA6ADkANgAzADIAMQAxADMANgA2ADYANwA5ADwAOwA4ADUAMQAsACkAKgAqACkAKAApACcAIQAaABYAFwAXABgAFwAXABMADwALAAcAAgD+//v/+f/5//j/9v/x/+z/6f/m/+P/4f/f/9z/2P/W/9X/1v/Y/9n/2f/Y/9n/2P/Y/9j/2P/a/9n/3P/d/+P/6P/v//b//f8BAAQAAwAEAAMABAADAAUAAwD///z//f8EAAkACwAHAAQAAAAAAAAAAgAAAP////8AAAAA/v/9//z//f/9//z/+v/5//v///8EAAYABwAHAAgABgADAP7/+//5//r//P/8//n/9f/y//L/8//1//f/+f/5//j/+f/7//z/+//6//v//P/7//v/+v/7//v//P/6//n/+P/9//v/9v/x/+7/7f/r/+X/5//f/+P/4f/o/+X/4f/i/+H/2v/R/9j/y//S/8T/yf/O/8D/w//F/77/t/+2/7//xP/K/8n/yP/N/8v/zP/W/97/4P/b/+H/5v/n/+X/4v/j/+b/5//m/+T/5f/m/+X/5v/n/+n/7P/u/+7/8P/z//X/9f/6/wEACAAMAA4ADgAOAA4ADQAOABEAFAATABMAFAAXABsAHQAfAB8AHwAeABsAFwAVABYAGAAVABAADgARABcAGAAVABMAFAAVABYAFwAXABYAFgAWABUAEgAOAAwACwANAA4ADwARABMAEwARAA8ADgARABQAFAAUABQAFAARAA8ADgANAAkABQAEAAUABQAEAAMAAwADAAMAAAD8//r/+v/7//v/+//7//v/+//6//r/+v/7//z/AAAEAAUAAwD9//j/9P/x/+7/6//p/+n/6v/u//L/9//8/wAAAgAEAAMABQAHAAwAEAASABIAEwAWABsAIAAjACYAKgArACsAKgAtAC8AMgA1ADoAPgA8ADkAOQA6ADkAMQA4ADcANgAuAC4AMwAlACkAIwAtACIAIwAeABoAFwAVABgAFgASAA4ACwAKAAcA///8//X/8P/x//D/9P/z//H/8//v/+//8P/q/+j/5f/j/+b/4//h/9//2v/b/9z/2//d/9f/0v/V/9b/1f/W/9P/zv/M/8n/xf/M/9L/0v/Y/9v/2f/d/+H/5f/t//D/8//1//j/+//+/wAAAQAEAAYACgALAAoACgAKAAsADAAPABEAFgAZABoAGgAbABsAHQAgACAAIAAjACYAKAApACkAKQAqACkAJwAkACIAHwAcABoAGgAbABsAGgAYABgAFQATAA4ACgAIAAQA///8//j/9P/w/+7/7v/s/+z/7P/t/+7/7//u/+v/5//j/+L/4//j/+T/5f/m/+X/5f/l/+b/6f/r//H/9f/5//v//v8BAAUACAAKAAwADgARABQAFQAXABkAHQAeAB8AIQAiACAAHAAaABsAHQAcABwAHQAbABoAGQAaABkAFwAYABUAFQATABQAFQAXABYAGAAYABkAGAAXABUAEQANAA0ACgAFAAIAAgAGAAcABwADAAEA+//6//r/+v/3//T/8//z//P/8v/w/+7/7P/p/+X/4f/a/9X/1f/T/9T/0//T/9P/0f/R/9L/0//Q/9D/0f/S/9L/0f/T/9X/1//a/97/3//f/+H/5P/n/+b/6P/o/+7/7//x//T/+P///wEABgAKABEAFgAjACkAMAA0ADoAPQA9AD4AQwA/AEYARABLAEkATgBSAE8ATgBMAFQATgBXAE0AWABRAEQASgBFAD4AOAA1ADIALAArACQAJAAgABgAGQAfAB4AGwAWABwAGgAVABAAEgAQAAwACgAIAAkABgACAAMAAgADAP//AQABAPz/9//1//b/9v/0//T/9v/2//f/+f/5//f/8//x//P/8v/r/+n/7P/v/+z/5P/l/+X/5f/h/9z/2P/Y/9f/2//Z/9j/2P/c/+X/5P/i/+T/5//r/+n/5v/p/+z/7v/r/+v/8P/r/+n/7//0//v//P/+/wgADAARABgAHwAhACUAMwA6ADQALAAwADIAKwAcABsAHgATAAMA+v/8//n/5f/e/9z/4f/T/8r/x//R/8n/vP/G/83/z/+//8b/0f/W/8T/y//b/9v/yf/B/8r/zv+9/77/w//I/73/vv/Y/+//6v/r/wEAFQAgABMAFgAfACoAJQAoACoAKgAYAAoA//8QAAAAAQD0//3/8f/r//P/BQAHAP7/BgAQAAQA5//x/wAAAQDn/9r/1//e/8H/u/+m/7z/f/9w/27/fP9h/0r/TP9I/yL/A/8X/xL/Df8N/zX/Xf9T/1j/d/+S/5b/m//D/+f/5v/b/wAAHQARAAYADwANACkABQAmADgASAA9AFQAWgA2ABcAIgBtAFYAPABgAOkAoABaAP7/IP8L/0j+pf+CAVwC6gGQAYIBMgGmAUgBbAHNAOwA6wC7AKgAzAB2ASoBnACUAP0AqgDs/ykA9wChALj/H/8JAOr/Ef/O/j//zv9B/yP/gf9m/67+FP6C/vD+pv6U/vD+UP9+/1b/yf8+ABUALgBUAFsAgwDdAAQBogHQAdoBJAIMAgQCMAKIAlwCVAKMAuwCKAMYA2ADlAO0A4QDaANsAzwD0AIgAtABcAHeAFsAJwBLAEkA2v8k/9D+nv6O/rT+rv7K/sr+yv7K/qb+qv6+/tz+4P7I/tb+8v7g/ub+4v6+/qD+rP6y/qz+iv52/nT+XP5g/mj+mv56/iD+HP5w/oL+eP7Q/uL+Jf+a/pj+pP4U/6r+rP4T/1f/N//8/hD/+P4B/xD/MP+h/5//bP+G/9r/FwAeAOX/tv/K/6X/pf+j/9j/y/+3/6X/jv9l/yn/Jf90/3L/Vv8v/yv/Tf9b/7P/4f+7/47/av+P/3b/Q/9Q/5v/pf+G/4b/f/9O/xX/D/8v/yr/Kf8P/zX/Fv/k/rD+oP6c/sr+vP54/nT+VP5e/nz+lP64/rz+rP6o/rD+0v7q/v7+wP56/pz+qv50/mj+dP7S/iH/SP+D/6j/o/98/2T/Nf+j/+7/BADN/2r/J/9u/tT9cP2E/ZD9qP1g/vT+XP81/0P/cv+//7T/3v///yUALwBjALIA3AAmAVYBpAGCAYwBIAGaAIgAVQAoABIAEAAkAHkAsQAOAXAB7gEwApAC8AI4A3ADyAMYBFAEUASIBPgEUAWoBTgGaAZoBugFsAWABXAFMAXoBOgEiAQ4BBAExAMQAzgChgHOAP7/P/+s/iL+OP2w/GT8mPyY/Kz8AP30/IT8wPug+oj6kPr4+iD7gPvw+wT8oPvo+kj6iPmo+ND3kPdg91D3cPfg94j4YPnY+jj7uPuA/Cj9ZP0s/SD+BP9DAMEAQAI4BHgFsAUABrAGUAYIBQAEiAOYAkQCRAOIA8AE2AUQB3AHMAaoBhgHsAeoB1AJcAwwD+ARgBXgGSAcYBzAG0AagBdgE5AOAAqoBbwCgwC2/oT98Pw8/Cj7IPrg+JD3cPVg8yDzkPJA8pDyQPQQ9eD1sPbA9xD3UPYQ9wD34PXQ9DD2wPaw9uD36Plg+5j7APsQ/ED72PmI+AD4YPeA9hD2QPYQ9hD14PY4+Aj5OPo4/ID9zPx0/GT8pPzw+jj64PtM/eD9BP4MABAC5ALAAxgF2AVQBjAFiATgA1AE+ASoBBAGAAkwCsAI6AVoBRgElAG8AcwDWAdwC/AMsA4gDTAKwAioBmgG4AkADwAQcA1gCdAK4AogCIAKABFgFGASABFAEIALCARo/aD8cPtY+ED2MPZQ9mD0MPXg9gD4cPkg+kj64Pfw9tD2sPbY+Jj8ff9eAXIBVAGw/2D86Png9wD3gPZg9dD0cPRQ85DzIPVQ9rj4YPkI+hD6kPmg+ND3kPgQ+lD8Av4f/8IAngAeADH/lP60/Wz8YPtA+Yj4oPdg9tD2IPig+gD8IPyM/Kz8PPyg+8D7DP0r/4T/lABsAmgDKASIA4AE4AXwBmAGeAXQBagGyAUIBBgFkAdACBgHaAcgCGgGKAOQAwAGyAdACdAKYA4QD0ANkApACYAJAAtQDaARIBTgFuAVgBIgDdAHdAG4+sD2MPTQ9KD04POw9AD3IPnI+Fj5QPoI+VD2kPPA8xD1wPYA+Zj8xP+NAGoA6P+W/lz8mPow+UD3MPYg9vD14PUA95j5SPuw+/D8hP2U/Lj5sPcw9/D2YPYY+ID6KPzU/Pj91v7I/pj9oP3I/Lj7wPoA+lD6uPmg+vD7EP1a/or+yP5e/rD+vP0g/VT9Sf/2ABwB0gEEA4gEQAN0A3gFWAf4BmgGyAdgCVAJ+AegCIAJoApwCVAIYAgACKAGcAXIBVgHEAmACaAKAA3gDlAPYA0gDWAOABCQD8APYBNgGIAXwBGAC0gGwPyw86DvQPJg9DD00PXg9/j4oPYg9UD2gPZw9xj4QPgw+Cj5DPw2/qb+6wD0ApQCDP9k/JD7oPlw9pD1MPcA+LD2QPYg+ED5IPmw+eD6gPzo+sj5CPmw+ND3MPig+gT9Pv9i/zAAngAJAGb+0PxA/ID7wPqQ+hj7MPxo/Ej9eP0u/vD+Jf8A/lD9SP0I/lj9ev5IAXADKAXYBQgG4AUQBkAFUASIBDgFCAYgBkAHsAhwCjAKEAqACjALQArQB8gHwAaoBvAFWAa4BzAKgAzADJAMMA3wDeAMwAmgClAPQBOAEkAUwBUgEtgF6PhQ9sDzYPHA8RD34Ppo+aD3cPew96D2gPeQ+CD5ePng+Wj6YPmQ+rL+IAHb/5j+wP7o+0D3YPQA9fD14PWg9kj4iPjA9yD3oPaw97j5qPqA+vj5UPro+cD3wPeg+tD9lP7u/hj/VP5Y++j58PrQ+pD5aPx4/Rz8CPtQ/Kj8WPsY+yz9mv8k/sz9Xv/2/0f/df9mAagC1ALMAwgFQATYAwgF2AUgBVAFMAdwCNgHcAjwCaAK0AmwCUAKQAqQCaAIsAgQCNAHgAdgByAH4AgQCpAJoApQDeAOUA3gDDAPoBFgD/APwBTAFIAOmAVE/pD3IPBg7tDxcPXQ9yD66Pr4+jD3sPUA9hD3EPfo+Cj68Pp8/ED9cv5TAIIBS/8k/JD6UPhA9QDy8PNw99D38PbQ+KD6ePlg9uD2EPp4+qj5GPoo+xj7MPno+Bj7dP3C/gf/eP7q/iz+UPug+Yj6yPtw+yj7VPxo/lb+lP2s/WD9SP2c/FT8UPw8/eT+Zf/k/6gBfAMwBDgDsAJIA8ACHAMgAzgE6AQQBigH6AfwCCAKwArACWAJ4AjAB9gGGAYYB/gHYAiACBAJIAngCMAIQAj4B/AIwAkgC7AKoAuADIAMgA/AFGAYYBUwD2AJRAHQ9oDvYO3g8XD1uPjw+ij+dP34+OD1IPQw9jD2YPWg9jj70Pwo/Fb+jAFEAxUAcP2Y+zD3cPNQ8RD0IPWg9oj5APuY+gD5wPmo+WD4APlY+rj6MPnI+UD7sPvQ+0z9Tf83/4z+Hv7A/dD76PlA+kD6SPvQ+9D9TP5k/Zz8CP0Y/UT8CPw4/Vz+Jv64/jD/2wBQAroBQAJgAmwDoAJoAmwCEARABTgFMAYoB5AIMAlACZAJYApQChAJYAiACIAJwAkwCfAIwAnACdAIyAcgCIAIYAggB/gHEApwCzAL0AowDfANcA2ADwAWgBlgFJALKAWo/nDz4OvA7gD2UPdA+mz9S//4+qD1YPQg85Dy8PMw+OD6cPuK/roBkgE6/yEA1QAM/LD1wPPQ8+DyMPLQ9Yj6+Ptw+wj7YPqA+KD2wPZA94D3GPkY+zj7WPtc/Hz9kP1k/Yj9cP30/DT8UPsg+2j76Pt8/HT9uv7C/oj9HPwM/Bj8aPtY+/z8MP4e/hj+P/9c/0//gP/6AHYBjgEoAuACXAP4A6gEUAW4BUAG0AawB+gH4AhwCTAJ4AhACQAJIAhABwAIIAiAB5AHsAeACDgHWAegB/AHoAhwCCAJ4AhwCgAMkAtACzAPIBUgFWAS4BEAEdgG2Pjw8kDy4PEA8aD1nP1GAED70PgI+JD2QPRg84D0APgc/TT9cP3q/kwCgAKY/rD8YPsY+eDzoPBg8kD1IPYQ98j50PuY+mj4APdQ9oD2UPbA9hj4MPpQ++j6gPtE/ND9xP2s/fD9ZP4Q/Wj7mPoo+rD5WPoQ+9j7wPuw/Pj7GPsg+uD5sPog+xj8HP2k/qj/MAAvAMMA0gFQAmwCuAEkAkACQAL+AGACVAOwBCgFEAZgCEAIEAkgCLAIQAlQCUAJ4AgQCKAH+AcACBgH0AfACZAKyAdgB7AJAAoYB9AGcArwDAAJUAjgDYASoBEgEOAUgBXwDTgEMPwg9nDxwPAg9HD7nv9R/wb+KPrQ9pD0YPMA9ED2sPmE/AD+Ff9WADwBvwA6/qz88Prw9+D0UPNQ9LD1YPcA+dD6mPrg+Yj4cPYg9uD2wPe4+Aj6MPt0/ED8sPtk/BL+OP/I/hf/kP4A/oz8QPuA+zj80PuY+1D8ZPzw+/D6oPpI+nD6OPtk/NT9Tv6g/00AtwBnAAsADABWAXwCxAKcAhQCMAJEAjgCXAMYBbAFYAbIBkgH0AZIBtAGAAjgCGAJYAngCAAIAAdgBygH6AZwBxAIAAhIBxAIgAgQCGgHAAngCXAIYAnwC2AOYA1gEAAVwBWgEGAOIAyUAgD1QO/w88D14PWQ+7ACcwBA+dD0gPTg85DxoPVY+37+Yv72/o0Al/+C/jb+Mv4I+wD3EPXw9FD00PQg+CD7oPvQ+rj5OPig9tD1oPZo+Lj5MPtw+/D6SPvQ+0j7iPss/V7+8P2E/HD8tPzI+5j6qPoA/Az8WPtI+zz87Pyc/AT8QPyY/AD8ePvA+yT9zP0a/hD+cP6+/mb+aP7Y/nIAjAFaAaABSANIBHgEIARABTAGGAaQBdAFsAYIByAH2AdgCNAIEAggB3gFCAVQBagFeAWIBTgHEAlACaAHYAjQCoAKMAfQBhAMoAugCFAJAA9gEkAQABCAE2AR6Ab4+6D28PMg8dDyqPhW/rn/4P0I+6D3APYw9HD00PaQ+tD9fP3A/Tv/NgCY/pT8xPyg+wD4EPTA89D04PSQ9Uj4QPug+7j4sPYQ9lD38Pdg95D5OPxc/Uj7aPkI+7D8GPxo++T8SP/Y/jD9EPxo/FT96Pxo+9D66Ps8/LD76Po0/UH/2P64/Pj78PyQ/OD72Pu8/cr/JgC2/ob+cwCEAWEAAAC6AZQDZALJAKwC6ASwBOgDoAWoByAHaAWwBhAI8AaAB1AIYAgQBpgFwAYAB8AFAAaYB+gHYAYYBzAI6AcACLAHEAngCEAIMAjwCfAMkA7wDkARoBRAFfAO8AfUA5z9gPMw8CD1zPzk/ez85QCgAVD7MPMQ8gD0YPVw9kj8gAKcAyQCQAEQAOT90Pow+TD3UPaA9RD2MPcg+aj7+PsQ+zD5UPdA9fD0IPYA+tD7XP2U/TT9WPyI+oD4MPno+qz8pP0c/Y7+KP8u/iz8gP09/4j94PrI+tT8OPvA+cj75v46/sD7qPwW/gD8YPoY/Mz96Pwc/Jr+YgHj/+z/sAPIBOABfP/4AfADfAJ+ASAEMAdoB+AFKAbIB2AIWAdIBngH0AhwCMAFGAWYB9gHYAUIBDAH8Ah4BqgEaAcQCdAHAAewCdALcAlgB9AJcAzgCnALEA9gEwATkA9ADXAKqANY+qD0MPQQ9ZD2KPtaARgDcf/Y+FD0YPKA8uD04PhU/j0A8AKQArn/oP1w/Mj6APdg9vD2IPfg9bD1UPnQ+9j7kPkI+Uj4EPZA9FD0cPdY+/T8rP2s/lb/5PzQ+ND2iPho+tj5WPs4AFQCaQAo/YD8VP2o+2D6iPqU/Eb+qP2k/JD8dP1Y/aj7uPvA/ED9nPwY+1D8vP1C/tT+KgCwARAC/gE6AYEAbAEkA3gEoAQgBNgDiAXQBOQD4AWwCbAKYAjIBvAGiAYABPQCCAZACJAIQAd4B8AHAAYoBPgEcAcACZAJUAmwCDAIYAd4B7AI4AlQDOANEA4AD4AQwBBQDpAJKAX5/3j5gPQg9SD6UP69/7kAo/+Q+rDz8PAg8nD0UPc4+yn/2AF0AQ4AR//M/vj84Plg91D20PUQ9PDzYPc4+2D7EPv4+wj7kPZA8hDzcPaA94D5eP3GAbr/xPxQ+wD7GPgA9pD3gPuE/Qr+vP47AAgBxP6Y/JD7lPy4+rD42PgI/Hz80Pvk/QIB+P9Y/JD7QPyA+pD4uPqi/rwAzgF4A5gCnv+8/Qz+dP2q/hAEmAYgBcgCiATwBRgD5gFYB+AM4AsACAAJQAloBfABaAJoBhAIoAigCLAHmAYABeADwANQBvAK0AxAC9AJYAogCrAHWAcQC1AOUA4ADuAPoBAwD7AM4AoQB4IBYPwI+cj4KPoY/S3/hP7I/Mj5oPZA9JDzoPXw96j5YPtI/Sb+Jv6I/fT92P0c/CD5APdw9uD1wPVA9yj6ePzQ/Lj7uPlg9+D0sPOQ9JD3UPts/Ub+Gv7U/Yj7MPlI+MD54Pss/U7+CwAYAWUARv+U/hr+PP1U/KD7+Ptk/Az8ePxw/Ub+gP7a/tL+6P1M/YL+OP/e/vj+wAFEA1wAtP5EATgCRP2Y+qP/vANIAlIBuAZwCmwCjPzSAWAIsAeACZAOgBTgDkAF/AK4A7IB0v54BcAMoA3gCIgFwAWABJsA0ADABmAK0AmgCbAKcAvQCXAJ0AtgDpANkAwADbAM0AsQDIALYAmgBbABbP4w+wj5kPnw+/T8uPxI/Hj7sPjg9UD1oPbQ96D4APo8/Pj8ePzo+zT8UPvQ+HD3MPdA9yD3gPhg+qj7qPtQ+zj6ePjw9oD2wPYA9zD4qPrE/PD8UPv4+fD4YPcQ9xD5VPyO/sT/oAAQAS4AeP5g/UD9aP2M/aT9jP14/Vj98PwE/Jj7uPvg+7D70Pu8/Db+fP68/s7/OgBK/9D+3P7M/jD+yv5mAJABxAHSAXAC9AEsAUwBrAFgAtgDkAcwDfAPQBEgEWALtP+4+mD8IgFsAlgGMA8AEjALSgH9AEgD1AAi/nQDUA0gDrAJ8ArgDmAQAAwACoAL0A2gCtAHIAgwC2ANwAqYB7gDJgDI+3D4UPjw+7T+6P1M/OD7OPpQ9wD18PW4+Cj6ePpw+8j7cPsQ+hj5QPrI+ej46Pig+Xj52PjI+fD6IPtA+qj5+PnA+eD4sPi4+XD6yPkA+ZD5+Pmo+XD5oPlI+uj6ePuE/AL+Y/+z/0//xP5k/tj+9P6E/oj+eP7A/cj7QPoY+gD6oPkQ+nj8dv6y/i7+tP04/ST8IPvY+4T91v5DAJf/yv5T/xEAKv+E/uoAfAN4Adz9VABoBegEzAJAB9APIBJADjAMwAvwBWD7ePtC//gF4AmwDAAO8Ar4BSgBVv5c/eYB8AZwCUAJEAwQD1AOAAvACnANsAxQCIAHkAkgDBAL4AkwC0ALcAYm/zj7OPqA+jj6oPsK/oH/hP0w+SD2wPWA9rD1sPVQ+Vz8oPso+dj4APvY+dD2gPao+Fj5MPdA96j5yPsw+zj6APuQ+yD6IPjA95j5GPvg+nD6kPtQ/Pj68Pgw+Qj7kPvI+hD77Pzs/ZT9rP0Z/9j/Nf9k/j7+qv7A/jT++P1U/p7+oP0E/GD7UPxs/Zz99P0h/w8AO//w/ZD98P1w/sb+4//iAIIBjQAZ/6D+uf9CAQgCBAMgBaAF4AIgAUgDKAdQCiAOYBTgE1AKhAIeAUQBrv90AVAKoBCgDLAHYAYgBQ4BSP0SAPAFkAkgCoAKMA3gDhAN4AmwCLAK4AtACfAH8ArQDaAMoAkQCcAI2ANe/uj7uPy8/Bj8iPzQ/Wz9oPuY+bD3MPZg9SD24PZg+Pj56Pvw+9D6iPl4+cj4kPdA93D4kPnw+fj5mPpo+xj7QPrg+VD6MPqI+dD4sPng+jT8APwk/Nj8nPyY+jD5kPlQ+5D7HPxi/v8A6wCU/sz86P1+/sj9Vv5wADgBgP+U/Bj8DP3Y/Jj8oPzg/fj9Yv5M/sj9rP34/o7+XP28/KT/1v8g/jT9/gCAAiIAGP+YAPgDOAK9/8YBkAQoBCQCOAQgCLAMIA+ADhANkAkoBRr+KPvIAZAJgAywC9AMkAvgBAD9yPt8/9ACuARQCHAM8AzgCdAG4AVIB7AHEAe4BxAK0AyADMAKMAsgDAAJ/AMcAfEApP8g/RD90f+YAEz+jPxI+yj4YPSw8iD0APdI+Tj7tPwk/Aj6MPgQ99D2MPdI+Bj6mPv4+4D70PoY+sj5ePlg+fD5SPqA+jj6WPoQ+4j7ePso+xD7mPo4+jj6mPqQ+zD8pPzg/MT8wPwI/Rz9RP1k/jQA3AC+AAUAQv98/jD9JP2S/lv/If+0/kz+rP0U/AD7SPzw/Vz9aP1C/mj/mP2U/Nz9YQBR/8j9/v9kA9QBZf++ARgFCAQwAagDmAewBvgEwAhgDkAO0AnwCfAKkAXR/9IBOAbACBAIUAuwDRAI6P/8/AoA1AGcAggHUAqQCiAI+AWgBvAHeAegB8AIwAowC9AJIAngCdAKIAlgBTwD0AKHABT+Hv7K/6sAnv40/Ij6sPdg9VD0gPVQ99j4+PnQ+TD4sPeA99D2wPUg9lj4yPkQ+mj6kPsE/ND6YPkw+ej5EPrQ+ZD6VPyU/QD98PuA+wj76Pkg+dj5OPsk/Ez8UPyw/Iz8sPsg+9j75Pz4/Zz+xP8zAK3/tv7e/nj+XP7w/aD+5v7M/Sj9TP3U/Cz8RPyI/Nz8ZPwA/Rj9KP3o/AD+Kv4M/oD9wP6i/sj9B/+WAWwCpgE0AmgEbAMwAFAAmAMQBhAIkAsgEEAQkAqIBoADiAEAAsAF0AqwDfAOkAtwBbIAmP90AewB1APoB8AKYAkABlgGYAdYBuAEqAZgCVAJQAjwCBAL8AsgClAI+AbwBBgChQAoASQCMALoAcYA0P6o+6j4MPcw9zD48Pjw+SD66PmA+FD3oPZg9vD2oPco+Oj44PmY+mD6+PnY+dj5iPmA+SD6iPuo/Ez9SP0g/Yj8kPuA+gj66PoM/Mj85PyA/TT9ZPz4+gj72Pso/fT9rP7i/iL/JP9W/gz+ZP4Y/+L+0P64/hb/tP6w/Qz9kP3I/Vz93Pxw/ST+NP6o/aD9hv7O/nT+TP4L/4r/nf+R/1YA7ACEAZwCHAMAA+ACVAOwAyQD1AMgCLALAA0QDTAOgAzYBu4BwANACfAJcAtgDoAOsAhoA5sAGAPYAtgCuAZQCqAJGAWYBGAFkAUIBOAEoAcwCegHMAdQCNAIaAc4BmAGUAYABUgDeAL4AswCRAIwAQYArP6A/HD6GPkA+VD5kPno+ej5UPlA+LD2YPXQ9CD18PXw9gj42Phw+Tj5mPiw+OD4+PgY+Tj60PuY/Kz8CP1s/Sz9ZPzw+xj8PPx4/JT88PwI/dz82Pyo/Ez80PtY+1D72Pvw/Bj+av4C/sD9eP3w/LD8IP3s/Wj+WP5a/i7+eP34/Cz9wP0M/k7+fv6U/p7+fP6C/uj+Uf/A/x0AGADo/6YATgEkAc4BLAP0A7QCVgH6AdADsAVACGALcA3QC8AHoASYBIgFCAeQCRALsAtwC0AJyARkA9QDMAXIA2AEGAcwCCAGaAOIBMAFUAT6AaADSAcAB+AEEAbAByAIeAWIBKgEOAUwBMwDwAMABCgDPgECACf/Fv8k/pT8KPso+/j60Pno+ND5UPo4+VD3IPcw91D24PXw9sD4UPnY+Lj4UPmI+ND3sPhg+oj7gPuY/Gz9QP0s/Nj70Px8/dz9wP3g/az99Pxk/Mj8UP1w/TT9xPy0/Iz8YPxs/PD8sP0S/qD98PyM/Jj8DPzQ+yD8nPyI/Nj7qPsk/JD8dPzE/Iz9Jv6M/Rz9RP34/V7+rv6u/9IAMgHjABcANwC2AawCcAIEAnwCMAOYAjADMAfwC5ALUAkgCEAIGAbYAjAFoApQDaAKUAuQCVAIuASsAxAFUAY4B7AHgAgoB4AG6ATEA6ACpANIBcgFsAQ4BfAGOAYQBIwD0APoA1QCSAKYA0gEUAOwAQIBu/9S/iz9LP0M/RT9oPzY+5j6UPqY+oD58PfQ9zD4kPew9jD3IPkA+cD3gPfg99D30Pag93j5yPoY+3D7IPzI+xj7CPug+7j82P3m/ub+jP4O/rj9FP3Y/Nz99P74/jL++P0A/qD99PxE/Qb+8P00/dD8DP3g/Hj8cPzo/OD8XPzg+/D7RPyM/KD8pPwE/XT9sP3c/Vr+/P6a/3D/pP8RAIsA5QAuARACOAPYA6wDWAPIA2AE3AM4BIgGcAnACvAJoApwCcAFcARIBoAJYAqACvALMAzgB8AE9AMwBSAGoAawCLAJcAjIBXgEMARgBKgEkAWIBoAHsAdQBrAEcATgBMgEEARYBGgFqASMA0gCHAIqAeT/Uv+O/zn/Dv4Q/Qz8kPvI+nD6GPrg+bj5qPnA+ND3oPc4+ID4YPhw+Cj54Phg+HD4ePmA+rj6CPvY+1D84Pvg+2D8vP2U/QD+Xv6o/tT+pP6A/mj+Yv5s/mL+Cv4A/kb+7P2M/Tz9gP0w/fj7oPtM/MD8gPzg+wT8sPsA+5j6SPsc/BT88PyM/Xz95PyE/YT9jP0o/Uz/DwALACj/NAEkAhwBZAF0AjgEIAK/ADQCYAQIBagFIAiACIAHQAZgBTgGQAegCeAJIAkQCcAI2AdABmAHAAmwCfAHQAdYB/AGEAXoBLgGsAd4BkgFgATYBEgEoANABIAFsAWQBEgDFAPAA7ADlAM4AxQDAAKlAKb//v+iAB8AJf+K/g7+7Pwg+yD6sPog+3j6GPp4+nj58Pew9gD3sPdg95D3kPiQ+MD3IPcw9wD4YPgI+Qj6sPqY+kj6OPqQ+lD7WPwQ/fj9YP4Y/oT9MP3U/Yr+qP4Y/4n/qP/a/nT+Wv5U/rj9mP38/TD+kP1o/Yj9+PyM/Dz8kPyE/Nj8hP1G/sj93P0+/tT9FP4q/vD+6P65/+MAVAJIAqIBCAJwAqIBuAHIBEAGIAYABigHUAi4BuAFoAcACRAJkAigCRAL8AgACNAI0AhACLgGAAiACeAI8AdQB9gGkAXAA4AE2AQoBQgF+ARgBMwDqgE6AegBSALkAvQC1ALMAQIBZAAoAGn/6f+N/3r/8v5g/YT9NP2k/Ij88PsA/Bj7QPrA+nj7OPuA+tD5KPrA+SD5qPko+mD6APro+fD5MPnQ+Lj5iPqw+tj6YPt4+/j6uPoM/MT8wPwo/dj9Jv7s/Iz8PP1s/bj9Gv4e/yT//P1I/TD9BP2E/Oz8lP2c/ZT8DPwU/Hj7mPuQ+yD80PtA+7j62Po4+rD64Psg/BT8ZPxg/az9sP2A/cD+Tf8CAMkAdAMYBSAFIAXABXAG2AWABmAI4AqgC7ALEAxACzAKMAkgCmALEAzADMAMwAsQCiAJkAgwCOAIcAmQCTAI4AYwBqgFKAXoBDgFOAWIBOQDpANIA+QCbALWAdwBKgFSAfgA/AD5AMgARQBt/wH/Af+e/lD+9P0A/oz9TP3o/MT8qPtY+zD7APu4+qD68Ppo+oj54Pjw+MD4gPjw+Cj58PhI+JD30Pco+Ej4wPh4+XD5UPlY+bj5sPkg+qj6uPto+1D7wPs0/Ej88PuE/ED9WP3Q/KD9/P0a/oT9BP4x/2z/W/9r/xYAxP8bAFsARgG0AWwB2AHyASACbAJAAwAECASwAxAEEAQwBHAEsAX4BZAFgAVgBUAFcAVwBeAFmAZIBmgGCAaoBYAF+AQwBTgFKAVQBRgF4AR4BEgESAQgBPgD2AMYBCgE2AOMA4gDCASsA7gCtALsAsQC3AHuATQC2gGrAFoA7gC2AGP/4P4p/+z+qP0k/WD9SP1E/LD7qPuA++D6oPqw+rj66Ppg+vj6yPqo+pD6wPpg+8D7MPyM/Fj8PPzE/BT9fP3U/QT+BP4M/uD9vP0e/sj+qP7K/mz+cv4k/dz8FP00/RT9FP3s/Gz8QPt4+oD6QPrI+aj5OPoA+nj4IPiI+FD4QPdQ9/D3WPiw99D3aPiA+KD3sPcI+rD7xPxM/Q7+5P1A/XT9KgAIA1gE8AVAB0gHUAYYBogHIAlwCpAL8AxgDVAM0AuwDIAM4AtgDJANsA1QDLAL0AvgCnAJEAkwCVAIGAfQBmAH2AaYBGAEzAOAAtIA8wDiAZ4BcAH+AJ0A4v6I/YT9Qv7w/k//jf+0/sT9lPzA/GD8uPys/Sb+9P3k/JT8rPwk/Hj7MPzg/Jj8iPs4+4D7mPuQ+nj6IPvI+iD6WPlA+tD6aPqg+ZD66PrA+oD6uPq4+3j7kPuA+0z8LPxk/Iz82PwY/TD9tP2c/fD9Bv7A/cT9Av5K/sL+rv6k/kn/Nf8y/+T+Cv98/93/GwCuAMsAVgGaAIUA8gCWAfoBbAKoAygEOAMMAzwD/AOQAzAEiAUYBrAFWAXQBYgFoAUIBhAHaAcQB8AG8AZQBggG2AZQB0AHiAbgBkgGgAX4BMAFIAZYBagEmASABLAD/AI4A2ADiAK6AWgBKAG+ADEA4v8HAJX/uP4M/rj9xP1o/VT9ZP2E/dT8ZPzw+9D7KPw0/KD8uPxY/Oj7gPt4+/D7aPz0/Oz8nPw4/OD7EPwQ/Iz8pPyk/CT8mPv4+pD7YPto+wT8+Pug+wD6KPqA+lD6iPkw+oD6gPmA+DD4iPkI+eD3QPhQ+KD2APWA9oD4WPmo+ID4MPhg9rD1UPeI+TD7wPto/Kz8WPvY+oT8kv4mAEABJAOcAyQDhAPABCAGiAZYB1AJEAoACgAK0AqwC2ALoAtwDLAMMAwgDPAM4AwADHALoAsAC/AJcAnQCbAJsAgQCIgHkAYoBZgEwASIBAgEsANcA0gCLAFwAFIAIwD//xcA3P8Z/1D+/P2Q/ST9DP1I/SD9xPx8/ET88Ptw+0D7aPtg+yj7SPso+wj7iPpg+mD6WPqY+tD6APvo+rj6wPoY+xj7IPtQ+3j7kPug+xT8ePyw/Lj8xPzk/Cj9HP1o/ez9Pv5W/j7+Yv5g/jL+ZP7G/sr+DP8O/0L/Xf/w/p7+mP6s/tD+4v4U/2f/WP8s/2X/qP/N/xkATwDdAFAB/wDvAIgBZALoAugChAP0AxAEsAMQBNgEqAW4BVgG0Ab4BkgGGAYAB3AHcAdoB+AHuAcQB6gG8AYgB9gGoAaABngGCAYIBXgFCAWoBFAEaATwA1QD+ALAApQCxAHSAZwBBgGbAHIARQAXAI//Of9l/7L+YP6Q/qz+iv48/vj96P1k/TT9HP1A/YD9AP3w/LT8cPzo+4j7kPu4+5D7EPso+9j6mPr4+TD6SPro+bj5IPlY+dD4sPho+Rj6uPng+JD4CPjg9yj4MPnI+XD5aPmo+TD5wPj4+Pj56PrI+uj6iPvw+7D7+Pv4/KT9fP0W/ub+hv+4//X/9gDGAc4BAAKYAhADdAMYBNgESAUoBUgFeAWIBbAFMAaoBuAGyAbYBpgGGAYYBmAGmAaQBlAGOAboBWAFEAUgBSgF4AS4BNAEmARABAgEEATgA6gDoAOAA2ADNAMYAwgD9ALIAqACkAKMAoACdAJYAhwCAALEAboBvgG8AYoBTgEaAbsAbwAhAPX/wv+Y/0P/Av+O/j7+8P2U/SD9uPyE/ET86PuA+1D7APuw+lj6IPrw+bj5ePlo+Vj5IPkw+ej4GPn4+BD5GPlA+Xj5uPnw+RD6UPqo+vD6OPuA+yD8lPzk/Ej9uP0o/oT+/v6t/yQAZAC8AB4BiAHUAUQC5AJEA4QDuAMABDgEaAS4BCgFWAVoBYAFuAXYBdgF6AUABhAGAAbwBegF0AXABbAFoAWQBXgFQAUIBcAEiARoBFAEOAQYBOADpANoAxwD9ALQArQCmAJYAhwC7AHGAa4BjgF4AUYBCAHrAMAApQB+AGEAPQAYAN//w/+R/4n/cf9S/z3/Ff8K/8z+oP5u/mr+Hv4Q/gD+5P3I/XD9YP1I/RT95PzU/Lz8iPyM/Iz8iPxY/CD8EPwQ/AD8BPwA/Az8BPzw++D72PvI+9D74Pvo++j7CPwc/Bj8JPw0/FT8dPyE/Kj82Pz8/BD9PP18/bD93P0E/kL+gP6s/tT+Bf84/3X/t//y/yYAWQCUANgABAEuAWIBoAHcAfwBGAI8AnACpALQAuwC/AIMAzgDUANkA3wDlAOQA4QDlAOQA5gDmAOcA5gDiAN4A3gDdANcA0gDNAMoAwwD+ALkAtACrAKMAnACWAJIAhwC7gHAAZIBYgFEAR4B8gDHAJYAdQBNABcA3/+5/5L/Yf8p/w7/9v66/pD+cP5Y/h7++P3Y/cz9oP2E/Vj9TP08/Rj9HP3w/OD8wPzA/MD8rPyg/Lj8yPy4/MT84Pz0/PT87Pwc/UD9RP0w/WD9kP2s/aj9xP30/Rb+Jv5M/pL+yv7g/uj+Gf8+/1j/dv+u/+//IAAsAGAAggCNAKoA3QAQATgBUgF4AagBxAHgAQgCIAI0AlACdAKEApACsAK0AsgCxALUAtQC1ALUAtQCyAK8ArQCtAK0AqQCjAKMAowCZAJAAjACIAIEAuYBzgG0AYoBZAFCATABCAHmALsAkABoAEQAKAD+/+H/v/+b/3z/VP8w/xT/6v7K/r7+qP6Y/oD+Tv4w/h7+Fv4A/uj95P3c/dT9yP28/bj9sP2o/aj9sP3A/cD9uP24/dD94P3o/fD9Av4i/ir+LP5G/mT+gv6W/qr+yv7y/hT/Lv9V/3f/hP+P/63/z//3/xEANQBTAGkAegCQAK0AugDQAOMA9QD+ABgBLAE0ATYBSAFoAW4BagF0AYoBkgGOAZQBogGoAaYBnAGcAZIBhgF2AXoBdgFkAVgBVAFKASwBHAEQAQgB9ADVAMwAwACxAJcAggBkAEcAJwAFAPv/+P/k/73/of+Q/3v/TP9A/z7/Nv8l/xH/Cf8B//b+3P7S/sL+xP7I/sL+vv66/sD+tP60/rj+wv7C/sr+2P72/gP/Ev8g/yz/Pf9N/1//aP9x/4P/nv+p/7X/zf/m//X/AQAHACMAKwA9AEMAWABeAFoAbQB8AJ4AmgCnAKsAugDJAMYAygDIANQA0gDNANYA6wDsAOMA1QDaAN0AxgC8AMkAyAC8ALIAqgCoAKEAnQCcAJIAkQCQAIQAeQBmAGYAWgBcAF4AYgBfAEcAQwAyAC0ALAApADIAKAAoABoAFwAVAAwACAAFAAUABQD8/wAADAAMAAIA+v/9/wQA+//s//D/9f/q/9v/4//w/+T/3v/c/+T/6P/b/+T/8P/3/+//7P/0//v/+v8BAP//9f/x//3/9//3/wUA/f/0/+n/7f/2/+b/4//n//P/8f/0//j/+P/4//T/+f/2//f//v8KAAUA/P/+//z////9/wMACQAAAPj/8P/y/+n/7f/x//v/+f/1//P/7f/l/9j/2v/Z/9n/3f/U/9H/z//W/9f/1//F/8r/y//H/8f/yv/R/9D/zf/C/8b/yP/J/8//0v/V/9P/1//b/+f/6P/s//L/6v/v//j/AgALAAYABgAGAAoACAAMABAAEAATABYAJgAcABsAGwAkABoAHQAuADgAMAAlACcAKgAnABoAJQAuAB8AEAAPABYADwAEAPr/BAD6//H/6P/g/8//zv/M/9X/0P/V/9L/4f/N/8v/xf++/7v/vv/B/7v/tv+3/8H/wP+4/77/v//A/7X/vf/C/8v/zP/U/9P/0f/S/9H/1P/V/9j/3v/d/+H/3v/t/+f/4//u//j/+////w8ADwAMAAYAFQAlACcAIwAtAC0AJgArADIAOQA3ADAAMwAzACoALwA9AEAAOwA6AD8AQAAtACcANAA+ADAALAA4ADMAIAARAB4AHAATAAkAEwATAAYA8//0//r/7f/b/9b/1P/U/9b/1f/X/9H/y//J/9L/z//L/9L/0v/M/8r/zf/S/9j/1f/Y/9v/2v/a/97/1//b/9r/3//p/+7/6//p/+f/6f/2//X/8f/w//r/+P/w//L/AAAEAAIACAASABMACAAOABwAIAAXAB8AKgAnACMAJwAvAC4ALQAqACkAKAAmACgAIwAZABkAIAAZAA8AGAAbABYACAAIAB8AIAAPAAgACwAEAPf/9v8CAAQA+f/4//r/9v/i/9v/4f/p/+D/4f/m/+j/3//Z/+L/3f/W/9f/4//h/9j/0//b/9//3P/c/+P/6f/l/+P/4//j/+T/4P/h/+H/5//w/+r/7//y/+v/7P/p//P/7f/o/+3//P8DAAMABQALABAACwAQABwAIAAdABsAIwApACEAIgApAC8ALwArADAANQAzADcAOAA4ADEALQAtACkAKAAkACYAKQAaABgAGgAWAA4ACAAQABUAEgAVABgAGQAYAAsAEQANAAkADAATABEACgAPABEAEQD8//r//f/5//3/AAANAAgA//8BAAUABAACAAQACQABAPr//P8DAAAA/P8EAAcA/v/6//L/7f/o/+b/6//r/+P/5f/g/+P/3//d/9f/0f/c/9n/1v/O/9f/0//O/8D/vv/E/7n/uf/C/8D/uf+s/7D/uv+6/7X/uP/G/8n/wP/G/9H/0P/I/8z/2v/d/9n/1v/d/+b/4//b/+L/5P/m/+r/7f/w/+7/8f/u/+j/6P/v//H/7P/v//X///////7/AAAAAAEA+v/+/wgACwALAAoACwAHAAUABwALAAYABQAEAAEA+f/y//f/+v/5//D/7f/w//L/7//p/+n/7v/y//H/7v/u/+7/5//j/+b/6v/m/+f/5f/k/+D/3f/h/+T/6P/l/+L/4P/j/+f/6//p/+v/8P/y//H/8P/w/+//6//u/+7/8f/y//H/8P/0//f/9f/x//L/+f/7//j/9//8//r/9//1//j/9P/v/+7/9f/4//b/+P/0/+3/4//f/97/2v/b/+H/5//m/+f/6//x//H/7//z//b/9f/2//3/BwAJAAQABAAGAAoACAAIAAsAFAAWABQAFgAbABwAGwAcACQAKAAlACIAJgApACIAFwAkAC0AKwAmACsANwAjACcAJQAyACkAKAAqACcAJAAfACcAJAAfABkAGwAbABYAEQATAA8ACwAMAAwADgAMAAcACQAHAAMABgAAAPz/+P/0//v/9//2//P/7v/r/+z/6//u/+r/4v/k/+f/5//l/+T/4//i/9j/zP/V/+D/4f/m/+3/6v/n/+b/5//s/+//8v/3//n/+v/6//b/9f/z//T/+P/4//P/8v/0//L/8P/w//X/+//+//z///8BAP7//v8EAAUAAQAFAA0AFAAQAAwADwAWABYAEQASABUAFgATABIAFAAVABEAEQASABQAEwARAAwACgAIAAQAAwADAAEA+v/1//b/+P/0//D/8f/1//X/8f/x//H/7v/n/+X/6P/o/+j/6//w/+7/5//i/+L/5f/l/+r/7//1//P/9f/3//r/+P/1//X/9v/7////AgACAAEAAgADAAQABwALAAsACAAFAAkADgAQABAADwAQABMAEQATABEADwAPAA0AEgAUABUAEAAUABYAGAAZAB0AGwAYABIADgAKAA0ACwAFAP7//P///wAAAgD9//r/8v/x//L/9P/x//P/8v/0//L/7P/r/+j/5v/l/+H/3v/b/9n/1//W/9b/1//X/9z/2v/W/9T/1//X/9n/2f/a/9z/3P/e/97/3f/a/9f/1v/Y/9v/2v/Y/9P/0//R/9f/1v/T/9D/z//V/9f/1P/U/9f/1//g/+H/6v/u//P/9P/z//H/+//2////AAAEAAUACAAVABIACAADABcAEQAZABIAKgAoAAwAFgAfABoACAAMAA8ACQAKAAEADQALAPz/+f8PABwAFQAIABgAIQAjABgAHAAjABoAEAAQABUAHAATABQAHwAkABkAEgAUABUAEAALAA0AFAAaABEADwAVABcAEwANAAsACgAGAAkAFQAUAAgABAAMABgAEwAWAB4AJwAlABkAFQAWABIADQASAB4AKAAjACgAJgAWAAsAEgAoACkAJQAXABcAEQAMAAcAAQD5/+X/5f/u//X/7P/d/9r/2//m/+7//P8EAP7/8//y//L/8f/4////EAAQAAsADgAOAAQA7f/m/+//9//7/woAEgAYABgAEwAYACYALgAvAC4AKgAvADkARwBcAGAATQAuACoAKAAvADQAPwA+ADgAJAAUAP//6v/b/+D/7f/5/xQAJgAtABAA5v+//8P/6P8UAC8AJwABANn/wv/L/9j/3v/T/8j/wv/b/+P/5//n/+X/8P/w/wIA9f/+//X/9P/p//n/AQAQACIAPgA3ACEA///n/+L///8NABgAEQAEAOT/3f/r//f/4P+5/7L/wP/T/97/6v/4/93/vf++/+3/FQAOAOv/4//8/yYAVQBSAC8A5f+z/9j/MABhAEgAKwBPAEwAGADZ/6n/hf9z/7v/aQDrAAABIwAL/9T9jP22/twAmgEGAQYALP9v/6n/HwDb/+H/wP/L/9b/7P9vAMEAdwAKAEsA1wB0AEj/SP/S/94AmQC2ACIB+gATAKb/QwDXAI4AzP+u/+X/EQAOAKwAFAGgABkAvf8GAP//tv8XAL8A+gD0AL0AFgA3AKb/l//Z/zcAWQCLAAUAxP62/ur+i/8GAB0ABQDO/l7+yP7q/6cAdQD//4EAUgEcAvACPAJ0/yD76Phw+3ABOAaABYoBzP2w/CD+cP9rAFABtAHeAWgCLAMIA9ABKAC2/lT+SwBEAzAFIATjAJ7+6/90AkADCAOOARoALwAeAXACYANEAg0A4PyY/FD9MP6I/WD7FP04/ib++PsI/QD8kPpw+aD7Ef8mAPT+Wv4qADMAV//w/RD+pP2Q/Hj9J/+WAVwCYAGjALH/8v6I/Yj8QPxE/QkAGAKyAdYABv7Q/RT/6ABgAR3/4Puw+sj8XP+6AeoBPAGtABIArP58/RT98PzU/b7+FQAYAogCaAE1AAv/gv4A/uT+Ov9wAMj/FgGUAlgDDAKT/9T/cQD0ADr/f/+EAMgBXgHFALwBEAKcAbEA2v9v/0T/xwDSATIBXP8UADgCtAMQAq8AAgGdAOn/9P6e/y0At/8e/zwAygG8AdIBwwDY/4D94Pz0/RAAEgGIAOIAggE8Ao4BLAG9AJIAR/+U/iT/lQCAAZABbAGOASQCVgFKAAkAHQDD/77/NQA0ARQC6AE6AZMAWwBmADIAAwDW/z4AugDzABABcgF4Ab4Aof9e/xsAkQAMAR4BLgE0AQQB3wAYAewAfQArAEYAEwDU/wgAdwDKAJQAkgDIAJsA6v82//b++P4d/wD/WP8oAOQADAGQAKD/9P6m/rT+IP9S/5H/+f8qAI4AmwBRAAkA5P+y/4n/b/94/wEAHgA8AAsAaADVAK8AfgATAPn/vf+Z/9L/0f8XAHoAwADmAMoAjwBvAEkAuv9g/zj/d/+4//T/gwC2AOMAkwA7ANr/UP8p//7+Pv9U/5D/t/9HAMcAqwAsANj/wv+q/1b/xv70/rT/CAAjAAgAQgA6AOD/Gv+i/nr+eP5A/oT+2P4z/yf/hf8PAPn/bP8x/z//Lf8P/+z+O/+9/xoAXwCFAJsA0gBGAF4AyP/W/wsAawCQAKUANAE6AVABFAEyAUABGgHLANwAqAB3AFoATwDqAKkAfQC4AKgAjwBGAA0AHwDk/7r/kv+c/+H/m/+E/3r/Z/9C/y3/P/9J/+D+ev6O/qT+1P5+/or+oP5S/jL+OP7i/jj/GP9L/5D/jf8p/+b+vP74/jP/mP+k/6j/4P9FAGgAfwBiAHIAggBpAFAATgCLAH8AmQDOAM4AEgE4ARoBMgEgAbsArgDxAOUA8wAsAZABFAJIAmACcAJQAiQCzAH2AQACAALQAdYBRAKYAoQChAKQApgCUALcAcoBhAH2AIUAfgCMAIAACAADAOf/o/9Q/xX/5P48/sj9bP1Q/dD8aPxE/FD8XPww/Az86PuQ+/j6qPpI+gj6KPp4+iD7gPvY+/D7RPxc/Fz8PPwo/Gj8ePz4/ET92P18/ub+df+T/5L/jf+Q/7j/AAAsAM8AMAHIAXAC9AKYAzAEoAToBCgF+ARYBTAF2AVABhgHiAcwCPAIQAlQCUAJgAlgCQAJsAhwCEAIEAjoByAIUAgQCIAHIAdoBkgFGAQkAyACLgEjAFP/bv50/YT8uPsI+9D5wPhw9zD2sPSQ86DyAPJw8eDwoPAg8MDvgO+g7+Dv4O8g8IDwEPEg8ZDxYPIw8zD08PRQ9lD3OPhY+TD6gPuI/Jz9hP5B/8z/lQBGAUQCZANwBIgFKAZoB0AIEAlwCjALUAzQDGANQA7ADqAOoA9gEGAR4BEgEgATwBKgEuARoBHgEIAQwA/QD1APQA6gDWAMwAtQCvAIqAdoBgAFYANYArcAHv+0/YD8YPvA+Uj4EPdQ9SD0sPLg8dDwgO8A74DuAO6A7eDsQO0g7SDtgO3g7WDu4O5g71Dw0PDQ8dDy8PNg9VD2kPdY+Mj4gPkw+sD6aPvo+3j8jP10/aj+Hv/P/wABjAF0AuwClAPwBOAFwAbYB7AIoAnACaAKwAvwC1ANwA1QDjAPcA+AEAARwBEgEoASQBJAEqARoBFgEYAQYBDwD4APwA7QDeAMAAzAClAJMAjYBlgFXAMAApsA0v6U/VD8CPuw+cD3YPYw9SD08PLg8WDxQPCg70Dv4O5g7mDuQO6g7gDvIO+g7wDwwPCw8aDywPMA9RD2MPc4+CD50Plo+vj60Psc/ED8MPy8/DD9kP1E/rz+HwCv/0YA+gDxAOABeAJ8A9AEOAUYBbgF4AVgBngHEAgQCrAJwApgCxAMQA3QDSAP8A9gEOAQYBBAEAAQoA/gDwAQ0A8QD8AOYA6wDZAMAAxwC3AKYAnYBygGiARwAl4BIQD8/kj9ePsY+mj48PaQ9dD0wPNw8lDxQPCA76DuIO7g7cDtoO2A7eDtYO7g7iDvUPBQ8YDyQPOA9KD1oPag95j4qPlY+vj6cPs4/GT8+Pxg/cz9KP4e/o7+rP5r/9P/wwA4AfgB3AJoA2gEeAQIBWAEuAX4BcAG4AdACCAJoAmQCoALYAxQDTAOQA/AD7AP8A9AEOAPwA+wD5APMA/gDiAO0A2ADXAMYAywC+AKsAlACPgGSAWsAwgClgBA/3T9uPsQ+rD4IPcg9iD1MPRQ81DyYPFg8ODvIO+g7kDuIO4A7iDugO7A7qDvUPBQ8ZDy4PMg9VD2kPeg+Hj5UPoo+6D7+PtI/Mz8LP00/Yj94P1G/nT+Bv/s/18A+wAIAswCSAQoBKgEoAXwBPgEcAWoBugGSAcgCCAJ4AmgCoALkAzwDfANMA+wDwAQ8A+gD0AQwA+wDwAP8A5QDtANIA3QDAAMkAugCjAKIAloBygG4ARYA6oBFQBY/rj8wPoQ+cD38PWQ9KDzEPMg8jDxoPDg70DvwO5A7kDuIO5A7kDuQO7A7gDvQPAg8VDygPPA9AD2EPdY+Dj5QPr4+mj7BPw8/Ez8aPy0/MD8AP38/Jj9Ov5+/n7/NAB2AbQC8AJ4BIAEUAQABfgEAAZoBvAGgAcgCMAIcAmgCqALsAxwDfAOQA/gDyAQIBCgEGAQYBDgD2APsA4wDlANoAwQDHAL0ArwCYAJYAhIB/AFuAQoA5IBhf/8/SD8OPqI+ND2cPXg89Dy0PEQ8UDwgO8A74DuIO4A7iDuIO4g7kDuoO4A76DvUPCg8cDy0PMA9WD2cPdg+Dj5WPpY+7D7OPyM/Nj8uPzE/ET9bP2k/fD9wP5O//z/ZAGoArADaARgBVgFCAYQBogG4AfYB3AIoAgQCQAKoArAC5AMUA2QDlAP0A9gEKAQABHgEOAQgBDwD1APwA7QDTANgAzQC+AKUAqgCWAIsAdABvgEqAMkAoMAuP64/Pj6WPlA98D1UPQA8wDyAPEw8IDvwO5A7kDuIO4g7gDuYO6g7sDuAO8A8LDwoPGw8pDzIPXw9SD3ePgg+Uj6APuw+3z8iPzQ/Az9WP10/bT9rP10/qD+kP8vAIoBvAKcA+AEUAUABlgGwAZgB4AIsAgACXAJEAqQCpALUAwADSAOwA6QD0AQIBGAEcARABLAEQASABGgEPAP0A5ADhANUAxQC2AKkAmACGAHMAbQBNADQAKAAPT+HP1Q+3D5gPfw9TD00PJw8XDwIO8g7qDt4OwA7cDswOwg7UDtoO0g7uDuoO9w8EDxQPJA8yD0APUw9iD3CPjg+OD5qPo4+9D7OPzQ/Mz8UP1U/fT9JP6W/tH/YwDyAVACkAPQBNgEuAX4BmAHgAhQCZAJoAqwCkALIAwADcAN4A3gDoAPIBCgEAARoBHgESASABLAEWARgBAgEHAPgA5wDVAMUAtQCsAIkAdoBugEsANkAqMAIP98/bj7cPqA+AD3IPWg89Dx0PCg74DuoO2g7EDsoOvg68DrQOyA7CDt4O2A7qDvcPAQ8tDy8PMw9VD2cPcQ+Dj5+Pmo+iD7yPuI/IT8JP1s/eT9Nv5C/jb/6f/6AMIB9AIgBNgESAUwBggHwAdACDAJ8AlQCjALoAtADHANsA1QDkAPYA9gEIAQQBGAEcARQBIgEuARgBEgEWAQ4A/wDhAOAA3gC5AKIAngB5AGaAXoAzgC6AAR/6T9+PtA+hD5EPeg9QD0YPIA8YDvgO5g7aDsgOsA68DqoOoA60Dr4OvA7KDtoO7A7wDxIPJg85D0wPXA9sD3sPiY+Vj6sPqI+9D7ZPzU/BT9vP3M/Wr+G//b/8QAvgEQA+gDyAQoBdAF0AZIB9gHYAhwCZAJIArQCsALgAzgDBAOAA5QD3APABCgEAARIBGAEcARgBFAEaAQQBBgD/AO4A0ADQAMwAqwCTAI8Ab4BUgECANiAcb/MP6g/CD7sPkA+ID2wPSA89DxgPBg7wDuQO0g7MDrQOsg60DrwOsA7MDsgO2A7hDw4PBw8qDz8PRw9nD3UPhA+TD6mPpI+7D7MPyQ/Lj8OP1k/bz9XP7E/pr/ewBsAbQCuAOYBDAFGAYgB8gHIAgQCZAJMArQClALQAyADGANMA6gDlAPgA8gEMAQ4BBAEWAR4BGgEYARYBHAEOAPcA+QDlANoAwQC+AJcAgwB8AFQAQIAzwBm/8I/mz8IPvI+RD4oPYg9aDzUPLA8MDvoO7g7QDt4OuA60DrQOuA6yDsoOyA7UDuwO/Q8ADy0POw9ED2QPdQ+Fj5EPoY+2j7JPxw/ND8GP1U/bT9Ev60/gv/nv+FAJwBjAK0A2gEcAVgBjAH6AewCJAJ4AmQCkAL0AtwDPAMkA1ADtAOQA+QD0AQIBCgECARIBGAEYARoBFAEYAQABCgD5AO4A1QDCAL4AmwCAgHyAVIBJQC+QBf/wr+WPwI+9j5SPgQ94D1APTg8mDxgPAg70DuQO2A7ODroOuA64DrIOxg7CDtIO4g73DwsPFQ83D0UPZg91j4oPlg+oj7DPzk/CD9pP2Y/dj9YP5Q/vr+Jf/w/7AARAFMAgwDcAQYBQgG0AagB4AIIAmACUAKwApACwAMUAzwDFAN0A2ADoAOEA9wD5AP8A/QDyAQYBBgEEAQ4A9ADwAPQA6ADYAMQAtQCsAIYAcABngEuAJSAZ3/GP5o/Aj7uPlA+BD3EPXw83DyMPEQ8ADvIO5A7WDsoOsg6wDr4Oog64DrQOyA7KDt4O4w8NDxMPOg9PD1cPeA+Mj5qPqg+9T8EP2o/Ur+av6q/uj+e/+Z/zsAzABSAWQC2ALMA8gE4AWQBnAHQAhACeAJkApQCwAMkAywDJAN0A1QDrAO0A5AD2APYA+QD9APgA/AD9APsA+QD+AOAA9ADqAN0AwADPAKsAmACAgHwAXcA3QClABH/4j96Puo+sD4EPhA9rD0kPPg8eDwoO/A7sDtQO2A7ADsoOtg6+DrgOtg7IDsYO2A7qDvIPGA8rDzQPXg9hj4aPmQ+qj71Pww/Vj+gP7u/mf/jv86ADcAjwAwAXoBRALgArQDkAQoBTgGCAcwCHAIoAkwCiALsAsgDMAMEA3gDfANkA4AD/AOUA+QD5APsA+QD8APcA9QDyAPAA+wDgAOoA3wDEAMIAswChAJ0AdYBtgEWAOoAQcAav70/JD7wPmA+CD3gPUg9KDyQPEg8CDvIO6A7aDsIOzA60DrgOtA68DrAOzA7MDtoO5Q8CDxAPNA9MD18Pa4+Mj5yPoM/LT8wP0W/rb+Q//K/zIAewDcAB4BcgH0AaACMAPYA5AEYAVgBugG4AdwCFAJAAqQClALgAsQDFAM8AxADYAN8A0ADjAOQA5gDpAOgA5QDlAOQA4QDrANYA0ADYAM8AswC3AKYAkwCCgH2AVoBMwCbgHN/xD+wPxY+/D5mPgw9/D1YPQw84Dx0PCg78Du4O3g7GDsAOzg6wDsoOvA62Ds4OwA7uDuYPBw8eDygPSw9SD3uPjI+Qj7FPwA/cj9cP4C/7r/QwCwAPwAJgGyARwCWAL4AlwDAASoBDgFAAbABmgHMAjgCKAJIAqwClALsAsQDIAM8AxwDbAN4A0ADmAOYA5QDnAOMA4QDuAN0A1wDSANoAxQDMALIAtQClAJYAgwBxAGgAQ8A7YBMQC+/jz90PtY+gj50PdQ9gD1UPMQ8uDwwO/g7oDtQO0A7IDrYOsA6wDrQOuA6yDsYO0A7qDvwPAA8tDzsPQQ9yj4oPnI+tj75Py4/aj+G//J/4sA1QAqAXwBxgE4AqgCWANsAwgEqASABQgGyAaQB0AIIAmgCVAKAAtwC/ALYAzQDCANcA3QDSAOYA5gDqAOoA6gDoAOQA4wDgAOwA1QDSANcAzwC2ALoAogCuAIAAjQBpgFIATIAn4BAwC0/iD90PtY+gD5kPcw9tD0YPNA8jDxAPAA7yDuIO1g7ODrwOtg64DroOsg7EDt4O2A7wDw0PEQ82D0IPaA9xD5ePqw+6j8pP2K/kP/IQCtAPEANAG+AQgCRAJ8AggDXAMIBHAEuATABTgGEAfQB3AIQAnwCZAKQAuwCyAMsAwgDWANoA3QDTAOUA5wDlAOUA4wDhAOEA7QDcANYA0gDbAMQAywCwALcApgCaAIaAdABtgEkAMYArkAT/+8/Wj84PqQ+Rj4sPZA9fDzwPKA8YDwYO+A7oDtoOwg7IDrQOtA6+DqoOtA7ODsgO6A73DwsPGA8+D0YPbA9zj5wPrw+zD9vP0X/6P/fwC2ADgBlgGIAUACOAK8AugCaAO4A4gE6AS4BSgGMAewB3AIUAngCYAKEAugCxAMsAzgDGAN0A3gDUAOYA6ADnAOgA5gDlAOQA4QDvANoA1ADfAMcAzwC2ALkArACbAIsAdwBjAFyAOUAgwBoP8q/nj8KPug+Sj4wPZA9QD0kPKQ8VDwYO9A7kDtwOzA64DrAOvg6oDrIOtg7IDtYO7A76DwIPKQ80D1gPYY+Ij5yPo4/Cj9XP7a/uf/jgAKAXABfAEMAhQClAKUAggDVAMABIAECAXIBUgGEAeYB3AI8AiwCVAKAAuQCyAMcAzwDEANsA3gDeANEA4wDkAOMA4gDvAN0A2gDYANIA3ADFAMwAtQC5AK0AnwCBAIAAfIBagENAPqAXsADf/Q/RD8sPo4+aD3MPbA9KDzUPIA8eDvwO7A7cDsAOxg68DqYOpg6oDqoOrA64DsIO5A7+Dv4PFA88D0cPaw9zj5aPro+wD9/P3s/qv/cQDoAC4BmAG+ARwCSAKIArwCXAOgAxgE0ARIBQAGmAZgBxAIoAhwCQAKsApAC7ALYAygDAANcA3ADeAN8A0ADgAOAA7wDfAN0A2wDYANYA3wDKAMMAzQCyALcAqgCbAIsAeYBkgFGASEAiQBtv8y/tj8APug+QD4cPYg9ZDzYPLg8ODvwO6A7cDsgOtg60DqIOrA6aDpwOpg6kDsIO0g7mDvoPBQ8gD0YPXw9jD44Pk4+4j8rP3W/nb/eQAqAXoB5gEsAoQC3AIgA1gD8AMQBPgEKAUABmAG+AbIB3AIIAmACTAK0AqACwAMwAwQDXAN4A0gDoAOcA6wDsAO0A7QDsAOoA5QDkAOAA6wDVAN0AxwDMALIAtACkAJYAg4BwgGqARQA/wBcgAE/6z90PuA+uj4gPcA9qD0QPPg8aDwYO9g7kDtYOyg6wDrYOoA6qDpQOpA6iDrgOyg7aDuoO+w8eDy0PSg9pD3kPnQ+gD8rP1+/o7/SwA0AbIBLAJkAogCDAMgA5gDrAPkA3AE0ASABRgGYAY4B7AHgAjwCGAJQApwClAL0AswDNAMAA2QDdAN8A0wDlAOkA6gDqAOkA5QDjAO8A3gDYANEA2wDBAMsAvACvAJ8AjAB8AGWAU4BKwCQAHF/1b+5PxQ++j5MPjg9jD18POQ8iDxAPDg7gDuwOzg6wDrgOrg6WDpAOqA6UDqYOuA7IDtoO7A77DxsPPw9ND2GPgI+lj77PwY/in/NgAIAegBcAKcAvgCQANsA5gDyAPkAyAEiATABGAFsAVoBuAGkAcwCJAIUAkACoAKMAuwCzAMwAwgDbAN4A0ADmAOcA6gDqAOoA7ADoAOgA5wDiAOIA5wDUANoAxADEALgAqgCTAIgAeQBeAE4AK+AUgAbv6A/VD7SPpo+AD3sPUg9ODycPFg8GDvYO5A7UDsgOvA6iDqoOmA6aDpAOpA6yDs4OwA7qDvUPEg84D0MPYY+Lj5GPus/Pj96P4xAP0AtgEMAnwCzAI0AyQDTANoA3AD4AO4AzgEeATYBKAF+AXYBjgH4AeQCEAJwAmgCgALoAtADIAMAA0gDZANwA0ADiAOQA5wDnAOcA5QDlAOIA7gDYANEA3ADAAMYAuQCoAJgAhAB9gFkAT8AoYBFQCG/gj9gPvg+XD40PaQ9SD0oPJQ8TDwIO8g7uDsAOyg64DqQOqA6UDpgOnA6cDqoOuA7MDtQO/Q8EDyYPTw9dD3QPmw+oz8uP0b/6H/KgFyASACoALEAiQDYAN8A6gDdAPEAwgEUAS4BOgEeAXgBWgGKAdIBzAI0AgwCfAJUArwCjAL4AswDJAM4AwwDZAN0A0QDkAOUA6QDqAOoA6QDnAOQA4QDpANAA1QDKALwAqgCYAIIAfQBUgE3AJaAbz/HP68/ED7kPkQ+LD2IPXQ84DyUPEQ8ODu4O3g7ADs4OpA6oDpQOng6ADpQOkA6iDrYOzg7WDvkPCw8mD0gPZA+PD5mPsg/ar+4/+7AGQBFAMAA9ADEAT4A2AEqASoBKgE4ATQBFgFkAUABmgGWAaIB6AHoAjwCHAJIAqACjALYAvAC7AMsAxQDaANsA1ADiAO4A6ADvAO4A4gD+AO4A7wDoAOYA7ADWAN0AzAC/AK0AmQCFAHuAUwBLwCKgFv/9z9UPzA+kD5wPdQ9rD0YPMQ8vDwoO+g7oDtoOzg6+DqQOqg6UDpwOjg6CDpAOpA64DsIO6g7/Dw4PLQ9ND24PiA+iT8kP1R/4MAVgFYAuwC7AMIBHAEWAR4BNgEmAQgBTAEMAUIBYAFGAYABngGEAeQBxAIoAjACEAJ8AmACrAKIAuAC9ALUAyADNAM8AxgDYAN4A1wDhAOoA6QDrAO4A6QDmAOAA6gDeAM4AvwCtAJsAh4BwAGOAS4AvQAmP/8/Xz88Po4+fD3UPYQ9YDzYPLw8ODv4O7A7cDswOvg6uDpgOng6MDogOig6EDpQOqg6yDtwO5A8BDyEPQg9kj4MPoE/LT9GP+lAKYBpAKYA7wDIAXgBJgEOAX4BAgFKAUQBegEKAVQBbgF8AVIBrgGAAcACEAI0AjwCLAJYApgCgAL4AqgC8ALIAxADNAMwAyADaANIA4gDqAO8A4wD6APgA+wD0APMA9QDtAN8AyAC4AKIAmQB/gFaASUAgIBUP+I/RT8kPoI+aD3EPbQ9JDzQPIg8cDvwO6g7aDsoOug6sDpAOmA6ODnoOfg5yDoYOnA6oDsAO7A75DxkPPA9QD4MPrI+6T9Av9fAOoB2AFAA7QDAARwBAgEGAQABCAEEARgBCgEOASwBPgEcAV4BTAGyAZgB+AHQAiwCPAIkAnACVAKYArACtAKMAuwC9ALUAyQDFAN0A1QDtAOUA+wDyAQIBBgECAQoA9AD1AOYA0wDNAKQAmwBwgGGARgAnEA0v5E/bD7UPrA+ED3IPbQ9LDzUPIg8QDwwO6g7aDsgOuA6mDpoOhg6IDnYOcA5wDoAOlA6gDsoO2A7zDxcPOg9dD3APoA/LT90P51ACgBRAIQAwAD9AOoA/ADrAOwA9ADzAPwA/AD7ANoBBgFIAWYBQAGeAbYBkgHoAfwBxAIkAigCNAIAAlgCWAJ4AlQCqAKgAsgDPAMYA1gDjAPABCgEAARoBGgEaARgBHgEEAQEA/wDdAM8AqACXgH2AVQBCQCewDY/mz9sPvg+jD50PfA9iD1kPTw8nDxkPDg7gDu4OwA6wDqoOig5wDnwOYA5mDmYOZA6GDpoOtg7YDvAPIQ9LD2ePhg+zz9Lf9XANgBaAIEA2gDKAQgBEgEaATwA4gEcASgBIgE8AT4BHgFCAYwBhgH6AaQBxAI+AdgCGAIgAigCFAIQAhgCHAI4AggCbAJcAoQCwAM4AzADcAOoA/AEIARQBKAEuASwBJAEgASABHgD4AOwAzwCkAJSAeoBcQDCAJNAJT+NP3w+9D6SPl4+KD2wPUA9ADzkPGg74DuwOwA7CDq4Ogg56DmoOVg5UDlAOUg5iDnwOhg62DtQO9w8mD0gPbo+KD6KP3s/iYAkAHuAaQCDANMA8wD7AOwA0gEiATABDgFOAWYBSAGSAbQBhgHSAeIB2AHkAd4B0AHGAcIB+AGgAaYBjAGqAYoB1AHgAgACWAKMAuQDIANoA7gD4AQwBEgEuASwBLgEqASABJAESAQ4A6ADfALEAqQCOgGWAX0AywCLgE0/+D9BP1I+4D6cPhw9wD1wPMQ8gDwwO5g7MDrIOoA6YDnIObA5cDloOUg5qDmoOfA6ODq4OwA70DxUPMA9WD3OPnA+vj8MP7O/8cApgFIAtQCoANgBLAEGAWwBSAGkAYIBxgHMAdQB0AHQAfwBhAHcAYwBvAFoAWQBVAFSAUYBYgFiAWoBXAGqAbIB1AIYAlQCmALcAxwDZAOQA9gEAARoBFgEmASgBJAEkASoBEgESAQwA6QDQAMUAqQCAgHGAWwA9YBPwCS/sD8cPuQ+Qj4YPbQ9BDzYPGg78DtQOzg6kDpoOiA56DmYOUA5QDl4OTg5QDnIOhA6QDsYO3A77DxsPOg9Sj4WPlY++z8Xv7r/8IA2AGgAsADQAQwBYAF2AWQBgAHeAcQCPAHoAd4B1gH6AYAB1gGWAZwBTgFsATYBHAEeATYBMAEeAVYBUAGyAbYB3AIkAlwCrAL0AyADdAOgA/gEIARABLgEqASgBJgEkASwBFgESAQEA9wDYALIApwCLAGKAUwA5AB/v9C/uD8QPvY+eD3YPbQ9PDyQPHA78DtAOyg6iDpwOig5wDngOYA5iDmQOYg54DooOng6yDtAO+A8HDy8PSQ9gj40PmQ+4T8tv6w/xoB8gFAA2gE8AQ4BuAGiAdACLAIMAmACRAJ8AgwCLAHAAcwBqAFMAV4BBAEsANwA8wDIASQBCgFSAWwBegFIAfYB2AIsAkACgALkAuADEAN8A1QDwAQQBEAEmASwBIAE0ATYBPgEkASABGgD1AOAAxgCjAISAZQBFQCVgBO/jD9SPv4+Zj4kPZA9XDz0PFw8IDu4OxA6wDqgOgA6EDngObA5iDmYObg5mDnQOlg62DsoO6A79Dx8PJQ9UD3oPiA+pD7zPyc/hsA0gHgAlgEAAUABvgGmAcgCeAIUAqQCaAJUAmgCPAH+AZYBhAFuATsA4QDcAMsA0ADrAOIBPAEmAX4BdgFGAZ4BiAHwAcACXAJcArAClALoAzQDUAPgBAAEsASQBMgFKATABTgE8ASIBJgEHAOoAwwCoAIKAYwBHwCugDO/mz9APyo+pD5cPjA9iD1APMw8UDvwO3A6wDq4Ogg58DmwOXg5QDm4OWg5mDnIOgg6uDrgO1g78DwQPJA8xD1EPcQ+Lj5GPuY/DD+nP8mAbACeARABYAGoAdgCGAJkAkgCvAJwAmgCOgHMAcgBhAFiARgA9wCzALsAdQCZAK8AogD2APABAAFiAU4BXgF6AWQBtgHAAkACqAKkAswDNANUA/AEKASQBNAFGAUgBRgFIAUABSAEgAScA8wDtALIApACBgGiAQ0AtwA3v6g/cj7mPpQ+RD3QPbg8+DxoO9g7oDswOqA6aDnQOdA5mDmAOaA5uDmYOdg6EDpIOvA7CDuQPBQ8fDyUPSw9XD32Piw+sj7sP1L/1gBcAKoBGgFuAYACMAIgAngCdAJQArACUAJ0AiIB9AGCAawBFAEmAPYAswCXALEAqAChALoA3wD0AQwBSgFYAVwBAgFGAX4BhAI8AkgC/AL4AywDZAPIBFAEwAUoBSgFOATgBOAE+ASoBIgEcAP0A3QCzAKgAjgBvgEDAP+AFn/LP3Y+yD6YPhw9rD08PIA8eDuAO0g6+DpIOiA56DmIOYg5sDl4OUA5sDmoOcA6UDqoOsA7SDuwO9A8fDyUPQg9vD3UPmo+7z8Pv/kAMgCSAQgBhgH+AcQCWAJ8AnQCeAJQAkgCQAIwAewBnAGeAVABRAFQARYBIwDtAOUA3QDbAMQA9AD9AMQBCgEkAMIA9AC/AOoBZAHoArQC8AMkA0gDnAP4BBgEoAT4BOAE0AS4BHgEaARgBHAEGAP0A1ADNAKUAl4B4gFjAMcAfr+LP0g+/j4EPfQ9BDzcPHg7yDuAO0g64DpYOiA58DmYOZA5iDm4OUg5uDmgOfA6ADqQOug7EDu4O+Q8XDzQPXg9qj4gPpk/B7+EADQAVgD2ARYBogHcAhwCcAJMApQCkAK8AmQCRAJYAjIB9AG0AXYBWgFkATQBIADdANYA5ACIAPgAqADqAM4BCgEoANQA/gCQAR4BfAHcArgC3AN4A2wDlAPYBAgEsASIBSgE4ATwBLAEoASYBLgEeAQ8A8ADqAMQAoACaAGUAR0AigAeP7Y+6D5oPdQ9cDzIPJQ8CDvYO2A6wDqoOig56DmIObA5UDlAOVg5cDlAOeg5wDpQOpg6wDtwO5A8BDy8POA9WD3QPkQ+/T8Kv/qAOwCgAT4BTgHQAggCTAK0ApwC7ALcAsAC6AKMAqACWAJUAhQCFgH4Aa4BuAFOAbYBDgFUARQBCAEGASgBEAFwASgA3ADPALIAxgF8AfACuAM0A1QDjAOIA4gDyAQwBGAEuASoBKgEiASoBGAESARYBAAD4ANQAwgClAIQAZgBGgCXQBQ/oT8gPpQ+KD20PSA89DxIPBg7mDsoOpA6SDogOdA54DmIOYA5qDlIOYg5+DnIOnA6sDrwOyg7eDuEPDw8bDzwPXQ91j5KPvg/Lj+fgB8AiAEgAWIBlgHEAjgCJAJYAqwCrAKsApACuAJsAkQCXAIMAggBzgHcAaABggG2AUABsAE0ARYBDAFoAVgBWgFKAQ0AwwDkAP4BaAIUAvADCAOgA0gDRANcA0gDpAPYBDAEEARoBDAEGAQ8A9QD0AOQA2wC3AKwAhoB9AFEASUAucANf+c/eD7EPqI+MD2wPQw82DxwO+A7iDtAOxA64DqgOkg6eDoYOhA6GDoAOnA6WDqYOtg7CDt4O3g7iDwkPEw89D0cPYg+ND5cPtQ/fT+eAD+AewC+APQBNAF0AbYB4AIEAlACUAJcAkgCTAJ4AhwCBAIuAdwB4gHGAc4B1AGcAbQBegFYAaIBuAHMAcAB7gFEAQEA/ADOAXwB/AKwAwADhAOwAwwDLALIAyQDMANsA4AD9APsA/gD5APwA7gDTAM0AqgCUAIMAdgBlAFEATQAiYBjP+k/Rj8mPog+dD3EPZg9LDyAPHA76DuIO6g7SDtgOyA6wDrQOqg6aDp4OmA6mDrQOxA7eDtoO5A76DvkPCw8eDyoPTQ9VD3kPgA+mD7jPz4/Rr/SgAYARgC7ALIA6gEcAVQBpAG8AYIBwAHAAcoBygHgAeAB8gHIAjgB+gHYAcIBwgHwAbQBwAIoAiACOAHoAcgBrAF6AXwBoAIcArAC5AMkAwADFALoAqwCsAKUAsADNAMgA3ADXAN8AzwC8AKUAkgCCgHiAYYBqgFKAU4BOgChAHn/2D+qPxQ+9j52Piw97D2APbA9ODz4PLw8dDw4O8g70DuwO1g7UDtIO1A7WDtoO3g7UDuoO4g78DvcPBA8QDy4PLg8wD1IPYg94j4qPnI+gD86PwS/uT+5v/RAKwByAJIA/gDUAToBFgF2AVoBrAGKAc4B0gHgAewB5AHuAeQB9gHwAfgB/AHAAhACDAI6AcACGgHgAcwB2gHyAf4B+AIQAkgCjAKsApQChAK8AnQCfAJMAqwCvAKQAtgC0ALAAuwChAKgAngCCAIeAfwBhAGmAUQBWAEuAPUAqoBlgAk/7z9ePxg+3j6wPkI+Xj4wPcA9yD2YPVg9IDzsPLA8TDx8PCg8ODwAPEw8VDxYPEw8TDxIPEw8aDxUPIA87DzcPQg9dD1YPZQ9zD4EPnw+cj6iPtA/Cz9yP2G/nb/3/+iAFQB4gGkAjQDmAPkA2AEwAT4BIgFCAaABhgHKAeAB7AH0AcACPgHIAhACGAIcAigCHAIcAhQCKAI0AjQCCAJYAmwCSAKYAqACpAKMAoAChAK0AkwCmAKoAoAC+AK4ApQCvAJMAlgCAAIWAfwBlAGAAZYBdgE3APgAt4BbgBm/07+gP20/Az8SPuQ+pD5mPig98D28PUw9bD0IPTA83DzIPPQ8nDyUPIg8vDx0PHQ8cDx0PEA8jDywPIg85DzAPSQ9ND0UPXg9XD2QPfg98D4uPlY+gj7sPtE/Cj9uP2U/kX/HwC/AFQB9gGoAvQCtAMYBKAEGAVgBcAFSAaIBuAGGAc4B4gHqAfAB+AH+Af4BxAIQAhACEAIcAjwCOAIkAnACeAJQAoACmAKQAqACqAKsArQCvAKIAswC0ALIAsAC5AKQAqwCTAJwAhQCNAHeAfYBkAGgAV4BLwDlAKiAboAzP8P/0z+ZP3I/AD8SPtw+qj52Pjw9xD3YPbA9WD14PSw9FD0wPOA8xDzwPKA8lDyQPJA8mDycPKw8hDzUPOw8+DzIPRg9ND0MPXQ9VD2EPfA91j4+PiI+RD6gPoI+6D7KPys/Dz9rP1q/ub+oP8MANgAKAGoASQCcAL0AiQDuAMoBJAECAVgBeAFIAZIBlAGSAZQBoAG0AYwB2AH4AcgCEAIkAjgCDAJYAmwCfAJIApwCnAK0AoACzALYAtgC1ALQAsgCxALsApQCvAJkAkQCZAIEAh4B9AGIAZYBagE+AMoA1ACbgF9AJ7/xP78/TT9hPzA+/D6IPpY+aD48PdA97D2APaA9QD1kPQw9NDzkPMw8/DysPKw8qDycPKw8tDyAPNQ84Dz0PMg9HD0wPQw9cD1MPag9jD30PdI+Oj4cPkQ+oj6EPtw+/D7lPwQ/fD9aP4c/7b/NgDZADwB0gE0AtwCRAPIA1gE0ARABagFEAZwBqAG0AYQB0AHaAfIB/AHMAiACIAIsAjACPAIQAmACdAJEApQCoAKoAqwCsAK4ArQCvAKAAsAC/AK0AqwCoAKQAoACrAJUAngCGAI0AdQB8gGMAagBfAEUASQA8QCGAJoAY8A3/8k/3T+nP3I/Cj8YPu4+gj6YPmw+PD3UPew9hD2wPUQ9eD0gPQw9NDzoPNw81DzQPNQ83DzcPOg8+DzEPRQ9LD0EPWA9eD1QPbA9iD3YPfg92j42Phw+fD5cPrw+lD78Pto/OT8XP3o/Zb+KP+2/0QA2wB6AeoBcAIMA4gDCASIBPgEcAXIBTAGeAboBigHKAdIB2AHkAfYB0AIYAigCKAIwAjgCPAIEAlgCZAJwAkACiAKIApACiAKMAowCiAKEAoQCtAJcAkQCdAIcAgQCKAHIAfIBjAGoAUIBWgE3AMMA4AC7AFYAbwAKQCd/87+Mv5w/eT8RPyo+wD7gPoQ+mD52PhA+MD3cPcQ96D2QPYQ9pD1YPUg9QD10PTA9ND08PQA9SD1MPWA9dD1IPaQ9uD2QPeA99D3MPio+CD5oPkQ+oj6EPtQ+9D7IPyI/Aj9fP34/Yj+Bf9s/wUAUQDeADYBoAH8AXgC9AJsA9QDGASIBMgEKAVQBZgF4AX4BTgGUAZ4BrgG0Ab4BggH+AYoBygHaAeAB7gHmAe4B9AH8AcACCAIQAhQCGAIgAhQCEAIEAjoB8AHoAd4BxgH4AaABiAGwAV4BRAFqAQYBHQD+AJ4AgQCkAEyAZ8ADwBb/67+HP6U/SD9nPwc/JD7EPuA+hD6mPkg+bD4QPjQ94D3YPdA9yD38Paw9pD2cPaA9oD2sPYA9zD3cPeg98D38Pc4+Ij44PhA+YD52PkY+lj6qPoA+3D7yPsA/Cz8XPyk/BT9uP1I/qb+9P7+/jb/kf8JAIMA5gAyAW4BGAKUAhQDBAPkAuwCTAPUAygEwATgBAAFCAU4BVAFSAVYBWAFuAUQBqgGEAdQBxAH6AbIBigHmAfwB0AIcAiwCKAIsAiACIAIkAiACKAIwAiACDAIEAioB5AHSAfABiAGgAUgBdAEcAT8A2QDgAKiAcEAYwAyAO//P/82/lj9xPx0/PD7YPvY+nj6CPqA+QD5iPg4+OD3sPeQ94D3YPfw9qD2cPZg9rD2EPeA96D3cPdA90D3oPdY+Bj5gPmo+aD5yPlw+jj7mPsw+5j6CPtc/OD9tP68/mD+AP7Q/ez9vP64//MAzAHUAYgBJAHhAPUAKgGsARgCgAL8AjAD4AIgAvQBJAKgAqgCKALQAdQBoAJYA5gD+AJQAlwC8ALwA3gEcAR4BFgEqARoBfAFcAaABogGEAbABaAFOAYQB2gHmAcgCDAJUAogC6AKIAlgB9gGQAiQCfAJ8AhQCNAIoAb6AZ8A+/9oBfgEOAJE/6j5cPiQ+Hz9Xv8O//D4cPOQ8HDwMPMA98j5OPgw9HDxoO9g7xDwAPJw88DzAPUQ9sD2MPXg8jDyoPFw81D2aPno+pj5IPhw93D3YPco+Pj48PnQ+zz9Of+x/zr+6PuY+tD6qPyQ/wACuAPQAuEACv9o/qj+xv+UARQDKATIAywD1ALMAoACvAJMA7AEEAbABrgHyAcACFAIIAlwCUAK8ApgDPAN8A4wD/AO0A7wDrAPgBDgEIARwBFAEWAQsA/QD2AQABBgDzAOAA0gC9AJMAlQCDgHgAW8AygCaABe/hz9yPuo+sD40Paw9MDzUPOw8gDy8PCg7wDuwOyA7CDtwO1A7mDuQO4A7kDtQO0A7qDvUPEA8yD0wPTg9CD1wPUg99j4mPo4/FD9UP7e/nv/EwDRAHoBMALUAvwDSAXoBSAGqAUYBcgEqAQYBbAF+AUoBngF4ARIBIwDKAPQApwC5ALQAkwCBALKAWABKAG/AAQBEAGSAbgBUAKsAnwC7AKAA4AE2ARIBWAGYAcwCLAIYAnACcAKYAuQDEANIA1ADKAMUA1ADlAPwA9gDxAOMAxQCqAJcAnACWAJwAiYBoQDIAFF/1r+zP24/Kj7OPrw96D1YPPQ8cDwYPCQ8EDwYO8A7sDsYOvA6sDqgOtA7ADtgO1g7UDt4Oyg7YDvAPGg8qDzYPTA9HD1QPbg9yD5QPvs/Nz90v5a/i7/DACaAbgC4APYBKgF+AVYBQgGoAUQBsAFoAaYB/AGiAZoBZAGAAY4BRAEUASABPADdANAA3wD+gFIAgACxAIQAiAB5gGIA2wDgALAAiwD6ASoBJAFsAZwBmgHEAjgCEAIQAgQCVAMwA0gDvAOwAzQCaAKIAxAD+AQIBLAEaANIAmABRgGUAmgClAM0Ap4BUwAcPws/Hz85Pxa/sj9yPrA9SDyEPCg7xDwMPLA8vDwYO4A7IDrwOmg6WDrQO2A7qDtIO6A7aDsoOsg7rDw4PFw83D0IPZQ9XD0sPVY+JD6sPvQ/V7/uv85/33/mAGMAoQDSAU4BwAI4AfQBggHGAfwB2AIIAmAChAK0AgACKgHmAaQBhgHoAdwB6gG8AXABKAEvAMYBDgEmAQ4BIAD8APkArwDqAMQBHAEAAU4BSAFKAawBtAGuAZgB0AIwAgQCUAK0A0ADVALsAhgCBALcAuQD6AS4BDACyAH2AXoBlAIwAogDcAKoAUeAIz9Hv6I/n3/FAGP/9j60Pbw9ODzEPMw86D0kPTA8iDwgO4A7eDr4OuA7WDvAO8A7uDtoO3A7ODsIO6g8KDxIPIg87DzUPMQ83D0kPbw+LD5APuU/RD88Pso/Rb/NwDYAUgDyASABeADgAQgBdAFaAYYB5AIcAiwB4AHgAfwBugGOAdABxAHwAbYBiAGSAVwBUAF4AQ4BKAEcAUwBfgDYAMABEAECASYBOgFEAYABlgFQAYIB1gGMAbQB5AJUAnQCMAIoAuADNAKQArwCbAJsAogDYAQoBCwC9AI6AYABvgHsAgwDNALCAcwAcT+yP2C/nwAZgHdAIT8wPcQ9SD1QPWw9MD1wPWg9GDxgO4g7mDu4O2g7sDvoPCA78DtoO3g7eDtgO7g7zDyMPNw8oDyEPMw8/DzEPVg97D5oPqI+iD7yPvQ++D8/P5WAVgCkAKYA+QDnAO8AxAFqAYAB1gHIAjAB2AHmAYYB9gH2AcACFgHkAegBhgG4AV4BngGuAXQBLAEgAXgBIgEeAQ4BGgEQARwBKAEKAUABfgEkAUYBYAFcAYoB0AIiAf4BqAG+AcAC/AL8ArgCNAHgAjQCPALAA+gDnAM8AdwBpgFcAewCNAKIAtwBoACZv+s/24ADAEJAG7/WP1w+SD40PYw97D1gPTg9bD08PMA8UDwwO9g7sDuoO/w8DDwgO8g70DuAO6g7pDwsPFQ8qDyQPPw8sDyEPRw9eD2gPcw+dD6wPrw+kD7oPzA/bT+fACIApQCgAKAAkwDkAP0A9gFuAbwBxgHCAbABkgGiAboBkAIAAiAB6AGsAaQBqgF+AWYBrAGYAawBWAFMAVYBVgFWAVQBegEKAXIBfgFIAY4BjAG0AXoBbAGUAjACOAIoAjIB2AHqAdwCpANUA1ACiAI6AdQCSALsA3AD0AOsAj4BKAGyAbgCJAJEArgB3wCQwDh/xoBkAA4/7T+rPyQ+ij5QPng91D1MPRw9KD08PMw81DyEPBA7iDuYO+w8ADxcPDg78DuoO2A7kDwsPFg8pDy8PLg8tDycPMQ9YD2QPdI+Gj5KPpA+rj6VPxU/Sj+bP+nAL4B5gEkAiAD6AMwBLgEwAW4BrgG4AaoBgAHwAaQBvgGcAfAB3AH6AaABjAGuAXQBWgGaAZYBngF+AQIBdAEEAUIBbgEOAUABWAFIAUIBYgF6AR4BcgF6AYIB1AG+AYQByAHuAbYB/AJoArwCLgH4AgwCfAIYAgQC3AMEApACZAIAAj4BWAEGAZgCQAIkATeAawA9v78/cb+rf9IAFz8gPnQ98D2gPaQ9dD2kPaw9LDyAPGw8KDwYPAw8DDwAPFw8IDvQO8A74Dv4O/A8MDxgPKA8hDy0PKQ82D08PRQ9pD3cPgI+bD5iPoo+5j7/Pw6/rr/FwAAAUoBngEcApAC3AOgBFgFQAVYBXAFqAXIBRAGeAaIBoAGKAY4BggGiAaYBbAFYAWYBdAF6ASQBdgEIAXYBHgEcASIBAgFYAU4BfAEUAUoBeAEUAXgBRAHYAZABmAHwAfIBjgGqAewChAKoAhgCOAI0AmQByAJsAvwCrAJYAnwCdAI4AaYBAAG+AeYBmAGOAWcA7///Pzk/Zv/SADy/gT9cPoQ9xD1QPbQ9zD4gPYQ9NDyYPHw8JDxIPKQ8RDxMPBQ8BDxcPAw8JDw4PBg8SDyAPMQ9AD0oPOw85D0cPZA98D4wPkA+hj6EPoo+/z8Mv44/zcAvwAIAe4AxgHcApwDaATwBPAFwAWQBYgFEAbQBjAHGAc4BwgHaAaoBtgGCAfgBkAGQAYoBpAFgAXIBRAG8AU4BdAEoARIBOAEaAWwBZAFiARwBHAE8AToBTAGQAbwBQAGEAZQBrAGgAfgB6gH4Af4B9AI+AdQCPAIEAnIBwAIgAnwChAKGAdYBogF2ANYBNgHMAjgBdgBtP7G/pz9rP5IANQAMP5I+XD3IPeA92D3CPhg+ED2EPMg8sDyYPJA8lDywPIQ80Dy4PGA8RDxsPDA8VDzsPQA9YD0wPOQ8/DzUPWA9+j4kPko+Yj4sPiA+Vj7tPzI/Tr+iP6O/rb+Y/+FAGAB+AGgAiADUAM4A4AD2ANIBJAE4ARwBXAFWAXIBGAEmATwBDgFgAUoBfgEQAQABCAEUAR4BGAEUARABOADzANYA9QD+AN4BHAESARABGAEwAR4BMgEUAUQBggG4AUIBtAGiAboBJgHYAjQB5gHoAfQCJAHcAVwBoAI0AmwCAAIEAhgBSgDOAOQBQgHmAXAA+4BjgBg/vT9P//m//b+KPzA+sD5+PhQ+AD4EPjg9vD1EPUQ9RD1oPPA8vDxkPKQ86Dz8PPQ8vDxkPFA8dDygPSw9ZD1cPRA9ID0IPVw9hD4cPmQ+Sj5SPno+bj6uPu0/AL+sv4f/zf/S/8kAK0AjAGMAmgDyAOoA3QDxANQBPAEYAXgBSgGsAVIBQgFaAWwBcAFAAb4BYAF4ASYBOAE2AQABcAEoATABIgECAT8AzgEWARQBCgESATABLgEeASoBFgF+ASIBOAE4AX4BvgFeAVIBtAGCAagBegH8AiwCPAGqAZACIgGWAWwCEALcAmIB0gEoAV4BUgE6AV4B8gGegF9AI4BpAE7AML+HP86/3j8ePpc/Ez8wPlw98D20PeA9yD3MPfw9lD08PHg8oD0UPUw9VD0gPPA8hDy8PKg9DD1IPWg9XD1IPWA9WD28PZg9xD4UPlo+mD6iPoI+zD7wPvo/OD+8v+b/zL/kP+JADABFAIkA5gDdANkA5wDUASIBMAEGAVQBVAFUAWABXgFCAW4BOAEOAWABWgFSAWYBMgDlAMYBLgEqARIBOQDfAMMA9gCRAPEA9gDhAMkAyQDUANMA4gDGAT8AxAEIARIBNAE8ATIBBAFYAW4BRAGcAawBlAGKAZIBsAGEAdYBzAIaAd4BqgFYAVwBngGoAWwBdAEYAH8AGgCwAT8AsT/dP6E/Qz9qPuo/VH/LP0Q+WD2cPjo+MD3ePjQ+OD3cPQg86D08PYA9sD0gPTw9PD00PPw9ID1cPXw9FD10PZw9zD3YPZw9sD38Pjw+Xj6EPsg+4j6gPpE/Pj9Nf9G/6r+mf+j/wAA7wBAAvACUAKcAiAD3APoA6gDCARwBMAE0AQIBQgFwAQoBHAEwAQIBTgFyARIBKgDuAPsAygEWAQoBKwDAAOIAuQCaANsA5ADNAP8ApgCjAJoA/wDMAS8A3ADkAO4AyAEmAT4BGgFOAUIBXgF2AVwBigGCAaQBvgGEAfoBqgHgAdQBiAFOAZACOAHKAZwBGwDVAIIAhQDiAXYBL3/gv6A/OT8ZP30/cL+0PzA+TD3cPfg9yj48Peg98D1UPQg9JD0EPUA9NDzwPNQ8/DzYPTg9BD0APNQ8/D0QPaQ9gD3APeg9jD2YPdI+ej6WPsw+1j7gPto/GT9XP7G/xoAJACLAGYBxAIAAwwDbAMIBOgECAXQBYgGYAbYBagFcAYQByAHCAf4BrAGSAYwBngG0AaIBhAGkAUwBTgFcAWYBTAFkAQwBBAEIARQBFgEOAS4A1QDmAPwAyAEQAQwBBgE4APYAygEwARABUgFEAXQBBgFeAXYBfgFQAZYBrAFyAVQBugGuAawBYgFCAbYBZgFoAWoBeAEkAKAAawBTAKEAmIBugHX/8j7oPqY+3j9qP3o+7j6YPlQ9oD1cPZo+Ij4gPaQ9aD0APQw86DzMPVA9TD0sPMQ9HD0sPQg9FD0IPWg9aD2APfA96D38PaA95D4gPpw+wD8LPxc/Fz8yPw6/m3/zAAoAXwBvgG6AUgCMAPsA6AESAXABSAG8AXIBTAGGAaQBjAH8AfYB9gGSAZABigGKAaIBtgGAAeQBQgFGAXgBOAEkATYBLgEOATUA5wDzANsAzgDPANwA3gDfAN4AzwDIAMgA1QDuAPYAwAE+AMYBDAEOARwBJAEIAUwBcAE2AQ4BTgFIAUABcgFMAWwBKgDGAVYBUgE6AMUA7QCXADC/5wBxAJ+Adb+0P0Q/DD7IPvw+1D92PvI+TD3oPbQ9uD2oPdA9+D2MPUw9MDzUPTw9ND0gPRQ9BD1IPWg9MD0gPSQ9cD1MPZQ9xj4APgw92D3kPj4+aj6OPvg+xz88PtM/Fz93v67/8H/+f/RAIYBxgEYAsACwANYBDgE+ATwBYgFKAU4BUgGCAeoBpgGOAfgBjgGMAawBmAH2AZwBogGSAboBZgFEAZABsgFaAUYBUAF+ATABPgE8ATABJAEgARwBHAEaARYBLAEqARgBDgEQASgBOAEiAR4BIAEiASYBJgE8ATgBHgESASABLgE4ARYBOgDEASgA0ADIAPUA6gD9AGMAJT/5/85AIT/4v8RAOj8OPoA+kj7cPzY+vj5qPnQ9zD2gPVg9zj4sPUw9bD1YPWA9GDzIPXw9ZD00POQ9OD1gPWw9PD1MPbw9TD2YPfY+Oj4cPdo+Mj5+Pmg+oj7lPyY/ID8lP2G/sD+W/+w/z4BtgECATgC5AIUA3gDlAPABAgF4ASIBQAGyAVYBWAFuAYAB4gGgAYYBigGCAYoBrgGMAagBagFmAWABWAFKAUwBbAEMATIBKgEaARgBFgEaASEA4gDEARABKAEMAQgBCAEuAPYA4gEEAX4BLgEiATgBDAFaAWYBaAF8AVwBVgFyAVgBlAGuAUABUgFyAUgBTgFqAWgBJQCNgFcAVQCcAIAAvQAtP8A/WD7IPxI/XD9RPzg+mj5OPgA9zD3IPjg91D3IPbQ9TD1YPTA9LD00PQA9RD1MPXw9ND0kPTQ9ED1YPZQ93D3QPcw94D3CPjw+Ej68Pow+2D7wPuc/Ej9qP20/mz/7/9SAEQB5gEIAjwCtAKwA3AEwARQBbgFkAX4BDgF8AUgBxAHCAeoBlgGCAbIBbgGcAcgBzgGEAbwBXAFcAXwBTgGkAXIBMAE4ATABGgE2ATQBDgEnAMQBMgEgATQAyAESAT0A8QDGATwBHgEtAMABGAEMAQYBGgE6ARoBKADoANIBEgECARABMADAAM8AowCTAPIAiACGAFRAJ7/Iv9k//r/Gf90/WT8kPv4+gj7iPso++D52PiA94D3oPfA9wD4APdQ9sD14PUw9gD2EPYg9gD2sPUA9rD20PZg9mD2QPfA9wD4mPgQ+Vj5YPlQ+UD6gPvg+zj85Pwc/RD91P2o/tP/OwBJANIAFgGAAfABzAKsA7gDuAMQBJgEWARgBDAF6AXIBVAFcAWABYAFCAWwBQgGAAZwBRAFYAUABZgEmARoBTgFiARYBCgEGATgA9QDOARIBAgEvAO0A4ADTAMcA8gDCAQgBBAE2AN0AzwDdAPEA0AEcASIBFgEzAO4A7QDMARIBFAEsATABNQDbAOEA+ACcAJYAkADeANgAnEAq/89/wj+mv6r/6D/CP54+4j6gPpQ+gD62Pqo+uj4wPbA9nD3oPcQ98D28PYw9hD1QPWw9hD3EPaw9VD2sPaQ9hD30Pdw+PD3kPew+Pj5CPoY+tD6ePsE/Nj70PzY/Xb+zP62/oD/WwDrAEIBzgGEAgADsAIAA1gEAAXABGAE4ASIBagFWAXQBYgGKAaQBZgFMAYQBtAF2AUIBiAGcAXgBFgFYAU4BRAFsATYBIgEIARoBJgEKAQ4BAAE4AOQA4wD8APUA9ADlAPEA1wDUAMsA7QDvAM0A2wDMANcAxgDKAN8A5ADJAMEA+ACXAKcAogCyAJ4AkwC9AHTADgAVwB8AM8Am//s/lD+tP3s/HD85Pyo/Jj7WPpw+pj6wPnA+Lj4CPkQ+DD3sPdw+BD4cPYg9gD3QPcA94D3ePgA+ND20Pbg98j4GPlI+fj5CPrY+cD5kPqw+yT8mPzA/Az9aP38/WL+ZP5J/+f/OgB5AMUAfAGEAVABngHUAoQDQAMMA5wDMAR8A3ADQARoBUAFOASoBDAFGAVwBOgEyAXIBdAEkASQBdgFAAXoBJAFsAUYBcAEeAXgBZgFAAVYBZgF6ASwBOAE4AWgBTAFQAVIBcgEeATgBLgFqAW4BIAEUAQQBBAEcAQYBZgE0APgAlACFAKAAlwD5ALKASgBVgC7/2n/wf8YACH/pP0o/Uz9+PzI+5j7uPv4+rD5WPkQ+gD6uPjQ97D3sPcQ9yD38Pfg9xD3sPXA9ZD2oPbQ9iD3oPfw9mD2QPZA9wD4OPig+OD4GPnQ+Dj5IPoQ+6j76Pt8/OD8NP2I/U7+OP/1/0cApgBKAVoBOAKIAjAD5APgA5gEEAUIBRgFgAUYBmgGsAY4B1AHwAZABsgGQAewB5gHyAcQCPgGCAYYBtAGWAdAB7AGkAbIBbgEwARABfgFUAW4BEAExAOIA7gC6AJgAxwDtAIsAjQCrgF2AAIAbwCaAHcAdQAdAJ//Mv4k/Yj9Kv5i/jD+MP6E/Tz8OPtQ+0j8bPwM/ND7wPuI+3D6IPrA+lj7IPsA+1j7gPvA+qj5KPoQ+1D7OPtw+1j8yPuQ+pD64PvU/NT83PzM/YT98PwA/Sb+Qf8V/0j/rP8fAAMAAgB0ACgBogDiAIQB/AHaAbIBiAHrAKsA3ADuARACjAEIAVQAwv81/3n/WwBoAKj/U//A/uD9WP2I/Yr+nP4O/qT9cP0U/eT8LP38/Qz+WP1E/eD9bv5u/tL+qP+B/97+c/+eAAwC1AJsAswCvAKwAmwDcAUgBxAHsAYQBiAGiAaIBxAJIAqwCeAIgAhACEAI0AgQCSAJ0AhwCCAIiAc4BpAF4AVwBcAE0ASoBKwD2gGFAHcA1AA0AIn/mf/E/iz98Ps0/BT96Ptw+jj6UPrw+Qj5UPlo+Sj5YPeA9oD3CPjA92D34Pfw9yD3QPbA9mj4APlY+Fj4ePmw+Sj5KPmY+tD7oPtY+7z8Dv64/RD94P01/6T/2P9aAOYB3gHyAPoAwAGgApQC7AKAAzgEvANMA/wCJAO4A9ADaAS4BKgE7APAA0gDwANYBLAE4ARIBGgE4AN8A6wDGATYBNgE/AMYBGAEpANIA0wDCARoBBgEzAOwAxADnAIIAtgCVANYA/QCSAIIAoAB2AD+AJoBIAKeAU4B4ACLAO//av+Q/xcAxQAMAK7/Kv9q/gr+CP7O/n7/iv+S/uT9vP1E/QD9mP1o/r7+xP3c/LD8iPxI/Bj8sPzQ/Ez8qPto+2D7kPpA+nD64PoY+2D62Pl4+VD5MPlo+aD5CPro+RD5APkY+YD5qPnA+Uj6OPro+eD5kPo4+0j7cPuI+8D7HPyc/HT9BP4M/jz+wP7y/mP/cAAiAeIBtAFAAvAC6AJAA6ADEAWABWAFmAWABoAGQAawBsAHkAiIBzgH8AdACBAIQAiQCZAJoAhQB4gHcAiwCDAJQAnACPAH+AY4B9gHEAjoB2gHsAYwBiAGYAbQBaAFGAVYBNADYAPcAxAE4AKqAcYAfwA/ADYAfgAFABD/RP1k/IT8QPw4/Dz8CPzI+nj5SPh4+Oj4sPio+Cj4kPeg9iD2UPaw9gD38Pbw9tD2kPZg9sD2UPfg9wD4CPjI+Cj50PkA+lj6MPug+2D8fP0+/pr+5P6u/68AogGAAlgDAAT4A2AEMAWABlgH+AewCIAIEAggCBAJIAqwCiAK8AnQCTAJQAlwCfAJcAnACBAIkAdwB6AGOAYwBrgFEAVgBPgDeANUAlwBKAEGAZoAagDr/0b/DP68/IT8vPy4/Hj8bPzY+8j6oPlA+cj5yPmQ+YD5ePlI+Vj4sPcg+Oj4+Pgo+XD5qPlA+Wj40Pjg+Xj60Pog++j74Psg+xD7SPx4/cz9zP2i/tT+eP6C/kL/RwCQAJ8AHgGQAWYBOgFQATgCCAJgAswCTAMIA5ACjAJwAqwCxAKgA8QDRAPcAnACVAIkAjACyAIgA4QCIALCARIBoACfAEYBggEAAYMAPQD1/63/cv/f/+r/V//y/hH/bv9b/wP//v7c/hb+Ov6W/lf/4f/+/mT+Dv4O/lD+O/8jAB4Ajv+U/kj+rP5+/z4ACAHmAFcAFwDW/+n/lgAKAVwBnAGqAY4BdAH8ALoAaAG8AaIB6gEQAtoBYAHBALcAPgFYAe8ADAEOAcsAZAAdAGMA+P8k//7+S/+z/3z/SP/K/pj+0P0I/VT98P0w/hT+4P2I/SD9gPxE/PD80P3U/aT9xP2s/Xz9MP14/WD+9v7Y/jD/t/+1/2D/o/8/AOsAggGeAVwCoAJoAmgCoAIAAzwD3ANABNgEyASIBAgE2AMoBKAEMAVIBVgF2ATABEgEWASoBPAEKAWoBIAEQAT8A+ADzAPoAyAEjAM4A0QD1AJwAggCCAIwAhACigEwAaYAdQDX/8z/xf+v/3X/wP5G/uz9cP0U/QT9NP3k/Kj8GPzA+1j70Pqw+tD6QPvo+nj6CPqI+Vj5aPnY+Sj6OPrQ+WD5QPko+UD5yPlA+oj6QPoA+iD6SPqY+tj6WPuo+8j7+PtA/JD8oPwQ/az9Lv6g/tL+D/9V/63/PQD4AFwBwAEYAjgCgALMAnADEARIBIAEqATIBAAFUAXABQAGAAbwBfgFIAZIBngGmAaABkAGKAYABgAGKAYIBigGuAVYBSAFqASIBCgEEATgA4gD7AK0AkQC4AF2ARAB7gAwAIz/Sv8S/9z+fP5a/sj9EP1c/Pj7GPwQ/Aj8uPsg+5j6KPoY+hD6CPoI+uD5ePlI+Uj5iPl4+WD5WPlI+VD5cPnY+Vj6SPo4+hD6MPqQ+hD7yPsg/GD8KPwQ/Gj81Pyg/WD+5v7o/uT+1v5M/wYAjAAkAWYBlgGmAdwBTALMAmADpAPMA9QD+AM4BMAEIAVQBVAFMAVgBZAFCAYoBjAGUAYoBhgGOAZIBmAGUAZYBlgGMAYYBugFyAVoBSAF6AQQBfAEqARoBMADGAOYAmwCXAJAApwB/AB6AOP/iP8s//r+hP4C/mj91Pyg/FD88Puw+2D7CPuw+lj6KPrY+Yj5WPlQ+VD5ePl4+WD5IPnA+LD48Phg+dD5OPpg+lj6OPpY+tj6SPvQ+1j8vPwc/TT9bP34/cb+Z//j/0IArAAEAUYBvgFsAgQDeAPAAygEaASIBKgEMAWwBfAF6AUYBkgGUAZYBogG0AbgBsgGyAbYBsgGoAZYBpgGWAZoBlAGSAb4BXAFGAXQBNAEoASgBEgEuAMwA6ACTAIAArYBhgFQAbAAHACP//b+iP4q/uj9lP0I/ZD8IPzQ+4D7+Pqo+kD6yPmA+Wj5iPl4+Sj5uPh4+Cj4OPh4+Oj4IPnQ+Ij4aPjI+Dj52Plw+pj6YPoY+kj62PrQ+4T8HP1c/VT9iP3E/Rb+rP5Q/+3/fADXAA4BTAFuAZIBEAKcAvgCcAPcAxAEIAQQBCgEmAT4BPgEIAVwBbgF4AXQBcAFmAVYBVgFiAX4BRgGAAawBVAF4ARoBDgEcASoBJgESATUA2AD3AJsAkQCYAJIAgQCwAGEATABuQBEAAwA+v+9/6T/mf9m//L+jP44/gj+Bv7c/eD95P2o/VT9AP2o/IT8qPy4/PD86Py4/FT8GPwQ/Cj8ZPx0/Jj8mPy4/KT8qPzA/OD8FP0M/Tj9hP3Q/QT+Ev4g/lL+Uv54/sT+CP9K/2H/jv/E/+j/7v8TADMAmwCpANkA+wAuAWYBXAFmAYQBoAGwAcYB/gEYAkwCOAIgAhQCBAIgAkQCiAKAAkQCCALcAeYBAAIMAiQCKALuAaIBbgFkAWgBfgGAAXABMgHxAN4A1ADIAJ8AjAB8AGkAUgAzAAoA2//L/83/zf+//5f/aP81/xD/E/8y/y7/Hv/2/rz+oP6O/p7+wP68/p7+dP5G/kD+Xv6K/pj+fv5M/jD+PP5g/ob+pP6Q/nz+cv52/or+tv7C/vj+2v7Q/ub+8P4F/+T+9v4O/yP/Dv9O/13/YP8//yL/c/9o/1n/Z/+D/5v/r//2/w4A7f+V/23/s/8FAD4AUQBOAFQALwAUAAwAJQBRAHUAgwB+AIEAnQCEAHsAdAB0AIsAlgCvANwA3AC9AKAAoQC3ALgAvADOAPkA/gDXALoAswDDANwA4wDYANcA0gDVANMAuQCsAKUAogCXAIAAdwCBAJcAjgBZAB8A+v8AACEAIAAWAPb/zf+n/5H/mv+W/5j/i/97/2b/Xf9i/2j/Yf9H/0D/Rf9Y/2T/bv9c/0v/O/9I/1z/b/+F/3X/Z/9S/1P/Zv+D/3v/eP+C/4b/lv+O/4j/kP+Z/5j/nf+1/9j/2P/M/9f/4f/p/9z/+v8TACoAIQAjAB8APgBJAFoAbwBNAGIAYQCHAJwAmQCpALoAtACmAMMA1gDYAM8A2wACAfgA2QDWABIBJgEYAfgABAESAQYBBAEgAUQBNgECAegA9ADsAOcA6gAEAQwB8QDFAMIApgCTAJ8AsgC1AJsAggB7AHwAaQBSAEsAPAAvACoAKgAaAAcAAADl/9z/wf/B/7f/r/+l/5L/g/99/3n/dv9t/1r/Uf9Y/1T/Of8v/zf/Pf87/zf/Mv8v/yj/J/8w/0T/P/89/zT/NP89/0n/U/9T/2X/Zv9o/3D/a/94/4P/hf+a/7b/w//K/7//sf/E/97/7//w//7/EQAVABgAFgAYACAAHgApAD0ATgBOADkAMQA2AEcATABKAFAAUwBUAEAAOwBNAFoAWQBIAD4AQgBMAE0ASQBNADwAIQAWAB4AKwAzACYAGwAHAPP/5f/i/+j/3P/V/8T/uf+0/7b/rf+d/5f/nf+g/5H/jf+T/5r/kf+H/43/m/+i/6H/mv+d/5r/nv+o/73/xf/F/83/1P/V/9D/3f/r//r/+v/6/w8AGwAhAB0AIQAeAB8AJAA0AFUAXgBUAEgASwBTAE4ASQBlAHQAeABxAGcAbgBvAGcAXQBiAGIAbgBuAGoAaQBiAF8AUgBYAFkAWABQAFMAWQBiAFUASgA9ADoAPwA8ADsANQAvADIAMwApACcAKQAjABoAFQAPAB0AFwAcABMAEQACAPj/CQAPABwABAAFAAAABgAHAPz/AQD8//7/9//5/wsAEAADAPr/8P/9//7/+P8JABkAFQALAAUABQANABIAGAAbABsAIgAhABkAGQATAB0AHwAtADQANgAuABwAIAAZACUAMAA0AD4ALwAsACAAJgAoACQAKwAqACsAKAAfACoALAAhABUADgAVABYADgAIAA0ACAD9//j/BQAKAPz//P/3//3/+//x//7/BAABAPT/8P/5//7/+//+//b/7f/t//T/8v/7//3/6//n/+T/7P/x/+j/7//w//X/8P/x//L/8f/1//H/9P/1//v/AgAEAPv/9v/2//f/AAAEAA0ADgADAAAA/P8DAAIADgATABYADwAJAAcABQADAAAACwALAA0ACgD9//3//f8AAP//+v/t//P/7//s/+//8P/u/+f/3//W/9z/3v/f/+L/3P/X/9H/0f/U/9n/0//R/8r/vv/F/8r/0P/Q/8H/vP+3/7r/vP/B/8H/vf+9/73/w/+3/7r/uv++/7n/w//O/83/xf++/8D/xP/I/8n/1//X/8j/w//G/8z/zf/M/8z/1//S/9D/z//N/8//2//g/+r/6f/u//D//P/u//j/+f/+/w4AFwAeABwAHgAlAC8AMgA0AEAAQgBGAEEATQBSAFoAWQBZAFMAUwBTAFQAWQBYAFYAUwBQAFEASgBRAEMAQABDAD8APgA/AD4ALgAlABwAIwAmAB4AFAAPAAAA+f/8//v//f/1/+j/5P/e/9j/3//k/9//2P/Q/83/yv+//8T/z//R/8f/yP/L/8L/vP+8/8n/yP/I/8n/0v/R/8n/xP/S/9v/1//V/9z/4//s//L/9P/5//f/+P8AAA4AEQAWAB8AHQAeACMAKAAyADsAOQA7AD0APgBBAEQAQABGAEQASgBPAE0ARQBAAEAARABKAEMAPwA9AD0ANAAuAC8AMgAtACkAJgAgABYADAAQABIADAACAAAA+//v/+r/5//m/+D/2f/O/8j/x//D/8D/uf+y/7H/sf+r/6z/sf+o/6L/nP+k/7P/rv+m/6P/of+e/6H/q/+3/7j/tP+2/7f/tv+z/7z/yv/U/9L/1//b/9//3//i/+7/7f/0//z/BQAFAAEAAgAJAA4ADwAUABwAHwAcABsAGwAgACIAIgAlACUAKQAqACQAKgAlACAAJgAkACwAJAAkACoALwAwAC0AKwArACoAKAAvADMALwAsACkALQArACMAKAApACkAJAAdAB8AHQAbABwAGAAVAA4ADAALAAoADAAJAAwACgAAAAUABAABAP///v8EAAQAAwAFAAMAAgD///n/AQD+/wIABwAHAAQAAwAIAAgACQAAAAgACwAOABgAGAAdABMAEAAUABgAHwAjACUAJgAeAB4AIQAnACcAKAAtACoAJgAkAB4AIQAiACUAKQAmACAAIQAeACMAHwAcABgAFwAfABcAFgATABYADgAKAAIABAAHAP//CAAJAP//+v/x//n//f/7//j/+P/8//b/8P/1//X/8f/t//H/9P/w/+3/6f/t/+//5//i/+b/5f/n/+j/6P/o/+b/5//k/+X/6v/u/+7/6//v//L/9v/1//b/9v/0//f/9f/+/wUABAADAP//AAD+/wIABwAKAAgACAAGAAMAAgAEAA0ADwANAAYABgAKAAwACwAJAAoADAAMAAsACQAIAAcAAgAEAAYACAAFAAUAAAD+//r/+f///wAAAAD5//P/8f/y//T/8//u/+z/6//o/+T/4v/g/93/2P/Y/9f/1v/T/87/zf/M/8n/xf/C/8T/xf/C/7//vv+//73/vf+9/77/uv+5/7n/vv/B/8D/wf+//77/vf/C/8f/y//R/9b/2f/a/97/4v/o/+z/8P/1//n//P8CAAwAFAAUABQAFwAdACQAJwArADAANQA0ADQANgA5ADoAOwA+AEEAPwA8ADsAPgA9ADgANAA9ADwAOAA1ADUANQAmAC4AKQAxACgAJgAhABwAGwAXABkAFAAOAAcABQAFAAEA/P/7//T/8v/v/+3/7v/o/+P/4v/d/93/3f/Z/9j/0//S/9b/0//U/9D/zP/P/9D/0f/T/87/yv/O/9H/1P/Z/9j/1//X/9P/1P/i/+r/7v/z//D/7P/u//P/+v8DAAcACAAJAAoADQAPABEAFAAWABoAHgAeAB4AIAAgACAAIAAiACYAKQApACYAJAAjACIAJAAmACUAIwAkACQAIwAeABoAGgAbABkAFgAUABIADwAMAAkACAAGAAAA/f/7//n/9v/y/+7/7P/q/+f/5v/m/+P/4P/f/+H/4f/g/9//3v/g/+D/4P/g/+D/3f/c/97/4f/i/+T/5//p/+f/4//i/+X/6f/s//H/8//1//P/8//0//b/+P/6//3/AAADAAUABgAGAAUABgAIAAsADwARABAADwAPABIAFQAXABcAGAAZABkAGQAaABwAHwAgAB8AIQAhACMAIwAmACgAJwAmACUAIgAhAB8AHwAgACIAHgAYABQAEwAWABYAFQAQAAoABAAEAAQABgADAAEA/v/7//f/9f/0//T/8//y/+//7f/r/+v/7P/s/+z/6v/p/+j/5f/l/+P/5P/i/+T/5v/m/+P/3//c/9z/3v/h/+L/4v/f/97/3v/e/97/3v/f/+H/4P/e/93/3v/h/+D/3v/b/9v/3//i/+H/4P/d/97/3//g/+D/5P/g/+X/4v/n/+b/6f/u/+f/5//o/+//6//1/+//+v/z/+7//P/4//T/8//4//7/AQAJAAgACgAGAP3/BAAQABQAEAANABMADwANAAoADwAUABIAEAAPABEAEAAMAA0ADQAMAAsACwALAAsACwAJAAYABgAHAAgACgALAAoABwACAP7//v8CAAQABAD///v/+P/5//r/+P/5//b/9v/z/+//7P/v//T/9v/y/+//7f/v//P/8//0//T/8f/y//P/+P/5//v/+//7//z/+v/7//3///8AAAEABAAFAAcACAAFAAcABwALAA0AEQATABEAEAALAA4AEQATABIAEgAQABAAEQASABQAFAAXABUAFQAUABMAFQAXABcAGgAcABoAGQAZABgAGQAaABsAHwAfACEAHwAcABwAHQAdAB0AIQAiAB8AHwAgACcAJQAlACgAKgAqACUAJQAoACwALQAsACYAIwAfACEAHwAjACQAJAAaABYAFAATABEAEwARAA4ACwAFAAYAAQD///3/AAD///n/9//4//L/7f/i/+//5v/p/+X/7P/j/97/3//e/97/1f/e/97/2v/V/9r/3f/X/9b/2P/d/9r/3v/h/97/4P/c/93/6P/m/+n/5v/j/+3/7f/1//D/8P/x//b/+f/5//r//f8AAAIABAADABEADAAOABAACgAbAAwAFgAnACsAHwAXABgAGQAqACUAJAAeACEAHwAdABMAGgAlACcAGwAQABcAGgAPAAwAFQATABIACQATABEABAD8//3/BwABAPb/+//7//f/8f/2//z/9P/u/+r/6//u/+X/4//m/+b/4v/i/97/3f/g/9r/4P/m/+n/7v/s/+r/8P/x//L/8f/6/wEACAAGAAYABgADAAkACgAPAA4ACQAKAA4AFAAXABYAFAAPAA4AEAATABkAFwAXABkAEgAOAAwACwAUABYAFQAWABUAFgAWAA8ADAAUABkAFAANAAsADgAKAAQAAgAHAA4ACwAOABAAGAAPAAwADAAWABwAFgAXAA8AGQADAPr/+/8LAPj/6f/m//D/7P/f/87/xf++/6//pf+w/73/uf+8/7//z//P/8T/uf/A/7j/u//K/+T/8v/s/97/1P/M/8r/3v8EAAoACgALABIADAAHABEAIwArAB8AJQAqACwAIwAUACAAJwA2ADoAPQAuACUAJQAmAB4AJwA/AFsATwBSADsAQwAYAPn/5f/z//3/9/8OABEA/f/a/9f/4P8PAC8AUQBZAGIAVwBDAE4AXQB2AHYAaACDAIQAcwAlABsAPAA3AAAAoP8YAGQAMwB4/07/CwB+AO0AtAAKAE7+rP3Q/YT/QAGgAdoB3gCk/wD+FP5I/7sAFgGcAN//df/4/pj+IP/U/0wADwDJ/7v/yv9V/+j+G/8e/6T/tP+s/9v/0P++/0z/gv/P/0wAYgD0//3/SQBeACAA8v9hALYAAgHBANgASAFAAfAA4gAcATQBuwCcAD4BiAE+AbYAxwDPAIEAaADkAGABGAFfAE8ApQBWANf/5v83AJ4A7ACUAQgCMAGK/4L+GP6+/goAVALQA2gCnP8w/TD9Uv51/6AA0QC1/xb+FP0E/Xj9xP3Q/Tz9ZPxM/Az9iP7H/1AAmAAAALr+5P1e/vf/DgE4ASgB3gBjAFH//P62/94AyAE8AmwCKAI6ARIAjv9t//7/KgFgAswCBAKOAG3/Vv/h/50AQAFQAYAA2v9L/y7/5P5Z/zoAdgEeASsAL/++/pb+KP6Q/Yr+3v+eAKL/kv7u/ob+sP4g/qr+qv6k/pD+zv+tAM//Fv8z/wgAn//8/ywBUAHt/7z93P0K/ykA2wBgATQBn/9I/ib+8P6X/1kATgAVAPr/4v8iAIT/W//Y/wABhgFGAdgBZgFcAf7/Dv5m/joAkAJEA8wCiAE7APD+xP4SAGwBFAIYAsoB1gEMAf7/pf+9/8T/zv/qAAIBwgH8AYwBKQB+/mj+jv4AAKMAKgEQAR4AeP5I/sD+W//B/9T/Wv/G/nX/YP+b/2T9nP26/sP/Qv/6/wIBNgCw/iz9oP7f/woAKQBWAc4BWAC8/vb+l//E/wwAHALsAqYBUACc/vz+Rf+q/24BCAN8AkQA0P5O/kz/mwBmAXoB1QAsABsAoP+b/1QBDAPyAaD/yP4aAI4AXf/4/5QB3gHe/uT8rv6UAcgBagFSAXsAxv5U/Zz+jAD4Ac4BgwDI/uT9Mv7C/s7/DgFYAmgB+v6s/ST+Sv6c/Wz/zgF0AuQAwf8HADcAPP6o/XMAhAIUAtf/Jv7e/uT+sP3G/pABqAPuAUD9kPvA/Pj95P06ALgC8AL+/xj9Cv4JAC7/rP2A/rL/of/S/qEA6AKOAbz+mPss/Zb/SAIAA+YA2f8J/y4AXgDY/9QC0AMyALz84PuM/ywB0AL8AoACvgCg/QP/4AA4AQMA7P/oAQwC5AGkABcAnv44/Lz8LQC4A6gC7QC9/wAAKPzQ+hn/KAQYBDAAIv64ADwCEP64+jj8yv8wAqgC3ALsAvT+GPkI+iEAfANMAt7/8gAuAdD8qPxXACAEqQAP/4v/xgEDABT+QgDeASYBcP+6AEn/JP0Y/TYBGATEAgwBjANMASz80Pfg+3AEUAcIBIwAKv+M/lD9ev6qAbQDIAKk/fT9+wD8AI//Av9IApQCjP74+wL+TAFgAT4BBAKgAuj9QPuo/H7+NP9gAkAGsAYHAED4wPpc/n8AfgBoBOAG8P8o+Gj5KAQ4B24BTPzw/V0A2P0A/T4BoAaIBCz8GPmo/ZQDNANy/hD91P+5AJz/SgHQBUwD+Ptg+W7+xgEyAUYBwAK8Am7+PPzd/xgDtAII/9L+pP0y/mgCAAU8A/7/Wv/m/mz+oPy0/3gE9ALS/lj9XABmAScA0f+MASwA6P2I/OL+GAJ4AhQDiQDo/sz9AwArALL/pP4WARgChP/y/n//bAPAAtf/APwQ+3j9/gCQBIAGiAXS/9j60PbQ9zr+IAQwCBAKYAeR/3D2gPOA+IoBSAVgBJAFSAYUAnj6APgg/HT/kv/4/jAEoAeQBCz82Pgg++T8H/+SARAIuAeAAmT8WPqw+bj5iP28A4AG2AIlAEQAwgHQ/gT92ADoAeT80PfE/CgFgAiQBcwAPv6Q+ZD24PmYAkgGSAaYBFgBSf94+mD5aPoA/TwBgAbwCbgFCgFg+pD2cPbA+4gF0AvQCeL/6Pmg+ID5ZP0gBFAJMAZA/vj5ZPwxALn/ZP+4AsAFhADw/aD9PgCh/zX/wAJ4BNz/SPuW/pgDeAGM/D7+GAQkA5D7GPvcAtAGGAIM/PD74P9t/+D+K/80A3AE9v9o/ngA+gDo/fD5XPxoA6AGtAMqAPT/Xv7I+tD6vv7oAzAFlAJmAIj9kPsE/qAC2AMxAHT8mPsK/sgBcATIBSwDkPxo+bD7XP0hANAEgAZIA/z9ZP14/r7/pv5CAIgC+wAY/q7+5AJVAMz9+AAoA0QBtP0I/fUAHAGI/Qf/+AIYBFYBqwCsADT98Poc/RQCEAUEAjgCpgHo/Mj5UPw8AuADSAWoAxIA8Pco+HT9EAQABYgEGAfAAAD40PRY/7gG5AIe/nMA9AKB/9D61P24BkgFwP2A+kj8C//q/k4BOAXgBSwBqPrA+dD7YP/wAjgD+gGr/8P/OP+e/tj6pPzOATAEdAKI/ej9mf8AAEv/pQC0AVr+SPz0/SAB6AJsAcsAcgAk/jT8L/8IAvgCOAJ6ADH/XPz4/DIBOAScAp7+lP2Z/2n/FP4KASAEOANo/uD8BwBcAoD/uPs0/fIBUAP+AdoBSgFpAOD8SPts/hACEANVABoAmwDwAAMA5P3A/sr/FAD2/m0AGAKGATn/UPx6/nQCMASIAjwARv6w+qj5/PyoBCAJ2AUE/xj7qPr0/Iz/iAKwA5AC5P+Q/fD9KQDUAoAC+ADC/vj9eP0s/Zv/IAM4BGgCpwC+AOz/oPyQ+gT9rgHcA0AEaATyAQD96Pio+wgAYAKsAuADkAO1AMT9dPzs/ez92v+KAcQCSAGCASwCUgH0/Qz8APzo/RIBuANoBOYBKQDc/jz9iPsI/cQBNAMkAvsArgFFABj9VPzq/jABOAFyAVwCogEW/sT8gv7yASgDgAAq/pj9NgBGAXUAHgHEAnADq//g+nj7xv+6AecADAKIBbAFKv9w+TD70f+lAPH/2AHwA+QCAv6E/aL/jwAs/1r/qQDgAG4AOP/ZADYBQgCq/h7+1P5mAG4B3/9rAFIBBAIDAJz93PzI/V7/7wAoA1QDoAICAYj++PqA+RT+CATIBZgC0/8ZAEEAVP7o/D//QAGbACz+sP70AaQDgAGgANwALf+A+4D6uP84BPwDIgHb/1oAfP4s/bj+8ADBAFP/9v/YAIgBhABLAMD/eP3g+2T92ACgA4wDqgE8/6z90P3g/fT+4f/9/1T/8v/eAeAC7gEy/0j9YPxI+/z8bgGgBWAF1gHA/ED7LPyU/Zz/hgGgAkgCfAD2/kf/Rv8W/sD93v50AHoB5gGYATsA9P6I/vj/wQBIAKMA/QBYAZgAjADTAOUAegDO/4T/2v7h/7ABkAOwA+MAlv7I/fz9iv7Y/yQCeAMYA9kAKABM/7D9XPyw/hACAAT0As0Ab//4/Tj97v7MAZwCSAFU/4T/uP94/zL/h/8GAcMAaf8T/wwAgwDy/9z+2v51AOEAFwCN/8b+pv7W/kT/yQAYARgAvv7u/lz/1v+p/wz/Rf/s/nb+4P4gAGwB2v8Z/4D/s/88/7T9zP1rAGgB+/+6/5QAogCU/07+Nv7A/1oAdQDeANUAnwAwAML/WP8T/53/WQCcAbgCVgEi/87+nP//AOQAOgBGAYYBsv/A/vEAzAJ0AmcAhv8hAHj/Lv6A//gBtAMsA8cAkf+C/rr+AP8IADoBogE4Adj/OP9x/7D/kP7Q/t0AJAKYAKL+tv7w/5z/mP1S/rkAxAGw/xb+GP8aAC8ACwC7//j+Ov5W/lX/GQB5ADYBcgHD/wL+NP7W/zAA+v57/0ABEAK9ADr/V//z/9b/Tf++/2cAPAE8AJ3/4P/5/zoA8P+H/3r/6//w/yYAQABsAD4Am/8p/0L/iwASATcAPP8j////nP8G/6b/JgGEAWoAHv+Y/0IAwf8f/wf/hwDKABkAyv+NAAgBXQCK/9D/RwAKAE7/cP+EALQBNAJgAnwBAgA8/oz91P52AbQD0AMsAsoAP/9Q/kT+cgBwAtACIAKoAaYBzgDQ/zsAGgEUAacAqgD6AZQCMALMATQBRgD7/9oArAEoAsYBrgFIAeAALwB2ABwB6QBQAKP/kf/d/wYASACi/8T+KP7g/cj9sP1E/gT+1P1M/cz82PyQ/Gj8APz4+8j7cPuw+8D7yPsw+xD76Pro+tD6GPvY+uD6oPoY+2D7oPv4+5D7sPuY+/D7QPwg/dT9+P0A/rT96P1i/i3/KwAYAVwBGAEaAaYBiAKcAlQDGAQQBfAFmAbQBrAHIAjoB/AHUAjQCIAJQApAC6AMUA6ADTAMIArQCPAI0AiAC3AN8A3wC4AJSAeoBRgFCAXIBbgFWAUYBKwCSgHe/gj9KPzg+yj8hPwg/Kj6APkg98D18PSw9BD14PXg9UD1MPRg8/DyQPJQ8tDyEPMw84Dz8PMw9BD04PMw9OD0EPUw9VD1EPZQ9qD2UPfg+ID44Pgw+SD5YPnI+ZD6qPsI/fj8hP24/cz9MP6c/qb/iwBQATgC6AJAA8wDYATgBAAGEAfQB+gHQAggCfAJsApgCzAMgA0wDoAOgA4gD9AOkA4QD+AP4BDAEcAR4BHgESAQ8A5ADoANEAzgCrAKYAzADOAKQAm4BVoBKv50/SsAhAJkAxQCBP94+iD3gPRQ9TD2MPdo+KD5+Pig9mD0IPJA8UDxYPIw9QD42PjQ99D20PSw86DzUPU4+Nj5GPp4+kD6OPrA+YD5gPpg+xT8CP3Q/cj+Hv9s/sz9oP3A/Zr+/v6Y/8f/A/9g/lz+AP/0/oD+7P3M/aT9zPz4/PT8JP0s/fT8wPxg/GT8SPys/FD9KP18/bz95P14/mr+Sv/m/30AAAGAAlwDkAOoA1gEeAWYBXAG2AcwCYAKYAsgDMAMoAxwDAAN0A1gDqAOMA9gDyAQIBBgEMAPYA6wDFAKIAkwCMAIkAnwCQAKIAjgA1wAXP3Y/er+YgDx/+z+PP1I+kD4QPYg9jD2wPZg96j4yPiQ9gD10PMQ89DyoPNg9sD3APiQ9lD2APZg9QD2MPeg+Nj4aPl4+hD76PqA+iD6MPqw+vj7FP2o/dz9jP0s/cD8lPww/fj9aP0E/Vj80PzA/Nz82PwQ/UT8aPuY+sD6APtY+qj6ePpo+9D6gPpg+/j60Pow+oD7PPxg/Yz9dv7s/rT+V/8qACQC7AIYBMgE2AVYBgAHUAhQCSAKEAsADdANQA+gD+APwA9wD8AP4BCAEeARoBJgE6ATYBKAEGAOUAsQCfAIkApQDMAM4AvQCWgEmP4E/Kz9wP7OABoBrwD4/fD5kPdQ9YD0gPOA9ED3WPiY+ID34PWw8uDvwO/g8YD08PZo+MD44PZg9JDzgPTA9dD2wPeg+cD6APsw+0D70PpI+lj6FPyA/YD+yv48//r+XP5q/tD+r/8p/+r+3v7I/sL+8v4b/7j+nP2E/BT8UPxA/OT84Pwk/Dj7kPow+pj60PpQ+1j7kPug++D7NPzo/Ej9nP08/p7+Zf+lAOAB5AK0A2gEaAWIBigH8AgQCiAL4AvwDFAOUA4wD5APgBCgEEARwBKAE4ATABPgEqARwA6gDIANMA9wDjAOEA2gDGAJQAWoBBADWAI2AbgCEAMcAv7+YPwI+0D4oPZg9sD3aPi4+ND34Paw9NDykPJQ8hDz0PMQ9UD2YPYQ9oD1cPQw8wD08PXQ99j4MPnw+fj58PhA+UD6ePvw+wD89Pz8/YT+Mv7m/rb+TP50/fD9/v6G/xP/MP/m/kr+PP0o/RT9vPwg/Fj7jPyM/BD8YPvo+uj5+PjQ+Nj54PrI+hj7CPsY++j6yPus/Jz9xP30/db+8v8QAWwCEASQBCAFuAVgB+AIIAoAC7AMsA1ADiAOwA4wD1APsA8AEgAVABbgFeAU4BPADkAKgArgDYASgBTgEsAQwApABBAB7AHoA9gEkAXQBfAElgHs/LD6cPfg9aD0wPZo+qj7GPso+MD0cPDA7sDvUPJg9fD1UPbg9UD1cPNA82DzQPMg9PD1UPg4+ej5ePmo+Fj4ePjo+dD7NP0w/Qj9GP0K/lT+Uf9q/5b/+P6e/ln/+//qAEQA6f/K/w//bv4E/vj9OP1o/Jz84Pww/az8oPtQ+0j6mPkg+aD5SPqg+vD68PqQ+0j7ePsQ/LD8ZP1s/T7+ov9cAXACVANQBOAEwAWgBkAIMAnACiAMoA3QDqAO0A2ADkAOkA5AEaATgBZAF2AWoBJwDZAJsAlwDUAS4BOgE2AQ4ArYBOQBjgG4ApAD0ANABVgE/AGS/nj78PYA9GDzkPXo+Rj7oPuI+BD0YPBg7jDwIPKA9ID1sPZQ9hD1oPRg9JDzUPNQ9KD28Pho+iD7mPpw+VD4oPjI+uj8qP0Y/kb+2P0M/tD9K//1/wwAgv9P/03/l/91/73/AQCi/x//uv6A/jj9UPzg+wj8VPyo+yD8iPsw+5j5EPnw+Hj4GPlw+Wj60PrI+qj6mPsM/DT8vPwE/U7+WP/xAFwCqAOYBCgF8AXgBpgHYAkAC+AMMA4gD+AP8A/QD1APkA/wD4ASwBagGWAZoBVgEHAMgAqgCkARgBSgFcASQA4ACQAE6gEIAmwDCAQgBPAE2ATgAYD9ePmQ9ZDyAPMA90j6mPug+cD2EPOA74DuoO8g8hD08PRA9oD20PWg9HDzIPIA8qDz8Pbg+Vj7KPsI+sD4wPdA+OD6NP2m/jb/LP/S/gb+Vv5F/4IAqwCbAMQAAAHEALUAgACTABIA1//8/o7+lP0k/bD8mPys/Hj8uPsg+1D6YPmA+Ij4iPjg+Fj5sPn4+Tj6IPoA+wj7EPz4+wj91P0c/v7/tQD8ApQDwASgBRgGeAfACIAKgAsgDcAOQBBAEKAOcA4QD0AQgBFAFcAZYBngFcAQUAwgCnAKkA1gFCAWIBNQDfAICAWUAvwBsAEgBMgDxANIAwACWv/g+TD2sPNg8zD1ePhQ+hD6wPcQ9HDwIO/A70DxIPOQ9FD2EPfw9gD1wPMA8wDykPNg9sj5gPsc/BD74Plo+Fj4IPrM/HT+kf97/93/lv64/vD+XP+D/2j/5/9CAJsAFAAiAHr/Nv8s/lz94Pwk/Oj7sPsI/BD7sPv4+XD50PcQ93D34Paw93D3iPio+ED4kPc4+Fj5uPqI+zD8IP3A/Yj9pP7z/4gC7APYBCAGsAeIB2AIMAngDCAPgA/ADyAQQBFwD7AOgBAgEyAWoBgAGsAXYBMADXAJkAugDuASgBXAFCAQoAkIBOABCALcAsgDSAT8A4QC/ADS/pD7YPew89DyMPRg9wD6oPpY+AD1MPFg7sDusPAA8xD1oPbg9pD2EPXA82DzoPNg9BD2MPn4+uj7OPtI+oD5ePlY+sT8/v7e/yMAhv++/3r/EgDMALkAfgARAFIBZgFeAZUAhgD3/5j/hv7w/bz9xPx0/Hz8aPzY+9j6uPlY+Sj4MPdw9+D3cPhw+CD4EPhw9wD4OPlQ+gD8jPwY/Rz97Pzc/Sn//gD4AoAFIAfwBwAIMAhACdAJ4AvQDcAQYBEAEmARgBHAD8APABIgFsAYABjgFcASIA7gCTAMcA8gEgASIA/QDOgHQATcAogDsANkAUcA8/8aAID+AP1w+0j4MPQw8vDzcPag9/D3sPYg9DDxEPBQ8XDzcPRw9QD2wPVg9XD1wPVg9mD2wPYo+Lj58Ppg+xj7KPvI+lD7xPyA/lD/l/9l/+b+3P5u/1kAHAFbAOT/df/S/xYA+/8fADr/Sv54/VD9RP1I/RT8+Po4+ij5ePnI+Pj4UPjA91D38PYw93D3MPeA9rD1MPZA97j5BPwY/jD+wPz4+qD6KPyI/rABsAQwCAAKAAoQCegHQAhoBoAJkA4gE+AVIBbAFAASEA4gDZAPQBSAF8AYYBjgFKAQYA3wDIANYA1QDTAMoAvACZAIKAfABKwBiv6E/LD8wP2W/mj+mPy4+KD10PLw8iD0YPUA9gD1QPOw8mDyMPPw83DzsPMg82DzMPTw9UD38PZQ9tD2kPfY+Ij5gPrg+iD7SPts/Hz9Rv91/0z/Bv+M/mX/y/8eAc4BEAEmAHb/vv8rAGkAEADK/n7+6P0G/pL+RP3o/Aj7oPno+PD4sPn4+AD5gPh4+Aj4aPhw90D2APUg9ED2SPn4/Hb/PwBA/gj6IPl4+ZT8+ACgBDAJAAogClAJgAgQB8AG2AegC6AQYBTAFiAWABRAEMANAA6AEEAUQBfAGIAXYBQAEeAN4AxADFALUAsQDIALUAvwCdgGoAOI/2T9FP2w/a7+kP6Y/Vj7SPjg9TD1QPVg9UD1wPQA9IDzUPTQ9OD1UPUg9eDz0PMw9BD14Paw97D4WPhA+Wj5gPlI+rj6qPo4+2T8DP61/w0Asf8f/1j+rP6A/5cALAHTAFkA2/93/1X/u/+T/5T++P30/Oj8GP0I/Xz8ePu4+bj48PeA+PD3gPew9zD4wPho+ND3UPZQ9PDx8PKw+Kj+KALsAgD/YPqQ9mD26PsUAwAI4ArACsAJsAfgBjgHAAkwCrALwA5gE+AWQBcgFWARQA7ADBAP4BPAF2AZIBcgFKARoA4wDBAM4AuQC5ALQAtQC5AJEAcwA/L/HP4U/ez9DP9z/7D8YPlQ9vD1QPZg9nD2wPUA9ADyAPLg8sD0MPXg9AD14PNA81DzUPRg9SD2QPeQ+Pj42PnQ+fj5mPkI+eD5SPvM/Yj/lwApALb/Tv6c/YT+4/9oAJgAewB4ANcAGAAlABj/ev40/SD9aP24/bz93Pzw+9D5UPng9xj5QPiQ9yj4IPcg+Rj66Pkg93DzEPLw8xD4iP5AApgDtv+o+nD2CPiA/BwCwAeQCsALkAmQCLAHQAnwCHAJ8AuADwAUoBWgFiAVYBFwDuANwBBgFCAWABdAFoAToBBgDnANUAxgCyAKoAlwCkAKcAmwBvgC2/+Q/cz8dP1w/j7+aPzY+Tj4MPfw9vD2UPZA9RD0APMQ9OD0kPYA90D2sPVA9FD0APSg9XD3WPj4+Aj5ePow+qj6CPpI+oD62PpE/HL+SwBEADQADP/4/or+YP64/oP/9f82AHUAbgBcACz/Hv6c/Gz84PsY/XT9RP0A/LD50PgY+OD3oPeA9vD1oPaA+Kj5uPiQ9iDzIPGA8TD1EP23ANQB4P6Y+qD2YPYY+r0AKAYACaAJgAjgB+gGYAegCBAJ8AowDsASoBVgFiAVQBJADxAOoA+AE4AWABggF2AVIBNAEIAOIA3wC3ALAAugC7AL4AqACCAFkAF2/oz9tP2a/q7+gP2Q+1j5gPdw9lD2wPXQ9PDzMPOw8zD0QPXw9ZD1MPQQ8xDyEPNA9OD1MPcg+Fj4KPgQ+Ij46Piw+ED5cPos/Jz93v5Q/yD/VP7E/dz92P0m/7H/dgB7ABQA/f+T/xv/2P1k/QT82PxA/cT96Pz4+hD6ePko+Qj48Pbw9gD2cPbg97j5sPkQ9iDyIPFQ8lD1wPsUADgCdv5Q+eD1oPbo+VD/YAXgB1AJcAf4BsgGyAaIB5AIQAtwDgASwBQAFmAUIBIgEDAPgBBAE+AVABdgFiAVYBPAEOAO0AywCzALIAsQDEAMMAsgCKAEeAE6/1r+wv78/vD+UP34+xj6WPlg94D2YPVQ9BD0EPSA9YD2YPdg9tD1UPSQ81DzMPQQ9oD3iPgQ+ZD5MPlI+Vj4wPgA+ZD6RPyM/UT/Ef+T/8L+Rv6c/cT9Yv5D/ywAxgDhAHQAQP/Y/rz9BP0c/CD82P3E/Xj82Prg+SD6qPig97D3UPZQ9kD2wPdw+ej4MPWA8pDx4PGQ9rj7//+9AHD8WPiA9TD34PrDAGAF2AewB7gGmAbYBdgGYAfACUAMMA/gEoAUIBVgEyAR4A+gEMAR4BQgF8AXABfAFeAToBFAECAOYA3ADFANMA5wDYAM8AggBlgCfQAtAC0AMABs/3r+7Pww+xD5kPcw9jD1kPSw9FD1wPXA9UD1EPXw8wDzYPIQ8+DzgPXQ9pD34Pdw95D3cPeQ99D3GPm4+lT8QP2c/cz9nP1o/VT9sP0y/vj+nP92AGIAuP9P/yn/N/82/sz9fP1E/dj8/PxU/Kj76Pr4+Xj5wPdA93D2UPcY+PD4WPlI+LD0EPJQ8SD0mPhU/QkAa/9Q/LD2UPY4+ID88gGABaAHAAeQBlAGAAdYB0AIEAowDCAPwBGAFOAUgBMgEQAQwBAAEsATwBWgFiAWwBRAE6ARUA8ADeALUAzQDEANsA2wC5AIgARyASMAPwCeADwBngAo/8T80PpQ+eD30PZg9nD2UPaQ9tD28PZg9nD14PRA9CD0EPRA9bD2gPdA+LD4MPlQ+AD4sPe4+ED68Pt4/Uj+Iv6g/Zj9zP0g/nb+E/9//x8A2//5/yUAHgBq/5b+kP0w/Tz9hP3I/ST9JPwA+0D6ePjA9+D2sPaA93D3GPmI+KD1QPIA8aDxIPVI+QT96P0Y+8D2EPRw9dj4wP0UAhAEqANkAtgC5ANwBZAGwAfgCIAK0AxgEIASgBIAEQAPoA6gD8ARgBQgFgAWIBWAE+ARQBDwDoAOoA0QDpAOcA7QDVALgAg4BdACzgHsAZQCUAKIAXz/Cv6Q+2j5MPhg92D34PZg98D3YPeQ9vD0APSA8xDzgPOA9HD1UPaQ9sD2cPZA9qD1MPYg96j44Pkw+xj82PtY+1D72Pt4/Ij9WP6k/rL+uP7U/kr/xv4a/lj+Bv7Y/eT9YP0k/TT8mPt4+4D6oPlI+AD4MPfg92j4mPjw92D1YPMQ8nDzkPbI+sD8PPyQ+AD2APWg9tj6vP4EAlACDgEMAXYBCAQABagGyAeQCGAKcAygD2AQYBEAEHAPkA+gEEAS4BMgFcAUABQAE6AR4BCwDyAPYA6ADuAOYA6ADeAKsAg4BqAEyANQA7gDGAM8ArcAfv5o/Ej6MPm4+PD4gPng+Vj5sPgw9zD20PUw9SD1kPXw9cD2EPcA+ED40PfA9pD24Pbw9yD58PrA+xT8cPs4+yj82PuU/Nz8NP28/ez9qv6g/u7+BP78/MD8OPyw/Nj8CP3g/LD7gPoo+aj4CPkY+FD3wPfg9/D3EPeA9QD0MPMQ9ND2uPmQ+6j6SPig9mD1kPdw+sz+qgFAAawA9v9mAEwC6AS4BkAIwAggCdAKsAwwDwAQsA8gDzAOkA8gEcATABVgFCATQBGgEPAPoBCAEEAQUA9QDvANwAwADGAKgAiABhAFoATQBFAE1AMYArD/kP0c/Hj7MPsw+xj76Pro+WD4GPiQ9+D2APZA9pD2oPYA9yD3kPdA9+D2MPbA9uD2kPfA+Pj58PpI+uj50PnI+Tj6yPqQ+6z8tPzg/KD8kPyQ/DT8CPyc/Lj76Pug+xj86PvQ+sD5UPkI+eD4+PiY+KD4WPjQ95D3UPaw9fD1IPdQ+aD6SPuI+zD5gPjQ+Lj6xP35/ywCpAFeAU4BkAKoBHAG8AcwCOAIIAlwC1ANwA5AD1AOYA4QDiAPABEgEsAS4BFgEJAP8A4gD0APQA/ADtANAAxgC+AKUApgCegHgAZIBVAE0AOQA0gDsgEVAKj+LP1U/Aj8RPwo/ID7oPqo+QD5OPjA96D3cPeA9yD3YPew97D3UPcg96D2wPYg9wj4sPhI+Wj5APnI+Bj5iPnI+Tj6gPrY+tj6MPsI+1j7KPvY+gj7sPro+qD68PqI+vD50Pn4+Oj4iPhw+Dj4GPhI+Ej48PfQ9rD1YPbA97j5aPvw+yj7GPmg+FD5MPse/goAVgEYAYEA8QBwAvwDmAVYBgAHcAdwCEAKcAxgDSANYAxADKAM8A2AD6AQIBEAEBAPcA4gDnAOYA6gDhAOIA0QDMALMAuACpAJYAgwByAGSAUQBdgEtANcAkwBJQDW/iz+qP2s/SD9SPzQ+xj7WPqw+fj4uPhY+Gj4gPiY+FD4APhg9wD3EPcQ9+D3SPiQ+HD4kPiI+Gj42Pgo+cj5sPkA+nD6sPrg+pj6+Pro+hD74Ppg+2D7OPvo+pj6cPoY+kD6GPog+sj5aPkg+oj5kPkQ+ZD4iPi4+ID6pPxU/UT8OPto+vD6PPxK/j8A+QDMAJIAHgEgAmADgATYBTAGQAY4B8AIYApAC2ALMAvwCkALQAzwDdAOoA7gDUANIA0gDTANoA1ADaAMAAyAC0ALoAogCjAJYAhAB1AGEAbgBZAFsARkA2QC2ABcADsADwAh//T+KP6o/RT9HPwY/ND7GPsw+kD6aPpw+jD68PnA+fj4sPjA+DD5ePnA+cj5yPmI+Xj5uPno+Uj6gPrI+sD6gPrY+hD7CPvw+hj7cPtA+0j7IPtY+yj7gPog+nD6UPrI+bj5yPkw+hj6kPkA+vj5uPiA+DD5IPus/Kj8XPyY+9j6OPuA/Jr+r/8BACEA+AC2ADYBSAKgA6gEgASoBJgFSAdwCAAJIAmwCJAIIAmACnALIAywC5ALUAsAC/AKEAuQC5ALAAtQCsAJoAnQCTAJYAhgB4gGUAbwBfAFiAXABGQDfAIAAlwBFAHHAJIACAD4/nD+AP7k/cD9QP3M/AD8qPvQ+9D76Ptw+yD7qPow+ij6gPrw+uD6yPpY+qj6cPqI+sj6OPuA+/j6EPtw+6j7ePto+8D74PuI+zj7aPsU/ND7aPtY+/D6IPvA+jj7MPuQ+kD6OPrQ+sj6WPoQ+hD6yPqo+8D72Puo+/D7APyA/IT82P3Q/ln/a/9//zoAiwCSAc4B9AI4AwwDEAToBMgFsAUABtgGEAdwB3AHYAjACKAIkAjwCBAJwAgACSAJMAnACIAIoAhgCAAIqAeAB+AGaAZABugFqAUwBfgEsATEAygDBAPkAogC+AHKAbwB2wB3AC0AVADr/yP/A//u/t7+Lv7w/SD+CP50/dz8EP3o/MD8VPyU/Kz8KPzo+/j7RPzw+6D7wPsk/ND7UPtQ+wD80Psw+wD7ePvw+3j7MPsA+6D7uPqw+vj6+Pqw+vD5mPrQ+lj6mPkQ+uD6YPpY+SD5OPpY+3j76Ppw+oD6cPuI+9D7MPwE/ZT9fP2A/Sr+4v4q/0f/EQDNANgAHgEAAuwCRAPcAhQDzAN4BNgEAAVYBcAF+AUIBvgFGAaQBvAG+AagBpgG+AYQB9gGgAZoBmgGSAYIBvgF4AWIBVAFIAXgBFgEGAQYBBgE3AM4A9QCoAKYAmQC7AFqASQBLAH8AH8A+P/5/8n/Zf/2/r7+mv5y/iL+6P3A/Wz9bP1A/Uj9EP3s/OD8uPyw/Kz8zPzI/JT8VPxs/ID8dPxc/Ez8RPwk/PD74Pv4+/j7wPt4+5D7ePtw+2D7UPtY+zD7OPtA+yj7EPtQ+3j7kPto+3D78Psw/BD8FPxc/KT8oPyw/Fj93P3I/bj9aP4Q/yb/4v5A/3AA3wBgAGEAOAEMAvoB8AF0AkADOAP0AkADIAQYBBgESAQABRAFoATIBFAFoAUQBTAFmAXABVgFGAWABaAFeAUIBRAFeAUABRgFAAUIBYgEiASgBJgEWAQABDAE3AOUA2gDbAMQA9gClAJ4AlQCtAGwAYYBCAGyAKQAjABoANr/tf99/2L/+v6g/sL+gP4+/vT98P3E/Yz9GP0E/Rj9vPyc/GT8hPwk/OD7yPuw+7D7SPtI+1D7KPvY+uD6IPsQ++j6oPqQ+qj62Pr4+vD64Pow+2D7WPtQ+3j74PsU/Bz8RPzE/BD9JP1Y/bj96P0s/mL+1P5N/4D/m//6/2sArQDkACgBgAHsATACZAK4AgADMANUA5QD5AMYBEgEaASwBOAE2AToBBAFMAU4BVAFYAVwBVgFSAU4BUAFKAUIBfgE4ATIBLgEsARwBDAEEAT4A8ADhANYAygD7AKkAmwCNAL2AagBdgE8AeMAmQBMAA4AzP+t/2//If/W/pb+Zv4a/tz9kP10/TT9AP3A/JT8cPxI/Bz82Puw+6j7mPt4+1j7SPtI+0D7OPs4+0j7UPtQ+2j7YPuY+5j7uPvQ+wT8HPww/HD8sPzs/AT9KP14/bD93P0E/k7+pv7c/hD/Tf+M/8D/+f9SAKIAywAKAUgBgAGkAdQBLAJoAogCuAIEAzQDQANYA6QD1APgA/ADKARgBGAEYAR4BKAEmASQBKAEsASgBIgEgASABHAEWARABCAE6APEA6gDkANkAywD9ALMApACWAIgAtwBqAFqASQB3QCbAGMAIgDm/5//TP8c/9r+qP5w/ir+7P24/Xz9VP0U/fT81Pyw/Jj8dPxw/Fz8SPwc/ET8IPwk/Cz8OPxQ/Dz8XPyE/JT8lPyw/Oz88PwM/Uj9kP28/cT95P0k/lL+iv6+/vT+Lf9Y/4n/vP/f/xMARAByAH8AsQDuABABLgFCAWIBgAGIAaQBwAHqAfgB9gEEAggCGAIYAiwCOAI4AjACHAIUAggCDAIAAvwB3gG+AbYBsAGaAX4BaAFUAUABFgHyAOAAzgC3AJUAdQBNACgAGgD8/+r/wP+n/37/bP9j/zn/I/8G/+j+3v7E/rL+nP6O/nz+av5Y/lb+YP5Q/kT+Mv48/jj+OP5C/lj+Zv5a/mT+ZP6G/pD+lv6m/rL+yv7Y/vj+CP8T/yf/Mv9F/2P/dv+M/5n/s//T/+3//f8SACgAOQBRAF8AhACWALYA2ADeAOMA6AAAAQQBDAEQASABMAEeASQBLgE0ASwBIgE0ATYBJgEAAfoAAgH/AOQA0ADXAM0AqACRAI4AjQBmAEsAVwBXAB8ABwASACEA8v/N/9v/6//A/5f/k/+s/47/b/9y/3f/gP8+/2T/Tv9K/yj/R/9f/0z/Ov82/1r/QP9C/1f/ZP9d/1f/aP97/3X/Yf99/4b/hP+Z/6n/rP+w/7j/0P/S/87/3P/l//n/+P8TADoANQAXACIARABcAF0AUwB2AIQAgQBxAIMAqACdAJgAiAChAKUAnACtAMkAyQCyAK4ApQC2ALMAuAC2AKcAogC0AK8AlACCAH4AfwB8AHEAcQBwAEUAMQA9ADEAFQAPABcAGAAAANT/z//0/9X/l/+O/6D/rv+R/3//g/+A/2L/Qv9V/1r/UP88/03/Vf9K/zP/Qf9V/0//OP9B/2P/cv9d/0P/Xv9+/3T/Yf9v/4v/kv+G/4//tP+1/6//vf/x//T/4P/m//v/FgAKABAALABGADwARgBTAE4AVABEAFgAZQB2AHYAbwB3AHMAeQB1AHwAbgCAAH4AfQB9AH4AewB5AGcAaQB+AIEAdwBZAG8AbQBkAF8AYgBqAGEAVABaAHAAWABcAEIAVgBRAEEAJwA5AFMAPgAwAC0AMgA0ABgAGAAEABgADgAKAAUA7//h/9v/+//6//n/3v/j/93/5f/T/9L/3//i/9j/zv/d/9T/1P/O/9T/3v/N/8z/2//p/+H/3f/r////+P/y//z/FgAFAAQADQAqAC0AGgAaABwAJwAlACIAOgAuADMAJQAyADAAMAAnACwAMwAtACwAKAA0ADAAJAAgAA0AFgAZABsAGQANAAMAAwAFAOD/8f/h//j/2v/G/97/7f/9/8H/zP/P//f/rf/E/9n/9f/h/6f/7//3/+D/tP/m//P/zf/G/+n/MAABALn/yv8kABcA8//g/ygAKAACAOb/HABCAAsACwAYADAAJAAfADAAOwAeAAgAJwAzACkAEAAnAC4AGQAAAPr/CwAJAAYA//8cAAoA2//f/+r/EwDy/+j/3P/l//b/1v/1/+v/+v/W/+//7v/Q/9X/yf/3/+7/yP+g/9j////S/9f/uf/k/8H/1//T/+H/8//F/9z/3//m/83/6v/k/8z/y//J/+//7P/H/87/zf/W/7//vv/k/8P/5f/F/9P/tP/K/9n/1v/E/5T/xP+9/97/tv/A/8P/s//K/8P/uv+7/5//vf/Y/+j/tP/M/9j/3f/T/6v/7//i/yAA8//Y/wIADAAXANf/MgAtACAA///0/2QAQgD///H/ZgB7ACkAHAAgAHAAUgAiABUAUQBiAC8AHwAyAEcAQADy/1IAZwAzALP/SgCRAAoAzf8MAKwAQACp/+v/eABOAJT/AwBuABUA3v+c/7IA5P/S/7T/bQAaAKv/CQAmADAAe/8HADQAAACu/yQASQDa/6j//f9BAK3/n/8oADwAlv+v/+L/KgDM/6j/EQCx/3n/XP9WADUAhf81/8f/SgCa/x3/wv9gANb/Qf8e/4YAMAD+/sX/6v+QAAv/Ef8EAMYA/v9X//P/ef8/ACkAVACQ/7P/ZQDjAKT/NP+IAEIB1v80/1sAQAFfAOz+3wD7AC4A+v6mALAB/v9k//P/yAFWAEn/MQAaAY0ASf/7/woBhwCt/9L/WQCbAOX/0f8OAHUAvP8RAAMA6/9OAKD//f/i/x8A9//l/7D/xP8vANv/nP/a//L/LgBm/5L/+f/Q/+T/bv8eAPz/y/+J/8f/AACV/8j/uP/2/9T/DACb//L/wv+d/ygA0/+l/8f/FQDp/+v/pv/K/+7/1v/1/6f/5f/H/0AAGACs/0v/EQA9AP3/2P+k/2wA5f8ZANb/KADn/xoA4P9ZAFkA9P/1//r/7wABANb/bP+cAWoAtP+t/7UA1gAMAPb/dADWABIAuf+RABgBCgAFAKv/fwC8AFUA6/8mAKEA+//p/9z/owBgAPD/yP8cAIQAYP8vAKH/wgDe/2b/r/9uAMn//v5jAPz/HAAT/7j/ggC3/w3/gP8CAcf/Cv/E/2AA/v/y/qX/dQADAFv/aP/xAGf/q/9d/6IAzP/u/gYAfAATAPT+4v81ALkAgv5W/30ALwCd/4D/qQA0/5D/1/9kACYApP6k/xEA1ACM/s7/BgByANH/iv66////vQC2/mwAjv/s/wcA7v5kAHr/eQCo/qQAMwCc/0r/m/8sAbv/nf/U/hYBtQAz/x//8wCaAKH/V/+g/84BIv/f/3QAwwCd//z+AgHUAJMA0v55ABIA6QCL/y0AYAGu/iYAWwCwALT/XgAiAJ8AJP+o/wkAkADkAPL+zQD9/xb/DQDy/+UAdgC4/vL/0ADE/9D/Xv9CANIAP/+8/8H/9wCB/8D+8QCUANz+fv8mAKIAIQDM/lIAWgF6/gH/4/84AlH/Uv67AOoAfgBY/fT/ZALq//D9Yf9IArr/Sv86/oIBrgFg/kr/0P8gASz/AwBOAOz/N/9RAOYAR/8g/7//7AE7/2f/I/9UAWEAWP7MAMQAwf/w/SYB1AGa/xr+2v9wAnIA9P2B/xQCrgCq/pr//QDkAXz+pP68AikA4v9c/ngC0P8tAJT++gGaAdD++v8z/ywBFwDYAWT/X/+//8wB+P+o/tT+DANGAfz9Lf+bAKwBPv6EAK8AAQBM/xwANACs/nYBSABBAGj9dP/qAWIB5P2e/xgBFv8AAIL+lAE+/67/5wCdANz9mv5UAxL/Hv/2/sz/VAIo/uv/ewC6AMD+u/9eABj+LgHg/7wB1v4h/0b/aAEK/5X/VgG4/3f/CP+8AXb/FwAw/74AJv/A/zABX//JAPD+bQCOAFf/7P5cAUoBVP7c/9YA7P+WAIj/uQAUALz/dQCf/xACFP2cAuv/ugDa/vT/kgEJAAcA6P1YAzEAKv69/6wCdQBA/T3/sALsAYj9lv6eAdEAyP2EABQCEP/2/nb+yAIn/5z95gHwAWr+GP2IAbv/swDI/lQADAGS/qL+8QD1/4j+VgGCAE4AGP1HABUAbAHa/vX/8gA6/lYABf8MAgr+7wAwANcAfP7s/VwD5v8+/zn/UALq/9z92P6wAuAC8PtS/ygCsgFu/jL+VAKCAAv/6P5YAlwA2v4Q/kQCUAJw/Q3/JAG4AgT/Nv7h/0ACSABs/UkAEAKyAdT9Qv/LACIBBP/+/ooAfAGMAPj97P9sAX4BeP2U/+oBWAHU/TT9GATt/0ABPPx2AfkAVP2gA57+6AD4+5QBoASQ+/b+agHcApr+sPyYAYj/9ADs/rgAkgFE/AsA5gA4Aez+hP04AgP/8gHM/Tv/rAEY/8z+qP68Ayj/Tf+I+5gFVgHg+oH/CALUAdP/dPz3/4AEr/+E/YkAev5UAU4BHP5oAeQCWP2I/NIBFAJIArD7Lv7oBhL+IPwc/oAHRv4i/8D79AP0Apj6y/+oAhwCIPxYAlb/eAAs/XkAtAN9ALD6aAL0AWIBQP14/nYBlAJG/rP/5wBw/5QAbgAmALr+YAJk/VMAWAK4/t4BWPzOAaQCA/8g/TQBZAKX/1H/QP3gBk7+TP0UAHQDJv5R/+//7AHgBED3OANyAYAC4Pqe/rgG8AAU/ZD3gAgUA6T+uPufAPADbP3L/2f/ZAI+AGwAEP8c/lr/AANIAhT92P5iAYMASPsQBOgCWP4I+7gC+AMM/bz8x//QBnD+iPvh/yADngEg+kgETAEA/cD9mAPSAeT8+v+F/8AFQPss/OAECAOc/Xj8MAPLACj/ePxgBKIBEv+M/eQAfAFA/EgDFAH6AUj6MAKwAWACGPuw/ogFtv6WAaD6KAP+//ACcP4s/lf/8P4kAvb/zAOw/PcAjv9s/vUAyP7A/gQCyAQ8/wj9UP1O/1gFoAGg++T9dAJoBID9ZPycATgCQAJY+n//cgH0Ayr+Xv+uAZD9TABA+0AG/wAg/3z87AKoAgz8WP3x/4gG8P18/Ez92AXSACD6iAFABM0AAPdnADgElAKA/mj9mAMK/9D7LP0wCCf/gPz/AMD+gANY+8wAkAKHAMD68P0gBkT90AFY/kYB7v6Q+5H/XANIBTD6Wv6gApAAsPvM/KAGeAPg/Sj6/v7IBFcAGPxI/sgHKPwI/nT9aAQ8ARj7WAAwBdAAAPfM/sgHCAUw+2j59AMgBZz8mPucA0AEh//s/UD+hALg/QgEy/9q/44BZPwxAKQCgAKsAFz9HPxUAWgEkv44/cYB0AJu/nz8XP4UA8gBOP2MAdIB4Pt4/JgCSAQlAMj8CP6WAWkA5PwOAfAE4P2A+3ADOgDo++3/QATcAmD6kP3cANAERP0S/ogDyAGg+6D68AhG/xj6+ABABfYBEPvQ+vwDuAeQ+az8bANcAsD7Pf9ABQ4BfPyQ+wAD6AVI+OD+8AZQAvj5TP3oBLT9xP8g/4AJQPtg+6L+6AYeADD3YAUIBUgCcPNwAVAICQDA+Xr/WAUyASj7+PmwCRADiPlr/4gC/gGg+4T+eAIIBDv/KPsQBOL+TP1GAHACyALI/Bz+LP/QB7D78PubALwCEAQQ+rD/iAGAART8QwB4BLz8nP3q/wACHgHI+9D/1AM3AED5GAHmAYEACgDI/kgDDP1w/Pb/0APyANT95P5MA0IBcPmQ/vADIAQu/oT9OQAwA6AAoP3V/5gCzf/A/kQCM/8wAukA1P9WAKT/2wBA/RgCtAAQApABDP2vADUA5wBM/fUAVAIEAHABjPz8/4EAkgHy/43/rAKy/lEAFP3LAJAC6ADf/3b/uf+NAAYA/ACs/xYA9v/0/2b/3//gAlD/8P9e/roAPgFK/pb+GgEIAi3/2v44ACACvABY/d7+PgG0/yr/9AKAA3n/CPpn/zgDKAEg/QABOALc/+7+sP44ApT9AwDEANQBRPzs/twDgAMs/iz+qP6Q/mYAaAOEA8D8Ov70AVwCaPzw+6gEsATg/gD7fQBkAtgA6f9MAPz+9PwaAAQDkAPg/fj9wP7Y//EASf+kAK7/tANDAHj6SPu+AEAHpAMg/Kj67AHcArT9NPxEAWgGegFw+rD80AMUAj8AkQB4/6D+MPtEA4gGzAEA+kD+qAIVANr+QP1gBeQDV/8A+0j8P/8IBAAH3P18/Hj8wAFIAhABrv9w/+r+qP62AQ7+yv6UAwAHoP/g9Ej5sATQCaYBOPt4/Kv/BQDo/SAB0AL8Asz9qPtY/coA2/+sAtgENAH4+ZD3XALQB2QDyPs8/L4Bsv7k/GIBIAZIAkD7yPuk/boA9P8wBKgF5P4I+ZD63P/cA3gDvgGN/3z8XP24/jwChANAApD90Psi/k0AnAIwAtgCeAE4+1D51P2YBAAGyAOU/JD7DP1d/zwCGAPiAa3/IP2w++n/kAIoAqYBWQC8/ND6kv4gBCgFfQBo+/j8pv6q/u4BUAM4ArD9yPzE/fz+9QAoA2AEiv4g+2z8OgEYBeYBqP82/97+LP5P/7wCsANcAtz89P15AKIBhADWARQCgQDM/RL+OALMAjQA7P5fAIAAx/9+/ooB1AI0Adz9UPyiAJACPAHM/8EAIgAN/xT+Mf+UAmYBD/9NALb/SP8A/yz/UAL9ADz+KP1vAPIAiAA0AAX/oQAW/1D9ov4KAZwD8P6Q/Sf/WgD/AGz+eP7uAcYBXP2w/Y4ARgGxAKn//P4KAFf/KP/4APcAjv/Y/lL/0QCVAIEAlv5i/zgCdAC0/VT+AgGQA2QAUPxH/7wCjAA4/S//OAEiAej+Jf80AtUAqP3c/m3/BACdAHgAXAIVAPj+5P3g/5IBAAHQACr/i//JAPgBpv46/nAB/AIYAKz9aP/sAqwCAv50/r4AOALa/4n/zAEXACL+3P9cAroASv4s/64B0gBg/bz92gGAAuz+MP2H/yQB9v7E/u//rQAs/xL+8P7z/8b/Xv/N/wP/oP/w/YD+jQCFAIz/hP7S/rb/lAAF/43/KwDM/zf/cP/y/57/AQCKAO7/cP7E/pIB7gF7/yz+v//mACkAzP5tAPAB7QDF/w7/MAHSAB4AUQA6AUQB/v9EAOIBYAI0AUMA4ABOAXUA+/9gAaQCUAJcAbEAyACoAOkASgGMAVgCCAIIAeL/bgEkAmgBBAAkAUgCbAHh/2AAKAJoAf//jP+CAYkAXv/s/4YBpQCG/pz+8v6G/6z+tv6I/9r/XP1M/Pj8Kv50/g7+fP1I/Qj92Ptc/ED90P3I/BT8IPwc/WT8aPxQ/fD9GP3g+3j8RP3c/q7+yP4u/xj+HP58/mUAfAE6AdcAggG0AeoBzAJoA9ADGARIBAAFMAWABfAGcAeQBggFGAYQCCAJgAgQCJAHuAYwB6AHAAkwCMgGaAaYBfAEIAQoBjAGQAQQAu8ACgGfAOEARACd/xb+yPzQ+wD8BPz4+kj6mPlI+LD3APgQ+dj4QPeQ9JD0APbw9QD24PRw9VD1gPRg9PD00PUQ9vD1sPRQ9QD2gPZg+CD5cPkw+DD4mPmw+6j7SPyg/Xr/zv/6/hUAPAJAA4gDeAQYB2AHmAcACeAJwAowCmAM4A3wDnAPcA8gEMAQYBDgEIARwBGgEaASoBKgEKAPQA4AD2AOoA1QDSAMoAr4B7AGaAX4AxAC/gG8AbT/Kv4E/ND68Pgg93D2wPbw9SD10PPg8VDxUPCw8GDxwPBg76DuwO+A70DvYO8g7yDw4O+g7yDx4PEw8lDxoPAA8XDyYPVw9yj4kPZw9ZD1UPcI+OD63PwA/VD9PP38/HT9Rf8CAVQCxAJEAkAE6AZQB2gGYAcQCCAJcArQC9ANUA5QDSAN0A5gD+APQBBgESAToBFgEWAS4BLgEsAQgBBAEMAQoBBgEAAQUA3ACiAIsAcQCYAJaAegBbgDQACY/fD8ev4H/2D9KPoY+UD4YPYQ9pD24PZA9XD0cPQA9BDz4PJw88DzQPPQ8hD0kPSQ9FD0IPQA8yDzIPQQ9rD24PUQ9vD1sPWQ9PD1MPfA+OD30PdQ+DD40PhQ+Gj6oPrw+VD50PrU/Jz8cPs0/Oz94P2C/hD+LgA0AYwBNAJ8A1gEQAXwBPAFKAeQCNAJ0ArgDLANMA2gDHAOkA+ADyAQIBFgEwAUgBMgEgAR4BBgEKARQBLAEFAP4AwACxAKAAqQCbAIaAdABIwB2v+q/lH/Gf9Q/bj6APjg9gD3wPew9oD2cPVw8yDyMPLQ81DzsPJQ8xDzAPMg8vDyYPRw9HDyYPOA9BD10PUA9sD2YPWA9FD1IPdA+Cj4MPig97D3YPcw+Fj5UPqY+qD5wPkg+sD7qPvw+xD8oPyM/IT9gv7P/8AAuv9WAc4BYAMABIgFgAaIBnAGQAcQCgAMoA1gDVAO8A7ADrAO4A4gEeASABYgF8AW4BOgEYARgBBAEsAUwBQgE3APUA2AC5AJYAnQCdAJuAZAAswBXAGf/9T9yPt4+lj4gPcw+PD3YPZw9ODyYPFQ8DDxkPKQ83DyMPFA8ODvQPBw8SDzYPJQ8nDyYPMA9NDzgPSQ9MD0EPUQ9mD3MPhI+Dj4APjw95D4iPko+7j7iPto+0j7OPys/Fj9NP1M/Wr+pP9aAIgACgGCADoB6AE4BBAG+AYgB/AHYAhQBkAIEAzADgAQoA/ADlAPEA/wDoARABMgFYAVYBZgFoATwBFgEUASQBKgEkASIBHgD+AMQAqwCIgH8AfgBcAF4AJbAAj+rPxc/AD6+PhA99D3wPZw9FDzgPPA8tDwgPBQ8SDyUPFg8ZDxUPEA8SDwIPHQ8oDyAPNA84D0YPSQ84D0kPSw9bD1YPYw9xj4EPho+ED4UPgo+Rj5wPkI+/j72PvA+5j7YPuI+wz8BP0k/3L/6/9q/4//w/9RAOgBSATQBYAFSAbIBSgHuAfgCCALwA3wDkAOoA6wDXAPUA+gEqATIBVAFQAUYBYgFYATgBAAEYARIBMgEsARwBAQDSAKaAfABmAGEAZQBZwDGgD4+2j7yPvA+oj4gPZw9hD1YPNg8zD0IPLQ8KDvcPDw8EDwoPGQ8tDx4O/A7yDxIPJA8tDy8PMw9AD0cPTg9FD1QPVw9SD3GPgo+ID5oPmo+Hj4MPm4+cj64Pvs/Pz8RPxI+7D7CPxI/Pj9mP9aAMb/a/89/9T/8ACMAqAE2AVIBpgGIAbABrAIcAoADWANUA6gDnAP4A9gEeAS4BIgE+AUwBYgFkAWIBbgFWASMA+AEKASoBQAE8APUA34B2AFiASwBogFxAMQApb+HPwo+XD48Pdg9wD1QPTw8xDzsPLQ8MDv4O2g7eDuQPAg8ZDwgPBA76DuAO+A7zDxwPLA8wD0IPSg8+DzgPSg9ND1kPfo+Oj4cPm4+Zj40PiI+Yj7FPyg+2z8VP08/Qj8GPzw/ED97P2C/lcA7wAXABYAbQDjABgCSAQ4BoAHqAbgBvAHIAlwC0ANgA5AD7APABCgEYASYBPAE6AUQBVAF6AYwBjAF4AVwBLAEIAQQBPAFcATwBGQDMAHYAXABCAF6AX0A6QBC//o+7D3gPZQ9gD20PSw88DzUPLA8IDugO1A7WDtIO7A7rDwIPDg7qDuIO6A7uDu8PBA82D0EPTQ83Dz0POw9MD1wPcw+ej58PjQ+OD4wPl4++j6cPu8/FT8sPs0/Jz9Dv6I/Mj8Dv6O/lj/lP8qAX4BgQCRAFgCQASABVAGgAd4B0AHQAmQC+ANcA7wDqAP8A/gEKASIBQgFGAVwBVAFoAXQBhAGaAWABPgEOAQIBJgEiAUIBNQDlgHgASsA6wDsAM4BDQDoPxA+aD2oPZQ9RD0YPMA8/DxwO+g7uDtwO2g7MDsIOzA7MDugO9A74DuAO7A7eDtYPBQ8xD0MPTQ8wD0YPTQ81D1KPhQ+pD58PjY+Uj6UPrA+nT8PPzY+6D70Pz8/Qz+6P0c/UT94Pxg/cL+0v8IAb8AxgC+//UAzAJYBHgFMAY4B4gHoAgwChAMMA6QDiAPQBDAEAASABMAFMAUIBUAFiAZQBoAGEAWQBRAEfAP4BCgE0AWoBHgDUAJoARIAWwCAAVgBAgAHPwo+DD38PRQ8xDzMPIA8UDvQO5g7aDsgOzA64DqoOsg6+Ds4O3g7+DuYO2g7WDuYPHw8cDyMPRQ9bD1EPRw9iD3ePiI+Zj6APzA+jD7VPzE/XT8cPt8/WT+oP6U/mD/R/+g/Yj98v6+/2oA0QDmAdACtgBoAaQCSARgBigH6AfwB9AIYArwC0ANYA5AEIARYBEAEiAUQBQAFCAUIBbAGcAZIBpAGoAX4BEgD5APABNAFAAU4BJgDDgHkgG8/4wBJAMgA5D+APpw9rD0QPLA8CDxcPEg72DsQO1A7YDrYOoA64DrwOnA6QDs4O8A8CDvoO2A7sDvcPCw8xD1APbA9aD1kPeA9xD4UPrw+yT8wPuA+2j94P3k/Tb+Zv5I/nz+EgD//3z+AP6A/pj/m/96AcUAKAEpADEAEAKiAXwDwAWAB9AGqAbgB3AJ8ApQC1ANkA+gEKAQQBIgFAATIBIAE8AWIBegGGAaIBtgGeAT4BAAD+AQABEAE2ATwA8AC5gEYP9Y/lwA/QAE/0T8GPmw9UDx4O5g8MDvoO4g7KDt4Owg64DrYOsA6kDoQOhg62DvAPBg8ADwwO5A72DwsPMQ9QD1wPYY+Hj4APgg+bD7hPw8/Lj82P0s/cz9nP7I/0j/RP3C/8b/SQDw/fj+m/9J/6//cv8ZAP7+IgCQAEwCGAKEAvgEeAVIBvAGMAhwCjAK8AsADoAPYBFAEiAUgBTgE0AT4BRgF8AYYBoAHEAcwBoAFgATIBGAEMARIBNgE0ARcA0oBbX/QP4C//v/jv7k/PD58PQA8EDvoO5g7qDtwOyA7IDq4OrA6oDsgOmA5wDpAOug7aDvsPGw8MDvoO/w8fDzsPQA9nD46PkA+aD4YPqA/GT9Jv6j/wb/BP4E/of/TQBS/5n/ngC1AFn/gP7U/uD+nP7q/jD/eP6y/sT+zgDqAJYANAIgA7AEEAWoBXAHkAgQCjALUA3QDsAQABJgE4AUwBMgFIAU4BWAGMAaYBzAHIAboBbgErAPYBAAEmAUIBPAElANuAQp/+D8lf9E/xL+IP3Q+SD0oO4A7mDuIO0g7YDsYOuA6gDqgOrA6qDo4Ocg6IDqYOxA8BDyoPEQ8IDvoPHA8tD0wPcA+pj6CPog+iD7xPws/Uj+tv9r/3L+rP40ALQAg/9C/lr+pv7a/pr+n/9Y//j8VPyI/Gj8jP3s/YD/SAAlAC4AlgE0AzAEmAVABlAIwAmQC+ANsA+gEKARgBIgFIAVQBYgFsAXYBoAHMAcwBwAHAAY4BKwDyASYBEgEyAU4BCQDEgDUP2o+1D8dPyM/Ej7oPdg8mDswOvg6YDrAOwg6+DpwOig6ADooOiA6ADoYOjA6YDswO9A8QDz0PAg8LDxcPPA9Tj4uPsk/MD76Pm4+3T+Zv5f/97/xQD+/mT+MwC6AdMAlv5W/jD+gP5S/uL+Wf/g/bD7sPpw+zj9KP7C/pH/dAAoAKEA2ALwBDgGAAcACEAKsAugDUAQgBKAE0AUgBSgFGAWQBcgGeAawBxgH6AegBugFYARUA+AEEAToBPgEwAQwArVAGT90PkY+uD7yPrQ+RD14O/A7IDsgOrA6EDqYOqg6eDnoOgA6mDqAOpA6QDpIOrg6+DxUPYw9tD0gPKw8iD0MPeo+iT+l//C/lD93PzM/TIA4ACkAawACQBzADYAXAHoAM7+NPyY/Mz9fP6K/mD92PyI+9j5GPlI+zj9hv4u/9L/ewCkAJQCUASoBlgH8AgAC2ANIA/AEGATIBTgFMAVIBegF2AYQBpAHEAewB1gHYAdoBUgD3APoBDgEeAQIBFADhAHQ/9Y+pj5WPiQ9zD3EPew84DuIOpA6QDpwOiA6aDnIOlg6ADp4OjA6uDqgOqA6uDsAO8w8kD2SPgA+RD2gPUg9rD4PPxrAPIARP98ABIALgCe/1gAVgF2ASIAyP+CALT/sP7o/aT8YPto+6j78Pxo+9D6CPnw94D4oPmg+/D7Lv53/6kAGALcAugEWAboB5AJAAywDkARABNAFUAWQBegFyAXQBnAGqAawB1AH0Ag4B8gGuAVoBAQDmAOwBFgEgAPAAtYBCr/MPkg9xD3YPYg9QDzcPGg7eDq4OgA6YDoAOhA5wDnAOnA6mDsIOzA7GDsQO1g7RDwEPXQ+ED6EPso+tj48PfY+bj+kgH+AdoBngFMARQBfAE0AiQCegH+AFAANf9u/ob+3P0k/YD8APzw+jD6oPl4+fj4EPno+DD6BPz4+yT9pP7cAewDYARwBRAH8AhgCqANoBEgE4AUoBWgF6AYoBgAGSAagBuAG0AeoB6AICAfoBogFIANkA1wDsAOQA/QDvAI6AA4+kD3gPWg89DzcPOA8WDuIOvg6aDoYOfA5gDogOcA54DpgOuA7cDtwOwg7SDuQO9Q81D3+Pqc/BT8EPyA+7j6wPsoABADcARgA8ACHAOqAT4BUgEeAaT/GwBVAEwA0P0g++j70Po4+lj6sPmA+cD3EPcQ+CD3UPeI+Nj7qPy4/Wj+QAIQBIgFyAVoB2AJQAzADyASgBXgFiAXABbgGMAZgBpAGuAcYB7AHkAfYB5gHgAYwBAwDEAMcAywDUAOAAzIB2T8QPZw8tDxMPKA8WDxYPDA7eDowOfg5kDmoOaA5+DnYOiA6SDsYO6A7cDt4O4Q8FDxAPVI+fD70PuU/Gj9qPxY+0D9rwA8AsACQAKcAnAClwCOAFUAbP9e/oz9If8Q/2T9OPo4+Tj5MPrI+cD3WPmQ98D3oPbA9oD3iPno+7T9qwAmAAgCEAZwB+gGQAggCmAOABJgFKAXABigF+AXYBmAGUAYoBlAHsAfgB6gHqAe4BsAFDAN0AlwCYAK8AzgDfAKbAKo+NDzcPCg7qDvwPAA8aDuwOtA6cDoYOeg5oDnwObg5+Dp4O2A73DwwPBQ8LDwAPFA9bD4DPz4/W7/MQBY/Wz87P0PAHwBgAK4A/wDjAIoATIBSwCc/4D+hP0o/Qj9+P3g+3D6QPh4+CD5oPcI+ED3APhg90D3WPh4+TD5QPvG/nYBGALgBGAH8AigCTAJMAtgDwATwBXAGEAZIBiAF0AZgBlgGaAawBxgHaAdYB1gG+AXYBKADIAIWAdACKAJcAn4BYj/MPhQ8sDuIO7g78DuoO1g7eDrYOmg6MDn4Oig6CDp4OmA60DuwO8Q8nDyQPOg83D1QPjQ+kz9eP7Z/3r/jv8N/zb/mwBsAnwCIAKcApgBWgG0AIv/8P5s/fD7WPvI+8D7SPtA+qj4sPdw9jD2EPeA9qD3CPhg+OD3ePho+cD6uP6UA3AGyAZACLAHoAnACUALkA8AFQAYoBkAGkAYQBiAFyAZYBoAG0AboBwgHWAcABvgFSAR0AzwBxgGYAaQB6AHWAXO/mD5IPNA74DtgO4g72DuYO7g7GDtoOqA6YDp4Org68DsgO3g7yDyIPMw9HD18PdI+Fj5CPuE/DD+1P6IAIYBZgHO//P/1AAEAQQB9gCgAWQCmQAIACv//PzY+9j5CPpo+lD6aPuY+qD5WPgw92D20PWw9iD5uPmA+RD5APqA/K7/GAQwCFAIyAb4BlAJoApgDCARQBagGMAYoBegFkAXoBcAGaAZoBoAG6AaQBsAG+AYoBXgD/AKEAhQBeAEEAaIBwgFiP6Y+PDy4O4g7SDtQO8Q8MDugOxg7ADsYOrA6WDrwOzg7ODtQO/A8UDzEPXQ9uj4EPoA+rD6APw4/br+u//+APcAngGkADD/N//C/yMADAD9/ywA2/9C//j8mPtw+nD4uPiQ+ZD6+PlI+RD5wPgg91D1oPZg+JD3CPjI+JD5uPwk/wgGsAi4BvgEqAVgB6AJAA0AEiAVABhgF6AWYBagFUAWwBfgGKAZgBmgGeAZ4BnAGEAT8A5ACqAHaASABPAFWAbABPj++Pjg8sDuQO1g7YDwMPDA70DuQO3g64DqYOtg7KDtgO3A7mDwoPFw83D2MPhg+HD40Phg+mj6FPxu/m//fwAC/6//Hv60/Hj9Xv4u/2b/VP+e/+7+VP3Q/HD7mPng90j4yPoY+hj6wPqA+hj5YPbw9rD4KPhg99D5mPrQ+pj7WgDIBjAI8AjoBigGYAeACUANQBFgFSAYYBhgFgAWIBZgFmAWwBggG4AZ4BcAGcAagBjgE4APAAsgCCgE2AQIBugGGAXf/9j6IPRg72DtYO5g8HDwEPDg78DuIO1g7GDrgOwg7UDuwO9w8BDy4PTw9yj4EPio+JD48PjQ+cT94v5hADgA3P++/vD7QPyk/RL/fP5f/1D/Gf9U/kT9KP2Q+zj5oPc4+SD62PnA+sj7YPtg9wD3cPdw+OD3sPdg+uD6WPuo+pT/gAToB0AJgAjIB6AHwAkQCyAPABQAFyAYoBaAFmAWABVAFmAYABqAFwAWABdAGWAXYBQAECAM8AiIBHAEiATQA/ACrP/I+9D14PAA78DuAO9g7+DvgO8g7wDu4O2g7IDrYO2A7sDvwO8A8oD2gPdY+OD3APmQ93j4SPoA/Rv/9v6SAEX/8v68/Mz8Iv6k/Sr+PP6M/iD/NP6q/qT9cPuQ+WD4yPjY+FD5MPqA+7j6oPiY+DD50Pjw96D3WPnI+fj54PtAAEAFMAkAC3AJkAjQB0AIgApwD4AUYBhAGWAYwBdAFUAVABcAGQAZABdgF4AX4BjgFmAVABIQDbAIgAYYBTADTAO4AkIBvPzA98DzYPHA76DuYO/A72DvAO9A74Dv4O0A7aDt4O3g7aDu4PGA9YD3+Phg+ZD4kPdw97j5yPv8/GH/LwDUALD+qP0k/nT9bP1w/XD+KP8+/1b/lv+g/2T9mPv4+XD5EPkw+eD6sPuo++j6KPoA+gD6MPlA+LD46Pj4+Tj7JQAABSALUAtQCXAIyAbABqAHsA2gFCAYgBgAGAAY4BWAFIAWABiAF0AXIBeAF2AYgBdAFmASAA4gCfAGqASAAzwDBAPHAIj88Pgg9cDxgO8g76DvgO+g7kDuQO+A70DuQO2g7eDtAO7g7jDxYPTg9YD3iPgI+Tj4QPfg+MD6aPt4/bT+5f9F/zj+cP20/Zz9oP2s/iH/XP+u/q7+zP4Q/lT8APsA+uj5kPmw+cD6uPso+8D5MPkA+oj54PeQ93j4yPpg+tz/KAbgCRALEAngB6AGMAaIByAOABSAF8AYwBcAGAAV4BVAFiAXwBeAFwAX4BbAF+AXYBYAE4AO4AmABhAEYANsAlQCqwAE/Zj4sPVg8+Dv4O4g7gDvQO5A7cDuIPBg76DsYOwg7WDtYO3g74DzEPXA9RD2gPcg+FD3IPfA+ND66Puk/LT9jP4m/tz8+PzE/dT9pP2k/n7/V/8Q/oj9Ev7c/WD8SPto+kj6aPtY+zj7oPqw+kj7CPsQ+nj4gPgw+Bj6wPzDAIgGIArQCzAIoAegBFgGcArwDkAToBWgF6AYgBgAFuAV4BcgFwAWoBVAF0AX4BcgGcAXABMgDXAIGAcwBVQCGAMMA9oAQPxI+MD18POw8aDvgO7A7QDt4O0g7+DwwO8g7sDsYOxg7QDuwO9A8qD10PZQ9+D3oPgY+bj4iPiA+eD7sPyM/SL+8v7U/vz9YP5Y/s7+Iv7K/pj+3P5u/hj+hP4U/Tz8GPtg+iD6+PrQ+1D6qPk4+pD7SPsg9yD3KPpA+uj7kgFwCFAKQAgAB4gHMAegBnAJsA+AFAAV4BXgFiAYwBZAFiAXoBZgFiAVABZAF4AYwBaAFSAScA4QCFAFYARwA4ACiQD2/iD7IPhw9TD04PBA76DvQO4g7eDswO5g76DuYO1g7YDtIO0A7rDwcPLA86D18PYI+LD3WPjo+Nj5qPow+1T8/Pws/jb+bv7+/k7/KP94/qz+NP6M/mL+ZP70/bj9MP3w+1D74Pmw+rj6YPmA+qj54PlI+lj52Pig9oD3APv1ACAESAZACNgHcAYQBXgHEAoADZAPwBKAFYAVABYAF8AYwBfAFuAUIBWgFiAXoBeAF8AXoBSgELALIAkgBwAFkANsA8oBOP6w+vj4MPdA9ODxoPBA72DuAO6A7iDv4O4g78DtgOxg7GDtAO+g72Dy8PSA9iD2MPaQ90D4IPh4+Ej68Pu8/KT8DP4f/13/Zv/i/vj/A/+q/t7+EQAOALr+8P5k/mj+HPzA+xD7QPug+1j60Ps4+nD8cPuo+JD2oPfg+yz/6AEIBtAIQAboBOAEQAdgCDALsA+AEUATQBTgFaAXgBdgF+AWIBbAFCAWwBagFyAYYBiAFiARoA1QCwAJEAaABNADuALR/4z8gPoY+BD2cPPQ8UDwAO6g7SDu4O7g7iDu4O1g7aDsAOyA7ADvgPBg8mD0MPVA9ZD1IPYw90D46Phg+pD7uPxQ/XT+wf+zAGYAqP9u/y4AhgAgAJn/4gA0AfX/oP3o/Zj+6P2E/Hj7tP1g+/D6OPwU/Jj54PdY+Uj+PALEApAFaAbIBSgEhAJQBrAIUA0AEMAQYBHgEmAU4BWgFcAWABZAFSAVwBRgFsAXwBhgFyAVwBEwDjAKYAggCDAGqARwAvUAJf8Y+3j4MPeg9QDzkPDg74DvgO5g7mDu4O4A7kDswOvg6+DsAO7A7sDwgPJg8lDyoPIw9FD1gPUA9/j4WPlg+hj7eP3E/hz+fP1w/pD/R/8v/8j/pgEyAS0ATf+K/9j+xP3W/ir+AP6U/Cj+tv9A/Zj5YPiM/Lj9zAHcApgFqAYoBdgDvAPgBNgHUAtgDZAOIBDAEcASQBVAFgAVgBNgE6AUQBTAFAAWYBjgGEAUABHwDpAMsAkACGAH0AVcA1IBtv9I/qD7UPkw9/D04PEA8IDvIO9A72DvQO+A7SDsIOzA60DrIOwA7jDwUPCg70DxkPJg8qDycPQg9kD24PaQ+Kj6mPtA/BT9FP50/nT+a/8c/83/XAFkAYEAo/8qAQgB9v62/43/LwBg/Rj9IgGw/9j64Po8AOgCVAIUAwgHQAegBDADWAWwCAAJoAuADgAQ4A6QDyATwBQgFCAT4BOgE0AUgBNgFcAWoBdAFeAT4BDQDRAMEAswCpgHGAYQBPQCBgCo/fT8YPuA+KD14POw8YDwUPBw8IDvoO7A7eDswOtg62DsYO3A7aDt4O5A72DvYPAA8jDzYPNg9AD1sPUA99j40PpA+7D7uPtc/ZD9RP72/tv/TgFeAF0AKP8K/0YANf/CAH0ACP/e/yQAXP8g/ZD86P4cAsQCjANYBfgGKAZIBKAGQAgQCbAJYAsgDTANQA4AEYATQBNgEkARQBGgEaARwBKAEyAVQBQAEnAPYA5ADaALcAkgCNAGGAQUAjYB1QDm/pD8sPoA+ND04PIQ8vDxAPFQ8KDvgO7g7QDt4OyA7KDs4OxA7QDtYO3g7lDw8PAQ8bDxsPKw8yD0YPXg9gj4EPmQ+Xj7wPvQ/NT9iv/L/5D+u/+NAGQBJAAsAbIBOAIAAmQB6AJ8AZgBowA9AKEAdAIgBZgGiAbYBjAH4AVgBkgHYAnQCbAKIAxADEAN8A6AEMAQsA8wD0AP8A7ADoAQABKAEiAR8A8QD9AM0AvwCuAJyAeoBWAEiANkAt8ATQAk/9j8wPkw97D18PQQ9ODzEPNA8jDxcPDg7+DuIO4A7qDuoO1A7SDugO/g73DwMPEA8tDycPKA83D00PXA9lj44Pmw+mD7MPxs/UL+aP7W/hT/1QB8ASwBaAGQAjAEuAMYAvQBvAO8AtABMAKEAyAFQAaAB4AIYAhwBsgGuAfwB7AIUAngC2AMgAxADDANkA5QD5AOwA2QDWAOAA5QDiAPkA/gDwAPEA6wC4AK4AmACWAHqAVYBQgFzAO2AeQANQBW/sj7WPog+bD3kPYA9sD1cPQw89DyEPLQ8MDvgO8w8IDvgO5g7oDvAPAw8GDwIPEQ8tDxYPKQ86D0QPVw9rD3gPjQ+ND5ePsY/Sz9MP1c/oz/cwBYAIsAcAG8AjgD+ALsA5gESAVwBNQDsAPwBPgG6AcQCTgHMAhQCIAIcAiACLAIgAlgCnAKoArACvALQA3QDBAKkAlgC9ALEAvgCjAMcAzAC6AJ8AhQCdgHcAcoB8AFEARgA0gDOAMgAsUADgD6/uD86PpQ+ij6gPkI+cD3EPdQ9hD2YPXg80DzEPNA82DyMPIw8kDzYPPg8hDzYPNQ8yDzUPTA9ED1kPWg9pD3qPho+UD6GPs4+6j7VPz8/Fj9Df8gAJYAJgFYAvACXAKgAlAD0AQgBNwDGAYwBwAHSAewCNAI2AfgBrgHkAiQCIAIIAmQCgAKgAkACSAJcAlgCCAI8AeQCMAIsAhwCOAI4AeAB4AGkAYYBWgFsARABGADKAP8AowCEALpAL4A4v/E/hz+mP1s/Uz8OPwU/ID7ePpY+TD5+Pio+ND3sPeA98D2gPag9tD2cPZg9jD2YPYg9vD1MPYg92D3YPdg9zD3sPcA+MD4wPl4+nD6yPrw+3T8DP1k/MT9Fv/q/6QAx/+yARACyAJ0AiwDdAOgA/gEIAVIBogFEAYQB7gHyAYwBUgH0AbwB0gH6AZAB4gHIAgYBzAGAASAB0AH0AVoAwAFEAfoBSQD4gEoBDwD4AMCAZAEyAI6AVABngHXAHT++v4KAbACCv4A/VYAEABS/ij7YPtY/cj9oPvo/Lj74Pu4+1D70Pn4+Rj6OPro+dD4sPkI+9j5WPo4+vj5QPlY+fj6KPtY+lj6GPvY/Oj8BP34+9z9ePyQ/Zz9IP1U/2kAjALqAU0AJP8kATgCVAKQAggCaANIA/gDGAQ4BAAFWAUoBYADnAK8A9AEcAbgBFAFKATABIAE0ASwBDADQAT8AigEoAKMA7AEwAQQBFAC3AIcAXwCjgDWAWQCmAEMAq4AoQByAM3/rv8b/6T+PP4U/3v/hP+c//D9FP5g/az8aP2U/ED9kPzY/CT96Pwo/dD7zPzo+3j8UPsw+8z8ePwU/qj8eP2Q/Lj8UPx4/DD9qPy6/mz+Of8o/lj+/P7M/xz/ugCgAEwB2v8bAGIB7AKUATwCgAEQAwgCEAJUA4wCwAVFAHgE6AIwBRwCbwC4BBAEEAXU/kAFMAZMA57/pAGQBU4BOAK8AgwDoQC/AIAF2QAw/sz+GARgBMD6/P1wBCAFOPvA/HgBQATA/UT8Av7UAqj9hP3U/WgBsP9I/Pz8+P51//j6TPzQ/pz/RPxg+eoA2QDE/ND57P4q/vL+MPoW/5//8P0w/Af/Tf9E/Hr+BAE9/zz9nP2QAEAA+v+8/sACQgCLANz9vAINABUAkABoAYwCWP+lAGQB1AKm/2UAkwCcA9gAFQDcAQYBRALx/+oBxAEoAigB/AMIAhf/OwD4/2gC0ADw//gD/gFiAM0AuQDD/3L/LgDGANIAYv/R/wYBkAGs//j+iv5kAEX//AAo/WUAeAB+/1z+yv56AEL+TP8q/2oA4P3Q/Qn//wCR/2z+vv7t/9T93P23/2T+sgH0/n7+IP6h/wQDPv+o/uz9wQDx/5D+b/84ARQDzv7cAG7+QALc/6QApgDTAOoBegDzAFf//AIcAJ0A5/+wAMYBOwBmAFT/uAE0/yQC0f/4AIf/xADn/0ABbgHh/0f/c//8AYwBPf9e/gwCYAJCAFL+b/9MAvP/t/+8/1oB6v54AWUA9v/LAEL+kQAgAdj+YP6OAJr/cv/NAIsASACI/dT8vP4UAfT97f81/2oBVP0Y/kD9SwDjACj80gF0/eUAZPyp/wr+wwDLAOz8hAGY+/AC2v5kASj9zgGRAMcA8P86/twA+QCeARz+9gFu/lgB1gCgAMr/MQDA/o4B6AL6/h7+dQD0A1QCcP9I/OYAnAIC/7j+YQB0AbcA9/+K/4n/GgD2/kwBUgArACwAIgGm/9P/GADu/vMANv8EAQ3/LQA2AB4BAACa/s4ALP9kAXT9DgF4/lIBrf9Y/23/4P3YAvD8NAHA+7IAPQDG/qn/IP+2/7b+KwDA/8r+xP1i/nMAPf90/4z9zAJBAHr/tf94/vv/ev9a/mj/pAHA/9v/HAHc/wwBfv7w/74AUQDc/iwBDAI0ABsArv8sA+b+0v4tAOgCn/+p//7//AIUAK7+MABGAdQAxP05ABkAtgF8/ngCvv50AjP/Hv90/7cA4AEs/iIBJP7wAkr+Ov7UAMABiAD0/RgAzP9QAlL+LAFb/8MAZAAp/y//sgAmARIAP/82/pABGwBA/tr+sQBwALz9TQBc/p4B/P4A/nD/Yv5MAP7+oAHw+5v/lv/Y/xT+nP6TAHYBvP2s/bkA9AGe/oT/sAAIApr+wP5QA0sATAFU/SQDFwAyAbr+UALFABYBvv9SAWYAhALyAQwB2P1wACgCPAHTAO7+iAPJ/xoBLP50AxMAuACDAD8AwgHA/LwCaAIcAqj9xv98ARwB1P5U/jgCkAHw/iv/dgD2AVf/yv9P//b/ugFD/xQBQP6QAeT9TgGg/QQAEgHE/tb+XP6M/6X/Xv/U/xD+RAFw/Yv/0P3dAB3/sP4A/uT9cAK4/Nf/KP6SAJ7+lP1s/2QBkP+E/mQBgv53AAH/YAGgAJj+K/8QAsH/JABnAAADDAFw/qr/6gCwAdH/CQBcArgCFABS/5QA+gEYAj7+sf8/AGQD6v95AFf//AOv/+b/Mv6EAugANgHG/sUAFALk/owAev9+AZb/m/8vAOL/CAHF/5j/7f9KAOj/MwCO/i4BZgBx/w7+4/+uAB7/4P+n/+//XP3w/Yj+kQCiAKD9VAAa/lL/aP3+/+b+QP/I/qT9UgGs/SYAxPwAAUz+gP9Y/jwBZAFQ/RoBJv4MAuT9CACMAPoBqP7g/oQCWQAPALv/XAHEAgUAm/+0AfQAaABZ/yACXgFGAcD/qQCIAbkAXgEUASQBggG8/t4BYv8MA5P/IAF9AGYBnAA1AEUAzwBgAUH/XAGWAIsAyf/2AMwAfQD6/uoA1wCZ/2T+TgGNANz/iv4yAfn/wv+0/QwBCAK4/Q//Zf+gACr/7P3q/x8Amv9Y/Zb+EwCa/6T+0P3Y/mQASv5t/xT9vgGu/tgAuPws/5n/MQAVAJD+x/9WAST+7P/E/jQCIf9sAMD+XAI//y//ZwBEAoYAlv8TAIgB5ADD/4wBvgB2ATT/TgEgAXUAmP/CARACggCm/mABkgEmAZD+yAHVAG4AAABy/8gCjf/WAJz/YALs/dr/HgHe/8YAbv5gAX//3gDk/loB7v4nAK//nQALAND+nwBu/zQAov4mALX/nP4gAUH/of/w/Wn/+f8BADL/1P3EAeD8cAFs/PYAkP6YAML+jv7i/ur/DwDk/Oj+OQBVAEL++P1l/9gBHP/o/UL/rQD2/6j+jAH6/h4A+P6hADQBMwDb/wUAoAI+/+f/WQBEARIBDwC1/8T/OAIPAAgCUf80Aan/xgCxAOv/CgHyABQCNP6iALH/tAInAGD+7ABiAV4AmP5AAYQAoQBS/noBJAFvAFD+xv/0AKL/zv9z/8oBN//Z/2T9zQCI/zwA2gB0/QoB9P0aANz9OAGk/7j/wv4Y/bYB6v4P//j7AAIVAFz/qPwXAAX/ugBg/bEAMP40/ib/lAC3AJj9of9sAiX/9Py4/i4BIgHA/qr+lALGAPb+YP8SAc4BDP9a/48A2gEP/+AAqABgA3//UAEgABwBbwCYAFwC1P7aAB8A6ANtABT/sAEIArgBPP7OADgAwgGe/zH/JgHa/0YB9P+uAB3/fAHiANr+DQCh/yoBwv5/ALH/ogEE/xz/gv9s/wsAgP/KACn/PAFE/hYBHP1a/jIBk/+cANT86/8oAIgAVP3g/icADQCe/vT9v//OAET//P6G/nYAnv9J/wL/sP4NAFH/lP8e/wMA9wAd/7r/dv7jAAgBdQAFAAL/+AFI/+cA8P68AY//XwDaAL0AoAAqANIAbAHe/3j/YAF0ASwBnP7cAhMAsAA0AGEAfAKw/hAAnv9MAsf/q/8VACABgAGE/1z+ywD/AOT/UgAS/6ACoP7EALD+CgGB/5r+hgEZ/0ABev5J/5IBmv6bABL+WgCj/7n/fv5U/iwBPf89AFD9pf9qANj+xv/8/ZL/nP6r/9H/Nf+z/5z/AQALAMj95ABM/ngAdv+3/0MASADRABb+0v8U/wQCX//4/lAA2AF2AfT8JAKB/ygD2P3hAGIBkQAwAHL/qALg/7MAHP1EA1oB2v+qAO7+mAPe/uj/rv5kAgQBwQDs/g4Bnf/oAS7/JgFPAGj+1gAfAHYBMf92/70APAEZAGr+TAB+Adb/wQC4/ZADkPwAAsz9agHo/p7/cgE1/9gAHP0rADL/MwA2/pYBSP1CAML+4//k/mL+pwB6//j/yPy/ADAAuf/Q/eD/EgEz/zL+vf9AARv/xv6k/ngCQP5oAPb+DAPU/1j9yQAjAEgBmP2q/1ADFAEoANz8MALkAKABvPxKATwCQf8qAfz9PANCAQkAtP4hAJkAHwA8AHoAsv/uAfr+vQBx/+cAyP93AAP/ZQDE/7X/PwDcAPoA1P2f/wwA7gFo/ZEALv4MAxf/6v6A/2gBDP+0/YIAbAF+AAz9bf9cACoBuPzu/xwCrwDU/Yz9IAKl/6f/6P08Auj/av6Q/t3/HgEM/SACVv4UAmj88AAc/1QBIP1nACkAegBb/0f/OAHT/6MAlP50AYX/fAAn/xgBuAC7/2QBdv6QAoL+jAE9/8YBzgD6/ygBuP1EA8r+sQB0/nwBMAMb/yv/RP4AA0QBhP5L/yACjgFt/3L+LACsArQAav4RACgBmABy/rj+QwCwAmz/xP2qAbMAVgGw/EACVgC6Acj7QgCIAaL+yv8c/8QDtP2I/rz+ZAPi/zj9dwAN//4AVP0KAW4A6f8r/9D+WAAw/uwAQ/+8/qP/Vf9UATD9uAD8AGACXP2k/VoArAAgAZj9sgG9/6gBUP0eAWf/fAK6/iwAdADEAI8AKP1MAv4BsgHO/r3/bAFYASkAegCMAu7+9v5uATQCwf/Y/jQCtAICAXD75gEsAkQCsP36/zUALf/VABAASALq/p8Arf+8AZD+5v5ZAAEAkP91/5X/iwA5AGQCDP2IAZj7fwBa/1gBmv6X/24ATv52Abj8BAKxANb+jP0GAIoB8P2sAF4BbwDA/lj8UALcAbz9oP0GAXwBTPzh/5z/RAL4/ez9/AHg/97+wP5aAXwAxP4u/9gAjgEa/0L/kAETALsAEP3oAsIASAKw/EwB+wBYAtT90f8mAYQC8P6z/9oBTQCoASj9bAFYAI0A9v7h/4oAAALzABr/6//RABP/xf8CAJgBHAIY/SwAcwCAAaL+1P7wAlEAoP+w+0ACmABQAOz9i//IAZT/0P79AEAAjwA0/Qj+UgEEA+z8QP9M/8QCegEA/BT++AGuAZz85P45/8gCVf8z/+b+WAHA/qH/x/8CAXr+e/+EAIP/xgADABL+kgHkAIYAKQDA/uMAOALa/9z8JAJcAgABgP6F/1wARAN+/pYAfAEoAKIAuv47ADj9vAGWAKwCaP79/xMAPAL5/zD9QAKd/ysAhv54Aqb/m/8O/qX/cAOQ/EAAywDEAtz9tP3Y/6oB+wDU/mUAr/9J/1kACAKgAMT9EAHyAXMASPwK/jwCPgGI/fT8/AKYAkf/SP3q/jIBFgAG/lIARv8bADD+B/93/6AApQCC/5//sP08AAf/1QCV/5b/fv9BAMUAef/a/68A3gGc/2j+2/9YAbYA2P1uAJQA/gFu/xAACAIqAKv/jP6eAZsAawB5/9YAJgCm/5H/+ABIAWoAeP+gADUAowBkAPv/2gDM//4AEv62AMn/sAFvAHv/TgAUAOQAhP06AUEAcAFg/f0ApgCAALD+rv6MAgcAIP/4/EwDBABmAcz9PwBuALH//f/o/iwBBwDQAoT/g//g/RABlwCA/8X/lf+6AVr+d/8DAJwBA/8ZANT+3wBa/+r/uv8qAPv/JAB1AHAA+AC5/z4Arv5mAXMAigBG/mMAMAKTAOH/eP6EAEIATwCy//oAjwDcANv/EwAo/0n/SwDAASQAJP60/83/wAJi/yEAPf9lADr+C/9zALL/OwDs/sQCTgBG/y7+igFYATP/tP2y/44BXgDu/mEAlAHCAUL/rv5j/5wBwwAmAMj/i/9DADoA0P/gAff/Uf8UAIABjAHS/tD9g/8oAj4Acv4F/ygBGAI4/gL+t//YAXwAbv66/jAA/gAe/tb/OAD+AAP/wP+j/5oAO//L/1kAw/+a/wv/egBPAD0A5v/4/wj/nP8qAOP/rf/L//8AAwBR/7L+MQAiAHz/+v7+/24AXQCW/3X/twA9AKn/Qv/eACkAogBY/+L/VgDH/+4AhwD7/9j+gf/5/xIAtv+v/7oAw/8cAMf/5/+V/43/oAArANL/kP8nAF4A7v+m/2H/1/+0/10A8/8FABkAywAYAFv/3P4y/6r/Yv/Y/xkAUgD+/kb/af+T//j/fv+X/4H/mf8JAN7/5P+C//r+Ov+L/2wAwv/+/3YA0gAbAHH/z/+PAG8AXf+U/0MAfQDTAMsAuQBnABgAbwCvAJUABQBRAOkAdAAEAML/YQDaAPEAlgDU/53/wP+BAEAA5v/T/2EApwD2/9H/CACoAJ0AngC9AMAAXQAlAEoATQC9/17/3P9XAGoARgB0AHcALQAHAC4Asf/q/iX/6/9EAJ3/SP+3/0oAGQAb/1f/g/96/6f/Iv8I/xT/+/+ZAHsAWf96/3QAcQBs/1D/DwAuAMD/m//P/9n/qf+W/yUAvP8j/2X/TQAWAIv/m/8OABsAqv+Z/48AUwCI/1P/KwBlACkAFwDfANEAPQAxANQA2gDTAHcA4wDhAOIAkgDJANcAEAHBAJoAUACdALkAmgBZAIoAVwBsALD/7//Z/4wAcwBEAPb/sv91/4j/uf92/33/wP4V/yH/CP8Z//z+fP9I/0n/YP+I/2H/Pf9q/3L/Jf+i/sT+If8V/7D+xP47/yb/A//c/uT+yP7S/ub+Hf9D/9r+9v7+/k7/Iv9l/3D/tP+C/0r/m/++/+z/tP+R/3v/q/+x/0QAKQBIAJgAxgD2AKgArwAMAbQBzAHGARgCTAJ0AnQCUAJ0AogCCAMYAwwDCAP4AjADXANQAzQDVAM0A+wCiAI0AigCrgEoAuoBigEkAfkAMAHWANIAdgAmADAA8P94/2n/0P68/kL+oP1U/VT9jP08/bj8oPzg/Dj8NPz4+wT82PtY+9j6IPow+hD6IPr4+Uj5CPlo+WD5uPko+mD6+Pr4+mj72PsM/Pj8wP3I/qL/DAChAPIBUAOgBKgF6Ab4B2AIkAngCcAKUAvAC1AMUAxgDQANgA2wDXANgA3QDLALwApACpAJgAh4ByAGUASwA3QCXALEAQYB8v9Q/3v/aP4q/lz+NP68/eT8yPto+wD7IPuw+lj6OPl4+PD3sPYQ9XDzUPOQ8+DyEPJg8YDvoO/g7oDu4Owg7CDrQOuA6wDsQO2g7/DyEPVg90j6nPzm/ywDuARIBlAHoAlQCyANoA5AEOARQBNgFCAVgBYAF2AXgBcgFwAXwBZAFsAUIBQAEwASYBFwD9ANQAswCcgGoAQAAm4AQgC2/sD8OPo4+aj6SPvg+3D7uPuI+2D7yPuU/ND8pP1s/bz8OPoI+JD3EPig+FD4QPdA9pD0MPOA8kDxQPGQ8MDvIO6A7KDr4OpA6uDqYOog6kDqIOpg7GDuIPFg9ND2OPhY+gj8tP7GAMAC0ASIBqAIcAnwC9ANQBDAEoAUgBVgFSAVIBbAFsAWYBXAEwATQBPgEgASYBBQDwAPkA5ADSALkAk4B6AF1ALV/zT+4Pso+2j7APrY+FD58PuE/T7+3P3Y/VT/zgB8ASoBrQBi/+L+dv40/pj8kPvg+xT8gPtA+YD48PZg9qD1IPTA8vDwgO8g7oDtQOuA6gDqoOkg6iDqAOzg7KDu8PCw85D10Peg+cj7vP4pAAACMAMoBRgHUAkgC3AMEA/gEKASYBQAFSAWgBbAFkAWwBXAFKATIBMAEqARwA8gEGAPcA7ADMAL4AmQCKgG8ATUAhr/hPyw+jj5cPhg98j44Pnw+hD88Pwy/qn/YgH8AjACZAHFALsA4wBr/+D+WP6Y/jD9qPw4+0D60Pl4+YD4gPZQ9cDz4PIg8jDwAO/g7WDs4OvA6gDr4Opg7EDuIPDA8QDzoPXg90j6GPxA/uH/OgFQAugDsAV4B2AJcAuADYAPQBAgEsAT4BTgFcAVIBXgE6ATABMgEoAQYA8AD1AO0A1gDMALMAoACmAIyAVABOYB8gGK/vD6APdA9kD1UPZg93D3WPiQ+Rz80P22/2QA2AFIAvACyAH8AJYAfv+5/1n/0P3A+8D6QPoQ+oj5qPig98D2oPXA9FDzUPLg8IDvQO/A7UDsYOvg60DtoO6g74DxMPNg9ZD3sPlY/GT+qABwAnwDUAR4BUgH4AhgCvALQA1QDrAPABHgEiAUoBRgFMAT4BLAEqARYBFwD0AOUA3wC+AKMAowCVAIuAYABUADLgEyABT/KP2w+aD2wPSg82D0wPXA9XD2oPdY+mT8AP5X/2QBlAI0A5wC3AGaAecAUADO/xb+PPz4+gj6sPnY+GD34PZA9iD20PSQ8/DyQPKQ8XDwQO9g7oDtwO2A7kDvcPCw8fDz8PUQ+DD6oPwF/44BPAOABNAF6AZQCHAJ8AogDHANMA6gD4AQABIAE8ATABRAEyAToBIAEuAQYA+wDqANYAwgC1AJQAmgB3AGaAWYAnIBGgHI/xT+YPvA93D2wPUA9XD1MPRQ9qD2cPkY+4D8Zv4hAIQCJAPUApwCVALsAXQBs/9G/iD9+Pto+lD5QPhQ91D24PVA9hD1cPSA86DygPIQ8XDwwO9g7wDvwO4A7+DvAPHQ8uD0EPdo+VD73P2VAEQDcAWoBtAHMAnQCQALAAwwDVAOIA9AEEARABIAEwAUYBTAFEAUwBMAE+AR4BCQD0AOEA1wC6AJEAjQBmAFvAO0AkwBXADc/lT8+Pkg9wD2QPWQ9aDzIPQQ9AD22Pig+jj8DP24/hgBuALoAjQCTAIAAgwBbP/E/fj78PqQ+cD34PXQ9MDzgPPw80DzwPIQ8rDx8PCQ8ADwwO/A74DvAO8g78DvAPHw8hD1kPeQ+bj7HP7rANQDMAbwB2AJgAqgC6AM0A3gDvAPoBDgEMARQBLgEsATQBQgFOATwBPAEuARoBDwDwAPoA0QDDAK0AgYB9AFWASkAkIB+P/m/oD8uPng94D28PZw9RD0wPTQ9FD2gPgg+3T8IP18/h0ADAJ8AkACfAGeAUgA3v7M/DD7wPnA96D2UPRQ87Dx8PHA8fDxcPFw8SDxUPHg8DDxUPEA8dDwMPAg8HDw4PGg86D1APcI+Vz83P50ATgEGAegCVAL0AzADbAOABDgEKAR4BHgEUASgBJgE4ATwBPgE8ATYBMAE0ASgBGAEEAPMA5wDHAKcAioBvgEHAOmAbj/UP5k/OD64PnA98D24PXw9SD20PQg9gD3ePgI+1z8sP14/pH/mQDGAfIBsAEmARgAwP6E/ED7cPkA+BD2UPTw8qDxIPFQ8JDwwPAw8YDwEPBA8MDwUPEQ8eDwwO8g8ADxsPLw83D1wPZA+fj7ZP72ACwDIAYACYALAA0wDvAOQBBgESASYBJAEkASYBJgEoASQBNAEyATwBKAEkASQBEgEJAPoA4wDSALEAnoBsAEFANaAdn/KP0Y+6D5oPgw99D1MPXA9MD0gPXQ9UD2cPcA+oz88P5m/0j/pwAeAVACJAJsAA//ZP3o+2D6IPig9iD1UPOQ8nDxEPFw8ADxgPFw8YDxMPEQ8XDx4PFA8kDxwPDA8FDxYPNA9KD1EPdo+RD8tP4IAZwD2AZACfALcA2wDgAQABGAEmATIBMAE4ATYBOAE2ATABRgFAAUYBNgE+ASABIgEfAPsA7QDBALIAmgBvAD/AE0AGr+6Puw+Rj4QPew9dD0YPPw89DzoPQA9SD2cPf4+YT8av5qAB8ApAAoAWQCZAF4ANr+2Pzg+qj5APgw9iD0gPLg8YDxoPGw8IDwkPAg8aDyEPJQ8tDx4PHg8nDy0PGA8XDyAPTA9bD2EPjA+dz88f+4AoAFuAdgCrAMgA8gEcARABNAFCAVgBTAFGAUQBRAFMATABSgEwATwBKAEoASwBGAEDAPAA7gDNAKwAjgBYwDQAEk/0T9+Pqo+CD3MPbw9NDz8PLg8uDzUPQA9RD3qPhQ++T85f8mAeQAeAHcAb4B6gGdAPD9wPz4+dD4kPeA9fDygPHQ8bDxQPGA70DvIPAg8QDyYPGA8MDwMPEg8tDxgPFA8eDywPQg9mD20Peg+rD95QCUA4gF4AegCtANgBCgEQAT4BMgFUAV4BXAFQAWABYgFUAVABQAFGAToBPgEgASgBCwDgAOkAzQC9AIiAbMA1gC9v+A/eD7YPnQ9+D14PTg82DyQPKw8mDzUPQw9ZD3ePkE/Pj9KQCYAc4BggEEAgwCUAFl//D96Pug+aD48PUw9GDzYPKw8UDxgO+g78DvIPEw8QDxAPHg8NDxkPFQ8gDyYPJw84D0cPVg9qD38PnA/HL/EALwA6gGsAkwDFAPIBHAEoAUIBVgFqAWABcAFwAX4BbAFQAV4BMgFAAUgBMgEqAQYA+ADoANAAzQCUgHSAVUA9cAPv5M/HD6wPig9vD0QPPw8oDycPLQ8mDzAPWA9vj4wPpk/XL/9wCWAWYBNAF8AEoAvP9w/fj6OPmQ9xD1wPPw8lDyYPEA8ODvgO8g8YDwUPFA8UDxoPFA8mDy0PEw8sDyEPRw9FD1wPWA9/D5PPyo/sQAXAOYBjAJ0AsADgAQQBIAFAAVgBXgFcAWIBdgF2AW4BVgFcAUgBQAFGATQBJAEdAP0A5ADdALAAoACLgF5AL4AND+oPy4+kj4IPaQ9JDzQPLw8aDxcPJA82D0YPbg9zj6MP1//18AjAB9ABgBRgHOACr/kP24+2j5cPcw9nD0YPOQ8qDx0PCA75Dw8PBw8UDx4PCg8eDxgPKw8uDyUPOQ86D0QPWA9dD2cPio+sT87P7uANwDgAZACZALMA6gEIASYBQgFUAWIBfAF6AXwBeAF+AWYBZAFSAVQBTgE6ASwBDwD3AOMA2QC+AJOAeYBMwCqwAy/kD8KPrA9zD2kPRg84DykPFQ8qDyMPQQ9aD26PhA+wT+3f9NAMr/dADcAAoB6P/w/dj7wPp4+AD3MPXQ89DyAPJg8eDv4O8A8BDxYPEQ8TDxQPGw8YDykPIg8wDzcPOg9ED1YPbg9tD4aPuI/V3/QAI4BEAHIAoQDWAPoBFgE0AVwBbAF4AYwBhgGUAZwBgAGGAXwBZAFoAV4BTAEoARwA+wDkAN0ArgCFAGCATKAa7/QP3w+tj4kPZQ9aDzsPIw8UDxoPGQ8qDzYPTA9rD4UPso/QD+Qv5O/on/MgDu/9T9CPvY+pj5ePgg9rD00PJw8sDxkPCg74DvMPDg8DDxsPCQ8ODwMPJw8qDy8PLw8tDz4PRA9XD2UPfo+ej79P35/1QCOAXYBzALwA3AD4ARoBOAFSAXIBjgGCAZgBmAGUAZwBgAGKAXgBbgFUAU4BIgESAQkA6wDIAKMAiQBUwDTAHW/lT8yPlQ97D1IPTg8sDx8PAg8aDx4PLQ82D1gPeg+qT80Pzs/Rb+7P6TAEQA5v7I+8D6SPrY+dD38PQg9ODy0PIg8vDwYPCA8BDx0PFQ8YDwsPDA8ZDykPJg8oDyIPMA9ED0wPWg9hj4qPoQ/cb+rwDYA4AG8AlgDAAPIBEgEwAVgBZgGCAZYBnAGcAZoBlAGcAYwBcgF0AWQBWAEyASoBAQD9ANYAtACbgGSARMAhMAWP2w+nD4EPYg9fDysPEg8RDxwPEg8nDzEPXQ9oj5yPs4/aT8UP3u/hMAQP9S/iz8iPoI+vj48Pdg9bDzUPPw8lDywPBQ8ADxMPHQ8TDxQPHw8ODxcPKw8nDygPIw86DzIPRA9LD1sPc4+XD7OP08/wAC0AToB0AKEA0wD4ARABQgFeAWgBggGaAZgBnAGWAZQBnAGAAYIBfAFeAUIBOgESAQgA6ADOAJsAdwBYADWAGS/kj8+Pnw90D20PQg86DyQPLw8tDykPOQ9UD3EPoI+uj7hPwo/Rb+O//W/hj9FPzQ+hD6APlQ9yD2cPRg88Dy4PGQ8XDwAPFw8aDxMPHw8IDx4PGA8pDyAPMQ80DzAPSA9HD1oPZI+DD6HPxA/Zv/jAKQBSAIIArADHAPwBEAFKAVIBcgGCAZABrAGeAZYBmgGWAZIBgAF6AVYBQAE6ARABDADQAMoAlYB3gFKAPoAH7+NPzA+UD48PVw9PDzMPMQ8+DyoPOw9BD2SPhI+gD7ePsA/Jj9dv68/ir+iPw4+6j6mPmI+HD2wPTg80DzsPLg8IDwcPAg8UDxoPCg8IDwoPEA8qDyYPJQ8gDzUPPQ9OD0gPVQ97D4WPrI+7D9tQDEAvAFAAhwCrAMQA8gEuATgBVgFuAX4BhgGUAZQBlgGQAZgBiAFyAWgBWgE6ASYBAAD2AMkArACDAG/APkAYv/tP24+xj5wPdA9uD08PMA9DD0UPQQ9QD34Pco+iD7EPvo+xD9kv6U/uj9IPxY++D6kPlA+WD2MPXw8+DyYPLQ8BDwwO+A8ADwwO+A74DvYPDw8HDxQPHA8HDxQPIg88DzwPSg9ZD2ePiA+lz8cv7yAGgDkAbwCPAKsA0gEEATwBSAFqAXYBhgGcAZYBqgGUAZgBgAGGAXYBWgFEATwBEAEJANYAwACnAISAbwA/YBHP+4/Vj7KPqA9zD2cPZg9LD04PQw9XD3yPhI+ej5YPpw+/D8HP74/eT8GPzo+xj7APro+JD3MPbQ9KDz0PIg8nDxMPGg8NDwgPBQ8FDwAPFA8ZDx4PGQ8VDxEPIA89DzoPTg9JD24PfQ+WD7TP17/+QCsAXwB0AKQAxgD+ARoBTAFSAXwBeAGOAZQBoAGiAZABkAGIAXIBaAFUAU4BGAEJAOAA1gCmAI4AZoBAgCVf9g/cD7gPkw+MD2MPYg9dD0YPXg9sD3WPiI+Xj6WPrA+yT97PxE/YT8ePsA+0D6CPl4+KD2cPWQ86DzEPNA8qDx0PAQ8YDwMPGw8NDwsPBw8eDxgPFQ8WDx4PHw8nDzwPMg9CD2gPd4+VD7gPzP/2wC0AUACEAKEA1ADyASoBOgFYAWwBfgGAAZYBnAGAAZ4BjAFyAXwBVAFYATwBEgEHAOAA2wCqAIOAYIBEYBfP+Y/VD7WPmQ95D2QPVg9ND0gPUA95D3CPjw+Cj6cPtI+4D83PyM/Hj7WPtA+mj5KPkI+DD34PSA9FDzYPTA84DyMPIw8uDxQPJg8nDyYPLQ8gDzcPLw8oDy4PMA9KD0IPUQ9jD34PiA+hz8NP42ANgCeAXYByALUA1gD0ARQBOAFcAW4BcAGOAY4BhAGUAZoBgAGAAXoBbAFcATABKAECAPgA1gC/AIcAYwBIwBgP/M/UD7UPlw93D2EPWg9GD1wPaw9gD3CPgw+VD6mPrQ+2D86Puo+8j6aPpw+Yj4KPjA9uD1sPMA82DzwPLQ8nDy4PFw8ZDxIPJg8rDysPKw8hDzIPMg84DzAPRg9ID18PWw9iD4aPm4+8D9EwDgAfwDGAeQCjANMA8gEAASIBRAFmAXYBfAF6AYIBngGCAYQBfgFmAWYBbgE4ASwBDAD7AOEAwAClAHOAXcAtoAqP5s/Ej6UPhA98D1APXQ9TD2YPbg9mD3IPmQ+YD6yPpY+yj7mPpY+lD5yPhg9yD3IPbQ9IDzsPKg8mDyQPIw8tDxIPKA8TDycPJg89Dy8PJw80DzkPPA8wD00PSg9dD1IPfg90j5IPvo/c3/FAGoAwgHEApQDaAOcA9gEUAT4BWAFsAWwBZAFyAYYBeAF0AWYBaAFuAUwBPgEYAQwA8QDiAM4AmIB0gF5AK8ANz+oPww+oj48Paw9RD1sPWw9dD1EPYQ99D3mPhA+YD5gPpI+qj5KPmI+DD4MPew9gD2EPUQ9LDy0PKQ8nDycPJA8lDy0PFQ8mDzsPOQ82Dz4PMA9ED0APRw9ND10PXQ9uD2YPhY+WD7cP4w/0gBxAOIBoAK8AyQDWAPQBGAE+AU4BWAFqAWoBegF4AXABeAFgAXYBZgFQAUgBIgEuAQUA8wDUALIAmIBjAEWALy/7D92PvA+QD4APeg9oD2oPaw9qD34Pd4+JD4KPnI+Xj6YPpw+cj4oPdw94D2MPYA9YD0YPMg8lDyAPJw8gDyYPJA8mDyYPIQ87DzQPMg81DzwPOg8zDzIPTQ9GD10PVA9uD3CPmg+3z9AwAEAgAEWAegCsAMEA6wDwASIBOAFOAVwBVgF6AXIBdgF0AX4BagF8AWwBUgFIAT4BJAEcAPQA3ACyAJIAfABCAC+v8S/iz88PlY+JD3IPcQ9yD3MPdw95j4wPj4+JD5GPkY+rD5CPnA94D2UPaA9SD1oPNA8/DxkPFw8RDxgPFw8cDxwPGg8RDy4PGg8oDygPLQ8mDyAPMA82DzAPTw9GD1QPZw9xj5SPvw/Kb/TAEABNAGYAkwDOANUA+gEMASABQAFKAVwBZgFyAXIBeAF6AXIBiAF6AWABXgFOASgBJgEMANQAwQCrgHAAV0AlcAhv7c/Bj7CPmA+MD3EPig9+D3mPgI+fD4EPnQ+Lj40Phw+KD3YPYg9dD0MPTg8wDzcPLg8WDxUPHw8NDxAPJQ8kDy8PHQ8cDxQPKw8gDzwPIQ80DzkPNw9MD0APbg9sD3sPhg+nj8rP6+APACKAUoB8AJcAzQDYAPABHAEkAUwBTgFaAWABhgGOAXIBggGMAXoBfAFuAV4BNAEgAS0A8QDhAMgAmwBwAFhALfADb/yP3A+9j6oPmw+ND4sPjQ+Oj4IPn4+Pj4aPgY+AD44PfQ9mD1wPTw88DzkPOQ8tDxsPFg8VDxQPEw8eDx8PEw8pDxAPGg8aDxcPLA8lDzMPNQ8xD0oPRw9eD2kPdQ+Oj5EPtI/WL/ggGkAzAF8AfQCSAM4A1QD2ARwBLAE0AUIBVgFmAXABjgF0AXYBegFsAWgBaAFcATABKAEfAPUA4ADMAJMAgQBuwDCAIFAGj+yPxg/Aj7MPog+uD5QPqA+Uj5qPlA+eD4aPhA9yD3wPWA9fD0UPSA84DyUPIg8rDxkPGw8XDxUPHQ8bDxsPHA8WDxwPFQ8QDyQPKw8hDzQPMg9ID0YPXA9fD2ePjY+Zj7/Pw2/y4BdAMoBXgHcAkgCyANYA4gEOAQABLAEgAUABWAFaAWwBYgF6AWIBbAFkAWwBUAFEAToBHwDyAO4AuACrAIqAYABagCpAAx/xr+bP0k/HD7SPuo+lD60Plw+bj5SPnI+ED3EPag9SD10PRQ9EDzkPLg8RDxIPHQ8CDxUPEw8fDwwPCA8JDw0PAQ8eDwsPAw8TDxUPLw8pDzYPRw9CD10PUA98D4KPo0/LD9Nv/oAAwDoAXoB8AJ4ApgDBAOcA/AEAASwBIAFIAUABWgFqAWYBaAFoAWgBagFSAVABRAE+ARsA+QDsAMMAtACbgH6AWcA8IBmQCj/0r+GP2Q/ED8MPvI+hj62Pmw+dD4aPhA9wD2EPXw9HD00PMw8wDykPGQ8ODwEPEg8RDxgPDA8LDwUPBA8MDwEPEw8QDxMPGA8YDycPOg88D0wPQQ9aD2UPcg+ej6vPxC/ov/lgFsA8gFcAeQCXAKIAyADfAOgBBAEYAS4BOAFKAVYBbAFuAW4BbAFqAWoBUAFSAUYBMgEmAQEA9ADbALcApwCKAGUASkAsYBRQAs/9z9bP1E/Kj70PpI+uj5QPmw+ID3sPYg9YD0IPRg8yDzkPKg8eDw4O8g8BDwIPDg76DvEPCA76Dv4O8Q8JDwoPDQ8CDxoPFg8lDzgPQg9VD14PXQ9rD3QPng+mD8/P1j/zwBFAMIBQAHsAgQCiALsAzgDYAPgBDgEWASABMAFEAUQBXgFMAVwBVgFWAUwBNgE4ASwBEgEBAPoA0wDLAKIAlQB3gFnAOQAuAAy//o/vT9PP1U/ED7kPrg+XD52PhY+FD3EPYg9RD04POA8zDzsPKQ8RDxwPDg8BDx8PAg8RDxsPCg8JDwEPFw8cDx4PHw8SDyoPKg85D0IPXA9cD1YPZg99j4gPok/JT9Cf9BALwBbANYBYAHIAkQCvAKwAsgDfAOYBBAEcARQBLAEiATwBOAFMAUwBQgFIAT4BJAEgASQBEgELAO0AyQCzAKAAnAB2AGqAT0ApIBbACs/47+5P0E/TD8aPt4+uD5cPnY+PD34Paw9QD1oPRQ9ED0YPPQ8jDy8PEw8jDyQPLw8dDxwPHA8fDxIPJg8qDywPLg8kDz4PPg9KD1MPaw9kD3sPeQ+JD5CPtc/Jz93v4nAKwBCAOYBPAFUAdwCKAJ0ArQC9AM8A3gDuAPgBAgESARYBHAESASgBIgEqARQBFAEaAQYBBAD4AO4AwgDNAK8AmQCMAG2AVABFQDhgE6AacAXv9A/gj9lPyY+yj7YPqA+aD4EPiA98D2MPbg9aD1MPWA86DzkPOA81DyQPKw8lDz8PIQ84DzkPSQ9ID0gPQg9YD1kPUA9tD2MPeg9/D3MPnI+Uj6yPp4/Dj9Rv76/iYAGAE8AoQCCASwBLgFgAaYB6AIUAlwCmAL0AugDFAM8AyADOAMQA3QDbANcA1QDaANUA3wDGAMsAsAC8AJIAkgCGAHiAaoBQAFGAQkA8AC8AH4ACcA7P4M/sD8QPwM/AT8GPuA+tD5SPno+Bj4CPjw9+D2kPaA9mD2MPaQ9bD10PUg9tD10PUA9sD2APcA98D28PaQ9zD4QPi4+CD5uPmA+tD6cPvg+xD9uP1e/qb+Q/+i/zEA5wAUAhgDbANIAwgE8ATwBSgHiAc4B/gGYAcgCVAJkAngCBAJgAnwCFAJUAkgClAJ4AiQCOAIQAhAB9gGiAbIBlAFqAQQBKAEMAR8A4gClgGUAaEAiwCF/9z+1P2Q/Uz98PxA/Jj7uPsk/Nj74PpA+gj6QPoA+nD5EPm4+OD46Phg+UD5YPkI+Wj5cPlQ+Yj5qPm4+cj5aPqA+jD7IPsg+/D7kPws/Oj7hPxE/mb/3P6m/rz+0P9D/7AAJgGYAt4BRgF8AjADQASAAgAEvAN4BUgEiAP8A2AECAagBFAFKAQYBkgFYAUwBfgFKAYwBYAEwAPwBKAEKATEAuQCFAJAA4gDnAOQApoA7wCIAiwDxf94/cT93wB+ATn/3Pyk/ez+nv7w/fj8qPyA/Ej8tPyA/ND7oPro+mD7IPzg+zj7gPsQ/Ij84PsM/KD7WPzw+0D82Py4/Dj9qPyY/iz+E/8w/fT92v5iAAkA/P2s/oL/iAL0AOwAZP8AAf4BugGIAisAywCGARADAAS+AUgCQAIIBFQD+gEEAnwCjAJkA9QDvAOAA5QBhAKEAwAECALtAMYBwAIwBHwCaAJeAVQBCAJsAlwCJACVABwB9ALLACgACADpAEQAUv/w/uT/AP+2/jT+LP87/xL+0v6c/Yr+4Pwc/hr+AP9o/Xj87P00/qT+8Pu4/Ub+6P+M/Jj7FP4g/xEAaPzI/ZT+TgCg/pT+oP57APn//v7U/tz+OgBiAC4BzP9mALH/TQD4AUIBPgEw/4sA2wBgA1wCdAAoAU8AsAP4ATACWABUAuACqAEeAfkAHAM8A9wAQAKoASQDBAGaAeACwAFaAcH/uAKMABgCwf+kAl4AZQBC/y4BVAGjABL+TP4W/pgBIAAj/yz9fP4zAEz+rv6M/GEALP22/pj9iv4A/tz9FwDg/iD+kPqt/7T/Ov+k/Gj9MgAl/4j92P05/3UA4Pxa/mr+CgEwAJT+8v5C/igCtP46ASj+agHg/2wA4v6RADwCXABIAdv/lgFOAVEAbAHJACwDev/vAG0AnAL0AgsATgE6AFQD5v9kAuoAhAIQARb/IAIUAAQC8f+0AZ//+gAjABQCmgDJ/2IAcQBb/2T+tP8sASsAbv78/0EAxwDs/Fj+TgDLALb+aPxR/2YAYAHs/OL+TP6yAVj9gP5G/lAC6v5w/nD9swCQAGb/Bv7Q/6UAIf8FABn/AgFd/4//4v9PAP8AvP6V//D/vgEOAXD/rP4oAWIBgAEbADsAGACa/kIB5gFQA+3/OP4CADQB6AKZ/5IBd//NAEMAjADSAV//3AD4/sACbf/YAYf/0AFNAMT+YgDF/2QBFv7nAPD+GAGQ/of/2wC6/yD/EP+hAOX/eP5w/if/4/+A/tb+ZAAO/2j/fP0TANX/0f9m/+L+Df+6/jn/gQB6/6cA0P3IALD+NgE9/3D/1f93/zABQf/T/93/PQBkAO//ef/R/9j/BAGG/+n/7v48AUUABwAt/+EAuf81AFP/LAGkAGv/Pf/aAGYBzf93ADEACAHl/zD/AAHqAI4A/P64/0YBEgHb/y7/0P+EAo//MAC4/K4BzACoAZr+Bv9CAHUA7/+R/7v/2QD4/foATP4cAeT91v9GANkApP4u/qX/JAEEAOL+3P6X/24AKv82AMT+YAAj/5kA2/8M/wL/DgBRADoAov6OAFr/RwBr/4sArwBP/ywAav5mAYD+CgEZAH8AIv9J/2AB6f+YAR7+PgEX/6IBBACuAHX/EAAMAdUAlwAO/9sAeQB+AUIA7v+n/2T/3AGEACQBJP8l/6IBov/iAWr+RAIB/+4BSP7qABEAkwDE/8b+xQDRAA4AIP6I/x4BagG+/uz9Hf+aAYcAWv9D/7T+QAB//9wBMv8wALT+HACHAAf/vP9I/xQBEf9K/yT/+P9YAa3/pP86/hgAxP+5AC7/KQAIANb/oP9C/igBDQA6Adz9qf++/5QBawAq/5oAfP/sAOr/lgEMACkABv8UAQIBEAEVAD8AQAFb/7UA/P6QAqwAIAEw/4n/CAGbAPIBBf8cAhf/4ACc/woBcgG3//X/2P4wAx4AhABc/WgBPgD2Ae7+WACg/iABjADoAVX/JP/c/3cAKQBM/lUAPAHN/8H/9v7vAGn/fP49/0AAov9q/qr+1v+IANT+AAAk/+gAbP1//zD+8wAR/0//rP6s/rgA9/8+Abj9vP9a/xoBkP9M/k8ARv8yAdr+aQA7AIwAyABq/1ABS/9eAbL/YABOAIgABAGZ/3oBuP+sAQT/KAETAHgBkgCnAIABvf98AW7+LAEu/6QBiQAUAS7/JP9eAUgAnAHw/XMAEwCSAN//cf+jACkAcP94/2r/3QA8/5n/AP+k//f/WP/Q/3f/BwA6/2L+WP+K//sAI/8d/3j+Kv8hANj+3v9w/h4AUP4EAHD/SQCw/l//eP8JAJT/kf9kAGoAJAAj/5UACgDJAKT/9AC+/woAVQBpAP4BWf/bAO//uAGwAP7/PwAGAQwCdgCEAJ0AYAFgANcAov8AAtD/WAFeAOAAoQA8/wIBOQA2AdD/Of9eART/XAG8/tcABAFj/ycARv5WAen/DQCg/rz+DADD//EAOf9D/+T+1P+b/+L/oP7z/6b+TAC4/oIA5v5R/yn/uP2pAF7+SgHc/dL/Wv9SAA8AlP3lAFP/DAKk/dcA5v50AWL/NQBSAer+9gB+/jgDzQB3AP7+fQDIAcj/AAF4/4QDwf86AY7+BAL6AKwBmv80AMT/1gCUAHQBcwAq/5QAIgDCAdv/df9dALkApAAAAL7+cAE4/jgCSP2EAnD9wgHq/qT/Z/+o/VgBVv60AVT9NgBY/iEAMP/J/3D+9/9c/6H/P/9s/t8AoP7//4D9dACN/xP/pP70/qEAzv52/xv//wAp/8f/rv4qAbb+ov/a/qsAdgAo/2gBaQDwAJD+Wv6cAioAlAIw/Y4B7AAGAZMABACoAqn/vABI/gQCfgFIAXwATAD9AKAAEQAEAfz/0AHC/ioBLv9+ASIABgHr/2AAU/+E/2sAdQBMAZz95gCA/tgC9P2SAHz9AAEK/1b/VgCW/9v/AP0GAJX/DAEc/sv/Mf/8/7j9vv6hAID/5P8A/S4BFP72/9D9LgBmAFz+ggDE/dYB/Pz2AZz9SAKM/YABg/9MATP/7P+mADsADgEF/9YBPf/SAfz+1gEZAF0ApgBa/0gC7P58As7+hAJR/8kA8v8RAKoBW/9YARH/gALu/9f/6v4xAKgC6f8KALb+dgEsARz/8//r/0IB1P8w/lYA4//TACj+BwB1ABABnf+U/o4A4P8OAIj9jgGc/iQBiPvKAMH/NAE1/2L+VAFc/SQBpP28AsT+jv6g/l//0gGs/m4BeP7fAHD+6v+FAEsALAFJ/1oA6P+CAOoAQP/+AZr/kAFs/XYACgFMAk4Bov5sATj/VAK8/UwC7v6YAib+CgFq//kA4v/h/2QCVgAQAdT8AgF0AKABHgC2/swAnv7RALX/tgEaAL3/qQAg/97/CP4EAqMADAFo/Nz/Vv8IAmIAEQAbACj+hwBS/nABtv5gADb/7f9m/6f//P+/ACX/7v+M/EoA+P0YA9z+2AFs/bf/hP9I/2YB4v6yAdD9NQBm/noBpAG8/wwAsP7m/xX/bgBYAT8Amf94/tkAXAGV/xoBkv+SAaT+egCXAPwAHADw/iABCgCUAGkARgB8AT7/IABgAF0AOAH0/mgCyv7YAST9BAJ9/7IB2P2NANL/7AHE/nr/T/88ALv/3v52ACH/8wDQ/VIB+/9KAfL+QP4C/x8AUQBQAE8A0f8g/xT+4/90AL4BbP79/yH/x/+F/0D+aAJQ/6QACP2+AH4A7QAu/77+Wf+B/zj/pAHy/xwCSP0hAF4AJALu/+j+Qv+WAc4BUv+mAMkAkALI/tP/Zv5UAqr/agD4/qkA7/9IAFoAIgEFAK//ev/xAOgBegAD/wEA5//kAJv/kP9uAZIAQQC0/TgBQQAYAmz/HAC3/7//yP4j/7sA/v+YAl7+UgGg/G4BNf+GAV//dP48AML+QAES/sYBFP7f/9D+TgCeAaX/EgFm/g4BdPyjAMz/BAIAANz9T/8c/zoBqQBcAMz/3P0kACD/NQCm/pEA9wAdAPL+qP8cAuIAzv5U/cIAHgHiASD/KQBz/wYAJv9kAZoB3gEHAFT+CQBf/3ACAgDYAZD+of9N/4sAjgGm/ywAnP69/9L+af8IAZYAmQDw/RQABgCKAYP/sf/8/uj++v5X/+4B1v8vAHj9xv+F/+z/QwB0AMUA1v8u/3wAYgA8AWL/1P+O/43/swD+/tgBrv84An7+tgAl/5oARADa/nIBGP+uAej8egEf//QB7P7CAKkAxP8tAA7+AAOc/84BCP26AML+dAFxAKYA4gFj//wARP2OABz/2AJWAD8Ayv4T//n/r/9+AdH/IgFs/X0Acv/4AXT/XgCk/nQAmv+3ABUAmv++/5b+GgAI/2wBoP+4AGr+mQB3AMMAhf9l/88A4v+GAVf/qgFU//f/jP40AOf/hAGsADIBY//s/sYAFAF0Aib+OQAA/ToB6P7aAXwBbgCIAMr+8gG0/oYA9P0MApv/sf9w/kwARAHZABwAMACOAHv/6v78/+4A8gEHAEH/jv5eAMH/FAFj/zEAcf9f/2b/awBr/+j+Kf/k/+wBdP8i/8b+ZgBxANT+wP8VAPoBxP5X/xX/oQDMABX/vADK/0gBPP7mAHf/yAG3/6QA6P8vACQAeAAOAeP/mADq/qIAVf+/AKUAxgAWAI//7v/e/kf/1v7dAMb/GgCm/sEArQDrAL3/Q/8AAF//JQCR//oBIAAhAJb+vwAMAVABwv/q/pL/pP7/AFYAtgFuAFP/bP+I/jEAZ/9lADL/DgAHAN7/2/+Y/1cAdf/k/hL/3//dAGwARADL/8X/hP8OAIX/G/8g/nb/hABSAfL/6P7a/vz+lP/m/9EAggAnAMr+rv+cADIBPwBU/87+iP9UANgBHAKsABgAA/96AJH/pACbAN4ADADs/tX/RgEQAo4BNQBT/7j+u//GAAQBggD2/rD/j//a/7L/pADmARIBFQDU/hT/PADAAIYB6f+O/17/UAChALv/dgCMACYBrv+0//H/PgCq/wr/ev9d//L+Q/9BADYBdgCn/3n/cP+V/0T/5f+Q/wn/Gv8wAKgAUQBO/5r/y/83AH3/vv8lAE0ASACd/w4ABgC8AWMA0f/I/SX/gwDzAC4AzP8gAZYA6/+L/3kAsgDE/wD/Gv9D/xYAdgBgATcAK/8g//H/lAAWAGEAAQBd/6z+C/9oAaQBlAHw/8z/Q/+X/04ASAE2AW4Az/8IABEAkwDt/1oA0//v/zP/l/84ANgAZgDA/1b/GgCy/77/V/9aACcATADq/i//rP62/7//4/8dAFz/dP8A/9X/4f8hANr/yv/5/4P/o//F/30A7P95/2n///8uAP3/PAB6AHoA6v/k/6EAqACPAAcAIQDd/+H/y/86AB8A2v+0/2kA7gAcAQIBhwCWAK7/ov+X/18AUwA4ANX/5/9VAIsA3gAxACYAxv+rAJcA7gApAOX/y/+q/w4Awv/9/6v/0v/4/5kABAEkAWwA1v9O/2j/eP/e/y0A6f/C/zz/7v+bANMAlgAVAO7/0/+x/3n/rf98/4j/aP+l/w4AYwBzABIADAABAFcAIADh/4j/1v+7/7P/n/+V/xEACgBcACcAhwAdAAEAsP+j//X/FABqAGYASwATAMP/FwBOALoAswABAM3/o//5/+j/GgAXAEYA9v+8/43/5P/t/8r/mP9r/8r/7f9rAC0AWACh/57/kv/P////nf+3/6n//P/t//X/JAAWACgAKgAqADIA7f/t/wQALAAGAPD/CwAKACMAUwBYAJYAUwAuAAUA7v/6/wMAGQDK/xYA3//n/9L/4f8wAEkAMADy/7//pP+5/8T/3v/Z/+D/AwDY/ywAJwDo/6z/tf/0/xIA5P/g//7/3//1/73/6//Z/7z/s//g/xcA///7//b/1//l/5z/f/91/37/l/+q/9j/1v/s/6j/xP/Z/yIA1P+Y/3z/g/+E/7z/rf/N/93/tP/b/93/OAAHABcA2/8RABkAPgAyAAoAAgDP/zMABQBFABEA6/8YAEQArgCKAF0AIQD+//T/FgAlABoA7v/V/wsAEwAyADYASwBGAPf/2P/v//r/7P/U/6T/lP+D/6D/nf+P/4X/c//Q//f/5v/B/7f/3/8tADsAWABsAFYAKgAeACoARQAQABAAagCOAIgANgAsAGgAJgACAND/8P8RAOb/AwD//xcA8P/w//r/HgD3/7//xf/s/zsAPgBOAEUAMQAZACAAUwBMAE0ARwBLAHwAgQCFAEwATgBMAF0AXgAlADEAKwA7ACUAEAAGAOj/6f/T/x4AKwBFABIA3P/M/+3/zv+u/7z/pf/Y/6z/1v/Z////1P+8/5r/o/++/8j/8f/W/+L/5//q/+r/0P/i/7j/tf+o/9b/wv+v/4D/pv+u/5r/nP+s//b/8//y//r/8//l/7b/qv+6/+D/yP/K/w4A9f8zAAcAJgAzABgAOgB7AMYA0wC1ALYAuQDiAJkAnwB7AG4AfQBhAFUARgA8AFAAcABPAFwALQBUADEAVQBNAFIARgAoADgAAQAQAPz/RQAdAPb/4//P/9n/sv/G/6r/3P/A/8X/rv/S/+b/3v/E/3n/W/9F/zn/Dv/C/sj+fP6O/oj+YP5Y/vT9Rv4Y/gD+2P3Y/cj9hP1w/Tj9jP2A/Xz9yP3U/Q7+NP7Y/ur+Q/8j/7X/zP/k/0oAogAGARwBZgGcAVwCaALwAiQDZAO4A+QDMASABMgEAAVgBVAFcAVQBRgFWAVoBYgFcAWIBUgFUAUwBRgFGAXIBOgEgAQoBMwDcAMYA8QCPAKwASgBggAOAJ7/WP+g/gT+YP3E/Aj8SPug+gj6SPmI+KD3sPZA9tD1oPVg9YD0YPSw86DzkPNw81D0IPRQ9JD0MPXA9ZD2UPcY+Nj4cPmQ+gj7DPw0/Xb+l/8wADIBTAJ0A7AEoAXoBpgHQAgACdAJgArQCmALAAwgDEAMYAyADLAM4AzADDANUA0ADTANIA1ADQAN0AywDHAMQAzAC1ALsApACrAJQAnwCAAIoAcQB6gG8AU4BWAEZAMoAhYBp/+m/gD9aPtQ+pj4QPeg9VD0QPPQ8bDwoO9A7mDtYOzA6wDqAOlA6CDn4OYg5uDmQOcg6CDpYOug7cDv8PGw9FD2gPho+hj9qv9kAWACjANQBBAG4AYQCEAJYAngCnALsAyQDAAOwA6QD6AQgBCgEMAPoA8wD2AOcA0gDIALgArgCfAIgAgACMAHEAgQCBAI8AeoB/AHEAgwCIAIIAioB2gHSAfwBrgGaAaYBsgGEAeoBsgGgAaIBigHYAYYBjgFIASIA7gBsQDc/pT9GPyo+kj5QPdg9eDzIPPA8VDwIO/g7WDsoOvA6gDqQOnA6CDooOeA54Dn4OeA6MDoAOrA6oDrIO1A7/Dx8PNw9tD50Pvc/bb/DAIgBNgECAeACFAJkAlQCWAKIAvQC7ALUAzAC+ALwAtQDKAMsAtgDHAMMAzgCpAJ0AjQCHAIcAeABnAEsANsAwAEEARsA6ADXAP4A1AE2AQQBkAG8AbgBkAH8Aa4BzAIkAhwCfAIgAlwCfAJ4AmgCqAKgApACgAK8AkQCdAIqAf4BrgF6APYAlQBEQDw/fD8WPtI+QD3MPUg9IDycPHA76DuIO0A7ODqgOoA6qDpYOnA6ADpwOgg6cDpQOpA62DsgO1g7wDxsPOg9dD4sPvQ/dD//AGgA6AFkAZwCNAJUAqgChAL8AowC+ALMAwQDYAMwAuwC3ALMAzAC3ALgApgCXAIwAhwB1gGqAWwBOgEzAJcAvoAEAFcAYQBWAKWATgCfALAA5AEUAVwBQAGqAawBlAHyAdQCCAJoAkgCoAKcApAC4ALIAwQDMALoAtgC+AKoArQCfAIiAfwBcAEoAPSAWcApP50/Uj7mPnw9+D1oPTw8tDxEPDA7oDtgOzg6yDroOpA6kDpYOng6ADpQOnA6UDqoOsA7CDuEPAA8sDzsPZw+bj7bv5GALACdAMgBXgGEAjQCGAJ8AmACgAKQAnwCfAJYAoQCiAKUAkwCWAJEAlQCTAIgAfABvAFIAX8A0gDjAI4AbQAHgBk/8L+kv6a//P/YACzAC4BoAKAA9gEgAUQBsAGKAcACKAI0AhwCVAK8ApQC7ALsAsADHAM4AxADSANsAwgDNALQAtQClAJ4AdwBqAE6AJKAXP/wP04/Ej6ePiQ9vD0cPMA8sDwYO8g7uDs4Osg62Dq4OmA6UDpwOhg6EDoYOgA6WDpoOrg62DtIO9A8aDzEPbA+KD7vP6ZACgCKARIBvgGIAgACtAJoAowCiAKsArgCVAKIArACkAKYAkACfAI8AigCLAIkAcQBogF6ARQBAwDmgGvAHr/L/8K/vD9cP06/lD+1P5H/3b/rgCQATgD/AO4BOgEGAZYBzAI8AgACfAJgAoAC6AL8AtQDPAMEA2ADZANMA1ADeAM0AzwCwAL0AmACOgGSAW0A0QCQgB0/rT8+Po4+ZD3IPZg9ODyUPHg7+DuwO1g7ODrQOvA6gDq4OnA6cDpYOkg6qDqoOqA6+DsYO7g76DxgPPw9lj42PrI/fn/nAKgA8gGmAfwCAAJAApwCyALYArgCWAKQAmwCUAJUAlwCIAHkAegBzAHOAboBWgFMAWYBNgDBAOyAdcATgB//2r+mP1w/fD9iv50/vz+Ov9AAE4BmAJgA2AEIAVQBmAHAAiwCEAJIArgCnALkAuwC+ALgAwADUANsA2wDTANIA0QDdAMkAzQC6AKcAkQCMgGaAUIBEQCbQCk/gD9IPs4+fD3YPYQ9ZDzAPKg8GDvYO7A7SDtYOyg6wDrAOug6oDqoOrg6kDr4OuA7MDtoO4Q8MDxYPSA9iD4APuI/e3/dAE0A7AFaAZoBzAIgAjwCGAIcAhQCLAIcAfwBpAGGAYQBtgFcAXoBHAESASYBCgE6ANsA+QCrALYARwBBgAp/6r+Xv5Y/sj9EP6y/kH/m/9uAGABRAJ8A8gE4AWoBnAHgAiQCVAK0ApwC9ALwAsgDKAMIA0QDRANcA2ADYANUA1QDRANcAzgCwALMArwCIgHQAYABXAD0AELAED+zPzw+lD5sPcg9qD0cPPw8XDwgO+A7iDuYO3g7CDswOtg60DrIOvA6+DrYOyg7KDtIO4A78Dw8PGA9CD2CPjI+lz98v4qAWQDKAWYBtgHcAggCfAIEAkQCQAJoAgQCGAHUAbgBYgFaAUYBTAEWAQoBLwDEAQYBBgEpAOcAwgDWAJGAb4AmAA9AK//Vv+X/87/OAC5AIwBRAL8AnAEcAWoBrgHoAjQCcAKgAsADCAMcAywDNAMQA0wDfAMEA3QDJAMcAwgDDAM4AtgC6AK4AkwCRAICAfIBagEHANoAcH/LP6w/Pj6wPkI+GD2oPSQ83DyQPEA8GDvoO6A7UDtAO2g7KDsQOzg7ODrQOxg7EDtoO4A7kDvMPCg8aDy0PQQ9zD5oPvg/SoA1AEgBMAFGAcwCNAIAAngCNAIoAjgCIAIkAfABugFiAX4BLgEkAT4A4wDcAN0A0ADEAM0A9gC/AJ0AoIBNAFNANT/tv9E/w3/2v5P/7H/TAD8ALoBoALgA0AFMAZ4B4AIgAmQCoALIAxwDIAM0AwwDVAN8AzADLAMcAwQDOAL8AuQC+AKkApgCoAJ4AiQB9gGwAWwBEADeAEOABz+PP2Y+9j5YPjQ9kD10POA8tDxYPCg7+DugO7g7SDt4Oxg7aDsgOyg6wDsYOwA7GDtQO1A7iDuEPAA8UDycPRg9hj5MPtU/Sb/5wA0A5AEQAbIBrgGsAbYBjAHAAcABwAGqAXoBHgESATQA9QDjANgA0wDOAMwAzADXAN4A5QDJAN8AuYB0AEUAcgAaQCz/wsAIQCjADgBoAF4AvwCSARQBZAGSAcgCHAJYArwCgALcAswDIAMMAzQDCAN0AxADIAMkAwQDBAMoAuQC5ALgApQCvAJ8AhQCHAHgAbYBHADRALNAHj/Gv6o/BD7CPkQ+KD28PTg85DysPGA8KDvoO6g7qDtYO0g7UDtwOwA7ODswOzA7EDtAO7A7gDvwO/Q8LDyUPSg9uD4oPoE/Zj+agEEA3gEaAUwBlAH2AbwBmgGoAZQBuAFOAVYBOwDAANEA0gDXAOcAlwCoAKsAtwCHANgA2QDMAPcAogCGAKYAT4B2QCpACwAmwDTAO8AmgGMAkQD0APYBOAFUAcACOAIIAoACwAL0AtADMAMkAwQDNAMEA2ADBAMEAzgC9ALIAuQCxALcArQCZAJoAnwCIgHAAeYBXgELAMAAtEAN/+s/Xj8QPtQ+aD3EPYw9fDzsPKw8dDwUPCg70DvYO8g7+DtYO6A7mDuAO5g7eDugO5g7xDwAPDg8NDxIPRQ9pD3SPnQ+yD+ZgDwAZgD4ARoBTAGAAewBtAFKAUYBTgF5ANMA4wCtgGsAZYBygHsARgBTgHiAXQCmAK0AlADiAMoAxwDqAKEAgwCPAFUAV4BQgFYAcQBdAI4A5wDcARgBWAGgAdgCFAJEAqgCkALgAtADCAMoAywDIAMQAygDJAMMAwgDGAMQAzQC7ALMAsgC2AKUArwCXAJQAjoBkgGEAWcAwwCAAFs/6T9kPxY++j5CPgA99D1kPQQ8/DxgPFA8UDwgPAw8ADvgO5g7uDuYO4A7gDuAO6A7mDuIO+g7zDwoPFw8zD1EPfQ+FD7zP2m/1ABEAO8A5gEGAXYBagFCAWIBBAE2APUAmwClAEmATIB2QAkAfsA/AAmAQgCbAJoAqgCIANkA0QD3AJoAmgCsgFuASYBZAEqAdMAigGMAvgC8AKwA+gEyAXYBoAHsAjwCIAJ4AkwCrAKwAqwChALEAtgCqAKsAqwCoAKkAoAC2AKQApACmAK8AmgCZAJ4AggCLAGEAYYBTAEJAJeAeP/BP70/KD7uPoo+YD3oPaA9WD0oPKA8oDxwPBQ8MDvgO9A7sDtIO5A7qDtoO2g7UDuQO7A7mDvMPBA8ZDycPRw9pD4cPr4/E//XADOAegC2ANIBLgEyARIBLQD2ALYAmACpAHUAFQAPQAZAOn/RwCDAEMA/ACoAUwCkAJwAqQCuAKkAjACCAKqAYABlgFEATgC/gH4AQADEAQQBOgE6AXABsAHQAhQCTAKUAowCrAKMAtACwAL8AogC9AKsApAC3ALUAvQCmALYAsgCyALIAsAC2AKIAqwCeAIyAeQBsgFwARMA6gB+AA8//D9xPyQ+4D6ePgA9yD2MPXQ8/Dy4PFg8UDwgO8A78DuIO7A7UDu4O3A7WDtIO5g7+Du4O9A8CDxAPIQ9BD2yPgg+oj7kP24/8gAogHcAlADEAQgBNgDhAP0AhgCLAJEAnYB5gAOADsAggB8ALkA1ADqAGQBIAK4AhQD+ALwAvwCfAKEAqACiAIgAiQCsAIMAyQDLANIBHAEEAWQBZAGcAdwB4AIUAngCZAJAAqwCiALAAsQC/AKEAvAChALsAtwC/AKoArACpAKkArgCSAK4AnwCFAIUAgACOgGuAVIBTAEfAKEAYIAL//U/ZD86PrY+cD38PWw9YD0kPMg8oDx0PDg78DvYO9A7wDvoO5A7yDvAO+A70DvUPCg8GDxMPGg8qDz4PWY+ID6UPxY/XH/5ABgAjADqAPwA1ADXANIA5wCbAGoAA4BigC0/+D+/v50/yn/QP8ZAGQAaACuACQC2AJgAmACbAJMAjgCKAJUAiQCEAJsAvACoAP8A3AEcAUgBnAGWAcQCGAI8AhACRAKoAngCTAKoArQCjAKwApwCvAK8AogC6ALYAuQClAKoArwCcAJYAlwCZAI+AeoB7AHMAf4BTAFGAQsA8oBkwCJ/7r+CP14+2D6gPiw9nD1sPSg88DycPHw8HDw4O/A74DvYO/g7qDu4O7g7qDuAO9g7yDwIPDQ8MDxQPPQ9PD2SPrA++z8IP4jAHwBCAKIAsACiAIEAqABBgF/AIL/V/99//T+RP4a/pT+qP4Z/8r/UgB3AFUAcAFYAkACvAG8Ad4B3gGiAdQBbAIwAoQCRAMYBGgEmASQBYAGyAbYBmAHAAhACEAIkAgACQAJEAlwCSAKEAoACjAKkAogC/AKUAswC9AKIAoACpAJQAkwCbAIQAjoB/AHoAdgB4gG0AXoBKADlALAAa4APP84/lD86PpI+WD3cPZg9ZD0gPNQ8oDxQPEA8fDw8PBQ8CDwYPAA8FDw4O/g71DwgPBg8aDxwPJQ9ND1wPfY+nj8EP6k/nkA7AEcAigCjAJcAkwBZQAfAAAAKv9w/kL+4P7g/cj9DP7m/uX/FgBwAEIBbAHCATwCgAIkAkoBRgHyATgC9AFwAgADwAN4BPAECAZABqAGMAfYBzAIyAfoB1AI0AigCBAJcAngCZAJMArAChAL4ApwC5AMsAwgDDAM8AtgC9AK4AnwChAKMAngCHAJUAngB9AHSAcoB0gFaATEA/gC3QB7/9L+rPxQ+gj4gPdw9gD1gPNg8zDyIPHw8HDxMPFw8CDwwPCg8MDvYO/g75DwAPDg7zDxMPJw8mD00PZI+Yj6EPwy/ov/3f/MAMwBHAJ0ATEAOwD3/+z+kP7W/mr+7P0K/jb+av5C/sz+8/+EADUATwAyAfAA4ABOAewBJAGVADABSALoAjQDOAQABaAFsAWgBqAHSAcQBzAHoAfoBpgGOAewB+gHUAhgCcAJUApQCmALoAuACxAMYAzwDHALUAsgCwAKkAlACcAJIAn4B9AI0AgQCZAI+AcgCPAG8AWoBAAEeAIQAXj/qP0I+0D50Pew9qD1gPQg9ODyQPLg8eDx4PGw8XDxQPEA8bDwQPBA8ADwMPDQ8FDxoPHw8rD0UPYQ+GD6FPw4/U7+Rv8rAEwAKwAyAGIAH/+K/g7+AP7k/aT9zP2I/Sz9WP0a/mL+1P6m/6H/5//7/zUA1wC/AI8AHAE+ASYBigGkApgDSAQIBWAFGAYYBogG4AZwBggG4AWIBWgFaAVgBngH+AfACGAJEAogCsAKQAugC4ALYAvgC7AL4ApQCoAKwAmgCaAJsAmACVAJAAmQCVAJQAmQCEgHEAY4BVgE8AIiAT//qP3A+6D5cPhw9/D14PRQ9MDzcPLw8cDxMPJQ8SDxMPHw8BDwoO+A78DvYO9g78Dw8PEA8xD08PXg96j5sPpY/Hz97P0+/nj+OP88/6j+IP7w/Vz98PwA/VD9bP3k/Pz8IP1I/Uj91P0u/qL+Yv52/gz/KP+F/yoA1gAoAUQBWAJsAxAE2ATYBagG6AZwBugGEAdoBogGaAbwBTgFSAWYB1AIcAngCfAK8AsQC1ALMAxwDLALkAtwCyALQArgCeAJoAnwCdAJYAlwCYAJIApgCsAJoAi4B7AGMAUwBEADDAIAAJj+nP0Q/Fj66PgQ+FD3MPZg9UD0oPOQ8vDxUPKw8TDxMPEQ8fDwcPBg8GDw0PBg8XDywPMQ9VD2cPeo+Tj7DPyk/Ij9Uv5y/oD+xv49/wf/JP5O/tz+uP7k/cj9WP5+/pz9QP1g/RT9VP1E/dz9+P3w/Sz+wP61/x4AcAHaATQCAAMABKgEOAXIBRAHuAaQBnAGCAcABxgGiAWQBlgGSAfIB+AJYAtAC5AMYAxwDEALQAxQDGAM0AsQC7AKcApwCsAKQAsQCwAKMAqgCsAKkApACtAJwAiAB8AFOAXsA4wCaAFYAFn/0P0w/Cj7YPoY+bD3oPZg9WD0gPPQ8iDysPEA8XDxwPEw8VDxAPHA8MDwEPFA8qDyYPOw9JD2oPco+Ij5APug+4j7UPy0/bD9oPws/QD+vP3E/CT95P3I/VT9/PyM/cj9dPyY/Bj9pPxA/HD8VP2U/fj93P5j/x8ApQCCAdAC6AL0A5gEIAXoBTAGyAbwBsAGeAbYBgAGCAboBagG6AZ4BxAKQAuwC9ALwAsgDCAMIAxgDFAMIAvQCvAKAAtAC6AKcAugC6ALIAsQC9ALMAvACrAJ0AgQB2AFSAQYBNgD7AHbALr/pP7g/Jj70Pp4+XD30PWw9LDzkPLA8ZDxMPHw8ADxMPFQ8QDxYPFg8eDw0PDA8ZDyUPOQ9BD2sPcw+Bj5yPrg+0j7wPtE/BT9vPzo+8j8RP20/OD8tP1S/gT+uPxE/ZD9wP3s/ND8LP3o/Bz8VP3s/bj+Cv+7/wYBggFwAWwC2AOABMAEMAVQBnAG+AUwBqgGiAYYBXgEmAX4BbAEEAbgB+AJAAvACiAMIAsAC3ALwAvwC8AKkAoAC7AKwAqgC9AL4AtAC5AL8AvQCjAKcAogCkAJqAeQBggGUATMA2QDiAJIAYz/Nv5Y/Uj78Pmo+ID38PWg9AD0wPOg8mDyIPKA8lDyQPFw8XDxIPGg8JDwMPEA8oDykPNQ9ZD2sPeI+JD5UPpo+nD6aPrI+rj6QPuI+8D74PvI/ET9LP0k/dD8fPzI+8D7sPsc/LD7uPvg+5D8zPxw/Z7+Vv8GAIwARgGWAe4BFAO8AyAESAQIBZgF4AXYBUgGOAZABeQDqATIBBAF8AX4BwAKQApwCpAKgAoQC9AKwAuAC7AKYArQCiALwAsADOAMsAzgCwAMQAzACzALkAqwCtAJoAiQBzAHqAZgBZgEqAOIAuIANv9c/qD84Pog+aD4QPfQ9cD0IPQQ9CDz4PLw8iDzwPEA8TDxoPEw8bDwgPEA83Dz4PNg9QD3sPc4+MD4yPmI+Zj54Pmg+iD7+PpI+yj8yPys/Gj9qP3s/BD84PsI/Oj7wPvA+6D8WPyc/FT9Vv4n/2D/bwAQAWwBJgEIApACfANIBPAEuAXgBXAGsAawBmgGCAaYBtgEgAT4BJAGcAggCQALwAsQC2AJAApwCjAL0AqQCgALwArwCoALgAzQDIAMoAvAC4AL8AoQCxALEAvgCgAKYAmQCIAHaAbIBbAEeAMIAiABRQDA/kD9KPy4+ij5wPfA9tD1kPTg89DzMPSA87DygPJw8qDxUPEw8fDx4PGA8qDz8PSA9bD2gPdw+ID40Pd4+Cj5YPlI+VD6sPo4+1j7LPzo/GD8uPtY+2j78Pq4+qD6QPs4+1D7uPtc/Nz8HP0S/rT+HP+J//j/UQC7AGABcAIkAwgEYAQgBVAFcAVYBagFcAVABJwDEAQoBqAHwAhwCkALkAnwCMAIYAogC3AKoApwC3ALIAuACxANQA1wDPALIA1gDNALYAtQDKAMUAtwCvAJ0AkwCFAHGAdQBsAElANcAxgCqQAs/kz9cPyY+ij5APiQ9zD2MPUg9eD0EPSQ8zDzoPLg8VDxEPJA8vDyAPPg84D0cPVA9tD2UPcg9xD3YPfg91j4wPhI+QD6gPqo+sD6KPuA+wD7oPo4+mj6MPog+sj6kPvo+4D76Psk/FT9iP0K/sb+cf/N/5b/sACqAcwCWAOcA1gEkASYBMAEkAXgBQgFOAR4BPAEsAaoB/AJEAtQCqAJsAnwCdAJMAqwCtALAAzwDKAM4AxADGAMsAxADSAMQAwwDEAMQAzwC4AMsAvgChAJUAn4B4AGOAaABXgFgANIAo4BtP9E/pz8APzo+kD5APiA95D2QPWg9ID0gPQQ84DycPKw8YDxwPHA8vDyIPOA8/DzYPSg9HD1kPZw9kD2wPZg9wD4SPi4+Mj5gPmw+Xj5IPow+rj5uPn4+VD6yPkA+rj6WPsw+9j60PtI/Oj8IP0s/sr+ev6m/of/HAE8AZ4BLAJoA2ADIAPcAxAEhAO4AkgDKATYBLAFwAfgCHAJAAhwCCAJsAjQCEAJwAoADAANcA2QDaAMUAsgC/AL0AxgDaANwA3wDBAM4AyQDBAMkAqwCcAIoAcwB9AHsAfIBvgEZAMIAgIA1v5i/qz9qPwg+1D6IPkA+ID3IPdA9vD0IPTQ85Dz8PJQ8/DzUPRA9DD0UPRg9KD0cPUg9mD2cPag9oD3wPfw91D4gPj4+PD4iPlo+Yj5UPko+SD5+PgY+Wj5wPmo+XD5kPkA+mD64PrI+yz8IPx0/FD96P1W/qD+Vv/h/zMAFAHkAZgCJAJ0AqACLALAApwDaAXQBtgGMAcACNAIIAlQCaAJwAnwCbAKkAygDfANAA5wDSANgAzQDPANAA8gDyAOMA7wDdANAA0wDYAMMAuACfAIoAkQCWAIoAfwBiAF7AKAAfwAOQD4/sj9LP24+zD6QPmA+AD48Paw9TD1kPQA9PDzcPSg9JD00PPQ88Dz0PNQ9AD1oPXQ9RD2cPag9tD2IPdw98D3CPhA+LD4YPlg+Vj5KPko+RD5MPmI+eD50PnY+Qj6WPp4+gj7mPvg+6T8fPxk/bj91P0W/oD+of8IAOQAQAHaAcYBtgEEAuQCcAOgA/gEuAXABhAHcAcQCJAIsAgQCdAJ8AmwCqALcAzADJAMUAxwDIAMwAwADaANMA7gDbANoA0QDZAM4AuAC+AKcArgCbAJEAlQCFAHUAZgBTgEQAN0AtQB2QAIAAv/+P0I/QD8UPuQ+rj54Pho+MD3QPcw9wD3sPZg9mD2QPZQ9kD2cPaQ9oD2gPaQ9gD3IPdA94D3oPfA9+D3IPhY+Hj4cPiA+Kj4yPjo+Oj4EPlA+Vj5qPm4+Qj6IPp4+qj6CPvA+7j7APwI/DT8PPzo+3D8FP2M/dj9yP3s/Sb+bP6Q/iP/S/+3/1gARgHgAZQCMAOgAwAEEATIBGAFOAYQB6gHYAiwCOAIQAnQCXAK8AqQCwAMQAxwDMAM0AzQDNAMoAyADIAMcAxQDAAMgAvwCoAKwAnwCMAIMAiwBwAHOAZoBXgEkAPEAggCBAEvADH/TP7E/ez8VPzQ+4D70Ppg+sj5gPkw+cD4WPgQ+MD3cPdw90D3IPcA96D2sPZw9mD2cPZg9kD28PXg9QD24PUg9iD2gPZQ9lD2kPag9gD3IPdw9+D3GPgw+MD48Pjo+BD5QPmg+TD6ePro+gj7YPuo+/D7LPyA/Bz9qP0+/vr+yv/BAG4BHAL8ApgDSAQABTAG6AbAB3AIQAngCZAKcAtADAANcA0gDoAO4A4QD1APgA+gD9AP4A/wD+APkA8wD7AOQA7ADSANsAxADJAL4AogClAJUAhgB1gGkAWYBLADzALuAd8Auf+s/tz9NP18/AT8ePvo+mD6wPlo+aj4KPjA94D3EPfQ9oD2cPYg9tD1wPVQ9TD1IPUA9QD1gPSQ9ED0MPQg9CD0oPTA9ND08PRQ9WD18PUw9pD28PZA95D3cPew9wj4WPio+BD5mPno+Vj6qPoA+1j7gPvo+2T8JP3k/bT+s/+LADQB6AGsAoADQARABRgGKAcQCKAIkAlQCgAL0AuwDHANAA6gDgAPUA+QD6APwA/wD0AQQBBAECAQ0A9QD+AOUA7QDUANoAwgDJALsAqwCeAIEAgQByAGKAVgBGQDcAKMAW4ApP+g/uj9NP2s/Bj8gPsQ+2D64Plg+dD4cPhQ+ND3cPcA9+D2sPZw9jD24PXA9ZD1EPUw9dD0sPQw9AD0IPTQ8wD00PMg9NDzQPRA9ID0APVg9bD14PUw9iD2IPZg9rD2IPeQ9+D3OPiw+CD5cPkA+gD6WPqw+ij76PvA/Jz9iP5o/wcA1ACYAYACZANIBEAFKAYYB+gHAAnACaAKoAtQDEANEA6gDkAPcA+wD9APABBAEKAQwBDAEIAQYBAAEHAP4A6ADlAOkA0QDYAMsAvACsAJ8Aj4B2AHeAZ4BeAEuAOUAqgBjACy/+r+Mv58/QD9rPz4+1j70Pog+sD5EPmw+FD44PeQ90D34PaQ9mD2APYg9sD1kPUg9QD14PRQ9CD0APTA88Dz0PPQ8/Dz4PMA9HD0sPQg9YD1kPXg9dD1EPYQ9nD20Pbg9nD3wPdI+Hj4APlI+aj52Pko+tD6SPs4/BD9Dv7e/o3/WwBCATACLANABCgFGAboBtgHwAigCbAKoAuQDDANEA7gDlAPkA8AEEAQYBDAEMAQIBEgEQARoBBgENAPUA/wDoAOEA5ADXAM8AsQCxAKMAkwCHgHeAaoBcAExAPEAqABrAARAOD+OP58/eD8aPzI+zD7uPog+oj5EPlg+PD3kPdg9yD30PaA9lD2MPYw9rD1QPVw9dD0wPSg9FD0QPSw8/DzwPOg89Dz0PMA9FD0oPQw9ZD1kPUA9gD2EPYw9lD2wPYQ91D34Pco+JD48PgY+aj50Pko+rj6KPvo+8D8aP2C/jz/FgD6AMwB3ALMA7gEsAWABnAHMAhACYAKQAswDCAN8A2gDiAPgA/wD0AQYBCAEMAQABEAEQARwBBgEAAQcA9gD9AOcA7wDTANYAygC+AKAAogCWAIiAewBtAFwATgA9AC+AEKAWAAgv+w/gj+aP3s/DD8wPtY+8D6UPrA+VD5wPhQ+PD3oPdg9yD3IPcw9+D2sPZw9tD1YPUQ9RD14PTg9MD0YPRg9DD0MPRQ9ID04PRg9bD1EPYg9kD2YPZg9nD2sPbg9lD3oPcY+Fj4mPjQ+PD4YPmg+TD6sPoo+/j7hPxE/SL+7P7H/80ApgGQAnADaARQBUAGGAfwBxAJIAoQCwAMEA3QDWAOwA5QD9APABBgEKAQwBAAEeAQ4BCgEGAQABCgD1APIA+QDvANcA1gDJALsArgCRAJQAiYB6AGwAXABNADtALQAfMAHwBr/3L+0P0M/bD80PtY+9D6QPrY+VD52PhY+OD3UPfw9rD2EPZA9hD28PXQ9WD1QPXQ9GD0UPRA9PDzAPSw87DzkPOQ87Dz4PNw9MD0QPWA9eD10PXg9RD2EPZA9oD2APdg99D3KPhI+ID4aPjA+DD5sPkw+sj6ePss/Lz8hP1s/hr/CgDfAMgByAKwA5AEaAVgBkAHYAhwCYAKoAswDEAN0A1ADtAOkA/QD2AQoBCgEAAR4BCgEIAQYBAAELAPgA8gD8AOEA6ADcAM0AsAC2AKsAnACPgHMAdQBnAFkASkA6ACsAHPAA8AVv+W/vD9TP3E/Bj8wPsQ+4j6MPqQ+Sj5sPgY+MD3kPcw9wD3sPaA9lD2EPaw9ZD1QPXw9PD0oPSA9BD00PMg9ODzAPQQ9ED0kPQQ9SD1wPXg9cD1oPWw9bD10PWA9tD2QPeg96D3oPcY+Bj4UPjo+Dj5CPqA+iD76PuY/GD9Lv7w/uz/1ADAAeACsAOYBHgFSAZYB3AIsAnACrALUAwQDbANIA4AD3AP8A9AEKAQABEAEQAR4BCgEGAQQBAAEOAPcA8QD3AOsA3QDPALQAuQCsAJ8AgwCBAHcAZoBaAE2APAAsIBxwA0AHf/ov4K/nD9qPwg/Lj7KPuw+kj6kPlQ+dj4CPjg95D3gPcg99D2sPZg9lD2APbQ9aD1QPUg9eD0gPSA9BD0IPQQ9ED0EPSg9MD0QPXA9fD1QPYA9vD1sPXw9UD2oPYw92D3kPfQ9xD4MPhY+Mj4EPl4+ej5ePpQ+/j7hPxQ/Rj++v7G/8oA+gG0AoQDWAQgBRgGKAdgCGAJcApgCwAMoAxwDfANsA4wD3AP0A8gEGAQgBBgEIAQABDwD8APcA9gD+AOkA7gDUANkAzACxALgAqQCaAI+AcAB2AGgAXgBBAEGAMgAjQBlQDg/zn/hv78/Vz96Pxc/Aj8qPsg+6j6UPq4+UD54Phg+Fj48PfA95D3UPcw98D2cPYg9qD1gPVQ9RD18PSw9ID0cPRg9FD0kPTQ9MD0gPXg9RD28PXg9cD1gPXA9QD2UPbQ9iD3QPeA91D3cPfQ9wD4kPjw+Jj5OPqg+kj7APy4/Hj9Nv5h/zEAEgH6AaQCkANYBEgFiAZ4B7AIkAlwCkALwAtgDBANsA1ADsAOIA9wD6APkA+gD5APgA8wDyAPEA/ADmAO0A1gDcAMAAxgC7AK8AlACWAIsAfQBiAGYAVwBLAD1ALOAf8AZgB8//r+YP7M/TT9sPxk/OD7cPsA+5D6APqI+Qj5oPhg+PD3sPeA93D3APcA96D2cPYg9tD1kPVQ9UD18PSw9LD0MPSg9HD0oPTg9AD1wPXw9QD2QPYQ9qD1wPXg9WD2wPYg93D3gPew98D38Pcg+KD42Ph4+Rj6gPog+8D7hPwc/dT9zP6d/5MAVAEwAvgCvAOQBJgFyAboB8AI0AmwCmALIAywDFAN8A2QDgAPYA+gD9APABAAEPAP8A+QD9APgA8QD9AOoA7ADWANsAzgC2ALgArACQAJYAh4B7gGEAZQBXgEfAOwAsoB5gA/ALX/Iv+a/hj+sP0k/bz8WPzQ+1j70PpQ+vD5cPkY+dj4oPhg+CD4GPig92D3IPfA9mD2APag9YD1YPUA9eD0oPSg9MD00PTg9FD1YPWg9SD2IPYg9qD1kPXw9eD1gPbQ9jD3cPeg91D30PfQ9xD4gPgY+Zj5IPrw+nj7HPzc/Hj9Rv5e/yIAFgH2AZgCoANQBFAFWAZgB5AIkAlQCjAL0AuADEANwA1wDvAOQA+AD7AP4A/wD/APwA/gD6APYA9QD/AOcA7wDWAN0AzwC2ALsArQCSAJUAiQB9AG+AVYBYAEpAOsArwB9wA6AHn/4P5O/rz9WP2s/Hj8BPyQ+yj7iPpQ+tj5SPkI+cj4cPhA+DD44Pew96D3QPdA9/D2YPZA9gD24PWA9VD1IPUA9SD1QPWA9cD10PVA9mD2UPZw9hD2IPYw9qD20PaA96D38PcA+AD4CPhA+Lj4uPh4+cj5UPoI+2D7+PvM/KD9VP4B/x0A5wCwAUgCFAP4A+AEwAXgBuAHwAigCVAKIAugC1AMEA2QDRAOcA7QDvAO4A4QDyAPIA8AD9AO0A5wDgAOsA0wDcAMAAwgC7AK0AkwCUAIoAcoB1gGuAXgBDgEkAOIArAB9gBBAID/JP+C/gD+aP0Q/cj8UPz4+4j7UPvo+mj6EPqo+Wj5GPnQ+Kj4ePhA+AD44PeA91D3APeQ9oD2IPbw9bD1YPVA9RD1IPVg9YD10PXg9RD2YPZg9kD28PXQ9QD2oPYA9wD3oPdw93D3UPeA97D34PeI+Nj4YPm4+Tj62PqQ+/D70PzI/Wj+Kv/L/+kAsAE4AhwDaARoBSAG4AYgCPAIsAlgCiALIAyADMAMkA0QDkAOUA6QDsAOwA6gDrAOwA5wDvANwA2gDRANIAzACzALgAqgCRAJgAiwB+gGOAawBfAE9ANEA6wCwgEQAVEA1f89/87+KP7g/Yz9GP3Q/Fz8DPxw+3j7EPvA+kD66PnQ+Wj5KPm4+OD4YPgw+ND3wPdg9xD3APew9rD2APZQ9jD2UPbg9QD2QPZw9uD2wPYA9+D2gPYQ90D2MPZg91D4qPiA9zD3gPeA9zD3OPiQ+Qj6CPnA+Mj5APtw+9j7DP20/cz9Jv6H/7UALgGOAbgCqAN4BDAFwAYACDAIcAiACfAKAAxwDPAMgA3wDcANgA7wDnAPIA8gDyAPAA8AD6AOAA9wDsANUA3gDCAMkAuwClAKcAngCEAI6Ad4BhAGSAXABGAEpAJQAt4BdgElAPn/3P8u/4D+Kv46/rz98PxA/Iz8APy4+xj7GPuY+uj54PkQ+Yj56PiI+Fj40Pew9wD3sPbw9sD2cPZQ9SD10PVQ9dD0APVA9dD24PXg9GD1IPeg9yD24PLA81D38Pc4+JD2IPdg9rD0oPRA+ND6aPmg+Kj4uPio+KD5MP1y/qj9nPyU/UoAwQDOAcQCVAMsA/QDcAZgCBAJwAiACfAJQAtADNANsA4ADtANQA6gDkAPQA8AEAAQwA6wDuAOQA/gDvANsA0ADVAMcAuQC8AKoAnwCFAI+AfgBogFYAXwBBgElALuAXYBtAANAET/Sf/6/kL+LP3w/AT9xPy4/MD7yPv4+qD64PqA+uD6qPkA+Qj5SPmA+Yj4IPhY+KD4cPeA9sD2kPdQ9zD2gPVQ9kD2wPUg9nD2gPZg9RD2QPdQ93D2kPVA9hD3QPcw90D3APfg9kD2YPcY+Gj5IPlI+bD3OPhQ+fD6NPxw/CT9TP38/Qr+GQDwAWgC3AI0A4gEKAUABgAHAAhACYAJ4AqgCyAMUAzADDANQA2gDSAOUA7gDUANcA2gDXANQA0gDUAMcAsAC4AKEApQCVAIUAh4B5AGEAaABbgE5ANAAzQDlALyAf4AdgAYAFT/VP9I//7+GP6w/bj9+P2U/dz8NP2c/HD8uPsk/FT8aPv4+lj6oPoI+hj6WPo4+hj5APjg92D4EPhQ9zD3APeQ9vD1cPaw9uD20PXQ9WD2MPZA9iD20Pag9kD2cPbw9jD3oPaQ9uD1gPVA9ij46PlY+QD3wPaQ9gD4CPrc/Cb+5PzI+7j7LP0E/9cAPAP4A9wC0AIIBIAFQAdgCBAKkApQCkALsAwQDZAMcAzgDWAOcA5wDoAOIA6wDDANMA5wDtANcAyADJALYAoACqAKUArgCOgHqAcIB9AF8AQIBSgFzAPAAnACLAIUASkAbQC7AGQAPP8Y/9T+Xv6I/lT+5P7w/Zz9DP3Q/Bj9BP3E/Gj8gPu4+oD7OPv4+jD6CPqI+XD4ePjQ+Bj50PdA92D3kPdQ95D2YPdQ99D28PUQ9yD38PbQ9tD28PaA9sD2IPfw9gD2YPXw9uD20PdQ+Ej4gPdg9WD2sPnI+xT8YPy4+3j7IPtw/aUACAIgAtoBnAIAA8wDSAUgCHAJAAnwCdAKsAuwC1AMgA1QDWAN4A0wD+AOoA1QDQAOoA5gDhAOUA4gDbALoAuwC7ALsAoQCrAJ8AiYB8gGsAbIBXAF0AQQBBgEYALoARwCyAF9AC4BHgGQAL//nv5l/77/bv/6/r7+GP5k/TT9sP3o/dD8NPwI/Hj7APv4+vj6OPpY+RD5wPjA91D3kPfA96D20PVA9rD2EPbw9GD1IPYA9dD0MPUA9rD1sPTg9OD1gPVQ9ID0wPTg9GD0QPXw9lD3MPWQ9HD1kPbY+Dj6QPzQ+zj5EPqw+7D+8v/dAG4BmAL+AYACqATYBhAI8AjwCSAK8ApgC9AL4AwwDVANIA6gDtAOwA5wDYANEA4QDzAP4A0ADcAMUAxwCxALQAtwCyAKkAhACKgHqAbIBcgF4AWgBNgCmAIQA8oBqAASAZoB7wCA/4f/f//Q/nj+Hf/I/1j+8Pw8/bz9zP2w/Pj8GP3o+/D68Pqg+xj7APpA+cD52PjQ95D3APgY+ND2MPbQ9qD2wPWQ9QD28PWQ9UD1UPUA9lD1YPUg9qD1UPXw9FD1gPUw9bD1EPbQ9gD3UPYg9mD1IPfA+Sj76Pv4+jj72PqM/DL+CAFQAtAB1AGEAigEsAToBsAIcAqQCnAJ8ApwDBANkAwQDdAOkA5QDkAOMA/ADuANMA6AD4APEA4QDeAMgAyAC5ALwAvQCgAKMAmgCJAHwAbQBoAGUAUwBBgE2AOUAvIBMAIIAloBrgDZACQBj/9w/9T/kQCb//z9kv5W/mb+wP3Q/Ub+EP3Q+7D7iPyQ+xD7iPqw+nD5CPjw93j4SPjw9sD28PaQ9gD2cPWw9eD1MPVA9WD1QPXA9PD0MPVw9ZD1EPUA9YD0YPSg9CD18PVw9pD2MPbA9GD0cPbI+OD6SPso+6j6EPrA+rD9aAGYAYQBRAFkAhgDCASYBnAIwAnACUAKEAsQC9ALcA0wDtANAA6QDiAPMA6wDWAOsA6QDoAO4A7gDbALUAvgC2AMUAswCiAKMAnAB+gGEAcAB2gFsASQBOQDZAJyASACWAJ8AYYASQCrAKT//P6M/+j/ev+s/lj+EP50/Rj9qP1c/pz9SPyg+/j6YPsw+yj7OPpg+cD4APjQ91D3IPcA9/D2EPag9aD1cPUQ9bD0IPVA9eD0QPSg9MD0YPRA9LD0cPWw9NDzgPNQ9ID0cPVg9mD2YPVA9JD0APYw+FD6oPtY+xj52PmI+x7+HwDuANACwgEIAUQCMAX4BhAIAAmQCvAKcAoQC3AMgA3ADVAOEA9gD0AOQA4QDwAPwA7wDrAPUA+ADaAMgAyQDBAM0AugC7AKQAkwCFAI0AdgBtAFmAUQBewDAAPAAowCDAKeAcwBOAFUABkAKgBjACoALf8BAFv/4P1M/YT+kP5w/lj9tPzA/Cj72Ppo+/j7uPoI+WD4aPjQ9/D2MPcA94D2wPWg9UD14PSg9MD0cPQQ9ED0YPQA9JDzIPSA9FD04PMg9HD0YPPA8nD0sPVw9nD1gPTA9ND0oPUQ+BD7qPvg+jj58Pk0/Pj9QgCUArACzAFWAQgDWAZoB5AIEApwClAL0AoADGANMA7QDQAP4A9wD/AO0A5gD2APkA8gD3APQA8wDnANgAxQDGAMYAyAC7AKcAmwCHgH6AbABigGMAUwBPwDrANoAiIBkgFAArwBigDY/9L/8v9n/x//uP8k/+j90P0G/vT9sP3U/cj9iPyo+1j7oPuo+8j6aPqY+Uj48PfQ9zj4IPcw9nD2MPbg9cD00PQg9fD0APQw9LD00PTg82DzgPTg9DD04PNQ9ED0gPOw88D0UPYw9tD0QPVQ9aD1QPcw+Zj7QPtg+gj66Pos/YX/gAE8ApQBmAFAAuADIAegCPAJMAmwCcAKgAzADBANcA7wDvAOUA7wDkAPoA/QDhAP8A8AD3AO4A0wDoANYAuwC0AMoAzgCjAJ0AggCFAHcAYgBvgFyAQQBHADuALSAbwB5gHIATgB3gAnAJT/uP/X/zYAHP9K/sL+gP42/sT9Hv4m/hT9uPsE/FT80PvA+oD6UPqY+MD3QPc4+Bj4MPbg9bD1sPWw9MD0IPVg9IDzkPNQ9GD0YPMQ8xD0MPTA85DzkPOQ8wDzIPOA9ED18PSg9LD0sPQg9WD2WPg4+hj6cPlo+YD6XPyC/pUAFAFrAD0AZgFwA1gGUAiACRAJQAhACXAL4AxQDaAO0A6ADsANMA4wDyAPIA+AD0AQkA8QDuANwA3QDPALgAwADTAMcArgCSAJmAfQBlAH0AdIBkAEEASgA+ACngGmAfAC+gGlAEMAXQAnAMT/+f8uAKv/qP5S/p7+DP/E/jj+Qv60/QD9fPxQ/Jj8ZPyw+1j6QPnY+AD52PhQ+LD3IPeg9vD18PUg9uD1EPVg9OD0MPWg9FD0gPSw9ID08POA9LD0UPTg81D0oPVQ9cD0APWg9SD1sPWA90j5uPlA+aD5qPpA+3T8C/8+AW8A7/+cAHwCQASwBeAHgAkwCbAIwAkQC/AMkA1ADsAOkA6gDpAOIA+gDoAPoA8AEEAQwA9QDjAMkAsgDdAN4A0gDEALAApQCCAH4AeACDAIAAbgBBgEXAJUAjwCoAMEA+IBaQDr/68AHgB1AK8AhQBf/2b+0v7+/ov/9P7A/rL+aP3w/Jz8UP2Q/PD7UPtg+nj5YPi4+Mj4EPgA9zD2UPbQ9bD1IPUw9aD04PMA9ED0oPMQ9NDzcPOQ82DzkPOw80DzYPRg9AD04POg9ID00PNg9ND2KPmI+JD3wPjg+eD5OPu4/QoA9f/4/uP/2AEsA5gDIAZQCLAIoAjgCHAK8AuQDDANwA3gDoAPkA6gDsAOAA9wD0APoBDAEGAPMA3AC7AMUA2wDYAN4AxgCvgHMAeACBAJgAfQBngFeARAAwwC3AJUA8wC6gFeAWEA/f/4/3QANgHR/yL/dP42/0//hP5I/+j+wP5A/fT8WP0c/bD8OPxU/Jj6QPmg+Ij5WPkI+HD38PZw9gD2cPXA9aD18PSg9DD08PNQ9GD04PMw86Dz0PNA8xDzoPMg9MDzIPOQ89D0IPRw84D0YPYw92D3APhY+YD54PiI+kD9pP6u/qz+BwDEAfoBBAPYBPAGeAe4BxAJkArQCoALEAyADeANsA1gDjAP4A7wDfAN0A4gEOAPcA8wDoAM8AtADCAOkA3AC+AKMApgCLgHcAe4B1gHQAU4BXwD+AKYAlACDAOmAToBJgHyAMcAWQAhAND/bf+B//n/Vv8X/zr/CP8E/8D9gP3w/Uj9WP2A/OD7GPvI+WD5oPkA+Vj4IPcg97D28PUw9TD1cPXA9KDzwPNg9JDzIPMA85DzMPMg8pDykPPg89DyYPLw8qDzkPOA80D0wPQw9cD14PbA96j4KPnY+bD60Pus/ET9jP5OAN4BXAL0AtADkAXABtgHgAkQC5ALUAuwC5AMsA2wDsAPwA8wD2AOAA4gD0AQYBHAEDAPQA3QDDANgA1wDeAN4AzwChAJEAjoB1AHqAdYB6gGIAXsApACPAKIAuwCtAIkAjgBuQC+AA8A4v9SAO4AcQDm/8H/1v+S/wD/yv78/oj+3P0W/rT9rPwo+yD6GPvw+gj6yPhA+KD3APfA9sD2QPcA9rD0gPTg9KD0QPRA9JD04POw8sDyEPQw9NDzMPMw8zDzYPPA8+D0oPTg9AD10PUg97D30PjQ+UD6KPog+4D8qP11/7cAAAJMAowCyAOYBRgHkAjwCdAKMAvQCtALgAzADeAOoA9wD7AOwA6QDrAOkA+AECARUA/QDDAMAA3ADMAN0A2QDSAL6AbgBngHMAjgB5gHeAY4BNABTAEUA6wDaANEAm4BHAG1ABIAkACAAFEAcQAqAKIAVAB9/8T+jv64/o7+1v5I/uD9oPxQ+5j6EPqw+tj6kPng98D2sPbA9oD2cPYA9mD18POg8zD0EPSA8yDzMPNA88DxMPIA81DzcPIA8uDxoPIg8wDzYPRw9PDzcPTg9UD3IPhQ+Cj5MPpY+nD7GP0b/z4AEgHAAYQCzAPYBOgGgAiACWAKMAuAC/ALsAzgDdAOoA8gEMAP0A6QDiAPABFgEWAQ0A6gDRANsAyQDZAOcA9ADMAI4AfAB0AIoAgwCFAIeAWEAnACgAPcA9ACWAJYA1ACtwCS/xIBwgAVAH//KwBaAaMA9f+W/0T//P3U/ZP/6P9N/xT9gPso+yD7cPqo+nD6ePlA+JD2cPYg9pD2wPag9cD0sPOg87Dz4PPg8xDzEPIg8lDy0PJg8hDyUPIg8qDyQPLw8pDz8POQ9HD0QPUQ9qD3gPjI+Ej5+PnQ+iD8vP3E/6IAowCmAawCUARABegGgAhQCoAK8AmwCgAMoA1QDjAPcA8QDyAOsA1QD8AQ4BDAD/AOcA1QDIAMwA0gD3AOMAvwCcAIyAf4B8gHQAgYBygG2ARUA5wCvAL0AuADxAJ8AiACUgFTAFoAfwCBAAoBNgEkAhgBNf96/lb/gP9g/7z/gP/6/hz8IPtI+xD7oPvo+hD7KPng9kD2YPaw94D3cPYw9rD0UPNw8+DzMPQw9PDzAPOw8VDxwPEg81DzoPKA8mDyIPLQ8qDzoPTQ9AD14PXg9jD38Pfo+Ej6OPvg+0D9hP4cALoAcAHAAtwDcAXYBvAIUAmgCeAJIAsADXANUA7wDhAPwA5wDkAPYBCAEAAQkA/ADoANgA3gDiAPUA6wDFAL4AowChAJIAlACGgHeAfwBhAGgASsA1gDNAN4AwAEiASAA5oBcgB6APsAtAGgArwDIAIQAPz+sf+AAEYA6wDJAH3/OP2Q+/j70PvI+8D7QPuI+aD3kPYQ9xD3kPbA9oD2MPXw8nDyMPOQ86DzgPMg86DxkPCg8ADyYPIw8vDxQPJg8iDyMPJg84D0EPXA9RD2EPdg91j4EPmY+nj7fPwo/lD/UQC0AHwBZANoBFAGyAcwCMAIsAlgCnAL4AvwDAAOAA4wDgAOgA4gDyAP4A5gDqANcA3wDZAOAA6QDNAKMAqgClAK0AmQCBgHMAYwBZAFcAXoBRAFKAPkAagBhAI4A8QD8ALKAWUApv9pALQCzAMEAnkA0v8uAHYAlP8sATwBXv/c/DD8pPxU/Lj7APuI+9D5YPdQ9vD2gPdA9wD2UPWw9GDzwPKA8sDyUPNw8uDxoPEw8XDwYPDQ8NDxEPLA8bDxwPFw8vDyQPOA9CD1gPYQ9zD3SPgI+cj66PpI/F7+sv8wAOIAOAJ0AygEuAXgB4AJwAngCTAKYAsQDAAMAA5AD3APEA9QDiAOMA7gDZAO4A9QD7AOcA1wDJAL8AoAC8ALIAwQCpAIYAZABagFeAawB4gHiAWoA0gCPAIkA2gEMAVQBAADkgFGAaoByAK0AzQD/AFvAOAAkAKoARoBw/+q/vj9iP30/Er+0Px4+rj5kPgY+PD2EPcY+PD2MPUA82DzMPNQ8gDyAPIA8kDxAPHA8HDwwO/g73DwsPDA8GDxcPHg8UDyMPJA8+DzYPXw9mD38Pew94j5uPrQ+7T9uv5mAPwAbgHkAkgESAUIB9AIAApgCqAKIAuAC8AMwA0gDwAQoA9AD4AO8A1wDlAPgBDgDyAPYA6gDJALkArgC/AM8AugCnAIIAdIBXAFyAbIB1AHEAV8AxADhAKUAugDaASIBPAClAGoARgC2AL0ApQCrAF2AToBQAK8AuABWP9O/sT9IP2a/pz9rP24+6D5GPiw9gD3APiw+Dj4QPVg80Dy4PGA8vDygPOA8mDx4O/g7yDwYO9w8CDxQPHg8GDwsPDA8TDyAPPg80D00PVQ9sD20Peg+CD6gPuY/Db+Ev8yAAwBPAIABOAEGAbgB6AJQAowCsAKsAtgDbANwA4AEGAPEA/QDsAOYA/gDnAP0A+gDwAOIA0gDPALIAygC6ALMAoACfgHGAfABmAGkAY4BuAF0ATwA3QDGAPIA8gDoANYA1QDdANgAwwDdAL2ARgC9AKwA8QDIANoAgwBlP+w/sb+ZP95/9r+mP1g+/j4APjA97D4OPkA+XD3APXw8qDxIPIQ88Dz0POg8qDwIO9g7qDvgPBg8VDx4PBg8EDv4O9A8eDy4PMQ9ID0UPQA9VD2APjA+ZD6aPto/ET9Lv6N/0IBwALAAxgFGAYwB/gHAAngCZAKQAtQDHAN0A3wDZANoA3QDSAOsA6ADpAOwA0QDTAMwAuwC7ALQAuACkAJMAiYB4gHcAfoBjAGgAU4BfAEgAQYBAgEGAR8AxQDBAOMAzAEEAS0A3gCsAGiAYwDMAUwBMwCVALzANX/u//w/hAAr//o/XD9yPpI+Qj4QPgA+Tj4YPdQ9nD1IPPA8aDxwPGQ8qDysPHA8IDuwO0g7sDvQPCw8EDw4O+g7wDvUPDg8bDzQPRg9HD0EPXw9aD3uPkA+0j8wPy4/bL+yP+SATADkAQABqgGuAdACBAJQAowC0AM8AygDbAN0A2gDfANMA6gDnAOUA4QDoANkAzgCyAM8AuQC8AKoAkQCZAI2Ae4BzgHEAdYBuAFeAVYBZAEKAWYBagECASgA6gEgAWgBCgDvAOIA3gDKAVIBdAF1AIoAmQB2gGSAV8AygEqAc7+yPto++D6OPsY+sj5GPkQ95D1QPXQ9NDzQPPQ8gDz0PGQ8FDwEPCA70DvYO+g7wDwAPAA8CDwgO8w8LDx4PKQ8zD0EPXw9RD2wPZ4+CD60Pvw/Ej+Av9R/zsABALUA0gFiAaAB3AIsAjgCDAKoAuADAANUA1ADWANYA3ADfAN0A2wDaANIA1gDOALcAtwC7AKMAqQCfAIgAjYBzgHuAaYBpAGQAagBXAFwASwBDAEyATYBCAF+AQIBZgE8AIkAsQDMAZgBogFKAR4A9oBbwDAAbwC/ALYAWn/YP4A/Kj6UPrg+4j78Pkg+CD2UPVA9KDzwPPQ8xDzMPLA8MDvYO8A76DvoO+g72DvAO/g7iDvwO8A8KDw0PGA8kDz4PPA9ND18PYI+Mj4MPqA+1D9yv6R/zAAdgEoAzAEeAWoBkAIMAmwCVAKIAvAC2AMMA3gDTAOMA4gDhAOIA6QDSAN8AxQDSANgAxgC7AKYAoACoAJ4AiQCGAIAAhwBwgHcAZ4BjgG0AUIBfAEKAVQBtgG6AZYBcAD1ALUAzgF6AWIB6AGeAbwA3cADwDAAawChAOkAsAANv4c/DD6QPpw+nj6uPrA+dD3cPUA9BDzMPNw8yDzAPNw8fDwMPCg7qDuAO8g8ADwoO9g7wDwMPCA8DDx4PEA85DzsPTA9ZD2UPeA+DD6EPtw/HD91v58AEoBcAKEA6gEIAY4B0AIUAmgCeAKsAvQCxAMYAxQDUAO4A3gDbANYA3wDFAMwAyQDEAMgAsAC1AKYAkACeAIAAnYB6AHYAfIBkAGqAXYBVAFmASgBAAFkAVgBXgFsARwAxgCNAMYBLgFUAXQBAgFpgF/AJP/VAA8AXYBEgFN/4D9gPso+rj5CPrY+YD5QPjw9rD1gPSA8wDz8PKg8qDxQPEg8cDw4O9g72DvoO+A7+DvQPDw8EDxUPHg8ZDyMPMw9MD1gPZw91D4cPl4+oD7KP1G/sf/2QAQAjgDEAQYBVAG0AeQCEAJwAlwChALgAvwC1AMwAwQDZAMgAwwDAAMIAzQC2AL4ApgCuAJwAkwCRAJcAjIBxAHMAfQBhgGUAYwBpAGCAX0A/wDSAXwBVgFOAXIBHwDqAMcA6AEKAU4BYgEsAMQAqQA1v+sAJwByQB8ABL+CP0w+7j66PnQ+ej5APlI+FD2APUw9ODz8PMg85Dy4PFw8SDxsPBQ8EDwIPCg7+DvMPCw8IDxQPIQ82DzEPPQ8wD1YPaQ98D42PkQ+3z8QP3k/dD+AwDqAVgDaATIBSAH2AdwCMAI4AmACoALgAwgDUANkAzADGANcA2QDFAMwAyQDCAMgAswCxALYArACbAIcAggCDAIoAgQCBAHwAaQBZAFgAVwBWAFYAVYBlgGkARkA2wDYASoBLQDcAQYBIwDpAKIAaoBdABBADEAHAA2/oT8kPvo+3D72Pnw+fD4GPig9jD1MPWQ9BD0EPSg80DykPFw8cDxIPHg7wDw4O+w8MDw4PAg8iDywPLg8hDzoPMg9UD2oPcI+aj5OPsg/CT96P3Y/uP/agFoA+gEqAWwBsAHgAiwCKAIkAlACyAMYAxwDBAN0AxQDAAMEAxQDCAMUAwADIALcAowCtAJsAnACGAI2AcACNgH2AagBhAGAAaIBdgEcAT4BOAEEAVwBEgEnAPoAmQDnAPQAlwC6gEMAzgCYACw/4P/bv/I/sz91Pxo/OD62PrQ+rj5APnw92j4APcQ9XD0gPRw9CD0QPPA8rDyYPHA8QDx8PDQ8ADxUPLw8WDyYPJA8xD0gPTQ9OD1oPbA93j5YPqI+6j8wP3o/lL/FgCqAQADoASQBcgGAAhACNAIcAnQCVAKkArAC8AMAA3wDAANEA3ADEAMEAwwDPALAAygC6ALEAuQCgAKoAkQCfAHwAd4B8gHyAcYB+AGcAb4BeAEsARQBPAE4AQwBAAE/ANIA2wCCAJQARwBTQBvAP7/q/++/iD+aP00/Ij6APo4+iD6uPkQ+XD4oPdw9jD1IPQA9NDzoPRw9MDzIPOw8qDyUPLA8fDxQPKQ8uDykPNA9OD0kPUg9iD2UPbA9qj42PlA+yT8EP0w/gL/1v/kAFIBoAK0AwAFaAWQBtAHQAmgCRAJ0AgQCVAKMAvQCxAMEAxgDFAMAAxgC1ALkAvQC0ALoApQCpAKsApgCpAJoAjgB/AHuAeIBwAH2AbIBlAGkAWoBLgEmARwBOADKAPMAuABsgEQAfAAOwD//yz/hv6g/ej8aPyA++D6WPrY+ZD52PhA+JD3wPYA9nD10PRQ9BD0MPRA9DD0sPNQ8yDzwPKA8pDyYPOw8yD0kPQw9SD2IPZw9pD2oPcw+Cj5OPqA+7z8gP1M/tr+df/b//8A/AEoA9QD0ARwBdAGMAcgCGgHwAf4B+AIUAlwCSAKgAoQCxAKYArACRAKwAhQCeAJQArQCXAIoAnwCFAIUAYwB+gH6AZIBrAFUAbQBZgFMAW8A0QDkAPYA1ACAgEcAgADQAKm/qD/fwAyANj8mPyA/Uz+4PsA+0D7aPyI+jj5uPiA+bj4gPeQ92D44PfQ9pD24Pcg96D1sPTA9nD24PUQ9XD28PZQ90D2gPeg9zj4WPjo+Aj5WPmQ+vD7FPwM/fT8hP7s/fj+Q//NAN4AiAGAAtgDvAPIA9gEuAUYBgAFCAa4BqAHMAcwByAIgAiACHAIYAgQCFAIIAhACHgHUAcACMAIQAi4BzgH6AaIBrgFuAXgBRgFcAWgBTgFYAR0A3wDQAPgAsgBWAE6AbYBDAFKACH/ev8o/8r+VP1U/Rz9zPy8/Bj8uPuw+kj7SPvw+qD5UPlw+Wj50Pig+AD50PiQ+Dj4wPeQ94j4oPiA9/D2kPfI+QD5+PjI+Dj6qPoo+QD6ePpU/GD7MPy4/E7++P2U/WL+Yv/HAM7/MQDHAJgCmAKEAuACWAOwBDAEOAXoBJAFIAUQBkgGyAZQBvAFeAaIB7gHsAY4BogGgAcYBwgG2AVoBvgGSAYABlgF0AXwBCAFQATgA6wDpAMkA8wC6AI0AmwCbAHnAMwAlwA3/2L+Gv85AEoA6P2Q/Uz9Fv6A+0z8JPyM/TD8+Pro+1j70Ps4+ZD7UPrQ+wj6iPlA+lj6RPzQ+Yj6uPgQ/ND6uPrA+YD7oPyM/Pj7OPsA/RT90P0w/SD+7PzE/nb/6wBHAHr+OP8EAqQDWQDm/pUAAAWABbwCGgFwAxAFMARgA/AC0AP4BEAFoAW4BKgEQAQYBWgEiARIBNgDuAQQBVAFgAOwAzwDWATAAhwCjAKsAnADqAH0Aq4BOAP4ANYASAASATAB4v50/0r/xgGG/4r/HP47/5L+iP06/sD87PxM/Tj+MP+I/Hz9zPxA/gj8APtw+8j8nPzc/Ej9sP0W/ij8hPzc/Oj88PvY+5D9Nv7O/oj91v5W/qj9rP1W/ur+YP3C/uD/kAGu/nf/ggAMAu7/k/9BABwCLgHwALYBYAIIA0IBXANQAZQClgCsAsQCvAMwAukALANAAygEFwAYAsgC8AT1AHr/9AH4AuQDz/8wAfsArAKvAM8A7P9GAeoAAQDY/1D/fgDd/yQAZv8ZACf/Pv6s/0z/xf+Q/aT+hP5LAE7/yP1u/hD9WQC0/ur+QPwo/+3/vP6A/Az94P8WAJT84P1y/rr/UP0K/sP/Sv6U/VT9FgEa/rb+EP1QAdj+Lf+o/RwARf8wAKr+PP+k/TYBtgHTAHD+zP4EAvL/UwC0/YQCpf8oAe7/dgGYADMAkALmAdQALP1IAuQCRAJ//8sAcANYArf/hABoAcwCd/8kAbQAOAKaAZMAVgFt/+ACif9sAgL/TAKSADgBP/+sANwBNgBrAHn/qwDUACn/GwBr/zgCFv9p/+b+qAB0AQb+VP/K/q4BpP2e/zX/KAEN/yT9KQCi/oP/4P15AEj+Sv8a/ioBwv42/sD+EACK/hj9Ff8KAY0A9P3G/x4AqADE/Cr+YwAAAW//ZP0iAPsA8AHA/YX/pv5oAkT+rP9Y/hAD8P+ZAKL+HAHQAD4Axf+EAFYBiP/zAOn/0AFpAIsANgBSANABQAB7AIT/tAFEAVwAJf+KAYoB3QDF/2MAIAEo/7wAUgFgAjsAWv5rABAAlAGy/pYB1P9mAHr/gv8CAUj+LAA+/jgCGv54ABz+PAE7/+j9Hv8g/8wAUP27AJz+2gAY/QT/8f98/yD+nv6VAMf/VP54/hUAcADs/if/ygDe/9n/YP51AAIA+v/B/8j/pP+S/3T/DgHI/6oBXv5MAZ7+sgF4/+j/8P8TAIIBlP8sACIAqQBJAIgA5v8wAGX/NgEpAKwAKf+CAXcAXAD8/jIB7f9BACz/RgGhAFf/Kv8SAWABqP8QAIAALgHW/wr/9wDwANEALv8NAAgBKAG8/7D/KP8cAgP/3ADc/HYBDwDiAdD+L//M/5MAgf+O/zf/YgEG/vkAQP62AQr++f/s/1wBxP56/l//OgHw/zP/V//k/0wAEv/mAFn/dQAP/yIBKgAo/9r+0wACAXcAYv4OATEAuABb/2sA/QBK/8MADP/iAWT+EAG8ACgBpv8e/24Bnv90AUj+qAHO/joBxP9QAUn/xP9lANMAgAAk/5sAGAC/ACYA2/8AAPL+pgE4AOAAEP8J/5gB0v6iAeT9aAJQ/vQB4P0YAWf/DgHe/0D/jAD8AOwAeP7V/+UA5AEf/67+sv+kAa0AN//v/yv/nABK/4YBCv/k/+b+SQCDALj+tP+O/0YBe/93/5b/w/84AXD//P8s/iIAof8eAU7//f/8/0QAaQAy/sgApf8EAnb+DwB6/0wBJgBN/+4Ajv97AA7/ZAGd/97/jP5aAcMAYQA8/+D/GgEn/2sAiP66AfT/9ABl/zz/VwCs/8QBrP7aAbr+pADc/poAsAHM/wcAav6EA+f/mADM/EwCXAAgAhb+QAEC/7ABIgA8Aiz/9v7//yQBMwAW/kYAZAJsAMr/sP6CAaj/lP5S/+cAOQDG/lf/ywDyAH7+7v9x/3IBTP02/wz+DAEw/9P/6P7E/hAAyP+sADz9yP4x/9YAKP9s/RUAgP9MAXD+yP98/93/9v/C/vT/bv5eAIP/v/+y/97/wwBQ/8MAJ//jAHr+NgDN/wIBOwCs/8gAd/9WAXz+tQAp/6wB1gAYAWj/KP+cAXUAwgEO/vEArwBkAQ4A1/8WAQoBNQBKAOT/cgHf/7wACgDlALEAeQBeAFcAiQB/AHL/JAD4/5YBNAC//3j/3f9wAUD/mwDE/qABGf+uADP/4QAO/9r/eP8IAEz/K/8qAAIAxv9o/uv/MP/z/6z+EAAJ/zH/lv9L//8A/P38/7b+ugAT/77++v7N/9AAEv9v/wH/ZgDe/igAZv4qAa7+xQCG/y4At/8H/6oA6f+CALr/Xf++AW//dgG8/hIBWgFtAH4AC/9iASgB1wBkAKb/hAGbACwCPACAABkA+wDZAHoABgD6AIsAYgEiAHYB/f94AGEAXP+CAcP/CAIQ/2sASgAYAVIANP66ABgAxAEc/p8AIv9YAeD+GABnAB3/5v+4/qYB3/8h/zT+0f95AOj+H/9a/tAB/P4FAPz8FAAe/6wAYv4v/zb+FQBe/1cAKP8S/pT/K/+oAFb+Vv4R/0gAff9Q/4z95wC4/foBIP3yART9cAEg/y8ASf8s/poBZv8sAkb+CgFC/xIBBwDsAFP/5AB7APQAUgA3//IBMQCyAcD+lgHGALcABQCUALgBIwBSAEgA7gHw/4cAiv8cAg3/hwCW//YBjwBg//4AugD3AIr+gv68Aev/pgGM/TgBHgBxAD3/jf/DAG7/hf9e/qEAOwA6ADz/0f+f/0MAdv4KADz+QAFu/o0Aiv4OAHz/4v+m/5D/HP+2/qn/4//mAOz9PACC/hACEv4hAAL+QgE5/5v/EwBdACcAIP5LAHMADgGA/iIALgDeAEr+lP8GAYgATQCY/ggCpf+XABL/KAFmAaP/TgFB/xgCQv6UAjr/rAKA/v4BKwCSAWL/kQDHAJQAmgCk/7YBnv9+ATr/vAHe/2UAYACr/zIBAv+6AfT+hAHE/rwAgv9OAJYAzv9aAAr/ggHx/7L/IP7p/5IBMwAZ/6b+rgD4ALj+Zf+C/+oA3P9w/hoAvP+MAIT+7/9YAHsANv9K/iEA/f/l/8z9yQAh/zoB/Pz/AJ//1AAL/yv/CAHk/TsAYv5IAvb+JP84/2QA/AAu/8MAcP9YAAD/fQBlAFMABwBPAFcA9wAHAOAAxv6WAUEAsgEs/sP/agE8AqIBeP5MAb//tAJy/gQCKv+kAg///gH8/1gBlv9kAPAB7ACXAMz96ADXAGYBBQA+/8IAov/kADEAmwBM/23/RgEXAD7/1P0CASgBywBs/c//vf8YAXf/pv+N/4D+8P/O/nYAfv6g/6D/bQBn/4n/+P4LALb+fQCc/VUAtP3yAfj+qAHQ/bX/TP8D/yYAnv48AXL+BQA+/t0AjAAm/6T/a/8WAJL+qP+yAKAAlf/u/t8A7gAS/zYAEgA+Acb+/P9vAOYAn/+M//wA+AC3/4wA0f94AWn/WgC+AMP/GgGU/ggD4P7mAfT8NAJg/zQC8P0gAZX/KALQ/lQAm//EAO//gf/VAOz/xAFq/jIBWP+eAVr/WP/Y/s8AQQBWAJv/WwDo/xv/s//0//cARP7y/yQAQwBC/0j96AGu/2gBEP1mAJn/tADc/qP/Xv/f/7D+ngGe/+ABMP3d/wYAgAH8/lr+D/+wAWwBlP5p/7L/OAKM/jIA4P0AAhv/BAE5/2QBpv+HAOT/LgEUAFYAbP9tACYBfgAJ/ysA/P+KAZb/Yf/gAPkAzgAO/lIBCQDEAc7+TABCALsAQ/9p/zoB0f/4Aoz+bAKE/P4Bqv4AAvr+Sv8EAQkATgEm/lgCH//eACT/2wCQAfj+fACc/hwC8PxwAI//tAFwAG7+UgBr/4YAIwCh/0AAgP0cAVf/nwDI/cUAaAHsALD+7v6YAQwAAf/o/GoB2/8uAfT9ZgDk/08ALv9LAJYAhwACAFb+9P9e/nABqv4yAaL+JwDY/8j/vQC0/lQAQ/9WAFH/nv7lAIf/eAHo/QwBWP88AXb+1v+q/7b/7P/g/jACMP9YAcz9IgGy/1kAMgAPAO0Atv/M/9D/t/85ACr/7f+T/7X/nAC4/kYBxP5cAoT95QAc/g4BWP+y/ukAUP/oAdD8FALC/ggCyP0OAWkANwA2/zj+pAKZ/3oBpP2AAWn/ZAEIAOb/EAEA/3YBkP2GACj+pAL//+QApP9CAAMA7v54AQIANAJI/e4ANP8EAur+vQAU/9sAj//KACYANP/B/8T+6QCe/iwBPv+1ABb+OwB9ADwA1v5w/kQByf8iAZz9IAHQ/lkAbv6sACr/BAHt/8YBpv+q/rz/xP88AlD9WAE0/XQCZP4gAiQBFQALAHL+oAJQ/lwA6PykAsv/CgH0/joBdwBcAK3/2gCJABb/fv7y/4YArAHm/zIAqP5CAcn/HAJJ/1wA4v9AAAgAlQDW/0D/oP8cAAwDLgCs/67+9ABsAX7////A/2gCkv4NAE//cAEIAeL+gAHV/4ACsP30AXr+UAJy/u8Aiv9PAKn//v/qADD//wDC/oYB0P6VAMj/GgBj/1P/SwDQ/jP/KP7iAUQAYAEu/jgBIgDLABP/+v50AAj/bwCm/rQCe/+aAMz9MAGbAAwBL/+I/tb/GP54AZj/TgE+//D+7/+u/swAGP8eAQD/8ABXAJUAhf80/2AA6v8v/zT/MAAMAXoAv//c/1H/Xv+5/9P/rP/w/fX/cQCAAtL/q/9z/ykAPADZ/2oBpADzACb+GwBYAFoB4//+/+L/xACuALYB2gEDACQAHP9CAb7+1f+9/2gBVABH/5D/vQB+AEMAd/9I/zr+vv4VADEAFwAO/oAA9v8pAKD+m/8yAVkAzP8k/lb+2v6C/2YBsP9E/+D+owA2AS//PQAWAMIBZ/+6/8X/7v/8/tL+kgDQAH//4P+1AEACNACv/3//ov98/9T+wAAzADwAvv/qAXIB+gA0/3EAWADwAKb/7f9IABkAZAE8AEoBJf/IAo0ATAGk/eX/OAEqAbz/M//oAbgAm/+K/rD/9v9O/1X/QQBp/+//sP+mAer/B/8m/6P/GACw/roAcABJAO7+8v7EAZ0ANgFB/z8Aqv7G/kP/kgCZAAMAqf9GAGj/OwAH/3AAUv84ABf/tf/M/5IAGQCF//L+PAB5/7r/nP5xAAUAEAHK/rH/ZP7J/7z/9P+bADX/vf/S/j0Avv8UAMD/6/+EAJj/3f+a/44Ayv+k/8r/TwBgAOb/QACPAHUA6v/x/9sAdgB7AO3/kADp/xMAo/94AEAAIAC//3QAnwCNAMEADAB4AOz+KP/k/lUASACHAOr/of8CAEcAOgEqABoA/P5aAPn/8wDB/7H/a/9k/zAA7v+KAA4AZQDv/6MAxwAgARYAsf/U/kf/Cv/2/6oArQBjAFL/JAC3APsAeQDk/9D/nv+c/0L/AwD7/4AASwBgAJsA4QDxAPz/xv9h/yIAyf+S/yj/+f8iADsANQDo/7kAQQC4ABMAowDe/+D/b/95/+//GACzAMsA6wCcAAgAIwAsAMEAyQDW/5P/Zf8WAOv/TQAzAO4ApQB+AOD/LQARAPP/4v+A//n/vv+RACoA1QCw/8r/iv8DAFgA+P8KAM//OQARACYAMAAIAB0ASQBHAE8A2//8/x4AYAAzACsAVQA3AEIAgQBrALMAPAAjABIADAAiAB0AVADa/30ALwBkAA0A/P8lAEoAOwDp/5n/Uf9e/3X/t//n//T//v+b/yUAAwC3/0b/Zf+7/9f/hv+i/9z/u//N/5P/6f/O/7r/tP8LAEQAFwAPAAEA8f/8/7r/jv+Z/6n/2P/7/z8ASwBTAOD/z//W/zcA4v/B/6D/v//E/ycALgB3AIcANwA2APj/WQD8/xEAkf/D/7f/7P/x/77/uv9Y/9f/kf8WAMP/mf+J/5v/FgD1/9z/gP9S/03/mf/W/wEA7f/1/zQAGgAlACQAWABjAPz/xP/E/+L/DwAgAAwA8v/Y/xAAGQAdAPf/wv8QACgAJwD3/9T/zP8WABYATgBRACsA6P/W/+r/AAC3/8T/SACVAJoANQBLAJUAZQAzAB8AVgCXAHIAsACtALkAaABTAGMAjwBwACQAKAAuAHIAagCBAG8ANgDw/9n/EQAFAAsA7v/p/xoAGAAdANb/2v/Y//n/9//C/9L/3v/l/9v/xf/P/7r/r/+B/9//8/8eANz/mv+Y/7f/j/9k/4T/df+0/3T/nv+n/9v/r/+U/2D/av99/4r/tv+x/9D/z//U/8b/2P8KAOX/3P/Q/xQABwDz/9T/HAAvABwACwAcAGYAWQBdAGAAawBhADQAMQBGAHUAbQB+AMAAogDNAJEAqQCiAFkAQAB1AKsArABpAE0ARwBdAAcAAADL/7f/1v/M/9T/w/+r/9D/9P/e/+b/u//e/6T/wf+r/63/qP+0/97/qv+o/6X/+//V/9X/1f/e/+n/rv+1/5P/0f+2/73/of+x/7v/2P/V/53/hP9x/4f/dv9a/1//Jf88/1j/aP+L/3L/y/+w/63/wv/l/xYABgAAAPb/JAAuAEYAlgB7AJgAkwDoAMUA2wDJAP8AxACSAKoAsQDAAJYAlgCYANQAnQC+ALUAowCfAH0AkgC/AKoAvQDLAOUABgHuANcA3gDLAMUAxADvAPkAGgEQAQgB7ADIAPgA2gDcAMIAqgB5AEoAJgAcAPb/wf+R/4X/Yv8w/yf/If8y//T+zv6w/qj+lv7A/oz+Yv5I/lT+ev6M/oz+Bf/U/r7+bv5g/t7+oP6u/qT+rv6k/sT+4v7m/vj+Af8n/+T+1v7S/gL/H/8L/xH/Gf/4/iP/Wf/R//n/GQBmAKwA2QDlADoBpgHsASwCkALkAiwDNAOMA0gEgASwBPgEOAVQBWgFWAWIBXgFWAUYBdAEoAQoBNADnANcA7ACaAIYAswBsAGiAYIBVAHZAHIAJgAIACj/nv5M/sj9WP2Q/ED86Pt4+zj7APuQ+nj68Pnw+bD50PnA+XD5QPlg+Hj44Peg95D3sPdQ9wD34Pag98D34Pdg96D3sPeg94D30PfQ90j4SPjg+GD5UPkQ+/D7kP0g/p7/bABwATQDyASwBqgH0AjgCeAKAAzQDDAOIA+AD2AQABHAEQASoBLAEkATIBPAEoASwBHAENAPgA7wDHALIArwCJAHoAVABCQDEALZAP//ov7I/bD8gPsg+/j5APlo+GD3IPcA9lD1kPRg9CD00PPQ8wD0UPQQ9DD0oPTQ9OD0YPWQ9ZD1cPVA9eD00PTQ9ID0UPQQ9KDz8PMA9PDzQPTQ9ND0MPTA9FD1YPXg9bD20PeY+ID4iPlg+ij7+PtM/Pj9rP7M/ygBEANIBAgGYAhwC2AN0A3gD6ARwBOgFeAW4BfgF4AXoBcAGIAX4BZgFqAVoBTgEgAS4BAgEMAOQA0QDKAJcAh4BpAFEARMAoYAJP6g/Jj6CPoI+bD48PeA9yD3wPbA9jD3sPfA9wD4MPho+Hj4cPhI+ZD52Pmw+aD6ePvY+0D8rPyA/Zz9+P34/WT+Ev5o/UT9MP1I/Lj72Poo+pD5kPhw+Ej4cPew9iD28PVQ9rD1MPaQ9QD2gPVw9YD1APYg9hD3cPdI+OD4YPmI+qj7TPz4/Kj9Pv5U/zcAmAFEA7gEUAfwCKALoAywDSAQgBLgE8AU4BRgFOAUIBTgFOATYBNgEuAQIBBADqAN0AwADBALAAqgCAAHaAW4BNgDSAITAD7+cPwA+5D5SPjw9/D2wPZQ9iD2cPaA9lD3UPjQ+Ij5kPkY+kD6CPtQ+8D7sPvQ+7j7aPzE/MT8eP28/a7+6P4t/yn/8P4I/2T+Ov6I/cT8sPtw+pj5+PhY+DD3kPYw9aD1oPRg9NDzAPQA9LDzEPRA9LD0MPTA9ND0kPVw9eD18PYI+LD4WPlo+vD6CPz0/G7+fv/V/4IBsALQBEgGMAiwCTALkAywDiARgBLgEsAUYBWAFYAUABTAEwATwBLgEYAQEA+QDFAMcAuQCrAJ8AfABvgE0AOMAzgCpwDG/gj+TPxo+qD48PeQ9xD3QPbA9ZD1YPVQ9jD3wPdo+HD4IPrA+nD70Puw/AT9FP2g/VD9lP34/Ez95P2+/pT+ZP7C/mf/o/8w/yT/Qf+8/tz9UP2Q/Hj7sPqo+TD5wPdA9yD2UPVA9bD0gPSQ9GD0IPSg9CD1QPWA9SD2kPaw9jD3wPeI+OD4oPmA+hj7NPw8/HD9iP6P/2kA+AH8AhgEaAXwBmAI4AlgC0ANYA7gD+AQQBMAFAAVABXAFOAUIBMAE0ATwBIgEYAPYA6ADXAM0AvAClAJIAgwB9AFkATwAqAB7gC4/+D9bPxQ+9j50Pgw+Aj4MPew9nD2wPYA96D3WPhA+UD6WPrg+qD7QPyI/AD9LP1o/RT9JP1Q/Zj9sP3k/dz9+P0y/vT91P2y/rD9wP2w/SD96Ptg+8j6APpQ+dD3YPeg9sD1EPWA9JD0QPQQ9DD0gPRw9KD0QPXQ9WD28PaA98D3wPe4+Ij5SPrQ+qD7oPw4/fz9tP4rABoB6gH8AnAEUAWYBtgHkAlQC0AMwA1ADwARIBKAEyAUgBXAFYAVgBXgFIATYBJgESARIBBwDkANkAtwCZAJIAjIB8AFGASsAmQCEgGA/3L+UP0o/Pj6oPlI+HD3sPZQ9nD2APbA9fD1cPaQ96D42PjA+TD6OPvg+yD8sPwU/UD9SP0I/UD9iP0o/Qj9XP1w/Zj9iP1c/cz92P2U/Xz9iP3w/AD8cPsA+zj6EPmA+LD38PYw9qD1MPXg9AD1MPVg9ZD1kPXw9cD2IPfA9xj4+Pgw+Xj5uPnI+lD72PtY/ED9Xv6K/hv/hwBmAZACiAPYBMAFyAa4BzAJ4ArQC+AMcA6gDyARQBLAE4AUABVgFUAV4BTgE+ASIBLgEGAQsA9ADaALYAkwCTAIcAdIBcQD5AIUAZYAaf/Y/lj9YPww+3j6cPnA91D3MPcQ92D2gPVA9iD28PaA98D4kPmw+cj6uPu8/PT8UP0U/gz+KP4o/iT+qP1c/YT90P1I/bj8vPys/JD8TPyQ/JD8gPsI+3D6WPpo+aD48PfQ99D24PVA9RD1gPQw9KD0YPTw9KD08PRQ9oD2QPeg98j4IPno+Tj6CPuI++D73PzA/Uj+mP5S/yIADgGgAUACOAPwA4AEeAWgBlgHUAiACQALEAwgDVAO8A8gEUASYBNAFIAUABTAEyATwBGAEOAP8A7gDfALYAqACVgHKAaIBcAFjAPkAYMARwC5/3b+HP6o/LD7SPqo+WD5APgw9wD3UPfg9oD28PaA9/D3yPgo+jj7QPuA+8z89P0W/jD+NP6s/lj+1P3s/ez9bP0E/Qj9SP2w/Cz8QPyU/ID8XPx4/Bz8sPvI+nj6cPqQ+cj4GPhg97D2IPYQ9tD1wPWA9UD2kPbA9jD3GPiY+HD5EPrg+jj7iPsY/Lj8ZP2Y/QD+XP4R/0z/tv95AO8AfgHsAcQCkAMoBJAEsAXABqAHYAhQCcAKgAsQDWAO4A/AEMARIBPgEwAUwBNAE2ASABFAEEAQQA+QDDALMAqgCdgH4AVIBuAEsANAAhACAAHJ/wP/ov4u/kz86Poo+rD56Phg+ND3gPcQ95D3ePiQ+Aj52PkQ+9D7TPwk/bz96P0y/vj+S//E/j7+7P0u/hD+TP1M/TD91Pxw/Fz8lPxs/Fz8FPxQ/Kj7OPt4+hj6oPkY+SD44Pcg92D28PUA9uD14PUQ9gD24Pbw9nD3GPjI+HD54Plg+gj7aPuQ+yT8iPwQ/Vz98P0u/rj+V//u/5cA+ABoAeYBfALgAqQDUAQgBaAFgAZQB3AIYAmwCvALwA0gD0AQYBGgEqAToBNgE8ASgBJgEFAPcA9wDuAMoAqQCJAIOAcQBgAFYARMAwgCcAEEAfP/tP6Q/dT9jPyY+9j5APnA+BD4KPjg97D3YPfw99j4aPmA+hD7BPy0/KT9BP7K/tz+zP4f/xn/yP7g/eT9nP0k/Qj9AP28/ED8EPwk/Gj8VPxk/PD7BPxw+zj7wPoQ+qj54PjQ+OD3QPfg9nD2cPZw9vD2EPcg98D3OPgQ+aD5APrA+hj7YPuw+xT8rPyk/ND8BP3I/dT96P1Y/vL+sP/J/08AzgBOAawBEAIsA7ADMASABHAFOAYoBxAIQAmwCtAL0AzADsAPgBAAEmASABNAEoARYBCgDxAPQA4ADXALAAlQCMgH6AZoBVAEkAPAAsoBxwCtAH7/Vv60/Yj9OPzQ+tD5KPkY+RD4KPjg96D3KPh4+Nj5KPoA+8D78PyU/bz9eP4b/+r+BP8q/xf/PP6s/cD9kP1o/fz8vPzM/GT8GPxE/JD8KPwI/Kj74Ps4+2j6sPlI+dj4YPjA9yD3kPYw9iD2YPbA9qD2APeg90D40Pgo+SD6YPoQ+0D76Pss/Pj7gPzI/Dj9ZP2c/cT9Vv6o/kv/HQCCAO4AQgHKATQCsAI0A6ADMASIBPAEAAZwBkgHYAjQCUALQAyADdAOgBCgEeASoBMAEwASIBHgEMAQIA8ADbAMoApwCVAIiAdoBvAEiAQwBHgDcAJ6ATYBqgB7/9z+HP64/BD7WPpY+jD5ePg4+LD46PjQ+MD5qPqA+zz8NP1i/pb+vv4I/3X/eP9C/xj/nP6U/fz83PzU/Gz86Pv4+zz8+PvQ+zD8UPxM/Dj8cPw4/HD7kPpA+vj5QPlo+AD4cPcA95D20Pbw9jD3gPdY+PD4UPnw+Zj6OPvI+xz8VPxk/ID8gPyw/Oz8DP0Y/Vz9cP0S/jz+5v4O/9b/ZQB/AEQBMgHwAfQBeAIcA3AD9AMIBLAEaAWIBuAHIAkwCjALEA0AD0AQIBHAEoAToBLAESARoBCgDxAOkAwADOAJUAh4BygHOAYIBWgEgAPEA5QC1AE4AYgAMAAI/yr+vPyQ+9D6CPoY+dj42Pio+HD4MPlY+vj60Pug/PD9iv7A/tL+ZP+s//7+4P6Y/hb+JP2Q/Dz8LPzQ+6j7uPuw+0j7uPvo+0D80Pvw+6j7MPuo+sj5UPl4+MD3IPfQ9jD28PWQ9cD1QPag9mD34PeA+MD4APo4+vj6+Po4+5j7GPtw+yj7oPt4+0D7iPsM/Gj8wPz4/ND9kP4w/2v/+P9iAAwBIgE6AbABOAI4AqwC2AIYBJgEIAVoBgAI8AlACsALcA5AEMARoBIgEwATwBKgEeAQoBDwDpANEAyQCkAJEAgYB0AGUAWYBAgEYAPMAiwC5AEiAVUAoP+U/mD92PsI+3D6wPmw+KD4gPh4+ED5+PkI++D72Py0/eD+Z//C/0sAYAA9ANH/of+q/uj9HP2w/Iz8OPyw+7D7qPug+wD8IPxg/CD8CPwM/Mj7KPtQ+uD56Pgo+JD3QPew9hD2wPVA9uD2MPew92D4IPnY+ZD6aPsQ/Pj7DPxo/JT8MPwA/Az8MPwQ/DD8ePyQ/OD8QP0O/sD+9v6J/xAAdgCIAPgAQAFyAUoBfAEsAgACTAKoAlAEEAVYBnAHEAkQCrALMA6gECASQBJAE8ATQBMAEuARABGAD/ANgAzQC5AJUAjAB3AHwAZABegEgATkA7wCcAIwAuwATv+E/sD9CPyY+gD6kPno+Jj46Phw+cD5UPrY+xz9Bv7a/rz/SgCAAGsAjgCdAOr/a//E/hj+VP3M/Mj8qPx8/Hj8sPyc/Fz8QPx8/Hz8DPyg+zD7oPqg+eD4YPjw90D3wPaA9nD2UPaA9vD2oPcA+Ej4CPlo+Qj6UPrA+hD7OPtA+zj7KPso+xD7aPuI+9D7+Ps8/Ij84Px8/R7+hv7A/tr+9v6Q/6//tv/c/28A3wA8AAoBqAEgAuwCSATIBfgGQAeACIAKQAzgDRAP4BCAEeARIBIgEqARYBDAD6AOkA0ADNAKEArgCDAIeAf4BhAGWAXABAAEPAMgAloBVABD/0T+EP3g+7D6uPmw+Vj5aPlY+bD5kPrw+uD7zPzo/aL+tP7m/jj/Nv/y/or+TP78/YD9+PyI/DT8XPx8/Jz8xPyc/ND8cPxc/PD70Ptw+8j6UPqo+fj4OPiA9yD3cPdg9xD3EPeA97D3APhY+AD5oPmQ+dj5OPqA+lj6ePqQ+ij70PqY+hj7wPoI+1D7PPxE/GT8iPxY/Zj91P3c/ar+pv6A/gL/AP+J/0D/kf8yANEA0wAaAe4BEAP4AwAFAAZwB5AIgAkgC8ANwA4gEKAQwBFgEsARIBFgELAPEA5wDVAMoAvwCcAIgAjQB+gGOAbABWAFKASwA+QCUALpAPf/Mv8C/pT8MPvY+oD6WPog+uD60PqA+zj8gP1w/sz+Sv9IADQA0v+2/5n/g/9s/kT+8P3M/az8TPzQ/CD9JP0Q/fT9yP00/Yz8rPx8/Fj7aPog+oD5UPiQ9xD3EPfQ9pD2gPew9zD3gPd4+Ej5EPko+Zj56Plo+UD5mPkA+uD50Pl4+tD64Prg+rD7IPyQ/AD9SP2s/bD9Gv46/kL+JP5k/lr+hv5U/tr+Pf91/xIA+ACgAeABBAO8A/AEYAU4BpAH4AigCcAKYAzADeAOQBAAEoASwBFAEWAQABDwDhAOAA2wC5AKwAiwCIgH4AZYBuAFKAVIBCgE+AIsAiQBsQDR/27+LP0s/Nj76PrA+rj6+PpY+7j7cPyU/Sz+oP4b/3v/kP+b/1z/xv7G/rz+4P1s/TD9DP3U/FT8pPwM/Wz9PP2Y/Gz8RPyQ+xD7WPoo+kj5oPjw90D3YPcQ9zD3gPfg9+D34PcY+FD44PhI+UD5APlA+Uj5GPmY+XD5OPoQ+0D7EPtw+yz8dPy8/OT8bP2Q/Rz9RP1k/eD9jP1s/dD9Rv4o/hb+uP70/lb/KQDoAJoBGAI0AgwDfAPwAyAFIAYIBzAIkAlAC2AMsA2wD4ARQBLgEaARABHAD7AOAA6wDWAM4AowCnAJkAgQCFgHAAeIBugFMAVYBDwDZAJOARwAW/9o/kz9+PuI+3D7QPsg+1j7mPwQ/Xj9PP7W/pT/Lv+O/0D/PP9S/kb+HP4a/tT9kP1Y/Uj9dP0w/bj9ZP1k/Zz8MPzA+0D7aPrg+Uj5cPjA91D3YPcQ9+D2cPcY+Bj44Pfw9xD40PfA9xD4SPgo+PD3OPiI+ND4gPg4+UD6sPoQ+2D72Puo+8D7jPyQ/Hj8aPxM/GD8APwg/Jj8HP3o/Cz9rP3k/cD9Ov5h/wcAsQDaAIwB5gF4ApwDsASQBXgGwAfQCKAKMAzwDWAPoBDAEWASIBIAEcAQIBDgDqAN0AxQDJALYAqgCUAJIAgwBzAGKAbgBTgE/ALEAeAAWP+E/sj9MP1A/Jj7yPuQ+6j7OPu4+3z89Pxg/bz9LP4e/ir+RP5U/jz+RP4s/lb+RP4c/gr+uP10/bT9yP1U/WD8iPxI/Hj7mPqA+pj6wPlI+aD4wPhI+ND38PdQ+KD4gPjg+Hj4IPgA+AD5EPkY+Zj5IPoo+sD5OPro+rD7gPuI+2j8sPxI/ND7aPww/cT88Pxk/BD9CP2o/Oj8LP0O/tz9PP7E/aT+lP6U/tj+ov+ZAAYBMAFUAYQCVANQBDAF8AWQB2AIgAlQC2ANYA8gEIARABIAEyASYBHAEKAQkA/wDTANAA1QDAALoAowCoAJQAhAB5gGkAX0AzQCxgFTAL7+mP0k/fD7CPtw+6D7WPuw+mj6SPs4+3D7CPwI/fT8jPzA/CD9dP0k/YT9BP5Q/rT9lP1Y/aD95P2I/Wz9QP0U/VD8cPv4+hj7APsw+vj50Pmw+cj4EPjg+FD5QPkY+bj5sPkw+YD4cPhY+cj5ePnI+Wj6EPpI+rj6WPvg+2j8kPx4/Ez82Psw/GT8qPz4/AT98PzM/Kj8MP0Y/TD9PP34/QL+RP1o/Yz9Ov7I/cb+nf9CAPf/3gBMAtwCiAMQBDAG8AbIByAJQAvgDMANABCAEQASABFgEOAQ4A8AD5AO4A6gDYAMEAywCzALUAkgCbAIoAd4BSgEfANEAscAZv8T/6j9ePzY+9j7LPwo+1D7+Pqw+qj64Pq4++D7EPwQ/Nj8+Pz0/JT8jP3g/TL+Sv56/gz+4P1c/eD9Av7I/Yj9uPyM/CD8aPsY+wj7kPqI+ij6mPnY+DD42Pjo+BD5EPmo+Aj5gPgY+GD46PgA+Qj5SPng+cD5oPnQ+ej6iPug+7j7APzg+5D7RPy4/Dj99Pxc/bD9LP3Q/CD9+P0Q/qD9IP5k/rz9OP3E/cb+DP9g/8j/VAEgAeoBHAIwA7gDaATwBVgGAAiwCNAKYAwgDuAP4BDgEAAQwA8AD7AOMA5ADjAOIA0gDZAMMAxwCiAK8AnQCNAGcAXYBGADvgF/AFEADv9s/aD85Pyw/Gj7aPrg+kD6iPk4+Zj5WPpA+tj6qPv4+7j7oPt8/Dj9QP2Y/cD9GP2w/Az9iP00/UT9nP3Q/UT9TPxU/Cj8oPv4+gj7IPvw+Tj5MPmo+bD5aPmw+ej5cPko+dj40Phg+Jj4EPlQ+bD5wPkY+rj60PpQ++j7MPww/GT8VPyk/LT8JP2w/Rz+Vv5A/jr+KP5E/nL+/P5N/0P/6v62/ur+5P51/3YAGAEAApgBKAK0AkADyANIBJgF+AagB3AIUApADOAN4A4gEEARABGAECAQIBCgD/AOIA+gD8AP0A4QDjANAAxwC1AKwAlACEgGEAXIA9wCTgHwAFcAVv9K/pT9tPyo+xD7mPow+pj5iPlQ+Wj5KPpg+mj6iPqI+nj7iPuY+6D7WPyc/DD8ZPzY/Jj98Py8/Fj9xP00/YD8fPzQ/Hz8KPvI+hj7sPoI+qj5UPpA+nD5CPmo+WD5CPkA+Dj4mPgY+OD3WPjg+AD5uPig+Sj6CPpY+uD6cPvg+gj7kPvQ+/D7ZPwo/RT+UP1g/Rz+7P5I/iz+Bv8W/5j+2P1D/wEA9f8tAEwB9gGsARgBoAGQAjAC3AKYBPgF4AZwB1AJ0AqwC2AMAA6wDlAO4A3gDUAOsA3ADdAOgA8AD/ANIA6wDVAMMAvwCoAKIAnYB0gHOAY4BAAD9AK0AuUA3f/J/4z+8PvI+iD7qPvg+Tj5mPrA+jj5APlY+hj76Pkw+ej5APu4+Sj5+PpQ/Kj7CPv4+6D8PPyI+zj84PxU/HD70PsA/Lj7OPtg+yz8iPsQ+xj7yPpo+tD5UPrY+Wj5KPlo+Uj5mPgQ+Uj5ePkg+dD5yPmY+XD5CPqw+nD6kPrY+qj7ePug+6D8EP1E/XD9ZP50/ir+ev7U/tj+9v4G/7D/1//F/+MAsAHmAY4BrAH2Ae4BggFsAtgDkATYBBAGwAegCCAJYAkAC0ALUAvwCpALQAwADEAMkAywDSAN8AygDNAM8AvwCtAKIApACvAIMAgYB6AG6AVABRgErANwAqIBtf9+/sD9EP08/JD7uPtw+2D7ePpY+sj6iPqw+TD5WPkg+ZD4cPhI+WD6oPqo+gj7WPsY+6j6EPto+0D7UPt4+7D7wPsQ/KT8FP0g/QT91Pw8/Jj7yPuo+3D7QPuQ++j7aPs4+zj7UPsI+4j6qPrA+lD6uPko+mj60PrI+gD7wPug+5D7WPvI+0j8QPxs/KD8HP38/BT9eP0y/jL+Cv6I/v7+VP9G/+n/lQDHAIwA/QBwAfgBrgFIAoAD+AOIBNAESAboBkAHWAegCNAIsAjQCGAJcAoACmAKcAsQDGALwAoQC+AKgApQCpAKgAqACRAJ8AhACKgHGAf4BjAG+ARQBPwD3AK+ASYBVAE9AEL/+v7u/pT+iP1Q/Yz9+Pxs/BD8GPzo+2D7gPuw+8D7kPuo+/j70PuI+6D78Pu4+6j7gPvY+9D7uPsE/DT8YPwo/Ez8RPwI/ND72Pvw++D70PvI+/D7qPug+9D7yPvI+3j7mPuY+3j7cPuI+7D76PsE/DT8YPxw/Jj8qPzc/BT9aP10/cz99P1C/lb+Yv7A/gD/Qf9U/3n/rP8OABQAVACgANYADAEUAWwBvAEkAlwClAIMA3ADsAP8A1gEqATgBCgFkAXABegFKAZwBpgGuAbYBjgHgAeIB6AHwAfIB5AHcAdwB3AHEAewBsgGwAZgBggGyAXoBZgF6ARwBEgEzAMoA6ACiAJAArABHgHrAIYAAQBB/xP/1v5a/qj9ZP1A/dz8YPw8/GT8HPy4+3j7ePtY+wj74Prw+tj62PqA+gD7qPqo+oj6wPrQ+qj60PrY+vD6uPoQ+zj7MPtA+2D7kPu4+6j7wPsc/OD74Psg/Ej8cPx0/Kj8AP0I/TD9TP2I/cT9nP3s/TT+aP5y/pb+3v4c/yf/Ov+q/8z/7f/j/yoAdgBrAIQAlAD4ANoAvQD1AD4BiAGMAbQBrgHUAegBFAIgAhQCWAKYArACyAL4AiQDTANMA1wDnAPAA7gD3AMgBBgEIARIBGgEkASIBIAEoATYBLgEoASoBKgEmAR4BHgEkAR4BFAEGAQIBNwDsANgAzwDDAPcAoQCRAIYAtYBggE4ARoB2gB9ABgA4/+t/0n/8v6q/nb+GP7Q/aD9eP0c/eD8xPyw/HD8QPwk/PD74Puw+6D7kPtw+2j7cPto+1D7WPsw+yj7IPs4+zD7OPtI+1j7iPuA+7D7uPv4+/j7GPw0/GD8pPy4/OT8CP1M/XT9mP20/fz9HP4+/nT+ov7k/gb/N/9m/6z/xv8OAAcAYwBzAJsAmgDCAAgBHgE6AWABnAHaAeYBHAIsAmwCkAKkAtgC9AIUAxADRAN0A5ADtAPcA/wDEAQQBCAEQARABEAESARoBFAESARIBFAEOAQIBAgE8APQA5wDgANgAzQD+ALcArACdAI0AvoBugF4ATYBDAHLAHkAJADy/6f/YP8f/9r+qv5o/ib+/P3A/YT9YP00/QT90Pyo/JD8cPxU/Cz8HPwQ/Pj7APzw+/D78Pv4++j7+Pvg+wT8APwE/CD8MPxw/Hz8pPzE/BT9CP1E/XD9pP3I/dT9Kv5c/nb+sv7u/iL/Hf9R/4z/xv/n//n/NABfAHoAqwDMAP8AIgFKAW4BjAGqAdwB9gEEAhQCRAJcAmACgAKQArQCtAKsAswCzALoAuAC5ALwAugC7ALcAvQC+AIAAwQD9ALwAtwC5ALMAsgCoAKMAoQCaAJUAiwCKAIQAv4B1AGmAZQBbgFMASgBCAHbALIAlABoAGEALAAUANv/yv+v/3v/a/9E/yD/Dv/q/tz+uP6m/or+cP5O/j7+QP4k/hb++P0A/uT9zP3I/dT93P3A/dD9wP3s/dz93P3s/eT9+P3s/Qj+Dv4g/jT+Ov5W/nj+hP6g/qL+xP7g/gP/Gf9B/2P/gf+k/7H/4P/s/x8ASwBiAIgApADXAOYAAAEcATYBTAE+AV4BbAFyAXIBegGgAagBsgGoAbwBwAG8AbQBqgG2Aa4BmgGSAYoBigFmAVgBXgFeASQBGgEUARgB3wDJANAA2ACkAIYAegCAAE0AIwAoAP//BACk/+P/lv+R/0//Zv9Z/y3/Iv8P/yb/4v7c/uD+2v7A/rT+vP7E/rb+oP6u/pz+iv6W/pj+kP6U/pj+sv62/rr+1v7Q/t7+0P72/iD/Iv8S/yj/Tv9a/2L/Z/+W/6n/sv+z/8/////3/xIAEQA8ADIAKAA+AF0AbwBpAIMAegCVAI4ApgCqAKMApwDPAM8AygDKANYA0wDRANEA4ADyANIA2gDqANgAwwDFANUA1ADDAK0AvwDuAM0AqgC1ALoAtwCQAJUAoQCkAI0AbQCNAHEAcwBRAGsAWgBKADMAQABDACYADgATACMAJQAEAO3/+////+j/yP/O/9D/v/+l/5L/qP9+/3D/X/+I/3n/Zf9x/23/e/9U/1f/W/9h/0j/Vf9e/1j/ZP9G/1X/Rf9P/0//Sf9S/07/YP9V/2n/Vv91/2j/b/9w/4P/iv+P/4P/if+k/6v/uP+h/9H/y//S/9r/4//y//T/9//6/x4AAwAtAA4AOwA1AEQAHwAuAEAAKQAeACIAIwA2AB4AMAAWADIAJQAxADoAKgAnAP3/FgD6/xQA+v8JAPv/CQDx//j/AAAAAAEA9/8OAAEACAD9/wUAEQAJAAgABQASAAUA+v/7/wcABgABAPb/GwAGABEA9f8QABoAHgAaABIAEgAeAPj/EAD1/wsA8v8DAPH/CQDt/+v/+v/w//f/3//u/////P8BAP3/CQAFAAAAAAANAAYADgApAAgAJAAAADQAHQAJAAIAAwA9APv/FwD0/2sA+f8aAPn/NABFAOL/MwAkAEcA7P9HAEwAKwASAOv/TwA5AA8A4f8tABQADgDJ/xcAHQAkAOH/7f8vAP3/+f/x/wQA+//h/+n//v8IANX/6//t/+//2f/n/+r/7//w/+3/5f/e/9j/zP/m//H/7P/x/+D/AAD6/woADgD+/zEAAAA2APz/PQAUAEgATQBEAGEAQwBmAFsAngBJAGAAcQBmAJAASwCSAFwAmwBdAGAAhQByAIcAWwCIAGAAkgB4AHYAfQBoAFsAfQBcAGwAVABcAGQAMgBhABYAUwAcAEsAHAArABUAIQBVABUAMgD3/zEABQAMAPP/9f/y//b/5P8JAOr/y/+9/+7/v/+0/8P/wf/5/5j/3/+X/9L/uf+1/8r/uf/l/4L/zP/N/+f/0v+a//L/8v/9/4H/wf/h/8X/1f+N/9T/uP/k/6L/qf/C/+L/zP+0/5j/IACQ/7b/jf9MAHn/gf8AAPD/1/8p//r/EADz/1r/4P9ZAML/hv8kAOz/cgAz/5AA6v9tAIv/SABkAPT/HwAFAL0A8v9IADsAjgD7/ygATwB3ABsANACkAHwABwAjAJ4AIwBeAAYAQgAuAOf/bABMAIIA0v8KACIAYgAIAPP/8/+rAN3/y//0/1cAkQBB/8r/FAG8/8f/Ef88AbYAwf/W/kQAsABK/0kAVv91AFf/VwCc/7T/Tv9uAHoATv/q/sEAZABf/wb/+P9MAVz+zv+3/1oBzP70/mAAKgAIAE7+tgAkAHb/F/8eAH0Avf8d/83/UwCn/7//ef8FALH/OAAH/4IAbf9IAOf/TP+eAMD/aAAt/3sA1P9nAAgAtP89AEgA//8WAKT/gAByAPP/QgAXAMoAqP/2/w0A1QAXAMv/pgCPAIoA4f9qAOL/1AC2/6AARwDA/zMA6QA3ALn/LwCUAHkAz/8xAJwAGAALADsArABZ/4b/LwAcATD/Yv+0ACAA6f/W/tAACQCn/zr/3wAaAK//dP+FACQAdv8/AEX/kgAY/1ABOv5EAJf/4ABv/6f/1f+LAK7/F/84AKYABwC8/l4Auv/VAMb/d//z/ykA0/9X/+z/4f+DAFD/q/96/0QAJQDA/tYAVP82AWr++/+W/zQBvP5u/zIBdf9FAGL+KAG9/9b/Mf/uALcA1v4eAJgAegDW/mUAygAmASH/SAA/AHYBLP4GAdv/FgEo/30A/wCqAB//rv9MAqT/HwAS/tQC7wCc/2r/WAHRAMj+CQDvAPEAgP7K/6YBhgCT/6j+uALI//H/nP5QAcoAKgAmAD3/WAJA/kAB6P+J/xgBB//uAcj+7AHM/hIB5P+jANEASP+0AIv/CAJq/pgAIf+wAlz+QAB2/+0ANgHI/WIB5f/vACj+sQAiARQAo/98/hwCNf/+APL+7AB/AD3/tAA5AJQAW/+SASj+pwDK/ggBMADO/0cAev8jAPD+Xf/aAOn/bv+D/6X/7f8eAMr+AQAgAJX/TgAC/20AT/9rAOj93/+DAO//tv5K/wgBtv+z/xD+KAHrAHD96f8sACgChP0AAHEA+gBO/hb+CAJ8AFj+av6mAU4B9P36/kIA+gFM/4T9ZAC8AFcA2v72/9//BAFr/94Afv8h/+P/+gAeARr+7f/+/7QCcP4J/5MAGAHe/uD+wAHYAKj+pP1kAmYBvP4M/ZYBoALC/oT9BAAEAo4AvP2B//wBiP7s/3v/bAFI/SIBbf/AAoj98v54APgA8/94/4MAQv95AMv/vwCs/Z8ApQDEArD9YP+2/5IBqP6K/0wBEgDK/4//jgAO/jEAPgFHAJD+fP40AhgBWv/A/FgCdP8E/i3/2/94Aqz+5gCT/6kAcP5sAH4BtP1rAJEAxACRAFb+KgElABoAKv8K/wMAd//IAVr/5ACU/jcAGP8FAJ4A+wA1/yj/XgBmAGb/L/9RAC8ANwDY/WACWABP/yQAFwCVABD/BQDSAOIBQ/88/nAB3f/X/ysAVgHeAPr+6gBIAFUAFAHy/nQD3v5eAZT9lAJp/0YAXgBt/xwC8v7A/+//1AEq/vP/kgAEArD/3v/q/6IBhgDY/lAB0ACC/zwAQP/1/+sAeQAGAQ//Sv7EAKEAmv4fAJYArQBcAF7/N//kAKf/2QBjAID+FgDS/sj//P0uAW7+bwC8/eX//f/k/VT/UP6yAeD93gAW/goAsADX/wcAdP6NAIT/dQDw/v8A0wBK/lgA5gGmAJX/0P2AAlQBxv5R/0QBVAEb/2T/YgFqAWL+kP8QAub/3Pxh/18AywDM/YD+jAKWALD+cP48AhoAUf9Y/iwBTAGH/1//CgCuAcP/lACw/ogBbwBU/rj+AwCQAtr+mf8e/ygD+v8i/lgBJP8AAQ7+JAF4AWUATAAaAUYBpv7I/uT/ugF6AXP/gv/0/20ADgAeAMP/uwCi/kz/bP7G/4b+pv+I/9T//v6g/lkAKv6m/4D9lv/m/kj/agGmACsAxP2PAKsATwD4/Yj+eABKAVAA2P/YAWQC/gBt/3T/k/90APf/TgHfAL0A+v+oAdoAYQDo/jMAof8rADD/DQA+ABgBmgGI/x0Abv42ABv/H/8a//0AwADsANQAVACXAJ3/nADPAP0AagC7AIYBcwBRALAA6AG+AZUAXwAY/4f/cf+bAN8AQQASACwAiwAs/6n/3v+WAJ//Hv8g/0X/j/86AAQBSQA6/73/AQBMAGb/Ef88ABABOQB7/6v/nADwAIgAIwBDAO7/3v/A/zIAnQCIALkAaQD3/83/xf8GAKL/jf9t//v/gABQAJQA5/9CAPL/uP/I/oH/2/8nAAgAXgDc//f/TQBdAB8Aaf+r/+b/fQBO/9r/JgB1ANX/FgAiAOP/z/90/87/dv8e/4L/eABlAO3/6//T/4T/NP9N/5/////J/z8APACK/5T/UwBEANj/yv/X/8cAEQAmAGsAXAAmAFcA0wDoAEMAHQCZAC0A5v8YAHMA1QDoAB0ADgF2ACEA2P98AM7/hP8qAJYAsADi/wwARgBkAC3/bP8lAOj/QgDR/wwAJAD4//H/CwAhAJT/PgAGADwAaQAmABwApf/U/73/ff9M/6j/mf+j/8f/ov8TAFH/z/85/0X/hP6o/2f/Mf8n/87/NwBG/zn/Vf9DAGb/4P7v/0EAzv9t/xQAJQAzAOn/w/91AOD/cf8AAJQAagBEAF8AaQA1AIL/2P/a/xsA+/9AAAEA4P/X/93/awAoAOf/0f/V/+L/BQD3/yQAaABjAEoA4/+T//j/3v/m/+H/+/+7/7b/0/+V/7L/AP+f/+7/2P/8/jT/ef85/xH/N/8LALP/tf8+/4z/f/8Y/13/nv+x/27/gf/p/0IACgCW/8//tv+R/7X/n//b/wkADgABAMX/CAAaAAgAyf8wAHoAoQBtAC8AzABmAFgAtwAOAfsAkQC1AAIBMgG9AJAA5wAOAc0A2AAgAYwBOAEmAX4B4AGSAd4ByAFgAvABFAK+AfIBngFkAdgB4gGkAS4BLgF+ASIBawCeACcAgv/u/m7+1v5s/hD+QP78/cT9RP38/KT8XPxo/Mz8sPwA/ej89PzU/Lz8jPy8/MT8+Pws/Nj76PsY/Hj7ePvY+/j7OPsA+0j7UPuY+4j7rPw4/SD9WP1c/kb/KQAcAXwC7AIEA8QCTAO0A8gD4AQgBogGMAawBoAHYAiwCEAKMAvAClAJgAiACCAIUAjwCXALIAswCmAJgAjQBugFIAa4BjgFqARgBHAESAPQAuwCtAIIAmQAXP90/Qz8KPvA+3j7GPtI+jD5MPgA9wD3cPfI+Nj5WPmo+GD3UPcw9qD1UPXg9aD0oPOw8tDywPJg8SDwIO8A7wDt4OzA7QDxoPAA8NDwMPGQ8SDwkPNo+SL+Af9QAegDrAKYAtgEcAnAC2AN8A+AEQAR4BFgEwAVoBTAE+AToBHADjAPYBJgFIASIBOAE6AQQAwwCQAIsAZ4BOADeASABCgEcAToBBAEXAIEAZD/BP9I/3AArAHMA7gESAYgBXwDfAJuASkAUAB3AJYBMgH1ADEAaP1o+5D44Pcw9sD0QPRQ8/DzIPQw9JD0wPMw86DxEPDA7sDtwOwA7gDwEPKw9GD1gPUQ9CDyYPAg72DvUPJw9oD3OPjA+RT80PwE/XD/OgFqAXoB/AJwBwALkA2AEGASwBGwDuANkA2gDoAQgBLAEiASwBAAD5ANsAyQDEALMAswCgAJkAegB3AHwAYoBpAFMAQIApb/6AAoA7QDnAM4BYAHaAbIBOQDAAY4BdgEeAYwB5gGKAT+AesApv/k/dD9nf88AIwA6PxI+9D4SPig9kD1sPXw9hD2wPTw9OD38Peg97D5WPmQ98D0EPWg8xDyIPMg9/D5gPt8/Fj80PfQ8cDucPAg8EDucPGw9MD1cPMg9bD4WPoQ+oD7cP5U/00AuAKgCOALIA4wD+AQ8A+gDYANAA6AEIAQYBCgD3AN4AvwCvAKIAywC1ALQAkACLAFqAO8AsACOAMMAtIAwAAMAswCoANYBXAFKARIA1QDAAXgBDgGoAjACpAIiAZwBGQCpADS/8L+Z/+C/7r/Z/9c/uD8WPuQ+RD3APVw9AD0oPQw9SD3YPdA+PD30PZQ9wD2APZw9ED0UPSg8mDyMPXY+cj8kPwQ+8D3cPIA7cDqgOxg78DxIPRg9BD1wPUA9cD3KPuw/Tz9xv4IAqgFUAgQClAPoBLAEXAP4A5ADgANUA3QD/APsA1ADDAMQAugCNAIIArACKAGMAZYBvQDdAIYBCgGgASsAmwD0ATEA8QCyAW4BygHwAUYB+gHoAagBoAIAArwCOgHOAXQBAQDvgHB/xv/ogAHAGP/cP2A/XD8sPrw99D3YPYA9pD1QPfg9yj4SPgI+JD4kPhw+Dj48Phg+MD2QPTA8jD0QPdY+sz8xPw4+kD1IPFg7kDsQO2A76DxwPFw8yD1EPYA+QT8pf+5AHMAxgG4BNgHIAqwDSARwBKgEoAQIBDADnANsAwwDdANMAzwCdAIAAkgCHAHmAeQB8gGMAO0A8gD0AL4ArgE8AYYBiAFYAUwBggFwARABuAH4AdoBxAJMArACQAJwAhgCDAGIASYApgBUACpACYADAA5/6D9WPxg+pj5EPlI+BD2oPaw9qD3QPZQ9sD38PfA9xD2IPdQ+Ej5oPnY+CD3oPPQ8fDx4PRY+Jj72PuI+NDzwO9A68DnQOhg7CDwMPHA8sD2mPmg+qD7k/+sAswC1ANAB6AKEAyADqARwBMgEwASoBCgDVALEAvwCqAKEAoACxAKIAjABggHCAeIBNwDUAT4BHgEAAWgBtAH0AdgB3gHkAYABkgF2AUAByAIMAmgCQAKsAmACNAGCAVYBFQDtAIAAlQBUABn/77+eP3E/BD7QPpY+Vj5iPhw98D28Pdo+BD3UPYQ94D2cPUg9sD1QPdA+Aj5sPqA+GD1APGg75DwMPNQ93j6SPtw+BD1oO/A6aDnwOdA6qDt8PBw9JD2UPrI/GP/qACAA7gFEAa4BkAJgA1QDyARABQgF+AT8A1gC1AK0AiABpAIQAuACjAIMAaABcgEuAK0AjADrAOcA/ADaAV4BsgHgAkgCiAJsAhwB7gGkAWoBrAJ0AtwCzALUAsQCcgF8AMwBCAEjAJCAZIBogC+/gz+Vv64/RD8aPpA+pj5YPgY+KD4WPlo+Xj4oPfA9+D2cPaQ9yD4sPnA+Bj7KPvQ+RD1EPAg8MDxsPTQ93z80PvY+CDyAO3g56Dk4OQA6aDtUPHw9ND4VPyY/e7+rgGYBKAEyAUQCZAMAA4QD8ASoBaAFMAQkA0QCzAHmAQgBhAJAAlIB6gG4ASwAkQBhALYA/QD2ASoBagFWAVAB6AJkAqQCiAKwArwCAgGSAaQCeAK4AqgC9ALkAmgBXADwAP4A8ACaAJcAoABDP+g/Wj9jP0g/Rj8QPtg+uD5mPnA+SD6gPsA+yj6qPg4+ID3APcQ9wD5wPmw+aD5mPpQ+kD0UPAg7wDyYPPg9Rj7KPw4+BDyAOzA52DjIOPg5uDsYPBA9Rj6XPyo/RMAxAKwAyAFQAfQCtAL0AxAEMAT4BRAEwARQA7QCVgFtAMIBVAGMAcoBzgGIAUQBGADmAPwBLgFWAZYBigGcAewCZAK8AqQDDAN0ArQCJAIoAkQCcAIcApQCxAKmAegBvAFKAR8AlAC9gFxAEH/cv9a/1L+Fv5+/qz9PPwo+3j78PqI+sj6kPtQ+5j56PgQ+OD3YPdI+Hj58Pmw+UD6WPmQ9sDyYPEA8KDvEPKg9oj7gPpY+WD04Osg5EDhoOEA5WDpoPBg9xj6OPrI/cAA1QAcAdAEoAgwCUAKAA1AEaASgBPAE4ASQA8wCsAFUAR4A4wD6ASABjgHqAYQBXgEzAMABPAE6ARoBaAGQAhgCQAKcAtgDAAMUApQCeAJkAiYBtgHsAnwCeAIwAhwCMgFuAOUArwBdwCR/9z/9/9c/mj9fP2s/cD8IPuA+9j62Pm4+XD6OPto+0j7WPrI+Vj4UPjQ92D3UPgY+sj6sPkQ+DD3YPRg8MDuQPBg8/D1aPms/Bj4APDg52DkwOJA4QDoIO+w9KD3mPo8/Tr+e//WARAFIAfgCFAKIAzQDeAQIBNAE4ASoBHgDWAI9AMgA6AC9gEkAyAGOAeYBaAEsAUIBngEIANgBAAGwAY4B1AKQA2ADBAMoAtgC8AIwAbIB0AIcAgwCFAJcAkYBwgFiATIAzoBaABqAXwB+v7A/UD+Uv5E/Rj9lv4Y/5j9ePxE/KD7yPoQ+0j76PpI+uD6yPqQ+OD3kPlA+iD4OPjA+ij5oPUg8hDzcPJQ8PDxgPgU/ID5kPSg74DooONA4gDmQOug8ND0KPjg+Wz8nv4CARgFoAigDOALkAtgC7ANUA+AEWAUIBSAESANEAlABd4BagH0AhgEnANQBGgF+AU4BbAF8AYABvQDkAMoBiAJwAmgCiANAA6ADFAKwAggCKAH6AaIB3AJwAogCdgGIASIAtMAnP5M/mT/bv8S/jz8xPzk/ET98Pzs/UP/jP7s/Jj7CPxw+9j5YPpw+wD84PuY+3z8gPvI+Sj4wPdw93D2QPYg9oD0gPSQ83DyEPMQ9aD2YPVQ84DywO3g52DmgOpg7gDuUPEw9kD5sPlw/KQDUAiwCnAMUA9wDUAJcAeQCvAO4BBAE6ATIBHAC8AGoAMEAoUAJwDaAbwCOARIBXgHUAmQCOAGYAXIBJAEkAQQB/AJ0AwADpANkAyAC8AIgAVoBZgGUAjQCMAI0AcwBr4B9P20/NT9+P3M/dz9Kv78/Vj8kPtY/S7/Q/8w/qT+rv4k/XD7wPsE/bT8cPwg/Pj7qPo4+rj5cPmI+PD3gPew9UD1EPUg9QD0APTQ9OD0sPOA9OD0MPMA7wDuIO5g7MDqIO0w8PDw8PAg93z+nAFoBJAK4A/AD/ALUAgQCAAH4AeQDeATgBYgFGARUA0gB6QBPQBPAM8AsAFkAzAHIAdwCIAIMAggB3AE1AMwA1gFMAegCWAMMA/ADrAMoAr4B9AG+ARoBdAHQAnQCIAGiAOAAPz80PoI+jD7nP0p/wX/GP/W/ur+PP08/CT96P2k/Aj88Pxe/hz+TP2Q/YT8APuQ+ND3sPfA+Bj5GPlQ+Yj4cPYg9PDy4POw8iDyMPNw9ZD1YPTg8oDzwPFg7WDrgO0g7WDq4OuQ8HD08PVA+wAEsAqQDHANAA/QDBgGQAJIBWAKIBBgFcAZwBeAEZAJ3AIFANj9Lf92AewD+AUACDAKsAlQCAAIiAeABQAD4AJABtAIEAxwD2ARYBHwDaAL4AeQBJgDSAVQCCAJUAnwCJgFMgBg/Jj7+Pqw+uj8QwAEArsAS/+S/+L+lPzA+oD7bPy4/Nz9mP+BAJf/3P3I+5j5kPcQ9gD2MPfg+OD5YPkQ+ED3YPUw85DxoPFw8gDzoPPg9GD1UPTA8vDxAPHA7QDr4OpA7IDsIOwg8AD3ePwKAEAHMA+wD1ALkAkwCEAFqARQCaAU4BsgGkAXgBEgC6ACAP+PABQCXANABUAIMAiIB0AHmAe4BygG4AOYAowC0AWwCKAN4BBgEgAR0A1wCzgHMATAAqgGYAowCvAIcAhgBr0ATPwI+2D8XPzU/YsAGALSASEAC/80/tD7YPoY+jj7aP38/pUAGgHaALr+FPzI+OD2APYQ9wj4EPmY+kj7yPnA96D2APXQ8jDxQPGA8uDzgPNg9ND0sPTQ8pDwgO8g7qDroOpA7IDtYO4g8bD3j/9IBHAIYA9AEXALGAUAAyAHMAkgEGAXYByAGDAOYAmQBUgBOP2CABgEmAaABQgGyAdQBxAHsAdAB2AEUgHvAMADwAawCYAOwBJAE+APEAvwBrwDSALIAzAIcApAC0AKMAhYBCP/DPwk/Cj8pPyO/kUA5QAeACgAXv9g/Yj72PpI+rD6tPwS//gAcAGPACv/NPzg+DD3IPcg9zD3mPhQ+gD7OPvg+fD3YPWw85DyYPGw8YDyoPNQ8/DykPMg88DwQO6g7cDsoOoA6sDtoPDA8uD1fP1gBRAKQAxAD/AP0ArgBRAI8A4gESASIBSgFqARkAjwBAAF6ATMA5gDiAXQBAgE3APQBugGyAVwBQAE1AOYBMAFKAdwClAOYBDQD2AOkAxACUgGkAUAB1AIsAlgCoAJuAaEAl7/9P0s/Gj78Px2/o7+eP7U/oL+8PyQ+mD6sPvg++j66Ps0/5UARADL/6kAOf8A+/D3QPdA9+D2UPfI+Jj6GPuI+XD3QPZA9PDx4O+A78Dw4PFg8RDy4PJQ8kDwQO5g7cDswOvg68DuYPHQ84D1OPka/jgEsAmAD4ATgBSgEaANUApACeAKUA3AEYARQBKQD/AJAAYYBYQDcgG7AJAC+ATYBaAECAZwB9AHcAdAB/gG8AUoB5AI4ArADSAQoBCgDLAKQAkoBpAEaAUwCEgH+ATYA2gDqQCw/fz8cP3Q/eT8QP3s/TD9fPzY/OT9PP3M/XT9cPxc/Nj8/P1f/3j/BP/g/cD7sPlA95D3APiw97D3UPiA+eD4APcA9iD1IPMw8QDwEPFg8XDxsPEA8rDxIPCA7+DuIO9A7oDvsPEw87D0oPbw+nT/WAWwDaAUQBiAFoASEA14B4gEsAjQDuAUoBVgFGASUAnkA/gADAHeANwApAEoAugEeAZYBxAIQAnACRAHDAMoA5AF0AfgCYAOABOgEaAMwAngCFAGDANUA/gF8AbwBLgD1AKoAT3/2PwQ/Fj8qPtg+6T8YP3W/gD/xP4U/kD9xPxQ++j7PP3s/3oBCAF2/3T9wPsI+SD34PbA95D38Pbg9mD4SPgQ92D14PTg8xDxoO/A75DwkPBg8XDyUPLw8MDwQPCA7kDtAO/g8KDwgPIQ9nT8lgCQBsAPYBcAGIAT8A+ACzAGSAbgCQAUgBkAGcATEA5wCGADg/+mAIACyAHWATQCIAbwBtgH+AfQCBAIaAN2AcQBeASoB9AK0A5gEAAPQAywCdgGYAQMA9gEQAbIBrgGeAbABAgCDv8Q/cD7oPkg+mD7oPwk/VD9wP2o/fj8LPxo++j6uPrY+0j9XP7M/tD+KP3Q+0D5EPhw9sD28Paw9wD4YPdA9xD3MPbA83DyMPKg8ADwUPAg8TDyUPGA8SDxUPGA8ODvoPDQ8IDxgPNQ8rD0oPlf/5AEkAvgFeAaIBWwDsALEAmYBGAGABOgGoAZ4BPgD1AM7APuAJwCoASSAcj/6gHIBGgFSAbwCTAKIAh4BKABcACgAYgFQAsQD3AP4A8gDeAJiAawBLAEMASIBSAHYAfYBsAErAOGAMj8KPso+qD4iPl4/DD+5P6s/uj+rP3Y+4j5oPqg+4T8tP2Z/wcADf+U/RT8APsY+uD4CPgw9zD34PYw9rD1kPYA9/D1YPTw8uDxIPGA8GDwEPKw8iDy8PAw8XDyMPEg8RDy4PMg83Dx8PIg96D5eP2gBSARYBbgFOASoBCACegCUAQgD4AVoBaAGIAXIBAYB5gDsAR4BmADdALEA9gCpAPQBCAIuAcoBUAEXAPmACYAEAPYBzAMoAzwDuAMEAnQBXgE8AVABdgGQAfYB6gGKAQgApAA9v4g/eD74Pl4+Qj6UPuw/Oj9uv5k/rj8APvA+cj5+Pqg/K7+UQAIAGT/hPw4+/D64PrA+Rj5uPgI+ID2kPUw9uD2EPdw9cD0sPOA8uDwAPEA85DzkPKw8YDxoPEg72Dv0PHQ8xDzYPKQ8sD0UPRA9Zj80AZgDaASoBeAF4AQuAbABIAIQA0AEuAYQB3gGMAPIAnoBggEeANIBCgF3AL8AYQCmARQB4AHmAd4BAQB5v4A/9YA3AMQCQAPoBAQDnAKwAeIBjAEQAVYB9AIQAnIB5gHGAWcAlYATv44/Wj7KPuY+3z8uP28/gL/fP14+xj6uPkA+uj6xPxs/9UATQDI/nz9KPy4+gj6+Plg+pD5uPjg9wD3YPaQ9YD1MPUA9SD0UPNw8oDy4PJg8yDz0PIw8uDw4O8A8NDwMPGg8eDy4PPg8rDyMPXQ+eb++ATgDgAWABbAD8ALIArQBtgHwBFgGuAaABiAE2ARAAwoBWgG8AcwCJAEuAP4BHAE2AQwBjAHtAOEALD/Of8JADQCQAZQCmALEAyQCvAI0AXIBcAGuAfgCLAIAAlgB1gGGASqAZv/Nf90/nz9SP1U/cj+iv5U/nD9cPwI++j5KPkI+nj70P2i/18AWACw/jz8UPoo+uj5ePog+kj64Plw+Sj4cPdA94D2QPUQ9JDz0PJQ8tDyMPMA8yDzgPGA8IDvIPBQ8NDw8PFQ8xDyUPGA8tDz8PTQ92D/sAhwDuAQYBWgE9AKYAWoBTAO4BFgFkAZIBtAFuAMIArQCXgHPANYBVgGcAaMA2AEYAeAB1AEDALJ/yT9rPwU/mgCwAUQCdALIAyACSAGzAN4A+AEsAegCSAL0AogCjAIiAXIAs0AJf8m/qj9Zv45AJsAUgD8/lD92Pro+Jj4MPng+fD6sPwk/ij/Gf8u/tD8CPuw+VD5cPmg+UD6uPrA+iD6aPnw93D2APXw85DzoPMw9DD0APSA82Dy0PBg76DugO5A7xDwoPDA8JDxMPEQ8SDwoPKA9lD7ZADQCMARoBNgD4AL0ArIB8AHoA5AGeAc4BcgFYATgA9wCmAHcAqwCugHWASIBSAGkAXoBWAFSATgANj8gPsU/W//1AIoBlAJ4ApQCWgGCAQwBLAFAAgwCuALIA3wCyAKIAm4B/gErAEXAFb/uP6X/1gBoALBAEr+VPyg+SD3EPfI+UD7kPs8/CD+VP4A/ST84PxY/Nj6mPmg+eD5QPq4+jD7yPsQ+4j54PZA9aD0kPRg9JD0EPWw9DDz0PDA7yDv4O5g7sDuYO+A7yDvgO/g7yDxIPEQ8pDziPh+/7gHIA7gEsATYA4gCaAEkAmAEAAVgBngHQAbwBPwDRANwAxwC/AI4AggCCAGsAXIBWgGsAVIBEkAfPxg+wT8Yv7e/zgFIAnoBygGgAVABbQCYALABSAK4ApQCuAKEAuQCegGKAWQAwwBUP/K/4YBMAK8AtYBwv9c/Pj4QPcw9wD4MPkQ+9j78Psw+1j7WPvA+rj5QPkY+dj4GPho+Oj56PoI+1D5iPgA98D1YPRQ9ID1MPZw9sD18PQw88DxsPBA8ODvAPCQ8IDwIPAg8aDxYPHQ8GDy0PMg9mj53AGQCTAPABAgDmANCAd4BjAKQBLAGGAbwBugF4ATIBBQDQAMAAwwCxAKsAgwCKAIEAnQB8gFfALQ/iD7WPq0/FIAjAJQBFAFOAWAA+oBiAEgAlwD4ATQBoAI8AhACeAJkAiYBmgEyAJCAQ8AcgHQAtADjAOEAtAA3P3Y+gD5CPkw+bj52PoY/PD8pPzA+yj7OPrQ+PD2cPYQ9xj4IPkA+oj60Plg+OD2IPZQ9GD00PTw9dD1QPVQ9YD0oPMg8ZDxMPEg8ODvAPHQ8dDxkPGQ89DyMPKA8DDzEPUA+b//wAggDVAOcA1QC2AIaATgCuARABfAFyAawBmgFMARIBEgEeAO0AugC4ALMAqQCJAKAAwACYAFTgEs/vD7hPwY/1gCKASgBEAEMALvAHwBrAJABBAF8AX4BgAHYAfACPAJAAngBmgFbANoAhACZAIoBCgEJANoAQkA7v4g/Mj6gPkI+tj5qPko+4j84Pwo++D50Pgg99D04PRA9yD4aPgA+nj6iPiw9mD18PSA9ODzoPXw9nD2UPWQ9TD18PJg8qDykPLw8JDwsPFQ8gDx0PEw84DycPHw8KD04PbI+qEAsAfgCjAKUAkACugHEAbQCwASYBWgFsAXwBhgFAARQBGAEUAPsAzQDaAOYA2wCtAL4AzwCTgFPAGQ//D8kP1SAPgCSATAAj4BgP8H/5r+rP90AUwD7AM4BPgEGAYQB7AH0AbwBVAElAOIAqwCLAPkA9gE2AQ4AzACwgBc/oD86PuY+1j7ePv4+7j9lPzQ+sD5QPnQ9lD1sPXw9/j48Pcw+Tj5OPiw9ZD1wPXQ9QD18PVQ9sD2kPWA9TD1MPTw8nDz8PLw8lDysPFQ8pDygPIg8nDyIPMQ8yDzEPbQ+mj+dAHYBGAKoAlQByAIIAqgCUAKQA/AFOAXQBegGOAUIBFwDzAPYBAADgAP0A8QDyANAA1ADNAIOAQUAq8A6P0Q/pIBYAS8A4ACZAJMARb+6P0v/wQA0ABAAvgEsAaABbgF2AVYBegCtAFgAmACkALUA5gEAAWwBKADYALj/4z9fPwY/MD7iPzE/WL+jP2o+4j6aPnw9hD2MPYg9+D2MPdA9zj40PZA9VD0QPXQ9MDzgPRA9YD1QPRw9eD1EPaQ9HD00PTw83DygPJw9LDzEPNg86D0cPQQ8wD1APfg92j46Ps7AOwDgAWwCJALoAmYBcAGgAmwC/AOQBRgGMAWQBPAEQAQwA9gDkARABKAD9ANAA6QDrAMYApQCuAHkAPWAHABogF4AWwCAATsAur/Ev7E/Qj9VPzY/T0AqwCGAPMANAIiAVQAHgD9ACAARv/g/5UACAIcA/AD7AM8AygBYv9S/kT+hP54/gD/4f9M/5j9WPzQ+xj7EPr4+GD4oPcQ9+D2wPbw9nD2EPYQ9qD1kPQw9ED0APTg8yD0UPRg9KD0gPTw9LD00PQA9SD08PMQ86DzwPMw9PD0sPZg93j46PmQ+0z9H/+YAbgEgAbgBgAHYAiwCCAJkAtQD4ASoBJgEqASwBBgDwAQQBFgEgASIBLgESARABBgDxAOEAwQCugHuAaoBRgF0AXgBQgFUAQsAgAAHv50/WD9sP3Y/db+Hv/8/vD+Av/a/gb+BP1o/FD8KPxQ/Tb/BgGYAfgB6AGzAG//wP6q/ur+ev55/0r/v/+x/4b/5P5o/pT8MPug+uD4QPgg+Jj4cPhg+Cj48PcQ9+D1UPWA9ED04PMA9PDzAPQw9MD04PQA9SD1oPQg9NDzUPTA9AD1APaw9uD2kPdY+LD5+PrM/Lr+LgDyATAD5AOABPAEQAbgB1AJAAxQDoAOMA5gDlAO8A6QDmAP4BCAEMAP8A9AECAQwA6wDgAOoAyQCjAKQAnACCAIEAhQCNgGMAUIBBgD6gHhAIoAEwBa/xH/QP+4/q7+Sv74/Xj9fPyo+1D7cPvI+zz89Pxo/RT9BP38/HT8+Pu4+xT88Puw+7j7lPzo/AD9XP3o/ID8mPvg+rj6SPpA+lj6kPrY+oD6cPpI+vj5+PlY+SD5oPio+Mj4EPmY+aj56PnA+dj5OPlQ+YD5qPmQ+Zj5KPpQ+mj6aPoI+6j7wPvg+9T8oP38/SL+PP/R/6z/NQAIAYQC0AK8AwAFuAX4BQgGqAbwBjgH+AcQCdAJgApAChALAAswCwALIAuACuAJ4AmgCcAJIAkACTAJAAnwB3gHEAfoBTAFkASYBPwDYAOgA2AD+AIsAvoB/AEsAUEABgDc/1L/3P4O/1j/If+8/v7+7v4+/tT91P2E/Rz9wPzg/Bz9yPyg/Nj8kPwE/Ij7kPuA+xj70Prw+rD6mPpY+oD6mPpo+jj6IPoo+hD6sPno+QD6APrA+fD5CPoI+tj54Png+cD5cPmo+dD5+Pnw+TD6YPpQ+kD6aPrI+sD62PpQ+7D72PsA/Ij8AP2s/ez9hv4q/5P/HgDHAKgBOALcAogDKAS4BEgFAAbgBnAHyAdwCLAIoAhgCCAJYAlwCVAJoAngCZAJYAlwCXAJIAmgCJAIcAjYB4gHgAdYB9gGUAZIBtgFKAWgBFgE3AP8AngCIALoAVgB+gDaAGYA6/92/zL/wP5e/gD+tP1U/fj8zPyY/Hz8MPwE/Mj7oPtg+yD7EPvo+sD6mPqA+nj6cPpw+kD6WPoQ+tj52PnA+bD5qPmQ+bD5qPnI+cj5yPnQ+dD52PnA+dj5uPnA+aj5mPmg+dD5APoY+kj6aPqY+pD6yPoY+4D74Psk/LT8GP2w/TD+wP6C//7/lgAeAcQBbALoArQDkARABdgFmAbQBiAHaAeYBzAIUAjACEAJsAnQCfAJEAowCjAKIAoACuAJsAmACVAJIAnQCIAIMAjQB3gH8AZ4BggGcAUIBXgEEASIAxADvAJIAhQCpgEyAdQAggD7/57/Nv8b/8T+fv5g/ij+4P1w/UT95PyY/Ez8MPzo+8D7WPtQ+wj72PqI+lj6OPr4+cD5iPmQ+Uj5OPlI+UD5GPn4+Nj42Pi4+Hj4gPh4+Fj4aPiQ+Ij4ePho+KD40Pi4+Oj4IPlg+aj56Plg+rD6APs4+5D7NPyQ/BT9uP1c/ub+k/9VABYByAGIAhgDrANIBLgEmAVwBggHiAcQCEAIcAiACPAIUAlgCXAJ4AkACuAJ0AngCbAJwAmACaAJsAkgCZAIcAgwCLgHOAfoBrAGWAbIBVgF8ARYBMQDEAN0AiACdAEiAfUAjwDp/1z/MP+s/lr+2P2I/VT9HP2w/Dz8DPzI+8D7iPtw+3j7ePtA+wD7CPv4+tj6mPqQ+oD6UPow+jj6MPoo+gD6GPog+vD50PmA+aD5mPmY+aj5qPnI+ej5+Png+RD60PkA+hD6OPqo+sj6CPtI+7j7+Pt4/Jz8FP10/QT+hP7I/mT/7/+EAAYBogFgAhgDcAMIBKgEAAVwBcAFSAa4BgAHeAcgCMAIUAkgCVAJEAkQCZAIYAhACIAIUAggCFAI+AeQBxgHyAZIBtAFWAXQBDgEAARcAxwD9AK0AngCvAH2AIIAIQBw/wD/1P6s/lb+Jv4Q/hr+vP2Q/ZD9VP0U/eT88PzQ/Nz81PwQ/Tj9IP00/Vz9IP0Q/fD88PzA/Jz8XPxs/Dz8PPz4+6D7kPsI+8j6aPoo+hj66Png+dj5yPlQ+Xj5ePmI+Rj5MPlg+UD5OPlA+RD6WPpI+pD6QPuQ+6D7wPuU/DT9XP3U/Xz+hf/e/zoA3gDqAVACzAJkAxgE+AQwBSgGOAfQB1AIsAiQCbAJcAqgCoALgAtwCwALEApwCRAKcAqQCiAK8AmACaAI6AfIBnAGqAWQBFgEPAN0AiQC2gGWAe8ACQCO/7D+rP0g/Vz9KP3g/Nz8UP0M/bT8lPwY/WD97PwA/TD9OP04/UD9Qv4g/gz+QP6k/mz+0P0w/qr+uP5M/hj+dP5M/sT9iP3U/Zz97PyA/DT84PvQ+pj6aPrg+Sj5GPmI+FD40Pd4+OD3kPfA91D3cPcg91D30PeI+MD4uPho+fj5gPqg+nD70Puo/Iz8IP0I/vj+8f+KAMQCbANIBLAE4AUoBqAGsAewCKAJ0AoADAAOEA/gD6AQgBFAD1AN8AuQDEANIAzgDqAPMA5AC2AKUArwCCgHSAZIBdQCDAGPABABigCL/53/Rf94/Pj5aPlo+cj4+PhI+kD7yPp4+jj7+Puo+9j7hPxA/UD91Pxs/Z7+Vv97AE4BaAEwAaMAEwDp/2IAYQAUAMb/5P8F/6z9VP3U/Vj72PoA+tD4EPdA9jD2cPag9dDzcPTQ83DyQPHw8aDyQPIg8vDywPNQ8zD0cPVw9uD28Pc4+Xj5yPk4+8j8tP24/k4A7AHMARwCVAMYBTgF6AW4B4AJEAogC9ALcA3ADpAOQA/gEAASoBIAEwAUoBUAE0APwA2ADNAKkApgDFAP8A1wCoAI6AZIBMQCdgFgAmr/1Px4/JD9aPxQ+yj8UPzA+rD3MPaA9qD3KPi4+WT8nPw8/WD9AP6S/nr+yP5LAJIAcAFGAbYBGAOgA+QDJAMQAmoB2gDc/3b/av+o/73/8P3E/Az8kPoI+cD4sPgg91D1gPRQ9MDz0PJg80DzwPIA8tDx0PGQ8XDywPPA9OD0kPTw9eD2YPeg+Ij50PtA/Kj8IP32/rP/q/9AABQCFAPsAagCiASoBdAFIAa4B+AIsAiQCFAKsAuAC8ALYA1ADkAPYBCgE8AUwBTgE0ARkA2QCaAIkAkgC7ANUA/wDAAKkAVABWwDDAKI/zH/RP5I+9D6APuA/ej9RP2A+2j6cPdA9ID1MPhg+uD6rPyS/wT/1P0w/cT/TQBe/3wAsgFYARcA2AGABJAEWAPQAmAChv/g/Pj88P2E/Wz9TP5c/Yj6KPhg+LD4sPaA9aD0oPRw8uDxEPOw9CD0MPQw9JDzAPIQ8QDz8PPQ9eD1MPco+Yj4EPnI+fD7wPtE/Lz8cP6U/lr+NgDyAegCyAGoAgAD4AIgAsQCiAQgBdAEgAVIBzAHIAjQCKAKcAtwCxAMIA3ADdAOQBLAFWAXABbAE6AQ4AooB9AHwAoADWAN8A7QDrgHfgFWAcADBwBw/ST8zPyQ+tD44Pv4/QT+uPoQ+rD5IPWA8wD2QPp0/BL+kwAqAXP/Cv9UAIIBNgDo/1gCUANIAhgCmANwBaAEMANUAmkAcP0E/Ij8pP38/Lz8rPyg+yD5YPcw9/D2kPag9ZD14PRQ87Dz4PTg9fD1oPVw9WD08PNA9HD2gPdA+Gj5KPqQ+fD52PoE/Fz8LP2Y/dD9eP0m/qT/bwAKAcMA1AB0AOX/wv8DAOQA9gEEAywDYATwBKgFeAaQBzAJ4AjACsALMA2gDXAPIBOAFSAXwBdAF0ASQAoIBxAKgAxAC5AN8A8gDyAItAKgA/kAMP7I/PT+TP3Y+cj4UPuc/bD8VPzg+oD48PUQ9pD20PeI+u7+wgEsAXYBvgHzAAQAFAFgA/wCugE8AlgEqAQoBKgEuAQkA3oA3P0E/cj7SPu4+/D70Pu4+mD5sPcw90D2sPVQ9CD0IPSQ8zDz8PQw9nD2QPbw9qD2MPXw9JD1CPh4+GD54Ppg+8D6cPqA+0T8WPww/LT8lPyM/CD9VP4A/6//4f81/2L+Pv6+/uD+Iv/D/yQBggEgAiADwASwBaAHoAhACTAJsAogDJAMgA7gEsAWgBdAGKAZABewDLgF0AagCYAL0AxQDvAPEAooBIoBYAC4/Qj7iPsI/Kj6aPjA99j6+Pv0/Nj6sPkw+JD1sPVg92j75P3RAIADQASMAzwBsgHUAngD/AJgBOAEKAQ4BFgFyAVQBFwDeAEw/wT9kPsA+9j6uPqQ+lj6EPkI+JD2UPYg9VD1gPVA9TD1IPWA9qD2YPeI+Kj4UPiQ99D30Pdw+Pj5KPuw/Kj8ePyk/PD7iPuY+0T8rPxk/Hj8jPzQ/ID8TP3k/cT9VP2o/Oz8BP1U/cT9iP73//0AVALgAiAE8AR4BngHgAlwC6AL4AvgDdAO4A9gE0AWYBqAGsAXgBGgCiAG2AUwCRAMoAugDIALkAfmAUj/Vv7M/BD6cPjY+Uj4wPYQ+Ij7jPwU/Aj7iPlw+AD2UPfA+LD79//MAmAFUAQQBMwDUATcA6ADuAToBJwDcAMgBLAEGAQ4A1wCbQB4/sD7EPrg+TD5sPiA+FD4IPcA9pD0IPVQ9WD14PQA9cD04PQA9WD2wPd4+PD4MPm4+eD4KPkY+jD74PvI+7j8UPyI/KD7cPzs/Mz8JP08/GT8GPyo+6D7kPz8/ND8xPzw/OD9yP2w/eT94P77/3MAfAGcAtADwAXoBpAIIArwCxANQA3gDZAOUA+gEOAVwBvAHCAY4BEwDVAJWAVYBTALkAsgC8AJoAgwBVgA1P2k/GD7uPmw+KD48Peg96D6CP2A/LD74PsQ+3D3wPao+FT8EP+YAXAF4AYABoAEUAQgBYgEuASoBMwDgAJ4AggDJAPMAlQCQgHg/vj7gPk4+ND3cPcw+Kj4wPeA9vD1UPag9rD2sPYg9/D2UPYg9nD3kPjo+RD7aPwM/OD6OPrQ+jj7uPuo/DT9EP28/FD8KPwI/Fz8kPyI/BT8oPtY+/j6sPoc/Lj8HP00/Pz84PzY+5D8OP3B/9b/wwB8AsQDEAVoBdAG6AegCfAL4A2QDSAN4A6gEMARoBQAG8AdIBnAEhANYAj4BHAEYAhQDbALcAlYB1gFDAI+/xD9kPqY+3D62Pgg96D34PrM/JT+AP+6/nj8qPjg9vD4yPtA/h4B0AQQB6gGsAWwBBgFMAXIBIwD3ALcAW8AAAGQAcQCAAPmAS3/oPz4+eD3MPdA91D3APig92D3YPaw9rD2APeA9yD3gPbA9aD1MPbg9wD6WPzc/Hj8qPvw+sj6YPro+oj7+Pyw+8j7KPsw+xj7cPrw+9j7GPyQ+jD58PiQ+WD6sPs4/ND8DP34/Dj88PuU/JD+U/8BAPoB/APEA2AE0AUwCsAKoAkwC+AN8A7gC3AMoBBgFIAYgBugG8AWUA+oB7gEwAVwB2AKoAtwCnAIoAWMASD+gPwE/Cj70Pno+Cj4QPho+HD6fP34/iD++PtQ+sj4aPiA+eD8m//YAaAEyAXIBTgFyASABIAEqAM0A9gCkAHYADwBTALaAVIBcP80/SD7cPlA+DD4wPeg9+D3cPcg97D2UPeg95D3wPeg96D3YPZA9qD3UPpo/Dz9dPzw+5D7+Poo+7j7lPwI/aD8TPxE/Bj7aPrY+iz8DP3o/OD7kPow+UD5WPpw+zT8TPwQ/Uj9ZPwo/ND84P20/vT/bgGsArQCfAPABcAGEAgQCWAL0AvwDPAN4A7wDMANYBOgGaAbYBlgF2ASIArQBKgGcAhACeAJ4AogCxAGOALW/+j92PuA+rD6aPmA9xD3YPlY+3z8TP0U/tT8qPlA+Lj44PnI+zD/vAIABaAFoAXQBegEmAQwBRAFCAQ4A2wCEAJYAuACuAOwAmkARP40/KD6+Pho+KD42Phg+ND3APdw9kD2wPbg96D4iPiQ99D2gPaQ9zD5EPs4/Fj8APww+1D6WPrY+kD7HPxg/AT9YPyA+xD7SPug+/D7ZPxY/CD7CPpw+Uj64Prg+1j8sPy8/JD8nPxg/ET8JP1y/8wAnAGYAhAEwASkA5AG0AiACVAKUAxgDgAOUAtQDHAPIBMAF6AZIBrAFOAO8ApwCNAGgAbgB2AIwAhACIgHGAXkAEL+FPw4+pD48Pco+Hj48Pmw+wz9ePz4+5D7GPqQ+Aj4UPks/Bj+pwC0AvADaAQgAxwDhAPsA4QDOALGATQCBAIEAhwCmAIIApMAzP4Q/Vj7UPqg+QD5EPno+LD4APcg9lD2oPeA+Kj42Pgw+PD2EPZQ9vD3OPpw+zT8iPzI+1D6mPm4+dD6kPvI+5D8ePyg+wD7YPvw+zj8WPuQ+7D7sPn4+MD5aPuQ+/D7wPxU/Sz8mPvY+yz9JP26/rwAPAGoAZYB5AIQBFAF4AbwCHAKUAugC+ALAAyQDeAPwBKAFmAZIBdgE2AOMAwgCpAHiAdgCCAJ8AgACpAJUAeWAVz9CPs4+Zj4iPmg+mD7MPvA/Az9UPxg+kD5kPjQ92j4APq8/Pr+GgGcArADYAMgBOADtAN4AxgDHANIA8ACZAMgBGAEIAQsAsEAhP5I/VD78Pq4+yT8kPtI+iD6YPiQ9nD14Pbg+PD4ePhQ+BD30PWQ9aD2APno+aj6GPzo+vj4sPh4+WD6SPqI+9z8rPyg+6D7hPzM/Dz8SPzw/HD8oPs4+5D7oPu8/B7+Rv4c/oD9VP3E/ED8ZP0f/zMAUgHWAUADcAPYA1gFWAcgCBAJwArgCjAL8AowDaAQgBPgFSAXYBZgE9AP4A2QDBAKeAcAB2AIIAsgDBAMUAmYBDL/2PrA+hj6+Pq4+0j8nPyI/KT88PqQ+VD4EPhA+ED4ePkY+/D84P2d/54B2AJ0AzADeAIMAlABfgHuAcgCEAQYBQAF5AMYAxIB/P3I/BD99P24/Zj8vPyQ+wj6MPgA93D3CPjY+ID5wPig97D1APUQ9RD2OPgY+Zj5cPlY+aD4MPho+Ej5+PqA+1D7SPvI+yD8fPw0/bz8lP3k/cD8qPuw+2z8wPw4/Tz+WP/i/pT9gP2c/dz9JP3Y/bf/0QBiAXACkAN4A/ADiAXIBlAHGAdgBwAJAAowDOAPYBKgE+ATgBOgEiAQUA5ADUALEAnIB1AJ8AvgDaAOMA0ACYACtP3A+zD7QPw8/kz/JgDW//z+7PwY+sD3MPfQ9rD30Plo+9j78Puo/W3/lgBEATACAALW/7j+Ev/m/4ABiALQBOAEkAQ0AwwCyP8A/oT9pP3o/az+jP7A/AD7GPno+Bj4sPiA+Vj5wPfA9vD1YPVg9XD28Pfg90D3wPew94D2APYA95D4APnY+eD6uPqg+WD5yPrw+4z8jPxc/Uj9BPzg+1j80PwQ/Qb+of/s/jT+vP1M/VD9XP0D/0wAlgB3AD4BDAJYAhgDwAQABggGWAa4BpAHcAjQCgAO8A/AEMARQBKgEQARkA+gDfAK4AgACSAK0AvADeAOkA1ACdgEGgFc/vT8iPwg/nz/4f+IAL3/LP4Q+zD3wPXA9UD3GPkY+1j78PqI+rD7YP0g/hv/0v50/uj90P3Y/t3/+wAwAnQD2AMsAwQCmwA0/67+wv6W//r/0f8P/yj+tPyA+9D6+PqA+iD6EPoI+kj5wPdQ99D2cPcQ+Nj4SPmA+ID3wPbA9tD2GPjo+Yj7KPuQ+tj5+Pi4+Nj5+PtQ/fD9WP3I/ID8WPwI/RT+S//P/2//j/+c/kj/tP9AAEQBwAGQAhQCJAL0AUQDtAOQBLAFsAZwB9AHcAiACRALYAzgDfAOoA/gECARoBBwDxANIAtACaAJ0AoQDdANkA0ADJAJWAZIA2IBwgDs/6//WADLAK0AR/+g/Zj72PmI+Bj4APlw+Cj4gPhw+fj5MPuo/Hj8gPs4+jj6iPtU/OT9xP70/nr+ev6E/0QAzAB3AAMAJf+K/rj+qf/+/zkAxv+W/nz9IP00/VD9GP0o/QT94Pt4+vD5uPkg+nj60PoQ+5D50Pfg9uD2QPdQ+OD5APtQ+2D6mPgA+LD3MPgY+mD7iPzQ/ET90PyQ/PD8PP00/nj+IP9Y/1f/mP/w/6MAigEkAqACrAKUAiACxAE8AlQDKAWYBpAIcAmACdAIsAjQCIAJIAsQDWAPoA8wD+ANMAwgCgAJwAlACsAKAAtwC4AL4AkgCEgGCAR+AY8AzABKAegBtAGWAfb/kP2Y+4j6MPq4+YD5uPlA+kj6+PpA+0j7KPtQ+oD6aPq4+qD74Pss/AD8pPyc/cr+ev95/9z+mv7E/ej9Tv4N/2r/HwALADwAp/8F/3z+tP3M/cD9jP2I/Xz9IP0M/Vj88PuA+6D6oPqg+YD5KPng+Jj5gPmo+Zj5gPng+Ej4QPio+Dj56Pn4+gj8OPwE/OD7DPzw+1T8eP1S/r7+4v6R/x4AZQDdAJwB6gFsAQwBvAF0AgADUATABZAGMAYYBuAF8AVwBZAGuAdgCZAKYAvAC5AKwAlwCAAImAe4B5AIIAmACdAJcAowCiAJOAdIBYgDoAJYA3AEkAWwBcgFyAScAm0A0v4K/kj9SP3U/d7+NP8w/77+wP04/ND6EPqA+qD6YPsg/ID8qPzw+2j70Po4+gj6KPrw+nD7cPtQ+zD7UPuQ+/D76Pug+1D76PoI+2D7EPy4/AD99Py0/Gz8PPwA/CT8VPy0/Pz8GP1Q/az9xP3Q/Zz9kP2o/dz9FP5U/qb+6v4T/1L/Tf+c/+T/+//a/8f/0v8QAEQAkwD6AEABdAFeAVIBKgEGARIBLgFiAYoByAEMAmwCyAL8AvgCkAJ0AnQCzAJAA+QDkAToBAAF8ASoBHAEUARwBKAEyAQQBVgFmAWgBXAFOAX4BKgEYARgBDAE9APcAwgEUARwBAgEmAMcA5QCbAI0AiACEAIgAgwC0AGmAZgBHgGUAPD/kP9C/xf/Pf9R/2j/QP8P/5L+NP7E/WT9DP2s/MD86Pw0/Tj9TP0c/bT8EPy4++D70PvQ+/D7IPxY/Cz86PsI/FD8QPz4+7D7uPvQ++D7CPx8/Kj8tPxw/Ij8dPxI/DD8nPws/UT9SP1w/aj9lP2M/cz9CP4o/hz+KP5i/pL+yv6+/iv/Av9e/5r/3P/S/7n/9v8iAG4AnQAOARABCgE6AVwBbgF6AYoB2AE0AjQCkALQArwCnAKcAtQCIANUA4gDtAPsAwgEAAQwBDgEQARIBHAEqATABKgEqATYBLgEqASABJAEkARIBBgEEAQoBOgDvAOwA3ADAAOEAlwCXAJwAlQC+gFaAeoA3wCoADsA8P/K/6f/Z/8E/7j+eP4a/rj9kP1s/RT97PzQ/JD8XPwA/MD7uPuo+3j7YPtg+1j7QPsA+9D6yPrA+sD6yPr4+iD7GPv4+gj7KPtA+zj7ePvI+/j7APws/Gz8gPyU/MD8KP1o/Yz9wP0a/m7+oP7k/iH/WP+D/+z/SgCOALAA+gBKAZwB8gEgAkwCbAKUAsgC7AIEAywDhAO8A/gDEAQYBAgEEARABGgEoASwBNAE4AQABfgEAAXwBOgE4ATABLAEuATIBLAEiARwBGgEOAQIBNQDpAN0AywD+AK8AowCPALwAYQBXAH/ALgAbQBKABgAov83/+r+tv52/hz+8P24/Zj9RP30/MT8jPxk/Dz8LPwE/MD7kPuA+4D7ePt4+3j7cPtY+1D7UPtY+1D7ePug+7j7wPvQ+wT8JPw8/Fz8kPy0/Nj8BP08/WD9hP24/fz9Mv5S/n7+rP7Q/vr+QP+U/8X/9P8dAEsAhQCwANoADAEwAVoBiAGyAdoBBAIoAkwCZAJ8ApQCuALQAtAC1ALIAsgC2AL0AvwCDAMEAxwDBAP0AuwC2ALcAqgCrAK0ArgCkAKUAngCUAIcAvIB5gGkAXABYAFSATABBAEGAdYAlwBQACoAIgD4/9v/u/+P/3H/Tv8y/wb/5P7K/rD+fP5U/kT+Qv4g/gT+9P3s/dz9yP3M/dD9xP3E/bD9vP3U/ej9EP4a/iz+Iv4m/jL+Qv50/pL+sv62/sz+6v4Y/0j/Uv9k/3P/jP+k/8D/5v8XAEIAUABeAG0AfQCaAMIA4ADxAPsA/QAaATQBXgFeAVoBbAFoAXoBigGGAYgBggGOAYwBigGKAYQBegFYAV4BZAFwAWQBWgFUASoB+gDbANkAywDCAJ4AlACCAGcAVgA8ACkA///x/+H/w/+7/67/pv+m/5//qv+V/2v/Sv89/z7/Ov9L/2D/dP9l/1T/Ov8X/xb/E/8a/xv/Jf80/zr/OP82/03/T/9R/1n/YP9l/17/av9+/5r/p/+y/7z/yP/S/8v/yv/f/+7//f8GACkARgBEAEgAYwBwAGgAXQB8AIoAggB5AJMArQCvAKQApQCrAJUAjwCGAKUAiwCqALQAxACpAJMAmACTAIoAewCUAI4AbQBbAFYATAAyACAAJgAsACQAJwAfAAAA6//o/+H/1P/D/8T/0P/Q/9b/0f/A/5b/cf+J/6z/tP+f/53/o/+d/4b/gP+F/4n/ev9m/2//df+A/4P/lf+k/4//e/96/43/l/+j/5//qP+p/63/uf++/7P/uv/J/9f/4v/o/9//1f/C/8n/6P/5/wQAHwAuACkAIwAjACsAMAAcAAgALABhAHEAbgBlAGsAYQBOAEwAYgB/AHoAhgCGAIsAdAB0AIAAhgB4AH4AnACnAJAAYwBIAFkAawBbAFQAXgBnAFgAQQA5AEUAVwBRAGMAZABMABQABQATABUAIAAmADwANAAPAOz/2P/C/7P/tP+8/+b/6v/l/8v/tP+x/6H/lv+S/6D/qP+7/7H/tv+n/5H/if+Q/6f/wP/H/7X/pf+h/7L/qP+3/8H/xf/P/9b/3P/e/9L/xf/K/7f/xf/A/8v/6f8TAAsA+v/7//v/8f/r/+L/8v8DAAsA7v/g/9f/4P8CAA8AGgD+/+r/z//a//D/CgAhAC0AKAAOAAAA/P8FAAUAEQAZACgAJwARAAIAAwAVACMAMgA4ACsAFAARAB8ALQAtADsAPAAvAAUA7////xcAHAANAPv/+f/j/93/2P/7/w8AGQAKAAoA9//Y/9z/8v8JAPL/4//v//7/CwAgADkARQAZAOj/2f/c/+j/DAAaADsAPQBcAHYAYAAjANv/6P/u//L//P96AM8AygBoADUAUQAJANL/0v8TAB8AZgDGAOIAjQDH/6H/9v9QAFsAgQC8ALcAPwDw//f/QAArAPP/FQA9AF8AUAAxACEA8v/J/9L/EQAcABAA/f/c/7n/n/+W/6n/7f8fAC4AGADQ/4j/ef+W/9j/CwAZABUAAADh/8T/yP8AACUAOAARAOz/1v/i/xcANAA6AAcA6P8HAEMAOAAJAP3/EgAgABIALABXAIEAaAA4ADYAIAALAPX/EAA1AGoAfgB5AGAAIQDx//3/DgAfADwAZwCAAFYANAAOABYAGwAiAEcASQAlAAgAHwAgAP7/zP/W/+3/BAADAPf/7//p/+3/CAAUAOb/u/+0/7L/rv+v/8v/GAA4ADMABgDl/+L/2f/P/9D/2v/F/7j/5f8PABQA2P/q/yMANQDP/1D/Y/+4/xcA9P/j/wEAOwDx/13/I/+X//r/AQDH//z/3v9O/wH/cv/B/8b/DwBzAGUAhv8h/2n/uv9o/3X/FQCPAGMALgAXAEEAgP9h/6j/NwAzACoAUwA6AOr/mf8MAC8ALAAkAHoAiQDp/4L/nv/y//T/KwBZAFwAeACeALMAjAD3/3j/KP8g/9v/xACgAYYB0AD5/63/gv8i/xb/yv93AJIAUwDpAAACVgETAG//JP4M/Sj8Vf/YAwgFbAK3//L+ZP5+/lb+pv+yAFQBnwCT/yf/bAC4AWUATP5q/iYAXQA7/5r/JgHw/2b+jv5oAeQBGwBV/+n/TACi/sr+z/8lAK//w/8IATgB7/8y/4j/tP+e/yv/pv+4AGQB8QDo//L+Dv9O//L+xv9SAWQCeAGx/6b+QP+j/xP/Qf+fALIBGgGS/1X/KwA8AK3/2P8uAWoBfQC9/wcA1//m/s7+2/+MAeQBBgHL/4L/Nf9C/yn/Uf+GANQBngFqAJr/mP/H/0v/Iv+J/8D/FADAAIQBlQDg/qT+l//X/zX/r/8CAZwBIgAt/w7/ef9a/1T/GACRAFkAm/+8/2EA4ACS/8r+xf8aAfz+TP0+/hgBXALOAToBjADo/iz95P0dAIkAf/8x/1n/+wAEAoABFQBM/1H/1v4a/rr+bAEoA4gBVv+2/uz+Nv4x/zgB/APAAjP/eP38/Tj+YP6ZAJwCIATIAlYBS//c/Fz8Yv4GAVQBNAIMAxQC6v4k/YL+UgCIAN0AwgEsAjP/fP7A/tD/ef/g/yQCSAJ5AHX/MgF+ATr+APp0/MYBcATgA1QCugBK/vj9zv4h/9j9wP0qARADLAIbAGwCjANkAfj70PdA+xQBYANaAQgCwAM4BKsAhP28/rj7OPo4+sYBuAQoAmwCeASQAxD78Phk/QwDnP+Y/EUAUAbgA7T9UPxc/yABtP1O/gsAmgGO/pr+AAO0A+oBMPzI+pz80gBUAVAA5QCE/6QAgP+3/8QDAAYjAKD3UPQ4+sACAAjYB/gEvAH4+0j4kPq8/hADKAJbAGgCKAQMAhz+kPyU/Gz9MP1+AfAGuAYY/8D61P6b//D7EPrDAJAI8AZ1ABD/b/+g+OD1oPn0AiAF+AVQCRgHyPzA8mD3dv/w/5D9dgGIB7gFOwDc/fYBeAE0/DD58Pls/isALAHUArgF+AdgBtb+YPfg9tj8aALnABoAvAJACPgFKwB6/ij+wPvQ+Kj8VAOoBJoB2APQB0AEuPog+JT9lwDo+8j45v8gCmALcAf4BOoBnP7g99D1kPdB/1gFEApoBr7/IPoY+Ej6NP30/Rr/MgE0Alz+gPeY+cwAUAmIBRwAUPpQ+VD40PwYBTAHIAaQApgAaPqA+aj+hAJ+ATD9sATwDCAMxANV/4j7wPMg71D0CAXgD4ATgA5QBcD6UPSQ9JD02Phm/tAFoAqACcAK4AjYBeD8MPAg7BDyUgFgDWARsAxoBWD74PPw9WD+sAKgAWH/0gAQAzwB/ADwA4AEov8M/vT85P3O//z/qQBmAPwB6AZgCsAGVP7g+JD0MPMY+igGkA5wDAgG2v7Q+LD2oPaM/2gDCAR1AKAALQDs/w0AFP1I/rj90v7C/y4AFQAvAJ8Akv+M/hEAiP8AAE3/MgB0AUv/PP5S/uj/aQDc/xQDsAZIAnj6+Pgs/PH/WQDeAMAE4AVIADj6IPoQ/QYBFgEd/+v/1v9Q/4z9vv5rABwC6gAhAN4AfP/M/RD7XPw8/Z7+MP+UAvAIEAswByT9wPUQ80D0CPlYAUAJUAsQCsgGMAKQ+5D1cPeI+vD8xv5sAXgEmAQIBegGuAT8/UD6TPxM/Ej4cPhQ/3AH0AYYBRAIEAjSAAD2wPQg+ID6MPsIApAMkA9QCWb/+Ptw+kD3APSw+FAB0AV4BqgHIAuQBuj7cPTg9mD6iPtG/5gEMAlYBhwDTALAAPj+DP3I+8j6qPkk/QgDEAmQCeAFCgFo/YD8+Pq4+eD6lP4IBNgF+AboBeQDVf/Y+fD34Pm+/tsA6AK8AwgFuAL6/hn/ggATAMj7QPpo/gQDbALo/sr/MARQBQgC7v7E/vD9uPqo+nj/wAQgBWwDCAPEArr+QPsQ+7z9zv5z/3QASANwBJADpAEgAI3/0P1k/Oj5uPtJ/6gCSAQgBTAF6ALA/Vj60Ppc/c//gAG8AmQCVwCu/08A2QB/APb/aQBIAAUAef8R/9D+qv4dAJkAagBtADQB1gGQARYBRABs/yD9vPy0/bL+gP/IAXgEqARoApj+ZP4K/gT9hPxi/m4BBALcATQDWAWEA3j+oPqw+rj8Iv5rALgDSAbgBTQCVP6g/IT8MPxw+1z8fAC4BHAGsAVoBNYB8P1I+0D7dPzE/dn/dAKgBNgEWAPQAp4BX/8Y/Oj6wPuI/UAAXAIABMAEOASyATr/2Px8/PT8uPxc/Rz/egEUA/gDnAOwATD+8PuQ+4D83P1p/zgC/AJoAqgBoAHSAG3/vP2U/Qz+PP65/x4BvAJ8AlAB7//G/vz+tv/d/6z/if9f/43/+v6A/r7/7wD7AAYBzgAnAPT+gP4M//f/jv9Y/lj+7P59/xkAcAGMAmQCfgEFAGz/2P7s/Yj8QPzE/c7/3AG8AvADbAOeATT/aP04/Hj7NPwk/qIAFAIEAywD+AK+AQYAV/+I/tT9hP0B/xYBeAKcAkgB7/90/tj9PP6e/5AApgEUAnAB5QAEAH7/qv7g/UD+UP+sAAoBrgGkAfQAKwDX/wwA7f+E/5r+ev4E//r/MgFEAnACjAFMAHf/R/+M/6j/gP/L/4gAewBwAPj/FQA7ADoAZACYAEwAxf+Z/87/l/8R//T+nv8AAIP/bv+EAHQBEAHG/9T+P/9//7P/M/+F/xgAAQDE/xgAfgCIABgA/v9fAF8A0P9S/5z/AgD7/xkAigAeASgByACFAAQAdP9r/63/pP9N/yz/i/9FAOgA9gDfAGkAdv/a/gD/Gv9i/zMA0gD/AM4AHAEuAcYAxv9E/z7/P/8s/87/MAF0AS4BVAEmASgA7v4o/rb+Tf9O/w8AHAHqAaoB/QAOAN7+8P2o/Tr+Sv/A/7IAJgGPAOL/xv8OAJn/jv9m/x//3P0M/hf/lQDWAL4AggEEAfv/nv4q//v/mf/s/k//RQDfAJYAcQAcAbQArP/0/s7+Wv+d/wgAdABzABgAX/84/1D/k/8cAPT/rv9+/9n//f/z/yX/Af+Q/+T/0/8n/1P/2/93AKoAsQCjACAA5f8ZAF8AwgDLAJ0ASwDa/7n/ewACAQ4BwQBVAD4Aw/+x//j/KwD0/1z/Gf9v/6r/s/9BAL8AuQD8/0v/C//4/pz+Xv7K/vP/1QD0ALEADgDf/2L/Ff9d/wkA1QAAAWIBsAHEAVoBTwCB//7+3v4a/wkACgGgAaIBLAHsALAAWQC//yH/2P6U/tL+hP9+AGwBXAGMALL/9P6o/lT+bP7S/qT/XwCyABIBYAGKASABngAaAPT/6//J//H/SwCTANkA+AD9AJgAy//u/oD+zv49/7b/LABDABQAuf/0/yYAKgAZADcALADr/6n/ff/C/+v/iwDIAOAAdwBPABsAsv/2/tL+GP+q/0gA8ABUAQgBzAB2ACYArP+M//j/HwD2/5H/gf+J/6P/0f9UALcA2AClADgAnP/k/s7+C/+4/28AxQAQAR4BagE8AY4AEwC7/67/Yv/A/pT+4P5d/8n/bABcAQACrAGrAO//n/9g/yX/T/+h/xEAIABtAGsAVwAfADIATgBDAGoAQwBGAM7/bv9P/5T///9lAJoAMgD+//H/PwBZAFIAbwBxAEUA8P/X/8//uf+k/2T/I/8M/83/1QBAAdwAPQD0/6H/Lf+Y/qj+1P4G/+j+L//4/+EANAFYARABSgA6/1D+Zv6M/pD+kv7S/oP/HQDZAIQBzAE6AU4Aqv87/1D/e//b/wQAu/97//X/yACaAawBDAH+/xv/6P7C/tr+4P4a/3T//v/FAE4BpAFgAcEAAABW/4D/PgA2AT4B1QDB/3T/t/8WAHMAaQBVABAA7/+8//P///+C/xz/5v4n/6T/TQDBALoAigBjALEAygCAAD8A4f+l/zD/Qv+B//L/PQBJAF8AMwB1AJMAqAB/ANj/gf+A/7D/0f/K/+D/0v/d/6H/yv/b/6j/Mf8r/2P/wf+7/5r/nP+7/+T/QwC4AAYBPgEMAQABrgAwAKj/Jv9L/8//KQBrAF8AIQC0/0f/K//D/zoAJQDX/5T/wf///yQAkgCGAF0AEwBBAFIAFQCD/wD/N/+v/3YALAFaAUIBSADe/9L/2//O/6//ov8nAIEAaQB+AGkAFABI/6r+VP62/vr++P7y/jn/5/+UABwBVgFMASAByQBwACcAT/92/kz+mv5J/5P/uP8bAFEAMQAJAJ0AGAE8Aa8Azv8Y/6L+kv5s/3kAoAFQAuQBGAHf/2H/Af8C/9b+zP4G/yP/Ov9t/wkAWwAEAaoBIALsAf4A/v8Y/5j+Uv5H/2QACgG7AAEA+f9HAMYADAHDAP3/6v5y/kb+fP4o/zoANAGGAWIBMgH9ACAA6v5u/vz+rP/0/7X/kv/M/y4AzwCCAd4BwAHRAO7/nv/E/ysAHgD7/5b/k//H/wcABQCu/1D/DP/e/sD+5P5S/33/YP9y/yAA4QAAAaMAKQDl/8//sf/7/yUA2v+P/3z/OAD2AJYBCAIgAgACogFCAQIBcQDQ/zT/zv6e/sD+D/9I/5z/xv/M/2f/Wf8L/xf/8v7o/lP/uf/t/9v/fQAeAV4BNAEaAdkAiQASANv/AwCn/+7+dv6M/vD+nP8XAEAA8f85/5L+Iv5I/r7+Y/96/xH/uP7E/ij/qv8nAGoAhwBIAIsArQByAOL/e/9h/5L/yf8pAAYAtv9+/4//EQB+APEAYAFuAfoAswCrAJsARwBIAHYAjAB9AND/cv/a/mL+jP5H/zAAuQDCALIAcAB9ABoBqgGeAeIApQC2AFQBbAGgAZYBJgGFAOD/gP++/vz9uP1Y/oT+nP4F/8L/aACPAGsAawA1AMr/sP8GAEoATQDw/3H/Kv86/3H/3/+x/4f/gf8k/+j+qP5+/v7+iv8eALsAjgBQAPr/+f8CAN//GQC6ANcAJgBz/xn/hf/1//f/WQCMAJkANQB7AJkAwwCKAG8AWgArACwAZABnAC8A9v/Z/1AAQQA+AF0AVQD8/4D/Pv81/3P/7v+fANUA9QC7AAQB/QDVAG8AOABzAKwAwQCuAOQAcQDy/87/UAC+AI0Avf8Q//T++v6b/+//dAB4AFUAdgBjAJgAqgDEAIsAcQA7APz/yf+e/5b/c/+W/yIAzAAQAaEADQDr/9b/sv9O/+r+pP6S/ir/LADWAIAA1f/N/0IA1QAIAQQBnADj/8z+tv5B/4j/VP/+/mv/IgCgACgBHgF/AL//Nv9X/1f/bv96/3P/ff+O/2EAhAG2ASgBIABa/+j+Ev8//1b/Gv+g/tj+Kv+c//f/7AC+AZQB7AA7AN7/sf+E/5v/h/9U/zT/UP9X/x//eP82ANoAegANAPT/8f+Z/x//ZP+2/97/9v9sAMYAQwCb/17/nP/J/7L/1v/T/5P/lP80AIoAfQAQACQASgBmAD4AdQD3AOYAjQBJAFMAZADGAK0AXQCg/4//BgBIABoAIgDUAAQBZgDY/8v/5f+j/5//9v9oALoAzwACAZkA9//c/0sAlQBNACoAwP86/5r+4P4oAPEA/QB6AD0A5/+y//f/pgDxAJwAGACx/1j/Wf9g/83/2v+2/2b/k//4/zEAZwBtAHEAXQDu/6//nv/O/7T/kP/6/q7+Vv6+/h//Yf/Q/+X/JAAdAFkAdACrAMEAvAC9AI4ARQAMAAUAuf90/67/GgBPAC8AQQBcAH8AfADHACgB/ABHAJn/d/9g/4v/wv8DAOT/bf9u/zUABAGIAagBngFOAYcAJAApAHoARQDs/7T/qv+o/8f/FQBDAEQAZQDkABQB5gAwAKv/lv+D/5n/c/9K/+r+qP7o/nP/CgBMAAoAl/8V/+T+GP+c//v/0/9+/xn/O/+2/wAANgAUAOL/t/9n/zD/F/8W/yL/FP8U/yT/UP9Q/x//Hf83/3f/hP9w/47//v8jAA8A4v/C//b/GQA+AC4ASwD8/7v/Z/9L/8b/RwDEAM8AnQBEANn/2v/x/00AYwDZ/4L/QP9Q/4P/9/9iAKQAxACmAHcAYgCDALQAsQC0APgASAFMAfcAAgHYALIAcQCbAMkAYgAqABEAeACkAMMAMgEmASgB8QDhANQAkQCtAOkA0gBDAP//DwADAN//9/8/AFYA7v+X/6b/nf9z/4r/4v/6/wAAh/9Z/1f/H/88/3H/o/9a/9L+mP6S/or+mP7Q/ir/GP+U/r7+zv6O/mj+mv4X//T+oP6m/sj+mP6M/oD+6P7W/mj+Wv6I/rj+pv7q/jH/7P7o/ob+eP5q/mj+0v4l/3D/QP8+//z+Jv99/xgABADF/6b/Zv+P/+z/SQC4AO4AxwDtACIBfAF8AbgBtAHEAd4BBAL4Ac4BrAGmATwCZALkAtwCkALgAjQDKARoBIAEYATAA2QDfAPMA+QDgAMsAxQDwAKcAsgCNANMA7QCgAKcApACgAJ0AlgCKALeAawBVAEIAakANAB1AHcAFgC//0z/Cv/e/ob+cv5Y/rj90PxI/Bj82Ps4+zD7sPvA+3j7+PpQ+5j7GPvQ+sD66PqY+vD5CPrg+Yj58Pjo+Gj5qPlg+Tj5iPnw+Vj6oPo4+5D7gPtY+7j7YPyg/Pj8RP2k/TT+hP4a/6b/VADoAJgBOAKMAiADyAOIBCgFqAVwBuAGSAeAB2AIAAmACXAJYAmwCdAJcAlgCdAJoAlwCQAJMAlACSAJ0AiwCIAIIAjwBwAIEAioB4AHgAcwB4gG6AWYBdAE4AMQA6AC5AHlAA8Ayf9b/4r+Av7g/dT9GP2Y/Fj86PsI+xj6mPkw+Yj4gPcg9wD3YPYg9sD1sPVg9bD08PTQ9WD2kPaQ9tD2sPYw9pD1QPWg9ODzIPOw8qDygPKA8iDzEPTQ9ID1QPZA9wD48Pio+YD6OPvg+6z8aP1a/nf/wwCgAbQCpAPIBOAFmAaYB3AIcAnwCXAK8AqAC9AL4AvwCwAM8AsADCAMcAywDMAMcAywDPAM8AygDHAMsAwQDKALUAtQC/AKMAqwCUAJwAjoB9gH6Ad4B7gGaAZABlAFaATIA4QDRALmAPj/o/+8/rD9UP1U/Sj9HPzI+5D7YPtg+tj5oPk4+Qj4EPfA9iD2cPWA9KD0oPQQ9PDzIPQg9dD14Pag97D3MPcQ95D3QPew9oD2gPVQ9KDyIPIQ8tDxkPGg8cDysPOA9HD2GPiY+aj6qPuU/CD93P3U/n3/BQB2AFwBMALMAggEmAUQB/gHsAjgCeAKYAsQDLAM4AzADJAM0AyQDHAMQAyADGAM8AswDJAMAA2gDLAMsAxwDPALgAtwC/AKIApwCSAJ8AgwCPAHuAdYBwgH4AaQBlAGyAV4BcgEGARcA5QC0gEOATYAYv+A/tj9JP3Y/KT8aPz4+3D7KPso+6j6WPrA+XD5uPjg97D3QPfg9iD24PXg9fD18PUg9oD2oPYg96D30PfQ9+D3qPig+Hj4qPiY+WD5kPfQ9uD1MPUA9FDzcPPA8zDzQPPg9MD2wPeQ+KD5yPoQ/Jj8sP2y/lD/1v8HAOgAfgEcAggDvAOoBIgFYAYQB+AHAAkACvAKYAuwCwAM8AvAC5ALgAsgC4AKEArwCSAKEApgCnAKgAqACqAKkApgCgAK8AlwCSAJUAj4B2gHCAegBvAF8AVIBdAEUARIBGAEEASAA+wCjALqAVoBlQAEAFX/nv6o/TT9pPxk/Oj7QPtQ+wD7APtw+hj6GPrY+Zj5KPm4+GD40PdA97D2sPaQ9oD2MPZQ9uD2UPeg9xD46Pgo+Xj4UPjA+KD56PkY+ZD5wPnI+MD3APdg9lD1UPTg83D0IPUg9TD2EPco+OD4EPqQ+3D8YP0Y/gn/o/8XAI8AAAFAAbIBlAJ4A4AE+AQgBjAH8AewCIAJYArgCoAL8AvwC6ALQAvACpAKYAowChAKoAmACZAJIAogCnAKQApACnAKMAoQCqAJAAlACIAH8AZwBtAFcAXoBLAEcAQoBAAEWANIA0ADJAOwAuIBPAHBAFQAkf8K/0r+kP3Q/Fz8bPws/JD7OPso+xj7qPpo+lD6IPqI+TD58PiI+Ej44Pfg96D3IPcg9xD3EPcg94D38Pc4+GD4sPg4+Tj5aPmg+WD6KPpw+pD6wPp4+hj60Pkg+bD38PXQ9aD1QPVw9XD24PZQ9xj4QPng+nD7RPw0/QT+fP6y/rz/JwBuAIMALgHqARgCzAIwBFAF0AWwBvAH0AiACRAKAAtwCzALsAqgCnAKwAlgCSAJ4AiwCGAIwAgwCVAJYAmACeAJ8AnQCbAJUAnACDAIuAc4B5AGEAbABXgFGAXYBMAEgAQwBOQDzAOoAzADsAJgAvABUAGpABkAsP/8/mT+OP7k/Zj9EP3Q/KT8bPww/Pj7wPuA+xD78PqA+jD6yPlg+RD5wPiY+Gj4UPgg+ED4kPjg+Lj44Ph4+fj5GPr4+dj6+PrI+qj64PoY+6j6YPrQ+vD6WPow+Wj44PcA95D2kPbQ9vD2cPeQ+ID5YPoI+9j7lPzc/Hz9Hv7U/hj/d//d/zYAogD7ANABpAKAA0AE8AS4BYAGeAdgCAAJcAmgCQAKMArQCdAJkAlgCfAIgAigCPAIEAkQCUAJsAnQCfAJEAoQChAK4AlACaAIAAhoBwAHYAYIBqgFUAUABagEoASIBHAEGATYA8ADpAMcA3wCIALCAQYBRACk/0n/wP70/aj9dP0U/aD8ZPx4/ID8FPwA/Az8mPtg+wD7qPro+Uj5EPng+GD4GPgg+HD4GPgY+Jj4yPgw+Rj5qPlA+mj6WPqI+hD7+PqI+oj60Poo+8D6QPog+qj5MPhw9+D2APfQ9oD2QPco+Oj4YPkw+sj6OPtw+yD83Pws/YT9KP6y/vj+/P69/zkAxwBMAUgCUAPwA7gEoAW4BkAHmAcwCMAIsAjQCMAIwAhACOAH6AcACJgHuAcQCHAIgAhwCCAJYAlwCRAJQAlwCcAI8Ad4B0AHcAaoBVgFWAUABVgESASIBFAE+AMQBBgEAASEAzADQAOYAtQBogFQAaAApv9i/1f/1P4e/sT95P3c/VT9HP1E/Rz9pPww/Az8uPs4+5D6EPrA+Sj5sPhQ+ED4YPhg+GD4oPjY+Dj5YPmQ+QD6QPpg+nj60PqY+nj6SPpo+nj6OPoo+kj6QPqA+aj4GPiA9+D2sPZA98D3QPiA+CD5yPlg+uj6IPvo+wj8xPxo/cD9KP6g/kD/Yf/v/84AsAFEAsACxAPIBHgF0AWgBpgHQAiACKAI8AjwCLAIgAiACLAIsAiwCJAIkAgACfAI0AgwCaAJ4AnQCZAJsAmgCRAJMAiQB3AHEAdwBtAFkAWABdgEYAQIBAAEIATIA5QDkAN8AxgDiAIoAtYBiAHpAB0Awv96//r+Tv7Q/UT9TP38/Hj8TPyA/HD8yPtA+xj7IPuQ+sD5gPlI+QD5QPjw9xD4APiw95D38PcQ+FD4iPiw+Bj5aPm4+fD54Pkg+nD6OPoQ+jD6ePqQ+hj6APrY+UD5SPiQ96D30PfA9wD4iPgw+Xj52PmA+vD6YPvI+yT8yPw8/aT9FP6I/hP/mP8jAL4AeAEkAqgCOAMQBNAEiAVwBnAHYAiwCAAJQAkwCRAJsAgACQAJEAkQCSAJMAkQCQAJMAmACaAJwAngCTAK8AmwCTAJ8AhwCLAHKAfwBngG2AV4BVgF+AR4BFAEiARwBAgE2APUA4gD9AKoAmgCBAJSAekAcwDx/3j/5P6y/ib+rP10/Sz92PyI/JT8dPzI+6D7kPtA+7j6KPoI+pj5APmo+LD4qPhY+ED4cPhw+HD4yPg4+YD5mPkI+nj6WPpA+nj6kPpo+lj6cPqo+oj6UPoQ+oj5wPgQ+AD44PfA9xD4kPj4+BD5MPnI+Uj6oPog+6j7ZPyw/MT8YP3g/XT+zv6U/2oAFAGqAVAC+AJkAwgEuAS4BZgGMAcACKAI8AjwCPAIIAkgCSAJcAnACcAJsAmwCdAJwAnwCVAKgAqwCoAKwApgCsAJUAkACaAIyAdYBxgH8AZgBvAF0AWIBUgFEAUIBcgEgARABAgEZAPUAqgCRAKyATgBEgHGACsAev8s/xP/ZP6o/Vj9XP0I/WD8PPwQ/BT8ePvQ+qD6SPrw+UD54PjA+MD4KPjA96D30PfA95D3kPcI+Hj4mPiQ+OD4OPlw+Tj5IPlo+Yj5mPlQ+aD50Png+Sj5kPhg+ED4wPdw96D3cPiY+HD4wPgw+aj5iPnA+Vj6EPt4+6D7NPx0/AD9rP0i/o7+Xv9qALoAGgHOAdACzAMIBNAE8AUAB3AH0AdgCAAJEAnACNAIcAnACaAJoAnQCTAKMArwCWAKAAtwC0ALIAtQC0ALoArACYAJEAmACNAHWAdgB9gGWAYIBvgFqAVQBfgE+ATYBGAECATEA0QDmAJIAggCiAEMAZ0AWwDd/xD/mP5Y/uz9bP0c/ej8xPx4/AD8yPtg++j6aPoA+oD5CPnY+Gj4EPjA97D3cPcg9/D2UPdw92D3kPcI+HD4ePiY+AD5IPn4+Mj4EPlQ+Sj5KPlg+aj5OPnw+MD4kPgo+PD3YPjI+Pj40PhY+fD56PnA+Rj6CPtw+1D7sPu0/Az9+PxU/VD+Sv9t/yAAKgEcAowC1AL4A6gE2ASgBbAGkAfgBxAIEAlACSAJIAmwCRAK4AngCZAKoApwCnAK0ApAC1ALMAuQC6ALEAugCkAKoAnACEAIEAhQB7AGgAZABgAGSAUQBVgF+AR4BCgEGATcAwQDjAJYAhwCdAHWAL8AjwD//4b/MP/C/jr+vP2M/Vz9BP3k/ND8fPzo+4j7WPvI+hj6sPmY+TD5mPhY+FD4MPiA92D3UPdQ9zD3UPfA9+D3MPhQ+Ij4mPiY+Mj4qPiY+Lj4APkw+Rj5aPmI+UD5uPio+KD4aPgA+Gj4EPn4+Pj4WPno+fj58PlY+gD7YPuQ+wj8uPzg/Pz8fP1g/tz+dv9cADYB1AEYAtQCtAMgBNgE2AXwBogH2AeQCPAIEAkwCbAJEAoACnAKwArwCtAK0ApAC2ALgAugCyAMMAygC0ALAAtQCoAJ4AjACHAIwAdgB/gGkAYQBtgF0AWYBTgF4ASwBEgEpANUAxwDuAIkAsIBfAEgAaoAKQDO/z//tv4y/uD9xP1s/Sz98Pyg/CT8qPtg+wj7kPoY+rj5aPkQ+aj4cPhQ+BD40Peg96D3sPeg97D38PdI+ID4qPjg+CD5SPk4+Sj5SPmA+Zj52Pnw+RD6KPrw+bD5cPlw+Uj5QPlI+ZD58PkQ+iD6WPqg+uD6APtQ++D7UPyk/PD8aP3U/TL+zP5z/xoAzgB6ATQCwAIwAwAEwARQBegFwAagB+gHAAiQCCAJQAkgCdAJcAqQCjAKUAoAC9AKkAoQC9ALsAugCzALgAvQCrAJUAlACQAJ8AfYB8AHKAdABtAF2AWwBfAEmAToBIgElAMgAwQDnALeAYABfgFSAY8AHgATAKv/5P54/kr+Av6I/SD9AP3E/DT8wPuw+zj7oPpI+hj6oPkY+bj4iPhA+MD3kPew95D3cPdQ93D3kPeA96D38Pco+ED4cPiw+Oj4+Pgg+SD5QPlQ+Xj5uPnY+ej50PnA+aD5UPk4+Xj5oPmo+dD5CPo4+mD6iPrQ+iD7YPuw+xT8gPzY/Cj9nP0c/pj+Ef+j/1MA+QB2AQwCuAJUAwAEiAQwBegFiAboBngH+AdgCKAI0AgwCYAJoAmwCeAJUAqACsAK8ApgC8ALsAuQCxALYAoACsAJ8AjACJAIkAioB8gGuAaQBkgGUAUoBXgFSAVgBMwDEATYA9ACWAIgAiwCkAECAcIAxgA1AJ//Mf8G/9L+WP4o/sj9jP1A/eD8TPzQ+7D7YPvA+lD6+PnA+Tj5wPiQ+Hj4SPgQ+PD3GPgo+PD3IPgg+CD4QPhw+Kj4qPj4+CD5KPkY+Tj5ePmI+YD5iPnI+cj5oPl4+aD5kPlg+WD5kPnI+dD5+PlA+nD6mPrY+ij7gPvA+xz8YPyc/BT9hP0S/pL+Kf/p/4EAEAGoAWQC+AJ0AwgEoAQ4BdgFaAb4BogH6AdgCLAI4AhQCZAJoAmACeAJYArQCuAKUAvwC9ALMAuwCqAKMApgCcAI0AjQCMAHmAcAB8gGIAaQBWgFKAXgBIgEaATQA0gD0AKIAtIBSgEYAfcAcgCv/43/hv/0/nj+LP5Y/gb+cP0U/QD9wPwQ/MD7oPtg++D6ePoI+qj5SPn4+Kj4WPhQ+FD4APjg9+D38Pfg97D38PcQ+Dj4SPho+ND42Pj4+Cj5cPmo+dD5EPoo+iD6IPo4+jj6KPo4+lj6aPpQ+mD6mPrA+sj68PpI+6j72Psg/Hz81PwE/Sz9iP0I/nz+CP+b/y4AyABSAeYBfAIgA8ADUAToBHgFCAaQBjAHwAdACLAIEAmQCeAJIApACmAKgAqACsAKMAugCxAMIAwQDNALQAuwCkAKAAqgCQAJ4AhwCHgHAAeYBlgGyAVABTAFOAWQBBgEoANoA+wCKALYAZwBWgHVAHEAEACT/xP/yv5+/ij+Bv7I/WD9+PyU/Gj8+PuQ+1j7EPvY+kj64PmA+Tj5wPhw+Dj4EPgY+PD38Pfg9/D38Pfg9+D3EPhI+GD4gPjI+Aj5EPko+XD5qPng+Qj6SPpw+nD6YPqA+oD6YPpo+oD6yPqg+sD6APso+0j7WPug+/j7TPyI/Mz8JP10/cz9Fv6K/iL/wP9MAMgAVgEMApACAAOAAzgEyARQBdAFcAYgB5AHAAiACAAJUAmwCeAJEAoACmAKQAqACqAKkAvwC8ALwAtwC1ALYAqwCbAJsAkgCVAIIAi4BzAHcAbQBbAFWAUYBWgEKAT8A5gDHANgAgQCugFwAccAUQATAOH/S/+e/mz+cP4U/sT9VP1k/Rj9ePzo+7D7gPsw+7D6UPoY+sD5OPmY+Ej4IPgA+KD3cPeA96D3cPdA91D3cPdw91D3gPfw9wj4KPh4+Ij4qPjg+Cj5cPl4+aD5+Pn4+eD5APpI+mj6QPpQ+pj6yPrA+sj6KPt4+4D7uPsU/Hz8wPz4/Gj9uP0E/nb+8P5//w8AsABAAbwBUAL0ApADCASQBEAFwAUwBrgGSAfIB0AIsAggCaAJ4AkQCkAKcAqACpAKAAtwC9ALEAxgDFAM0AswC7AKgAowCoAJEAkwCYAIkAcQB9gGqAbQBUAFaAVQBagE9APEA6QDkALsAcQBfAEEAUgAVAAvAG7/3P6+/qr+SP6g/bT9gP3w/Fj8GPzg+3j7wPqw+oj62PlI+eD4mPgg+MD3gPdw9zD3QPcQ9xD3APfQ9hD3APfw9iD3QPeA94D3kPfg9wj4APg4+Gj4wPjA+Nj4GPko+Uj5aPmQ+aj5oPnA+Rj6QPpA+nj60Pog+0j7aPsA/Gz8nPzk/GT9+P1A/r7+d/8PAL4ARgHqAYwCEAOkA0AEwAQ4BeAFcAYIB6gHQAjgCGAJ8AlgCrAKwAoQCzALYAuQCyAM8AwgDTANcA0wDYAM0AtwC1AL4AqACvAJwAkQCUAIwAdgB/AGeAZABvgFwAUwBagEQASQAxADkAI8AsIBUAEaAaEACACP/1f/E/+g/mT+Mv7k/UD9zPx8/Bj8qPtI+xD7wPow+qj5IPm4+FD48PfQ95D3QPdA9zD3EPfg9gD3APfw9uD2APdg94D3YPeA98D38Pfg9wD4QPjI+Mj42Pjw+ED5YPlQ+WD5mPnI+bD54Pkg+kD6cPrQ+gD7KPtw++D7SPxw/Kj8OP24/Q7+Wv4e//H/hwDKAJABUALUAkQDtAOYBBAFeAUgBsgGYAf4B5AIEAlgCbAJEApQClAKcArwCkALgAvwC4AM8AyADCAMwAuAC+AKYAogCgAKgAnACEAI0AdAB9gGoAZQBtAFsAVABdAEQASoA2wDsAJQAuoBsgFSAcMAVQAAALH/Lf/W/qr+dP4C/oT9NP24/Ez88PuY+0D70PpA+sD5WPm4+DD44Peg91D3QPcg9zD38Pag9qD2sPag9oD2kPbw9hD3APcA90D3YPdA93D30Pcw+Dj4YPiA+MD4sPjQ+ND4EPkw+Tj5gPmQ+bD5yPkw+kj6ePoI+3D7uPv4+2D84Pwk/YD9OP7s/l3/zv9xAE4BsgEkAtgCmAMgBJAEOAXwBYgGEAfAB4AI4AhgCcAJIAowCmAK0ApAC1ALsAuQDAAN8AzADOAMoAzgCwALAAswC1AKsAlQCfAIYAh4B0gHQAfYBgAGyAV4BfgESAQYBMADTAOoAjAC7gFyAeUAfgA5AMT/WP8g/wX/sv5S/gj+jP0Y/ZD8OPzo+6D7IPug+iD6ePkY+Yj4OPjg98D3wPdw9yD3EPdA9wD3oPaw9iD3IPfg9hD3gPeQ92D3kPfw90D4OPhY+MD46Pjw+OD4EPko+Vj5kPmg+bj5yPkI+kD6QPpg+tj6IPtQ+6j7APx4/MT80Pxo/Q7+nv74/p3/iQAEAX4B7AHEAlQD2AM4BPAEiAXoBYgGIAcQCIAIIAmgCQAKIApgCpAKgAoQC4ALIAwwDJAM4AywDBAMsAtgC1ALcAoACuAJoAnQCNgHoAdYB/AGOAYIBuAFgAW4BEgEIASYA/QCjAJYAuoBSAHeAL8ATwDA/2n/W/8I/4T+ZP4w/sD9OP3U/Jz8KPzA+1j7+Ppw+sj5cPn4+GD4EPgA+ND3UPcg91D3QPcA98D2APcg9wD30PYQ9zD3QPcQ90D3sPfA99D30Pco+FD4OPho+Jj46Pjo+Pj4IPlA+UD5WPmw+ej5+Pk4+rj6+Pog+2D7APxs/MD8IP3Q/Yj+5v6F/x8A/ABeAcgBZAIoA5gDGASYBDgF2AVYBhgH6AewCGAJ4AkgCiAKMAqQCtAKEAuwC3AMwAxQDHAMgAxADKALEAsQC7AKEAqACUAJ4AgACGgHGAewBjAG4AWwBUAFmAQwBNgDTAO8ApgCZALAAQIBpAByAB4Ahv9N/yz/7P5Y/gD+rP2A/fz8oPxE/Mj7WPvg+nj66Plg+eD4mPgg+MD3oPeQ91D38Pbg9vD24PbQ9rD28Pbg9sD2wPbQ9hD3MPdA91D3oPfQ9wD48Pcw+Hj4sPjA+OD4MPlg+WD5YPmI+bj56PkY+lj6oPow+zj7gPvw+3z8EP08/dj9Wv4L/6f/VAAUAboBPAKkAkQDvANQBAAF2AVIBtAG4AeACDAJkAkwCtAKoArQCjAL8AsgDGAM0AxQDYANQA0wDTANAA1QDNALYAsAC1AKsAlQCdAIUAjAB0gHCAeIBigG8AWIBegEiAQIBKQDHANwAhgCrgEiAdkAdABVAN7/Z/81/+D+gP78/dj9hP0M/YD8FPx4+/j6MPro+WD5+PhY+AD44Pdw9xD34PYg97D2gPaQ9rD2cPZg9mD2oPag9mD20PYQ9xD3EPdA95D3gPdw98D3GPgg+Ej4ePjA+Mj4wPj4+ED5aPlw+bD5KPpY+rD6GPvI+xD8cPzo/ID98P2O/qH/wABQAWQBGAKgAtQCFAPwAxAF+AUwBvAGMAjACPAIkAlQCsAKwAoQC5ALMAwADEAMwAwADRANIA1gDUAN4AxQDNALQAugCjAKoAlQCcAIIAiQBzAHgAYYBtgFgAUwBZgESASQAwgDfALUAWQB9ACxAEMAEwCl/2H/yv5c/gb+3P1g/fz8xPxA/Nj7KPug+lD6qPlI+fj4gPjw93D3YPcA96D2kPaA9pD2UPZg9qD2gPZA9kD2gPaQ9qD2kPYQ91D3UPdA95D38Pfw9xD4MPi4+Mj4sPi4+Bj5SPkw+XD5uPkY+ij6gPrg+qD7sPss/ND8+Pyw/RT+8P64/5MASgHKAQQCcAK8AqQD9AOwBKAFwAZYB/AHoAhgCfAJ8AlgCtAKYAtwC8ALQAyQDLAMsAwwDVANQA0ADcAMcAywC/AKoAogCoAJAAmwCFAIoAcoB+AGeAb4BYgFQAXQBEgE1ANgA+QCZAL8AbwBVgH8AK4AVgD+/3P/JP/I/nr+EP64/Tz95PxI/Lj7WPvQ+lj6qPlA+ej4YPgA+KD3kPcg9/D2wPbg9tD2sPbQ9sD20PaA9qD2oPbQ9tD2APcg90D3YPeQ9+D3APhQ+Ej4ePhg+Hj4gPjQ+ND4APkw+WD5yPn4+XD64PoY+zD7cPvw+4D8XP12/mz/2f8hALYAZgFKAQQCzAKsAzAEsASYBWgGCAegB3AIMAlwCbAJgAoACzALcAvgC1AMIAyADPAMIA3wDMAMsAxgDJALAAuwClAKsAnwCJAIIAh4B/gGsAaQBggGqAU4BcAEIASAAzADsAJIAuIBrgFoAd0AcAAmAMz/WP8B/77+XP7k/Vz9/Pxs/Nj7UPvg+lD66Plg+QD5aPgQ+LD3YPcg9+D24Paw9qD2gPaA9mD2YPZQ9mD2gPaA9pD2gPbQ9rD24Pbw9iD3gPdw98D3sPfw9/D3MPhA+JD4sPi4+AD5IPmI+dD5UPqY+nj6APtY+xj8vPyM/dz+eP/H/wYAgACwAFABwgHMAqgDOATQBMAFsAYgB+gHcAgwCZAJAAqQCvAKgAvAC1AMsAzADOAMMA0wDfAMkAwwDMALMAuwClAKAApwCSAJoAgwCKgHQAcIB6gGUAa4BVgFuAQoBLwDXAPwArACNAIAAmgBIgGkAIQADQC9/2f/2v6s/hD+pP0Y/az8+Ptw+9j6cPoQ+oj5MPnA+Hj4EPjA93D3gPdA9yD3APfQ9uD2gPaw9qD2wPaw9qD2wPbA9tD28PYg90D3QPdw94D3sPew9yD4UPhg+JD4yPg4+Xj5wPmA+rj6mPro+gD7CPyw/FD9ev5t/7H/2P9XAJcA/QCKAUQCfAP0A8gEYAVoBtgGMAcQCLAIQAmACSAKsAogC2AL4AtQDHAM4AzwDGANMA3QDJAMUAywCzAL8AqgCiAKoAlgCbAIQAioB0AH8AZYBgAGYAXoBOwDjAMQA6ACXALgAcIBUgHRAFgA8P96/wD/gv5M/rj9SP3M/Gj8IPyA+zj7uPpA+qD5QPnI+Fj4APiA95D3IPcQ9+D24PbA9oD2gPZw9nD2MPZg9qD2wPaw9tD2EPcw9yD3QPeA96D30Pfg94D4mPi4+Pj4SPmI+Zj54Plw+vD6MPuo+9j7ZPx8/Dz9/P3g/nn/SgDPAEIBhAHAAYgC3AJcAwgEMAXABWgGOAewB1AIgAggCZAJ8AlQCpAKQAtQC8ALQAygDLAMkAyADGAMEAyAC2ALIAuACjAK4AmwCUAJwAhQCPAHSAd4BgAGqAUQBbgEQATkA1gDqAJIAuQBbAH8AIMANgCU//L+hv4w/sj9XP0Y/bT8OPyY+xj7yPo4+sj5QPn4+HD4APjQ96D3kPdA9zD38PbA9pD2gPaA9mD2UPZQ9mD2gPaw9uD28Pbg9hD34PZQ92D30Pcw+Hj4yPjo+Pj48Pgo+VD5sPlA+uD6ePvw+yD8VPyc/Bj9Ev6i/nb/GQCMAMcAJgGGAfYBZALoAqQDaAQIBZgFSAa4BvAGKAd4BwAIYAjgCGAJ8AlQCqAKAAtQC3ALMAsAC8AKcAogCgAKIAogCvAJoAlwCRAJsAggCHAHsAb4BUAFyASYBHAESAS8AzADjALYAUIBwQBYAOX/Wf++/jj+yP1Y/Qj9uPx4/Aj8iPsg+6D6KPqY+Tj5+Pio+Fj4GPjg97D3gPdg90D3UPdQ93D3cPdw94D3gPeg93D3kPew9wj4UPiY+PD48PgA+Sj5YPmA+bj5QPrA+hj7IPuY+9j76Pv4+6z8tP04/oj+6P5I/2n/cf/5/7gAfgEMAugCFAPsAqACJAO8AwgEWAQIBeAFcAawBhAHYAd4B3gHsAfYB+AHIAiQCCAJYAmwCSAKUArwCVAJ4AggCPgHCAfoB9AH4AcgCPgH2Af4BmAGeAVwBIwDDANEAygDHAMIA/ACvgGNABEAFQDl/0n/BP+8/tj92PyI/Jj88PzE/Ij8ePwk/Ij7oPoY+rD5SPmg+KD4UPkY+mD6UPro+Xj5+PjI+Bj5KPkQ+fD4CPng+PD4UPlg+jj7WPsw+6j6gPoo+hD6ePoY+8j7PPy8/Pz8RP00/Tz9BP3w/OD8VP0q/h3/CgA1ALQAlwDhAKwAHAGIAQwCNAJIAqgC1AJgA9ADeATwBDAFUAVoBaAFgAVABTgFAAaIBjAGyAWwBtgHuAfIBtAG6AeIBxAGAAUABlAGaAWgBaAF0AVgBdgEuASQBMwDQAS8AxADrALaAV4BBAHeANwBSAGwAMIALAC+/iz9rP14/kL+aP3s/Vr+oP0k/OD7cPxo+4D6CPvA+wD7QPpI+vD6APuY+7T8gPsw+RD4UPgA+Rj56PkM/Dz9kPyg+7j6WPpI+hj7KPvQ+gj7NPxI/ZD9vP1E/jz+oP0Y/bj9tP76/lX/av8n/4T+nv4YAGIBQALQAvACLALjADIAhQAgAYYBMAJkA8AEeAWABeAEWAScA9gC9gHCAWQC1ANoBQAHEAjoB4AGmATUAnoB3ABgAYwDOAZACPAIQAioBvgDxwB4/hL+Qv/CAXgE4AYACJAGQAN2/0z98Pvo/KH/XAKwAyQDAALuAKEA2P+c/gT9sPu4+jD7DPzU/cwAaAKKAbUA5v+Y/QD7EPiA91j4CPqw/CIAuAJqASj+8PuY+uj5UPnY+lT94P2o/FD8XP3k/Uz92PzQ/bb+Pv50/Zj9WP1E/Uz9jP3E/fj90P7v/wABdgFMAWQBu//s/JD7PP3T/zIBDAIYAtQBjwDx/2IBSAO/APD+9v78AEoBNgDaAdACHAIN/xYBOAU4BvQC9f8C/wX/Mf+aAPQC7AOABIgDcAN0AtQCBAICALT9nPyM/s4A+AR4B6gGBAJk/hz+nf+//yQAvAEkAhQBkf9sARQD5AK2/wr+aP20/Uz+u/84AUIBIAGeAFgAnP9B/w7+mPz4+0z9xf+SAXgBEgB8/nL+Zv6k/bj7gPtE/Vz+8v5cALwCcAIo/nj7YPw+/uD9IP2o/Zr+1P3w/Y3/jALIAbT/Sv6k/sH/dP7Y/bD82P3W/h0AIAFgAtQCm/8c/aj9PAFYA8MA5v7o/iH/gPvo/DQDIAgIBRL+UP0UAXABRP5J/7QCqAQSAWD+5P8wAnIA6Pze/oACQAX4BhAGVAMU/ZD5+Pq8/lAAtAKACTAKsAKQ+6D8Vf+7/0D+dAEIBwAFrAJ8ANgADPwY+lr+xAIgBhgDbgAWAMP/FP2E/I//kAIwBXQBzv6O/7v/sP1U/UwALP72AAgCmASUA6j8ePkA/KL+wPx3/0gEUAUQAyv/8P2s/cT80Puy/nQAM/+kAXYBgQAQ/Aj7DP09AOgDwAOkAtL/QPsQ+Gj5WP1yAdAEgAbABsYB0PmQ9vj56PwY/Qb+gARoBtQC/P8EA+gBDPyI+mj9LgGI/Cj7/f9wBPQD0ALMA5wCTv7I+iz80v6lAMQCAAVMA6EA1v/G/n//pv7I/cT9DP5YAXgG4AdQBOIAIP6Y+/D4oPs7ABgFAAUABaQDIAIzAPL+sP4A/YT8gP2QAdIBHAFwAcwCxAMWAXT/Fv5A/ZD9bf8PAIz/g/94ATAEYAOs/oD7rP7bAKv/JP36/zAFSAII/Bj7C//6AEL//gB4BQAFyv4Q/BT9cPsI+HD7YATQB1gH/AMYAtT9MPrg+aD6QP2R/74BrACNAPgDEAiQBMz9bP1w/dD5YPZg+8wDcAfcA3QCKAREAuD+YP0o/qj84Pp8/PkAbAPoAwgEQAZoBOr+mPkI+ur/9AHD/wYA4gFoAzwDMAKIAroAQP3U/dD+ZP7u/oQAmAOUAwgCnQBcAXP/sPuc/H//6AANAL8A/gEMAigBvgHuAdL+9PwN/y8A4P7Q/dr+PAKUAhgBJ//XANwB7gD4/mb+yPyM/Hn/mAAsAmwDMAScAvz+cPwg+2D7qP12ARAHQAUy/mD6kPzAAo4BZP5EACADEAIQ/Xj7LP01/xj/kAIQA+wCwAI2Afz9+Pgg+hz8LACyAVgE2ARkA8IB3f9s/Ij54Pqs/hwAmv/IAQgFiAS+AGb+GP+w/rj84Psc/AD+qAJoB/gGPv+w+uD91AGhAMD7KgBkA4ACVP0I/nQCGANe/tD7mgCYAer/bP4QAgADjP/Q+1L+7AMYBBABggCJ/zj7gPjw/RAG4AbYBPAD1AOc/gD2wPek/ef/zQBQBRALoAXI+wD7xP58/Nj4AP2IB4AIGAFQ/c0AWgGA/KD6fP77AEEAYv4lAOABTgEMAXABOAH0/5T+APzw+yv/MAFMAugAcQDkAIL+dP4NAEQBLv+g/MD8YgCAAcgD+ARUAy7+wPeA+Rj90wDIAOwC+AQIBLj9OPpg/+QDzP+g9/j6LAM4BPL+bP74BVAFNP3w+az9iv7s/FT+UANwBZ8AOv8yAZIBkwCe/yT9aP1A/Kj8xf/wAigGaARSAaIAwgFpAOj6aPs0AKr+qPumANAJYAwYBJj6cPug/gn/JP0a/lQBKATUAx0AaP2yASgHcAW4+0j4zP1UAYX/H/+gBgAI9P7g+Hz9lAG4AIX/UAWwBcz9kPeU/TAFlANmAUADmAFo+6D2YPu4BEgFLAHx/3QCJAKO/nD7NP0RADIBxP8nANQCcAJZ//j84Ppo+pT83AKIBUAFwgG8/tj88Pfw+f4BYAdIBHD9GPuA+7D8mv98A2gGOALY/rj8IPuo+BT9SAXQBnAC3P4YAHz/aPw4+87+OAR8ApgB0AHxABMA1PwY/AD9qQA6ASIB6gGQBQAIkAGo+mD3KPpM/WkA2AewCMAEUP0Q/uIAmP+o+uD8OARkAxEAhP/4BNgEYgD4+aj66//oAegB9AJ0A5ABAP8eAIAC0AFg+7D1oPgqACAEqAXIB/AJiAeA/AD0wPj4/Rz8ePnU/WAHSAewBEAGMAp3ADDwoO54+TAD0AFgAqAIEAmwAaj6iPzS/sj7uPvQ/fD/eP+TAOgCsAIKAeb+qv99APT9LPw4+0j9egHIAkwDzAJMA/v/mPoQ+Nj8QAI8AjwCtAMQBer++PrI+mr+gAHoAJACSAMOAdT9s/84AqADWgGE/RD8hPxmARQDrAKIAdUAPQAIAygE2wCo/Pj76P4Q/2z8gP7AB1AJOAS0/TT9zP1A+lD7yv/YBcgFIAN4ArIBLwC4+8T89v+XALcAJgGQAooB4v9g/ZD/uAOoAnQCWgCSAGz9gPgg/IwDUAZaAaT9IwDQAkcATPzq/ugCTAJg/cD7V/+ZAMAA3P46/vD9yAIgBn3/qPoU/PgEQAIw93D4vAKoBET9TP6IB+AHaPuA9n8AaASU/Nj4G/8wBLT9HP0YBRAIDAEI+bD78P70/Ej7CAJYBkwC2PvQ/DADvAO0ARr/8v6s/RD72PwiATAFeAOc/zj+yQDsAEr+8f9AAoADD/9I+sT82AJwBC7/YPwJABgF7AIW/hL/4AOkArD6mPhHACAHqAFI/TACOAXO//j4TPwQBTAEmPu0/mgGsAUl//j69P4rAHz+gP2QATAErAMWAQz8UPuF/+YBOgHoAgAE1ADQ+Tj5gQCQBPr/YgDgBggFMPtA9cD6RAIoAwUAcv6u/+AE2AQ6ACj7PP2CABj80PpQ/lAGgAfYAej9MPvA+LT8+AVwB/YB+P+Y/Qj6gPdg+e7/SAWgCegHJAPo+uD36Ptw/KD5GPvQBbAJIAcwAzL/SPq4+KD7zPyD/1AGkAkwBBD8EPtwAQ8AGPlA+5AE6ARi/1wCyAYgBYj8IPmQ+zgBlAJC/xIBgAT0A6T+AP6oAogEzv5A9+D6XANABb8APQD4A0ADMv+Z/xL/8Ptc/Oj9IALkAhAF0AbmAaj6QPis/CgBBANFAFYBNgFnADoB/ALSAej/zP3Q+OD6Mv4OAVgCqAZYB6wDLP4A+5D7uPmY+Oj84AZgBtAECAWYBDj88PTw+n8AyABg/Mj+CAbABRT8UP14BHAE8Pvo+nT/vAFg+zj7QAMABJoBkgFoBZf/OPjA+ZwCGQAQ+hj9cAeQC2wD6/9w/kz8EPcI+RX/PAOwBGAGmAYwAxD/Wv6o+nD6yP2R/27+YwAgCAAKEAJo+eD4ev4q/oABiASYBZT/1P16/o0AbADz/7IAJ/9o/fD9dgEgAiQDdAMUAsYAZPyI+yT9vv+t/7T+uwB4BPgFvP/A/MD+OP+I+oj79AJQCPIBMPvY++UA9ACI+4r+/AOoB6gCfP6E/Nj5IPqQ/RwB/AJoBHgFsAXs/Vj4yPi4/RoByALkA6wCu//g/Qj++P3c/CH/HANcAyIABP1A/tUArAAg/Rf/nANMA5QBDP5w+5D7rP1AAWAEGAVEA2QBdf8Q/Jj5wPz4AhgESQCiAUwClwBg/hj/VANAAVj7APo4AtADkAHIA1gFYAMu/sj7QP6MAB7+zv5yAcABGAG1AMj/mACYAnQDAgEg/jD/ZgFJ/2D52PmSAYAHcAikAzEAPP3U/OD7DPzo/Rb/AAL6AVACCQAYA4AHCAdQ/TD1kPYQ/s8A2v7sAOAFIAjAAu7+YP/O/uj5kPic/J0AQAQYBSgFeAPu/5j6sPio+fz+yf8n/+4ACAZQCFACmPsI/PD8ePuQ+YT9TAKkAjT/XAFACJAHcAKI+7D4KPig+Cj7kgEgCGAIaAVQAugAVwCI/QD4cPeY+yAAaAPABlAJKAcU//D3wPe+/gAD5v/7/+wCUASIAWb+GANgBoL+MPRg+FgEUAlIBZgCSASN/7D2YPbh/yAHwAWQAWYBvv8Q/uT8HgFIBOwD3v44/cD8qPt8/dQCOAfwBHb+lPzX/yQBGP4w+pj5Yv5gBegHGAXKAEj+hf/4+oD3aPqEARgG0AWaAYz/+P90/UT8ePsM/r4BaARAAqoBuv9o+hj5AP64BOgDXv9M/e4BCgEU/bz8HgFwAvL/jPwA/Yb/Yf/CAAAFSASCATL+8PvQ+ST8igD4BPADGwBn/2QCSAAw/Tj95gC/ABj8mPv/AAAFoAUIBRIB8PoA+Sj6pAEoBSgBa/9sA5QDtv6s/Qz9qv5FAGQCKAZIBIT9qPgs/Yv/mP+wArAGsARk/67+3QBS/2D7Lv74AoQCU//I/loBKAPNAJz/rv+oAJgBLAMEABj7CPmw+yX/HAKgBWAJUApQAeD3sPaQ+MD4gPsMA/AMwAt6AQj7xP2h/1j8MPvU/TAA4AGYAGoAdAPwBQwAkPuE/M3/4P+o+oz9OAaQBHz8uPqEAigFggDw/c4A+gGs/ND5aPxY/kb+cAJQCUAIx/9A+XD4SPyo/YoAkARABggB5Pxg/Uz9Iv/oA9AFugB4+/j7PgFwAZr+Qv84AhQCUv6j/4gDmATq/tj6MP4gAxQCbPyo/PwDiAVi/zD9hAIYBOD74PkaAYgGbAGc/MwDDAMA+nD3NAFgB2AARP3gASgHigCY+xT+//9k/LD5ZgFwB/AGTQBQ/9gANP0Q/A7+AgC3/5n/QAA0AWsA6P0KAbwDgQBdAEQBkwBI/KD4+PhOAcwDAARcA2gEZANo/Gj58Psc/tz9gP3iAXAGmAOoARYAIf/Q/UD7nP3E/NT9HAIQBJQCLv8sAmAFjAFA+vj4GPuU/GD/bAJ4BzAJ7APg/Tj6OPrw+tD87AIgCHAGjgA4+wD9zAFq/oD8xP1IA1AJAAayARr+yPzI+wD6QPu2AZAGYAgoBMD+jP1Q/U7/s//E/lIAWAJQAb0AQgF0AQgCZP1I+7j89P4YBdAEuABM/aT+iAL8/dj7A/+QArgADP7QABgFRgEg+5z82gEEAhT8N/9IBggFqPmw+FQCqAZ7AEz9lAFsAhj6wPXZAIAJsATo/qYB6gGY+hj4Qv+QBNIB2PvG/mgEpAH8/Zj+GAGi/nT8Qv4IA5gEaAENADj9IPuQ+ZL+uAVYBwwD/PxQ/MT8KP0k/rAC2AQgA4//ZP2i/nX/4Ptw/cwDMAigA4T9MPwS//D9qPmU/CQDcAbIAtACpAP7/8D7+Phw+wz93P7oBTALmAdwAED8CPyI+Rj4HPxMA6AIeAZEA9AAuP3A/RT+nPzA+2D+TALIA+kASgDYBIgGQv+w+YD7FgBn/xz9kP8sAmwCYAIYBTAFeP/Y+pj73Pyc/Pj72AFACAgHAAF4/aD+BP7Y/ET8Nv6iADgCRAOwBIIAKPxw+qD7mPtr/4AFMAdYBAwASP4E/dj7MP32/2v/IP22/rAB8ARQBCgC4gDk/RT85P2Q/8j9hP4CAYX/C/8kARgEeAb8A8T/vPzQ+RD4KPtN/8QD+AUoBogEqv94/fz8GP0c/ND7M/98A0ADrAIwA6QD4gFA/Rj7sPsU/xQCTAKWAHUAkAKwBGoBXP6+/l7+OPvA+dr+AATIBdAEQAVwBLP/YPpI+Wj8pv6o/vYAvAOYBJgDVAMIAv3/fPxY+tj5RPxeAHwDmANIBEgEOAJn/yT+BP5c/Nj6+Psk/mwAOASQCDAJQAIA+0j6yPuQ+vD6YP/wBPAFCAR4A4gCKv4I+4D7qPww/QD+1AOABzgGDwD4/Bj8oPtc/VMAOANeABP/lAAoAp7/CPyI/ggEAAXI/rD6lP3yAPD9qPre/hAGsAjEAQD+PP4M/XD6GPo+AcAGWAXMARkA7P8s/VD6VP0gApAEWAMcAVoBdAJL/2D9PPya/gwBeP9gAQAFwAYWASD8UPzk/hj9LPxT/zwDCAV4Anf/KP50/cT+GwCD/6D+XgDeAZoAPgBgAYwCDP5w/B7/MQDO/goBCAP6AJz96PzyABgDgQBs/nL+EP3k/dQCQAT0A5gAWPuI+WD7Iv8cAogDQAPEAyL/oPs4/JQBPANE/rD7Y/+IBRgC9wBoApACJv6I+Yj75P+cA9gANgGABOAF3wBQ/OT8SP7K/hz/mAHEAoQCgP86/+j94P7AAXgCmgBA/ET86wD2ARP/SP8UA1QDrQDI/2gB5/+o/ED74Pz2/qABOAXYBVQC0P1m/sP/jP3g/Mz9kAK4BCwD5P9W/tD+Kv6k/vz9YgB4BCgEqP/Q+1j8iPwH/0MAkALsAHkAfAIwAqT8+PjU/NQAVgE9AHADqAbrAFD58PlH/6kAhv/CAHwCJAKi/vT8k/+YAlkAsP3I/Z4B+AGaAK3/K/8q/wf/BgGIBGgENQAA/bD8cPtU/BgBeAaIBlQBvP4lAM//6Po4+xX/yAERAMwAkATYBJQA2PyG/nj+JP3s/XQA1AL2AaABIAL4AGT/7P1s/fT9GgGEA9QC7v+g/m0ALv9M/dD9oAIYBIQBev7U/Ab+QQAYAlYB1AFuAez+jPxw/KMAfAOIAcb++QAYA6H/UP1R/xwCKAFM/kr+JgEWAQv/Sv+g/+D+7v68ABgDAATYAXL/fv7E/Tz9pPwW/pwA8AL4AmQCWAKsANT9Tv5f/+D+uP3w/SIAwAGuAbQA4gEUAn0Amf/U/ej8SP0r/5oB9wBYAQgCegHG/zz9wP14/gP/s/+cArACif9M/az9m//k/9v/6gBMAxwCKQCo/x8AgP9y/+z+qP6u/8oBOAJcASwBygAcAbf/UP9x/24AdP4e/goB1ALwAtIBIAJUAIj+KPx0/Yf/1gD+ARACRgFnAAQBXf+M/aT8oP5yANYAZgEUAsIBnP4M/Qz9yP2j/8gBQAMAA2cA0P2g/dz9qP0G/8gAAAPgAjAB4ADvAHn/PP3I/Tj/CABw/6f/UAHcAR//rP6+AGgBuAC4/qz93P4OABYA9//y/6sA3gBv/1z9uv7cAWgACwBkAVwCXACQ+6j7IgH0A9z/uP8wA9wCnP1Q+az9aAOIA/L/Z//uAF//8Ps4/CoBdAM+AQ7+qv5cAeIArv9z/4QACf+A/RD++AAoAvAAZf+5/3cAEgCKAPz/S//2/uD+nv7I/jUATALYAhQBjQBQAJP/IP5s/Wb+9v5tAPYBBAPgApoB1P+k/vz9gP1Y/hv/uwCAAuACeAIcAa4AjP8M/mj+z//H/8X/FAAkAogDlgEmAC8AgP/o/ZT92P+cAZgCHAIKAe3/dv9q/xEA1f8u/zr/JP+b/94AdAF+AZ8AjACLAG3/0P0w/uz9nv5h/w0AoAK8AvQB2gDD/xz+UPpg+dT8kAG8A7gCcAFQAjIBCv74++j7yv5h/xP/0f9FABABUALQAvwBVv7w/VD/Cv5g/Er+hAOIBDgBOwDUAm4BmP20/Iv/rgD2/sL/FAJYAtIAxAC4ATgAUP2Q/VsADAHR/0QAvAGUATUAKACVAE3/Wv40/+IBXALQAPj/HgHjAMz+/P26/yQCsAGf/xb/FABrAFj/dP/rABgB2P9M/hn/3P8vADMAbwDz/+z+ZP4Y/zAAGwB4/5D/w/8f/4T+vP6J/wYAh/8T/+D+N//S/4P/9P7W/tL/FAH2AEgAaP9s/uz9Av5s/iP/SACQAWwBbQA5/+P/j/86/sD9bv+/ANAAdwDVACwBgP8C/hr+OgB6AXgBUAG+AR4BX/88/pT+2v8OATwCsAOgA9QBe/+A/qr+Yf8IAUwCKANcA+wCQgGf/5j/HQAkAesANgG0AvgCkgHh/yoAygAAAGP/BgBwAQwCfABt/7D/UgBgAJT/qf/7/6b/0P1A/JT92v9HACEA7P/m/6j+XPxI+/D8WP3Q/Cz9lv47/97+Xv6Y/jj+1Px4+3j7wPzI/Xj/QADD//b+8PyA/CT9uP2Q/ob+Tv/S/8H/Xv+j/wgA+QAqAXoApwBkAYwC4ALEAjQD6ANoBJAEGAVoBegEMATIBLAFKAZQBjgGkAboBkAGSAZQBlAGOAZABfAEWATwBMAE6ANUA8ACcAIkAZoAbABYAPz/jf+M/sD94P0U/eD76Poo+vD50Pko+uj6uPuY+nj5EPl4+HD3MPYQ9uD2UPdA9qD2cPfQ9/D3IPfA9iD2sPQg9BD1IPfA+JD5QPrQ+9j6mPp4+iD8aP51/7MA5gFwA4AE6ATwBrAI8AnwChALcAtwC5AMYA1wDTAOwA9AECAQ0A/AD4APgA7ADDANkA0ADWAMAAsAC+AJoAggCNAHoAaoBDgD4gEAAaH/CP9S/97+Iv7k/Aj8oPrI+CD30PZA9gD2kPYA98D28PVQ9cD04PSg9ED0YPRw9GD0gPQw9AD0kPSg9LD0UPSw86DyMPGg7yDvEPGw9ND4qPpo+9j5APnw9vD1APe4+FD7+P64AuAE6AVABygHQAa4BLgEkAcAC6ANgBDgEgAToBFAECAPcA9wDwAQ4BEgEuARABGgDzAPQA2gC9AK4AkwCVAIUAjgB/AGCAXQAxADpAFjAEf/fP6s/fz9nP0U/fD8LPzY+iD58Pfg91D4EPiI+ED5qPnQ+JD3kPcQ96D2wPYg9wD3QPfQ9/D3oPdg9tD1YPXg9KD0EPXg9NDzAPPg8nDy4PEA8mD0oPaw9tD3OPkg+nj4cPcw+JD5MPsw/Q4BiASgBvgF+AWQBkgHIAdQCNALIA6AEMARIBNgE8ASABLgEaARABLAEaASABIAEUAQQA/ADaAMYAyAC8AKoAmACOAGsATUAqwBCgEZAIf/Vf+s/n7+5P3M/OD7yPqQ+SD4oPew9+D3CPnA+Rj6gPmg+ND3cPdw9wD3wPc4+Dj4IPlw+VD6MPoA+tj4APdg9rD1QPUw9aD1cPbA9qD1QPQg9BDyAPFw8RDyAPXA9+D6HPxA+5D58PfA95j4yPoq/igCoAToBpAIQAkQCrAJ4AkACoAL4A0gEOASIBWgFcAUIBPgEYARYBBgEMAQoBDgD0APgA4ADpAMAAtwCXgHuAUoBDwDfAI0ASMA+P78/RD9tPzA/BD8KPvg+eD4APjQ9tD2sPYg9/D2cPdg+Dj40Pdg90D3UPeA9pD2cPdQ+DD5OPoY+yj70PnI+Bj4oPZg9cD1UPdw99D38PcQ+JD2APQQ8uDwsPEg8qD2wPmM/Ij92Puo+ZD2APbQ92D69P0IAqAFIAjQCLAJ8AhgCJAIsAjQCpAOgBKAFeAW4BYAFQATIBGgEKAQQBGgESARwBCwD5AOwA1wDNAKwAjQBhgFEAT0AtIBdgB4/4L+bP3k/ET8mPuw+iD5CPgQ9yD2EPYg9jD2APaw9vD28PYA9/D2kPYw9lD2oPaw9yD4KPn4+bj64PoA+5D60Pno+Aj4kPfQ9yD4+Pio+Gj4MPeQ9aDzMPHQ8KDy4PQA94j7NP0E/eD6YPcw9bD0QPZY+pf/1AMIB9AIgAmQCbgHyAfQB/AJoAwgEEAU4BaAGMAX4BVAFGASABJAEoASwBLgEUASwBDAD+AO4A0ADHAJwAf4BYgEzAK0AQoBhP9y/oD95Pwc/PD6uPlg+AD38PWA9SD1oPSQ9ND0kPXw9XD20PZA9oD1IPUQ9WD1QPZg94D4oPm4+lj7+Ptw+2j6OPnw94D3cPc4+Fj50PlY+Vj4sPZA9ODxwPBA8RDzYPbw+Wz94P0E/Aj5YPUA9JD0kPmQ/UgD2AYQCRALQApQCWAIyAcACaALwA9gE6AXYBrAGaAXABUgE0AS4BGgEiATYBNAEuAQYBDQDjANoAvwCcAHSAWEAygC9gD0/5z+3P2Y/Kj7yPpg+jj54Peg9lD1YPTw8wD0APRQ9LD0cPXw9TD2QPZA9vD1YPWA9VD2IPcI+Lj5UPuI/PT8gPyI+8j5EPhg98D3ePhg+cD6+PqQ+XD3EPVg8uDv4O+A8bD0mPi4+k7+oP0w+XD2IPTw8+D12PoeAagFkAhwCkALoAowCUAIYAlAC2AOYBLgFiAagBogGoAXoBUAFMATIBSgFAAUoBNAEmARQA9gDkANYAtQCbAG2ASAAtcAEP9K/lT9mPso+8j6uPmY+OD30PbA9ZD0oPMg8/Dy4PLg8+D0sPWA9gD3UPdQ9tD1IPag9kD30Pfw+Dj6ePuE/MT9Xv78/AD7+Pig94D2wPYI+Jj5EPqI+Wj48PXw8oDvIO6g78DwIPWY+RD8IP24+vD3wPSA8wD1aPna/ugC4AbACUAL4ApwCpAK0AoADJAOYBIAFiAZIBpAGqAYIBcgFsAV4BXAFWAVgBPgEQAQwA6gDaAMkAsgCqgHMAXMAmMAjP7w/MD7+PpI+oj58PgA+PD28PXg9MDzAPOg8pDy0PIw8/DzoPTQ9UD2APcw93D3QPeg93j46Pjo+Dj54Pps/Ar+Bf+4/7z+HPzI+TD4oPeQ99j4aPpQ+vD52Pjw9sDzAPFg78DvMPIw9RD6JPyw/Kj6YPfA9FDzEPZI+mz+GAMQB8AJkApQCmAK8AkgCuALYA9gE0AXABoAG0AaYBjgFkAWYBYgFkAWABbAFKASwBAgD8ANwAsACoAIkAagBMQCHAEk/7j8OPtQ+nD54Phg95D2oPXQ84DzcPOg88DzQPRw9FD0IPTQ8xD18PRw9RD3kPeA+fj6APzs/Ej7iPoY+Tj6yPtA/lYA3AFkAev/yPxQ+hj5WPi4+Aj44Pj4+BD4IPZQ9MDysPCA8KDyoPUo+Qj7cPrg+KD1sPMg9CD3oPv0/1AEKAdgCWAJ4AlACiAKEAuwDIAQ4BRgGGAb4BsgGwAZoBYAFsAVoBXAFYAV4BTAE4ASABEAD3AMMAlYBrgDmgGhAMf/U/+Q/lD9uPtA+cD2kPQw8nDxgPEw8rDzsPRw9fD0wPRw87DyEPJA8uDz4PRg9jD3YPrA+2T9HP60/Rj8EPsA+uD5+PvQ/d0A7AMgA9wA/P4g/Ej5APcQ9vD2APdg91j4oPdQ9oDzUPJQ8iDywPNw9gj4GPjg9tD1sPXA9vj4uPxAAPwCUAXgBhAI0AiQCeAKcAywDmASABZgGCAagBrgGMAXYBYAFgAW4BUgFsAVIBVgEyASIBCgDXAK0Ae4BQADQgGa/7r+Zv6A/RT9mPs4+QD2sPLA8DDwAPGg8iD10PVg9rD1UPXg8+DywPMA9ID1cPUo+BD6QPwA/iz+f/9p/4T+Vv6c/dz8pPxW/tX/vAGQA0AECAOIAFD82Pgg9vDzQPTw9GD2EPcA95D2APXA8jDxgPBw8FDxwPKA9BD2kPeY+ID5iPow/D7+KwAkAqgEOAcwCQALMA3QD+ARABTAFoAYABoAGiAaQBlAF0AWQBYAF+AX4BjAGIAW4BIgDiAKqAZ4BLwDWAN4AhIBZQAU/xD9YPow9xD0IPFg76DvAPGg8pD0MPWA9IDz8PLA8sDyYPOA9ID1APcg+HD6APzg/Cj9Cv4g/+T+oQDkAfABZAAzAJb/0v8GAOkAGAJsArEAev8w/YD6OPjg9VD0oPJA8oDycPNw8yDzkPIw8YDvYO/g7sDvQPGA85D1UPcY+Wj7xPwQ/lv/uAH0A3gG8AkADSAQwBHgE2AVABegGIAa4BtgHGAb4BlAGCAWQBagFoAYIBpAGaAV4A8ACjAErQAU/9z/lwBGAUQBo/9Y/Mj4MPQg8ODswOvg7ZDw0PMA9gD30PWg8kDxsPCg8aDzAPYA+RD7fPws/vD+oP7k/fT9iP7O/2YBqANABTAFCATAAsABRwCv/+T/l//2/uL+qP7E/Xj7APnw9cDy4O/g7kDv4O/Q8GDxsPHQ8DDwYO9A7+DuYO9Q8fDz4Pb4+QT94v6e/54AMAJQBKAGoAnQDJAPYBHAE0AWoBhAGuAcoB5gHYAc4BvgGSAYoBYgFkAYwBkAGsAZIBVAD2gHzgFO/nD8FP4SAIgBPAC0/dD5YPTg72DsAOuA62DtoPFw9KD2cPXg80DxAO+A7+DwkPTA9wj7cP1a/iL/c/9U/wz/5v5B/+AAHAJgBNgFSAb4BVAElALyAHz/Of/S/lz/kf8H/5T+kPwQ+uD28PMA8SDvQO7g7oDvgPCQ8eDxQPFg8MDvIO9g72DwsPLg9Uj56PtS/uv/dgFUAqADuAUwCIAKcA1gEGASYBQgFkAYwBlgGsAbYB5AH2AeAB1gGaAWoBJgEwAUYBbgFkAUIBIgDKgFEgBA/SD7QPtA++j7+Psw+rD3QPQg8IDsAOvg6+DtgPAw8xD1MPVw9ODzUPPQ8+D0UPaI+Dj7dP0sALABbAKYAlACMAI4AoACOAMwBMAECAXgBJAEpAOcAqoBeQD6/vD92Pxo+3j6mPlY+DD3EPXw8gDxgO9A7qDtwO1A7gDvAPCA8BDxIPFA8cDxcPIA9ED2gPko/Db+MgC2AUgD2AT4BjAJ4ApwDLAOgBDAEmAUgBYgGKAZwBoAHCAdIBwAGgAYABWAEUAQQBEgFOAUwBOAEUAMyAZwAST9wPsA+jj6SPo4+wD6gPig9oDyYO8A7aDsgO5Q8fDz0PVg9iD24PWA9RD2MPfo+JD6DPzI/af/1gHMAqADQAQABOQD2AOMA/gCpAIEA5gD/AO8A6QD3AIYAbD+CP3Q+5D6OPrw+fD5CPmw90D24PMQ8QDvAO4A7qDu4O8g8eDxMPIA8uDxwPFQ8rDzoPVQ95j5+Psw/r//GAHIAtAE2AbgCOAK8AsgDRAO0A8gESATIBXgFwAawBsAHSAdoBvAGIAUYBDgDhAO4BGgFCAVoBSgEWALuATy/mj7+Pnw+UD64Ptw/Nj7GPqw9kDygO5g7cDtAPCw8lD1IPdw9nD28PWg9bD2sPco+Uj6sPvc/Z7/xQCOATAClAIMAxADPANUA9gCaALoAeQBsgFAAuQB2QCk/8D9jPxo+2D6qPkA+ZD4APgw96D2QPWg8+DxYPBg7yDvIO8g8BDxMPLw8nDzQPSg9HD1QPag90j5+PpM/Vf/TgF4AkgE+AWABwAJQArwC9AMYA3wDkAQwBFgE6AVYBfgGMAZgBogGQAXQBNgEFAPAA3wDuAQwBLgEkAQIAyoBcEA0Pxo+hj6ePp4+0T86Pt4+vD3wPQA8YDuoO2g7sDwcPPQ9SD34PaQ9jD2QPbA9tD3KPmA+gz8uP2P/y4BCAK0AhgDsAKAAoQChAJEAhwCmAK8AgQDEAN8AkQBi/+Y/ej70PoI+uD54Pm4+VD5MPig9vD0cPNA8hDxcPBQ8ODwYPEA8sDyMPOw8yD0APXQ9RD3MPjI+Sj79Pze/tcA3AIYBFgGcAfACCAKgAvgDKANgA7wD2AQoBFAEqAUIBagFyAZwBmgGKAWYBOgEAAOAAzADSAPwBDAEMAPEAyoBpQCjP5U/BD7gPpo+8D7gPtA+gj5sPaQ88DxcPDA8ODxkPMQ9WD24PZg9wD4QPj4+Mj5MPro+rD7LP3s/kcAYAE8AqQCaAJUAjACaAE+Ad0A8wCOAagB6AGEAbAAP/9I/QT8sPpo+vD5YPlY+fj4SPgQ9/D1EPXg88DyYPJA8kDyUPIQ81DzsPNg9PD0IPbg9rD3MPmI+rj7AP2m/g0AJAH4ArgEGAZoB5AI4AnQCkALkAyQDUAOQA/AD0ARIBKgE2AVIBeAF+AW4BWgFCAR4A3QDNALcAzgDSAPkA/ADDAJAAWnAAD92PrI+ij7iPsI+9j6oPlw97D0YPJA8QDwkPDQ8ZDzoPVw9vD2QPeQ94D3kPi4+QD74Pvo/Bj+T/+kAN4B6AKUA6QDiAMcA8ACUAIMAiwCUAIwAtQCxAIEAt4AL/8w/WD7+Pkg+Qj5oPhI+Bj4cPcg9iD18PNA8wDyAPGg8bDxQPKg8oDzYPQw9eD18PaA99D4gPnw+rz8eP4jAEwCeAP4BKAFMAZgB6AI0AmgC3ANwA4gD+AO4A6ADqAOsA8gEqAVoBYgF4AXwBWAEkAPoAwgC3AKMAvADfAN0A1wC6AHYANW/jj8uPow+qD6APsI+9j5GPjQ9jD1IPMg8lDyAPMA9HD1QPdo+HD4QPmY+Tj6+PrI+2D9fP7a/kEAHgE4AowCTAMYBBgE8AOQA+gCUAIiAW8AeACHAJgAjAD4/8b+CP0g+3D5CPgQ9+D2wPZg9iD2sPVA9VD0gPOQ8jDy4PHg8UDyEPNg89DzwPSQ9bD2sPc4+Uj6cPtc/NT9gf/+AIQCEARoBQgGuAawB9AIcAkQClALQAwQDbANoA5ADmANIAygDHAOABAAEsAUABVgE0AQYA3QCmAI8AdACDAJEAqwCbAJoAcwBJgAFP2o+gj5APm4+mj7iPuo+pD5kPew9aD0YPSg9DD1MPaw9zD5APr4+jD7UPso+1j71Pzk/Wz/WgCsATQCgAJAA3gD6ANQA5QCZAIgAmoBKgEQAf4AbgD8////wv9w/uT8OPug+Rj4oPfA91D4IPhQ+ID3kPbQ9fD08PQg9XD1oPWw9qD34Pc4+DD4mPi4+HD5iPpc/IT9uv7t//QAxgHuAQQD+AMABaAFyAZgB7gHqAcQCBAJAAoQC0AMIAwACsAHWAcQB1AJgAxAEYAUwBJgEdAOgAv4BzgG+AX4BmAIkArgDDANgApoBhgCEv64+wj7CP1+/iP/uP+A/iT9APsQ+VD34PXw9HD14PZI+Ej6kPvI+7j7UPsI+zj7UPvI+6D8bP1k/rv/4wCoAaQCvAJoAl4BZQCk/0D/HP8TAEQAHAEoAbMAb/+K/uD80Pso+3D5QPno+DD5SPl4+Yj5GPkY+OD2kPYw9mD2sPbw9qD3sPhA+fD5QPpw+gj6ePnY+aj6aPzQ/Tf/4QCwAUgCCAPIA2AEwARIBRgFmAW4BbAFiAVABnAI4AoADeAM4AwwCkAFtAPIBFAIAA3AD+ASABRAEVANYArIB1gFCAQABuAIYAugC0AMkAlIBd3/YPxc/DT8fPyI/bz+Cv4c/OD6iPkY+HD2kPXQ9cD20PYw+ID5aPnQ+GD4KPnQ+Vj6qPsw/PD7ePx0/bD+gP9YABQBdgCO/7r+LP8d/07/qP8GAKEAvP+K/3//wv7Y/ZT88PuA+9j66Prw+uj6MPr4+Nj4UPgw+DD4KPiQ+Fj4yPiI+WD6gPqY+yD8bPzo+7D7jPwA/cj9yv6VAOIBYALgAhAE+AQwBLAD8AMQBBgEcARoBbAG8AUgBiAGuAVQBVgFYAbwBsAGgAVwBNgD3AP8A7AGAAjwCYAL4AyADBALQAkoB5gF9ANQBXAIwArgCpALEArIBpgD8wD8/x7+BP2M/az+0f9E/0oA1v+A/Xj6wPhQ+ID38Pbg9wD5UPlw+cj64Pug+0j7cPsg+wj7wPp4+/T8aP0a/tz/zQA+AcsA1AAcAAb/Vv6a/vT+Ef/k/n3/yf93//j+bv6o/cj7EPpA+UD5YPmw+dD6cPvA+zD7GPt4+vD4kPew9uD2UPeA+MD5IPuY+yj7GPs4+yD7yPoY+4j7wPwW/rv/iAGgA9ADqAQIBdAEeASEAh4BdACiACgCQAZgCkAM4AsQCVAF5AH5/58AJAJ4A3gGIAjQCDAI+AYoBYQCMAAXADAC4ASwBuAI0AkACJgF6APYAzAEQAS4BfAGcAcoBwAH4AaQBewD/AIkA1ADaAMABBgENAN+AR8AQf9w/pT9CP2c/Hj7KPo4+cD48PcQ95D2APbw9DD0EPQA9PDz0PNA9MD0EPWg9XD2UPeg90D4qPkA+wD8YP2y/s//fwBGAXwCfAMIBJAEEAUoBUgFiAUoBpgGoAbABqAGUAbIBVgF+AQgBAQDgAJIAhgCEALyAbAB1gDi/xj/iP5o/gj+Jv6a/tz+J/+V/97/1f+S/5v/PQD5AJIBeALgAiADvAJUAogC4AIsA9ADqARYBXgFgAVQBdgE7AP4AsQC1AIcAzgDcAOEAygDSAJSAVgAeP+2/kr+MP5m/pT+5P7O/rj+Vv7w/Wz9NP04/TD9LP1Y/cj9IP6K/tb+Zv+x/7v/g/+H/13/Wf9g//j/nABSAZgB2gFwAfIAZADU/63/if/J/9n/BwAZAP7/q/8c/8j+eP5W/iD+NP5U/jr+Fv4M/gj+7P3A/az9uP24/eD91P0G/jr+UP54/sD+OP97/2f/NP8T/7z+bP4q/nb+kv6I/gD/Lv/i/6z/Ov/w/jj+jP20/Zz+Pf8jAHcAlwAEAKb/sv/L/23/K/+q/w0AZQCMADwB2AFaAckA/QDvAL4AUAAEAYwBkgHsATwCvAJwAnoBUgFEARAB9ABkAfQB/AHCAdIBxAGUARQB3ADjALwAhAAIASIB4gD2ACgAuf8d/1z+gv6g/nL+Sv5I/uT9eP08/Qj9OP3M/Nj8IP3Q/Gz8+Puo+5D7qPsM/MT8sP1Y/pD+nv4y/lD99Pzo/MT9M/91AKYB2AF8AcoATAA0AD0AewAkAfoBjAIwAxAD6AIgAowBeAGgAQACjAIUA/wCqAIYAnQCuALsAsgC9AIkA8wCdALcAjwDCAOUA9wDiAUoBuAGYAdwCCAIsAfgB9gH0AdYB8AHIAiwCMAJQAqACnAKoAmQCHAH4AXYBNAD4ALcAugCvALWAVcAdv7Q+yj5wPZQ9YD0kPOA80DzEPMg8yDzkPNw84DywPHw8LDwQPEg82D1cPco+VD6KPsI+3D6UPpo+sj6LPwg/g0AagG0Ab4B8wDY/9L+0P76/kX/q//1/34AhgBIAAQAhv/4/nL+dv6W/tL++v44/7H/BQB6AAIBuAHwAQgCNAKAAvACdAMYBAAFyAVABuAG4AbwBrAGWAbwBYAFaAVIBUgFMAUoBdAEMARsA3ACigGGALf/TP/i/nL+Fv7E/Wj97PyE/BT8mPso++j66PoI+0j7qPsI/Fz8sPzo/Az9BP0I/Tz9hP3w/WT+EP+V/6n/r/+p/6j/kf+H/5X/wP/c//P/KAAsABUA1/+k/4f/hv+U/8P/6v/n/9T/7f8bAFIAfwCuANwA/QAYAVoBhgG+AegBKAJ0ArAC/AIQAxwD7AK4AqwCsALUAgADLAMkAwADsAJkAhQC1AGiAYoBdAFiAUYBFgHmAJQAUgAlABAADwAgABEADwAVAAgAHQAeACYAQwBYAFwATwBUAHQAewCEAKwAzwDmAMgA0gDEAKcAcABqAGAAbABKADcANgDb/7f/a/9t/z//EP8P/yb/Gv/0/vr+/P7k/sD+wP70/v7+7v4F/1T/aP9t/2P/k/++/7j/y//4/x8AFQD3/wcAPgA+AFUAcACXAIMASgAmAC8ABADt/xoAPAAnAAMA8P/5/+7/zv/T//L/7f/0/yMAQwA8AD8AawBvAIIAdgCfAJoAjwCYAKUAtwDAAMkA4QDrAMoArwCzAJwAVwBNAFwAXgBOADgAJAAJAOL/uv+x/6D/c/9b/0D/NP8q/xv/Cv/u/uz+yv6q/qj+iP6E/oj+fv6c/qz+mP6Y/oL+Yv5u/nz+jP6M/qT+yP7S/tT+zP7O/tL+1v7q/gz/Jv8v/yj/QP9d/3P/fv+I/53/q/++/7v/1//8/w8AKgBEAFoAdwCYAJ4AmQCcAJUAmwDHAP0AJgFGAUgBWgFQAUIBRAFSAVwBTAFeAV4BWgFKAVABPgEeAQQBAgH3AMkAtACzALQAowCUAJcAkQBrAEcAKQAVAPf/7f/z//7/7//R/8z/sv+D/1j/W/9X/17/Wf9q/5L/iP90/1n/U/85/0L/Wv9z/5//l/+A/2v/Zv9w/3L/eP+0/87/1f/Z/87/z//M/8z/zf/q//7/HgAkABcAFAALAAgA8/8KABcAIAAtAEkAaQByAGcAdgB6AHwAggCGAJAAjQCXAMUA6wDvAP0ADAEGAfAA6ADiAPYA4QDsAOsA8wDcANMA5wDaANEAnQCiAI0AgQBxAFMAVQBGAE4ASwBIAEsANAAFAOH/v//C/7f/pf+v/7j/oP+P/4f/ff92/3D/dP9t/2n/ZP9e/03/Uv9c/37/jP+k/6X/lf+B/3D/j/+h/87/8v8DAA8A+P/4/+f/7f/u//H/BwAgADkASQBLAFsAWABIAEQASwBgAFoATQBQAGEAYABYAGYAewBnAD8AOgA3ADgANQA7AFsAYwBdAFkAZgBpAFsAUgBYAFYAXQB6AJUAjACJAHgAUwBAADcAPgA8ACcALgAuACkAEAD8/+b/zP+8/67/r/+n/6X/pP+Z/4H/ff+B/4b/jP+J/4j/d/9b/1z/Zf98/47/sP+8/7z/qf+a/5b/iv+L/5n/vv/Q/+H/6P/j/+n/6v/s/+n/4v/f//v/BwARABkAHwAcABEACAADAA0ACgAHAAwACgANABoAKwAyACwAFwAQAAcAAQAYACsAMgAtAB4AIAAeABsAGgAeAB8AIAAqAC8AMQAZABsAIQAqACcAOwBGADEAGAAUACQALwA0ADsATgBAACMAIQAoACcAFQAIAAMA/P/Z/8P/sv+j/53/rv+1/7z/rf+g/4r/d/9K/0n/R/9N/2H/Z/9n/1//YP9l/2b/W/9Y/2j/bf97/4j/qv+7/8n/zf/S/8v/zf/T/9X/3v/m//b/AwAKABAADQAVAAMACgAgACkAMwA/AEoAQgBEAE4AZgBpAFoAUwBWAE8AUwBhAGUAZABcAFgAZABmAGsAgACGAHcAbgBuAHAAbwBpAH0AkQCMAHwAggCCAGgAXABhAHUAbQBpAG4AcwBhAEgAOAA6ACsAEgAMABUAHQAiAB4ADwD//+v/4f/g/+P/2f/U/9P/yP/G/8v/zf/P/8n/uP+x/6f/oP+e/5z/mP+m/6f/rf+u/6D/jf+E/4f/kf+e/5f/m/+l/6r/o/+o/7r/yP/J/8z/1//c/93/5P/+/w0ADwAUACYALAAmACsANAA4ADQANAAyADMAMQAsACMAEwAMABUAGQASABQAHgAVAA8ADQAcACMACADy/+7/7P/l/+v//P8CAPb/6P/k/9n/y//E/9f/6//3//r/BQAFAP7/8//y//j/8v/7/wgADgAFAP7/AAAEAAIA/v///wEA+//w/+v/5//o/+j/6P/s/+7/8v/o/9T/zv++/7P/tf+2/8L/vv/K/93/6P/o/+X/6f/v//H/9v8HABEAEQAWACEALwAwAC4AOwA9ADoANgA4AEQARgBGAEcAPQA0ACoALAArACsALgAsADAAKAAZAB4AGQARAA8AEwAcABkAFAAOAAIA9//s/+T/7f/o//D/+f/4//L/7//w/+b/3f/U/+f/8////xEAEwAUAAYABQAMAA0ADwATABoAHwAhADAAPgBIAEcARwBIADoAMAAvACsAMwA6AEQASwBIAEQARAA8ADcALQApACoAMgBCADkAOQA1ADIAIAASAAgAEgAXABEAHQAcAA8ACwAIABUAGAAVABcAIAAoACAAGgAfABoADwAKABEAEAAIAAIA/f/9//T/5P/f/+X/4//k/+D/2f/T/87/zf/J/8z/1v/c/9z/3//o/+3/7P/j/97/2v/Y/9//4//z//v/+P/3//L/8P/u//L/9f/x/+r/6P/l/+T/5f/p//D/6//k/93/3//i/+D/2v/Y/9z/4P/g/9z/2f/V/9H/z//V/97/4f/e/+D/3f/e/+H/5//z//b/+f/2//n/AgALABAAEgATABkAHgAeAB0AHwAhAB8AIQApACsALwAtACgAJQAjABsAFQAUABcAFwAQAAoACQAGAP7/+f/z/+7/5v/l/+X/5f/b/83/v/+u/6H/mv+d/6H/pf+t/7H/sv+u/6//rv+s/6j/qP+v/7X/vf/H/9D/0f/K/8T/xv/K/8//0P/V/97/5f/g/9//4f/i/9//3v/i/+X/4P/f/+L/5//l/+P/7P/+//7/+f/6///////0/wcADAAWABQAHAAkACYALwAzADsAOAA6AEEATABQAFAAUgBWAFYAWwBeAFwAWwBTAFEAUwBRAFAATgBKAEoASQBLAEsAPgA5AC8AKAAmAB8AFgANAP7/9P/1//D/6P/e/9P/yP/C/7//yf/h/+f/4v/e/9P/yP/G/8f/yv/P/8//0P/R/8//y//E/7//v//B/8j/z//Q/9L/2P/c/9//5v/u//T/9f/y/+7/7//t/+3/9/8BAAUADgAbACAAHgAWABUAHAAfAB0AHgAlACgAKgApACcAJQAgABkAGgAZABUAEAANAAwADwANAAsADgAOAAsACgAQABYAFAAPABEAFAASAAsABAD///v/9//6/wMACwAMAA0ADAACAPP/6P/o//L//f8CAAgABwABAPX/6//j/9z/2f/c/+T/7f/0//L/7f/m/+L/4P/e/93/3f/b/9r/2//f/+f/6P/p/+j/6v/v//L/9//+/wQACgAPABEAHQAnADMAPABHAEgAQgA6ADMALgAtAC4AMgA0ADcAMAAsADIAOAA5AC4AIQASAAgABAALABIAFgATABIAEAAJAAAA/P/7//j/8//v//D/9f/5////AwADAP7/+f/1//L/7f/v//P/+v///wMAAwD9//f/8f/w/+//7//t/+r/6f/n/+j/6f/m/+H/3P/W/9T/0f/R/9T/1P/T/87/zf/M/83/z//H/7b/qf+g/6D/of+m/6//vP/A/83/zv/O/8T/uP+y/6P/qv+7/8//2f/p/+n/7P/W/8H/vf+l/53/sP/Z//7/FAAgABYADQD6/+7/+v/+//b/6//s//r/+////wMACQAHAP3/9//3/wAACAAIAAwAEQAVABoAHAAbABYADQADAAAACwAdACYAKgAkAB0AFQASABwALgA+AEMAQQA4ADIALAAqACYAHAARAP7/7//o/+v/9v8EAAoAAgD3//X/+/8FAAsACQAKABEAFAAYAB4AHwAUAAUA9f/g/9P/z//V/+j/+/8QACEAJwAjABIA+//o/+b/8v8FABEAFwAYABIADQAGAAEA9f/h/8//zf/a/+z//f8IAA0ABwD+//D/7P/y//j//P8DAAgADAAMAAwAEAAXACIAMABAAE4AUABDADAAHAAUAB0ALQBBAFUAaQBzAHYAdwBwAGUAUgBDADkANQBAAFMAcgCJAIoAdQBRADEAHQAVABcAIQA4AEoASwA4ACgAGAACAPL/8f/r/9z/zP/U/+b/8P/z//X/9v/m/8z/v//G/8z/x//I/+X/4f/h/9L/zP/B/7b/vv/L/9j/3v/n/+n/7f/p/9r/zv/D/8D/xf/E/7z/wf/E/83/3P/m/+r/4//g/+r/9P/6//L/2//P/7z/vf/Z////HQAYAP//3v/M/8L/yv/g/+3/4v/l/xYAcwDiAAIB5gCUABEApv+E/6z/9P84AFEAVQBNAD8AMQAWAPj/1f+w/6T/uP/u/zcAbwB1AF4AQwAeAPb/1v/A/7H/s//D/+L/CQAMAPT/7P/q/9n/xf/B/9P/6f/2//v/DQAkACAAEQD9/97/vP+l/6v/0//s/+b/3P/V/9L/zv/M/97/+/8IABIAKQBGAEkAOQAtACUAEADq/83/vf+1/7P/wv/r/xwAOgA7ADYAIQD0/87/wf/c/xQARgBjAG0AUAAgAOb/xf+1/6H/oP+0/+T/HwBNAGAAYABCABMA4f+9/7z/y//e//X/EAAsAD8ANQAiAP7/4v/R/9P//v8wAFEAXgBbAEoARgAqABQA/f/y/9b/wf/F/8v/0P/c/+7/BQARAAYA3f/O/9z/6v/z/+j/1f+u/5b/ov/N/wAAFwAOAPX/yf+f/5//zv8UADkAMAAVAPr/9v8IADYASAAnAOz/v/+x/8X/8f8uAGcAhAB9AGQARgAiAAAA6P/f/+D/5v/2/wsAGgAKAAAABQAdADkAQgAuABYABwASAEsAjACqAJUAYwAuABcAJwBJAF8AVAAbAOf/1/8IAGcAwQD0APYAxwCtAK0AnQByAB0A2P+n/63/8/9fAJYAjAA5AOj/vv9//5f//P90ALUA0AC9AHQALQDc/7X/u/+0/5r/lv+w/8n/zv/c/97/x/+Q/03/NP9R/6b/+v86AGgAXAAZALf/Xf8n/xH/F/9C/47/2f8OAB8AJwAOANL/f/9I/1f/gv+2/+P/8P/7/woAFQAbABUA/P/K/4X/VP9Q/5D//f9aAIwAbwAvAAEADABjALkAzgCyAGEACwDj//z/VgCpALkAhQBEACEAJQBYAIIAfQAyANT/q//Q/zEAgQChAJ0AfgBWADYAEQDW/4r/Yf9b/3f/r//t/wUACQDa/5b/Zf8+/0T/Zv96/23/cv/C/y0AXAA5AMz/Q//k/tj+QP+z//j/3v+a/3P/a/90/4T/l/+h/77/uf/J/+H//f8bAAYA0f+Z/4n/fP95/6b/2P/+/+L/4P/3/woA4P+0/9j/MgB9AJAAoQCcAHIAGwDc/+j/7v/W/+z/MACEALcAvwDIAMUAdAAtAAgAFQBPAJkAwwDDAJAAPAAWAAYA+/8AAAkA/P/9/xEADAAWAFQAoQC5AIIANQDV/7n/0P8LAD4AKADZ/5f/qP/9/zYASABQAAcAlv9X/3j/y/8VADsATQBAAAYAwv/F/wgAKAADANj/tv+t/9X/MQDeAC4B6wBlAPX/rf+E/5X/2P8pAA8Azv+2/8P/s/+d/6//uP+s/4b/o//5/0MAUwBhAFEAEwDF/4r/oP/7/00AZgCAAG8ADgCq/3v/p//q/w4AFQARADEASQBuAJYAqABgALz/aP+J//T/XQCJAHYAUQDx/6v/xP8DABIA2v+t/6T/3f8JADMASQAkAN3/vP8HAHcApgBMANL/ff9j/4z/5P9NAIkAdABDABwABQDf/77/kf95/33/hP/J/yoAXgBEANb/VP8s/17/hv+d/6r/pP+p/8T/5v8qAD8A5/9S/+7+Af9Z/+f/XQBwAAYAif9s/8n/agCQAC0Ap/9c/4P/BwCWANsApQACAFb/DP9W/9z/UQBxACcAxv+8//v/ZACjAK8AXQASADcAigDhAMUAPADn/+3/CwAvAEMAcgBOAAMA7f84AIoArwCKAFUAPQAoAE8AvQBEAUgB2wBYAP7/+/8LAP//1v/X/wIAMgBXAKYA2gDHAF8A5v+D/y//1P7q/qf/UACYAIcAbQAYAFP/vP6i/vz+Wv92/5r/yf8BAE4AzQAEAXsAhv+u/nj+xP5U/wYAhQCdAHcARwALAM3/fP9v/4v/iP+U/9//MgCkAMoAowBjAPv/s/+m/wUAUgB7AKYAxQDKAIkARQDw/7v/x/8CAGoAowCrALAAwQCvAEMAAAD1/7v/jf+p/yIAiACXAIYAeAAvAJ//NP8s/4j/6P8SAGMAkgCKAFUAIQD9/8v/nf+i/+X/IQAoAOn/xf/J/8n/rP/N/+D/sv9z/4//4f/1/8D/SP89/4n/5v84AFgAPgCy/zL/8v76/nH/GgB3AGAA8P+d/5L//P+fAAwB8gAxAEL/Hf90/wMAegDjAEYBCgEnAGT/Df88/6D/9/9gAG8AOAAkAEwAlQCTAF0ACQCm/27/c/+6/08ArwC+AGMA4P98/43/5P8PAOr/tv+j/97/cQCaAC0Apf9l/3//6v9OAG4AQACz/zj/MP+U/ygAVwB3AC8At/9q/5D/LQCIAEkAh//k/s7+Uv/f/yIAJwDr/6z/af9p/4H/zP/Y/7P/4f8hAP7/xP+z/w8AIwC7/y//QP+f/6r/n//1/1sAQgDT/5L/uf+v/2z/Of+d/yMAGwAjAIEArgByAOD/qP/a/+//6/8aAJ4AqQBxAHQAuwAoARwBkgD9/4v/ev8dAMgAXgFGAc4ALgC4/6j/FQBvAG4ADwCk/zz/HP9//3QAXAFgAY4A5f/J//f/NgCjACQB+wBCALj/t//6/+L/2v8VAEIAxP9V/3P/5P/t/8X/z//0/+z/yv/p/xQANwAhABwAIQCK/5L+PP7a/s7/agBVANz/XP/2/g7/tv9DAGgA/f+U/8D/JgCKAPUA9AAvAOr+HP56/rz//QBwAQ4BTQDG/93/RgBvACEAkv9m//7/ygB4AW4B1AARAJn/gf+X/9X/FwBrAKcArwCZAN8AGgECAY4A1P+G/4//+/97AOMAsQAGAFT/Bv9V/+r/UABqAIEAOQDZ/5//uv8RABwA3v+f/5n/1P8iAGQAZgAAACr/mv6a/iT/1P9NAIcAWgDf/0j/If9M/5X/x/+R/0n/Rf93/9D/LgAuAOz/lP9F/xb/O/+Z/+P/KQA3AFgAUgA0AEEAVQA4AMT/oP/Z/2AAtQCsAIsAbQA/AN//9v84AE0AAwCx/7T/yv/N/8j/LwB4ABsAcv8Y/2T/uv/Y/wkAjgCzADwA2v+6/+7/HABKAHEAfwA2ALf/o//r/ysAPQBIAGwAhwAdAIX/fP/j/yQAFAD8/x4AJwDP/7z/9P8XAKf/9P40/+P/GgDx/+z/NQAoAL//tP87ALoASACi/9f/NwABAJ3/sf85AH4AMwANAPT/+//X/7X/+/8EAOD/lf+s/ywA4QBoAVIBwAD4/3j/+P4A/9v/DgFoAbYAEADL/+3/CAAKACUA7/85/47+HP9XANIAmQBBABkAyf9c/23/9f9uAE8A7P/t/wkA0f+L/9X/MwASANP/1P8UACYA3f8EAFYAFABn/yj/1f+BAIMAMAAJAMP/Q//y/of/ogAmAeIAUQAGAMT/dP9q/8D/JgA8AEMAhwDvAO4AKwBq/yf/Hf9Z/8v/cADQAJoAOwATAFEASwDk/4r/Yf9q/27/z/+MABABBAGHACAA7P/3/xYAUQCCAI4AZQAuAC0AKwD5/9j/pP9K/yD/Qv+5/0sAzwD4AG4Aaf9+/oT+af8RAGEA1ABKAe4ABACQ//3/+/88/7j+I/+z//n/kAB2AeoBSgEyAGf/Uv9J/5z/MwBsAFIAXgB8AJQAqQDEAKMA0//q/hj/1P81AFAAjwCqAGQAzP/J/4sADAGUAK//ev8T/7L+6v4lAEgBZAG4AFwAUAD0/3L/Qv+O/5b/H//2/p3/NwCEAKsAwAB8ALv/9P68/gj/Zf+m/8v/7f8/AEcATwAfAMz/hP89/+z+G/+c/wkAFADj//X/AwA2AF0A0QDQAFUAqP9W/0j/Lf9p//D/cgBAAAYANACIAHgA+f+//3X/IP/u/nH/ZQAQATABDgECAasABQBy/2//yf8gABsAIABSAIYAPgAGABYAUgCGAFYABACa/7r/1v8iAGoAiwB6AAIAz//r/3cAfwAsALD/i/+5/8f/JgBnAFYAmf9+/zcA0ADOAFgA2P9r/wv/8P5v/7//tv94/8j/QQA5AJz/TP+x/7P/f/+B/wsAbwAkAJH/Xv/a/z4AGACj/03/UP+m/yUAjABeACYADADw/xAAUAAJADz/NP/F/5cAwgB5AIEAlgAwAHX/LP95/7L/TP8+/6r/VgAkAQQCRAIcAXv/fv6+/tH/4QB0AZoBUgGeAHgAnwCRACMAk/87/9j+3P6X/9YAqgGCAaEAwf9R/0T/xP8qAOb/g/+u/7QAcgFAAYsAof+4/lb+4v4KAP8A5QBfAAAAnP9m/6j/IgA0AK7/O/8i/3T/KQDnACIBUwDm/jL+jv4t/9v/cADGAB0A6P68/pX/SgAmAAAAEADa/1v/b/8uAKwACQAf/+b+H/+u/zkAxgDXACoAUf9c/xQAkgCjAD8A+/8bAHcAxQDaAJ4A9f8X/+z+q/8wAJ0AvgCoAFQA4f/J/xcARQAKAMX/i/+w/7L/DgCtALsA/v8//wf/TP/o/1QAmQBpABwArP9u/97/nQAQAZEAg//I/t7+iv+OAOYAegB1/5D+tP6c/6MANgEGAUwApf9h/5v/9/8yAE8AHwCy/3T/5v9RADAAwv92/2D/if8gAJIA+QCoAO7/Yf9S/7//aACMAFYA9P+d/5T/kP/m/5gAoQDI/yv/Vv9AAM8A/gAmAQIBSQAm/6T+JP/i/3wA1wAmARoBnQAAAI3/df+8/9z/6/8lAGwAcAAWAAgAVQDEAKYA2v9i/5D/v//n/z0AlQB4AO7/j/+g/xEAWAAWAPL/8f+t/2b/m/9pAA4BNgHLAEIAsP8x/17/3P8+AB4AwP/V/2gAmAB5AEAA1/9V/wn/PP91/7L/IwBkAG8AHgC2/6H/wf+l/zf/2v4u/w0AywDnADYAt//b/zIAHgDc/4r/G/8F/8f/WQC8AJMANABEABsAvP+C/93/KwAnAAgANwBuAKYAvwD2APsAKwBA/z3/6P9UAD0ASQDZAEwBhwDa/9z/BQD6/6r/zv9oAJkAZQBLAOL/vP+h/zcAmQAzAKX/h/8GACMAAgAwAJIASADC/43/zv8xABAAGQBxAFYAkv/u/mH/VgB9ANX/QP9i//f/GgAZAPP/uP9l/y//cf8RAHEAHgDv/+v/GwAIAL3/6P96AAcAAv/2/u//pgAuAJ7/r//K//r+5P73/6UA0v/I/k//fgAUAZcAbwBGAFz/zP5o/6IA4gCgAJIA5wCFAG//+P5t/6T/ef/L/18ABAH7AOUApQD7/yn/9v5m/9b/v/+j/wMAawC3AHQAIwCR//b+1P5n/yQApwDzAMsAxgBgAJ//Af/8/rH/sgBEAQQBMgESAVYAUf/K/g3/Sf8p/3v/1QCOARQBUQBOABgAA/8M/nj+eP/r/xUA4gCIAccAx//h/54AiQCd/xD/h/+V/3L/GgAEAZwBLAGNAIMAkgDc/97+0v6i/3AAfwBvAEwAUwD9/1H/k/82AGAA9P98/3X/b/+Z/1AADgHzABwAt//5/1UAAwCS/53/Xf/S/vr+DQDyAPYAgwAPAM3/if9+//P/UwAwABsAhQD0AKsAFgCs/4z/O/8M/2b/GABbAL7/Rv+w/54A8ABWAPv/GQCz/0L/dP+bAGwB1QCY/0H/pf/P/5H/qf8cAA8Ajv9J/9//oABVAOv/zv8aAPD/d//V/4YAngCv/0H/m/8pANz/f//q/3sANACx/+D/MwD3/47/pv8+AH4ACADQ/zAAVQDr/2//Zv+x/8f/vv9F//T+CP+5/50AxwBRALj/Wv86/1X/AwCLAHMACQDk/y4AZwB3AIUAdgDM/x3/Av+v/38A9QDSACMA7f8IAPv/wv9M/23/1v9cANoAZgFyAZAAmf90/+L/EQAkAHAAyQB9AOb/zv+TACwByAAQAMD/2v/M/7v/FgBKABQAtv/z/18AXgDd/5X/3f/8/7n/lv8CAEcA6/8w/w7/a/+y/0YAFgFoAcAAFP8i/rb+1P9PACcAIQAtAOr/h/+Y/0AAwQBPAF//bP4K/nb+WP9/AFQBLAGuAB0ADgAKAPT/IwAYAK//Hf8f/8P/rQBOAW4BCgHq/97+AP8DAK0AawDH/7//AABVAPAAfAFAASsAjv9y/8P/CABpAMYA1wBLAKT/mf/q/7cAAgGRAN//pP9AANEAtwBkAN//MP/c/mj/sQAmAfMAbQAfAKr/+v7o/lr/hf9C/9T/gwDjAIwAOACQAE4AUf/u/uf/cgDJ/2//IgAWAbYADAALADwAgf90/qr+JQAeAbsAOwAoADAAyf96/9j/LADO/zj/9P6d/6QA6wBuANT/Q/81/0D/lP95AFwBHgETAGr/XP/H/8b/pf/3/1sAWABRAFkA6/9N/y3/ov8aACcAHAC6/5z/9v+jAPYAQAA2/9b+bf9ZALgA4wAqAYsAV//M/mP/OQBgAPf/4P8NAP3/qf/u/4oAUABF/7r+AP9B/1z/sf/mAGgBwgDU/1//Kf/M/g3/8//0AMIAfwC9APgAoAALANn/n/9h/0//6f+WAO4A0gDAAFEAg//k/oT+hv4I/8z/VwDZAAYBvwBFALf/qP/r/zsANwDe/83/0/8IAFUAtwCRAIr/zP7g/pb/UwCTAE0APQDu/6r/+/+GANoAlQAkANz/BgANABwA+v+T/wv/6P6z//YAngHMAKX/AP8I/4T/AQBwAJ8AYAAqAEoAfABwABcAjv9i/6j/9v97AAYBUAEkAV0AlP/D/6gA4QBnANb/rf/t/yoAMQBcAGoA6v8p/8j+If+n/zsAiwB4AAIAgf+Q/zcAWgFmAUEAEv+2/kv/HACYAKMAZwDq/3P/Uf/F/3wAAgHpAAEAGf8b/3L/tv+y/+3/sP8m/3L/aQA0AVUAYP7M/a7+dv/B//D/mwChABsA/f+iAOgApwDO//L+jv6A/ir/FAAMAUYB6wAtAGz/qf87AN//lP4q/if/OAB/ANQAkAHCAe4A/v+u/4r/nv4s/kv/hgD6APEAQgFsAXcAcP8g/4r/HwBDADUA7/+r//L/EgGsAfMArf+k/mL+pv5c/00AqAA1ANL/7v8GAOL/Yf+C/woADgDy/2UAvwD6AH0Aw/+B/xL/3P4Q/+z/aABZAGYApADoAIoAHABx/87+tv5A/x0AdAB9ALQAAAGGAJD/c//X/3P/0v76/vX/hwBXAF8A2ADbAAkAXf9L/8L/IAAxAKYAyQCQACUAsf+F/5D/of/c/z0AggBvAPH/rP+a/43/k/8qAKMAfwABACYAjwCbAEUAef9O/33/7v+HAL8AmQAJAM//u/+G/6f/OQBnAC0As/+O/5b/9/+4ADYBGgEdAMr+mv7m/l//0v9sAFIBigHHAPT/Qf8o/53/+P9mAIYAegB9AG8AjQCVAJAAJABy/zj/cP+h//T/QgCkAIMA5P9t/57//P/8/67/g/+N/+j/ywAWAVUAWf8Z/5z/cwAMATYBCAEHACP/Gv/A/2kAQABcAC4Avv9e/7T/0gBsAfQA4P84/zH/2v9fAHkAWAAUAPb/4P8MAAgAQgAdAJ3/2v+LALAAYADj/0oArQBTAH//b//4//j/mv/U/2wAdwCi//T+X//D/5f/G/9x/0UAKAD4/3EApABeAJf/TP+u/5j/Xf+G/ywAFwCP/5P/AwCRALMAOwCW/9b+oP6+/5YA5ABVALT/Wf8n/1L/OQDYALIA5/9U/wX/2P4c/yQARAFOATkAkf+W/8n/y//w/4gAXwCa/1T/o/8BAMD/q/9SAO4AkABIAHUAwgBlAB4ATABlADMABABNAFkAFQDq/0kAuQAgANj+ev44/y4A5wD5AJUAFQB8/1v/7/9UAFAAx/9h/8D/UAClAPgA+QAwAOT+Fv6M/v3/SgF2AcMAEgC+//r/SwAnAKD/xv5g/jb/ngCuAUgBEAAP//7+V/+w//L/5//H/7f/8/8lAJ0AsQBfANX/NP9G/7H/QwCUAPAAxwAdAFP/BP+G/zUAhgCjAPIA1gB5ABkACwAtAPD/i/+D/9P/QAClAOUA5QBiAEr/ov64/nb/WwDrABoB6ABbAMv/vP/d/w0ALwDm/3D/c//w/4oA6AB/AP7/sP9t/z3/ff/5/yMAMQAoAIMAjQAoAPj//v/I/zj/Mf+s/2cAnQBVAPv/vv92/xH/b//w/yAA3v+y/+P/EgAOAO//TgCPAB8AaP8g/4L/5v/8//7/ZwB1AOb/dv81/4T/GQCIAHQAQgAIAKj/gv+l/+T/AwD4/xEAmgCKALP/OP96/+X/5f/Q/04AzQBXAPf/IQCCADEASP+H/0wAXQDo/9T/WgBVAKz/cv8KAIQAv//u/n3/PAALAIP/fP/9/zgA9/8lADEAPwAUAO//MQAOAOv/tP++/+//lwBOATABeQC2/3D/2P58/jb/vwBYAZQA4P+n/+H/8P8RAJEAsQDt//D+UP90ANgAmQA2AAkAz/94/4z/9f9nAHwARABZAIEASgDk/+D/5P+i/5H/u//v/+7/m//b/zUA3P8s/wj/4P+nAJgAPgA3AP7/f/8Q/5H/swA8AeYALgDg/6v/S/8G/0L/w//2/wkAbAAgAVYBgwCL/zH/Bv8b/3H/DgB5ADAAzv/U/2AAkgAxAML/eP9v/2X/yv+QABoBEgF7AO3/qP+x/7L/z//y/yYAJAABADAAdQBXACQA4v+Q/4D/l/8BAJwANAFkAb8Ahf9k/lb+Nf+y/+D/igBUAQIBAgCq/2cAXQBb/97+i/8JAOj/RwAuAZIB2QDm/1j/UP8Y/3D/KwBUACUAYgBxADoAMgB6AJwAxP/Y/lX/LAA1ABUAagCMACgAe/+x/8EAUgHrAFQAZwDI/wb/8P79/9sAzgBLAFsAoQBVAOT/qf/V/7j/N/8U/6j/9/8eAHYAxgDDAEAAiv8f/xb/UP+o/9v/8v9fAHYAegA4APL/9v/p/5L/sf8oAGYAIQCb/5D/if+t/+D/eQCLACsArf+C/3X/Mv9h/+D/QQDp/9v/XgDVAL8AUABIANr/KP+8/h//0v86AFgAXACCAEYAr/8n/zH/qf8uADAAKwBfAJoANADb//3/ZwCuAGwAJwC2/7b/nv/n/0cAWAA2ALj/kv/I/4wA2QC0ACYA1f/k/9L/EwAoAOn/9P7Q/rj/ngDiAJAABgCI/zr/Uf8aAHYASgDc/x8ApwCgAOn/fv/Z/7//gf+Q/zwAqwA1AGr/L//S/1QAQADR/2f/TP+U/yAAnwBlABcA+v/O/+r/RQD3//r+0v5T/0oAmgBMAGgAkwBIANL/1v9cAI0AwP9I/2X/0/+WAJAB8gHaADH/IP4+/kP/XwDzABQBwwD3/+r/WwCyAKUASAAFAIn/Qf+7/9cAogGEAZ8Asv8s/wj/k/8QAMT/N/87/1QANgEcAZ0A3P/U/k7+Af+IALwBfgG/AEAAsf9k/7z/WACCAPD/XP8p/2L/EQD4AG4BugBO/6r+Cf+X/0kA9AA+AUgAtv5w/kT/yv+H/5D/3v+//0v/jf+MABQBVgB7/17/gv8MAKgAKAH/ABYAGf8e/7b/EQAbAI7/K/9o/xgAxgAIAcsAEgAM/87+tP9eANoA3ACMAAoAiv+H/+r/DADC/6L/iv/A/8n/PAAEARwBUQCm/2z/d//h/0MAowB9ABcAe/8A/zf/7v+lAIIAr/8D/w//tv/RAEQB7gDp/9b+vP5u/1MA8wDhACwAhv8y/1D/mP/N/w4AKQAMABAAoQDpAIEA4v+G/3T/pf87AJAA1gB4AMH/RP8r/37/GgA2ABcA6//J/9v/y/8LAMYAwgDJ/y//Vf8QAFgAdADeAAgBdQBf/9D+/v5R/8f/awAiAUwB3wBIAKr/Q/9o/8X/IQBhAHoAMwCP/0H/ff8qAGcAzP9C/0T/Zv+w/0IA2QDiAE0AtP9y/7T/FwAbAB8AGAC2/0T/N//O/3IAzgCqAEcAvv84/2X/8/93AHQAGAD5/1YAewBsAEUA5/+I/2v/p/+9/8v/KgBuAH0AWgA9AEoAPgDm/2v/D/9N/yAA9AAgAToAYv9g/+3/NABKACYAm/8n/43/GQCqAKoARgA6AAUAof9h/7H/DAAXANn/y//T//3/JQB+ANMAagCo/3H/zv8tADoANwCdABIBjgASAAkAGAAAAJ//mv8uAIwAggBVALv/f/90/xYAoAB8AAoAv//j/+D/4/8/AMIAnwAvANX/tv/a/97/JwCgAIsA5P9U/6X/gwDNAGMAz/+Z/9z/BQA4AD8AEQC4/2j/av/V/zYA9v+3/4f/qv/M/7L/3f9yACkAQ/8i/wEA0wCXABgAEQAQADL/9v7h/54A+f/a/vz+2v+CAF4AaQBRAF//rv4i/0oAvgC7AMAAEAHbAAEAef+B/1z/Gv9h/+D/ggCsALsAewDm/2D/Z//D/xAAEQANADYAUwChAKoAeQDq/17/Qf+d/wAAXQDPAMAAnwBKAM//Vv8Y/2j/SwAKAQABMgEcAXIAav/C/uD+Hv8F/zD/PwDdAIcAAgApACoAXf+U/s7+dP+p/8T/jgA+AawA0v/b/1wAQACg/03/r/+b/1z/zv9fALcAewA+AGgAkAAeAFf/CP9W//n/WAB/AE4AMgDT/xH/JP/l/4IAbAD2/9H/uf+j/xEA4wA2AbIAKAAtAIYAYQAHACgAFgCX/3T/DgCtAKoAQQDZ/6//nf+1/wwALgDn/9L/SQDXAOQArQBQAOv/cf9Y/8r/YgCYABQAiP+A/wMAiQB3AEwAOQDB/0f/R/8RANsAywABAJP/rv/S/7T/wv8TABwAz/96/7v/OwAXANn/2/85ADgAy//P/y0AUwDB/4H/1v9ZACUAxP/t/18ARAABADQAYwACAGL/Qv/U/1sATgA/AHcATwC8/1z/h/8JAF8AkAAzALH/T/+Z/10ApwBaANz/g/9N/zf/uP80ADcABwACACoAJgD///j/AgC+/5b/t/8QAEQASwAeAKj/mP8BAEMA//8w/9z+Iv+o/zoA5QAwAYcAhP86/7L/EwAVABwAUgAsAK7/bP/0/5MAZADU/6X/3f/1//D/NgBOAPH/a/9t/+f/XwBrAGEAhgBQAMP/X/+M//3/MwD//+D/y/+V/73/fAA+AWYBcwBZ/wv/Rv93/6X/KwC/ANoATgC//77/CAAkAPP/m/9J/yv/OP+u/4AA7QDOAEYAEgDu/87/4f/4//7/rP99/7r/RgCdAJwAdQAKAIz/gP/2/1UAIQCy/6T/wP/k/yYAiwCbABgAt/+w//P/+f/q/xEAUQA0ANH/lP+O/+T/DQD3/w4ARwBnAC8As/+R/7X/wP/X/xwAlgBYAL//b//f/24ARQDK/4v/Wf8Q/3L/KgDiALcA8//E/9T/nf+K//T/TgD3/5X/4/+QAJ0AHgD//zEA6/9f/0//IQCzAIEAggD0ABABRgBk/zT/cf+g//7/kgD+ALMA0P8p/0v/xP9iAHcAGADU/9b/IACIAPoACAGXAJn/9v5a/woAgADAAOMArwADAJr/xv9QAGEABgCc/4v/DQB9AJcAUQDf/5//qf+8/7n/zP/z/9b/wv8FAFIAVgD6/7n/8/9AAF4AMAAGAN3/rP9Y/3b/BwBiAGAA9//Y/7D/aP9l/7f/NgByADgA/v8kADEARQBhAC0Axf9X/1z/uf8qAF4AIADb/8j/2P8nAGwAVwDi/2D/Of+i/2sA3gDRAGkA1f9p/1P/zf9vAGUAyv9V/7L/gwDnAKkARwDH/xD/5v6X/6wANAHiACAApP+G/6f/4/8HAOz/mv9j/4X/CQCLALEAKwCO/2X/ov/K/8v/2P/r/wkA+v8wAJ4AqQD5/xz/Fv+4/yoAKAA4AGgARQD5/9T/8v8dAAEAxP+7/9X/2f/7/zAAGQDT/5P/aP9w/+7/hgDdAL8ATAAVAPT/i/9a/7D/VACqAFsAUwB7AH4AUQDe/2X/9P4D/4j/WADBAL4AhwBFADwAKgASAL7/mv/Y/zwAggCRAHoAVQD0/5z/jP+7/wYAQAB3AGwAGgD0/x4ALQDy/4v/Y//I/2kAtACrADQAnf9E/07/r//4/xwAAwAyAGoAmgB2ADYAPAARALn/X/+n/z4AaQBBAB8AIgASALr/vv8WADEA6P+j/7P/+f8lAAMA5P8QACwACgDE/8X/+v8QAA0ADAA5AFoAKwDH/6r/x//Z/xEANQBMAE0A2v95/33/3/8GAOX/0//m/wQACwA0AGkAGQCn/2z/qv8rADMA3f+q/6z/vf8JAF4AagAdAKL/UP9I/9H/egDiANIALgCR/1j/v/9qALcAWACf/w7/NP/i/4gA1ACQANr/g//F/wYACgDT/6//r/+M/+H/fQDQAI8A/f+U/23/nv/l/zkAJQCx/3z/v/9AAMAADAHkAFcAef/2/jf/m//9/zcAUwBGADQAJgANANn/bP8//07/hf/O/zkAgwCiAJgALgDh/4j/Xf+Q/9P/1v8BAGQAtACzAFUA8v+c/1r/UP/A/0wAYgBAAAoA//8EAO7/5P/E/5L/kP/j/yEAVQBeACcA5v93/4n/5/8mAC8ATwBcADEA3/+i/7r/mv9U/5f/YgDJAH8ACADH//H/CgADAAcA/P/C/5X/tP8UAIcAggAuAOL/qf+R/5P/vP8EAE4AMAAQAFwAnAB9APD/cP9M/63/BQB2AJYARAABANz/7/86AH0AjQBoAPn/ov/D//L/OQBxAIQAPwDM/5v/pP+5/+f/UACCAEgA1P+S/77/BQAqACsAZgBAAAoADwAhACQADgAJAPz/AgD5//7/LAA4AB8ACADv//7/HgAQAOT/r/+d/9v/JgA3ADEA//+j/33/m/8EAI4AegAUAOP/DgAQAO7/y//X//z/4P/w/wkAIAAlABYA///i/5H/bP+x/wMAQQBbAFoAYgBlAEEA4/+I/4v/5v82AAAAlf+d/xkAeQBrAB4A6P/W/7H/wP8XAGQAUwAWAOj/JQAJALv/v/8KADYA6f+d/6//+P/R/4r/s/8lAGAANQAHAP3/+P/4/zYAfgBoAA8A0P/I/+D/y//c//n/5f/X/9r/0//F/8X/8f8PAP7/7P/l////AgAZADUAJQDm/+P/EwBCAEcA+P+8/4H/af+a/wQAeADNAOAAdwDG/03/df/p/0AAYABhAEQAAAC9/7P/5v8cABEA6v/S/9T/4P/9/1cAjAB6ADUADQAlAEYAAgC6/8D/DgAoAPr/DwAsACYA/f/d/wQAFgDj/+D/FwAZAAQABABZAGsAHgD8/ywAOwDf/5D/tP8DAAgA9/8tAGgAXgAMAAMAHgDp/5//n/8LAD4AKgD9/+T/2P+s/6b/3P8CAAgAAwD9/xoAAwAOADYAGgAFAPH/BwAOAAwANwBXAD0A9P+m/4j/tv/i/yMAVgBPADsAJAD7/73/jf9u/4H/vP8dAHIAagBKAPz/yf+q/8j/FQAeAPv/2v/0/wkAEgAmADsAQQD6/63/nP+h/7n/HAByAHUAIQDQ/7z/wf/Z/wwALwAvABYA/f/b/7f/3P8dACUAzv+F/53/CgBVAH0AhAAqAKX/Y/+h/w0ANgA6AE0AOQAZANz/6P8QAPX/0//W/wYAEwAbAEAASAAZALv/gP+Z/9X/8v8JABkAHwA0ACwA//+x/3b/hv+y/woAUwCFAIEASQALAOT/vv+j/53/sP///zYATgBVAEoAHwC9/3X/bP+q/wkALgAAANT/1/8CADkARAAeAL7/bv98/9D/RwCaAJQAPgDL/3j/ff/U/y0AQgAqABYACAAbACQAGQDi/5X/hf+0/w4ATwBXAEMAHgDm/8T/2v/3//L/zv/F/9b/+P8wAEcARQAQAML/nf+H/6f/DABZAF0APgAmACgABwDa/9z/6f/v/+z/IABMAE8AFgDn/97/9/8PAB0AGQDr/+z/6/8DAAoAEQA8ACoA5f+1/8z/9P8OADIAXgBgAAUAw//k/0sAcABAABEABgAKAPb//v8xAFYAHwCy/4z/tP/Q//H/OwCIAHsAEgDC/8z/1f/S/+j/FAAtABoAAgAZACkACgD0//D/5P/S/9T//f8/AHIAcAA9ABAA3P/C/7f/xv/V/+P/9/8CAAUAAwD2/+r/9f/3/9T/sf/S/xwAUwBUADIABgDi/8r/y//s/xIAFgABAOj/5v/4/wIA//8AABgAHgAdABcAAQD3//H/AQAxAEYALAD3/7P/m//D//X/BwADABMAHQAUAAgAAAAJAA0A7f/n/wkALQAwAAcA5f/d/+P/3//j//H/5P/A/6D/vv8VAEwATwAoAAQA//8KABkAOwBRABMAuv+c/8T/DwA7AC8AAgDA/4X/fP+s//H/GAAfAAgA8v/z/xAAKwArABoAAQDd/8j/5/8hADsAFQDi/9n/7v/7////CAAaAA8A//8TAEEAWgBMADQABADI/7n/4/8eACQA7v/N/+j/AQAMAAsA+P/U/7z/yf8dAHsAiwBYABIA5f/K/8r/AQBWAGgAPwANAPn/EQAVAPr/3f/a/+3/FQArAC4AMQAmAAgA4f/Z/9j/1v/a//z/MQBVAEQAIQABAOH/xf+1/8n/8f8OAB8AGgAUACQAJQAIANr/vf/I//f/FgA1AD8AKQD3/9z/9f8JAA8A9P/6/wcADgAGAPr/BgD7/+X/x//d/x8AQAAyAA0A7P/f/8L/v//6/ywAIgD9/+b/7/8FAAgADAAQAAoA+v/m/+H/8/8DABAAFQAeABkAAgDZ/7j/uP+//+r/GAA1ADsAEgDn/8z/4f///xAAHQAOAPz/8v/+/yoAOAAbAOn/y//S/+D/7P8IACYAEgDp/+P/AAAPAAQA///2//b/7P/4/zEAQwAfAOP/zf/k/wEAFgAfAAkA8v/1/wUAGAAuABwA4v+//7//4/8GABMAJgAeAAMA4P/h//z/DQADAOL/2v/l/wcAKAAvABEA6f/N/8b/4f8JADAALAACAOH/1f/j//r/GwApABwA+P/i/+X/7v/x//X/AgD+//f/7P/m//3/DgAVAAwA9//k/+f/5P/s/wQAFQAZAAIA4//R/9r/6P/7/xMAFwAQAAEABAAcAC0AIgAJAOT/z//p/w0AJgAgAPj/1f/B/8T/0P/k//P/+P/9/wAAAADy//f/+P/z/+3/CAAkAB8ABADr/+P/5f/s////GwANAOj/4v/6/xQAGQAaACQAJQACAOn/5//1/woAHQAbABYAAwD6//X/7f/Q/9P/2//w/xMAJgAqAB8AGQAZABcADgAPABsAEwACAPn/DQAdACEADwD0/9v/0//e//X/EQAeABwAEwALABAAGAAgAAYA+v8AAAYAFgAlACMAAgDf/9L/6P8AAAgACAAEAPL/8P8DABYAIgASAPP/4v/d//H/HwA1ACUABQDp/9b/zP/R//r/HgAWAP3///8FAPf/7v/4/woAAwD8/wcAGQAPAPT/7f8AAP//5//c/+v///8QABcAFgANAPf/6P/s//z/BwAWAB4ADAD9//3/CAAVABQABAD6//D/8f/9/wUAAgAEAP3/BAAHAPz/7v/r//T/AgALAAMAAwAHAAAA7f/r////FAAYABMADQAAAOv/5////w8ADAADAAEA+P/r/+z/+/8EAP7/7v/g/+H/7v/8/wYAAAD1//D/7P/w/wMAEwAGAPH/5//+/xcACwD8//f/8v/s//P/EAAmACEADAD6/+7/5P/l////FgAWAAQA/P/5//n/8//0//T/6P/w/wMAEQAPAAcABgAEAPv/9v8BABIAEgAFAP//AQAIAA0ADQANAA0AEQAOAAkAEAAJAAMAAgD//wQA/P8CABAAFwATAAcA///9//n//P8JAA8ACQAEAAMABQD+//j/AgAEAP//9f/1/wEABgAKAA8ACAD///b/+f8BAAkAEAATABUACQD5//7////8//n//v8HAAcACQALAAkABAD5//L//P/+/woAEQAMAAQAAAADAP//9P/r//X//f8HABoAHwAbAAEA8f/v//P//v8GAAkAAwDz//L/+v8DAAIAAQD///P/7P/v//X/AwAMABIADgACAPn/+//+/wQA/v/3//T/+f8DAPr/+//9//7/8//q/+j/9/8BAAMAEwARAP7/8f/t//7/BwAFAAQACQALAAAA/P8EAAIA+P/0//7/BQACAAAAAgAIAAMA9//z//v//v8CAAUABQAEAAIA///5//n/AQAEAAIA//8EAAcABgABAP3/+v/1//X/+P8HABAACwAEAP3/+v/4//7/BQAFAAEA/v/7//f/+P///wgABQD7//H/8//8/wEAAQAAAP///v/7//n/+v/7//j/8//3//3/AgABAAIA///7//n//v8KAA8ADQACAPz//f8CAAUAAwD///z/+P/1//T/9v/2//L/7//y//X/+//9//z//P/9//n/9v/2//3////6//X/9v/4//b/+P/7//z/+P/2//n/AQAEAAEA/v/4//P/8v/5////AgAFAAUA///5//f/+P/6//j/9v/4//n/+/8BAAsADgAFAPr/+f/+/wQABgAIAAwACwABAPv//P8BAP///f8AAAIA/v/6//7/BgAEAP3//P8KAA0ABwAHAAkABgD4/wIAAwAMAAYABAADAAEABAAHAAsABgAAAP3///8DAAMAAgACAP3///8CAAQABwACAP7//f/7////AwABAAEA/v8AAAYAAwAEAP//+//8//7/AQADAP3/+f/+/wEAAgADAAEA/v/7//f/+f8IAA0ACgAHAP//9v/2//r/AQAIAAcAAwAAAP7/AQACAAEA///+/wEABAADAAIABQAFAP//+//8////AQAAAP7//v/7//v///8DAAEAAAADAAYABQABAP//AQADAAIAAAAAAP////////7//v/8//n/+P/4//n/+f/4//f/+v/8//v/+v/8//z/+//8//7////+//z//P/9//3//P/7//r/+P/5//z/AAABAAEAAwACAP3/+P/4//v///8AAAIAAQD+//n/+P/4//n/+v/6//3/AAADAAQAAwAAAP7//f/9//7/AQADAAIAAAAAAAIABAAEAAIAAgACAAMAAgACAAQABAADAAEAAgABAAIAAwAFAAcABwAFAAIAAQABAAEAAwAFAAYABAAAAP//AwAHAAcABAD///v/+v/9/wEABAAEAAMAAgABAAEAAQACAAMAAwACAAEAAQABAAMABAADAAIAAgACAAIAAQABAAEAAgACAAQABgAFAAIA/v/8//7/AAAEAAYABQACAAEAAwAEAAQAAwACAAIAAgAAAAEAAgADAAIA///8//3/AQAEAAEA///9//////8AAAAAAgD//wQABAAHAAIAAgAEAP3/+v/9/wEA/f8AAPz/BQD///r/BAAAAPn/+P/9/wUABgAHAAMAAwAAAPn//v8GAAcAAQD+/wQAAwABAP////8CAAIAAAAAAAEAAwAAAP///////wAA/////wAAAQABAAAA//8CAAMABAAEAAMAAwAAAP///v8AAAIAAQD///7//v8AAAEAAQAAAP/////+//3//P/+/wIAAgD+//v//P8AAAIAAAD9//z//P/8//3//////////v/9//3//f/8//z//P/9//3//v8AAAAA///8//v//f///wAAAQABAAEA///+//3//v/8//r/+f/6//z//f/9//3//P/8//z/+//7//3//v/+//7//f/9//3//P/7//v/+v/6//v//v8AAP///f/6//n/+f/5//v//P/8//3//f///wAAAAD///7//P/7//r//P/+/wEAAQAAAP7//f///wEAAgACAAMAAwABAAAA//8BAAEAAQABAAMAAwD///3//v////z/+/8CAAMAAQD//wIAAwD9/wEAAQAGAAEAAQAAAAAAAQACAAQAAwABAAAAAAADAAIAAAAAAP3//f/+/wEABAACAAEAAAD9/wAA///9//7//f///wAAAAABAP///f//////AAABAPz//P/+//7/AAACAP///P/7//n/+/8CAAMAAgACAP///P/+////AQACAAAA/////wAAAAABAAAA////////AQABAAEAAAAAAP////8AAAEAAgACAAAA/v/9//3//v///////v//////AAAAAAAA//////////8AAAAA////////AAAAAAAA///+//7//f/8//v/+//8//z//P/8//z/+//7//z//P/9//3//v/////////+//z/+//7//v//f/+/wAAAAD///7//f/8//3//v///wAAAQABAAEAAAD///7//v/+/////////wAAAAAAAAAAAAAAAAEAAQABAAEAAAAAAAEAAgACAAIAAgACAAEAAAAAAAEAAgACAAEAAAAAAAAAAgADAAQABAADAAMAAgACAAIAAwADAAIAAAD/////AQAEAAYABQACAP///v8AAAEAAQAAAP7//f/9////AAAAAAAA//////7//f/+//7///8AAAEAAgABAAAA///+//7//v/+/wAAAQACAAAA///9//3//v///wAAAAD+//7///8AAAAA/v/+//////8AAAAAAAAAAP///v/8//3/AAACAAAA/f/9//7//f/8//z//P/4//z//f8CAP7///8BAP3/+//8/////P/+//j/AQD9//r/AQD9//n/9//5//7///////z//f/9//j/+/8BAAIA/v/6//////////3//f8AAP///v/9//7////9//z//f/+//7//v/9//3//v/9//z//P/9//7////////////+//3//P/+///////+//3//P/9//////////7//v/+//v/+v/7//7//v/7//n/+f/9/wAA/v/8//z/+//7//z//f/9//3//f/9//3//P/7//v/+//8//z//f/+///////9//v//P/+//7//v/+////////////AAD///3//P/8//7///////////////7//f/8//3//f/9//7//v///wAAAAD///7//f/8//3///8BAAEAAAD+//3//f/9//z//P/7//v//P/+////AAAAAAAA///+//7//v8AAAEAAQAAAP7//f///wEAAgACAAIAAwACAAEAAAABAAIAAgACAAQABQADAAEAAgACAAAA/v8DAAMAAQD+/wEAAwD9/wEAAAAFAAEAAgABAAAAAAAAAAIAAgABAAAAAAADAAMAAQABAP7//f/+////AgABAAEAAQD+/wEAAAD+/////f/9/////v8AAP7//f////7///8AAPz/+//9//3///8BAP///P/7//n/+v////////////z/+v/8//3///8AAP7//f/+//7//////////v/+////AAAAAAAA//////7//f/+////AQABAAAA///+//7//////////v/+/////////////////////////////v/+//7///8AAAEAAQABAAAAAAD//////////////v////7//f/9//z//P/9//3//v/+////AAD///7//f/8//3//f///wAAAAAAAP///v/+//7//v/+//////8AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAEAAQABAAAAAAAAAAAAAQACAAIAAgABAAEAAAAAAAEAAQABAAEAAAD/////AAABAAEAAQABAAEAAQACAAIAAgACAAIAAAD+//3///8BAAIAAwABAP///v8AAAEAAgAAAP7//f/9//7////////////+//3/+//7//v//P/8//3//v/+//7//f/9//3//f/9//7///8AAP///v/9//z//f/+/////v/9//3//f/+//7//f/9//3//v/+//7//v////7//f/8//z//v8AAAAA/f/+///////9//3//f/5//z/+/8AAPz//f8AAP3/+//8/////P////n/AgD+//r/AQD///v/+f/6//7//v/+//v//f/+//n/+v///wEA/v/6//7///////7//v8AAAAA///+////AQD///7//v8AAAAA////////AAD+//7//f/9//7//v///////v/+//3//f/+///////+//3//P/+//7///8AAP////8AAP7//P/9////AAD9//r/+//+/////v/9//3//P/8//z//f/+//7//v/+//7//v/9//3//f/+//3//f/+////AAD+//z//f///////v///////////wAAAgABAAAA/v/+////AAAAAAAAAAABAAAA///+//////////7///8AAAAAAAD//wAA///+//7///8BAAIAAQABAAEAAQAAAAAAAAD///7//v/+////AAAAAAAAAAD///////8AAAIAAgABAP///v///wEAAQABAAIAAwACAAAA//8BAAEAAQABAAMABAACAAAAAwAEAAAA/f8FAAQAAQD9/wIABQD7/wAA//8FAP7/AQABAP/////9/wIAAAD///////8BAAAAAAACAP7//f/9//7/AQD/////AQD9/wAAAAD+/////v/9/////f8AAP///P/+//7///8BAPz//P////7//v8BAAAA//////v/+v///////v8AAP7/+//8//z//f8AAP///v/+//7//v//////////////AQAAAAAAAAABAP///v/+/wAAAQABAAEAAAAAAP//AAABAAAA/////wAAAAAAAP//AAABAAAAAAAAAAAA///+//////8AAAAAAAAAAAEAAQABAAAAAAABAAAAAAABAAEAAAD+//7////+//7//v//////AAAAAAAA///9//3//v//////AAABAAAA//////7//////wAAAAAAAAAAAAAAAAAAAAABAAAAAAAAAAEAAAAAAAAAAAABAAAAAQABAAEAAAD//wAAAQACAAEAAQACAAEAAAAAAAIAAQACAAAAAAD///7//v///wAA//8AAAAA//8BAAEAAQAAAAIAAgAAAP3//v8BAAIAAwAAAAEA/f///wAAAgABAAAA/v///////v8BAAEAAQACAP7//v/9//z//v/9//7//v/+//7//f/7//z//v/7//7//f/+/wAA/f/9//z//v//////AAD8/wAA/v////7////8/////f/+/wAA/f8CAAIA///8//z///8DAP////8BAAIAAQD//wAABAD6/wEA/v8BAP3/AAAKAAAA+f/8/woA+v////f/EQADAPH/CgAMAAMA9P8BAAMAAgD///z/DwADAPH/9P8IAAwA/v/2/wcABQD///T/AgAMAP7//P/+/wQABQD9/wAABQACAP3/AwAEAAMABAADAAEAAQACAP7/AQAEAAIABAADAP///v///wIABgACAP7//f8BAAMA//8AAAEABgAFAAEA/f8AAAYABAABAAEAAgD9/wIABQADAAIA/f8BAAAAAQD5/wEABQD//wAA//8DAP7//////wQAAQD7/wUABAD+//z/AgADAPv//v8FAAMA///7//7/CwAAAPv/BAAFAP//+/8AAAcABwABAP3/BgAEAAIA+/8FAAkA///9/wYACAACAPv/BAALAP7/+f/8/wwACAD5/wAACgAGAPr/AwAJAAIA/P/6/wwABgD9//n/BQALAP//+//1/wcADQAEAPL//v8HAAgA9f/3/wcAEgD0//f/EAAMAOn/+P8TAAoA9P/3/xYABgDz//T/DgAPAPX/+f8JAAoAAwDh/xsAAwD9/+n/GwACAPf//v8IABUA4f8CAAUAFQDr//X/HwAJAOv/8v8TAP//9v/3/wcACwDx//L/FAALAPr/9//x/xMA9v/u////IwD7/+j/9v8lAAEA3P/4/x4AFACu/xwAMAAEAPX/xP9PAPD/mf/y/3sABADJ//b/2/8TAOj/KgD4/+3/7v8xAP//of8BAG8AFQCT/9P/bQAvAJD/8f9GAFUAbv/P/3UAOwDA/6v/WAAxANX/zv8nADUA2P/Z/zgACADf/wwA9f8dAPX/7P8UAAQA6f8mAP3/zv8kAPr/DAAIAO3/AwAxAOT/1f8lAB0A+P/d/wUAOwD0/8z/9P8iABQA1//5/zEAGgDY//H/FwAEAPr/7v/+/xIAGQD3/xMA3//z/ygA+v/M/wUANgABAO3/6P8SAAMA4v8JAA4AAQDV/yIAOADW/7P/JwAqAO3/7f/v/zAA9v/w//f/BgD9/xEA8P/x/wwAOQDW/5//UQBSANL/Wf+WAGsAt/9t/xwAdwD5/73/CABKAOP/vf8bAEgA3f8QAOT/w/8eAFAA/P/K//f/PgAWAI//yf+HAG0Amv+f/1kAAQABAID/eQCUAKn/Vv9gAGAAbf/4/ywAkwCj/3//WABlAIv/a/+zADkAmP/P/1kAUwCB/4r/UgBvALX/nf+jAOf/zP+h/3YAOwCH/8z/bAA1AJ3/7f8uAMQAUv9t/1cAZAC+/97/gwDK/73/9P9SAE4Ak/+0/xIAbAB//z8A6v8fAI0Akf9J/wMA1gC6/w0Aif9sAKQAOv////3/2gAX/8b/vwBNAIb/Wv/NAGcAxv/O/okAAgHR//j+OgDrAAkAH/+J/0oB6f9w/+P/AgHv/9T+EQDKAK0AP/+s/wMAzACT/37/CgGw/4X/FgBSAOD/QQAXAF4A2f9k/3b/dgDkALL/9P8WAJT/8v+S/3EA3ABQ/23/gQBMALL/hf/y/+oA8f8u/6T/UAEQAG7+agA2Acb/wv6q/x4B7QCo/jD/MAIOAGT+qv4QAgIBYv40/1gBxgGw/WL+0AF8Aaj+pP5UAawAu/8w/pQAtgGt/0//o/+BALL/+f9RABkATv9eAO8At/+k/o3/zAFrACz/ev4oARIBwv59/zoBzwAy/gj/iAGAAXL+cv5WAdoB9P4U/mkAqgFuAKL+Af+aAez/xv7pAGUA4v/0/qEA2P8OAMD+KgHmAHn/mP+N/4H/s/9oAaoANv/6/joBYgDY/vz93gEEAqr/Av6CAGYAhP74AGoBif+K/g4BdwDu/kX/IgGAAqD9YP12AZwCaP6Y/5QBXwDq/lD9lAHnAKX/jgA8AbT+FP7SASkAZ/+f/yMANgEG/hQAMAFUAKn/0f9oAOz9d/++AFwCmf8k/zUAQ/9G/oUAOAIoAE7+h/8UAnX/vP29AAgDXP5W/roAeADl//z+cgFyATz+iP2eARAC6P1o/1AC+v+s/XL/IAIQAA3/6/+lABgBbPzXAL4BEAGY/XMAGAFo/87/IP5QAl4BbP60/hwCVwBa/mH/RgGkAZr/Xv5sAMMAuP6tAGoBtP9p/0v/6gCK/xT+2gEUA1D+xP10AJAAEwCK/98AoAFi/wD+sQCM/3L/jAHUACQAbv7Y/4n/OQB9/94B0wDM/X7/VwBaAbr+GADAAKQBlv6Y/fkABgH2AM3/KwDM/zD/vP7eAEwCa/92/qr/KAESAdD90/++AZEAJ/+e/lYAAgHY/rf/MAJ8/8D83f9IAwwBPP6c/TQCqgF0/IL+sAIoAzL+dv4zAEYBuv5u/u4BpgHl/9j9Vf/+AOABzv4n/+YB5ABm/mj8dAGgA2oB4PxH/1IBlv46ADUASAIb/7T9ugA4AKr/yf/kAcYBxP4w/az96gHcAlQBhP88/kj/vP+T/+AA2AClAEf/NwCL/6z+xv+2AdwBhP5s/hX/oAFIALQApQBA/kr+jf9sArMA/P3I/lACxAIW/tD7kP9wA4wBFv55/84BCgBY/sf/wAHB/5L+vACsArT+bP2BANAD4P/c/Vb+6AD0AMj/GwABAEcAHP+XAIL/n/97ANwAuP/O/tb+wQDWAb4BUgDc/YD92v/aAcoByv82ALoAoP/M/Z7+7AGuATYBDwA2/x7+ev4sApQD7gAE/YD+VABtAOr/LgGEAkQAYP6S/hcAQf92ABwCyAGp/5z8L/+iAcIBjv+m/40Apf9s/kz+RgEkAlwBnP+s/kD+tv6FACYBAAF5AEsAnv4I/m3/8AHuAaH/D/83/9r+SP6OAVAD4gDA/Xb+qv+M/83/+QAMAtMAUP4U/lz/sAC0ALoBjABQ/k7+m/+LAMUAZAFjAIf/6P12/igBigHEAFEA2P9e/iL+3f9UAjACNQC6/sb+Jf8v/0ABzAE8AfL/IP9S/jT/ggC+AVgBMP95/zf/0P8uAJYBZAE9//j9VP/EAGoACAHoAAYBVP9o/Xr+3wDzAAIBIgGn/3z+Sv6z/9QAxADS/9r/CwAJ/xv/FAAcAYEAsf++/j3//f/OALwBkQBx/9D+JP8F//7/LgGQAcQArf91/wL/Mv/q/w4B8wDE/+T+Vf86ABsA0AB3AHH/2P45/6b/CwCeAAgBoAAm/zb+Of9hAMH/FADtABYASP8X//z/1ADK//T+4P/EAHv/cf9jAMIANAAU//j+BwCQAF0A8P+t/7L/lP/p/4oA8ABDAIP/Qf+Q/8r/JgB7AAIBMQBF/9r+Vv8zALUASwDI/2r/i//5/ycAbgBOAMD/Pv9h/wsAHwB/AHcAXgDy/13/hP8AAKAASgAwACsAZQAZADgAZwBjAFgA5f/+/83/2v90AKsAXAD6/9z/uP+E/3j/5/9sAC8An/+l//r/3f/K/woAIACe/0D/yP9cAJIAJgDb/9b/jv9t/8//GQA0ADkAKQC6/4L/9/9hAGoAMADO//D//f9iAGgAMQABAOP/PQBcAAMAGQAdAMcANwB0/1b/+/9uAHAAOQDx/6j/l/8OACQAJwDf/77/tP+F/6//WQCkALYAiv9V/5n/CAAKANj/dACUAB0Amv8BAAMA6P/4/3MAIwCP/9H/iAC6APX/zv8TAAgAyP8HAHwAqQBiACsANQD5/5j/0f+KAJcACgCn/0wAigBOAOX/GABQAAkA3//+/2wAhQCBAD4ACQD5/wMAIwBKAD0ANADz/8//tv/F/+z/8//h/8X/af8U/y7/pP/B/1b/A//o/gH/zP7i/jj/L//8/pb+YP52/pT+6v4u/wb/B//K/sL+yP60/qT+0P4m/1v/PP9b/1r/Vf8H/+b+OP83/x7/d/+9/+z/2P+a/7z/o/+f/9L/awAMAYIBqAHaAagBZAFmAboBnAIsA7wDOARABLwD6ALsAhQDhANQBCAFcAXgBEgEIATUAwAECARIBFgEzAPMA5wDcAPkAiwCEAJYAcAAegBoAJAA6f8U/yT+QP3s/Jz8pPxw/Dj8yPsQ+7j6oPpA+kD68PnI+UD5UPkQ+aj5cPnQ+FD44Pdw96D3SPgg+UD5APm4+AD44Pfw92j5OPvY++D88PzU/ET9zP25/7gA/AFYA1AEAAW4BVAGmAdgCLAIIAmwCTAKYApgCrAKIAtgC2AL8AtQDNALwApgCqAKgApACgAKIAngCNAHqAdACOgHYAfYBaAE+AJUAmACLALgAcIB+AAAAEn/uv68/gj+Fv6M/Wj8CPwE/ND7SPto+tD56Pgo+CD3YPeQ9nD1kPWw9fD0cPJg8IDvIO+g7qDvMPEA8mDycPFg70DtgOvA60DuMPLA9SD4YPhI+aj4APmY+cT8ZAKwBjAJQAtADVAOUA2wDsAQABHgEYATYBbgFaAUwBQgFOARQBAgEKAQAA8QDSAMMAvwCHAIwAkQCVAGuAJaAX4Ap/8NANIB6gHKAI//UP6k/mD+af/SAZwCHAJSAeQA6wAyARQBQAIkAtAB1wD2/6r/xP+5/9b+uP04/BD58Pfg+Cj6uPmA9lDzMPEA76DuYPAQ8/DygO9A6yDoIOfg6WDvgPLQ8oDv4O6A7MDqYOzA74DyIPWQ+FD6wPoU/AT/nAJMAxwDeAZAC1ANkA+AEgAUwBLgEcAQYBAgEOAQIBRgFWAUIBJQDsALAApgCYAJwAlgCkAJWAfIBDwDTAN4BNAEeAToArsAgv7Q/ckAHAOABKgEsASMA6QBEAHoAngFsAUoBeAFEAZoBJADoARwBCACawAsAFH/SP66/pH/RP44+rD3UPeA9hD2IPcA90D00PAg8MDwwPAA8BDx4PGg70Du4O7w8BDx0PDQ8MDvIO+A79DxwPQQ9yD3kPYw9dD1IPZQ97D71gDwBgAJQApQClAKMAkgClAM4A/AEYATwBNAE+ARgBAgECAQ4A/QDXAMAAzwCxAL8AlgCZAI8AYIBPoBEAJoAoAE+AawBzgFGAFy/mz9wv5oAWAEUAcACKgGGAVIA7QCkAMQBUAGOAYYBWwD2AN4A2ACNgHR/1r+YPxA+1D7kPrg+AD4ePjw9wD24PMw9LDy0PGQ8aDxUPIw8iDzEPOA8oDxkPJA9MD0cPRw8mDwAPCw8dDz8PQA92D3IPeQ9DD00PTw9ED1UPlq/tQCYAfAC2APsAyQCLAGgAjACgAPgBRAGYAYYBRgEKANMAwAC7AL8AzgDRANoAtgCtgH0AVgBLQDnAJsAcwC4ASoBWgGsAW0AvT92Pvk/RwBgAMABWgHcAiIBRgDcAMwBJAEAAWABRAFcAKeAewBxgGsAFD/NP7o+1j6ePl4+LD3YPjo+JD3kPaw9OD1cPOg8VDyIPOg8mDyIPRw9dDzUPIw9ND0MPTQ8rDzQPMA8aDxoPLg8yD0YPRA9iD0oPPQ88DzgPMg9BD4SP6wBXAMYBLgEdAMGAdYBfAIEA7AE4AYIBwAG2AVYA+wDPAL0ArwCnALQAsQCmAIcAhQCGgFvgHH/xMAT/8QARgDuAWAB8AGOAToAO//hABUApgEiAfQByAIEAhwCJgHMAa4BTgFMAQ0AnwAjgBi/8j+7v4w/sD7iPig9zD3wPXA8zD1cPbA9aD2cPaw9lD0MPEQ8eDxwPJQ86D1YPcA+JD18PRA9OD0sPTQ8/DykPIg84DzkPKw9AD1APQQ9CD0APQw8ZDxEPQQ+LD+kAngE8AXwBMgDtAJCAfoB7APoBggHKAcIBpgFwARkAogCSAJIAnwBpAH8Ac4BygGmAXABEgCbv9m/q3/SgHkA6gFUAgACQAGTAOiAdwCOAXABVAIQAkgClAJwAggCHgG8ASEA5QCvQCI/tT81P04/uT8GPvY+BD2MPSw8gD1sPbw9rD2sPfQ9mD1IPSQ9AD10PVQ9aD1gPYA9xD3EPeA9kD2APXw9NDzUPNQ8hDyIPJw8nDxUPDA8QDyIPMg8sDy8PGw8ODyQPeF//AJQBUAHOAYIBHwCSAJgAqADoAWQBygHUAbABZgEIAMoAcYBXAEIASsAjAC2AMoBhAI8ATYAiACIAGQ/+r/0ANwB0AJkApAC5AImASoAzAGcAcAB8gHwAhQCKAGiAboBWAESAKMAvcAjPxQ+Uj6TPw4+/D6yPqI+SD1MPJA9DD2YPeo+Ej6yPnw+ND2UPYw9qD34PeQ9vD3wPho+eD2IPbg9lD24PJw8SDxsPGA8CDx8PFg8SDwIO+A8NDy4PJg8hDycPFw8dDz4PrABuATIBzgHGAXQBBACvAIIA5gEwAYgBtgG8AW4BCQDHAIWAbkAxQD4ALiALsA5ALQBbgFyASwBBgE8AP0AVgDQAYQCQALYAsgDOAJsAXMAxgF0AcwCEAH4AZgCKgEZAJ4AsQCbAEu/mz+sP1Y+7D44PhA+gj6wPjw90D30PWA9fD24PhY+Rj5APlw9/D2QPaw9oD2KPiY+ID3MPaw9LD1UPXw9KD0cPRg8aDvwO6A72DvQO7g7iDvcPBg74DvoPEA8wDzUPBw8DD0Zv7ADEAaQCGAIKAawBAQCKgGQAtgEYAWwBpgHUAZ0A8gCEgFcAMJ/8D9iAHYA/wD2ASQB4AI+AaIBlgHeAYABZAGEAkwC1AOwBDgEEAM0AhIB4AFiAPUAigGaAYYBYgEOAUIBBwAKP1Y+xj6ePio+LD5kPsg/Aj88PtI+oj4YPZg9QD2UPfA+GD5qPrY+mj5QPdw9WD0cPMw88DywPMA9JD0sPSQ9dD0EPPg7wDvMPCg7uDsQO4w8MDwsPEQ8XDyYPOg8TDxgO+g8LD0+P4wDgAbwCHAIWAcYBMgDBAJ4AjwDSAU4BggGsAWgBJgCmgFoAE+AIz9GPxF/2gCQAQABWAK8A4QDWAIMAjwBzgEJAPwCKARgBOgEeAP4AyQCAgDQAEgA7gDwANsA/wD3APAAjAC0AA0/7j9nPxQ+jj5CPkw+3z8kPyM/YD+kPtA9xD2sPYA97D2aPi4+lj6YPeA9oD2gPUw87DyoPPA9LD0oPUw92D2sPTQ8UDwQO9g7aDroOxA7xDwYPHA8bD0kPLw8EDu4O0g7zDw6PtADYAdgCSAJQAfABagCmAEAAXACMANYBOAF+AWABJgCzAHYAIk/Mj46PqM/dD+0gHwCIAOcA4ADcAOMA1QCPADqAUAC3AOoBEAFCASkAu4BTQCuwDxABADIAWwA0wCrAJwAtMAUwBmAYgBMv6g+aj5+Pq4+fD56v6YAqsA4PsI+UD3wPTA8yD3FPx8/VD8uPo4+QD2wPPw8uDyIPNg85DzoPMw9ED1cPXQ8/DyQPHg7+DsgOyA7aDugO4w8ODzUPVg8xDxAPKA72DtAPFlAIARYBwAJIAloB+gFDAJ4AUABbAGQAqgEIAS4BBwDzALoAUrAOD9qPxw+6j7aAD4BeAJYA3AEUAV4BNwD1ALIAm4BwAIAAsADtAOIA0wCdgF3AMkA4wCIAJ0ATAB7gHfADkAfAIIBAQCjv9X/wb+YPuw+eD7PP7w/UT9ZP3s/Jj5MPew98D44PiI+ej6UPrg9xD28PRA86DxMPKg88D0YPTA9GD14PSQ85Dy4PEQ8MDuYO2A7QDugO+w8eDzgPNg81DyoO8g6yDqQO4A9roBIBCAIEAmwCWgH+ATsAc4Ab4BMAeQCnAN4BHgE7AN6AeYBuAEaACA/Lj9t/8+AagCoAhwD6AT4BRAE6ASQA+gCbgGMAagB4AIwAjgCMAI0AbABUgFAAUgBQADZgDm/i8AzgGEAiwDmAS4BeQCZP7c/ED86PjA9xj68Pwg/Hj6SPrY+ED3EPbQ9wD6IPrY+Tj6MPlQ9vDzQPTg9WD1MPXQ9DD0wPMg8+DygPJg81DzsPLg7+Du4O5g7iDuMPCQ9HD1MPMw8uDxIPBA7iDzPP+wDIAXQCNAKAAj4BRgCmgHeAI4A9AHEA4gENAOQA1ACqgHwASQArsAGgAGAAABFAKgBgANABGgEQATwBRAEmAM8AjACOgHAAXIBBgHYAj4BgAHAAngCZAG1gHa/5L/QP6M/jwCQATIBMwDoANkArD+tPzg+zj8EPt4+kD7WPpI+CD3mPh4+WD5EPpw+4j6UPcg9ADz4PIQ87D0QPcg+KD3cPYA9cDygPHQ8QDyoPCg79DxsPGg7iDuIPIA9GDxMPHA8nDzAO6g6+DvUPZw/PAHYBgAJAAmwCJAGbAPqAfIBCAF4AcAC0ANYAzACWAI8AagBiAECAWABJgCpf8SAOQD4AdADeARYBQAEyAQoA5QC1gHYAWABtAFjAN0A8gGkAjAB9gHgAgYB3wCCP/9AEQD6AJwAtACfAKtAMT9sPq4+WD5CPmw+BD6QPuo+yD5MPdQ+PD5IPqo+sj7RPwg+dD1YPOQ8zDzUPLQ87D2sPeg9ZD00PTQ8mDvYO1g7hDwAPBQ8aDzYPXw88Dy4PIQ8jDxYPBA7uDuUPKQ9+j9gAggFoAfACBAHcAZgBEABywC+AZACnAKwAqgDPALeAboBAgGIAfwBAAFYAbQBewCAAKYBhAKUA0gD2AQgBBQDsAMAAxgCrAGUAOEAWwCDANoBJAH8AlACtgH0AVoBWwDHAKSAEsAowAMALD9YP1y/lT9VPzQ+nD7CPxQ++j4mPgo+dD4kPfQ+ND77P2M/Dj5YPcQ9lDyAO9A72DzMPWQ9RD3UPjA9tDy4PAA8CDwEPBQ8VDygPNA9KD04PMg88DyMPFg70DtgO2A7nDzMP3wCaAUwByAIYAhgBnQDqAJMAhQBvAFIAlADiAMgAjgCAAJ8AWyASIBvAMwBggFcAZwCBAJAAqwC0AP8A2ADIANwA2ACvAGcAaoBUgElgGwBCAFQAV4BaAGgAigBzAIEAZoBKwCQABE/cj7rPz6/jIAjP7s/cz8kPlg9oD1oPdo+RD50Plw+kD7sPoI+eD4+PgQ+FD2kPIw8QDy4PKQ8yD2ePgY+PD1cPMQ8lDwsPDg8PDx4PIw85DxMPBA8LDw4PCA8JDwgO9A66DswPMOALALwBcAIsAmgCBAFWAOQAmYAiYBiAYACwAL8AlwDJAMUAgYA0wC6AK6AXgBYASoBpgGkAgwDIAPYBDgEHAPYAzgCXgH6AZ4BagFaAeACNAHMAV4BPgE6AUgBhAHEAgACKAF5AFa/qj8IP2w/TYABAIgBOgBIP1o+dD3oPfw9vD28PjI+tD58PdQ+Oj5mPmA9wD30PUA9ADxYPGg8zD2YPbw96D4QPaA8xDyYPEA8KDvMPLg86DywPEA8kDxYO9A71DwIO+g7ODsEPHg+BQDYBKAHgAkgCOgHUAV8Al+AZ8AmAQwCOAKgA1wD9ANMAiEA64BdgERACEAtAO4B7AIUAmwDOAQ4BIgESAOAAxQCaAFqARABlAIIAggCcAI+AcIBlAE+AMIBRgHYAcgB9AGaAVYAfj+kP2Q/bD97v69AL3/2Pz4+UD5aPng96D4ePrY+kD50Pew+Zj7KPvg+mD7EPmA9LDxoPBg8/D0QPZA+PD3oPYw8/DxUPGw8MDvcPFA84D0gPPw8jDz4PKA8EDu4O1g7uDsIO8g92QBAA3gGEAkgCaAH8AV8AugA1H/KgFACAANsA3ADSANIAmQAzQBQwAkAIr+NQBgBEAGmAeACVAPoBLgEsARQBBgDWAIaAVQBaAG0AXoBEAFeAbwBAADEASABiAIGAfgBfAFBAMNAET9lP12/4QAFgFUARwCQgAU/Lj44PeQ9oD28Pcw+uj6EPog+WD6kPmY+Gj48Pcw9dDzAPOw83D08PUA9+D2EPYg9dDyoPDA7wDxsPEQ8zDz8PTA9EDzcPEg74DtoOwg7QDtIPBg9nQB0AzAGMAiwCTAHgAUUAroAz7/OgEgCHANgAzwCiALIAm4BTwBhv8wANP/YP15/9AEUAiACrANwBIAFUAT8A4gDbAJuASkAgAEyAa4BQAGoAdwCOAGYAYwCJAI8AXABLgEwAIdAGH/pAGwAYwBDAKwAtYAnv5q/nz8kPgQ9ZD2wPiY+SD5mPqQ+4D5aPiw9iD2wPWg9VD0sPSw9gj4QPZA9eD2QPZA8+DvMPEg8SDvIO6Q8dDzwPMA88DzYPMQ8QDvIO7g7kDvQPDA9TD/8ArAFUAeQCLAHsAVQAtwBEACMAN4BcAI8AoQCYAIoAh4BgAERAMcA44A5v7Y/rIBoAQQB3AMgBFAE+ASQBGwDhAKyAVoA+AE8AVgBdgEiAXwB+AHMAhACpAK8AjAAzoBiAGDABL+YQAYBPAE3ALFAOUASP64+sD4+PiY+CD3APdA+Fj5GPnA+Hj48PeA95D20PUw9eD1kPVw9TD18PVg9ZD0EPXg9PDzQPBg76DvwO8g7+DwYPJA8iDxwO+A70DvAO9A7sDvsPJY+BACMA5gG8AjQCVAHiATwAgAA8gBGAKIBeAK8AyACpgHiAeIByAEDAI8A1gELAK7/zwDAAlQC9ANABPgFgAVABAQDAAIzAMkA3gFuAcQCJAIcAjgB9AGUAjwCTAIKAaQBJQDWwDA/h3/ggBmAXIB9gFkAQgAvP0A/Mj6uPro+bD4cPiQ+ND4QPgI+Aj5cPnI+KD38PaA9cDzwPIA84DzQPNQ83DzIPRQ88DyAPIQ8oDxIPDA7gDwcPEQ8BDxQPMw85DxQPCg73DxMPQg+sgFABJgHEAgYB+gGWAQIAmwBQAFeAWoBzAJAAkACXAIkAfgBpAFYAXcArYBdwBIAZgDAAjADQARgBIgEiAScA6gCAAGwAfQCNgHoAiACqAK+Ac4B5AIMAnoB1AFYASgBLgCRgGvACwCiAKUASwBvv/W/iT9CPzI++z8CP2o/KD6MPk4+Zj4gPeA99D4mPjg9lD1IPUw9QD0MPOA9AD18PQw9HD0cPQA8/DwIPCg72DuoO0g7YDuoO9Q8BDxoPHA8KDtoOwA7fDxUPgwBAARAB3AIqAf4BlgENgH+gFgAngEWAeYB7AIoAmQCcAIGAeoBcgDwgFBAGkA7gCkAqgHAA5AESASIBIAEoAOIAmwBnAI4AjACLAIoAqQCrgHGAdQCAAJSAdQBTgEzAOMAtoBUALUArgCmgEKAOj+GP5E/Uz9xP1g/rb/pv5A+zj5CPlw+MD3uPiQ+oD6OPjQ9bD1kPVg9CD0oPTg9ODzQPMg82DzMPNA8hDxEPDA7yDvAO5g7WDuoO6A72DvsPDw8HDwAPDg8rj5ZAJgDKAXQCDAHwAZwBDQCugEmAGABOAIYArACPAGgAhAB5gFCARQBNQCoAHcAbABRAOQBrAL8A8AE4ATIBPQDzALAAioBjAHoAdgCFAJQAkACPAGSAeQBwAH+AV4BKgD5AIwAvoBTAIgAoYBhQBw/kT9aP3M/Mj7uPyQ/vD9ePv4+Xj6OPro+FD5cPrI+dD2wPSw9FD0kPNw8wD1kPVQ9FDz0PKQ8nDxUPCA72DvwO7g7mDvgO+A76Dv0PCA8cDxcPDA72DvkPFA93QBAA2AGIAfQB8AGWAQEAnUA6ACoAUwCpAKYAuACsAIoAZIBUAEEASgAmgCMAPUAzwDmAYwDGAQIBJAEgASAA8QC8gHWAcwCFAJ4AkACvAKoAlgB9AG6AYwBzgGSAWYBIADwgG/AJYAdAE8AsQBxgCT/3r+jPxo++D7bP0k/rD7KPqw+tD5MPcQ9jD3QPcA9RD0YPXw9aD1sPSQ9WD2YPVQ9MDzUPMA8hDwoO/g78DvYPAw8FDwgO/g7sDuwO7A76DwQPFg8pD36v4QCKARABpgHqAbgBPgC1gHWAWgBTAJIA2ADVAKgAioBvADTgHMAVgD4gGkAngDyASwBXAI0AyAEGASQBJgEEANgApwCAAI2AdACXALoAvgCZAI4AfYBgAF8AToBagFsARQAywCfgGg/8b+dv/KAPn/Mv7c/Zj9tPzI+3j8ePw8/KD6YPn4+JD4IPjg9gD3gPaw9YD0kPMA9FD0APWw9ED1QPXA80DxIO+g7oDuoO4g70DwAPFQ8CDvIO+g74DvQO8A8FDxEPSg+SAEQA8gF6AcoB1gFwANuAXgA8AFsAUQCcAMAA0wCUAH8AbABVQCgAG8AJoBzAEUAlAEYAhADaAQ4BEAEgARwA0QCRAGuAdgCLAI4AjAC/ALkAkQCAAIgAigBhgFKARIA+wByv8WAYIB+wAcAHcAgQDQ/hz+8P0w/nj8+Pow+zj6wPdg9qD3EPgg94D28PYA9uD08PMg9OD1EPbA9nD2YPXg9LDz8PHA7wDvYO+A7uDtAO5A72DvoO6A7iDwMPBg76DuEPBw9HD6qAPgD2AawB5AHcAV0A0AB5gEGAbABxAMkA1gC/gHoAbYBuQDXgGAAcwCZgG3/ygCKAegCuAMYBEgFKAR4AygCgAK8AhwCCAJMAuQC2ALwAkgCQAJAAgACMgGgAYwBbACFAJcArwC5AKAAs4BlwBK/kT9oPyc/Ez8BPzo+0D7ePow+fD3gPcA9zD2IPVA9oD1YPVQ9ZD20Pfw9iD2EPYg9QDyMPBg8ADxsPAw8CDw4O/A7iDtoO3g7yDwwO+A71DxgPCA8DD0LPwQB8AQQBlgHMAbQBRwC0AFkANwBtAJgAvADFANcArABVQDtAOQAyQBZf8MASgChAMwBaAKAA6AD6AQwBCwDWAKkAgwCCAJAAqwCzAMUArgCfAJUAqwCBgHOAeIBigEtAEUAQQCwAHlAGQB3gFTAID+nP3s/cD94Pvo+7j6APqQ9+D2YPaA9kD3UPfA9lD1YPUQ9MDzoPPA9KD28PWg9NDzgPKQ8QDwEPDQ8KDvoO4g7SDtwO3g7iDwIPGw8UDx4O+A7/DxEPkUAlAMABZgHAAd4BbwDcgHMAa4BXAH4AsgD6ANoAlgBwgHUAVAAuYBKgFzALUAiAIIBhAI4AuwDiAREA9QDNAKgAnwCEAKgA1wDtANAA1ADdAL8AlQCNgHoAegBegDzAJYAkgB+f8KAAcAYgCc/zr/G/+8/tT9fPz4+0j7wPrQ+YD5aPmY+fD48PYg9pD04PNg8wDzMPQg9RD24PXw9BD0sPIw8UDvIO9A7+DuoO2A7aDuYO8A8EDxwPIg81DxQO9A79DyYPi6AfALoBXAGaAYgBEgDLAIcAbwBvAJcA6gDiALgAlwCYAIsAW4AygDRAHy/3oAHAKIBXAJkAxwD9APkA8ADRALUAkQCnALIAzwDOAN0A5QDYALgAqgCSAIIAYQBfgD4AIEAaQA5AHAAuwBtgDaACYAYv7k/BT9XP0U/Hj6ePoA+7D5sPg4+ZD4EPcA9TD0IPSw85DzEPQw9XD1sPSg8+DyoPHg74DugO7A7sDuQO6A7iDvoO8A72Dv8PBw8SDwgO8A8wj5WQAwCEASABcgFgASkAxQCUgHuAdwC9APoBBgDjALUAjgBrAE2ARQA1AC1gFKAdAB2ATwCGAMUA4wD1AOUAwwCtAIoAkQCzAOoA9AEEAQ0A6wCxAICAeIBtAGoAW4BJAEjAKrAC0AiAHSAbMAkv/K/sj9KPzY+yj8uPxI/BD7aPrw+bj4UPeg9rD2YPaQ9RD1sPWA9aD0UPRA9FDzQPIw8fDwYPBg78DugO4g7iDuIO6A7QDu4O7g77DwcPAQ8MDvYPII+O0AEApAEWAVIBNwDrAIcAe4BTAJ8AzgD2ARIBCgDYAJUAVkA6AD3AKMAPgAoAIwBOAFoAnwDBANkAtwCpAJUAmACAAKYA0QDyAQQBBgECAPYAzQCLgGYAagBkAGMAa4BeAEgAJqAQgBHQCc/gT9QP1S/mT/Iv8d/1D+aPxQ+nj4kPdg9xD3YPZQ9mD2cPYQ9vD1QPZw9WD04PJQ8oDxoPHg8QDy0PHA8FDwgO8A7mDtgO2A7WDtIO/Q8ODwgO8A8LD2LP1AAoAKYBFAEjAO0AqgCZAIIAigCoAPQBKAEWAOYAvgBwgF0AL4ApgDOAMwA6AC0AQgB8AJwAqwDPALMAqYB6AIIAnACcALkA6gEEAQ8A+ADmAMQAmQCGAIyAYYBsgFAAV4A6wCZAIEAu0AeP+M/pj98Pxw/az9IP20/Lj7yPpY+WD4UPcA9lD1IPVQ9QD1UPXg9XD1gPQg83DyUPFw8XDxgPFQ8bDwAPDg7kDuwO0A7oDtIO4A8GDvYO8A72DvMPMY+VACUArADrAO8AwwCsAGUAZQCEAMIA4gD+AP8A6ADNAI4AZQBUAE1AKcAsAC2AMgBWgGAAnwCqAL8AnACNgHUAiwCHAKQA1QD1APAA/QDvANoAvgCUAJsAiAB/gGgAYABUwDVALuAQYBnwBRAKj/nv7k/Xr+/P3o/KD7SPu4+oj56PiI+PD3wPZQ9QD1APXw9OD00PRw9NDzQPIg8iDywPHg8EDwsPBg7wDvgO4g72DvwO/Q8BDxgPFg7zDwwO+A8xD73APQCgANEA2gCiAGkAPABVAJsAwAD2ARgBDwDeALIAkAB2AFuAQgBbgECAWQBVgHYAjgCdAKoApQCWAHEAf4BhAIMArADIAO8A6ADnANEAxwCmAJQAgACMgHoAd4B4AGeAVwBHADmAJGASoAIv+m/jr+XP1Q/Uj8CPtA+uj5WPmg+LD3YPbA9dD04PQQ9aD1kPXw9JDzwPLw8ZDxAPGg8GDwoPAA8GDvYO+g7yDvIO5g7oDvYPAg76DwAPLQ9ED6jAHACHAMMAu4B6AEQAKIA6AH0AzAEWAS4BEgDvAKoAg4B6gG2AagBzAIWAfwB0AIEAmgClAL8AugCtAJEAgoB+gHgApADdAOABBQD9ANkAtwCSAJEAlQCZAJIAn4BzAG+AT4A0gD0ALyAYYBcABK/zz+8PzA+9D60Pkg+RD5IPno+OD3EPcg9hD1APTg83DzgPMA84DyoPKQ8jDyUPGQ8IDvwO7g7eDtYO6g7sDugO+Q8MDwIPEw8FDwkPAw8/D5jAHgB0AJgAlIBSwDhAHkAiAHsAuAD4ARoBDQDrAMgAoQCOAGcAe4ByAJUApQC6AL8ArAChAK8AkgCXAIMAlQCSAKMAugDKANsA2ADfAMwAuQCiAJEAnwCCAJkAjgB7gGaAWoBMwDGAM4AsABygDX/zv/pP5g/bj7oPmA+AD4MPcg9/D2QPYA9dDz0PIA8oDxoPEQ8hDywPGA8TDxgPBA78DuYO4A7mDuQO/A7+DuoO5g72DvIPDA75DycPVg99z81ALQBeAEaAM8AngBIALQBfAKwA5AEFAPIA6AC+AJsAgwCdAJIAqgC1AMYA2gDHAMEAswC1AKYArQCdAKgAoAC/ALkAxQDVANkA2QDLALYApQCkAKsAmgCYAJ4AiQB4gGSAUIBEwDMAMQA/QCiAIIAp4AgP6I/Aj7ePq4+Yj58PiQ9+D1YPSQ87DyIPKg8eDwYPDA7wDwIPDQ8HDwEPAA7wDuQO1g7CDt4O2A74Dw4PAA8kDwgO8A8NDwEPUo+kcAKAQIBbgD8AEuAWoB4APQB9ALEA1QDTANcAzAC+AKoAogCrAJIApAC2AMMA0QDQAMIAtgCqAKcArwCmAL0AvgC3AMsAwwDcAM8AsgC/AJMAngCFAJMAlgCIAHaAYgBUAEtAOwAxADoAIsAoAB+ADG/zf/uP1E/MD66PmA+Yj4oPfg9sD10PTw8rDxwPAw8CDwUPDQ8CDxoPBw8KDvwO7A7cDt4O7A7sDvcPDQ8SDyIPLQ8UDxgPHQ8ZD1WPkq/v4BJAOEAlcAiv+dAJAC0AWQCcALoAwwDEAMYAtgCoAK4AkQCvAKoAxwDuAOAA/wDcAMYAvQClALMAygDEAMUAzAC6ALkAuQC2ALcAqgCfAIsAgwCMAHUAfABjAGcAXABFgEXAOkAnwBxAAwAJP/i//o/uz9EPwA++D5CPlw+Ej4YPdA9kD1EPTQ8+DygPLQ8WDx4PBw8IDwkPCQ8FDw4O/A74DvAPAA8GDw4PDw8CDxkPBg8RDzcPRQ9sj5DP2Z/woBtgAtAKz/HgB4AhAGMAlAC2AM8AuQC0AKcAoQC2AMoA0ADmAOgA6wDrAOMA6QDkAO0A3gDWANQA2gDOAMsAxgDCAMEAyAC2AKQAngCIAIMAjAB5AHAAeYBWgEZAPQAigCfAEeAdwARQCu/5j+JP3Y+yD6yPmw+Yj5MPmo+LD3cPYw9RD08PMg83Dy0PGQ8YDxYPGg8bDxgPGw8ODvwO+g78DvUPDA8PDxIPMA9HD0QPQg9MDz0PQQ99D6jv7iAJIBkwDf/5T/pgEIA8AFQAjACQALcAuQC3ALYAtAC3AL8AuQDBAOIBCgEMAP0A6QDYAMwAsgDAANMA5ADiANgAzgCvAJYAkACSAJwAjwBwAHMAagBcgEMAREA7gCOALuAXgB9gAeAGz/rP4M/sz94Pw4/Gj7wPro+TD5mPjw94D3UPaw9UD1wPQg9ODzwPOw81DzAPNw8tDxgPGA8dDxAPJQ8gDzwPOg85DzwPMQ9HD0QPXQ9kD4oPmg+pT84P3Q/Vb+0v6g/00AGAJ4BKAGQAjgCEAJEAngCGAIAAkwCsAL8AzADdAOoA4gDsAMUAxgDKAMsAwwDQANwAygCwALIArgCZAJIAnACGAI+Ac4B7gG0AXoBEgEnAM8A9gCgAKGAQgBpQAmAMr/1v7Y/RD9ZPws/Oj7qPsI+zD6iPng+Dj40Pdg9yD3kPaQ9aD0QPRQ9LD0EPXQ9KD00PMg8zDzUPPw83D0cPUg9lD2IPZA9jD2MPYw99D3YPmQ+pj78PzU/Wj+iP7g/lH/SABUATQCAASABagG8AZYBygHOAdoB4gHgAhACZAKUAswCzAKYApgCsAJAAkACVAKQAuwCxALsAowCcAHgAbwBgAHeAfoBzAIIAggBiAEFANEAkIBugCUAWwCDAPAARYAcv7I/Pj7XPys/Dz9HP2E/Kj7GPtA+uD5WPnY+Kj48PjI+Nj4cPjA9xD34PaA9wj44Pcw9yD2QPZA9jD3mPgg+hD7+PqA+UD3oPag9yj7qP2U/bj8ePv4++D8Iv5v/xcASwAAAID/ov8yAYQDAAXQBMgDUAOkA2AFYAYYB6AG6AUQBlAGCAdgB4AI0AiQCHgHmAZwBvAFgAbYBrAHqAcIB8gFIAVYBAAEEATkA1AEyAQYBRgF8ANoAgoBNwARAFgAqgB/ABQAif/g/pT+6P2k/RT9SPx4+/D6qPtM/Dj9SP20/LD76Pn4+GD4aPl4+pD7LPzQ+/D6uPkA+eD40PkY+7z8vPy4+3j66PmQ+nz8Kv4V/1D9JPz4+0D9Lv54/r7/uwAwASgAAgDX/3P/3P0PADQDqAX4BLwCiANAAr4ASQB4BcAIOAYABKgDGARUA3gEuAVQBHwDQAXwBsgEEAI0A/AFuAQlAGQDoAcwBncAy/+wAoAE5AIoA2gEmATrAHb+zP7MANIAUv/F/wABfwAG//r+awC0/uj6uPm4/ej+7v6S/mj/nP5M/Cj6CPyw/JD8QPzo/OD7wPoM/Ur/1v/m/gj8GPuQ+Tj66PsZ/x4ABADI/3//XP0Y/Ij84P3e/oT+EgC4ANYAY/9k/o7+bP4h/14BWAPwA5QDIAFA/pj7OPydAAAFyAaoBsAEpAGS/qj8M/9MArQCCASgBIADagGCABgBSAFcASABJAEUAowDaANwAmIAfQDBAIEAnP9wARQD5AJMAhoBwf9U/tr/gAFUAcr+uP2s/uv/MwDDAEQBHf+U/KD8Dv4qAHQCCAGk/JD5UPvW/y4BAALRAMn/NP34+Zj7gv5YAWUAPQDq/xAA9P74/cz9aP7C/9r+hP/lAKwCEgHe/kz90P02ALEAjgGsAJAA+f/NAKkAiQCc/87+2v8sArwCGgEfAPEAaAJuAYz/Tv82AFYAz/8GAWACoAIEAuACUgH0/mz+zP66/p7/1wCsAlgGQAbwAsP/8PtQ+Lj4m//YB1AKOAXN/7z8CPvA+Sr+3ANQB6ADbv4g/Rj84Pu0/IgCAANgAhr+iPtk/HD9qgAGAOD/gv7SAYr/AP1g/DT+jwClADD/AP7mAHQBLgBE/nT8UPte/gsAPAKcAkUAKAHIBGADkPqg9dj5nANACEAExAD+ATAAaPxs/OT9PAB8AswDYAQ0Asz+ZP2U/gn/lAD4AY4BIAIkAsIA9v51/2UAcAEdAK3/nQDYACYBVgEIA7kABAD0/VL+7v88AlgCkv60/U7/IAP2AGj+7PzCALYBEgEIAcD86PrI+wYAyAJUAeIBLALgAvj9IPlo+lD9B/+QAVQCHALMAUz+vP07/zL+mPtw+yH/3AGAAmoBEALoAPj8SPtY/d//Gf8DAFgDUATA/jz9JAAoAt3/yP2K/hoAUv/m/lwBcAQIBCYBuQBU/ez8OP0CAGADOAZ4AyD/lP4b/7P/lP2J/3ADWAXs/jz8IAHkA6ACjP0E/gsAKAEBAEIA+gHYA2IBXv6Q/tD+o/+u/0sASAFoAtUAPQBIAlwARP0M/DT+MAFQBPwCwP8Q/fj5JP6UAbIB7v7rAM8AbPxQ+QD8lAMgBEb++P2e/wD/8Pvy/kAD/P/I+/T8fgE9/w7+1P50AiH/NP1O/7AC5gHc/gD8sPos/IgDOAdgBPL+/PxK/oz91v6UATgGGAI0/iD9P/9AATwDYAfYBTD9EPZ0/fgDxAPgAUAEYAYxAAj6mPycAnACXv5cASgFoAXsAs7/WP0E/A7/2QCwBCgEMASWARj9mPk4/vgDwAOYAmsAPf8a/37+ygB0AiQDrP3w+yj9IAF8A/D/Bv5K/or+gPsy/kACuATU/sj5kP1i/qz+IABMAZT+IPzQ/dwCmgEm//z+9P2o+SD4qv7oBZAFNAJUAOb+8PuA+LT8kANwA6b+IPzfANgE6APw/iz9nP2I/zj96v7cA+AIUATg/qj78P2/ANYA6wDQAmwC6P+mANQBAALz/z7/g//sAOwCIAKyAcQAJAGLAAj+V/+gBaAGdAFU/CD7IPsQ/TAF8ArgCdv/kPaA98D8rQDQAvAGmAT8/zj8WPwO/nT8jPwa/jwDnALGATgAGgG4/CD3aPpNAPgCfgB8ADz/PP8g+wD9FAIbAID8/v4AA84AsPxg+8D+xwDo/qIAGANtAAj9rPzC/+oASgFKARYAPv4c/TL+QAEYA5wDmQDn/3T+TwBs/7b/twAsApgDqQC+AHQB4P9x/xACvAP2AWH/BQDDALr/eP8YBKgEmgBo/tQAewCOAJABcATwAuD8ZPzgAkgEhgFoATQBtv9k/HD8bAFIBDgC3P30/U8AYwCq/gz+MAEIAw7+QPvw+goB+ANMA6L+bPz0/DT9sPxo/qgCsAMu/4D9aPzE/lz8sP0oA5AE0P1o+ub+KAKb/3T+zP8rADT+pP2AAFYBzwDc/3gCcAAw+4D7GALABLEAKP6AAVIAoP3g/ogEcAWTANz8jP0wAfj9DAGwBRAEtP5E/uAAdgBtAN3/uAJmAfMArgFcAqr/AP6x/+UA6gD4ABgDCAMcAeL+jP3Q+7z9oATIBVQDkP1o/CL/bv7u/3wBSASZAJT+yPu2/jgAigErAAL+FwCpAHj9CPtk//wD4AI4/AD5aP54AxIAOP0b/0T90Puu/swDtAKH/8D7OP2gAFT+UP5MAZACXP2w+3L+vAPYBSUAJPzI+/T9jP7KAbgEYAX7AMj8UPug+x4BcAU4BpL/UPwy/4QDPQBw/eIBRAIQAcYAyANEAgz9GPs5AAgFwARcAioBXAAw/dD8Zf8ABvAG3AOs/eD4UPuiAXgFqASIBd7+kPuQ+6j+4AKeAcT9hP4wB5wDGPrQ97MA3AMYAXj8VPxE/VT/iAIoBogBaPtg+kD80PlY+AwDIAq4BIL+oPw8/lD6UPfA/SgEWAJI/dj9CALyAYD9PP6jACkAUPs4/Y4BuALw/tT9HP7G/mACwAWABXT9SPu2/2QDxf8U/kQCZAI7AEz98f+QA/ADeAJ4AeMA0P1I/2P/B/8aASgE4APIAWgCggFI/xj76PzCATgFgAQQBJAD9P+E/Oj4xPwIAWgFqAeYBNT88Po//zwBaQBQ/O//WAM0AeD9Ov9UA7ABCP3Y+7b+zgGj/3b+8P6P/8L+AP68/rEAwAHg/Sj6aPy2AeAEXAKA/nj7SPxQ/tj9Cv/GAIACG/9L/+0AXgCA/bD96v6u/vT9nf/4BCgG0gDo/Oj+qP5c/e//lAMwAd7+5v9YA3AEnv8J/xkAkQDE/Uj8I/9IBfgHEARwAOb+yP3w+/z8tP8IBNgDYASAAyYBLP7c/Dv/KgE8AisATgDEASoAgAERAKABYALe/pj7APvOAaAE7AEK/lD9nv6Z/8YBGgGe/07+Tv7s/oz9LP3H//QB6AHOAYoB9PxY+9j5cPqV/zwDCAVsAYT/Jf+W/gj6sPf5/1AGuATo/mT/af/4/pz8/P6aAMD9ZP0KAFAIuAZs/cj5TP3y/lT9cP7wA7AJeAT0/Jj57v7YAmQCG/8S/iP/LAG8AngFSAIK/oj9Uv4iAdP/q/+cA7AFtAIQ/tT8yv+E/3oBCAIwBOAABAL9AAz/WPwU/RADmAWQBDT+ZP0k/Dj8Ov9kAsQDKAV6AUD96Pko+x4AtgH4AEEAVAPqAVz9gPv6/rYAFP2A+2T/2ANUA6gC/gGkAPj6wPew+dH/tgHwAzAISAYT/8D24PZF//gDnAJ8/P3/PAMCAUgBEAOwAoj9uPgo+A4BmAVQBOwCIgGH/9T+3P5lACIBXABM/GD9/P1MAgAIYAi0ArD70PeY+MD/yAXYBs4BDgB7/xQBb/+A/dz92AJIAp//6QBAAsD+sPq6/gAFOAVCALn/0gDo/HD3JP14BzAIKAIX/yABuPsQ9+D60APwBYACPAKhAFj92Pki/rgAif/w+/X/eAPSAbL+Qv9WAF7+8PtE/AcAsgAUAfAC4ANw/8D6IPuo/Z8AIgEIAzwD2AE4/dD7YP1T/zQCagFRANoA6AMYAIj6gPiQ/7gH6ASx/7L+jAGg/tj7dv9IBAAFZQCo/Gz+If/I/fz+wAJoBlAF5P4Y++7+BAK2/wr//AJoBDUAKPg4+7wDaAaIA0QCngAA/KD7FP7cA1wClP0i/usA7AG7AH4BeP/a/hz9dP1n/2MA0ABG/yf/i//yAW0AnP5hACcAOPtw90z9GAXYBzwDdP5Y/KD66Ppk/aYB0AIwAxoAvP2s/fD+bv4w/6wC1ANH/yD6OP1oA7gEqAAE/iv/2P0E/YYA4ASYBAgC8QDE/tj7oPv4AWgFUgEY/Gb++gHcA+wCSANkAg3/EP3g+8j92/8gAgADdANUA0wDDAJs/1D8uPqA+jj+VAMYB7gGzANo/mT84PsY/Cr+hAEYBGwDRwAU/8gBYALC/kj8WP3m/lj/6gCUAooB8v4Y/lwAxP9Q/az9XP/w/w//PACyAaIAVP5o/nP/jv6e/oP/UAA+AAT+QP4OAM8AagAsAGcAFf/G/vr+agG0AUQAZP3g/R4AqAJIA/4B3P9s/Qz8fPzd/ywD2ANiAZ0AUQBt/2D93PxmAHwCygFSATACqgFl/9j9IP+uAVACngG2Adb/6P38/dD/OAIMAoIBfABCADH/j/86ACH/fv7i/u3/4gDYAdQCvABV/+T+NP6o/YT8yP0MAqwDHAI8ASoBff9M/WT8BP0l/ygAxQBmAa4BnQDR/zv/cP6Y/VL+2P5hADwCiAEiAB//sv6t/xQAr/9tABoAXv7g/ZQACAMkA/4A2v4E/vj8JPwA/tAA/ANABXgDmACY/cj82Pz0/ZP/FAEEAwADmgFlABIAXP7M/ar/UgFuAZ8A5QDKATABMv8HAMQBKAKX/zr+sP/tAIgBMAJsAgwB7v74/Yz9hP1w/g4BPAPoAigBogCHAGj+oPsU/B3/mAHgASIB5QDEADYAd/+s/gb+mv4u/hr+R/8eAZwCJAKjAOT+PP4C/qz+m/9PAGAAMwAHAGn/Sf/g/0EA2/8+/1b/Uf8S/2b/UgDjAIkAjP9u/4f/AP+G/rb+JgDYAAYB6ADrAN4ASACC/1r/Uv/d/xsAHQBOAL4A9QCJAFwAPwD9/xb/7P4p/1EAIgHtAAwBxQAEAPL+d/8EABIAtP9YANgAnQAjACUAswDD/8r+oP7G/0YAzwBEAZoB0gCO/8b+Jv5M/tz+YQBYAWYBpQDx/5v/SP8q/1n/wP+a/xkATQBtAFoAoABqABEAuv8SAML/dP96/+T/egB5AI8AmQBrALz/a/9A/xr/1v52/7IAYgG4Ae8AIgAQ/27+Wv4S/wkA0QDmAL8AQgAXADUAJwCK/2z+Iv56/sf/mQCcAfgBeAGHAH//Cf+w/rD+Nf91AMMA6wBMAZYBNAFfAHH/3v5Q/lr+Ov/UAPQBNAJ6ASIAU/8x/0f/sv/I/xEApgDLANYAvgAbANP/vf/m/2YACgDR/6//6v8/ADwAkgAiAfAA9f9I/wb/hP8pAE8A3wAqAfwAPQAnANP/s/9Y/2X/uv8gAGcA3QDMAFkAn//c/gL/Q//e/5kA5gCiACsA0P+B/0D/bv/n/wsAgQBlAKgATgAuAA4ACwA2AHcAkgB6AMgAVwDi/7n/NgCMAJcAJgDD/7L/ef8VAE4ApQCWAGcAbQAhAOr/2P8GABoAcwCBAEsABQD9/w0A7f/c/xUAWgBZAC4A9P/z/6L/gv9H/0P/Z/+I//H/RgB2AAQAav8s/xj/X/+y//L/6v/7/3v/i//R/7r/O//M/hn/vP/n/yIA8/9c/wz/tv4f/1b/yP9GAGEAeQAkAAYANwDO/4H/RP9J/5b/UQDDAOwAxAD8/8D/if+q/9b/VwDcAKoAUwAXABoAbgCvADABHAHUAJkAggB5ACgAWgC0ACgBzwCTAFAALQAOAOH/YADOABgBGAEMAfYATgC0/3v/mv8FAEoAtQD3ALQAYQAtAIb/HP/I/i3/vv9/AMgA/QA0AfUAYQDf/4D/M/9U/0D/ff9c/0L/lf+C/+D+WP4c/tj9QP0c/YD9Hv58/vz+J/8j/9j+YP5G/tT9QP0E/Qz9YP1c/dT9NP5+/mb+cv7q/gX/zP6o/uj+Rv+b/ygAAAFWAWQBigGyAXQB9AHKAf4B4gFoAqgCTAP8A4AEuARgBOwDKARoBKgEYAXYBegFgAXQBMgEOARwBIAEYAQwBKgDNAPgAoACvAFoAfUAtgBDAGsAiQA5AOj/a/82/+b+wv4h/1P/KQDFAEAB4QCs/y7+lPyg+lD54Pio+JD48PcQ9wD2cPQw83Dy4PEw8VDx0PHA8uDyoPNQ9ID1kPYw+HD6PPx0/ZD9dP0A/TD9hP5kAfgDOAaQB5AH0AboBFgDkAIEA0gEYAbQCHAKQAtwCzALAAvgCpALMAwgDBANYA1QDoAOUA6ADrANUAzACnAJQAkgCMAH0AdAB8gG4AVYBZAETAN0AtQB+AE8AkwDmAQQBPQBP//g+0D4UPUQ9NDzAPWA9DD1APQg8qDwwO7A7ADr4Ong6iDrAOwA7sDuQO8g7qDuwO7A7tDw4PLQ9BD3CPng+xL+YQCoAjgEeARwBDgEcARoBHgEeAUwBhgGMAawBeAEyAM4AkQBQAHgAYwDiAXoB1AJ0AnACoALgAywDVAOQA8gEIAQQBHAEQASQBHAEMAPEA6gDDAM0AtQC1AKsAjQBnAEPANgAmQCLAKkAgwDRANUA4gDFAPeAVz/3PzI+JD0cPFw8KDwYPFA8zD2sPiA9uD0kPHA7MDoAOdA6MDroO7g8MDy8PFQ8XDxQPEw8tDw8PGw8qD12Pnu/jAEyAeAChALoAgQB6AFqATIBNgE4AXgBeAGGAcoBhgENAP8AVkAFwB1ANYByAK8AzgGEAiQCdAKQAxQDWANYA0QDjAPABDgEOARoBFAEUAQgA8gDnAMIAtQCnAJAAgwBtQDUAIiAeQA0AF8A8QD1ANEA0gClAGQAe4BsgHj/0T90Plg9VDxIO+A7kDvsPGQ9Vj4yPhw9QDxoOsA5+DlQOcg6+DskPBQ8GDwgPCw8EDx4PCA8FDxkPNA92j8RAKABoAJ0AvgC0AKsAiwBxAH8AUABSAEgAQoBPQCwAK6Aa4AjP/E/n7+1v7W/6wBoAPIBWgHMAngCrAM8A1QD8APQBDAEEARYBFgECAQ8A5ADtANYA0ADLAKUAkwCOAGQATQAUcAqf9I/wEAYgGQAswCjALEAuACGAP0ArwCoQBI/Gj4EPWA8eDuoO8Q85D10Pe4+Uj5YPbA7kDqYOhg5QDmoOqg7oDvoO+Q8CDxAPCg7/DwoPFw8qDz8PeA/IgBWAYgCiAN8AwgDeAKwAiIBnAFzAN8A6ACcANAA7QDHAKhAHb/kP4Q/oj9+v6hALQCeAQgByAK4AuQDQAQYBGAEUASQBKAEUAQQA/ADrAOcA6wDjAO0AwQCzAJ4AcQBsAEVAOmAZr/7v6e/2wBWASoBYAF+ATwAwQDgALUAgQC6P8U/Pj4cPVw8SDvYO/Q8XD0EPaw+YD44PTQ8MDr4Ogg56DowOvA7kDvoO9Q8ODvMPDg8SD0APTw87D1sPiM/OAAUAYwCmANUA5wDhAMQAnIBvAEKAOsAUACoAEqAWUA5gA5ABT/4P2W/pj+bv41AHwCYAVoB/AJ0AywDwASoBOgFMATQBKAENAOsA0wDUANQA3QDPAMkAtQChAIeAbQBNgD6gFVADT+Lv78/lAAoAMwBlgHIAX0A6QDFAMYAs4BfgGM/kj68PYA9EDxgPAw8hD00PbQ+FD5WPjw8gDvwOog6CDoAOsg7mDuAO4A74DuQO0A7+DxgPNA87D0MPj4+0wA+AXACiAOkA/wD8AOYAzQCLgFeAMeATb/HP4W/uz9zP2I/TL+eP6c/Sj9qP1k/zgBXAPIBnAKsAxAD+ARgBSAFUAVIBVgE0AQcA0gDHAK4AkQChAKsApgCcAI2AdYBUAE7AJkAZX/sPxc/AT93f/wAtgGIAjwCBgHuAbYBMAEWANUAKz8YPiQ9dDwQO6g7hDyoPMg9vj4sPoY+JDzoO5g6uDnIOYg6ODrIO5A7gDugO7g7lDwUPAw86D0QPVA9+j6TgGoBiALUA8AEmARsA5wC0AIQASsAOz+Qv7E/cD8sPyY/Gj8OP1k/h3/iP74/mcAtgGQBLAHQAugDbAPQBIAFGAVgBYAFmAUABIgD3AMsAlgCHAHaAc4BqgGOAe4BsgF2ASIBTQDsgGO/yX/CP6i/vgBoAawCVAJgAmQCCgFQATQBNIBgv5Y+/D3UPTA7kDtQO8A8RDzgPZw+oD64PaA8+DvYOoA54DnIOrA68DsQO1A7kDuYO9w8UDzAPWQ9hj4yPkg/SwDMAnwDSARQBMgESANkAlYBTQCTv7g/DT8iPtA+rj5QPvY+xT9Ev7t/2IANQAiARwDcAaQCaAMcA/AESASYBJAE4AUQBWgEyAS8A7AChAI4AWIBUgEoAVoBqAGmAVIBLgF2ATABNQDMAQAA3sAk/8AA/AFiAeACPAIgAcIBvAF2ATQAvn/yPvw9+DzAPAA74DuQO9g8UD1APhA+AD3oPQw8EDrIOlA6QDqYOsA7eDsoOyg7MDuoPBw8iD0EPZQ9+j49PwMA7AIYAzQD4AR4A/wDFAJOAZ0An//zP3E/Gj7WPpw+nj6kPuc/SX/9/8pAHEAzADCAYADcAfgC/AOgBHgE8AUwBMAE6AS4BFgEFAO0AxwCqAH0AW4BeAFkAboBwAJYAhYBrAEiAQ0A9AC7AOYBWAEzAPoBeAGQAaYBRgH6AVABZgDZAOgAaj9aPkg9/DzcPEA8QDxgPGQ8hD1EPZw9nD1UPSQ8IDrQOng6SDqgOvA7CDtQOyA7GDuQPGQ8dDykPRw9jj4gP0ABXAKUA7gDwARAA+QCzAIiAaoAywArPzA+rD5YPgo+Bj5BPzq/jEAigGsAsQC0AEYAoAE+AcwCjANYBBAEkAToBNAEiARcA8gDgANoArgCEgHuAUgBEAECAdQCJAI8AjgCPgGgAS4AigDLANIA/gDYAQwBOQDwAQoBpgG4AZoBqgFlANmAQz/UPyw9zD1QPMQ8bDw8PHA89DzoPNw9fD1kPNA8QDvQO0A66DqIOyA7MDsYOwg7SDuYO5w8ODwUPFg8gD1aPns/5AHAA6AEYAQAA9QDPAJ2AdoBUADl/84/ED5UPlQ+kD7sPwZ/4wB7gHAAc4BsALkAygEYAWgB6AJwAoADeAQABLAEsASoBKgEbAP0A2wC8AJ6AfIBvgFyAZ4BzAJIApACiAJgAdgBgAFtAOUAiIBEAGuAMoAIALMA4AFGAY4BjgGmAVoA3QCRgFk/aj5MPWA8nDxAPGg8SDzQPRQ9LD08PMQ9ODxUPAg7qDsQOxg6wDrYOuA7MDtAO1g7uDvwO/g79DwAPTA9yL/YAjQD6ASQBMAEvAO4AqQCDAIwAXy/6D7sPng91D4aPox/+MAPADcAEQCJAOwAvQDgAW4BhgHwAiwCrAMYA7AECATgBPgE6ARoA/ADWALYArACJAIQAlwCMAI8AhACjAKYAmACEgHwAWgAyQCUAF1ABj/m//FAFgBYAIgBNAFuAaQBUAFmARIAj7+6PsQ+RD2sPPQ8qDy0PJg8sDysPMA9FDzgPLA8IDvwO1g7QDsQOvA6uDqQOtg7GDtoO3A7qDucPBw8SD1KPsgAlAKYBDAEwATIBAgDdAJmAc4BVwDf/84+sD3CPgI+uT8qP5C//0AAAEGAcQBmAO4BBAF8AXwBlAJgArwC0APwBEgEiASgBIAEmAP0AyAC2AKMAlwCLAIUAhoB+gHUAnACdAIYAhwB+gFsAP4AjgCHAEXAAgBfAJuARYBbAKYBOgEkARgBQgFtAL9/yb+YPtY+eD2sPXw85DzoPMA83DzkPNQ9NDywPDg72Dv4Oxg66DqYOtg6iDqgOtg7eDuwO+Q8ADyUPLA87D4Tv9ABqAMgBCAEeAPcA0wC1AJUAjABUQBBP3Q+FD32Phc/FD+aP/EABoBNALYAjgE+AVgBjAGKAZwB4AIQAqwDPAOQBFgEaARwBEAERAPUAwgC9AK8AngCFAImAfoBlgGMAYACYAIAAcYBrAFIAV0A1wDcAOkAlgBbAEsAoACgAI4A4AEUASUA5ACRgEi/2j8aPoQ+GD28PQg9JDyIPJQ8sDygPOA89DzsPIQ8ADugO2g64DqIOlA6SDpwOjg6UDrwO3g7uDvIPKg9KD4Tv4QBsAMwBBgEVAPgAuwCEAIWAe8A5D/GPx4+dD3mPhw/I7/AQD3/4wB5AOwBEgFwAdgCAAHoAWQBtAIIAoADJAOYBAAESASQBOAEgARQA+ADnAMcApwCYAIYAfABfAG4AfQB2AHSAcwB+gFUAVgBYAFUAQoA0QCXAJ4AowCMAMoAzgDIAOcAigCKgHl//T90Pvw+dD3sPXg85DysPEg8bDwMPFw8XDxQPCA74DuIO7A7GDrgOsA64DpwOng6uDqYOyg7ODtAPHA8pD26PqgAegHwAzAD2APQA1wCjAJUAewBPoByP0I++j5gPp8/LT9TAAAAawCjAOIBagG2AZoB3AHOAfABXAGsAhACsAJUAvQDuAQgBFgEcASIBKwD2AO4A2gDXALoAjwB3gHCAe4BqAHoAjYB+AG4AYoB+AGsAaIBaAE/AJcApwCuAKsAjADXAOsAqACdALCATUAJP5Y/AD7qPjQ9jD14POQ8gDy4PGA8mDywPEg8TDwYO+g7iDuYO3A7CDroOpA6yDrgOvA6sDswOyA7gDxUPXo+5MAUAZQDGAQAA9ADVAKUAkAB9wDLAHw/WD68Ph4+sj8eP7q/lIAdAKQAwAEQAZwCAAIAAYgBQgGKAaYBdAHIAqAC0AMcA7AESATgBLAEUARYA9gDZAMEAywCqAIiAe4BmAGMAcwCKAIYAioB/gGGAeoBdgEAAXQA8QBGAFyAXAB4wDKAVADWATIA+gCjAIeASD/KP2Q++D4APbQ8yDyUPEg8SDxIPGg8KDwsPAg8ADwgO8A72DtAOxg64DrIOrA6QDqIOtg66DrgO/g8pD2QPpaAYAJ8AxwDiAOkAywCmgHMAa0AwEAIPu4+eD5cPpk/Gz+rv9CAPABGATwBkAIIAkgCcgHYAbABegG6AeQCBAJUArwC5AN4A8gEuAS4BIgEsAQ8A8wD+ANIAwgClAIkAe4BigGaAZIBxAHUAb4BlAHIAfABTAFMAUABFgCcAGmAegBIALsArwDQATEA7QCoAE7ADr+0PsI+QD2QPSQ8pDx0PDg8NDwkPBg8KDwAPEw8MDv4O4A7oDsgOsA62DrwOqg6kDqwOrA6gDsoO5Q8qD3YPwwBOAIEAwADoANMAuQCZAHUAUcAg7+8PoA+7j6GPuQ/KL+AAAiARgD2ATgBwAJAAmgCEAH6AaoBRAGAAjACPAIIAlAC7ANsA+gECASIBIgEQAQYA9AD3AN8AqgCHgHmAa4BSAGcAbQBugGQAaoBogH4AYABuAE0AOUAhQBIgGMAEwAngDcAKYBJAJ0AvgC3AHt/+j9wPvY+TD3IPUw81Dx4O+A7+DvwO8g8GDwMPGw8BDwIPDA76DuIO2A7MDrIOrA6eDqwOuA64DroO3g8YD1aPwMAzAJ4AuAC3AOsA6gDFAJWAbsAmL/IP14+1D78Pu4/Gj9mv6QADADqAQYBnAI4AlACUAHEAcQCIgHsAYIB6AIUAlACeAKEA4AEMAQ4BCgEYARoBDgDjAOAA0QChAI4AVYBbgE8ARgBVgF0AXgBSgH0AcgCIgHYAawBGQCVAEYAb0A5/+b/1UAbAGEAXABbAEoAZj/EP2Y+wD64PfQ9ZDzEPKw8CDwQPAA8GDwIPGQ8UDw4O8Q8aDwQO8g7UDt4Ozg6kDpYOpA7ADr4OlA7SDy2Pgs/jgE4AlQDbANoA4wDyAPAAsIBkgDGgBe/hj8VPxU/LT84PwE/qABeASoBmAIkAkgCoAJAAlACdAIUAeIBiAGkAa4BmAIAAsQDVAOABDgEQATgBKgEcARQBDADWALcAmgB7gFYAQ4BBAE+AP4A6gEgAVABhAH+AbwBTAFgAMcApMAZQDW/0L/nP7g/qr/mP8k/yP/Uf8M/rD7EPvY+eD34PXA83DygPCA7+Du4O5A72DvQO+A7+DukPCA8ODugO7g7mDuIOwg6wDuAO5A66DqoO9Q9pj5W/9gBtAKcAugC+AOsA8wDGgHaAX8Asr/LP2A/fD9RPxk/BD+YgA4AqgEGAcgCRAJ8AgwClAJoAjIB2gH4AbQBTgGgAcwCeAKIAxADoAPgBBgESARQBAAEHAOIAxwCvAIUAdABdwDBAOEAxgDJAMwBNAFQAZQBlAG6AUABRADlAEoAbcA7/8R//j+PP9l/xL/EP8d/7T+wP1w/OD6IPng91D1UPPA8fDw4O/A7uDvkPBA8IDvIPBw8VDxwO9Q8PDw4O9A7SDt4O4A7qDrQOwA75Dx8PJ4+WACkAYwB7AJ8AzgDSAN4AogCsgG3AF9AMQAZQA0/qz9H/8wAMEAEAQAB1AIgAiACHAKAAkwCNgHsAf4BngFUAZYB9AIcAmwClAMIA7ADtAPABGAEPAPoA5QDdALUArACCgHeAVYBLADOAPYAggDAAQABVgFCAbIBdAFsAQIA+IBfAGDAJn/3v7q/vL+2P4N/9D+Mv9i/oD9mPzQ+1j60Pfg9aD0APMA8SDvwO8w8KDvYO+A8LDwwPDg76Dw0PHg74DtYO4g72Dt4OsA7MDtgO3A7cDxmPi0/YQBAAZwCsAL4ArQCzAMUApABjAETAL0AOr/1P64/sj96P3m/0wC4AM4BRgH8AiwCGAIEAkgCSAIOAaABnAG4AUYBvAGQAlACtALcA1AD0AQQBAgEKAPcA4gDQAMYApACHAGAAXgA+wCuAIgA+gDYAQIBfAFYAbIBSAFeAREA/ABxwBeAMP/G//K/s7+vv6M/q7+ov42/lT9bPwY+3D5sPcQ9lD0gPIw8XDwwO+g7wDwYPAQ8ODv4PDw8YDxYPAw8DDw4O5g7YDtIO6A7IDqIOxg8ZDzMPa0/DQC2AZwCBAKgA0ADUALcAmgCAgG0AJuAU4BQwDo/Tb+wP/YAFgCsATQBtgHAAgACfAJsAkQCBAIgAfoBtAFmAWgBjgHQAhwCYALMA3gDoAPYBCAEKAPEA+ADeAL0AnoBzgGyARwA/gCjALIAnQDqAT4BXAGYAZABtAFiASUA0gCQgH//2b/0v7I/sT+qP60/qL+jv4o/oT9HP0A/Kj6ePlA99D1APRg8vDwUPAA8KDvAO+A7zDw4O8Q8JDxAPIQ8cDvQPDA8vDwIO4A7uDtQO4g7tDy4Pcs/Fz+lAKgCGALsArACtAM4ApQCOAFoAU4BHwBg/+3/+D+Cv6T/xQCIASwBPAFQAiwCeAJUApACmAJ6AfwBqAGuAYoBmgGQAdACJAJcAvwDCAOgA4AD6APUA+gDoAN4AuQCVAHyAXABNgD6AKIAqgCbANIBPgEyAXQBUgFqAQQBCADDALqAAEAZv8J/9T+Jv8v/+j+wP5s/uT9IP14/Kj7YPqQ+OD2UPXQ82Dy0PAw8ADwAPBA7yDvgO9g8ODvgO+g74DwEPBA74DvsPBg74DrgOvA7vDxYPMg9nz88gDEAlAFsAhwC4AK4AiQCOAIEAasAwADHAJiAND+nP4mAKwBQALQAwgFAAYoByAIUAmgCTAJMAigBzAHEAc4B7gGKAdgCKAJEAuQDLANMA5wDvAOIA/gDiAOcA3gC3AJYAdwBpAF5AMUAzADnANoA6gD6ATYBWgFsASABFgEdANkAkgB0ACKAB4ABgAsAHsAYgDq/wr/lv7k/QT9yPt4+kj5oPfg9RD0IPMA8gDxIPDA78DvwO9g72DvoO8A8EDvAO8g77Dw8PDA76DvgO7g7oDugO/A8+D4APvY/TQCwAXYB/AIEAnQCeAIeAeABsAFgATgAqQBMgBVAM0AhAHYAtwDuAVIBigGmAeACbAJAAnwCBAJAAkACLgHMAhACEAIAAnQCjAMoAwADaANAA5wDYANMA2QDGALwAlACNAGeAVgBAAEZAMQAxgDvANgBEAEMAQwBAgEbAMUApoBPAGDAKD/A/+J/3z/UP/6/iL/2P7s/Qj9fPzI+2j6IPng91D2kPSQ81DycPGA8HDwUPCg7wDwYPBQ8ADwoO/Q8EDwMPAw8BDxEPKA76DuAO9w8DDyAPWw+Ej8XP8oAqgEwAZQCEAIMAgQCJAH+AYIBvAE7APkAvYBDgGCAYAC0AOgBHgFYAYQB9gH0AhwCYAJUAkwCaAIQAjIB9AHIAjgB7AI8AkQC5AL8AvgDAANoAwwDAAMgAuwCmAJEAgAB4AFGARQAzQDUANQA2gDGATABJgE4ANwAygDYAJqAcQAPQD+/2//Mv/8/jb+Uv7U/Xj9mPxM/AD88PoA+pD4CPhw9qD0oPMQ87DxoPAA8HDwoO9A7yDvgO9g72DvwO+Q8ODvAPGw8dDxwPDg7jDwgPCw8cDzKPjw+sT8CQCAA8AFYAbQBsgHMAhgBzgGiAb4BYgEeAMYAygD+AJgA+ADUAX4BWgGQAfAB7AIkAmACZAJkAlwCVAJkAgwCIAIAAlACfAJcAsgDLAMAA1QDeANIA0wDKALYAugCgAJ+AfwBugFUAR0A6gDGAT0A0AE6AQQBXgEcANMA+QCrAG5ALYAYgCN/5P/PP/S/lD+jP2Y/Wj92PyE/DD8CPt4+Wj4IPeA9TD0YPOA8kDxMPBg8CDwQO9A74DvAPCg7wDwwPAw8YDwkPDg8DDxoO+A7hDw0PAg8tD0QPho+5D9egAABMAFoAVYBrAHAAgAB6gFGAa4BWAEKANkAwAEFAM8A2AEEAbwBhgH0AfwCHAJ0AgACXAJkAngCDAIEAgQCEAIsAhACQAKsAqgCzAMsAwADfAMcAywC9AKkArwCaAI6AcIB4gFYATcA9wDQAQoBFgE8ATwBLwDhAMcA4wCSgERAGIAJwBR/3r+nP6W/lb+kP2w/dz96P0Q/XD8yPuQ+tD44Pew9oD1APTg8mDycPFQ8CDwYPBA8ODvQPBg8SDxYPCQ8LDxIPJQ8IDvAPGw8WDw0PBg8tD0MPfA+WD+3AA4A/AE+AUYB+AGUAcgB4AGyAXABTAFeATIA/QDIAR8A+gDcAWwBqAH+AdQCJAIEAiACJAIQAgQCMgHwAcQCMgHwAjgCbAK8AqgC+AMQA0wDSANkAwwDBALkAkgCcAI8AfQBqgF0ASQBDgEOASABMAECAXIBPQDvANUA5QCTgFbAMr/i//Y/l7+Wv6+/lT+AP5k/qb+Pv6U/fz88Pvo+oD5gPhQ9yD2EPUQ9ADzoPFQ8WDxIPGg8NDwkPFg8RDxQPGw8SDxUPBg8DDxcPHA8GDw0PHg8fDx8PNw90j77P31AEADcARABXAFkAZQBpAFeAVQBeAEsARoBJAEEASEA0gEYAXgBaAGqAdgCPAHoAeYB+AHEAjwB0AIEAioB+AHgAhwCcAJAAqQCnALgAuwC+ALwAsgCxAKUAkACZAISAeoBmAGsAVQBHQD1AOQBDgE4AMoBCgEgAPwAmwC9gHLAOv/Zf/I/n7+Hv4U/lT+Kv4G/oL+fv7A/Tj91Pzw+4j6YPmo+Cj40Paw9RD1UPRw84DygPJw8lDywPHg8XDxYPFg8RDx4PCg8ADxQPEw8SDxkPFQ8mDx0PGw84D2ePmw+zT/+gG4AswCKATwBFAF2AS4BCAFCAXgBOAE8ATYBMAEmARQBTgG+Ab4B2AIkAjQCKAIwAgACRAJ0AjQCKAIkAigCEAJcArACsAKQAugC8ALgAtwC3ALoApwCeAIEAlwCEAHmAZABkgFcATwA5gEOAQwBFAESASYA0ADwAJoAmwBsv+Z/2v/dv6s/Sr+Zv5K/uz9Nv7W/jD+XP34/KT8aPso+jj5wPjA95D24PUw9WD0cPMQ89DygPJg8kDy4PFQ8SDx8PCA8JDwcPAw8cDxoPHA8VDyYPLw8WDyoPQA+ED6FPwj/3gBiAEcAhgDwAQgBSgEsATYBZAF2AQ4BRgGkAXABGAFYAeQB4AHIAgwCdAIoAfgB9AIMAlQCIAIMAnQCEAI8AiACuAKwAqACkALYAugCnAKcAoQChAJgAhACLAHIAfwBlAGUAWoBLAEEAVwBFgEaAQoBDgD3AIkA0QCRgE2AMP/M/86/vj9NP5Y/jr+cv7Q/uD+2v4A/4j+fP0c/Ej7oPqQ+dD4aPjQ95D2kPXQ9CD1UPRg8wDzAPOQ8lDxMPGA8ZDx4PBQ8DDx8PHw8QDy8PJg88DyoPIg9DD2QPi4+dT8Ef/H/64ANAJkA4gDpAMoBKgEmAQIBfAEKAW4BOAEoAUABqgF2AbwB9gHaAdgB1AIUAggCFAIwAlgCTAIsAhgCbAJEAmgCdAKgAoACuAJsApACkAJEAkwCWAIOAcABzAHqAaIBZgFOAbABSgFKAVQBXgEnAOUA3wD7AIoAgwCzAF9AI//Sv8//+j+kP78/nb/FP8Z/yX/Q/9m/gT9WPyg+9D62PmI+Wj5mPiA96D2oPbA9bD0MPQA9BDzwPEw8XDxYPEw8FDwEPFA8eDwAPHg8RDyMPEg8ZDy0POg9HD28Pgo+6z8hP29/y4BgAEYAgAD4AMoBDgEoAS4BDAE/ANwBBAFSAXgBcAG6AaABnAGKAfwBtgGIAcQCEAIuAcQCAAJEAmQCLAIkAmwCTAJcAlACgAKQAnwCIAJ8AjYByAIcAioByAGAAY4B+gGUAZwBhAHuAb4BHgE4ASIBFQDAAPkAgwC9AAsAPr/Kv+O/nD+Yv58/qD+ZP+v/x7/Lv50/Wz8EPto+nD6WPqA+dj4+Pio+KD30Pag9jD28PTw84DzUPMw8iDxMPEA8cDw8PCQ8XDyQPIQ8hDycPKg8mDzEPXw9mD4oPnQ+8z9wv6p/yABdALkAvAC5AMABfgESASwBIAFUAXwBJgF2AYQB1AGeAa4BkgGKAZQBhgHKAcQB3gHyAfgBxAI8AjgCIAIkAggCQAJkAjwCNAJYAlgCDAIEAnwCKAHGAfABzAHsAawBhAIcAhoB2AH6AZIBrgEyAS4BIAEsAPsAoAChgGnACIAAQBs/2T+dP7k/hX/Kv9v/23/iP40/QD86PtQ+3D6MPog+sj5KPmg+JD4OPhA92D20PXg9BD0YPPw8kDycPHw8GDxoPGQ8VDywPJA8sDx0PHA8jDz4PPQ9Tj4QPnQ+bD70P2I/pb+IABMApQC5gHkAigE3APoAmgDyAQgBfAEkAXYBhgHCAYgBnAGEAbgBSgGuAbYBkAHwAfQB/AHUAjwCPAIYAgQCXAJIAnACBAJ0AlgCbAI8AhwCWAIeAd4B+gHAAcwBmgHMAiwB+gGsAaoBqgFuAQIBUgFEAQUA8ACVAJCAdz/5P/K/0n/av6W/on/T/8A/7j+1P7A/XT8sPvI+5j7mPqA+mD6EPoA+Yj4iPgg+CD3UPbQ9QD1EPRQ8wDzMPKw8eDxEPIw8mDyQPNw88DysPKA8yD0gPSQ9ZD3UPmw+Yj6iPwA/iT+3v58AMwBvgF8AbQCsAMcA9QCzAMIBUAFuASgBaAGuAbwBRgG4AawBrgFWAYIB1AH4AY4BzAIYAjIByAI4AiwCBAIIAjgCKAI4AcQCNAIUAjgBngGKAfIBhAFaAUoBlgGCAYQBjAHSAZQBTAFYAXoBAAEMARgBFADLAIQAqgBqwCs/9v/AwAh/6D+S/+T//L+OP44/iT+sPz4+wj8BPxo+7j6yPro+gD6iPmI+XD5sPjQ93D3IPdA9oD1IPUw9cD0IPSA9OD08PSQ9GD0gPSA9ID0wPTg9fD20PfA+Lj5yPqQ+3z8XP04/p7+Uf+p/83/+P+WABoBZgH+AagCEAMcA2wD1ANABBAEWATABPgEqATYBGgFgAV4BbgFmAboBuAGgAfoB9AHMAcYBzAH+AbYBnAH+AeoB8gG4AawBgAGsAUYBrgGsAa4BvAG+Aa4BjAGYAZIBgAG2AXIBYAF+ARYBDgElAPUAowCuAKEAkQCCAIoAvwBagH0AN4AnwDR/1//CP+4/iz+mP20/VT9qPwU/OD7YPt4+qD5IPmQ+GD3cPZA9jD2cPXw9BD1MPWQ9NDz4PMg9LDzcPMg9AD1cPXQ9YD2kPcA+Ij4gPmI+lj7sPtE/PD8LP1E/Rr+9v5+/9//fwAaAUoBlgEMAtQC8AI0A8gDMARoBGgE8ARYBaAFuAVoBtAGIAdwB4AHwAeIB1gHgAeoB7gH6AegCFAIEAi4B5AHkAcIB3gHEAgQCMgHyAeoB4gHKAcIByAHIAe4BngGeAYYBpAFyASABDgExAOwA7ADuAOQAywD9ALUAmgCwAGCARgBhQDY/zj/+v6c/uz9pP0Y/Xz8qPvQ+jj6UPkw+BD3kPbg9fD0kPRA9PDzgPPQ8sDyIPKQ8WDxkPGg8RDycPJA8+Dz0POA9HD1MPaw9rD3oPhg+cj5SPo4+8D7KPzw/Mz9gv7o/nT/MQC5ABQBtAFoAvQCTAO8A0gEgATYBDgFqAVABpgGIAeQB/gH8AfYByAIIAgwCMAIYAmQCVAJ8AgACcAIUAjACJAJgAmACXAJkAmgCQAJ8AhwCVAJ4AjgCDAJkAjIBzgHgAfoBhgG0AXwBcgFAAWoBIAEQARYA9QC0AIsAiYBnQBdAJv/6v4Q/uT9YP1I/Jj7CPtI+jD5MPiA94D2MPWg9DD0cPPA8mDyUPKg8SDx0PDA8FDwIPCg8PDwYPGw8TDyAPNA88DzgPSA9WD2APcA+LD4UPn4+aj6oPto/GT9Qv78/rr/iQBWAf4BzAIkAygEuAQQBaAFIAaoBrgGGAeoB1AIkAjQCEAJkAlgCSAJUAnACbAJkAkQCuAJ0AkgCVAJkAlACUAJkAkACtAJgAlwCWAJMAlACRAJYAngCJAIMAgACBAHkAYwBsAFYAWgBIgEKASoA+ACxAKMAr4BVgHuAEsAQv98/lL+sP0U/Vj8KPyw+5D6yPlY+aD4gPeg9hD2UPUw9JDzUPPQ8iDywPGg8UDx8PDA8LDwoPCg8PDwsPEg8pDyUPPw85D0QPUg9kD38PfA+Gj5WPoY+5D7jPyA/WL+Af+//70AiAEgAqwClAMQBIAE+AS4BTgGeAbQBlgH2Af4B2AI4AhgCWAJkAnACeAJkAlwCaAJkAmQCXAJoAmACaAJQAmgCcAJgAmQCWAJgAlQCTAJUAmACWAJAAnACHAIyAdgByAH4AYwBogFiAXwBDAEpANsAwwDgAIUAuQBaAG3AOT/nP8d/0D+3P2Q/Qz9fPzI+2D7iPqg+RD5iPjA98D2MPaQ9dD0EPSQ81DzAPOA8kDyIPLg8cDxwPEA8jDykPIA86DzMPSg9GD1EPbg9nD3MPgA+eD5mPpA+wT8wPxk/ST+5P6+/10AFAHcAXwCBAOkAygEuARIBcgFWAbYBkgHqAf4B1AIkAjgCDAJUAmACYAJcAlgCVAJYAlgCXAJUAlgCWAJYAlQCSAJAAnQCKAIgAiACHAIYAggCBAI2AeABxAHuAZYBtAFgAUwBagEKATAAzwD0AI4Au4BsAE0AbsAVgDl/1P/uv42/tT9WP3A/FD86PtA+6D68Plo+fD4UPiw9zD3kPYA9mD14PSA9CD0sPNw8zDzAPPA8sDy4PIg80DzkPMA9HD00PRA9fD1cPYQ97D3ePg4+ej5qPpY+/j7zPxI/Sz+xP5v/wEAxgBuAQwCnAIoA9gDMATIBGAF4AUwBrgGIAeQB/gHIAiQCMAIwAjwCBAJEAkQCRAJIAkQCRAJAAnwCOAIsAiACGAIQAgQCPAHwAe4B5AHWAdQByAH8AaIBkAGCAa4BYAFIAXYBGgE3ANwAxgDxAJkAhwClgEiAaQATADi/yv/nv5M/uz9XP3w/ID8CPyI+/D6iPoY+pD5APm4+Dj4kPcg97D2YPYA9qD1UPVA9RD14PTQ9MD00PTg9AD1UPWg9fD1QPaw9hD3gPfw94D4CPm4+VD66PqI+yj8zPxg/Qb+qv5O/9r/bwAOAZYBEAKQAhADlAMQBIAEAAVYBbgFIAaYBvAGQAegB9gHIAhQCHAIgAiQCKAI0AjwCNAI0AjACLAIcAhgCDAIEAjoB6gHiAdQByAH0AaYBkgGCAawBVgFEAW4BGAE3AOEAxwDwAJAAuABggEUAa4ARADw/4r/Df+g/kj+0P2E/QD9xPxc/AT8kPso+9j6ePoo+sj5iPlI+QD5yPh4+Ej4EPjg98D3sPeQ93D3cPeA95D3oPfQ9wD4MPh4+Kj48Pg4+YD50Pko+oD64PpA+7j7KPyM/PT8ZP3Q/Tb+qP4P/4D/4/9ZANcAPgGiAQwCdALYAjgDnAMABFgEkATYBCAFWAWIBbgF6AUIBhgGOAZIBkgGSAZIBjgGKAYQBggG+AXoBdAFqAWQBWgFUAUwBQAF2ASwBHgEUAT8A8gDiAM0A+wCpAJ4AjAC5gGaAXgBEAHLAIIAPwD7/5D/Xf83//b+sP6C/lT+/P28/ZD9cP1M/Qz95PzE/JD8ePxU/Dj8GPwE/Pj78PvY+9j74Pvg+8j72Pvo+/D7APwQ/Cz8TPxU/HD8iPy4/OD8AP0w/VT9hP2k/dT9CP5C/nj+pv7U/gL/Pf9w/6v/2P8EAEMAewCyAOIAHAFaAZgBvgHeAQgCOAJgAnwClAKgArgC0ALcAvQC/AIIAwgDFAMcAxADFAMUAwwDEAMIAwgDAAPwAuQC0AK4AqAClAKIAnACSAIwAhAC5gHCAaIBggFYATABAgHuAMgAmQBuAEEAIAD1/9X/rv+S/3b/UP8s/xL/9P7W/rT+mP6G/mz+VP5E/jL+Iv4S/gb+/P34/fj9BP4G/gj+DP4W/hj+FP4U/h7+JP4e/iT+Mv46/kj+WP52/pb+pv6m/rT+zP7e/uL+9P4Q/y3/N/9E/1v/gP+M/5//wv/k/+z/+P8WAD0AUQBZAHoAnwCtALQAugDZAOAA3wDjAPQAEAH1ABABCAEQAfYAAgEOAQoB+wD3AAgB+QDuAOgA5gDcANYA0wDcANAAtgC4AKYAkgCJAIIAdwBlAFYAWQBHADgAHAAFAPv/3//S/9T/yP+v/57/mP+Z/5X/gf+J/47/jP9//4b/mP+h/6L/jv+P/47/fv9//5L/m/+T/5L/jv+S/47/kf+P/4f/if+c/6f/ov+g/6P/rf+y/7D/vf/Q/9b/0f/d/+H/3v/k/+z/+v8DAAIACgAmACkAGgAYACQAMgA3ADoARwBSAFcAUwBZAF8AYwBhAGQAZwBtAGwAbABtAHQAcwB1AHoAfwB/AHMAbwB0AHEAYgBVAFcAVABFADkANgAtAB8AGwAlACcAHQAXABMAEwACAPD/6//r/+j/6P/n/+D/2v/J/8D/tf+z/6v/ov+e/5r/mf+S/47/gv+C/3z/ef94/3f/ef95/3b/d/9//4b/iP+D/4v/k/+X/5n/nf+m/6//r/+4/8D/w//M/8P/yv/J/8j/vP++/8b/yP/I/8//1v/h/+H/5v/k//L///8EAAUA///9//r///8GAA4ADwAUABcAHQAcAB8AJwAsADAANAA+AEMASABOAFcAWwBXAFQAVwBXAFMATgBNAE8ARwBFAEEAPAAxACcAIwAiAB8AGwAYABIACQAGAAEAAQD7//n/+P/4//P/8f/r/+P/3v/Z/9H/yP/D/8H/wP+3/6n/p/+u/6v/rv+y/7j/vf/B/8T/0P/K/9P/0//W/9r/3f/y//r//P/+/xYACgAVABQAJgArABsAMABDAEMAPABCAEsAPAA9AEQAVABYAEcASQBYAFwAWgBVAGUAawBoAGIAZQBmAGIAXwBaAFUAWQBYAFcAVwBUAFIATgBJAEcASQBPAEwARQA/ADUALQAnACgAKwAsACQAFwASAA4ADwAFAPv/7v/i/97/1P/U/9D/0//W/9j/z//L/9D/1v/X/9T/0f/J/8v/zP/O/9T/zv/J/8L/w//B/73/wv/D/8X/yf/N/9b/3v/h/+P/6f/u//n/BAAKABMAFgAZABgAHwAqAC8ANQA1ADoAOwBDAEQARgA/ADoANwAxAC4AJQAoAC4ALgAvADMANQA2AC4ALwA2ADgANQA4ADsAOAAzAC0ALAAnAC0ALwAuAC8AMAAxACgALAAvACwAJAAVABoAEwAEAAAAAQD///T/7P/k/9//3f/e/9n/0f/I/8r/wP+2/7P/uv+u/6b/pf+o/5n/lf+W/5X/kf+M/53/nf+Q/4T/if+K/4D/f/+O/5H/lf+E/5r/k/+S/47/pP+f/5f/qP+9/7//qv++/9f/1//L/+H/+//7//r/BAAeABkAGAAwADAAMAAyADkARwBEAEgATgA8ADUAOwBRAE0AQABAAE8AWQBWAFUAZgBtAHEAcABlAH0AiACDAIkAeQCLAHcAYABlAHYAcQBfAF4AVQBmAF4AWQBMAE0ASgBUADwALwA3ADoAJwAOAA8AHgAPAPT/+v/w/9j/w//T/+D/z/+7/7//z//E/6z/sf+x/5z/g/+D/5D/jv+F/4H/gP+D/37/ff98/4L/ff+L/4f/gv+I/4f/iv+N/5D/mf+h/6j/t//A/77/rv+w/7D/wf/H/9D/2f/T/9//5//3/wUAEwAfACUAKgA1AEQAUABVAFQAYABiAG0AdQBvAHYAbQBoAGoAYwBpAHIAcABoAFwAXABlAFYAQQBCAFMATAA+AD0ASwBDAC8ALgA4AD8AKgAuADYAPAAkABoAEwAUAA4AAwASAAQABgDx/97/x//f/9X/x/+5/7z/x//R/8n/x//M/9D/wP+5/8r/t/+j/4L/kP+e/5r/iP+e/53/g/9o/3L/mv+l/6b/sf/H/7b/l/+l/8X/1P/S/9//1v/R/77/wv/Z/9f/3f/p//r/DwACAAMACAATAB8ALAAwADgASQBYAFQANwBFAF0ASgBOAEsAlQCUAIEAcgCdAJcAaQBpAKgAtwCGAHYAgwCnAI8AegBbAFYARgBDAFwAdQB/AGkAQgAuABUAKQDi/8j/BQCEAJsAoP9g/xoApQC9/8L+F/+w/+7/AAD8AIwA7P+S/r7+k/85/3X/+f+hAIz/rP54/qn/z/9P/5D+Nv/6/5j/DP8d/+7/r//6/rb+4/8UAEb/VP9N//f/o/8r/3f/zf/A/xv/U/9l/9X/9/+l/3r/yP9CAEgAhP8s/5f/nQBTAFz/2P/CAIMAoP+J/xQB8gBy/6L/QgH4Aa4ASwAoASYBUv8F//UAXALbADT/zAD8AeMAbP/V/xYBOAAJ/6cA6AKUAnoBigA1AJz9DP3SAKQDCAI2/hj+OwDK/0r+Nf+cADYAfP5q/lYABgE2ASIBgwAK/2D9bP2w/gP/Q//X/5n/MP74+/j7rP1U/gD+KP6V/5X/TP78/Vz/wP+4/tj9Jv+lAJgADAFKAXwAjP4u/iYATALyAZgAOgBSAHb/Bv+IAOAB8AEiAaAA2P/y/mr+ywDSAVAB0f8/ALwB+AF+/vD97/9kA1gCev5y/2QB5AKj/+r/BgFYAln/rf+AAhADjQA7/yACwwCA/o7/QARQBQYAXP3D/9ABVACPAFQDwAOsACL/UAD5AHsA3gBQAs4B4/8dAGIB4gBj/1T/MwAy/8D+dv88AjgDuP+c/cz99v47/3v/XAGIAocAqP3U/ab/hP/s/mX/qgDK/yb+6P56AVIBbP5Y/t7+C/+I/gsAHALhAE7+3P1i/7X/Tv93AKYBh/+s/Ur+egCQADwAYgBo/0r+5P2jAEgADv+U/o4AR/84/YD+aAE8AWj9XP0OAL4ALP52/oQB6gE0/qj9+f8MAbb+WP4qAeYBZQBg/sr/6gCp/wD/gACEAZUA9v8KALQAZQAgAHMAegDa/xwAmgAoAOL/fgCDAIL/hP6R/xIBMgDE/lT/EgHFAJ7+EP7z/4MAhv+2/tb/ugCE/1z+qv4EAFEAvv9y/87/xP8G/1r+nv7n/3YA2f8m/yv/rf/s/kL+8P4QAOP/vv7I/pYAdQCE/vj99v9cAfL/Zv7D/+wBEADQ/Yj+UAEUAsr/V/9lAM0AwP6o/pkA3gGeAMz+c/8gAQgBhf+v/8cAwgDI/sD+WgF4AuEAiv4F/xwAlwDOAAgBFgHN//b+l//4/+kAQAKsAZkAvv46/+f/JgHIAYoBfwD4/pv/KgGcAUsAXv/S/z4AYQBZADoBpAEEACz+Wv6hAJYBdgGlAOcAUv+A/V7+jgHIAqgAJv7m/l4BQgFO/5L+p/9bAN//kf8IAbQBVP+c/eL+nACJAAIA/QD4AUb/cP2q/vABXAHO/4P/3ABzAAD/LP8SAN0AcwBCAbEAmf8I/+L/mgAaAF3/DAHSAUwBXv9g/m7/7gA2AcUAAAAmAGwAIgDh////zQB2ACQA0wDQAGIAgv83AC4BqQDX/zsAFgFzALH/gv/zAM4AqgDbAJoA7P5g/gAAHAIMAh//XP87AFUAhP4E/wQCKALm/pT8hP9QAlYByv4r/50Aov8Y/hz/HALAAqT/+PzU/d8AaAIkAYH/Rv/I/uz9fP6OAcQCXADo/XL+nf8o/0P/MAEwAsb/XP2I/ssApgEvABcA4P/y/sb+9v8YAdUAbwCb/3T/gP4u/0wBqgFNAJ7+xv5L/+X/ZQA4AaAAeP+y/tz++f9UAGgBpAAA/+j9jv8YAT4Bpf+H/10AsP8W/6T+qQDgAVgBoP9+/gb/QQChAEoAwgDMAAQBHABR/5r/e/8z/9f/lgFAAmgAav6I/pIAzgAe/w3/7ACSAYf/AP6M/0wBiQAE/nz+2QDuAQ4AkP5I/3n/Kv9q/osAhAGKANz+R/84AFX/jP64/5ABbQCO/n7+MADm/0D+tv9IAtABzP1Q/Or+cgFUASYAoABkAMb+6P3s/x4BpACh//T+LwCaAEYBIAGt/xL+5P1DALwBkAKCAe3//P1I/Sv/1AEwAz4BYv/a/uT+N/9bAGACXALc/yb+nv8oAqQBTv/G/g4BKAGzAGwAcAGkAFL+uv5yAVACMgBP//8AOgEG/2r+RgE0A3cAXP3E/jgCgAKh/8T9q///APYApP/I/1UAFP8q/qP/0gHSARj/VP2M/joAPQCK/xMAgwBt/yL+Xv7v/78A7v9t/0//qP6w/ur/SgHjACf/Hv6y/t//RABsAGgAwf8m/3f/hv+L/04AgwCn/xj+tv5JADwBCQBl/6X/ev8C/3T/TAGHAIz+zv6NAB4B7P/6/n0AfAF7/1b+VP/dALMAVgDmAMUAq/8F/4T/3wAWAC0AEAHSAOT/Sf/N/0b/GgAuAVQC2v/s/qj/+QDe/1L+IAGkAkIB1P3Q/sQBjAH0/tT+5wB6AVX/+P2mANIBHAC0/l3/CAFiABz/lv/PAN0AQv8L/xUAswDPAAMAY/+i/kf/wwCEAqQAJP4Q/hgAvgErAG3/AgBaAEv/7P6DAD4BOgDm/p7+cf8TANoANAEUANj9LP7Z/yYBGgFbAHYANP8i/g7/igF4AsQARP/m/2oAKP9c/xQBFAIRAC7+kP9AAkgCzf88/hP/2v/0/8IAcAGsAcP/+P2K/lwArgGzAJT/Af9T/w0AVADTAMQA/P+S/sD+QgCcAV4BZf+q/mL/dQDtAGwBNALyAML+uP2c/4QCDANgARwAkv/C/8//iQAYASIBbgBh/0P/CAASAagA2v9D/9L/dAATAND/IQADABP/kv7e/4YBSAGf/5D+2v4J/2D/2ADqAQoBvP6O/pb/9/9E/9f/FgEcAfr/CP+p/5T/4f/j/yoAmf+z/3IAFgFvAJz/8P7W/q//2ABkAS4Ak//M/9H/yv6i/pYAZAEXAH7+P/+SAGQAV/82/6L/sv+w/1cAJgEpAOL+Tv6G/0IBEgEUAC//EABzAGj/Af/3/3oBCgEv/zf//QAwAf7+yP2y/yQChAFO/yz/qwB5AAT/df8CAZIByP83/+3/ZgCk/5r/YQBDAKX/D/8tAKkAEwAJ/+r+p/94ANsA0P9z/47/IwAFAO7/RQBsAP3/b/+k/5H/x//hAPQB2gAk/uj9NwDSAacAGf+x/9EAXgDi/lz/xQA2Ab7/5P6J/1sAgf9O/4AAIgG6/8z97P7YAAABqf8h//P/ef+e/j7/3AD3AHX/zP7m/j//JP8dAGIB0gC4/qz9fv48AOMAawCn/yz/dv+g/zMAqQCcAJ7/uv4O/wIA4gAUASoB0gBB/yD+tP7qACgC5gEMAD7/lf8NAG4AogDpAJsAyP8u/xoALgEKAVUA6v/G/8D/WQBYAXgBbQA2/4D/UgCOAPYAIgHiAKL/Hv+V/4gABgHlALcAsP8b/0r/bQB8AfAA9f+J/7r/5/8PAKAAyQAwAPr+mv8SAXwBzv+u/g3/FABsAIIA9ACrACT/Nv4Y/4gAAAEdAMf/yv+j/0P/Gf/w/10AuP8c/4T/WQBYAEb/Zv4J//z/NABVADQA6v8Z/3b+cv9+ALAAuf9t/6b/5//1/7v/EgAJAIv/Y//K/7cAJwCO/8D/cACkAPL/ff9mALcAoP9G/0MAagEKAfT/aP8bAIQATgBBAGUAaAAsAAkANgBXACIAnf+3/7wA0wDQ/y7/Zv9MABEAeP88ABgBWgCg/pz+yf+LAEoAPgDVALsATP+u/v7+5v+uAIUAeADV/8D/fP91/3n/u/9GAE4AEAAWAGQAef+0/vj+LwCmACkAEwBUAOf/PP5K/tz/YgECAcL/UP8A/+b+af9pAMwAPwD+/wsAnf8A/0n/YQCSAM//u/+8AAoBtv+u/lb/owASAbgAkgCpABcAX/+U/5gAuAFoAY4AEgAIAEYAZwDWAPsA1gBgAGYAoACIAE4AbACpAGsANQCMANEAUQCf/9r/qwDGAG0AdgCcAD0ARP92/50ALAHHANf/3v/r/8T/nv/n/44AlgAHAKr/s/8XAEEABwDi//H/BgDW/9T/DwA1AJb/UP9N/+P/BwC7/7L/ov9R/8r+X/8rAC4AX/8Q/0b/Zv8n/2r/aAB7AJ7//v5P/6z/xv/K/zsAdAAfALz/nf/N/9n/GABTAG0ALwD1/9D/1/8iAD8ANgD1/ykAWgA+APj/9////xcAEQCOAKYAbAApAA4AJwAIACUAfwDHAIcAaABzAGMA6v/R/zEAcwDDAIcAlwBeAAIAz/8OAIcA3gDNAHYAzv9//9v/kgD3AIMAKgCz/8P/jP/H/yAAIADy/6n/wf+s/2r/aP8LAM3/O/8F/2L/yP+2/3n/kf99/xH/8P5d/8L/vv91/w7/7P4h/0H/sv+H/zb/P/8t/3H/pv9c/1D/L/8+/+T/2P/m/7P/s/+p/0L/Tv8PAJIAYQDW/3j/2/8OAPj/SgBtAGQAsv8LAFUAmgBnAEYAVwBDAAMAXgCsALIAcgABAEIADgAZAGgAsgBjAPr//v8lABAAEQA7ABEAPwCk/xgAKAA4AN3/uv8SAB0A8v+//4QAVgDO/0r/zv9RAFkA9//I/xEAjv+x/7P/NAAwANr/DQALAAoAuf/P/+b/bwBlACEABgAwAF8AHwDy/zUArQCXAEAAJgCqAKIAowBsAJgAsAAWABQAuABSAeAANAA3AG4AcgBSAI4AtwCiAI3/7f+6ANcACQBC/4X/1f+L/4b/vP+v/1n/nv7Y/sr+5v7S/q7+pv4E/sD9QP5s/qr+Uv7Y/Wj9lP3Q/RL+Zv7k/Sb+8P3Y/Zz9EP7O/vL+6v7A/sj+1v4I/83/IgAqADgAngAoAboAuAAuAQwCEAJIArACBAPcAnACIAOgA8gDjAMIBAAFqAQwBDAE4AQoBcAE4AQYBQAFiAToBAgFAAVIBDgEYASABKwD4ALgAtACiAI4AtIBUgH+AF8A/P8e/7L+zv6E/rT95PyU/Bj8UPso+yD7uPq4+RD52Ph4+LD38PZg92D3cPbQ9XD1oPVQ9ZD1wPUg9oD1IPUQ9qD2QPdg93j4UPmo+fj52Prg+3T8SP1a/kj/OwC3ABACQAPUAxgEAAU4BigHIAjwCNAJgAoAChAKsApACzAMwA2QDnAO4AzgC+ALoAywDRAOQA/ADpANIAxgCzAL4ApAC7AL0AsQCtAI2AcgB2gFgAQwBDAEEAXUA3ACf/9A/bz8lP0w/uD9jPzI+WD3APWw9OD0sPXA9fDzsPAg7WDtYO1A7uDtwO1g7EDrIOrA6oDrQOuA7MDtwPBw8GDwcPFg85D00PUo+ED65Py8/D7+EAAEAiwCEAMwBQAGIAhgCTALgAvQCiALgAuQDHAOcA/AELAP0A6wDaAMoAzgDcAQABLAD7AN0AxAC9AK4AqQDeAOMA5QDLAKgAngB7AIEArwCfAIYAjYB7AHqAbABOwDBAOIAtADjANAA2AB9v5c/GD6GPuI/Hj8APtQ+KD0oPFg8NDxEPMA8sDvgOyg6kDqoOlg6qDqQOoA6aDogOjA6MDpQOvA7CDt4O3A79DxAPMw9MD1wPfA+fj7U/9eAC8ACAGQA+gFUAcACFAJcAogCtAKoAygDaANEA8gD3AOcAyQDPAOEA+wDmAOQA1wDPAKkAtADaAMEAwQCtAKkAlgCRAJEAvgC2ALoAigB/AHUAhACNgHUAmwCFgHOAWYBkgGzANaAQgCZAMoBKQDmgG4AKj86Pi4+Cj77PyY+9j44PRA8qDtAO4w8CDy0PHg7UDrQOlA6ADnYOjg6eDpAOoA6mDpAOlA6SDrIO0A74DxIPQg9UD1IPZg+LD64PxdAFgDmAToA8AEkAawCLAJEAqgC0ANYA2ADUAO4A4gDzAOAA9QD9AO0A0gDhAP8A4QDcAKwAygDKANsAywC7AKEAoQCvAJkAvgCsALUA0wCyAJcAiwCLAJwAngCSAK0AhQCGAIeAcoBYABAALIBDgFQAS0A1wCOv/g+Tj40PnI+wT9LPwA+YDzQO7A7KDvgPIg8sDwgO1g6uDnYOfg56DpYOpA6kDqAOmA6QDqwOvA6+DtUPDQ8UD1kPY4+ND3ePhw+/L+iAIkA9gE2AX4BRAHUAhACgALcAuwDLANUA3ADVAOIA6wDQAN8A1wDCANMA0wDmANAArwCQAKwAuQC3ALcAuwCUgHyAfQCfAKIApQCwALkAkQCDgHoAjwCbAJQAkACYgH2AZ4BngHiAXoAggCVALIArQDhAMeAQr+0PqI+Ij4IPqg++j6cPeQ8wDwwO0A7hDwcPEw8eDsIOog6YDoIOjA6CDpIOrg6WDqIOuA6+DrAOwg7gDwcPPg9RD4sPmg+SD64Poc/rABcAXQBggHqAagBigHkAjgChAMUA2wDUAN0AxgDGAMgAzADBANMA3QDKALQAsAC/AJQAnwCAALkAswC3AJcAh4B6gGsAiQC1AMkAqACiAJkAkgCBAIwAlAC3AKgAmgCDAHKAd4BvAG2AXkA3ACFAOAAwADmAI8/9T8IPsA+fj4oPlQ+gj5cPaQ8QDwAO4g7mDvoPCg7yDsYOog6QDqIOhA6GDpAOvA6+DrwOwg7UDtQO2A7xDzEPfI+ED6WPuQ+vj6pPxIAUgFOAc4B3AHeAc4ByAIoAmgC/AM4AygDZANwAwwDJAL0AsQDJAMgA1wDCAM8AogCYAIYAiACsAMcAwgCwAJKAfABtAIwAvQDUAMQAsQChAK8AjwCEALkAsQCzAKQAkACPgH+AeYBwAGOATIAsABnAKAA0ADYgHc/XD7oPkw+HD4kPm4+lD4QPSQ8QDvwO1g7uDvkPEA8ODsgOrg6SDpIOig6CDroOzA7GDtIO0A7UDsoO3w8GD1KPmY+jD7yPqw+sj7jv7kAigGkAgQCNgGqAaYB6AIEApgCyAMoAwwDaAMoAzAC4AKMAuwC1AM4AyADIALUAowCNgHoAkgCwAMQA1gCyAIcAboBjAMQA2ADJALoAsgCmAJAAoADAALwApgCaAJIArACCAIgAhYBzAFVAKiAaQCdAOwA0YBMACw/Fj7SPjQ93D4WPiA+PD2wPTg8ADuoOwA7aDvQO8g76DtoOug6IDmwObA52DqAO3A7qDt4OoA6qDrQO6Q8WD28PmQ+gD5qPiA+aj7Yv+0AhgH4AZwBUAFUAXYBiAIQAnQCvAKoAtADGAMIAtACkAKoArQCkAMoA0wDRALcAhgCHAIAAlwC+AOYA7wCtgG8AbwCOAKMA4wDkANgAuACcAJ0AoADKALUArgCWAKoAlwCPgHUAgIBwwDEgGQAhAENAPAAbcAfv4w/FD5MPr4+MD3YPaA9jD3MPSg8UDvgO7A7cDsoO1g76DuAO2g6kDnYOYA5+DqAO4A7yDu4OtA60Dr4O6Q8yD3YPng+QD6GPgY+sT8PAFwBOAEuAU4BQgFYAX4B7AIgAnQCbAKsAsACwALUAvwC0AK8AgACwANYA3wChAMUAqgBygGsAigDWAOgA2wCQAJIAe4B5AK0A0wD5AN8AsQCkAKQAoQCwAM4AsQC3AJ6AfACGAJkAjYBCADxAIkAwADSAN2AU3/UP3Y+2T88PpI+GD3YPZA9iD1wPOA84DxIO/g7cDsYOxA7QDv4O6g64DoQOhg6IDp4Oqg7KDuoOzA7ADt4O8Q8VD04PcI+Vj5SPgw+4z95QA0ArQDSAQIA4AEiAZACEAJ8AjwCVAJAAjgCPAKwAyQC0AKQAowCpAJUApQDGAMcAl4B/gHgAqQCxAMEAzACjAIIAhQCbALMA6wDvANgAsACtAJgAvQDPANcA1QCuAIgAjQCAAJWAeABqAEsARcA/wDZAK//zj+/P28/bT8zPxg+1j54PSA8/DzsPXw9VD1gPNA74DrAOrA7GDvoO+A7gDt4OqA6KDnwOjA64DtIO+A72DvAO/w8ND0UPZw9yD5EPqQ/Oz9DAGoA/wCXALkAjgFOAdQCKAKIAzQCoAI2AcQCQALoAxADhAOgAtgCaAJYApQC5ALkAvgCgAKsAnwCqALAAtQCmAKIAngCBAL0A0ADwANEAvgCTAJ0ApQDHAOoA1gCzAJEAjwB7gHgAdAB/gGgAWABOAClgEdALr+bP0c/fD9vv4Y/SD50PXg8nDyoPNg9qD30PTA72DswOxg64DrAO+Q8ADvQOyg6MDoYOkA6cDsYO6g7gDugO9g8rDzUPSw9dD48PkQ+w7+JgAIAqQC1AK0A9QDaAZgB6AKEAuAClAIEAgACkALIAxgC6AMgAzgCuAIkArwC1ALcApQCpALcAqwCeAKEAwADCAKEAnACoALcAzADGANEA0AC7AKEAswDDAMgAvwClAKIAlQCHAHmAZQBoAF9AO0A7wDogHX/9T96Pw4/JD8RPwg/FD5EPaw83Dz0PPg89Dz4PKw8QDuYOwA7IDsoOyg7MDrwOug6iDpAOnA6MDqIOqg7KDtAPBA8VDw8PIw9tj4mPgY+gj74P6b/5IAjANQBUgFYAX4BgAIgAhwCAAKUAwwC0AK0AtwDXAMAAqgCiAM8AuAC4ANMA2gCyAJwAmQC1AL8ArADOANIAxgCnAKsAvAC8ALMA0wDiAN4AswC+AK4AngCLAJAAsAChAJ4AdYBUADOANMA6AD0ALWAVQASv4E/ND7+PvA+oj5oPiw98D1YPSw8/DywPGg8ADwwO9g7uDtoOyA68DqAOrg6kDq4Omg6WDqQOpg60DtQO6g7eDugPNQ9tD3gPdw+oj78Pl4+xr/gARQBqgFqAbABdgEaARgCQAM8AugC5ALgAwwDMALMAsADCAL4AuwDVAOEA4wDFALwAkACQAKMAxwDuANgA2AC7AJMAlACrALIA0ADoANoAywCkAJIAmQCMAI8AnACiAJ2AYIBoAEWAP0AdAC4AMYAj0Ak//a/pj8kPpQ+uD5sPkA+KD38PZw9CDyMPFg8MDvUPDg72DvAO2g6mDq4OlA6uDqgOrg6cDpIOoA64Dr4Ovg7KDusPAw9PD2yPi4+OD4KPmo+vT8CAGIBlgGAAYIBeADgAR4B1AKYA1ADQAMUAxgDdALYAsADIANAA7ADXAOwA4QDqALsAqwCqALIA2ADdAOoA4wDMAKMApgCxAMEA0wDrAOAA1gCxAK0AlgCqAK0ApwCkAKYAgIB9gF4ARYBVgEgAKMAkQCbwDO/rz9VP0Y+yD5qPmA+ej4oPYw9eDz8PFg8BDxUPFg8GDuYO1A7EDqAOog6wDsoOqg6aDpIOqA6qDrgO1A7eDtUPCQ80D2MPcA+fj52PhY+dz8rgEoBIAFSAbABbACjANgB6ALYAzwC8ANwAtwCrAKUA2wDVANwAxgDSAOkA1QDbAMIAwAC/AL4AwwDRAOcA4wDXALsAqAC1AMEA2QDpAO0AyQCvAJ8AoQC3AKQArQCrAJyAcAB1gHYAZwBGAEeAOEAuYA1ACpAOb+JP34+jD6aPkQ+ej4kPeg9UDzwPJg8VDwQPAg8CDvIO2g6yDrAOuA6mDqoOoA6uDoQOmg6mDroOvg62Dt4O9Q8eDzgPdQ+PD20Peg+ej7Cv+MAQAGiAUcA3gC+AToBhAJgAvADeALEAtACiAMAA5gDeAMEA1ADZANkA2QDQANcAwwDDALwAwQDUAOQA1ADYAMUAtAC5ALsA3wDfAMQAugCnALcAqQCqAKQArwCBAIcAiwB8AGYAVYBRAEagGWAFwB3QDs/oz9uPyg+mj4iPjY+Aj4MPYw9DD0MPIw8ADwAPBg7yDuAO0A7MDqQOqA6oDqwOnA6IDpgOoA6sDqgOug7CDtoO4g8mD1cPbw9pj4UPg4+QD7kf90A0AEWAUABMQD6AQAB9AJ8AtQDSANwAswCwANEA7gDSAN0A2gDpANkA3gDtAOoAzQC9AMgA2QDSANsA5ADrAMUAvAC3ANIA1QDXANQAwwC0AKMAtADEAKIAlQCZAIqAeYBvgGUAagBLACMAK8ATcAz/+n/8T9GPvQ+WD6EPnQ+DD3QPag9FDyQPLg8ZDwoO/A76DuIO2g64DrwOvA6uDpwOmg6iDqwOkg68DrwOsA6yDukPAg8tDzEPYw+MD3aPj4+Iz8Kv9oAZwDWAQgBKAEiAVwBvAIgAsgDCAM0AvADFANkAxQDcANMA6gDKANEA+wDkANYA3QDEAMIAyQDOAOgA6wDLAMUAwgDBAM8AywDUAMkAoAC+ALUAugCZAJEAqQCLAGiAcoB1gGoATIA9wD8gA9APf/wwAm/nT8kPvw+tD5QPhg+JD2gPWQ80DzsPKQ8BDwwO/A7qDt4OtA7MDrgOpg6gDqYOrA6cDpgOog6+DqYOtA7eDuYPAQ8hD0gPZA98D36PjI+pD8O/+YAVACKAS4BNAEqAWQB5AJ8ApwCwAMMA0gDNAMgA3wDcANEA1gDhAO0A7gDcAOcA4QDbAM8A2wDjAOYA4ADrANYAzgDJANsA2ADLALEAzgC7AKQAqwCjAK0AgwCAAImAdIBpAFcAVgBGgCpAGAAeQAov8G/mD9IPzA+kD6OPm4+ND2oPUA9aDzoPLQ8TDxgPAA7+DtQO3A7ADs4OtA6yDrgOqA6iDrQOtA6+DrwOyg7SDv4PDQ8tD0gPWw9oD3GPlI+qT9G/9kAFACCAPoA2gEIAZgCKAJMAogCzAMQAxADHAN8A3ADSAOYA6QDhAPAA+AD8AOQA6wDYAOoA7wDhAP8A5wDmANgA3wDQAOUA0QDfAMQAzAC0ALgAvwCrAJ4AjACDAICAe4BlgGOAVUA0gC7AFyAWUAVP/M/lD9aPv4+lj6cPnQ98D20PWQ9DDzcPIA8sDwYO8g7qDt4OxA7ODroOvA6uDpwOng6UDqwOpA68DrgOzA7aDvIPGQ8hD0sPXA9cD3iPlA+4j9+P5vALQBlAJ4A4AF2AZgCJAJAAqgC1ALcAwwDaANEA5gDpAO0A4AD4APoA+ADwAPsA4QD0AP4A9gD3APEA+QDiAOYA6ADuAN0A0gDbAMEAxwC1AL8ApACkAJkAi4ByAHeAa4BegEcAOIAogBwwBMADf/Hv4c/ej70Prw+Qj5GPgA92D1gPSQ84DykPGw8MDvgO6A7cDsgOzg6yDrwOog6qDpwOmg6SDqQOrg6uDrAO1g7uDvsPGQ8pDzoPTw9Qj4yPkE/MD8bf/8/xoBsALwA1gF2AYwCEAJIAqgCoALwAzgDAANsA2QDqAO4A6AD6APgA+ADwAPcA+QD3APQBAAEHAPUA8gDxAP8A6QDkAOwA1gDdAMgAzgC5ALwApACoAJsAgwCJgHyAZoBZAEUANYAqAB4wAIAOj+uP2c/Pj7uPqw+aj4wPeg9kD1cPRQ82DyUPGQ8GDvYO6A7QDtwOzg6yDrwOpg6gDqAOqA6qDqQOsA7ADtwO5g77Dw0PIw8xD0wPXQ90D5qPpI/B7+ef+MAM4BQAPoBNgFcAeACMAJUArwChAMUAwwDUANUA6QDjAPIA+wD3APwA8wD6APABDgDwAQQBBgEOAPsA9gD3AP0A5gDoAOwA0QDcAMkAzACzALkArwCXAJkAi4BygHCAYABQAE5AIYAgQBYwBB/0r+HP3w+yD76PnQ+HD3cPZg9WD0UPMw8mDxIPBA70DuQO1g7ODrgOug6mDqoOmg6aDpAOng6SDq4OpA7EDtwO7g79Dw0PFQ82D08PXw93D5APs0/AT+U/+eAPABMAPQBBAGUAeACIAJIAoQC5ALMAwQDbANUA7gDoAPkA/QD8APABAgEGAQYBDAEIAQwBCgEGAQIBDAD3APIA+wDiAOwA1ADbAMEAzACwALYAqwCeAIMAgIBxAGMAVABCQDKAIwATcAKP80/vj8HPwI+8D5qPiA93D2UPUw9FDzMPIQ8RDwYO9A7gDtoOzA60DroOpg6iDqwOlg6QDpwOmg6eDqwOsA7UDuYO+g8KDxYPIA9AD2QPcA+Wj6ZPxk/fb+oQCSASQDqAT4BWgHcAigCVAKIAugC4AMQA0gDtAOYA/gDwAQIBAgEGAQgBDAEAARABFAESARABHAEKAQIBDAD6APMA/gDlAOwA1ADYAM0AtQC7AK0AnwCHAIMAcgBjgFUARQA3ACYAFoAHj/TP54/UD8QPvo+cD4sPeg9mD1UPRQ8zDyEPEg8ADvQO5A7YDsgOvg6qDqAOrA6SDpgOng6EDpIOrg6gDsQO1g7qDvwPBQ8dDyQPTw9QD4+Pgg+zj80P1O/5UAFAKgAxgFgAaoBxAJ0AnACoALEAwQDeANIA9wDyAQgBDgEKAQwBBgEYAR4BEAEiASQBIAEuARwBGAEQARwBBAEPAPgA/QDnAOoA3wDDAMcAvQCgAK8AjgBxAH4AXYBPQD4AIUAuQA0v/y/tD9jPyI+3j6SPkA+ND2sPXg9JDzYPJQ8TDwYO9g7oDtYOzA6yDrgOog6oDpYOng6ODo4Ogg6SDqQOsA7UDt4O6g76DwEPJg88D0YPZA+AD6qPsc/RL+4P96AZgCAASwBRgHQAhQCTAKsAqwC0AMIA1wDsAOkA8gEGAQgBCAEIAQ4BBAEYARoBHgEaARoBFAESARoBBgEAAQsA9AD8AOQA5ADcAMAAxgC6AKEAogCTAIKAfoBQAFAAT8AugBFAEcAOr+/P3s/ND7qPqw+YD4UPdA9hD1QPQg89DxwPDA7+DuAO5g7WDsoOsA60DqYOrA6eDoYOmA6YDpQOqA66DsoO2g7uDv8PAg8lDzsPTA9iD4+Pkg+8z8ZP50/yIBUAIABGAF8AboB0AJsAnQCkALgAzwDNAN0A5wD+APABBAEEAQoBCgEEARYBGAEeAR4BGgEUARQBHgEIAQYBDAD2APAA9wDvANEA1wDPALUAuQCqAJ0AjIB8gG2AWwBLwDuALEAdwAy/+8/qj9uPxQ+2D6+Pjw98D2oPWA9HDzsPIw8WDwAO8g7qDtQOzg60DrgOpg6sDpgOkA6SDpYOmA6kDrIOxg7WDugO9A8JDx4PJQ9OD1UPcg+XD6BPxE/dL+7/+SARADUAT4BTAHMAjgCNAJkApgCzAMMA3wDcAOAA+QD8AP8A8AEEAQoBDgEAARQBEgEeAQwBCgEGAQ0A+wDzAP0A5QDrANQA2gDBAMcAvwCkAKQAlACHgHcAaYBUgEZAOkAoIBeACL/3j+kP1A/Gj7MPoA+dD30PbQ9TD0cPNQ8qDxMPBA70DuYO3g7IDrwOvA6oDqIOqg6SDpQOnA6cDqYOsg7KDtYO6A71Dw8PHw8mD0YPaQ9xj56PpE/Kz93P5kANoBbAOoBEAGQAdgCFAJ0AnwCoALcAxwDUAOsA4QD2APoA8AEAAQQBBgEOAQABEAESARwBCgEGAQABDgD2APQA/QDlAO0A3wDKAM8AsgC6AK8AnACPgHGAcgBkAFEARcA0ACUAFBAGH/UP5c/Sz8EPvo+cj4kPeg9jD1IPQg8zDyAPEA8ADvIO6A7SDsIOxA66DqgOpA6oDpgOmg6UDqoOsg7CDtQO4g74Dw4PCw8uDzkPVA96j4KPqg+xz92v7M/7ABLAOABEAGMAdACEAJcAoAC/AL4AwwDqAOEA/wDwAQQBDAEOAQQBGAEaARABLgEeARwBHAEWARIBHAEGAQIBCQD/AOcA7QDSANsAzQCwALYAoQCUAIKAcgBjgFKAQoA2QCJgE/AFb/KP4g/QT8uPqQ+Zj4UPdg9iD1EPQg8yDy0PAA8CDvwO1g7UDs4OtA66DqgOrg6WDpwOgA6gDqQOvg66Ds4O3g7sDv0PAA8oDzMPXg9ij4yPmY++z8Uv7f/zYB3AJYBAgG+AYwCEAJ4AkwC9ALoAzADZAOIA+QD/APQBCAEMAQ4BBAEaAR4BHAEeARwBGgEWAR4BCAEAAQABCAD9AOUA6gDcAMMAxgC6AKAAqgCMgH0Aa4BZAEmAOgAmIBeQCM/5D+PP00/CD7+Pno+ID3sPag9ZD0cPNw8nDxIPBA76DuYO0A7eDrgOsA6+DpAOoA6mDpAOkg6uDqgOsg7EDtQO5A72DwQPFA82D0MPaQ90j52PoM/Nj9Yv/rAAQCGARIBQAH0AcgCfAJYAvAC+AM8A2gDkAP4A+AEGAQ4BAgEcAR4BHgEUASwBKgEkASQBIgEqARgBEgEaAQIBCQDyAPUA6QDdAMUAygC2AKkAlwCJgHeAZgBXgEJAM8AgwBEQAL/+D96Pxw+5D6EPkQ+AD38PXg9KDzMPOw8dDwoO9g7iDuwOxA7ODrAOug6mDqAOqA6YDpwOng6oDrQOwg7SDugO8Q8IDx8PJg9PD1YPcg+Xj6APyk/R3/XQAYApQDAAWIBqAH4AiQCcAKoAuADCANQA7QDoAP8A9AEMAQABFAEYAR4BEAEgASIBIAEsARoBFAEeAQQBDwD3AP0A5ADoAN0AwQDDALMApwCYAIcAdABoAFUARcAwAC+QArACT//P3w/Mj7yPqI+aD4YPdA9gD1YPSg8wDyQPFA8KDvQO6g7eDsQOwA7ADrQOtg6iDqAOog6mDqIOsA7CDtoO1g7uDvsPAA8iDzAPUw9qD3cPm4+jz82P1H/6gAKALAAzAFoAawB/AIsAnQCrALYAyADSAO4A5wD9APIBBgEMAQABFgEWARgBGgEcARoBFAEeAQoBAgEOAPcA8AD1AOsA3wDFAMUAtACsAJoAigB3gGuAVoBGADaAJUAXIAHv9k/kD9TPwQ+wj6+Pjg96D2sPXQ9NDzwPIA8sDwAPAA70DuYO3A7CDs4OtA62DqwOpg6kDqoOog68Dr4Ozg7cDuAPCA8NDxQPOw9HD2QPdI+Yj6OPyY/Qv/kgAsArwDOAVABrgH0AjACfAKsAugDGANkA7wDpAPIBDAEMAQABGAEcARABIAEiASQBIAEuARoBFAEcAQYBDQD3AP0A7QDVANgAygC+AK4AnwCNAHuAaQBbAEoAN8AoQBWwCD/0z+TP1Q/Hj7MPoQ+Sj4EPcQ9iD1QPRw84DyUPGQ8KDv4O5A7qDtwOxg7CDswOug6yDrgOuA6+DroOyA7aDuIO+g8MDwQPKg8/D0cPbg9zj5mPo8/KT9Bf9dALoBUAPoBPgF4AaACJAJcAoQC/ALwAywDWAO4A7AD+APQBCgEMAQABFgEYARwBHAEYARYBEgEcAQYBDQD4AP4A5QDpAN8AwQDBALcApQCXAIgAeQBnAFcARIAzgCNAHU/8L+1P0E/dD70PrI+bD4gPeg9rD1wPQA9PDyEPJQ8VDwoO/g7gDuYO0A7cDsYOwg7ODrwOsg7ADswOxg7cDtIO9Q8ODwsPEQ81D0wPXg9nD46PlI+8z80P2q/74AWAJ0A/AEeAZIB6AIcAmQCkALYAzwDAAOcA4wD6APQBBAEIAQABFAEWARwBHgEcARwBFAESAR4BAgENAPYA/QDuANYA2QDKALwArACfAIQAgwBygGKAX4A+QCxAHAAJH/ov6U/Yj8ePtY+kj5SPhg9zD2MPUg9FDzoPKg8QDxEPBg76DuAO6A7QDtAO1g7IDsYOxg7ODs4Oxg7SDuwO7A77DwoPGw8vDzEPVw9rD3APlY+sD7KP0q/rz/BgFcAqgDwAQABiAHQAhACUAKEAvwC7AMUA3wDaAOEA+AD+APIBCgEMAQQBEgESAR4BCgEGAQQBDgD2APsA4wDmANoAzgCyALIApACYAIcAeoBrgFgASIA0gCYAF1AIn/Xv54/Uz8MPsY+kD5QPiA93D2kPXA9NDz8PIw8rDxIPFg8ODvQO8A74DuYO4A7gDu4O1A7qDuoO5g78DvgPAg8aDxkPKw8+D0APYA9/D3MPlY+rj75PwQ/oT/mgDUAdQCCAQ4BVgGkAdgCEAJMAowCwAMwAxQDcANcA7QDmAPsA8gEGAQYBBgEGAQYBDgD+APkA9QD+AOMA7QDQANUAygC+AKMApQCXAIoAfQBtAF0ATAA5gCsgHWANj/5v7E/eT82Pvo+gD6MPlw+ID3sPbQ9TD1cPTQ80DzkPJQ8qDxMPHA8IDwYPAw8CDwEPBg8FDwoPDw8EDxwPFw8iDzAPSQ9JD1YPZg94j40Png+uj7xPwi/kL/WQB6AXAC8AMoBLgFqAbQB2AI8AhAChALwAuwCyANsA2gDaANkA5QD/AOIA9gD1AP0A4QD3APgA7wDbAN0A1ADWALcAvAC9AKkAhwCFAIkAfIBfAEaATcAyQCSAGpACIAzv6g/eD8XPxA+0D6mPlg+Wj4cPeg9gD3IPYQ9bD0sPTg88DzAPOA8wDzsPKQ8uDy0PKw8jDz0PNw8+DzQPQQ9VD18PWw9sD3wPd4+Dj5uPoY+6j7+PwK/rT+Fv9dAJQB2gGUAqADiARIBXAFqAaIB2gH4AfgCHAJgAngCbAKQAtwCpAKcAtQCzALEAuQC+ALsAogCuAKYApACRAJIAmQCLgHEAfoBiAGYAXQBDgESAO4AjAC2gF2AAkAo//e/vT9oP0g/RT8APyo+9D6wPmo+cj5OPlI+Fj4UPjQ9+D2UPcI+AD30PZg9zD3gPbw9nD4wPdw92D3ePgQ+cj4APkw+gj7OPro+mD7tPyE/CD9jP0k/ij/Mv+x/xMAmAE6AZoBMALoAqQDlAMYBGgECAWIBHgF+AU4BugFKAawBggHAAdABqgGYAdoB7AGeAbQBsgGYAbABRAG4AWwBbAEGAW4BOQDmAMIBEwDQAJ0AqIBqgFOAUIAqP8VALf/sv6C/tL+RP7w/Ej8yPyk/dj76PvQ+5D8gPoA+rD6qPvQ+ij5UPsg+pj6SPlY+lj6wPq4+mj6ePv4+ej7cPvQ+0j7pPwg/KT8VP3g/HD9Ov6S/rj99P6c/hAACAC7/10A7ADz/zABCANGAWUA6gFYBKgDdgHdANgD6AR0AqACQAQQBFwDkAPgA7QDVANUA5AEuAMYA2wDZAMAA1wD/AI8AgAD4AKYAoQBxAE0AjgCGgF9AHABgwC8APf/kwAA/88ABACC/iz+Ev/DAKj9GP44/dv/fP4Y/Mz+wv7A/Lj8xP5w/rj8fPzg/Rj/IP3Y+3D9ewAM/YD8Vv6w/az+YP3I/Mz+PAAw/Yj9mv9i/xL/zP0x//P/kv8W/qQA6gH8/s7+aADQArL/1P5qAdgCsQDF/7UAvAJwAc0A1wB4AuABbwA8AjACtgEYAfwCdgEAA9kASAEEAqwClAI9AOoBdgHkA2MAPP8wAsgDAAL2/qIADAJcAov/wwCBAPoBvQBU/5MAPAG9/yEAQgGu/vr/ef8o/zgAvwDw/Wr+SgGw/ej/mv4E/nL/PP6U/hn/QACQ+6r+HQCA/kz9QP1QAGkAXPx8/GEAXgFE/Kz90gAcAcj7rP30AsP/UP7Y/AwDMABa/qL++AKDAL7+AwDGAW//ZAFUAlwBvP25AFADJALp//j+SAU8AV3/lf9ABQYBcwC9AKQC1AK4+zgDIAZUAYT8zwBQBCgCLv5z/1gEDAMc/TAAlAIUAu7+JgFTALj+tAFZAHQBBP7w/+z+NAJc/MT+7AJY/gj+Jv5f/1j+rP82/pz+LADg+zz+ov5p/4r+aP7w+yj+zgEI+47+rP6VACT9gPq2/4gC0Px4+2QCfv6w/Tz8nALjAFT8iP3sAgQAdPy6/5AEggEw+87/pAJ4AuD9yf9IBMQDoP3O/pQDXAOeAab+wAHsAbgDzAAyAQwBsATCAGoABgBwA0QD7AJ4/v4BeAMT/zQB0AIEA3T/uQBEARgCFAFdAOz/DALJAGIAgwD4/dgCRAKc/tj67gGkAtz9lP7p/xQCmPyw+yr+JAMSAAj7egAP/4z9QPuPABUAjv44/Kj9VAKI/Bj+TPzkAYr+2PzY+0wDvgA4+n0AXP7JAAj8Pv6KASAE0Pr0/BgFl//8/M7+eAJIA0D+YP3QAsgB2P7c/igDfgEwAD4ALAGmAU8A7AHpABoBcAIv/1ACO//8A7YACADGADACOAP4/wP/LAJIA/b+XABUA2MAP//RAEgC5gEo/asAYAMIAKD7zAFwAnH/uP2PAJoB8v6o+mACOAQA+3z8sQCGARD+ePud/wQCb/+g+Yz+rgGe/pz97Pxz/9kAwPwS/or+DgEc/aUAeP1g/lD+nf/7AMD9+P5MATT9lf8A/kwCff+w/nD+WASK/rD7hgEoBOj/SP1DAPQCBADw/SQCZAIkATD9zACwA3L/UP34AuAERP84+1wCaARIAVj7WASIAkL/CP7L/zAHev8O/ncACAdg+pT+uASAAk0AlPx4AvkAGgHM/ZwDRP++/ln/fAEAAYT9sgFNAHkA8PtVAMgAJ/+gAmL+ZP6Y/WwACP+EAWD+av50Atj6ZAGM/LAB9P16ARr+aP0E/XgBjAIw+h7+7gBbACr+xPwi/jgFjP/w+Tr/+gFY/gP/OAVk/ez+CP5YACgDBAFU/eH/SAY8/Wj9qgBIA3wCWgDE/G3/8AQTAOwB+f/yAaT9zQBIAyoB+//yAVAEKP3k/l7+kAhQA/j6cgDABNL/AP1wBOwC1ABw+xwCIAREAcj8CgEEA67+xP1v/1gFtABI/hD8VAIU/dcAoAKE/dQCyPsw/YT9wAOI/mYA/v4A+ugC4gBk/PD4wAVkAiz86Pk6AdMAWQCE/BAChP5A+vD9WAUwBOD2HP74ByH/cPiU/VAFsAS8/LD6SAVMAQz9sv4QBDADtPwA/jADsATQ+87+mAOwBsD7wP4IA6gDUv84/tgF1P+a/ij+sAjAAXD7UgHcA4AByPwwAskAEAQ3/w7+CAPE/pcAVAN0AuD7/AJiAQj9RAEcApUAvPy3ANkA0AP0/Ab+4gH//3T9VP1UApwBwwDg+8ABQPrg/GgD5AAqAVj65PxoAc4BGPqQ/oACZP8w/Lj7NQCQAhX/UPxM/fT/Sv7X/y8Ahv6e/oL+c/8W/tAAWAK3/xv/FPwF/xACGARP/xD9BAMC/pz/gwCABET+A/9MAhAB3gCs/doBUAaV/xD6ygFoBu0A3PzoBLT+zP9CANoBAAb0/Tz9iABIBXL+Kf9uAUgCQAQG/uj6KAPkA/j/Ov98/pAEQv5FAFwAaALA/ST94AIPAFwDqPu4/pQDFP3o/6D9kQAsASACgPug+mAD1gEkATD5ov64AlH/qf8e/jH//P2O/63/4P81/3r+KAM8/3j6UAFA/VACCALA/IT8gAKwA9z8aP1Y/AgGnAEQ+9j9SAYMA9j5UAAn/5gEQP2YAowCTP4q/tj+kAYwAkj9mPiACHgE4Pym/jL/AAlj/7D7fP0oBkwD6gCCAJT+av5gA7QB6ARC/8j50AJYBJQB/P1+/tgDGASq/mD5LgHwBPwCQ/8w+zAE4PoEA+//kACA+9H/pAPA/qL/EPpKAWgBbPyg/IgEoPwrAIwAzv6o+3T8KANIBG3/oPcAAiAE6P2Y+JYB2AaF/0j52f8gBHL/RPzw/jgFsPw4/S7/sAh0//D3WgEwAlUAEPmtANAItANE/BD2xAKYBToBAPrYBAgESPuB/8T8AAYQBEL+JP0yAU3/cP9ABUYBMP3mAET+pgHYASwBhAB2ASj9bv6hAAYBcALoBMYAkPdg/JAFwAV8/YL+oPxQBZoAcPpE/6gHoP2Y+N//4AQYAsD7pv4MAvEAgPVTAJALcAKQ9hD6+AUXALj79PyQCLYBSPjA+6QDJgEw+rgDAAJzAKD3UwBIBUQDOPj0/FgDoAKs/tT9rAJoAZj+sPu0AR4Bpf/kAEgERP4w+44AogFgBQj7hv7YAewDiP26/nAD4PvYAnr/kAFg/BQBKAdWAej64PeQByAH5Pyo/GgDVAMk/tj7+gBABh8ASPzCARADlP6E/hYA7AGQBBj7sPwgBoAD/PxA+fgDAAR5AFD3MAPABcD6WPtAATAIGPvA+CoAEAgk/XD48AISAVr+oPlmAZACtP58/gUAIP+w+ewCtALY/Vz91wAEA/j5yP3UA3gG4PsI+wQBcgCg/gr/4AYIARD9UPr2Aa4BVAH8/fYBHAMLAJj7mPjQBQAJfAJQ+bD68AFYBIsAQALoBHj6uPooBLAFWv5s/oAF4Aa4+gDx+AVgDtgFcPqM/Mz8IP/IBegFYAOo+9b+UALaASj8GALwB20AgPng+ykAkAR4B5wC0PfY+5j5nAOgBoACkPxk/pj8RPysAVj9GAbwBej4UPSEAXgF1P7oAaQAlPzw+Jj50AjAB+D3EPnABJX/oPYwAlAIzAOA9lD4mAU0ApD8sgHgBBT+uPjC/lgFiAQ0/Sb+MAPU/g7+6P0wBjgEL/+Y+eoAGAXsAsT8gv4EA0QClPw8AUQD/f8KAdz9RANKACz/igCqAWIAwAK8Ai7+DwASAXD+7v/IAfgGPAMw93D8AAWoBGD8uP2gBQwCwPow+lgG3AOg/HD79ADZAIz8lQCwBtD/kPnw9uz+4AlABKj4zPyM/ngCEAOQ+XT8+AUMAuj51PzC/vADiAR4/eD4vPzg/cgDsAaA/uD1cP2cApAAsAHo/Jz84AW9/6j5ev4iAWAFmAQY+AD2kAfQCNf/sPw4+5b+CAUE/wgCSAWU/y7/cP4M/UD7sAiwCWQDGPqQ+N8AcAp0A4j7NAOZ/9b+yALABbb/8P/Y/ooA4ANQ+fgDwAxgBODy4PWoBRAKMAQI/ab+mP5g+gX/uAcIA7j5NgDQAhj9QPdcATAKdAPg8/D0MAiQCDr/APqo/JL+7P1i/2AE5gGt/yz8YPuU/CcAeAZQBYL/MPaw+54B8AWIAqT9IP3w/vv/Uv53AIQDsANI/aj4VPz8A8AGPgFs/ej6FP8iAXACEATW/zL+APy+/woB1ALAA4wCvv5I+9z8MANwB4gDpP2Q/VL+0gGoAlQB6gGmAUX/kPoOAdACOAXXAKD9fP6CAMMA6P6QBbwBpPzg+dQDMAMGAOj9xv8kA5z9WPtO/1AGC/+V/5T/Sv78/bD/9AFx/8z9pP5IBfH/KPs0/IoBTADN/zABC/+Q/jj7IgHsAsz8CPvoAjQCwP1I+5wBQAJc/VD7FgF0Auv/bQAaAej+YPjK/3gGnAOY+Vr+CAUuAVD8CP1IBOIBmPxM/pQDxwBD//EAIASg+8D39gAgDOQDMPhk/P0A6AXU/Jb/sASAAwD7Iv7YAyT/kP9gAhAJAP7A9vD98AmoBUD8oPsYAkQCiP24AHgFfAGO/hz+QP2A/PQCuAWoBfj6cPa+AIAEMABRAKD+VP6+/gb+qgGzAPD7AP60AlD+4PrQ/dAFgAVQ9/D2FQDwBloBVPwo/ggCSv4A+aQCTANpAKD7QgEAAYD9oPtABGAFOPt4+gAA4AaOANT9EAGAAlj74P2cAyAD5f8w/xgEDQAw/HT8EAYoBJr+TPxlABADXgFJ/2kAfAOE/tj7FwDYB9IBnv5Y/H4BbAKk/XADOAVkAqD6YP1IAaQCWAIUA1gDcPvE/fgBXAN6/j7+1AL/AJj8Uv7EA+ADmP3Y+mj/jv8z//QCsAR8/Qj5Jv54BGAEWPqw+uYBCAXY/LD6XgH4A2gAMPkg+wgDnAPk/gr+XP3s/Jj9oAUgBJD66PhgACgHsP34+Q4BcAgrALD3wPoYBdAFNgB+/qj8QPsQAgAIQARI+0D49AKgBW7+2PlgBEAKXP+g9gD6QASIBtAEBAJ4+9j4ev7gCBgFUPs4/cAF2ASg+Ej7kAcQCbT8cPdpACAF5AHXAPACwP8g+DD8sAQgBYr+O/84BE7+8PY8/JAK+AZY+gD3KAA4BQwCnP2V/zcA6P14/SgBfwA+/sAFXAJQ+TDznAHADYAIcPcQ9RADQAOQ/FD+KAVwAjz83P3Q/+D9GQDoBbgFiPhw86QA8A04Bij4UPutANb/jPzAALgH8ANc/Dj5+PwU/igDEAmwBqj6EPWu/qAG7AIlAIYAxAEe/tT8UP/4BBgFggHY+xD6DP1IBkAJjgFY+yD8l//eAXIAdAJIAiwDQP5o+7T+AAK4AswB8QCg+5j8fACwBOAC2Ptg+k4ACARS/kz9ogHMApD9YPq6/gAC8gEo/wwAyP98/CT9SALQA3b+9PxV/44BPP9y/hkAWAN4AIT8rP3P//wB7AARAJL/f//K/icAYACEAHj/LACA/9L++P5lAMQC2wDCAAz9fPzN/wgEeAPi/lj9NP/hAHj/lQDIAj4B7PxY/WUAAAJ9ACgCbANg/vj5WPxQBOAGhAE4/Oj9BP/X/3gB+AHWAfb+mP5z/3v/J/90AkQDlP5w+9T9aAPQBFIB1PzE/Qj+LABoAgwClgBw/3YATP7e/rT96gHgAqj/8P1g/h4BeAAMAFz+oP3G/q4B+APGASD8OPsJANwCMAGEAIEAagBs/qT9nP6iAXwCpAGY/2D9ZP6sAcgDGgCY/jj8iP7EAXAEoAOo/nj85PxzAHoAMAFgA4oBQP54/Ej+rwDMAowCXgGW/hT8Gv+YA4ACG//i/oT/4wC3AIQAUAF6AfT+pP6DAIgABAPAARv/Zv6I/04AkAKoAh4A/P2U/bkAAALSAQwBugD+/gD89v4YA0gC3P7q/rX/uv+w/tYASAIR/3T9Hv6HABABZgHeAP//+PwA/Or/TAP2Afr/PP1g/Nz+GALKAYMAaf9S/m7+nP1mAMACmAMS/3j8DP44AKwBVAOcAdT9/PxA/lABbANwAmH/Sv7Q/ej/GgEwA6gBLwA2/pj8EgBwAkAEagFC/nD8/v4wAiQDCAKD/6z9UP0QAagDyAK5/wb+9v4K/8v/SALEA2gBgPzw+hf/JAOcA1QCwv7g+1T89P/UAhwD3QAk/UD9I/8tAKEATAF9ABj/GP2E/X4B6AK5/0z+bv7e/rz9ZQDYBPwCZPxI+eT93AIIApn/fACqAEz+aPzQ/oYBWgE3/yv/hf9mAEr/Q//oANkA9P7g/akAvAJWAYj9zP3yAP8A+f+TAIABXwBM/qb+/f88AdEA5gCSAI7/8/8UATIB+f+u/zgAvwDcAJ8AtAECAREA3v5m/44A2AKgAaP/9/+2/9r/nf8cASgCXgEY/lb+3P+3ANUANgFuASv/fP3G/hgBJAF0AGgAFf8S/uD++AE4Ap//uP0c/xwAY/+m/yABBAKN/6z9BP4NAMMAlgCmAIf/nv4q/tv/uAIuAXb+YP2D/wQBf/8R/7gBSAN5/zT8/PxoAJAC/QCKAKv/VP4T/24BjgHD/wz+T/8WAYYAUv/R/14BuQBh/8D9dP4eAVQDiAEw/uD8YP+YAqABRACw/4AA+v9p/2H/IQCSARoBzwAe//b+3/9uAc8AAv8O////ggH1AB4At/8A/4n/aQChALP/nv+yAKYAvP5W/gIBdAE+AE7+bP4lAJsAUwBNAKH/iP7a/hIALQDu/+z/BADi/nr+Wf9KAQIBGf9m/sD+i/+1/woAVAC7/4D+lv4L/2wAZQDo/5n/f/+s/kr+GwCYAe0A1P4c/wAB7wBz//T+WwB4AM//WQCCAVoB1f/C/4j/df8PAMYBCAIzAKj+ZP/4AI4A9v8rAHMA5P8e/6T/8AACATUA4v4j/9L/ZQAaAYcADQB1/9b+af9QAP0A6QA0AKn/cf+2/ob/MgF0Aev//v5T/zgANwC2/6IAFAFKAPz+ev9QAOL/HQBBAMgAHwDW/nj/KgBNAOv//f+I/2z/I/8NAHkAgf9d/4T/vP+b/8b/FwD0/0//C/+l/7T/5f/dAJgAlf8k/o7+MADlAN4A7v/M/5T/P/+F/4kAfAGjAMH/MP+B/4gARgFMAccA+v82/wUAVAF+AdAA/f8mAHwAUQDMAGwBIgEAAFv/QP9jAE4BegFWAc//gP7C/ikASAEcAcP/H/80/2b/tv/A/xYAPAB1/3b+sv5t/9L/4P8b/yH/4v4f/4P/2P/K/4j+Ov45//H/0f8B/7D/Z/+g/oT+hv+8ACsAb/8P/0v/G//h/zcAgADn/4T/yv8ZAOf/UwD4AEcAAgBzAF4BegHRAGoADAFeAUABxgEwAiwChgFIAegBGAKmAdoBuALQAoACbAGkAewBIAI0AhwCWALKAe0A/gCYAZIBngF2ATQB6v9q/+T/YgDtALr/yP6e/qb+cv6E/lr+yP0c/Yz8lPyw/GD9XP0M/Yj7YPrA+hD8ePww/ID7+PoI+2D7cPuI+4j7SPvo+3D8qPsw/Oz8ZP3k/KT8HP2a/uT/Hf9L/4L/xv+ZAFoBbAJcAvoBhAK0A1gESARIBVgFmAWABRAGaAcgCNAHgAcgCCAIkAhACEAIAAlACYAIoAfwBzAI6Af4BiAHSAeYBigF+ARQBYAEdAMEAxADlgGUAGEAKQAB/0D9YPxs/Oj7gPpI+pj5+PhQ91D2UPXQ9FD0gPRg9MDyUPIQ8YDxwPBQ8IDwwPCw8ADwoPBA8RDyoPFg8nDzsPRw9XD2OPnA+UD6SPts/SUAtgGQAjgEmAVQB4AIYArAC7ANEA6QDtAPIBGAEoASgBOAFGAUwBQAFaAVIBVAFOAT4BNgFKATwBJAEgAR0A+QD7AOUA0wDBALsAkwCKAG+ARYBLACrQAX/xL+wPyY+/j5cPfQ9ZDzgPJg8/DzkPIg8EDu4Oug6uDqwOyA7aDrAOrA6GDpYOfA50DpYOrg6oDqwOsg7CDtAO2A7iDv0PDQ9DD48PkI+ND3qPhA/bIB2ARwBqgFeAaYBsAHkAqwD6ARgBIgEIAPwA/gEEATgBXAFoAUoBSAE2AVwBLAEaASABOgFMASYBJAEIAP0AxADLANMAwADOAJ0AgYBwAGoAXABGQCTgHzAIoA4v9q/jz9WPvA+ND4SPng+bD3sPbA98D14PJw8ADyIPOw81Dz8PKg8SDuQO2A7eDuIO9A8HDwAO7A7EDrIO2g7iDuwO7A7oDv4PCw8oDycPJg8hD00PWQ+Fz85P1I/eD7bPzM/voBeAVACKAIkAeIBngHUApgDaAOIA+wDgAOYA6gD+AQYBBAEEAQgBBgEMAPQBCQD1AOsA3QDXAOQA0ADXAN8AoACSAIgAkwCpAIUAZIBTAFpANoBFAESAIsAYH/pgC5/8T9cv5g/hb+TPzo+vj5UPpg+kD6GPt4+GD3APVw9jD2QPfw9UD18PRw8vDwoO8w8qDz0PLg7yDvoO6A7eDsoO6A74DvIO9A78DxcPJA8qDxAPNg8/D0OPkI/Oz+fPw4+2D8zP6MAkgGMAlgCRAIaAYgCIALMA7ADyAQIBAQD4APwBDgEeARoBDgEOAQABKgEUARgBDADoAOcA5QDyAPUA5ADWAMUAtgChAKwAkACfgHuAb4BvAGsAXYBFQCbAEpAJIBMAIeAVf/+PyU/jz9QPxQ+kj7UPuY+/j6IPhA91D2cPaw9xD3IPRg9QD28PLg8GDvYPFA8jDx8PDg70DugOxA7QDugO3A6wDuwPHw8QDxcPDw8KDx0PGA9ND3GPu8/BD9mPz4+3D9pQAwBWAI8AhACTgHUAiwCuAMMA/wD8AQwA8AELAPgBHgEqARIBFgEGARABGAEWARoBDADoANIA6QDqAOwAwQDJALgApAClAJAAoAB9gFEAYYBkAH4AW4BWwBvf+r/6EA5gHm/+8AwgCw/sD6CPkI+sz8QP2U/ID7cPiQ9UD24PfQ9wD3cPaQ9CD0gPJA8eDxoPGQ8WDwgO8A7mDugO6A7oDsAOuA7GDuoPAA8nDx4O8A7wDwsPIg9pD5IPsQ+zD6aPoE/En/CAOwBUAImAdABigHIAkwDAAOgA/wDyAQ0A8gEEARIBFAEkAS4BEgEmASoBGgEEAQQA+gD2AP8A9AEOAOAAyACZAJsAlgC4ALYArgB8gEIASkA+AEkAX4BUAE6gCF/5T+Av84/3b/jQDb/2T+GPsg+oj5ePmY+mz8sPtw99D2UPaA9tD1gPWg9PD0UPKA8ADx4PAQ8RDwAO+g7ADsQOzg7cDtoOsg64DrIO0A8CDxwO8g76DvgPCQ8/D1QPpI+0D6iPhY+hD9aADIBPgG6AdwBXAFuAegC6AM8A3gDvAPwBCwD4AQ4BAAEkARgBHAEsASQBJAEaAQgA7wDbAN0A8gEZAPQA2QCnAIMAjQCLAJgAqQCSAHuAS4AgwCEAPcA3gDmAKiAQUAFP7Y/ST98P3g/dD93v5w/Yj7SPlo+Pj4GPlw+4j7EPpg9tD0MPZA97D1APRA8/DwYPIQ8wDzMPHg7mDt4OoA6yDtoO9g78DsgOtA64Dr4O1A8SDz0PEg8LDxMPWA9+j4YPpY+3j7rPzx/1AEQAZoBkAFoAYwCeAKEA4AD3APAA9gD0AQgBEgEwATwBKgEWARwBGgEkATABOgEYAPgA2wDWAQABEAEFANEAtACQAJcAlgCRAKAAgABgAFeAOEA9gDYARoA90AdP8b//T/f/+m/33/+Pww/DT9dP6c/UD6APlg+xj7YPqQ+Hj5MPhQ98D3oPYA9qDz4PAw8YDxoPNQ8wDy4O4A7ODpwOgg7MDuYPLg7uDq4OgA6oDtMPAw9ID08PNQ8lDz4PYo+WD7yPw2/m7/XAJoBMgFWAYACFAJYAmADOAOQBJgEXAOwA4gEEASIBQgFqAV4BLgEIAPIBHgEuATYBQgErAOUA3ADLANMA4gDmANMAuwCDAIUAhoB7gFOAW4BWgFsAP0AlgDdAKTAHr+IP5K/4IAPgBO/3r+7Pzg+3T8FPwc/dz8qPrI+jD7MPqg96D3KPqw+ZD28PNA9cD1UPMQ8bDwIPIQ8fDwwO9A7cDpIOjg6+DuEPBA7UDroOqg6sDrQPCw86D0IPUg8vDyoPTg9wj9qP4YAM7/pgGAAtQD0AYgCKAK4AugDSAPoA/wDjAPYBBgEKASYBSAFYAUgBJgEOAP4BBAEeAToBLgEXAPAA6gDEALYAygDKANMAuQCaAIAAiIBqgD4ASoBYAFhAOUAyAD0AGNALj+yP/a/8EAxP+6//r+jP0w/WD84P10/hj9iPsA+0D70Pqo+fj5qPqg+VD38PWw9dD1UPRw9MDyEPFQ8DDxMPHA7uDqgOqg60DtQO+A7mDsgOng6ODrMPCA8sD04PRQ87DxwPCQ90j7K/94AFwASgElAJADGAawCSAK8AtQDjAPABBAD0AQIBBgEgATgBQgFsAUIBRgEgARQBEgEkATQBPgESAQ8A5wDYAMUAwwDGAMkAowCmAJ0AeYBQgEIATQBGAEmAO4ArgC8QD7/1L/Nv5J/+j/JADy/uD9yPzA/Ej9/P0C/qD8SPzI+4j7APpA+uj6QPrw+XD3gPeg9mD2oPWg9XDzcPDA8ODxEPKA74DtYOyA64DqwOug7aDuwOyA6mDq4Ong62DvgPTA9qD1EPPQ8ADzsPek/H4AlgGeAfgB1AKsA2gFoAlgDEAN0A1gDgAQ8A+AEOARwBKgEkASQBSAFSAU4BGAEKAQQBGAEYARQBFwD3ANMAzwCgAKgArwCnAKMAmwBuAEGASYA6gDAAQsA6IBbAGSAf0Ajv9O/nr++P76/vT+Bf8I/zb+VP3k/Lz8PP2c/dj9eP3g+0D64Plg+uD6CPrg+JD3IPdA9+D1MPTg8mDy8PGA8SDxwO+A7aDrIOzg7ODrgOpA7WDuYOsg6kDowOoA7zDyEPbg9YDz4PCw8jD2MPoi/t4BUATIAvQB1AIIBVAI0AvwDnAPoA4AD0AQQBLgESASQBLgE+AU4BTAFAATIBLAEKAQoBAAEsARYBDQDvALsApQCXAJcAqQCjAJAAegBKwDhAMkA8ACJAJUAhQCLAFMAIn/qP5C/g7+tv7w/mj/9v5a/gr+WP2M/LD8OP4X/xj+pPx4+wD7aPvQ+sD6iPoI+tj4cPdA9uD10PTw9ND0IPOQ8EDwQPHg8ADvQOug7GDtoO2A72DvoO3A6EDpQOzQ8SD04PQg9nD2sPNQ8XD2gPqa/8ABMANgA2gCRAKIBXAJQAoADNAN8A9AEAAQgBDgEEARABJAFOAUwBRgEwASYBEgECAQABHAEeAQ0A/wDSAMQApQCTAKYAqgCXAIUAfgBXAEQANIAyADyALYAiwCPAFhAPD/6f/a/xn/yv4z/57/o/9p//7+HP70/fD98P49//T+cv6U/YD8sPvw+2T8aPyY+4D6IPkg+JD3MPdw9kD1APXw87DyoPEw8QDwIO/A7QDuwO0A7SDtgO5g7wDrAOnA6sDvQPOQ88D1cPUQ8zDykPQw+Sj92v8CAWgD8AFAATADgAYQCVALAA1wDcAOUA7wDlAPoA8AEUASIBPgEqASYBGAEKAPkA+AEEAQUA/gDkAOwAxgCzAKIAkACSAJMAmACLgGSAUABBgDPALcArQD0ALOAcsApgAAABv/Z/9xADcATv95/8P/qv9//0v/G/9W/5r/n//i/0H/YP6Y/dT8DP2o/eT9wPxw+0D6gPmg+KD30PdQ9wD2cPQg82DyoPGw8EDwAO/g7YDswO3A7qDvYO7A6oDqgOpA7vDyAPVg9bD2QPQQ8tDzgPeA/LUAvAFkAlQCJAIEA/AFcAhACpAMkA2gDlAPEA9gDyAPQBAAEuASIBOAE2ASYBBgD2APgBBAEOAPgA9wDmANYAvQCTAJQAkQCcAIYAjABngF/AOwAmACqAKcArACSAJKAWsAQP/w/in/nv8BAGb/GP+G/2T/Xv+4/pr+A/+6/8P/ff+A/67+BP5Q/WD9ZP0Y/eT8SPyo++j50PiY+CD4UPfg9iD24PRQ82DyQPKg8KDvAO+A7mDuYO2A76Du4O0g7IDrQO6A7uDwYPRQ93D2EPXA80D0cPfg+4YAmAKAA/ABxgE4A2gFgAiwCiAM4AzQDWAOkA7wDpAPYBBgEOAQIBKgEuARgBAQDwAOsA3ADoAPgA+gDUAL8AlQCAAIUAigCGgH0AUIBRgEIANAAjwCvgEaAVoAigDWAEwAof8v/wj/mP6K/rz+jv/v/8D/a/8k/0//a/+5//X/sP+h/yD/7v6c/vj9Qv7E/Xj9JPyw+0D7EPqY+Xj4SPhg99D1APVQ9PDy0PEA8QDxwO+A7uDt4O0g7iDu4O1g7mDsoOwg7eDuUPHw8mD20Pbg9fDzgPWw99D6Xv98AmwDKALiAQgDiAX4B/AJYAxADQANEA3ADVAO8A7wD0AQIBFAESARoBBgD3AOYA5wDrAOwA4gDvAMAAtgCRAJMAkQCWAIuAcQBvgEQASIA7ADHAN4AsQBjAF0AdIAjgALADUAyP+r/ycAtgAuAID/e//p/1QANgD8AHgB2ACL/3n/mv/y/lj/Lf/u/n7+PP3s/Gz8OPtI+uj5WPlo+Dj48Pdw9vD0wPPA8kDyUPGg8YDxMPBg76DuwO6A7qDuIO+g7+DugO/g8DDzoPQg9YD3sPcA93D3YPl0/O7+WAEsA7wDtAKQA8AF+AegCUAKUAwADfAMgAzQDFAOsA6AD+APIBAgDxAOQA1gDSAOwA0QDmANMAxQCjAJQAlwCWAJoAigB4AGiAXoBHgEGAR8A+gCYAJIAswBzgFqAUgAn/+b/87/awAqAesAXQBn/47+Cv8eADkADAEWAc4AOgAW/1L/iv8+/wf/Vv8p//r+0P0M/TD8qPvA+ij6MPoQ+gD5iPgw99D1gPRw87DzwPPg8mDyMPJw8ZDwAPBw8KDwQPCw8ODxUPOA8wD08PVQ9yD24PbI+ED7eP3w/aX/MP+g/2IBlAPIBcAG4AeQCJAIQAiQCYAKgAvwC6AMUA3gDMAMIA3ADLALEAswC1AMUAxgDBAMkApgCaAIQAigCDAIIAjgB+AGoAXwBOAEaATgA7gDPAPwAtQCVAIcAtABJAHQAMYA2ACIAewBbgH/AFwAKQBSAHYAbgEEAr4BzABoAPz/EADY/8//sP+Y//b+JP7Y/Uz9fPy4+5D7SPtI+4j62Pmg+ID3gPYA9iD2wPWg9eD0IPQg85DywPKQ8nDyMPLA8iDz0PPQ9PD1APZQ9cD0wPYY+Zj6mPz0/Vz+HP2w/Mz9vv+YAqAEsAawBoAFCAWYBXgGuAfQCBAKQArACdAJcApACrAJQAlQCUAJkAkACmAKIAqwCLgH+AaYBuAGYAfAB+AGoAWoBKAESAQQBAAExANEA6QCRAJsAngCqgEqARgBGAHhAPIAcAG4ASQBJwAFADYAXQCuANsAAgGZAD0A0/+S/8D/1P+v/3T/LP+M/nT+Iv6w/UD9BP3E/ET88PtY+zD7ePrg+WD5wPhY+MD3sPdQ9xD3IPbw9YD1MPUg9RD1UPVg9cD1EPYw9kD2gPZg92D3sPcg+QD7FPwc/HT8LP3g/JT8KP6EAFwCqAKUAsgC7ALsAqQDwASwBTgGaAbYBtAGYAZ4BsAG0AbgBgAHUAewB4gHKAfwBoAGOAboBRAGcAagBlAGAAaIBfAEkARABHgEaAQwBOQD6AOcA/QC1ALcAuACeAIIAkgCCAIYAigCPAJ4AYIBVgGGAZoBKAF8AaIBOAFmAJUA2gDRAFwAHAA3AML/VP8Q/xL/sv5o/gD+zP1w/Sz9/Pxc/Nj7QPvY+oj6OPow+vD5MPmY+Dj48PeQ92D3QPcw9yD34Pbg9nD3sPdw95D3KPgo+YD5APmg+SD7kPvg+2j8gP38/ST9OP3W/ngABgEmAZIBqAF4AZoBGAOAA6gD7AOABOgEgARwBBAF0AWABSgFUAXgBUAGUAZQBgAGAAbABeAFKAZABiAG+AXIBYgFKAXwBBgFEAUIBZAEGAQABBAEIASUAzwDIAM8A8wCkALgAtwCqAJEAhQCGALmAc4BugGyAZwBMgEAAdsA0QCrAEYACADS/8f/ef9A/x//Bv+8/ib++P2o/fD9pP0w/cj8pPyI/OD7aPt4+5D7KPt4+jD6KPrI+VD5KPmI+Tj5gPiA+MD4APmA+Ij42PgY+Rj5UPnY+VD6gPrQ+jj7oPvw+9D7TPwc/Tj+pP70/sT+Sv/f/x8AQwCBAFwBwAEEAtgBbALwArgC/AJYA9QD3AMQBJAEoARwBFAEAAVYBTgFMAWwBdgFeAV4BdAFEAbgBbAF8AXoBaAFoAXgBbAFaAVgBWAFOAXgBMAE2ASABDAEOAQwBOADcANUA2QDDAPIAqQCrAJYAtIBqgGgAXwBGgHGALIAdQADAJ//rv+D/zr/0P6g/nT+Hv7c/bj9hP0o/cz8oPxo/DT8EPzY+7j7UPsg+wj7wPpY+hD6CPrY+fD5iPl4+XD5MPkQ+Rj5WPlo+Uj5QPmI+dj5GPpQ+qj6wPrI+vj6SPu4+0j8GP0s/RT9NP3U/Vr+mv72/pr/BgAeAG4ACgFyAYQB1gFkArgC4AIsA9gDKAQ4BHAE0AQIBRgFcAXgBQAG2AXoBSAGOAYgBhgGQAY4BggG2AXIBcAFiAVQBRgF8ASgBHgEUAQgBMQDfANMAwgDvAJwAkQCGALgAZoBRgECAcQAnQB9ACMA0P+u/37/SP/8/tD+mv5y/kT+JP70/az9kP1Y/Tj9+Pzc/NT8tPxs/DD8FPzo+8j7mPuY+3j7MPsI++j68PrY+sj6wPqw+rD6qPrA+uD64PrY+vD6IPtI+2D7gPvA++j7HPx0/Lj8AP0k/VT9pP3k/RL+av7i/kD/f//X/0QAogDNABoBigHUAQwCQAKcAugCDAMcA2ADrAPcA/gDCAQgBDgEUARoBIAEmASYBJAEiASIBGAEUARQBFgEMAT8A/QD5APAA6QDhAN8A1wDMAMYA/QC9AKkAqACeAJgAjQCKAIQAtIBkgFgAWYBQAEQAd8ApgBxAEsAFgDj/7n/cv9W/zH/7P66/or+Ov70/cD9rP2A/Uz9HP3k/Mj8kPxc/ET8KPz4+/D7BPwM/PD7oPug+6D7qPu4+8D78PsE/BD8DPxM/Iz8uPzk/Bz9RP1U/ZD93P1G/or+wP76/if/WP+x//P/HABYAKAA5gAwAVgBagGIAawB2gEwAmQCcAKEApwCtALAAswC1AIEAxwDEAMYA0ADaANQAyQDGAMcAyQDJAM4AzADLAMIA/AC4ALIAqQCqAKsApACYAIwAhQC8AGwAWYBUAFaATQB7wC3AJoAcgA/AAkA8v/D/5D/Yf9M/xD/uP6Q/nr+bP44/gD+1P24/Yj9WP04/RD9EP34/Pz87Pzk/Mz8sPyg/Kz8yPzI/OT85PwI/SD9OP1Q/Wz9kP2w/dD9/P0s/lT+fP6W/tL+G/9B/23/mv/C//H/HABPAIcAoQDfAPoAMgFgAZIBsgHeARwCOAJAAlgCdAKYApwCvALIAuAC7ALwAugC3ALsAuwCAAP4AtwCuAKoApwClAJ8AmgCXAI4AggC2gHMAagBkAFyAVwBRAEWAe8A0gCzAIoAYAA7ACYAAQDX/7b/lv9u/0n/J/8D/97+uP6U/nb+XP5Q/jr+HP4A/vD93P3Q/bj9uP28/bT9sP24/bj9vP3I/dj99P0E/g7+LP5Q/mj+dv6S/qj+xP7e/vT+LP9D/27/kv+0/9H/9P8jAEYAVgBYAJgAowC/AM8A6QD0ANIA4gAAAQYB+gAGASABBgEOARgBJAEiAQwBGAEsASoBHgEIAQgBAgHyAOYA4gDdANUAxQCvAJYAlwCRAHsAbgBgAFoASAAvAC8AHwAYAP7/7P/n/9//5P/l/+b/1f/E/6r/j/+I/4v/nf+O/2v/Xf9b/2//Z/9l/17/U/89/yv/Gv8T/xv/Iv8d//z+7v7a/vD+AP8E/wT/+P7+/v7+Hv84/zP/MP8z/zX/Ov9B/1b/bf9z/3b/ff+J/5T/rP/A/8n/0P/c/+v/AAASACgANwA5ADoAPwBRAE4ASwBMAFMAUwBKAFsAYgBoAHQAawBiAF8AXQBsAHUAewCLAIwAeQByAHYAdgB8AIQAlACcAKAAnwCYAIoAgAB2AGcAaQByAHQAcgBmAG4AcgBnAF8AZgBlAFAAOQAnADAANQAzACEAEQD9//b/7P/o/+X/4P/B/6f/l/+f/5//mv+Z/4j/ef9m/27/Z/9k/1b/X/9i/2j/Z/93/4H/gv9q/2z/dP+U/53/v//A/8D/wP/E/9D/yf/c/+3/AwANABwAKgAfABcAIwAxADMAPABMAFcAQgA7AEcAVwBcAFAATABBAEMASwBSAFUAXABGADYAKQBIAFMATwBQAE0ASgAvADwAUgAxAAwA7f8IAAIAAgBeAOwA0QBHAN//0v8+AG8AmwBrAD8ADQACAAoAEwBlAJEAYAD8/93/GQAPAMf/5P8aAEUA/f/4/ygAEACw/2b/kP/I/93/2v/M/5b/VP83/0z/Wv9Q/2H/ZP9s/2T/V/9b/23/Vv9X/0n/KP9S/1v/h/+i/4v/Tf8x/yD/Jf95/6//yv/J/7T/0f+l/53/0f8iAGAAeACMAJ8AdgARAOT/6v/4/93/5/9yAB4BZAHYABoAqf/W/2IAzAAAARYBFgH8ANwAlQBkAGoAgwCiAI4AsgAIATYB2QAWAI3/1P9aALIAEgH+ANEAjAB4AKQA6gDLAGgAAQD7/yMAMQCz/xD/L/8K/6L+Vv4t/0L/4P7M/tT/FgFWAQwBugBQAKn/UP96/zMARQDM/1j/Zf82ALwAlwAFAGn/6v5q/lj+5P6U/93/j//+/sD+TP6W/iL/6v/v//L+tP18/R7+K//IAIYBWAGAAKT/Ev/A/tz+jv/AAPsA1QDnAMUAPgCL/0b/lv9gAEgB4gFAAj4BbgAlACcA3/8gAAQBwgFkAUAAEwBCAG8Azf+O//H/NwBTAG0AbwDd/13/vf9OANf/7v7g/p7/XwAHAP3/IgDy/1b/rv6Q/lP/GgAUAIIASADb/77/Y/9Q/+b+HP8f/7z/dQB2APv/l//p//D/wv+p/2IArQADAFT/qf8+ACIAhv+Y/5QAQADW/z4AzgA4AG3/3P/gABYBFQCi/7f/EwASAJ4AfAHCAMD/ov9TAKsA9QAuAfwAdP+G/ij/uQAQAu4BRAGtAHD/nP4i/3QA8wA9AFcA+QCDAEn/Hv/v/x4Ac//Q/wABTgHa//j+dgAoARf/Uv7A/yQBpQCy/xkA2gB//27+RP8oAQoB0f/X/zoALgD+/nL/6QAcAQ4Ahv/d/4D//f8iALMA0wCoAIoAqv9X/0n/4P/P/z//yv+KAbYBif9G/nf/5gDg/xv/hv/FAHQAeP8UAPwAagBr/zkALgF6AGj+rP5dABoBaQCs//f/y/8s/5L+rv5tACAC2gH+AIf/CP8Y//7/+v+PAMsAtAHOAQgBcv8o/uT+oQCUAsgCQgEUAPz/GP+g/ib/9AFgBBwDhP6M/KD9O/9IAQgCBAIsAnAB9P4c/Ur+4P+eAHv/DwD0AtADqgD0/fz8BP14/Wj98v6KALAC/AL6AOD9iP16/xT+QPzM/E//eAESAeABdgGq/+T90PwQ/GD77P2YAfQDcgEA/6z9LP3s/ar/FgHE/8j9Zv6NAKcADAALAMj/yP2W/r4AbAHxAAwBfgGG/6T+PP9QASABxv9hAPQBrP8s/roB/APcAW8AWAGiAEIAsv+QBLAFhAK6/1QCtAFs/tT+lAA0A9gBVgBWAboBGv6A/DL+2/8kAIz/L/8+/hz9wP4gAgwBpP0g/WD+Hf9Y/Qj+WAOQBdb/WPsA/ID+0/9kACACNAN4Adz+rP4s/tP/5AMYBcQCxv40/nT+3P02/jwCzANSAPD8sPxl/6z+qP6PANwBg/+I/RX/vgDMAXgC2AI9AIT95P1qAIgAxP7+/zACUAKqAJD/7v9O/jz9Qf/4AG7/6P00/kwBJANYAUQBgASoBTwBKPsw+TD9HP8A/mgBYAhAC2gEaP0s/Gj9iPqQ+SL/8AXIBqwCIgHoAtIBHPwo+pj8GP5o/ED9pAPwBugEQv4o/dz+RP+M/2T9kPxo/AIAQASAA4QC5AL6AGz8wPco+Dj8vALoBcAFtALI/sj9oP34/CD85Pzd/9wCSAXUA7YAIv4I/QT8kPsCALgDaAXUAU3/xPwA+rD7OgFABQACsPxI/WwDwASA/aD3IPpOAagEOAOEA7gEMgBY+pD6Zv4zAGr/egAYA8IAEv9aAYAFjgCg++j60v9SAfb+sv5YAtgGMAYoBA3/cPrw9wj5hPwAAkAGcAoQCogEwPsg9YD26P0IA1gDsgEUA+AEAANa/uj8Uv+0/oz8+Pw7/xQBPALABPgGQAMY+wj4MPqg/WIAvAOwB/gGkAIu/nD8uPjg94D74AK4B4gFIATkA0QCqPuo+Jj7Jf86/vD7OAKQCVAKtAJY/Pj6WPt4+tD5vP4YBaAHfAPF/zIBKARs/6D2sPUE/CIBDAIYBhAK0AY4/cj4OPtM/az8tPygAOADfAMkAkACPAPU/wz82Piw+eb+dANIA3ACmARQBLgAgPsw+wQAQgHo/pT+TAJwBOwCygF4A6gCIv4g+qj7cgAsAlQCnALEAyQDQgDY++j7fv5UAfIAa/8UAggEOAOG/+z+ef9U/iz80P54A2AEcAK4/80A2wD8/az8av9YAXoBpgARAIQBZAHn/5z+Ef+Q/xgA9f/s/tr+G/8RAN7/IgArAIIB9AEwARUAbP0Q/CT8ZP4YABQCgAPoA+ACSAAQ/oT8pPzk/Sr/sf8RAO0AigHMATQBrgH8AOj9sPuI/Mj+ZgB+AeACdAOSAU7+iP38/tz+j/+wATAClgEWAJH/2f+i/tz93v+UAtcA9P4Z/0EAiwBs/w7/3ABsAU3//Pwo/YH/YAGuAaABSgEz/7j8BPwc/lkAbAFsAdgBswAA/7j9+P28/qH/zf+xAEwBXAL8AuwBAADc/Uz9EP4RACQCtAKUAuYBuAFaAVgA+P5G/oD+pP6y/0AB+ALoAhwChwDm/vD9UP3w/ab+tv9KARwCygEIAVAAPf+U/Tj8zPzI/mQAEgEcAlgDsAKAADz+fP1Y/aD9H/8aAfACCAP2Ad4ATQD5/37/Wv6o/bD+YwB4Ab4BfAKgApwB5/8c/pj9jP2E/hP/uf/UABQCZAPIAiYAwP1o/ID9Fv6Q/qX/1AFEAywDpAEQABj/eP5e/jL+4v7a/8IAXAG6AUQCuAKYAdv/2PzU/L7+kQDuAMAALALIAoABVP9O/z3/ev4W/qb/2wC+AOoA3AEgAlUA6P4q/5T/W/+R/7EAiAFQAQYBEAHRAKf/Hv+9/x8ADAD3/1oB7AF6ASwAr//J/1L/EP9N/48A4wBmAOf/NADBABgANv+y/nr+fP5U/gD/of/G/1//Ef+m/hj+cP1s/fj9UP50/lz+hv7C/ir/3P5A/rT9jP0e/kL+kP4o/6L/zP+I/0f/Ff8G/6r+vv4Y/1H/HgDZAAQB1gD4AJMAggAmAM8AWAE6AToB1gEwAigCMAL0ASwCsAHcAXAC+AJQA3QDkANEA9QCTAKMAuQC/AKEA/ADSASEA7gCSAJQAhQC4AF4AhwDFAMoAt4BeAEiAdAAZgBcADYAv/9m/zj/yv4i/nj9BP3o/ND8rPxc/Oj7UPuQ+iD64PlI+oj62Pkg+YD4KPiQ+Jj4uPkA+gD6gPlw+Mj4GPlI+cj5wPoo+yD8NP3g/Wz+NP46/mz+7v7R/wYBcAKUA7gESAVIBUAFWAUwBsgGkAdACCAJUAkACcAIAAkwCUAJwAnwCUAKIApwCVAJUAkACdAI0AjgCGAIsAfoBogGeAYwBlAGKAb4BVAFUAQQBHQDEAPwArwChAIMAoYBFgH6//T+PP2c/Kj7oPow+mD5sPjQ9/D2gPbw9RD1oPRg80Dy4PCw8MDv4O+A8FDwgPAg74DugO2g7KDrYOyA7nDw8PFg9eD3ePoI+4D6OPpQ+nj78v5gAuAGYAnQCgAMkAsADGAMoA1QDYAO8A7QDkAP8A4wD4AOEA7QDaANAA1QC6AJeAfwBfgEYAWgBgAHEAeoBSADcgFIAIIAaAEYAjQDzAOcA0QDTAO0A3gEcAVwBvgG2AdIB4AHQAfwBgAIYAgQCVAJkAjYBwgGSAVoBDgEnAPIAhQCjgB8/hD8iPrg+MD2sPXA9CDz4PFg8EDvAO5A7QDtgOxg7EDr4Okg6eDnoOhg6gDsoO0A7xDwQO+g7eDtwO6w8ODzyPio/mgBCANYA8QCvAJoA7gF0AhwC8AMwA7gDgAPYA5wDoAPoA6wDUAMkAowCQAJgAigCNAHSAbABRgEnAI6Ac3/jv5M/WD9+P1n/1IAFAA3/2T9zPwA/TL/8QDEA7gFOAYAB6AGqAagBqAHUAjgCtAM8A7gDwAQYA+gDeAMAAyQDDAN4AyADIALcAoQCEgGEAU4BPACLgHs/0z9oPqA96D1UPQQ9BDz0PIw8YDvQO7g7MDsYOzg6+DrYOsg66DrwOsA7QDuoO8g8JDwwPAw8EDvgO8w8ZD1wPkF/ywDaAQYAxAChAGkAtgFIAhAC1ANoA1gDrANQA3wDLAM0AyADHAKUArwCMAHeAeoBZAFmAN8AgIBmv92/oz9yP2A/TL+MP68/kz+fP4O/pT9zP2o/Qv/XgGAA2AGQAhwCQAKIAnACNAI0AmAC3ANYA+AEeARIBKAEeAQ4A9gDgANgAygC2ALwAqgCiAJWAfwBbgD/AHf/zT+uPsg+cD28PQw9JDz8PJg8kDwAO/g7eDswOwg7cDsAO4A7cDsYO3g7QDuYO/g8IDxQPLg8SDy0PDg78DwsPSo+WD/DAMgBZAEbgGMAHMAZAIwBQAJwAuADZAOcA0wDBAKcAhACEAIUAiQB+gGkAY4BMwCNAL2AbIBv/9u/rD8IPsw+xD7IP30/cD+pf/G/8b/p/+B/7j/NABIAcQDoAbgCCALQAyADMALUAugC/AMcA6gDwARoBFAEUARwBDwD6AO8AwADMAKkAkQCWAIkAdIBngEzAK2AI7+iPxA+kD4APaw9NDzkPPQ8iDy4PAg72DtQOxA7GDsgO3A7qDvQO9A70Dv4O7g7mDvIPGQ8jDzEPMQ9NDx4O9g8iD1oPtjAJACgARAAgABewBqAcgDOAYQCXALQAygC/ALYAtwCcAIYAiQCCAIKAdIBkAEbAJbAMwAjAB4AXkAG/9c/Tj7gPoA+gj7QPxU/vz+4v9DABUAygC6AOQB6AIYBPAFAAhQCXALMAwwDeANwA2gDsAOcA9AEAARQBHAEGAPQA7QDDAMYAuwCjAKMAkQCMAGGAXsArYAzv6g/BD7APow+DD30PUA9fDzEPMQ8vDwYO7A7ODrYOsg7MDukPCg8RDy4PBA8iDwoO4A7yDwUPOQ8zD2cPWw9HDy0PIQ9kj6ZP2x/8ACngFcAt4BYANoBAgG0AewCcAJcAkQCpAJcAnQCHAJ0AlACYAH4AU0A5wAQv/e/ln/bADDACIBMAD0/cj7UPp4+Uj6wPv0/en/JgEUAnAC6AK4AwgFCAYoB7gH4AgQCqALoA1QD9APIBCgEIAQwBAgEQARQBAAD2ANEAxAC7AK0AqgCiAKEAloB6AFLAMOAfz+MP2I+6D6yPno+ND34PYg9vD0APRQ8nDwYO7A7CDsIO2A7sDxkPOQ9HDzUPKg8EDtgO1A75DyEPTQ86D0EPRA85DzcPSg9qj46PpE/W0ATAHUAhAEcATgBPgF0AZ4B9gHkAdwCMAIsAnACmAKUAlQB7AFCATsAQAA1P4+/sT9dP74/wgBnwAi/xT9YPrg+DD50Prk/Mz+EgE4A5gEiAVwBtAGWAaIBjgHwAgwCvALIA4wDwAQYBDgEGARIBHgEPAPgA4wDfAL8ApQCvAJUApQCqAJcAh4BvwDKgH6/lj9hPzg+8D6CPpw+JD38PbA9sD1cPRg8hDwoO2g7KDrIO2A7nDyEPUg9VD1cPKQ8GDuYO2g75Dz4PSA9TD1YPTA88D00PUA+BD5QPoI/Oz9RADsAtAFaAYQBwAHsAZAB8gGEAggCUAJsArAC7AL4AkwCAgGwATAAtABIAGT/2j+Cv4c/ykAKAHCAK//WP2Q+uj5EPro+5j+hgFIBKgGEAjQCFAIQAcABxAHgAjwCtAMAA8AECAQoBAgEIAQ4BAgEUAQYA7ADPAK0AkwCWAJwAnQCQAJWAe4BJIBrf8A/jj9IPyo+7j6ePnQ9xD3cPYA9fD0oPSw8zDyoO+g7wDtQO0A7kDwUPTw9DD20PVQ9DDxMPBQ8CDycPSA9hD3QPUQ9aD08PVg9+j4ePqo+9j8sP68AbgEkAawB/AHMAdQBkAGGAdgCJAJMAswDBAMIAvwCXgHaAW8A0wCHAKUAFr/zv5q/qD+Uf+PAMQAd/84/Sj7yPkg+gD80P5cAnAFkAdwCHAIwAcwBwgHEAgwCnAM0A3wDsAPgBDgEAARYBEgEkARIBBgDsALcAogCVAJsAlQCuAJ4AcoBVIBeP+E/Yz8lPyA/HD72Pmg9/D2UPWA9PDzwPOA87DyUPFA8SDuQO5g7YDu8PDQ8ZD1MPYQ9gDz4PHg76Dv8PHA9PD20Pbg9YD0YPQg9QD2IPhA+Sj6IPug/aIArAO4BhAHOAcQBrgEQARQBBgGEAkQC7AMIA2wC5AJaAbYA7gCVAIIAjgBCgFm//7+7P4a/8sAnwC7/8D9qPuQ+kD6APwK//gCqAVoB1AIoAjYB0gHwAdACQALoAtQDZAOIA+gDwARwBGAEaARIBHQD0AOsAtgCuAJEAkwCbAJAAngBrgEpAIIAFr+eP3Y/GT8aPoA+sj4APcQ9nD1cPUQ9dD0MPQQ9BDxwO8g7mDuoO6g7lDyQPQw9lD3gPbg88DwYO/A8LDz8PTw9hD3sPUA9fDzEPYw96D4APlI+uz85v7cApgFkAe4B1gGwATcA8AE6AWgCPAKEA0QDdALkAngBoAEBAMcAmQBVAGOALT/TP64/Tz+rv71/2f/A/84/bD64PkY+2T9kQAYBHAGwAdAB5gGCAfIBwAI8AlAC6AMYA2wDUAPgBCAEMAQgBFgEUARMA+wDfAKgAmwCAAJcAkwCWgHEAZcAzQBqP9C/jT9LPwA+0D6SPkQ+AD3IPYw9nD14PSw9ODzUPMQ8eDuwO7A72DvsPFg83D1EPhg99D30PPA8UDxwPHQ9KD2cPgA+PD1wPTg9YD2sPdg+LD5aPuw/L7/2ANwBogHEAe4BeAEWAOgBKAGQAjACnAM0AzwC9AIaAY4BHgCVAEGASgBbADg/kT+jP0W/i//Uv/I/8D+sPwQ+wD6+PoU/mgB0ARgB4AIcAjIBygHwAdQCcAKcAuwDFAN0A6QD6AQABEgEuARABEgEOAOsAxACiAJUAjwCNAIoAh4B4gF4AJNAAH/TP2A/Nj7gPuw+lj54Piw93D2cPVw9QD1wPRQ9LDz4PKA8QDv4O9Q8FDx8POw9lj5mPgg9xD0QPFg8TDygPVQ9yD3QPbw9PDzIPVQ9nD4gPlw+Qj7eP3c/xwDUAXwBlgGsAW4BIAEUAVYBhAJ4ApgDNAMQAswCSgGoAP6ARQCggEkATwAA/8C/qT9KP6y/rf/dv7Q/Cj7aPro+ZD6SP3JALgDuAUIB0gHsAZwBmAGqAdgCFAK8AvwDDAOUA/wD+AQABFAEGAQ8A4QDYALsArACbAIcAjgB6AHOAboBFgDTgEK/5T88PuI+3j7wPoY+3D58PcQ9wD2APag9VD14PTA83DyMPHA8eDvIPAg8YDzAPew9zj4oPYw86DvIPCg8eD0oPaw9qD1kPNA81D0cPWg9oD3gPeA+dj7xv70AlAFOAYoBogFuARoBMAEkAWYB7AJAAxwDQANcAsgCNAEEAPsAVgBggH8ADQAIv+O/gf/6P8RAPr+DP0o+8j5kPlY+nT9iv+4AsAFEAfQBpAHiAYYBpAGwAaQCWAMAA7wDkAQABBgEKAQ4BAAEVAPoA1ADCALYAogCjAKkAlACBAHgAWQA44BZP/o/cj8DPx0/Oj8CPxY+rj4UPdw9bD1oPXQ9WD10PPQ8sDxUPDg7kDvcPCA8yD2UPcg9xD1kPBg72DvQPLQ9eD2QPeA9UDzYPMQ9PD1EPfA9wD4kPoo+2T+zgGQBCgGYAYgBiAFQAWwBIAFgAdACUALUA0gDiAM4AnoBXgDJAKmASgC1gFiAS4AEf+q/sr+E//T/8r+kPzw+gD6APsA/Aj/sAE4BKgFeAZYBxgGYAWABLgFuAfgCcAM4A6wDzAPEA9wDhAPgA8AEEAPkA2AC4AKQAoQCnAKsApACUgG5APvADgAB/+A/ij+Bv6E/eD7OPsw+sD4QPdA9pD10PSA9BD00PPA8+DxkPCg8ADxEPMw9CD28PUg9MDxoPBA8aDywPTQ9mD3UPaw9UDz0PKg82D1YPfo+aj5ePtM/Sr/6AEoBHgGSAZYBigEyATQBFAFgAhwCuAM8AygDOALQAhABTACvgG6AeoBCALOAUwAfv74/Ub+NP9t/xz/Kv6I+3j5QPlQ+8T9TAFABQAHkAcIB6AFKAWABIAF8AfwCnANIA9gEKAQYA+QD7APgBDwD3AOMA2AC3AL0AvADEANsAuwCDgF2AJmAD0AGwB+AL7/XP7o/Lj7wPqw+Cj44PZQ9RD04PKA8iDyoPHg8cDy0PJw8oDyAPKQ8SDyoPEA8zDzAPPQ86D00PXQ9gD3YPZg9HDyYPKw88D2UPl4+7T87Pz0/AD+yQBYAlgEwATYBCAEkANgBDAG6AdACUAKkArQCagHyAUoBAQCnAHOAB4BWwAj/xn/Zv6Y/QT9+P3I/wL/fP7Y/Cj7YPo4+hj9wAH4BVAIcAlgCOgFQARQBCgGkAjwC5AOMA/QDwAQoBBAEUARQBCQDpAMAAtAC8AMIA4ADqAMYAq4BowDhAHLAJMAcAAtAN7+Cv4o/BD6KPlA9yD2YPVA9GDz0PEw8ZDwMPFA8kDzkPMg8+DxcPCA8GDxYPLg8zD1oPWQ9XD1IPbA9tD2wPWA9YD14PXQ9sj4EPv8/Dj92P2Q/ub+rQAoAtwDkASIBCgE7ANwBFgFsAdgCMAIgAhAB9AFkASoA2QDzAFEAOj+ov5A/qT9eP1W/uT9MP88/xYAQ/98/Gj7uPn4+kD9AAN4B3AKwApACEgFKAPIA4AGQAqQDaAOgA/QD0AQgBFgEoAS4BCgDkAM4AugDCAOoA+QDyAOYAuwB+AECAP8AY4BngH8AGcAOf9I/WD70Pmw9+D28PWQ9MDzMPJA8TDxcPGw8tDy0PIQ8jDxAPCA77DwAPJA8yD0APUA9qD10PQQ9SD18PTQ9PD1YPd4+AD66PoM/PD8oPzI/eT+/v9WAaQCqAOoA7gD5AO4A3AEcAVgBmAH2AYgB1gGOAUwBNwC2gGrAHP/Zv5A/kD9pP38/Sz/d/8i/xoAA/9U/XD7APrg+tT9hAI4B9AJAAnYBiAEgALEAxAGUAogDbAOsA6QDtAPgBAAEgASQBFgD7AN8AzgDbAPYBDAEBAPIAxQCFgFMATMA8ADqAPUAlYBT/8w/bD7SPpQ+VD4wPZQ9SDzUPJw8TDxkPEg8tDxIPFQ8IDvQO8A78DvcPGg8tDykPPQ80D0QPTw8wD1oPWQ9WD2kPcg+dD6SPtg/PT87P1o/or/tgDKAeQBJANcA/ADKARYBPgEUAWQBRgGgAYoBtgFQAVwBPgCXgGEAJf/5P4S/uT98P7H//D+uf99/1j/C/9c/Uz9qPvM/NP/GAOoBiAIQAiQBhAEyALQA8AFEAmwC+ANgA4gDnAOoA9gEIAQABDADuANYAwQDYAOgA9AEFAP0AzQCfgFWATcAygEUAToAwwDKgHQ/iT9oPvQ+rj5sPdg9nD04PIA8rDxYPLg8tDy4PEA8aDvwO7A7kDv0PAQ8gDzMPNw8wDzgPOw8yD0gPRg9eD1YPag9yD5wPqY+9j8pP2K/qz+Tf/a/68ASgEIAjwD1ANgBIgEKAUYBcgE8ATABMAEOATsAwgDDAIOAX4A1/8i/7z9Mv5e/pj+cf8qAI4AYP8Q/nT8kPuw/K7+iAJgBeAGwAbwBPACMALQApAFEAggCqALcAxgDOAMkA3gDoAPUA9ADiANgAxwDAAOAA+wD2APcA1ACyAI+AX4BCAFKAUIBVAE6AIQAQj/eP1k/FD7kPnQ91D2QPUg9JDzAPRw9AD0wPKg8VDwYO8g72DvsPBg8ZDy4PLQ8gDzoPKg8vDyYPOg8+D0sPWQ9tD3MPmQ+ij7NPwI/cD9FP7g/gsA7gDMAWACiAMoBLAEaAQwBegE6ARIBYAF4AV4BeAEKAQcA1QCcgGiAdAAfQAvAD0A5gDvAMgByAEWACT+EP1A/fD+TAEoBBAGOAYwBeAD0ALoAjAEUAbACPAJMAqwClALIAzgDOANUA6QDXAMcAuQCyAMcA1QDrAOwA3AC8AJAAigBrAFiAUgBZgEkANoAhwB2/98/kj94PsQ+qj4MPcQ9tD1APVA9WD1wPQw86DyoPEQ8XDwQPAw8cDxQPKg8kDzkPNw8zDzUPNw85DzoPQA9mD3UPhA+Tj68Pqw+8T8uP1E/sj+Uv/4/5MAjAEIAzAEgARwBEAEUAS4A/gDcATABMgEKASoAyADYAKeAV4BEgHBAB0AFgCQANkAxQDzAMkA4//i/gL+Pv/oANgCkAUwBtAFQARIAzQD0ATwBdAHcAkwCjAKMArAClALYAzgDKAMEAxAC+AKYAsQDMAMYA0ADQAMEApACNAGuAVQBWgFyAQQBBQD+AHhABH/aP1U/Dj7EPqo+HD3wPZg9vD18PXQ9cD0wPOw8vDxEPGw8HDx0PGA8gDzgPPg89DzsPPQ88DzAPSQ9MD18PbQ98D40Pmo+gj7wPuM/Ab+Sv6Y/iz/+v8uAaoBsAK4A7gDhAOUA9gDlAPkAzgEiASYBLADHAP4AmQCIAK2AbIBXgEKARYBCgEUAe8AZwAfAIz/SP+j//v/jgEkA8gEGAUgBTAEKARIBBAFiAbgBzAJUAnACbAJcArwClALEAzgC0ALkAqwCpALsAsQDEAMUAwQC2AJAAjwBvgFSAX4BMAE+AOsAooBPACg/mD9NPwo+wj6GPlw+KD3IPfQ9qD2QPYw9UD0gPOg8gDyEPKQ8kDzUPPg81D04PSw9ID0EPVA9cD1EPbw9ij46Piw+Xj6SPto+wj8oPxw/bz9PP4D/8//TgDKAIwBDAI4AjACAAIQAiACBAJIAoAChAJkAmQCFAKkAToBoQBxAAcA/P/k//D/EQDc/73/qv9D/0T/nP/D/0sAGAFsAsgDWASoBPgESAWYBOgE0AWAB4AIMAngCfAJMAogCoAK0ArwCjALYAswC/AKEAtgC5ALEAuQCrAJUAjQBvAFuAWIBeAEmATYA7gC9ABw/57+qP3A/OD7KPtg+jD5sPhA+MD3EPeA9hD2MPVg9MDz0PNg9JD0EPVw9ZD1MPVA9bD1EPaw9hD30PdA+Jj4MPng+Zj6kPsM/Mj8zPx4/eT9QP4X/4D/aQDRABIBCAFEAY4BfgF0AW4ByAGqAWYBEAFiASgBtABlAGYAXwCi/7r/zv/7/5j/ef91/3P/UP8O/0b/y/9oAAwBJAJUA9QDOAUQBegEaASoBFgG0AaQCAAKEAugCrAJgAkgChALwAvwC7ALcAsgC5ALAAwADJALQAtQCsAIQAdABhgGyAVwBQgFaAQAAzABAQDk/iT+QP2s/Hz82Pu4+uj5IPnQ+Hj48PdA95D2MPag9cD1sPUQ9oD2kPaA9mD2QPYQ96D2QPcY+Lj4cPiQ+AD50Pm4+nD66PpY+6j7cPvA++T82P1M/oL+2v6w/oL+fv7E/tz+0P7Y/tD+kv6A/oj+rv7m/rb+8v6q/hb+3P3o/dj9kP20/WD+Pv6e/mj+iP4h/xH/Rv9lAIoBqALoAxAFKAcgCEgH0AbABiAHoAiQCoANcA8gD3ANoAtwCiALMAxQDoAO8A3QDAANgAzwC0ALkAqwCQAIaAbQBIAEqAR4BHAE8AIAAYP/1P1o/JD7yPpQ+wj7wPrI+fD38PZg9lD2QPaQ9QD1cPWw9aD1cPXA9QD3QPdA9zD3wPcA+Jj4wPm4+jD7KPtg+/j7BPxI/Ez8aPy8/MT8FP3c/CD9sP0U/jT+LP28/OD80Pwk/Vj9ZP1U/cz8uPu4+6D7aPsQ+3D7UPwk/MD7APzA/Bz9TP0o/Xz9rP1g/bT9Vv+aAAwCvAOQBVgHIAjgCYALoAzwDOAMkA2gDoAQgBOAFkAZ4BmgFiATAA6gDHAMgA4QDyAP4A3wCpAIYAUQBDgCKgHq/hz9oPsI+vj5uPrw+oj5EPdw9WD08POw8zD1cPfA+CD50PiA+ND3oPeA+BD6mPug/Hj9AP4s/o7+hv7c/Zj90P3w/eD9ZP18/Wz+aP2o/DD76PpI+vj5+PnA+kj6wPl4+ID3kPdg9kD3UPeo+AD5aPiw+Hj4SPk4+Xj6YPoo+wD74PtA/Ez8dP20/Qz/AP4c/tD+ZwD0ABABigFAAjQCIgG+Ab4BYAOsA1gEkAUgByAIkAmQCwANUA9wD4APwA4gDoAPwBFAFsAagB3gGgAVwAzQB+AF4AaQCoAQgBBwDOgElwAG/6D9xP1o/Dz8UPuI+Uj62PmQ+uD6kPlQ94D0cPOA9SD3GPrk/Ab/9P1o+7j5SPnA+GD5BPyC/zoBOAA1/1T+2Pwo/ID7OPwA+8D6UPvI/ND8FPw0/Gj7wPkA9/D14PYI+Cj5OPpA+1D6iPhw93D3mPgI+Zj6uPsc/Nj78Puo+5j8nP0w//z99PxA/XD95P3k/Xr+mv8RAAn/AP5s/kz/yv+t/6sAYgH2AWQBTgHcAfwCqATYBSAJUAtQDQAOQA/AD/AP4A/gD6AQ4BPAF8AbgBygGuAVgA9oBgADsASQClAOwAuAChgFnv5g+ZD5APx8/MD6mPlQ+XD48PhY+Wj68PlQ+CD3gPbg9eD3+Pvs/jj/Df+A/uT8EPq4+YD7rP2E/sP/bACj/zj9kPqw+eD5KPmY+OD48Phg+TD54PgY+ED3gPbg9VD1MPZQ90D4KPlA+pj4gPko+XD4wPhA+zj9Nv4I/qT91P70/fT8tPwa/gD/fP7c/eD9dP2Y/Nz83PzM/Mz8YP08/eT8aP0V/yz/Dv/q/6YBMAKGAXgCEAWIB7gHgAmwDIAPABAgESASoBOgE6AS4BNAFsAYoBpAG4AZ4BVADRgFNAK0ArgF0AigCTAIbAJI/OD4sPcA+Bj6cPnw+lj5YPnw+WD7EPtQ+zj7OPpo+Tj5+Prc/TYBxgGwAF//UP1k/JD6sPqU/PT9nP2E/Wj8cPtI+CD2kPbw9nD2QPXg9Rj4ePgQ98D2kPcQ+ID3APYQ93D5cPpg+zz9hv50/cj7iPuI/Ez9uP2a/14AYwBJ/57+vP1M/eD9Vv5k/Sz8KPvQ+0D7SPrg+iD7HPwI+2D7DPxU/cz9/P26/kMAOAFGAcgCGAUAB1AIkAmAC/ANUA8gEKARIBOAEwAT4BJgEsATIBVAGGAZgBkAFsANGAVU/xn/7ACEA+AGcAdEApz8oPcg+ED3wPfw99D6sPt4+SD6iPuO/tj+7P10/Lz8APyw+3r+OgHcAqwBZgDd/6j8ePrg+FD7xPxk/Gj8MPtw+SD3cPaA9nD1cPUw9uD2QPYQ9sD36Pi4+Bj5GPpI+VD4GPks/Dr+Jv72/gn//P7A/Jj8tP3w/hn/JwC8ANj/9P3o/Gz9XPyA/ND7MPyw/Bj7WPsY+5D7cPrI+ij7cPzQ/Hj9T/9+AK8AsAAYAlQDkATABVgHMAlgChALgAwADsAOYBBAEWASIBPAE+ASgBFAEKARQBQAFsAWwBTAEFAIMv+Q+rD7jv5QAVAD0ARsArj58PSA9hD6iPio+OD6bv5G/ij9dv9KAWYBmv5A/rb+iP18/Xb/GAJwAkoBff/M/PD5sPho+Cj40Pf4+Fj6IPlg9vD0kPSw9NDzAPSg9YD2APeo+Kj6uPsA+6D68PoA+8D6sPvg/d//BAHxAIEAHv8c/ZT8rPy0/Az9aP3Q/RD9hPw4/Fj8CPvw+Qj6UPqg+Sj6APsA/Pj7qPuw++D7SPx0/U//kADOAWACHAOMA/AD0ASQBdgGgAgACuAKAAzgDPAN0A5wDyAQ4A/gEEAQAA+wDQAPIBIgFMAUIBRgEKAHCP14+aj8Av8+/8gCYAaQBFD84PYo+Xj5WPmA+jD/ygCk//T+VAGkA0ACVgDQ/rT+Lv6s/bj8Fv4YAAwBvP44+9D5APiQ9bD0APdA+QD4UPaw9oD34PUw9ND0cPYQ9/D2UPfQ+WD7MPyU/Kj8xPzY+yD7aPt8/Xb+9P6M/tz+Av4A/Gj6UPvI+2j7gPuE/GT84Pow+nj6uPuY+kD64PoQ+0D6+PkI+xz8YPwk/NT8HP24/Yj+SgCQAQQDyAPkAzgEAAUwBqAGSAcwCKAJ4AlQCjALAA1ADnAPUA8QD1AOEA7wDPALsA0AEgAVABVAFAASMAow/YD3gPri/qQBnAMQBsgGu/9g+Rj42PlQ+jD7iv4IAmACxwBoAEADhAMMAg//sP72/kT95PxA/scALABA/mj8APog99DzYPSw9uD3YPdg+Kj40PfQ9pD2oPZQ9kD3CPio+aD7KP0k/oT+cP58/Xj8iPsY/Lj85P1S/qb/iv/8/WD8OPtQ+0j6ePqI+/D7aPvQ+hj7GPsQ+3j7oPss/OD7kPv4+/j7cPww/dz9Ov78/R7+Zv5o/7AAdAKcA/ADUARgBKgEyARQBTgGGAdwCFAJcAqwCpALAAxQDbANkA6ADjANcAzwDMAMMA4AEqAUIBZgEvALRANg/Gj58PuWAMwD4ANIBcADVP+4+sD5UPsI/AD8qP2mASwCpAGUAjgEpAOKAQz/1P1o/dj7YPz4/HD+Of9A/fD6cPfw9eD0UPXA9QD3ePjI+MD34PdQ+Dj4wPew99D4sPkA+6D77PyC/jT+TP00/Jj7ePog+iD6RPw0/Xj9gPzA+4D6iPnQ+Cj5APqg+hj7OPtQ+8j6MPvI++D7sPto+/j7sPv4+0T8vP1w/hj+7P0Y/bT9Tv7g/i8ATAKcA9QDtAM4BHgFQAXQBFAFOAcwCBAIkAgACiAL8AvQCxANgA7ADlANYAtACyAMsA1gEMAVgBhgE8AJjAHE/Yj6KPiA+xAEcAVoBBACKgFc/nj6uPn4+3r+hv/GAAgDOARQBFAF8ATQApkAG/8A/RD6aPpQ/FT+/P3E/Hj7gPhQ9WDzwPNQ9RD2cPdI+HD4OPhQ+HD4kPjw+LD5WPro+pj7bPzM/eD+jv7E/bj8YPtY+ij6KPtQ/NT8wPzk/OD7+PlQ+ID48PiA+dD5GPsw+9D64Poc/HD8aPyc/MD8wPy0/Lz8QP34/cr+4v7S/lD+fP64/jn/8/8UAgwDbAP8AhAEQASQAxgEmARYBhgGSAcQCVAKEAvgCoALAAzQDPANkA2gC1ALoA2AD2AQABTgGGAWIAwcA+z9qPog+Lj53wAgB2gFLAOIAuwBOP94/FT82v6oAiAClgHAAogFSAewBSAFgAQ8AqD9iPkA+ej6kPs4+9j7gPyo+vD2IPUQ9VD2sPbg9oD3sPgI+Uj4OPmA+gz8WPxs/Ij8QP0Q/Qj9YP3k/WT99PzA+/D6gPnQ+SD6YPpI+gD6IPpI+YD4KPg4+ZD6cPtw+/D7lPyY/Nj89Pzc/Sr+kv5g/az9TP2M/VT97Pwc/hT+fv5s/RT9EP5w/ycAZgGMAigEkARYBOADwAToBQgHUAYgB4AJ4AqwCeAJEAzQDnAMcAqADHAOQAwQCDALQBLAFaAWoBVgEoAKFAAg+MD3aPuW/lwCUAWYBjAFNAHk/RT9qP1Q/gr/nADYAigEAAVoBYgGOAeQBSQCWv4M/Oj5YPhA+ID6oPtw+9j6KPnw9zD24PSw9OD1EPco+PD4aPkw+tD6iPuA+0D8jPyY/Lz89PxA/Tz9kPww/DD8cPt4+pD5WPlQ+Tj5oPnA+ej5EPlA+cD5mPpQ+6D7iPsY/OT8lP0C/i7+1P54/xD/RP7M/QT98PzM/Ej9iP1g/QT9GP0g/Wj9Bv7w/ur/oQDgASgDyAOgBGgFkAbYBhAHaAdgCDAJQAoACyAK0AqwC0ANQAzADOAMkAtQCOAKwBLgF2AW4BJAEdAJJP2Q9XD3YPqA/Nr/cAWACGgE6AAeADkAO/+e/psARALEAjgDWAUQB1AH4AZwBgAEUP/Q+vD3IPfg95j5OPto/FT8qPqQ+LD2kPaw9kD2UPYw9+D3MPgY+dD6iPzg/MD80PyI/Dz8ePuQ+/D7+Psg+5D6cPoY+gD5cPhY+fD5qPno+DD5KPkY+eD42PkA+2D7aPto+7D7bPz4/Aj9tP1c/lX/av6o/aT9Qv5s/bT8rPxk/Wz8oPso/OT99P3Y/dL+nADMAUgCeAMwBLgEWAUoBkAG4AYACZAKIAnAB1ALYAvwCKAIAAzADaAJmAWwCNAMEA5AD4AToBbAEvAL4AWgAHD7CPhY+Dj7VQAYBJgFUAV4BHwDywAh/xQAEAK4AmgCRANoBMAE0AQgBpAGiAMt/yD7gPiA9iD1gPaY+Hj6wPqA+eD4oPgY+CD3wPYA+Pj4gPhw+Mj5APzo/Az9mP00/qD9bPww++D6yPqQ+gj6wPlA+kD6APqQ+bj5APqw+RD5EPlY+dj5sPrw+zj9oP0Q/sT9OP04/ND7oPyc/Uz+vP4e/3r/3P70/UT9HP0A/Uz8HPzs/ND9/P3o/Yr+vf/+ALgBzAK4A7AEoAS4BMgFoAfACFAI0AhgCkAKQAggCIALsAzwCqAJIAuQC0AHyAbwDIASoBHgEeARIBIQC0ACXv6Y/Hj6QPgI/XwD6AbQBZgE2ATwBEQClACsApAEjAPMAaAB4AOoBEgEaARYBfQDev9g+3D48PbA9aD1EPcg+YD5EPmw+Mj48PhA+YD5IPo4+nj5MPgY+DD50Poo/CD9EP6W/tz9bPwI+2j6wPmg+Fj44Piw+XD5GPkw+RD6aPpo+lD60Pr4+nD6MPoI+6T8sP0e/hz+4P2M/bT9dP6w/5gApwD7/x7/Xv64/Sz99Pwg/SD9AP0A/RT9TP14/RD+9v6W/3wAqgGsAlgDYAToBdgH0AiACUAKAArACKAIIAnwCCAIMAjgCIAIQAdIB+AIkArQCyAOIBDgEJAPMA0gCrAEoP/I/Hj6gPdQ+4QCIAhAB8AFkAd4B1gDH/94AfAE3AN7APcASAUwBoADPAP0A3AEDADQ+oD3oPeg9iD1QPWI+Az8SPsQ+hD60PuY+zD6mPkg+hj54PZg9oD48Pm4+jT8hv5p/z7+vPwY/MD6IPl4+LD48Png+fD5IPpQ+kj6SPrQ+gD7+PrY+pD6UPpg+hj7yPtc/Oj8nP1o/k//6f94ANAAbADX/z7/6v6s/vj9SP2Q/MD7CPvA+lj74PsQ/Nz89P0R//n/LAFcAxgFAAa4BugHcAioBxAHIAdYB4AHuAcQCHAI+AeQB+AG+AYwCBAJwAiACUAMcA5wDpAOIBFgEiANcAXCAA7+iPqo+Cj87gFwBfgEkAeAB9gGWAVABEQDJAKUApgC9gGTAFACtAMcA6oAbwANAAT98Pgw9wD4OPiA92j42PkQ+4j6yPkQ+gj7GPug+aj4UPiI+LD3APeA9wD60Psw/Kj8Iv7K/sD8MPoA+kD6GPkA+ID4SPoQ+iD5qPkw+wj80Pt8/GD9XP2Q/LD7aPso+xD7ePsc/LT9lf8kAXQBlgHaAWwBvv9a/iz+IP4Y/dj74Pt8/OD87Pyg/Wj+qP6i/hj/awC2AegCGASQBRAHMAigCMAIQAmwCXAJsAhQCNAIAAlgCKgH6AegCMAIcAiQCNAJsAoQC0AMoA5gEAAQsA1gCqAG0AGU/tj92v6UADwCWAWwBYADXAPYBLAFgATQA+gECAUkAuIApgHMAkACxwCWAAMAJv4g+0j56Pgo+Rj50PgI+QD6oPqo+eD4qPlw+tD5OPjw9wj40PYQ9oD2UPiI+ZD60Psw/Wj9wPxs/Kj7CPsQ+pD5wPig9zD38PfI+ID5qPo4/DT95Pxg/ID8CPxg+zj7wPsk/Nj76Pu4/Jz9Pv5A/2sAXAGVABgAxP81/7D+0P04/ej8dPzw+7D7APw4/Xz+7v6U/20AXgGsAeABGAPwBDgG4AaoB4AIoAigCOAIoAngCTAJ8AjQCCAIoAcQCMgHwAf4BwAKUAqgCjALUA7QDmAMsAoQCaAGhAAE/aT+UAGAAYYBOAQwBdgEtAOQA/gEoAV4BYQDuAJMA9wDGAOGAfABzgHS/zD80PoA+2D6SPjQ9+j5IPt4+mj6GPt8/AT8WPqA+bj5IPmQ91D2wPZI+JD4iPhQ+RD72PvY+2j76Psk/Nj6SPmg+ID48PcQ98D2EPiw+WD6YPvc/CT9jPyY+0D7EPsg+pj5APoY+vj5oPr4+5z9rP7R/zoBEALIASgB6ABnAIj/0v7Y/fz8+PtY+zj7sPvE/BT+Bf+8/9sA9AGUAjwDaATYBcgGGAeoB5AIsAigCNAIYAngCaAJUAkQCTAJsAhgCFAIwAjQCIAIkAmwClALkAtADTAOwAxwCYAG8AQQArj+Bv9oAuACTAHAAaAEYAaIBDgEQAaQBigETAKYA2AEmgE6AO8AXQAg/rj7gPz4/ID7aPrI+iD7GPpA+Yj6OPv4+lj6SPqA+iD6KPjw9zj4EPjw97D3gPg4+Qj6YPoQ+3j78PsQ+6D6IPoY+RD5iPgw+ED4ePhQ+bj5KPpA+2T8SPyQ+/D6OPvQ+ij68Pkg+oj62PqA+4D8cP2k/gEAnACrAAgBQgGSAFr/av5C/kT9wPto+5j74PuY+2T84P2w/sX/7wB0AlgD7AOwBIAF0AX4BegGSAeAB4AH8AdgCHAI4AiwCGAI4AdQCEAIuAcwByAIMAmwCCAJQAtQDRAN4AvACnAJkAa8A6ACgANIA0wCaAJcAwAEsAOoAygE8ASABBgEMAQQBAgELANkAn4BgwCQ//T9pPyE/LD8GPwA+0j7yPug+8D66Pr4+/D7wPr4+Sj66PnQ+Gj44PiY+ZD5YPnY+ZD6oPrI+uD66PqY+mj66PlQ+Sj5SPlo+UD5GPnA+aj6SPuQ+yT8TPyI/ND7WPsg+yD7APt4+oD6APug+xz8PP2C/nX/GgCSAOwA2gCaAGQAGgBi/z7+/P3A/SD9XPyM/FT9wP1Y/UL+CQBWAeQBeAIYBCAFOAWABYAGQAdYB/gGaAcwCGAIMAgwCDAIEAiACGAIgAhQCFAIkAhQCIAIQAmACtAKEAogCZAISAeIBYAEUAQQBNQD4AMQBIgEIAWoBBAEAAT8A1AEmANoA9QD6AM8AygCrAGQAZsA+v4u/mD+FP4Q/VD8ePyc/MD7wPqA+vj6+Po4+vD5iPqY+tD5iPko+pD6UPqQ+QD6kPoo+rj5+Pkw+qD50PgI+Uj54Piw+Ej50PmI+Xj5IPqo+rj6oPrY+oj78Pqg+qj6KPv4+qD6EPtw+7D76PsQ/cT9Xv4I/23/u//Q/9P/6v+x//7+uv6k/iL+tP1w/fj9zP00/Yj9iP5J/6T/OwDAATwDrANQBNgFSAegB3AHMAjgCFAIcAcgB/AGwAbwBmAHsAeQB9gHkAjgCOAIMAqQC0AL4AlACSAJAAh4BXgEGAV4BOACTAMABbgFuAR4BCAFgAXQA/QC9AOIBHgDaALAAtACkgE6ABgAIgBI/0z+EP42/qD9zPyk/Lz88PsY+/j6qPp4+uj54Plg+Vj5uPnw+Qj6OPrY+qD6CPrQ+WD66PnI+ID4IPkQ+RD4EPi4+GD58Pjo+Lj5KPoI+vj5mPqo+pD6oPq4+sD64Prw+iD70PrQ+oD7wPvw+3D8hP16/s7+yv7S/6IAVgDD/+f/cwDv//7+jP42/+D+KP6k/Zj+Xf8Q/zP/BwBGAX4BtgG0AnAESAXoBdAGAAgwCdAIAAhoB7AHiAe4BlgGSAeQB9AHiAdACFAJ0AnQCfAJcApwCsAJYAhoB/gG8AWQBMQDKASgBCgEEATABFAFwATsAwgEMAR8A7gC7ALoAgwCWAEUAekAEwBb/1f/Pv/A/jz+Iv7o/Uj99Pyo/Ez8oPtQ+wj7QPq4+Wj5aPk4+RD5sPlA+lD6OPqQ+sD6gPrQ+Zj5CPqw+fj4oPjw+Aj5ePhw+Aj5kPmg+aD5KPq4+qD6SPqY+gj7CPvY+gj7QPsw+/j6EPtY+5j7oPtY/FT90P1A/q7+uP/O/37/k/9EABkASv/G/vz+D/8q/gD+xP5F/wn/8P7L/44A0gBeAUwCKAMoBKAFuAbgBmgHAAjgB8gGIAboBlgHyAaQBsAH0AgQCLgH4AjwCbAJIAngCYAK4AngCHAIIAg4BzAG8AX4BcAFWAVoBYAFGAXIBMAEuARgBCgE8AOYAwQDfAI0AqgBLAHMALcAYQC8/2z/Q//k/jD+yP20/YT97PyA/FT86Psw+6D6YPoo+uD54PkI+ij6aPqA+oj6WPog+hj62PmI+Wj5iPl4+Tj5+Pgg+Tj5QPlY+cD5SPpw+oD60Poo+zD7GPso+1D7aPto+3D7mPu4+/D7IPxg/Lj8TP3Y/Ub+lv4Q/3D/n/+h/6f/xP+8/6H/av89/0f/fP9S/yT/Tf/4/0sADgB2AHwBLAIEAsACgAQIBkAGOAZYB7AHwAYYBrgG8AYIB3gGcAdQCNgHeAcQCPAIcAhQCOAIgAkgCWAIIAggCEAH+AXoBSgGkAXQBMAE6ARgBLADpAMgBOwDcANkA2wD+AIgArABlAEsAYUANQAdAL7/HP/O/pz+NP7E/Yz9YP34/Hj8FPy4+zD7mPpo+mj6SPoA+gD6GPoI+tD5wPng+dj5uPmQ+aD5oPmQ+Wj5YPlY+Tj5EPkY+UD5gPmo+eD5CPog+mD6mPrA+vj6OPt4+6j7uPvg+wj8DPwU/Ez8rPzw/Cz9pP0q/oL+tP7g/kb/kv+L/3X/lf+0/6v/hP9m/6P/+P/P/53/8P9yAK4AgQDiAMYBfALEAkwDoATIBRAGwAXoBTAGGAYQBjgGcAbYBnAHMAcgB0gHAAjwB3gHyAeQCAAJAAh4B/AHMAjwBtgFYAbwBggGEAUgBZgFGAVABPwDiARgBLgDQANEAyADbAL2AaABbgFAAecAYwD2/8z/iP/g/or+dP5i/tD9TP0k/fz8cPzg+7D7qPtw++j6APsQ+7D6YPpY+oj6OPr4+QD6GPrw+Zj5gPmQ+Yj5OPlI+XD5kPlg+Yj5wPnQ+cj50Pkg+lj6iPrA+gD7OPtY+1D7UPtQ+3D7iPuI+9D7PPys/Oz8KP2w/Rr+Pv5G/o7+3P7G/pD+jv7A/tr+yv7Q/iz/bf+e/7j/0/9PAM8AFgE6AeoB/AL0AzAEmASwBSAGoAUIBbgFmAaIBiAGuAYQCLAHkAeIB1AIkAhQCIAIAAkwCcAIkAhACBAIoAdwBwgHqAaABoAGKAZgBUAFcAX4BGgE8AMYBOQDHAOAAnQCWAKYARQBDAH/AIgAAQCX/1L/9P6K/jT+2P2w/YT97Pxk/Bj8+Puo+xD78PoY+wj7oPpg+pD6cPoQ+tD5+PkI+sj5mPmo+aj5cPlY+WD5iPmY+aD5yPng+ej5CPow+lD6cPq4+gD7MPtY+3j7qPug+5D7qPvg+yD8bPzM/CD9bP2k/eT9Fv5I/nr+ov7C/uT+/v4E/xr/SP98/6X/tP8JAG4AqQDTABgBlAH0ATgCyAKoA4gEEAVwBQgGWAZABjAGkAY4BzAHaAcQCDAI+AfwB3AIwAigCJAIQAlwCSAJsAiwCLAIEAioB5gHqAdAB9gGmAZwBugFeAUwBdgEoARQBOADdAMUA8gCZALcAZABYgEyAa8AQgD1/6//Ff+Y/k7+AP6w/TD97Pys/Fj84PuI+zj7+Pqw+nD6UPow+iD66Pmg+Xj5WPlA+Sj5MPlQ+Wj5OPkY+SD5CPn4+OD4OPlo+Xj5iPmo+dj56Pn4+Rj6cPqg+sj62Prg+hD7IPsw+1j7wPs8/HT8pPz4/Fz9lP2E/bj9+P0q/i7+NP6K/rb+1P4F/0T/X/+P/8P/EwAXAJYA3QBcAUgB6AH4AqADGAR4BGAFmAU4BSAF+AW4BqgGAAeIBxAIAAjgBxAIYAjgCNAI4AjwCBAJEAmgCFAIIAhACNgHUAcQByAH4AYYBpgFuAV4BfAEWARYBFAE0AMMA8QCoAJEArwBXgFSARwBrgAbALX/Yv8Z/6T+Jv7g/bj9VP3E/GT8OPz4+2D74Prw+tj6YPow+jD6CPq4+WD5aPlQ+fD42Pjw+Nj4mPiA+KD4mPh4+JD44PgA+eD4APlY+Wj5aPmI+eD5GPoQ+jj6gPqw+rj60Poo+3D7wPsU/Gz8wPwQ/VT9oP3M/Rj+Wv58/qb+0P4C/yv/Uf9m/67/6f8dADkAjQACAS4BWAGqAUwCqAIsA/AD0ARIBVAFiAUgBmgGIAa4BpAHyAeoB9gHoAjwCJAIsAhgCbAJYAkwCcAJoAnwCKAIoAigCPAHiAfIB7gHIAeoBnAGWAagBSgFAAXABEgE3ANwA0ADoAIkAv4BtAFEAe8AqgA1AML/W/8o/5D+TP78/az9bP3c/Jz8cPwE/KD7UPsg++j6kPpY+lj6GPrQ+XD5cPlQ+Qj56Pjg+OD4sPiY+Kj4oPh4+Hj40Pjg+MD42PgQ+Uj5EPkg+Yj5wPnA+cj5QPp4+mD6iPrY+jD7WPuo+yz8hPyg/OD8QP1g/Yj9sP34/QL+FP5W/nr+pv7E/hH/Iv9C/2X/yv/r/+3/bwD6AEABrgGIAmgD8AMgBHgE6AQ4BTAFwAV4BtgG+AZAB7gH4AcACBAIoAgACQAJMAlACUAJAAngCNAIkAhgCFAIMAjIB3gHUAf4BnAGAAbYBZAFCAWQBFAE/ANcA7wCeAI8AtQBegE2Af4AngAQAMP/WP/8/qr+Yv70/Zj9UP34/Ij8FPzI+5j7OPvY+qD6qPpw+jD6wPmw+YD5QPnw+Oj4+PjY+Ij4cPiY+Hj4WPiA+LD4yPjI+Oj4EPkY+Sj5aPmw+cD50PkY+mD6YPpo+qD6IPsw+0j7sPso/Hz8jPzY/FD9iP2g/fD9Nv5y/nz+rP7s/hr/MP9j/6n/of/l/zsAfACdAMUAPAGiAeoBYAIoA8gDMARYBMgEOAVgBZgFKAawBugGKAewB9gHIAhACIAIwAjACAAJIAkgCfAI0AiwCJAIQAgQCBAI6AeQBzgHGAfYBlgG8AWwBWAF8ASABBAEzANwA/gCqAJoAhACsAF6ARgBzQBuAAkAyv9w/wr/xP50/hr+qP1I/Qz9sPw8/Pj72PuY+zD7+PrY+qj6gPog+iD68PnA+Xj5aPlw+Uj5KPkw+UD5GPkg+Tj5QPlQ+XD5gPmY+bD50PkI+hj6MPpg+pD60PrQ+gj7YPuY+7j7APxc/Lj88Pwo/ZD94P0E/iD+Zv6u/rz+2P4b/0//Q/9q/5r/uP/a/yQAdAB/AI4A4gCOAQACWAIsA+gDCAQYBFgE6ARABVgF2AW4BvgGCAdYBwAIIAggCEAIwAgACdAI0AgQCRAJwAiACJAIcAgQCOgH2AeYBzAHuAZ4BggGmAUwBRAFwAQwBOQDdAMUA4QCSAIAAowBQAEmAdAANADi/7X/b//I/nr+cP4e/nD9CP0U/az8IPyo+7D7oPsY+8D6yPrA+kj6APoA+uD5oPl4+Vj5YPkw+Qj5CPno+Oj4APkA+RD5IPkg+Vj5QPlA+Xj50Png+cj5EPpQ+nj6WPqY+gD7YPtg+6j7PPyg/MD86Pxs/az94P3Y/Ur+jv6e/tr+9v5D/1P/c/+H/67/7P87AEkAjgChABABbgHQATQC0AJoA7gD/ANABMAECAUoBYgFIAaYBqgG+AZwB7AHsAfgB2AIoAiQCJAIwAiwCFAIMAhQCCAIwAeQB4AHUAfABnAGOAbgBVAF4ASwBEgE1AN0AzgDyAJUAgQCsgFSAe4AsgBlAAYAof9h/yb/sv5e/hT+7P2U/RT9/PzI/Hj8APzA+7D7cPsg++j68PrQ+pD6YPpQ+kD6+PnA+cj5wPmI+Xj5cPlw+VD5QPko+UD5QPk4+VD5cPmg+aD5yPnw+Sj6IPpg+pD6uPrg+gj7gPvY+wz8ZPzE/Aj9EP1E/aj94P0e/mr+pP6w/rz+B/8X/yP/Rf+J/7n/qf+3/x0AZQCKAMsAaAH0ASgCfAIQA4ADoAPQA1gEwAQYBYAFAAZwBpgG0AYoB2gHgAfAByAIUAhQCEAIUAhACCAIAAgACPAHsAeAB1gHKAfYBogGSAboBXAFIAXoBIgEIASwA3AD/AKIAkQCDAK6AVQBEAHHAFYA7f+p/2j/HP/a/pj+Uv7w/ZT9RP0A/az8dPxI/Bz80PuQ+2D7IPvw+sD6sPqY+mj6OPoo+hD6+PnY+cD50PnA+bj5uPnQ+dj56Pno+Qj6OPpA+mj6kPrI+tj6APs4+2D7kPvY+xT8ZPyc/OD8TP2A/cT99P1K/pL+vP7O/hb/T/9B/1L/hP/D/9b/3f8VAHgAnwCAANEAEAF6AawB/gGMAuwCGANUA7gDEARgBLAEMAWgBeAFIAZwBsgGAAcgB5gH0AfwBwAIIAggCBAI8AfgB9AHqAeAB3gHUAcAB7gGgAYwBsgFgAUoBegEaAQgBNADcAMEA7QCiAIsAtoBbgE2AdgATADy/77/d/8V/87+iv5E/tz9dP1A/fj8oPxQ/Cz8+PvI+4j7aPtI+xj72PrA+qD6ePpQ+lj6SPoQ+gD66PnQ+bD5gPmQ+bD5mPmY+bj50PnI+dD5APo4+lj6cPrA+vj6GPtI+4D70Psc/FT8qPzs/Cz9fP3Q/RL+TP6i/tT+/v4e/13/kP+h/6P/xP/X/7v/yP8RAFgAXgBvALYA+gAoAVIBwgEUAlwCjALsAkwDbAPMAzAEkATYBDgFoAXIBfAFSAaoBtAG4AYgB1gHUAcwB0AHYAc4BwAHAAcAB+AGkAZgBlAG+AWIBUAFAAWwBGAECATIA4ADBAOoAlgC7gGgAVABDAGnAFoACgCc/z//6v7E/nT+Gv7k/cD9fP0s/fj8yPyc/Gj8OPwg/Az82PvA+6j7gPto+0D7KPsQ+xD78Prw+sj6qPqI+oD6cPpg+mD6aPqA+mj6cPqY+rD6yPrY+gD7OPtI+2D7kPvA+/D7IPxo/Lz8AP1A/Xz9xP30/SD+UP5s/rT+3P4J/yD/M/9i/3f/jv+f/83/4v/w////NgB0AKoA3AAeAXgBqAHcASwCXAKoAugCLAN8A7QDAARABIgE0AQwBXAFsAXgBSgGSAZYBngGoAbIBrAGwAbABqgGkAZgBlgGEAbgBZgFYAUYBcAEcAQgBLwDZAP4ApgCOALGAWYB/QC0AGEACACx/4H/KP/W/oL+RP4a/rz9iP1Y/ST96Pys/IT8TPwU/OD7wPuo+4j7ePtw+2D7QPsY+xj7+PrY+uD62PrQ+rj6sPrA+rD6qPqw+sD6yPrY+gD7IPs4+1D7ePuY+8D78Ps0/Gj8nPzg/Bz9WP2Q/eT9Nv56/sT+Gf9a/43/z/8RAGYAlgDRABYBUgGOAboB7AEMAjACXAKMArAC3AIQA0wDeAOMA7QD2AMIBCgEWASIBLAEwATQBPAEAAUYBTAFSAVQBVAFWAVIBTgFIAUgBSAFAAXoBMgEqASQBGAEMAQIBNwDrAN8AzwD/ALAAnwCTAIEAsYBigFSAf4AxQCUAGUAGwDe/6//df8x/+r+wv6c/mT+Iv78/dT9oP14/UD9JP3w/Nz8zPyw/ID8ZPxA/CT8CPwA/PD7APzo+/D7+Pvw++j7+PsI/AD8CPwM/CT8OPxM/GT8ePyU/Kz81Pzo/BT9OP1s/ZD9uP30/Rz+Sv5s/p7+1v4A/zT/Wf+e/8n/6f8mAFMAfAChANgAAgEiATIBXgFwAZABoAHEAc4B2gH2AQwCGAIkAjgCQAJMAkACSAJoAmQCbAKIAqQCqAKwArQCyALgAtQC4AIAA/wC9ALsAgQDAAPwAuAC5ALUArwCnAKQAnwCWAIwAgwC4AG0AZIBdgFSASoBBAHdALoAlgB0AF0APQAZAPb/yv+f/37/U/8y/xP/8P7K/qz+gP5m/jL+Av7o/ej9zP2o/ZD9dP1s/VD9OP0o/SD9CP3s/OD83PzI/Lj8tPy0/LT8pPys/LD8qPyc/KD8rPy4/MD81Pzo/Pj8GP0w/Uz9aP2Q/bz96P0O/kL+ev6c/sT+D/9P/4r/u/8BAFIAjgDFAAwBWAGAAa4B7AEoAlwChALAAvwCKANIA3gDnAPIA9wDEAQ4BFAEaAR4BKAEoASoBLAEwAS4BKgEoASYBIAEaARIBDAEEATsA8gDnAN0AzwDBAPQAoQCTAIYAtIBnAFkARoB3ACQAFcAEQDK/4n/Tf8P/9j+nv5i/ir+7P28/ZD9WP0k/ez8vPyU/GT8SPws/BD8APzo++D70PvI+9D70PvQ+9D74Pvo++j7+PsM/Bj8MPxA/Fz8ePyA/Jz8sPzM/OD8/Pwk/UT9bP2c/cD97P0O/jz+av6c/sj+/v48/2n/q//W/xYATwB7ALsA7wAqAVYBhAGuAdYBAAIoAlQCdAKQAqwCwALUAuwC/AIYAywDMANMA1ADTANIA0QDRAM8AywDJAMQAwQD8ALYArwCoAKcAngCYAJAAjACCALoAb4BmgF4ATABDAHzAMUAjwBbADMAAADb/7T/mf98/1j/Of8d/wX/3v6+/qL+jP5s/lD+QP4q/hb+BP70/fD95P3Y/dj92P3c/dj93P3Y/dT90P3c/dz93P3s/fD99P38/Qz+Hv4m/jj+Pv5M/mD+fv6W/q7+0P7w/hT/J/9G/2T/hf+i/7f/y//k//7/HAA9AGAAhQCmAMoA6QACARgBLgFAAVABXAFmAXABcgF2AYABigGQAZQBpAGsAbQBtgG6AbwBxgHKAcwBzAHOAcQBvgHAAboBtgGsAagBsAGuAaQBkgGMAXoBYgFQAUQBMAEmARgBDgEAAfQA5gDcAM8AvwCpAI8AfQBnAE4ALgAeAAwA9//f/8j/t/+o/5P/fP9d/z//I/8G/+j+1v7O/tb+2P7c/uz+9P76/vL+3v7E/rT+rP6q/qr+qP6i/qj+nv6i/p7+rv64/sj+0P7g/ub+7v7s/uz+6v7c/uL+1P7e/uj+/v4Z/zL/Sf9i/3n/kP+O/47/fP9w/2D/cf9t/37/of/K/+z///8fAD8AUQBSAF8AYwBhAFkAYQByAHsAiwCpAM4A7AD/ABIBMAEyAS4BOgE0AUYBOgE8AVwBjAGaAZQBigGqAbABngGCAVYBUAEqAUQBKgHmAPsA5QD0AGUACwCGAJIBrgFoATwBIgFWAZAA7/9S/5L/uv99/zz/cP9rANgAlwA8AIoA4wBAAGr/VP9e/2P/jP6E/v7+F//6/sr+Gf9N/xT/2P64/oj+OP7Q/cj9qP2I/cD9yP0I/jT+VP6u/tD+uP7i/sL+Sv5K/vT9DP4S/uz9Bv4u/ib+/P1g/n7+vP70/nv/ZADdAKQBdAJQA8ADpAOEA4wDJANMApgBVgFoAfcAwQBCAYwC6AMYBNQDkANYA/wC3gHRAFUARAA8ANb/e//J/10AyQDPAJcABAF+AaQBXgHfAH8AcQASAKT/iv+a//L/BgASAEUAzQAcAfkASgBaAEwAxP8y/6z+PP/0/pr+Sv4i/z3/EP/0/j7/Z//w/qz+Rv4E/pz9MP0M/Tz9VP1c/bj90P1E/p7+jP6i/mr+Xv4A/rj9mP2Y/ej9EP42/sT+9P5w/63/1v8uACQA+f/K/6//1//u//H/+P8zAHAAkACyAAABWgGqAcQBxgHiAcIBnAGQAWgBYgE2AUoBZAGWAZIBxgHEAdQB0gGkAbABggFyAVIBMAEkARABHgEmARYB+gD0AAoB+wDXAMIA1wDBAIsAWwBMAFAATgA9AEcAUQA+AGAASwA6AB4A+v/u/97/uv+Q/5T/gP9+/1f/Of88/1H/Xf8z/y7/N/9G/zL/Hf8u/z3/Iv/8/vD+FP80/yf/H/8m/1z/Wv9F/zn/YP9w/3//ZP9v/67/v//W/7H/2v8DABsAIQAkAFAAUwBOAD8AQQBgAGEAbgB4ALQAyQD8AAgBFAEoASQBKAEMARABBgEGAfUA0ADVAPoABAHsANUA0gDQALwAjgCJAG0AYABQACMAGwAHAAUADQDe/8P/t/+j/4j/c/9w/4r/hv9g/3P/e/+J/2n/a/+H/5z/mP+C/53/m/+1/5L/rv/I/8P/3v/C//X/4f/j/+T/r/+6/63/l/+g/5T/pP/B/8n/zv/S/8j/1P+9/7n/0//F//D/5P/s//n/5v/5/+b/MAArACMAPABVAIwAiwCxAM8A7AASARYBKgEuAVIBYgF2AXABfgGcAYIBXgFqAWwBVgEeASwBSAEeAckA3wDlAMcAggCQAHoAPAACAMr/y/9+/2T/Q/8Z/9z+zP6S/pb+Ev4G/uT9uP10/UT9XP0M/eD8tPzk/Oj8rPyo/ND84Pzs/OT87Pww/Qz9LP1U/Uj9iP2Q/Zj9uP3U/Rj+OP4q/mz+kv7Q/gL/+v4c/zv/Yf9T/17/tv/1/w8AMQBjANQAEgEWAX4BuAEUAvQB+AFwApQCwALYAvQC/AI0A2gD1AMIBEgEmATgBAAFGAUwBSAFKAU4BTAFUAUYBfAEWAU4BQAFEAUYBTAF6ASYBFgESAQABFwDJAP0AngCBAKKAWQB4wA/AK7/Qf/m/kD+2P08/fj8aPzQ+1D7APuY+vD5iPkQ+ej4UPjA94D3cPdQ9xD3MPdw94D3oPfQ9yD4aPho+MD4GPmA+bD5CPqI+sD6ePvw+4z8FP1A/aT9+P3w/eD9+P3o/U7+Wv7I/gb/G/99/8f/OgCcABoBegEkAlACmALwAkQDyAPcA1AEeATABBAFUAW4BSgGOAaYBugG4AYwBxgHcAcACIAI8AhgCWAJEAogCoAKgApAC4ALQAvgCnAK8AkACZAIIAjwBxAIwAeYB7AHMAd4BogF8ASsAwACGgAS/mD80Pp4+cD4UPiA9+D2QPaA9ZD0APSw81Dz8PKw8qDykPLA8mDzkPQQ9aD1UPYA90D3cPcA+Aj5yPmY+sD75PyI/TL+2v69//z/mADoAOcA6QBvAHQANAAdAEwAPQDY/xj/nP4M/nz9BP2Y/PD7YPv4+pj6SPqY+fD5WPpo+jj6IPvI+4j8dPyA/Sf/nv8aAGkAdAIwAzgDdANoBSAGKAZgBtgGEAjYBsAGiAcwCGAHEAfQCFAJ0AlgCUAJYAgYB3gH2AeAB0AIwAiwCcAIIAjgCIAJQAngCOAJIArAB0gGUAZgBgAGWAUABlAG0AU4BeAEmAScA9gCOAKdAKb+8Pyo+xD6APmI+Nj4wPg4+HD4IPiw9yD34PYw9wD3sPbQ9pD2cPZw9lD3wPhg+Uj6uPpg+7D7mPuc/IT98P0I/jT+ov6c/r7+IP+D/9f/GgDT/zX/6P54/r7+fP5q/mT+JP6o/ej8yPyQ/GT8ePzA/JT8hPyI+8j68Ppw+5j7BPxU/OT8gP14/Tr+J/8oALYANgG+AaACZALoAhgEmARwBbAFiAbQBdAF+AVYBvgFuAUIBuAGSAagBfgFMAZIBkAF0AVoBqgGSAb4BmAIYAkQCfAIUAmACmAKYAlQCZAJQAiIB6AGGAcYB6gGGAcACGAIuAcgB7gFkASAAvMAmP+I/bD7oPrQ+Sj58PdA+DD4kPdw9iD2wPUQ9cD0IPXQ9QD20PUQ9gD3EPcg+ND4yPkI+mj6MPvI+2j74Pv8/JD9+P3I/a7+yv7o/rz+6v+1AA0AIv9s/lT+KP1M/Bj8vPyU/ND7ePuw+yD70PoY+xj7IPtg+uj5MPpg+QD52Plw+rj6ePpg+6j8MP2g/az+2P/iAGYBFAL0AlADuANoBHAFEAbQBjAH6AbgBtAG4AYIBsgFOAaYBvAFwAXIBXAGQAbQBVAG0AZQBhgGaAfYB0AIIAjQCKAJcAlQCQAKAAugCnAJ0AgACKgGOAZYBzAIkAgwCCAIaAdgBggFNAMYAkn/zP2I/OD6+PgQ+HD4sPdw92D3oPeg9mD1MPVg9XD14PRg9TD2kPbQ9mD3aPhw+aj5iPo4++j7TPzo/BD95PzE/QD+ZP3A/Wj+ff+7/4P/IAArAMn/av5s/aj9UP3E/ET88PsA/Cj7+PrA+uj6cPvw+oj6OPrg+aD5QPmI+SD64Ppg+zD7iPuA/HD9Lv5F/8f/+wDIAfABNAJEA4AEGAVwBQgGMAc4B7AG0AbYBhAHUAb4BRgG+AUQBaAEGAVoBbAF4AWQBZAFkAWQBUAGgAaAB+AI4AiwCNAIIAlwCeAI8AhQCcAIOAcIBogGOAe4B1AIEAlQCQAIOAawBLgCxgAy/1D9VPwg+/j5qPjQ95D3wPdg9+D2wPYw9hD18PMA9HD0sPQw9UD2oPfg9zj4GPmY+Rj6CPpA+6j7fPy8/IT9tP2w/dz9cv7+/mv/uf+h/8H/CP/2/kj+IP7Q/UT9fPxM/AT8iPtQ+2D7kPsA+1j6SPro+fD4QPgw+JD44PiA+Wj6APtY+8j7UPz0/Mj9Lv6V/0oAywBwARQC+AKoAwgFOAY4BlgGqAbIBsAGWAawBtgGeAa4BZgFyAWoBYgFGAagBmAGUAYYBpgGuAZQB/gHUAjQCIAJIApQCrAKkApgCtAJoAmQCeAI+AdQB/gHYAiACBAJYAnwCCAHwATcAtsA6P54/Uz8qPto+nj4wPdA90D3wPbw9tD2QPZA9VD0IPSQ8wD0sPSA9hD4oPgw+aj5UPqo+kD7FPy4/Bz9dP2Q/ej9Pv6s/ij/af8zAAYB3QASADn/hf/0/tT9SP2I/WD9LPzo+7D7LPwg/DT8hPwY/Jj7yPog+gD5EPno+fj6iPrI+vj7dPxA/JD8KP4m/3z/R/8kAIgBEAJsAjQD0AQIBhgGkAZYBoAHoAf4BsgGyAZYB0AGcAXgBOAFiAUQBUAFKAZ4BgAGoAUwBkgHUAdoB7AHUAhgCYAJ4AnACvAKoApgCTAJwAjACLAHYAfIB5AIoAhwCLAI8AiQBxAFGAMGAST/5PxI+2j6cPk4+ED3YPdg9tD14PUA9jD1kPSw9LDzcPIg8nDz0PVw9pD30PjA+Wj5cPmQ+oD7HPwQ/Hz83PxA/Uz9+P26/kUAWgEUAcIAdAAfAPb+Ev44/tD+SP7w/OT81Pys/AD8KPyE/Vz9mPyg+yj78Pno+LD4UPmg+vj6APuQ+yj8OPww/Q7+xv5P/6L/0f8tAPYA1AGMA+AEQAb4BvgGKAcQBwAHGAfQBtgGcAZIBogF6ARABXAF+AWgBWgGkAYoBngFGAaoBqAGyAZQB6AIgAjACKAJ0AoAC5AKoAqgCfgH0Ab4BvAH0AeQCHAJ4AnQCDAIcAewBWgDowCG//z9EPxA+mj54PgQ+BD3UPZQ9tD1sPWQ9SD1sPQw8xDz0PKg83D1oPYQ+Hj46Pho+TD6kPoQ+4D7KP2M/aD9fP3I/VT+RP/Z/yABYgHgAAAA1v76/hn/hv6G/mr+AP7I/cz8KPzI+wD85Pxc/Kj7+PrY+bD5oPh4+Hj5EPoo+gD6UPoI+wj7aPtg/CL+6P78/if/AADhAPQB0APgBOgFMAa4BtAGSAbYBvAHkAj4B1AHqAdQBygGGAZIByAIyAeIB2AHkAdYBoAGWAYQB8AHoAhQCcAIoAkQCiALIAsQC+AKYAlAB/AFIAbQBtgHAAkQClAKcAngCAAHyAQ0AkAB8v+E/cD7UPvo+hD50Pdw91D3IPYg9cD1APbg9CDzcPIw8xDzwPMQ9ZD24PdA+OD4OPkw+aj5YPqQ+zT8cPzk/Lz8wPxG/iMA3QCxACQBJgFtACj/sv5D/9r+fv5a/rT+WP7w/Oj8MP1w/Qj9UPzA+6j6gPkg+fD4KPmA+ZD6KPs4+5D7iPvA+1T8oPzE/V7+uP4h/wgA7QCsAigEoAVYBtAGAAeQBmAGsAZwB+AHIAjABxgHIAYABmAGyAaYBxAI0AcgB4gFyAUYBmgG2AbQB0AJkAnwCIAJsAoAC6AK8AnQCfAIIAdQBmAG6AaYB5AI4AkgChAJ+AboBJQC/QB1AMr+KP1I+xj6ePlA+MD3APcA9+D1kPQQ9MDzwPLA8eDxgPLA8lDzUPQg9VD2cPfA9wj4oPhY+bj60Po4+8j7zPwk/WT9bv5+/xIAY/+e/2wAcACg/wf/A/8C/2b+VP1Q/aT9eP0U/eT8QP2Y/JD7+Prw+ij66PnI+Dj5iPmQ+Tj6wPpI+4D70PsU/VD9SP3Y/cr+FP/s/pcAXAJsA0gEkAW4BvAG0AVwBogH8AcIBwAHSAdgBugFSAZACJAIMAhgCCAIGAfYBVAF8AVIBvgGgAjgCbAJcAlwCRAK8AmwCcAJoAnwB6AGuAZQB2AIAAlQCnALoArACLgGoAXEA+ABFgGTABn/WP1g/Ej7gPnA9wD4QPhQ94D1IPWA9IDygPHQ8kD0oPTQ8xD1gPZQ9uD14PcI+eD4IPjw+Pj5yPoA+5j8rP78/n7+2P6M/2H/Wf+6/30AJgAz/9D+5v6k/qL+fv7M/rj+eP3o/LD86PuY+0j7gPug+oD6cPpI+vD5KPqA+2D7MPvw+1D97Pxg/IT9Q/+U/1b/gAB8AnQDVAOgBFgGmAZ4BtAGEAhAB7gG4AbgBsAG2AZIB8gHqAfwBwAJcAgoB7gFWAWwBfAFUAYQCDAJsAhQCPAI8AmACcAIwAdACBgHYAYYBogH4AgQCeAJUArACnAIgAYwBTAEjAKIARoBMgCH/zz9kPvw+cj5MPlA+PD2UPaw9IDz8PGA8qDzYPSQ9LD0kPVw9SD1kPTg9WD3sPfw9oD3+Pjo+VD66Pt4/r7/3P78/Zb+wv4S/iL+sP+cAN3/3f/V//H/xv9+/3L/4P5I/gz9IPxQ+3D7OPzQ+zj7MPuo+/D6oPnQ+RD6yPl4+Yj5CPuI+4j7FPy0/cD+VP9Z/w4AZgFUAewBnAJABFAFQAXIBWgG6AZoBqgGKAfAB4AHgAeQCAAJcAgACDAIkAcYB9gGqAcgCFAIcAiwCVAKYAlQCeAIQAnoBwgHGAegBxAHgAfACCAK8ApACiAKEAmwBjgE/AKcAvQB/AEQApUA7P1g/AD86Pro+BD5wPhA96D0gPNg9DD0gPNw9BD2MPZQ9CD0APVA9VD18PVQ92D3EPdI+LD5oPpw+yD9Tv7Q/Yj9nP0i/gT+6P0P/+//2f+f/y4AGgDT/xf/W/8k/yb+YP0s/QT9JPzI+zD8dPyY+/D6yPqw+tj5GPnY+Yj6ePqA+qD6HPyA/Bj9uP18/pX/QACEAIQB4AK8A1gEwAQYBqAGkAaABlgH8AfQB7AHUAhwCYAJUAlQCfAIkAiQCEAIAAkgCWAJEApAChAL4ArACuAJEAnQCGAI0Ae4BwAIEAggCBAJMAoQCuAJkAn4B/gFAARUA2wDdAL+AVoB0AD6/uz8FPzY++j6KPmA+ED4EPdw9eD0cPWA9iD28PUw9jD2cPXA9CD1IPYw9jD2EPfw92j48PiA+RD7+PsU/HD8qPyk/KD8zPwY/pb+Df/R/+b/uv8c/xn/5P6a/lz+bP5O/iT+IP14/WD9OP04/AD8+PvA+sj5iPlg+gD66PmA+jj7QPtA+1D7NPxo/Bj8cP2O/nD/KwAMAWwCBANYAxAEyAQQBVgFsAXIBoAHIAgwCUAKcArwCeAJcAogCqAJ0AmwCrAKAAswDCANoAxgC7AKsArACcAIoAlgCnAJ0AfQB/AIEAnIB4AIoAnQB0gF7ANwA2gCtgBUAPYAjADg/Zj8QPxg+8D56PgQ+SD40PbQ9XD1gPVQ9XD1EPYg9uD1YPWQ9aD1QPWw9UD2UPaw9nD3iPiQ+HD5sPpQ+5D7gPsM/Az8OPyQ/Lj9Lv5M/pz+Uv8j/+L+Ff9F/5j/6v7W/vD+Qv4U/jD+dP4S/mj9RP2Q/Pj70PuI+wz8sPvI+1T8aPxg/Bj8UPyI/MD86Pzs/d7+Xv/V/8AAuAEsAjwCeAKYA+gDOARgBMgF4AYYB7AHUAgACaAIsAjQCFAJwAgwCfAJoAqwCzALQAvACmAK4AmwCUAJcAnwCCAJQAhQCGAIoAhgCEAIIAhQB1gGGARIA+QC3AHvAKYAgwCi/yb+GP3g/Pj70PrQ+RD5UPgw94D2wPbQ9uD2EPdA9xD3gPZg9kD2EPYg9mD2oPbw9oD3aPgI+bD5SPoQ+2j7IPtI+4D70Ps4/NT81P1c/nL+mP7w/gT/U/8Y/0z/YP8I/8b+fP64/gP/wv6m/pT+UP7A/Uz9LP1g/Rj95Pws/Uz9ZP0U/UD9cP1o/VD9jP34/Tj+RP64/o7//f9zAJcASAFmAY4BygGcAtgCTAO8A2AE+ATYBGAF8AX4BYAFmAUwBnAG+AaoBzAIIAjAB9gH6Ad4B6gHuAfwB5AHQAdoB3gHKAcoB5gHwAf4BnAGOAbYBSgFaARYBCAEYAPYAjwC3AE0AXAAIQCJ/+D+Dv54/Qz9WPzQ+7D7qPtQ+wD7wPqo+jj62PnA+bj5gPk4+Tj5KPk4+Uj5mPkI+jD6OPo4+kj6MPpw+uD6GPt4+6D7+Ps8/Gj8xPwY/Vj9uP3Y/fj9Av4e/l7+iP7I/gX/Jv8Y/xj/9P4R/+r+AP9I/2L/ev9S/13/bf+Y/4//uP/c/97/3P/q/z8AcwCuANAACgFIAVwBeAGwAfABHAJYApwC5ALoAhADVAOcA7wD5AMYBFAEYARQBHgEmASoBKgE0AQIBRgFCAUgBXAFcAVYBVgFaAWIBWAFMAU4BUgFMAUYBQgFEAXQBGgEIAT8A6wDYAMEA/ACvAJUAtYBmAFYAfAAbwAkAN3/Vf/Q/nL+Ov7o/YD9OP0I/bj8bPwA/Pj7cPtA+xD7GPv4+sD60Pq4+qD6ePqo+pj6cPpo+nD6gPqQ+nj6sPrw+uD6GPtw+6D7wPvQ+wj8SPxU/JD8vPwA/TD9PP2U/dz9+P0M/jj+fv6m/rT+4P4z/0j/XP9s/6z/5//h//z/KQBoAGIAfADWABABKAEoAToBSgFqAZYB1gHqAfQBKAJEAkQCTAJQAlQCYAJgAmgCjAKMAnwClAKsApAClAKkAqQCrAKQAogCqALEAqwCrALIAuAC6ALsAgwDHAMIAwQD9AIQAxADFAMMAxwDIAMQA/AC4ALMAqwCiAJoAlwCJALaAaABjgFgARoB6gDHAKEAXAAoAAQA1v9//0z/NP8E/7r+hP5W/iL+BP7M/aj9gP1E/SD9/PzM/Jj8fPxM/ET8PPxA/Cj8EPwI/Pj7APzg++j74PsA/PD7APwI/CD8OPwo/Dj8UPxs/ID8nPy8/Pj8DP00/WT9hP2w/cj97P0S/kD+Wv6G/pL+2v70/iH/Q/98/7v/2P/5/yQASABtAIAApgC/APYAGAE0AVoBdAGUAaYB3AEEAhQCKAJAAmACeAKIArQC5AL4AgwDKANIA0wDZAOAA6QDrAOoA8wD4APwA/AD/AMIBAAE+AMABPAD2APQA8QDsAOgA4wDcAM8AwQD3ALEApgCcAJIAhAC3gGWAVwBLAHhAJ4AXAAMAMD/ev8//wj/yv6G/kb+Bv7E/YT9UP0M/dD8lPxo/Dj8FPzo++j7yPuw+6j7mPug+3j7cPtw+3D7WPt4+5D7oPug+7D76Pvg++D7BPwk/ET8XPyo/Oz8EP00/Vz9pP3c/RD+TP6C/sL+8v4u/2H/jv/N/w0AQQBuALEA9gAgAU4BjgHGAfoBHAJQApQCxAL4AhwDVAOMA7gD6AMQBEAEYAR4BJAEoATABOAE+AQQBRgFKAU4BUgFQAVABTgFMAUgBQgF4ATABLAEmAR4BFAEGATkA8ADhANMAxQDzAJ8AiQC7gGeAVgBEAHGAH0ALADj/5r/TP/2/qj+WP4O/sz9kP1Q/RD91Pyc/GT8NPwM/Nj7oPto+zj7CPv4+tD6uPqg+pj6mPqI+oD6iPqQ+pD6kPqo+tD64Prw+ij7WPuI+6D72PsU/Ez8dPy0/Oz8NP14/cD9EP4y/nz+tP4N/07/hf/i/zgAdwC0ABYBcgGmAdwBJAKEArACzAL8AkwDgAOcA8AD+AMQBCAEQARwBKAEoASgBKAEsASYBJAEkASQBIgEcARYBEgECATYA7wDpAN4A0gDGAP0AsQCjAJoAjgC9gG6AY4BWAEWAdsAqQBlAC4A7//C/3z/Qv8R/9T+mP5a/jD+EP7k/az9kP2A/Vj9IP0E/fj83Py8/LD8pPyQ/HT8dPx4/ID8ePyE/ID8gPyI/Jz8tPy8/OD89PwM/Sj9PP1k/Yj9oP3M/QL+Nv5o/or+pv7W/g3/Ov9h/5r/0P/7/ycAUQB8AKgAwwDsABwBSgFwAYABoAHIAfQBDAIgAkQCXAJwAnACeAKUAqACsAK0AsACyALMAtAC0ALYAsACoAKMAoQCeAJsAmACWAI8AhwCBALsAc4BogGGAVoBMgEMAfQAzwCaAHcAZABIABMA7f/S/7X/if9m/1P/PP8Y//b+2P6+/o7+aP5Q/j7+IP4A/vj96P3I/az9oP2U/Yz9dP1s/Xj9dP1s/Wz9dP1s/WT9YP1s/ZD9pP2o/bD9yP3c/eD97P0c/jz+WP54/pr+xP7i/gD/HP8+/1n/iP+x/9X//f8iAEgAYQCPALQA1ADvABYBPgFsAYYBpgG4AdAB5AH0AQACBAIIAhgCIAIcAigCMAIwAiwCKAIgAhgC/gH0AeABzgGoAYoBiAF0AWwBQgE4ARwBCAHvAMcAsgCOAHQATAA1ADIAIAD9/93/wf+z/4f/Xf9U/0b/KP8O//r+7v7g/tL+zv7K/sL+wP62/qj+ov6Y/pr+lv6q/rj+wP7C/rz+xP68/sj+2P7k/vr+/P4P/xX/Lf87/0b/X/9u/4X/lP+l/87/5f/x////EwAwADcAPABPAGQAZgBhAHoAmwCkAKMAuADIANYA2ADfAPwABgEKAQoBEAEYARwBHgEmARYBDAEMAQgB+wAGAQQB5gDVAMoAywC9AKMApwCcAJQAhwCDAHkAZABaAEwARAAtACkAKQAaAAMA+P/y/+H/1v/S/9b/yP+x/6n/nP+U/4f/k/+W/5X/i/+M/43/hP9+/3j/f/9+/4z/lv+Q/5//qv+//8H/v//C/9b/0//W/+b/9f/+//v/AgAJABkAGgAlADUAOAA/AEAATgBaAGMAZgBzAHEAZQBvAHUAgQCCAHEAbwBjAGAAWABVAFAASABIAEMAQgArADQAKQAcAAkAGwAeAAwA+f/4//f/5v/X/9v/7f/Y/7n/uf+8/7n/pv+p/6r/rP+X/5z/lv+I/3z/iv+Q/5//m/+w/7L/vf+i/7b/ov+e/6f/rP+u/5//qP+1/8D/uf/A/9D/xv/C/7r/zf/L/9P/1v/a/9H/1f/W/9X/1f/a/+H/4//b/+T/6f/7/+X/+/8OAAkAEAAdADEAHQAWAB0ANAAzADAAPABGADIANABBAEUARwA+AEIAPQAtADEATQBSAEIASABRAE0ANQAlAD8AQwAuACUAPgBBABkAFQAkADYAEQAIABUAHAADAOv/6//4/+f/0P/Q/8z/wf/C/8n/yP/C/7j/uv+8/7z/t/+9/7//qv+k/6L/of+n/6v/q/+y/6r/qf+s/7H/rP+1/6r/vf/R/9X/0P/Q/+D/8v/8//P/AAARABIABgASAC0ANwAxAEIAWwBdAE8AUwBzAHIAaQBtAIwAhQBzAHwAiQCLAIEAhAB/AHoAdQB0AG8AXwBdAGUAWQA/AFAAagBVADsAMwBTAFYAMgAwADgAIgD7/wAAFwAUAPb/7f/9/+z/zP+6/8r/yP+3/6//vf+u/53/k/+j/6b/iv+T/6H/pf+J/4L/kf+c/5f/kP+g/7L/rP+e/5n/oP+m/5//nf+l/6v/t/+y/7j/0f/E/7H/u//G/9L/s//D/9T/4f/R/9r/7P/0/9v/0v/q//D/2//R/9v/6f/U/9L/4P/k/93/4v/k//P/5v/s//X/8P/m/+f/8v/p/+j//v8BAAwA9f/7/xkADwAFAAwAJQAtABsALQA+AEcANAA5ADYAOgAUACcAQAA8ACcAKQA7AC4AEwAUAC0AIAAIABYAIgAqAAUAFAAdABkADQAYACEAEgD4//X/DAAQABAACgAaAPf//P/8//H/9f/f//P/+P/y/93/6v/x//7/+f/k/+7/+f8XAOT/+f/8/xcA4v/+//7/IgD8/+H/GgAkAPr/6P/p/wUA5//u/wQAMgADANb/3v8HAPj/4v/X/wMA8v/g/9f/AAAAAPj/6f/w//f/6v/r/wYA+P/2/+X/7P/j/+X/7v/8/+H/AwD2/wwA+P8YABEAKwAVAAUABwABAEMAPAA6ABwAHAAvADMANAAxAEUAOQA0ABAAGAAcAEQATQBMADkAPQAzAEwAPwBIAEUARQBTAEYASAA9AFgAOgBEADYANQBGABoAOwAjADQAGgA2ABoALAAXABUAHgAFAB8AIwAgACAAEAAQAAgA+f8FABUAGgALAAEAFgARABMA/P8PABAA///9//z/HwD9/wsABAAOAA0A6v8FAOr/DAD2/wgAGAAHABwA9v8EAOT/6v/f//7/+P/v/8n/4P/K//T/xP8BAL7/0P+p/8b/7f+6/8D/n//j/5//v/+t/wYAf/+t/6n/BgDQ/2D/6//Q/9P/KP/o/x4Ax/+M/6H/FQCl/9r/+f8RAL3/7f9NADMAvP/1/4QApgBu/xEAfgDXAMD/5v9WANoACwD1/yYA1wAjAPz/+f+iAHAAAgAcAHsAbwAcAPT/ogBoADMAu/+NADMATwDs/28AQgBCALL/YAAMADMA7/9KABQA3f8BAC4AAwAEAL//OQCu/8b/p/8xAOX/yf+u/y4AzP+g/63/AgDx/3P/vv+4/+//lv+x/9L/3P+E/9f/0/+o/8//pP/6/3v/lP/I/xIAy//Q/+b/6f/T/33/5v8eAM7/zf8GACkAFgDn/xQALwBLAA0AEQANAFsAMQAxAAwAUAA1AEoA7f9SAEcAOgBFADEAQADs/2QAUwBnAB8AQQBYAEoANwBiAIsAZwAQAE0AOAAVAE8AcAAoANf/0v+DAAQAMgDA/y8ARACT/93/tv90AKT/6/+j/yMA1v/F/9P/u/8qAIr/1v+g/yQAxf/W/8r/mv8MAKT/EQCg//j/pv/5/8D/9P/R/8H/w//1/xIAuP+x/8L/DQDj/57/2f/h/ycAoP/o/9r/KwCl////0//S//P/6f/2/+b/9v+j/ywAHgDl/+v/EQDo/5r/5f9HAIUAzv8PAOT/ggBu/0oAAACwABwAq/96AOf/kAB+/wgB3P/HABMAEAB8ANj/6ADO/8IAcP/IAN//NgD5/0IAQgAvAD8Apv9tABQARADh/2kA2/9yAO//NABuAN7/2P9NAL8Aov9y/7v/pQCEAMr/lf9iAEMAv//j/yMA7/8/AML/NwDm//n/2/8pANL/HgAlAM3/KwARADcAp/8zAAEAPgC4/8P/IwDp/1sAl/+yAHb/lQCc/yMAzv9KAKAAiv8xAKD/8wCg/2QAh/+oAO//fP+oALj/BwDm/+T/tABP/1IAk/+pAM7/U//m/z0AuP8DAL7/4v/DAEr/vf///0oAs/9q/xUABQBhAGD/QgA9AJz/gv/Z/6gAa//k/5T/+ABG/5X/zP9yALb/tf+R/3EA0v/v/7r/bwBtAGD/zwBL/5sAW/9IAAUAhwAGAIL/UADP/9oAFf9jAOv/LgFu/+7+cwDx/xQB1P56AAAAvwB6/xIAnP/HAMv/uf8GANP/AQD1/1kAnP+IANv/hv9pALb/AgCW/0IAp/+8APP/m//FAOT+vAC3/7sAJv9EACsAFACx/3z/iQAIAZT+WQBw/xIByv6b/9AAwP+3/57+ggH4/sEAOv5+AfL+GgAj/5oAgv8XAFL/CgCa/pYARAATACz/SP/kABj/+v9o/uYB4P6u/0r/XAAPADH/UQBZADwAhP3PAI0AAQAu/7D/HgFNAPj+PAAeAFYBWv7BAMf/mACDAMv/ngBw/uQBwv6wAar+MAHb/8MAyP5xAAoBqv/EAMD/NAB2AL7/0ADB/2QBV/+RALD/IQBmAWz/OgC0/3YBcP7wAHr/dgHw/0D+oAF3/zAAP/9WAYr/RgDs/tQBnP++/wcAqADh/4D+LwDQAIUA8P69AKD/0QAY/pj/owD6/8T/nP56AJv/9wB6/moAqv6UAZj+AACe/t4BMv9iADz+ugBKAOT/PP96AKQALf8cAKD/MgFo/xwAAwAmAKIAf/9CAAEAmgDk/w0Akv6YAS8ARgBS/3gAeAB8/o4A///UAef/tP5jALT/BAFo/uIByf9aAKv/hv+GAez+GgGS/lQCYP6KAXb+ngH+/7j+4v/0/x4B9P3yAXT+cAIi/rn/mgBjAPT+fP/8AM7/w//O/jMAwwBV/4L/vgC8/zAA2P5wAC0AJQDp/2P/oP+w/xz/nAAA/9oBGv5gAQr+qgEF/7//UgBH/5QBHv/y/7sAuv+y/wIALgD7/+D+eABu/4sALv5sASsAOwCw/lYBUP9gAL7+FgGLAKD/jP5MAacA7v4/ANP/ygBX//j+mwB9AJQABP+/AIQAWQD4/wUAzf8MAgD+9gGU/dwBO/+wAWP/8//l/18A0f/M/wgAJAL0/dQBaP2oAoT+GADc/1YBJP/u/h8A5AC3/3X/WAAIACUAqP4qAYj/hAHC/koBcACN/xP/6gByAIkALP7YAbb/kgAP/yABBgFO/9gAxP2cA0j9aAFdAE4BZv9o/5gBxv6mAbz9PAIy/usA6v4iATf/nv8PAPf/BgDg/ukA1P+nACn/bgDY/8T+KALc/nIBf/8e/6ABLP7kATr+5AIc/bgCEP2EAUT+wwBeAP7+rv8nAJ8AYP6EAHv/XAE6/xL/iv+sAQsAQv9MATP/jQDY/oQCtv5QATr/7P8GARX/SgC0/74BiP43AO//tv+mAT7/iwDO/pQA8v4WASr/HAEW/8b/xQDk/WgBAf98Aj7+fACY/gwCyf9+/vABVv/UAJD+ngGI/3AAHv4QAfT/YwBd/xsA9ABG/tIAUv50AhP/9ABN/5n/kf+o//YBlP1kA9T9YAHA/t//lwAFAOcAIP2YA7r+ugDI/OACyv5MAdD9/AGc/qoAKf+IAtP/Ov9v/5sAEgHg/BIBhAJy/7MAVv7AAY//gP5V/xgBsf8M/0D/MQBgAT7+JAEc/yQC+PyCAGL+iAGS/i4AVgDo/q0AvP5QAtD9NwCu/gwBHv8K/mgBwv5AAZj+twAUAAUAcQAw/ywB/P3sAMX/ev+k/0wAKAG+/nABCv9+AUT+aACN/x4Bnv8iAAgBhP5IAVD9TAEA/8kACQCkAQD/h//mANT+TAKI/TgB8/8pAPX/2P/NAD0Aif8HAEP/FgH+/rIArP8jAEAAbgCaAMv/aAAyAE//KACS/0gB7/9PAEX/S/8eAdz+IAF2/kgCnv6yAKP/NgER/+P/zv/3/y0A/P59AEQAYgBK/tgAV/8cAOb+IgH8/gcAAABi/wgCTv4+AQD/vQCC/83/Iv8RADgBmP/9/4X/qAD6/tcAXP5UApT+JgHh/4cAWwDi/vkAPv9iAUn/Z/+iAcz9WALY/bYAtQC5/8oAfP4SASUAUQCb/wAABgF9/74BMABnAPj/+P8oANb/WP+pALz/8gAZ/wACbv5LAPL/eP5WATr+kALO/ugALP+mAOoAZP1YAfr+BAJw/Z4BhP7EATz+OADZAHr+qAFY/XwCJwDA/97+JAAUAOb+cABu/tgCHP5IAYj9CgEH/8EAIf8aADr/fwAB/2oBDABB/5wA8v5YAWz/Nv9tAGEA9f/E//T9UALk/FACDP3kA5T8UAKm/mUAef/g/fIBUP7UAjz9QAK4/vj/WP+WAWb+NAEb/04B1/9o/oYBzP/GAZT9yAFVAH8A+v5fAIYBYv/O/3v/NAIU/5QAxP62AWL+lv9m/ogBCQBG/5QBnf8sASj+Xv7AAVT+xAKU/OIBfwDq/7L/QAAGAej+pQB4/YYB7P9MAI0AegDZ/1UAKv8GAUr+GAL8/SQCpP7nAMQAawBmAOv/dwBQ/+r/8P9EAvj9hgGg/jgCoP7BAGz9PAJ8/zv/qQDKAMwA+P3VAIoAtgHe/qIA2ADiAMj9b/+sASkAawBY/tgCZP74/6j+VAHVAGj+kAHw/oIB1PwkAhT+bAJ8/VoB4v+nAEH/BgA3AK7/VAC+/owBGP9kAd7+fgGn/4L/eQD4/oABIv4IAmD+BAJO/hYAiACw/joBHf8QAlz+EAJ7/3cAoP7w/lACOP/ZADT+zgEWAKj+agDO//kAHgAC/xIABwAOANP/JwBxAA4BcgCC/i8A3gAUABb+PAE+/7wBpPyAAQgBFgEr/0EAIAJE/b4AJP4oA5L+Kv5NAMv/owAY/mgC9P41ACr+OwBWAJb+JAEUAJYACv/7ANsAOf+wAOD/egEQ/a//fgCuAUMAof8eAVf/qADU/eABwv7eAXz+zAD8/oIAtf/g//MAiAC0ABz9tAC5/9wAtv/w/h4Byv4u/9//ogFU/+L+mQCm/6T/CP0qAb0AbwC8/PgAaf/CANT/qgH/APT9owCa/uoA7P1WADsAfACW//j/rgDR/yn/UwCk/Xv/Pv60AX//yAJA/tsA7P9g/7kAOP8kAej/kgBY/ugAlgE7/wIAKQAkABb+Jv8SAXYAwv/k/eABxQAe/s4A1AAoATb+EwDJAJUAH//N/ygCmv+//88AFQCCAbj+pwBcAAYAsABf/1wCQf/OAbT9WAEM/0IBGv5vAL7/HgFU/93/YACD/9P/Kv9UAIL/iAH8/owBzP+6AIMAnv6s/2MAIQDz/1wAiQAXALj+Kv8/AFQBUv5pANX/7v/+/hb+6AGP/9EAdP4mAbH/zP/L/9H/IQDe/n7/wQA3/9gCnP5WAI4A8P/p/xX/nP4MAWwB0v56AL0A1gBc/wEAtv6qAOb+WADG/4sAg/80AKcAiQBk/xIBjP/l/yIB+v+7/4QAkP8aAUcArP7tANMAsP/Y/dkArP/RAEj/xf9eAJH/Xv4iAGwAi/+2Ae//7AHI/WAAKf+tAJT/nP7gABwANQBQ/jACuv5b/17/PgBEAQj/EABLAL4BKP1gAPb/iAGy/8j+CgF//8f/lv/zACAAFv4GAO7/t//s/QcA/QCdABD/ev9eARYARv6G/l0A5v82ANf/wgAHAOP/2f8CAUr/8QAoALf/yv8m/xwBCgAKAaL/xQDC/0wAhgAFAHQAtf/TAIH/qf+VAMoAIgGL//AAXgBrACz/6//W/9r/ff+r/0gB6f/TAC7/sQCs/9D/MgBZAIoAGwDR/38A5/94APb/IQDa/37/cQBn//0A+f9QAT7/XgBj/xoAiAAW/xIBs//TALz98wCv/44ApP6CAJUAxv/r/wD/XAJE/5kAsv4wAeb+gwAnAOwAyABv/yYBrv4LAH7+OgEIACcA5/9IABIAf/9AABQAJgFc/qkAxv+HAGT/0AArALAATv+sACAAhv/I/6j/qQD8/jcA8f/lAB3/EgA4ACcADv9R/2kAwf/BAMX/LgHZ/6X/Sf/w/4v/FgCj/+MA4P9e/wUAVwD8ACb/SABy/rYAZP5sAL8AuACCAIn/HAFk/9f/tv5aAdb/5f+T/7AAzwBeADYAkAAMAI//Z/8pAOX/fgBxADUA9v8xANb/7wDh/1AAOgC0/7X/ZgCU/6v/p/+e/ywB3P/m/4H/4//5/+7+dP/x/zABY//u/4L/FgA6ABr/PADy/ycAZP5tAHD/lgBK/0IAQwDg/3L/CgBiAMj/DQAP/10AK//Z/0QATADl/7X/EACR/5n/RP9+ALv/UQCY/6MADABMAN7/xv8mAO//IgBL/wgB7v8fAFb/LQAfAB8Ax//T/yIArP5SAKP/nQAWAN7/dABW/9D/Tv8YAFP/MwAwABUAyP/I/5oA8//U/8H/KQAQAPX/HABvAAkAsv/p/6j/pf8P/+H/7P9uAK7/m//h/1r/aP9Z//P/CACCAID/CQBGAGEA3P+N/8b/8/+n/1wA6ABcAH0A4v+uAHT/qv/v/3IAmgDe/2IA1gCmAI0AhgBpALX/3P8sAKYAuQD6/8oAsQBoAJ//6f+qADQAGADd//7/1v/D/9QAXwAqAMX/TgBYAEv/rf/s/6cAuP/y/x0ANwDD/4H/YwBbAAwA+/+CAOkAHwAaAF8AQADo/23/PAAAAJ3/sf+jAGwA0v9t/5r/kP9f/9z+Tf+N/zX/XP+b/5n/AP/K/2r/nP8s/nj+Yv9q/8j+0P5KAOr/MP9W/wAA7P8r/3P/CwC8/3v/k//QADkAyv8iAKgAbQCn/1oArQCXAMf/DgBMAc4AxgC5AHgBzwD9/zIA6wBsAFUAmwBAAZAA5QDHAIIBEgFsAUQBQAEcAUYB0gGeAV4BDAKsAZIBFgGOAVoBjgHdAFwBfAC8AF4AcwDKACAANQCx/7H/LP8d/+L+uP6c/iT+IP68/RT+bP1c/RT9DP24/Ez8ePyM/Kj8QPxQ/KD8ePw0/DT8RPww/Fz8ZPz4/Bj9JP0o/ZD9nP2U/eD9Cv7s/qj+NP9Z/ywASgCoACgBegHwAQgC/AIQA3QDVAMoBEAEiATIBBgF4AWgBSgGeAYgB7gGgAaABjgGkAbYBrAH4AfoB9AHKAd4BlAGGAYgBlgF+ATABBAEnAMkA3ADMAMcAkgBzQD9/03/lP4g/pD98PxA/JD7+Po4+tj5GPnw9yD30PZQ9qD1MPXQ9HD00PNQ81DzUPMw81DzoPPw8yD0gPQg9cD1YPYA99D3yPho+Xj6mPuU/Mz9A/+OAGYBYAJAA2gEMAXgBfAGQAjQCFAJQAoAC8ALIAyQDMAMsAxwDIAMsAyADNAMMA2ADNALgAvwCsAKoAqQCUAJgAgIBwAHyAWgBcAEOAQoBEwDDAOEAnwC7AGAARoB9f+N/yD/yv6g/vT9Yv5E/dT9UP04/Tj8OPv4+sD56Pjg9yD40PdA9xD2APbw9JDzwPJg8sDy4PGw8eDx8PEQ8vDxUPIw89Dy8PLw8mDzAPSQ9JD24PdY+aj6APw4/RD+2v5gADoB/AFQA+AE+AX4BjAIIAnwCfAJAAogCjAKwAkgCkAKsAqACgALIAtQC5AKQApgClAJ8AiIB2AH8AZYBuAFEAYYBrgF6AUoBdgFgANwA1ACgAIAAloAqgGQAhAE4AOgBNwDrAOUAR4B+AB0AHQA/gD2AbYBmgHeAcQCkALdAJD/iP70/GD7uPo4+/j62Plg+YD5kPcw9sD0kPTA8wDycPFA8dDwQPDA8HDxAPLQ8fDxEPKA8RDx4PFA84D08PWA91D5gPoQ+/T8lP5R/20ABAJEAxgEIAWgBtgHsAgwCTAK0AqwCtAKQAuQC3AL0AtADEAMAAzwC6ALYAuQCqAKMAowCcAI4AcwCEAHGAeIBjAGMAWABHgEAAQsAwQDvAOAAsIBFgGgAogDhANoBNQDKAOuAVsAPgGjADoBTAG0AiQCfgH+AfIB4AHPANn/Yv70/Dj78PqY+iD6oPkQ+bD44PaA9UD0YPNQ8gDxYPCA7wDvIO8g78DvQPBg8HDwAPCg78Dv4PDg8VDzQPXA9rD3GPkY+6D8OP6H/1oBjAJAA2gEEAagB6AI4AkQC4AL4AvwC4AM4AzgDEANkA2gDVANYA0gDSANgAxADNALwAqQCRAJsAgwCBAIQAcAB+AFUAVwBEgEmANsAygDWAIIAdQAnAHcAtgDIATYBLwCEALaABEAAACbABgBfAIMAvoBBAK4AvgBZAGRAGj/8P1o/Az8QPs4+5D6gPqg+SD44PYQ9UD0IPOg8QDxAPCg7+DuIO8g7+DvoO/g74DvIO+A7+DvIPEA8vDzEPUA98j4uPr4/Dr+rP8+AaACPANwBAgG2AfwCBAKsAvwC+AMAA2gDcANsA0QDoAOUA4ADgAO8A3gDUANYA2wDLALgArgCXAJgAjgB+gHwAcABrgFYAXYBCgELANcA4wCMgH8AMIBCAOUAxAEIAQ8A/cA0wBMALQATQAWAQQDugEgAtIBUALAAT4BcwAx/7j9kPzo+xj78PoQ+ij68Phw90D28PSA80DyQPGw8GDvgO7A7oDuoO7A7gDvgO/A7qDuoO6g73DwcPEQ89D0QPbA93D6JPwW/qL/bgHUAoQD8ATABcAH4AiACsALgAxADYANcA4wDiAOMA6QDkAOsA2gDdAN8A2gDSANwAygC/AJcAngCCAIKAe4BoAG+AWABIgEoAS0A3ACCAIYASAAAQD8AJwD/AIMA9QCaAKkANz/CAA0AYEAXgF0ATACSAIQAowCoAKmAScAzv6c/Yj8mPuo+6D6yPqY+Sj50PbA9YD00PLg8SDwgO8g7oDtQO1A7eDtYO0g7iDuoO3g7EDtQO4A77DwkPKw9BD2APio+iT9jP4zAFgCtAPwA6gEoAb4B9AJgAvgDIAOQA6wDlAPIA8AD9AOMA8gDyAOYA5wDoAOUA7wDUANwAtACnAJkAjgB+AGeAZoBsgF+ARoBGgERAPMAgQBowAwAM8AxAKEAnwDUAMQAkwBtQA2AaUAhgBqATACEALGAVQCOAM4A6YBLgFOAKL+0Pw0/ED8OPu4+tD5aPlA9+D1YPRw81DyMPDg72DuYO3A7IDsQO1A7SDtoO2g7eDsAO2A7SDvAPDQ8fDz4PUY+Nj5nPz2/q8APAKMA7AEAAUIB3AIoAoQDFAN0A7wDgAP8A7gD6APoA+AD1AP8A5QDpAOgA5wDqAN0AxQDKAKQAmIB0AI2AYIBlgFqASABKgDCASkAnACMAHkAGoAewBIAXAC4AK0ArQCugHrAK4AAgGmAXwBQAF4ApgCDAM0AtgCaAIiAff/ff+g/WD8uPtg+xj7UPlA+ID3oPUA9IDykPGw8KDu4O2A7SDsoOuA6+DswOwA7GDsAO2A7IDsQO0g70DxMPKA9ZD3QPrA+2j+9gD8ARwDOATQBXAGYAgQCrAMEA6wDgAQQBDQD/AP0A9AEJAPsA7wDpAOwA5wDvAOwA5wDfAL0AqQCTAI0AaABtAFeAXIBKgEUAQQBMQDeANIAjwBYAF+ARAChAKAA6wDRAMAA/wCrAKuAYgC4AIIA/AC6ALUA/QCNANEAogC8QB+/8j+sP0w/Jj6wPrw+cD4oPYw9qD0wPIg8WDwwO/g7aDs4OvA6wDr4OrA62DsoOyg7ADtAO0g7eDt4O9g8uD0MPdg+uz8dP6WALwCsAPIBHgFKAcQCQAKUAxADgAQoBDAEEARIBGAEGAQQBCQD/AO0A5QD1AP4A4AD3AOwAwQC4AJYAggB2AG0AWwBdAEOAQ4BEgEUAPEAngC5gFiAQQB5gFYArQCjANsA2ADuAKcAowCqAK8AhwDaANkA3gDWAN4A9ACXAKiAdMALv+M/Zj8uPvo+vD5UPnA9yD2IPQQ8+DxUPAg70DuIO4A7ADrYOsA62DrwOug62DsQOwg7IDtgO0A75DwUPPA9uj44PtQ/pEA8gFwA6AEWAXQBoAIQArwCzANcA8AEGARYBGAEeAQABDgD/AOkA6ADYAO4A6wDqANoA1wDJAK8AjgB3gHkAUYBbgEUAQYBHgDoAP8A6gCKAJSAVwBQAEEAWAC7AIcA3ADjAN8AwQDXAIwAwgD0AI4A3gDQAP4AiADBAPkApABjgBq/wL+DPxQ+7D6CPqw+GD3MPZw9KDygPHA8ODuAO5A7MDrIOsg6iDqoOog6+DqYOsA66Ds4Ovg7UDu4O/Q8VDz4PdA+4D+1v8kAsgCyASYBGgGUAgQCuALUA0ADwAQ4BCgEYASABKAEEAPMA+ADtANkA2QDgAPEA4wDfAM0ApgCagHOAdABmAExAPcA4QD+ALsAkADQAMIAiwB6QB9AGoACAEYAtQCDANEA8wDCAT4AmwDwANcAwwDhAO0A7gDfAOwAwgEnANoAnIBSQBs/uz82Psw+wj68PiQ90D2sPQw8wDy0PBg7yDuwOyg62DrwOpA64DqAOsg62DrgOsg7GDtYO4A70DwwPJQ9HD34Ppt/8ABTALoA+AEGAZAB1AIUAtwDEAOUA9AEWARwBHgEoASgBGwD/AOcA4wDoANMA5wDvANQA3wC7AKoAgIB0AGOAXwA6ACaAI0AhACJAIAAvIBogGeAOD/Qv/8/sr/3wB+AeYB3AIYAyQDTAO4A3gDSAPkAkADRAPkApgDQASwBPwD0AIMAkMAvP5I/WT8cPv4+RD54PdQ9qD0wPOA8lDxQO/A7YDsIOug6oDqoOpg6oDqoOoA6+DqoOtg7KDtAO5g79DwIPOg9Zj5zP3VAMwCOASYBhAGUAeACGAK0AwAD4AQgBKAEkATQBTgFEATABIAEQAQoA6gDXAOwA7wDvANMA2AC6AJAAhIBmgFlAPGAbYBRAE0AfAASAGkATgB+v+J/5z+Tv7+/nH/dADHABAC8AKIA7ADkANIBNQD7ALgAtwC2AK0A3gEQAWwBMgDUAO8AeoAAv+4/aD8YPs4+gD50PfA9tD1cPQg83DwQO+g7cDsAOxA6wDroOog6yDrYOsg60Ds4OxA7QDuwO7g8FDyUPSQ92j6BP7DAPADiAaYB+AHgAkQCtALMA0gEKATwBLAFMAUIBXAFGAUwBPAEWAQQA+wDgAOIA5gDpAO4AxAC6AJkAdgBQAERAPcAUcABAChAJMA8f8xAJYAEAA0/sD9lP0I/hL+3v6yAPIBJAKgAigE2AP0A5gD5AN0A7ACeAO0A8AEkAQIBQgF8AO4AmQBrwBS/qj8SPuA+tD4UPfw9lD20PTQ8mDxAPAA7mDs4Otg64Dq4Olg6uDqoOrg6iDsoOyA7MDswO6g72DwMPPQ9Tj52PrG/lwDaAagBxAJUAuACzALsA0QD6ASwBOgFcAVoBWgFcAVIBUAFKASgBCgDyANwA0ADXANUAwgDEALuAewBRwDoALSAG3/Uf+O/kD+8P3Q/vj+3v4s/jr+OP0g/FT8WP2U/nf/ZwDoAYACWAJoA6QDnAPoAsACtAK4AvwCcAMIBAgEhANUAzACswC8/0D+JPxo+tD4gPjw9mD2cPVw9NDysPCA7+DtgOwg68Dq4Org6YDqwOpA6+DrAOzg7MDsoO2g7iDwAPKg85D28PkQ+4j+pAEYBXgHsAngDMAN8AwQDoAQ4BFgEgAUgBegFsAVABVAFaAVIBMAE8AQQA9QDDAMcAwADAAL4AnACVgGEASWAZUAov+S/jz+jP3Q/Gz80P3g/Qr+QP34/AD9EPyk/Kj9/P4uAGcAAAIoArgC6APQBFgE9AMgBIwD7ANgAyAEaARoBEADEAN4AgIBk/+m/mj9KPso+XD3oPaw9TD0UPNA8gDx4O6g7YDswOsg6+DqAOtA6qDqIOvA6+DrQO0g7iDvQO+w8CDzUPSw9hj5PPwg/i0A2APABwAKMAwwDqAQABCwDyARIBOAE8AUYBYgGGAWIBUAFiAVQBMAESAQcA6wDPAJEApgCvAI0AhABhgFZAG4/63/yv5A/dD7CPyI+9j70PoI/Tz8sPzY/GT8IP3g+0j+mP4wAG4ACgEgAiwD8AP8AxAFeAT4BKAEMATQA1QDtAPEAxwDZAKQAegAvf/o/aD8APsQ+bD3kPXQ9HDzcPJA8WDwQO/A7aDsAOzA62DrYOsA60DrYOtA7MDswO1g7zDwQPFA8gD08PWg9sD5JPwM//8AyAPQBsAK0AzgDqARQBKAEWARYBKgEsAT4BTgFwAY4BZAFWAUgBMAEaAPcA7gDMAJEAnQCJAIeAeYBygGoANCAaD+PP58/FT8APz4+8j7kPvY/Nj9+P2I/cz96P0E/pT9KP82ADwBtAJQA6AEYARgBeAFIAYQBhgFAAVIBPADzAP8AwgEcAP0AhwCygD+/lT90Ptg+nD4oPZQ9SD04PIA8oDxgPBg7+DtIO0g7IDroOvg6yDsAOzA7GDtAO7g7jDwgPFQ8vDyYPQQ9mD3QPkU/N7+8AB8A7AGwAmQC9ANgBAgEgASIBFgEqAS4BKAE6AWQBjgFSAVIBUgEyAQUA+gDhAOoArQB7AIgAdYB+gF+AVABMwAXP+C/nz9aPvY+7j8BPxg+6D7yPzY/VT9Ov4O/tz9cP3u/iwAwACUAVwCcARgBEgFeAUIBkAGMAZwBdgEWATMA2AEsAOEA7ACKAIeAQ4ATP7k/ED7CPog+GD2MPXw8wDzIPJw8SDwgO9g7uDtAO2g7ODrIOzA7ADtoO0g7mDvEPBA8TDy8PJQ9PD10PZo+Aj6lPwc/joA/AIQBtAHUAqADWAPoBDAECASABKAEEAQwBLAEyATQBQAFIAUIBAwDyAOAA5wCzAIsAjoBigF9ANABjAFQANVABAA4v5I/AD7oPvg+zD70Ptk/ED9dPxk/cb+xv74/XT+vv+MAOwAuAHkAjgEiASYBRAGCAbABeAF8AWQBYAECARABIgDAANUAhACEAHx/5r+SP3Y+4j6aPng92D2wPRw8/DyEPIg8WDwAPBg74Du4O1g7SDtQO2g7UDu4O5A7zDwIPEQ8pDy0PMg9QD2IPdg+Lj5EPtA/dT/7AG8A5gGAAlgC7AMAA+AEMAQwA/wD+AQYBBAEIASQBTAEgARoBBgEMANUAvgCwALUAioBYgE6AWgBOgDZAOEA70Alv4o/uj8UPyQ+0z8DP3g/AD9AP6c/i//zP8SAFIARwAcARgCtAIoA1AEwAWgBcgFQAZoBhgG6AVQBsgF2ARQBDgE+APoAogCJALHADr/Yv74/ZT8YPuQ+pj5sPfg9fD0cPRA83Dy8PGA8bDwIPDg76DvgO+A7+DvwO/g74DwUPHA8bDy0PPw9KD1MPaA96j4cPmI+oj8Kv4fANgBUAQwBjAJUAsADjAPYBCgENAPsA6wDoAP4A9gEUARABNgEcAOMA5ADlAMUArACNAH2AUwBJADeARYBFgDxALlAE7/7P3I/Sz9ePyI/AT9iP2s/Fz+Kf8W/7f/SQAeATcAQwCEAQgDDAMgA2gEYAWgBRAFkAX4BYgF2ASwBCgE8AKEAv4BDAJKARgAW/9e/lj9WPx4+6D6wPmA+KD3UPYw9TD0oPMg85DycPEg8eDwgPBA8MDv0PDw8EDxUPHw8YDykPJw80D0MPVQ9cD2OPgg+Zj5uPqg/Hj9Ov5nACwC2ANgBaAIEAvgDKANkA+wD8AOcA3wDeAPYA7QD2AQ4BCQDxAO4A1wDKALEAqQCIAG+ARABIAEaATIA2wDiAKZAOT+OP7Y/cz8bPzE/Pz8UPzo/Dz+aP+B/2D/e/9t/0z/kP+gAJ4BFAIAA8gDwAPAAygEaAQ4BNgD7AOQA/gCpAJ4AmgCygHtAAwAPv8A/uj8IPxg+9j6sPmw+PD3oPfw9pD10PQw9MDzkPLw8QDywPHQ8cDxIPLg8TDyYPIA8wDzQPMw9JD08PRA9SD38Pdg+Mj5aPtY/DT8+Pwn/7X/3QC+AXgFMAfwCPAKsA3wDcANwA0gDnANgAvwDaAOUA8QDhAP8A5ADcAMMAzwCxAJuAYABnAFIAQsA4gE2ASwA3wCZgGhAD7/ov4a/vD9RP1Y/Xr+6P6l/3sA8QD1AJsAAAE4Ae0A7ADYAZgChAK8AqgDGAQ4BKgDZAOsAxgDkAJUAlwCSAIgAZUA6f+2/7D+SP0Y/QT9FPxI+pD5qPnQ+DD34PYA90D28PSg9HD00PNQ8xDzwPOA89DygPPQ8+DzwPPA9CD14PRw9XD2EPfg9sD3UPko+rD5GPuI/Aj9TP3k/R4A1AD+ATgEmAfgCOAJ8AtQDqANwAugDMAMwAyADKANMA8gDmAN4A3gDSAMYApACsAJ4AcYBcAEsARYBJgDfAPoAxACwQCG/0z/1v7o/Yj9vP0C/jD91P24/kAAZgBqAJMAjABxAHIAEAHaAWwC9AJwA4wDlAOkA7QDUANUArQCnAIsAuQBYAKQAqABgwAEAL//zP1c/DT8YPww+yj62Plg+lj5oPfQ94D34PZQ9RD1UPVQ9cD0APUw9ZD14PQQ9bD1IPbQ9ZD28Pag9xD30Pbg92j4oPho+UD7KPx4/Fz8mP3w/Uj97P3E/2gCHAIoA4AGUAlACgALUAyQDJALkAowDEALUAuwC6AMIA2QCzAMMAwQC4AJoAhoBxAFFAOUA1gE+AJkAugCEAOYAU8AfgCPAPj+UP4k/hr+rP3Y/br/IgHRAHYB4gE4AkQBKgHUAeYB7gFkAkgDxAOoA6wDGASUA6wCHALOAUgBlwCiALAAkQD1/xkA4/+m/qD9nPxQ/Aj7CPpg+Yj5ePng+Nj4CPmo+KD3UPcA9+D2IPYg9kD2sPag9vD2oPfg9+D30PdA+Bj4IPiA+ED5EPmY+Pj4uPlY+uD6jPyc/WT9OPyU/Kj9uP2A/Wz/lAGYAjADsAQYB+AHcAgACYAJQAn4B3AI0AjwCDAJwAlQCiAKkAmgCcAIeAc4BtAFyATYA1QDlAPAAzADGAP8AqwCkAHnAI8A9/8i/3L+/v4w/3H/hP9mAPgAHgEGASgBjgFKAfQAKAEEAiQCLAJwAggDAAN8AiwCQAK0AfoAfABFAN7/jv97/73/cf82/8r+NP6k/az8WPwE/Ij78Prw+jD78PrI+rD62PpQ+uj5kPno+cD5mPkI+nD6+PqY+sD6yPr4+rj60Pqw+rD6ePoQ+vD52PlQ+jD7APwo/Az8nPwg/Oj70PuE/GD94PxU/Yr+3f/MAOwBTAOoBAAFEAVoBQAGKAZIBsAGgAcgCDAIoAjgCPAIAAlQCMAHQAfIBjgG+AW4BdAF2AVYBWAFMAWwBPgDaAPoAngC5AG4AdoBzgHmAQgCHALKAdQB6AG+AXABXgF2AbQBYgHsARgCgAJQAjAC/gHCAUQBGgFuAfgAywDAANIAewAuAPf/vv8m/2L+Hv6c/Qz9hPwc/PD7iPsA+8j6mPo4+sj5WPlQ+UD5IPkQ+Rj5YPlQ+Rj5QPkg+Rj58PiY+RD6ePoI+0D7+Pp4+oj6yPoo+xD7+PvY/JT8nPxE/fj9UP7I/Rz+OP9M/xX/FgB+AWwCfAK8A9gEkAUQBcgFkAb4BpgGiAagB6gHUAcwB+gHIAiAB0gHMAcIBzAGoAVoBSgFUAQQBFAEMAS4A1wDlAMsA8ACoAJoAoYBIAFUAUoB7wCmAIgBrgFSAQ4BlAGmAQABywD+AFwBfwD0/1QAlwBMAMP/3//9/2f/7P6i/pj+Xv6g/bT9jP2U/YD9WP18/SD96Pyk/Iz8wPu4+8D7sPtI+yj70Pvw+6D7aPvo++j7OPuo+kj7uPtI+wj7qPtc/AT80PvI+5j8+PvQ+wT8FPwA/Ij76Pt8/Az9PP2w/S7+1v6U/hz/7P4T/+7+nf8GAF8ALgEYAlQDTAP8A/AEkAXoBMAESAUoBcAEwATIBUAGuAW4BRAGQAbIBCgEeAT8A9ACQALQAhQDmALIAqAD5AMQA7gC5AJwAoABJgFOAUwB/AAWAdABLAIEAoAC1AL4ApQCvALoAsgCdALgAiwDaAPoAvQCGANoAsQBSgFAAagA4f96/4f/Wf+y/t7+2P7Y/hb+sP2I/eD8PPyA+1j7yPpA+mj5CPmI+FD4wPfA9yD4aPhw+PD34Pg4+TD5wPc4+PD38PYw9iD2cPjA+AD5gPk4+tj4gPfg92j40Pgo+ID4QPnI+bD6MPx8/Rz/HAAiASYBLgF8AiAEIAXABTgHIAlgCaAJ8ApQDHAMkAtwC+ALIAvACVAJkAmQCeAIcAhQCNgH+AYgBmgFgASIA8QCBAJIAdwAEAFYAU4BfAHeAfQBXgH9ACYBFgHGAIUAEgFgAWABYAHWAWQCCAKUATYBxgAAAEH/7P5+/iz+6P3U/WT98Pyk/ET8kPuY+gj6qPkY+Zj4uPgI+Sj5IPlw+Qj6SPpo+pj6GPtY+4D7+PvY/IT9Mv7y/tL/oQAaAX4BDAJsApACqAL4AlgDmAPwA3AEyAT4BAAFOAUABcAEaARIBLwDdANIA3gDjAMIAzADLAMYA5QCHAIMAugBTgHtAAoBHAHTAKYA4gBUASYBrwB5AMUAjABEAAAATAB1ADMA/v8yAHgAfQA1ABQAPwDi/4D/Pv9s/5P/e/9e/6L/i/9I/yr/Lv8y/wX/0P66/rb+tv6+/tr+yv6+/tj+3P62/pb+1P7G/tD+pv7w/gD/AP8c/0f/Z/9Q/zf/N/86/xD/9P4t/1H/M/8r/zz/Tv9H/1b/Zf9y/1T/Nv85/1L/Nf9I/z3/Pf84/yX/I/8B/xD/AP/q/vL+0P6+/qb+gP6G/pj+fv6m/rT+jP6C/oD+ov58/nb+mv7O/uj+/v41/3j/hv+Q/8P/CgAlAAsAMgBrAKEApADPABYBRgFsAVYBhAGkAagBtAG6AbQBnAGsAboB2AH2Af4B3AHGAbwBtAG6AZABmgGSAXgBUgFMAVgBQAE2ARIB9ADKALUAkQBfAEgASAAlAN7/uf+g/3X/Lf8S/xn/C//k/t7+7P7k/rz+rv62/rr+lP6E/qz+wv7I/sD+4P7g/uL+uP6w/sz+0P7y/v7+NP80/0L/Tf9D/3v/m/+o/6L/tv/n//T/0/8NAEEAVABoAHoApwDPANgA3wAQARYBNAFKAXQBrAHQAQgCCAI8AkACOAIcAhwCIAIcAgwCGAIkAiQCSAJkAoACdAJQAkgCOAL2AdoB0gHCAaIBkAGEAYoBUgFGASAB+gCcAEAAIQDv/+b/kf+S/2j/V/9E/xH/Bf/U/q7+Yv4m/hL+FP7w/ej93P38/fD9vP3A/dz9zP2o/aD9nP2Y/Xz9kP2g/bj94P0O/iT+PP5E/lb+Xv6C/rb+6P4K/xL/Uv9h/4b/rf/X/xYAFgA/AFEAigCvAMoA7wAUATIBRgFQAYoBtgG6AcwB2gEMAhgCHAIwAlwCWAJEAkgCdAJ8AkwCUAJMAjgCDALkAeoB1gGwAYgBgAFuAUwBMgEqAf0AwwCeAJQAYwBVAFQAKAD8/9H/wP+h/1f/LP8C/+L+sv6W/or+av5S/ir+Dv7o/cj9xP28/aD9lP2Q/Xz9eP14/Zz9sP2k/bT9tP20/aT9xP3g/Qr+Fv46/nD+jP6u/sD++P4S/zX/Vf9k/4D/pv/g/xIALwA1AGgAegCQAKUA1gD5AAQBEAEeAT4BRgFQAXQBigGCAXoBhgGYAawBrgHOAdwBwgHCAcwB3AHkAdQB1AHOAbwBrgGuAaABhAF0AWYBXgEkAQ4B8QDNAIUAcAByAFgAHgD///L/zf+X/23/d/9W/wj/1P7I/rj+kv58/nb+iP5o/mD+XP5G/hb+AP7o/dz9xP3Q/eT9EP4A/ij+Nv44/kr+Xv5o/lr+aP6G/rT+0P7q/ib/Qf9e/2b/lf+q/8v/6P8VAC8AVACEAKsAzgDnABIBLgE2AUwBWgGAAWgBagGKAZABlgGmAdoB4AHYAdAB7AHyAeoB4gHqAdABuAG6AbwBvgGyAagBmgFuATgBLgEoAfgA3QDYAMgAoABtAGgAcgBTACIAIwAiAOX/rv+W/57/bP87/y3/N/8c//j+6P78/vb+0P64/qb+hv5y/nj+gP6A/nb+dv56/oL+gP6K/qL+mP6K/or+jv6e/rL+yP7o/vr+CP8i/z//Qv9Y/1X/Z/+F/6P/rP+2/8j/4v8IAAkAGAA0AEoAOwA3AE8AZQBlAHAAlACsAKkApADMAOQA3ADTAOgA8QDeANgA6AD0AO8A9gD6APcA7wDxAPQA3gDEAL8AtQCNAHsAjgCFAGkASABRAGYARgAuADAAKQD6/93/6P/z/97/zv/g/+P/yP+i/6L/o/+T/4L/l/+d/5z/nf+z/87/uP+z/8H/0P++/7T/v//P/8n/xf/T/+b/6v/n/+//8f/w/+v/6f/r/+f/9v8DAAIAGAAZAA4ADQAEAAwA7v/Y/9X/2v/Z/9z/6f/3//X/7f8CABYAEQAOABgAJgAiABAAJgA3ADwAOgA3AEIANwAwAD4AQQBAADYAPQBCADwARABHAFUAUQA4AEAAOgAqAB0AHgAtAC0ALQA/AEUAQwA8ACsALwAUAAwAEQAUAA4AEgAsADoAPwAqADIAIQALABQAGQAtACIAJgAyADQANwA/AEsATAAvACEAHAAaABAAEwAnACoAJgAqACMAHgASABAAEgAHAPb/7v/p//L/8v/t/+z/6P/1/+T/3//a/93/yv+6/6b/nv+U/3j/h/+Y/5P/h/95/4f/iv98/3z/g/+N/4T/g/+i/7D/q/+p/7r/yP/B/7z/wf/H/8j/w//B/8n/xP/K/9f/3//q//L//f/4//L/+v/9//r/+f8IABcAIAAlADcARgBEAEMAOAA8AD8APQBIAEwAVQBXAGMAcgB4AH0AiwCLAIAAcgBqAHEAcgB3AHMAaQBoAGcAYQBiAF4AXABPADoAMAAjABsACQABAPv/8f/l/+P/2//R/8D/rv+o/53/nf+T/4z/iv+G/4X/gP9+/3j/b/9k/1z/Vv9X/1T/Uv9Y/1f/Yv9n/2D/ZP9u/3H/cf9t/3z/if+I/5L/n/+v/6r/sP+5/8j/wv/C/77/yv/P/9T/6//n/+7/5P/q/+z/4P/k//X//v/7/wQAFAAeAB8AJgA+AEIAOgAtADsASQBNAEoAUgBdAGQAZQBvAIgAlwCVAI8AngCcAJIAiwCWAKMAoACTAJwAlwCDAHcAdABzAGYAVQBYAF4AVABNAE4ASwBAADIAJgAXAAoABgD7//j/6//l/9f/z//H/77/tf+s/6P/pP+l/53/nf+p/7L/qP+g/6X/qv+l/6H/n/+d/5j/k/+Y/6X/p/+t/7H/tP+4/77/w//D/8v/z//V/97/3//l/+r/6v/1/wIADQAZAB0AGQAeACgALwAtADMAQQBKAFUAXABgAGgAZQBkAGUAaQBuAGkAZgBlAGsAbQBrAG4AcABtAGAAVABUAFIAUgBQAE0ATgBPAE0ASgBRAEwAPQAwACUAHwAYABMAFAAQAAUA/P/1//D/4P/X/8//xP+1/63/qf+e/5L/kP+Q/4f/ef91/3r/d/9s/2n/bf9w/27/aP9u/2z/ZP9i/2z/c/9z/33/jf+T/5H/mf+p/7j/uv+7/8z/2f/i/+7/+v8BAAIA/v8BABEAGwAgAB8AJwAuACsAJgAyADkAPAA/AD4ARwBJAEUAQAA9ADUANwA3ADQAMwA0ADkANgA4ADcANQAtACwALwA8AEIARgBMAFEAVABSAFEASwBBADoAOQAxADAAMwA3ADcAMwAsADEAKwAoACMAIAAUAAUABwAGAA0ABAAIAAgACAAIAP///v/3//b/6//l/+r/8P/x//H/7f/0//H/4//l/+7/7v/t/+7/8f/5//r/AQAHAAkADgAPAA8AEQANABEAEQAbACEAKAAvACwAMAAoACkALAArADMAMQA1ADEANQA3ADQAOAA0ADEALQAkACkALgAvAC0AKAAqACoAIQAYABwAGQANAAMABgAJAAAAAQAAAAgABgD9/wcADwAQAAkABAAIAAYAAQAEAP7/9f/w//H/6v/s//D/5P/d/9T/0v/P/8H/wP/C/8X/wf/E/8n/zP/O/8r/zP/I/8X/yP/O/83/zP/O/8//0v/S/9n/4P/e/97/3v/h/9//5f/r//T/9//6////AgD///n//v///wAAAgD+/wMABAALABEAFAANABEADwAKAAsADQAUABYAFAAPABIAEQAPABEAEwAUABAADwASABkAFwAaABkAEQAQAA8AEgAVAAwACQAFAAMA/v/9//7/+v/3//X/+f/t/+v/5//k/9f/1v/a/9n/1f/P/8//zP/G/7v/v/+8/6z/pP+j/6T/n/+a/5j/of+b/5f/lf+S/43/kP+T/5z/nv+o/7P/xf/B/8v/zP/M/9D/0//a/9v/3//p//b//P8BAA8AFQAZABUAHgAkACoALAAyADMANAA0ADQAOAA5ADgAOAA3ADgANwBAADoAOQA8ADoAOgA+AEUAQwBAADsAQABEAD8APAA/ADcAMQAxADEANQAxACsALAAoACEAJAAoACcAJAAhACEAHgAPAA0AEgASAAgACAANAAYA+//1//r/8//r/+j/7v/t/+T/3v/l/+j/4P/Y/9b/0//T/9X/2P/f/9//4P/k/+r/5v/n/+3/5//i/+D/4P/j/+f/5//s/+7/7//z//f/8//1//H/9f/5//r/+//8//3/AQAJAAcABgAIAAwACAAEAAcADAALAAsAEQAWABQADwAXABsAGAATABgAGAAQAA0ADgAQAA4ACwAHAAQAAQD+/////f/4//f/+P/y//T//v/+//7/+f/+/wwACQACAAMAAgD8//b/+v8CAAIA//8EAAcABQD7//v/AQACAPv//v8CAAMA//8AAAcA/v/5//r//f/4//D/8f/1//T/8P/w//X/9f/w/+7/7v/v/+3/7P/v/+7/9P/5//j/AgACAAAABgAGAA4ACgALABEAGgAgACMAKQAvADEALgAyADcANgA0ADIANwA5ADIAOAA9AEIAQQA+AEEAPwA8ADwAOgA6ADQAMQAuACwALAAqAC8ALwAmACsAKgAoACUAJgAtAC0AKwAvAC4ALAAkABkAGwAQAAsADQAMAAcAAwAHAAcABAD3//j/8v/r/+v/6v/x/+n/5v/n/+T/4v/d/9v/2v/N/8f/xf/G/8H/v//E/8T/wf++/7f/tv+0/7P/tv+1/7P/s/+z/7z/vv/A/8L/w//L/8n/zP/P/9b/2P/b/9z/4v/n/+b/8//8/wAABAADAA0AFQAUABYAGQAhACAAHgAoACsAKAAnAC0AMwAzADEAMAA0ADUALwArAC0AKAAnACcAKAApACYAJQAeABcAFgATABAADQAOABAAEAAOAA8ADwAKAAMA9f/z/+//5f/h/9r/1//P/8v/yv/D/77/u/+0/63/pf+i/6X/p/+p/6f/pv+s/63/rf+w/7L/tP+x/63/rv+t/7D/r/+1/7r/vf/D/8n/zP/Q/9L/1P/a/93/5f/n/+r/8P/0//r//P///wIAAQACAAMABwAMAA4AEgAYABkAIAAiAB8AIgAmACYAJQAhACUAKAAjACYAJwArACUAJQAlACkAJgAlACEAJgAnACcALgAnACoAIAAhACAAGQAbACAAIQAeACAAIwAiAB8AHgAjAB0AFwAQABUAFgAUABIADwAPAA0ACgAHAAkABgD+//P/9P/t/+b/4f/j/+b/5f/f/+b/5f/g/+D/4v/m/+f/5P/r//L/8v/z//b/+f/4//X/8v/x//P/9//3//3//v8CAAEABgAIAAgACgAKAAoADwAQAA4AEAAVABcAEAANABEAEgAPAA0ADAANAAsACgAOABMAEwAUABMAEwAUABUAFQATABUAEgASABMADwAPAA4ADAAQABIAEwAVABEACgAJAAkABgAAAAAAAQD//wEA///8//z/9v/z/+//7f/s/+f/4//h/+X/5f/i/+L/4P/e/9b/0v/U/9P/1f/W/9b/3P/f/+H/4v/o/+X/3//b/9j/2P/X/9n/3P/d/9z/2//e/+D/3//i/+T/6P/p/+//9f/5//3/AwAKAA0ADQARABkAHQAdAB8AJAAqACwAKQAtAC0AKgAqADAANgA2ADwAQgBBADwAPABBAEEAOQAyADUANQA0ADUANAAzAC0AJAAiACgAKAAkAB0AHAAbABMADgATABEADgAJAAQABgABAPr/9f/x/+z/7//x//H/8v/z//T/8f/v/+j/4f/X/9L/z//T/9L/0f/R/9D/z//K/8X/v/+4/7T/sv+v/7X/uf++/8D/v/+8/8D/u/+5/7f/tv+z/7D/uv/E/9T/2P/l/+7/9v/9//3/AgABAAQA//8AAAgADgAQABAADgASAA0ABAAJAA4ADgAQABMAGAAhACYAKwAtACsAKQAjAB0AGgAVABMADwARABEAEgARAAwADQAEAAUABgAGAAwACQAKAAUABwAFAP/////5//T/7v/o/+//8v/x/+//7P/u/+3/6v/p//H/8v/s/+v/9P/6//f/+f/3//v/9f/u//j//v8AAPn/9//9//z/+v/+//r/9f/0//j/+/8HAA0ABwAGAAEAAgABAPr//f///wIAAgAJABAAFQAaABYAFwAUABQAGQAfACIAJAApACsAMAAvADEALwAkABwAFAATABIAFgAZAB8AIQAiACMAJAAgABgAGAAWABsAHwAfACcAKgAvADAALgAlACMAGgASABIAFQAdAB8AHgAZABsAGQAWABcAFQATAAoACAAMABQAEgARAAoA/v/6//b/9//3/+3/5v/i/+X/6P/t//D/8P/v/+z/7v/p/+7/7f/q/+L/6f/1//3/AwAFAAkACAAEAAEACgAJAPz/+v8AAAsAEwAaACIAKwAjABsAFgATABAAEQASABsAIAArADYARQA7ADkAKAAcABgAFQAWABMAFQAaACAAIgAjACcAHQAOAP3/+v/5//v/+v/4//H/7f/o/+b/6v/o/+H/2v/V/9f/2//o/+L/3//b/9P/0//W/9r/1P/L/7//wv/G/8j/yf/J/77/uP+4/7r/xP/F/7//vP+6/7v/xP/M/8v/xf+8/7f/t/+z/77/y//O/8v/0//f/+D/3f/a/9//3P/e/+r///8OABQAGgArADUAMwAuACwAKgArAC4ANgBFAEkASgBMAE4ARwBCAD8AMwAqACcAKgA3AEMASQBRAFQAUgBRAE4ARQBAADIALwAuACoAKAAoACcAJwAmAB4AGwAdAB0AFwATABYAGgAYABgAGQAUAAYA9//0/+//5f/Z/9X/zv/D/8L/xv/Q/9b/1v/V/9v/4//p/+//7v/o/+D/2f/U/9z/5f/g/9n/zv/Q/9n/0v/N/8v/xv/B/8P/1P/p//P/8//z/+//6f/e/97/4//h/9f/2v/i/+3/8v/2//v/8P/s/+//+P/9//7/BQANABMAFAAXABsAFAAFAPn/9v/5//r//f8FAA0AGQAhACcANAAuACYAJAAdAB8AFAARABMAEwAOAAcAAwD9//P/5v/k/+X/4v/i/+X/7//1//T//P8CAAQA/v/0//D/6f/j/+D/2//c/9r/3P/i/+z/+P/8/wUABQD//wYABgAIAAkADgAWABYAFAASAAYA9v/e/8j/xf++/8T/0f/b/+P/7f/7/wAA/v/v/+j/3P/Z/+T/7v////z/+v/5//P/8v/s/+f/4f/U/9b/4f/z//7/CAASAA4ACgAFAAEABQAHAAwAEgAUABUAFQAWAB0AGQAVABQAFAAeABwAJAAqADAALQAqACQAJQAkAB8ALQAxAC4AKgAkAC0AMAAmABwAEQAOAAMA/v8JAAsACAAIABQAIAAhABwAEgANAAQA9f/w//f/+v///wYAEAAZABoAFAADAPP/7P/n/+v/9v8FABEAGAAdACQAIgAWAAAA5f/c/9j/2P/i/+n/8f/v/+//9P/z//T/8v/o/9//3P/k//j/CAARAA4ACgAOABIAFgAdABoAEwAFAPv///8EAAsACQAKAAoADAAVABwAGgASAAMA9//3//v/BgAHAAgACQAKABAAFAAYABQACAD9//n//v8IAA0AEgAUAA4ADwANAAoADQANAAgAAwABAA4AHAAjACwAKwAoAB4AHgAfACQAHgAWAA0AEwAcACUALgAiAB8ADwAOAA4ADgAdACQAIgAcAB8AJAAjAB8AGwAYAAMA8//r//b/+v/3//D/6//u/+7/7v/w//L/5v/R/8P/xv/D/77/vf/F/9D/0f/L/9D/yf+9/7X/tf/A/8n/zf/d/+v/7//y//P/8//r/9r/zf/M/9j/5//q//D/6//m/9z/2//b/9b/0//Q/9b/5//1////CgARAA4AAwADAA4AFgAVABIADgAMAAkABwAJAAgA/v/3//X/AAAQAB4AJAAlACkAKAAuADQAMAAtACgAJwA0ADwAPQA2AB4ABAD5//X/8f/s/+//+P8EABgAKAAyADIAHwAOAAEA/f/8//P/6//n/+r/6v/p/+n/4P/N/7P/qP+0/8b/3f/t//j/BQAOABUAGwAgAAwA7P/U/8r/0v/c/+b/6P/h/9b/z//T/9//4v/k/+H/5f/w/wUAGAAgAB8AFgAJAAAAAgAOABkAGAAQABAAGgAoADEALwAvACUAHwApAEMAWQBdAFgASAAzACQAIwApACMADQD5//z/CQAcACsAKgAfAA8ABQAVADUARAA5ACAADAABAPj/+f8BAPn/6//f/+D/8v/3/+v/1//H/8P/1//y/wwAHgAgABoADwAFAO//0v+y/5//m/+v/8T/1//f/93/1P/I/8L/vf+5/7n/uv/A/9f/7P/3//L/3f/F/7n/qv+m/6D/l/+L/4b/nP+6/93/6//7/wIACgATABIAGQARAAcA9//5/xEAJgAwAC8AIgAZAAMA8f/5/wEAAAAAAAUAGgA1AEUASQA+ACoAGAAKAAkAEgAXABoAGAAiACoAMAAnABMAAgDr/+z/+f8NACQAIwAcAA8ADgANAAcABAD0/+j/4v/r/wsAHwAeAAsA7//j/97/3//o//f/9f/s//P/DAAhACIAGQABAPL/5f/r/w4AJQAmABAA//8AAAQAAgD9/+f/0//S/+f/CgA2AEQALwAaAAUAAQAAAPz////4//P/9f8JAB8AJQAaAPf/3P/K/8//5f/7/wcADQAWACYAPwBNAFIAQAAcAAIA+P8DAA8AGgAYABcAEQANAAgA/f/p/9D/x//L/+T//P8MACIAKQAsACYAGgAJAAAA7P/l//X/EAAsADMAJwARAAUA+v/5/wIABQAGAAMAEwAyAEsASAAzABIA9//2//3/EQAaAAkA+P/t//b///8DAPz/8f/r/+3///8LABkADADy/93/6v8DABQAGQAQAAYA/P/0/+//8P/X/7P/qv+9/+j/DQAmADMANQAcAAcA/P/3//b/9v/1/wkAIQBAAFEAUAAkAP//0f/E/9f/8P8MABwAMABIAF8AaABmAFkANgAXAAYAFgAvAEEAPAAmAAMA6v/Z/9j/4v/l/9z/2P/g//n/EgAiAAUA6v/T/8r/3//3/wUA9f/a/8P/yv/a/+H/3P/N/7b/tf/G/+D//f/3/97/yP/B/9D/6v/1/+n/yv+m/5P/lf+e/7n/xf/B/8H/1v/t/+z/3v/G/7j/qv+2/9P/9P8CAP3/+v8EAP//5P/K/7j/tf/H/+f/DwA3AEMAQQA9ADoAMQAsAB8ABwD9/wYAHgA+AEwARgA/ADEAKgAsADEALAAsACgAPABTAF0AYABZAE0AQgA1ACYAIwAeABIAAAD//wwAGAAYABcAFAALAAUADAApADoAPAA1ADUAKgAYAA0AAwD8/+3/1//N/9f/5//w/+3/2/++/6j/nv+s/9D/5//j/9//4P/z/wMA7v/X/7v/ov+b/7H/3v8HABUAEAADAPH/5v/j//H//v/7//L//v8SACYAJwAeAAgA4f/W/9//8//7//3/BgARACAAKgA2ADwAJgAFAO//8P/7//v//v8FAA8AIAAnAC4ANQAYAPv/7//s//7/AQAYADQAQwBDADgALAAYAPr/3P/Z/9//5f/v//v/DgANAAEABgAGAAQA9v/t//P/9//4//H/4f/T/7//tP+y/8D/0P/Q/9D/vf+o/6b/mv+h/7T/0f/s//z/EQAfABYA+//R/6v/p/+q/8z/9P8HAAwAEAAQAAIA5v++/6v/nf+0/+T/DgAwACgAHwAVAA8ADwAHAP3/8f/m//T/CAAdACQAJwAhAAgA9//x//r/GAAuADUAKgAWAAsADgAdACoAIwASAAcA//8EAPv/AAAFAAcAAgD//wIAGAAqADIAQAAtABMADAAgAFQAcABqAFMAMgAbAPr/7f/y/+f/5P/6/y8AXgByAGQAPgASAOT/w//L//P/FQAxAEUAWQBkAE0AEwDE/4X/bP9y/5//3v8RACIAHQAaACAAFwD1/8z/tv/J/+j/CAAmAC4AGgDt/9D/0P/Z/+T/2//B/7D/r//B/+L/9P/u/9D/wf/Y/wAAJgA4ACIA9f/E/63/vv/h//z/+v/6/wEAFAA0AEEAOAAUAOz/6f8IADYAVwBQADkAHwAUACIAMwAtAA0A8P/x/wkAIQA2ADsAOwAuAB4AIwAnAC4APQBAADoANQAvADsARwBIAD0AGQAFAPr/BwAJAAoABwAJABsANwBIAD4AHgD0//b/9P///wEABwAoACcAFAABAPL/3f/J/9z/AQAYAP3/4v/n/wMAAgD1//T/AgANAAgAHABGAFMAIQDd/7L/nv+N/6X/6f8sAC4A///Z/9j/zP+9/6n/lv+L/4n/qv/s/xsAHQAEANn/r/+T/4T/m//N//f/CAD+/wIACAASAA0AAwDk/8L/wv/Y//3/FwARAAcABwAFAAEA9v/0/+f/3f/s/wsAJgAuACsALwAtACcAGgATAAoAAwD//wAACwAYADAAMAAmAPr/v/+5/9n/EgBEAEoAOQAnABYAJwBDADMA+P+3/6v/yf8EAD4AWgBRACQA6v/f/+3/8v/U/6j/pP/M/xcAVAB6AG4AGwCx/3T/f/+s/67/pP+i/8X/+P8VACUAJQD3/5z/cP+T/9//GQAxADgAOgAdAP3/8//4/+r/u/+i/7L/3P/+/xkAGQARAAQA7v/r//T//v8BABMAJQBGAFgASQAiAO//3v/w/wcAHgBCAGMAcABrAF8AUgBGADwANgA0ACoAHwAlADMAOAAqABIA+v/t//j/FgBIAGkAUwAjAPn/2f/a/wAAPQBpAE8AOAAlAB8AEQDM/47/WP9R/4D/2v8iAEIANwAUAP7/3P/A/6T/nP+s/8r/6/8WABsAAQDR/6n/mP+Y/67/xP/d/+D/1v/k/wYAEQD8/8//tv/M//r/DAALAOT/qP98/3D/nv/B/9D/w//Q/+P/+v8CAAoAHgARAPP/3P/2/ycAOAA3AC8AIgAPAO3/AwAmACsADgDw//T/CgAjACYAIwAsACUAGQAQACAAJwAWAAcA//8KABcAEwAGAP7/6f/I/9r//P8hADMACQDw//P/DgAXAA4AAQDu/9//4v8DACcACgDr/9///P8lAA0A1f+4/8H/2P/+/yEALAATAN7/yP/R/wMAHQAYAAcA1v++/8r/GQBnAGwAJgDP/6r/2f8tAGkAawA0APT//P9HAHgAYgD9/5z/gf+a/wAAXQB0AFIAGAAAAAYAHwARAOT/l/9Z/3D/zf9UAL8A2QCeAD4A1/+a/6n/uP/G/8//9f9BAKAA2QC/AF8A1f90/0T/V/+Q/9//IgBcAIAAawBPAA4A0f+z/6b/of/D/wkATAB8AHQAQQDy/7D/oP/E//z/EQAQAPj/8f8MAC0ATQA9AB0A/P///xUARwBaADQA9f+o/6//3v8PADQASAAoAPT/yf+8/9b/0P+9/9X/GQBDAD4AMgAeACMADQDx//X/CQANAPf/+/8iAFAAPgAZAAsA///2/+3/EABBAGIARgAzAEwAWQA5APP/wv+w/8b/2v8MACUAFAAHAAgAKQBXAFkAMgAMAOX/1//s//v/GQApADQAJQD9/+D/w/+x/6z/wf++/7n/qv+r/9r/DQAWAPn/AgDx/+P/zf+0/7L/tv+u/5T/mv+k/7P/1v/o/+T/vv+X/6D/yv/u/+7/0v/I//D/JQBBADUAEADk/9n/0//j/wQA8P/e/+D/CwAJAPX/2P/k/w8ADgAUABAAHwAwABkA8v/T/7f/u//j/xEAPgBOAFAAbQCMAIUASQAIAAgAOABgAFwAVwBkAIQAfgBlAD0AFADq/8P/z//s//H/0v/h/wcAUQBAAB4AGAAIAPj/z//F/83/1P/I/9P/AwAoAC8AGgD4/9D/tf+7/+z/JAAzACcAFwAYADAAIgAMAM//hf9i/3z/pP/O/9P/z//P/8L/v/+r/7H/o/+1/9z/GQA2AD4ASgBeAG8AMwDr/7X/sf/L//r/VQCcAJMAOgDm/9v/CwAtACwAMgAxAAsA4P/f/w8ANwA6AA4A///4//j/6f/x/yYAKwAWAAYAMABXAFoAJAAHAPn/7f/J/8H/BwA0ADsALwAsACkAAwDN/7z/yP/C/8r/6P8kADcAIQAkACoAAwCj/1D/Uv95/6n/0/8SADIAKAD2/+P/1v+f/3D/dP/T//3/BwDs/9j/4v/g//r/EwACAMX/k/+W/9D/6//8/wkA+f/s/+H/9v8KABQAFwAOAPf/yP+i/6v/8/9DAG0AhgByAFcAJgDr/8D/s/+9/93/BAAYADAAPwBqAGkATAAUAOD/0P/I/+n//v8DAN3/5P8jAFQAXQAfAPT/6f/r/+v/9/8CAPL/5v/x/xgAPgBbAHUAegBfABoA1f+j/6n/1//t/93/vv/Y/yMAjACfAIEANQDW/5P/hf/A/wgAQQBbAGkAUwA4AAsABAAJAN//tf+X/6//4/8iAGcAagA3AOL/xP/m/w8ACAD4/wAABwAlABsADwDs/7b/nf+i/+7/IwBDAD0AKgABANL/rv+8/+L/9f8SABMAFAAdAC8AOAAXAOr/yf/T//L/8v/F/6//u//T/xsAVQBzAEEA7f/L/+f/LgBdAF0AEQC4/37/pv8ZAGQAWwAaAPP/0P/w/yMAWwBKAO3/s/+1/wgAUgB4AH4AYAAoAPv/CQAbABIAzf+T/4H/of8HAFgAlwCAADYA6/+8/9P/CgAcAPP/4f8MAGIAjwCHAE8A//+8/4r/o//W/wsAFQAaADQAUgBeAD0AIwAcACwADQDs/+7/EQA6ADIALAAlAAEAvv+M/6D/xP/s/+v/AgAeABkA/v/x/xMAEQD0/8X/xf/a//H/7//S/8r/rv+N/47/yf/4/wsAEAAXABoA4v+u/6D/w//h/+r/4//w/+f/wv+7/77/vv+0/6//0f/+/wUA3f/R////NABKAEQAQQAJAOr/3/8PADMAIgACAOz//f8RAC4AMwA0AAkA2f+z/7H/0v/2/yYAQgBVAEsAKAAFAAoAIQAaAPL/zf/Z/wAAKQB/ANEA3gCFAA8A1f/F/8f/zP8AACMAJAAYADgASgApAN3/jP+A/37/m//H/wcAHQAaAAoA+//l/8D/pf+p/8P/zf8FAD0ANwD3/6f/mv/B/97/9P8GABgAAgD6/xEAPQA/AOb/qv+l/8L/2f8BAC8AQQDy/5T/lP/T/wcABAD9//P/9P/z/xsAUwBVACwAGgBJAHcAbwBFADQAIwD//+H/8v84AIMAuwDDAI8AQADh/8f/2f/1/wMA7P/u/xUAVwCKAGsAGgDa/6//kP+g/+//NAA7AAoA3P8PAFIATwAaANX/l/9r/4v/7f9QAFEACgDU/+f/NABGACoA6f+b/2//gv/Q/zEAXwAZAJ//U/9g/53/2P/b/6j/dv98/6H/9v8+AEoADQDG/8D/2/8OABAA3P/G/87/1P/s/wQAMgAkAOj/u//I//b/DwACAP7/CwAJABsAPwBoAFUADgDX/83/6P/2/+v/2v/j//7/KgBIAHgAkACHADwA4v+q/5//n/++/woASQBwAG0AcwBtABsApf9c/2f/lv+l/7r/6f80AHsArgC1AHcABwCJ/1r/aP+M/8z/FABNAHQAdABLAB8A7//M/6T/cv9Z/3r/xf9LAJ4ApwB6ACwA8P/J/9v/5//q/+P/7/8cAD4AQAAcAP3/7//g/+H/6v8GACkANAA/ADAALwAtAAoA4v/K/9P/6v/9/yEAQwA0AP7/0v/H/+L/BwAGAA8AFwAqADgAPgA5ABQA8f/o/wMAIgArAAgA6f/p/+z/5P8FACMAGwDs/+P/BwAYAAYAyf/U/xQAPAA/ADQANAAMANX/rP+t/+b/HAAhAA8A9P/y/wAALABgAHcAVQD8/6n/uf/d//X/+f8WAGAAeAAxAOL/sf+u/6r/pv/a/wUADwAJAAkALwBCADYADwDV/6z/lf+w/w4AWQBoAC8A8P/S//H/KQA+ACcABADq//n/OgBVADcAEQD3//P/DwAsADsAOwAZAOv/2P/s/y4ARwBYADMABQDz/woASwBwAFUA/v++/7v/8/8OAAgAAgAKABoABgD7//T/BwD3/9n/7v8RAPL/y//J/xEAMAAAALf/uf/a/9L/v//l/xYABADF/5n/o/+g/5D/hP+6//T/5//W//L/FgAiAPz/1v/A/6P/jv+f/+z/BgD+/+7/9/8xAEkAHQDf/7T/r//d/+//HwAtADIAFwD3//b/DgALAO//yf+q/3//af+V/xUAjQCcAFIAIQAiADUAQABaAIIAZQAbAPb/GQBVAEQAHQAEAAkA6//v/x4AVQA/APf/y//e/wIAFAAmAC0APwA8AD0ARwAKAJb/Tf9s/7//AgAGAPj/8f/d/9b//v8tAEAAAwCw/7T/8/9EAI8AjwAuAID/B/8r/8D/TQBiABwA1//P//z/HwAOANL/kf+C/8n/IwBxAHEAPgADAOL/2v+8/6H/qf/k/yMANAAlAEgAawBlADoAAQD5//3/EQAzAGYAZQAoAOT/yP/k/wsAEwANACgAJwAPAPn/+f8TABYADAANACAAQABRAFsAWQA+APD/rP+U/7H/5v8MAC4ANQAgAO3/0//Z//D/BwDx/97/6f/+/xMAJwApABcA9P/I/53/lf+l/7X/1v/s/wwADgABAAcADQAAANP/x//c/wQAFAAIAPv/9v/r/8f/0f/w//n/0/+r/7H/yf/Q/8X/5/8RAAIA0P+3/+L/AQD1//T/KQBLACQA/P/w/w4AGQAPAAkAEgAOAPD/9v8WACUAGgAUACkALgDp/5b/lP/P//T/9P/v//z/+v/X/9////8EAMP/cf+k/w4AOgAnABQAKwAkAPL/5v8cAFgAKgDc//X/MQAoAPP/5/8mAFYALgAEAPT/DwADAMr/uf+6/8j/vf/U/ygAiwC4AJYAVQAcAO3/m/99/9P/ZACUAFcAMAA5AFMASAAjABAA6P+a/2X/yP9zAKYAagAfAAYA8//O/8b/4//8/+b/x//g/xEADADi/97/7//p/+T/+v8nADkAEwAVACgACgDF/6P/4f8cABUA+P/9/wgA7v/A/+H/SgCFAGkAJAACAOj/t/+W/6T/2P/+/xQAPQByAH0AIwC+/4z/hv+m/9D/EQBBAEkAQgA+AFgATgALAL//jP+Q/6f/2/8rAG4AhQBoAEMAKgAkABIA8P/T/9f/5P/r//7/GgAaAAQA0P+o/7L/xf/c/wQASwBzAEEA4v+k/7j/8P/9/wQANwB+AHMAOQAdAEEAKADM/5D/vv8BABgANgB9AMEApwA/ANr/y//G/8j/1P/p/wkALQA7AE4AZgBvAEIA3P+N/6v/4f/s//D/GAA9AD0AGgAiAF8AewA6AND/vf+f/3//iP/0/18AdQA+ACgAMQANALb/aP9l/3T/Zf9k/6//+f8oADEAOwA+AAQAo/9p/2//lP+r/7r/4P8pAEIASQA2ABwA9v/E/5n/pP+//9j/5v/u/xEAJQBJAFQAZQBAAAAAsv+E/2//Y/+E/73/9f/x//X/FQA5ADEA/P/l/9P/xf++//b/VgCVAJAAbQBpAF0AKQDh/8j/3v/5/+T/3P/3/yAADwDz/wEANwBqAFgAIgDk/+P/zv/K/+b/CAAOAN//2P8GAFsAWwAhANn/xf/b/+j/DwAjACEA6f/1/0gAewBdAA8Ax/+j/5H/jP+y/7//u/+t/+X/NQBNAA0A2f/8/w8AEwAVAD0ATQAYAMv/wf8TAE8AKADO/6f/wv/2/x4ARABBADUAIgASAC0ARwAWAKr/mf/P/yQAQwA7AE4AWAArANj/tP/U//T/y/+3/9v/QQDAACgBRAHQACAAjv9q/67/EABGAE4AOwATABgAJAAjAAAAvP93/zf/PP+R/xoAiwCoAGkAFADg/9b/9f/1/7f/jf+t/yIAggCIAE4A5v+D/1n/hv/m/zkAMgALAPv/8v/3/wAACgD9/8L/gv9Q/2H/wv8nAEoADwCg/2L/dP+g/+3/JwA4AO3/hv+V//z/TgBBACAACwDr/7f/t//6/y8AAgCw/5z/xv8ZAFEAdwByAC0A1v/P/xAAQQA7AAAA1P/c/wsANQA6ABwA3f+T/4n/0P8BADkATgBIADkAIAAYABsAFgD8/9//vP/F/8b/9P9BAGUANQDq/8D/z/8OADYATgA4ABgA5f/M////SwBkABYAmv9S/2j/tf8aADcAEwDG/5L/uP8TAG4AjwBmACIA+v/z/wcADgALAAsAAADv/+T/EAAsAA8A2//I/9z/BQBDAGIAggBYAP//sf+t/+D/HAAYAP7/4f/H/7//w//x/y8AKQDb/6//yv8mAFYAYwBzAHAANwDF/3r/kf/J//j/EwA9AFIANAD1/8f/yP/m/+P/3//1/woABgDm//P/JgBaAE4A/P++/7b/uf/G/+T/CgAVAAwADgAZADYARgAkABAACQDl/8r/3v8xAHoAlQB0ADoA+P+7/7b/0//z//X/9v8eAGYAegBhADkADgDY/7L/uv/L/+X/EwAyAFAAUAA9AC0AFgDg/57/hf/A/yIAZgBvADMACwAYAD8ANwAAALf/g/+E/9D///8oADUALABFAEMAKAD7/+z/7P/q/+b/9v8EACAAOgBYAGIAHQC3/5f/sv/P/83/0/8HAE8AQwAsACkAFgDt/7P/rv/d//7/+P/x/9j/6f/5/y8APAAKANL/uf/O/8n/xv/v/ycAFgDk/8b/yP/W/8X/z//0/+3/rf9//7z/IgAsAOX/rP+9/wIAEgAUAAsA+v/j/9n/AgBEAFgAJQARABUAJwAYAP7/AAAbAOr/nP+u/wsASgAiAOP/vP+x/3z/kv/5/z4AGQDa/xAAdACqAGUAKQAMAN3/x//x/1MAdwB4AG8AjABxAAQAp/+e/7T/v//z/zcAgwCCAGoAOAD5/7f/lf+k/73/s/+r/9T/BAAnAAcA6//U/8H/wv/v/x8ALwAvABsAMwAnAOb/pf+p//X/RwB5AGcAbQA6ANz/i/90/4T/if+F/6j/FABNAEEAIQAvACEAz/96/3z/rv/O/9v/FwBbAEgAJQBMAJoAkAAkAL3/xP/K/7X/zP8NAGIAdgCGAMsA7gB/AMH/b/+T/9P/3f/8/x0AQAA0AAoANABfAEcAAADE/7X/uv/T/yQAcwB8AD8ACgABAAwA5/+l/43/gv+P/8//NAByAGQALgD///f/+f/v/+j/4f/Q/93/FwBJAC0A6v+j/3n/V/9O/3b/vP/d/7b/ov/k/08AfQBQACsAHQDg/5n/kf/f/xYA8f+x/8X/CAAdAO3/4f8CAAQA1f+0/+H/JAAWAAoAKABdAE0AAADp//X/6/+o/5z/zP8IAPf/5/8WAF4AXAA/AEkAVgA0APr/7v8jAFIAQgAxAEsARgAAALr/tP/o/wUABQDS/7n/uP/b/yAAPQAmAPH/zv/R/9f//P8RAAsAAAAGACEALQATAO7/4P/a/+D/6f8MAC8AOQAZAOz///8qABkA2/+I/33/of/a/yIAbgCJAEIA5//U/+7/8P/V/9H/9P8DAPP/7P8vAHEAXgAoABoAKQAdAPj/+f/3/+D/uv/G////NwBCAEcAXwA3AM3/cf92/7X/3f/O/9f/5f/a/+7/UgC7AMMANwCn/5H/tv+8/7//CgBtAIAAQAARACcAQwAiAN3/of98/2f/b/+7/z4AhgCAAEwARQA+ACAA8/+2/4n/Yv9t/7H/FgBgAGwAVgAxABYAJAA8ADEA9//B/8v/8f8kAFQAeABxACoA/P/1/wIA3P+h/5r/xv/e/8z/y//q/x8AFgD8/xsATQBLAA4A2f/o//7/8/8KAD4AcwAzAOf/5f8sAFsAIgDi/8z/xv+6//X/QABuAD4A8v8GAB8A/v/W/+f/BwDu/+j/GwBaAEMA8//m/xUAEADg/9j/LwBlAEwAWQCnAMEASACw/33/oP/K//b/KgBTAB8Atv+I/9b/IAAmAND/hP99/5r/0P8MAEUAPAAAAKr/kv/K/+3/7P/l//H/+P/Z/9r//P8jAAYAxv+X/6f/8/8OAPz/3f/Z/wEALwAwAAsA4f/P/7T/uf/u/xUABgDR/9T/LQBlAEkA8P+9/7H/qf+d/97/UQCAAHAAPwBJAC4A5P+5/83/BAAQAPP//P9OAIEAkACMAGsANgDw/9b/8v8kAC8ACQD+/xoALwA/ADMABQCp/1D/P/+N/wwASABTAFEAPwAlABoAOgBPAP7/kv9p/7j/FQAVAOP/1P/I/47/gP/A/x8ANQANAO3/DAAiAAwA7f/r/+n/xP+g/6b/z//i/97/uP/D/+7//v/j/7n/tv/a/x8ARwB5AJgAcgAPAL7/5f8rACMA0/+6/+//IgA1ADIAQwBZAEMAJAAvAE8ATQAoAA4ACQAKAAAA7//9/zwAZQBnAEwAIwALAN7/jv+E/9v/UQCGAFgAXABwAG0AQADc/5//X/9N/2//3f8wADwAJwAoAFUARwARAN3/7f8TABUA+P/q/93/0P+1/7D/xf/Y/+D/3v/v/+D/tP+d/67/u/+y/5n/sv8ZAH8AhABMAAIA0f/E/8X/5//r/9z/uv/a/xEAOQAqABMAJAATAOn/uv/K//f/+//q/+P/8f/+//X/KABdAF8AIQDb/8L/0P/q/+f/6P8VAC4AMgAqAEoAZgBcADkACwD+/wMA8//Y/9b/yv+n/7f/4/8cADAA5P+r/6v/1//i/9n/5f/2//n/+/8bAEIAIAABAPv/LABWABAAp/+N/8v/CwAzADkAMgAbAOX/x//R/xgAPAAhAPP/uP+1/9z/NQB3AF8A9P+I/3H/x/83AGMANADk/9H/JACEAHoAGQCg/2X/gP/D/1kAxQC4AGYAIgAgACwAJwDj/5X/PP8J/0r/3f+IAO4A5QCMACEAuv98/37/b/97/6X/AAB2AOoAHAHhAF0Ax/+B/2H/Zv99/8L/GgBxAJ0AfABlACkA8f/N/63/jv+V/8f/BwBFAFIAMADw/8v/3v8IAB0A/f/Z/63/ov/Q/xgAZQBnAE0AKQAlACAANAAtAPD/p/9j/5r/8v8wAEkATQAMALf/ef9v/6D/p/+f/97/TwCAAFYAJwAOACoAFwDv//n/IAApAPj/5/8UAEoAHgDh/+H//f8NAPr/EwBEAGkAQAAxAFwAdQBJAOb/sf+9//n/DQAhABUA/f8IABUAPQB5AIUAUQAMAMz/wf/g/+L///8xAG4AdwBEABcA8P/R/7f/wP+6/7r/mf+R/9f/MABIACQAMwAnABcA6P+2/7f/zP/N/67/wP/b//T/FQAYAAIAxv+S/5n/wf/h/9j/tv+4/wEATgBuAFQAJwD6/+//0v/H/+D/xv+6/8X/AwD8/9r/sv/Q/xgAGgAYAAMAFwAzABoA6v/I/7T/v//t/xIAMwA7ADsAXQB3AGEADADB/9T/GgBAACMAFgA9AIQAfQBJABAA8//P/5b/kv+u/7r/n//L/xYAegBTACIALAAzACIA1/+5/8L/0v/G/9b/FQBEAEwAJQDq/63/lf+v/+z/IgAsACsALwA/AGEATgAoAMv/cP9a/5D/u//a/+H/+v8SAAIA9//f/+r/0P/b/wEAPQBAACgAOABpAIkALwDF/4z/mv+5/+b/UACsAJwAIgDG/+L/OgBcAD8AMwArAPT/s/+n/+f/IQAwAAEA+v8CAAoA6f/d/xgAMQAoAAcAJQBJAE0AAwDZ/9P/2f+4/6n/AABFAFkAQgAvACkADQDn/9n/3v/S/97/BgBCAEoAMQBBAEAA9f93/yr/Sf9z/53/0/83AGkAVwAcABUADwDE/5H/qv8cACQABQDh/+f/CgARADkAXAA6ANf/jP+J/8L/2P/w/xAABgD9//7/IgAsABUAAAD0/97/p/+D/6H/AgBcAH8AlwB4AEsABADA/5r/jf+T/7P/4//3/xgAPACCAHYAOgDx/8H/tP+T/6L/s/+4/4n/ov8VAGwAcgAdAPb//f/2/9v/2f/w/+n/4//7/zUAZgB6AIEAbgA6AN//l/9p/33/vv/k/9v/u//o/0oAvgC4AIAAKADP/4z/df+z/wIAPgBWAGcAVQBBABkAGgAeAOb/s/+Z/7z/7P8cAGUAawA2ANr/y/8DACsACwDq////DgAgAPn/7f/e/7b/of+m/wAAMgBJADsANQAbAPH/xv/O//T/BAAaABAACgARACIAJQD8/9T/xv/k//3/5P+o/5//yf/t/zYAagCDAEQA6P/T//v/OABKADoA6P+S/1z/mv8pAHoAaAAiAAkA5//+/ycAXQA5AL7/ff+M/+7/NQBaAGwAWwAeAOX/8/8DAO//pP95/37/p/8KAFQAmgCNAEwA+/+9/8z/AAAMANX/vv/u/00AdwBxAEcACgDH/4L/kP/C/wAADAATADoAaAB6AEsAKQAiADMAAADJ/8v/BwBIAEAAOQA+ACYA5P+t/8n/8v8PAPD/+P8ZACEACwD+/ycAJwACAMT/xf/i/wAAAgDs//3/9//f/9X/AAAeACIAIAAkACYA5/+v/6T/0v/4/wQA+f8EAPz/2P/a/+f/6P/R/7b/x//o/+b/uv+4//H/IwAvACUAMAD+/+T/3f8WADgAFwDv/9X/5v/z/xAAFwAVANv/p/+I/5P/wv/z/ywARQBSAEYAKgALAA8AHwALANH/pf+1/+H/BABbALcAygBtAPj/0v/R/9P/zf8FACUAGwAFADAAUgAvANX/fv98/3j/kv/B/xMAPABGAEAAOQAkAP3/5v/p//n/8P8eAFEAPwDt/5L/jv++/9j/8P8MACkAFAAPADMAbABmAPX/tf+4/8z/x//g/xcAOQDr/4z/m//o/x0AEQAHAPL/5v/d/xUAYgBlADEAHABMAGoASgAPAPv/5P+4/6P/y/8lAHUArAC1AHoAIwDB/6//xP/U/9r/xv/X/w4AXwCSAGIABgDL/63/i/+P/+b/QgBTAB0A8/87AH8AYwAWANP/ov9y/4r/8/9iAF8ADADd/wgAYgBjAC4A5v+k/4T/k//Z/z8AfQBBAMf/d/9//7L/2f/I/5j/eP+R/73/HAB4AJgAVwD0/9n/7v8bAAwAzf/K/+7/9P/3/wEAPQA2AOz/p/+r/9X/4//U/+H/CwAWACcASQB6AGYADgC+/6H/uP/I/8L/vv/e/xEARwBaAHkAiQB9ACUAu/99/3n/hP+w/xIAZACIAG8AZQBcAAUAgv8t/zb/af97/53/6P9VAK0A4ADiAJoAHACO/1n/af+O/8r/EwBQAHwAgQBbADMAAwDc/6v/bf9I/2X/tP9EAJ8AtQCZAFIADwDV/9n/2v/T/8D/x/8DADMAPgAjABQAEwD8/+3/6v8HACsALwAzACUAJwAiAPj/0f+9/8H/yf/Q//X/JgAsAAoA7P/j/+3//P/l/+X/6f///xEAIAAwACIADQAAABAAHAASAOL/xf/P/9b/zv/0/x8AJAD4//P/HQAsAAcAs/+4//3/JAAjABgAJwATAOn/yf/M//v/HgAWAAYA8//4/wYAMwBrAIcAagAVAMn/3f8AAAwAAgAUAFgAaAAWAMf/qP++/8j/wf/r/wwADgAFAAwAPgBUAD0ACADK/6j/lv+w/woAVgBsADkAAQDr/wkAMwAzAA0A6f/V/+r/LABGACoAAQDi/9v/7f/7//f/7f/N/67/rf/K/xQAOQBcAEQAHAAGABYAUABtAE0A+P+7/7b/6f8JABAAGAAlADIAEwAAAPT/BADz/8//2//5/93/wv/O/yoAVgAoANr/1P/t/93/x//t/xwACgDO/7D/0v/l/+D/2f8NAD8AKgARACIAMQAoAPT/zf+9/6P/lf+s//n/CgD4/+L/6f8fADUADADV/7P/t//y/w0APQBCAD8AHgD5/+7//f/0/9L/qP+H/2D/V/+Q/xsAlwCqAGQANAAxADgAMQAzAEgAIgDc/8f/+/9EADkAGQAAAPn/xv+7/+f/KgAmAPL/2P/0/xkAIwAtAC4ANQAqACsAPgANAKP/Y/+K/+D/HgAaAA8AGQAXABwAQwBhAFwADwC4/7f/5/8cAFMAWQATAIf/Jv9Q/9j/TwBXABwA6f/p/xMANQArAPL/rP+N/8P/EABVAFcAMwAKAPD/4//F/6z/tf/v/ywAPQArAEkAZgBhADYA9P/W/7z/tv/O/wgAGwD4/83/x//x/yAALgArAEEANgAXAAMACwArAC4AHAAQABQAJwAwADcANgAhANz/o/+U/7j/8P8SACwALgAbAO7/1f/Y/+v////m/9D/3v/6/xsANQA6AC0AEgDy/9L/1P/r//r/DgAQAB4AFAD6//H/6//c/67/nf+v/93/+//9//z/AwAAAN7/3//7/woA8f/N/9P/6P/r/97/+/8iABAA2/++/+f/CAD9//z/MQBXADMADAD//xoAGwADAPL/8v/m/7//w//q/wUABQAGACcAQQARAMr/x//+/xoAEAAJAB0AJQADAP//FgAbAOL/kv+4/xAAMAAcAAwAJwAkAPL/3v8HADYACQDE/9//HgAfAPn/8v8lAEMAEADj/9T/8P/y/9X/2P/d/+b/0//f/x8AbgCOAGcAKwD9/+D/ov+J/9H/SwB0AD8AJAA1AEsAMQD9/+b/xP+D/1f/sP9MAH8AUQAaABMACgDg/9L/6f/9/+f/zP/o/xgAGAD1//P/AgD3/+j/9v8gADUAEwASACEAAwDF/6T/2f8MAAEA5P/r//3/8//U/+//OgBWAC8A9f/m/+H/xP+y/8D/6f/+/wsALwBeAGoAIQDX/7b/sf/F/97/EQA3ADwAOQA6AFEAQwAEAMD/jv+M/53/xf8HAEMAZABdAE0APgA6ACwADQDs/9//2//U/93/+v8LABEA9//a/97/4//r////LABIACUA5f/E/+P/HAAlAB4AMQBVAD4ACQDx/w4A/v+8/5H/uv/z/wwAKgBgAI4AcgAeAM//xP/A/8r/2//s/wIAIgA1AEkAXABeADEA1/+P/6n/5P/+/w0AMwBRAE0AJgAgAEYAUQAPAK//pP+Z/5L/qf8NAGsAegBDACwANAAZAM//j/+P/6X/ov+p/+z/LABSAFEATwBGAAsAtP+H/5P/tv/K/9n//f89AFEAUwA9ABsA6/+1/43/nP+1/8r/3P/w/xgALwBQAF0AawBDAAMAvv+d/5T/kv+0/+b/FQAPAAgAFQAmABcA3v/E/7P/sP+1/+j/OwB3AIIAbwBwAGQANADr/8f/z//k/9r/3P/z/xkADwD+/woALABGACgA9f/E/8z/yP/X//3/HgAjAAAAAgArAGUASwAFAML/r//E/9P//P8YAB0A9P8CAEoAbwBMAAgA1//K/8H/uf/T/97/1//B/9//EAAgAO7/x//r/wEABgAAABMAGwD0/8T/xv8GADQAGQDe/8r/6/8ZADIAPQAeAAEA8P/u/wwAHgD6/7L/t//r/zAARgA2ADYALAAAAMz/xP/m//v/0P+2/8f/DwBvAMMA2wCFAAMAof+f/+f/NQBTAEkANAAYACIAMAAzABgA2/+c/2X/av+r/w8AWwBmADYAAADu//3/KwA2AAEA0v/Z/y0AegCBAE0A8f+f/33/of/o/ycAIgAEAPP/6v/4/w0AHgAZAOv/t/+J/5L/4f85AFkAJAC+/4L/j/+y/+3/FwAiAOr/n/+3/xUAYgBdAEEAKwALANz/1f8GACoA+f+o/4v/pP/i/w8ANAA4AAoAy//N/wsAOgA3AAcA4f/l/wUAJwAzACQA8/+0/6P/1P/0/x4ALQAoABwABgADABEAGQAKAPX/1f/U/9L/9v8zAE4AIQDh/7n/wv/2/xwANAAiAAQA4P/Y/wcAQQBRABUAuP+B/5D/zP8bADEAEQDV/7H/0/8aAGAAeQBVABkA8//v/wMAEAAQAAwAAADw/+b/CwAlABAA5P/I/8v/4v8PACsAUQBBAAYAy//B/+T/EgATAAMA7v/a/9H/1v/8/zAAMwD//+T/7f8jADkAPgBNAFAAKADY/6T/tf/d/wIAFwAuACoAAwDO/7H/t//T/9r/4//6/wkABwD2/wkAMgBTAEUACgDe/93/5P/2/w0AGwAMAPT/7//z/wUAEwACAP7//v/l/9j/6f8fAEkAUwA2AA0A4f+5/73/2P/x/+//7v8JADsASQAvAAgA5P/B/7D/wf/X/+//EgAqAEEAQgAxAB4ABADb/7L/pf/Q/xgATABXACkABAAEABwAHQAAANH/rP+n/9z/AgAmADIAJgAyAC8AHAD+//T/9v/7//f/+/8AABUAKAA+AE8ALQDz/+L/9v8TAB4AIQA2AFwAUAA/AC8ADgDm/7//u//Z/+7/7f/v/97/6v/1/x0AKgAQAPD/4v/2//r/BAApAFQARwAcAPn/7P/x/+f/6P/1/+j/w/+w/+H/KQAyAAAAzP/H/+z/9P/1/+z/3P/J/8T/4/8VACYA/v/s/+v/+//6//P/+v8PAO3/u//L/xIARgAyAAkA5//Y/6n/sf/x/xwA/P/D/9j/FABDACMA///w/9P/yP/n/y8ATgBOADsARwA7APr/uf+q/7z/zv/5/ywAaQB1AGkAQQAUAOj/yP/C/8r/yv/Q//D/GgBHAEAALwATAPv/6v/w//X/8f/r/9j/6//1/+3/4f/1/yoAXgB6AF8ATwAYAM//mf+Q/6X/uf/I/+T/KABCADIADwAHAO3/tP+C/43/vP/h//z/MgBnAFwAOwA/AFkAQADx/6b/p/+u/6P/s//e/xwAMQA8AGUAggBHAND/lP+l/9P/4P/4/xEALwAuABEAKABAADEA///V/9H/3//x/yAAVwBlAEMAGwAPABkADgDn/9j/z//T/+7/GgA1ACgAAgDf/+H/9f/+/wIAAQD8/wwAOQBiAFoAMAD7/9r/xv/C/9f//f8TAP//7v8IADsAVwA6ABkAAwDX/67/rf/f/wMA9P/K/8j/4v/z/+L/4f/y//T/4f/Y//3/LAApAB4AIwA6AC4A///v//X/8f/J/8L/4P8KAAYA8f/2/w8A///n/+3////2/9b/yv/s/xgAIQAcACoAIwD4/83/yP/u/wcAEwD5/+v/4//r/w0AIAAWAPX/3P/f/+b///8JAAMA/f8BABMAGgALAOz/2//W/+j//f8VAB8AFgAAAOP/7/8QABIA9v+7/6b/u//w/zQAbAB7AEMA8//R/9n/6f/u/+z/9P/5//3/BwA5AGgAWQAgAO7/2v/U/9T/9f8OAAkA6v/j////LwBCADkAKwD5/7P/gP+L/8P/9P/+/wgAFwAaACUASgBwAHUALwDY/7X/w//X/+r/EwBEAFMALgD7/+T/5v/f/8n/rP+Y/5n/sv/o/zsAbgBwAEQAKwAdAAsA9//R/7n/of+k/8n/CgA/AFAARQAtABQABQACAPz/6P/H/7v/x//p/xMAOABLADUAGAD6/+//4//U/87/2v/p/+7/+P///xYAGwAMAAUADAARAAwA8v/j/+X/4v/v/wMAJQAaAAEA7f/8/x8AKgAVAPv/6f/P/+b//P8dACMACwAPABkADQD+/wkAGwAaAAoAAQAEAPn/5f/j/wAABADt/9L/8/8uAEYARwBSAGUASwANAOD/5v/7/w4AHwA6AEgAIADh/9b/5f////D/0//S/+P/9f8FACIAKAAXAOj/xv/W//r/FgAjADUANwASAPH/4f/3////8//i/97/+/8TACAAIAAYAAoA+v/p/9P/vv/J/+L/+/8PAA8AAgDx/+j/8//8//f/3P/U/+L/BwAZABwAIQAhACAACwABAO7/1v/N/9L/7f8NABoAFAAWAA4AAAD2/+P/2f/U/+T/AwAbACkAFAAAAAAAAgAFAAgACwD7/+L/2P/1/y4AUABLADMAEgD0/9v/7/8gACoA//+8/6z/3P8TACQAFwD4/73/jv+Y/+D/LQBFACgACQAKABsALgA5ADYAGADo/8L/zP/6/x8ADwDs/9X/1f/O/8j/2//7/w8ABAACABoAMwAoAPv/2//V/8j/uf/G//j/IAAjABUADgAXACIAIwAcABUA/f/k/+//DAAkAB0A/v/g/9//8v8SADEAJQD8/9P/v//K/+f/FABEAE8ATQBIAEMAPgAYAN//q/+f/6v/1v8BACQAPwBHAEkANgAfAPj/3f/Z/+n/BAAcABsAFgANAAcA///1/+v/4P/Y/9T/0v/i/w8AMgA+ADgANgBCAFcATgAyAAAAzv+o/6T/x//j//L/4f/u/wQAGgAUAPL/5P/S/8n/v//d/xcANgAuABoAEAATAAEA8P/+/wgA9//h/9z/9v8OAAcA8v/w/wEAEAAHAPj/9v/z//T/+P8RAB8AFADt/83/1f/k/wEAEwAcABwA/v/n/97/+f8EAPH/3P/N/93//v8mAEsARgAdAO//2v/r//3/+v/w/+n/3f/a//H/FwAkAA0A6//I/8r/4f8HADUAOQAWAOT/1f/v/woACQDz/87/wv/d/w4AOQBUADoAAwDk/9v/6P/x//L/AAADAAwAGwA5AFMAUQAtAOz/u/+p/7r/2v/t/+r/5v/r//7/JQA+AD8AFQDZ/7v/vf/e/wAAJQA6AEQAOgAkABAA/f/s/9z/2v/b/+n/9f8BACAALAAlAAcA4f/I/8r/yf/c/wEAIgAtABYA9f/i/+3/+P////z/5//W/9L/9P8oAEQAKwABAN7/3f/+/xEAFgAJAOj/3v/o/w0AKQAvACIAEwANAAQA+v/e/9D/vv+2/8f/AgA4AEcAOAAdAA4ABQD+//b/9v/k/9D/3f8BACoAOAAsABwADwDx/9z/0v/X/+j/+P8BACAAOABOAEkAMgD6/9r/uv+5/9D/3f/n/+f/8v8JACQAMQA1AC0ADQD2/+z/BQAjADsANwAhAAcA/v8CAA4AHQAXAP//6//q/wMAGgAiAP3/5v/i/+z/CAAaABUA9v/e/93/BQArADQAIQACAOT/5f/6/xQALgAjAAAA6f/p/wMAIgAiAAcA3/+5/6z/v//g/xQAMAArAB0AIgAgAAkA8v/k/+r/5v/s//b/BgALAAMAAgALAPv/0f+1/73/4v8NACUAKwAtAB4ADgAKAA4ABADz/9n/vf+9/9D/5//9/wIA/f8EAA0AGwAjAB0ACwAFAAAAFAAlAB4ADwAEAAQACwAQAAQA/P/q/9L/v//H/+b/AgAOABIAEgALAAIAAgAYACEAEwD5/+r/4v/j//X/CwAcABUA+v/o//b/EwAhABYA+v/f/9n/5f8DACcALAAEAOH/0//q/wMA7//W/8P/u//G/+v/IgBQAFUANgAPAPD/5v/p/wEAEwAPAPj/8f/8/w0ACgD2/9z/vf/A/9v/AgAcACoANAA8AEAAPAA2ACwAEgDx/93/3f/n/+r/7v/5/wQAEQAOAAkAFAAMAAYACQAEAAsABQAVADEAQgA6AB8AAQDo/9P/xf/L/9b/2v/f/+3/DAAmADUARwBHADkAHAAEAAYADwAVABEAAAD3/+7/7f/t/+7/6v/Y/8//xf/E/9//7v8AABEAIwAzADMAKwAZAPf/2P+8/7X/2P/2/xcAJgAiAB0AHwAiAAoA4f+v/6P/sP/h/yAAQQBJACUABwD5//b//v/7//D/4//R/9j/7/8NACAAJgAcAPr/3P/Q/9r/AAAdACcAGQD+//H/9/8IAB0AGAAHAPX/6f/x//D//f8BAPr/3//E/7n/z//4/xgANwAvABIA///6/xIAFwD//+H/yP/P/9j/6v8JABQAEgARABsAIwAcAA0A/v/8//b/5v/k//r/EgArADUAMAAfAP3/1f+w/6X/s//E/9v/9v8WADAAPgBCAD0AIwD3/8//uv/T//r/FgAoACQAHQAQABAAGgAWAAgA6//H/7X/wP/k/w0AHgAVAPn/6P/y/wQAEwAUAPz/2//B/8D/3/8AABcAFAARABEAFgAfAB8ADQDx/9j/1P/p/wEAFQAPAAIA+v/3//n/+//+//r/8//y//r/CgAZABkAFQANAPj/7v/l/+T/9f8AAPv/8//u/wEAFQAbAB0ADgABAPT///8MABcACwD8//P/AwAXAB0AGAD1/+L/xP/E/9P/7P8TACUAHAAHAP////8FAAsACgD//93/zv/e/xUAPABFAC8AFgAJAAkAFAAiACsAGwD4/97/5P/x/wUAGAAqAC0AGQD4/+//6//u//X/+f8AAAUABQARABwAGgAOAP3/7f/k/+T/8f8NADIASgBEADcAHQAKAPn/9f/z/+n/3//V/9X/4//w//j//f////X/6P/w/w4ALAA1ACwAFwAFAPz//P8EAAYA9P/b/8f/xf/T/93/2v/U/9n/4//1/wgAEwAgACoALwA5ADQAGwD8/9n/wv/D/8f/x//G/9f/9v8SACkAKQAcABAABgAPACQAOAA8ACsAGgATABoAGAAGAOf/vP+X/4L/k//H//b/FAAWABMAHgA3AFAAXABZADIAAwDs//b/FwAxAC8AFgDx/9D/wf/I/9v/4f/f/9X/1f/l/wQAIgAwACoAFwABAPP/+P8KABUACwDx/9v/1v/h/+z/6P/j/9X/0f/i/wkALgA9ADcAHwAFAPv/BQAQAAkA7f/R/9D/4P/4/woABQDu/9b/z//m/xIALAApABQACAAMABcAKwBCAEEALQAQAPf/7//m/9j/y//O/9z/+P8QACMAMwA3AC8AGAD//+b/2f/e//v/HwBBAEkAQAAvACIAFgAHAPb/5v/d/+L/9v8RADQAQwA5AB4AAADq/+b/3f/W/8f/vP+6/83/+f8dADUAKQAdAA0ABgADAPj/9f/o/+T/5P/3/xoAMAAyACIABQDz/+D/1//l//b/+f/2//L/9f/+////+v/u/+H/3f/c/+H/7//6/wkAFAAkACsAKAAZAAEA9f/o//L///8EAAYA9f/r/+P/7P/1//j/+f/t/+j/8P8DACEAKwAhAAoA8//r/+z/8P/x//H/5P/Y/9z/8f8GAAsADAABAAIACQAVAC0AMgAhAP//6f/t//j///8BAPP/5//t/wEAEwAiABkA9v/d/9H/3f/w//v/CAALAAwACwASABkAFwAIAOn/0//L/9n/9f8QABwAGwAVABAAFwAeACMAFwD8/+X/2P/f/+//BQAQABIABQD2/+r/4v/g/+H/6v/s//D/8//3/woAGwAkAB4ADADz/+v/6P/0/wgAEwAUAAYA8//k/+r/9/8CAAQA+f/v/+v/+P8OACEAHAALAPP/5f/0/wcAFgAVAAAA8P/o//D/9v/4//H/5P/b/9v/5v/o//L/9f/8/wUAHgAyADcALgAbAAcA9//t/+X/5//j/9v/3//p//j/AQACAP7/+v/q/+L/4v/t/wAAFgAhACwAKwAnABsADwDt/9v/yP/G/9n/8f8MACIANgBEAE4ATABCADMAGAAAAOz/7P/x//j/9//v/+P/3v/g/+b/8f/1//b/+/8IAB4AMQBEAD0ANAAwACwALQAqABsA/v/m/9j/4f/u//X/8//u/+b/7f///w8AHAAYAAYA+v/3/wAAEQAZABQABQDv/+D/3f/c/+f/8f/x/+n/6//w//P//P8HABQAFwAYABUAEwANAAQA+f/1/+j/0//D/8P/0f/q////BwAJAAEA+//+/woAEQAWABcAEQASABwAJgAuACkAFwAEAPL/5f/f/9v/1//e/+T/9P8EAA0ADwARABIAEwAWAA8ACAACAP3/+v/+/wsAGAAeAB8AGQARAAUA/f///wEA///5//b/8v/x//j/AQAEAP3/7f/b/9b/3P/m//D/9P/1//r/AwAQAB8AJQAWAAQA8f/s//L/7f/m/+L/4P/n//b/CwAcACAAFgAIAPn/8f/s//L/+v/+//v/+v/5//z/+f/z/+v/3f/a/+D/7v///w8AHQAoAC4ALgAqACMAFgAFAPn/8f/w//L/9f/7/wEACwAPAAkACwADAP3//v/7/wEAAgAMABsAJwAtACoAIQAXAA4ABgAFAAMA/f/4//T/9//7//z/AgACAP//+P/0//n/AQAKABEADgAJAAQAAgADAAcADAAHAAQA/f/0//n/+//8//z/+v/7//v//v8CAAMABgAGAAMADAAQABgAHAAXAA0ABAD8/+//4//S/9L/1//o/wAADwAYAA8ABgAAAPz//f/7//b/8//u//X/AQAQABYAFQAMAPn/6f/g/9//6v/2/wQADAAOABAAFgAXABgADgABAPD/4//j/97/5P/q/+//6//p/+T/7f/7/wUAFgAXAA8ACwAGAA0AFAAVAA8ABwADAP3/+v/+//z/9f/t/+z/7f/v//T/+v8DAAoACQAIAAwADAAPAA0ABwD+//T/7//p/+v/8//4//r/+/8AAAUACQAJAAQA/f/0//P/8/8AAA4AFAAVABEADQAJAAkACQAEAPr/8f/p/+f/6//z//z/+//1/+7/7f/z//n//f/+////AgAEAAcACAAHAAIA+//4//j/+//7//z/+v/6//z/AgALAA4ADgAGAP///f8AAAIAAQD8//b/8f/s/+n/5//j/97/2v/b/97/5//w//n/AwAMABEAFQAVABYAFAALAAAA9f/v/+r/6v/r/+3/7v/x//f/AAAGAAYAAQD5//L/8P/2/wAACwAWABsAGgAVABAACQAAAPT/5//e/9v/4v/z/wgAGQAhACEAHwAdAB0AHAAXABIADQAEAP7//f///wAA/f/5//P/7f/p/+v/8//6/wEABwAYACUALQAwADAAKgAXABQABAD///H/6P/i/+D/5//u//b/9//3//b/+f///wUABwAKAAkADQASABQAFgAQAAYA/v/0/+//6v/k/+T/5P/q//X/+f8AAAIAAwAIAA0ADwAQAAkAAQAAAP///v/+//j/8P/r/+j/6f/6/wcACwANAAkAAgADAAgADgAUABUAEQAPAA4AEAARAA0ABQD7//P/7v/s/+7/8//4//v//v8BAAUACgALAAkABgADAAAAAQAEAAYACQANAA8ADgALAAcABAACAP3/+P/0//H/8//2//n//f/+//z/+//5//f/9v/z//D/7//x//L/9f/6//7/AQAFAAcACAAFAAEA/f/5//f/9P/y//H/8v/2//v/AgAIAAwADQALAAQA/P/3//b/+f/8/wAAAgABAP7//P/4//T/7//r/+v/8P/5/wMADAATABcAGQAYABQAEAAKAAIA+//4//j/+/8AAAQABwAJAAsACwAKAAgABgADAP7//f/+/wIACAAPABUAFwAUAA4ABQD+//j/9f/z//P/8//1//z/BwASABcAFQANAAMA+v/4//n//P///wIABgAKAA4AEAARAA8ACQABAPn/9f/z//X/+v/9/wEAAwAFAAYABgAFAAIAAQABAAMABgAHAAYABAABAAEAAgADAAMAAgD+//3//v8BAAIAAgD///3/+v/4//j/+f/7//v/+//7//3/AQAFAAQAAwAAAP/////+//7/AQAAAAUABAAIAAQAAAD///b/8P/u//D/7P/0//P/AAAFAAQADwAMAAUAAgACAAUABQAIAAMAAAD+//n/+f/8//z/9//z//b/+P/7//7/AAAFAAcACQAJAAkACgAJAAYAAwD///z/+f/1//P/9P/0//P/9P/3//v/AAADAAUABgAFAAQAAwADAAQAAwAAAP7//P/9//7//f/9//v/+//7//v//P///wMABAACAAAA//8BAAIA///7//j/9v/2//b/9//5//r/+v/7//v/+//8//3//v8BAAMABQAHAAgABwAEAAAA/v/+//z/+//7//v/+//6//r/+f/3//T/8f/w//H/8//0//f/+v/9////AAAAAAAA///9//v/+P/2//b/9v/2//f/+f/7//3/AAACAAEA///7//n/+P/4//n/+//9/wAAAQADAAUABAACAP//+//4//f/+f/9/wIABgAHAAYABQAEAAQABAADAAMAAwADAAQABQAHAAcABwAFAAMAAAD8//n/+f/6//z//P8EAAcACgAJAAoADAAFAAgABAAHAAIAAgABAP//AAABAAEA///9//z/+//9//7//f////7///8CAAMABwAGAAUABQABAAEA///7//v/+f/5//v/+v/7//r/+v/9////AAADAAAA/v8AAAEAAQADAAAA/P/8//r/+v8AAAIAAQACAAAA/f/+////AAACAAMAAwAEAAYACAAIAAcABQACAAAA///+//7//v/+//7///8AAAEAAgACAAEAAAD//wAAAQACAAMABAAEAAUABQAFAAQAAwACAAEAAAD///7//v/+//7//////////v/+//3//f/7//r/+v/6//r/+v/7//v//P/8//3//v/+//7////////////+//3//P/7//v//P/9//7//v/+//7//f/9//7///8AAAEAAgACAAIAAAD///3/+//6//n/+v/7//7/AAACAAMABAAEAAQAAwACAAEAAAAAAAEAAgAEAAUABQAEAAMAAgABAAEAAQABAAEAAQABAAMABAAGAAcABwAGAAUABAAEAAMABAAEAAMAAgABAAEAAgAEAAUABAABAP///v///wAAAQAAAAAAAAABAAIABAAEAAQAAwADAAIAAQABAAAAAQABAAEAAQAAAP///v/+//7///8AAAIABAAFAAUAAwACAAEAAQABAAEAAQAAAAAAAgADAAMAAgAAAAAA///+//7//v/+///////+////AAABAAAA/v/9//7////+//3/AAD9/wEAAAAFAAIAAQACAAAA/f/8//7/+v/+//f//v/9//n////+//v//P/9/wAAAAADAAEAAAADAAAAAAADAAMAAQD9//////////7//f/+//7//v/+//7/AAAAAAAAAAAAAAEAAAD///7//v/+//7//f/+////AAABAAEAAAD////////+///////+//3//f/9//////8AAP///v////7//v/+////AAD+//z//P/9///////9//z//P/8//3//f/9//3//f/9//3//f/9//z//f/9//3//f/+///////+//3//f/+//////////////////7////+//z/+//6//r/+//7//v/+//8//z//f/9//3//v/+//7//v/+//7//f/8//v/+v/6//r/+//9//7//v/9//3//f/8//z/+//7//v//P/9////AAABAAAA///+//3//f/9//7//v/+//7//v8AAAIAAwAEAAQABAADAAMAAgACAAIAAwACAAIAAwACAP///v///////P///wAAAQAAAAIABQABAAUAAgAGAAIAAgABAP//AAAAAAEAAQABAAAAAAABAAIAAAAAAP7//v//////AgABAAEAAgD//wEAAQD+//7//v/9/////f/+//7//f///////v////z/+//9//3//v////7/+//8//z/+////wAA/v///////f////////8AAP///v/+//////8AAAAAAAAAAAAAAQABAAEAAQAAAAAAAAAAAAEAAQABAAAA///+//7//v/+//7//v/+////AAABAAEAAgACAAIAAgACAAEAAQAAAAAAAAAAAAAAAAD////////+//3//f/9//3//f/9//3//f/9//7//v/+//////8AAAAA//////3//P/7//v/+//8//3//f/+//7//v/+//7//v////////8AAAAAAAD////////+//7//v/+//7//v//////AAABAAEAAgACAAIAAQAAAAAAAAAAAAAAAAAAAAAAAAAAAAEAAQABAAAA////////AAABAAIAAgADAAMABAAEAAQABAADAAIAAAD/////AAACAAMABAADAAIAAQACAAIAAQAAAP3//P/8//3//v///////////////v/+//7//v///wAAAAAAAP/////+//3//f/8//z//f/+//7//v/9//3//v///////v/+//3//v///////v/+//////////7//v/+//7//v/9//3//f///////f/9//3//v/9//v//P/6//3/+/8AAP7///8AAAAA///9////+/////f//f/8//j//f/8//n/+v/6//3//f/+//z//P/+//3//f///wAA///8//7//v////7//f/+///////+//3//v/+//3//v/////////+//3//v/+//3//f/9//7//v////////////////////////////7//f/+////AAAAAP////8AAP///v/9//7////9//z//P/9/wAAAAD///////////////////7//v/9//3//f/8//z//P/9//3//f/+////AAD///7//v//////////////AAAAAAAAAQAAAAAA/v/+//7//////////////////////////////wAAAAAAAAEAAQABAAAAAAD/////AAABAAEAAQAAAAAAAAD///7//v/9//z//f/+////AQABAAIAAgABAAAAAAAAAP/////+//3//f/+/wAAAQACAAIAAwADAAMAAgACAAMAAwADAAMABAAEAAIAAQACAAIA//8BAAEAAgD//wAABAAAAAMAAQAGAAIAAwACAAEAAQABAAIAAQABAAEAAAABAAIAAQABAP///v/+//7/AQAAAAAAAQD//wEAAQD//wAA///+/////v///////v8AAAAA//8BAP7//f////7//v8AAP7//P/8//v/+//9//7//P/+//3//P/+//7//v/+//7//f/9//3//f/+//7//v/+//7///////////////////8AAAAAAQABAAEAAAAAAAAAAAAAAP////////////8AAAAAAAAAAAAAAQAAAAAAAAAAAAAAAQABAAIAAgACAAIAAgACAAEAAAAAAP///////////v/+//7//v//////AAAAAAEAAQABAAAA///+//7//v/+//7//v/+//7//v/+//7//v/+//7//////////////////////////////////////wAAAAAAAAEAAQABAAEAAQABAAEAAQACAAIAAgACAAEAAQABAAEAAQABAAAAAAD///////8AAAEAAQABAAIAAgACAAIAAgABAAEA///+//7///8AAAIAAgACAAIAAgADAAQABAACAAAA//////////////////////7//v/9//3//f/+//7////////////+//7//f/9//3//f/9//3//P/8//v//P/8//z//P/8//v//P/9//3//f/8//3//v/+//7//v/+//7//v/9//3//v///wAA/v/+///////+//3//v/7//7//P8BAP//AAACAAIAAQABAAMAAAAFAP3/AwACAP7/AwACAP///////wEAAAABAP///v8BAAAAAAABAAMAAgD//wEAAQACAAEAAAABAAIAAgABAAEAAgADAAIAAgADAAQAAwADAAIAAwACAAIAAQABAAEAAgACAAIAAgACAAIAAgACAAIAAgACAAEAAAABAAIAAwADAAMAAwADAAMAAQABAAEAAQAAAP7//v///wIAAgABAAAAAQABAAEAAQABAAEAAQABAAEAAAD//////////////v////////////7//////wAAAAAAAAAAAQABAAIAAgACAAEAAAAAAAAAAQABAAEAAgACAAIAAgACAAIAAgACAAIAAgADAAMABAAEAAQAAwADAAQABQAGAAcABgAGAAYABgAFAAQAAwACAAEAAQACAAIAAwAEAAQABAAEAAQABAADAAMAAwACAAAAAAAAAAEAAQABAAEAAQABAAEAAAAAAAAAAQABAAEAAgACAAEAAAABAAEA/v8BAAAAAQD+////AgD9/wIA/v8EAP//AQAAAAAAAAAAAAEAAAAAAP///v///wAA/f/9//v/+//7//r//f/8//v//v/7//3//v/8//z//P/7//z/+//8//z/+//9//3//P/+//z/+//9//3//P/+//3/+v/7//r/+P/7//v/+f/6//r/+f/6//v/+//8//z//P/8//3//f/+//7//v/+////AAAAAAAAAAAAAAAAAAABAAIAAwADAAQAAwADAAQABAAEAAQAAwADAAQABAAEAAQABAAEAAQAAwACAAIAAQABAAEAAQABAAIAAgABAAEAAQABAAAA///+//7//f/8//z/+//6//r/+v/6//r/+v/7//z//P/9//z//P/7//v/+//8//z//P/8//z//P/7//v/+//7//v/+//8//z//f/9//7//v////////8AAAEAAQACAAIAAgADAAMABAAEAAQABQAFAAYABwAIAAoACgALAAsACwALAAwADAAMAAsACwALAAwADAANAA4ADgAPAA8ADwAPAA4ADgANAAwACgAJAAgACAAIAAgABwAFAAQAAwADAAMAAgAAAP3//P/8//v/+//5//j/9v/0//H/7//s/+r/6f/o/+j/5//m/+X/5P/j/+L/4v/g/+D/4P/g/+D/4P/g/+D/4f/i/+P/5P/l/+b/6P/q/+z/7f/u//H/8v/1//f/+P/6//z//f/+/wAAAgAGAAgACQALAA4AEQASABEAFQATABgAFwAdABwAHQAhACEAIwAiACgAJAAtACUALgAvACoALwAuACoAJwAoACgAJgAnACQAIgAlACIAIgAjACMAIQAbABwAGgAYABYAEgARABAADQAKAAcABgADAAAA/f/7//j/9f/y/+7/7P/p/+b/4v/g/97/3P/a/9f/1P/S/9D/zf/L/8n/yP/G/8T/w//D/8T/w//E/8T/xf/G/8f/x//K/8z/z//S/9P/1//b/+D/5P/l/+j/6v/v//L/9//7/wAABAAJAA4AEgAVABkAHAAgACMAJgApAC0ALwAxADUANgA6AD0APgBAAEEAQwBEAEQARQBFAEMAQgBAAEAAPwA9ADwAOgA5ADcANAAxAC8AKwApACYAIwAfABwAFwAUAA8ACwAGAAEA/v/5//f/8f/s/+f/4f/e/9f/0v/N/8j/xP+//7//uv+4/7b/s/+y/7D/r/+t/67/rf+s/6v/q/+r/67/rv+v/7D/sv+x/7P/s/+2/7b/u/+8/8D/wv/E/8n/y//R/9P/1f/c/9//4v/l/+b/7v/l//H/7v/1//L/+f/5//r//v/+/wUAAAAFAAUACAAKAAsADQANABAAEAAWABcAGwAfACAAJgApACkAMAAtAC4ANAAxADoAOgA+AEEAQQBEAEgASABLAEoASQBOAEwAUgBMAFAASwBHAEgAOwBGAEUAQwBBAEQAPQA7AD0AOAA5ADYAMAAqACkAJwAlACAAGgAWABIAEAAHAAEA/P/3//L/7v/n/+f/4f/c/9j/zv/K/8D/uf+1/6v/pP+f/5z/mf+S/5D/iv+I/4b/f/9+/3z/ev96/3v/e/9//4D/gf+L/43/j/+U/5T/mf+h/6T/q/+z/7z/wf/N/9f/4v/s//b/BAANABsAIgAoAC8ANQA6AEUATABZAGIAbAB4AH0AhgCKAJMAngClALQAvADGANEA2wDmAPAA9gD7AAIBBgEQARABFAEQAQ4BDAEGAQQB/QD5APAA6gDcANYAywDBALIAowCVAIcAdABiAFEAMwAqAAYA9//b/8//rP+h/4v/cf9Z/z//Jv8K//D+1v6y/qL+hv5q/lr+RP48/ib+HP4K/gL+7P3o/dj91P3I/bz9tP2s/az9pP2k/aj9oP2k/aT9rP28/bz93P30/RT+Ov5g/o7+uP7o/hf/U/+B/73//v83AHwAwAAKAVIBnAHwATQCiALIAhADVAOQA8QDAAQgBEgEcASABKAEsATABNAE0ATYBOAE2AToBMgEwASgBIAEYAQwBOwD0AOQA2wDNAMIA9wCmAJoAhACzAF0AUQB0QCoAD8A///C/zP//P6C/hb+kP1c/fz8oPx0/AT8wPtg+wD7uPp4+iD6yPlg+Sj52Piw+Hj4QPgw+BD4CPgI+PD3EPgY+Cj4QPhw+Kj48Pg4+ZD58Plo+uD6aPsQ/Kz8YP0I/rL+Zv8ZAM8AigFIAgQD3AOIBFgFEAbQBoAHIAigCDAJsAkQCoAKwAoACzALUAtQC2ALUAswCyAL8AqgClAK4AmACRAJsAggCJAHEAdwBsgFKAV4BNwDRAO4AiACmgH/AGwAy/8u/47+8P1s/dj8UPzI+zj7uPow+sD5KPnQ+Ej40PeQ9zD34PaA9jD20PWA9UD18PSw9JD0YPQw9CD0EPQg9BD0IPRQ9ID00PQw9YD1APZQ9tD2MPfA92j4MPk4+kj7lPz0/Wn/5wA8ArQD6AQIBiAHAAjwCNAJgApAC/ALkAwwDaANIA5wDtAO8A4AD9AOoA5ADuANYA3wDCAMkAvQCjAKMAlQCLAHoAYQBjAFoAToA1AD6AIkApoBIAEdANX/5v5e/qj9GP2I/AT8oPtI+yD7mPqY+jj66Pmw+Yj5OPkA+ej4aPiI+PD3kPdQ99D2kPYw9hD24PXA9dD1sPWw9bD1UPUw9eD0oPSQ9GD0YPSQ9KD00PTw9CD1cPWA9UD2kPZg96D4MPnY+rj7yPyE/WL+O/8YAGgBXALgA8AEOAY4BzAIYAlACtAKQAsQDFAM4AxADVANkA3ADcAN0A0QDuAN8A3wDaANUA0ADXAMAAyAC7AKEApQCaAIEAhYB8gGKAa4BUAFwARwBOQDhAMYA6QCIAK6AQwBggANAH7/9v58/iz+5P3A/Yj9ZP00/RT92PzE/HT8TPzo+5D7UPu4+kj6qPlI+cj4iPhg+CD4GPjg94D3QPew9iD20PVQ9fD00PRg9DD04POw83DzQPNQ8zDzgPOg8wD0cPQQ9ZD1IPbQ9oD3mPio+ej6OPyw/e7+WgByAeACCARYBagGqAcACdAJwAqACyAMgAwwDWANIA5gDjAPUA+wD+APsA9wD+AOgA6wDfAMUAxAC7AK8AlACaAIEAhwB7AGEAZQBXgE2ANEA5wCJAKUASgB1ABlAPX/ff/m/lr+6P2g/Yj9kP24/cT95P20/YD9WP0c/fT8qPyQ/Cj82PuI+yj76Ppg+uj5qPk4+SD5uPiw+Cj4oPcA9wD2UPWA9NDzYPPw8oDyQPLQ8ZDxYPFQ8QDx0PDQ8LDw4PAw8WDx4PEA8qDyQPNw9KD1kPdw+Zj7lP1F/woBTALUA9AEWAZoB9AIAApgC2AM8AywDdANkA4gDwAQoBCgEUASYBKgEkASwBEAEUAQgA+ADoANoAxgC7AK4AkwCZAIsAdAB5AGAAZIBWgE3AP4AlwCvgEOAbIA8f9k/8T+BP6k/VD9UP10/cD9FP4O/vz9tP14/Qz9yPxk/Cj88PuI+0D72PqI+jD6yPmI+SD56PjA+ID4KPiw9/D2IPZA9WD0sPMA84Dy4PGQ8RDx4PDQ8MDwoPCg8JDwgPCw8MDw8PAQ8XDx8PGA8rDzMPUg9yj50Pv8/QgA9gEIBDAFwAbgCGAJQAtQDEANAA9wD4AQoBCAESAS4BLgE2AU4BQAFSAVwBQAFGATYBJgEUAQ4A7ADWAMcAsgCnAJQAiAB6gGGAaABbgEIAT8AlgCYAHdAN7/cP/O/hT+zP0Y/fj8xPzQ/CT9VP2E/fT98P0I/tD9kP1g/Qz95Pyo/Hj8DPzQ+1j7+Ppw+jj6oPlw+UD54PiA+PD3QPdA9mD1YPRQ84DysPHQ8FDwoO9A78DuwO6g7uDuwO4A7yDvIO9g72DvYO/g74DwUPHQ8yD10PfQ+rD8U/98ACQDYAT4BsAIMAoQDEANQA5gD6AQgBCgEeAR4BLgE8AUgBUgFmAWQBYgFmAV4BQAFAAT4BFAEIAOAA2gC2AKQAkQCNAGKAYoBaAE+ANcA8wCHAJeAbMAxf8L/1j+iP0o/aj8dPxg/HD8qPzo/DT9eP2k/az90P3Q/bj9wP2c/Uj9BP2I/BT80PtY+/D6kPoo+rD5aPkA+Yj4APgQ9zD2IPUg9CDzEPIw8VDwYO+g7gDugO1g7SDtYO0g7YDtYO2g7YDtwO2g7SDu4O5Q8CDy0PSg98j5qPyW/tUA4AIgBTAI0AnwC6AN0A6gEGARgBIAEyAUgBSAFaAWIBcAGGAYQBhAGCAYYBcAF+AV4BQgEyARgA+ADSAMoApwCRAIuAbQBZAE1AMwA1gCxgE6AZQA3f8A/zL+MP2Q/Aj8qPuo+5j7wPsI/Fz8fPzM/Pz8UP10/aT91P3Q/bj9hP1M/ez8dPwk/KD7SPu4+ij6mPkI+bD4APhQ92D2YPVA9DDzEPLg8MDvwO7g7eDsYOyg64DrQOsg60DrQOuA68DrwOtA7ODroOyA7YDv8PHA9Fj4cPqE/X//jAFgBCAHEAmgC9ANYA/AECASwBIAFKAUYBUAFgAXABigGIAZYBlgGQAZoBhgGEAXYBagFIASgBBwDpAMoApQCbgHiAYQBRgEBAMcAnYBrQBUAIH/Cf9M/oj9wPyw+2D7wPqA+qj60PoQ+6D78Pt0/PD8IP3Q/eD9QP5S/gz+Gv64/WT9JP2Q/Hz8BPxo+/D6MPro+Vj56PgY+GD3MPYw9TD0APMg8sDw4O/A7qDtwOxA7MDroOtg62DrgOtg6+DrAOxg7MDswOxg7kDvYPLw9ND3SPt4/Hv/1AFABLgGkAnwCxAOABCAEaASwBMAFaAVYBbgFsAXoBggGeAZwBmgGWAZ4BigGOAX4BYgFUATQBEADwANUAtwCegHYAbwBIADkAKCAb4AXwCa/2T/tP5U/pD92Pxg/ID7WPv4+hj7KPuQ++j7OPy8/Cj9sP0c/pj+0v4o/zT/TP8X/9j+Vv4C/qz94Pwg/FD7cPrw+RD5YPiw94D2wPWQ9LDzMPKA8UDwAO+A7uDsgOyg60Dr4Oqg6kDq4OmA6uDqoOqA64DrYOwA7uDvkPLg9VD4oPt0/awAMANABcAIkAqQDRAPgBHgEiAUoBXgFcAWYBcAGOAYwBlAGmAaQBogGuAZgBlAGSAY4BZAFQATABHQDqAMoAqwCAAHeAXAA6gCoAGWAPv/mf8d/+7+ev4a/lz9/Pxs/PD7yPsw+zD7APv4+kj7YPsY/Cj89Pww/dT9VP6K/tr+1v6q/lD+AP7s/eD8NPxo+yj6iPmQ+ND38Pbw9QD1kPOw8sDxMPAA8KDuwO0g7eDrgOvg6mDqQOoA6aDpwOkg6mDqwOmg6mDqIOxA7tDw8PPQ9sD5iPyi/wACMAWYB7AK0AzQDkARYBJAFEAVQBbAFuAXIBggGQAa4BmgGkAaYBogGsAZoBmAGGAXoBXAE+ARgA+QDXALUAk4B7AFgANkAi4B2f9c/9D+jv4o/kj+mP1U/eD8iPwg/AT8yPuI+7D7ePuw+9j74PtE/JT8XP3U/Uz+7v5a/4L/bv9G/0H/5P5m/vT9kPzg+4D6oPlg+DD3QPaA9KDzgPJA8VDwYO9g7gDuAO2A7MDrgOtA64DqQOog6sDpAOqg6UDqoOkA6qDrAO5g8JDzsPYA+QT9kf+sAvAFgAhgC6ANQBDgEWATgBQAFuAVQBegFwAYgBkgGWAaoBngGQAaoBngGcAYIBiAFiAVQBNAEZAOwAwwCuAHWAYIBHACywCB/4r+2P2c/Xj9VP1A/RT9zPyQ/Ez8DPwc/MD7yPuA+7D76PvQ+9j7YPyk/Fz91P2M/vL+Hf+Z/2n/ef8T/6L+Lv5o/YD8UPso+iD5wPfA9vD0wPOA8lDxUPCg70DuwO3g7CDsoOuA68DqYOpg6qDpoOlg6UDpQOlg6YDpwOpg7EDv8PEQ9Vj4yPou/joBuARIB5AKAA1gD+ARQBOAFGAVYBYAF8AXQBigGMAYgBmgGcAZIBoAGoAaYBkAGcAXABbAFIAS4BBwDjAMMAroBwgG8AMUAmoAVf+w/n7+Qv7k/Zj9fP1c/TT9PP0k/UT9CP3Q/Hz8XPws/CT8JPwg/GD8qPw8/dz9NP6m/s7+Jv9g/2H/PP+E/uj97PzY+6j6SPnw92D24PRQ8+DxcPCA76DuoO0A7SDsoOtA6wDrwOpg6gDq4Ong6YDpoOlg6WDp4Ong60DtQO8A8xD1APkE/Fr+LAL4BCAJ4AvQDiARABPgFEAWQBfAF2AYABlgGeAZABrgGQAaABqgGgAaIBogGcAYYBdgFoAUIBKgEFAOkAwQCgAIaAX4A7oBKQA2/yL+9P1M/VT96Pyw/BD9LP1I/cD9iP2E/Wj9QP1A/fz84PzQ/Mj87Pw4/Wj9Cv44/vT+Af8P/1D/L//k/mr+wP2E/JD7iPoA+ZD38PXg84Dy4PCg72DuQO0g7IDrgOpA6sDpgOlg6WDpYOkg6WDpoOjA6UDpwOlg64DsEPCQ8WD1EPdQ+mT9ZQBYBJgHYArgDIAQABKgFCAVgBZgF0AYABlAGWAZQBmgGaAZoBmgGSAZIBnAGIAXYBYAFYATIBIgEAAOMAywCfgHyAWgA+ABNQAV/4T+wP0g/ez8bPyY/Lj82Pwc/ST9PP1g/UT9cP2E/WT9gP2A/UT9jP34/ST+pP4B//D+Df83/zT/8P6A/qz99Pz4+zj7APqA+BD3MPXw82DyAPGA70DuwOzA66DqAOqA6QDpIOmg6KDoYOhg6EDowOig6KDpoOoA7SDvwPGw9GD2APrI/J0AoANoBoAK0AzQDyASYBNAFYAWABigGAAa4BkgGsAagBpgGkAawBlAGSAZ4BcgF6AVYBQAE0AR4A/ADSAMAAowCCAG/AOkAuMAx//0/uj9HP2o/ET8BPws/ET8NPyM/LD86Pws/TD9EP08/Zz9oP3g/cj9HP4K/hj+Yv4o/hb+0P20/VD9sPw8/FD7qPr4+dj4kPdA9sD0YPMg8nDwAO9g7WDsIOtg6mDpwOhA6MDnwOcg52DnQOeA5yDoYOmA6qDs4O7A8SD0EPeI+Yj83P8kA1AHYAmADOAOwBBgE0AVIBagF+AYwBlgGkAboBogGwAbQBugGkAawBlgGMAXQBYgFUATwBFAEPANgAxwClAI0AYoBcADIALnAJX/qv7M/YT91Pyc/LT8fPy8/JD8rPxA/HD8sPzM/Gj9qP1s/dz97P20/Q7+7P3k/ZT9eP1Y/Yj8UPyY+7j6SPpw+Uj4cPcA9iD1kPNQ8vDwYO+g7mDtgOwg62DqgOkg6YDoIOgA6KDnIOiA6ODowOkg68DsYO+g8YD0UPfw+YD9hQAoBHAHgAnADIAOgBFAE0AVIBdAFwAZ4BlgGoAaIBvAGiAb4BqAGsAZIBngGIAXwBZAFcAToBLgEPAOIA0gC2AJsAcQBrgE8AKMAWAAKP96/tT9UP3w/BT9tPzQ/Ij8nPw4/Dj83Pxg/Bz91Pz8/Nz85PwI/Vz8qPw0/DD8+Pug+0j7ePog+lD5sPjQ99D2oPXA9IDzMPLw8KDvYO5A7UDs4Org6QDpIOig5yDnwOYA5wDnoOdA6CDpQOqg7CDuYPCQ8wD2SPr4/BEAUAPIBYAI0AsgDuAQIBIAFSAWwBdAGWAZYBoAG0AbgBtAG0AbgBpAGsAZwBggGIAWABYAFEATABFQD5ANsAtQCgAIqAaABDgDBAJKAEj/Bv5c/Wj8SPyw+yj7UPsA+zD7APsg+yj7oPuY+wz8RPwE/Aj8uPsE/Fj7KPsY+0j6kPrI+fD4mPiQ9wD3cPaA9aD0kPOg8nDxYPCA70DuQO0g7ADrIOoA6WDooOeA5yDnoOdA5yDoQOmg6eDrIO3A75DysPXY+Yj8CwDgAoAFoAjQC4AO4BDAEsAUoBbAFyAZoBmAGiAbQBuAG2AbQBugGuAaIBogGaAYIBegFiAV4BMgEkAQIA/QDEALQAn4BpgFtANQAhwBKv+K/pz9oPw0/ID7aPsQ+0j7GPsw+0j7SPuo+9D7+Pvg+wj8BPyo++D7GPsI+6j6SPrI+VD5cPgg+LD3kPZA9iD1kPSQ86DysPFQ8MDvQO6g7aDsYOuA6iDpIOkA6MDngOeg5+DnYOig6SDqYOzg7ZDwcPPQ9vD5TP2XAFQDqAZACaAL4A4gEaATIBVgFqAXoBgAGuAZgBpAGmAaQBqgGmAZ4BiAGGAXYBcgFuAU4BNAEmARwA8ADjAMUAqQCEgHSAV4AxACsAD4/2j+WP2Q/FD7oPvY+vD6sPqI+kD7MPvw+1D7MPzg+4j8ePw0/BT8GPuo+7D6iPrw+fj4wPgA+AD3gPYw9bD04PPg8lDy8PAA8CDvQO5A7UDsIOtA6mDpoOgA6IDnQOdA52DnIOjg6ODpQOug7RDw4PJA9lj5mPzg/zwDgAXACJALoA6AEQATIBUAFuAXIBngGWAaQBrgGqAaABsAGoAZwBjgGOAXIBeAFuAUQBQAE2ASYBAQD5ANEAzgCgAJKAeIBUgE8AJ4ATMApP6U/dz8RPxw+wD7kPrA+hD7IPtw+yj7yPvo+xj8ZPy4+/j7iPtw+zj7UPrY+SD5iPjA99D20PUA9RD0MPNw8mDxgPCA76DuwO3A7MDrAOsg6oDpIOlg6EDoIOhA6ODoIOlA6sDqQO3g7rDxkPQQ91j6WP1nAFAD+AUwCZAM4A5AESAT4BSAFsAXYBlgGSAaoBqAGsAaIBrAGeAYwBjgF4AXgBagFYAUgBPgEkAR8A9wDmAN8AtwCvAIKAcABnAEVAO6AXcAF/8K/pz9kPwg/Hj7QPsw+yD7IPsI+1j7WPtg+9D7aPtA+0D7KPvQ+pD6+PlY+bD4EPhQ92D2gPWA9KDzsPLg8aDwoO+g7qDtwOzg6+DqAOpg6QDpYOgg6CDoQOjg6EDpAOvA64DtEPCA8kD1UPj4+nz9yQAwA5gGQAngC8AOIBDgEiAUgBUAFwAYwBhgGaAZgBkgGWAZABmAGCAYQBfgFiAWoBVAFEATYBKgEUAQ8A7QDSAMIAvACTAIwAYoBewDsAJiAeP/qP64/RT9lPy4+zj7sPqY+oj6WPow+vD5APoA+jD6yPmA+YD5UPlQ+cD4APhg9wD3MPaQ9ZD0oPPA8gDyIPEQ8ODuwO0g7UDsgOuA6uDpQOkg6SDpwOgg6QDpYOoA60Ds4O3A76Dy0PRA+HD5jPwM//ABGAWAB8AJMAywDqAQYBKgE4AU4BUgF2AXgBegF6AXwBdgFyAXABbgFYAVwBSgFCATgBLgEQARIBDQDqANsAzgC7AKQAnIB2AGYAX8A7ACPAEHAB3/Xv58/Zz88PtI+zD7APvI+kj6ePow+jD6IPqg+aD5iPmA+QD5sPgg+KD3QPew9vD1APVg9JDzsPLQ8bDw4O/g7gDuIO1A7KDrAOvA6kDqwOkg6uDpAOug6+DrwO2A72DxwPNA9lD4sPoo/Q4AjAIQBYgHkAlgDBAOABAAEaASIBTgFMAV4BUgFmAWwBZAFiAWQBVgFcAUwBSAE+ASYBLAEUARQBBwD0AO8A3QDCAMAAuACbAIkAdgBsAEqANQAmABfABI/zD+fP3g/Ij8BPyA+zD72Prw+qj6ePow+iD6IPrw+bj5IPnI+ID4EPhg96D24PUA9ZD0gPOw8qDxsPAA8ADvYO7g7GDswOtA64DrQOqA6sDq4Org6yDsIO2g7rDwkPLg9LD2qPg4+8D9YwBEAsgE+AZQCVAL4AyADrAPQBFAEgATIBPAE+ATIBRAFMATYBPgEuASgBIgEmARQBHAEMAQ0A9AD6AOAA6wDcAMAAzwCgAKAAnwB6AGUAUYBPACwAF/AGn/Tv6g/bz8JPyg++j6oPpo+gj66PmY+bD5mPmo+Uj5CPkY+aj4YPjQ92D34PYQ9oD1oPTQ8+DyEPJA8TDwYO9g7uDt4OzA7ADswOsA7IDrQOxA7CDt4O0A79DwgPJw9JD2SPhQ+tz8zP4GASADUAUoB9AIoAoADFANsA6gD0AQ4BCAEcARIBIgEiASABIAEuARYBFAEeAQwBBgEOAPYA/gDoAO4A1QDaAM4AsgC4AKUAlQCAAHIAYgBfADvAKAAasAff/O/tT92PxQ/Mj7gPsI+0D6UPro+fD58PmY+Zj5aPl4+UD5+PiY+Fj40PfA9/D2gPaw9RD1cPTA88Dy4PEg8XDwAPAA78DuQO4A7qDtAO7g7UDuIO+g7zDxkPJQ9PD14Peo+Uj7gP0K/4QBDAMQBeAGMAjACfAKIAxADRAOoA4wD7APIBDwD0AQIBAgECAQIBDwD7APoA+ADxAP0A5gDlAO8A2ADSANkAwADHALsArQCfAI4AcoB+gFOAXQA8ACxAGtAAEA0P42/lT93PwQ/OD7KPu4+rj6IPqg+iD6GPro+Qj6APrA+ZD5APnY+Mj4CPiw9wD3EPbQ9QD1QPQw83Dy4PEw8bDwAPBg70DvgO9A72DvgO/g7yDxIPJg83D0EPbg96j5APuc/CT+DwAgAnQD8AQoBoAHwAjgCcAKIAsQDIAMIA1QDUANgA2QDRAOoA3QDaANsA0ADrANcA1ADSANAA0ADZAMIAzAC2ALAAtACoAJgAjIBwAHKAZABRAEcANUApABrwDA/zf/av4w/mj96PyM/AD86PuI+1j7SPsg+xD7yPrI+sD6cPpQ+hD66Plw+Sj5wPgo+JD3IPcw9rD1EPVA9ODzMPOw8iDy0PGQ8UDxYPGg8dDxUPIA88DzsPTg9RD3QPiQ+ej6MPyo/RL/XgCWAcgCAAQABRgG4AagB5AIQAmQCUAKYAoACxALgAtwC7AL4AvQCyAM8AsQDNAL0AvQC5ALgAtACxALwAqgChAKsAkwCbAIAAhIB7AG2AVIBZAE5AM0A4wCBAJUAc4ASAC+/2n//v6q/kD+7P2c/XD9WP0g/ez8lPxo/DT88PuI+0j78Ppw+mD62PlQ+dj4QPjA93D3oPYw9rD1YPUA9YD0IPTw8wD04PMA9CD0UPTw9HD1EPbA9oD3UPg4+UD6APsc/Oz8GP7q/tn/mwCQAVgCDAPEA1AEAAWABSAGcAbwBjgHuAfwB4AIsAgQCVAJgAnwCfAJEAowCkAKIAogCgAK4AmwCXAJIAmgCEAIsAdYB6gGKAaABfgEkATYA2AD1AJQAuYBVgEcAZwASgAlAMD/cf8p/8D+pP5Y/gb+2P2A/UD94PyA/DT80PuI+yD7uPpI+vD5kPkw+Zj4UPgI+KD3YPcA97D2gPZg9jD28PXQ9QD2EPZQ9oD20PYw94D3EPhw+AD5oPkw+vD6gPso/LT8ZP0C/qz+Yf/r/7gAKgHcAUwC8AKAA9wDiAT4BHgF6AVQBrAGAAdgB8AHAAhQCIAIsAjgCPAIAAkACQAJ8AjgCLAIcAggCNAHgAcoB8AGWAbYBYgFGAWgBEAE2AN4AxADtAJQAggCqAFUAQABnABiABQA5P99/zT/1P6a/j7+9P2o/TD92Px8/AD8oPsY+7j6QPrY+Xj58PjY+GD4KPjQ94D3UPcw9yD38PYA9/D2MPcw93D3oPfw9zD4cPjY+CD5oPn4+Xj68PpY++j7XPz4/Hz9+P2W/g3/vf86ANYAWgEAAngCIAOYAygEsARABbgFMAaoBigHkAfgB1AIkAjwCDAJQAlwCXAJcAlQCWAJEAnwCMAIYAgQCMAHUAcQB7AGUAbYBXAFAAWoBDgE1ANkAwQDnAJAAtQBbgEWAbYAUgDq/4D/FP+6/lr+8P2M/Sj9zPxo/Aj8qPtA++j6oPpI+vj5qPlQ+RD52PiI+Ej4GPgQ+PD38Pew97D3wPfA9+D3APgg+Ej4mPjQ+Bj5YPmo+Qj6cPrQ+jj7qPsc/KT8EP2Q/SD+sP5C/9z/XgDrAHYBCAKcAhwDsAMoBLgEKAWoBRgGeAbYBigHiAfIBwAIQAhgCIAIgAiQCIAIcAhQCCAIAAjIB4AHOAfoBpAGOAbYBXAFCAWgBEAE0ANoA9wCgAIUAqIBMAG2AFcA4v+D/xD/sv5c/vz9nP1M/fz8uPxw/CD84PuY+2D7KPvw+sD6gPpg+jD6APrY+bD5ePlo+Uj5QPkw+TD5MPlI+Vj5gPmQ+aj58Pkg+mD6mPrY+jD7ePvg+zz8nPwU/XT96P1k/sz+S//D/0QAwAA0AbYBMAKsAiQDlAMIBGgE2ARIBZAF8AU4BoAGwAboBiAHOAdYB2gHcAdwB2gHSAcoBwgH4AagBngGMAbwBagFSAUIBZgEUATkA4wDLAPAAmQC7AGWASIBwQBiAP7/l/88/9r+hv44/vD9pP1Q/Qj9wPx8/ET8+PvI+5D7cPtQ+yD7CPvo+tD6uPqg+pD6kPqI+pD6iPqY+pj6sPqo+tj66PoI+zj7YPuo+9j7APxE/Iz83Pww/ZD95P0y/or+6P5H/6X/+/9WALgAEgFyAcABHAJwAsACEANQA5gD3AMgBFAEiAS4BOAEAAUgBTAFUAVYBWAFWAVYBVAFOAUgBQAF4ASwBIAEUAQQBOADpANkAxgD1AKMAkAC+AGmAVwBCgG/AGgAGADJ/4n/RP/4/rD+ZP4m/uj9sP10/Tj9CP3U/Kz8hPxc/DT8EPz4++D7yPvA+7D7qPug+6D7oPuo+7j7yPvg++j7APwY/ET8ZPyQ/LT83PwM/Tz9eP2s/eT9GP5Y/qT+5v4t/3X/vP8CAE0AkwDZACIBbAGuAfABLAJsAqAC1AIAAygDTANsA4wDnAO0A7wDwAO4A7ADqAOgA5QDhAN0A1wDRAMoAwgD6AK8ApACaAI4AgQCzgGWAWoBOgEGAcwAkwBiAC0A+v/C/5L/YP80/wH/0v6m/nj+Sv4s/gT+4P24/ZT9fP1c/UT9NP0g/SD9DP0M/Qj9DP0M/QD9IP0c/TT9PP1Y/Vz9dP2M/aj9yP3c/QT+JP5O/nL+nv7A/vL+Hf9L/4j/sf/l/xkAQQBxAKAAyQD6AB4BRgFuAZIBvgHYAfQBDAIcAjQCTAJQAlwCXAJcAmQCYAJcAlQCUAJAAjACJAIQAhACBALwAdwBxgGgAYoBeAFeAUgBKAEMAe8A1AC3AJcAcgBYAD4AJAALAOv/zv+1/5//gf9p/1f/P/8y/x3//v7s/tr+yv68/q7+mv6S/pL+iv6A/nb+cP5w/nL+cv50/nr+gP6K/pL+nP6o/rb+wv7U/uL+9P4E/xj/Kf88/1P/a/+G/6D/tf/P/+//DAAkADkAUwBqAH4AkgCgAKoAsgC8AMgA0ADWANoA3wDlAOQA2wDXANIA0gDUAM8A0QDLAMgAvQC5ALMArACkAJ0AmACQAI0AhAB+AHYAbwBmAGEAWgBVAEwAQQA4ADAALQAjABoAEQAJAAAA+P/q/+X/2v/R/87/wP/C/7j/uP+z/7L/rP+h/5z/l/+P/4j/fv9+/3f/eP9x/2z/b/90/37/gf+F/4T/h/+L/5X/mv+i/6b/s/+6/8H/x//Q/93/5P/y//z/CAAUACIAMQA/AEkAUwBcAGQAawBtAHQAdQB5AHoAfgB9AHoAdgByAHIAbwBxAHAAbQBpAGYAZgBjAGEAWQBcAFoAWABUAE0ASwBKAEcAQQA8ADgAOAA5ADkALQArACcAJgAlACMAIAAmACIALAApAC4AKwAuACsAKgAjACUALQAYAC0AGgAhABkADwAZAAsA///8/wEA+//4//7/8f/o/+P/3v/j/+D/1f/O/8j/yv/B/7r/uf+5/7b/tf+x/7H/rv+x/6z/q/+t/6v/rf+w/7H/tP+y/7H/r/+2/8D/wv/G/8j/y//L/8r/yf/O/9P/1P/V/9H/1f/a/9z/3f/Y/9v/2f/Y/9T/0v/Q/9f/2v/e/93/4v/v//j/BgAKABEAGwAkAC4AOABCAEQASQBPAFEAUgBRAFIAVABVAFMAUwBWAFQAUwBOAEsASQBIAEcARABBADwANwAwACsAJQAfABgACwAIAAIA/v/4//H/7f/l/+D/2f/R/8v/xv++/7z/t/+y/67/qP+i/6D/mv+X/5b/kf+R/4z/iv+B/3z/ef92/3P/bf9s/2n/av9t/3D/c/91/3n/ff+B/4D/g/+H/4//lv+Z/5z/n/+o/6z/sv+1/7n/vf/D/8P/yv/M/9b/2f/m/+v/8f/3//z/BAAIABIAGAAmAC0AOgBAAEwAVABdAGIAcQB3AIcAhgCUAI4AlwCcAKAAowCdAKYAoQCjAJsAmQCSAIwAiACEAIIAewB7AHUAbwBlAGIAWQBRAEoAPwA9ADMALgAmABsAEQAEAPf/9P/s/+T/1P/I/8X/vf+7/6j/n/+W/5L/lP+K/43/jf+X/5f/mP97/4L/j/+U/5b/fv9//4D/mP+T/43/iv+T/6f/pf+c/5j/p/+4/7f/sP++/8T/2f/X/9r/5P/r//3/CAAOABkAGwApADQAPQBDAEoAWABfAGUAbwBxAH8AgACEAIkAkwCPAJgAmQCSAKIAkwCTAI4AhQCDAIoAgwB6AHUAagBmAGIAUgBMAD0APgAzACYAFwALAPz/6v/Z/8r/zf/G/8f/uf+5/77/sP+d/4L/f/+I/47/fP9i/1T/Xf9l/1X/P/8v/0X/Vf9P/0X/OP9O/1r/Uv8+/z3/UP9u/23/Wv9a/2j/i/+U/4v/if+f/67/x/+v/8T/v//Q/+v/4f8BAO//JQAfAGQASABmAHYAmQCPAHMAbwBcAHAAWQBSADoAWwB6AHsAoACZALcAwQCqALQApwC9ALgAtACxAKsAzwDlAPsAJAEyAXIBogHEAe4BHAJUApwCsAKoAogCWAI4AvYBmAEMAYoAJACy/zb/lP4Q/rT9bP0w/ej8uPzA/Nj8AP3w/Bj9RP3M/Qb+Mv5g/qb+J/9h/4X/kP/V/xcAOQAxABYANQBRAEsAFQDY/9X/3v/m/5z/df9s/6H/kv+G/0//eP+1/7n/2f+m/wIAJQBlAEwARgBvAIoAvgCOAJ8AhgC5AL0AoACCAHAAfwB2AGkAMAA0ACwAMAAVAAYADQAXABoAFwAXACcANwA6ADsAOgBVAFIATwBAADkARgA7AC0AFQAYABoABgDy/93/2f/J/7f/lP+I/3r/cv9p/1P/Uf86/zz/Lf8t/yj/Kv8u/yn/Lv8w/z3/Sv9d/2r/ev+G/5H/rP/F/9H/3P/d//X/CgAcAB8AIAAxAD4APwA9ADgAQABRAFEASgBFAEAATgBOAEEAPAAzAD8ANgA4ACUAJQAcABMAGAADABAAAgANAA4ADAAXABsALQAuADQAPABHAFYAYwBiAHAAgQCMAI0AiwCEAJkAlwCbAI4AhwCUAIgAigBsAGEAWwBRAEoAKwAoACQAKQAqACYALQAzAEYAVABaAF4AaQBxAH8AhgB9AIIAfgCBAHQAaQBXAFMASgA5ABsACgD5//3/2//l/8z/0f/I/8T/wf+u/7b/u/+6/8H/p/+4/7z/wf/V/6n/7f/L/wMA6v8NAPv/FgAlACsAQQAvAFUASgBYADwAUwBGAFUAVgBDAGQAZAB5AI0AiACOAKkArQDBALkAvwDCAMUA1QDHAMQArwCjAI0AkgBsAGEARwAtABwA8P/g/7f/tv+N/2z/X/9B/0z/Mf8y/zX/Rf8n/yP/MP87/1z/S/9E/zz/T/9Q/07/Jf8n/yT/Iv8K/+j+1P7K/tr+tP6o/qb+sv7S/tz+1P7k/hb/Pv9e/4D/jf/J/w0AJwBDAFUAiACkALgAtAC6ANwA4QDpANAA3ADiAPkA7QDrAOgA9wACAfoA7QDeAOIA5gDfAMQArgCiAK0AnACKAHkAfgCFAHcAewBqAHMAZABlAGIAWwBiAFoAWQBMAEUAKQAsAA4A/P/z/9f/3//A/7n/lf+U/4D/d/9o/1b/Wv9A/0r/Mv9B/zn/O/88/0D/Tf9X/2j/Y/96/33/ov+j/7b/yf/Y/+r/AQACABgAHwAYADgAGgA4ACEAPQAoAEAAMQAdACYAHwAdAA0A9//5/+z/9v/h/9z/4v/r//r//v8XAAwAIgAqAEcATgBqAHEAjACPAJ4ApQC1AMUAvwDJAMAAygCyALcAtQC1ALcAqACsAJYAowCPAJ0AjACLAH8AdQB7AF4AVgBFADAAIAAPAP//4P/H/7r/of+L/3f/YP9T/0v/Kv8j/wT/+v4A/+z+5v7c/tj+4v7W/vL+1v7g/tb+wv66/qL+iP6S/nT+Zv5I/kT+OP4y/g7+Av7s/eD9/P3A/RD+8P0I/gL+6P0Y/hD+GP4k/jz+Ov5i/oz+sP6u/uD+Ev9f/7n/1f9AAG0A4QAsAXAB6AEcApAC0AIkA3ADpAMQBCgEaASgBLAE2ATQBNgE4ATIBMgEoASgBIgEYARYBCAEEATQA4QDQAP0AsQCVAIUAm4BPAGrAFYAxf9a/+L+bv4S/nD9DP2U/Dz8wPtQ+7j6SPro+VD5CPlw+OD3kPfw9pD2IPbg9ZD1QPUA9QD1sPTg9BD1IPXA9RD2wPaA90j4WPkw+mj7ZPyw/eb+IwB6AbQCGAQgBXAGkAdwCMAJcApgCxAM0AxwDfANkA6gDhAPIA+AD2APwA+gD1APgA8QDwAPUA7wDZANwAxwDGALsArwCQAJEAi4BtgFSARUAxgCygCm/1z+LP1A/Dj7MPpQ+Rj4YPdQ9jD1APSg8mDxMPDg7kDtgOsg6qDooOdA5oDlYOQg5EDkQOQA5SDmgOfA6cDroO6Q8NDz0PZw+cj8Zf94ArgEaAdwCVAL4AywDnAPYBBAEWAR4BFAEuARYBJAEmASYBLgEQASoBGAEUARYBHAEGAQQBBgD1APYA6QDSANMAxQC3AKQAkgCEgHQAbgBagEMASIAyADFANYAnwCIAJAAsACTAKsAlgCKAIYAooBQAEKACr/hv5A/ZD82PrY+eD3MPdg9EDycPDg7YDtwOqA6cDmgOVA5aDkAORg40DkoOTg5WDnIOgA6oDsoO5A8UDzMPXA9xD7SP0N/2gB7AJwBVgHYAgACuAKIAyADSAOoA7QDlAPwA+gEGAQYBCAEGAQ4BAgEGAQYA8QDzAPQA7ADTAMsAugChAKMAngBwAHGAZ4BegEIASQAzQDMAOAA1wDNAOkA8ADGASgBNgE4AQQBVgF8AToBGAErANEAyQCRAFKAAr/CP6M/Ej7gPnw9+D1IPQQ8qDvwO3A6yDq4Oeg5iDlIOQg48DioOIA42Dk4OTA5uDnYOpA7ADvYPJA9LD3KPoU/QcAQAJwBNgGkAgAC8ALwA0QDvAPgBBgEYARYBEgEoAR4BGAEQAR4BDAEIAQ0A+wD5AOUA4gDvAMMAzQCgAKAAkwCHAH8AV4BaAEEASoA7QCgAJQAqwCwAIAA1wDiAOYBGAF4AWQBpgGAAc4B5AHEAfoBmgGqAVABfwD8AImAbb/Xv5w/Lj7qPiw9rD0QPJA8EDt4Opg6ADnQOUg5ADi4ODA4ADhYOLA4uDjQOWA52DqoOzA7yDy4PUw+RD8av5yARgECAeQCRALgAyQDSAPgBCAEYARYBJAEiATwBJgEqASABKgEiASABKAEQAR4BBAEEAQ8A4ADiANwAvwCmAJMAgYB3AF+ATMAygDGAJ8AUwB9gDyAGwBZgFkAnwCRAOIBAAFoAUABkAG0AaoBrgGeAYYBigFsATgAwgC+AAw/z7+EPyw+rD4cPZg9dDxkPCg7UDr4OgA52DlIORg4qDhYOAg4EDhIOKA42DkAOcg6cDrIO/Q8fD0kPjQ+1z+SgE4BMgGsAlACwAN8A2QDyARwBHAEgATYBPAE8ATgBMAEyAT4BIAE0ASoBEAEcAQQBAQDzAOMA1ADGALAAqgCHgHWAZ4BdAEnAN8AhwCsgE6Ab0A6wCXAG4BygE0AvwCMANYBMgE6AW4BUAGEAZYBngG2AVQBZAEhAOoAkABBQAw/rD86PpY+WD3IPXg8mDvIO4A6yDowOWg48DhAOHA30DeQN6A3UDf4OBg4uDkAOYA6sDsYPCQ88D2kPr8/VQBzAPQBfAIEAswDXAOUA+gEGARIBMgE6AToBNAFCAU4BOgE2ATYBMAE6ASIBJAEYAQIBBQDzAOAA2QC5AKgAkwCNgGmAW4BNQDCAOQArABOAHoAO8A5gAKAXwB5gH4AqgDQATwBPAFQAbgBhAH0AbYBpgGSAbgBbAElAN8AjoBz//0/UD86PmY+MD2QPQA8uDuIO0A6oDnwOSA4mDhgN8A4ADdQN2A3cDeQOHg4mDkIOdg6iDu0PFw9Wj4YPyQAEADAAZwCAALwA1gD6AQ4BBAEkATwBPAFGAUQBSAFGAUABRAE6ASgBJAEuAR4BDwDwAPkA6ADYAMAAugCWAIQAfoBZgElAN8AuwBagEGAWsAjAB7AMEATAGQATwCSANIBOgE+AWoBlAHMAhgCJAIYAgwCPgHgAfIBlAFeAQMA44BEwAK/mj8QPrY+OD2EPRA8qDuAO2g6sDmYORg4kDgAN8A3sDcwNvA24DdAN/g4CDjYOVg6cDs4PAA9PD3lPzS/+wDUAYwCdAL4A5gECASoBLAE0AUoBVAFYAVYBUgFeAUIBSAE0ASYBJAEcAQ4A9gDqAN0AzQC0AKEAmgBzgGEAWEAygCTgFUACsAZP8+/1P/Wv/9/1sANgEYAkADUASIBeAGuAcQCSAKMAuAC6ALkAsAC0ALQArQCXAICAeoBegDtALg/1r+KPz4+UD54PWA8zDxQO4g7CDp4OXg4sDgAN8A3kDcANuA2kDbAN2A3qDg4OJg5iDqAO5A8vD1ePqK/sgCqAXgCNALQA7gEGASYBPAE4AUIBWAFUAVQBXgFMAUwBMgE4ASwBEAEYAQcA+QDkANEAwwC8AJgAjgBqgFpAM8Av4Ay/8C//D9iP1s/XD9nP1e/ib/IQAUAZQC2AOYBZgGAAiQCbAKsAsgDIAMgAwQDMALMAuAChAJ8Ae4BrAEWAM0AdL/WP2Y+4D5UPfw9VDy4PCg7SDrAOjA5ODhwN8A3gDdANuA2QDaQNoA3IDdoOAg42DmwOqg7qDykPfw+yYA2ANoB2AKsA3wD8ARIBNAFMAU4BRAFUAVQBXgFKAU4BMAE0ASgBEgEUAQIA/wDSANAAygCgAJaAcgBogE9AJEAer/iv6s/VT90PxA/Lz8eP0w/iD/ZwBSASADsAQYBtgH8AhgClALwAwwDeANkA2gDTANcAyQC7AKcAkwCDgG4ASwAloBQP/8/Hj7ePnw94D0IPMQ8CDtIOog52DjoOBA3sDbQNsA2UDYQNjA2IDbgNxA4GDjYOfg60Dw0PSo+br+RAPwBrAKcA3QD0ASoBPgFOAUwBWAFSAVoBTAFCAUgBMAE0ASoBGAEAAQcA8AD7ANkAygC1AKUAmgB0AGsAT4AqgBZAB2/0z+nP2g/dz9kP68/hUAGgG8ApAEmAWYBwAJkAogDKANQA7QDpAPwA+wD9AOMA2QDIALMAqgCJgGoAT4AmQB9v4M/Qj7UPkA+ID10PMA8UDvwOyA6QDmwOFA4EDdwNsA2gDYgNcA2IDYgNoA3YDfwOOg6MDsYPGg9rj7xQCgBVAJ4AyQD0ASoBNAFQAWIBXgFeAUABSAE6ASIBLgEaAQcA+ADuANYA0gDWAMgAuQCoAJcAiQBzgG+ARIA/AB2ABd/4b+pP2M/RD9qP1W/j7/9QA0AhAEEAYwCOAJ0AuADbAOABDAEKARgBFAEWAQkA8wDkAM8AoACQAHaAUsA0IBrP7k/FD7sPno+BD2kPRg8wDxAO8g7QDpYOWg4sDfgN0A20DZwNeA1wDYgNiA2kDdgOHA5eDpQO/g8+j5E/8YBFAIoAxgD6ASABTAFYAVIBaAFcAUgBNAEoARoBAgEKAOcA6wDHAMAAwgC/AKYAoQCgAJcAhIBxgGMAX4A4gCSgGb//T+CP6E/Yj9tP2Q/lr/BAGoAqgE0AbgCFALYA0QD6AQABLgEqATQBTAE0ATYBEgEHAOwAxgCrAH+AWcAzwCxf/E/PD7uPnA+MD3oPUg9LDygPGA78DsQOgg5QDiQN/A3EDaQNgA14DWANfA2ADbQN7A4gDngOxQ8YD3pPxIAoAH8AqQDiARYBNgFGAVIBWAFAAToBFAEEAP4A3gDDAMsAvwCoAKIAogCuAJAArwCVAJgAhwBygHwAXQBDQDnAEsAKr+6P04/cj8lPxE/Yz+CwCMAewDAAYgCWALkA3gD2AR4BLgE0AUwBQAFGATwBEgEIAN0AvwCQAHIAU4AjwBC/90/aD7oPnI+UD3MPfw9LDzUPJA8WDuYOsA5+DjgOAA3UDbwNiA18DVwNbA18DZgN1g4aDlIOuA8DD2+PueATgGMAsgDgARwBLAE6AUQBQAFIASoBDADsANoAwADBALgAqAChAKYArgCRAKMArgCRAKIAnwB8gGgAVQBKQCGgEQ/9j9OP0k/HD89PyM/RT/cgF8AygG0AhgC0AOgBCAEuATABUAFSAVYBTgE4ASoBAwDvAL4AngB7AFrAN0AWIAvv64/fj7kPpg+mD4sPjg9qD0gPLQ8QDvAOzg5yDigN+A28DZANiA1cDVwNRA14DZwNyA4cDmgOwA8hD3VP0MApgHAAzwDgARIBLgEoAS4BKAESAQEA7wDMALAApwCjAKQAoQCxALsAvgC/ALoAxwDBAMAAuQCWAIoAb4BOgCPAG1/zj+gP10/XT91P6ZAGwCmAUACCAL8A2AECAT4BTAFeAWoBbgFeAU4BKgEcAPMA3QChAIAAZoBLQC/wCi/wv/GP7g/fT82PoQ+7j5YPlQ94D0IPKw8ODugOmA5oDfgNzA2YDXANbA1ADUANZA2IDbQN/g5EDqwO8A9nj6rv/IBCAJwAyADtAPoA/gDyAQkA4gDrAMEAsACnAJQAmACYAKkAtwDDANIA1gDfAMQA1gDBALgAkoB2gFQAOqAc7/jv7M/RT9fP3a/gkAoAJABeAHgAswDkARoBPAFaAWgBegF6AWoBUAE4ARsA7gDOAK8AeABtwDLANEAjIBjQCM/+v/N/9O/pT9uPp4+uj4QPdg9QDxwO2g7CDqQOUA4cDcgNmA1wDXQNZA1oDXQNkA3WDgIOWg6cDvIPWQ+cj90gF4BjAJcAwADZANQA1wDYAMAA1QCyALUAogCvAJUArAC0AM0A3ADYAOAA4gDSAMgAtACjAIQAZABCwCnQAWAFL/Ff9D/5UAogEIBBAG8AhQDLAOwBGgE6AVYBYAF2AXYBagFSAUQBJgDxAN4AswCrAJ0AagBWgE9AOMA/4BlgEFACUAM/+E/BD7MPhA9hD2UPMA8GDtwOvA6eDnoOMg4IDcwNqA2QDZgNkA2YDaQN3A4IDkAOkg7iDz4PcM/LUAGAToB+AKUAwQDeAM8AwQDAAMYAvQCoAJUAmgCAAJ4AmQCtAL0AwgDRANkAzwC+AK8AnwCMgG2ATsAggC8QDgANMABAFkAQgDAAVAB7AJoAtwDiARQBNAFGAVQBWgFSAVIBRgEiAQQA4QDJAKMAkwBzgGgATEAzQCBAKsAS0Aqf8C/kT+2PsA+rD3sPUw9bDxAPFA7WDrAOqA6GDlAOIA3oDcwNrA2YDawNoA3EDdgOHg5CDpgO5A83D38PsTAHQDCAeACfAKQAzgC/AL8ApgCiAKwAnwCUAJoAgwCXAK0AtQDbANEA4wDhANIAyQCuAIOAdIBdQDwgFDAHv/sv+1AFwB4AKYBBgHwAnQC7AO4BAAE0AUwBWAFQAVIBQAE+ARsA8ADsALUApgCLgH2AawBpgF2ATkA2wDwALGAQ0APP5c/Kj6IPig9XDykPGA8MDtAO2g6sDooOdA50DjYODA3IDawNsA28DbgNyA3SDhwONg6SDtMPLQ9nj7wP8oAxAGkAnwCnAM8AzwC/AK0AmACTAJsAnwCGAIsAiwCtALoAywDiAPsA5ADuAMkAswCaAHMAaIBKgCJAEEAdIBwAJQBJAGgAiACuAMYA+gEWATYBWAFsAVIBWAE2ASoBDQDmANkAtgCfAI0AfgB/gHmAeIB9AGaAVoBFgDEAKU/9T8ePpg+MD1UPLw8KDvIO6A7cDrYOuA6sDpwOhg5mDiQN3A3UDcAN1A3EDcgN1g4CDkQOng7cDyoPfI/PIAgARQCAAL0AyQDaAMkAvgCVAJkAjQCMAIoAcQCLAIAAoQDBAOMA9gDyAPsA3wCxAKEAhIBoAEAANKAdgATAGwAtgE8AaACbALgA7AEAATwBTgFQAWwBWAFCATQBEQD6ANUAxgCzAKQAlgCFAIAAnQCBAJEAf4BagEoAIkAYz9UPuI+ED2UPSg8VDwoO5g7oDuYO3A7SDsAOzg6mDnAOSA4cDcwNlA2oDbANyA24DdQOGA5sDsMPKw91j7y/+8AxAIcAoAC9ALUAtgCqAHUAdQBlgHEAcgCEAIoAlgCsAMsA7gDwAQcA/ADeAKIAjYBVAFYAMiAaEAQgG2AYAD+AYwCrAMIA/AEYATABRAFCAVIBVgFGASABFgDxAN8AzQDNANcAwADPALsAvwCzALQAsACdAG4APCAKj+OPvY+dD3APYA9DDyYPJw8VDxEPHw8FDxQO9A7cDsAOlg5QDhgNzA2QDZANpA3ADdAN8g42Dp4PBA9Zj5gP0YAfADIAbYB4AIYAiACIgHEAbwBVgG0AdACVAKAAtgC9AM8A3wDnAOIA6wDGAKgAeYBEAD5AK0AqAC0AKkAzAFcAjwCwAOIBDgEKARgBFAEeAQQBCwDzAP8A6gDRAN4AxgDkAP4A8QD0AO0AyQC6AKsAmoB5AEDgEw/kD8CPv4+Tj5WPig95D2EPfg9vD0EPQQ83DyQO/A7CDqAOhg5mDhQN6A2QDZwNqA3YDfAOEg5ADpAO7Q8pD3kPkA/Az+6gHoAhAEQAUYBjAHsAdYB5AHsAhQCrALQAxwCyAMcAwQDfAMIAxQC5AJIAdgBRgElANQA7AD4ATYBXAG8AcgCpAMcA0QDvAN4A2gDQANUA2gDTAOIA7gDoAPsA8gEOARwBEgEQAPMA0AC1AJiAe4BSQDNwB6/qT8XPw4++j6GPrA+VD4MPcw9kD1oPPA8eDvIO4A7CDqoOdA5uDjgODA3IDaAN1A3cDewODA46DngOzg70Dz0PZo+ID9NAG4A8gEpAOoBigHMAnQCMAIUAmwCsAL0AqwChAMQA1QDvANQAyQCvAIoAgwB1gGCAXgBCgEkAV4B9AIgApgC+ANIA/QDvANgA3ADWANoA1ADfANMA6ADgAQQBEAEsARgBHgD8ANMAvwCLAH6AXgAxwBpP6w/dj8TP0A/fT8YPsg+jj4oPZA9bDzkPJw8aDv4O0g7ODqgOnA56DkoOEg4MDfgN7A3cDegOHg5GDpQOyA7mDxYPTo+sj9gAPYBGgF0AVoBVAGSAewCOAJEAuACiAK4AsADeANsA4AEIAOYAuIB3AGSAZwBmgFCAUQBigFkAaQCEAL4AxQDSAOcA5ADbALMAtADIAMsAxQDEANQA7wD6ARwBIgEgARgA/gDBALkAjwBtAEHANoASMAmP7Y/DD9uP04/Uj7GPnQ9hD1gPMw8nDxIPCA74DuoO2A7IDroOnA5sDjoOGA4EDfAN7A3qDgQOSA6ODrkPDg8ODxOPhW/lQBcAMwBdgF6AUoBWAGkAjgCbAKEAtgDfAMUA0ADuAPIBEQDkALSAdIBrgF0Ab4BpAIYAhwCSAKkAvgC5AMYA0wDSAMkApgCbAJgAswDLAOoA9AD8AQwBGAEuARoBBgDjAMAAqwB4AGYAaYBagENAN4AgQCIgA5/6j92Pzw+QD3YPTw81Dz8PJg8gDysPHA76Du4Oxg66DnwONg4UDfAN9A3gDgoOJA5MDmwOng7MDvQO4Q8XD1uPm0/5wC0ATwBHgF4AVgCDAJsAmQCiALsAtQC+AMIA6gD1APgA2QCzAIIAewBSgHwAfgCbAJIAnwCSALsAxwC8ALMArACYAIEAngCqAMkA3ADiAQoBCAEBAPAA8QD9ANsAvgCXAI6AfYBygH8AWwBFwDPgHO/vz8OP2s/DD6QPcw9vD14PRA85Dz4PNQ8yDwgO5A7YDqQOeg5MDk4OLg4IDfgOHg4mDkAOeA6aDroOxA7aDt8PBw90j9PAOABWgEQAWABOAFwAgACmAKIAoACvALUA2gD4ARwBDAD8AMMArIB3gHoAigCbAK0AvgCtAK4ArgDLAMEAxAC8AJsAqACvAK0AvQDYAOIA/gDYAN0A7wDdANIAzQCtAJsAjoBxAIqAeoBTgFqAO8Al4AnP+k/vD86Pko+KD3EPYA9lD1wPVQ9CDzMPIQ8ODsAOmg5sDlYOMg4QDgoOFA4gDkAOSA6IDpQOuA6SDrQO3A8PD2xPwYBVAG+ARIApAFKAaABwAJoAoQC8ALcAxgDgASQBJAEdAO8A0ADKAJgAhwCJAN0A2wDcAMAAywDaAM0AtACxAMAAtQC+AKUAygDHANsA5wDlAPIA6gDUAMoAwwDOAJsAgQCeAJwAeoBvAFQAWIBHgBl/9A/lT8aPqY+AD4cPfA9nD1oPSA9CDzQPFg7uDrIOlg5gDkgOPg4mDiYOIA4wDj4OMA5GDmgOag5UDoAOvw8LD08PzoAzgE8gESASsAcAJoBnAHYA1QDaAM4A3AEAAS4A9wDyAOQA6wCwAKgAqgDKAPYBAAD2ANEAxgC9AKUAuwCtALQAzADbAMcAwADIALsAtwDQAN4AuAC+ALwA2wCyALEArACpAHqAZ4BTAG0AYgBFwD7f9h/wT8SPyI+vD5oPiQ9TD1sPOw9eDyYPFA7kDtIOqA5QDmIOUg5eDiIOPA40DiAOKA46DmYOdg5oDogOxg8bD06PpjABgDo//8/cj+CAIwBcAJQA7QDiAQwA4ADoAQABFAD0AQsA0wDsAMcA5gEMARIBJwD+AN0AvwC1AL8AugDLAN0A0QDuAMcAvgCpAKkAuwCwALcAwwCzAMAAyQCgALoAjQCFgH+AZoBVgFcAXEA4AC7v4G/lj8NPxA+1j6KPgw9hD1kPSA85DxQPCg7oDr4Oeg5SDlAOWg5EDkgOKA4iDigOKA5IDloOeA50Dp4Ovg8KD2ePsVAIcAfP5A+tj63gCYBlAK0AwgEVAOMAxwC/AOQBEQDzAPcAzAEAAPoBFAEiATcA8QDiANIAyADLALAA/gDuAQ4A2QDPALUAvgCjAJIAlwC0ANUAwADEAKQAlwCAAHUAeIBTAGqAVwB3gEEAPrALn/3v74+7D7CPvQ/MD5MPlw9OD0EPPw8RDyYO7A7aDqIOmg5wDoYOXA5ADloOIA4+DiAOUA5wDo4Oig6UDqoO9g9Tj6QPuY+rj6YPv4+w4AEAawDMANAAtwC9AKUAxgDgARwBIAENAOABFgE2AUYBIAEWAQEA6gDWANIBCgEUAR4BDgDZAL0AqwCyALkAsgCpAKYAvAC7AKIAlwCMAGkAYwBfAEKAZ4B5AGQASAAqYA8QDg/hT+nP18/Vj9YPvo+WD44PZw9DD0wPKg8aDvoO6A7IDqIOqA50DnAOYA5mDlYORg5aDmIOiA6KDpAOsg7cDvAPTQ9xD5iPhY+RD85P2IARgE4AjACgAKkAnQCoANsA6gEIAQ4BCgEAARoBJgEyATwBHAECAQgA/AD2ARQBEAEWAPwA2wDOAKYAsADBALUAuwCVAJ4AhQCJgHCAdgBqgFCAU4BXgFoAVIBagEkAMgArABjQBLAJr/awD0/vD9JPzw+uj5SPjg9sD18PQg89DxMPAA78Dt4Ovg6uDp4OkA6WDowOiA6EDp4OgA6qDrYO0g79DwAPOQ84D00PXw96D6yPti/pMA4AJYA4gEsAWIBxAJ8AnACvALIA0QDoAP0A+AEGAQYBCgEPAP4BDgEUASQBKgEeAQQBAgECAQ8A9AD0APkA4wDvAMsAxADCALEAqQCNgHIAd4B5gGUAY4BSAE4AKcAU4B8f8gABL/av4g/ST84PrI+fD40PcA91D1EPTg8rDxgPCg7kDtAOwg66DqQOrA6QDpoOgg6CDogOhg6WDrgOtg7MDt4O0A75DwsPKg8yD1kPZY+cD7pPxo/vr/4gEgA/gEoAbwCIAKcAvADLANcA4gD6AQABEAEgAToBOAFCAUYBSAFIAU4BNAFKAUQBRAFIATABOgEeAQQBDwDyAPsA3QDAAMIAuwCZAISAdABjAFEAQkA9QBqAE+ANL+oP1E/Kj7aPpQ+UD4gPcw9tD0kPPQ8TDxAO9g7gDt4OvA6mDq4Ong6CDo4Ofg54DngOjA6cDqIOtg6+DsQO2A7oDv4PCA8jD0gPaQ+ED66PsA/uL/igHQAjAFaAcgCRAKwAvwDAAOYA+AEMARwBLgE6AUgBWgFcAVIBZAFqAV4BWgFSAWgBUAFUAUIBNAEuAQwBCAD4AOYA1wDDALkAlQCCgHcAb4BMADrAKGAZoALv82/tT8oPvQ+sD56Pig98D2kPWA9CDzIPJg8aDvAO+A7aDsIOvA6gDq4Ojg6ODnYOiA58DnwOhg6qDqQOuA7ODsIO4A7xDwkPEw8wD1QPdI+Rj77Pyg/i0AxgF0A6AFaAdACdAKYAxwDUAOUA+AEOARwBIgFKAUwBWgFaAVIBYAFuAV4BUgFgAWoBXAFCAUQBNgEiARYBBQDzAOIA3QC3AKAAmYB4gGKAXwA/gC+gG4AFH/Sv70/ND7yPqQ+fD40Pcg93D1sPQA81DyQPHg78DuoO2g7EDrQOqg6SDpIOjA50DnQOfg5sDnwOhA6WDqgOsA7CDtIO6g7/DwIPLg8/D1wPfI+eD7mP2b/w4BoALQBFgGIAjgCXALoAzwDfAOYBCAEeASwBPAFOAVIBaAFoAW4BYAF8AWABegFoAWABZgFeAUoBPAEuARwBCAD4AOIA3AC5AK8AjQB2AGMAUABNACgAGCACr/3P3M/Jj7iPqI+SD4UPdg9iD1APQA87DxoPCA7+DtgO2A6+DqYOpA6eDoYOhg5wDnwOZg5mDnYOgg6cDqAOvA7ADtIO4g75DwcPIg9GD2wPeI+eD7XP1D/xIBvAIgBRAH0AjgCYAL8AwgDhAPYBAgEkATgBRAFeAV4BYAF2AXYBeAF8AXoBeAFwAXwBYAFmAVoBSAE+ASwBGAEDAPkA0QDBALsAkQCCAH6AXoBEgD7gHfAOP/nv6M/aD8kPug+mD5IPgQ9/D1wPTg8+DysPGg8GDvAO4A7eDr4OqA6iDpoOjA5yDnIOeA5iDnQOcg6UDpYOvg66DsgO1A7qDvIPFg83D1MPeg+Gj6hPw8/pf/mAHoAwgGwAcQCaAKkAswDUAOgA8gESASoBOgFEAVoBUgFoAWwBYAFyAXYBeAF+AWQBagFQAVQBSgE6ASwBGgEFAP8A1ADBAL4AmQCCgHEAbwBMQDWAK6ALT/dP6E/XT8oPuw+nD5WPgw9xD2EPVg9IDzYPJw8RDwAO/A7aDs4Osg60DqgOnA6ODnYOeA5wDn4Ofg58DoQOsA7KDsgO3A7mDvsPBw8oD0wPYQ+Oj5kPuw/bT+wQCEAuAE0AYACCAKMAuwDHANYA/wD4ARoBIgFAAV4BWgFWAWwBZgFsAWABcgF8AWgBbAFUAVYBSgE0ATQBIgESAQEA9gDeALkApQCTAI8AawBcgEgAMkAvkAuf+S/lz9dPy4+7D6gPlo+HD3YPZQ9UD0oPOA8nDxcPAg70Du4OxA7IDroOrA6QDp4Ojg5+DnoOcg6ODoQOlg62DsQO2A7uDuQPBA8TDzsPQA96j4OPo4/KT9cf+RAOQCqASIBlAIcAlwC0AMoA1gDrAPABFgEmATYBRAFWAVgBWAFcAVwBVAFiAWQBagFSAVIBSAE6ASwBEAEfAPMA/gDYAM0ApgCfgHuAbQBaAEcANwAjQB8P+i/nz9gPyg+9D60PkQ+QD48Pbw9TD1YPRw82DykPGg8GDvgO6A7eDsAOwg66DqwOlg6cDowOjA6MDooOlg6mDrgOwg7iDvIPBg8JDxsPPg9KD2mPjo+fj7WP0B/4EAMAIoBOgFwAcQCcAKUAwQDWAOMA+AEOARABPAE6AUYBWgFcAVwBXgFQAWIBYgFqAVABVAFIAToBJgEeAQABDgDsANIAzwCpAJIAjQBqAFmAR8A4QCMAHf/wb/vP24/Ij72PoY+lj5YPhw94D2kPWQ9NDzAPMQ8jDxEPBg72DugO3A7ADsYOug6mDqwOlA6UDpQOkA6kDqQOuA7ADuIO8g71DxcPHA8lD04PXA93D5CPvU/Er+VACAAVwDGAUYB6AIYAqwC+AMMA5AD2AQgBHgEuATABVgFSAWABagFmAWgBagFoAWgBbgFYAVgBSgE+ASwBHAEMAPwA5wDQAMgAowCcgHeAYoBfADnAKGAYMAe/86/iT9JPw4+yj6YPlo+JD34PbQ9QD1EPRw84DykPHQ8ODvIO/A7qDtIO1A7MDrIOuA6kDqIOoA6gDqwOoA6wDs4Oxg7sDvEPFw8eDyMPTw9HD2YPhY+lj7mP3A/mUAqAKwA4AFYAegCKAK0AsQDVAOgA+AEKARwBLAEwAVYBUAFoAWYBZAFiAWABZAFuAVgBXAFGAUgBMgEoARABDgDuANkAxwCwAKcAgYB5AFEASsApIBkQBu/4r+aP2A/GD7MPpQ+Vj4gPfQ9jD2cPXA9BD0wPIg8hDxcPDA7+DuQO7A7UDtYOzg6wDr4Opg6kDqYOqA6uDqIOsg7ADtAO5g7zDxkPLA8qD0oPXg9kD46PkA/OT9Kv9+ALgCCAQYBgAHsAhQCiAMYA2QDsAPgBDAEeASoBPAFKAVQBbAFuAW4BbgFqAWYBZgFuAVoBXgFOATIBPgEaAQkA9ADhANsAtwCgAJUAcQBnAEGAPgAbUA2P+2/pD9wPyQ+1D6mPlQ+PD3APdg9uD1EPVw9FDzIPOw8aDxQPDg7wDvQO5A7gDtAO3A68DrQOvA6gDroOoA6wDrQOtg7EDtoO4Q8IDxAPOw84D0kPWA94j4WPpY/Pz9ef/eAEQCMASYBbgGoAhwCgAMYA2wDmAPgBBAEWASgBMAFCAV4BUgFmAWQBYgFmAW4BWgFWAVwBQgFOASABLAEKAPgA5QDRAMAAuACfgHgAYQBbgDHALbANP/3v7Y/Zj8uPuw+rD50PjQ9zD3gPbg9TD1gPSw8xDzgPLA8TDxgPDA7yDvYO7g7WDt4Oxg7EDs4Ovg64DrwOsA7ADsgOzA7ODtQO+A8BDycPOA9GD1cPaA9xD5ePpM/FT+Yf+aAFACCAQgBaAGAAjgCQAM0AyADmAPwBDgEGASoBLgE+AUYBXAFcAVIBYAFsAVoBWAFYAVwBTgEyATwBHgEOAPQA5wDXAMAAvACfgHAAcgBZgD+gHnAOr/sv6k/cz8+Pvg+sD5CPkw+MD30PaA9sD1IPWQ9AD0YPOw8kDyoPFQ8XDwAPBg74DuQO6g7WDtYO0g7eDsoOzg7KDs4Oxg7UDuAO8A8JDxkPIg9FD1cPbA96j4wPk4+8j8dP4DAIwB2AJQBGAFWAdgCMAKgAzQDQAPoA9AESASgBJgEsAUABXAFQAW4BXAFoAWIBaAFaAVgBXgFCAUABPAEcAPUA8ADuANAAyQCvAIkAdgBkgEiAKUAUAASv8U/rT8YPwA+xD7GPlw+DD4APgA98D1kPXQ9HD0IPMA8yDzMPLg8dDwsPBA8GDvoO5A7uDtgO3A7WDtAO1g7UDtoO1g7cDtAO8A8JDwgPGg8nD0QPZQ99D4CPrI+kj74Pxy/soAfAKIA7gEuAUoB7AIYArAC6ANQA+gD2AQgBEAEyATYBOgEyAVABbgFSAWwBXAFaAU4BTgEkAUgBNgEuAQYA7ADZAMYAzwCpAJsAeQBRgF4AOuAbH/KP+U/jT9aPug+qD6IPpQ+MD34PcQ96D2oPVg9TD1cPQQ9KDzYPMA83DyMPKA8VDxoPAw8ADvwO4A7wDvwO4A7kDuIO7A7qDuIO+g7xDwMPFg8qDzcPTA9cD3SPlg+uj72PyE/YD+VwDQApAE0AWIBoAHkAjQCQAM0A0AD0AQQBHAEQAS4BLAE8AUwBSgFCAXYBYgFaAVgBXgFIATgBOAE+ASABEQDzAOUAwQC5AJ8AmwCHgGsANwAuoBFQBf//D84Pxw+5D6aPnY+OD3CPgw97D2gPWA9YD14PQg9KDz8PNw80DzcPKw8qDyUPFA8TDxYPDA76DvIO8A78DugO7g7gDvoO4g70DvoO9w8DDxYPLQ8mD0wPUw94j4cPqI/Bz+cP4U/oH/2gEABFgG0AeACHAI4AjgCkAN4A6gEGARQBKgEUAS4BOAFUAUwBSAFUAWIBcAFQAVIBSgE0ATABNgEqAQYBBgDnAMUAnACHAJAAkYB7QD0AFsAIsArP7Q/Vj8oPug+gj5IPhw93D3APaw9mD2IPbQ9GD0cPQQ9FDzYPOA9MDzIPOQ8dDxQPLw8fDxgPGw8IDv4O8w8FDwUPAA8FDwEPBA8KDxcPLg8qDyAPRg9bD2oPdQ+SD7jPyE/Wz/XgHWALMA/gEYBoAIMAlwCYAJMAqgCqANgBBgEQASgBEgEmASwBPAFGAVIBUgFOAVQBWAFYAUwBOgEoARQBKAEWAQwA6wDaALAAmIB1AIMAggBgwD+gCO/zH/Mv74/LD7EPoA+ZD4oPcQ9lD20PZw9uD0QPTw9GD1UPRg8/DzgPQw9MDzsPMg8zDykPKA83DzoPIg8YDx4PGw8EDx0PEA8pDxYPEw8eDxoPLQ8uD0cPTA9BD30PfA+Tj6cPsq/sf/hAEeAYgCxAEYBCgGkAnQCpAKQAmQCXAMUA7gEMAQ4BLgEoASgBFgE8AUgBTAFKAUQBWgFAAUABPgEyAS4BDAEKAQwA9ADVALgAngCGAGWAbYBUAENAJZ/2L+BP3w+9D6OPpQ+YD3QPag9bD1UPXg9LD0cPSw82DzwPOQ8wDzoPKA87DzgPMQ80DyQPLw8XDyYPOA8yDyAPFA8BDx0PHg8WDyIPJQ8kDxQPKg8gD0QPQQ9ZD2APc4+ED4APw4/KD9A//AAXQDWAPUAvACiAYgCHALsA0gC6AJgAtgDkAQ4BCgEWAUIBRgEuASABTgFGAUQBVAFiAVgBNAFMAUoBIgECAQABHAEEAOEAxwClAIEAcgBoAFIAQ4AkYBVv8Y/SD7qPoA+rD5mPig9mD2wPQQ9aD0YPQg9DD0cPTg8kDzgPJw8zDzcPNQ9MDzsPOQ8rDy0PLg8nDzYPPQ8zDyEPEA8bDxQPKA8sDzoPLg8hDyMPNg8xD0wPUw9+D4YPfg+aj6IPzY/C7+RAJYBKgD0AKoAyAFmAfQC4AM4AvwCvAKcA3wDwARIBJgE6ASABOgEyAUIBRgFEAVgBWAFOATYBTgE2AS4BBAEAAQABDgDuAMMAqACBgHKAYgBXwD+AJUASb/OP0c/ID6cPlQ+Yj4KPjg9cD0wPRA9DD0QPRQ9JDzkPMw8+DyIPPA8iDzUPNg84Dz4POg8+Dy8PKA8rDyMPPg87DzkPLA8XDxEPKA8rDzAPSQ83Dz4PNw9JD0IPXQ9pD48Pkw+lj8IP3Q/bD9LQCQA0gE6AUQBiAG2AVQCZALIA5QDdALkA3gD+AQIBKgE4ATIBSAEyAUABWAFYAVwBWgFIATgBQAFIATYBKgD0AOYA5QDxAOgAvoBzAHuAV4BHADSAPyAU3/tP0Q/Mj7WPk4+fD4aPiA9vD08PTg9ID0APOA8/Dz0PSg88Dy0PIg8hDzcPMQ9JDzQPMQ8wD00PPQ8tDyEPPQ89DzkPMw8wDzYPKg8kDzwPNA9CD10PXw9CD1cPXg9uD3+PiY+kT87PxM/aT+Kv8oACACoASQBvAFuAagBlAIEAmAC5AO0AzAC2AMYA+gEaAToBNgEkARIBLAFIAVABUgFGAUYBMAEoASgBJgEbAP8A7gDhANIAugCrAJyAb4A4AD4AM8AiQATP5Y/Zj7qPmA+dD5WPhA9gD2MPUA9UD0cPSA9KDzcPNw87DzEPNA88Dz4PNQ85DyEPMw8zDzAPQA9RD04PIg8jDzYPRg9JDzcPNw84DyQPNA9OD0MPVQ9QD2APag9dD2yPjQ+Xj5CPuY/Pj8Iv4W/7IBZgGCAVAEcAfABhAFGAagCXAL0AwwDBAMkAvwC9AO4BIgFEAUYBIgEYARQBKgFQAWoBbAFKAToBCAD2ARQBKAEnAP4A0ADFAK0AjgB0AHwATIAygC8gDq/iT9EPww+uj5QPrY+fD3YPWA9ND0oPOQ8zD14PWw9KDy0PEg8tDywPOA9CD1oPPg8uDykPJw8yD0wPQA9fDzMPQQ9MDzYPMQ9MD0UPTQ83D0oPVw9cD0cPWg9nD3wPew98j46PnA+ij7rPzI/e7+WABqAIYBwANoBOgEeAbwBzAIqAfwCPALMAyAC2AM4A5gD8ANMA8gEiAVYBRAE+AS4BGAEoAUwBdgFmAT8A+gEOARABGAEUAQQA5gCyAJsAhQCNgGgAVgBEABYv80/hT+KPwI+nD56PiY+ZD3EPaw9IDyAPNA9ND14PQQ9IDy8PFw8mDyMPRw9ED0YPOg8xDzQPPQ83D0cPSQ8wD0sPSA9RD0cPOA9OD0UPRw85D14PUQ9dD0kPVA90D3MPcw98D4sPmw+pD7dPwY/dz9nP77/5QChAOcA8QDAAXYBsAHUAgACoAKUArACeALIA6wDqAOQA9AD0AQwBGAFOAUgBLgEaATYBVAFeATABLAEWAQwBEAE4ARcA7wChALAAoQCTAIgAhgBYIB0P7k/cb+iPzk/FD6aPhA9hD2cPdA9fDz4PGA8mDzgPMg84DycPFg8ODxsPJg84DzwPLg8gDyAPKQ82D00PSg8yDzkPNQ9LD0oPWg9SD10POw8wD10Pag9uD14PWQ9sD2kPdQ+Bj5WPqg+Uj6iPvs/NT9cP7+/38A1wBMASAEqAZYBjAGoAaACGAJkAoAC8AMEAygC1ANYA8AEAAQwBGgEmASwBCAEoAV4BYgFiAVYBRgEiAR4BEgFIAT4BFAENAOIAwQCvAI4AhACaAHsAVMAm7+tPww/fz93PzA+jj5APfw9AD00PTg9UD0IPOA8gDyUPHw8JDy0PIg8lDxoPEA8xDz0PLA8rDyYPIQ86D0APVQ9HDzYPOg9ID14PVg9vD1wPRA9DD1oPaw9/D3oPcw91D20PbA+Mj60PtQ+6D60PoA/Lj9gP/iAJIBggEAAkADIAWwBnAHMAjgCHAJEAoAC9AMEA4ADZAM8A2gEIASYBKgEuARQBGgEQAWwBmAF0AUoBOgE8ASoBIAE4AVQBTQD0AOAAzQCjAJQArQCogHoAPpAGAAMv6I/HT88Pvw+mD4kPaQ9ZDzkPMQ9ED1YPPQ8dDwEPGQ8cDwoPGg8XDy4PGw8dDxIPIQ8qDyoPPA80D00PNA9CD0IPTg9PD1YPag9kD28PUQ9SD10PYg+ID4kPdA9+D2gPco+Lj5APuw+wj78PrY+wT9Lv4//+0AngHgARQC6AIIBRAHaAcQCKAIMApgCtAKAAywDYANAA6ADwAQIBBAEAATIBQgEiAQoBNAFyAXgBYAFIATUA/gD4ASIBYgFLANkAygC4AJ2AYgCSAKgAhsAi7/LP8S/qT86PzE/Jj5sPaw9eD24PWQ8wDzcPMg81DyMPJA8pDxcPBw8GDyYPKA8rDykPLg8bDx4PLA9OD0EPQg9AD0IPSQ9OD1oPYQ9kD1sPVQ9pD2sPbA9jD3APfA9qD3ePhI+OD3aPhA+SD6yPqI+xj8LPxE/MD9Yf+hAFgB8AGAAuQCMAToBWAHkAgACSAJkAmQCgAMsAzwDFAOkA7wDtAOwBBAEqASYBHAEeAT4BOAFOAWwBcgE3AOkA5gE0AVYBJAEdAOIAuYB8gG8ApACzAI1ANoAj7/nPzo/MD9HP4Y+7D3sPbg9uD1MPVQ9MDz0PNw8/DzcPNw8oDxoPFQ8pDz8PRA9EDz0PLQ8tDz0PSw9cD14PRA9BD04PSQ9aD28PZA9nD1sPXg9kD3QPcA93D3cPcw97D3oPjo+JD4qPg4+Sj6EPtw+9j7fPwY/dz9zP7m/xQBxgHuAcACIASQBXAG+AbYB9AIQAmgCdAKwAugDLAM4AxQDcAOwA9gEYARgBEAEcAQIBJAFWAXIBZAFPAP0A/QD3APwBFAFIAR4AvABnAFOAfwCGAIIAeQA8r+HPxg+zj8iPxo+xj5MPfQ9cD0wPTQ87D0MPQA8iDyUPNg9ADzIPEQ8XDyMPOw89D0kPSQ8yDywPLw9PD1EPaw9bD1oPSw9GD1sPaQ9wD3kPaA9qD2EPfQ90j4GPiQ9wj4yPgQ+ej4cPlI+uj6kPrY+uj7DP1k/ZD96v6W/3QAAgE4AkADvAO4BPAFWAdoB0AIYAkACmAK0AogDGAMYAyQDYAOwA7ADmAQYBGAEcAQ4BGAEkATQBOAFKAWgBKwD7ANAA/gEKARoBHQDfAJ+AWYBAAGYAdABwgFTAE4/cD6WPrA+oD7MPsg+dD1oPOQ88D0cPTQ8xDzwPKQ8gDzUPMg86DyEPKQ8pDzMPTg9FD1gPQA9GD0MPUg9oD2YPfw9kD2EPag9qD3APgY+Ej4qPgw+KD34PeI+ID5uPlI+XD52PkI+rj5OPrY+rD7DPyE/JD97P3k/Vz+0v94AJ4BQAKsA0AEiAQ4BSAGoAfYB8AJYApwCvAKsAuQDLAMAA1gDvAOIBDgD4ARABHAECARQBJAEsAToBWgFmAUAA+ADnAOABAAESATQBGgCoAGCAWoBkgHUAawBqgErP9Y+ij6yPuo+yj7UPng96D1APQw9ED1kPTg8pDyoPJw89DzUPNA87DygPIA84DzIPQQ9ZD10PRQ9HD0cPSA9RD2YPYw98D2QPbg9XD2QPdQ9/D3EPj4+Ej4EPeQ98D4gPng+Cj5CPpg+qD50PkY+1j7MPtk/Iz9QP6O/qL+uP80AEMAugFYA3AEGAUgBjgG8AUgB8AIoAkACuAK8AtADEALMAwADUANIA4wD2ARYBAgEOAQ4BEgEYAQABNAFkAVwBGgECAOQAwQDUAQwBKgDtAJOAeoBVQDhAKIBbAGIAQU/kD7WPpI+dj4kPmQ+mD3oPRg8yD0wPRA86Dy8PIw8xDycPLg88D0MPSw8oDyIPNQ9JD1cPbA9rD1MPWw9LD14PbA9yD44PcA92D3sPcA+BD54PlA+Wj4IPiw+Aj6+Pno+VD6MPpI+aj5gPro+9j7GPs4/KD8ZP20/aj+JP+K/67/5gAIAlADXAMwBAAFeAVIBYgG+AeQCXAJEAnwCaAKUAqQClAMMA2gDLAM8A4gEOAOsA1gD+ASQBEgECAS4BOAEkAQQA8gDoAMwAswD0AP0AywCJgFeATgAcQCvAPYA4gBdv7I+8j4YPfA+Gj6MPng9lD1APVw9CD0oPTw9NDz8POw9GD1YPXQ9DD1cPVg9MD0wPUw9yD34PaQ9tD1IPbw9rD3OPgA+KD3sPew9xj42Pgo+bD4kPjo+Nj4wPjI+Pj5MPrY+ID4SPmI+nj6iPqo+nj78PrY+uj70P0e/pz9lP51/yAAKADkAfgClAMMA6wDUAUYBrgGqAfgCBAIsAcwCMAJYAogCmALsAtAC1AL4A1gDyAPgA3ADaAPwA/gD8ASwBMgEfANoAzADPALUAwgDqAO8AvQBngFOARYA4AD8APwA8AApP0k/Yj8MPu4+Rj6YPkA+AD3sPdo+HD3kPYw9nD1UPRg9aD3uPjw94D2sPYA9qD18PUI+Lj4EPiw93D3wPfg9vD2KPgw+Vj4sPdw+Ej5OPl4+Mj4OPnI+Fj44PjI+dD5mPmw+fj5YPlw+ej5mPpo+zj7WPsU/GT8iPw0/Qr+gv78/qz/lgAuAdABOALwAigDzAO4BHAFmAbQBkgHKAdgB7gHAAlwCcAJkAoQC1ALoAtgDPANQA4QDgAOQA/QD6AQoBFgEuARsA7wDEANoA0ADlAOIA7QDKAJSAdIBuAFgAVABbAEbANEAfL+RP6k/XD8sPvw+lD6yPlw+XD5+PgY+CD3sPYQ9nD2IPcY+Bj4IPcw9pD1QPVQ9XD2MPdQ96D2IPbw9QD2MPbA9lD3MPfw9pD2oPbA91D3oPfQ97D3IPdg94D3IPiY+BD4WPhg+Lj44Pg4+dj5QPpg+rD6QPuI+1T8MP3g/Ur+6v6w/0QAowCeAYQCAANYA0AEkAUQBlAG2AbQBwAIAAiQCLAJEApgCvAK4AvQDPAMcA1wDgAPIA9wDwAQIBGAEWARwBGAEUAQ4A7QDbANwA1ADSANUAxACuAI8AZIBlgFGATAAlgCLAH3//j+yP3Y/LD7mPqA+Tj5CPnQ+Kj4APhA95D2EPbg9TD28PXg9YD1kPVg9RD18PRA9VD1EPXA9MD0UPWw9eD1MPYg9iD2IPYw9rD2MPcw94D3GPjw99D38PdY+ID4aPjw+Ej5kPng+Tj6mPqY+pD6EPuo+1j8sPx8/Sj+dP7C/hv/FADRAGYB3AHYAnwDCASIBCAFEAZoBrgGkAcACFAIwAhgCfAJYAqwCgAL8AtgDLAMcA3QDVAOsA6QDwAQgBDAEMAQoBAgEHAPsA7ADSANcA3wDHAMEAswCrAIcAfIBbgEKATcAuQBzwAUANT+tP2E/OD7IPvQ+Wj5OPng+AD4EPcQ94D28PWA9aD1sPUw9QD1EPUQ9aD0UPTA9KD0cPRQ9MD00PSw9OD0QPVA9QD1QPWg9eD1wPUg9sD2sPaQ9qD2IPcw9yD3cPdg+Lj4yPhA+fD5IPrg+Uj6wPqA+/D7WPy0/Tb+ov4N/wUAnwAKAdgB0AKcAxgEuATQBWAGwAZ4B1AI0AgwCYAJAAqgCsAKYAsgDIAM4AxgDRAOcA7ADkAPABCAEOAQQBHgEUASABKAEQARABDQDnAOMA4QDoAN0AwwDKAKoAgQB2AG+ATEA8gCJAIaAZj/ev5c/Uj8APsg+sj56PgQ+JD3UPeg9qD1IPUQ9YD04PPA8+DzgPPg8tDy8PKg8mDyQPKg8uDyYPKg8hDzMPNA88DzMPRw9MD0IPWA9cD1APaA9gD3cPeg9wD4iPjA+CD5sPlo+rj6OPvA+zD8aPyw/JD9Uv7W/mz/SQAgAZoB9gGMAowD/AOQBFgFAAagBhAHeAcwCJAIAAlQCdAJIApACpAKIAuQC8ALcAwQDUANoA0gDpAO8A4wD6APgBDgEOAQgBFgEaAQwA+wDhAOgA3gDNAMsAxwC3AK4AiYBwgG4AToA/gC5AFvAKP/Tv78/ND7GPso+hj5QPiw99D2EPYw9QD1oPTw84DzcPMg85Dy8PEg8hDyoPHA8XDxwPGg8RDy4PEg8oDygPIg81DzsPMA9HD0APVQ9fD1QPaQ9uD2EPeg99D3WPiw+GD5yPkQ+pj6OPvg+xT8ePzY/Cz9nP0U/vb+mf9fAOQAbAEQAmAC3ALYA1gE0ARwBTAGsAYwB2gHQAiwCOAIMAnACQAKIApgCuAKYAugCyAMAA2ADbANUA6ADvAOcA/AD4AQIBGAEUARABEgEAAPEA4QDcAMoAyADOALsArACRAIEAbgBOwDGAMgAswAxv9c/vz8oPu4+kD6SPmo+ND3QPdw9oD10PTA9DD0wPPQ80DzEPOw8lDycPJA8hDyAPIg8nDygPKg8rDyAPNA87Dz8PNg9LD0EPXw9RD2sPbw9pD30PcY+Jj4+PhY+ZD5UPqo+hj7cPsI/ID8sPwM/aT98P0s/pD+Hf/X/z8AxQCUAQAC+AFEAjwDrAMQBKgEeAUABhAGYAbQBqAHsAcACHAI4AgACQAJYAnwCTAKgAowC+ALQAygDPAMgA3ADQAOkA4gD+AP8A8AEOAPQA8QDjANMAzQC0ALAAvQCvAJ4AhQB9AFgARQA0wCbgFvACr/CP68/AT82PpA+uD5+PgQ+KD38PYg9oD18PQA9YD0sPRQ9CD0APRw87DzYPOA84DzsPMA9BD0MPRw9MD08PQg9XD1wPVQ9oD2APdg94D3GPg4+OD4OPlg+aj5APo4+nj6uPoY+7j7aPys/BT9eP2s/bz9Hv52/s7+bf/8/7UAOAGmAQgCVALgAkQDyANoBBAFeAWYBRAGYAbIBjAHmAcgCJAIkAiwCNAIMAlwCcAJkAogC7ALAAygDOAMQA2ADfANkA7gDkAPoA/gD2APsA7gDcAMwAsQC+AKoAqACsAJ4AhoB6gFUARkA2wCYgGGANL/RP4A/Rz8kPv4+hj6sPn4+HD4kPfQ9qD24PXQ9cD10PWg9SD1APXg9GD0IPQg9HD0cPSQ9ND0APUQ9dD0APWA9dD1APZw9tD2IPdA91D34Pco+ID4CPmI+cD5+Pkg+lD6uPrQ+jj76PtQ/JD83PwI/Vj9iP3M/VT+5v43/97/aQDPADIBpgEUAqACCAOYAwgEiAT4BFAFmAXwBUAGgAYABzAHWAeoB+AHEAhgCPAIgAkgCoAKMAvACyAMgAzQDJANsA0wDqAOMA9gD1APAA8gDhAN4AswCxALwAqAClAKsAn4B5gGMAVYBCwD2AGeAZEAYP8Q/kD9ZPy4+wj7gPoI+hj5IPiA9wD3UPbg9aD10PWA9UD1APWA9ED04PPA86DzkPOw8/DzQPRQ9HD0YPSQ9MD0APWA9fD1APZQ9pD2wPbg9kD30PdY+Lj4yPgg+UD5gPm4+Tj6yPpo+4j7LPx4/JT8vPww/az9Hv6a/tT+wP8wAJgAKgHEAWACuAIcA7ADIARoBOgEaAXoBTgGoAYAB0gHgAe4B/gHMAhwCNAIgAkgCrAKUAvwC2AM0AwQDYAN0A1ADqAOUA/QD+AP0A9gD4AOIA3ACyALUAvACnAKkAqQCSAIeAbYBGAENAMMAi4BawA7/8j9xPwg/Gj74PpY+kD6SPlw+HD34PaQ9tD1oPWA9ZD1MPXw9ND0UPQw9NDzwPOw8/Dz8PNQ9JD0gPSQ9MD0MPVQ9dD1QPZg9qD24PYA9zD3oPcY+MD4KPmQ+YD56PkI+nD6+PpQ+/j7MPy0/OD8CP18/cz9WP7E/lL/rP/8/58A7QCCAQQCZAL8AlgDtAMYBHAEAAVABaAF+AWABtAG8AZAB4gH2AfIBwAIcAjgCGAJ4AnACjALoAvQC1AMkAzgDAANgA0QDnAOoA4wD/AOEA4wDeALEAsgCgAK4AnACWAJMAjgBrAFCARAA4ACjgFoAF7/UP5U/VT8WPtA+/D6UPrA+TD5QPhA95D2EPbw9YD1gPWA9UD1EPWQ9LD0cPRQ9DD0UPRw9FD0gPTg9OD0APVw9fD1QPZw9tD2APcw90D3UPfQ9yj4cPgA+aD5yPnw+Rj6iPrY+jD7kPso/KD85PwE/XT92P08/pT+Bv+0/+3/bAAEAZYBFAJ8AiwDoAMYBEAEwARABXAF2AUgBpAG+AZIB5gH+AcwCFAIgAigCOAIMAnQCVAKEAugCwAMgAzADMAMMA0wDYAN8A1wDvAO8A6QDuAN4AywC8AKYApACjAK0AlgCUAIqAZQBbgEhAOoAsYB3ADb/4b+kP20/Bj8iPsQ+8j6IPpI+Zj4APhA95D2MPZQ9gD2sPWA9WD1EPWQ9GD0cPRg9GD0UPRw9JD0kPSQ9OD0QPXA9SD2gPbQ9vD2APcw92D3kPcQ+JD4EPlw+dD5EPpQ+pD6+Ppo+7j7FPyQ/Oj8SP14/RT+ov78/lv/4v9DAMEALAHEATwCsAIUA5AD+ANYBLAE6ARQBZgFyAXYBSAGcAagBugGIAegB6gHEAhQCLAIIAlQCRAKkApAC1ALwAsgDCAMEAxgDBANgA2gDYANIA1QDLALMAswCuAJsAnACYAJQAigB7AG0AWQBLAD7AIcAhQBEgBd/27+YP2o/Dj8oPs4+0D6cPnY+Ej4oPcA93D2UPYw9uD1kPVA9RD1wPRg9KD0gPRQ9ED0oPSg9KD0gPQA9YD1wPUQ9jD2gPaA9tD2wPYA9zD3oPfw90D4ePjw+PD4QPl4+RD6UPqA+hD7gPv4+8j7WPwE/Xz9nP0e/sT+Sv/I/zIAHgFUAa4BQALYAkQDnANIBNgEEAVABZgF4AUwBigGYAawBggHUAdwB+gHcAiACPAIUAmQChALgAsgDAAM0AvAC+ALgAxADUAOMA9gDpAMsAsQDKALkApwCbAKYAvwCbAIkAggCMAGUAVIBNgDyAIaAcIA8v9+/jD91Pz0/Bj8iPvA+jD6mPmA+ND3EPfA9lD2IPYA9pD1MPUg9fD04PTQ9LD0cPTw8yD0YPQA9IDz8POw9GD1oPWw9aD2wPbw9tD2MPdA97D3IPhI+Aj5aPm4+Sj6SPrQ+lj7YPvQ+2z8QP00/Yz9CP6W/jv/rf/MANABbAKgAggDYAO0A/gDKAQ4BYAF0AVQBvgGsAdwB3AH4AcwCHgHyAaYBjgHUAfABvAGaAfQB/gHsAjACZAKgApQCzALkApgCjAKsAswDQAO4A2gDdAMsAwwCzAKcAhwCKAHCAf4BUAGAAeABogFgAPcAoYBNP+g/RD9yPvY+dj4OPnQ+ZD56Pig+MD3wPZg9RD1cPRQ80DzwPMw9BD04PSA9oD30PeA92D3APcg9kD2kPZw9pD2UPeA+Pj4APmg+Yj6CPog+WD4WPiQ94D3cPeI+LD4OPlY+fD5APq4+bj5cPmo+bj5wPko+tD6cPvo+wT9uP0D/zn/kgC2ARQC9AJ0A6AF4AUIBoAGcAhgCdAI8AcACTAL0ApgCnAJEAowCcgHoAb4BhgGAAbwB9AJkAuQC0AOoBGAERAOwAtADIANYBDgEQATABIAEWARQBCQDUANcAzwCpgGQATABFgF0ASsA3wDIgGg/ID6kPrA+YD3APXw88DyYPGw8dDyAPQA9PDzYPTQ8zDzwPPA9AD1sPNA8zD0QPXg9dD2KPjw+DD48Pfg9zj40PfQ93D4WPjg97D3CPnQ+aD5SPlo+Rj5cPhg+FD5EPqA+tD6iPsA/MT8rP26/nj/4v/H/5EA7ACIAcIBYAIwA8QDMAQoBQgGsAZIB/gHMAhgCHAI0AgwCeAIYAjgCEAIIAgACFAI2AdIBggGMAWgBMQCYALwAZgBVgFQAgAEgAVQCBAM4A6gDbAL8AtQC2AKMAlwCwAO8AzgDBAOIA8QDfAKMAkQCPQDs//U/qL/EQC4/xsApP/M/nz8EPtA+bD2cPRg8sDxsPEQ8hDzcPTA9UD3kPhA+OD3kPcw98D2UPZw9qD3OPgw+QD6CPu4+5j7IPuY+gD6QPiQ93D3OPiQ+ED5SPpo++j60Pqo+uD6yPkw+Sj5uPkw+gD6yPtA/TT+RP4s/6X/hv8j/4n/sACbAAIBcgFgAqACOAPUA5gEWARgBNgEqAS4BNAEUAb4BhAHqAbgBvAGEAeABlgGAAZYBYQD8AIIA0gD9gH7AHIBSAEDAHP/AARAChAN8A1ADiAOQA0QClAKgAwwDMAKQAtQDXAOEA6ADVANkAs4BswCxgBFAP7+YP4E/wj/ZP54/Uz9FPwo+gD4MPYw9QD0kPNg85D0wPTg9WD3WPjg+DD5QPkY+FD3APdA98D3ePjY+Pj4aPnI+bj6sPrA+qj5oPiw9iD2cPbQ9rD3WPhw+cD5gPk4+iD7YPtY+4j7uPtY+0D7MPzs/Xn/T/+B/67/9f+EAFwBUALIArgC/gGEAugCNANcA5QDYAS4BEAE4AOYBKAFUAbYBuAGyAYgBlAGIAeQB3AHsAa4BSgFMAMsA0gDzALYAvgBrAAf/+T/XAMACLAK0AyADXAO4AzAC9ALcAzAChAJEAmgCmAMYAyQDaANYAuoBkAEPAKaAPr+PP2I/SD8sPt8/Pz82Py4+jD5kPfg9UD0MPSA9BD0oPNw9OD14Pbw90j50PkY+fD34Pcg+FD4MPhg+Pj4kPhQ+Dj5YPpY+6D6YPlQ+ID30PYA92D3SPgo+Bj4mPh4+TD6sPoA/Hz88PtY+6j7AP0o/cz9Kv7+/qT+mv4BAHwBLAIsApQCAAM0AzQCIAKMArgCGAPoAlwDrANIBGgFcAYIBzAHCAeYBxAHMAcoB+gGkAYQBngFKATcApwCGASgBLQCjgBMAHwA3gGgBGAJAA4ADfAN8A5gDxAOAA2gDLALgAnwCGAKQAzQDAANYA3ACrAGaATAAzACqP/W/jT+qPy4+uj6LPzo+0j6MPmo+LD3YPbw9QD2YPWQ9HD1cPYQ9zD3EPhA+Wj5MPkA+UD5QPl4+CD48PdA9/D2QPdw+Nj4iPjg98D3sPew97D34Pfg98D38PeQ+OD4EPrg+hT8sPzY/BD9NP2c/Ur+Wv5I/hr+gv7w/t3/AgHCAWwCXALUAkADwAIMA4wCMAO8AtQCAASABJgFwAXgBpAH6AfYB5gHcAdYB7gHgAegBnAFWAUoBZQDyAKkA7gESANOAGEAiAFoAigFkAlQDiAQwA1ADuAPQBBgDVAL8AmwCLAIEAhgCoAMwAzQC1AK8AhYBvwDgAJaARsAjv5k/CD7EPuQ+2D78PqY+gj6KPnA9/D2MPbA9fD0wPTQ9TD2sPaA96j46Pjg+PD4OPnw+PD3MPcQ91D2MPZQ9nD3gPeg9+D3MPhY+Fj4SPhw+MD4kPiA+Dj4uPiY+bj6MPu4+4D8sPww/Yj83P0K/iD+fP0g/W7+9v7D/+v/hgAkAf4BIAI0AuYBIAIsAvIB1AHgAqgDUATQBFgG8AfoB8AGuAeACAAJoAb4BWAHMAdIBTgDSAT4BJQD/AJsA6QCUACX/7ABMAbQCZALIA6wD1APMA+QDwAPoA1AC5AJEAlACQAK4AqwC9AKgAnQB1AGSAVQBAADFgFj/5D9JPyI+lD6APu4+uj5gPl4+aD4oPfA9nD2wPVw9BD0IPUQ9uD1wPaw9zj4MPhI+JD48PjA95D2MPbw9RD2APaA9nD2IPbQ9sD3cPjw90D4MPnI+SD5CPkg+fD5YPq4+uD7oPxk/Fz8PP1o/tb+JP4U/rb+4v4o/6L/GwDiABYB7gGEAqwC1AKYAvQCHANoA6wD8ANYBFgF4AawB0AIkAgQCTAJ4AggCcAIUAgIB9AGuAVYBKgCXAMQBCgDQgEcATQCeAKkA8AH8AwQDQANMA6wD8APkA1ADeAMoAoQCCAIIAqQCtAJAAqgChAJiAYgBUgF9ANCAaD/Wv5I/Hj6KPpA+vD5GPmQ+JD4KPjA99D3QPcA9kD10PQA9XD1kPUw9nD20PbA93j44Pj4+PD4wPgA+AD34PYA9wD3YPYw9pD2EPdA96D3qPhg+aj5cPmI+TD6YPpA+sj6WPv4++j74PvY/IT98P2g/ej9Wv5m/lL+9v71/4gAiAA4Ae4BtAKsAoQCeALcAgwDgAOsAxAEGAVABmgHAAeYB2AIMAjAB6gHYAlgCFgGAAZoBigFIAPOAYgDuANQApQBeAKQA4QDaAWgCEALwAuQDGAOcA/QD7AOkA2ACzAJ6AeQB1AI8AiACUAJkAgQCAgH+AVYBBgDlgEk/0T9CPyI+/j6qPlg+eD4KPjg97D32Pgw+QD4kPbQ9bD14PVg9WD1cPVg9VD1wPWQ9mD3wPcQ+JD3IPcQ99D2kPbw9XD2oPZw9gD2sPbw95j4kPgY+cj5APoQ+hj6IPvg+5D7cPtg/Oj81Pyk/Az9Hv4+/rz9FP4x/8f/UACgABgC+AKAAvwCYAMgAxwCiAJIA8QDgAN4BIAFqAagBrAH0AiQCIAIwAiQCWAJAAioBngGaAXUA7gCxAL0ApgCWAKYAhgEqAT8A2AGMAnACyAMoAxgDvAPEA+QDfAM0ApwCDgGWAcgCSAJgAigCOAIEAhIBqgFqATgAooAVv+W/nj9+PsA+4D6kPkg+HD3KPig+Aj5gPgQ+KD38PaQ9qD2MPZw9gD2gPVQ9bD10PZg9/D3gPfQ95D3EPfg9iD3MPdA9sD2oPeI+Fj4SPj4+Lj5QPl4+dD6MPto+2j7WPxI/WT8MPyU/dT9rPxA/GT9dP6s/Vz9+P5JACcA0P+gAYgDLANUAqQCjAOsAtoBuAI4BMgEUAQABcgG+AdgCOAIgAnQCfAIoAhgCDAI4AZgBdwDmAOEA3wCeALIAqwDpAN0AxAEEAa4B/AIoAqQDNANwA1gDhAPoA7ADNAJUAg4B3AHAAjwCJAJQAjgB1gH8AboBTAFvAMiATn/FP6k/Sj8mPqw+Qj54Pfg9rD38PgA+QD4UPdA9+D2sPWA9eD1wPXQ9ID0APWQ9TD2EPaw9jj44PeQ9iD2oPYw96D2QPaQ9jD3sPfA91j4KPlQ+XD5APo4++D7QPyc/AD9QP0s/fj8xPxA/TT9IP1E/VD9qP1w/sv/UQDhAIABDAJ4A5ADDAMIA3gD3AIsAtgC3APgBOgEyAXIB+AIcAnACdAKAAsACrAIYAj4B4AGYAXABPQDLAPoAjgDqAN8A1ADEASYBOAFqAcACWAKYAvADJANIA2ADBAMYAtQCRAHUAbgBjgHiAeACDAJUAjoBkAGmAXoBOQCnAAq/wr+oPy4+5j6+PkQ+eD3gPco+OD4MPiA90D3EPcw9tD0APWQ9RD1kPRg9ED1cPWw9fD1IPdA9xD3EPeg98D3EPdw9lD2MPcQ9wD3YPeI+Aj5APmA+SD7qPtQ++j7AP1o/dz82Pzk/cj9cPzQ+zD8jPw0/GT8RP1W/gj/6P8kAbABRAJYAgwDVAMwA0wDPAM8A3gDYATgBBgFaAYwCDAJkAnwCUAK4AnACDAI+AegBhAF3AOMAzwDgAJYAmwCtAL0AsgDwATYBTAHMAmACjALgAzgDBANoAwQDCALUAnIB4gHEAhACDAI0AhQCaAIiAfYBnAG6ASEAmIBhACP/8D9NPzo+wD7UPkQ+ID40PgI+cD4sPhI+PD2YPbw9eD1oPXQ9JD0oPTA9BD1kPXg9YD2QPfQ9wD4IPgg+ND3MPdg9mD2kPbA9nD3cPiI+YD5+PnQ+tD78PvQ+6j89Pw4/bz8YPwA/MD7aPtw+3D7iPuA/DD9Fv6g/sn/7AA6AWgBZAJAA9AC0ALcApQDxAMgA3ADYATIBXAGCAewCGAJEArQCRAKUArACWAI6AZwBmAFaAS0AsQCDAMwA8QCLAOABIgF6Ab4B8AJMAvQC+AMIA0QDXAMoAvgCtAJUAmQCJAI8AdgCPAIAAkgCIgHIAeoBhgF7APIA8wC5QAj/xz+OP2g+8j5MPlI+cj4CPlA+Rj5KPjw99D34PZQ9lD2IPZg9SD0QPTA9FD1gPWQ9nD3sPdA91D3oPdQ91D2UPWg9QD2kPbw9qD3APnQ+aj5kPng+jD8kPxg/JD8WP1w/KD7kPsg/Az8CPv4+nD8YP2c/PT8NP6w/y0AJQASAZgC5AKoAlQD8APMA0gDmANgBDAFuAUYBlgHQAgQCfAJUArQCnAKsAkgCRAIEAeoBbAEoANcA3QDPANQA8QDyARABTAGeAdgCfAJYAoAC0ALEAswCgAKkAkACQAI+AdACLAHUAdAB2AH6AYQBhAGyAX4BOwDpAOgAtwAL//w/Uj9sPsw+pj54Pkw+VD48Pc4+DD4oPZA9pD2kPYA9uD04PTA9HD0oPRQ9UD2oPbA9lD30PdQ94D20PUQ9pD1gPXQ9cD2kPeY+Gj5qPrA+sj6YPtQ/BD9QP24/Nz89Pw4/Fz8cPx4/Fj8OPwY/ST9fP38/az+0/8pAOYA+gHEAugCCAN4A8wDmAM8A6wDeAQABXgFWAaYB0AI4AiQCQAKMArwCYAJkAigB7AGCAb4BCAE/AMoBAAE5AOIBIgFCAawBtAHEAngCbAJUApwCmAKwAmACRAJoAhQCMgH2AeQB2AHIAcAB+gG4AaQBgAG6AUIBQAEoAKEAZAAvv5w/WT8MPwI+9j5QPlI+fj44Peg95D3cPew9mD2gPYQ9iD1kPRw9PD0wPRg9WD2wPYQ9xD34PaQ9uD1kPWw9fD1gPaQ99D4mPlI+vD6WPv4+rj6OPwQ/Uj9MP0Y/RT9tPyA/Kz87PzA/Jj8xPxM/YD9GP7a/mL/2/9dAEIBrgEMAqgCSAMsAwADUANgBDAF0AVYBkAHAAggCKAIQAmQCZAJQAnwCDAIWAfABnAG8AUwBeAE4AQgBVAFiAU4BvgGGAeAB1AIEAlQCVAJcAmACUAJ0AiQCKAIUAgACHAHiAdwBygH+AbwBvAGgAb4BXgF0ATMA6wCoAFwABP/DP4E/Rj8+PoI+rD5wPgw+LD3YPcQ92D2MPYA9rD10PSQ9DD0YPRA9ID0APVQ9aD1cPUw9ZD0QPSw9ID0kPSA9WD3KPmQ+cj5yPoI+4D6uPqI+7D8nPw8/Ej8oPzw+zj7iPv4+2z8DPwo/Oz8nP0g/nj+H/+3/0wA4QC0AUQCmALgAtgCKAPcA4gESAUgBuAGiAewBxAIgAjwCBAJ8AiwCGAIEAiQBzAHAAegBlgGUAY4BmgGMAagBqAGAAcAB5gHIAhwCMAIsAjwCPAI4AhgCGAIQAjwB4AH+Ab4BuAGgAYYBvAFuAVoBbAEQATUAwwDIALwADcAJv/8/bz8qPvw+hj6MPlQ+LD3UPfQ9oD2wPWg9XD18PRA9BD0cPRg9AD0MPQA9VD1YPTA83D0UPTQ8zDzQPSQ9uD3UPho+aj6gPpQ+rj6uPu8/JT8yPzs/Bz9WPwU/FD8jPyM/Kj8KP2M/Sz+fP7G/tr+Lf/O/y4A5ABiAQwCiAKkAqQCfANgBOAEmAWIBjAHMAewByAIkAjQCLAI4AiACHAI8AcACKAHMAdABxAH8AbQBvAGEAfgBsAGAAdIB5AHqAf4B3AIcAhQCDAIgAgwCPgH2Ae4B1AH+AYAB/gG4AZIBigGCAagBQgFwARgBJADbAKGAcAAqv9C/jj9pPzI+8D6kPkQ+ZD4APhw9/D2oPbA9UD14PSQ9FD0MPQQ9BD0MPRA9FD08PMA9KDzcPMQ85DzEPXw9tD3qPhw+QD6CPrY+aD60PtE/Jj78PtU/Aj80Pug+xT8NPw0/IT8CP2c/dj9Av4c/iD+Uv4b/7//JACSAB4BqgGyASwCYANoBPgEcAVQBuAGIAdQB+AHYAhQCBAIQAhgCEAIMAgwCGAIIAjQBwAIIAhQCPAH6AfwB9gH2AcgCLAI0AjgCPAIAAnQCIAIkAiQCHAI6AfoB/gHqAdYBygHIAegBjAG+AXYBWgF0AQgBHwDmAKKAZ0A4v/i/tz94PzY+wj78Plo+fD4QPhw98D2EPZw9QD1sPSQ9FD0MPQw9ED04PPA87DzcPPQ8iDy8PIQ9AD1QPbQ96D42PjI+Hj5cPr4+lD70Ptk/Cj80Pv4+0D8VPws/KT8EP0c/Wj9Av5q/lT+HP6Y/in/mP8gALAAcAGYAaIBJAIQA9gDoARQBdAFOAaYBhgHYAfQB0AIYAhwCDAIYAhwCGAIIAgwCFAIIAj4B/gHgAhACNAH4AcwCIAIUAiQCAAJIAngCHAIoAjQCHAIQAhACDAIAAiYB3AHUAcYB5gGWAYQBrAFIAW4BCgEOANYArAB4AC1/97+JP44/RD8GPtw+vj5+PgI+MD3APcA9kD1sPSg9CD0gPNw80DzQPMQ8wDzcPIg8sDxgPHw8bDyUPTA9bD2MPfg9zj4cPi4+Oj5wPrQ+rj64PqI+4D7GPtg+8j7NPzg+0z8KP2g/bz9oP0m/kD+7P43/9//mAAKAUIBgAEUAqQCeANQBNAEWAW4BTAGYAbgBmgHuAfoB9AHIAhQCIAIoAiwCPAI4AjACKAIoAjACMAI0AiwCOAIYAnACdAJAArwCeAJoAkgCQAJQAkQCbAIMAgwCBAIgAfYBuAGuAYoBmAFKAXYBEAENAOAAiAC8wD4/yr/ZP6c/Yz8iPuo+hD6IPlA+ND3IPdw9oD1sPRQ9PDzgPMA8xDzYPPA8iDy8PHA8TDxsPBw8QDzcPQw9QD24PaA95D3wPfo+MD5WPpY+hD7mPtI+2D7wPss/HT8cPyQ/FD99P0Y/kD+Wv6q/tD+Jv/z/7gAmgGsAQgCcALsArADQATwBFgF4AUIBogG4AZoBwAI8AcwCEAIcAhwCMAI4AgACeAI8AjwCNAI4AjgCPAIwAiwCBAJkAmgCWAJwAnACUAJkAjACAAJ0AhACNgHAAi4BxAHgAbABqAGAAZQBfgEuATAA+wCXAK+AdwA5f8x/6r+pP2U/Jj7+PpY+lD5kPhA+FD3oPaQ9RD1kPTg80DzIPMQ88DyoPJQ8jDy0PFQ8TDxgPHA8hD0QPUg9qD2UPcI+PD3wPiw+Wj6yPrI+oD7sPsU/Fj8nPzo/Pj8QP2Q/Rj+Wv7o/vz+Gv9G/6j/mwDuAFwBFAJ8AuACLAO8A8AEaAXQBRAGcAbgBlAHgAcwCIAIoAiACIAIwAggCVAJcAmQCcAJgAlgCYAJYAlgCXAJoAnACdAJ8AkgChAKoAkQCeAI4AjACEAIIAgwCNgHGAeoBnAGeAboBUgFwASQBOwDyAIMAsIBPgEuAEv/pP4I/sj8iPuo+kD6ePlg+MD3EPeA9oD1wPQQ9IDzIPNw8kDyEPIw8vDxcPEA8bDwoPDQ8IDxYPPw9KD1APaw9nD3sPdo+Cj5EPqw+tD6GPuI+9j7PPy8/Nj8JP08/cD9Ov6E/ub+Wv9p/2L/t/98AAoBegG+ATwC1ALoAowDWAQABXgFmAUYBlgGoAYAB8gHAAjoB+gHEAhgCHAIgAjQCEAJ4AiQCLAI8AjQCLAIwAgwCUAJAAkgCVAJQAngCFAIUAgwCBAIsAdwB0gHCAeIBjgGAAaYBWgF6AQ4BIQD/AJkAnIBwAAsAJz/mP60/fz8LPxI+yD6gPnw+Fj4IPeg9vD1IPVg9LDzQPPQ8pDyUPIg8uDxYPFw8aDwoPAA8QDyYPMQ9CD1UPbg9gD30Pe4+LD5APpw+hj7kPvY+xD8kPwg/Xz9dP30/Wb+gP7O/jn/mv+9/wYAggDzAHYB5AF4AsgCHANsA/gDqAQQBVAF8AVYBpAG8AZgB8gH+AcQCCAIYAiQCNAIMAmACcAJoAlgCdAJcAmACeAJIArQCTAKMAowCjAKoAmwCZAJMAmgCKAIkAgwCKgHMAcIB3AGAAawBVgFqAT0A0gDmALoAV4B2AAZAFf/dv6E/Yj8gPvA+hj6QPlY+KD3IPcQ9lD1kPTw84DzwPJA8kDyEPKg8WDxAPEA8cDwoPCA8bDykPOw9JD1QPaw9uD24Pfw+HD5WPrY+nj7uPsA/Gz8fP2Q/cD9Wv78/iz/N/+z/xcAkQCLALwAZgH4AUAClAIMA1wDtAO4A3AEEAWIBcgF+AVoBuAGEAc4B4AH0AcgCBAIEAiQCBAJUAlACUAJcAmQCVAJcAnwCQAK8AnwCRAKIArACbAJcAkwCdAIcAgwCPgHuAdQB9gGeAb4BcgFgAXYBDAEnAMAAxACagG1AIYArf+o/sD9/PxU/Aj7QPro+SD5APgQ94D20PUg9XD08PPA8wDzYPJg8jDyAPJQ8UDxYPFw8fDxsPLw8/D0oPVQ9tD2YPcg+KD4mPlg+gj7CPuA+6j7iPwY/ZT9Fv54/hT/Hf+S/7z/WgCuAKUARAHEATwCQAKQAkgDXANwA6ADkAQoBUAFeAXwBUgGWAaIBgAHkAeoB8AHEAhACIAIsAgACRAJIAlACTAJQAlQCYAJsAmQCZAJ0AnQCZAJMAkACfAIUAjoB5gHeAcAB0gGKAa4BXgF6ARoBCAElAOsAtwBfgG6ABsAXv/a/hz+NP1M/KD72PrY+SD5WPig98D2APZw9RD1YPSw80DzkPLw8aDxcPFQ8XDxQPGA8fDxQPIQ89DzwPRw9fD1wPaA90D4KPnA+WD6kPrg+mD7APyY/FD9av6i/tj+EP+M/+f/JACtAEYBxgH+ATAClAL0AiQDiAP0AygEiAToBJAFwAXQBRgGSAZwBogG+AaAB5AHkAe4BxAIIAggCGAI0AjwCOAI0AjwCAAJAAkQCUAJUAkgCRAJ4AiwCFAI6AewB2AH+AaYBmAGEAawBTgFwAR4BMwDSAPQAjgCmgEWAWwA8/9Y/5r+8P08/ZT8wPvw+jD6YPl4+MD3EPeA9vD1cPXA9DD0kPMg8+DygPKA8pDysPLQ8iDzsPMw9OD0gPVA9gD3wPdQ+AD5wPlI+sj6KPuw+wj8qPyA/eT9qP45/4r/x//V/3YA/QBoAeoBlALoAkQDWAOQAxAEUAR4BNAEWAWoBQAGIAZwBqgGsAbYBhgHUAeQB5AHwAfgBwAIIAhgCJAIwAjQCOAI4AjACLAI4AjgCAAJ8AjQCMAIcAgwCOAHoAcoB9AGoAY4BtAFgAX4BMAEMAS0AxwDlAL2AXABzwBSAM3/+v6O/uT9GP1g/OD7APtA+nD5sPhA+ID30PZQ9tD1QPXA9ED0APSQ81DzQPMw80DzUPOQ8/DzYPTw9HD1EPbg9nD3IPi4+GD5APpw+vD6SPvA+2T89PzA/Wr+B/9l/5T/0P9fAOwARgHyATwCzAIIAwgDhAMQBEgEgAQIBXgFyAX4BQgGUAZoBoAGoAboBggHEAdAB1AHWAc4B0AHcAegB8gH4AfgB9AH8Ae4B7gHuAegB7AHmAdwBxgH4AaYBkgG+AXABWAFGAXIBHAEIASQA0wD3AJ4AuoBXAHuAEoA2f9E/7L+PP6Y/Qz9iPzw+1D7sPow+oD5CPmY+PD3oPcw99D2cPYA9rD1cPUw9QD1IPUQ9UD1QPWA9dD1QPag9gD3sPco+Mj4MPm4+Vj62Pow+7D7QPzI/Ej9xP18/vT+ef+k/zQApgDjAGoBygFUArACDANkA7AD3AMYBDgEuATgBDgFcAWoBdgFGAYwBkAGgAaIBsgG6AbYBtAG6AbwBuAGAAcABxgHEAf4BuAGuAa4BqAGkAZwBkgGMAYABsgFiAVIBRAFwARoBCgE2ANwAygD1AJwAgQCoAE0AdEAWwDZ/27/5v5g/vD9fP3w/GT82Pto+/j6cPoQ+pD5QPnY+Hj4MPjw97D3cPdA9xD38Pbg9tD28PYA9yD3UPeQ9+D3QPig+Pj4YPmo+QD6aPrA+hj7gPvY+1j8uPwY/ZT98P1k/sz+Of+a/yQAWgDqAFYBrAEYAlgCzAIcA1QDlAMIBGgEkATQBAgFIAVABVgFiAWoBcAF4AXIBdgF4AXwBeAFyAWwBbAFqAWABVAFUAUwBfgE0ASoBIAESAQIBPADnANUAwQDtAJ8AjQC/gG0AWoBBgG8AHgAMQDw/6T/Zf8R/8r+dv40/gD+vP14/TD9+PzE/Jj8YPw4/BD86PvA+5D7ePtY+0j7OPsY+wD78PoI+wj7IPtA+zj7YPuQ+7D74PsE/Dz8bPy4/Pj8NP1k/Zz96P0Q/lb+kP7s/jT/Z/+g/9z/FQBBAIEAtAD6ABgBRAGEAbYB8AEQAjwCWAKAArACzALsAhQDMANYA2QDfAOEA4QDiAOEA4gDiAOQA5QDoAOMA4gDhANgA0wDPAMoAwQD1AK0ApQCeAJEAiwCHAL6AdABoAGCAU4BGgHmAM0AqwB7AEkAHQAFAN3/sf+X/37/Yv8y/xD//v7e/q7+pv6a/oj+Xv5M/kz+Pv4o/iD+HP4k/hD+BP4G/vj9AP7Y/fz95P3w/ez9/P34/ej98P0C/hz+EP4e/jr+QP5I/lT+XP50/n7+kv7K/uT++P4g/zj/Sf9m/3//o/+z/8b/8/8RADgAQgBVAGwAcACDALcA4QDyAPgADgFEAVQBZAF0AYgBpAGYAZoBngG8AcABtgG8AbgBpAGYAZ4BnAGiAYoBggF6AWoBVgFKAS4BIAEcARABAAHrAMIAoACHAF4ASABEAB0AAAD2/97/x/+s/4H/bP9l/z3/H/8l/yD/D//k/tT+2P7U/sr+wv7U/sz+zP62/rz+uv60/rb+0v7e/uD+6P74/gf/EP8K/xT/PP9N/zv/PP9N/2b/av91/4v/uf/Q/+n/+f8UABEAEwA2AFAAbgB0AIoArgC/AL0AwQDLANEA6gDjAPkA/AAGAQQB/QAKARABEgEKARIBBgESAQgB/gD6AO8A8ADwAPMA9QD0AOkA3wDPANsA0QC5ALoAsQClAJ8AgwB5AGUAPwA7AA0A/P/h/8f/qP+m/5z/g/95/3n/av9j/1P/UP9A/0L/Kv8Y/w//C/8X/xD/Hv8K/wX//P4E/wT/CP8K/xL/HP8a/x7/Jv8//0X/YP9r/37/jf+P/5//rP+9/83/3P/x/wYADQAcAC8APwBCAEcASQBUAFQATgBQAFQAVQBSAEYARwBKAEsAPwBBADwAPgA1AC8AMgAuACUAIgAkABQAAQDw/+n/4//i/9r/3f/l/9z/1//T/8n/0v+7/8f/uf+x/7H/r/+w/5b/iv+I/5z/gP+U/5z/uP+u/5T/wP/O/8X/vf/b/+z/3v/u/+D/7P/Z/8P/0f/o/+j/3P/g/wEABQADAAgAKAA4AC0AMAA7AEIARQAvADcARwBEADUANwBCAEIAMQAsACYAJQAbAAoAFAAaABcAEgANAAcABQAAAAwAFQABAPz/BwAOABcADAAsAD0ASQBDADsAOQAyACsAHwALAPL/3//H/8f/pf+H/3z/ff99/3D/f/+I/5n/qv+x/7//xv/I/87/3v/d/+H/5P/i/+r/6//v/wEAGQAmAC4APgBSAF4AXQBYAF4AbgBmAF4AZABuAHgAdwB5AIEAeQBzAGkAWQBNAEAAMQAyACcAIgAiACgANAAyAD0ASwBZAEoAQgBCAEkARQBBAEoAaQB4AIwAlwCdAJYAkQCHAHkAZQBZAGUAVwBDABoABQD9/xQAIwA0AEgAagCEAJEAhwCYAJYAjwBdAEEAIQAOAOf/3v/h/+X/7f/1/wUA6P/g/8H/of9v/0X/LP9A/0r/Vf8+/2v/av9y/2r/iP96/3j/ev+G/3P/Wf9o/3D/cv9v/4P/r/+y/6z/uf/H/8D/uv+8/8D/w/+w/7T/0v/l/+7/AwD+/xoABQAuAIUAugCtAIQAmwCgADQAxf+s/9r/DwBpAIgBYALoAlQDkALSAcv/+v6R/87/kP4K/sT+pf+7AJQAZgEMAhgD6AIoAoYBSAGeAbkAVv+k/j//Xf9Y/uT98v6F/37/sv4CAA4BgwCz/4n/OwDN//T+tv7g/qr++P3U/WD+GP6w/fD9LP6e/kz+hv6a/xoASABfAAcAvv+o/8D+kv6G/pD+7P5E/3L/RQCWAboBiAFoAWoBuADw/tD9bP1M/cz81PxA/h4AhgGcAtAD6ATABLwDIAM4AzwDHAL1/5r+1P14/RT9xPzA/YL/IgFUAjwDYARIBXAFyAR4AzACmAG1AJH/Ov4A/az8JP14/fz9+v77/zYBxgEcAnQCBAP4AsoBrADoANUAQwDC/7n/EgEbACf/SP4U/5z9dPw8/Bz9Cv6I/qj/ewBuAX4BhgFwAe4AsP/Y/jj+sP2Q/hD/jP95ADAB3AG4AcYBhgFiAZQA4P7E/cD8APv4+tD6IPsQ+4D6wPp4+2T8RP3e/p//PwDsAIIBrAF+AbABCAJIAuIBKALgAiQD9AIEA9gCzAI8AsACwAKAAh4BHAGqAHgAzP9c/2YAOgCz/xr/4f////P/+v6G/sL+av5c/ob+Yv5K/q7+if/u/n7+av5I//L/kf/i/tf/YgDW/4L/MP7O/kD/df+9/+8AlAJEA2gE9APIBHQDrALEAQwBOABg/jr+Kv6O/i7+I/+SABAC8AGQAlwD9ANIA+oBOgGKAMz/Uv7Q/fT9rv5G//P/DgFUAngDmAPMAvYB7AFkAd//gP7c/UT+TP70/ZT+RABqAZYBngEMAgAD6AJgAlwBUQB//7b+TP7M/dT9Qv6y/iX/pP9oAKQBDAKmATwB4wCpABIAOf9y/tj9mP0g/fz8TP38/eL+KP8Q/0L/wP/W/7//gv9f/5D/c/8i/3X/jf/J/xMARAB3ALsAnwB8AG0A1v+2/2f/h/+f/4T/zf/3/30ASQBZAEYAyP/X/2T/0v6i/o7+vv7Q/sT+0v4F//r+8v76/ib/ov/b/2MAqADMAAwBLgFeARYBMAHcADAAmP9y/2n/Af+G/nz+1v4y//z+8v5H/7r/pP+r/9H/PgB1AEkA5P/A/4//lf9e/6P/i/9E/yX/8P9ZADUAYgBCAXgBSgHxAAABOAHqAJ8AXABkABMAAwCr/97/+P4V/xH/LP8O/xP/e/88/2//j/9TALEAogCMAN0A9gDjAH4ANAAtAHP/Kv8U//b+HP8f//T+Af8x/3z/iv9m/2T/XP+x/5v/V//+/vD+1P66/gH/iv8KABUAhwCsACABQgHAANgADAH+AEUA+f85AHAAlQA4AAEABAAPAAUATgAOAC4AhADwAO0ACgHAAAABQgEkAbwAmQCvAKwAzwBlAP3/hQC8ALcAxgC/APUAYAE4AZYApADZAKcAggBYAMEA6ADLAI0AVwB3ADwAawAUADIA5f+M/6H/jv9z/1n/Wv/F/zQABwDW/0YAfgAUAMP/6P8RAK//Ef8v/3P/bP/6/kD/qf/j/5v/iP+//7L/wP+j/9v/xv+t/9f/4P/t/3z/Z/8Z/xn/3v7+/iD/R/9b/0X/Tv9u/7L/ef+h/2f/ov+1/6b/8//S/wAA+v8NABQA+f/9/yYA7f/z/zAAQABQABoAIgBjAIIAWQB4ACAATwCi/1b/E/9C/z3/B/85/6n/+P88AGcA5AA6AVIBTgFAASwBwQCNAIYA4wCtAPgANgFcAW4BvAEwAmgCmAJoAngCdAIQAlgBYAEAAdoAHgDG/6j/Yf9b/yf/Zv8Q/8L+Mv4W/sD9UP1E/UD9LP3k/OT87Pyo/Jj8nPzQ/Hz8SPyU/HT80Pyg/Mj8KP3I/WL+fP4o/qT9xP3c/bT9WP1I/Wz9rP3g/YD9VP0g/bz98P1c/dz8WP3I/Wb+rP5C/6kAGALwA2AF4AaYB0AIUAkwCvAK8AswDWAOYA+wD5APYA/ADgAOkA1ADYAMUAvgCSAIYAbABJwDWALhAD8ANP+q/sz9bP2Q/UT9AP1k/GT8+Pt4+uj5QPnw+AD4QPcw9yD38Pag9jD2oPUw9QD1wPTA80DzUPOg87DzEPOA8/DzUPWQ9QD3QPbA9jD3APfw9rD1YPUw9RD1EPaQ93D5QPtk/fX/aAC+AWgD8ATAByAKoAsQDSAOQBHgEyAWoBeAGUAbIBygG8AaYBoAGeAXgBYAFOAQ0A0gC4AIqAUYAhn/bP00/Hj6+Pho+AD5+PqU/Cj92P0W/nD+rv4L/xH/DP6c/uT9EP4M/fj7IPv4+ij7QPpA+XD3YPYA9SD08PJQ8QDw4O8A8ADwYO/A75DwgPKQ8yD1IPbw9dD1sPWw9qD24PXA9OD2IPbg9ODzYPLQ9KD4cP0EAhgE4ASYBZgHoAf4BxgHoAkgCqAKEAlIB4AIYAwgEgAVoBYgGUAaQBtgGyAaABmAF4AXYBTwDnAI8APvAFr+UPwQ+wj72Plg+Dj4gPew95j5HP3D/y7//P10/QD+nP4Y/73/W/8T//z9DP3I+wj5IPhg+Cj5KPhw9jD1oPVQ9QD1QPQQ9JDzMPRQ9JDz4PKA8qDzwPXg9sD2gPZA9yD5SPqo+OD2cPVQ9SD04PJQ8QDyMPTQ9zj9AP+KAZgCmAUwBLAEAAWABkAJ4AmwCWAIAAmACzAP4BIAFUAZIB2AHsAeYB9AHyAeYBxgGYAUYA/wCMgDKQCA++D5MPnI+BD4APcg90D3gPgw+uj7kP6j/7UAWwDn/6f/hgDYAawBRAHrAFMAEP7E/Oj74PqY+aj4OPjg9yD2cPRg9GD0YPOw8jDz4PPQ80D04PRg9dD1UPd4+TD6APrY+dj6ePow+ED2EPVw84DysPIg81DzgPUg+lgBPAOKASgD+AM4BIQDGAXgBRAGaAfgCAAL4ApwDCAQ4BXAGKAa4BvgHQAgACBgH2AawBdgFEAREAuYBIj+6PoI+fj4QPdQ9pD2wPew+fj5QPpg+xT/5AGIA0wCYAApALEAwwDu/4j/GP8J/9D+zPzw+RD4gPdI+ED4APew9TD0wPMQ8/DyEPLQ8bDygPMg9HDzoPPQ9DD3sPl4+jD78Poo+2D6KPlA99D0MPPw8oDzAPOA8iD0iPlF/yQBpAIQA7wCYARwBMAFaAVwBoAIQAowC7AJAAsQDqASgBWgGAAbQB0AIAAgAB9gGyAZ4BWgEdALUAWg/gj54PVg9CD0QPPQ9PD2SPmo+fD6jP1/AJQC9AMwBAQD9wAgAMz/xv5s/RD9VP2U/Oj6APmQ99D1sPWQ9lD2EPVQ82Dz4PJQ8nDxgPKg81D0IPWw9WD2YPYA+Mj65Pw0/bT8mPzw+3D6wPdw9uD0MPPA8jDzoPOg88D30PxQARwDWANoA4QDwAQgBegGuAU4B4AI0AnwCbAJsAxgDwATgBdAHOAeQCAAIQAiwB4gHIAXgBKQDXgHJwC4+ADzQPFw8TDy4PKw9FD3qPmI+3D+lAGAAygFOAZIBZwCa/88/g7+lP1A/KD7uPsg+xD5EPcA9vD10PXA9RD1wPMg8uDwEPFg8TDxcPEQ8zD00PUg9jD38PiA+5j9mv7w/tT97PxI+7j5oPew9YD0kPQw9DD08PQA+BD8bgBUA2AFIAXABIgEaAWgB4gHSAeYB5AKcAqAC8AMsA5gE4AXoB2AIsAkQCRAI4AiIB+AGuATkA9gCHwBCPlw8aDtYO0g77DwIPOQ9dD3aPv0/jgCyASIBrAIeAdgBSACuf8C/qz8oPx4/LD7SPkY+MD2APWw8yDz8POA80DyoPDg70DvYO/g8HDyUPNA9JD1oPfY+Bj6qPu4/Z7/AAA2/7z9VPxI+vD4EPdQ9WD0cPTA9ND1wPd4+rz9fgFIBOAEYAR4BHgG0AjgCGAIgAigCdAJ8ArgC0ANIBBAFUAcgCAAJEAlQCZAI8AgIBtAFsAQoAmwAkj60PJg7SDrIOug7GDwEPNg9Zj45PwwARgEqAagCFAJEAjABBwCqv/0/Ej8GPxo+2D5EPfw9eD04PJQ8fDw4PFA8YDwIO/A7oDuIO8A8ZDycPQg9oD4CPoA/Iz9Gf8GACEALgD2/rz8wPkQ+HD20PTA80DzAPSA9WD3SPqw/cEAsAPwBRgHcAdgCAAK0AqQCgAKoAmwCUALQAwADRAOABHAFwAgACOAJIAngCYAI8AdYBlgE9ALYAQc/dD24O4g6gDpAOwg7nDwQPNA9wD88/8oBMAFIAlgCtAKwAgYBgQCpv64/JD86Pqw+ID2oPQg9NDxAPBg72Dw8PDg8VDxEPAQ8ADwAPHg8aDzQPWw93j52Poo/DT9EP4v/4j/TP+k/aj6WPjw9dD0APOA8jDzYPQA9rD32Pno/EsA9AIoBUAHMAhgCZAKQAwwDIAKsAlwC1ANUA2QDMANwBNgGmAfACUAJ4AmQCXAIKAcYBVwDtgH3AHQ+mDxYOsg6KDoIOqA7XDxEPXY+cT9lAJYBWAIgArwDAANUAowBrABmP7I+1D6kPfg9fDzwPLg8IDv4O5A72DwgPEQ8sDxkPAA8NDw8PEg8+D0YPc4+cD6UPxM/Sj+7P4fAHMAaP+k/Cj6WPiA9sD0wPNg89DzEPUg91D5KPso/b4AIAQgBigHkAggClALAAwwDAALcAoQC5ANQA4ADbAOwBSAHMAigCZAKIAoACWAIAAcIBSQDGgFVv4Q9+DuYOmg5oDngOqA7tDyoPYQ+40AmATQCPAKMA2gDjAOEAsgBpYB3P0E/Mj5UPdg9GDyEPFQ8ADwAO8g78DwMPIA82Dy4PBw8ODwEPKQ85D1APi4+pT8Gv4c/z8A/wA8AvABYwC0/Jj5APdA9XDz0PGQ8VDyAPTA9eD3aPpA/a8AqARoB5AI4AmwC9AMEA2ADJAM4AtwDAANsA4AD9APYBXAHgAmwCYAKcAmQCSgH2AZIBOwCgwDZPwA9UDuoOeA5qDoIOzA7/DzsPfo+4YBOAYACqAL0A0wD1AOwAnABF//tPzw+cD3IPVw8UDvAO6A7uDu4O7g7xDx0PIg80DyoPAQ8NDwAPMw9CD1YPb4+Nj6hPzk/Wn/EAHCAcwBQQAk/cD58PZg9dDzUPJA8WDxgPNQ9VD3APoA/WYA2AQACAAK8AowDDANQA0ADRAMoAuwCoAMwA0AD0AOQBIAHMAkACgAKEAoACXAH4AawBTgC9ADkPvA9IDugOaA48DlAOpA7zDzYPdY+2YBCAfwChANIA6QD1AOIAuwBfX/8Pso+TD3YPTA8ADugOyA7cDuQO8A8QDy4POA9JDzcPJQ8QDygPNQ9UD2UPZA9zD5QPvc/D7+LADGARgCQgF8/lj7EPgg9iD1sPOQ8nDxwPJw9DD3IPq4/GMA4ANACPAJ8AqQC8AMwA0gDfAM4AuQC9ALsA3QDzAPwBCAGIAjQCeAKMAmgCSAIUAbQBUADtAFFP3g9oDvQOkg5IDkQOhg7ZDxUPWo+cD+eASACTAMYA3gDgAOUAuQBoQBVP2I+nD4wPWA8oDvIO4A7gDvoO9Q8HDxoPKg82DzgPKw8RDxQPKQ8+D0QPXg9Rj4OPpg/AL++/+3AJIBcAAA/0D8iPjQ9qD08POg8XDxQPGg8zD2ePnE/P7+kAM4BhAKIArACrALEAwQDVAL4AoACiAK0AtADUAOQA+gFEAegCYAKcAnQCeAJAAgoBnAEvAKaAIg+kDzgOyA5SDjAOaA6sDtcPIg98j8fAIgCJAMgA6wD1APgA1QCQAEb/+U/Cj6gPeQ9EDxwO/g7uDvIPCQ8GDx8PLg8zD0oPNQ8gDykPIQ9AD1EPWQ9eD2KPkw+1D9rP7r/98AmwCF//z8cPow+LD2wPTQ8oDxEPGA8pD12PgQ/N7+ZAK4BdAIAAqwCrAKEAxwDCAMAAuACSAKQAswDWAOEA+gEQAYwB9AJUAngCcAJwAjYB2AF6AQgAgTAOj4UPLA66DmAOXg56DqIO+w86D53P3IBPAJgA0gD1AP4A5QDPgH/AOv/+j7KPjg9VDz4PAA8IDvQPCA8aDx8PHg8yD1gPVg9PDzgPMg9DD0cPSQ9ND04PXQ9yj6OPyU/S3/IgBVAP7+HP1A+2D5wPeA9YDzgPKQ8uDzsPWg+KD7jP5GAagEiAeACOAIUArgC9ALYAtgCkAKgAogC8AMMA7gECAUgBlAHwAkQCeAKQApQCWgHmAXQBBgCSAB8Pig8ODqwOZA5cDkQOcA7mD0yPls/+gEUAggDiAQgBAADwAL8Ae4BO8AEPtw9gD0wPLg8QDwgO9g7jDwwPCg8pDzIPTw9HD0UPRw86DysPKQ8sDy8PMw9SD3sPf4+lT+Z//m/xcASQBI/lz88PlA94D0MPIw8tDxkPKA86D2yPqg/fkAUAQAB5AIMAowDOAMkAwwDMALkAsACwAL4AugDQAQgBNAF6AbQCBAJYApACoAJgAg4BgAEsAKHAPQ+xDzAOvg5oDl4OPA5IDqIPLI+DT9dAGQB0ANABBgEUARUA1ACgAHoANU/eD4wPMA89DxEPDA7qDtwO6g8BDzcPTA9MD1QPXg9ID0IPRg89DyMPMg9ED1oPVQ9nD52Pwq/ycAegAuAMD+NP0Q+3j4UPZg9CDz4PIw8tDygPUo+Vz8g/+oAhAFOAdQCaALAA1QDbAMIAwwDOALIAxQDKANoA8AE6AWgBlgHYAiwCdAKYAnwCEAG2AUcA14Bvr+MPdA76Dp4ORg4wDl4OhA7mD0MPpr/8gEQAnwDSARgA+wDyAOEAn0A7j/BP1A+NDzUPEA8SDxQO9g7uDuIPLA80D10PVw9WD0APTw9NDzoPMA8lDzgPMw9DD1YPjg+pz9N/+2ADEAVP7Y/Az8qPrw95D14PMw8oDwAPKA9AD2UPgc/AsAsALIBBgHEArwCyANoA2gDUAMsAvADIANEA5wDiARoBOAFkAZ4B0AIwAmQCeAJYAhIBogEoALAAWw/pD2QO9g6GDkYOTA54DrIO9g83j62AHwBaAJEA5gEOARwBEQDhAKxAP5/zD9aPng9IDxYPEA8YDvIO6g72DxAPTA9SD2oPVg9HD0APVA9fD0QPSg8/DzoPVA96D4ePr8/Hj+If+A/jz9VPxg+yD62PiQ9kD0UPJg8jDz0PTQ9kD5ePyD/8gCqAQgBzAJkAsQDWANUA2gDBANwA0QDwAQ4BDAEcATABdAGoAdwCAAJAAmQCQAHwAYwBCACrgED/94+KDv4OhA5+DnQOkg6zDw0PSA+tv/mAWwCiAN8A8gEaARMA1QCfwDaAAk/Qj5sPWQ8ODuQO+g7+DuAO+w8HDzoPVg93D2wPUw9qD2EPcQ9gD0UPNg88D0MPVQ9tD3OPp0/DT9pP24/Az8ePvg+gj64PfQ9RD0gPPQ88D0kPaY+Nj6aP26ANQCyATgBqAJ4AuwDDANYA0ADeANwA4gEKAQoBHgE6AWwBngHIAgwCPAJcAkgCGgG+AUUA3IBvUAuPow80DsoOcg5kDnIOqA7aDyYPc4/ZQC+AdADNAMsA7wDyAPkAkIBQYAXP3o+tD1APIg7+DuYO+A76Dv4O9w8ZDzkPYg99D2IPVg9TD2oPWQ87DxMPLA8nDz8PQA9hj4cPp0/F7+7PxQ/Yj8NPww+5D5OPgg9eDzwPPA9GD1EPb4+Aj8Y/9CAbADYAbwCCAL0AzQDYANoA2QDmAPsA8gEKARABPAFEAXYBrgHQAhwCNAJYAkoB9AGUASUAvoBJf/GPkw8qDrQOdA5yDpoOtg70D0YPhM/aADgAhAC1AMkA5QDxANiAf4AuL/7Pxg+lD1wPHg7sDvwO8Q8RDwQPCw88D1GPg4+ID2cPUg9mD3YPXA8oDxIPKQ8zDzAPQw9mD4UPo4/CL+wP0w/FD8pPyU/GD6APjA9sD1QPUg9eD10Pfg+RT9WP8MAUwC4AQQCKAKMAzQDFANsA1wDpAPoBAAEUASABSAFuAYwBsAH8AhwCOAJIAiwB0gFyAQcAr4BCD/KPmg8gDsIOhg6IDq4OzA7wD0SPiU/IoBAAZQCZAKoAsADSALMASuAQgAbP2Y+hD2sPOA8XDx0PFQ8qDyQPIQ9LD2MPgg92D1gPWg9tD14PNg8jDxMPKg8fDyEPTA9XD3OPrI+8z8YPzo/Lz8CP0k/Ej6cPkw9zD2wPWQ9rD2wPdY+vj7Hv5HAFQCgAQIBzAJMAsgDGAMAA3gDZAOIBCgEaASYBNAFaAYgBtgHkAhACRAJYAjIB+AGYATUA3QB7QDIP3g9QDvQOtg6iDrQO3g74DyAPaA+Tf/AAToBQAIgAuAC3AJuAUkAggB/P0s/Gj54PXw8jDyQPRA9CDz4PLA9bD3IPhw92D2oPZw9nD2APVQ85DxQPGA8eDxAPOg8wD14PbQ+fD6uPr4+sD7BP18/Fj7ePqQ+ID3cPbQ9qD3APgw+Uj7YP2W/mEAWAKwBDAHUAlACsAKAAtADHAOkA8AEAARYBJgFMAWYBkgHAAfQCHAIgAjACCAGsAUQBBgDAAHDgHI+gD0IO8g7UDtIO4A76Dx0PPg9+D7zf+kAygGsAgACaAIcAWcA/8AS/88/fj5APcw8wDzYPRQ9HDzsPPA9eD3YPjo+Ij4UPh4+Bj40PaQ9ADyQPEA8dDwoO9Q8DDy8PPg9eD2wPgI+rj6WPso/JT84Psw+jD5mPgQ+ID34PdQ+ZD6MPvI/Lr+cAD0AVAE4AawCLAJYArwCuAL8AyQDqAPQBDAEQAUIBfgGaAcQCDAIoAjACPAHyAcIBaAEWANAAlYAuj6oPTQ8KDuAO6g7UDv0PEA9CD32PpB/wQB0AMQBkAHkAUAA8QAzf++/xj8yPhA9lD1gPWw9CD1wPWg9qD2qPiY+Xj6UPm4+Lj5APhg9UDysPFQ8SDwYO/g7gDwYPGw80D2gPZw+ID68PvI+3D7rPwg/Dj74PmA+TD5IPig+ED6CPzA/Ij9Z//uAawDwASQBmAIgApwC5ALEAyQDGAOgA8gEUASoBOgFeAY4B2AIAAjwCIAI0AhgBzAF0ATUA/ACbAE6P0w95DzUPDg7wDwYO9A8cDzAPeI+Qj8lP8MAvgDmASgA8IBgwAQAO7+gPy4+MD3oPbA9iD2sPVA9/D3gPgY+bD54Pko+oj6APmA9/D0cPOA8oDxcPDg70DvAO9g8TDzEPWg9eD3aPho+Zj6WPqY+/j60Po4+gj5oPhg+ND6CPtY+3z8/P3g/3IA9gFQBNAFOAfQCGAKMAuwCqALMA3gDkAQgBFgEwAVgBdAG2AfQCIAIoAhACAgHYAZ4BWgEQAMMAZ6AXD7IPcw8/DwMPFg8XDycPNg9YD3WPqk/VkATgAGASIBWABcAPj+JP1g+6D6mPkY+ED3MPc4+BD5ePlI+gj6yPlw+uj7OPtQ+YD2IPbQ9BDzQPEA8ADwEPDA78Dw0PGg85D1APcw+Gj4qPmw+XD6APso+mD5CPjw+Oj4QPnA+dj6jPyY/Tj/FAFoAogDyAWQB9AI0AmwCtALQAygDBAOsA8AEeAR4BOgFmAZoBwAIMAigCJAIKAeYBwgGQAVIBAQC4gFBwDQ+8D3EPUQ8lDykPMw9HD0APZI+Nj7/P2G/mn/If+j/9H/Cv8E/Xj7cPqo+bj5kPjQ9/D3WPjg+XD6sPqg+mj7OPsw+4D6APnA9iD14PTA80DyAPAw8LDwMPFw8bDykPRw9VD2YPcY+Oj48PhY+fj5GPnw91D30PcA+Yj5WPoQ+1T8jP1+/4gB1AJgBAAGgAdACeAJgApACxAMkA3gDoAQIBGgESAUIBcgGqAcQB5AIGAfYB2gG2AZ4BbAEmAOQAkgBLP/sPsI+ZD20PRw9ID0MPXw9Vj4wPkU/Dj9dP2w/ej9+v6o/Sj8APv4+XD4cPdA98D3wPeQ98D3kPjo+QD7GPuQ+3D7iPvo+pD5sPfQ9WD1cPRw8zDxEPCA8FDxUPIg8/Dz0PSw9cD2KPhg+Dj4mPho+Qj5EPjg9mD3oPg4+Yj6IPuQ+6z8LP9OAbACgAMoBTAIYAmQCtAK8ApwDOAN8A8AEcAQYBKgFMAY4BoAHUAeIB+AHiAdABvAGEAWwBKQDlAJEAVXALz84PnY+BD3wPVA9QD2gPcI+Rj6qPrg+4D7+Ps0/CT8YPso+jj5YPhg98D14PZQ95D3UPfA9lj4gPlw+gD7WPuA+xj7sPpY+YD3IPZg9UD10PNQ8tDxIPKQ8lDzkPSA9eD1EPYg97D3CPgI+HD4mPhQ+Aj4wPfg97j4yPlY+yz8oPzk/ZH/QAKMA7AE0AUgCIAKYAuACyALkA3ADsAQ4BCAESATgBXgGGAbIB0gHUAeoB5AHGAagBgAFiATwA6QCoAG8AGc/nT8kPqo+OD2APfw9yj4+PhI+uD6yPqI+iD7gPtA+wD6IPlI+GD3gPYQ9qD2wPbw9jD3APew97D4IPr4+jj7APu4+sD6KPmo+FD3oPaw9dD0UPRA87DzwPPQ9PD0gPUw9kD2sPYw9iD3kPdQ91D3IPeg91D3YPdw+MD56PqY+3z8NP0Z/w4BAAO0AygFAAdQCaAK8AlQCzAMsA7QD6AQABLgEgAVgBgAG0AcQBwgHaAcwBtAGoAXgBWAEhAPMAsoBxADUAB8/rT8aPr4+Kj4qPjg+Lj5WPow+uD5sPnA+dD5iPmY+LD30PZQ9tD1oPWg9SD2APcw9wD3gPfY+Lj5WPr4+tj6KPs4+sD58PgA+KD30PZw9pD1MPUg9WD1MPYQ9pD2wPbw9tD2wPaA9lD20PaQ9mD2cPbA9jD3APgg+VD6cPtY/Mj9Rv8sAagCzAMQBXAGAAiQCcAKYAuwC6AN4A5AEEARQBOgFcAX4BogHEAcIBygHAAcIBtAGKAVoBOgENAMUAn4BYADtAFw/7D9yPv4+tD6IPso+1j7IPsQ+gD6APo4+Sj5CPgw90D2kPUA9SD14PRw9VD24PYA91D3ePhQ+Xj6QPrA+pj6ePoA+hD5OPgA+KD3APdQ9hD24PVw9dD1gPaQ9gD30Pbw9oD2APZA9rD2oPYg9kD20PZw9xj4wPhY+hj7wPtI/YL+UgBcAewCaAQABdgGQAigCXAKMAsADUAO0A7gD4ARgBQgFyAZYBrAGsAawBsgHCAbYBjgFkAVIBIgD6AL4AhgBrAEmAJeACb+EP2o/Iz8nPwA/Fj7ePpQ+Sj5wPjA98D20PVg9VD0wPPA87DzkPRQ9eD1UPZA9gD3KPio+fD5kPn4+Rj6UPmQ+Ej4sPeA9zD3UPcA99D2sPbA9nD3sPfQ9wD4cPfw9mD2oPYQ9tD14PXQ9cD1EPbA9hD4EPkI+qj6IPx4/ZD+XgCCAeACKASABQgH4AfQCIAKIAzwDJANAA8gEEASIBVAF4AZoBhgGaAagBuAGgAZoBcAFoAToBFQDvALkAl4B+AFyAOkAeb/0v6A/uD9aP2U/Lj6KPr4+MD4IPeA9uD14PSA9FDzQPNA87DzoPRA9dD1IPWg9aD2UPfg9yD4oPgg+PD3kPdg9+D20PZw93D3APew9uD2UPcw92D3EPgA+MD3EPdg9nD2oPUQ9jD2APYg9iD24Pbg96j4KPow+wj8xPz4/XX/bQBeARgDcASQBWgGgAcwCWAKwAtgDVAO8A6AEAATIBaAF0AYYBlAGQAaYBqgGYAY4BaAFWATwBBQDjAMYAqQCMAGOAUMA/cASgBEAGf/BP58/Gj7IPoQ+QD4UPcw9rD1EPWA9ODz8PKw82D00PTg9KD0kPXw9QD24PZA98D3IPjQ9/D3IPcQ92D30PcA+JD3oPfA94D30PdA+Nj4mPjI+PD3kPcQ96D2IPfg9tD20Pbw9iD3kPdY+Hj5cPpA+xz8FP0s/ur+FwDeAdwC0AOwBIAGQAdACCAK4AtgDbAN8A5AECATwBRgFoAXABgAGUAZwBgAGEAXYBbgFKASQBCQDuAM8ArACZgHwAWkAwADMALfALv/jP48/Rz8yPqw+aD4IPdQ9iD2MPUg9NDy4PKg81DzoPMA9FD0gPTg9JD1wPXg9ZD2APew9qD2cPbw9pD3APew94D34Pdw99D3IPgA+FD4SPho+LD3gPcg9zD38Pag9iD3EPcQ90D3QPd4+OD4yPk4+8D7yPxA/YL+sv+SAOIBYAPIBKAFcAb4B7AJQAsQDFANwA4gEOARgBOAFOAVYBegF4AXABfgFoAWgBXgE0ASwBAwDxAOgAygCmAJ0AcoB5AFWASsAs4BXQDC/vz9qPwY+6j5oPiQ96D2sPVg9cD0YPTA85DzoPOg8/DzgPTg9OD00PQg9YD1kPUQ9lD2wPYw95D34PcA+Jj4CPl4+ZD5IPlY+Yj5UPlo+Qj5KPmg+OD34PfA9zD4aPhQ+Jj4mPgo+cj5oPp4+0z8DP2k/dz9hv6p/yYBXAKcA6gEiAWYBgAIMAnQCiAMgA1wDsAPoBCAEkAUIBWgFYAV4BVgFQAVwBTgEwAToBFgEPAOUA1QDDALIArgCKAH8AWIBOwCYAJKAen/fP7Q/Lj7aPoI+fD3MPdg9tD1gPXg9JD0EPQQ9HD0cPRQ9ED0sPTg9AD1EPVg9QD2IPaw9qD24PYQ93D3ePi4+Dj5CPlY+Sj5IPmI+XD5APmg+Fj4WPgI+MD34Pc4+Ij4mPi4+FD5SPrY+rj7HPxo/AT9vP2s/rT/IAHkASgDQASoBRgHEAiQCdAK8AvwDLANoA4gEIARoBKAE4ATgBNgE4ATYBPAEuARQBGAEFAPEA4QDUAM4AuACgAJkAf4BogFKAQQA7gBtAA5/yb+mPw4+zD6ePk4+GD3MPYw9tD1MPXA9KD0cPTQ8wD0APRQ9ODzkPMA9GD0oPTA9AD1YPUw9nD2MPew9/D3sPiw+Lj4yPgg+Vj5MPmw+Nj4UPlI+Qj5qPj4+Ij56PkQ+lD66PoA+5j7IPy8/DD9jP28/cz+ef+JACoBjAIgBPgE+AUgBvAGyAegCUAKEAsQC2AM4A3gDmAPkA/gDyAQoBBgEOAPcA9QD0APoA7wDPALQAywC3AK8AiACNgHGAe4BWgE/AMIA3ACbgEzAD3/Av4s/ST8APtA+pj5SPlI+KD30Pag9oD2QPbg9aD1wPXw9eD1gPWw9fD1YPZA9lD2wPYw92D3kPcI+GD4gPiI+AD5OPmQ+UD5YPmI+cD5gPqY+uj68PpQ+7D7+Pvg+yj8nPzg/LT9AP6g/qT+3v6y/wsAmADQAMYBUAJ4A7wD4AToBUAGqAbABnAHEAiwCDAJsAlgCtAK8ArAC0AMEAzQC+ALUAwgDFALgAqwCvAJEAqQCLAIyAdACCAHcAZgBaAE7AMsA3QCggGGABEAQf/M/gD+KP00/JD7oPug+lD6GPlo+Gj4gPio+BD4wPcQ96D38PfQ9xD3EPdA98D3sPdA92D38Pdg+Nj48Pjo+PD4KPlQ+QD6uPnI+eD5gPrw+tD6qPrQ+rj7APy4/Dj8RP1c/fj9Zv6w/nD/Mf8CADwABAEwAUQBaAJ8ApAD/AJQBBAEUAWQBYAFUAZQBugH8AYYB1AGEAmQCJAIOAdwCIAKUAkQCQAHQAngB8AIuAaACDgHQAdYB5AGMAYQA7wDYATIBFACMAGQArQCCAP1/wUAWv/D//T+E/8A/vj9LP0A/Sz8KPzo+5D72PpA+mD6qPrg+Rj6sPnY+SD5CPnA+Sj6cPnI+Cj48PnQ+Tj66Pjw+XD6YPv4+nD5MPpw+kj9LP2c/PD7MPzo/Ur+fP7o/Wz+7v6C/5T/iv8uAGIB+gFUAkwBAALEAcQDLAPsAywDaANIBGAEoAWABKgFwARgBRAFAAX4BQAF6AXQBDAGcAXoBbgE+AQIBVAFaAWQBFgEYARwBJgEpAMsA5wCUAKUAmACTAKKAQ4B9QB5AK4A3v/7/5X/Jf+M/7z+QP8O/n7+RP4E/uT9nPyc/YD8vP20/Gz95PyM/Jz8UPwA/cj7OPyA+wj9UPyQ/Hj7GPx4+0z9tPxG/vj72Pxg/Oj9mP3E/JT9GP3m/oz8Zv+k/X8A5Px2/6n/pAB1AKz99AHe/5YB0P1oAYQCnAHKABMALAKyASgCFALHAJwBSAIwBMYBQgA0AnwDkASQ/kgCPAPIBWQAXgE4AoAFkAHAAbcAaARWAQYBEwAcAmQCSgAKAQIB2AE9AFUAqgG0AE8A6P0oAgkATAEw/qsAiP+XABD+CgD2/n7/8P5W/0H/uP36/mT/9P72/vD8f//o/Cf/zPwZAKD98P5c/Wf/SP6s/TT+xP2S/7j8NP8I/tT/4P1k/uD+g/8B/2D+Yv+4/vb/fv7b/7L+Cf+w//kACgETAK//mP8OAB3/dP99ADUA4wAIAQQBswB9AOwAZAEYAdIAzABeAZACVgHqASoAcAJeAawCrwDeAagBVAHoARQB8gHW/yQBQAFYAvEALQBvABwBbAHUAHQB8gDCALf/+f8zAJ4BrgDI/rz++v4YAjb/wf8+/s//8v80/dD+iP3HAJj9HP+8/Xb/Tv7A/cj+Nv7G/wz9Zv6s/eH/wv40/iD+xP0kAFb+IQBg/Zz/9P2JAPz+8/+U/t7+Wv9hAL4A5P7I/q7+IAE7ABX/aP78/0oBMwDP/yj/EAHc/xgB0f9wAM7/rgDMABABXgH9/1QB8ABOAUoBqAAJAGv/eAFIAjQDHwDGAN3/aALF/3QBbgBEAoIBwP9IAaL/gAJ2/kwDyf/sAqD/jf+6AND/+AIE/pQB1Pz0Ar7+mgB4/XL/3v+Q/zz//PyS/6b+uQAO/nn/tPzh/xT/SQDI/kj9Iv7C/zoB2P3Y/Aj9IgGYAef/qP0q/3EA+f/G/xD/nf/j/4n/ogC6/0sApP4PAI7/oQCdAPb/vgAIAGIBp/8MAXX/FAHy/24ASgExANoBNv/QAsn/ZAJB/+oA8ABmAYAClP94AWf/qAOLAEgCzv4sAWQBRgEQAvH/0QDsAGgBAAPV/0IBLf/KATwAlv/g/jMAMAC4AFwAMAACARb/Pf9w/8//Zf8e/pL/Rv/BAGj+zv/A/u7+uP78/uD/4P1G/3L+IAFg/fj+Gv52AFz+zv6m/nkARv8e/8f/y/9wARj+cAHU/SQBwP3aAJL/HgEYAIL+IAFl/4gC+P2gAfv/wAJQ/0D+TAGVAFQDLv4IAZf/eALV/8QAe/9gAfoA3P83AL//zAF7AAwBIQBkAb0Aj/8iAZ4ABAL+/rkA5f+oAkoB7P+3AMT+mAIdAGQC0P6cAdIAHAGH/wMALAEoAtj+hACG/14B9P5J/4AAev+S/9z9cAES/soA+PywAdj9vf9M/RQAHP8KAOD9jv6Q/cYA0gC6/yT+vP3SAHL+FQC4/GgBNP4TADj+lv89/9r+6gBh/6b/wPuNAHcAoACC/iv/gAGAAFT+Vv/O/wQC0P35/0D/zAGhANL+LADc/aQCuP1MAsD9iAIo/xwBvP6VAL4BMgCbALT/cQBkAfT+kAEj/5gD6P4kAZP/9gGEApX/eAFK/6gDav5wAsH/7AJ2ANb+egH3/9oBYf+iART/QgHk/iACQv/+/07/CQDw/o7+2//FAIkAnP5/ADn/jQDc/NL+RACJAPT/cP1EAOT/rAEw/ZL/qP0UAjj94P9Q/dgCrv7h/zz9JADT/3r/zP4u/6MApv49AKT+lwA//03/FABC/14Bjv44AMz+GAH6/6//mP6bAJkAQwAzADn/lwDc/YQBJgHMAnwAFP6OAGX/JAPo/tgCj//GAWsAnQC8Anr/xAIm/mAEwP7MA7z+1AIFAMr/BgFPAIQDfv4wA4L+VAOk/hwBmAAXAMH/Ff+CAZf/gf8m/gEAbQCh/9L/rAC6/6v/Rv7S/+7/m/+l//D+/v7o/sT+5wCw/mQBgPwiAfz8gAEg/mr/Kv+k/rQAZv7S/7r+dP+w/pH/1P6N/5D+UADw/vT/JP7iACj/UADM/e4AeP6NAIT+wgCc/+r+yP4oAAIB9v5OAGr/7ABy/zr//gDeAOUAV/87AHgBgAH8/3QAmf+8A9r+fALU/HADZwAEA2T/AgDoAAIBuAAtADsAsAKU/pgCxP0QAzD+OgHJ/4oBXf/u/r3/vQBFAP7+j/9W/68AoP68AIz+mACg/nwAlP/G/r7+8/8DACgAvP3SALD+LwAs/uX/YQAw/nUAxPwkAgD9YgEW/3cAGP9W/jwBFv7GAbj82gFY/VgBpP78ALL+Mf/3/9v/5QAy/sQAA/88AYT/pP8MAHL+vAJQ//oBwP5r/wACcv7cAvD8MAQc/XgDzPyQAlX/GAEAAC7/BAKmAL4BDP4gAbIA2AJY/2f/DAD4AfIBlf8eAdL+GAIc/+ACCP/4AEP/JgAoAaj+7QAR/0gC8v4JAKr/CwDeAYb+hABk/TABaP5KAWj+igCp//7+///E/NYBHv5QAnj8WQCS/k4B0/9E/vgAQP7+AMz9hgGk/g0AoP2gABoADQCE/87+VgFs/e4ADP3AAu7+JAFs/sz+fADQ/swCHP3cAuj8dgFO/uUAbAEK/2gAbP2IBHX/1AG4+7gCMQCwA3r+aAEd/1QC3gBsAk4Awf8oAZMA1gHc/hQCpAK0AO4AEP+sAvX/4P+K//oBGgFJADkAyQAYAgD/tgEo/6gCDP3cADr+eAK+/3IAwP+g/o4BU/8wAnz8mP9Y/h4Bef9s/ZEAuP7KAST+JgDJ/6T/MQDU/YEAEv6JALj+AP9T/17/2QBy/qcAPv4OAez9SwD+/skAuf8N/18AOP4yAQT9kAD8/cQBJAD1AMT+VP5oATj/PAIg/TIBFQAIAUgAX/9yAZkASgDt/9X/1AH+/84Atv/UADIBqQD8AIEANAEMAWr/2gDJ/9QC5v9iACT/DQA4AkL/wAE0/rwC6P64ATD/SAFQ/zUA5/8cACIAhf/uAM7/cQAm/qoA3v6hAFL+hwDE/lf/vv/k/moBbP2aAC7+HgG6/vD+zv6I//kAmv6//wL+qgDo/b0AXP12ASD+vwAk/2n/6P/I/a0AIv6bAOz+zv4yAaj9fAGM/RQBcQBb/xIA6P10ATsAiQCN//T+eAE1AGwC3P9PABMAbwBEATgAiwDFADsAqgG0/6wCgP/9AOr/if+sArj/OANs/rABPwDYAdUAEv5+AaH/PAP0/egBjv5EAlH/iwBKAbT+dgFK/tQC5P8hAMT+RwD0ACL/XQCc/iQDvP7IAKj8xQCO/1wBlP5I/5r+uQDm/5YAW/9i/hEAU//NAET/mv6+/+3/5v/W/2j9jgG4/AwDyPsoAwD8QAIu/qv/Of8w/TgCzP0QA9D8mgEe/hwBK//sAOz+DAHq/40AJgD+/tYBTv+uATT+4AEYAPcAzv+sALIBJQCLAMz/HAL5/z4B2v7cAcb+WgF0/5YBTAB0/9gBQQBOATz+ev4MAqz/xAIg/XwBtv+zAHD/mf8IAQX//v+g/RIBcQCMAFH/PP9m/3wAUP5yAHz9AALk/WIBvP0sAI3/HgDj/8D+PP8g/ogAKf+KAQj9mACc/RAC+P1WADj9kgAP/5P/WACW/0EAdP2FAK7/ogFg/j4Aif+YAJD+Hv8gAb//7ACw/TQCqP6jAFD+gwAuAR7/hAEu/ggCfP2cAqz+aAJU/lwBOgD2ANT/EADQAPT/3ACK/9gBaf8wAXr/mgE2APr/oABp/7oB6P44Auz+lAGu/jgAEwCz/w4Bmv7OAJT+TAJz/6f/GP6h/zQCuv8cAAL+9wATAAL/Mv+Z/20AuP92/s7/LwBDABj/cP9OAIgAtv9G/qP/if/v/7z9ugDA/lwB8PxLAK7/8wD9/7z+xwDw/OIA9P1wAub+jv4a/w//8gGg/tYB/P2mAJ7+sQDuALf/6QAn/z4Buf/LAPf/pP9+AZEApAEG/m4A8wDkAgYBSf9GANn/OAIG/xQCWf/cAqD/BAI3AGoBJQBAAMYBCgEeAez9eQC8AOIBxgA3/7oApP82ASkA9wCG/8H/vwBx/6//zP2iAXYAOgEE/QwAJ/9wAcP/1f/i/yr+ZQBG/ugAfv5eAGj/DwBP/1X/i/+V//r+tf8W/tH/LP5oAT//mAEk/mf/Ev/s/nMAav9cATL/xf+S/nYAMgGO/6j/yP66/yX/PAAqAXMA2P+K/pkA0QBy/2QAov/dACP/LAB9AMkADgC3/0oBfABVAIUAAQCOAcP/6AChAFAADgERANgCsv+QAQj+SAIjABgCzv7ZABcAkgH8/9v/CgCC/+P/C/+6AOr/JgFk/gsAjP+wAMj/jP72/hIANgBAANL/wP+Y/4r+l/9o/xIB1P4vAG3/gP9W/x7+igF7/9IArP3R/37/gwDF/yX/J//w/j3/EAGs/zoBnP0Z/8b/xwD+/8D+C//LAIQBkP/W/97/uQAw/z7/3v4WAfv/tQCg//IARQC8ABYACAHx/8YAq/9tABgBugD2/zsAaAAuAQQBAABiAeMAwQD+/toAsQBcAaX/rf8yANYAz/+8/zAAagBIAsn/uQC0/UcAnP+zAM3/EP+FAJf/rgC8/loBIf+Q/wr/zf8MAU3/7P/c/ssA2P0TALv/hAFiANz+ff8b/y8AwP/Z/zz/TP6b/5L/xf/s/k8A9gArALL+9v7jAE0AZP6E/Wr/eABsAA7/R/9g/6v/vP70/1X/0QCL//r+9P4y/zYBWADKAPr+KwD3/60AbgAGAMMAFgC9AK7/fQBKAXYBSAGq/7UAbAAaAbz/IADH//L/h/+y/yIBVAB2APD+NwApAHQASwBZADUA6v84//7/nf8AAH3/uP82AOn//AC0/0AB3v8wAVH/DQB8/6//eQAa/wgBbf8kAXT+1ACb/6wALP8mAJwA0v/9/3z+lgF//7wAQP7GANT/GAHv/wQAvQCz/9UATP7m/9D+ZgFzAI0Aqv+4/9H/Z/91AB8AQgGe/tb/Vf8oASQATgAa/+//rP+aAEAA1P+8/zb/QQDo/xgBPACHAC//TACTANYA0f94/1QALAAoAe7/6AAkAEAAqf8VAHQAWgEYAe0Ay/9Y/y4AewD0AEb/GgDq/vYAAwCcASIBXQDi/27/EAHP//L/sv74AIsApgDn/04AXQALALj/RABAALj/7P7A/54AagGvAKH/PP/R/yUA6gA1ACcAlP+z/+v/+gAYAK3/Z//+/zIBCQB+/wj/pf/O/xL/Z/+9/4AADf/0/vL+oP/k/+D+ff92/1MABf/k/27/QACR/8j/s/8LAPH/NABCAC0AigD//5MAGACfANQA0ABbABUASQAAAAIA5f/XAJoAqwDQ/0oAJQA9AAMABABoAF4AhwAiACwBhwBTAGT/wf/7/1UAEwDC//L/k/+pAE8AiQARALf/AABp/8P/bP/K/0//q//V/7n/dv8l/8z/1//e/8X/1v8mAO3/2P9k/y3/6P5D/yX/R/8P/6L/FQBKAO3/bP9o/x//cv+v/xsA1/+q/w7/Pv+S/73/p/9I/0X/rf/2/2oAXgDA/5j/Sv/E/4j//P9oAJcAnAAdAFAAiACSAFwA/f/O/4z/GgBvALoAowBSAKsAvgDHAG4AdgC6AI0AaQAWAPf/HQBRANwAggBNADQAnwC3AE0ATwBjAMwAbQByAFQAYAAtAAYAYQB/AHoATAB1AJgAXwAZAP7/3f/p/+j/NwA6AO3/9/86AAwAdv/0/gv/Rv9x/yz/NP91/6T/l/9o/zn/F/+G/0//QP++/i3/wP/9/6P/l/8bABYAsf97/6z/xv+h/6b/3//c/+P/2/8tAOn/qP+N/7z/w/+4/w8ARQAlANT/0f90AHQASQDs/wsA0//A/9r/aQBxAFIAFwA7AA8AHQDD//j/7v8xAAEABgAUAEcASAAxAPf/QwAfAC0A6f8zACsAcwDu//P/jf/z/xUAKABFABsAKgAEAEAAPwBZADUAJQAVAPX/8f/H//X/qf9//4T/tf/N/8L/3P8JAPv/uv+a/8T/tP+M/1j/Z/9M/0D/U/92/4X/V/9N/6L/3/8CANr/vv/T/4//dP9c/5j/pv+l/4H/bf99/6T/3f/L/8z/qf/6/+7/IAAMAAAA9//B/9v/rv/C/7D/uv/c//3/IgA3ADcARABJAGwAWACGAMgA1wDIAGsAdACTAIsAigBsAHoAigCHAHMAjQClANYAxwCsAKcAnQCrAGcATAA/AE0AWABPAEUAnQCTAJ0AaAA3AFIAggCrAJ0AmgBaAE8AQgBFAEMAPgAiAAYAuf97/0z/b/+J/6//0/+W/5T/l//N/9n/zf/N/6//kf9Q/1D/R/8//x///v4X/9b+5P72/tL+8v52/qb+fv5q/q7+ov4A/8j+H/8o/1L/S/8Q/zr/8v4r//7+Hv8X/yD/j/+N/+D/8/8uAGAAhgCgAPQAJAEwAVYBeAGYAcgBDAIYAlQCZAKgAqQC5AIYA3wDlAO4A9wDoAPMA6wD0APAA5gD0AOYA5gDiAM8AzgDFAMUA0AD8AKUApgCPAJ4AuAB3AGMASwBrwBdAHEA8f+J/xv/hv4Y/iD9AP2Y/Dj8iPsI+/D6+Plw+aj4KPiQ9zD3oPYg9oD1oPVQ9ZD1QPUA9UD1UPXA9dD1oPbw9pD3MPhQ+SD6CPvI+9D82P1g/iUA/QCIArQDcAQoBvgGUAgQCZAJ0AmACuAKYAugC8ALEAwADFAMcAxwDGAMMAxgDGAMUAxQDMALgAsgC+AKgApACRAJUAggCLAHoAaoBnAGQAZgBcAEgAPoAlQCvAH1AIj/gP6s/Tz8iPuA+qD5EPkg+JD3YPbg9RD18PNg8+DxUPFQ8CDvIO7g7ODroOpg6sDpoOng6QDqAOvA60DtwO6A8PDxMPMQ9bD24PiI+nT8FP6K/xwBcAJoBKgFQAdQCOAJIAtwC3AMQA1wDhAPoA/gD8APsA+QD9APgA+wDrANkAxAC7AKsAkACSAIMAf4BngGYAYYBlAGcAaQBlgG6AawBhgHWAeIB6AH+AbYBigGyAVoBWgFGAX4BLAEWARwBPgDMATMA2gDjAL+AUYBZQAv/wD+5Pw4+xD6cPgQ9wD2MPQg81DywPCA8CDv4O5A7iDuYO1g7UDt4OzA7GDsQOzA7KDsAO6g7kDwcPLw81D2MPgo+hT8mv70ALQC0AMoBTgG0AcQCRAKIAuQCxAMcAzwDDANwA0wDnAOUA4wDvANAA7ADeAMsAzAC7AKQAlgCAgH8AUYBUgEmAO0AngC4AJ8AvQCmALsA1gECAWABcgFgAboBkgHiAeQB2gH8AewB2AH8AYYB0AHKAf4BqgGEAY4BqAFaAVABGwDqALyARwA7P5A/VT88Po4+RD4kPZA9VDzwPKQ8GDwgO4g7mDtwOvg60DqYOpA6eDo4Ohg6QDqQOkg6wDtoO+g8dDykPTA9Rj4mPto/YX/0ABEAkgEKAXABlAIsAngCvAKkAwADRANUA7QDmAP4A6gDsAOQA4QDpAN8AwwDAALIArwCBAI2AYwBnAFeASoAxwDHAOEArACzAJAA4wD6ANgBKgEEAWwBXgG8AZIBzgHoAfgB+gHEAi4B+gHmAdoBygHqAZIBsAFcAWgBJQDkAKOAU0A/P64/Tj84PoQ+dD3UPbg9EDzEPKw8CDvIO6A7QDsIOsg68Dp4Ong6ADooOiA6GDpIOlA6qDrYO3g76Dx4PMA9bD3CPoA/Lz+GgAoAtwDqAVgBwAIEAqwCmAM0AzADSAOoA5gD5APIBCwD7APMA9QDzAOUA3gDJALsAoQCVAIOAfIBRAFzANAA/ACMALUAXQBjAGoARACwAL0AlwDwAOgBAAF6AVgBvAGKAdgB9gHIAgQCGAIgAhQCEAIEAi4B2gHCAcYBsgFqATUA5ACeAEaANT+ZP0w/Nj6aPnw94D28PSg83Dy8PBQ8MDuoO3A7KDrgOvg6SDqoOig6GDogOiA6QDqIOuA7IDv4PAQ8yD0oPYY+ZD7wP2V/ygB4AIIBXAG2AfgCCAKgAuwDOAMgA1wDhAPgA9wD6APkA/wDhAPcA6wDbAMwAvQCqAJQAgIBwgGkARUA2QC4AFoAeEAsgB7AHMA4gCaASgC0AKAA9wD6ARoBagFkAYQB0AHkAfoByAI0AcQCAAIQAgQCMAHqAcgB+AGGAbYBQAFAAQsA+YBpABK/wL+wPww+6D5SPig9kD1oPNA8vDw4O9A7qDtIOyg66DqIOqg6WDo4OiA6CDpwOiA6aDrAO0g75Dw8PFA9CD2CPkQ+5z9rP7cAAQDqARYBsgHMAlACqALQAxADeANkA5QD5APwA9wD6APgA9QD7AOIA5gDUAMMAtQCgAJyAeoBlgFKARMA3QCygFUAdMAuwDoACABUAH+AbACKAMQBNAEmAXwBZAGUAfgByAIUAiACKAIsAjACNAIwAiQCCAI0AdwB8AGKAaIBWgEeAM8AjIB2P+g/lD9APxw+rD4YPdw9TD0gPIg8aDvYO7g7ADs4Opg6iDp4OgA6KDnoOdg52DoAOgg6mDrIO3g7uDwQPKA9DD3ePnI+8D9Df+2AZQDeAWoBmAI4AnwCnAM0AzQDXAOQA8AELAP4A+gD4APoA8gD4AOgA3gDNALEAuwCbAIUAcgBjAF6AMoAygCjAHtAIkAnABzAPkAPgHMAcACbAP8AwgFwAVgBvAGeAcgCDAIsAjQCMAI0AigCGAIQAjAB4gHCAcwBpgFoAQgBBgDFALoAMz/kv5I/Sz8oPpg+YD3YPbQ9CDzsPFQ8ADvoO1g7GDrYOqA6QDpgOhA6CDooOdA6CDo4OkA6+Ds4O5g7yDyUPSw9pD4APv8/Av/WgFIA9gEeAZwCAAKYAtADDANAA6wDoAPIBBAEEAQIBBAECAQwA8gD6AO8A0ADRAMEAvQCaAIUAdQBggFIATAAtwBfgGYAJoAEQA+ACcAyACgAQQC+AKAA6AEaAWABjAH0AdwCNAIYAmQCbAJcAmACVAJIAmwCDAIgAfQBlAGUAWABHgDUAJkAQsA+P6k/VT8QPvI+Xj4wPag9fDzYPJg8aDvoO4A7SDsIOtA6kDpwOjA6GDooOcA6GDowOlA66Ds4O0A8MDxcPRA9uj4+PrQ/Kb/OAGgA9gECAdACAAKYAvwCxANwA2QDgAPgA/AD9APwA/QD7APUA/wDkAOsA3gDPALEAsACtAIyAe4BqgFmARAA7gCDAJ4AQ4BrABtAKgACAG0ARgCqAJQAxgE+ASYBYgGSAewB4AIgAggCQAJUAkwCTAJ4AhgCPAHUAeYBsAFCAVYBOgCCAIAAdP/vv50/Tj8yPqw+WD4APeg9VD0kPLg8SDwAO/A7YDsoOvA6iDqoOnA6ODooOiA6GDoAOng6sDrYO3A7nDwsPLg9FD3SPmQ+1T9xv+UAbwDOAXIBrAIwAkQC/ALwAxgDUAOcA7wDhAPsA4AD4AOkA4gDqANIA1ADKAL0AoACkAJ8AcYBxAGCAUQBDwDHALEAVwBxACVAG0AdACrAEwBogFMAuQCyANoBHgFIAbwBrAHQAjACCAJUAmQCbAJsAlQCeAIYAjoByAHWAaYBbAEtANsAmAB7f8G/7z9nPwo++j54Phg92D2APWg83DyQPEA8CDvoO3g7ADsoOvg6kDqAOrg6aDpAOpA6oDrQOzA7cDvMPFw8oD00PbY+Jj7+Pzq/tgAwALgBFgG8AfwCEAKcAuwDNAMwA0ADkAO0A4gDrAOoA3ADWAN0AxwDGALIAsQCpAJgAioB2gGyAW4BKgDFAPyAVIB0wBvADgA///7/zIAXgD1AHoBFALEAnQDYARYBfAF2AZQByAIkAjgCBAJYAlQCVAJ4AigCAAIQAfQBrgF+ATUA+wC0gGuAIj/QP4c/QD8uPqw+Sj4MPfw9cD0YPNQ8uDwUPAg7wDuIO1g7IDrQOsA62DqIOoA6oDqAOvg6wDtgO7g77DxMPMg9TD3CPlg+1D9Q/+nANQCcAQgBtAHwAjgCeAK0AuADOAMIA1QDXANsA1QDeAMoAxQDCAMQAvACvAJMAmgCMgHGAfwBTAFQAR8A8wCGAKSARAB4AC3ALMAqgDGACgB1AFsAhgDsAOIBGgFOAYIB5gHcAjgCIAJ4AkACjAKEAogCtAJcAngCDAIgAegBsgFsASEA2ACNAHz/7j+ZP1A/AD70Pmg+GD3MPYQ9eDzwPLA8bDwwO8A7wDuYO2g7EDs4OuA6yDrQOtA68DroOwA7sDuwO/w8RDzYPUQ97D4EPvg/DX/tQCMAjgECAa4BxAJIAoACyAMMA2gDQAOIA4wDlAOEA4ADiAN8AxADAAMIAtwCoAJkAgACBgHUAYIBVgEdAMMAywCrgEsAbYAsQByAJYAtgAQAY4BHAKAAmQDGAT4BNAFkAZoB/gHkAggCaAJ4AkgCiAKEArgCcAJMAmQCPgHIAcwBkgFSAQUA/ABvgCD/z7+QP3I+7j6aPlo+BD3EPbA9LDzcPKA8aDwoO/g7kDuwO1A7QDtYOzA7ODr4Oug7ADtQO6A7uDvsPCw8hD0oPVg9xj52PqY/An/CgAYAkgDKAWYBvgHwAjwCcAKoAtgDGAMoAywDAAN8AyQDAAMgAsQC7AKEAoQCTAImAe4BvgF+AT0A0wDpALyAXoBzAB0AEQAIwA2AGEAowAkAa4BOALMAnwDYARQBRgG4AaYByAI0AhgCcAJIAowCiAKIArwCbAJMAnACOgHMAdQBmgFWAQ4AwwCzwC0/4T+TP04/Bj70PnA+KD3gPZw9VD0UPMw8nDxkPDg7yDvoO7g7aDtIO3g7IDsoOwg7QDtIO6g7oDvgPDA8cDz8PSg9jD4wPnw+5j9Yv+KAJgC7AOYBQAH+AcgCTAKEAvAC0AMQAywDNAM0AyQDBAMoAswC9AKEApwCZAIwAcgBygGSAVoBKAD2AJIArQBNAHeAJUAeACRAK8ACgGCAdABWAIAA8wDSAQoBdgFuAZoB/gHkAgACXAJwAnwCQAK4AngCXAJQAmwCOgHQAdwBpAFqARsAzQCDgH+/9b+uP2I/Dj7QPoY+QD48Paw9cD0sPOg8rDxsPAA8GDvwO6A7oDtIO2A7IDsgOyA7CDtAO1A7uDuwO/w8JDysPNA9QD3mPgw+gj8fP18//gAjALMAzAFoAbQBxAJ0AmQCiALwAtADEAMUAxADPAL0AtwC+AKIArACRAJYAhwB6AG2AUgBVgEcAOkAvQBcAEEAZwARQAVAEIAlQDlAGYB5AFsAjgDzAOwBEAFAAbYBqgHMAjQCDAJYAnACeAJIArACcAJYAngCFAIwAfoBggGSAVIBFwDEALnANP/uv7E/WT8WPtY+ij5KPgg90D2QPVQ9HDzkPKw8TDxgPDg74Dv4O6g7gDuAO4A7iDuwO7A7sDvcPCA8YDywPMA9ZD2APig+RD7qPxq/u3/kAHEAjAEgAXABugH4AigCXAK8AqAC9ALAAwQDAAM4AuQCxALkAoACmAJsAgACCgHSAZ4BagE+AMIAzQCjgEQAX8AHgAmAKv/rv96AIYASAHCAf4BLAPYA/AEgAVQBiAH6AfACFAJoAnwCYAKAAvgCuAKsApgCiAKkAnwCNgHIAcgBnAFMARAA8wBtACV/3j+PP24+7D6gPmo+FD3UPZA9UD0kPOA8sDx4PAg8MDvQO+g7mDuIO4g7iDuIO6A7uDuwO+A8GDxMPJg86D0IPaQ9yD5iPoo/Lj9Uf+8ACQCjAOwBBAGEAcQCPAI4AlgCgALYAuwC8AL0AvAC6ALAAuQCjAKgAngCEAIWAeQBvAF2ASABDQDdALwATYBGgEWACoAh/8UADAAegD3AG4B2AGIAtwDKARIBbAFqAZ4B1AIsAggCYAJAAqQCqAKoAqACnAKUArgCRAJMAhQB6gGyAWoBHwDbAIwAScAxv5U/Qz86Pq4+bD4cPdQ9lD1YPSg87Dy4PEg8YDw4O9A78DugO5g7iDuIO4g7kDuoO5g7wDwsPCg8YDywPMA9VD2oPco+aj6HPyc/Q//eADUAUgDeASgBcAGsAeQCIAJIAqwCiALgAuwC7ALsAtQC/AKkAoQCoAJ4AjgB0gHUAaoBYAEyAMQA/QBkAHoAG4AyP9K/57/hP/a/xUALAASAcgBsAIkAyAEqASgBZgGSAfIB4AI8AiQCSAKQAqgCqAK0AqwClAK4AlACbAI8AcoBzgGMAVoBEQDOAIgAdL/cv48/RD82Pqo+Zj4YPdw9nD1kPTA8+Dy8PFQ8dDwEPDA70DvIO8g7wDvIO9A76DvMPDg8LDxcPKA84D0sPUA91D4mPkA+3D82P05/18AsAHgAhgEQAVQBiAHIAjQCIAJQAqQCgALMAtQCxAL4AqQClAKwAlgCYAIAAj4BmAGgAV4BPADrAI8AnQBmwAaANb/G//+/gr/N/9o/+P/FADdAIYBaAIcA+gDyASQBYgGAAfAB1AI8AiwCcAJIApQCkAKgApQCvAJQAngCDAIgAdwBqAFkASUA5gCYgEyANT+pP1E/BD70Plw+ID3YPZw9YD0oPPA8hDyUPGw8BDwoO9g7yDvIO8A7wDvQO+g7wDwwPBA8UDyEPMw9DD1QPaQ9+D4OPpw+9D8DP5O/3MAqgHIAswD8ATYBbgGYAcwCOAIcAnACTAKYApgCqAKgAowCgAKUAlACUAI0AfwBjAG2AVwBNwDCANIAlYB5gAuAL3/V/8y//L+5v6M/7f/PgC1AGYBNAIsAwAEyASQBWAGCAfIB2AI8AhgCdAJUApQClAKUAoQCtAJYAngCAAIMAdIBkgFaAQcA/YB3gCV/2D++PzQ+1D6EPng97D2kPWQ9LDzwPIQ8mDxsPAQ8KDvYO9A7yDvQO9A76Dv4O9Q8BDxsPFQ8kDzMPRw9WD2cPeo+Mj5WPtc/Kz9qP7e//0AEAJEA/wDKAXoBbgGiAcgCJAIMAmQCSAKEApQCkAKYApACvAJUAkwCUAIEAgYB4gG0AWQBGAECAOAAlgBNgFnAAAAxf8y/wf/Jf+G/8L/OwDFAE4BQAI0AwgE+ATIBaAGaAdQCLAIcAnwCYAKAAswC2ALYAsgC/AKoAoACnAJgAiYB8gGsAWIBEQDLAK6AKj/UP7I/Ij7EPrI+LD3cPZw9VD0kPPA8iDyYPGg8DDw4O+g72DvgO+g78Dv4O+A8BDxcPEg8vDysPOg9MD1kPag9/j44Pkw+0D8PP1u/pP/ugCuAcACrANoBGAFOAbQBpAH2AewCBAJcAnACbAJ8AnACcAJQAkACUAIAAhQB+gGAAYYBcgEzAMIAywCXAHEAGAA9f+S/yv/7v43/3z/1f9jAKoAvgGAApwDaAQ4BWgGEAcgCJAIUAnQCWAK8ApgC7ALgAuQC1ALIAuwCiAKgAmgCLAHuAawBYAEVAP+AboAWf8G/rD8MPvY+Tj4MPfg9bD0wPPg8vDxUPGg8ADwwO9A70DvQO9g72Dv4O8g8MDwYPHg8cDyoPNQ9GD1YPZQ94D4WPnA+sD7FP34/fz+FQA0AQwCRAPUA7gEcAUoBuAGcAfgB1AI0AggCXAJYAlgCVAJQAkQCZAIQAiABxAHsAYgBugEeAScA/gCZAIsAeQAwf/k/57/Hv8P/8b+NP+k/xQApABUAf4BNAMgBEAFEAbgBrgHsAhACeAJQAqwCmALcAvQC6ALYAtQC+AKYArQCdAIEAgIBxAG4AScA2gCDAGy/3r+9Py4+0j6wPig90D2IPUg9CDzYPKw8QDxcPAA8KDvgO+A74DvwO/g70DwsPCA8fDx8PKA82D0QPVQ9jD3EPgg+Tj6WPts/IT9Qv5U/xMAGgHkAcQCWAMQBNgEWAXoBUAG2AYYB2gHyAfAB/gH8AfoB8gHkAcYB5AGKAawBQgF0AQABCQDmALaAUgBXwDq/13/+v74/oD+fv5o/sb+WP/Z/38ANAHkARwDCAQYBRAG8AagB4AIUAkACoAKAAtwC9ALEAwADPALkAtgCwALQAqgCYAIoAegBngFMATQAngBFADA/lj9wPsw+uD4YPcg9uD00PPA8uDxUPHA8ADwgO9A7yDvIO9A70DvwO8w8NDwcPEQ8gDzsPOw9LD1oPZw94j4iPmg+rj7vPy8/Zz+q/90AHwBLAIAA8wDeAQwBagFaAbABkgHiAcgCDAIgAiwCJAIwAiQCEAIEAiYBwgHWAYgBigFsAQIBDgDnAJ4ASIBWwDJ/2v/Hf+y/qD+jP6u/gD/f/8KAJYAcgFgAnQDeASQBWgGQAdQCPAIwAmACgALkAvwC1AMYAygDHAMQAzwC2AL0ArgCfAIAAi4BqAFWAToAooBDQCU/gz9iPvw+Vj4APfQ9ZD0kPNw8uDx0PCA8ODvYO8g7yDvAO9g78DvwO+w8BDxsPFg8nDzQPQw9SD2EPco+Bj5OPpQ+1D8TP1C/kT/IwD7ANoBrAJ4AxgE0ASABRAGgAbwBmgHoAcQCEAIYAhgCIAIQAggCNAHQAfgBlgG0AVABagE2ANEA1gCogEMAWsAxP+J/wb/sv6I/kj+lv7c/iH/tv8QABYBxAH8AugDCAXIBfAGAAjACJAJMArgCoALMAxADIAMsAyQDKAMcAzwCzALwArACRAJ4AeYBlgF/APIAiwBsv8m/oj88PpQ+cD3MPYA9cDzsPJw8aDwAPBg7+DuYO5g7iDugO7A7iDvoO8w8BDxsPGw8oDzcPSA9ZD2kPe4+Kj54Prg+yD9JP4E/ykA7ADMAagCpAMwBDgFmAUoBsgGYAfoBxAIcAiQCLAI0AjgCKAIgAhACOAHaAf4BigGiAU4BUgEzAOoAiQCMgF7AAAATP/o/lr+Nv4O/gD+EP5g/l7+cf/R/68AYgF8AnQDyATwBbgGwAdQCGAJAArAChALoAsQDDAMkAxgDFAMEAywC1ALcArQCbAIwAeQBjAF5ANsAvkAcv/g/Vj8mPrw+GD34PVw9CDz8PHg8ADwYO/A7iDuAO7A7cDtAO5A7sDugO8w8ADx4PHQ8tDzwPQg9iD3UPhg+Wj6uPuk/OD9qP6C/5IAIAH4AZQCZAPoA7AEQAWwBRAGgAbwBkAHaAdwB6gHgAeoB3gHUAcQB8AGSAbYBUgFgAT0AzQDiALaASQBLgCf/+D+UP7o/Yz9YP0c/Tj9VP2o/SL+qv5K/zsABAEEAjQDWASIBdgG8AeACHAJEArQCnAL8AtgDJAM4AzgDNAMwAxQDMALUAuQCqAJoAhYBygGqARcA+ABHACM/uT8YPu4+fD3YPbA9HDzMPLg8DDwQO+A7gDuoO1g7YDtwO0A7oDuIO/g77DwoPGw8qDz0PQQ9kD3cPig+dj6APwo/TL+Ov8cABoB8gGgAnQDGATIBGAFAAZwBtgGQAeAB+AHIAgwCEAIUAggCCAI4AeoB0AH6AZoBrgFMAV4BLQD7AJoAoQBzwAZAFX/uv5U/uD9tP2M/YT9fP3c/Rb+kP5E//T/4QDKAbQCCAQgBVAGqAdgCJAJIArgCoALAAyQDNAMUA0ADTANAA3ADJAMEAxQC3AKcAmgCDAH+AUwBJgCHAGm/9j9QPxQ+sD40PZw9QD0IPIw8eDvQO8g7gDuYO0A7UDtQO3A7QDuoO5A7yDwUPFA8mDzgPSA9QD3OPi4+cD6DPz4/Db+UP9FACwB9gHUAqQDOATYBDgFuAUoBqAG0AYYB0gHcAeQB9gHkAeIB2gHGAfwBpgGEAboBQgFmATgAzQDeALeAQ4BUgCZ/+D+Xv7A/TD9JP0g/fT8JP0c/WD98P2E/lz/OwByATwChAPQBOgFOAdgCHAJYApACxAMkAwQDbANsA3wDQAO0A2gDTAN4AxgDMAL4AqgCYAIOAfgBUAEmALWADL/kP0Y/Ej6IPiA9rD0QPMA8nDwQO9A7qDtIO3g7IDsYOyg7ODsoO0g7gDvwO8A8UDyQPOg9KD1QPdw+AD6KPtM/Gz9Yv6+/4oApAFcAlgD/AOoBEgF0AUoBrAGCAdYB7AHuAfwBxAIAAgACOgHsAcYB/gGmAYQBpAF+ARQBKQD8AIYAoYBvgD5/z3/mP7o/XT9DP3Q/MT8nPzQ/Cz9UP3Q/WT+J/9UAEIBaAJgA8AEAAZIB1AIgAkgClAL4AugDAANQA2ADbANwA2ADVANwAygDFAMwAvgCtAJ0AhwB0gGoASkAv8Au//g/Wj8cPpg+LD2oPSA84DxIPDg7qDtAO1A7ODrgOug68DrIOyg7GDtIO5A74Dw0PEA84D0wPVw9+j4UPrY++z8TP5h/28AhgFgAhwDAARwBDAFaAXgBTgGmAbIBtgGAAcYBygHSAdgBwgHAAe4BpgGSAbQBWgF4ASQBNgDSAOAAvIBSgF1ALf/7P5C/qT9XP24/Hz8OPxI/HD8wPw4/YT9Pv4J/xUADAEwAkwDuAQoBnAHkAigCZAKgAtwDBANkA3QDUAOYA5wDnAO4A3ADWANMA2QDPALEAsQClAJQAhoBuAEBANgAcH/OP6M/Gj6oPig9tD0APMw8eDvQO5g7aDs4Otg6wDrAOuA6wDsoOxA7YDuoO/g8EDysPMg9dD2YPjw+Wj7qPxG/mn/hwCeATwCbAMgBOAEWAXQBTAGgAbwBiAHMAdAB0gHaAegB5AHeAc4B0gHIAe4BlAGEAagBRgFmAT0AygDrALeAUIBJwCf/87+AP7g/TD9zPyE/GD8SPyM/Oz8TP3Q/Xj+eP8UAEYBUAKoA+gEQAaAB4AI4AmQCrALcAwwDXANAA4wDkAOUA4wDsANkA0gDcAMQAzQC9AKQAoQCSAIkAbQBIADDAGc/yD+ePyQ+nj4cPZw9LDyQPGA7wDuwOzg6yDrwOpg6iDqoOpg6wDswOzA7QDvYPAA8rDz8PTA9lj4MPrQ+1j9sP7c/0oBLAL0AuQDgAQgBcAFCAZYBnAGwAbwBvAG6AbYBqgGkAbABpgGIAaIBrAFiAVYBdgEGAS4AzgDgAIcAj4BkADj/0v/ev6o/ST9pPw4/Aj84Pug+6j7+PtY/Nj8iP1Q/jn/CwA6AUQCoAP4BGAGyAfwCDAKEAswDOAMcA0ADnAOcA6wDoAOcA5QDuANkA0ADZAM8AuAC6AKAArwCKgHkAbwBBQDHgEw/5T9BPwY+kj4EPZg8xDy4O+g7gDtoOtg6gDqgOlA6WDpoOlA6oDrwOzA7SDvwPCA8nD0MPbQ97D5ePs8/fz+DACSAWwCkANgBMgEaAXYBVAGmAZwBogGqAaoBrgGsAZgBmAGaAZABkAGIAbABZgFgAUoBZAEGASgAwgDRALOAfIANwBu/9L+EP5M/Zz8JPzI+6D7WPtY+4D7mPtA/Lz8tP2O/o7/hgCyAeACOAR4BcAGUAhQCWAKsAtgDBAN0A0wDnAOoA6ADjAOEA6gDTAN4AwwDMALAAvQCiAKcAmgCJAHkAYoBYgDuAGM/wD+0PzI+ij5YPaQ9DDysPDA7uDsoOvg6WDpwOig6IDoAOmg6cDqQOxg7QDvwPCw8rD0cPao+ED6RPzg/Zj/HgE4AmgDMATwBGAFuAUoBjgGOAY4BkAGEAYIBvAF2AWYBXAFaAVABTAF6ATgBLAESAQwBJgDPAOYAiQCggE4AWQAv/8Z/5T+EP5M/QT9DPwk/Pj7yPtM/DT8tPwI/Qj+qv67/6cAvAHgAvwDOAVoBpAHsAgACiALIAwADZANEA6ADrAOwA7ADlAOIA7ADWAN0AxQDMALYAvQCmAK4AlACcAI+AcYB/AFUAR8ApIAdv4E/Uj7SPlw97D0YPIg8ODuoOxA66DpwOhg6CDogOiA6IDpgOog7ODtQO8w8SDzcPWg93j5aPs8/c7+YQDIAQQD0ANoBBgFcAV4BagFaAWYBXAFKAUABeAE6ATQBLAEuASIBIgEqASYBGgEMAQ4BAgE8ANMA6wCOAKIAQwBVgCO/+L+Mv60/Qz9nPzo+8j7uPvA+/j7ZPyk/FD9EP4O/+7/EAFUAjQDeASYBdAGqAfQCLAJgApwCwAMoAzgDCANUA1wDTANIA2wDIAMIAyQC3ALsAqgCiAKIAqwCWAJEAmwCFAIkAc4BsAE0ALoACj/fP0A+0D5wPaQ9BDyAO8A7sDroOog6UDooOeA50DowOgA6gDroOyA7oDwcPJA9CD2UPhY+jD8zP3w/icASAE8AgQDVAOgA6wDwAPMA8ADjAN0A6ADaAN0A6gDcAO0A9ADEAQQBAgEIATkA9wDcANkA8QCbAKIAaoA5/9b/07+Av5s/aj8OPzo+6D7WPtg+1D7JPyI/Dj95P2S/p3/lgCsAcQC0AOIBKgFcAZoB/gH8AiACSAKwApQC8ALEAxADGAMgAxwDHAMQAwwDNALwAuAC1AL4ArQCoAKoAqQCiAK8AlACdAI4AewBqAE2AIZABD+DP3Q+mj40PXg8jDxAO+A7aDrIOqA6QDpAOkg6WDpYOqA64DtwO7Q8FDyEPRQ9gD46Plo+xT9QP5f/2gAAgEgAnQC2AL0AiwDIANYA1wDPAMsAzgDoAOkA+AD6AO0AwAEWARIBBgEzANwA0QD5AKsAsQBRAFPALz/Cv8a/qz91PzA/FD8BPzo+7D70Pvo+5D8JP2s/Zz+GP/P/7cAmAGcAkwD+AO4BGAFaAbYBlgHqAdgCOAIUAnQCQAKcAqACgALMAswC1ALQAuAC2ALUAvwCtAKgAqACmAKEArwCdAJQAlQCYAIcAfIBmAF7AOiAaj/VP2Q+yj6CPhw9TDzoPBg7+DtgOwA60Dq4OkA6qDqwOoA7EDt4O6A8JDyEPTA9bD3IPkI+yT8uP3s/rD/zwDqAPoBIAKoAtQCtAIEA9QCHANQAywDSAN8AwAEAAQgBCAEyAPwA/gDqANIA6ACAAKAASgBLwCA/3j+8P0s/az8SPwo/Az8EPwM/GD8wPxg/fj9av5e/+v/7ADmAZACOAOoA7AECAXgBfAFeAbwBhgHwAfgBzAIcAgQCXAJ8AlgCpAKAAsQC0ALQAtgC1ALYAswC8AKcAoQCsAJwAlQCRAJ0AigCIAI8AdQB1gGiAU4BGwCVgAq/lj84PpA+RD3EPRQ8SDwAO5A7aDrwOog6uDpoOrg6uDrAO2g7nDwAPKw81D1QPfI+CD6sPsg/QL+Gf+k/yMAcwC4AEABWAGEAWgBWAGyAcQBBAIUAkACnAL4AggD6AKwAsACsAKIAiwCagHeAEMArv8K/2z+1P1I/cD8UPzo++j7EPx0/Nz8KP2M/Tz+DP/n/4sAWgH+AQADhAMoBHAEsAQYBXAFsAX4BSAGMAZgBrgGwAYYB2gH6AdACLAIAAmACaAJEAoQCnAKcApgCpAK0AnwCSAJQAkgCbAIoAggCGAIUAiACEAI0AdYB2AGoAXMA7YBXv/0/Sj8oPnw91D1APPg8KDuAO1g7GDrIOvg6sDqwOrg68DtQO+Q8WDyEPTA9bD3wPlw+tj7iPyk/cD+HP8z/yf/lv+5/97/SAD///v/HwBnANUABAF4AawBHAJMAggCYAI0AhACigESAW0A3f8p/1b+fP3Y/Cz8EPxo+yD7gPrg+jj7+Pu8/Dj9Nv4J/zsAHAH4AcwCsANoBCAFmAWQBagFmAXQBbAFGAagBfgFuAX4BQgG6AW4BtAG2AcgCLAIQAnQCVAKkArwCkALgAuQCwAL4ApQCkAKwAlwCUAJ4AiwCOAI0AgwCbAIsAhgCIAHiAb4A7wCJgHm/uz8qPqQ+FD2kPSQ8SDvoO0g7GDsIOwA7MDr4OtA7QDvEPHQ8jD00PVw9wj5iPqQ+7D8dP0S/sj+xv4e/wT//P7a/jv/Sf9r//v/zP/0/1oA0wBqAdYB7gHqAfAB5gHKAWgB/wD//5b/6P4o/mD9hPzY+6D7cPto+2D7OPuw+1j8UP1i/i3/LgAuAUAC1AK0A1gE+ARYBbgF2AUQBsgFSAUIBdgE6AQIBeAEqASYBKAEIAXQBSgGiAYQB7gHkAgACXAJoAngCUAKQApACsAJUAkgCbAIcAj4B9AHqAf4B0AIkAgACQAJUAkACeAI2AfoBgAFHAOTAFT+6Pu4+YD3wPTQ8mDwAO6A7CDsYOug6+DrAOxA7SDuUPAg8uDzoPXQ9pj4sPkY+7j7fPwc/WD92P1I/nz+Nv4g/lr+gv4u/5//8v9ZAI8ABAGgAdIBCAIEAtwBbgH2ABAAOv9s/mz9oPzQ+/D6gPrg+aj5sPkI+nj6+PrA+4z8mP3q/vP/CgGwAbgCeAMoBIAEqATwBLgE+AQABdgEyARwBFAEUARQBFAEmASwBAgFQAWwBfAFSAaQBuAGOAdwB6AHEAgQCDAIAAgACNgH8AcwCCAIYAgwCGAIUAiACPAIoAlwClALUAswCvAKAAqgCZAIeAYQBEAB+P7c/LD6QPiQ9WDzQPFg7yDuYO0A7cDsQO1A7uDu4O8Q8bDyIPSQ9QD3EPhA+fD5kPo4+9j7bPzg/Ej9XP3o/Tb+av6S/tL+hf89AM8AQgEiAUIBXAFAAWYB+gCbAMf/9v4q/mD9mPzY+4D7SPvo+gD74PpQ+9D7iPwo/QL+wP6q/5AAMAHyAYACGAPYAygEaARoBLgEwAToBBAFAAVABUAFMAWABQAFOAX4BEAFSAXYBCAFoAToBJgEoATwBOgEcAWgBSgGoAYgB7AHAAhgCNAIkAkgCmAKEApQCnAK4AlQCqAKIAtwCzALsArQCvAJcAmACOgGQASeAVP/DP3g+3D58PaQ9GDyAPGA7wDvIO7g7SDuwO7A76Dw8PEw87D0cPbQ9yD5EPqg+jj7kPtE/Jj8OP2E/WD90P34/V7+kP4C/1z/2v9GAJ4AAAHMAEoAXAA5AEwAbf/E/pz9vPw0/Fj76Ppg+jj6IPqY+uj6cPvI+3D8kP14/m//+P+rAAoBBAI8AtwC+AI4A6gDXAPUA3wDyAPAA8ADGARQBKgEmARoBFgEcASwBIAE0ARoBFgE5APEA+wD/AMgBJAE2AS4BQAGoAZIBwAIAAnQCNAJ4ApAC7ALgAswC9AKQAtQC4AL8AswCyALsApwCtAJ4AgoB+AEaALi/xD+WPw4+rD3IPXg8kDx4O/g7kDuwO3g7YDugO+Q8PDxEPOQ9KD2KPho+TD6APuA+0D8hPzA/Bj9FP1A/Yj9/P3Y/QT+Ev6C/jT/tv/j/+j/qf8y//7+Zv4O/lj9vPzw+yj7kPrg+dj5QPmI+SD6APuw+0T85Pzc/T3/LAAMAZ4B6gGUAtwCKAMoA9AC1AIcA3wDkAOcA5ADrAP0A5AEAAVABWAFSAVABSAFsASQBCAEuANMA/QCbAIMAqwBtAFIAtAC6AO4BCgG4AZACPAI0AmQCrALwAxADTANMAzgC5ALMAvgCiALoAogCvAJgAnQCfAIcAhAB1AFaAPYAO7+mPx4+vD3kPWw85DxwO+A7uDtYO3A7YDugO+w8CDy8POw9WD38PiI+sj7tPyE/cj9qP2k/YT9uP0o/gr+Bv6g/Uz9kP24/TT+cP54/oD+Rv7c/VD91Pxc/Oj7SPuQ+uD5QPmo+FD4QPig+BD50PnA+uD78PwY/jz/awBeAQwC8AJcA8gDjANcAzQD6ALcArgCqAKgAjwCsALMAkADmAPwAzAEYASgBGAEAAR8A+ACfAKIAjgCrgH4ANQACAHyADQCFAMIBIAFAAeQCMAJIAoACyAMIA3gDaANcA1QDKALIAuwCiAKQAnwCGAIkAigCLAIsAigB7gGSAXEA9QBrf8o/Xj6QPjg9SD0UPLQ8MDvwO6g7gDvwO9A8TDyEPSQ9SD32Pjg+Xj7oPyg/Qr+gP0U/dT81Pzk/Lj8hPwQ/Nj7yPvg+xD8kPzI/Pz8DP3M/Nz8KPzg+2j7IPvA+kD6IPqY+Sj5+Pgg+bj54PrA+3j8mP2c/p3/1QDOAbgCVANkA6ADiANIA/QCnAIwAkACvgGqAewBpAEoAsQC1AMYBHgEwAQ4BTgFCAWQBHAEVAOMAiwCdgFWAasAnQDEAFIBEAJcAwAFwAYwCOAJMAuADCANQA3gDbAO8A2ADRAMIAtACjAJwAggCMgHYAdQCNAIwAlwCQAJkAgoB7gF7AOoARr/APyo+TD3QPUg86DxsPDg78DvMPCg8UDzIPWw9qD42PmY+/j8JP7e/rL+iv5e/mj9vPw0/Lj7oPsg+2D7WPuw+5D78PuE/Oz8UP1c/aj9vPzA+8j6UPrg+fj4OPjA93D3gPfg91D4OPko+jD7CP0g/tz+AwDuAOoBUAKMAnwCKAJ2AfsA0gDEAIQANwBPAIEA7ABUATQC2AKYA0AEiAQwBVgFWAXoBEgEiAPUAggCrgH7ALYAhgC3AHYBWAI0A0AEAAYwBxAJQApgC2AM4AwQDTAN8AxADKALIAvwCvAJoAiAB6gGIAfgByAJwAnwCfAJQAnQCdAIkAdIBVACbP+8/Nj6EPjw9aDzQPKQ8WDx4PFg8pDzkPRw9iD4uPk4+xj8/Pzg/QD+8P1k/aD8qPsI+5j6UPqI+nD6CPp4+hD7wPsM/LD7CPwY/Gz8SPxA+zj66PjQ93D3EPcQ94D2gPbA9mD3yPi4+Sj7dPys/bb+sP97AAABogHQAZgBGgHmAFAArf+x/0L/x/84ADEAVADdAL4BfAJgA9QDUARwBFAE0ASYBHgEsAP8AmQCEAKMAR4BJAG2AOwAzgGwAugD0AR4BcAGsAewCPAJoAoQC4ALYAtgC8AKUAowCiAK8AkgCZAI2Ad4B/AHAAlwCvAK8ArgCkAKYAlQCFAGCARUAZz+UPxY+kj4kPYA9TD0QPSw9DD1oPXA9rD3sPiw+bj62Psc/DT8ZPw8/DD8WPsI+0D6+PmY+RD6gPrw+lD7oPvY+wT8DPyg+4D7uPpA+jj5UPiA9/D2gPZw9lD2QPaw9qD3yPiw+Xj6qPuo/GT9Ev6K/rL+ZP5s/qr+4v7O/r7+sv7I/h//9v6f/0UAmwAIAVAB2gHsARQCkAJcApQCmAJ0AmQC9gH8ASACbAI8AhgC/AHcAbwBIALUAlwDCAQ4BOgEkAWYBvAH0AiACSAKsAogC/ALMAwQDMALkAtwCzALsArgCcAJYAkACYAJEArwCmALIAvACpAJwAfIBYgD4gEUAJj9iPtA+aD3UPZA9mD2kPbA9kD3ePhI+Vj6uPpY++j7MPyQ/JT8jPzo+1D7CPvA+rj6kPp4+sj6GPuA++D70Puw+2j78PpQ+oj5QPlI+ED3cPZg9qD2cPbQ9uD24PcA+Tj6kPt4/JD9Uv4j/0H/U/9S/4v/Nv8w/5f/m/9S/yP/o/8UALwAswDYAEwBZAF+AXQB9AEoAqgBxAFUARQCMAIgAlQCTAL8AuACMAO0AhQDnAIoAkACgAIgA2ADkAP4AyAFOAaIB7AIMAkwCmAK0AqAC9ALAAxACyALQArwCQAJoAiwCAAJIAkwCeAJ8AqAC5ALUAsACiAIwAWIA3ABQv/Y/Hj6IPlw97D2kPbg9vD2YPfo+OD5mPqQ+lD6yPqA+tj66Pr4+kj6gPlw+ZD5GPoI+mD62PpQ+2j7sPvA+8j7ePuQ+hD6aPmg+HD3oPZA9nD2wPbw9uD3cPhw+Sj6GPuU/Bj9gP3Y/Xz+cv4E/nz9CP2M/dj97P2c/iH/Pv/z/7kAagH2AVACHALUAVQBvQDIAH8AfACNAHUAygA0AbIBaALEAkQDeAP8A8QDMAPoAlwCQAKOAdwB0AH8ATQCbAPQBPAFSAcwCKAJIArQCjALQAsQC8AKUAvwCiAKwAjYB+gH0AegCKAJYApQCvAKkAvAC0ALUAm4B3gFEAONAJD+5Pwo+7D5iPhg+ND34Pc4+Bj5cPro+qD7APtg+kD6OPqw+oD6MPq4+fD5MPpw+oD6SPuQ+wT8ZPy4/HT88PvQ+oj6+PlY+ZD4QPfA9oD2MPaQ9kD3wPfQ+Hj5OPqw+iD7PPxc/Kj8xPx4/MD8GPzI+yD8kPzw/HT9OP4N/37/zf8+AC4BkgGYAUIB9gBQAMH/uf9x/7z/2P92AAABNgHyAewC/AOgBAAFcAUoBQgEIAPQAtACZAIIAtwBoALkAjgEGAWABqAHwAgAClAKYAvwCgALwAqwCvAKoArgCbAI6AeABxAI0AiwCZAKEAswDFAMEAzQCsAJEAhIBYACMABk/oj8gPvg+mD6UPlw+MD4mPmY+gj7OPtw+4j6CPqg+UD5EPmw+BD5iPnI+RD6UPrw+nj78Puc/Jz8yPsA+5D6APog+aj4IPiw9yD30PZg95D38PdA+DD5EPpA+sD6+PpI+2D7gPvw+yj8IPwo/Dz8dPzU/Oz9zv51/yQAiADzAGwBJgFaAXoBQgHfAI8AOwBRACEAawD8APYBwAIAAywDZAPcA0AE2AQABbAE1AMMA0wCcAFqAbwBFAKcAqgC2APgBLgFwAYACIAJQArwCeAJIApACnAKYAqwCpAK4AnQCdAJ4AmwCYAJ4AmAClALcAsgC+AJkAjoB4AG6ASMAlAAkP7k/Gz84PsM/Fj7aPrw+Qj6WPpA+oj6YPqg+eD4YPgY+ED4GPmQ+fj5iPrQ+tj7CPxU/Fz8ZPyw+6j6yPnw+HD4cPcA90D3UPcw90D3wPcw+LD4sPjY+AD5CPkY+VD5yPno+fD5UPoI+0D7APyw+zz86Pyc/d7+Zf/R/9z/q/8HAPv/FgAJACwA3P8h/1n/hf+y/woA0ACYASQC3gHuAVwC8AIIA4AD9AOgAyADUAKoAnAC7gHsAd4BIAJ4AuQCzANQBAAFSAbwB8AIMAlQCWAJIAnQCBAJ4AnACWAJkAnQCUAKQAqACgALIAsQC7AKAAugCsAJ0AhoB5gF6APAAkYBj//4/bD9lP04/Uj8RPxA/CD7kPr4+hj74Ppg+dj40Pig+HD4CPpA+3j7APtQ+6D7+PuI+5D7yPv4+mj5aPg4+JD3YPdg9+D3CPiw9xj4ePh4+GD4MPhI+Ej4gPdg9/D3UPjo+FD5IPp4+jD7sPuk/HT9JP4K/xf/Mf+E/wkAa//q/kj/JQBHAN//zP9XAO8AIAH0AcgC6AKYAkwC9AL8AjwDgAPAA/QD9APkA7QDHAOcAtwCwAJwAhACtAEQArgCkAOABQAHWAeQB2AIQAmACXAJ8AhwCdAI4AgACeAJQAoACqAKEAvAC8AKQArwCeAJYAkQCQAJAAgAB+AEGANKAVEAfP+K/nT9DP1Y/Az8EPvw+uj6wPpY+uD5+Plo+dD4MPjI+ID5EPrg+TD6uPqw+rD6MPvQ+8j70Pqg+Qj5EPgw9+D2cPfw95D3APgg+Fj4OPgQ+HD4aPhA+ID3UPeQ9yj4OPmg+Rj6kPqo+2D8kPyc/VD+sP6+/o7+F/80/9T+gP4r/8H/OQAIACwABAEGATABHgHwAWgCDALYAZwB0gHMAXACQAPEA5QDJAMoA9gCNALwASACogHwALoAmgGEArAD6AQQB0AI+AcACCAIIAkgCUAJYAmwCTAJEAmwCdAK8AsQDDAMQAzgCxALIAqACTAJwAlACoAJ4AdQBkgF1AMMAvYBpAGPANj+4P1S/sT9dPyo+6j7wPuA+iD6OPpQ+ij6+PmA+qD6iPrI+hj7OPsQ+7j7BPyg+yj7qPow+kj5IPjw91D4mPiA+Mj4mPiI+Aj4OPhw+Dj4CPig94D3YPeg91j4SPmg+QD6oPpw+6j7wPvU/PD9Uv4Q/sT9uv7a/vD+8v5w/zUAhwBCAJ0ALgFOATgBMgEMAlQCBAKyARQC8AIgAxwDJAOcA8gDVAPgAt4BQgE4AacA8QBYASgCGAOoAygFcAaQB0gHyAboBnAH4AcwCNAIQAlQCZAJUArgCqALoAxQDOAL8AqACsAK4AnQCeAJMAoACXgHuAZoBpAFPAPcAZABHgHv/9D+eP5y/nj9YPwg/DT8kPuI+kj64Prw+oj6aPq4+tj6MPvQ+gj7EPvI+uj6oPpQ+uj5EPnQ+BD4sPfQ9+D34PdQ96D3gPcA93D2YPaw9jD34PZA9zD3gPdg9+D36PhI+ZD5oPmg+uj6ePto/Pz8KP1U/Wz9yP08/cT8dP1o/vz+Uv/k/2AASQAjAHIAHAHHAJ4A1AA2AXABhgEoAjADZAMMA3ACFAJUAaYAjQDPALEASAHYAngEUAWgBWAGeAb4BZgFYAcQCQAJkAgACfAJgAoACkAL4AxwDGALcAsgDDAMMAsACyALYAvQCUAJcAkwCUAIEAc4BtAEQAPGAQwBmQAkAJr/xv78/Vz9mPxI/Dz88Pvo+5D72Pq4+sD6UPvg+gj7OPvw+qj6SPqg+vj5aPn4+Dj5mPiw91D30Peg92D3cPeA94D3kPZQ9tD2sPbA9tD2YPeQ92D3wPfw92D44Phg+XD6kPrY+oj7QPws/Yz96P20/Tj9kPwU/UD+0v4a/6T/XwDfALAAfwAsATwBKgG5AF4B7gH+AVwCwAJcA9ACRAKUAbABqgBTAGUA0wDEAqwDiARQBJAEwATQBMgEwAWYBsgHIAe4B9AIAAqwCbAJ0ArgC0AM8AogC/ALIAzwCtAKoAuAC1AKEAmACfAJIAngB9AG+AUYBEQCjAFIAfkAiwDf/07/aP7A/QT9hPyU/Ij8IPxQ+/j6oPvg+/D7APxk/HD8iPsY+wD7yPpA+sD5EPpA+qj5APkQ+fD4+PhI+Fj4iPjg92D38PaQ99D3oPfA9wD4EPhQ93D3CPjI+Pj4IPko+rj6CPtY+4D8+Pyo/CD8fPwA/Rj9BP3s/Tz/jP/w/x8ADgHWADgAJgBKAVoBPgFKAf4B2AIkAuABHAJoArIBVgDJ/43/XACoAcQCyAMgBDAEfANoAlgDeARwBZAFQAbgB2AIyAcQCKAJMAugCjAK4AqgC9ALgAswDNAMMAxgC7AKoApgCjAKYAoACkAJ8AfgBsgFuAQoBMgDNANAApgBLgGrALj/Pf/6/o7+uP0s/RT91PyE/Hj81Pyw/ET8BPzI+2j7WPoY+lj6YPog+pj5cPkg+bj4aPhI+Bj48Pew91D3UPcw9zD34PbQ9uD24PZw9nD20PZQ93D3kPcw+Lj4kPmo+Qj6oPrY+sj6APtw++j7KPwo/Nz8jP0s/qb+E/8//2n/UP+S/yAAQQC1ACIBugFsAVoBhgGmARIBawAmAIcAhgCIAIQBTAK0AhgC+AFoArgCVAKQAgAEKAVwBXgFCAYoB2AHGAe4BwAJEAkwCSAJQArQCnAKQAqQCsAKgApgCnAKwAogCnAJ0AhACJgHuAYIBuAFCAWQBMwDJANoAqYBAAFxAAAAhv8g/97+RP78/bD9NP0A/aD8oPwQ/Ij7EPsQ+5j6QPpI+kj6CPpQ+RD5qPig+Aj4CPiI+ID4ePg4+Fj4GPiQ9yD3UPeg94D3gPfA9/D3KPho+Hj4+PgQ+SD5iPmw+dD5IPqQ+gj76PoY+6j7IPyY/PT8iP1K/pT+zP5r//v/RABfAN4AbgHSAdoB8AEsAigCFAK4AbYB+AEcAiwCbAKIArQCoAJwAoQCtAK4AowCBANUA8gDxAP4A3gE0AT4BBgFyAVoBsAGCAdYB3gHYAdwB8AHcAiwCPAI4AjwCPAIkAiQCBAIEAjgB8AHcAcYB/gGiAYIBpAFUAUYBaAEKATwA7wDUAPQApACYAIMAqABJAHqAHUA7f9s/xL/wP5w/vD9YP0o/ZT8oPsQ+8j6wPqQ+iD6EPrQ+Yj52Pgw+Bj48PfA94D3YPdw9yD3EPcA9yD3QPcg9zD3UPeQ96D3sPfw9xD4WPio+Lj48PhQ+cj5+Pl4+pj6QPvI+/D7MPyg/Cz9ZP2M/dD9Sv50/mz+ov7E/gP/3P7q/lr/0//7/yYAkgDQAPcADgEEAUgBggHGAVQCwAJQA+ADEARYBLAEMAXQBRAGiAYIB3gHkAeoBzAI0AhQCZAJ4AlACjAK8AkACvAJ4AnQCbAJ0AnACXAJEAmwCGAIEAiwB0gHGAewBjgGqAU4BfgEmAQgBKgDgAP0AlwCxgEiAaYAuf9D/4z+IP5Q/az8+Psw+6D6EPq4+XD5EPmQ+DD4kPcw96D2QPYA9tD1cPVg9VD1IPUQ9SD1UPVA9UD1cPWQ9aD1wPUQ9oD24PZA96D38Pco+Gj40Phg+QD6ePog+6j7APxE/JT8/PxU/dD9Yv6i/gD/Tf92/6z/qP/1/zsAiQDhAFYBzAEMAiQCPAJYAmQCxAIkA6wDEARoBPAEMAVwBdgFYAbYBnAHwAcACDAIcAjQCBAJUAmgCTAKcApwCqAKoAqgCmAKMApgCnAKUAoQCtAJoAkwCZAIcAhACBAIsAdYB/gGcAbgBXgFQAXIBJAEGATAA3wD2AJYAq4BHAFzAMP/Lf96/tj9IP1o/Mj7MPuo+jD6wPlQ+eD4WPjA9zD34PaA9iD24PXQ9dD1kPWQ9XD1sPXQ9eD18PXg9QD2IPZg9pD28PZg99D30PcI+GD4sPgA+Yj5QPrA+kD7WPuw+zT8hPzA/AT9oP0c/ij+lv6i/iD/KP8Q/27/wP9nAGwAyQDlAFABLAHyADoBogEQAmwCzAJEA7ADvAMABHgE6ASYBQgGgAYABzgHeAdwByAIgAggCVAJoAkACjAKIAoACiAKgApgCkAKUAowCvAJcAkgCQAJ8AigCGAIUAjYB2AH6AbIBjgG0AWgBRgFwARgBCAEGASQAxQDZAKyAdcA9/9d/8L+Mv5g/bz8UPy4+wj7cPrw+Yj5+Pgw+OD3oPcw97D2QPYQ9uD1kPVg9YD1kPWQ9WD1QPWA9UD1EPVQ9eD1MPZg9oD2wPZQ92D3gPcA+Jj42PhQ+cj5SPqo+vD6MPu4+zj8jPwc/Wj96P0+/lr+kv7e/hT/gf/B/zQAgADTANcAvQAiAU4BvgHYAXwC8AIoA0wDtAMwBHAE8ARgBSAGYAa4BhgHcAeoB9gHcAjQCEAJYAmwCRAK4AnwCRAKMAoQChAKIAoACuAJUAlACSAJ0AhwCFAIMAjwB2gHCAfoBoAGCAaIBVAFOAXIBLgEaAQYBJwDvAIIAiABVACO/+b+fv78/TD9xPzo+2j7qPoI+lj56PhQ+BD4gPfw9oD24PWw9YD1YPVw9WD1QPUQ9eD0sPSA9ID04PQA9WD1kPXA9VD2QPaQ9vD2YPfQ9xj4gPgA+Xj54PlI+sj6OPuQ+wT8kPz4/Ej9sP34/VT+fv4H/3D/u/8FAFEApAC/ALIACgFmAYIBuAEQAowCtALoAjwD2AP4A2gEsARABagFAAZYBpgGOAdAB7gHIAiACOAIAAlQCZAJsAmwCeAJAAoACvAJ0AkQCtAJwAlgCUAJQAnwCNAIkAiQCEAIAAioB2gH8AaIBjAGCAb4BcAFeAVQBZAE2APYAuIBKgFVANT/YP/c/lT+gP30/CT8YPvI+ij6qPlA+eD4UPhw99D2QPbw9cD1wPXg9cD1gPUw9fD04PTA9AD1MPVw9aD10PUA9hD2UPbA9jD3oPfw95j4EPlo+dD5GPqY+iD7WPvw+3D88PxI/YD9uP0S/lL+yv4Z/2j/rv/l/w0ANgB1AKsADAFEAXQBqgEQAkwCjALwAmwDvAMYBGAE8ARQBbAFCAZIBtAGQAd4B+AHMAiQCOAI8AhgCYAJsAngCQAKEAoQChAKEAogChAK4AnACYAJYAmACRAJ8AiwCIAIYAjQB6AHIAfoBpgGcAZgBmgGGAZ4BdAE+AP0AiwClgHlADkA2P8B/1z+hP3I/Dz8QPvA+gj6iPnw+DD4gPfQ9lD2wPWQ9aD1cPUw9QD1sPSA9FD0MPQw9GD0kPSg9ND0APUQ9WD1wPUg9mD2EPdg9+D3SPiA+Aj5YPnA+VD6wPpo+7j78Ptc/MD8BP1I/dT9RP6g/uz+Mv9Q/7T/t/8xAFMA0AAMAUgBsgHmAUgCjAIsA2AD7AN4BMAEKAWQBfgFYAawBhgHoAcACEAIgAjQCCAJMAmACbAJ4AnwCRAKIAogChAK8AngCeAJwAmwCXAJcAlACRAJwAiQCBAI8AewBzgH6AbABtgG2AaQBvgFiAXIBIgDwAIoAooBEgEmAGn/xv7Q/eD8WPyY+/D6GPqQ+fD4SPhg96D2QPbA9WD1APUA9QD1wPRw9CD0APTg8/DzAPRQ9ID0gPSg9BD1MPVw9fD1YPYQ91D34Pco+Kj4IPlI+dj5YPoI+2j78Ptk/ND88Pws/aD9PP6U/tr+SP+F/9f/4/8fAI8AygA8AZgB7AEkAmgCtALgAjQDwAMYBKAE+AR4BQgGOAagBtgGSAe4ByAIQAjQCCAJMAlQCZAJ4AnwCQAKAApQCjAKEArgCeAJ0AmQCYAJYAlwCSAJ8AiwCLAIIAjwB6gHQAdYB/AG4AawBrgGeAaQBcAEEAQsA8gC2AFqAdkARgBe/3T+5P0Q/WT8aPvg+kj6iPmQ+OD3cPfA9iD2wPXQ9bD1UPUA9cD0oPRQ9BD0MPRQ9GD0cPSQ9OD0EPVQ9aD1EPaw9gD3YPfQ90j40PgA+XD56Pl4+gD7UPvQ+0D8kPzM/BD9gP3o/UD+gv7a/g7/U/9e/6j/DABDAJwAygA8AYgBngH0AUgCxAL4AnwD4ANwBOAEKAWoBQgGYAbABiAHcAfwByAIcAjACAAJMAlQCYAJsAnwCdAJ0AnACbAJgAmACUAJYAlACSAJEAnACJAIQAgACMAHgAdIBxAHGAdABxgHiAboBWgFsASMA1QDpAIoAmwBngDx//T+IP5E/ZD8+Ps4+4D62PkQ+Tj4kPcA91D2wPWw9ZD1QPXw9KD0gPQw9PDz8PMQ9FD0QPRA9HD0oPTA9AD1YPXw9WD20PYw96D3CPhY+Mj4MPnI+UD6wPo4+5j7+PtM/JT89Pxo/dz9OP6I/rb+/v4n/1v/qP/t/z8AoADSAC4BaAG6AfwBVALQAjwDqAMYBJAE6AQ4BZgFAAZ4BtAGOAeoB/AHMAiQCKAI8AgQCUAJgAlwCZAJgAmgCYAJgAlgCVAJcAlwCXAJMAnwCNAI0AiQCAAIEAjoBwAIwAegB/AHcAeoBvgFWAWIBMgD7AKsAjwCdAFbAJ//7v70/Tz9SPwA/DD7YPqY+dD4MPhA98D2cPYw9vD1kPUw9dD0gPQg9PDz8PMg9ED0YPRg9JD0oPTg9AD1cPUA9mD24PYw98D3APhQ+Mj4WPnY+WD6wPpY+5D78Pso/LD8FP2Q/Qz+Tv7W/uL+Cf85/4v/tv/7/0wArQD+ACoBhgHaAUACmAIYA3wDCARgBMgEGAWABQgGQAbgBiAHoAcQCFAIoAjQCCAJcAmQCcAJ4AkgCvAJAAoACjAKEArQCQAKQAogCqAJYAmwCXAJAAnACHAIwAiACFAIkAigCBAIMAeoBsgFEAVABIADRAOQAtgByQAPACT/CP48/XD84Ps4+3D6iPmQ+KD38PZQ9vD10PVw9VD14PRg9AD00POA83DzoPPA89Dz4PPw8/DzQPSA9PD0YPXg9XD2sPZA92D38Pcw+Kj4aPno+Xj60Pow+6D7+PtU/ND8VP3s/Tr+lv7g/hj/R/9h/+X/NQCBALsAHgFoAaAB/gFUAuACIAOUAxAEeATABPgEcAXwBVAGmAYYB6AHAAhACJAI0AgQCSAJUAmgCaAJsAmgCeAJwAnACdAJ0AnwCeAJ4AmwCaAJcAlwCQAJ4AhwCJAIkAiQCKAIwAhgCMAH8AYoBpAFwAT4A3gDIAMwAnYBqgCv/9D+wP0U/Uz8kPvo+vD5GPkY+GD30PZw9iD20PWQ9VD1wPRA9DD0EPTg8+DzEPQw9DD0MPRQ9JD0wPQg9bD1MPaA9vD2QPeg9wD4SPjA+Fj5uPko+nD64Pow+4D7+Pt4/PD8QP2U/fT9Hv46/nD+yP4C/z7/kf/6/0YAcQDpADoBmgHaAVwC0AI0A5QD4ANgBLAECAVwBQAGYAbIBjgHkAfQB/AHEAiACLAI8AgQCTAJQAlQCTAJQAlgCWAJgAmACYAJYAlgCUAJEAnQCLAI8AiwCAAJYAlgCQAJcAjIBxgHeAawBTgF4ARABGADtALkAeYA6f8Y/3b+hP3I/Aj8KPsQ+gj5SPjA9yD3wPaA9kD24PUQ9cD0cPRA9CD0IPQw9DD0MPQw9DD0QPSg9OD0QPXA9QD2cPaQ9vD2QPfA9yj4mPgo+aj5EPpA+sD6QPuw+yD8oPxE/Zz9zP34/U7+vv7a/h//oP/c/zIAVQCmAAoBRAGYAeQBdALAAhgDeAPsA0AEcAQIBXAF4AVYBtgGMAd4B6gH2AcwCEAIYAjgCCAJEAkgCTAJYAlwCVAJkAmwCaAJ0AnACeAJoAmgCWAJcAmgCaAJEAoACjAK4AlgCXAI6AdgBwAHSAbIBTAFmASsA6QC6gFCAUUAa/98/gT+EP3o+yD7+PlY+Xj4IPhw9zD3sPbw9YD1EPXA9GD0UPRA9DD0QPQQ9AD0EPQw9GD0kPQA9VD10PUA9jD2kPYA95D30PdA+LD4KPmQ+eD5YPrg+oj78Ptc/Oz8YP10/bj95P0a/nr+uv4H/4H/uf8dAC8AiQD8AGQBiAHkAWACwAL4AjQDsANIBIAE4ASgBQAGeAbQBgAHkAfgBwAIQAiwCBAJIAlQCUAJgAmQCXAJoAngCTAK8AmwCTAKQArwCaAJgAnwCTAKcAqwCtAKoArACRAJkAggCHAHKAfQBmgGUAU4BJADdALEAQQBQQCZ/6T+hP14/Hj7UPpw+bD4IPjA9zD3sPbg9UD1cPQQ9BD0sPPg86DzoPNg81DzQPOA88Dz8POQ9JD08PQg9XD1kPXw9WD2APdw9+D3YPi4+Aj5WPn4+bD6IPuo+2j8HP0Q/Sz9nP0i/m7+mv4c/7b/SQA3AG4AvgA6AWYB7AF4AvwCOANcA8gD/AMoBKAEKAXQBYAGuAYoB1gHuAfYByAIcAjACAAJYAlgCZAJcAmQCfAJEAoACgAKEAogCmAKMAowCvAJsAnACQAKkAqgCvAKAAtgCkAJ0AhQCAAIwAcQB9AG4AUgBeAD/AIsAjgBngDR/y7/CP7A/Fj7WPpY+bD4GPiQ9zD3cPZg9aD0APTA86DzUPNw8yDzAPPQ8oDyoPIA80DzcPPA81D0kPSg9JD0QPXA9TD2cPYw97D3sPfw9yD4OPmA+fj5sPpo++D7mPs4/Mz8UP0o/VT9mP74/uD++v7t/14AbwAVACoBLAJUAjACpAKIA6ADkAMABCAFWAWYBSAGKAd4BwgHOAcQCNAIsAiwCDAJ8AnQCUAJUAmwCWAKQAoQCoAJoAkQClAK0AqAClAK0AlQCUAKwAtwDBAMgAvgCgAKIAmwCCAJsAmQCJgHuAaoBZgEvAP8AkgC+wAvAO3/8P7k/Cj7SPqI+YD4SPgo+ND3QPZA9BD00POw82DzgPNg88DyQPLw8VDyYPLQ8uDyUPPg8+DzEPTw84D0MPXA9RD2kPbg9xD4wPeg9/D4OPpQ+nD6cPug/ID8NPzM/Ar+zP4w/sT+CwBPADcACQD1AMYB5gFIAtAChAMwA0QD4APABBAFGAXgBQAGGAawBlAHeAeoBwAIkAiwCAAIQAjACbAJsAiwCEAJMAogCoAJwAmQCbAIQAkAChALkAogCiAJcAkwCrAK8AsQDIAMQAtQCZAHYAjwCQAKQAjoBkgGoAXUAwADRAMIA9UAaf/u/kf/GP2A+rj54Pjo+JD38Pfg9iD2EPSA8jDzYPPQ80Dz8PJQ8sDx4PHA8ZDyEPOA85DzgPMA9FD0APWw9AD1MPZA9wD4gPfA9wD4qPh4+XD6uPsA/Dj8APxo/Cz9zP0s/pj+WP7M/qP/xv/D/yYAmgAmAcIAdgG0AhADBAIEAvgC1APQAxAEWAXwBdgEWAQ4BiAHeAcoB3AHUAgACLgHEAigCaAJwAjQCFAJQApgCcAIQAlQCmAKsAjwCEALYAugCWAIcAngC1AMYAwwDIAL4AjQBjAIEApwCnAIWAdABhgFUAIMAnQDwALQAbD/fv5c/aD7MPqQ+Wj5UPig9yD3cPaQ9TD0YPOQ8kDzQPPQ88DzYPIg8mDxQPKw8uDzUPRg9AD00POg9LD0oPXg9QD3QPeA9/D3MPhY+DD5OPrA+lj7FPwU/ej8JPyY/Hr+nP9Y/rD+9f+cAKn/bf/wAN4BugHPAEACYAMQAyQCHANQBAgEXAMoBEgGYAZQBTgFkAawB0gHSAdQCMAIYAiQB8AI0AlgCaAIgAnQCdAJoAgwCZAKcAqACeAIsAlACoAKAArACYAJcAoQDEAMUAsgCZAIIAioBxAIYAlgCBgG7APEAtgCrgEgAmwBzQCI/gj8mPtg+ij66PhY+GD30PZQ9pD1gPQA8yDzEPNQ86DzUPNQ8zDyYPEw8gDzAPTA89DzcPTQ9ED0cPRg9XD2sPbQ9pD3ePhY+MD3mPgw+jD6aPrA+9j83PzA+xT8yP2M/gL+Mv6Z/wgAb/8p/z0AlAH1AIUAoAHgAuQCiAKAAnQDuAOsA+gDgAWQBugFcAXIBRgHgAewB9AHcAiwCLAIwAhACcAJcAmgCZAJ0AnACQAK4AnQCWAK8AkACtAJwArwCoAKEAqACkAM8AzwC9AKcAkgCOAH4AgAChAJcAdYBbQD6AI0AmADvAL1ACr/2P2M/Pj6+PkA+sj5IPiQ9uD2gPYQ9ZDzYPPQ87DzYPMA9ED0cPKQ8TDyoPOA9IDzMPTg9KD0wPOQ9PD1MPYA9oD28PeA+ID3gPdY+RD68Pkw+pj7wPxk/Nj7nPzs/Qj+Rv7A/nX/CgCg/xoACwAUAXABPAH4AXgCFAMkA/wC+AI4BMAEyAQoBTAGGAcQBugFsAYQCDAIyAeACAAJkAlQCMAIoAnQCVAJsAkwCrAJkAnACTAKMAqgCVAKwAqwCgAK8ArgCiALIAvwC0AN4ApgCNgHwAhACVAJ8AigB9gEuAKkAnwDoAMwApwAVP9w/YD7KPsg+/j5wPgg+GD3EPYQ9QD1UPRQ82DyIPMA9KDzgPIQ8mDyIPJw8tDzgPTg80DzYPNw9LD0oPSQ9UD2oPbQ9oD3wPcQ+Ej4sPjo+oD6gPqI+3j8EPwQ/Kj8nP3G/ij+fv4j/4D/k/+0/3IAyAC8ADoBFAJAAnAC0ALMAvwCxAPwBEgFCAWABUgGYAbYBWgGEAiQCPgHyAcgCdAJwAiQCPAJQArACfAI0AmQCvAJgAkwCiALYApQCpAKoAsQC2AKsAvQDOAMsAuQCmAJQAiwB9AJwAsgCcAGrAOoA7ADZAMAAxQDbAEs/oz8BPx4++j68Png+HD4YPeg9RD10PRA9FDzUPLQ8lD04PNw8vDw0PEw8yDzEPPg82D0sPOg8nDzUPWg9dD0sPUw91D3oPaQ9qD4wPnw+Pj42Pro+xD7KPuU/HT96Pwc/bD+k//K/nr+7/8WATgAyv+oADACqgGuAawCHAP4AgwCZAPIBCAFsAQoBfAFIAbIBQgGeAcACLgHMAiwCLAI8AjwCDAJ0AnQCaAJ4AmQCYAJMApACnAKcApwCmAKgApAC3ALUAuAC1AMIA3ACpAIsAgACVAKUAmwCRAI0AXYAsACMAVgBJwCjAD5/w7+oPuI+lD7MPxo+UD3APdQ9yD20PNQ9DD0wPNw8rDywPNA89DxIPFw8oDzgPOg86DzcPOw8+DzEPTQ9LD1YPZA9hD28PYI+Cj4sPfw+GD6SPog+sj6OPwo/JD7APwq/ob+wP3w/X7/ZAA8/6r/BwBUAQ4BogB0AsQCXAKCAewCwAMYBAgE+AQoBqAFEAWwBQAHeAdgB5gHQAjgCNAIEAmgCZAJsAngCQAKQApQCjAKEAqACgALgAvgCrAKIAtgC5ALcAugDCAOoA1QC/AJUAmwCTAK4ArAC+AJGAZAA2gEWAVoBegDkALnADj+IP1U/Ij8aPsA+qD58Pew9uD10PXw9KDzYPPA88Dz8PLQ8gDzEPJQ8ZDykPSA9GDzsPKQ8xD0oPOw9AD2MPZQ9XD1YPfQ92D3kPdQ+UD6iPmI+bj6LPwQ/ID71Py8/Zz9rP2o/rb/wv9V/7L/xwDKAIYAJAEoAnwCfALkAWgCAAMwBJAEwAQ4BfAEmAUQBqAG+AaIB5AHkAdACNAIUAkQCQAJgAnQCYAJkAkACkAKUArACXAK8AogC8AKEAvgCtAKAAzwDHAN0AyAC1AK0AjQCGAKcAzACmAIuAW4BKgETAMoBWgFGAMj//z8NP0E/dj74PqY+lD5IPfQ9dD1sPVQ9BDzsPOA87DyMPJg8lDygPGg8aDyYPNw8/Dy8PLQ8sDyQPOw9LD1QPUw9fD1cPaw9jD3MPjw+Pj4WPk4+uj60PpY+xj8oPwQ/fj88P1K/zj+xP61/x0Ak//v/3sArgHSAekAIAJoApQCZAJgAwAFEAWgBMAEwAUYBpAG4AZYB5gH+AdwCMAIcAngCdAJYAlwCSAKoApACkAK8AqAC9AKUAqAC1AMYAsQC2ALQA3wDdAMgAzwC2AK0AigCXAL8AygCmgH8AWIBPwDiATABaAFEALo/fz8+PzY/Hz86Pqw+hD44PVQ9WD2YPWg82DzIPNQ82DyEPIQ8oDy0PFg8ZDyEPOg8+DyUPKA8vDysPPA9KD1UPaQ9QD1sPWA96j4gPho+Fj5mPoY+vD5IPtA/Pj8yPz0/CT+lP4Y/uD+AwAeALT/KgAKAV4BOAGUASACnAKYAuQCtAPYAygE0AQ4BYAFCAWABjgH6AbwBggHwAjQCAAJIAkACtAJwAggCWAKYAswCsAJ0AowC+AKoApwCxAM0AvgCiAMwA0QDQAMMAuwCjAKIAlQCnAL8ApwCIAFaARABAAFiAWQBOQCkf9U/DT8dPwC/mD8EPpg95D2QPbw9FD10PSg9PDyEPJg8gDzwPJw8VDy0PIA82Dy4PKA9HDzUPLQ8SD0EPbw9eD1gPXg9eD1gPa4+Ij5qPko+Yj5APqA+nD7HPzk/Fj9gP18/bz9LP6i/y0Ac/+//zQAHgHiAAABugGUAlACSAI4AxgE8AOQA+AEiAVIBnAFoAU4B0AHSAcoB9AIMAlQCXAJ4AkgClAJYAmQCjAL0ApQCsAKkAvgC4AL0AtQDAAMIAzwDHANoA2gDGAL4ArwCvAKMAsgC1AKoAh4BlgFcAV4BlgGWATIAWT/bP0s/Wj9Ev5k/ej54PaQ9WD24PWw9TD1sPSg8/DxAPIg8tDyYPKA8jDzgPKQ8tDyYPMQ85DyQPNg9AD1cPXw9dD1IPVQ9RD34PgQ+aj4APnY+fD5sPnY+nj8LP3w/OT8uP2k/fD91P4wAIYArP9M/wsAUAEkAVgBHAKMAowCbALMAsADYASIBBAFcAUQBYAFAAbgBmgHoAeYB0AI0AhgCUAJQAlACUAJAAowCoAKoAowC0ALAAsgCzALAAxQDKAMAA3ADOALMAsQC1ALQAvACuAK8AkQCRgH2AWoBdAFEAZIBHgCGgAy/hj9aPyA/dD9oPuQ94D10PSQ9RD14PSA9mD04PHg71DxIPNQ87DyoPJA8wDyoPFw8sDzwPOg8qDy4PTg9dD1IPWw9JD1EPZA98j4sPmY+ZD4iPhY+Qj7MPz8/Gj9NP3s/MD8RP1R/5kArwCy//z+1P/EAHIBdAFEAlQC5gEsAhgDKARABAAECAVQBVAFMAVgBngH6AcgB2AHAAkgCWAJcAnwCbAJYAnQCSALsAsgC2ALgAsADIAL0AuQDIANoA0gDRANYAwQDMAL4AvgC+ALMAsACkAIGAfQBuAGoAbQBdwDTAFy/nT9Zv4x/yz+QPto+ND2oPUw9LD1QPcQ9pDzUPEw8bDysPHQ8TDzkPOw8gDxAPIQ81DyoPFw8gD1oPSQ9ED0YPXA9UD0YPVQ9zD52Phg+Fj4IPgw+fj56Psk/fj8APxE/AT92P3I/jD/EADK/+f/f/+2/yAB0AF8AvAB3AFYAugCkAMwBIgE+ATIBHAFqAVABggH0Ab4B2AIoAigCKAIgAngCUAK0AnQCeAKQAtwC7AL4AuADNAL4AvgDIANIA4wDUANkAxADJALwAvwDJAM8ApgCHAHWAfYB5AH0AawBVwCg/86/j7/qP9R/yj9gPoA+HD1wPTA9iD3UPYw9TDzYPIw8cDxoPKQ8+DzEPOQ8vDxIPGA8iDzYPOA8+DzcPTA9KD0YPSA9bD1MPaA91j4UPgA+ED48Pg4+nD6KPyg/KD8sPwI/ET97P0q/+X/DAAaAAP/PP97ACIBGAKYApACOAIgApACKANgBDAFiAWgBfAEMAUwBhAHsAcgCFAIoAhwCNAIMAkACjAKwArwCkALYAtwCwAMcAzgDMAMMA3ADRAO8A1gDYANEA1gDVANMA2gDMAKsAnwCFAJUAmACFAHKAWAAoEAZgDFAOcAs/9Q/RD6YPfw9WD20Peg9+D1APRA8pDxAPLw8bDyAPPQ8qDxAPFA8ZDxAPKw8QDysPJg83DzwPPg8zD0sPNw9ND1UPeg98D28PZQ9xj4CPl4+sj7uPtI+wj7uPvM/Lz9ov5M/w3/lv5w/hj/8P9/AJwBIAIEAmABmgFYAhADAARYBNgE8AQQBUgFKAbIBiAH4AdgCOAIsAjQCCAJEApwCtAKIAugC/ALwAsgDKAMYA3QDRAOQA7wDXANIA2QDVAOkA6ADTAMIAsgCoAJoAkgCqAJ4AfYBBwDtgEVAF0A9AHJAIz9qPkw9rD2EPcA9wD4UPZQ9HDxgPBg8fDxwPIg8zDzIPHg71Dw0PAg8vDxsPGw8pDy4PIw80D00PPA80D08PVg9+D20PZg91j4CPiw+Pj5kPvA+1j74PuE/Ej9UP0y/hn/BP8w/y//EQDkAD4AjAAsASwC0AKYArgCGAN0A6wDYARwBVgGaAaQBmAG2AaQB1AIEAngCYAKMApACpAKIAvwC4AM8AzgDfAN8A3QDRAO0A4wD8AOwA9AEBAPMA7wDVAOoA2wCyAKwAuwCwAK0AiQBnAFPAI8AlgCJAP8AKT8oPvA+dD3kPbA90j4sPdw9CDyYPHg8KDxQPPQ86DyIPEQ8JDwoPBw8KDxwPLA8nDyAPJg8hDzUPMg9GD1UPWg9UD2MPeg97D38PcY+bj5GPqg+nD7dPyg/Ij8fPzs/Lz9mP4w/9j/8v8q//D+Wv9fAAwCtAJ4AnQCPAL+AXgC0APIBaAGSAaoBcgFEAawBtAHQAnACnAKwAmgCUAKUAvgC6AM8A3ADlAOUA1gDdAOYA9wD4APwBAAEcAP4A2gDdANoAywC+AMMA7QC/AHcAUQBqAFhAN0A+gC7AGI/mD6CPq4+fD4MPdg91D2gPTQ8mDxQPIw8kDx8PBA8YDxEPEQ8BDwkPCA8ADxUPEg8oDycPKQ8iDzIPRA9LD0kPUg9uD2wPeQ+Mj40Phg+ej50Ppw+3D8sP2U/ZT8iPzM/eL+i//m/4oAowCX/03/eQAsAqgCeAKMAtwCBAOQAogDYAWIBigGcAXABaAGYAfQBwAJIAqQCjAK4AlgCsALEA3gDbAOoA7QDqAOgA7QDuAP4BCgEaARoBFAEAAOMAwgDaAOwA6ADjAMoAvgCIAEOAMgBVAGiAV8Ah3/ZPxY+vD3iPho+dj4EPdA9MDy8PFQ8eDw8PHA8rDxYPDg7iDwUPEg8MDvgPDw8bDxUPHA8VDz0PNQ8/DzAPXw9QD20PZY+CD5mPhg+Mj5wPqo+wj8pPy4/bD9TP1Y/RD+K//d/4sAyAAVACAArwBIAb4B4AFgAiwDIAMgA2QDMAS4BOAEuAUoBrgGwAZgBxAIoAjwCFAJQAqgCoALEAxQDNAMYA1ADqAOcA6wDhAPUA/ADwARYBFgEEAOsA0QDaANAA0gDeAO8AvgCNAFmASYBJAESATwAjIBsP04+oj4gPjo+Kj4IPdg9aDzsPGQ8NDw4PFw8jDx4O+A76DvQO9g70DwQPFA8dDwgPCg8YDywPLw8gD0APUw9fD1YPaQ9xD4WPjo+ND5EPsI+6D7PPwU/VD9WP3Q/WT+eP+7//b/DQBdAMQA8AA2AXAB9gGcAnwC0AIgA1QD5AN4BAgFmAW4BfAFuAYwByAIsAhgCXAJwAqAC6AKcAsgDKAOcA/QDjAO8A5AD1AOwA/AEQASoBEgD3AOsA2wDKAMQA7gDqAN4AlAB1AGeAQIBPQCYAOuAV3/IPxQ+bD4QPfw9qD2wPVA9FDyYPGQ8FDwAPDA7+Dv4O+A72DvwO9g74DvAPAQ8JDw8PAw8kDzAPMA80DzYPRQ9XD2YPfg91j4gPjw+Aj6sPqI+5z8mPzI/FD9aP04/gH/RQAIAM//FAD8ABgClAGwAaQCjAMoA5AC7AOYBKgE+ASABWgGOAbQBngH4AgQCWAIgAngCkAL4AuAC7AM4A6gDwAP0A0gDiAQYBAAEeAR4BJAEiAP4A4wDjAOQA6wDkAQAA6ACsAHqAfIBjgF9APkA+QCT/8g/ej6EPrY+FD38Pag9eDz0PLg8rDxwPDg7+Dv4O9g76DvgO9Q8ODvIO/g76DvkPBw8TDyoPLw8tDyIPNg9ND04PXg9vD3WPig+JD4GPmQ+qD78PtE/KD8cP0O/rj9Rv6Z/yMA7P+h/5UAcAGMAcgBYALUAmQCfAK0A/AE8ATIBPAESAZwBqgGAAdQCOAJgAmQCbAJAAtADPAMkA3QDtAOcA6ADqAPYBDgD6AQgBLgEiAR4A2ADiAPoA4gDkAO4A0wDBAK6AeoB6gFUAT0A3ACMwAA/Yz8yPv4+dD3QPYw9RD0APNg8tDy8PDw8ADwoO/g7gDuoO/A70DwoO9g78Dv4O9Q8EDxEPJA8jDzgPPQ83D0APXA9nD30Peo+Pj4sPno+bD6oPsI/Ez8/Pz4/bL+UP50/jL/pv/K/x8ABAHwAbAB9AF4AqQCCAMwA1AEGAU4BSgFCAZQB+gHcAjQCDAJUAogCvAKQAyADSAOwA6ADhAPoA9gD/APwBEgEgASABLAEcARQBCADzAPIA9ADpANYA0ADQAL8AjQB7gFqAN0AfYAAAA3/wL+4Pvw+bD2UPXA9BD0wPMw81DzYPKA8GDvwO/g78DvoO8A8ODvgO/A70DwUPFA8ZDxwPHg8XDyEPMw9AD1oPWA9iD3cPew97D4aPm4+Tj62PqQ+0T86Py8/TL+DP7o/dz+YP/H/3UARgHyARACJAKkAiQDzANwBAgFiAUQBggH6AfACDAJgAnACXAKgAtgDFANYA5gD/APoA9wD8APwBCAEeARgBLAEmASgBEgEaAQABAQD6AO0A4wDlAM0ApQChAJWAfwBPQCzgFXAFD/YP5Y/TD7WPlw94D1EPRA89DzwPNg8oDxQPDg74DvIO+A70DvgO8g74DvwO+Q8KDwMPGQ8fDxwPHg8UDzwPRw9SD1APYw9xj4oPfw97j54PrI+sD6+Poc/Fz9qP0c/tD+1P4t/2D/UwDkAFYBxAHoAkgDxAIsA/wDgAXwBaAFmAZAB4AIkAgACeAJYApgC/ALkAzgDAAO0A5AD/AOUA/QD4AQwBDgECARwBCAEPAPcA+ADiAO4A0wDkANoAsQCuAIsAfwBbgEbAPMAosAWP9O/gT96PoY+Wj4APfQ9fDz4PMg9LDzwPIQ8vDwYPAw8KDvoO+A7+DvIPEg8YDwYPCw8LDxQPEQ8RDyQPNQ9DD1UPXg9dD1QPaQ9xj4KPgA+Wj6BPyY+xj7DPyE/Tb+IP6S/hz/MQC0AOUAjAHQAbQCcAP8A2gDeASYBTgG8Aa4BlgHqAfACAAJwAlgCtAKAAwQDGAM0AxwDcAN0A2wDtAOAA/gDkAPgA8wD+AOoA6QDpANwAxQDIAM0AsQC1AK0AgoB2gFIAX0A6QCbgGwAF4ACv4E/HD7mPqA+bD30Pag9rD1cPXw9PD0gPOg8iDysPEg8TDxkPEQ8kDy0PHQ8aDx8PEg8kDysPJA80D00PQg9bD1cPbw9iD38Pd4+Cj58Pn4+qD7OPyY/FT9Dv4Q/p7+Yv91AO8ARgHyAbACpAKMA7gDuAQQBeAFAAagBkgHcAcgCDAI0AigCXAJQApACjALYAuwC3ALIAzADGAMUAxQDJAMsAyQDCAMMAwgDHALMAuQCiAKgAnwCKAI4Ae4BhAFeARABFQDTAKBAHYAkP9O/qD8uPtI+0j6aPmg+Cj44Pbw9fD18PUg9cDzAPMA9GDzwPIA8lDy4PLg8uDyEPLA8tDy0PMg9NDzoPSg9ND1wPUw9zD3oPeo+Oj5mPqQ+Uj6YPvk/fT8zPy4/UQAEAEnAHcABgEEAygCpALEAmgF0ASwBdAGMAe4BgAGuAfgCBAI+AbQCJALkAqgCfAIcAqgClAKcAkQCtAJgAqgCjAKgAkAChAKIAlgCPAH4AeoB7AGqAeQBogFqASYBMAESAPSATwB4QASAe3/fP/E/eT+eP1U/SD7CPp4+oj68PpQ+WD4gPfY+Nj4APjQ9nD2kPdA99D2EPaQ9mD3EPgA+CD3cPZg9wj4SPnw9yj4KPj4+YD6cPpg+jj6WPxM/Kj8qPvs/Gj+Av88/+z+qgAPALoBogCiAfQBjAKAA0QD4AM4BKgEAAXQBDgFAAWQBRgGgAbQBjgG0AZABwgHEAc4BvAGUAbYBtAGYAbQBugFCAfYBegF+AQYBbgFWAQgBcQDMAX0A6wDIAO8AhgDtgFQAloB4gGUAGkABQBdAOT+xv+2/mL/NP0Q/Uj9Vv7c/GD8gPvk/ID8WPuY+1j6xP1I+Tj8QPq0/Ej6EPlY/CD7rPxw90T9QP1M/DD56PoM/hT8jPwU/NT8gPy4/VkAdPx4+y7+ugFMAID5NP7UAkQDePtg/hAC4AT6/lP/hgAIBa4A+gAsAWAEcAOIAWwCtAN4BFwB6AE4BGAEWALe/ygFQAUkAy8AUATQA+gEBQBgAwADlAPGAdwCoAJsAaQCAARiAfcAXADMAgIB7gCz/6wCDwAwAfT+BAIB/y3/7P/V/+7/8Pw5/4L/GwBU/Rj+Vv4pAMj9ZP38/VD9cv7g/Fj+rPwC/tz9sf98/dD7NP1c/VL+ePzE/AH/Av60/Sb+cv58/VT9dv7I/rz+dP2K/mf/gwDA/ir/Yv4qAeP/FAHs/UwBngFUAV0AlACYAsMAwgFuAbgCDAECAdABXAMEAqABlgEIA9oBUAH8AToB1AP2Aa8ApQAcAhgF/wClAEUAEAPiAVr/UgBAAUQD5P4yAZb+gAIh/yIAHv+k/78AbP6m/5j9kAGI/iv/zP1g/w4AZP4R/2j9+P8A/TIA9P2H/3T92v6y/s//Pv9o/Xz9jv6BACn/QP1A/VkA5QBq/oz97P35AHj+Rf/Y/Y3/Gv5QACQADf/a/xz+/AAYAE//dv5eAPL//f/3ACQBAgES/97/TQDEAmj+xgHw/7wDCv++AND/mgGcAsz9CASG/tADvP2eAaP/2AGQAqj9oALY/GgFov4EAqT8EAOxABQBBf9E/jIBOACaAcj8NgEg/a4Ba/85ABD+ov5q/s0AvgEc/bj8ov7AA84A1P0A+2YAVALg/mD9Yv45AHYAWf/I/mL+lP/S/u0A1P4AAEz/jQBj//f/QQAy/lMA5v70AbT+5f/7/6ABnACg/j4BMf9sAkz9KAJk/kQD9v9iAL8AC/8ABbT9tALA/NgCDgF8AMEAXQCmAfIA4gGEATkAVAA/ACwCy/8EAXb+eAO9AIgBhgBS/z4BoP/D/wj/wwC//8P/qwDp/0IBOv6CAG7/RgAu/k4A9wC0/vX/4v7UAmD9MP/E/rQCoP26/lD+8AH8/ij+L//7/wwBFP2WAOT97AH4/DQC+PyYAmD+Uf9p////JAOA/LgBnP1ABFD9Zv4oAFACtAFU/fcAhf/EAxb+rAGW/tQBgQBTAFr/pQDIARgBmAD+/lACYgCs/7j/ggHoAaj92gF3/ygEU/9P/9wA9P/sApr+3AK4/KACTADsAQT+mgD8ARQDJv4j/x4BCAOK/ikA2QDuARz/Vv5ABMj+5gFY+7gE/P1IAfD7/AEB/w4BRP0nAGb+CAJ9ACf/WPz4/vgBwP5R/8j7GARY/awBkPtIA/z9/f91/9L+igCI+tgCMQDOAYD73f/GADQBYP0C/gQARgHY/U3/wP50AQD/5//8/mT+LALc/VQCaPtAA1T83AJ4/IwBigDN/4j/C//GAI7/FABqAC3/LAJk/jIByP5UAuIAjP8WAOj+oARE/SACjP5sA2//Y/8WAb4BvgHC/qgDtP6oArz+qAPh/1AAaf8IA9//OwC5APACegGU/eoAvP/uAVj9BQDAADQCtP54/vj/5AC8ART8yP+g/fwD5PwaAKz8QATM/df/oPuoAsb+bAAI/Yn/PAEs/V8AvP3QAQ7+gf+8/rn/DgAQ/9T+Rv+yAHj/BQCk/f4B//8VAIz9OgDRAGP/QAANAGYBUP7O/ov/DAHCATT+rgEY/pIBVP6AAY//6P9MAaj+1APk/LADhPxoBFz9+gHQ/ngCnAIO/lAD3P3YBCj97AL1/0QDH/9DAJgCWAFIAB4AqgHEAl4AuP/cAXMAZgE+/hAC9/9cAWf/6v+IAO//4ACsAEH/cAH8/HACtPwEA0j9GAFK/rMAzf9J/xr/wv5wAA7+PQAE/vz/8P3dADr+2f88/b0AtP76/vT8PQDS/g3/rP3PAB7/Cf/E/V8AogEw/cD/uv48AeT+ev53ACkAiwAM/rn/twBnADb/yv5O/1wCVv5yAWT8iAR4/jgDnPwYARoAhAE8AIr/9P8IAnr+tAEm/mwDOv70Abj+GAPE/hsA8v+UAkgAsP/4/yQBrgFo/7oBYv8YArr+4gG2/20AVf+UAVABBwC6/mIB4wD+APz9SgEeAN3/ov+K/nwCsP2KASD+OAIg/Wr/gADo/tAAmPzWAVz9/AEQ/cwBuPy4AKL+oAD6/gr+mwCK/jQA0P3X/zv/Wv4MAcr+GwBE/a7/QQCS/2kA0PxgA8D7xAMY+1wDcP1cAsj+vv8eAFUACgFo/bQAXgD2Abz9gP+1/ygDaf/k/rX/eQB0AcT+nAIQ/kgB0v7SAcQAwP+KADcA5AI8/3YAEgB6AWoBFgBGAML+FAP6/+gCDv6IAQwAdAGQAKT+QALX/ywDoPyaARX/TAN1/6z+mQAyAEQB/P3gAYD++QC0/TgCz/8KANj9yv/2AOD+7v+4/SgCEv4eAVT8GQDW/icAaAFM/IABKPxEAsD8zAFG/nj/7v6Q/eQCjP0DAKj6CAQB/xACsPrwAQT+bANM/RQBjP2J/9gAEgGvAPT9PgEEAz8AUP4E/8ABCAEaAFz/SAK1AGAA5QBAAeYBvv4GAfv/aAL4/UIBZ/8QBBb/4AH6/nQBbgF/APgBGP3IAeH/6AP2/j//qgHYAVACBv5iAbX/NAK1/2//XgAp/8wB1f8eAfj+JAGqANb+BAGi/j4BWP2AAVL/lgHo/Rz/AQBT/3wAfP06AZj91AKA/QIBNPzC/oABBP9wAGj7SAF2/2YB5Pwb/6v/OQDO/m7+WP9VADD/k/++/qIAI//v//b+of/X/2T/HP/g/4QAVAG+/pX/Uf8+ATYBTf/QAJj+HAP4/QQC3P1QApz+/gBJAIwANgDk/2QBoAAxANr+FAIqAPgB/P3cAlH/DAG4AEUAVALI/WwBIf+8ArL+RwCW/+wBHgHZ/4D+XACoAUb/IgGM/awDsP36AbT9SAEx/+T+VAEH/yYBUv59/4YB6v7YAHT9HgG+/3cAUv5c/gIBrv9PAKT9sv+PAJj/dADs/aD/fP6QAO//lv9z/1YACgDXAED+PAFk/jsAu/+q/yIBiP9sAdz93QDu/iwCfv74/nkASgHmASz8GAJu/tgDWP0cAdH/fABrAFr/kAI8/qIADP18A9gAmv8ZABj/mASW/qAAKP0kA7oAWAJs/WQB7P7QA2P/SAFT/wf/gAE8AHYBfP6N/2sA6AH7//z+av6YAsj+jAM4+8gEoPrABFD8LAKE/cz/MALy/vwBmPsUAlD9GANs/PAC0Ps8Anj+qwC6/hL+DAKK/oABIPyEAhT/0QCQ/R4BiADV/+T+SQCIAbb+7f9M/lADGP3KAVT+pAMn/7b+SABAAJYAjP1b/7ACjgAaATT8zAJM/2ACbPxiAa8AfP9GAOT9PAMfAMYAxP3UAOb/UAEc/hYBPP6QA+j9rgHM/TQCV/9KAYj+JACf/5j/LgHq/44BmPxOAaL+gANM/DIBPP2YAxH/1P8J/6wA5/8W/uEAIgAUAeD8ngAt/2wBlPxCAIQBjwAY/1j9jAK2/u0AeP18Arn/ev90//b+bgHc/FgDPP0gA9D73AIU/sQBuPwEAREANADP//r+6gHQ/jgBGP40AtL+QwBl/7YA/ADi/sQBKv68AkT9HAL2/tYBQwCB/2gBpP1EA8D9awBs/dQBmAIy/0D+FP4YA6cAuP44/swB2ADu/xT+UwBeAQEAI/9JAFIB7v9u/qD++ACEAZ3/CP3qAfL/mAJY/GACU/+EAlD9FwCoAMT91QBm/uQDqPza//j93AKZAFT+aQBg/VgB1P1sAqj+1P8g/xcA0AC4/jAAsv5Y/7QADwBRABz8agHUAWwDNP1Y/RsAJAEkAjT9nAH8/WADiP3IAoj9AAJK/sgBHAESACr/BP2gAt4BugHk/Rr/XAHaATgBjP9yAB3/0gC2AR8Aqv64/sADdgECAfj6eAIEAYADOP6o/xb/Vv9+AYP/nAEO/vIB8/84ApL+x/+w/3wA+f8MAJb+rAD//6AD2P1SAdj7gAEt/9oABP+C/wwBNP4wASz9FAJx/4f/Tv7H/z8AlP6KAP0A+P/k/uz9cAHvAFT+YP+s/wIBzPycADj/QgEc/gj/+wDP/x3/Nf9TABEAAv/d/+b/UQCa/7j/0gFs/tUA6Pz4A/7+yAJc/GwCzv/4AjL+ZwAyAIIBgADW/1ACwv+YAmz9LAK8/6IBgv5X/1gAMALNAOT+Wv9pAFQAVP+BAAwA7gGk/UwBov/LAHL+Jv8sAxkA6wBE/OABBwCCAXz+g/+r/1kA/v98AVT/MAA4/db/LgDcAfT8V/+U/2AD8gD0/C7+awAgAlj9xv7Y/WQCY/+hAD7+UgGw/qEAKP/tAM7+mf9C/9L/iQDj/yb+VwDKAKYABQBa/loBmgDx/yj9fAEWAbwA5P3K/xwARALQ/k8ARAHRAOQBPv43AJT8HAJt/ywCJv5RAGsAtgH3AGb+UALY/ggCUv/EAnP/4f+C/83/OAIo/aABdgB0A+j+hf+l/zAB9AB1/+j/BP/h/1AAFgHy/4z/0AGSAfj/yP0x/zIBov+k/dz9mgFoAZr/ZP5P/44AlADA/jcAiv6fAI7+M/8k/rv/dwCP/4H/tP18AAT/YQBi/j3/Kv93/77/FP85AGMAPAHV/43/OABoAJAAxP7MAPj/MgG0/7oAhgEeAAcAyP40ASYAegAq/0EAh//M/9D+sv+p/+X/e//d/z0APQDhAIz/HAEb/+wA6P1vAFb/0QByAJD/IgFU/9wBPv5cAhP/0gGE/sABUQA2ALj/Sv98Av7+8QBw/UQDav90Anr+3gDc/7z/CABW/v8APP+0AiL/6ABI/toAnv8RADcAqv8OAXL+nwBV/5QBxP6oAH7+9ABe/64AXv/I/+b/QQCNALX/hQBt/7UA2P78AGz/NQC0/kQAXAE0AAUAeP5kALT/TgD4/mUARgBgATMACwAw/73/ZwChADwAov42AHb/RAILAIIBhv9nACr/0v8oAA//FABE/yACPgChAID/eAG8AFkAWP/o/+7/r/9Y/5gAxwDHAIT/fP/S//gAowAlALj/sP8BADUAlP+oANL/kgDvAIIBUgHm/7n/TAB4AXoApf/x/94AsgFu/1//Tf+wABYALf8y/07/JQBu/tr/Q/87AIL+cP8A/y4AH/8n/xz/N//J/zL/1f+U/24APABPAFL/ov/t/xcANwArAAABTgCwAPn/0gAIABIAtP+OAIcAdQAyABQACgFCABwAQP+cABoArQCq/+b/WgA2ABwBeQCTAM//NgAbAOP/xv99/zIAn/8mAM3/0f+k/9P/lQA9ABcAyf8mAC8Axv9z//b+P/8U/8T/ev/l//b/sACdAGIAx/+A/6j/c//T/5L/1f8K/1r/Lf9n/6L/Wv9x/4r/z/8ZANj/uf+W/wr/A//C/j7/8P5x/9L/HwD//8b/EQAtABUAWP8v/z3/Rf/W/9T/6v/R/wAAXwB9AFcAJABvAMIAcAAhANf/GwBbAI0AngA+AEUAZgDuAJ8AVgBwALcA/ABFADoADwBuAFMAfQCxANIAwAC8APsA/gCsADgAVABgAIEAcACJAKYAnwCnAMYAbwDf//D/JwBjABUA4/8AAFYAbgDd/8H/n/+f/8T/P/8n//b+lP+8/+H/Wv+L/+v/xP9O/yf/gv92/07/Vv+H/5L/iP94/8b/hf9e/1n/r/+e/3b/lf+j/4f/Xf+A/wgA1f93/zT/q/+M/5z/lv8eACQACAD+/10APgBhACgAfQBlAHMAGwAqAEEAggBTADcAAwBPAD4AKAAQAGYALQBpANP/EgDL/zoAKABBADUANQAqABcAUwAoAHIADwBJADQATgBLABUAUAAYABwAIABqAFcAXQCeALgAlQBYADYAWgAVANz/p//V/7L/ov+s/5n/cf9M/27/j/+h/1D/Zf8x/zf/Bv/+/vr+L/8p/w//Lf9W/4T/sf+7/6b/u/+c/+3/uP/K/7P/w//W/77/sf98/37/bv+Q/5b/pv++/+P/x/+n/3//o/+W/5P/x/+4/6b/f/+1//T/AgDo/xMAXgBgAGIAVACkAMcA2QDlAOoABAH/ADoBOgEWAQwBOgEoAWABJAGmAWoBJAHIAKwA1QDMALUAWwCgAEgAgwBsAGsAfAB6AIQAGgDn/8b/sv+7/7//pP+X/1H/W/+Y/83/qv/A/8z/AgC3/4j/Yv9z/1r/Gf/2/tz+rv5q/kL+KP5K/rz9vP2c/Xj9aP38/Cz9HP1I/RD9BP0U/SD9KP1M/dT98P0g/pT+8v6I/yEAjQAwAX4B2gEkApgCtAJ4AtQCBAMYAzQDVAPAA+ADGASoBLAEKAU4BYgFoAXQBQgGIAYoBuAFmAVQBeAEgAT4BHgEKAScAygEQAQQBKwDgAN0A0QDdAKUArwBzgEOAeEAgACV/5f/HP9p/2D+hv50/ZD8wPtI+/D6APpQ+XD4kPeg9sD1EPWA9LDzEPPg8pDy8PEA8uDxMPJw8vDyQPPg81D04PTw9TD2IPdA+Pj5UPtk/Kj9Cf/6ADgCKAR4BcAGAAjgCOAJ8ApAC+ALYAzgDCAN8AzADAANEA0ADdAMIA1QDfAMkAxQDGAMkAtACyALkAoACiAJcAigB0gH4AY4BhgGWAVQBVgFOAU4BYgFqAUABYAEsATcA9QCqAJgAjAC6QAQAKD/4v7A/WD8gPto+jD54PeQ9/D1wPTA87DzQPNw8eDv4O7A7YDsAOzg6gDqwOjA5wDogOeA5yDoQOmg6mDrgO0A73DxsPPw9Zj4SPqs/Ej+2QCoAggFiAbAB/AIoAkgC8ALUA3gDTAPkA9AEIAQgBDAEEAQ8A9AD5AOYA3gCxAL4AngCDAHcAbwBVAFeATsA9ADSAPsAmwCwAKAAhQCmAHwAQACyAFAAlgCwAI8A6AD+ASIBQAGaAYIBwAIMAiQCJAIAAmACIAIMAcgB9AFiAXABCgEIAMcAhoBogDZ/zj+GP1Q+/D5mPgg96D1EPRA87DygPIg8cDv4O2g7mDt4Oxg7IDqIOqg6GDpAOng6QDroOyA7uDvsPHA85D2+PhY/PL+wwBMAlgEkAZQCBAJcAowC+ALUAxwDFANsA1wDiAP0A/gD8APMA8gD9AOEA5ADcALIArACOAGoAWkA+QCRgG7ADcAS/8I/87+gP/m/94AJAHIAcoBDAJEAqwCdANEA/QD6APoBLgFQAaQB+AH0AlgCnALUAuQDJAM0AyADKAMUAzQCkAKoAgwCMgFqATMArwCIgGf/0j/hP2Q/OD6ePqQ+cD3cPYA9VD08PKA8pDxwPAg7yDuwO2g7YDr4Otg7ODr4OpA6kDqwOlg6oDsoO7A8GDxQPMg9pD4YPto/uEAxAJgBMAGkAgwCQAK4AvwDHANcAzwDMAMgA0QDlAO0A7wDRAOEA7QDdAMgAsQCzAKUAkoBxAG6ANUAlwBegB9/+D9DP2s/GT9RP2I/ST+n/9uALcAIAG0AVACOAI4A/wD+AMwBEgEgAXQBegGoAeACDAJIApwCiAL0AtgC9ALwAtAC/AJMAlACJAGWAX8A9QCBAGM/3b+ZP2I/Ej7SPpY+bj44PbQ9tD14PTg8zDzcPIw8TDwoO+A7iDuoOwA7SDsIOzg66DrwOuA6kDqoOvg7YDucPAA8nD0kPY4+RT8Ev4yAIwCuARABngHQAiQCQALcAsQDLAMwAyQDPAMwA2QDcANkA3QDSANoAwQDGALAAvACVAIAAewBawDfAI2AWEAE/90/uD91P20/ej9dP4G/wIAjwCqAAQCGAKAAiwDaASoA3gEGAV4BSAGGAYIB8gHoAjwCLAJUAqgCgALEAuQC/AKYArACdAIyAegBogFQARUAgIB1v+Y/lj9hPzA++j6wPnY+ED4UPdQ9kD1IPXg8yDzIPKA8fDw4O8A72DuIO4A7eDsYOyA7ADs4Ovg6+DsgOyg7ODtgO+w8rD0YPfA+Yj6gP1CAFwDuASQBvAGsAlgCiALwAtwDAANQA3ADWANIA3QDPAMcA2gDcAMUAwADIALQAvQCeAImAdwBiAFvAMUAhAB2P/a/kT+0P0Q/vz9uP1k/vb+n/9nAAwB5AGkAuwCNAMoBHgEiATQBHAFAAbYBZgGKAfIBzAIwAhQCZAJAAowClAKIApwCaAIEAgAB8AFcASgAxAC/AAF/3z+bP1g/Ij76Pq4+qD5ePhA+LD34Pbw9eD18PQQ9BDzIPLA8QDxAPCg7+DuYO7g7eDtwO1A7SDtIO1g7cDt4O1A73Dw8PIg9ij4+PlA+zr+OwDQAwAFEAdQCGAJoApQCwANUAxgDQANkA2ADVAMQAwwDOAMUAyAC7ALEAuQCqAJsAmgCDgH4AUgBSAESALkAMv/HP8s/tD99P10/ZD95P0m/8j/JABaAUQC/AKAA3AEaAWIBbgFWAbgBtAGCAcQB3AIUAiwCJAIUAkwCcAIoAkwCWAJgAjIBzAHeAYYBaADQANcAZoAqP78/Yz8gPvA+mj66Png+Ij48Peg9wD3YPYA9sD1APVw9DD0cPPA8iDyAPIw8bDw4O+A7yDvoO6A7mDuQO4A7uDtoO5A7yDwcPKw9ID3gPm4+wT+zv9yAbwDSAfIB8AI4AiQCiALQAvgC8ALwAsgC4ALUAsACyAKYApAC7AKMAqACXAJcAiwB1gHmAYgBUQDWALUAfD/xP78/fj9oP0A/TD96P08/rr+0f82Ab4BJAIMA1AEuAToBMAFIAZIBvgF8AVwBogGiAYIB5AHoAfQByAIUAhwCCAIUAggCEgHCAZ4BfgD/AKsAd0ATf8m/gj9GPxg+5j6cPq4+dj5YPkY+eD4wPhg+AD4wPdQ9wD3APag9QD1cPSQ8/DyoPLQ8UDxoPDA8ODvwO+A78DvQO/g7oDv4O9A8dDycPVg+ND4GPtk/RUAqAG0AqAFYAcwCBAI4AnQCUAKYAogC1ALYAoQChAK4AowCmAKMAqAClAK4AngCbAIyAcIB6AGeAXkA5QCVAEyADv/4P5i/pT9mP3Q/Wj+Bv9g/zkAdgF0AvAC1AN4BBAFyAUoBsAGoAawBqAG8Ab4BqAHcAcgCGAIoAhQCNAIwAiACJAI+AewB7AGmAVgBKwDXAJkARsAHP86/gT9gPzY+5D7EPsg+7j6iPo4+hD6mPko+dD4OPjw9zD3wPZg9vD1UPWw9DD00PMA89DyAPIg8nDx8PBg8BDwEPAg72DvgO/w8ADyUPPQ9mj5WPoA/MT99QAoA5gE0AV4B0AI4AiQCSAK4AmwCdAJEAtwChAKUAngCUAKcApQCgAK4AnQCNAIMAhgBygG2AQYBIQC3AEPAGH/gv7Y/bT9vP30/dz9nv6r/1UA6QBAAswCcAP0A7gEgAWABTAG8AWgBlgGeAaABpAGEAcgB/gH+AfwB+gHIAggCAAI6AdgB5AG2AUQBdgDyAKyAcgABwAU/zD+fP0k/Yj8YPzo+3T88PuY+1D7YPtQ+4D6QPrY+Yj5wPgQ+OD3QPeg9tD1sPVA9bD0APTQ80Dz8PLQ8cDxUPEg8BDwEPAA8MDvgPCw8eDzIPao+Bj6+PuE/fj/yAKoBBAFkAaYB+AIEAkgCbAJgAnQCUAJgArACQAJYAmACXAKgAmwCXAJ8AhgCHgHAAd4BVgE5AJMAtYAef9g/iz+pP0k/ZT9Fv5C/rL+3//tAHYBPAI0A+wDqASwBDgFGAboBVAGcAYgB+gGyAbYBqgHEAiACIAIsAiQCIAIcAggCAAI4AZYBogFsARcA+ABXgEHAJr/Yv4c/kD9wPxU/GD8bPzQ+zT8oPvY+4D7OPv4+nD6+Plw+Qj5ePgA+LD3MPeg9mD2sPWQ9QD1YPTg86Dz4PIg8jDxoPBA8KDvYO/A7gDvwO7A8EDzsPWg90j4qPvo/cL/oAEABBgFSAYYB3AIgAgwCGAIkAhACaAIsAjwCOAIoAjQCBAKsAlQCTAJQAmACBAH8AVABfADXAIuATUADv+0/Sj9YP1U/aT9Fv76/o7/OwCUAaQCbAPcA4AEaAVwBVAFmAUQBjAGMAaIBqgGiAaIBiAHAAgwCDAIoAjQCMAIAAgACFgH6AbYBTgFOASsAoQBtQDl/yP/hP4Y/pj9dP1U/Sj9WP04/UD9WP0I/UD9aPyc/Kj7oPtY+4D6YPqQ+Zj5uPio+Dj4APhA95D2QPbA9WD1gPTA86DykPEw8cDw4O+g7oDuIO/A7kDvEPKg9OD20Ph4+sj9Tf8aAeACaAXQBQAGMAdYB1AIqAeQB7gHUAiQCIAIgAiQCPAIMAngCYAJcAlACaAIUAdwBqAFAAR4AigBgwAg/xj+XP2U/ej99P2u/qv/xgAQATQCOAMYBMAEOAW4BQAGuAVIBlgG2AZoBhAHYAeoB+AHUAjgCFAJoAnQCQAKcAkgCVAIyAe4BggG4ASYA8gCHAEqAab/W/+c/qz+qP4s/lj+Vv5i/gz+EP7g/ST+fP38/Gj8MPyg+2D7oPpo+jD68Pmw+Sj56PhI+WD4MPgg9yD3UPbw9ED0sPPg8uDwAPBw8EDwgO6A7QDugO5A8BDygPRQ9xD5qPoU/W7/yQCkAgAEcAX4BXAGGAc4B2gHiAdACGAIgAiQCBAJAAkACaAJAAogCgAJwAhQCBAH0AXIBGwDzgGwAHn/+P4Q/mz9aP3A/TL+tv7K/48ARgEUAjQD2AOYBKAECAWABXgFuAXYBSgGSAbIBmAHyAcQCEAI8AhACXAJcAmQCdAIEAgoB6AG8AWwBGADmALaAfEAKABt/xj/gv5E/nL+mv4Q/uz91P0i/sz9hP1s/Tz9AP2k/Kj8ZPwY/Lj7sPu4+zD7SPvg+uj6SPrg+Yj5oPjg9yD3MPew9YD00PJw8iDx0PCA8FDwoO4g7aDtAO9Q8HDw8POQ9kD4APrw+3L+gv8CARQDCAUoBSAFyAWwBggHwAa4B2AIgAggCOAIwAlgCSAJ0AlACpAJsAjYB7AGEAWIA6QCkgE1AOL+bP7E/XD9qP1G/jf/nv9nACwB8AGUAlgDIASwBOgE8ARYBWAFoAX4BbAGUAfAB0AIwAhACWAJ4AkQCjAKAAqQCeAIMAggB2gGeAWIBNgD/AJgAqIBLgGkAEsA1v/X/27/Pf/M/qz+SP46/uj98P10/XT9SP2U/Vj9SP1g/fj8EP2I/BT9nPz4+4D7KPsw+1D5APkg+fD38Pag9tD14PTw8tDyIPOQ8jDxIPAg8GDv4O4g73DwkPEA87D1EPhg+gj8Fv7y/3QBFANoBKAFCAaABsAG8AYoB2gHIAjQCPAIUAlACVAJoAnACRAKwAnwCPgHqAZwBQgEoALQAeMAv//Q/ib+Xv5m/qL+Zf8xAPsAigEMAtACPAPoA0AEcASIBKAE+AQYBZAFQAbQBmAHAAiQCDAJMAlwCXAJcAkwCYAIyAe4BuAF4AQgBGQD0AKUAmAC4AFoARwB/QDEAIUARwD1/2T/+P6G/jL+9P2M/VD9KP1M/Zj9vP3w/Zz91P3Q/Yz9TP34/LD84PvY+lj6KPoQ+eD3sPeg97D2IPWQ9BD0oPPg8QDy8PJA8MDvgO5g7wDvAO9g75DxsPNA9Xj4OPtY/Yz92f+YAYgDWASYBOAFYAb4BSAGuAY4B3AHMAjwCJAJcAlACXAJYAnACEAIyAdwBvgEfANMAkgBRwBU/x//xP5i/mD+6P4j/6D/iQB8ARwCVAJwAvAC/AIAAwwDZAO0A/gDgARwBXgGAAewB1AIAAkwCVAJ0AiACOAHOAeQBgAGYAWYBOgDWAPwArgCyALYArQCMAKiASQBrwBCANv/Tv/K/lL++P24/aD9yP0o/pz+/v6Z/xQASwBrADkA0f9+/7z+Fv40/Sj8QPuw+vj5gPl4+Sj5oPgY+ND3gPdg9lD1kPTQ87DyMPEw8GDvoO6A7sDuYPDg8EDycPVQ99D6dP04ADMAUwCcAUgDEAQ0A+QD6ARgBcgEAAWYBsAHcAdACNAJUApgCfAI8AdACOgG2AVIBAAD4AFcAEP/iP6w/qr+GP++/mP/IAC/AMsAbAE8AmACMAIoAjQCZAIAAnwCMAPUA7AEIAVoBmAHEAiACBAJEAmwCLAIMAhwB4AGGAaoBTAFoAQ4BAgEeANQAzADjAM4A2wC0AFQAZgA7P+g/2n/C/9o/lD+Rv60/ub+Z/8iAGMA5wAiASwB2gCIAC0Aj/+w/sD9OP2U/Mj7cPtw+0j76Ppw+vD5aPlY+FD3gPaA9VD0oPMw8tDwAPBA7wDvgO5g71DwgPDA8FDyEPbA+Fj7UP1Z/woB8f9IAUQCHAMcA7AEUAWIBrAGMAdQCJAI4AmACqALcArwCXAJwAhYB9AFWAWYBNwCcgHlAGwAa/8p/5L/fABqAPT/IgBEAHcAIACkAOUAHgEwAYoB5AGAAkQDOASoBMAF6AZwB9gH2AdQCAAIaAcoB9gGiAbIBTgF4ASIBPgDpAN8AxwD1AKcAlQC6AGOAQQBOgBZ/87+zv6E/kb+PP6g/qb+jP7O/ob/IwBOADsASgAeAML/bv8z//D+Xv6w/Rz9kPxI/Aj8wPtI+8D6IPpg+Xj4sPew9pD1cPSQ89DyQPJQ8ZDwIPDA78DvoO8A8DDwkPBw8aDyAPVw9yj6/PwI/4UA5wB6AYwC0AJwBMgGEAeoBtAGeAfwCIAIcAlgCtAK8AkwCZAIoAeABlAFEAVQBJADgAKuAcMALQC8ALoAbAB8ALUAjQCJ/63/eADCALwAFgE8ApQC4AIUA3gEQAW4BZgGGAdYByAHaAdoB2AH+AZABwAHaAYABsAFOAV4BPADIATsAwADpAJwAroBEgGQAOEAaACk/3f/cv+W/9b+Ff+j/7D/X/+n/zEAYgBcADgAUwBNAOj/+v/U/5T/P//Y/oL++P1o/RD9aPyw+wD7uPqo+YD4UPdg9uD1wPQQ9JDzoPIA8oDxIPFw8MDvAPBA7yDwwO+w8VDyQPPA9Yj5sPzo/dj/TgEIAiwBvAFwBHAF6AWIBngHUAiwCLAJAAogC2ALkAtwCuAIYAiYB4gGuASQBJAEXAO8AT4BhAFsAUoAqAAkAf4A8f9y/5X/UgD4/zYACgHwAawCLAP4AwAFIAaYBugG0AZAB4AHeAcoB2gH2AeIBxAHAAcgB7AGuAUwBcAFMAUYBAAEyAPsAtQBAgFWAaMAi/+U/33/Jf+S/qr+Of/u/pT+uP4B/87+ZP7Q/i3/Mv8e/zz/Sv/w/oD+lv6C/gD+dP0Y/Wj8+Puw+1j7kPrY+Uj5qPiw99D2IPZg9TD0YPPg8gDyEPFg8GDwEPAQ8EDwkPBA8SDy4PPQ9Uj4gPrg/Nz+VwAMAewAwAAsAcgDCAWQBXAHgAjgCPAIwAngC9ALkAowCjAKwAkQB9gFUAZgBUgEAARYBKwD0gFGAUACBALhAOf/XAD4/x7/+v7O//7/2AB+AfQCuAOYAygEYAV4BXAF+AU4BrgGWAaYB9AHqAfYBzAIcAgACNAG0AYIBwAGQAXIBHgEEATsAvAChAL0Ae0AlwDOADUAb//o/tb+dv5C/k7+gv4A/qT9ev5E//j+kv5c/hP/wv4C/kr+fP4K/iz9ZP2c/ez8RPwg/Pj7YPuQ+pj5yPig94D28PUQ9cDz4PJA8oDx4PCQ8ADwgO8A76DvoO/A70DwUPJw9GD2IPnI/Dz+Hv5A/jn/h/+H/zIBjAMwBmgGAAcgCHAJkAkwClALMAvAChAJEAi4B8AGQAboBRgGCAaABYgEIAN0ApgCaAJCAR0AIAB0/7D+jP6l/4MApAACAYgCgANgA/QCpAOYBMgEKAWgBTAGwAYYB+gHYAhwCFAIkAgACLAHiAcwBzAG2AUABgAGeAWABEAEEAQQA+ACIAK0AWYA6/99/+z+Zv56/qD+YP5Y/mb+cv5M/pL+mv5W/hr+zP28/ZD9FP1k/TT9yPxc/KT8kPxE/Bj7SPvQ+nj5gPjQ97D3sPaA9XD14PSA84DyIPLg8TDx4PAA8RDx0PBA8VDz8PTQ9gD5OPuw/Az9PP2o/bz96P3B/xgC8ATIBagGyAdgCPAIsAmwCoAKwAnQCUAIWAcoB2gHMAhIB1gHCAfoBWgE2APYA4AD9AG0AJUApgD6/2f/GQDbAFgBVgHEAXgCeAJcAowCYANgBIAEuASoBdAGEAeQB7AHkAjQCFAIcAiACOAHuAd4BwAIuAfoBuAG2AbwBWAFWAXwBGADeAKEAtQB2gBM/73/ZP/i/tz9Tv5u/sT9SP2s/SD+AP1g/JD8vPyo+3D7gPug+zj7uPqA+5D72Pqg+jD6wPlo+KD3gPfw9uD1oPVg9cD0oPOg8nDy4PHw8JDwAPEg8dDwkPEw84D1YPaQ+CD74Psw+/j6GPzM/Hj9qP8kA9gEKAT4BGgHIAgQCIAIYAowCzAJUAiwCYAJkAhgCAAK0AmQCBAHSAfIBigFAAQgBNQDaAJeASwBJAHCABIBXAF+AXQBUgFWAQoBUgFwARACjAKgAqgDEASQBNAEuAWIBmAGIAbwBmgHkAa4BmgHYAhgBzAHyAcQCBgHaAZAB8AGiAUwBBAEEARMAlwBXAFIATYAVP9M//j+Iv4w/qT9TP1w/MD7wPs4++D6qPow+sD5uPlw+RD62PmQ+Vj5aPng+ND3IPfA9uD2IPbg9ZD14PXw9ODzUPMw88Dy0PEg8gDy8PKQ8kD0wPUQ9wj5sPlI+hj6cPrg+pD7tPxA/4wAKAKUAogEsAV4BhgGcAcACUAJsAjoB/AIkAlQCVAJEAtwCyAK8AjwCAAJeAcIBigGQAYIBYwDfAMIBIADLAO8A7gDoALcAbYBigHwACYBvgHqAcoBOAIMA/ACBAPwA5AEIAS0A0gE8ASQBJgEyAXABtAGgAa4BjgHgAZQBkAGkAYABsAEgARIBPwDSAO8AqQCeAKGAX0AKQDC/3D/dv4u/vD9EP0g/LD70PsY+3j6GPpI+tD5WPno+Ej5KPlo+CD48PeQ94D2UPZQ9gD3oPWw9dD1YPXQ9BD04PQg9WD0IPQg9cD1oPWg9sj4EPo4+nD6+Pq4+hj6kPsI/fT9xP4zAOABVAIoAoADiATgBIgEgAVgBsgFiAVwBpgHwAd4B3AI0AgwCKgHmAe4BygHuAYIB9AGAAZoBXAFyAVYBegEAAWoBBAELAMcA+QCiAJUAnwCiALyAcQBBAI4AhACLAJoAkAC5AGSAe4BKAIcAnQC1AL4AsACuALgAuQCsALMArAChAJMAhAC4AG4Aa4BwAGSARoB/QCdAEwAy/+i/5P/Mv+q/mj+Pv7I/Vj90PwE/cz8TPzo+8D7yPtw+zj7KPsI+6D6EPq4+cD5cPkI+dj4wPiI+OD3sPew93D3IPdA92D3kPeQ9+D3cPjA+Nj48PhY+Yj5uPno+ZD6SPuY+xj84Pxk/dD9HP6i/nP/+f8mAKoATAEEAlgCuAJAA+gDEARgBKgEIAVABWAFoAUoBiAGGAYwBogGsAZ4BrAGuAbIBqAGeAZ4BkgGIAboBZgFuAUYBQgFoARwBBgEIAQQBMQDjANEA0QD1AK8ArACoAJMAlACRAIwAiwCyAEMAhQCzgHSAcwBogFqARwBIAEKAfUA1wCrALYAjwBCAC4AFwDW/5v/VP9S/0X/6v7o/tj+4v6s/oD+hv5o/kb+5P3w/fT9xP2w/bT9rP1c/TD9AP3k/Lj8uPys/FD8BPwc/Bj84Pu4+6D7sPuw+4j7ePuQ+2j7KPtA+0D7GPso+zj7aPuI+6D7oPv4+yj8RPxo/KT89PxE/XT9sP3s/T7+fP7Q/iP/of/o/z4AfADqADIBYAGcAfoBWAKEAswCGANoA4wDvAMIBEAEUARoBJgEwATQBNAECAX4BPgECAUoBRgF+AQABfgE+ATgBOAE0ATABKAEmASQBEAEKAQQBAgE2APIA6ADbAM0A/AC3AKYAnACIAIcAuYBtgGCAVABKgHuAMMAggBkADwAJQDy/9P/rv+A/2X/Lf/4/sb+nP5g/kj+AP4W/sD9pP18/YD9TP0E/fj84Pyw/Fz8JPwU/OD7wPuQ+5D7mPto+1D7QPs4+xj7CPsQ+xD76PrY+uj6+PoY+yj7WPuA+5j7uPvw+xT8OPxo/Lz8CP08/YT96P1I/oj+4v4z/4v/xv8NAGsArwDqAEIBqAEIAkgCkALgAhgDQAOEA8wD9AMYBEAEaASQBKgE0ATwBAAFEAUgBSgFMAUYBSgFEAUABeAEwATABJgEeARgBDAEAATkA7QDoANUAzwDHAPgAqwCbAJEAvYBrAFKAUYB3QCmAGgANwAFAKL/e/9W/wD/rv5+/mj+GP70/eD9xP2U/UT9IP0I/dj8vPyQ/Gj8SPww/CT8CPzg++D7yPu4+4D7gPuI+2j7UPtI+1j7WPtQ+3D7ePuQ+5j7oPu4+8D76PsE/DT8TPxw/Jj8uPzw/CT9cP2g/dz9BP46/oj+xv7+/i//a/+r/+3/IwBfALEA+wA6AXIBqgHUAQwCUAJ4AqwCyAIAAxgDUAOIA5gDwAPYA+gDEAQYBCAEIAQwBEAESARQBFgEYARQBEAEKAQoBBgE/APoA9QDqANsA1QDGAMEA8gClAJoAiwCDALMAaABXAEeAfQAsQBzAD4AAgDU/5b/dP9T/yb/5P6u/nz+RP4U/uD9zP2c/Xj9YP0s/Qj96Pzc/MD8sPyo/Kz8tPyg/LT8xPzM/ND81Pzs/Oz89Pz0/Bj9OP1Y/Xj9nP3U/fj9DP4w/lr+kP6e/sT+Av8x/zr/bf+o/9//5v8SAEwAegCCAKEA1wAQASYBSgGEAaIBzAHAARgCDAIwAjgCcAKAAoACiAKUAqwClAKgArQCtAKgApwCmAKMAnQCXAJkAkwCNAI0AhwC8gHWAboBpAF2AUoBOAEeARAB8QDmANMAkgBdAFEASAAbAOz/x/++/5z/dv9X/0z/P/8P//7+5P7m/tD+vv7M/sr+rv6S/pD+hP6I/nb+fP54/m7+av56/mj+WP5a/mr+dP6C/ob+lP6Y/oj+oP7C/sb+zP7k/gD/DP8W/xf/Mv9U/0D/PP9r/5T/sP+w/8j/5v/1//j/+/8mAC4ASABPAH0AigCQAJcAuADGAMMAyADdAPUA8wDaANgABgEaARIBEgEuAUABQgE8AT4BWgFIAUwBTgFoAUgBJgEsAS4BMAEYASABLAEqAQgBAAHuANcAyQCoAK4ApACcAIkAdABnAFQAPwAlABcA9////+D/1v/Q/77/rf+i/5P/k/+Q/3v/bf9X/2X/Tv9D/0j/Qf85/zv/Of9B/zr/Kv9C/zP/R/9K/1D/Rf9x/3n/eP96/5D/hv+U/3z/gP99/5f/if+O/5P/iv+i/6b/zf/M/9f/uv/B/77/vv+3/7//0f/K/8L/vP/K/77/vP/B/8D/zf++/8f/vf/P/8v/1P/i/+T/4P/W/9X/3//V/93/1v/d/97/0f/K/8X/zv/X/9P/1v/S/+L/x//U/8T/2P/L/9v/4P/q//H/7//u//j/5f/n/+//9P/1//D/BwAHAP3/9v/9//3/CQDo/wEACgASAA4AJwA4ACYAFgAMADgABAAUABYATAArAAEAIgAjACYA8f8dAAwAGwAPABYAUwAtABEAGgBTADIAIgAcAEAALwANAP7/KABJAAsAJAAoADwACwABAP7/HADx/9L/8P/z/9r/z//X/8z/3f/E/7n/t/+q/8f/xf/N/4z/sf+V/5//kv+y/7b/qf+W/6n/pv+z/4T/p/+4/5z/fP9V/7f/r/+b/3//tf/R/7j/sP/L/+f/1/+z/+H/CQAgANP/LwAsADsAGwAWADkASgAlAE4AXQB1AHkAZACeAGAArwBrAKUAnACvAMEAwgCxAK0A7gC/AJ0AsADJANUAdgCkALgA3wDDAHgAtgC3AJYAYQBQAIAAcwBVAHkAYACNADwAWwBbAFYAOwBIADoAYAAqAA8AIQALAAYAIwD8/9T/9//j/woAmv/9/9j/DAAEAJz/BgBz/xkAkP82AIb/+//C/+n/f/9w/83/FgC9/4T/g/+0/73/Ef8cAIH/6f97/7f/qP+S/4f/p/8mAIX/Zf+E//T/2/8n/9X/sf/4/4j/0v/9/7H/lf+R/6z/l//Z//z/QgBv/zoAJADy/+D/qP+HAML/AgDz/1MAzwDp/6AAsf97AGMAHwD3/1oA4gA/AH8A8f/5ACYAbQCLANkAQgA3ABEA3gA4APn/kQDM/+IAkv9QAc//QAAJAO0AoAAl//wAzP8YAWj/pwAAAPoAQP8zAKIAp//V/wQA4AAG/38ACv+IAcb+8P+y/+gAJP/O/okAbP+gAGL+KwD4/4D/Bv/V/yAAmv9D/3r/JgB5/x7/IgBpAEL/j/8u/zoADwBe/5//EgBNAAH/zv+w/yIA5//I/ycAb/8TAPv/jQBs/9j/yAB9AMn/GP+MANoAdv9q/2oA+QCo/yv/IAAOAc//fv+LAGkATACR/1UAkACk/18ANwAAAJL/aQCDANX/w/92AKYA//+6/0gAywAy/yoAowCCAGr/VADq/44Bff/G/2AAZwBxAL//eP+j/xoBpv8yAMP/WgD+APr+vf/Y/xgBtv5uAPL/BgG4/0z/FwDOACAAAf/m/08AcgAO/4b/GgF7/2EAyP7lAI//nv8lAI3/BgDO/l8A5QD6/nT/pAAm/2UAEv7QADD/gQC1/zz/jgBE/gQBCv+PAHT/zv/E/43/UQCS/0z/JwAzADUAPv+UAOb/1gCO/hwB2/9PAP7/GAHS/40AKv/L/yYBdgCJ/+r+kAChAKYBAv7BAKIAqP8P/wsAdAGn/9v/uv4gA/T8BAHg/fQDVP24AOT+qAF1AAz+cAGU/xwCYP2oARf/ZgGq/rkAwv+sAZj+3AE//7wAP/9r/8wAbgFMAEoAW/8+AXoAkQAa/40AvgH4/8//pwBpAEwBMP82AasAkgDe/kYBwAFsAPwAGP+wAgP/XgB1/zgCPf9MABkApgD6AeD8lAFl/wwC0P32/zgB+/+bADj9jAO7/yQByP2NAJYA+P/AABz/QgEi/yQB5P6i/w7/fAEwANj9DgB//3YBVP78AZcAs//w/WgAhAGg/nD/Z/+8AWEApv4RAPz+zAFw/cYBpP6X/74AkwAlACT+8QDe/j4BaP60/zoB2P7M/yb/QgEt/7j/d/9cAj7/bv7w/roAIAIi/qUAeP7oAaD+5wDs/YUARf+oAKYAbP1AApT+vAIM/ZwA3v4nAPL+PgGqAcj9JAH8/GQDiv5s/hb/YAJWAOL+DAD6/hACIv7YAPb+7QDy/rD/VgG6/ooAVP6sAp3/TgGe/tMAtgAh//MAfP3pABQAsgHC/7sAGAFOAAEAzv6N/6r+kP6CAD4BmgAwAN//sAEqAKL+v/9dAKz/Bv/vAMv/YwDf/1QBxgB9/4r+JQDkAPz9yv+AAor/QAA6/qAAkQDA/fz9HAEEA5T87v5Q/+gB+/8o/0kAuAKWANz9QP4JAI4BiP9pADYAWQBU/UL+IP/gAJr/XP76/qIASv4x/0z/+gE+ANf/4P2zAI3/gf+NAHf/LQDc/d//XgBAAVsAcv8UAa//UABFABIBeAARAHoBfgDQAHcAhAFaAJQAOP8AAPoA7f8MAXQAgAH0ANwAmADPAIMAp/8OABoAFAGpAOAAbQD7AFABWP9+/2b/UgA0/7n/UAGAAM0Awv4zAFMARf9F/+r/fwCM/q//9//ZANz/lf9BAI7/av9e/vr/7/+nAIr/7/9mANb/AAHeANj+/P6c/aYBxP7U/tz+SAFQAaP/uP7I/iH/Vv+w//D+h//8/mwAzADNAHv/mwBx/x4BSPwt/xUASgGr/5b+iAKQASAAHP1eAYL/zP6A/UwB2wDe/of/ZgH2AZT+0P4LAPz/fP6C/gAANwBE/8QAUgGhAFz+oP8qAbr/5v7+/mwC0AAXAFH/PgGoAf3/fwBuAIgBKwDP/xYAbwDMAOb/OABaAJz/9v/4/soA5P8RALb/yv/A/1b/kv/n/7IA8/8KAGH/T/+h/0T/Nf9n/3f/k/8LAOH/d/8qAIn/7v88/y3/tP+H/3b/KP/q/ysA0ADKABoA+f9x/xL/Cf/6/pf/n/+q/+L/nwDn//P/4P90/5v/sP54////2ADsAFIBhgEYAaAADwBLAOUAXAD/ACgBmAFRAFoAZAACAaQAZAD9ALwAlP/0/oz/jf+z/6X/1P/5/4n/If+y/8z/Xv8w/8P/8v8UAPn/fwCuAPIAIgALANb/6f8nABwAcwBUAK4AQQCxAKYAwgADAMr/Rv8g/2X/iv8zAJ0A3QAoAC4AGQC1/9L/Zv9C/9z/DgD6/4oA8gAGASwBwwCd/4T/Lf+8/9z/ZQB9AMsAngC2AIwAMQD6/7v/MwAgAP7/+f+fAAIBsQCNAHQAZgD+/43/U/9I/63/5/8CAcMA9wAnAAAAFgAmAM3/wf+GAPr/owAFALIA8wD8AKgAyf+c/y//af+I/wAADQBCAGYAOQDr/yz/LP8G/8b+8P7Y/nX/x/8hANH/sP9C/8T+V/8K/7L+7P5V//j/zv8FABIAHADD/4D/a/9D/2r/vv+cAF4AUAAhAHYA1/+a/5X/pf90/4T/IAAaALr/HACTAF0Amf/B/woAjP9m/3X/QwAdACUAdQDaAIwAcQBYANwAaQB4AO0AggGyAdABaAL6ASACpAEgAlwCKAI4AsAC8ALAAvQC2AJgA9ACvAIEA5gCSAL8AdYB7gHYAZABnAEiAfEALQDP/+//pf8G/8j+pP74/Uj9QP0s/bj8GPyo+9j7wPso+zj7UPto+yD78Ppw+1j7SPso+xj7YPpo+qD6cPtg+7j7NPx8/Dz8BPxg/ED8sPw4/ZT9Sv4U/gj+BP9w/7r+Af9J/+L/EQDq/14AeAFcAjgC0AJUA3QDoAMYBJAFUAZYBgAH+AfwCBAJMApQC5AM8AwwDWANYA2ADbANUA6ADoAOYA0gDPAK8AkQCcgHwAawBZADJgED/5D9FPw4+mj5mPjA93D20PWg9cD0oPTA9AD1QPUw9dD14Pbw9vD2APfQ9lD3UPdg+AD5OPlI+Wj5ePlA+GD3QPaA9tD1gPXw9bD2EPfA9TD1QPRQ82DyQPJg80D1UPbg+Nj7qP2O/83/9QDeARgD4AMYBqgHAAtADWAPABGAE2AUQBRAFAAUYBRgEwAUQBVgFqAX4BdgGKAYQBeAFSAUwBOgEcAOgAtACCgFkAIYAQIBfQBm/nz8EPpg93D0gPOA84DzMPOA8gDykPGg8XDz4PYo+LD46Phg+ED3UPaQ9zj6PPy8/Wz/jgB6/oD80PuM/Fj7iPrw+aj52PhA9+D2UPbg9QD1oPPw8MDtoOyg7EDuoPBA8iDykPFQ8SDwQO/g7mDzoPbw+BD7iP/IAtgE6AVwCCAKwAjwCJAKwA0gDtAPABLAFIASoA9gD4APgBAgDkAOwA8gD/ALMAugDVAO0A+AEGARAA+gClAJcAjgBtAF4AQwBbQDrAK0AkQCgQDM/hv/WP2I+AD3oPfQ9+D2MPaQ9wj4YPeA99D3wPcA9/D24PfA94j4GPoQ/MT9IP78/cz8wPuI+hD7WPk4+lz8+P2c/YT8RPwg+5j4sPYQ9qD0QPNQ8mDzkPNw82D0gPTw9HDz8PHA8dDwIPPg9AD4gPvo/hQDiAWABiAGyAUYBNQD4AS4BzAM8A4AEUASABOgELANwAzADbANkAzwDFAOkA/wD2AQYBLAEmAQUA6ADaAM4ArgC7AMgA2gDCAKuAcYBQwD+QCH/8L+OP6w/ET8MPsw+sj40Peg9iD18PMw86DzcPVA9ij4QPrQ+pD6CPoY+yj7sPrI+lj9VP5e/tL+Lv6C/hD9LPx0/dT9rP14/Hz8QPuQ+fD2oPag9QD1MPOA8aDwQPGg8XDxgPGQ81DzsPKA8wD0sPXw9qj7BADcA2gHsApAC/AIcAW4BLAF4AaQCVAOABEgEEAQoA8gD7ALAArgCsAKAArgCFALIA2QDgAP0A/AD4ANAAtQCoAKkAoAC9ALAA1gC4AIYAYQBdADDAKo/yn/QP0Q/ED6OPlQ+DD3oPZA9WD0YPMg8xD0UPbA98j4qPnI+jj7sPuQ+3j9lP2c/Qr+yP4K/tj9zP0s/kL+Fv4Y/Rj9gPxY+wD6ePjg9qD1MPQQ8yDx0PBg8HDwgPCg8MDwgPGw8oDy4PNQ9ID2IPg4+4kA+ARwCZAMEA7QCygGEAPsAqAFqAfQChAPYBDgD5ANIAsACoAJmAd4B9gHYAjQCLAKsA2AEIARYA8gD0AOAAywCfAJoAzwDQAOwA2gDNAJ0AYwBcADtgBI/ij9yPvQ+VD4uPgQ+AD3IPYw9mD0MPIQ83D2mPjo+FD77P3W/hj9fP30/1oAPgDu/58ANwBx/wD+kP4D//L+lP1U/HD8cPqI+LD1cPWw9NDyQPDA7yDvAO9g7gDvYO8A8MDwMPHg8iD0wPTw9eD30PrA/jwDwAgQDqAQoA5QCjgGCARQA0gFIAlwC7ANsA5QDaAK4AhgCGAH+AYYBmgGEAdQBxAKUA3AD0AQIBDgD0AOcAxgCuALYA1wDpAOgA3ADIAJ2AXoA4gC/ABw/QD7+Pkw+SD2EPYQ9+D2wPVQ9CD1oPRA9FD1UPhA+3T8lP3q/sz/nP/H/3gAqwALAA3/qP6o/YT9SP10/Rj99PwA+8j4wPbg9KD00PLQ8aDwgO9g7YDsIOwA7WDtgO0g73DwIPIw8uDzQPYA+Jj5IPvJ/1AFwAtAEKARIA+ACuAFxgGIAGQDuAdAC1ANoA5gDtAK8AYABgAHoAbYBBgGQAlACkAL0A1gEeASgBIAEuAQMA6gDGANsA7QDyARwBBQDpAJSAZoA73/kPwQ+wj7gPiw9jD2gPaw9eDzoPPw80D0MPSQ9dD3uPrA/I7+jgCaAdQBRAEoAWIBFgGLAPH/EgA1/+T9sPyw+5D6CPmg96D1sPRA87DyYPGQ8GDv4O3A64DrYOwg68DrIO5A8PDxsPOg9DD3wPjA+Jj6KPyMAMgFkAyAEqATIBFADLgGFAKVAMQBYARQCeAMAA4ADTAKwAiIBQAFuARoBQgFwAVgCQAMMA7wD2AUYBZAE8APgA/ADqAMkA3gEWAV4BLwDqALyAfUAoD9uPv4+xj6EPhg9pD2MPYw9ZD1sPUg9iD2QPbQ9uD4SPsc/7ABeANwBUAGUAQIAigCXAKGAfz/KwC+AN7+6Ps4+9D6MPkw9tD0gPSQ81DxYPBA8KDuwOyA6sDqQOsA66DrIO5A8XDyMPRw9Xj4APgA+aD51PwmAbAEwA1gFEAWYBFAC1AEiP/o+0z9DAIQB9AK8AzwDBAKAAbQAoQC7gEkAawC2AbgCdALoA5AE+AVwBSgE+ATQBEwDjAN4BCAFIAUgBNAEXAMkAVpAED9oPsI+hD5GPjw9bD0gPRw9ED0APVg9hD30PYw9wj75v6HABwDOAegCFgGuANEA5ADQAIcASwCvAJWAOj84PoA+vD3APbQ9FD0gPPw8fDwYPAg8GDvgO2g60DrgOog60DrIO6A8SD0gPVA98D5UPo4+Uj58PyS/3ADwAkgE8AWQBJgDKgFMv/o+fD3kP3UAlgHQAqQDFAKeAZABP4BVAFyAZwDiAYwCTAM4BCAFGAWgBcAGKAWwBIwD5AOoBCgEuAToBTgEmAOEAioAZD9yPqQ+AD3APbg9AD04POQ8xD0MPYA96D2gPdA+nT8QP4CAVgFwAd4BygHGAcoBlADrgHOARYBI/9Y/YT82PqY+GD3YPbw9EDzkPIA8mDxMPDg74DvQO6A7CDroOqA6gDsQO7Q8VD0cPbg96D4sPfQ94j48PlY/PYBoAmwD8ASoBJgELAGcP6A+AD2QPgq/qAF0AvwC4AKcAlYBzAClQDkAsAEqAVwB5AMwBBgE4AVwBjgGSAYIBRgEOAPMA+wDuAQ4BJgEyAQ0Ap4Be//gPoQ91D1sPTA9ODzgPMQ9ID1YPZg9iD34Pgo+4D7kPzXADgE+ASYBsAIgAnABvwD/AJSAb//7P24/Sj9MPuQ+aD4UPcg9QDzoPKQ8uDwMPDA7xDwcPBg70DuYO1g7SDtIO7A76DzwPZ4+ND5OPss/ND6oPn4+wgAOARgCIAOQBPAETAL6ASg/VD3wPM4+cgCgAaQCpALQAvoBzgEcAM0A9gEQAaACAAL0A0gEWAUoBaAGSAbABnAFOASABIAEEAOwA8gEgARYAxQCNAENv9o+OD0IPRg8/DwUPDQ8lD1QPUQ9ij5aPoo+wz8Qv/AAYwC8AQ4B3AJAAnoB8gH6AU8A+kAQwC6/lT80PoA+pj4YPbA9MD00PTQ88DyMPIQ8aDvgO5g7iDuIO7A7mDvgO+Q8NDz0PXg9aD3KPvI++D5oPoQ/f7/h/8QA1AKMA+ADrAMgApIBAj7MPZA9iT8mgHgBgAKkArQCPgFMASYBDgGgAeACeAJcAxgDQAPwBAAFeAY4BmgGYAXIBWgEZAPABAQD2ANIAtwCfAFyQAU/Wj7ePhA9JDxkPDA7+DuoO/Q8xD3OPiQ+bj7aP4yAOUA9AHgBBAHoAeIB0AI0AfQBSACgQA3AFL+kPuo+cD4MPcQ9BDz0PLg87Dz8PIA83DywPDg7ODrwOwA7cDt4O/w85D20Pag9yj44PgI+Nj4oPvE/eH/wAG4AlgFIAiQCdAIqAdoBqYBsPpw+Nj6uP1x/1wDYAnwCHAFJAPYBNgGWAZwCbAMwA4gDeAM4A4AEGAQgBIgGEAaYBqAGGAXIBYgElAOwAqgBmYBlP7C/uD/xP40/Jj5oPWA8ODrAOuA7cDvcPMw94D7P/+4AFgBDAMABagEAAXABVgHsAcYB6AFqAWABPoB5P7I/Gj68Peg9ODxoPHA8uDygPKw85D1wPOA8KDuQO4A7QDsgO4g8qD1wPZo+ND5EPog+RD58Pk4+wD9rv5OAaACCASIBEAF+AXABfgCFwAC/oj9kPsQ/DIA7AOgBBAE4ASoBpgEeASQCBAMQA3wDGAOgBBAEHAN8A1AEIAS4BTAF2AcgBzgGoAYgBLQCUQBhPzY+2T9rP7yAdgAFv5Q+DDygO4g66DrYOxQ8FD1+Phc/EUAKAQoBrgFEAQwBMgDwAKQA4gFAAigCKAHiAXlAOz8sPjA9MDy0PKQ80DzsPEw8zD0wPIg8HDw8PAA78DswO2g8MDx8PIQ9eD3iPjQ9/D3SPnQ+Vj6GPwu/7IBOAIuAZACHAPcAvIB6AEcAjwCff8k/vH/MgGiAAwCMAUgBgAFkAR4B+AJgArgCoANsA9QD9AOoA9AECAPYBCAE6AXgBtAHwAhgB9AGTAOIATI+0j5gPvGALgE9ANeAUz9APfg76DrQOtg7cDuoPLQ9xj9/gC4A6gH2AcoBtgDBAIYAZ4AtANQBxAJYApACogGxv4o+CD1IPNQ8eDwUPNA9ZDzYPJA8gDyQO/A7MDsIO1A7cDtwPAw9JD2sPcg+JD4gPjg94D34Pio+8r+DAHYAsADaAPAASkA1P90//z+RP8QAGoBlAFoAVwC+AN4BLQDcAOwBdAG+AfgCfANQBDgDuAPgBEgEYAPEA/wD0ATgBXgF8AdwCCAIYAcABUQCxcA+PlQ+ZT9TAHAA3QD8//o+iD0QO6A6yDrwO2A8MD2oPvB/1gCSAVwCLgGwAN0AfQCIAJDALgCIAkQDNAJ0Ac4Ba//wPYw8uDxAPMw8zDzIPXw9bDzEPEA74DuIO1g60DrgOzg7hDx0PMg9iD4WPhY+HD3IPfg9wD5uPpI/gwCDAPQAlQCzAFFAHD+AP5Y//z+Pf8+ANwBIAJkAhAD2ANEA0ACZANIBagHkAmAC8ANQA+QD3AOAA/gDvAPYA8gEyAXABxAH2AfgCFAHAASeAXI/bD5YPpM/YQCQAWYAqT9CPhA8mDswOkg6zDw8PPw9nT8JAKQBHgEcAVoBkgEpwD5/7gCiAP4BCAIQAyADNgHtAIo/SD3wPJA8vDz0PVg9wD4IPbQ8oDwAO/A7KDrgOtg7ODswO1Q8MD00PYQ92D4iPnQ95D1gPZI+rz9eQDsAigFmASoAen/F/+q/g7+8v76/3sA8QDdAA4BRAEMAuwCkALgAoAEUAUoB8AIIAwADmAOoA4AEIAQ8A4AD0ASQBYgF+AZoB4AI0AgIBlAEUgHgP44+lj7jgDQAeoB+P+A/ED1gO/g7CDrIOxA7/DzGPig+3T/SAMABZAE9ANoA6gCeAGqAQQD0AUwCBAKQAqIBzwDyP0A+BD1sPQw9ZD1IPaQ9tD1MPOg72Du4O3g6wDqAOtA7QDuQO+Q8pD2sPcA90D3IPh4+Lj4OPvK/koBSAJgAhwCRAH8/5v/cP90//v/3wDNANkA7QBeAS4BFAG6AbACSAMYBMAG8AgwCxAMAA4gD1APQA5ADyAQgBDAESAVQBlAHMAfgCJAIuAZgBGAB4D+8Prc/EQBSATUAqwAAP2A9iDuIOsg7EDtQO+w8jD3oPrA/WgAsAPgBHwD7gEuAI4B+gGkAgAGEAnQC2AKIAf4Apz+OPqg9yD3OPiw+HD3YPaA9WD0oPFA78Du4O1g7ODpYOqg7YDvoPDA83D2APdA9uD2ePgA+Uj71P1iAOIBZAIYA5QCmgE0AUwB/QBOAZIBSALcAbABzAI4A8gCXAIEA2wD2AO4BMAHIAoAC5AMwA0gD1AOEA6AD0AQQBEAEuAV4BkAHQAggCKAHuAU4AjMAQL/IPtE/gwCuASEAmT9sPcQ8SDtoOoA60DtwPDw8/D1APnm/uwCzAJwAcwBugH0/rz9DAEYBtAIkAnwCiAKAAa//+j7CPpg+SD4QPfw9yj4QPaw81DywPDg72DtIOwg66DqwOsA7ZDwkPKg9ED1sPSQ9ID1KPgI+oD8Xf+QAZIBmAC7AE4BGAHbAPwA2AFQAjwC+AIEAyQDvAPgA+wChgH+AQgE0ASIBdAIgAxwDBALwAwgDqAOkAwADoARQBPAEoAUwBqAH0AhQCCAGKAQ0Aa7/3j8NP4QAnQDYAE5/0D7APRA7gDrQO1A7SDugO8g88D2wPiw/WQBmALwAAD/ZP5E/RD+mgGABgAKkAuQCnAInAOA/6z8MPs4+lj5QPlA+ZD4EPZw9EDycPCA7iDsQOqA6QDqwOvg7gDyQPRA9WD04PMQ9JD1cPeg+wT/zgHcAfQBKALYAggDsAIcA0wDFAPuAaQCOAQwBJgEqASgBLwD6AE0AjwDkAUIB6AIwApwC/ALEA3wC1AOQBAAESAQoBCAFCAWQBZAG0AigCGgGBAP0Ak4Atj8UP2yAbAEugCW/tD6MPaQ8EDuoO6g7kDuYO7w8IDz4Pio/fgAKALVAFL+yPuA+xT9jAEYBbAJoAugCkAIeAR8AYz98PrA+nj68PoA+nj5OPkA96DzwPGg72DsAOrA6aDrwO1A8ODxMPQw9BDzMPLA8iD0APcg+uD82P+qAe4BvgH+AcACRAJiAUQBEAKUArgCtAPYBPgF6AXQBCgD0AJkAmwCYAPYBaAIQAmACiAMgA2ADNALEA5AEAAPkA7gEEAVQBagGKAdgCAAG+ASIAxgB4f/yPtYALgE6ARgAZD9APng9JDwwO/A74DtYO6g77DzUPbY+Qr+RP9o/hj8MPsg+9z85P7IBHAHEAkACQgHIAYcAnYA6P0U/hD+9PwA/Dj70Poo+WD3EPTw8UDv4OxA7KDsIO9Q8aDyQPMw88Dy8PGA8RDzEPaQ+ED7dPxO/7YALgHwAJQBTALOATQBEAEkAhgDQAS4BEAGGAYIBWwDKAPwA7AD6ANIBRAI4AlgCcAK8AsADbAMUA1ADgAQEA/AD2AT4BVAFgAZwB2AHiAaYBIQDTgGFQAg/uIBsAXgBIACJ/+g+sDzwPDA78Dv4O6A71DwAPJg9kD6IP6g/RT9yPs4+kj5sPmw/bQCcAaQCCAJoAcwBawBaADY/rz9vP3I/DD9QPyY/Ej7aPgQ9vDyoPCA7UDsgO2A7zDx8PFg8hDyQPEA8UDxUPKw9AD3EPng+vD8XP4D/8z/owB4AQAB6gB2AXACOAMYBGAF+AUwBtAFMAV4BEAEqATIBXgGmAeQCHAJcAoAC8ALsAsgDEANEA5QDnAPABIAFCAV4BZAGyAcgBkgFcARUAvYAYL/NAPIBSgFAASUAYL+EPeA8YDx4O+A74DuUPBQ8QDycPUw+Tj7MPpg+Tj4wPZQ94D6fP4wAlgEEAfIBigFbAIiAU8Amv/Z/6r+0v4Y/qz+mP2Q+5j5kPeQ9LDxAPDA76DwkPCQ8eDx8PEg8bDwQPCw8KDxUPPQ9PD2gPn4+qD7KPxw/Xb+bf9z/5YAtAGIAuwCaATYBfAFmAWoBcgFKAUYBdgFiAZ4B5AI0AjwCfAJQAtQC6ALMAzgDJAMcA0wDwAQYBFgE4AXABmgF8AWoBZAEcAIiAQQA3AFyAMoBpgG6ARq/qD3gPfQ9NDxwO9Q8pDysPJw8uD1GPnQ+fj5sPng98D1QPZQ+AD8vP6kApAFGAYIBQADZgFxAAYAJgADAKMAPQB/AMf/xv5A/cj64PcA9WDyUPGA8ZDxcPKw8tDy8PFA8eDwwPCw8BDxkPJA9MD2oPg4+tj7yPw0/XD9Dv6i/pL/wQBsAhAEYAXwBagGcAb4BcgFEAZQBkgGKAcQCOAIgAmQCoALsAuwC2ALYAuAC9AMsA1AD4AQwBPgFeAWIBdAGAAYYBIQDeAK4Ai4BKAEYAiwClgGYwCW/rj7QPcg9IDzQPUQ87DxIPJw9ED1wPbo+Kj4sPdQ9XD0UPUw92j6PP7PAHQCYAP4AvgB0gC6APUAnQATACUAvABKAGAAbQD6/gj8iPgg9uDzgPKg8kDzUPOQ8pDyMPLg8FDw4PCQ8ZDwwPBQ8pD0kPXw9kj5qPpI+nD6CPv4+7z8aP55AMgBAAPoA7AEqASwBLAFcAYwBhAGCAcQCDAI8AjwCnAM0AtQC+ALEAzwCzAMQA7gD+AQgBEgFMAVIBcAGGAY4BXAEVANsAiYBjgFQAlwCTAHAAbwA3T+kPkQ9+D3IPfw9ADzYPNg89DzUPbg93j4MPdQ9nD0UPOg9DD3YPpU/GcAggFvAH8AtQB4AfH/0f+7AHABcABSADIBpgFsAcD/Vv7Y+zj5EPeg9vD1oPWQ9ZD0APRA82DywPGQ8UDxYPEA8XDx0PKg85D1APfg9wD4mPiY+Wj6UPrA+37+RQDpAEwBXANYBHAEMAXgBtAHCAeoB/AI8AkwCcAK4AwADaAMcAzADUAN8AzQDiAQoBCgEEATABVgFWAVIBfgFaARIA1gC4AKuAb4B2AJQArwB6gEwAHc/YD78PlQ+QD44PbQ9cD1sPXA9kj4mPhA9/D1IPXw8zDz8PRg+Kj6yPs0/YL+3P5u/tT+L/9y/7b+8v7o/xkAYQBcASgCMAHp/4j+JP0A+9D56Pko+bj44Pdw95D2MPVQ9AD0YPNg8iDyYPKg8sDyUPMw9ND0QPWw9UD2oPag99D4WPrI+7z8WP6s/ygBBAL4AoAEcAUYBqAGMAiACaAKYAtgDMANAA7gDaAOYA8wD/AOcA/AEOAQ4BFgEsAUQBWAFQAVoBPAENANsAvgCcAIAAjACdAIuAeQBewDBgE8/jz96PtQ+gj4EPfw9vD2UPcA+Nj4QPjg9gD2wPQQ9JD0APbw9lD4oPk4+xT8aPwY/ez9nP0k/dT8GP1M/Vz9Wv5T/83/n/8w/1r+OP18/JD7yPpA+gj6kPn4+Gj4gPjw90D3kPZw9hD2MPUw9aD1oPVQ9bD1sPYQ90D3EPjY+DD5oPlg+kD7+PsA/Tz+h/9AABgB5AKwAzgEGAVQBsgGGAeACNAJYAqACmALQAxADPAL8AzgDXAO0A7AD2ARYBGAEcARoBHQD6AN0AxgDGAKAAlwCWAJsAiQB3gGOAWYApIA6P/K/jD9JPzY+2j7gPrY+fj5mPkA+Rj4YPcA91D2kPbg9qD3QPjY+Cj5iPkQ+jD64PoQ+5D7yPvI+/D7PPzQ/Ez9yP0O/hT+1P2M/QT9vPzc/AT9BP24/Az93PxQ/Mj7mPug+5D7WPtY+7D7WPsg+0j7mPuQ+6j70Pso/PD7iPv4+zz8kPyo/Pj8YP3k/bD93P30/Zz+pP7I/nj/JQBkAOkAZgFcApACyAJwAygEUASQBFAFIAawBkAHkAiACeAJQAoAC4ALgAoACkAKUAqgCYAJwAnwCaAJMAlQCRAIOAdgBqAF4ATUA8QDbAO4AkQCSALoAUABgwBJALr/pv4O/hD+3P2g/YD9sP3U/VT9WP0k/dz8ePwk/Aj86PuY++j7APwU/AT8MPw8/Aj86PvQ+7j7uPuo+5D7sPu4+6j7kPto+1D7SPtQ+yD7GPsY+xj7MPsQ+0j7UPtw+2D7SPsg+yj7KPsw+2D7qPvQ+/j7TPxM/FT8MPxM/FT8mPyc/Nz8EP1I/VT9gP3Y/ez9Hv5A/qL+1P4t/8T/VQACAX4BNALQAmgD/APABKgFAAYgBrAGCAc4B5AH8AdwCNAIIAlACYAJoAmACZAJYAlACQAJoAiACFAIAAj4B6AHWAfYBogGEAZwBagE+AN4A9QCRALIAWYB9QBdAN3/Wv/Q/jz+yP1I/dj8bPwY/MD7mPtY+zD7CPvg+pj6cPpY+iD6APrY+dj5uPmo+Yj5mPmQ+Wj5aPlo+XD5cPlY+WD5ePmQ+Zj5oPnY+fD5EPoo+mD6iPrA+vD6GPtQ+2D7mPu4+/D7GPxc/HT8jPy4/Mj8FP0U/VD9hP3g/Sr+dv7S/jL/m//X/zcAqwD4AGwB9AGEAiQD8AOQBDAFsAUQBogGyAYQB5AH6AdQCKAI8AhQCZAJwAngCQAKAAoACuAJwAmwCWAJIAngCLAIcAgACJgHMAeoBggGkAUQBYAE9ANkAwQDfALUAUQB6QBaALn/JP/C/kz+tP1k/ST93Px0/ED8EPzA+3D7SPsI+wD7oPqY+nj6WPoo+vj5APrw+dD5uPnA+Xj5SPlY+VD5QPk4+UD5aPmA+XD5oPm4+cD52PkQ+lj6gPqY+tj6EPsg+0D7YPug+9j7APxE/JD85Pz4/BD9WP1w/YD9rP3w/TL+bP6s/hb/f/8FAH0A+gBqAZgBBAKgAkAD3AOQBCAFqAXoBVAG4AY4B2gH2AdACIAIoAjgCOAIAAnwCBAJUAlgCTAJIAkQCeAIcAgQCNgHoAdAB9gGeAYoBrgFIAWIBCAEfAPgAoQCEAJ6AcYAVADM/1P/xv5U/vz9wP1w/fz8qPxQ/Pj7qPtQ+yD7CPvg+qj6qPqQ+oj6aPpg+mD6WPo4+ij6IPoY+gD6EPo4+kj6YPpA+kj6UPpQ+lj6WPp4+rD6+Poo+3D7iPuw+8D70PsE/CT8UPx0/LD83Pw0/WD9jP24/QL+Ov5G/nD+oP7U/ur+IP9d/8j/9P88AJ8A3QA4AXIB2AE4AoACwAIUA2wDAARQBNgEQAXABRgGUAaQBtAG8AYYB1AHeAeAB6gHuAe4B6gHsAewB4gHeAcgB9AGgAZIBggGuAVIBegEkAQIBHgD/AKQAgwCkgEUAbEAMACz/1//CP+4/lb+Dv7M/ZT9TP0U/ej8vPyU/Gz8TPwo/Az88PvY+9D7yPvA+6D7oPuQ+4D7gPuA+4j7ePto+3D7YPtY+1D7YPto+2j7gPug+8D74Pv4+wj8DPwI/BT8LPxA/Fj8ePyY/Nj85PwE/Sj9PP1g/Vj9mP3I/fz9EP5a/nb+iP6W/rT+9v4J/zz/lf/m/x8AWgDIAAIBPgGCAewBcALQAjQDhAPQA0AEiATIBPgEOAVwBZgFyAXwBTAGYAZYBngGmAaQBogGcAZgBkAGCAb4BcgFsAWYBXAFSAUABbgEYAQQBLwDaAMwA+gCmAIgAsoBfAE4Ae4AfgApAML/cP8a/9b+jv5Q/hb+yP2E/UD9EP3k/Nz8wPyU/Gz8XPxw/GT8XPw4/Dj8QPwo/Bz8LPw4/ED8SPxk/HD8cPxg/Hj8iPx4/JD8vPzs/Pj8FP04/Tj9RP1I/XD9hP2E/XT9jP2g/bT90P30/RD+Cv4u/kT+Xv6Q/sD+5v4V/zr/ZP+J/4z/n//V/xkAawCrAPgAVgGIAbwB1gEEAjQCaAKQAswCEANEA4AD3AMoBGgEcASIBKgEyATgBMgE2ATwBDgFKAUABfAECAX4BKgEaARYBCgE4AN8A3wDNAPcAoQCqAJ4AhQCsAGgAX4BBAHCAIEAZgACAMD/j/98/yX/6v6a/p7+IP78/dT9wP10/SD9LP0c/RD9DP1g/UD9IP0Y/ST9LP0A/UD9iP20/Yz9mP3A/bz9tP2c/ZT9fP1c/Uj9cP18/Yz9RP1A/Sj91PyU/Jz8vPxg/CD8VPyI/ET80PsA/FD8gPvo+nj7+PsA/aT8IP2k/Sz9tPz8/Oj9PP40/1X/Mv+i/on/BgEYAbUARgG0AuwCjAIAA1gEwAQIBEAEcAWoBVgFaAVgBlAGoAXIBWgG+AZgBhAGYAZoBiAGwAXwBeAFWAU4BTgFMAXYBEAE0AOQAxgDwAKMAtwB2gHmAVAB2ABDABIA2P9G/7D+nP6C/jL+uP3c/eD90P1Y/UT9XP0E/az8KPwg/PD7yPtw+8D7KPxw/JD8uPy4/Ij8YPwU/FD8TPxQ/Iz8UPw8/CD8YPys/Iz8aPxA/Oj7yPug+0j7IPvA+tj64PqQ+nj64PoY+/D6oPqA+pj6IPrY+ej52Ppc/ND9cv9KARQCAAIQAgQCNANoA3gEUAUwB8AHcAgwCVAKEAvACvAKcAowCrAJYAnACZAK4ArQCoAKYAowCaAHkAYABmgFIATYAlAC+gFYARYBKAEMAUYAY//S/lb+wP20/Rr+2P7O/hj/jf+P/7L/BwBgAE4AHwBEAMYAzgD8AFgBHAIIAuwB7gCFAID/Hf9s/gL+Gv6w/Wz9gPw4/Ij7cPpw+dj4EPhw9qD1IPWA9aD0sPQg9SD1kPRw8zD0oPMw86DysPNA9HD00PQw9tD3cPfg98D3wPjw93D3sPeQ+cj6cPsU/ez9Mv9t/xwCSAawCVAMAA7gDnANYAwgDPANcA/gEWATwBJAEcARQBLAEXAPIA4ADWAKeAegBWAGuAa4BdgFEAUAAsj+CP2g/JD7OPqo+uD6oPoY+tj6GPwc/Hz8jP14/VD8ePtM/QYA4ADOAbwD0ATQBHgE4AVgBlAGcAZIB7AGCAWIBOAEoAWgBPQDiAP8AZX/8P3o/Oj7uPoQ+lj5EPgw9vD1wPUg9ZD0wPTA84Dy8PFQ8vDxIPIw82D0sPSQ9OD1sPZQ92D34PeQ+Fj4ePjo+Mj5OPqQ+yT8EP3k/ND8wPzA+zj8yPto/DT8zPzU/Bz+9gCgBdAJIA0AD3APMA2ACfAJYA3QDRAPoBHgFOAUQBBAESATgBJQDpAMwAp4B1AEiASgB5AH6AZoBqgFygGY/RD72Pno+BD52Pqo+kj66PrM/Jz9lP0e/jz+fP1E/CT9gv46ACgDIAboB4AI4AeoB5AHOAcwB3gH0AaIBhgHiAaIBmgG0AaIBSwDgQCu/hD7sPnQ+cj5yPg4+Dj4MPfA9XDzAPRg81DykPHw8SDyYPJg89D0QPag9QD2MPYg9uD10PaA90j4GPn4+Yj6wPpQ+1j7IPsA+nD5YPn4+SD64Pro+oD7CPvQ+pD5OPkY+nD60PsYANgGwAuADqAPgBHADfAHAAlwDWAQgBGgEUAVwBXAEiARIBKAEWAOUApQCHgFXAIKAVAEMAYoBoQD9gCi/uD6APjQ9kj4wPgQ+fj5kPpo+4D7qP3h/8IA5v7c/qz/XgAwAVgDCAcQCfAJ0AqAClAJ0AiQCKAI0AdIBtAFoARQBLQDEAQ4A+YB8f9U/dD6CPjQ9/D38PfA9zD3oPaA9UD1MPUg9XD1YPVA9VD1cPVw9rD34PgY+lD6yPqA+gD6mPnQ+pj7uPtg+3D7kPuQ+kD6YPpI+lD5oPeQ9+D3CPgw96D3QPhQ+MD3cPew9yD4YPfo+aT9jgEoBzAMQBDAEDAPAAyQCkALsA7gEWAVwBTAFIAVABZAEyARQBBADjAKYATYAuAC0AJkAvAEUAVIAmT+4Pro+YD2APUA9rD3ePlQ+Wj7bPyc/Qn/DAFyAdr/Yv/pAOYBsAIABcAIEAtQC+ALcAtgCgAJwAeoBxAHAAVEA5ADyAKYAl4BWAEZALT9SPqw9wD2QPUA9ZD1cPZg9hD2sPWQ9tD1EPVg9RD2MPaA9TD3UPgA+vD5WPuw/FT84Psw+2j7wPqQ+gD6mPqw+sD6EPvI+nj6QPkA+DD2QPVg9cD1oPXw9fD1UPew91D3QPeA9yj4WPhI+uz+qAUAC1AP4BIAEwAPcAswDEAQoBJAEiAW4BYAFoATQBMAE6AQwA0gC4gH7AJBAKMAEAKkAdIBRAL2/1D7IPjQ9+D1wPQQ9oj5cPsA+8j7Lv7y/wgByAEcAxADYAKoAsgDMAWgB3AKUAxQDKAL0ApACZAHGAaIBSAFjAPYAdcAGAAh/4L+XP50/Tj7QPhg9nD1IPXw9OD1EPfQ93D3YPcg90D3IPcA+Lj4CPlg+Tj6MPsY/Mz8LP1M/aD9OP2g/PD7cPso+/j6iPrY+oj6cPrQ+Bj4cPew9RD1EPTA9ID08PRw9eD1UPbA9rD3MPcw98D3gPmY+jj94ASwDQATABNAEwAUsA+wC+AMoBFAFcAVwBSAFkAVwBJAEUARUA9gCygHsAE/AFv/jP8n/+//iAIAAgr+WPlw91D3EPdg9oj4qPvY/PD81v7eAUAD3AOYBKgFWAVABBwDaASoB/AJoAswDBAMIAvgCagH+AUQBUAE+AJ2Aa//Gv8u/kD+cP0w/cD7QPnw9jD1wPSQ9HD1kPbQ90D4yPjY+Jj40PhI+TD6UPpo+jj6NPwU/JD8nPzE/aD+UP28/Gj7APu4+aD4SPgg+Rj5oPhg96D2cPYw9pD0gPMQ85D0wPTA86D0gPcw+ND38PZ4+Vj6MPho+PD8kAQQCRANgBOAF6AV4BDQDWANIBCAEsAUIBdAFmAUoBIgEUAQAA/AC7AH2ANmAdD+YPzs/F7/sgHwAF7+DPyo+YD3sPVQ9nj4kPqA+6j92//ZAFwC7ANYBTgGCAaIBPADYAQABjAIoAnwCqAL4AuACWAH8AWoBCQD5gHBAPf/lv4g/UD9iP1A/bD7mPlo+OD2UPVg9GD1kPaw90D4YPnY+Qj6SPmQ+fD6YPso+/D6WPtQ/BT9SP0m/ij+gP0s/Zj8YPsI+hj5KPno+GD48Pcw9yD30PYA9+D2cPVQ9BD0oPQA9dD1UPZA99D3UPiw+Wj5ePkI+tT8Af+8AsgHcA8AFCAVwBSgEyARsA0QDiASABUAFAAV4BSAE6ARgA9gD+ALuAc4BBQB5P2g+7T8/v5KAK3/Vf/A/ZD6wPaQ9bD28PcA+Vj7TP45AIABoALABHAGiAZYBsAFKAXgBFgFwAaQCRAM4AyADEALYAkIB1AEpAKUAYQAE/8q/pz9hP1k/bT8SPvw+Vj4APcg9UD0wPTg9cD2YPcI+WD6qPo4+gD6IPpY+vj5cPrI+3D8FP0A/Uj9gP1g/az8DPxo+wj7GPr4+KD3QPfQ9tD20Paw9+D3oPbg9KDzUPMw82DzsPSw93j44PcA9/D3EPtY+QD6WPzU/nIBAAZwDKASgBRgFMATABJQD/AN0A/gEWATwBRgFcAT4BDAD6AOMAxwCGAFFAKU/lT8vPwi/ij/AAA/AOD+iPsg+BD3MPag9uj4MPwc/1AAUgHcAsQD6ARYBaAFIAaIBdgEKAToBBAHkAkAC9ALcAuQCUgGfAPWATABQgCB/7T+5P4y/qD9oPxY+8j6kPkA+HD2QPVA9VD1EPbw9qD4EPpY+rj6cPow+sj50PhQ+sD7WP1g/TD90P04/aT8sPvw+yD8sPuw+tj5sPhg9+D2cPbA9gD3sPew95D1EPSg8xD0APQw9ED3SPlY+DD3cPco+WD6SPkA+yD9d/9AAlAIEA+AE+AV4BNgEVAP8A3wDfAOYBHAE2AVoBSgEuAQYA9wDdAKIAjIBMUABv4A/dj9lv8iAVQCbgFV/9D7sPjA9iD2oPdo+sT9qv/+ABgCRAO8A+gDsAQYBqgF2ATUA1AEWAUwB3AJUAsADGALUAkoBsgDmAHyAGEAXwDXAI8ANv/8/Wj9sPzQ+zj5uPiA97D2wPVw9QD30PcY+TD6gPto+6D6QPmo+LD46Plw+3T88PyE/RD9MPz4+jD7yPuY+0j6SPqo+QD5gPZg9hj4ePhw91D2kPcQ99DzIPJQ88D00PVg97D4ePnI+PD3WPmA+oj6wPrc/K//kAQAC6AQQBTAFCATQBAADkANwA4AEUATABWAFWAU4BFAEPAOEA0gCpgHMAV+ASz+aP1X/3gAEgFQAQ4Bpv5o+nD3wPYw9wD46Pr4/d7/mAD0AE4BIALYAjAEAAWwBIgEOASwBBgFwAYwCaAK8ApQCRAIEAaAA9UAqAA4Ac4BXAHK//j+FP68/Gj7OPpQ+VD4EPew9vD2sPaQ9kD3UPiY+fj5APp4+aj4cPjA+Lj5sPqw+xz9rP38/BT8oPtQ+1j7QPtY+yj7QPqQ+YD4GPhw90j4GPgo+AD34Pag9eDzwPJg9ID3OPig99D3WPng97D3WPkY++j78Pt5/wgFMAqwDmASABQAEgAPoA0QDnAOIBBAE+AV4BUgFGAT4BEQD8AMUAsQCYgFeALMABYAFwDcAAgCwAHC/7z9yPpw97D14PUg+ID6yPx2/0EAFADi/5MAoAE0ArwC6AN4BIgEUAWoBnAIQApgC8AL8ApQCUgHCAWUA3gD5AOgA2gDTAIIAQn/GP1U/FD7GPp4+OD3sPcg92D2wPag92j4YPjg+ID4sPeQ9pD2YPfo+Cj6oPus/Lj8QPyQ+xj7uPlI+sj7QPyg+5D6aPtI+mD4UPhQ+ej48PcA9xj48PZw9AD0sPVw93D3IPiA+AD4EPcA+Kj52Plg+pj7dP7CAVgGIAwAEEARYBAwD4ANcAxQDVAPoBFAEwAVABbgFEATgBFAD6AMYAmoBwAG8APcAnwCbAOkA5QCPAE8/4j8gPmw9lD2sPfo+UD8VP54/7r/Gf/q/mT+qP7F/+MAEAKIAjAEaAVwBigHsAjwCdAJgAhIBxgGmAT0A9ADyARYBYAEIAPOAcz/1P1U/GD76Pqg+UD4oPeg94D3wPeg91j4APhA9pD1APXA9AD18PYw+Xj6iPow+7D6KPrg+ID5aPqA+uj6YPto+4j6+PkA+sD6+Plo+fD4wPjw9/D2YPbw9cD2oPcg9yj4wPeQ94D2gPYA+Fj5MPmY+Tj8Tf8wBGAIAA3wDpANsAugCnAKYAswDaAQABNAFOAUIBWAE+AQQA6ADAALYAlwCNgHaAcgBsAFGAVQBPACpgD4/TD7cPgQ+JD4EPrw+8T9df8L/xD+EPzQ+9D7hPws/sMASAP0A9gEWAUQBugFMAZwB7AIIAhIBxAHeAZ4BhAGiAYwB8AF7AO0AqkAjv4s/fT83PyY+4j6aPrg+dj4YPcA96D2IPVw9FD08PTw9KD18Pag9xj44PcI+ND3MPdg99D3ePhg+fD5GPsY+0D7+PoI+yj6APoo+mj5YPkI+WD5MPkQ+WD5cPog+gj5IPgY+JD4ePiw+bj6QPs0/BL+4AJAB+AKIAyAC0AKuAcwCOAJsAxAD8ARYBNAE+ASwBGAEFAOwAwwDNALkAvACmAKcAnwB7AG+AWwBOQCLwAk/kT8SPtQ+wT8/Pxw/Sj+oP1M/LD7ePro+bD6tPx9/9EAugFMAnwCqALAAmgD6AT4BagGyAbQBkgGIAZABlgGmAZwBtgFUAQkA5IBfgDL/zr/A/9m/nz9uPto+lD50Pdw96D2APYA9mD2APZw9YD1oPUA9qD1sPUg9rD1gPVg9UD2APdw92j42Pl4+jD6CPoA+nj5CPlY+ej5aPpg+rj6sPuY+8D70PtA+6D60PlA+vD6CPuQ+4z8Iv7O/1wCUAaQCXAKEAkYB0gFYAToBbAJEA3gD+AQwBDwD7AOUA1wDBAL0AoAC5ALEAzwC+ALQAqQCPgG8AWYBIgCfgFAAEP/8P4G/+r/l/9B/+z9MP3o+3j7OPvY+4T8/P1W/1YAWAE2AR4BtgDAAZgC4ANgBKAFeAVIBbAFWAYYB6AGcAb4BXAE0AJoAtgCBAOkApQC+gF0ADT+gPxg+7j5OPn4+JD5OPko+PD3APfg9eD0sPRQ9dD0EPVg9dD0gPRw9HD1YPbA9hD3QPfw9rD2EPco+PD4OPmw+Yj5SPkg+cj5iPqw+uD6YPug+zj72PtA/Lz8gPxE/Ej94P6QAcAEMAcgCDAHAAbgBCAEIAUoBxAK8AvQDPAN8A1gDQAMwAoACmAJMAlgCiAMwAyQDOAK8AiIBvgEyASgBDgEXANoAqAB9QCzANAAtQDt/8T+pP1s/KD7sPuk/OD9yP5z/5f/Cf8s/sT9Bv68/lr/qACuAWgCVAKEAhgDSAMsA8QC5AK4AsACkAIAAzwDIAMEA2QClgECABT/FP5A/XD8XPxw/Hj8aPzQ+8j6iPkQ+FD3IPcw91D3MPdg9+D28PbA9tD2APfQ9nD28PVA9vD2APg4+CD5cPmA+Rj56PiQ+dj5OPpY+hD7yPtE/PD8JP2o/bT95P18/hb/hgCEAQAD8AOwBLAEaAToAzAEGAUgBtgGuAdgCHAI4Ad4B4gHiAeYB8gHUAgACfAIgAggCHgHcAZABlAGSAZYBugFQAWwBPwDGASIBLAEOARAAxgCOgHZACIBzgE0AgQCfgH/AF8AHwD1/wEAAgDy/77/pv/y/zkAVAANAK3/c/8u/wT/D/9z/9H/2P/I/8n/bf8A//b+TP+3/3j/Qv8E/1T/8v5m/kz+Ov5G/jr+PP7s/eT9vP2g/Zz9dP1M/TD96Py0/Kj8nPzA/Lj8oPyY/Hj8QPw4/Cz8EPzQ+8D7APwY/FD8SPx0/Dj86PvQ++j7QPxI/Kj8/Pww/TT9ZP2k/aD9oP3U/TD+Zv5i/qT+Rv+Y/7b/3/8JACAAQAB8AP4AQgGMAdYBRAJMAkQCiALoAkQDNANoA4QDtAO8A8gDKARgBGgEYAQwBBgEGAQYBDgEMAQgBDgEWARwBEAEIAQYBOwDsAOoA4gDiANgA2gDZANkA1ADGAPYAqwCjAJEAhwCCAIgAjQC7gHGAXwBTgEeAfEABAHVAJsAdAA4APb/wf+0/6T/cP82/xj/6P6a/kz+Rv4c/sz9nP1w/Vz9IP0E/QT9zPyc/HD8bPxo/ED8OPwo/AT84Pvo+wT88Pvo+/j7DPwI/OD7GPwc/Dz8VPyA/MD8yPzw/PT8IP04/WD9mP3U/Qj+SP6Q/r7+9P4x/3T/kP+t/7r/zv8ZAFUAugDlAAYBNgFcAYABigGkAd4BGAI4AlgCfALEAtwC/AIIAzQDHAMcAyADMANIAzwDVANsA2ADSAM4A0ADOAM8A0gDQAMcA+wC3ALUAuAC4ALUArwCoAKEAmwCVAIsAiACDALoAcIBpgGIAVYBJgH6ANoAsQBwAEoAGwD2/7j/eP9G/xH/1v6s/nz+RP4A/tD9nP1w/UT9KP0E/cT8hPxg/FD8PPwk/BT8DPz4++D70PvI+9D72Pvo++j76Pvo+/j7GPw0/FT8bPyA/Jj8wPz4/BT9MP1Y/Xz9sP3U/QD+Jv5a/pL+xv74/i3/cP+c/87/+P89AIAAvAD4ACoBYgF+Aa4B3gEkAlQCcAKYArQC2ALwAggDFAMkAzwDRANQA2ADYANgA1ADUANQA1ADRAM8AzgDJAMUA/gC6AK8ApACbAI8AhAC9AHoAdQBugGcAXoBUAEYAe0AyACkAH0AVAA+AB8A+v/Q/7b/ov+H/1n/Kf8K//D+zP66/rb+vv6q/pD+iv58/k7+Ov42/jz+Jv4W/hr+Hv4K/gL+Av4Q/gr+CP4Q/hb+Lv4c/kT+UP5y/or+tP7G/sT+yP7c/gL/D/8x/1H/aP91/4z/pP/B/9H/3f8DABoAKwBHAFUAVgBZAGgAgwCcAKoAvgDHAOAA6ADuAPwA8QDmAPYAFgEoASYBDgEMAQIB+QDyAPQABAH9AO0A2wDjAOUA2gDdAN4AxgCmAJgAmQCrAKwArgCgAIQAbwBsAFoARgA3ADMANgA6AC4AIAASAPb/7/8AAP3/7v/h/9D/wv+0/6b/pv++/7f/oP+n/7X/vP+k/4z/h/+I/4j/iP+f/6v/tv+x/7f/tv+t/6b/sf+3/7P/qP+m/6z/rf+e/4//n/+4/7b/rf+t/7n/vv++/8X/2v/h/+H/6f/+//n/7P/6/xMALgAxADEAOAA/ADUANAA6AEQAXQBoAH8AhwCLAH0AbQBrAHQAhACOAJsAlgCfAJoAlACLAH8AdQBtAGYAagBwAGoAWwBKAFQAWgBTAE0APQAsACAAEgAQAA4ABQAOAAMADAANAA0AAQAOABcADAD6//T/8f/w/+b/6v/t/wAAAQD2/+v/3v/g/+L/9//6//j/6v/k/+j/8v/z//f/9v/r/9r/0P/W/9X/3f/e/+X/6P/k/+P/4v/j/9//3//f/+P/2f/X/9j/2P/Q/8v/xf/B/7n/r/+p/6b/rP+3/7n/t/+x/63/o/+h/53/pf+q/6r/qf+n/6P/oP+k/6j/rP+q/6f/rv+2/7L/sP+x/6//r/+w/7X/zf/K/9r/3P/g/+L/5f/2//b/9f/5/xUACAAaAB0AJgAQAOf/9P/8//b/8/8FAA8AAgAUABwAJwAXAAAAEgAqADEALQAsADkAMgApACsAOAA+ADoANQAwAC4AMAApACgALQAqACQAGAARABIACwAJAP7/+//8//P/9P/0//f/8v/m/8//wP/B/87/3//e/9r/3v/f/+b/4P/n/+b/4P/T/8X/vf/B/9T/4//n/9v/0v/C/8j/x//L/9P/0//V/9D/4P/b/8//xf++/7z/t/+3/7//zP/N/87/0P/R/9T/2v/h/+v/+P8DAAwAFgAeACYAKAApACoAMgAzACkAJAAlACsALwA4AEkASABLAEsASgBUAFgAWABhAGcAaQBqAGMAZABoAGoAZgBuAHUAdwB0AHEAbABhAFEASQA+ADwAQwBLAEcAQwA/AEMAOAAmACQAJwAiAA0AAQD+/w8AGQAhABgABgDu/+P/3v/p//D/9P/l/9r/2//j/+H/3//h/9n/1v/L/9j/1f/h/+L/6v/i/9n/z//U/9z/5f/c/+X/4//k/+L/7v/o/+X/4f/c/9L/yf/R/9T/1f/O/9T/0v/L/9H/1//Z/9P/2f/n/+r/6P/v//b/8//y//7/DQAJAAcA/f/3//v/BwD//wEACwAuACIAEgAOABEADwD7/wEAAADb/8//xv/i/9n/FwCsAAABlADh/2z/Pf+O/9f/YQB9AH0ANQABAO3/AQBeAGoAOQD+//3/GgD4//P/VQBvAGIA/P8dAEMAEQC//5j/0v/0//3/9//x/9f/xP+4/9b/6f8EABcA9f/u/9T/v/+7/7//wP+4/47/i//X//H/NgBBAAcApf9x/2b/mf/+/yEALgAOAPT/CwDr/yUAYACRAJAAaABPADUA5v+v/8T/2P+6/7T/VQCiAZACPAK3ADX/hv4T/xoAKAEcAngC/gHxAPb/Tf87/5n/CABXAHEA2wAkAc4AyP/W/tj+rv+QAIYBTALuAQ4BHgDI/6f/hP8O/6b+Wv5I/mj+av74/fz9Yv7g/Tz9lP0X/xT/5v6U/3IBIALpAKT/8v5Q/vj9tP5gAOoB0gEmAYoAvwBgAWoBtQD5/7H/T//A/iv/zgBQAgwCgQD2/lb+rP1+/vb/tgFIATL/dP2w/dr+NAAQAmACygHn/2r+uP3M/dj+sgAEAj4BrwCCAA8AIf+K/j//WQDzAFIBsgGCAYz/EP84/4//iP+CABACkAL/AGT/jP/A//j/Rf/q/74AFAEMAbQAFwAT/5r/3gASAcr/BP8gADYBTAEgAGkAYwAIACv/qP4i/5oAOAHqAI4BpgAmAJv/pP44/hT+q/+kAKgCzAI6AaH/1P5U/+L+B//U/34BegG7/3n/GAHAAXMApP5H/w4B9f81AJwB2gG6/5r+KgCGAaUAUv60/hYAQgFxAGQBjAKQ/7T9pP3U/h0AKAFOASgA5P0G/v7/vALEAgoA7v5E/pj8HP3R/zwDBAMEAL7/6f/O/rj9/v4gAeQAF/9nAGQCoAEo/hr+1gGLAGj8kP0YAjAExAEO/xEAFAC4+xj8gAEYBgQCAv7k/5QBpf9c/BcAoASUARz9Zv4QAusAXf99/9QCVAKc/nj9Jv5ZAL0AAAE+AKj/cgF8A+8AoPuY+/sAMARNAPj9Gv90AoEAoP1e/6AArv54/VwBKAMp/7D6Sv6kA8gCtP2c/ZYAIQDc/Lj7FwBgBeADuf9E/sj7fPwG/owB6wBAAc4ARAJxAIz9YPx4/S0AWAJUA1YA5P3s/cb/AP6M/VUAOAb8AwT9ePkI/Tn/rv/cAmwDSgEI/lj8cPsm/hgDWARmAVD81/+4BKgBUPvQ/MgAbgAg/l7+MARQBQgEpgD4+/D3aPv2AVQBPAHkAawC2ALk/7YBHgGo/QD7+Pq4/TT/UAWwCZAIXgAo+uD36PmA/8AFQAfUASj9cP4wArMANAAIAt4AZPwg/hQCHAPsAl8Apv/s/Zj93AAABVgCGP1M/iP/1Pzu/xgHmAfW/xD6kPqk/O7/RgGwCHgGYv5A+Ez8af99ADgCUAHSAWD9MPxvALgDQgCg/S//rAA//4D+jf+yASABWwD2AYn/4PxM/ikAAAAQ/R0AYAfABPj6ePmg/p8AyP9cAIADVANs/cD6Ev/7AAQCvAImALD98Pv4/L7+JAMQBiAGnv9Q+pT8KQD9AD7+TAH0Al4ByPxU/uAECAWoAHD80PsA+/j7mACYBwAJIAOM//T+nv5w/HD6vPzI/UX/nAKABWAE1ABt/8wBvwA4+oj5cP+eAUz9TPzeASAHfAMU/0QDeAXQ/QD0QPak/UQBvgCoBLAK4AkgAoD5cPfI+cj7aPuw/8gEWAUIA3QCiAVIArD5MPLg95cAEAS4BWADDAK6/hD/bACU/tr+vP4o/dj6yPrMADgHUAsQB2T/gPgg9pj6pf8sAhgDcAPQBBgEoANuAPj7YPgw+Cj9HAMwCPgGEARd/zT9ePpI+qQA+AWABXD++Ppi/5gESANw/RD8GwCoA9ACjQAiAE7+gPo4+7wASAVoBOgAfP9r/+z8zP2wABQDhACK//7+TAFYAqQC0gFtADYA7P4O/iD6wPsyAbAF0AUgBOQCugEU/ID3APhY/XQDkAbIBigEB//c/Bz+7v/A//L+i/9d/+T/RAHEAuQCQgH2AAEARP3A+/z9SgFkA+ADCAOcAEj7gPm4+wz+Vv54AcAFyAaIAkj74Pno+YD6XPwoAcgETAOwABQB0ATUA+r+oPmo+Bj7cv7YAkAGoAjoB8QCOPuA+Bz8RQA//zz9yABoBuAH4ATsAqf/SPrg9lD5yP4AA6gEGATcAoQA+P2U/QL+3P3g+9D7jP1AARAGuAY4AwwADv9E/WD8RPyT/5wDsAKAAH8AsAI4AwgCgAAw/9T8sPv8/JYAhAPAAxAEGALX/7b+Mf/0/lj/W/9OAKAAgP9SAL4ApgHlAF8A5v5o/Vr+5gA4AmIBDADa/k//Ff+O/igA8gFAAqgCwAGG//T93P3w/gkAXACFAHYBXgE4ABQADgFmASUAK/9k/oD+/P5a/7T+FP5b/4wBTAOwAuwBJgCc/TD7mPqo+zT9R/9SASwDZAOgAjIBPgDW/rD8SPxg/CT9iv5qAfQDiAQ8AzwAuP0E/Bj88P1KADoBTAJwAuYArP/c/sj+eP70/cb+SwBeAeIA+wCzALn/Iv8k/8n/QgA9AHT/1P4D/ysAoAFAAqYBQACY/mD9fP3y/ocA/AAoAaoBPgHRAPr/7v8kAEgAdACfADEA3f/v/4wAxQCgAJAAPAFqAVMALv99/y0ACgBI/6j+jP8hAKwAAwAhADcAfv+Y/nr+yP4h/1j/t/9cAEoAq/8t/1T/k/+L/7P/7/9WAHEAggCcAAsAdv+b/93/nf9W/5L/EACmADQBYgFEAUUA0v78/Vz+7P7J/wYBlAFEAawAtwBeAKv/rv5g/qz+Av9J/2IAKAJoAs4BfgGyAEr/AP5k/Wb+x/98AMwBnAL8AgwCwAAx/+T9pP1k/vf/jgFMAjADRAPaATQAgv+A/w3/Nv+6/wwAaP8rAHABpAIEAuoAdQAq//j9FP1w/iEAuQC4AEwB3AHcAc0AuP+X/wj/pv7a/m3/gAAqAYABegEEAUoASv/w/vD+T/8AAAQA2f/S/08AaQA1ACn/tv4f/3P/jP8f/1n/wP8ZACkALgABAEH/1v4I/1//BABiAJAAZwDU/5D/LwC1AL8AeAABAMD/SP9m//j/bgCAACEAsf+m/5P/of8+AKsAhAC1/wn/xP7q/ub+4v5C/zoA7gC8ABEAG//Q/nb+cv4T/wUAzADFAL0AhAAqAMH/Kv/s/sD+1P5V/2oAUAF+ARABHQCE/0//X/9p/3D/pf/A/xsAlwBGAcwBQAHe/6L+8P0i/pT+bf9bADwBgAEcAawARQDr/17/CP/y/l//DwCYACABbgFYASQB0QB3AOP/If96/nj+WP9SAAQBSgHqACsAX/9P/3b/o//d/z0ASgAWAP7/AQBFAEcAmQCHADoAff84/zP/E/+q/uL+YP/o/00ApACQAMr/O//0/vT+AP+B/24A5gDWAHQALQDS/5r/mf/p/xMAIgAhAA8Avf9e/5v/FADBAC4BFgHbAGoAQgDj/1z/Qv9h/8H/+P/K/8n/AgBNAHwAsQD3AO0AIgAC/4D+tP41/8//kAAMAToB6gDFAFwA2/9k/2b/kP/E/zQAdAC8AG8AGgDz/w8ASQCbALkAOADW/87/TwCkALwA0gDAAGcA+v/P/8b/w/+5/4L/Of8q/+X/8QBiAe0AIQCS/0D/NP9d/xUAvQAaAeIAwgAMAW4BRAHkACgAKP8u/tD9tv7F/28AnACTAJYAXQA6ADUADQBY/47+Wv6w/qD/hABEAVIBkQCz/3f/nf/h/8b/QP98/h7+vP6Y/2MAtgC8AIgASQA5ACQABwCc/xr/wv6+/oj/ywAAAggCLAF7/4j+gP74/pX/6v8tAEAAXABlAMEA0wA3AJn/Mf9A/5r/QgDaAPcAtwB/AL0AxQB8ADwAAQDi/5v/yv8ZAHwAswDGALsAWwBkAGUAZQAYAF3/Bf8a/2b/w//1/ygAEADw/5//pv+f/2X/Df8g/1T/rv/Q/+b///8PACkAaQCOAHQAXQALANv/jv9U/0b/Tv/P/5YADgEcAbUAGAB3//j+3P6S/0wAfgBUABYAFQAYABoAZgBGAPr/uP8CADQAKwD1/9H/EQBSAMYAOgEwAcgAtv8v/yT/Vv+s/w4AXQDmAAwBnQBCAOT/ef/0/tD+/v7D/4gACAFIAVwBZgFSARYBpgAiAL3/dP9c/4f/T/8P/z//yf+NAMIAkQB0ACAAdP/e/i3/uv8nABIAw/+B/1b/fv9vAF4B9AHGAZQAOP/k/ZT98P3g/pz/RADeABgB4QBgAAIAZf83/07/j/9i/6r+EP7c/Tb+uP4cAGgB1AHpAIL/2v7A/hf/nP/n/+D/qf8DAJsAHgGMAfoBJAKIAXMAlP8l/5z+Kv6w/jYAlgEsAsoBCgF1ABIAKwB2AJEAZACm/x3/Sf8YABwBbAE+AYIAAQDE/73/tv97/0j/P/9o/8b/YAAgAVgB/ACNAHYAagDx/0v/tv5w/pz+B//5/6YArAB0ACYAaACmAO4ABAGrABAAhf9O/3j/lv/U/wgAHgAaAE0AlgCYAHkAIgCw/wj/E/9U/xkAkQDsAHYBqAFWAacAngCXAB4AeP9J/zr/Uf90//j/rQClABkAvP+c/5b/6f8zADYAv/8u/+r+6P5r/3EAqAHyAU4BewDq/4z/af+r//3/GgDe/zkAiQA9AJX/Of8c/yP/O/+i/33/DP/O/gj/mf/q/2kAHgFWAc0ATAAMAJP/6P78/pj/DQA5ANn/0/+C/z7/sv+1AJABoAESAVwAaP/s/nr/hAACAboAxwD1AGoBNgESAZQAfv92/vT9Sv6C/sL+eP/CAB4BBgEiAU4BEgFdAJP/Ev+W/nL+LP9iACoBcAE2AZkA5v+S/5T/xf87/9T+6v62/pD+ev6k/nT/GwC4AEwBwgDa//z+2v4J/xr/o/+wACYBngD//7P/EgBkAE0AfABLAM3/Ef85/1H/bf9S/4D/rf/K/zkA3ADkAGYA5P+W/+f/z//V//j/1/9s/xv/M/9q/8D/VgDrANcAmQAKAPH/fv8+/xz/Uf/q/24AogCLAI4A8f9s/2D/4f80AAMASf/o/iD/iP90AMkADAG/AF0ATAALAAsAHwBJADMAUABXADcA9P/A/9b/x//E//z/NwAQAFD/iv5y/qD+Bf9W/9L/UwC+AIIBaAKoAq4BVgC4/7//CAAeAAwAv/85/3T+7v4IAMgA2QCQAMkABgH2ABABrgDr/z//J//6/5kAPAGWAXAB6QAsAD0ArABEAFr/av4G/kD+ZP/LAOYBCAJqAVoBOgH7AI8AwgDKANb/wv5K/pr+Jv/B/58A8wDAAI4ApwB5AJn/J/9S/6H/Fv/K/hn/Zv9E/xP/sf8hAAQAy//4/+n/+v4w/hr+gv7o/lT/KACBAC0AGQCdAJYA9v9A/2r/qP+g/1H/cv+//37/Xv+c/+T/9P9VAGoAEgAk/z//HAB0AAYA5/+IAG4Ai/81/7b/KAAOAFgA3QD8AKMAUABYAKz/8P4p//n/WwA1AJcAowBBALH/MAB4Aa4BIAFtABQAhf9W/w8AFgFmATgBEgHRADsAJABJALcAhQBAAA0AIgApACEAPwATANb/4//R/8//t//f/9n/rP8c/xj/Ov/p/yoAKgBHAAIA4f/F/x0AMgAmAOT/rP+K/2D/Qf9e/5//aP8i/1r/s/+9/4n/j/+L/2n/If9S/6P/lf9R/0L/rf/s/1AArwDgAJUA8//N/ygASwA5APD/q/9i/wP/Sf/w/7sAAAEgAQ4B6gC+ALkArABcAPX/0P8YACgAOwAGAPT/MACFABYBTgFKAQIBuQCtALYA3gDlAI8ANQD2/xwAdwACAYABaAH4ADoA+f8SAO7/2f+f/4L/if+E/7X/DgBjAJ4AqACjAJcAkgBPANL/lf+l////LgA3AG0A4QDLAIMAMQAIAC4AJQANALH/jf8W/+7+0v76/pf//P8qAN7/gP8k/77+1v4c/4//qP8K/8b+oP7G/vj+XP+X/4L/Yf8m//T+6P4b/2r/av9b/4D/qf+D/xT/KP8I/wL//P6N/x4A+P/1/+//RAAtAA8AWgAPAPH/uv+8/8r/pP8IAJEAoQAzABwAUAAzABUAVADGAOwAkQB6AOUAHAEeAWgB1gHeAcwBRgEcARYBwQDaABABUgEwAdgA3QD3AA4BNAF+AegB1AFcAZoBugGAAWgBwgFIAhgCwAHYAeABZgEuAfIAMAHnAGYAYABhAD4A4v8XADMAwf/X/6L/s/+A/2H/kP9h/yj/iv5E/oz9NP0k/Yj9KP3E/ND8uPzQ/Nz89PwM/eD8XPww/Bj8HPzQ++j74Pv4+yT8ZPxw/FT8QPww/Ij8ePzY/KD8KPw8/ET8+Pz4/BT9XP08/Yj9SP4P/4T/df+Y/+r/4//4/0oA5wAoAeIAMAHkAWwC7AJ8A8wD8AP8AzgEUAR4BIgEUATIBPAE6AQQBRgFcAXYBTgG2AZwB6AHiAfgB5AI8AigCLAIEAnACPgH4AaYBlgGWAW4BHgEeATUA/AC1AJwAtgBzABLADIA0P+4/sT9OP28/DT8mPtw+xj7aPqI+VD5YPkI+bj4OPjQ96D3MPcA97D2cPZQ9mD2gPaA9qD2wPbg9tD20PYQ9+D2wPaA9vD2MPdw92D3kPd4+Cj5UPkA+gj7YPvY+wT82Pxc/cj9HP6m/kH/vP9+AGwBLAJwAtwCfAO4AwgEsASwBQAGUAbwBtgHQAiACAAJ8AlwCoAK8ArwC8AM8AygDZAOYA+gD7APIBBgEEAQwA+gD3APUA5wDUAMkAtgCuAI+AeAB1gG0AT8AuQBzgDt/1f/e/9V/97+fP7Q/Uj9KPwQ+0j6sPkA+Vj44Peg94D3APgw+ID4qPio+HD4wPdQ9xD30Pbw9XD18PSg9DD04PMg9JD08PTg9AD1IPVA9UD1UPVw9bD18PVQ9rD2gPdY+DD5ePlY+hj7yPsI/FD8QP38/PT8/Px4/aT9gP3o/VD+wP6+/pX/TgB1AEwA7ADyASQCxALYA3gF6AVABhgHoAgQCeAIIAmQCdAJkAiACKAIQAnQCNAIsAmQCoAK4ApgDKAN0A4wD2AQYBHgEAAQEA9QDuAMoAuACdAGIASwAvACZALIAWQCrAFNADD+zP1M/qz9mPzA+7j7iPro+OD4YPlw+Vj5sPlI+lj6kPpA+4D7cPsg+3D7CPuw+fD4mPhA+ED3wPZA92D3wPaw9lD3gPeg97D3YPgg+FD3wPbw9vD2oPYQ9wD4oPh4+Pj44Pmw+lj7OPyI/bD9PP3c/Oj8SP38/FT9gP1s/TD9fP3s/Yz+Ff+q/wYA/v8LAAUAGwBYAIkA4gDWABYBagEwAuwCqANYBMgEGAXgBRgGoAaQBrgGoAYwBngGWAbgBsAGEAeoB2AIQAnACZAKIAsgDFANAA4QDiAO4A5QDrAMEAuwCrAJiAYoBBAD0AIQApoBjAIwBCADrAHSAeACwAIiAe//0P4i/lz8wPso/DD8IPxw+9j7PPyI/Cj9OP0w/QD93Pw4/LD7gPsw+7j6CPqo+Zj5MPmA+FD4sPgQ+fD4KPlo+Wj5GPkY+QD54Phw+Ej4IPgA+MD3iPgg+ej58Pm4+lj7qPvg+8j7dPx0/Dz8yPvg+wz8GPwc/JD8YP28/T7+lP4d/2//3P+Q/6n/ef+v/+b/dv/r/0MAEAFKAWYBUAJ4A0gE8AR4BSgGaAYIBoAF8AUwBlgGsAWYBRgGWAZQBgAHkAggCvAJcAmQCmAM4A2QDWAOsA/QDjAN0AsgC9AJqAeABeAE6ASEA0gDQANsA9gCYAKoApQCCAIAASAADv9e/qj9UP2Y/KD7kPu4+zD8FPyQ/Bj9FP20/AT9VP0c/fD8XPws/LD7EPto+ij6APrg+dD5gPk4+dD4+PjY+PD4APnA+Kj4aPg4+Fj4WPgw+CD4IPiI+ND4UPnw+Yj6KPtw+9j72Pso/Dz8ePzI/Lj8bPw0/Gj8nPzc/Bj9eP0K/oL+DP+K/5P/t//l/yYAKwA1ADwAYAB1AKEA9AAkAaIBLAL4AuADWAQIBUAFOAUwBVgFUAU4BQgFMAVoBRAFcAXoBRAHOAcACMAIkAmwCdAKAA3QDkAPUA4gDkANgAvACUAJIAgwBqgE4AM4BHADWAP0A/gDdAN4AtACoAKqAYEAJwCW/+T9kPx4/Kj84PuY+yj8tPyc/GT8CP2o/cT9bP2Y/Yj9xPzg+1j7+PpY+rD5WPlQ+fj46Pjo+Oj4CPnw+BD56Pig+HD4WPgo+JD3QPdA90D3MPdg9xj44PhQ+cD5aPoI+2D7qPsQ/Fz8PPwA/ND74PvQ+5j7wPvg+0j8uPxU/QL+kv7a/kP/cv/e/8//8P/P//f/7//Q/+j/KgC+AC4BvgEYAqQCYAMoBIAEwAQYBWAFOAWQBIAFyAVIBRgFiAWQBugGoAZwB4AIAAkgCRAK8AsADYAN0A3gDQANgAtwCmAJUAgAB/AFQAV4BBgE7AMIBOwDqAN8AyADoALoAXYBvQDE/9L+xP0c/Wz8SPxc/Fj8dPww/Ez8iPyc/PT8JP0s/dj8LPyw+0D7wPpI+tD5iPlQ+Sj5GPkI+RD5QPlQ+UD5GPkY+RD5yPiQ+HD4OPjw99D38PdI+GD4sPgQ+aj5IPpo+uj6WPvo+yD8aPx8/HD8bPx4/JD8nPy4/AD9UP24/SL+qv4j/4X/xP8wAJQAzgDtAPUAAgEKARgBOgFoAeQBSAKQAgwDnANIBIgEqAQwBaAFmAUwBZAFyAW4BWAFuAXQBtAGcAYwB2AIgAggCXAJMAsgDHAMMA3QDdANEAxQC8AKAAqgCJAHKAfYBugF+AQgBRAFgAQoBAgE6AMcA0gCtAEUAdj/qP4I/mD9tPxo/Fj8ZPxU/Cz8WPyk/KD8qPz4/Nz8iPxI/CD8mPv4+oj6YPog+pD5KPkY+eD4wPiw+Aj5QPkA+dj40PjY+Ij4SPgY+PD3sPeg96D38PdA+KD4+PhI+ZD58PmI+iD7cPuQ+7D7sPug+7j76Psc/Ez8fPzk/Gz91P0+/sz+ZP/X/yUAiQDwACwBNgEYATABUAE8AUgBgAG4AQwCWALMAmwD8AMYBFgEwAT4BAgF+AQoBVAFWAVABUgFiAXABRgGgAY4B/AHkAiACYAKYAuADDANQAyQC/AK0AqQCSAIyAeQBygHyAVoBdAFyAXQBBgEsASwBIQD4AKUAlgCFgG7/8z+mv7o/Tj9xPzM/AD9vPzU/Mz88Pwg/UD9NP0w/Tz93PwU/MD7gPs4+5j6GPrw+dD5iPl4+YD5wPm4+Vj5kPmI+Vj5QPkY+ej4YPg4+Bj4EPgY+ED4kPjA+AD5UPno+Uj6iPq4+iD7OPso+1D7iPuw+5j7wPsY/Gz8uPws/az9NP6U/hf/n//x/0UAfgCkAIQAbwCfAMcA5gAKAXwB9AFcAtgCWAPQAyAESARgBKAEsATYBPAE8AQwBVgFWAVwBRgGuAYIB9gGSAeACFAJ4AnACgAMgAwgDHALQAsAC3AJAAlQCBAIgAfwBrgGaAYABngFSAWoBFgEAATMA9gC2AEOAUwAS/8W/rT9iP3c/Fj8HPxc/DT80Pu4+xz8RPzo+7j7sPuI+xD7wPpw+kD6EPrQ+YD5QPlY+WD5GPkY+Tj5SPkQ+aj4yPiw+GD4CPjg9wD4wPew9/D3OPhg+Hj48Pho+dj5SPrI+hj7OPtY+4j7wPvI+wT8YPyc/Lz8GP2w/ST+bv7K/l3/7v9XALAADgFeAWABYAF8AaAB5gEsApAC5AI8A5QD6ANgBNAEIAVYBZgF0AX4BRAGKAZoBngGmAbQBkgHsAfgBxAIUAiQCOAIUAkQCjAL8AtwDJAMQAygC6AKcApAClAJwAhwCDAIaAd4BhAGEAZIBbgEQAQgBKQDoAL0ATQBZgBV/6j+TP7o/Xj9GP2o/CD88PvI+4j7cPto+6D7WPsA++D6sPqI+hj6+PnY+bj5WPk4+SD56PjY+JD4gPho+GD4YPhI+Cj4KPgg+OD3oPeg98D30Pfg9zj4cPiw+OD4UPnY+Sj6aPrY+kD7WPuA+7j7OPws/FD8tPwc/Yj9xP1A/sT+Lv9z/8D/NACZAPAAFgFAAXQBrgHuASQCZALUAigDaAOoAxAEWASgBMgECAVYBXgFmAXYBQAGMAZ4BpgG2AbgBpAHkAfQB4AHMAiwCMAIkAmQCuALkAvgCrAKwAoQCgAJEAkgCeAIEAhABwgHoAY4BkAF0ASQBCAEiAOoAigCggHCAI//xv5g/gr+VP2Q/FT8PPyY+yj7yPoo+zj76Pqg+sj6qPpI+tD5mPm4+aD5cPkw+SD5APnY+HD4OPhI+Dj48PfA99D38PfQ93D3YPdw9yD3APeA97D34PcQ+GD4yPjI+PD4mPn4+Qj6SPq4+hj7IPtY++j7SPxk/JD8NP24/ej9YP76/oT/t//v/4gA9AAeAWABsgH4ASgCdALcAkgDpAP0A0gEgATQBEgFiAW4BQAGOAZQBlAGcAaYBtgG6AYoB3gHuAfQB9gHMAhgCIAIsAiACYAKEAtgC3ALcAvgCsAJEAmgCWAJgAgQCPgH4AfIBtAF2AWwBdgE9APIA9gDeAJcAfEAWwBN/+j9uP3A/RD9TPwU/Pj7cPuY+sj62PqY+jj6SPpw+ij6WPlg+ZD5UPkQ+QD5CPmw+GD4OPhI+OD34PfA99D3wPeA97D3kPdQ9zD3MPdA9xD3IPeg9xD4CPgw+Ej4wPjg+Cj5oPnw+SD6UPrI+hj7KPto+/j7YPx4/NT8gP0W/mD+gv46/8j/2/8RAKAASAFkAZIBCAJYArAC6AJsA+QDIARgBMgEGAVABZAFwAXgBegFCAYwBlAGqAb4BkAHUAfABwAIIAj4B0AI4AgQCUAJYAqQCyAMIAzwC8AL8AowCrAJIAoACmAJAAmgCAAIGAegBjgGEAZ4BegEgASwA+wCDAJgAV0Ac/8D/4T+4P1Q/RT9nPzI+0j7MPsg+8D6mPqw+pj6GPqw+Zj5oPl4+WD5cPlY+Rj5wPig+JD4OPhI+ED4IPjg9/D3APjA93D3YPeA94D3QPeA9wD4aPhg+HD4gPgQ+Rj5YPnA+VD6qPqg+tj6SPu4+8j7PPy0/AD9RP3U/WL+vv4e/6v/KQBFAGUA/ACEAbABnAEMApwC5ALIAmgDIARgBIAEsARgBZgFmAXoBTAGGAYABigGgAa4BvAGWAegB4AHeAcACFAIUAhwCPAIsAngCXAKQAvwC6ALIAuQClAK0AlwCYAJYAmwCPgHoAc4B4AGaAb4BXAFoATMA3wDhAK0AQYBeQCx/7T+Gv7M/Xj9zPxk/CT8yPsw+9D64PrA+mD6EPrY+bD5mPlw+Wj5gPlA+fj4yPig+ED4MPgA+CD4GPjQ98D3wPeg90D3APcg9zD3APcA94D30Pew96D3APhw+Ij4yPgo+cj52PkQ+ij6qPrg+gD7iPv4+0z8dPwc/Yj92P1U/tD+Jv9+/+v/eQDJAOQATAHKARQCQAKAAjgDaAOIA9gDYATYBBAFcAXIBegFwAWoBeAF8AVQBrgGOAdIBzAHaAfIB5AHqAeACCAJIAkACfAJ8ApACwALYAsADAALAArgCRAKwAmgCFAIcAgACAgH+AYgB6AGEAU4BLwDKAM8AqYBjAHwAMP/pv4U/oj94Pxw/Ej84PtA++D6iPpg+hD66Pmo+ZD5UPk4+VD5EPkw+QD5sPgY+PD3UPgw+ND34PdQ+Aj4UPcA95D3cPfA9rD2YPeA9wD3APeg9yj48PfQ92j46PgY+UD5yPkY+jD6WPqg+vj6UPuw+zj8gPzQ/GT91P0k/oT+Af+K//T/8P+JADABngGYAdQBeAK0AtwCBAPAAxgEWARwBCAFqAWwBcAFyAX4BagF4AUYBsAGCAeIB9AHeAeQB6gHEAgQCIAIYAngCbAJ8AlwCnALUAsACyALYAvgCuAJoAmQCUAJIAi4B9AH2AcoB5AGcAaYBUAEMAMAA9ACDAI4Ac8A8P+m/qj9aP0Y/WD8EPzo+5D74Pp4+nj6MPrY+Yj5gPmA+WD5kPmQ+Sj5yPio+ID4GPgA+Fj4aPgQ+MD34Pfw95D3QPeA96D3cPcQ9yD3sPeg95D3gPcI+GD4MPh4+Oj4cPlo+Xj54PlI+lD6WPrY+oD7oPvA+1z87PxQ/VD93P1g/sz+/P6X/24AwgDyABwB0gH8ARQCYAIYA2gDjAPgA2gE8AToBAgFQAU4BSAFGAWYBRAGmAZQB4AHOAcAB3AHqAeABzAIMAngCaAJwAmQCgALwArAClALkAvQCjAKUAoQCjAJYAhQCEAI2Ae4B7AHMAcQBggFcASwA+gCeAJQAqgBhgCJ/8L+FP5E/ez8uPxg/ND7aPtQ++D6ePpA+gj60Plw+XD5oPmA+Tj5APnA+HD4APgY+Dj4OPgY+PD34Peg93D3gPeA91D3UPdQ9zD3APcA92D3YPeA97D3KPhQ+Hj4yPgg+Wj5iPno+Tj6uPrg+gD7ePsA/Ez8oPwQ/ZT9DP4+/pj+H/+c//3/dgDfAGYBggHQAVQClALgAigD8AMwBHAE2ARYBWgFOAUoBbgF+AXgBYAGOAfYB4gHaAeoB9gHqAewB7AI4AkwCjAKgApAC3ALEAswC+AL4AuQC/AKAAugCsAJIAnwCPAIgAhQCBAI4AfwBugFKAVYBKADBAOgAkQCQAGCANH/Ff8o/pj9PP3k/FD8+PvY+6j7MPvI+uj6iPpA+gj6MPoI+pj5YPmQ+SD5uPiw+Nj42Pg4+CD4GPgA+FD3UPfA99D3gPdg97D3kPcg9+D2cPeg93D3kPcg+Gj4QPiA+Pj4WPlA+VD5GPpw+kD6mPpg++j7yPsI/Oz8hP2g/cz9YP4K/y3/aP8sAMwAFgFSAdIBOAKUAgADcAMABGAEuATABMAE+ARYBVgFiAXYBaAGEAcYB3AH0Ae4B0AHqAdACAAJUAnwCeAKEAugCpAKUAvAC7ALsAvQC1ALcAoACsAJgAnwCNAIwAhgCOgHaAcoB+gF8ARQBMQD1AIIAgQChgGWAHL/8v5q/oD94Py0/KT88Pto+0j7KPvY+pD6kPqg+ij6wPl4+UD5CPkQ+QD50PjQ+Nj4gPgQ+MD3sPeQ9wD38PYw94D3YPfw9iD3IPfw9tD24PZg94D3oPfQ9wj4UPhY+Jj48Pgg+WD5oPn4+Vj6uPpA+4j70PtY/OT8UP3U/fD9eP74/kX/f////8kAOAGGAcYBbALoAggDiAP8A4AEiASYBPAEUAVYBVAFwAUoBoAG0AYgB1gHiAdwB5gHyAcwCCAJoAkQCmAKsArwCsAK4ApQC7ALUAugCmAKEAqACRAJEAlQCSAJkAhQCPAHIAdIBlgFwAQYBGQDvAI4ArYBFgE1AEz/wP4+/rT9AP3E/JT8HPyA+wj7MPvw+qD6iPqI+mD6mPlA+fD4+Pi4+PD4EPkQ+bj4cPgo+ND3kPcw90D3EPcg9wD3IPcw9yD30Pbg9gD38PYA92D30Pfg99D3KPiQ+Kj4kPjQ+DD5UPlw+eD5iPoA+0D7uPtE/MD8wPw8/eD9Qv6Q/tz+cP/b/0QA6wBKAaoBCAJwAugCGAOYAxAEYARYBIgE6AQwBVgFwAVQBngGkAaoBiAHYAeoByAIoAgACWAJ4AlACsAKEAtQC1ALcAugC5ALUAugCoAKMAqgCWAJgAngCbAJEAlgCLgHuAbABQgF2AR4BJAD7AIsAooBigDZ/2X/+P50/vD9tP0g/bD8CPyw+4D7MPsI++D64Pqo+lD68Pmg+WD5UPlQ+XD5gPlg+Sj5qPg4+BD48PfA95D30PfQ96D3YPeA98D3gPeA94D3wPfQ9/D3WPio+OD4EPlg+Vj5aPmo+VD6iPrA+kj72Psw/FD82Pxs/ez9/P0o/tL+QP9y/6j/TgAGASoBggGyAXgC/AIkA5AD9AOABIAEoASwBEgFiAWgBdAFKAZwBngGiAbIBmgHqAfwBzAIcAgQCVAJoAkwCsAKIAvwCiALEAsQC4AKAArACbAJYAkACRAJYAkwCXAI2AdAB4gGeAWoBFAE6AMkA0QC5gEUAfn/FP/A/k7+wP2E/Tj9rPzY+zD7KPvI+oD6aPqQ+lj66Pmg+YD5cPkI+ej4APkg+eD4sPiI+Ij4WPjQ96D3sPfA96D3cPeQ99D30PeQ96D30PcA+OD34PeI+Nj44PgA+YD52PnY+cD5+Pmg+vj6APuI+0D8iPzc/DT9uP0a/mb+rv4Y/3r/pP8dAI4ACAF+Ad4BRAKwAgADaAO4A/wDQASoBOgE2AQgBWgFsAWgBegFQAZ4BmAGuAZAB3gHoAfYB6AIsAjgCFAJEAqACoAK8AoQC7AK8AmQCbAJUAkACSAJcAkgCbAIcAggCIgHWAbQBVgFqAS0A0gDEAN0AmQBSQDD//j+RP7Q/cD9sP3k/GD80PtA++D6iPqw+rD6gPoo+gj60Plw+QD5KPlA+Tj5EPkQ+fD4yPhQ+ED4EPjg99D3oPfQ9/D30PfA98D3sPfQ99D3APgw+ED4sPjY+Aj5KPk4+cj58Pn4+VD6yPog+0j7kPso/JT82Pwk/cj9TP5w/q7+Rv+3//f/cADtAH4BtAEkArgC/AI0A6QDSASYBKAEAAWABXgFYAWoBTAGcAaQBtgGeAdgB4gHgAfwB0AIYAjwCCAJ0AkACoAK4AogCzAL8AqAChAKsAlgCWAJYAlwCWAJAAngCGAIuAewBgAGkAXgBBAElANYA6wCqgGrAAMAMP9K/tj9wP2U/fD8MPzo+zj7kPow+kD6ePo4+hD68PmY+SD5wPjo+Aj52Pjg+ND4mPhY+DD4KPjg97D3sPfA98D3oPfQ99D3sPeA95D30Pfg9zj4mPj4+BD5EPlI+YD5qPkA+mj6yPrg+jj7sPsE/Hz80Pxc/fD9Ev5w/uj+eP/W/y8AdAD/AFYBtAEcApQCCAM8A5AD7ANgBMAEOAWQBcgFsAXABQAGGAZoBtgGMAd4BzAHcAewB+gHAAggCNAIYAmACcAJYArgCvAKsAqwCqAKAAqACVAJQAkQCdAI4AjgCHAIqAcQB1gGcAXwBEAEyAMUA0QC1AEEAR8AFf+W/hL+YP38/Mz8dPy4+yD7sPow+sD5oPmY+YD5WPkA+aj4cPg4+Gj4UPhQ+Dj4QPgw+ND3kPdw95D3MPcQ91D3gPdw90D3UPdw91D3APcw98D3EPgw+FD4yPjo+Lj46Ph4+cj5IPow+tD6OPsw+5D7HPyc/PT8RP0S/oL+qv4H/6b/CQDz/3AAHAGWAcwBMALMAmQDOAOQAzAEwATABOAEeAWoBZgFkAVIBqgGqAbgBkAHeAdIB0AHsAfwBwAIYAggCYAJsAnwCYAKoAqAClAKcAoQCnAJMAlACVAJEAkACTAJ0AgACCgHyAZABmAF4ASoBDAEaAOYAuAB4QC1/x7/9v6y/uz9mP1g/Yj8iPv4+vj6+Ppg+iD6ePpA+mj5UPl4+Wj5APng+BD5MPmQ+ED4cPho+ND3gPfQ9/D34Pew99D34PeQ9zD3YPew9+D3APhQ+ND4sPiY+ND4IPmQ+cD5OPp4+sj6APs4+4D76Puc/Oz8WP3o/aT+5P7w/l3/GQBTAFsAyAB8AQwCAAJcAhgDeAOUA+gDqAToBOgEMAVwBZgFwAXYBVgGgAaIBvAGGAcQB/AGCAdgB6gHmAcwCOAIIAkwCZAJEAogCsAJQAmACRAJoAhACJAI8AigCHAIMAggCCAHOAawBWgFsAQABLADMAOsAnABjwDO/2//5P5C/sj9eP2k/Pj7EPvI+qj6aPo4+ij6GPrI+Yj5EPkQ+Sj5EPnI+Kj4wPig+Dj4CPgo+GD4CPiw9/D3EPjw96D3wPcA+MD3sPfg90j4iPiI+ND4CPk4+TD5UPmw+RD6kPqo+tD6CPto+7D70Pts/Aj9iP3c/Rj+pP4F/0H/dP8CAGwAyQDnAEAB6gE0AogCzAJwA/ADAAQ4BKgEGAUgBVgFoAUIBvgF+AVoBrgGwAa4BvgGQAdIB1AHyAdQCLAI0AhQCfAJ8AnwCbAJsAkwCZAIUAiQCIAIoAiwCOAIwAjYBzgHqAYABjAFuASYBPADNAOYArYBhgCQ/1r/JP9A/tz9dP30/Nj7CPsY+wD7mPo4+lj6UPpw+Qj5KPlg+Tj5EPlI+SD5kPhY+GD4WPgI+BD4YPhI+AD40PcY+CD4wPeg9/D3EPjw9yD4ePjY+Lj44Pg4+Xj5gPmw+Uj6iPqY+sD6UPuQ+6j7EPzE/Dz9XP3Y/Yb+3v4J/0H/AABhAKoA+gBwAQACVAKMAhgDjAP4A1AEmAQoBVgFkAXIBRAGMAZIBngGqAboBggHIAdQB1gHkAcwCFAIwAgQCZAJEAoACnAKkAqwCiAKwAmgCWAJMAkwCbAJ0AlwCTAJAAkQCAgHqAYYBqgF0AR4BFAEHAM0AlgB8wA0AFv/2v6Q/tT9qPwQ/Oj7gPvY+qD6qPqI+uj5gPlw+Vj5GPnY+Pj48Ph4+CD4IPgA+LD3oPeg97D3oPdQ93D3cPdA91D3UPeQ94D3kPfg9xD4IPgo+HD4mPio+OD4QPmI+dj56Plw+oj6+Po4+7j7RPyk/AT9dP00/jb+qP42/7H/9P9XANgAYAGeAdYBiAIMA2QDsAMwBMgE+AQ4BaAFAAYwBngGsAYQBzgHWAeQB8gH4AcACFAI0AgQCWAJwAlQClAKkArgCtAKUArQCaAJoAlwCUAJ4AlACpAJ4AhwCPgHaAdABggGKAZIBUAErAMUAxgC7QB/ACcApv94/tj9dP2o/Kj7IPsw+9D6UPoA+uD5mPkY+QD58PjQ+JD4WPhQ+DD4oPeQ95D3YPdQ90D3gPcw9zD3YPdA9wD34PYQ9xD3EPdA99D38Pfw9wD4ePiA+ID44PhQ+dD50PkA+pD6sPoI+3j7IPzI/Aj9pP38/UL+pv7Y/pP/yf9UAPMAZAHgAQQCnAIYA5ADsANYBPAEKAVQBbAFQAZ4BoAGwAZwB6AHkAeoBzAIcAiACLAIMAmgCaAJ0AkwCrAKcAqwCuAKoApwCtAJ4AnQCeAJIAowCiAKwAnwCKAImAf4BmAGGAZ4BcAEKAR8A8wCmAH+AIkA2f/S/iz+sP3Q/Pj7ePto+xj7ePpA+hD60Pkg+eD4CPm4+HD4QPhg+CD4oPeQ96D3cPcw9xD3IPcA98D24PbQ9sD2kPag9tD2sPaw9gD3YPeA94D30PcY+DD4OPiQ+Oj4YPlw+dD5WPqY+uD6QPv4+4T8yPxY/dj9SP5u/uz+f/8ZAHUA6QCaAQgCXALQAmgD5ANgBMgEOAWIBcAF6AVIBqAG2AZAB2AHsAfQB/gHMAigCLAIIAlgCaAJ8AkAClAKgApgCiAK8AngCaAJsAnwCfAJoAlQCTAJwAjQB6gHSAfwBkAGqAVIBXgEjAO0AhwCXAFNAJn/HP9a/oz99Pyg/BD8WPso+9j6aPrQ+Xj5YPn4+Kj4iPiY+HD4EPjw9/D3wPdg92D3UPdA9xD3EPcw9yD3EPcA9zD3MPcw92D3wPcI+DD4gPi4+PD4APlA+aD50Pk4+mj68PpA+4D7DPxk/Nj8YP24/Rb+Xv62/vr+U//I/1oA9ABsAfYBXALYAjADmAMgBKAE+ARABYAFuAUwBmAG2AYoB3AHuAfABwAIAAhgCHAIkAjgCPAIAAkACRAJcAmQCbAJ4AnACYAJUAnQCKAIcAhgCKAIYAggCNgHeAfgBlAG0AVIBaAE3ANAA6wC6gE8AasAEAB6/8L+Gv6Q/Qj9ePwk/Nj7iPsw+6j6SPr4+Zj5UPkY+Rj54PiQ+Fj4WPgo+OD3wPcA+PD30PfQ9+D38PfQ9wD4MPhI+FD4ePio+Pj4yPgo+Vj5uPnQ+Qj6WPqA+qj6yPpI+4D7sPsk/JT83Pws/XT92P0g/jb+rv4W/zj/kf8qALIANAGuAVQC5AIgA3AD5AN4BKgEuAQABVAFoAXABRgGyAYYB1AHeAeQB7AHuAfQB/AH4AfYB6AH0AcgCGAIwAjgCKAIIAjoB2gHGAegBqgG4Aa4BngGYAY4BogF6ARoBNADZAOcAjwCAAJUAX4AKAD//2D/tv4i/rj9bP3E/ET88PuA+xD7oPqA+nD6CPrg+cD5iPko+fj48Piw+KD4aPho+FD4OPgI+AD4GPhI+MD46PgI+Rj5SPlA+SD5aPm4+Qj6QPqQ+uD6EPso+3D7sPsc/DD8lPzo/Cj9kP3s/ZD+8P5C/53/7/8NADUAbwCqAEABpgFoAgQDdAPwAygEYARoBFgEcAToBCAFkAUABqAGGAcwB0AHOAdQBwgH4Ab4BjgHKAdgB6AHsAeoB2AHcAeYB3AHSAc4B+AGiAawBUgFAAUYBdgEsASoBJgEYAT4A4gDoALUAUIBvgBTAOf/qf84/wv/8v6U/jT+mP3o/Cj8cPvQ+rj66PrY+uD62Pq4+lD6+PnA+bD5YPnI+Ij4qPjY+AD5QPmY+cj5iPk4+Uj5YPl4+cj5EPpI+lj6UPqo+gj7SPt4+4j74PvQ+7D78Pto/Oz8aP3U/UT+cv5O/lr+ov7i/hL/bP8XAJ4AJAG8ARgCeAJMAhAC5AHWARACAAOEA+QD9AN4BDAFwAXYBZAFYAXYBPwD5AIcA7ADMAVQBjAHkAiACGAHuAUgBFgCvgHEApAEeAbQBlgGkAVwBIAD2AK4AvQC5ALYAsQCQAMsA3ACfgFVAO//wP+8/0oAqAByAOP/e/8W/6b++P0Y/YD8QPxE/Ij8QP0G/kT+qP2U/Gj7ePrY+SD6CPvQ+wj8EPxw/HD8QPzA+0D78Pp4+gj6cPqo+8z8WP0s/aD8FPyw+7D7KPzs/Fz9dP2Q/bz9xP3E/TD+0v5D/2H/WP+S/7n/sP+z/zgA6gBiAZgB4gEkAgQCegFIAWIBjgHqAWACKAPwA3gEiARYBKwDQAOsAlgCdAJQA1gEeAR4BKAEoASQA5wCzAIsA/gC4AIwBGAErAIsAaQCmAS4AxAC5AFQAkIBd//v/2QBeAIAA+gDLAPRALL+BP+A/67+6P0C/5UAzwDq////YgDe/zH/4P4o/sD8HPyY/GT9kP1I/gQAnwC3/37+NP50/Sz8wPlY/Gz8jPzc/Xf/tADk/5X/Iv6Q/DD74Pqg/Gj9bP5kADgBsv50/Jj9ov9R/3D+1P9AAWz/EP1o/Wz//gD+/6r/3ADsAUoB2/8NAI0A6P/U/ez9RQA8AjACyAH2ARgCBgGRAEACqALoAE7/DP+2/tb+tP+AAtAE4ATEAzQCzgCc/pj9lv7T/6UAigEEA1gDEAMIAmQBSwCm/oj9bv4SADgB3AHIAaQC3gFQAcT/dP8v/6r+FP56/hcAOgFkAjgCtgGJAOT+wP2A/WD+3P4q/xwAOAJ8Arv/gP3Y/jEAVP4I/Nj9+AGUAfT9WP2YAQACCf80/5H/i//s/ZD80P1y/7j/cAKUAkABKgDQ/sD9rPwo/SIAEwDe/7YBcALn/xD9Cv9cAYYAZP4LAOACwAGs/lH/fAHb//z9PACoAloBWP/u/uL/5f8IArAEdAK6/iL+Hf8F/wD+Vv+QA5gEFALsAG0Ajv7o/RIAwQBv/6T+LQD6AdwBGAFSAfEAjv/0/aj+PADCAFoBlgHRAMj+tP2m/lwA4gGsAsoBWACC/zX/F//G/qb+7P6K/4UAZgHyAYQB+gBjAFb/4P2A/bz9eP5s/04BxAJ4AlIBlQAh/7D8WPsQ/EL+NgDsAfgDAAQQAm7/AP0o+2D6sPs7/0wCQAR4BegEZgGY/KD66PnY+2f/yAKYBIgDaAEpAL4AFABY/uD9rP3g/LD9Yv5/ABAEeAQUAvQBiAL9/5D9KPsY++z8F/8sAbgEiAYYA67+WP1s/Tz+Ov7Y/0gCmgE5/7T+uQBMAcX/Vv4s/8wAtQCu/+P/JAC5AC0Adv5G/kX/Y//C/rX/3gHAAsAC+gAu/gD8VPyK/vwAXAKiAeYAAABg/j7/ZAI0AFT+NP77ALwB/f/UADYBzv9A++j9jAOYBFwBWv9W/0j/6P2Y/rEAWgD6AL8ABAEpAJgBUALMAAD+CPwg/V7+SALYBZgFmP8U/JD9DwCa/37/5gFcAkr/wPzF/0QCaAFQ/oz+tf8J/9D9ff+QATYBHADa/4kAtgAyADr+vPyo/Nz+OAFgAjAC1QBo/jL+bP9SAO7+qP2k/oj/6/+sACQDSANH/zz9DP6I/7D/HgBEAIT/yP0y/n8AVAMQAr4A0P++/zcAPf8q/wr+Df/Y/9oAQgEwAsQCHQCo/cz9EAGoA9oBFgDp/9j/0Pug/IgCUAe4BMj90PzNAIoBpv4M/8oBWASOAfj95v7AARAAyPt8/YABeAQ4BSAEDAOo/sD6iPoY/hT/fAAgB0AI9AAg+0j9UABPACz9D//8AywCIgBH/9QAxPyw+77/dAKwBGABJP7W/hkAiP7I/QP/KAHsAwUACP1v/zgBbv8q/2QAwPyg/38AeAKcAnz9aPtw/h0AmP33/9wCgAGCAEv/6P4g/yz+FP2h/6n/+P2iAUQCBgFE/dD8qP1u/+QCfAOwAs0AmP1I+7D70P2JAAgDiATQBYADlP0o+uj8MgAd/wj9BAJgBKQBVgBoBKgDYv70/CT/EAJw/Cj6Qv+IBHAEQAPgA1gClv6A+/D78P3r/zACOASkAmgArf90/pP/rv+2/rj9PP0ZAGgEsAWwAooAcv9o/dD6gPxm/3QCGAJwApABBAFvAH7/8v6c/VT93P0QAd8An//D/yABnAK9AIL/+P2Y/eb+0wB3ADD/9v4DABQCQAIh/0T8wP5CAfYAGP5F/5QDkAFU/KD7wP5fAP7+0wBwBQAF4P5I/GL+PP1A+ej7CAMABQgFFAOsAXz+VPwU/Zj9XP44/zQBgQDG/9gCAAfUA5L+mP/n/xz8uPhg/EQDOAbgAugBqAMsAuD/mP4T/8L+6P2i/pIAagHAARwCUASkA6MAAPw4+6wAiAJN/67+AQDgAQwCDgEgAhoBNP43/+3/rP4w/p7+FAH0AX4BmwAIAuIAaP1U/ocAgwCG/hv/DgGMAbsA6gGcAiT/CP1J/ycAjv40/az98gAwAg4B7v56AJQBqQDi/nb+fPxw/KH/6f9MAG4BlAK2ATz/oP1Q/DT8bP0UAGAF7APs/VD6KPyYAvIBqP62/+wBTAFQ/Tz8/P3M/jr+HAL8AlAC1gHWAC7+yPqM/JD9GgAGAWwD6ANAAiQBXgAu/jj8VP0dAGcAv//WAQgEBANXAGn//QDRAML+dP0U/WL+/AEQBkgGFQAE/HL+WAKOAej8QQC4AqACxP6u/sgBkAK4/rj8IgEcAs4AWf/OAZQCIgBk/Iz9MAJwA8QBpgGpAHD8SPkM/TgDoAOkAjwCPAM5AMD4wPnM/aL+cP7kAaAHdAPY+5D8ZwAI/kj6nPyIBOAE7v6M/HAAXgGE/dT8d/9yALD/HP64/4cA2v+iAIwBhQCO/1D/uPwo/GD/kgGcAmUAJv9yAKj+ZP7w/4IBMgA8/hb+TwBCAOQBOAOYAkb/qPpw/Iz+AgEaAXwCDANEAnb+gPyyAKAEXAFQ+rz82AIkA0z++P2YBZgF1P60/IH/pv4A/RX/sAPwBDAAi//EAYgBKAFAAYT+UP78/Iz9AgC2AbAEOASKAfT/YgF2AYj8gPymAOT+EPzI/1gGwAigAkD7yPzE/9P/jP24/Yn/igHqAeX/Gv7YAPAEYASE/ID5AP2v/xn/HP+gBQAHAv9o+dz8JABAAGj/MASgBA7+APiY/BwDCAKeAUgDKgGk/KD4qPuAAggDxgCOAGQCRAL2//D86Pys/lgAdv+v/2ACtAIuAC7+3Pxk/GD93gEYBBgFKAIz/1D+QPqY+/wBeAY4BEz+OPzE/BL+gQCIAzAGGAIO/yj+QP1o+pz90AQABmwC5/+HAH//PP1U/Fr/fAMEAXIBrAIWAXv/ZP2g/S7+vAAwASQBkwC0AygHSAIU/Ij4EPvw/fD/uAWABjAEFv40/qUA9v84+1D8JAI8AZ7/UQBoBPQDvwCg+tD5wP2G/2cANALIAooB//+gADgB1f/w+gD3sPnC/9gCCAVgBtgGyAXQ/WD2gPlY/Qz9UPtQ/agEeAVoBHAFcAgmAEDzYPIw+kQC0gGgAsAHoAfOART8LP0M/pD7oP3U/+QADgAEAbwCeAFaAIv/dwCzAG7+Uv7s/Tz++QA8AnQDTAIoAogAQP0Y+8j9bAFuAUACuAPABAEAcP2c/I7+WAFMAfQCkAJ6/3z9rgC8AjQDggGw/uT8fPwGAUACSgEjAML/0P/EArwDxgCg/dj8/P44/2D8tP2IBYAGJAP+/uD+hv64+ij8xP8QBMQD6AFqAYAA7v/A/BT+CABL/4X/IAAmAcIAXwBs/TT+zAFyASwC1f+x/4z9uPmk/HwCwAQSAS7+4f++Aeb/FP1R/2wC4AEy/jj9FgB0AHkAov+g/7z+MAKgBDv/8Pug/HgEaAOg+hj7BALsAsD9+P6QBfAF7Pyg+WQBiAMU/UD6uP6oAkT+B//gBAAGzAD4+uD80P4c/Zj8uAK4BeYBuPyg/UACKAJcAfH/mf86/kD8/P2UAEQDcAI/AAT/VQBsAOL+UQD5AKwBBf/Q+9j9qAIoBPz/aP2q/zgDaAEm/hr/eAI4AuD80Pqx/9AE0wAy/iQCeAOn/3D6EPwoAyADWPyL/ygFtAM3/1D8A//S/pj9UP3CABgCXAJ4AhD+4Pvy/joBggASAdABDgGY/Cj7EACoA/H/VwBgBTgD+Ps4+Gj8iAFUAu8Asf9f/6ADKARzAND7Bv4yATj9CPyC/nAFIAaTAOz9pPzI+eT8iAUoBkgBzQCo/oD6wPio+uL/KAQACMAGfAMQ/OD4/Pys/WD6sPvwBSAIYAV8A9QAgPtw+Vz8YP23/8gEIAfMAwD+fPxyATwA4Pkk/CAE/AJM/rwCCAaYA5z96PtY/LL/VAEn/7YA2AL4AiMAh/9iARwCuv7I+JD75ALwBFIB4gCUA7wBRP69/y3/KPyM/Sr/qAJkAiAEoAWvAJj6mPlG/sQB6AJhAMIB1QBY/7oAoAKCAEz/Lv+A+uj7XP6bAIABUAX4BZgDQf94+9j7APu4+Zj8CAbABUAE6AOkA5D8wPbQ+7H/2QDg/dr+WATYBPT8ZP7AA0QD0PyQ/Dj/wwDI+wT8KAOcA4gCwAL4BFT+WPjA+nACf/84+yX/iAeQCUQCQQDM/hz80Pf4+iwACALgArAFcAZoAnj+ov7A+wj7eP0O/5z+OgCwBpAIkAJg+4D6UP5c/e4A4AMoBA///v75/64AkP9S/60AZP/U/W7+4gBhAGAByAJEAjQBOP2s/LT96v6c/nD+pACIA+AEiv9o/RT/NP9w++D8FAPgBpIBXPzU/J0ApwD4++j+UAPIBtwCJ/8A/WD6APvQ/X0AaALYA7gEQAVy/rD5+Pkk/tAAOAI8AywCxP9g/rb+7v4c/h8ALAPMAsz/EP3w/XQASgGs/okAQARQA7QBGv4Y+2j7Gv5UAUAEaAVsA/EAYf8M/cD6zPz+ASADMQBQAYIBfQBg//n/dAPEASj8KPoEAc4B4f+oAqAEYAOi/wj97P0g/9D8BP7NAEgBNAEOAZr/BgDqAZQCLgDc/Wv/jAFU/7D5qPqMARgG2AZ8A+UArP0s/VT8dPw2/t7/HAMgA8wCk/+QAUAF2AQs/aD3KPk//wgBIP+FAIAEqAYwAgD/HP9+/qD6aPqk/U8AtAP4BGgEfALN/yz8iPpI+oj+wP/7/xABCAWwBxAD9Pws/fz9lPxw+nD91gHoAg0AfAH4BvgFlgHA+1D50Pkg+9z8YgFgBkAGxAMwAc3/5P8o/oj5cPkw/TMASALYBNgG8AQk/xD6cPmW/t4By/8+ANIByAKEAdz+yAFgBFj+IPYQ+QwCWAbwA+wBZANNAIj5gPho/uwClAIoAfQBmgBZ/3T9Tf+KAawC5P/C/pj9JPys/QwCmAXUA+z+6P18AE4B7v6Q+7D6Yv5QBLgGqASvAHr+RABI/PD4mPuKASgFEAVqAdz/PAD0/YT91PxE/jQBQAQ8AngBKgAM/Gj7Lv/QA7wCbv80/lQCXAG0/Zj9LgHmAUwADP5U/sz/xv7A/6ADIAMqAUv/PP0A+5j8uf80AxgDVwAT/yQBhv+E/dj94gBcAaz9QPxW/5wCQARoBKwAEPyQ++j7HgEYBHIAmv5YAugCgP/q/lD9VP4vAGQBMAT4Ayr/gPrE/Xb/Of+kAagELAPB/5X//wB1/3z8vv76AVQBeP9E/3AAfgF5AGUASwBAAMYAZAKu/wz8+Poo/XL/sAFoBCgHAAjjAAj6iPlw+pD6SP3kAmAKUAkKAeD7Jv5U/xT9lP2B/9L/IAHYACYA4AEwBM4A7P2g/Qz/Xv8g+/j8kASwBAv/PP30AQwDUP9Q/Xn/MAFw/sT8fv5T/+D+7AE4BuAEhv/g+8D6OP1y/tIAqAPIBNsAAP5G/gT9Ov60ApAEeQCo/PD8twDzAAr/tP/qAYYBnv5t/zwBJAIb/9T8rv5sAqACCP6U/KIB/AOG/7D8owCYAw7+SPvN/9gEYgEc/SgD7AJw+wD5GQAIBTgAOv6aAbAFCAGQ/Rn/hP9U/ND6xwAwBVAFiwAQAPkA1P0M/TD+Nv/X/2MACgCJANIAcv46ALAC0gBgAYgBRADs/Tj7wPn+//QCOARcAzwD5ALw/YD73Pye/t7+Zv70AbAF1AIYAab/Kf/I/tz8GP84/ir+CAHEAgQCQv+EAXAEtAEU/PD62PvI/JL/FAJoBegGfAOo/jj78PrI+1j9PAKwBrAFGgHQ+5D82gBQ/jj9hv5oArgGuAN1ADb+qP1c/Uj84Pw8AQgEAAWyAUT+Vv5S/hYAugCF/+//1ACK/33/aQAYATwCcv5M/PD87P28AngDRgG4/lf/iAKQ/gD8tP2oAPUAOAC4ASAE+gBQ/Ij8z//5AIT97P/ABFgELPzQ+uIA0ANNAHb+2wDOAUT8OPit/3AG4AMZAAwCOAF4+yD6Ef/EAgACKv6w/wwDhwBC/q7+aABU/6T+Qf+uATQDcAE7AJD9ePzA+0L/8APwBUQD1P2U/ED9ev54/3ACmAOYAgQAwP1M/ub/0P2w/kADiAY0Ax7+JPzE/nj/5Pze/nQDoAX8AYIBLALd/yj9CPsI/Yj+BADoBGAIMAVMAMT9XP0o+0D6DP3eAfgFwATkAgYBKP5O/rz+WP1s/Hz+DAFEAtIApgDIAxgFw/84+6j7uv4d/3T+cgD8ATwCHAJgA0gC9P1I+2z8vP04/sj9bgGYBcgEgQCM/ez90P1G/gr+9v7XAEgCwAKIAwUAxPwM/Dj9sPxG/0gE8AU4BOkAe/+q/nz9Fv6Y/6b+XP1e//wB2AR4BNgCuAGo/mj85P2C//j9J/8MAtAA9/9GAQADkASsAr7/Ov4g/Ej6jPzY/wADwAQYBdQDAgA8/rT96P1Y/ST9ef9QAuQBzAGEAqgCFAHY/Xz8cPxa/nIARAGmAGMAjgHAA7wBnP7E/VD90PtA+wv/vAKIBBAEpAOYAlX/uPuY+sz8sv7u/mYA/AGoAkQCaAKaAUgAfP04+xD6gPsS/wwCdAJgAxgEmAKn/8D9IP0U/Oj60Psa/uEA7AOwBgAHFAJ8/HD7SPxw+6j7ov7wApgEAASkA2wC5P5U/Gj8EP1k/fT9WAK4BZAFfAG0/mD9CP0y/nj/OgHj//n/FAGqASkAhP4fABQDwAMBAIT8NP1L/4D+wP23ACAF8AZAAt7+xP2M/ND7rPySAQAFWARYAncAiv/U/aD8sP73AGgCCAJ0AHkA5AGfAF//0P1g/o//TP6x/8QC6ARWATj+sP7o/7z9uPzE/kYBtALiAcUA6f+E/tz+zP8z/5z+OACqAdkAUgC0AGQB9P3o/GP/CADY/tYARAJ3AD7+gP3k/yABOP+A/kT/XP51/4QDhAMwArb/0PtA+gD8h/+IApQDeAKUAoD/yPzQ/FEAfgGw/hD9Mf+IA74B9gHIApoBCP5w+3T8Sv4YAXsApgHoA4gELgES/tD9IP54/gT/RAF8AkQC8f8IADf/jf/fABoBOQBQ/SD9TwBwAdj/uv8IAiwCfgAVAOgAvP+o/az8jP2u/qAAcANABCQCbP/k/wYAiP0k/T7+uAGsAxwD8QAj/1L+pP2I/kj+sf8IA4wDrgC8/aT9XP2i/p7/wgFAAdUA8gHSAQr+OPso/Zv/ZAATABACEAS8AIT8LP3g/ycA2P++ANMALQDs/sL+jwA0AvQAVP+m/ikAQQDv/5P/Nf+l/xQAfgF8AygDJQCc/fT8UPy4/SQBoAToBMABlf/8//f/hP2c/Sj/hwANACoBlAPYA3oBNf+I/3r+KP24/X//QgG0AWAC6AK2Afj/UP5M/XT92f/sAQAChwC8/48AWv+8/Sj+XgGcAp4BHQCM/lT+fP86AXABpAHoAC//3P10/Xb/YgHaAKn/vgCeAX3/Xv6f/wQBUQDI/uz+dgBdAF3/sv9z/77+/v58ADwC5ALaAX4Aff9c/tz9eP0y/tb/tgE4AuYBxgGtAAz/JP9Y/x7/1v4x/yYA6AAIAbwAcgGQAZUACQDG/rT90P0I/64ArwAqAbgBdAFgAHj+Rv6K/mf/ggBsAkgCRwCY/tz9QP6s/nz/iwAQAqwBAgG0ADwAT/8V/5r+8P1s/kEAWgFyAYIBFAEOARAASP/0/mL/Mv4W/uD/WAH6AaABzAGnAIr/3P0k/tT+jf+1AEIBAgG0AEgBMwDS/sT9mv60/0QA/gDMAagB4v+k/uT96P0G/64ACAJcAgYBR/+m/jT+4P2W/o7/FgGcAeMAlwClAO7/qP6S/t7+Y/9Q/5L/kAAcAcP/qP+2APAAwQC4/9z+P//Q/wkAYQCFAJIAgACk/yb+bP7n/6f/RQA6AXoBYACU/fz8kv9eAQkAhgAwArwB8v5s/Pj9qgCgASIBOAFeAff/Av68/bL/AgG4AML///8CAb8ARAALAFEATf8i/ij+z//eAIgAtf/1/5IAfQCOABEAhP/4/rz+sv4D/8b/2AAMAUgAgQCSABgABf9e/nD+NP7C/h4AsgFAAswB3AArAGj/fv6A/qj+TP9MACAB1AG4AaoB7wC8/0T/N//C/t7+Ov+2ABQCzAFsAVwBeADO/uD9hv6a/8kAWAFOAdIAZABPAIcAUADz/+H/rP+8/6MAXgHCAWIBfAHMAWYBUAAFACr/A/9B/7f/XgHmASgCPAIQAh4BXP7A/ED9+v52AOAA5gC0Ab4BnABR/17+Ff8I/7r+3v72/mr/QQAKAUgBiP/q/mP/yv5k/VD9gP+UAKn/dP+3ABAASP6Y/Vb+ZP6Y/UD+dv+B/5z+rv4g/3D+9Pzw/FD+1P6A/tr+Xv8w/9j+J/+H/7T+Lv6M/uL/iQCgAP0A/gEQAkQB3wAgAcAB3gG2ARwC4AI4A/QCAAN0A6ADVAOkAsQChAJUAmgCKAOgA5ADeAN4A8ADUAOoAkQCIAK0AWgBYgHUAUgCYAL+ATQBxwCqAFwA0/8h/zH/iP+L/87/tv8k/zb+SP2E/AT8yPvQ++D70Pt4+8D7WPvI+nD6QPrA+XD5WPlo+ZD5KPkw+Rj5UPk4+Uj5kPno+SD6UPoA+0j7APsw+kj62Puc/UH/uAC0AdQAa/+o/vb+5f/0AfgEQAdgCCAJ8AjACKgHIAfwB/AI4AnwCgANQA7wDYANEA1gDAAMYAswCzALQAswCyALwApwCjAKIAk4B6AFQAQMAxACyAHkAdwB9wDe/xP/WP1Y+7D5GPnA+Jj4uPgA+Sj5gPhQ91D2kPXA9GD0oPTA9DD1cPUQ9jD2APag9fD0YPQw9OD0sPVA9kD2gPag9mD2gPbw9tD3APgY+CD4QPhY+Bj5+Pro+5T8CP0E/ZD9rv7m/i8AagFIAjAEeAVAB/AHkAgwCVAJ8AlAC2ANkA9gEmAUIBVAFaAU4BPAEkARwBCQDyAQgBAAEeAQIBCQDpALUAhABbgD6AKwAggDSATQAxQCqv/0/HD6sPeA9nD2APdw+GD52PnY+Vj40Pbg9LDzkPMQ9MD1MPeQ+Fj5gPk4+dD48PeQ9/D2wPZQ9/D3oPiI+Rj6yPmQ+dj4YPjg96D3MPcQ95D2YPYg9kD2gPaw9nD2gPbA9oD2APcg9+D3+Pio+Sj6+Pqw+6z8Fv4y/1oB4gEoBDAG4AgwCoAJgAmwCfAK4AzAEGAUQBggGcAYwBagEwARkA/wDkAPQBCgEUATgBPAEcAOMAvIBuACwAAyAVgCVAN4BKgENALo/vj68PfA9XD0kPXQ99j5CPtY+3D6ePgQ9rD0gPQw9aD2oPgo+gj7SPsI+8D6WPqA+RD6WPoI+kj68Pp4+/D7KPwA/Gj7SPoY+bj4oPhg+Hj4YPjw9yD3gPZA9gD2wPWA9TD1APXw9MD1cPYQ98D3EPgQ+Xj5ePqY+wT9Yv7k/3YBKAPIBGgHcApwC7ALMAtADLANIBBAFOAXABugG2AaoBggFaASABGAEeARYBOAFQAWIBWAEmAO4AnABcQCIAJwAogDSAQYBIQCM/94+wj4kPUw9CD0YPXA9vD3GPjw9mD14PPA8qDyQPOg9CD2kPcY+Dj4yPiw+Gj4mPgY+Tj5qPko+gD7QPsQ+xj7EPvA+hD66Pkg+gD68PmI+Sj5aPhQ9/D2kPYQ9uD1APbw9dD1YPWA9bD1sPXw9XD2APfA99D4wPkg+1z83P1X/yQB8AJwBcAHYAkQCtAKgAuADAAOwBBAFWAYAByAHQAcIBkAFuASwBGAESAToBWgF2AX4BXgEpAOwAmQBSwD8AFIAggD1AMMAxoBOv4o+tD2UPSg8vDycPOQ9PD04PRg9LDzcPIA8oDxwPHQ8sDzEPUg9oD3IPjA+AD58Ph4+bD5APro+nj7WPto+1j7gPtY+5j7CPyo+8D7MPuY+vD5SPnw+Gj40Pdg9xD3APcg97D2gPbg9VD1IPVw9RD28PY4+Ej5GPp4+tD7KP1o/kEAJAKYBMAGYAiACrALsAwQDfAN4A+AEkAWABvAHYAeABwAGSAWIBJAEkATgBWAF4AY4BfgFEAR0AxgCIAEBAJoARgCsAJgA8wCZwBQ/Ej48PSg8pDxEPKQ82D0UPRg9AD0EPPQ8XDxkPFg8jDzYPQA9qD3ePgY+Sj6OPqo+gj78PuA/Kj8PP0Q/Vj9FP0o/Wz9RP0g/ZT8cPyI++j6cPoo+mD5aPiw9wD3QPbA9aD1sPVg9QD1EPXw9BD1cPUg9hD3sPdo+Pj5aPvU/Jb+SAEUA8gEYAcgCWAL4AsQDXAOwA9AEYAUQBlgHaAfACEgHgAbwBZAFIATYBTAFsAY4BjAFyAVwBBgDCgHQAR8Ab4ARAAuAcwBcQC6/gj7MPcQ8wDwYO+g79DwIPIg80DzwPLQ8WDxwPBw8ADxAPJg8yD1EPdo+cD6APtg+xj7EPtg+wz8qPxI/eD9ZP64/uL+qv6S/nz9PPyI+xD7yPrQ+pj6ePoI+QD40Pbw9SD1YPRw9HD0sPSA9MD0YPXQ9ED1YPUA9pD32Pgw+8T8uv5NAAQCMATABegH8ApwDLAOABAgESASQBNgFqAZIBzgHsAg4B9gHGAYYBYgFCAU4BTgFcAWABVgE9APEAxAB1gDUQBm/jz98Pzk/YD9oPzo+UD2cPIg7yDt4OzA7QDv8PCw8ZDyoPJA8hDy8PBw8IDw8PEA9dD3gPt4/QT+yP3g/Kj7kPtw/FD9/P4NADoByAHsAbMAjv/c/fj7iPpY+tD6iPsQ/Kj7uPoY+cD28PTA81Dz8PIg88DzYPTA9OD0EPWw9PD0gPWg9uD3GPow/Fb+8v+qAfADmAUACHAKMA0QD0AQgBGgEkATwBQgFwAbAB6AIMAhQCHAHaAZwBXgEyASgBLAFOAVoBVgE7AP0AoQBrgAUP0w+wj6YPss/Bj9OPuw95Dz4O5g6wDqoOqg7EDvoPCw8gDyUPEw8MDuYO7g7YDwAPMQ94j6zPzU/ZD9fPwY+yD7aPvs/O7+sgBUAuAC/AJAAmkAhv6M/Ij7APvg+qD7YPww/Ij7kPnw9xD2QPQw88DywPLg8hDzoPPA88DzAPTw81D0sPTw9WD3WPlY+yz98v62APgC2AWAB3AKYAyQDiAQQBEgEsATABWAFmAZQBzgHoAhwCJAIQAegBiAFEARYBCgESAUIBaAFcASUA7ACFgC2P2g+kD50Pho+nD7wPsY+7D3sPOA7iDroOmA6sDsIO9g8dDy0PIg8hDxgPDQ8BDxIPNQ9Qj4EPso/Q3/EP/s/hj+mP02/ub+mADMAaQC+AKsAiACwwBg/wL+1PwU/Hj7UPtY+xj7MPr4+ID3sPVA9DDzkPJw8kDykPKw8sDy4PIg86Dz4PPg9OD1IPew+Ij6kPxk/iwAQAJwBKAGEAnACxAOwA8gEWASoBNgFMAVwBdgGgAdYB8AIkAiwCDAHCAZYBWAEaAQwBJAFKAUYBQgEYANsAeKAej9CPpY+SD5sPqI+7D6WPlA9pDywO1A6wDrgOsg7pDwYPJA8yDywPFw8EDwYPBw8vD04Pfo+rD8kv6k/sT+HP7A/UL+yf+WAWgDqASYBCgEbAI2AfL/H/+u/mz+2P1c/TD8aPsA+qD4oPeQ9iD2kPUg9TD0UPPw8RDxoPBA8cDx0PIA9AD14PVw9mD3APgY+Vj6GPyg/poBMAQoB4AJ4AtwDcAOIBCgEQAS4BJgFIAVoBdAGsAdQCDAIGAfwB3gGWAVIBOgEcASgBEAEoAQkA/wDAAJiAYAAlj9+Pjg90D3OPi4+FD5WPjA9WDyoO/g7EDrgOug7ADvwPBA8yD1kPWQ9FDzEPIg8vDzIPfo+rb+zAA0AgAC5QD8/57/zv/wABwCYAOgBKgEYAQkA+ABEQCo/nD9QPxo+wD7kPqo+bD40PdQ9oD10PRQ9KDz0PLg8SDx0PDA8DDx4PGQ8hDzAPQw9aD2APh4+Zj6uPvY/Cz+UwDwAsgFsAiQCzAOABAAEeARwBGgEYARABOAFUAZoBygHwAhgB/AG0AYQBVgEiARIBEAEgARIA8gDhAMkAkIBnYBDP4Y+gD44Pbg9+D34Pew96D1oPMg8QDvAO4g7YDtwO6A8ADzIPUw9mD2wPUw9RD10PWQ9zD6dP2g/7wBRAP0A8ADIAO4AjAC/AGgApwDqATwBFAFOAX0AwQC7P8m/hj8uPoA+vj5wPlo+dD4APhg9pD0IPNQ8tDxEPLA8kDzkPMQ84DywPGw8YDyMPQQ9jj4IPq4+/j8vP1s/oL/vACkAsgFMAlwDcAQQBOgE+AS4BDgD+APIBKAFYAZwBygH8AfgB3AGuAVgBPAEKAOwA7QD7AP0A7gDBAKWAbQAs7+NPyI+YD3IPeQ9pD2MPbQ9WD0UPJQ8ODu4O5g7oDvMPAg8ODw4PGg88D0IPZw93D4wPgI+Vj60PuM/Vn/jgGwA8gEcAWQBfAEFAPEAd0AHgE0ApgDQAWQBWgExgGS/jD7cPjA9vD20PfY+JD5KPnw98D10PIQ8RDwsPDg8RDzgPSg9ID0oPNQ80Dz0PNQ9TD3oPk4+3j9H/9JALEAJAGIAoAEIAcgC3AO4BBAEiATABNgEoARQBLAEqAUQBYgGeAcoBygHEAa4BbAEnAPMA4ADUANMA1ADEAKmAfYBCACBP/A+7D44PaA9VD1wPUQ9hD1QPOA8cDvgO5g7iDv4O8g8FDwwPCg8RDz0PRQ9sD3MPiI+Ij5OPqA+xz93v7rAMQC8AQQBngG0AUoBHACUAFSAQACdAPYBEgFeAR0Avr/PP2Y+rD4EPjg97D30Pfw99D3sPYQ9eDz0PIw8kDy4PIg85DzkPMQ9GD0APXw9QD38Pd4+ED6oPs0/Sz/3gBMAvQCuAMYBtgH0ArADAAQIBIAE0ATgBOAEsARQBGAEuAUwBaAGgAcwBwAGuAWoBKQDsAMkAsQDGAM8AsQCxAJoAboArb/QPwA+UD3QPbQ9oD3MPhg9yD28PPQ8ZDw4O+A8DDx4PHA8jDzQPRA9RD2gPYA96D3UPig+Sj7TPzc/cD+nf8yAZQC+APgBMgEWASsAngBvACEAWgC1AKMA3QDjAIqALD9MPxg+nj4sPeg98D3QPdA98D2wPXg9KDzYPNQ8/DyoPNw9BD1cPXg9SD20PUg9tD2sPf4+JD6qPyO/mT/3QD6AaACnANgBJAG0AiwC9AOABJgE4AT4BJgEkAR0A/gEKASIBXAF8AZwBpAGWAWIBMgEJAN0AuwC+ALEAyQCgAJoAbUA4cAYP2Q+1j5SPiA94D3oPfg9qD1IPTw8jDxwPAw8YDyQPOw8xD0IPQw9KD0kPXg9hj4QPlo+kj7LPwE/QT+F/+z/3YBCANIBCAFUAXgBGgDGAJKAaAB1AEkAtAC2AKwARMA8P1c/FD6EPiQ92D3YPdA90D3QPfA9mD1kPSQ87DzcPNQ9ND1EPdQ99D3gPdQ96D2UPYw96D4UPqU/EX/OgFAAnAChAJMAlgC1APABhALIA5AEGASIBMAEsAQgA/ADqAOgA8gEyAVoBfgGEAYoBagEtAPUA1QC6AKoArACgAKYAgIBygFJAIg/8j8wPr4+PD38PdY+KD3EPcA9tD0wPMA81DzUPRA9MD0wPQg9fD0UPVg9mD3gPi4+bj68Puc/LT8SP3k/cr+FwCuAUQDQASYBAgEIAPKARgBzwClANwA6QAWAZYAsv8q/qT8APtY+fD3cPcQ94D2YPYw9gD2UPXw9LD04PTA9CD10PVw9tD2APew9+D30Pfw96j4MPmg+dD6TPxI/uv/CAJIA7AD8AKsAqQDOAUgB9AKMA5gECAR4BBAEJAOcA0wDeANoA8gEeATwBXgFQAVABOAEOANYAvAClAKAApwCSAJ2Af4BawDoAGz/5z9wPug+vj5EPnA+Dj4oPeg9lD1QPUw9XD1UPXQ9fD1sPWg9cD1sPZg9wj4KPmo+nD7+Pt4/Ez9oP3I/aT+MQCCAXACHANYA8wCBAJWAWIB7QAaARYBwgCuAL7/Av82/lT92Pv4+nD6oPn4+ED4EPgg95D2UPaA9pD2wPZQ99D3YPho+PD4qPkY+jD66Po4+4j7gPuI+8j7SPyI/Q0AlAIoBFgEmAQ0A4ACtAJ4BDAIYAoQDRAP8A8AD9ANsAzACzALwAvADfAPABJgE6ATwBKAEMANEAwACxAK4AmgCVAJUAgAB5AFCAQYAhIAkP4Q/QT8YPvg+sj6MPow+WD4sPcQ98D2oPaA9lD2IPYg9rD2YPdI+Oj4mPkY+nD6QPpQ+6D7NPxI/Vj+Nv9MABIByAFoAtYBVAHeAJ4AiwCmAPIARAEQAX4AFQAu/zD+DP3w++D6CPqA+UD54PjI+Cj4kPew9jD2UPaw9jD3sPeg+GD52PlA+vj6KPuA+1j7gPsE/Lj7gPtg+8j8Kv57AIQC2ATwBXAEaAOwAoACYANQBZAIoAtwDYAO4A7QDZAMwAqQCuAK4AvwDKAPQBHAESARkA/QDdALEArgCKAIIAg4B6AG6AXwBLADTAL3AIz/oP1o/ND7UPvQ+iD6gPn4+ED4APjA90D3QPcA9yD3EPdQ9yD4oPjo+Aj5kPnA+UD6YPtw/GT9kP0K/sL+Lv+p/yYA0gAKAegA9QD2APgA3QB+AH4ACQCD/zj/zP6Y/oT95PwQ/ID7UPoI+vD5iPmw+ND30Pdg9yD3gPdI+BD5wPmQ+rD7lPys/NT8ZP2A/WD9tP3Q/Yj+Kv62/nL/QgBeAZgCKATABKAE1AOoAs4BYAJUA/gFMAhwCvALIA2ADCAL8AmwCDAIEAhgCTALgA0wDtAOkA7QDPAKQAmQCGgHMAYIBtgF8AWoBEgE5AOgAgoBvv8A/+D9hPzA+yj7QPow+ej48Piw+Ij4qPiI+ED48PcI+DD4MPhA+Ej5CPrQ+lD7OPy0/Jz8ZPzc/GT9/P2M/rP/1wAgAW4BUAFgAWQAQv+y/pz+yP6a/lr/t/+y/7r+1P0Y/aj7SPpI+Qj5ePhI+Ej42Pgo+SD5WPnw+Uj6IPqg+gj70Ps8/OT8vP0A/1v/LwDFALwAMACE/rj9WP3Y/YP/IALABNAFiAV4BLACXgE8AfgCCAWQBkAJ0ApwC5AKoAnQCMAHIAfQB8AJwAvgDPANUA7QDNAKQAnQCJAIAAhwCHAIyAfIBhgGeAUgBKwCyAEiAUwALv/Y/mj+TP0I/FD70PpY+gj64PnA+Rj5ePhw+Oj4QPnA+XD6EPtA+2j7CPyM/Aj9QP3U/Qj+Rv4B/6f/dACIALAAtgB4ALf/Tf/m/jr+5P3E/fD9BP78/bz9TP0Q/Aj7OPrQ+YD5iPm4+cj5CPog+pD66Pog+9D6yPrA+uD6aPsE/AD96P34/hwA9gDKAVgCTAIQArABRgEoAUABKALQAtgDCAXgBRAG4AX4BEgEGANQApQCTANgBGAFQAYIBzAHmAb4BXgFsAQIBPADQAQQBXAFqAUwBpgGSAbwBRgF2ARABMADrAPIA9ADpANIAwADkALgAVYBRgECAV8AS/8y/qj9mPxY/Fz8sPzo/AD9/Pzw/GT88Pv4+gj7qPog+/D72Pyo/cz9Pv4s/kL+Cv6i/rr+/v6G/wkAZwCrAAIBAgFiAcAAeQBHAGX/rP7A/TD9mPyg+9j6EPo4+WD4YPcA99D2YPYw9jD2sPbg9gD3MPdA9xD30PbQ9oD3sPeI+Nj58Ppo/Ej9Ev7A/or+cv7i/h4A3gEQBFAGAAiACDAIIAjYB7AHYAiwCTALYAwADaAN8A2QDeAMgAxQDNALEAxgDDAM0AugClAJ2AdwBjgFWASsA5wCfgH6/3b+FP0Q/Ij74Ppg+qj5GPlI+LD3MPfw9sD20PbA93j4QPmo+TD6YPo4+nD6CPvQ+6z86P1D/2UAEAGQAdABpAEMAa8AVgAdABYATADcAOAA2gBjAMH/5v6s/bz8uPsY++j66PpQ+6j7yPuo+yD72PqA+qj6KPuo+5T8EP3I/Rj+vv6F/0AAYgFMAlQDEAQABXgFsAUABjgGkAYIB2gH2AdACDAI4AdAB3AGOAWIBKwDqAOEA5ADnANwAzADlAL2ARoBcgC0/wP/xv6O/gv/cP+e/yYAawB4AGYAXwBRACQABQBqAPQA0AGAAlQDxAO8A5QD5AK4AmgCeAKUAlwCRAL2AdIBhgEyAdwAMwBe/5r+4P2M/fj8gPw4/Mj7QPvA+kD68Pl4+SD5GPkY+RD5EPkw+Qj5OPlg+aj5APpA+oj6gPpg+lD6wPoA+3j7APxo/MT8mPzQ/Hz8QPyQ+yj72PqQ+mD6UPow+mj6MPpQ+rD6wPpA+yD7uPts/GT9Vv7H/xQBCAKMAsgCgAPkA2AEYAWoBtgH8AgQCvAKUAsAC5AKcApgCrAKoAuADFANEA2QDMALUAoACSAIoAcgB4gGmAYgBqAF2ASwA5ACCAHc/zf/qP4w/qj9RP3I/DT8HPxA/HD8tPy8/Mz8WPzw+/D7NPyY/DD99P1e/pT+WP48/ir+2P3k/ej9KP50/q7+3v5o/sT9CP1I/Mj7WPtQ+5D7cPtA+5j6KPrA+XD5sPn4+UD6MPoo+ij6OPp4+kj7hPzI/UH/YQBaAdQB9AFQAswClAOwBBgGkAfwCPAJsAoACwAL8AoAC+AKwAqACqAKoAqgCmAKQArACeAI0Ac4B2AGOAVIBFwD0AL8AZABngHCAawBbAE0AXwAjP8K/tD8QPsA+nD54PnA+tj70Pxo/XD9RP2E/DD8wPuQ++D7nPyM/Uj+i//b/xUAsP/+/p7+Bv4I/gL+Gv7s/Vr+Vv5Y/iz++P3A/Sj91Pyk/Lz8kPxg/Hj8JPwQ/LD7wPsA/Nj7SPxs/BD9IP2A/bz98P3Q/fT9Bv4o/vj9OP5Q/vz9lP1s/Tz94Pys/Iz8rPx8/Mj7wPuQ+zj7MPuw+wj8XPxw/KD8FP1A/Uz99P1O/rr+4P5h/wMAeQDJADoBgAGUAaQBCAKQAvwChAPcAxAECATwAyAEaATQBBgFWAVgBUAF+ATQBMgEuATgBAAFCAU4BSgF4ASIBEAE2APYA6QDxAPIA4wD0AJUAigCugGUAT4BBAG/AGAA/v/I/4z/Cv+2/nL+Kv7g/YT9YP1Y/dz8tPyw/ND86PwA/RT9KP0c/TT9oP3Y/TT+aP60/qz+ev5g/mD+cP5m/ub+TP+M/8D/4//m/4T/9P6g/mr+Uv5W/tD+M/8n/wr/zv6M/g7+4P0Q/pL+DP/D/4cANAFiAboBDAJQApQCwAJ4AwAEgATABAgFUAVIBVgFkAXABcgFkAVQBfAESATEA1gDDAPcApQCjAIwAqgBIAFnAMn/af8O/xH/+P4X/y7/HP/k/tL+nv6E/qD+zv4Z/z7/Q/+C/6P/3v8EAEUArQCmANQA8gDqAOgAugC+AJ4ARQAgAPL/3v+B/y//+P52/hT+sP1o/Tj93Py0/JT8VPww/PD70PuQ+0D7KPsY+wj7KPtw+9D7JPyA/ND8HP1E/Uz9oP2g/Rb+bv74/qf/8v9wAJIA9AAQATYBbAFkAVoBXAF0AbYB/AFkApACmAJ8AjgC9AG2AWwBXAFEAWgBggGiAcYBwgG6AcIBwAHAAfYBPAKoApgCsAKcApQCSAJUAlQCcAKMAlQCgAI8ArYBSAHyAMMAZAA0ACwAAgDa/6T/iP9a//7+tv50/lj+Fv7c/cD9mP1s/Wz9eP2E/Yz9nP2Y/XD9LP3k/LD8aPwg/BD8FPwk/CT8PPxc/FT8PPwc/Pj70Pug+6D7sPvA+/j7OPx8/Kz8AP1Q/aj95P0e/mT+qP78/ln/7/+TAD4B2AFcAsQCFAN4A/gDOASABLAE4AQQBTgFeAWYBdAF4AUABggG8AXABXgFGAWoBEgEAATYA5gDbAMYA7wCWAIIArQBUAH9AIoAMwDX/5P/Uv8y/wL/3P7c/rr+vv6s/oL+ZP5W/kL+PP4y/lb+YP5A/jD+DP7k/YT9TP38/LT8TPwY/Mj7qPtI+9D6gPrQ+Xj5EPn4+Pj44PgI+VD5iPmw+Rj6ePrg+kj7wPt0/Bj9sP1Y/jr/7v+QABABwAF8AiADyANwBAgFgAXQBSAGoAboBjgHiAfQB/gH+AfAB8AHgAdQB1AHWAdIBzAHGAcAB9AGeAYoBvAFmAVIBRgF6ASgBEgEGASoA1QDzAJ0AvIBcgEAAY8AJQDG/3j/Lf/i/oL+Iv7Y/YT9GP28/ID8OPzw+6j7YPsY++j6wPqY+oD6QPoY+uj5yPmw+bD5uPmw+dj58Pn4+Rj6GPo4+nD6mPrg+jD7WPt4+5j7oPvY+yz8lPzs/Fj9yP0s/nT+sv7s/jn/iP/1/2gA0wA6AYAB3AEsAowC3AIcA1wDjAPAA9wDAARABHgEsATYBAAFKAVIBUgFKAUABcgEkASABIgEiAR4BFAEMAT8A8ADiANQAyADzAKUAlwCIALWAZgBVAH8AKcAZwArANP/df8q/+b+oP5e/jD+BP7E/Xz9LP3o/Kj8dPxU/ET8NPwc/Az8APzg+7j7uPuw+8j74PsA/Dj8XPx0/HD8hPyA/KT83PwY/Wz9pP3I/eD9/P0u/mT+jv7u/j3/f//A//L/GAA8AGAAigDVABoBeAHMAQQCMAJIAmwCbAKIAqACwALkAiADVAOIA5gDrAOwA7ADsAOkA5wDiAN4A3QDhAN4A2wDaANQAywDBAPQAqwCYAIsAtwBqAFmATgBKgH+AOMAjgBjAB8A4f+l/1b/Iv/o/sz+sP6Y/or+dv5E/hr+5P3Q/bz9mP2M/Yz9fP1o/Wz9cP2E/ZD9qP28/cD90P3Y/dT93P3s/Rz+PP5u/oz+nv6o/pr+uv7M/vr+L/9W/4z/n//D/9H/7v8IABgAPgBkAJUAyQDtAB4BRAFaAXQBkAG4AdYB4gHsAQACDAIQAhQCKAIsAhACEAIIAgQC/AHqAeoB3gHMAbIBqAGiAZIBdAFiAUoBNgEwAToBIgEIAfAAtQCJAF4AQAAoAP7/8v/j/9n/uv+f/33/Uf8x/w///v7q/t7+0v7G/qb+kv6Q/o7+lv6S/pL+hv5m/lj+UP5c/mr+lP64/tz+6v72/gH/Af8H/w7/NP9N/2n/iP+W/63/v//P/9j/3//a//b/CQAXACIALAAtACgAJgAiADMAPgBEAE8AUQBVAF4AcQCBAI0AhQCKAJIAkQCpAL0AyQDNAMAAwwDIAM8AzgDQAM4AyQDIAMIAwQCiAJEAhgCLAIEAiQCQAHwAWAA5ACoAHgARAPz/+//t/9T/y//O/8z/vv+u/53/lP9v/07/Lf8Q//j+Af8M/yH/J/8v/yf/J//8/vT+6v7g/ub+6v7y/vb+A/8T/yD/Hv8a/yX/Jv8t/zH/S/9c/3H/fv+R/5f/ov+v/7n/xf/N/9r/5//v//r/+/8RABAAHQA8AFQAaAB6AJEAlQCfAK4AzADdAN0A3QDmAOUA6gD5AAABAAH2AOcA5wDlAN8A6wD1AO0A5QDeANkA0QC9AL0AxwDFAK0AowCYAHYAVgBDAEcAOwAyAC4AMwAmABAA+P/w/9//v/+r/63/sP+2/7j/rv+j/5P/jP+M/5H/hf96/3f/a/9k/2r/c/9+/4b/hf+N/5D/kP+N/4v/f/+I/4v/l/+i/6D/lv+T/5j/o/+1/7L/s/+4/8H/v//E/9b/7P/2/wAAEQAdACIAIwA2AEMARABEAFMAWgBVAFgAYQBmAGIAYABcAFcAUQBIAEAAMQAjACIAJQAbABMAFwAMAAYA//8GABIA/P/i/9L/yv+9/7r/w//M/8T/tv+u/6H/j/9//4f/mv+q/7H/wP/I/8f/vP+3/77/t/+7/8j/1v/S/87/z//Y/9z/3v/m//P/+f/4//n/+////wMACQAVAB4AKwAvACEAIAARAAEA/P/w//H/4v/h/+z/+f//////AwALABEAEwAfACgAJAAdABoAHgAeABQAGwAdABgAEAAIAA8AEAANAA8ACgAEAP3//f/+//7/AgAAAAYABgD5///////+//7/BgAWABsAGAAXAAoA///0/+z/+//9/wgAFQAdABsAGAAZAA0AAADs//X///8KACAAJgAsACAAGwAeABwAGwAYABUAFAAJAA0AGQAmACsAMQA+AD8AOQA3ADAAMQA0ADkAQABBAEQASgBLAFIATwBKAEcAQwBLAD8AOQAuACgAFwAJAPz//f8DAPv/BAAEAPr/9P/t//b//P/4//v/AgASABQAEwAbABcADQAIAA4AEQALAAQAAAAAAP7/9v/z//v//v8HABAAFAATAA0ACAD///n///8HAA4AFAAeACYAKAAjACAAGwATABAACwAVAB8AHwAjACIAJgAnACsAMAAsACUAIAAVAAsABgAGAA4ADQALAAMA/f8AAAEA///9//f/8v/q/97/2f/U/9P/zP/N/8//z//M/8r/wf+8/7n/u//F/8n/0P/P/9D/1f/Z/9z/3P/d/93/3P/c/93/3v/h/+H/4//q/+v/8v/4//n/AwAPABUAGgAcACYALwAuADQAOAA+ADsAPgA9AD8ANgA1ADIAOQA5ADMAMAAcABMAAAD9//v/8//2//z/+f/v/+r/5v/g/9f/z//N/8H/uP+v/7P/r/+n/57/mv+f/6f/rf+y/7r/u/+0/6v/r/+u/6//sP+3/7v/t/+q/6r/o/+c/53/pP+u/7X/t//B/8r/yv/L/9D/1f/X/9v/4f/n/+//+f/3//r/9//6//j//f8AAAQACwATAB0AKQA0ADoAQwBOAFUAVABYAGMAawBrAGsAbABvAHMAdgB8AH8AeQB1AHEAbABrAGkAZABeAFwAVgBPAEcAOgAyAC4AKgAuACwAJAAbAA4AAQD+//z/+P/x//H/9P/u/+r/3//T/87/yP/I/8r/yv/K/8X/wv/C/8f/x//C/73/tf+v/6T/n/+i/6D/of+i/6P/qf+x/7b/t/+9/7v/uP++/8f/0//c/+T/6//t/+7/7//z//f/9P/4//r//P/6//z//////wEABgANABAAEwAaACUAKQAqAC0ANAA4ADUALAAqACUAIAAeACMAJgAjACMAIgAdABgAGQAeACEAHgAdACYAKQAmACAAFgAMAAgABgALABUAFwATAAoACAAHAAIAAAAHAAgACAAHAAMAAQD5//D/6v/p/+j/7P/r/+b/4P/c/9r/1P/S/87/0f/W/+H/6//1//b/9f/z//L/8P/u/+3/7f/v//f/AwAKABYAHQAiACQAJgAnADAALgAsACYAIgAdABkAIAAhACUAHQAfABwAGQAWAA0ADQAKABAAEwAZACQAKQAoACQAHQAfABoAEwAYABoAFgATABEAEQAUABYAGgAcABwAHwAeABwAHgAeACUAKAAvADAALwAqACIAIgAcACAAIgAhACIAGgAXAA8ADgAKAAQABQABAAIABQAGAA4ADgAKAAYAAAD///z/9f/u/+3/5//e/9j/2P/S/8f/wv+6/7j/tv+y/7n/uf+3/7L/tP+6/7r/t/+2/6//q/+u/7T/sv+0/7P/qv+p/6f/q/+v/63/tP+4/7z/uf+3/7L/rP+n/5//nv+d/5//o/+l/6T/pf+r/7D/t/+5/73/v/+8/73/wf/L/9P/3//n/+3/7f/r/+f/4v/e/9z/4v/m/+z/8f/z//3/AgAGAAgACAAGAA4AEwAaACQAKgAvAC0AKAAhACIAIQAgACEAIAAjACMAJwAsADEALgAvAC4AMAA8AEQASwBMAEUAQgA/AD8APAA5ADYAMAAsACcAJQAaABcAEwARAAsADgAOAAQA+f/w/+r/5v/j/+D/4v/f/9j/2//f/+L/4P/c/9X/0v/C/7j/r/+p/6n/sv+7/8j/zv/Y/9z/3//R/9P/zv/R/9j/3P/i/+b/7f/1//3//v8AAAQAAwAGAAsAGQAkAC0AMAAyADAAMwA3ADsAQABCAEEAQAA+AD8APgBDADsAOwA/AD8AQwBEAEMAOgA3ADUAPAA/AD8APgA/ADoAOwA9ADsAOQAuACEAGgAUABAAEgASAA4ACgAHAAkADgAQAB0AKQAtACgAJQAfABEABwABAAQAAAD///3/+v/v/+L/1P/M/8D/sP+o/6r/s//D/9L/3v/q//H/9v/8//7/9//w/+j/2//X/9v/4//u//X/9v/5//j/9v/1//P/7//2//n/BQAPABQAFwAZABsAGwAZAA4ABgD///j/7//s//D/9v/5//z/AQADAAQACAAUABkAGgAXABYADgADAAIAAQD///v/9v/y//L/8//x/+7/6P/g/+L/5//u//3/BwAHAAgABwALAA4AAADx/+X/3f/b/+L/7f/2//j/9f/w/+n/6P/s//n/CQATABMAFAAPAAkA/f/1/+//4v/g/+H/5v/q//T/BQAWACMAKwAvAC8AKQAeABcAFQAVABIAEQAQAAwACgD+/+z/4P/O/8P/xf/J/9z/6f8BABgAKAAsACcAHgAUAAoAAQACAAIA///+//7/AwADAP//AwABAP7/+v/3//v/+////wIAAQACAP7/+v/y/+z/5f/W/8v/uv+o/6f/pf+r/7T/vf/C/7//u/+0/6j/n/+X/5f/qf+5/9P/6P/v/+3/6P/g/9D/wf+y/7b/u//N/+T/8v/8//P/8P/t/+3/7//s/+b/3v/Y/+P/8/8GAA8AFAAPAP//8P/m/+H/6P/y//v///8FABAAIgA1AEoAWQBgAGcAaABvAGgAaABjAFwATwBBADQANgA9AEMAVwBaAFoAXwBpAIAAkACVAI0AfQBwAF8AWwBhAGEAXgBbAFgASQA1ACAACwAAAP7/BwAfAEIAXABxAHsAdQBeADQA/P/A/5P/f/9+/5D/qv/B/8v/y//E/7v/qP+S/4D/ff+U/7b/2f/6/xMAIgAkACAAFwABAOL/t/+J/2r/Zf96/57/wf/b/+b/7v/+/w8AIgAxADAAJQAWABAAHgA3AFQAYgBrAGwAaQBlAFYARQA1ADEAQQBZAHMAgwCEAIEAfwCFAJMAmwCTAHgAXQBPAFEAXQBtAHUAeABsAFYASwBBAEEATgBVAE0AQAAtACMAGgAOAAQA6f/Q/7f/tf+3/8H/yf/U/+P/8f/x/9//wP+W/4X/c/96/4X/kP+p/7D/rf+l/53/lP+R/57/pf+m/5X/jf+Y/7n/0v/i/93/yv+3/6P/n/+k/53/gP9b/0n/Vf91/7D/7/8dAB8AAADc/83/x//X/+b/5P/Z/83/1v/2/xEAGAAPAO//x/+v/7P/1f8KAD0AXQBhAGQAaQB7AIYAiwByAEgAKQAQAAsAEwAWABMADgAGAP7/+/8LAB4AMgBMAGQAcwB7AIAAjwCeAKUAkwBuADgAAwDa/7//r/+i/57/iP+A/3b/cP+Q/8X/CQBIAFwASwAvABIADgAYABIA/P/j/97/6v8HACIAJgAOAOP/tP+g/5v/nv+i/6v/xv/u/yAAQgBKACwA3/+K/0//RP9f/3T/k/+s/9D/+/8eADYAOgAkAPL/3P/v/x4AVAB+AIwAewBHABEA7f/b/8v/t/+x/7T/xP/g/xoAUQB+AJ4ApQChAJEAgwCBAI8AkACGAGUAKwDm/57/gv+V/7P/xv/d//v/HgBEAGQAewCMAJkAmwCRAHoAYgBVAFMAUQBAABgA2P+a/3r/eP+U/6//pv+G/27/aP+O/9n/KwBfAEIACgDD/4z/av89/yD/Af8D/yv/gP/R/w8AKwAjAA0A5f/K/73/y//u/xAAIQAuABsAAADf/8H/pf+I/3f/bv+F/6b/yv/7/y8ARwBJADwAOwBVAHkAeABbABkA1f+2/8D//f8yAFQAVgBfAGAAbgB6AIMAhwBsAE4ANwBHAG4AhwCSAIIAWwAwAAIADgAuAEQASQBBAD8ARgBlAIgAngCpAJgAegBVAEMAMgAfABAA+v/s/+f/2v/D/7H/o/+Z/7X/zv/j/+3/yv+x/6b/tf/A/8r/z//O/8j/yv/c//n/7//y/wAAGAAnAPb/rv+L/6H/0v8OACwAHgDx/8D/v//Z/xcAOQA2AB0A4P+9/8f/FwBkAGwAKQDJ/43/p//5/0IATwAdANf/zf/+/ygAIgDg/5//mf+8/yUAfwCNAGQAFwDi/8r/1v/Q/7n/ff8+/0D/gv/9/3UAqwB+AA4Afv8d/yz/aP+6//T/JwBbAJwAzQC/AGwA2P9W/+7+zP7e/iH/c//P/xQADwD+/8v/p/+k/6j/pP+6//H/LgBqAHsAVgD8/5z/a/94/6H/o/+P/2z/av+X/+L/OgBaAFUALwAeAB8APwBIACMA8/+m/5r/sP/h/x0ATQAuAOH/jP9Q/1L/Yv+P//D/YwCaAJQAjACHAKcApgCAAFAAFgDY/6T/qv/e/xgADADq/9j/yv/R/+L/GQBUAIMAgQCPAMIA3gDBAGkAFgDe/9//5P8AAPD/uP+U/5f/zf8bAEIALQABALz/h/+Q/67/8v8rAE4APQD1/67/cf9b/2v/kv+E/17/OP9F/6z/KQBmAFgAVgAoAAQA4f/C/8T/0f/c/9T/7P///xkASQBeAEsABQC//7j/5P8WACcAFQAQAD8AggCyALEAeQAjAP7/+f8eAF0AWwBdAHMAswCzAI0AUQA9AF0AWQBSACEAAwAOAB0AIAASAOr/3P8HAEgAhgCbAJwAtgDYANQAlgBOAEkAdwCTAHcAVQBIAFwAYgBeADwAAgC9/4P/jf+q/6r/f/+F/6X/+v/8//L/+f/s/+P/wv+//7//wv+6/9n/JwBoAH4AYQAeAMr/jf96/5T/sv+x/6n/qf+7//H/BgAZAPb/rP9//5r/0f8PACUAKQAmAAQA5f+x/6X/hf+M/5z/uf+z/6z/x/8DAEAAGwDW/4n/cv+L/9//awDOALoAMQCr/43/1f8gADQAKAD1/5D/Of8l/2b/vf/6/+j/zv+g/4j/gf+m//v/AQDa/6z/wf/k/wMA8P/v/+f/0v+h/5H/4/8pAFAAWgBUAEgAKgAAAPD/7P/W/+D///8zADoAJwBBAFYAIwCf/y//K/9f/63/+v9aAIYAegA/ADQANgD1/7H/nv/5/xUACQDS/7D/yv/s/zYAcwBmAAsAtP+t/wAANABIAEEADQDo/8v/1v/h//D/CQAQAPf/qP9p/4L/DwCyAAoBHAHZAJEASAD//8j/r/+r/7X/wP++/9v/AgBEAE0ANwD+/77/pP+n/wMAVAByAD0AQQCeAOYA5wB0AA4A2//J/8r/7f8HAPT/5P8JAGwAyAD4AAoBDgH0AJcAHQC9/8L/EgA1AAcAtf+0//v/eACZAIEAIQCR/y//Lv+l/ygAiQC3AMcAkwBIAPP/5//1/8X/i/9M/zv/Rv+F/wMAPAAGAHX/J/9I/5P/r/+9/97/5P/2/9v/2P/U/7j/t//F/w8AIgAbAPv/6f/O/6H/c/9v/5j/yf8kAEwATABGAF0AgQB6AF8ASwBhAGwAMgDL/6T/vf/d/zQAgwDAAJgANwAdAF0A3gAwASIBngAQAMv/IQDiAFwBRAG6AD0Ayf/O/w8AYABJAMP/av9a/7z/KgCHALsAowBLAPb/+/8gADQA/P+2/3T/TP+K/9//TwBOAOr/Zv8L/yn/gf+r/3j/V/9//+7/PABWADIA5v+X/0L/Qf9c/4f/g/+E/7L/5v/6/77/m/+q/+7/7v/T/9f/DgBcAG0AeQBsACIAqf9E/0X/Y/+S/4f/nv+4/7n/rf/A/xsAQQAzAOz/0//d/w0AMAAmACMA8f/A/7z/AgA6AFEAUQA/ACYAzP+L/4n/zf8PADoARABSADkAAwAKABcABgDa/7j/3f8WABsA3v/D/+z/GgAmABUADgDE/7X/2P9aALgApABeABAAAAAFAC4APgA7AOn/lP9i/3j/v//7/z0AWwBrAFIAKgAbAEYAcQBYABAA0//O/+X/AgB1AOQA6gBrANX/lP+D/4n/mv/9/y8AIAD//yoASgAsANb/cP9T/yb/Lf9g/8P/+v8hADsAPgAmAAYAGwBUAH8AbwChANQAowAeAKD/mP/F/8//4P8OAD4AIAAdAF4AwgDRAFIAFAAnAFAAXQCMAMYAwQAYAGj/U/+a/83/tP+j/3z/bP9z/83/MQAgANX/zP8lAGEATAASAAgA8P+5/5z/xf8iAHYAyADzAL4ASwC7/5P/oP+r/63/jP+K/6n/9v9GADQA3f+f/4D/XP9i/8r/SAB3ADsA6P8iAHcAZwAPALj/eP85/0n/tv89AEEA1P97/5j/DwA0ABoAzf9l/xr/Iv+N/zMAlwBMAJ7/F/8K/1b/p/+g/0T/8v4E/0T/z/9gALYAjgAfAO3///9JAEcA/f///zUAOQArAB8AYQBUAO7/j/+R/8n/4P/R//L/SAB3AKEAzgD9AM4AWgAEAPf/GAAaAPD/z//m/xkAVQBgAIAAmgCmAGgAGQDq/+7/9f8kAJcA5gACAdgAwQCeABkAcP8e/0b/i/97/2b/iv/7/4MA8gAQAaoA6/8p//z+Pf+W/+7/LwBRAG4AdQBWADEA9P+9/23/A/+2/s7+N/8IAJkAxwChADkA3/+r/9L/3//B/3//Yf+X/9X/9P/m/+r/DAAWAB4AHgA8AHgAogDDALYAsACdAFEADADv//7/BADv//7/NQBFABkA6//h/wsAOAAWAAkAAwAqAF4AiACgAHoASwA5AFgAagBPAPn/u/+1/7v/vv8EADwAKgDi/9//GgAiAN3/Yf9t/9T/FgAkABoAJAD0/7H/fP97/8X/EQAZAPr/wv+9/+P/QgCtAOcAyQBIAMb/z//3/w0AAwAeAHsAfgDw/2v/Qf94/6f/rv/i//z/7//k/wAAdgDQAOEAnQAlANL/tf/w/4QA5QDdAFIAt/9q/5v/+/8VAN3/nv+F/8H/SACRAH8ATQAXAAEAFAAeAAQA1f+H/0z/Tf+A//D/LQBiACoA2f+u/9X/QABrACQAjP8d/xH/af+v/8j/zv/M/83/o/+O/3z/l/+N/3r/sv/r/7z/h/+b/z0ApgB9APr/x//F/6z/qv8CAEoAGgCl/2f/kv+p/6T/nv/o/x4A4v+5/+D/DQAlAAgA9P/m/7j/sv/4/3oAbwAYANr/6P9GAGwAKwDQ/4r/jP8BAFgAsQCiAHwAPwANAAYALwA2AAYApf9D/+j+2v5C/ygA/AAoAcIAdgBxAIcAmgDBAPsAywBbAC0AbgDSAMQAlABlADYAxP+V/73/EQAMAN3/1/8MAD0AUgB0AIIAmACdALIAtAAiAD//yv4H/4L/zf+3/43/cP9L/1n/w/8gAEAA8P+Y/7T/FQCSABgBNAGXAHX/rP7U/pP/KAAUAJv/Nf8s/4T/6P/9/6r/Mv8Z/5//PwC2AKcAXgAYAP7//P/U/5v/fP+x/wgAOwA4AGkAkwClAJEAVQBBACEAFQAjAGMAbwAyAOD/t//l/zUAXQBWAFoAJADe/7D/r//d//H/8f/0/wgAOgBnAI8AmQBsAOz/ff9T/4r/9/9KAHgAZAAkAND/s/+//+D/9f+8/3//fv+r/+3/JgAsABYA6/+u/3H/av+N/6j/y//S//L/+v/y/wUAFAAKAMT/ov+l/9b/9f/u/+X/6v/s/8r/6/8nADkA/P+o/5P/pP+r/53/z/8CAOH/kP9b/4L/nv+G/4j/5f80AB4ABwAWAG0AsgDBAKgAggBHAPf/6f8PADIARwBiAJIAowBEAMD/n//O/+j/1P/C/9X/5f/S//r/PQBPAPH/bf+f/xgAPgAdAAUAMAA5ABYALgCKANAAgwApAGoAuQCJABsA7/8tAGYAQgAgAAIAEwAMAPX/CADx/9P/nf+k//3/gQDeAM4AdgANAMb/ZP9H/8H/jgDaAIQARQBSAJMAogB5AE0A8P9P/9L+Of8XAF8AGgDG/8H/zP+w/7j/5/8QAPb/zP/k/wgA8//K/+7/KAAoABIACAASAAgA1v/1/xUAyv9T/zD/q/8cACIA9//i/8D/cf8v/3n/GABlADwA7P/Y/9H/tf+s/8n/9f8JACkAcwC/AMcASwDQ/5n/iP+z//D/PwBdAD8ALAA4AGwAYQAMALj/ef9u/3T/p/8CADoAOAAOAPz/BgAsAFEAcQCNAKQApACPAIUAfABgAFMAMgD5/9H/u//T/xoAfgCsAFQAtf87/0j/uf/z/w4ASQCMAG4AJgAYAGYAUgDP/2n/fP+h/6X/4/9oAOAA2ACEADUAPAAyADsAQQAUANj/1v/0/y4AbQCjAKQAOACu/6f/0f/E/6H/rv/G/73/i/+r/zgAmgBdALz/bv/8/qr+wv6D/zcAYAAhACQATwA3AOT/l/+H/2L/EP/s/kP/nf/s/yQAVABXAPr/hP9Q/2H/fv+B/3D/cP+0/+D/EgATAPn/0/+n/3X/g/+l/7//vf+s/9n/DQBpAKQA9QDvAKcANQDk/7j/j/+l/9j/DgDy/+n/GQBhAG0AJQD2/73/i/9q/63/LACMAKgApwDEALsAdwAhABIAKgBAABwAEQArAFwAUABJAGwAqADiALsAWADZ/8b/vP/b/wUAFgAKAML/vv/8/3EAYADz/27/Sv+M/8f/FwArABYAu//f/3MA2gDJAGAA7f+t/47/j//H/7v/h/9P/5f/CQA5APX/wP/t//D/8f///zUAJwCu/zb/M/+v////yP9S/x3/Wf/T/zEAagBIADUAQABGAGQAdQA3ALv/xv8gAKUAzwCyALQAoQA/ALr/hf+n/7P/TP8S/zv/2/+xAHIBrAH8AAEAa/+Q/yEAnAC+AKoAegAvAEQAdgCPAGsAEQC6/1b/OP+M/0EA1wDmAHQA/v/R/+f/NgA4ALj/RP9G/+n/fQCLADgAr/9G/0f/u/9OAJoAUAD1/9j/zv/k/xoATwBDANf/Yf8B//r+af8CAFYAAgBI/+7+O/+s/xsARAApAI//3v76/rH/UQBYAD0AJgDn/3z/XP+q/+r/mf8g/xD/T//R/z4AlwCUACEAo//D/1QAqQCcADMA4f/c/w8ARgBFAAAAkf8v/0P/yP8SAFUAVgA3ABEA7//9/ysASgA+ACoA9f/c/6z/yv8fADQA1P9k/zr/a//g/zIAcwBXABkAxv+7/zoA5ABCAeYAGwB5/2j/xP9bAHUAFQBy/wj/Sv/y/54A5QClACQA0f/K/w0AUwBtAGIAKgDj/7T/6/8bAAwA4v/W/+//IwCKAMsAEAHVAE4A2//Q/yMAlwCrAIAALgDR/6//rv/y/1YAVwDo/63/1v9mALUAzADkANIAZQCk/zP/Y//F/xIALABJAEEAEQDe/9T/9v8pADAALwA4ACoACwDo/yIAjwDzAOgAYADv/9X/0v/T/9P/0/+8/57/m/+0//r/MgAdABMAAQC7/4n/sP9AAMEA7wCoADkAxP9c/1j/hf+m/5X/h//D/zoAawBhAD8AEgDQ/5f/jv+M/6T/4/8GAA8A7v/S/+L/4P+S/xb/yP4B/4z/8//z/4f/XP+2/0oAdwA1AMD/XP9C/5v/zf8BAPn/1v8HACgAIAD3//n/AwAFAPP/8P/2/yYAXwCzAOQAfgDl/7//AAA7ADkANgBtALUAegBVAGgAYAAoAM3/0v8pAEwAJAD+/8r/7v8VAHMAfgAhAM//vf/1/+7/4f8mAJYAmgBeAC4AMABZAFUAWgBVAOz/Sv8G/4X/QwBpAP3/h/99/83/5v/i/6z/bP9I/1T/m//8/zgAGgAYAAcAAwDk/8T/1/8TAMn/Rv9Q/9f/TgAtAOP/tf+n/1D/f/8uAHoA8P9D/3j/GwCJADgA9//O/3H/T/+k/zYAQgAjACEAYAA1AKP/ZP+w/+j/2/8PAGQA0wDfAOYAwgBrAP3/2v///wwAxv+P/77///9EADcAMwANAOD/3/8jAE8AOgAiAPz/HAAFALz/iv+u/x4AoADxAMYAwgB9ABoAy/+//+3/AQDq//v/igDOAKcAaQCKAIEA/f9W/zj/dP+Z/6r/+f81AN7/pf8XANAA7ABiANH/yP+X/1T/h//y/1wAXwCEAAQBSAG5AND/e/+f/8b/oP+l/7r/7v/4/+H/OgB+AF4A6/9v/zX/Mv9z/w0AjgCJABUAyf/H/9r/p/9V/zr/Af/O/gb/rP89AFIAIAD0//v/BgAEABQAFQDy//r/SgCJAF8AFADR/6z/cP9L/3L/tv+l/zD/Av94/zoAqwCbAI0AjwAxANn/4/9YAIoAGwCE/3D/tf/g/9D/4/8HAOj/p/+e/xMAnQCjAJYAlQClAHMAGQAeACwA/f+A/3H/tf/+/93/vv/1/zMAAwDD/9P/6v/O/7X/7v9rAMYAvQC1ANEAqgAnAKj/e/+R/4T/Vf/m/rj+9P6e/2QAnQBTAOX/qf+t/8f/HgBAAAUAuP+p//z/UQBsAFsAPwDt/67/r/8FAFUAXwAvAO//FwBoAHsAVgD2/+T/BABYALgACgEGAW4Awf+F/7j/5v/6/wcAGQD//+b/GgDEAEgBIgG2AHMAZgA9AAIA/P/v/8j/m//L/xsARwA7AC0ANQDt/3f/OP9q/6L/mf9T/0r/e/+w/yoAwADjAFkASf+0/vr+gv+5/7H/0v8AAPj/0P/k/1IAsACBAPP/SP/Y/tb+J/+5/0oAZwA6AOf/6v8PADoAdgBcAOb/Ov/w/k7/DACnANYArgBCAOX/CQCLANsAoQAeAOf/6/8ZAGsAxwDkAI4ASwAbAB0AHgA9AGMAZwAWALj/xf8MAIAAkwBDAOP/zf8ZAGMATgAKAMf/n/+5/w8AnwC4AJUAWABTAFQADgDN/7f/sP+N/8f/AAAsABAA7f8rAC0Awv99/9b/GgDH/3//uv9BAEEABwAJADQA4f9R/2b/MgCtAEkA4P/3/04ARwAMABEAFwC6/0v/OP+d/wwAFgDZ/7X/hv+K/4P/k//c/x4A+/+Y/3z/rP/+/+T/lv+a/+X/BQD6//j/3v/J//z/YACjAGMA5/98/5P//v9TAFEA5f9//3v/5/9gAGsANgAmAOT/fv9X/63/KwBKABMABwAjABoA2v/z/1UAYADi/3j/gv+m/7L/vf9bALEAXgDL/5X/wv/S/+n/HQBwAD8ADgA4AJEApgBaACUAAQDo/9D/CABbAIMAWAA4ABEAw/9r/yn/J/9S/5H/yP86AIoAfgBVAC0ARQBnAHEASADs/7b/o//b/ygAYQBWANz/jf+j/wsAXgBgAA4A2/+9/8P/CABIAF0AHwDM/47/rf/O/9z/uf93/0b/bP8CAKcA9wCYABIAzP/S//n/HQA4ADYAGgAJAA4AGQACAOv/z/++/8P/wP8KAH0A0wDTAH0AJwAjAGUAYQAnAOj/vv++/9T/6v8uAGUAOQDR/4z/uP8RAHcApACFACgA1////4sAMAEGAS4AW/8Q/0H/lv/Z//X/9P+9/5//2/93AAABIAHDABQAlf+r//j/OwAoAPT/kf9J/4X/9/84AK//yP6U/hr/k//D/9H/HQAZANL/uP8QAFkARQDI/0z/Jv8p/4L/8v9fAF0AHADa/7v/+f8hAN7/PP8B/2L/2f/9/yYAgQDGAIcAFQDW/7//Wv8W/3L/8v9EAFUAjwDOAJIALwAGADoAYgAnAN7/vv/l/0oA5AAWAaUAAgCV/5T/nf+N/43/jv98/4r/0/8LABMA7v8TAFkASwARAA0AKgBhAEcACgDs/77/rP+6/woAGwD7/wkAUQCkAIYANQDI/4j/gv+a/8f/xv/I//r/UgB6AEsAPwBRABUAv/+e/9H/9v/o////VACBAEQABgAIADQANADx/+v///8rAD4AQgA2AA0A+f8cAF8AYQAcAMH/qP+4/8j/0P8CAAoA1v+e/9v/NAA5AAYArv++/wIARAByAGoASAD6/8r/p/+V/8n/IwBAABIAvv+o/8j/FABiAH0ASgDX/2//j/+0/8T/zP8GAHcAiAAgAMX/m/+7/+3/AgAnACYAGwAlADoAcACTAJYAXADs/6f/o//O/xwARABQACIA8P/n/yAASgAKAIT/Mv83/43/DwAzAPb/uP/F/yUAsAD6AOsApgAvANP/wv/q/zQAKQAbAMv/kv+m/xkAvwDyAJQA8/+l/73/FQAsAAcA4f/b/wgAIABEAEMAUAAyAAkAKgBbADUAAgDw/0sAaQAnAMz/5v8pABsA8/8MADcAFADC/5z/w/+9/4//cv/J/zQANwA6AGkAeABOAO//vf+r/3f/V/90/9P/w/+W/6//DQCHAJUANwDK/3v/dP/U//H/8/+g/3n/c/99/6H/8/81ADkA9f+u/2f/UP+E/xEAiAB5AA4A6v8PAC8AFwD3//D/lv8g/wL/SP+d/4z/kv/S/yQAHwBEAKQAAgHgAJcAigCpAJoAVAAmAPX/2f/R/woATQD4/1H/Hv+V/yIAVAAhAPL/6//o/w8AcwCeAHQA9f+S/6b/6P82AJYAngAkAGD/Df+G/0sAwgCdADwABAAnAJAAyAB9AM//KP/2/l3/zv8ZAPj/vf+m/8z/BQAHAOz/1v/t/wgACgD5/zkAcQB6AEcA4/+3/6v/1/8UAFEAOgDk/53/l//f/zIAVQBWAHAAagBcAF0AawB+AFwAIQD2/+r/AwAhAEQASAAeALX/a/9k/5v/6v8aAD0AQAA0AB0AMQBPAGEAWgAWANr/3f8OAFAAcwBRAB4A9v/a/7r/vv/f//P/DgARADwAUQBEADoAIwDy/5X/dP+T/93/+f/Z/6v/kv+A/17/gv+//93/wP+d/7P/2P/t//r/PABlADMA4v/I//3/FQD0/+D/CAANAMD/jv+P/8z/9/8IAAAA8v/Y/7T/w//n//P/9f8RAE4AfABEAOX/2f8PABwA7P/C/9r/AwD6/wwALgA4APP/lv/X/1EAbwA/AB4APQA2APX/5v8TACEArP9G/4P/3P/S/6T/uf8VAEYAGgAIAAAAFwAbABEAHADw/9D/t//a/yoAkgDjANgAkAA3APf/kP9K/3D/2f/q/5D/fv/N/0UAdABvAHAAQgDY/4f/5v+BAIAAGQDO/9f/3//B/83///8iABgAGQBXAIoAcAAxAB0ACwDN/6f/r//U/+H/w//n/wUA0/+D/3n/2/8aAPr/z//b/+3/3P/D////ZAB9AE0ADwAHAPz/y/+Y/4H/hf+O/7v/HgCKALgAbwAiAAEA6v/j/8//x/+n/3D/af+k/xcAVABBABoA+P/6/wAAJgBqAJcAkwBkAEEANQBCAEYANAAIAOb/y//F/+T/FAApAC0AEgD0//7/FQA/AHMApACbADcAuf9r/3f/rv+q/5b/sv/3/w8AFgA9AJAAhQAhANb/8f8bACgASwCFAJ8AYgAPANf/3v/L/8v/0P++/6//3/8nAGcAhQCCAFYA7v+O/6n/7f/x/9D/0f/r/wcADQBFALAA5ACqAEIAMQD8/8L/pf/i/xIA///V/wIAUwBYAB0A4P/W/8j/nv+G/6//x//f/wMAOgBgADsA8P/F/7X/qP+R/4f/mv/d/wAAJAAzADcANAAlAA4AFAALAO7/xv+e/6T/qv/T/+3/GgANAOT/sv+g/5v/iP+X/7j/5f/e/+7/KwBwAIEASwAoAPX/vv+I/4z/tP/M/9H/2P8IACQAEQDq/+v/DgAzACkALgBCAF8ASgA7AFEAfgCjAIAAOQDe/83/uf/H/93/1f+6/4j/p/8BAH0AjwBkACcAGwA4ADoAQAATAM3/Z/9v/9f/HAARAOr/4P8IAC8ASAB5AG4AQQADAA8AJgAMALP/ev+h/63/tf/H/wAAFgDb/5b/mv/s/xwA8f+j/4P/s/8QAFIAawA1AA4AFQAwAEoAMgDT/1n/T/+A/8z/5//m/w8ANAAsABwARgCXALYAWgD6/8b/5/9GALMA1gBYAKv/Sv9x/9//MAA2ABwABADs/x0AZQCfAKYAcgAuAN7/x//9/2YArQCTACwA0//H//H/MwArALz/Wv9c/+P/bACVAG8AFgDL/8D/CQBtAKoAfgA2AAgA4P/e//r/GQAIAKj/Qf/8/g3/e//8/z4ADwCe/3f/xv8oAHsAjgBsAPb/bf9p/7//+//N/5L/eP9q/1//lP8KAFgAIwDJ/7r/4f8vAGMAgABZAPH/lv+x/w4ALQABAKz/ff+U/9//NgBnAFgAHgDl/+//PwBeAHgAYwA0AP//zv/F/9D/yv+h/3//V/9g/3j/0v9PAJAAbQA6ACsASQCHAJUAigBBAPD/pP+J/73/BgAtAP3/of96/7X/IwCWAKAAWADv/63/xP8BADAAKADm/5r/ev+L/7//5v/2//7/BAAUAC8AegCqAJEAUQAdAAkABAAhACUAOwAZANH/mf+Y/8P/+f/5/+b/zP+2/7b/w//u/yIAIQDm/9L/6P8oADUALgBDAFAAMgDb/5f/k/+k/8P/6P8fADwANwApACQALgBJAFYAYgBeADMA7P+c/4v/pv/P/8j/hv9X/2n/m//f/x4ATQBRAEIAPgA6AEUATQAvABcA9v+5/43/lf/c/yAASABDADEAHgAJACMARgBJABsA8v/9/zIAOwAUAN//sv+R/3//jf+Q/5D/rP/O//n/FAAqAEgAVAAwAPD/yP/t/0EAeABsAA8A0P/i/y0ATAAuAPL/vv+u/+X/BwAlACQADAAiACwAHQDz/+j/8v/z/97/0f/N//D/GABJAHYAXwAlACIAVgB5AGkARgBLAH4AdABlAGQATQAeAOP/1/8BABoABADr/7//yP/Y/xYAMAAPAOL/y//m/+3/9P8cAFUAUQAoAAUA9v8BAAQADAARAOn/pv+K/8r/LABAAAoAy//H/wYAJQAyABcA7P/G/7b/x//q//X/xv+p/5v/o/+p/7X/0P/7/9b/jP+V//f/UABOACcA+//g/5n/nv/y/x4A0f9g/2v/vf8PAP3/6f/o/8//1v8eAJQAvgC0AKYAygDLAHUACwDY/63/af9J/1L/mv/H/+v/9v8BAAsAJgBRAHQAZAA9ADAAPgBrAGIARAAUAO//3//p/+f/0//K/7H/xP/U/9X/0P/v/zcAiwDOAMAAwgCfAF0AEADU/67/hf9Z/0L/c/+P/4X/ff+t/9z/1v+x/7f/1f/j/+L/DABBACwACQApAHEAegA2AOf/8v/x/8f/vP/H/+f/2//e/yMAbgBQAN7/rP/O/wIA/v8FAA4AIAATAOX/AwAzADYACwDa/8v/xv/O/w4AYwCEAF0AOQBEAGoAagA4ABgA+v/h/+r/IABOAD8ACADX/+L/BQATAA4A+//j/+z/KAB5AJoAiQBSACAA9//j//H/DwAVAN3/pv+w//f/RABOAEMANAD4/7//t//y/xoAAAC8/6z/yv/t/+z/9v8PAAcA7P/S/+n/EAAAAPH/9f8QAAQA1f/U/+D/2v+l/53/zP8KAAsA8f///ywAKQAZACcAOwAfAOj/yv/g//r/7f/n/wkAEADh/6n/pP/f/wMAFwD1/9n/w//Q/xMARgBDABAA5P/g/+X/AAAHAPT/1f++/8n/4f/w/+3/6//b/97/9P8tAGIAcgBSAAkA7v/6//j/3P+K/1L/RP9s/7z/FwBZAFQAKwAiAEMAYwBpAFgAQQARANb/sP/d/yEAKAD5/8j/zf/j//L/HgA9ADIA+v/a//T/LgBIAEIAPQAQAMD/ff+A/7b/5//q//P/DAASACoAaACsAMcAhAAmAPP/5//N/7b/uf/b//b/7v/e/+T/CwAyADoAGgDd/7v/uv/P/w0ANgAzAAQA8P/o//f/CgD4/9r/qP+U/7T/+v9BAGwAcwBRABcA/v8OACIABADH/53/jf+g/7n/8v8jACQAFwD5/wUACgD9/+//6v/q/+b/4//m/wYACgDx/9z/5v/+////2f+1/6//vP/b//7/GwANAPL/0//j/xcAMwAqABYACQD//wsAEQAWAAIAzf+m/6T/n/+U/7D/yf/Z/+//FQBQAHcAbwBaAFAAPgAmAAUAHQA3ACoAEwAdAE8AaABUACsABgD///L/DABBAGUAWgAnAAoABAAPAPn/3//G/7n/qf+///z/LQBDADUAIAA1AEsARQA0ACUAGAD+/woAIwBCACgA9P/U/+P/CQAbABkA5v/T/9r/AwBCAEgAIADQ/6H/pf+5/87/2P/U/9D/0f/s/ygARwBHACkABwDs/9L/3//9/wAA4/+5/6z/vv/K/8r/wv/T/+7/DABDAGgAewCIAIkAhgBiACEA+v/n/8n/i/9X/1v/h/+w/93/DgAqAC8AJgBDAGwAYgBMAEwAbQBtAB8A3P/J/9r/z/+e/3b/bf92/6T/9f9HAGkAUQBQAHMAkAB6AEUAJAASAAoA7P/K/8b/yP/N/8f/wP+r/5f/jv+X/7n/v/+p/5v/sv/t/ysATgBYAGMAVQA/ABIA5//h/93/uv+c/5X/nv/J/+X/BQATAAAA2f/U//7/NABEADkAMQAvAD8AQQAvABAA8P/U/6//k/+Q/6n/xP/W/93/9v8UADUAWwCIAJwAbQAvABQAJwBCADIADgD0/+n/4P/m//z/7f/I/47/kf/P/w4AQQBsAI4AnQCbAJIAhQBkACcA/v/n/9z/yf+v/7H/v//C/8H/zf/r/xcANABHAEEAQwBIAE8ATQAxAAAAyv+0/77/0v/L/8D/w//l/w8AJAAyAEEAVABSAFAATABGACMA+v/e/9L/0f/B/63/nv+b/6L/rv/Z/xAAQABOAEQATABTAF0AXgBDAA8A1v+n/6j/0f/r/+z/4f/j//3/HQA4ADcAKgAPAPb/6P/n/+T/5f/T/8f/uf+3/8f/1P/g/9n/3v/n//3/EwA5AC8AEQDy/+7/FQAQAPD/0P+7/8P/5v8cAC0AFQDp/9P/7/8WAC8AKQAfAB4AFQAMAAwACgAGAO//zv+3/7z/2//q//L/8f/p/+T/4v/z/xkANQAzAB0AGwArADsARgA/AD4AKwAFAOf/3f/u//r/8//o/+P/5f/t//v/DAAZAA8A8//X/8r/zv/m/wAA+f/U/7j/v//j/wkAEwAWABYAFgAqAEgAZABaADkAFgD3/+H/1//S/87/xP+1/7b/yf/u/xQAJgAWAPn/6//7/xgAJgAZAPj/2f/O/9//9v///+z/3P/j//j/CwAOAAkAAgD8//P/7//4/wUACQADAPP/4P/O/8j/zv/b/+D/3//l//v/IwA2ACoABgDX/7f/ov+c/5f/l/+q/8j/5v8FACIAOQBNAFYAUAA+AB4A///7/wkADwAAAOr/6v/+/w8ADgARAB0AKAAfABsAGwAeABYAEwAcABUA8v/L/8b/0//Z/9b/1//1/xAAKwBMAHEAfABaAFkASwBXAEcALQAKAOn/3P/Z/+H/3//d/9D/zf/i////GQAsAC0AMgBCAEgAVABNAC4ADwDv/97/1//J/7//sf+x/8T/1f/y////AwAMABsAMgBOAFYASQA6ABkA+f/j/9r/0P+6/5n/gP+d/83/9/8ZACAAFAAQACEARABrAHMAWQA3ACcALQAoABMA+f/b/8D/rf+i/6n/wP/T/9P/2P/u/xMAQgBiAGgAYgBRAEUARwBGADEACwDs/9n/0//J/7j/rv+w/7v/zP/l/wMAIgA5AEwAXABhAFEAPgAwAB0A+f/F/5b/ff9w/2L/Xv9n/3b/k//E/wYAQQBmAHkAhQCHAH8AZAA6AA4A4/++/6D/i/94/3H/eP+F/5L/mv+q/8r/+/8nAE8AaAByAGwAYwBZAEMAIwD4/9X/vv+z/6//tf/A/8v/2P/k//f/DwAkACsAJwAfACAAIwAqACoAJgAiABoAEQAOAA8ACwAAAO7/7//0////BwAVACgAMAAyADQANQAzACYAHwAfACoAKAAYAA4ADgAVABIABgD0/9v/wv+3/7b/vf/B/8n/1//q//3/EAApAEIAVQBdAFoAVABQAFEATQA5ABYA9P/c/87/xf+8/7D/q/+y/8j/6P8BABEAFwAcACQAMAA9AEIAPgAuABwAEQAHAP3/9v/s/9//0v/I/83/3//2/wQACgAPABsAMgBHAEkAPgAoABMABQD7//D/6v/a/9z/2P/h/+f/7v/5//D/6f/t//3/+P8EAPz//v/4/+f//P8DAPn/7//x/wMAFAAqADEAMQAoABcAGAAkACYAFQD6//P/7P/h/9j/0f/Q/8//zP/N/9b/6f/0//z/BQAKAA4AEAAQABIAEwAQAAYA//8DAAsAFQAXABkAGgAVAAwAAgD8//f/7P/d/9P/zf/M/9D/1f/g/+r/8//9/wcAEQAfAC8ANAApABYACAABAPv/6v/R/7//tP+x/7n/yv/c/+z//v8SACsAQQBNAFUAVABLADwAKwAaAAYA7P/N/7H/oP+e/6T/sP+8/8r/2v/u/wQAGAAoACsAKQAmACQAHwAQAPz/6P/Y/8v/wP+6/7//yf/V/+P/8f8AAA0AGAAfACIAIAAaABEADgAJAP3/6P/P/7v/q/+h/5z/m/+j/7P/yf/j/wMAJABBAFkAZQBnAGIAVgBIADsAKgARAPL/2P/J/8X/wf+9/77/yf/R/9//7v8GABsALQA+AEwAUwBKAEEAOQAsABoA/f/z/+z/5//h/+P/8P/q//n/AwAZACIAJwAmACUAJwApACsAJAAZAAsAAAD6//b/6v/i/9n/1//i/+z//f8MABIAHAAhACcALQAlAB0AEwAKAAgA/v/3/+z/3f/W/9X/1v/c/97/2//i/+v/9f/+/wUABwAIAAkABAAPAB8AJAAlACMAGQAVABYAFgAWABIABgD7//X/+P/7//j/8//u/+//9P/4//n/+////wAA//8BAAYADQARAA4ACgAFAAIAAQADAAMAAQACAAcADQASABIAEgASABEADQAHAAAA+//2//H/7f/r/+j/5f/l/+f/6f/q/+j/6v/v//L/8f/w//D/7v/u//H/9P/3//n/+//+/wIABAADAP7/+f/2//T/8//y//L/8//z//L/7//s/+z/8f/2//z/AQAFAAcACgAMAAwACQACAPr/9f/y/+7/6v/n/+X/5v/p/+7/9v/+/wQACQANABQAGwAhACMAIwAjACIAIAAbABcAEgAMAAEA+f/x/+3/6v/p/+3/8//4//7/AwAJAA0AEwAVABgAGAASAA0ADAARABYAFgAQAAkAAgD///7//v/6//T/8f/y//b/+f/8/wAABAAHAAgACAAJAAwADwARABEADwAPAA8ADgANAAgABAACAAIABQAHAAUAAgD+//3//v8BAAMABAADAAIABQAKAA4AEAAQABEAEgAQAA8ADAALAAgAAwD8//j/+P/9//3//P/5//f/+f/5//f/+v/2//z//v8IAAwADwAVABcAFAAQABcADAAPAAIAAQADAPX/9f/2/+//5v/j/+n/7//3//r/+/8DAAUABwAQABkAHAATABIAEwARAAwAAwD+//z/+P/0//H/8//2//b/+f/9/wEABQAHAAgACQAJAAUA///6//f/9v/0//P/8//y//P/9f/3//z/AAACAAMAAwAEAAcACAAIAAcAAwAAAP3/+P/1//X/9//1//H/7//y//r//v/9//v/+//8//z//f/8//r/+f/3//f/9v/0//L/8f/y//P/9P/3//v//f/+//3//P///wIABQAFAAYABwAIAAcABwAFAAEA+//2//T/8//w/+3/6//q/+r/6v/p/+n/7P/v//L/9f/3//r//f/+//3/+//6//j/+P/8//7//v/9//z//P/8//v/+f/2//T/8f/w//H/8//1//j/+v/7//z//P/9/wAAAgADAAAA/v/9/wAABAAFAAUABwAIAAgABQAFAAUABgAGAAYACQAJAAcABQAGAAcA////////AgD+//r/AQD9/wIA//8JAAoADAAKAAoACQAKAAwADAALAAkABwAHAAoABwAEAP7/+f/4//X/9//6//n//P/9/wAABgAFAAQABAADAAYABQADAAIA/f/6//v/+v/7//n/8v/x//T/9f/5//v/+P/3//j/9P/2//z//f/9////+//8//7/AAACAAIAAAD/////AAACAAIAAQAAAAAAAgADAAMAAQAAAP///f/8//v//P/+//7//f/8//z//f/+/////v/9////AQADAAQABQAGAAcACAAHAAUAAwABAP///v/9//3//P/7//v/+//7//r/+f/5//r/+v/5//n/9//1//T/9P/z//P/9P/1//f/+v/9//7//f/8//z//P/8//3//f/+//3//P/7//r/+v/5//r/+v/8//3//v///wEAAgACAAIAAgABAAEAAAD///7//P/7//v/+//7//z//P/8//3///8BAAQABQAHAAgACgAKAAwADQAOAA0ACwAIAAUAAwACAAEAAAAAAAEAAQADAAUABwAJAAsACgAHAAMAAQACAAQABQAEAAIAAQACAAQABwAGAAQAAQAAAAAAAQAAAP///v/+//7//f/7//r/+v/6//v//P/9////AAAAAAAAAAD/////AAACAAIAAAD+//3//f/9//7//f/8//v/+v/8//3//f/8//z//f/+/////v/+//7//v/7//r/+P/8//7//f/8//v//v/+//v/+//1//X/8f/2//X/9f/1//n/+f/2//7/+f8BAPn/+v8AAPr/+f/+//r/9f/x//L/8//1//T/8P/y//T/8v/0//n//f/4//j/+//+/////f/8//7////+//v/+//8//r/+P/5//n/+v/6//n/+v/7//v/+v/5//n/+f/6//r/+//6//v/+//7//z//f/+//3/+//6//v//P/9//7//v///wAA///+//7/AAAAAPz/9//2//n/+//6//f/9//4//n/+v/7//z//f/+////AAD///7//f/9//z/+//7//z//f/+//3/+//8//7/////////AAACAAMABQAGAAYABQADAAIAAwACAAEAAAAAAAAAAAD///7//f/+//7//f/+////AAABAAIAAQAAAP////8BAAMABAAEAAMABAAFAAUABAACAAAA/f/8//v/+//8//3//v///wAAAQADAAUABgAHAAUAAwABAAEAAgACAAIAAwAEAAYABQAGAAcACQAJAAkADAANAA4ACwAMAA8ACgAKAAgACwAHAAIABgACAAQAAAAGAAYACAAIAAgACAAJAAoACwAKAAoACAAHAAsACwALAAkABgAGAAMABAAGAAMABQAEAAMABwAHAAUABgADAAUAAwACAAIA/v/9/////v8AAAEA/f/8//7//f///wEA/v/8//v/9//2//n/9//2//f/9P/0//b/9//5//r/+v/6//v/+//8//3//P/7//r/+//7//z/+//7//r/+f/5//n/+v/7//z//P/8//3//f/+/////v/9//z//P/8//z//P/8//3//f/+//7//v/+//7//v///wAAAQACAAIAAwAEAAQAAwADAAIAAQABAAAA/v/9//v/+v/5//n/+f/5//r//P///wAAAQAAAAAA//////7//v/+//7//f/9//3//P/8//3//f/9//7//////wAAAQABAAEAAgABAAEAAQABAAAAAAAAAAAAAAABAAIAAwADAAQABAAFAAYABwAHAAcABgAGAAYABgAGAAYABgAEAAMAAwADAAQABAAFAAYABwAJAAoADAAOAA8ADwANAAoABwAGAAYABwAGAAUABAAFAAgADAANAA0ADAALAAoACgAJAAcABgAFAAQAAwABAP7//f/8//z//P/9//3//v///wAAAQABAAEAAQACAAMAAgABAP/////+//7//v/9//v/+v/6//v/+//5//n/+f/6//v/+//8//3//v/9//z/+//8//7//v/8//z//v////3//f/5//n/9P/3//b/9v/1//n/+f/3//7/+f8CAPz//P8CAP3//P8BAP7/+v/3//f/9//5//j/9P/1//b/9P/0//f/+//3//b/+P/7//z/+v/6//v//f/9//z//P/9//3/+//8//z//f/+//z//f/+//7//f/8//v/+//7//v/+v/5//n/+f/5//n/+//7//v/+//6//v//P/9//7//v///wEAAAD/////AAABAP7/+v/3//j/+v/5//f/9v/3//j/+f/6//r/+//9//7///////7//f/9//z/+//5//r/+v/7//n/+P/4//n/+v/5//n/+v/7//z//v///wEAAQABAAAAAQACAAEAAQABAAIAAwACAAEAAQAAAP///v/9//3//v////////////////8BAAMABQAFAAYABwAIAAkACQAIAAYABAACAAEAAAD///////8AAAAAAQACAAQABgAHAAcABQADAAIAAgABAAEAAAAAAAEAAAABAAAAAgACAAIABAAGAAgABgAHAAsABwAIAAcACgAHAAMABgABAAMA/f8CAAEAAgACAAIAAgADAAQABQAFAAQAAwACAAUABQAFAAUAAwADAAAAAQACAP//AQAAAP//AgACAAEAAwABAAMAAgAAAAEA/v/9//7//P/+/////P/8//3//f///wIAAAAAAAAA/f/8//7//P/7//v/9//2//b/9f/2//b/9f/1//b/9v/3//j/+P/4//j/+f/6//r/+//7//r/+v/5//n/+f/5//r/+v/6//r/+//8//7//v/+//7//v///////////wAAAAAAAAAAAAD///7//v/+//7//////wEAAgADAAUABgAHAAgACQAKAAsACwAKAAkACAAGAAUAAwACAAEAAgADAAQABAAEAAQABAAFAAUABgAGAAYABgAGAAUABQAEAAMAAgACAAEAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA/////////v///////v/+//7//v/+////AAAAAAEAAAAAAAAAAAABAAEAAQAAAP7//f/9//z/+//6//r/+v/7//z//v8AAAMABAAFAAQAAgACAAIAAwABAAAA/v/+////AgADAAQAAwAEAAUABgAGAAcABwAIAAkACQAIAAYABAADAAIAAQAAAP///v/9//z//P/8//z//P/9//7//v/9//z//P/8//z/+//7//n/+f/4//n/+P/2//X/9f/1//T/9P/0//X/9f/1//T/8//0//b/9v/1//X/+P/6//n/+//4//n/9f/4//b/9f/y//X/9f/w//f/8f/6//T/9P/8//r/+v8BAAIAAQAAAAMABAAHAAcABAAFAAYAAwACAAMABwAEAAIABAAGAAcABgAFAAgACgALAAoACwANAA0ADAANAA4ADwAQABAAEAARABMAEgARABAAEQARABEAEAAPAA4ADgANAAwADAAMAAoABwAFAAQAAgACAAEA/////wEAAQAAAAEAAwAFAAMAAQD/////AQAAAP3/+//6//n/9//2//X/9f/1//X/9v/2//f/9//5//r/+v/6//z//f/+//7//P/8//3//f/8//v/+v/7//v//f/+/wAAAQABAAEAAwAEAAQABQAGAAkACgALAAsADAANAA0ADQAMAA0ADQAOAA4ADgAMAAsACwAKAAsACwAMAAwADQAPABEAEgATABMAEwASABEAEQAPAA4ADAALAAoACQAIAAkACgALAAoACQAIAAcACAAGAAUABQAEAAUAAgADAAAAAgAAAAAAAQAAAAIA//8AAAUA//8CAAAABAACAPz/AgD6//3/9f/6//b/9//2//X/9f/z//X/9f/1//T/9f/0//n/+P/4//n/9v/4//X/9P/1//D/7//v/+v/7//t/+r/7P/p/+v/7P/r/+3/7P/r/+//7//x//T/8f/x//P/9f/3//z//P/8/wEA/v/9/wIAAgABAAMAAAD9//3//P/8//7//v/9//7//v8AAAEAAgADAAMABQAGAAgACQALAAsADAALAAkACQAKAAkABwAGAAYABQAGAAYABQAEAAMABAADAAIAAAD////////9//v/+f/3//b/8//x/+//7P/q/+n/5v/l/+L/3//e/93/3P/a/9v/2v/Y/9b/1f/T/8//zP/J/8j/yP/I/8n/yf/J/8r/y//N/9D/0v/V/9r/3v/h/+T/6f/s//L/9f/6//3/AQAEAAgADgARABUAGAAdACIAKAAtADIANgA9AEIARwBNAFMAWQBdAGMAaQBvAHQAeQB8AIAAhACFAIkAhwCMAIsAjQCJAIoAhwCDAIAAewB1AHAAagBmAF0AWwBVAE4ASgBDADkALwApAB8AGAAKAAEA8//n/93/1P/L/73/r/+l/5v/j/+E/3z/cv9r/2P/Wv9T/0j/P/84/zH/Kf8g/xn/EP8L/wD//v72/vL+8P7u/u7+7v7u/vL+9v7+/gb/EP8c/yj/Nf9G/1X/aP94/4r/oP+0/8r/4f/5/xMAJwA9AFMAYgB7AI0AoQCyAMEA1QDtAPYACgEUASQBKgE4AUIBSAFQAVoBZAFWAW4BXgFsAWQBXAFsAWABYAFiAWgBVgFQAVIBRgFEATwBKgEeAQ4B9gDlANEAwQCgAIEAaQBQADMAFAD0/9n/u/+h/33/Xv9D/yH/Af/k/sD+pv6G/mj+Sv4u/hT+9P3Y/cD9qP2U/YD9cP1g/VT9TP1M/Uj9VP1Y/WD9aP14/Yz9oP28/dD98P0M/jD+Vv58/qj+2v4L/zr/bf+h/9j/FwBNAIUAuwD3AC4BZgGeAdYBCAJEAnwCsALkAhQDQANwA5gDwAPkAwAEIAQwBEgESARQBFgEWARYBEgEQAQwBCgEGAQIBPAD1AO4A5ADcAM8AxAD1AKYAlQCDAK6AWIBDAGoAEcA4v99/x3/sv5U/vD9hP0s/cD8ZPwI/Kj7WPv4+qj6UPoQ+sj5gPlI+RD54Pi4+KD4gPhw+Hj4gPig+ND4EPlQ+cD5IPqg+iD7sPtI/Oj8lP08/uD+j/82AOEAaAEMAoAC/AJgA8gDIARIBIgEoATIBNgE2ATgBMgEwAS4BIAEkARQBFAEOARABCAEOAQ4BEgEaARwBLgEyAQABTgFgAWwBfAFMAZQBpAGkAawBsAGqAagBngGQAYYBsgFgAUgBbgEWATYA2QD8AJoAt4BWgG+ADgAlv8A/27+wP00/Xz8DPxY+9D6YPqw+WD5wPhI+OD3oPcw9/D2wPZw9mD2QPZA9kD2YPaQ9sD2APdg98D3IPiY+Bj5qPlA+tj6YPsQ/Lj8VP30/Z7+Lv/N/2gA4gBeAdQBJAKAAsQC6AIMAxQDJAMMA/ACwAKAAlQCDAK8AW4BHgHSAJ0AUwAaAPn/wP+w/63/ov+t/7j/2f8FAEQAhQDIACwBggHoAVgCzAJAA7ADOAS4BEAFwAVQBsgGQAewBxAIYAiwCOAI8AgQCQAJ0AigCDAI2AdQB8AGIAZoBbAE9AMsA3QCsgH3AFAAl/8M/3T+9P18/QT9nPw4/OD7ePsg+8j6ePoY+tD5ePko+ej4oPhY+Dj4APjg9/D3wPcA+AD4WPiI+Oj4QPmY+RD6gPoA+3D7+PuM/AD9qP0k/qz+QP+8/ysAkwAEAVIBogHkASQCMAJgAmQCeAJ0AlgCTAIcAgACxgGWAWQBMAEGAdQAqAB0AEoAGQARAOf/0f+9/7v/qP+w/8r/2v8HAD0AjwD4AGgB9AGIAjwD5AO4BIAFUAYoB+gHoAhACfAJcArgCiALUAuAC1ALQAvgCpAK8AlQCaAIqAfYBsgF6ATIA8ACugHHALT/2v7Y/QT9WPyQ+wj7cPoA+pD5QPmw+KD4MPjw99D3cPdw9zD3IPcQ9xD3APcA9yD3MPdw97D38PdI+Jj4+Phw+dD5aPrQ+kj74PtU/PD8hP0M/pD+Gv+r/w8AdwDhACgBZAGaAbAB1AG4AbwBqAF+AW4BHAHmAKgAWQBKAPf/z/+Y/1z/Tv8m//r++v4G/+L+B/8K/yb/Tf9+/8X/6/9fAMoASAHYAXQCMAP8A7gEkAVoBkAHEAjgCJAJMAqwCiALgAvAC9ALwAugC1AL4ApQCpAJwAjYB8gG2AWwBJQDhAJSAVoAJ/84/jD9SPyA+7j6EPpw+fj4ePgg+OD3kPdg90D3IPcQ9wD3APcA9yD3IPcw93D3gPeg9/D3IPiY+Mj4KPmg+fD5kPrw+oD78Pt8/AT9gP0Q/nj++v5f/7H///9gAIEAxwDQAPYA3ADcAMsAnwB4ADMA0f/a/3D/ef8J/wD/5P6o/sz+eP6u/mb+xv6W/rj+3P7m/hX/Nv+P/5z/6f8qAIEA/gCGASQC1AKsA3gEYAWABkAHYAhACTAKAAvgC4AMIA2QDeANIA4QDgAOsA0gDbAM8AsACwAKAAnAB6gGiAUoBPQCwgFjAGf/HP4g/TD8SPtw+sD5CPlw+OD3kPdA9wD30Paw9sD2cPag9qD2kPaw9sD20Pbw9kD3UPeA9/D3EPhg+MD4CPmI+fj5cPrQ+mD78PtM/OD8YP3M/VL+lv4O/17/pf/o/wUAMQBVAFIARgBRABwAEwC5/6f/dP83/yb/+P60/pD+cP5U/nD+SP42/kr+RP6A/pr+oP7e/uz+UP9z//j/WgDLAJ4BSAJAAwgEKAUgBmgHcAiwCdAKsAvADIANUA7QDlAPoA/AD7APcA8gD3AOsA2wDKALgAogCegHiAYoBagDWAL2AIz/QP4o/fj7+PoY+iD5oPjQ91D34PaQ9jD28PXQ9aD1oPWQ9YD1wPWw9eD1APYg9oD2sPYA92D30Pcg+Ij46PiI+dj5kPro+pj7HPy0/Cz9uP0s/pb+Ff9c/8X/AgBCAHsAtADDAMYA0gDEAKgAZwBwAMj/1v+e/1n/VP/U/uz+lP6i/qL+gv6I/oT+nP6+/s7+3v4O/yj/Xv+c/+D/SQDNAFQBOALsAvgD+AQABlgHYAiwCdAK4AvwDOANoA5wD+APQBBgEGAQIBDADxAPUA4gDTAMwApwCSAIeAY4BZgDJAKlADD/4P2U/Hj7UPpg+YD40Pcg97D2QPYA9sD1cPWA9TD1UPUw9TD1MPVg9YD1gPWQ9cD18PUg9oD2sPYg93D38PdQ+AD5aPkA+qj6QPv4+3j8QP3k/Vr+/P5D/6X/7v8lAG0AlwCoAJ0AkAB5ACYAEgDF/2r/Kf/u/rr+VP4o/uj9zP3Y/bz9wP20/bz93P0C/gz+OP4w/mr+jv7U/jH/qP8iANMAngGoAqAD2AQIBlgHwAgACmALkAywDfAOwA+gECARgBHAEcARgBEAEWAQUA9ADhANkAsQCpAI+AZQBbADJAJ4AOr+cP0w/PD6uPnI+PD3IPeg9vD1oPVA9SD14PSw9KD0gPRw9JD00PSw9PD0EPUw9WD1oPUA9kD2wPYQ96D3GPiw+Fj5+Pm4+lj7NPzw/Lz9Rv4o/53/NAClAOMANgFkAXgBiAGaAZYBLgFYAbkAlQBJAPD//f9p/1L//P7Q/nj+jP5O/j7+Ov4c/ij+Nv5e/lr+ZP5u/qD+tv4N/2L/q/9fABIBDAIYAzgEiAXgBnAI0AlwC9AMIA6AD6AQwBGAEgATYBNgE0ATABNAEiARABDADkANwAsQCkAIiAbQBPwCWgFe/xz+YPwQ+wD64PjA9yD3YPbQ9YD18PTA9JD0YPQQ9DD0IPRA9ED0UPSA9ID0sPTw9DD1cPXA9TD2oPYg97D3QPjo+KD5WPoo+wj8wPyQ/WL+BP+o/yMAqADEADgBSgFuAY4BcgFcASIBzQBhAB0Asv+P/0r/zP6C/kz+zP3Q/az9fP18/VT9dP2U/ZD9zP24/Qr+Av5g/nD+Af8o/4//UAAQAQACCANIBIAFMAfACEAK8AtwDeAOYBCgEYASoBMAFKAUwBSAFAAUQBNgEiARsA8wDoAMoArgCPAG8AQYA0ABq//Q/Uj84Pqw+Zj4kPfw9uD1cPXw9ID0MPSw85DzUPNA8yDzAPMA8wDzMPNg84DzwPPw82D08PRg9RD2wPZg9xj4MPm4+fD6uPuI/GD9Nv4g/5r/VQDUADwBdgHAAdQB1gHMAZ4BZgEuAbUAMwAIAHj/ZP++/pb+Tv7w/dT9lP2M/UD9QP1c/Wj9fP28/Xz91P3o/ST+Cv52/lL+2P4n/6n/gwAgAZQCzAOwBRgH8AjACkAMMA7QD2ARoBLAE6AUIBWgFYAVYBXAFOATwBJgEbAPAA4QDCAKEAjwBfQDBAIJAEz+nPwg+6D5gPhw93D2sPUg9YD0QPTA84DzYPMw8xDzAPPg8gDzwPIQ8wDzQPNw83Dz8PMw9ND0QPXw9eD2sPeo+Hj5uPp4+6D8YP1q/iP/1v+OABABhgGuAQACCAL+AbABTAHzAJ8AFgC1/07/2P52/iz+4P2Q/Zj9VP2E/Xz9hP2c/bD99P0O/iD+OP4a/iT+IP4G/iD+9P3c/fT9JP6Q/i3/ggCSAVADGAVQBzAJIAtgDVAPoBGAEwAVYBYgF+AXgBiAGOAXABfAFYAUwBLAENAOYAwgCtAHuAWIAzwBc/+o/UD82PqI+Zj4sPcg96D2IPbQ9UD1IPXQ9KD0IPTg86DzYPNQ8/Dy0PLQ8sDywPLw8jDzsPMw9BD14PXw9tD3GPlw+mj7jPy4/ZT+zf9zAFYBqgE4AqwCvALYApACSALCAXIB1AAyANL/TP/w/oj+RP4G/vT9vP3g/ez97P3s/fz9Mv4i/i7+Dv4W/sD9qP1Q/ST96Pys/IT8gPy4/Oj8sP3w/gkAcAJoBPAGQAkgCxAOIBCgEuAUIBcAGCAZwBkAGiAaYBlAGIAW4BQAE8AQMA7gCyAJAAfYBIgCUQBK/qj8WPs4+gD58Pcg96D2QPbg9XD1EPWA9DD08PNQ8/DycPJA8gDy8PGw8VDxcPFw8eDxQPLA8pDzsPSw9QD38Peg+dD6GPxE/YL+If9QABIBggEoAhQCHAIYAggCZAHkABAApf8d/2L++P1E/RD9rPzI/GT8aPxc/Jz83PwY/UT9VP2s/Yz9wP2k/WT9MP38/Nz8dPwU/BD8wPsE/Cj8zPzY/U3/YAHEA4AG8AjQCxAO4BDgEyAWYBhgGiAbQBxgHGAcABzgGoAZgBdgFSATYBDADdAKQAhgBVgD/ADI/tT8IPsA+vD4GPjg9kD2wPVQ9SD1oPQA9JDzQPOw8lDy0PFQ8RDx8PDQ8LDwwPAA8UDx8PHA8qDz8PQg9pD3yPgQ+rj75PwY/tL+yP+EAAIBogF4AYIBegFQAR4BegDK/yj/pP42/qz9QP3o/Ij8tPyI/Kz8kPy4/Dz9cP3Y/bz9MP78/WL+Fv4A/tz9dP0Q/XT8hPzI+8j7mPuA+/D7WPxs/RP/egEIBBAHIAoQDaAPoBLgFAAYABqgG8AcAB3gHIAcABxgGoAYQBbgEwARkA5AC5AI4AW0A5oBzP+w/fD70Pro+YD5aPig98D2gPbQ9XD14PSg82DzcPLQ8RDx4O+A7+DuIO8g7yDvYO/A75DwoPHA8kD0gPXw9pj4CPpo+9D8/P0C//L/vgA6AXgBrAG4AaYBcAEEAc0A9f9t/8z+fP4S/vD9fP2U/UT9fP2g/cj9QP5C/uz+A/9F/zr/Cf/2/s7+wP78/WT9fPz4+3j7EPvI+lj6QPpQ+hD74PuM/ez/JAMAB1AKgA1AEIATYBagGSAcoB1gHqAeoB5gHuAcABsgGWAWIBQgERAOoAowCOgF+ANQAmIAqv5s/cz8NPyw+9D6EPoA+Yj4kPew9kD1EPRg8xDy4PCA70DugO2A7aDt4O1g7uDuwO9A8aDyUPQA9rD3MPmg+hT8MP0C/qD+Fv+R/0X/Jv+w/nL+Iv7w/dj9eP0w/fD85PwE/SD9aP10/bj9Cv5U/oT+sv7W/h3/VP95/1r/+P66/jb+EP68/Sj9fPzI+yD7kPpA+tD5sPmQ+fj5WPpQ+9D8tP6mASAFYAlwDLAPwBKAFUAYoBvgHcAdgB7AHaAdYB3gGiAZABYgFKARIA9ADCAJAAdgBagEjALVAKr/nP4k/pT9JPwY+5D5wPhQ9wD2oPMw8sDwoO+g7uDsAOzg6kDrgOtg7CDtgO7A72DxUPPg9OD2SPjI+ej6uPtA/Oz8yPwQ/ZT8dPwk/LD7kPt4+7D70Ptk/Gz8+PxE/fj9Uv4D/1z/kf/W/wcAFQC//8n/cf9I/wD/dv7c/YT92Pxs/AD80PuA+xD7gPqQ+jD6APoI+sj5+Plo+oj7IP1c/0QBoAXQCbAMYBAAEgAWYBhAHKAdgB7AHuAdAB6AHSAcgBjgFiAUoBLADwANQAqgCEAHgAb4BPgC4AG3AHQANv+s/ej7uPoI+ZD3YPUA8zDxwO9A7mDtYOyA64Dr4OvA7ODtAO+Q8DDy0PPg9WD34Pjw+aj6MPug+8j7sPtA+8j6YPoo+uj5EPoY+nj6GPvQ+5j8ZP0a/gf/0v+PAO4AQAFeATQB9wBjAB8Aaf8m/3T+Ev6M/RD9sPyY/ID8ZPxo/Gj8SPyw+9D7WPtI+2j6EPqA+fj5aPrI+yr+aAHQBFAIYAwADyASgBWgGQAdIB5AH2AfYB9gH8AdQByAGWAXQBRAEiAP4AsACkAIQAc4BqAEIAMkAigBcwAn/6D9+Pv4+Sj4APbA8zDxIO+A7SDsIOsg6qDpIOrg6mDs4O2A70DxAPNA9SD3yPiw+TD6oPrA+pD6+Plw+YD48PeA93D3cPfA94D4oPn4+jD8cP2o/tj/6gCoAfwBUAJAAiQCTgGzALr/Dv9G/sj9TP3U/JT8iPyo/OT8PP1Y/ZT9KP3s/HT8GPz4+kj6IPmI+GD3sPdA+OD6gP4gA/AH4ApQD0ASABeAG0AewB/AIcAhQCHgH+AdABsgGWAWoBNgEBANIAuACfAI8AewB/gGaAboBYAErAM6AYH/1P34+hD4sPTQ8cDuwOzg6kDqYOkg6aDpgOpg7EDuwPDQ8vD0sPZ4+AD6APoo+vD5iPko+VD4IPdA9oD1cPXw9VD2QPco+PD5+PtU/eD+MQCqARQDPAMQA3wCyAGsAccAEgCu/tT9YP3Q/RL+cP7g/mn/vABYAd4BCAKqASIBVQBw/+j9aPuA+dD3sPaA9bD0UPRg9oD5bv9IBFAJIA1AEKAW4BlAHQAfQCBAIAAgwB7AG6AYYBagFKASIBBwDbALwArwCpALYAvwCkAKsAnQCLAG/APhABz+uPqQ9/DzYPAg7QDr4OmA6aDpAOrg6sDsAO8Q8YDzAPXA9sD3uPgQ+Vj48Peg9jD2gPXw9ED08PNA9MD0IPaA90D54Prk/NL+hABWAQwCYALYAjwCTAE/APj+VP7Q/XD9zPyE/AT9pP6n/7AAhAG0ApgDkAQoBdADHANyAcAAqv5g+xj4UPZw9dDzsPJA8gDygPWg+er/AAXgCSAOwBKgFgAaoBvgHGAegB1AHYAagBhgFUAUIBPAEUARkA8QDzAPABCAEEAQcA9wDvAMkAooB+gCtP6w+iD3EPRg8ODsIOsg6qDqIOsA7ODtYO+g8aDz4PTQ9WD20Pbg9iD2MPXg88DykPHA8MDw4PCg8fDyQPQA9lD3qPnw+oT8oP14/gL/lv7s/Vz9KP2U/Kj7GPwA/HD8yP2u/tf/UgAcAmQDqAQABZAEmAToBKQDSAMSAWH/Sv6A/dD7APkA93D3APdA9vD0EPRA9fD2yPxQATAFkAjACwAQgBIAFYAW4BigGWAa4BkAGcAX4BXgFsAWgBZgFSAUABMAE6ASgBLAETAPoA0QC1AIiARRADT9EPqg92D1MPJA8EDugO4g70DvoO+w8FDxEPIw8zDzoPNg8+DzUPMg8wDywPGw8SDyUPIg8xD0wPTg9YD2gPeg+Kj5uPro+nj7kPvQ+7D7uPsg/Lj8XP0g/qL+Ev9+AEwBtAL8AsQDyAPUA3AExAOAA9ACuAJ8AvYBhAAaABr/sv4k/eD7KPog+KD2QPbg9ODzIPPQ9jz8nwDQBCAI8AogDoAS4BRAF6AXQBiAGeAYQBjAFaAVQBaAFoAWYBYAFSAUgBQgFGAUgBEgEEANAApgBrIBeP5Y+iD4sPWA8xDx4O8A7+DvcPCA8BDxEPEg8TDxIPHg8HDwIPBw8DDwAPDg74DwoPHw8tDzUPUA9mD3sPfg9xj4cPjY+DD5GPnI+KD4EPko+pD6oPuY/Gb+8P8GAegBPAIsA7gD+AOoA5gC5AJgAmQC8gG6ASYB1gE2AUgBrwBf/+D9PP1o+6j4APcQ9SD04PLA84D2GPvM/5gEkAigC8AN8A/AE8AVQBdAF6AXoBaAFkAWwBVAFoAWwBegFyAXoBXgFGAVQBWgEyARsA3gCVAGTAJr/5j7gPlg+HD3kPZw9JDzQPNw86DzEPPg8UDwgO9g7wDvQO7A7cDuAPDg8LDxYPKA84D0oPXA9uD2cPaA9XD1YPVg9bD1IPbw9rD3uPgo+jD7hPz0/dD/uAAUATYBOgGqASwCZAJ0AiACRAK8AuwC/AL0AnwD4AOwA/gCKALMADX/0P1Q/MD6aPjQ9lD1MPQw8/D0wPlE/gQCeAYwCqAL0A2gDoARwBTgFaAXYBYgFsAVQBcAGaAZ4BlAGkAaIBmAFyAWIBUgFMAS4A9QDGgHCAWqAVoAAv5Q/MD6SPnQ+MD2MPUA88DyIPLw8KDuoO2A7ADsQOzg7KDuYO8w8WDy4PJg83D00PRw9WD1kPUg9RD0QPSQ9JD1oPYo+Bj5MPrQ+ij83Pzg/dj+Z//b/yIAPQCyAJABygF0AswC4AJUAqwCqAKsAngChAIsAmIBeQDo//b+rP0Q/bj7MPrw9zD2QPVA9MDzYPc4/G4AgASABZAIsAjQC4AOoBEgFEATIBQgFeAVIBWAFqAWYBkAGkAZwBfgFYAVIBbAFSATIBAgDcAK6AdwBGAB2f+v/9T+jPxA+vD3cPag9LDzsPEA8EDuIO3A7GDsQOxg7QDvMPDA8TDyUPJA8nDyYPNw84DzsPOg8/Dz0PRA9UD2YPeY+Fj6KPs4+5j7JP0g/uL+Jf96/5H/PQBeASACnAKgAkADvAOwAxADNANIA3wCDALgAR4BfgDW/4z/ov4U/fj7SPp4+ND1UPTQ83D1IPho/L0A1AIQBMAF8AkgDDAOYA8AEsATQBOgE8AS4BNgFqAYgBqAGeAYwBegGAAYQBYgFeARAA+QDDAKcAcYBSAE9AMgAzoBzP6g+yD50Pbw9CDyYO/A7UDt4O1A7QDtIO7g7qDvoPCw8KDv4O5A7yDwoPAA8DDwsPGQ80D0gPQw9TD1MPaA98D4YPkA+uj7Uv45/zH/7v7o/qf/dAEAA9ADCAQwBAgF4ATsAzADkAOoA0wDiALUAEv/9P5A/6f/HP4A/Dj6SPhA9rD0oPSA9fD3wPpq/uT/ngE8AygHAAuwDYAP0A9AEYAQwBFAE2AToBQAGKAaYBsgGoAZgBkgGmAYgBYgEyAQwA1wDLALgAkwCYAIoAeIBAQBxP3A+fD2IPXw8oDwoO5g7sDu4O6g7uDugO5g7uDtgO3A7KDrAOwA7SDuQO/Q8JDykPMw9OD0YPQA9LD04PUA+Pj4APsY/Z3/UgHaAIr/nP4HAFgCeAXwBtgHcAZoBUAFeATsA/QD2AQgBTgEEAIKAdP/Qv9e/3X/LP7o+cD34PZA9vD2APgI+5z9dP8yARQC/AIYBRAJYAygDdANQA9AECARoBKAFCAXoBdAGUAaABoAGSAYYBgAF6AUoBJgEBAP8A1ADdAMEAtACfAG0APC/0j8sPmg9yD1UPMw8gDxUPDg76DvoO4g7QDsgOsA6wDq4OkA6mDrAOxg7UDvYPCQ8BDxIPIQ8bDwAPPQ9JD28Pjg+bD8hf/1//0AG/+e/hb/MALIBpAIwAlwCAAH+AT8A1AErAMABRgGQAZYBA4BjQBG/+7/zv5U/UD6IPfA9lD2UPfQ98j60P3y/hj+yv7w/8AAvAPAB9ALsAxwDaAO8A/AEaASABRgFgAXgBhgGCAYoBcgF8AXYBagFOASwBEAEMAOAA2ADIAKoAcIBTAChP7o+gD5IPeA9UDzoPEQ8ADvAO0g7CDrQOpg6UDpYOmg6cDpoOpg62DrAOzg66DsgO0g7sDusPCg8oD0APfQ99D64PoA/YD8uPwa/q7+xANwCBAM0ArgCGgFGAUABCAEeAUYBxAJgAmACEAGwAMIAnIBHgBU/Xj66PnQ+cD54PkA+2D8rPz4+xz9iPy8/Kj98gC4BVAIEApQC6AMMA1gDqAPwBGAE0AV4BYgFyAXgBfAF2AXwBbgFeAUQBQAEoARgBHAD3ANcAswCYgFQAKK/0j9oPvQ+OD2IPWQ8kDwoO6A7QDsIOsg6iDpgOiA6MDoAOmA6ADpYOkA6cDp4Ong64DsAO7g7xDyoPPA9dD3KPqY+nj6jPwM/TIA6ANACmAN4ApwCLgFIAWoBdAFQAnQClAMQAtgChgH2AMUA9ABmAC+/qz9bPxU/AD76Pro+lj6yPr4+lD7qPrY+qz80v8IA8gEUAYgB4AIwArAC5ANsA/AEQAT4BMgFAAVwBYAF+AWABfAFoAVABVgFYAUgBNgEUAQcA4ACyAImAW0A7AALv4Q/Cj58PaA9KDyIPCg7QDsQOvA6SDoQOhA6IDoQOeA5sDlIOWA5UDmAOjg6IDqwOsg7iDwkPJg9ND1APaQ9kj4QPsa/ygFsArgDPAKAAc4BhgE6AUQCVAMcA8AEUAPoAxACDAFiASYBvAFsAWwBEgCGv9E/AD8uPsM/ZT8xPwM/GD7TPyE/DH/7gBoAswDUAR4BdgG8AjwChANUA5AEEARIBJAE8ATwBSgFeAXIBigF0AWIBVgFYAUABOgEqARAA7wCoAIKAc4BNoASv9M/KD5YPbw83DyMPAg7kDsoOng58DmAOfg5oDkYOPA4oDiAOMg5IDlYOYA58DoQOtA62Dt4O+A8cDy8PPg97j8IgFIBcgH2Ab4ArkAOAOwCOAMwBHAEoARkA0wCjAK0AdgCXAMsA6gDBAIaAOJAPH/rwBoAUsAHP+Y/dj9BP2I+8T80P6+/08ALgDpAEABZAKgBbgHwAhACdAKUA2ADiAPwA+gEaASoBOgFEAVYBUAFUAWQBUgFMAR4A/QDrANoA0QC8AIeAWcAoj/4PuI+XD3APfQ9DDyoO+A7KDpYOfA5QDlgONg4gDi4OGg4SDgIOCg4IDhQONA5WDnAOmg6aDrAO8g8eD0QPvZ/x4B9/+8/WUA5ALQB5ANQBGAEFAPAA4wDiANsA6QD0ARABIAD6ALQAngCOAJgAnQBygFPAOQArYAPAL4ARgC3QAUAW4A3v7g/pr/tAIQBDgEKAT4BBgHIAiwChALsArwCtAMUA9gEKARgBIgE6AR4A6gDhAPQA+ADyAQcA7QCigH8AQYAzgBf/+w/aD9cPtI+CD1sPBA7eDrwOrg6WDowOdg5sDjgOGA34DfAOBA4EDjAOWA5eDkgOQA5uDo4Ozg8VD3EPlY+nj4EPh4+jL/KAdACoAMYA3QCiAJQAsgEAATwBKgEcARYBBQDnANYA/AEJAO8AwwCzAIGAYwB8AJoAmgB0AECAPgArADUAQoBDgEdAOIBHAF+AS4BoAHUAggCPgF4AaQCUAMYA/QD7AO0AvACiALQAyQDfAOgA+wDsALEAhgBQAEZAIgBBAEHAN/ADT9oPqA9sDyEPFw8aDwwO9A7iDsgOlA5gDkQOKg4gDjYOTA5gDnQObg4+Dk4OXg6MDtQPFw9BD1cPVw9OD2aPp0/sgBAARoBhAIQAiQCIALkA3gDOAMgA0AEMAQoA/gD1AP4A7gDIAMoAvwCjALoA3QDEAKwAcABSAGeAZIB3AIGAc4BvAFcAYwBgAFKAVwBzAIkAewBqAHQArgCuAK0ArwCMAIkAkgCwAMsAmQCRAJQAkQB+AFUASgAzQDSAJuAfz97Py4+kD5QPfA8+DysPGA8GDvoOxA66DowOYA5gDl4OQA5SDmwOZA52Dm4OVg5iDo4Org7ZDw8PNw9bD1QPWg9ZD3iPtxAAAEcAigCLAGGAWoBTAIUAuADoAQABGwDcAMIAygDPANgA4gD6ANsA0gDQAOUAzwCUAJMAoQCnAJgApwCtAJkAf4BsgGSAYoBwAJYApgCbgGQAbIB6AI8AigCRAK8AlACVAIqAdoBrgGEAhQCAgHIAW0A9wCmgGzAMr/9P14/eD7iPpo+HD1MPQg8/DxUPDA7WDsQOuA6gDpwOeg5kDngOcg6KDoYOhA6CDo4Ohg6uDtcPFA9AD2wPRw85DywPVY+tQBqAQoBuAFdALUAPwBuAegDeAPcA+gDVALkAnAChAOkA+QD5APQA7wDPAMcAyADCALsApQC+ALMAtQC4ALcApACEAGYAfACAAKIAvgCoAJoAYIBmAHEAnACeAJcAogCiAIwAXQBVgGcAfwB1gHeAZoBLgCogEMAcT/tv4q/8j9BPzY+RD4UPbQ9CDzQPFA8IDuQO2A60DqAOlg6GDnIOcA6CDoYOiA6MDoQOkg6SDrYO8A8/DzoPLQ8fDyYPRA9ir+zAKwBBgE1gAUABABiASgCpAP0A8wDTAKcAmQCyANgBAAEUARIBCwDjAOoA3gDdANUA1wDpAOMA5gDnANoAxwCpAJUAmACpAMEA6QDAAJWAcoB+AIwAnQCeAKYApQCUAHoAWIBTgGQAeYBxgHIAVAA7wCBAIQAXj/Mv5m/qT+wPwY+uD3oPYQ9lD0APOg8aDvAO6g7ODq4Omg6MDogOlg6YDowOfg50DooOig6MDqoO6g8cDycPIQ8cDvEPIQ9nj8OgH+AdgBqP8+/sj+aASACJANYA2wClAJgAiAClAN8A6wD/APAA/wDcAOMA/ADcAMcA3wDvAO8A0gDoAO8A3QCiAJQAogC8AMwA3QDBAKoAeoB2AJAAoQCtAJYAqACXgHcAXgBKgFKAfABwgG6AOwAhADYAKTAPT+XP6A/lL+uPzY+rj4UPag9SD1QPNA8TDwgO/g7cDrwOkg6SDpYOnA6cDowOfg5yDpYOnA6GDqQO4Q8fDwIPFA8cDwEPIw9AD8cQA+/5f/8/8Y/2T+fAIQCfAM0AsgCfAIcAlwCjAMQA/gDzAP0A1gDpAPcA7wDZANoA6gDuAOUA5AD4AOYA1wC8AKEAqgC7AN0A1gDGAJkAgQCTAK4AmQCuAKQArQCWAImAaQBYAG0AdACDgHkAUwBKADjAJsAen/fv9MAB0AOv6Q+qj4APiA92D2APXw87DxoO/g7SDsIOvA6YDqwOpg6sDo4OdA6ADo4OfA6IDrYO7w8LDwAPAg8EDuIPGA9tD6mv7U/rr+nP3A/G7+2AMACZAK4AlwCIAI4AcACtAMAA/wDmANMA7QDjAPUA7QDZANoA4gD4AO0A6ADkAOEAygCnAK8AqgC6AMwAwQC8AHgAYQCHAJQAnQCAAJ8AjYBxgGaAXoBGAFgAYIB1gFtANUAzADZAJqAI7/tv+q/+z+3P3Q+0D5sPdw90D30PVA89Dx4PBA78DsgOtA68Dr4OpA6sDpAOlg6KDnAOkA6YDroO0w8NDwoO9g7gDuUPGw9BD72Pwi/nz9kPvw+6T9nAOQCMAJEAnQCPgHMAgACsAN8A6ADqAOoA4gDyAP0A6gDmANYA2wDiAQkA9wDsANYAzQCpAJ8ApgDPAMIAxACnAIsAYYB2AIcAnwCDAIoAcAB0gG6AS4BCAFEAYABgAFOASoA+wC3gG2ANX/ef8iAIf/cv6M/HD6yPgI+FD30PUA9RDzkPEg70DtIOzg6+DqQOpA6mDpgOgA6ODnwOig6CDqAO3g78Dv4O2g7eDu4PCA8qD5yP2M/nz96PoI/Hr+MAJQB4ALcAuQCbgHQAiQC3ANYBBgECAR4BDwD9AP4A9AEFAPEA9gEUASwBGAEPAOMA6wC5ALIAzADaAOMA7wCyAIYAb4BnAJAAqACSAJAAiQBsAEeAToBKAFsAWQBRAFcANMAlwCKAIQAYL/kP7q/rX/jP4o/Oj52PhQ+GD3YPYQ9SDzEPEA70DtwOxg6wDrIOtg6gDpgOcg56DngOhA6ODp4Owg76DvAO9A7iDtYO9g88j5pP1g/rz96PvA+wj9MAMoB+ALgAtwCbAIQAgwC6AOQBCgEOAQIBDADyARoBEAEMAOQA9gESASgBAAECAQMA/ACzAK8AvwDLANYA3ACyAJcAZQBmAIUAmwCHgHoAfQBkgFZAM0AzAEiAWABdgDPALqAcACDAKYAKj+ZP6G/tT+IP7w/MD6CPhQ92D3MPYw9ADzsPEg8KDtAOyg62DroOog6gDpQOcg54DoIOmA6IDpYOyg7mDugO6A74DvAPAQ8VD5Kv44/dj9Sv4I/lj95QDgB9AMkAwACiAJsAkwC2AN4BAAEsARQBAAEAARwBAAEZAPoBBgEWARABAgEAAQMA9wDBALkArwCwANkAygC3AIwAbABvgHkAfABxAIWAcwB5AFEARoA0gE4ARQBdgE2ANEAywDdAJuAVv/Nv6Z/5YAEwDo/Nj6APqI+DD3oPbw9kD1cPJA7yDtgOxA62DrwOvg6kDooOZg5kDnIOcg56DoYOvA7eDtAO6A7yDt4O0w8VD1CPuE/Zb/xv5c/Mj6zv7wBaAKQA1gDKAKkAcQCLALIBAgEmARYBFAEGAQ4A4AD3APIBHgEWAQMA/gDvAPwA0gDBALQAugCqAK4AsgDLAImAUQBugGAAeYBegGkAjoBzAFgAM4A/QCMASYBeAFyARsA3QDQANiAWIASQC1AK0AugC4/7z9wPo4+dD40PjA9yD2oPWw8iDvAOxg7KDtwOxA62DpwOiA56DmoOcg6ODowOmA6yDtgO9g76DuwO7A7lDz8PbY+9X/hQA8/qj6uPzMAsgHsAuwDhAOYAqQB5AJ0A7gEYASIBMgEuAQUA+AD0AQoBDwDwAQoBBQD/AOUA6gDaALgAnACIAKYAuwCsAJ2AdwBoAE+AOwBRgHSAdgB1gGaAV0A7ACmARgBVgFMAXIBdgE2AS0A8gCzALvALABBAIGAcABFQDk/ej6cPhg+ej5+PmA9sDzgO8g7sDswO0A7WDswOlA54DmwOUg58Dm4Ogg68DsoOrA6+DuAPBA7gDucPEQ95D8OP7bAOX/vPwA/D4BEAjgDPAOcA0gDqAKQAmADGARoBXAFKASABHAEKAPoA/gEGARQBCAD8AP4A/ADiAM4ArgCfAIsAhACfAJIAnwBygGlAOUApQCqARYBvAGkAbIBDwDqAJkArQD4ATIBfgFWAVABeADQAMUAswCZAIMAs4BzgEcAsz9PPzI+bD52PhA+Zj44PWg8YDs4OxA7eDrYOwg6yDnwOUg5WDlYOVg5ADooOtg6+DqQOzA7kDugOwA76DzsPfM/J4ByALM/pj7Bv64BOAJUA2ADyAQkA5QC7AKsA0AEsAV4BWgE4AQoA+wDiAQIBHgD2APsA2wDhAOgAwQCuAIIAkoB4gG2AVYBzAH2AVgBOQCnAIcAtwCSAQIBQAFWAS4BKAEyAPcAmAEYAXoBRgHyAYAB9gEqAQYA6QCUAIoA5gFyAJvACj9oPsA+nj44PgI+qD2MPFA7uDt4Oyg7ODrQOnA5sDkAOSg5WDmgOVg54DogOkg6sDrgO3g7kDvQPBg8lD2SPzTABgC5QB9/wIAQARgCmAPwBBgEMAOoA1wDfAOwBKgFgAXoBOAEQAQ8A7QDyAQABFQD1ANsAxQDCALAAmoByAGGAYgBsAFoAVIBIQC0gB+AP8AUANIBTAFOASkAkYBGAHkA8gGUAgwCNgG+AXQBDAFSAbgBxAImAdoBtQD4gH6ACgBTAJnALL+SPyg+iD3cPVA9UDywO7A7IDsIOqA6sDoAOgA5cDgQN+A4uDkIObA6IDpoOnA6IDpQOvg7uDw4PMg9yD5DP1nAIQBlALAAnQDAAdQDaARYBNgEGAPIA+QD+APgBOgF8AXQBXAEIAPkA1gDTAOIBAAD0AMwAkACQAJQAbwA6QCyAQoBYwDcAPgAogB6v6c/YD+ugGMAxAGIAdoBP0ATf9OAeAF0AgQCvAK0AmIB1gF+ARYBoAI4ApAChAIGAVQAgoByQBLAHIAHf88/ND54PYw9LDxwO/g7kDrgOlA6IDpQOmA5UDjQOAA3UDeYOTA6YDtQO0A6yDoYOcA7HDxUPag+Qj9vP9S/3f/tALgBWAIUApQDmARwBGgEkAUABRgEcAPABKgFWAXgBagFEASIA+gC2ALsAxwDIAMAAvgCZgHCAUIA9oBAAL+AfYBegG4AagBygAa/zj9rP1eAPQCAAUAByAGUAQwA0AE4AaQCYAK8AogDMAKYAlQCRAKYAvgCsAJMAjABQAEqAOgBEACIv/w/Pj5CPhw9QD1MPQw8KDroOkg52DlQOSA6MDowOUg4IDaANpA3gDlAO2g7wDvAOyg6EDpYOzg9Cj8ugHAAhADOAHmAEgFsAvgEKAR4BGAEiAUoBQgFSAWgBTgEwAUwBSgFOATQBNAEdANoAtACnAJoAiwBjAHmAXqAR4BDALcAW//rP0o/RT9yP34/Yr/PwCw/0AAiQDoAAwCOAMQBpgHwAjQCQAKkAmQCUAKUAuQC7AMYA7ADpAMIApQCKAGQAWoA4wDtAMIA/T/kPzg+BD10PKw8WDvwO7A7YDq4OYg5ODiIOGA32DhwOIg4YDdwN0g4oDk4OYA64Dw0PEA8GDvsPJ4+Gj9KANQBnAHIAZgBwANQBFAE0AUQBTgFAAVABTgFWAX4BdgF8AT4BAgDqANwA0QDQANoApwCFgFuAESAND+Af8XAEgBqf9I/kD9APzw+6j7GPyw/d//2wCsAzAEuARABDAEGAXgBUAJkAyAEIARQA9wDDALkAswC8ANQBFgEsAP0AsQCCAF4AJmAcgCaAO4AvL+GPtA90D04PEg7yDugO0A7IDpQOcA5mDkgOAA3wDfwODA4KDhAOTg5CDj4OPA5kDsAPGw9QD6sPqo+YD7Cf+AAkAGwAgwDoASgBSgFWAUgBJAEUATYBaAGGAXABlgF+ATMA+wCgAL0AkQCxALQApoB9ADeAH8/ZD7IPqg+xT+rwCv/4D9+Pt4+vj60Pvw/Lv/UAJYBMgFOAVABUAFaAZgCEAKQAxADyAQoBAgD6ANgAzwC4AMwA6AD1AOMAxwCogHYATEAUb/i/8R//j9sPso+YD2sPKg74DtoOwg6+DpwOrA6WDmgOJg4SDhwOGA36DgYONg5eDlQOeg6MDnwOgA7ODywPik/RQCoATQAm7+AP1sAQAJ4BAAGOAZgBcgEmAOsAwwDgASIBWgF+AWIBOQDsAJOAdAB2AIEAgIBWwDpALyAW8A6P0A/Wj74Pmo+rj8av/U/+z/yf9u/lz9yP0cAZgFIAjgCHAIgAcgB8AIMAuADSAP0A/wD8APsA6ADTANYA1wDcANcA1ADFAK8AdoBYgCJwA4/wb/PP5A/Fj5kPZQ9JDykPFA8GDvAO7g7ODrYOrA6CDn4OWg5YDlgOVg5QDl4OXg5oDngOiA6iDtwO2A7oDxgPcs/c4BmAWwBRH/YPu//ygGgA5AE2AWoBdAEmAM8AhgCqANYBLAFqAWIBHgCnAIMAcwBgAGUAZIBngF6APUAvAAsP8y/kr+qPwU/Mz8Uv9sAiwDhAL8/wL/pf8YArADuAYwCSAKYApQCYAJ0AnwCtAMAA+gD/APAA8QDrAMkAtAC/AKUAuwC+AKQAiwBRwDygEXABL/tP3c/Bj7CPmA9xD2sPQA8+DxIPHg7+DuoO6g7WDtQOzg6gDpYOiA6ADpAOkg6iDrIOtA6+DrQOyg7IDusPJo+Gj6zP28A2AFwAOE/kT+rf84BcALQBNgF8ATEA3gCVAKMAhgCiAOQBOAE6AP8AqACIgFCAS4BPAE4ATgAxAEuAPoAXX/TP74/Vr+0v4A/5H/QAGQAngDMAOUAlACGANgBKgGkAgQCvAKsApgCrAKYAswDHANEA4ADkANoAxADMALMAtACkAJ4AgACMAGmAVYBGAClwAY/+D9aPzg+qj5EPlY+GD3gPZQ9ZDzkPHQ8JDwMPAw8ADwIO+g7QDsoOoA6gDqgOpg6uDqYOtg7CDsQOwA7SDvwPAQ89D3fP5YAiQC8AI8AVD9YPpM/8AKwBFgE4ASUA/QCiAFcASwCMAOIBDAEKAPMAs4BlADEAPYBKAFIAREA0wCyAGWAEL/VP94/0T/Kv4U/hz/9wDEAtADIAUABSgDKAJEAwAGQAjwCTALMAtwCpAJ4AlgCgALAAxADYANYAwQDMAL0AoACfgHyAeIB/AGGAfYBkgFzAKZAH7+FP2A/BD80PuY+yD74Png95D1oPRQ9PDzcPMw8+DygPEg8CDv4O6g7YDsYOvg6gDqAOqA6gDsQO2A7iDu4O3A7aDwsPQQ+p4BmAU4B6QCMP0w/Fj+bAFACqAToBdgFMANEAiYBvgG0AnwDWAQIBAADvAK0AbwBPwDuAMoBIQDiAOGARIATAEcAp8AxP76/mb/0v7E/Wn/lALQBNAFIAb4BcgE0ANoBPAGUAmQCqALAAwADRANoAuQCmAKgAqQCoAKMAvwC1ALcAogCUAHQAWwAzwDtAOIA9ADHAPxAPT9UPso+gj54PhY+RD6WPnQ95D2YPUw9CDzQPPw8iDyQPEQ8YDwIO+g7YDtQOyg6oDqQOuA6yDsIO1A7+DtYO6g70DzCPgA+ncAGAXwBZgCTP/4/bb/aAWgDCASIBQAE6AOkAoACCAIUArQDFAOcA4gDXAKwAfQBugFOAR4AVUAIgCMABoBhgEeASEAE/8e/kz9VP0m/uD/PALMA/gE4AQYBOwD0ARYBggHEAhwCcAKIAtgC4ALQAtgC0ALAAugCiAKAApwCSAJ4AigCHAHiAV4BKQDtAJQAe4ABAFlAGb+aPwg+4D5YPnA+PD4YPgQ+HD3cPaA9QD08PPg8sDxsPHg8SDx4O/g7kDvwO3A7EDrIOvg6oDrwOyA7gDtIO6A7mDwsPLA9XT9wAFYBHgDfALk/fj62v6gBtANABJgE+ARsA1wCLAFMAgAC6AM8A2QDZALoAjIBuAE0AQIBIwCMAFWADkAOQB//3r/OwCmAAQAKf8a/6z/oAB+AVwDsAXwBeAFAAZgBnAHoAcwCAAJAAqQCsAKEAywDIAMMAvwCXAJYAlACBAI4AiwCeAI0AaYBVAEkAIOAcIB5gHPAOX/ov60/WT8iPqw+hj7sPrQ+VD5kPhQ90D34Pcw9zD2cPVg9HDzoPGg8bDx4PBA8CDvQO0g60DqYOsg7SDsgOzA7EDuQO7A7oDzsPbo+kgBkAVABasAgP2E/Y7/aAOwC4AT4BWgExAOYAqwBqAFQAjQDGAQcA8ADeAJGAegBAADAAI8AkwCDQDu/vD+pf9l/zX/n/+C/0z+LP2Q/YL/qAHEA0AFEAbQBWAF+ATIBYgGkAjgCVAKEAuwCxALAAowCuAKMAtwCqAJ0AlwCYAHcAdIBxgH+ASwAgQD+AKgAhwCiAFUAD3/RP2E/FD7QPug+5j85Pxs/Dj6gPkA+JD3UPdw9+D3wPeQ9uD1QPXw8uDwIPCg8KDuQOvA6iDtwO9g7kDsoOwg7MDpYOsA7zDzwPfY/EAEkAXwA7gAUP38/G//QAYADWARoBMgFPAPUAqYBigHUAmQCuAMkA6gDPAIiAbwBJgDgAFYASYBnv8u/qT9Ev5R/0j/eABhADP/pP1g/er+CAEkA2gFoAZoBzgH+AWYBYgGQAjgCYALUAwADTAMkAqgCZAJgArgCtAKMAvQCnAJSAcABjAFGAVIBOADlAMIBJwD/gHEAMn/3v6A/eD8nPwY/eD8mPwo/CT8aPtQ+tD56PjI+CD40PeA99D34Pfw9eDysPDw8EDwIO/A7SDtYOxg6wDrgO5g72DtgOuA6wDu0PAw9oz8rAH4BCAEcAJb/7j98P+gBGAJwA3AEMAR4A/QDPAK0AmQCPAIMAqQC1AKMAlwCFAHIAVYAqoBXgDM/oj9YP30/dj9hv5u/50AWf/w/Sz91P3i/moAcALwBAgHAAdwBlgG0AYQB1gHgAggCtAKYAowCjAK0AmQCUAJoAkACdAIiAf4BUgFSAUYBfgEWAT4AsACsgFjAPL/MgBRANL+mv5S/tz9qPxc/Jz8uPyg/KD7SPtw+hj6APlg+aj4IPiw95D2wPTw8hDykPFQ8IDvIO6A7aDq4Omg66DuUPDg7YDrAOug62DucPW4/FwCIASoA9IBzv6M/YD/fAOACCAN0A/AEGAPAA0gDCAL0AmACWAKoApgCUAI8AegB9AFgAQ0A3gB0v68/AD8rPyA/Yz+MwBeAO3/cv5Y/ej86P34/3ACmARgBTgGAAaoBbAGsAaAB3AJ4ArgCVAKYAqAClAKoAkQCpAKQApACZAImAeYBpgFUAVABXgEKASkA2ACigFyAUQBbgCA/7b/G/9s/XT8HP2w/fj8cPzk/Oj8cPvg+Tj5cPlA+MD3YPcQ91D2MPXg8+DycPFg7yDuoOzg6wDrQOug7ADvgO/A7iDtAOuA7LDwqPh8//AB3AMEAwIBvP7U/qAA+AXACVAN4A8gEHAOkAzACxALkAowCpAJUAkwCfgHEAeABpgGQAawA88ATv7Y/MD7wPsw/SoASgGyAEv/SP6k/fj8aP0mAMgCCASwBPAEgAWwBVgFQAYQCLAIgAgQCaAJkAkACQAKMAoQCgAK0AkQCZgHkAaABigGyAVABSgFqAQkAxACuAHyAYgBFAERAPf/1P7I/Vj9hP3w/Rz9bPyk/DD86PoQ+iD6mPlY+cj48PdQ98D1oPRQ9CDzIPLA8MDvoO6A7SDtoOwA7cDuwO/g7sDr4Org7SDy4Pco/QQCTAJaAYz+gv5M//YAcATwCAANoA1ADhANMA3ADDALIAvwCqAK8Ah4BxAIqAdIB+gGMAeoBawCpf/k/Rj9qPy4/U7/zP97/2n/H/+Q/XD9cv4fAAgB/AHMA1AE/ANIBCAGsAe4B0AIoAnQCbAIUAgQCYAKIAqACiALcAvgCQAIAAjABigGWAUwBTgFsATgA1ADMAOcAUwBlwDw/4b+fP08/RT95Pyg/Mz8kPzI+yD7cPrw+YD54PgA+QD5WPhg95D24PUg9YD0MPNA8jDx4O/g7qDtIO1g7QDugO+A70DugO2A7ADu4PEA+LT9ZQD8/0H/q//E/eT9BABYBMAHEAoADJAMAAxAC4AL8AuQCzAK4AmwCXAI4AcQCHAI6AdAB4AGcAQYAc7+xv6P/yH/nP9PAKMAwP+c/qr+BP/I/nH/8ADqAagBdgEoAlQD/APIBCgG0AYoBzAHQAewB4gHyAegCDAJAAkgCTAJwAhQCOgHcAeoBqAFyASwBNwDhAM0AwwDSAKSAeUAwP/i/hL+4P1M/Wz9CP2o/Gz8EPyg+xD7kPo4+iD6gPng+BD4cPeA9sD1MPVA9CDz8PGA8UDwgO+g7sDuAO+A7wDwQO9g7uDtgO9A8zD2oPo4/nb/0P4w/fj9Ev8ZAAQCyAVQCNAJEAqgCmALcAuQC/ALEAwgC3AKkAmgCYAJsAlACtAJsAggB8gEnAIGAbMA6wD8ABABEAGZAN//cv8p//r+Tv9p/+P/CwADABoAzQDUAfACOASIBMgE+ARgBZAFGAaoBvAHIAigCKAIkAhACLAIcAhACOgHwAaoBvAFQAXABPAEqAQQBGQDeAKUAW0AuP8P/9L+Tv48/qD9SP2U/Az8WPuw+pj6+PlY+cD4OPjw9yD3gPYA9vD08POg8iDyQPGA8ODvgO+A7xDwgPBA8ODvQO+g78Dw8PLw98D78PzU/az9Mv4a/tz9sP8cA3gFAAdACEAJwAlQCnALwAxwDFAM4AtgC9AKsAmQCRAKsApQCrAJIAhIBqgEbAO8AsoBqAFOASIBpgCY/wf/9v4o/1T/Rf85/6r+MP6o/uj+af8dAA4BFAJQApwCuAKQA/gDoAQwBWgFwAXoBVgG0Ab4BiAHUAdYBwAHQAbIBRgF2ARwBPQD6AN8A+ACIAKQAfUAXQCy/+z+Zv6c/Xz9pPww/Lj7mPuQ+6D6EPqQ+Rj5KPhw90D30Pbw9SD1EPUQ9VD0cPMg8+Dy4PIw8pDyYPLg8RDysPLA85D0MPZg+Lj6YPxI/Rz9eP3E/c7+LQCmAbAC2ASQBqgHUAgACSAKsArQChAKYArwCWAJsAngCYAKMAoQCgAKIAkgCJgGqAWoBNwDSAPsAkwCngF2AWABGgGdAHUAbgDL/xD/yv62/ob+3v5q/woAnwDbAF4B8gHaARQCbALoAhwDQAO8AygESARwBLgEWAVoBUgFMAX4BMAESAQQBOgDzANUA+ACsAIEApwBAAHBAE0Akf8N/47+Lv6Y/Uj95PyQ/Dj84PuY+zD7uPpA+hj6uPmA+Tj50Pg4+AD4UPdg9xD3oPaA9oD2sPaQ9oD2cPbw9kD3sPeQ+LD5sPp4+9j76Pvo+1T8bP0W/uj+wv/DAFoBvgEkAvQCbAPIAygEqATYBJgEyAQYBSgFOAVABXgFQAUABdAEgARABPwD9AP0A8QDYANEAxADtAJYAjACQAIgAvoBrgGOAWgBYAFqAX4BogGeAbwBwAG4AbgB7gEcAiwCQAI0AiwCLAI8AkgCRAI4AkgCYAJQAigCBAIoAiACDALyAdwBpAFeARwB/gDOAJQAiwBiADUA3f+m/3b/Xf85/xL/7v6o/k7+/P3o/bz9hP1M/Qz95PyY/GT8JPzw++D7oPuA+3D7SPso+xj7IPso+yD7OPs4+yD7CPsY+yD7SPtg+4D7wPu4+6D7sPvY+xT8PPyI/OD8IP1E/ZD9+P0s/mr+rv4c/1//eP+H/8v/KgB+AMoADgFQAY4BvgHuARwCZAKcAuQCHANIA0gDcAOQA9gDAAQIBCgEKAQoBCAEGAQoBDgEMAQoBDAESAQYBEAEIAQoBBAEKAQwBBgE8APMA8wDnAOQA4gDaANAAzQDGAP0AsQCfAJ4AkgCDAL4AdwBpAFsASYB/ACtAGgAJwDm/8D/bP8x/wT/yP52/jz+Bv7o/cT9eP1g/Sj9/Py0/Iz8gPxk/Ez8EPwM/Aj8APwQ/DD8QPws/Bj8+Pv4+wz8OPxc/Fj8ePy8/ND80PzY/Oj8DP00/Uj9ZP2Q/ZT9oP3M/ez9+P0m/lj+kv62/sj+4v4t/1v/aP+J/8H/DQBGAHcAsADlAB4BTgGMAcgBDAI4AnACpALYAvgCEAM0A2ADiAOkA8AD1APYA8wD1APcA9gDyAPAA8gDzAPEA7ADrAOQA3QDZANYAywDAAPYAqgCjAJkAjACBALaAaYBeAFAAe4AswB2AEkAGgD6/8j/jP9Y/yL/+v68/ob+SP4y/hD+8P3I/az9oP2E/WT9RP1A/Tz9OP0k/Sj9MP0s/Tj9PP1E/Uz9SP1Q/WT9aP18/Wz9kP2c/bT9vP3I/ez9Av4Y/ib+Ov5M/lT+Yv5e/n7+ov68/tL+5P4C/yD/SP93/5n/sf/I/9//AAAaADkAbwChAMoA7gAcAT4BZgGKAcAB7AEEAiwCWAKIAqQCuALUAvAC/AIQAxwDHAMgAyQDKAMwAzgDNAMkAwgD5ALUAsACqAKQAnACVAIoAvoB2gG0AYwBagE+AQgB2QCwAI4AbABBABcA7P/J/6D/gv9d/yz//v7U/q7+jP5c/lr+WP5E/jj+OP5K/kL+MP4k/jb+DP4O/hj+Jv4w/hj+Pv5S/kr+SP5a/m7+aP6I/rT+0v7a/tL+7P4P/yf/Qf9Y/37/nP+x/8T/yf/T/+3/AAAJAAwAKgA8AD8ASwBfAHIAeAB2AIIAkACYAJIAkwCjAK8AuwC+ANEA5gDuAOYA2QDSANkA5gDjANkA0wDSANUAyQC5ALMArgCoAJEAbwBOAD0APgA3ACcABwDx/+3/4f/W/8v/xP+x/5T/iP94/2r/Xf9V/0v/Pf80/zX/Nv8q/yH/F/8V/w//FP8R/xH/DP8N/xD/Fv8u/zz/Qv8+/z//Pv9O/1D/Uf9d/2n/ff+E/4H/g/+S/5v/mP+Y/67/vv+4/8j/5P8EAAUAFgAtAEgATgBbAFwAbAB5AIYAqACWAJYAigCRAJUAhwCGAJMAmACHAI8ApQCkAJYAkQCtALMAngB8AIUAjwCIAG0AYwBlAFYARABDAFwAZABPADMAMQAgAAYA8//0//r/+v/q//b/5P/D/7b/uf+5/67/oP+e/6b/oP+h/6b/ov+c/57/p/+f/5b/oP+e/6H/l/+g/6D/oP+q/6v/pP+a/5n/pf+u/6b/qf/B/9T/xP+8/8j/0f/R/9b/4P/l/+H/4v/u/wMACQAWABgAFgAXAB8ALAAoADQAOwA/AEYARgBQAFoAVABYAHAAhgCaAJ8AkQCTAJsAowCdAJ0AqwCrALEArwCoAKgAnACRAI8AkACUAIIAaQBbAFwAWwBKAEUARABGADMAGwAXABEADAD8//D/6//q/+j/4P/p/+P/yP+u/53/kf+K/4L/hf+D/3n/b/9v/3X/a/9t/2r/Yv9Z/17/Yv9Y/1D/XP9y/23/Y/9n/3f/ff95/4D/lf+m/7D/sf+9/7z/uf+3/8L/y//J/9b/5//r/+H/4//p//X/9//y/wIADgAYACMALQAtACgAHQAaADIARwBJAEEARABLAEAAKAAzAEMASgBNAFAAYABrAHAAbABsAGMAbQB4AHwAgQCCAIgAfQCAAIQAggB0AG4AbAB4AHcAdQBuAGYAZABhAFoASQA2AC4AKQAVAAkACAAJAAYAAwD8/wQA+//8//n/+//s/9P/1//Z/+b/1//b/9z/5f/u/+n/7//s//H/6f/k//X/CwASABUAFwAsADQAJgAqADwAQAA6ADQALAAsACwALwAyADIAOwA+ADUALgAhAB8AFAAbACYAMgA3AC0ALwAfABsAHAAaACIAGgAbAA4ACwAFAPf/9P/t/+X/3f/O/9T/2//Z/9L/zv/X/93/2P/U/97/3f/P/8n/2P/g/9X/2P/a/+D/2v/L/9f/4f/i/9v/1v/Z/9z/3v/r/+j/3//c/+X/4f/t////9v/u/+f/7v/x/+D/3v/f/+X/4v/n/+z/7f/0//T/+P/0//f/AgAMAAQA/v////7/AgAEABMAHQAYABAABAD8//D/9f/7/wMAAwAFAAkABwD8/+r/5v/g/97/2v/K/8X/xv/N/9D/z//F/87/zv/L/83/0//d/97/3f/U/9n/1//V/9f/1f/S/8v/x//F/8r/yP/P/8z/uv+5/73/yP/O/8b/xf/A/8D/vP++/73/uv+8/7//yf++/8H/w//E/7b/vf/L/8//yv/I/87/zv/M/8//5//y/+b/5f/v//z/AAAEAAwAIAAlAC0ALwAlABoAHwAkAC0ALgA8AEsAZwBfAGsAZgBiAGkAbgByAGgAZgBnAG4AaABmAHEAbwBqAFkAWgBXAFcAUwBSAEcAPwA5ADAALwAqACkAJgAdABgADgAWAAQA+//7//P/8f/3/wEA9//p/93/4//n/+P/4v/p/97/1f/W/9b/3P/Z/9L/z//H/73/w//O/8z/zf/P/9X/0v+8/7r/xf/J/8H/yv/V/8v/wP++/83/x//F/83/3//i/9r/1P/l//H/7f/p/+n/5v/q//H/9f/8//3/BAANABkAGwAkADIAMgAwAC0ALAAwADkAOwBBAEAAPgA/AEEANgA1ACkAKwAzADYALgAoACYALQA4ADAALwA0ADkALwAjACMAJwAfABsAHgAdABIAAwAEAP//9f/o/+7/6P/X/9D/zv/Q/83/y//E/8H/v//A/8L/wf+//8H/v/+1/7v/0P/Q/8n/wP/N/+j/7P/u//P/9v/t/+v/9f///wEAAAAOABUAEgAHAAgAEgAaABkAJQApACsAJgAnADAAKQAsADQAPQA0ACkAJQAlACAAGQAcACQALAAsACgAJQAnACQAHQAbABgAHwAgAB4ALAArACEAIAAgACgAGQAPAA4AFgAYABYAGAAaABgAEAATABQADQAAAPb/9f/t/+D/3v/c/9j/0P/I/8b/wv+//8T/wP/C/8D/wP+7/7f/vv+8/8L/wf+2/77/tv+s/6X/o/+k/5z/mv+f/6j/rv+1/6//sv+r/7H/vv/G/8r/0//j/+f/7v/s//r/+P/3/wIACwAXABEADwAVABoAIAAnADMAPAA2ADMANgBCAEIARwBWAF4AZwB0AHQAdwB3AHwAfQB1AGcAZABfAGEAWQBMAEUARQBIADkAOwA2ADoALgAnAB4AJQAfABMAJwAwACkAIgAdAB0AGQAUABMAGAAVAAoACwAdABsADQALABoAGwALAAEABgAHAP3/9P/1/wEA+v/z//7/CgAMAP//+//z/+j/4v/l/+f/6//y/+3/7//r/+r/6f/m/+b/2f/c/+f/5//n//T/BQANAA0ABwANAAkABAD6//X//f8AAAoAGgAsADkAOQA+AEMAQQA2ADIAOABFAEsATwBQAEgARAA8AD0AMQAlABwAGgAPAAkABgALABwAHgAsADsATQBNAFEAYQBjAFkASgBHAD8AMgAYAA0AAgDn/7//p/+X/3z/Yf9a/13/Z/9u/4z/sf/e/+n/6f/0//7//f/s/wAAKQBAACkAJgAuADgAGwD///L/6//O/8X/xv/B/6j/nP+3/87/zv/S/wQAMABJADwAQQBNAFkAQgAxACUAJwAaAAoA+v/c/6T/e/9H/zP/Ef8A//b+EP8L/wn/Iv9L/0//QP9V/3v/qf+4/9n/8f8fACEALQAUACsA6v/Q/7z/uP+b/5P/o/+t/5r/n//f/wAABAD7/xMAPwA7AEcAdACSAJoAfACHAJMAgwBtAFsAVwAhACcARwAwACkAsP+//9f/9//S/8P/+f8kADcAPABaAF8AhwBFACkAMv9o/woAvv6U/Hj40Pgw/Pb/NAKQBDgHUAj4B4gEDAJv/zj+qPsQ+Xj4UPqM/dL+kf8YAQQDNAPYAaoBPAIKARP/FP0K/gr+UP1w/SL+Q/+a/tz+v/8dAKr/4P6K/1sASQB8ALIBBAMQBPwDmASIBbgFuAX4BBAEPANoAgQBhwA7AB0ABwB5/wX/L/+l/zv/Mv9x/+b/0P8//8T/NwBaAPD/q/8bADwA9f/C/zwAnAAOANb+NP68/sP/BQAg/9r+pv6w/iD+RP2U/UD+5P7q/t7+Xv/O/z4ALACA/x//bP/8/zMACQCv/+P/YgAdACkAiwCwAJMA4f8y/wD/7P7Y/nr+Ev7Y/pz+rP5C/hr+Bv8I/jz+FP7T/4f/MAD7AL4BMALSAdQBJAEZALr+av6m/sL+kP4s/z4AwABuAUwBXgE0AWgA8/9O/3X/kv8uAAABTAG4AQgCfgEEAn4BtAEwAWkAFwDf/0YAVgAKAekACAECAdYAYwDY//7/DgALAJD/SP+h/z3/4P68/nT+ov48/gL/O//q/37/HwDY/+n/2v+9/5cACQAfAKH/XABFAFIAKgBdANQALABnACgALQDG/77/aQBPACsAMgAoAYABoAEaAbIBsgH1AMYACgBoAA0ACwBGAK4AkQAoAGkAkP+//97+H/8z/5X/+//i/54A1gBaAQQB4QCIAGkAjf8b/+b+T/9k/2X/BgCmALwBlAEUAkACaALUAQwBugAiAL//8v6o/qb+Sv/A//L/bAC2ADYB3wCIAF8AmQAvALf/q/8gAI4AkADdAOAAwwBsAND/3v+4/3b/Nv8g/2X/Xv9f/2z/v//c/7H/Pv86/yH/I/+8/sL+MP8U//b+0v5K/6X/e/9E/0b/oP81/2z/lf8uAAwA6//c/+D/tP8+/5P/z//n/wkAGABiAKQAfwA1ANX/zf+y/6b/Vf9F/1z/bP9m/1P/JP9j/2T/Nf9X/7T/CwAHANP/CQCwAHYAFQDq/xUAcABrAG8AsgCFAC4A6f/l/6v/o/9R/xj/JP9M/3T/jv8rAF0AjwBHAL3/pf+X/3P/4v7W/uD+pv9o/z3/eP7u/rX/3P8R/0j/lP/8//7+Fv54/3j/PABr/8z/o/9o/w//i/8hAFj/AP9W/wUAmP/J/2QAbQCAAI//fQCnAPcAwgBlANoASgCoAPMARgECAS4BpgAoABMAw/8cAOz/dQBCAdIB8AGMAU4BpgC/ACMAwP4k/8H/tgAEAckAMAG8AYoBJAEOAR4BsgDbAIQAgAByAKEAxwCSAOcA2gBQAbgA6QBgARYBKwBd/wAAQADu/5H/ev9xALAAHAA9ACAA9/9h/0D/OP83/4f/L//l/8r/eQBTAFwAPwArAAsAev+N/3v/8v+D/1P/jv/g/zsAVgAPAEIAyP+A/+7+7v4a/wv/Wf/o/rX/WACMAIoAXABBAMH/Zf8H/5z/zP+Z/4z/5v8/APT/ov++/xwAsv/U/q7+ov4A/3z+WP4V/9H/MwD6/+7/JgBlACIADwADAA4Awv9a/6z/x/+R/2H//P5W/4b/tv8BAB4AfQCeAJcAwP80/wX/Ov/a/sD+Jv+f//r/2v9VAMsAbgAhABYAHQCp/+7+Xv8iAAgBygCNAOcAzQDDAH3/SP9D/1H/GP97/24A/QDjAKYAcgGmAR4BYAC0AC4BOwAt/zv/+/8FANX/bQAcAQ4BPABGAIcAhwCc/3X/sf8fAO//sf8TAH4A1QCuAGAANADd/y3/iv5Y/r7+U/+0/1MAIAHMAZwBfgFCAdsA5v92/kT+xv5n/zsA7QDaAdYBmAESAWcAs/+a/gT+lP3o/aT+l/9mANsAQgEmAb0A0v81/6j+CP6I/Xz9cP4z//X/MgB4AKAABAGCACgB3QDzAEsAj/8wAEoAJgH0AJwBoAFIAlQCOAJMAqABBAJOAW4Aq//P/0gAJgD6/3gArAHEAfUAgQAcAcoAw/+G/pL+zP64/tT+Wf9SAMcADgHCADcA/P97/6r/VP9y//n/7f+6/4r/6/9mANsA1QCgACAAzf/4/7X/KP/S/hj/tP+q/5b/ov+K/6j/Pv8b/+b+Bf+J/xsAbgAGAKH/of/S/9L/8//Q//n/CQDq/4D/G/8Y/1n/2P96AEQATwAuADEAMwAbADYAsQDXAPwAzwBGAC8A5v/S//b/OwCfAOIA/wACAUgBSgF9AMj/of+4//H/iP+o/yAADAFmAWoBFAGWAPz/Of94/uz9jP4k/5n/hv/e//r/8v+NALsA6QDI/7D+jv7m/iT/6P5T//L/lwCOAIIAzgD8ALoACgB5/wn/CP/k/rz+3P4e/4H/v/86AFsApQBLAFr/wv72/ur+2P54/gX/r//v/6L/of8aABYAbf9R/5n/5P8aAAMAfACfAF0A4/+i/83/kP+D/zUArACYANj/6v7Y/qT+ev5Q/qb+G/+f/0sA1AA+AWQBXAHbAOP/kv5I/kr+B/+m/0IAlQC6ALwAGgFGARoBzACVADUAn/8p/03/p/8vALYAggH0AcABIgGgAM0AUABv//D+8v4t/1D/mP8nAPgABgFQAQgBVwAV/27+kP6a/pj+ov5m/ygAuADTAPkAegHWAZ4BEAGmAGQAfgCdAJIAtQC5AI4A7wBSAZABSAGnAFcAYQANAJf/bf+N/6b/yP8RALwAOAEqAcwAoQBtAAEAm/9M/2H/T/+8/r7+cf+fADoBWgH+AAYB6gDCAGYA2f9z/xn/Jf8Y/7X/TAC0AL8AewBFAKz//v56/rr+2v72/tz+K/+P/9D/0v8MAGgADwCf/yb/R/9d/1P/PP+E/9//AAAjADcAbQByAB0A1v+Y/33/hP/A/8//FABOAKMAtQBjACsAMgAwAMT/af8q/y//Zv91/4z/jP+V/6v/0v/M/3P/PP8T/03/lP/e/0oAngC1AH4AaAAZAOj/+f9DAIEAfQBDABMAVAB+AIkAeACHAIoAgABCAAAALQBmAG0A+f9h/xr/J/+C/9b/UACQAFsAIACL/xD/sP7S/g7/Yf+R/2r/S/9j/5D/jv9q/z//if+5/4f/Zf+j/+X/6P/I/6L/qv9c/3j/q//p/x0A4f8OADkAHAAVADYAiwCIAB0A2//6/0EALwDZ//f/OwBGAFEATAB2AJIAagCIADwADQDd/87/IAAtAHYATwAyAPP/GwBxAGMAOAAGABkA0/+x/+b/jQD+AP8AJgEKAeoAnQCgAOUAEAH5AHAADwAGAAgAHQAzAEMAZABPAD0AFgALAEIAUwBuAFQAPwADAN//lv8//2j/5P9QAG4AVQCHAMsAiADe/03/RP9X/yP/8v4y/4D/3//x/z0AhwCQACEAkP9I/wX/yP6w/gX/uP82AIYA1QD7AO0AQQCD/y3/wP6q/rj+Ff+X/+T/UgCPAOUA8wCjAE8Aif8A/3L+Pv6O/gL/yf8zAKYA1QAaARgB2wBmAPT/ev8i/0D/1v9pAPUAfgHIAe4BmgEiAQQBCAEYAZsAEgDh/1AACAE4AVYBfAG4AUYBzwCEAMAAmQAqAAwAFQDo/87/PADJAAYBzQC6AFEA/v+K/6j/wv+1/7T/HwA7ABkAWQDGALMAKgA4/+T+uv5+/rj+WP+X/8T/1v/I/6z/W/9X/w7/Vf8K/xf/EP+I//f/WACaAKoAxgBUAOL/Y/8l/yn/Vv+N/9H/0P+z/9f/FQBkAIcAVwDi/03/Bv/i/lb/m/+MAOEAKgEgAc8AjgBnACAA9P/Y/3z/av9Z/8T/GADGADIBeAE2AckALACk/yL/5v5C/2z/nf+l/9H/HQD6/wgAxf/7/17/1P5w/jD+Qv6M/hn/Qv+K/3n/Uv/G/nb+ev6O/h7+zP38/Vr+fP7K/mL/0//W/1X/JP9y/l7+YP7G/iX/RP+V/7b/GwBPAM0A1wDkAN8AuADNAHQA+wBcAeYBugGwASQCXAKEAnQCZALyAfwB6gF0AnQCUAJUAhQDmAOYAwwDeAK0ArwCxAJsAjACIALgAQgCzAHEAdYBDAJMAiACpgEyAdcA/gDDAH8A5P+I/3D/VP8U/wj+Cv48/qz+kv4e/qj9aP1M/XD9XP3Q/Fj8wPuI+2j7GPvw+hD7IPtw+rD5+Pio+Kj46Pj4+Mj4wPhg+Lj4kPn4+UD6UPp4+rj64PrY+gj7mPtg/ED93P1+/gD/rP+SABIBrgE0AsgCRAO0AzAEqATwBGAFgAYgB8AHuAcwCOAIMAkwCXAJgAkwCQAJQAmgCaAJ8AkACgAKcAnQCIAIcAhACAAIAAgQCNgHmAcACKAI0AhQCLAH4AbYBcgEUATwA5QD3AI8AogBjQCS/zf/AP84/nD9TPww+zD6kPlg+Rj5KPhA9zD2IPWQ87DykPEA8YDvAO8g7mDtYO0g7SDt4OwA7SDtYO2g7eDuIPCg8bDyEPRg9TD2oPZQ9xj4APm4+SD7GPwI/YL+wQDgAgAFaAZAB8gHEAfQBsAGQAiwCfAKoAugCwALMAoQCmAJAAqACWAJYAlACaAIQAiQCYAK0AtQDDAMAAzACyAMwAwwDVAOMA6ADvAN8A3ADsAOcA7wDeANkA2AC3AKEAqwCQAJMAf4BXgE4AK0ASQBngBu/yr+BP3Y+4D6oPno+BD4UPfA9vD1kPQg89DyQPIw8RDwYO8A7+DtwOwA7GDroOqA6sDqAOvg6iDrYOyA7eDuIPBA8iD00PWA9/D4mPnY+dj6uPtw/Bz9sP5JAGoBpAIoBIAFeAaoBwAJkAlQCBAIkAhQCOgHYAmwCrAKQAqQCGAIiAdwBuAHgAjACMAG2AVYBngGYAeQCKAJkAkQCsAKgApACnAKwAsQDdAMQA3wDDAOgA6gD8APIA8wDlANoAwAC9AJsAggCPAHUAiAByAGmAR0AwgDRAGb/2T+eP3c/Ij7QPrg+QD54PiA+BD4cPew9YD0EPPg8dDwIPCg76DvIO8g70DuAO7A7SDtYOxg62DrQOsg7IDtYO/g8dD0APcg+Wj60Pss/BT8ePxQ/Vj9zP21/zoB1AIYBBAG0AfYB5gGeAfgBxAHyAZwBjAIqAZoBwAI0AkgCeAF6AT8A+ACOAEIAlwCOAM4A0gE2ARABIADYARYBQAGuAaoBwAI8AfQCAAKkAqACsALgA2wDqAOYA5ADmAOkA1QDZAMcAtwChAKkAmwCGgHyAa4BhAGMAVcA3oBXv8M/rj9WP2I/Cz88Pvw+tj5gPkQ+fD4OPjA9kD1wPOA8uDx8PHg8YDxIPFw8KDvwO4g7sDtIO2A7MDroOtg7ADugPCw86D2uPi4+Sj68Pk4+bD50Pqw/Bj+cf8QAWwCnAKwA1gF2AYIBigG2AbQBagEQATgBlAIwAfYB6AHyAYIBQwDqAO4AmwBtv9YAMgA/AC6AcwBAAJQAmACpAJoAqwCWAQABngHgAhwCSAKEArgCkAMMA3ADXAOABDwD6AOEA5wDpAOEA6ADTAMUArgCEAIQAhYB3gGEAb4BNwCIAFmAGz/VP64/bD98PxY+3j6YPpA+oj54PhQ+DD3APbA9PDzUPMg80DzAPNA8oDx8PDA70DvwO6A7mDt4Otg66DswO5w8UD1SPiI+sj6wPqo+Tj5yPng+yb+sgBoAtgD5APABMAFaAZgB1gGIAeYBqgE1AOoBYAHEAlwCcAJQAgABkQDlAIQAkwB7ACPAGEAUAAgATQBFAEIAVoB3gGpAMEAEAIQA8AEmAYQCbAJ0AmQCrALAAzwC0ANMA9AEPAPwA/gD6APAA/ADjAOUAzACqAJUAnACKAHqAZABbADPALZAJr/oP6Q/Sz9CPzA+vj5gPk4+Sj5qPgg+OD2QPag9bD0UPTg8wD0kPMg89DyYPLg8SDxwPAQ8MDvAO+A7mDtYO3g7vDwIPPQ9kj6HPwY/LD7sPrY+VD5YPxl/1wCLAOgAygGKAVgBbAFCAcQBwgGwAWwBLAEyAWYB9AIEAnYB9AFhAO8AeAA4wBmAM//FwCXAAoAKv+4/ur+0v7M/jn/rv+8/50AlAKYBFAG4AfACOAJIAoACiAL4AsgDQAPgBBAEaAQYBBgEPAPEA/gDcAM0AsQCxAKgAnQCLgHWAbgBHADtgGX/7j9tPxU/BD72Pkw+Qj5wPjQ9zD30Pbw9cD0MPRw86DzMPPw8lDyAPIw8uDxkPFQ8IDwMPBg74DuAO4g7uDt4O2Q8FDz8PZA+Sz85PxQ+7j4SPjI+GD7RP7iAUAFWAQABWAEyATUA0AFyAYIBlgFMAT4BJgG8AcwCfAIwAeABIQCRAEOAOf/UwCSASQCPAKJAC7/Lv4K/qz+nv4m//3/8AC+AbwCaAQgBsAHUAigCOAIwAgQCTALcA2gDwAR4BBAEaAQ8A9QD4AOkA6gDfAM8AuwC0AL4AkACSAI+AZoBLQBowAjAHD+fP1Q/az8oPpI+aD4EPiw9+D2oPaw9kD1YPTw82DzwPLA8kDzgPLQ8ZDxMPHw8JDwoPCg8IDuwO3A7cDtAO8g8bD1MPmI+/j7CPxQ+mD4CPjw+q7+7wCwBBAGUAX4A3wDOAXgBXgG0AaoBqgFKAXoBlAIEAmoB7gGIAUcA+AAlP8CAXwBYALOAXwAPP/M/dz8iPyY/cj9Bv5e/nn/EQCWANYBvAOgBcAGAAcgB3AHkAhACkAMIA7gD4AQgBAAD8AO8A6ADhAOIA5gDhANgAuQCtAKAAowCPAGSAYgBBQCcQCXABoAtP2s/Cz8MPuo+aj4IPiA91D2QPaw9XD1EPSA87DzgPOw8vDyMPLA8WDxQPGQ8eDw4O/g7oDuQO5g7iDvgPHQ9PD3gPpY+5z8gPsw+Sj5IPuk/eoASASABtAGaAQ4BJgDyATABhgHiAdoBeAFSAfQB/AH8AfQBzgGEAMaAY8A7v9FAAwCGAPEATn/qP2U/Vz8mPx4/Tb+9P76/oj/bQBiABgCGAQoBoAGMAbQBpAHsAjACqAMsA4gEEAQABAAD7AO8A7wDgAP0A4ADsAM8AtAC1AL0AowCXAHcAW0A94B8AD//3b/rv6c/cD74Pr4+Wj4YPeA9oD24PWg9QD10PRg9MDzEPNQ8oDx0PDg8ODw0PCw8NDwAPBA7mDtIO2g7cDuAPIw9gD6OPs4+9j6qPlg95j4QPyMAMQDcAWABsAEaAM0AygEAAdoB0AIuAdwBkgGQAeQCNAIqAcYB4AFoAKPAMIArgFUAigCHAJFAMz98PuY+1z8RPz4/Fj9yP34/ZT9zv7b/3YBYAL4A1AEGAS4BAgGsAjgCmAMMA1QDmAOwA0gDYANUA6QDnAOgA6wDTAMkAvwC3ALcApACKgGMAQcA3ACYAGpAMX/uv50/fD7aPlw+LD4KPhw96D2UPZw9ZD0kPNw88DykPEg8QDxYPGA8GDwQPAQ8ADvQO5g7eDsIO0A7+DxwPTw9wD78PtY+vD2MPeg94j6+P7wA3AImAbEA0ACbAJ8AtAEcAdQCSAJ4AfgB6gHQAjwCMAIWAfgBfQDFAM4AjgCrAMoBAwD0QD6/kz9TPyA/ET9AP7M/fj9Kv4A/mb+Mv9xABwCaAPkA7AD/AOIBeAHIAqwCzANAA4ADqANoA3gDYAO4A4gEKAP0A4ADhAOIA3QDJAL4AlgCEAGeAX4BAgEKAI+Ad3/gP5c/Cj6iPnQ+ND4EPgQ96D18PQg9ADz8PEg8aDwIPBQ8EDwkPDA7wDvoO7g7eDsoOvg6+DtwO/w8qD16PhQ+tj5sPdg9SD2yPjo/TwCUAYwCCgFBAKuASgCEAWoBlAJUAtgCtAI6AcQCDAI4AYIByAH4AbYBLAEEATkAzADWAK8ASIAgv4k/Yz99P3g/T7+Xv5k/uT9iP0o/eb+eQAgAowDiAPkA/wDsAXwB2AJEAvwC1AMAA0QDWANkA0ADpAPEA9ADrANMA5gDoANsAwgC0AKsAi4B8AGKAW4A8QCEAJbAI7+sPyI+wD6WPk4+GD3EPaA9UD1gPPg8UDwUPDg7xDwAO8A7yDvoO6g7YDs4Ozg6yDsYOxA7qDxUPSQ9wD6aPrA9xD1EPXg93j8HAIQBnAI0AV0AggBHAF0A0AHEAswDHALoAlgCMAGWAeYBwAJAAn4B4gGqAWcA8ACTAN8A5AC2/+y/kT+iv68/Cz9MP5s/aT9aPwY/ej86Pyg//MACAI2AcoBwAMYBcgFQAfQCPAJcAqAC7AMgAzADIAOYA/ADlAOAA9QD6AOIA7wDTANkAtQCqAK4AjgBkgF2AS0A7wBqv/A/gT9wPtI+hj58PdQ9nD14POg8gDx4O8g74DuQO4A7QDtwOwg7eDrIOrg6CDoAOmA6wDwgPOg9eD1APUg8+DwsPJw95D90AEgBIAENAKO/5v/4gHYBXAIIAsgDWALIAkgBzAH8AcgCqALUAtgCSAHCAagBbAE9AMYBKQDFAJ8/4z/Sv/6/uT9WP2M/SD8mPv8/OD+pP9e//L+Qf99/5gA2AIgBWgGMAdgCAAJ8AigCYALEA2gDfANkA4gD6AOEA/wDyAQIA9QDgAOcA1ADBALUApgCQAIgAa4BNgCCAGU/4b+jP0c/LD62PgA92D1sPPA8oDxcPCA72DuAO0A7ADsQOzA6+DpQOgg54DnYOlg7YDxMPNA80DyQPFg7/DwcPbk/Kf/pgFwAoj/9P7w/rQCwAewCFALUAwADQALAAkwCTAKAAxADXAOcAzQCbAIEAiAB4gGwAXYBeAEnANEAdcAAQA4AHz/7P2w/LD73Pzk/bv/bf+A/lj9Lv57/4gAnAJYBGgGAAfwBugGKAeQCAALoAygDYANIA7gDtAOkA7ADnAPgA+AD7AOwA3wC9AKYApgCmAJGAcwBawD/AHM/1b+eP1A/KD6gPjg9VD0wPLA8bDw4O9g7qDs4OrA6sDpQOhg5yDnIOcA6GDqIO2A70DtAO3g7UDtYO+A8oD6uPy8/ID6YPpM/Ij9TAEgBhAJSAf4B5AIIAowCWAJsAsQDgAOQA2gDEALoArgCSAKcAlwCBAIEAjgBUwDjAEoAXYB9gFIAQoASv4w/YD90P3A/Rr+Ef88AFsArP8TABwBZALQA0gFgAb4BlAHQAgwCQAK8ApQDHANQA4QDuANIA5QDnAOYA7wDTANQAxwC5AK4AnACIAHwAXkA1gCmQCS/9D9VPzQ+tj40Paw9BDzoPFw8IDvQO5A7ODqAOmg5+DlQObA50DqQOuA64DrYOog6KDn4Ozg8YD1IPd4+Ij4wPSQ9Hj5EADgBGAFOAbYBXAFYATIBkAKoAyQDtAOAA6QDGAL0ArgC3AMAA2QDEALgArgCDAH2ATsA2AE8ASwBDwDdAJkAcv/Bv/w/lX/uP/IANQBBAJsAdEAFgHAAcQCeAQYBrgG6AbABxAIIAhwCFAKYAwwDVANUA1QDaAMEAwADBAMoAxQDIALoAqACRAIGAaQBNADmAMgAkMAWP6Q/Hj6WPig9mD1UPRg8lDx4O9A7gDs4OkA6ADnwOYA6GDpoOsg7IDroOgA5mDngOkg7/DyQPZQ90D04PBw8hD3yPvg/6gDqATQA0YBhgHsAwgHUAqwDLANAAxgC9AKcApwCtAKAA0ADVAM8AsACnAHYAXgBZAGoAawBUAFSARgArsAPwACASIBkgHmAfABigHTAJwBsAFkAnwDKAT4BJgF6AVwBrgGGAdgCCAJ8AlwCuAK8AvAC2ALAAuwClALIAuwCmAK4AlQCYgHCAY4BegE7APwAoABk/98/Uj7ePoY+WD30PXQ9FDzYPHg76DugOyA6sDpoOlA6kDrgOzA7QDrYOnA5+Do4OtA7jD00PWA9LDxYPFA8+D2wPtd/1gBSgGaAOr/qAAcAwAH0AlwCoAKEApwCRAJsAlgC9ALgAtwCwAMQAtQCbAHWAdQB1gHYAcwB1gGKAVoA7ACjAKIAkgDMANgAxQDyAKMAlgCbAPAA5AE0ASIBRAGOAaQBtgGsAeQCJAJUAqwCrAK0ArQCsAKsApQC1AL0ApQCvAJQAlQCHAHuAYoBigFaATUAjIBf//A/hD9WPuQ+qD4APcw9JDzQPPA8QDvAO3A7CDr4OlA66DsQO7A7ODqgOkA6YDpoOxg8NDz0PPA8UDxQPEg9PD2WPvU/Rv/2P6A/ZT+eQB0AwAGqAdwCBAI4AcgCFAJ0AnwCUAKwAoQC5AKcAqwCYAI2AeAByAIcAgACMAHqAZABWAEeAQgBcgF0AWgBZgEaARQBKAE6ARABTAGYAYoBogG4AZIByAHEAiACCAJAAlwCSAKIAqQCWAJIApACjAJUAkwCdAIMAgAB9gGmAXYBAgEBANsAtEAPP86/hz8YPsA+sD3cPbw9WD1UPNg8DDwwO5A7ADq4Oog7iDu4O0g7SDrYOhg56DqAO/g8bDx4PGg8ODvIPDg8uD3qPrA/LD88PuY+4D82v48ArAEyAWoBuAF4AUwBuAGUAjwCOAJIAoACvAJ4AhACEgHeAdQCAAJkAiQCNAHKAYgBRAFAAawBggHiAZABkgFgATQBDgG8AYIB1gGIAZ4BmAGuAa4B9AIMAlgCAAIMAgACUAJkAkgCuAJYAngCIAI8AdQCPAH+AcwB5gGkAXIA8QDaAOsAsMATP/w/jL+mPsA+jj5cPiQ9iD1cPVA9PDwIO9g7kDuoOyg7eDwgPHg7aDqQOnA6SDtwO9A86Dz0PCg74DvwPFQ9LD3+Pqk/Ej7wPqw+hj8Bf9AAXAEEARABFAEuAR4BZgFOAcACOAIMAlACSAIgAfYBjAH+AfQB2AIkAigB2AGcAVoBQAGQAYgB3gHwAZ4BbAEIAUwBrAGaAdoBzgHgAbQBfgFSAdACCAJAAmACNgHWAfoB4AIkAnQCYAJoAj4B6AH+AYQB6AHAAgIB+gEMAQIBKwDjAJgAjABxf/U/Zz8nPxA+5j4APgo+KD2cPTQ8lDy8PCg7sDtAO/A7zDwwO/g7mDsoOkg6oDtQPEw8oDy0PBg74Dv8PBA9DD3aPlI+gD66Pjw+ID6pP0oAMABpAJgAlgC9AFIA0gESAV4BjAHAAgwB6gGGAbYBSAGAAfoB9AHIAdIBgAGoAWYBRgGCAeIB2gHsAZABkgGaAYYB7AHUAj4B4AHqAewB0AIMAjQCIAJwAmQCRAJAAkgCYAJwAkACuAJcAmgCPAHwAfYB9gHgAcQB0AGuARwAxgDcAPkAlYBBwAr/7D9qPto+gj6aPnw9wD3sPZQ9DDxIO/A8BDxYO8w8ODvAPAg7sDrYOwA7aDuAPDw8dDxoPAQ8ADxIPOg9ID2qPi4+Rj6APpA+lD7DP2O/0gBiAIsAmwCWAJcA4gEWAVwBigHuAfgBmAG0AWgBhAHcAfQB3AHQAdIBuAF+AUwBsgGYAdgB5gH8AZQBigGAAcwCMAIoAhgCBAIkAcwCOAIAAogCiAKAAqgCaAJsAkwCoAKsAqgCgAKoAlACRAJQAmgCGAIIAjYB5gGgAWQBDgETAPsApACPgEg/xr+bP3Y+0D6sPjA+sj5sPZQ9NDxIPHA77Dx8PJA8wDwYO1A7cDtYO0g7XDw8PCw8ADvQO9Q8ODxoPKQ9ND1kPXg9gj4mPng+Tj6gPuY/YT/igDuAN4AJgF+AUwCSASgBTgG+AUQBXgEkATwBDAGGAcAB2AGeAUoBUAFaAWoBSgGmAbABqAGWAZABuAFMAYwBxAIoAhwCNAHkAfYBzAIAAngCTAK8AnQCYAJsAkACmAKwAqwCnAK4AmwCXAJMAkQCeAIcAggCNAHwAaYBcAEsAQwBCQD6AFmAd3/CP4o/Cz82Puo+pj52Phw94DyMPAQ8bDzIPTQ8RDxQO8A7aDr4OzA7+DwQPDA7kDvgO6g7qDwEPPA9MD0UPQQ9TD38Pfo+LD56PpQ/GT9+v4jALQACgBKAIgBPAPgBGAFiAXgBOADlAPABDAGoAaYBjgGqAUYBeAEwAWoBmgG2AVgBiAHmAY4BoAGEAf4BpAGcAfACBAJUAjYBzAIkAgwCXAJIAqgCkAK0AngCRAKYApwCmAKoAqQCsAJ8AjwCAAJ0AhwCBAI0AfoBqAFwAQIBLgDdAO0AkYB1v5Q/bj74PtY+3j7UPoA96D00PHg8RDyIPKQ8kDz8PBg7eDrYOwA7qDvwO/g76DuwO0g7sDvcPFQ8iDzoPPA9ID1QPZg92D4sPlo+gD7mPzE/sL/if9Y/5n/DAGoAlgEKAWYBGgDuAKYA9gEuAXIBUgF6ASYBNgEGAUQBSgFkAWYBfAFQAbQBtgGcAYYBjAGcAZAB3AIMAkQCUAI2AeoB8AIwAlQCjAKMApQCvAJgAlgCXAKsApwCnAKQAqgCSAI+AeQCLAIAAiQB0AHAAZ4BJwD1ANAA7gCvAETALj9YPvI+wD8kPsA+jD4wPaQ8zDyYPKA82DzwPKQ8eDv4O1g7YDu4O+A8DDwMPAA8ADwsPDw8RDzwPOA9LD1oPaA90j4CPm4+dD6GPxs/Yj+fP9OADMACADuAIwCxAOYBKAEAAQAAxwDAAUwBjgFFAMQBDAFeARoBQgFyARwBKwDiAWIBqgGCAaIBkAGIAUgBbgGMAlACbAIkAiwB5AHsAhwCnALEAtQCpAKUAuQCrAKwAqwC7ALMAuwCoAKkArQCbAJIAlACVAIoAdwBzgGIAUQBOwDkAM8AoUAGf+A/Yj8iPso+0j6uPgw95D1IPQA87DyUPJA8pDxwPCA7+DuYO7g7qDvMPBQ8EDwwPAg8bDxcPJA8xD0oPWQ9oD3MPgI+Qj64PrQ+wj9qP2i/iUA0AAZAI4AHAKIAygEWAI8A+gDAAQQBdAF6AWQAtgB0AIABnAGMAW4BDgFYATkAkAFsAawB5AGYAb4BZAFkAWwB9AJIAkwCOAH0AgwCTAJsAmACnAKoApgC7ALgAvgCnAK4AogC+AKUAuAC4AKgAmwCMAIkAjQB0gHgAawBZgE9ANwA3gC1wBg/1T+jP2c/FD7+Pmg+BD34PVg9ZD0UPNQ8mDxgPDg78DvwO+A7wDv4O4A7wDvYO8Q8DDxoPHg8TDyEPMQ9BD18PUQ90j4QPkY+qj60Pu8/Dz9Av5f/2gAFAHzAGwCKAM8AoIAsAGQBXgGMAVsAyADTAKlAKQC8AX4BlAFOAMEAzQDCANAAygGOAcwBvAEyAQgBcgFQAbwBmAIUAhgCGAIgAiQCFAI8AjwCWALwAtAC2AKsAkQCnAKAAvAC6ALgApgCSAJ8AjACOAIYAioB0gGoAVgBbgETANYAvwBzgBc/0L+lP1A/FD64PgY+KD3oPaQ9aD0YPNg8lDxwPDg8BDxwPAA8MDvwO8g8DDw8PDw8cDy4PIw88DzkPTw9dD2GPjg+Ij5gPqI+4z8mP0q/p7+1v6sABQCKANIAlgCzAKyAVwCzAPIBpAHoAQ+AWwBGALMAtgEQAboBWAEMAJ4AogDSAQYBfgFWAbQBYgFwARoBZAG6AaIB8AHEAngCeAIoAdQCGAJAAoQC8ALEAyQClAJ0AkQC9ALcAtwCxALcAqACRAJcAkQCbAIAAiYB+gG4AWYBIQD3AIQAnoBegCE/6z98PsY+xD6SPlA+ED3oPYQ9YDzoPKw8kDyMPGw8GDwQPDg7+DvIPBg8IDwQPHw8SDykPJA83D0EPUg9vD2APhw+Cj50PoY+xD8uP3e/iP/EP7p/2QBAAPsAtYBrAIYApgCOARABqAFCAR8AqoBJAJAA/AEcAVgBRAEvAJkAsQCUATABVAGoAUIBRAFaAUABpgGeAegB+AHgAjwCAAJ0AjQCFAJIAowC2ALUAvgCpAK4AqgCsAKEAtACwALIArgCXAJ4AgwCBAI0AcQBxAG4AQQBCgDEAI2AY0Ay/9Y/qD84Pog+oj5iPhw93D2YPXQ8+DyEPIg8nDxcPAw8GDvoO9g78DvoO+g7wDwgPCA8XDxEPLg8sDzkPSw9XD2QPco+GD5QPrQ+tj7LP04/s7+ZP4JAPb/zAHcAhwDnAK2AAwC1APABdAE2AQYBIABdgDYAWAEQAVABTgEZAOAAgwBqAJQBUgGkAW4BKAEwASABaAFoAawBwAIYAjQCOAIAAngCOAIIApAC+ALwAtgCzALAAsACxALUAyQDPAL8ArgCQAKIArQCSAJ0AiACEgHCAYgBbAE7AOQArYBfAEoABD+qPz4+1j7kPlQ+PD3MPcQ9eDzcPOA8iDycPGw8EDwQO9A7xDwEPCA74DvEPBg8KDwwPFg8hDzMPSw9DD1MPWA9oj4wPnw+XD6SPsM/Gj9NP5y/7D+kv8IAbwCGAMYAdoBfAJwAhwD8ATQBfADRAFIAKoBBAJYA3gF8AWIBAABqQAcAiAEIAVwBVAGaAVABPgDcAXIBogHgAfIBwAJoAigCPAIwAlACkAKAAvwCzAMoAswCzALcAsADGAMcAzQCwALsAmwCaAJ4AnwCYAIOAeYBpgFYASkA3gDQAP+AdX/Iv6U/Rj8aPuQ+pj5SPhg9rD1QPUg9IDy8PHA8bDxoPDA74Dv4O8A8BDwAPBA8ODvwPAA8rDysPJA88D0gPYw9qD1UPfY+Tj7GPu4+3j84PyU/RP/DAEKAd//lQCoA2ADfALoASgCeAM4A+AEsASQAwQCsADLACoBDAPwBIAFeAPGAXgAxgB4AqgEeAbQBVgEEAR4BAgF6AUAB3AIUAgQCLAI4AgACVAJ4AlwC4ALsAvwCxAMsAvQCvAKwAuADOAM8AsAC4AKoAkwCXAJ8AmgCTAIcAZoBdAE2ANIA/wCiAIWAcD+BP00/Lj7uPrw+bj4gPfw9QD1UPQA9HDzIPJg8RDx8PBA8CDwUPCw8KDwgPDQ8HDxIPLA8nDzsPNA9CD1sPbA9yD4+PjI+WD6GPvU/ND9+P3w/cD++v8oAaAArgHYAjgCgAEYAe4BKAIwAzAEnAPoAR7/wP4JAHoBtAKQA8ACVgHX/6H/xQDMASgDcARQBHADrAJ0AzAEEAXYBegGoAdgB+gHkAiACDAIsAhwCvALAAwQC2ALMAvACsAKsAugDKAMgAvACqAK8AkgCQAJoAlACdAHUAagBSAFtAPcAnQCsAFtAJ7+lP0Y/Pj6+Pn4+Dj4gPcA9rD0IPSw8mDyMPKw8eDwQPBA8ODvIPBg8LDwcPCg8GDxAPLA8hDz8POg9MD10PWA99D4iPmI+hj7uPsc/FT9Y/9dADYA+P42AIIB2AJwAzgD8AKMAeQAlALQBPgEYASYAu8Ai/9T/zwBLAPYA0gDtgEvALb/FAC0AWADyAOwA4gDPAOIAggDYAR4BWAG+AbgB9gHmAeIB3AIcAnwCYAKgAtQDLALQAvgCkALoAsADKAM4AzwC6AKUArgCeAJwAlACcAJoAgwBqAE4ATMAzwDjAKKAXcAXv64/AD8YPvg+eD4MPhg9xD2kPQA9EDzoPIw8uDxgPEQ8dDwcPAQ8FDwQPHA8cDxEPLg8lDzkPNg9KD14PaA9yD4wPmA+sj6aPvE/Bz+nP6i/ln/wQBOAXABigFYArACTANgA1gD3gHcAEQC1AMgBVgDSAETACb+iP7DACQDoAPgAtb/Ff+u/h3/ZgEYBOgEIAPeAXYBoAJABPAE8AVABzAHAAd4BzAIMAkQCVAJcAqwC2AMgAwQDAAMYAvwCsALIA3wDYANoAuACiAKwAngCVAKMAogCSAHEAW4BFgESAN4AuIB4QCC/jD9IPwY+8D5mPgQ+CD3sPWA9NDzQPMg8iDxIPFg8eDwQPAQ8MDvAPCg7/DwMPKA8jDyUPKw88D0MPVA9qD3aPgo+Yj6SPsE/Iz8OP30/lAAXwDdAC4B0gFkAngC4AKYA8AEkAQ8A0QC7AFsAzAEmASIBFgCfv+w/T//6QB0AxwDcALsAGT+IP0c/hwC1ANABHwCigGmAUgBwAIIBSAH6AboBcgGAAggCIgHkAjgCcAK4AqgC4AMUAxgC/AKgAvQC5AMQA3QDOALcAqQCTAJMAmwCWAJ4AdIBkAFqARUA7IBfgE+Aej/TP6Y/Bj8WPrQ+ID3oPcA9yD1wPQA9BDzcPGg8ODwcPGw8MDvkPAg8BDw4O8Q8SDyUPKA8jDzQPSQ9DD1cPbw98D4CPnI+Xj7mPwg/dT9fv5R/yAA8gCGARQCDAI4AuACiAMYBOgDpANoA6ACgAJMAnAC8ANoBPQC4f94/WT9a/8uASACkAOcAfL+4Pyw/Y//SgFcAyAE9AMoAuUAZAGgA2gFAAdQCOgHqAdoBwAIkAgwCcAKIAzgDEAMwAsgDGALYAvgC9AMIA1ADNALwAvwCmAJsAgQCRAJQAgQB6gGeAV8AxwCOAHJAO3/pv7o/cT82PoQ+SD4QPeA9tD14PRA9EDzUPKw8SDxoPDQ8NDw4PDA8CDx8PAQ8aDxMPIQ8+Dz4PQQ9SD28Pag93D4mPng+tj7uPyE/Z7+Hf/C/3gAhgFQAswCRAOIA7wDoANoBGgEAAXoBIAEkAOQAigDoAOABCgEEAM0Apb+fP2g/pgB3AMYAxACLQBA/oz8uv5yAQgEgATEAzwD8AGAAQgCgAS4BlAIUAgQCNAHOAfQB6AIEApwC2AM0AxADMALQAsACyAL0AugDKAMMAxgC5AKEAoQCTAI8AcwCHgHgAZQBRgExAISATQAgf/G/qD9hPwA+xj6OPjw9mD20PWg9GD0oPPg8jDyEPEA8dDwsPCg8BDxMPFA8WDxsPFw8tDysPOA9HD18PXg9qD3kPhw+bD6sPt0/Ij9UP47/63/GAAEAcIBYAK0AmADCATUA+wDmAMIBBAEOAQwBMwDKAO2ARQCuAKQA7gClf84/sj9aP3g/pAA9gGsAZP/nP3E/Nj8Zv7LAFgDSAQQAyYB+AD9ALACsATwBnAIAAmACJAHyAfoB0AJ8AqQDIANMA3ADMAL4AuAC+ALwAwgDVANgAyQC8AKgAlACcAIUAhACDAHCAaoBHgDMALOAPH/vP74/XD8ePt4+iD54Pdw9pD1oPTg81Dz0PJQ8pDxsPBg8DDwYPDw8ADxQPGA8cDxIPKg8lDzYPSQ9YD2gPfw90j54PkI+xD8QP2s/gT/CQAeARACaAJ8AjAD6APYBPAEGAVQBSgFEAUoBcAEsATYA7gDuAMYA1gCCAK4AUoBjwDY/gz9HPwo/RD+fv/Z/+T+oP1s/Aj7GPzE/SQAYAEQAgAC8wAAAXcA9AIwBZAGAAgwCNAIIAhQCDAJMArgC6AMsA2QDSANcAxgDHAM0AxQDTAN8AygC9AKIApACbAIIAjYB1AGEAUQBKACjgEYAAf/eP7c/Ij7GPo4+fD3kPaA9dD0EPRQ80Dy4PEw8YDwIPDg7zDw4O8Q8EDw4PAw8YDxkPIA8xD0YPSA9aD2wPfo+Oj5KPuo+xz91P0z/zUACgEQAtQCrAP4A3gEiAToBDgFuAW4BTgGuAWgBXgFuARABGwD4AKEAsYBQgEEAc8AhwBD/3D9EPvo+Vj6FPz4/Vr+2v5o/Tj7CPpo+rD7GP4NAAwCoAJYApIBUgGkAqwDwAXIBxAJAAogCsAK0AogCxAMUA1QDrAOoA6wDnAOEA4ADjAOEA5ADWAM4AtAC5AKwAkgCRAI0AZQBQAE3AKMAaAAp/+U/gT9cPv4+Xj4cPeA9sD1oPSQ88Dy8PEQ8VDwAPAA8ODvwO8g8FDwYPCw8FDxIPLg8pDzcPRw9UD2UPdA+Hj5iPrg+/j8DP7u/qL/hQBQAVwC8AK8AzAEkAQABUAFmAWIBbAFeAVoBRgF6ASABOgDWAPEAjACogH2AGYAHQDg/0f/Mv4o/Rj8WPvg+hD7QPxs/TL+nv4e/sz9OP1c/Y7+VgCuAYwCiAMIBMAEOAXgBQgHQAhACTAK0ApQC5AL0AtQDOAMcA3gDeAN0A1wDfAMQAzQC0ALAAtACrAJIAlACHAHWAZ4BVgELAPmAckA4//q/sT91Pyg+7j6sPn4+PD3MPdA9pD18PRg9CD0wPOg85DzsPOA88DzAPRg9OD0MPXg9XD2IPew95j4SPko+vD60Pu0/HD9Nv6w/l3/HwCRADIBzgE4AtwC1AIQAwgD+AIwAxgDZAMwAwQD0AJIAvgBYgEUAY4AQwB//+z+Zv7s/TD+Mv78/SD9PPy4+0D72Pog++D7SPzk/ET9fP3A/bD92P18/nD/UAA4ATgCyAIYA4AD/AOYBIAFEAbABkAHiAfABxAIMAiACLAIwAjQCKAIkAhQCPAHsAdwB0AH2AZoBhAGkAUIBZAEMAS8A0ADvAJwAiQCoAFCAb0APQDK/zr/zv5W/tz9fP00/dj8aPwU/MD7WPsg+9j6iPpI+iD66Png+dD5qPmw+bj5uPnA+bD5uPnQ+fj5GPpA+nj6kPrY+hD7SPtg+4j74Psc/ID8qPwA/WD9kP3I/fz9SP54/p7+7P40/2v/q//S/yUATgCAAMAA5AAuAT4BiAGeAc4BxAHgAeYB+AEMAhwCLAIsAlgClALIArQCwALEAqACpAKYArgCqAKYAqACpAK0ArQCwALMArACmAKYApQCkAKEAoQCnAJ0AlwCVAJYAkQCKAIkAiACHAIMAgwCCAL4AeIB0gHWAcYBwAGqAZgBfAF0AXwBfgGGAXQBZAFUAUoBMAE+AUABSgFEAS4BGAH6ANoAyACwAJEAaQA6ACQA+//e/7b/lf94/1L/SP8o/w3/7v7G/qT+gP5i/kT+JP4c/gb+AP7I/eD9yP3E/cD9rP20/aD9nP2k/bz9sP28/fD9AP4A/vj9/P0G/hr+KP5C/kj+WP5c/lr+YP5w/nL+hv6A/oT+fv56/l7+UP5o/mD+Wv5a/mL+eP5w/nD+cv6A/o7+iv6W/qr+xv7Y/uz++v4V/y7/W/+I/6j/w//e////IABAAGkAmgDFAOgACgEuAWIBmAHQAf4BJAJMAmgCnALEAvgCJAM8A1ADaAOIA5gDuAPEA8gDxAO8A7QDpAOUA4ADZANMAywDEAP4AswCpAJ0AkgCDALgAbYBeAE0Ae4AswB5AEkACwDW/5j/Vv8a/+L+rv56/lL+IP70/dT9sP2E/VT9OP0c/fj8zPy8/KT8lPxw/Gj8RPxE/Dj8NPw8/Bz8HPwc/Cz8OPxQ/Fz8hPyQ/KD8zPzo/Pz8GP1M/YD9oP28/eT9Nv5k/pL+wv7+/i3/Vf+O/9X/GQA8AFkAggC9AOEAEAFOAYwBugHeAfQBHAIoAjwCcAKwAsgC5AL0AggDIAMoAzgDSANIA1ADVANcA0wDRANEAzADJAMIA/wC4ALAAqgCiAJkAkgCKAIMAugBugGSAXQBSgEQAe4A0QCwAIcAaABFABoA8//U/77/qf99/1n/Lv8M/+r+0v64/qD+jv5w/lj+RP40/iL+GP4K/gr+Gv4M/gT+9P3Y/eD96P30/fT9/P0I/gL+Cv4O/g7+Ev4W/ir+Qv5Y/mL+YP5o/nj+lP6k/rb+0P7i/u7+8P4B/yT/Qf9Y/3D/hf+Y/7D/yf/m/wAADAARACsAUgBxAJYAsADJANIA3ADwABABKAE2AUoBWgFoAXYBlAGgAaoBuAHSAeQB4AHmAfIB+gHwAfAB9gH2AeoB2gHKAbgBogGOAYIBeAFcAUIBKAEMAeAAtACgAIIAZAA+AB8ACwDr/8v/q/+S/2f/Rv8w/yf/J/8U//T+1v7E/rD+nP6M/pr+mP6I/nz+dv5o/mL+Wv5S/lr+Vv5o/nL+dv56/nr+gP6E/pr+rP64/sL+3P70/g7/Gf8q/zb/Sv9g/3n/jf+g/7n/1//8/w8ALQBPAGAAdACHAJkAsQC8ANkA5wD8APsADgEwAUgBZAFiAXoBfgGMAZQBngGoAagBrAGqAbYBwAHGAbQBqgGgAZoBjgF+AXwBfgFiAUwBPgEoAR4BDAH/AO4A0gDDAKgAiwB0AFkASwAxAC0AGAABAN7/tv+k/4b/f/92/2r/Wf8+/yz/Fv8P/wT//v76/vz+8v7u/u7+9v76/u7+6P7u/vL+9P7y/vj+B//+/gT/Ff8x/zz/N/9T/2P/bv95/4r/qv+8/8P/zP/d/+////8PACUAKAArADoAVgBdAG8AfABuAG0AeACFAIwAiwCUAJ8AoQCcAKEAnwCdAJcAlQCUAJIAlQCUAJQAggB5AHQAagBoAGMAYQBUAD0AKQAcABMACgAQAAYA/v/p/93/0P/D/7n/sP+5/7j/t/+y/6f/ov+l/6b/o/+g/5H/mP+U/5H/kf+X/5P/jf+I/4L/i/+M/5H/l/+d/5n/lf+Z/5z/qP+k/6b/ov+X/6D/q/+x/7D/qP+i/6X/q/+u/7n/uP+7/77/xP/N/8j/0v/Y/+D/3v/z/wQABgD+/wIABwAIAA4AGAApACUAFwAYACoALgAtADAALwA5AC8ALwAwAC4ALAA8AEYASQBHAEoAQwBGACsAKgAiAB0AHQAkABsAEgAOAAwADQACAP3//P/z/+b/3f/h/9v/2P/L/8v/vP+5/7j/tv+7/7z/wP++/77/wf/C/87/yf/M/9b/3f/e/+v/8f/p/+f/6f/3////AAD+/wUA/P/6/wgAEwAXABkAFQAUABkAGQAoADQAMAAvADEAMAAuACoANgBGAEkAQQBLAE4ARQBAAEoAVwBTAFYAYABqAF8AVQBUAGEAYwBaAFcAXQBdAGIAagBpAGQAXABYAFYAVgBLAEYARQA1ACUAIwAiAB4AHQASAAcA/v/x/+z/6P/Y/9H/yP/H/8X/vv+s/6X/oP+d/5//lP+O/4v/iP98/3n/ff+A/3n/ef99/3n/cf9u/3n/ff94/3b/f/99/3f/e/+H/4z/jP+T/5X/m/+h/6r/tf+8/8L/yv/V/9v/6P/+//3//f8CABAAIQAfABcAGQAbABUAIQAyADwAOQA4AD4APQA1ADMAPwBMAFIATQBTAFAASwBHAEsAUABIAEkAUwBXAEwASwBMAFIATgBOAFQAWABVAEoASQBJAEgASABFAEcARABCAEMANwA4AC8AIwAnACcAJwAdABkAGgAfABgAFAAPAAcAAAD4//r/+f/s/+P/4P/d/9v/0f/Y/97/2v/Y/9T/1v/Y/9X/3v/f/97/3v/f/+X/6P/x//f//P8BAPz/BQANAAgADQAVABwAHQAYAB8AGwAXABMADwAYABkAHwAlACoAHgAfACMAHQAcABEAGAAYABcAIQAjACIAFwAPABAAEAAQABYAEwAOAAIAAQAIAAwADAAPABQAFAALAAwABgAIABIAGAAhAB4AGwAfACIALAAtAC4ALQAvADUAMgAxAC4ANAAsADAALQAuADMALwA6AD8ANAAsACcAKQAvACcAIQAeABkAEQAJAAoAAwDw/+z/7//t/+T/2v/Y/9T/0f/K/8f/zP/I/8r/z//Q/83/yf/H/8H/v//D/8f/x//I/8z/yv/J/8T/x//J/8T/xP/C/8r/0//T/9b/2v/d/9//5P/p/+7/7v/0//L/7v/w//b/AgAHAAgABgADAAUACQAJAA4ADgAKAAQA/f/9//z//P/7//z//f/8//n//P/2//P/8v/w//X/9v/4//T/8f/w//L/8//1//b/9f/z//D/9P/2//n/+v/7/wEAAQACAAQAAQAEAA0ADAAMAAwADQAQAAwADgARAA4ACAAIAAgACwAAAP//9//9//3/+v/7/+7/6v/i/+X/5f/l/+X/7P/o/97/3P/W/9H/zf/M/83/wf+3/6//tf+1/7L/rP+s/6v/rf+w/7P/uf+4/7T/r/+3/7f/tv+7/8f/zf/Q/8r/0P/R/8//1//j/+j/7P/t//P/+v/3//f//v8AAAEAAAABAAIABwAOAA0AEQAOAA8ADQASABUAGAAaACEAJgAsADEAMwA6AEIARQBDAEUATgBVAFYAWQBcAF0AYABlAG0AdQB0AHMAcQBxAHIAdQB1AHMAdQBzAG8AbQBnAGAAXwBcAF0AXwBWAEwAQQAyAC4AKQAiABcAEAANAAEA+P/u/+H/2f/Q/8z/yv/G/8D/tv+v/6z/rf+s/6j/p/+j/57/l/+U/5n/mv+c/53/nf+d/6D/ov+j/6n/p/+i/6P/qf+w/7j/vv/D/8X/xv/J/87/1P/W/9v/4v/n/+j/7f/x//X/+v8CAAoADAAPABYAHgAgAB4AIwAqAC8ALgApACsAKgAmACcALgAyADEAMwA1ADAALAAwADcAOgA3ADQAOwA9ADwAPAA6ADMAMAAuADEAOgA6ADMALAApACUAHwAbACIAIQAaABYAEQANAAgAAAD6//n/8//0//D/6v/j/97/2//W/9P/zf/J/8T/xf/G/8n/xf/A/7z/u/+3/7X/sv+w/7D/sf+3/7j/vv/F/8f/yv/N/8//2f/d/+T/5f/q/+f/6//2//z/BgADAAsADQARABQAFgAbABsAHwAfACQAKQAuACoAKgAoACkAKQAlACoAMwAuACwALgArADIANAA4ADwAOwBAAD8APwBAAEAARQBGAE4ATwBPAEwARQBGAEIARgBLAE0ATgBLAEkAQwBEAEQARQBHAEYAQwBCAEMARgBKAEgARABEAEEAPwA5ADMANAArACUAHwAhAB4AEwATAA4ACgAFAP7/AwAEAPz/9f/x//L/7//q/+j/4P/Y/9T/2P/T/9L/0f/F/8D/vf+9/7z/uP+4/7v/vP+4/7n/t/+4/7b/tf+2/7b/uP+4/7v/uP+2/7f/t/+6/7v/v/+//7z/uP+4/7z/v//I/8z/0v/S/9X/1v/Y/9r/3f/n/+z/8f/0//b/+/8DAAkADQASAA8AFAAWABcAGwAgACEAIAAdABcAGQAYABgAGAAaABgAFQAVABUAGgAVABQAEQAMABAAFAAVABMADgAJAAgACQAGAAcABQAEAAEAAAAAAPr/+v/5//v/9v/8//7//P/2//X/8//z//X/9P/4//b/7v/s//H/8P/u/+3/6//v/+b/4P/b/9f/1P/Y/9r/2//b/97/3P/i/9X/1v/S/9L/0P/R/8z/yf/H/8X/yP/F/8X/x//H/8T/xP/M/9D/1//W/9z/2//f/+L/5f/t//H/9f/5//3/AwAFAA8ADwARABcAHAAgACcAKwAnACkAKwAyADUANwA0ADcAMwAyADcAOQA5ADgAMgAwADMAMAAzADgANQA0ADEALgArACUAJQAqACoAIQAhAB0AFQAOAAwADwAKAAoACQAKAAIA/P/4//v/+v/x/+r/6v/n/+b/5v/k/+T/4v/h/+H/5f/i/+H/4v/d/9j/2f/b/9z/3//c/9v/3P/a/9r/3f/Y/9v/3f/h/+X/5v/j/+j/7P/w//f/9v/4//r//f/8//3/AQAGAAcACQAMAAwACgAJAA8AEgARABAAFQAWABQAFwAfACMAIwAlACMAJgAoACoALQAtACsAKAApACcAJgArACMAIAAgACQAKQAkABsAFgARAAkABwAFAAQA/v/3//L/6//i/9v/2f/Z/9r/0f/Q/83/y//H/8f/y//J/8n/zP/M/8b/xf/E/8n/yf/M/9H/1f/Y/9T/1//Z/9z/4P/f/+X/6P/v//j/9////wEAAQAIAAoADgANABAAFQAeAB8AJAAmACcAKwAsAC8AMgAvAC8AMAAwADIALQAwADIALgAtACsALgAxADAANgAzADMAMAAtACsAKwAsACsAKQApACAAHwAcABIAEAANAAwACQAEAAUAAAD8//X/7f/s/+j/5//n/+f/3v/e/93/1v/V/8v/zP/J/8X/yP/H/8T/vf+6/7z/vv/A/8L/vf+4/6//rv+w/7L/s/+0/7j/uP+y/7P/rP+t/7H/tP+4/7b/tf+6/7r/vv++/8T/yP/P/9b/1//d/+D/7f/q//T/8//7/wMABAARABUADgAMABAAEgAaACAAIgApAC0AMAAyADsAPAA4ADkAPwA+ADkANwA3ADQAMAAqACYAKAAjACAAJAAoACYAJAAkACAAIQAhACQAIgAiACgAKQAuADEAMwAyAC0AKwAmACcAKQAmAB8AHQAdABwAHQAeACIAIAAiAB0AGAAVABgAGgAZABYAEgASAA4ADgALAAsACgAKAAsACAAIAAIA///4//f/9P/u/+j/4f/c/9P/zf/M/8v/zP/L/8n/x//I/8n/zf/T/9f/2//g/+X/6f/t/+7/7f/y//b/+f/9/wQACwAPABYAGgAeACEAJwApAC8AMwA2ADkAOQA5ADoANwA0ADcANgA7AD4ARwBJAEoARwBGAEIAOwA6ADgAOAA4ADYANwA0ADMANQA2ADMAMAAvAC4ALwArACgAHwAZAA8ADgANAAgABAD///X/7P/n/+r/5f/p/+f/6f/o/+T/4v/d/97/1//a/9n/3v/b/97/3P/Y/83/yf/F/8b/wv/J/7z/wf+9/7z/uv+6/8P/vv/F/8b/1f/c/9//4//p/+v/5f/v//T///8CAAsAEgAYABYADQAIAPz/+//9/wQADAARAAYABgD//wMA+P/4//7/AwAJAAUACwADAPP/4P/V/9L/0f/l//3/HgDm/+f/5P/z/xYADwAYAOf/4v/G/83/1//q/wMA+//o/93/7P/0/93/5v8WABcAJwATADoATgAzAB8AKQA3ADUALAAuADYALQAjAB8ALQAhABEAGwAXACAAIAAZABsAEwDw//X/7v/e/wAA+v8aABQAAQDr//3/8f/x/xkAFwAtACQAIwAvACQAPAA7AEsAVwBhAF4AWgA/ACEAJQAOAAYA5v8EAD0AWgBJAA8ABQAMACoATQBtAGoAXABQAF0AgQCBAJAAlwCdAIoAagCEAJMAkQB8AHgAdgCNAIEAaQBrADUADAAgACgAYQCJAGQAQAAAAFQANAAiABEAKACKAC4AFgAlALMA/v/r//P/PQDq/47/hv9x/0f/kP6I/lL+VP7w/ZT9vP2Y/eT98P3U/ej9xP24/YT9iP2o/bj92P3M/Qz+mP6O/vr+EP/I/gT+FP18/MT8cP04/vL+3v6q/or+pP62/gH/cf+P/5X/aP9+/7D/fv+U/93/PQCSADwBRALQAmgDVAMQBCgESAQYBPgD7AMcA5wC/AH0AXgBGAGnAEwABgCH/3//YP8v//r+Av82/xf/8v7y/jD/5v7a/qT+Bf/4/sT+Bf89/2b/Rv9t/4b/5//d/93/PwA3AHoAKABlAGcApQC4AKIA9gAoAX4BcgG+AcYB0AFyAVABXgEWAcEAbQBRAA4A2f+A/2v/bv9w/3T/sv/r/x4AbwCcAOMAGgGSAb4B8AEcAjgCOALqAcgBugGSASwB0AC2AL8A1ADIAP4AFgEYAR4BWgGoAdIB3gHCAagBmgGYAa4B5gEEAiQCNAJIAnQCoALMAuAC6ALEAqACUAIAAroBMgGjAOT/Nv/C/mD+CP7k/Zz9uP2Y/bD9AP5S/pr+sv4A/y//H//u/tD+rv5o/jT+4P3U/aj9aP1w/Zj9uP3w/W7+yv4j/3n/OwBEAFkAigCOAGsAyv8w/6r+1P0g/WT8CPzo+8j7YPzY/Kz9Av7O/mf/KAAcAZIBDALIAhAEKAU4BmAH0AjQCcAKcAuwC5ALIAuwChAKQAlgCBgHKAYYBZgEEARcA+ACxALQAkwCrAEIAq4BagHaAB4BewAs/1b+MP08/Jj6qPmI+LD3kPYQ9mD14PQw9DD0oPTg9OD0cPVQ9fD0sPSw9CD1wPRA9cD10PYA92D3ePgg+Xj6IPu0/PT9fP7o/oL/i/8r/5j+zP3o/Nj6cPnA90D2UPWQ9AD1sPXg9lD4+Pkc/Yn/UAKoBVAJ8AwADyARQBOAE2ATQBLgEmAUABaAFkAXQBbAE+ASwBDwDqALEAogCEgFnAIyAZMAGP/H/94BMARgBcgFcAegCWAJwAjwCLAIUAaIA0IBEv6Y+kD3gPVA9IDysPAA8KDvoO/A7+DvMPDg8PDxAPPg87D0gPbQ9/j4aPmg+rD74Pus/Vv/vQBnANX/Zv+U/kz9YPsQ+uD4cPcA9+D2IPfw9yj5MPvk/Lj9Mv5Y/bj76Pm4+JD3wPVw9UD2QPjg+oT9TALoBpAL4BCgFeAZoBugHGAdwByAGoAX4BSAEfANIAowB/AEaAOIAv4BwgH6ATQCgAJQA/ADSAVABcgFOAagBvAGWAYgB1AIkAhQCFAJAAnwCAgHCAaYA9gB3v5s/Ej6MPcA9WDyoPDg7QDsAOvg6WDpAOpA60DsgO4Q8vD1iPmk/O3/yAHMAvwCXAMsA8IBVAF/ACP/GP1g++D6SPpI+rD6MPqo+GD2gPVQ9qD20PeA+qz9A/9l/xD+8Prw9wD2MPUw9WD0MPQg9WD2sPYg+pf/cAWgCoAPIBOAFCAVIBXAFSAVABNAEeAOsAzQCZgHEAaYBfAFAAaABvgFcAZABKQDlANgBHgEsARIBFAEUAT0A4AF4AegCsALQA0QDUANMAugCAAHuAR4ArL+cPu4+LD0QPEA76DtAOzg64DsgOxA7EDsoO2A78DwMPNA9mD4uPmg+4b+bgA6AcQCGAQ4BAQDFAKOAcD+wPyI+xj7kPrY+ID4YPjQ91D3EPcw9yD4SPqS/8YBUAJtABb+TPwo+HD1wPTQ81DyEPMQ9LD00PaQ+n3/mARACnAOwBBAEmAUIBbAFQAUQBMgEsAPsAyACvAIwAaYBfAFkAaoBWgEVAPEAugCuALMAiACgAOkA1AD8APABDgHUAlgDFAOkA4gDtAM0AsACpAHCAXQAVD9QPlw9gDz4O+g7mDvwO6g7SDt4O3A7cDtIO+Q8fDzkPUY+JD6MPyw/jYBvAPYBFgFIAYgBUQDWAHSAML+DPzw+xj7UPmg9uD14PZA9zD2EPag96D50Pvf/yQCJAIeAWz/LPzQ+fD2kPXw8jDy0PLg8iD0gPW4+vP/EAagCmAPABPAFKAWwBegFyAWQBQAEsAOAAvgBwAGkASoBCAF0AVoBQAFYAX4BQAGwAXoBXgGmAZYBTAFiAUoBrgHUAogDCAN0AwADMAKYAkgCKgGMASNAOj8MPkg9bDyIPHQ8GDvgO6g7SDtgOwg7KDtgO/w8IDysPSw9xD5+Pro/ScAvgG0AnwDeAPIAtoBJAHT/6r+pPxE/Bj6CPhw94D28PUA9mD2gPYA9aD2SPv+/lQApwAgAiAAtPz4+Xj4wPYg9FDzkPPg89DzQPck/MwB6AbAC4AQ4BJgFYAXABmgGIAXABWgEfANsAkoB4AEeANcA5gDSAT4BIgFuAUABjgH4AdACEAI6Ad4BxgHYAaIB1AJUApQC0AMcAxwC/AKwAnACKAGzAOv/9D70Pdw9CDyIPBA7+DuAO4A7aDs4Owg7eDtoO/A8VDz0PSg9gD5cPuw/SIAUAGQAgwDMAOIAqQB5QBl//T9fPz4+tD48PYQ9oD2cPUA9VD14PaQ97j46Pt7//kAeAJ0A2ADWv+g+pj4kPcw9YDzwPMQ9OD1aPgc/VAC2AbAC6AQwBTAFmAYABmAGIAV4BLQDzAMYAmgBagEJAMYAzAEYAWwBgAHEAggCNAI8AgwCTAI0AcoB1AGsAaYBpAHwAiQCVAK0AoAC+AKoAm4B1AFMAKS/nD6sPYA9PDw4O4A7YDsIOxg6wDrwOtg7IDtAO9Q8YDzMPXw9+j5BPws/c7+3P+MANMAjQAOADr/jP4a/mT8YPuA+lj58PdA9yD2EPaA9YD1EPfo+Gj5MPvw/k4BkAIMA2gD7ABU/OD34PVw9GDzUPNw9QD4sPlc/RACiAfgC4ARQBYAGUAaoBlAGKAVABNgEFAN4AiYBAQCXgFIAcgBhAOABaAH+AfwCJAJoAkgCkAKMArgCEAI2AfYB+AHEAiwCHAJ8AmgCiALIArIB2AF4AKL/4j70PfA9ODxAO/A7ODrgOvg6uDqYOsA7MDsgO4w8eDzIPZQ+GD6MPys/f7+JACQAO8AzQAYAAv/CP4k/QD8yPqA+Zj4QPcg9qD1kPWA9XD1APcg+eD6UPxY/iQB5AL8AlQCPgFc/SD4EPUA9fDzgPPw9aj4OPwo/g4BAAeADMASgBfgGgAbwBnAGIAX4BTgEHANoAnYBfQCmAFYAXACiASIB8AIwAnQCbAKUAswDAAMcApgCZAIwAhwB7AGEAfgCIAJQApwC4ALsApQCIgGrAMIAFj8CPmA9RDy4O4A7YDroOrg6uDqIOvg62DtIO9w8eDz0Pbg+LD60Psc/Vj+zP4l/8f/DgAV/xz+rP0c/WT8iPsY+lD5CPhQ95D2UPZg9uD2oPdw+Tj7cPw6/psAaAJMAgQBS//k/aD5gPVQ9FD08PWQ9kj6SPyE/s0AOAYgDsATwBbgGKAbYBpAGUAWABRAEMAL4AcoBGEAEP5i/7oBSATQBaAH8AmgC5AMEA1gDdAM0AtACsAIUAdYBQgFeAVwBnAHYAhgCSAKkAmgCHAHAAXKAUD+mPpw9kDywO4g7EDqYOlA6SDpoOng6qDsAO+g8YD00PdA+rD73Pzg/aL+uP4i/9D+SP5Q/bT8QPyA+xj7kPow+nj5CPm4+Cj4cPfQ96j4OPmg+bj6/Pz8/Rj/bgCOAaIA2v60/Bj78Peg9SD2QPgw+Sj4oPp4/uACaAbQC+ASIBeAGeAagBqAGIAVYBOAEFAMgAbMAqoAoP+rADADCAVABkAIUArwC7AMkA0QDuAMIAtgCeAHYAbgBSAGiAbABhAHgAggCoAKYArgCcAH8ARsAjn/kPpw9UDxgO4g7GDpwOeg58Dn4OfA6aDsgO+w8bD08Pf4+Qj7PPxk/dT9sP20/Sz9jPyE/Fj82PvQ+mj6cPog+hD5sPhg+OD3cPfw95j46Pgo+VD6RPwk/Rb+8P5g/3z+JP2Q+5j62Pho+Ej4kPgg+Kj4yPr4/cwCCAegDcASgBbAGWAbQBlAF6AVIBNAD+AJmATuASUAIwAKAeACgAQ4BsAIEArAC0ANsA4ADzANwAuwCbgHKAeYB4AHeAYoBtAGIAiACCAJ4AgACGgGxANIAZT9SPnA9ODwgO1g6oDo4OZA5kDngOhg6iDtQPBw82D2ePho+oD7AP1M/eT8fPwA/KD7YPso+3D7UPu4+oj6aPqo+uj5aPnY+MD4WPhY+BD5YPkw+uj6jPyw/TD+4P5M//j+sP18/ED8oPsA+wD7MPt4+6j7zPyaALQDIAmgDoAUQBigF8AYoBgAGKAVoBIQDjAJcAXkAp4BTgFMAnQDUAWoBoAIEApgC3ANUA+AD0AN0AoQCqAJ0AjwB9gHQAdIBigGIAeQB2gHIAfQBmgFIANr/1z8KPnQ9HDxwO2A6qDnAOdg56Dn4Oig6sDtwPDg8zD3SPok/NT8uP02/iD+ZP00/RD9jPyA+zD7APvA+qj6oPqI+rD5QPlo+XD5WPmw+Zj6UPsQ+0D7WPzY/Zz9tP3W/ir+cP1E/Nz8LP2A/ND7hPyQ/bD9XP6kAZgFwAtgEQAVgBaAFwAYoBhAF0AVYBEQDPAHcARAAxQB6ADOAVAEoAVwBmAIsArQDKAOQBDgD3ANYAvQClAK8AioB8AG0AVIBNgDkAQ4BVAFaAVABfgDRgFU/nT8MPlA9VDxoO0A6sDn4ObA5qDmYOdg6SDsYO8A8zD3APpQ+6T8dP30/YD9pP08/Uz8sPqo+ej5uPmI+Wj5yPno+UD5wPlA+oj6qPq4+vj6oPqA+tj6gPtU/Bz9KP2E/Yj8hP0w/pT9aP3I/cL+3v6S/o4AzAKABBAIoA3AEsATgBSAFkAYwBdgFSATgA8QC8gGKAUIA1QBZAFUAyAFKAVQBnAIIAsgDdAOcA/gDiAN0AvAC6AKQAlwB/gFwARsA4QDmARoBdgF+AQQBBgCDAAA/jj74Pbw8mDvoOvg6MDmQOYg5oDmgOeg6uDtMPHg9Pj4gPuA/FT9BP7C/k7+TP2c/MD7qPqw+bD5yPnA+ZD5+PlA+jD6YPrI+iD74Pp4+wj7iPow+gj7APww/Aj96P1O/hb+eP5B/2//Zv4u/zcA2AA5AJgBGAUgCGAKIA7gEWAUoBQgFsAXIBZAEtAPkA3QCQAG2AJUAkQCgAIYBIgFiAZgB9AJ0AxADgAOsA5wDvAMMAtACWAJmAc4BpAETAM8A6gDCAVQBUAF8AOkAqAAxv6Y+7D3MPTA72DsIOlg5uDkYORA5YDmIOhA6+DuAPPg9uD5HPxg/aj9fP30/Mz8NPzA+pD56PhY+Fj4kPhY+QD6UPrY+sj6WPug+wT88Pvo+zD7GPrA+UD6UPsY/GT85P1E/kT+Nv5Z//X/vABSANoATAL4AigEkAcgC+AMAA/gESAVoBXAFWAVgBSgEeAN0AqQCGAFIAMsA3QD3APsAwAGWAdgCNAJYAtwDcANAA6gDTAMsAqACTAJUAgQBswDcAPsA5gEiASIBBgE3AJuAQ3/IPyo+FD18PEg7mDqgOcg5oDloOXA5qDowOqA7aDxIPZI+WD7wPxQ/VT9uPyk/HT8qPsw+pj5GPmg+ND4wPmw+sD62PoI+zD7mPtE/ND8GPy4+hD6CPro+YD6BPwo/az96P2c/qL/DwAUATwCiAJcAswCwAToBoAIUAoADbAPYBHgEoAUgBWgFKASABFAD/AL0AiwB0gGIAWABAgFsAaYB1AIAAlgCuAKYAzADVAOAA0QC2AKQAogCcgHSAa4BAgE1AOoBBgEYASEA9wC4gC0/rD7gPhA9VDy4O5g6uDmoOVg5iDmIOZg56DqgO2A8OD02Pi4+tj7HP1s/Xz9gPxc/Iz8wPtI+hD5GPkw+dD5EPpw+3D7QPu4+6T8sP2Q/SD9qPxw+yj7IPug+7z8LP0k/q7+gf/l/zoBzAKcA2gD7AMABYAGkAiQCgANkA5AEEASwBNAFAAUABPAEcAPMA0AC0AJsAdoBTgEGAQYBrgGgAfQCCAKMAqACnAM8AwADZAKwAlwCWAIKAfIBsAF6ANcA0wD5AMMAwQCpAJcAsb/rPzY+ZD3QPSw8KDt4OnA5uDlYOYA58DmoOeg6uDt8PBQ9BD32PlI+3j8tPxs/Pj7QPwA/Jj6gPkw+XD4mPhI+Xj66PoQ+2D7BP2s/az8PP0g/XD86Pow+3D7oPsU/ID9Zf8q/07/1QA0A6ADPAOIBLAFIAYgB8AJ8AuADKAN0A9AESARwBCAEeAQYA5gDEAMgAsgCRAHwAYABmAFcAYwCMAJAAlQCaAKUAuwC8ALYAsgCoAIMAioB/gG0AU4BfAEiAPUAvACEAN8AkAClgEy/3D78PhA91D0oPDA7ADqgOdA5mDmQOeA5+Dn4Opg7oDxQPQI+HD6+Pu0/Hj9vP28/JT8ePz4+4D5IPiI+ED5UPko+vD6mPtI/KT9Lv8F/3D+qP3c/dz8NPyU/KT8tP34/RP/q/+eAHABCANwBLgEYAV4BuAHoAlgC4AMgA2gDgAQgBBAEPAP8A+QDvAMEAwwC8AJIAhQB5gGMAbABRgHgAigCHAIsAjwCYAKcAogCiAK4AggCFAH6AYYBjAFOAQoBMQDVANEA6gCYAKoATQAHP0o+jD3IPVQ8kDuAOug6KDm4OVA5sDmAOdg6IDroO/Q8nD1CPhI+kD7ePss/Gz8+Ps4+wj7yPlQ+AD4yPiA+QD68PkY+1T8QP2G/vL+lP74/Oj74Pvg+7j7QPvI+5j8sP2+/kEAbgEsAhwDCAUYBpAG2AdgCRALgAtgDLANgA5wDkAOAA+wDpANAA3QDKAMcAsgCrAJ4AhACBAIAAgQCMgHMAjACMAIEAkgCVAJMAkQCVAI8AcwB+AGcAY4BXgEOATUA/ACfAIEAucAbP6k/Pj6OPgg9bDysPAg7QDqQOjA52DnYOZA56DoYOpA7TDxoPTA9tD3aPkI+2D7YPug+8j7+Pqw+XD54Png+YD5KPpg+4j7uPsw/R3/u//Y/sD9IP0s/Qz9zPwQ/bD8gPxY/YT/rgBSATACfAPABIgGMAhgCVAKgAvgDFANMA5wDsAOoA6ADgAOMA2wDJAMMAygCyAKkAlgCYAIEAgwCIAIIAiAByAIgAlACeAIIAkgCSAJAAhoB2gH+AYQBpAFmAXoBDgERAOYA6wC3QCy/vz8SPvo+LD1YPPw8GDuIOug6QDpoOdg5+Dn4Okg62DtUPHg9ND2YPjI+eD6OPtw+xz8YPw4+0j6sPrA+rD6kPq4+5j8WPys/Aj+uP+a/5b+0P3s/QT96PyQ/Tr+9P1c/bL+VwDaAfQBsAIoBFAFeAbgB4AJEAtACxAM0AygDcANwA0QDtANgA3gDEAMgAygDLALwArwCVAJ0AiQCEAIcAgQCNAHIAiQCBAIoAiACDAI4AeYB3gHeAcAB5AG6AVABegE6AQIBMACKgFDAG7+RPyw+YD3YPUQ85DwwO0g7EDqYOkg6ODnwOjA6aDroO7Q8cD0MPbA92j5OPrY+Vj6yPtY+xD6ePnw+dD64Ppg+qD7fPwQ/Gj8Kv4z/yr+eP38/GT9yPwk/Cz9wP1Q/Qz9Zv7O/7IAagHwAjAE2AToBZAIUApwCuAK8AvwDNAMMA3QDcANwAzgDFAN4AzwC+ALkAzAC6AKYAmQCWAJwAjQCHAIMAjoB4AIgAiQCEAIIAiwBxAIoAgQCHgHwAYIB4AGMAUgBCgEtALiAKz+SP0g+8D4sPag9NDyAPAA7uDsAOxg6gDpYOkA6gDrgOxA70DyYPQg9kD3YPhI+bj5qPr4+iD6KPnY+bD6oPoY+0j7APxg/LD83P2o/kL+rP2A/Tj9qPxs/LT8wP2k/Wj9Hv6H/xIBrgGoAhgECAUABpAHgAngCgALkArwC8AMwAzADDANkA3wDKAM4AwwDXAM4AugC0ALcAqwCVAJMAmwCFAIAAi4B6gHEAggCPgHkAfQB6AHmAegBygHsAawBWAFKAVgBCgDcALGAPD+1Pw4+zD5oPZw9DDycPAA7gDswOqg6aDowOcg6ODooOpg7bDwEPMw9AD18PbA99D3MPio+LD4cPew9/j4gPlo+aj5GPso/Pj77Pyc/i7/av7U/SL+2P08/cT9iP5U/tT9yP4yAHwBMALAA0gFGAb4BqAIkArwCkALkAsgDDAMIAygDPAMoAzgC/ALIAxwDEAM4AvAC2ALAAugCkAK8AmgCRAJYAhACBAIMAgwCCAI+Ae4B3gHYAewBzAHkAbABUAFgAS4A7wCEAK0AD7+UPxQ+9j4APaQ9GDy8PDA7kDsgOtA6kDpYOiA6CDpgOrA7MDvYPKg8/D0EPbg9uD3QPjw99D34PdI+Fj4MPmw+Zj60PrI+7j8SP2g/ST+Lv9+/pz9PP16/lr+eP3o/eT+nf+k/1AB3AMQBZgFqAbACJAKsApgC1AMoAzgC6ALoAzwDFAMQAywDIAMcAxQDCANwAzgC8ALAAxwC9AKAAvQCvAJIAkgCZAJQAlwCPAIIAmQCBAIYAiwCEAIEAfYBtgG0AXIBAgEOAM6Acz+vPxw+/j4APZA9JDyIPEg7gDtgOvA6kDpYOhA6UDqQOsg7fDw8PJQ9CD0cPWw9vD2oPYA9xD3sPYA9xj4cPmA+Zj54Pps/ED8YPzE/eD+hv4k/TT9Ov6E/Rz9vP3e/gL/G//EAEwDWATYBGAGEAgwCaAJ4AogDCAMcAtQC9AL0AvgCyAMUAwADHALEAyADNALYAvQC5AL0AqgChAL8AoQCkAJgAnACTAJEAmACYAJ0AiQCKAI0AhwCMAHQAfIBggGSAWABGQDRAIfADD+GPww+hj40PVQ85DxwO/g7SDsQOvg6kDpIOmg6SDrQOzA7VDxkPMg9FD0EPWQ9rD2YPZg9gD3kPYg95D4mPmw+VD6iPs0/ND84Pwy/rT+EP6Q/cD9JP4a/nD+FP+8//f/0gCkAiAE+AQYBnAHsAiwCaAKkAtgDEAM8AsADOALQAzADKAM8AvgC1AMAAzQC4ALoAswC3AKkArgCtAKMAowClAK8AmQCXAJ4AmwCcAIMAhQCCAIwAeQBwgHmAagBRgFiAS0AyACbACa/lT8WPoA+ED2IPQQ8gDwYO7A7KDroOqA6cDo4OhA6UDqQOzg7pDxAPIQ8xD0cPSw9GD1gPWQ9WD18PVw96j4WPhY+cj6oPvI+4z89P2K/nL+vP0k/jT+HP56/gD/8f9HAMEAaAIIBAgFCAZwB3AIgAkwCkALsAvgC/AL8AsQDDAMoAxgDCAMEAxgDLAMUAwADEAM8AsACxALcAtQC4AKIAqgCjAKsAlgCXAJQAmACPAHMAjwB9AHaAcYB3AGMAXYBDAEIAOOAdX/Bv4o/Aj6WPhw9jD0sPLw8ADvQO1A7EDrYOpg6WDpAOrA6mDswO4A8SDygPKw81D04PQg9eD1gPbA9ZD28Pfg+BD5APrY+tj7XPwk/ej9PP6W/lz+XP7w/UT+TP8IACUAEAEcAoQDeATABZAHcAggCRAKMAsQDCAMMAyADNAMgAyQDOAMIA2QDDAMkAxQDIAMEAxADBAM0AvQC5AL0AtQC1AL8ArgCqAKUApACpAJQAngCJAIEAjwB+AHiAeoBggGiAXQBIADjAFUAHj+NPxo+sD4sPZg9FDyUPHg78DtYOxg7ADrYOlA6SDqwOtg7GDuEPEw8uDx0PIw9CD1QPTA9CD14PVg9jD30Pgg+pj66PrI+8j8TP3k/ST+Pv6u/kL+ov7Q/koAqAD0APgBUAOYBFAF+AZwCBAJUAnACXALIAwADAAMwAygDOALQAwADSANQAwwDMAM4AywCyAMIA3ADKALMAvgC1ALkAogChAKUAoQCcAIMAnQCFAIIAgQCAAIcAd4BxAHcAZgBYAElAMMAlkAxP7I/LD64Pgw92D1kPNw8WDwIO9g7aDs4Oog6iDp4OjA6aDqIO1A7zDwwPAQ8jDzkPOg83D04PRQ9AD10PbI+BD5CPnY+iz8MPwc/MT94v6s/lb+jv5a/+r+ef/m/woBsAEgAvQDMAVwBrAHwAiACTAKMApAC+AL8AtQDCAMYAxADKAM0AygDLAMgAyQDHAMcAygDLAMMAyQCxAMUAsAC+AKAAuQCrAJAAkgCTAJ2AfwB0AIMAiAB0AHaAfIBuAFUATsA/QCBgF1/8D91PwA+jD4sPZg9SDzAPHg76DuAO5A7ADr4Ong6eDpwOrg68DtUPAA8bDxoPJw8+DzwPMQ9LD0sPSA9TD3sPko+lD6MPvM/JT8TP16/uz+CP98/m//hQAYAFcAkAGgAuACfANABXAHkAcgCDAJUApACgAKkAugDNALoAsQDKAMYAyAC5AMsAyADMALoAzwDMAMgAzADLAM4AvQC1ALgAvwCmAKYArwCfAIIAmgCHAIEAiYB9gHGAeoBsgFUAVYBGADQAL2AFH/tP3o+/D5SPhQ9sD04PJA8TDw4O7g7UDsgOsA64Dp4Ogg6kDsQO1g7sDvIPGQ8VDxwPIQ85DykPIQ9KD14PXA9zj5WPuo+tD6CPyc/RD9eP3G/q7+kP5m/voAjgGUAdABoAPgBDgFIAYgCIAJ4AgACaAJcAqgCrAKkAvgC8ALUAvgCxAM0AuwC9ALMAxwC9ALYAxgDBAMwAugC1ALgApwCsAKMArACQAJIAmACLgHmAeQBzgH+Aa4BsAG0AUYBcAECASIAlYBPwBu/mD8wPow+aD3wPVg9MDykPHA70DvgO6g7EDr4Oqg6uDqgOuA7WDv4O/w8LDx8PHg8ZDykPNA84DzkPQg9sD3YPhA+mj7mPuw+7D8oP0c/gj+RP5j/1f/2v8aAZACBAMUAxgESAVABpAG6AewCTAK0AkQCmALsAtgC5ALkAuwC/AKIAvQC/ALIAvwCmALAAuQCsAKYAtwCxALsArQCrAKcApQCtAJ0AkwCZAIQAiQCIAIAAi4B6gHeAfoBugFqAVwBagDLALAAI//wP1g++j5KPkg92D1YPTw8iDy4PDA7wDvgO0A7EDrwOuA7MDtQO4Q8BDxYPFw8bDxcPLg8gDzYPMg9MD1cPbA99j5qPpQ+9j7CP1c/Wz9OP4i/77+0v7A/24BtAJgAzAEaAXIBfAFMAdgCIAJcAkwClALsAtQC/ALkAxADMALEAvgC+ALYAtgC5ALIAtQCkAKcAowC7AKcArwCnAK0AkQCSAJMAmgCBAI2AdACOAHUAdYB1gHOAdYBsgFgAU4BXAErANUAyQCrQD0/kj9uPvI+bj4sPfA9sD00PNQ8zDy8PAA8ODuAO7A7SDu4O6g74DwkPFA8gDykPGw8gDzIPOA82D0QPUg9hD3sPdI+aD5uPpw+7D7kPwQ/Xj9nP38/XD+Pv9/AKQBsAIkA3wD/AOoBPAEyAVwBngHYAgwCCAJwAkACtAJ4AkgCvAJ8AkACpAKgAqwCVAJcAkwCcAIEAmgCUAJ4AgACdAIMAioB+AHMAhwB9gGUAeoByAH+AZYB0AHYAYIBugFGAYwBWAEwATgA4ACRAHXANX/Lv7Q/CD8KPvI+fj4GPjQ94D2kPUw9JDzIPNQ8oDygPIg8yDzMPMw83DzEPNA8yDzgPNQ87DzYPTg9FD1wPVw9iD3CPiA+Gj5SPqQ+tD6+Po4+/j7PP1+/pL/jgBYAeAB2AKkA4AEKAUYBtAGGAfQB1AIMAmwCdAJIApQCqAKwAoQCzALEAugChAKQAowClAKcAqQCqAKIArACcAJoAkgCdAIkAiACGAIkAcgCDAIoAdAByAHIAeYBlAGaAZABmAFgATEAxwDDALZACsADv/I/az8uPvI+sD54PgI+ND2gPWQ9KDz8PJg8vDxwPFQ8RDxAPHA8IDwsPBg8JDwQPCg8ADxMPGg8fDxgPLg8kDzIPRA9VD28PZg97D30PdY+ID5APuI/NT9X/+GAD4B/AEgAzAE+ATgBfAG8AewCGAJUAoACyALgAvwC3AMwAwADWANQA3gDKAMwAzADMAMIA0ADeAMMAwQDLALgAsgC9AKwAoQCtAJQAngCGAI0AeABxgH0AZ4BjAGsAUgBTAEWANwAqIB9AAFACv/OP4s/Qz86PoI+vD4APgg9yD2MPVA9GDzkPLw8UDx4PCQ8DDw4O+g70DvQO8A7+DuIO+g78DvEPCA8KDwcPEA8oDyoPOQ9ND1cPYg97D3EPjY+Mj5SPuo/Gj+9f80AZQCfANYBEgFUAaIB1AIkAlACiALkAtQDOAMMA2QDQAOgA5QDkAOMA5QDvANoA3QDdANsA0QDfAM0AxQDBAMsAuQC1ALsAqACjAKwAkgCZAIMAiQBxgH6Aa4BkgGyAUwBcAEzAPcAjgCigF4AJv/5v7Y/cj8oPu4+tD50Piw9wD3APbw9ODzQPOQ8uDxMPHw8LDwMPDg76DvoO9g70DvYO/g7+DvAPBw8LDwYPFg8YDyAPMQ9ND0gPWw9gD3EPdw99D4+PnY+0z9LP+kALwBtALYA7gEsAXwBhAIEAnQCaAKwAugDMAMIA2wDQAOEA4QDnAOkA4QDuANwA2gDVANMA0wDQANcAwgDCAMwAtQC9AKkAogCpAJUAkACaAIAAiQByAHuAZIBsgF6AVwBYgE8ANgAzwCOAGJAPj/OP88/iD9RPwQ+9D5+PhA+GD3UPaA9aD0sPPw8mDy8PGA8fDwkPAw8ODvwO+A76DvYO9g74DvwO8A8JDw4PBg8bDxUPIg85DzwPSg9aD2oPbQ9vD30Phw+ij81P3S/woBPAJMA6gEYAWoBvgH4AjwCQALAAzQDIANoA0gDmAOcA7ADgAPEA/gDsAOcA5ADvAN0A3wDZANQA0ADYAMIAzACzAL4AqQChAKwAlwCcAIUAgQCGgH2AaIBkgGyAV4BfAEaASAA5ACzgH8ACoATP+Y/sj9nPyI+4D6oPmg+LD34Pbw9eD08PMw82Dy0PEw8fDwcPDg74DvYO9A7+DuwO6A7qDuwO7g7kDvoO8A8JDwAPGw8TDyQPMg9OD0cPUA9tD2APd4+Aj6yPvw/dL/FgF0AngDcASwBeAGwAdwCaAKkAtADCAN0A0gDqAOsA4gD0APYA9wDzAPEA+gDlAOQA7wDcANgA1gDfAMYAzgC4ALAAugCmAKAAqgCSAJsAgQCHgHEAewBmgG8AWABWAF0AQQBIwDwALUAc0A/v80/1D+nP2o/Lj7oPqQ+Xj4gPeA9tD1APUg9FDzcPIg8nDxAPGw8GDwAPDA76DvYO9A7yDvYO+A74DvwO9Q8NDwUPHA8WDyAPOg84D0cPVw9gD3oPeA+Aj5iPo0/HL+cgB0AVADWAQgBSAGaAegCOAJQAswDPAMsA1gDvAOQA9QD7AP0A+wD7APwA9wDzAPsA6ADkAO4A2QDYANQA2gDAAMoAsQC6AKMAoACtAJYAmQCCAIwAfwBqgGQAYYBpAFEAXQBCAEkAOwAgQCOAFQAID/1P4o/hj9LPww+wj6yPjg9zD3gPag9dD08PMQ8zDycPEw8dDwcPBQ8ODvoO9g70DvYO9A70DvoO8g8BDwkPBg8bDxYPKg8pDzYPQQ9dD1APfQ9yj40PgA+kD7XP1I/xIBqAIIBPAECAb4BnAIwAnQCiAM0AzADfANoA7wDpAPsA+wD+APsA+AD0APMA/gDnAOAA6wDXANIA3ADGAM8AswC6AKQArQCYAJMAnACEAIgAfABpgGGAawBXAFEAWABAgEfAPcAiwCWgF5AKz/yv4E/nz9pPyo+8j6mPmo+JD34PYQ9lD1cPSA89Dy8PEw8bDwcPBA8MDvwO+A72DvQO8A7wDvAO9A74Dv4O9g8ODwcPEQ8kDyMPPg84D0gPWA9pD3SPjg+Bj6APsA/ID9rf/eAfwCiATQBQgHMAgQCWAKgAuADCANEA6ADhAPgA8AEIAQQBAgEAAQ8A/AD3APIA8AD4AOAA7QDUANAA1wDOALYAuwClAK8AmwCUAJcAgQCDgHmAZABuAFaAVYBeAEKATAAwgDeALQAR4BPQC//+z+FP5k/cD80PvQ+tj5yPgI+BD3MPag9eD0APQg83Dy4PFQ8cDwgPAw8ODvwO+A72DvQO+A72DvgO+g7zDwsPDw8LDxQPLA8lDz8PPg9MD1YPaQ94D4ePkA+hj7cPyg/ez+zgCYAlgEgAUgB6AIQAnwCRALIAzwDNANQA4wD9APABBgEGAQgBAAEAAQABCwDyAPAA+ADuANQA2QDJAMsAtwC+AKYArwCTAJ8AggCKgH8AZYBsgFgAXYBHAEOASUAzQDoAIIAnQBvwAXAG//mv4O/mT9vPz4+yj7ePqQ+ZD4wPfQ9jD2YPWQ9PDzUPOQ8vDxUPHw8FDwEPAA8KDvwO+g76DvgO+g76DvwO8Q8HDwAPGQ8eDxAPNw8xD00PSw9XD2gPcg+BD5SPoI+wD8fP28/tn/gAFMAzgFsAYwCIAJkAogC6ALcAyADUAOMA9AEKAQwBDAEMAQgBBgEEAQ4A/QD3APEA+ADuANYA3ADHAM8AtQC/AKoAoQClAJgAgQCFAHyAZoBugFiAXIBGgEzANYA/QCjAIwAooB2QAtAHz/uv4e/qj9HP1Y/Jj7yPoA+hj5OPhw97D2APYQ9YD04PNA87DyEPKg8RDxoPBg8DDwIPAQ8BDwAPAQ8CDwYPCQ8PDwYPEA8pDyQPPw86D0QPUA9uD2wPeo+JD5mPqQ+3j8kP3W/kIAjgEQA9gEuAYQCIAJ8AqwCwAM0AzgDYAOoA8gEAARoBFgEWARIBEgEcAQoBCgECAQkA8AD4AOwA0QDYAMAAyACwALgAogCkAJsAjwB2gHoAYoBrgFMAXABPgDeAPQAnACDAKmARwBoQDm/zr/sP70/Zj9DP2M/OD7GPtg+qj56Pgg+FD3oPbw9TD1kPQQ9GDzsPIg8pDxMPHg8LDwcPCQ8HDwcPCQ8KDwsPDQ8DDxkPEA8oDyEPOg85D0IPXw9aD2oPeA+Fj5OPpo+zj8FP04/kP/dACSAQwDyARgBoAHQAnACnALEAxADGAN0A3QDmAPQBDgEIAQgBCAEGAQoA+wD2APcA/QDjAOwA0wDWAM0AtQC8AKUArACVAJkAjQBygHsAYYBogFAAWIBAgEbAO0AmQC2AF2ASIBpgAsAKT/9P5w/sD9IP2w/Bz8mPvg+ij6aPmo+PD3UPeQ9tD1MPWA9ODzUPPA8jDysPFQ8fDw0PCQ8GDwUPBQ8GDwkPDA8ADxMPFg8cDxQPLA8lDzAPTg9JD1MPYQ9/D3yPiI+YD6cPsk/Ez9Lv5m/14AjgEMA7AEGAaQB0AJgApAC/ALEA2ADQAOwA4AEOAQoBDAEOAQ4BDAECAQYBAgEOAPIA/QDiAOMA3ADCAMwAtAC7AKIArACeAIIAiQBxgHmAYABnAFEAWQBOgDaAP8AmgCFAKkATQB1AArAG//wP4i/nz91Pxs/Nj7UPto+qD5EPlg+LD38PaQ9uD1QPWg9DD0sPMQ84DyQPLg8XDxMPEw8QDx8PAA8UDxgPGg8fDxEPJA8pDyIPOg80D08PSg9XD2EPfQ97j4oPlo+lD7GPwA/ez95P7u/yIBLAKQAwAFsAZQCOAJMAtgDCANUA0QDiAOcA+AEKAQoBBAEUARABFAECAQIBAgECAPcA4QDnANwAxwC9AKUArgCUAJoAggCEgHiAZABSgF8AT4A3QDCAPUAsQB4AB0ALAA8P8+/+7+kP5A/lT9rPxg/Oj7GPvg+pj6APpI+Wj48Pdg95D2APbQ9VD1sPTg81DzIPNw8kDyEPIA8nDxQPEg8UDxIPEA8WDx8PFQ8jDykPIA85Dz4PNg9DD1EPbg9qD3ePgI+cD5sPqo+5D8RP08/hP/uv/pAOAB6ALYA1gFwAYgCCAJMAuADHANUA1wDSAP8A6wD2AQgBGgEeAQYBCwD+AP8A+gDyAPgA6ADcAMAAwQC4AK8AkACWAIuAcwB2AGeAXQBFgElAPsAqwChALmATYBagD3/6H/P//+/sr+PP7I/XT9sPwo/AT88PuA+7D6gPog+pj5EPlo+Dj4sPfg9jD2EPag9RD1gPQg9AD0kPPA8oDyoPKw8gDykPHQ8UDyYPJA8qDyEPNg84DzIPSQ9FD1oPVg9gD30Pew+Gj5kPoQ+2z8MP3Y/Q3/IwAEAaQBcAIYBAAFUAbABpAIkAkAC7AMgA4QD5APABBAEGAQwA8AEiATIBPAEYARIBHwDyAQYBCgEFAPUA2wDEAMMAuQCZAJoAmgCJgHcAYoBqAFsASEA0QDFAPIAnwCbgHpAIUAsP9V/17/hv8X//j9KP0U/cT88PuQ+7j7SPug+rj5SPlo+aj48PeQ93D3QPcg9pD14PTg9ED0oPPQ8/DzoPNw8gDyQPJg8gDyIPLA8sDykPLg8lDzsPMg9GD0MPXA9SD2IPfQ91D46PgA+sD6aPsE/Rz+qP7c/pj/3gDEAQwCYAOIBCgFCAbwBvAIkAmwCjAM0A2ADrAOgA+AEOAP4A5AEEARABLAESARgBCQDtANoA5gD3AO0AwwDGAL8AkACBAIsAhgCMgGQAUYBRgElAPMArQClAI8AWUAVwCdAMH/Hf+2/sr+VP6M/Xz9hP04/UT8YPsg+xj7YPvg+jj6aPnY+Ij4aPgo+KD4OPjg9vD1oPWA9YD1gPVg9XD1MPRQ86DzMPTQ86DzwPNg9GD0sPNw9AD1YPUg9aD1kPag99D3OPhg+Bj5WPlI+pD7oPws/ez9Yv4w/5D/DQBgAVQC4AJMA1AESAW4BYgGcAjgCXAKAAtwDNAOUA7gDRAPIBCwD5AO4A5AEAARIBDQDxAO4AwgDCAMMA1ADKAL8AlACAgHkAaoBmgG2AVIBRgEeALeAUwCnALcAZ4AIQBNANH/3P9W/6j+6P1E/Yj96P1I/az82Ptg+6D6UPqY+sj6kPp4+Rj48PdA+GD4OPjQ91D3gPaQ9UD18PUg9nD1wPRg9GD0IPSw8zD0oPRw9NDzsPMA9OD04PTQ9CD18PVw9qD2gPcY+ID4YPjw+BD6cPsc/Jj8RP3I/U7+3P7n/7MAhgH+AXQC7AKcAxAFCAboBtgHUAnwCbAKsAtwDfAOoA7wDZAOsA4ADjAOUA9gENAPsA5ADRAMYAvQClAMUAwACyAJOAdQBtAF0AUwBqgFcARgAxADTAKQAT4BRgHvAFIADQAeAIf/kv5w/lD+8P24/bj9Xv48/bD78PqY+7D7MPvQ+lj6EPpQ+ej4SPlw+Zj48Pfw9/D3UPdg9lD20Pag9sD1cPWQ9ZD1UPUA9TD1IPWA9VD1EPVQ9UD1oPVg9gD3UPfA9+D38PeI+Gj5UPqg+jD7yPuE/NT8jP3g/pb/OAATAPgAzAGIAhQDGASQBAAFMAaQB7AIcAkQCmALQAxgDYAOIBCQD3AOsA0wDqAPkA/AECARYA+QDEALUAygDXANUAzgCiAJyAcYB/gG0Ab4BUAFCAVQBAQDUAIcAooB6wCmAL8AXQDT/y3/2v78/cT9Gv6k/jD+kPzo+wT8FPxg++D60PrQ+ij6gPmQ+Xj5APmA+Fj4cPgY+CD34PaQ92D2wPUA9kD20PVw9RD1QPVw9bD0MPWQ9UD10PQQ9cD1APYA9jD2APdg99D3ePjI+Pj4cPlQ+uD6SPtI/ED9yP0O/r7+w/83AKAASAGMAuwCAAPYA3AFOAa4BlgHwAhgCuAKgAvgDDAOgA7QDiAPABCAD1AOcA4QD3APYA9QDwAPMA3ACmAKEAtwC/ALEApgCNAFcAToBHgG6AX4AwwDfALoARgBmgCXAJ4Al/+0/kH/Mf+W/uj9bP1U/cj8PPwk/Yj9mPyQ+nj5YPp4+yj7QPqQ+Xj5OPmY+Ij4IPkI+WD4wPdQ94D3UPfQ9vD2UPeA9pD10PVw9mD2YPVA9cD1UPYg9tD1APZA9oD2sPYw99D3CPiA+Bj5SPmo+ej54Pqo+0D8iPxs/Qj+XP7q/vz/JgEeAVwBbAIkA6ADIARIBUAG4AYoB4AIMArQCjALQAxQDXAO0A4QDwAPoA4QDuANgA5AD8APQA9ADSAMgAswCpAK0ArAC/AJMAd4BHgEuAVQBRAFCARUA6oBsADGAHYBEgED/8D+P/9V/zb+jP2U/gD+sPzA+wD9Fv7o/Hj70Prw+pD6kPo4+/j66Pnw+Oj4UPlg+Sj5yPgA+KD3sPew92D3APcQ97D2wPWw9VD2APcg9nD1cPUg9sD1kPUw9uD2gPbw9dD2gPcw+KD38PeY+eD56PkI+kD7kPvY+xj8eP1o/m7+7v7j/9EA9gB+AVgCMANkA3wDcAR4BRgGuAa4B5AIsAlwCiAL8AvQDOANwA5AD2APMA+ADqANcA1wDnAPIA9gDrANAAxACiAJMArgC4AKQAioBkAGSASsA6gEGAYIBeQB8gA0Af4B7wBmAJwAn//y/ur+hv/o/rz9gP3w/fj9XP0M/QD9QPxY+3j7sPtI+xj72Pqo+nj5qPig+aD6GPqo+AD4WPhA+ED4iPiY+MD34Pbw9nD3cPfA9rD2UPfw9oD2cPaw9vD2EPdQ93D3wPfQ93D4sPi4+ED5OPq4+jD7WPuo++j7jPxY/RD+mv7W/lP/rP91AAIBsAFMAqwCLANsAwgE0ATIBWgGSAfYB6AIkAmQCqAL0AsgDdANYA4gDiAOYA6ADbAMEA2wDiAPUA3gC4ALgApQCCAJ8ApQCxAI6AS4BVgFWARMA7gECAUcA+IAVABMAYcA3P/L/xcAL/8U/uT9mP6M/lz9aPxY/Fz9kP2g/FD7yPow+yD7+Pro+tj6+Pnw+Aj5oPn4+VD5cPig+Jj4EPiA99D3cPgo+DD3cPbQ9uD28PbA9uD20PaA9hD20PYQ97D2oPZQ99D3APjw9+D34Pjw+ED56Pmg+vj6CPtQ++D7bPzE/Kj9UP7O/gP/of8ZAM0AaAHAATwClAIwA/wDqAQABbgFiAYoB8gH4AggClALwAswDOAM0A3wDaANwA3wDXANcAywDDAO0A6ADOAKwAqgCZAIkAjQCQALyAcwBDgDOARoBIgDuAOwAzQCWQCw/wIBLwAE/2D+Vv/K/xz+NP1E/fD97PxM/MD8JP1E/dD7SPtI+zD7uPpI+2j7qPqg+SD5yPkg+iD6QPmw+Mj40PiQ+HD4oPh4+Bj4oPfw99D30Pdg98D34Pdw93D3cPfw93D3EPeg91D4yPiY+Lj4sPjI+ID5CPrA+hj7GPuQ+9j7UPzI/DT93P0i/qL+F//p/ygAgwAgAcoBdAKgAkAD3AOABNAESAVYBugGmAcwCGAJIArwCkALEAzwDGANwA1wDuANAA0wDQANcA2ADfANYA0wDMAKkAlwCcAJcAkACrAIEAbMA+wDIAVoBTAEzALYAr4BsACFAAoBZwBZ/x//I/9g/wz+AP4I/sj9aP3Q/Lj9aP0M/QT8oPuI+4D7MPwc/Pj6IPog+lj6YPpg+nD6sPkQ+bj44Pgw+Zj4WPiA+Gj4kPdQ92D34PeA9xD3EPeQ93D3EPfQ9vD2QPdg9+D3OPhw+MD38PfY+ID50PnQ+dD68Pow+/D68PvM/Mz8WP2I/Yj+4P4z/6H/hQAOAToBvAEsAggDRAOoA0AEMAWoBdgFoAagB8AIkAmQCTAKMAsgDJAMwAwwDRANUAxQC9AL8AwgDcAMcAzAC/AJoAfAB9AKYAqgCIAGqAUABdADKATABIAEvAJ6AaoBZAEyAPr/RQD7/wH/hP7w/nr+KP6o/az9ZP0A/Yz9bP2o/KD7gPsY/CD88Pt4++D6IPrg+VD6wPpo+uj5gPko+bj4iPgQ+Wj5yPhI+Ej4QPjw97D38PcY+MD3gPfQ9+D3UPcQ95D38PcA+MD3EPho+Gj4YPjI+Dj5oPkA+kj6iPrY+jD7sPtM/Mj86PwU/YT9Kv62/hz/Rv/6/zMA4gAWAcgBPAJUAjgDQAMoBGAEKAXQBQAGCAfQB/AIIAnACaAKMAtgC8ALEA3gDEALMArQC8AM0AuwCwAMsAtwCYAHUAigCqAJIAgIBzgGwAS0A7AEaAWIBbACZgHuATAC4AFxAGMATgAQAIr/H/8g/x3/kv7I/dD9cv5U/kT98PzM/Lj8+PsA/MT86Py4+zj6oPpg+3j78Pqo+nj68PlY+Wj5APr4+TD5EPmw+KD4CPhY+ID4gPhA+LD34PfQ9wD48Pcg+CD4SPg4+HD4wPjA+Bj5QPmo+bj5gPpo+vj6EPuI+zT8JPzs/OD8jP28/RD+2v5i/8f/xf/z/70AuAE0AigCeAIIA6gDgAMQBLAF0AZIBjAG2AbQCBAJUAnwCjAMAAwQCnALkA2gDBAL8ArADHANwAxgC0ALsAqgCBAJUArACiAJIAdIBrgFAAWgBFgFcAUgBHACrgFmAYoBsgFeAX8ASf8f/03/Uv/e/gH/bv6k/aj9gP3E/Wz9GP30/OD8SPzI++D72Pug+1D7aPsI+9j6mPpo+kD6yPl4+cj5yPlw+Tj50PiQ+FD4iPjI+Ij4OPjw90D4KPg4+ED4YPhQ+Dj4WPjA+AD5EPlY+aj52Png+RD6cPr4+jj70Psw/Cz8KPyU/ED9mP3E/RT+pP7i/kf/qf/8/y4ATwBEAaYB5AEsAtgCIAMsA2QDWARABWAFSAYIB6gHqAaIB3AJcAtwC0ALcAvwCvAJAArgDDAOcAyQChAL4ArgCZAJQApACzAJ8AfAB3AHSAbwBNAF6AXABPQC+AJsA3ACLAEeAV4BiQAgACIAAwBC/5r+vv4C/+T+Rv4K/oT9UP1Y/Wj9RP0I/cj8PPzI+3j74Pv4+7D7UPvo+qj6CPro+Sj6WPrY+Tj5IPlg+TD50PjQ+Oj42Phg+Fj4uPjw+JD4OPhA+ID4iPiY+MD4CPng+Jj4APmQ+SD68PnY+SD6ePq4+kj7uPsU/OD7APw4/Aj9eP3Q/Sz+LP48/nD+HP+r/04AywAOAckAsgCgARwDXANwAqwDOAQ4BNgE6AXwBngGuAVgB4AJMArQCQAK8ApACrAJMApQC9ALQAsgC5AK8AkACQAJoAmgCTAJAAg4B4gG0AUgBagEyASYBBAE6ALYAXIBBgEcARQB4gAPAND+jP5q/qj+lv7w/bD9PP38/MD8kPy4/LT8QPzQ+5D7oPuQ+0j7IPvo+tD6uPqw+qj6QPro+bj5uPno+fD5uPlo+Rj58PgA+QD5UPlQ+Uj5APm4+PD4GPlY+Uj5YPlg+Vj5cPmg+dD54Pn4+VD6kPqY+qD64Ppo+8j74Psk/Hj8wPzs/Cz9qP00/oT+uP7+/oD/p//Q/0wA3QCoAYgBkgFoAhADzAJ0ApgDqARABRAFiAWQBvgFcAVIB6AJsAnACRAJYAqACrAJYAqwC3AM0ArwCnALQAsACjAJ4AmgCrAJUAjQCJAI+AbIBYgFCAaIBaAEKAQABNgClgHEASgC2gEuAXEAHQC2/wv/6v5J/xP/bv40/sz9iP1o/Yj9XP0U/bz8gPxo/AD82PsE/OD7wPuI+3j7OPuw+oD6wPr4+rj6cPoo+uj5uPno+fD5EPrY+bD5oPmA+XD5iPnQ+eD5iPlQ+XD5oPm4+fD5MPoo+vj5+Plw+uj6APsY+2D7wPvo+wT8aPzc/Bj9QP1g/cT9Iv5U/or+zP4H/1P/iv/W/1YAuADIAPMAVgHOATgCaALIAggDTAN0A/wDsARQBQAGMAaABrgGaAfACJAJcAlACUAJUAgQCVAKwAvwCgAJgAigCDAJYAjgCIAJkAiIBkgFQAZwBlAF+AToBJAE8AJAApACQAMsAu8ApADcANgA5v+4/1z/D/+0/rb+5v6w/iT+YP0Y/Xj9vP2g/Sz99PzA/FT84PtE/KD8qPwg/Fj7uPuY+1j7QPtg+2D7uPqg+rD6wPpo+hD6OPpQ+jj66Pno+cj5sPmI+dj58PnA+aD5oPmo+Yj52PlI+nD6WPpg+oj6wPrg+lj70PvY+9j76PtI/Jz81PxI/aT9tP28/R7+pP70/iX/Rf94/9b/HwCCAAgBRAGeAaABtAFUAhQDsAPMAygEWASQBLAEAAbYB1AI6AeQB1AI0AgACYAJkArwCjAJcAlwCQAKsAlACXAJAAkwCHgH8AegB/gGCAaoBQgFgARIBBAEqANkAsABeAESAQwBswBzAJ3/2P6I/rT+vP48/gr+qP1Q/fT8FP0s/RD9zPxw/Ej8KPxk/IT8JPwA/Mj7mPt4+2j7yPuQ+xD7yPrI+gD7kPqA+pj6iPog+vD5SPqI+lD6+Pnw+ej50Png+Tj6gPpg+hj6APow+mD6kPro+hj7CPsg+1D7sPv4+wz8RPyo/Pj8RP2I/cD9HP5e/qT++P5g/6f/6f9BAH8AoQDJAEIB3gFMAngCoAIAAyADbAMIBMgESAVABUgFoAUABngGQAdgCFAJIAmQCIAIEAnwCUAKYAuQCzAKUAlACfAJAAqQCZAJwAlwCIAHEAc4BwgHKAbQBWgF2ATsA4QDdAPkAgQCegFcAR4B2AAoAIT/K//I/r7+dP5g/kD+uP1s/fz8EP3o/Nj8xPzE/Hj8APzw+9j7APzg+9D70PuQ+1j7UPtI+wj74Pro+iD7+Pqo+pj6aPpI+jD6cPqo+pD6SPpQ+kD6APrw+Rj6qPpo+kj6WPpg+oD6ePrQ+hD7MPsw+1j7sPvY+wz8RPyg/OT8LP14/aD97P1G/pb++v41/3r/qP/i/zYAggDYABYBrgEwAjgCXALIAhADXAOQA7gEKAVIBYAEMAXQBSAGQAcwCEAJQAgoB5gHoAhQCZAJgApgCoAJUAjgB6AIEAlQCcAIUAhoB2gGEAbwBTgGyAU4BVgEqAMkA5gCHAK6AbABWAF0AP//kf+b/yb/pP6K/pT+Nv64/XD9YP1M/QT95PzU/LD8XPw0/BD8CPwQ/Nj7iPto+3D7cPsg+8D6yPro+mj6OPqw+rD6WPro+Qj6aPog+tD5OPpo+hj6uPnI+Sj6IPoQ+kj6cPpQ+hj6YPqw+tD6EPsw+4D7iPug+wT8VPyc/Pj8PP2A/bj9CP5g/rD+/P5A/3b/w/8yAK8AyQDoADgBnAH4AUACsAIAAzADIANYA8gDYATYBBAFkAWgBWAFQAU4BogHcAiQCEAIMAgACJAHQAggCmAKUAmACGAIoAjIB3gHYAigCIgHQAY4BoAGIAVoBMAEyATQAzACbALkAvABrgBQAI8ABwAH/0v/W/+u/rT9jP3w/eD94Pz8/HD9BP1k/CT8YPww/Oj76Pso/MD7ePsg+3j7kPvg+gD7EPsA++j6mPqo+pD6WPpo+rj6kPpQ+gj6UPpg+kD6SPoY+iD6KPpg+pD6WPpA+oD6sPqo+tj6KPto+1j7OPvI+xz8EPxE/NT8YP04/Uj9tP0O/nz+sv46/5n/tf/Y/0MAsgDvAEgBdAHUAUwCtALgAvwCcAO4AxAEcARgBfgFAAaABdAFoAbQBoAHEAkgCtAJwAhQCNAIIAnQCbAKwAvgCjAJcAhgCIAIYAjQCBAJsAgQB+AFsAUwBRAF6AQYBXAEJANkAuoBlgE+ASQB6AApAKf/Jf/k/n7+YP5y/hL+hP0Q/RT9CP3M/Oj80Pxk/Oj7mPvg+xz80Pvg+6j7UPvI+uj6EPsQ+/j62PrI+oD6IPoo+nj6gPpY+jj6+PlA+gj6MPog+iD6GPrY+Qj6YPqQ+nD6gPqo+pj6wPoo+5D7wPvI+/D7RPyQ/Jz8KP2Q/bj9pP38/Zj+8v7Y/l//5P8RAAEANQAgAX4BiAH8AYgClAKEAsgCuAMoBCAEWAQIBVAFKAW4BQAGgAagBjAHQAhgCFAI6Af4B/gHAAiACFAJYAmwCAAIQAe4BtgGcAeIBwgHkAY4BYgE+AP4A3gEjAMMA2QC6gFOAaUAjwCSADMAZf8B//r+kv4M/vD9Cv7U/Qz9nPyg/LD8oPww/DT8aPzo+4D7gPug+2D7MPsQ+4D7aPug+oj6sPq4+nj6QPqo+qj6IPoA+lj6MPrI+dD5SPpA+uD52Png+SD6mPng+RD6YPog+hj6kPqQ+oD6mPqA+4D7iPvY+yj8bPxk/LD8RP2Y/az9Iv62/uD+/v78/qL/3/8WAMIAVAGsAcIB6AFAApgC2AJ0AzAEgASoBNAEQAVQBVgF+AUYB5gHIAjgCMAIEAhwB/gHEAmgCZAJIAoQClAIMAdIB9gHIAhYB2gHuAdgBvAE4AQQBbAEqAOcA4AD4AKAATwBygFiAU0Aqf/R/2b/mP5a/rr+xP4e/pz9XP04/cj8qPwQ/Vj9xPxg/DD8APz4+5D76PvY+8j7yPtQ+wD74PoY+wj7CPvo+gj7iPoo+lD6mPqI+jD6aPqA+nD68PnI+Uj6SPpY+mj6kPqA+kD6ePq4+hj7aPtQ++D7+Ps4/Jj8rPwo/VD9dP3U/Uj+aP4P/4b//P8WADQApgD3AGQBugGQAtACCAPsAqADKARIBLAEGAW4BagFwAUABsgGCAewB3AIcAiACNgH+AdgCNAIYAkwCRAJ0AgQCCAIcAeYB5AHsAdIB6AGSAagBVgFcAQ4BEAEtAMMA5gCqAIUAloBGAEkAdcAwf9B/zf/GP9y/lL+wP5g/rj9TP1Q/SD9vPyk/PT87Pxw/Az8+PvY+6D7uPug+4j7MPv4+tD6gPpo+nD6ePpQ+hD6CPrY+Zj5ePm4+bj5qPlo+VD5cPkw+Tj5UPmo+dD5oPnY+fj5OPoo+oD64Po4+zD7aPvo+1T8mPzs/Gz9tP3s/Rz+lP4J/4D/1P+KABwBUgGkAagBPAJ4AsgCKAPIA/ADaATgBGAF2AXgBTAGYAZABjAGkAZwB/AHcAiACDAIiAcIBzgHUAcYB4AHcAcwB4gGMAY4BugFcAUQBQAFoAToA8ADzAN4A+QCaAIwArIBEAHgAKQAcgAEAL//sP9C/9j+gP46/tT9aP0s/ST9/PyY/GT8MPwA/KD7cPtY+xD72Pqg+pj6YPpI+lD6YPpA+vj52Pm4+bD5kPm4+eD50PnI+bj54PnQ+fD5IPpQ+mD6iPrA+tj6KPtg+8j7FPxM/JD84Pz0/DD9dP3s/Wr+sv4D/0r/YP95/7b/JgC3AAQBVAGSAdQB+AEsApgC6AIoA0ADgAPcAxgEYASgBMgE4ATYBAAFGAUIBQAFUAWABaAFoAW4BbAFeAUwBTgFUAUwBTgFQAVABfgEuASwBMgEiARYBCAE4AOYA1ADUAMMA6QCQAJQAjQC6AGIAUwB2gCyAHQAfQA7AKX/b/85/yf/mP6Y/qb+OP7U/Xz9iP0s/ej8zPz4/Az93Py0/JD8nPxg/Gj8VPz4+xD8GPxI/BT8GPxA/FT8JPwA/PD7LPwY/AT8APxk/Jj8fPyQ/Pz8RP0U/dD8MP18/Wj9RP3E/Rb+Wv5I/o7+7v4G/7j+Gv+E/+T/AgAlAHwAowAIATYBgAG0AZwB3gHaARwCUALMAhQDWAN0A5gDhAOIA6QDwAPYA7AD5AMABEAEMAQgBAgEEAT4A/ADzAOwA6ADUAM8AxgDKANMA0ADQAMMA6QCNALsAbIBsAGkAYIBjAGSAYQBUAHrAK4AZgA9APf/xf/C/9j/yv9//yv/+v7K/qL+Xv5g/k7+Gv7M/Xj9WP1U/Wj9SP0M/dT8xPy8/MT8xPzI/Nz8yPyc/Jz8ePx4/Iz8hPyA/Fz8hPzo/OT8AP3g/Pj8AP3o/Bj9PP2o/cT98P0g/mj+ZP50/qT+1v40/zL/X/+Y//n/JQA/AE0AfgDrABQBcAGIAa4BvAH6ATQCYAKAApgC6AIoAywDBAP8AhgDaAOEA2wDbANwA7ADyAPMA8ADoANMA0gDVANYAzADFAPkAugCyAKsArQCpAJYAv4BsAFcAUYBZgHIAcwBXgEAAZYATgDn/wMA6v////X/xf+P/yv/Fv/s/kz/JP8P/5j+FP4O/g7+WP78/fT9pP28/Yz9YP1c/Wj9jP2A/YD9MP1U/VD9UP1o/YT9cP2U/Zz97P38/cT9yP0g/ir+xP20/Qj+hP64/pL+lP7u/vj+wv7I/sz+JP9u/3b/j/+E/4r/aP+h/9j/JAA2ABIAUQCJAHwAMAA9AG8AyQCcAJgAwQAUAUABBgEgAfMADAG5ALcA+QAuATgB/gA4AWwBnAEkASgB9AD6ANYAvwAKAd0AHAEsATgBWAH3ABAB1gC1AFEA5v8hAG8AtgDkAL4AyADHAGwASwAfAOz/wf/T/wUARwBbADsAIgC//2//Rf9f/2H/Wf+a/5T/g/8M/xn/KP88/wv/F/8s/yD/Mf80/4z/u/+y/1j/Z/8j/yX/A/8u/2z/rv9j/x//Xv+E/6//gf+l/87/1/8r/wj/jP/W/xUAu//F/87/AQD9/+L/2P/d/7f/pv+h/8v/QgBgAFMASACMAGAADwAaABYALQDx/xUAhwD+ANEAOgBDAA4AfgBKAGcATACyAMsATgBfAHUAIgHkAI8AngCUAJEAPQCyAP0AsQB/AIMA5gCdALUAlADbAJQAzQC5AMYAwACsAIgAOAA/AAABYgEWAWsAXABfAOz/5f/5/30AKgDZ/7T/FQBTAGUAdQASALH/Of+e/6j/LQBZAGMAIgC5/73/t/+6/7b/tf+p/2L/gf8YAO7/if85/7X/kv90/1P/x//x/2L/Hf9q/9T/cP+a/37/if9A//L+Yf9x/7H/RP9c/zL/bv+k/6L/m/8y/1f/Yv/j/6T/r/+D/2r/rP9P/4X/2v8mAMz/x//C/0AAOADt//v/1P+s/1X/6P/PADwBEAGZACgA/f+B/6n/TACoAI4ANQCVAPwACgESAKr/yv+PACsABwA6ABwBJgGRAAoAGQCIAF8AoACZAM4AVQASAA8AfACpAHMAXABLAK0AbABGADcAWwA+AOv/AABgAFsAMgDD/6L/c/92/0YA0QDVACUAc/9C/27/6v9RAI4AKQDd/+T/3/+9/2r/vv/f/wgA1P8dABoAAQCR/xn/lv+p/87/8f+uAJEAOwBw/6D/KAAEAM//lv/j/6j/ov/G/+j/FgAUAG0AaAAKANb/3P8IAPf/MgBjACAAxf+K/+3/SQA5AGUAYABnAM3/0f8JAF4AUwAgAK8A0ACUAB8AFQCbAJgANQDL//P/QgArAFcAdQCBABwAAgA1ACQA1//T/yYAWQDo/6P/kv/X/9z/DQBkAAUAoP9G/23/2v8bADsAOwAHACwARgDy/7T/2f9wAP7/pv9C/x8AfQBdAO7/qf+C/yv/ff/1/2MAWAADADwAuP/e/5v/HQA4ABMArv+f/8X///8tAE8ACQCU/4H/gf/Q/7X/LQAfABQAs/99/8P/5v/1/8D/yP/4/9D/6//v/9v/jP9Z/3//tP///4T/6P87AFkA9f+8/9X/0v8JAJb/3P+w/wkAGgArAOz/3P/g/wYAIwD3//3/4v/5/7z/uv+w/87/ZgAlAIIA1/+G/67/4P9BAKf/4P/a/0EAS/9L/5P/MAAbAIX//P8fADwAyv/m/y0ADADf/6P/9P9IAIsATwDz/6z/7v9WAEIA7//1/9L/jP+F/8r/PABJABcABwA3AD8AQAB4APn/mP9n/wgAWQCjAHEAdAD//5b/hf/I/1YAOwBYAPj/DgAfAEoALADV/wwAAQBHAEQALgC//3b/qv9FAJ0ASQDn/83/s/9S/37////KAG8A0/+O/6L/yf+I//f/PgBgAGr/H/+R/9f/yf/B/zwANwDn/w7/gv/Z//3/l//H/+3/oP+C/1EAowB0AFv/aP+b/4//Y//P/7IA0gA4APv/6P/O/2P/e/8GAB0AMgBhAIgACAEaAYQALQDW/zcAMgD//+f/UACxAKAAWQB2AM4ArwD7/5v/3/8VAAoA8/9LAM8AzgCAACMAUwBwAKsAcgD9/+n/rP/h/83/aADnANgAXQAqAIoA9/+s/3r/agDfAMEAcABQAP//kP+C/2n/DgARAJMAgwCZABsAjf+6/9r/ZwCz/7f/tf+AAIIAi/+T/7r/EgCF/07/kv+s/5j/QP8HAFYARwCp/3//r/9n/1D/kf8cADYApv9p/43/6v/R/3H/s/8AAD0Av//S//X/NQDK/8f/0f8IABYAAAAaAAYAzf+F/+X/+v/n/5v/wf/f/+j/sP+r/10AeACBAND/yv8FACEA6/8NAFIAfwBaAPz/0v/D/wsA1/9/AD8AhwA7AAUA+f+0/yQADQAKAKj/xf9nAIQAjQACACcAIQAAAM7/sP8ZAC8AKwAAAOX/JwB6AM4AmQBTALX/ff/B//7/FADR/wUAywDKAO3/IP91/wcA///q/xIAqQAnANz/zP8VAI//d/8NAF0AOgA6/9H/DwBrAIX/av+X/9D/JQDI/zQACACq/yX/Mf+4/2wAXQD7/xkAIwAMAEz/Y//M/y0A5/8CAOr/RQAuAHQAZwAZABMA0P9xAG0AZQBfAD4AZABhAPv/6v+x/6EAlwCoAPP/PwDj/9P/uf/z/7IAOgBiABMAZgA8AEsAjwB6AAoA7/9PAKkAewAQAF8APQAiAOz/LwCNAFYAEwAPAFsAXgA9ADkAcwBfACkAwv/3/8r/+v/8/58A3ACVABkAfP+Y/z3/g/8ZAGoATgBv/73/LgD0/5n/gf/I/9n/Tv/w/r3/cQBrALz/Nv9M/47/gP9B/1v/yP+I/2X/of8oAGQAYf/a/mj/y/+y/0P/9/9pAPH/Z/9f/x8Av/89/zf/KQAuAAwABwBOAP//pv/p/1QATAAuAGYAPQDR/zX/7P+fAK0AQwDm/+H/eP/j/0AAdgA+ADwAcgANAMP/mf9cAFEAcwAyAKcATQAVAAwAKgAAAAIASgB2AGUAKAB5AF0AEABl/7D//f8vADsAHwBWAAkA9P+8/9D/sf/U/yIASgAhAO//FwDL/5r/PP/D/0wADQDb/6z/9v+//1D/ev/e/0AAAwB6/7j/7v8AAKj/tf9tANUA7f8J/1z/PgAmAGv/d//q/1oAef/F/1gAswDr/1//iv+4/zAAi/8qAAQA3v9h/3X/DwBRAFcAdf+n/7b/DgDO//T/GAD1/8f/gf/R/xQAKQAVALH/cP8t/7b/PgC0AJgA/P+5/6b/3P9L/6b/RwAQAWAAqv+//4IAVgD9/2gAvAA7AA7/vf/DAPcAGACw/2UAWQDu/+7/1ADhAAMAd/+T//f/+/9bAIYAfACi/7H/8v+sAKMAPADn/5//GQDS//n/9f9WADMA+f/3//P/WgATAO3/sv9q/7T//v8IAckAuwCD/2P/9P8tACAAr/9PAHwAiADi/ywAcQDn/5//ov8OAL//nf8HAHYALgCo//H/TAAGAKT/eP8tAB0A9f+d/7j/AgDt/wAAt/8hABMAAgApANT/9f8KACUAMwDe/wYA7v9YABEAHQDW/8j/sv8pAFUARQD3/+H/6//7/83/+f9mAFoATwDk/yoALAAFAN7/lP/9/2cAcgBiADEAFgDx/8H/k/8/AKsAeQAEAMH/4v8YAAkAWQAlAAIAt//4/w8A1/97/0D/0v8aAAwAFQAOAKYAAQCg/37/7P/f/47/h/9cALwAKAD3/w4A//8V/yL/Rf8iAPX/1v+u/8H/5P/5/xMAtP/E/7z/BQASAJYAYwCU/1v/m/+GABsAj//x/5UAOwAp/2f/HACvAAMA0P/L/7//Cv97/zoAzgC2AOH/OQDS/8P/I/+z//r/MQAkAPz/DADp/zoA3P81AC4AswDBAFQAKQAYACQAOf/T/6EARgGwAKr/+v92AF8AKgBCAIUA6/8JAPL/9P/N/yAACAEgAWYAu/81ACcAgf9J/18AAgHFALr/i/87AEMA/f8+ACABHAH2/wX/uP+MAIsAtf8tAHUAYgC6/7H/NAAAAKL/hf8IABcAyv8MACIAWQDf/xUAMAAbAJn/Ov91/6z/3f8RAJ8AWQAtADX/af+z/wEAKQD6/2kAWwAyAKf/f//Y/+P/8P+v//X/DADn/+3/AQBiAIv/0P84/9j/av9Z/7D/HQAjACL/lv/g/00Aif+O/5L/LwDm/8r/egCGABYAVv9g/7v/hgBYAGgAcQAYAF3/uP5A/zUAKAGzAC0A3P+x/3n/sf+9AAoBzQDr/zIAcAAwALb/GABFAJMAYQCaACEA4f/5/xQAIwCu/xwAZQBNAHv/r//7/8v/V/+N/2kAMgBYAGX/u/9C/x3/OP/O/zQAggBoANz/XP8d//L/GQD+/+z+Yv9a/xMA4f9MAJsAEQDE/yD/pf8m/x7/K/93ACMApv+s/xEAewD2/6D/5v/0/17/Q/+4/z8AjQA3ANb/pv8jAMj/IwBn/xAAeQAaALb/ef9R/5T/DQCeAJgBSgCT/zD/FQCBAPb////IADYBewDQ/4f/jQCKANb/DgARAH8Al/9aAE4A8gAOAOj/x//0/y0ASgBOALv/AQDF/5cArP/Q//P/iwA+AL3/Vf8V/x//cP88AGMA1gB6/1QABgB2AHb/Qf9KAPYAiwCg/+cAowAjACD/awAiAaEA8v7w/kkAOQCNAOr/wAB+AAsAoP8p/2D/kf8uAD0ANgEWAaQAsf+v/0MA3f9Q/9D/PAFOAfP/7v4IAGYA/P+S/sD+D//e/kj/uwCSAS8A3v7K/q3/8P/9/7oAOAG3ACf/3v+oAFQAA/9k/rz/1wDVAOUAvADNAFQA0f+7/yz/sv8OAGgA6/9c/8D/SAEyAYYACf9I/kD+TP9OAL4AbwD0/rf/a/+h/xD/iwC6AYYBkgBZ/0v/of98AAwBTQAR/yz/OwBoADn/7P+VAHQB0v+A/9//sf/0/mb+KQC5AIcANgAmAcgBZQAZ/2j+Bv9b/03/8v9IAHgAhwAoAW0A1f/Q/kL/9f+tAEEA3/9cALYAWAHPADEAfv+tAGUACQBi/kj/cQCdAKX/u/9uAf4AkP/i/pT/s/8O/yP/BQCeAEUA0/+GAAEARv8+/5n/EACd/6kAGQAaAOz+ff9sAeQBxAGZAGIAiP8b/zj/7f/eAOsAhgDj/3n/NwCP/yMAKQCAAED/5v4YACYBKAGS/8H/cgDA//7+WP/qAP8AqQAu/0f/zv7C/ykAWwDBANP/1v/y/oT/X/+5/0n/zv9CADsAiP9W/zQAp/8W/wf/8v8UAMn/5/8iABkAPP+G/2IAawDs/5b/8P/A/9v/AgBbABsAU/95/z0AVQA8AEUAnQCTADT/5v4h/0QAKgACAOj/9//z//j/QwABAMf/ov97AOsAIgE+AMb/KwCIANoA/v/W/+r/BADd/zoAQAGYAdcAAAB0/1b/Hf+h/7AA6ABMAIT/1v9NAGYAagCBADgA/P9M/z7/kf/2/3sAEwDV/woA3QC8ALH/gv/e/5MA5P8h/07/SgBFANL/lf89//P/CgBrAC0AKgCR/7H/oP9q/8X/BgAAASYBDAFxANf/rv/k/7gA6QALAHb/if8VAOT/6f8ZALoAzwAyAJL/pf/N/83/s/+O/9//IQBLAHEA9gBPAIr/+P6H/14AIADk/9j/hQCfAC4AXgBSAK8AfQAmABEA1v/9/0EAqABfAGQALwD1/zoAgAB+AFkA7P/B//j/vP/M/wwAUgAqAIIAVQAhANL/lf8cAJgAswBNACoAHQAdANf/yf8yALEAfgDJ/yoAGQCk/0D/pP9lAF8A9f8kAIoAUwAoAJr/8v/t/6j/gv/b/ykAKABeAHUAgwCBAOf/ff+H/6D/yP/z/0cAZABPALX/k//C/wUAn/9s/27/T/9G/3r/mP8HADwA+f/N/5f/wP+f/7//ov/h/wAAPgBNAB8A8v+c//b/6/85APH/h/+Z/9z/cQB6AHwATwD7/8H/zv/u//P/9/8eAFMA8f/C/97/QQBjAOL/sP+d/5v/tf/w/wwABADr//P/8f/e/6X/ZP/O/xkALQDr/6z/xv8WACAAWwCjAJQANwD5/wAA9f+J/5T/UADMAKQAEwAEADEA1P+B/2f/o//T/7H/AgAvAEkAAADY////OAD+/4X/Z/+i/wwANwB5AJ4AeAATAOL/+P/b/+D/2P/3/z4AUgBbADgARwBQAF4AKgDT/9j/7f////r/5//p/9T/rv+E/8n/5f8eAAoA6//8/xIA0/+w//H/BgAxAPf/EABBAGIALgAUAPn/6v/O/9r/FQAcADIASQBXAEIAHAAwABQA7P/r/ysAOAAQAOn/IwArAPP/rP+//wIA8P/R/+v/EQD6/63/kv/L//j/1f/S/xwAKQBVAC8ATABSAMr/nP/h/zgAYQBPAHIAjQCFACEABgDb/8X/4f/o/+r/yf+8/83/7//S/8v/rP+y/4f/ov+V/5H/tf/o/wQA0v+q/43/ov9t/3f/hP+n/7D/eP96/0//h/+B/4z/h/+g/8L/wv+u/57/rv+h/6//rP+o/7T/iv+X/5D/mv+T/23/rv+S/3L/cP+i/8j/6//I/8j/0v/B/+j/LgBZAIsAnQDNAKsAnQC6AN4ABAHnABABUAFOAT4BSAFwAZABcgFmAXIBlAGyAaoBqgHcAcYBtgGoAdIBCALQAdwB+gHyAXgBGAFMAWIBfAF8Aa4BhgE4ARoBGgESAQoBJAHzANUAlgCYAG4AMgDe/93/uf8J/7D+Zv5Y/gj+iP1Y/RT9uPxk/BD8HPy4+2j7GPuo+tD6uPrg+jj7CPsg+8j60PqQ+uD66PpY+6j70PsA/DD8qPwI/Wj9nP3k/ST+lP4P/7v/LwBuAL4AigDxAHQB0AHAAtACrAPEA7QDEAQQBNAEsAUgBsAGcAfoBzAIYAjwCMAJQArACnALEAwgDKALwAtADIAMcAxQDNAL4AogCuAIUAh4BwgGwAToAn4BeP9q/iT9+Ptw+2D6wPgQ99D10PTQ8+DyQPIw8ZDwEPBg7wDv4O7g7gDvAO+g7+DvoPAA8RDyQPNQ84DzgPMA9ZD2oPdI+RD7zPxY/on/8//o/83/g//7/6MA0gG4ArgDgARQBbgEUASkAzgEmATsA4QD/ANoBIgEGAVAB+gHoAf4B4gHmAeQBhAI8AnAC0AOwBAgE4AUABRgFCAUgBMAE8ATIBSgEqARQBCwD4ANcAsAChAIaAVMAvL/iP2I+yj5iPhA9xD1kPOw8QDwIO5A7UDtgO3A7EDswOtA66DroOwA7oDvgPDg8ODwQPLg8rDzgPRQ9ZD2APdQ9xj5CPtg/KD7KPoA+VD4UPmY+xT+I//3/+3/CwCU/cT8oPwM/KT87P20/jb+Fv/8ANgCnANUAvQBQAIaAUwA9AEABOAFQAegCCAJwAjAB7AHEAmgCbAKEAuwCzAO0A9gEgAVYBfgGKAX4BWgEyAToBOgFEAWoBZAFSASoA7ADBAM8AlQCIgGKAS2AKD9RPyY+7D60Pgw9zD14PFA72DuoO5A7wDwcPBg7+DtgO3g7UDuoO5g72DxAPKw8rD0oPYQ9zD3sPeI+ED4gPeg+Nj6TPzA+xD8+PsA/Bj7OPsg/Gz8/Pyc/IT9sP1I/XD8QPzY/AD94PsU/Cj9FP6D/0L/tAD0ABIBcwCGAIwAbgGKAZAC5AIgBOAEWAXABugH0AiQCHAJsAnwCVALYA1gESAVoBfAF2AWABWAE4ATABQAFKATgBIAEYAPwA7ADZAM4ApoB3wDnv90/ED7kPuo+8D64PfQ9IDy4PDg7mDu4O7A7kDuIO7g7sDugO5A70DwEPFQ8JDwwPHQ82D0gPaw9xD4APgg+DD58Pjg+Gj5sPpg+2D7MPs4+0D7YPuY+/D7+PsQ/Fj7mPuI+0j8uPuY+xT8AP3U/PD8sP3s/r4A3v+QACkAWADg/5oA6gFgAs4BmgEoA6gE8AUIBpAH4AgACVAIqAdQCdAL4BDAFeAYoBjAFmAVgBLAEWATIBRAFAATYBPAEmAQQA7wDAAM0AcQArX/vP7I/dT9jP3Q/GD5QPWw8pDwIO+g7gDvIO/g7oDv4O8A8MDvIPAg8GDvIO8A8GDygPOw9bD3EPmQ+GD3YPdg96D3WPjQ+VD7VPyQ/Oj80Pxg/PD7WPt4+6j72Pus/Dz9EP5Y/jT+WP1w/Jz8dP1I/hz/nwDqAH4B9gCWAQACIAIoAvgC1AM4AqgCmASgBlAIIAnwCKAJMAlQCJAJwAogDkARYBWAGCAYoBbAFGATQBKAEuASABOgE0ATYBLgEJAOAA0ACbgG9AJPAGT+DP7o/sz9HPyo+MD2sPNw8ODuwO9g8ODvUPBw8TDy8PCQ8MDwAPEA8YDwoPEQ9DD14PYA+DD56PjA96D3UPc4+PD4KPoI+zj8qPwM/Sj8SPtQ+6D6KPp4+uj7xPxI/UT9EP1s/JD7GPuQ/Iz9sP4M/6r/IgAIADsAGgHYAXABjgEeAdgB7gGIAkAEYAa4ByAHSAeoBhAIAAigCoAMYA/gEWATYBcAGOAWQBMgEiARYBKgEgAUgBXgFCATIBCADZAKwAeoBTAECAJu/yf/9f/g/gj8oPhg9vDy4O9A74DxsPEA8hDyAPMg8mDvAO8Q8ODwsPCQ8YDz4PRA9fD1UPdw98D2cPbw9rD3IPjY+ID6kPtY+zT88PvI+kD6aPpw+pj6aPvs/Lj9tP3I/Iz82Psw+xT87P1E/5T/r/+K/5j/5/+IAFYBvAHOAeIBfAGEAfwCSATIBZAFKAZ4BvgGmAegCTAMIA1wDcAPIBOAFAAWQBdgGEAVIBHAEKASIBWgFWAVgBWgEeANYAqgCWgHgAWABJwCQAEt/z7+sPy4+hD3kPRA8nDw0PBg8XDywPEA8ZDwgO9g7sDtYO+g8KDxQPLA8rDzEPSg9ED1EPbg9RD2oPbQ9sD3GPko+jj6yPoI+/D5sPnY+Rj7SPvw+sj77Pwc/Qz86Pto/Fz8gPwE/aL+jf9m/67/IQAbAFcASgH2AVwCvgH8AdACbAPQBNgFkAagBhAH6AeACYAK0AvgDEAOcA+AEuAVIBigGOAXwBXAEuAQYBLAFYAWYBdgFUASoA6gC3AJgAhoBiAFUAQcAwgApv5s/RD7kPdg9EDzAPKg8WDxYPKQ8lDxwO9A7sDuoO4A73DwoPFA8jDyMPNA9PD0sPQA9TD10PWA9iD3oPio+aj6sPlI+Qj5WPk4+qD5SPqg+4j7oPoI+yT8ePww+5D7EP1w/Rr+Mv68/1UAyP8YABQBugEUAnACKAPgAlQCxANgBaAGyAZQBwAIIAgACdAKQAxADNANoA9gEaATIBYgGaAY4BVgE2ASYBLAEuAVYBhAF2ASUA/ADEAKQAj4ByAIEARQAtsAiQD8/Sj7sPhw9gD0kPEw8bDx8PKw8iDyoO/A7aDtQO4A7xDwAPFA8fDw0PGA89DzsPOg81D08PRg9ED1cPdQ+fD4WPig+KD4QPjA+Kj60PpI+sD5kPpQ+5j7BPzY+zz8HPxc/Oj8XP2U/mD/XQCT/+7/uAAwAUwBXAEgAmwCtAKcAzAFuAaYBngGgAdACFAJQAqQCwANEA6QDyATIBaAFuAWoBYAFEARoBDgEgAXgBZAFkAUwBDwC/AJUArQCQAHIAUgA+ACygD8/TT8CPpQ9xD0EPKw8WDyUPNQ87DxgPCA7cDs4OxA71DwYPDg8NDwQPLg8dDxcPJA8yD0IPPQ9KD10PbA93D46PiA94D3UPjg+XD5IPmI+sD6QPp4+rj7RPxY+1j7qPwU/QT9cP0T/8EAtv8SAKoAIAGwAc4BgAKoAgADOARwBRAGUAbwBgAIUAjwCCALUAygDLAMkA4gEuAToBUAGMAY4BUAE2ARABMAFUAWIBggFgAUkA/gC/AK4AqgCrgHeAVgBIwDzwDs/Vz8oPrw9hDzIPMA9JDzcPPA85Dy4O5A7EDs4O6g73DwoPBA8UDxgPDA8QDyIPJQ8sDygPSg9DD1UPc4+KD3wPaA9rD3SPgw+VD6APtY+ij6MPuQ+7j6uPqg+6z8ZPzs/TL+I//2/ub+GQBz/w4AbAG8AmQCMALcAtgDmARoBDAFMAbABsgGcAjwClALMAuQC1AO8A6gEIATgBZAGCAWYBQgEuAS4BKAFEAWYBZAFaARcA2AC7AL0AqwCBgHIAa4BI4BDP+g/ij80PgA9eD0YPTg88D0EPXw8oDv4OzA7IDu4O6Q8IDxsPBw8HDwkPFg8VDwgPEQ82DzMPOQ9FD3sPeA9hD2oPYg9uD2sPjI+hD7EPl4+pD6IPu4+dj6APxE/Lj8CP1I/pz9lv6i/rH/Pf9J/2ABAAJAAhQCVAK8AzQD+ANIBSAGCAdIB+AIMArACvAKUAxQDrAPIBGgE4AWIBigFiAVABSgE4AUgBUgF6AXQBfAEjAPgA3gDEAM0ApACgAJgAbwAsYBov8U/Xj6GPhA94D1QPYg9oD2APOg76DuIO6A7oDv4PFw8TDwYO9g8JDwwO/A73DxoPLg8fDx4PPQ9cD1UPXg9bD1YPUw9oj4OPqQ+Uj5wPko+tj5EPo4+wD8GPyM/CD9IP3M/QT+if/N/zn/GQAEATACMAIIApAC5AJsA9wDQAVQBjgHkAeQCPAJQAogC+ALkA2wD2ARgBOgFUAXABagFAAT4BPgFIAW4BZgGEAXoBJQD6ANkA5QDcALgAtwCqAHyANkAvoAqP1g+6j5UPiw95D3MPcw9mDy4O9g7qDuwO6Q8ODxQPGA70DuAO/A7sDuoO8g8bDx4PCA8dDyMPTw86DzUPRQ9GD0kPUQ+Ej56Pjg99D3UPjY+Mj5aPt4/LD7qPtw/GD8TP3I/eD+Z/9g/6P/oQDUAcoB+gHIAVwC7AL0A2gFsAY4BzgHkAfgCKAK8AuQDHAOoBAgEoATIBUAF4AWYBTgEkAVYBWgFkAYABjgFkASAA9ADmAO8A1ADXAMYApAB3QDXALJ/2L+ePxA+iD5KPiw94D2cPQQ8qDvgO6A7iDvwPDw8NDwAO4g7KDsgO1A7uDucPBg8ODvAO9g8GDyIPJA8nDysPPg8zD0QPYg+Bj4cPZg9nD38Pgw+iD7SPwU/DD7EPtk/Az+oP4W/77/kQAuAFcAxgG8AtACnALIAggEuAQIBpgHYAgQCDAIkAnACtAMIA7QD4ARYBJAFIAVoBYAFUAUABSgFMAWQBdgGIAXoBWAEFAPQA5gDjAPwA1gDAAJoAWQA6QCWgA0/Yj8ePvI+eD3kPfg9nD0wPGg70DvoO+A76DxgPLg72DtIOwA7SDu4O6g79Dw4PAA8IDvYPCw8eDy4PJg88DzkPTw9dD2CPjA99D2MPbQ9yD6iPss/Pj7APzA+7D7RPxu/g4AewBaACwAoADiACQC/AJYAzgDpAOQBMgFAAeYB5AIMAgwCEAKgAzADfAOABFgEgATIBOAFGAXABWAEmAUgBYgFwAWwBZAFgATQA8QDtAPcA/QDQAMEAswCIAEwgEeAR8AzP1s/Fj68Pnw98D20PRA8+Dw4O/g72DxUPHg8HDwoO5g7SDsIO2A7oDv4O/g8EDwgO6A7+Dw0PHw8XDygPOw9BD1QPVA9rD2MPaw9mD3mPgY+tj6qPv4+uD6qPqA+zD9bP5//xP/ff/8/zkA9ABOAUwCmAJYA6ADkAQABogGMAfAB0AIgAnwCiAMkA5gEGAQYBKAE4AUYBUAFEAUIBTAFAAW4BegF6AUgBIAEaAQYA9wD4APQA6gC1AIwAaoBLgC4wC4/0L+zPwA+3j5KPlA96D0MPLA8UDykPIQ8sDxMPGg76DtgO1A7iDvQO/g75DwAPAg72DvgPAQ8aDxwPLQ8/DzkPRA9ZD1kPWQ9QD3EPjA+LD5CPtI+4D6UPow+7D8hP38/Wf/PgDe/53/LAA6AQQCBAIMAygEoAQABbgFKAfoBhAIoAhwCuAL4AxQDhAPABHgEWAUIBQgFUAVYBRAFEAUQBdAGMAW4BSgEwASoBCAEGAR8A8ADkAMsAnIB6gFEAT8AoMAgP4s/bD8yPro+GD3UPVQ8/DxgPIA88DygPFQ8CDv4O1g7cDtQO+g74DvIO9A72DvYO+A7wDwMPHg8bDygPMg9DD0YPSg9CD1APaw99D4+PlY+hj64PlI+hj7SPwQ/m7+Ov8m/7r/KACgAPUAtAHUAlQDtAOwBKAFcAbgBYAG2AeQCZAKQAugDQAPYA8wD4AS4BPAFAAV4BOgFCAUoBSAFgAY4BaAFIASgBHAEYAQABHAD5AOIAwACfgGuAW4BLACyAA//zT9GPwQ+xD5EPdA9NDz8PJw8qDykPKQ8SDv4O1A7YDtQO0A7iDv4O7A7QDtoO1g7oDuwO7A79Dw8PCQ8UDyoPKw8pDy8PNg9cD2kPeI+MD42PjY+Cj5IPtI/Hz9UP6A/oj+UP8AAO0A3gFQAqgCtAN4BDgFMAYwBjAHIAgACfAJgAvwDKANMA+gD2ARABPAFOAVABXgE2ATgBXgFSAYoBcAFsAUoBJAEuARABGAEIAQMA6gChAJIAhIBvQDEAK1ACX/UP1g/GD7iPmw9cDzUPRQ8+DysPIw8iDxAO+A7UDtYO3A7QDuwO4g7qDtgO2g7QDugO5g7wDwkPBQ8RDyIPJQ8mDyUPNQ9ED1wPYo+ND4SPiI+Ej5MPqw+0D9Pv5M/rL+Mv/q/6EAfAH0AnADPAMABLAFQAb4BRAHkAggCfAIgArwDGAOMA6wDWAR4BLAEsAU4BXAFAATgBPAFWAX4BbgFYAVIBQgEiARgBFgEaAQYA5gDLAKYAh4B0AFcAM4AbX/fv4E/ij88Plw9+D1IPSA85Dz8PIQ8yDx4O+g7uDtIO3A7WDuoO3A7YDtwO2g7cDtoO1A7mDvIPDg8EDxcPEA8uDxIPJQ8+D0MPbA9qD38PfQ9/D3QPko+zT8uPxE/dD9ZP6a/tn/NAEkAggCnALYA1gEuARwBXAGmAdQCKAIIAowDNALMA1gDmAPYBGAEuAUgBUgFOASoBNgFQAW4BYAF6AWgBTAEoASgBIAEsAQIBBADqAMUArwCCAHOAVUAwwBlQCm/9z+4Puo+fD3UPYg9XD0gPQw9KDy4PAA8CDvgO4g7mDuoO4g7uDtQO4g7qDtgO1g7iDvMPDg8DDxkPGA8dDxsPJg83D00PUQ95D30PfA94D44Pmw+rD7GP2Y/RT+YP70/oYArgCkAXQCSAPwA0AEcAWwBUgG8AYwCJAJYAoQCzAMYA1QDRAPgBAgEkAUABWgFAAToBOgFMAVgBbAFqAWQBVgE8AS4BIAEmARgBAgD6ANMAvwCWAIYAbsA1ACbgH4/wP/tPz4+qj4sPYQ9aD0cPRQ8yDzYPFA8ODuIO4g7uDtQO7g7UDu4O2g7WDtYO3g7SDuoO8w8GDwsPAg8ZDxEPKg8sDzIPUg9sD2UPcA+MD32PiI+nD7IPyo/Kj9rv6W/oL/4wDMAZgBpALAAzAEuATABJAGGAcwByAI0AmACrALcAygDYAOYBCgEQATIBTgE+AToBMgFEAVQBagFsAVYBWAFCATwBLAESASoBBQD8ANsAswCjAI8AbIBDwDOAH1/zf/LP1w++D4APfg9ID0gPSA84DyIPFg8IDuQO0A7QDuwO0g7QDtwOyA7ODrQOwA7WDtwO1A7qDvYO8g7+DvkPAg8RDygPMQ9ZD1sPUg9vD28Pfg+Jj6qPuo+zj8NP1Y/o7/LAAGAfABgAIgA+ADeASgBQgG8AaQB1AIcAqQCkALsAyQDSAO4A9AEuATABQAEyAUgBTAFOAUYBZgF2AWYBXgFKAUQBNAEiASYBGAEFAOwAwAC5AJMAeoBWgEEAIaAdz/TP5Q/PD5sPeg9mD18PQQ9VDzAPLQ8ODvYO7A7cDugO5g7mDtIO3A7eDs4Oyg7aDuAO4A7xDwsPBQ8MDvwPDQ8WDyYPOg9QD2APYg9hD3IPjg+FD6wPvo/Hj84PyW/s3/mAAVAFwC9AJsA0gEoAToBeAF4AaAB8AIoAkACxAMUAwwDaAOQBBAEWATIBTgEwAU4BNAFaAVABbAFqAWABagFIAUoBNgE8AR4BHgECAPMA0gC3AKIAgIBhAFaAO+Aab/lv58/dD6QPig97D2kPWA9AD0sPNg8WDvoO9A78DuAO5g7qDuIO0g7SDtAO5A7cDtgO7g7mDvoO9w8ODvUPCg8ODxcPOw8+D0sPWA9RD2UPYo+Aj58PkA+2j7QPxA/Nj9xP67/zYA/wAkAngCDAPYA2AEGAUoBlAHQAggCeAJIAswDJAMYA5AEOARoBIgEyATABNAE2AUABagFcAVQBXgFIAToBIAE0ASABLgD0APgA2AC8AJ4AhgB8AEoAMwAlYBJv9s/Rj8GPow+MD2sPbw9YD0QPMw8uDwgO8g70DvAO9A7gDuoO0g7SDtIO3A7YDtQO7A7kDvYO+g7zDwMPDw8HDx0PIQ9ID0IPWA9SD2kPag9/j4yPmw+jD7IPyc/Hj9Rv6G/3gA0QB+AWgCaAOAA3AEEAU4BlAHwAdACcAJAAtQC2AN8A1AD2ARYBIAE2ASwBJgEyAUABXgFSAWIBVAFMAT4BKAEuASABLAEEAPsA1QDGAKIAmAB+gF9APQAsIB/f8S/sD7qPrA+DD3sPYA9mD1oPMQ8uDwMPCg7yDvQO/g7mDuoO3g7cDtgO2g7eDtoO7A7kDvgO8w8HDwQPCA8TDyUPMw9FD1wPUg9pD2MPeg+ID5kPpI+yT8pPxk/TL+Ov9WABoBtgEsAgwDEARgBPgE2AXYBsAHgAhQCdAK4AvACzAO8A7wD8ARwBKgE4ATIBNgE+AUgBUgFkAWwBUgFaATwBMgEwATQBJAEfAPwA1ADCALUAn4BxAGYASkA7wBBwD0/Xz8iPpw+ID3UPdQ9qD0oPMQ8tDw4O8g72DvAO9A7sDtQO1A7aDs4Owg7WDtwO3g7aDuwO4g74DvoO9g8KDxsPKw86D0MPXQ9QD2APdo+GD5OPpI+9D71Pxw/Sz+rf+oAFQBsgGcAlwDUASABEgFqAYgB9AHAAlACpAK4AtQDAAOYA+wD+ARIBNgE2ASQBMgEwAVoBWgFeAVABVgFMATQBPAEoAS4BFAENAOkA3wC2AK8AgoB2AFsAPAAkAB0v+U/Uj7EPpw+ED3oPbw9aD0EPPg8aDwwO9g7+DuoO4A7sDtYO0g7QDtwOxA7YDtwO0A7sDuIO8g76DvEPAA8cDxsPLA8wD1IPXA9cD2gPeg+Jj5APuQ+1j8MP00/hv/4v/rAIwBgALQAvQD2AQwBcgFEAcACEAIUAnACmALoAzADPAOgBAgEKARYBOgE2ASIBNgFGAVgBVAFYAVwBQAFOASgBPgEkASwBDwD7AOcAxAC/AJ8AhoBigFSAO0Aq0AvP7o/ID7iPlo+OD3wPaw9RD0MPPA8ZDwoO/g76DvYO7g7eDtgO0A7eDsIO0g7WDtIO5g7sDuoO4g76DvEPDQ8NDxYPOQ80D0wPRw9VD2MPfA+GD5QPr4+qj71Px0/cr+gP+jAO0AeAGQAkwDEASIBKgFgAaoBzAI4AjACoAK0AugDVAO4A+AEAASgBJAEiASIBOgFOAU4BSgFOAUoBNAEwATwBJAEiARYBDgDnANEAzQCjAJwAc4BogEeAMAAvAAXP7A/Fj7KPoI+RD4APfg9XD00PIQ8kDxoPAA8MDvIO9g7iDu4O2A7WDtYO0A7uDtYO7A7uDuIO9g7zDwAPHg8YDyoPOA9PD0cPVQ9nD3qPhY+Uj6OPsA/MT88P3S/tr/NgBeAVQC1AJAAxgE0AWwBcAGWAfwCLAJIApACxAMkA3QDUAQoBCgEWASYBLAEoAS4BMAFUAVoBSAFAAUYBPgEkATgBKAESARoA9gDvAMwAugCtAIWAfQBeAEQAO6Ae//EP5w/Lj6MPrg+ND3kPZA9SD0gPKQ8QDx0PAg8GDv4O5g7kDuwO2g7aDtgO3g7UDuoO7A7sDuYO8A8MDwAPGg8nDzMPSA9GD1EPbw9ij4CPmI+uD64PuQ/Kz9lv6C/6QAYAEkArwCeAM4BAAFMAZwBlgHUAhwCYAKwAqwC1ANkA6gDsAQgBEAEoASQBLgEmATABSgFIAVoBTAE2AT4BJAE0ASIBLgEAAQoA4ADcALMAogCcgH+AUABVgDtgFBADr+nPyo+jj6EPnA93D2cPXg8yDyYPHA8HDwoO/g7mDuoO0A7aDsgOzA7IDsoOwg7YDtgO3A7SDugO5A7+DvQPFg8iDzkPMg9OD0APZQ90D4oPl4+gD7yPsU/fj9Mv89ABwB7AGIAhADAAQQBbAF2AYwB0AIgAlgCuAKgAvQDJANIA+wD0ARABLgESASIBLgEiATIBVgFKAUoBOAEsASYBJAEoARgBBQD2AOUA1gCxAKUAmgB6gFcARYAywCfwCm/qD8cPvg+bj4cPgA95D1QPQA8wDyAPFg8ODvQO/A7gDuwO1g7SDt4OwA7SDtYO0A7kDuYO6A7kDvoO9w8EDxQPJA8+DzgPRQ9ZD2YPdY+KD5oPpg+1D8XP1k/mL/bAAmAfgBxAKMA5AEeAUQBvAGEAigCGAJgApgC/AL0AzgDfAOIBAAEKARYBKgESASABOAE4ATABQgFOATwBIAEiASwBFgEfAPgA8gDjANkAswCnAJcAdoBpgEgAP0AakAyP5g/Yj7MPoI+Zj4QPfQ9cD0QPNQ8jDxkPDg76DvoO5A7gDuIO0g7QDtIO3g7EDtoO0g7qDuoO7A7mDv4O8A8fDxoPJg8/Dz0PRQ9WD2kPfQ+Nj5YPpY+wz8GP1Q/oX/lgAaAfgBhAKAA0gEMAVgBhgH0AegCOAJUApQC+ALcAwwDnAOwA/AEAARYBFAEeARQBKgEuASQBNAE2ASoBEgEWARgBAAEDAPMA4wDdAL0AqQCVAI4AbIBTgE/AIEAooAIv9w/Sj8qPrQ+fD48PeQ9lD14PNg85DysPEw8aDwAPBg78DuwO6g7oDuYO6A7oDuwO6A74DvwO9A8IDwsPFQ8hDz0POA9OD00PXw9gD46PgA+tj6wPtM/Cz9eP6c/4wAOgEMAvgCfAO4BDgFGAbABsAHsAhgCRAKwArgCwAMsAwQDQAOcA/gD4AQIBBAEIAQ4BBAEYARoBGAEQARIBDQD2APQA/gDiAOEA2wCxALIAowCfgHqAZ4BTgEYAPyAQQBmv9A/sz8UPug+pD5wPiA98D2gPWg9NDzIPOw8vDxoPEg8bDwgPAg8DDwEPDg7wDwAPBA8JDwEPFg8bDxUPLg8tDzYPQg9fD1sPaA9zj4UPko+iD78Pv0/Nz9lv6H/xIASgHYAbgCnANwBEAFyAV4BgAH6AdwCGAJQArQClAL4AtADPAMUA2QDjAPQA/QDhAPoA/wD7APgA/AD5APAA/gDdAOoA3QDMALgAuQC4AJsAgACCAIMAVcA/wDlAOoAeT/4v9Y/jz8wPvY+0D60PcA+ED40PYQ9MDzEPYA9ADxIPFQ8zDyYPDg70DxAPEA8KDvMPFg8fDwoPCA8WDyYPLA8tDzEPVw9SD1IPYA+DD5MPhI+Rj7DPwk/Fj9Ov7Z/2P/ZgCQAXgC2AIIBJAFCAUoBbAGcAcwCDAIgAkAChAKwAkQCwAMUAywCwANoA0gDcAMMA1ADnAN8AwwDZANIA0gDPALQAzQCgAKQAqwCdAIuAfAB/AGIAWcAwAEkAMgAn4BsAA+AEb+iPwQ/VT8cPoQ+jj6MPnA9xD30PZA9oD1APWA9DD08PNA9NDzIPPQ8uDzIPPg8rDzQPQQ9BD0IPXA9MD0kPUg93D3QPfw9yD5YPmI+eD6jPxo/Fj8Ov46/nT++f/kAeABawA8AmADqAQoBKAEiAa4BigGCAYACEAI0AhwCDAJQAmwCRAKkAlwCoAKgApQCWAKkAqACkAKYAmgCQAJ0AiACAAJ8AdoB+AGkAYoBsgFsATMA0gE6AOkAjoBNgFKAXwAH/92/pj+1P3U/Cz8ePzg+mD6wPoQ+nD4cPiI+ND3APig9lD2UPcQ9yD2YPbw9kD2MPVg9RD30Pfw9kD2WPiQ9+D2QPY4+Xj6YPn4+ED6HPzg+ej78PuU/bT9Rv7u/nL+sv8jALACBwDqAJwCqAP8AqADIAQwBHAF8AQYBegFcAY4BsAHeAZIBuAGsAbQBxAJuAbwBCAI0AnoB9AE2AQQCCAJkAWoBEgHaAYABQgFiAT0A4ADMAR4BDADLgE8AjQC1ACwAIoAiP92/wIAsv4A/uT8KP7k/SD8UPs8/KT84PpY+3D6APtw+kD7KPkA+aD6CPtw+pD3EPpw+nD7sPiY+Uz8aPlY+sj7UPzA+pD6LP1c/dz8UPts/UcAxv48/OD+Zv9G/0YADv8iAXACHgHu/4wCDAO6AWAC0AKoBEwDLAPABAgGAASAAqAFgAaYBIQCgAaYB3AEUANQBSAGOAW0AwgFkAXgBCwDUASoBQgDtAPoAxAESALgAjQB+AJ4A+wBjADk/zgCEgGbAFz9zwAUAtr+WP1g/SoA1P7E/dT8kP0E/fT9SPw4/Hz9SPzY+wj8kPto++D8yPoM/FT9wPo4+tT8VP3w+qj8cPqg/ND9+Ps0/iz9ZPzo+1QAOP6s/Nz+TABGASD9NP2AApACs/+o/iADhAJa/4MAUAXcAwT/RAIABNgEKgDQAnAFYATbAFgC4ATgA/ACmAXIAioBUAIwBpgEugFYAvgDcAUy/0ACWAQgBAkAjAEoAmAB1/8xANAGav8g/Bf/8AI6AbT8kP6iAZkAQPxQ/JABpP4w/TD9gP50/Ez93P+4/CT9EPvY/Sj9/PxI++b/aP2Y+YT9yPx4/cz87P0g/dT87PyQ+9L/3P10/pT9mPw8/pMAkP8g/AYBfv/P/7T8nP+YBLX/9P0uAVgCZP4AAWQC/APY/lT/yAMsA5T/vAFIBcwCOP4hACgFJANeARwB8ASIA0D/KwBQBFAEZgFpACoBsAMwArgCcgDwAfYB4gFW/m4BgAIcA60ABP8L/0QClv+e/qACRAAe/wD+YwDH/53/S/+I/mj/Cf+I/lD/YP62/gwBuPzg+07+QAIs/mT8qP/8/cz9OPv6/ooB//9s/LD84gCI/Cj+V//jAID+7P0O/87/ggAE/YAAtP6cAZj9JP/2AQQCyP0m/kQCdv6gAYz+pALMAoT+SP1gA4QCJP3cAGACOAKZ/xT+cAJoAuz+LgD2AYACPP+VAJQB4QC1AJwAwAEgAKsAAgGg/94BdP94Aqj+qQBGAb4ApwDs/eMA2gER/7z+YAE9AF7+pf9mAKb/bv6M/s4BAf9w/K//KAL8/cj9JP+1AFz+xPx4/9QC4PxI+1YBvf8S/mj9A/8sATj+4Pys/ZgBev+Y/R7/hP7IAFf/0P1YAHb/ZAFC/s///P24AGYBeQCP/4D+xAFAACT+zAHj/2wCpv78/+4BPgG8/ecAIASVAKT97wDQAkgBd//mADwCagBfAM//7ALXALb+KAIoA5b/MP4KAZAEeP/8/jUAmAPW/pf/zABYAZQCKPzWAYoBEP9w/FgElgEg/eT/ev90AgD+rP8SANMAZP0EAEQBMv9K/nL/1AG0/Rj+/P66AcT+zv5IAWz8UP+6/rIA2P+w/sb+7f8KALj7VAL0/V4BLP5TAGj+Sv7RABABZv4g/VwCmwC4/u7+5f+EAqgBEPxt/2QDhQCS/5ACpgHE/GACmgCIAQQCw//AAFwCZAEs/dQC3gE6AYABcv+u/6ACTAOe/zQBx//2AXT/oAKoAQwA3gEaAYAAzP0MAtQBcAQI/WT+IATQ/0j+6wBIA7b+fv62/9gCL/8e/hf/3AEJ/2j9VQCYAPIANPzw/sr+xP8g/sABkP5s/GgBQPseADj/NAAI/uz/MP1E/XgDNPyQ/PH/YASA/Gz8n//6Abj++P6O/pwBJP2Q/swCpAL0/dD7qAWAAWj6FgAIBEgDuP5I/ogCDAO8/WgAMAP4Akb/Kv8MA2gCogD6/hgE1AIAAcD9dANMAtcAiwDIAQQDMP3aAcgC2AM4/LX/KASG/wn/LP9UA9L/+P8S/nAAJAF0/aACiQCE/dj9kAL4/Sj9BAECACf/9PyAAJr/e/8k/LD/jv+I/cj+sP4AAbz9tP1g/Vn/sPoeAT4B6PwY/7j7bQBc/2T9bP3FAAUAMP1e/ir/WABAAJD91P6J/0EAZf8SALD/Tf8WAUb/EwBZAMwBHAGc/ogArv9wAhwCwgBo/1ABTAP0/bQBZAI4Ajr/XAKEAr0ALgFAAJQDlAIq/qMA6ATGAfb+UAH0Awb+GAKwAVoBmAGk/WQChgEEAcr+OAEMAbkALAFw/RD/zAI8ADL/cP/C/xwCsPxJACf/OgBK/gP/jgGU/UwAYPxqACIAyPt0AfT86v8g/4D+KP3I/UQCmP0K/oT8xgHZ/wT9kf/E/YP/OP8oAKf/+P6w/14AcwA0/Rb/FAME/SwCyf9k/1YBuQA/AGD9ggGFACAEOP4T/+ADeAJk/vj96ASB/6wCzv60A84AH//QAiYAlAOk/qv/PAFABvr+cP8wAjcA9APQ/OoAjAFsA5YAn/+R/9X/tAG4AXz+WgEg/l///ALO/rIAXP7U/gwCev94/Vz95ALcALj9ZP16/qgC8Pn4Acz9Kv9Y/RsAiwBU/ML+SPvuAcL+VPw7AOAAaPsNAGz+jv78/RH/vAFB/2z9gPyAA7r/BP34/RQDZgHE/PT++AK/AFz9dP86AawCfP1cAXABIAMc/Br+iATm/iYBBf/gAxwDYP7B/3D92AVoAQj/F/+gBGgAtv7cAij+QAWI/xL+0wC6AdEABwBwAuL+IgBsAdD+LALQ/9r/eAA2ACz+MAHtACIAsf8UAQj+vPysAaAB9/+Y/bD//P3MA9z8vPxwAawB6Ptk/awCYgHU/TD8iQDpALz+qPooBEADgPvg+qAAHAOo+9j+6gA8A0D7hPw+AQQBNv7w/VgEgP1D//j8VAMuAO7+iP0gAqgA/f/V/wQBmAHq/vf/jv4YAzAAZgFQAaoBxv55/wwCGACoA4T9DAPeAH8AaP++AfYBlP0YBML+OgHc/sADyAM0/bD+2v/wBSb/QP24A8QC7v7E/YL/TAJAAhb/eP+KASL/Cf+p/3T/YgHUApj7bv6AAlD/kv7A/IAEPv+s/Ij6kAQyAVD7JwAmANwBgPiy/rQDKAJg+lD9uAIg/Dj+5P7MAyf/DPwOAI3/Tv6o/SAFY/8k/BwA6ADzAOj7RAN0A5v/uPkYAPADFQDUAMUALAMs/bf/K//MA7kAmAJLALMA8/8WATYB+P6ABiQCWP80/UwBQAW0AXr/EAK4Arj7dACIBYwCNP7l/0wDOAFI+xz98AkwA9j7LP1gAvz9Nf/oBJQBXf9o/NMAKgEH/8z9+AJuAWj7qP40AaH/wgBEAsD+ePmSAKj8jAPgAID/lv4q/pD8VP6MArD7CAQqAWD4IPwYBDgALPwsAlP/qP1A+xj9QAiL/zD42AEoBLD64PrYBYADXP5Q+vQAcAR4+4D+GAVYAez8OP3UAmABHABRAPIBfAHE/P8AGACIBE4BjQBG/nAByAEMASz+IALIA4YANP1sArEAQADQAi7+nAKa/pf/JAIoAWL/xAJUAHz8Zf/QAXb/PgEsACQDPv/I+P4AiANeAXj7OwD4BIj9OPuw/mgFUv5w/FT+mgGz/1j8oAE4Agj7fP18/JQACAR+/rD7YgGg/SQA3P8o+s0AOAXI/aj6+AAeAEIBwP90/WD+nAF8/RgB8AJq/tD85AJF/07+iAOC/sn/QAS4/dT/rgBY/pwDVANw+17+KAcJADD+4/9TAGQCgAJo/cgD9AIU/qkA2/9vACX/0AbpAEoBUv6C/gACMARU/ez+CAcE/SEAWgHaAeT+7f9U/pQDWATQ98gFkATM/eD5lv8wBvUAKP7s/aADsP54+SgDsATc/ND62AS0ADj8KPpkAlAFOP14+O4AkAdY+2D8C/9xAIT/Kv7s/zgC3P3G/vT+mP7H//oATAKM/osAfPznAH8AdgHG/yL/bADH/yoBcv7SAOQCcgDA/S7/TAEGAWACUf9iAJz/pgHa/94ADAJw/swBdP3AAagBbAElAJ0AJgBY/lEATAFgA94AEv4yAOH/SAEEAOr/MgGUAZb/+PqAA08AbAJo/h0AHACiABj+wPy4BlX/ZPwU/YAFFP1m/qj/lQAwApD7RP1sAtwCgPq4A+AA6Prk/UwB3gG6/hT/fwCYBGj5ePqQA2QDPPyZ/xAD+P0g/fj62AScA8D5kP3YBXv/iPuO/mAFXv5Q+xIASAWa/7D8iAEcA57+YPdgBFgHRP6Y+YAFWARw+7T8rgCwBtj+oPvAAsAFKPzI/RgCAAXI+gz8kAT4B5D8MPlwBIYBRAIY+fwD4AQ2/jj6jAIgBVj7Yv6oAkAIwPgg+jgEqAXM/ID8ygAQBOz9oPrABKgE4Pq0/QAC1P3g/egCxADQA3D4KPvYBqT+OPuIAnMA2P5Y/iT8wAN2/0j5wwDABLD9yPui/tgEeAFQ9rP/3AM8AyT8nP2QAqQCEPuw+jAIwv9j/zT8uATzAFD8AP3YBlIBmPk8AngCWASQ+8j/sAR6Abj4YAMYBiv/Pv48AYgGqPy4/A8AQAhq/hL+dgBcAloBQ/+0/3wBnANc/JL+iAKYBaT8kP/c/LQD9gGQ+4AFpABA/8j6sgFSAVr/4ADQAjgC4PhKAaIB0P/Y+zwBCAXA/Sj7vwDsA1L/uPqi/igEuPxc/SwDXAMQ+wT8UAHMAYgAiPhBAGAEoAF4+cz+QAIoAH8A8PoMAOwDRv/4+7YBtgCe/qj9eAVC/4j6Df88A+AF8Pjs/TgEQAVI+4j77gEoBa7+GP4IA47+DP0YBBAFzP8A/Lj7wAdcA3D70PxACAgFyPiA+/wAOAa0AK8ACANI/MD6cwAQCUf/OPkYAkgHbACw9FQBgAnWAdD3eP1ABwoBwPtoAQgEcP3w9lQCYAb4/7D7pAFIBUD6APh8ASAKdv6o+WL+zALn/2j+KP7wAUD/yPzi/2gDsP2I+4AI3v7A+QD3YAeAClcAUPWs/SAKgPoI+VgEQAjM/Xj6vALyAOD62/9gB3gE0PUY+RAIEAoA+/D36AXoAIj7pP2gBVAHcP3g+0b+yv8g+1gEwAocA3D3ePnYBDQCIP3gAtwDQgCo+wT/XQAsA2YBBALk/Uj6TP1gCCAGAP3U/Vb/0v7u/ob/GAWAAmgDUPwY+2L/9v9AAnwDTALY+XT9EgCgA1gCIPu8/LACtgEQ+ikAQAUYAjD7WPofAF4ABgEGAeADAP7Q+PD9WASsAoT8YwAUAbD/oPwV/94BWASe/vj87v6g/XQCgAKWAbb+8P0M/oYB5gB8ACIANgGO/oz9Wf8CATwDCwB4Ahj7oPtCAZgF0AIk/JD9FgEcAUD9VAH4A3H/wPqk/2wC4QAA/twDiASQ+ij5f//4B0AESP0g/QQBMP1I/tACJALYAJz9wQDG/wD9JP6IBXQC0PqU/B4BeAR0Acj+7P0MAUD8KgCQA/0A2ADi/+QAaPxR/7T9CAWkAqD9ZP9W/xgBFv7GAJD/ZP+C/0gBlAMqAGj7uP3AAkAB8P6EARwCIwBc/Zj+cv+oARoBnAEAAdD9Rf+oAkgCoP1oANT9PQB2AaQDYAOw/bT8iv6EAqz+/AAwBXgA3P0U/Tn/1QDOAawBdAL6/gD7MgHABE//8P31ANj/RQBY/3IANAN4ARD9Rv9yAMT+8ASMAYL+V//N/3L/VAI8Auj/3P78/dIBEgFNADYBEAPq/uj5UQAYBMEAPP4qAf8ACv5g/NACJAN0/U7+MQAYAZ7+EgCuAbABMPwI/NoBJAJ8/8IA/P1o/Cr/yAHwAPj/Xf+w/u7+OPxWAIQCIAO8/WD9Sf88/mEAKARQASj94P2u/nYA+AGKAaX/Xv9c/c//bADMAn8A4ADW/sD7YAAeAUgEFgGM/tT8gv+aAUQBzAHFAOL+gP3eAGAC7gH///P/jQD4/eD+gALUA3QBBP3A/DMAbgEAAjADs//w/OD9IABVABgCbAL2/pr+XP4G//7/1AAcAWQBrP2g/DoBDAJ+/j//KQCO/xj8AQC4BVQCDPyY+vr/YgGO/rf/SAN+ARD9+PuJ/30A6//9/+oASP+N/0z+E/9KAckABf+0/Z8AKAK4AFT9Tv+aAYb+Wv4yAYACTgA6/jP/SP9g/4P/sgE4Ac7+DwA4AQgAnP4YAEIBlwCj/yoArALHAA8AS/+e/xoAcALPAEkA+AEiAOb/GP9EAZQCIAEq/iIA/AD0/wUAwAF8Atr+uP1vAO4B8P8QAMIBh//E/Rv/8AIgArz+iP7kAOD/wP18/xACOALu/lT+KP/Q/zX/SgBAAU//iv4i/mIA4AL6/3j+LP65/87/lP1g/2AD6ANW/gz8yP1ZAFIBv/+gAer/qP2b/xgC6QDa/rz+4QCnAJj+4P60AbgC4f/o/pD9dP6AAdgDpgFc/lD9CAA4AsX/jwCwATgCoP9s/vb+mgCEAkYBKgHU/kf/3gA4ApgAtP6o/zsACgEHAOwAbAGc/2//qP+n/yf/owCYArcA6PyU/fYBcgHR/zb+SP+EAPb+Hv8CAdoA9P7m/o3/2P5Q/7wAcgEi/6j9dv4gAaEAP/+b/6//ZP9u/h//YgBSABX/uv4K/ln/Yf+4/3EASgAy/tj8Mf8IAfL/CP6L/3gB1v80/ib/NgGq/9z9lf9qAf8A5v9QAVoAYP6U/h4BJAJuAK3/FAFyAUT/U/8gAYIBOABh/0MAYgHRAKYAJQBNAIn/1P/9AKMAbAEkAab/Gv8N/0kAwgB+AOsAagCc/sL+egC3AHv/ff8EADEA0P5I/oQARgGX/3r+2v+9/7L+Rv8EAO4Af/88/nH/gf/8/nD/gwBt/5L+Wv4+AEIAzv4k/9D/vv/K/lD/OQCWAK3/Of+l//L+8v66AJwB2wAC/7D+rP8RAGoAUQDrAM8Ae//+/un/QAEqAfgAGAB2/9T/jQA6AZQB/gDb/yIA4gDzAMQAwAA+Ad4Adf///34BBAJqAZ8At/+B/8z/+wA0AmAB/P97//H/ogCNADgAoABiAJf/G//w/tj/uwALAOj+yP76/gP/Of/2/nr/mP4u/oL+O/9Z/yz+0P28/rT+2P0I/uX/r//M/Vj9Ev4H/7b+Ef/C//j+wP2Q/nL/oP/o/oH/SQALAKz+q/8oAYAAyv8SALABhAFWAbYBdAKiAfwALAIIA5ADjAIwA1AEwAOgAtgCGAQQBBgEhAMoBCgExAOwA5wDzAOwA6ADqANQA1gCEALUAnwDDAJYAToBUAE8AdP/X//w/5P/9P2Y/eT9Lv7s/Qz9sPsA+sj5gPoM/Cj7qPmg+aD5aPgA+Hj4CPk4+bj4KPg4+ID4qPjI+dD5GPiY+Gj6sPuo+2j7kPuc/Ej91PyK/ggAeQC3AOoAMAIAA3ADkASYBeAFQAbIB5AIQAlwCbAJMAqQCvAKwAuQDGAMEA0QDOAKcAtwDIAMoAuQC/AK8AkwCEAIAAlQCBgGQAUYBVgD2AF2AUIBVf8K/oT93Pyg+zj6APqY+cD3MPaQ9jD2YPUg9BD0IPNw8gDyMPIw8qDwkPAw8LDw4O9g8GDxAPLQ8eDwYPFQ8qDz8PNw9bD2sPeA9wj4iPpg+0j8XP0N/xgBSAIYA2gEYAWQBggH8AiQClAMMA0wDYANQA5ADwAQYBHgESARYBCgEEARgBGAEUARoBAgEGAP0A6gDqANsAwADNAKsAlQCbAIGAdwBSAEDAMEA2ACOAHQ/x7+wPwU/Hj7GPsw+wj6mPiA9+D2EPbw9aD2sPUQ9GDzQPTg84DyYPGA8SDzsPEA8ZDxoPAA8KDv8PCA8XDy4PJw8+DycPFg8kD0IPcA+OD4IPnw+dD6gPv4/CL+GgF4AnADGASQBegF0AaAB9AI8ApADOANUA4wDtAMMA3wDQAQwBAAESARQBAAEPAOUA8AENAP4A5ADhAO8AzgDEAMMAtQCQAIoAdgB/AF0AT8A5gC7wCm/4//yv5c/cD8PPxo+zj50Piw+Sj5APiA95D3APcA9rD14PWA9aD0UPUg9cDz8PEA86D0MPQA83Dx0PEw8TDwEPLw8wD08PNg87Dy4PLg88D1IPfg9wj4KPko+lD6YPtc/KD9xv5xANIBjAMIBEAE6ARYBeAGsAjACoALgAtQC2ALIAwADeANAA+gD1APMA+ADjAO0A7wDsAOYA5QDiAOEA2QC/AKkAqQCSAJgAjYB0AG+AT8A1QDDAIeAb8AEwCy/pD9IP2U/Mj7kPpY+hD6UPn4+Ij4MPjw9mD24PZQ9tD14PTA9WD0MPNw8nDz0PXA8jDxwPCg8HDwoPFQ88Dz0PLQ8dDxAPKQ8iD0IPZQ98D2MPdI+Ej5MPpw+6z8zP05//cA6AL0ArwD9AOIBRgH8AjwCgAMIAygCzAMYA3wDvAPwBAAEeAQwBCgEAARIBHgEYARwBAgEEAQ0A+gDpAN8AxwDJALkAqQCUAI0AagBYAEwAMEA2ACVgG+/wz+CP2Y/FD8aPug+gj6ePlY+AD4EPdQ9vD1MPaA9gD1UPSQ9GD0YPLQ8MDx0PQg9HDxUPAA8ADvoO4Q8mDz4PJA8jDxoPHw8TDy4PQA90D3UPcA+HD4wPkA+zD8nP16/nsAYAIgA8gDMATwBGAG+AeACgAMsAxQDEAMsA1QDnAP4BCAEcAR4BCAEEARgBEAEiASwBHgEPAPoA8gD4AOcA3wDIAMEAvgCXAIgAfYBZAE7AMsAwQDegEOACD+2PyM/CT8ePug+lj6aPmo+HD3QPfQ9jD2EPYA9qD1UPSQ9LD00PMQ8SDwEPTw9ADzAPEw8ADvAO/A7zDy8POQ8vDxYPFA8UDxkPOg9RD3MPdw92D4ePkI+iD7mPx8/Zz/3gEcA2ADoANIBLAFAAdACVALYAyQDCAM0AwADgAPYBCgEQASgBFAEeAR4BHgEUASgBJAEoARwBCgEEAP4A3wDTANsAwACyAK4AhgB3gFsAR4BAAD7AKsAAgA1P1E/fD8YPtY+/D5cPow+RD4YPcA9/D2EPbA9aD1QPWA9OD0cPRQ8iDx8PEg9HD0gPFw8DDwAO+A7gDwIPLw8vDx8PAA8cDwwPBA8wD20PXQ9RD3aPj4+FD5WPr4+yz9zv4EAWACGAMEA9wDGAWYBtAIoArwC7AL0AtgDJANoA6gEGARQBFAEUARoBGgEQASQBJAEqARABGgENAPAA8gDpAN4AzQC7AKoAmACMgGiAV4BJQD5ALwAYAAIf88/jz9UPwg+2D6QPp4+dD4kPdQ9wD3YPbA9WD1IPXA9HD0UPTQ89DxUPFw8gDz4PLA8aDxoPCg7iDugPAQ8vDxAPKQ8bDxAPFg8WDz0PSw9RD2MPjA96j4GPrw+kj7jPyG/pMAvgG0AhAEUARIBMAFYAggCjALIAxQDAANkA3gDWAPABGgEWARgBGgESASoBGAEQASABJgEWAQABCwD6AOoA3QDAAM8ArACZAIiAdQBggFkAOMAu4BqgBq/3D+1P3I/Pj6cPpo+ij6oPig9yj4gPew9gD28PWQ9fD0wPSQ9BD0MPMQ88DyoPLg8fDxcPLA8VDwIO8g72DwAPJw8vDx8PEA8mDyMPIQ83D0cPcg+ND3mPmI+Jj5aPsQ/Tz+v/+gAHQC0AQ4BOgEgAV4B4AJcAqADDANoA4ADuANoA5AEEASYBMAE6ASABIAEmASIBLgEuASwBLAEMAP0A9AD1ANQAygDMAKIAkwCNAHYAawA6QCJAKeASwAWP/o/kj9SPtw+pD6+PkY+bD4SPhQ95D2YPbQ9TD18PRw9FD0sPNw80DzUPLA8RDxQPEQ8sDx8PDg74DuQO7A79DxAPNA8mDxYPJA8kDxsPKw9pj4kPhA+ED4YPq4+sD7fv67/6H/MgGwBMgEwAU4BWgGIAigCcAL0A0AD3AOAA6ADbAOgBGgE8AToBJAEsARwBEAEiATQBNgEqAQYA+QD+AO8A0QDfALYArwCCAIKAdABtgE/ALSAfwA8/88/8T+TP2w+7D6SPrY+TD5sPgg+MD38PZA9sD1kPWQ9SD1gPRg84Dz0PNg8+DxEPGw8fDx8PFg8aDwQO8A7yDvYPBA8pDygPNw8kDxMPEA81D1IPcg+bD4gPhw+Tj6jPys/Kj9JAHUAt4BEANwBlgHWAaYBZAIEAzADWAOYA6wDnANIA4AEEAT4BNAE2ATIBJgESARABPAE4ATABFgEAAQQA8ADpANkAyQCmAJ4AhgCLAGIAVABAgDYQB4//EAPgB8/fD7wPsY+6D5YPnA+SD50Pfg9kD3kPbg9cD18PXw9EDzEPRw9DD0MPKA8RDysPHA8YDxwPGw8EDvQO7A7pDw0PHQ81DzUPHg70DxEPSg9eD2oPcw+Vj5EPgw+iz8oPyK/lIAvgFsApADYAXIBogFmAXACKAMQA5QDaANYA1gDUAO4BBAE8ATIBMAEmARABEgEuASQBOgEkAR0A+QDuAOUA7QDCALYArQCfAIgAcABtAENAOeAQgBqwAuAAT/uP0Q/OD6qPoQ+uj5QPnQ+LD34Pbg9sD2QPZQ9RD1APXA9LDzMPNA8wDz8PEg8YDxUPJg8gDxAPAA72DuYO9w8QD0kPPw8RDx8PEw8iDzkPaA+DD5oPeo+Nj58PoQ/CD96v+z//YBLANoBDgF2AXoBlAH8AgQDCAPsA7QDVANUA4wD6ARwBMAFKATQBLAEeARQBIgE4ATQBNgESAQ4A7gDqAOQA3QC2AKEArACFAH+AXABKQDVAJGASgA/f8B/6z9LPzY+rD6iPoY+kj5yPjg9/D24PYg93D2kPWQ9aD1cPSg85DzIPRg8xDysPHw8UDywPFg8UDwYO+g7qDvcPEA81DzgPLg8RDx4PHQ81D24Pjo+FD4oPdo+Tj7NPyc/Oz+UAJGAaQCpANIBYgGwAaoB+AJkAyADUAPsA4gDvANAA+gEoAUoBWgE8ASgBJAEuASQBOAFKAUQBLgEHAP8A7QDuANEA2gCiAKUAnQB6gFCAVoBBAC1gBsAO4AUf8s/Sz8gPvA+oj5+Pnw+dj4YPfA9qD2MPbw9QD2wPWQ9LDzkPMg8/DywPJQ8oDxIPFw8bDxIPEA8KDuQO4A7yDwkPKA89DyUPFw8FDxMPOQ9fD3oPlI+ED3gPgQ+/D70PzK/psANAJcAZADcAUABogGeAfQCZAK8A2QDuAPgA7gDPAOwBFgFGAVoBRAEuARoBKgEuASIBSgFAATQBBQDuAOsA6ADUAMgAvwCXgHyAZgBhgFEAO8AUABggBP/yz+WP10/CD7SPr4+aj58Phw+KD3IPew9qD2MPag9VD1sPSA9KDzQPNA8yDzgPKg8ZDxgPEg8TDx8PDA7+DuoO4g8DDyEPMQ80DyMPGw8HDyoPWA9/D4GPkg+OD3GPk8/KT9dv6v/yYBXAPAAdADUAc4B+AGkAhQC7AM4A3wDgAQoA7gDdAPwBMgFqAUgBNgEsASYBLgEoAUgBTgE0ARkA+wDnAO0A2wDfAL4AkQCPAHwAYwBcQDUAK2AVQAhP8J/5T+VPxA+zD76PlI+Xj5iPk4+AD3gPbg9rD2EPaA9VD1YPQg9GD04PPw8hDykPLg8RDxUPFA8gDyEPBg7gDuYO9w8ADywPNA82DxAPAA8cDykPXA9xD5wPgw96D3UPkk/Ej9iP2bANcAMAHYAjAEwAXYBSgHUAlQC8ALkA1wD6AO4AyADeARYBTAFKATABMgEoARYBKAE8AUoBOgEsAQsA5ADjAO8A3ADPALoAnYB+AGUAZYBUADpAGkASwBiP8w/kj9wPzQ+8j6YPoA+lD5uPgA+FD3APdA98D2wPVQ9RD1EPWw9AD0oPMw81DyEPJQ8lDywPHQ8YDx8PCg70DuwO/w8ZDzMPPg8oDysPHA8VDz8PZY+JD44PiI+MD4iPkc/Iz9If+q/24AYAKgAqgEcAV4BlgH4AgQCwAM0A0QD3AOQA2ADoARABQgFGATIBNAEsARABMAFEAUoBOAEgAR0A+QDrAOQA9QDSALkAkgCTAIWAbABDAEOAOAAbgA+//i/pj9jPxw/Nj7uPro+aD5WPnw9zD3EPg4+GD3MPag9eD0QPVA9TD1APUQ81DzgPMg8jDyEPLA8sDyAPEg8KDvIPCA8LDy8PNQ9HDywPGw8fDz4PVA9+j4IPmw+SD4qPj4+hr+SP6I/o4APAKUAiwD2ATYBhAIIAdgCaAMUA4QDtANIA7wDqAQ4BFAFWAVoBOAEkASYBMAFGAUgBQgFEASQBCwD8APMA8QDoAM4AqgCVAIkAcgBhgELAOgAqgB3P/c/lb+GP0A/Cj7QPvY+lj5UPiw93D3cPfw9uD2oPaw9bD0IPSQ9GD0EPTw8jDzwPIA8mDxUPFA8gDxIPGw8MDwIO+A7qDvMPJg9EDzIPOw8XDwMPMw9hD3kPho+WD5KPnw9xj63P1D/1j/7P9+AWQCdAOoBRgH+AbwBnAJEA1wDlAOwA1gDiAPQBAgEkAUwBUAFUATwBHgEcATIBUAFcATgBJgEIAPUA9wDpAOQAwQC7AJcAigBlAFAAVEA3gCYgAFAFz/EP7g/HD7MPto+kj6wPko+RD4EPcA9wD3APdA9pD24PWQ9HD08PNg9CDz4POQ8wDzEPIg8YDyMPEQ8eDwoPGQ8YDvIO9Q8UDzcPNQ8/DysPFw8rD0kPZo+Bj5cPig+OD4mPnc/Hb+J/9j//L/YAEIA0gF+AZwB+gGsAcwCpAMwA7QDzAPgA7ADoAQgBLAFKAVQBWAE8ARgBJAFAAVwBMgEyASwBCgD4AOkA5ADTALsAkQCXAIAAewBWADqgGZABEAQACR/07+OPzg+sD5qPkI+oD5EPlw+ID3IPYA9jD2YPZQ9kD1EPWw9JD00PPw8mDycPJQ8xDzcPKw8fDwwPCg7+DvkPDQ8RDxwPDw8eDxkPEw8pDzMPOg9AD14PZI+GD3IPdo+RD7sPsg/VT9lP7i//oAYAKoBPgFEAfgB1AH8AhQC1AN8A+gEGAPoA7AD6AR4BNgFAAVwBTgE4AS4BLAE4ATQBMgEuARQBDgDrANAA3ACyAKMAnACKAImAbkAxgBrgDhACcAUgB3/+j9ePuQ+VD5MPoQ+tj56Plw+ID24PVQ9lD3wPaw9aD1wPWQ9cD0QPQQ88DyYPOQ88DzcPMw8zDy0PDA7/DwgPIQ85Dz8PJA8oDxQPJA9CD1UPYg9jD3APdg9rD44Pq4+8D7TPxk/LD9Wv8UAdYBvALABFgGMAcYBwAI8AkwCwANIA/gD7APIA8AEGARQBLAE2AVwBUAFEASQBLgEkAT4BIAE6ASoBDADQANoAxgC7AKYAkwCbAHoAWgA/4BRgFaAKwACwBs/8j9yPt4+rj5YPrg+lj6QPmg+KD30PZw9rD2IPfw9iD2oPXQ9dD0MPQg9IDzkPNQ89DzYPSA80DyYPFw8cDwUPIg9FD0cPPA8XDyIPOg8yD14Pco+GD2APXA9uD4GPtE/CD8NPzY+2T8wP5MADgCtAJ8A4gEoAWgB/gHUAmwCTAMEA3gDbAPYBCgEGAPQBAAEkAUIBXgFIAUIBLAEMAQQBIgE+ASwBEAD4AMEAsAC+AKAArgCHAIiAZAA6wBngEqAQQAgv/s/uD9vPy4+lj6wPkY+cD5oPko+Sj4oPZA9pD1APaA9rD2APZQ9fD0IPQw8zDzAPQw9EDzIPOw8+DzsPJA8SDx0PFg86DzQPTg8+DyIPNg8yD0gPYg+LD34Paw9uD3qPgw+vD8eP0U/Kj6zPzS/4YAlQDYAWgE0AQQBVAGAAgACTAJEAuQDHAO4A6gD4AQkA+gDyARIBMAFUAVYBOAEiAR4BDAEcARwBLgEYAQIA3gCtAKcAoAC6AJEAhIBiAEtAIMAroBAADi/xb/MP4I/cD7YPu4+gD68PjQ+WD5MPkI+DD30Pbw9dD2oPZg91D2IPUw9TD1YPVw8zD08PSQ9NDzgPNA9PDzMPMQ8tDy8POg9ID0IPTA8xD0IPWw9RD3wPdg91D3UPeo+AD6cPq4+1D8DP3g+5D83v4/AGsAcgHwAmgEeAUoBkgHoAeQB1AKwAyQDuAOMA7ADmAOAA8AEWAToBTgE4ATQBKgEIAPwBHAEqASABEQDxAO8ApQCtAJgApwCagHgAbsAzwCfgBwAB4Axv92/kT9jPyY+jD6wPkQ+TD5qPjY+Aj44Pag9jD2MPbA9QD2cPZw9lD18PTQ9MD0YPRQ9MD0APWA9PDzwPMQ9JDzEPRQ9ODzMPRA9ID0YPTw9LD1IPZQ9mD2QPdQ9/D3MPnw+RD6GPoY+wD85PyU/Mj96v5U/8z/iAEkA+QD8AQIBmAHeAegCJAKcAwwDcANMA8AELAPYA+AEMARQBMgFIAUgBPgEUAQoA8AEQASABLAECAOcAswCjAK0AkACaAIyAaABDACLAF8AQ8A1v4S/pD9jPzg+qD6APro+OD34Peo+KD40PfA9vD1IPUw9VD2wPZw9uD1MPXg9MD00PRQ9ZD1MPWQ9ND04PRw9LD0APUg9aD0YPTw9HD1YPUQ9WD1APaQ9tD2cPfQ90D4WPjA+Kj5WPr4+qj7iPzY/Bz9nP1k/sz/PgHWAXwCyAMwBQAGkAYgCMAJ8AoAC/AMcA9QD0APoBCAESARIBEAEmAVgBbgE6ASQBFAEQARQBJgE8AR8A6ADMALgArQCdAJUAkQCFAFKAPmAecAwQCV/+D+MP10/JD7cPqQ+QD4GPjA93j4UPgw9/D1YPVA9VD10PUg9tD28PXQ9FD0gPRg9bD1oPWA9UD1IPXQ9CD1oPWQ9XD1UPWg9aD1kPVg9cD1APag9sD28Paw9wD4wPcA+CD54PlY+qD6CPvw+6j80Pxw/fj9Gv/K/10ApAEkA1QDEASwBdAGAAiwCHAKoAvQC0AMcA+gEaAQsA8QD0ARgBGAE6AUQBVgE6APoBAAEgASwBBAEYAQ4A6AC0AKQAuwCuAIiAeYBtgEUAMsAmgBvv8K/tj9JP5g/aj76Pmg+Cj40PcY+Aj5YPhA9/D1APXg9KD1kPYg91D2APXA9LD0IPVg9bD10PWA9VD1YPUg9SD1UPVw9cD14PXA9eD1sPVA9VD1IPbQ9kD3UPdQ9zD3UPeg9+j4yPkA+hD6QPqw+gj74Pug/FD91P0g/rj+oP+7ALoBUAIsAwAF8AX4BqgHEAkwCjAL8AvgDeAPcA/QDnAPwBDAECARIBNgFQAUIBCAD4AQwBGgEYAQwBDwDhAMAArQCoAKYAlwCOgG2AX4AygCigFwAfT/pP70/bT9dP24+/j5KPlA+Yj5uPlA+XD40PeQ9hD2wPYw92D3IPdw9sD1YPWw9XD20PYw9vD1QPZg9gD2APaA9mD2QPZA9hD3MPeA9iD2kPbw9hD3oPdA+HD4EPig9wj4KPno+Rj6CPoY+lj6uPro+tD7sPww/Qj9EP3c/Tz/PAC1AIgBXAKUA8AEMAZgB1AIcAjQCTALMA3gDqAPgA8gD7AO8A6AEaAS4BRgFAARYA9AEOAQIBEAEcAQ4A9wDXAKEAqwCkAKEAlAB+AF0ATEA3wCbAEZAMr+dP7M/ST+EP1g+gD5uPhA+UD5GPk4+bD4wPYw9bD10Pbw9zD3QPYQ9qD1gPWg9VD2MPZQ9hD2IPag9mD2MPYw9lD2gPbw9mD3cPfw9pD2cPbQ9pD3SPho+ED4oPeg90j4IPmg+ZD58PkI+nD6ePq4+mj76Pts/NT8ZP2I/Tz+/P7A/5cAlgE0AxAEsATYBegGyAeQCIAKEAwgDVANgA7wDhAPcA5QD0ASABKgEkAS4BGAEAAPUA/gD2ARwBCQDkAMUApgCWAJsAkACbAHcAVMAzACkAEWARsAAP8q/mz98Pv4+mj62PnQ+ED4MPhI+DD4YPdg9sD1oPUw9jD34PZg9uD1kPWA9cD18PYw9/D2sPaQ9pD2kPbA9mD34Peg94D3oPew98D3YPcw9+D3oPj4+Fj4APjg92D4sPj4+Ij5wPmo+Xj5APoQ+pD6yPqQ+wj8OPx4/PT85P3w/Qj/3v/WAOoByALYA4gEeAXQBvgHYAnQCbALsAzwDbAOMA/gDkAPIBBAESAS4BGAE+ASABEQD+APABHAECAR4A8QDiALAAnQCaAK8AmwB8AGWAUYA9YB2AAiAYgA9v6I/Qz9SPwI+yD6+Pjg+PD4mPiY+Aj4APfA9TD1wPUg96D30PYQ9qD1APVw9VD2MPfg9yD3YPYw9qD2MPdQ99D30PdA+PD3gPfQ9yD4IPiw9yj4CPlQ+YD4MPio+JD4iPhw+QD6KPrY+VD56PlY+rD6iPsQ/BD8sPsM/Kj8UP2a/mb/t/8PALMA8gEkA8wDmAXIBngHcAgwCeAKgAuwDNANEA8wDyAP8A/AECAQwA8AEgATwBKgESAQoA8ADoAOIBCAEFAOQAvgCfAIUAgIB6gHuAfABZACgQDpABwAi/+A/gD+YP0o+/D5EPpA+sj48PdA+JD4oPdA9kD2cPYw9tD1IPbw9qD2MPaA9cD1EPaQ9oD38PeA91D3IPfQ9lD3MPi4+CD58Pig+Kj4QPhw+Hj5QPro+bj5YPnI+Zj5IPlI+pD6kPoo+nD6sPrQ+qj66Poo+8j74Psw/Iz8VPw8/ED93P3u/gX/TP9+AIgBNAIwA6gEoAUABngGkAhwCmALsAuwDJAOcA0wDXAPYBHgEMAPQBCgEQAS4BAAEZAP4A5wDuAOwA/gDVAMQArACCAIEAhgCIAHoAWwA+4BPAAiALsAngAa//z8wPso+2j6ePoI+oj5+Pgw+Bj4sPeg9lD2MPbA9vD2IPcQ93D20PWA9ZD14Pbw9yj4CPhQ98D2wPZg91j4QPlo+fj4gPgQ+Jj4APlw+dj5EPoI+oD5OPn4+Hj5yPno+QD6ePp4+hj6IPoQ+mj6gPoo+3j72Pu4+3j7WPtw+4T8iP1C/ir+ZP7q/pL/XQDmATgEEAWwBKgEEAYwB6AIUAoADRAOUAzgCpAMoA5AD/AP4BBAEbAPwA4QD+AP0A+wDkAPwA5QDQAMAAuwCoAJUAj4B4AHeAbgBNADLAL3AEwATADt/8b+dP1Y/Ij7cPpQ+kD6IPpw+Zj4uPgQ+ED3oPaQ96D3YPdA9zD3gPfg9oD2MPco+CD4CPhw+Mj4iPgQ+ID4cPmo+aD50Pkw+gj6yPm4+Tj6iPpA+xj70Pro+nD6SPqY+jj7GPsw+yD78PrY+rj6KPtQ+8D7mPvI+8D7BPwg/OD7NPxk/Hj93P38/Q7+fP5c/hX/MAE0AzAE1AOoA3AEwAS4BcAI0AzgDHALIArQCnAMYAxAD+ARABLwDoANIA5QD9AP4A+gEGAPwA2ADHAMUAzAClAJEAkgCVAISAeIBcwDTAJoAWgB5AGeATcAQP4g/ED7YPsI/ID8iPv4+dj4SPjw91D40PjY+Cj4UPdw9wD40PeA91D3CPhQ+Cj4OPh4+bj4SPjQ+HD54Pkg+gj6SPpo+oj5SPoQ+0j7IPvY+uD6KPtQ+0D7mPs4+xD7EPsI+/D6SPtw+xj78Po4+2j7ePso+0j7mPuo+4D76PvA/Iz88PvA+6z8NP3U/Qz+6P7q/77/YQBAAnAEmAQIBPADUAYACGAIAAsQDYAMQAqgCXAMMA/AD/APQBBgD+AN4AzQDkAQwA/wDTAOgA0QDIAKIArgCuAJoAdwBkgHqAYoBHQCkgGyAcMA8P9bAOT/LP0Y+yD72PuY+6D6gPqQ+ij5oPdQ90D4EPlo+MD3gPdA9zD3APew92D4cPjA99D3oPjQ+LD42PgI+qD6EPqo+QD64Pr4+hD7gPvA+7j7cPs4+6j78Pso/GT8ZPx0/KD7gPuQ+wT8uPsM/Ej8APxo+/D6gPuY+9j70PvI+wz8sPuY+8D7GPwI/ED8yPw8/cT93P3E/dD+g/8WAUQC9ALQAxgECARgBLAGEAkwChALoAvgCpAKYAqwDKAPIBFADwAO4A2gDQAOEA5wD8APkA7gC6AL8AtwCtAJQAmgCRAIIAawBWAFmAR0AR4BogGeAZMAJv8y/pz8oPtg+/D7LPxY+2D6+PgY+Fj4sPjI+Nj40Pgg+ED30PZw96j4cPgg+AD4sPiQ+Ej4gPiA+eD5yPnw+YD6sPoI+hj6iPq4+3j7APuI+9D7aPtQ+lD7+Puc/ID7WPuw+wj7qPqI+nj7ePtA+6D60PrQ+lj6iPrI+jD7IPsA++j6QPtw+1D7KPtw+wD8HP1U/Uz9bP3w/SH/JgCqAWgDIAQ4A+wCYASABhAI0AnAC7AMcAr4B8AKkA1gD5AP0A+QD+ANwAywDcAP4A/wDsAOcA7ADGALUAtwC4AKQAkwCcAIuAdABhgFyANgAlwCPAMIAzgBLv9G/oT90Pws/cD9YP3Y+1D62Pmg+YD5oPko+gD6uPjg90j4iPhI+Dj4yPgw+Qj50PgI+SD5APlw+XD6GPvg+tj62Pro+tD6SPsA/KD8mPww/ND7aPuo+0j8rPyo/Hz8NPzQ+6D7iPuo+9j7yPu4+6j7SPso+6j6EPsg+1j7cPsg+7j7QPsw++j6cPsM/Nj74Ps0/Bz99PzY/MD9Yf8kAGMAGALgA6QDwAE0A5AG4AdwCKAJMAvQCuAIkAiwDNAOwA5wDrAO4A2QDOAMMA6gEEAPYA3gDBAN4AxgC8AKgAoQCmAJwAj4B1gHQAaYBFQDaAPoA1QDMALJANL/Xv58/dz9xP56/mz8+Pqw+sD6SPoo+lj6YPqQ+cD40PhI+fj48Pj4+Gj5CPlg+Yj5uPnA+VD5yPlo+gD7+PoA+4j6qPrA+kD7+PsA/Nj7UPtY+9D6kPug+yT8sPtI+0D7qPoA+6D66Prw+pD6SPpI+lj6KPqY+XD5KPqg+lj62Pm4+Tj68Plg+SD6ePtA+6j6EPqg+zj86PvU/KL+hwCA/6v/MAIkAzQCWALABHAHcAkACSAJ0AnACAAJUAswDjAPoA6wDTANsAxgDOANoA/QD0AO8AwQDJALgAtwCzALQApgCcAIIAiwBvAFOAVYBAAEcAP8AjQCGgHP/xD/Zv4O/h7+5P3w/KD7CPuI+nD6gPpw+kj6wPnQ+Mj4EPkQ+Tj5MPk4+fj4GPlQ+Yj5iPlY+eD5SPrI+tj62Pqo+qD6sPow+/j7NPwU/Lj7gPuI+5j74Pt8/Jj8bPwQ/Mj7mPug+8D78PvY+4D7YPsQ+xj7+Pro+hD7+PpI+zj74PqI+uD6EPso++j6KPu4+3j7ePu4++j8ePyM/JT99//QAAYBlAE0AiACZgFABDAIcAn4B3AIAAnQCOAIUArwDYAOkA3QDDANEA0gDEAN8A6AD5ANcAzgDNAMMAswCsAKgAqwCQAJoAiwBxgG4ASoBNgEcAT8AwwD2gGVAKb/S/+c/7//Cf8G/sj8RPz4+/D7IPz4+6D70PpI+gD6QPpY+jj6MPpY+jD62Pnw+RD6OPow+mj62PpA+yj7+Pr4+hj7OPuw+/D7NPwU/Kj76Pvg+yj8HPww/Ej8KPwA/BT8JPwM/Lj7yPuI+5D7aPtQ+1D7APug+pD62Pq4+qj6sPoY++j6MPrA+YD6UPto+iD7QPzQ+9j6qPrA+xj9IP2O/ocA1gDM/03/OgEEAxgECAVABvgGyAZwB1AIwAkQClAKQAvwC5AMoAzQDMAMkAwgDAAMAA2wDZANMAygCtAJkAmwCTAKIAogCTAH2AU4BSAFaAXQBDAE8AKuAdMAJgD9/woAev9i/kD9tPyA/Dj80PtQ++j6wPpo+ij64Pl4+WD5KPmA+cj5uPlo+Qj5GPkw+Xj5+PmQ+oj6cPrg+bj5SPrw+mj7kPuQ+2D7cPs4+3j7+PsY/BT8LPw4/ED8yPuo+zT8EPzQ+5D76PvA+yj76PpA+zD72PqQ+gj7EPuI+qj6kPoo+5j6EPpg+vj6MPv4+pD7qPtg+8j6WPtI/Z7+lv72/jEAof9DAMoA8AIABcgE2ATYBSgHYAcgCAAJMAowCiAKEAtADJAMAAwwDOAMgAxADEAMEA2gDIALsApwCuAKMAqwCTAJEAjoBngGUAZIBpAFqATUA+wCHALkAVwBEAGwAPz/Jf/k/aD9cP1k/Xz88Ps8/OD7OPt4+pD6YPoI+hj6yPoQ+wD6ePnI+Qj60PlA+vD6iPsQ+yD6aPr4+tj6WPsc/ID8wPsw+8D7RPxE/Nj7JPy0/Jz8BPwA/Hj8ePwc/AD8KPxE/BD8BPw4/Pj7gPvw+jj72Pvo+zD7IPtI+2j7CPu4+jD7iPso+8j6kPvY+8j7WPuQ+zT8ZPzI/Bb+2/8HAEX/OP8zAHABpAJ4BJAFaAWwBEgFOAbYByAJkAlACmAJUAlgCqALoAuAC/ALgAtAC+AKYAuwC6AK4AmACaAJQAnQCCAIuAfIBrgFiAW4BZgFaASIA7wCUAJQAugBQgECAQoAtv5w/qr+kv4W/kD9vPxo/PD7YPuA++D7mPs4+5j60Pr4+qD6wPq4+rj64Pr4+kD7cPso+wj7OPuo+9D74PsE/Nj74Pvg+xz8VPyc/Dz8APzw++j7APxU/LT8kPz4+2j7sPv4+/D7LPwI/AT8YPvI+vD6WPto+0D7cPtA+wD78PrY+hj7+Pro+lD7mPvI+wj80PuQ+9D7bPys/bz+sP/Q/7H/W/+p/1ABVAMIBYAFSAUQBUAFCAaoBzAJ4AlQCqAJ0AlQCtAKcAvgCxAMwAtwC0ALoAtgC7AK0AmACXAJMAkACXAI2Ad4BpAFUAUwBUAFOAS0A8wCKAJ+AUIB6wAWAFn/jP40/uj9nP0I/az8+Ptg+9D66PoY+/j6OPro+eD5oPmw+ej5YPrg+Wj5uPkQ+hD6wPkw+qD6iPpo+qj66PqQ+nj6sPoo+2D7MPvA+8j7IPuo+gD7sPvY+/D7IPyg+wD74Poo+8j7qPuw+4j7CPuQ+pD6EPs4+yj7GPsI+8j60PoI+0D7IPso+5D7qPu4+0D8qPyA/HT8/Pws/i//+/+NAKcAeQCQAAAC2AMYBeAFKAY4BiAGMAaIB1AJcArwCoAKsArQCkAK4AoADOAMgAzgC6ALsAvgCmAKUApACvAJUAkgCbAIoAd4BvAF6AWQBQgFiAQIBDwDcALAARoBxQBFAPD/Mv+m/l7+nP0g/Xz8WPzI+3j7UPtY+8j6uPm4+cj5EPrQ+fD5+PmY+WD5sPk4+hD6GPpY+vD6oPpQ+uj6GPv4+uj6UPvI++D70Pvo+yT80Puo+9j7gPyY/HD8mPxI/GD8LPwA/ED8cPyY/Hj8LPzw+zz8wPuo++j7LPxE/AD86PsY/CD88Pv4+2j8qPz8/Cj9VP1Y/SD9uP2s/rf/OwDUAAYBKgE+AVwCfAO4BCAFSAa4BmAG0AZYB7AIEAmACVAKIAvQCjAKwAqwCvAKgAtADAAMEAuQCqAJQAkQCYAJAAowCeAHkAYQBqgFuAWQBWgFeAQAA4QCWAIYAnYBzgBEALL//v4y/mL+Jv6Y/XD8yPsI/Bj80PsQ+/D6YPoI+uj5QPrw+mj6qPmQ+Rj6APrY+dj5gPoI+1D66PmI+gD7sPqI+uj6WPtg+xD7cPvA+1j7APtA+9j74Pu4+6j78Pvo+1j7ePvA+wT8+Pvo++D70PvA+7j78PsA/BT88Pvw+xD8UPxQ/ED8WPx0/KT80PxA/ez93P24/dT9aP4r/5n/SwDxAJoBngH4AbACkANQBOAEsAVYBtgGuAaQB2AIsAjACBAJAArQCpAKAArACsAKQApACuAKkAuACmAJMAlACQAJQAhgCHAIuAagBaAFuAVQBSgEMAT4A+ACwAGEAbQBMAElAAIAhv+i/gb+5P3U/XT9XPws/HD88PuA+zj7OPvQ+nD6iPqw+nD6aPoY+lj6aPrQ+Uj6qPrI+rD6WPqY+tj66PoI+2D7YPsQ+xD7iPvI+6j7mPuA+3D7YPuY+wj8BPzQ+8j70Puw+5D76PsQ/AT8oPuw+9D7uPvg+/D7JPyg+5j72PsM/ET8QPxo/Fj8iPy0/CT9gP14/bD92P0i/nb+R//+/0wAiQDgAFwB2gG0AjADxAPMA1AEeAXYBRAGeAYYBzAHQAeYB3AIIAlQCfAIEAnwCLAI4AhwCWAJAAnACGAIcAiwB+gGyAZgBigG4AXYBYgFuAS8AwQDvAKsAuACrALgAS4BVADn/8X/4/+u/yr/iP4M/tz9qP2U/Yz9KP2M/ET8WPyw/MT8YPwA/Hj7qPvQ+1T8jPx8/Az8sPuQ+6j7KPyU/Cz95PwM/Ij7oPuM/Bz9HP3M/HT8KPwY/Dj8oPwA/QD9vPxY/Az8KPyE/Pj81Pxs/Pj7EPyI/Kz8jPxo/ID8ZPyA/Jj8yPzc/Kz8DP0k/VD9eP3o/Sj+Mv4u/nz+B/9v/xoAsgD2AAgBLgG4ATwCxAKMAygEaARYBIAEOAXYBUgGiAbIBtgGyAYAB3AH8Af4B+AH4AfIB8AHkAeoB3AHeAcgByAHIAeoBkgGwAWABSgFAAUIBRgFkAScAwQD3ALgAugCwAK0ArQBAgGzABYBEAFAAMr/z/8PACn/qP7I/uz+vP14/fj9iv7U/aD8TP0I/TD8iPs0/fz9TPx4+8j7KPxg+7j7nPzg++D6KPsc/Hj7cPoI+3D8qPtY+YD6SPwA/Pj58Pkw+5j7iPpI+ij74Pu4+uD5UPqg+9D72PoA+8j74PtY+3j79Pwk/QT8qPtA/az9rP24/WD+hv5A/g7+Wv/n/zoAeQC8AH0AcwC8AaQC1ALwAtgCkANUA8gDqAS4BYgFMAWQBXgGOAYwBuAGeAcoB4gGMAegB6gHMAfwBjAHkAZQBvAG6AZYBiAG4AVYBRgECAQABTgFaATMA3gDzALyAXABXAKgAlQBCAEWAXAAqP99/+z/+/9z/67+Gv4g/pr+oP4U/kD9VP1w/Qj9ePxE/Yz9vPwA/Nj70Pug+4z8AP1c/Oj6mPpA+8j7BPw8/Bj8uPr4+bD6SPto+zz8FPxg+gD5wPng+9j7qPvw+kj70Pqw+eD6MPz0/Kj7WPug+2j8qPzc/Cj9WP2k/ej8gP2g/uD/XP/S/qr+CP84AHcAbAGiAawBRgGGAfABnAIwA1gD3AOABFgEcAOoA8AE2AWoBSAFaAWwBcAFaAXQBUAGWAYABlgGyAVgBegFEAaABUAF2ASIBJgFwAWgBAgEoAPUAmACFAO4BKgEeAIoAUQBPgHi/yoBfALoAhQAUP55/6P/V//y/qcAb/8I/7T9hP1K/lj+JP/I/fT8GPwu/rj9yPyw/Iz8ePxc/CD8oPvI/PD8QPxI+8D66PpM/BD8BPwI/CD64Plk/GT9UPpw+GD6pP1E/eD54PmY/KT8wPoI+6j7KPzo/Ez9RP3g+6D76PwG/mz98P1q/hr+dP66/n7+JP68/5AAvAAk/3j/4gAwASQBQgFcAnIBaAI0AigCTALsA5gEkAJYAqgD8AVYBGgDsAN4BVgEnANABtgEGAToA2AFeAUsAygEUAV4BsgDxgGIAxAEXAMIBOwDuAPcA3ABdgGoAvAC2AFQAUQC3AFMAQoANAF4AZz/DP9AAMoAuv6o/lMAYAAc/bD89P6b/2L+aP3o/XT+BP2c/ET9rv78/RD9yP0Q/Jz8QPyU/Tb+ev7I/FD7kPzo/a7+fPwU/ab+4f8Y/Dj7uv6HAPb/QPxs/QH/pP8a/+j+Tf8gANL+av7z/5///f9oAKYA6P9ZAHr/FQB4AvgAmv+C/7wAhgEcA0YBQwDGALL/FAK0AgQCXgBMAgQDsgCJ/9YAeAU4BCD/6/9sAiQDPwDCAbgEwgEB/8cAOASeAZUAzgH8A78Awv6mAbADEALiAFIBLgCA/twCEARgAQz+6v/kAkQASP77/wgFEwA8/bz+FAExAID+xgEcA+z9IPm5ANADdf9M/Av/XAMu/2D7Tv4gApwA2Pst/xQASv/a/nX/0P64/Cr/4v6eAA7+/P72/+T9KPwQ/1YBWv5H/5b+3v4o/oD9Zv/j/78AhP0M/vD9ZADqAYj94Pzs/9gBZP0O/tgAfAMI/hj7tAEYAbL+rP8YAz8AZPwg/ggEcAHs/dwAdAM5/2j77gAwBXgB8P3sACADpwCE/PUAYAXEAQT+gv5gAuQCfgEZAJMAZgA+AWf/if/KAXAEYgGG/nz9tQCsAm8A4P+4AiIBsP05/ywBIAK//9//qP9MAHkAyP9vAPL/kwAwAID9KP30AlQDMv/8/Ib/6P/Q/MH/XAIgBJ7+aPvO/lQA1//i/ggD+QD4/oD9gf86AVb//P+m/8oBNP+6/+b+xAK5ALT8O/9eAVYB/P58AdgApAF0/LT9ZANMAQD+VQAsA4r/PP34/fQB8AGC/hcAKAKi/yj+Gv8iAbcAIQCyALr/c/9g/1AAJwCL/2ABf//z/z3/IALt/2r+R//EAKgCIv5R/2gCMgBu/rr/kAE6APr+pgCyAVj/dP0UArACRv4U/s4B7ADa/nj+TAI8AoD8IP0gA2QBkP2K/3IBtwDE/WT9YgEMAsX/Sv7S/4AAeP+8/+z+twDMAez+H/9I/WoAfgF4AQD/1P0SAF4AS/9o/joBEAIy/uD+uv5QAtb+FP70AXAC8P0M/GgBEANX/yL+fwAeAf7+KP7PAMIBpf+I/iYBdAFI/QT+aALYAqD+4Pt8AhYB3v4O/toBmgFk/iT+N/84A2j8uP8cA4cAwPvS/vAC4P8U/wD+/gHo/or+TACSAQn/EP5UATkAhP7M/UQCsAEp/3j+BQB1/3D+lAL//7kAiP5S/zgBZv5QAHoA9AE6/qkA8v4hAGb/hgFcATj9lv9oAiQBZP3P/0QC4gGW/pD8DgGABLD/Iv7yAWr/4P2YALACkv9ZAPL+yf++AUr+oP7fAIACuv5d//7+n/+YAhcAhP54/vUAwP+MAEkAtABc/v7/6wAu/qr/dgAYA0D/UP3k/nwDCP9M/bwCAgF6/uD9TAIuASb+UP3SAcQBMv+S/uYAEgEK/hz//v5AAgr/wgDHANT9Ev7BAAwB5P1cArL+NgCU/pD+TgE6Adz9MPxwBeYBiPsA/FAEMAKc/aD9qgFnAEL+wv84BBoAUPtc/+gEcwBg+UQC8AWc/8j8gP4oBIkA/PzoACAETQBc/XX/lAOCAdD9egDoAjgDvPxQ/ywCYAIg/4cArAGG//j/9gBABIz9uP04ARAExP4c/TwD7QBcAAj+igDVAFEALQA0AR4BFPywAaoBVP6c/kQCfgH8/e//tQBWAUD9Jf9AAVABsv7h/0QBYf+O/zD9JAGL/3b/2gGKAbT8GP4aAWQA8QCs/IAA8AGK/9z94P6sAef/Bv/c/rr/nAEV/xj/lv+v/zkA5f/C/6D/wQDy/7D+8P7Q/4ABIwB9AAr+B//EAev/iv4D/xADzv52/goBPgHU/uD+bgBCAQsAWP3EAAwD1v7k/LQB3ACY/pb/FALW/u7+Wf/aADACKP0zAMgAFgH0/w3/lv7UANgCUf8J/5gAVgHN/1j/lf8gAiX/MQBIAZ8A0/+s/iwBPwD5AP7+bwCGAUb+dAKa/kn/bAEgAToApPz+AUwCqv8G/iYAKgE+/xwBdAACAKH/zf8mAXr/HP7jAEIBc/9T/9YBsP0OAe3/5P10AJn/7AKC/lj+7v4sA+P/OPvLADgC6ACE/NkABQB7AKD9awBEAXL+IwDc/MADcgEA/cD9YgGMAQD/jv7o/mQDrf9E/8z9IwAQAfkAwf9u/hwAGQDR/2ACef9E/k8ANgDQAiP/1PzOAUwCCgHk/E//OAMT/xj/1/9gA7z88gC+AZIA5P3Q/YgCzAEyAcz8xALtAFT9IAFcAin/ZgDKAMACQP/4/CwCkAO7ANj7OAKsA77/DP32AcwDqP6Y/WIB/AMX/8L+uACgA1L+2PyWAEgELgAQ/VwCBAGLAID8zP6oAjQBYgGA+tYBKAKg/fr+UQD1AFb/bf9s/AQCBgES/lD/b/+9/9b+3v8f/6z/fgAU/ToACP/6/twArf++/pz/lf8y/hr+UAIiAWD9/P4X/9QB3/8g/vj85AM9AEz8IwDAAxkAIPvJ/ygDlAGA/PL+qATEARj54v5oBQgBTPzQ/kAF0v5Q/M7+oAQxAJj8sgHaAQP/iPzQAvkArADM/EQBAALV/6r+kAAWAcz/Sv8q/2ABswDRAEL+vAEo/+L+VAAzAKQBlv5xAD7/DAIg/QkA4AHM/u///f92ASj9sgFWAT8AiPxS/rgE8QCc/RT9mASCAIj79f8oAZACYf/4/b0AqADe/gD/CAE7ALYB8f90/OX/1APO/vD8QAEgArYAiPlgAXAEUgBQ+4MAvAOk/Bb+RQBgBmD9aPrWAcACgP7U/EAEFAHA/QD9qAEIAiD9XgHEAd7+jPxIAjQCYP16/+YB6AKo+mz9XANkA0r+OP6uAXD/7v6o/sACMgCMAML+mQAy/14AfwBN/wgBUAJ0ACD7cgCMAgwD/P1c/dgCx/+s/ZkAoAQS/qD8ngFoAtb+OPsQApgG6P5Y+MoBNAO0/kz/PAMZAEz8gAAcAeYBWP2j/yQDBQBE/S0A4ALK/mcA7gFc/aD+bgCYAk0ANAKA/HEAdgCq/hgC8P8iAFIB/wAY+mYBqAU8/SD+DALqALT8Cv7wAjAE+Pyw+YAFzAKA+YP/KAVUARj6dv7QAzABmPte/2gFrP3g+yIB8AGMAPz8/gCQAZL+Qv6w/0wDl/9IAIz9TABQAZEAeP5K/9wB7gFc/RL/xgEiABj/bAACAPP/agDi/iAC3P68/wQCUv4Q/ugBlAF2/0n/vgHIAJz90PwgBHgE4PsI/tQCPANE/OD78ASgAoD+LPysAsYB7P0h/wgCEgFg/ID/1gEOAYwCsPv2/gADDABb/0f/yP2cA4wDWPtc/SQDeAHs/gcA/P0OARQBwP4QAAACEP1s/5ACH//y/soBeP6i/wQDVP3o/iYBHP8wA5j/GPsOAdgE0P24+7QBJAEeAZz+IP7KAeUA+Pt4AEQBfv7FAHwBDgGA+/P/1v5oAxEAQPsUAlADRP1g/IgEKf9s/tz+wgFgBOT8gPy8A1gFaPgO/uAEKAQU/lD7YAR+ART9AP5oBdgCCPiiAdAFOQDA+Lv/oAYcAkj6iP3oBpoBGPoE/jAFyv8E/7//BAIHAED9wwDMAWj/CgFwAV7+o/8RAOQBmv5cAdT/owAZ/xb/4AKI/4X/Pf9wAvj+kP30AZ4BKgFE/RsAqAA4Acj+yv94AcD/bP4q/mwCXQDzAAz9dgFkACT9FgB6ABADpP60/dz/1wDH/17+GAKa/sP/GQBo/g//DQCgAhD+SAA4/JYBiwAE/Y//PAPFACj4UAJUAkX/wPt8AZAC7/+g+yz9sAZD/wj9bwCmAeD7sP9sAtcAe/+M/cACg/9w++j9iAZsAZz8l//eAKj+cP16AVgEjgGo+SYBnAMq/nD9tAKkAsL+NP3QAq4BuP3Y/yQD9ADI+un/cAUgAzD68v74BXgA4PlK/ygF7gEu/vD9bANM/xT8hgAQBNH/wPw2/ggG5//w+S7/4AT+AQD7jf+3/xgEaPsP/+wDe/8M/EL+cAbw/kD77PyYBkwAyPqs/uwCvALo/Kj9TAKXAPj8bQB2Abj9RgGMAZD/DP5K/qcAiARs/Cb+fAOU/mX/qAGC/2j/3P3a/ugFJgEo/JT9EAOQAlz9QPxgAgAHLP1I/ID+0AO2AXj8XQAwA9gA8PnUAuACKgCI+0QCUAS4/fD7MALABRn/OP1i/uQDqP2i/pAEQAJc/Aj+2AMtAFj8mP0YBWgDhP0g+zACLAL5AJb/3P34AHQBuv7s/kgEYQCE/nj9AgFoAdb/4P5kA8IBUPmU/zIBsAOG/97+JALc/VL+8P8IA4T9QwA4BMwAiPto/FAF2AN8/aD8vAFgAqD9kP/gA5MA3Px5//wBlP6Q+yIBGAUUA1j6gPv4AQgC9v4m/iUASAGKAUD87P3AARQCJgD+/sr+vP0I/lAE4AQ+/vD6A//QBeb+RPyJ/wgF2ALA+9D9NAFpAIoBhANSAED6pPx4A4AFUf+4+dABQASi/qj5O/8wBXwBj/9y/tz9uPsDAHgH3gGg+jD7YAQoBND6UPzQA0AFSPx8/FAC4AGk/Sz+iAQuAWD6eP34BHAFSPz0/P4BsgHI/ZT9MAQIAjT9tv5YA9wAaP24/sgBdgF9/2b+vAFoARb+bgDwAYb+8PucA5gE1AGA+aj8mAUcAzj7OPzQBpgCkPvM/QACOAHc/AwBKAMS/sj6QAAwCJn/uPiW/sgEWgDg+mwB2ATaAAj7cP0oA+r+XP/QA/gE+PxQ+eEAiAQIAHT9pAIIA+T9cv45/7ABfQD4ARkAeP04/SwCKAWY/2D9SAGtADT9BP58AjADpAEk/4f/ZPwc/gIAFAMcAw7+dP6y/tX/+v4SAE8AFADWADD+wP29/5wCoQAI/vj9Z/+d/0r/YAHeAfL/VP2K/nQAzP6T/+QB4AGs/tz9Hv/4AFAAHP+h/2kABf+9/4EABQDLAJf/Uf96/t7+BgCcAf4Ahv+e/n//awDh/9n/aP9MABwAmgGb/97+rP8WAbQBMv9r/ygA2wDO/77/LAFWAeL/RwDyALj/5P1BAOwCOALK/9j9OwBCAeb/vv+8ADYBzgDB/97+XP+o/3gB6gHa/2z+lv8AAYEA3f9U/1cAngA6//7+ewCTAPsAfQCu/nr+gP4hAH4BLALY/xP/2v6w/rP/uf8GAdwBsAHV/wj+PP5d/xACbAIlAAb/F/8MAAQA4/85ABYBWgDU/n7+RQDBANQAzQBN/1b++P2s//YB1AL2/wv/rv6q/l3/nf88AdwB+QDU/qL+Uv+A//UAgAG4AKv/xv6T//wAKgFUAHMAXwAp/3b/sgBkAQAC8AD6/zH/nv7P/84BBAKiANMAq/83/zr/vv8QARQBrwB5AP7/Qf+X/zIAiwAHAPb/NACc/48AEgGCAIX/K/+9/zEAEgDVAEoBnAAeAD7/ef/s/3MAygASAXkAgv/c//L/KgDIAD8AnP+x/8//8P/0//T/RABbADf/2v5t/24AIgD1/9r/B/+u/mX/pP8DABAAuf/B/0L/U/9h/9//zf8AAOj/yP+A/5z/AADR/wYAgP86ADYAif9V/47/ZwBWAFUAQQDH/2n/yP93AJYA/f/p/2QAFwDD/8f/cADyADoAl/+Y/5r/3/9uAGUAAwCE/2L/Zv+c/5L/Lf/j/1gAEwB1//7+W/8cAPL/2/9pAIIALQARAFgAfQCR/2b/cADwAI4A9/+KABwBDgBH/0T/BwB9ACwAegBQAAYAgv9d/5z/GwAeAMn/sP+O/4D/U//b/3MAKwBO/yv/wP+//9v//P/9//T/vv/k/+L/CgAeAHsARQCE/5D/AQBxAIYASgBEABgA4P+Q/+n/KACqAKgA9f/J/yUAz//C/zEAEwAYAGn/s/9QAHkAGAA5ABgArv87/4f/gwCKAGIAbwBfAMT/lv82AGoABAC7/1EAZgDb/3b/NwChAPv/Uf9c//L/5//n/0oAfQABAHX/aP/M/w4AvP/7/2YADwAMAOD/ewDoACcAkf/H/3MA8gDwAP8AIAH8ADkAXgBUAF4A1AASASQBtQADABcAoAC5AIMAXgB2ADYAZQAgACcAOwB0AI8AKQC6/6b/QAAlAAsAnv+U/8v/uP9q/zL/of+I/3f/K/9L/0n/eP+q/6n/j/8R/y3/af9y/6b/LP9s/4j/iP8X/8j+bf93/9j+qP4D/x7/Pv/i/vD+0P4y/gb+lv7G/pb+ov7w/pj+DP7k/Xr+3P66/pL+5P6w/lT+hv7C/ij/8v4G/yT/J/8r/3j/of/k/9v/kf+9//P/0AAOARQBLAGMASwBgAD7AL4BhAKkAjADVAPYAtwCbAPMA1AEsAQwBRAFmATQBEgFsAVQBYAFKAbQBUgFIAWABXgFmAQoBBgEAAR8AygDNAOEAoYB6gAXAJj/Df9L/0z/dv58/dT8GPww+9j60PoI+8D6cPpQ+sD5IPnQ+AD52PiI+Mj4EPnI+HD4UPgY+OD3QPew9/D3oPfA99D3kPew9sD2EPcg98D24Pcw+RD5aPiI+Gj5+PgY+TD74P08/jD+OACWAaUAfgEwBegHkAmwCJAJwAvQC5AN4A8AEkARABCAEAARIBEgEiAUIBRAEkAQUA4gDbAMAA0gDUAL8AnQB5gGAAWIBOQCJAEOAGD/wv6o/Rz+0v7k/dj6oPmg+Zj5EPo4+0D9TP0g/Nj7+Pto/Mj8vPyE/VD9tPwU/PD7aPy4+yD6CPhw9oD1QPWQ9aD2UPZQ9SDzcPGQ8FDw8PBQ8jD0MPSg80DzEPMw8pDyYPNQ9DD0APUw9iD3kPe4+dj7gPwc/iYAgAJgA7gEWAeQCRAI0AiwDEAQQBLgESAVQBTgEmARABTAFuAUoBMgFQAWoBLAEOAPgBAADvAKcAlgCPgFiAWIBkAGeAR0Ah4BTP9k/bj81P3F/zYBMAEhAA//sP1Q/PT82P0d/38AxgGsAoQC+QCa/7D+KP58/hH/6AAwAigCegBI/pz8UPxE/Lz8lP38/Pj6QPlw94D2MPZw9fD00PTg87DyUPIg8wD0QPQQ9ODzsPMQ8xDzMPSQ9SD2IPbA9nD2UPWQ9JD0EPWw9PD0oPXA9YD2kPgA/Dz+iv6y/jr/SP0k/H7+eASgBxAJcAxQDRAKsAX4B3AOQBFgEqATQBRgEmAOgA4AEMAQAA/ADvANoAuwCYAIkAe4BhAFBAPoAVYB2AFYATMAv/99/xr/FP7c/Rb/GADAAAYBMAIgArwAlgDOAcwCDAMwBDAFkATkAmQCZAOYA+wCFAOMA6gBAP8e/0gAaAAj/w7/9P6s/Jj5aPig+JD4WPh4+Aj4IPfw9eD0YPTw9DD2QPdg9wD3kPdA96D20PbA9zD4QPcQ9oD28PZA9gD2MPXQ8+DwQO9A71DxkPRA+cz8Hv+U/rz9kPuY+oT8eACYBuAJoA0gEQAQgAuQCnAMwA+AESAToBTAFOARQBBgEAAQYA9QDgANIAowCDAHuAZYBkAFeAQEAaj+Wf/p/2H/8P4wATgCugDc/qMAhgFyAfgBmARoBpAFeASwBHgFwAS4BPAF8Ab4BuAFiAQwBIQDCAJuAOb+xP6S/j7+7v5c/iz98PrI+CD3MPbg9bD3CPlw+Tj4gPdA94D2UPbg9mD4GPno+cj64Pqw+ij6qPq4+XD4oPfg96D34Pbw9sD28POA8TDxgPDg7eDswO7A8tDzQPj4/QwDIAOF/7EATgBlAAwDkAqAEeAUwBXAE2AQsA1ADhAPgBCgESASIBFgDxAO4A3QDMAJGAcoBQwDQAGgAWADcASIA6gBsf+M/dD8UP1q/hoAfAJ8A/ADuANkApwC0AJwA5gE8AXQBvAFcAXwBAgFEAUABZgExANEA3oB1v9l/2r/mP4o/YT8BP2E/Gj6KPlQ+uj6WPmg9xj46PgY+OD2gPdI+PD3IPgo+Ij5GPpg+kj6GPqQ+QD5UPnA+Hj56Pmo+CD2QPQA9MDzwPGQ8WDxoPEg76DtAO0A7QDt8PBQ9pD87gCIBIAIKAbAA/QBaARgBnAMQBSAGMAYgBUgEvAOUAyQC3AMcA7QDZAM8AsgC6AKYAlIB2AE3AKcAD7/TgAcA6gFmAXYBJAEeAOYAVoANAE0A3AF8AZgCGAJUAjABVgEuAMIBMAEWATABCgFUAQQA+ABtAKsAjwB+v50/qD+JP1A+xj7HP1M/Qj7OPoY/HD7yPjg94j5sPkA+VD5YPqA+/D5QPhQ+XD5uPgY+ZD6APvQ+jj7oPqA+ZD4APgA98D1wPSQ9VD0EPOA8sDxQPHg7xDwoO/A7eDqIOwg7/DxAPWo+9gDSAdgClAMwArYBugEYAhwDYARwBVAGsAZwBPgDTAKcAlACAAJYAowCwAKsAd4BxgHwAawBDgCFAGMAcQBRAIoBuAJgArAB+AF2AQMA/YBpAPoBiAJoAkwCdgHgAVYAwwCSgGUAWwC5AOEAmoBjAEUAfD+Hv6x/1sAmv4I/Nz8Fv6Q/Bj78Py0/Wz84Pm4+oz9lPyo+tj6+Ptw+0j6CPoQ+9j5EPmY+KD5GPko+GD4gPk4+KD3gPfA97D30Paw9nD2QPVA87DyAPPw8nDxUPEg88Dz8PDA62DrIO5g7wDyePl6AYgH8AtgD6AQEAyACaAIUAkADAAQwBUgF4AVABOgDpAHBAPoArAEIATsA6gGQAgoB6gGgAcIB9gEzALYA9wDaAQ4B/AKoA1gDQALQAmgBsAEuAMgBYAHkAgQCKAGEAW8A8YAYP47/8AAIAH+/8r/tQC0ADX/DP8AAQACZAEbAOH/JAAc/2b+WP62/tD9WP1U/Fz8dPwA/fj7yPrg+oj6qPmw93D30PdY+ID3oPdQ+Hj4cPeg9sD2IPZA9tD24PcY+Dj4kPdA9dDzQPPw8nDwoO/g8EDzQPOA8bDwoPDg7QDtwPHA+f4BoAngEOATABKQDUAIGAbYBUAKcA9AEuASQBJQDzAKuARsAkwClgEQAbwDOAY4B3gHoAnwCvAI2AUIBfgFsATABKgHgAugDVAMkAvACUgGqAFxAAAC3APgBBAF0AXIBcADAwCA/gr/K//Q/Wz9Tv+gADIABABAAeAB/wC5/+D+rv60/dD9EP2s/cD+Yv5w/UT8QPvw+iD74Pmo+dj6APuo+XD4aPmo+FD30PbQ90D4cPeg9+D3cPiQ94D34Pdo+FD3kPeg9yD2cPQg9ED0gPPw8UDyQPMg9HDykPLw8eDvAO3g7ZD2bgCQCPAPQBWgFFAPUAkgBjAFoAbwCtAOgBBAEEAOMAuoB0gE/AL4AuIBzAEYBLAG8AcwCZALUAzACugHAAdABlgFUAV4B7AK0AsQCxAKUAi4BOoBAgEwApgDUASgBKAEcAN+ASwAzf+tALIAFP+rAJYBEwDi/ggBNAIcAk4BlAGMAvEAfv4Q/Qz9vPxo/OD8WP3k/AT8sPuw+hj66PpQ+3D6aPm4+fj5QPgg9zj4wPnY+LD3mPgI+YD3oPUA9iD3EPcw9rD3WPjQ90D2oPTA87DywPFQ8VDy4PKA80DzQPOA8sDwUPHg9ln/QAjAEEAWoBYgEOAJIAh4BWgFYAdQDKAP0A9gDHAKQAgoBDQBugCYATwC4APwBdAI0AuwDKAMoAwADOAJwAbYBEAG8AdwCSAKUAuAC4AIWAOeACIAhACjAKoBQARABSADPAH2AJ4Ayv+y/pH/qAFwAbP/QQD0AUIB1v/IAJgCVgGL/5D+MP4A/aD78PtA/Uj9aPy4+5D70PoA+nj6IPuA+3D6kPlw+aj5KPhw97D3QPgY+JD3gPjI+HD3cPdY+AD4wPaw9gD38PZQ9sD1QPaQ9WD0kPSg9HD0kPOQ84DyYPDA70Dx8POY+WgD8A5gFeAUABNQD7AK2AQoBLAGAAugDHANAA+wDcAJCAVkA+oB3gBv/3MAaATQBuAHkAlgDZAPIA1gC6AKUAkIBtgE8AbACMAI6AfgBzAGsAKzAF8AVQCfALgCsAMwAzACkAKkAkIBkAEgA9QDGAJmAVgCfgFk/9r+PAFcAjIBv/+iAAQAcPyo+YD6PPxI++j7SP2Q/pD9OPuQ+7D7gPqQ+Fj5uPng+Dj4sPjA+FD3MPaQ9oD3kPbw9cD2kPfg96D3APiQ+MD3wPZw9mD2sPWw9PDzoPMw82DyQPLA8gDzAPIg8KDvwPEA9wUAQAoAEiAXoBcgFIANSAcQBVAFcAXQBvALUA5ADFAIYAaABIQAOP4w/4QBtAKYBPAIoAyADcANMA+QDiALyAdIB+gGuAXwBUAIUAkoB2AFKAU0A9YAe//mAMQCLALoARQDUAMIAswBcAJAAuQBXAJ4AsABHAH3APn/KP9A/8r/AwB9/2r/xP9e/+D8oPv4++D70PpQ+rD7yPwU/KD6oPoA+2D6KPmI+AD6MPrY+MD3kPcA+MD34PaQ99D4YPng+FD54PkQ+aD3UPdQ9wD2QPXg9ZD10POA84D0IPUw9JDzQPQQ82DvYO+g9Lj76AMgDSAVoBhAFsARkA0QCJAFcAXABnAHoAjACXAIuAV0A7ADpAKgAJQAgAOIBfAFcAigDYAQ4BBwD9AOoAxQCNgE8ARoBtAGEAaoBkgHgAXEA44BGAEaAcgCTANgA8wDMAMYA2AD+AM4BAgEWAO8ARQBZQBAALsAWgFIAvABUAEaAKz/cv+M/qD9rPxY/PD7RPxU/Bj8ePxw/Bj8mPoY+gj6gPnY+Hj48PiA+iD6KPhQ9/D3sPeg9tD1EPiA+dj4wPcI+Qj6yPhA9wD44Pjg9nD0gPTQ9CDzEPMQ9ED1IPWA8+DxUPDg7/DxQPi8AQAMIBXgGGAYgBTwDlAIbAM4BPAGyAaABogHuAd4BWwCkAKoA3wDhAI8AwAG6AZoB9AJEA4AECAPQA2gDDAKgAaoBcAFEAZQBYAEwARYBOwCQAEkAXQCGATQBDAEXAOQApQCqAHeAYQC3AKoA4wCzAEkAGb/5v4P/4v/FwBRAEz/Bf+o/t7+dP6G/qT+5P0A/SD90Pyo+8D6kPp4+vj4EPjY+Wj7UPrY+FD6ePrw9wD2QPew+JD34PYA+HD6KPro+OD48Pk4+ZD3QPfw91D3gPXg9CD1UPUA9TD1kPYg9xD2kPSg8pDycPKg9AD7YAQwDSAUYBcgGIAUsA0QCPgESAQQBEgEYAVgBkgGQAZ4BtgFKAUgBCAEAAMQA5gF2AcQCUAM8A+gEIAOgAuwCRAGKAToA2AEmATAAygF2AQEA7YBrAKUAxAD9ALcA2AEPAPoAnQDVAPUAzAEuAQgBFwCZAFX/0T+dP76/lT/RABIAc4BuQAc/xD+TP2Q+8j6kPt8/AD8pPyM/az8APsI+mj6CPoY+eD4YPko+bD3sPZg93j4QPhg9zj4cPlI+RD4YPeg92j4kPfQ9hD3OPhw96D1gPVg9jD2kPRg9BD1gPUg9ODy8PIA8xDz0PS4+rgCgAsgE4AXoBegFOAOCAf8AcEA9AFwAngCmASIB/gGOAQIBAAGoAScAcgB4AR4BmAG4AiADFAPMA+QDTAMoAgwBSwDhAJYAtgCGARgBQAFSATUA7gDUAOoA8gEYAX4BNgD1AJAAhgBZQCkASwDwANwA1wC3AG3/3j98Pzc/Tb+ov7g/4oBLAJ+AAf/5P5O/pz8sPuo+8j7OPuA+qj6IPuQ+kD6KPrQ+fD4aPgQ+Cj4OPig+GD4aPjo+DD5GPkY+VD5OPl4+cD44Peg9zD3UPYw9QD1QPWA9WD1sPVQ9nD2IPYA9bD0YPOg8uDzMPi4/kgHQBBAFqAXQBWAEKAK4APb/8gABANAAvACoAUgCMgGcAPQBFgGsAQUAkwDKAaQByAIEAtAD+AQYBBwDgAM0Ah4BXgDCAN4A0gE0ASQBCAFyAVABSAEGAQ4BagF2AQ4BIAEqAOAAmAC8AKMA8QDfAMsA3wC/wBL/2z+oP58/1wAvgBaAXoB+AAl/5T9CP30/Gj7oPtE/Nj7OPto+/D7oPvA+tD5CPoQ+Rj4KPiw+PD44PgY+Rj5SPgw93D3sPdg93D3SPiY+CD48Pfw9xD3APaA9ZD1gPUw9YD1YPbA9iD2wPXw9ODzAPLQ8RD0iPn+AAAJoBEgGEAZIBRgDXAI2AXxAAb+YAFwBMgDdAKMA6gG2AWgA+QDQAawBjgFmAQQBzAJwApwDLAOoA4wDXAKIAioBnAEWAIQAqwD5APQArACKATIBUgFaAXYBpgHiAWUAyQDnAL/AAcAIgGEAgAD8AJwAnACJAJBALj+dv5t/3QAUQC/AEoBSAHw/wb/7v5q/mz9IPwk/Kj7aPrQ+VD6IPvQ+pD6aPqQ+sD6QPro+fj5EPq4+fD4MPjA9zD3gPfQ90j4oPho+Sj5CPgQ9wD3IPcg9rD1QPYg94D38PYg9yD3oPZg9bD08POQ86D00PeU/QAFEAygEsAVABWgEdAL6AX4ARoB6gBeAaQCaATYBCgFsATgBZgGsAXEA6gEeAbgBmgGIAfwCqANEA1AC1ALQAqoBrQDpAIoAzQClgFwAjgDrAM0A7gEsAXABagFOAVIBLwCFALWARABugDAAeQCRAKaAYwB7gCe/zX/wf9ZAIIAyQDeAVgCiwAR/zz+Lv7g/LD7YPsE/Aj8kPtI+9D74Pv4+vD5aPno+WD5+PiY+Vj6WPrA+Qj6uPkw+bD3sPfg9zD34PYA98D3sPcI+Dj40PgQ+dD4mPgY+JD3YPcw9zD2oPVg9eD0QPRg9FD1sPfg+mAA0AfgDmAT4BRAFAARMAswBXACLALKAfwAlALABYAFKAOcA9AGuAbQBEAEyAZgCJgH+AfgCRAMYAwgDPALUAp4B1gFIATYAmwCBAPgA8ADGAT4BIAFcAUgBRgG2AboBVgEDAOAAoABoACFAC4BBAJwAkQCOAJ0AagALAD7/wAANwD1AEABUAEGAeYARwAw/1T+3P3M/HD7uPrw+vj6sPrI+rD7oPuw+jj6qPpg+vD5wPk4+hD6kPkg+UD52PiI+MD44PjI+Gj4MPiw91D3EPcg93D38PeQ+ID4gPgA+FD3YPYw9ZD0kPOg8xD0IPXQ9sj6cAFgCPAN4BHAFGAUsA4QCIgFYASmAIb+qgAQBWgFrALQAwAG6AUIBKAEIAaoBhgGUAfwCVALQAzQDEANUAzACqgH0AQQA/wCCAPoAZACwAT4BWAFUAXABhgHiAWYBLgFyAXEA8wBmgEAAqIBrABuAZQC4AJEAkYBGAFEAQoBTACyAGABqgHbAAsA//+S//T9TP1k/QD9kPvY+tj6mPoA+rj5EPug+zD78Poo++D6CPqI+ZD5YPmY+ED40Pdw9xD3UPdQ92D3oPfg97D3cPdA9/D2wPaQ9hD3cPeA92D3YPfg9oD2gPVQ9NDycPLA8kDzgPUQ/PgE0AtgEGAUoBZgEUAJSAUYBP4B+v4g/iwCqASYA9ACQARwBRgFsARoBXgGcAbgBSgH8AjwCkALwAuQDMALUAmoBmAFMAQEAzwCkAKYA+ADQAQABfgFWAVwBQgGCAZoBbgEoAPqATAB6gDcAF4BQALsAiADuALaATgBfABTACAAeABHANoADAFkAKb/W//g/1n/av4Y/rj9bPzY+lj6UPoY+jj6yPrI++j7cPto+zD7ePrA+bD5wPlA+aD4MPhY+Fj4cPiY+LD4+Pjo+MD4QPjA91D3APdA95D3APjg99D3gPdA96D2QPYg9mD1IPQQ9WD3sPreAAAI8A4gEwAUwBFADcAHrAOQAYAAzP7u/2gDiAXIBGgEyAVYB6AGEAUIBjAH0AZABrAHoAlwC0AMMAwgDCAKQAjIBYwD0AJ8AsACyAKYA7gEIAZABvgFYAYwB4gGSAUwBHADRALMAGgAwADGAWACzAKwA/gDBAPyAXoB2gB/AN//jwBwAawB5ABnAB8A1//i/gz+jP34/Aj8CPvA+mj6SPp4+hD7iPsw+zD7IPsI+zD6wPng+cj5kPmQ+Cj4YPhI+ID3YPew9+D3sPdg9wD4oPh4+PD3APh4+Ej4kPcw99D24PZw9vD10PXw9cD1EPUg9bD3XPyAAeAHEA/AEyATMA+AC8AI2APg/fT90P8GAUgBkAKQBHgFIAUwBbgF4AXIBSAG0AaIBqgHMAqQC2ALMAuQC3AJMAbQA4ADSAP0AbYBHAOABNAE8AQoBgAHAAewBggG4ATEA6gCrgGoAC0AjAAIAV4BYAGyAWwCIAJEAcYAcAAXAAUAkABWAcABhgFgARIB/v9w/pj9JP2I/HD7KPvY+nD66PlI+rj60PoA+0D7QPsQ+7D6UPrQ+eD54PmQ+RD5uPjI+ND4CPhQ+MD4EPnw97D3KPiw92D34PbA99D3oPeg9yD4UPhw97D2EPag9UD1QPXQ9PD0SPgk/qwDYAjQDqAUABTADsAJKAaYAtj98Ppk/ZP/KAAYAbgD2AWoBlgGgAUQB5gHWAbwBIgFYAhACuAKQAsQDDAMEApABjAEiAN4AgoBDAHEAkAEKAXYBZgH8AjgCGgHYAbABcwDtAExABcAOgB8AKEAkAGgAgQDBAMMA5QCWALkAfQBjAHgATwCTALuAeYA0P/M/sD9zPw4/BD8cPw4/ND7qPvw+1T8NPwc/OD7hPzA+zD7YPpQ+oD60PkA+tj52PlI+Tj4kPcA+GD42Pjw+DD5iPmg+bD40PeA90D4IPjg9sD2QPiA+PD3sPYQ+Kj4gPaQ9DD1YPfA90D5FgDQCPAOgBHAESAQsAyABhIBbf9P/9n/2gDIAQwDSARABCAEgAR4BSgGEAYwBpgGqAcgCLAIYAowDDAMwApgCRAIaAbAA4ACNAL+AWQCLAMgBCAFKAaYBiAHAAeQBgAGmATAAkYBxwD0/3z/wP+YAIYBLAI8AowCgALMAWgBQgEyAf4AFAFMAV4B4ACg/8L+xP0A/XT8bPx0/Fz8mPsA+zD7gPtw+0j7mPtA/Dz8ePsI+5j6WPo4+oD6qPqY+kD6EPpo+bD4UPhA+Ij4ePiA+Mj4sPho+HD4kPho+Fj4MPiQ+GD4KPiI+Aj4YPfg9pD38PbA9SD10PaI+JD7KAIAC+AQYBEAEYAQcAyoBIEA8P9nAEEAbgAAAwAEiANwA6gEmAV4BbgFgAa4BgAGeAYgCLAJUApQC0AMIAtwCHAGKAXIA8gCfAIAA6wD8AOwBKgFiAZoB/AHcAe4BpAF0ANAAiAB7wDJAJ8AGgEAAtAC/ALcAgwDFAMQArIAt/+d/9L//P+yALIBZALqAQoBEgBn/47+oP0c/eD8nPwg/ID7ePug+zj7GPsY+5D7iPsY+8j6CPso+yj7EPto+5D7QPuA+vj5iPkg+Xj4GPgY+JD4wPh4+Bj44Peg+Mj4YPhQ+ED54Pmw9yD3ePgY+WD4APi4+Pj4UPZQ9aD49P3YAkgH4AzAEAARUA7QCgAHEANuAND+Ff8IAEABwAKkA+AE8AVwBngG2AYQB1AGeAWIBegGUAhwCcAKkAvwCkAJQAdQBigF4APIArACvAPAA1wD3AOIBSAH+AYIBvAFiAXsA5ABQwA/AHQAQwA2ALsA+AGcAoACgAJkAjACtABp//b+d//b////nAAeAQwBFwAV/0D+Pv7s/ej8OPw4/PD7+PoI+jj6UPt4+zj72PuE/Cj8kPso+8j7ePug+uj6mPoA+qD50Pk4+SD4cPcI+PD3YPcg93D4+PiQ+Pj4OPmo+Tj5+Pg4+TD5OPig9/D3gPig9wD2sPTw9ND10PZQ+uYBIAggDCAO8A8AELALoAXyAaQA6v5U/hj/yAEwA1QDAAToBMAEgASYBBAF6AQ4BfAFgAfACPAJ0AqQCsAJgAhYB+gF2AS4A8ADFAPwAmQDCASABPgEsAVQB0gHCAYYBWgE4AMIAs4AzADEAUIBigAGAVgCvAIMAnwC9AJgAgQB7ACuAX4BvgBIAfoBIAHd/zD//P5y/jD9WP2E/fD76Ppo+/j74Pro+eD6bPwY/BD7KPtU/ID8gPsQ+4D74Pv4+hD6mPmA+Rj5CPjQ93j4APmI+CD4yPjQ+VD50PjY+Hj5OPl4+Gj4CPn4+DD4+PiI+UD5CPgg9+D2kPbQ9SD3ePtgATAHkAwAEUASkA9AC6AGJAM2AJb+WP5J/1QBaAIQBHgEwASIBQgGgAUQBfgFEAb4BUgG+AfwCZAKgApgCkAKoAhYBrgE8ANkA8wCcAI4A3AEAAUIBVAF2AVgBhAGYAVYBRgFFAN8ARwBOgEYAW0AGAGIAoQDWAMoAmIBSgG7ABAAuf/MANoBGAK2AQ4BIgF+ABv/Ov4C/lT9TPyA+0D7gPu4+3D7APso+0D74Pog+8D6GPsg/FT8OPvo+rD72PsQ++D5APqY+nj5QPjg91j4QPjQ90D4cPnA+Tj5GPkA+cD4GPlI+YD52PnA+eD5YPmg+Pj44PiA92D2IPbw9jj4UPtyAXAIcA1gD5APIA5AClAFyAGZAAAAxf8UAQwDOATQBNAE8AQQBYAEnANoA5QDMATQBGAGEAnACyAN8AygDEALEAhgBPgBfAEcAcYAHAJQBDgGOAZwBlgGMAZQBfgE2ATABOQD+AJcAjQCGAI+AXYBFAKMAtYBbgHCASQCEgG7AFwBeAH2ABoBBALeAWAA2v9NAOL/Yv5o/TD9cPyo+4D7UPyM/Jz8hPzg+1D7UPoQ+kD6QPrQ+oj7mPvw+qD6YPvA+qD5sPng+aD5gPgQ+HD4kPjg95D3EPhQ+PD3wPfw9+D3UPio+MD4cPio+Fj5+PgA+CD44Pgg+CD3wPYg9xj4sPoEAFAGEAuADbAOAA4QCpgFoAJaAf0AWQAAAbgCsAMgBNQDcAS4BTAF2AMUA3gDnAOwA8gEkAdgCvALoAxwDCALAAjABPwCBAIAAeEA/gGoA9AEQAWQBbAFuAVgBRgFuAQwBMADhALwAFIAOgBiADMANAFgAnQCogHmARgD1ALGAcsA4gCjAB8A5f8dAPf/kf+N/9z+sP2U/Oz83Pwc/ID8zP1W/oj93Pyk/Hz8QPvw+Xj6WPtY+7D6yPqA++D6IPpI+dj5CPvg+mD6cPrg+hj6yPiQ96j4WPnw+Gj4IPk4+kj6ePkw+Sj62Po4+nj5oPiw+Ej4sPco+KD48PgQ+FD44Pnk/VQCmAZQCsANwA6gDLAICAaABFwCxgAyAbgDMAXgBFgEIAVgBTAE3APkA7QDuAOQBEAFaAZwCUAMMA0wDKAK0AnQB9gElAJsAjACfAEsAZgCeAQYBdAEIAUwBiAGYAWABLgEwASMAl4ACADpAKEAZf9r/98AsAGuAL8A5gF4AmoBNwASAegB8QCa/6kA4AG8Acn/dP5k/uT9APzY+rj7VPx4/FT8jPwk/SD9SPzo+0T8YPwE/HD7CPvI+rj5sPgQ+bj5SPqo+lD78PsM/ED7GPqg+fD48Pcg98D3EPnw+YD5+PkQ+1j7sPrI+Yj5qPgg93D2IPcg+FD4GPmQ+hD7yPro+jz9FgA0A6gGQArgC5ALMAqwCDAHCAQcAlACHAOwAiAC/AJYBEgExALIA5gFsAWYBGAEmAaoB6gHMAiQCXAKkAnQCMAIOAfIBIAD7AIwAkgAhAAIAkwD+AMgBagGWAdABrgFUAUwBIwC8wA9ADYAtv9g/+n/GwCvAHQBGAKIArACVAOcA5wCvAHKAAgB9QDb/5T/TwCsAOH/7v6W/hL+SPyI+oj6WPuI+2D7EPy8/Nj82PxI/dT9dP2k/GD7kPmg99D2kPfA+AD6yPsM/dD8oPvw+uD54Pdg9kD28Pd4+Cj5iPo0/HT8mPtA+7D6sPng97D2gPbQ9qD3CPmA+nD74PuY+1j7qPsg/X7/fgGwBBAI0ArACuAJ0AngCGgGrANkAwgEiAMMAjwCkAO8A8gC8AKgBKAFKAWgBegG4AcgCAAI0AiACTAJAAmACHgH+AVQBMACCAEVACEA4wDUAUAD2AS4BQgG2AWYBcgEUAMQAlABhgDN/6P/BAD//63//f93ALAAjwCDAMEAOwCF/zn/ef9X/yD/Rf/D/9H/qP9//0X/FP6I/Kj7yPrA+Yj5UPow+2D7gPs4/Bj9oP3o/fj9eP0Y/Pj5APjw9sD28Pe4+YD7VPwA/Aj7+Pko+fD3oPfY+Jj5mPkw+sD79Px0/Fj7yPuA+wD68Pfw9lD3oPcQ+Gj5UPuM/BT9OP2s/QT+vv4UAPIBIAQ4BngHcAgwCbAJkAnACPgH6AbgBZgEyANYA3QDsAOIBBAF+AToBOgEUAWABfAF+AZQCPAIYAlwCSAJYAiQB/gGIAaIBDADRAKCATQBuAH0AkAEEAXABUAGCAb4BHwDuALQAb4A8f+k/9H/NQBYAGEA1gBGAVoBtQDp/+r/1P96/x3/XP/l/wcArP+6//3/yf+8/qj9aPyo+yD7uPrI+tD6aPs8/JT8TPyw/Gj9vP3Q/MD8WPxQ+wj4wPY4+MD5oPpo+6T9Vv5A/KD5cPlA+pj5aPkY+pD7vPzY/KT8mPwo/YD8kPqQ+PD3EPhg9yD3aPgo+4T8oPz0/Bj+jv4e/l7+PwD2AQwD2AN4BWAHUAggCDAIYAgQCMgGYAXYBNgEqAQQBCgEoAQQBbgEKAQwBLAE8ARYBZAG0AdACHgH8AY4B9gGQAWABJAEOAQYA2ACIAP8A8wDEAQwBfgFmAXIBKAEgASkA5AC+gGiAZ0Ac//W/qz+0v4D/1//8/9sAJcAkgBYADwA+v+w/4X/rv+9/4D/I//+/pb+1P34/Hj86PtQ+xj7UPuQ+5j72Psc/Jj8wPwI/ST9EP2o/ID7+Pl4+HD3QPZQ9uD38PkY+xj7kPu4/OT8MPsA+yT8HPwY+xD78Pz0/aD8mPvw++D7EPoQ+Jj4APko+Fj40PmQ+9D7VPx0/nEAzQC7AMIBkAMABFgEQAWgBlgHmAdwBzAIIAhQB/gG+AawBugFKAXQBBAFGAUQBWAEmAS4BJAEyASYBPAEsAUQBvAFmAV4BZAFQAWYBIgEcARYBLwDIAQIBWAFUAX4BMAEEAQQAzACVAFFANz/GwDv/zb/6v5h/+v/gf+P/1MAiAD4/37/GgAhAIX/YP+U/8j/Yf8a/9z+bv6w/Wz9iP0Q/Sz8gPtA+8j6aPqg+lj7UPwI/Yz9eP2E/bz8YPvg+LD2APYQ9hD2kPeo+vz86Pw4+yj6kPnI+JD32PiA+1T9WP20/c7+TP6s/BD7cPtw+4D50PfQ9yj5GPpQ+2D9Nv/e/1b/vv7E/uD/EgHuAWwDOAW4BvgGGAcwCGAJEAlgB0AGsAWoBDwDEAO4A1gEeARABMAEyASYBGgEuAQ4BQgGyAZYB9AHYAiACAAIUAfYBlAGmAW4BKAEYARgBNgEiAWQBbgEvAPUAq4BbgD5/xgABgDI/4j/i//b//f/JwC+ANAAnABYABAADgARAHsApADMAHwAlQACACL/jP5m/mj+8P2U/fD9Zv7U/VT98Pwo/dj8aPxo/BT8UPtI+gD62PkI+uj5wPmQ+TD5aPkI+sj6OPt4+6j7gPvI+tD6aPtE/ET8QPws/Cj84PtY+wD7cPsM/Mj7CPzI/ND9HP7s/ZT+gP+9/1j/Mv8VAMoA/gBuAYwC6AM4BCAEOASQBPAE6AQABXAFaAbwBjAGkAXIBRgG+ATcA+gDiAQIBAAD9AKgAxgD5gG+AbAC3AJAAmQCvAOIBGAEUATwBJAFcAVgBcAFYAZYBTAEaANUA+wC4AE6AdAA6P/4/n7+6v7G//j/OgD8AKgBxAGyAeABqAEuATwBEAFvAJP/CACXAMEA2ABSAWYB2wCo/xD/oP74/Xz9dP14/bz8IPyY+1j6ePhw99D2QPWA87DyMPNg8sDxkPIA9hj5yPow/fT+vv4Y/Nj5ePnY+Yj5MPp8/Lj9VP0E/eT8nPw4+xj6MPrY+mD7OPyq/vQArgEwAmwC5AHVAC8ArwCQAVwCMAQwBhgHAAfIBqAGEAYQBZAEsATcA9ADmAS4BTAGsAbABxAIGAdwBfAESAXABUAGQAcwCAAI+AbYBYgFIAV4BGgDoAJQAqYBpwAxAHMARgFaAYAADABu/5j+gP1M/cz94v4V/9L+UP/x/1wAjf9W/9T/UwCh/5P/VgAgAaoAyf8oAEgAfv/g/UT93Pww/ED74PrY+nj60Pn4+Nj40PiI+Hj4+Phw+eD5QPoQ+zj8BP1Y/aD9PP50/nj+Jv5g/gr+5P1Y/eT8vPyc/JT8YPyY/Cz97PwY/Zj9zP40/0X/CgAaAYQBdAFoAsADwATIBPAEeAWYBdgEoATQBAAFAAW4BKgEaAR4BCAE3AOIA3gDGANwAggCZALcAtgCyAIQAyADkAJMAnwCuAI0A+QDMASYBNgEQAVQBQAFYAXoBQgGsAUABmAGaAYYBlAGCAeoBngFiAQABCAD9AFIAekAr//o/YT8FPxE/NT8AP50/sT98Pvg+bj4mPig+Ej6sPuk/HD97P2+/uD94Pw4/ID76Pnw+DD5mPmo+Xj5UPp4+gj54PeQ92D3cPZQ9pD32Phw+RD6cPsg/GD7yPqo+mD60PnQ+dD62Pt0/Ej9Cv5M/vT91P3w/dz9KP7w/hEA0QDbACoBfAGEAUwBTAGyAfAB+gE8AvACwANgBMgEOAWYBbAF0AUIBigGEAZABnAGkAaoBuAGYAd4ByAH6AawBmAGsAU4BegEcATsA4ADEANAAkoBgwCv/8b+Pv48/jD+5P3I/YT9DP1w/Cj8SPw4/Pj7sPuA+0D74PqI+lj6KPoI+uj5qPmQ+aj54PkQ+lj6uPoY+1D7gPvw+3z8FP3c/bb+Yf/5/5kAKgGEAfYBtAJsAwAEIASIBCAFUAUIBQAF2ATQBBAEvAOgA1QD+AJkAkAC+AGWAUgBeAF+AZ4B3AFoAswCbAMoBMAEOAWgBQAGKAYABgAG4AWoBTgF0ATABKgEAAR0A9ACMAJOAVQA1f9Y/4j+xP1g/Sj9BP1o/ND8+PzE/IT8fPzA/LT8zPxc/Uz+uv7m/lH/qv+O/4b/h/9u//j+/P4R/+P/BwB/APgApgAcAI//fP+Q/3L/WP+I/2P/O/83/5T/kP8u/yb/Nf8N/8r+3v5d/5r/nf/a/1MAcgDLAO8AVAF4AYIBlgHSAdAB4AH+AfoBRAKcAtQCtAJsAiAC9AF2AToBDAHKAFIA/f+S/1D/Jv+k/kr+HP7E/cj9DP4s/lT+yP4O/+j+BP9H/4X/gP+f/wAALgAgAFkAuQCpABYAWv/W/jr+nP1M/VT9CP2c/IT8fPxA/MD7gPt4+3D7YPvI+zz81Px8/fD9Rv4s/tT9iP0o/cD8rPzw/Bz9QP1s/Tz9uPyM/Hj8oPyk/Lj88Pxs/Hj7UPvQ+3D8dPzE/Kj8YPsI+kj50PqA/Nj9ZP/NAIABmgCCABoBwAHqAZQC3APwBLAFoAa4BxAIsAfIBjAGeAVABdAFqAaYB+AHUAjoByAHQAaoBWAFEAUQBTgFcAUgBTgFeAWwBYAF2ASgBFAEEAQgBMAEEAXoBIgEMATIA0QDDAPoAowC/AFMAbIAYwD+/6f/cv8H/xL+JP2c/KT8fPxY/HT8XPzw+2j7QPto+2D7GPsg+2D7YPsw+4j76Psc/BT8MPxY/Dz8TPx8/Lz8BP00/bj9Hv5M/oj+6v5H/0T/Wf+r/7//5/9lAPYARgGSAdoBGAIgAhgCLAJUAkgCTAJ0AogCvALIAtQCxAKIAmACIAL4AcYBogGsAYwBhgGuAaIB1AG2AdgB/AEYAmQCgAK4AqwCoAJ4AsAC0ALsAvQCvAKIAhQCrgGCAVgBOgEEAaAASQDv/4r/Ov8N/5r+AP6E/QT94Pyg/Jz8bPzw+5D7QPsY+wj78PoI+/D62Prw+iD7aPuo++j7NPxI/Dj8GPww/Fj8lPwc/YT91P38/fj9Gv4G/gr+Kv5Y/pb+xv7m/iX/bv+K/+P/5//Z/8T/uf/i/yYAggDgADIBTgFiAUIBfgG+AeYBGAIgAgACvAHAAcABtAHeAQgCGALCAYIBXAFeAUABCgECAdkAkQB4AIAAhQCFAHoASADn/4X/bv+W/9f/4P/l/+n/2f+I/3f/mf/E/6b/k/9r/1L/S/89/4D/8P////r/pf9o/0r/Bv/e/sD+tP56/hz+yP3A/ZT9RP0U/ej81Pw8/Lj7qPvg+xj8wPzQ/cz+Ff+2/oz+lP5s/uL+9f8aAZoB0AGsAjQD6AN4BEAFcAUYBfAEaAUgBpgGgAcgCDAIqAcAB+AGgAZYBkgGWAboBXgFSAVABTAFuARQBKQDkALKAS4BFgHjAP4AsgBEADr/jP78/Zj9QP00/fD8nPww/PD72Pv4+wT8CPzo+7j7iPuw+9D7+Pss/Ej8JPwY/Bz8ZPxk/Gj8SPxc/BD82Pvo+2j8lPx8/HT8sPx0/Cj8LPx0/Kj8jPyg/Nz88Pzk/DD9oP3A/bj9sP34/Sj+XP64/l7/pP/D//z/MgB9AK0ADgGYARQCWAKAAtQCDAOAAwAEmAQIBQgF4ATIBAAFOAWIBegF8AWQBRAFsASIBHgEkASQBDgEmAP4AmwCGAL4Ad4BzgGGASgBwABtAAQA8v8SAAEAzP9c/yn/Lf9A/3H/u//z//j/8P+//9T/FQAxAH8AvACtAHAANAAqAGEAhgBuAHcAUwAeANL/wP/D/6z/kP9w/1//HP/8/uj+4v6Y/m7+Lv68/Xz9RP1Q/Wj9iP2I/WD9+PzI/Lz83PwA/VT9pP2M/ZT9pP3A/fj9MP5u/qT+mP6W/pz+vv72/vr+V/9z/1r/Tv9r/4//vf+j/6X/tf+Z/4n/rv/h/x0AGgAcACMAHgBLAFAApgDRALkAwwDdABYBVAGMAdwB6AG0AZoBpgHKAeABIAKIArQCoAKEApACnAJkAoACmAKMAoQCcAKoApgCgAKYArQCtAJ8ApQCpAKoApQCtAL0ArwCoAJoAnACOAIcAmgCeAJEArwBYAEEAZ8AaQCMADMAn/8N/2r+Dv6A/WD9PP2U/Jj7aPrA+VD5MPlA+VD5IPmI+PD3kPdA9zD3UPdw93D3cPeQ96D30PcI+JD4wPjA+Nj4CPmg+Uj6MPsU/Iz84Pwg/YD9Av6i/m3/RwDbAFABuAEwAtgCjAMwBKgE+AQYBTAFeAXoBYAGAAdQB3AHeAdYB0gHaAeIB5gHqAeAB3gHaAd4B5AHgAdoBxgHwAZYBhAGCAYQBhgGEAb4BbAFUAXoBLAEaAQYBNgDqANwAxQDyAJ8AiwCugFGAfgAkwAUAJj/QP8P/8D+eP5C/uz9ZP3o/Ij8RPwQ/OD7yPuo+2j7YPtg+3D7YPtg+2D7UPtQ+3j70PsA/Cz8TPyQ/MT88Pws/Wz9rP28/eT9Cv5M/o7+wP4K/zz/X/91/5z/v//i/xwAXgCWAMwA+wAuAUgBbgGOAbYB0gHwAQwCKAJMAkQCXAJcAlACQAIoAiACGAIcAhwCJAIwAhwC/AHIAaABbgE2ARQB7QDHAJoAhQBxAFAAMQAiAAAAwv+U/4T/ef9l/17/hf98/07/GP8R//b+2v7a/vT+8P7K/tD+/P4N/xD/FP83/zz/Kf8z/z3/fP9Z/4H/pP/I/8n/yv/S/7n/nf+d/8P/v//E/8f/tP+z/7b/qv+Z/4f/Yf9J/zj/Hv8R//j+7P7W/rT+pP5+/l7+TP4e/hb+7P3A/aj9nP2I/WT9VP1I/Sz94Py8/LD8qPyc/KD82PzU/Mz8vPwU/Xj9lP2s/bz9qP2Y/dj9Vv74/jr/Zf+v/8X/0f8TAF8ArgD2AEQBmgHiAQQCHAJwArACzAIAAzgDUANQA3ADoAPIA+AD6AMQBAgE2APYA/gDGAT4A9ADxAOkA4gDdAOAA2gDRAMIA8gChAJEAhwC/gHgAZ4BSgH+ALUAegBEAAwA4f/G/43/TP8j/wr/8P7C/or+cv5S/hz+8P3s/ej94P34/fz9Bv7w/dT93P0C/hr+Jv4+/lb+nP62/uj+Cf8e/yr/Gv8w/1j/g/+a/8f/1//s/+7/7f/p/+f/6f/e/9j/3//m/+X/8P/f/+n/4v/F/7z/qv+g/6P/rf/J//L/9/8jABUANQBMAHQAmQC5AOYA7gDwAAgBJgFWAWQBogG2AdAB8AH+ARgCNAJ4ApwCvALAArACnAKkAqwCyALUAsgCxAKsApACaAJoAmgCXAI8AhAC9gHMAaABfgFiASwB6gCuAIMAQAABAMr/jv9V/xP/zv6E/jT+6P2o/XT9QP0Q/dT8iPxE/AD8wPuY+2j7QPsY+/D60PrA+rD6qPqY+oj6iPqQ+pj6wPro+gD7GPsw+2D7kPvI+wj8YPyM/Nj8GP1c/Zz9xP0M/kL+dv6c/gP/Ov+B/7v/+v9EAGcAtAACAS4BZgG+ATACdAK8AgQDQAN8A6QD9ANIBHAEmATABAAFMAVQBXgFmAWoBbgFwAXABbgFyAXYBdAFwAWoBagFkAVoBVAFGAXoBLAEeARoBEAEEATAA2gD9AKMAjgC6AGeAS4BxgBIANL/av8H/6z+HP6A/eD8VPzY+3D7GPvA+mD68Pl4+RD50PiY+Hj4SPgQ+OD3wPfQ9+D38PcQ+Aj4IPhY+JD42Pgo+YD54PlI+qj6GPuI+/j7bPzQ/Ej90P1g/ub+Xv/F/yAAewDSAEIBqAEYAmwCvAIQA2QDwAMIBFAEgASoBOAE+AQYBUgFeAWoBcAF2AXgBeAFyAXABcgFyAXIBcgF0AWoBYgFaAVABSgFEAX4BMgEqASABFgEQAQYBAAE2AOUA1gDHAPgAqgCfAJEAgwCxAF8ASoB3gCWAFgABQC8/2//K//a/pL+Sv78/aD9aP0w/dj8dPwo/AT80PuQ+2D7QPsQ+8j6kPpg+jD6MPoQ+ij6GPoo+jD6QPpA+kj6gPqg+qj6yPoY+1j7cPug+wT8TPyA/Lz8DP1s/aj99P1c/pr+4P48/4H/u//u/zkAjQDIAA4BYAGiAcQB8AFEApQCyALkAhQDXAOEA6wD1AP0AzAEWARwBJgEoATIBNgE4ATwBAAFAAUABQAF6ATgBNAEsASYBIgEYARIBBgE7APIA4QDRAMAA7QCeAIoAuABsgFyASAB3QCKAC4A1/+J/0X/Af+w/lz+JP70/bz9fP0w/fD8rPxw/Dz8APzQ+5j7cPtI+yj78PrQ+sD6qPqY+oj6iPqQ+pD6kPqQ+qD6wPrg+gD7OPt4+7D76Psg/Gj8wPwQ/XD9wP0Q/lj+sP4g/4P/7v9TAK4AAAFaAbQBIAJwArwCEANYA7AD5AMYBGAEkATIBOAE+AQoBVAFaAV4BYAFmAWwBagFqAWoBaAFeAVoBVAFSAUoBQAF6ATQBJgEUAQgBPgD1AOEAywDxAKYAlACGALMAXoBJgHqAIAAJwDc/6L/XP8N/7b+Zv4q/uj9iP1I/SD91PyI/Cz8BPzA+5D7OPsA+9D6qPqQ+mj6OPoo+jD6IPr4+cj5yPng+fj5APow+lD6aPqY+sD6KPtw+5j70PsQ/Iz8DP1g/cD9Av5S/qL+B/9U/9H/MwCrAO0ARgGcARACRAKUAqQC7ALsAuQClAIwAlQCfAKUAlgCWAKYAugC/AJ8A1gESAW4BRAGgAboBgAHGAeoBmAGMAZoBlgGYAVABKQDlAPQAvgBeAHoAmADBAO8AqgD0AQcAlr+uPvk/Hr+OALYA3gCbv+g+4D8qP1C/iT9QP2a/k//VP6w/Vz9iP2k/MD6IPro+qT8dP2Y/MD7kPtQ+yD6mPnA+Tj7wPvw+jj7PPw8/Vj8WPtg+yz8wPw4/Cz81PyU/bj9kP3Q/Xz+pP4i/uD9uP4BAJQA3AAYARAC9AJUA5QDaAN4A6wDIAQIBegFuAYAB9AGOAbYBagFuAXYBTAGGAf4ByAIuAfIBtAFYAW4BbgGgAeoB7AHMAc4BvgEsARwBdAFSAVIBMwDrAOoA2wDRAL9AMn/ef9L/6z+8P1A/dD8gPtg+nj5kPjQ9zD3sPZg9hD2cPXA9ODzQPMw82DzEPQg9AD0YPSg9ED1kPWg9kD3APgw+Mj4oPpI/LD9XP45//X/bQDLAAACkAPwBNAFOAbIBoAHuAcQCFAI0AgQCTAJYAkgCkAKIApgCQAJsAhACLgHgAjgCKAI4AYABoAFqATABMgEoAXIBAgEbAPcAgwCxgHiAVQCFALyAVACVAJYAacAfAAuAFEANgAYAdwAtf++/nj+KP60/bT91P1G/iD9EPxI+zD6ePm4+Jj4EPgw90D2kPWA9DDzcPIg8jDy4PGg8bDx0PFQ8UDwkPBQ8TDyUPPQ9OD2IPfA9cD1APdg+hz9PgC0AjwDxAGSAPYBOARgCCALcA2ADLAK4AqAC5AMEA2ADnAPEA+ADiAOoA4wDlANMA1wDOAKgArQC4AMQAsACUgH2AaoBcgEgAVwBlgGyATIAsgB9ABtAPIA4gGgAsQB4gAFALD/Mv8Z/1L/8P9YAAMAZf9m/lr+qP1g/YD99P0k/pD95PyI/Mj7aPow+fD42PgQ+CD3gPaw9dDzgPLg8aDxgPFw8VDxMPFQ8MDvQO/g7mDvMPEg86D0EPVA9XD1sPWg9hj5UPxg/ub/fwCIAa4BnALYBIgHQAqwCuAK4AqwC7ALUAywDUAPgA/QDgAPkA6gDoANcA3ADZANYAwgDOALEAxQCkAJ+AeoB5AHMAfoBgAGkAUIBMAC6gG6AdgCFAP4AhQCOAFVAMv/SgDEAP4AbQCp/zX/ov6U/lL+fP5m/qz9AP1U/Nj7GPzQ++D6cPlA+ID3APfg9hD2gPXw8yDy0PBg8HDwAPAg8GDwMPAg7+DtYO2A7QDuAO9A8kD0kPXA9ZD0UPSg9PD22Ppa/wwCyAKKAb//tgBYA5gHwAoQDcAMMAuACnAKMAxQDbAPoBFgERAPIA5gDvAOkA6ADtAPIA8QDqAMAA3wCzAKoAjACQAKkAjgBxgHCAeYBLwC3AKkA/QDXAMwBPgCAAGY/5z/2wAiABoAtgDx/wr/tP08/g7+NP2E/Rj+3P2E/Jj7XPxY+2D5GPm4+YD5gPdg9gD24PRA83Dy4PIw8nDwAPAw8JDwQPAA8EDvAO4g7YDtoPDw8uD1EPZg9LDycPKg9AD4bPwKAdQBxP7w/Mz9lAGwBEAIUAsQC7AJUAggCVALMA0gDyAQgBBAD/AOoA8AELAPkA+wD5APkA+QD/APUA5ADAALEAvAC2ALUAuwCuAIOAagBQAGaAYABpAFkAUgBDQCYAFMAiwCNgGLAIAAr/+6/uT+Tf+E/ij9WPwU/SD9PPzQ+0j7kPro+KD4mPiI+OD2kPXA9NDzsPIQ8vDxEPKg8ADvwO1g7sDvQO/A7gDuYO7g7IDukPGg9JD10POA8mDyMPRg9uj7DwDGABH/6PsE/rEAOAWACGAKoApACYAI0AiAC/ANgA9gEAAQIA9QDyAQABFgEEAQgBDAEGAQ4BBgEcAPQA2QC7AMcA0wDaAMMAxACvAGCAbABkAIwAdIBtAFMATAAlgB/AHEArwBPQBj/8//Sv7c/fT9DP68/WD7mPso/OD7gPqo+Yj5qPgg+MD3oPdw9iD0YPNg8+Dy0PEA8dDwoO+A7gDuoO6g7iDuwO0g7eDsIOyg7qDy8POw8zDxAPLw8QDzsPbQ+w7/1v5o/Sj8KP0h/7wDQAlQChAIiAb4B6AJMAvgDIAPoA9wDuANUA8gESAQYBDAEGAQwA/gD6ARwBHAD0ANkAxADUAN4A2QDeALsAlACBAIIAgACNgHQAdgBVAEYANgAyQDuALgAWAAff+2/pD/Uv/o/hL+MP1A/Hj76PsM/LD7aPqI+eD4APiQ97D3oPbg9JDzsPNg82DyMPEA8XDw4O4g7qDugO8A7oDtgO7A7SDswO2A8QD0oPPw8eDxgPKA81D2qPo6/nj+iP2k/Kz97P/4AkAHwAgQCfgHmAewCCAL0AywDrAOMA/wDsAPoBBgEGAQIBDAEKAQQBGAEWARwA+wDVANIA3gDSAOMA5wDEAKQAjgB+AI4AjQCPgHWAbgBLwDKAMkAwwDiAKyAcQAmP8y/9L+tP6O/sj9aP2s/GD80PsI+yj6UPkw+fj4QPhg95D28PRQ86DycPKQ8jDyQPAQ8ADvAO6g7WDtIO5A7gDuIO0g7eDsIO4Q8cDyMPNA8oDxUPLQ9ID3oPo4/Yz9jP2U/Oz9bQA4BJgG2AeACNgHEAhwCBALEA0ADvAN4A5AEIAQ0A9AD7APYBAAEUAR4BHAEbAPIA5gDcANcA7gDsAOkA0wC/AIcAgQCYAJYAkACBAH0AVgBIAD1AKcAkAC0gFCAQkAWf/Y/tD9XP30/OT8DP1s/Oj7wPrw+CD4QPio+Lj40Pfg9sD0kPKw8VDykPPA8lDxYPAg78DtgO3A7UDuoO5g7qDtIOxg7ADuAPBQ8vDy4PLw8ZDxgPOQ9vj5+Pt0/SD+gP1o/R//1ALQBcAHQAjACLAIQAjACeALQA5gDnAOIBCAEGAQMA+gD0AQABEAEoASoBIAEQAPwA3QDdAOUA+gD2AOcAyACkAJwAhgCcAJYAn4B4AGEAU4BOwDEAPQAmACegE4ATUAFv8u/nD9eP2E/XD9yPzc/ED7GPnQ+Ij4aPng+HD48PfA9bDy0PHg8mD0EPMw8nDwYO/g7gDuYO7g7qDuIO5g7YDtAO2A7cDuoPDw8tDyIPPw8UDz4PRA90j6qPx2/kL+WP58/vH/QAMQBsAIkAlACXAIIAmAChAMUA4gEAARoBBgECAQ4A/QD2ARwBMgFAATIBGgEHAP0A6wD2AQgBHwD9ANUAygCjAKgArwCtAKYAn4B3AGaAWgBGAEmAO0Au4B7gFoAdL/rv4Y/pD94Pyg/Jj93P2Y+8j5cPhY+BD44Pf4+Gj4UPYA9PDxcPGw8jDz0PIg8aDvoO5g7eDtwO4A74DtAOzg7ODtoO1A7UDvEPFQ8aDxYPIw9DD0IPVA99j5CPw0/T7/PQCW/5//8AFoBbAIQAngCQAKIAnACTALAA7gD2ARoBEgEPAOYA5AEEASoBOAE2AS4BCgDhAPQA/gD2AQIBBAD0ANYAtwCvAKMApwCuAJIAkwBwgG4AUABfwDZAK4AsQCmgErAIj/uQA+/nj8JPyo/bD9QPz4+9j6EPqA90D3IPgY+Rj4QPaw9KDycPIw8qDykPIw8aDvYO4A7qDuwO4g7oDtoO0A7aDswOzA7mDv4O/Q8JDxAPOg83D08PWw9jj4GPtG/vD/z/8//3sAVALYBEAIwAlQCqAJQAqAC/AK0AxgD6ARwBHwD0AQ8A/gEIAQ4BLAE8ASoBFAEGAQEA/QD2AQwBCwD0ANgAzACyALYAsQC5AK0AhYBzgHmAbABXgEKARwAxgCyAACAUoBLABi/iz9JP0A/bT8oPxs/DD76Pgg+MD3aPi4+PD3cPaw9NDzkPKQ8oDycPKQ8YDv4O5g7kDuQO6A7kDuwOzA7GDs4O3g7QDugO6g74DwAPJg9KD0QPRA9LD2kPnQ+w7+KQCBAIj/cP8UArgFIAiACVAKoArwCcAJQAtwDZAPgBDgEKAQIBDwDwAQ4BBAEWAS4BIAEaAPwA4ADyAP0A4QD2AOwAzgCpAKUAugCkAJIAjQB+AG8AUIBQAFAAS0ApYB1wBIAPL/BQAs/z7+IP0A/Nj7LPzU/HD7WPpQ+ED4gPjA9+D30PfQ9sD00PKw8tDykPKw8iDyoPDg7kDu4O7A7sDuIO6g7aDtIO1A7qDtgO2A7hDwcPGg8tDzgPTg9PDzsPUI+YD89P6r/0sApv+b/wQBOAWACXAK0AlACWAK0AqQC1ANUA8AEWAQABDwDwAQIBCgEKASgBLAEcAQgBBAEKAPEA8QD0APAA/gDRAMoAsACwALcAqQCXAI+AawBnAG2AXABPgCkAL2AS4BewA2AM//vv6w/eT8MP0k/Ej8tPwY+7j54Pcg+PD4APkw+DD3wPXg8wDzgPLA81DzcPIw8RDwQO8g7oDuIO8g7yDvYO0g7aDtoO1A7oDuwO9w8EDycPQg9VD0cPTQ9Rj4uPrQ/YAAvAEpAFP/DAHUA7AHwAmQC1ALsAlgCSALMA5ADwAQYBAgEYAQ8A9gEKARYBIgEmASoBFAEdAPoA9gEJAPQA/ADnAO4A3ACyAL0AoQC1AKQAlwCCAHeAboBYAFkASoAzgCpgFUAfn/mP+D/0H/4P7g/Bj8GPxs/Ij7OPt4+nD5gPgg+Cj4EPjw9oD1sPQw9HDzwPJQ8jDygPHA8EDvwO6A7uDugO5A7iDuYO3g7UDtAO4g7uDu4PAw8hD0YPRQ9BD0APWw92D6VP0K/4oAcgDo/l//8AIwBwAKcAoACSAJYAlgCmAMEA9gEMAPgA/QDuAPABCAEAASgBLAEQAQABCgEGAQkA8QDxAPwA7wDUANUAwgC4AKwAqwCnAJIAggB4AGYAU4BcgEOATUAhwCEAI3ANr+ev4IABwAJv7A/Hz8VPxo+0D7APtQ+/j5IPlo+JD4IPhw9lD24PWg9fDzwPKg8gDzwPGg8ODvMPCg7+DuoO7A7gDv4O5A7kDuIO5A7qDv4PHQ89D0YPTQ83D04PXQ+Ij7dv4rAG7/7P6s/rYAeASgCFAKkAlACYAIoAkACzANsA9AEOAPkA4AD0AP4A9AEcARYBLAEOAP0A8gEOAPgA6QDhAPsA5gDUAMYAuQCtAJ0AgwCrAJ2Ac4BkgFGAXgA4gDjANUA94BbQCk/y7/sP5G/oL+Fv4w/fj7iPso+6j6aPrw+Zj56PiI+GD3sPYA9mD1EPVw9BD0gPNQ8vDwsPAA8BDwgO9A7+DuAO6g7SDt4O0g7qDtoO3A7eDu4O/Q8ZDzsPSg9ODzIPRQ9mj6LP54/wz/nv7u/ksAqAI4BnAJMAowCbAIkAkACxAMgA6AEMAQYA+QDrAP4BBAEYAR4BHAEYARYBGgECAQMA+QD5APIA9gDmAN0AwgC7AKcApACnAJgAi4B2gGEAUwBIgEYASUA+oBDAGeAOT/Wf/O/or+/P04/cz8WPzQ+/j6mPp4+tD56PhI+AD4gPew9pD18PRQ9NDzIPOw8rDxIPFA8IDvgO9g72Du4O1g7uDtIO5g7eDs4O0A7uDuQO/Q8GDysPOA9JD00PSw9aD4FPxe/pb/XP+C/3EAYAJYBZAH8AkgCmAKIArwCiAM0A0gEEARYBHgD9AP4BAAEoARgBFgEqASQBKgEGAQYBCgD2APYA/QDxAPAA2gC/AKwAowCgAKIAogCTgHYAWwBJgE6ARoBOADfAIWAT0A0f+l/6L/av9w/rj99Pxg/Bz8sPtQ+0D7iPrQ+fj4cPjA91D3sPZg9uD10PQQ9CDzcPLQ8bDxcPFA8QDw4O7g7oDuwO5A7kDvYO7g7YDtYO6A8GDxUPLQ85D1wPSA9MD08PeA+xD+mv8UADr/+v4MARgEIAegCLAJcApQCmAJUAoQDVAPIBAAECAQ8A9AD+APABHgEYARIBGAEUARIBAAD+AO8A7QDoAOMA5wDQAMoAqwCSAJMAkwCbAIsAcYBmgE5ANkA0gDnAMQA5IBRQCR/wz/aP48/mz+nv6g/Wj88PuY+0D72PoI+8j6EPoA+Rj4sPeA9+D2YPag9QD1QPQg8+DyYPIA8kDxwPAQ8MDvoO6g7gDvoO8A78DtQO6g7kDvIO/A8NDzIPVA9ZD0YPTw9fD3aPuQ/oEArP9Q/93/agEoBPAGQAlQCpAKwAkQCiALMA2gD8AQoBDQD9APQBDgEEARoBEAEqARIBHgEGAQ4A9QD7AOcA5QDqAN4AwQDOAKEAogCZAIQAgwCEAHeAVwBMwDiAOsAiACAAJqAQYAtv6A/pL+Tv7g/XT9LP18/Ij7EPsw+yj7qPog+kD50PgY+LD3UPcQ92D2kPWA9JDzQPOQ8mDy0PFw8aDwwO+g7oDuoO5A7wDv4O4A7kDt4OxA7UDvYPDg8uDzEPQg9NDz4PNA9iD6tP24/47/mv5d/3QAhAJ4BdAI8ArwClAKcAmQClAMoA4AEaARYBHQD0APIBBAEeAR4BFAEuARABHAD1APIA8AD8AOIA7wDfAMoAtACoAJIAmQCEAImAf4BugFKAT8AvgC7AKUArYBywAUAAD/nv5K/jz+CP5I/ZD8CPyw+6D7ePsg+8D68PmI+fD4qPhY+PD3YPew9hD2MPXQ9ODzkPPg8mDyMPKg8dDwwO9A7yDvAO8g78Dv4O9A7yDuYO0A7qDukPFA9CD28PWg80D0sPVI+BD7TP6hAGwBFgGCAIgBIARYByAK4AtwDAAMMAuQC6ANIBCgEQASABLgESARgBDgECASIBOgEuARYBFgEFAPsA7ADsAOYA4QDUAMgAsACiAJEAgACHgH8AYQBsAE0AOIAmQCGAIkApIBlgCh/4z+NP4u/lb+KP64/SD9oPwA/Lj7kPvg+8j7APtQ+qj5OPnw+ID4KPjA9xD3gPaA9dD0APSg89DykPLA8sDxAPGg76DvgO8g7yDvwO+w8KDv4O2A7SDu0PAQ8yD1EPbw9dD08PSg9kj6YP28/9AB4AEUApQBfAMABjAJcAswDPAMsAywDEAN0A6gEMARYBKAEmASwBFAEUARwBEAEgAS4BEAEeAPAA9ADvANYA2QDHAMoAuwCpAJcAhYB8AGQAbQBQgFOARAA1ACZgGUAIIAKACG/zP/WP7g/RT9JP0A/dD8QPzY+8D7OPvA+pj66PqY+mj5KPm4+Fj4APhg90D3UPaQ9eD0YPTw8wDzUPJQ8qDxcPGA8IDvYO9g72DvIO9A75DwUPDg7oDtIO7A8KDyUPUA9xD3EPYg9dD2mPkM/ZH/LAIYAwQDYAI0A8gFMAgQC+AM4A2ADQANAA2ADiAQYBHgEsASgBKgESARQBEgEYARoBGAEQARkA/ADsANMA3ADCAMYAsgC0AKEAkgCPgGIAZQBdAE/AOYA7wC8gE0Ab4AEgCK/w7/oP6A/sj9LP1E/VT9MP2I/CT86Puo+zj7MPt4+3D76PoY+mD5mPiA+CD4MPjA9xD3IPYQ9cD0EPSQ8xDzwPKg8gDywPBg8BDwEPDA71DwMPHg8ODvgO9g7wDwsPCg8zD3UPhA9yD2MPaw9xD7IP6yAVAD+ALsAvgCgARABjAJIAzgDdAN0A1gDZANwA7QD0ASYBLAEiASYBEAESAQ4BAAEWAR4BDwD7AOwA2QDBAMIAxgC+AK8AngCLgHmAbQBSAFSATIA0QDbAI0ATUA+f/e/z//8v5w/jL+cP2U/GT8uPyc/LD8VPwA/ED7yPoQ+/D6MPvA+nj66Pk4+aD4KPhI+CD4gPeA9jD10PSQ9DD0sPNQ81Dy8PHw8JDwcPAA8GDvIPBw8BDw4O+A76Dv4O5A79Dw4PMQ9oD3oPdA97D2wPb4+ez95gGsA3gEwAN0AzAEsAUACdALEA7wDqAOsA0gDTAOQBDgESAToBMAE+ARgBBgEGAQwBBgESAR4BBgD+ANoAzQC4ALQAsACzAKIAnwBwAH4AXQBEgE5ANMA3gCyAE0AaAA7f9R/+T+mP74/bj9mP1Q/Rz9zPzA/ID8JPzo+7D7oPuA+2j7KPu4+ij6kPko+dj4iPhQ+LD3APcg9lD1sPRA9BD0oPMQ8yDywPFQ8aDwMPAg8HDwcPCQ8MDw0PDg74DvMPDg8dDygPQg9wD4APko+DD4IPpM/N3/lAK4BEAFMAV4BWAGIAiACkANMA+gD4APIA9gDyAQQBHAEgATQBOAEkASoBGgESARwBCgEAAQcA9QDrAN0AwQDAALkArgCeAI4AeABtAFQAXgBGgEiAN8AsYB1ACAAFcATAAhAGv/zP4u/tT9qP30/QD+Av6k/Xz9IP3w/Mz8kPxk/Bj8uPtI+wj7sPpA+vD5cPlg+LD30PZQ9rD1kPUQ9XD0UPOQ8rDx0PCg8JDwsPDA8BDxAPEQ8QDvQO7A7sDvAPLg8rD0kPTg9LD0EPYw+KD5QPsI/Rv/jP8EARQCOATYBSAHYAjACaAKcAuADDANMA5QD6AQgBGAEeAQYBAgEGAQwBBgEeARgBEgEKAOMA2ADEAMMAwQDMALAAvwCcAIMAcQBmAFcAWoBZgFyARkA94BsAAkAEkAAgEmAZcAkP9Q/nj9ZP2s/Qr+YP48/sj9RP34/LD8oPxg/Aj8uPtg+zD70PqI+uD5QPmQ+PD3QPew9mD2EPaw9SD1QPQw81DyoPGA8YDx0PEQ8nDywPHQ8IDvQO9g74DwMPPg9FD1MPSA8yD08PQw97j5RPz8/QT+BP5a/hUAnAEYBDgGsAfgCIAJAAqACiAL4AuADdAO0A9AEEAQ8A9QDyAPYA8AEKAQoBAgEAAPEA5ADYAMAAywCzALoApACnAJgAiIB6gGSAbIBSgF2ARoBGADBAJUAfgA+QC9AHYAKwB7/5r+3P2c/dz9EP4S/sz9iP0k/cT8qPyo/Jj8WPyw+yD72PqY+mD6IPq4+Rj5aPig9zD34PaQ9lD2oPXA9KDzwPJQ8nDy0PKQ84DzYPMw8lDxUPAg8FDxcPJQ9AD1YPVg9fD0gPSg9YD3ePkg+xD8kPyA/Qz+Sv+lADQCvAMABSgG2AboB7AIgAkgCqAKkAtADAANoA0ADvANsA2wDYANcA1gDXANQA3ADCAMEAzwC1ALEAoACSAIiAcYB8gGsAbIBuAGSAaoBXAEDAOqAV0ApACKAcQCyAOUA8gBA/+w/Oj7HP22/osAGAFpAOz+dP2s/ID82Pwk/Xz9pP2A/RT9mPzY+xD7cPqY+WD5sPkQ+ij6oPmI+FD3APZQ9WD18PVQ9jD2sPVQ9aD0cPRw9OD0APVQ9MD0MPXw9UD2QPaA9vD2cPdY+LD5SPto/JD8oPzk/OD9af8uAeAC9AOABMAEGAXwBfAGMAiACXAKoApwCmAK8AqwC3AMEA1gDTANsAwADKALgAtgC1ALQAtgC1ALwArACZAIkAfYBkAGIAaABgAH0AYoBugEyAOEAooBXAGMAagBLAEgAUABDgHz/yz/Gf8J/6b+cP5Y//j+CP1Y+zz8Uv60/vT9hP1s/ZT8APtA+lj6APvo+9j8DPwo+rD4EPmg+Sj5KPgo+Jj4iPjQ95D3sPfQ9wj4OPjw90D3IPcg9xD3kPYA93D4ePm4+dj5sPq4+oj6IPnI+nj7WPyM/cb+HwAEAfgBxAEeAf8AkgHgAqQDWAXIB/AIoAZYBBAFYAeACPAIkAoQDIAKeAdYBnAHMAkwCcAIYAkQCnAJuAcgB0gHmAZoBJgDEAX4BvgGyAVIBMgCOgEOAdwCaAQgBNgCcAFv/7T9MP0R/2gBeAJwAowBTgBg/vj85PxE/Uj9XP0g/ob+3v7w/hT/Gv4U/Dj68PnY+rD7gPyE/Nz8CPxY+0D6MPpQ+hD6GPlQ+Ij40Pig+Tj6yPqg+lj5SPiA+Ej5EPl4+Fj5yPtM/OD5QPiw+sT9LP0I+wD8dv+j/2j8APuU/gIBbQDkAPgBTAPgAi4BlgBwAXgCUAWYBhAHGAfYBRAE5AIQA1gFGAYwByAJ8Ai4BfgC6ASYB1AHUAUQBvgHQAd4BFAEIAZwBQgESAXoBrAFRANiAVQBOAJoBYAIeAbSAaH/5f/s/wD/nv/4AvAEuAOUASv/IP0Y/Uj/rP/c/Zz8vP0y/xL/dv6M/rD9MPuQ+Pj4YPuA/fD+4P4E/cj5UPdg9+j4IPtY/eT9kPzo+lj6gPow+kj5+Pio+ej6XPzs/Y7+aP60/cz8QPvY+QD50PkA/DT/LAJoA5wC7gCA/nD7UPl4+Xj8qABoBCAHqAfIBdgBSP0g+qD54PtuAIgFsAmwCwAKgATY/TD6APpI/rAEsAnACogHyAIGAPUAVAJ4AlQCjAIAApABCAFkAkAFOAXIAkQDkAX4BEwCmP7s/CD9CP98AigHIAkoBTb/qPz0/D7+O/8IAigF7AOG/zT9uv6T/8j9SPwS/u4AYgEiANL/bf+8/iD9WPuQ+hj7OPyU/b//4AHQAv4BsP2w93D0QPdY/YQCiASoAjP/sPsw+kz8n/+o/bj7pPz3AEQDZAIMAsT/8Pqg9WD6UATgCOgE9/8S/tT9NP2w/cb/agDKAHIAwAHMAnAE4APcAJD8aPlI+mT+UAagC6AJmABw+nj7U//JAPQBgAR4BIEAIP2HAOAEmATV/0r+7P8aAZEAJgHUAvwCKAKwAVACvAJUAhUA3P2s/XwAAASYBRAE9ACU/mj/iAEgArj//P0A/6cALAIABLAFQAOc/Gj5QPwKAcACqAKoAfb/7Pxk/M7+8AFRAMT94P2uAOwCHAFy/nD7OPtE/Oj+lgFkA0gCdP3I+Zj7+gH4BbACNP5Q/ED7cPdo+ugEUAygBsD6APjY/W4AoP3c/eQBcAWMApL+rv5hADz98PdI+SIAiAcQC6AIFAIY+aD0APfs/FAAkASQDFAMsQBQ9rD3eP2w/07+sgHgB9gGUAOx/8z9GPgw9zj+CAYwCigGfABO/lb+MP1A/ZX/4AKoBRwCpP4WAN4BfgDM/jj+aPuC/2AD6AagBUj+ePkQ+5j9dP0SAagFmAUMA3P/cP3g/Nj7aPtm/uoA4gEQBsAFxADo+HD2yPhq/pgFIAlQCJQDFPxg9iD2sPkc/2AEwAdgCLgDmPuw91D70P4M/gz9HAKwA5MAyf9QBIQDSP2A+/D+9AHQ+7D4bP2kAzgFIAVQBVACVPww+Bj6bv4oAvAE6AXEAvT+hP3E/VkAtQC+/mD8yPvp/+gGEApYBhwB7PwY+gD4MPvlAGAGEAZYBHQCugFWAL7++P3o/Mj8pP6kA6gE9gG9//4AUAPAATH/aP2w/RIAtAIkAv7/jf/eAZAEPANo/YD54PwUAdoBVgBAAxgHuAIQ+lD3UPu+/sr+1AGYB6gH9QCY/Dz8APnA9OD4QAMwCNAHCAThADj8MPkQ+kj8Cf+RAM4AJv5g/QwC0AfYBPD9ZP3M/QD6oPbY+yAF0AigA8P/UACM/7z9zP35/wIAcv4W/tL/mQClAF4BYASAA3L+SPn4+rQCWAXUAMj9DP6E/zcADgGgAjYBZP51/2wA6P5K/j3/fAEcARgAeQCQAv8AdP18/n4ByAEi/87+egAyAeMAdALsAkb/DP3j/zwCZwC4/LD7rP+MAggCgP+3AHwC+gGK/8D9aPtg+3r+IQD+ARgEWAUIA9z9sPlY+Bj6uv5oBQAMcAiA/AD0YPZPAEgDFAGwAhAG8ASy/vD6oPrw+nD7LAEYBagGwAZIBDT+MPeg92j7uQDAAsgEKAUoBHwCHABI/AD6+Pu5/48AJQCkAiAFfAOq/yL+qP9oALL+NPwI+4D9cASgCqAI0P3A9jD6qwAsAgr/bAIABSwD9Py4+xz/qgBg/fD7OgGwBJAEJAIMAjoAGPwA+GD6+AFgB2AIAAc8AdD3gPLw91gCCAeYB7AGYAWO//D2sPaA+mT8AP8YBpAMEAfQ/Mj6eP0o+1j4UP0wCOAJHAKU/Jz+yf+8/Pj76P8wAwADPAB5/6P/CwBCATAChAHHAF4A0P1U/Df/8AJgBEwBiv7i/pj+0P+mARgDtAHS/tT8Fv6p/7ADeAZwBFr+qPiQ+k7+hgFEAmAEyATGAYD7sPmMAPAGLANg+qj79AIYBIz+lP0IBUAGkf88/IL+Qv7o/Fv/aAQ4BdP/tP1s/68AjAEMAoL/pP1Q+xz8tv8QA1AFzAL8/tD+kgFqAYD8CPxU//D8YPkU/pAHoAqoAvD4SPkQ/k8AfP7c/br/lALmAWj9qPrE/7gGGAbk/Jj4YPyU/wD/0f+gBqgHkP4A98D52P4YAigE0Ag4BqD7kPOw+CQC+ASYBegGhAOI+0D1GPm4AjgFDAL6ABgECAUiAbD7QPtE/o8ANwBUAXAEKAUsApj+EPtA+Yj7GAMgCNAIUATe/sj6YPbY+SgEgAtgCHL+4Pew92D7QAHwBvAJWAWd/8D6kPfA9XD7wAVwClAHiAI4APz8aPig9jD7BAMABTgFqAQcAsr+cPoY+bD60P4OAML/zQCABkALwAUo+yDzsPMo+dz/IAmAC5gG8Pzw+l7+pf+I+2D7XwAgAQMADAEgBgAGUABI+MD3oP2AAigEeASUArj/5P2jAGAEOAQY/hD3QPdw/XADsAdACuAKCAd4/HD0CPk1ALMAIP3Q/TgEoAWwBWAIMAtCAZDxIO/I+TAFwAZABjAI6AW+/gD5APuE/o7+2ACIAoQCPADv/5IA7P6I/UL+wAGUA2QBU/+k/dT8Ov7T/ywCaAIsAvD/XPwg+qz8BgGYAkAD7ALGAVj8QPlQ+az9GAMABXAF6AHY+2D4QPx6AVAEuAKA/tD7CPzxAGACBQDA/Kj7vP3YA+AGFAP0/JD6yPxs/Tj7uP0AB9AJmAUe/+D8aPtI+Jj6IgFACLAIeASIAPD9/Pww+0D9jgAIAmADwANcA8wAmP0w+hj8SAI4BZgGzAPBAHD70PbA+kgDWAdYA47+4P7mAMT/lP2Y/8QC+AGo/ST8X/9AASQB3P7Y/U7++AKoBXr/ePrg+4AEyAOY+qD5WwB0AhT+CP/ABSAGhPyo+F0AMAR8/kj6JP2eAJj9bP94BhAI2AFQ+pj6aPyo+7j8aARgCGwDEPyw+9cAsAJcApQACv+w/OD6Fv4MAzgG8AMw/0j8IP14/mX/xAJIBHwD/P6o+mj8sAHoAyAAWP03AJgEYAMj/0b/pAKMAZj7APoiADAGLAOZ/xACCAO0/qD5EPy4AxgEdP3a/mAESASN/2T83v4K/4D9OP0mAcwD5AOuAUj8uPmc/WgCpAOcA1gCbP+w+SD49P0IBBwDkAPYBnAD+PkQ9MD4QgFwBUgEeAEVANwCCAKU/Zj5ZPyaACz+jP10AVAIoAcnAOj5QPYg9WD8AAlADZAIYAPk/HD14PFQ9VH/gAiADvAMqAZo/GD2gPig+aj4GPxgCGAOUAwQBsb+gPew9Dj47PzEAyALoAy4Bfz8ePrs/nD+0Pmo/OgEwAU8AggFKAdAA6D6QPcg+gIBcATAAiAD1AP0AUD9/PwQAfgCzP7w+Pj7mAP4BfgBiP8VAAP/9P2WAFYA2PyU/Jz9uQAgAmAFUAaC/yD3APbY/GADqAW4AgQBFv6A/Bj+NgGwASYBY/9g+uj6tP1PADIBgATABQAD5P2g+oD7IPvI+nD+aAboBZgDdAIEARj68PXY/AgEuAVCAdf/qAElAFj5TPxoBFgHKAJ7AFgB4/8g+ZD4bACQAxAEAAVAB/gAmPrI+44B1P1o+FD8UAfQDKAHoAM+/yj6EPVY+PL+PANABbAHuAcgA4z+jP3o+sj5yPv8/VD/8ALQCdAKEAIA+ID1UPpI/VQD+AZYBsP/9Pwo/VL+cP7w/sn/bP6U/R3/EALQAZABsAHJAP7+kPtI+9j8Of8LAJsAdAJ4BCAEKv6Y+ij7gPwY/Pr/EAdACjgD2PqI+ND70P2I/N4AwAZwCvAF1P/o+vD2MPco/JQC8AbACDAIYAUs/KD1gPZA/dgCIAagB4AFfgCE/KD7HPzg/KcA0AXABvACbP7I/dr+ev74/H4AGAagBggE0v6A+pj5PPwEAYgFKAcQBcIBlP4I+xj5dPzEAgAFGAK0AV4Brf/w/TH/BAMaAWj7kPkiALQCCAK8A6gExAEo/Fj5UPus/pX/sAH8AgQCmQBS/1T9yPzo/q4BYgHj/0wBGAM2ACD50Pcw/ugEGAfoA8AAzP1U/fT8EP57AFoBUAGm/rD9KP1QAmAIQAnYADj4wPbI+5T+cP63AOgEKAeAA6YAlwCM/8D6kPjo+gL/qAMwBlAGEASWABz8APpA+k7+oP/j/z4BQAVQBxQDgP0Q/cz92PxI+8j9QgGAAfD+pADQBvAH0APY/Lj44Pew+Ij7jgGQBwAIiAT2AKH/c/8k/Rj5+Pjk/PMA2ANgBsgHsAQg/SD3gPdK/sQDEAPiAbABRAFN/5z9VAHEA+T94PV4+JgCAAlYB8QDmAHo+zD1APYj/0gHcAhABQQCaP14+uD5sP4IBDgGnALu/gz8WPpc/OIBKAaoBOL/ev7eAJYBdv4Q+sD4qPz8A9AI+AdcA5z+qPzQ97D1cPo0A6AIcAgABG8AgP4g+7j50Pm8/cgC+AZIBmAEZgBA+pD3CPt2AQwDkgHfAKwDRAJG/tz8P/9bABL/iPyc/Cf/8wBkA1gG2AS8AAD8qPig98j75gEAB9gGFAN2/9b+5Pyg+0z9QAEkAij/Gv4yAagEuAUgBEj/2Pmo+PD69gFoBnAEGAIsAyACXP0Q++j6PP6IAhAGkAgQBt7+YPjA+az8Tf/wAzAIkAaWAUD/8P6g/LD6fP58A6wDJgFfALcAVACM/ob+kv8qAaQC1APnAOD7APlA+mD9cgFoBjAK0AmSAVD48PTw9ZD4Lv4ABkAN8Ao2Acj52Png+wD8eP1AALQBpAJqAS0AEAGIAhP/uPv4+8T+7v+4/QAASAXkA6j9UPsl/9gAT/95/0gCSAPj/5D8yPsM/Mj91ALIBwAHRgH4+2j5UPsu/qQCEAYQBu8AWPxo+/j7pP9YBcgHTAOk/Qz8eP4e/6b+UABgA0AEkgGhABYBYAFW/uD7zP1gAoADl//s/bIBhAOm/2j9xgDYAtj9QPs+/+ADRAKc/0ADwAEY+wj5Q/8QBDYB7v94ApAEAwA0/JT8lP2Y/NT8RAL4BVAFTgBk/Yj8MPtA/Aj/kAG8AsACTAHa/rT8KPtw/coA9gEwBNAEiAJI/aD4UPek/AIBzAN4BDgFoATL/2D8LPz4/DT9aP25AJgE2AP4AvwBzABG/6j81Pzo+yj9LAEQBFgEAAOABAAFXwC4+dD3ePnA/LwBeAZwCkAKSAQU/DD2oPXw+Ej+EAbQC4AKpAMQ/Ij5APtI+nD7Yv/YBQALgAgYA6T9ePrQ+CD4qPqgATgHAAmIBcIAPP54/Fz8iPzM/ND+OgHMAYwCUAN0AgkA+Pqg+CD6ZP1QA4AFEAQIAc7/mgDg/ED6mPsi/7kAIAHgAqAEwAG0/ED7RP30/vj9qwCYBAgEVP2A+yEAiANWAV//VQDu/2D7UPkhAMAG8AUIArUAlP5o+gj6Tv/YA/wD+gCVAIIBaP/A/RD+AQBjAJQAegEoA3gDFgGY/pD7yPos/JgBIAdACOQDgP2Q+lD6SPys/2gEgAbwBMcAIP0M/Gj84PuM/jgEUAjYBVUA0PzE/DD8wPqk/QQDgAZYBWAEUAN7/yD7cPiw+XT8owDIBiAKOAeyAUT9oPoA+AD4dPykAhgH2AbABCgC5P6A/cD8yPvI+xL+LAEsA/wCNAOoBCAE9v54+nD6dP3O/i7/PAFQAygE9AOgA3oBHP0w+hD7cP2T/+QAOAToBhgFEwAw/MD7gPzc/Vr/fgEkAwgE0AOgAgz+ePog+sj8Lf8YA1gHiAekA3b+sPso+yD80P4+AVwBigBYAXACKAPWAfL/SP6M/MD8Uv+GAVwBdAGaAT7/eP2A/tcAEAOQAuoAWf9k/ej7HP2O/wACUAMQA5oB2P7c/Tr+/v72/u7+/f/0ANL/Ov8eAAgBrAAQ/7D+Ef/H/z4A8v/E/pj+7v9gAiwCWwBJ/37+UP2o/Aj//AGIAwADCAI8AWj/dP0g/Rv/oABZABYASgDEANoAjgEcAjACSgAE/nD8CP1M/+0AKAEYAlAD0AIYAbL/B//c/Rz86Ptc/QYARAMABugFLALY/Tj8EPxo+1D8Pv/YAjAEXAMwApYAUP6w/Lz8bP08/gT/nAGYA2wDCAHk/sT9zP3W/mb/p/+u/lj/dADYAPH/C/8tANwBbgFe/uj7qPy8/kT/0v+YAlAFwAT6/xz8EPtA+7j8g//4A4gG+AQsAZj9LPwg/PD8fv94AlAEvAN8Af//KgBV/y7+wP0E/78AsgB2AdgCTAOyAPb+hP/5/3L+uP2t/xwCYANcA6gCMAHS/tD9HP5S/gH/1ABwAqgCfAL8ARoBMv40/cL+ef9B/+IApAIAAmsAuv8YATgB7v5E/fT8TP0V/7wCoASwBCQCqP3I+lD72P1HAKgBbgE4ATn/zP16/gIBhAEW/yz9oP3j/73/OgDgAHMArv50/dj+iABgAaf/Cf9+AH4B/P9g/qz+UP8V/9b+ZgDeAcIB6P/0/ij+hv5UAGIB6QAF/7b+NQCUAMP/nP+uAKgAr//e//AAmQD6/tT9bv7T/24BmAKEAjgBhf8k/zX/jP70/pP/GgE0AtwBwwD8//z/9f/d/03/gv92AIAA2v8y/wYAnQAuAawB/gHMAAP/PP4e/vj9wP7YALQC9ALGAYsAb/90/Uz8lP3l/0YBvAHEAUgBPgCO/sT9bv4y/xz/Iv/a//EAzgA5ALv/l/9o/17/KwDjAPz/XP5w/Ur+Xv+NAOIBnAIQAjYA+P50/lr++P0R/5YAOgH6AOQAOAFcAAf/xP7b/yAAQ/9E/0AAFAHDAFIALQC4/1f/7P6S/+4ARAJEAh4Bjf+k/rj+9v7J/woBcAIkArgAk/8y/7P/HwCvABgByAD3/wv/6v60/6MA7QB6AFMAqwAxAA3/pP56/3YAdADf/zMAbwASAIb/cf+9/xgAigAwAWIBagBG/3b+ev4s/3cAAAJsAq4BbACI/yH/2v5a/0IAIgFeARoBtwCVADIACQDE/z//Tf8UAAIBVAGgAMP/tP+///X/8P/d/4n/T/+j/2QA4wDIAIYAsv9z//D+0v62/4EADgGGAAIAof+3/7j/cv9c/4j/y//S/zEAYACIAGgA6f/y/uj9PP5O/9P/agAWAXwBzACf/77+PP7I/bT91P4cAOEA2QCYACUAUf9G/sz9AP7a/tP/HwAzAEIAPgDA/+b+2v6F/7T/ev/X/1sAwQA9ABIAhgCTAO3/3P98ABgB/wBqAUwCWAKMAaQArQDoAIYBRALUAjADYAPMArgCRALqAaABuAHWAVQCcAPIA3QDuAKcAmgCqAH/AOAA/gBAAZAB6gGcAkgCdAHvAHUAIwA2/5j+wv5Z/6f/6//d/5X/zv6A/SD9JP0o/Tz9mP2g/ej8ePzA/MD8NPx4+zD7iPt4+3j72Ps0/Pj7WPso+3D7wPv4++D76Pq4+Rj5SPqw+2j8xPy4/Oj72Prg+cj5yPpE/Hz9nv7m/jD+oP3Q/eT9BP6u/k4ACAK0AoQChAL4AhADdANoBJgFgAaoBlAH0AewB8AH0AdQCPAI0AlQCpAKoApACqAJ0AiACHAIoAiQCDAJcAlwCDgHKAZYBWgE6AMYBHAEKAR8AyADwAKoAREAIP+6/jj+4P3I/bz90P2M/Qj9jPxo+3j68Pn4+SD6YPpw+tj6cPrY+UD5uPhA+LD30PcA+Kj4sPgA+fD4QPhg98D28Pbg9iD3UPeA90D3wPYg9mD2QPbA9XD2IPcI+FD4UPjg+Pj5wPow+zD7PPzM/LT9Bv8wAYADIAXoBSAG4AVQBTAFSAb4BwAKEAyADSAO4A0QDbAL8ApACyAMMA2wDbANQA0wDNAKsAnQCDAIEAgwCNAHSAeQBtgFAAUABFAD0AJ0AigCHALkAUoBpABPAPr/b/9O/5H/df9H/y3/bf+F/5z/c/+w/5H/U/+0/+v/fADLABgBYgFCAQABqgCYAKEA4gC0ALoAnQCbAEcAgv/y/jj+iP2U/BT8sPuY+yj7sPrw+WD5kPig90D3EPfg9kD20PUw9eD0MPRg9HD0IPSQ8wDzEPMg8xDzwPOQ9ID1APYg91j4cPmo+jj7MPto+kj65PxO/xAC0ASoBrAGSAWwA5ADGATYBRAIAAvwDAANoAyQCwAKQAioB3AIYAmwCvALUAwgC/AI2AaQBegE+AS4BagGuAZwBTAEKAMIApABUAG2AbwBrgGuAYgB9gAzAKr/ev9P/0L/w/9bAHUAHQDV/7P/vP8FAMcAgAGcASIB1gDPAMYA7wCuAdwBCAKMAT4B6AC/AAIBPAFqAWIB8gBeAMT/Xv/I/mL+Dv7U/bD9YP3k/Iz8UPuw+tD5kPlo+TD5aPnw+Hj4cPfQ9jD28PWQ9bD1EPYA9qD10PRQ9MDzcPMg9KD0MPUQ9qD34PgQ+bj5mPqw+jj68Pmg+sz8YP6uAPQCWAS8AxQDLANgA6AEaAUYB9AIsAkwCiAKEAqQCfAI8AhACVAJAAqACkAKgAmQCMAH6AaABngGoAZ4BiAGqAX4BCgERAMAA+gCvAJQAmwCRAIQAsYBlAFYAQwBsgASAd8AFAHUAGwBsgH0ATgCYAKAAlQCPAIsAqAC+AJ8A7gD7APUA5ADJAPsAgAD8AKsA1gDhAMIA3wC3gHpAKIAQQD7/4H/NP/M/lT+NP0c/Cj7oPpI+jj6qPmI+bD4wPfg9lD2QPYw9oD1QPVw9AD0UPMA85DzoPMQ89DxsPFA8mDyAPPw9PD2GPjQ+JD4CPjA91D3gPj4+sD9XwCUAnwDPAMIAmoBBAI0A0gFcAegCeAKAAugCtAJ4AhgCPAI8AkQC4ALEAyQCzAK8AjgB0AHKAeYB7gH0AcABwAGCAUwBOwD8AMwBNQDLAOgAiQC3AG8AYYBqgHCAYoBeAFIARgBwQC8AN4ADgFoAdIBXAJYAlQCKAL4Ab4B7AF8AkgDrAOAAxwDuAJUAiACKAI8AmACMAIkAgQCgAGsAEAAz/99/w7//P4I/67+Fv5A/Vz8mPvg+pj6oPqQ+mj6UPqI+cj4wPdQ9zD30PbQ9qD2sPbQ9VD1oPSw9AD0sPMQ81DycPHA8fDzYPYA+JD4YPkQ+ED2kPVQ9rD4OPtU/hIBPALqASABygCwABoBeAJQBeAHkAlwCgALkAoACSAIcAhACTAKYAtgDEAMQAvwCTAJgAj4B+AHMAgQCLgHQAfQBlAGQAWIBBAEwAOUA2QDWAM4A+QCfAJIAgACzgG+AcYBpgFSAUgBWgGYAZ4B1AEMAkACMAIgAjACdAKoAhgDdAPYAwAE0AOkA0gD7ALEArQC1AIAA9wCGAOwAkACXgHVAEUAGQDs/wAA9v+8/+T+3P3c/Aj8uPuI++j7aPvI+hD6YPn4+LD34PfQ9+D2oPbA9nD2APbw9OD0wPQw9IDzQPMw84Dy4PEg8kDzsPSQ9nD44PhA+OD2EPYg9oD3WPqk/WMAogG6Ae4AMgA4ABgBKANIBRgHoAhQCbAJgAkwCfAIwAhACSAKAAvgCwAMoAvQCpAJsAgwCDAIYAgwCOgHcAfQBjgGcAWwBPgDYAMwA+gCxAKQAmACDAJoAeoAngBwAF0AXwBSAFQAJwBSAIEAngCQAHAAewCJANkAGgGKAdoBMAJkApgCgAJgAkgCRAI8AkgCeAKgAqwCnAJMAvABagHTAGYALQAnADkAJQDd/wD/HP4M/TD8sPuY+9j7yPtI+6j64PnY+ND3kPew93D3IPfw9oD2wPVQ9FD0APXw8yD0gPNQ82DyoPFw8VDygPOQ9LD2OPh4+PD2UPbw9dD2oPgo+6T+zAAeAckAcQArAGgA+AFABKgGIAgACaAJgAnQCLAIIAmgCUAKIAvQC0AM0AsAC3AKsAkACbAI4AiACBAIyAeYBzAHgAbQBXgFwATsA1gDGAPgAnwCaAKoArACPAKcAQoBsQBfAJ0ABAFmAXYBYgEuASYBJAGEAQACSAIoAu4BKAKUAvgCYAOwA4gDEAOcAnACkAKQAogCpAJ8AiQCpAFCAf0AiAAcAM3/tf+y/2H/2P5G/pD9/Px0/Bz88PvA+zD7gPoY+rj5QPng+JD4UPjg94D3QPfw9oD24PWA9QD1kPQw9NDz8PNA87Dy4PKg8iD0EPY4+ED4cPfA9nD2oPZw9/j59Pwp/73/z/8jADYAq/9yAHgCSASgBRgH+AcACZAIIAjoBzAI4AhgCRAKkArQCpAKUAqgCQAJQAjQB0AHOAeIB2gHMAewBhgGaAUwBJgDLAPoAuwCqALwAvgCaAK0ASQBnAAtAGIA2ABqAY4BoAFkARYB3gDgADoBggEEAkQCtAIAAwgDHAMkA+wC5AIoA5ADzAOsA5QDIAOwAlQCUAKAAmwCWAIIAo4BDgGvAJsARgC8/xD/iP4K/nj9MP34/JD8KPzQ+1j74PpA+qD5GPlo+AD4GPgA+LD3UPdw9pD1oPTA9FD1MPUA9LDyUPKg8QDyIPMQ9QD3gPaQ9jD28PXA9QD3OPhI+sD7OP3M/kb/4f/Z/6AA3AD2AbgDqAUoB9AHYAiwCGAIYAjwCJAJ4AkgCkAKwArQClAK8AmACQAJIAjQB4AHSAcQB6gGSAbIBVgF2AS8AwgDiAIMAggCIALIAvQCSAKSAcoASQDd/x4A2wCIAY4BhAFmAQoBgwA+AHoA6AB8ATQC5AJEAwgDnAIMArABoAEwAgADYANcAxwD2AJYAsYBdAFMAS4BEgEUASoB/QCOAPz/O/9u/tD9eP10/Wj9PP3U/CD8cPvY+kD6wPko+cj4ePgo+AD40PdA93D2gPUw9TD1MPVA9fD0oPSQ81Dy4PFQ8sDzMPVw9jD3MPYg9ZD1cPbQ96j5iPuQ/aj9hP3o/az+lv/PAGACQARYBagFOAa4BjAHQAf4ByAJAAqwCuAKsApgCvAJ0AngCSAKUAogCqAJ0AgwCJAHaAcgBzgH8AZYBqgF6ASIBBAExANoAzwD4AKcAlwCPAIkAgwC8AHeAYQBXgE0ARoBYgG8AfQBEALiAc4BngFcAZAB7gHAAgwDDAMQA+ACYAIYAgwCTAKcAoQCkAKQAjwC8gFKAfgAxwBsAE4A9////xUA1f90/7b+KP5Q/cj8rPyc/Nz8cPxI/PD7GPs4+qD5YPkI+bj4GPnQ+MD4cPeA9zD34PbQ9sD2gPbg9MDzsPMw9TD28PZg+CD44PYw9fD0IPYg+Ij6MPw8/Sj93Pyk/Bj9dv6x/3ABkAKcA2AE6AQoBWAFEAYAB2gHMAgACaAJkAngCGAIoAhwCDAIUAigCNAIUAiwBygHmAawBUAFCAUQBfAEqARQBBAEpAP4AlgC3gHmARQCFAIsAogCSAJwAbQAfACNALIAxACkATwCKAIEAtwB8gHaAdoBXAIEA2QDWANkA1QDCAPQArQCxAKwAngCTAJEAgQCxgF4ASABygBEAMb/Zf8M/77+Xv4U/qD9NP2A/PD7kPso+8j6oPp4+lD6SPr4+cj5SPkA+dj4kPiA+JD4kPgQ+CD4EPgo+MD3IPeQ9jD28PUQ9qD3oPhI+PD34PcA+OD3sPcg+ZD6EPtw+9D7BP3w/MT8Nv5A/7n/DwBQAUwDQAQ4BKgEEAUoBSgFaAYwCCAJYAmwCaAJkAmACGAIMAmwCaAJ4AkQCrAJ8AggCCAIgAcoB8gGuAaoBrgFEAXoBDgEgAMEA6ACYAK2AYIB2gGSAeEADwDL/0L/jv5q/tD+Ff/+/v7+Df/Y/mL+aP7o/iT/Ov+i/wQAMQAOAGwA2ADgANwADAFcARYB6AAsAYwBrgGwAdgB3AGKAdIAoAC9AKoAowB8ADgAk//0/oz+Nv7A/Tj9xPwA/Ij7mPpA+tD5mPmQ+dj4APiQ92D38PYg9sD1wPWA9WD1YPWA9tD2gPbg9YD2YPbQ9WD2oPeg+SD6KPro+rj64Pno+dj7Jv54/zcACgE+AWkAQwB0AQwDsAS4BZgGyAZYBigGyAZYB5gH8AeACKAIgAiwCOAIsAjoBzAHAAd4BvgF6AUwBhgGYAVwBNgDDANAAsIBpAGSAWABWAE4AagABAB5/3D/R/8y/2z/2v/1/8r/x//y/xAAGgB+AO4AIAE4AawBQAK4AvQCJANkA3wDeAOEA8gDCAQ4BGAEUAQ4BNwDoAOEA2QDEAPQArAClAJYAuQBjgH4AIEA/f/l/8//dv/4/nz+Cv5k/RT9wPy0/Hj8GPy4+3j7IPsI+wj72PqY+jj6OPoA+gD6+PkQ+vD5qPlw+VD5KPk4+WD5aPmw+bj5yPnI+aD50PkY+lj6sPoI+2j7sPuo+9j7WPy4/AD9qP2E/kz/rP/X/5sAjgH+AVQC9ALkA3gEsAQwBTAG2AYIBzAH6AcQCNgHqAcgCLAIgAhQCIAIsAgACGAHWAdoBxAHcAZQBjAG6AVgBdAE2AQoBKgDZAN8A/gClAJYAiACrAEaASIB9wCgAFsAUAAHAKv/Xv8i/yL/qv6A/r7+nv5E/gr++P0C/sj9yP3w/Qz+9P20/cj96P3A/bD9/P0s/j7+EP4U/mD+Pv4s/jL+gP5y/kb+WP5c/lj++P38/VT+WP7g/YT9hP14/Xz9sP3k/bz9bP1U/UD96Pzs/Ej9lP2M/Vz9bP2Y/Wj9JP08/XD9UP1A/aT94P3M/aD9pP3M/cj9lP28/Rb+NP44/lz+dv50/lr+bv6i/sb+7P4Y/zb/Sf9F/1v/Wv9s/6r/7v8TAEoAcQCFAIMAkwDOAPwAGgEuAWoBmgGmAboB1gHmAewBJAJoApQCqALQAuwC9AIMAzQDWAN4A6ADvAPUA8gDyAPsA/wDGAQgBCgECATsA9wD2APcA8wD2APUA7gDcANEAyADDAPYAqACfAJkAkQCCALOAZYBSgHxAKoAfABSAB4A/f/M/53/V/8f/wD/sv6a/l7+QP4U/vz96P20/YT9YP1U/UT9FP0I/QD9AP3c/Kz8nPyQ/HT8bPyE/JT8fPxg/HD8dPxw/ID8pPzI/MD8vPzQ/OD86PwI/UD9bP10/ZD9wP3s/fj9Fv5a/or+tv7m/jP/a/+J/7n/+f87AGoAoQDiABoBSAGGAdYBFAI8AmwCmAK8AuQCBANEA3wDnAO8A9AD3APwA/wDEAQQBBgEGAQgBDAEIAQgBBAE/APkA8gDrAOYA2gDTAMQA9gCqAJ8AkgCCALWAawBgAEkARgB5wCrAGMAKQAWAN//of+E/2r/L/8A//j+0P6S/lD+Mv4s/hb+/P30/eD9xP2g/YD9eP10/XD9eP10/XD9cP18/Wz9YP10/Xj9gP2M/Zz9uP3A/cD9uP3M/eD95P30/RL+Mv48/jz+Rv5g/oD+nP6y/rz+yv7Y/vD+Cv8Z/zH/U/9x/4L/i/+g/8P/4//y//z/BgAXACgARgBfAG4AeQB+AIkAmgCvALsAxQDWANwA4QDuAPIA/QAEAQgBDAEMARQBHAEaARYBFAEUARwBGgEkASYBHAEKAQIBCAEOARgBDgEKAQgB/QD0AOUA2wDNAMIAtQCpAKYAmwB9AGIAUAA/ACcACwD+//T/3//G/7L/oP+R/3z/b/9g/0z/Rv9G/0v/Rv8+/zP/Jv8U/wb/Bv8A//z+BP8M/xH/Cf8D/w7/Jv8n/yD/G/8l/yf/Iv8p/0D/Uf9T/07/XP9k/13/Xv+B/5f/nf+i/7v/2P/X/9v/+f8ZACkAHgAuAEUAUgBNAE4AdQBwAH8AjACoAJgAjQCVAKwAtACxAMcA0ADOAMwA1wDdAN8A1QDaAOgA3QDcANwAygC+ALoAvwDEALoAugCxAKgAnwCQAIgAdwBeAFsAZwBhAFQAQAAwACwAEwAGAAcAEQAJAPb/6v/j/+P/0//L/9H/wv+d/5D/m/+k/6v/o/+U/3//cf9w/2z/X/9e/2f/av9m/1n/Uf9O/0b/PP9E/1H/UP9W/1r/Uf9H/0T/UP9k/2z/Yf9r/4D/ff9x/23/df9//4L/jv+h/7T/tv+0/7L/t/+8/8X/0P/h/+7/9//+/w0AEwAUABoAKQBBAEgAQwBIAFcAXQBZAFkAYgBkAGAAagB5AH4AdgB8AI4AmACbAJcAngCjAJ4AmACfAKIApQCsAK8AtQCtAKEAkQCQAJIAlACZAJ0AngCVAJAAgwB/AHgAcgBsAGYAZABmAF4ATQBCAD0APgA2AC0AKwAmACAAGwAYAB4AHAAdACIAHwAjABgAEwAQABQACQD6//b/+P/0/+7/6P/s/+v/7f/i/9b/0P/N/87/zv/O/8L/tf+s/7L/tf+5/7r/vP+4/63/p/+p/63/rv+3/8D/xf/B/7//xv/I/8T/xv/O/9b/2//f/+v/8P/x//T//v8HAAoACQALAA8AEwAcACcAJQAfABkAGwAeABwAGwAiACQAIgAgAB0AGgAYABgAGAAUAA4ADwAUAA0A/f/5//X/8P/u//D/8v/w/+P/5P/X/9D/yP/J/8b/v//D/9H/0/+//9X/zv/O/8P/yv/l/9n/0//l//H/6//o//r/9//m/9r/5f8AAAEA9f/6/wEABQD6//7/DwAYABcAFwAYABsAHgAhAB4AHwAjACQAJAAgAB8AIgAbABEABwALAA4ABgADAAEA/P/q/9r/1//j/+z/6f/h/9T/zf/F/8X/wv+6/7j/tP+x/6j/ov+l/7H/tP+s/6L/oP+h/6H/pf+j/6T/pf+g/6j/sP+3/7D/rP+y/7H/tv++/8T/zv/P/9L/2f/g/+L/5P/k/+j/8f/6/wYACwASABAADAAHABAAIAAqADAALQA4AD0APAA6ADgAOAAyADAAMAAwADMALwArACsAKQAqACIAGgAbAB8AIAAgACMAJgAmACEAHgAYABYAIQArADQAOAA9AEAAPQA4ADgAPgA6ADcAOAA2AC8AKAAsADUAOgA2ADIAMQAvACoAJAAkACoAKgAkAB0AHgAbABAACwANAAUA/f/0//f/9P/l/+P/6//z/+v/2v/g/9//1//K/8v/3v/N/9H/yv/R/7z/t/++/8P/wv/B/8//zP/A/7v/yP/Q/9H/0f/g/+v/4//i/9//1//Z/+D/6v/y/+r/7f/1//r/AgD///7/9v/5/w8AIgAhACIAIQAhABwAFAAeAC0ANAArACUALAAvADMALQAwADEAHwARABgAHwAiACIAGQAVAA8ACwAKAAkABwAMAA0ACwAIAAEA/P/3//P/9v8AAAMAAQAAAPT/5v/i/+P/6P/s/+b/4v/v//L/4v/Y/9n/3f/Z/9P/1f/j/+n/3//c/93/4v/i/+T/5P/j/97/4f/i/+P/3P/a/+H/8P/0/+r/5//u//X/8f/y//b/AQD9//X/+P/7//r/8f/6/wsAFAAXABoAHQAXAA4ADwAfACYALQAzADkAQwA5ADMALgAtAC4AMAAzADYAMgAuAC4AKQAqACgAJwApACsALAAuACgAHgAcAB4AJgAiACIAIgAcABYAEAAKABAAEAAPABAACgAPAAoACAANABAAAQAAAAQAAgD5//T/7v/1//f/9f/m/+j/6P/j/+H/3//f/9H/y//D/8//0f/U/9D/z//G/73/u/+8/8H/wf/G/8v/zf/K/8X/yv/N/9X/1//X/9X/z//N/9f/2P/Q/83/1//a/9b/0f/Z/+X/4//d/93/5f/o/+P/4//r//T/7v/o/+r/9v/z//D/8////wEA/f/9//v//v8AAAkACgAKAAAA/P/+/wEADAAWABgAHAAQAAwADwAXABQAGQAbABsAGQAgAD0AKAARAAAAGAAtABkAIQA8AEUAKAAcACgAOwA6ACcAPABSAEMAJQAtAEUAQQAiACwASABUADMAJwBDAEkANQAWACYAPwBFADYAOAA9AC0AIwAkAC4AMAAnABgAGAAlAB0ADwAEAP///f/1/+j/8f8FAAkA+//g/9P/3v/3/w4A/f/j/9z/7/8AAP7/+f8JABIADQAAAPf/BAAGABcAGgASAA4AEAAbACEAHQAUABAAIAAfABMADQAjAC0AGgD8/woAFAAOAPD/+/8GAP//6v/n//L/6f/b/73/zf/a/+X/5P/o/+z/2//a/9z/3v8CAA4A9P/V/8j/2v/1/wIA8v/t/+7/+f/7/wsAIgAvAB0AAQAcACoAQgBlAHcAdwAyAA8AXADNAMUAagBSAJkA0gCrAGUAcACsAKcApABwAF0ACAD4/3UACgHOAJ3/Rv8TAM0A9/8P/+D/GALHANb+BP40AWQDWAGW/iD9oP2A/br+xf9SAYj/SP08/Jj8TP3A/eD/lQAE/7j9Gv5h/zH/3P5L//X/p/9J/zYAGAHEAF0ALwCS/67/qwAQAqgClAGOAJUAaQCJAN8AfgGIAfIAPAC6/34ASQBUAHMArgBwAEr/Ov/g/8oABQDQ/9r/gf+c/4b/2gCoAJf/mP4Y/woA3v8ZAA0A8f8D/w//Cv/+/k7/QACkANX/pP6o/vL/UgBwAKn/j/9T/y8AnwDh/1v/5P92AUwA2v6Y/gABJAHd/zz/bgDOACr/wv6CAM4BywCw/6z/ugDv/3H/HACQAWwBLgBf/3v/pQDkALEAZQB2ADYA0/8CAI8AFgHKAC0A1P8aADkAdACoAPgAvQAMAJv/8/97ALUAjwBtAJkAJgB//yH/zv/RANgACwC8/wUAKwCM/xD/tf+JAHoArf+a/zIAagCw/0f/uv8rAAsA0P8HAEwA1P9p/3f/GwBAAOf/1f/y//v/xv+f/xQAOwAAAKv/1/81AC0A6/+S/wkA6v+s/87/DgCEAOD/iv82/9j/zf/t/+D/+f/P/3T/+v78/pH/AgDl/4z/iP8r/wf/T//t/+j/KP/I/h//hf+7/+H/AgBl/4D+mv5Y/+f/GwAoAEkAY/92/n7+qP+IAKMAjABhAJ//EP+O/10AsgBEADoAhwBuAPv/KQCcAHUABgDl/3YApQD7AOoArgCp/+b+X//VAKQBngGvAFn/Af/4/sr/+gDAAVIB4P+w/mr+Vv+XAGABEAHI/9T+vP7Y/ycAqgBXAEcA8/+N/5n/vwCuAZMA5P7E/VIAjgHYARgBpADs/1r+6v53AMYBdQC3AIIBAAGC/8T+HQD9AKQAQwAgATgBnQCP/03/UP8HACYBdgHSAOX/c/9t/4L/NgAcAcsAEwDn/x4AAgCJ/6D/qgDwAGIAuP/B/xYAFAANAMH/if+m//z/YwAKALL/2v/o/z3/6P59/48A+QBNAFv/oP6w/hv/PgAoAfQA9v/U/rT+Vf8BAPYAlAHjAA3/Dv4C/8QAoAEuAY0Apv/U/sL+wv8IAZwBOgH+/57+Ov5+/ywB1gEAAZT/zv4Z/x8A/gAwAVkAaf/G/lT/NgAiAUYBmABy/3D+1P5OAIIBQgEyAFr/+P6c/pP/TAEgAvMAI/9E/lb+i//3ABwCNgF9/wr+HP4u/zYAcgHqAJX/Rv7g/jwArABlAO7/JQB9/yX/NwCwAZYBnf/I/ob/sgB6AKEAHgG7AAf/KP6u/4wB2AG+AI3/4v7m/lL/kAAeAacAAwCA/xn/Lf+N/64ABgH2/5D+zP7D/0UASgAXACUAe/8X/07///8WAPP/8//k/9X/0/96/0f/Yf93AKsA4P93/9z/CwCB/37/gwACARcAIf9Y/1IAvAB8ABQAqf8r/3H/fgBkAd0Alf/Y/l3/EgBjAHEArwBSAAz/zv6V/7YAiADy//T/VQDQ/0D/FgCvAGIASv/R/9wA9QDb/6L/iwCFAMj/xf+2AMEANADs/3AAYQDj/wcAsAC1AP3/jv/A/1sAzQCtAGMAHgD6/7D/df/9/78A3wA6AKb/S/91//P/gQCEAOf/Av/q/qv/OgDUAGIAjv/8/jX/sf8YAGIARQDD/9L+8v7y/xoB2ACy/37+bP55/58AoAFeAQMATP7A/QD/KAH4ARIB/f8Y//D+Wf8aAOYAJgFQAPr+sP7l/4YBkgHn/6r+/P4KAM8ALAEaARcA/v64/tr/BAFaAf4ABABD/+z+nP+eACgBEgFtAIb/mP4U/4MAdgH1ANP/Av/6/mj/DwDvABIBPgAG/6r+lv+JAOUAbgANAAkAgf9J/5z//gAmAbr/oP5N/4oA6ABxADQA+v/G/lb+6v/0AQQCZwCm/qL+5v70/8wARgHFAJv/xv5I/jb/dABYAWkA5P6Q/k7/6v/S/wYADgAg/07+Gf/hABgBUf9M/sb+oP/P/xAAygBaAMb+QP5q//QAIAGxAA8AL/+o/kv/3ACYAUIBPgC0/33/tP/DAGoBCgHV/zn/wv+iAPIAtgBrAMb/X/+1/6kALgGEABf/Nv+v/1oAdwBcADsAR//G/v7+QQCVAGYAzf80/xf/I/81AHkA/P+W/+T/6f9D/1//jQBUAS8ABv+V/9oAZwCZ/9P/xwCoAMP/2P+JANIASgAKAPb/6f8aAGIAlwAwANj/CABRACgA4v+d/8D/QQB7AC0A2/8SAHQALwB+/7n/TADEAKIAhgBRAL7/l//0/4kAnABEAAgA+v/p//f//v/s/63/Vf+d////eQBlAPn/eP9A/27/w/9IANMAhwDn/3z/UP9x/9j/WgDWAE0AvP+7/+L/GACS/0n/yv+eAOUAPgBo/zr/jv+s/6D/5/+CAFEA3/9c/z//Xf/x/28AcwDj/8f/MwBLAK7/Tf8AAFEAmADbAFgBggD0/uj+LgC2AZQBCAGXAPP/Gv8b/7QA6gGeARUAZP91/9D/IABvAMoAGABq/0H/wv86ABEAu/8w/xv/cf9jAM4A0P/U/vL+U//N/y8ACgEIAcP/YP7e/j0A6ABYADkASwDS/4T/uv+dAJEAvv+v/2wArAD1/1f/QgDkALQAcwB0AJEA4P+D/wEA0QDHAIYAeQBXALr/bv/9/3UAdgD9/wUAwP9r/6T/egC8ACYALv8//6X/BgBEAHsAQgCk/1v/0////8j/yv9zANEAFwA9/0z/KwA8ANf/7f83ANj/mv/J/+r/vP9E/yUAswBRAGb/i/8TAOX/d/+l/6AA4QBcAHr/EP9F/7H/LwChAKoA4f/W/rL+YP9vAIcAt/9N/2r/uv/Y/wQAAACt//T+B/8uAOIAbgBm//L+Qf+k//7/ggAEAVMAzP4m/jX/6QB+AX8AcP8D/wP/lf/XAGIBvAA8/7r+Zv9oAAQB/gBlAED/SP83AEIBSgG5ADsA0//A/zgAVgF+AdQACQAZABwABwAgANUAPAFPAJL/lP9OAEAA4f/S/2QAawC1/1r/m/8VACAA9P/k/9z/kf+g/ykABADD/5X/DAAtAMH/of8LAGMAFQDz/+3/1v+5////jgCEAPD/dv/f/zAADgD9/woAHQC+/5T/4f9dAE4A9P+2/1v/Rf+F/yYAbwAyAJX/P/+G/7T/tv+S//P/MwBOAOP/df+r//L/NgARAA4AEwAPAA0A+f8lAEcAWQB0AEMA6/+S/8j/MQDGAPEAgQD//yAAUQATAOT/LwDdAMYANgAHAIQAXQDZ/+L/PwCoAEIARgBbAPX/kP+r/2kAvAAQAHX/wf8hABgAs//G/zkAFwDH/6D//P8GAHD/if/5/zEA5v+C/7H/lf9+/4f/qf+h/4T/zv/t/9T/Uv9z/47/g/+f/xMASABw/xL/Kv+c/5T/pP9WAFkAoP/Y/ur+mP8kAGkAWwDv/47/O/9s//n/ZQCaAD0Azf95/5b/EQBcAFsACQD6/zQAnAByAMz/ff/J/zIAZACVAMEAqgDk/zH/bP80ANAAoQBdAG4AHwCp/1r/6P+MALoAWAAuADEA4/9b/2f/CwB/AFQA+f8vAPv/mv9Q/5P/OQAKAM//7/8qAB8AzP/a/9P/zv/d/ykArgCSAE4A5v+k/6P/6/+EAOUA2QBEAL7/Wf+u/0oAzgCsACUAxf+7/8r/6f90AKwAlwAVAG//eP///50AqQBSAPb/5P+7/5f/1/9pAI4A2f+a/8v/HADp/+H/MQA+AIj/S//a/0UAHAD0/zwA9P+H/4f/KAAxALP/i/8xAC4Aiv+O/0UARgDg/7f/5P8LAJj/yP+YAHgA+/+2/+//BADv/wUAMQBxAPj/1v/M/ysAGQAGAPr/DwAKAOv/FQA5AC4A0v/L//X/ZAB4AEcAGADG/7r/CgCgAOUAugBKALr/t//J/6cACAECAZwAEQCl/93/IgB7AL0AWQAfAPb/BADk//z/CwAnABgAOwA4ACoAxf94/6//vP8VADwAewBKAJ3/Wf9H//7/NgB3AGgAKwC//4n/wf+//0wApACvACQA0v8FACwAFAArAK4AugBVADQATABJAAAAEQCfAHoAMwD3/zsAMQAyABsALQA1APr/MQDz//j/CABcAHYA+v/g/87/MAA2AF0APADP/3D/8/+pAG8AwP9A/4H/o/+8/3H/9P+w/yf/7v7a/kP/BP8g/1b/av8K/4r+6v4T/97+oP7S/jH/Nf8I/9z+ov6U/sT+LP9i/zf/Ef8x/2j/8v4S/13/b/92/9f/FAABAGH/Gf+C/7v/BwBNAIoAZwDW/4j/KgDCAMgA/wAcAQwBfgBhABQB0gEQAoABSgF6AYoBmgEsAqQCXAL+AcIBGAJsAowC3ALQArgCVAJMApwCkAKYApACcALMAbYB6AE0At4BLAEaAZUAggCWAP4A9wDt//r+6P4g/xD/Mf81/5z+xP1I/aj98P3U/aT9cP0I/TD8GPyM/PT8yPxY/Az8+PvA+8D7GPzg+4D7IPtg+6D7wPug+1D7IPv4+jj74PuU/ID8APwo+9D6gPvM/Aj+Tv7k/RT9ePzI/Oj9ev96ADYBoQBUACMA3wCYAkgD1AOYBIAFgAW4BTAG0AYYBxgH0AhACmAKsAmQCfAJgAlwCWAKAAxwCxAKoAnwCVAJEAkQCUAJ4AhAB6gGqAaABngFWAS8AwAE7AIAAmgBdADM/1r+2P0A/rT9vPzw+6j7mPqA+eD4sPig+CD44Pcw+GD3oPaw9TD1EPUQ9cD1YPbw9RD1kPQA9JDzEPSA9UD24PVw9dD0oPQA9OD0sPbQ9lD28PXA9WD1APXw9gD40Pdw9rD2KPkI+lj6iPvU/Pj7HPwC/tcASAM4BIAFcAVwBbgF4AdwCwAOUA9gD4AO0A3QDoARYBPgE8AToBOgEqARIBLAEuASwBHgECAQ0A6QDeAMUA2ADFAKMAmACIgHuAYYBmAFsAN4AvYB+gGSAN7+Av7I/Zj9fPwQ/SD9WPuQ+Vj5SPoI+hj5iPl4+jD60PcA92D4aPig93D38Pcg+ED2wPWA9iD2sPXg9KD1QPXw9GD0MPRw9ODzkPQg9JDzAPTw9UD2sPVw9OD0gPSw9BD2wPcI+LD20PUw99D2sPd4+Cj7FPwo+6T8tP08/9L+3AEYA3wDWATABgAKMApgCrAJMAqACmAL0A8AE0ATABFgD4AOAA7wDwASoBSgFKAR4A4QDbAM0A3wDjAPQA7gC6AJkAhACEAI8AdAB1gGsAa4BfgEIAQYAm4B2gCbAE4BLAJQAvf/XP3g+wj90P3o/dL+r/8E/lD66PjA+mz8iPss/Fj9kPxA+VD3CPjg+Ej5IPkw+uj6APiQ9RD1YPUQ9vD2sPcw99D24PUg9JDzQPRg9VD2QPbQ9vD20PWg9bD28PbA9TD1gPZY+YD4MPdQ9vD2sPaQ9tj5iPvw+pj6TPy8/bz9iP2s/+QCBAMYBKgGwAiQCPAG0AfACIAKMAyQD0ASoBBwDXALsAxADoAQwBFgEoARgA1gCyALoAwwDVANkAwQC6AI0AZQBsgGYAewBlgFKAM4AoQCVAIUAhABMgFaAKL+GP6a/8X/NP5s/XT91P2g/GT8Av70/iT8UPoQ+7D8NP3o+zj8ePyo+lD5yPl4+lj6SPkY+nj6+Png9zD3sPcg+ED38PeA+HD4QPeA9pD2cPZA9lD3ePkQ+eD2MPYo+HD5iPiw96D4cPl4+GD3QPgY+VD28PZo+TD7GPtA+dD6wPrY+tj7eP6xADQBiALMA2AECAQABiAIAAnQCHAJ0AvQDGAN4A7gDpANkAxADQAQgBBgEAAQ8A4wDVAL8AqwDBANsAyAC0AKAAigBVgF0AbwBzAH0ATwA7ADZAKMARgCDAOQAjgBLQBNABYA6v7c/oX/rP/E/gb+Sv6G/tj9vPzU/LD8dP24/cz9sPzw+6D7CPsY+yD7SPvY+lD66PkI+kj5wPiA+Aj5uPgQ+Aj44PcY+JD3sPcw9/D2APio+OD44PcI+CD4SPjY+Hj5qPnw+ID3wPig+XD4EPeg9mD34Pf4+Qj8EPwY+2D5wPlQ+gD8BgBwBJgFcATsAqgCZAPIBFAIMAzADBAMoAuQDPALoAvwDDAPYBAgD4AP0A/ADjANQAzwDJAMUAtQCxANYAyQCdAGQAZQBiAGGAYAB3gHOAV4AjQB3gEMAuIBOAKwAtQBcf+G/rD+LP9K/7T+xP7M/az9OP2E/Aj8HPzw+yz8dPyg+/j7CPuo+RD5oPlQ+jj5CPlI+Uj5oPcQ99D3GPjg9yD3APgA+MD3oPbQ9+D38PZQ9yD4uPgA+Cj4APmw+Cj48PdI+uD5wPho+ED5OPp4+OD2IPcQ97D2WPmI/Lz9cPv4+ED4oPgA+83/mAQwBrgEHAJAAQQCvANACGAMgA2QC3AKAAsQC9ALYA2wD/APAA/QDmAP8A5wDXAMsAwwDCAL0AugDEAM4AmgB1AGsAWQBZAGQAhAByAF1AJoASgC9AEUAlADMARwAYb/zP4C/3b/IP+i/9f/AP+g/TT9BP2s/AT88PvI/Lj8tPyc/Ej7qPkQ+ZD5mPmo+YD68Pow+RD3EPdA+ED4wPeg+HD5qPjw9rD2OPiQ9+D2oPcY+Qj5GPgI+DD5KPmg9/D3EPnw+Sj5WPno+dD50Pfw9gD4IPeA9rD2oPok/lz8oPrY+Dj4oPhg/DYBcAaoBugD5gGgAXQCIAXACeAMsA1gDFAKIArACxANUA7gDkAP8A8gD3AOEA7QDfAMcAvwCnAMEA0gDKAKYAngB/gF0ASYBnAIgAfIBWAEaAMMAuIA8AEwBJQDOgGfANoAfv9w/Z7+OQCp/9z9sP2W/lT9IPsY+2j8nPxI+4j70Pwg/Kj5OPjo+GD5WPkY+XD68PkI+MD2EPdA+CD4wPeY+PD44PdA96D3UPdQ98D3UPgo+aD4IPjg+PD4+PgY+Rj5OPmI+cj6gPoo+dj4OPmI+VD3oPZ4+Pj5MPu4+2z9gPvQ+LD2MPqa/8QCcARIBYAFAAKAAJACIAhgDEAMIAwgDKALAApwCkAOABAQD7AN8A6gD6AOUA1ADfAMcAuwCrALgAxwC5AKYAmQBgAFUAXABtAGYAZgBhAFNAJhAMgBbAOYAsIByAKQAtj/5P3I/uAAqf+2/iL/8/84/mj7XPwQ/Xz8EPvI+5D9zPxo+mj5gPpQ+VD4ePh4+oD6oPiQ99D3EPgg91D3MPio+Cj4UPdw98D3YPcw95D3KPiA+Pj4wPhw+KD4wPgY+fj4OPkA+jj60Plg+TD5oPmQ+OD2YPdA+OD4WPk4+yD9NPxg+FD2iPm0/HsA0ANoBvAEPgGbAIgCiAVgCLALsA1ADLAJ4AnACyAM8AywDvAPgA7QDFAOoA+wDfAKEAtADOAKYAqACyAMYAnQBcAFmAagBegEYAbYB1gFyAEsAXQCQAJCASgCGAOyAUT/dv7X/9H/LP7s/Q//2P5Q/YT8nPyc/Jj7wPpY+8D7sPuo+4j6oPlw+JD4gPjQ+Kj5aPmA+HD38Pbw9uD3sPew9wj4SPjw9zD3sPdw+JD4EPio+JD5sPk4+Sj5GPog+rj5yPkY+8j6YPqo+uD68PnI+Cj5OPmY+Hj4ePqc/VT8GPs4+uj5wPmA+mAA6AUoBmgDlAJgAowCMATQCPAM4AxAC7AKEAvQCnALwA1AEHAP0A2wDqAPwA5QDUANQA1QC7AKMAyQDcALEAngB1gHQAZQBWgGEAgYB+AEwAP8AvYBfgF0AnwD2AIkATUAzf8m/yH/Of9W/37/5P3I/UD+aP2o+zD8PPwo/ND7mPuQ/PD7YPrY+Kj48PhA+Zj5EPqg+Qj4oPdg9xD3gPeI+ND48Peg91j4EPjw9lD38PiA+Uj4MPjg+VD6qPgA+Nj5APtw+Wj5yPqo+2j62PhA+ej5cPgQ95D4iPqg+2j7kPu4+9D5wPcI+v7+1AKgBGgEWAQ0AjIAFAMQB+AKcAswCyALkAsQCnAK0AyQDsAOUA6ADsAOAA9ADgANYAywC2AL0AtwDKAMUAtACIgGSAbwBsAGSAaYBtAGyAQwAkoBZAI8AxwCfAHgAQgBRf9g/gz/oP9i/gj9Fv7K/gj92PuY/NT8IPsA+qj7dPyA+6j62Ppw+hj4cPeA+aj64Plo+AD56PhA95D20PdI+YD4sPcA+BD5IPhA98D3+PhY+Vj40Pgw+gj6CPk4+Tj6OPoQ+kD6GPvI+5j6UPqQ+sj5SPkI+SD60PpI+zj8NPxw+3D6CPog+1D9iAHQBHgE3AKEAZgCeAPgBWAIsAsADEAKwAnQCvALsAswDXAOcA8wDuAMkA5QD8ANIAsAC7AMMAygC7ALEAygCZAG6AXgBvAGKAZoBpAGuARYAvABWALQAQACoAJIAiIA+P6w/3//Qv7o/TT/H/8E/Xj8cP1M/Xj7wPoQ/MD8APuw+pj7uPtY+aD3OPnY+Yj5qPhI+dD5CPiw9jD3qPjA90D3oPeY+ND30PZQ90D4EPhQ9yD4QPlQ+dj4oPgo+WD5CPmY+Uj6gPpg+oj6WPro+cj5OPlI+Rj5oPmo+lj7yPtY+4j66Plw+UD7Uv9QAogDxAI0AuQBmAHcAsAGcArwCZAJwAmgCgAKQAqADLANYA3gDAAOwA6QDfAMgA3ADJAKUApADEANIAswCSAJAAiwBWgFWAfAB4AFYASABOgDyAEQAdgCKANEAQEAZwBZAH7+AP7y/vD+NP1M/HT92P2M/ED7gPsk/AD7WPqI+xD82Ppw+Uj5YPnw+Lj4gPko+iD5APjQ97D3APjQ9yD48Pfw9/D30Pcw+CD4OPhw+Pj46Pg4+cj5GPoA+rj5IPqY+rj6uPpw+6j7MPvQ+sj68PpA+iD6wPrQ+9D7PPyk/OD7sPrI+rz8CP/ZAKQCEARUA8YA0gFoBOgG0AegCCALcAqgCFAJ8AvQDFAMoAxQDrAOcA2QDaAOYA5wDIALYAwwDfALkAvwC4AK6AeYBnAHAAjQBlAGWAagBagDuAIcA1gDjAKSAX4BMgGz//z+UP9p/4z+lP1s/YD9LP2M/KD8gPy4+zD7KPvI+9j7mPrg+nD6KPmQ+HD5yPno+Sj5qPj4+ND3MPeQ95D4aPig96D3GPjQ92D3EPhQ+FD4kPgQ+RD50Pgw+cD5mPlg+Sj66PrA+lj6GPuw+8D6uPkg+vD6kPog+rj7yPzI/Fj7cPpY+zz8GP18/2QCYAOUAtoAkAG0A5AEAAagCAAKgAlgCCAJQAswC/AKIAxADQAO4AyADbAOIA7AC5ALcAyADPALsAvwC9AK0AgwB2AH2AdQB8AGUAaoBagEsAMoAzADlALsARoBnwBKANP/Jv+Y/lb+FP40/Sj8nPxE/aj8aPvA+jD7SPt4+nD6gPv4+mD5SPn4+aj58PhY+Vj6aPkg+PD3qPjQ+PD3UPjY+HD48PcA+AD5oPgI+Hj4YPmw+fD4KPnQ+Vj6uPnA+bj6ePsg+6D6iPv4+xj7ePoQ+7j7YPsg+9j7AP24/Hj7+PuU/Lj8uP2C/9gB7AFqAaABCALYAvwDEAa4ByAIYAiACNAI8AlACkALUAvgCzAMMA0ADZAMoAxQDOALMAtwC+ALAAyQCpAJgAkwCPgGyAbYB4AHWAXwBDgFAAUMAzgCLAPUAhYBMAC/AIcA+P6K/iP/sv4M/cT8kP08/QD80Psw/LD7yPq4+pD7CPvI+Qj6aPrw+QD5UPkg+rD5aPh4+OD4qPjA9+D36Phw+OD3oPeQ+MD4sPfg98D4WPlo+Ij4OPl4+dj48PgQ+pj6OPog+gD7IPtw+jD6yPoo+7D6OPoQ+6j7aPtw+8j78Puo++j7+Py4/oz/PQAKAUIBJgFQAegCwATABcAGyAcQCBAIQAigCXAKMAqgCgAMUAxgCyAMsAyADEALMAsgDMALAAvACiALIApgCEAIsAjYB7AG4AZQB2AGsATgBHAFUAS0ApQC5ALwAYwAhQDhABoArv5W/sj+HP4Y/Sj9jP0U/ej7sPsQ/Nj7KPvw+kD7APtA+gj6oPq4+tj5mPnQ+ZD5APnY+ED5WPnw+KD44Pj4+Kj4yPgw+Tj5SPkg+Yj5oPnA+cj5APp4+nj6sPrA+gD74PrY+vD68PrQ+rD6EPs4+yj7KPuQ+5j7oPvg+4j8iP0Y/ir/8/91AGsACgEUAgADIARQBYgG+AYYB9AH0AggCVAJoAowC0ALMAvgC/AMIAzQC1AM0AxADPALIAxgDHALYAogChAKgAmgCJAIsAgwCAgH0AbIBvAF8ARgBDgEeANUAv4B6AFaAVIAvf+C/w3/NP7Q/ej9jP24/HD8SPwM/ID7MPsw++D6aPoQ+kj6CPqQ+WD5UPkA+WD48PeA+BD40PfA99D3oPeA91D3oPcQ+HD3kPfg9zj40PfA91j4uPig+Kj4QPlY+UD5IPlg+WD5UPlQ+bj52Png+Rj6YPqg+pj6EPuQ+wD8uPy4/aD+Qv/J/4wAAgHiAbwC8AOIBVAG4AaIBxAIwAgwCYAJwApwC1ALwAuADNAMwAxQDMAMIA2gDGAMoAywDPAL0ArgCsAKAAoQCXAJYAmgCNAHeAdYBzAGUAW4BJAEoAOYAlQC5gE4AVwA6v9a/8T+Bv7k/ZT9HP2Q/Dj8APxY++j6wPqI+gj68PnQ+Yj5MPno+Pj4sPgo+OD3QPgQ+MD34Pew95D3YPdQ93D3YPeQ97D30Pfw98D3CPgo+FD4mPiw+Aj5+Pg4+VD5QPlQ+Uj5mPmo+eD52Pkw+oj6qPqw+vj6uPss/KT8iP2M/k//rP83ACYBFAKsAowDGAUYBnAGIAfgB7AIsAhgCWAK8AogC2ALUAygDKAMsAzgDNAMwAxADKAMUAzACyAL8ApwCvAJwAlwCUAJgAgQCKAHCAcgBnAFGAUoBGgDwAJgAq4B3wCfAAMASP9g/gr+8P1Q/cj8fPxE/Mj7APvI+pj6QPq4+bj5oPkg+bj4mPho+PD3gPdg95D3QPcQ9yD3EPfA9nD2oPbQ9sD2sPYQ90D3IPcA90D3oPfA9/D3GPig+ND4iPjI+PD4+Piw+Aj5gPmY+cD5EPqI+rD6qPoY+8D7MPy0/Jz9lP5H/7b/VgBaAQwCzAL4AwgF+AWwBmAHMAjgCEAJAAqgCiALgAsADLAMEA1ADWANgA1QDSAN8AwQDdAMUAwQDNALQAuQCoAKMArgCTAJwAiACKgH0AYYBqgFyATEA0gD4AJEAngBCAGSAKX/uv5i/hT+gP34/Lz8ePzA+/j66PrI+nD6+PnY+Rj6ePnw+MD4iPgY+MD3wPfA96D3cPeA92D3MPcQ9yD3YPdg94D30Pfw9/D34PcY+FD4ePio+BD5WPlo+Xj5mPmg+XD5cPnI+Sj6QPpo+tD6EPsQ+0D7sPs4/Oz8gP12/jH/1f8zAOUA4gGMAnwDoATABYgGOAcACJAIIAmQCTAK4ApQC7ALQAzwDPAMMA1gDWANUA0gDTANMA2wDFAMEAyQC1AL0AqgCkAKwAlQCdAIUAhQB8AGAAYgBTgErAMkA2gCpgEKAVYAtP/C/lb++P1w/aD8YPwA/Kj7APu4+pD6CPrw+VD5SPnY+LD4MPjQ98D3MPcg9xD3EPfw9sD20PaQ9pD2gPaA9tD20PYQ9zD3cPdQ96D3wPfg9wj4QPig+Lj42Pjw+Aj5+Pjo+Cj5UPnQ+fD5SPqw+tj60PpY+wT8oPxI/Rb+7v6r/8j/rACYAXACVAOIBLgFeAYAB7gHkAjwCFAJMAoQC3AL8AuADPAMYA0wDWANsA3ADYANoA2gDTAN0AxgDOALsAtQCwALgAogCsAJAAlQCJgH8AY4BjAFmAToA1ADfAKWASABXACa/+b+kP4M/lT9nPxQ/OD7QPsA+5j6QPrI+TD5GPng+Hj4GPjQ94D3UPcg99D28Pag9rD2kPaQ9oD2MPaQ9oD24Pbg9iD3YPeA97D30Pco+Bj4cPio+Oj4+PgI+Uj5QPkw+Tj5gPmw+dD5GPqA+qD6mPoY+7j7LPyU/ID9cv7u/nH/HAAcAeQBjAJ4A9gEmAUoBvAGwAdQCLAIUAkgCtAKIAuwC2AMsAzwDPAMQA2QDVANMA0wDTAN0AxQDBAM4AtgCyALoApwCuAJUAmwCDAIeAegBugFEAVwBIwD3AJEApABzwD1/57/3v4q/rT9PP1w/AD8kPtQ+wj7UPo4+pj5WPnw+Ij4aPjg97D3gPdQ9wD3wPaw9sD2kPZw9nD2cPZw9nD2gPbQ9tD28PZQ93D30PfA9/D3UPhw+Ij4wPgA+Uj5KPlI+XD5qPmg+eD5SPqQ+qD6+PqQ+9D7XPy4/Iz9Lv6c/mX/MAAoAcYBoAKQA3AEQAX4BfAGmAdQCPAIkAkACrAKMAuwCzAMsAwwDWANkA2wDdANsA2gDWANYA0QDbAMkAxwDAAMkAswC6AKEApgCfAIcAjIBxgHKAZ4BXAElAP4AlwCpgHxAHMAuP/S/lL+sP0M/XT8CPzQ+1D74Ppw+gj6oPkI+dD4cPgw+AD40PeQ9yD3sPag9nD2cPZg9pD2kPaA9nD2cPaw9tD28PZA95D3wPfw9yD4WPiQ+Jj40PgQ+UD5aPmI+bj52Png+eD5OPqI+qD6+Ppw+9D7GPxw/AT9mP0W/pb+g/9HAAgB1AGkAnwDKATIBKgFeAZIB+AHcAggCYAJ8AmACiALgAsADGAMoAzgDNAM4AzQDMAMgAyADEAMIAzgC3ALMAuACiAKkAkwCZAI+AdwB8gGIAYoBXAEsAPMAjACmgHnACoAov/I/iT+dP3k/Iz82PuY+zD7uPpA+sj5QPnY+Hj4APjQ96D3QPcA97D2YPYw9vD18PUA9gD2APbw9fD1IPYg9kD2gPbA9vD2MPdw98D30PcA+ED4iPiw+Oj4GPlo+Yj5mPnA+ej5EPoo+rD6APs4+7D7JPyM/Bj9VP0m/oL+Uf8CAMgArgFcAhAD3APgBFAFOAYgB8gHYAjwCJAJMAqgChALsAswDIAMsAwADTANEA0QDRANEA3wDLAMkAxQDPALkAsAC6AKEAqgCQAJsAgQCFgHmAbQBfgEGASAA9gCPAKIAbYAAgAo/1j+9P1w/dT8WPzo+3D7EPtI+uD5qPn4+JD4cPhA+OD3gPdg9wD30PaA9pD2oPaA9nD2cPaQ9mD2YPZw9rD28PYA93D3kPfQ9wj4QPhg+MD4yPgQ+Xj5kPm4+cj5IPoY+lD6iPrI+hj7aPvY+xj8dPzM/Gz94P1m/vT+r/9NAPkAwAFcAiQD0AOABFAF+AWIBkAH2AdgCNAIcAnACVAK4AogC6ALsAsADDAMIAxgDEAMUAwgDBAMwAugC1AL4AqACgAKoAkQCaAIAAiYB+AGKAZwBcgEEAQwA5QC5AFWAWkAy/8S/47+rP0s/dz8PPzw+1j7EPuI+hD6mPk4+fD4wPhA+ED40Pew92D3IPcA99D20Paw9uD2oPag9rD2oPbA9uD2QPdg95D30PcA+Dj4WPio+Nj4GPlQ+ZD56PkI+jj6aPqY+tD68PpI+5D7yPsk/ID80Pws/Zz9IP6Y/i3/r/9UAPAAiAFMAvgCkAM4BPAEqAVQBvgGkAcwCKAIMAmQCRAKgArACkALcAugC+AL4AsQDBAMEAzgC9ALoAuAC0AL4AqgCjAKoAkwCcAIQAioBxAHgAbYBTAFaATIAxADQAKyAeIAXwCl/xD/hP4a/nz9BP2c/CD8wPso++j6mPpI+vD5oPlo+fj4sPiQ+Fj4KPjw99D3sPdg93D3UPdQ9zD3QPdw95D3sPfQ9yD4UPhw+MD4+PhA+YD50Pkg+kj6aPrA+vj6SPuY++j7PPxg/LD89PxQ/aT99P1g/rz+LP+C/wYAbwD6AHgB6AF0AvQCkAMIBKAEGAWYBQgGgAbwBmAHwAcgCIAIwAjgCCAJUAmACYAJsAmwCaAJsAmACWAJQAnwCNAIgAhgCPAHiAcoB7AGMAagBUgFuARQBLQDJAOoAgACegHrAHkA4v9s/9r+bv4C/oj9LP2o/FT86Puo+1j7+PrI+oD6OPr4+cD5iPlI+RD54Pi4+Jj4gPhg+Ej4QPgw+ED4MPhA+Gj4gPig+MD4+Pgw+WD5kPnY+Sj6SPqI+sj6CPtI+3j70Pso/ID8uPz4/Dz9hP3M/Qb+WP6q/u7+Pf+E//H/OQCJAO0AcgHEARQCaALwAkQDkAP8A2gEyAQYBXAF2AUgBlgGoAbQBjgHGAd4B4gHoAeQB5gHuAeYB5gHcAd4B0AHEAf4BsAGeAYoBvAFuAVoBfAEsARYBNwDcAMcA7ACNAK4AWQBAAGFAAkAiP8n/6D+LP7Q/Xz9GP2g/ET8APzA+3D7OPvw+sj6iPpI+jj6GPoY+uj52PnA+Zj5mPmg+bD5uPnQ+dD58Pnw+Rj6UPpo+nD6sPoA+zD7aPuY+9j7HPxM/JT8BP1E/Xj92P0y/mj+qP7k/jD/lf/Y/woAdgDbABwBVAGEAeQBKAJ8AtgCJAN0A5wD7AMYBGgEkATABAgFQAVgBXAFmAWwBdAF0AXYBfAFEAboBdgFyAW4BZAFYAVABSAF+ASgBIAEMATgA3gDTAMMA7wChAIcAuYBggEcAcUAbwANAMX/kf8x//b+jP5Q/uz9oP1g/Rj98Pyc/HD8NPwk/ND7qPuI+3j7aPs4+zj7OPsw+xj7APsY+zD7EPso+0j7YPuA+5D7uPvg+wD8HPxc/HD81Pzk/CT9UP2w/cz97P00/nb+uv7o/jL/ef+n//z/IABfAJMA4QASAT4BeAF2AaABygH0ATACUAJgAogCvALAAuQC+AIgAyQDNAM0A0QDTANIA1ADVANQAzgDHAMMAwAD3AK0AqACiAJoAkACHAL8AdIBnAGWAXABTgEkAfcA6AC0AIYAawBQACgA9//l/8X/qv96/0//Tf8f/wD/1P7i/rL+vP6o/pD+mP5w/nj+jP6E/mD+kP6M/rb+lP6m/rr+wP7U/qD+4P7k/gT/7v5X/zz/Uf9G/03/nP91/4H/yf/d/8z/4v8hAA8AQAAQACcAYAB0AIYAqQCOAKEAogCsAK8A8QDiAOoA+wDuAPQADAH6ABwBFAEiARoBMgFGATgBQgEsAfIARgEyATgBIgE+ARIBHgHpALoA7gCwAPsA2wCeAG4ATABoAFoAPwAcAAwA8f/s/8//uf+q/9D/wv+W/2//cv9j/33/Ov9A/xj/6P4J/wT/BP/C/ub+vP7M/pb+oP7e/pL+0P6+/tb+sv7a/sT+6P7Y/tr+I/8D/yT/K/85/1H/QP9Y/2z/gP+U/7b/2f/L/9n/AAD4/yQAEAAsADoAPABSAEgAkABSAIUAjACLAJgAcACxAGwAxwCWALgAxQCjALIAkwC0AKIAxQCwANkA0gCvAJMAswCzAMwAiwD6AIgAggBZAJcAuABhAFEAQQCvADwANwAwALcAqP/7//f/awAWABz//f/t/9T/jv7b/1EAM//Y/lf/4f/S/gX/sf9M/57+5v7R/2T/hv6I/tX/8/+c/cD+4f+0/yz+kv5l/7X/qv7I/i3/0//c/vL+IP+v/6b/Ff93/7z/6v95/1H/KwA0ALD/PP+nABIAKAAFAHcAcwB7ANX/0ACKAHsAdQDzAKcAHwDnAAIBrQDVAJMAWAGHAKoA0wCEAQABrgDGAKIByQB7AOQAZAH+AEIA/gD7AOsAcgCTAAoBpADw/+oA5AA2AF0AWQC7ANH/uf9oALEA6v8BAD4AEwDZ/yL/AACEAFb/cf8bAAUAdf9u/7X/pv+L/3v/d/9H/6b/jP+F/w7/S/9X/5L/tv51/6D/Lf8Y/2j/U/+i/oX/mf+W/wT/Pf+L/3r/KP9o//L/cv/O/rH/yv/w/rn/KwCH/8T+R/+PAJ3/+f9F/y8AOQAx/9H/5/+/AJ7/NwAJAFoAFgBnADEA7//jACAAPQD+//wANgB1ADMA9P/UABUAfgA6AKkA5/9gADAAUgBEAP3/6v+GALkApf/D/xUAmQAaANj/FAAeAGwAkv/3/zgAPgB6/3YA7/9c//r/OACi/+3/LgAg/0IAdgCL/4D/DwDG/07/d/9UAJ0AVf9O/67/fQCK/sj/uf8QAZb/uP5XANT/yv+q/hwBEf99AI//fv/w/yH/VwBx/z0AWP4SAZb/ef/u/yUAfP/v/3cABf9wAD8APwDv/ykAMP/xAOz/rv9YAQEA8v6OAAwCnv++/nX/ggEUAmf/8v5KARQBLP+QAKsAGAB7AH0ANAFnAPH/LwA8AQkArwAIAQsAiAAsAb8AgP/CAI8AHgHW/0EAyACdAHsA9v+EASr/0ABVAFEAU//jAJYBHv+W/4r/wAG0/5v/SP+yAZD/KP66Aa3/Wf8a/3oA0QCy/nj/R/9+AWj/4P0nAGIA5P4tAIz/SP8sAar+hv4mAKYA8P7M/uv/9/9cAEb+5f+GABj/Yv7h/zoBBf+Y/gEA1gGa/qr+agDUAO7/nv+z/9YAOgDp/9P/8wBlADn/nAFn/6EAnf/EACwAMgFtAFz/cgByAPoBKf/d/3UATAOo/wz+5ACmASgCYP5rABYBfgE1APv/CQDsAUEAgP+UASgAzP+3AGYB0f92AYv/Ff8kAlEAnP/A/70Afv/cAbT/M/8QAVb+uQChALIACP4KAO8A+P8z/4D9xAHIAVj9cP5gAKoBKP1Y/kACHwAg/SD+dAJc/3j+AP7oAT3/gP1l/xoBD//c/h8Aif9Y/LsAcAHq//j8av7KAaP/zP1M/fADhP6s/db+CAF/AFT97f/IAi8AYPliAawD1P9c/cL+MAORABj99v6wAnwBaPzsALkAyf9RAF4B+f/I/bgBsf9QAqb+ZAA8ArkASP3AAEADBP84AU4AtACKAHj/3gAYAZgCnv7yADj/zgCIA27/yP7dABgD2P1w/6QAeAQv/2j7iANyAeD9pv50A6MAHP3Y/QgEeQB0/AEAQAMF/+j6AwDgAwEAhPwbAHoBPQA4+/j+EAODAKT9mP3AAKEA8P8o/m7/0v4uAQr/Sv4I/5wC3f8a/+T8e/8kAkIA3P1QAXQBkP1R/1EArAEe/7z/ov/ZANoA0v7v/9P/5ABwAZb+uPxEA1wDtv54/cwB3AE0/UoAUAGgBPL/3PxXANABrADw/VgEvADq/xb/2gAAAkD/dwBF/yADb/8yARL+BAPGAQj9a//MAcoBRv7SAdL/VAPs/Az93AOgAcD8F/+8A3oAJv50/UgBjALE/d7+AALt/9r+3P6aALj/Jv9OALL+jP++/5n/0v66/gwCLP7a/pT9CAN2/0z9bP7Q/9QCuPwK/jgCdP/o/Nf/cALI/qT8IgBwAnj/EPvGAcAD2P2I/JoBUAGO/hj9OAL4A1D8UPtYBCgDQPxi/tIBwALg/qz8XgEYAyMAjP19ABAC5f/a//D+OAG8Afz9BAGw/tIAdf/0AXkASv7a/5UANAAI/oYBtAJU/oj/Dv5ABDH/YPx2AegEzP4g+7oBwAPg/sD9pAFcAkD+UP3CAcgC0f+U/PABtAPU/Dz8gAKYBKz+4Po0A6YBSP7w/DAD+AIO/oz8tP5YBmj7Pv7wA7wC4PpQ/XwDUAD+/wT9JAPe/sD96/+oAuT/QP0EAaEAEf/Y/NgC+gFi/07+KAAF/wT+AASb/1QB0P2N/ywBEP6CAGoBDAM4/HoBuv7lALL+eALcAoz8Dv4kAyADDP1H/wgCfAPi/lD7ZACQBikAWP1sAlT/RP3m/xAF6f9SAED9iv+sA5b+AP7BAPgEAP5E/jb+/wCQBMv/Ev5M/hoBtP5sAfgBmAFE/O7+ZALs/QL/vgBIBRz/+Pp0/HgFzwAQ/BAD5QDc/Aj8JANEA+7+GPtzAGQCXP9k/QQB6AKm/uz9dPy0AvH/QAKEAfT9YPy0//IB4v5ABTz+FP86/nH//gFcAij+oPvYB3QC4Pkg+8AGgAT8/YD8AAI5ACz+FAH4BpEAOPiI/lgHdAKw9rQB8AgrAKD6uPywBYoB1PwVAEgEzv+w+4z/aAUMAuD6Iv+4A1gD6PpA/rQCWANc/Ur+7AEB/9L+qACQBZD8WPvs/1gFN//I+7wCxQB4ABz9JwDUACkAOgAQAbIAOPpUAYwCGv9W/toB2f+U/AABqgHOAXj7HP7aAZoBwPxt/zQDHQCI/uD60gAhAN//hALcApj7WPu9AHAC4AJ4++T+ZAL6/yz9Jf8wA4oAPv7M/Wr/0AGw/wYBkQD6/l7+lv80AbwAAALD/6T9TP4lAIQCrAEUAaj9Ev79ADgA2f9bAAgEpP0c/fkAYAIO/77+DAKWAVb+QPv4ARAGDv8w++oA0gEY/pb//AOr/7z9iP0cAogDkP2y/zABTAIA/6D9Iv4MA1AEA/9g/UP/xgFfANX/Pv8UAlz9OgDGAYIA4P+I/fkAOAD3AAr+SwBoAsr+EALY+4b+bAPsAgD/kPqkAUgDTQDo/L//egGs/jQBlQCa/1r/hv9SAR//tP0fALYBcQC//+0AePxkAZYBBv5Q/qX/QAWo/6T8+P1YBT4BePkr/xgEWAMY/BUA/ABmAJT8ZgHcA97+lP10/LgG4ANQ+5D7nANYBFD+VPwc/4AG4AEy/lD85v+eAawCbgHk/vD9tv6SARgFY/9E/MT/yAFoA/D9YPsMAigF2AFI+yD8XAIcAdIBRP9UAXj7EgEgA6wA5Py4/KQDOAIzAHj8PAKGATr+RQBUAHj9yQA8A9QDQPzg+bwB0AQYAJj68gHkA/b+cPoGALgDiP+0/GsAiAJU/VD9NAGgBDT9+Pm8/bgEPAGo/EgBiAHt/6j5APxQA8gDDAIQ+gwAKAEA/aT+zAKIA1T+yPzI++ACeAPT/7X/ZP/m/sT+XABaAUoBsgFI/T7/bP65AOwCRAK+AG7+YP0U/Q4B0AVABBz88Pu1//QDwgEY/rj9oAS2ADD75v9YBhwCSPtC/ggDDgHo+74B4Af1AND0KPwQCMAE+Pv8/AgGXf8A+SD9qAZYA2z81/+KASz+SPqUArAFIgGY+Pz9qAT+ATz9nP7wAc3/kPzE/UAD9gEc/wP/+QAY/Sj8vgHkA7cAqPv0/nIBlAHg/Iz/rgHC/jP/kADVANT8BAIAA1//SPkU/VAH7APw/Mj6dAKWAYD9b/+YAZwC8v5Q/mwBwAAS/jD/7gGcAjoBjP3Y/GQC4ATU/cD7dAFwBJYBePmQ/+AEzgFQ/FgAhAPU/Ej9swDoBoj/EPpi/yQDowBs/TAD9gFu/4j8Pv+gAZ0AVAKWACD/vP1aAaQAev5SASgEpAGQ+Uj8qALYBeIB6P7a/uj9Av8HACgDZAEOAQ7/5v5L/w8A2v7q/7gEKAQI/JD2tf/oB2gFcPzA+nEArP9W/iwCQASO/nT8tQAYAVz8qPvABZAJqP5w9Fj7YANoBugCKgAE/eD6g/9EAnACnP7l/3oBdv9Y/Nz9oAP4BMoBnPyg+ID8kAMgCGAErv6o+NT8VgEkAuwBSAH0AXf/KPuo+uQCCAe6ATD9YPyg/JD9/AJYB+wCUPp4+DwBiAMrAK4BlANnAAj5OPswA0AGzAH8/j7/8Pv8/LQBcAWQBBT9QPtA/uUA9QAQAuwDfQC0/Kj5rP8gBTAF7P6Y/KD94f/yAO4B3AKbAFz9XPzR/6QCzAIwAHQAWP9g/nj95v4gBLgDaP5A/Gb/dAFSAKr+u//QAYz/CP3JADwCggDI/bD9HAGXAPH/kv90Ae3/lv68/3X/+v97/9T/jwDCADoBGP2w/hgC+gGK/wD8zP0ABLADvP2c/SAB2AG9/0L+mP4+AawBMAHYAPr+oP0jAAQD0gFm/tz+xv+uAfgBhv5i/rUAdgFaAXL+XP0sAtwDPv9I+4b+UAJwA70AqP6z/0j/fP5RADgA4AC8AuoBsv9o+8D9kgEQBDIBOP3u/p4AIgHhAHoBLP64/Z4AfAIiAcr+TAC4AkoAKPos/dADOAY/AGj7hP0i/xQAcAGMAs7/hPxq/ugABwDE/fP/QAPLAGD7XPzEAhAEvP6w+9T9nwCKARYBqQA7/5z9Xv7O//b/qgEGAfL/Xv44/Tj/hAHoAqQArv4k/Qv/zgEMAqUANv+D/9z+Hv+nACACvAF//8z+tv49/5AATALUAWb/IP3a/kgCrAIWAfD+e/9j/4v/qQDgATwCaACC/pT+jP+OAQwCPAFY/17+DP8yADQCOALOADj+Iv78/iAB2gHLALoAv/+C/qD9EgG0AlwBov7m/rT/2P/9/woBrAL4/2z9gP3FADYB3wBEAEMAUf+K/gsALwAoAEv/FQBYANn/Zf8VANcAJwAe/zb/FAD3/zIB0ACw/9r+yf95AIgA3//WAJ0An/8v/6X/tQCRANAAdwDY//T+cADSAfsAlv6m/ooAGgEIAUkAiwABADj/8v5e/z8AOgF2AfcAYP5Y/Wr/KAJEAoD/LP52/rQAIwBfAMsAkADk/wX/ff9a/9f/2AAsAvj/fP02/iQBlALuAPr+8P5g/6//6f/HACIBZAFuALj+Ov56/4IBcAKRAK7+qv6j/x4BwAEHAN7+xP4NALoB0gDD/5b/eQATAFT+4v6YASADrABo/uj9gf8KAcEA/gCCAFD/Wv43ACoB2wCr/7L/BQBq/w//bQCIAc8AFv/4/S3/7P/PAEgBlQAQ/2L+Rf/+/yUAMgCEAO3/VP/w/h0AjwAvAEn/Af+F//H/7f/o/80AvP+C/nD+xP+eAI0A6f+D/w7/av7a/6sA6ADW/wr/av9l/+r/MgBuAOn/GgA0AL7/o/8qAPAANQBK/0f/NwDJAHEACwDD/0P/O//a/ysA/P9f/63/OQBUAHr/Cf98/5j/n/+s/xMAUgAiAAD/Ff/u/00A9/9r/5L/tv+e/00AqAD//2b/U/8KAMr/5/90AMwAgABb/4D/jADxANwATAC1/0n/CwAMAZgBDgHC/+P/TAA/AO3/vwC+ARoB7f9W/9j/nAA2AaQBoABd/0j/mgBeAX0A3P8ZAIkAAQD7/50A6wBMAIX/zv/z/+n/PAAIAf8Aaf+a/jv/RgCBAAYA/v+p/xf/Xf9dAE4Ah//c/jj/t//h/5r/0/8gAGD/4P4S/4L/1/92AD4AcP8w/pr+dAAGAcT/CP/w/xMATf9j/y4AVACX/4j/+//l/57//v/3AE0AAf8n/3YA+gBDAAQAHgACAGv/u/8CAfQALQC7/wsA1v9s/xsAMAHvAPP/uv8zAGUAmQB1AJcAYQBXAEcAlADoAA4B+gBXAAMAnQDfAOMA1wDhAIIAWAAwAJ0AhACxAIUAUABGAO3/EwAcADYACgDT/53/lP/W/+P/of9W/4T/Nv8I/zD/gP9n//r+2P72/gL/zP7U/hT/6v56/oT+2v7y/vj+3v7C/o7+WP5q/gP/Kf/2/qz+dv6+/qD+2v4L/2X/Pv8K//7+MP9//8L/7/+z/5T/f//x/zsAbABbAEcAdwCVAMgApgDoAOEA4wAYAU4BngGkAY4BSAFMAXwBmAHoAWACMALQAWIBlgFMAkgCQAIgAjACJALeAQQCUAKAAlQC/AHwAeABPAJEAvwBogFSAVwBhgF2AWIBPAHiAD4A7//3/1cAbQD0/1D/8P6g/oz+rP64/oT+8P1Y/SD9LP0I/QD9AP2w/GD8RPww/ET8MPwg/OD7wPvQ+wD8FPwA/AD8CPzo+9j7XPyU/ID8ePyk/Oz86Pws/cj9QP7c/ez91P64/rD+s/+nAMgAyQAyAEYBsAKsApADiAP4AyAEwAQYBpgGAAcQB4AHkAfgB7AIUAkACgAKsAmACVAJEAoQCnAKwAkgCWAIMAiQCCAIgAdwBiAGgAWIBNgDEASIA1gCUAE1APX/Of+M/hj+RP1c/DD7OPrw+YD5EPlQ+JD3EPdQ9tD1YPVA9SD1wPRA9CD04PMQ9MDzwPMQ9DD0IPQg9ND0APVQ9VD1kPUQ9sD2IPeg9/D3mPjo+Ej54Pko+5D76Pvs/Gj9Hv5w/rX/XAFsAqQCeARgBsAGwAagBiAJ8AnwC2ANEA+AD1ANAA4gEGARwBCAEWASYBMAEgARoBFgEWAQIBCAEAAQwA6wDSAN0AuQCXAI4AjwCGAHYAXYA5QC3ACT/9z/C/+4/UD8SPs4+qj4oPdQ9/D2APaA9QD1sPTw8yDzsPJQ8lDy8PJQ81DzIPOw8qDy8PIw8zD0EPUA9QD1gPWw9bD18PXA9oD3sPew90D4sPiI+Ij4EPmQ+cj56PmY+uD62Prg+hD7ePuY+zj8oPzQ/Jj92P1K/lD+zP76/1YBDAIsA9AEiAUQBWgFeAdgCOAIQApgDdAOoAzQC0AMEA5wD7APYBGAEUAQcA4wD9APkA+ADxAPAA8QDsAM8AsADBALoAlgCLAHiAfQBvgFgASoAhoBNQAVANr/if8y/qj8wPvQ+jj66PnY+Uj5ePjg95D3sPcw98D20Paw9hD2EPYw93D3EPdw9tD2YPdg96D3aPjY+ID4GPho+AD5kPmY+bj5sPmY+bj54Pkw+mD6qPpQ+vD54Pko+qD6YPow+nD6mPpY+lD6aPrg+gj7WPv4+9T89Pz0/Nz84P1c/0YB+AJgBLgEvAMABAgESAfgCuALMAzADGAMMAwwDMANQBAAEiARgBBgEGAQgBDwD5APUA+QD2APYA+wDgANUAvQCAAJEAqwCYAImAZABTwDMgFXAIQBUAGm/9j9UPzA+8D60Pm4+eD5sPjA97D34PeA9/D14PSQ9RD2IPaA9rD2kPZw9cD0sPVA9vD2oPco+AD4cPdA9xD4iPhY+ID4oPkA+nD5OPlI+Yj5MPlo+SD6YPpI+kD6iPqo+Qj5OPno+XD6aPoQ+yj78PmY+Yj6qPvg+3z8VP34/Uz9yP50ALAC4AIQAnAEcATwBDAGEAmAC+ALsAuQCjALcAxADsAPgBBAEHAPYA9wDwAQQBDgDyAPkA6gDlAOYA1QDKALcArgCBAIEAjIB+gGCAXYAiYBVQDe/8//O//c/Zj8+Prw+WD5SPnY+ND3kPcw9+D2YPYg9gD2sPWg9WD10PUw9jD2QPYg9rD2APcA9xD3kPeA+Kj4sPio+Cj5gPmA+ZD5CPpI+gD6aPow+qj6ePqg+lj6OPo4+hD6qPoo+kD6CPqY+YD5oPmA+qj6IPpA+jj6IPsI+7D7BPyI/BD9wv69/wYByAHEAhgEqAKkA3AFgAjgCaAL8AxgC5AKwApgDQAQwBAAEQARIBFQD9AOIBAgEUARQBCwDxAPgA4wDYAMEAzQCsAJ8AjwCNAIEAewBLQCugFkAVgBugDb/6T+pPzQ+mj6YPo4+rj5mPgQ+KD38PZg9jD2gPbw9ZD1YPVA9tD2EPZg9aD1cPag9pD2cPeA+Aj4IPeQ96j4uPgQ+ZD52PkI+lD5UPkQ+gD6CPpQ+tj6yPqA+qD6IPrI+SD6gPrQ+rj6mPoY+xj6yPkQ+nD6UPto+xD8yPvA+6j7PP2I/hf/aP8yAUADxAKYA/gDMAQYBQAH4AqADPALAAtwC5ALsAuADSAQwBJgEZAPoA4QD1APIA/AEMAQsA/ADbAMMA3gDDALkAmgCQAJuAeQBlAGiAUoA1gBegByABEALf9g/uz8kPs4+sj5yPmA+eD4gPgg94D2oPZw9hD2IPZg9mD24PVw9UD2sPZA9hD2APeA9/D3sPdw+Fj5MPgQ+MD4IPrI+vD6mPqo+lj6ePrI+rD7yPtY+4D7+Ptw+zj7+PqI+9D7IPsg+6D7iPug+oj6APtI+7j6WPu0/Lz8OPsA+pT8+v7m/uL+ZQB6AeIBTAJcA4gE3APQBRAIUAowC5AKIAugChALQAzwDXAPQBBgELAPAA4gDXAOoA/QD0APgA6QDXAMcAtwC5AKsAkQCbAIYAjYBvgEIAQQAzwCLAHlAIAAZ/8i/rT8mPsQ+0D6IPpo+sD5kPhA97D20Pbw9tD20PYQ99D2oPbw9eD1oPbw9kD3cPfw9xj4ePho+Kj4CPkw+Rj5kPnY+hD70Poo+lj6oPog+1D7kPu4+3D7EPvQ+vj6IPug+7D7YPvA+mj6WPpA+sD6MPuw+mD54Pko+1T8uPuI+pj6uPsE/Gz9JQB+ATQBNQDJAI4BqAKYBLAGIAnwCPAIAAlQCUAKcAvwDNAN0A0wDvAO4A7gDeANAA5wDmAOsA6QDoANAAwwCwAL4AlACTAJYAmQCBgGkASYAxAD6gHKAbQBqQDY/jz9yPxM/Cj7IPpg+mD6WPng91D3gPcA90D2UPYQ9wD3kPaA9kD2EPbg9bD2UPcA+Fj44Pfw9xj4UPjg+PD5APoo+rD6APvw+rD6gPug+9D74Pt0/Kz8SPww/Oj7VPwg/ED8ePzQ/Az82PvQ+4D7gPuo+/j7mPsI+5j7XPzw/Aj8GPzo+xT83PyK/toBlAIgATsAzAD8AcAD4AUQCNAIQAgQCJAIkAngCgAMIA3QDWANYA1QDoAOMA7wDQAO8A0ADpAOoA5wDaALwApQClAK8AmwCWAJEAjwBYAEIAR4A/gCWALyAcUAAP+w/Sj9yPwA/ID76Pqw+hj6ePiA+Cj4YPfw9tD34PfQ91D38PZg98D2kPYQ90j48PjA+Hj4gPiQ+Jj4kPko+nj60Pr4+uj6uPoQ+5j7gPuo+zT8mPws/LD74PsM/MD7aPvY+7D8lPyI+4D7gPtg++j6wPpg+7D7MPvw+pD72PsI/KD74Ptk/Hz8QP1s/24B5gFMAXsARAEUAjgEYAdgCLAIuAfgB/AIcArgCjAMYA1ADSANIA3QDTAOIA6ADUANkA2QDdANsA3ADDALkAkQCQAKQAqQCQAImAZgBTgEKAMUAzADoAIqAUz/ev70/QT9aPzw+1D7uPro+YD5ePmg+FD3EPeQ97D3oPfQ9/D3IPeA9pD2EPfQ9zj44PgA+Wj4MPh4+ID5APo4+pD62PoQ+8j6QPvA+yz8kPug+0z87Pzs/Ez8bPxg/ND7APzA/Ej95PxA/LD74Psg/OD7MPxM/Oj7yPuo+zj8nPz0/Nj8TPxE/OD87P2V/wYBPAJkAcz/aABAAvAE+AUQByAHwAdoB7AHoAnQCmAL8ArACzAM0AyQDJAMUA1gDJALgAsQDeANUAwgC/AJgAmgCLAIYAkQCZgHqAXoBFgEpAMoA5ACvAGqACsAdf+U/oD95PxI/Ej7GPtg+3D7QPrY+ID4YPgw+Dj4CPlQ+ZD4MPdg9/D3IPjg92D4OPnw+Oj4qPho+cj5QPmQ+Tj60PqY+hD7SPtg++D6+Pqo+wz8KPxE/Fz8CPyo+6j7BPxg/GT8VPyI/ET88PsU/Ej8SPwY/Dz8QPxY/DT8mPwI/TT9SP0k/Uz9kP34/Xr/GgGyAdwBlAH4AVwCGAMYBTgH4AcAB7gHUAgQCWAJQApgC2ALgAvQC5AMsAwwDEAMYAzgC3ALEAyQDAAMkAqwCWAJwAhwCKAIgAhAB6AFEAW4BCAEFAOYAnAChAFfAMH/W/+Q/nj97Pyk/DT8oPuA+1D7ePqQ+fj4OPlo+Tj5ePmA+Qj5kPiY+Nj4CPlA+ZD58PnQ+cD5APpA+jj6ePqY+gj7OPt4+5j7kPug+4j72Psk/GD8WPxw/Jz8lPx4/Gz8pPzM/Lj8xPwQ/QD90PzA/OD80PyY/ND8CP0g/Qz9bP28/aj9aP10/eD9av5R/4gAZgEmAcQAoAEAAqACjAOABQgHQAbYBVgGsAcgCJAIAAmwCeAJ0AlwCgALwArwCeAJQArACpAKgApACoAJsAjYB7AHwAeoB2AHuAawBdgEKATAA2QD8AI4AogB7gBqACwANv82/nz9RP0s/dj8ZPz4+6j72PpY+jD6aPpw+nD6WPpo+sj5kPm4+RD6+PkY+kj6oPrQ+kj6cPqw+uD6sPro+lj7oPuI+2j7qPug+7j7wPsA/Aj8IPwY/CT8IPwY/Bz8DPwo/ET8jPyI/DT8OPxI/Fj8UPww/Fz8ZPx8/GT8zPw4/ST9nPxg/AD9yP2Y/lf/iwCWADv/Gv98AEQCXAM4A9gD6AQQBdAEUAVoBggHOAewB1AI0AigCAAJEAngCGAIQAgwCdAJsAnQCDAIsAdoB0gHEAcQB9gGWAaABfgEOAS0A3ADIAO8AhwCsAESAZwAPQB2/47+Sv5A/h7+vP1I/fT8TPzY+3j7qPuY+5j7qPtg+0D7wPqo+tj6EPtQ+0j7UPtQ+0D7WPtA+2j7sPvA+/D78Psg/ET8MPw4/Dz8hPyc/LT8kPzk/Cj9HP3U/Lz8LP1A/Tz9TP2w/cD9TP0Q/XT9BP7U/Zj9vP3w/ez94P34/Xr+Qv56/sb+uv6q/rL+bP8pALYApgB4AJkAXgHuAcACxAIYA7QDaASABMAEWAUIBlAG4AUoBvAGgAdAB4AHkAc4BxAHOAfwB9gHWAcAB7gGoAYABhgGMAbQBRgFoASQBCAEfAM8AzADpALsAbIBjgE0AckAdAAIAKn/SP83/1j/2v5Q/kb+JP7s/Xj9dP2A/XD9IP0Q/fj81Px8/Hj8uPy4/IT8TPyI/JD8YPw8/FD8dPxA/Fj8bPyQ/Ez8VPyM/Gj8SPwc/Jj8sPyI/CD8aPyY/GD8APwk/Pj8FP3U/Az8NPyE/PD84PwE/XT8RPzo/Ij9wP2o/Lj8xP1a/mD9mPy8/Vr/HQAk/xL+GP5U/6cAzAAMAJAAXAG6AVQBZAFcAvQCtAKYAkwD7APAA+ADgASoBDAE5AOABFgFUAUQBcgE0ATIBLAE8AQIBRAF0ASYBGAEMAQ4BDAEMATUA7ADcANkAzgDAAPMAnwCPAIIAhACyAFmASIBFAHXAHcABQDU/+7/4v+W/wn/lP6u/p7+gv74/aj9tP2U/UD9KP3s/Kz8dPxw/Fj8GPwE/Bz8MPyw+5D7iPvA+5j7iPvY++j7uPtI+3j7wPsQ/MD7oPvw+/j7+PvA+zj8fPyE/CD8HPzM/Dz9GP30/Bj9hP3U/QT+Iv4k/nb+6v4e/+7+Lv+l/0kATAALAF0ApADLAN0AVAGiAXYBYgH+AcACdALoATgCGAO0AyQDkAIoAwgECASMA3wDEASIBEgEAAQwBFAEYARgBNAEiAQQBNQDkASgBNwDaAMYBGAEhAPEAvwCpANoA7QCQAJYAlwCdAL8AQACAgFKAWQBXgHGAEoAmQBWAA4Ab//J/4T/Q/8g/+b+pv5g/kL+Nv4y/nj9oP3g/Zz9LP3s/Pj8BP3U/Lz8mPyA/Hj8XPyw/HD8LPzw+zT8lPxM/CT8YPzI/Ez8APw8/Az9SP1w/Jj8QP3c/fj81Pzk/fL+Gv8A/sD9aP7O/zkA4f86/57/7gBcAeYAuAAgAa4BBAIMAhwCTAKUAtwCQAPUAkgC8ALsAwgETAPQAjwDGAQIBBgD6AKAA/QDjAPwAiQDjANUA6gCTAKgAswCtAI8AjAC+gG0AZABiAFGAeAAwQDuAAYBTwCs/6L/DQDh/0T/6v78/hn/1P6o/n7+VP7Y/fz9Pv44/sD9gP2A/Xz9sP1U/Uj9OP1Y/Zj9eP0o/ej8UP1M/XD9WP2E/XD9eP2Y/ZD9yP2g/dj90P04/iL+OP5A/oT+wv6Q/qD+4v5b/07/Nf9i/9b/uv+7/xkAcACDAEQAjQDiADYB8wAiAUIBzgGGAXgBjAEcAmgC/AHWARACcAJ0AhgCLAIsAnQCYAJIAjwCFAIoAiQCbAIcAgwCDAIEAt4BugG2AbABpgFsAXgBagEmAcoA5wAIAegAgwBKAIUAgQBJAAoAGQD7/9b/uv/X/8r/gv9n/3f/ff9j/1D/Tf8e/wv/Ev9K/xv/+v74/gz/F/8J/wL/Cf/4/hP/K/8m/wP/E/9G/3X/Tf8j/xr/cv+m/6P/g/9Y/5z/wP/U/5T/uv+//xUA2f/H/xUAHgBYAOv/EwATAFQAJABhAFYANQBIAGgApQA3ADkAaACfAFsAJgCcALUAngAuADUAawCVAIkAggBPAFgAZABvAF4AXgCEAH8APwApAG0ApQBuAEEASwBTAE0AGQBEAHMASwAtAOr///8GAA4ACgDo/xsA+//4/73/iv/S/wEALgC7/5j/dP+7//7/3P/E/4b/nv+T/7P/ov93/4z/g/+s/4r/VP9B/33/wf+m/4T/G/9M/17/6P/L/2H/SP9A/5r/0v+g/3H/d/+c/5f/l/+5/8r/3v+R/7v/tP+//6z/3v8wAP7/wv93/+r/9P9AAOv/x//D/7v/GADr/yIAz//u/83/z/8YABwAz/+n/7X/MAA0APD/vf/a/wkA8f/a/7z/MQAyAFAA9/+x/wcAMQBFAPj/JAAQABcAKAAnAEYABgD5/ycAUABQAAMABgATADcAEgALABAAEwBXAAsADgAZABMAFAAFAE8AJgDv/9b/WABOAOz/m/83AEEADACw/+z/DQDv/wIA/v8SAKH/IAAMAE0Adv/z/zQALgDo/9n/PwDy/+T/vf9QAEYA6P/O/xAAJAARAPP/5v/9/woAVAA6ANP/wP8SADgAGQAaAAQA8/+H/+X/kgCfAOz/Nf+z/10AhwDz/9D/GgAbAAIA7v8QAAgALQD5/00A+//A/5P/QwDDAFgA1/9v/+3/RwCpABUA+f+0/xMAQwBmAP///v/x//b/HQBFAD8AAAD0//r/VQDR/5n/JACFADEAZP+L/ycAoQDW/yz/iv8ZABAA0f+z/wwA1/+Z/5b/sP/i/6X/HQDU/9L/Nv+S/y4AGwBd/+j+w/9HAEwARf/6/o//LQDl/2X/gv/V//v/v//B/6j/3v+i/xgAGwAxALb/uP8SANT/GADi/z8ACgAIAA4APwAyAOP/EQDo/24AMABlAB4ADABNADcAPwAGAEMAMgCfAAsAMQBcAIcANQD2/xgAfADVAFoAGQASAJAASwB/AGAARAA7AF4AjAB9AE8AEACfAFkAgwC9/yoATAD9AGEA+v/c/z8AcABoACoA7f/g/z8AZgBKAOT/rf/v/wYAdwD2/xUA2/+0/93/6v8TAOr/BwCS/8T/5v/0/8T/w//L//b/8/+o/7v//v8QAP7/5//j//n/5//2/ywA///U/+P/MwA1AAAAsf/O/zAAHQAyANb/JwALAAEA/v8OAEUA/P8NAOj/SQAoAOr/NAAKACYAz/8nAPj/RAAVAA4AMwDw/x8ACAA4AKr/WQDu/1AAvf/k/1MATQBSAG7/NgDX/1sAhP9cADYASwAPAMf/OgCt//n/UgCCAOD/Y/8bAGoAzQDS/53/xP8ZAC0AhwAiAD4A1//G/6v/IABiAF4AFACO/8T/DgAZADQA7//D/3b/q/8dAE4A7P+j/zX/6v+5/9X/U//R/xoAbQDg/+D+Af9N/6sAogDr/x3/5P6F/wwAGQDW/5X/nv+c/3b/U/9q/zEAGQDg/w//UP9Z/1QAFwAlAHz/Kf+E/9j/dgDg/xEAjf/W/63/yv83AMb/IQC1/zoA/v8WAKr/3f8FACsAXADi/77/4/86AJUAJgDL/6n/1f8zADIAQQASAOv/AQDa/0IA/v8vAAYA//9HAOH/TwDQ/z4AOAAwAEIArv9EAMr/aQAWAFMAOwATAEcAHgBSANL/CQAMANMAgABSAJX/pv+1/5oAjwDtAJb/lf+P/2gApAAcABYAhf8gAHv/pwA/AOUA0P6O/7j/oQCJAEb/ogCE/9X/av6MABIB8P8z/xX/AQDu/1EARgAM/xr/2//vANn/9v7S/7cAqQCY/cL/GgFUAaT+6v65/xYBpf/e/8H/3ABw/x//j/9+AOEAu////6r/6f/c/yEABAFBAOH/xP6vAOX/iQDb/2AALwBMAEn/CQDX/7IAiwBxALP/Mf9RAJkAfADJALH/fwAO/ygAEwAkAToABwDs/6EA8P/L/yoAuACZAIH/RgD1/3kA9P8SAFQAKwBG/9v/JAAFALEAPgA1AJL+yP6q/+MAfwAxAPj/d/9Z/5T+7f+/AM//tv/V/6X/Vf+a/y4AYgD4/w//C/9o/6cAbQBVACr/gf91/+T/Dv/5/3oAfgA8AGz/Av+O/kEA/QBUAfz/+P7s/o//jAA2AXoBNwCk/rr+vP+7AIQCqAEu/8z9XP6SAQAB8gHj/08A//9I/vL/KQCwAlEAfQDu/uH/2P+RAAIBmQAKAb7+ef9T/9wB4wCbAI7/2v5nAKr/GAHd/88Aev9WAMD/DAB7/6X/ZgA+AdoAvP5o/jT/QAEQAUoAZv9v/4r/7v7h/1sAYAGu/18Acv6E/on//wDxAPL/Iv+g/bv/cQDsAB4B9f+o/QD90P6iAXgCngCp/w7+JP/U/G0AXQAsA2oAdP5V/xD+QQDo/QwD7v88Apb+Kv6e/1z/0ALM/2wByPw+Afz+ngAlAAAB/gBS/87+PP2gAWwBBAKT/6r/pP12ADQAjAB0ALz+RAD4AYgCZP0o/AD+tAJQBDkAhP2a/rgA+//dAMX/rf8xAHj/FAGNAIwAR/9gAAH/DQBKAOn/BAGaAMwA6P5IAMb+LAF3/wgAAgAwAP0ADf/KAWT+IgHs/RQAHgAMArYBAP6O/zj+HAOb/8YApP3tAPAAnv8gAvD96f/g/rwAWgEZ/5oAJf9QAuH/6P3O/lcAOQBOAXEAnv+1AGD+T/8gAaIBiP96/sT/KwCgATUAOAF8ACH/tv68/3QB+P8GANwAcAKu/nz+Jv/iAGQA2wAeABwBcf9a/if/+gBEAsL/7gHM/Xj/8P0GAXIBqAJfAIz9Wf/m/koBlP6EAT4BJAOs/dD7yv8yAZADlv7H/8j+hwBI/7z/6f/MAZIAlP4u/xT+8/+iALABwv/NALj+5P1eASYAjABw/iAAi//gAssAZP7U/0z91gEeAQACkP5SAJgA5v69//7+EANoAgb+tv4m/9ABnv+bABACt/9I/rz9+gHKABgCBv/9AJj+/P0O/xACDAOaAaj+dP0k/OoBdAJIAjj/mP5UAM7+GADg/ZgDuf/k/+T9pv45AOP/nALXAOL/EPr8//cA0gCI/zv/tAJyAHz+NP0wADQB6P2JAL4AYAKLAIL+fP1g/c4Bnv/UAjb/5//2/nP/Av4ZAMACN/8uAMj9KP/cAAoAhAGw/5YB+PsU/j7/VAJoBJz/G/88/Y3/UP06AQgCeAPAANj7sv/+/qkAIAFkAXr/zP7w/ooBnAHwABABdgC4/bj8Nf9QA0wDuAFKASj/uP6Q+wf/XAMgBOEAZP1K/zQBjAG8/kH/Kf8MAtz+e/9xAAgEy/80/rT80v6EAboBwgAWAV8AIP09/13/lgGwAJMA3/+e//EA/v5oAGMAowB7ANT9iP3wAcADUAL4/lz9APwE/OwBmASYBmQBwPoo+tT8TAEoATgFsAH6/1j9jP2i/y3/XgEl/1gCAP+eAKb+BALLAET9Rf/A/u7/7v5oAhABLAMP//T82v6E/UT+CAIIBdwCAP9M/FT8ev8YADgCcATOAEr+4PtA/zABIAJ4AtL/0v4M/Z7+FAFEAuwCwv4ZACT9FQA5/xgBfAHOABACPv46/uL+GgA8AWgCYAEjAFT+3P2O/vr/IAF8A3wC3v4Y/fT9fP6OARQCiAI6AdD8iPtl/+ABbAFkAtv/XP4U/dj8dQBsAoQCpf9o/uj+bP58//P/7gGgAxv/yP2Q+igAlAJwBIAB4P0K/hD9pP6s/xQDbAPq/5f/mPu4/l7+mQAEA2AD4v7g+5D9VwDzAIgB7AALAND+ZP1S/qj/UAK6AaoB7f9k/Jj8BAAgA1gC1P9EAPz9ev42/8oBwAIMArX/3Pyb/8D9OAGsAwwDZf/4/q3/gP7FAGD/MAIGAT4BNgAQAH7/2P7oAFgBBgHU/ocAEgFwATQAJf8H/yD/MAKLAAACSv/A/g0Ah//gAJ//mAGS/+4AhP4XAJz/DgAkAJ7+dwBoAa3/Tv6x/4sAqwAR/3j9+P5wA0IBK/9A/+j91P5iAHgCf/9EAdr+hP48AOr+p/9vABQCAv7o/tr+vP8IArUAS//Q/Qv/3P7qAPMAiAFSALr/Iv7o/B8AkAEYA84ASf+I/n8AHv9q/noBPAG0ARQBZQCS/vj9Lv5oAeQCvAKRAFf/qP5k/Wf/VACwBGgCAgFE/oD80P0gASgDCgEQAyD+VP5B/xAAmwAAAR8AhP7IAvYATP4s/vYBsAEOAXL+0P0I/vsAEALYA1wCmv4s/ez9tP50/dgC8ARYAk0AbP1s/pr+dv5kAMwCCALT/37+QP+2/5n/pgA+AWgByP1o/p7/ngGuAHMAUf+S/tL/nP++AQ//tv/I/1oB0v5U/ev/Lf9qAZr/6P8XAFIAGv+U/ooACf/HANn/9v4F/7sABgGoAGABh/81/6T9Qv/1/wQC1AHCARIBEv9W/iD8GP+pANACDAO0Afz9qP0v/3P/jAFS/38ACAEyAI3/jP/rAEEAYv+e/tL++wA/AHMAdgDT/7z/nv+//1H/fQAVAEj/4v+FAIIBYACG/1z+Y/80AaYAFQAr/8QASP9FACoB+gDh/8r/QP8A//D/0/8CAQQCSQB2/pH/vf9R/9H/mgDi/qX/of9SAEIBWP+X/3X/9v+G/o7+4v4gAYgC3gCd//D+1P4K/l3/f//mATABaAEQANT+3P4C/hMAkgDEAUgABQBoAAb+4P96/owAhgElAKP/ov4gAfIACABW/lD+wf/BALQCpgHIABgATP8c/4T+5P6XABACXALgAfwBXv5O/jD9jP0mAYQC9ANQAbAAuP5L/6D+DP05AHACNAOqAEABP/+d/7D+GP9o/0b/CgFCALwDvAIz/7D9KP4c/n7+dwAEAtgEIAIK/1j87P1n/6EAvABTANcAPAGCAMsAxP7k/dP/SgA8AW0ACgAqAQABaAAk/sj9wP9L/90AfwAMAp3/2gBg/gD9eP10/mYBPAL8Ahf/zP4s/Yj8Jv/XAO0AaAIyAaD/wP1o/Sj/MgDqANj/tAGoAT4A3P6Z/+j/yv7S/ioAJAL8AdgBRQD4/+D9LP2g/akAcgG8AfgDpgFe/0z8sPx3/wwBYALQ/hwBfgGG/wQARgDM/5T+jv4M/coAgAKAAUYBvf+K/gz+xP4z/1sACALf/4kANP/W/mAALAE7AGH/Ff9y/sD/4gEkAUH/ZgCm//L/b//A/uz9YAEWAUYA5QBpAFz+kP19/yYBVAIcASkAr/8l/7T87P4IAoACQgFv/zcABv7U/fT9DgEIAjYBMAG//yf/aP0+/6//WgHm/9gAOAGiAGH/iP/p/wAAsv8Z/1MAogBcAdYAxAHH/67+aP4+/gsAsAB0ApoBqAFY/gD+PP5e/igAggCcASgBCAIr/7j99PyC/iQCvgHMADb/vwBq//z9VP8HAOgBKgH0/j7/8f+C/6n/qQA8AVAB3/9A/jf/rwApALsA1gG2AMv/0Pzw/gQBKAI6AfEASAAC/k//zv98AnQAav7I/qr/qwA3AHgBVgDq/7z+6v7v/5D/nwB9ANYAJgCFAEcAm//JAEgAh/+Y/Uf/4AFUA8IBaf/u/mz++v70/jQB8AHoAuAAVP8W/pT+W/9CAUwDlAL9/0j9zv6EAAgCFgH4/0sA9v78/hsADAFzALUAdAD4/jT+xP7kATwDYgBk/LD9D//HAIIBVAJOAbz/ZP+I/Rz+Mv6r/2gB9AFCAYYAswCT/2j+nP2Q/NT+FAFkA+wCbAIm/kT9IP1k/UwAwgFYAhQB2P8Q/sn/BgEp/0n/H/+m/iv/2gDAAT4Bsf+o/Uz/K/9Q/m8AcAGmARMACgC4/yv/NP7A/i4BLgFoARQBbQBMAIj+3v7N//cAegG2AWgCiwDe/2T+7P+2AEYBAACGADgBRgHb/2n/aP8X/zb/Fv++/78ATAHR/3QA7/84/0D+BP1u/iwBlALIAqABjv/8/Cj8gP2LAOwCkAKkApYAXv6I/OT8bgBiAZoBcABKAd4A9P9C/1D+fP7C/isAUgGYAQAC6P6u/8UAn//g/iL+MP5yAeQC2gAQAZ4B9f8S/mj9SP1RACQCvgHxAFwAvP44/gb/Jf9a/8gAQQCHAC4BNf++/sv/tP+sAJQArv+3AHgAjv4a/p8AiAFcAnQByP+N/67+VP3s/v4A5AJgBFgClP/E/Pj9nP63AFgByQC6AXwBqf9i/t//gv4j/1UAFAHKASoBQgD3/+X/0P2o/0YB8gE9AAT+lP4S/3EA+AAOAfv/Gv58/vj9tP2K/uIALAJiAXj/yv7E/8T+EP3s/QoBcAIsAiAAov5k/nz+XP+3AGABIAKKAJz+Zv5z/74BNAKgAY3/Gf/m/rD/7gCoAVwCSAHm/8j9RP3+/qwAjgE2AYIBxwB3/+z9hP1K/kL/1f/NANABxwCK/xb+iv7O/k//NQCwAOgAGAC5/8EABAHsABAAmP/0/kr/FgCEAFgCtAIQArT/9P7A/aL+/P+yACACYAJKAbr+cP/m/uL+Gv+UAMgAzQBGAO7/pAGLADL/Gv7W/sr+VwAmAfIBXAIgAZj/PP1M/cL+BALoAlgCJAFx/2b+lP64/0wBUALcANIATwCz/0f/5/8EAMUAJgH6Ad4AoP/i/pD+a//0/wABLAEMAZj/3P9dALb/dP4a/xAAQQDiAH4ACgFnAJz/wP6k/g7/gP+5/4EAov93/+8AogHEANL++P3s/Pj+s/+6AcwCIALhAKD/kf8g/kT+Qv/EAcoBMgF4AEYAlwA/AOf/DQBZ/2r+mv7x/34B6ALOAXX/Gv6o/Vr+QwBuADIBwAGJANb/Yf/8/fz9Hv/CAGgCbAHQ/3D+iv7S/sL+HACwAfQBsP+S/tz9sv7n/+v/0ABAAcUA5v4f/9b+Wv93/x4AbgBsAKQA/QDtAFkAnf9u/uz+6v4qAK4BNALAAdsAvf8y/qj9JP4LAAgBVgHNAAYBNwCs/xP/qv4k/6v/6f9GAJABvQDM/z7/zP9tAL4A6v8d/8T+WP4SAOQACAK8AcEAxf8i/uD9MP6I/1MAhgHmAfgA2v80/47/KP/a/tb+g/+LABoBpgHoARIB8f/q/tj9YP0Q/kwAgAKEAxgCKAC0/lz9IP0i/tv/FAG+AewArgCFAO3/5v4U/h7+tP65/1wB7AFUAY8Aov8+/yj+Xv4v/xAAhAArALQAbAE6AXUAVf84/tT9JP/RAPABDAIcAaEAk/9u/hL+qf/AATgCnAFCAEH/If/c/w4B7QCgAJEAwwBiAIX/sf+HAC4BrAB0AHEAIgCr/5n/VQBaAPL//f9nAKsAKgD2/yIAVQBAAMj/0/84/8j+nv8EATABsADl/33/T/8f/7z+P/8+AHQAhgA/ALz/x/+hAB8ATf9i/ur+VwDXADQA+//DAC4AHf8I/4j//P8BAAMAxv9w/4j/2f9sALf/3v4I/5r/4P/7/3wAEgDc/rD98P3X/yYB3gFwAWIAlv5Q/cT9Uv+oAIYB1AE8AfL/OP+m/iX/vv9pAFcAhADTAPwA+gBVAMn/0P+E/4j/KgBiAdwB1gG1AJD/ev4c/83/oABgAQ4BsADo/4//Qv97/7P/6f9jAEwAEgAGADsAvv81/yz/ev/B/+j/WgCOAEYAjP9D/3z/W/9X/5//MgBgAGgAUQAZAHX/pP5u/in/+//PADwBLAGdAD7/TP4U/sz+nP9nAMYAxgBxAAQAgP/K/nb+pP6G/ysA0QC3AIgAQwDn/8T/df9g/1D/iP8NALkAYAGoASwBRQAq/4j+lv6u/xAB6AHoAeAAFACF/yb/V//q/8EATAEIAX4AQwAWACgAKgA4AGwAtQC9AJEAnQCPAJ8AkgA7ADIArQDMALIAWwD6/yQAYgCRAIsAsQA5ANf/cP9R/8r/RwDOAOcAjgDB//r+7P5a/2IADgG4AC4Aef/u/rz+Kf/i/5UAvgBMAKT/Of/2/v7+Kv9G/6P//f9KAB4A8/9R//r+zP4E/4T/m//T/97/+f+3/33/hv9U/5P/tv/F/9z/4P8kAIoAlwAcAN//zf+5/wsAmQAaAXABGAGCABsA0v/k/2kA7QAqAYwBIgGLAB0A1v8WAHsA/ABYATQBuwBVABUADwAPAF4AvQCUALMAkwA4AOj/1/8KAAsA6f8DABgA6/8QAOD/AQD7/6X/bf9z/4j/ev/Z/xcADwAnAL3/V/8f/x//Xf/I/z8ARAA2AJ//Yv9+//3/+f/2/x4A2/+2/9n/0P8IAFEAKQAwAC8APwAXABAA5v/0/yIAYQB1AHQAOQDt/yYADwBbAEUA2f/A/8//TwB6AHEAXADt/4//hv+p/9r/4P/2/w4A5f+8/6L/vf/f/3v/O/9H/2j/k//H/6j/cf9f/0H/AP/S/s7+vP5K/7X/pP9o/9T+aP5g/lz+uP5M/6T/nv91/zP/zv5C/j7+8v58/97/4v8YAFAA0P9w/yb/Xf+v//b/mgD8AB4B6gC4ALwA7QDPAKIAsAAEAXQBsgEMAlACKAKgAVQBZgF6AdIBHAJ0AtgC5AK8AmwCYAJQAoQCoAKcArwCxAK4ArACmAKMAjgCxgFwAYoBngHMAcgBdgFWATYBhAAbAPv/sf+4/2n/fP97/2H/4v5S/rj9TP3Y/Lz87Pzg/NT8qPxg/OD7kPtQ+xD78PrY+gj7APvY+rj60Pqw+kj6APrQ+RD6OPqQ+hD7MPsg+9j6uPro+kD7WPvg+6j8HP3M/fj9TP6K/pL+Av8xAE4BRAK8AkwDEATIBDgFGAaoBkAH+AdgCAAJcAmgCSAK0AowC1ALUAtQC/AK8ArQChALcAtQCxALcAqgCRAJ0AhQCAAIkAcAB3AGkAWABJADAAPuATgBkAAYAF3/tv7Y/bz8kPto+sj5QPmI+Bj4IPeQ9pD1MPWQ9PDz0PMQ84DyAPLw8RDyUPIQ8qDxIPGA8FDwkPAg8ZDxAPJA8iDyIPKw8TDygPIw8yD0sPXQ9qD38Pfg91D44PgQ+7j9+gAwA1AEiASIBHAE+ARoB/AJgA3gDyAR4BFAEdAP8A5AEEAS4BRAFqAWwBUAFGAT4BKgEgATwBIgEiARABBQD2AOUA3QCwALMApQCAAHuAVoBGgDfAIIAn4BVwCE/qz8MPsg+tj5CPqg+SD5SPhg90D2UPXA9JD0kPRg9JD0UPQQ9LDzkPOQ81DzMPNA86Dz8PNQ9JD0sPSQ9GD0MPQg9KD0wPSA9QD2YPag9tD2wPZg9mD2kPYg9xD4SPkY+mj6gPqY+gj7kPt0/Ez9jP5h/wwBeAOYBHAFyAaYB4AHEAgQCAAKwAygDuAQgBGAEQAQ8A4QD7APQBEgE6AUgBSgEyASIBAgD4AOsA5QDwAP8A6gDZAMcArACEgHcAZQBogFKAXAA7ACSAEiAF7/xv7w/az8sPug+mj6CPrw+dD5+PiI+MD34PaQ9lD2YPZw9pD24Pbw9uD2cPYg9tD1EPaA9vD2QPeA92D3APcQ9zD3QPcQ92D3cPeQ95D3YPeA97D3gPdw92D3kPdg90D3UPco+ED44Pig+bj56PkA+oD6CPtQ+xD7iP1dAIwCwATgBDgFYAOAA3AEeAfQCmAMoA6wD3APwA1ADdAMIA7AD4ARwBNgFKATABJAEOAOkA4QD8AP8A8QD+ANgAwQC+AJsAjYBwAH8AXQBDAE6AL8ARoBQQCT/67+eP1Q/Pj64PnA+bj5+Pmo+dj4sPeQ9uD10PUQ9oD20Pag9nD2QPYA9vD14PUA9kD24PZQ95D3kPdQ9wD3EPcw95D3wPcI+DD4CPjw96D30PcI+OD3wPew94D3gPeA97D3sPfA92D4sPhQ+Uj5oPmg+cD5+PkA+zD9dP+GAUQDYARAAxACFAKIBMgHEArADPANYA7gDbAMAA2gDUAPYBDgEgAUABSAE8ARYBCwD9APYBBAESARYBDgDkANEAzgCjAKUAmQCLAH2AbIBWAEcANAAi4BhQDI/+j+pP0w/Oj6OPow+ij6EPpA+RD48PZQ9uD10PVA9kD2YPYw9jD2EPaw9XD1kPUA9mD24PZA91D3MPew9pD2sPYg94D3wPfg97D3gPcA9/D24Pbw9gD30Pag9pD2UPYg9lD2UPbA9iD3sPcg+Fj4IPg4+DD4cPlA++j9lQCwAkwD3gGeAQIBPAOoBkAJ0AsQDpAO8A0wDbAMEA3ADoAQ4BKgFCAVQBSAEuAQ0A9AEAARwBHgEQARABDgDYAMsAugCsAJsAhACBAHyAVwBEQDGALtABMAHP9Y/tz8ePtw+tD5oPlQ+SD58Pcg91D2oPWg9aD1oPWQ9YD1kPVw9VD1QPXw9FD10PUw9sD2EPcg9yD3kPaQ9uD2UPfg9+D3CPjA94D3IPcg90D3QPdg9xD3MPeg9nD2cPaQ9uD2EPfQ9zD4YPiI+Jj4qPjo+CD6KPzy/igBPANAA8gCmgFsAZgE8AYwCrAMYA6wDgAOYA2gDIANAA/gEAATQBTAFAAUQBKgEAAQABCAECARYBHgEGAP0A1gDGALIArwCGAI0AfYBuAFkARUAwwC0wCj//z+JP7o/Bz88PpQ+sj5aPnY+Bj4wPfw9tD2kPaA9lD2APYA9hD2cPaA9pD2oPbA9hD3YPdw97D3wPcA+ND38Pcw+GD4iPhg+ED4GPgA+MD34Peg94D3YPdA99D2wPbA9jD2cPZg9jD3cPeA99D3UPi4+Cj40Phg+lj8jP9eASQDTAN4ApwBYALYBFAIMAuADRAPwA6ADoAN4A1gDgAQwBGAE2AVIBVAFOASYBGgEGAQABGgEcAR4BCgDwAOcAwAC9AJIAlACJgH4Aa4BXAEtAJCAXsAcf/K/uT9xPyg+4j6qPko+bD4YPjA9xD3YPbw9fD1sPWg9cD1oPXg9dD1MPYA9jD2QPag9hD3MPdA93D3wPeg94D3IPgQ+CD4OPjw9xD4kPdw9zD3YPdg9+D2APfQ9kD2QPbA9QD2wPYw95D3oPcY+Mj4IPjw92D4iPqM/fv/CAPYAzgD0AEoAegCgAUQCQAMkA4wD+AOEA6wDRAOcA6AEGASYBRAFeAUwBOAEkARwBBgEUARoBEgEWAQMA+QDXAMAAsgCgAJyAdAB+AFwAR0AwgCAgF3AFn/Nv4c/YD7UPp4+eD4WPhA+KD3IPeg9hD2cPUQ9dD0wPQQ9TD1sPVQ9pD2YPbw9SD2YPaw9hD3kPcw+ID4oPiQ+ED48Pcg+CD4kPig+Lj4aPgY+FD40Pew90D34Paw9oD2gPYg94D34Pfw91j4kPgg+AD4iPhw+Uj7aP0wAcQDvAOUAoYBQgG8AggGQAkQDbAO0A6wDtANsA1QDbAOoBDAEoAUoBUAFWATwBFgEMAQYBBgEYARABHwDyAOUA2QC6AKMAnwBxAHIAYIBRgE8AJKAUcAC//s/cj8kPuA+mD5uPhQ+PD3UPdw9vD1sPVQ9dD0wPSA9LD0oPTg9ID1APYA9hD2IPYw9mD24PaA99D3QPho+ND48PjA+JD4YPiY+Lj4yPjI+Fj4oPhI+Cj4APhg96D2kPZQ9sD2YPdg96D3YPgo+ND30Pfg93D4YPmw++b+DAKAA4wDoAKcATYB2ALQBsAK0A1AD5APgA7gDVANgA0QD+AQQBPgFKAV4BRgEwASwBBgEOAQgBGAEcAQcA+QDvAM0AuwCnAJcAjQBtgFkASMA5wCngHLAJP/bv78/Hj76Pnw+Kj4qPiI+ED4sPfg9vD1EPWw9JD00PQg9cD1UPaA9nD2MPZQ9lD2kPYQ96D3MPh4+LD4yPjg+Nj4uPiY+JD4oPjA+Lj4wPiA+GD4MPgA+LD3IPeA9iD2cPaw9iD3oPcA+Cj4APgA+OD3APgg+LD5LP1eAEAC6AMoBLACTAIkAogEoAjQCxAPQBCgEJAPoA6QDuAOIBBAEqAUQBagFuAV4BMgEuAQoBBgEaARABIAEQAQMA6ADPAKgAnACIAHwAZoBVgE8AKgAVQAb/98/jT9GPyQ+oD5iPg4+CD48Pew9yD3UPbA9UD1EPUA9fD0UPXw9ZD2APdA9/D2wPaw9iD3cPdI+AD5MPlo+WD5QPkA+RD5GPkQ+TD5EPnY+ND4YPgQ+MD30Pdw9xD3gPZg9vD1MPYA93D3wPfA9+D3CPgQ+OD2CPho+gT9mACoAnAEMAMsAv4ASAJ4BWAIMAxAD8AQ0A9AD+AN8A2ADgAQgBIgFUAWIBYgFeASQBFAEMAQYBGgESARABCADhANoAtwCoAJMAiIBogFIAQMA/4B2AANADP/EP4E/ZD72Pmw+OD30PcI+Cj4APhQ90D2cPXg9ND0EPVw9dD1YPbQ9jD3UPcg99D2APeA9zj4GPmo+bD5iPkI+fj4EPlI+aD5wPmY+Rj5wPiY+Hj4GPjg93D3MPfg9rD2YPYA9lD2cPYg91D3wPfA95D3IPdA96j44Pq8/XMAOAOQA4wCUgG6AdwDOAYQCiANMA8gEGAPwA5QDuAOQA+gEcATQBWAFuAVYBSAEiARgBBAEeARIBJgEQAQQA6ADDALIAowCdAHwAaIBTgEMAPaAWwASv9a/pj9zPyg+wD6aPhw9zD3oPfg97D3IPcg9iD1QPRQ9KD0UPXg9XD2APcg9zD3APfw9gD3cPdw+FD56PnA+TD5yPiQ+Oj4QPmo+cj5gPnQ+Dj44Pew96D3gPcg9+D2cPYA9tD1gPWQ9cD1YPYQ94D3UPdA95D2EPdg+AD7UP6YAagDGAPQAlQB1gFoBEgHcAoQDiAQYBAgECAPYA7gDuAPABKAFIAWQBdAFoAUIBIgEQARoBFgEkASoBGwD/ANoAwwCxAKsAjIB4AGIAXoA9ACdAEBAO7++P10/Yj8EPuA+Rj4QPdQ9+D34Pew9xD3APZQ9QD18PRw9dD1UPbA9jD3kPdg91D3YPeA9xj4CPnI+TD6uPkw+fj4EPmY+cj5KPrQ+Vj5yPiA+Gj4QPgw+MD3oPcA96D2cPZQ9kD2UPbg9oD34PcI+PD3sPeQ91j4YPqI/WEAOAPcA9ADoAKqAdgD8AVQCaAMMA9gEGAQ8A/gDsAOkA8AEQAT4BQgFmAWIBVgE+AR4BCgEAARYBEgEQAQkA4gDcALUArACIAHWAYYBSAEDAMQAsIAbP8G/jj9ePww+1j6+PgY+HD3gPew94D3cPeg9kD20PWw9aD1sPUg9oD2MPew9yD4SPg4+CD4MPho+Aj5iPn4+cj5kPl4+Vj5cPlg+UD5+Pio+FD4SPjg94D3IPfw9lD2MPZQ9tD1EPaw9RD2QPaA9vD2kPcA+JD3CPiQ+Xj77P5MAWQD9ANkA6QCCAP4BEAIIAsQDiAQYBCAEJAPgA8wDyAQoBFgE8AVIBbAFWAUQBLgEMAP4A+AEMAQIBDgDiANYAvQCWAIQAf4BfAEAATsAs4BUwDu/gD+zPww/ID7ePpQ+TD4YPcA9wD3IPcQ96D24PVg9WD1UPVw9dD1APaA9uD2sPfQ9+D3sPeg9+D3OPjY+HD54PmQ+dj4CPmw+Kj40PiI+Ij4APjw95D3YPcQ92D2UPZA9sD1IPbg9fD1UPZw9gD3QPfQ96j4APjg96j4KPug/i4BEASoBCgEMAPIAqgEIAeACoANABDgEMAQIBCgD5APkA9AEeASwBTgFcAVoBQgE0ARQBBAEAAQYBDQD/AOgA2wC4AKEAnoB4gG8AQIBHACbAGNAHT/mv74/dz82PvQ+nD5UPiA9zD3APeQ96D3kPcQ94D2sPVw9XD1sPVg9uD2wPd4+MD4mPgY+Bj4CPhA+ND4oPlQ+lD6APpg+cj4aPiY+JD4yPiI+JD4SPjA97D38PaA9gD24PUg9kD2QPbQ9vD2MPcQ96D3KPgQ+Gj4ePko+6T94P8MA8AESARsA0wDIARIBpAJYAwwD0AQQBBAEJAPkA9AD6AQQBKgE+AUgBWAFMAS4BBwD4AP8A6gD1APcA4QDQALIApQCDgHwAVgBGwDcAJ4AaQAhP/g/eT86Ps4+5j6sPng+LD30Pag9sD2MPcg9xD3wPYg9qD1kPWw9TD2kPZA9yj4uPjQ+KD4QPjw99D3aPhI+cj5KPr4+cD5QPnY+Ij4UPhY+Cj48Pfg94D34PdA97D2QPbQ9cD1UPZw9tD2IPfw9hD38Pcw+GD4CPkA+rD7nP10ABQD8AQQBXAE/AOQBCAGEAnwDHAP4BDgEIAQcA8wD2APIBDgEUAToBQAFYAUIBNgEWAQcA/wDiAPIA+QDlANwAugCvAI4AfoBqgFkATgAtgBjwCW//b+TP7g/ej86PuY+iD50Pcg92D3APiQ+Oj4gPiw96D2sPVw9bD1YPYg9yj4wPgA+QD5iPgw+KD3kPcQ+ND4oPno+cj5QPmw+ED4APjw9/D30Pew95D3oPeA90D30PZQ9vD14PUg9qD2YPew98D3EPiI+CD5aPnw+ej6XPww/t0A9AO4BbgFuAWIBXgFSAdwCRANIBBAEcARwBBAEKAP8A8AEQASIBMgFKAUIBTgEmARwA/QDmAOgA6wDvANQA1gC+AJMAjwBhAGQAWQBBADxAFEAF7/sv70/UD9qPyo+3j6ePmo+Ij4WPiA+LD4cPg4+MD3MPfQ9oD2kPYA93D3QPjY+AD54Pho+PD30Pfw93D4qPgo+VD5IPng+Kj4SPjQ96D3QPcg9yD3MPdA95D3MPfA9iD28PXA9dD1UPZA99D3WPgA+RD5EPnw+Ej5gPpQ/Cz+sAGYBMgFmAUIBPAD7ANIBlAJEA0AEGAQQBCQD8AOoA1ADgAP4BAgEuASYBMAE+ARYBAgDwAOkA1gDWANwAyACzAKEAlACHgHWAZQBfQDSAKsAPb/WP9L/wj/dv64/Xz8EPsQ+kD5uPi4+PD4YPmA+RD5gPjA9zD38PbQ9jD34Pdg+Nj4KPkI+cD4QPjg9/D3gPjo+DD5SPkQ+ZD4YPg4+Dj4IPjg97D3kPeA92D3gPdQ98D2IPYA9kD24Pag9zD4YPhg+Kj4wPgI+Rj5yPk4+3T9uP8cAjAEGAWoBAgEaAQwBVAH8AkgDUAPMA+gDuANEA6QDgAPABDAEMARoBEAEoARgBDAD3AO0A2QDYANQA2wDJALAAqQCLAHEAdgBmgFGASwAj4BcAAEAKn/ef+o/oz9RPzg+rj5KPkQ+Tj5qPnw+fD5WPkQ+KD2APYQ9nD2QPdw+Bj5MPnQ+GD4IPjA96D30PcQ+Gj4kPi4+Ij4gPgo+AD48PfQ98D3cPcQ99D24PbQ9uD28Pbw9gD3IPcg92D3kPfw95D4CPm4+VD6CPuY+zD8EP3W/vYAnAOQBeAGGAe4BigGAAbgB+AJ0AxQDyAQIBAgEGAPgA4ADhAO8A5AEAAR4BHAEUARwA/wDaAMYAsAC+AKsAowCoAJ4AjoB9AGcAWYAwAC9gC1AF0A7f+c/yr/Nv7E/JD78PqA+vj5gPm4+RD6APqo+SD5cPjg98D3wPdQ+Kj4uPjQ+LD4ePjA95D34PdQ+Mj4GPmI+Xj56Pjw95D3oPco+Hj4iPhI+AD4oPdg98D3GPg4+Aj40PcI+HD4+Pj4+FD50Plg+lD7GPwM/Yj9pP04/mr/fAGsA8gFQAfABzAHSAYABkAHMAnAC3AOoA+gD7AOkA3gDLAM4AxwDVAOQA+QD8APYA8wDvAMYAtgCqAJEAngCAAJoAi4B3AGAAXsA6ACbAIoAgAB0v+S/gz+xP0A/TT8PPws/Jj7+PpY+vj5OPlo+ID4SPmw+aj52Pmo+dj44Pdg9xD40Piw+aD5SPmY+BD4uPgg+aj5GPmA+KD3sPaw9lD3APiY+ED50PmQ+fD3IPaA9dD1oPaA90D5gPs8/KD74PmI+FD4IPlg+gj8Ov5d/1UAPgG8AlAEkARwBGAE0ARIBQgGwAegCiANMA5ADlAN4AugChAKoAowDKANAA/wDwAQwA6gDCAL0ArQCZAIoAhACoAKEAkACAAHmAXUAzwDPAPYAVQAUABhAJ7/nP1K/tD+rP24+1D7iPso+hj5IPlY+hD6cPgY+LD4aPjg94D3oPdY+KD4SPlo+Xj4OPhg+KD38Paw9/D4APkQ+MD48Ppg++j4cPZg9rD3kPiQ+Kj5OPuQ+ij5cPgA+QD62PlQ+bj5sPnY+YD6mP0QAc4Byf+U/Nj6WPve/vwBUARIBZgG0AegB5gGSAZoBgAGmAagCPAKwAzQDdAOkA4gC2AI0AlgDHAMQAswDMAN8A2gC8AJsAngCMgHuAfwCIAJqAe4BWgEyAMAAzwCYAJUAq4B0v+Y/hj+pP2o/Hj8mP1Y/pj9EPsw+WD4SPg4+BD5iPpQ+5j6gPno+Lj4YPhw+Ej5SPlw+XD4GPhQ+ID4qPnQ+oD7OPuQ+rD5uPhQ9/D2kPeA+Cj6QPuU/Kj8yPso+zj6MPlg+Hj4IPkg+0z8CP4RAOoAtP9c/aj7yPsc/Yb+XgAYA1gFYAVwBVAFKASkAowC2AQQCHAJ4AmwCuAJMAgIBkAGAAgwCyAMsAsQC2AK0AlACeAIYAcIBvAFmAYQCKAIgAiQB8gGCAZsA7AAtv5c/rT/9AHcA5gEEAP+/hz8OPuI+rD5+Pqk/Yr/Af9M/Kj6KPo4+Yj4OPlY+tj6oPpY+lD7iPuY+uD5WPmA+HD3MPe4+ED74PwY/ZD7QPrA+LD3wPfA+Hj6LPxQ/aj9lP1A/ND6GPrI+cj52PrY/Mz9B/+vAFgBVwDs/cT8JPzA+0j9WAMAB1gFeAAXAJwDeAVYBIQDsAUgBpQD9QBwBKAI0AoQC4ALUAzYB7wCBALQA1QCQALwCIARoBTADvgGigEI/kz9UgBoBUAKMAxwC5AIwAWIAoj++Ppw+Qj9lAIQBrAH+AYcA/j9GPoA+bD5sPlQ+XD6nP3iABACXAF4/3T84PdQ83Dx4PNY+a7/LAPoAWT9ePgQ9gD2sPew+QD78Pvw+5j7TPx0/n//hP04+dD18PWI+cr+8AJoBAQC0P2o+nj5CPrQ+7D+jAFQA+gD4AM0A34BGv9Y/bD9i/84AvAEAAdYB0AGMARgAhYBuwCqAZADwAV4B+AIIAmACOAFMAMLACr+Kf8sAwAI8AlACvAIQAZgAfz9eP59AKABiAMwCFAI/gEE/Pb+EAWABDwA/P94AhgBRPxo+xr+tgAEArwD+AJu/lj5sPkI/U7+FP3U/AT+Dv5Q/AD8WP1a/jz+jP24+0D5gPgo+dj6yPs8/VL/UP+g/fj8mP5M/hD7cPV4+Rj7yPsu/sgBSATsAnABuP3o+XD3sPf4+1P/FAPQB5AI/gA4+ej5VP5n/8D/QARgCIgERv58/cwAWAPrAJn/TAKABQAF/AH+AaQDzAJI/mD9LALABjAGmAMsAqgBt/88AKgFcAi4BG//nP30/Pz8RP7EA1AJgAnoBQAC/P7w+oD5/PwQAewBbgFMA/QDcAL1/8D/VP/w+1j5fPxuAVQCbgDU/mYAnv/a/gb+yv44/jj8kPoo+9j9PwDUApgCrQAE/jj7MPr4+jD9Lv48/vb/UAOQAgD8OPgU/VgCPgDw+9D9QAMkAeD5IPnsAfgEEgE4AYgC9gHw/ZD5cPqm/nIB6AaACLAGoANT/2D7SPng+sIAbANwBZAIIAg0Alz8Pv7uAf0A1P1qADAGiAWbAAoBcAQcAkD9JP8EA+oBWv58/Hb+6QBwBiALUAZ8/OD3qPiQ+ZD6Xv8wCDALMAb6ANz80Pcg9iD7Z//e/4n/5AH4BAgF3gGA/vj6QPew9SD6qgHoBoAIoAZ8ATD6IPXA9ej6XAAYBHAEMAMsAkQBqP/A/Aj5MPfw+KT9VANIB9gHqAWqAUT9qPmA+MD4QPpc/QgDgAiACgAJmAVV//D2oPHg8ij6CAOwCiAQYA/ACLL/gPfg8bDwoPXX/zAK4BAgExAP8ANA9oDuAO5w9iQDAA3AD4AKnAKs/aT9rP24++D6WPsM/Pb+rAGABTAJuAZSAED++v4c/ED5YPfY+ID9+APwCCAMcAmK/nDz8PAA9iP/2AXQCcAK6ASw+2D26Phk/Gz9OP6wAegFaAY0AxoA9P38/Gj7uPlA+3n/CAIEAkQDIAYgB7gE9P1w9lDzQPcO/1AH4AsQCoAEWP6w+Rj6Jv5I/XD9IQA4BkAJmAdgBRsAePjg8FD3YAUADTAKoAS8ANT9GPug+3r+5P7a/8IATAMoBRAIkAcUAuD50PPg9Oj6SAZgD5AOTAJY+AD4bPyI/rT/MALgAWj9OPtoARgHKAXQ/fD6uPuo+2D7WP8gBCAEdgFfAIIBoAFD/4j6cPcY+Hz9aAQgCRAJeAQs/UD58Pmg/Kj9lP58AbADiATABDgFmAFA+ZD1cPljANAEEAdQBugBSPuY+ID7lgHEAggCgAFkAtACdwC2/nD87PyY/Zz/CAK4BPgEeQA0/OT8+AJQB1AEmf8k/Xj7oPYY+jgHwBHADH7+ePjw+zj98Ppo/fQDYAloBtIAEABMAQz8MPSA9jYAcAqgDtAL+AQQ+hDyAPIo+Qj/wAWwD2AOs/8g9ND2iP0+/2T82v9IBuADWAAK/9P/QPlg9vj8SATQB6ACJP3g/G7+UP0M/bH/9AJYBLz9SPnM/DQBfAFmATQBEPxC/kQAUAM0A+T8OPm4+5T+eP7YArgGIATAALT9xPz8/Mj8SP1aAfABHwC4BJAGBANw+vD2kPjg/cgFEApQCqgGgv7Q9mD16Phi/igE4AiACxAInP54+MD7/v+Y/Vj6zADABGAC5gHgBzgHE/+Q+2j+pgHo+UD2JP3gBQAIcAdQCJAF0P0A9tD0iPj8/eADkAgACIAEawBs/Ez8iPsA+sD54PssAvAJAAxIBnn/YPow9tDzoPgiAMgGIAeQBbAC1wDu/vj80Pt4+oD60PwYA9gE5AJuASgCrALu/gz8cPow++j+pAOABFAC2wDQAXQDnAEo+4D2CPucASAEEAP4BaAJTANQ+LD0IPmw/RX/OAQQDOALdAJI/Gj8WPmw86D3UAOgCTALEAgQBB7+KPpY+hj7LP0YABQDqAEpAEgEIAp4BmL+SP3Y/Dj4MPWQ+0AGIAtYBkQCNALl/8D7QPq4/JT+3v4IADACsAIAAgwBUAJuALj7gPdo+kgEiAfmAUT+nP1Y/bT88P2mAdQBl/9sASACCf+0/Ez8jv5z/4L/IAD8ArQC+v4U/+cA8P9k/Mz8EQBiARwB+AJwA+b+DPwG/9kAV/8A/Sz8rv9oAgACjv9gAQQDogHk/nT90Prg+mD/ZgEEA+gEaAUIApz86Pko+bj6W/9QBoANMAlk/JDzsPVAAFwDJAIoBbAIiAXg/GD5mPoY+2j7fAKgBlgHAAeABLj9APbw9rj6zABwBGAHsAbkAqr/nP2o+1j7dP48AmQBTf/qALwCsgExAOkA+AKiAYj9SPqQ+SD8kAKACTAKZgEo+ij7/v6Q/vD6UQBABXAF7v8G/gsAUv84+gj5bQAQBQAFLAP8A8oBwPvg9eD3tQDIBtAHmAcYA4D5wPLA96ABYAUwBgAGiAXn/7D2YPeI/Lj9Hv4IBLALuAaA/ND7LP/4+zD4KP2ACNAJgAEo/K7+Wf+w+5z8MAIwBWQDJP9A/gT+8P19APADeAS8Al4A0PvY+Uz9UAHYA5QCKgFiAdz+6P0p/5gAAwD2/rj+7f/j/9QCKAVQA2D9GPhY+7T/JAOYA+gE7ANNAKD6cPn0AAAIaATg+rD7jAIwA1z9HP0wBggHWf9Q/G7/7v6M/ND+CARABRkAgP6HAP8APAFKAYL+vP2A/JD9cwCwAlgFbAMK/5D9dACMAWT9NP7kAQj+qPi0/DAGIAp0A+D6gPsX/8H/DP0w/b7/WAK8AQb+DPypAOAGKAbA/CD4OPss/kr+IQAwCBAJSv7w9Sj5vv40AYgCMAgAB2z8QPPQ95wBaASgBWgHPAMI++D0APlUAngEaAKQAugE7AOt/yj7CPvY/TMABQBuAVAFcAYgA2T++PnA9wj67AHIB3AK0AZxACj7cPVQ+EgC8AmgCDcAOPrA+BD7GwAgBrAKgAYxAHD6oPbQ9Jj7IAewC6AItAMMAID7kPfw9rj7MANwBLAFkAYQBAoAoPrw9wD4fPyo/1IBIAOwCGAMeAT4+ODxEPSA+RX/yAeQCmAHbv4g/Oz+Pv8o+gj6Vv9J/17+xABgB5AIuAMQ+kD22Pms/aQA3APoBCQDhwAQAYACdgEs/LD2EPjM/ZwC8AZwCgAM0Ais/XDzEPY0/Cb+JP3P/9gGSAeIBpAI4AqN/0DvoO2A+KgEOAcgCUANsAk4/+D2qPhU/MT8NgHgBEgFnALiAewBzP40/FD8YQDEA5wCbAGa/wr+hP53/+oBRAIwAvT/TPyA+rD93AG0AjQDSAMsAiz82Pio+OD8QAJABGgGmAQ2/vj4GPuu/gwB8gAm//j9Qv6cAvwCmf+Y+wD6JPwgAwAH2AOk/gz8wPy4++j4vPx4B/AJcAWV/5D9MPsg9yj6nQBgB+AHCASpADj+9Pw4+sj8kQBkAZgCQAMQA7IALP7g+rD8aAJIBJgFFAN/AJj7cPc0/FgEcAd0A8D/EABpADb+sPxvAHgEqAO2/sT8qP9nABcAEP+d/6n/QAOABYv/CPvQ+/gDvAKo+TD6ygFgAzz+9P6IBXAFWPsI+EQBAAUC/jj58PxgAWT+gwAgB3AHegAQ+RD6ePwU/HT9cAUACRgDGPuY+oz/CgGgAWgB+QB4/nj7/PyWAPwDvAJn/4D9lv5s/2j/QAIgAxgClP2Q+TD8dAIoBY8AyPwy/1gDHAIH/4IAKARMApD6EPh+/vgEiAKzAJAE4ARB//j4uPpEApACZPzi/+AGaAa/AOT8mv6E/fD7BP1gAsAFUAaQBCz+MPqs/E4ACAKMA9ADPALo/FD6cP6YAqMAHALoBrADEPuQ9gj7YgH8A3QD7AAx/4gCoAJI/pD58PvX/wj92PxMASAJYAi5/6j58PXg81j7QAlgDcAIoARg/ZD0EPEQ9ej+8AfwDZAMIAfk/DD24Pcw+eD3YPuwB3AMsAowB/cAIPig9GD4+PsiATAI4Ao4BjD+4Ppc/9D+kPmU/NAEqAPs/nADAAdABIj9EPvo+wYAjAHu/rYA/APUA0sAuAB4AzwDwP0Q98j5FAJ4BQwDQAPIBEIBTP11/wD/WPtE/Mr+2AKgA/gFCAerAID4IPfo/IACSATMAWoB1P6k/Fr+/AF8AkQCMQCg+Uj5CPy6/rQAoAXQB0gFVP+Y+oD6EPro+Gz84AXIBSAEWARwAzj7UPUo+xYBBAPj/4X/FAMYApj65PxgBHAFCf8c/k8A1P8Y+fj4lAEIBEQD9AOoBiYAGPmY+jgBvP3o+Fj9EAhQDLAFzAGs/mD6EPVg+K7/uAM4BaAHAAjoAnT9jPxQ+nj6xP0AAE8AXAKwCPAJRAIY+WD3+PuQ/bwCiAZQBg4AfP3c/T//v/9zAKQB6v+0/bz9eQBIAcwCEAR4AwgBiPu4+ej63P2Y/yQBCATYBogGc//4+qj6uPqQ+Ur+OAcADOAF6P14+oj7cPsQ+S7+cAVAClgGEgHM/Aj48PaQ+mkAwASgBgAHKAYa/pD3sPcs/XIBvAMABUgDyP9g/WD9Ev5i/ioBsARYBHwAwPwU/V//BQC8/hQCmAZoBSgCQP1w+TD5gPzEAZgGIAgwBfEA7P2w+nD4ePuIApAFTAMwAwgCmv9U/UT+DAK9APj7cPuwAtgDVAFoAiAD2AC4/Oj68PyO/9T/4AFkA+QBIAAo/5T9dP2h/zgC+gFuAP8AsgHC/sD4GPnE/xgFaAZsA5wANP1c/AT8jP03AO0A+ADg/vz9ZPxbAGAGaAcaANj4gPco+wT9bP2MAMAE+AaQA/YAYwBo/rD5sPiY+7r+2AKgBQgGSAQ2Afj8cPow+lD+DwCXALoBEAUQB/gCzP28/cz+DP44/F7+QAF6AW//nAGAB2AHFAOY/Dj5IPmY+qz9PAMACBgHqAOBAEn/u/9q/pD6MPqU/QQBeAMABsAH2ATI/QD48Pdw/uADAAP6AY4BEgE5/2z96gB4A+D94PVQ+OwB0AeIBsQDNAI8/OD0cPUc/oAFsAYABVADIP+A+4j5vPw2AYQD5QD8/pz9TPws/uQCcAVMAvT8hPz0/0wBUf/A/BT8VP5IA5gGkAUEAST9ZP2g+hD5EP0QBOAH0AZEAoD/Jv6o+6D7xPweAOgD2AYIBQQDsf+o+iD59PwYAzAETAJGAaADHAJw/mj9q//kACoAKv4o/uP/qgDYAvgFcATrAHT9uPpg+Wz8PgGIBbgFgAIhAMcA5P68/KD9JgF+AfT9SP0mAdgEwAVQBMP/0Poo+dD5QwAgBTQDKAEgA7QCZv7w+/j56PsVAMQD8AaQBR//GPno+iT9CP5EAagEcAP6/7L/lQA+/kD7pP06AcUAAP9k/6oA6wDR/7v/MQCkAFgBkAI9ACD8wPlY++z+/AKIBgAJkAgOAbj4oPY4+Lj67P4oBUAMoApMAXD62Pv0/cD8qP35/z4BvAIoAtQASAG8AqL/wPzc/GL/lQDQ/bL/YAV4BG7++Pvi/6YB7P+h/+QB0AKm/zD9MP10/Y7+wALQBkgF6//4+4D6ZPx2/voBAAWwBJj/HPxc/ED8Sv6UA5AGpAIw/fj7tP4v/+T9vv7IAcQCgwA5AB4BVAEg/mD7MP1kATACRv4Y/a4B8ANQAND96gDsAnj9SPoS/hwDpgFa/3AEmANU/MD5yv/sA8j/DP5OAbgEPAE4/kH/1/9M/fj75wCwBFAE8v/4/ub/hP6s/uL/+wA+ASABZwC+/33/aP4kACACuAHkAngDsgHQ/Uj6OPl6/kgCOARIBHgExAMJ/yD8iPyo/ez99P1kAaAEjALiALn/XP/O/jD9hP7E/fz9YwDsAYoBs/9MAugE9AE0/DD6yPoc/Af/ZAJwBgAIcAQs/rD54Pi4+Sz8HALAB3AHnAIs/RD80P0U/Hj7fP3oAiAIaAYIAqz90Pvg+tj5kPtKAcgFuAY8A8P/lP5w/ej9oP6S/g//+f82AEoB3AIsA1QCAP6Q+2z8Sv6kApwDdALPADwBMAPM/zD9nP1B/4T/tf8cApAEjAJs/mj9mf/BAHL+0v9EA+gC1PzA+zQBmAR8AmIA6AABALD6IPgQ/yAGYAVoAnwCoQA4+3j5tP3CARgCwP/xAEgDdAH4/lT+R/+y/pT+GgCgApQD9AEbACj9YPtI+9T/aAUAB2AD5P0I/PD7+PxV//wCgAREA5IAPv68/dD9hPxK/kgDyAYwBDn/uPz0/Tr+kPxY/pgC8AQEA2wCzAJQAGj8sPn4+jT9GgBgBbAICAbOAED92Pvw+cD5OP2cAigG4ATEAiYBFf98/ib+aP1M/bT+YgB+AVABsgGQAwgEKwCc/Jj8iP5o/nT9zP74ALwC9APwBGwDuv74+sj6ZPzs/dr+aAL4BWAFcAEa/nz9SP10/eT9Dv97ANIBQAMgBLAA3PzI+yD9HP4gAUgFuAWgAsz+AP2o/AD9Af/+AJoATP8ZAOIBPAMMAvT/Qv5c/FT89v4iAbAA0ABaAVn/4P3M/uUAHAOUApQAuv7M/HD72Pyq/4wCCASoA/wBVf86/iT+xP74/gr/LgAsAUcA3//IAMIBcgHF//L+3P5q/87/Y/+I/rD+dgBgA2ADagGZ/8z9sPsI+xL+sAHYA9wDAAPMARz/HPxY+2j9Tf+Q/wQAsAAyASIBqgEUAmgBwP5k/ID70PxY/xABbgF0AmwDiAKrAF7/hv4w/bD76PvI/ZMA1AN4BkAGHAKQ/Qz8GPx4+yz8Nv8wA/gEgARoA5ABtP5k/Cz8IP0+/mv/vAJ4BTgF4AHE/kD9oP01/z8AtgDG/z8AMgFuAU8Aff/rAPwC0AKq/6z89PzM/j3/7f/0AhAGyAUkATT9yPtA+9D7Zv6cA/gGuAX4AWD+rPyg+7D7Qv6iAdgDcANIARMAPgA4/8D97PzQ/S7/PP+eANwCwAPJAHz+xv6+/rz8FPyQ/ngB3ALgAlAC4QA6/iT9mP2s/ej9cP8sAc4BEALUAdUAwP3g/IT+2v5U/hcAFAJyARgA5v/QAQgCUv9M/aT8jPyW/vgCWAWwBfAC/P3A+nD7PP7rAHgCbAJwAnQA1P59/wwCNAJS/zj9vP04AF8AVAFYArYBdv/8/UX/tQBiAYz/+v63ANQBaQDm/jr/lv/0/qb+ggA8AgQCJQAp/zL+UP4MAGABSgF7/xH/bgBmAFL/Lf+HAJwAmv8PAAIBFgDU/bj8Dv4sANwB0AJUAnkASv74/WD+Bv60/l7/CgE0AsoBpwDk/5j/1v5Y/vT90P6DAEQB9QD2/8j/b//8/y4BPAJKAXX/dP70/YD9TP6bAKgCHANcAoYByQDK/nT9NP7C/8MAhAEkAjwCgAG5/9j+bP9RAGoAdgDqAEQBZQCK/3X/5P8DAHYAqAEYAkkAJv5Q/Tj+L/9vACwCMAOkArUAmf+8/tj9IP1q/jgAHAGWAVQCCAOmATL/0P0A/pz9GP3I/oQBTAPgArABVQDQ/rD9KP04/j0AAAJEAvoAVP+w/v7+X/8FACgB8gHLADf/iv70/sn/SAAcAXQB6QCz//b++P6c/10AiwBvANUAaAHuACr/Cv5a/mb/6v9SAEwBtAHWAH3/4v7M/gD/uf+6ADIBaQBS/wf/Wf+F/6r/QADuAOwAXQAAAJj/P//c/g7/zv9gANIA2QDUAE4AwP8j/4D+jP5L/z0AmwBMAND/FgBGAF8APABe/9j+Of8iABgBeAGMABEA0/+s/zAAPgCpAIIAbAB3AEUAYgDvAHAB6ADo/1n/fP8JALkARgH8AQgC3gHZAJkAeABDAOP/bQDmAZACOAKcAagBCAGc/7L+uf/gAGwBpgGqAYQBmABR/6D+0P6p//b/wf+t/3j/MP+I/hD+Yv54/iT+hP1k/Zj9lP0Y/fD83PzA/GT8UPzc/Bj9rPxY/Gz8dPyE/FT8NPwg/FT8UPzE/Ez9IP44/kL+Lv5Q/iz+Gv58/oj+6v4i//P/DAGoAY4BmAFiAdIAYwADAOAAKAHMApgEWAaYBsgE6ANAA6QCLAI4A/gEWAeACHAJwAmACKAGgAVIBVAF8AVIB8AIQAlwCHgHEAdgBvAE0APEA6wDKAMcA4wDNANYAskAcf84/oT8gPto+3j7YPsY+/D6qPrA+Wj4QPdg9uD1APZg9hD3UPcA97D2QPbQ9QD2QPYw9nD2APdg97D3KPjw+Ij58Pnw+Rj6YPqQ+vD6oPtM/Oj8lP04/qj+I/+W/wIAWAB6ANsADgEiAYAB2gHEAlADAATwBBgGAAfwB+AIEAmwCBAJYAoAC/ALUA2wD+AQ8A/QDpANQA1QDfAN8A+gEIAQMA8QDpAMEAswCkAJgAjYBzAHcAawBfgDNAJMAFD+xPzw+7j7OPto+lj5KPgA99D1gPWA9YD1cPXw9LD0YPQg9BD0EPRw9OD0QPVw9aD1MPZw9lD2sPag9wD4SPiY+Gj50PmI+Yj56Pkg+vj54PlI+rD6OPtg+5j7wPu4+7j70PsE/Fj8AP1E/Wj9HP3I/Jz8EPwE/JD8NP1C/m3/IgDlACYBRAFAAVoB3gEoAxgFgAcwClANgA9gEKAPkA2QC4AJgAogDSAQQBPAFSAWoBQAEZANcAuQCkAKYAuwDHANIA1gC9AIeAVUAqz/LP7U/Tb+xP4q/lD90Ptg+SD3QPVw9PDzIPSw9KD1oPVw9SD1gPQw9ODz8POw9ND1sPbg96j4EPko+bD4sPho+Sj6KPs0/Nj8TP04/Rj9PP3o/Dz9iP2A/Uj9HP3w/Aj9ePzQ+2j7SPsw+yD7aPuY+4D7IPv4+uD6wPrI+uj66Pog+uD54PmA+mj7lPxC/ur+lP60/rL+Lv/o/6IBEASgBhAJYAxgDkAPsA2wCxALoAnQCvANIBLAFWAX4BYAFKAQsA3gC4ALcAywDcAOIA9QDtAMEApYBpgC4v+y/nr+Fv/+/yYAmP4Y/Gj5APdg9dD00PQQ9RD18PQA9UD1QPUw9YD1MPXQ9CD1EPZA90D4ePlA+uD6gPv4+5j8EP1w/XD93P1A/vj+0/+XACIB2gANAPL+UP5+/nj+sv6A/h7+OP0A/CD7qPpQ+hj6KPoA+kj6APrY+UD54PhA+MD34Pfg98D4OPnI+Zj6mPvA/IT92P3C/tL+rv8TAO4BEATQBsAJ4AzADsAPMA+ADpAN4AvQDIAO4BEAFSAYABkgF0AUgBDQDbAM8AxADnAPoA8gDlAMsAmQBhgEpgHk/5D+IP6Y/Xj9tPwo+zj5wPYA9TD04PPQ85DzUPMg8wDzMPPg82D0YPQg9ED0MPQw9YD2EPig+XD6+PpQ+8j7sPwg/dT9EP6k/kP/s/+VAHQB+gFWAUsAx/9Q/+T+JP+B/17/aP6g/YD8oPtA+5j6kPpw+tj5mPmA+Xj5YPk4+dj44Pdw95D38Pe4+ID5ePo4+yj7sPtI/AT9aP5i/54AdAGwAnAEcAcwCmAM4A1wD6APcA5QDqANoA3gDiARoBQgFyAYgBdgFcARYA5wDFAMsA2ADjAPoA4ADeAJWAbAA/oAI/+g/dj8zPyk/OD72PpY+XD24PNA8hDycPIw8/DzAPRw84DyEPKQ8kDzMPQQ9bD1IPaw9sD3EPm4+bj6kPtU/Gz93P4zAPYAAAF0AFAAPQDWABACVAOEAyQDFAKAAakAUf89//T+rP44/qD9FP2s/MD7IPsA+nj5iPgY+FD40Pjg+Ej5+PgI+ZD4oPcQ9/D28Paw92j5kPvU/Vf/XABEAAr/yP24/Z4AUAQACFAMoA/AEKAQkA9ADvAM0AuQDZAPQBPAFsAYYBngFoAT4A8ADSAM8AxgDnAP0A5QDSAL0AewBEACJgBs/ij9fPxk/KD7EPuI+XD3QPUA8+DxAPJA8jDzkPOw8xDzgPJg8qDyIPPw88D0EPYg99D3ePgQ+aD5MPog+5D8Sv7S/8gAOAHgAJYAhgC1AIQBKALoAhwDAANUAowBwgDc/wn/uP6A/g7+nP30/Dz8+PoI+tj4WPjg9/D3OPiw+Nj4oPiY+Bj4cPfg9tD2IPeA90j4+Pio+YD6PPw+/hQAZAAWAN7/sP/B/5gCmAYAC2AOoBBgEWAQAA+wDTANIA4gD6ARYBSAFqAXYBfAFQAToA+QDYAMkAwwDQAO4A2QDAAKGAdIBNgBvv8W/gz9APxY+7j6QPpI+XD3wPXg88Dy4PFg8hDzsPMQ9MDz0PPg8+DzYPRA9dD1oPaA97j4yPlo+vD6yPuE/IT9yv47AD4B4AH6AeYBdgG0AfwBaAIMAxADxAJYAiACPgGkAEUAv/8+/5D+Nv5c/ZD8aPu4+tj5EPmY+JD4+Pjg+PD42PjA+Cj4OPhA+Oj4aPmo+Xj5oPjw93D4OPq8/EL/VAL0AuwBh//g/Qf/0QDgBPAJYA5gEGARwBBQD2ANsAuAC+AMoA8AEwAWwBegFyAVIBIgD7AMQAxQDBANkA1ADSAMcAoQCHgF2AIlAFD+HP1E/PD7mPvQ+sj5iPgA97D10PQw9NDzkPNA84DzwPNg9PD0wPUw9pD2oPaA97D3MPj4+AD6yPrg+9j88P1L/7//YgCuANcAwgDOABYBogEQAiQCbAI8AvwBcAH2ADMApv8K/6T+Rv4s/sj9IP0Y/ND6yPno+Fj4GPgw+Gj4kPig+Nj42Pgo+bj4oPjA+Dj5oPnQ+UD6kPkA+UD48PmY/YIAEANABEgDfAEu/6j+pgBABHAIwAwAEIAR4BBwD4ANIAygCoALYA3gEAAU4BVAFuAUwBFADgAMgApQCsAKMAtQC3AKEAkIB1AFxAIUAOj9VPyA+xD7GPvo+vD5+PjA92D2kPUA9bD0QPQA9GD00PSw9XD2UPdw92D3UPdg9zD48PgA+gD7qPtQ/Aj96P32/pr/IAAbAA0ATABnAOIARgFuAaABlAGkAWQBNgHRAHwAaP/Q/mD+WP5Q/ib+KP6A/Uj84PrQ+VD52PiQ+Gj46Pgg+aj5SPrA+vD6sPow+mD60PnY+Zj6GPtw+4D7cPvY+0T9Tf9YAYgCGAP2AY4BEAGYATwDIAawCDALUA3ADrAPAA+wDTAMwAsQC9AMkA/gEWATABNAEgAQAA6ADEALoAowCWAI8AfoB3AH0AbQBagD4ABY/qj8aPuY+lD64Pkg+Vj4MPjQ97D3QPeQ9gD2QPXA9GD1MPZA99D3kPg4+bD5+PlQ+oD6oPqY+vj6BPxg/cz+wf+pAM0AigAnAPD///+8/9z/+/9qAIsA4QAqAf0APAAO/xb+6Pxw/Bz8qPxE/Vz9DP0s/Dj7yPnw+Hj4UPhg+JD4qPhg+WD5wPkI+kj6wPrw+kD7cPuQ+0j72Pp4+nD6IPsg/U//5ACGAXYB6QAd/3L/+wBIA4gFqAcwCZAJsAhQCPAIkArwCwANcA6wDoAOMA4wDuANwAxwDEAMoAwADYANwA1QDOAJ2AZoBOwCmAJQAxgEOAQoA5YBgf84/SD7cPlA+MD34Pfo+BD6uPqY+qj5iPgg90D2YPbw9vD3sPiw+dD62PuY/Jj8QPxg+4D6cPo4+3z8iP44APsAIAFeAKD/kv4C/tD97P02/tD+oP8NAAEAjf/c/qz94PxU/Aj8EPyc/PT8VP1U/fD8jPyQ+6j6+Pm4+dD5EPo4+uD66Pqo+hD7QPv4+8z8+P2S/mD+xP34/Pj7sPvg+5z9Rf+eAMQBwAEuAR4AdP+k/6sA7AGcA1AFyAYwBxAHuAb4BgAIAAlgClAMAA0wDUAMgAvACiAK8AnAChAMIA3ADSAN0AtACWAGaARYA1gDGATgBNAFIAW4A1oB0P4c/BD66PgQ+Qj6gPvM/Kz9PP2w+/j5EPhQ9yD3QPjg+Zj72Pw2/oz+TP6U/eD8NPyg+/D7iPxO/n3/kACKAdQBfAGQAPP/Lf94/uz9Lv4Q/6r/p/+0/4f/xv4o/lT9/Pyo/ND7uPv4++D7IPxs/Nz8VPxQ++j6iPpA+hD6IPrI+jj7cPvw+1T8aPxY/MD8fP0w/pb+DP9R/8j+OP6g/Yz9Fv7u/oH/UAB6AB8A2//E/+//wgCWASgCPAPgA0gEYASYBBAFyAV4BnAHIAngCoALUAugCkAJMAgwCEAJIAswDKAMwAuwCiAJMAdwBnAF+ASoBPgE6AR4BPADWAJ8AEj+vPzY+4D7uPvo+zD8APxw+wD7sPpg+vj5kPlg+Tj5uPmA+rj73Pyc/Q7+oP1Y/ej8FPzg+0T8PP1A/hv/BQBgACEAY/9O/qj9KP1M/aD9AP5Y/iz++P2c/fj8VPzg+2j7WPsw+zj7YPuY+/j7IPxU/Dj88Pv4+zT8WPwA/QT9JP04/VT9GP1s/UD+B//m/1wA/gByAVQBLgGRAEwALAAvALgAsAEkAhgCAAK0AWwBPgEgAT4BcgF4AcgBHAJkAvQCSAN4A7QDAASwBEAFsAUgBkgGGAa4BaAFQAbwBrAHYAjgCMAI+AcwB2gGiAXwBIgEoAT4BDAFKAX4BFgEWAMwAuoAGgB///D+oP6e/pj+nP6I/hT+pP3Q/OD7IPvA+tj64Pqg+zz8BP1g/Zj9SP3E/OD7WPvo+gj7aPvY+6D8+PyM/Wj9MP2s/IT8wPtw+2D7cPvI+zD88Pxo/Yz9jP2M/RD9SPwI/FD86PzI/bz+if/Q/83/wP9Y/y//KP9l/7v/GQCNAAIBCgHYADkADQCZ/zD/fv+w/xMA7f+G/yv/uP5k/jb+Iv4i/uD9sP1o/Tj9eP3Q/WD+qP7m/hn/a/+E/8H/8/9UAOUAvAEAAzgEmAVwBvAG2AZ4BlAGeAYIB8AHwAhgCcAJwAmQCWAJkAgACDgHyAaIBjgGQAZABugFUAXQBBgETAOkAiwC0gFWAQQBIAEkAS4B8gClACsAgP8N/+j+Dv8K/x//Df9E/0X/N/8I/7D+Kv6I/Uj9LP1k/aD9vP2Y/XD9BP2Q/Cz8uPtY+xD7uPqY+mj6SPo4+uj56Pnw+TD6kPrI+uj6sPqQ+jD6KPp4+vj6wPt4/Fj9+P1K/n7+eP6K/ob+aP52/q7+LP/Y/2MA5gAyAVABGAHQAIkAcABOAIIAyQBeAXwBjgG0AcYBqgFsAXoBfAF4AWoBfAGaAbQBoAHIAfIBYAJwAswC4ALoApgCoAKcAtACFANIA7wD1AMoBFgEaARYBCAEEAT0AxgEIARwBMAEuATIBIAEIATAA1QDJAMkAzQDjAOoA+gD9AOIA0gD5AJgAuABngGuAZgBbgFgAQIBcQBW/4L+GP5E/ZT8QPtQ+nD5mPiA+DD5yPmA+fD4gPcg9tD0UPRw9MD0kPXA9tD3SPiY+HD48Pdw9+D2YPeo+Nj5IPtY/Cj9SP1U/dT9Tv7W/jb/vP/mALIBIAKEAvQCLAM4A6gDaATwBCgFGAUgBSgFQAVwBSgGuAYoB0gHyAaQBiAGwAWYBUAF2AQ4BIADsALoARIBEQBx/xb/G/88/0b/c/9q/yT//v78/uz+4v7M/qj+mv7W/hn/mf+KACYB6gEoAroBUgF1ACMAOAAEARQC0AJ0A4wDDAP2Ac4Aef+y/jz+VP7I/mr/3P+t/8L+VP0k/DD72PqY+vj6aPuw+xj8TPyI/Kz8XPxY/Mz8DP38/Wr+Yv/7/7cAEgH8AVwDeASABUAGAAcwBxAH+AZwBngGwAYgB7AHYAigCGAI6AdYB6AGaAVABCwDVALMAWoBxAEQAgQCigGeAI7/Mv4o/bj8cPxg/ED8bPz4/ET9rP3o/fT9tP10/UT9PP1E/XT98P2U/kv/DAC7AM8AZADO/zL/xP6W/tr+Nf+F/1T/D/+8/jj+xP04/bz8VPwQ/Bj8QPyA/Gz8LPz4+7j7yPvw+zz8jPzE/OT8OP2Q/QT+ZP7M/if/r/8yAK4ANgFkAdYBsgHSASACmAIwA1wDlAOcA0gD0AJ0AhgClgF8AZgB0AEIAsgBXgHPAAQAav/0/rj+oP6S/qj+rP6c/pb+gv52/kb+WP5w/nb+pv7O/v7+Lf8r/2L/nv/n/xEAJQBgAHQAbQBUAFAAXgBpAFQAOwAoAAgADAAEACUALAAUAPf/s/90/yz/GP8o/zD/MP8s/zr/S/9K/zn/L/8G/+L+5P4K/0z/ev+X/5v/pP+u/7z/5v8jAEkAYgBYAEMANgArACcALAAlABkAIQAWAP7/tf9u/yr/8P7e/vL+CP8H//T+yv7A/qz+jP6A/oL+iP6K/pr+rP68/sz+0v7c/gn/Nv9Y/37/lv+y/9X/6/8gAFgAlgDoABIBRgFkAW4BZgFKATABDgH2APAA/AAcASQBMAEuASwBEgHgAL0AjgBaAEMALwAVABAAIABLAEgAOwA1ADAAHgAPACgAhgDRAC4BggHiAeoB3AHcAfYB8gHOAcwB2AHSAcIBxgHYAdABpgGIAWQBdgEiARgB/QDwANcA5QD5AP8A5AC3AJoASgAzACAAAwADABMAFwAdADMAJwA4AEUARgBvAJAAtADOANwA/QD3APUA/QDcAOUAogBlADIA/v/D/4n/Tf8t/wH/nP5c/gD+sP30/JD8hPwo/CD8uPvg+xD8HPx8/OD8CP2U/Bz8yPvg+yD8zPyw/UT+wP5b/5z/qf+Q/23/Y/9u/3//vP88AHQAYQBiAG4ANAAYACMALAAwABAACwBjAKUAxwAOAXoB5gE4ApgCAAM8A3QDoAPkA0gEkAToBEgFiAWwBbgFmAWABVgFGAXABFAE1ANIA7QCNAK6AUQBwAA+AMj/SP+k/uj9TP24/Bj8mPs4+9D6aPoY+sD5kPmA+WD5WPlo+XD5gPmY+bD5+Pkw+oj6CPuQ+wD8NPx8/Mj8DP1M/aj9Bv5+/uD+PP+F/7v/4v/2////BgAwAFwAlAC1AOQADAEsAVQBegGiAc4B5AEEAkgCbALQAvwCYAOgA+wDMARoBLgE8AQYBUAFaAWYBaAF0AXQBegFGAYoBiAGCAboBbAFcAUwBfAEiAQoBLgDXAMEA6gCaAIYAq4BLAGpADYAxP9Y/wb/uv5u/h7+7P3Y/bD9hP1Q/Sj9/Pzc/ND8yPzQ/OD8AP0o/UT9TP1M/Tz9KP0s/UD9ZP2Y/bT9xP3Q/cT9wP3Y/ej9CP4m/j7+YP6I/rb+4P78/hH/F/83/1j/iP+5/+X/DQAyAFQAjwCzAO8AIgFMAXIBkgHGAeQB/AH8ASgCJAIwAkACTAJgAjQCJAIkAv4BxgGkAZQBcgFgAVwBSgEgAdoAoQB6AFQANAAQAPz/7//P/7r/pv+J/3j/bv9m/07/Q/87/x//CP/u/uL+4P7M/sL+vv7C/rz+rP62/rz+vv64/rT+vP68/rL+sP62/sj+6v4J/yP/MP8z/z3/Qv9J/1T/Zf99/4j/jv+Y/7L/2f/y/wIAAgD1//7/CQAUACEAMAA5ADkATQBiAHUAhACOAJAAiQCBAHsAegBwAGYAXgBgAFwAYwBpAGoAWwBRAEwAQQA+ADYAJwARAAEA8P/2//v/9P/5//b/6v/g/87/tP+l/6T/pv+f/6f/v//E/8P/xf/Q/8v/xP/B/9P/z//c/9X/5v/9//n/DAD5//D/1v/H/8X/x/+4/7v/0P/O/8f/x//O/8r/s/+q/6v/pv+B/3r/iP+f/5r/kv+X/6T/rf+z/8v/6f/z/93/2//k/+n/7/8EACQASQBAADoAOwAqABUAGwArADoAPQA8AEsAVQBRAFAAUABQAEkAVQBkAGQAcwB2AIEAfgCBAIQAhACGAIkAhQCIAIkAjACXAJwAlQCMAJQAigByAGoAcAB0AHAAawBhAFUASQA9AEAAOAAsABcAAQDs/9z/2P/I/7z/sv+f/5D/fv9g/1D/Qv8v/zj/Pv88/zz/KP8V/w7/Ff8X/xH/H/8p/zD/Of8y/y7/LP8u/zn/SP9e/2v/cf9x/3z/kv+c/6X/pv+x/7b/sf+6/83/5f/2/wIADAAdADIAPABDAE0ASAA+AEgAXgCCAJ4AuADMANUA1QDVAOAA4wDlAOwA+AD4APoA/gAAAfcA6wDsAOwA3wDPAMwAzwDKAMAAvAC2AK8AlwCAAGsAVgA8AC8AKwAhAA8AAQD0/9f/wP+u/6j/pP+U/47/kP+S/4n/gf9x/1//WP9S/1n/b/+A/3//cv9q/2//Y/9k/3b/iv+Y/6T/rP+1/7z/s/+3/7f/wv/V/+P/7f/u//X/8//z//X/+/8AAA8AIQA/AFQAYQBjAGMAZABlAGcAbABzAHcAkACmALMAxADPANIAzwDAAMIAwQDIAL8AwQC/ALMAtQCzAMYAvQC3AKkAoACdAI8AgwByAGwAaQBnAGYAcABtAGEARAAnABgABQDt/+3/7v/j/9z/z//I/77/s/+u/5//k/+K/3z/cf9f/17/W/9l/27/c/93/2T/XP9R/07/Wv9l/3f/ff+D/3//ff+A/4L/gv+I/4//nv+r/7r/z//g/+T/5v/n//L//v/8/wEACwAUAA8AEAAiACEAHwAZABcAHwAcAB4AKQAyADEAKAApADIAMwA3ADkANgAsADcAPgA7AEEAOAApABcACgAJAAIA+f/0//j/9f/w/+f/3P/R/8T/u/+0/7b/tv/A/8H/uf+y/6r/qP+l/6L/o/+d/5P/h/+I/4j/kf+Z/6b/qf+m/57/k/+O/4L/hv+P/5r/qP+x/7b/v//K/83/1v/O/83/0v/b/+T/8f/8/wEABQD+//z///8GAA4AFQAaABsAIgAlADIANgAzADQALAApADEAOgBDAD8ANgArACkAJQAmACcAKAAqACcAMQAvACgAHgAiAB8AHwAnADQANgAsACQAIQAnACUAKQA0ADgAMgAxADUANQAyACMAHQATAAMA8v/m/9r/1//b/+b/6//x/+X/6P/W/8L/sv+n/6L/pv+t/6//sf+u/7L/tP+s/6b/ov+k/6D/pv+w/8T/zf/Z/9z/2//d/9v/4P/l/+v/8f/1/wEAAQALABIAEAATAB8AKAAwADwAQABCAD4AQwBQAF4AXABdAF0AWABYAF0AYQBlAGAAWABaAFsAXQBsAHgAfgB8AHcAeQB2AG4AbgB9AH8AeQB6AHoAdABlAGQAZgBnAGAAXgBdAFcARgA3ADMALQAcABEADQANABMAEgANAAMA9f/k/9//3P/S/83/yv/C/77/vv++/8L/v/+2/7D/qf+h/6H/mf+X/5b/lv+Y/5z/lv+O/4f/gP+D/4X/hf+B/4T/if+K/4r/k/+c/6H/o/+m/6n/pf+k/6z/uf+9/8L/zf/V/9r/4P/r//D/9v/2//X/+P/6////AwAEAAMACwAUABYAHwAjACQAIwAeACYAMwAwACcAIwAgAB4AHgAjACkAJQAcABIACwAAAPj/+P8FAAwAEQASABUAFAAJAAYABAAAAP3/BAAJAAwABwAHAAoACgAHAAMABAAAAPz/+//6//////8DAAQAAQAIAP//9//x/+T/3v/X/9j/2P/X/9f/4f/r//D/7//s/+7/7P/s//H/9v/5//n/+f8CAAMAAgAGAAoADgALAAoAEAARABYAGAAYABcAFAAVABYAHAAfAB4AJwAlACEAJAAlACcAJQAmACsAKgAqACYAHgAbAA4ACgAJAAkACgAQABEADAAKAAMAAwD2/+//8v/3/wIACgARABEABwD///z/+f/6//j//P/+////BAAOABcAGQAZABwAFQASAA4ADQATABgAIAApACkALAAqAC0AKgAoACUAHQAiACQAJgAeAB8AGAAUAAoA/v8EAAQABQANAAwACAACAP7/AwAKAAoACAAKABEADgAKAAsACgAEAP7//f/+//z/+P/z//X/9v/q/+j/5//o/+v/7v/w/+7/7v/u/+7/7//z//r/+v/8//3/AQABAP7/+//z//T/9P/1//7/BwAKAAoACgAJAAoADAAUABQAEgARABEAEwASABgAHAAfABwAFwAVABgAGwAbABgAGAAaABsAGAAUABIADwAMAA0AEgASABQAEwARABAADgAQABMAFQAUABAACwAKAAoADQAKAAYABQAEAAIAAQAAAAAA//8BAAMABQAJAAsACwANAA4ADwANAAsADQAOAAsABwAFAAUABAABAAAA/f/6//X/8//y/+3/5P/a/9D/xv/A/7//wv/E/8f/yv/I/8X/v/+8/7n/tP+w/6//sf+0/7r/wP/D/8D/vP+6/7v/wf/G/8n/z//U/9j/1//a/93/4P/h/+H/5f/l/+X/5P/o//L/7//0//7/CQALAAcAEAALAA4ACwAVABkAGwAbABwAHgAfACIAIgAhABsAGQAZACEAIwAnACsALgA1ADoAPwBEAEAAPgA8ADgAOQA3ADQANAAxADQAMwAwAC0AJgAgAB8AGwAZABcADwALAAsACQAIAAYA/P/0//H/6v/o//D/8//w/+7/5v/f/97/3//i/+X/5f/k/+L/4P/f/93/2//a/9j/2v/b/9z/3P/b/9v/2v/a/9r/3f/i/+T/5P/m/+n/7f/0//v/AQAFAAkADQAPAA8ADwARABUAGAAbAB0AHwAjACUAJwAoACcAJwAnACcAKAApACkAJwAnACgAKAAnACYAJQAjACMAIgAhAB8AGwAYABYAEwAOAAkABAD///z/+//8//3/+//5//b/8f/s/+n/6//u//H/8//0//H/7P/n/+L/4P/e/97/3//h/+P/4v/g/9z/2f/W/9X/1P/V/9b/1P/T/9H/0f/Q/9D/zv/L/8n/x//G/8f/yv/O/9H/1v/a/9//5f/s//L/9//5//r/+f/4//j/+//+/wIABQAGAAYACQAOABQAFwAVABIADwAQABMAGQAcAB0AHQAdAB0AHAAbABoAGAAYABYAFQAUABMAFAAUABMAEQAOAAsACQAHAAYABgAIAAsADwASABIADwALAAgACQALAA0ADgAPAA4ADAANAA0ADQALAAoACwANAA4AEQAUABcAGgAaABsAGwAeACAAHwAbABkAGgAbABcAGgAXABoAFwAcABoAFQAQAA8ACwACAAgAAQAKAAMAAwANAAcABAAIAAcAAwACAAgADgAUABQADQAMAAsABgAFAAoADgAHAAQABAAEAAMA/v/8//7/////////AAACAAEAAQACAAIAAwAEAAMAAwACAAIAAAAAAAAAAQABAAAA/v/6//n/+P/3//n//f/////////+////AAD///3/+v/3//b/8//x//H/8//z/+//6//q/+3/8P/u/+r/6f/p/+n/6v/r/+z/7f/u/+//8P/w//H/8//2//r//P///wEAAwADAAEAAAACAAUACQAKAAsADAANAA0ADgAPABAAEQASABUAGQAcABwAHAAcABwAGwAaABkAGQAaABkAGAAVABIADwALAAcAAwAAAP3/+//6//j/8//s/+X/4P/d/9v/2//b/9z/3f/e/97/3v/d/9r/1//T/9D/zv/P/9H/1P/W/9X/1f/V/9f/2v/c/9z/3f/d/93/2//c/9z/3//h/+D/4//i/+D/3P/c/+H/3//j/+f/7//w/+7/9f/0//j/9f/+//7/AAAAAAEAAgAEAAcACgAMAA0ADQAOABMAFAAWABgAGQAeACIAKAAuAC0ALwAtACoAKwApACcAKAAmACgAKAAmACYAIQAeAB8AGwAbABoAEwARABMAEQASABIADAAJAAgABAAGAAsACgAIAAgAAgD+//7//f/+/////f/7//v/+v/6//r/+f/4//f/9//2//b/9P/y//H/8P/w//H/8v/0//T/8v/x//D/8f/z//b/+P/6//z//v///wAAAAABAAEAAgADAAMABAAFAAUABgAGAAYABQADAAIAAAD///3//f/9//7///8AAAEAAQABAAEAAgACAAMAAwADAAIAAAD+//z/+f/3//b/+P/6//3//v////7//f/7//v//P/+/wAAAQACAAIAAAD+//v/+f/3//X/9f/0//P/8//x//D/7//u/+3/7f/s/+v/6f/o/+b/5v/m/+b/5f/l/+P/4v/i/+P/5P/m/+j/6f/r/+3/8P/1//n/+//9//7//f/+//7///8AAAEAAQABAAIABAAIAAsADQAMAAkABQAEAAUABwAHAAcABwAIAAoADQAPABAAEAARABEAEQAQABEAEwAVABgAGQAaABkAGAAXABYAFwAZABwAHgAhACMAIwAhACAAIQAjACQAJQAmACYAJQAmACcAJwAkACQAJAAkACQAIgAgAB8AHQAbABkAFwAYABgAFQARAA0ADAALAAcACAAEAAYAAgAIAAUAAQD8//v/9//u//H/6f/v/+f/5//u/+n/5v/r/+n/5v/m/+r/7v/z//P/7//y//P/8f/y//b/+//2//X/9v/3//f/9f/0//b/+P/4//j/+P/7//v/+//+/wAAAwAFAAUABgAIAAkACQAKAAwADgAPABAADwANAA0ADAALAAsADQANAAwACwAKAAoACgAKAAkABQADAAIAAAD9//3//v////7/+//6//3////9//n/9//2//X/9P/0//T/8//z//T/8//y//H/8f/z//X/9v/3//j/+f/5//b/9f/1//f/+f/5//j/+P/4//f/9f/0//P/8f/w//H/8v/z//P/8//y//H/8P/v/+7/7v/u/+//7//u/+7/7f/q/+j/5P/i/+D/4P/h/+H/4P/e/9v/2v/a/9v/3P/e/+D/4//n/+r/7f/u/+//7v/u/+7/7v/v//L/9f/3//j/+f/7//7/AgAEAAUABQAFAAUAAgACAAIABQAGAAYACAAJAAgABAAEAAgABAAGAAgADgAMAAoAEAAOABEADQAUABMAFAATABMAEwATABUAFwAXABgAGAAXABkAGAAWABUAEgATABMAFQAYABUAFgATABAAEQAOAAsACwAJAAsACgAJAAkABQAEAAQAAAD///3/9//2//f/9v/3//j/9P/z//X/8//1//v/+v/6//v/+P/3//j/+P/6//v/+v/5//r/+v/6//v/+//7//z//f/+//////////////8AAAIAAwAFAAYABQAEAAQABQAGAAcACAAJAAsADAANAA0ADQANAA0ADQAMAAwACwAKAAkACQAIAAcABgADAAAA/f/7//j/9//2//X/9f/1//X/9P/0//P/8v/y//L/8v/y//L/8v/x/+//7f/r/+v/7P/u/+//8f/x//D/7v/t/+v/6//s/+3/7v/v//D/8P/w/+//7//v/+//8P/w//H/8f/y//L/8//z//P/9P/1//X/9f/1//b/9//5//z//v8AAAEAAwAFAAgACwANAA8AEQASABMAFQAYABoAHAAcABwAHAAcABwAHQAdAB0AHQAdAB0AHQAfACEAIQAfABsAFgATABIAEQAPAA0ADAAMAA0ADwAQABEAEAAPAA4ADAALAAoACgALAAwADAAMAAsACQAGAAQAAwACAAMABAAFAAUABQADAAIAAgADAAQABAAFAAUABQAGAAcACAAGAAYABwAIAAgABwAGAAUABAADAAIAAAACAAQAAwAAAP7///////3//v/8/////P8CAAIAAQD9/////P/2//v/9P/9//b/+P8AAPv/+v////3/+//5//z//f8AAP//+//9/////P/8////AwD///7///8BAAEA/v/9//7/AAD+//z/+//8//z/+v/8//3//v/+//3//v/+//////8AAAIABAAFAAYABgAEAAQAAwACAAEAAQAAAP7//P/5//n/+P/4//f/9P/z//T/8//x//H/9P/2//X/9P/0//b/+f/4//T/8v/x//H/8f/x//H/8f/y//L/8v/x//H/8f/y//T/9P/1//X/9v/2//T/8//z//T/9f/1//X/9v/3//b/9v/1//T/8//y//L/8//0//T/8//z//P/8v/w/+//7//w//H/8f/y//L/8v/x/+//7f/s/+v/7P/t/+//8P/v/+7/7v/v//D/8f/y//T/9v/5//z///8AAAEAAQABAAEAAgAEAAcACgAMAA0ADgAPABAAEgASABEADwAOAAwACgAJAAkACwANAA0AEAARABIADgAPABMADwARABEAFgAUABAAFQASABQADgATABEAEQAPAA4ADgANAA8AEAAQABAAEAAOABAADgANAAoABwAHAAUABgAIAAQABAABAP7////8//r/+v/5//v/+v/6//v/+P/3//j/9f/1//T/8P/v//H/8P/z//T/8v/x//P/8v/z//j/+P/4//r/+P/4//r/+v/8//3//f/9//7//v////////////7//////////v/+//7///8AAAEAAwAFAAYABwAHAAcABwAIAAkACQAJAAkACQAJAAkACAAHAAUABAADAAEAAAD///7//f/9//3//P/7//n/+P/3//b/9v/2//f/9//3//f/9v/1//T/8//z//L/8v/z//P/9P/0//T/9P/0//T/9v/4//r//P/8//v/+v/5//j/9//3//j/+f/6//v/+//8//z//P/9//3///8AAAEAAgADAAQABQAFAAYABgAHAAcABwAHAAcACAAJAAsADQAPABAAEQATABQAFwAYABoAGgAaABoAGgAbABwAGwAaABkAGAAXABYAFQAUABMAEgARABAADwAQABAAEAAOAAsACAAGAAYABgAGAAUABAAFAAYACAAJAAkABwAGAAQAAgAAAP7//v//////AAAAAAAA/v/9//z//P/8//z//f/+///////+//3//f/9//3//v/+//3//P/9//7//v/8//z//P/8//z/+v/6//n/+f/4//j/9//5//v/+//5//f/+f/5//f/+f/2//n/9v/7//r/+f/2//n/9//z//j/8//8//b/+P8BAP3//f8CAAEA///9/wAAAQADAAIA/v8AAAEA///+/wEABAAAAP7///8AAAAA/v/9//7/AAD///7//v////////8AAAEAAgADAAEAAQABAAEAAAD/////AAAAAP///v/8//v/+v/5//f/9//3//b/9P/z//P/8//0//T/8v/y//P/8v/x//H/8//1//T/8f/x//P/9f/0//H/7//v/+//8P/x//H/8v/z//T/9f/1//T/9f/2//b/9v/2//b/9//3//X/9P/0//X/9v/2//b/9//3//f/9//3//f/9v/2//b/+P/5//n/+f/6//r/+v/5//j/+P/5//r/+//7//z//f/8//z//P/7//v//f///wEAAwAEAAQABgAHAAkACgALAAwADgAQABIAEwAUABQAEwATABMAEwATABQAFQAWABUAFAAUABQAFAATABIAEAAOAA0ACwALAAoADAAMAAwADgAPAA4ACwAKAA0ACAAIAAcACgAHAAMABwADAAUAAAAEAAIAAgAAAP///v/+//////////7//f/7//3/+//6//j/9f/1//P/9f/3//T/9v/0//L/9f/0//P/9f/z//b/9v/2//j/9f/2//f/9f/3//f/9P/1//j/+P/7//7//f/+/wAA//8BAAYABQAFAAYABAAEAAUABAAFAAYABQAFAAUABQAFAAUABAAEAAQABQAFAAUABQAFAAYABQAGAAcACAAIAAgABwAFAAQAAwADAAIAAQD///7//f/9//z/+//6//n/+P/3//b/9v/1//T/9P/0//T/9P/0//P/8//y//L/8v/y//P/9P/0//X/9f/1//X/9f/2//b/9//4//n/+v/7//z//P/8//3//v///wEAAgACAAIAAQABAAEAAQABAAIAAwAEAAYABwAIAAgACQAJAAoACgALAAsACwAMAAwADAANAA0ADQANAA4ADgAOAA4ADwAQABIAEwAUABQAFAAUABUAFQAVABUAFAASABAADwAOAA0ADAAKAAkABwAGAAUABQAEAAQAAwACAAEAAAABAAIAAgABAP///P/7//z//f/9//z/+//7//z//v///////v/9//z/+//6//n/+f/6//v//P/9//3//f/9//z//P/8//z//f/+//7//v/9//z//f/9//3//v/+//3//P/8//3//f/7//v/+//8//z/+//7//r/+//6//r/+f/6//z//P/7//n/+//7//n/+//5//r/9//9//z//P/6//3//P/4//7/+f8CAPv//f8FAAAAAAAFAAIAAAD+/wAAAAACAAAA/P/+/////f/9////AgD///3//v8AAAAA///+////AQABAAAA//8BAAAA//8AAAEAAQABAP/////+//7//f/8//z//P/9//3//P/6//r/+v/5//n/+f/5//n/+P/3//j/+f/6//r/+P/5//r/+v/5//n/+//9//z/+v/5//v//v/9//v/+f/6//r/+//7//z//P/9//7//v/+//3//f/9//7//f/8//z//P/8//r/+P/4//n/+v/5//j/+f/5//j/+P/4//j/9//2//b/9//3//j/+P/4//j/+P/3//b/9v/3//f/9//4//n/+v/6//r/+v/6//r//P/+/wAAAQACAAIAAwAEAAYABgAHAAcACAAJAAoACwALAAsACgAKAAoACgAKAAsADAANAAwADAALAAsADAAMAAsACgAKAAkACAAIAAgACwALAAsADgAPAA8ACwAMAA4ACgAKAAkADAAJAAUACQAGAAcAAgAHAAQABAADAAIAAQAAAAEAAgABAAEA///9/////v/8//v/+P/4//b/9//5//b/9//2//T/9//2//X/9//1//f/+P/4//r/+P/4//r/+P/6//r/9//3//r/+f/8//7//P/9//7//P/+/wIAAQABAAMAAAAAAAEAAQADAAQAAwADAAQABAAEAAQABAAEAAMABAAEAAQABAAEAAUABAAFAAYABgAHAAcABgAFAAUABAAEAAMAAgABAAAA//////7//f/8//v/+v/6//n/+f/5//j/+f/5//n/+v/6//n/+f/5//n/+f/5//n/+v/6//r/+v/5//j/+P/3//f/9//4//j/+f/6//r/+v/6//r/+//8//3//v/+//3//P/8//v/+//7//v//P/9//7///8AAAEAAQACAAMABAAFAAYABgAHAAgACAAJAAkACgAKAAoACgAKAAoACgALAAwADAANAA0ADAAMAAwADQANAA0ADAALAAoACQAJAAkACAAHAAcABQAFAAQABAAEAAQABAADAAIAAgADAAQABQAEAAMAAQAAAAEAAgADAAMAAgACAAMABAAFAAYABQAEAAMAAgAAAP///////wAAAQABAAEAAQAAAP////////////8AAAAAAAD///7//v/+//7///////3//P/8//3//f/7//r/+v/6//r/+f/5//n/+f/5//j/+P/5//v/+//6//n/+//7//r/+//5//r/9//9//z/+//5//z/+//3//z/+P8AAPn/+/8DAP7//f8CAAEA/v/8//7///8BAAAA/P/+/wAA/f/9/wAABAAAAP7///8BAAEA/////wAAAQABAAAAAAABAAEAAAABAAIAAgADAAEAAQABAAIAAQAAAAAAAAAAAAAAAAD+//7//v/9//z//f/9//3//P/7//z//f/+//7//f/+////////////AQADAAIAAAD//wEAAwACAAAA/v/+//7//v/+//7//v/+///////+//7//f/9//3//f/8//z//P/8//r/+P/4//j/+f/4//f/9//3//b/9v/2//b/9f/0//P/9P/1//X/9f/1//X/9f/0//P/8//0//T/9P/1//b/9//3//f/9//3//b/9//4//r/+//7//v//P/9//7/////////AAABAAIAAwAEAAQABAAEAAQABAAEAAUABgAIAAcABgAGAAYABwAHAAYABgAFAAUAAwAEAAMABgAHAAcACgALAAwACQAKAA0ACQAJAAkADQAKAAYACgAHAAkABAAIAAYABgAFAAQAAwACAAMAAwADAAMAAgAAAAMAAgABAAAA/v/+//z//f////z//v/8//r//f/8//v//P/7//z//f/9/////f/+/wAA//8AAAEA/v/+/wAA//8BAAQAAgABAAMAAAABAAUABAAEAAUAAgACAAMAAwAEAAYABQAFAAYABQAGAAYABgAFAAUABQAFAAUABAADAAMAAwADAAMAAwAEAAUABAAEAAMAAwADAAQAAwACAAIAAQABAAAA///+//3//P/7//r/+f/5//j/9//3//f/9//3//f/9//3//b/9v/2//f/9//4//j/+P/4//f/9//2//b/9v/2//b/9v/3//f/9v/2//b/9//3//n/+v/6//r/+v/5//n/+f/5//n/+v/6//v/+//8//z//P/9//3//v/+//////8AAAAAAQACAAMAAwAEAAUABQAFAAUABgAGAAcACAAIAAgACAAIAAgACQAJAAoACQAJAAgACAAIAAkACQAIAAgABwAHAAcABwAHAAcABwAGAAUABAAFAAYABwAGAAUAAwACAAMABAAFAAUABAAEAAUABwAJAAoACgAKAAoACQAHAAYABQAFAAUABgAGAAYABQAFAAQABAADAAMAAwAEAAUABQAEAAMAAwAEAAQABAAFAAMAAgACAAMAAwABAAEAAAABAAEAAAD////////+//3//P/9///////9//z//f/+//z//v/8//3/+f/+//7//f/7//7//f/5//7/+f8AAPr/+v8BAP3//P8BAAAA/v/8//3//v8AAP//+//9/////P/8//7/AgD+//3//f///////f/8//3//v/+//z//P/9//3//P/9//3//v////7//v/+////////////AAAAAAAAAAD//////v/9//3//f/9//z/+//5//n/+v/7//v/+f/6//v/+//6//r//P/+//7//P/7//3///////7//P/8//z//P/8//z//P/8//z//P/8//z//P/8//z//P/8//z//P/8//v/+v/6//r/+//6//r/+v/6//r/+v/6//r/+f/4//j/+P/4//j/+P/5//n/+f/4//f/9//3//f/9//3//j/+P/5//n/+P/4//f/9//4//n/+v/6//n/+v/7//v//P/8//z//P/9//7///8AAAAAAAABAAEAAQACAAMABAAGAAYABQAFAAYABwAHAAcABgAGAAUABAADAAIABAAEAAMABQAHAAcABQAGAAkABgAHAAcACgAJAAYACgAIAAkABQAKAAgACAAHAAcABgAFAAYABgAGAAYABQAEAAYABgAFAAUAAwADAAEAAgAEAAEAAwABAP//AQAAAP/////+//7//v/+/////f/9/////f/+/////P/8//3//P/+/wAA/v/+/////f/9/wEAAAD//wAA/v/+//7//v///wAA/////wAAAAAAAAEAAQAAAAAAAQABAAEAAAAAAP///v/+//7//v/////////+//7//v////////////////8AAAAAAAAAAAAA//////7//v/9//z//P/7//v/+//7//r/+v/5//n/+f/5//n/+f/6//r/+//7//v/+v/6//r/+v/6//r/+v/6//r/+v/6//r/+v/6//v//P/9//3//f/9//3//f/9//3//f/+//7///////////8AAAAAAAAAAAAAAAABAAEAAQABAAIAAgADAAMAAwADAAMAAwAEAAQABQAFAAUABQAFAAYABgAHAAcACAAHAAcABwAHAAcACAAIAAgABwAHAAcACAAIAAgACAAIAAcABgAGAAcACAAHAAYABAADAAIAAwADAAIAAQAAAAAAAQADAAQABQAFAAYABgAFAAQAAwADAAQABAAFAAUABAAEAAMAAwACAAIAAQACAAIAAgACAAEAAQABAAIAAgADAAIAAQACAAMAAwACAAEAAQACAAIAAQABAAEAAQAAAP///v/+/wAAAAD///3///8AAP7/AAD+////+/8AAP/////9/wAA///7////+v8BAPv/+/8AAP3//P8BAAAA///9//7///8BAAEA/v///wEA///+/wAAAwABAAAAAAACAAIAAQAAAAEAAgABAAAA//8AAP///v/+//////8AAP7//v//////////////AAAAAAEAAgABAAIAAQABAAAAAQABAAEA///+//7//v/+//7//P/8//3//P/6//r/+//9//3/+//6//z//v////3//P/8//z//P/7//v/+//7//v/+//7//v/+//7//z//P/7//z//P/9//z/+//7//z//P/7//v/+//7//v/+//8//z/+//6//n/+v/6//r/+v/7//v/+//7//r/+v/6//r/+f/5//r/+v/7//v/+//6//n/+f/5//r/+v/6//r/+v/6//v/+//7//v/+v/7//v//P/9//3//f/9//3//f/9//3//v8AAAAAAAAAAAEAAwADAAQABQAFAAUABAADAAIAAwACAAEAAgADAAQAAgACAAUAAQACAAEABQAEAAEABQADAAUAAQAFAAQABQAEAAQAAwACAAMAAwADAAMAAgABAAMAAwAEAAMAAgACAAAAAQADAAEAAgABAAAAAgABAAAAAQD//wAA/////wEA/////wAA//8AAAEA/v/9//7//f/+/wAA///+/////f/9/wAAAAAAAAIAAAD//wAA//8AAAEAAAAAAAAAAAABAAEAAQABAAEAAgACAAIAAwACAAIAAgABAAEAAQABAAIAAQABAAAAAAAAAAAAAAD///////////////8AAAAAAAAAAAAAAAAAAP////////////////7//f/9//z/+//7//r/+v/6//r/+v/6//r/+v/6//r/+v/6//r/+v/6//r/+v/6//n/+f/5//n/+v/7//v//P/8//z//P/8//z//P/8//z//P/9//3//f/+//7//v//////////////AAAAAAAAAQABAAEAAQABAAEAAQABAAIAAgACAAIAAgACAAIAAwADAAQABAAEAAQAAwAEAAQABQAFAAUABAAEAAQABAAFAAUABgAFAAUABAAFAAYABwAIAAgABgAFAAUABQAFAAQAAwABAAAAAAAAAAEAAQACAAIAAwACAAEAAQABAAEAAgADAAMABAADAAMAAwADAAMAAwADAAMAAwADAAIAAgACAAIAAwAEAAMAAgACAAMABAADAAMAAwADAAQAAwADAAMABAADAAMAAQACAAMAAwACAAAAAgACAAEAAgABAAEA/v8CAAEAAgAAAAMAAwD//wIA/f8EAP7//f8CAP7//f8BAAEAAAD+//////8CAAIA//8AAAEA///+/wAAAwABAP//AAABAAIAAQAAAAIAAwADAAIAAgADAAMAAgACAAIAAgADAAEAAQABAAEAAAD//////////wAAAAD//wAAAAAAAP//AQABAAIAAQAAAAAAAQABAAEAAAAAAAAAAAD+//z//f////7//P/6//v//v/+//7//f/9//3//f/8//z//P/8//z//P/8//z/+//8//z//P/8//z//f/+//3//P/8//3//f/9//z//f/9//z//f/9//7//f/8//z//P/8//z//P/8//3//f/9//z//P/8//v/+//7//v//P/8//z//P/8//v/+//7//v//P/8//v/+//7//z//P/7//v/+//7//v//P/9//3//f/9//3//P/8//z//P/9//3//P/8//z//v///wAAAQACAAMAAgADAAIAAwADAAIAAwAEAAQAAgACAAUAAgACAAEABAADAAAAAwABAAMA//8EAAMAAwADAAMAAgACAAIAAgACAAIAAQAAAAIAAgACAAIAAQABAP//AAABAAAAAgABAP//AQAAAP//AAD////////+/////v/9/////v///wAA/v/9//7//P/9/////f/9//3/+v/6//3//P/9//7//f/8//3//P/9//7//f/9//3//f/9//7//v/+//7//v//////AAAAAAAAAAAAAAAAAAABAAEAAQABAAEAAAAAAAAAAAAAAP///////////////////////wAAAAAAAAAAAAAAAAAAAQABAAEAAQABAAEAAAD//////v/+//7//v/+//3//f/9//3//P/8//z//f/9//3//f/9//z//P/7//v//P/8//3//f/9//3//f/8//z//f/9//3//f/9//7//v/+//7//v////////////////8AAAAAAAABAAEAAQABAAEAAQABAAIAAgACAAIAAgACAAEAAgACAAIAAwACAAIAAQACAAIAAwADAAMAAwADAAIAAgACAAMAAwADAAIAAQABAAIAAwAFAAUABAAEAAQABQAGAAYABAADAAEAAQAAAAAAAAAAAAAAAAD///7//f/9//3//f/+//7//v/+//7//v/+//3//f/9//7//v/+//3//f/8//3//f/+//3//f/9//7//v/9//3//f/9//7//f/9//7////+//7//P/9//7////+//3//v/+//3////9//3/+v/9//3//v/8///////8////+v8BAPz/+/////z/+v/+//7//P/6//v/+//9//3/+v/8//3/+//5//v//v/8//v/+//8//3/+//6//z//f/9//3//f/+/////f/+//////8AAP///////wAA///+//7//v/+//7//v/9//7//f/9//z//f/+//7//v/9//3//v///////v///wAAAAD+//3//v8AAP///f/7//v//f/+//3//f/9//3//P/8//z//f/9//3//f/9//z//P/8//z//P/7//v//P/9//3//P/7//z//f/8//z//P/9//z//P/9/////v/9//3//f/9//3//f/+///////////////////////+//7/////////AAAAAP///v/+////AAAAAAAAAAAAAAAAAAD//////v/+//7//v//////AAAAAAAA///+//////8AAAAA///9//3//v/+//////8AAAEAAAAAAAAAAQABAAAAAgADAAQAAgACAAUAAgACAAEABQAEAAAABAACAAQA//8EAAMABAAEAAQAAwACAAIAAwADAAMAAgAAAAIAAQABAAIAAAAAAP7//f////3///////3/AAD///7/AAD+///////+/wAA/v/+/////v8AAAEA///+/////P/9/////v/+//7/+v/5//v/+//7//3//P/7//v/+v/7//z//f/9//3//f/9//3//f/+//7//v/+//////////////////7//v///wAAAAAAAAAA/////wAAAAAAAAAA//////////8AAAAAAAAAAAAAAQAAAAAAAAAAAAAAAQABAAEAAgACAAIAAgABAAEAAAAAAAAAAAAAAP////////7//v/+//7//v///wAAAQAAAP///v/+//7//v////////////7//f/8//z//P/8//z//P/8//3//f/9//3//f/9//3//v/+//7/////////AAABAAEAAgACAAEAAQABAAIAAwADAAMAAwACAAEAAQABAAIAAgABAAEAAAAAAAAAAQABAAIAAgACAAIAAgACAAIAAwADAAIAAAD+////AQACAAIAAQAAAP//AAABAAIAAwACAAAA/////wAAAAACAAMAAgAAAP7//f/8//z//f/+//7//v/9//z//f/8//z//P/8//3//f/9//z/+//6//v//P/8//z/+//8//z//f/8//z//f/9//z//P/8//7/AAD///7/+v/7//v//f/8//z//f/+//z//f/8//3/+v/9//z//f/8/wEAAwD9/wIA/f8EAP////8GAAMAAQAFAAcABAABAAAA/v8BAAEA/v8BAAIA/P/5//v/AAD///7//v8AAAAA/P/7////AQABAAAAAAACAAEAAAACAAMAAwACAAEAAgADAAMAAgAAAP///f/9//7///8AAAAA///9//z//f8AAAEAAAD+/////////wAAAQADAAQAAgAAAP7/AAADAAQAAgAAAP//AQACAAMABAAGAAQAAwACAAIAAwAEAAUABQAEAAIAAQABAAAAAAD///3//f/9//3//P/7//v/+//7//z//f/+//3//P/+/wAAAAD/////AAAAAP////8BAAIAAgACAAIAAgACAAIAAwAEAAUABAAGAAcABgAHAAcABwAEAAIABAAGAAYABQAGAAcABQACAAEAAgABAP//AAACAAIAAQABAAIAAQD9//v//f8CAAQABAADAAMAAQD+//3/AQAFAAcABAAGAAQAAQD//wIABgAGAAUABAAFAAQAAgABAAIAAgD///7/AwADAAMAAAAEAP3//v///wMABQADAAcABAADAP//AQABAAAA//8AAAMA///9//z/+//5//f/+P/9//////8CAAMAAwD///z/AAADAAUACAAHAAoABAACAAYABgAIAPz//P/1//b//v8FABIACwD6/+f/4v/b//L/DAAXABkAAADp/9j/5P/3/wgADwANAAYA8//h/+X///8TAAwA//8BAAAAAQD//xIAIQASAP7/+/8HAA8ACwATABwAEAD1/+n/+P8EAAYABgAIAAcA9//t//f/BQAGAAcACQAKAAsA/P/8/wQABAADAAYABgAEAAAA+P/1//T/9P/1//b/+f/2//T/7//q/+j/6v/t/+//9f/6//7/9P/m/9n/zv/N/9b/7P8BAAUA+P/j/9X/1f/g//X/DgAbAB4AFQALAAcABQAMABIAGgAdAB4AIgAqACgAHAASAA8AGAAgACUALgA2ADIAIAAMABQAFwAUAA8ACAAKAPX/6f/m//f/7P/Z/8z/zf/M/8v/2v/v/wEA+//n/+L/9f8LABoAMwA8ADkAKAAeADUASwBXAFMASQA4ABwADwAXACkALAAPAO7/zv+4/7X/yP/i/+X/yv+s/5j/lv+q/83/7v/4/+n/1v/K/8r/1//t/wIABQD9//P/7v/s/+z/8//4//r/+P8FAA8AFQATABAAGAAaABgAGwAnACoAJQAkACYAJgAbAAwABgD+//b/+P8JABEACgD2/+X/2//Y/9X/7f8EAAsABADv//z//P/6//b/AgAUAAsABAAOACgAIgARAAYA///3/+////8jADMAGAD8//D/5//b/9///P8VAA0A9P/g/9v/1v/Y/+T/9v/8/+3/4f/g/+b/7P/w//P/8v/v/+r/5//w//z/AQD4/+r/4f/m//H//v8KABAACgD7//L/9/8HABcAIQAjABsADgALABIAIAAmAB4AFQAMAAkACwAOABUAEAAAAPD/7P/4/wMADAALAAMA8//l/+X/9f8EAAcAAwD2/+v/5P/o//L///8CAPz/9v/y//L/9v/9/wQABwACAAMAAgAFAAcAAwAAAPv/9f/1//r/+P/2//L/8P/u/+z/8v/3//j/9f/0//T/+P/6/wUABQALAAcAAQD+//X///8DAAoABwAIAAYAAwD2//H//f8EAAMAAQAKABAABQD9/wQAGAARAAEA+f8DAAcAAQADABIAFQD3/9n/2f/z/wAACgAfACwAGgD0/+T//f8WACMAMAA8ACwADQD3/wIAHgAhABoAFwARAAAA8v/7/xEAHAASAPv/9f/x//P/+f8KABEABQDw/+f/6f/v//T/9//9//j/6v/f/+r/+f/7//b/9v/1//H/8//+/w0ADwAAAPf/9P/4//7/DAAYABUACAD3//H/9v/7/wQAEQANAP//9P/o/+j/6v/q//j/+v/y/+f/6v/z//D/7v/s/+//9f/3//7/CgALAAAA8f/y////DQAUABUAFwAPAAIA/v8JACEAJgAdABIADQAQABIAFAAWABYAAgDt/+7//v8NAA8ABQD3/+j/2//g//n/EgAYAA8A///4//n/CAAXACcALAAjAA0A/f8CABAAGAARAAoABwD9/+3/6P/w//n/9P/s//D/+f/z/+n/6v/u/+P/2P/h//H/9//r/+b/8v/y/+L/2v/j/+v/7f/x/wMAGAAQAPT/6v/v//T/+P8LAC4ANAAfAAcAAAACAAUACgAZACsAIgAXAA4ADQALAAYABAABAP//+P/7/wUAEAAMAAMA9P/p/+T/7v///w8AEwAOAAgAAAD8//j/BQARAA8ADAAOABUAHgAaABoAFwAYAA8AFgAqADYAOAAiABkADQAFAP3//f8IAAoA///s/+n/7P/o/9r/2f/g/+b/5f/m//X/AQDv/+D/3//m//b//P8FAAwAAgDx/9z/2v/p//n/CQALAA8A///s/97/4f/7/woAFgAWABAABgD1//P///8UABUACwAHAAgABQABAAcAFAASAPr/6//3/wcADwALAA0AEQD8/+r/7/8NABgACQAFAAMAAAD1//P/CQAVAAcA9f/4/wgACwACAAMABAD+//T/+v8DAA0ABADs/+j/6//w//b/AQALAAgA9//s//T//f8GAAwADwAPAAkABwAEAAMA9v/z//b/+f//////AADy/9v/zf/X/+3//v8OAA0ABwDv/+L/5//+/xQAGgAeABUACQD9//j/BwAWABIAAADy/+r/9//+/wgAFQAWAP//5P/c/+r/CQAXABwAGQAJAO7/3f/q/wIAEwAGAPz/9//w//P//P8KAAwA+P/h/+D/8v8CAA4ADwAMAPn/3//U/9////8OAA0AAAACAPn/5//i//b/CgANAAcABgAOAAIA6//s/wQADQAHAAQACAANAPT/5P/s/wAABwAIAAcACQACAPf/7v/7//T/+//3//z/AgADAPX/6//o/+b/5v/e/+D/6v/p/9//3f/u//n/+//s//D/9P8BAAsAGwAxADEAHgAKAAcAEwAZACUAIwAnACMAFQALABAAEAAEAAEABgAXABwAFQAHAAMA8//t//r/CQASAAUA7f/f/+X/8v8LABkADAD1/9z/0f/g/wIALwBCACYA9f/g/93/4////ykAQgAkAPf/4P/q/+z/8P8EABwADgDi/9P/7P/9//r/9P/z/+3/1P/L/+P/AQD///P/8P/h/9D/0//s/wkADwD9//L/7//h/97/8/8IABYACwAFAAYA///z/wMAHwAtACUAEwATABgADgAFABYALAAnAAkA+v/8//j/6//x/w0AFAD3/9z/5v/1//b/+v8RACAADgDx/+7/EAApACgAJAAkABkAAQD6/w8ALQA0ABEA/v8BAAYABQD6//r/AQDy/9//8P8SABoA+v/W/8f/wP+9/9b/CwAiAP3/wf+w/7j/w//V//7/HgAFANv/0//m/+z/7v/+/xUACADr/+//EAAdAAQA+/8HAAoA/P/4/xkAKQAYAAUA//8PAAEA8f8FABgAFQD//wcAHQAcAPr/7P/6/wIA//8DACAAKwAJAOr/7P/7//7/+f8SACYAEwD3//H/CgAYABMAGgAfABgABwAHAB4ALwAwACUAFgABAOH/4//2/wMADQAPAAYA7//S/8//2P/m//D/+v8NAAgA+//y//X/7f/v//H/7f/v/+j/+v8HAAkAAwDt/9f/xP/I/+f/CwAgACEAAQDZ/7n/xf/x/xYAJQAjAA0A4v/B/9X/BAAtADQAIQAMAOn/z//n/x8ASQA0AAsA9//y/+3/8/8jAEUAMwDt/9f/6v8GABUAHQA2AB0Az/+r/9b/HAAzABoAEQAKAOD/sf/D/w4ALAAEAOn/9v/5/9z/0v/8/xkA/f/P/9n/DQAbABEAFgAfAAoA3//Q/+3/EwAgABwAEQD+/+L/y//T/+j//f/9/+7/6P/q//7/CgADAPr/8P/o/+b//P8jADcAJQACAOP/2P/p/wgALwA1ABAA3v/I/93/AQAaACoAHgD4/8//xP/q/x0AOAArAA4A8f/d/93/9v8QAB0AEAD6//j//P8DAAAAAAACAP3/9//9/woADQABAPL/9P/5//7/+//4//n/8f/t//f/AQANAA4A9v/r/+3/9/8IABEAFwAOAPr/7f/z//j////9/woAAwAIABEAFQAKANz/2P/t/woADwAfADgAKQDU/5b/u//4/wcA+/8RACEA2/+K/5z/BgAiAOH/vP/l//j/y//K/ywAcQAbAKX/q/8IACIAFwBTAKIAagDQ/4v/5v8zACcAJwBfAF4A9v+j/9r/PwA2AP3/AgAfAAAAy//v/00AYwASAMn/1P/j/97/8v89AGAAIwDV/8//7//8//7/GgBAACwA8f/e/wkAJgASAPz/BAACAOb/4P8IACsAHADt/97/2//N/8v/+P8qACIA+P/W/9D/xP+1/9D/EwAlAPz/2f/O/87/vv/C/wIAKwAJANT/2/8EAAIA6P/p/wIABwDj/+n/IwA/ABYA3f/e/wMAHAAiADEAQgAfAOD/zf/8/0AASAAfAPP/3//e/+z/BgAmADAA/f/A/8H/AQBFAFkAOAAQAPL/3P/k/x4AaAB5AD0A8P/c//P/DwAXACUAMAAVANT/uf/p/x8AGgDm/9n/9P/0/9T/1P/5/wcA3P+9/+X/GQACAM3/y//i/9P/v//q/y4AKQDa/7n/8f8YAPr/4v/6/wIA3P/N/xYAZgBFANz/sP+//8v/2v8hAIEAbwD//7D/vf/l//f/BgAsAD4ACwDu////HQAUAPX/7//x/+f/5f8RAEMATQAoAAwA9P/X/8T/5v8jAEcAPwAuACYADADm/9L/+v8lAB0ACgATADEAQQAhAAgA/P/v/8b/yP8GAEEARwAAANv/y/+//6n/t////y4AFwDg/+T/DgAMANz/1P/3/w8A8f/l/xoARwASAMn/vP/d//j/6v/0/yAAJgD0/77/yv/4/wkAAgAGACIAGADt/8z/2/8OABYAEAAUABsAFADq/9n/+v8uACYA///3/wkABwD0//z/KgAqAOX/uP/j/xsAIwABAP7/FwDv/8H/1v8fACsA7f/Q/+P/AwD5//X/GQAcANn/qf/X/zAATgAfAPn/4//Q/8r//f9BAFoAHADG/8D/5P8GACQANwAyAPr/v//B//7/IAAbAAIA6v/Z/9T/8/8UABEA4P/M/+D///8fAC4ANgAIALz/pv/t/0YAYgBTACwABQDN/7X/3/8lADoAEADy/+z/+P/1//T/DgARAOT/u//I//X/KwApACEAKAAiAPT/x//C/9//DAAcADIATgBAAAAAwP+9/+T/DgAQABYAKAAoACAACgAGAAsA8v/M/8f//f86AE8AJAAOAAEA3f+w/7v/DwA/ABkA6f8XAD0ABACx/7j/AgAYAPT/8/8zADAA1f+t//H/OAAfAOX/5v8NAO//vv/X/yEANgD3/77/1P8EAPj/0f/e/+z/+v/h//D/IAAtAPL/yv/a/wMAGgATACIAMwATAOv/+f86AGQAVwAcAPX/3v/n/wIANABlAFYACwC0/5n/yP8IADkALwApAA4A5v/U//v/KgAxABMA+P8FAB4AHgATABgABgD2//L/AAAdAB4A+f/X/+X/EwBFAEMAEQDm/7//qf/E/xMAcwBxAAAAmf+b/7z/zf/p/yUARQAIALj/sf/v/wMA9v/t/wIA9v/G/8n///8lABgA7v/V/9T/1P/W/+b/DgAxAD0AEgDN/8D/+f8pAB4ADAAUACAAAADZ//z/QQAwAPT/2f8TACgA9//e/ywAVwAOALf/wv8YABoA3P/m/0MAVQD0/6z/1/8SAAAA8f85AHYANgDV/9P/KwBAABQAEQA7ACsA3/+8/+3/KAAdAPf/8P/p/8L/of+/////GgAOAOL/5f/w//P/9v/0//T/7P/j/+f/GwBAAD8AEwDR/5T/gv/F/zoAhwBuAB8A2P+z/6D/xv8oAHwAYgABANj/6//o/8//8f8zACwA1f/D/xQAWQAeAM7/5f8fAAgAzf/u/1MAUQD7/9//DwAvAOD/sv/7/zYADgDf/ycAbQA5AMH/w/8VABUA2//u/2AAdgALANT/BQAnAN//sv8DAEMADwDS/wIATgAyANf/x//n/+X/uf/V/yQANgAKANX/2P/V/7f/yP/0/w0ADQASACIAKQAUAA8AAwDr/8f/yf8LAEIAUwA+ABsA1v+g/43/r/8AADIASgA6ABYA7f/C/8H/1f/3/xEAJQAyACAA8//W/+T/+/8CAAIAEQAUAPL/xv/X/yUAOAAkAAMA8P/U/7L/yv8pAGoAQgDq/8n/3P/i/9L/6v8zADwA7f+W/7z/DwA1ABsABQAMANf/gP+Y/yQAjwBvABUACAABAM3/n//w/2kAXgDx/9H/GwA5ABYACwAyABYApf93/9P/VwBcAC0AJAARAMr/g/+P/9b/AwAMABwAOwA2AAoA2f/I/77/z//7/zUAXwBbAEkAIgDm/7z/yP/s/wEADgAgADEAEgDb/6r/tf/p/wMADQADAOn/xf/A/+v/MgBQADkA/P+3/5H/p/8KAHAAiwA6AM3/n/+i/9n/IwBhAFwAFADS/9b/CgAqAC4AGAAGAOn/2//+/yEAIwDs/7v/uv/c/xcAMgAgAOz/wf+w/8X/6/8uAFUAJQDc/8z/BgAsABwAAQAIAAsA6f/g/xcAWQBBAPb/wP/c//n/9P/5/w8AMgALAND/xP8DADoAJADs/9n/9//r/9D/7f9AAHAAJgDg/+L/GAABANf/AgBkAHwAJQD//yoASwABALH/zP8XAA4A1f/+/0gAMQDG/5L/zP/q/73/vv8uAHsAVwD9//b/CgDN/5L/yv88AFIAFwDz/wkA/f+k/43/6/9DACsA5P/r/wIA+f/j/xQATAA2ANP/q//X/wgAFwASAC8AGgDM/4z/sP8EADAAHgAEAP3/3v+9/8//IABVACEAy/+x/9D/7f/+/zsAdgBHAML/jv/G/wUAFAApAHIAcgAUAMn/AAA1AAcAz//x/y4AGQD2/yEAZgAhAL7/uf/9/+3/rf/X/0wAeQASAN7/EgAEAJH/ZP/f/2MAUQAGAA4AOQD4/6v/z/8uACcAwv+3/zMAiABOAA0A+v/n/5b/a//A/z4AWgAnAA0A8f/J/53/vP/w//7/4P/5/0sAZwBIAAIAzP+f/5r/2v8xAGIAVQA2AAwAt/+P/7b/DQAwABcAHgA1ACQABgAcAD0ACACf/6f/LQB3ADYABQAmAB4Ay/+V//r/cwBLAMP/rP/7/xwACgAYAEYADQCU/33/8v9vAFkA9P+6/8v/5v8UAFQAaQA5ANL/j/+o/wYAZgCCAEIA0f+N/7T/+P8gACIAHQD8/8b/wv8JAEwALwDE/5j/7P8rABYA7v/5//b/sv94/8v/QABSAOr/pf/K/+7/7f/1/z4AVwAUAMv/4/85AFAAEQDL/8n/6v/8////JABHADkA4f+t/7z/AQAWABIARwBxAE8A6f/C/+v/+//U/9H/HwBOABAAv/++//j////x//3/BQDm/6//yf8kAGUAXQBBACMA7v/L/8j/9P8rADcAMgAUAOr/6//4/xwAEgDt/87/0P/c/+b/GgA4AC4A/v/i/+n/7v/p/97/6v8MABkAIgAkABoADwD2/+v/8P8QADsAOgASAAQAJAA9ADQADADz/9f/nP+Q/9D/LABQAB4A7v/P/7P/jP+j//X/NQA6ADAARQBAAP//v//D//r/HAAHACQATwA8ANj/sf/x/xkA9/+7/9v/NwBTAB0A9P/x/9n/uf/P/yQAYABVAAUAtf+P/5//3v8xAGYAVwD+/6H/b/+1/yoAaABkAFMAQwAcALn/i//O/y8AZgBZAEkANADu/7v/yf8BACAADAD9//f/8P/2/w8APQA2APX/r/+e/7P/4P8XAEEALQABAOr/9f8TAPz/yP+8/wYAUQBwAGcANAD3/6//k//U/zYAcABDAP//zP++/7n/7v80AFUAGQCv/53/2/85AE0AKQAVAAwA9v/B/8f/AgA5ACwA+f/6/zIAHQDj/+P/JQAtAN//of/v/0cAMgDd//n/QwAaALf/oP/9/xoA3v/D/xAAVgAfANL/8f8HAML/fP+u/yQARgALAOj/FAAPAMH/p//k/xgADADO/8f/AgAhAEEAQwA2AP7/yf+x/+n/NQCIAJIAUgDt/6n/kP+o//j/aACLACMAev9H/5H/6P8QADQAYgA1ALz/m//+/2IARgAIABIAOwABANL/DABuADoAyf+y/wwAMAD6//7/PwBTABMA9f8tADQAw/+T/xAAlABwAOf/qP/G/8z/q//f/ywADgCb/3P/5v91AH4ASQAkAOH/ev9o////wQDiAFMAu/+J/5//uv/k/wEA9P/J/7//CgBSAEwA/f+v/4f/pf/n/zUAWgBRADEABADl/8j/6/8MAPP/tP+q//r/ZwCbAH0ATgDy/4P/Sf+X/yMAiwCQAFIAIgDa/47/ff/C/wgADwDz/wAAQABlAFwAQAAVAOP/qP/C/ysAkgCnAHMANQDu/7P/kP+2//n/FgATAAQA8P/u//X/+f/2/9z/xP/K//H/AgATACkAIwAJAN7/0//P/8X/wv/r/xEACgAPADIAXAAxAOP/wv/u/xMA/v8TAFMAYwAAAK//v//t/93/rf/c/xYA6v+L/5//IwBYAAsAuP/g//7/r/+P//b/ggCBADUAFgAgAOb/ev+O/yMAdwBGAB0AQQBJANn/d//B/2MAbQAEAOf/LgBNAPT/y/8UADkA4v+M/+r/jQB5AOT/s//t//f/qP+w/0kAnwAxAJ//x/9OADMAxv+7/xkAPQDl/9H/KQB/AE4A6P/I/93/z/+r/9v/RgCaAF8A3f+A/3D/o//F/wsAcwCuAEYAhP9U/8P/LQAiAPj/DQATANn/uv82AMkAgwC5/27/wv/9//L/IgCgALIAJAC1/+L/GgDP/3f/uf8yACgA8P8mAHUALwB9/1f/2P8MAMT/3P+KAOkAWACb/6L/4v/C/4P/7f+yALUABwCa/9n/CgDB/6D/AQBpAEMA8f8NAEMAFACH/2H/2/87ADQAFwAqACQA0P+e/9n/QwBBANr/of/I/wkAHwAvAEcAOgDh/4j/kP/W/xcAKAAlACMAJwAlACcANAA7ABUA3v/E/8j/BgBQAG8AXgA8AAkArf9Z/2j/6/9pAGkAHAAIACUA9f+f/5//AwAeAMv/n/8SAH4AagAZAAwADwDB/3P/if8dAH0AdQBOADIA+P/K/7H/uv/Y//v/AQDw/+L/HQB1AEcAv/+F/6f/zP/F/wUAjwDBADMAhf+l/wMA///Y/zkAlABTAKj/oP8zAGsA///H/xQASAD5/63/DwBzAEIA1v/X/w4A7P+R/6b/JQBdAB4A7////xcA0/+Q/6z/8v/9//X/AQA1ADYA6/+p/6n/yv/b/wAAMgBgACgA2f+3////LwAmACMAQgBNAPH/uP/i/zMAGACp/4//xP/g/7r/2f8zAEQAzv9v/6j/AAD+/9X/GwCOAJ8AMgDi/+r/+v/E/7f/FACJAIQAGQDG/73//P8RACIAMgBIABMAzv/m/z0AjAA3AM3/r//q/wsA8/8IACIABACi/7L/SgCTABEAl/+u/xcANwAkAFwAiwA4AJ//s/8dACkAr/+G/xMAZQATALf/4/8IAL3/a/+5/2QAjgAXALL/w//4/wQA7//0/97/tv+5////RABGAPr/lf+w/xsAYQBAAAAA5/8GAPz/5/8LADYAFACa/3T/zP9GAGEAOwDq/2f/Cf9M/y8A5QD/AIgACADJ/6n/6v9kAKgAZQD7/8//5/8gAFgAiQBdANn/V/9N/7j/HQBNAEcABwDV/+//QwBkAA4Ah/9V/4L/8f+BANAArAD9/0f/H/+A/woAfQCjAF0A6f+v/9r/NQB9AIoAGwB4/xX/aP9GAL0AowA9AMj/M//O/jj/OAC0AEkAyv/L//n/3P/m/zkAWADD/zH/iP9TAKwAZAAWAOD/jv9F/6H/YwCdACMAvv/d/zEAUwBCADkAAACb/3H/0P+DAK0AVgD0/7b/if+R/9X/RABoACIA6//x/ywAQABBADkAHwCt/2L/mv8gAIgAdQAkANX/rf+e/8z/LwCCAFoA3/+R/7r/SwCqAKwAOACP/yf/Rf/e/30ApABKALf/Uv9h/8j/OgBkAEgADgDo/+P//P84AEUA9v+N/5v/BgBlAIAAPwD6/67/ff+R/xgAlACwAFAA2/+3/9X/+/8oAEgASAD9/3T/XP/M/2IAggAzAOv/zf+V/2j/pv9WANcAsgA0AOD/tv+L/3n/0f9TAJ0AagAOAOb/zf+i/47/0/9BAGkAKgDX/8T/BgAsACIAFQAEANf/nP+u/wwAWABXAPr/tP+x/6z/s/8AAGYAbgAaALr/rf/K/+X/FgBhAGwAEwDK/9j/JQAlAOz/1v/0/wQACQA8AGQARgAHAOT/4//f/83/3P8ZACMA/P/u/yEAUgAdALT/bv+I//H/UQBrAEkABgDf/9b/GwA4ABUA4v/J/+D/AgD//wsAPgA6APD/pv/P/w0AJgAVABIAHQDl/5v/yP9DAFsABQDd/wIAHgDK/4r/4v9LADkADQAgAGAARQDg/8f/4f8EAAgATABkABoAqP+q/xAAOgAXAAoAQQAaALH/of8EAFoAQQAJABIADgC3/4r/7P9lADIAoP+A/+z/TQAjAN//2//u/8D/r//z/1EATgDa/7b//P82ABIA8f8JACkA3P+I/+X/pQCtAP7/jv+x//T/t/+v/ycAbwDe/1X/uv9XAEcAmf9n/7j/0f+m/wcAuACyABYAsv/0/woAtP+R/yoAqwCBAEkAWABbANf/X/9p/8v/BAA0AH8AsABZAOb/4P8FAOz/lv+P/9v/KAA2AGkAjwBeAOf/fP94/5b/of+y/zsAzwDpAIMA5v+u/6D/hv+S/ywAvwDFAFIAAQAgAP3/cv8l/5L/8//b/8X/QwCwAFEAkf9v/8P/r/9l/9L/pgC8ABsAvv8wAF4A2f+C/+X/NgDe/4r/0P9UABMAk//T/4QApgD4/53/u//d/8H/vf85AJ4AUAC7/5r/yv/l//H/IgBXADAAz//a/0MAiQBiAB4AIwA1ABkADQBCAEkA6/+R/5H/1P/6//P/AQAaAPf/zf/+/0UAFwCy/6b/FQBnAFsARgBlADwAmv86/6T/TwBZAN//t/8SACsA3//0/3sApAANAG3/tP9SAGYA9v/e/yMA9/9q/0D/v/8nAND/ef+6/ysACgCl/8r/TABbANz/x/84AH8AGQC8/+z/RgAHAKL/xf8oABgAw//N/ygATAD6/8D/AAArAP3/4f8eAGcARADx/7H/uP/i/xoASQA5ANf/if+a/+D/GwBGAFkANQDk/87//P8/AD4ACQD8/+3/5//v/zUAdABSAPL/n/+6//3////e/93/HQBUAEwAGQD0/8L/dP9T/73/XACIAD8A+f/v/87/lf+X/w0AawA0AOH/AgBgAGIAGAADABwA+f+u/9H/OgBgABcA6P8SACkA5f+8/woAPgD4/4n/n/8YAEsAKQAeAAYApP8t/0n/GQDQAKwAJwDe/9r/vf+l/wEAlADPAFkAxv+q/9z/HwBFAEsAKwC3/0//Sv/D/zIATwBCACYA7P+l/67/CQBcAEUA4v+h/57/w/8WAHEAdQAHAJn/nv/q/xYACgANAAEAyf+7/wgAhACeAGgAFADq/7//lv/E/yUAXAArANv/z/8CABgA9/+3/5r/ov/L/xgAcACaAE8A4f+n/8X/3//9/xwASQBPAAoADQAqABcAuf+H/8L/EgAHAPr/aACnADQArf/M/zsADACF/4D/EwBAAOn/3/9vAJgAy/8X/13/CQAhAOv/JwCyAJ0AGAD6/1EAcQD8/4j/uv8hAE4ASABdAGQANwCz/1v/gv/Z/yEAMgAxACsAKgD6/7z/vf/Z//f/IgBGAEAA/f/O/8z/+v8eABcA5/+x/6L/6f9WAIMAOwDG/6r/uP+l/7j/JQB4AEUAx/+m/+r/BADK/8L/BwAcALj/mf8KAHkAagAeAC4ALwC5/zn/f/8kAGEANgAVADcA9v9//2z/y//x/7n/sv8aAHoAcwBVAFcARgDQ/4H/qf8OAD0ARgBoAIwAeAD3/5H/gf+F/53/4/9jAMQAugBdAAgA+P/6/+n/zP/T/+3/8P/6/z4AcQAuAJ//KP9C/7b/EgBGAHYAdwA7AP7/8P8lACwA/P/K/+j/IABNAFwAMQDS/z///v5X/wsAiQCMAEgAAADO/7P/rf/P/+X/6//n//T/KAA9ACAA7P++/4//df+U/wgAkACdADEA6f8EACwALwAEAPb/9//J/5z/0f9PAHoAMQDL/6L/pv/R/zAAlgCyAEMAvf+3/0sAwAC3AEcAxf+I/4v/zv8nAGcAUgDs/4b/Z/+t/zQAcQBDAO7/5f8NACsASABaACoAs/9c/6j/cwC6AEEArv+Y/8n/2//t/1EAfgA5AKv/gv/r/1gAZAAZAPX/zf+g/4v/uP8SACcA2f96/6D/JABbAA8Axv/Q/+D/qf+X/+L/XQBpADEAUAB2ADUAov9h/5T/w//Z/xUAfACYAEEA3P/E/+f/4v/Z/8v/tv/A////YwCOAG4AKwDy/7n/kv+3/+3/CQANACEAVABHAP//9/8KABMA4P+9/+L/IAA3ACwATQBQACUA7//k//D/y/+w/7z/+/8/AE0AMQD0/7j/nP+c/6v/tP/f/ygANQARABkATQBLAAQAuv+5/9T/0P/8/14AqQCIABoA4P/R/7j/k/+1/wcAQgBNAE4AUAAcALr/hP+p//D/DQD7/xQAHQD7/7//1P8QAAEAyP+z////XgBoACgA8P/b/9f/8P8rAGQAZgBEAP3/w/+//+z/JAA6ABwA3f+U/4D/nv8FAFYATQAWAO//3//L/4v/jf/r/04AggBkADAACgDh/9H/0//e/+b/4v/r//z/IQBMAE0ALwD3/8j/s//H//b/MABLADcAAgD9/xIADQDm/5z/bP+R/xAAaQBvADEA0f+f/5v/zv8tAG4AaAAUANr/z//v/woAMwA1AAkAt/+M/9r/RwCIAFgAAADd/+X/7v/V/9r/+f8XAAgA5//2/ycA/v+5/6//5v/y/8z/0f9NAKIAbQAEABAAQQAPAMP/y/8qAEEAFwAZAGsAmQBEANn/2P/V/6f/of8EAHYAdgAiAPD/AwDj/5j/lv/Z//T/2f+w/9j/NABXAGEALwDs/6X/of/c/0AAawBsADEA3v+X/43/sP/l/xQAMgAQALn/bP+b/wsAQwAoAAUADwADAN//+/9IAFUA9f+r/8f/AADc/8D/6f8fAOH/nv+8/x4AMQD3//3/NgBNAB4AAQAaAAkAuP/E/0wAlQA4AKz/mf/w/yAACAAUACkAAgDR//f/fgDNAHIA+P/E/7T/rv/s/3UAwgBhAKn/U/+K/+H/+//v/9r/1v/5/0EAmQCWACcAoP9o/4v/5/8yAFYASgArABAA8f/T/63/v//P/77/tv/u/1kApQCZAEEA4v94/zP/S//L/0IAZQAvAOH/wf+j/4v/n//b/wAA/v8FAD0AggCMAFoAFgDT/6z/n//c/zsAbgBRAAsA2f+4/67/tf/m/x0ALwA1AD0ASABhAGMAQgAPANT/uP/Q/w4ALAA2ADMAFgD2/8//x//N/9X/4P8FACMAMwBWAHQAbgAaAL//lP+2/+r//v8hAEQAOADs/7//zP/m/9z/xv/y/yIAHwANAEIAlAB9AAYAnv+q/7//nv+x/xQAawBLAPT/vP+p/4f/Y/+Y/wcAMQALAAIALgBAAPf/uP/k/z0AJgDe/+z/QABiABUA5P///wYA1P+4/w8AbgAuALD/pf/w/wsA2P/d/zoAVgD8/7H//f9nAC4Ayv/F/wwAHADX/9j/IwBXACYA4f/a//T/+//7/y4AYABiAA0AuP+g/8j/DAAZACQAOgA5AN3/Z/9z/9j/DwDr/8r/9/8qACkAGwBLAGgA8/9f/2H/1/8eABwAMwBvAF4A9f+x/87/6v+//6r/BwB5AIQAaQB3AHAADACE/3L/x//n/8//BwB6AJAADACV/7L/4f/P/6f/3/9BADMA4v/X/y4AVgAYAOz/DAA3ABgA7P8GACgAFgDW/9//PwBuAEcACQDw/97/r/+h/8r//f/r/6v/pP/f/x4AKwAgABUA+P+//5r/u//+/zAANAAmABwAIQAiABwAFgAPAOX/uf+3/+P/NgBtAGgAQQAQANX/mf+P/9L/KgBJABwA7v/+/yEABgDX/9H/8f/k/8X/5f9XAJEAYAAIANn/uv+U/5z/4P9LAGwATAAoABQA+v/y/+P/z//C/8//5v8KADgAdgCEABcAjf9l/4n/uP/L//b/MAA1APL/xP8HADwAGgDg//X/DAD4/9f/DABfAFgAAQDj/xkAQgAjAPv/HAAyABYA9/8MACoAFQDl//L/MABFACIABQD4/+v/sP+E/57/3P8AABkALQBKAEUAGwADABIAJwAlACQAJQAoAAUA9P/4/x0AEwDn/9H/0//W/7H/tP/k/xUADwD2/xcAQAA8ABIAEgAkAAwAw/+X/6//yv/B/7n/7/8nABsAzf+l/8D/6v/y/wgAQABsAEkABADr/wAAIAD+/8z/sf+6/6v/q//c/w0AIgDk/8X/5f8qAE0ASQBXAF4ATwAqADsAagBHAMz/kv+2//T/+v/h//D//v/l/7r/4P8NAA4A8v8UAHgAjQBFAAkAHQAoAPf/yP/s/zQAOAD8/+H/BwApABQA4//R/8//4P8GADkASAAqAPr/4v8SADEAAQCl/3L/g/++/97/9f8ZACMABADN/8//AAAsACIA+//F/5v/tv8hAJUAnwBMANP/jv+M/6P/1f8AAAcA6P/b//j/JwBQAFIAOAD3/7b/n//P/ykAWABKABsA8//8/ykAPwARALr/gv+g//L/TwCTAIkAQwDZ/5v/tv/5/y0APgAlAPf/3//3/zEAXQBWACEAxf+X/7v/JwCdAK0AcwAmAO7/w/+3/+z/LwAZAMX/pv/a/xUAEAD///D/yv+B/3P/0v89AFgAKgAGAPv/8v/r/wsAKgAFALr/rf/m/yoAQQArABAA7f/S/9j/BwA/ACYA7f/R/87/yv/S/+P/+P/o/8D/x//x/yIAJQAXAAcA9P/F/8z/FwBjAHkAUAAiAAcA+v/p/+H/6f/q/83/vP/g/y4AdwBwADMA3v+i/6f/3P8dADgAGQDu/9L/0//r//r/8f/S/8D/x//m/woAIgA4AC4AAwDl/wgAQQBVAEcAGAD8/+b/2f/j/xQANQApAPf/3P/t/woADQARABIACwDd/6f/vv8BADQAIQD2/9//0P+u/6T/2v8wAFcAPwAcAAkA+P/s//7/OQBhAF4ALgABAPL/7P/p/+3/+f/7/+j/0v/Q/+T/CAAMAPr/5f/S/8r/1/8BACAAHAAMAPH/7P/9/////v8BAAIA/f8CAA0AHwApACwANgA0ABcA8f/u//v/BADq/9T/4/8FABwAHwAYAPb/zv/M/+X/9v/v/+X/8/8XACEAHgAdACAACADJ/5j/mP/R/x4ASAA9ACEACgAOABYAKAARAOH/yP/P//L/EQASABIAGQAEANf/r/+4/8f/z//J/9D/6f/3/wAAIQA9ACIA6f/T/+P//f/0//P/HwBCAD4AOAA1ADoAIwD5/+n/7f8OACcAPQAkAPr/3f/p/wgADAAFAP///f/k/9r/+/8eACUAEwAHAA4ACQD7/wUAJAArAAIA5/8BADQASwArAAsA///+//r/CwAiACAA+P/L/9f//v8LAPX/4v/V/87/v//T/xwAWAA4APj/5f/5/woA9/8HACQAEQDL/7r/9/8eAAIAwv+2/8j/x//K//n/IQAGAN//3/8KAA8A7f/h/xAALAAXAAIA+P/s/8P/rv/A//D/FwA0AEUATQA4ACkALAArABYA6//a/+3/EgAnADoAKwABAND/qf+l/6v/uf/S/w0APwBNAEYALwA0ADEAKAApAEIARQAzABoACQADAOD/uP+w/8z/2v/c/+j/CwAXAAEA7/8DABIA/v/y/xkAPQAqAA0ADQApAA4AyP+p/7T/tP+g/6n/3v8WABIACwA1AFcAPQDy/9v/4f/m/+P/7f8dADIACgDX/8n/yv/A/7b/x//o//n/BgAuAFQAXQBGACwALwAsABAA9P/q/+H/2f/d/+v//f/7/+T/0P/L/9X/8f8VACIADgD//xMAPgBZAFkARgApAP7/2//h/wkAKQAiAAcABAAXABkAFwAtADoAGADf/8b/6v8NABEA/P/3//P/0/+9/8f/5v/y/9z/2v/1/wwABwAFACUAOgAlAP//AwAeACUABADx//3/DwD7/+//AgAPAPv/5v/t/wEABADu/+X/9f/z/+D/4f8AABkACgDt/9b/4f/4/w4AHQAXAPn/4//q/wUAFwAbABYACgD+//z/AAADAAQA/v8BAP3/BQAJAA0ABgDy/+3/5f/1//7/6f/R/8P/3P8EABUAAQDk/8z/xP/b/xYARwBOADAADQD8//f/AAAQACcAJwAFAO7//f8hADIAIQACAN7/wf/C/+7/GQAhAAEA4//g/+f/8P8EABwACwDb/7P/xv8AACgANwA4ACIA/f/i//b/LwBRADQACADx//X/+P///xYAJwAbAPX/2P/b/+7/BAAIAPT/3f/N/9b/8f8WAB8ADwD7/+//9P/9/wUABwAGAPf/6v/y/woAIgAvACUADQD0//D/BgAeACEACwD6//X/+f8IABkAIwAVAPz/6f/m/+T/4P/i/+b/6//o/+j/8/////v/6//a/93/7f/+/woAEgATAAsADwAZACEAFAD9/+L/2//j/+7/AwAKAAIA8P/f/9z/5f/l/+b/8v/w/+D/2f/m//3/CQABAP3//P/y/+3/+v8jADIAIAAMABIAIQAgAB8AOABOAEEAEwD1/+n/4f/X/9//+f/+//L/7v8CABsAFAD8/+3/7f/r//T/HgAzADkAHwAHAPv/CQAOAAYA/v/0//z/BQAhADwARgAuABIA///3/wAA+//z/+b/1v/Y/+T/8v/1/+j/2f/S/9r/7f/8/w0AHwAnACcAHAAHAPn/7P/k/+X/3f/c/93/4P/d/+T/9P/9/wAA7f/a/+H/9P8RADsATwA3AAkA3//W/+X/9v/5//b/8v/w//D//f8XACoALwAlABcAEwAgADYAOgAmAAIA4f/b/+P/7f/v/+H/z//J/9X/6v8CABQAJAA0AD4AQABIAFkAYQBUADMAFQADAPr/8v/u/+X/zP+1/7X/y//j/+j/5//v//v/BgASACIAJwAWAP3/8P/1//3/+//u/+L/1P/F/8H/zf/h/+7/8v/2/wcAJABCAFUAUwA9ABUA9v/i/9//5//p/9v/xf+1/7P/u//E/9D/1//c/97/7/8TADUARgA+AC4AIAAZABsAIQAeAAsA7//d/9z/5P/t//r/AwAGAAkADgAlADUANwAsAB8ADwAAAP//DAAaAB0ADwABAPT/5//c/+D/8f/5//L/6//0/wsAIQAvADUAKgAVAP//+f/+/wUABgACAP7/+f/0//T/+/8BAP//9P/p/+f/8/8AAAcACAAEAAIAAAADAAgABQD4/+r/5f/s//f///8DAP//9f/y//n/CgAaAB0AFQAOAAkABwAOABQAFgALAPX/5v/k/+v/7//r/+H/1//c/+n//P8NABMAEQAOAAsAEAAPABQAFgAXAA8ACQAKAAwAAgDq/+v/3//h/+P/7/8GAAUABQAWACQAHQAKAPz/9P/5/wEACAAPAAYA7f/c/97/6v/s/+z/9f/9/wQABgAMABsAIwAfABEACQAKAAYABAABAPn/8v/o/+L/5v/x//j/9v/1//b/+v8BAAkAFAAaABIAAwD2//T/9//3//P/7f/n/+f/7P/3/wQACwANAAwACwAKABAAHgAnACMAFAAEAP7/AAD+//j/8P/p/+L/4f/o//P/+v///wAAAgADAAYACwAQABIAEQAQABUAHQAiAB8AFAAJAAMAAgAFAAgACgAKAAcAAwACAAAA+v/z/+3/7P/t/+3/7P/u//H/8v/v/+7/8P/z//b/9//4//f/9v/1//X/9//5//f/9//8/wQACQAJAAYAAAD6//b/9P/1//r//f/8//j/9f/z//L/8f/t/+j/4v/d/+D/7P/9/wcACgAHAAcACQAJAAoAEQAVABQADQALAAoACQAFAAEAAQD7//X/8v/2/wAA/f8AAAcAFAAWABYAIgAfABsADgAOAAwADgALAAcA///4//b/9v/6//r/+f/3//7/AwAJAA0ADAANAAsACQAOAA4ADQAHAP3/+//2//L/7//s/+7/8P/0//v//f/7//v/+/8BAAkABwADAAEA/v/7//v/+P/z//H/5v/e/+P/7f/1////AQD9//v/+f/9/wcADQAPAA0ACwAMAA0ACwAGAAAA+//4//b/9v/6///////9//v//P8BAAUABwAIAAYAAwADAAYABwAGAAYABgAIAAgABgAFAAYABwAHAAYABwAJAAkACQAKAAkABgADAAAA///+//r/9//1//b/9f/2//f/+P/4//j/+v/+/wAAAQABAAEAAgACAAIAAAD9//r/+f/4//r//f8AAAIAAQD9//n/+P/3//j/+v/9//7//f/7//j/9v/y/+//7v/u//H/9f/6//7/AQAAAP////8AAAEAAgABAAAAAAACAAUABgAGAAcABgAEAAEAAQADAAQABAADAAIAAgABAAIABAAFAAUAAwACAAEAAQABAAMABQAFAAIA/v/8////BAAGAAYAAQD9//v//f8AAAIAAwADAAMABQAGAAcABwAHAAYABAACAAAAAAABAAIAAQAAAAAA//////7//v/+//7/AAAEAAgACQAHAAMAAAD+//7/AAABAAEAAAAAAAEAAgACAAAAAAAAAP7//f/9////AQD///z/+P/6//z//v/8//r/+v/8//v////9/////v8DAAQABQAEAAcABQD7/wAA+f/9//j/9f/9//n/9f/7//7//P/3//f/+f8AAAUABAAHAAgAAQD9/wEABwAFAAAAAAABAAIA///9////AAD///z//f8BAAEA////////AAAAAP////8AAAAA///+//7///8BAAIABAAEAAMAAQD/////AAABAAEAAAD//wAAAQACAAMAAgACAAMAAgD///7/AQAEAAMA///8//3/AAABAAAA/v/9//z//f/9////AAAAAAAAAAAAAP7//v/+//7//v/+/wAAAgAFAAQAAQAAAAEAAgADAAQABAAEAAIAAAAAAP///P/5//f/9v/2//b/9v/2//f/+P/3//f/+P/6//v//f/9//7///////7//f/7//n/9//4//r//f/+//3//P/7//r/+v/6//v//P/8//7/AAABAAMAAwABAP///P/5//n/+//+/////v/9//7/AAACAAMABQAHAAgABgAGAAUABgAFAAMABQAFAAMA///+/wEA/P/7//v/AQACAAAABgAFAAcAAgAGAAcACAAHAAYAAwABAAEAAgADAAIAAAD9/wAAAAABAAAA/v/+//z//f8BAAEAAwACAP//AAD///3//P/6//r/+v/7//3//P/6//v/+v/9/////P/7//v/+v/8/wAAAAD+//3/+f/3//r//P/+/wIAAAD+//7//v///wEAAQAAAAAAAAABAAIAAgACAAAAAAAAAAEAAgACAAIAAQAAAAAAAQADAAUABQAEAAIAAQABAAIAAgABAAEAAQACAAMAAwAEAAQABAAEAAQABAAEAAMAAwADAAMAAgACAAEA///+//z/+v/5//j/+P/4//j/+f/5//n/+v/7//z//f/9//7///8AAAAA///9//v/+f/4//n/+v/8//3//f/8//z/+//7//v//P/9//7//v/+//7//f/8//v/+v/5//n/+f/6//v/+//8//3//v///wEAAgACAAEAAgACAAMABAAEAAQABAACAAEAAQACAAIAAwACAAEAAAABAAIAAwAFAAYABgAGAAUABQAGAAYABgAFAAIAAAD//wEABAAGAAUAAwAAAAAAAQACAAIAAAD+//3//v///wAAAQABAAEAAAAAAP///v/+//7///8AAAEAAQAAAP///v/8//v/+//9////AAAAAP///v/+//7///8AAP///v/+////AAD//////v//////////////AQAAAP7//P/9////AAD///3//v/+//3//v/7//z/+P/9//7/AAAAAAMABAD+/wMA/f8DAP3/+/8AAP3/+v///////f/4//j/+P/8/////f/+/wAA/f/7////BAACAP////8BAAIAAQD//wAAAQD///7//f////7//P/8//z//P/9//3//f/+/////v/9//3//v/+/wAAAQABAAEAAAD///7///8AAAEA///+//7//v8AAAAAAAAAAAEAAAD+//3///8BAAAA/f/6//z///8AAAAA//////7//v/+////////////AAAAAP///v/+//7//v/+////AQACAAIAAAD//wAAAAAAAAAAAAABAAAAAQACAAIAAQAAAP7//v/+//7//v/+//7//v/9//z/+//7//z/+//8//z//v///wEAAQAAAP7//f/9//7///////7//f/8//z/+//6//r/+P/4//j/+v/8//7///8AAP/////+//7///8AAAAA///9//z//v///wAAAQACAAQAAwADAAMABAAEAAMABQAGAAcABAAEAAYAAgABAP//AwACAP//AgAAAAIA/v8DAAMABgAGAAYABQAFAAUABgAGAAYABQADAAUABQAGAAUAAwACAAAAAAACAAEAAwACAAEAAwADAAIAAgAAAAAAAAD//wAA/v/9//7//f///wAA/f/8//z/+//8///////+//7/+v/5//v//P/8//7//f/7//z//P/9//7//v/9//3//f/9//7//v/+//7//v/+////AAAAAAAA///+//7//v///wAAAQABAAAAAAAAAAEAAQABAAEAAAAAAAEAAQABAAEAAgACAAIAAgACAAIAAgACAAIAAwADAAQABAAEAAMAAgABAAAA/////////v/+//7//f/9//3//f/9//3//v8AAAEAAQAAAP///v/9//3//f/9//7//v/9//3//P/8//z/+//8//z//P/9//7//v/+//7//v/+//7//v/+//3//f/9//3//f/+//7//////////////wAAAAABAAIAAQABAAAAAAABAAEAAgABAAAAAAD//wAAAQABAAIAAgACAAIAAwAFAAYABwAGAAUAAwACAAMABQAGAAUABAADAAMABAAFAAUABAACAAAAAAAAAAAAAAABAAEAAQABAAAAAAAAAP//AAAAAAEAAgACAAEAAQAAAP///////wAAAQAAAP/////+//////8AAP///v/+////AAD///7//v/+//7//v//////AAAAAP///f/+/wAAAAD///7/AAABAAAAAQD/////+//+//3//v/9/wAAAQD9/wIA/f8EAP///f8CAP///f8BAAEA///9//z//P/+/////f/9/////P/7//3/AQAAAP7///8AAAEAAQAAAAEAAgACAAEAAAABAAEA//////////////7//v/+/////v/+//7//v/+////AAD//wAAAAD/////AAABAAIAAQAAAP////8AAAEAAAAAAAEAAQD/////AAACAAEA///8//3///8AAP////////7//v/+//////////////8AAP///////////v/9//3//v///////v/+//7///////7//v/+//7//v///wAAAAD///7//v/+//7//v/+//7//v/+//7//f/9//3//P/7//v//P/8//3//v/+//3//P/9//3//v/+//7//v/+//7////+//7//P/7//r/+v/7//v//P/8//z//P/8//3//v///wAA///+//3//v/+//7//v///wAAAAAAAP//AQABAAAAAQACAAMAAgACAAUAAgADAAEABAADAAAAAwABAAIA/v8BAAAAAQABAAIAAQABAAIAAgADAAMAAgABAAIAAgADAAQAAwACAAAAAAABAP//AQAAAP7/AAAAAP//AAD//wAAAAD//wAA///+/////v///wEA///+//7//P/9/////////////P/7//3//f/9//7//f/8//z//P/9//7//f/9//3//f/+//7//v/+//7//v/+//////8AAAAAAAD///////8AAAAAAQAAAAAAAAABAAEAAQABAAEAAAAAAAAAAAAAAAAAAAAAAAEAAQABAAEAAAAAAAAAAAABAAEAAQACAAIAAgACAAEAAQABAAEAAAAAAAAA//////7//f/8//z//P/9//3//v/+//7//v/9//3//f/9//7//f/9//3//f/9//z//P/8//z//P/8//z//P/8//z//f/9//3//v/+//7//v/+//7//v/+//7//v/+//7//v/+//7//////wAAAAAAAAAAAAAAAAEAAgACAAEAAAAAAAAAAAAAAAAAAAD/////AAAAAAIAAwADAAMAAgACAAIAAwADAAMAAgABAAEAAgAEAAQABAADAAIAAgABAAEAAQABAAEAAgABAAEAAAAAAP//////////////////AAD//////////wAAAAAAAP/////+//7//v////7//f/9//7//v/+//3//f/9//3//f/9//7//v/+//7//f/9//7//v/+//z//v////7/AAD//////P/+//3//v/8//7//v/7////+/8BAP3//P8BAP7//P8AAAAA///+//7//f///////f/+//7//P/7//z////9//z//P/9//7//v/9//7///////////8AAAAA////////AAAAAP///////wAAAAD////////+///////+/////v/+//7//v///wAA//////7//v///////v/+/wAA///+//7///8BAAEA///9//3//////////v/+//7//v/9//7//v/+//7//v/+//7//v///////v/+//3//v///////v/9//7//v/+//7//v/+//3//f/+////AAAAAP//AAAAAP//////////AAD////////////////+//7//v/+//////8AAP///v/+/////////////////wAAAQABAAEAAQAAAP////////7//v/+//7//f/9//3//v/////////+//7//v/+//7//v///wAA////////AAAAAP////8AAAEAAAAAAAMAAQACAAEABAAEAAEABQACAAQAAAADAAEAAgACAAIAAgABAAIAAgADAAMAAgAAAAIAAgADAAQAAwAEAAIAAgADAAEAAwACAAAAAQABAAAAAQAAAAEAAQAAAAEAAAD//wAA//8AAAEA/////////f/9/////////wAA/v/9//7//f/9/////f/8//z/+//7//z//P/7//v/+//7//z//P/8//v//P/8//z//P/9//7//v/9//3//f/9//7//v/+//3//v/+//////////////////////////////8AAAAAAAABAAEAAQABAAEAAQABAAEAAQACAAIAAgACAAMAAgACAAMAAwADAAMAAwADAAMAAgABAAAAAAAAAAAAAAAAAAAAAAAAAP////8AAAAAAAAAAAAAAAAAAAAA/////////v/+//3//f/9//3//f/9//3//f/9//3//f/9//3//f/9//7//v/+//7//v/+//7//v/+//7//v/+//7//v/+//////8AAAAAAAAAAAAAAAD///////////7//////wAAAQACAAIAAgABAAIAAwADAAQAAwACAAIAAwAEAAUABQAFAAQAAwADAAMAAwADAAQABQAFAAUABQAEAAQAAwADAAMAAgACAAEAAgABAAAAAAAAAAAAAAABAAAAAAD///////////7//v/+//3//v/8//z/+//7//r/+f/5//r/+//7//v/+f/6//r/+//6//j/+f/6//n/+//6//v/+P/6//j/+f/3//r/+//3//3/+P////v/+v/+//v/+v/9/wAA///+//////8AAAIAAQACAAMAAAD+//7/AQAAAP7//v8AAAAA/////wAAAgADAAIAAwAFAAUABAAFAAUABQAGAAUABQAGAAcABwAHAAcABwAHAAcABwAHAAcABgAFAAQABQAGAAYABgAEAAUABAADAAMAAgACAAQAAwADAAIAAwAFAAUABAABAAEAAgABAAEAAQABAAEAAAD//////v/9//3//f/8//z//P/8//z//P/7//v//P/8//3//P/8//z//f/9//7//v/+//3//f///wAAAQACAAMAAwAEAAUABQAFAAYABwAHAAgACAAIAAgACAAHAAcABgAGAAUABQAGAAUABgAFAAUABQAFAAQAAgACAAIAAQABAAEAAAD//////v/+//3//f/9//7//P/7//r/+f/6//n/+v/5//r/+//7//v//P/9/////v8AAP//AAD/////AQAAAAEAAQACAAMAAgACAAMAAwACAP//BAACAAMAAQAGAAIABQAEAAQABAACAAUABAAFAAQABgAFAAQABAAFAAYABAAEAAUABQAHAAcABgAGAAMAAgADAAIABAACAAEAAQABAAEAAQD+/////P/9/////v8CAP7/AQD5//f/9v/0//v/+P/3//f/9//w//T/9v/0//T/7v/t/+3/8f/w//H/8v/0//X/9P/0//T/9v/4//X/9f/6//v////8////AAAAAP///////////P/9/wAA///9//z/AAAAAAAAAAD//wEA/////////v/7//r/+//8/wEA/v8AAAIAAQACAAMAAgAGAAUABgAGAAoACQAIAAYABwAJAAkACgAKAAsACwALAAoADAANAA8AEAARABIADwAQABAAEgATABEAEQANAAsADQAMAAwACgAHAAUAAgABAAEAAAAAAP7//f/8//v//v/+//7/+v/7//n//P/5//j/9//5//f/9v/0//f/9v/0//L/7f/w/+f/6f/j/+v/5v/o/+j/6//q/+n/6f/r/+r/6v/k/+X/6//u//D/8f/0//T/9f/1//////8GAAMACgANAA4AFQAYACEAHgAeACQAJgAoACkAMQA3ADcANwA+AEUARABGAEgATgBRAE4AUQBNAEoAQgBCAD0APgA4ADYAMQAtACYAJQAfACIAGAAeABIAEgALAAIAAwDw/9//xv+0/6T/lv+J/4H/eP9y/2P/V/85/x//9P7g/rz+tP6u/rr+wP7E/rT+rP6U/nD+Wv46/oj+uv5D/77/QwCmAKAAnQCIAMIArwDfAPcA9AD/APQAFgE0ATQB/gDaALEApgCIAK0A1wD4APwA3wDbANYAxgCuAIQAXgA9ACIAHAAmACcAIwALAPH/6P/o//r//P8IAAoABQD6/+f/2v/O/7X/lv9+/3X/ev+D/4n/lP+d/6v/tf/C/9v/8/8GABUAHwAoAC8AOAA2ADIAKAAhABgAGQATABAADAALAAcACQAVABsAGwAcABgAFQAMAAkACAAGAPf/6f/a/9H/zP/M/8//0v/M/8f/zP/O/9j/4v/m/+//7//+/wkAGAAhAC0ANgA4ADoAPgBGAE4AVwBZAFwAXQBaAFQAVQBLAE8AQgBAADkAMQA7ADIANQAvAC4AMAArAC0AKwAxADIALAAjACQAJAAhABoAFwANAAIA/f/4/wEABAD5//v/8P/2/+7/8v/1/wAACQAPAAYAFwAaADEAJgA7ADcANAAsACkAMgAgAB8AEgATAA0AAQAIAAEAAgD1/9X/+f/d/+//4f/y/93/4//e/9z/5f/Q/+L/2P/g/9P/4P/S/9X/2P/Q/+7/4v/o//D/2v/b/9X/0f/W/83/2v/b/+L/7f/o//L/9P/x//f/CQAGAB4AGgApADcAKAAwAAoAEwDe/77/tP+U/7P/mv+X/4r/gP9h/1v/bP9n/3b/dP9//47/of+p/7j/tf/K/8//1P/f/+n/AwATACMAIAAzAEQARwBIAFAARABGADkAIQAeABEA/P/2//n/7P/k/93/4P/l/+j/4v/n/+7/7P/r/+r/7//r/+z/5f/u//f/8v/v//T//f8EAAkAGQAnADUAPwBDAFwAYABfAGUAaQBwAGcAZwBaAFEAQQA2ADIALgAsAC8AMQA0AC0AHwAdABgAEAAUAAgAEQACAP3/9f/x/+z/4//Y/9D/0//K/9X/0f/f/97/3//q/+b/7P/r//H/6//u/+z/8//u/+b/5f/b/9f/0f++/8P/s/+i/7H/kv+s/5X/qP+X/6z/sf+y/8b/1f/u//b/CQAmACgARQBHAE0AZwB5AH0AggCKAHsAdQBuAHQAZQBqAFkAXgBlAFsAZABzAHoAfwB/AIwAjACXAJ8ApACxAKEAmgCPAHoAYwBDADoADAD//9j/w/+w/4f/c/9e/0H/Q/8u/zb/KP8r/yv/MP8u/yz/Hf8h/wv/8v7o/sD+sv6Q/nL+Rv4k/gj+5P3U/cj9pP20/Zz9oP2k/aj9tP3U/dT99P0M/iz+SP5o/nr+hv6q/r7+9v7m/kr/SP+R/8n/1/9EAGYArADtAIABugEEApgCxAIgA3wDyAMoBGAEkATQBOAEMAUwBVAFcAV4BZAFiAWQBYgFeAWYBWgFWAVQBSgFCAXQBJgEQAT8A5gDKAPEAlgC0gFWAbQAKABs/+D+JP6Q/fj8UPzQ+yj72Ppg+gj6wPlY+Uj5EPnw+OD4wPjQ+MD4yPjY+Lj46Pjw+PD4CPno+Oj48Pjw+Oj48PgA+Qj5KPlQ+Xj5kPno+Tj6kPr4+mD7yPtE/Lj8HP2s/Qb+ov40/+P/XAAAAdIBJAJgAxAE6AQQBtAG+AdACZAKwAsADQAOMA8gEOAQwBEgEmASwBKAEkASwBEgEUAQIA8QDpAMYAvQCbAI8AboBTAECAOeAWkAaf8Q/jD9CPxw+5D6uPkI+XD4wPdw98D2YPbg9YD1gPVA9YD1sPWw9TD2kPYw99D3gPg4+eD5kPog+7D7BPxg/JT8qPyw/Gj8PPzI+1D7+Poo+sD5MPmg+CD48PeA93D3QPeQ97D3KPiQ+Aj5sPlI+hj78PuQ/ID9SP4N/0UAfACGAeABZAIIA1gDQARoBEAFmAW4BnAHcAhQCYAKsAvQDJAOgA8gESASYBNAFEAVgBXgFaAVIBWAFKATQBKgEAAPIA1AC/AIyAaQBKAC4AD8/mj9QPzo+hj6IPlg+OD3kPdg92D3YPeA97D3APh4+MD4+PhI+aD5yPkA+vD5APog+kD6QPp4+nj6gPrw+hD7YPv4+xz8pPwY/aj98P1o/qr+tv7c/pb+Zv7s/Wj9qPyw+/D60PnI+MD3wPaw9dD0IPSg80DzwPLA8qDyMPNw8yD0IPWw9QD30PdQ+TD6QPu0/IT9vv51/1QAMAGeAbACTAMQBPgEoAXoBjAIsAnACmAM4A2QDyARABMgFKAVwBagF2AYQBhgGAAYYBdgFsAUABMgEeAOkAwQCpgHCAXAAo4AeP6s/Dj7oPmY+LD34PZg9iD2EPYw9oD24PZQ9wD4aPi4+Ij5qPkw+lD6qPrg+vj6KPso+2D7aPu4+/D7CPyM/Lz8SP3M/VT+yv5w//H/ZADSANoAzAC+AHQA3v9k/z7+WP04/ND62PlY+DD3MPYA9RD0EPNw8vDxkPHA8ZDxMPKw8qDzsPSw9RD3CPhw+ej6PPww/aD+WP9PAFoBWAI0A2AE6AQgBiAHgAjACSALoAwgDiAQoBFgE+AUQBbgF8AYgBkgGmAaQBrgGSAZgBcgFgAUQBKAD/AMMAqAB9gEXAIEALT92PvI+WD48PbQ9eD0YPTw8zD0UPTA9HD18PXA9mD3EPjY+ID5EPq4+hD7aPuw+8j7FPwY/FD8fPy4/NT8EP1c/bz9Tv6i/jr/sP8yAH4AvQDsANUAvABsANz/Bf8g/hT9IPyo+lD5CPiQ9pD1cPRA84DyYPFA8aDwwPDQ8BDxMPIQ8yD0YPXw9gj44Pk4+8z8Fv5v/64AiAEMAygEIAUYBhgHIAiACbAKEAxQDQAPYBAAEmATwBQAFkAXYBggGaAZ4BngGYAZwBjAFyAWYBRgEtAPcA2gCqgH6AQ8Aqr/IP3w+rj40PYw9dDzoPLQ8XDxMPFw8fDxgPIg8xD04PQA9vD24PfA+Ij5WPrQ+pD78Pss/Jj8yPxM/Vz9iP3A/cT9XP6E/vL+IP9+/8H/5P8cAOP/9v+9/23/4P5g/lD9hPxQ+3j6APmw93D2QPVQ9FDz8PGQ8YDwgPAA8CDwwPAA8WDyEPOQ9ED1QPeQ+ED6+Ptk/cj+GwDSAQgDaAS4BcgGEAhgCbAKAAxwDdAOIBDgEQATYBSgFcAWwBfAGEAZ4BkgGgAawBnAGOAXgBbAFOAS4BBwDrALQAlQBsgDZAGs/nD8SPoQ+GD2sPRQ80DykPEw8UDxYPHA8UDyEPPg88D0sPXA9uD3ePho+VD64Ppo+wT8WPyg/CD9RP1M/bj9wP3s/Ub+UP5u/pb+0v7E/t7+6P6M/mb+Qv68/Uj9SPyg+8j6yPno+MD30Pbw9RD1APRg81Dy4PFA8TDxIPHw8MDxkPJg82D0gPWw9nD48Pl4+wj9Pv7x/3QB9AKIBJAFKAdwCCAKYAugDGAOsA9gEaASABQgFWAWYBeAGIAZwBlAGmAaQBqgGeAYwBdgFqAUoBKAEPANgAuwCAAGUAOfAET+0PvQ+YD34PVQ9NDywPFA8dDwsPDg8BDx4PFg8jDzEPQw9QD2APfw98j4sPlI+uD6qPvw+2D82PwI/Xj9YP2w/cj9OP5S/m7+fP7i/rT+Dv/c/sj+mv5U/gL+lP3k/Cj8ePug+uD56Pjw9wD3IPZQ9VD0kPPg8jDy8PEw8qDxMPLQ8qDzAPWg9UD3MPjg+aj7CP2i/gUAigE0A8gEEAaQB8AIUAqgCxANgA7QDwARoBKgE+AU4BWAFsAXQBjgGCAZ4BjgGKAYoBfgFoAVABQgEkAQAA6gCzAJuAYYBMoBHP/k/Nj6oPjw9lD10PPA8uDxUPEw8TDxYPHw8ZDyUPNA9CD1IPYQ9xj4yPjQ+VD6OPuw+yT8ZPzw/DT9OP1A/VT9WP1k/aD9gP2w/ZT9uP2Q/bj9ZP0s/Rz9wPyE/PD7kPsI+1D62Pn4+ED4kPfQ9iD2gPXQ9BD0gPNQ88DyEPNQ84DzIPTw9PD10PYI+Dj5ePoQ/Fz9wP4MAGwB7AJ4BMgFWAegCCAKsAsQDYAOABAgEYASoBPAFKAVgBYgF6AXIBggGAAYoBfgFkAWABWgE+ARABAADvALsAlQB+gEjAI9ACr++Pvo+Sj4gPYA9cDz4PIA8pDxcPGg8eDxAPKg8mDzIPQQ9aD1gPZQ9zj4+PiA+TD6sPow+5j7DPz4+0D8VPxw/HT8hPyY/KT82Py8/PD8yPzY/MT8sPyg/FD8PPzo+9D7KPsI+3j6EPrA+SD5sPg4+OD3YPcA98D2EPZg9iD2UPbA9gD30Pc4+PD4yPnA+oj72PzQ/fz+LQBqAaQCEARwBbgGIAiACRALcAzwDWAPgBDgEQATIBQgFcAVYBagFgAX4BbAFkAWoBXAFIATIBKgEMAOAA0AC+AI4Aa4BKgCnAC2/rz8APuI+eD3sPaQ9aD0QPSA85DzYPOQ8+DzcPSQ9HD18PWA9nD38PeQ+Dj54Pkg+rj6EPtg+5D7oPvA++D76Pvo+/j76PsE/AD8DPwQ/Pj7APzo++D7uPug+6j7aPtA+xD7wPqQ+lj6OPrI+aj5YPkI+dj4ePgg+Aj4APgI+ED4ePjI+Ej5mPkI+gj7ePt8/Gz9Kv5Q/0IAUgGoAtgDIAVIBtAHEAmQCrALQA1gDpAPwBDgEeASoBNAFIAU4BQAFeAUgBQgFEATYBJgEcAPkA7gDFALkAmoB9AF/ANUApoA3v48/fj7kPp4+XD4cPfg9lD2IPaw9ZD1gPXA9QD2EPaA9pD2EPeQ9+D3QPiQ+Pj4YPm4+QD6KPpw+qj60PoI+wj7SPtY+6j70Pvg++j7GPw8/BD8cPwQ/FD8SPwo/Az8+PsA/Lj7sPt4+1D7EPvw+qD6gPog+gD6uPnI+dD5qPkY+hj6sPrQ+kj72PtQ/PD8lP1a/gX/0/+5AKoBaAKcA0AEcAVoBrAHcAjACZAKwAvQDLANsA5ADyAQoBBAEUARYBGAESARABFgEMAP4A7QDfAMgAtQCsAIWAfoBWgEwAJOAer/mv5g/SD8KPsw+mj52PhI+ND3kPeQ94D3kPfA9+D3IPiQ+Mj4OPmI+dD5SPqA+sj6+PoY+2j7WPuo+5j7qPvA+6D7yPu4+8j7yPvA+8j7yPvI+6D7wPug+7j7mPug+5j7oPuo+6D7qPuA+3j7WPtY+yj7EPvY+vj68Pro+gj7GPtI+2D7wPuo+0z8WPzM/FD9iP0i/n7+DP+h/yMAwABuAUACIAPMA7gEgAVYBjAHIAgACcAJ0ApwCxAMsAwwDZANwA3QDdANoA2ADQANcAzgCxALQApwCVAIUAcYBiAF9APAAsABowCv/77+/P1I/aT8DPyg+0j7GPvo+sj60PrQ+uj6APso+0j7mPvA++j7GPws/Fz8aPyE/Hj8ePxw/GD8UPww/Bz8DPz4+/D7yPvI+8D7uPvQ+8D7uPvY+9D74Pvw+wD8APwc/Dj8SPxc/FT8cPxk/HT8WPxs/Gz8bPxo/Gz8cPxs/JT8jPy0/NT85PwY/VD9iP3E/Qr+UP6c/gb/f//d/2gA7wCMASQCuAJsAwgEqARwBRgGuAaIByAIwAhACcAJMApwCqAK0ArQCsAKoApgCiAK0AlQCcAIUAiwBwgHUAaQBeAEGARgA6wC9AFsAcEAMwC2/1L/8v6o/lr+LP70/dj9uP28/ZD9qP2k/bD9wP2U/az9oP2g/Yz9bP1k/TT9LP0Q/cT84PyA/Iz8XPxg/DT8MPwU/CD8DPzw+yT8APwE/Az8FPzw+yD8FPwI/CT8APwY/CD8DPwA/AD86Pvw+8j72PvI+8j72PvI++j7APwI/DT8XPx4/MT85Pw4/YT9vP0e/mL+4v4g/5D/AgBPAOsAUAHgAXgCDAOIAxAEmAQQBbAFIAawBhAHcAfYBxAIMAhwCJAIgAiQCIAIUAgwCPAHiAc4B+gGcAYABpgFEAWYBCAEoAMgA7QCKALQAWwBCgGuAE8AFQDM/4n/Tf8Z//r+0v6y/oj+bP5E/kD+Dv70/dT9rP2U/XT9UP0g/fj81Py8/Jj8dPxk/Ej8PPw0/CD8JPwo/CD8LPw8/Ej8QPxc/Fz8YPx4/Hz8hPyQ/JT8jPyU/Iz8hPx8/HT8fPx4/ID8ePyE/IT8kPyc/LT8yPzg/BD9KP1k/Yz9zP38/Ub+iP7W/jj/df/e/zMApwD7AGIB1AE8AqwCFAN0A+wDSASoBBAFSAW4BdAFMAZIBogGqAbABugG8Ab4BtgGyAaoBnAGSAYIBrgFeAUoBdAEgAQoBNADbAMQA6wCOALiAYQBMAHUAHkAKADh/5v/U/8W/9b+pv5u/kL+FP7s/cj9qP2U/XT9YP1E/Tj9HP0E/fT82PzE/LT8pPyM/HD8UPw8/DD8EPwI/PD76Pvg+9D7wPvA+7D7sPuw+7D7sPvA+8D70Pvo+/j7DPwc/Dz8VPx0/JD8rPzM/OT8BP0w/Uz9iP2k/eD9Gv5S/pL+zP4O/0//nP/G/zYAXwC7AAgBTgGwAe4BOAKUAuACHANkA8QDCARQBJgE0AQIBTgFaAWYBbgF2AXwBfAFCAYABvAF6AXABagFgAVoBSAF6AS4BHgEOAToA5gDUAP8ArgCYAIQAsYBcgEmAdwAmABTABAAyf+N/07/FP/c/qT+dv4+/gz+3P2o/Xz9UP0g/fT8xPyY/Hj8UPws/Aj88PvY+7j7oPuY+4j7iPt4+3D7ePuI+5D7oPuw+8D72Pv4+xj8OPxQ/Hj8nPzI/PD8GP1I/XT9rP3c/RL+QP6A/sD++v40/2//rP/p/ygAXQCaANYADgFGAYABuAHsASACUAKAArQC6AIQA0ADcAOcA8QD7AMQBDgEWARwBIgEoASwBLgEwATABMAEsASgBIgEaARIBCAE+APIA5QDaAMwA/gCyAKQAlQCHALcAaABZgEqAe8AtgCBAEMABwDP/5r/af8x//z+zv6a/mz+Ov4S/uT9wP2c/XT9VP0s/RD99PzY/Mj8rPyk/Jj8mPyU/Ij8pPyY/Kz8tPzQ/Nz89PwM/ST9PP1U/Xj9lP2w/cj95P38/SL+NP5O/m7+gv6o/sz+6P4I/yr/Sv9x/4z/s//S//L/GwA2AGIAhgCmAMsA6wAKATIBUgFwAZYBrgHOAeoBCAIgAjQCUAJcAnQChAKQAqgCuAK8AsgCzALMAtAC0ALMAsQCvAKoApgCgAJsAkwCLAIMAuYBvgGWAWwBOgEQAeUAtwCMAGIAMwAPAOb/vf+Y/3H/Tf8u/xD/8P7U/rz+pP6O/nb+YP5M/kD+Lv4g/hL+Bv4A/vz99P3w/fD99P34/QD+BP4K/hD+HP4o/jT+QP5Q/l7+cP6A/pL+pv68/tD+6P4C/xr/Mv9L/2L/eP+S/6r/xf/f//j/EQAsAEUAXQB0AIkApAC9ANYA6gACARgBLAFCAVIBZgF0AYYBkgGiAbABugHGAcwB0gHaAd4B3gHiAeAB4AHeAdgB1gHQAcYBugGsAaABjgF4AWQBSAEyARQB+ADXALsAnAB7AF4AQQAgAAIA4f/G/6f/jP9v/1P/Ov8g/wf/8v7g/s7+vv6u/qD+kP6G/nz+eP5y/mz+aP5o/mj+av5s/nD+eP58/oT+jP6W/qD+rP68/sz+3P7s/gL/E/8m/zn/TP9h/3X/iv+e/7D/wP/R/+L/8v8DABIAIQAvADwARwBVAGAAawB2AH4AiQCSAJoAoQCpALAAtgC7AMEAwgDKAM0AzQDOAMsAygDKAMEAwgC1ALUAqwCoAKEAmACQAIwAhgByAHoAZQBmAFkASwBNADoAKwAlABcABADy/+v/3f/Q/8b/tv+v/6b/m/+Y/5L/kv+K/4X/h/+F/4L/gf+A/4L/g/+E/4L/gv+G/4b/h/+J/4n/jf+P/5H/kv+V/5n/mf+d/6D/pv+r/67/sv+2/7r/vv/C/8b/zP/P/9L/1v/Z/97/4f/k/+b/5//n/+r/6P/n/+f/6P/p/+b/5f/k/+f/6v/n/+X/5v/p/+r/7f/x//T/+P/9/wMACAALABAAFAAaAB0AIQAkACgAKwAtADEAMQA3ADwAQQBEAEcATABQAFMAVABYAFkAWABZAFcAVwBVAFMAUQBOAEwASABEAEEAPQA7ADgANwA2ADUAMwA0ADUANQA1ADYAOAA6ADsAPgA9AD0APQA9ADsAOAA0ADAALQAnACIAHwAZABUADwALAAYAAgD+//v/+P/1//H/7v/q/+n/5v/j/9//3f/b/9b/0P/P/8j/x//B/73/uv+z/7H/rf+q/6n/o/+m/6X/pv+k/6L/q/+i/6j/pP+u/6v/sf+1/7j/u/+//8f/yf/N/9D/1//Z/97/4P/j/+n/6P/v//H/9P/6//z//v8FAAYADgARABIAGAAZACEAKAAsADMANwA6AEMASABPAFQAVwBcAGIAZwBpAG4AcQBxAHQAbgBrAG8AawBoAGsAZwBiAGMAXwBeAF0AWQBVAFQAUABMAEYAPQA3AC4AJgAbAA4AAwD3/+z/3v/V/8r/w/+9/7X/r/+o/6P/m/+Y/5L/i/+G/4P/gP9//33/e/98/37/f/+B/4P/hv+J/47/kf+W/5j/mv+e/6X/p/+p/6r/rP+w/7H/tP+3/77/w//M/9b/5P/y////DwAeADIARABUAGQAcQB8AIgAkQCYAJ8ApACrAK4AsACwAK0ArgCoAKYAogCgAJ4AmQCUAJIAjgCJAIEAeAByAG0AZQBdAFMASwBDADcAKwAhABMACgD8//D/5f/a/8//xv+7/7P/rP+n/6P/mv+b/5b/mf+Z/5//of+s/7r/yP/Y/+r/+v8LABUAHQAbABwAGwALAPj/4f/M/7X/nP99/2L/RP8s/xb/CP/8/vb++v4C/w//HP8x/03/aP9//5b/r//C/9P/4v/v//n/AQAJAA0ADwARABQAHAAcAB8AIQAvADoAQwBGAFAAXABvAHwAigCWALIAywDoAPkAFAEyAVABZAFmAWQBZgFgAUoBJgH4ANEAoABuACwA9P+//4//Yf85/xH/Bv/8/gj/Df8k/0n/gv+5/+P/CQA3AIgAmwDBAMoA+AAeAQIB7QDXAMgAcABAAMj/Z/8z//j+2v6Y/lz+Vv6M/qr+tP6w/gf/Uf+e/7v/4/9DAJYA0QDqAPkAGgE4ASYB9QDDAIEAXgAOAKb/Vf8C/8z+eP48/gT+3P3A/aT9lP2M/Wj9UP04/TD9JP0M/QT9IP1U/Zj93P1Q/vL+sP98AE4BOAI0A0gESAUgBugGiAcgCIAIkAhgCPgHcAeoBqAFiARcAzwC/gC//5r+jP2k/Nj7KPuQ+jD6GPow+mj6uPpI+wT8yPyE/VT+av+QAHQBRAIEA9gDoAQIBSAFAAXQBIAE4AP0AvABBgErACn/FP4M/Uj8sPso+6j6YPpg+qj68Ppg+wD80PzU/bz+qf+VAIQBYAIEA3gD0AMIBCAECAS0A0wD3AJkArIB/wA+AKH/Ev9g/sz9SP38/Nz8zPzM/Oz8UP3g/Wb+5P5V/+7/+ABMAfgBGAKwAlQDTANAAxwDNAPoApQCtgFCAcIAWwCi/+z+PP7A/YT9NP2s/Fj8ZPyo/Lj8zPwU/aj9XP62/g3/fP8RAKQABAEaATwBeAGsAbABWAEGAe0AzgB5ABAAp/+E/2r/Nf/i/sj+wv7c/vL+5P7+/jH/ev+8//D/FQBnAMEA9QAoAToBZgGCAX4BVAE8ARgB+ADEAH8AWAAoAP7/zv+r/4r/gf9z/3j/gf+X/7f/6v8dAEkAggCuAN0AAgEWASQBNAE2AS4BGAH6AOUAwwCnAHEARQAZAOX/v/+V/27/RP8b//b+4v7K/rT+nP6U/pL+oP6m/qz+yP7o/gX/Iv9Q/4D/r//R//P/GgA/AFEAVwBYAFEASwAuABcA9P/Q/7f/mv97/2D/T/9K/0//T/9W/2P/gP+a/7j/zP/y/yEATQBsAIEAnwDCANgA4gDlAPMACgEcARwBGAEWASIBJgESAQIB8gDsAN8AxgCrAJIAfwBhADwAEQDp/8r/qf+A/1n/PP81/yj/H/8W/x//NP8//1n/av+W/7X/2P/s/xMALABDAFQAWABOAEEALgAbAPH/1P+t/4//ev9Y/zb/JP8g/xr/HP8f/zL/O/9R/2T/i/+o/8T/5v8JACcAPwBRAGMAbQBzAG0AWwBCACMABgDz/83/qv+K/3P/Wv9B/yr/JP8g/yD/LP86/1D/bv+Q/7T/4P8SAEgAfwCzAN0ABgEwAUABUAFWAUwBRAEeAfMAxwCbAIAASgAWAPf/xv/M/7X/sf+3/73/1v/7/wIALQBQAH4AqADQAPMAGAFEAWIBfgFgAYgBZgF2AVwBPAE8AQIB3AC2AJMAQAAJANn/lf9x/0r/JP8E/+T+wP7I/sL+2P7K/uD++v4L/yz/P/9j/4H/mv+//8P/2v/3//n/FgAaACgAOgBDAFkAaACBAJMAmwC2AM8A6wD9AA4BJgEqASoBFAEGAeYA5QC2AI4AXQAxABQA5P+0/4T/cv9N/zj/HP8N/x3/Of9d/2v/mP/D//7/QwBuAKcAxgD+AAgBGAEuASgBHAEWAfYA2AC6AIYAYgBAAA4A/P/P/73/qf+Z/5f/ff+H/4z/mf+//9D/7/8AACsAMwBcAGAAXwBkAFkAVwA4ADQAHQADAPX/2v+z/6z/nv9//3j/WP9Q/0n/Jf8Y/+r+3P7O/qT+nP5q/mT+Mv4g/uz9rP2s/Wz9ZP1M/Sj9KP0o/VD9WP18/aT92P0o/mr+wv4P/4L/+f+LAOkAXAG2ASwChALUAgQDPANoA4wDiAO4A4QDqAOQA8gDvAOkA9ADrAPkA9ADAAT8AxgEIAQ4BCgEUAQoBDAEEAT8A8QDpANkAyAD4AJsAkQCygGIATQB3gB6AC0A/f+Y/3v/Bv/m/qj+RP4Q/pj9MP24/CD8iPvA+uj5OPlI+JD3sPbA9SD1YPTA8zDzsPKA8lDyQPJQ8oDy4PJA8/DzsPQg9UD24PYQ+FD5ePqo+zj9mv6o/ywBEAKkA/gEeAbAB9AIEApgC8AMoA2wDoAPYBBAEaARABJAEmASgBJAEuARYBHAECAQMA9ADiAN8AvwCrAJYAgAB8AFsAScA5QCkgGZAOD/G/+u/hb+rP0g/fj8dPwo/ND7IPsI+4j6EPqI+cj4GPhg98D2EPZw9dD0IPTQ80Dz8PKw8mDykPKQ8rDywPLw8gDzIPNg82DzYPOg85DzwPPg88DzEPRQ9JD0IPWQ9bD2APiI+VD7LP1k/8QBYATIBlAJsAtwDuAQQBNgFcAWYBiAGSAaQBpgGuAZQBkAGMAWABUgE2ARIA8ADeAKoAioBvAEzAKaAcj/BP/A/Wz9oPx4/Ij8lPz8/Pj8nP20/fT9YP5c/r7++P4V/zn/Rf9O/xP/K/8R/+D+dv4g/rD9NP0A/Wj8QPzI+3D7GPug+vj5WPnA+Bj4MPdQ9iD18PMg8/DxIPEA8ODuwO0g7SDsYOvA6mDqgOrg6kDr4OvA7EDuoO9g8tD0oPf4+gb+sAHgBPAH0ArwDeAQoBPAFSAXYBiAGcAaIBsAG0AaYBnAGEAX4BWAE+ARIBCgDkAMQApACOAGoAVABPgCfgG6AMv/SP8m/rD9tPzs/Kj8yPug+8D6uPqA+lD6+PnY+fj54Pmg+sj6GPvA+wz8+PxM/ZD9RP5K/ub+8v5P/zj/DP/s/nT+EP50/TD8yPuY+ij5IPjQ9pD1YPTQ8rDxgPBg72DuYO2g7ODr4Oug68DrAOyA7GDtgO4g8JDx0PTA9ij68Pzg//AC0AXQCMALcA5AEYATABWgFuAXQBlgGcAZgBmgGEAYABeAFSAUYBLgEPAOUA1gC+AJUAgQB4gFEAQsA7oB6QDm//b+Xv7E/Vj9lPwc/GD7+Pqo+lD62PnQ+RD66PkQ+ij6WPoo+4D7BPxY/PD8VP3I/Yr+YP7U/hD/Wf8Q/+r+Tv7g/WD9hPzI+0j6QPng98D2QPXw80DyEPEA8KDugO2g7IDrQOvg6uDqAOtg6yDsYO0g7wDxIPQA9rD5LP0gAIwDWAZQCZAM8A+gEiAVoBYgGMAZoBoAHGAboBsgG4AaYBmgFyAWgBQgEyASsA/gDTAMsAqwCdAHgAZ4BMgD0AKYAQQAEP+G/sj9VP0k/DD7wPoo+vD5WPm4+KD4oPgI+fD42PgY+Zj5aPqw+hD7UPvI+1T88PxA/ZT9vP30/Rj+oP08/XT82Pto+2j6+Pjw95D2gPVQ9NDyYPEA8ODuwO2g7IDr4Oqg6oDqoOoA66DrwOyg7mDwcPPw9Vj5NP1fANwDgAYwCuAMgBHAEyAWABggGUAboBwgHeAcgBwAHCAbIBoAGMAVwBQgE4ARQA/QDDAL4AkACQAHOAUABKACDALCADr/SP7A/Zj9zPyY+4D6wPng+Xj5CPkw+Bj4UPh4+LD4gPjY+Hj5YPrA+iD7UPu4+4D8SP1w/bj9/P30/Ub+1P0w/Yj8IPxg+1j6MPmw93D2MPUA9HDy0PCA7yDuYO3g6+DqYOrg6QDq4Olg6uDqYOyg7lDwsPMg9oD5Gv4+AYAEuAdQC9AOYBKAFYAXQBngGqAcgB2AHuAdoB0AHUAcoBpAGMAWwBSAE2ARMA9gDBALYAlQCFAGsASsAjwCCAG7/4z+ZP00/YT8JPyo+hj6aPko+Wj5wPhQ+GD40PgA+Uj5oPlA+gj7HPx0/Pz8OP0G/rT+Q//O/6v/EgDu/53/Gv+E/tT9zPzg+0j60Phw9+D1sPTw8nDxgO9A7sDsYOtA6kDpwOgg6EDoAOiA6IDpIOoA7SDvkPFQ9aj47PyoAFgEiAdwC1APIBNAFmAYQBqgGwAe4B5AHwAfYB4AHqAc4BqAGKAWwBRAE+AQQA7QC+AJoAj4BngFWAPeAbwAuf9M/hD9wPug+/D6EPog+fD3sPeA96D3UPcg9/D2YPcI+ID4EPnI+dj6wPug/DD9zP1+/ib/2f99AIYAnAA0AEMAif8l/wb+GP0E/Ej6+Phg9zD2UPTA8iDxoO8A7kDsIOsg6uDooOjg58DngOdg6ADpYOpA7ODtgPEQ9Cj4qPuH/1wDqAawClAO4BFgFSAYwBmgG0AdgB4AHwAf4B4gHuAcgBtgGWAXwBXgE2ARUA/ADLAKUAlAB3AFiAP6AYIA7P44/SD8UPtY+qj50Pjw91D38PbA9uD2wPYw92D3GPhA+Kj46Pn4+hz8YPyo/fj9CP+j/97/nACPAAYBpAGsAGUAZf/u/rj+SP0k/Dj6KPlw93D2YPQQ8+Dw4O8g7uDsAOug6eDoAOjg5wDnoOZg5gDooOhg6mDsQO/A8TD2OPoC/lQCmAXgCbANQBJAFcAYYBsgHaAfQCDAIcAhwCGAIQAgYB4AHAAaABggFqAT4BCADpAMUAqACFAGYATYAlAB2f84/oT8aPvw+jj66PjQ94D30PbA9hD2IPZg9rD2UPdQ9/D3yPjo+YD7gPww/QT++v5IAJgAMgEkASwC+gEMApIBcACVAK7+nP7Y/Lj7mPkI+JD24PTg81DxwO+A7oDsQOuA6oDo4Oeg52DnIOeg5qDm4OfA6aDrQO2A73DzUPfY+8f/FAPwBlAL8A+gE6AWQBmgHCAfACFAIcAhwCIAI0AiQCAAHsAbQBqAGKAVIBPAD5ANwAsACSAHaAQsA+IAb/+A/YD7yPpg+fD4wPfg9uD1YPUw9RD1EPUw9VD1EPYw96D3iPhY+dj6yPzc/S3/s/9/ALoBYAKoA9QChAMsAwwD1AJ8AewAa/+M/gT9UPuw+YD3UPVA9KDy0PBg7gDtIOsA6mDpQOhA5+DmgOZg5sDmoOag5wDpYOtA7cDv8PLA9tj6fv+8A2AHYAuQD4ATgBfgGoAd4B/AIQAjwCNAJAAkgCPAIQAggB0AG6AYwBVAE8AQwA0wC2AIgAZIBFwCKQD4/YT8yPrY+VD4IPcg9pD1EPVg9BD0gPMg9ID0QPWg9VD2kPcI+ej62PuQ/fL+cADYAbgCiAMoBDAFsAXQBTAFgAQoBIQDsAJGAUr/zP24+xD6wPcw9tDz0PFA8IDuQOxA6iDpIOcA5wDmYOXA5IDkIOSA5YDmYOcg6SDrYO6w8RD1SPjk/HQBSAaQCnANABFgFUAZ4BxAH0AggCGAI8AjQCTAIsAhQCAAHyAcIBlgFoAToBGgDjAMAAmYBmgE7AKfAE7+TPyg+pj5EPjA9uD0YPQw9ODzwPMw8wDzkPPQ9ND10Pag9/D4APuw/Cr+q/8EAewCIASgBGAFsAV4BrgGsAbwBYgE4AMgA8QBWAB2/rD8MPu4+PD28PQQ86DxwO8g7mDsQOpA6SDo4OcA54DmQOZA5aDlwOag5yDo4OnA68DuEPKg9fj4BP1sAhAHMAvADiASYBYgG0AewCAAIsAjwCTAJYAlQCTAIkAhgB+gHEAZoBXAEoAQoA3wCqAHQAWAAqsAn/8A/UD7ePmo+ID3cPZA9dDzsPOw89DzoPMw83DzUPQw9mD3EPhA+cj6pPz2/noA5AFIAxgFWAZQB8gHoAeACMAIQAiAB9gFiATIAygCnwA4/tD7aPlA+BD2oPPw8YDvYO5g7MDqYOkA6ADngOfg5qDmIOUg5oDm4OcA6UDpIOsA7jDxoPTQ96D7xP8YBQAKgA1gEUAUYBmAHEAgwCHAIkAkACWAJYAkQCNAIYAfgB3gGYAWABMgELANgAuwCCAF1ALNAJr/0P0k/Hj6OPk4+FD3UPaw9ODz0POQ9BD0cPNQ84DzgPVQ9oD34PjQ+ej7Cv6z/1wBcAKwBFAGaAeIB8gHIAiQCGAIyAdYBrgEOAP8AWoAKv5w+2j5cPcA9VDzIPGA76DtAOxg64DpQOjA5yDnQOdg54DmQOZg5mDngOjg6CDqgOuA7tDxAPXI+Iz8xACIBdAKEA9AEiAWwBkgHsAgACPAI8AkwCUAJUAkACKgH+AdoBuAGOAUYBAwDkAMkAkgBwAEBAIdAA//lP3I+6j6gPnw+JD3sPVQ9DD0oPTw8/DzsPIQ8+DzAPVQ9lD3wPjI+mz9nv7CAEACsATABlAIMAkgCfAJ4AkgCuAJkAjQBgAFeARWAbD/oP2w+0j54PYg9UDyIPHg7kDu4OzA6+Dp4Ohg6ODnIOhg5wDnAOdA50DowOjA6ADqoOuA7tDwMPTw9gD70v8oBQAJUA2gEYAVQBpgHeAfgCLAI4AlwCVAJcAjwCFAIAAfABzgF2AUIBHADsALEAmABgwDWALgAEP/fP0Q+0j7QPoA+kD3gPYw9bD00PTw89DzsPKQ87DzoPSQ9ZD2APnw+mD8dv7u/6ACeAQ4BiAIwAiACWAJoAlACbAIqAeABogETAJ1AKr+7Pyw+jj4UPaA9LDywPAA8IDugO3A7IDrgOqg6WDpYOgg6MDnoOfg54DnQOjA6IDpAOtg7KDuwPAA9SD42PyHAOAEMAqAD0AT4BbAGoAdwCDAIoAkgCRAJMAjACMAIYAewBvgGeAWYBMgEPAMoAoQCDAGQASUAkABsv+k/lD9GPzQ+qj5gPiw9rD10PRQ89DygPLw8vDy0PKQ8+D0EPco+TD7GP2+/gIBdAPgBUAHQAgACSAKAAqACbAIsAe4BsgFSASoAU//qP0E/Oj62PjA9rD0EPRw8vDxwPAg74Du4O0g7SDs4OrA6iDq4Ong6WDpIOlg6UDqAOuA6+DsgO4A8SD0EPeY+x7/3AOgCCANoBEgFaAYwBvAHsAgwCKAI8AjACPAIUAgYB6AHMAZQBdAFMAQ8A2QC6AJEAcABUAD1AHvAGD/3P3k/DT8WPvI+aj4cPaw9ZD1APUQ9FDzYPNA9ED1MPYw96j4mPu8/dv/AAHMAhgFQAcwCUAJAAkgCeAIIAnQBxgGiAQoAwQC+P+4/fD74PoQ+TD4oPYA9HDzYPIw8qDxEPDg7qDtQO3A7EDsAOvg6uDpAOpA6iDqIOpg6qDr4Owg7qDv4PCA9JD4PPx+ABgEQAlQDUASQBbAGCAbIB4AIcAiACOAIgAiACEgH4AdgBugGGAWwBIgEEANoArwCKgG+ASUArIBygD5/1b+WP2k/MD7WPqQ+GD38PXA9bD0QPTQ8zDzIPQQ9VD2sPeI+JD7pP3q/3wBPAOIBUAHAAlQCQAJsAiACKAH4AZABWADEAJvALj+LP3g+pD56Pjg90D2QPWw87DyYPIA8vDw4O+A7uDtYO3A7KDr4OpA6oDqQOqA6uDpQOpA6+DsIO5A78Dw4PIA9xD6gv4IAqAGYAsgDyATwBUgGeAbAB5AIAAhQCGAIOAfoB7AHKAbwBnAFsAToBDwDfAMkAr4B/AFaAQgA+ABMAF0/0f/Vv5I/SD8GPrY+AD40Pfg9mD1YPRQ9AD1wPVQ9oD3oPiY+hT9MP+6APwBYASYBmAIsAiQCFAIsAggCAAHqAUgAxAC7QBAACT+kPuI+pj5SPkY+PD2YPUA9ZD0EPTA8tDx4PDg76DvQO5g7YDr4Org6gDrIOog6gDqIOvg62DtoO7A7/DxAPTg9kD6qP2QAUgGwAogDkARYBSAF8AaIB3gHoAf4B+gHyAe4B3AHIAboBlAFyAUABFgDyANoAsACcAGOAVsA0gC4gBNAG3/xP6g/ZD7ePq4+GD48Pfg9qD1YPTA9ED1kPVg9iD3sPig+mj80P2BAK4BlAOYBQAHwAdAB4AHWAcwBygGuATcAukA0v/m/qT9yPsA+vD4oPjQ97D2oPWA9GD0wPMg81DxIPCg72DvIO+A7SDsIOvA6sDqAOsg6mDqoOrg66DsYO3g7gDwoPLQ9HD3UPqc/QQCiAaQCyAPoBEAFAAXoBpAHUAfgB+AHmAegB7AHUAcABpgGKAWYBSAEZAOAA3QCyAKAAmYBiAEwAKEAmwC2QAN/3D9KPwI++j52Pgw96D2EPZw9tD1QPUA9qD34Pno+oj8uP14/3IBcAMQBbAFYAboBlgH4AYwBhgFcAR4A94BJABg/lz9sPzA+6j6SPlo+LD3EPdg9hD1APQg80Dy8PCA70DuoO0A7WDsIOsg6oDpIOpg6oDqYOug6+DroO1A78Dv0PEQ80D1qPjA+tz91gDIBTAKQA5gEWAT4BVAGSAd4B4gHyAfoB7gHsAeQB1gG8AY4BegFaATgBAQDqAMwAvACjAIAAboA6ADZANEAl7/oP2s/JD7ePqo+LD3cPZA9pD2UPZw9vD2APgw+sj7XP2G/mQAcALUA1AF6AVwBogGEAe4BgAGiASAA7QCoAEfAM7+mP2Y/CD8QPtQ+kD5aPjA93D3MPYg9dDzwPKg8YDwYO+A7sDtwOxA7IDrIOsg66DrIOzA7KDsQO2g7kDvsPAg8RDzgPPg9RD48PrK/nQBqAVQCpAOYBAgE2AVgBmAHAAeAB6AHQAdgB1gHWAbQBngFsAVYBTgEdAOcA3QDLAL8AnAB/gFqATsA7QDwgFL/0z9IPx4+/j5EPjA9vD1cPWg9SD2kPZg99j4APuo/Ar+0f+oAZADQAX4BfAFcAb4BQAG+AWwBBQDBAL1ALL/Tv6M/eD8qPwo/GD7sPq4+Wj54PiQ+DD3wPVw9MDygPGQ8GDvQO4A7WDsAOxg66DroOtg7ODswO3g7aDuAO+Q8LDxoPLA8lDz8PWw9wj6GPx0AFAFAAnQDGAP4BHgFSAZoBygHeAdIB0gHkAewByAG2AZoBfAFeATQBFgD/ANYA2QDOAKoAjIBmgGIAY4BfgCmwBQ/rz8oPtQ+hj4sPag9TD1MPVw9eD1EPc4+RD7/PxK/pn/ngH0A2AFoAXABWgFSAWwBEAEUAPKAYoAxv8R/wz+MP0M/Rz9VP30/Pj7IPtQ+tD5EPng96D18PNA8gDxgO8g7gDtYOzg64DrgOsg60DsIO0g7sDuQO9A70DwAPEQ8jDycPJA8gDzoPSw9pD5DPxwAXAF4AnwDeAQ4BNgGAAcIB4AH4Ae4B2gHsAdwBugGcAXQBYgFAASMA9QDuAN0A0ADdAKYAmwB3gHaAd4BfACHQAQ/hD8QPoY+JD24PRg9DD0IPTA9LD1APhY+qD8Nv7B/+gBoAOABYAGSAboBagF+AQwBPACpAGnAN7/s/90/sj9iP2E/dT9zP2Y/fj86Puw+sD5UPjg9uD0QPNg8YDvAO4g7eDsYOyg7KDsIO2A7YDuEPAA8YDxkPEw8rDyYPKA8rDyUPPQ8yD0sPRQ9pj40P2MAmgHwApwDSATwBYgGmAcIB4AH2AfQB8gHUAbABrgGIAXYBWgEoAQ0A5wDrAOQA7gDFALcArACUAIeAaABKwCFQBc/Zj6MPjg9eD0YPRA9ODzwPNQ9LD2OPlA+4T9vP6YABwC9APoBPAESAXQBPAEEAQgAxwClAFuAdUAlQAHAIz/b/+///X/l/9+/oz9bPxQ+2j5UPeg9cDzIPKQ8ODugO2g7ADtoO2g7cDtQO5A76Dv0PAA8oDx0PGw8aDyIPLg8KDwEPLA82DzkPNA9aD3zPxuAWAGMArQDUARQBVgGAAb4BugHIAdIBxAG8AYABjAFiAWoBRAEiARgA8wD0APEA9ADtAMgAtQCoAIKAbEA0oB7P4c/KD5UPcg9eDzIPSg9BD1MPUQ9mj4WPq4/KD+3//sAPIB3AI8AxQD5ALEAmQCgAHKAJsAdgCbADoB+gDeADgApQB0AD0AkP+A/kj9UPt4+dD3cPaQ9IDy4PFg8CDvwO4g7kDuIO4A76Dv4O8g8CDwwPCQ8WDxEPJQ8eDwcPHQ8aDxEPEw8jD1EPYg9mD3wPpV//gCgAhQDOAOIBGgEyAXwBigGQAaoBqAGWAYgBcAF2AWIBVgFUAUgBLAECAQABAAEMAOAA0gCzAIoAZ4BHAC3P8o/VD7IPmA91D2cPUA9nD2gPdI+Gj4QPlw+xT9cP6//yUAbQCFADYBSgG2AW4BugEAAjACzgEUApwC9AJEA6wCJAKSAfYAWwAh/w7+kPzo+gD5cPdA9kD1EPTQ8rDx8PDQ8ADwwO+g7xDwEPDg73DwIPAg8CDw4PCA8WDx4PDA8SDyoPLQ8mD0wPUg9hD3gPmQ+8D9UgAwBnALgA0QD0ARwBMAFsAYYBmgGWAYYBfAFyAXoBZAFWAVoBTgEkARwBCQD9AOYA4ADaALqAe4BbQD5gEEAFz90PsI+dD3oPYA9tD1UPYA9yD40Pj4+DD6aPvY/Db+Lv9z/zn/Rf/z/3sA1QAMAZIBTAKcArACRANUAwAEsAM8A4ACegFBACH/8P2Y/AD7ePkA+GD2gPVQ9MDzEPOA8rDxsPCQ8JDwUPDg70DvIPDg76DvgO/g7zDwQPGA8WDysPJQ8gDzQPUw9iD2MPfI+Jj66PtH/8QDUAhwC2AOQBEgE0AUQBZgGWAa4BmgGOAXoBZgFqAW4BXAFOASQBJAESAQ4A5gDjAO0AxACtAHQAWYAp4Azv6U/eD6yPig9+D2IPdA90D4sPh4+ZD6aPtE/ND8Gv5a/+v/wP+D/8X/KwDpANQBgAL8AkwDnAMgBIAEuARIBPwDYANkAhIBff9c/ij9BPyg+vj4gPcg9jD1gPQA9DDzUPJg8bDwIPDg74DvgO+A74DvYO+A7wDwYPDw8MDx4PJQ80DzoPOA9KD1IPZg99D4uPnY+XD8vAEoBqAIMAwgECASQBQAFWAXoBlgGeAZwBjgFwAW4BXAFmAWABXAEyATABIAEaAQoA/wDaALcAl4B+wDLAGq/rj96PsQ+mD4EPdA91D3YPiY+GD5wPlY+sD6mPtA/Ij8PP2I/UL+Wv4G/+L/HAFYAnADEASoBNAEgAXIBSgFOAREA2gCbAFHAL7+sP1w/Ij7KPqA+XD48PYQ9lD1gPRA82DyUPFA8IDvwO5A7qDuYO6A7qDugO/g72DwIPFA8sDyQPNQ9PD08PTA9CD2SPhY+Tj4GPrk/VYBkAXQCOANYA9AEYASABVAF2AWoBaAF4AXIBWAFAAU4BQAFaAUIBQAE2ARwBCAEBAPAA2wCjAJsAY8A0gAJP6A/HD7EPpQ+ZD4APhw96D4YPnw+Rj6EPqg+tD6+Pqg+zj8sPyg/W7+gf9MAGQB2AIgBLAEEAVgBUgF+AQ4BGADeAI4AUkAkP+y/oj9oPzo+0D7mPrA+YD4EPdQ9TD0IPPw8bDwwO/g7gDuAO6g7kDvgO/A71Dw8PBw8RDyoPKw8oDzwPMg9KDzQPTA9XD3MPgY+Zj7Pv4uASgFMAtQDkAP0A9AEuAU4BRgFSAWgBZAFuAU4BTAFIAV4BUgF2AWYBSAE2ASQBGAD7ANQAvQCKgFNAPWAMj+KP0g/ND7IPtI+jD58Pgo+Xj52PmI+ej4yPjQ+Ej5+PkI+9D7gPyk/fr+fwBqAWACkANgBGgEzAO8AyQDuAIgArgB7gC5/1r/Sf/a/gj+UP20/JD7WPrw+CD3IPWA87DysPGg8KDvIO/A7uDuQO/g7yDwAPAQ8HDwkPBA8KDw8PBA8WDx8PGQ8qDzwPTQ9iD40Pno+jz9/gCwBaAKwAzgDuAOwBBAEwAUABSgFcAWoBbgFcAVABZAF+AXQBiAF+AVQBTAEmARUA/wDdAL8AhQBkAEuALa/xL+Jv6Y/XD8yPo4+oj5qPhI+LD4kPig9zD3QPcw+PD4+Pkw+yz8KP1o/u3/hQBgAWAC8AJkA1wDDAPwArgCpAKUAvYBlgGoAFsATQB9/3j+OP0c/FD7qPnQ9yD2wPQA9PDycPJw8bDwIPCA8ADxAPHA8FDwsPBg8EDwYPCg8NDwAPEA8tDyEPMA9OD14Pcg+QD6mPtu/iwBGAbQCeAMgA1wDcAQ4BEAE+ATgBVgFmAWYBYgFsAW4BeAGIAYYBegFSAUQBLAEMAPYA7ACwAJEAfQBXgDWAFEAMr/iv6w/Dj7YPpA+WD44PcA+LD38PYw9uD2EPig+Aj6qPq4+3j8cP2A/iD/YwDOAOIBXAKMAqgCwAIkAyADdANQA7AC3AGuAZgB8wBt/yD+JP1U/ID6oPiA9zD2APUw9IDzgPKw8VDxgPHw8JDwEPAA8ADvQO8g8IDvgO+g71Dx4PFw8cDxMPSg9vD2cPeo+Sj7WP6CAUgGEAogDNAMUA7wDwAS4BJAFGAWoBZgF4AWoBcgGIAZoBmgGEAYABZgFCATwBFgEEAOYAxwCmAIMAZwBMQCRgGw/zD+zPyw+gj5YPiQ9/D2IPbQ9fD1kPUQ9vD2oPdI+Cj5CPqg+lj7aPxM/ej9Jv7a/gAARACdALAB+AFMAtQBZAIcAsoBcgFAAdMAOf/E/Qj9jPww+2j5+PjQ90D2QPVQ9LDzYPIQ8nDxAPEg8GDvQO+g7wDvwO9g7wDv4O/Q8BDxYPCQ8QD1wPVA9dD1yPgw/Oj9vAI4B8AJUAogC0AOkA9gECASYBVgFkAWgBbgFyAZQBkAGyAbwBnAF2AWgBVgFMASoBGgEMANkAugCSAICAYQBCgDKgHS/qz8kPqw+QD4QPfA9tD1APUw9TD1EPWA9fD14PYw99D3MPhA+aD5oPrY+/T8UP38/db+pP9lAIoA/QDIATgCTALMAfgB2gFCAVcAc/++/sT92PyI+zD6uPjw99D2MPYg9YD0gPNg8lDyYPGQ8KDvoO8A8IDvYO4g74Dv4O+A7xDxoPJw8hDzkPXg93D5sPrO/9gEkAYwBxAJIAuADHAOgBBAEwAUwBQAF0AYABkgGSAb4BvAGmAZABnAFyAWYBVgFKATIBDQDkANkAtACYgG4AWMA1IBtP6g/MD6SPkg+ID3gPYA9cD0UPTw8+DzEPSw9JD0gPRA9dD1oPZA95D48PmY+uj6yPuw/ND9HP6O/mz/LgBUAJIAvgDvAKoAVQAXABv/cP5Y/cj8+Pv4+sj5oPgQ+CD3IPYg9cDz8PPw8vDx8PCw8DDwUPCA7zDwYPCA7yDv4PAg8hDyEPPQ9KD3yPgY+3r+sAKwBAgGqAewCZAKkAsAD8AR4BPAFGAWgBeAGGAZwBngGmAaYBoAGoAYIBfgFWAWwBWAE6ARIBDwDXALMAkwCEgGpAPSAcf/XP6g+2D6iPmA+ID3EPYg9UD08PNQ9PDzQPPw8uDzoPTQ9GD1YPYQ94D3APjI+LD5UPr4+jz83PwQ/az9ov5D/5T/P/85/+L+vP60/kr+oP3Y/Lj8EPwQ+xD6gPlA+Wj4YPfQ9gD2EPUw9BD00PNQ87DyEPNQ84DyMPLA8uDzUPQw9bD2cPhA+Sj7Rv4qATQCGAN4BRAHYAggCdALwA7AEAASABNAFIAUgBXgFuAXgBdAF+AWwBbgFUAVABWgFIATwBEAEDAOwAzQCnAJQAigBhgEIALuANj/Cv4g/Gj72PpY+XD34PYA94D2IPWg9MD14PVg9RD18PXQ9rD28PWQ9uD3aPi4+Aj5cPrA+uj6WPvg/Cj91Py8/KD9zP0U/aD8bP38/VD9ePxg/LT8sPtA+/j60Pro+XD5SPnQ+Dj4WPgg+Fj4IPfg9vD24PaA9oD2cPeA9wD4OPgo+sj6OPvQ/LD+4//H/4EA2gHUAxAEsAXwB0AJ0AlwCgAM8AxQDcAN8A7gD9APcA8gEKAQ4BCAEEAQoA/gDrANEA2ADCALMAqACYAJ+AdwBogFeAQYBJgCrgHkANP/OP9k/nD9oPug+zT8QPxo+ij5GPqA+mD5aPjw+Hj5APlg+Oj4aPnY+ID4YPko+pD5OPmw+ej5IPrY+ej5CPpQ+kD6QPoQ+ij6sPqw+lj6WPqA+mj6+Pko+qD6gPoo+hD6gPqQ+gD60Plo+rD6iPpo+sD6EPtg+8j7ePwc/cz9ev7W/hD/4//lALIB/gGgAvQDuAT4BHAFwAZ4B5gHAAjACIAJgAnACYAKwAqQClAKgAqQCmAKUAowCuAJcAkQCdAIkAgQCIAH6AZ4BvAFaAWIBAgE6ANkA4gCwAGcASQBngD1/8r/Y//I/lz+BP7w/TT95PzM/Nz8YPwo/JD78PvQ+9D7YPtQ+6j7WPsw+9D6QPs4+/j62PrI+jD72Pqw+uD6+PrQ+oj6oPrQ+qD6mPpw+lj6YPqQ+rD6YPpY+qD66Pqg+nj62PpY+zj7OPug+yz8PPxE/PD8iP2o/bz9Ov7Q/gT/DP+i/zgAiADQAGIBBAJAAkwCrAJcA5gDyAPoAygEiATIBPgEKAVQBaAF6AXYBdgFEAY4BlAGOAZIBkAGCAYQBggGIAbgBagFmAWYBWAFGAXwBOAEqARQBCgE6APEA0wDFAPUApwCIALkAaABSAHmAI0AeAAEAJT/Vv8z/9D+Uv4y/h7+2P1g/Qj95Pyo/FD8NPz4+7D7YPtI+xj72Pqg+pj6cPog+vD5APro+bj5qPm4+dj5yPnA+fD5EPpA+lD6ePq4+uD6MPtw+8D7CPxY/Kj84Pw8/ZD9Fv5i/rj+9P5t/+r/OACHANgAYAG+AQgCOAKoAhADUAOYA+gDIARQBJAE6AQgBUgFWAWYBbgF8AX4BQgGOAYwBjAGMAYwBigGAAbwBfAF2AWoBYgFaAU4BfAEsASQBEgE6AOwA3QDJAOwAlgCDALQAVoB6QCWADUA3f96/yz/zv5y/hj+yP2M/Uj98Py0/ID8UPwk/PD7wPuI+2j7UPs4+xj7APv4+vj66PrQ+tD62Prw+vD6EPtI+3D7gPug+/j7JPxA/HD8sPwA/Sj9RP2A/eD9MP5k/qz++P4//3L/rf8BAEMAhAC3ABQBVgF4AaIB+AE8AmwCgAK0AugCBAMUAzwDbAOQA6ADtAPQA9gD4APUAwAE2APgA9AD6APMA6ADfANsA2ADIAP8AtQCsAKEAlACKAL6AbgBggFWARQB4wCyAHQAKgDw/7r/hf8+/xD/4v64/pL+ZP5U/jD+9P3E/bj9tP2Y/XT9VP1g/VD9PP0o/Tj9TP1A/Tz9OP1Y/WT9dP2g/cD9zP3M/eD9Av46/lz+eP6M/qL+2v4I/xH/Hv89/2b/k/+4/9b/9P8HAB8AUQB6AIIAlwDFAOkA/AAAARQBQgFoAVoBWAF+AaABrgGmAagBuAG4AboBvAHUAdIB0gHSAd4B1gHGAboBwgG4AZwBhAF+AXgBXAE2ASABKAEYAfUA3ADPAMQApACKAHsAZwA+ACcAIgAMANb/rv+e/4r/c/9G/zH/I/8L//L+2P6y/pD+hP5u/mz+ZP5e/kz+Pv4+/jz+RP46/kD+RP5a/lz+aP52/o7+pv6u/r7+3v78/gv/Gv8w/2H/dP+I/5//uf/P/9n/7f8JACEAKABAAEoAdQB8AIkAkQCzAMcAwAC7AMEAyQDNAMQAygDFANYA2ADXANEAwgDGAMkA3wDTAMQAsgCxALAAqwCcAJ0AmwCRAIUAewByAF0AVwBRAEwAOgAqACwALAAiABQADQAHAPr/4f/X/8j/u/+o/6H/m/+R/4D/a/9Y/0j/QP8+/yj/Hv8N/wz/Af/+/vb+9v7w/vT+/v4I/wz/E/8j/zL/OP85/0b/ZP95/4L/k/+h/7n/y//e//D/DwAfAD4ASQBgAIQAlwCyAKAAswDGAN4AzQDkAOoA9wDpAOMAAAHxAN4A3wDmANcAvQDPANcAzACfAIYAmgCbAH4AZgBUAFsARQA4ACwALQAnABcACQD6//b/+f/n/9r/y//B/73/tf+x/6//q/+o/5r/lf+X/5T/l/+X/57/nP+Q/4H/df+I/5H/nv+Q/4b/f/+E/5f/i/+N/3j/ff95/3f/bf9r/3v/hv+X/5v/mP+i/8H/5P/v//f/8P8OACoAUABZAGMAegCFAJwApwC1AMAAzQDVAOAA7AD9AAwBFAEMARABEAEWARABBgESAQQBAgHgANsAzQDQALgAoQCLAHcAdABkAFsAOAAqABYACwACAOv/x/+8/7n/z//E/6//n/+n/6X/kP+H/4X/ov+h/6H/kf+F/5X/lv+Z/4v/nP+c/5T/k/+W/7T/n/+Y/6T/uf+w/5H/iP+O/5z/lP+L/4b/kv+V/5b/h/+R/4z/k/+F/5b/kf+F/3f/mv+f/4n/g/+r/8n/rP+Z/8r//f/2/+z/GABTAD4AUABHAKUAcACbAJkAzQC1AMIA7wDrANoAswD4AP4A8gDOAOQA2wDKAMUAxwC1AIwAoQC1AJYAVABMAEsAWAA6ACAA7v+y/9T/DAAlALf/cf+P/9r/zv94/2P/mv+6/5T/Zv9y/6j/o/9//6n/lv+h/1f/j//m/wYAuP9l/5D/v/8DALr/l/96/8f/3f/P/3H/i//N/97/m/93/67/wP+5/43/wP+R/4n/oP/u/9P/cP9+/8r/AwCn/5H/y/8HAOr/0/8LAE4AUgAqADwAYACpAJIAlQCIALUAwwDiANcA0wDZAMQA6AD1APgAwgCxAMcA9ADRAKwAnADUAM4ApwB5AH4AnAB2AHwAWABcACUAFgASAPn/4f+7/9v/2//f/67/r/+G/5j/gv92/3n/V/9s/3X/kP92/17/VP9w/5n/eP9t/0H/kf+r/8P/cf9P/2T/uP/Q/5X/ff9x/9L/rf/K/3T/k/+A/8X/yf/L/43/a//C/+X//f9e/4H/p/9PAMX/o/+K/w4AGAD//+X/6f/9/9n/GQBCAHEA8P/7/woAuwDYAI0AOwBSALUAoACGAHAArACwAI4AnQCVAKsAQgCpAKIA9QBuAGoAgACzAJYAZwCzAH8AigA8AHYATgAJAPv/NABpAPv/yv/T//P/sf+h/7n/9/+g/5//d//c/2z/nv9t/6L/c/+N/+f/zP+Y/2b/8v8FANb/Kf+E/wwAXQAiAK3/kf+t/zIAgwD8/5X/Q/9NAIoAiACK/97/WwCMAA4AL//j/0kA5QDw/+f/wf8sAHMAHABXAHH//f/u/+gAYADN/9X/ZgDcAO//zP8CAOsAaADV//D/ogDLACAAPAA5AMkAKgCXAIsAegAQAA4AAgGcAHIAef83AE0AyQBVAAQACwDC/4QAPgB0ANP/PwDT/xEAjv8HABUAXgAzANz/x/90/6b/AwBJAOb/cf8A/77/BwAAAHP/Vf+S/7r/rP/s/9v/pv8s/6P/RgAbADL/fP/3/4MAv//J/8X/EQAc/+D/YQCLAFz/J/+KAIUA5/+y/tv/rgD9/3z/fv+9AMb/v/94/+EAcABy/y7/vf/fAGEA8/9J/xMAxgAMAfv/Kf/h/9AAPgG6/9//EgAsAZYAZgB8ACoAGABmAKAB5ACx/zH/JAHAAcYAB/8DAAABIgG+/7n/cgCaAGgAhv++AFH/ngAO/8gA4P4YAEv/sgDa/wn/+P7a/qoA3/8yANT9U/9Y/+gAjv7W/gL/yAC9/5L+wP5L/zsALf+m/wD/cP9K/2H/f/+I/34AMv8P/4L+3gDrAOn/av5d/3cA7//Z/wD/UgDu/7wACwBf/yL/MgBWAdf/8P5B/3AAbAEVAGUAyf8hAC0APACEAH3/9ACTAI4BmP9LAOr/EgGSAM0AbwC7/2UAaQC6ASIAggB3/6AATQAeAesADQBgAAcANAH4/5kAIgAoAef/+//8/7YAQwA9AHcAnf8AACb/PAEK/24ANv52AXj/1f+c/vT/ewAM/5f/sP6aAMD+tf+L/0wAsP50/rn/ugAoAEb+tP6T/4wABgDt/3D/B//7/9j/ZwD8/sX/ggAuACf/tP58ACoAnAA6/yQAuP/M/8r/PQB8ALL/oACU/7YA9v6SAPD/MAEiAA8AFgACAH4BHQAKAXz/cAF9ALcApv9tAD4BdwBhACIA9wDk/8L/VQBgAWEAH//d/2QBEgHj/w7/ZQAQAEEALADDAKL/Ef/Y/zAB1gDa/of/jAClAPz+3v4IAFoAZP/O/ocAwAD9/4T+av8bACoAA/8f/yIAdADw/wD/pP/g/7f/3v6u/zoA2P5w/pz+BAJGAGX/IP2b/6sAMgAeAB7+Rf8K/8UAfgDO/tL+GADfAP7//P0d//r/NgGnAKD/sP/0/ukAEgHpAKL/xv7cAM4AjgGV/+b/NAAfAP4AjwC8ATr/aACt/4wC0/+O/zX/AAIuARMAjv47AKIBjwBj/4b+EgBIAPgA4/+cAJ//BP/Y/pMAfgHZ/3P/hP4gApj+ngBC/uQCGP/M/zr+YAFiAfz+hP8+/1QCtf8cARr+PwBA/xwCNwAyAAr+dgHdAOgA5P38/vn/KAEfAJX/Gf8K/zYAIwDcANT+TP/4/lwANgGs/xcAXP4IAV0AZAAX/1//4ADL//QA2v6iAYT+YQAV//AAR/8a/58AbQAUAoj9LAHg/joBzP7CABACbP8X/8z99AO6AdIAIP3f/4oBCAHx/xD/SAE8AQIBhv5s/78AKAJ9AFb+O//7/2oBAwCAASYAkf+4/rAAPgFG/3T+1f/eAb8Ahv7O/4kA3AHs/on/O/8eAOMAaAB/AKz+gwD3//gAzP5Q/yAB5f/a/yr+NAGX/10AnP4gAfH/IP/I/hj/VAHK/kIBGP62AFD9SAG5/4cACP4y/noBk/9+AcD8VgEk/yACoP7+/uT+LgBIAjcAjAFK/iQBMf91AHT/5v9MAPoAZAKsALX/TP71AOYBZgGw/mf/hgG+AagA2P50AdMAfAGQ/psA7QCIAbT/rP5jAJj/nAHo/o4BXf+UAP7+OgCs/8r+8P5Y/xYBFv+l/z7/hAE/AAH/u/8tAHgAsP3W/gAAqgHDAFz/fv+y/nf/Bf+8AHH/NP+u/1n/AgFO/1IAuP6Y/sL+s/+sAaf/uAAd/wYAcv4t/6gAjgHVAGL+zv6l/ycAlP8oADABTAA0/tT9i//oAfn/Ev/k/dABMgAkAYD+FQCP/xwAfwAqASoA9P53APYBugHm/gT/NAGcAnoAIv+2ANgCMAJfAMT+KgEAARwC2/83AC0AKAALANUAMAETAJj+Bv6EADYBpQDu/l7/jQDq/7r/G/9lAGQANwDQ/6f/Xv+7/wYBzgBFAIj+vv5N/8QAGgHAAAgAKv+0/2sAlP/S/u7/nwCHAFD+fP8rAF4BQP8e/2j/0v6o/hj+GAGk/6L/cf9gAYoACv+A/qn/fAHq/tP/8v77AOX/fAEeAZsA2P6S/+7/wAAD/zMAwAHFAEIAAP+QAZL/4AGt/+gBYP3s/ub+CAEQAAL/YAKnAEIAZPyOAAwBnQCM/YD/dAFGAcf/Y/94AswBGAD6/mv/hwDJ/9n/XAAIAXIBEwDh/yL/FwAoAVwAdP8M/n4AYgC4AaT+Jv/3/+IAzACE/tT+mv7k/6//PADu/wX/vv6u/+T/GQDu/un/wP/s/3T+h//0/y8AUgB9/x4A5P6J/9r/hwCu/yb/V/8IAAMAS/+EAAoBsgEmAEQAXgAWAQoAPP9Q/2kAdgHqAEoBNAAYAQcA6f+G/7H/6v8X/6n/7f/yAPwAjgBdAOP/L//i/jP/bgBEAHoAuv+FABIBTAH+ABUAPQA0/1P/oP4SABgBtgGbADsADgDAABAAkf8s/8j/QgA2AIsArQBeAX0AbwDO//n/pv9N/67/PgBlAAkAOwDHAOkACwAC/w3/j//4//T/TAD7/8//Lv/G/8n/u/95/wwASgD///v/af+0/y//CwAoAEUAjf8MAJgA1QDZ/7D/Wv+p/9r/XgB7ANP/8v8WAGMAlf9w/+H/PgAdALj/z/91/5r/hv8iAJ3/l/+T/x0A+f9f/zL/aP/l/1AA+f/K/3//CgBDANP/xf/z//EA6wC3ABcAcAA4ACAADQDGAGwBLAGVAFEA0wCLACEA2P/F/ywA3v92AFsAkQAgAFQAYwAJAB4AiP8TANP/EgCn/7X/2/9PAL8Akf9m//L+yf9L//r+lP44/77/2P/m/4H/7/8DAB0AM/9y/r7+2f92ADcA5/8mAJ8ApwAGAM7/mv+r/2n/jP/b/20AUAC9AOQAkwC9/wz/lP/T/7j/g/+2/2AAbQBYAF8AUAAJAHT/lf+B//P/AwCNANUAlwACAL7/3/8lAFAAAADa/3f/zf/F/wsA8P/m/7T/mP/X/77/8//Z/xYA6v91/zb/fv8jAEkAaADE/6b/nf+u/6f/iP+H/5//yv+1/woAMAAZAN3/tP+w/6P/lP+K/3b/h/+Y/+H/IgDm/xkAFwBaAAQA4v/T/xIAcQCjAOEAjwCmALsAAAESAbAAiACVAJ8AiwCKANAA3gD1AHsApwCEAHkA9f8OABkAYgBuADsADwCv/37/l//W/7X/l/8+/1z/X/9G/03/NP+N/5H/Z/9T/53/3v/j/6P/YP+n/wMAMQBrAEUAOQApAOv/DwDr/+v/w/8OABwAVwBaAC4AHgDY/6T/uP+s//T/pP+5/+//GAAmAAgA3v8JAAYAo/+1//X/SgBYAF4ASgCEAJ4AnQCLAEYAOABSAHMAdwBgAFsAZwBvAJoAeADw/97/2f9GAFEADAA3AEgALwDF/wwAMwBTADoANACAAGcA+P8XAEkAcwCdAFwAnwBgAH4AcwCbAJcAgQB+AFAANQD+/wgAvf+8/8v/8/+S/0f/af+O/4z/2P7W/vT+JP+q/nb+fP6Y/ob+kP7G/or+Yv4Y/hT+4P3E/ez9XP6C/k7+VP5y/or+Tv5k/oL+0v7C/pj+3v4G/2f/Xv+I/5X/1P/j/8n/EQBKAK8AzQDxACQBcAGIAcoBDAI0AlQCkALcAvQCHAOMA5QD7APYA2AEkARQBDAEiASwBIgEOAQoBMAEcASYBEAEYARABKgDUAMcAwQDrAKIAlwCUAIQAkABvQAVAHj/zv5m/hD+2P2g/QT9ePyo+yj7oPoI+qD52PiA+CD4EPjg98D3sPeA93D3APfQ9oD20PZA99D3MPiQ+CD5aPkI+mj6iPoI+6D7ePzM/Zj++//yALIB7AEUAkwDMATwBMgF0AaAB2AI8AigCTAKwAoACwALAAsQC+ALoAzgDBANAA2gDDAMoAuAC7ALQAsgC+AKcArgCRAJkAgwCLAHuAZoBUAE2AKcAcYACAAj/zD+mPwI+7D5MPjg9gD1YPTg8iDywPAg76DuwO1A7QDsoOtA6wDrQOvA60DsAO0g7WDuwO8g8QDyEPMw9XD2CPiQ+Tj7UP0c//0ApAJkAwgEoAQoBiAHoAjQCtAMQA6wDfAN4A3ADSAOEA8QD8APQA9gEEARQBLAEoASwBIgEgARQBDgD1APMA9gD6AOMA7QDZAMkAsACXgHeAXkA7QCdAHfAJr/Yv7A/LD70Pmg99D1gPOw8QDw4O7A7SDtIOyg6uDpoOhg6MDnQOfA54DogOkg6gDsAO5g8BDxEPFw8rDzIPbA98j6IP0g/rT+JP8eALQB5AM4ByAJoAkwCTAI8AfgByAJIAuQDDANAA3QCyALcArgCtAKsApQCoAJEAnACcAKsAzQDUANwAyACmAIiAfoBxAJsArAC4AMcAwwCzAK4AggCLgGaAbwBYAFMAXwBJAFQAUABCACRP9M/XD6KPiA9kD2gPaw9rD18PJw8IDtQOvA6cDpwOmg6sDqAOwA7gDu4O1g7qDuAO8g71Dx8PPw9iD5KPrw+3j8mP0N/7wBYAMgBOgECAYwB9AH8AiACpAMkAyADYAM8AvgC8ALUA2gDdANgA2ADQANMA3wDVAOgA7gDAAN4AvQClAKMApQC/AL8AvwCmAKAAkQCKAGYAXQBOgEIAVgBFAEWAPcAfgApP6Y/aD74Pmg+ID3gPcw9nD1sPOA8kDvYO3g6+DqwOpg6uDqIOtg6wDtYO4A7yDvoO5A70DwwPDw84D2WPkg+zj8KP0E/dj9qQDcAtAEkAUgBrAHSAdwCBAJ8ApgC9ALwAvQCnAKoArgCxANoA2gDCAL0AmQCGAJYAvgDDAOgA2gDHAKcAg4B2gH4AiwCXAK0ApwCkAJEAggBzgGIAV4BDAEwARoBPwDTAPAAvUA2P8o/nD7qPnw97D3IPew9oD1IPSg8eDuIO3A6iDqoOnA6UDpQOmA6qDr4O3A7EDuYO7g7aDtoO/A8oD1YPjg+Uj8YPys/VP/XAFQA6AEAAZoB6AHsAiwChAMkA1QDkAOYA0wDOALAA3ADjAPcA+gDhANYAuQCiAMYA5QDrAOQA3gCxAK+AdwCHAJsAkgCrAJkAn4B6gGUAYoBcgEeAMQA9QCWAKgAlACSAG8/3T+1Pyw+rD44PdA97D28PWA9ADzoPAA7gDtgOvg6aDpgOkg6QDpAOmg6qDrAO0A76DvQO9A7uDuAPFA9BD4yPrk/JD+Jf9lAJMAUAJIBCAG4AggCUAKUAvgDIAO8A7QDsANsA3QDKANMA4gD5AP8A6wDsAN8AuAC4AMgAwADSAMQAyAC8AK8AmwCaAI+AdgCAAIEAgQB+gGqAb4BYgEpAPkAv4BqgFYARoBuwAS/1b+DPwY+6j4UPcQ9jD18POQ8uDwQO/A7mDsoOtg6sDpYOjA5yDoYOhA6gDtAO/Q8RDycPDg7sDucPJA9gD6IP3a/yQCMgEQArACoAQYB4AIEArAC/AL4AzgDkAQYBGAEKAPUA6ADQAOMA7ADrAPgBBAEMANEAywCmAK8AkgC8ALgAsAC2AJEAnIB7gG8AUwBsAGUAYQBmgFIAWYBFwDnAIEAT4A1P9t/2v/uP7o/TD9TPx4+pD40PYg9QD0EPIQ8RDxIO+A7uDsgOzA6mDooOig5yDnAOgg6sDt8PEA8gDygPAA7yDvwPGg9mD6OP9qAagCHANAAuQDIAVwBiAJ4AqADMANAA/AEMAR4BEAEfAOkA6wDZANAA+AEIAR4BGgEHAOkAsgCVAJYArAC9ALsAuQCsAJ8AgoB1AGaAWIBdAEKAWoBHgFoAUwBIwD4AHZAAr+Hv5q/gn/9P2A/QD+APxg+ZD2wPXg87DxAPFA8XDwoO5A7QDtYOug6QDooOdg58DmoOcg6+DuwPHg8rDyAPGg7mDwcPLw9uj8ZQAYAzAEjANIBCAEkAVYBxAKoAwwDtAPQBAgEkASwBHAEHAPQA7QDoAPABAgEaARwBHgD6ANoAtQCcAJgAqQC+AMUAvQCqAJ4AgQB5gFIAUABWgFcAQoBeAE6AQIBFQDpAFD/2r+4P2I/pL+PP4c/gT9IPsI+cD24PRw85Dy0PFQ8YDvQO5g7SDsQOsA6YDoYOeA5uDl4Obg6cDtcPGA8iDzoPFA7kDtkPCQ9oj7LgAMA/gEeAT0AqADyAPgB2AJwAzwDgAQwBAgEcARoBEgEVAP4A6ADuAP8A+gEIARABIAEeANoAsgCuAI0AmwC3AMUAzQCsAJUAhoBogFyASYBegEOAUoBYAEQAS8AxQDZgGW//z9MP5K/pb+Nv6I/Qz92Prw+LD2QPSg8+DyIPKQ8YDwAO6g7EDrgOog6cDnIOgA6ODmoObA6MDrQO9A8nDzcPIw8GDuQPBw9bj6lv9gBFgF2AS0A3ADwAQoBvAKQA4gEIAQoBAAEkASoBEgEcAQIBBwD9APABFgEcARwBGAEBAOwAuQCVAJAArgC6AMwAuACgAJEAggBsAEKAWABqgFMAXQBJgEqASUAqACsgG6ADT/Mv4+/zb/Rv6U/Ij8oPtY+TD3IPaA9LDzUPNQ8aDwgO7g7MDrYOqA6iDpQOgA52DngOdA58DoAO3w8VDzUPLg8CDwkPAg81D3Fv7IAYgEgAVgBYAEKAT4BlAJQA2AD6AQgBFAEWASwBPgEkARYBBAEWARIBBAEGARoBJAEfAOcA0ADBAJQAkwCpALQAuQCmAJ4AgIB/AEcAS4BLAFeAVABYgE7AN8A8wCGAIOAbv/AgBo/6b/FP9y/kj9yPuY+hj54PdQ9tD1QPUw9LDyIPCA7sDsgOzA6oDqIOqA6cDogObg5mDnAOmg65DwYPQw83DwgO4A8aD0APeM/CQCkAWQBFAEsAP4BMgG0AlwDUAQYBBAEEARIBKAE+ASQBIAEmARgBGAEGAQ4BGgEkAScA8gDRALsAlwCQALUAxwCyAKUAkwCPAF8ARABPAE0ASYBHgEGARAA8QCqAJYAV4A6v5s/+b+0v4M/i7+CP2I+xj6WPlw+FD2YPWQ9ODzYPJQ8CDvQO1A7ODqIOrA6aDo4OgA52DmQOZg5yDroO1g8jD0UPFA7kDugPKw9Wj6Wv+4BFAGtAM8A/wDqAUQCJAMIBCAEgAS4BHgEmASIBIgEuASgBLgEgAToBJgEqARgBLgELANAAsAC3ALEAuADJAMYAxQCbgG4AVQBQAFyATQBTgGWAWAA4QCKALUAbwBzgB4ALn/ov/A/lL+Rv5c/Wz8qPoo+nD50Pfg9eD1EPYA9FDyYO+A70DtQOvA6oDrIOtg6YDoIOgA5wDl4ObA7BDx4PJg8rDxoO7g7rDxYPbw+18A4AT4BdAD9gFoA3gGoAkQDeAQgBJgEuARoBIAEsAR4BFgE0AUwBOgE+ASABMgEoARgBCQDaALwAsQDOAMUAzgDGAL4AhQBlAEAAVwBCAFyAUABvgEXAJwAcgAPgGgAEMARQA6//T+KP4I/pD9pPyo+2j6APrI+ND3oPZw9hD2EPWw8lDwgO9g7WDs4OqA7CDsgOoA6mDoIOhg5ODl4OqQ8WDzMPNg8kDvwO4w8HD0qPpoAGgEKAagBGwCmALoBNgH8AvQDyASABLgEcASABNAEUAQABJgE6ATgBJgEyATYBJAEHAO8A0QDNAKEAvQDEANwAuwCRAIgAZIBcQDMAQ4BSgF2ASUA6gCZgFzAF4AkABZALD/C//M/tD+qP6I/aj8uPvY+nD6aPmQ+SD4EPgQ9nD1sPNA8TDwIO9A7gDtIOzg64DrIOqg6eDngObg5WDp4O2A8DDzYPNw8KDu4O4g8wD4ePxuAWAFoAQMAvwBCARIB6AJ8AyAESASIBEAESASIBJAEUARIBOgFCAUgBKgEiATgBGwDzAOMA4wDXALEAzADJAMsAqQCCAI0AYYBSgEaAS4BKAEpANEA9wCRAFRAIz/ov9J/0H/Iv+E/97+qP1g/Kj7CPuY+ij6QPqo+TD4sPZQ9qD08PKQ8eDvcPDA7WDtgO1A7ODrYOsg6SDnIOZg5mDrgO+g8bDzoPFw8EDtAO+Q8pD4kP7AArgEJALh/5wAaAMYB9AKwA0gEUASABGwDyAQIBHgEYASwBNAFSAUQBPAEqASABJwD9AO8A4AD4ANYAzQDNAMkAsACZgHgAc4BxgGKAUoBcAE/AKOAZgCiAOIAQEAlf/p/8D+cP2c/iMAM/84/Qz8wPsw+wD6aPoI+yD6wPeA9vD1YPTw8uDxoPHg8ADvgO2A7UDs4OuA6oDpAOmg5+DpgOzg8DDxQPNg8SDvYO7A78D0yPomATAEUAN5/3r+1wAYBNAHwAwgEeARgBCgDiAPEA+AEOASQBXAFaATgBPgE+ASwBBAEEAQgBAAEFAPgA7wDdAMgAuACrAIsAfAB8gHCAdYBgAFdAPuAb4BfAIMAhIByQCuAD//hP0A/eD9Mv5A/aT8aPxg+7j5OPlY+Rj5IPjg9wD3YPXA80Dy8PGQ8ADwYO8A7qDsgOzA7MDqQOhg6CDpAOvA6sDtIPTQ8zDwIO6A72DwUPPQ+cYB4ASxAFr+Of8MApwCEAcQDYARABFQDvAOkA7QD6AQQBTAFKAUgBNAFEAUoBOgESARIBHQD0AQIBCADxAO4A3gDNAK+AewB9AJMAlIBzgGwAXgAxQCzgHwAhQDsAHtAPQAmf+Q/Yz9fP5+/lz9vPzQ/BT8oPoA+qD5CPlo+OD3wPdA9mD0UPOw8rDxwO9g76DuwO1A7ADsQOzg6cDoQOiA6WDqIOtg8LDzkPIA8EDtoO5Q8bD2sPxcAsQC5f8b/0D/KAEcA+AJMA/AEUAQwA1wDrAOIBAAEQAUYBXgFcAUgBTgE6ARgBAAEMARQBHgENAPIBAwD8AM0AngCEAJMAnACDAIQAhIBvADBAK0AVgBHAFeAZ4BRAFU/5D9oPy0/ID8lPzI/Kz8wPvQ+qD52PjI+Hj4KPig9yD3APbw8yDy4PEw8iDxAO9g7iDuYOxA6wDr4OtA6iDogOgg64DsoO2Q8aDzwPLg7QDtAPJw9ij7t//gAY4B+v5+/mAAOASQCEANoBBgELAOAA7QDYAPgBHgE0AVoBXAFMAUwBPgEUARYBEgEsARgBHgEAAQ0A6wDDALQArwCNAIcAlwCVAIwAXIAlYBtgEEAhgCtAGqAccAdP5c/JD8IP0w/az8IP3c/Fj7+Pkg+rD6gPmg98D3WPiw91D2UPWw9LDyYPEQ8eDwQO/g7WDuAO4A7IDq4Olg6oDoYOkA7ODvAPFg78DyAPBA7QDu0PPY+oz+zP8tAHn/1P10/jwDEAiQC/ANoBCgD3ANcA2AD2ASoBMgFWAWIBaAFCAVIBSAE8ARIBKgE4ATQBJgECAQEA9QDZAL4AqgCmAK0AnQCKAHgAWsA/ABVALIAnwCmQA3ABoA7v4Q/QT8EP2g/bz8oPtA+zD7OPqI+YD5WPmQ+HD3EPcg94D28PQA9KDyoPIA8sDwoO5g7uDuIO5A7MDqIOwA6wDpIOhA7EDwwPCg74DyQPPA7sDsoPIA/D7+4/8zAGYAW/8Y/dgBMAmADJANEA8AEEAOYA1ADgASoBQgFeAV4BTAFOAUoBSAE+ARwBGAEoASQBLgECAQ8A5QDMALoArQCVAJUAlQCWgHCAVoA8gCOAKIAfQAawCh/x//rv4s/hz9JPxQ/AD8sPuI+oj6uPpo+kj6APmg+DD3QPfw9oD2QPbw9IDzAPJQ8mDxMPAg7mDuQO/A7eDrIOsg7IDqgOhg6WDu0PGA76DxUPMw8UDtAO+g9m7+PgA0/6QAjP/u/tL/cAVwCrANwA6gD0AP0A0QDoAQIBPAFEAWQBWgFMAU4BTAE4ASIBJAE0ATIBLgECAQABAwDnAMcAuwChAKsAmACZAIIAagBEADiALkAY4BlAHmAO7/NP+e/vj8AP1Y/CD9IPw4+1j7cPvY+nD5IPrI+Dj5MPcI+ID3gPZg9vDzYPQA8oDykPEQ8EDvgO4g7+DtgOyg62DrQOlA6KDqQO6A8KDwsPEg8mDuAOzg7wD4PP3C/ir+Gv+c/vz8OP8wBQAKsAvQDdANQA0QDHANgBAAE2ATgBNAFCAUQBTgEuASIBKAEkATwBIgEiAQ8A/gDpANMAxwDGALEAswCpAIUAd4BVgFoAQoBLgCKAJ6AVUAuP8Q/+r+CP6A/Rj9+PxI/Ij7iPsI+zD6sPmg+Wj5OPlY+MD3APdw9mD1sPSg84DzoPLg8QDw4O7g7mDuIO5g7SDtgOxg6qDoQOrA68DtoPDw8lDzgO8A7WDvkPRo+Mj7rP/4//T98PtU/mwDSAYQCSALoA3QCwAMYA1QDyAR4BGAEgATIBMgFOAUABRAEqARABJgEmASoBKAEUAQ4A1gDPAMIAwQDIALQAsACfAGsAVwBYgFcAR0A3wCggGkADIAxv82/47+uP0k/YD8XPxg/Pj7APsw+hD60PlI+Rj5APko+OD2IPYg9mD1QPSw82DzMPLw8DDw4O/g7iDu4O2g7eDs4OqA6sDqQOzg7QDwoPEA8hDxoO/g79DyIPfI+9j9R/9W/jT9vP00ATAGoAjgCbALsA5wDCAMIA1gEMASABJAEiAUoBXAEyAT4BKgEmARQBHAFAAVYBMwD1AOUA4wDaAMAA2gDsAN8AngB/gGEAbYBXAF+AXMA9gC5gGCARwAYP8v/yz+zP10/Ub+GP2Q+6j6cPoY+hj5WPno+aj5sPdg9jD2oPUg9cD0UPQQ86DxIPGA8ADwAO/g7gDuYO3g7CDsYOuA6uDqgOzg7iDw0PFQ8hDx4O8w8NDzgPhc/FT+WP8K/gz98v7cAigGUAjwCkAMIA2QC0AMIA4gEIARgBEgE+ASIBWgE0AT4BGAEGARwBJgFCAUYBLADgAOAA4wDSAMYA0gDxANUAlYBhgH2AZgBSgFMAZ4BaQBvQBIAQgBC/+4/Qv/cf+I/Zj7EPyU/Cj74PnY+QD6GPno+LD42PiQ9yD2UPWQ9JD08PPQ84DysPHg8BDwAO9A7kDuIO4g7UDsYOyg62DrYOyg7oDwMPGA8UDxgPDA8AD0ePhI+xT9FP7Q/Vj9lP7MAlAG2AdACfAKUA2gCsAKAA8gEcAQQBAAEqAToBNAEgATQBPAEaAQYBIAFUAT4BBQD0AQ8A5gDFANYA7wDvALoAmACCAIiAbYBsgGUAYIBBQDqAKyAaIAhv9VAHn/bv6U/cj9kPxw+4j7CPso+rj5CPpw+Qj50PdA9+D28PVQ9TD1QPSA8xDzMPLg8IDvwO9g70DugO3g7SDuAOxg6qDqQOwg7SDuEPGg8iDxoO5g72DyQPXg92D7zP3M/ID70PyKAAADXAPQBzAKQAqwCVAKQA3QDUAOgA8AEsARoBFAE8ATIBLAD2ARQBMgFKASIBIAEiAQkA5gDeAOAA8AD2AN8AvACtAIAAiQB7AI2AcoBmgECARUAxgCcADJAEgBEADC/tz9Mv5s/fD7KPs4++j6APrA+dD5GPko+AD3oPZQ9lD1YPXw9AD04PIg8qDxsPDg7+DvgO/g7gDuoO7A7oDsYOtA7ADvcPAg8YDycPIQ8QDwYPIw9kj5QPs4/Mj8TPxY/RT/jAIQBUAGEAhwCAAK0AogDPAM4A3gDkAPQBBgEuATQBKgEAAQABGgEQASABMgE6ARYA/wDUAOcA7QDrAOgA6gDDAKoAmQCUAJyAeQB1AHWAZABEgDYAOUAjYBcABLAM//nv48/mD+/Pxo+7D6oPuI+yD6oPmo+Qj5cPdQ9zD30PYQ9nD1gPUg9JDyAPMQ83DysPCA7wDwAPBg78DuwO7A7SDtQO1Q8LDxYPJQ8VDxIPLg8VDzcPYY+1D8SPuA+tj8iP6K/6QBeAVoByAHEAewCMAL0AtgC1AMgA4AD0AP4BBAEiAS8A7ADoAQYBGAEaARQBIAESAOgAzgDVAPAA/ADWANcAxgChAJAAkQCSAIMAf4BkAGCAWwAygDeAImAZUAVQAnAGr/NP5o/az8mPtA+wj7MPug+qj5APlw+ND3sPaw9kD2MPYg9fD0UPQQ81DyoPFg8vDwEPCg74DwwO+g7uDtYO0g7sDuUPAg8tDx0PDQ8RDy4PGA89D2sPpw+3j6KPuc/NT96v5yAWgEeAXQBXAHMAmQCVAJgApQDGANMA2gDqAQ4BBwDzAOsA6wD2AQIBGgESARMA/gDVAN8A1gDlAOcA4ADaALEArQCWAJQAmgCFgH2AYQBgAG+AQgBNgC3gFCAaEAuQCKAIz/Iv5o/dT8GPwU/PD76Pt4+qj56Pko+bj4kPeg90D2sPWg9cD1sPWw86DzsPKQ8RDwUPAA8kDygPBg70DvwO4A72DwkPEw8iDyMPIQ8vDy8PPQ9VD48PjY+bD6yPvo/ET+SADSAcACCAS4BRgH0AeACGAJEArwCtALEA1ADtAOMA7QDcANcA5QD8APQBDwD6APIA4wDZANwA0ADjAN4AwQDDALQAqQCWAJ0AhwCEgHkAZwBugFKAUABIwDlAIwAmIBDAHtANr/dv7k/eT9VP0A/WT84Psg+yD6yPlo+WD5KPlI+PD2wPWw9cD1YPXg9GD0IPQw8vDwsPCQ8aDxwPDg8PDwQPAg78DwkPGw8XDx4PFA80D0IPQw9bD20Pdw+FD50Ppk/Cj+2v6+/4sA1gGYA/AEAAYIB5gH8AcwCWAKAAvQC3AMAA3ADLAM4AwwDpAOIA4gDhAOIA7ADZANIA3gDBAMIAzgCwAMMAtQChAKQAlgCCgHAAdwB5gGgAUABQgF4APQAtgBlgHeADQABwArAPL+sP0E/cz8RPyY+0j70Ppw+rj5MPng+BD4wPdA93D2sPWg9QD28PXQ9LDz0PKQ8pDy8PLw8mDzgPJA8sDxoPEg8iDzoPTQ9CD08PNQ9dD24PcQ+MD42PnY+gT8MP2K/un/6QB8Ab4BkAJoBDAGeAdwB7gHAAjwCCAKIAuQC5ALUAxQDJAMMAzADLANkA1QDfAMMA2gDMAMIAywCyALsArwCoAK0AkgCZAIyAfYBkAGCAYYBuAFMAUgBPQCRAIcAuABYgGjACAAa//e/mL+3P2Y/dz8YPyg+yj7uPpo+kj6ePkY+RD4IPig91D30PaA9oD2oPVg9SD1IPWQ9AD0UPSw9AD08PMw9BD1IPSA85D0UPYg9qD1EPY4+Mj4APiY+DD6VPzg+rz8rv46AKD+cP4sArQDMAMgAqgGUAjABVAEMAggC+AIoAhAC0AMoAlgCmAOUA3gCXAKIA/QDtAI8AmQDwAPyAfYB/AMQA7ACCgHEApQC2AG4ATQB2AJ4AXwAtgEGAYwAxIAogFIBMoBoP18/aoBkgAs/Gj7SP5Y/eD6kPmY/Az8OPlg+Ej6YPnQ9jD4wPp4+LD14PVY+FD3YPVA9rj4kPZw9OD0EPhg9nD0YPaY+FD3gPSQ9nD5yPiQ9sD3YPq4+uD4wPog/Uz8YPvY/Ab/aP5a/rsAnAO4AScAIAL8AwgEYAOABQAIOAYIBUgHwAhgBxAH8AgwCiAJkAfgCKAKoAogCbAI0AhwCSAJIAlACBAJkAgYB0AGyAYAB7gFQAY4BrgEhALEAlAEzAOIAVABfAFxAKD+pP/WAHz+AP4S/iD9GPsE/F3/yP2o+hj5sPsw/MD5gPkM/Kz8EPlg+Bj5SPvA+VD5iPnY+dD5wPig+ej5+PpI+Sj5qPmI+jD7uPpA+zD7mPt4+tj7lPxk/Qz9FP14/Yj+2P64/WL+LACgAYsAd/9KAEQClALQAWACVAPsA8AC3ANwBGgE/APQBTAGMAXwBCAFaAdgB6AEKAS4BgAHaAXIBdAHEAeYA3ACkAVQB1gDyAP4BTAHBAG1/xQD+AXgAub+XAM4AmwB1P2pAMsA7/8Q/3b+r/8A/ET/BP+w/vj6iPxc/fT9pPwg++D8QP0Y/MD5MPyo+6D86Ptg/Cj8ePoI+bj8AACw+hD3OPuyAfz+UPgY+Fb/vwDw+fD5vP77/4D9HP2q/sj9SPzw/foB3P9M/aL+qAH5ADn/9P5dAKACeAF0AXkAdAGgAvQDWAIeAeABtAK4BOACqAI+AcgFkARUAZsAdAPoBzQCMgFMAcgFPAPu/+QDkAR8AaP/xAOoBJsA1P6IAggFHQC8/AYAEAZ8Acz9mf8UAQABQP2c/QIB4gEI/Sj9cgBy//T8CPwgAKz/2PsY+gAAdgFY+2j6nv6oAaj6IPlE/1gCkPxI+sT9tADw/GD7kP4CAQz+CPvY/nf/fP4w/YQAGP9tAFT9yP1Y/7ABNALE/Tn/mv84BBH/gP2AAeAELAIg/d3/6AJgBCAAYgE+AYgCSAFpAGwCmANUAhQBVALxADADfAG2ANwC4ANBAJz+CAQgAmwDSf/B/8oBpv/sAKoBiAPQ+1r/iALHAED8aP24BJgCGPpY+iwDbAP4+qD8nAJ+AXj48PuwBY8AcPpw+sgEif94+lT8IASGAMj63Pw6AZj9bP4UAkoB4Pks/DgDCAIs/ED7AAYCAZj7gPuQBrQBDP3m/rgDIAKQ98ACEAmcApj4JP94BwwDSPvK/nAHcAQg+93/CAUkAyb+WAJwAzP/rgBcAgAGA//6/28AiAVY/q//YAXKARoAIP4UAgQBjAFn/88AIAOI/Yj+P/9EA/oAfP0Q/HgAWAQw+/j9QgCIA+j7CPkyAeADDP0A+swD/P5Q+4D6yASAAkj5IPr4AwgBUPgM/YAG0AJw9jj7vAP8Aij5QPxgBYgD4Pio+qQDQAQ6/sj6nADQAEgBGP63AKAAHANU/vj9gv5gA8ACzgEC/ggB7AJg/csAsAIgBEX/EgBdAPQB1gF2AaQACAEeAZoB9gBe/ngEoAT0/2D6qgEgBrQAL/+MAWAFwP0o+8X/eAa0Apj7LAK6AeT+oPo0AngD6/8o/Ej+AAXw/F7+lP0IBdD9+Poo/YgF0gFA+c0AewAcAXj4aP5wBOQDMPmo+6AF2P+I+hD9eAQkA1D7+Ps8AzYBtPz0/IwDFgE4/QT+5QCEAej9FwCNAO7/rAD4/QQClv50AmD/pf/0/xIBsAJp/8X/agEcAoL+8wD0AloAFv/YAaACnwCw/ZwCOATe/kz8PAM4BOz+qP0YA3gDAP6o+5gE8AUA/KD9uAJoA+T9lPz4ArQDMf+I++YANALe/kL/Rf8gAJ//5P2FAND95QB0/xACwPyw/AwAkAHtAMj8PwA0Agj95P0L/xgEnv5s/RL/4AO0/eD6XgHoBML+uPrM/+wCHf90/OoBhAKK/ij7oAHAAzT9MPw0A7gEjPzI+ZQD4AT+/kj6QARQApT9gPwYAogGGPzg/RwCKAY4+fz9uAXcAvz94PvABGABSP8k/kgFkf8s/VEAtAN2ASz8uAKEAnMAoPsqAYgC3v8EAt7+owCE/dgAKwBcAUv/X/+kApD7CALM/egBhP14AkMAUP04/awBAARQ+0j97gBkAvj8WPxPAJAEFv4w+sD/NAEK/uT9SATo/Xj9FP3wALQBAv5Y/roAYAPg+2r+wACKAQYA2f/6/jr+gAETAPwCfv6T/7z92gHKAdr+9/+iAXADOPzc/kH/4AXpAGz8LgFgAxz/qPwABMACzf9c/BADzAMhAOD8BAKQA2b+3P4IAdAE/v4zAK7+3AFQ/bABiAMe/oABDP4wAaT8YgGmAAwCWP7A+1gEOQAc/Cj7EAZgAWD7EPusA5cA+Pwc/TgE9v6w9+z94AV4AkD2oP6gB2H/cPa8/PAGmALY+eD7QAb8/9D5BP4YBkgCmPmU/QgEmAIY+sD+CAQQBMj6Bv+sAiQCJv41/8gF+P0a/pL/uAcYAFj8IAIIBPEALPyMA4QCmAJ2/k0AkALo/VQBjAPAAoz8qAKIArj+nf9oAYQD9P3L/1IBuASk/eT+YALyAGb+Hv7EA0QB5wC0/RQD6PxY/WQC6AEWAfD7GgBOAUAAwPul/5ACAv9A/Rz+QgDV/6j+cP6y/kr/3P1u/2r/Jv6+/nD+df/Y/Qj/jABo/xH/sPwi/50AzAA4/tT9RAOI/kz+iv44A+D+yP3DAAgCsACk/CYAcARtAEj8/ACgA70AJP20A4YA7QCS/6YBIASg/kb/RAFwBCH/fP+wAMQC7ALU//T9pgFYAu3/mwBY/3gECf9rAD8AlgGs/6L+ZAMMACwCcP0qAIwC0v4sAZr+hQDP/ygCWP4M/XIBvQC0AHD7Ef+2Af3/4P7M/Vz/Jv56/jL/M//q/jb+wQBp/zD81//w/JEAx/8q/k7+QgBqAVD9OP7A/EgD6v8E/YL+/AKWASj7cQCo/xADMPyeADgCKQDW/pz+QAQWALr+sPsgBfgBMf8ZAC//SARr/6f/gv4cA8gBjAEEAAMAyADIAjUACALMAbz9iAEIAjADw/8E/oACkAOKABD8NAKwA/wAPv9N/5gFJPwSAYoASAOw/CD/mASCAVr/uPrEAlgBXP2Q/RgFYP4c/Z7+6AG4/qj6jgDYA9L/8Pc0APwDGv/o+LP/UATc/rj5cADABHL+WPpE/hgFkP1s/Hb/6Aau/zD5NgBcAhYBePo4AKAFVAEU/RD71AM0Alf/yPtUA5QCZP0NAMT+7AMxACX/mf96AVUAcf9kAqwA0P5iARsABAF6AGIBIgFyAJb+2gC8ASAApf/gAqgCnP2k/VgCgASW/iT+Hf9IBl8ATPxF/9gFd/9I+p0AyAVcAQD6Yf/wA6QBUPfR/xAIXgFw+CT9OAYM//D69P2oB3T/gPlC/lAEXv8Q+eACUALY/zD4WgF4A4n/cPng/9ACKv6g/Mv/cAOi/lD9rP32AYL+WP7CACAD5v7o/FAA+P90Avz8mgGgAAYBPP5xACgDUP3EAWH/0AEY/Y0AkARKATr+4PtABNQBtP2K/3gEtALQ/dj8sQAABEIAZf+kASQCtv92/iz/rAFgBWT+NP0EApgCQQC4+zAEGAQ2APD3TAJABsD9AP1WAfgGGPq4+dwBsAi8/WD5lAMqARz8+PlABWgD8Psc/E4B5gDw+OIA1AMY/+j5zP1gA/j7kP3YAYAFYPpQ+aEAxAJM/2j8iAP4ABr+2PlsAbgBiAIY/kr/YQCRACj/sPv8AzAEjQCI+gT/UASOAZT9uAGwBrD7yPl8A7AI2v7g+mgD2AbY/bD1sAVQCZ4AiPp4AjwCsPtw/4gF2AWo+vT8AATgBED8ZP6wBbwBRPzo/agCvgEeAQgDNgAgAID4TABwBQgEZPwy/rwBwP/k/oj6CAUYBQj8IPlMAvwC6PoM//gEEAII+FD3qAdgBlj40PlABhQDAPWU/GAGYAXw91D7oAYEAND3AP+wCP8AYPeA/MgFeAI4+uz+4AXT/+D6sPu4BNACQv9I/KACwAFE/vD8ugEIBIEARPzkAFgDLv+N//r/sAS2/sT9iwBoAlUAjAHoAuz+sv6KAIQBHwDy/tgEwATg+mz8jAMIBbz80PzoBQgEHPyA+iAG8ARY/HD7hAMwBLj7LP24BbADCP0Q+Y//YAW4AHD6qAAKAQgBtP4I+/7+7AKfAAT8dv8t/zYA7//+/wf/yP7E/MgABAON/9j7jgCkARj9+f+HAED+DgGVAPcAkP7g+oABqAY0/pD3BAPYBo//iPpu/vAC8AFI+tYB+AXq/hT9YAC8Aij6Jv+IBHAGcP0g+3QB+AVW/sD68ARgApD+bP4IBpIBdPxw/NAD6AWY+KL+oAjIBhj40PhABbAGvP2c/MAFnAPw+Tj8oAd0A3j4VP5gCMADUPbo+zAIWATQ9gj5QAh4Bfj66PoYArQB4Pq4/FgFoAEk/Xj8egDZ/1j9yv/2AZIBFPwo/rD/ogF/ANb+PP6B/1wAEf9J/2YBNAJ4/nz8+P5kApIBkP4JAAgAeP/o/TYBOAQbAPD9mP1gAW8Abv8uARwDQACs/HD9ngE8A6IAOv9eABf/H/9aADwCCAInAGoAkP2L/1r/nANoAon/rv7n/9QAYP1YAvACywAY+6YAOALCAMj9IwDIBKT+UPrc/BAGBAGD/5D/WgEc/lD8uAAUAhUAGP7EA2wB2PxY+zgCKANB/+D9CwA0Aoz9SP+SAQsAfPys/54BigH4/V//FAHh/3z9uP7UAFgBmAGiABD/aPxkAHgC9ABA/Ov/9AO0AXj+rP1wAVsAWP6c/+wCuQC9/5gAxAI6/kj7NwAYB/wCEPtE/YgBAAW8/Sj+7AEcA5T9AP4kAisA0v4L/1gFgADw+vz8EAYgBfD8sPqFACgEAQBm/rABsALZAD7+Dv7c/ooBgALcAnf/rPx0/2gBbwDaACj+av6RANQB6AFU/sD8uv58AjX/sPzi/uQDUASQ+5D5LP4YBKgBtP1O/mgBhwAI/M3/hAFuABz9pgCgAa3/7PwwAfADlv4o+7D9UASgAsX/4v/9ABr+Ev7BAKYBWQB9AGgDPgHI/QT9pALEA9z/dP17APAC9gFW/1j/vAESAIb+zP9MA1QBQABQ/5gAb/80/agBUAQsAjj9Jv7LAKAACf8GAIwC6f9s/3YAtQB+/nj+wgH4APj94P3wAcwCDf9U/bb+VP8w/rz/IAHM/1r+vv+eAPz+hPxa/uMAnwDc/uT+fAC2/zb/FP6G/msAcwDE/wj/7v6+/4v/9wDVALT+uP1c/0gCEwCI/tv/GAIvAGj96v6EAkgCNf/U/qj/9P4uAKQCBAPc/2j9hf+GAa0AXP8QApQDMABU/Yb+YgEkAjAC4gHF/7z9+P6gApAClP/y/vsAugHk/kT/RALgAmP/ZP23/1wBJgEWATAC/wBQ/cj8XQB4ArIAp/9yANX/iP38/YoBjAGg/mD9Qf9UAH3/Tf9lAAUA/P00/av/owANABQBRAAC/qD7ov7AAhQD6P6U/YIAXwAC/rj+GALeAQD/eP72/1MAtv+4AGACjv9M/FT+WAMQAzv/rv5ZABIAPP6o/2AD4AKK/zb+lv87/yf/mgHcA2IBrP1a/hwBHAFfAG0ATAFDAEr/tf8gAYQBMgEQAAn/bv43AOwBdAFdANP/Kf8j/+j+jADXADQBCgAI/+7+N//v/2UAeABY/wj/2P7K/1MA7/9I/wb/lv/I/rD+3P8oATkAcv6Q/oX/0f91/8v/fACY/3D+8v41ABwAmP/H/9n/AP+i/mL/DgHJAIP/+P4y/8f/q//w/1oAigCq/1D/W/8TAG8A2QCFAJv/Kf98//cAzgDWAB8AIAAhAC8AmACRAKEAiQCWAGUAkQDqAFQBxAAFAPr/fAC0ACIBdgHIAK7/Sf/d/8cAswA0AGgAPACR//z+VP9HAEQA8f91/07/Yv+V/9v/gv87/zj/ff/y/wYA4v/+/4L/HP8Q/6X/TwDBAI4Auf9O/w3/f/8yAKMApQAfAMH/pP+B/7r/8/+OAHQAKAAHALb/9f9kAIQANwDY/wYAmwCIAEIAQgCDAFQA0P/9/68AfABjAGgAMgAlAJ3/PQCoAJIADwABADgAMgBWAFAAdgAhAMP/wf8CAEkAAAD6/8//i/9r/53/4f8HAM7/e/+Q/1D/fP9o/7z/rf84/zf/nP/D/zD/MP9s/0P/yv4j/6j//v81/xv/F//o/vb+PP8fAOH/PP9H/5L/of+3/8j/RgBwAFMAcwATAFEAswAmAT4B8QBaAVwBigEUAcQBGALYAeABKAKsAhwCiAFAAswCkAIAArQCAAM8AtwBGAKMAgwC7gEAAkACfgE4ARYBWAGlAF0AvQCfAOf/kP+s/wn/TP4Q/tz+vP4C/jD9kP0c/Sz8GPwQ/Hj86Puw++j7uPvw+rD6wPrI+hj7yPpQ+0D7+PqA+oD6uPs4/Fj8SPyg/ND8xPyg/az+5v4M/+D/sADwAMgAggEoAjwCPAJAAwgF0AVwBVAFEAVQBFAFEAeACFAIAAgwCBAISAeIBzAJIAqgCSAJIAkQCfAIcAjwCOAIKAcgB6AHeAdQBggFMAScA8wCUAFgARoBb//E/VT8iPuQ+lj5APhw90D2wPTQ89DyoPLw8SDxAPAA8FDwEPBA8FDw8PAQ8ODvEPEQ8+DzMPRg9WD2QPaA9qD4APsk/Mj8Vv6U/6D/UgBcAjAEcASwBKAGgAeAB1AIQAoADHALMAuQDLANgA4gD8AQoBFgEQARABIAE6ASwBLgEkATYBKgEWARwBFAESAPUA0QDNALkAqQCQAISAaoAxIB2/9k/kz9aPto+Sj4IPaQ84DycPFg8cDvoO4g7cDtIO3g62DrIOsA7CDswOxg7aDt4O3A7SDugO8A8YDy4PMw9fD1YPYA97D4gPps/HD9rP5UABwB5AH8AawCKASQBbgGaAfIB5AHiAZABYAGkAnwDBAN8AugC9AKwAmQClAOABFgEcAQQBBgEGAO0A1gEEAT4BGAEMAQ4BAQD7ALcAqACgALsAlACeAHQAUQArL+BP5s/dD8WPuY+qj4oPXQ8hDxMPJw8SDwgO5A7yDuwOwA6wDrYOyA7MDsgO3g7gDuoO3A7IDvwPBw8eDzoPXQ9sD1wPVo+Nj66Po0/Gz/nwCkALgAwgG8AkwCJAMoBtAGeAZAB3gHyAW8AygFkAnwC3AMEAzQC0AJGAeQCnAOYBCgECARYBHwDVAMcA5AEWAR8A9AEOAQAA8gDUAMUAsgCXAHIAiACDAHIAW4AkD/kPz4+uj60Puw+8j5UPYw8xDxIPHA8GDwkPAQ8WDvIO0g7IDsoO4g7cDt4O4A8ODvQO+Q8DDysPJg8sD0UPcI+OD3MPpY+4j7zPzg/ZQA/AGMAhwDqAIABPAEUAbABagGgAigCNAGSAUoBxAI4AiACtAMcAwACiAIUArwC0AMoA1AEMAQwA2wDBANkA6gDnAOcA8gD2ANAA3wDLALwAhwBzAIuAfIBkAFkAQ4Avj98Pvs/Bz8UPtI+nD5wPYg83DxUPLQ8vDwMPAg8ADw4O1A7WDuYO7g7QDuwO8w8YDwkPFA8qDykPIA9DD3QPnQ+Wj6aPvg+8T8Bv5mAKwCYAMQBJADCAX4BMAFYAYgB+AIIAhACEAIEAjgBZAFsAggC1AMoAogCtAK0AgQCDAKgA4ADxAPsA0wDZAMkAvgC/AN8A5gDXAMoAvgC/AJcAcYBxgHyAaoBLwD7APOAar+2PvQ+1D7EPpI+TD5cPcA9NDxcPFg8UDwcPBw8IDvwO1g7QDtIO1g7QDuYO+A71DwsPCw8ZDxYPIg9CD2oPcg+dD5CPsE/Lz81P41AJABCANQBPgE4AR4BagGAAcAB8AH8AmwCYAImAd4BzAICAfACRAO0A3QCsAIYAowCsAKoAxgEEARsA3gDKANQA0QDMANMA8gD+AMEAwADYALwAiIB6gHGAYwBdAFAAUUAyT/OP0c/Nj6kPmg+pj6MPfg9HDywPGQ8CDwYPBg8IDv4O0A7cDs4OwA7YDt4O3g7gDwUPBg8KDwsPKQ8/DzQPZo+ED6wPnA+jD9+P6A/rL/dAOoBJAEXAMgBkAH+AUABrAIoAowCAgHgAgQCcgG8AZAC8AN8AtwCVALkAqwCeAK8A3QDxAO4A1QDpAN8AuwDIAO0A4gDRANYA1wDFAKAAqwCGgHEAZABjgGsASoAjIAHP/o/Cj7QPu4+lD5oPdw9dDz8PEg8aDwUPDA7wDuAO5g7QDswOtg7EDtAO3A7aDugO8g72DvkPHA8vDzcPWw91D4yPhw+lT83P2I/m4AWAIwA1QD4AT4BRgFaAZoBwAJ4AeACFAJ0AfQBvgF8AkQC0AL4AogDBAKgAjACcAL4A3ADQAO4A0QDcALcAxgDaANMA1wDRANQAxACwALEApgCPAGqAaYBkAFMAQ0A+YB3P64/DT8BPzw+nj4QPiA96D0wPEQ8QDy4PCg7gDvQO/A7eDrYOzg7WDt4OzA7WDvIO+g7pDwkPJg8yD04PUQ98D3KPkA+/D8Cv4s/4wAugGIAoADyAQIBcAFWAaYBhAHEAgwCGgHYAaQBnAHIAiwCfAKUAvQCQAJIAmwCTALYA3wDfAN0AyQDPAMEA0QDSAN4A1ADSANEAwADKALEApgCOAG4AYQBuAFEAUYBMwBXP4M/SD9FPxQ+gj6MPkw97DzsPKg8sDxYPDg7wDwYO5A7UDtQO5A7aDsQO2g7mDvwO5A8ODxoPIg8+Dz8PWQ9yD5yPkA/ED9sP2M/sMAKAIEA0ADGAS4BZgFaAWQBsgHoAeoBjgGEAegBhAIYAkgCuAKYArwCTAJEApwC2ANwA1QDVAOgA3QDWANIA6gDkAO0A0QDtANgAxQDIALAApACHAHEAfwBhAGMAUkA1cAsv4G/vj8wPtA+0j6GPhQ9dDzIPOQ8vDwQPAQ8ODuAO5A7eDtgO2g7MDswO2A7sDuoO8A8fDxAPKA8qD0cPbA9zD5yPrM/HT8sP2A/xABDAKUAhAEgAQ4BegEYAaIB4AGqAbQBqAGEAfQB9AIcApwCsAJsAlwCfAJ4ApwDCAN0AwADVANUA0QDQANkA3wDVANsAygDNAMMAzwCqAJ0AjAB4gGqAY4BggF4AK4ASUAXP7w/PD7uPsg+kj4kPaQ9YDzoPJQ8eDwIPBA7wDvQO4A7iDt4O1A7aDtIO4A7+DvwPAQ8kDyUPMA9ED2sPew+MD6dPxQ/TT9yv6zAJ4B/gFcA/AEMAWYBJAFCAeIBuAFgAaoB8AHmAfwCJAKcAogCQAKwApgCkALwAxADTANoAwQDeAN0AwgDXANAA6QDCAM0AygDGALMArQCYAIkAeQBtgGCAY4BAAD9AFTAJD+gP2w/Ij7EPoI+GD38PVA9JDzEPIw8TDwAPCg7+DugO5A7oDuwO1A7uDuYO9w8CDxYPLQ8oDzAPWg9kD4CPnI+iz8IP2M/QH/sgCOAagCXAOQBNgEuASIBSAGgAZoBogGQAeAByAIQAhACeAJIArQCeAJ0AowC0ALIAtwDCAMAAwQDLAMwAzgCzAMoAvwC/AKkArQCiAKEAiIBygHKAYYBZgE9AOQAlgB6/8o/zT9IPz4+uD5EPgA9xD20PSw8yDygPFQ8IDvYO8A7wDvgO7A7qDugO7g7oDvkPAw8ZDygPOw9MD1IPd4+Jj5mPro+0z9WP5x/+8ARAIYA6wD/APoBGAFeAUgBigHkAcwB7gHQAgQCaAIsAkQCxAL4ArgCiAMIAywCyAMIA1ADaAMwAyADQANYAwADCAM0AtwClAKUApgCRAISAdoBkgFSASEAwADwAG0ADf/6P2Q/ND6sPlo+GD3EPYA9cDzsPLQ8aDwoO9A7wDvoO4A78DuIO8A7wDvgO8Q8EDxkPLA8wD1IPYg9yj4KPlg+mj7CP1g/sD/yQDaAewCeAPgA0gEUAX4BYAGCAfwB0AI2AdwCDAJsAkwCgAL4AtgDOALQAyQDPAMoAzwDHANgA2wDVANYA3ADEAMsAtACwALAAqwCQAJEAgwB6gF+AT0A1wDAAJSAXQA/P58/Sz82Ppo+Qj48PYw9vD0oPPA8sDxsPDA70DvoO8A72DvoO9g78DvgO8A8LDwEPJQ87D04PXQ9hD4ePjw+aj6XPyk/fD+GwBwAUwCiAKUA1AE2ARoBUgG+AbYB7gHYAhwCOAIIAnACcAKIAuwC8ALQAwQDBAMMAxgDKAMcAzQDBAN0AzwC+ALgAugCgAKkAlQCUAIWAfIBvAFuASYAwwDXAIiAdD/Gf86/jz8+Prw+cD4gPdA9nD1YPRQ8wDyMPGg8GDvgO9A70DvYO+A76DvQO/A7wDwIPEQ8mDzAPUg9gD3gPe4+Nj58PpY/NT9fP+YAGABXALkArQDWAT4BOgFwAaQB/gHoAjACNAIEAnQCYAKMAvAC/ALYAygDDAMEAxQDGAMEA2wDAANIA2QDAAMUAvwCvAJ0AkwCdAIEAg4B2AGYAV4BBwDnAJ4AcsA6f98/lT9mPuw+gD5EPjg9vD1APVw85DyoPGA8MDvgO9g72DvgO/g7wDwgO+g74DwEPGQ8WDzEPUA9qD20Peo+MD5ePoE/OD98v7//+IAqAKUAuACIAQQBYAFOAZYB1AIwAhgCNAIYAlwCRAK4ArACzAMUAxwDJAMUAwADMAM4AzgDPAM4AyQDPALQAvgCiAKkAkQCQAJMAhIB6AGkAWoBEADrALSAfIA9v/M/tj98PvA+qD5iPgg9xD2gPXw89DygPHQ8DDwIO+A7wDw4O/g78DvcPDg7zDw0PAA8lDzYPSg9cD2oPdY+HD5kPoM/AD9gv7z//IAoAEcAhQDfAOQBBgFAAYIB7gH6AdgCKAI0AggCbAJgAoAC5ALwAsgDOAL4AvgCzAMIAwwDEAMAAywCxALgAoACnAJEAlgCBAIQAeYBqAFqATQA7gC8AEKAUMAFf/4/bD8sPtY+kD58PcQ9xD2wPSg84DyoPGQ8ADwoO/g70DwQPCg8LDwwPCQ8PDwAPKA8yD0sPVg99D3qPhw+QD7OPzY/Fr+MwBeAaIBRAJkA9gDMATQBBAGGAdABxAIsAiQCHAI8AiACQAKkAoQC8ALkAtQC2ALgAugC5AL4AvwC8ALQAvACjAK0AkQCeAIcAgACHAHqAb4BbAEGATwAlwCYgGgAKD/av5E/QD8APu4+bD4oPfA9nD1IPRA8zDyIPFg8GDwQPBA8JDw0PAA8QDxwPBw8WDy8PJQ9BD2IPfw99D4+Pko+9j7UP2S/lAAIgEMAswCfAMIBFgESAUYBpgGmAcQCIAIkAiwCCAJMAngCRAK8AogCzALQAsQCyALEAtQC5ALcAtAC/AKcArgCWAJAAmQCFAI6AdQB6AGwAX4BCAELAM8AtABCAH2/wf/sP3I/Gj7UPpg+Zj4cPdA9iD18PPg8sDxEPEQ8dDwMPFQ8bDx0PGA8aDxsPEQ83DzAPUQ9qD3qPiw+Cj6MPtU/CD94v40AEwBMAK4AmgD0AMwBCgFKAaYBnAHIAiACGAIUAigCCAJoAkQCsAK4AoAC7AKsArACqAKwAoAC0ALwApQChAKoAnwCJAIIAjoB5gHwAYQBpAFmASwA+ACRAJMAZAAqv94/oT9MPwA++D54PgA+AD34PWQ9MDzcPJg8eDwwPAg8cDwUPHA8aDxMPFg8WDywPLA8zD1QPbg9wj4GPlQ+lD7NPxo/QD/5P9eASgCtAJIA5gDoAQoBegF6AaIB0AIIAhwCKAIMAkwCQAKkArgCuAK8AogC9AKwArQCjALIAsQC/AKUAoAClAJ4AhwCEAIwAdoB8AG8AUIBUAEdAOgAhACKAG3AEP/Kv4Y/dj72PqI+fj4wPcg95D1gPSg8zDyYPEA8eDwQPFA8XDxsPGg8RDxgPGw8jDzQPRg9RD38Pdo+Dj5sPqw+8z8Cv5f/+EAVgFAAjgDlAMQBLAE0AWIBhgHwAcgCJAIoAjACEAJ4AkgCoAKAAvwCsAK0AoAC+AKAAswCyALEAuACjAKwAlgCfAIgAhQCOAHMAeYBvAFAAUgBHgDrALmAS4BMQAj/+j91Pyg+3D6YPlo+LD3YPYA9SD04PLA8RDx8PBg8RDxQPFw8ZDxIPEw8TDycPLw82D0EPZA99D34Pjo+dj60Pss/YT+4f+gALoBbAIcAzQDKAQgBdAFiAYgB6gH+AcgCKAI4AhACcAJUAqQCnAKkAqgCoAKkAqQCqAKkApgCiAKoAlgCdAIkAgwCMgHMAe4BggGcAWgBPgDKAOkAuQB2QAXAPz+vP1o/Ej7ePpg+Wj4kPfA9kD1EPQw8+DxoPEQ8XDxIPKg8XDxoPHw8bDxAPIw82D0QPUw9kD3sPhY+fD5MPtw/JD9rv7y/0IB7gGEAjAD6AOIBCAFSAboBlgHkAcACHAIoAjgCIAJMAogCmAKcAqQCmAKUApgClAKkApACkAK0AlwCeAIgAgwCLgHeAf4BpAG0AUYBUAEjAPUAjgCrAGvACQA+P7U/aT8cPtQ+oj5WPiA9/D2gPVQ9HDzcPLA8WDxkPEQ8tDx8PHQ8UDyEPJw8jDzUPSQ9VD2oPfQ+KD5iPqI+7z8vP3s/j8ALAEwArQCkAMgBMgEiAVIBgAHYAfAB0AIcAigCCAJwAkAClAKcApwClAKQAoAChAKMAoQCgAKwAlgCQAJkAggCNgHaAcwB7gGaAaYBegEMAR8A8wCFAK4ASgBPwB0/yz+LP2Y+4j66PkQ+Vj4EPfA9kD1MPTw8uDywPLg8VDy0PIg82Dy4PLQ8kDzwPOQ9AD2IPcA+PD4QPrI+nj7pPwY/kv/IQAgASQC3AI8A/ADqAR4BegFmAZAB6AH2AcgCJAIwAggCaAJMAowCkAKYApQClAKEAoACjAKEArACXAJUAnQCFAI8AegB0AHwAZIBpAF2ATcA0gDrALyAaQByQAiAAD/5P3Y/Fj7mPqo+Qj50Pfg9lD2APXg81DzYPKA8uDxoPFA8pDykPJg8qDywPKA8xD0APVg9mD3oPhw+Tj6OPtk/IT9iv7N/5sADAJkAmQDAATABEgFwAXQBigHoAf4B5AIoAjgCGAJkAlACnAKcAqACrAKcApACkAKUAogCtAJoAkwCQAJUAggCKAHUAe4BkAG+AXwBFgEQAMMAzgCaAEIAXgAUv9C/hj9BPzw+pj5APlI+AD3APZw9YD0QPNA8lDyEPLA8YDxcPKQ8oDygPKA8nDzoPNQ9PD1IPcg+Aj5OPpg+xT8/Pwo/mj/ZwBUAWQCbAMIBJgEUAXwBVAG8AbIBzAIkAgACUAJwAmwCTAKgArACvAK0AoQC/AKsApwCnAKUArgCdAJgAlACcAIcAj4BzgHyAbwBXAF2AQoBLADHANIAo4BlgCe/6D+ZP20/HD7ePpo+aD4YPcw9sD1MPQA9MDyUPIg8sDxcPGQ8dDxAPJQ8nDyAPMw8yD0EPVQ9jD3iPgA+tD62PvA/MT97v7Z/xwBGAIUA9ADkAQ4BaAFGAb4BogHAAhwCMAIEAkgCVAJcAkACjAKgAqQCtAKwApQCiAK8AmgCWAJMAkwCRAJgAjoB1gHoAa4BQgFoARABIAD3AJoApABrgDb/wL/SP5A/Sj8wPvA+pD5wPgY+CD3oPUA9WD0sPPw8mDykPIg8sDx0PFg8tDyAPMQ88DzIPSw9MD1IPdQ+Dj50PrY+5j8XP2I/pT/jAB4AWwCpANgBPgEcAUwBngG6AZ4B/gHoAgACYAJgAmwCbAJEAowCmAKsAqwCtAKkAogCsAJgAkgCQAJEAmwCEAI2AcQB0AGiAXABDAEvAMkA9gC0gFGAUMAVP9w/oD9yPwY/Ej7OPpo+aD4gPdw9qD14PRQ9IDzAPOw8mDy8PHw8VDygPLA8kDzsPMQ9GD0MPVQ9lD3iPiw+RD78Puo/NT9xv7H/6IAxgHwArADOAQwBagFMAZQBtAGeAfoB1AI4AhgCWAJYAmQCQAKIAogCoAKoAqACjAK8AnACVAJMAngCNAIYAjoB2gH0AYIBhgFqAQgBJwDCAOcAggCOgGSAHr/BP8G/jD9fPyY+9j62PkQ+UD4cPeA9pD1APVQ9ODzUPPQ8vDysPKg8qDyUPOg8wD0QPSg9DD14PWg9tD3KPlw+qj7qPy4/Xz+MP9PADgBPAJ8A2AEeAUoBtgGGAeQByAIkAgQCaAJIApwCrAKwArgCuAK8AoQCyALAAsAC7AKUArgCYAJIAnACJAI+AeQB+AGMAaQBdgEKAScA+wCaALMASABdACj/8z+3P38/FD8ePuo+hD6OPlY+ED3kPbA9RD1QPSA85Dz8PKA8qDygPJQ8kDy4PJg8/DzMPSw9KD1IPbA9uD3UPmg+rj7wPz8/eL+mv+ZAJ4BmAJoA6AEkAVABugGQAfYByAIkAjwCKAJ8AlQCuAK0ArgCsAKEAsQCwALAAsAC+AKcAoACpAJUAnACDAIsAdAB5AGCAZgBVgE1AMoA4ACFAJOAeoAKwB6/5z+7P0s/WD84PsA+4j6gPnY+CD4QPdQ9sD1UPWg9AD0oPOQ8xDz4PLw8hDzQPMw8+DzUPSg9AD1wPXQ9oD3ePi4+cj6sPu4/Nz9wP5G/z8AbgGsAjQDSAQwBfgFWAbgBnAH6AdgCLAIcAmwCeAJUAqwCrAK4AoAC1ALQAvwCsAKgApgCuAJsAlQCeAIgAgQCHgHyAZIBqAF0AQwBLADPAOsAiACcAG5APL/Lf+o/uD9IP1Y/AT8aPuA+rj5GPmo+ID34PZg9iD2YPXw9ND0QPQA9IDzAPTQ8+Dz8PMQ9WD1gPUg9rD2sPcg+DD5cPqo+7T8pP2y/n3/QgAGATAC/AKwA7gEaAVYBtgGUAdQB8AHMAigCAAJIAmwCeAJ0AmwCQAKMAoACsAJwAlwCfAIsAhwCMgHOAfgBrAGoAXwBHAE2AMMA1QCEAJKAcQARADK/yj/DP4A/XT8yPuA+0j76PoY+oj5APkA+AD3wPaQ9sD1QPXg9AD14PTw9OD0oPSg9LD0cPXQ9VD2YPfA+ED5qPmY+sj7LP28/bz+zv/sAOYBfAIMA9gDoAQIBeAFuAY4B0AHmAcQCCAIoAiQCEAJoAmACXAJIAmwCUAJUAmgCHAIkAhwCMgHOAdoB9AGkAU4BPQDcAOkAgYBtAAbADf/Zv5+/vL+hP2w/Fj8+PvA+vj5GPp4+sj5sPnA+Vj5sPfw9jD3oPag9YD1cPaA9jD14PRQ9hD2APZQ9QD2MPag9pD3KPlQ+rj6wPv4/Gj+7P4CAGABogFAAngDoATYBdgGMAhACKgHsAeQCBAJsAiQCAAJkAlgCcAJgArgCsAKIAogCjAJgAmACXAJEAkQCFAI6AewByAHuAYIBbwCxAEWATQAjP4e/qz+rPw4+jj5APvY+hj5cPew9uD0kPKg8eDywPNA9FD1sPXQ9KDzoPMg9IDzYPPQ9ED2YPjo+cj7tPxk/Zz90Pz4++j8tv6UAAQCLAP4BGAFYAWABeAFUAVYBUgF0AVIBvAGoAiQCQAKkAhACHgH6AZoBoAGCAeoBxAIkAhgCRAKwAqQChAKsAkQCSAJoAngCiAMwAvgCiAKEApgCPAFaANyAdH/mPyo+7z8CPxg+QD3sPYw9aDzYPJA8lDxYO7A7ADtAO/g7zDx4PFA8gDxUPBw8ZDy4PPw81D2kPeY+XD7MP2W/tT+A/+G/rb+Tv4uAFwCcANABIgEWAWYBEAEKATIBNgE6AT4BHAFgAbYBlAH4AbwBtgGUAbABbAFYAcgCBAIAAmgCbAKwApwC3AMEA0ADdAMIA5QDuAOwA3QDtANEAygCjALMAtQCLgE6AFe/xD76Pjw+ID4kPaw80DzcPHA74DugO4A7cDpQOgg6YDqgOzg74Dy0PLw8BDxUPLQ8+D0wPfQ+QD7NPxQ/mYAsgFcA5gDUAKhADoA0gHwAogDIAXoBcAFMAQ4BLgE4AQwBGgDAARQBKAEEAVwBkgHEAdIBvgFiAawBqgGqAcQCRAKgAlwCrALAA3ADeANgA6QDiAPgA5QDwAQoBBAD8AM4AtwCnAJGAeAB8AFh/9o+XD1gPUA8hDxYPIw9TDxAO6g7cDtwOug6KDoAOgA6KDpMPBw9OD1wPVg9pD1EPPQ9Mj4yPu0/FX/lgFwAtACwASoBiAFTAGy/9H/fwCKATgEWAcQB+AE+AKAAgACrAH4ASADkAOMA2AECAbgBzAI0AeABhAFQAT4BDAHUAmAC3AMkAwQDAAMMAxwDFANYA5AD/AOoA6gEEARgBEAD0AOEAzoB8gEYAWgBSwDc/90/Fj4sPGg7mDvEPGA78DvIPDA7QDr4Opg6sDogOeg6QDswOzA72D2iPjw9XD0EPeY+CD3SPg0/jYBbQC0APQDmAawBbgDnANoAtj/nP2O/7ADgAXIBHgDpAOcAyIBnv/YANACwAKWATwDcAUIB0gHQAjwCPgHsAVYBTgH0AgQCjAL8AzQDbAN4AxQDWANwA3QDYAOwA7wDnAPYBDAEEAP4AxwCzAJ6AVwA/ABoAKu/oj60PfA8+DuwOvA6wDuQO/g7QDvoO4A6kDnIOVA6MDnwOog7rDxoPOA9GD2cPYQ9yD4SPmo+Yj6UPxn//wCcAUABrAFsASYAvr+4PxG/moACAKIArQD2ATmAeT/egDuAd4AJ//MALwD6AS4BLAGwAkgCnAHOAUQBrgHIAiQCOAKcA2QDOALsAxgDsANYAwADZAO0A7QDgAQQBGAEWAQcA9gDpAMkApQCaAHoAXwA4AC2f8k/MD3cPOQ8GDtYOzA7ODt4O7g7YDuQO3A62Dm4OVg5qDoIOxw8OD0YPZA9vD1cPaw9gD4ePoA+8D6zPzPAGwDcAWIBgAHgAM6/4T8PPwI/Vj9OgFwBBgEvgGAAaIBDgHB/5v/rgDeARADCAXAB8AJsAoAC5AJUAcoBxAIgAmgCqAM8A1gDYAMkA2QDtANsAwQDYAO4A0ADQAO8A8gEIAPYA8ADzANUAoQCRAIUAZoBFgDlgEc/RD5cPZA8yDvoOxg7UDtQOsg7IDvQPGA6+DmwOhg5yDjQOUg77D0EPOA8TD1wPew9LD0EPmA/Nj4oPeY+7QAVANoBIgHeAYcA6D9+Psk/EL+SQDEAjwDLAMQArwBWgG6AB4BlAG6AYYBpAMgByAKQApgClALkAn4BWgFwAiQCyAMAAxgDRAO4AygC5AMMA7QDTAN8AzwDcAOkA9AEEARwBCgD7ANYAwQDNAKEArACGAHeAUQA+X/yPvw+OD1sPJA7gDsYOxg6wDrAOzA7qDvIOuA6GDm4OMg4+Dl4OyQ8nD0QPTg9cD1IPSA9KD24Piw+DD7Ov6wAXwDYAQgBrAFSAOH//z9yP0A/y7/TACsAugEMAU4A9QCDAJKAXD/IAGoBBAHyAYACHAKIAvgCdAIIAowCpAIcAfQCCALcAzQDIANQA0wDLAKsAogDGANwA1gDRAOQA5wDiAOYA7ADqAO4AxwCvAIUAigByAFsAOYAkwAEPqQ9WD0kPJg7qDqoOtA64DogOgg7CDvgOzA6UDnwOXA4+DjoOqw8DD0gPQA9VD1cPUA9rD20PfI+bD7UPy8/pQByATwBTAGAAXAAm3/ZP1A/ZD+fgDcAsAEMAYABnAEJANQAjgCMALYA5gFAAfQBzAJEAtAC0AKoAlgCbAIeAcgB2AIQAmgClALIAyACzAKYApgCuAKMAugDJAMgAxgDfANYA5gDaANwA6wDHAJcAgwCNgHmAXQAwQDjAAE/ID4YPVw84Du4Opg6IDogOmA6oDswO7A78DroOUA4qDjwOVA6IDsEPNg9XD08PMw9kj4MPZQ9bD3GPug+4T8twAABUgHUAZIBiAGsAMqALr+ov92AUACvANwBkgHmAZoBMADoANsA5gDiAS4BrAI0AkQChAKYArACuAKAAoQCSAJMAi4B/AI0AqQC4AKIAkQCbAJEAqgCrALgAwgDGALEAtADDANEA5ADeAMoAygC/AJyAe4BygG0ASEAk4BAP/Q+zD4EPUA84DvAOyg6UDnAOfA6sDswO0g78Du4Opg5MDhgOUA6uDsIPDw9dD4cPZQ9ID2OPiw9mD2MPo0/iX/Vv88A4gHAAhgBrgFmAWsA6oAh/8cAVQD+ARAB0AIwAj4BggE0AKEAsgDSARoBQgHAAkAClAJwAkwCjAKUAjYBpAG4AaYBrgGQAhACrAKQAmwCEAIoAfoBhgH4AmQC6AMEA3gDPANgA3wDYAMsAywDDALMAmYBtgGGAbABDgDOAPQAfj8YPYQ9ADzMPBg7MDqIOqg6UDqQOxA7kDvAO1A6SDm4ONA5YDogOww8AD0gPag9tD10PYA+KD3IPfQ+Jj71P0hAPgCUAbgB7gHYAbgBOACSAHdANoBZAOYBbAHAAgQCFAIWAeYBVQD3AKcAnACXAO4BaAIoAnwCZAJ4AigB4gGaAagBugGuAYgB4gHkAiQCQAKgAmgCCAIMAewBpgH4AkwDNANUA/QD3AP4A2QDIALMAugC/ALwAsACgAHeASMAdr/oP6o/pz8EPgA9LDw4OwA6gDroOtg7MDrgOwg7eDrIOjA5iDn4OYA5+DowOyA74DxMPNQ9nD4sPiA+ND3cPdY+Oj5tP10AngFqAW4BTgF0AS4AsgBDAIMA9gC2ALQBGgGWAeIBgAH4AaoBTQDIAJIAmwDOARoBagHAAnACOAGkAagB8AHaAeIB9gHmAe4BiAGiAdgCEAI8AcACKAH0AZQBlgHAAmQCjAM0A0AD8AO8A3ADGAL8ApgCxAM8AtAC8AJGAcgA24Agv+m/mD9iPso+VD1IPDA7SDtwO3A7UDuAO+g7eDrQOvA6sDooOeA5oDngOng7ODv4PFQ9AD2wPaQ9oD2sPe4+CD5GPtg/nwBoAJgA+AEgAWIBIQDhAPAA+wCEAIIA5gFqAfACFAJwAkACCAF7AMsA5gD4AO4BJAFSAbgBggHIAfoBjAHUAcIBzgGaAZAB4AHSAfIB6AIwAdQBogFQAagBoAGKAegCRAMcAzgDKANsA0QDTAMkAxwDfANwA5wDlANwAqgCPAF3AKSAUIBzgBg/pD7UPmQ9iDy4O9g78DvIO2A62DrwOtA7CDsgOuA6gDoQOag5UDnwOrA7mDygPPQ9GD1wPaA9gj4sPpI/Oz8QP1f/1AByALwAxAG8Af4BxAHoAUgBOAC8AJoBHgGUAkAC4AKQAhwBjAF2ARgBJgE2AV4BVAE7ANQBSAHgAjQCbAJEAkoB3AF6AToBAAGSAe4B8gHsAYIBkAFoAQYBfgG0AggCtAKsAvAC+AKcApwC+AMgA1ADtAOwA5ADfAKUAiIBsAENANgAoABDgDg/hT8mPjQ9RDzEPCg7UDtgO2A7ADsoOxg7SDs4Okg6SDoQObA5MDmwOpg7hDxQPMg9SD1UPUQ9oD4GPpo+oD7UP3y/tcAJAMgBVgHwAeIB2gGQARAA4wCcAMgBegHgAqwCtAJ0AdIBmAF2ARQBegF0AWgBHgEaAR4BcgGAAjwCLAI4Af4BRAF3ANABNAEGAYYB2gHiAdQBjAFwAPQA1gFGAdQCDAJQAtwC8AKoAoADPAM8AwgDWANQA5ADeALQApQCZgHqAXsA4gCsgELAMz9uPtA+XD2QPOQ8MDvwO5A7qDtAO7A7aDsIOug6uDoYOeA5kDn4OjA6mDtMPBA8QDyUPMA9UD3OPgg+dj5GPr4+tz8hf8UAngEwAaACMgGwAVABCAD/AJoA/gGEAlgChAKwAnQCHgHAAcgBygHEAZABRAEiAR4BWAGuAcgCOgHmAdQBogFsARwBNAECAWoBUgGkAYwBjgF0ANABBAFSAZgB7AI0AkACrAJUApwC+AM8AyADdANgA1ADWAMwAvgCgAKUAiIBvAEqAMYAkUAoP5E/BD5wPWA8wDyQPCA74DuIO/A7YDsYOuA6oDo4Oag5uDmgOcA6CDqYOsg7EDsIO4w8IDy4PMw9uD3APh4+Bj5yPoM/Ij++gE4BagH0AeABmAE5gF4AWwDUAagCGAKwAswC4AJsAiwCJAIKAcQBmgGmAbABigH0AigCSAJsAiQCDAIIAdABtgFoAXoBQAHcAiQCPgHQAdIBpAFmAV4BvgH8AiwCXAKgAuwCzAMsAzwDPAMkAyQDLAMkAxQDLALsApwCbAHwAXoAzACiQBy/hD84Plw90D1gPMA8qDwQO8g7gDtoOuA6gDpgOfA5oDmwOZg52DoIOlg6WDpYOqA60DtYO9A8nD0YPXA9nD3wPjI+dj6CP0FAEADsAWABygH4AWoBIAE+AW4B0AKgAzADOAMMAzgC2ALcAoQCvAIwAhACMAIAAkQCsAJoAngCKAIUAgoB0gGgAVABoAGCAegB0AI6AeIBrgFCAY4BpgGAAeIB+AI4AnACiAMAA1gDeAMkAxQDEAM0AvgC/ALgAsQC0AKMAmgB1AFXAO1AFr+fPyY+kj5cPfQ9YD0QPNg8QDwgO4g7eDqgOmA6MDngOdA5+DnQOiA6KDoIOnA6eDq4Osg7hDwkPEA8zD00PWg9lD4CPoY/Wb/qgFsA7AEYASIAwgEwAQgB8AIwApgDEANEA1gDfAMwAvgCtAJYAlgCcAJ4ApQDFAM0AvgCkAKMAnYB2AHYAcQB3gH0AdgCDAICAcgBpgFOAU4BcAFuAYAB+gG6AagB8AI8AkgC7ALkAsQCzAK4AmQCaAJ4AlgCgAKwAkgCQgH6AQsAhIA1P3M/JD7uPqg+bD3EPZA9GDykPAg74DtgOtg6sDpAOlA6MDngOeA58DnQOhA6aDp4OlA6oDrIO2g7kDxEPPQ9FD14PbY+Ij6FP0N/5QBnALUAtQD2AQwBmgHsAjACvALUA1ADjAP0A7ADbAM0AtACxAMMA1QDgAPsA5ADvAMsAuACrAJQAmwCKAI4AjgCHAI+AdQB2AGqAVYBXAFmAXwBdAF8AVoBvgGEAjwCIAJsAnQCXAJoAgwCEAIuAfQB+AHMAj4ByAH4AWkA3YBvP74/KD7mPro+aD44PdQ9sD04PJQ8UDvgO1A7ODqwOkA6UDo4Ocg6CDowOig6UDqYOoA6kDqQOtA7ADu4O8A8tDzYPVw90D5iPvo/Jz+GwAoATgCMAPABEAG2AdgCbALEA0QDqAOgA4gDrANsAwgDXANIA6ADuAO0A5wDvANEA0wDNAKIAqgCUAJ8AjwCHAI2AcYB4gG8AXABagFwAWoBYgFUAWYBeAFMAbABnAH8AfYB6gHEAd4BtAFQAWwBDAFaAWABYAFuARgA/gA0v7E/BD7CPqQ+Xj56PjQ93D2wPSw8uDwIO8g7uDsYOwA7KDroOuA68DrYOtg62DrgOvA6+DrAO1A7iDvsPBg8kD0IPbg98D5IPsI/BT9fP4oAOgBmANYBZAGmAeACPAJYAtQDOAMYA1wDXANoA3ADSAOEA4QDrAN0A3gDTAO8A1QDUAMAAvwCSAJUAkQCdAIMAhgB/AGOAYwBkgGCAbABXAFKAXgBKgEoARgBcAFCAaABvAGCAdABmAFuARABKQDaAMABAgEpAPAArYBnADa/mj9uPug+lj5ePg4+KD3wPZg9UD0kPIA8eDvIO+A7kDuIO7g7aDtAO0A7UDtYO2A7eDtAO8Q8JDwQPEg8oDz8PTA9qj4kPqE/IT9oP7O//AANAJMA8AEIAYgBxAIIAmACuAL4AyADZANcA0wDQANAA0QDbAN8A0ADgAO4A1gDYAMwAtQCxAKEAmgCCAJoAioB6gH+AfgBzgH6AbYBtgFmARQBCgECAR4A5AEIAUABTgEgARIBDQDSAIEAiwCfgEYAVYBzgHGALr/O/9c/jT90PsY+0D68PgY+CD4kPdw9pD14PQQ9CDz4PIA82Dy4PAA8JDwAPHQ8IDw8PCQ8TDx4PCw8fDywPMA9ED0cPWg9hD4sPnA+6T8kPxA/Oj8Tv7P/+IBEAOABHAFAAcACIAIkAgACVAJ8AjwCBAKIAvACzAMwAwwDYAMAAygDJAM8AqACcAJoAngCMgHAAhQCVAJsAigCJAIiAfYBcAEaAQ4BMgDxAP4AxgEIASsA8wDmANkA6QCQAIoAo4BjgBt/zj/pv/z/6r/uv/E/zT/tP2g/Oj7YPt4+qj5iPno+ED4UPdA94D3oPfA9+D3QPcw9kD1MPSg8+DyUPNQ9ED1UPbg9kD30PYA9mD1QPUg9dD1kPdI+WD7LPwk/cz9sP3Y/PT8Gv6u/+IAqAEgA7AEwAV4BbAFMAYgBjgGMAdQCAAJgAggCNAIAAlwCfAJgAvQC7ALgAkACFgHAAfABrgGmAdQCCAJoAlACYAICAeABUAEeAP0AjgCIAIAA2AEIAV4BegEAARgAn4A8/8JAN3/DP9q/zMATACZ/y7/nf+3/4b+8PxY/LD7qPqw+aj5OPog+pj5yPlQ+uj5KPmI+ID48PeA9oD1gPVg9tD2UPfw95D4QPiQ9/D2wPbw9vD2oPfQ+Pj5uPrw+mj7WPuY+/D7WPy4/Hz9iv5R/7z/HADAARwC1gHiAfQDKAVABDgCyAIYBXgFiAVYBuAJ8AnwByAGQAaQBSQDrAMQB2AKYAoQCxANkAsYBi4BSAGYA4gEwAQgBwAJ0AgIB0gGcAXcA9QBogAMAfwBTAMIBDgDeAESAG//wf+LACIBZwCk/pD9vP2C/j7+dP10/Pj7mPro+XD6oPsI/ST9jPyA+hD4IPeQ+Fj6iPpw+aj4wPjY+DD5IPpg++j7CPvQ+dD40PjY+fD6iPuA+sD5EPr4+xr+hv+q/9b+Av4Y/dT8zPzI/RP/YABiAUgCgAPQA8QDuAJcAjgCKAJwAqgCgANoBNAE8ATgBFgF+AVYBjAGcAWYBKgDXAOUAzgECAVwBdAFuAXABXgFyATwA+ACLAJGARgBlgG8AvADcATwBGAEaAOqAZUAAgDF/63/of9MAHAAGABB/xb/xv+OAGsAOwA//yz+fPxQ/Gz9Cv7s/FD7MPtM/Lj81Pwy/ln/cv/U/Mz80Pz4+yj5KPjY+mD8vPwc/bMAEgHo/cD7lP0O/6j9SP2U/bD8cPsg/SsA+v6U/fb/nANIArz9gv98A24BEPvo+5QBbANy/wf/BANoBSAC5ACYA2gFCAKA/vL/ZALsARkAOAIwBWgE8AFUAuAF6ARuAIT+0ADqAZoB9AGoBYgGOAQYAkQCfAGw/vj9Hf/S/nj+LQBgBKgG4AUgBNACE/+A+9D5MPxA/QD+AACEAqQDBAJCAbMAOP94/ID7EPzs/Gz8QP2s/gD/Q/8VALABzgEIAe7/Hv5w+qD3qPiQ+7j+4QBQA6gE/AHo/oT9rPxQ+9D6jPyq/nn/Zf9GAIwBfAGD/0T+oP4vAI4AjQAIANAACQBq/sj9/P5gAOEApAIoBNgDfgGMAJoB3AEwAND+O/8lAGQAyAEYBAgFCAUIA4IBmgEMA9wDsgDw/Xj99P/AAaQCWAT4BYAE2v+4/Rb+7v85/zr/agC0AZwBRgCIAL8AgwAC/vz8lP1C/y8Au/9K/3j+kP5K/i3//v7M/hT+aP5K/ykAZv+A/VD9tP4mAHT/dP5b/xQBLQC8/bD8lP3k/UT9Zv6KABwCSAIoA3QCl/8s/Hj6UPvo+zD8R/84BLgGmAYIBgAElv4Y+ND2OPvm//4AfAJgBMAEXAGx/3YBvAOAAuz+3P7E/Yj9DP1KAIgDKAUgBKoBiAGiAPABWgDk/uz9IQBcAckArv9mAIQCgAJ2AOT+cwCmAM8Ayv+i/nj8kPrQ+3MAmAJ3ACcAsASQBwACUPmA9hj7Nv74/Nj9OAGYAqAA2v5R/5z/tP7O/ucAfgH6/wT+lP1w/UT9PP0a/koAegGAAhQCaAEIAJr+OP3A/Jj9TP5//zMAYAKgAzgEQgEu/tj9rf8gAdz9GP0u/tQBjAJ6AYACGAMYA2QCKAIVABz8kPpQ/e0A5AEUAygGMAnQBcgADP5s/Bj72PmY/J4BzAMsAxAE+AUQBGD/JPwU/Xj9EP3k/mwDsAQ0AY//pQBNAKj72Pqv/1QD/wAD/xYBXANLAIj8cPzI/dz8+Pp4/TwBTAMkArgB3QAdAHz84Pr0/GwABgEC/vD9a/9zAPj8aPweAYgE/gHI/T//wAJsAmT9IPzg/aX/tv5e/rIBqARIBKAB2P/0/pL+iP0e/jYAgAEWAeUAFAMgAxgCRP8G/qz+wP/oAfgBtQCK/gwBGAOEAVn/VAHQA8sAQPtQ/M4BAAN8APYBsAVwBMn/VAAQBCgB+Pvo+r//WgBw/rb/cAQwBSwCawAkApwCfAG4/ej56PhI/eYBXAKQAXgCMATR/3j8qP0SAZb+bPxW/k4Anv5A/TgE2AY0/yD3OPquAJL/BPz4/2AGMATE/BT83//b/7j78PseAAQDZAOSAY4AQP6o/Xj9Uv/i/+AB2AL5//D8LPxc/sT/z//q/7YAAALQAA4BPALAAvL+GPsY+4j+9QBi/y4BHAPoAn7/bv+kA4gEsgCy/sX/TP5w/S7/cAOIAgMAPAJIBoAEwwDjALIBLPxg9pj6NAPABsgEMAZgCQgFePsg+DD8sP6A++D55f94BsAHNAP4AAIB+P+I+rD4ZPzyAQQCs/9Q/ioAWADU/QD+AP9p/8j9XP6sAAgCqADE/eD8Zv72/qD9NP2Q/0wDvgFM/vD+jANQBJ3/iP2Q/Rj8ePgg+2gDYAjIBOD+FP+e/jj93PyyAUgEzgG+/gb/qgD8/Cj7HP10ApQCWAJABZAIgAS8/GD7qPy8/Sz82f9YBCAELwB+AbgFeAO+/gf/rAOUA8T9APyL/7cAcP7+/nAE0AasA00AowCcAd//wP7e/kf/FP70/EQAQAM4BcwCUgGjAJj/lP3o+8j8xv6h/9//dgHMAXEAtv+cACAA8P0A/b7+lv5c/Jz8owDgAcP/ZP+GAWsAFP3c/LgBnAHo++D6cP/0AooAkP6cAbQChv5o+iT9HAK6AYr+Uv60AcgCv/8y/tD/sAKjAFj9sPuV/6wD0APcAQwBwgHI/6D7yPynAAwDnwA7AJgCkALc/Qj9KAKwBCcABP21/2wCKgBU/oQAugHD/6r+xgHgAi4AMAAQBFQDLP3g+nIAbALU/hD9QAJUA6b+wPxEARAFawCE/Qn/ZABI/FT8CgEgA6YAuP1XAHYBZwA0/vD+I//4/rz+Ov9+/77+Kv9S/oD+Fv+6ABQBqgDQAcH/dPxA+iL++AKoA1QAGP8OAaz/UP6o/LsAdAJaAZj9GP1pAM4B6v4s/K//DAPYAKT8Hf9gBbAFpv6o+6f/egHe/mb+EAKfAPT8cP04BNgGTgGk/XIADAO0/aj6Gv+YBIQCQP28/SgD+AWoAlwAAP9u/rT8BP5dAL4B1ALsAv0AlPyw/c4BQASg/7z81QCsA7cASP3k/7wB8P84/qgB/AKE/iD6pPywAYYBwv+WAOACg//g+pD5sv64AigDMAAc/aD+LP58/qr+9AHQAfj9mPog/fACSQCQ+2D96AUYBaD9cPrY/ocAcv5I/ej/dv/U/lwDmAeYBOT9iP5mADD6YPXo++AGcAi8AzgEEAdcAVD5sPle/0P/sPq8/egEgAaoArAD6Ab4BMT94PvU/ab+kP0A/oj/gP6OAcgGMAnsAz8AJALoAdz8CPng/FYAqv8Q/Wz/jAPIAzgD2ALUAqUALP8Y/ZT8wP2w/tH/OQCIAtgCUAF0/dD8MP4z/z8AcAH8AioBIP9A/Gj78PnM/QAEgASMAPz8jQBoAlr+4Pnw/NwBfABM/HD98AKIAz7+0Ptz//ACoQAW/jf/dgEtAMz8XP0YARQDwgAW/mL/AAKgA/wCXAGm/xj+fP0Q/Wz/hwCEAGcAkANwBfgCNgDZABwCdP7Y+TT8HAOIBF4B2gAgBKABiP0Y/u4BnAFw/Lj9rAPoBYsA7P0eAdgCBv5g+Wz83ALUA7YBpALUAwwC+PsA+8j8Ov4o/jgAoARYBDABwP2U/j8A2P2Q/PT80v+4ADD/WP4tALwCQABI/Hj6Ev72AKIAlv9O/y0AFgAyAI0ATgAV/2T++v7U/jj95P3T/+wCaAJ/AFIBcgEE/pj5RPxoAqAEPwDe/wAFGAUc/WD4fP/wAyQBkPyKAbgFoQAQ/Gj/kARJ/0j5zP1gCZAI+v+k/bYBFAK4+fD33P9ACFAGWQAu/xQCZAE4/z7+oAC3/4j9aAAoBGgEGAB0/mAB+AEE/hT8cgAYBDwCM/+4/rIAKv76/pf/ZAGm/8D/ggESAPz8mPoT/7QCwALY/z7/0P3s/ZT89PxM/xwC5APqABT+Bv4GARUAiP2C/sQCgAIO/jT9zAAcAbj82PtQAHgDsQBAAeAEQAWA/Uj41PwlAPj9bPwQBDALKAXI+iD5PAHEAuj86PrsAegEKgD4/qwDkAhQAjj6kPkW/gwAFP8SARAE8ANuAWb/JgGeAeP/NP2I/Kz8Vv5sAPwDIAegBav/yPo4/egAPwD4+8D9OAIYBET/FP5cApwDOv5g/CAC/AMI/VD4Vv5oA3gAPP3oA8AH7P8g+BD8fAMqAAT8RQBYBpYAkPkQ/AQCXQBo/KQAlAN+AOj6Wf8oA/v/6Pre/qAD7wDM/Nz+RAM1AOj73PyEAYkAlv5IAXgFGARM/sD85P11/xz94P3CAAgE8AJX/6z+mQDcA8//kPzw/lgFoAMA+hj4HACgBigBYPwkAjAI1ALg+qj8cAT4AzD84PrMADgCUPwQ+mIBUAhIBQD+ef+4BXgDGPw4+pgBvAJw/Lj4Jf+YAzoANQDQBCgHKv+w+uL+CAS3/2D5QPuG/zABxv4nALACuAIW/xj8Sv6+ALUA0PwY/RQBoAGU/SD8xAI4BWj/ePjo++wCpANGAJH/VAIvAJz8cPuL/2YBwwDe/lIA2AGz/yT9qv5wBQAGswCM/Nj+fgEq/4T9Wf9fAFj9gv6gA0gFFAIwAngFnAIY+pD36/9wA1L/OPtC/4ADaAPoAhgE6ARqAQj+RPxo/Kz8bP6KAMABxAIQBCAECAMEAa7+0Pog+hj84AHIA8gBhAAEAmoBaP2I/AUAIAS+AKD8Hv+IA6oB/Pw8/t0Akv64+8D+WAQkAmT9Qf8QA9oA4Puw/bMAGP+I+2b+VAOiAfj9pv5mAXAA7P2e/3wC6AAU/az9cAC8/0L+W/80A8IBcP4u/tQCoAOy/6j82P5CAdP/1P0BANwCgAE4/hj95AD8Adf/AP5zAAgEbAJ4/Zz8dAAQAgcAcACIA8gDRv7A+gj/9gExAJz+hAIQBTYAyPvo/RwD3AE0/sT+AAL8Acj+Ov50AD0A3P1Q/CcAKARMAgL+7P54AlQDfP2w+Q7+yAI8AWD+jgEoBSQDDP3w+xb/4//4/ED9oQBwAlsAu//UAeQCIAGs/ez9zgB9AFL+zP2C/wQBWP9w/iABWATGAcD9pP1sABQCeAH9/xcAkv4A/fj8vPwU/sgA0AXgBUwCPv9tANoAlP1Q+9T9egFb/1D+GAGkAx4AWP3w/5gD9AFo/eD/oAKaABT8gP1sAhQDaADP/44BYgGEACQBDAEG/xT+l/+w/tj7HPyEAVAEogEsAKQDsAUUABj6KPrU/db+yP0o/ywCLALFAN//DgGsAVEAiv5A/Xz96P0QAJIBHAK8AMb/TgDkADsAGP/n/78AOv/c/LT94wDMAeP/Wv+0AUwCiQAO/44ATgED/7j9HP9EAeT/xP0W/h4ApQAXAGgA4AHKAVgARv+//0MA3/+U/gT+3P50/3//WP+oARgDpAIHACr/FgBh/4D9LP0zAGIAxv44/qIBLAIjAFv/7gEgA1D/NP0A/+wBs/+o/dj9HQBHAIL/nAD0AbwCwAHoAAn/UP5S/nL/6/9lANgAQgBJ/2L+vf8EAFz/A/8zAKsAlADz/2oAOwDM/6z/3P+5/1b/hv+o/8v/2f8QAckAAgB0/9IA/wBd/2j+1v53AIkAvgBiAdwBogCN/9T++v7O/u7/gAFcAY3/9v6+ABQBXQCa/h3/cP5s/Sb+dgEgA4IB2QDYAXACtv7g/GL+dADs/mD9Hv8oAlAClwDoADgCagGg/jz9rv7IACgBMQAyAJUAigDD/4b/gQAuAb//Tv9UABwB4P+0/RP/DAKwAg4A8P6oAHYB4P50/MD+rgGQAUf/Rv8uAecA+P6s/iIB9AD2/uj9rf9qAJH/0v7W/0YAgv93/ycA/ABIAOb/w/9t/yz/DQAEAfEAaAA/ACAA/P6S/gz/ZwB1AGgA+AD2AZoBPAB4/8r/AQDY/sD+HgB+AcIAFwAiAPQAyAAnAJYADwBq/8L+hf9dALEACgFmAVYBfgBNANv/Wf8a/4//5P86/xH/vP9WABEAzv9GALsArQDIABIBlACg/xv/M//M/j7+hv7R/7IA1AD7AP8AbwBf/03/mP/1/5f/B/8V/xn//P4F/2H/CQDe/8X/jwBCAQ4B5P+T/1r/ZP6U/Rz+mv8fALX/9///AHIBLAFCARABGQDS/pD+QP82/+D+T/98AMoATABzACQBTAHJADwAq//K/q7+f/8dAMn/1f/cAHYB4AAZALEAHgGTAOn/JABtAK3/Qv/0/6sANQDF/5MAdAEqAa4A9AAWASkAZf/o/1EAcP8B//v/FgG4AP//OgDiAJwA1P+//y0AAwDB/+7/of9Z/4v/kQBwACn/nv6V/w0AD//w/k0A3AC5/x7/EgBZAED/tP5y/9j//v4f/5sAYAFbAKb/LgAgAE//If8hAF8ANP/S/rz/iQA5AFwABAHpALn/NP+1/wgAuv/U/zAAZAD6/8//0//7//7/+f/T/8b/BwCIAIEAXAB+ALUAeAApAAYAlwCUAH4ACgACAPv/yv/r/18AzgCTAF8AXwCYAF8AAwADADwAFQBs/2T/0v/Z/07/Ov/H//f/tP+v/0oAiQD8/6T/2f/5/37/Lf9C/1H/F/8a/43/BADg/8P/DQBzAKAAeQB8AF4A9P9N//z+5P4P/zL/dP+S/7z/AwA2AE8A8v/k/7r/uv+z/57/kP9o/3P/hv+k/8L/3v/x/wgADwBIAGYAaQBNADUA+P+T/4b/w/82AGIAPgBMAH4AhwBzAFcAWQBlACMA8//W/+r/AgASADQAPQByAJQAhgBUABMA/v/7/6z/lv+1/wsAIgD3/97/2f8GAM3/4f/x//r/3/+X/4b/hf+f/8P/9P88ACMA8P+k/3T/q//U/8//tf/k/+//4f/S/+z/JQAkAAgA9P/o/+r/2v/u/wMAAQA6AEkAogCuALQAcwAEAP3/z//O/67/0P8cABcAOABFAF8ATwA+AD0AQAANAN3/CQAmAB0AGgBDAFYASQA8AFcAcwBcADoANgATAMz/6P/N/+P//f/y//X/z/+i/4r/jv+h/7j/mf+O/4H/iv97/1P/h/+R/2P/cf+U/3P/L//o/hf/M/8J/0//W/+5/4z/hP+4/8n/sv9q/6H/uv+c/7f/vv/1//X/6v/l/wkAFAAlAGIAewDBAKQAuQBpAKAAugCZAHYAgQCBAIwAvwC/ACABTgFwAXQBsAGyAagBhAGcAYoBpAG8AdYBKALWAf4BBAL2ASAC8gH2Ab4BuAHYAcQBiAFqAQABqwBpAEoAUgD5/9n/1v/K/5f/SP9K/0r/0v58/jT+9P28/XT9cP0g/fD82PyQ/Jj8UPwQ/Cz8PPwg/Pj7wPuY+3D7MPv4+gj74Pqw+mj6kPq4+nj6kPro+qD74Pvo+3T87Pw0/Tz9hP1E/sL+Mf/w/90AoAEoArgCtAOwBGAFAAaoBqAHMAjQCGAJIAqwCsAKMAuQC+ALEAwgDGAMUAxQDAAMwAtgC+AKYAqgCdAI6AcoB3gGqAXgBAgEKAMEAvkA8f8Y/zT+VP0E/ED7iPpo+aD4oPcg92D20PUg9eD0cPTg8zDzoPIA8kDx8PCw8HDwEPDg7+DvoO9g72DvgO9g76DvAPDw8KDxoPLQ8zD1YPZw9wj5mPo4/Lz9e/9mAQwDuARABhAI4AkAC9AMYA4gEKAR4BIgFGAVwBUgFuAWoBfAF6AXQBcgFyAWABXgE8AS4BHAENAPIA8wDvAM8AsQCyAKgAhQB7gFQATEAk4BKwDi/rj9pPzI+4j6yPkg+bD4APiA9/D2kPZg9sD18PXA9bD1EPXg9JD08PNw87DyUPKQ8fDw0PCA8HDw4O/A74DvoO8A8ADwMPBw8JDwUPCQ8LDwcPFQ8pDyMPMQ9DD1cPYo+Bj6aPsY/Wz+OwBgAbACMAQYBhAHgAgwCgAMYA2QDiAQgBHgEqATgBVgFqAXQBeAF0AXYBYAFqAUgBSgE2ASgBAwD8ANMAvQCZAIEAgoB0AGgAUIBIQCjgFRAA3//P3c/BT8EPsw+rD5WPnY+KD38Pco+MD30Pfg9wj40PdA90D3YPfg9xD4KPho+CD4MPgw+DD4WPhA+Dj4CPig9zD3IPdg9gD2cPXg9HD0gPRA9BD0cPPw8rDyEPIA8sDxMPJA8nDyMPNg85D0cPXA9oj4sPmI+6z8Wv7p/4IB7AK4BFAGEAggClAL8AwADmAPoBDgEUATYBTAFeAVABZAFuAVQBWgFGAUoBOAEiARYA9ADsAMQAsgCjAJMAjwBogGgAWIBKQDoAKMAY8AkP9y/mD9bPy4+7D6UPrA+XD5OPkg+dj4kPig+KD4kPj4+Nj4IPlA+Rj5EPkw+Wj5QPkg+fD4CPlo+Aj4CPiA94D38PYQ9nD1wPQw9MDzwPNg8yDzQPJQ8rDxgPFg8YDxAPJg8tDykPOg9HD2UPcA+fD6cPxM/sf/zAHkAjgE6AWoByAJEAuwDGAOYA9gEKARYBOAFGAVoBbAFiAXgBagFoAWwBXAFOATIBOgESAQYA4gDUAL0AmgCNAH2AaYBQgF0AMUA7ABsAAKAJz+nP1g/HD70PrA+Yj5+PjQ+Ij4MPg4+OD38PcY+DD4aPj4+ED5qPnI+eD5EPow+kj6qPrQ+sD6kPpg+pD5gPko+bj4UPjw9zD3sPYA9jD1oPQg9LDzMPOg8vDxUPFw8RDxEPFA8eDxgPKg8+D0EPYg+ED5OPuY/B7+9P80AQQDeARoBlAI4AmgC9AMIA4gD4AQYBKAE4AUgBXAFUAWoBYgFoAWIBZAFSAUIBMgEmAQYA+ADVAM0ApQCYAIuAe4BogFqATcA9gC0AH8ANf/mP5I/XD8mPtw+sj5cPkg+XD4EPjQ9+D3sPfg9yj4gPig+Nj44PkQ+iD68Plg+pD6WPp4+oD6oPog+uj5YPlY+cD4cPjg93D3MPcg9sD14PRw9MDz4PIw8gDyEPHw8EDwcPBw8MDwcPEg8pDzQPXA9qj4ePr4+4j9Nf/EAIwCQAQIBrAHYAnwCgAMcA3wDiAQwBEgE0AU4BTAFUAWYBbgFqAWwBYgFiAVQBTgEmARsA9QDtAMQAvgCVAIgAcwBhgFOASEA+QCvAGfAJr/Vv4E/fD7EPtg+rD5cPhg+KD3QPfg9tD28Pbg9jD3UPew9/D3WPjo+DD5YPmY+dD58PkA+gj68Pm4+Wj5SPnY+ID44Peg9wD3gPbg9TD1sPTg82Dz8PJQ8pDxYPGg8HDwwO/A7xDwMPDw8JDxMPPQ9HD2OPj4+bD73Px+/m8AjAKABFgG+AdQCbAKQAyADdAOQBDAESATABTAFOAVYBbAFqAWABcgF0AWoBXAFKATABJgEBAPsA0gDLAKUAngB5AGkAWQBNgDvAIcAjIB+v+6/oj97PzI+xD7WPq4+Qj5UPjw96D3YPcw91D3gPfA98D3IPiY+AD5UPlg+aj54Pn4+QD6APro+aD5YPko+cD4OPjA9zD3sPYg9mD1oPTQ8yDzcPLg8SDx8PBg8KDvQO9g7wDv4O7A7xDwcPFw8pDzwPWg99D5GPsE/eL+tQDEAvgE8AZwCCAKsAsQDZAO4A8gEYASwBMAFaAV4BYgF6AXwBcgGOAXQBfgFgAWIBVgEwASgBBQD1ANoAtgCuAIkAfYBQgFMAQcA1ACRAF2AIL/Mv48/Wz8uPvo+ij6yPkg+Xj4APjQ95D3oPeg9+D3APg4+ND4UPmQ+dD5IPo4+lj6YPpw+oD6SPrI+cj5ePkA+Vj44Pdg98D28PVg9eD0APRQ87DyMPKg8QDxcPBw8IDvIO9A74DvAPDg71DxIPLg82D1UPfg+aj7DP3M/l4B9AIABVAGgAhACpALAA2ADqAPgBAAEkATgBRAFQAWwBZAF0AXIBcgF+AWQBYgFUAUABNAEQAQkA4wDaALEAqwCHgH2AWwBMQD6AIIAhYBTQBY/0r+TP1w/Jj7EPuA+sD5SPnY+Dj4OPgI+PD3GPhI+FD4oPgQ+Xj5qPkQ+kj6mPrI+uD64Pqw+rj6cPpQ+vj5kPko+Xj4sPcw94D20PXw9FD04PPw8lDyoPEw8XDw4O9g70Dv4O7g7iDv4O+A8ODwoPJw9KD2EPj4+Yz8JP75/8gBnAPYBYAHQAnACoAMYA2wDkAQYBGgEsATgBRgFUAWoBYgFyAXIBcAF4AW4BUAFQAUwBJgEeAPcA4gDZALAArACCgHyAW4BIwDoALGAekA4//6/hr+VP2k/ND7CPuI+ij6WPnw+KD4iPgY+ND3IPhY+HD4qPgg+Zj52Pko+kj6mPrQ+sD6wPq4+qj6cPpI+sD5cPng+ED4gPfA9vD1MPVg9KDzEPMw8rDxAPFw8ODvYO/g7qDuQO5A7iDugO4g72Dw4PGA88D1EPeQ+Uj78Pwp/3IBCAMYBSgH8AiQCuAL4AyADuAPQBFAEoATYBQAFeAVQBbgFiAXIBcgF2AWABYgFQAU4BLAEWAQoA5ADcALQAqQCDgH0AWoBLADgAKuAcMA0P/W/ib+pP3A/GD8mPvg+oj66Plo+TD52PiQ+GD4WPiA+Hj48Pgo+Vj52PlA+pj62Pro+jj7SPsw+zD7CPsI+5D6GPpo+ej4IPhg98D28PUw9SD0oPPw8jDykPEg8bDwQPDA76DvQO8A7yDvQO/g77Dw0PHg81D1gPco+Sj7ZP10/tsAEAMgBeAG0AhwCvALcA2gDqAPABFAEiATABSgFKAVIBZgFqAW4BbgFoAW4BVgFYAUYBPgEcAQcA/QDSAMsAogCaAHIAbgBKQDvAKIAYwA4v/Q/jT+ZP3g/DT8wPtY+6D6UPrQ+aj5SPkg+QD50Pjw+Pj4SPm4+Sj6gPro+kD7sPvg+yD8JPxI/Hz8PPwY/Nj7cPv4+lj6sPkA+Sj4cPeA9rD1sPRA9GDzkPJQ8pDxQPFg8ADwwO+A7yDvAO+g71DwwPAw8qDz0PWg91D5IPtM/Rj/KgHsAnAFSAeQCJAK0AuQDWAOwA+gEMARwBJAE0AUABVgFcAVIBZAFkAW4BVgFeAU4BPAEoARQBDQDjANsAsgCoAICAeoBXAEYAMUAmIBlgCx//b+QP6Q/QT9ZPzw+0j7uPoo+pj5UPno+Mj4wPh4+LD4qPgI+TD5wPkg+pD64PoQ+2j7oPu4+7D7yPv4+3D7SPsI+3j6CPpI+Zj44Pcw93D2kPXw9FD0UPMQ8yDy0PGA8cDwYPAg8ADwwO9A7+DvYPAA8cDxMPOg9TD36Pi4+pj8lP49AEwCYAR4BtgHkAkgC9AM0A3ADiAQABEAEqASgBMgFMAU4BSAFcAVgBWgFSAVoBTgE8AS4BGAEDAPsA0gDNAK8AiAByAGuASQA5ACVAGvAOn/+v5U/qj9BP1c/PD7MPvQ+lD68Pl4+VD5CPno+ND4uPj4+ED5aPnI+UD6yPoQ+0D7qPsM/DT8SPxk/Hz8YPwE/Mj7OPsI+1j6yPkY+Xj44Pfg9lD2sPXw9DD0kPMQ88Dy4PFw8RDx4PBg8ADwIPBw8IDwMPEw8hD0UPUQ90j5UPug/Fb+YgBEApgE8AWgB3AJsAoADFANwA6wD4AQgBHAEiAT4BNAFKAUIBXAFEAV4BSAFAAUQBOAEkARIBDQDpANAAxgCqAIcAfoBXAEdANAAigBQABu/7D+6P00/aj86PtI+7j6QPrI+VD5CPkI+cj4uPh4+Jj48Pj4+Cj5yPkw+qD6yPpQ+6D70Ps0/ED8kPyM/HD8QPwM/Lj7MPuo+jj6mPkI+RD4kPcA90D2YPXQ9PDzgPPQ8iDywPFA8WDwIPAg8ODv4O8A8MDwsPHQ8jD0UPZA+Bj6mPuE/Vz/2gDQArgEuAb4B5AJ0AoADGANQA4wDyAQABHgEaASIBOAE8ATQBRgFEAUIBTAE0ATIBJAESAQ8A6wDUAMEAuQCTAIsAZYBSgEAAP6ASABTQB7/9T+OP54/bz8OPy4+zD7qPo4+gD6uPlw+Uj5WPlY+Wj5oPng+Uj6mPoY+4j76Ps4/HT8vPzk/Az9EP0A/eD8oPxE/Nj7YPvg+kj6qPkQ+XD4sPcQ92D2wPUQ9UD0sPMg83DysPEg8aDwUPDg76Dv4O8Q8HDwIPEQ86D0sPUQ+MD58PvE/SD/VAEMAxAFiAZACNAJ8AowDHANsA5gD2AQgBFAEgAToBMgFIAUoBTAFMAUoBQAFIAToBLAEYAQMA/wDaAMYAvACXAI+AbYBXAEVANoAkIBeQCO/8z+DP5Q/bz8OPyA+wD7ePog+tj5iPlo+Uj5KPlA+YD5qPkY+mD62Po4+9D7MPyA/Nz8GP0w/Tj9QP04/Rj9+Pyk/Dj8BPxQ+9j6OPqw+eD4MPiA9/D2EPZg9dD0IPRQ8+DyYPLA8WDxoPAg8bDwIPBw8NDwIPLQ8pD0EPYg+Jj5OPtY/YH/9QBYArAEQAbwBxAJoArwCzANAA4wDyAQ4BDAEYASQBOgE+ATYBTgFKAUYBTAE0ATgBKgEYAQgA8wDtAMcAsACoAIOAfQBcgEnAOEArwBwwD5/wn/QP6Q/ez8UPy4+xj7ePrw+Xj5OPko+ej40Pjo+AD5OPmQ+eD5aPro+mD70Ptg/LD88PwU/ST9PP00/Rj9/PzQ/Ij8IPyw+2D74PpY+tD5IPlw+LD3MPeA9rD18PRA9IDz8PIQ8tDxYPEA8WDwUPCQ8ADwcPCg8TDzgPSQ9ZD3gPk4+wD9ov7XAJQCIASQBYAHwAjQCSALcAyQDZAOYA9gEIAR4BGAEgAToBMgFCAUQBQAFIATwBIgEkARQBBAD/ANoAxwCxAKsAhwBzAGCAXwAywDRAJwAXkArP8B/xj+SP2c/CD8SPuQ+vj5uPlg+RD5GPk4+VD5aPmg+SD6cPro+jj7yPtk/Mz8HP1M/ZD9lP2o/ZD9pP2M/XT9TP0M/bT8VPwA/Gj78Po4+pD52PgA+ED3gPaw9fD0APSQ87DyMPKQ8YDxcPHg8PDwkPAw8dDxkPLg8wD2YPfA+KD6fPwy/gUAWgFEA+AEcAa4BwAJUApQC6AMoA3gDvAPwBCgESASwBJAE2ATwBMgFOATQBPAEgASQBEgEBAPAA7gDLALcApgCRAI0AaABYAEpAN4ApABlQC0/77+yP3s/DT8ePuw+jD6mPkg+bD4kPiw+KD4mPjY+Bj5ePl4+cj5SPqo+gj7QPvY+xj8YPxo/Kj82Pzo/PT8FP0g/eT8rPyA/Cz8kPsw+5j6GPow+Yj48PcA92D2wPUQ9YD0cPNg87DycPIg8tDxUPKQ8YDx0PGw8qDz8PRQ9uD3ePko+8D8UP5MANwBeAMwBagGAAhACXAKoAvADOANwA7gD8AQoBEgEqASIBNgE8ATwBOgEyATgBLAEcAQsA+QDmANcAwgCwAK0AioB3AGGAUoBPwC4gHBAKj/rP7E/dD80PsQ+0D6cPnI+Gj4KPgA+ND38Pcw+GD4WPhw+PD4QPl4+eD5OPrY+hj7aPvg+wT8gPyM/Oz8AP0s/Uj9KP1I/eD8xPxc/ND7WPvw+hD6YPmA+Aj4MPeA9sD1MPWQ9AD0UPNw86DywPKA8oDycPKw8VDyoPKw84D0YPbQ9yD50Pqk/Gz+CgCkAUwDGAWIBngH8AhQClALcAywDQAP8A/gEIARYBIAE2ATwBMAFCAUABSAEwATQBJgEaAQgA9wDnANcAxwC0AKUAkQCAgH8AW4BMADeAISAeH/8v4U/vj8HPxQ+6D6sPnw+Kj4qPh4+GD4gPi4+LD4YPig+BD5QPlo+ej5ePqw+jD7YPu4+0D8UPy0/Az9MP1I/Tz9HP3I/Jj8aPzY+2j7APtg+rj52PhY+MD3EPeA9uD1cPXA9ED00POw8wDzwPKA8rDyYPLQ8YDyEPMA9ED1wPZ4+Oj5YPsw/fr+MwCcAUAD8ARYBggHcAjACQALAAwQDbAOkA9gEEARQBLgEgATQBOgE+ATIBOgEkASwBHgENAPMA9gDnANcAyAC6AKYAlQCEAHQAYIBcADeAJQAfn/FP8+/jj9aPy4+8j6EPpo+fj46Pig+Ij4mPjI+Gj4aPiQ+Nj4IPko+ej5gPrI+uj6UPvI+1j8dPzY/DD9dP1E/Uj9VP1c/dT80Pyg/Fj8sPvo+nD66Pn4+Ej44Pdg98D2IPbQ9VD1kPQQ9PDzAPRg88Dy8PKA8zDzoPNQ9HD18PYI+Ej6oPso/Xr+m/9OAXgC0AM4BaAGwAcACQAKQAtgDHANkA5gDyAQABGAEQASIBIgEmAS4BHAEWARwBBAEJAP0A5wDpAN0AwQDFALQAoQCSAIIAfwBdAEbANwAlwB/v8P/0z+kP24/Nj7IPuY+vj5cPko+fj46PjY+Kj4uPjA+Nj44Pgg+Wj5APpQ+pD66Ppo+6D70PtA/Lj80Py0/Lz8qPzA/ID8fPxk/Dz8sPsY+7D64Pkw+Zj4IPiQ9/D2sPYg9qD1EPWg9DD0sPNQ81DzYPNQ8+DykPMA9FD0QPWw9rD4MPrA+yD9Jv5E/xQAmgEQA0gEiAXgBhAIMAkgCnALgAxQDVAOQA/gD0AQgBDgEOAQ4BDAEMAQwBBAENAPQA+QDvANQA3QDAAMAAvgCRAJAAjoBtAFuATEA6gCbgGFALn/ov6g/fT8VPxY+2j6yPmY+Sj5kPh4+ID4YPhI+Cj4YPhw+ID4wPgg+ZD5uPng+Vj60PrY+kj7qPvg++D78PsA/Az8BPzo+xz86Pug+0j76Ppo+qD5IPmg+Fj4kPdg98D2YPbw9XD1MPXA9JD0YPRg9GD0MPTQ9KD0APXA9fD2uPgA+rD7HP34/WL+b/+YACQCjAPQBCgGcAdwCHAJkAqgC6AMUA1QDjAPsA8gEIAQwBAAEQARABEAEeAQYBAAEHAPAA9gDtANcA2wDJALoAqwCbAIqAeYBqgFoASEA2wCrgHEAJT/pv7g/ej8EPwY+8j6IPqw+Vj5UPn4+PD4mPiQ+KD4KPhg+OD4MPkg+Xj5wPkY+jD6SPqw+uj62PrQ+hD7IPso+wj7MPso+/D6wPpo+gj6YPng+HD4APjQ94D3MPfA9mD2APaQ9XD1IPUg9UD1IPUQ9UD1YPVg9cD10PaI+Ej6cPuw/ND97P2Y/nX/HgHoAggEQAW4BtgHkAiACeAKwAtwDAANUA7wDkAPcA/wD2AQQBBgEIAQABGAEOAPoA8wD5AOAA7QDTANgAwwC2AKwAmQCIgHmAbwBfAEpAO8AtgBuwDW/+D+8P0c/UT88PtA+6j6CPrI+Xj5IPkI+aD4ePg4+Bj4WPiA+MD48PhA+Xj5iPnA+dD5GPpY+lD6WPpA+mD6ePpw+oD6mPqQ+jj6APo4+TD5sPg4+AD44Pfg91D3IPfw9tD2cPYA9vD1EPYA9vD1MPag9tD24PbA98D4QPoo+2z8jP0E/nz+Mv9xAIwBtAL0A0AFaAZoB9gH0AiQCXAKMAtADKAMYA2wDSAOkA6wDlAPkA/gD1APQA/gDhAO4A2QDZANIA2gDGAMgAuQCkAJgAiwB7gGwAX4BDgEIAMYAj4BhwB5/4L+4P0Y/VD8kPsw+8D6YPoY+tD5mPlY+RD5MPnw+ND48PgQ+UD5OPlQ+Zj5kPm4+aj58PkQ+uD56Pno+QD60PnI+fD5APrA+UD5OPnY+JD4IPgQ+AD4sPeQ95D3kPcQ98D2gPZw9kD2MPZw9uD2IPdw9xj42PiQ+Tj6OPvo+wD9YP1a/mH/CwAYAQwCZANwBAAFeAXgBXAGMAdQCLAJoAogCyAL8AqQCrAK4AvADIAN0A3gDYANsAzwC8ALwAvgC9AL8AvgCzALcArACdAI6AfwBpgGIAaABfgEQARwA0ACTgGoAAEATP+6/l7+6P0o/ZD8QPwA/Jj7MPsA+8D6oPpo+oD6mPpo+lD6UPqA+nD6ePqY+rj6uPqY+qj6wPrY+uj66PoA+9D6uPrA+qj6iPqA+kj6MPoA+sD5iPlo+VD5QPko+Rj5EPnQ+LD4ePiI+Kj4APlg+dD5OPqI+vj6UPv4+5T8LP3U/Xr+Q/8AAL4AVgHuAXAC4AJEA9gDgARABQAGuAYwB1AHaAeAB5AH2AeQCHAJIApAClAKIAqgCUAJUAmQCQAKAAoACgAK0AlQCcAIgAggCLAHQAcYBwAHeAbIBRgFeATYAxQDpAJYAgQChAEYAaoAJQCA/wr/tP5s/vj90P2s/Zz9ZP0E/dz8kPxg/Cz8LPwo/Aj8EPz4++D72PuQ+5j7aPto+0D7UPs4+zD7CPv4+vj6mPqA+mj6OPrw+fj56PnQ+aj5cPlw+Uj5EPng+Oj44PjY+ND4GPlA+Xj5sPnw+VD6mPr4+oD7HPyo/DT9rP1K/sL+Lv+v/yYAswAWAagBJAKAAugCIAOIA+wDaAToBEgFYAV4BcAF+AVYBrAGIAdgBygHCAdQB5AHiAeYB7gH0AfAB4AHeAdgBzAH2Aa4BrAGWAYIBtgFmAUoBbgESAQQBLwDZAMUA8wCgAIUArgBYAEOAcQAjwBiABsA0v+B/0j/9P7A/oL+Qv4O/tj9rP1g/Rz94Py0/HT8OPwg/PD70Puw+4j7ePtQ+yj7EPsI+wD74Pro+tD6wPrA+rj6uPrA+rj6sPq4+rj6uPq4+sD62Prw+hD7MPtQ+3D7mPvA+/j7NPyA/NT8EP1Y/Zz9+P00/oL+0v47/5D/u/8TAGYAwwDmACIBeAG4AfYBKAJwArQC3AIYA2QDnAPYA9wDKARQBKAEyAQQBVAFiAWwBcAF2AXgBfAFCAYYBiAGOAZABigGIAYQBgAG6AXIBaAFYAUoBfAEyASQBFAEGATcA5ADOAPwArACZAIMArwBdAEkAcYAeQA4AOf/k/88//r+sP5g/hb+yP14/Sz98Pys/GD8FPzQ+5D7UPsg++D6uPqQ+lD6IPoA+tj5wPmg+ZD5iPmA+XD5gPmI+Zj5oPmo+cD54Pn4+Rj6SPpo+oj6sPro+iD7aPug+/j7TPyY/Oj8MP2I/dD9Iv5u/uT+If+A/9r/MACIAMkAJgGIAcYB/AFIAqgC6AIsA4ADwAPwAxAESASQBNAEEAU4BWAFkAW4BdgF+AUIBigGSAZYBlAGYAZwBlgGSAYwBhgG8AXABagFeAVIBQgFwASABEAE+AOwA2wDGAPAAmgCFALAAWwBIAHLAHMAEQC0/2H/C/+w/lD+8P2Y/UT98Pyg/Fj8GPzQ+4j7UPsY++j6yPqg+oD6YPpQ+jj6OPpA+jD6OPpI+lj6cPqA+qj6wPro+hj7QPtw+6j76PsY/FT8kPzg/DD9eP28/Qj+UP6O/tj+Hv9x/7f/9/88AH8AyAACAT4BcgGiAdgBCAI4AmgCmALEAugCGAM4A1gDdAOMA6gDvAPUA+gD/AMIBBAEGAQQBAgEAAQABPwD9APsA+AD3APAA6wDoAOMA2wDSAMsAwQD2AKkAoACYAI4AgQC0gGoAXgBRAEQAecAugB8AEQAEwDe/5j/aP87/w//0v6W/mz+QP4K/tj9rP2Y/XD9TP00/SD9GP3s/PD84Pzk/Nj84Pzo/OT85Pzw/Az9GP0o/UT9VP1s/YD9mP24/cz95P0Q/jT+VP58/p7+uP7Y/vb+G/85/1j/f/+g/9L/8/8WADcASABeAIgAsQDSAOgA9wAUASgBQAFQAWYBgAGGAZABlgGyAcYB0AHeAegB5AHaAdwB4AHqAegB5AHeAdgBzgHIAboBqAGcAZABjAGCAW4BVAFAAR4BCgEAAe0A1QDAAKUAiQBrAEQAJQASAO7/xf+x/6P/kv9v/0r/L/8X/wD/5v7c/tD+wv6q/qL+lv6M/oL+gv6E/oD+dv52/nj+eP5w/mj+dv6M/o7+lP6i/rr+zP7c/vL+EP8q/z//Wf95/4n/k/+t/83/8/8LACMARABiAHQAgwCSAKIAuwDLAOYA+QAMARIBEAEaAR4BJAEmASoBJgEqASQBJAEeARYBEAEKAQYBAgH+APIA4gDQAMwAyADAALUAqQCbAJEAgwB6AHIAXwBWADwANAAoAB4AEAAQAA4A/f/s/+P/2f/Q/8D/uP+s/63/oP+S/43/h/+M/4//m/+T/4b/df9x/3P/df9z/2//bf9n/2H/Yf9n/2f/a/9u/3X/e/+A/4r/mf+l/7L/vP/J/9T/2P/j/+////8IABAAFAAbACAAIQAnAC4ANwA9ADoAOwA8AEMAPwBCAEIARQBEAEIARQBDAEEAPgA/AD0ANQApACEAIQAnACMAHAAMAPr/6v/k/9z/4//X/9X/w/+7/7z/vf/A/6b/kv+B/4f/ef+P/5L/lP95/1j/a/9y/27/Yf9h/1//Wf9v/3//i/91/1b/Xf+A/5z/pf+i/6j/of+k/7L/0//q/+b/4f/i//r/GAAkACcAJAAiACUAOQBNAFcASQA8ADUAQQBTAF8AbAB1AHcAeQB6AHQAbgBzAIQAlwCSAIwAiQCHAIIAcwB9AIoAiwBxAE8ANwAtADQAQQA+ACMA/P/p//n/DQALAP7/6//f/8z/zP/W/9//4v/K/7n/rP+r/6z/tP+2/7b/sv+q/7H/tP+3/7X/s/+t/6v/tv/J/87/w/+x/6n/rf+x/7f/uf+0/6r/qf+2/8f/x//E/7f/sv+4/8b/zf/U/9b/2//Y/9b/2P/s//7/BQD9//D/+/8XAD8AUgBIADsAOQA9AEwAXgBxAGkAYABZAHAAfgCEAJEAowClAHkAYQB6ALoAvgCVAHYAmQCxAKMAhQCaAKoAqQCUALAAswCJAEkAYQCCAHwAVQBXAFwAIgDa/9//HAAsAAIA0f/X/8L/xP+j//n/2//N/5P/pf+n/6j/q/+b/5//cf+J/37/l/+b/7H/qv91/0//Rv9l/3r/sP/O/7P/Yf87/1j/mv+x/53/gv9K/0D/SP+w/+f/1/9z/0D/S/91/7P//P87ANr/Wf8Q/8H/ewCyAJAAmf8h/5z+kv8aASgCbAGy/57+qP4xAHYBJAJKATQASf9R//P/NgEkAtABOQAA/4T/5gDUAYoBFgEOAGP/T/+8APQBrgFfAF7/of8LAHEAvgDkAGQAi/9h/wQAoQCPACYA1v/k/+z/CwA+AEYACgC3/53/1/8pABAAxP+f/7v/7f/l/6T/kv+P/5f/nf/h/wkAzP9R/yr/iP/z/yIA9v/K/4n/Zv9r/7r/+f/n/6r/fv+n/93/BADa/77/nv+j/87/+v8KAPj/1f+9/8f/4/8MABAA8v/e/9f/GQAuADwABwDa/9L/KQCKAHwAOADj/xMAMwBvAGsAhABYAB0A+P9JAJQAhgBlADIAXQAOAC4AUADpAIUADADE/0oAqwCsAF0AKQAdAP7/HQBaAJUAJADC/5r/HQBuAFsA/v/V/8f/pf+p/+X/MwAHAJH/Uf9b/6z/kP/O/5//vv9d/1b/ef+4/7j/lP/J/7j/xv+Q/6z/rf+W/6D/0P8NANH/i/+F/6b/sP+t/8H/5v+//8L/qf///7T/xf+V/9H/wf/M//3/BgD4/8P/5//f//f/s//4/y0ATQAqABcAGAABABkAcgCEAG0A7/8jAF4AzwCXAK4AxQCpAF0A3f+AAPQAWgGdAHQAawCWALEAhAD4AJYAgwAaAMIAEgG8AFQATwDKAHQARgBVAPsAwwAKAN//XwCxACEA+/8JAHwACwAdADEAFQCW/2P/RgBVAAcAC/9a/47/9//C/6v/kv/Y/gr/Tv8sAN3/0f8c/wL/mP4b/+X/fgA2AC3/0P7S/kj/1v9SABQAUv+i/jr/8P8FAJb/b/+n/5v/cP/u/1YALQBi/6D/YQBoAI3/3P9/AN8ADwA2AKoAxABY/5n/6QDcAdwA3P+tANgAfwCE/9MA3AEkAQwA2v8+AdUAtQBKAGwBRAFKAMv/+/8aAfcA3gAHABgAdADJAFEAmf9BAL8AwgBH/4//IwDLAP//tv9UAPL/OP8c/9cA9ACT/1b+q/+3ACYAzP48/xsABQD0/iX//v8TAG3/yP75/2r/7f+g/rz/6v62/yD/DgDv/1v/pP7g/WD/PQA4AVf/5v50/qH/xv5E/93/dgF7AJb+9P3w/poAXAB1AID/ev8q/2H///+RADwBqv/6/mj+lACeAXIB9/+G/7b/X/8HABwAeAH4AKgAtP9G/8D/tACEAT4Acv+G//X/JgGsAIQBXADB/zD/n/+iAFEAygEUAWIBzv5P/4j/QgEYAfAAeQBO/6X/2v+0AYYARwCs/or/pf/iACwBnQBHAPD+i/8p/88AvgBUAW//G/8k/0cAQwBhAJEATv8b/37+7QCU/4QAMv6zACj/bf++/lcArgCO/rT+eP4EAXb/wP9k/9n/Vv4c/gcAYgEGAar+ZP6+/vP/wgCiAeQACP/G/hv/gQA9AGIB9AGvAAD+qP1VAKwBAAJ0AKwAmf/s/sb+rQDwATQB0ABW/xkAvv49ACsArAHtAEwAff/0/qoAVAB4AdH/EAEhAOz//v4VAJYBxAA5AJ//qAB8/0H/HACmAcYA5v55/wQBBAGA//T+WAA1ACYANQAeAb//jv7u/hYBVAE7/zf/VgCpALD+YP7i/9YAFf+Q/Yr/SgEEAX7+nP48/4v/Kv5G/0wBrAFY/zT9mv4xALEAN//1/zsAvP6s/Xr+dAK8ASgAFP1u/tf/iwCsAVkA9P80/iT/TQBvAMoAHAGpAH3/0P1x/8QAXAJgAS8Amf/W/okAaAHEATEA1v5OABQBIAJcABgAmf8Q/w0A9AD8AmUAp/+A/jgBWQDl/xAAhgG/AJz+Av7pAEwDagH8/az8ov5+AIwBdAG6AYf/0Px8/EgA+ALAAW3/Tv6SAG7+w/95/4ADEwAQ/7D9DgHUAfX/6P+c/4AB9f96Afv/BQB+/nsACgGQAev/fgFlAIb/8Pzq/iwBhAKQAA//SP4k/mv/HwDWASEARv+Q/az+sADGAEIBZv/kAKj/qP+4/lAA5AEKAeEAe//OAWr/SgBK//0Ahv+H/2wBzAHgAdz8c/9V/84Blv/PAAgCSP9k/Tz8CAOEA0ACUP2M/e7+Zv84AMMA2AICAWj+6Ptk/voBbAMUAdj9Qv7+/nsAZgCcAmQB5P7M/A7/9AFCAcz/CP9sAP//2P4tAOoA9gHg/jb/ov5IAF4BTgF5ACz+wf+Z//4A4P7c/1IBVwAX/6D9mQC7/2AADf/YAYsA7P6I/Zz+JgHU/4YBnP9UAaz9ov/+/jQB6v+T/xIBef/jANT9kAF4AEQCKf+q/t7+wf8MAj4BBANEALIAwP02/gL/BAEUAkgCaAIAAPz9hPww/5wBWAKl/zn/EwCjANr/9v7SACwA3v9U/ej/YAGEAiUAfv4b/y7+of8S/lYBSADvAAX/i/89//z9Gv5k/ggBFwCHAGP/RAA//1b+4f9YAJ4ApP1o/rz/0AG4ARIAhP+k/Tb+lP5sASABegAQABf/aQBD/3MAL/9i/ir+ov/YAs4BsgH4/mD+SP2A/sQB0AOAA07/6P16/g4AxABaAWwCNAE5/xT+wP8gAqYAgv+q/igCJAE8Afb+u/9O/5r/UAHAArgBZv4K/gwAEAJIAZYA9ACmAKT+rP1RAEQD/AJOAID97P67/4IBLwBKAPf/rf+V/6AAZgEbABj+/PzG/9IBBAIOADH/EP9a/ur+6P+YASIBn/+c/pL+1P76/34BVgHk/wD+1P2W/u//mAAAAVcAAf+C/mr/Gv/O/gAAEAE+Aez+Rv9s/9kAov9CAOIAdQBG/3r+GAFmAFEAAACYAcIAPv+6/hkA5AHq//v/pv+SAM//xgBSAbIA5P7C/lf/BgE0AIoB1gFTAHD+fP3d/6b/pALGAQwDwP1M/WD9fgBKAbYAWAMgAUX/uPp4/lwBrAKNAF8A3AAs/6z9yP0IAgADaAFw/3r+7P54/o//KAEwAtgBMv8S/jz9tP7LAIIBcAF6/9f/mP5n/8j9E//RAL4BSgF4/ir+6P1c/wYARAF4AYL/8P3g/QX/agB7ACYBgQCk/6j93P5oAIQBlAExANH/QP4D/1UAHAKeATUAl/++/7D/0P77/wwBvAEzALH/1P+UAOX/9v4Z/y0ALgG3ALcAvP9SAN//AQBLAHkAmQA7/3b//v+CAcoBswDT/w7/Hv9d/8EAQAL4AaAAZP6k/vD/iAHiAT4BpwDu/lD+Jv5PAAACXAKYAFH/kv42/1X//P9hAAYB/QD8/3D/Jv8YABYAlwBeAIcA5f/m/ub+7/8kAWIBRgHoAAwAdv6s/aj+rwDiAe4BigEWAKT+YP16/sP/3gACAWwB6wCr//L+iv6C/4T/kQCfAJ8ASP9j/xUA/gCFAA8AQP/o/iT/2v/bALAA5ACIAPv/hv70/QL/GADJANUADAFPAEb/TP66/kT/GwD4AIIB+ABB/3z++v48AFQBDgGDAHj/gP+q/6f/FgDMAOABggEjAOb+Pf+3/w8ArQDkAZQCKAE+/2r+ef9oAAoBigE6AbsAI/9i/7T/qgCYAMYArwDt/9L/OP80AEkA0wBRAAoAuv+m/x8APP+v/+X/WgHwAAEApP4w/rD+XP+TANgA+QBVAJD/Sv50/Xz+cQCeAdAAbf/q/h3/e/9Y/wEARgAhAB3/uv7s/uD/EgCtAAoBVADK/lj9QP6l/7AA3ACXAIAAXv98/mj+Rv///+//QQAHAEQA5P8zADMAxv/0/tr+pf+PACQB6AB+ALr/vP+y/y8AMQADAK3/vP9vAN8AaAEcAZMAoP+Q/or+if9iAQgCGAJwAD7/sv7o/oj/EQCqAMsAvwDy/7f/nf9o/27/i//2/xkA/P/m/7T/u/+m//v/RADd/8r/i/8WAAkAawCCAJQAfQAZAB8Ai/+k//n/2wBiAcwAIgCi/3//Pv9i/ycAlgDPANf/sP9Q/0r/yv5e/xsAuQCgAO//XP/c/sb+c/+2ACwB3gDN/1r/Rv+B/wYAOgDCAJoAHgCf/9P/IgA7AAAArf8JAHwAagBaAO//wP/X/83/RAAlANr/Mv+I//j/dwChAB4Atf8M/7D+/v6M/3kAGwDg/5D/nf+A/0P/1P4H/5n/jf/8/y4ATQDN/2b/Iv99/wUAQQBjACYAHABYAJEAfQAvABEALQB5AAoBTAGqAGMAWAAIAX4BLAEkAQoBsQAOAMUAugFgAgwCcAEoAdwAQwCYAG4BKAKYAigCFAI+AdkAfADwAHQB3AH8AW4B0AAmAFUAEgBNAFwApADn/w7/3v4i/3n/ov5y/lz+jv6o/fj8AP1M/XT9kP3Q/Sj9JPwY++j6QPsM/ND8nP1A/eD7mPpA+qj6EPsQ/Pj8nP0g/Vj86PvA+wD8FPwU/cD9zv76/sj+rv52/rb+Lf/v/40ARAGeAQgCeALMAhgDjAMYBFAEqASQBWgGMAdAB9AHAAjYB5gHIAjwCHAJYAlgCfAJoAkwCYAIsAjACFAI4AfQB9AHUAfgBlgG6AVIBTAEYAN0AvABkgGWATwBVABf/+z9wPxw+yD7GPu4+kj6YPmY+FD3YPbA9XD1oPQQ9KDzcPMQ80Dy8PGg8VDxEPEw8UDxIPEQ8XDxkPHg8cDyAPSg9bD1IPYg9rD2YPc4+ND6XP36/mX/6v8QAO8AIAK4A8gFgAfwCNAJMArwCpALUAzgDPAN4A5gD8APABDgECARABGgEIAQQBBgDyAPcA/QD5AP8A4wDiANEAygCvAJ8AmwCUAJgAjAB4AGMAUQBCQD8AJgAkQCTAEuAMr+mP1E/eD8uPxA/Gj7UPpI+bj4mPgw+PD3MPeg9tD1wPRA9NDzsPOw83DzcPNA85DyEPIw8RDxIPFA8qDyMPPg82DzEPMg8qDyYPNA9MD00PWA95D4wPhQ+nj7wPyo/Lj8rP2h/1wB3APgBbAHSAcwBkAGqAZgCKAJAAwQDdANQA0wDLAL8ArwCmALoAzgDXAOMA6wDPAKIAlwCAAJMAqQC7AL8AowCRgH+AWYBRgGqAbYBuAGKAbIBGgDaALOAewBNAK4AmgCFAK3AJ//4v5k/gX/Tf9q/0j/iP4Q/vT8/Pzc/AT9nPws/Dj86PtA+1D6EPrA+Zj4MPgA+HD3wPag9UD1APXg9GD0oPMw8zDy4PCw8NDwEPLg8uDy4PKw8kDyUPFw8MDxMPMA9QD3mPkg/Hj76PnA+DD5+PrM/RQCwAVYB9AF2AT0AzAEuATQBmAKUAxADfAMQAwQCyAK0AkQC4AMIA0gDhAOYA0ADPAKwApgCpAK0ApgC4ALcAqgCZAI6AdYB9gH6AcwCJAHaAbQBcgEKAS0A/QDqAMQBCAE/AMMAwgCCgE5ABEAcAC2AXQC3gH1APv/I/+c/Tz91P2+/t7+bP5K/hz9QPsY+Xj4YPjg+ID4iPjA90D2oPRg83DzEPNA8sDxYPEw8RDxoPAg8VDxgPHg8NDwIPEA8YDwYPEw81D2QPgg+vD6APrg93D3oPlo/fABsARwBlgGgAR4A6ADOAVIB/AJoAxwDuANQA3wC+AK4ArgCkANMA7wDmAOwA0ADdALwAuQC8AL4AqACkAKoApgCtAJkAlwCFAHsAaIBsAGYAYgBvAFGAUoBEQDIAP4AsQC3AKUA1wDpAKOARAB3gCJALgA8gFAAvQB5gBtALj/1P7E/hr/3/+R/9b+zP2k/AD7sPmA+bj5gPm4+CD3IPbg9LDzEPNA87DyQPIA8UDwIPDg72DvwO+g8MDwgPAg8CDw4O/g7wDxIPRA95j5+PmI+Vj48PYg+CD7hP/sAmAFCAZIBUgEEANwA+gEEAcQCtAMEA6QDfAL4AqACSAJcAqADIAOUA7ADQANMAxwC3AK8ArACqAKgArgCmAL4ArgCbAI0AfQBnAGyAYYBzAHwAYwBkgFQARQAxwDJAMwA3wDxAN4A8gCEAJsAQYBwAAkAa4BsgF8AQIBswDw/wP/dv5e/lb+8P1M/aD8kPtI+iD5qPgo+ED30PVw9GDzwPJA8uDxAPKg8YDwoO4A7sDtwO3A7YDuQPDQ8GDwQO+A7wDvYO4w8cD0KPnw+vD5ePnQ99D3MPmQ/TgC2AQoBmgGIAaQBEAEiAVYB8AJEAyQDoAPQA5ADJAKgAqACpAMcA6AEMAP8A2gDKALUAuQChALgAvwC1AL8ArwCsAJoAhAB+AGsAYwBggGQAYQBugFEAWQBNQDdAKcAUoB4gHMAmADfAPwAoQBYwCB/+n/QQDcAIQBygFuAaYAzf+c/mj92PwE/Wj9qP2k/Pj7sPoA+WD3kPYw9iD1MPOg8tDyYPIw8ZDxwPGQ8KDu4Oxg7sDtAO0g7nDwAPNg8TDxMPAg8CDvoPCg9VD6kPt4+gj7IPoQ+rD6kv48AqgEmAUIB4gHgAboBZAGUAjgCUAM4A4gELAO4AygC3AL8AuADWAPoBDAD4AO0A3gDFALsArwCsAL0AvQCzAMcAugCZgHyAbYBsAGaAZoBhgGmAXwBMgEsAT8A1gCJAH4AG4BOAI4A3QDsAJ+ATwAlf+d/wAAygBoAeoB5gGGAbcALf/4/TT9VP2U/ej9tP0Q/cj72Pl4+HD30PaA9eDzEPPQ8mDyUPIA8tDy4PEA8KDtwOzg7ODrQO1g8LDzoPMg8cDv4O6A7uDvQPMw+Mj6OPuI+jj70Pqw+gT84v4AAsAEkAaQB+gHmAbQBUAGcAhQCzANIA7ADUANoAwgDHAMQA0wDuANsA0gDnAO0A2wDNALAAuQCpAK8AowC1AKYAnACFAIuAcAB1gG4ATUA4wDcAQIBbgEEATMAmoB9f+2/8sArAEkAgAC8AGcAbAAnv8v/2r/EwAYARACtAIMAp4A3v7o/az9HP7A/k7+5P2c/Jj7WPpo+YD4MPdw9aDzcPLA8jDyQPIA8vDyoPJA8KDugOwA7ODrAO1Q8FD08PQQ8+DwYO/A7nDwcPNI+ID7jPxQ/BT8TPxY/JD9Uf+EApAFYAfQCPAIEAlQCKAHMAnwC1AOgA6wDrAOwA4ADvANEA9gD6AOgA0QDgAP4A4ADlANMA2QC2AK4AlACjAKYAlACXAJMAmQB9gFOAQYA2QCEAPIBGAF0AQgAwIBov8u/oT+t/9EARAC0AGOAVEA/v74/eT9sv4UAFgBAAJMAcr/iP5w/Vz9WP1O/hD+LP3I+yD7kPrA+Cj40PfQ9hD1wPIg89DxMPGA8HDxkPNg8vDwYO9A7gDsoOvA7VDxQPRQ9fD0APOg8XDw4PFw9VD5YPwu/tb+hP5o/vL+tP+sASgE6AbQCCAKEAsAC7AKgApAC+AMQA5wD5APwA+QD+AOUA8gDxAPgA7QDYANQA3ADcANYA0wDNAKYAlwCBAI2AdgCKAIEAgQB/AFmASwAiwB6AAkAhADHAPcAhgCvQCE/pz9AP5e////fwAoAW4Apv9C/ij+bv5e/yQAqQDpAPH/Rv8w/rz99P20/pD+3P1U/Ij7OPow+bD4sPhw+GD3UPWw9ODxAPGA7yDwkPGg8QDz4PHA8EDtIOxA64DrYO7g8SD10PXA9JDy4PCg8GDx0PVg+sT9/v5T/3b/wv7w/i7/7AGwBPgGAAnACvALoAuQClAKUAuQDNAN4A6wDwAQsA9gD0AP4A8QD/ANIA2wDGANcA2ADVANcAwQC9AIqAeYB/gHeAcYB2gHmAcoBugDcAIMAnABgQCUAQQDDANGAS8AqP+k/j7+Qv5U/5EA+v/n//n/gv/k/oL+Cf84/6z/eAABALr/Gv+Y/m7+dP2U/VT9vPzQ+xD7aPqA+dD4wPfw99D1UPQw8nDx8PBA8CDycPJQ8sDxAPGg7yDtAOxA7CDvEPEQ9ND2sPaw9MDwwPAg8oD1OPk0/QgBqgBY/0z+/v7i//UAUAPgBnAKAAuAC8ALcAswCqAJcAuADfAOgA/QDyAQwA8QD4AOAA4wDdAMYAwQDWANEA6gDcALEArQCKAHUAYYBugGsAeIB6gG+AWwBKwB3P+Q/8sAkgFiASACiAIcAfr+7P1c/aT9kP1Q/9QAjAHAAKz/Tf/c/tz95v4VAOoA1AAIATQBxAAu/27+jv4u/ij9vPxs/Zz8wPpg+ZD5iPmg9+D0kPPg8oDwwPAg8oDzwPPQ8fDxIPCg7kDtgOwg7uDvAPPA9eD20PVA9CDyYPHg8sD2kPtm/uT/mQAAAMj+bP6x/2wCUAQAB9AJcAtgCyAKYAkgClAKoAtwDSAPYA/ADsAOMA/ADhAOAA3wDAANIAwwDPAMQA1gDPAKoAmgCFAH8AWgBUAGEAdoB/AG8AUwBCQCQQD3/3IAqgFYAoQC/gGKAZkA4v7U/dz9vP6v/6sAggHoASIB+v8b/23/4/9TAPwAjAHCAZABRAG8ABcAkf+a/qj9NP2Y/Sz98Ptw+qj5wPgQ+BD2wPWQ9ADyQPDA7zDxoPFg8rDysPEw8GDtQOwg7EDtwO/g8vD0wPUA9bDzUPKg8UDz0PYo+lT9af/kAAoAIP/+/jUA+gGUA+gGwAkQC/AKYAqwCoAKcAowC4ANcA5QDjAOAA9QD6AOwA1gDUANEAwwC5ALgAxQDDALMApwCTAIaAaABTAFMAVIBRAFQAUwBEADhgHq/x7/iP/1/1IAwADx/wAA/P7s/Xz9yP14/hL+3v7s/4UA5v9U/3z/e/+4/4T/nwAOAWABZwDPAK0ABACj/y7/tP7c/VT9RP0s/Cj7qPm4+Wj4kPfw9hD2gPQg8SDvoO9A8QDykPPg81DyAO8g7ODrwOyg7nDxIPTA9bD1UPSQ8wDzwPKA9Cj44PuA/mYAFgFoAEz/Zv9SAWgDwAUACEAKMAvgCqAKEAtgCzALUAygDbAOkA6gDhAPQA+QDgAOoA1gDGAL8AoQC0AM8AswC2AKYAmIBlgFwATQBCAF8ASABWAFcASAAuAAlf/8/j7/GwCUAZABIAFSAOz+JP4Q/tb+Tf+J/1oAOAE6AZIAowDfAIMAOwDbAAwCYALSAToB5AFcAY4APwBnAPf/1v6U/Sj9kPwA+yj6OPnQ+JD3sPaQ9UD00PHA72DvYO8g8TDykPMQ80DvAO2g60DsgO3g8CDz0PXQ9aD0MPTw8/DzgPQw96j6AP6nAHYBuAFSAY0ACAH4AiAG4AgQCtAKcAsgDBAM8AsgDJAN4A3QDVAOQA8AEIAPkA7QDpAO4AxwC+AKIAsAC7AK0AowC6AJ2AYABUAExAO4AqwDkAR4BGwDEALzAEL/uP2U/Zr+v/8EAGEAMwD4/qj9DP0Y/pT+Kf87/44A5QCtAK8AqwD+AHcAXgCKAXQCjAIgAjQC5AGYASQBsQCmAPn/0v5q/qD9IP0c/Mj6uPmo+Gj4MPeQ9TD0YPLw8CDvAPCA8gD0cPMw8TDwgO2A7ODrIO/A8lD0EPWA9dD20PTg8+DzUPZA+fD6kP6SAQADigHy/0ABqAJoBAgGMAkAC3ALUAtwC1AMIAwADIAMcA3wDYAO8A5ADkAOEA7gDfAMwAtwC6AKkAkwCSAKwAqQCXAHOAYQBTwDNAJoAggEmAMYA1gCUAKyAAL+oP2Y/Yb+1P7B/7UAawDc/nT9AP6A/fz9WP7B/2YAVgCtABAB+QAPAN7/VgAKAX4B6AE0AkgCigEkAfQAbQDp/1z/8P4s/uT9cP2Q/PD6UPlo+FD3UPbw9WD1kPTg8WDvQO+g74DwUPGw8vDywPCA7SDsQO7g7uDwEPNQ9kD3IPbw9dD1QPYg9kj4BPy8/6wBwAKsA6QCDAKoAtAE6AagCKAKAAxwDCAMYAxADTAM4AtwDAAOsA5gDtAOMA9ADtAMUAxwDEALgAngCLAJwAkACcAI8AdgBhAESAIkAvYBoAHSAUwC8gFKAVEADP/o/dz8HP3k/cD+U//0/1D/YP6Y/cT9yP38/Z7+g/94ALMAKAEWAUQBqwBXAMoAhAEQAnwC5AL8AswC5gFwAe8AewDm/7b/kf/i/kD+NP00/Pj5APlo+AD48Pbw9bD1kPMQ8UDvcPDA8lDyAPOQ8+DywO/g7ADusPCg8pDzAPeQ+FD4UPbw9TD3oPcA+cj7XQDUAtgDZANEAxADGAPYBAAHcAkwCzAMkAygDNAM4AyADEAMAA0wDrAO0A7wDuAOIA6gDOAL8AuQCxAKQAlACWAJ4AioB0AHGAZgBIgCGALmAewBKAGCAeIBOgHF//j+EP4g/dD8PP3c/oL/X/8V/+T+9P1k/XT9XP5G/5v/iQAiAYYBIgFcATgBTgFOAdoBeALAAggDCAM0A6QCFALUAWYB9ABtAEsADwAJ/wL+vPwo/Kj6SPlY+BD4sPfQ9bD0EPPg8eDvgO4Q8cDzMPSA88DxUPBA7uDsQO5A8lD1wPbQ97D4YPiQ9oD1QPdQ+Yz8Z/8QAyAFAAVsA4gCjANABIgG0AhwCwANIA1wDeAMwAyQC7ALkAygDYAO4A4gD3AOYA3ADOALEAtwCnAJAAmwCHAIQAiQB9AG6ASQAwACYAG6AD4AUwBMAIgA7/8c/wD+wPy4+2j7PPxw/T7+hv5Q/nj9uPx4/KD8UP0Y/vL+zv98AKUAggAGAHYApAAuAaIBPAK8AmwCdAKEAtgCjALgAZwBQAEMAWQALgCt/wH/+P0E/dj7+Ppo+Yj40Pfg9qD28PVg9EDy0PCg76Dv4PAg8xD0cPNQ8UDvwO7g7oDvoPKQ9dD3IPhI+Ij4APiw94D38PoY/vQAjAO4BIgFCAScA0gEKAZwCBAKAAzQDIANIA1ADcAMgAygDFAN8A0gDqAOcA6QDZAMMAwQDPAK0AkgCZAIUAiIB0AHgAc4BqgEAAN8Ap4BuQAmAHoAzwCyABMAu//O/qj9tPzM/Nz9fv5C/3L/hf/m/i7+iv6w/mz/cv9uAP8AggGMAaQB8gG0AUgCKALcAgQD6ALAAqgC9AIEA+ACYALcAWwBxwDx/7X/LP/G/sz9xPzI++D6QPnA9+D2sPZg9mD1cPQA81DxAO8A78DwwPLQ87DywPIQ8QDvYO5A8JDy8PSw9sj4sPlY+bD4SPgw+UD6BP3UAMgDEAVwBegFCAXABMAF8AfQCfAKEAywDRAOYA3gDOAM4AyADNAM4A1ADjAOsA2ADQAN8AsgCzAKUAlQCOgHMAjYBzAHeAaIBfADcAK0ARgBbQDe/x0AwgCGALT/D/9c/nT9dPwk/Qb+9P7+/iT/QP/O/kb+NP68/lH/tf9MAOQAigGcAVoBngHIAQwCHAI4AsQCkALMAmwC5AIMA5wCQAJeATQBRQDu/2D/MP+y/tz92Px4+7D6ePlY+DD3cPaQ9gD2gPSA8lDxoPCA74Dv8PHg8xD0sPKw8GDwQO9A79DwsPTg9rD3kPiw+Fj5WPgY+Fj5YPxU/5IBpAPQBOAECAQABIgEcAaACMAJwArwC8AMcAywC2AL0AvAC9ALQAxQDbANoAzQC6ALgAswClAJsAhACKgH6AbgBsAG2AXIBHwD9AKaAQ4BhwBGAAQA/P8BAOn/aP9+/tz9UP1k/Yj9Uv7a/nb/Z/81/0D/nv5D/9T+uv82ADwBAALuASAC3gHUAaYB5AE0AvwCEAPgAqQCnAKAAkwCmgFuAUQBzgAYADX/9P7g/nz9nPyI+0j7+Pkg+FD3QPfg9jD1IPQQ9EDzsPDg7oDvYPDg8YDyQPOg87DxIO+A7iDw8PGA9LD24PjA+XD56Pi4+HD5ePqg/G7/bALABAgGqAUABQAFkAXoBkAIcAowDPAMAA0gDfAMYAzgC5ALYAzwDEANYA0wDbAM0AswC4AKoAnACBAIUAcgB7AGeAbgBbgEoAOoAtYBwAA4AP//0v+x/4//zP91/7D+uP1o/Rz9LP2M/Yz+b/+d/2T/Lv8L/7L+rP4U/wAAzwBsASACWALoAYwBZgHeARACXALUAggD+AKwAqACWAIAAnwBQgEGAXQATQC4/1X/YP6c/ez88Pv4+vD5UPnQ9+D2IPZA9jD1YPRA8xDyAPDA7uDvMPLg83DzQPRQ8xDxYO/A72DykPSw9hD5iPt4+xj6ePk4+jD7PPx//0QD2AUoBjgGoAYwBpgFeAaQCCAKEAsgDAANMA1wDOAL0AuQCzALgAvwCyAM4AuQC2ALoAqwCcAI8AcoB3AGIAYABrAFKAXQBAAE/ALMARQBdwDh/7n/DgCFAE8ABgCS/y7/nP4U/j7+4P5d/+//ewDqAO0AUgD+//b/QwCbAFABIALsAvgC9ALIApQCXAJcApACOANIA5ADRAMcA3ACAALGASgBFgGdALYA7v8b/5r+7P14/dD7ePto+/j5ePjw94D3EPfQ9aD1gPUw9NDxYPDg8HDxIPJA8/D0EPWw86Dy4PFA8pDyIPTQ9mj5KPvY+wT8aPvQ+uj6gPxT/ygCqAQoBnAGQAbABbgFYAaAByAJcApQCwAMIAwADGAL0ArQCvAKsAqgCrAK8AqwChAKsAkgCUAIIAdIBvAFgAU4BcAEcATwA0QDhAKaAdgAEgBb/w3/Lv9m/5T/R/8I/4D+BP6o/YD9yP0Q/rz+X//w/x8A7/+h/0n/Hv9t/zYAGAG4ASgCTAI0Ar4BhgFqAYQB0gEwAqgC0AKkAkQCngEKAY0AjgB+AD8A/v+o/zT/Rv54/fz8pPyI+3j6EPpw+Sj48PYg91D34PYA9SD0wPNg8cDwEPFA8yD0QPRQ9BD1kPSA8iDyAPOg9GD1GPgg+/T8oPwg+wj7ePv4+7T94QDUAygFuAUIBiAGqAVoBSAGiAfgCEAKkAvwC4AL4ApgCiAKAAoACmAKMArgCeAJQArwCQAJMAh4B1gGIAWoBPAE8ARwBPwD6ANkAxwCwwD9/3n/8P4N/53/TAAbAI7/5v50/vT9yP34/YD+/P5p/9//NwBTAB0A5P+l/3r/n/9PACgB1gFEAmgCQALKAUwBJAFSAagBEAKcAhQDDAOQAuIBVgHxAIkAQQBvAI8AWwDZ/0P/uv4U/hz9QPzg+2D7sPoY+rD5QPlo+KD3EPcw9kD1YPTw89Dz8POg9AD1oPVw9ZD1YPaA9VD1YPWQ9iD3ePgY+3j9JP7k/JT8GP24/Sz+1P/sAtgE8AQwBTgGaAZ4BVAFEAb4B6AIUAnwCVAK4AnQCJAI0AgACZAIYAgQCFAIcAgwCLAHIAdwBlgFWAQYBCAECARQAzgDQAPYAggCywA7AMX/Tf9G//j/jABdAN//Xv8b/8D+tP7W/jj/t/8MAHEAnwDGAHsALQDt/wcAhQAIAVgBtAHyAfYBxgGMAagBmAGMAZwB2AEgAgAC/AHgAZgBMAHKAIUAMQDm/7n/wf+9/1z/5P5E/mD9hPzY+0j74PqQ+kj62Pk4+WD4wPew9rD1YPUg9QD1YPSQ9PD0MPVw9RD2UPcA90D2gPWw9fD2sPfw+Rz8kP2Y/dT9iP28/dT9pv6mAGACcASYBbAGWAawBWgFqAVIBhAHcAhwCZAJYAlACVAJoAggCMAH8AfIB2gHmAfAB6AHyAZoBvgFSAVYBJADLAMIAxQDTAM4AwADXAIyATAAbP9T/2T/mP8LAFEARQCL/9b+SP78/eT9WP4k/9H/LAATANX/Zv8L/+z+Cf9p/wEArAD8AAYB2QCxAG8ANABYALAA6gDcAOMAFAEiAQYB2ACdADAArv9v/33/cP8///7+tP4u/qj9IP2A/ND7IPuw+jj64Pmo+XD58Pgg+GD34PZQ9tD1cPVw9YD1oPVA9gD3sPew95D3cPcw93D3IPjY+eD7LP0y/vr+1P4M/vD9zP6sABQCqAMoBegF0AVYBUgFsAUoBsgG0AfACDAJAAmwCHAI8AfgB+gHEAggCPgHoAcQB9AGwAawBngGGAaoBegEQASYA5QDpAOYA6QDYAMEAxQCRgGpAI4AkAC8AOcA2gC5AB8Amf8g//z+P/9h/4H/tP/a/67/c/9+/63/3f+w/7D/2v8cAAgABABUAJcApQCeAKAApgCTAD0ANAB2ANMAKgH3ANYAnQAsALn/Uf9X/2b/Uf8j//r+6v4+/nz9yPxI/Az8mPuQ+1j7+Ppg+uD5iPkw+bj4cPjA95D3IPfA98D3APiA+OD4MPng+PD46Pg4+Xj5cPpk/LD9lP64/sb+av5y/k//bgDoAQQD/ANoBIAEqATwBIAFkAUIBpAGGAcAB9AGEAc4B/gG4AZAB3AHEAdIBugFOAYIBtgF2AUIBsAFAAV4BEgEIAR4AxgD9AIQAwwDwAJwAjACygEQAbcAmgDOALoASQBEAMAA6QB8AC0AEwDl/2r/KP+7/zAAGADT/9n/+P+M/wP/zP7o/uL+uv4A/1b/Rf/a/mj+Kv4K/uj91P3c/cT9vP2U/XD9RP0Y/dj8lPx0/ID8hPxo/DD8SPxE/DD8EPz4+7j7UPv4+uj6OPtA+2j7aPuA+zD7wPqY+rD64Prg+oD7FPx0/Hz8pPzU/Lz8kPy4/Mz9gv7Q/l//9P8rANX/wP+NADABhAH0AcwCsAOgA6QDMARoBGAEYAQABaAFyAXoBYgG6AbYBnAGcAZgBjgGQAa4BvgGEAe4BpgGWAa4BSAF+ASwBFAEIAQABOQDMAPkAnQCDAKaAf8A9gDCADMA9f/o/9D/af/U/pT+YP7c/Zz9uP0M/tz9mP2w/bj9dP0Y/SD9WP1A/VD9wP1K/kz+NP5e/mj+Pv70/Ur+jP6c/tj+Rf+t/1r/LP/+/rb+Pv7o/Sj+Vv5K/hD+/P2c/bz8BPyg+0D7oPo4+hD6+PnI+ZD5kPkw+bj48Peg92D3YPfA9zD4wPhY+ej5GPoA+vD5EPpY+sj6oPs8/WD+Kv95/ysAPwAEAGUATgHQArAD4ARgBigH6AZoBqAGIAfYBwAJgAqAC3ALAAugCnAKcAqQCiALgAuAC0ALwArwCRAJcAgQCJgHKAfQBhgGAAW0A8ACPAJ6Ab4ACgBc/07+EP04/Nj7iPs4+xD7APuY+uD5OPnw+Pj4YPkQ+tj6UPtQ+yj7GPsY+2D78PuY/DD9lP3w/Sb+NP4Y/vz94P3Y/ez9FP42/hr+4P2U/Vj9OP0U/cz8gPxg/FD8YPyQ/OT8GP0w/TD9VP2s/Qb+fP7y/nT/1P9kABQB4gGoAkADvAMoBKAEGAW4BVAG0AZQB9AHMAiQCOAI8AjgCKAIoAhQCCAI+AcACNgHgAcAB3gGoAWYBLQD4AJsAt4BbgH+AFYAhv+K/pD9wPxM/Cz8PPw4/Ej8SPwA/Gj7GPso+3j7mPuY+xD8ePxs/Hj8DP3w/UD+Av4A/k7+VP4W/lb+q/9dALIAcgCXAHEAYv/S/gr/0P/a/wAATwCBAP3/GP/S/rz+tv54/qL+W/8Z/9r+kv6s/l7+cP6e/qr+Xv7g/ez9AP4e/nT+Fv9X/zP/+v70/t7+Wv5m/hz/vf8yAIYAsQByAHn/0v7A/ib/Zv+b/yMAQgDi/zj/5P6a/kr++P0e/o7+jP6A/lz+Wv4S/tD9xP3k/fz94P0E/m7+4P4y/5X/3f/F/5//uf8BAIUAHgHiAXwCsALcAggDFAP0AgQDiAMQBFAEeATYBAAFsAQ4BDgEMAQABKwDpAPIA4gDGAPoAsgCWAK4AUIB8wCqAEIA7f+9/4z/Vv8A/5L+Lv7M/XT9GP0I/Sj9KP38/OD82PzE/Hz8VPxk/IT8mPy0/Az9UP1c/WT9kP24/dD98P0g/lb+mv70/kb/jf+8/+3/BAAMACwAbgDFAO8AJAFiAYIBjAGGAbAB1gHuAfYBDAIkAhwCFAIcAkACQAJEAkQCXAJcAkgCPAI8AjwCSAJcAogCpAKoApACfAJ8AnACgAJ4AoACiAJ4AnACQAJIAiQCAALIAbQBpAFwATgBBgHkAKwAVgAmAAEAyf9y/y//Hf/s/pj+Tv4q/gz+1P2o/Zz9cP0o/ej83Pzc/Mj81Pzs/Oz81PzI/NT82Pzk/BD9VP18/Yj9sP3s/fz9DP42/oT+sP7M/gT/Pv9n/3n/r//6/y0ARgBfAIUAnQCxAN8AHgFWAXABfAGOAY4BkAGiAbgB1gHuAfoBCAIYAiQCIAIQAgQC5gHmAeIB6gH4AfQB6gHiAcwBxAGcAZQBigGCAW4BaAF2AVwBKgHZANUAkgBqAFMAVgBeAA0A0/+x/3z/Gf/U/tT+0P64/qD+lv50/iL+0P28/cD9vP2o/bD9tP2c/Xz9dP10/Xj9gP2g/az9wP3U/eD97P0E/jD+bv6O/p7+vP7i/v7+EP9H/47/w//d//T/GQAlACIAMwBcAJAAvwDnAP0ABgH5APQA9gD7AAwBGgEqASwBJgEiASQBLAEwASgBFAH0APIA9AD+AP0AAAECAegA0wC+ALwArgCnAKMArgC1AK4ApgCUAH4AYwBVAFQAXgBeAFUAQAAwAB8ADQABAPD/1P+w/5r/e/94/3L/av9d/0H/Lf8V//T+zP7A/sb+yv7C/s7+5P7Y/sD+uv7M/sb+xv7W/gP/Cv8g/yv/SP9Q/0D/X/9g/2X/Xv+F/7v/0v/V//j/KQATAPb/CAA3AD8AJwBJAIgApAB4AHwArgDJAJsAggCtANwA2wDlACwBagFUAQ4BCAEaAQwBAAEyAYABngFyAVwBVAEkAe0A7gAaATgBOAE4AUABKgH1ANgAyQCzAJkAmwCbAIAAbABUAEcAHAACAOz/zP+b/3n/cf9s/2D/X/90/2v/O/8Q/wP/7v7I/sj+7v4M/wz//v72/uL+xv60/tL+6P7y/u7+7v7u/u7++v4F/xb/G/8Z/yL/Hv8V/x3/M/9L/2//iv+d/6D/f/9m/2//m//D/+H/CwAlACgAGgAPAB0ALwBAAFwAiQCwALUAqwCjAK4AwQDNAN8A6wDzAO0A3wDlAPoADAEQAQYB/AD3AOwA2ADSANYAyQCvAKIAnQCcAIYAcABcAEkALwASAAEA6v/b/8r/uv+m/6D/mv+B/2D/VP9h/13/Uf9V/23/cf9c/1j/bP92/2v/Zv9//4z/g/97/5b/sv+w/6r/vf/S/8X/uv/F/+b/+P/2/wkAJgAzACAAEwAMAAsACAAOADIAXwBxAF8ARgA4ADUAKAA1AFoAfQCQAJAAjQCKAIAAZgBdAF4AcgCDAIcAiACCAHkAYABTAFQAVgBLAEYATQBfAGEAXQBUAEUALAAYABEADQAFAAQAEwAYAA4ACAAAAOz/0v+8/8z/0//Z/9T/4P/g/8b/u/+7/9P/yf/E/8T/0P/Y/87/zf/O/9T/z//L/9T/6P/q/+L/1v/c/+z/7f/t////DQAKAAQAAgASAB8AKAA0AD4ARwBEADUAMAAsADcAOgBKAF0AaABnAEsAPwA1ADcAPABGAF0AYABbAEQAPAA7ADAAJQAlAC4AMgAnACMALgAvABwACQAEAAYA+P/j/+j/8v/u/93/3P/q/9v/xv+3/7r/v/+2/7r/yf/S/8f/uf+3/7n/sv+x/7H/rv+p/7H/r/+t/7P/qf+b/4z/i/+X/5n/nP+j/6//sf+y/7T/tf+2/7X/v//L/9v/6P/3//n/8//1//f///8FABQAJQAoACYAJwA0ADUAOwBEAFMAVQBPAE0ATQBMAEMASABOAFAAUABIAEEAOAAzADIANAAmACIAIAAbABUAEwAUAA8ABAD2//b/9//0//X/+v/6//H/7f/t//L/6//k/+X/3v/c/+D/5//r/9//0//K/8b/wP/C/8b/w/++/7v/w/+5/7D/qf+s/6L/oP+r/7f/sP+g/53/o/+n/6D/qP+3/7H/o/+k/7H/tv+x/63/uv+6/7L/sP+1/7T/uf/E/9z/6P/w/+3/+//z//X//P8GABAAGwApADEAMgAwADcAOwA4AD0AQwBNAEsAUwBcAGgAaQBqAGUAYABcAFcAWQBbAF4AXgBYAFQASgBLAD8AMwA1ADkAOQA4AD4AOwAwACAAIAAnACUAGwAYABMABgAAAAEAAgD6/+r/4v/f/9b/0//f/+T/3v/X/9j/2v/L/8L/zP/a/9T/0P/e/+P/1f/G/9P/4P/h/9z/6f/2//P/5//u////AAD4////DAAUABgAHgAoACcAIQAhAC4AMwAwADMANQAxADAAMgA3ADsANQAxAC8AKwAnACcAIQAhAB0AHAAeAB4AFQALAAEA/f8DAAIA/f/3//f/8P/n/+X/6//r/+T/4f/k/+L/1f/R/9n/3v/W/9b/3P/a/9P/z//U/9b/1v/S/9D/z//O/8//z//K/8r/0f/T/9D/2f/g/+P/3v/i//n/BAD+//z/BAAIAAMACAAcACgAIgAeACMAJwAcABgAIgAyADEAMgA5AD4ANAAqADAAMgAtACoAMAAwACUAGAAWABUADAACAAAA///0/+n/4//g/9z/1f/V/9T/0f/Q/8b/xf/B/7f/tf+y/7f/sv+u/6//t/+7/7v/vP/A/8P/wf/G/9T/3P/e/97/5//v/+z/7//4/wAAAwAEAA4AGAAZAB4AIwAnACUAJgAtADQAOgA9AEYAUABLAEsAUgBVAFQAUwBdAGgAaQBtAHEAcgBuAGQAaQBqAGkAagBxAHAAagBpAGYAZABUAFAAUgBQAFQAVABYAE8AQAA4ADYAMgAtACgAKAAfABYAEgAUAA8ABQABAP3/8v/o/93/2f/U/8//zv/O/8b/v/+z/7L/r/+s/6f/pv+w/67/q/+o/6//qv+l/57/of+s/6f/q/+2/7j/tv+u/7X/w//K/8z/1f/m/+7/7P/0/wIABwADAAoAGAAfACAAIAAnADAALgApADEAMwA0ADYAOgA+ADwAPQA8ADsAPABAAEMAPwA/AEAAQwA/ADkANQAvACoAIAAgACUAIQAaABIADQACAPr/+f/6//L/6v/j/97/1v/N/8z/zf/J/7//uP+3/7f/sv+t/67/sP+x/7D/rv+u/6z/p/+o/63/tP+0/7b/tf+2/7b/tv++/8X/zf/O/87/0v/Z/9//5v/q/+//9P/3//j/+//9//////8DAAcACwAOAAsACQALAA0ADAAKAAwAEAAQAA0ADAAPAAwACQAGAAgABQABAP7/AgACAP3/+f/0/+3/4v/e/+D/4f/h/+T/6f/n/+T/4//n/+j/5v/p/+//8v/y//b//v////f/8v/z//f/9v/1//r/AwACAP3//v8DAAMA/v8AAAoADgAIAAYADQARAAkAAQANABQAEAAKAA8AGAAJAAwADwAdABgAFgAZABwAGwAYACEAJgAkAB0AHwAjACEAHAAfAB4AHAAcAB0AIgAfABkAGAAWABQAFAARABAACwAHAAoABwAFAAEA/P/6//b/9P/2//L/6P/n/+j/5//n/+P/3//b/9P/zf/Y/+L/5P/m/+f/4v/d/9z/4f/q/+//8f/2//b/9f/z//L/8//y//X//P////z//P///wAAAQAEAA0AEgARAA8AEgAUABMAFAAcAB8AHQAdACEAJQAgABsAHQAhACAAHQAdAB4AHAAZABoAHAAcABUAEQARAA8ADQALAAcABQACAPz/+f/3//T/7v/q/+z/7f/r/+n/6P/p/+f/5P/k/+P/3//a/9r/3v/g/+D/4P/h/93/1v/R/9L/2P/c/+P/6f/t/+r/5//m/+b/5//q/+//9P/5//z//v/9//v/+//+/wEABQAJAAwADgAQABQAGQAeAB4AHQAeAB8AIQAkACgALQAwAC4AMAAxADQANQA6AEAAQwBDAEIAPQA7ADcANQAyADIALgAlABwAFwAYABcAEwAMAAUA+v/1//P/9v/1//H/7f/o/+H/2v/V/9P/0f/O/8n/x//D/8D/wf/C/8P/xP/E/8T/wv/C/8P/x//L/8//1P/U/9H/zf/L/8z/z//U/9n/3P/a/9f/1//Z/9r/3f/f/+L/4//j/+T/5f/n/+f/6P/m/+b/6v/w//D/8f/x//P/9P/0//X/+f/0//r//P8BAP////8FAP7/9//4/wUAAQAHAAUAFgAUAAQACwAOAAUA+P/9/w4AFAATAA4AFAARAP7//P8NABgADwAGABAAEgAJAAAABQAMAAcAAAAAAAQAAQD4//f//P/8//f/9v/0/+//6f/o/+j/6P/s//H/9v/2//X/9f/z//H/9P/+/wYACgAIAAgABQACAAQACAAMAAgAAgD9//n/9P/3/wEACQAGAAAAAAAEAAoADAASABoAGwAZABwAJAAmACcAKgAsACoAJAAdABsAGAAYABwAIgAkACEAGQAQAAsADQAYACAAIwAjAB4AFwAPAA4AEgARAAkAAAD7//f/9P/0//j/+f/3//D/6f/l/+T/5f/u//n/AQABAPv/9f/v/+v/7P/z//v/AgAEAAgACAAEAAQACQARABQAFgAZABwAHwAiAC0AOAA8ADoAMwAwACwAKgAwAD4ASgBHADkALgArACcAHwAkADQAOwArAB4AIQAgABEADwAfACkAEwD9/wAABAD0/+b/9f8KAPr/4P/e/+n/3f/E/9z/8P/0/+D/4f/m/9f/x//M/+H/3//V/9D/0//M/77/vP/B/7z/uP+9/8D/xf/G/8z/2P/b/9z/3P/S/83/zf/Y/+n/6//x/+z/3v/P/8v/1P/a/9b/0//g/+r/8f/8/xQAGQAHAPX/9f8WACwAQgBiAG8AWgA9ADIAMwA4ADkAQgBHADsALAAmACMAHgAhADIAOgArABwAHwAiAB0AKABHAFoASwAzACgAHwALAP//FQAnABIA+P/4/wQA///1/wAAEwAPAPX/6P/y//b/8f/5/wsADwD4/9b/zP/R/83/zP/X/+T/4v/M/77/x//S/9H/0f/j//D/5P/U/9v/8f/8////BQAJAPT/zv+7/8L/1P/g//H/BgAGAO7/0f/G/9H/4P/x/w0AHAAbAAwAAgAGAAoACQACAPz/9//2//j/BgAWACIAIAARAAMA+//6////DAAeADEAMgApABgACwAEAAAACQAYACQAJgAlABwAIgAgACEAIwAwADQALgAmACEAIQAcABAABQD8//T/1P++/8P/1f/m/+7//v///+f/yf/L/+X/8//x//r/AQDq/8L/tf/I/9P/yv/I/87/wv+i/57/xP/o//f/AgASABAA9P/p//v/FgAdABwAGgALAO7/2P/g//X/AwAJAAcA/v/p/9//7P8IACMANAA2ADAAHgATABsAKQA1ADIAJwAcABgALQBRAHUAkgCSAIEAYwBFADAANQBKAHQAiACXAKMAoQCGAE4AOQAzABgA7f8GAEYAiACkAMgA8ACVAOb/Z/9f/4n/xf8xAJgApQAmALT/t//f/97/2P/2//3/r/91/5f/8v8ZAAUA7v+2/03/4v7A/vL+NP93/7T/z/+y/3j/Uf9O/2T/lP/Q//D/9f/w//j//f/1//n/AgDv/8H/oP+X/6D/rv/h/yUASwBLADUAHQD9/+j/AgBBAHQAgQB6AHYAawBnAH4AowCxAKEAiAB9AH0AiQCoAN0A/QDfAKIAXgASANb/v//o/y4AZQCFAIcAZQAnAP3/AAAoAEcAUwBTAEQAMwAxAEkAVgAwAM//Yf8G/9j+5P4t/4//1P/l/8D/jv9q/1n/Zv+X/8v/5v/b/7b/iv9n/1r/Zv97/4r/iv9x/1L/Pv9O/3v/pv/C/87/0P/K/8//9P8kAEoASQAmAOP/k/9e/0f/Yv+l//j/HAD8/8z/uP+t/5n/s/8hAIgAnQCDAJkAqABzAD8AbACdAFsA1v+t/8P/rv+T/9//ZQCBADsAKABoAHsASQBTANAA/gDyAN4A+QDfAGkADwD2/+n/sv+N/4r/o/+w/77/8v8pAFMAcQCEAIkAkwCVAJUAnwCvALQAgwAzAO//vP+H/0D/CP8F/+D+qP6u/in/y/8fAE4AjADAAJQAYwCMALUANgBc//z+Q//o/2UAFgF+AdMAYP8g/sD98P2M/mz/XQDIAK8AiABjADEA+v/d/7r/W/8b/17/1P8MADsArQDQAD0Abf8R/wj/Af8//yYAOgFyAf4AyQDZAJYACADd/xUAAgCM/1v/x/9MAGAAZACSAIIA7P82/xP/nv8zAJkAFAGCAXoB3QA9ABQAIQDy/7P/yv8PAAwA7v81AMkACgHBAGgAJQC1/xn/zv4f/7H/FQBFAH8AgQADAFj/4v7O/gL/Vv/c/4UA6QDyALkAiQBNANP/TP/Q/pT+lv7M/ir/nf/r/+r/nf8x//7+Af8k/2H/yv9UAMAA3QDXAKsAXQDf/13/Mv87/0T/Rv9q/7D/DAAnAEMAWwB0AEwAEAATAD0ATAArABgAOwBVADQA3//F/8r/sP+p/+j/VQBqAFAAbwDSACgBQAFUAWYBCAFGAL7/v/8AACcASAByAE4A1f93/67/GQBZAHgAigBuAAoAsf/H/zsAsAD4AAABwwA7AJz/Nv8l/0//hv+0/87/4P/N/7n/xP8BAEgAWgAiALn/L/+4/qD+CP+z/0AAeABGAOj/n/+q/wwAgwCwAHwA7f9b/xP/UP/W/08AfgC1AOEAswBQAOH/sf9O//r+Rf9CAAIBKgHtAJ4ABwDs/mj+0v6t/0cAzABiAXwB+AArAN3/BgAdACoAVQCHAI8AZgBrAHsAYADf/w7/Zv4s/n7+Dv+4/4UAIAFOAf4AjAAjAJ//F//6/m3/CABxAJcAtACbAEgA+P/T/8f/nP9o/0T/Df8D/1z///+kAA4BSgFCAcQA/P9M/wj/Hv9U/8D/AwDp/4L/S/+w/0oAswDyANoATgB//wr/Yv8hAMIAHgE0AeAANAC//8L/DQAZAOz/rv9n/0f/a//U/zkAXABtAJcAlgBGANj/mv9m/1T/mv8tAHkAawBBAC4A8v97/3L/3v8uABIADACWACwBagGUAZIB6QCh/5L+jv5B/0QADgFeAewA7f8B/2D+Gv42/vD+lP/n/wIAVAC8AJwAcQC+AEYB/wArAOf/HgA0AMP/4/9lAEQAD//Y/Zz94P00/tz+JwAUAfQAKwCv/6T/d/9G/4T/0v/t/+P/BgBPAFkABADG/2b/5P6m/hf/7f+uACwBUAE2AbwARAAOAPz///8QAOz/Xv/Q/r7+CP9w//r/ugDRAEoAzv8KAK0A+AAgAXwBqgFoAQQBHgFMAYoAO/9e/jj+Ov5s/in/SADgAMkAvQAOASIBlwAfAFIAhQAjAN3/TABIAYYBMAH/AKUAdv/k/Xz9RP4z/4b/DgDGAMQA3v9Z/8b/CwC9/33/7v9aAEMAHwCFAMgAVgB7/9L+fP5U/m7+Fv9DACwBMAGNAMn/Uf/4/s7+I//F/0oAPwA5AJ4ANgE8AY8A9f96/wn/1P42//D/ggBtAE8AdQCLAFQA5P+z/5z/sv/B/xIAbACHAFkANwCsAHoB/AGgAbUAif+G/gD+PP5Z/4QAGAEmAfYAmgAHAGj/9P4O/6T/XAAWAaAB0gFyAXEAZ/8M/03/eP95/4//1P/7/9n/rv+6/6H/NP/W/uj+cP///6oATgGSATQBSABm/wD/W//U//j/sf82/+j+8P5R/+r/gQCzAGoA7f+4/woAuQAgAfYAkQA1AIb/tP5M/sj+HP/u/iX/KgAoAa0AVv/I/gL/Mv+x/wABjAKwAqgB0QC/AIQA9P9j/wH/iv78/Rr+3v4iADoBwAFMATMAf/87//D+tv5l/5wALAEGATIBngEkAcj/FP8u/+L+zP2c/TD/5gDoAaQCTAPEAosAbv6I/Yj91P2K/tb/swCRACkAWwCoAGkA5f9b/9L+VP6W/uT/SAEMAlgCfAIYAgYBuf8d/w//Lf+t/9gAhgE0AQkAHv/2/tL+9P53/0UAfwBIAE4AggCmAIIApgB1ALX/B/8Y/73/FAB8AFQB2gEmAfD/kf+f/+L+HP5q/qH/WQBgAK4AOAEmAUMAff8g/9T+gP6K/kH/5v8mAAYAwf+J/1f/UP+z/00AqACYAGYAdgBlAAwA6P+JACoBGAF+ABcA0v8//7L+bP60/h3/yv/eALwByAHaANH/Cv+q/vT+4f/EAEwBNgHCAPX/Xv99/xwAtgCcAOz/bv/4/tT+Kv8aAFYBDAL2AVIBIQDw/mr+qP6Y/58AVAFgAY8Aj//6/gD/BP8C/1j/y//S/8L/8P+ZADABdgFeAdcA2f/g/mT+FP4M/ur+wgAEAuQBJgGLAPf/hP8NAG4BXAJOAZr/zv7U/v7+Jf9BADYBEgH6/yr/QP9R/yr/KP+R/+z/OACXACQBkAF6ASgBrQBFAOv/5v+D/7L+jv50/2oAlwARACkASwCk/6j+1P7k/xYAi//W/+gAGgHf/+T+Rf90/6b+EP7a/uT/yP/V/woByAEEAYn/Gf+Q/2b/U/8oAGwBkgHrALgAvABpANX/gP8E/+j9CP20/TP/pwByAcoBUAEAAPL+VP9nAB4BQAFQAcYAYf9O/vD+sgAEAlgCOAJmAVf/NP28/PD95v5w/2wAbgFiAVAA6v+WACAB9AAuAWoBsAAo/6r+jf9UAGwAhQDZAEAAmv5w/R7+zv/bAAIBFAEGAZsAMABvAA4BIgEYANL+aP5K/hb+0P1K/pf/oQDrAOkAzwAoAAb/VP74/poA9gFYAvYBQgEJALj+FP5e/s7+Qv5Y/az9U/8yATACeAIUAhgB0P80/1j/b/9v/6f/RgCoAO8A6wB+AI//nP6S/vT+Vv+0/7oAnAHEAUwBBgEWAckARAA2AJgAXQCk/zT/i//W/5j/Uf+H/8P/rf/W/60AogGeAXsAYf/M/tz+l//lADwCwAL8AZIAHf8U/gj+0P7A/zcAcwCpAMsAvQBuAFUACQBJ/5r+hP6q/nr+iP5C/3kA8QC8AKkAlQD4/wH/8P7H/9IAXgGwAfQBfgEgAK7+Yv6K/or+bP7Y/ob/o/9K/1v/RwD6AKYAvv8H/67+cP6m/pP/AgHKAXABeQBG/6D+uv6R/7wA4AEgAh4BzP88/3z/4f9iAF4BcALwAQAAeP4e/hD+8P2w/l4AWgGmAAkAdgAOAbsAHACuADwBqgDy/10AUgHvALL/W//l/8L/ZP64/cT+BgCDAO8AkAGGAVUADv8K/4f/BABTAJsApgC8/8T+Dv4C/pj+FwC+ATgCkAFEAPL+eP3k/A7+fABUAsQCZAJeAef/iP50/rD/rAB5AIT/EP8d/yP/nP+iAI4BlgG/APP/Zv8O/wT/rv8QAd4BrgHhABAAE/8k/mj+3P9AAWoBxQCgAIUApf+Q/pL+u/9hAAgA1P95ANsAXgDO/2IAZgFiAVYAhf9i/wP/SP48/m3/jACGADQAiAAWAbcAnv8G/wL/lP4w/sD+JQAeAesAhQBzAHwABQCF/6j/zf+3/37/3/+zADIBOgHPAFMAk//U/oD+2v5g/9P/JACQABYBQgEEAboAOgB3/yr/X//5/9EA6gHsAngCbAAu/jT9KP0U/fz9XgCMArgC1gF0AYYBgwAS/7z+Rv9A/+D+Sv9SABwBMAHiAAMA8P74/cD94P16/v//ugEoAtABBAI0Aj4BRP8S/mj+sv6a/i//ewDUABsAav/k/+QAHgHdAKcAiABS/yz+Tv4OAKIBEALgAbwBFAGO/2j+YP4I/w//2v4t/83/y/+5/5oA8gHAAkQC7QAz/3T9lPwI/br+mwBMAtgCfAJQAf3/Lv/m/vj+eP8OAEIAMAC2/xP/VP5c/vr+vv/j/7j/ff/u/jr+IP5K/78AigGWAYQBXAGxACcAQwDZAGcAJP8a/uD9Xv7w/r7/6QAkAiQCoADG/vj9IP58/gP/XwCoAegBEAGWALQAowBoAFoAmAAqALH/jf8SALQAPAHiAfoBmAH6AM0AdgAJAOr/IwAjAKT/oP+g/z3/Iv7k/dj+9f+8AD4BUAFPAPD+Xv40/wIARwCmAKwBNAJUAdv/G/8x/wD/6v6V/8EAPAF5AHz/rv48/i7+qv5l/8L/zP/8/44APAGQAY4BwABF/y7+vP1k/ej8oP1d/z4BHAIgAgwCbgEnADP/FP9+/6v/cP+T/8f/9/+lANQBXAJ4Adb/Jv78/Nj8Hv5pADgCuAIQAoQBzgCw//7+IP/J/+//5/9QAPYAZgHGAUACGAIKAaP/0v5c/sT92P0p//8ABAJQAjgCJgHy/lT9rP2A/2oBhAIQA6ACGAGO/7z+Rv78/dD91P3A/cD9mP4xAJQB8gGSAdEAgv9G/mD+tv/eAM8AZAB1ABoA2v7E/fD9nP60/pD+KP8GADAA2v8sAN8A4wCfAKkAJAEeAWcAm/+Z/wsACQCw/0T/S/+I/7//TwAkAWgBoQBx/zT/7f9vACQBCAJcAnABDgBY/xb/kv4k/uL+7/9xAGQA7QDOAcIByAAaAPb/zv+L/1T/of/x/yUAGgDa/8n/yv/Q/7X/nv+d/7f/FgAEAdgBDAJKAQQAAP+e/iz/WwBMAXYB+gAbAAf/PP40/uT+ov8VAI4ADgHkACwAnP9e/1H/cf8DAG8AqABrAOv/Wf8H/3z/RABPAAUA7P/7/43/3P5w/xwBoAGSANP/0f+p/9j+Bv+gAKoBwADY/nz9kPwA/NT8cv+AAhAE0AOAAoUAnv7Y/UL+Sv9tAFABMgEpADn/Ef+T/8//rf++/7L/BP+K/jb/swDaAUACGAJqAVQAIv9s/oD+9v54////cQCjAHcAaACNAKsAUgB6/wv/Cf+i/34AWgEYAngCRAK4AbsAQ//8/ZT9Cv6Q/gD/vv+aACYBMgHtAG0A1P8v/4r+Cv5G/k3/oACMAZoBUgGtALn/7P4G/1P/+v6M/v7+3P/hAIAB/AFEAroBmQCT/yL/rP5k/pz+g/9nAOwAEgFeAVwBVgDu/lz+uP4L/1f/MACqAawCAALzAC0AdP+w/lD+5P74/5oA6gD5ACAAEP9a/ub+m//W//H/KAAOAC7/wv6B/4QAkwBcAK4A6AAoAPL+uv6I/9D/T/8A/3n//P/e/8r/LACPAGcA1f+p/6T/ef8Q//L+nP+xAFoBDgGFAPP/Uf9q/vD90P4uABIAYP/M//wAHgFeANEAOAJUApAA7v/xADAB3f/4/nX/r/81/2n/LgEcAtQAjv/L/5MAbwBiAD4BSAIoAjwBvACuAAoAe//B/30ALgFQAVoB9gBDAH7/TP95/73/8/8PABcAMwDeAJ4BGAKgAWIA1v6E/fT8mP0Y/0wANgGOARQBxv9O/rT9Lv72/r//HAGuAagAxv6U/XT9jP3A/eT+nAD6AAsAav96/xD/Iv4E/gb/Q/96/lD+lv+3AH0AZwAWAVABEwCG/vD9Dv7E/ez9lf+eAdgCoALaASwBXgAW/9T90P3a/gcAzgCmAZwCAAMYAlkAev9v/1P/Pf+z/5MAqgBvAPAAEAKAAt4BOgHSAEUARf/O/qr/pgAiAXgB3gEQAqAB8wBDAMf/af92/+v/JgAIABUApQBOAXoBZgEwAZAANP8c/jb+OP/8/wsAFgB1AKgAJABO/0j/nv/g/uj9xP3S/qb/2P8AAH4AggC6/wX/A/9E/yL/AP80/9D/EwBy/9z+3P5e/zz/iv6C/hn/U/+g/ob+kP+nAHgACwBqAM0A8f8E/z7/2P+1/z//lv+dAB4BxACHAHQA+P8m/7D+3P5c//z/xAAeASoB5ADUAA4BSgF+AXgBBAEuAJX/yP8HACMAngBqAdABPAHCAOUAKgHLAKwAWAEAAtwBiAGsAY4BMAHvAPsA6wAIADH/+v6F/5MA0AGsAnQCiAFkAJv/Rf/E/9cAlgFkAdIAQgDQ/0f/+v41/6f/p/8n//D+LP9B/wX/wP46/9X/qf/g/kL+HP6w/dj82PwW/k//Lv9i/jL+OP5M/Vj8zPxm/kj/mP7w/fz96P1E/fj8uP1O/jL+qP1Y/VD9cP3c/Wb+1P72/hr/Dv/A/vb+n/86AEkAVACoAKUAWwAmAJsA+QAWATYBeAF2AXIBnAEYAkgCoAIwA1gDWAMYA/QCDANsA6gDuAPAA6QDmANoA5wDSATIBIgESASoBLAEzAPkAkgDdAP4AqwCPAOsA0gDiAI8AsIBjgCK/1D/9P6y/un/7gGcAnACVAIkAkEAgP0s/ST+Mv4g/Qz9xP18/RT8CPsA+7j6mPmg+KD46Piw+KD4yPgY+eD5SPq4+dD4gPhw+Cj4wPco+ID5UPoA+rD5APrA+vD6uPqA+wz94P2s/aT9zP4wAHcAVAB8ASgDLAMAArIBmALEAlQC1AI4BIAEiARoBIAEmASoBDgF4AUoBoAGwAdACAAIIAjgCAAJ6AdIB5gHaAdoBugFWAbIBrgGmAbYBogG6AVgBRgF+AS4BKgE4ASgBBAEyAOkA7ACeAFdAKn//v4Y/pj9rP4kAC4AfADaAYgC0gAm/pz9oP7E/YT8eP0y/uj7wPdg9VD1sPSg82D0oPZA91D2EPYg96D2cPXg9XD34PeQ9xj4UPmw+cj4wPgA+lD6CPmo+Bj6CPsQ+5D7sP22/7P/C/+G/1YAWACh/woA1AEQA1wDSAOMA0gEYASkA3QDYARoBXAFqASQBTAHAAeYBXgFsAbwBsgFeAXoBugH+AYQBlAG+AaYBrAFwAVIBmAGyAWYBdgFsAVoBbAEAAS8A4QD8APAAzQDZAOYBJgEWAPkAqQDSAP0ALz/awDUAKj/sP7c//UA7P+Q/uz+jf+o/mD9ZP06/sz++v5HAP4BJAMQA2IBBf/4+8j4cPWA80D0gPbA99D3kPdI+ND38PVw9ID1IPfw9pD2wPdo+tj6cPmg+cj78PtI+Wj4yPkQ+oj4ePiA+3j9zPw0/LT9RP7s/PD81v5jAFIAzQA4AtwCjAKsAmgDZAMwA7QDKATYA/QDEAXYBWAFKAUoBpgGYAWABNgEUAVIBJQDaATIBcgFOAWwBcAGcAYYBfAEkAWoBWgEKASABdAFMAXIBLgFkAUoBBADcAOAA4ACaAJ0AzAElAOcAyAE5AOoAvoBIAJ+ARkAt/8uAMf/ev/u//sA6QD6/8v//P8P/yb+Mf9YAegCYATgBsAHcASX/yD86Phg9PDx8PRQ+Vj58Pfg+Ij5EPag8lDzQPag9hD2iPiY+xD8wPpI+zD8sPoo+RD5UPmQ+Ij4YPq4+6D7GPxw/cz9VPx4+8D8zP3Q/W7+PADOAaQBRgHgAWQCFALQAXgCpAP8AzgE6AR4BWAF6AT4BCAFAAXABEgFqAVoBTgFiAXABaAFkAXABbgFGAW4BDgFWAVoBfAFUAboBTgF0AS4BFgEQASgBPgEuAQ4BPwDAATkA4QDwANgBGgEpAO4AjwCvAG8AOz/XwCnAHUAJQBaAJoA9/84AMcA1AAbAHYAwAF8AboAhAKQBiAI4AVYBOQDqf8A+AD0MPXA9qD1cPbA+rD7UPgA9UD1kPVw9ED04PbA+ZD66Ppo+5D7EPtw+iD50Pcg92D3MPfg9rj4SPsE/Cj7MPtM/OD7OPpI+pT87P3w/Z7+iwDKATIBRADEAGIBYAFsATwC4APQBMAEqARwBbAFKAV4BMgEOAXIBBAEmAQgBdgEeAQ4BdgFgAXABNgEaAWwBGgEgAW4BsgGWAaIBpgGuAXIBOgEGAXQBCAE6APoA9wD3AMIBGgEuASABMAD8AJEAsABGAHIANUA3QC9APkA0gBfAFIAcAGsAU8A6/9SATYBiv4q/hwDcAjgCEAI0AgYBhj+kPUQ81D1wPXQ9Rj5yPyg+yD3QPQQ9LDzgPJw8xD3qPk4+sj5gPoI+xD6IPm4+JD4kPfw9oD36PhQ+gD72PsA/Cj76PnI+dD5EPp4+7T9WP8tAEABtAFSAakALgCBAE4BTAJoA8AEgAX4BbAFGAV4BJAEUAQABGgEQAXgBWgFYAXgBegFeAVgBcgFiAXgBMgE4AT4BNAEEAXgBRAGAAYIBtgFWAXIBLAEuASoBCgE3APMA7wDyAPYA0AEYAQABDQDgALsAcwA2//D/4YAlwBZAGEAzwCUAIP/ff/SADIBGgEoAScAOf9p/2gCIAZwCBAJgAhABZz+gPcQ9TD1IPWQ9Xj4mPtI+wD4sPWQ9RD0EPKw8uD1MPgI+ZD5mPpA+2j68Pk4+Uj4gPcw97D3GPho+Uj7qPw4/GD7ePtw+3D6OPrw+yr+X/8FAC4BNAL6AbgAZgB+ASgCSAJQAxAFQAZYBqAFgAUIBRAETAOgA5AEQAVgBZgFqAVQBfgEEAVYBSAFGAV4BaAFcAUwBdgFMAYIBqAF6AUYBnAF8AQABcAF8AUwBZgEqASABPgD2ANwBDgFGAVIBHwD/AJAAmQB6gDIALEA3wBsAOb/tv+L//b+oP5CAAQD5AP0AXYAfgD2/6b/wAIACXAMAAqQBRQCiPvQ9LDxwPPA9kj4KPqw+4j6sPag87DyoPFQ8RD04PcY+QD5ePrY+4D6ePjg9xj4sPYA9dD1WPhA+lD7fPww/RT8iPqw+Xj5uPkI+yj91v6I/xwA2ADuAD4Ayf+GACwBtAAKASQDUAVQBpAGIAfQBggFHAMAAxAEwARgBbAGYAeIBkgFAAXIBJAEaAToBAAFqASIBJAE0AR4BRgGYAZIBlAG2AUQBXAE0ASYBWAF0ARQBWgFmASUA4AESAVoBFgDiAJkAs4AcP/6/h//wP9GALUA+f9h/83/sf9q/ib/JAMwBXQCd/+DAMIB5AD4AoAJoA7QCxgEcv4Y+1D18PAw8nD30Prg+qj5oPjQ9yD0EPEQ8cDzEPZw9mD3APnI+vD6gPmg+Lj4sPdA9TD0EPbQ+Gj6IPvg+5D8cPsw+Qj4OPmY+hj7ePwS/iH/Av/m/j//1f/i/+7/egAQAZoBOAMYBaAG4AYABxAGeAQ8A/QCzAMABTAGgAb4BfgESASYA0QDvAPoBOgFWAWwBLgEmAUoBUgFIAaAB2AHsAUQBbgEcAVwBYgFCAZABrgFmARwA6QDEAUABkAFeASYBDAEIAGk/sD/4gHkAAX/1f/8AvQBcv6U/iwC9APaAb4BeANEAub+Pv7UAtAIUAxADJAK+AXE/bD2YPMw9FD3mPpQ/BD8EPrA9uDyMPDg75DxIPQA9vD3qPkQ+kj5kPiw+Dj40Paw9SD2kPaQ97j5iPv4+zj7OPo4+SD4cPfQ+Gj7FP0C/kr/TABh/4L+iP6H//z/0/92ADQCgAOABBgGYAdQBwAGOAW4BBgEGARABWAH6AdIBzAGUAVIBHQDmAMYBVAG8AUwBegEwARoBEgEiAVIB4gH2AYoBqAF+ATYBLAFyAbABlAGkAWYBKwDZAN4BDgFGAXABDgEwAKkAKX/v//r/+n/vQCkAdYAHQD6//v/bP68/pgB1AMMAmYAygH4AgACUAOQCQANEAkUAyIAbPwg95D0oPe4++j68Phw+JD3APQA8eDxoPNw8xDz8PTg9sD2YPYA+FD5APhA9uD1APbA9UD2mPhQ+3T8HPyY+7D6oPkQ+Wj5+PoM/Sb+cP5+/sD+Lv8U/xP/z/98AIQAOQAEAewCsARgBZgFuAWABTgEGAN0A+AE+AUYBhgGMAboBZAEjAMIBDgFuAVABegEQAXYBIQDTAN4BOgFyAV4BfgFYAa4BfAEgAWIBpAG2AXgBJAEUAR4BLAEAAWQBRAGQAW8ApcAUQBFAI7+dP7WAagE/AKr/48AywC0/Vj7tv4IBCAFMAOsA+AEHANvAMgBKAaAB7gFiAO4AfL+sPtY+RD4oPeg9qD1UPUQ9pD3YPfw9XD0cPMA8qDwsPHA9KD3aPgQ+aD5mPhA9mD0oPRA9rD3kPmQ+2T91P3o+zD6gPkg+rD68PpI/GD+Wv83/x7/AQDZAPYAoACtAHgBiAIAA1AD0ATgBvgH0AboBcgFcAXoAwgDqATIBlAHmAaQBuAGOAZwBBAEiAVYBpAF6ARwBSgGqAXIBMgFAAfgBsgFAAbgBpAGeAWoBQAGoATMA0gEgAUQBUgFAAawBUADigFcATwBvv8qAMwC9APMAo4ARwDx/zL+IP0H/0gCxAM8AzgDSATIBLQCNAFQA1gGGAXwAgQC8ALDABz8IPrg+bD3sPNA85D2uPk4+Xj40PcQ9dDw4O6g8LDzsPVY+FD6gPpo+BD2oPTA89DzUPVA+Ej7HP2c/UT90Pug+nj5uPnI+nD8HP5z/9X/IQA/AE4AhgA1ALYAPAG6ASIBygGYAxgFKAZgBxAJYAjoBSQDJAL4AZACSAWwCLAJoAgABwAFsAK6ACgCWAXwBXAFiAa4B0AGkAPMA+gFEAbQBHAF0AdQCBAG6AQYBjgGsASgA9AEqAUQBfgD2AOYBCAEnAJQARQBwgDA/9T+4v/0ANgAV/9U/+MAlAGdAN4A/AKUA6ACwAGQA2gF2ARQAyQDXAN8AQL/fv7O/jT9aPng9UD0gPRA9TD3GPlg+RD3YPPA8ADvoPBg83D1cPZw9zD4YPbQ88DyIPRA9cD1APiY+5D9TPzw+kD70Pso+8j6VPyy/j7/Df/F/3IBCAIuAZIAtAGgA+ACHAG6AXQDiAQYBSAH0AkACmgHSAToAuACFAOQBMAHgArgCqAIyAUcA4QBhgH8AqgF+AfQCKgH0AXsA/AC6ANwBagGcAfoB9AHyAZABSgEMAV4BVgExAPIBHAFQARkA1AEiAUwBLIB1ABUAAb/OP3g/S0APAGuAEEAagCd/9j+Dv8wAIIBFAJcAnwCjAIMA3ADkAJ8ASoB1wDS//z9HP1Q/LD5MPZQ9GD10Pag97j4wPlw+ID0APHg74DwAPKw80D1APcg9xD2oPQQ9DD0oPQg9RD3WPps/Gz8KPy0/GT8MPtY+2j9Rf+9/5oASALkAqAC4gGYArwC6AL4AvQD0AQABQgFiAXQBpgHGAeQBRAFkAT0AwAEmAZACeAIkAaQBbAE4AIQAnAE2AeACBgHaAagBYwDHAJEAzAGYAiACdAJwAioBrgE/AMgBJgFWAdQCEgHmAUoBXgEPAPEAkgEEAUAA+wAQgDe/6T+Uv5PAPYBNAGi/x//EP/6/rr/vAFkA2QDKAOYAiACygFsAjgD6AIoAtgB4ADM/jD9YPto+fD28PXw9vD3UPiA+Fj4gPYg87DwQPBg8EDwUPEA9FD2gPbQ9RD1YPSw8gDx4PKA9iD6bPxi/uL+FP1Y+jD5YPpk/Fr/GAIQBEgE7ALuARwBFAE0AjAEiAWoBZgFUAWgBBgEuAT4BRgGWAUABTgF4ATIBEAFeAYABogEiAOgAzAEeASYBTgGoAbYBbgE7AOwA7gEQAa4B7AIcAkQCXAHGAVYBFgF4AU4BkAHcAjoBxAGYAQwBIgEIASQA5ADaAMMAuz/fv+z/wYBywD3/5T/QP8b/yz+Lv8IAegCaAKiAZQBogEUAacAfAHIAvQC4gGaADz/+PwQ+5j56Pi4+Fj4WPgw9+D2sPbw9kD1UPPQ8bDwgO8g7wDxYPSw9TD1oPSA86DxgO/g78DyYPYw+mD9jP50/OD5WPgg+Kj5cP7EA3gFWASAAiYBFgCG/zQCuAV4B1gGaAUgBcgEKAQQBDgFGAYgBmgFIAVABWAFAAUIBHgEYAUoBeADpAPgBDAFeAT4A1AFMAUoBLADWAXwB9AHOAeoB0AIGAfIBcgFCAd4B9AGYAeACGAIyAawBbAFcAXgBEgEEASUAygCBgHjAAwBvAAVAEP/8v6E/hb+nv70/uz/UwDMALAAWgBzAMn/rv8LAHoB7gE+ASkAOf+o/cj7APsY++j6oPkA+VD5OPlA+KD3IPew9XDzIPIA8iDyIPKg8xD1UPUg9CDzcPJQ8RDxcPJA9qD58PpI+wj7OPq4+ID4iPvo/7wC8AMIBHQDKAKxAL4BGARoBmgHcAf4B4gHUAaoBfAFgAZoBrgFSAZYBpgGgAboBsAGkAWoA/wCtAIwA9wDeAT4BHgETAMUAzQDpAPIBPgFsAaQBkAGcAboBcgFMAbIBsgHkAewBwAI2Ad4B8AGuAa4BjAGYAW4BIAExAP0AmgCOAJ+AbsARgCK/wX/qv4L/2f/b//O/2AAHgBL//b+gv+K/wv/Iv/M/7L/kP7E/TT9lPzQ+kj64Pm4+Vj5GPkY+Yj44Pdw9jD1APRQ8wDzoPIQ86DzwPNA88DysPIQ8nDx0PHg83D1kPZA95j4CPlY+Jj4KPpQ/JD9ff+eAfgCuAJQAoQC5AIoAzgEOAYgCKAIMAlgCZAIOAfYBVAF+AQoBcAG4AggCqAJIAhwBfwBhP8eAKgC6AT4BVgGoATyAb7/xP9IAYwCKAQoBagFGAWgBBgFOAXwBEgFSAYYB0gHiAcwCPAHSAfYBlgHWAeIBpgFGAWwBDAEmAN8A/gC2AHUADQA2v+s/3//uf+L/0D/8P76/vD+iv48/h7+av4w/sD90P3U/Sj9PPyY+0j7gPrQ+aj5CPrg+UD5cPjA99D2wPXQ9MD0gPQw9PDzwPOQ8wDzkPJg8kDyYPIQ8xD0wPRQ9RD20PZQ96D30Piw+mj7aPzM/ZH/3gAoASwCrAL0AswC2AOABXgH8AhgCuAK8AkgCMAG4AVYBYAGsAnQC2AMwAqACHgFdAFLAKoBWAQABqAGIAZgBGIBIf9T//UAlAIABGAFwAUoBfwDeAN0A+QDAAUwBlAHoAdoB2AHSAcIBxAHSAfgBoAGcAZABhgGmAUoBcgE0AMkA3gCHALMAVQBygBzAFUAEAAjAPn/lf+8/jD+nP2c/Rz9hP1s/Tj9ZPxg+5D6uPlw+cD4GPlI+Qj5UPiw9wD3QPag9UD1cPVA9fD0kPQg9PDzsPNg85DzkPPg83D04PRw9QD2wPYw9wD46Pgo+kj7bPwg/UD+bP+uAEwBUAIoA0gDDAPEA1AG8AigCjALcAsACtAGIAUoBvAIwAvgDLANwAxQCYgFtAN4AxgEOAVAB2AI6AcABXwCVQA//4X/kAFwBPAFwAV4BLwCgAFcAZgC5AMoBdAF6AXABbgFgAWwBagFcAWIBdAF2AVYBVgFUAWABLADjAOQAwADhAIUAgQC3QAkACQAlAA5AKf/e//8/lD+VP0w/Vz9DP38/Lz8NPww+xD6gPkA+Zj4qPi4+PD4KPiw9zD3gPaw9QD1EPUw9RD1gPSw9MD0MPSg87DzMPRg9HD0IPVg9gD3EPcw9xj4+PjQ+fj6YPxE/cD9iP6R/0YByAHQAhQD7AK8AwAFeAewCTALQAuQCRAH8AVQBtAIoAqQDEANwAwQCkgHsAXoBPAE+ATIBlAIMAgYBjgEJAIpALn/VAFYBKAFcAWoBDwD+AEEARAC5APIBDAFmAX4BZAFAAUoBUAF+AToBJgFEAboBZAFYAWwBNQDdAPEAwgEUAOYAkgCkgHRAGEAtgDqAHAAlf8Q/0b+nP3Y/Oz8NP28/Bz8cPsQ++D5uPhQ+Cj4MPjA9wD48Peg95D28PWQ9QD1oPSQ9OD0oPSA9ED0QPTg84DzoPMA9JD0EPUA9rD28PYQ99D3uPjY+Wj6kPtk/Pz80P3k/nwAIAFAAYYBCALsAoAEMAdwCYAJIAiwBjgGKAYABzAKUAzQDGAL0AkwCDAGUAX4BTAH4Af4B0AI0AeIBRwDuAFmAawByAIoBUgGeAW4A1ACogFGAeABmAMgBaAFIAXQBHgE4AN8A7wDQASwBAAFmAWABcgEzAM0AxAD5AJEA5wDxAPoAt4BPAHRAKgAuwAgARQBSQBm/7L+Rv6o/Wz9eP0s/aT8EPxA+3j6WPng+KD4qPiw+Jj4SPiQ96D2sPVQ9SD1IPUQ9TD1MPXg9GD0QPRw9ED0gPTQ9JD1MPZw9iD3kPcY+ID4WPk4+hj70Pug/Hz9Iv4k/zUA2QC8AM4ARAKwA4gFGAegCDAJkAcgBsAFoAb4BzAK8AuwDCALsAjoBigGKAa4BvgHwAjwCPAH6AZ4BfADJAP4AvgDEAXIBfgFYAUYBOQCbAK0ApQDmARABUgFyARYBEgEEAQQBDAEoAToBAAFIAXoBLAEGATcA+QD3AOwA4QDIAPcAgwC5AHkARwCqAEwAXkAwv9G/3r+WP4k/sz9GP1k/MD7EPsw+lj58Piw+KD4kPhw+BD4gPdw9tD1QPUw9VD1YPWA9VD1cPVQ9QD1APUg9XD10PUg9tD2YPfQ9/D3gPhI+Sj6qPpo+3T8DP2Y/Qz+UP9IAPT/AwAOAZQCqAT4BRgHSAcQBpgEaASoBYAHcAnwCjALIArYB4AGyAUwBsgG2AcQCVAJsAgYB4AF6AP8AkwDOASABUAGUAZwBXAEHANYAlgC8ALEA2AEkARABMwDhAMsA8QCAANAA3wDsAPUAxAEjAP4AmgClAKIAqgC0AKgAlQCdAEIAdkAxADHAJUASgCn/8T+QP7o/eT94P2M/TT9PPxA+3j6EPrY+bD5yPnQ+Zj5yPhI+MD3IPeQ9nD28PYw9xD38PYg9yD3oPZQ9pD2IPdQ96D3WPjI+AD5MPmw+ZD6qPoY+/j75Pyo/VT+S/8pAIoAZwAxADwAEAFEAnAEGAYgBxAHWAb4BEAEiATwBbAHsAhACTAJkAgAB1AGGAbYBRgGmAaAB4AH0AbwBQgFgAToA3gEEAUoBagEEAToA6ADfAOwAyAEAARYAxgDFAMwAzgDcAOUA4ADGAPYAigDCAOsAqQCmAKkAkQCKAJYAjACngHrAGoANQC//6n/4v8MAKn/3v4k/kz9jPwY/Cj8jPyA/FD8mPvY+rj5KPkY+TD5kPmY+YD5wPjg90D3cPfw90D4gPhw+DD4oPcQ98D20PZA9zj4IPlg+qD6oPpA+sj5iPlo+Sj6wPuE/br+kf/z/7L/Cf/s/Uz96P3g/+gCsAXgBgAHQAXgAgwBMAHoAigFKAdwCPAIUAgIBwAGOAVwBPgDmAQYBngHEAgACAgHwAVIBLgDGATgBFAFWAXwBCAEuAP8AwAFWAVABKgCeAGWAYgC0APgBAgFIARgAp4Auf8dAFQBgAKsAkACXgF6ABgAp/9f/+D+nv7c/jj/ZP8Y/9L+MP6A/az8PPw4/FD86Pxg/ZD9FP0Y/MD6mPnw+Ej5SPo4+wz8ZPzI+3j6wPjA9+D3yPgQ+lj7KPwM/Cj7OPqg+bD54PlA+rj6GPuQ+yj8HP3g/Ur+6P0g/Xz8LPzQ/Oz9tf9AAVwCmAK4AZAAnv+I/5QArAIIBbgGWAaYBLACygEgArADwAU4B8gGiAW4BOgEMAXgBAAFmAUQBogFQAVYBQgFpAOoA/gEUAbIBQgEnAOUArQBwAGABGgGIAUgA5IB2wCXAMQBHAOYArgBEAKcAh4BZv/w/5gB7wCe/vD/SAKgAfz92Py6/mEAsf+b/8oANgGS/gz8CPzQ/TD+FP1Q/ar+Cf8I/lz9pP1g/MD5ePiA+rD8JP6Y/gj/9P1w++D48PiA+Sj6sPrA+5D82PzU/aD+Xv7Q/Bj6uPgg+ID5GPxX/woBCgENANr+vPxI+1D7xPy2/gAAjAFcAnACYgHt/yz/M/+TAOwCqARABegE9AJtAH7+Xv/QAiAG+AcwCAAHKAQGAX7/+wBEA2AEsAWgBngGAAVcA8ACqAKUAkQCRAIsA4AE6ARwBIQDIAMsAr0Ax//VAFQCRAO8A6QD0AJ2ARABAgFEAKz+BP72/qAA6gGYAjwCPwDY/bj8IP22/msA+v+w/dD7jPws/2kAwwCF/9z9QPvw+Oj5qPxD/1L/0P5i/gz+iPzI+hD6cPqI+yz8tP1o/18AsP7g+9D5sPlQ+5j84P1q/vL+hv74/WD9+Pwc/Ij7uPwZ/08AyP9V/6H/3f/k/uj9LP7A/tj+Lv/qAOACwAN0A/ACUAEt/wb+iP7j/+oBIAS4BiAJoAgwBQYBGP2w+tD70gGACSAN8AooBsgBSv40/Iz+nAMACKgHyASwAjwBeQCaADwDUAQwBMgB0P/0/xQBwAJ0AmQCFALsAngBcP+u/nf/igC6AOUAfgGkAvwBmP8s/bD7MPuw/AP/NAKUA0AC5wCGADD+qPhg9fD4lAAABdADKgGY/3D8oPjw96D6VP69APIBhAL9AJD9ePrY+RD7RP3e/uL//QAOAXj/hP0M/Uz9jP3c/Oz80P36/n4AegGkAXj/lP2w+6D7LP3E/+sAc/+6/tr/agHW/yr+Fv50AFABrQCJAGr+yPyg/I7/CAP0A+AEEAVIBCMAmPsI+xT9f/9kAhAF6AaYBhADoQCD/8j9+Puo/P0ACAWIBvgFWAX8Arj+CPy4/Az/WQCIApgFgAYwA14AbgC0AAL/AP2M/bH/0ACgATADMAWoBBYB/P1w+0D76PvO/kADsAY4BZkANP0w/Bz8QPtc/aYBKATPAAb+ov9iAcP/IPvA+pT9gf8a/9b/eAL0A8sATPz4+lj7YPx0/az/zAGsAkQBuf8W/yT9+PrI+nD9qQBEAwADaAA0/dD66PxY/10A7/8sAeIAUP3w+iD9bAJMAycAhv8bAEH/cP16/ywDAAKM/iL+fwAaACb/sf9kAjwCPgHQAQADAAIR/0D8qPso/ngE8AdQBjgC4P/E/qD8kP22AeAFvAIQ/1H/oAFQAhwD+AWwBNT8YPag++ACwAQgBBAGSAfsAGD5CPmY/eH/R//4AsgH0Ah4BIT+OPpg+CD75v4YBMAGUAfsA8D9EPmg+hr/xABaAQQBigFYAfX/y//w/+7/fPwQ+/z8ZAG8Ay4Byv5C/tz98Pv8/aYBxAMUAAz8WP2E/XT9uv68ACEAxv7V/wAD1gG4/nz9SPxA+Vj40v7QBgAISAR0AWz/OPuw9mD5oAAsAzABRgDYA0gGfAOc/dD6EPuc/Dj87v5YBYAKGAfC/+D6UPv4/GD9Pf9YA7gEcAJaAcIBpgHA/sj8gP0XACgC0AGoAQgCNAKfAE7+DgDQBMAEYP9w+jD6+PvE/jAG8AzgC88AoPUQ9ID42P0YA0AKgAvQBfT9APrI+dD4MPoL/6AGEAmgBzgEIgHQ+nD0oPbC/iAFuAWIBQgELgGQ+3j6Zv6u/6D+fACIBPgD4P5Y+8D8+v5y/gAAyAJUAvj+ePyA/v8ApgGMAOD+bP2c/Ij99v/EAtgDnAHT/2L+3v5o/Yz8Iv4kAYAD7gFKAT4BQv/o/UP/mAEyAW//lP/8/2z/iP+UAqwDEgHO/pT/o/95/4QAvAKiAUj9FP10ArAEaAKAAPn/5P74+9j7sgB4BMwDSABK/4UAJgCc/vj9qQCgAgIAlP2s/dQC0AU4BGv/HP1A/dD80Pz3/2gFmAYQAgn/qP3c/bD7/PzIAqgF8AGK/lEA8gEF/wD9jP6DAOj/Tv+GAegC3gEMAJMAUP+A+4j7yQAQBLAB/v7fADoAgP1w/UQCMAQVABD8QPxV/zj++v+wA8QDK/9g/IT9dP6+/rr+WAHKAUQBTAB3/6D9JPy8/H7+LgFcA9AESAPO/2D8GPpA+ZT8OASIBxAGvgBw/Uj9SPxc/bT/DAPQAnIBqv4u/5sA0gH8/yD9kv72AP7/Fv79AEgF+ANk/Wj6I/9sA/oAmv4lAOP/Mv4KACgFiAVaAdT8fP3V/4L+WP6gATgEhgAg/eb+0AMgBeP/SPvw+oT9af9wAjgFaAWnAPD7OPpY+zYAiARABWIAEP0Y/p8AoP6w/AwAQALuAdkAGAIoAZz8qPno/EACWATMAj4B2f+Y/ED7bP2EA7AFIAMg/SD5UPtfAGADTAOQBAYBtPy4+ej7fwBHANT95P+wB2AGyP3I+Zz+4f8w/BD6bP1QAUgEIAfACOACgPrg9rD3cPdg+TAF8A7AC+gCSP1Y/Hj4cPU4+2gDUAVQAtgBkAQAA2T9JPye/hsAXv78/ygDnAPh/3j9RP1q/kQCQAZoBgoAoPwy/mcA4P5s/swBHAKA/8z8Mf8kA8gEjAOMAVf/LPyc/Az92P2wAMAEiAVUA9IBv/+Q/JD4UPrv/0AF2AbYBvAEbP/Q+UD2iPms/qgEMAkACNAARPxc/Vz+UP3w+jj/EATMAwgB6wAAA7gAWPuo+aT9pAKwAiABcABKABb/oP3k/QsAXgEi/1z8pP1YAvAFaATX/0j7gPpM/BD93v7iAUAEkALyASQCfgCk/Cj7qPvw+xz9YAFQCPAJGATk/Tz8uPoQ+eD7fgHQAhwCUAPoBTgF7v6Y+1j7EPwo+yD8ugHACAALkAZgASj9ePkQ9wD5Tv6gBGgH8AiYB9QCqPzQ+Pj5AP36//UAyALwBIgDhAKh/zD/ev8s/UD7oPuUATgFaAOA/xL+7P7N/zQBJgEhAFT+KP2o/a7+9/9AAqwDOANWAWX/UPyg+3D62PonAJgFIAgYBBMASP4w/ED3MPYy/9gHMAgIA+YB6QAk/bD3CPlA/UT+9f8YBJALoAme/lD3kPeg+ID4LP24BjAOoAkjAOj5CPvY/FD8PPxg/joBfANgBVAHVAMM/WD66Pqw/Tr+dwAwBlAIIAT4/Vz8Zv5e/nn/XAHQA2oBNgHWAAcA/P0e/nQCiAQkA9T9wPyU/Fj9rABABPAFcAY8A5r+4Pnw+CD9hQDoAlgFAAkAB8r/aPrY+rj7IPoo/HADoAnQCLAF8ALu/iD3UPNQ92f/xAPgBrALQAqiAVD2UPRo+9j/oP80/RwCQAboA1wCbAMgA5z8gPWg9GT9qARYBsAFeASAAuj+1PwE/Zz9MP2o+7T9ZQAwBPAHkAdAAtj6kPVQ9jT9sASgBhgDNAE5ALX/FP3w+3D9HAHc/3r+zgEABET/APqQ/YgD2AIB/2YA0AJa/qD3+PugBUgHKAJoALACZP0w95j5YAKIBWwD7AN4BL0A0Ppw+2D+e//A/ZIBKAYgBigCDgBu/wT9ePrg+2IBqARoBZAE7APj/xj7IPp0/EcAzgGcAygEEARIANT8gPu4/HT/mv+t/4ABaAUQA5D8KPkW/sgDRAGY/Uz+vAIAAZD8gP7gAswD+P4w+3j90P/4/uz98AA4BVgEQP4Q+wr/JAIr/7z9FAL8A+T+sPdw+0gCcAOIATgDnAMw/dD5PP3IA/IAIPsE/FUANAJmAfACeAJw/2D7CPuk/b7/pgFqAZcALQAMAbz/gv4sATACKP6I+MD77AOgB0gEdwBi/xT9EPuo+/QA2AQQBigDzv8A/bD78PsL/7gEAAfAAqz8/P0cAiwD6P+Y/RT+qPxk/WACEAdoBVwCWgFa/kj5IPl0AegGqgE4+jj8eAFYBAgFAAYMA3D8qPi4+GT8nv9QAwgG2AX0A2ACxwDM/UD6qPiA+Lz8eANAClALAAf4/dD48PZg9zD8qAIwB+gFiAEG/34BSAEA/Aj6TPyY/aj9egGYBgAGsP8I/Oj+mv44+yT9lAGkAun/ygCgA1QCLP2Q+1z+wP7c/vIAuANYA0D/xP2+/in/qv6H/zAC4AE0AI7+ZwB8ATgAuP0G/zgCHAOkAID/UQAhADT+0P37/2wCTAJLAL4B+AJ4Aej82PmY/JwBaAQYBWgEYAGg+wD4sPrcAagFeAQ4BNwC6P0Q+Lj4OACoA2wCcAGQBOAEnQAw/ND6CPtY+rT86AKgB2AHcgCk/Xn/uP5w+nD3CPt0AzAGRAN0A0AF3AFI+kD3QPo9/4wATgHkA+gExgHW/u7+Ev88/VT8UP38ABgEgALZAKIAJQC9/1b+3P1A/4r+IPxw/egDuAcwB0wDZP4w+qD20Pa0/GADAAlwDEAJ7wDQ9xD30Po8/nz/XALAB6AHCAJ+/q//BP1g+RD7bAGgBZAD8gHIA8wCuPxA/AIACAJa/mD7hv7eARgEYAZQB7wCAPsQ+Xj5SPkw++gCwAlACIQCPAE4Asz8kPTQ9KT91AMgBXgEqAQ0Avj8MPrw+3T/zAFsACD+Uv5tAPwCAAO2AWD+HPxg+7T9QAEcA7ADsAIYALj7EPqY/ZAB7gE2AFQBEAN8AUD+cP2O/uT9PPw6/ugCIAS0Aej+hP9A/3j9MP01/2IB2AAMAIQBxAIoAoX/TP1M/Kz8TP2C/oQCQAZ4BggCmv4Y/Uz9RPx0/CQB+ASgA8//VAHAAtL/sPso/X8AxQDo/rQA4AXYBMz/RPzQ/LT9Fv8uAbgDAAWsA3ABXP04+wj9kAEgAywC1gEMAa7+NP2Q/wQDAAN7/2//BgDU/mD9Xv4lALYBIAMgBUwD0v6o+zj7OPw8/W4BsAXABRACygBRAOj82PhY+nD/jALYA6gEEAawAkD9IPoY+gD7dP2qAQAFKAOCAPoB9AO6AZj8mPrI+WD6oPtIAlAIsAecA4oBTgFs/DD3CPgG/4IB2QAsAiAGSAe0A8b/SP4A/HD4OPiw/SgFwAlACCADFv8E/YD7sPvg/LwAfAN0AmQCpAPqAdz9WPs+/nwC3QDM/ZL+CAIYAgH/7v+ABPgE3v6o+mj7IP4Q/ygACAXgB7AEqP5o/Sz9SPwY+9T9BALIA1gEUAVQBF4AWPzw+Xj6YPtf/wgFuAdQBqADxgBQ/JD44PiE/d4AAAI4AmAEkAQ8ApT+fPxY/JD7KPtI/XQC3AP0Aa0AOAL4ApUAgPxI+mj5WPmY/bQCeAcgCKAFWgGI+zD44Pc4+iD99AFQBhgHgATUAQIAFPww+AD4uPsmAGgDYAawB6AERQCM/cD7MPng9zj8AANAB5gG0AQMAy//6Pro+ZT8fP+tAH8ArALIBFgE4AGD/7j9uPuA+w//VAK8AnwCTAN8A9b/UP0u/rH/bv5s/ML+OAPQBFAEdAMQAcj84Ppo/d0AJgG6/1ABmALeALT+EQDEAiQCoP9E/cj78Pvu/rQDeAQkAooAkgC4/nj7CPyo/7oB9wAYAjAElAIA/hD81P2w/ej7zP3MAhAFsAIEARYBeP9s/ND7UP56/vz82P68A2gFUAO8AB0A4v7g/Lj7zPx4/nj/ygF0AwQDTALcA1wDwv4g+XD55P0gAD4ADANAB6AFcwBc/gD/GP7g+/j83f/nAGQBlAOYBdwCjv68/cL+Tv7o/agARALt/7j87P1oAvgDeAOQAsAAQPyQ+AD6nP48AuwDsATIA+oAVP5c/ED87Pyk/lr/IQC6AUwD2ALq/9D9Av6k/QD97P3fALQCnAIIAeT/Cv50/aT9Rv8CAX4Aiv/I/mH/hf9x/6n/vQBsAdL/BP48/qn/h//c/uX/VgEQAbT/zf9FAEX/nP14/sEASgG6ALsATAFeAED/df98ACsApv5q/uv/EAGIARQCqAIwAqb/uP18/cL+tv+fAGwBugFmASIBLAGNAB7/qP3g/Sf/4wBCAVQBpAHWAXgBNAB9/8z+vP0g/XD+hgHMA7wDeAKjAEj+wPvY+57+IAGSATAAGwC0AHUA1v9//4n/Qv9a/tz9WP5G/38A6gDWAOIAdgFOAWL/mP1A/aD+vv83ABgBmAKkAlIBf/8y/kr+sv7J/wYBpAKoArQB1f88/vj9cP7u/3YB0AKQAqQA0P5u/kMA/AG2AdwAJgCZ/4D+OP6h/wQCYAPsAsoBmwAY/8D9RP3A/Rn/rQB8ArAD8APuASn/0Pxg/JD9dP6k/7QAuAF4AV8Az/8A/77+TP6C/gP/Bf9N/xoAwQBVAKv/SP/M/nj+nP4O/+H/BADo////pv9p/2H/TP+g/s7+2P72/gH/Ef8QAPsATgEKATcAOf9O/rj9TP6r/4oBxAKAAqACEAJwAOT+zP4eAPwAKAH+AVQDbAP4AggCNALsARQBtABuAWACYALUAtwDcASQBCQDzgHgAA8AtP87APwBcAMwBAgD5gHkAJAAm//0/v7+6P7s/ov/KgC1ALUAgv9e/jT9zPxg/ID8uPw8/Xz92P3g/cj9DP2o+xD7IPqo+gD7+Poo+xj7BPxQ/Dz8wPtg+vD4cPj4+CD6GPsM/OD8jPyw+xD7kPtc/HD8wPx0/ST+1P4YAFIB0AGcAdYBQAKgAggDdAMgBegG+AeQCMAIoAiACFAIIAmwCuALIAwQDCAMkAvACXAIMAmgCnALMAtwC6AL8AlwB6AFMAUABYAEMAX4BfAFIATWAVAAQ/8K/tj8gPyU/Ij8EPzo+7j70PrA+AD3MPag9aD14PVw9hD3IPfA9tD1APVA9NDzkPMw86DzcPRw9dD10PWQ9YD0MPPQ8QDyAPPw9KD2oPeA+Gj54Phg+Jj4KPnY+hD8PP6xAEADuARYBZgFkAW4BYgGYAiQCqAMcA7ADyAQQBDAEKAQgBCAEEARwBHgEcARQBJgEkARwA/ADhAO8AwQDMALoAvwCoAJUAgYB6gFrAMsAsgBjwAaAD//Gv92/nz8ePpQ+RD5APlI+dD5YPrI+iD64Pkw+Vj4GPgQ+MD4SPmY+QD6ePpo+gD6KPmg+JD3UPfw9sD20Pag9uD2EPbg9KDz8PJA8tDx0PEw8hDycPFQ8ODuwO7g7rDw4PLw9Sj4wPl4+pD5oPhI+Fj5DPx4/3wDIAYwCMAIYAjAB/AGuAdQCWAL0A2AEIASIBNgEoAQMA/QDbAN4A6AEAASABLgEUAQIA6AC0AK8AgQCNAHcAigCBAImAZwBJAC6/96/jL+tv4D/0j/qv48/tT88Prg+SD5cPko+gj7pPww/fT8OPx4+5j6OPrw+lj8+P2i/j//XP/a/vT9CP1c/Mj7WPvI+4T81Pyg/Oj7IPsw+RD3wPXw9FD00POA8xD04POw89DycPGg72DtoOxA7eDuAPNA9jj54PkI+AD3kPUw9eD2OPpC/nwCWAZACOAIMAgoB+gFYAXwBlAKYA7gEaAUQBWgEwARUA6ADdAN0A7gEMASwBMAE4ARwA8gDbAK4AgwCIAIUAlACTAJIAigBTwDvACQ/9b+Cv96/2v/hf+W/iL+WP10/Jj70Pr4+hD7EPwg/Qr+Sv5S/ib+EP6w/cD95P2i/gn/Fv+0/73/p/8C/9z95Pzw+1j7YPsw+xD7OPp4+YD38PUg9ZDzYPOg8tDygPLA8aDwoO+A7gDtwOuA7WDvQPMg9vD3WPhw9/D1oPVA9qD5CP0IAVgFcAdACbAIgAhIB4AHkAiACmAOoBFgFMAVQBXgE4AR8A+ADyAQYBHAEkATYBNgEsAQwA5QDCAKsAgQCAAIIAjYB7gHOAb4A6YBh/80/rT9tP0k/uD9oP24/CD8WPuo+qD6aPpI+uD6EPsc/ID8fP18/YD9QP1E/dD9LP6g/gD/bv+p//D+Uf8F/y7+qP10/ND7CPvA+nj66PkY+YD3oPWw9KDyYPLA8UDxcPEw8cDwgO+A7eDsYOsA6yDsoO9w9LD2gPiI+DD3APZA9VD3cPqk/uQCEAfQCSALgArACTAJgAjACSAMABDgE8AWwBdAF+AUwBFAEGAPYBDgEYAToBQgFOASoBAgDrAL8AjQBygHQAfgB/gHCAfIBTQDTABG/tz8cPyI/Bz99Pwk/Yj84PsQ+6D64PmA+Xj50PnY+tj7yPyw/ST+IP54/XD9sP0c/oz+Lf/k/xcADQB8/+7+4P1Y/UT84Pt4+1j7KPsA+jD5YPeQ9fDzwPJQ8iDyoPEA8pDxIPFg7+DtwOyA6yDrIO0g8ED0sPbI+LD54Peg9XD1IPdo+jX/RAOQB2AKIAuAC5AK0AlACWAKcA0gEYAUwBegGIAXQBXgEeAQgA/AEIASQBSAFYAUoBOgEMANoAowCOgGGAdgB+AHMAjABqgE5gEL/wT9wPuo++D7EPxs/Cz8sPuw+rj5MPnI+Fj40Pg4+YD6YPvg+4j89Pzk/OD8/PyY/ej9ZP4I/xn/e/9B/zv/zP4+/nj9iPzw+3j78Pqg+mj5CPnA9zD2wPSw81DyAPJA8cDwwPAw8ADvoO5g7aDrIOvA62DuYPHA9JD3OPmg+BD30PVw9pD4APxIAQgGoAkwCxAMMAsgCqAJcAlwC4AOYBIAFgAYIBhgFuAToBGgD3APoBBAEuAT4BOgE8ARIA9wDJAJ6AdgBhgGKAZQBkgGSAWQA0QB0P7w/Lj7EPv4+lD72Pv4+8j7UPug+vD5GPmQ+Lj4cPlQ+oj7vPyc/R7+Fv4I/tT9vP3Q/Uj+3v51/+7/EADF/yL/Mv4U/SD8UPvg+oD6MPqo+dD4cPcA9mD0APPg8fDwsPBw8ADwgO/g7iDuwOxA68Dq4OvA7aDwQPQQ+Ej4YPdw9xD2MPf4+Ez83gHYBcAJcAuQDAAM8AqgCiAL4AyQD8ATIBfAGKAYIBdgFCASoBDgEOARYBNAFOAU4BMAEmAPcAwgChAISAegBuAGoAZYBsAE6ALAADj+wPxY+xj7IPtw+6j7oPsg++D6QPrQ+WD5GPkw+Vj5+Pk4+4j8gP16/qj+wP5e/n7+JP5s/uL+V//j/0YAqABVAKL/kv4c/cj7+PoI+hD60PmI+XD4QPeQ9QD0MPJw8fDwkPBQ8HDw4O8A7+DtYOyg7IDrYOwg8JDzcPeI+MD5ePjA9xD3YPgY/E0AWASACIAM8AwgDdALQAsgCyAMYA5gEsAVIBhgGUAYIBZgE4ARABEgEeARIBOgE8ATwBLAEAAOcAugCOAG8AWgBbgFkAWoBJwD5gH1/zT+OPwA+0j6SPqw+lD7wPuo+zD7gPro+Vj5QPlo+aD5YPpo+7D8+P3k/kT/RP/o/or+Yv6a/t7+a//t/1IApgBwAND/wv5I/dD7ePrY+cD5mPlQ+aD4UPeg9dDzgPIg8ZDwEPBA8MDvgO+g7gDuoOxg6yDroOyg7zDyUPa4+Dj50Pdw9nD3mPhY+8H/KASgCNAKIAwgDEAMAAswC7AMwA7gEQAVQBcgGIAXIBVgE8ARIBFgEcARgBKgEmASQBHQD8ANYAtACSAHGAaYBRAFoATwAxgD2gFoAAb/TP3A+3D6IPpA+pD6SPvg++j7APtg+sj5oPl4+dD5uPrA+7j8/P0r//n/+v/8/5//dv+Z/9z/ZgDVAGoBkgGYAQgBSwAk/8T9cPxw+yD72PqY+sD5wPgQ91D1wPOg8rDxIPGg8GDw4O/A78DuAO6A7ODrwOug7EDwUPOA92D5SPnY+DD4IPfI+Iz8AgFoBWAJoAtgDVANoAzwC9AL4AwgD8ASoBUAGKAYoBegFeASwBEAEeAQ4BGAEoAS4BEAEZAPgA2wCmAImAZABagESAQQBGQDMALFAEn/zP34++j6sPlA+ZD5QPoY+5D7UPuQ+tj5APnQ+Bj5+PkA++D78PzU/Yb+Jf8w/53/nP+Z/8H//f/BAPAAOgHxANgAbQDE/+z+vP2g/Jj7EPvA+kj6mPnY+FD30PUA9ODy4PHw8ODwsPBw8CDwQO9A70DtoOwA7ODs4O/Q8TD2+Pgo+nD5SPjQ97D4gPuu/+gD8AdAC7AMQA3gDCAM8AtwDCAO4BAgFAAXIBggGGAWABRgEUAQQBDAEIAR4BHAEaAQEA8gDaAKUAgYBrAEGARkA1QD2ALQARUAKP7Y/Ej7MPpg+Rj5EPkw+XD5qPkQ+vj5qPlY+SD5QPmI+SD6QPtk/FD9Av7q/tj/GwAIAP7/3/9CAGAA6ACGAX4B1gEEAYkAU/92/nD9JPy4+8D6yPrw+ej48Pdw9nD0APOQ8VDxQPBQ8EDwgPAA8EDvIO5g7WDroOtA7MDuQPJg9aD5MPrQ+Sj4QPiQ+Jj6Ef+gA7AHoAqADHANMA1gDLAL4AxwDqAQoBMAFoAXYBdAFgAUYBIAEWAQwBAgEcARwBGAEAAPAA3gCtAI2AbIBUgF0AQIBCADcAKiACL/qP2Q/Az8IPv4+gD7CPuQ+sj5APoY+oj6mPrg+kD7MPvQ+hD7+PsM/QT+yv7y/4MAXwBJAHQATwAQAKEA/QB6AcwBagESAcv/Uv4o/WD8uPsw+zj7uPqA+Vj4IPew9TD0oPIw8pDx8PAw8SDxIPEw8EDvIO5A7UDswOwA7uDwIPPQ9Uj5APqw+fj4oPho+VD7Of/8A+AHUAogDLAMAAwgC7AKgAxQDoAQwBIAFYAW4BXgFCATYBHADwAPkA+gEIAR4BAgEFAOEAyQCcAHsAbQBSAFqAT8A2gDRAIGAUv/4P2w/Aj8oPuY+2j7cPvY+gj6IPp4+qj6GPto+3D7UPvo+jj7RPxc/cj9CP+i/woAzv+C/zcAMQBXAK0AkgHmAfQBHgG3ALP/6v7Y/XT9QP3s/BD8uPtY+kD54PfA9gD2APXg81Dz4PJg8tDxcPFg8ZDwoO8A78Du4O7A7sDvYPLA9CD2yPhg+ij7+Prw+Tj7DPzG/xAE0AcgC/ALgAywC+AK4AogDJANwA8gEiAUQBWgFKATIBKwDxAOkA1ADnAPkA8AEAAP8AwQCxAJqAegBggFuAQ4BOgDRAOMAs4BNAB2/kj9RPws/Az8yPvg+7j7WPtI+0j7ePu4+4D7QPsw+2D7MPwA/Zj9iv4c/1T/KP9W/6L/LQBAAJ0AGgG+AWoB1QCOAOP/AP9Y/kb+/P2k/cD8+PvA+rD5qPjw93D3cPbw9QD18PPg8jDyMPJQ8eDwsPDA8EDwwO+g78Dv4O9w8PDxoPUY+AD6UPt4++j6uPnY+pT9UgHgBbAIIAtQC7AKcApACqAKAAywDUAQABIgE8AT4BIAEUAPEA7gDdANsA5ADzAPMA6QDEALgAn4B7gGmAUIBQAEuANIAwQDkAEoANr+pP3c/Cz8wPvI+7j7GPsQ+0D7ePsI+8j6+Pow+9D60Pqo+3j88PyM/eT9eP5o/rz+Bf8s/83/NwCnAA4B2gBLAE4A1v89/zL/Of/O/gb+ZP2w/Az82PoY+pD5yPgI+CD3sPbA9cD0wPOQ8+DywPKA8jDywPEw8SDx4PCw8PDw4PFQ9JD1SPh4+pj7cPvY+Rj6kPvs/VgB4AWgCAAKsAkgCRAJMAkQCoALcA2wD6ARYBLgEgASYBAAD9AN8A2gDiAPcA9AD4AOEA3QC4AKYAkQCLgGAAY4BcgEsAQYBBADwAFaACz/HP6g/Uj9IP2w/Ej8bPx8/Cz8+PuI+8j7KPuY+zz8mPxw/Az9NP24/Tb+Rv40/6P/af9K/wYASQCBADwAFwAZAKn/h/9w/yn/WP6Y/dD8WPy4+yj7cPqA+bj48Pdg94D2kPUA9RD0QPOw8vDyIPOw8qDyAPLQ8SDxkPDw8DDyIPQQ9sD4sPqQ+7D6IPmo+Yj7zP38AXgFMAjwCEAIMAiACMAI4AmACxAOoA/gEKARIBKAEBAPAA4ADmAO4A6wD9APQA+gDXAMsAuQCoAJkAiwB4AGEAZgBUgF2ASAAzACbQBW/57+CP7o/ZT9ZP2k/Sj9nPxo/AT8oPvA+vj64PuU/Kj83PwQ/WT8ZPys/LD9Vv54/vD+Yf+l/5P/sf+//3n/HP8w/wv/+P6y/tz+hP5g/WD8mPsQ+zj62PkY+Vj5MPgA91D24PVg9QD00POQ83DzAPOg8jDzMPOQ8sDx4PHA8qDzoPVQ+Oj58PoQ+kD6qPo4+zj9JgAIA0AF0AagB8gHeAfYB/AHkAlgC8ANUA8AEDAPIA9wDqANcA0ADvAOsA6gDrANAA7ADGALYAugCtAJAAhoB4gHYAbYBQAF4AS0A7wBcwD7/1X/vP6m/tT+uP6g/SD90Pz4+5j7gPvY++D7UPwE/Sj9EP3I/Mj8DP2w/FT9ev42/2f/Qv90/5//Bf8i/+L+A/+c/kD+hP6A/kz+aP2U/Mj72Pog+rj56Pk4+Wj4cPfQ9iD2cPUA9bD0IPQw8xDzIPMw86DyMPJQ8kDykPKw86D1EPeg94D4MPlA+Rj6cPqo/KD+fQAMA9AE4AXgBaAFqAUwBhAIkAqwDOANoA1gDdAMYAxQDPAMUA7wDcAN0A0QDpANcAzgC3ALUAqQCSAJIAnACNAHeAfoBrAFkASEAwwD8AFIAXYBcAEEAUgACACL/7z+Cv4g/hT+xP24/Qr+Xv4k/hT+Iv7Y/ZD9rP0e/q7+0v76/lf/Tf9F/8b+hv4C/qz9uP3Y/Sb+LP7o/Qz94PsI+2D6UPpg+ij6sPlQ+WD4YPfw9lD24PWQ9WD1gPUw9dD0wPRA9BD0wPNw9HD1IPYw98D3kPhA+dD5sPqw+6T8UP1q/u//DAIoBGgFAAbABaAFiAZwBzAJwArgC3AMIAzgC6ALEAxADEAM8AugDKAMsAwwDAAMgAsQCiAJEAkgCbAI4AdYBzgHcAaABZgEUARUA3wCGALgARACuAHjAIsAJgDt/1n/5v5y/lz+QP6Y/hf//P7I/jj+4P3Y/aj9Ev5C/pj+5v6w/t7+tv56/gb+xP0k/SD9SP28/ZD9NP2M/Lj74PpI+jj6SPog+vD5iPnI+AD4oPaw9qD2oPag9sD2sPaw9QD1YPQQ9VD1wPVg9kD3gPdw9yj42Pi4+SD66PoA/BT9sP3u/lIAZgGAAkwDyANoBNAEyAU4ByAIEAmgCUAKYArACaAJ8AkwCtAKMAvAC8ALEAtACqAJEAnwCPAIUAlACXAIgAcoB9AGGAZ4BdgEmARoBMQDQAPQAmgC2gG0AS4BywCXAPj/yP/K/+v/nf9S/+b+mv6K/nz+9v5P/0n/uP5Y/mz+iP7a/vD+2P48/uj9rP3M/fT9vP2c/Qz9uPwA/KD7KPuQ+pD6ePqg+sj5QPnI+KD3APdw9gD3cPcw9yD3wPaA9vD1gPXg9UD2oPaw9nD3WPhA+dj5EPrY+TD6uPqw+0D91P5FAN8AFgFGAaABkAKoA/AE8AWYBhgHiAcQCHAI8AhQCWAJAAlACcAJUAqgCpAKcArgCTAJsAiACJAIQAggCIAI+Ad4B1gGcAXABHgEKAT4AwAEoAM4A0ACogG4AVgBBAFgAAYA7/8BALf/q/9+/wv/jP6U/tL+7v7g/mT+RP54/pz+2v6O/lT+BP5s/Tz9VP30/SD+rP0E/Sz8mPvo+sj6IPtQ+wD7iPog+rD5IPmQ+Jj4mPh4+Hj4OPjw99D3oPcI+BD4MPgY+BD4KPiY+GD58PmA+tj6OPuY+7j7SPww/X7+b/9LANEApwD0AJ4B0ALEA6gEIAXABcAFyAUoBhAHsAfQB9gH6AeACPAIoAlACUAJUAgACEAIoAjQCHAIYAiACDAIYAfIBlAGaAXwBOgEwAUwBtgFUATwArwBugE8AsACdALUAQQBVAAsAFwAbgA1AD7/tv6o/t7+Z/+0/7H//P7w/Yj9sP00/nb+av4O/iD+UP30/GT8cPwk/ZT9dP0k/JD68Pnw+kj80PzA+zj6IPnY+Gj5SPow+3D7gPoI+dD34Pco+YD6UPuw+rD56PhA+UD6EPuI+5D72PvQ+wT8QPwg/Tj+EP+9/8P/j//2/o7/oQBUApQD9AO8A8wChAIkA0gEWAXQBRAGOAZYBngGiAagBpAGuAYIB0AHWAf4BvAG0AYQBxAH4AZgBpAFSAUYBWAFeAVABfAEGAS0AwgDBAOgAjwCsgFOAVYBZgG+AUoBTgDK/sT9Jv6C/0sAXgDg/oD9LPxg/Kz9rv5G/vD8GPyI/OT8nPxU/Nj7FPwQ+/j7RPxg/Nj6uPmY+oD7MPxw+/j76Po4+VD4OPp0/LD86Psw+iD5QPkY+7j8kPug+jj7NPyY+9D56Ptq/vD9CPsM/Nb+9/9w/Zz8TP63ABkA4P/QAPoBHAHm/woBaAM4BAgDMAKMArQCGAMwBOAG0AbABMwCVAMYBFAFWAXABpgGgAUABNQDSAQQBfgFOAagBJQD6AKkAygE2AQQBcAEeAJ+AUQBzAK4AoAC3AKoAogB2//4/9wADAFzAEoAPwAlAAT/9v5M//7+wP5E/hb+Jv4K/6b/gv9w/TT8cPzc/KD9MP7+/j//kP1E/FD8cPxc/Mz8iP3A/TD9DPwQ/Jz8bP0o/YD8+Pt0/Jj80Px0/Lj9Qv7w/cj8NPyM/Cz9wP5L/5T+CP3o/HL+5/8GADH/Nv4M/mj+BgC6AcQBXgGN/2j+hP+gAjgFXAO9AGb/5ACEAlQDWAQIBUgElgE2ASQCyAR4BAAEWAOgAwgEUAOIA2QDGASwAoACIANYBFAEhAJiAVIB9AIgA1wDsgGeAMf/vwBsAmQDMAKD/1r+9v5TAJEASgA2AD4AVv8g/uT9Sv7w/lL+Wv4i/kL+2P3k/ez8aPx8/Vj+Hf/c/Uj7GPpA+yD9cf8UAQcAJPzw99D30PtPANIAjgBI/kj88PhQ+Xz8tQDiASH/Lv4Q+2D7UPu8/iIBjAL0ANz80Ptg+zYArgH4AnQBZgEc/0z9kP0nABgEuASwAir/N//8/oIBGAMIBCgDnAF2AGwBugHQ/5sA4ARACJAEJP5Q+/H/+ATwBIwDgAJ8AZcAWQA+AXwCwALmAeYBQgEUARIBcAG+AQwCKAF7//z/jwDWAegApwCwAAABIADm/lX/Rv8eAID/fwDB/1YACP4k/QD+9v+2AdT9tPzg+33/gQAY/zD+8Pzw/AT+7v8fAHb+KP2c/Zb+DP4m/vj+3gElAET+nP14/fD+vv4i/wsARwCe/vj+TQCkANf/RP7k/jL/mP/e/9QBGAISAMX/RQAwAcT+vv5GAZwD3AE5AAUAXgGWAEIATAGkAhQCXf+T/4YAVAIwAmADyAFcAej9vP1lAOADoAQOAY4AQ/9uAPz9Lf8UAwgFIAJ8/YD90f/AAhwBXgGIANIATP+0/dD+XAHoAgwCUAD0/Wr+YP5i/9kA0gGNAMD+xv8o/2MA2v44/lL/BwBuAQMAQ/+g/Gr/ygA+ANr+jf/6AMP/7Pwi/hQC2AKy/y//sP+1/9T9tf+wA9gBkf/0/JMAfQDeAE8A9gEuAET+XP1LAHQCQAQQAgj+APvQ/RQCFAMcAvr/GAHQ/cj9kv54A3wCLAFI/7z9mP0E/ZADiAUwAlD84PzC/2QA4P63/6ACdALk/m7+m/8OAWL/HP9i/5oA1ALtAOX/5Pw4/1z/3AEFALoA/wAO/mj9JP5oAboBygCm/qj93v7Y/QAA0gAUAvj+ePw8/Nj+uALe/04Azv78/uT8+PwzAJgC2QBS/mn/AP5k/zX/rgGMAKz+Zv5eAHj/Y/8wAagDpAH4/Iz9Vv8kAdL/nAE4BEwDKv6k/Nn/zAKwAkP/KAD+AAADIgBIAOAArANaADz+GP4sAvACHAK3/1QAKAFD/0cAnQCaAb7/uf9kAIgBlAFWAFL/uf9SAM7/HAA3AAQDoAH0/Zj71v7AAtwCTAInAAD+ePqw+9UAAAboBJ7+xPyI+9T9Sv94AvoBvv/M/aD9/gCM/2oAKv7+//D9sv46/wQCFgGU/fD+QP5HAND9HP+Q/64AyP7k/+ABSf84/Jz8YwBQA44BVv/M/lT9JP3+/qAD0APxACD9bPyw/vIAwAOIAzABmP50/H7/ggCUA84BLgHX/wMAXABEADcA8gDAARYBkgG/ALz/JP9qADQB4AEyAa4Bvv9g/Qj9VAGoA6AC///E/gz9BP26/iAEKAVF//j7NPzm/ikAcwCEAtYBqP74+oT8xwA8AmYBev8U/xr/ZP1+/pD/8AMsApEA0Puw/P7+ZAHgAQAB0AADAJT8MP0w/gQCeAF6Abb/mv9g/HT8JQDYAzQCKP+o/Tb+iv7w/noBJAJ+AU7+1P2w/Ur+EwA4AwQDHv/g+07+NwA8AQwALAK6AK7+nP3e/sQClAF4AdL/sgCo/Wj/mAGOAVoBmP90ASYAzwAZ/8UAZ//aADQBiAEXAIz+bwB4ANQALf8GAHMADwCKASYA6P9A/rv/sgCkAZcAOf/KAFz+5wAy/iwBNACwAVz/YP6E/nMA0gCG/oH/pQB6AID9zP1CAGwDXgDQ/Bj9qP98AVQBiAKs/uz9DP1AADwC4AFgADP/BACs/cD+lgDUAmQBZP5c/GT93AFMAqQCjP5c/lj9E//Y/5UATAKuAXkAAPxy/iUAkAOyAGD+vf+KAZYBwP/JAGr/rP+E/0ADjAMuAXT9Jv6SAE4BdAJYAiQDFv+k/Xj8UAFIA5gE1AKY/ST+WP3dAPwAlANUAQsAmP6I/jgC8v9i/kD9lAP0AmkAFPxc/kD/bAJ2AZIBuP3A+7j9uAAYAigArgFoAqT9kPkg/IYBcANCAa7/xQAe/nT82P2wAbgCmf+q/s7+nP8i/nIA4gH4ApD++P3o/WUA8gF8AfQAlP2i/7EAxAIo//j9UwD+AYIBlv68/5D/DgGH/7H/AAGPAMwAdP/z/5H/JAJAAa3/hP/c/vD/Vf9QAnACuAL8/lj+7P6M/24AuAD0AigCZAJU/pj+tPy3/8wDWANGAVj9SP+1ALQBcv9FACwB6QDI/mr+KwCwAQ4Brf8j/9//Rv9p/2v/oP9BAJD/gv/r/68AkQAy/rz95P3VAJoBYwDk/vz99/+U/t3/8P6mACj+lP5P/+z/PwCk/ykAg/8U/gj9x/8UAQgBlP4kAMz+C/89/8r/2wCK/vb+cf8MAQ3/4v7Q//wBggHs/oT9Y/+9AGQAEAFWAFgCn//u/47+9P/j/3kAeAJCAdkAOP7A/iIB7QBUARIA8ABCAG3/Wv4FABQDLAJIACz9Rf9SARwCngFW/w3/Qf8IAWIB8QCHAOwARAFgAeT+xv+u/q0AlgGmASACGAHw/wT9XP7P/yADOgHw/1wATgE3AHD8/P8IARQD+v7q/l//kf8dAMMAsAJ0/wj9+Pq+ABQCKgGtAHD/3wC0/Fz8OP2IAmgDSAFg/Yj9RP7+ABcAIAAc/xb+GQCnAFUAuv6w/uUA1AEdAOT9pP7gAAYB1gGW/+4B6P2jABb+FwCP/wgCgAOQAND+iPvE/hkA1AKOAWwCEP6A/lT+1f+hAGgBCAPxAA//EP3TALoBaAHc/1gBMgFu/+j+UgEIAxYBmf9F/ywB0v58AH4BaATcAYT+NP8A/xb/VP4AApgFJAOg/vD6/v6AAWwCuP/hABgAcP2E/jP/MATkApv/NPy8/L7+YwC2AdgBagCz/wz91P3Q/vUA2gDHAFr+Pv4O/o//MgGcAeL/oPwi/r3/hgEu/i3/vP5kAs3/kP4g/mP/DP4c/nYB6ALDAIj8uP0h/+EAKv/EASwDaADU/JD8aAFmAXgBZACkAjIALP5I/hAAzgEyAOQC4AAmAUD9JwDTAM4Bcv/5AJQBxQCA/0r/uAFEAbAB7P+8APT+Z/9fAFACfALYAIgAMP79/4b+GgHDADwCAgGs/2T/Ov5GAQ7/Kv8Z/yQCBAMQ/xD9SP1kATQBJf82/8oAAQAo/iz9mP/KAR0AUv4F/yoABP9c/XL+PgFYAu7+UP3l/7X/Df88/dgBhAJwAUD8rP2x/8P/QAFWAcQCyP3w/CL+4AJEAqP/T/9W/o3/ov4KAUgBFgF+/2D+/P44//AAewAKADoAkf/+/qT92ADwArwCBP58/NT+zgDsAT0A/gFOADMAQP2P/xgAQAL1AFIB1QAa/+D9jP3IAkAEjAJc/nT98P5WAGQBTAKUApn/TP4I//z/q//wAFAD5gEg/pj6uP/8AmADZP+i/mj+WP7F/4gAJAKwACIAD/+7/6r+fP+KALIAY/8b/0//KgFGAZ4BsP0U/oD8KgCWARgCgADl/w3/JP0g/7v/vAJIAaD+lP2t/8wAIwCUAZoA4P6k/Ub+ggHmAVD/Nv+qAHkAeP7h/3AArQAY/0P/5AEuAer+vv7F/2kAZf9ZACgBJgGK/7L+rgCr/zgA7v5wAgoB9gBG/l4AEgFsAej+hf/MAO4BNQCZ/yQAMAAEAR7/NgHFAOf/6P0V/2wBUAOmAez+3P1K/sj+1gDcAgQD4gAI/fj9Pv/MAJQAggEcA1kAJP7I/PAA1gE2AQD/b/9nAGAAtv+hAFT/+P70/Zz/nAHxABz97P3O/4wCMgGo/TD9hP8WAHL+2P8iAVgCjf/k/Xj9DACm/z0AeQCsAAD/qP7N/1oA5QAG/8z9FwDJAJMA6P8t/yUACgDu/lj+dAGiAf7/Sv76/uD/GAFo/04AxgFnAL//hP3q/ur+3AJEAt4Brv6M/m7/vQCUAJr/DAIEAP3/iP+YAXYAvP9s/8f/6gHk/m4BAALOAYj+Cv57ACgC9AFQABgAuv+Q/9AAqgHjABP//gCcAAcA1P24/6wBhgB+/pr+pAJYAcj+sPxe/ggA2wBJADoBEABu/kz9uP1MAFABHALD/w//GP3e/vX/UAHkAIb/Iv8W/8T/dP8PAGgBdAEeAFD+YP9IANMAXv+YACoBlAGRALH/ZgC0/hf/SP8cAvIB+QCo/6b/if9D/8z/1wCGAaYAYf+O//3/vQC6ABYAbwDd/0cAAP48AKAAaALxAF4AEgCt/wX/EP7oAeoBDALE/noAVv9O/7j+UgCAAm4A7P6E/aoA1/9WAVkARgAx/1z+pv7i/joBBAJEA3D/OP3E/IT/kQCWAaQC5QBH/2z8vP7+AHwBiP+rANj/MQCe/sr/nv+D/3X/zwBMARoALf/K/pr/yP4IAVQBEgEo/sz+rQCJAEMASv/IAG3/gv6C/rQBdAEiAUn/uf9Q/pD+uwCIAoYBpP1H/5//TAIaAAwBKQA9/5z9Hv/qAX8ApwDh/5wCnv+g/Xz9+QCMAQIBGQChAPH/Ov4i/9ABYAKGAFj+hv78/ogBBgEoAmsAQv9P/5j/fv+eALMAgwBmAZYA5QBq/lT9rP4EAiQCfQBw/4D/uf+8/Iz+pwDsAksASv4k/sT+Y//s/agBdAC2ADj95P5o/tH/DP+ZAOgA4v5C/+j9FABK/+cA2wBqAbb+2v4H/5X/rQA+AYgDpgA1/2j8VACzAHIB7v+rABwBwf8g/wn/bgFo/y3/oP6AAtEA4/+k/bb+dgG3ADwCYAByAKD9iv6y/wwCDAPAAYYBiv6G/7L+ZwBIALoBAALCABv/PP/LABIBdgD8/k4A1/9JABEAMgF7AAgA3AD+AKEA0Px4/UH/AAMMAiIBZgAK/zT+4Px3/5YB/AFx/5v/Hv9rAEz/aQDs/xT+Av62/tYBVQBDAK7/zQB0/qT9UP4cAQIBYv9V/+T/8/89ABYBLQDS/gD9r//mACABvv8MAdABMf9A/Qz9LgAEApAC4AEu/8z95P2+AO0ACwBcAHgBRgEm/mD+ZgCwASgAnv8IAQoB/P4z//0A4AF+/+T+NgBGARIAZP/fAB4BUAA//2IBBwDY/qj9wQD4AeIBof+G/5v/e/9a/5D/kwBg//oBvv9H/7j8UQA8AroBWv5g/VgA8/8J/xX/rAF+AYb/jP6D/+P/awAmAeoBk//g/TL/+AEUAn7/8v9t/xH/QP57AAwDhAGm/kT8wP1s/hoB9AJ0A1oAkPzw+xD+/v8gAkgC+gFe//j9IP1S/xoBTAKpAGD/av6q/5EAigASAfIBBgG0/zj9Av9YABwD9AKQAeH/6P3Q/XT+dAHUAXQCDgFAAAD/4P1o/h8AlAI8AUMAl/8qALL/uP6r/xcAtQCV/xUAVQDU/yv/nv/GAPf/ov8e/xMAQP+k/wcA2gFIAWP/ev64/fL+Xv9QARQCdAIYAHz+IP0+/q3/eAHMAbgA5//K/hEAqP+FAAX/8v6Y/7YADAEkAL3/bv+3/y//3f8iACEAuv7q/sX/QgEoAb8A2P8e/ij9Av4iAUADwALT/1L+cP1g/tr/4wAYAkQBPACA/hb+kP54ADwBeQCg/zr/uf9w/9D/5f+OAb0AjP9+/pD+QgA2AXgC9wDMAHj+nP7K/hUA7AE4ArgBh//G/ir++P5wABwCmALvAFb+VP0i/0wB7AG4AUMAZ/86/m7+Qf9uAUgCnAHm/7z+Gv+///UAPgAKAb//6v8oAE4BzgEbAEP/nv4KAE8AigD9AKsAUwBq//j+nP6J/2QALgG4AFz/6P4E/wn/Ef8pAGYAXgA2/4j+uv6z/0QAjwDWAGX/Gf9g/tb+4/92AbABkgEdAHb+HP5c/lkAnAGkAggCbADK/sD96P5qACYBLgGqAe4A/v+k/jz/fwCHAM4AZQCnAAsAyf/L/68A1ABjABYABgBr/13/Yv8MABIBxAHEAJz/zv5q/hf/S/9CARwCfAI1AHb+DP7o/hwApgEsAjAB8/+C/pL+dP/GACwBTAEWAMj/BP+v/77/eAAQAXMApwCX/7f/Ff9g/yMAqAEEAukAB/+Q/Rz+iP88AggDBAKi/6D9tP20/qsAPAJsAtcAdv5A/Yj+ewCaAa4BTgAG/zL+wP7X/9YAOgGUADUAiv+k/jL+FP9WAIoBYAFaADz/Lv6I/eL+aQB2AdAALAAcACr/Cv7E/Xr/KgECAc3/d/+j/8D/TP9+/9T/4f9d/7n/KQDQAP7/XP+3/2cA0QD7/8L/hP+c/3L/HAB2AYgBiwAT/3r+/v7f/7YA7wD3ADIAi/8x/4f/fwAiAd4AAwCq/8j/FABfAHgAKAHVAEsAOf9n/9X/8QDeAH8AyQBLAP7/YP8IAKcAKAELAKn/hf/2/5YA6wAWASsAQ/+i/uz+if9WAPMAbAC5/zH/fP8p/xL/Pf8hADAAk/9M/6r/WwDw/6z/eP+T/zT/Ef/S/3sAxwBDAMz/IACV/zr/DP+l/zIANgByAEYBbgHv/2b+AP7s/lUA8gCOAUoBXQCD/2L/c//b/yoAsQD1AI0ABgDR/3AAqgDuAE0Ay/+Q/w0AMwBgAKoAIgFyAVUAqP8+/9z/LwCMANYA2QDpADUAHQCx/xsADgA6ADAALwCjAKIAxwB7ADkA7v90/8b/UwCoAFQACQD3/9f/ff9o/xYA5P+F/9b+3v5o/wQAMwAKAEj/Wv4K/mb+Af/d/zkA6f/G/hT+Gv7U/iX/NP9m/z7/3v5a/nT+6P5O/yb/G//S/hH/wP7g/hX/Wf9X//b+Hf9k/6f/gP+W/yIAHgDP/3P/rf8bAIIAFgFoAWgB8gDjAMAA6gB2AUgCmAJMAvwBCAJYAggC+gFMAowCeAIwAmgCqAKAAjACkAGcAbgB5AEgAu4B3AF+AfkAkwCSAN8AGAEaAbAAZACh/0//jv+N/2L/Ev/m/rj+HP64/dD9/P28/QD9cPwU/MD76Ps0/GD8APw4+5j6cPqY+vj6gPuI+3j7CPsA+xD7MPuw+1z80PzY/OT81Pwk/Rj9pP1Y/gf/eP/q/5IAPQA1AHQAXgGkAoQD5APoAxAECATYBNAFWAaoBkAGOAZwBsgG6AdQCEAIAAh4B1gHQAeAB8AHIAjYB/gHKAdgB/AGqAbQBVgFeAWABZgFOAUABWgESAP8AYIB/wC9AMD/l/88/0T+GP1o+6j6OPp4+YD4kPfA9mD1APXA9CD1gPQg82DygPGQ8bDxQPIw80DzMPMg8xDzoPPg86D00PXg9rD34Phg+Rj6QPpA+xT8UP3A/vf/PAGwAVACLAMgBBAF+AXgBiAIYAgACeAJkArQCuAKcAvgC4AMUAzwDPAMsAzgC+ALgAxQDGAMAAxwDOALMAtACkAK8AnACfAJYAnACAAIMAcIB6gGuAV4BegE9APMAvwB+AGMAZ4ASQAt/+j9LPzA+jj6oPkg+fD42Pig95D1kPNw8hDyoPEw8tDywPIA8qDwoO8g72Dv4O8w8eDyMPOw8yDz4PKg83D08PVQ9/D4mPlw+tj6mPvA/Dj9Cv4B/yYA5AD6ATwDzAPkA9QDgATYBEAFeAUIBkgHqAcgCOAHaAdYBlgGqAeQCMAJUAlgCcgH2AZgB3AIsAlQCTAJ8Aj4B/gGOAeQCLAJgAkQCcAIAAioBlAGuAZYB4gHyAeAB9AG2AWIBPADcANsA3wDbAM4A1QCWgE3APr+Jv58/cj8BPyY+9j6EPrA+MD3IPYw9TD0gPNw8yDzQPPA8hDyMPFw8JDwsPDg8PDxQPIg82DzEPRg9LD0UPXA9TD3EPjY+XD7gPyo/fj9VP6A/kT/WQBYAsADuARIBVAF8ARwBAAF4AWIB3AIcAhQCIAHcAcQB2gHoAhgCeAJQAnwCGAI2AcgCMAI8AkgCnAJkAgQCNgHmAdgCIAJIAqACfAIcAiwB7gGcAbYBkAIYAgQCGAHIAbABOQD+ANgBPgEsAQQBKQCWAG1AFMA+/+w/6b+SP3g+6D76Pq4+hD5KPhA9sD00PPg80D04PNA83Dy4PFw8ODvwO9w8MDwIPLA8gD0APRQ86DzgPOw9PD1CPjw+VD7+Puo/Iz9mP1I/uD+9v9wARAD+ARgBjAG4AVoBQAFcAWwBnAIoAkwCfAIsAiQCLgHcAegCDAJIAlACRAJAAkQCJgHQAhQCFAI+AfwB7AHuAYQB3AH4AdwB2gHaAdwB0gG6AUwBqAFSAaQBuAGeAaoBfgEMATEA+gDWARoBOADIAO0ApAB4QA0AOr/oP5A/Yz8aPwM/Nj6kPkA+MD10PMQ88DzwPOA8+DyIPIg8QDvgO5A7qDugO/g8GDysPJg8jDyMPKQ8qDzcPWQ9xj5KPpw+3T8AP14/cj+S/+t/7UApAKwBLAFUAZIBgAGIAUABYgGwAdwCNAIgAmwCYAIIAgwCHAIMAhQCEAJYAkQCbAIsAjQCAAIgAcACGAHcAfgBhAIAAjgB0AHyAaoBrgGeAbwBsAGsAawBVgFuAX4BWgGoAXwBKAD0APsAkADjAPAA/QCggF0AH7/1P5Y/ej8iPx4/Lj7GPqY+GD2QPTQ8nDyUPPg83DzwPGw8ADvAO4A7kDuoO8w8NDwEPFw8bDxEPIA85DzAPVA9vD36Pgw+jD73Py0/dL+sv+KAFwB7gEYA8AEMAYYB2gHYAcoB+gGEAewB/AIoAlQCiAKgAnQCWAJIAlACLAIMAkQCTAJUAnQCWAJmAcwB3gHCAdwBsgGgAiwCMAH0AbYBogGeAWYBagGkAeABsgFwAXABYAFUAWYBcgEGATUAmADMAQ4BIQD2AJqAfL/W/9o/ij+nP0g/Tz9kPuY+ZD3MPVw83Dy8PPA9JD0sPKg8CDvgO0g7QDuEPAQ8ODvwO9Q8GDwcPCA8QDzYPSA9ED2kPcQ+Yj5sPpo/Hz9ov4HAFIB1AFUAlAD6AQIBmAGsAcgCJgHEAewB/AIQAmQCVAJ8AngCcAJcAmQCSAJQAhwCIAIAAlACbAIgAgQCJgHEAeIBrgG4AZQB3AHgAc4BygHEAYIBsAFaAaQBmgGcAYoBtgFCAaoBWAFKAUoBAgEUAS4BLAExANkArABOQBh/yP/QP72/qj9MP3Q+0j5oPbQ8zDzUPOg9PD0oPRA8oDvQO1g7EDtQO4A8EDwwO/A72DvoO8w8EDx8PJA9LD18PZ4+ID5YPo4+3z8Bv4//9QAmAEcAzAEEAUoBtgGSAewBygHyAeACPAJcApwCkAKYAkQCbAIYAmwCRAKoAkwCfAI8AhQCLAHuAfQB/AHcAeAB8gH+AawBhAG6AYAB8AGeAYAB+AGSAY4BpAGsAYABsAFCAYgBqAFgAUoBWAFmARoBNAEEAQoA8wBYgGZAID/ov74/bT9/PwU/GD6gPew86DxsPHA8lDzYPSA8zDwYOwg6qDqIOuA7EDuAPAA8CDuwO0g7kDu4O4Q8fDzEPZQ93D4kPnA+VD6DPzY/Rr/bQAwAqgDqASQBQAHsAfgBngGaAcwCCAJUArQCxAMcAoQCfAIMAkwCbAJkArwCkAKMAnwCDAIcAcIB5AH2AfQB/AH0AdwB8AGgAZwBlAGKAbABogHYAdgBzgHCAdIBgAGYAbIBkgGMAZYBkAG+AQQBWgFGATUA/IBQgEYAbX/Mv8M/oD9FPw4+xj6CPjw9NDxcPAA8GDxwPJg8rDwoO3A6sDooOhg6gDsIO7g7mDvIO7A7eDtwO5g8CDyoPWg90j5OPkw+6T80PwA/uT/YAKMAvgC4AT4BjAIgAiQCDAJIAggB/AHAAqgCwAM8AuQC8AJUAgQCDAIQAmQCaAKUApACSAIsAeIBnAFUAaQB+gHQAdIB5AHMAeoBeAFyAbwBkgG4Ab4B2AIIAf4BqgHeAeQBkAGMAdgBzAHSAYoB9gGkAXoBKADxAMsASgBVgD9/8L+LP14/KD7mPlQ9TDzQPCA8ADxAPOA89DxYO4A6yDpQOiA6YDr4O0A7yDvwO4g74DuQO7A7zDyAPXw9sD4cPtg/JT8QP3i/lkAYgE0AmAEIAYgB7AI4AlACkAJEAiQB/gHQAlQCxAN8AzQC1AKcAgYB4gG4AfACdAJIAlACaAIKAYgBGgEeAXABYgFoAZwB2gG4ATYBOAFoAUYBagF8AZQBzAHYAcQCOAHQAcYB8gGGAcIB4gHuAewBzgH6AaIBZAEbAPAAoIB1f8JAJr+nP3Q+5D7UPrQ9eDxgO/g7qDvsPBQ8iDyQO+g6oDoYOfg54DpYOxg7oDv4O8g7yDvgO6g78DxgPRg9wD6VPw8/dT9qv5RAGABVAIIBOAFIAeACAAKUAuwC7AKQAmgCMAIsAmQCyANYA1wDAALsAgIB/AGMAcACIAIQAkQCYgH6AWwBEAEtAPgA+gE+AVQBggG2AXgBaAFMAWoBfAFcAYQB7gHgAigCNAIcAggCGgHQAegB6AHIAgQCEAIGAfQBRgEKAOkAWcAn//i/hT9IPyY+1D6oPeQ8sDvwOwA7KDt4O/Q8ADwYOzA6ODlYOQg5QDpwOsA7mDvwO+A7gDtoO1g77DyUPVA+Vj8zP16/q7+SgCmAYQCIARwBuAHsAiQCuAL8AwADGALcAqwCcAJkArgC4AMIA1wDNAKkAi4BrgFWAVABfgGwAjQBzgG+AQoBIQCeAG4AlgEKAV4BRgG4AbIBpgFyAXABeAF6AUwB0AJAApgCmAKwAmACMgHSAegB/AHsAhQCTAI4AZoBXQDJgHJ/8z+Iv5M/Nj62PpQ+TD20PEA7qDrgOlA66DtQO+g7aDqQOjA5ODiAOSg54DqwO0g7wDwYO+A7iDvgPAQ9JD36Pvw/p8AfAGoAuQCEATYBRAIYAkgCtALQA2wDcAN0A1wDXAM0ApACpALwAvAC5AL4AugCuAHmAYYBcAEGATYBIAFkAXwBEQDxALCAcIBCALcApQDUARwBSAGoAYgB/AHiAdYB8AHUAlwCvAKkAvgC1AMgAtAC0ALUAqQCVAJYAngCJAHsAZABcgCN/80/tz8ePog+lj5WPjw8iDtIOoA6QDo4OlA7CDuYOoA5wDkYOJA4sDjYOdg60DuwO8w8JDwsPBg8tD0IPew+2n/NAOgAzAG4AfwCEAJEAoADPALUAxwDcAPYBEAEWAQ8A5wDAAJwAiQCVAKwAqQC/AKqAegBJgCVALjANcAZAIwA6wC8ADwAcwBZAEUAlgCVAOUAwAE4AVIB5AIUAogC3AKgAlACqAK0AqQC6AN4A4ADqAMMAxACyAJcAcwCNgHKAfIBBADDALo/ZD7sPjA91D3UPaQ9KDv4OlA5mDkQOTA5wDrgOtA6ODkgONg4eDgYOMg6UDtwO7A8DDzYPQA8zD16PgQ/OD+mAEYBuAHEArQC1AN4A2QDOAL8AvQCyANsA/gEKARoA8wDRAKAAaIBIgEIAbgBvAHuAcIBuwCPgD6/uD9cP4g/7wAwAFGAbgCcAOQAxwDsAMABAAFqAVgCOAL0AxwDYAN4A0QDAALgAuQDCAOUA5AD0APUA2wCgAIMAjABgAG0AToBDwDwQBg/kD6ePgg9mD1cPOw8hDxYO6A6YDkgOMg5IDl4OeA6kDrgOhA5SDlIOZA56DogO0A8vD1sPf4+sD7sPsM/fz+wAFwBGgHIAtQDQAOUA+wD+ANcAuwCbAKkArQChANUA5gDWAJKAa4BNQBWwCmANACAARsA1QDTAJYAWL+Zv4k/vz+xv+eAQgEaASABqAH4Ad4BxgHAAiQCfAJcAwgD6AQwBBQD0APIA4ADVAMoAywDHAMwAsgCwAKoAjYBsgEwAI6AfP/4P3Q+5j6YPmQ92D0oPKg8qDxQO4A6sDnwORA4wDkoOdA66DrAOxA62DpYOcg52DpYOxQ8dD1EPvc/AD+Gv7A/pT9nv74AmgGgAjgCGALIAyAC2AKcAqwCRAHuASYBEAGQAfQB0AIgAcoBY4B6v7s/GD9T/+iAXgDIASQBBwDWAGf/+//3gFYAngEGAfQCdAKYAqACvAKoArwCYAKMAygDVAO8A7AD1APMA4wDFALEAowCUAIAAjQB2gHYAfwBUgEvAI0APj9+PtY/Ij7KPuI+ED3oPZA9SDzIPJQ8CDtoOjA5aDloOaA6QDtAPAg8ADugOvA6IDowOqA7rDzAPiM/KD+nv5k/fz9sv6JAJwCUAWQByAH6AbwB+AJMApACSAIIAbYA60ATgAMAogEaAUYBWgE9AHO/sj8LP0I/4kAEAJcA5gEQASEAwAESARgBGgFeAZIByAIYAlgC4AM8AwADVAM8AswCxALYAuwDNAN8A2QDcAMQAtACfAGKAbwBogGqAWoBXgF9ANMAWH/BAAo/5z9QP0Y/ID5EPfQ9bD2sPfw9TDzYO/A6kDngOSA5uDpgO5Q8dDxQPCg7QDrAOqg6gDvEPSY+Iz8Uv74/nD+yP4y/2cAlALQBMgE6ANQBHAFuAZwBwAIsAgYBvAAOv5Q/vr/7gAgAhgE/AOUAZb/iv8EAJAATAFUA9gEeAVoBagGIAiACAAJgAgwCSAJAAkACnALcA1gDlAOcA1ADCALEArwChAMEA0QDZAMsAvgCRAIGAewBsAFsAQABbgEzAOAAhQCxAKiAW8ALv85/1D88PlQ+Gj4IPmA+cD30PRA8IDrYOfA5eDm4OmA7UDwoPEQ8sDv4Oxg66DswO7A8oD3oPvm/kj/KgCPAJUA9gC0AUwCnALoAtAC8AJYBBAGQAd4BggE8QBi/oj8BP0a/iwAxgEUAbgAZgDCADwA6QD6ASAD3AOMA1AFEAiQCbAJQAqACmAJoAggCRAKsArgCzANkA2QDKALUAvACmAK0ApwC0AKwAkwCvAJwAd4BigGGAaABHgCjAPQAwwCYAEoAyAEmAKZAJb/Iv5o+7j5CPmI+jD6gPnQ9pDzYO9A6gDnYOUA54DpQO3A75DyUPLA8CDuAO4A7wDxgPSQ+Fz8IP/CAIYBDANwAxgE5AMwAxADYAJ6ARYBZAJwBCAF6AQYAy4AzP0k/CD8xPxS/jb/D/+1/zsAhgEcAuACGASQBRgGQAbAB3AJgAoACzAL4AvQC+AL4AtQDEAMIAzQC8ALYAzQC1ALkAoACmAKEAmACcAJkAgwB/gFOAWkA8gCoALMA6gDMAM0A8gD9APkAqgCsgHo/w7+kPxU/Mj7CPuY+aD38PTA8aDsAOjg5WDlgOag6CDt8PFw88DxkPCA74DvYO9g8rD3NPzU/kEAEAJAA2QDaANQBCgFCAW0A64B9//G/9QAaAJAA4wD5AJiANz8IPs4/Lz8JPxg/G7+MAApAD8AxAJ4BQgG6AU4B+AIAAlgCKAJ0ApgCzALYAsQDOALkAtgCiAKMAqwCtAJ4AhQCeAI4AhoByAIQAlQCOAFEAUgBAADqAEMAlAEEARYBPgDSASIA+QCoAMcA4ACmgFGANj+iPwE/MD6wPfw9KDyAO9A6mDlIOMA5CDlAOkA7mDyEPPg8CDv4O4w8KDxMPWA+kP/SAGQAQgDeAQYBaAFIAaoBmgFZAJMAIn/jv8+/0AAngAVAKT+IPzg+Yj5ePpQ+wD88Pym/tD+KAB4AXQDQAUQBxAJAAqgCiALcAvwC5ALcAwADRAM8ArgCjALEArgCEAJ0AqQCbAHwAdoB/gGaAZwB8AIUAjABeQDGAMMAt4BwAEABCgFaAWYBGQDrAMQBKADUAOAAvACcwAC/ij9gPtQ+TD2gPQw8UDswOdg5CDhYOCA4wDqgO8g8nDzQPQg8qDvkPGg9bj5+PuF/2ADSASoA2AE2Aa4B0AHKAZoBUgC/v4c/ST93P30/fL+sP5I/qT8+Ppg+2j7CPyk/ND8wP7A/5YBaAMIBnAIUAqwC5AMsAwADKALwAuQDOALIAugC6AL0AogCpAJAArwCJgHwAegCLgHMAdoBzAIUAjIB7AGcAa4BVAELANAA9gDSARwBMAEEAU4BbAEoARIBHAESANoAqwBUf8W/nD7gPlw9pDzMPGg7ODnIOQA4uDgAOLg5yDvoPPQ82DzIPSQ8+DyoPWw+fD9BAGcAcgDWAUQBtgF0Aa4B6AG2AO6/wT+8PzI+sj5ePtw/WD9HPwc/Az8QPuQ+8D84P3c/cr+DAGQAhAE0AawCcAKwAsgDdANsAuQCqALsAwAC+AIwAnACWAIEAdQCKAJYAigBsAGAAdgBpAGUAbAB3AIkAgYB9AFWAaoBVAEhAMIBUgGOAXgA4AFMAa4BTAEuAQIBfADoAJcAaIAIP8A/LD5IPiw9aDyIO8g60DnIOOA4CDhIOVg6zDwwPOg9YD18PXw9jj4yPmM/boATAFAAggD0ASgBbAFcAdQCLgGmAKp/8D9APvA+Aj4OPqo+7D7UPvw+wD9EP1s/Wj/dgFUAc4AdAHgA6AG+AYACvAMwA3wDDAMYAwgC7AJsAlwCoAJ6AfYBugGuAaYBqAHYAhwCNAH2AfIB0AHgAeoBwAIWAdAB/gF8ATQBDAFeAXwBJgESAVwBSgEwAQoBcAFeATYAzAEzAImAZz+jP3w+6j4IPWA8mDw4Owg6eDkQOGA3+DhgOag66DwsPWA91D20PVg90j5sPmI+8j/cAKCAYcAmAIABTAExAMoBSAF+gE+/uD72Plg9+D2iPhw+dD5sPog+2D76Pvo/jIB8AGcAgAEYAXIBLgFwAhgCxAMsAzwDTAOkAywCmAK0AkQCYgHuAaIBnAFOAWABbgG0AdQCJAIkAigCAAIiAeoB3AIYAjwB0AHeAYwBlAFCAXQBBgFiAQIBHgDzAOcA7AChAK4AzwDIgFFAFj+KP24+pD3oPXQ8iDwwOyg6cDlAOKA4GDigOZA64DwYPQQ9lD3kPew96D4aPrc/Ar+7P+kACgBDgGsAtAEQAVIBNQDmAMzALj7WPl4+kj5UPdY+ED6QPrA97D4dPzy/iwAggHsA1AFSASIBIAG0AhgCoALsAzQDCAMkAvACqAJwAlgCdAIGAfgBagFeAWoBKAFcAiQCQAJ4AjACaAJYAjwByAJUAnwB5AGoAYgBggFOAToBHgF2ASQBMgEAAWABBgEOATwBCgE1AIAAnkAf/84/Aj7kPjg9WDyQO7A6wDoQONg4KDiYObA6yDwsPSw9zj4EPj4+Cj68PoA/Iz9bf94/2v/BgGQA/gD3AOwBCAFKAOf/6T94PwY+vD30Pfg+Kj4YPew96j5WPts/bgADAMIBDAEgAToBJgF+AeQCpALsAtgDHAMMAvACbAJ4ArgCVAHiAbQBsAEXAIQA+AFUAdABzAI0AnQCVAIQAiwCXAKYAnACGAIIAeoBbAEaASgBMgE+ASgBOwDaASoBKgEgARgBcAFuATIAjwCHgGy/qD76Pmg+AD0MPCA7aDrgOaA4eDhgOTg50DsYPGw9lj4kPh4+Vj7EPto+/T8wP2w/UT+kP8+ACYBPAIoBBAE3AL0AeMAov5I+9D5yPlY+Qj4kPdI+JD4QPmI+4r+cAFkA3AEGAUABuAGgAgwCkALIAwADVAMwAqgCvAKwAmQCCAIAAgwBggEsANgBNgE+ARwBoAIIAkACbAJwArgCrAK4AqwCkAJ4AcAB6AFUAS4AzAEUAQgBCgE8AQ4BegEkAUIBggG6AQgBCwDtAG4/4z+rPzY+WD2QPRQ8UDtgOkg5kDkYOEA4wDowOxA8dD1aPg4+aD4aPlg+/D7yPo4/BT+lP1w/Pz95ADQAVQCIAOQBGgDnQCM/vz84PsA+sj4WPkY+Tj4WPjA+dD7iP6vAAQDKAQABSAGuAYQCNAJcAugC+AKwArwCiAKwAjACEAK0AloB9AGmAYYBTgDnAOgBYAG4AawB7AIAAnACCAJUAoQCpAJIAkwCKgGeATAA0ADvAK8AtACrAL0AsQD9ANwBJAEgAVYBcwDvAIkAtUA5P0o+5j54Pbg8iDwgO4A7KDnIORA5ADkAOZA6rDwUPUw9fD2mPgo+QD5EPrQ+8z8DP08/cz9Zv7d/0IB6ALQA5AE5AOIATn/Tv7E/CD6ePgA+eD4MPeA9rj4oPtA/f7+CAKQBDAFSAWAByAKcAvwCmALMAzQCoAJgAjgCIAIEAhQCKgHaAbABGAEaARgBCAF6Ab4B3gHuAfgCLAJUAkACoALsAsACkAISAfABcgDuALAAlgC8AGwAiADWAPIA3gFeAZoBeAEuAV4BTQC4P/W/3j9QPlA9TD0gPKA7gDrwOlA6ADloONg5kDqwO6A8lD1sPYA+Nj4oPnw+Yj7uPxw/GD8XPwi/lL+2f+EAugFgAZIBTAEUAIsAAT+AP3Q+4D5wPcQ99D2oPZo+MD7+P6DAFwC4ATwBjAIsAnQC0ANoAxAC1AL0AqwCeAIsAgQCYAJ4AhQB9AFEAVYBFAE6AQ4BpgHWAe4BngHcAgwCVAJoAowC3AKUAjYBmgGWAXYA+ACJAP4AvQBgAKgA3AEuATgBIAFSAV4BJgD6ALWAeL/VP3Q+iD34PQw8uDuAO0g7ADrQOhg5kDoQOqA64Du4POw93D2kPYY+Qj7cPrY+cj7ZPxY+2D6qPy8/pYAIANABqgHsAWoA5wB4f8O/sD8OPtQ+TD38PVg9hD3QPmo+4L+ZgGMA9AFEAhACgAMcAygDEAMsAuwCkAJ+AdgCKAI8Ae4B3AHsAYoBbgDeAPQBIAFoAUwBmgHgAfgBjAHwAiACgALgApwCjAKwAiwBtgFaAWABPgCKAIwAiQCaAIoA2AEAAW4BUAFiAS4A+QClgEr/0z96Pqw9+DzIPGA74DtIOvA6uDqYOpg6WDrAO/g8MDxsPSw95D4EPcQ+Cj6YPnw9zD5SPug++D7jP0kApgFGAdwCOgH2AVUAjIA0P6s/Dj6+Pgg94D1IPXg9Yj5qPv8/hQCyASABzAJQAsQDDAN8AwgDLAKIArQCHAHYAc4BxAIcAdgBugFeAUIBbAE2AQIBvAGcAewB7AHUAjACKAIIAmwCaAKEArgCFAI6AdQBsgEuANsA5QCYAFqAfIBHAN8A0AEwAQIBSgEuALYAdYATv/g/GD6kPgg9WDx4O7A7SDsoOpA6SDqQOsg6yDswO+A8tDycPTw9rD4oPdA95D4uPkA+WD4yPko/Ij9o//cA8AGgAcgBlAEcgG2/iz92PsA+7j4EPfQ9TD10PV4+Cz82P7LAIQDyAYwCZAKsAvADRAOAA1wC8AJwAhIBzAHAAfABpAGcAZYBrgFgAUgBhAHUAcgCHAJ0AkgCcAIMAmACQAJoAhgCfAJUAkQCLAHaAdQBiAFOARgA2AC3AE8AvgCvAMIBEgEAARsA7wCoAFsAHT/+P2Q+2j4cPXw8pDwAO5A7IDrgOrg6QDqgOuA7GDtYO9Q8lD0gPQg9cD2APgw91D3kPl4+tD5GPtW/mQBOASwBSAI0AhABSQCg//Y/jT9cPuw+XD3kPWg9OD1sPdA+ij9EwAUA6gFAAhgChAMEA7gDXANEAzACtAIWAeoBygHUAYABfAFCAeABnAFqAbACGAJwAlQCpALEAswCsAJcAnwCGAIcAigCAAIaAfYBiAGsAVQBfgEKASEA3QD/AP0A3AESAUYBpgFAAQsA7wCZAGC/1b+nPzQ+ZD2EPRA8oDwAO6g7MDroOtg64DrwOyA7qDvEPFQ8+D0kPXA9cD2APhA+OD3MPkg+5D7ZPzk/hgEWAaoByAHyAbwBJYAzP5E/gj9IPnA9kD1cPWg9JD1qPjI+3T+SAGQBPAGwAhwCgAN4A2gDAAL4AngCAgHsAWoBfgFqAWYBdAGAAdQB8AHAAkgCmAKUArACmAKcAmwCDAIqAcoB2gHcAfYBjAGgAZABgAGQAZoBggGKAVABIgE4ASgBOAE2AXIBagEoANMA0wC+QBB/3D9QPvA+GD20PNw8SDv4O2g7GDrIOvA6wDsYOzg7XDw0PFQ8gD0YPXQ9VD1sPaY+Cj5gPjw+QT9J/+YAJgDIAjgCAAH8ASgBNQC2P64/GD7WPmg9iD04PNQ9DD2+Pi8/Pr+HAFYBBAHoAlgDHAO4A1ADCALsAqgCTAIkAdoB7gG+AVYBnAHYAjwCIAJIAogCgAKsAqwCrAJ4AgwCFAHmAZwBrgGeAaABWgFqAZYB+gGsAZQBwgHAAZYBSgGwAZQBgAGCAaIBZgEdANMArUAXv+g/XD7WPlw99D1QPOQ8MDuAO5g7ADroOoA62Dr4OuA7aDv8PBw8eDyMPQw9XD1cPYw97D30Pdw+cD74v4MAggFEAewBzgHqAWwBE4Bbf+o/Zj6kPfA9YD00PMA9AD2cPng/Jz+GAGABNgHoArADBAOwA0QDYALEAowCbAIkAgIB4AGsAaoBggH6AfACUAK0AmwCVAKYArwCVAJkAjQB6gGMAZ4BoAGGAYQBpAGoAZAB6AHeAdQB9gGWAYABqgFcAWABTgFuAS8A5QDHAPoAXUA+P6M/bj7ePmw9+D1kPNQ8QDvwO1g7MDrgOuA6+DrgOwA7oDvIPEA8lDzcPQw9fD1sPbQ9xj4UPjg+Qj8nP42AcAE0AfACIAHoAYABSgDJAC4/ej8EPkA9nD0wPSg9eD2yPjY+vT99wDkA8AG4AngDFAO0A1ADSANAAzwCSAJsAkACeAG+AVAB3AIYAjQCFAKUAuQCkAKcAqgCvAJ0AggCIgHcAbIBTAGMAaoBhgHuAfgBxAI8AjwCIAISAfwBqgGAAZYBRAFOAVABOwCCAKqAaoA9v5c/Tz8iPpo+BD2UPTA8pDw4O6g7YDswOvA6yDsYOzg7KDugPBA8bDxgPMA9bD0IPVA9jD4UPiA+Nj6aP4EASQDqAZwCVAJIAiABWAErAKVAIT9iPrg9/D1kPTg9JD2APjg+Vj77v50AvgFcAggC8ANAA6gDRANkAywCyAKUAmwCKgH6AY4BxAI0AgwCUAK8AoACxALUAsgC2AKUAmwCOgHIAZABQgFKAVIBXAF0AUgBogGgAdgCLAIMAigBwgHIAaABUAFcATAA3QCnAEuAPz+Dv5g/Tz8cPrA+FD3oPVg86DxwPDg7kDtQOzg6yDs4OvA7MDtAO8g8FDxgPJA8yD0oPWA9WD2EPgo+UD56PmM/awBFAPIBOAHgAnYBjwDMAOAAqL/NPwo+uj4oPWw9FD2sPgQ+Rj6tPyX/9YBmASwCKAKwAuQDPAMIAzgCnAKoArgCUAIMAjYB9gHEAhACVAK8AkACjAKAArwCWAJkAmwCDgHuAZ4BkgFsARQBQgGQAZABkAHAAiACEAI0AjgCNgHoAZABrgF+AQwBFwDoAKCAUQAPv84/nT9YPwA+xj5UPeg9QD0UPLQ8MDvIO9A7kDtgO0A7qDuwO6A70DxoPEQ8tDyQPTA9ID0cPXA94D4gPjQ+aD9ZgDaAbgEQAjACIgGUASABJQCmv7Y/Dj86PmQ9lD1kPbI+FD58PqE/dL+2ADIA8gHYAmACWAKAAtgCpAJsAngCXAJ+AfwCBAJoAiQCAAJMAqgCcAJkAlwCfAIQAiwBxAHKAaQBagF+ASQBNAEYAXoBXAGaAdgCKAIkAigCOAIYAhQB3AG6AUIBXAEHANAAoIBnQCC/4D+lP2Y/DD7sPlI+ND2UPUg86DxYPBg7yDuoO3g7QDuwO0A7gDvoPCg8DDxgPKg85Dz4POw9JD2IPcw91j5IPxw/Yf/rANgByAIiAYIBkgF3AKW/zD+MP14+nD3gPYg9/D20PcA+mj8QP0a/+wBwAQwB+AIwArAChAK8AmgClAKAAlgCPAIEAmgCAAJ4AmACiAKsAoQC4AKAApgCWAJYAiIB+AGGAZwBQAFkAXoBSAGuAb4B/AIIAkwCXAJUAnwCEAIeAewBsAFCAVIBKADoAKWAbMA1v8K/9D9mPxA+9j5aPjA9hD1MPPQ8aDwwO8A76DuoO7A7qDuQO8g8LDwIPEA8gDzIPMQ8+DzEPWQ9fD1wPcI+pD7HP0UAWAFeAdgBxAIQAh4BVACwgHOAGj9GPrw93D40Pfw9hD52Pps/GT9RgBMAxAF+AYACTAKYAnwCJAJ4AlQCQAJEAkQCVAIYAlQCiAL0AowC7ALoAtgC5AKAAqwCBAIQAc4BiAFCAVQBbgFMAbwBiAIgAhACQAKoAqACiAKcAnQCKAH0AYwBpAFEAUYBBwD/gEYAUsAyf+Y/ij9cPtA+tD4QPfQ9SD0YPKw8MDvQO/g7qDuYO5g7kDvQO8A8NDwEPJg8rDyoPOg9ID0wPRQ9qD3cPiY+dT8oQDAAjgEcAdQCLAFRAPSATAC6P4g/AD6QPnA99D10PfI+UD6GPrQ/FT/qAGoAvgEgAcwCMgHQAiwCGAIcAiwCPAIQAhQCHAJoAowC1ALcAvAC+AL0AtAC5AKMAlgCHAHeAYQBqgFUAWYBRgG6AaAB8gHcAgQCYAJgAmACVAJoAioB9gGgAbgBWAFAAVABEwDMAJIAZUAo/8O/lD8iPrA+DD34PVA9LDyMPEg8IDvIO/g7qDuoO6A7qDuYO8Q8LDwAPGw8VDywPIA81D0UPVg9iD3iPmw/Dn/RgE4BHgHeAdwBSAEEAS2Afb+XP3Q/Fj64PYA98j40PkA+qD6cP3g/hIAxgGoBOAFSAZAB3gHeAdwBzAIIAlgCRAJoAlwCiALIAzwDCANwAyADGAMAAzQCqAJ0AiAB4gGGAbIBWgFcAVIBuAGMAeYB3AI4AhwCJAIUAkgCTAI2AcwCKgHiAYgBogGIAawBLwDCAOEAeH/ev4E/ej68Phg9zD2cPQg8zDyAPHg76DvwO8g70DuAO5g7mDuYO7g7sDv4O9A8EDxMPLg8rDzUPWw9gj4oPmM/DD/GAKQBDAGoAUYBAgDngE8AFD9zPyo+0D5APgI+QD6OPqg+mT87P3E/k7/ygHcA/AEgAW4BdgF0AUIBzAIcAhwCOAIoAnQCQALcAxwDNALkAvwC0AL4AlQCRAJwAcQBlgFkAVYBTAF6AWwBrgGyAawB6AIsAjQCAAJ4AiACJAIkAhQCCAHiAYgBmgFsAQIBHgDnALSAW0A5P70/Kj7GPrQ+ED3wPUA9FDykPEw8dDwIPAA8MDvAO/A7iDvwO9g74DvcPAg8WDx4PHQ8yD10PUQ9wD5sPoY/KD+BALIA6ADuAPYA4ACEADO/vj+AP0Y+yj6sPqg+kj6EPtc/Pz8NP3c/V//vAA4AtgDkATgBDAFEAboBrgHwAhQCQAJcAmQCnALoAsADNAM0AywC0ALkAugCvAIEAgwCBAHAAUYBVgGqAYIBiAHIAmACJgHsAkwC2AKIAnQCFAKwAnAB1AIMAgIBzAFUAWQBdgDaAI4AhgCof84/TT84Po4+aD3MPbw9NDy8PEA8iDyEPEw8KDvYO9g76DuwO7g7oDvYO+g73DwIPIA8wD04PWg90D5aPos/Zn/qwCEAcQCZAO0AkgB/wAiAJL+XP0A/fj84PvA+yj8/Pyw/LT8YP0i/pD+a//5AJACrAN4BHgFIAbwBrAHEAiwCGAJUAlQCdAJMAvAC9ALUAygDSANEAwgDDAMIAvgCFAIYAgYBogD+ASYB4gHKAeIBwAKsAgwCGAJcAuACkAHIAjQCcAI6AWABvgGKAZYAxgD+AP0AjoBCgHCAPD9KPsg+vj54PcA9dDzUPMg8lDxYPGA8WDw4O5g7gDvYO7g7SDuwO5A74DvcPBw8pDzYPQA9iD4SPqQ+2D9P/9qAMMADgFyAUwBKQDy/nT+8P0A/bj82PzA/Fz8oPz8/DD9CP1M/eD9Pv7S/kAAFAI0A9wD0AToBVAGAAfoB4AIoAiQCNAIEAnACeAKwAuQC0AMkAyQDCAL4AogCyAKSAd4BbAFAAWgA0AFAAlwCXgHOAcwCjALIAkACWAK8AmIBwgGEAhACLgGqAWoBggGGARwA5ADOAN2ATf/iP0s/HD6gPko+KD2UPUg9KDzMPMQ81DyIPEQ8IDvYO+A7iDuwO7A7uDuwO+Q8QDzoPMw9UD3uPiA+Tj7rP2M/nz+Lv+RAJ0Anf89/+X/P/8C/oj9Ev7s/XT9YP24/bj9rP3w/dT98P1O/ln//P8GAWwC2ANoBMgEyAXYBlgHaAfQBzAIMAgwCBAJ4AnACnAL4AuAC7ALcAtQC0AKYAlwCJAG8ANMA8AE0AVYB8gH8AmQCtAIcAgwCiAKoAgAB8gGiAZYBmgGSAdoB2gG8AVABRgEEAOUAiAB/v5o/VT8WPsY+dD40Piw9rD0MPSg9FDzgPFw8GDwAO/A7eDtYO4A7oDtgO4A8ADxwPEg8/D0sPXw9mj4+PmY+7D8hP1S/hT/gf+5/9b/FwBk/4j+EP40/uj9KP0o/QD+DP54/Zz9lP4x/1T+1v78/xgBaAFQAuwDmATgBJAF6AYQB0gH+AegCJAIoAjgCdAKoApACzAMIAzQCqAKEAuACvgHCAdYBmgF3AMABLgHgAjQCKAI8AiwCAAIMAgQCHAH0AZoBlAGyAZAB+gHaAcIBugE6ANcAiIB3ACcAOr+JP08/AT8APvw+TD58Pfg9VD0oPOw8lDxkPBA8MDvgO5g7kDvQO/g7qDvAPHA8bDxIPMA9XD2UPdQ+Aj6YPsg/AD9lv6q//H/yv/P/w0A/v9O/7r+4v5O/+z+fP7Y/mD/cf8B/+7+Bv8Z/y7/CwCiAKwBdAKEAxgEwATQBWgG4AaoBtgHcAgQCDAIoAmwCoAKQArAC8ALcAtwCmAL0AoACXgHeAcIBpgEUAUwCFAK0AjgCZAKQAoACKAIEArQCKAGUAYACHAIYAfwB2AJgAhABYgDoAN8AvEA7v8CAGH//P2k/Gz80Ptw+jD5UPew9XD0MPMQ8iDxAPFA8ZDwoO/g74DwUPDA77DwwPFg8kDyAPNw9VD30Pc4+Hj5OPtw+9D7AP3a/mH/LP7o/bL+If9I/gr+A/90/2D+1P3S/mP/5P6E/pz+hv7G/iz/NwBSAbYBvAI4A0wDvANgBSgGoAUQBjgHwAc4B+gHwAmwCpAJ4AlACyALEApACXAKQAkABwAG+AagBngFGAZwCXAK0AiQCWAKgAmYB5AHYAmgCKAGgAfACaAJkAd4B7AI4AeIBPwCMAOcAt8AIgDEAUIBY/9M/az8QPxg+mj4cPcQ9yD1QPMw8oDycPLA8eDwQPAQ8ADwAPCg8HDxUPLQ8iDzUPQw9pD3OPg4+Gj5cPpw+hD7BP2g/nr+3P34/Vv/6v4A/lr+oP/w/sD9tP0t/7r/Rv5g/jH/g/+U/q7+0/8mAewAbAEYAkADNAOMA6AEmAU4BVgF2AUIB2gHWAeACIAJYAmACNAIcAmgCPgGEAfYB8gGGAXgBNgHAAhwBgAHUAnwCRAJwAggCdAIwAagB4AIQAnwCHAIEAnABwgHiAbgBYgEmAPUAkQCWgHaAbACiAFm/9D9xPw4+5j5IPkw+TD30PVA9WD14PSQ8zDzMPPA8eDwEPFQ8gDzIPOw8zD0wPSg9SD2IPcI+FD4qPjo+Pj5uPvM/OD8DP3A/cT9KP24/JT9XP5g/Yz82PwG/sT9MP0A/ST+9P3U/GT84P3A/iz+mv74/4oBIAFcARACNAPQAoACcAOQBAAFOAWIBgAHIAcAB1gHOAdQBqAGyAZ4BsAFwAaIB/gGeAXIBagH6AcYB6AIwAowCvgHMAdACCAIgAcgCFAJYAkgBxAHyAeYB3AGYAUABQAEkALYAowDYAM4AloBIwCI/jz9/PzI/Kj7WPqA+cD4kPfw9hD3gPZA9eDzEPRA9DD0EPTg9ED18PTQ9FD1kPbg9sD2EPdA+KD4wPiQ+Tj7JPyo+1j76PtU/BD8EPyw/CT9wPxo/Oj8RP1I/SD9OP2I/SD9yPxY/QT+Nv6Y/lj/DwBoAMEAQAHAAQgCDAKoAggDaAP0A3gEUAVgBagFsAXQBcAFKAYgBvAFYAbABugGqAZ4BhgHYAcoB0AH0AiQCWAJ8AgACXAJgAggCEAJQAoQCoAJQAmACRAJMAjQB7gHSAd4BhgGeAagBuAFEAVQBEwDPAIYAXsASwBn/zT+VP20/KD7qPqo+SD5QPgg94D2MPbQ9YD1YPVQ9SD1wPSw9PD04PSg9OD0YPWw9fD1kPZA96D3YPcY+Bj4IPg4+Kj4IPmA+Yj5APrg+oD6YPqw+iD7KPso+6D7PPx4/Iz8QP3w/Vr+vP5Z/wIAWwC6AEoBygEsApwCUAPoA0gEuAQwBXAFmAUgBpgG+AZAB5AH0AcACPgHEAiwCOAIAAmwCaAKMAsgC6AK4ArwCmAKgApwCwAM0AsgCwALAAswCnAJgAlwCdAIwAf4BwAIYAcgBugFgAVgBAgDYAI8AlgBIQAU/6D+aP24+yj7mPqw+YD4oPcA93D2UPXQ9JD0IPSg8yDzIPMA8/DyEPMg8/DyMPPQ8zD0cPSg9FD1oPWA9cD1cPbw9uD2gPdA+Oj4APk4+Rj6iPq4+tD6iPso/HT89PyY/SL+gv7c/r//LgCuAFoBrgEYAiACqAJgAwgE+AOYBGAFoAWwBegF2AYgBwAHMAfQBzAIEAgQCMAIIAnACLAIgAlACiAKUAqgCgALcAoQCpAKAAvwCqAKAAvwCnAK4AlgCSAJ8AgwCGAIAAiwB0AHQAe4BugFYAWQBOgDmALkAUgBYwAP/xz+uP14/Cj7aPr4+dj4MPeA9jD2kPVA9MDzAPSA87DykPIg8zDzoPLQ8mDzkPNw88DzkPTg9PD0gPUA9kD2UPbg9pD3sPew92D4+Pgw+Uj54Plo+nD6iPpA+/j7ZPyU/FT9PP5q/sr+a/9TAKYAkgBEAegBVAJgAkgDAARoBGgE6ASoBdAF0AU4BugGCAcQB3AHIAhgCHAIwAhwCaAJgAkACnAKsArACvAKQAtQC/AKMAuAC3ALMAswC1AL8ApgClAKQArQCUAJIAkACZAI6AcACDAIeAcQBpAFuAR4A/YBYgH9ANj/2P7w/Sz9wPtA+qD5wPig97D2UPbA9bD04PMA9MDz8PKg8iDzgPMg8wDzsPPw86DzgPNQ9PD08PQw9fD1YPZQ9lD2QPfg9/D3GPjQ+Gj5WPmI+RD62PoQ+zj7IPwI/Xj94P2u/oP/3f8RALEAhAHaATwC7AKIA9QDQAS4BEgFaAXoBVAGoAboBvAGaAe4B8gH4AeACOAI4AgACXAJ4AmwCbAJEAqQCmAKUAqwCvAK4ApwCrAK4ArACmAKoAqgCiAKsAmACUAJwAhACFAIMAjAB2gHwAc4B0AGEAU4BHwDnAHoAKYADwC8/oD92Pzo+3D6YPno+DD4APcA9pD1APUA9EDzUPNA88DyoPIQ80Dz8PLw8mDzYPNA83DzUPTg9BD1QPXQ9UD2IPZw9kD30Pfw9zj4yPhA+VD5kPlQ+uj6MPuw+3D8LP20/Sb+zP7T/8D/PQACAaQB1AFEAtACYAPMA9gDmAQoBYAFkAXQBUgGaAZ4BtAGQAdQB4gH4AdACGAIsAgQCSAJEAlgCbAJ0AnQCRAKkApwCkAKQArACqAKMAowCoAKMArACWAJgAlwCaAIUAiACIAI+AegB3AHYAdYBhgFYARsAyAC7QBiAP3/Cf+0/dj86Ptg+nD5WPgI+BD38PUw9QD1UPSA81DzMPMg8wDzEPMw82DzQPMw84DzsPPw82D00PRg9eD18PVA9mD2APdw97D3IPiw+Bj5SPlg+fD5uPoY+3D7JPzc/IT94P10/lb/6f8HAJ0AhgHyAQgCkAJEA6QDqAM4BNgEMAUwBXgFAAYIBvAFOAbABgAHsAYAB4gHmAeoB8AHcAiwCHAIcAgACTAJAAkACWAJ0AlwCVAJwAnwCbAJgAmgCaAJYAngCMAI0AhQCMgH0AegB5gHSAdAB+gGWAagBagEtAOMArwBEAEYAF7/+v7Y/bz8MPuY+rD5sPiA9+D2oPaA9bD0QPRw9PDzcPNg8/DzEPRw86DzMPRA9PDz8PMA9XD1gPWw9YD2APew9vD2wPdI+GD4oPho+bj5qPn4+bD6GPtA+9j7tPwQ/Uz9/P3S/i7/P//5/+EA/wAkAaoBkAK4AsACVANYBJAEiAToBKAFsAVIBcAFOAaoBngGkAZoB3AHWAdwBzAIUAhACHAI4AgQCdAI8AhgCZAJYAmQCeAJAArQCbAJ0AngCYAJYAmACTAJ0AiACHAIIAjQB6gHuAeAByAH4AaIBtAFsATIA+QCuAG2AEsA1/8O/7j9xPws/Lj6cPmo+Jj4cPdw9tD10PVA9WD0YPRg9GD00PMQ9KD0YPQw9HD0EPUQ9dD0gPVg9nD2YPbQ9oD3cPdA9+D3wPjQ+Lj4EPnY+fj5wPlw+lj7uPvQ+2j8ZP3A/eT9iv5t/+j/EwCrAHwB9gHwAVQCBANQA3QD5AN4BLgEuAT4BEAFeAVoBdAFMAZQBmgGuAbwBiAHMAeIB8gH6AcgCDAIcAhwCHAIgAjACMAIsAjgCPAI8AjACMAI0AiwCHAIgAhQCAAIqAdoB3gHGAcIB/AGCAeoBjgG6AU4BQgEAANcAs4BugDt/7v/JP9g/Uj8kPsA+7D5UPiY+PD38PbQ9dD1wPUA9WD0cPTw9ID0IPRQ9LD0YPQQ9HD0APUw9UD1oPUA9iD2IPZw9tD24PYg96D3APgo+Fj4sPgY+Vj5sPlY+gD7SPvQ+4D8IP10/dz9lP5A/7j/9P+lAA4BbAGcASwCtAI4AzwD6ANIBFAEcASwBBAFSAVwBagFUAZgBnAGsAYIBzgHMAdwB9AH+AfgBzAIUAiACGAIoAjQCOAI4AgACSAJEAkACRAJMAkACdAIwAigCDAI6AfgB/AHuAeoB6gH0AeAB6gGMAaQBZgEUANgAhAC1AGWAJT/RP8u/rz8ePvI+rD6gPmA+PD3sPfQ9sD1gPWw9UD10PTQ9FD1APWg9JD00PQA9bD0IPWQ9fD18PUg9oD2gPbA9uD2cPfA9/D3GPiA+Lj42Pgw+aj5QPqI+hj7uPsY/JT8IP2c/Sb+nP41//T/UQDbABYBqAHqAWQC0AIoA6wD1AMwBFgEeASoBNgEKAVgBagF0AXQBSgGQAZYBngGkAb4BgAHGAdIB2AHkAdoB4AHoAcACOgH0AcACEAIUAj4BzAIcAiACEAIEAhACPAHiAc4B3gHcAdAByAHUAc4B8gGEAbgBRgFGARkA5gCHAIsAcoAEwBC/1L+YP18/Kj7oPpI+rD50Pjg94D3MPew9jD28PVg9iD2wPWw9QD2wPVg9aD14PUw9hD2YPbg9vD28PYA98D30Pfw92D4yPgQ+ej4SPnQ+fj5KPq4+mj7oPvo+4D8DP1s/cj9WP4M/1P/i/8mAL0A0AAeAYoBUAKUAtQCPAO8A/QD8AMYBIgEsAS4BPAEOAWgBYAFsAUYBkgGWAZgBuAG6AYQB/gGOAdgB0AHcAeYB+gH6AcgCEAIUAhgCGAIgAhwCIAIkAigCEAIIAgACNAHoAeIB6AH0Ad4B0gHMAfgBkAGYAXYBCAEPANkAgACrAG+AKj//P5k/hD92Ptg+1j7WPpo+bj4gPjg9/D24Pbg9qD2EPYQ9mD28PWQ9aD1EPbw9bD1EPaw9pD2cPaw9iD3MPfg9mD3GPg4+Aj4KPio+Nj42Pgg+cD5OPpw+rD6UPvA+xD8ePwY/bT9Iv64/jD/wf8TAI0A4gBQAcIBUAKoAuACLAN4A7ADzAP4A2gEgARoBJAE4AT4BAAFKAWgBcAFwAXoBUAGaAZgBngGqAbQBrAGwAYYB1AHOAc4B5AHyAfAB4gH4AfwB7gHeAeAB8AHSAdAB1AHiAdIBxAHcAdgB9gGUAZQBgAGuATUA/QD1AN0AmwBLgESAYv/9P34/Yz9dPzo+sj6uPrI+Xj4OPiw+CD4MPfQ9kD3APdw9vD1QPZA9hD2APYQ9mD2UPZQ9lD2gPbA9tD2sPbA9kD3gPdw92D34PdI+Fj4OPjY+Hj52Png+Sj6APto+8D7EPwA/Xj9wP0E/rj+ZP+4/8P/bQACAVYBdAHcAXACuALAAtgCpAPQA8QD6ANIBHAEWASIBAgFaAVABXAFqAUABvAFKAaABpgGiAaoBvAGCAcQBzgHmAeYB7AH8AdQCGAIIAggCHAIUAgACMgHUAhACJgHaAcgCLAIIAh4B9gH+Ac4BrAE+ATIBTgFmAOwAhwD0gG6/0D/2f9G/1z9VPxc/PD7MPr4+Gj5SPlY+HD30PdI+HD3wPaQ9tD2sPaA9sD24Pbg9mD2UPaQ9tD20PYg90D3QPdw96D3oPeg9xj4SPiA+LD4+Ph4+eD5IPpA+sj6OPvQ+yD8uPxA/QD+Lv5u/jz/2v9CAGkAEgH0ASQCDAJwAigDZAMQA4wDQASABDAEEATgBAgFuASoBCAFkAVYBUgFmAUgBtgFmAXoBVAGYAb4BTAGmAa4BmAGUAbYBhgHIAcYB3gHYAc4BxAHYAeIB1AHCAdYBxgHyAYABxAHcAcwB0AHuAbYBRAF4ATwBIAEXAMkA8ACtAFaANj/0/8b/8z90Pzc/BD8wPr4+ej5ePmA+Aj4QPiQ+ND3YPcg9yD3APfQ9kD3UPcw99D28PYQ9xD3QPeg97D3sPfA9wD4KPhA+HD4oPi4+MD4IPmw+fj5+Pk4+qj6+PpQ+5D7UPzM/BD9SP3E/TL+nP7s/nL/8P9DALcAKgGOAYYBtgFUArgC5ALsAnwDmAOIA2wD4ANgBDAESASABNgEsASABMAEQAVYBQgFCAVABaAFmAWwBcgFAAYIBiAGYAawBuAGCAfgBrAGwAbwBggHCAdIB2AHyAbwBUgGsAcgCFgHmAagBkgG6AQ4BLgFmAVIBLgCfAJUAuoABwAjABwAoP4s/TD9OP0M/Nj6kPpY+oD5IPmQ+Wj5iPig99D3EPiw97D3CPgg+HD3APdw98D3sPeQ98D3wPeQ98D3OPhY+DD4OPiY+MD4oPjo+JD5qPmg+RD6wPoI++j6YPtE/MD82Pxo/Vr+tP6M/uj+tP9QAHsA6gB6AdIBsAHqAWgCzALwAhwDeAO4A5gDgAO8AwgEEAQgBGAEmASgBJgEoAQABdgEKAUwBYgFaAUQBZAFkAXgBagFAAYwBgAGaAbwBjgHgAY4BvAGaAfABnAGsAcwCLAGKAWwBqAIEAgIB0gH6AdABgAEmAQ4B2AGkANMAlwDFAPtADAA+gCOAez+PP3A/Ur+MP04+yD7WPvY+hD6EPpQ+uj5wPgQ+Fj4GPk4+Yj4CPjQ9yj48Pfg9yj4wPiA+JD3sPdw+ND4UPhA+Lj4+PiI+JD4ePkI+nj5gPkg+hD74PoY+7D7UPxw/GD8XP0k/mL+PP6+/kT/tP/k/4sAMAE0AUQBVgH0AQgCpALMAhAD2AIUA6ADcAOIA2ADQAR4BAgE7AOIBBAFqAQgBLAEyAXYBQgFEAXYBUAGYAVgBdAGyAd4BpgFmAawCOgHEAaIBmAI8AiwBpgGgAhQCHAG8AVQCMAJcAhQBpAGEAdIBXAEwAUYB3gFsAK0ARACxgGyAJQAmgBd/4z9/PwQ/ZD8kPv4+tD6MPqw+bj54PkI+Xj4IPgo+FD4IPhQ+CD4oPcg90D3kPfA98D3sPeQ92D3wPfg9wj4APjg9wj4EPgw+Lj4CPkA+RD5WPno+TD6qPog+4D7yPsM/Oz8aP3Y/RL+jP4O/27/4v9+ABIBMAFaAawB/gFMAowCEANUAyADOAOMA9QDxAPMAwgEUARIBFAEmASwBLgEqATQBAgFEAVgBVgFSAVoBeAF+AWwBbgFYAbIBoAG4AZQB2AH0AX4BagH4Ah4B2AGAAd4B1gGmAUACMAJMAiYBQAGsAaQBVgEUAUQB/gEFAKgAcQCAAK7/7v/nwDH/1j95PzM/fj8sPow+nD7SPs4+rj5MPqw+TD48PcA+bD5EPmg+Jj4YPjQ9/D3qPgY+cD4MPgI+Aj4UPiA+Ij4gPhY+HD4SPhI+KD4OPko+cj48Pi4+Rj68Pkw+uj6cPtQ+7D7rPyE/Vz9NP3o/fL+Yf+C/+X/lwDYAJ0A9wCeAVACFAL8AVQC4AL4AtQC7AJ4A4QDaAMkA6gDKARABPwD0AMYBHAEsAR4BLgEGAUgBYgEaARYBTAGsAWoBDgGOAc4BgAFuAW4B8gHIAZgBsgHmAfIBYgFoAcwCNAGIAZIB/gHkAaABcgFaAYwBcgDCATABEAETAIkAcgAZwDP/6v/GwBn/7T9DPyA+wD8BPzo+4j7EPtg+nj5WPmQ+Qj6KPqI+Qj58PgY+Qj5mPiY+Nj4yPiQ+Ij4wPi4+Fj4SPig+Pj4+Pi4+ND48PgY+Uj5ePn4+Tj6QPpg+rj6QPu4+wD8cPzM/CT9kP0A/ob+wv45/8n/egDMANQALAGMAc4BCAKIAhgDNAMAAwQDZAPEA7gDrAP0AzAEKAT0AxgEeASgBFAECARIBBAFKAWwBLgEGAVgBagEmAToBdAGEAYABRgG+AZQBjAFYAbQCBAIoAXQBfgHaAdgBuAFYAiACNAFcAXQB0AJEAZgBHgFiAbIBEQDmAT4BYADz/8IANQBbAHM/4n/RwC8/hz8mPtA/Xj9sPsQ+5D7aPto+uj5cPqo+sD5aPkY+lj6wPl4+Sj52Pi4+Fj50PmY+Rj5yPjA+Ij4sPho+ZD58PhA+Kj4WPlo+Vj5mPnw+bj5yPlw+kD7WPtg+5j7KPyU/Bj90P1E/jD+MP7q/tn/TwB4AOQA/gDbAP4A4gG4AsgCbAJ0AtQC5ALYAiwDtAPAA0ADKAOIA+AD1AOYA8gDEAT4A7wDEARIBFgE5AOgAygEqASQBKAE4ATgBNAE2ARIBbAF0AXgBfAF0AWABeAFMAZABjgGSAZYBngFAAWgBnAIsAa4BBgEQAWgBDgDWATQBagEcgBq/5wBaAJTAPj+qACCAPz8ePtI/T3/VP3w+ij7CP1c/Kj6yPrQ+4D7kPno+Wj74Ptg+iD5WPkY+jj66PkA+lD6sPmw+GD4OPkQ+sD54Piw+Oj4IPk4+SD54PnA+Uj5cPlo+jj7CPv4+jj7yPsw/KD8WP3c/fD97P14/jT/1/8YAGsAbgBvAOIAiAEQAhgCEAIUAhQCQAK8AkADbAMoA/QC9ALUAiQDiAPkA8ADTANEA2QDlAOUA9QDIAQYBPwD8AMQBHgEkAR4BMgECAVYBSgFKAXoBTgGmAXwBOAFKAcgB9AFaAUoBvAFcAVYBkAIEAjQBRgEkAS4BagEUAV4BfgEuAL2AHABKAL8AfMAqACP/3D+xP1w/kD+TP1k/Cj8NPyo++j7PPxg+yj6kPmY+jj7qPrw+fj56Pno+Mj4mPlw+sD5oPg4+OD4SPnY+KD46PgI+ZD4GPgQ+SD66Pnw+LD46Pmg+pj62Pqo+zj8cPtg+4z88P0e/rD9TP5Z/73/uf8yACwBcgFAAUgBHALoAiADHAMgAzADKANkA/ADiASYBCgErAO0A/gDSASABIgEcAQ4BAgEGARIBIgEwAToBKAEaASoBCgFUAUQBUAFqAW4BYAF6AWYBngGwAWQBagGcAcYB6AGuAaABrgFiAWwBvAHWAdgBigG0AWwBIgDAAWgBrgF2APIAqwClgFEAN8AiAKsAX3//P0u/iL+rPxk/Ej9sP0g/KD6GPvw+1j7KPr4+ZD6mPrY+bD5SPoQ+vD4MPjQ+Kj5QPnA+Kj4+PiI+OD34Pdg+FD4APgo+Ij4qPhY+Jj4APk4+WD5+PmA+rj6wPpY+wD8TPyA/Ez9+P0c/j7+9P77/1gAQQCrAGYBnAGuAQACDAMkA9ACsAIcA8wDrAOQA9wDKAQQBJwDfAPcAygE7APkA9gDGAQQBMADuAPQA9AD+AMoBIAEcAQ4BCAEEARIBJAEaAXIBSAFoAQgBWgFWAUQBYAG8AYgBqAEeAVoBqgFCAVgBagH6AaoBPgDEAUwBUADZAO4BIgFhAPiALkA8ADJABAAiQBQAb//zPxI+4D8oP18/Yj8SPzw+yD7KPpY+pj7yPuI+kD5IPlA+qj6+Pl4+Wj5QPmw+Ij4kPlQ+mj5APjQ98j4KPmg+Aj4iPjQ+Fj4SPgo+dj5qPno+Oj4CPro+vj6EPu4+wD8EPws/BT9NP5u/mD+1v6W/z4AlwCxAPkAXgGyATwCnAL4AhADFAMQAzwD4AMwBDgECATsAwgE8AMgBFAEgAR4BDgE+APsAzgEeAR4BFAEKARoBKgEaARoBKgECAUgBcgEGAWoBcgFKAUgBbAFWAY4BngFGAawBhAGqARIBbgG+AZwBQAFgAa4BmAE4AK4BNgFWATcAsQDmAToAUr/WgCIAqYBHf8p/6cAfP5I+9D7EP7I/jD8gPtk/Gj7oPn4+bz89Pw4+hD5mPkI+nj5oPkI+yj70PjA97D4uPl4+SD5qPlA+Qj4cPeY+GD58Pjw90j4GPnw+Cj5mPkg+sD5CPn4+YD7KPy4+5j7PPyw/IT8XP3U/vL/kP/q/oL/aAACATYB0AGYAogCIAJYAkwDzANsA0QD7AOYBGAE3AMABEgEGATgAzAEwAS4BFAE6APEA8QD7ANABMAE6ARoBOgDnAPsA3gE0AQYBfgESAXgBJAEiAQgBagFyAWoBbgF+AVwBUAFcAXYBaAFiAXoBZAGGAZgBcgEAAX4BJgE0AQIBbAElAOoAmgCEAJmAVoBwgFwAWEAyv4U/hb+8P00/uT9eP0Y/WT8mPsg+0z84Pw8/Bj7cPqg+gD66Pkw+1z8aPvw+Gj4WPng+YD50Pmw+gD6IPhw97j4oPno+Gj4GPmI+ej4oPjA+Xj6sPn4+Nj5WPvQ+7D7wPsU/PD7+Ps4/a7+Z/8a/+z+N/9r/wMACgHmASQC2AHIAQQCYALgAlgDuAOIA1QDcAPQA+wDpANoA5gD9APIA6wD0APkA3ADzAIoA6wD9AOsA7ADvANwA+QCPAMQBIgEaAQIBCAEQAQ4BEAEwAQYBQAF2ATABLgEyATABPAEIAUgBegEsASQBHAEUAQQBPAD9AOkAwADuAKAAiwCdgEMAUIB1wDF/yP/Mv/8/mT9YPyg/YT+dP14+1j7qPsg+4j6JPxS/lz8SPnA+DD6ePpY+tD6NP0E/Dj4QPdY+RD7wPnY+eD6qPo4+PD28PiY+jj54PcI+RD6KPlQ+Ij5mPq4+ZD4oPmY+7j7WPvQ+2z88Pt4+7j8oP5D/9D+0v5c/23/g/+SALYBBAK+AcoBHAJMAqwCJAOMA3QDFANcA9ADCAT0A9gDqAN8A3gD0AMgBPwDkANIA0wDYAOoA8gDuAN8A0ADHAM4A2QDuAPoA9QDoAN8A7wD5AMIBFAEkASYBGgEUARwBJgEmATIBAAFMAXIBFAEQAR4BKAEaAQoBBgExAMQA6gCoAKMAjwCtAFMARgBeACh/3z/af/4/ir+sP0U/lL+zP28/ND7uPtM/ET9oP1g/VT8GPuQ+nj6mPuQ/TT+RPzA+jD64Pqg+iD74Pxk/YD70Phg+Uj7gPsQ+vD5qPsw+1j5sPl4+xz8CPpQ+Qj74Pw4/FD7EPzc/Dz8aPvg/Oj+Xv9G/tD9tP6G/7n/8v+7AJABPAHDAAYBSAL0AmQCJAK4AkgDIAPEAkADUAToA9wC3AK0AxgEUAM4A7QD7ANEA9ACaAPEA3AD4AIoA6QDmAMoA0gDgAOIA1wDaAPkAxgECATcA+gDOARwBHAEaAR4BIAEYARgBNAECAXgBGgEYASwBMgEsASABIgEOAS0A2QDNAMYA9QCVALYAZIBQgEUAVkAqv9w//T+gP56/g7/B/9s/bD78Puc/ez9jP1E/Tj96PsI+oD63Pz8/Uj8CPww+/j62Pkg+iz8zPx4+7D56Pkg+jD6OPrY+sD6uPko+QD6qPpo+mD6iPp4+mj6uPrg+zz8uPuA+zT85PwE/cz9mP7m/l7+cv6I/8QAEgHzAAIBYgHYASgCwAKAA4gD7AKMAvQCCARoBDAEIAQIBKgD8AIsAwgEgATsA0gDaANkA/wCtALwAkQD/AK8AugCOAP8AoACaAJwAqgC+AJcA5QDTAPQApwCwAIYA6AD8APUA4gDWANIA0gDfAPYAxAE0ANQAxQDEAMsAzADAAO0AkACwAFsAWoBbAFMAX0Ap/89/yj/7v5s/i7+Iv60/dj8hPz8/Fj92PxI/AT8sPs4+yj75Pyg/QD8WPrI+Yj6wPr4+kD8CP1A+/D4WPiA+Zj6mPoo+7D7uPqI+ND3iPn4+vj6oPrg+jj7uPog+sD66Psw/AT8dPxk/dT9SP1E/dT9fv6c/vr+6/+1AJwACQD7/2QAJAG2AXwC4AKgAjAC/gFAAsACMAOkA9wDlAM0AxAD4ALoAigDrAPkA3wDFAP0AgADqAJ8ArwCSAMkA8gCtALIAsgCgAKcAjQDhANkAygDPAOMA4wDaAOkAwgEUAQYBLADwAP0AygEWARgBGAE7AOEA2QDwAMIBMADlAMsA7QCQAJAAiwCFAKGAYQB+wBuAJn/z/+d/+r+xv7W/oX/hP4s/bj88PwY/Qj9HP5e/pD90Pug+mD7dPyM/bj9UP0Y/GD60Pl4+jz8DP3U/Jj7QPp4+Zj5EPqo+lD7MPtI+mD5KPkA+nj6UPpo+iD7cPsw+/D6ePtE/FT8jPxw/Zb+qv5Y/nb+g/9eAG4A4ADyAbACcAIAAkQCWAPYA8gDQAQoBQgFMASoA2AEKAUIBeAEUAVYBWgEaAOQA2gEiAQYBPADKATAA8gCkAIEA1ADFAPQAjQDPAOwAhwCLAKcArwCyAIkA2gDGAOAAnAC0AIgAzQDZAOkA4wD2AKEArQC0AKsAlACYAI4AroBFAHcALAAZADq/6X/6f+K/7T+yP3c/fz92P2I/XT9dP2Y/Gj7WPuA/Nz8MPyA+3D7OPtY+kj6ePs8/Kj7gPqg+ij7gPqA+rD7lPwo/Kj64Prw+0j8SPyw/GT9zPyw+1D8gP0s/rz9gP3g/fT9NP2I/br+Jf+o/ib+fP62/rT+/v6h/9f/hv8s/wAAsQB7AJoAxQAGAQQB9gDMARwCwAF0AbwBRAIsAiQCrALsArgCbAKoAjQDPAMwA3wDnAOAA4AD0AMwBEAEOARIBGgEYASQBMgE2ATgBOgEAAXIBLgEqASwBMgEmASwBIgEKATAA4gDoAN4A3ADVAP8AmgC3gHAAcgB/gHCAYQBOgHnAIQAZAA2AFkAhAAZAMr/m/+d/3//Vf8Y/yD/wP5m/hj+fP5s/tD9VP04/TT9lPw0/Ej8tPxQ/OD74Pt4++j6KPpw+ij7WPtA+9j6cPrg+Yj5yPmA+kj7YPv4+mD6APow+rj6YPvI+/j70PuA+5j7BPyc/Pz8HP1Y/eD9LP6Y/ur+Vf+Z/8r/UAAeAQACiAKoArgCrALoApQDsARwBagFUAUQBQAFEAWYBVAGyAaQBugFgAVYBVgFkAXoBfgFeAXIBFAEUAQ4BOwDxAOcAzgDtAJgAkQC9gGMATABOAHtAL4AoACqAF4AwP+U/6n/yf+9/9z/vP9e/8r+zP5B/2H/U/8f//z+oP5u/nL+xv7I/mr+Iv78/cz9rP3I/ej9vP1Q/Rj99Pz0/OT8AP38/Nz8tPyQ/JT8oPyA/Hz8uPzA/NT83Pzo/NT8rPzg/Cj9ZP2o/cj97P3Q/fj9VP6e/sj+5v52/5j/cv9p/+n/fABNADEApAAkAfAAlADwAEYB/gBZALAATgEkAUAAHwCJAG0AtP+b/zoAVQCM/yX/g/+w/y7/1v5H/5L/Lv+G/g//Nf8G/4b+sv4w//z+4v4S/0b/Mv8H/xv/oP/v//L/EQBMAHYATwCVABoBeAGoAaABzAHUAQgCIAJIApwC0ALQAsgCoAL0AvQCnAKcAgQDeAPcAlgClAIEA3ACZgHSAdwCDANYAngClALQAeH/LgCYAuQDuANkArwBlwA0/6f/LAL0AygDsgFhAEb/fv7k/qcAxAH7ADf/Lv6o/fz8XP0y/gz+AP14/Nz83Pzw+1j72Pvw+0j7aPuo/Cj9JPxY+9j7UPzw+zz8tP22/qj9iPzk/OD9Hv7o/b7+qv9b/2T+pP64//D/cP96/5kAFgF2ABAA0wB2ARABwwA6ASACNAKGAaYBcAJ0AvIB+AGoAiwDDAOUAtwCaANAA+QC+AK8A+ADRAOwAhwDdAM8A6QCvAJIA8QCFALCAUQCbAL+AZIBpgGqAT4B6QAEAXgBQgHAAH8AzgDcAJYARQCKANgApgBoAFsApwByAD4AOgCfALcAuABQAEgAHAD6/x8AHAA1AOf/e/83/+b+3v5+/pb+WP4I/tD9aP0U/Zj8tPyo/HD8JPzw+9D7WPvg+vD6WPto+zD7KPs4+9D6cPq4+oD7yPtw+1j7qPu4+4D7uPtI/Mj8uPzI/Bz9YP1k/Wj97P14/rj+wP7y/lX/ff9y/4P/6P9QAF8AcgCJAJ0AlwBtAJUA3AD0AOMAxwDlAAoBCAEEAfQAIgFUAWQBpAHGARQCOAJIAlQCoALsAlQDeAPoA1gESAQgBNADgAT4BAgFCAVYBVAFiAQYBGgEcAWIBTgFSAXABIwDlAJoA7gEQAVwBHQDyALAAWIB5gHAAhwDNAI6AZAAAQDS/wAASQAkAJP/P//a/rL+jv5Y/gT+dP1k/fj9OP4A/lj93PyA/Aj8VPwQ/ZT9RP18/BD8wPt4+5j7aPzg/KT88Pug+6j7ePuA++j7aPxY/Pj72Pv4+xD8FPxg/MT8BP30/Aj9XP2w/eT9AP5i/tL+Kf9V/6z/QACfANcANAGmARQCXAK4AjADjAPIAwAEUASIBLgEuATgBAgFIAVYBUgFKAXoBLgEuATIBLAEkARoBBAExAOAA3ADXANMAwwDzAK0AngCIAL2AdYBugGKAWQBXAEsAdkAmgBpACsAAADf/wQA9f+P/zD//P7o/rz+pP7M/tz+qv5O/lb+Xv4a/tj98P1q/mz+8P24/Qj+JP7U/bT9Lv6G/i7+zP0K/lj+Jv68/SL+qv56/sT91P1k/nr+/P30/X7+lP4i/gL+hv7S/nz+SP6u/g7//P6c/hb/M/8j/+z+Nf+R/6P/nP+X/63/gv+x/8z/DgBGAFIARQAKAAYALQB1AG0AiwDBALMAaQAuAGUAnwBxAFoAgwCnAIEA+/8tAG0ANgDd/+T/UwBYAPj/1f8lAOT/Xv9A/x0AngBlAEsA2/++//z+Iv9uAFYBUAGSABEAYf8p/6D/0gBYAfcAvQB5APH/bP/J/8IAGAGeAGMAvwChAPb/BgDAANcAFAAhAPcAXAGmAO3/egD7AGkACwCxAGQBAAFaAJAA/QCeAAIALwDxAOMANwAsAI8AhwD8/4P/uP8GAMT/tP/q/9//g/8R/xb/V/9V/z3/Qf+E/4r/Wv8b/wv/IP8W/zv/eP+l/6L/jP9n/17/hf+l/8v/EwBcAIQAgQBSAEYAXABQAI0A6QBAATAB5ADHAJwAhgCHALwACAEkAdoAoQBpAFsAbABwAHEAawBxAF4AUwA0AD4AJwAnACQAPgB9AH0AbABwAIQAggCWAIcABgEkASoB9gAMAVYBRAEqATYBggGCAUQBKAEmAVgBDgHmAP8A/QCrAEIAZwCVAE4Ax/+Q/3b/N//O/sD+A//O/k7+6P3E/ZD9NP1A/Yj9fP0M/aD8qPys/IT8mPzQ/PT81PzQ/Oj8AP3s/AT9ZP2k/bj9wP3k/eT93P3s/Q7+NP48/kL+Vv5Q/hr+Dv4e/i7+Mv4k/jD+MP4u/kL+Xv52/l7+Xv6g/tr+Gf8q/1f/lP/M/9v/HQBmANUA/gAyAYYBxgH4AeYBQAK4AhQD+AI4A4wDvAPAA8gDkAQQBRAF+AQQBQAF0AQ4BQAGqAZgBrAFYAU4BTAFSAWIBcAFaAXABEAE0ANsAygDEAPgAlgC2gFSAdUAVgDH/1z/4P5W/hD+4P2U/fz8ZPwU/LD7WPso+yj7KPvg+qD6gPpQ+iD6IPpQ+pD6mPqw+tj68Pr4+gD7QPuY+9D7APxA/Ij8wPzk/Aj9QP10/az9+P1Q/qT+0v7u/iP/YP+R/8n/KQCbAOsAHgFOAY4BxgH6AUwCsAIIA0QDhAPAA+wD+AMgBGAEqAToBAgFIAUoBSAFIAVABUgFSAVABTgFOAUgBfgE2ATIBKAEaARABCgE+AO8A4ADSAMIA7QCdAJAAggCvAFwASQB3QCQAE4AHADV/4X/QP8X/+z+sv6C/mz+Sv4I/tz9wP2o/Yj9ZP1k/WD9JP3g/Nz8+Pz8/Nj8zPzc/ND8oPyQ/LD82PzE/MT84Pz0/NT8uPzk/CD9NP0c/Tj9cP14/XT9iP3Y/fz9AP4S/lT+mP6A/qb+zv4F/w3/OP90/5n/nv+p/9b/8P8JAB8AQABfAHcAiQCsALcAuwDVAOkA+wAWAS4BOAEyASIBMgEyATgBNgE+AVIBPAE0ATYBNAEiARQBFgEuATQBGgEcARwBHAEIARABLgE4ATIBFAEcASgBIAEoAUQBRAEeAfwA7QD2AAAB/QDyANEAsgChAI4AdgBZAEMAOgAkAP7/5P/b/7//lv99/27/Vv9D/zH/L/8e//L+1v7a/tr+wP6s/qz+tP6w/pz+lP6S/o7+iP6S/qb+sv6y/rb+vv7U/tT+1P7s/g3/I/8w/z3/VP9q/3j/j/+3/9X/5v/8/yQASABcAG4AiwCgALQA0wD1AA4BHAEqAToBTgFaAWgBegGQAZ4BqAGuAagBrAGwAboBxAHOAcgBugGwAaQBoAGUAYwBggF8AWwBXgFOATwBLgEcAQYB9ADrAN4AzgC2AKAAiwB3AGMASwA0AB4AAwDo/87/t/+n/4b/c/9e/0z/M/8Z/w3/Av/w/tj+xv6+/rD+ov6U/pr+oP6W/or+gv6E/ob+jv6e/qr+ov6a/p7+sv7A/sz+4P70/gD/Cf8Z/y7/Q/9a/3f/jv+e/67/yv/n//v/DAAjADwATABjAHkAiwCWAKIAuwDRAN4A6ADyAPoA/QAIARgBKAEsASwBLgEwASwBLAEuAS4BMAEoASABGAEQAQwBBAH4AOQA0ADJALsArwCdAIYAcABhAFAARgAtACYAGAAIAPL/3//d/8z/r/+Z/6L/hP91/2D/Yf9c/zD/KP8z/yz/EP/+/gP//v74/vr+B/8L//L+4P7w/gP/Df8I/xX/IP8c/xj/IP8v/zv/Qv9N/1f/Yv9r/3L/f/+J/5L/of+u/7z/y//f/+j/6v/y/wAAEgAeACoAOgBBAD8AOwBDAFEAWwBeAGMAZgBiAF8AXgBhAF8AWwBcAFwAUgBFAEMATABNAEAAMwAsADAAMAAsACwAKQAcABAADwASAA0ABQACAAEA/f/y/+z/6//o/+H/3f/b/9v/2v/X/9H/x//B/8D/xv/K/8j/xP+9/7f/s/+2/7f/s/+u/6z/sf+x/67/qv+r/67/rP+s/7H/t/+5/7r/vv/G/8r/zf/T/93/4//m/+n/7//4/wAABgAJAAkACAAMABUAHQAjACsANAA3ADkAQABJAFIAVQBZAGAAYgBcAF0AawB5AHYAbgBtAHQAcgBrAG4AewB6AG4AZwBtAGgAWQBTAF4AZABRAEAAQABBADQAHgAlACwAIwAOAA8AHQAGAPr/8f8BAPn/8v/z//X/6v/Y/9n/3//d/9L/y//K/8f/u/+6/7f/rv+n/6L/p/+o/6L/n/+Z/5P/lP+R/5T/kv+Q/5b/mP+b/6D/oP+f/6H/pf+z/73/uf+7/8D/w//I/9H/3P/m/+j/3//k//P/+/8IABcAGgAUAA8AEgAhAC4ANgA5ADkAOAA5AD0AQQBBAEEARgBKAEkARwBKAEoAQwA+AD8ARABHAEUARQBCADcALgAwADUAMgArACkAKgAnAB0AFQARAA4ACgAHAAcABQD9//T/8P/w/+z/5v/i/+L/3v/Y/8//yv/H/8H/u/+8/73/uf+z/7L/tf+1/7P/tf+4/7r/vf/C/8f/x//F/8X/y//R/9b/3P/j/+j/6f/o/+j/7P/v//f/AAAIAAoACAAIAAoADQAQABQAGAAbAB0AIAAiACEAIQAiACMAJgAqAC4AMAAuACsALAAwADIAMwA1ADUAMwAwAC4ALgAxAC8ALgAtAC0AKwAqACwALgAuACwAKAAmACEAHgAaABsAHQAZABAABwAEAAUACAAKAAcA/f/z/+3/7v/v/+7/6//n/+P/3v/b/9n/2f/Z/9n/1//V/9L/0//W/9n/2v/c/97/3//g/+L/4//i/+L/5v/r/+7/7f/p/+X/4v/h/+T/5//n/+L/3//d/9r/2P/W/9b/1v/W/9T/0f/R/9H/0v/O/8n/yP/M/83/zP/K/8b/wP+//77/xP+8/7//v//F/8L/wf/L/9D/x//D/9X/0f/V/8z/2//m/9P/1P/l/+3/4f/W/+D/6f/r/+r/9f8DAPf/6P/x/wcAEAAGAAwAGAAZABAADwAaACIAHwAdACIAJwAjAB4AHwAgAB0AGgAbABwAHAAcABkAEwAQAA8AFAAVABcAGgAbABYADgAOABMAGQAaABsAHAAbABkAGgAeACAAHwAgACIAHQAVABMAGgAdABcADwAMABAAEwASABMAEwAOAAkACgAQABIAEQAQABMAEwAQAA4ADwAQAA8ADgAQABMAFAASAA4ACQAIAAgACgANAA8ADQAIAAQAAgAEAAMA///7//j/9//2//P/8P/t/+z/6P/k/+P/4f/g/93/3P/d/97/3v/e/+H/5P/l/+X/5//t//T/+f/7//v/+f/6//3/AAADAAYACQALAA0AEgAYAB8AIwAnACwALgAuADIAPABGAEkARwBIAE4AUQBRAFUAXgBhAF0AWQBdAF0AWABUAFsAYABZAE8ATQBOAEcANgA5ADwAOQApACUALAAdABMACAARAAoABAABAAAA+f/r/+j/6v/q/+L/3v/d/93/1P/T/9H/y//H/8H/xP/H/8P/w//A/73/vv+6/7r/uP+z/7X/tv+4/7v/t/+z/7P/tP+8/8D/vP+8/77/vv/B/8b/zP/P/87/xv/I/9H/1v/e/+j/6v/n/+b/6f/z//7/BQAJAA0AEAAUABoAHwAjACUALAAxADMANQA3ADgANQAzADMANwA7ADsAOwA5ADMALgAvADIAMAAtACwALwAuACkAJgAmACQAIQAfAB8AHwAaABQAEgATABMAEQAQABEAEQAOAAoACAAGAAIA/v//////+//0//D/7v/r/+f/5f/k/+T/4//k/+X/4//e/9r/2v/c/97/4v/n/+r/6f/m/+X/5v/n/+r/8P/2//j/+P/4//r//P///wMABgAJAAsADgARABMAFAAUABUAGAAbAB0AHQAbABgAGAAZABoAGQAYABgAFgASABAADgAPAAwACQAGAAQAAQABAAIABQAFAAUABQAHAAgABwAEAAcACQAIAAMA///+//7/AwAFAAQA/P/0/+//7//u/+7/6v/m/+H/3P/Z/9j/1v/T/8//y//F/77/u/+6/7r/u/+6/7v/uP+3/7b/uv+8/7//xP/L/9P/2P/Z/9r/3//m/+//9//9/wIABgAJAAwAEAATABgAHQAiACQAJAAmACsALgAsACgAJQAsAC8AMQAyADEALwAsACcAKgAkACQAIAAiAB8AHgAkACgAIwAbACQAHAAjAB0AKwA3ACsALgA4AD0AMwAuADEAMQAxAC8ANgA9AC8AHgAhAC8ANQAsADAANgA1ACsAKgA1ADwAOQA5AEAASgBJAEQARgBKAEgARABDAEQARAA/ADkAMgAuACYAIQAfAB8AHgAaABIABwD8//X/9v/0/+7/5v/f/9//3f/e/9//4P/k/+X/4P/d/9z/3f/f/9r/1//R/9H/0f/Q/9D/yf/D/7n/uv+7/73/vf/A/8T/xv/D/7//wP/C/8P/x//M/9T/1//W/9T/1//c/+D/5//v//n//P/+/wEADAAXABkAGgAbACEAJAAkACcALgAxADMAMgAzADMAMQAyADIAMgAwAC4AKAAoACgAKQAoACEAGwAWAB0AJQAvAC8AKwAhABoAGgAcABwAGQAUABAADQAKAA0ADwAHAPn/8//z//f/+P/5//n/8//o/97/3v/k/+//+f/7//f/6f/o/+X/6f/p/+n/6//p/+//7P/w/+X/4v/W/9b/0P/T/9f/3//f/9T/yP+8/7f/v//J/9L/0//M/8P/vP/A/8z/0f/S/8z/zv/K/8v/0f/a/9f/0v/T/9b/1v/P/9H/2P/h/+D/5P/o/+j/5f/X/9f/5P/6/wcACAAOAA8ADQABAP7/DAAiACsAPQBEAEUAJgADAO3/7v8DAC0ATQBYAEEADAD9/w0ASABeAFoAMwAQAAQAFQBOAIEAhQBRACAAHgAxADgARQBFAEoAKAATACAATgBkAFkANwAnABsAGAAaAC0APwAzACAAGgAiACYADgAAAAAABAAIABEAGgAcACAAEgAIAOX/2f/o//3/+P/2//X/+P/j/7n/rP+7/8P/v/+d/43/jf+k/8n/2v/Z/8D/pP9p/1z/hf/n/wQAxf96/3f/xf/u//b/vv+R/23/mv/u/yQADwDE/5j/cf9t/4z/3/8TAPP/p/+A/5//yf/j/8b/vP+9/7//0//g/w0AAwC+/1b/m/8QAEwAuv/E/x8ANwDD/wz/4v9hAF8AT//i/0QAYgDV//z/iQBWAKb/Uv9mAPAA9ADA/4D/CwCOALgAKQBGAFwAFgCg//j/QgHeARwBt//M/ub+ZP+6/ywAhP50/LD7YP6MAlAECgFQ+uD0MPQo+Y//fAN8A9IB4f+y/qb+tv8SAeoA3P++/5wBuASAB/AHUAW8AIb+a/+wAtADpAPwArACMAI+AQwCEAM8A+oAFP/G/vP/1wCYABkAV/8l/5b/wP9r/2T+qP5w/wQAgP+q/0QAKgHTAKcAgAG6AZIBpQAaAcQBHAJmASQB1AFyAWQByQAUAvYBMgHT/7T/kgC4AKkAdADmADwA4//E/70AggBu/6b+5P4o/8r+jv7a/o3/VP/y/uj+W/9W/wP/0v4Q/6P/DgAcANv/9f+CAL0AeQAOADYAOwDM/1r/CQAqAXIBXgAo//D+hP9rABABIAFXAFv/xv4c/5v/FQBPACwApf/q/rz+DP9c/0L/6P7m/hH/Zf+Z/7P/of9U/8z+YP5Y/tb+t/94ALEASwB9//r+B/95/9z/9P/r/+f/0f+P/2H/jP/i/wwA5v+f/5H/m//S//z/CwCz/x//4v45/7f/5f+6/6n/pf+L/5H/y//W/2T/zv6y/jD/o//n/xIALgBJAAcA5f/B/7f/s//B/9D/wf/Q/wgAjQCvAJIAIgD0/wQAFQDv/7T/qv/R/xAAGgDh//7/QQB/ACcAxf+s//3/0v9Y//7+ev8GAEsAQwBjAIgAPwDY/1//Av+2/gX/uP86ABkA+P8xAHsAWAAKAOv/+/9x/wj/H/+8/0QAlACsAHcAYQAhABsAy/92/x//KP9O/6v/OgCqAAABAAHeAH0Axf8O/9r+Hf+I/+L/JABCAHQAjwCvAJAAOAC7/4P/i/+P/5b/uf83AJAAngCMALgADAH+ALAAXwAbAAcAJwBpALMArQCnAAwBZgFUAfYAqgCAAE8AHwABAPX/+/8iAH8ArACZAHkAhgByACQA/f8jAFUANgD//xAASwB7AG0AcACIAJIAiACHAHwAVQADAKH/if+s//z/NAByAJYAiABYABAA+P/q/8b/b/9A/13/uv8YAEcANgD2/8H/mP9//1//YP+P/7z/s/+S/57/zP/v/+v/x/+R/2j/Y/+G/4f/gP+R/8n/6P/P/5//lf+1/77/wv/I/xEAYgBwAFEAKwApACMARABhAJAAggA2APT/5P/5//P/9v8IABwADADy/+b/2v+7/5b/cf9W/3P/mv/0/xYADwDn/8v/w//B/9r/3v/r//j/JgBSAG0ARQAUAPz/BAD4/7n/nf/E////BgDU/7//AwAyADAAHQD6/7D/VP8k/1v/ef+g/7j/5f/e/7r/mv+O/5L/bv9i/1T/TP9P/2z/qP/h/zIAggCfAF0A/P+i/1r/Dv/6/iH/av+V/9D/UgDUABQBFgHmAJAAEACt/4P/ev+F/7n/GQBfAI8AjgCPAFwABgC7/4P/dv9s/43/u//0/yUAVwCSAJAAWAATANT/nP9y/1b/fv9s/1v/W/+i//v/JAAwAC8AWABEAD0AGwALAAAA6f/s/9D/s/+z/9//DQARAP7/7//R/5H/Vv9d/4P/cf9J/2z/0v8fAEQAUwBrAG0ATgApAPD/vf++/93/CgAOAAsAHwAmABMAEQA5AG8AhwB2AGMAWgBbAFoASwA4AFMAYwBKAPD/qv+O/3v/ZP8o//7+BP8+/4P/nf+N/4P/qf/Z//T/AQAvAE0AUAA7AC0AKAA3AG8AuADAAJEAMwATAPz/0/+0/8D/7v8TAPv/5v/X/7r/yf/g/wMAFwAHAO3/wv+S/4P/l/+x/6z/vv/9/yIAIQAZAEQAbgB7AGwAcABkAE0AMAA3AEQAZQC9APEA1ABxAE0ATABtAIsAgQBQAOj/n/+h/7H/q/+f/8D/zf+q/3H/e/+X/6r/n/+f/7b/rf+3/8n/7P8WAD0AdQCVALIAngCKAFcAGwATAFIAZwBUACoALAA0ACgAGABGAHEAagAvADAANAADANX/yP/q/8z/g/9c/2r/jv+l/+X/UwBTAAIA0f/r/xkADwAaAFwAsQCzAJcAlACAAEkAJQAFALT/Nv/S/gL/Rv9r/3b/ov+2/7f/pf/e/wYABADr/+3/1/+X/2r/jv/G/+H/4f/+//r/xv+Q/6D/0v+w/2j/a/+k/8P/xf/1/04AmgCcALYAswCAABYA/v8BANf/kv+O/8X/pv9V/zv/jf/t//7/3f/V/+X/7/8UAEUATAA7AEoAiADdAPYA6gDTALgAlwCJAHsAhgCGAGUASgBKAGoAjgCeAJwAfwBSACQA///s/9T/qP9m/x7/J/98/9T/4v/T/9D/BQAnAEMATABDADUANABdAGkAfAB8AH0AYwAlAOj/s/+K/2j/e/+G/33/Rv8k/x//Vf+X/8v/8f/g/9j/3//v/9X/qP+A/2//Xf89/zP/O/9F/1j/bv+r//H/MwBrAKQA1gAAASYBNAEsAQYB4QDEAIAACwCv/4L/eP90/2L/Zf90/53/v//4/ygAOwBaAHAAmwClAKkAqQClAHsAOwAjABUAJQA0AF4AdgB3AGkAVgBtAHUAfAByAHEATwAWAN3/u//I/77/nv9u/2X/i/+8/wAAOQB4AJcAhwBsACUA3f+5/9T/3f/B/5X/df9Z/0P/MP82/1P/bP+M/5L/bf9J/1b/Uf8//zX/O/9F/xv/Hv9V/4D/jP+E/7n/AAAAAP3/JwA0AAAAtv/F/wkA/f+3/4n/sf/k/+v/KwB+AKoAqACoAMwArgB3AGUAhACLAFkAPAAmABAA4v8OAFEAbABUAE4AcwBPAEEAagDMAOMAvQDMANYAsABzAIMAuwCoAFUAFAAXACcADgD7/woA///Z/77/vf+r/47/mv/G/+3/+v8NABMABQDc/83/BQBOAE8AKAAKAA4ABQC8/2n/Tv9O/0r/L/8z/2z/hf+o/97/QQCeAMMAwACxAJ8AcgAsAPb/yf+n/4T/bv95/2b/Tv8m/yP/Wf+A/8f/IgB8AK4ArwDFAOwAHgE0ASwBEgHIAHMAKAADAPb/9/8AAAYADwAJABsALQA+ADIAFQDc/6D/h/+V/5j/lP+i/6r/vv/F/9z/IQBxAK4AtACYAHwAcABeACoA8//l/+T/oP9s/4L/z//a/7//0P8SABgAIABdAKkAsgCNAKAAlABRAPH/4P/X/5D/Sf9r/5H/ev+E/+3/OwAxAAYANACJAHoAZACVAKUAgQBMAE8ASgATAOX/3/8HAOP/wv/N/woABAD8/wwAOgA/AB0ABwAGAOz/zP/Z/+//9P/F/6r/wP/m/w4ARABmAFYAIgAAAAAAGQASADUARQBHADQAIAAPAAUA1//C/8D/rP+E/1n/RP8y/0T/YP+X/6X/rv+l/7f/pf+T/6j/w//R/7j/wv/J/8D/s//H/w8AIAARAAUAGwAPAP7/BgAQABoA/v/W/47/Wf9M/2j/bf9t/4b/s//D/+j/MQCTAL0AugC4AJsAigBYAEgAJgAEAMD/hv9g/zT/U/9g/5//wf/z/zsAcQDLAP8AJAEAAfEAEAEyASIBCAHSAJEAYQBgAIYAfQBQACIAagCRAJgAfQB6AKIAlgCQAJ0AvQCdAEkA+v+5/3f/P/8h/wj/2v6u/rT+2v4J/xb/Nf9R/3f/lP+u/6T/Tv8u/zn/S/8z/w3/4P7C/nr+XP50/oD+gP5e/mL+bv50/qD+CP9k/27/Yf9p/4f/fv+P/7X/yP+6/4D/g/+z/8//2f8BADoAUwBZAFEAZQB+AK8A7AAeAUABVgGKAbYBuAG8AdYB8gEEAhACJAIoAuQBsAHmARwCPAJAAlwCgAKAApAC2AIQA/ACxAKsAnQCEAKqAZYBcgEgAcIAkAB0ACgAAgAhAE0ARAAbADMAZwBRACMACADt/53/KP/m/pj+Hv6Y/Uj9HP3g/LD8xPzk/ND8xPzU/Az9KP08/Uz9TP0A/bD8hPxY/CD82Pug+5D7YPtw+4D7yPsc/GD8nPwA/YD94P0i/lL+mv7M/uz+9P4s/13/qv/V/ysAkADmAEIBmgHoATgCrAIsA3ADuAMABFAEgASoBMgE0ATYBNgE6ATwBAAF+AQQBRAFCAUoBQgF4ASgBJAEcARIBFAEKAT4A6ADWAM0AwwD1AKIAlACJAKgAS4BuABdAAEAk/8R/6L+Nv64/Sj90PyY/Ez82Ptw+0D7+Pqo+lD6KPoA+qj5OPn4+MD4wPig+KD4aPhA+Bj4GPhY+ID48Pgw+Xj5sPno+XD66Ppo+9D7DPxs/MD8OP3E/T7+vv4+/67/LwDBAIgBTAIIA7gDaAQABYgFEAaoBggHWAeIB5gHsAeoB9AHwAfAB7AH6AcgCAAIQAhwCMAI4AggCZAJUAlgCfAIwAigCNgHQAeYBtAFwAQABFgDzAJcAuABvAFAAeUAAAHPANYAmABBANL/DP9Q/mT9mPxg+1D60Pjw97D2wPWw9NDzoPMA83DysPGw8bDxkPGw8TDysPIg80Dz8PPw9LD1QPag9pD3QPjI+JD5kPpw+/j7lPxQ/UL+2v6d/3wAIgG4ATwCEAMIBMAEkAVoBmAHIAigCGAJIAqACrAKMAtgC6ALgAvACwAMMAxADIAMwAzQDOAMIA1ADWANAA2wDKAM0AuQCzALwArQCcAIMAhgB3gGiAU4BagEEASMA6wDpAPUAkQCugF+AUgAEP8U/hT9GPtw+RD4gPbQ9CDz8PHg8IDvYO5g7mDuoO1A7cDtQO4A7gDuQO8A8GDwsPDg8TDzoPPg8xD1MPaA9uD20PcQ+aD56Png+tj7PPyw/LD92P6G/wwA+AA0AvgC5ANIBWAGQAcwCAAJ8AmAChALwAswDDAMUAywDLAMgAyQDPAM8AzwDCANYA1gDWANwA0QDhAO4A2wDYAN4AxgDMALQAswCkAJsAh4B7AG4AXABRAFMAQoBJgDQAOIAuQCFANAAhYBIwBv//D98PtQ+vj40PZQ9NDygPEQ8KDu4O0A7aDsQOxA7ADtIO2g7YDuIO9g7+DvMPEQ8mDy0PLQ84D0oPQA9eD1oPYA93D3QPhA+fD5kPqQ+5T8WP0k/hr/DgD1APoB5AKwA/AEqAXQBogHgAhwCTAK8AqQC2AM4AxQDaAN4A0QDuAN0A2gDXANMA0QDdAMkAywDLAMsAyQDLAMoAyQDCAM8AvQCzAL8AowCpAJ8AgwCMgHOAe4BhAGYAXoBCgEvANsAygDrAJkAngC1gEWAfb/hv6Y/BD7EPkw91D1MPNg8TDwYO5g7aDsQOzg64Dr4OuA7GDtwO2A7qDvcPBw8RDyYPOQ9BD1UPXQ9aD2sPbg9gD38PcA+ED40PjI+Wj6wPqA+5T8wP1k/pv/AAFYAhwDOAQwBWgGGAeAB5AIYAkQCnAKAAvQC+AL4AsQDHAMYAxwDHAMwAxwDAAMAAwQDAAMkAuAC6ALgAsACwALAAuQCiAK0AmwCQAJYAgwCNgHMAegBjAG8AVQBfAEEAW4BDgEcAM4A1ADhALkAnAC1AE+AJL+uP24+2j5gPcQ9uDzEPJQ8EDvYO4g7WDsoOvA66DrAOzA7KDtoO5A7wDwAPFA8oDzIPTg9MD1gPaw9sD2UPfQ9+D34PdI+Cj5aPnI+SD6YPsY/Ez8gP2U/hAA9QA4AmwDUAQ4BegFCAfoB6AIMAngCRAKQArACvAKAAvQClALUAswC+AKEAswC8AKgApwCgAL8ArgCiALQAtgCwALAAvwCrAKkAogCrAJ4AiwCFAIYAfYBoAGQAaQBegE2AQIBUAEVAMsA8ADoANEA/ACVAJqAbT/gP1I/Ej6iPjw9QD0sPKw8GDvoO0A7SDs4Otg64DrYOwA7cDtoO7A77Dw4PHg8iD0MPUQ9tD2IPew9wD4cPjA+Mj4MPmI+cj5+Plw+ij7BPxo/Pz8Kv5C/1sAhgGsAvQDwASQBXAGgAegCGAJIAqACvAKcAuAC+AL4AswDPALwAuwC7ALsAtgC0ALMAswCxAL8ApwC1ALEAvwCrAKUAowCgAK0AmACSAJ0AggCPgHQAc4B8gGEAYgBuAFaAUIBbgEsASkAxwDjAPQAywDrgEqAR0ADP7I+wj6qPig9jD0gPKQ8QDwgO5g7UDtwOzg6yDswOyA7eDt4O7g7yDx0PHQ8nD0QPUg9tD2gPcQ+ED4yPhI+YD5iPlo+fD5MPpo+gD7sPs4/Aj9jP2Y/uz/8wD2ARgDMAQwBVAGQAdQCEAJEApQCrAKEAtgC5ALgAuQC8ALoAswCyALMAsQC7AKYAqQCoAKgApgCkAKcAowCgAKgAmACXAJMAnACGAIUAjoBzgHCAf4BqgGOAbYBTAGwAUoBcgE4ASYBLADcAPoA3QDlAKSAQYBef+8/LD6sPng93D1sPNg8pDxAPCg7kDuwO0A7aDsIO0A7oDu4O5g8ADxwPHA8gD0kPXQ9fD20Pdw+MD48Pig+bj5wPmY+Sj6cPro+uD6kPtc/Jz8lP2O/q7/xQDCAfgCCAQIBVAGgAdgCEAJAAqwCgALAAuAC5ALkAtACzALYAswC7AKsAqQCnAKAArgCTAKAAogCtAJAArQCbAJYAkwCTAJ8AiQCHAIUAgwCJgHGAcAB9gGOAYQBqAFmAUwBXgESARYBKAD5AIYAwgDcAJ2AckAx//A/Sj7WPnA9yD28POg8hDygPAA7+DtoO3A7EDsYOzA7KDtAO7A7sDv0PDA8eDyEPQA9bD1APfg9yD4YPi4+Fj5GPlA+bD5CPoo+hD6mPoA+5D7RPxA/Wj+SP84AGgBlAKgAwAFcAaQB2AIQAkgCtAKEAtAC5ALsAugC3ALsAugC1ALAAugClAK8AnACdAJwAmwCZAJcAlgCVAJMAkQCeAI0AiwCMAIkAiQCEAI0AdgBxgH4AaIBigG8AWIBbgEKAT0A6gD4AI4AgwC/gEqAREAgf9i/ij8WPkw+AD30PSQ82Dy8PGg8IDuoO1A7QDtIOwg7MDsQO2g7WDuoO9Q8DDxMPJA82D0gPWQ9oD34Pdo+Lj4UPl4+ej5WPrw+hj78Ppo+/j79Px0/Tr+D/9HAAQB3gFMA3AEwAV4BnAHkAhQCRAKsAogC4ALgAuwC/ALEAwgDBAMsAtgCwALsArACpAKUAoACiAK4AmACXAJkAlQCcAIwAjgCMAIoAiACJAIkAi4B2gHcAdgB9AGYAZABgAGAAVYBFAE3APAAkACJALWAewAr/+V/xD+SPsY+eD3YPdA9SD0YPPQ8hDxIO+g7sDuAO7A7KDtQO7A7qDuoO+w8EDxcPFg8sDzgPRw9XD2YPeg97D3gPho+cD5+PmQ+ij7UPtQ+/D7DP1s/ez92v7m/60AegFoAtgDoARYBXgGmAdwCBAJ4AmgChALQAuQC+ALIAxADDAMIAwADJALQAsQC+AKoApgChAK0AmQCXAJQAkgCdAIkAhgCFAIUAhACDAIAAjAB2AHGAcIBxAHkAYwBuAFUAWYBPwD2AM4A1wC5AHiAYIBogBl/5z+FP3Q+pj4sPdA91D1EPRA88DyAPEg7+Du4O5g7oDtgO1A7sDuAO8A70DwwPAg8fDxEPMw9DD1APZg9hD3gPdI+OD4gPkg+pj6GPtI+9j7hPxU/fD9gP6Y/4EAMgEkAjgDIAQYBRgGAAcwCCAJ4AmQChALsAswDJAMwAwADZANYA0wDdAMwAxwDMALYAtgCzALsAowChAK4AmQCfAIsAiwCGAIAAjoBwAIEAjYB2AHUAdYBygHwAaYBlAG8AVABXgESATEAzADhAIkAsQBJAEpACH/rP0Y/OD5KPjA9sD10PRg86DyIPEg8CDvIO6A7eDtoO1A7aDtQO6g7gDvAO/g76DwkPFA8mDzkPRA9eD1EPbQ9qD3WPgA+VD5OPoI+zD7kPtw/Iz9JP7O/s//JAHsAaAClAO4BPgFkAZ4B5AIgAkgCqAKcAvQC0AMgAygDPAMMA0wDRAN0AxwDEAM4AuQCyALEAvgCkAK0AmwCYAJEAlgCDAIIAjIB4gHcAegB3AHAAegBqAGeAYQBsAFaAUIBUAEvANYA8wCMAK2AUIBtgDv/yj/Cv48/ID6oPgg9+D1gPRQ9EDzQPLA8IDvQO/g7YDtoO0A7qDtwO0g7sDuYO/A7xDw0PAA8sDyoPOQ9JD1UPZw9uD24PfY+Ij52PnY+qD7BPw8/Az9cv5K/+T/sQDoAQgDpAOYBJAF6AaIBwAIQAkQCvAKYAsADGAMkAzwDAANUA2ADaANcA0QDZAMUAwwDMALUAsgCxALkAoQCsAJwAlgCaAIMAggCEAI4AegB7gHsAd4B+AGsAawBlAG6AUoBbgEGATIAzgDVAIwAroBOAEoAE//nP6E/XD7QPnw9+D2QPVQ9KDzQPMg8mDwIO/g7oDuIO6A7SDuoO5g7sDuIO8w8FDwwPBQ8XDyoPNA9DD1MPbQ9iD3sPeo+Kj5WPog+/D7cPwI/cT92v7H/4AAfAFsAkgD/AP4BBAGCAdoB0AIQAkQCtAKkAtQDAANIA1ADYAN0A0ADgAOEA7gDZANMA2gDKAMMAwADIALIAvAClAK0AlQCfAIgAgACJgHcAeoB1gHIAcIB7AGUAbwBagFWAXwBGAEyAMsA9gCAALAAewAawA0ADL/Nv4o/fj7WPrA92D2wPXQ9IDzoPLg8pDxoO+A7qDuwO7g7YDtIO7g7oDuwO6g76DwoPDA8ODx8PLQ82D0gPVg9gD3IPfw9yD5oPmQ+mD7RPzA/DT9dv6A/1AADgHYARgDrAOABLAFuAZ4ByAIoAjACcAKUAvwC6AMEA0QDWANgA3wDSAOEA6wDYANMA3QDIAMIAzwC6ALIAuACkAKAApwCcAIUAggCMAHgAdQB0gHMAfABoAGCAYIBqgFIAW4BGAEEAQwA5ACUALiATgBjwA6APf/tP6M/Yj8YPtg+VD3gPYA9rD0kPMA8wDzgPHA72DvgO/A7gDugO4g72Dv4O5g73DwwPCw8BDxcPJw8/Dz4PRA9oD20PaA96D4sPmw+Sj7EPy4/Cz98P13/xkAzwBoAcQCuAN4BCgFgAZwB6gHoAhwCYAKMAugCzAMYAywDBANUA1wDZANkA1QDfAMoAywDFAM8AtwCzALEAtwCvAJwAlACZAIwAeQB5gHOAcIB8AG2AZoBgAGuAWYBVgF2ARYBBAEpAMUA0QCBAK4ARQBWAAwAKX/9P6g/Tz8MPvI+bD3QPbA9cD0kPOw8oDy0PFA8ODuoO6A7gDugO1g7kDvAO/g7mDvMPBA8LDwoPHA8rDzIPTw9MD1YPYA9+D3yPhw+SD6MPsM/KT8iP2Y/qf/9P/7AEQCcANIBOgEAAa4BqAHgAiACYAKAAuQC/ALMAyQDEANwA3gDeANAA7QDYANMA0gDQANYAzQC4ALgAsAC4AKIAqgCfAIIAjwB+gHuAd4BygH8AaABigGAAbABZAFCAV4BBgEuANEA5wCDAJ8ARABYADW/3P/zP6g/Qj80Pqg+SD4gPaA9fD08POA8qDxsPGw8ADv4O0g7uDtIO3A7WDugO8A74DugO8Q8NDw8PBg8sDzUPSQ9GD10PZw9xj46PjY+aj6OPtU/Jj9Sv7m/l3/vQCSAYACgAMQBfAFGAbgBgAIUAmgCWAKUAsgDNAL0AvgDMANMA7ADQAOUA4QDqANkA3ADWANgAwQDOALkAswC8AKkArwCRAJgAhgCCAI2AeYB3gHCAeIBoAGaAbwBZAFUAXoBFAE2AOQA0ADmAKYAUgBswAJADz/yP78/Yz84Prg+dj4QPfQ9TD1kPRA8yDygPGg8eDvYO4g7mDugO7A7QDvAPBg8EDvQO+w8HDxcPHw8QD0kPTQ9AD10PYI+Bj4cPi4+ej6QPss/GT9jv6u/iD/eQC2AXgCXAPwBOAFIAZoBsAHAAlQCfAJwApgC2ALoAuQDIANcA1gDcANAA6wDXANgA1wDdAMEAygC1ALMAvQCoAKMAqgCfAIcAgQCLgHoAdoB/AGiAZoBlAG6AWwBVgFIAWYBCAEyAOQAygDUAKOAe4AdwDu/xn/Wv7I/Yz8APuA+aD4wPcQ9sD0MPTA82DyMPGA8GDwIO/g7eDtAO+g78DuYO8g8HDwgO+g73DxUPLA8iDzYPSw9RD2oPaA9+j4OPm4+ZD6gPuQ/ID9Tv7G/q//oADCAdwCEARgBSAGcAboBhAIIAngCVAKAAvQCwAMUAwgDdANIA5ADhAOAA4gDhAOwA1ADaAMQAzACyAL8AoQC/AK0AkACbAIsAjoB1AHeAd4B/AGOAYYBlAGCAaABdgEyASQBPQDgAM0A9QCGAIuAVgABQCJ/7b+rP28/KD7UPrI+ID3wPaA9WD0YPOA8qDxkPCA7+DuQO4g7uDtgO7g7mDvgO9g74DvQO9A8PDwgPGg8uDzcPTw9MD1wPbg93D40PgI+uD6gPsU/FD9kv4v/93/rgBsAswDuASgBVAGcAfYBzAIQAlwClALUAvQC5AMQA1gDbANMA5wDkAOoA3ADfANkA3QDEAMAAyACzAL0AqwCoAKwAnwCJAIQAjoB4AHMAcAB5AGYAYYBugFqAVYBdAEaATkA7wDWAO8AiACRgHHABYAef/C/hT+FP3I+4j6KPkg+AD3APbw9NDzAPNA8kDxUPCA7wDvgO4g7sDuYO/g7+DvwO9Q8MDvIPCw8DDygPNg84D0UPUw9rD2oPeY+ID5QPqY+mj7gPzQ/Ub++P7h/0oBcAJAA5AEKAYIBygHiAfQCMAJMArACuAL4AzADOAMsA1wDoAOIA5QDmAOQA6QDXANkA2gDCAMkAuQCwALoAqQCgAKgAnACIAIIAioB1gHYAdYB7AGUAZQBjAGiAUABcgEoAQYBFAD3AKAAt4B7wBAAML/E/9A/gD9APzo+sj5sPgw9zD2UPWw9DDzAPKw8cDw4O+g7qDuIO9A7wDvgO+Q8KDwAPAA8LDwwPFQ8tDy4PNA9ZD18PWA9kD4KPlw+VD6CPto/KT8fP1C/pr/awAOAYAC3AMwBegF0AaoBzAIsAhQCUAK4AqgC1AM8AwwDWAN8A1QDlAOEA4gDkAO0A0ADdAMgAzgCzALoApgCjAKsAkgCdAIkAjoByAHsAaQBqgGOAawBbAFYAUIBUAEKAQoBNgDHANgAjQCvAHwAAcAmP8a/+D96Pwo/JD7oPo4+Qj4EPcA9sD0wPMg85DygPGA8KDvoO+A7wDvQO/A71DwIPDg7+DwYPFg8WDxkPIw9DD0kPSA9fD2YPeA98j4QPoo+xD7BPwc/fj9Mv4P/8cAvAG0AswDQAVIBtgGeAeACPAIEAkACvAK0AtADNAMcA1gDWANkA0QDkAOsA2ADUANwAwQDKALIAvwCnAKkAlQCSAJ8AiACOAHIAfgBoAGCAbYBQgG8AVQBaAEYASIBDAEgAM0AyQDsAKgAQQB6ACAAGL/Uv64/Sj9ZPw4+3j6oPmg+BD38PVA9ZD0oPNw8uDxYPGQ8ADw4O8g8DDwwO8w8KDwAPHA8EDxYPLA8tDykPOg9KD1gPUw9sD3oPjY+Lj5IPsk/Iz8pPz8/RD/c/9CAMwBlANYBCAFWAZoB4AHMAjACKAJUAqgChAMUAygDKAMAA2gDWANgA1wDaANEA1gDOAL4AtAC3AKMAqQCWAJ4AiACHAI8AdwB+AGUAYgBvAFuAVgBdgEyASoBCgEwAN0A3gD8AIEAooBoAEIATEATP/+/lr+EP1E/JD7KPvY+YD4gPfQ9tD1gPTA8zDzYPJQ8XDwkPAw8MDvoO8A8BDwIPDg72DwUPFw8ZDxkPKQ8+DzMPQQ9TD2wPYw9zD4iPlQ+tD6iPvc/HT9sP2S/rr/JgEoAqgDGAVABggHUAcQCKAIYAlQClALEAxgDOAMUA1gDaANQA5wDjAOkA2wDaANIA1wDPAL4AsAC3AKMAoQCtAJQAnQCEAIoAdYB1AH8AZYBhgG6AVgBeAE0AToBHAEhAMgAwgDoAKgARgB4QAmAPr+Dv68/Rj9CPwA+xD6MPnw9+D2APZA9VD0QPNw8sDxIPGg8EDwAPDg7+DvwO/g7xDwUPCg8ODwgPFA8uDycPMg9PD0YPXw9eD2QPjw+Ij5oPq4+1D85Pzg/aT++/+gALQBsAPYBBgGqAawB1AIkAhQCTAKcAsgDKAMAA1QDdAN4A1QDnAOcA4wDrANAA5gDQANUAwgDIALkApQClAKQAowCcAIkAhgCGgHCAeAB1gHoAaoBegFGAaABdAEeAS4BBAEBAPIArgCPAIaATcAyP8U/xL+UP28/OD7yPqY+bj4sPfA9uD14PTQ8yDzgPKw8RDxwPCw8GDwEPAQ8JDwoPCQ8MDwoPHw8SDyoPLA81D0cPQQ9RD28PZQ9yD4SPlY+oD6IPtU/Dj91P02/ioAZgGwAowD4ASABqgGyAaoBwAJkAlgCgALQAyADHAM8AzADfANsA3ADdANsA0gDQAN4AxADDALwArACkAKsAmACZAJ4AjQB5gHkAdwB8gGcAZoBiAGeAVYBXAFEAWIBAAEuANcA/wCuAI0AloBgQDH/wr/Nv6M/RD9ZPzw+rD5IPlo+PD28PVw9cD0gPOA8iDyAPIw8XDwkPDQ8KDwUPCw8CDxQPFQ8aDxcPIQ82Dz4POQ9GD18PVw9mD3OPgI+ZD5cPpQ+2T81Px0/Yr+8v8wAfgByAMwBTAGMAbQBjAI0AiQCUAKUAtADDAMgAwQDeANsA3ADcANsA3QDYANIA3ADFAMgAsAC3AKMAowCtAJIAmACDAIyAdIB9AG2AbABhAGmAVoBVgFKAWYBBAE3AOUAwwDqAJkAt4BPAFYAFP/yv5c/qD9mPzo+yD7MPrw+AD4YPeA9mD1UPTA8yDzQPKQ8SDxAPGg8GDwYPCg8MDw4PAQ8UDxwPEQ8qDyIPOw82D0APWg9WD2MPfw98j4kPlg+kD78Puw/LT9ov66/98AbAKkA9AEyAWYBlgHoAfgCIAJQApgCxAMYAzADAANgA3gDdANsA1ADgAOcA0ADfAMoAygCxALsArACiAKkAkwCfAIoAiIBwAHEAe4BlgG0AXIBZgFKAWYBGgEOAToA3gDBAP8AsACAAIwAZsAEwBF/2z+pP0k/ZT8UPtY+sj5wPiw96D24PUg9VD0oPPw8pDy4PFw8QDxAPEA8TDxQPFw8aDx0PFA8oDyEPPQ83D08PSg9VD28PbA95D4kPkY+tD6uPuI/ET9Bv4Z/zYAFAEUAngDuATABWgGOAcQCDAIEAnwCTAL0AvgC8AM0AzwDCANcA2wDbANgA0QDcAMkAwwDKALIAugCmAK4AlACRAJAAlgCKAHEAfwBpAGEAbgBfgFuAUABYgEeAQoBLADLAM4AwADYAKaAUgBywDK/0H/jP4C/iT9YPzA+8j6CPro+Aj4MPcw9oD10PQw9GDzwPJA8qDxMPEw8UDxUPFg8aDxwPHg8RDygPJA88DzQPQA9ZD1MPbA9qD3mPgg+eD5sPqo+yT8/PwQ/uj+1f9wAMABDAMABPAEEAbwBmAHwAeQCGAJcArwCmAL8AtQDCAMUAygDEANEA2wDLAMUAxADHALIAvACpAKwAkwCQAJkAggCIgHQAfQBkAG0AWIBWgFOAXYBIgEOAS4A2QDMAPMApgCPALcAVQBoQD6/4j/yv4U/nT9yPwI/GD7iPrY+Qj5IPgw92D2kPUA9YD04PMw88DyMPLw8aDx0PHw8TDyMPIw8pDy0PIg85DzQPTg9DD18PWg9nD3QPjQ+Hj5QPr4+qj7iPyA/VT+DP/R/3gAngGMAlgDgASQBXAG6AZ4B3AIAAmACQAK0ApgC2ALwAsQDHAMgAxADIAMgAwwDKALcAswC9AKMArQCaAJ8AiACCAIyAdgB8AGYAYoBrAFMAUQBcgEiAQgBLQDVAPgApgCUAIkArwBCgG2AAMAav/W/kr+qP0w/Vz8sPs4+2j6yPko+Uj4cPfQ9jD2oPUw9cD0QPTA80Dz8PIA8/Dy4PIg81DzcPNw88DzQPSw9BD1kPUw9uD2gPfw98D4gPkg+qj6aPsw/PT8pP1G/jj/9P+UAGwBRAJIAxgE2ATQBYAGKAeQB1AIAAlgCbAJQArAChALEAuAC9ALwAuQC5ALcAswC+AKYApQCuAJUAnwCLAIYAiwB1gHAAeYBhAG4AVYBQAFqAQwBCAEcAMoA7AChAI0ArABbgHyAJgA7P9n/+r+dP7I/Uz93Pwk/JD7+Pp4+uj5MPmg+AD4UPfQ9kD24PVw9QD1sPRw9BD04PPA8+Dz8PPw8yD0cPSg9OD0QPXA9SD2oPZA98D3ePgI+aj5YPoY+8D7TPwM/aD9Tv4I/7X/vgBgASwC7ALEA4gEWAX4BcgGmAcACIAIQAnACRAKYAqwChALIAtgC3ALsAuQC1ALEAsAC5AKQAogCtAJkAkQCbAIQAjIB1gHyAaQBhgGuAVYBegEiATwA6ADRAO8AmACFAKsATIBuwBeAOb/V//E/kr++P1Y/eD8TPzI+zj7qPog+qj5GPmw+Dj4sPcg98D2cPYg9uD1oPVw9UD1APXw9AD1EPUQ9VD1cPWw9RD2YPbg9lD3wPc4+LD4QPno+ZD6MPvg+4T8IP24/Vz+Ev/A/3EAIAHYAXgCJAPUA4AEOAXQBWAGCAeYByAIkAgQCXAJoAnwCTAKgAqQCqAKoAqwCoAKUApACgAKwAlwCSAJ0AiACAAImAc4B6gGMAbABWAF6ASABAgEkAMgA7QCTALiAXABEgGvAD0A5v93/wb/mv4w/rj9WP38/Jj8RPzQ+3D7CPuo+kD66PmY+Uj56Ph4+Ej4APjA95D3YPdQ9zD3APfw9gD3EPcQ9yD3YPeg99D3APhY+LD4EPlQ+cj5QPqw+hj7oPsw/Kz8HP2w/WD+4v5q//7/mgAqAa4BQALIAlgD6ANABPAEMAWoBQAGcAbIBggHWAeQB9AH2AcQCEAIQAhQCFAIUAhQCDAIEAj4B6gHaAdABwAHuAZoBhgGyAVgBQAFmAQ4BNQDWAP8AqQCLAK8AVgB9QCMABwAsf9o//j+lP4q/uT9lP00/ej8fPw0/Nj7cPs4+wD7wPp4+jj66Pmw+XD5UPkw+fD46PjY+LD4qPiw+Kj4sPi4+ND4APk4+Uj5ePnI+fD5MPqI+uD6QPug+/j7ZPzc/Cj9iP38/XD+6v5Q/87/VgDJADgBlgEQAnwC6AJIA7ADCARoBLAECAVQBZAF2AUgBmgGmAbABugGEAcoBzAHOAdAB0gHOAcgBwgH8AaoBngGUAYYBsgFiAU4BdgEgAQQBLgDWAP4ApgCQALiAXoBJAGyAE0A5P+U/zT/1P54/hz+1P14/Sj9zPyI/Dz88Puw+3j7SPsI+9D6qPqA+lj6MPoA+gD64PnI+cD5uPnQ+dD52Pnw+Rj6OPpo+oD6yPr4+ij7WPug+/D7JPx0/Mj8IP10/bz9Hv5q/tb+Lf+F/+j/OgCVAN4APgGWAeoBSAKYAuACJANYA6QD5AMgBFAEiATABOAEEAUwBVgFaAVwBYgFiAWABXgFaAVYBUAFGAX4BNAEmARoBCgE5AOgA2QDIAPcAogCOAL0AZwBUgEEAbwAdwAqAOL/oP9X/w3/zv6M/kj+CP7M/ZD9XP0k/ez8wPyM/Fz8QPwc/AT88PvY+8D7uPug+7D7oPuo+7D7uPvY++D7+PsQ/ED8SPx8/KD80Pz8/CD9dP2o/dj9IP5q/qz+1P4k/2z/tP/5/zYAhgDAAPsAPgF8AcgBAAI4AmgClALAAuwCDAMoA0QDcAN8A4wDoAOsA7gDsAOkA6wDpAOkA5QDiAN4A1gDPAMcAwgD8ALUArgCkAJsAkACGALoAbwBigFSARwB2gCnAHAAQAAPANX/nP9n/z//EP/k/rr+mv5u/k7+Jv4Q/gb+9P3o/cz9vP2k/ZD9lP2M/YD9eP14/Xz9gP2E/Yj9lP2Y/aj9wP3M/eD99P0S/iL+Nv5Q/m7+lP6u/sz+8P4Z/zf/Xf+G/6r/x//k/wkAJwBOAHEAkgC9AOIABAEsAUgBaAGIAaQBwAHgAfgBEAIoAjQCRAJMAlwCZAJkAmwCbAJkAlQCUAJEAjgCKAIMAvoB4AHGAa4BlgF6AVoBPgEgAQYB5ADDAKUAjABpAEcAIwAGAOz/1f+3/6L/hv9u/03/Nf8W//T+2v7E/rb+mv6C/mz+XP5G/iz+GP4Q/gb+CP74/QT++P38/fj9Bv4E/gr+Hv4s/jz+PP5a/mj+dP6E/pr+tv7G/uL+/v4c/yf/QP9h/3n/kf+r/8T/5v/9/xoAPABTAG8AfwCbALQAygDiAPYACAEQAR4BNAFIAVIBWgFeAW4BdAF8AYgBiAGaAZABjAGUAZABiAGGAYQBcAFsAVwBUgFIAUYBOAEiAf4A5wDmANQAuQCVAI4AjABuAEsANgAhAAsA6f/Z/8b/sP+Z/4X/ef9j/z//M/8u/yP/Cf/2/uz+4v7W/sj+tv60/qb+pv6o/qT+nv6i/qb+qP62/rL+xP7c/ur+Cv8c/yb/Pv9T/2r/ev+S/6D/uf/C/9D/2//e/+f/6f/4//v/CQASACEAKwAyADYARABYAGQAgACTALAAygDcAPMAAAEYATABSgFWAVQBWAFoAXIBbAFiAU4BUAFOAUQBNAEaAQwBBAHwANQAtgCiAKcAhQBjADUAMQAgAAQA3P/T/8T/sv+z/4b/ov91/3b/bv+a/3b/ZP91/3z/iv9z/33/ev+N/5z/df9q/3r/dP9c/zj/Cv/8/tb+lv5s/jD+8P2Y/UT94Px4/CT8wPuA+1j7KPtw+9D7gPxI/SD+K/8UAPkA3AHAAqQDkARwBQgGaAawBvgGEAfIBjgGmAUABVAEgAOAAm4BigCv/wT/Gv5c/cz8tPyA/CD84Pvg+2T8uPz8/Dz9vP2G/jj/yP8iAJ4AMgHEASACLAJMAnwC0AKkAlgCAALmAdIBfgH8AJgAYgAmAAUAif9d/zj/Pv9P/zb/SP9E/5L/yP/8//f/HwBvAKYA0QC1AMEA6QD3AOEAsgCMAH4AXABCAAMAvf+P/33/b/9F/yL/E/8v/0L/VP9X/27/l//J/wEAFwAwAFEAlADEAMAAxADNAPAA8QDbAMQAuQCxAJ0AgwBVADkAFAAJAPb/2P+3/57/kf+A/2z/Wv9Q/0r/Qf80/yn/H/8X/xf/E/8G//r+9P78/gD//v7w/ub+7v7y/vr+AP8D/xv/Kf82/zv/Pv9M/2D/cP9y/3f/d/+H/47/lP+U/5P/mf+k/7T/tv/A/8T/1P/m/+r/9P/1/wUAEgAfACkAJgAzAD8AQABFAEAARwBJAEcASABJAEsAQwA9ADQANAAjAB4AEwAMAA4ACAAJAPb/+v///wQA/v/4/wQACgAdACkAMgBHAFsAawB8AIYAggCHAIkAlACSAIoAgACFAIUAhQBkAGIAYwBkAEgANAAfAAgA9v/r/9//wv+m/5f/hP9z/1H/O/86/zb/Ov8J/zT/Fv8x/yf/Lf8t/y7/Uf9Y/2b/U/9t/4P/kv+e/6f/s//V/9v/5//6/+P/8P/8//f/+P/+/woAGgAYACAAJgA4AFEASQBlAHAAhwCfALkAwgDHAMsA0ADqANsA0wC6AMEAtACbAIsAcAB+AGQARwBEAEgAUQBfAHIAfQCTAJ0AuADMAOsADAEeASIBNgFGAVABUgE+ASgBIgEWAewAyACkAHEAVAAoAOz/xf+i/3//Z/9L/xX//v7+/vb+6v7a/ub+C/8p/z//Rv9q/47/t//K/9n/6//9/wQABwD5/+b/z/++/6X/ff9O/yT/DP/s/r7+mP6K/oT+fP5w/nb+jv6m/sr+6P4T/zv/eP+w/9X/+/8QADwAYwB5AIQAkwCmALMAvgCiAJgAhwCGAHYAZwBaAE4ATQBCAEQAOgBJAFEAZgBxAH4AmQCwAMwA2QDoAO4A+gD9AAIB5wDUALwApwCNAGUAQAAgAAoA5P/Z/6v/pv+O/4H/af9i/1//Uv9W/1b/WP9Y/1L/Xv9W/2n/Zf9h/3X/ef+C/33/jP+Y/6//vf/S/9j/3v/c/+j/6f/n/9//2v/f/9L/zv/J/8j/xv/A/77/s/+u/6P/pP+h/5//l/+X/5P/lf+Q/5D/lf+U/6L/r/++/8r/2P/t//j/DQAmADwAWQBuAIAAnACyAMgA4gDvAAQBEAEeASABIAEiARwBDgEIAeYA4wDZAM8AzwC/ALIAwACxAMMAtQC6AMMAxQDgANEA2gDfAOcAwwDCAKQAnwCNAGYAbQBOADEAJQAdAAgA4f/j/9D/1//R/8v/0f/I/8D/vf+8/8//xv+3/6j/nP+R/4H/cP9T/0H/OP8f/wj/AP/y/vL+7P7k/vT+9P4N/xb/K/89/0f/YP9l/43/rf/E/+j/8P8UAB0APAA8AF4AbAB7AIQAfgCRAJ4AvAC+ANAA3wDnABIBHAEqAUQBYAF2AYYBkgGSAbABrAG2AZYBhgFsAToBLgH+AMcAmgBfADQA+P/H/4n/b/86/zH/If8N/xb/Cv8o/x//K/9I/1z/h/+f/8j/2P8OABoAOwBkAF8AdwBhAHsAZABhAFwALgAbAAEA4v+9/5z/df9R/yX/9v7S/or+YP4g/tT9wP10/Vz9IP0M/fD81Pzc/KT8wPy4/MD84Pzg/Cj9MP2E/dD9DP5u/rT+E/9i/8f/EgBsALwALAGCAdoBHAJsArwCGANUA3wDtAP0A+wDKAQYBDgEGAQoBEAE+AMABMgDvAOYA3QDWAMgA/wCAAOsAtQCkAKIAngCiAJ4AnwCjAJ8AqACbAKUAowCfAJ4AmQCPAIAAtIBYAEwAaQAFwDJ/xX/kv7s/VD9pPzo+0j7mPrQ+VD5oPgY+KD3IPfA9mD2IPbw9bD1sPWw9bD10PXg9TD2YPZw9vD2wPZA93D3oPcg+KD4KPmg+Xj66PrY+4z8vP3E/sL/JAEoAkgDgAQIBiAHUAiACWAKkAuADCANwA1QDoAO8A4QDxAP0A7ADoAOQA7gDTANsAxADMALQAuACvAJcAnwCFAImAcIB0gGwAUABUAEWAOQAqgBvQDr/9r+3P0A/ST8SPtY+oD5yPgw+LD3MPfg9nD2YPYw9kD2cPZw9sD2APdw96D38PdI+GD4qPjg+Oj4KPkw+RD5MPnQ+Jj4YPiw92D30PZg9uD1UPXw9HD0YPQg9FD0cPTw9JD1gPbQ90D5GPvU/OD+BgE8A2gFmAeQCdALkA1gDwARQBKgE4AUYBUAFmAWYBbAFiAWABbgFIAUQBNgEmARABDADnANYAzgCnAJUAh4BjgFmAMEApoAFf/Q/VD8WPsg+gj5IPhg95D2APaQ9TD1EPXQ9PD0QPWg9UD2APfQ96D4iPmA+kj7QPwU/bz9rP5F/+H/PQC3ANsADAEiAfQAsAAuALb/Sf9i/sj9iPwE/LD66PnY+LD30Paw9bD0sPOw8sDxAPEg8KDvAO/g7qDuoO4A76DvYPCg8eDyAPWg9ij5WPvQ/QIAyAIwBaAH0AnACyAO4A/AEeASYBQAFaAVoBXgFYAV4BTgFKATABOgEWAQ4A7gDaAMwArQCUAIAAewBUgENAO2AbAA6P9y/tj9qPzg+xj7aPoo+nD5MPmw+Hj4sPiI+Jj4wPgI+cD5IPro+qj7NPws/eT9rP48//j/qQAqAcYBEAJkAlQCbAJIAggCvAHpAFIAb/+g/pz9hPyQ+0j6MPkA+ND2oPWg9LDzoPKQ8bDw4O8g76DuAO6g7WDtQO1g7cDtIO4A7yDwkPFg8zD1YPfA+VT8+v58AUgE0AZwCdALYA5AECASIBTAFYAWoBeAGAAYoBgAGIAXABeAFcAUIBMgEkAQYA4ADXALAApQCBAHKAWkA8gCXgEEAML+hP3M/MD7MPv4+ZD50Pi4+ED4APjg98D3KPh4+Oj4OPkA+rD68PvU/KD9kv5Q/5UAZAEcAsgCOAOkAyAEGAQYBMgDhAMoA1QCngGoALn/uv7M/YD8YPsY+hj5oPeQ9mD1MPQw8zDyUPFA8MDvAO+A7iDu4O2A7cDtwO1A7qDuoO+Q8ODxUPOA9XD3wPl0/Cr/zAGIBCAHkAlwDCAOwBAAE2AUYBYAF6AYYBgAGaAYYBhgGCAX4BXAFKAToBGgEIAOAA0AC1AJyAdABngE8AJ2AREAFf+4/Yz8aPuA+uj5WPmg+BD4wPew98D3wPeA9+D3OPjw+JD5KPrY+vj74PwM/vz+xP/RANAB2AKIAygEiATgBCAFSAX4BJAEOAR4A3QCoAFnACv/JP7U/Hj7OPrA+ID3MPYg9cDzsPKw8cDwAPAg76Du4O2g7UDtAO0A7QDtIO1g7QDuwO6A7+DwgPIg9HD2mPhI+/D95wCIA5AGIAmwCyAO4BAAE8AUABcgGEAZoBkgGmAawBmAGaAYQBcgFgAUoBLAEHAP8AwgC1AJUAfQBRAEQALRAG//RP5I/fj7GPsw+qj5WPnI+GD4CPhA+Dj4UPiA+ID4APmQ+Qj6oPpY+zD8LP08/lT/JQA4ATACUANABOgEkAUIBmgGcAaoBngGIAZwBcgE4APAAm4BLgDO/nD98Pug+gD5oPcw9vD0wPOA8nDxcPCg7+DuQO6g7UDtAO3A7MDs4Ozg7CDtwO1g7oDvcPDw8aDz4PUQ+Lj6bP2rAJQDyAaACUAMoA4gEeATgBUgGAAZIBpgG4AbABtgG+Aa4BmAGAAXIBWgE2ARgA9ADUALQAkoB0gFXAPyAR0Awv6A/ej7ePsw+jD5sPjw95D3QPdA99D20PbQ9lD3oPfg93D4+PjY+aj6kPt4/Kj9yP7b/yQB6AEQAwgE8ATYBUgGuAboBgAH8AawBgAGcAV4BHQDTALWAFT/4P04/OD6OPmw9zD20PSw81DyUPFA8KDv4O5g7uDtgO1A7eDsAO0A7UDtYO3g7WDuAO/A7xDxMPLA89D10PdA+ij93v80A7AFIAmAC3AOYBHgEiAWwBeAGaAaoBsAHOAb4BtAGyAaIBmgF4AVoBOgEZAPYA0QC8AImAagBMwCxgAh/4T9WPwA+xD6APkY+JD3MPeg9jD24PXQ9cD1IPZA9pD2EPeA91D4GPnA+aj6wPsg/Sz+e/+1AMwBBAMoBBgF4AWoBiAHmAfQB7gHiAfgBjAGSAVYBAwDegEHAGT+xPwQ+4D58Pdw9vD0gPOA8iDxUPBA78DuIO7g7UDtAO0g7cDsYO1A7aDtAO5g7gDvoO9g8JDxcPJQ9ND1CPgg+sz8mf/YAlgFwAgQCzAOoBCAEsAVIBdgGYAaABwAHAAcYByAG+AaoBnAF+AV4BPgEZAPwA1QC/AIGAfwBCADMgGw/w7+NP3o+/D6IPpQ+fj4mPgg+AD40Pew98D3wPfw9zD4ePjo+Hj5OPqI+nj7SPws/XL+YP+ZAKgBtALQA6AEuAVIBgAHYAeoB9AHgAcQB2gGkAWQBDQDogFMAKD+1Pwg+6D5wPdA9vD0QPNA8kDxEPCA7+DugO5A7iDuAO7g7SDuYO6A7uDuIO9g78DvIPDw8EDxAPJA8zD08PWg99j5KPwU/74B2ASQB7AKMA2wD8ASQBSgFqAYIBpAG4Ab4BtgGwAbIBoAGUAXQBVgE+AQMA/ADJAKUAhgBrgEWALrAD3/KP4s/TD8QPuQ+gj6aPl4+UD5KPnQ+PD4+Pjo+Aj5SPmQ+fj5SPrA+jj76Pt4/FD9PP5M/xMAeAFgAkwDcARIBQAGuAZIB4gH0AeYB1gHyAYQBugECAR8AigBbf+c/YD8cPro+GD38PWQ9IDzUPKw8cDwcPDA76DvgO9g70DvgO9A76DvwO/g7yDwIPBA8LDwAPFQ8eDxoPLQ8wD1sPaw+AD7/P1qAHQDyAaQCSAMgA/gEUAUYBYAGEAaoBrgG6AbABvgGoAZgBigFoAUYBIAENANsAswCTgHOAVIA9ABNQDC/qz9/Pxs/Oj7QPs4+9D60PoA+8D6sPrI+nj60Pqg+sD60PoI+3D7mPsA/ID84Pzc/Xz+R/9qAGQBbAKAA4gEeAVIBuAGeAfgB/gH6Ad4B/AGSAY4BRgEpAJMAXz/5P0I/ED6iPgQ95D1IPQg8xDycPGw8FDwwO/A76DvwO/g7yDwQPBg8KDwoPDg8ODwAPEA8RDxUPFg8eDxYPJw81D08PWQ98j5lPxq/0ACqAUwCPAKAA6gEEATIBVAF6AYoBmAGkAaYBpgGYAYQBdAFUAT4BCADqAMUAowCDgGaASAAhYByf/Q/rT9CP1o/BD8uPtQ+2D7CPsg+wD7wPrg+pD6wPqw+uD6oPrQ+ij7aPvQ+zz8uPx8/Wz+Iv81ADgBXAJYA2AEcAU4BsgGOAfQB+gHwAeIB/AGaAZABWAE0AJoATMAbP7Y/FD7wPkI+BD30PXQ9PDzQPPQ8hDyEPKg8cDxsPHw8QDyAPIw8hDyUPJQ8nDyQPKQ8kDyYPJg8nDy0PJA8xD08PQw9tD3gPlM/Ir+0AGoBHAHYApgDHAP4BEAFOAVoBdAGOAYABkgGaAYoBeAFqAUwBIAEdAOkAygCqAIoAYwBZwDBALJANv/F/9O/rT9HP3c/HD8XPwY/Pj76Pug+4j7mPtY+yj7SPs4+3D7ePvw+1z86PyA/UD+CP/i/xgB8gHsAmAEuAToBdAGWAeAB0AI8AfIB4AHwAZABkAFIATAAooBEgCS/gT9uPtw+tj4sPeQ9qD14PRg9PDzkPMQ8yDz0PLA8uDy8PIA8xDzQPNA81DzUPMw8zDzMPOw8vDy0PLw8kDzgPNQ9DD1cPbQ99D50Pt0/g4BzAP4BtAJEAyQDqAQwBKgFOAVYBfAF6AX4BfgFmAWIBWgE6ARIBCwDdALIAoQCEAGuARQA/wBDgHd/+b+ev7o/Xz9KP2s/Ij8hPwY/ED82PvA+6D7gPuA+3D7UPuQ+7D7CPx4/Lz8hP1e/uj+0f+kAJ4BwALAA2gEQAUQBogGEAdwB2gHMAfQBqAGuAXwBAAE9ALMAXkAOf/o/Zj8iPtQ+lj5SPhA97D2APbA9VD1MPXA9PD0kPSg9KD0sPTg9ID0sPSw9GD0QPQg9CD00PPA85DzgPOw86DzAPSg9AD1IPbw9rD4WPpg/Oz+cAE4BMgGMAmQC3ANwA/gESAT4BRgFQAWoBUAFmAVABXAEwASgBCwDgAN4ApwCTAHEAagBBADNALaABsAVf/a/qD+tP2w/SD9JP3Q/Hj8iPx8/HT8KPwU/AD88PsQ/FT8lPy8/ET9sP1c/uj+pv+bAFABTAIMA9gDiAQIBdgFQAaABmgGOAbgBaAFyARIBEwDlAJqAU0AbP/k/Rz9yPvI+gj6CPkw+ID3IPdw9mD2APYw9vD14PXg9dD14PXA9fD14PXQ9cD1oPWQ9XD1IPUA9eD0gPRw9FD0QPQg9ID0oPRQ9eD10PYI+FD5QPtg/cn/mALwBGgHwAmgC/ANwA+gEUATQBSgFAAVQBUgFEAUYBNAEoAQsA4wDWALAApACJgGUAUIBOgCIAI6AVQA6f+M/1//1P6E/lD+Hv74/bj9zP2g/UD9XP0k/Rz9DP34/Ez9oP3M/Sj+iP5G/+D/nABkASgCzAJ8AzAEmAQoBYAF6AUYBtgFgAUwBbAEKASEA7ACwgHVAL//2P7k/ez8IPx4+5D6APpQ+eD4ePhI+BD48Pfg9+D38PfQ9/D38PcI+AD48Pfg97D3cPdA9/D2YPZA9tD1cPXw9LD0kPQw9ED0QPSg9OD0sPVg9qD3GPno+kD9mf8wAlgE4AYwCfAKoA2AD0ARQBIAE0AUQBQgFMATYBNAEmAR0A9QDrAMIAugCXAIQAfABegEtAM0A1gCpgFOAa8AbQAVAKP/NP/g/q7+eP46/uz9tP1o/ST9KP0k/UT9jP2w/UD+nv4i/8H/hwBkASAC2AJoA0AEoAQ4BYgF0AXYBeAFcAU4BYAE6AMQA3wCfAGMAKb/fP7g/dT8+Ptg++D6OPrQ+WD5IPnw+LD4yPi4+MD4oPi4+JD4oPho+GD4MPjw99D3kPdg9/D2sPZA9uD1gPUg9dD0kPQw9DD0APRA9DD0gPTQ9HD1QPYQ96D4iPrw/AL/TAHsA5AFgAcACtALgA6wD8AQwBGAEuASIBMAE4ASwBHgEJAPkA7ADFAL4AmwCHgHIAYABQgEJAM0ArgBJgG/AGsA8P9s//7+/P5c/nr+Hv6w/Zj9eP1c/TD9eP14/aD9KP6M/sT+Vf/T/48ASgHiAbAC5AKkA7gDUAR4BIgEwARoBEAErAMYA6AC2gE8AYkAxP/8/hD+fP2s/Az8ePvY+pj6IPrQ+aj5iPlY+UD5SPk4+Xj5UPlg+VD5SPlA+RD5EPnY+Lj4aPhI+BD4gPcQ96D2cPYQ9tD1YPUg9dD00PSQ9CD1IPUw9QD2YPZg95D4YPpM/JD+pQC8ApAE6AbACCALEA1gDrAPABGgEWASgBKAEoAS4BEAEQAQMA+ADWAMIAuQCbAIGAdgBkAFOASIA7QCSAK8AUQBrgBiANr/g/9F/zv/sv6K/nD+OP4c/hL+JP5I/oD+1P4q/4L/+/9fADQB4AFkAiQDgAMQBFgEkATQBBgFEAUABZAEOASMA/ACQAKCAeIA5v9A/1b+jP3E/Pj7oPvw+pj6EPro+bD5cPlo+Wj5ePmQ+cD5oPnY+cD5yPno+bj5sPlo+Uj5IPn4+MD4YPgA+LD3MPcA95D2MPbw9ZD1UPUw9RD1QPWA9bD18PVA9hD3GPj4+bj7wP2l/wwBzAOoBXAHoAlwC+AMYA5QD0AQoBAgEUARABHgEOAPMA9QDiANwAuACrAJYAhgB1gGcAWIBKQDHAO8AigCkAEYAa8AZgD7/6T/cP8a//L+iP5c/hj+9P0M/iT+TP52/qr+HP9Z/7X/WgDpAIQB+AFgAqwCAAMwA2wDnAOMA2wDNAPkAmwCyAFWAZoAFABa/7D++P04/bD8IPyI+0D74PqY+lD6QPoY+vj5IPoY+jD6UPpA+pD6WPqg+mj6kPpw+iD6IPqw+aj5OPkg+cj4aPjg92D3EPew9nD28PWg9VD18PQA9SD1MPUw9ZD1IPZg9kD3APmY+pT8Zv7z/3gCQARYBlAIcAqgC8AMQA7wDgAQIBBAEEAQIBCQD7AO4A3gDKALcAqACUAIQAdgBnAFeATQA1ADxAJkAtoBdAHjAJUALwD+/8T/VP8n//T+3P6I/oD+dv56/rD+yv4M/2X/fP8hAIYASgGWAUQCtAIUA2gDtAPwAzAEOAQIBPQDjAM0A4gCDAJaAbkA6v8c/5L+jP1A/Uz8+Pto+xD78PqI+pj6gPqI+pD6sPrI+hj7MPtI+1D7aPtY+1j7APsA+7j6cPoQ+pj5SPko+Xj4YPiw93D3APeQ9nD2EPbg9WD1UPXQ9fD1sPXQ9QD2MPYw9zD4kPlg+9z8cP5TAFACMARQBkAIEAqAC8AMEA4gDwAQYBDAEMAQgBAAEFAPYA5ADTAMEAsQCpAIkAd4BmAFsAT4AzQDhAIQAm4BJAHEAGwAKwDb/5f/Tv9E/wX/2P7Y/s7+2v4U/xD/Uv+h/9D/PACfACgBoAEsAqgCCANoA6wDEAQgBEAEOAQoBMwDcAMAA4wC/AE8AXQAw/8I/1D+qP38/Gz80PtY+xD7yPp4+nj6cPqQ+pj6sPrY+vj6MPtg+6D7yPvg+9j7yPug+0j7QPvo+tD6aPoI+qj5CPnA+GD4aPjg94D30PaA9gD2MPYg9kD2APaw9cD14PVA9mD24PcA+UD66Pt8/Xv/IgEkA0gFSAcACYAKEAxQDWAOAA/gD2AQgBAgELAPUA9ADjANUAxACxAK8AjYB8AGsAWwBAgEcAPgAkQC2AFWAewArQCAAIcAPwANAMj/mP92/1r/Yf99/4j/hP+5/9P/DABWAMoAQgGgASACgALsAjwDiAO8AwAEEAQQBPQDyANcAwgDkAIUApAB1QAxAHj/1P4o/pD9/PyM/Oj7mPsg+/D6sPq4+qj6uPqo+sj6yPoY+zD7SPtw+2j7kPtY+3j7QPsA+8D6gPqA+rj5ePlY+aD4YPgw+LD3gPfQ9pD2YPYQ9sD1oPXg9eD10PXA9fD1EPaA9nD3cPjw+Vj7BP20/lsAOAIgBEAGEAiwCQALMAxADRAO8A6AD6APoA8gD6AO8A0ADSAMEAsACuAImAeYBpAFoAT8A0gDwAI4ArwBcAECAasAfQBMACIA2P+C/0j/+v7m/sD+sP6w/q7+wP7S/vz+Sf+Q//7/gADpAGwBtgEwApgC7AJEA3QDmAOUA3wDJAPQAmAC7gFsAdEAJQBn/7j+EP58/ej8ZPzo+4j7QPsI++D64Pro+vD68PoQ+zj7UPt4+4j7wPvI+7j7wPug+3j7SPsI+9D6qPpI+uD5qPlo+Rj5wPiI+CD48PdA9yD3QPdQ9qD2MPZQ9kD2QPYg9kD2gPbA9uD3CPlw+oj7XP3m/r8AoAJQBHAGUAiwCTALgAygDXAOMA+wD/AP4A+QDzAPgA6QDZAMsAugCnAJUAg4B0gGaAWABAgEeAP0AnACKAK0AU4BGAHlAKMATwD2/9P/n/9x/0b/Pv8t/w3//v4f/1P/Zf+s/wAAeQDOAFYBwAFEApgC9AI8A5ADuAPUA9ADtANgA/gCpAI0ArABDAFrALv/Av9M/qD9BP2A/PD7kPs4++D6qPqA+oD6ePqQ+qD6wPr4+hj7OPt4+5j7wPvg+9j70Pu4+3j7QPso++j6mPpQ+vj5qPk4+dj4gPgw+AD4oPdg9yD30PbA9rD2EPfQ9rD2IPcA9+D3yPgw+kD7gPwS/pz/XAHQAogEIAa4BwAJIApgC2AM4AxwDQAOIA4ADvANQA3gDPALIAtQCpAJwAi4B9gGEAZgBcAEcATIA1gD0AJkAvABoAFaAfMApwBmABkA8/+R/3//T/8i/zD/+v4i/0T/QP9p/7T//f9DAMIAGAFwAbQBEAJcAqgC6AIAAyADAAPsAqgCjAJIAuQBfgEIAWoA2P83/6r+Gv6A/QD9dPwQ/KD7SPsg++j64PrY+tj64Pr4+iD7QPtw+5D7uPvQ+8D7sPuY+2j7SPso++j6uPpw+hj6wPlo+fj4wPhg+Aj40PdA9wD3sPbQ9vD28Pbg9rD28Pbw9oD3IPjw+Fj6CPus/Bj+kf8MAdgCMATgBUgHkAjgCdAK0AtQDDANgA3ADcANkA0wDZAMAAxgC5AKwAngCBAIGAdwBqgFKAWYBOgDdAP4ApwCFALQAXQBGgHMAIMANwD4/7b/lf8v/xn/9v7O/tb+uv7q/vT+FP9Y/43/1v8FAGIAowDzADABdAGqAbYBugGmAaABeAFcATQBCAGyAEUA6P93/wr/jP4+/tT9YP0A/aj8fPxU/Cj8DPzw++D72Pvg+/j7+Pvw+/j78Pvw++D70Pu4+6D7ePtA+xj7+PrQ+oj6QPr4+aj5cPko+eD4mPgw+PD3wPfA98D3wPfg99D38PcQ+Dj4mPgo+TD6GPs8/Ij9iv7s/64BKAOoBDAGgAcACfAJEAsADMAMYA3QDQAOAA7wDYANEA2ADNALAAtACoAJoAjYByAHaAbYBVgF6ARgBPADmAMsA+wCkAJYAvQBygFsATQB4wCEAEgA7f/B/23/Qv8D/+z+xP7S/uD+/v46/2r/vv/7/zMAhQC8AOAAJgFCAVQBWAFKATYBHAHlAKUASAAOAJX/JP/U/mT+/P2g/UT99PzM/Ij8dPxk/Ej8ZPxA/FD8XPxU/GT8VPxk/GD8XPxI/BT8GPzY+9D7oPto+1j78PrA+nj6OPrg+ZD5QPkA+aD4mPgw+Fj48PdA+CD4MPhY+FD4gPiY+DD5yPng+qj7iPzc/eL+LAB+AfQCQASQBdgGuAfQCMAJoApQC9ALIAwwDFAMEAzQC1AL4ApACqAJAAlgCJAH8AZIBqgFKAWYBPgDtAM8A+ACmAJoAlACHALeAZYBeAEuARQBzwCTAFIADgDB/4//Wv8E/+b+sP68/rr+rv6g/s7+1P7U/v7+K/9j/4n/q//j/xYANQBaAHAAhQBrAFgAMgD4/7v/Uv8F/7j+Vv78/az9TP0E/bj8ePxQ/Aj86PvI+7D7mPuQ+4D7gPuA+4j7kPuw+6j7yPvA+7D7uPuo+5D7ePtY+yD7EPvA+pD6SPow+vj50Pm4+aD5qPmA+bj5uPng+Rj6cPrw+pD7YPwY/Tb+GP/5/yYBSAJsA3AESAVQBigH8AewCBAJwAngCRAKUAowChAK0AmACSAJkAj4B3AHyAZYBrAFSAXABFgE8AOkA0ADFAOwAoQCdAJIAhgCDALoAdABuAGKAXgBFgEIAaQATwAXAKn/Yf8y/9L+pP5y/kL+QP4W/hz+IP4Q/hj+EP5C/kT+YP6G/qb+0P7k/gr/G/8l/yL/Gf8a//j+yv64/o7+fP5G/kb+KP4E/vD9zP3M/Yz9gP1w/Vz9VP1E/TD9IP0Y/fD85PzQ/KT8fPxA/Bz82Pu4+3j7OPvo+qD6ePoo+hj62PnY+bj5wPnY+dj56PkY+kj6ePrA+ij7sPtA/Pz8gP1g/g//3f+JAHQBIALQApgDIATgBEgFqAUgBnAGsAboBhgHKAcYBxAH8AbQBqgGkAZgBjAGEAbgBbgFmAVwBUAFKAXwBMgEqASIBEgEEATgA5ADTAP4ApQCSALgAXoBEgGvAFIA/f+c/1T/DP/M/oz+Wv42/iD+EP4A/uz99P30/Qj+GP4q/j7+Vv5s/nr+iP6k/sD+0v7e/uz+9P4B/xz/Jf86/0H/QP9G/0X/R/82/zD/Kv8n/xb/Bf/+/uL+0P6y/pT+bP5I/iL+AP7Q/Zj9dP1I/Tj9FP0I/fT85Pzc/Oj8AP0U/UT9YP2g/eT9Kv52/tT+I/+C/+D/NgCSAOYAUgGQAeABHAJcAoACpALAAtgC3ALkAuwC1ALUAqwCjAJkAjQCDALSAaABaAEoAe0AsgB1AEQAJQD+/+b/4P/Y/9z/6f/7/x8ATABsAJMAvAD+ADwBcgGuAfYBNAJoApACxALgAgADDAMwAzgDLAMkAxgDGAPwAswCtAKEAmQCKAIAAtABqAF6ASwBNAHqANQApwCOAFMALQAMAPD/yv+a/4P/Uf8r/wD/0P6Q/l7+HP7c/bT9aP00/QT9xPyU/Gz8TPw0/Aj8+Pvg+9D70Pu4+8D7wPvA+9D76Pvw+wz8HPww/Fj8ZPx8/JT8tPzE/Nj8+PwU/Uz9bP2Q/cD98P0Y/lj+rP70/kT/jv/a/yoAfgDdADIBegHaATQCiALcAiADaAOsA+QDEARABHAEkASwBNgE4ATwBPAE8AT4BPgE4ATIBLgEmARwBEAEEAToA7ADeAM0A/gCsAJkAhwC0gGAATgB5gCiAGAAFgDN/4//UP8T/9b+oP5u/jr+Cv7g/bz9mP1w/VD9OP0k/Qj9/Pzs/Nj8yPzE/Lz8tPy0/Kz8qPyo/Kz8qPyw/Lj8xPzY/OT8/PwI/SD9NP1U/Xj9mP28/eD9Cv4s/lb+cP6Y/rj+2P76/hv/Pf9j/4f/o//A/+L/CAApAE0AcwCdAMkA/AAoAWIBlAHEAf4BJAJoAowCvALkAhQDQANcA4QDqAPIA+QD9AMQBBAEIAQYBAgECAQIBPgD5APIA7ADkANwA1QDMAMIA9gCqAJwAjgCAALIAY4BUgEWAdkAngBiACoA9//C/4r/V/8r/wH/2v6w/pL+cP5U/j7+JP4M/vT94P3U/cT9uP2w/az9pP2c/Zj9mP2g/aT9qP20/bz9xP3U/eD98P0A/gr+Gv4o/jj+Tv5g/nj+hP6a/qr+vv7O/t7+6v76/gD/F/8a/y//PP9P/2L/cv+K/6X/xP/G//f/AAAeADEAQQBnAG8AegCZALIAvQDGANgA3ADjAO0A+QAKARQBFAEaASIBLAEwATIBPgFCAUQBSgFIAUgBRgFIATwBNgEyASYBHAEOAfsA7gDbAMkAsQChAJIAeQBkAE8AOwAoABIAAgDz/+P/z/+6/6b/lf+F/3X/ZP9T/0X/OP8s/yH/E/8K/wP//P7u/uL+4P7i/uL+3v7Y/tj+3P7e/uD+5v7q/ur+7v74/vj++v4A/wX/DP8P/xT/Gv8h/yf/Lf80/z7/S/9a/2z/d/+G/5b/qv+9/9L/6P/+/xMAJgA8AFMAYwByAH8AjwCdAKkAswC8AMUAzQDQANQA2ADZANgA1gDWANUA1ADSANEAzQDNAMgAxADCAMEAwQC/ALwAtgCvAKcAoACWAI4AiAB9AHUAbgBnAGEAXQBXAFAASAA8AC4AIgAeABUACgD///b/7v/k/9j/0//N/8j/vv+7/7T/rv+m/6H/o/+d/5j/kv+M/43/fP92/3H/cP9n/13/av9f/2P/Wv9k/2L/aP9u/3f/fP+A/4n/k/+f/6b/rf+y/7//wv/M/9P/1f/c/9//5P/v//T//v8IAAwAGAAfACQALAAtADQAOgBAAEsATwBSAFsAXQBjAG8AbwBxAHQAdgB3AHwAfgB9AIMAfABzAHUAcgBtAHEAcABpAGQAXQBXAFMATwBJAEIAPQA5ADUAMQAsACYAIQAfABwAFwAUABEADAAHAAEA+v/3//L/7f/n/+D/1v/Q/8v/xP+8/7X/sf+w/6z/p/+j/6D/nv+b/5n/lv+U/5L/kP+R/5L/kv+S/5P/k/+U/5P/kf+Q/4//jP+M/4z/jf+M/4z/j/+U/5j/nf+k/6v/tf/A/83/2P/i/+v/9v8AAAsAFQAhAC4AOwBFAE0AVQBcAGMAagBzAHsAgQCGAIoAjQCPAI8AjQCMAIoAhwCEAIAAewB3AHEAbABoAGUAYQBeAFkAVwBVAFQAVABTAFMAUgBQAE0ASQBHAEIAPgA4ADQALwAqACcAJgAlACUAJAAkACMAIgAgACAAIQAgABwAFgASABAADwAPAA8ACgAEAP7/+//2//H/6v/l/+D/2//X/9T/0f/Q/8//0P/P/83/zP/M/83/z//R/9T/1f/X/9f/1//W/9X/1v/X/9r/2//c/93/3f/f/+H/5v/q/+3/7//0//n//v8BAAQACQANABAAEQAUABYAGQAaABoAFwAZABsAHAAbABkAGAAYABMAFgAOAA8ABwALAAkABwAGAAsACwD//woA/f8EAPj/8v/4/+v/4//m/+P/2//R/87/yf/H/8f/xf/J/8r/xv/H/87/2f/Y/9v/4//p/+7/8v/2//z/AAADAAUACQAOAA8AEAASABQAFgAZABwAHgAiACYAJwAqACwAMAAzADUAOAA6ADsAOQA1ADIAMQAtACkAIgAcABcAEQAMAAcAAQD9//r/9P/r/+X/4f/f/9n/0P/J/8X/w/+//7r/tf+x/6z/qP+k/6D/nP+Z/5f/lf+T/5D/jv+O/43/jv+P/5P/mf+e/6P/p/+t/7T/u//C/8r/0v/Z/9//5f/r//H/9P/2//f/+v/8//3//f/+////AAAAAAAAAAABAAEAAQACAAMABQAGAAgACgAMAA4ADwATABgAHQAhACQAJgAnACkAKgArACsAKwArACwALgAxADQANwA6ADwAPQA8AD0APgBAAD8APQA6ADkAOAA2ADMAMwAxADAALAArACcAJgAjACAAIQAfABwAFgASABEABQACAP3//P/z/+v/7v/k/+T/2v/f/9r/2v/Z/9n/1//W/9f/2f/b/9v/2//a/97/3P/e/93/2f/Y/9T/1P/V/9L/1f/U/9P/1//W/9b/2P/W/9n/2v/c/+H/4P/i/+f/6P/u//X/9P/4//z//f8DAAkACwAOABIADwAQABYAFwAaACAAIAAhACMAJAAnACsALAAtAC8AMAAxADIAMgAyADEAMgAyADIAMQAwAC8ALQAsACoAKAAnACYAJAAhAB4AGgAXABQAEAAMAAgABAABAP3/+f/1//L/7//r/+f/5P/h/93/2//Z/9j/2P/X/9f/1v/W/9X/1P/T/9H/z//O/8z/y//J/8f/xv/F/8b/xv/I/8v/z//U/9n/3f/g/+P/5v/q/+7/8f/1//j/+v/7//z//P/8//3//f/+//7//v/+////////////AAAAAAEAAgADAAMABAAFAAYACAAKAAsADQAPABAAEwAWABoAHgAjACcAKwAuADEAMwA2ADgAOAA3ADcANQA1ADUANAAzADIAMQAwAC4ALAAqACgAJgAjAB4AGAAVABIAEAANAAoABQAAAPz/+v/3//P/7//r/+f/5f/j/+H/4P/e/93/3P/b/9j/1//X/9j/2f/b/93/3//h/+L/5f/m/+f/6f/q/+z/7f/t/+z/6//q/+r/6//q/+j/5//o/+j/6f/n/+f/6P/o/+j/6P/p/+n/6//q/+n/6P/q/+z/7P/r/+r/6//r/+j/6v/k/+T/3v/h/9//3f/c/9//3f/Y/+D/2P/i/9r/3f/m/+D/4v/q/+n/5//m/+j/5//q/+v/6f/u/+//7f/x//f////+/wEACAANABIAFAAYAB4AIgAlACcAKwAuAC8ALwAwADEAMQAwAC4ALQArACoAJgAkACIAIQAgAB8AHwAeAB4AHAAbABoAGwAaABgAFQATABMAEQAQAA8ADQALAAoABgACAP///v/9//n/9v/z//P/9P/y//D/8P/w/+//7//w//L/9P/2//r//v8AAAMABQAJAAoADAANABAAEQARABEADwAQABAAEQARABIAEgASABEAEQASABEADwANAAsACgAIAAYABQADAAMAAgABAAAA//8AAAAAAQACAAMABAAGAAgACgALAAwADgAQABMAFgAYABkAGwAcABwAHQAcABsAGgAZABgAFwAXABcAFwAYABcAFwAYABoAGwAeAB4AHwAfACEAIwAjACUAJgAnACcAJQAmACIAJAAhACEAIQAfAB4AHAAdAB0AGAAcABwAHAAaABkAIAAVABkAEwAYABEAEgAQAAwACQAFAAQAAQD9//n/9f/w/+7/6P/l/+H/2v/Z/9T/0//S/87/z//O/8z/0P/O/87/z//L/8//0P/S/9X/1P/W/9r/3P/h/+P/4v/l/+f/6f/q/+7/7f/v/+7/5//n/+j/5f/l/+j/5P/k/+T/4v/k/+f/5//p/+v/7f/w//H/8//2//j//P/+/wAAAwAGAAsADQARABUAGwAhACYAKQAuADEAMwA2ADcANQA1ADUANAA0ADIAMAAuACwAKQAlACAAHAAXABIADgALAAcAAwAAAP///f/8//n/9//3//X/9v/1//j/9//5//v///8DAAYACgANABQAGAAdACIAIwAjACQAJAAjACEAHwAdABoAFgAPAAkAAwD8//f/8f/s/+f/4f/c/9n/1f/R/8v/yP/E/8P/wP/A/7//v/+//8D/w//H/8r/0P/U/93/5f/u//f/AQAMABcAIQAqADQAOgBGAEgATwBPAFYAVQBZAFoAWgBZAFgAVABRAEkARAA5ADIAKAAZAA0AAAD3/+r/4//X/9H/xf/C/77/wP/B/8L/yv/O/9j/3//q//f//v8HAA4AFgAaABoAHgAfAB8AHAAaABUAEAAKAAMA/f/w/+n/3v/X/8v/wP+x/6j/m/+T/4b/gP91/3L/bP9s/2T/Z/9p/2z/cv9w/3f/f/+J/47/lf+a/6j/sv/F/9T/6f8BAB0AOQBcAHMApgC9AOwAAgEoAUgBYgF8AYABjgGEAZoBbAF0AUYBOAEkAeEA1ACfAIcARgA0AAYA6v/6//P/DQARACAASgCAAK8A0wDgABABIAEwASQBBAHtALcAdgAbAKj/Pv/A/jz+qP0Y/ZD8HPyw+1D7CPvY+tD64PoY+2D7yPtM/OT8lP1K/gL/yv+RAFgBDAKsAkQDyAM4BJAEyATgBPAE4ATABIAEIAS8A0gDyAI0ApwBAgFuAN//Tv/G/k7+7P2g/WD9OP0o/TD9UP2M/dT9KP6O/gL/e//w/2sA6QBiAc4BLAJ8AsQC8AIYAywDMAMkAwAD1AKUAlQCBAKsAUYB3QB4ABcAtP9a/wT/wP6I/lr+Ov4g/iT+Kv5C/mL+jP7A/vj+Mv9w/6v/5f8fAEIAcgCLAJ8AqACdAI8AdABYAC4AAQDN/6D/c/9H/xz//P7c/tL+yv7A/tD+0v72/hv/Rv9y/5n/z//7/y0ARgBlAHYApQCMAKIAbQB3AFkAJwAVAMf/rv9i/0D//v7Q/qr+iP50/lj+Tv5E/l7+jv54/rL+xP4J/zT/ef+i/9j/EgA1AG0AewCUAKoAtgCmAKAAfQBxAFcAJQAKAN3/wf+2/5r/fP9r/1v/Zf9c/2n/Yf9y/4//lv+z/7X/0P/i//j//f8GAA0ADgAhABEAFAD7////9P/r/+r/1P/a/+P/7v/3/xAAHwA4AFoAeACZAMIA3gAAASIBNAFOAU4BWgFSAUQBLgEEAeMAuQCXAGMALgABANn/sf+Z/23/Xv9R/0b/Tf9P/2D/df+X/7T/2f/2/xYANgBXAG0AgACJAIwAlACHAH0AaQBdAEAAHgD8/9n/vf+e/37/Yv9L/zr/Nv81/z7/Rv9b/3z/nv/A/+b/EQA/AG0AkACuAMkA4wDyAPkA9wDyAOgA1wDAAJ4AfwBeAEEAJwAGAPj/6v/o/+X/4//s////FgApAEAAUABtAIMAmgCmAK4AsgCxAK8AoQCSAIEAbwBXAEMAKgAXAAAA8f/b/87/wP+y/7X/pv+0/6j/uP+9/8//2f/o//v/BAARABoAJAAuACwALwAmACQAHwAHAPr/5v/W/8T/rf+Y/4P/av9h/1L/UP9D/0H/Qf9E/0T/R/9L/03/T/9N/0r/Sf9I/0f/T/9T/1X/XP9b/2f/aP92/37/i/+S/5z/qf+t/7r/u//B/8P/yv/P/9L/2f/c/+L/6v/x//D/+f/8////AgD//wcADAAbABwAHwArADcARABfAGMAewCHAJYArQC0ALwAzgDMANYAzwDLAMAAsQCkAH8AZAA6ACwA9f/n/7n/oP+G/1H/S/8z/x7/Dv8W/x3/J/9L/1z/eP+Q/6n/zf/3/w8AIgAnAD8AQABCAD0ANQAoAA0A/v/e/8P/sf+V/4H/cP9g/1f/Vv9V/1z/X/9v/3L/gP+S/6H/qf+s/7H/sv+q/6X/m/+c/53/nP+Q/5L/mP+n/7n/wv/c//H/EAAsAEsAagCKALcAzADhAO0A+QAGAQ4BEAH4AO0A1gDFAKwAogCOAHMAawBbAEwAUABFAFUAVwBqAHMAhwCOAJ4AqACrALgAqwC5AKkAnwCQAGQASQAUAOr/vv+L/1j/Kv8I/+r+1P7A/rL+ov6e/pj+jP6K/oj+dP5u/mT+VP5Q/jz+Kv4q/hz+GP4U/gb+HP4Q/iz+OP5e/nL+qv7Y/vr+Rv9m/5D/vv/Y//v/8P8QAA4AGAApABoALwAkAEAAOABDAEkAZQB9AKoA1QAGAToBhAG8AQwCTAKgAtACOAN0A8wD/ANIBJgEuAQoBTgFkAWwBeAFCAYoBkAGYAZIBnAGSAYoBugFqAUoBbAEEARoA7ACzAESAQIALv8o/jj9ZPxw+7D66PlI+Yj48PeA9/D2oPYw9vD1wPWQ9ZD1gPWA9bD1sPUA9kD2kPYQ92D38Pd4+Nj4cPnY+Wj62PpQ+/D7OPzM/Hz9oP2w/qj+Af9+/6L/1f8ZAOAADAHQAQgCmALMAngDUASwBGAF8AXIBnAHUAgACcAJ0ApgCzAMAA2gDUAOsA6QDwAQYBAAEWARABJAEkASQBLgEYARwBDQD7AOIA2QC7AJwAewBTQDCgHc/oT8WPpY+DD2UPQA8wDx4O/A7sDtYO0A7QDtAO2A7eDtYO5A78DvoPAg8TDyIPMA9CD1EPZQ93D4sPn4+ij8UP1M/hP/6P9fAMcADAEQAUQBEAHWAIQAs/8//5T+KP7g/XD9QP0M/Qj9MP1k/Yj9+P1K/gD/t/9ZAEIBSAJQA0gESAUwBigH8AfQCGAJIArwCqALoAzgDfAOABDAEaASYBQgFYAWABcgGGAYoBiAGAAYIBdAFYATwBCQDZAKmAYUA0j/YPvA9zD0oPEg74DtoOxA7GDswOyA7WDugO9g8MDxoPKg84D0IPUA9mD28PZg96D3IPjw90D4kPiY+DD52PnI+mD7UPwY/cj9TP6A/r7+4P52/kz+hP0k/dj7GPso+nD5uPjg93D38PbQ9vD2MPew93D4KPkQ+qj6YPs8/Pj8/P2e/jL/2/8HACQBdgF8AhADUAQgBTAG2AaoB6AIMAlwCkALAA2wDUAPIBCgEWASQBMgFCAU4BWgFYAWABcgF6AWoBXAFIAR4A6AC9AI4AWEAnr/sPtw+FD24PPg8tDxEPFQ8aDxkPLA8hD0EPVw9cD2QPdw96D3YPfQ95D3gPdg99D2IPcg92D3gPfQ96j4UPmI+kD7+PuE/Oj8NP3k/AT9IPxY+2D6gPl4+HD34PYw9sD1kPWQ9aD1MPag9qD3iPiY+bD6QPsw/LT8WP3Q/VL+tP7Q/gX/a//H/3cAUgFgApgD6AQwBngHYAjACQALUAxgDdAO8A+AEKARwBJgEwAUoBSgFMAVgBagFkAXQBdAFyAWoBRgEgAP8AvgCBAGjAKA/0D82PjQ9tD0cPOg8gDyoPKQ8gD0YPRQ9VD2YPeY+Nj4MPnY+Aj5CPnA+ID46Pjg+OD4SPnQ+Xj6kPqI+0T8+PzI/bj9mP14/eT8OPxQ+1j6GPmQ95D2cPXA9ED0QPQw9JD0APXg9ZD2cPeg+Lj5YPoo+8D7+PtU/Ej8kPy8/Bz9KP3c/V7+O/8TAFwBxAJQBHAFqAbQB4AIUAkgCiAL0AsgDJAMcA0QDpAOoA9AEMARQBJAFMAVoBfgGOAYwBkAGSAXwBOAEJAMUAlwBfgBVP5g+oD3kPUg9CDz8PJA83D0cPVA9qD3yPiw+Vj6IPtg+8D6+PmA+Wj5oPhw+Fj4yPhA+aD5iPpg+/j73PwA/s7+2P50/sT9pPxQ+yj64PhA96D1MPTw8nDy4PHQ8dDysPOA9ND1QPc4+FD5cPrA+0z8rPyY/Iz8ZPwQ/Cj8JPxg/JT8VP0c/s7+GQBcAdgCMARABYgG6AZYByAIgAggCUAJwAkwChAL4AtQDQAPIBDAEQAUoBYgGOAZYBsAHQAdoBtgGWAVQBEADcAIcAUCAST9ePlw93D1cPRg9HD0YPWQ9hD4SPkg+uj6yPtI/Cz8mPvA+iD6SPnY+Gj4UPgw+MD4yPmw+oj7ZPzw/Mj9lP6g/vj9yPww+5j5MPiA9tD0UPMA8uDwgPCw8MDwkPHQ8oD08PUg91j4aPlw+jD7yPv4+6D7MPuw+nD6QPoY+mD6APuY+5j84P0K/2IArgEUA0gE8ARwBdgFEAZoBgAHKAfABzAIMAmwCoAMAA4AECASYBSAFgAZQBsAHWAeAB+gHyAdQBqgFUAQoAtoBzQDif94+zj4UPbA9dD0QPVQ9tD3KPk4+kD70Pt4/Ij81PyQ/ID7YPr4+CD5GPmo+BD5gPmQ+nj7oPyA/Rr+ZP7K/sz+EP6Q/BD6CPgQ9oD0IPPQ8cDw4O/g7wDwgPCg8eDyQPQQ9sD34PiQ+UD6+PoY+5D7WPs4+xD7+PpA+6j7HPyk/GD9hP6k/0EACgHAAYQCWAMIBCgEGAQ4BHgEGAVYBXAGcAdgCOAJsAtADkAQABJgFKAWwBggGqAbAB0AHmAe4B4AHaAZ4BMQD1ALAAacAqT+gPu4+MD28PVw9QD2kPaw9xj5aPrw+iD7cPt8/Dj98Pz4+2j7UPsY++j6YPsM/Fz8TPwY/dz94P1A/Rj9LP3U/Dj76PjA9tD0wPKQ8SDxMPDA76DvkPAQ8aDx0PLg85D1oPbA99D4+PjQ+BD5IPpo+jj6QPrg+jD7UPuo+2T8PP34/aD+jP8cAHEA8ABGAZ4BQALAAqwCNAKsAogEmAX4BWAHMArQC7AM8A5gEUAUwBRgFkAZgBuAG6AbgB2AHuAdQBwgGMATUA5gCcgE7QBQ/fD50PYw9XD0gPSQ9bD10PeQ+Uj7SPug+3D8pPxo/WD9UP18/Nj7RPxc/LT8GP34/Sr+lP04/WD9xPyA+5j6GPqw+LD1oPIg8RDwwO4g7gDuYO4A72DvIPCw8SDzQPRg9fD2YPi4+cj5oPlY+iD7MPuA+/D7oPw0/Nj72Pt0/NT8mPxQ/UL+2v7W/ob/nQC+AFQBzAEwAqACGAOIBPAF6AdACaAKIAyQDbAPIBJAE2AVABjgGSAbYBxAHuAeoB3AHIAbwBfAEeALYAjkA2P/SPvY+AD3sPTA9LD1QPew94j58PuE/aj9QP3k/YT9hP2Y/eD96P0o/WT9qv53/2f/l/+K/zf/zP20/Dz8YPv4+bD3oPXA8/DwYO8g7qDtwO0g7mDuoO+A8bDyUPQA9UD2kPew+OD4gPlw+pj6APoI+uj66PsM/Hj7yPtg/Nj7OPto+3D8iPyY/HT9YP4//2P/DgC8AKgBSAIgA9QDOAXoBuAIIAqgC2AN0A6AEAASABRgFSAXYBkAHGAdQB7AHsAeYByAGMAUoBBACwAGtgHs/hD6IPYQ9YD14PXw9QD36PhQ+zj8IP5B/+T+RP6E/Q7++PyI/Hz9kv64/tr+wP8xAAEAcP7s/rD9PPxA+lj4YPfA9NDyEPCg7qDtgOzg60DsYO3g7gDxQPLw83D1MPbA9gD3QPhw+Vj5yPnY+cD6IPvY+lD76PtQ/Fj8YPsw+0j7APuY+ij7OPwI/Xz96P3g/qz/UgHWAdAC/AM4BTAGeAdACeAKYAywDQAQIBLAEkAUoBXAGCAboB1AIEAiACHAHSAbQBdgERAMoAjIBHv/GPrQ98D2QPYA9nD3UPng+Yj6HP2r/yIA7P+e/2D/cP4k/jr+iv6k/5AAGAIUAnYBHAEEAZ0AZv6U/Bj7KPlQ9uDzcPIw8UDvYO2g7ODsIO0g7aDusPCw8+D0gPUw9uD2kPeA94D3YPhI+Xj5YPn4+UD7iPtY+/j7VPx4/Ej7sPqo+jD72Pq4+5j8vPxI/Uj+hv9MAGIBbAO4BEgFwAYACZAKQAuwDMAOQBCAEeASoBTAFeAWgBqAHeAfACHAIIAfABugFYAR0A1gCaAEwgDg/bj6oPfA9ij4kPkw+Vj5iPvw/d7+Q//J/y8A2v++/nz+I/+F/x//3P9UAVwCpAEaAcj/LP88/qD8YPoo+KD2IPTQ8eDv4O5g7SDtAO1A7aDt4O7w8IDyUPSA9YD2MPeg9qD36PhY+Vj5YPno+oj74PoY+zT8dPy4+yD7GPpI+kj5GPl4+jD7CPyY++D8ZP5I/8D/cAFkA8AEUAW4BuAIYArACiAMEA6wD6APYBFAFOAVgBfgGWAegCCAIEAgwB1gGaAT0A6gC0AHgAJK/7D8cPkw96D3wPhg+fD4OPpY/CD91P1M/gEAUf8S/qj+OwDPAOv/dQDkAZgCqgHXAEMAh/8s/Tj7UPoI+SD3kPQQ8yDyAPAA78DtwO0A7mDu4O6A73DxEPMQ9CD1UPaQ9gD3UPcg+Dj50PkA+gD74Pq4+uD6+Ppg+lD6kPlQ+fj42PgQ+Xj5cPro+8z8eP0k/sX/5gCcAngDiAXoBhAIcAlwCtALwAwQDgAPoBDgEeATQBUAGAAcwB5AIEAg4B6gG0AVABAADTAKEAWQAGj+MPxQ+sD42Pkg/BD8UPpY+8T9HP7U/ar+dgBKAGb/dv/mAQgDoAI4A6wDrAOeARgBlgD2/qj8aPsA++D4APaw9KDzsPEQ8IDvoO8g7uDtQO+g8GDwoPAg8+D0YPUw9ZD2MPcw90D34PgY+oD5wPmY+UD68PlY+YD4ePgY+SD5SPg4+JD5WPq4+tD6LP2e/sz++v48ARQDEATwBFAHoAmACgAL8AswDlAPoA8gEcASYBRgFQAYwBugHsAfgB5AG6AWABLQDYAKMAeQAnX/FP2o+tD5APtY/Bj8SPxo/Az95Pyo/IL+7f+T/8D+D//yAEAC9AJ8A5AE7AM8AroAxv8s/2D8UPrI+aj4IPfg85DykPKA8WDvYO/A72Dv4O6A71DxsPHA8VDy0PPw9GD14PWQ9oD3QPgQ+Xj5UPng+RD64PlQ+WD5EPm4+ID4WPlw+dj4KPlQ+pz8XP3e/ggADgGYAUwDOAXQBjAIkAkwCyAMAA2QDTAPwBCAEgAU4BRgFgAZwB1AIQAiACAAHaAYYBLwDeALAAlwBCEAuP4S/uj7kPuE/YL/nP4c/Iz89P18/bj9Rf8rABD/iP59AEwCsAJEA6wD8AIuAWoAw/84/lj7QPro+aD3EPWQ86Dz4PFw8ADwIPCA70DuwO7g78DwAPHQ8fDygPRA9TD2UPcI+KD4EPlA+Zj5mPmo+Yj5YPkI+Yj48PfA9xD4SPh4+ED4OPlI+gz8hP2B/wgB7AGgArgE8AYYB4AI8AowDOAMoA0wDiAQQBHgEeAT4BQAFyAZIB3AIMAgwB6AGwAXQBIAD3ALUAdYBEwBAP/o/TT9NP4o/vr+jv7k/eD8qPxU/j7/bP+y/hQA2QCMAEoBwAOABKQCqgH+AbQBuP5w/MD70PrQ+PD1wPRQ9DDy4PCA8NDw4O/A7mDvgO/g7zDw8PAg8eDx4PLg9JD18PWQ9+D4kPjQ98j4sPkQ+bD3kPco+BD3kPWA9sD3CPgA97D3yPkQ+6j7gP2W/xoAWADzAFwD2ARwBSgHsAlwC8ALEA1ADmAQYBBgEuATABagGOAagB/AIYAgQBygGCAUwBCQDJAJoAYAA3QAd//H/6P/Yf94/xcAuP6U/Lz8UP6c/lL+mP4BAGUA0P9aAXAEuASgA2QC9AJMAmX/xP0k/bj7OPmA95D2gPWA8yDyAPJQ8VDwwO/g7+Dv4O9Q8PDwAPEQ8UDzIPWw9YD2UPgw+Yj4KPgo+Qj6gPlI+GD4aPgA9xD2oPbA95D3MPdg92j4wPlY+yz9nv7E/3gA8wD6ARAEuAVgB/AHcAkAC0AMIA3QDoARwBLgEqAUQBigGiAdQB/AICAeQBhAFEARkA7ACugGKAX+Acn/If+CACkAVv9l/2r+EP0U/OT89P1a/gT+IP/Q/wEALAEIA5gEkAP6AYIB6AAt/2z9wPyw+/D5QPjw9kD28PRg84Dy0PGw8MDvgO8g7yDvAPBQ8BDwsPCg8hD0MPVg9hj4wPgg+Gj4aPko+lj5mPio+CD4APcg9vD2kPdg95D3GPjo+ND5sPuw/UT/iP8gACYBXALsA7AFmAeQCKAJkApgDOANcA/gEEAS4BJgFCAXYBpgHQAggCAAHmAZYBXgEtAOUAxACegF+AJEAQ4BEAI+AScAzP9//zz9iPyQ/Yb+Sv6U/Wj+5v6X/5AApAIABLwDPAK2AOMAx/8a/lD9APxo+oj4YPdQ9qD1kPSg80Dy4PAQ8CDvAO9g74DwwPCQ8LDwEPJg9PD0oPWg90D4UPcg95j4uPnA+AD4WPgI+KD38Pbw9zD54PjI+Gj5OPpA+4j82v42AB0A/gDoAaADAAWoBjAI0AhgCeAKcAxADVAPQBGAEkAToBQgGEAbQB3AHqAeoBugFgATYBEQDzALkAgYBmQD7gA6AXgCqACG/z7+qP1s/Oj7hPxM/ZD9RP1c/eD9TP/6ACQDHAPsARoBHwDK/tj9sP3c/Kj66Phw+GD3APaw9ODzkPOg8YDvgO6g7mDuQO5A7yDwUPDQ8MDygPQA9sD2YPew98D3IPgQ+LD4oPhw+AD4UPfw9uD2kPdw98D3YPhA+ej5KPtg/ez+nv/p/9UAmALwA7AEmAYACLAIYAkwC0ANcA4QD0ARIBNgEwAVIBmgHOAdIB2gG8AZQBTgENAPUA6wCeAFUATgAzACLAI8AhAC0P8s/ST8OPwU/Bz8wPz0/Oj8PP10/rH/GAK4AgQC1/9t//j+kP2k/Nj7ePtw+fD3gPdg92D2sPNQ85DygPCA7uDu4O9A70DvUPAA8tDxoPIw9eD2MPZw9cD2cPfA9nD2IPi4+Dj40PdQ+DD5APgw+DD5YPkw+WD5IPtk/Lz9jf/nAJABngEIA7AEiAU4BvAHIAngCcAKYAzwDvAP4BCgEoAUIBYAGQAcoB6AHkAcYBmgFKASABFADuAK2AdwBmgEMAPEA4AEoAJS/+D9HP7g/Oj6EPwu/rz9BPyc/M7+uv9FACQBEAJZAHL+UP2Y/Rj9SPv4+qj5wPiQ99D24PZw9fDzAPOQ8eDvYO+A7xDw4O8w8CDxsPGg8sDzkPUg9tD1MPbw9jD3wPYA+PD3wPcw95D3yPh4+PD32PjY+Uj5UPnI+mD8nP20/qQAbALwArwC2AMQBtAGMAfIB0AK4ArAC6ANwA+AEeARoBNAFcAYwBpAHEAcgBpAGOAUIBGADlANEAsQCMAFKAUgBewDLAMgAxABNv4A/ET9SP0U/Oj7+Pz4/LD8qP1j/5EAff+k/yEARP5g/FD7PPyQ+2D5+Ph4+Uj4YPbg9QD2EPRA8aDwIPEQ8ODuYO8w8cDxwPAg8pDzoPQg9FD1MPaQ9TD1sPXw9sD2YPdw92D4wPdg90j4ePho+Hj4EPnw+aj6GPzM/r8AKALYAsADSASwBMgFIAeACGAJkAoQDIANsA+gESATYBTgFeAXwBnAGoAbIBzAGQAWIBNAEfAOEAxgCpAJYAgQBjAG4AVoBGwCxgBiAFL+OP0w/JD9CP2E/ID9kv7w/uz+YwCnADwAiv5i/oD9CPyw+hj6KPpI+Wj4cPfw9nD1IPRg80DyIPHg76DvAPBw8EDx4PHQ8qDzIPSg9CD1kPXw9bD1MPXA9QD20Paw98D3APiA96D3KPg4+Kj4IPnA+UD6qPuU/b//VAH0AgAEAATsA5gEUAZgCDAJUApAC0AMEA2AD0ASoBOgFCAW4BdAGQAbYBtAGuAXgBXgEqAPgA3AC1ALIApwCBAHQAb4BMwD9ALUAdH/iP1A/RD9HP0Q/Yj9NP6q/i7/R/+u/1f/3P4o/jz94Puo+sj6aPpQ+sj5yPgQ93D1MPUg9NDyQPGw8GDwgO/A77DwYPKA8sDy4PPQ9HD0kPRg9QD2EPWA9CD1UPYQ9/D20Pcw+KD3MPfQ96j42PiI+DD5KPtM/FD91//4AQwDFAO0AmAEaAWIBoAIgAoAC1ALkAzADwASIBTgFAAWoBegGIAZIBoAGoAYwBXAEiAQUA6gDPAKcApACdgHeAXIBFAEEANYAX7/hP48/ZT8ZPyY/FD90Pxk/UL+nP4+/lr+qv7E/WT8SPsA+4D6uPmI+UD58Pdw9rD1cPUg9DDyUPFw8IDvQO+A7/DwcPEQ8iDzoPOQ8/DzwPRw9fD0cPSQ9DD1wPVw9pD3CPhg92D3GPiA+HD4SPgg+RD6SPpI++T97P+2AZACVAO0A1QDEAWABiAIoAkgCpAK8AuADkARwBIAFAAWYBcAGIAYwBlAGgAYABVgE4ARYA6ADHAMAAxgCsAHEAcIBogE6AKmAdAAgv4s/Tj9hP10/QT9vP12/vD9IP7e/tD+Qv5c/bz8yPvo+pj62Ppg+gD5UPgo+GD3MPZg9aD0UPJQ8eDwQPFg8UDxcPJw80DzIPNg9BD1IPXg9OD0QPUQ9RD1MPag93D38Paw97j4oPiA99D4gPmQ+Tj5OPpo/Pj9AQBkAYQDzAOoAwAEMAWQBtgH4AhQCdAKsAyADmAQQBKAFKAVoBWgFuAXgBigF6AWYBUAE7APgA7gDRANYAsgCXAI6AYYBXAEhAPuAc//nP7I/lb+TP1s/eT9xP0c/Sz99P3k/Sz9iP0c/Rj8sPpY+hD7+Pko+XD42Pig9+D2QPZw9WD0sPKw8hDyAPJg8SDyIPPg8hDzkPMQ9GD0APSg9JD04PMQ9ID0gPWg9fD1sPaA92D34PaA9/D3EPgI+KD4OPq4+3D9of+6AZwCGAOEA+wDgAXYBpAHkAjwCVALwAxQDoAQoBKAE4AUgBWAFgAXwBYAF6AV4BMAEdAPIA/gDUAMYAtACnAImAfwBlAGWASoAoYB1ACI/4D+aP6A/gj+hP3E/cj9UP0Y/Zz9aP1M/Gj7OPsg+yD6kPlA+dj4IPhw92D3kPZA9XD0wPOA83DyEPLg8jDzUPOQ8/DzgPSg9LD08PTg9FD0UPSw9FD1oPUA9rD2IPdQ97D34Pfg9wD4CPhI+FD5uPrE/Hb+SwBQAawCrAL0AoAE2AXoBkAHoAigCtALMA1AD6AR4BJgE6AUwBUgFqAW4BZAFuAU4BLgEcAQ8A+QDpAN4AsgCgAJYAhwB7gFcAR4A0AC0AAvAA0AiP/i/nT+nv5a/qD9nP0e/sT9aPyQ+3j7UPuI+hj60PlA+Tj4cPeg9zD30PUA9YD0MPRw80DzgPPw8/Dz4PNA9HD0sPTQ9PD00PRg9AD0QPQA9cD1IPYg9iD2kPbQ9sD2sPbw9iD3MPcI+MD5NPxA/TT/zgCEAQACSAJoA+AEAAaoBjAIcAkAC6AMUA4AEQASYBNgFAAV4BWAFqAWIBZAFeAToBLAEeAQABDgDlANAAxQCqAJ4Ai4BygGCAX8A5gCqAH2APgAgwCB//j+zv58/uz92P3E/Sj9wPvY+uD6iPog+jD5oPhA+DD3cPZQ9gD28PTw82DzUPMw85DyIPOw85DzIPNA8/DzIPQA9PDzEPTA83DzAPTQ9FD1oPWg9RD2EPYg9mD2QPbw9fD1IPeg+HD6FPz0/aT/GgDUAO0AzAIUAwAEwAUoByAIQAmAC8ANQA/wD4ARgBPAE8AT4BQgFmAVIBSAE+ASgBGAECAQIBCwDkAMcAvACoAJMAg4B0AGoAQkA4ACIAKcAdYAjgDR/y//gP6I/mj+qP0I/XD8sPvw+kD7KPt4+mD5qPhA+JD3oPYQ9tD1wPTg87Dz8PPQ85DzIPRw9CD0sPNQ9KD0cPQg9CD0IPSg88Dz4PSA9VD1gPVA9kD2EPYA9nD2sPag9XD2EPk4+hj76Pw+/0UASADlAHQCVAOsA7gEmAZACLAIIApQDIAOYA9gECAS4BLAE+ATwBSgFEAUIBPgEiASgBFAEPAPYA/QDXAMYAuwCmAJgAhwB6AGCAXgA8QDBAP+ARoBwAD3/zr/ov52/kb+XP2s/Hz86Ptw+yj70PpY+iD5iPjw93D3sPbw9XD10PSA9DD0QPQw9CD0IPQQ9FD0EPQw9FD0QPQA9PDz4POg8+Dz8POg9ND0cPRQ9WD1UPUg9dD0UPXg9fD2iPio+qj7yPxs/pr/kgDVAOABzAK8A7gEEAbAB/AIYArAC2ANoA7gD8AQwBHAEuASoBIgEiASoBFAEYAQQBDADwAP8A1QDUAMMAsQCkAJYAgYB+AFIAVQBIQDyAIUAjQBRADU/0z/zv4o/pT9YP2c/AD8kPso+3j6sPkw+aj48Pcw93D2QPaw9eD0kPSA9GD0IPQA9FD0UPQw9ED0oPSQ9CD0cPRw9KD0IPRA9GD0sPQQ9TD1APaQ9fD1sPVg9XD1MPag9+D44Plo+wT9pP3Y/vv/XgGYAUACqAO4BDAGeAfgCGAKYAvADCAOkA9gEGARQBKgEmASIBJAEgASwBFAEQARQBBwD7AO8A0wDfAL4AogCnAJYAhYB6AGoAW4BNgDJANsAnQBuABaAM3/yv7s/bT9DP1U/Lj7OPuQ+uD5MPnQ+FD4YPfg9nD2UPbg9YD1UPVA9SD14PTw9BD1IPUg9cD08PTw9OD0oPTA9CD14PTw9OD04PWg9YD1oPWg9XD1MPVw9YD2CPjw+HD6oPus/Mz9Fv7D/4YAbgFQAjwDkAT4BVgHoAgACpALkAwADkAPIBAAEYARIBLAEaARoBHgEYARQBEgEaAQ0A/QDmAO4A3QDLALAAtgClAJUAhwB9AGwAWIBPQDRAN4AnABvABXAID/ZP6Y/TT9WPx4+9D6MPqw+aj4APjA9yD3QPbA9ZD1UPXg9JD0UPRg9CD0EPQw9BD0APTw8wD04PPg8/Dz8PMA9MDzQPRg9PD0EPXw9MD0MPSQ9DD0kPVQ9lD3qPgI+kD78PvI/ND9/v63/1MA7gFcA0AEiAVwBwAJ0AnQCoAM4A3wDpAPgBCgESARABFAEWARYBFAEWARIBFgEJAPAA+gDqAN8AwADEALQAqQCcAIwAeYBtAFMAUIBEgDlALwAdkAEABV/8z+5P3w/Jz8KPxI+1j6+PlQ+VD4oPdA98D28PXA9bD1kPUg9eD0MPUA9aD08PQw9cD0IPRw9LD0YPQQ9BD08PSQ9DD0UPXQ9RD1YPTA9BD14PTQ9CD2oPeo+GD5WPrw+4D8QP30/WH/TwDdAFwCiAP4BAAGYAewCGAKUAvADNANMA+QDyAQoBDAEOAQABFAESARQBHgEMAQIBBAD8AOUA7ADcAMUAyAC5AKwAnQCAAI6AbIBQgFIAQ0A2QClAHzAAYAVv+O/sD9CP1o/Pj7QPuA+rD5CPlQ+LD3UPew9nD28PXg9bD1gPUA9dD0IPXQ9ND0gPSA9MD08PMg9AD0oPOg87DzYPSA9FD08PMg9MDzYPPA82D0QPWw9fD2OPhA+fj52PoQ/LD8oP1m/rH/wAAYAkQDWATABfAGUAiACSALcAxgDfANwA5AD6APkA8AEIAQoBCgEIAQgBBAEKAPQA/gDiAOQA2QDAAMAAtACmAJkAiAB0gGqAXQBMADwAIcAnwBagBq/9D+Iv54/Vj86Pto+1j6ePn4+ID44PcQ9+D2cPbw9XD1gPWQ9fD00PTA9AD1kPSA9JD0kPSQ9AD0UPTg8wD0UPSw9ND00PSw9JD0IPQQ9MD08PSA9SD2cPdA+Aj5UPr4+sj7rPyM/bD+gv+1APABUANYBHAFsAYgCHAJsAowDBANwA1gDhAPkA/gDyAQYBDgEOAQwBCAEEAQ0A9QDwAPcA6gDfAMMAyQC6AKoAnACOAH4AbABSgFOAQgAzACfgF6AI7/jv7E/TD9PPyo+8j6GPpY+aj4GPig9zD3sPZA9gD2wPWw9SD1EPUw9SD14PSg9MD00PTA9FD04PSA9FD0kPTw9FD1MPXg9LD00PRw9KD0MPXQ9fD2IPdQ+CD54Pm4+nD7cPxo/Sj+G/8OAIwBiAKoAzAFYAawB9AIcAqAC3AMQA1ADrAOEA+wD2AQwBAAESARYBFgEQARwBCAECAQgA/gDoAO4A3gDCAMYAugCpAJgAjAB9AGsAWQBNgD2AKmAbgAtP/4/uj97Pw8/HD7aPpw+dD4OPiQ9wD3YPYA9pD1APXA9GD0MPQA9NDzkPOQ87DzoPPQ83DzgPNA82DzwPMQ9FD0QPSw9ED0gPSA9HD04PSA9TD2APfA96j4oPlw+gD74Pv4/KT9WP6y//8ACAL8AmgEoAXQBugH8AjACpALQAwwDdANUA6gDkAPABBAEIAQoBDgEKAQgBBAEAAQkA8QD5AOIA4wDVAMwAvQCtAJ8AgwCCAHIAYoBVAEXAMAAhIBVgBS/0T+kP3g/MD7uPoQ+kj5SPhw9wD3kPbg9UD1APWg9PDz4PPw88DzMPMQ81DzEPPw8rDyIPMA85DyQPPQ89DzoPMQ9HD0cPQg9KD0cPXg9XD2EPdg+PD4sPlw+pD7jPz8/Cb+L/85AAgBQAJQA6AEiAXQBvgHYAkgCkALUAwADbANUA7wDmAPABBAEMAQABHgEOAQ4BDgEGAQQBDgD1AP0A5ADqAN4AwADEALQAowCUAIOAdgBlgFUARUA0wCSAFKAIP/qP68/bD8yPvw+uj5MPlI+ND3EPeA9hD2gPXg9DD0EPSg82DzIPPg8hDzgPKQ8pDycPJg8nDysPLg8uDyAPOQ89Dz4PMg9JD0APVA9QD28PbA94D4UPlg+iD7APzo/Oz9zP6//7gAwAHQAswD8AT4BfgGAAgQCeAJ4ApwC1AMwAxADbANQA6gDtAOMA+QD6APkA9wD0AP4A5wDjAOwA1ADZAM4AtQC3AKsAkACSAIMAdIBmAFeARYA2wCfAGaAGX/fP7Q/eD8BPww+3D6sPm4+Bj4cPfg9kD2wPVQ9aD0MPTQ88DzcPNQ8yDzEPMA88DyAPPw8iDzUPOA88DzEPRw9ND0QPWQ9RD2UPbQ9nD3MPjo+Ij5WPr4+qj7hPxQ/Tz+7v7T/5kAcgFMAhAD/AP4BNgFkAaIB0AI8AiwCUAK4ApgC8ALMAywDAANAA0QDSANQA0QDfAM8AygDHAMAAzgC3AL4ApgCtAJQAmACPgHUAeYBtgFEAUoBFADaAKAAb8A4/8M/zr+aP2w/OD7EPtw+sD5MPmg+Bj4oPcg94D2EPbQ9XD1EPXw9OD04PTA9LD0wPTA9ND04PQA9TD1YPWA9dD1QPag9hD3oPcg+Lj4GPmQ+TD60Ppw+/D7oPyI/TD+1P6L/4QARAHaAaACaAMoBNAEgAVYBvgGeAcgCLAIYAmQCQAKUAqgCrAKAAtAC1ALUAtAC2ALQAsQC+AKwApwCiAKwAlgCQAJcAgACJgH+AZgBtAFKAVwBMgDHANoApwB1AAkAH//2P4i/oz9EP1U/Kj7EPuY+jD6mPk4+cD4YPgA+LD3kPdw91D38PbQ9tD24Pbw9hD3MPcg90D3QPeA96D34PdQ+Lj4CPlo+eD5OPqQ+vj6YPvY+0z85PyY/Sj+cP4K/7L/LQCJAA4BmAEwAsACFAPEA0AEeATQBEgF2AUwBngGyAYAByAHKAdQB3gHoAeQB6AHwAfAB4AHOAcQB+gGsAZwBigG8AWoBTAF0ASYBDgEsANUAwwDtAI0ApYBNgG9ADwAov9Q/+7+Yv4E/qj9XP3w/JD8UPw4/Nj7iPtY+wj72PqY+pD6aPpg+lj6YPpI+jD6UPpI+nj6YPqQ+tD6EPtI+4D7wPv4+zD8YPy4/AT9ZP2g/fj9bv6q/uj+P/+N/+b/IgBgANUAEAF0AZIB6gEgAowCuALsAiwDXAOAA6wD0APsA+wDIARABHAEkASQBJgEiASYBHAEaARYBEAEEATwA8QDnANwAzgDIAP4AsACXAJIAhwC6gGcAUYBGAHFAH4AOgAdANf/iP8r/+b+oP5G/hz+AP7k/bj9kP1k/Tz9GP3w/OT8wPzE/Lj8tPyw/LD8qPy8/MT81Pzg/OT87PwQ/Sj9TP2U/cT99P38/SD+PP5q/pL+zP4J/yb/Lf9i/5H/2P/z/x8AcQCYAK4A3AA6AUABMgHvAFIBYgGOAcIBCAJYAggC+gHuAf4BxAHKASACQAI4AhgCFAIIAvABuAHGAb4BvAGSAYQBbgFQAT4BDAHdAK0AjwBvAEwAQQAzAOr/ov+B/3r/b/8t/w3/C/8J//j+3v7K/rz+wv64/qD+Xv5Q/lL+av5O/ir+UP50/mL+Wv5U/ob+jv6W/qb+iv6K/mr+qv7q/iD/Nv9D/0v/av9X/43/2P/q/9D/pf+//87/8f8MAGgAmgCAAGsAYQCZALIA2gDbAL8AjgCSAM8A9ADzAM4A0wD1APgA8wAIAfMA4wCWALcAogDDAPcALgE8Ad0AsACpAKkAbgBfAIcAjAA7AC0AdwCDAEcABgAHAOb/3v/e/xwA5P+7/4b/f/9s/xT/X/88/0D//v4e/zb//P7U/sT+MP8K/87+6v4V/yX/sv7a/iH/df8Y/wT/L/9Q/zL/Cf9+/9T/4f+c/5b/n/+v/3z/rP/T/+n/GQBTAHUAggBnAKMAwgCmAGIArgD2ABwBKgEmAUgBIAEWAQoBMAEkAUgBcgFCAR4BEgEWAQ4BAgFyAYIBOAHpAP0A+gDjAMoAGgEoAdUAgwB5AMgAvQCJAGcAZwAjAA0AJgBlAF0AFgDp//7/7P+n/2T/k/+9/1H/Cf/m/j7/FP/o/gn/eP84/5b+kv60/t7+Zv6u/gf/If+E/nr+/v4H/6z+hv4P/xD/7P7C/lT/cf9D/yD/R/9b/zH/P/9p/8f/BwD7/+v/5/8LAAUA3P8LAF4AqQCHAIEArgD6AP8A1ACzAKYAfAB9AP4AHgFQAfMA2ADGAL4AowC1AAIB9wD7AKcA2ADZAAgB1wCtAJUAlgD2APsAGgG9AFYA7v/b/wIATwBaAEIAXAA8AAIAwf+K/2j/d/9n/0X/Uf+K/7v/jf8I/8T+9v4R/wn/GP85/x7/Bf/o/h3/NP8a/yH/NP9a/yj/J/9J/43/r/+y/5z/Vf90/8f//P/Y/8D/qP/I/+b/GgB4AIwAWwAoABoARgBeAJcAuACoAM4AdABpAE8A+gAmAcAAaQC4AEIBRAH3AOAAJgGYAFgAxACGAVoB5wCFAOsAhQB5AIYA6QD7ALoAygB/AJ0AmgAWAeoAZQA1AGgAYgDi/9X/DQDn/23/mv8LAPT/I/8//6v/tv8E/7T+Xf9s/y//SP/W/+j/LP/y/gX/9v6k/tL+X/94/1v/Of+o/7n/jv+e/6X/ef8W/zr/uP8GAOb/2f8kACEAHAAEADYAEADu/37/XwB3AI8AMwApAIgASQBbADUA6QCdAHYARQBjAJUAQwClAH0AVwAAAE4AiABeAEEAkQDuAFsA7f8sANUAPQDE/9z/bAA7ANn/HACCAIoA+P/b/8L/mP+c/6z/7f/Q/+f/EwALAI7/RP84/33/1v/g/6b/f/+m/6H/R//S/lb/t//T/0z/Of81//T+Bf8e/1f/GP8Q/1X/vv/D/6P/ff9I/yj/EP+t/8n/DQAYACkA8P+P/6j/7/8wAE8A+v8IAPX/7//Z/y8ASQCUAEoAawCTAEgALwDQ//r/RgCfAK8AbQA9AGYAtABvABUAAgClAIcAggBVAJYAlACgAJEAhgBFAEoAqACgABwAwP9uAKUAkgA8AIMAKgCW/+P/bwD1AAAAdf9//4//X/8q//X/GgDT/xj/T/+E/5H/eP9d/4z/9P7y/gr/Zf+U/3r/g/8b/x7/Iv+n/67/BP/M/n//nP+H/0L/9f8oALP/9v55/w0A+f9Y/9H/gwBYAAIA9//BAKoAFgAdALAAzQBAABsAeAHMASYBlwCiAAIBWAApAKEASgHqAK0A6QAkAZUAZwDdAOoAngD0/40AqgC0AMIAOgEAAWQAx/9aAKoAjgBpAMEAxQAuAJn/8/8mADkAEgCKAJcAuP8I/0X/KADd/xn/F/+z/5v/Sf9Y/5z/p//6/nL/f/8z/1j+xv5m/yD/dv6C/nD/dP/s/n7+6P5a/2H/QP9h/27/Fv/w/m3/0v/o/2P/+P5v//H/JAD2/wAA/P/4/7P/AgCzANMAjwBRAI8AwwDAAMoA+AAwAcAAHgAWALAAQAHyAAwA8f9/ACIBJAFaAQwBwAANAEMAwAD1ANEAjwC/AFEArADrAEgBywBDACkAEwAJANn/lwDCAK4ACQD6/7z/nf+C/9D/QgDK/5D/af++/1b/DP/8/nH/V//O/rj+Pv+9/7D/Qv8T/xP//P4J/3T/cv92/0D/Vf8h/9b+9P6A/+L/Y/8t/1T/r//q//P/MQAaAOX/m/8bAGAAGgACACcAmwBKABgAPgDMAJMABwAGAA8ATwBXAOsANAE8AcMAfQC7AJUAcgBKAOYAKgE4AbkAcwDEAOIAvgA4ABwATACWAOkABgFEATwB3QB6AN//mv+6/1UAjwC/AJkAHQCk/57/tP9R/wb/Jv/W/7n/MP8R/7b/cP+w/qb+Dv9//8b+BP+I/5D/5v6E/gT/G/+E/mj+i/8qAKL/uP70/rD/kP8Y/wn/vv/f/1r/nP87AEoA4P97/+//yP+k/7v/IgBTAAkATgBKAEUAwP87AI0AYAAZACcAhADJ/8X/IQDxAOAAqAAwAUIBtAAfAHsAKgEmAaIATwBoAKEAjAC1APYA5QCVADYAOwBwAIoApQCgAKcAigB7AKIArQBlAMv/6/98AL0AjwBqALgAwgAwAHn/s/8RACcAw/+z/zwALgDc/1T/h/+m/4L/C/8T/17/SP/0/tj+aP+z/5z/X//I/+L/rv9N/23/0f91/0j/lv9MAFkA+//Y//z/DwD3/xMAawBUAPT/rf+//wIAKgBsAJUAjgBEACcAMABzAGIAPAAIABMAZQDQAAoBCgEcAdMAiQA6ABAAbwDrADYBywBDACAAcACNAFAAZADdABoBjwBvALUACgGLADUANAA6AKH/j/8tAKYAfwAgACkAzP9n/zv/s//H/5f/jP8GAM7/T/9k/+f/rP/o/nL+rv4N//j+Yf8AAOD/Vv/2/jL/Qv8l//r+LP95/z3/RP+B/wgA3P+7/4z/xf+5/67/zv/8//b/xP/m/ygAcQBQADYAOABAAFcAdwBwADQA9//e/+X/IQBNAM0A6wDXAKsAkgBkAEMAFwA6AGMASQBQAGIAcAA7AEMAUQB0ADUADwD1//z/yv+z//X/GgAkAP3/JAAzAAwA3P/J//P/tf9+/3b/of+e/5b/s//M/+3/0P+U/0v/Qf9e/3r/bf99/5f/i/84/y3/RP9e/yn/+P7q/sz+/P4z/5z/0/////j/BQALAAYAOQAeADcAJAAoAAEA3v8KACgALADU/8n/AABKAGUAgABZABQA+/8qAHcAdQBbAFgA1ADxAN8AoQCRAL4AswCxALgA3gDZALkAngCSAIwApADSABABCAHaALUAvADaAK8AcwAuABUAGwAtABAAyP/Z/wAAGQAkABYA9P/R/3z/c/+M/5v/nv+J/4z/fv9r/2//r//L/67/df9U/0D/R/+G/7f/wv+o/3P/gP+v/7z/s/+v/67/j/96/17/cf9+/4z/k/+M/43/d/+U/6//vP+5/7v/zv/Z/wYAIwAlANH/r//q/xgAMAAjACwALAABAPf/NQBDAC8ALgBUAGIASABKAJQArwCEAE0AMgAyAP3/CQA9AG0ANADu/w0AMAAUAOz/BwAwAC4ACQAjACQAGwABAB0AMAATAPv/AgAKAOL/0f+3/8H/vf+p/57/l/+A/4f/n/+g/7r/uP/C/87/3/8IAP//CgD9/+H/t/+//7n/nv99/2//h/9//33/ev+j/5j/gf9L/0f/PP8+/2//pf/o/yYAgwCvAKgArgDCANEAzwDCAKkAmQCLAIIAdwBoAGgAWABeAE0ATABsAHwAmgC5AMAAoABwAD4A+//r//j/CgAkAB4AFwAaABsALwA2AGgAfgCYAJ8AlACHAH0AjwCEAFAAMQASAOf/t/+t/8b/1P+v/4v/i/+U/5P/rf/e//z/4P+n/5P/nP+x/8//6f/p/9H/xv+o/6v/uv/N//D/4v/0/xMAQwBhAIQAjwCGAIMAcwCJAKcAtgCTAHYAWQAvACoAOABTAFEAbQBtAGMAcAB8AIEAkQBzAD4ACgDj/8z/5f/M/8r/2//n/wUABAAiACAANwBoAHMAiwBoAFYAVQBQAC4AGAAAAMj/fP85/w//1P62/q7+jP54/nL+ZP6K/rT+1v4l/17/av94/4v/sv/H/9f/6f/p/wwABgASABcAKAAbAO7/+P/M/6H/tf+9/+n/5f/v/wwAMQBJAFQAjAB6AJQAxAASATgBagGQAdoB9gEIAjwCcAJoAmwCbAJsAu4B5AHuAf4BzgG6AdgBpAGiAYYBsgGkAXgBRAFWAQwBvwBkADIA5f99/0j/P/8I/8z+rP60/oL+Kv5A/ij+Bv7Q/cT94P2g/Zj9mP3Q/aj9bP1s/Uj9FP24/ID8MPyQ+wD7kPoo+uj5ePk4+Uj5EPng+AD5kPlA+pj6ePuE/FD90P2U/q//WQAgAFoAIgCHAH8AXgFMA5AEQAUYBkAHqAfQCBAKEAvACmAKsAqACsAJQAkQCkAKwAlACYAJEApgCWAJYAqQCqAJcAhQCJAH8AWoBMwDCAMmATj/7P14/Aj72Pmo+Wj5iPjA96D3wPfw9xj4gPjI+Kj4GPgI+FD3oPbQ9mD2QPZw9TD0kPPw8oDyYPKg8rDysPJQ89DzAPXA9TD30Pj4+RD7cPvI+/D7UPx4/Fj8mPzQ/Bz9Jv5//yAByAIgBAgGIAiQCmAN4A8gE6AVIBigGqAcwB3gHUAdYBwAG+AYwBYgFEARAA4wCkAHCAUgA1IBy/+m/vD9/Pw4/WT9Jv7c/tj+0P4c/+b+FP7g/eD89PzA+0D7YPow+1D7aPsE/Hj8RPyo+oj5kPfA9UD0wPHg74DuAO1A7MDs4O0A70DwMPFw8pDzgPRw9WD2MPdw9wD4gPfg9uD2EPcA+Aj4mPgg+bj5KPuc/Lb+oQBeAXgCQARoBZgFGAY4B4AIgAlgCvALgA2wDeAOYBGgFGAWIBnAGwAdoBwgGsAYgBagE4AQoAyYB1ACwv4M/Xz8yPtw+wj7ePuM/OT9F//O/1QC5AJQAkIB8AApAA7/Qv4m/oD9sPog+Rj5YPkQ+JD3sPco+FD2kPRQ9FDz4PJQ8VDxMPEQ8MDvYPFQ9FD1gPbA99D4cPmo+XD6UPrY+ID40Peg97D1EPXA9bD10PUw9jD4IPko+bj7tP75/+n/nwBIAhADuALkA2gFqAXABcAHYAowCzAMIA7gEGASABQgF0AaYByAHGAdoBqAF0AUoBFQDoAJgAVSASz9oPpA+qD6QPro+fj6APxM/dr+HwAUAiQD/AJ4As4BRAGDACYAKv8c/oj80Pqg+XD5APpw+Qj5APlA+HD3EPaA9dD0cPSA82DyQPJQ8oDyYPMA9aD2gPdA+Lj40Pn4+cD54PnI+Sj5APjw95D3YPfw9lD3MPgo+eD5yPpo/ET9qv5Y/00A8gAuAXABfAKQAyAEsAToBcgHgAlwCnAM8A6gEcATQBbgGYAcYB0gHYAdYBqgFsASIA8gDIgHCANd/7D88PqI+gj7wPuI/Lz8yP7f/9IBvAJMA9ADCASgA/YBeAD8/6r+eP3I+0j6YPmI+Gj5EPkA+dj40Pho+JD3APcw9hD1cPOA8iDyEPHQ8DDxsPIQ9KD0cPWg9rD3WPi4+AD52Pjo+Nj42PjA+Jj4kPhw+Nj4aPmw+Rj6WPuM/Kz9iv47/wUA1wAaAYQBgAI4A4gDMASwBYgHAAmACvAM0A+gEeATIBegGuAcIB5AHiAdoBmgFeASgA/gCxAHAANW/lT8qPro+tD7iPvw+3z83P0/ACgCPANAA4gEYASMAhQBhwBNANz+4Px4+zj6KPlQ+ED5ePqI+ej4APkI+Qj4sPYA9lD1APSA8vDwgPAg8BDxUPKA8wD0oPTw9fD2IPgA+Tj52PjQ+GD5oPmQ+WD5wPlA+vj5oPl4+oj7DPwY/VD+/P7a/ib/+P/HAAQBhgG8AlQDtAMgBcgHQAmACkANYBAgEsATIBcAGwAdgB3gHYAewBmAFOASwBBgDKgGKAMaAEz8MPrg+pT8GPxQ+1T82v5SAIQBMAPQBNAEeAMQA34BvADW/xj/NP1A+yD5sPio+FD5UPng+Wj56PjI+Fj44Pew9tD1QPQw82Dx4O8g8IDwEPHw8RDzsPOg9OD1MPfw91j4cPgQ+eD4wPgQ+VD5YPmI+AD5aPmA+aD5WPrI+5z8UP0i/gT/kP+p/6oAnAGIAoACUAMYBfAGgAhACoAM0A7gEOASQBaAGeAagB3AHuAdQBtAFwAVoBGwDZAJmAUiAZj8IPvQ+4j8gPvI+xj9kv4RABQCwAS4BcgFIAVIBPwC+gEcAbn/PP4U/Bj6MPhA+CD5mPkY+bj4EPlA+Yj4ePiA+MD3wPXw8xDz4PGQ8HDwUPGw8cDxYPLA8+D0QPag95j4sPiI+DD5EPpI+gD6+PnY+Vj56PiA+Sj6cPqA+rD7DP20/Rz+/v43AMIA1QCwAdACVAM4BPgFEAggCSALIA3AD+ARQBQgF4AZQByAHWAeQBwgGiAX4BNgEEAMMAl4BHz/MP3s/KT8QPzA/Ar+Pv6g/4QC+AQwBmgGeAbwBRgEoALwASwBeP6w+xj6kPhQ9wD3IPj4+Nj4qPgw+eD5EPoA+oj5iPiw9rD0QPMg8pDxwPBA8EDwoPBQ8WDyIPSw9cD2oPdA+Cj5wPmw+ij7GPtI+rD5aPmo+YD5ePkw+jD6APuQ+zT9Yv4Z/07/aQCeAVgCxAIIBIAF+AaIB/AIcAvgDYAPIBEAFQAYIBrAG8AeAB8gHSAaoBZgFGAQEAwACDgEVwBA/Sj8ZPxI/aj8yP3W/gYBCANABOgF0AaIBrgEcAOMAsoAGf9A/fD6kPhQ9rD20Pbg9oD3mPgg+XD42PgA+kD6aPgA9+D14PNA8QDwUPAA8IDu4O1g76DwgPFQ80D1kPYA94D3gPlg+qj6wPrw+nj6+Pl4+Uj5+Pl4+eD5OPrw+jT8rP28/lb/LwC0AGYByAKwA7AEsAWIBkAIEAoADNANABBAEoAUwBeAGsAcQB6gHgAdwBngFkAUgBEgDCAIIAQEAZj+UP2o/aD96Px4/fT/igEsAlgEkAbIBjgFYAT8A7gCZAC4/oT9APvA91D2APeQ9rD2kPdw+Pj4uPho+Sj62Pn4+MD3MPZg8/DxYPGw8KDv4O7g7gDvwO+Q8dDz4PSA9XD28Pfw+JD5wPoo+5D6uPkA+mj6EPr4+Vj6oPpo+hj71Pwi/jr+pP4qAO0AtQAcAmgEaAU4BVgGoAhgClALUA1gEGASgBPAFeAa4ByAHKAcAByAGUAWoBMAEdAM+Ac4BCACGgCU/uD91P0C/sL+4P9oAfwCSATwBSgFoARABKwDDAJfAIj+wPww+pD4cPfg9rD2wPYw+KD4SPnI+Wj6YPog+nj5oPfw9fDzkPIg8UDwQO8A78Du4O5g8IDx8PKg9MD1wPaw9xj5YPqA+lj6KPoI+pD5YPnI+aj5CPnQ+Pj5cPsc/Az9aP6Z/+D/lQBkAsADMATQBOAFoAeACHAJwAtQDhAP4BCgE+AWwBlAG8AcwBzgGqAYIBfAFMAQkAyACIgFBAPyAD8ASP9o/ij+If9FAFACuAO4BOAEQAWQBbgE7AOsAqgByv50/Aj7GPqI+CD34PaQ97D30Pf4+CD6QPqI+Yj5aPkY+ED24PSg8+DxkPAQ8MDvYO9g7xDwgPHg8kD0YPWg9tD38Pgo+tD68Ppw+kj6gPo4+tD5kPl4+cj56Pmw+ij8gPxI/Sz+d//YAKoB8AJABDgF6AUwBwAJYApgCyANIA+gEEAT4BWAGGAaIBuAGuAYIBigFiAUgBCwDEAJSAa0AzgCWgHb/6z+LP4l/7QAkgEMAwgEaAQ4BBAEUASQA1ACBwBG/lj8WPqQ+OD3QPdQ9oD2sPbQ96j4aPkY+hj66Pno+Cj48PZA9aDzIPIQ8YDvAO/A7oDu4O5A8PDxMPMQ9MD1sPcY+bD5kPqg+xD7kPrw+hD7EPrw+Cj5APpg+Sj5mPo8/ED85Pzo/qoAygFMAugEoAaoBhAHQAkQCzAMEA2QD+ARYBRAFsAYwBqAGmAZwBjAF6AVoBIAELAMYAmYBjAE8AL6AEYAY/9D/7//ogAsAiADxAOcA7wDnANwAywDegF6/0j9iPuQ+Xj4CPgA9yD24PUg9wD4OPi4+MD5sPmQ+MD3UPdQ9vDzIPKQ8WDw4O7A7aDu4O6g7oDvcPEQ8xD0gPXg9yD5ePlo+tD7EPwI+7D60PoA+nD5wPlA+ij6sPmw+lT8OP0O/o7/JgGwAtgDoAUQB8gHQAnwCdAKkAxgDiAQYBJAFaAXwBgAGWAaoBpAGaAWABWAE2AQ4AxgCnAIoAU0A2QCxgHpAM//nQD0AegC5AJYA+gDaAOEA7gD+AL0AN7+ZP04/ED6EPnA+GD3oPYQ93D4uPhw+Ej5yPmo+Xj44PcQ+CD2sPNg8iDyYPAA7+DugO9A74Du4O8Q8iDzkPOg9VD3SPi4+AD6mPtg+0j6MPog+6D62PmI+lj7QPv4+XD7AP2w/Uz+cv/UAQwDSASABTAHEAjQCNAJAAugDNAOYBFgE6AVIBcgGAAZABlAGSAYwBXgEwASABCgDBAK8AdABsAD8AKAAt4BIAE4AQgDaAOcAuwCUAOIA4QC+gG2Abz/EP0E/Jj7WPpo+MD3kPgY+HD3uPjQ+cD5qPjg+MD5MPjA9qD1QPUQ8yDxUPAQ8GDvQO6g7uDugO/A7zDxQPPw8/D0cPag95D4iPiY+bD5GPnI+ND4ePk4+ZD56Pmg+tj6aPuw/Oj9/P4ZAKIBdAPYBLgFsAaoB0AIUAmgCgAMkA4AEWATQBXgFsAXYBiAGKAY4BdAFSATQBGAD+AM8AkwCPAFUARgAsQC5AI8AswBzAKQA+QC9AKMAwAEjAI6AcUAx//I/QT8qPvw+vj4APiY+Dj5yPig+ID56Pko+ej4CPlo+KD2APVg9DDzwPFw8CDwwO8g70DvwO+Q8NDwsPFw89D04PXA9uD3uPjo+Cj5OPlg+TD5QPmY+fD5MPqA+kD74PtQ/CT9RP5s/xYBXAKwAwAF8AUQB3gHsAhgCUALcAyADmARwBMgFcAVABcgGAAYYBfAFmAV4BKAEJAPkA3QCqAI8AZgBRAElAMYBNQDCAOoApgD3AOQA4gDpAPQAt0Ayf85/7j90Pto+uD5GPlQ+GD4QPm4+UD5QPno+Tj6kPkY+bD4gPfA9UD0kPPA8jDx4O/A78DvYO/A74DwgPEQ8kDzoPRA9jD3sPew+Cj5ePk4+VD5cPm4+ZD5uPk4+tj6SPuY+3j8Bv4P/+P/eAF4A9AEIAUIBmgHcAgACJAJgAsgDTAPYBFAFOAVYBbgFiAYYBigF2AWABXgEyARkA/QDcALYAlwBzAGaAXQBEAE6APsA4ADGAOAA9ADtANIAtQBBgGC/7z9sPzg+0j68Phw+Aj5+Phw+OD4sPmw+Qj5EPlw+YD4wPbg9VD14PPw8QDxwPAg8ODuwO5g7+Dv4O+w8DDycPMw9BD14Paw99D3GPjI+Pj4yPiw+Aj5gPm4+SD68PqQ+wz8DP0A/h//VACqARwDWARwBRAGQAe4B4AIYAmQCuAMQA+gESATQBWgFeAWgBegFyAXgBVAFGATwBFwD7ANQAzACXgHiAYgBjgFKATsA+QDVAPEAuQCrAMIA4gBMgGhAFf/tP10/Hj7KPrw+OD4IPkQ+aj4APlA+Xj5QPkg+cD44Pcg92D2QPXA88Dy0PEA8UDwIPAg8DDwAPBg8IDx8PHA8vDzEPWQ9WD2kPcY+Bj4SPgY+Vj5OPm4+cj6WPsI+9j7IP1o/ZD9NP9mAQwCPAK0A6AFgAbABVAHQAkACeAJAA2gEMARgBJgFGAWwBZAFsAWoBaAFUATgBKgEdAPQA3AC5AKQAgIB1AGUAZIBXgEnAPQA4QDaAPYAsACBALbABUADv8C/kT8IPtA+hD6UPlQ+eD5uPmQ+Zj56Pmg+Tj5gPjA99D2oPWg9PDzsPLA8QDxoPBw8BDwYPBQ8LDwQPEA8tDyUPMg9OD0kPUg9pD2APcg94D3wPeA+CD5gPlI+kj7BPxI/OD83P1r/zQAywC4AmgD/AMQBSAGGAcQByAIoApwDSAPIBFgE8AUYBXAFSAXIBfAFYAUoBOgEsAQUA/QDRAM4AmwCMAHKAegBtgFMAWIBGAECAS4A1gDCANAAiwBDwCW/17+1Pyg+yD7oPrY+dj5QPog+nj5mPkQ+tj50PhA+MD3sPZg9YD0IPTw8pDxMPFw8UDxgPCg8EDxcPGA8eDxQPPg8/DzkPSg9TD2MPaQ9nD3sPfA92j4oPlY+nD6ePs0/BT9PP1A/nz/kQCUASwCqAM4BKAFIAa4BogH4AgQCxANQA/AEYATABRgFaAWIBdgFuAVYBXAE4ASoBGAEIAOIAzACvAJIAnIB1gHIAcYBhgF4AToBFgEiAPkApACWgEUAAf/HP74/KD74Pqw+qj6YPpQ+nD6cPog+tD5yPlw+YD4UPew9tD1sPRw87DyEPJg8eDw8PDw8ADxsPBA8TDycPIA84DzgPTg9FD1wPWQ9rD2oPbg9gD4sPgo+Xj5sPq4+yD8aPx0/S7/zv9/AIgBeAOIA2gEiAWABhgHeAcwCcALYA4AECASABQgFQAWIBZgFwAXABbgFOATABOAEeAPUA4QDXAL0AlgCRAJ0AfgBjgGKAYABSgEKATsA5QCQAGrAAUAbP6Y/Dz80PvY+vD5WPqg+jD64PkQ+kj6ePmI+GD4wPdw9iD1QPSw81DycPHw8ADxUPBA8EDwUPDA8LDwkPEw8rDy4PLA82D0APWA9YD1sPVA9sD2UPdA+Nj46PnA+qD7SPwc/fD9Ef9BANoA0AH0AmgEAAVwBTAG6AYgCGAJQAxwDmAQABLgEyAVABYgFqAWoBYAFeAToBPgEsAQMA9QDuAMEAuwCaAJEAmoB4gGMAYYBmgE4APgAxQDygHQAFwAL/98/VD8APxg+3D6WPrQ+pD6IPpQ+lj6EPog+aD4GPjw9iD2UPVw9BDzMPLw8ZDxIPHw8BDxwPCA8BDx8PHg8dDxgPJA83DzwPPQ9JD1MPVA9bD2wPfA92D4MPpQ+0D7ePs4/Yb+uv5k/60ASAJAAuwCIAUQBlAF8AXgB5AJ8AoADdAPABIAEwAUgBVgFgAWwBVAFYAUgBNgEuARYBCwDmANQAwgC4AKkAngCLAH8AbgBVAFmAS0AxgD5gEwARcAPf/Y/QD9+Pso+9D6mPrY+sD68PqQ+oD6OPrA+QD58Pcg90D2MPVQ9IDz8PIg8pDxgPFw8QDxsPAA8VDxcPGA8dDxEPLw8SDyMPPw8wD00POg9LD1APaA9vD3WPkA+oj6oPsA/dj9pP0o/0cAnwA0AYQCMASoBOAEoAUwB0AIwAlwDAAP4BAgEqATIBXgFcAVgBUgFcATQBNAEqARgBBwD+ANYAywCwALcArwCGAIgAeQBkAFoAQABBwDwAHXAGkATv8u/kj9yPzI++D60PpQ+zD7qPqg+rD6MPp4+eD4OPhA9/D1YPXg9AD0IPOw8pDyIPLQ8cDxAPIA8rDx4PFw8jDyEPIw8sDyYPNg8/DzcPTQ9GD1cPaA90j4EPkQ+mj7JPzQ/Hj9fv5d/5f/tgB6AYACxAOgBEgF4AUYB0AI0AkgDNAOoBAgEmAT4BSgFYAVgBUAFWAUQBOAEkASYBHwD5AO4A3ADLAL4AowCrAJQAg4BwgGYAUQBPQCZAI2AUAAEv9U/oT9rPzo+1D7KPvg+hj7MPsQ+7D6QPoA+jj5EPhQ98D20PUg9XD0APRQ89DyoPJg8mDy0PEQ8oDyMPIg8jDyMPIw8kDyQPPA8/DzAPQQ9dD1MPYA9wj4mPko+sj6DPwY/XT9VP4Z/0IAlACSAXAC1APYBGAFGAYoB5AIkArgDFAPIBHgEkAUIBXAFeAVABYgFaAUoBMgE0ASgBHAEMAP0A5gDaAM4AswC0AK4AiYBygGWAUwBCQDMAJGAQIAnP7s/VD91Pyw+0D7GPvw+sj60Prw+nj6wPko+XD4kPdw9rD1IPVA9FDzIPPA8nDy8PHQ8cDxcPEw8YDxsPFQ8eDw8PCQ8eDxYPLw8oDz8PNA9AD18PXQ9uD3oPjo+ej6mPus/Ez9PP46/17/3/+uAfACxANIBEgFkAb4BkAIkApADQAPQBBgEmAUABXAFGAVoBWgFMATQBMgE0ASgBHgEGAQIA9QDbAMYAwwC/AJ8AhoByAGkAQIBEQDrAGvAMj/4v64/Uj9FP0M/Ej7+Pow+xj7gPqI+nD6iPkQ+AD4oPeQ9iD1oPRw9JDzsPLw8kDzQPKw8aDxAPIw8bDwEPFQ8cDw4O8A8RDyUPJQ8vDykPRw9MD0EPaQ9yj42PgA+vj62PtA/Jj9TP7+/qj/5QAQAtgCOAQgBcgFoAboB9AJsAuwDdAPoBHgEqATwBQAFQAVYBTAFAAUYBPAEoASABIAEQAQcA8gDrAM8AtgC0AKcAjQBjgGoARQA6QC+gHwACT/ev6g/pT9oPwU/DT8mPu4+uD6APug+jj5APlQ+KD3cPbw9ZD1YPTw85DzwPNQ85DyoPKA8pDxIPHg8CDxgPAw8HDwoPDA8ADxMPLA8iDzIPMw9BD1sPWA9uD38Pio+YD6gPto/PD8lP3M/tz/YACOAQADOAQIBegFAAdgCOAJAAxQDgAQwBGgEqATABRgFIAUABSgE+ASwBIgEsARQBEAEZAPQA6QDaAMkAsQCiAJyAcIBlgEkAMMAxwC8gBFAM//uP70/Yz9JP1c/HD7KPvg+oD6CPqw+UD5YPig99D2QPaA9RD10PRA9AD0gPOg83Dz8PKg8iDyoPEw8QDxEPEA8fDwQPHw8WDy8PKA80D0cPTQ9LD1APfA91j4qPmw+pD7APzU/Oj9nv6N/z4A9gF0AtADGAUgBuAGsAdQCUALAA0QDwARIBLAEiATwBMAFOAToBMAE+ASgBIgEuARgBGgEFAPMA4wDXAMIAvwCYAIGAe4BRgERAPYAiACGAEmAGL/lP6k/dT8dPwA/ED7sPqA+qj6GPpo+QD5UPiA95D2QPYQ9rD1EPXA9PD0UPTw87DzoPPQ8jDywPHA8cDxkPHQ8QDyUPKg8lDz8POQ9MD0APWg9YD2gPeA+Dj5SPpY+wj8nPx8/ZL+u/9EAP8A1AJkA4gE2AUIBxAIAAlgCuAMcA/AEEAS4BJgE4ATYBNAFOATwBMgEwATwBKAEkASwBGAEHAPAA7gDNALIAogCbgHUAaABLADcAPIAnYBrwAGAKz+gP20/Fj86PsA+5D6ePow+rj5UPkg+Vj4UPeA9iD2sPUQ9dD0kPRg9BD04POA8zDzsPIQ8rDxUPFw8WDxgPGw8UDyoPIw85DzIPSg9KD04PTQ9SD38PfQ+Lj5APu4+xj8CP1Q/i7/nP+5AMgBWAMoBGgF8AagB0AIgAlgDDAOYBDAEOARYBKgEuASQBNgEyATwBJgEmASgBJgEmARYBAgD7ANYAxwC6AKMAnIBwgG0AToA+QCTAK4AbQAgf9i/nj9pPzo+4D7CPuo+iD60PmQ+WD54Pgw+GD3cPbw9aD1sPUw9QD10PRw9PDzoPOA8zDzsPLw8dDxsPGQ8bDxIPKQ8qDyEPOg8yD0UPTA9ED18PXA9oD3wPiA+WD6QPsU/Kj8ZP28/rj/egC8AcgCeAT4BLgFmAegCGAJIAsADtAPgBCgEKARIBLgEQASYBJAE2ASIBJAEsASABIAEYAQUA/ADTAM4AvQCtAJyAf4BrgFsARYAwADSALWAKH/xv4Y/sz8WPwo/Bz8IPuo+qj6UPpw+cD4iPjA9+D2cPZw9iD2oPVA9YD1QPWw9GD0QPTg89DysPKQ8qDyQPJg8uDy4PIA80DzEPRQ9ED0YPSw9GD10PUA9yj48Phg+RD6GPuQ+0j8DP0+/m7/4/+EAeACpAO4BLAF6Ab4B4AJkAuwDYAO8A6ADyAQgBBgEEARoBGAESARIBFgEQARgBDQD/AOwA3ADMAL8AoQCsAIeAdABmgFcASUA7gCAALzAB0AAv8m/nz97PyA/Bj8mPv4+mj64Plw+ej4gPjA9zD3kPZg9gD20PXQ9YD1MPWg9FD08PPQ85DzYPNQ83DzUPNw86DzEPRg9JD0oPSw9LD0IPXQ9dD2UPfQ93j4SPnA+fD5EPvI+6D87Pww/mn/jQCoAWAC4AMgBFgFiAZgCEAK0AsADcANAA6QDpAP8A+gEOAQQBEAESARQBEgEUARoBDQD+AOIA6QDdAMIAwAC/AJwAjIB9AGEAZwBUgETAMQAuMA1v8U/6b+Nv6k/cT8IPyA+9j6MPqQ+SD5ePjQ94D3IPfg9pD2QPYA9nD14PSA9KD0MPTw88DzwPNw83DzoPOw8/DzsPMQ9AD0IPRQ9LD0MPXA9UD2wPZw9wD4kPgo+Yj5ePog+/j73Pz8/UD/OgDdALABXAMgBKgFYAcwCdAK8AvQDKANcA7gDuAPoBBgEeAR4BHAEqASwBKgEmASABJgEcAQABAgD4AOQA2ADKALcAqwCaAI+AdYBmAFSAQgA8YBCgFxAJb/tv7E/Rj9TPxI+2j6yPko+VD4kPcA92D2wPUg9eD0cPQA9KDzMPPw8kDy4PGw8dDxsPGw8cDx0PEQ8gDyQPKA8qDysPIQ85DzIPTQ9JD1QPbw9nD34Peg+Dj5MPoI+/j73Pwa/kD/FgA0ARACoAOoBEgGEAiQCRAL4AsADWANwA5QD2AQYBHgEWASoBIAE0ATIBPAEmASQBLAEeAQQBCwD7AOsA2gDLALkAqwCZAIqAfIBjgFKAQYA/YBAgErAID/pv6s/bD8oPu4+sj5IPlw+LD30PZA9rD1QPWg9DD0wPMA86DyQPIA8oDxUPEg8SDxEPHg8BDxcPGA8aDxAPIw8mDysPJg8/DzoPRA9fD1kPYQ96D3oPhA+fD5CPsI/PD83P0A/+3/1QDqAewC2ATYBRAHEAlgCjALAAwwDQAO4A6gD+AQoBEAEkASYBIgE8ASwBJgEoASABIgEcAQ8A8wDyAOYA1QDIALQAqACXAIaAfYBQAFEATUAu4BKgF0AE//eP5Y/YD8aPtY+tD5EPkw+FD34PYQ9lD1wPRA9PDzcPPg8oDy8PGA8TDx8PDg8JDwsPCw8LDw0PDw8EDxcPHA8QDyYPLg8mDzQPTg9KD18PWw9nD3GPjQ+LD50PqQ+7T8pP3G/u7/YQDoASADSATIBTAHwAjQCeAK4AvwDLANkA6gD4AQABFAEeARIBJAEkASIBIgEsARYBHgEEAQgA/QDuANAA1ADEALcApwCZAIcAdYBjgFWAQ4A4gCYAGjALj/oP68/ZT8yPvw+ij6YPmY+ND38PZA9qD18PSA9PDzYPPg8kDyEPKw8VDxEPHw8PDw0PDQ8CDxMPFw8XDx4PFQ8nDy4PKQ81D0APWA9UD24PaA9zD4IPnw+YD6mPuM/KT9Xv6H/4MAmAGQAoQDIAU4BsAH4AgQChAL4AvADKANcA5QD0AQoBAAEWARoBHAEcAR4BGgEYARQBHAEEAQkA/wDvANUA1wDJALwArwCdAIoAe4BpgFkASMA6gC3gHnAOv/9v4I/gT9CPxQ+3j6oPnQ+Cj4oPew9gD2QPXg9FD0sPNg8+DycPIA8vDxoPFw8UDxgPFw8aDxsPHA8TDyQPLA8iDzsPNA9MD0YPUw9rD2cPcY+PD4wPmQ+kj7MPwc/dz9xv6G/6wAtgGIArQDIAUoBmAHkAigCdAKoAtQDBAN8A3ADnAPIBCAECARIBGAEaARoBGAEUARABGgEOAPUA+QDgAOMA1QDMALoArACbAI0AeoBoAFmASoA5gCvgG8APD/yP7A/bT88PsI+xj6WPmQ+OD38PZA9pD1APUw9NDzYPMA86Dy8PHw8YDxMPEQ8TDxMPEw8WDxgPHw8QDyUPKw8jDzoPMQ9ND0gPVA9vD2gPdo+Bj5yPnA+oj7bPwg/Rj+Af/u/+oAsAGoApQDmASQBdAG4AfgCPAJsAqACwAMAA3ADUAOwA5gD/APQBBgEGAQgBBgEEAQABDwD1APsA5QDrAN8AwgDFALgArACdAIwAcQB9gFyATQA7AC3AHyAPr/GP8g/iz9MPxQ+3D6qPno+DD4cPcA92D2wPUw9bD0UPTg86DzYPMg8+DyoPKg8oDyoPKg8rDy8PIQ81DzwPMQ9GD0wPRw9eD1YPYA96D3SPjI+Hj5MPro+pj7hPxg/Rj+xv6G/1gADAHoAagCmANgBAgFGAboBqAHUAgACcAJYArwCnALEAyQDOAMMA2QDbAN4A3gDeAN8A2wDYANIA3gDHAM4AtQC+AKIAqgCcAIIAg4B4AGoAWwBPQDGANcAmwBrADb//b+NP5E/YT8wPsY+1D6uPkY+Xj48PeA9zD3wPZg9hD2wPWQ9WD1IPUA9eD00PTQ9OD04PQA9TD1cPWQ9cD1EPZQ9rD2IPeQ9xD4ePj4+KD5GPqI+hj7sPs8/ND8ZP0c/rb+If/R/2YACAGgATwC5AKIAwgEoARABbAFKAa4BiAHeAfYB0AIoAjwCDAJUAmACZAJsAnACcAJsAmwCXAJQAkACcAIcAgQCLAHQAfoBngGEAZwBSAFaATYA0ADtAI0AnQB+wB7APX/Rv+6/kr+oP0M/Yz8JPy4+zj7uPpo+vj5sPlw+SD54Pio+Ij4ePhI+Ej4SPhQ+Cj4QPiA+Jj4yPjo+DD5gPmg+eD5IPqI+tj6MPuQ+9j7MPyA/PD8TP28/SD+hv7k/ij/pP8EAH0A0gAgAYIB7gFcArACEANkA8wD/AMoBGgEqAToBBAFUAVgBXgFmAWwBeAF6AXwBdgF0AXYBcgFuAWYBXAFQAUgBfAEuAR4BCgE9AOgA0gDDAPQAowCJALYAYQBMAHTAJMAZgALAMP/Wf8r/+j+kP5S/gL+xP1s/UT9EP3Y/LT8iPxg/ET8GPz4++D7wPuo+7D7qPu4+8D7yPvg+9j7+PsQ/DD8aPyM/LD81PwM/TD9WP18/az98P0M/jj+cP6s/ub+G/9j/67/7f8RAEMAgwC2AOQAFgFOAZIBugHoASACXAKAApwCyAIAAwwDHAM0A1wDbANkA3wDmAOcA4wDdAN8A2QDTANAAyQDKAPoAuwCwAKoAmACTAI0AhAC5gG2AaoBdAEwAfoA5QCrAHUAQQAfAAAAvP+K/1z/H//0/tz+rv6C/lT+Nv4q/gb+4P2w/ZD9aP1c/Xj9iP1k/UT9TP1U/Vj9SP1o/YT9lP2M/Zz9yP3s/QT+DP4i/i7+Nv5O/oj+xP7c/vz+Ef88/2D/iP+w/9j/8P8hAFAAeACYALgAywDdAPsAIAFWAWwBcAGEAZQBjgGWAaoBsAGyAawBpgHYAeABugGUAYoBjAFyAWgBaAFwAV4BKgESAf4A9wDQAMUAtQCdAHMAZABaADoAEAD5//z/DAD4/8b/sv+v/5X/bP9Y/1H/TP9F/y//MP8a/wj/9v4M/x7/Gv8c/yL/Hf8E//r++v4U/xj/Kf9C/03/a/9i/2f/Zv9z/4P/nP+o/8D/3//s/w0ACAAbAB4AKAA6AFwAbQB9AIMAegCHAJAArgCwALcAxgDBAMMAygC+AMIAuwC0ALgApwC0ALQAsQCcAJYAdgB1AHsAcwBiAF4AVwBXAEwASAArACcAHAAYABkAAADr/8v/wf+y/7//w//N/7z/qv+T/4b/hv+K/5T/i/+R/4D/g/+A/4j/kf+S/5X/iP+C/4P/kv+d/67/tf+v/5//nv+k/67/s//A/8//0//C/7n/x//c/9//1f/Y/+3/8f/w//D//P8KABIAHAAxAC8AIAAUABYAJgAxAEsAUwBLADAAIQAtADYANwBGAEEAQgAnACAAKAApAP//4f/m////IgAVACUA6/+z/4n/vf8QAAAA0/+5/9r/1f/d/+H/1/+s/2X/d/+7/+//0/+1/47/df9M/2//rP/W/7b/f/+A/4r/kv+Q/6n/x//F/67/pv+9/7b/w//Q/9b/2v/U/+X/5//v//T/AwD//+v/2f/7/yMASwBaAEMAHwDq/+D/HABrAJYAYAAhABIANgBkAHAAcABkAFcAUQBkAIwAsQClAHMAOgAjAFEAnwDWAK4ATwATACAAZwCUAJQATAAGAOv/JwBqAHcALAC6/0b/If94/wkAQgDX/zL/5P4b/1f/h/+S/4D/Xf8i/x7/TP+Z/6f/aP8q/xb/S/95/5b/mf+H/4f/j/+r/7L/t/+q/7z/6P8DAAMAwf+t/9D/HgBxAG8AXwArABEAIgBYAJsAowCRAG0AJgD1/7b/wP/C/5D/bP9q//T/lgDnAOsAowBRABcA7/+PAP4AgAEkAZsAJAF5AO0AqACUArADQAJj/6z9cP98AaADGAO8ArAAAf+m/nQAgAJkAkwB+f9P/4P/YACEASoBp/9i/mr+sv/YAH4B8gA7/8T9xP0s/3QAowDb/7L+1P3k/Sv/GgDV/3b+cP2o/az+tf/X/4X/Vv68/QD+Gv///9P/N/+Y/rj+5P6d/yMAJwCh//z+FP+8/2gAdABZAOX/rv++/z4A0QDFAGAA5P8IAFkA9AAQAegAlQCSAOAAIgEsAf4A7QDUAAYBXAGGAUQB9wD8ABwBIgEKAWABbgEqAZ8AzABEAUQB2wCMAKgAtQCiAIYAugCDAB4A1//3/yoADQDA/3X/ev9+/1//Of8s/yP/7v60/qr+7v4X//7+rv6Y/pj+qP6Q/rr+3P7w/rj+kv6c/r7+7P7k/vD+8P70/tb+9v4x/3X/cv9L/z7/Uf9o/2D/u//g////uv/K/wEAUwBtAEEAUwBYAIoAmQDUAPgAEAH0ANoAAgEwAWoBRAFcAVQBXAFiAVwBjgF8AVgBJgFKAWIBfgFYAVABIgECAeMAAgE8AS4B/QDNAN8AmACTAIMAywB1AEwA//9BAGMALwD3/7//5v+l/7//nP/F/4P/FP/U/hn/af9A//L+tP7w/sb+sv6Y/sj+3P56/qL+eP7U/m7+ov54/vD+sv6i/uL+lP6u/lD+yP7S/hX/G/8z/zn/sv7e/kP/yf+h/4z/vv/V/6//mf/K/0kAEABPAHUA0QBxAHgAkwDyALIAmADyAMwAIAHHAGQBfAEiAbEAvwBIATYBUAEwARoB4gD8AH4BdgFIASMAmgCGABABvwDgABQBsQCUAGT/mQBRAM0AKgDK/zQAtv+KALb/RgBb/y7/DP+h/97/Hf8s/+z+m//Q/tD+iv5m/+T+fv7S/hv/ov9A/kD+JP49/yb/Tv9F/17+QP4Y/tz/8P/g/2z+DP6y/lf/JgBSAOj/cP68/nD++f9cAP8AmQB5/77+fv7E/xQBQgH5AHkA5f/2/yoACgGuARgBvQD0AC4BQAGCAMkARAGeATABHAEqAecAOwAaAYwCzAG1AIv/LgAuAdAAEAI4Av4BIP+4/lsAmgFsAUQAYgEmAf7/dP7D/5YBmQAhAHv/mQC6/6r+BP+kAGYBCQAT/07+F//+/uX/hf91/7r/XP8D/2D91P76/+cAAv/A/ST+9v5B/0z/egB//wr+XP2c/8EAYf9W/iH/vADG/07+Jf8mAJIA+v5R/7cAigC5/8T++ACPALoB0f+JAI//zv+SAMgB3AKsAWoAfv7A/zIB7ALIAfIBaAHUAVv/qP5zAJADMARoASYAbf+rALIAuAGoAa4B8QBm/1b/XACMAoABMwCg/bH/ugDBAMcAOwAyATT/Ev8a/o//JwCHAFQBvP5S/u7+BgBDAJL+eP5A/iH/gv64/28AHQCP/4D9VP2w/Ij/dAC2AUX/CP6E/QT+8P63/7cADv+2/rz9uP/N/40AmP9s/oj+wP5lAGAA1wACAOb/Rf+8/kcAgAH6AFwAxv+hAAgAwwA2ARQBwgEJAOgBHwCvAIv/SAIsAgABmgC5AFQCmwDq/wkAOAI0ATgBcgGQAZX/WP6CAMwCbANTAAv/jP6y/s8ABALkAv4ASv9g/kb+bv6mALQDoALN/xj9VP08/gIA3gCgAmQBkP7A/IT8ZP7z/zgCVAFyAKj8nPwE/Zb/cAECAYkAoP0+/uD88P6x/yQC9gHE/pz8iPzq/ysA+wDeAMwA+v6E/ET+yQBeAbj/uf/nAKMAdP/u/nwAAQBkAKMA1AGNACb+If9qASQCd/+v/8IAvAGRAH3/qgFyAYX/XP2I/1wCwAJOAX4AYwCs/+j9FP+aAfgCKAI8/nb/r/9sAfQAwAA0AmT+YP78/NQBsAOCAY3/lPyW/sL/igEiAS3/Bf9+/1P/Fv7M/kQBZgEwAFz9lP3c/nL/+f+n/6b/xv5T/1IAHf9K/uj8uf+rAHIBUgB//1z/WPw2/vP/cAORAHj9oP3qAM8Ayv+A/4gAdABg/aj8uwCQBBgEPgA4/Vz8Xv42AMACEAUEAmT+CPzw/ugBcAGQAFYAqAKo/hf/XP5EAigBPwAEALABxAFA/nb+av6UAegCWATcAFr+8PtM/0IBRgGGAeQCZALY/4j7rP2ZACwDjAJzAIb/GP2w/pT/GAJoAjcAmv7c/RP/QP8iABoA7gEwAZL/VP64/dT+gP5iAIgBbAMB/+T+/P0o/lL+hP10AnQChAHw++D9Df+N/6H/iQBQBED/EPvw+TQBkAUIBA8AjP1o/kT+C/+WALAD0AOMAKz8tPwUAUgEqAKe/qz+Lv+UACsAkAJAAvT/7P6b/1QCzQCl/8T/dgGAAfj+lwBSAZwCTwAGAOD+Wv8IAlABqAFu/9oAnAG3AJz9jv5YAogCfgE2/ggAmP7C/vD+dAJIA4kAzP1o/Jz+fv6sAkIB0gFM/bD98P5w/wUAKf+2ATP/rP5o+5D/1gFsA/MA8Py0/Fj7EP+vAGADOAPoAY7+FPwg/Lj8z/9wAxAFJAO+/pD7ZP3BANIBDABEAHIBGgFt/3j+0gFsAtwBSP3s/YgAbAIsAzwBXAIEAED/3Py5/6AACAPQAxwDegEI/ST99P3qAbQBmgHIAQYB9v5g/bYBgAO0AkT9YPzm/ngBZAMkAWwC9v4M/mr+Fv+WAJL/8ABHAHABUwDXABYAhPyQ/Kj90AF8AjgDxQD4/Xj7uPrk/nACRAPm/wD/Xv4M/dT8Iv7GAY4BkP/c/aD+FgHA/ej8qP12AcIBIAH8/oD+0PyI/VwBRAOWAXj9fP3Y/9EAFQAHAOgCdAF0/WD8av68A3wDfAGO/tz+ngDkAIb/OACCAE8AtABuAUADCAI2/gT8Uv4gAsQC8AGEAcAAJf+k/bb+bgHmAagBXgHq/1r+Vv6HAAgDwAJZAJb+G/8h//z+PgF4AfQAqwAOAMr+uP3N/5MATgG+/gL/tv8+ABL/Tf+qAc8AOP6Q/eP/Iv7S/qz/KAJgAuz9OP05/04B2f/s/gz/1P4K/+kAYAJ0Arb+VP1g/ab+Wv6gAmAENAKo/6D7sP3g+6wBXAMQBoYBXP1A/eD8vP6c/+gF0ARCAaD6fP2BAPoAygFEAVgEbgAA/Kj7hgDIBJAE4ALv/0z+lPzs/AwBmAQgBqgC9P7Y+0j8gQAAAtgE1gE2AX8Aav+8/ez8sgAgBNAEVACc/UD9Vv72/wQCwALdAC7+ZPwc/RoA3QBIA8wB9P2I+xj82//mATADRAK8AGD82Prs/EQB+AMYAuwBcwCM/Uj7KP10AZwDFAFa/6T/fgEHAPT9P/+u/9MAMP9H/+r/lwAEAToAuAFvABX/xPzs/GX/5gFABBgCZgFU/qj8EP0M//gCsAOAAqz+WP3Y/fb+cAGYA+QDwwDA/AD7Xv6CAWQDEAJ0AZX/Ef9u/pz+5f/iAHACqQAAAKL+sf8yAEgAngBqAfMArP54/Xj+JADxAI4BzAHuAa3/4P1U/Rr+Of++AKQD8ALwAIT9WP7k/dz9qv4pAPQCwgEyAZT+Kv7I/PT+KwAgAUP/zf8YAJMAlgAvABgABv6E/tb+4v+4/5oBcANoAtr+mPws/n7+Vf8CANADKAR0AXL+oPyY/Tz9cAAkA/gDwgH0/dD9WP6tAOQAOQDUAIABpwCo/qj9kf+oAggCJQAfANoAef/c/KT9nAHYBIACi//u/r7+Cf/A/koBlAGMAVT/MgC5/8z+P//3/5wBcv9W/0f/aAFNAD3/8v6k/hEAv/9BAEz+cP4e/5wAEAEYAOH/Sv5U/Vj9cP5NAIYBRANQAmT+gPp4+wcAdAIgAmoAqQDI/8z9dPwx/wAC5AMeAVr/qP0k/Rj+RwCYBEgEAgFI/ez8xv5cANoBvAJYAor/VP6w/58A9wDmAC4BJgBm/iT+CAIIBOACNf8w/Rz9mP48ASQCoAJ8AQgB1f+B/+j+3P5P/1v/RwA0AWgCCAOYAqYA6PtY++j7KgFwBNAEXALE/9T9uPza/pb/7gGaAfr/if8BALkAXwAWAb//EP74/YL++wDKABYApwC+AEb/yPwS/sz+fgCmAOoAfAEe/wr+uP2o/mf/0f9AAawB9wCm/vz97v4+/18ARAAQAmABRgCy/g0ACAFaAM7+Tf86ARgClwAUAEUA7/8UAPL+GwDz/4b/BwBWAdwCOAJg//z8RP0J/7cANAPoA6wDKwC4+xz8Pv6CAcAChAOAA38A7P3M/Iz/QgAmABMA9QAgAhAB9/+J/2D+Iv6s/Xn/lAHgAMb+8P//APwB3v9c/Az9Df/C/8z/vgEAA8QCvf+g/GD8AP56/zIBtgGOAQ4AZf8N/4L+3v4m/o7+WAHiAdwAF/8W/nL/6/80/53/6gEeAVr+MP2I/sAAOAIYAawB4AB+/jD9fPyw/iYBMASYA1QB+P14/Qj+H/9W/3IAwAJEAZcAyP8PAD7++P01/xwBiAJGALQBdgE0AHr+6v7YAaQClAHK/zP/P/9TAFQC0AJyARgAIACO/mT9vP0cAXADGAJAABQA/AAq/sj7jPwJAGQDSAN8Acr/gP3Q/CT9af8QAvgCngHm/tD9wP1YAKABwgEaAFr+LP7c/kwAWAGUAsgCzgAA/sD8Gv6y/5kAbAFMA0wDfgFs/iz9lP2s/Y//lgHoAwgDbwCi/iz+hv7+/vv/+AAkATgAv/+KAAQBcgFrAFv/sP5g/tz+jP9YAvQCBAPvAD//HP6Q/Qj+uv8YAzADzAGK/6b/cP74/Uj+CgCoAZIAif/J/44BsAAiAIT+QP5i/tL+IgCeARgDbAJzAOD8+PtI/Q8A0AHoAoAC+/8u/tT8kP7d/wUAawCWASABggDi/m7+GP7a/pYA7gGqAYAAQv+W/lz+bP6BAPcAzgCM/3sAmgB3/x7/4P4SAMH/r/9gAFoB6AB+AL//zf8+/6//YQBAAMz+vP50AXwCEANFAO7+TP30/A7+8gD4AgQCdAE8AB8AcP3w/MD+NAGeAbYAy//r/+H/sv+pACwBHgCM/sz91v7nALgCGAI2ATz/SP62/qD+m/+EAaQB2AHkAEH/MP7M/CD+3AD4AgQCNQD8/qz+0P3s/If/tgG0AsoA0P5K/iD+MP5y/twA4wB4ABr/b/9m/43/Tv++/1z/KP8jAJoAsgHkALIADQAN/+j9nv7G/xYBEAJ4AhgCWv/Y/WD9V/++/0wAxgDmAeYBlQA//+L+VP+o/lH/1QBYAqsAvv8I/5wA6AEsAVIBg//e/uD9E//jAKQCbAOwAjoBfP7E/Vz9ov5bAAwC1AKwAdcAeQDv/+D+8P1s/tD/cABAAeQBRAJYAYQAov8s/pT8+Pv2/lACGAQcA6IBpP/U/Gj7iPuc/gABhgGMAaQB4ABC/wz9rPx8/Fz9tf/iAUQD3AHbAIr/Sv5A/ez9/v9yATQBCgHsAUwCnAG1ACz/yP18/cr+7gEYAwADwAGhAFD+2Ptw/O7+AAL8AnwC0wB0/pj9Av5d/37/PQCuAQgCrwCa/hH/0v/C/2v/WACyAf8A4v8SAKAAFwD0/o7/rQDpACoAIgDYAKwARgBQAHkAnv4I/ir/agEMAmQBgwBYAMT/tv5+/lf/HQClAHwBGwCA/2X/5wCKALj+vP38/qkAoP8g/zIA/gDX/37+/P6U/5r/fP+K/8r/J/+N/6cA2QBP/2T+bf/Y/3oAGAEkAnABXv60/Iz9jgBkAqgDhAOyAZT+TPz4/AX/PgHoAggDhAK5AHH/rP5H/87/GgBYAA4ByAE0AooBUwC0//7+TP50/lz/wAGwAvACvQCm/qD9QP00/uX/6AFUAgACdAAs//z9cP1K/uT/PgEEATwBPAFOAKj+nP06/vz+8/+/AMABhgHv/9T+ov7S/rT+X/86AMsAoACvAPcA0wAm/8D9lP1A/rb/EAGQAswCSAGc/tT8XPyA/RL/7wDqARgCkgFlAAn/LP3g/ET9ZP96AWwCRAL/AOP/9v50/oD+J//A/yEAgwB0ASACDALLAGD/2P0E/ej9HgCQAkADDAI2AOb+7P0K/sD+CQBkAYQBNgFVANv/mf9V//j+Ef8dAAQBQAG6AEEA8/+n/6b+kP5p/54AaAHtACYAPf8s/7j+Sf/t/9cAWAGHAKf/2P4V/4v/TAAoASwBawAO/1j+Wv/lAJQBPgGPAIv//v60/j//cQCgAbYB7wAUAI3/Tf/8/sz+9P4QAIMAVgF2AdMATf+s/bj9kv4DAJcAAAESATgAm//0/uz+Yf8UAJYAlQAqAPH/YwCTAGEAUAA+AM7/kP+U/2UASgF2AfkAYACK/7b+A/99/8cA2gH2AToB8f+M/hj+9P5SAMABLALSAZkAOf9g/mz+qP9uAO4AhAGWAaIAY/+g/vj+NP9Q/wAAcgDqAHUA6v+e/3f/FP/i/kT/pv/1/3cAwwAqATABagA+/5b+gP7+/ikANAE4AugBvQAG/27+wv5f/0cABgEIAccAQwDG/7//6v/5//D/EwAjAIAAXgBjAAAAEQD6/9v/FgC+/wkA7f9BALkAxAArAC//zP4Q//f/0wBUAbYA2/8//z7/s//h/1AAcgAnALT/n/9VAOsAkQDd/0D/8P40/6z/NQBtAF4AFQCy/4r/B/+s/vL+l/9AAI0AOQDH/zz/mv6Y/lf/CgCPAKQAsQAMAJz+5P1w/uj/3QDuACABHAFcAC3/XP6m/k3/EADYAIYBXgGIAGX/Mv+e/93/1v+p/+T/BgBCAKYAPAFIAWMAff/W/u7+hf9DACABoAHCASIBWwCj/1D/hf/I/z8A5gCKAbABTgGiAAgA1/+M/8L/OAACAYIBeAHlAKEAbgDK/4H/Zf/f/ycALwAvAKgA5ADJAB4ALP9+/ij+sP6Y/4sAKgEmAWkALv9w/lD+iv7Y/qL/hwAGAZMA8P+P/13/Hf+4/vz+g/8FAEwAnwDlAJcA6/8O/8b+3P7a/nz/UgA+AYIBEgGMAKr/Yv6Q/Qr+cv/iAMoB3AGKAUAA2P78/dD9Vv55/80A2AHiARgBMgBi//z+vv44/+P/xgBeAYYBEgGLADAA8v+6/1P/qP8XAKMA4QAIAR4B0wBQAIj/Of8T/3X/7f+bAB4BOgH4ACIAZf/K/tj+UP/t/8cADAHYAE8A1v+c/0v/TP+h//z/+v8oAEsAiwCEAP7/iv8n/wD/Rv/F/0kAbQBwACcAxP9q/1//XP9i/1j/mv8QAEoAUAAGANn/lv9R/1D/of8FAG0AQgAnAOX/hf9A/1j//f9TAGAASQA9AOD/Mv8W/5j/WgCrAMgArAA/AMX/fP+q/93/UgCrAOoAwwCIAG8ATAAWAMb/+/9WAJcAwgDEANAAdADY/4z/iP8NADgAVQBqAC8AGgC9/5z/yP/u/yUAGAACAPv/HwAkAGwASwARAOn/6P8WAFkAuwD4AAwBigD8/6T/wf8mAJQAOAEoAfUAaQAKADUA+/9HAGgAmwC5ALgApAB/ABUA7P8oACQAJgAcACYAMQD3/w8ARQA8AAcAzP+y/1j/Tv+I/zQAiwBIAAsAfP9q/yz/N/+g/83/9P+r/9D/wP+r/4z/O/8w/z3/Zf91/67/tP+l/4r/Y/90/z3/Of9D/xT/MP9Y/7D/3v/r/5v/N//g/pD+5P5U/83/AADr/8//hP87/yb/RP+S/wIANAANAPf/5v/a//X/EABBAH0AaACFAIYAuADIAMYAHAFSARoBEAESAXwBfAGwAQgCJAIsAuQBDAIUAhgCNAJwAnwCwAKcAsgCkAI0AvgBMAJIAiQCOAIMAtoBZgE+AWwBbgEKAcIAqwCJADcAy//M/8n/j/+H/3P/HP+K/hD+0P38/dj95P3A/XT9KP2c/Hj8gPxE/Aj8+PsI/OD7qPvI+7D7YPsw+xD7iPvY+9D7uPt4+yj7APtg+xD8ePyA/Ej80PuY+2j78Pug/Bj9VP2c/bD9sP2U/aD97P2q/lP/KQD9ABYBEAFmAbIBQALoAtgD0ASIBcAF+AW4BhgHaAfIB0AIIAmACSAKoAqQCkAKAAowCkAKkAqQCpAKkAoAClAJoAggCIAHKAeoBpgGSAZgBUAEYAPUAgwCUAHDAFAAjP+E/sD9RP2A/Kj76Ppw+qD5uPgo+LD3cPcg99D2oPZA9pD1MPUA9cD04PSw9CD1MPUw9SD14PSw9ND0UPWQ9TD28PVA9oD2gPag9rD2YPeQ98D3EPig+Dj50Pkw+gj7yPvA+3z86PzU/S3/fQBsAkgEgAUwBgAGmAZYBxAJ0AoQDRAPYBCgEGAQoBCgEAARABIAEyAUgBRAFKATgBLAEcAQoBDAEEAQcA8gDsAMgAtQChAJAAjwBpgFYARsA1wCbgFIAE//Fv7s/JD7aPqg+cj4sPhQ+PD3UPeQ9uD14PRg9JD0QPWQ9QD2UPYQ9gD2UPXg9RD2kPZQ96D3cPiQ+Nj46Pg4+XD5mPm4+dj5SPow+mD6WPoI+wD7sPqw+nj6qPoA+vj5YPrI+mj6SPoI+lD64PmA+SD6SPqQ+vD5EPoQ+pD6APq4+uj7fPyg/dD93v4u/6D+7P68//ABAAS4BlAIwAjYB2gG+AWIBkAJIA0ADyAQkA+gDhANwAvgCxANsA6wD0AQABGgDyANYAswCtAJ8AmAClALYAqQCLAGSAUwBCQD1AKMAmYBLAAl/8j+AP7A/Bz8kPtw+lj5cPgQ+FD3QPew93D44Pcg93D2kPVQ9TD1cPYQ+LD4wPjQ+Lj4UPgw+MD4uPnQ+lj7ZPzY/Lz8SPwk/Cj89PzQ/YT+vP7I/o7+RP4S/mT+ev5M/vj9oP2U/ZT9kP08/TT9nPzg+4D72PoY+8D6kPpY+kj6QPqg+ZD5QPl4+Tj5UPro+mD7YPtY+/j7DPxQ/er+gAGYAqIBhAKcAlgDlAPoBEAIwAlACnAKoAvQCoAKoAowDNANIA7ADjAPQA+gDbAMUAywDMAMkAzwDNALwAqQCZAIEAhgB8AGGAZoBUAEpAPQApABuACw/zT/eP5M/dD8ZPyI+4j6QPow+vj5cPmo+ND4UPgg+ED4GPmQ+aj5YPkI+vD5cPlI+VD6+Pqw+2T8+Pyg/bT8DPxQ/PD8SP0C/sj+hv8N/+j9yP2E/XT9iP0K/lD+9P0g/YT88PtY+/D6CPtQ+8j6OPrQ+UD5cPjg98D3sPdQ9yD3APeQ91D3YPcQ+AD5OPlo+MD4EPlQ+ij7sP1IAsgDAAPMAZUAVgEUAugEYAkQDeANIA1gDLALsAqQCoAM4A9gEaASoBJAEiAQkA1gDAANMA5wDkAP0A6QDaALkAmwCJAH8AbgBQgGYAVIBCQDugHOADz/YP68/Zz86PsQ+yj6yPlY+Qj5qPjw92D3YPYw9vD1gPYA94D3SPhY+LD4MPjw9zD4cPiQ+fD6ePxE/Sz9CP1Q/AD8aPyA/dz+yf82AFcADABr/87+jv7e/sv/5f/8/63/D/8E/gz99Pzw/Pj8gPz4+7D74Poo+nD5OPnI+ED4IPjA92D3UPfA9qD3APhI+FD5APmI+OD3YPig+Xz8BwDMAkAD9gHr/5D/7gB0A9AGQAswDXANAAwQC9AKoAqgC2ANABHgEWAS4BEgEJAOEAyADIANkA4ADxAOUA0QC3AJIAjAB+AG6AU4BWAEUAMYAmYBWAAW/wz+RP1o/Pj6YPq4+XD5OPmI+LD4aPgQ93D2IPag9oD2sPZg90D4sPjg+Mj4GPnI+MD4UPnI+mT8+PzE/ej9oP3o/Nz8Av6C/mz/gv9zAHsABQBy/zP/Lf/I/i3/C/9//8r+BP6A/eT8uPwU/PD7cPvY+oD60PlY+RD5YPhA+JD38Pag9pD2cPaw9kD3UPjg+LD4cPhA+OD3SPiI+5z/7AKoA1QCNAILAO3/aAJQB4ALwA1gDiAOUAygCrAKYAwAD+AQABOAFIATQBEwD5AOsA0QDlAPgBBAEDAOYAxgCwAK8AgQCMAHyAY4BSgElAPIAuABnQCe//j9ePxw+9j6gPoA+tj5wPnI+JD3sPYw9gD2IPbg9nD3gPcw93D34PdQ+Ij4+PiA+cj5MPpY+zD8TP14/bz9uP3Q/fj9ev4Y/9f/bwDTAOUA9wBJAL//pf+D/9D/7v8RAAAA2v5G/lD9BP1c/Bj8NPyI+/D6uPmg+aD4EPiQ96D3QPcw9qD20PYA94D2YPd4+RD5oPeg9kD4WPpo+1D+rAIQBHwC6ABFANQBfAKIBYAKIA8gD0ANIAywCjALkAvgDmASQBRgFKASABEgDwAOQA5wDyAQoBAgEOAN8AsACzAKIAkgCLgHAAcgBcAD/AIEAwQCNwAA//D9YPyg+mD6ePpI+rD5KPmQ+HD3IPYQ9hD2sPaQ9oD30PfA97D30PeA+LD4EPlg+WD64Pqg+2D8JP2M/cD90P0e/nb+jP6h/5n/XgBTAM8AqwDB/7f/A/86/6r+2P4B/wr/Wv44/Sj8aPs4+yj7SPpA+oD58PiQ94D2APfQ9oD1EPUg9cD1cPQg9HD2IPg4+MD1cPWg9nD3OPj4+2IAdgFmAVsAogDoAG0A8AKAB+ALkA2gDkAO4AxACtAJQAywD2ATABVgFSATABBQDhAOUA8gEAARABHgD6ANcAxwC/AJAAlgCIAHeAY4BcQDQANQAnwBhADe/nD9yPsg+yD6GPpI+sj5qPiQ96D2MPaQ9ZD1QPbg9gD30PYw95D3sPew9zj4IPlA+dj5qPoU/GD8tPzw/ND9bP5w/sz+MP+x/9H/mQA2AWYB8QBfAHkAIgCN/17/pv/h/3z//P52/nT9pPwY/Mj7cPuw+jD6uPmo+OD3wPdA98D28PVg9WD18PQw9mD3cPhw92D2EPag9kD3wPnM/Lf/CQAKALEAdAGiAXgB4AQwB2AJ4AvQDUAPYA3QC/ALgA0wD2AR4BOgFCATwBCAECAQwA9gDyAQoBBQD7ANEA1gDIAKsAjwB1gHKAa4BDAEuANQArEA//8I/8T9FPwo+wD7kPrA+Tj5wPhI+FD34Paw9sD2kPbA9mD3oPfw90D40Pjo+Kj4QPn4+Qj7QPvw+9T8fP3I/Qj+6P4R/2D/CP/T/8wA7gDsAO8AQAHoABAAi//P/53/h//u/jf/zv4K/oD9vPwc/Jj7iPpQ+qD5YPno+AD4gPcA99D2cPRg8+DzwPUI+OD2wPdw99D0IPPg9DD40Pv0/Kr+jv/K/nD9Fv5QAYgDIAUoB9AJoApwCnALUAzQDIAMAA7ADwAR4BCAEWAS4BHAEEAQgBDQD6AOwA4AD+AO8A3QDJALkAmQB8gGkAYYBkAFeASwA64Btf+W/sj9+PxE/Nj7OPvA+WD4CPjQ92D3IPfg9tD20PXA9fD1gPZA99D3WPhA+AD4GPiA+HD5OPpg+xD8ePzY/MT8cP18/fz9yv5A/zoAEACJAE4AMgDr/8D/9//o/+7/P/9P/8D+kP42/sj9ZP2Y/Oj7oPso+/D5yPjo+Ej5YPgQ91D2cPZA9aDzEPVw94j4IPiA9sD2kPVw9ND1qPom/mT+Iv4E/rr+TP6M/nwBAAW4BlgHMAiQCfAJ4AkwC7AMoA0ADlAOEA/QD/AP8A9AECAQsA+ADtANYA1wDXANEA2ADDALwAnoB8gGYAbYBUAFoASIAzwCOABi/37+Nv4c/Wz8mPu4+uD5CPnA+Lj4oPjw96D3MPcg9wD3YPfg96j4+Pi4+DD5CPnY+dj5sPqg+3j8ZP08/Yz9Gv4+/pj+6v5x/44A1wAmAbQAZgBaAFcARAAvAIcAegDQ//L+mv4d/wz+pP0Q/XD9gPxQ+hj6MPtg+1j50Pc4+ID4YPYQ9XD2IPdA9yD3EPgg+UD3MPXA9fD3WPnQ+nD9of9A/5D9aP2i/pMAKAKoBAgHyAd4B+AH0AigCWAKMAuQDOAMAA2gDQAOcA7QDtAOUA6ADaAMYAwwDDAMkAxADIAL4AnACAAIqAYQBtgFmAUIBagDsALwAdcA2f91/wf/GP70/DD8yPuQ+zD7+Pp4+tD56PjA+LD46Pj4+ID5+PkA+qj5WPmA+eD5MPrY+pj7APwg/Fz84Pzg/MD8FP2w/VD+Tv6k/hD/Qv8H/9D+4v7S/pT+iv7c/uD+3P6Q/pb+Qv7Y/aj9MP0U/cD8zPxk/Dj8qPuY+7D6QPoQ+jj6mPnI+DD5MPrg+vj5OPpY+oj5CPmY+bj79Pxc/RT+Hv8J/1T+zv6hAP4BNAJAA8gEiAUwBXAFGAfAB2AHaAdgCPAIoAjACLAJYAoACkAJMAkQCVAI+AdQCLAIkAjgB3gH0AYQBnAFQAVgBSgFqAQoBKQD8AK0AnwCXALeAVQB1wA5ALL/jf+W/5b/Nv+q/kr+zP1w/Tz9eP18/Vj9YP08/ST9vPyk/MD85Pz0/Pz8DP0Y/Qj9MP0Y/UD9IP1E/Uz9bP1s/aD9sP24/ej9zP3g/cz93P0E/jT+Iv78/T7+Xv6O/lL+bP66/oL+IP5Y/n7+pv46/lD+mP5+/tT9aP3g/Q7+zP2I/dj9EP6g/VD9VP28/bz9mP3Q/Sb+Tv4y/nr+1P7y/uL+A/92/63/of/H/ycAegB5AI0A8QA2AVABUAGAAdYB8AEoAnACrALIAsQC8AIsA1wDiAOsA7gDxAPkA+gDGAQoBEgEQAQwBEAEMAQ4BCgEMARABCgEEATwA9QDvAOQA3wDWANEAyAD9ALEAoQCUAIwAiQC+AHAAYgBUAESAcwAsACRAGgAGADl/9D/mv9Y/xH//P7W/oj+Vv5A/gj+1P2Y/aD9VP0k/ej83PzQ/ID8ePx4/HT8TPxA/DD8LPwA/OD7EPwU/Pj74PsI/Cj8BPzg++D7IPwE/Oj7+Psw/DT8BPwE/Ej8dPxU/FT8bPyk/Jz8sPz8/Dz9WP1k/Yj9zP3g/fz9Wv7Q/hH/P/9k/6b/4f8MAFMAqgDyACIBXAGaAcYB6gEYAkQChAKgAtwC/AIkA0gDaAOIA7QD4AP8AyAEKAQwBFgEcAR4BIgEoAS4BLgEuAS4BLgEqASQBIgEmARwBFgEKAQQBOwDxAOgA3wDWAMYA+ACuAKMAlwCNAL6AcIBnAFYASYB3gCFAFgALAD//7b/d/84/+b+nP5g/i7++P2w/Xj9TP0g/dz8kPxo/ET8KPz4+9j7wPuo+4j7YPtY+2D7WPtI+0D7MPsw+zD7OPtI+1D7WPtY+3D7kPuo+8D7yPvg++j7BPwk/Fj8hPys/NT8+Pww/Wj9tP3g/Rb+XP60/vj+L/+A/9f/JwBhALwAFgFkAZoB3AEsAnQCvAIMA2ADqAPIA/gDMARwBJAEsAT4BCAFUAVgBXgFmAWgBaAFmAW4BbAFqAWoBaAFoAWABUgFGAUABegEwASQBIAEUAT8A6gDYAMQA8gCfAIsAvABlgFIAeoAiQAoAMP/av8E/8D+bP4S/rD9WP38/Kj8TPwA/LD7cPtA+xj74Pqo+oj6cPpg+jj6MPow+ij6KPo4+lD6cPpw+qD6wPrw+vj6KPtw+6j76PsA/Fj8mPzk/Cz9dP3I/RT+Wv6W/u7+Q/+Q/7f/+v9CAJEAzwAIAVIBngG8AeQBGAJEAnwCnALIAuwCDAMsAzwDTANoA4ADlAOYA7ADtAOsA5gDkAOoA6ADqAOgA5QDfANUA0gDOANAAygDFAMEA/QC0AK0ApwCjAJsAjwCHAIEAuABrAF+AV4BPAH3ANMAsgCPAEoAAQDu/8X/lf9r/0n/K//2/sL+mP58/lj+Mv4a/gT+5P3I/bz9vP2Y/Yz9gP1c/Vj9ZP14/YT9dP2A/Yz9lP2g/bT9yP3k/QL+KP5I/mj+kP6q/sb+2P4M/z7/Yv+O/7P/2v/w/wYALABTAHQAkwC7AMMAywDIAOUAAgEOARwBKAE+AUIBPgE6ATABMgE+AUIBQAE4ATIBPgEyASQBGgESAfsA5gDdANoA3QDIALkApwCZAIIAegB3AGYAXgBHADkAIgAGAAkABAD3/9//y//B/73/uf+y/7H/o/+g/5n/kf+M/37/i/+I/4n/hv+h/5z/i/+G/6H/qv+i/6j/t/++/6D/jf+f/7j/rv+i/6X/n/+i/5H/oP+j/57/of+3/7n/rv+i/57/mP+q/5f/tP+3/7//wP/D/7H/pv+y/7X/vv+5/8P/0P/N/83/0v/i/97/4P/W/+L/3//x//7///8NABEAFQAPAAsAFQASACEAFQAkAC8AKQAhACUAIgANABQAIgA4ACsAIwAZAB0AEwAdAC4ALAApACgAKQAqAC8AMQA7ADEAEwAcACkAKAAkAC4AQgBDACsAHQAvACkAEQAdADoAQQAbABMAHgAhAP///P8MACEAEwD9/wUAEgAHAAQABQD+//P/7f/1//v/+v/p/+D/2v/J/8D/w//H/8D/vP+u/6r/qf+n/6//uv+x/7b/rv+4/7v/sv+c/7D/y//X/9j/zf/a/9//2//W/+3/AgABAPP/AAARABAADgAdADgAOgA3ADsATwBLAEMASgBfAGUAaABuAHAAfAB7AHYAbwBxAHgAeAB0AG0AdgBzAEoANAA7AEcAOwAdABAAEgACAOv/8//1/9z/uf+u/7n/s/+f/5X/nP+S/3v/X/9i/1b/Uv9T/1//Y/9R/1D/Vv9V/0n/Wf9x/4P/ef96/4n/k/+S/47/ov+2/8H/v/+//9D/zP/M/9T/3//2//X//P8eACsAKQAZACgANQA7ADQARQBSAFYAVwBfAHEAcQBpAG4AgQCHAIMAewCGAIUAhwCVAJoAoQCeAJgAlACAAIIAhwCNAIYAgACGAHYAYwBkAGQAbwBgAFMAYwBmAFMAQwBBAEcAOwAtADIAMAA1ACkAJAARAAAA7f/w/+3/3//d/87/xf+i/5P/lP+I/3b/Zv9m/2H/VP9K/07/R/87/zP/OP84/y3/Iv8n/yr/Iv8a/yT/IP8j/yj/Lf8v/zH/M/9I/0v/Tv9V/3D/if+Z/5H/jf+n/7b/xP+//9f/6P/2/+//8f8JABQAEQAcAC8APgA5ACcAIgAoACsAOQBHAE0AQQA7AEwATwA/ADIAQgBUAEAAKgA1AEkARwAbAA8AKgArABQACwAmADIAHwAPABwAHAAKAAkAKQBDACwAFAAiADgALQAdADEARwAkAPf/BgAtAC8AGwAhADwAKAADAAEAJQA3ACoAKgA4ADUAKAAuAD0ANQASAAgAFAAMAPb/8P8CAAgA7v/Y/9D/xv/A/8n/3P/c/8X/wf/F/8D/tv+2/8T/u/+k/5z/ov+C/1//Zv+S/5j/eP96/6H/uv+c/6D/0v8FAPv/7/8iAFoATAApADYAfgCeAHwAQwBoAJwAeQAvAC4AegBvACQACABhAIIAPgApAIMArwBlACMAhgDYAKEAUACEAMgAmABIAIEA0QB6APH/7/9hAD8AzP++/y8AQgDZ/7f/KABoADcA+/9NAIAAcQBkALsA6AC2AF8AkQClAF8AGwA5AFEA1/9t/4H/0/+l/1L/OP+b/5n/jP9n//T/KAD4/87/PgCPAHMANAA7AG4AHgAPACEAOgDe/1z/Uf9o/1r/TP9H/1L/MP8v/3r/v//f/7H/ov+W/5//+f/S/7j/P/8y/43/BgA7AGsAmwCVAFsA4wAgAlACngEoAMQAxAAC/8j9EPxA+1D4EPgM/TgEMAQk/vj4kPeg+sj70P0b/yQChAP6ASv/xv6QAvQDIgCQ+2T9+AKgBGACQAOABZgEU/8e//QD2AXIAqwA5APQBUgDXAHIA0gFBAI0/pP/NALKAGD+7P64AXoB+P4J/8QAygDi/sD9av6//3v/ef9BAJsAKgB6/8r+dP4x/4P/D/8m/lj+gv+J//b++v4dABYAiP7Y/RX/qwALAAD/fP+4AGgAUv/U/9YB1ALWALr+tv4YAA4BxgCJAAYBXgH/AOn/Tf/w/8wAHAGAAEEASAFIAkQChgH/AK8AzQDrABYB3QBIAFAAngCYAP//CgDWAOQAdP8B/+n/bAA9AFj/SQA/AMz/vv4FAHEAx/8y/+j/eABo/6b+yv6U/4T/Qf/r/7QA3/9Y/qT+wv///wP/gP6K/wAAsv+C/54AIAE+AFn/jf/d/6v/L//3/5EA2f/W/oj+IP8b/8b+9v4//87+/P34/bb+8P6q/ur+fv9t/7b+Nv5i/pL+kv7W/g//Y/9c/7z/4P/J/xf/7P4I/0P/hv9x/87//P8hAEYAeABxACQAxf+n/6T/wf/z/0AAJACo/2//3v8dACoAFAAqAE4AQwBeAKwAHgEsAWAB/AD6AIAB4AHQATwB0wBKAPP/v/8zAMoAqAB+AHUAigDv/3P/Vv+6/3b/4P7G/vT+Jv8V/zn/cv/I/7j/w/+s/8z/4/+l/73/FQA6ACkA7f/K//X/3f/0/xsAlgDQAJEAGQDb/9P/rP9+/1f/Uv9X/4f/2//B/63/P//6/mz+6P2s/dD9/P3k/ez9MP6E/tb+Fv89/wT/1v70/oD/DQB9ABgBfAGYAW4BogHAAWwBKgEuAUQBXgH3AJQBUAKkAigCiAEUAXMAxP9p/wUArABSAZwBCAIYAuABNAKQAvgC4AKUAwgEWATIBHAFaAaABsgG8AZ4B7AGwAU4BTgFWARUAzADLAOEArQBhAEgAcH/gP6Y/OD6GPmA9/D2APbQ9ZD10PXQ9cD1IPaA9mD24PXQ9XD20Paw9/D4cPoM/ID87Pzk/AT9iPwg+4D6+PqY+1j7gPvU/Mz9vP28/MD8ZPxg+zj66Ppo+7D72PvE/b//mgDIAVADEAU4BfgF4AZ4B1AIEAqADEAP4A+AEOAQgBAwDzAOgA4QD3AOIA4gDxAPEA8QD+APQBBADxAOwAzAC2AKkAlgCRAJYAgYB3gF2ALd/3j9kPtQ+SD3gPUA9XDzUPHA7wDvoO2g6WDmgOUA5cDk4OVA7NDyMPVQ9lD40PdQ9ZDxQPPA9zj7gP94AwAF4ALIAUACeASoAv4BRgGY+0D1MPSw+Bj7mPsc/RD+UPvw9IDy4PTA9SD0wPSo+Hj54Pcg+UD+vALIAkgDGAWYBqAFWARwBiAKEAxQDbAPABIgEsAQoBHAEuARkA9wDWAMwAsgCwALgAxADbANgAwAC5AJkAcwBmAFEAUYBMgC6AGAAZACJAPcAuQCiAMYAyYBVv/k/YD9Hv5s/nL/iQD4AOIAGgDu//j+pPyY+TD30PSw8uDv4O3g7YDtAO7A7YDvQPGQ89D1IPj4+lT9qP70/bj+AQD+AYgCiARYB2AJOAfoBKwDTgG8/pD7EPyg/Iz86PvU/LD9UP1o+oj5UPhA92D0EPJQ8WDyUPXI+Cj9yP/fABgBEwCw/+z/5ACqAQQDyASABuAIoAsQD+ARYBPAEoARkA9gDeALoAtwDGANcA4QDxAPQA7wDAAM8AoACWAH0AUoBHADlAP4BAAGcAfgCHAJYAg4B8AGEAaIBIQDXAJIAkABmAGmASoBcABy/qj88PlA9wD1UPKA72DtgOug6UDpwOqg68DqYOqA7MDvAPTY+XACYAcYBwAFCARUApz/sP/4A1AIoAeoBvgF0ATR/3j7EPqQ+QD3sPQg9XD0gPOQ8WDz0PZo+Sj5gPdQ9gD0wPMg9TD48PuR/1ACmAJUAjAEgAUgBmAGwAiAC2AK0AjQCRANIA8gDlAP4BDQDyANAAtgCwAL4AmwCWAJMAj4BpAG4AZAByAIYAgYB7gEOAS4BJgFqAVIBmAHsAZYBagEMAVIBZgEcATQA3gC9QDu/+T/Dv/o/Wz86PrQ+AD3wPTQ8lDwIO6A7EDroOrA6uDr4Oyg7hDxgPWY+tz/AAWwCGAJ2AagBKACvgCW/pQA3AMoAygA0f+V/wz8SPlw95j4EPfQ8uDyQPNg8uDvQPGg9Uj4iPkw+mD6QPjg9zj6HPxI/Tz+mf/EAPj/AgEYA0AGmAcACZAJMAkACWAJIAvQC9AMAA3ADJAMwA2ADtANgAzQCyAMgApwCHAHcAeQB7AHMAhQCSAJMAhAB6gGmAZoBsgGEAcgB4gGYAb4BfAFKAaIBqgF8APUApwBs/8g/cD7oPoo+WD3sPXg9CD08PEQ8IDuYO1A6+DpYOrA7CDvoPPQ+lwBkAUQCPAJYAnoBLv/+f8QAQj/Wv7+/nkABPzI+Dj5HPxg+0D2IPVg9ZDz4O8w8GDy4PNw83D1CPlA+gj56PgY+ij76PtI/Lz8QPwQ/CT9Vv7E/wwDIAcQChALcAsQCxALwArQC8AMMA1gDRAO0A7gDjAOoA3ADSANAAxwCrAIyAaoBRAGoAfgCKAJ0AkQCQAIgAdAB4AHqAeIB1gH6AY4BjgGgAZwBgAGiAWABMQC2wDg/vT8mPrY+CD34PWA9MDyIPFA74Dt4OvA6gDqoOmg6kDu0PLQ+Mb+EAVQCfAJUAdIBZgE+AET/6P/SALC/5D6MPgg+mj6oPdA+GD6oPhA8yDvEPFg8sDxgPEg9fD3QPhI+ID4mPng+vj7CP3w/Tb+5P20/Dj8sP3Y/ywCeATgB6AKIAtQCoAKkAxADdAMUA1wDsAOIA4ADuANYA2QDCAMwAtwCgAJAAggB4AGoAcACsAKEArQCYAK0AmYB9gG4AdgCFAH4AagBxAIwAeYBhAGwAWIBHACIgCC/gj92Prg90D2wPUw9ZDzgPEw8ODuwOxg6oDpYOmA6gDt0PGg+CIAEAYgCpAL8ArQB7ADZADl/9cAXf8Y/Vj5iPhg98D0IPXQ+Nj5IPcQ9KDzMPMA8rDwEPMg9mD30PeI+Ej5aPl4+kj7NPyA/br+1v4E/BD7RPyk/Jj9mAAgBdgGgAZIBzAK8AvwCyANgA+AEBAPkA4QD7AOEA0wDKAMsAtwCqAI6AYYBugFeAZoB+AHgAhACdAIQAjQB5AI8AhwCGAIkAhgCLgHkAZgBhAGQAVgBNQC3gGEAJj+wPtw+dD3cPYA9ZDzwPLw8ODuYO2A7IDrwOog7CDvUPM4+b//YAUQCQALwAroB7QCmgA0AP7/kP1I+4j7wPcw9IDz0PUw91D2kPUg9eD0oPNw8pDyQPSw9lj4aPiY+Nj5uPo4+lD6dPxw/qj9bPyw/AD9UPto+qj8pgBEA3AEwAXwB/AJUAvADPAOQBCgEOAQoBDgEIAQcA9ADvAMMAxQCqAIuAYIBkgG8AaoBxAIUAkQCtAJ0AiwCGAJkAmwCDAIQAgACFgGWAWgBagF2ATYAyADLAISAZT/2P1Y+zj6uPnQ98DzkPEg8eDuwOsA6uDrgOyA60DtUPSI+3T/zAPwCcAMQAtQBggEKAN2AeL+lP2Q/Jj6APfQ9PD0APXA9VD1gPXw9OD0IPSg8wD1UPYI+Pj4wPmI+rD6yPqQ+vj6GPvA+5D8cPyA+8j6QPvI+9T8Rv9wAiAF8AU4B1AK4AyADqAPYBGAEiASIBGgEEAQoA+wDRAMkApACegHQAa4BWAGuAYgB3gHsAgQCVAJIAnQCZAKYArQCdAJcAnQB0gGcAbwBegE5AMoA7AC/AC0/4b+6P0Y/Tj7iPnA90D2cPWA8qDv4O7g7uDs4OnA6mDvQPKA9TD9IAeAC0AJoAjgCIgG9gGd/2oAXv4A+rD2UPaw9ADzcPMQ9sD30PZA9tD04PMQ9FD1EPcI+Oj4APpo+lj5SPkI+hj7CPxQ/Hj8mPt4+kD5MPgQ+dD63P3s/2oBmAOoBlAI0AngDAAQoBFAEQAR4BAAEaAPwA5QDiANcAqwB+gF6AVABiAGkAboByAJ0AiwByAIYAkwCvAJYAowC2AKsAgAB3gGWAYgBtAEWAQQBJQDxAEhAGMA5v/o/kD9qPzo+9D4YPWA9ODzIPHA7WDtAO6g62DqQO/A9vT8ZgGQCAANkAogBlgF2AXgA4QA7P38/Aj54PTg8/DzgPRg9Rj4gPkA+BD2APYQ9vD1oPYA+HD5MPhA+ID4EPmo+bD6BP3E/bj9QPyg+ij5mPjo+Pj5CPto/Oz+vABgAjAFgAjACyAOwA9gEaAR4BBAEGAQgBDAD7ANUAvACOAGEAVIBNAEUAYIB0gHQAfAByAIgAiQCbAK0AtACxAK4AggCBgH+AWgBZAFuAT4AuoBcAKoATQAqv+VAOT/xP1A+6D6aPmQ9dDyEPPA8YDtwOog62DsgOxg74D3tQDoBVAIMApQCmAHUAQQBGADcwB8/ND5cPZg88Dx4PFQ84D0YPbg94D3APYA9qD3+PjQ+AD56Pno+eD4oPeA+KD58Po0/KD8vPyQ+6j6oPlw+TD6CPuI+wT8qP0HAKwCQAWACOALgA5gEIARIBKAEoASwBFgEGAOIAxwCeAG6ATMA5wDpAO4BPgF4AZoB0AIkAlgCtAK8ArgCvAJcAj4BjgG0AUwBWgEvAMoA4QC3AG+AQgCCAJUAb4AhABI/5D8+PkI+YD3wPPA76DuAO4A6+DoQOtg8LDyQPag/rAFMAmQCFAIUAn4BkgEaALvABj92Pig9sD0kPJw8aDzoPWw9WD2wPdg+PD34Pcg+YD5+PhA+AD5WPnI+Yj5wPmo+pD7GPxQ+wD7GPtg+6D6qPqY+zj8qPxQ/QQAxAIgBUAIkAtADiAQwBGgE4AUIBQgE4ARUA+ADOAJoAfABdgDSAOEAwgEmAQABgAIcAkwCgALAAwADMAKsAkACZAImAcwBuAFMAUABLwCvALUAjwCIAGMAaYB4/+U/nn/pf9c/bj6iPlo+PDxQOzg60DtgO1A7EDw4PQ4+Fj62/+wBsAISAcoB4AIOAWsAfb+nP2I+mD3sPUA9RDzEPKg8xD1APbA9uD4gPpg+qD54Pgg+LD3gPhw+dj5QPpQ+ij6UPn4+Kj5APqQ+fD5gPoQ+yj7oPv8/GL+awBcA5gGAAnQCgANcA8gEUAS4BNAFAATABEQD6AM4AmgBxgGwARIA8ACaAOABEAF6AZACRALoAvAC+ALEAvQCWAIsAdYB7gG0AUABVAElAOsAxAEeARgA/gBBgFSAJT+EP1c/dj+FP14+LD0kPKA7gDpoOlg7pDx4PDA8XD34Psa/iwBAAagCbAIiAYABdQDEADE/AD7mPkQ+BD2cPSg88Dz8PPQ9FD22PiI+gD60Pgw+Cj4cPeQ90j5YPuw+1D6KPrA+nj6qPng+YD6EPrA+UD6aPoI+rD6eP1hAFgCUAWQCUAMsAwwDkARIBPAEmASIBNgEjAP0AvwCXAISAbABAAEEARIBLgE8AV4ByAJ8AoQDIAMYAyAC9AJIAhoB0AH8AZoBrgFWAWYBGAE2ASIBbgFuASIAiwAOv6s/dD8cPyY+/j6cPeA8YDt4Osg7WDtAO9g83D34PcI+WD9PAKIBMAF6AbwB+AFiAL//w7+oPsg+dD38PZg9nD1wPTA9MD1oPeA+Mj44PlQ+oj4YPaA9uD3+Pjo+LD5yPq4+vD5+PkA+8j62PmA+aj5aPlI+PD3APig+CD7CP/gApgGEArADSAQYBHAEgAU4BPgEqARIBBQDZAJkAaABMgDoALeAXgCSATQBXgGoAfQCUAM4AywDOAMYAwgCvgGKAY4BkgF2ANwA8ADYAM8A3AE4AUABqgFsASIApz/uP30/ej8QPpA96D08PAA7ADroOzg7uDwEPTQ9zD6YPsg/rYB/AO4BGAFAAZwBGAB/v44/Qj7uPgw97D2oPXw9ND0IPWg9cD2EPjw+BD5EPlw+CD3sPbw90j5KPmg+bD64Pro+ej5ePtY+xj5WPiQ+iD6APfw9bD2mPgo+jz9UAOIB4AK8A1AEoAUgBSgFeAWwBUgErAPkA1gCZAFEAQwBHwDPAL4AggF8AYgB2AIMAqwDBANsAxgDBAM4AroBxgGSAWIBFQCQAH6AWwCZALIAggFeAaYBXgEuAPuAZP/FP3w+3D6UPfw89DwIO5g7MDs4O7g8VD0MPeQ+YD7OP3h/4QC9ANIBKAESARMApf/eP3I+xj6cPjA9jD28PWQ9TD1wPVQ94D4cPgw+TD62Pgw9oD2uPiA+VD4EPjo+8j8iPoA+ij8VP0A+sj50PuU/ED48PSA9vj4EPmA+rkAOAWACMALYBGgFIAV4BZAGWAYYBRgESAPYAuoBpAEaAR8A8IBcAK4BNAFUAboB2AKwAvQC9AMEA5wDVAL0AlACBgGBAMiAbsAkwCpADIBbALYAzAFOAbQBjgG8AS4AhYAtP2I+8j4sPVw8kDvQO1A7WDuMPDA8uD1iPhQ+vj7iP7vAFwCQAM4BFAEQALe/3T+QP3w+tD48Pew97D2cPWA9VD2gPc4+Nj4sPko+mD5APjw9pD4sPkA+TD4gPrA/ED6gPew+OD7cPu4+Dj5cPqg+LD1UPXQ9xD5gPkY/IwBuAVwCSAOoBJgFQAXABjAFwAWIBNgELAMIAngBvgEpALTAHABCAOgA0AEsAZgCYAJMAkACyANIA2wDMAMQAuwB3AE6ALgAWMA/v/qAJ4BrgEIA5AFkAYwBtgFkAWEA1AA/P3Y++D4IPUQ8iDwgO7g7YDuUPDg8qD18Pcg+iT8sv4SAZgCwAN4BFgEwAKbAJT+7PxY+6D54Pjg9+D2IPZQ9lD3yPjA+QD6uPk4+pj5SPjA9ij4APpw+SD5yPnY+/D6QPig+FT8IP1Q+4j6yPow+dD2APbw92j5QPro++L+tAIoB4AMIBFAFWAYABngFwAWYBWgE1AP0AsgCqAH7AJFAP4ATAKYATwCgAUgCPgHoAcQCrAMUA0wDcANUA3QCeAFUAP+Ac4A3//4/8oAiAEoAlgD8AQgBugFQAVoBHwC9P/c/AD6kPcA9MDw4O6A7qDuIO8g8eDzYPaA+AD7kP3Z/8ABkAMQBEwDTALYAAv/vPyA+zj6SPiA9pD28PaQ9bD1KPgg+vj5UPlY+4D7oPmw95D4uPpg+Wj4sPlA+xj6IPmI+Wj64PrI+5T8YPvA+Rj4oPeQ9yD4sPmo+xz9V//MA2AJ8A1AEqAWABnAGIAXYBaAFOARcA/QDGAJYAWUAt8ASAB8AKQB4AMQBfgFsAdQCRAKcAowDGANgAxgChAIeAWkAmsAm/8JACIAx/85AK4BBANwA5AD+AOIBMgDggHQ/oD8EPrg9iD0EPLw8KDvQO9g8NDx8PPA9SD4mPpk/ef/TgH+AfQBUAI2AST/xP1g/QT8wPkY+Bj4QPcw9jD2kPcw+AD4cPh4+tj5CPmA+ED5APmQ9xD5cPqY+iD5aPqw+vD4GPjY+Sz8wPs4+nj5KPmw9xD28PeA+mj7+Pv6/tADgAggDYAR4BWAGMAYgBfAFeATIBKwDxANMAoABxgEXgEUANAARAKYA9AEMAfQCKAJ8AmgCoAMIA0gDJAK8AiwBggDiQB5AF4BwQD3/yIBTAO0AwgDMARoBpAGGASkAr4Biv74+aD3YPbw8yDxwO9A8ADxAPHw8iD2WPhA+gj9kv85AMoAAAIEAvQA7v9D/8j9GPsQ+rj5QPjA9gD3GPjA9zD3KPho+vD5QPmg+Wj6+PgA93D44PjQ9wD4iPqY+3D5CPiQ+SD7+PlY+qD8xPyg+XD2gPeA+Cj48Pdo+lD+eQDwA2AJsA8gFOAWoBggGUAYgBVAE6ARwA+QDIAI0AS0AdL/XP8bAKoBuAPABVgHcAjACXALMAyQDKAMAA2gC+AH6ASkA1gCRwC0/yQBNAIwAdgADAMgBUAE0AMIBYAFXAL8/XT8mPsw+ID0QPOA8hDxwO9w8ZDzoPSg9aj4KPz0/YT+kwC4AXgB9QBCAQIBCP+Q/Lj7ePvI+ZD34PYw+Hj4UPfg9mj4MPqg+Wj4EPnY+SD4kPdA+Oj48Pio+Jj6sPpY+mj6SPog+tj5oPvY/OD6MPgA+PD3wPYg9kj44Pro+0L+6AOwCQAOYBJAFyAaABkAGGAXIBXgEUAPkA2ACggFcAGOAEgAqf90AHgD+AXABpAHAAkACyAMAAwwDHAMkAsQCeAFcAOAArYB6gDYADAChAO4A7AD4ASABhAHKAaABQgEzgFi/jD7sPjw9pD0EPIg8dDxYPLA8lD00PZw+TD7oP1CALYBggFCAQACmAH+/8b+Zv4E/bD64Pmw+bj4YPcA+AD5cPhg92j4WPqA+uD4OPm4+RD4kPZQ9yj54PjI+DD6+Ppg+lD5YPpQ++D6mPoY+/D5IPdA9eD10PZQ9gD3APrc/P//wARAC0AQgBOgFmAZgBkAF4AVYBTgERAO8ArACEgFCgEE/0oAPgH7APQBKAW4BxAIMAjgCVAMMAwAC2AKMAroB0AEZAI8AqIBTQBcAMIBuAI8A+QDgAUgBigGqAWYBNQCmQDw/XD7mPgg9XDzMPLw8FDwkPFA80D0wPV4+FD7kPzg/SgApAE2Ad3/EwABAPD+5Pys/OD7kPmA+CD5aPk4+JD3KPnw+dj48PcI+uD6WPk4+BD5wPmw94D2gPho+lj5cPgg+Uj6iPkA+dj5YPqQ+Zj4WPig9zD2IPWw9QD38PfA+gL/oAMACBAN4BFgFIAVYBbgF0AX4BRAEvAPsAygCIgF9ANUAtP/OP9oALgBmALQA2AGkAiwCZAKIAyADDALcAkgCJAHAAUsArYBYAIGATsAZAFUA0gEMARYBegGeAZoBLgDIAPRAGT92Pro+MD14PIg8jDy8PGg8ZDzoPXg9uj4XPzS/kb/IwD6AYgCQAEZAGAA6f/c/fj7APzI+pD40Peg+Fj5oPhg+HD5OPp4+Wj54PkQ+uj4oPg4+SD5oPeQ93j58PnA+AD4aPnA+iD5qPiY+fD5IPiQ9zD4IPkQ9wD1EPag+Uj8Uv+4BAAKoA2gD+ARoBSgFmAWABbAFeATYBAADMAIwAboBFgDBAL4AN8AFAHkAdwDUAagCPAJQAogCyAMkAuwCaAIYAgYB1gEhAIQA3ACEgH1ADAD0ATcAwAESAVIBfwC9gFkAhYBaP3A+oj5oPcg9HDywPNg9EDzYPPQ9fD3GPl4+gD+ZwDt/3r/vQCkAUUAqP78/rz+dPwA+0j7APuA+bj4YPnQ+kD6GPkY+vD6iPqY+VD5OPnA+OD4sPiI+Gj4ePgg+TD5QPk4+gD6iPkg+TD6yPkg+dD3QPi4+DD3cPUw9WD3aPlg/KIB+AfwCwANQA/AEwAXgBbAFQAXIBZgEXAMIAsAClgG9AIUA2ADJgFJ/2ABaAQIBcgFMAjwCbAJUAkwCvAJYAggB3AGMAVQA1gCeALOASABiAJ4BJgEeAR4BZAG4AT0ArACgALv//D7gPpA+YD2IPOw8jD0IPSg8rDzcPco+QD6mPsi/3QAdP8j/4EAJAFi//j9YP3w/GD7KPpA+oD60PkY+Zj5+PnI+dj5QPpA+jD6APqQ+ZD4kPfQ9zj48PcA9yD32PhI+WD4oPgQ+iD6iPjA9+D4KPkw98D1cPeg97D1YPRw9oj5ePwuAdgG4AoQDdAPABPAFOAU4BWgFuATIBCQDfALgAgIBVgEuATUAooAFAGkA9wDAASIBpAJ0AlwCDAJYArQCIAGIAbQBhgFaALYAdgCXAIsAUQCuASQBfgEAAXwBagFyANgAuYBTwBs/bD6iPjg9iD1EPTw8/DzIPRQ9VD20PeA+TT8zP06/tL+q//1/5b/Lv+e/mr+CP2I+wj7UPso+zj6OPrw+kD7uPoA+6j7+PuY+zD7APtQ+oD5yPg4+Zj4MPig+Fj5CPmQ+Kj5gPrg+SD5mPlI+8j54PfQ9wD56PiA9uD1YPew+Aj6wv6QBNAIAAvwDWARIBNgFOAVgBYgFcASgBAwDrAKqAcAB3gGWASEAuAC2ANoA+QDSAagCMAIcAgwCbAJoAgAB2gGcAYoBUwDnAJAAvIB9AH4AvgDuARoBVAGkAbABSAFWAQUA7QBNf8E/UD7MPlQ9pD1IPXA9KD0IPWA9tD3QPnY+rD84P2o/uz+F/8L/8j+AP94/hz9KPwU/Kj7uPpw+pj74PvA+mj6iPtM/ID78PrY+3D8APtY+Tj5sPmI+MD3OPjo+Nj4iPgg+Sj6YPrg+fD5CPrQ+ej4APiA9yD3UPZw9sD2MPbA9ij5Tv6AA+gGAAswDsAQQBIAFAAVQBYAFSATYBHgDgAMQAmAB0gGkAWABBQD5ALkA9gEmAVYBuAHIAmACIgHQAdwB2AGkASYA/QDJAOYAQ4BJAJgA0QDnANgBZgGaAaoBYAFYAXwA1ABuP+G/tD78Phw96D2UPUw9AD1sPXQ9ZD2uPi4+nj7TPwW/vz+mv4G/tr+N/8c/uj8lPyU/Kj7EPso+0D8LPzQ+8j7UPzc/Gj8GPyI/HT8mPug+hj6SPng+LD4aPig+FD4WPjg+Cj5wPn4+Rj66PkI+kj6WPnQ93D38PfQ9wD2UPWg9hj4YPpG/ggE4AeAClAM8A+gEoATABQAFSAVoBIgELANUAxACqgHmAYQBvgEGANwArQDaATIBIAFAAc4B4gGEAYQBmgFMATcA5QDWALtAO0AfAESAXIB/AJwBFgESATIBVgGEAWkA4ADwAIFAJT9hPwg+5D4sPZg9rD2kPWA9bD2cPjo+Gj5cPtk/LD8gPzw/Fz9BP2U/Kz86PyQ+xj7KPvQ+6j7kPss/Lz8oPxM/Lz89PyM/AD80PuI+7D6mPkI+dj4WPgA+BD4WPhA+Lj4GPlw+YD5wPkY+sD5GPmA+PD3kPeg9mD2EPew9vD1UPag+X7+nALgBdAJEA5QD6AQoBIgFQAVgBPgEsARUA8QDGAKgAkQCAAGeAVYBTgEuAOoBBgGEAboBeAGQAfgBVgEMARABLgCuAG0AcgB1wBEAJgBIAN0AwAEqAUYB/AGeAagBngGqARoAiIBpP+E/Tj7wPng+ID3gPaQ9tD24PZw96j4yPmg+lD7LPyI/Ez8LPyY/Fj8DPy4+/D7gPtY+8j7XPzM/Aj9mP2w/RT+5P3M/bT9bP3g/Ez8wPsg+3D6uPmY+YD5cPl4+bj5GPow+kD6QPqY+gD6EPrQ+Sj50Pcg98D3kPeg9gD2wPbg92D34Pny/hAEGAcQCeAMsA+gEEAR4BPgFMATgBFgEFAP8AzACmAJsAhwB5gG0AVoBeAECAUgBpgGsAaoBnAGiAVQBJwDKANsApgBaAFGAdUA0wBuAawCCATIBKAFYAbgBqAGSAbABbAEJANcAfX/Ov6A/Oj6+Pkg+cD48PcQ+JD46Pg4+Wj6KPtY+2D7GPtA+8D6gPqQ+rD6UPow+nD66Ppo++D7/Pyg/fT9DP6g/pL+WP4S/hr+eP2Y/DT8ePuo+rD5aPlw+Uj5EPlY+fD5IPq4+eD5APoQ+mj5CPng+HD4gPcA9iD2oPYg9xD2wPSw9qD5RPz//zAEYAjQCmAMUA6gEOARQBJgEoASQBHQDsAMsAuACsAJAAlgCKAH8AZ4BmAGwAaYBtgGsAYwBigFnAOUAooBMgFiAAUA+P/I/8f/CAAQAWwCvAM4BegFWAbQBmAG0AUIBTAEEANSAcL/8P3Y/Jj78Ppw+vj54PmA+aD50PlY+sj6GPsw++j6kPpI+vj5EPpI+hj6GPpw+uj6ePsE/Mj8qP2o/iv/ff9x//T/kf8h/7T+gP4Q/sT8DPzA+2j7mPr4+Uj6mPq4+kj6YPpw+jD6EPo4+gj6kPmg+HD4MPhQ98D2kPag9sD2IPdg91D4iPqQ/kgCuAUgCDAKMAygDXAOIBAAEeAQkA+QDvANwAxwCzAK0AqQCmAJkAgACCAISAcQBxAHqAbgBZgEvANIAv0AHQD5/4P/D/8Q/zz/Y/9w/8kAiAJcAwgE2ARoBdgEaARYBNgD5AKGAaYACgBo/jD9lPyk/AT8WPsg+4D7iPtg+0D7iPtA+5D6CPqg+XD5yPiY+MD4UPlw+dD5wPpA+xj8kPyI/RD+cP6o/sz+vP4O/gr+nP1Y/bD8TPwE/KD7QPvg+gD7sPqQ+tD6KPvg+pD6EPog+gj6gPkA+XD40PdA9/D20PZg9hD2kPZQ9/D30Ph4+3T/5AIwBWAHEArgCrALQA0wD6APwA4QDgAOQA0wDLALoAugC/AKAAvgCtAJ4AigCBAJEAiwBtgFwAQEAywBJADj/yL/Xv6G/hr/Xf9d/xMAXgFwAngDEASYBGgECASsA0QDdAJsAdkAHgBg/5r+TP70/az9TP1k/Tj9tPxM/BD84PtI+5j6KPrA+Sj5sPgA+fj4CPko+ej5ePoI+5j7XPzY/Bj9XP2k/dj9pP18/TT9UP38/Nj8yPzY/Nz8nPzU/NT8zPxw/DD8MPzY+5j74Ppw+qD5kPmI+QD58Pfw9kD3oPdw98D20Paw90D30Peo+Vz8vv6VAIQDiAbwB1AIAAqwCzANYA3QDeANcA3QDLAMQA3ADLAMYAyADPALIAvQCkAKwAkwCaAIWAeoBQAEAAP8AeQAWQAgALr/U/+B/ywA/gAiAdQBxAJEAxwD6AL4AsQCXAKmAV4B7wBTAO//1//B/9X/af9X/xT/7v5C/gj+nP0E/Xz8mPsA+0D6sPko+Uj5QPlo+YD5sPkQ+kj60PpI+9D78PsU/Pj7FPwg/FT8WPw4/Iz8mPzQ/Mj82Pz0/Aj9CP0Q/fD8rPwQ/OD7mPuI++D6APpY+XD5yPnw+ND3cPco+Hj4cPcQ91D3wPYQ9yj4+Prk/bn/YgHoAwgGMAdwCBAKsAuQDLAM8AywDKAMcAzgDGANkA2ADVANUA2ADEAMwAtQC2AKYAmACLgGQAWUA4wCxAEKAUgADwC+/1L/Wf8HAFkARgDkACABZgE2Af8A+wCNAJkADwBAAPT/8/8wADoAWwBaAFMA9f9s//j+uP40/nz9pPz4+yj7gPoo+vD5+Png+eD5EPo4+ij6OPp4+pj6uPqg+tD6yPqg+qD6GPuw+8D7wPsY/KD88Pz0/DT9dP14/VT9SP1g/QD9PPwk/DD8KPwg+6D6yPqY+lD64PlI+cj4yPjI+Mj44Pdw90D3MPh4+VD7EP5kAIwBHAPwBNAG6AewCCAKcAvgC1AL8AtwDJAMAA2ADVAOIA4gDgAOkA3gDGAM4AsAC+AJkAiAB9gFKAToApgCMAIqAYgAZQAHAJT/jv/Z/wMA6v/n/wMAAABr/xD/cf98/5H/qf8KAD0AUABPALkA8gDTAFAANQASAI3/+v5W/vT9OP2Q/CD86PuA+wj7+PoI+xj74Pr4+vj6mPpI+jD6WPoA+vD58Pkw+kj6YPqQ+uj6SPuA+wz8ePx0/Dz8NPxM/KT8RPwg/Ez8NPzw+6j7aPtQ+wD72PqY+uj5MPnI+LD4EPiA9yD3IPdQ9wj4kPoI/Xz+r/9sAfwCIATwBHAG4AeACOAIcAlQCpAK4ArwC/AMcA2QDVAOUA6gDRAN8AygDKALYArQCeAIIAfABcgEaASkA/wCpAIoAkABtgChAF4ABQDq/wsAl/8l/+T+tP58/iD+jv7a/vr+zv78/n3/iv9z/27/2P+C/+r+sP6s/mz+mP04/Vj9LP3M/Fj8bPyI/AD82Pvg+8D7WPvI+sD6kPpY+gD6KPpI+jD6GPpw+sj6uPrI+kD7mPt4+5D76PsA/ND7wPsY/GD8APyI+9D72Pto+1j7EPvI+vj5cPmQ+Rj52Phw+Hj48Pfw94j40Plg+/T8+v5YAAIBTAGgAuwD8ARABYgGoAcQCHAIYAnwCsAL8AvgDKANQA6ADUANQA3gDIAM8AvQC5AK0AmgCPAHKAdoBsAFIAVoBHQD1AI4Am4B/ADVAKMAAQCE/2H/Dv/A/kb+XP5y/n7+aP5U/n7+XP5o/pz+2v4F//j+Fv/2/uD+5P4O/8L+cP4C/uD9+P14/RT9WP1I/fD8RPxQ/FT8uPvo+gj7GPvA+hD6UPqg+nj6GPo4+uj6gPpw+rj6wPqw+nj6iPqA+pD6uPrY+hj70Pr4+gD7sPqI+mD6EPpI+Rj5qPlI+Tj4sPco+Aj54Plo+3T9C/+B//v/7QDYATgCxAKABJAFQAZoBpAH4AiACZAK4AvQDAANAA3wDBAN0AxwDHAMMAzwC3AL4ApQCmAJ8AhACMgH+AbQBfgE9ANAA2ACMAKsAWIBxgBNAP7/OP/c/nT+Wv7k/bz9oP2U/Tz9WP2Q/Zj9kP24/QL+1P2M/bj9TP4m/oD9oP34/cD9BP0g/aD9sP1A/cD8/Py8/FT86Ps8/Bj8kPsg+yj7MPu4+mj6oPrA+qj6cPpg+rj6ePpg+lj6mPqQ+kj6OPrI+oj6gPpQ+tD6+Pp4+uD5wPnI+bD5yPmQ+WD5GPlQ+UD6UPvA/Eb+ef8SAFwA1gDmAQgC9AJQBGgFaAbYBjAIAAkACvAK8AtwDFAMcAxQDCAMwAtQDMAM0AxgDPALsAvQCtAJgAnwCCAIAAcIBngFkAS4AwgDoAI8AtIB4QBGAJn/Cf9s/sj9aP1Y/Rz9+PzQ/Aj9zPyU/LD8tPzc/LD80Pz0/Pz87Pzg/BT9CP3E/Kz8wPwA/dj8rPzI/OD8jPxM/AT8MPz4+4D7GPtI+1D7wPpo+qD64Ppw+ij6MPqI+gD62PnI+Tj6APqY+TD6UPpw+gj6aPqw+kj6GPqY+Yj5YPnA+UD6GPqI+Tj5uPlw+ij7+PzG/pv/vv8FAMEAOgH2AVgDyAQABmAGIAcwCBAJ4AkAC8ALEAwADGAMkAygDKAMYA0ADvANcA0ADYAMgAugCjAKIApgCXAI4AdAB2AGOAXABFgEpAOIAtYBEgEGAPT+WP4o/rD9DP28/Jz8KPyw+7D70PuI+0j7IPtQ+0D7EPtQ+7D72Pvw++j7+Pvw+/j7HPxA/Ez8dPx4/ID8iPxs/Hz8XPxQ/Ez8XPw0/OD70Puo+8j7oPuo+7j7qPuI+1D7WPtI+2j7MPs4+xD7+Prg+sj6uPqI+oD6YPpg+lD6SPqI+lD6CPpQ+hj7KPz0/JT9fv4E/zn/rv95AIIBGAK8AqgD4ASABQAG4AbYB6AI8AhQCeAJMApwCtAKUAvAC+ALEAwwDBAMkAsgC7AKcAoACnAJ8AigCPgHcAfYBlgG2AUABVAEhAPIAtwBHAGKAOX/Zv/0/nj+Jv6E/Sj9uPyQ/Dj8LPzo++D7yPvY+yT88PsM/ET8YPwk/CD8QPxY/HD8gPzM/Oz85PzA/Nz83PzU/KT8pPyw/IT8iPxQ/Ej8MPz4+9j7qPuI+2D7IPs4+zD7IPsY+wD7EPvo+uj68PrI+rj6YPo4+kj6yPpY+6D7GPuw+hD7cPvw+zj8+Pzs/Tb+JP6m/mr/3v9WABIBxAEoAkgC/ALUA4AEuAQwBQgGcAaIBtAGUAeIB9AHAAhgCHAIUAhQCGAIcAgwCCAIEAjgB4gHUAcYB7AGQAboBbAFIAWwBEAE0ANkA+wCrAJMAtgBVgEEAaQAHgDL/3X/K//S/l7+IP7g/Zj9XP1I/Sz91Pyg/Gj8UPxM/CT8DPwI/BT8+Pvw++D74PvY+9D76PvY+/D7+PsE/Bz8OPxU/Ez8RPxk/LT8xPyo/Jj87PwY/Rz9/Pwk/Uz9NP1U/XT9sP2E/YT9zP38/QD+5P0I/kr+Xv5m/pL+vv76/ub+H/9B/3v/n//l/wUANABsAKgA3QDWAPoAQAGKAZQBygEcAjwCWAJ4AsQC9AIIAyQDPANUA1QDdAOwA8wD2AMIBCAEEAQABBgEOAQgBPQD8AMABPAD0APUA9QDvAOYA4wDhANYAyADCAP8AtgCwAKsApgCYAIkAhQC+AHUAZQBeAFgASYB3gC3AJQAZgAtAP7/2v+g/1f/Pf8f/+7+pv5y/lT+Kv4A/tj9wP2Y/Wj9TP00/Qz96PzA/LD8nPyE/Gj8SPw0/Bz8FPzw+xD8APwM/CT8JPww/Cz8TPx0/HT8SPxE/Hz8qPzE/Nj85Pzw/AT9IP1M/Wz9qP3Q/fT9FP5I/oL+tv7U/hH/Wf+T/6v/4v88AHkApQDTABgBYgGMAcYB/AE4AmwClAK8AuACEANAA2wDdAOAA5gDxAPkA/ADAAQYBDAEOAQwBDAEOAQ4BDAEKAQABPAD4APYA8ADmANoAzQDDAPgArgCiAJMAgwC2gGiAWIBJAH2ALsAdgA9AAAAwP92/zr/AP/K/oj+Tv4c/uD9qP1g/TD9+PzY/MD8rPyA/FT8PPww/DD8HPwc/Bz8HPwc/CD8OPxI/FT8XPxs/JD8qPy4/ND87PwM/TD9SP1k/YD9pP3M/fj9Fv5C/nL+pv7U/vb+Hv9K/3j/qv/f/xMAPwBlAJEAxADdAOsADgE+AWQBcgF+AZwBzgHuAQgCKAJIAlgCWAJYAmQCbAJwAmwCeAJ4AmgCUAJcAlwCVAJEAkACRAIoAggC/gEAAvoB0AG4AaABjAFqATgBMAH5ANoAuwC9AJcAbABLADkAIgD///b/4//I/6v/of+R/4T/Z/9P/0f/LP8j/yb/Ev/2/uT+1v7U/sb+yP7E/sD+wv6+/s7+zv66/q7+vv7C/sr+zP7O/ub+4P7k/ur+CP8b/yD/Kf8z/0b/SP9U/3X/lf+L/3r/ev+J/6v/xP/U/9j/5f/6/w4ADAAQABwAKAA2AEAATABaAGIAYwBrAHkAegCFAJsAogCgAJoAngCtALoArgCoALcAvAC6ALYAtQC0AKkAnwCeAKoArQCpAKAAnwCcAJgAiwCGAIEAeQBtAGsAagBfAE4ARABIAEoAOQAoACAAGAAKAPz/8//i/8b/uf+5/7L/m/+M/4n/if+I/4H/gf+F/4P/e/97/3X/bP9p/2j/d/+A/4X/fP97/3z/fv+B/4f/lP+Y/6L/pP+v/7n/wf/D/8P/w//O/9f/1//U/9f/4f/o/+r/8P/2//j/+//7/wcADgASABwAIQA0ADQAMwA2AEUASQA9ADcAOwBAAEIAPwBIAFEAYgBsAHEAcwB0AHgAgQCPAJAAhgB3AHQAcgB1AHkAgQCFAIQAggCBAHwAcQBuAG4AawBfAFQATwBMAEMAOQAyACoAIAAUABQAEQAMAAYACAAMAA0ACAACAPj/7P/r//H/7//m/9v/1v/R/8z/w//D/8D/v//D/8b/x//L/9P/3f/g/97/4//w//z//P8CAAYACQAQABcAHwAoACcAMgAwADMAMwA5ADYALgAsADYARAAyAEsATgBVAEwASABcAFUARABDAEMANwArADUANAAfAAIA8f/3//r/6//h/9r/1//L/8P/xv/M/8r/xv++/7z/vf/B/7z/tP+z/63/qP+g/53/oP+d/5X/hv+F/4n/hv+F/4n/kv+O/4P/ef+A/5P/pP+t/6n/p/+o/7L/vf/A/8T/x//N/8//0//a/+3/AQANABEAEgAXABcAIQAnACgAJQAYABUAGgAoACgAIwAlACUAKQAxADgAPgBAAD8AQABFAEYARgA/ADUALgAqAC0ALAAwAC8AKAAZABEAGAAfACcAHQAbABoAGwAeAB4AHQATAAkAAQD9//3/+P/r/+T/4v/j/97/0//H/8f/w//A/77/vP/B/73/u/+w/6X/p/+r/7H/s/+6/7v/uf+2/7X/uv+1/6//r/+v/6n/oP+f/6n/uf/B/8T/xv/L/8//1P/W/+D/6f/r/+n/7v/3//v/+P8HAA8AEQATAB4ALQAoACQAMQBIAFUATQBSAFcAWQBVAE0AXQBUAFUAUQBfAFEASwBFAEcARQA+AEwATABAAC8ANgA8ADsANwAzADgAMwAwAC8AIQAUABQAFAAYABEABgABAP7/CAASAA4A9//f/9//9v/6//H/4v/c/9n/zP/J/8z/2//X/8f/v/++/8b/xv/J/8v/xf+l/5P/mP+n/7f/r/+i/5n/oP+o/6//rP+x/7v/wP+//8L/zf/X/9j/0//c/+T/6//3/wEA/P/t/+z//v8TABkADQARACEAJwAmAC0ANgAwACMAGwAsAEMARQA6ADEANQA2AD4AQQA/ADgAMAAzAEAARQA+ADQANwBEAEgARgBEAEoARAA2ACsAKwAsAB0AEwAMAAQA9P/t//P//f/8//j/9f/v/+j/2//f/9j/1P/W/9v/6P/i/9P/xP/C/8P/y//O/8//zP/C/8X/xf/S/9b/0P+9/7b/w//g/+7/2v/E/8D/2P/p//L/8//r/93/3P/l//3/BQD9//j/7P/z//X/EAAgADMADADq/+j/CQAgABwACwABAA8AJgAyADkAOAAyACoAOQBMAFUAOgAdAB0ANABSAFUATwBCACsAJwA0AE4AUgBGADUALgAqACMAJAArACYAEgD4//X/7P/q/9z/4//u/+r/7f/l/97/0//T//D/AQD+/+D/2P/Q/9f/2f/m//X/3v/E/7b/zv/o/+b/2v/N/8X/wv/B/93/6f/j/8H/sf+8/9H/0f/F/8P/tP/C/8H/1f/X/9P/tv+p/5j/rP/K/9j/2v+b/8T/xP/h/7H/oP+t/8f/z/+6/8b/rP/N/w4AHgDy/4P/Xv+k/xoAPAAvAO3/uP+A/6b/AgB4AHgADgCh/5H/3P9YAJwAcQDy/4z/pv8+AMgAywBgAO3/yf8eAH0AugCaAIYAMgATAPD/BQBfAKAApgBAAN//tv8QAFsAegBBAAYA+P/1/xAACgAkADMATgBJABgA4//S/+7/JQBCAC8A9v/G/7n/2v8KABIAEgDO/7f/ov/T/wEAAgADAOX/4/+x/9j/0v/6//L/2f/W/77/4P/2/woA1/+Y/4H/tv8KADwAOgD2/6P/if/S/yoAWgARAMz/pf/R/wUALAA+APD/zv+t/+r/JgAsACUA7P8BAO7/LABIAEQA/f+k/6n/2P9PAJAAkwAcAGn/Qv/w/8AAFgGEAOj/TP+C/z8AMgFCAUYAQf9M/1oAHAFIAYMAAAAw/87/jgB4ARgBFwBz/0n/FACgAL4BIgHi/7L+O/+eAD4BRAEwAHn/D//n/9oA1gBWAMz/j/9Y/zj/mABoAYIAYP50/u7/PgFnAKL/cf+9/wX/Kf87AEwBlgDw/n7+cf9gAFYA+f/Q/0P/zv7o/kEArQBdAHP/Y/80/6f/kP9aAFkAMACx/47/f/+1/0sAoAAhAL7/ff/I/8j/NACXAPYA+v91/0f/HwBEAEgAcwBUALf/Kf+0/5kA2QBTAOb/dP/D/+j/0ADnAGAA3P+p/6X/wv/DAGIBSgGz/zb/m/8UAEYAbwDvAI0Ah/9I/2IA6gA0AH7/oP8eADgAvP+7/+X/PQAPAMX/ef/C/67/vv9m/w4AdABoAJH/4v4C/7P/6gD2AB0A/v7K/l//LgDVADABOgCq/qj98v4MAfQBiAGu/9j9mP2x/5wCiAKtAF7+RP4J/zIAaAEkAkIBlv7w/d7+nAHKASYBmv/u/kD/mf8QAX4BtgGX/2r+gP5iABgC3AGGAMb+7P6P/14BwgEUAUL/iP7B/4IB9AE0APr++P4SALcA4ACWAMz/B//g/iIABAFCAcj/Bf9e/iD/iADeASQBH/8e/n7+VwB2ASIB4/+6/rT9oP4aARwD6AG0/sT8hP0AAMsAKAJAAWMAXP1w/UH/kgGiAWn/8f8B/xkApv6Z/9H/1gCqAA//Sv90/t4Axf8QAPT+1gCyAMn/2P7i/u8A0gB6AOb+JgCY/3YASABdAK3/Y/95AMoBVgGo/UT9xwDIBDwDpv5w/K7+7AFWAaoALgBjAMz/Xf+P/zoA0QDv//7/Tf8PADYAjAAzADsA3//k/sv/GgBaAeD/tP+P/wwBNgFuADMAK//c/zH/WAGmAfgC+f+w/Rb+pgDkA+8Aj/9k/TAA6wDQAJoApv+n/3D/sQBPACoAxP9uAGsA9v7u/sD/YALWALH/Fv9j/zoAt//z/2gAGwBS/uL++QAMAvQAuP5k/rj+S//U/4oBiAFd/4z+b/8CAXr/fv6M/zwBQQBp/3P/tQCw/77+Bf/jAI4Bq/8o/2r+hf/g/zwCBAK8ART+6Py4/rIBNAPyAOQAsf/F/8j8pP3MAXgEOAJo/UT9a/8AAigAEwDD/8EAy//Q/nP/lABaAb8AiQD8/oX/aP/9/58AsADi//z+zwC9ANABh/8A/oj+6f9MApAB1wD4/WD/9v+G/1L/mwCkArkAIP3U/J0AjALIACwA//+q/3z9vv6QAlwCdACE/YD/lv8lADUA1gH0AGT+kPx4/jQBGARcAsj+WPuI/aQAwAE0ARIAcAF6/rD90P0gAtgB0wAu/7z90P3k/DwCzAMiAST8zPwWAJgA7v4g/ocAogBk/rL+vgDWAQH/FP0M/fH/NAM8AssAjP1W/jD+jQClABgCZALQ/nT9yP0SAUgC7AEnANL+Y/88/ooA5AEsA3gAtP1s/cD/7AK0AAAB1/8vAKL+Pv6VABwCCAEH/yEAc/+rAH0AOgEWANL+jv8UASgAU//eACgDrAE2/kr+wf9rAOD+UwCMA4AD6v6s/P7+GAK8AZz+FP+KAOIBAP+s/oAALAP6//z8NP08ASgC0ADQ/rD/fACG/jD/dACEAUT/rP1a/rAA0AGoAFD/ZP9o/4b+gP44ANwDKAPq/sD7eP3VACgCVAN4Au3/CPuw+lf/EAVgBZUAfv6w/Oz96P4cAnwC3QDe/nj+WgGCAA4BOP8bAKT++v6NAEADrAKo/gv/7P7YAML/FQCUAGkAIv89AEgDkAH0/cz8KP+oAjgCEAFtAKT+MP30/UgCCAQwAsD9ePtc/TIAtAPgA6wBYP54+2D9cv84AyACkgDg/vb+2P+y/7T/7/9qAI3/LQCxAGgAgP/s/g3/KgBiAWACsgBs/fj7qv5eAVwCwAF2AJj9sPuo/CQC2AQyAQb+0PwO/iz/XACgAoQCeP/w+/D8lgDkAeQAEv8f/5T/Yv7g/hAAbAMQAq3/OPyo/eoAcAIMAkkAbQD4/0j+6v7p/7oBjQBcAEYA3wBS/pD9IgAEA+wBcP9e/hX/Rf9Y/xIBPAI4ArL/GP4g/XD9zf9cAxAEagDI/FD98v5YAJIAfAJEAez+GP3w/U4BrgH0AcYATQAs/Qz+YAAsAS4Buf8CAcgA+ABX/0v/fv7E/0oB5gFGAYj/GgB//4X/xv4iAAIBtgBqAeL/Pv/I/SL/vAAgAsIAVv+v/3j+8P++/uIAWAHwAfv/fv5e/nz/+P87/yYBgALtACz9bPwt/8QCIgFy/oL+9/8ZAJn/zgBg/zr/cP4xAJ4BCgGg/zD/jwAc/5T/sQA4AhABVv6E/MD9ZgGoAtACtP8y/sD8lP32/tgA/ALsAoQAMPzU/Ar/8gHmAFT/hQB8AasAN/+V//r+Qf8LANwCWAOxAFj9oP3G/wYBQAKQAnAC5P5g/Kj75v8oA0AFhAM6/oz8gPtQ/pIAyAMEA1IB8P7A/f7/Bf/E/VL+TAPoA8YASP3M/Tf/egH+AVQCpP/I/Aj9aP/aAeQBqAMwBGb/oPoY+1X/WAKYAtgCzAO2ACz9yPyp/4gBfABuADYBKAEW/zf/nQCqAWv/2v4K/3YAagEEAYIAJv56/2EAngFQ/1T+fQCmAQoB2P6c/6X/KwCO/mz+7f8TAI4AKgCMAPr/4gBp/y7+aP6K/m//xP/yAXACMAIM/9T9oP3o/Qz/gwD4AmADzAJm/xT+qPtA/WYBoAL+AWv////oAIoAmv4O/5IAaQD4/gb/FgGIAjgBd/8+/+X/Rv8B/xv/s/+bADYAjQAyAc4BlADk/dD8wP02AUgDJAPIATEAy/8o/pz+bf/XAOr/dACCAV4BwQCN/17/8v7o/TT+uACcAroBCgBcAOT+hv7c/kQA8wA8/87++v9IAQcAQv+1/xwBUwA8/nD9rv8KASQBegG8AAgBbP7M/cj9gv+XAEwBRAK2AGb/qPzs/GH/PACAAewA+ACY/+z9yPx+/nwBpgFnABj+4v5JAPgALgGp/5T+EP4a/x8AvQCUAdABdAI0Acz+Hv5Q/RL/vAB8AuwDoAPtAFT9bPxw/RsAkACEARgDvAOqAJz8vP2P/7IBYgD/AHQBsgDS/1YAFAIIATb+hPxbAJ4B4QCbAAoBCAIK/8j8cP0GATgCiQDO/lj/YADSARQBwQAN/0D92v5uAGoBywB5ADYBNAF2/8T9vv6JAHABgAGhACQB1v5H/1T+Zf9AAOoBpAKTAJL+0Puk/CD/5AE4A6gC3P40/Zj8TP3e/oQB5AMgAwUAvP2+/nf/8v5+/8gBcALLAFj/ugBuATMAiP7W/pn/Rv4X/9IA4APkAmYATP9s/XD7qPoK/zgEQAVQAtL+6v5L/4z+PP1d/z0Arf+tAIAB1AMQA7v/FP30/Gz+2/94ARQCwAF4Aaf/uv8uAG0Aq/+I/mT9Hv7m/+4BnAP4Aq//wPuw+wb+JgBEABoBoAGYAnIAyP0w/ST+GP5l/yACVAN9ANz8tPya/pMAlgBgAtQC/P8U/OD7wf/6AeQC8AIwAx4AxPxA/Gr+rQCqAagDTAN4Adz9bP2C/nT/gv84AVgCTAFp/6b+8v+QAHsAvf9y/zz+9P2U/xQCEAMsAi0AyP3g/Dj8NP59ACQDbAMwArb/FP1U/ZD8cP19/1ADEAXOAcD9cPzg/uj/jP+VAAwCAgGS/nT9CQCoAqgBGADV/7n//P3U/K7+1AIIBWgCyv8L/6D9gPz4/HoB+ASoBDwA2P20/Ej8pv5wAXADTgE4/+7+6QDBAFT/Wv/4/ob/Hv/u/1IAnABxAB8AmgBRAGMAtP68/Qz+Yv+WAJIBIASIBLYBbPyI+uj8lgDYAlgD1ANAArX/EP1w/QL/9wBGAdIB6AE1ABb+rP0aAVQDOAIO/xz9dP3G/sgA8AJwAw4Bgv5A/aj8BP2n//ACeAOKAKT9QP8EATwBe/+Y/j7+eP4DALYBNAMIA3AC8wCj/yz+5P3M/tj/AAFIAlADhAPMAtMAPP1w+/j6EP6GAVQDFAMgAsT/sPyI+wD83v43AKH/h/97APsARgBUAIH/BP4o/aj9MAAoAewAVAHSAYcAJP7Q/QL+4P5X/wIBCAMwAk8AxP5U/hr+pP41ABQCuAJWAWYA9P9j/0z/qv82AW4BEAEjACIB/AGoAbn/mv7Y/vP/lgBmAe4BXgE3ADL+Wv7I/vD+6P6N/2ABLALTAHD+QP3w/Hz9wv88AsgDcAIF/3T9QP10/iEAOAKwA1gCFwA6/iz/FgBSAPj/sv9JANgAbAGOAd8AAwCe/jz+Nf9T/4b+kv9mAcQDQAPA/1D9qPxg/Kz8PP94ArgE4APvAFT+DP1Q/Az9wv67AO4BhAJUAgQBv//Q/aj8Sv7n/x4BZgGXAKEAawDb/wEAcgEiAcL+EP1w/dH/YALYAnwD3AKUALj9APvo+mz9CAI4BeAFtAOoANT9TPzo+6j9IgHcArQDfAOIAtX/0P0k/eT9N/9b/1QBvAJgAkkAEf+F/wgAm//K/mD+KP4E/w4B4ALUArgBYAAG/qj70Po0/ccAmALUAugCuALs/wz8GPow+7T+vgGkAwgELAK3/xj9HPw8/aT/XAGGAdAAAACKAM0AogCI/2j+1P0w/kr/qgAkAggDgAJzAFr+SP1E/aj9Bv+mAbQDWATUAp8APv74+2j7IP2NAPgCsAMYA7gBm/+0/cj8dP24/vv/QgFwAuACcAL8ADX/+P2M/fD9nP6KADwCfAMsA7gB7P8w/uz8xPzK/uMAXAK4AgQDugGG/4z9HP3k/VD+/v6bAPgCRANQAjIAbv70/Fj8NP1E//gB1ANYBJwCDwDM/Qz9dP3w/rgA5gGAAvABlgHrALP/bP4m/lz+bv+EALwB9gFkAaAAFACR/x//yP4A/6n/RgBMAYIBDgHf/5n/sf9k/zX/D/+Z/wAAZgDbAEwBAgEiAAf/jP6Y/m7/lQAiAUYAK/8f/6P/ogCBAC4AP/9k/hD++P4cAHIAhAB2AOcAPgBs/zP/l/+g/4z/1f+uAC4BHgEsAYoBPAEfALT+Jv7m/p0A9AGcAigCwwCi/7L+ev48/8n/sACaAfQBbgHe/6r+mv5q/8v/CAB4ABIB4ACm/03/q/8sAAMAg/+A/7n/3P+9/5wABAG4AN//b/84/1L/ZP/7/3kAjwCmAJAAwQCOABEAof9B/wj/h/9dAAwBRgE+AfAA+P8a/4T+7P5d/+v/cQD6APIAcwCz/zL/Mv/u/s7+Tv9XAKMAkADh/47/nv+P/+n/r/9X/+L+Av+U/2EA/AAcAdsA9f9R/6z+bP7A/sL/8wBSATABwAAqAFn/mv5W/sr+jP90ADgBggE2AasAFwBm/6j+DP5Y/nn/7ADwASgCgAHk/4z+lP3Y/dj+pf85ALoALAFmAcIA1P+o/pz9kP2E/jgAZgH+AeoBHAHu/9T+bv6m/vj+Yv9HAFwBDAJAAmgB6/9s/qj9Qv6D/7wAfgEQAvAB4gCH/7D+sP5B////vAAIAQYB3QC3AC0As/+p/wsAZQAjABsATQCaAKcAnwCxAFwAsv8+/3H/3P8MADEAjAC9AJIAKgDR/43/Mv87/8n/8//s/+z/NgAxAND/TP82/4T/m/+J/6//1//a/wwA2f+o/4D/2f9UAEUAr/9p/8P/2/+o/8r/OQBiABYACgAXAA0A8v8MAG0AZQA5AEYAlgB1AAIA9P8RACwAJQBtANMAgACz/zL/bf/D/zIAxwA2AeEA9f9l/1D/Yf+n//n/kwCxAIYAEQDn/9b/yv+6/8//7f8xAFsARwBoAIMAZABBANX/4//x/2YAmQCdAIoAWQAdAP3/BgANABIA7/8TAC0ARQAtAOn/u/89/wH/J/+J/7n/tv+a/23/A/+a/oT+xv4H/y3/d/+1/6r/Vf8E/7b+ov7A/h//vP/z/7T/W/8K//7+5v4K/17/wP/F/57/df+X/5f/ov+W/4v/mf+k/xMAUgCIAHsAcQByAFIANgAiAGIAoAAIAYIBugGOASoBvwCFAKsALAG2ARwCbAIYAroBWAFMAYgBngGyAcQB3AHeAa4BmAGaAZQBYAEWARwBKgFWAToBHgEeARAB0gCMADcAGgDs/8X/ff99/5D/kf9d/+D+Uv74/dD91P3c/QD+9P20/Tz9yPyw/KD83PwM/SD9BP2s/FT8NPww/Fz8XPyM/MD81PzM/ND84Pzk/Nz84Pwo/WD9pP0O/nr+nP6m/qr+xP7o/h7/qP8XAGIAnwBuAbwBSAGwAYABcAJoA6gDmATQBCAFWAX4BagGCAc4B3AHAAgwCMAIcAnQCUAKIAoACuAJgAlwCQAJMAnwCPAIgAiQCMgHkAY4BTgEtAPcAnACCALqAcEAYf9W/uj8sPuo+vD50Plo+ej4MPhA95D2oPUA9cD0IPTA83DzkPPg89DzwPNQ87DyUPJQ8gDzoPNg9AD1gPVw9UD1gPWg9TD24Pbg9/j4MPqQ+gD7QPug+9D7kPys/c7+aP8SABAB2gGsAggEYAWIBlgHWAfQCCAJcAkgCkALwA2wDoAQIBFAESAQAA+QD0ARIBLAEmAUwBTAFCATIBJAEQAQ0A4wD6APQA9QDiANkAtgCSAHsAWwBBADIAHF/xv/LP6c/KD7sPpQ+FD2sPTA8+DyUPKA8nDzgPPw8lDyQPEA8MDuoO7A7xDxQPJw8+DzgPOw8hDyIPLA8mDzwPQw9rD2IPeg94D3gPeg9zj44PiY+Uj6GPvA+xT8bPzw/BD99Pzw/Cj9HP1U/Qz+1v5q/4X/Wv8P/6j+jv78/sX/IAFgAhgEmAXQBfgFaAVIBQgFUAbgCKAK4AxADkAPcA6QDHAMIA3QDqAQIBLAE6ATYBLAECAQAA8gDuANYA5wDiAOAA1gC6AJGAe4BRAFyAQwBBQDAAJWAKb+hP2s/Oj7+Ppo+rD5APkw+ID34PZg9hD24PUA9hD20PWQ9WD1gPXw9ZD2wPYg92D38PYg91D3KPjI+Fj5EPp4+oD6OPoA+iD6UPro+mD7JPyI/Iz8IPyw+0j7SPug+7j7BPwk/AD8yPuA+yj7WPso++D6IPsg+3j7qPvQ+wD8qPuw+xD8FP34/m0AbAJ8AxgE/APYA5gEMAVAB2AJMAtQDVAPgA9QD5AOMA4QD8AQABLAE0AUwBOgEsARYBEAEeAQQBBwD3AOIA3gC0AKMAnwB4gGyAUQBSAEDAIQADz+MP24+2D7WPvA+oD5OPgw99D28PXw9KD0kPRQ9ID0EPWw9RD2YPVQ9cD1oPWw9eD1IPbw9kD3uPgg+mj6+PlI+aj4iPhQ+FD50Po8/Iz8rPx0/Mj74PoQ+lD6sPo4+/D7hPxg/ID76Pqo+oD6IPpI+nD6iPow+qD6IPvw+jD7ePvg+xz82Ptg/aT9CP9eALACsAUoBmgGgAaYBlgGiAfACaAMYA8AEcARIBGAEFAPEA8AEEARgBKAE8ATIBNgEiARUA/gDcAMIAxAC4AK4AmwCCgHeAXcA3gC+gCS/+D9wPxI+xj6yPn4+Hj44Pfw9uD1sPQg9IDzcPNQ8+DzcPQw9dD14PUw9vD1kPWw9XD2UPcA+Lj4yPng+mj7UPsw+zj7CPvY+lj7IPwU/VD9lP24/Qz91PwA/OD7oPvo+wD8CPwQ/Fj7IPtI+tD54Pn4+cD5WPno+CD5yPgA+Sj5yPk4+lD6SPoY++D60PuY/Mz+MgGwAhgFuAVgBogFOAagBgAI4AqwDaAQQBLAEkASABFAELAPABHAEiAUABVAFcAUYBMgEgAQEA/gDdAMAAwwC4AKQAmwByAGkAT0Al4B1/8I/nj8+PoI+pD5gPno+Dj4IPdw9XD0UPPA8gDzQPMQ9ED04PRA9ZD1YPUA9XD1APZg9rD2cPfA+Hj5uPnY+qD7wPso+yj7OPsw+8D7QPxg/Wj++P3U/Wj9iPzg+4D7sPuw+xj8VPz4+6j7EPto+gj6KPkw+RD5MPmg+ZD5mPlg+Xj5qPlg+hD6QPpI+jD7OPxo/QkAvAFwA/AEAAaYBogGsAaQB5AJoAugDmAR4BJAEwASgBEAEUAR4BEgE+AUIBXgFCAUQBPAESAQsA7ADfAMMAtQCkAJIAhABrAEhAPSAeL/DP5g/Aj70Pn4+Hj40Pcg94D2gPXQ9JDzQPMA88DyEPPA8wD0IPRg9OD0sPUA9nD2MPeQ90D30Pew+Pj50PoQ+0z8GP3w/LD8cPxQ/Hj8iPzM/Zz+Ff98/uz9jP30/Pj7RPws/BD8wPuQ+6j7WPuo+lD6IPpo+dj44PhY+SD5oPjw+Lj5iPp4+hD6aPqY+lD6+Pvw/ScAPAKYAwgGiAYYB3gHeAeACKAJIAwQD0ARoBKAE0ATgBKgEaARYBLAEkATIBRAFOAT4BKgEaAQsA5QDQAMcAoQCWgHKAZ4BQgEAAOYARQAAP7Y+3D6WPkY+GD3sPbA9mD2YPXg9GD00PNA8/DyIPOQ88Dz8POw9HD1YPZA9+D3cPiI+Ij4qPhI+eD5APvg+8j8WP0M/jr+tP1g/ST9WP14/cj96P0e/sT9hP0o/RD9nPwI/Jj76PpQ+rj5qPmA+XD5uPlQ+ej4OPgQ+ID3MPfw9lD3KPjw+DD5SPqg+kj6gPpo+zD9Ev+WAQgEwAVIB5AHEAgwCPAIsArwDBAPIBGAEqATgBPgEsASABPgEkATgBMAFKATABNAEkARIBBgDoANEAxQCoAIcAZIBXwDSAJeAawACf8M/VD72PlY+PD2APbA9ZD1wPRA9BD04PNQ88Dy4PIg81DzUPPw84D0IPUA9tD2IPiA+Fj5mPmo+Sj6oPp4+2T8QP2E/Yj+rv6M/pL+tP76/lD+kP60/rT+Lv7c/fD9oP1k/bz8oPzw+0D7IPog+pD5OPlQ+Tj5IPmg+FD4IPig97D3cPeQ+ID4MPkY+sD6cPvI+nD76Pyk/tkA0AMwBsgHUAjACGAJ0AngCrAMwA6gEEASYBNAFGAUoBPgEwAU4BOAE4ATYBOAEqAR4BCAEEAP4A1wDAAL8AhwBmAE3AJYAQoAhv+w/oz92Ps4+rj4UPcQ9nD14PQA9KDzkPNw8/DzcPOw81D0gPTg83D00PRQ9fD1sPZw+Mj50PpI+8j7APzo+xD85Pzw/W7+H/+h/6z/xP/o/xoA7v+S/3b/LP+K/tj9oP10/fD8mPyQ/FT8YPs4+kj5+Pjg97D3wPcA+BD4sPeQ93D3APeA9vD2UPfw91D4QPkw+vj6SPtE/KD9+v5wAcwD8AagCKAI0AkgCvAK8AuQDUAPoBGgEqATwBQAFaAUQBQgFMAToBNgE+ASYBKAEWAQgA+gDmANEAzwCfgHsAXsAygCfgBC/7j+tP2I/Pj6gPlQ+ND2oPUw9aD00PNA8+Dy0PIA8/DyYPMw9ED0cPQA9WD1cPXQ9UD3UPiA+cj64PuI/Jj8pPxQ/eT9Xv4K/wwAkwBSADgAdQDTAJ4AWQD//xEAL/9w/hz+gP0M/TT8+Pso/GD7aPrA+VD5OPig94D3cPeg9yD3IPeQ90D3QPdA9wj4iPjo+JD5EPqw+oD7MPxE/Zb+yADkAxgGUAiACfAK8AqgCzAM4A1wD2AQ4BFgE6AUoBQAFeAUABVgFEATIBOAEmAR8A/QDpAOQA1QDDALQApACNAF1APiARsAMv7w/BT8+PrA+dj4EPiw9vD1UPXg9AD0YPNA88DygPKQ8nDzEPRQ9AD14PVw9mD2sPaQ98j4MPlI+pj7wPz0/Mz88P0q/tz+XP8eADoB/ADOALAA+QBLAAYABQDp/0T/rP6C/gr+SP00/Az8uPsA+3D6wPko+WD4gPdw94D3MPcA9xD3EPfA9sD28PZw95D38PeQ+ED5CPrQ+qD7sPxQ/Vb+igCoAjgFcAewCTAL4AtADEANwA4ADyAQgBEAE8ATIBSgFMAUoBQgFOAToBOgEmARgBBQD5ANYAxQC3AK0Ag4BwAGQAQcAhEA7P6c/Yj7gPpo+aj4gPcg9vD1oPXQ9DD0EPSw8xDz0PIg83DzsPNA9BD14PWg9jD34PeY+BD50PnY+tD7VPxI/eD9Tv6a/kb/GAB9AOMAPgGwAYQBIAH2AMcAoQDb/5b/iv8h/47+9P1U/fT8HPyY+xj7qPoY+lD56PiY+Bj40Pfg99D3gPeQ9+D34PcA+Dj40Phg+dD5YPqw+4T83Pzc/QP/bQAkAjAE+AZQCZAKEAzgDOANYA6AD6AQgBFgEgAT4BPAE+ATABRAFMATYBPgEkASoBBwDwAO0AwwC7AJ0AjAB8gF1AP4AccADv9Y/UT8qPrY+Uj4wPdQ9gD2gPXg9MD0gPRw9PDzAPTA8xD0wPQg9bD1MPbg9qD3GPj4+ND5GPu4+2T8EP3I/V7+kv4s/5j/8/9DAKcAOAFgAaIBQgHmAIMADwCR/1j/hP74/cz9KP1c/OD7WPs4+yj6oPlA+ej4KPig94D3YPfw9sD28PaA94D3oPdI+DD4gPjg+HD5UPr4+sj7WPxg/TL+Q//yALQCEAVoB6AJgAvwDEAOkA7wDiAQ4BCgEWAS4BJgEyATABMgE2ATYBPAEoAS4BGAEOAOYA3AC4AKsAh4B1AGOASUAgIBsf9Y/uT8kPuA+pD5gPig97D24PVQ9RD1IPWQ9KD0QPQw9LD0gPRg9dD1oPbg9rD3MPjg+GD5GPpA+8j70PxI/RD+av7k/nH/EwBLALoALgE8AUAB9ADxAKEABgB8/zn/GP8O/qD9gP34/AT8WPsI+6D6UPpw+Uj56Pho+LD3kPeA91D3IPdA98D34Pco+Kj4EPmY+dD5ePpg+/j72Pww/Tj+Tf81AE4BVAP4BEAHAAkQC+AMEA4QD8APgBAAEYARABJAEkASABIAEuARABKgEaARIBHwD9AOQA6gDBALcAkACLgGqASEA4QBBQCO/gj9QPzw+iD6UPmo+LD38PZw9iD2wPVQ9XD1QPUg9TD1MPXQ9RD2cPZQ9/D32PhA+bj5UPoY+5D7WPzg/Iz9CP5Q/qr+Af9L/1n/bf/w//7/DgA6AAAA2P9e//L+hP7o/Wj9zPxw/Nj7GPuQ+iD6KPrI+XD5UPko+dD4mPg4+Ej4KPg4+CD4aPjo+PD4MPmI+Tj6mPpA+/D7xPxs/TD+7v4LACABFAKUAxgFAAegCMAKkAzgDWAPABDAECARoBEgEqASoBJAEkASABJAESAR4BBgEHAPoA4QDtAMwAtQCuAIkAe4BVAEmAKwAPb+lP1U/DD72PlQ+eD4WPiQ91D3QPfg9sD2sPbQ9rD2QPYQ9kD2QPZg9sD2UPcg+Gj4QPnw+aD6OPsg/Pj8mP0c/oj+Dv92/0b/Nf+E/4D/d/9k/4X/Zv8d/6r+rv6O/iD+0P2Q/Rz9sPz4+6j7MPvw+qj6KPr4+ZD5SPkg+TD5APkQ+VD5ePmg+dj5UPpo+qj64PqA+/j7ZPwE/Zz9nv4I/xoAPgGgArwDYAU4BxAJ4AqADAAOIA/QD2AQABGAEYARABLAEaARABFgEMAQ4A9QD+AOYA5wDaAM0AvACoAJMAjgBpAFKARgApAAAv94/dD7yPro+eD4KPig92D3EPfQ9uD28PYw9xD3EPcA9xD3APfw9lD3oPew9xD4gPj4+Gj5APrQ+oj7dPwQ/bz9Xv60/vT+Ev8w/xP/jv4G/2j+Fv7M/YD95Pyk/Ez8APwg/Ij7SPso+yD7uPpw+nD6YPoA+pD5cPkQ+cj4qPig+LD4yPgI+YD52PlY+qj6QPvI+zz87Pyo/UT+6P7M/5wAcAFIAogDkAQYBngHIAkAC3AMwA3QDqAPQBAAEUARABJAEsARQBHgEEAQoA/ADjAOgA1wDNALEAsQClAJsAcIB+gFqAT0AtgBSwCC/iD92PvI+rD52PgQ+LD3UPfg9vD2APcg90D3gPeA97D3oPfg9xj4QPh4+Ij42Pj4+ED5qPkI+oj6UPv4+4j8GP2Y/VD+sv7I/tj+K/8O/8L+qP48/sD9NP3I/HT82PuQ+zj7CPvQ+nD6YPpY+lD6YPpA+lj6+Png+Qj60Png+aj58PkQ+mD6gPrw+nj76PtM/Nz80P1I/uL+tP+ZAFgBHAIUAzgEkAW4BuAHgAnACrAL8AywDaAO4A5gDwAQIBAgEOAPwA8wD6AOMA6QDdAMQAwAC8AKwAkQCQAIOAcQBvgEEASwAnYB3f+C/jD9MPzo+gD6iPm4+GD4KPgo+Cj4CPio+MD4GPno+AD5aPlQ+VD5QPlg+WD5KPlQ+XD5kPm4+VD62PpA+8D7bPz8/Gj9tP38/U7+Mv4k/iT+rP0g/XD8HPyo+xj7kPpg+gj62Pmg+bD58Pn4+Vj6aPrQ+uj6yPoY+yj7WPsY+0j7YPuI+8D7CPxg/KT85PxU/fj9cP4J/7v/ugCWAXwCXAOQBKAFiAb4B+AIEAoQC/ALsAyQDdANUA6wDtAO8A6wDrAOgA4wDgAOgA0ADVAMcAvgCjAKYAmQCNgH0AZwBcgEmANwAhwB9f8Y//T96Pzo+zD7sPoA+rj5gPlY+Uj5cPmo+aD5gPm4+cj5yPnY+eD5+Pmw+Zj5oPmY+aD5oPno+Uj6kPrI+kj7uPtI/MD8KP2U/dD9CP4i/ir+9P2s/UT97Px0/Oj7kPsw++j6oPpw+nD6kPrg+vj6ePuw+wD8fPzA/Pj8QP1c/Yz9tP3g/fD97P0U/i7+VP5+/vT+c/8xANgAlAF0AkQDQARQBWgGaAdwCEAJMAoAC6ALQAyADNAM4AwQDfAMoAyQDFAMAAygCzAL0AogCoAJAAkwCJAH+AYgBlAFgAR4A5gChAGYAL//1P74/RT9YPzI+zD7wPqA+mD6MPog+hD6+PkA+tD50PnQ+dD5qPmA+WD5aPlw+Wj5gPmg+cD5CPoo+oj6yPoY+4j7GPxw/LT82Pws/Tz9KP0M/cz8hPwk/MD7YPsA+7D6iPo4+nD6KPp4+oj6yPoI+0j78PtU/Mz8IP2k/cj9CP5a/m7+iP6m/sb+D/9c/4D/8f9iANYAcAEcAtwCjANgBGAFYAZQBzAI8AjQCWAK4ApQC8ALAAwgDAAMAAzgC2ALMAvACkAKwAkACXAI2Ad4B7gGGAZoBYgE5AMgA3QCsAEAAToAlf/G/iL+rP38/GT8FPzI+3D7MPvo+pD6cPow+gj6GPoY+vj5EPow+iD6MPow+jj6YPpo+lD6ePqg+sD6yPqo+tj62Pr4+jD7MPtY+2D7mPuA+6j7oPuI+7D7yPvY+9D72PvQ++j78PsA/Bz8UPxg/Hz80PwQ/WD9qP0Q/oj+C/9Y/9H/KwB7AL0ALAGIAdoBWAKUAhADaAOsAxgEYATYBEgF6AVYBugGWAfYB0AIoAgQCTAJcAmACZAJgAlwCSAJ0AiACCAIyAc4B9gGSAbgBUgFsAQwBLwDHAOUAhACfgEQAYYAHACi/xz/iv4a/pz9ZP3U/JD8MPzw+6j7QPsA+8D6ePpA+hj6+PnI+dD5uPmw+cD52PkI+hj6SPpA+mj6mPqw+tj6+PoY+zD7SPtQ+2D7ePuY+7D7wPvA+9j74PsE/Dj8VPyA/Jz8wPzs/Az9PP1w/aT93P0m/lL+gP7C/vb+QP9//8b/EgBkAK0ADgFkAbYBIAKIAgwDiAPoA2AEwAQgBYAF6AVABogG2AYYB1gHeAewB9AHyAe4B4AHWAcwB/gG0AaYBoAGKAboBcAFcAUwBbAEaAQQBLADRAMMA5gCOAK+AT4B8QBoAA8A0f+W/0r/9P66/lj+AP64/XD9PP38/MD8iPxI/CT86PvA+5D7aPtY+zj7GPsQ+xD7GPv4+gD7EPso+zj7OPtI+1D7UPtY+2D7cPuQ+6j70Pvg+xj8QPxk/Iz8wPzs/CT9QP1c/aT9+P1M/pL+zv4x/3z/yP8EAD4AmADqAEgBegG2Af4BVAK8AiwDfAPIAxAESARwBIgEuATYBPgEEAUQBRgFMAVgBYAFkAWQBYAFcAVoBVgFQAUgBQAF2AS4BJAEWAQYBKgDSAPsApQCNALqAZIBTgEKAbAAZwATAM7/mf94/z3//v7m/uT+zP6e/n7+Tv4w/gT+Bv74/ej9vP2I/VT9HP3s/Kz8gPw8/Cz8APzw+9j7uPvA+9D72PvQ+/j7CPwM/Cj8RPyI/JD8pPyw/OD88Pz0/Aj9QP2M/bT99P0s/mL+iv6e/rz+4v74/if/Xv+V/9f/FwBGAI4ApADYAAQBJgE6AWgBkAGqAbYBsAHOAeoBBAIcAjwCVAJgApACqAKwAtQCDANIA1ADbANgA2gDbANwA3QDYAMsAwgD5ALUAqQCSAIMAsIBagEUAc8AmgBtADYAEgD0/+z/4P/l//X/DQARABkAJAAYACMADwAsAEUANwALAM//lP9K/wf/rP54/iT+4P2s/ZT9dP1M/VD9UP1c/Wj9nP3c/Sb+Tv6E/qb+sv6y/qj+pP6m/sD+vP7C/tj+0v7K/qj+nP6c/pr+rv7A/vz+Kv9g/4r/tP/i/+f/8/8WAEoAZwCGAHwAgQBvAFoATgBEAEEANABaAGkAkwCoAMoA7AAWAUgBegHKAQgCSAJUAkACGAL2AdYBsAGMAWwBUgFGATYBLgEMAQIBAAEEAR4BGgEWARQBEgEGAeYAqABmAEUADwDF/3n/Of8F//D+xv6w/q7+rv60/rD+yv7W/vL+E/8z/zn/Mv88/zv/Uf9E/x3/8P7k/vb+Gv8v/zD/Pv9O/1v/X/92/4r/k/+Y/4r/ZP9R/zL/Jv8J/wP/AP/4/hH/K/9N/1//TP9H/3L/mP+3/6f/s/+y/6v/lP+e/5j/pv+v/7b/1P/g/w4AKwBnAIoArwDRANwA7wD/ABoBDAECARQBQAFOAV4BbAGOAY4BgAFcAUABCAHKAMIAtgCeAGcANAAPAMP/d/80/wD/4P6+/rb+vP7i/g3/W/+r/83/8v8PAEUAcQCNAKgAwQDYAOgACAEMAf4A1QCvAJQAXwASAOD/k/9Z/x3/5P7C/pj+gP5e/mz+ev6K/rD+5P4u/17/kv+2/93/FABGAIgAuQDiAAwBNAFgAWABTgFKASIB7gC9AKkAoACOAHoAawBmAFAASAA/ADgAUwBlAIQAggCFAIwAkQCCAGwAagB1AJAAkgCUAIwAjACNAJUAewB5AHUAbwA7AAsA/v/k/9L/mv98/3//k/+o/53/kP98/4X/nv+s/6z/xf/b/+b/0v+7/6v/sP+1/6//jP9l/xz/Bv/y/uT+1P7O/vD+Iv8p/yn/Lf9E/3b/k//C//P/KQBwAKcA1QDzAA4BKgEuASIBIgEeASYBEgEAAdkAuACHAGAARAAqAAQA5//f/9X/8f8HAA4ABgAZADgAYgCHAIYAhgB5AGwAbQBWAGIATwBpAHcAggCKAKEA0gD5AAYB6gDaAMMAxgC3AJIAbgBKAEsALQAXAOL/wf+q/4D/VP9J/yf/F//w/uz+1v6+/oz+fP6I/pj+lv6q/tj+/P4r/z//av9+/6H/sv/J//n/GAAvAFQAUQA8ABoA9//n/7z/kP9Z/1//Vv8//yv/Fv8R/xX/CP/s/uD+xv76/gv/NP82/1b/hv/M//7/PQByAKwA0QDnAOAA0QDCAMIAvACnAGwAOQALAOL/tP+D/3P/Xf9C/0H/V/+a/8f/BQA6AJUAzwAaAVIBnAG+AdgB4AHaAcgBrgGyAZgBegFSATYBOgEmAeMAkwBhAD8AIQDg/43/U/88/y3/K/8Q/wD/Bv8X/zr/cP+X/93/KgBmAHgAawB6AJwAvQC0AIsAVgAvAA4A6P+k/1H/FP/Y/tL+xv7c/uL+8P7+/hH/I/8k/yP/I/8//1b/d/9t/4D/mP+l/7H/nf+b/57/yP/u/yIAOABFAEsATQBKAFQAcABzAIEAdQBpAGMAWABIACUABADx/+n/8P/4/wYAEwAyAD4ASwBaAG4AlQCxAMgAzQDbANEAzAC6AJoAiwB3AFoAQgA4ADIAQAA/ADIAHgAeAB0AGgAfABcAPQBTAH0AlACkALUAwgDZAMkAvwCmAKAAlAB8AEgAAgDT/5T/ZP8t/wP/4P7I/rb+nP6M/nT+ev6I/oz+iP6O/sj+Ev9Y/3z/qP/h//j/EQAIAAoADQAmACUA/v/I/4n/Y/85//7+wv6o/qT+vP7K/tD+7P46/5b/4v8hAGUAzQAcAWQBigGeAb4BsgGqAaYBigFeASgB5ACPABwAtf9f/xn/wP5W/hz+HP4W/gz+EP4u/n7+uP4L/07/qf8fAI8ABAFCAYwB1AEsAmACeAKEAnQCVAIAArIBQgHQAF0ADQC+/0L/6P6e/nL+Pv4I/uz92P3o/fD9JP6Q/vb+WP+0/x0AiQDqAEgBnAHoASgCWAJkAlACJALUAXIBAgGCABMAt/9X/wX/ov5m/kb+JP74/dj9+P04/nL+mv7g/jj/qP8DAEwApwD7AEwBdAGAAYABdAFkAT4BDAHRAJgAagAhANz/f/8p//r+zv68/qj+uv7q/hb/U/+O/+j/UgCeAN0A/gAmAUoBZgF0AXoBhAF8AXYBTgEkAe8AwAB9ADIA6/+t/3//Zv80//7+1P62/rj+tv7C/vL+Rf+s//T/NwB7ANEAMgF2AZgBoAHSAegB5AGgAWoBJgHMAEMAyv9c/+7+kv5G/gT+rP18/VD9XP1U/WT9oP30/TT+iP7u/lj/s/8JAFgAoADKAAIBXAGaAawBwgHKAdwBzAGwAYoBYAFCAewAvQBrADYA8v/d/7H/i/9a/0f/TP9G/z3/Mf83/0b/Zv93/6L/vv/t/ysAawCpAN8ABgEwAVQBdgGUAbwBxAHqAfYB/AHkAcABigFgARQBxABkAAcAvv9k/yD/yv6w/or+mv6S/qr+xP4D/1b/kf/b/xkAiwDXABYBNAFGAVwBRAE4AfcAtwBjACsA7f+a/0r/Af/Y/qb+cv4u/hb+FP4+/kj+Uv5U/oz+xP7y/hH/NP93/6z/6//n/xYAOwB2AJoApQC0ALQA4QDXAOsAyAC4AJYAaAA8AOz/uf9m/zr/5v6q/pL+oP6e/pz+mP6s/vL+K/96/5r/1v8HAGoAsgDfAPIA8wBAAXABhAFiAVIBWAFMAQ4BpwBWACsADwDV/4n/Rv9B/07/aP9G/yL/Lv9g/4z/jv+T/33/sv/u/ysAPwBGAGgArwDcAM4AugCsANEAxACpAHQAVQBLAEsARwAEALn/f/95/2z/Vv82/yX/Rf9X/3r/k/+0/9z/BAAyAEMAUgBaAHMAiACQAH8AVwA7ABYA8v/S/4z/UP8k/yL/Jf8R//j+7P70/vr+JP9F/3//qv/b/yAAVgB7AJ4AxQDpAPUA+wD+APcA7wDsAN4AyACRAEMAIgD5/97/sP+S/4X/Z/9f/2j/hf+N/6j/0f8OADMAYgCaAN8ACgEaATYBNAE4ATIBMgEcAfkA0gC5AKkAggBZADYAEgDw/9f/wP+s/5j/j/+Q/3r/ov+5/+L/CAA3AHYAvADzABYBNgE8AWIBZAFmAToBGgEGAQQBvQBXAAcAv/+S/zX/5P6e/or+hv5o/kj+PP5U/nD+ev5m/nj+mv7m/hj/I/8n/0P/hv/A/9H/2//2/x8ARwBPAE4ASQBWAGoAaABjAEAASgBaAFUANQAeACQAGAAmABUAHQAVABMAAAD6/97/2P/K/8P/tv+l/5r/lf+Y/6//2P/T/+H/6P8iAFAAZwCFAK4A3QDuAOgA6gD2ABABJgEyARoB/ADkAOAAvwCiAHsAZABPACUA///Q/7b/nv+K/3L/Uf8r/y7/MP8t/xz/Ev8a/x3/Kv8p/yj/Sv9b/1f/Xf9m/4v/o/+z/6j/rP+5/8b/y/+o/5z/r//a/+j/5P/d/w8ATgBtAGMASgBUAHIAmgCOAFIAOAA/AEgAFwC9/2z/Tv8w//z+pP5m/m7+jv60/pz+hP6g/gD/Uf91/3//uf8CAHgAtwDXAP8AIgFeAYABfgFWAUQBQgE+AQwB2ACTAG4ARQAJAMz/gv84/wz/Bv8A/+b+3P7o/jP/Wv9k/4L/uP8BADgAUABqAKEAzQAGAfgA/QD1ABoBLAEQAeIArACpAI8AYwAhAAAA4//I/6z/fv9W/0H/Qf9R/1r/Xf9s/5L/zP/y/wgAFwAhAE4AZAB2AGoAVQBGAEYAPQAXAP//1v/R/7v/qf+S/5T/iv+a/5z/if+I/6f/0//e/+7/8/8jABYACAALACMAJwAEAAMA+/8gACYALwA4ACcAMwBMAHkAXwBLADgAUwBRABwAyf+f/5r/gv96/1P/Xf9h/4j/jP99/2n/fP+k/8z/2v/t/y0AagC7ANYA7gD4ABABGgEiARoB+QD4ANsAxwCUAGgAMQAIAOT/tv+6/5D/jf9w/1//Sv9O/1b/Xv9x/3T/p//N/+r/3f/k/+3/AQD1/+z/4//q/+3/+f8FAPT/4f/m//3/5v/P/6f/tv/D/7P/xP/P//D/9/8CAAcAHQAkAAsAAgD1/woA9v/w/8j/qP+m/4P/Zv9E/zn/Qv9H/0b/R/9Y/4P/tf/h//T/IwBeAJoAxADEAOAACAEoAS4BKgEoASABEgHgAK0AhABmAFAAJwD0/9H/yv/R/7D/hP9c/07/Pv8m/x7/Kv9P/2z/jf+///z/TQCMAMUAEgFKAXYBlgG8Ac4B0AGsAYIBPgH+ALIAXgAGAKH/Wv8a/9j+qP50/mb+av6G/qD+rP7a/hX/a/+b/8j/7/8zAGkAhgCEAIwAfwBpAE8AJQDq/7P/jf9y/1L/If/u/uj+9P78/vj+7v4T/0H/nP/N//f/HABbALgA+wAaASoBQAFoAWIBTAEiAfsA2QCyAIEAMgDp/63/kv9b/xX/0P64/rz+sv60/pz+qP7c/gn/Pv9I/3D/r/8FAEgAcQCVALYAzQDXANEAvgC1ALEAswCWAHUAPgAdAAkA5v+5/3//Xf9W/0b/Qv89/0T/Sf9e/3D/jP+u/8j/7P8AAAoAEwAtAEIAUwBPAEsATQAzAA8ACwANABUA8//J/7X/xv/R/8v/u/+8/9b/5f/e/8D/t//Q/+z/8v/T/87//f8rAFIAWwBvAHsApgC7ALoAtwCuAL4AtgCaAG8AVwBHACQA8f+1/3T/Sv8q/xT/8v7K/sL+yv7m/vD+Cf8y/1P/if+s/+D/BQAxAGEAmQC+ANEA5wDtAAIBBgH7AOIAygC2AKYAfQBOACoAEwAGAO7/4f/F/8f/xf/K/9L/3v/n/+v/9v/w//z//v8FAA0ADgAIABgAKwAhACYAKwArAC4ALgAtACcAEgADAAQA9//v/9H/2v/u//r/AQAHAB4ALQAtACwAIgAtAC4APABFAEYARAA3ADIAGwASAAEA+P/n/+b/3v/q//n/AgD8/w0ADwAjADsAQABEAEwAbABvAHsAbAB7AHkAcQBbAEwATABBAEsAIgARAAcAAwAIAOf/x/+l/5r/nv+a/4j/ev98/5H/ov+i/7P/xv/j//n/CgAiADAAQgBaAF4AVwBDADAAIwALAPP/zv+1/6n/lf+L/3X/Wf9V/2L/bv95/3X/gP+Z/7X/vf+7/8P/3f/z//r//v/v//H/6P/i/+T/0f/O/87/2v/j/9D/zP/R/+X/9v/8/wIAFAApAEIAXABrAHUAbAByAHQAdABsAGIAZQBeAF4AXwBYAFAARQBEAD0APAAtACcAKQApADsARgBLAEwAVABqAIcAnAChAK0ArgC3ALcAowCRAI8AdwBfAEcAJgAYAPr/2v+z/5X/cv9c/0v/T/9G/0X/Tv9O/1n/Yv9x/37/jv+i/7z/zP/Y/+r/+v8JAAMACQALABQAEgARABQACwD8/+7/5//e/9L/xP+5/7b/rP+i/6n/mv+l/5j/pP/A/9z/7/8DABgAIAArADMANQA4ACYALAAvADQAKQAOAAcABgACAPf/8P/i/+n/7P8BAAMADwAdAD4AUABdAGYAbgCGAJIAnwCYAJQAjQCNAIsAdwBmAFMATwA6ACkADgANAP3/8f/k/9j/3P/Y/9v/1P/S/9r/4f/p/9//2P/X/8n/w/+3/6L/k/+I/3P/ZP9O/0z/V/9h/1//Xf9v/4j/mv+3/7j/yv/c/+f//f8EAAgAGAAcACIAHgAZABcAEAATAPn/8//u//r/6P/0/+//8f/w/9//+v8CAAsAGwBBAGMAfQCnALAAwwDLAN8A+wAEAQIB8wDkAOEA1AC1AJ0AfwBpAEgAMgAVAPj/9//j/9H/x/+9/8T/zv/V/+f/7/8JAAwAKwBCAFcAbgBoAHAAcABmAGQAVgBWAEwAQQAbAAgA+f/s/+X/w/+v/5T/jv93/3X/dv9q/4T/gf+A/4L/lP+m/77/x//B/8n/wv/W/8L/yP+z/5H/iP93/1r/Qv80/yj/J/8p/yf/RP8//2T/iv+o/+P/CQBeAJsA2AAaATgBbAGOAbAByAHiAeAB6AEEAgwCJAIkAjgCMAJQAmgCgAKUArQCzALgAggDGAM0A0QDTANkA1QDVAM4A/QCzAJcAhQChgEeAZ4AKgDT/z3/5P54/hL+xP1o/Sz9xPyM/GD8LPwY/Oj72PvA+8D7oPt4+zj7KPv4+tj6gPo4+uj5uPlo+Sj50Piw+FD4SPgw+Bj48Pfw90D4UPjA+AD5iPkY+tj6oPuM/Hz9rv6x/xYBWAKwA/gEcAaoBwAJUApwC7AMcA2ADkAP8A9gEMAQABEAESARoBBgEOAPEA+ADnANYAxQCyAK4AiYB2gGQAXsA+QCngF7AJT/hP60/eD8IPyA+7D6GPqQ+RD5oPgI+OD3YPfQ9gD3MPZQ9vD1YPUA9aD0EPSQ8+DzYPOw8zDzQPMw82DzEPRA9DD0EPSQ9LD04PQA9bD04PQQ9fD08PTw9CD1UPUA9oD24Pbw9+j4iPpI/Nz94f8IAogEGAeACRAMcA4AEWATYBVgF6AY4BnAGmAbYBsgG2AaIBkgGCAWQBQAEqAPgA0AC+AIgAZoBJQC8wCp/0j+UP1A/Ij7OPu4+mD6QPow+kj6oPrw+jj7kPsA/ET8rPzs/AD9aP10/cz9Pv4y/pL+aP6W/r7+uv7m/qL+gP5A/hL+vP10/dj8WPzY+1D78PpI+rj5OPnQ+CD4cPdw9uD1APUg9FDzEPJw8aDwAPDA76DvYO8g8GDw0PHA8pD00PUA+Aj6IPx2/s4AnAMABqAIYAtQDdAP4BGgE0AVoBaAF+AXQBhAGOAXgBcgF0AWIBWgEwASwBDgDjANMAsQCSAHCAVkA6gBFwDS/mj9qPyQ+3D66PlI+dj4cPhY+Bj4OPiY+Dj50PlY+gD78Pu4/Nj9ZP6H/w0A2ABsAQgChAK8AtgCIAMIA7wCiALUAWoBzQA3ADf/IP48/Wj8mPvQ+pD5wPig9zD3UPaQ9WD0sPPw8kDyQPEA8ADvIO6g7eDsoOwA7KDswOzg7cDuwO/Q8UDz8PUg+MD6cP25AAAEsAYQCpAMEA9gEcATQBagF8AYYBlgGQAaIBqgGcAYYBcgFsAUYBOAESAPwA2gC4AJoAc4BWgDrAFeAAz/VP3o+6j64PlY+aj48Pcw9xD3EPdQ95D3APio+Hj5qPoo+yj8KP1c/nn/YQA2Ab4BiAJUA8ADAAQABOADuANEA7gCCAIuAZIAef9U/iD9JPwQ+wj64Piw92D2cPWg9IDzkPKg8eDwMPBg76DuoO0A7WDsQOzg68DrQOzg7IDtAO+g8PDxoPTA9mD5kPwG/ygC4ARgCHALMA6gEKASABXgFuAYwBkgGqAaoBqgGuAZwBhgF6AVwBSgEuAQkA6gDNAKAAkAB4AEkAKtAHX/BP6o/MD6uPkY+Xj48Pcg9/D2wPbg9lD3YPfQ99D4qPnY+uj7/Pwc/jv/yADSAfAC4APQBFgF8AVABnAGYAYYBpgFqASUA9gCsAFpAFX/zP2A/ED7GPqg+MD3gPag9ZD00PPw8jDycPHg8DDwYO/g7kDuoO1A7cDsQOyA7GDsAO0A7uDusPAw8jD1UPeA+gz9wP8IA8AF0AjgC9AOoBBAE+AUQBdgGAAZgBnAGcAZYBmAGMAWYBUAFKAS4BDADmAMoAowCXgHeAVsA+ABggAe/w7+VPwg+1D6sPkY+WD4sPfA9+D3GPhI+Hj4+Pjw+fD6FPwg/R7+hf+6ANwBNAM4BBgFIAZwBqAG6AbABnAGMAZABTgE9ALkAX8AOf/I/Wz8OPvY+bj4gPew9rD18PRg9HDzwPIg8oDxAPEw8KDvAO8g7sDt4OyA7ODr4Ovg64DsIO1A7uDvEPKA9PD2cPog/WgAKAOQBgAKYAxAD6AR4BNAFkAXYBjgGKAZgBnAGeAYYBdAFiAVwBNgEqAQgA7gDFALAApQCJAGAAWEA0ACxABg/+j98Pwk/DD7KPpQ+YD4aPh4+Gj4cPiI+Oj4oPmw+rD7yPz8/Tb/kAAAAjwDMASABWAGOAdwB5AHqAdQB9gGGAYABYwDDAKqAPD+iP3w+4D6KPnw99D2wPUA9RD0sPMA82DywPEQ8ZDwMPCg7wDvYO5g7QDtIOyg6yDrAOvg6kDrAOxg7eDukPFA9GD3kPqo/RIByAPwB9AK0A3AEOASgBTAFiAY4BhgGYAZQBmAGWAYIBdgFUAUIBOgEQAQ4A1wDPAK0AlgCGgGUAXUA3wCRAGf/zD+1Pws/BD78Pmg+Cj40Pfw9wD48PdY+Oj4APow+4z8xP0Q/9IAEAJ0A9gE6AUAB+AHMAhwCFAIEAiQB3AGqAU4BNACSgGS/8j9LPyo+nj5CPjQ9vD1EPWQ9MDzMPPQ8rDyUPLg8VDxsPBg8ODvgO/A7uDtIO3A7GDsAOwg7GDs4OwA7qDv0PGg9LD34PqY/nQBEAXQBzALcA6gEAAUgBXAFqAXABmAGaAZQBkgGCAXYBZgFeATIBKAEJAPMA6gDCALoAlwCIgHcAYoBXAD7gGeAKr/WP7Y/GD7UPoo+WD4oPcw9wD3QPdw9yj4CPnQ+XD78PzI/mYAFAKIA8gEgAawB9AIMAlwCWAJIAngCBAIGAe4BSgEjAL/ADv/kP3A+1D68Pjw9/D2sPUQ9YD0QPTw84DzAPOg8jDyAPJQ8aDwAPDA78DuAO4g7eDrwOtA64DrwOsg7CDtQO8Q8qD0gPdg+7j+1AKoBbAIwAsgDwASgBTAFQAXoBcgGEAZwBhgGOAWYBYAFSAU4BJAEYAQUA9ADuAMkAuACoAJcAg4B8AF6ANIAsYAeP/o/Tj8wPpA+Qj4UPfA9oD2kPbQ9uD3sPjA+RD7qPx+/m0ADAKMA5AE4AUIBxAIsAjQCNAIcAioByAH+AUgBawDdALUAE3/tP1I/Dj7GPro+OD3IPdA9iD18PRg9MDzUPOA8gDyYPEA8XDwwO9A76DuAO7A7aDsYOwA7MDrAOxA7KDsgO3A7oDx8POg9sD5hP2QARgEEAewCdAMIBCAEmAUABUAFqAWABggGOAX4BYAFoAVQBRgEyASIBFgEJAPMA7wDHALMAqACQAIwAbYBNgCGAFR//z9jPwg+7j5EPiQ9wD3IPdg97D3KPiA+ZD6qPsU/WL+LgDSAYADMARgBRgGMAfoB2AIUAgQCMgHYAcAByAGIAVABCQD6gFPANr+lP2E/DD78PnA+HD3YPZg9aD0wPNw85DyAPJQ8QDxsPAQ8ADwYO8g76DuQO7A7WDtwOzA7MDsIO0g7cDtIO8A8SDzAPYA+bT8k/8sA2AGsAggC0AOQBFgEwAV4BSgFaAWYBfAFwAXIBYAFWAUwBPgEkARgBCQD6AOkA2gC7AK8AhwCCgHaAVYA/4Anf/Q/aD8APuI+Sj4gPfQ9rD2APdQ9zj4aPmg+tD7AP1i/g4AhAEgA1AEMAXoBcgGoAdQCFAIQAjYB7gHMAdoBpgF4AS8A5gCIgHZ/2D++PzY+zj6EPmg94D2UPVA9IDzwPJA8rDxMPHw8GDwkPBA8ODvYO8g76DuoO7A7SDtwOxA7CDsgOzg7EDtwO6g8FDzAPYw+cj84wAwBPAGQAnQC4AOABFgE0AUoBSgFIAVgBWgFSAVABRgE8ASQBJgEWAQoA8QD5AOsA3wCzAKAAnoB7gGcARgAh0AXP4k/Zj7cPr4+ED40Pfg9zj4oPh4+bD6TPzQ/UT/mQCyAQwDeASoBVgGwAYQB4AHqAe4B7gHoAc4B/gGwAZIBsAF6ARQBFwDXAL2AGv/yP0Q/JD62Pgw92D14POg8qDxwPAw8MDvgO+A7+DvAPBQ8GDwgPCw8HDwQPCg7+DuAO6A7UDtAO3A7ODsQO7A7wDy8PSo+Ej7dv5EA3gG0AngC6ANoBCAEmAUoBTAFIAUwBRgFeAU4BOgEqAS4BJAEqAR4BAgEKAP4A7QDdALEApQCEgHGAW4Auf/xP1g/AD7yPlQ+KD3MPew9yj4MPlI+kj78Pxm/hQAlgH0AjAESAXoBbgG+AY4BwgHCAdgB2AHYAcoBwgH2Ab4BtAGoAbwBUAFCATEAhoBRP8k/TD7WPlA92D1gPPg8eDwcPDA76DvYO+g78DvcPAw8cDxsPHw8RDyoPEQ8aDwwO/g7iDuQO2g7WDsYOxg7vDwsPTA9lD6xPzeAKgEsAggDNANoA4gEKASoBIAE0ASoBKgEqAS4BFgEaAQABFAEoASIBIgEQARwBAgEEAOYAwgCgAI8AV8A84AVP4Y/LD6gPlw+KD3sPcI+Ej5mPoo/LT9wP71/w4BcAKQA0gEkASoBLAE6AQIBSgFSAV4BcAFWAb4BjAHoAcgCIAIsAhQCKAHWAYIBSwDGgGc/vD7gPkw9zD1UPPA8YDw4O/g72DwoPDw8IDxEPLQ8lDzAPTg80DzkPLg8RDxQPDg7mDugO2g7IDrgOsA7MDsEPDQ8wD3APk4+4L/PAPQBpAJAAugDHANoA4AD6APIA+QD4AQwBCAEGAQgBCAEcASQBOgEyATgBLAEYAQ8A7QDIAK0Ac4BZgCEwD0/fD74PqA+vj5qPl4+fD5CPu0/LD+tv9hAKoAYgFMApwC8AIIAwQD3AI8A7ADMATABPgFUAdACMAIEAlQCZAJkAmgCcAImAfoBTAEYAIdADD+BPwA+tD3QPYA9QD0QPPA8sDyIPOQ82DzYPMg84DzwPPA81DzwPIA8nDxkPBA8EDvQO8A74Dv4O6A7WDtQO2A75Dx8PPQ9qD5IPvw/VgBmAQoB3AJgAoQDAANEA7wDkAP8A/gEEASQBJgEmAS4BIgFGAUwBTgE0ASQBEgECAOkAtwCTgHUAXEApsAtP5U/cD8rPyo/CD82PvY+7T8nP1W/hv/Yf+W/9//DABfAMgABAGaAUQCDAPwA5AEkAXQBvAHAAmgCZAJIAlACOgHcAdoBuAEXANAArUAJf9I/aj7GPr4+AD44PZw9RD0sPNg8xDzkPKg8mDyQPLw8YDy0PJw8tDyEPPQ8rDyAPJg8jDxUPFw8YDxgPHA7iDugO5A8BDygPSg9nj4GPt6/moBuAN4BtAIIAtwDBANgA0wDhAPQBBAEcARYBGgEWASwBNgFMAU4BRAFIATYBKgEDAOgAtgCSAH4AQ4AuP/RP4U/ej8+PzU/ED82Pts/Az9bP2M/cj9Ov6S/qD+XP5c/mr+0P7D/+EADAL4AigEsAVwB5AIMAmgCdAJUAlQCFAHKAYgBdwD0ALEARsAHP+w/Xz8CPv4+ej4UPcw9rD0QPRA8wDykPGQ8SDxwPBw8PDwsPBA8dDxkPJQ8kDyQPIQ86Dx0PHA8TDy0PGA7yDvAO6A7sDvUPOA9YD2APlY/GL/+gFwBCgHYAmQCgALMAzgDBANUA4AECARQBHAEWASoBOgFKAVYBYAFgAVABTgEXAP0AxQCnAICAbcA/QBaAAi/4T+Of86/yn/wP50/qj+WP4C/rz92P3M/Xj9oP3I/Qr+PP4S/6oAYAJMA4AE8AVYByAIYAjwCAAJEAgYB7gGwAUwBJADMAO4AhAC9wB4AHf/9P3A/LD78PmA9+D1IPWQ8wDyMPHw8BDxsPBg8bDxgPEA8gDz4PNw8wDzAPNw80DygPHA8DDx4PAg8LDwIO+g7SDukPCA80D1gPdQ+qz8LP6lAIwDeAX4BtgH0AmgCuAK0AuADeAPoBAgEiAT4BOAFGAVwBYgF+AWABWAE0ARwA4ADJAJqAfYBXAEOAPCAYcAwP/C/8b/kf8P/1L+LP1c/Gj7aPuQ+3j7RPw4/ZD9DP7a/kkA0AHwAlAEqAWgBlgG8AZIB5gHSAewBhgH2AZABqAFYAXQBIAE8APMA4QCCAH6/nz9yPsA+sD3cPYQ9SD0MPNg8hDyEPIw8tDyMPOw8jDygPKg88Dz8PJg8nDyMPOg8sDx8PFw8gDywPKw8jDxwO9A70DyEPSQ9sj4MPoc/Lj90wB0AxAFqAbwCEAK8ApgC/AMkA6wDwAR4BJgEyAToBMAFSAWgBWAFYAUQBKADwAN0ArACAgGEAWIBIADxgGBADoA0P9Q/2j/6v70/XT8IPvY+rj6+Pro+wz9Jv7m/oX/NQAKAVACrAPABOAEGAVwBdAF0AUgBlAG4AbQBpgGcAZoBqAFiARABPwDFAN4AS8Alv4A/eD6QPnw96D2YPWA9FD0MPNw8nDy8PLQ8lDyYPJA8gDyMPJA85DzIPOA8uDyMPPQ8rDx4PKg8xDzMPJA8ZDwoO8Q8fDzkPbA+Mj56PvQ/aL/JAKYBPAFAAewB1AJMArAClAMoA5gEKARgBLAEyAUwBTAFWAW4BUAFCAS4A9QDQAL0AigB5gGoAWoBLQDCAKUAOv/wP8e/9j9BPyg+uD5MPkA+dD5YPto/CD9Ev7i/in/eP9qAJoBDAJIAmACHAN4AzAEEAWwBVAGeAaABsAGWAYwBSAFsATUA7AC4AH3AFD/3P3E/MD7+Plg+JD30Pag9WD0YPRg9AD08PJw8xDzwPKg8rDyIPPA8pDyIPMw88DyIPIw8yDzIPMw8wDzkPKA8ADwQPHQ8mD0sPaw+Jj6yPvk/SAAMALAAxAFSAY4B0AIwAkADLANoA4gEIARwBLgE0AVYBbgFgAXIBYAFaASIBAADjAM4AqQCUAIiAd4BqAEaANYAv4B+wAd/2j9wPtY+ij5GPnw+Qj7+PvQ/Dj+Fv4A/rr+pf9g/8L/GQDOAJQB4gFcA+AEeAWQBZgGMAcoB3gGIAbwBRAFQAQgBJADYAIsAb4A6/9m/tj8mPvw+aj4kPcA9zD2wPQQ9MDzYPPQ8rDyEPOg8pDyYPJA8kDyoPGw8WDyoPJQ8rDyIPOA83DywPDA76DwYPGQ86D18Pbw9wD5oPt6/qj/ZAGkAoAEQAVABpAHkAogDBAO8A9AEWARYBEAE8AUoBYAF+AWwBYgFWASgBCADxAO8AygC+AKsAm4BygG2ASwA6ACegFaAET+oPsg+kj54PiY+fD6aPxE/Ej8nPzI/Dj8GPxk/aj9sP2o/eb+dQAEAWQCKARoBVgFOAVQBXAFIAUQBegEwAQIBDgEwARoBGADmAK6AVUA/P6c/OD7aPrA+MD3gPfw9jD1cPSQ9FD0QPOA8oDycPIQ8sDxYPGg8ZDwQPCw8UDyEPKg8IDwoPBA8BDwkPBg8lD08PXA95D4KPno+pT82P++AQgDYAMABSAG0AiwC0AOwA8gEOAQ4BCAEUAS4BRAF8AXABigF+AVwBJgEAAQwA4wDTALAAtACrgHiAVQBdgEOANwAWcAav4w+zj5KPnA+TD6OPuQ/KD8iPvY+pj6qPrA+gj7WPxo/Jj81P2E/7YA1gEUA6AEEAS8A4gDIAQgBFQDEARgBOAEgAR4BPgEMARwAmwBCAE4/3z90PuQ+0j6EPlY+Dj4cPdw9bD0UPQQ9CDzQPJg8lDygPHQ8NDwIPBA70DvEPBA8EDwQO9g78DvwO+A8NDxwPPw9PD1oPdo+OD5oPyE/6YBsAEUAvwDUAagCIALYA8AENAPABCgEYASQBOAFWAYwBkAGWAXwBWgE2ARQBFAEQAQMA6gDCAM4AnoBxgHUAaQBCwCqQBC/6z8IPsY+wD86Ptg+9j7ePvw+YD4ePhI+SD5ePlg+nj7aPtw++z8Yv5n/7b/ngCSAXYBWgFMAmgDwAOgAygEqATwBKgE8ATgBBAE2AIYAuIACwDw/mr+jP3E/AD8APsg+rj4cPdQ9jD2oPXw9ID0APTw8qDx4PCg8JDwwO8w8FDwEPAA78DuYO/A7zDwEPGw8pDzsPTA9eD30PmQ+9z9yv8iAbgBKANoBeAGUAqQDQAQgBDwD+ARIBOgFGAWYBjAGOAXwBaAFkAWQBUgFKAT4BIgEWAPoA1gDDAKAAmgCIgH6AXkA0QCtQDk/rD9+PyM/Kj70Pog+nD5sPhA+JD4+Phw+Dj4WPio+PD4aPmg+rj78PyU/bT+aP9t/6f/UAD5AHYBcAHMAlADdANkAzgEwAMMA8gBxgC3AIz/FP/i/vD+0P2Q/Ij7sPpw+QD4kPfA9gD2EPWA9ODzUPNw8hDyEPFQ8MDvQO8A74DuwO6g7zDw0PCw8VDysPIA83D00PUI+Dj6QPyA/j0AUAFQAvADWAX4BjAIsArwDuARABOgE+ASIBMgE2AUoBbAFwAYgBfgFkAWYBRgEwAToBJAEBAPkA1gDHALYAqwCRAICAa8A/gBHQBi/oj9eP0g/TT8uPtQ+kj5EPhg9xD3wPbg9hD3QPeA92D3QPhQ+aD5APpQ+qj62PoA+xD8CP06/pb+aP/Y/7f//f/Q/xIA///B/93/iv+W/3T/JP/8/l7+uP0A/dD7aPvQ+oj6sPnQ+Fj40Pcw90D2cPVw9BD0EPOw8sDyMPMQ89DyoPPQ8+DzgPMg9ID1gPZg91j4GPq4+9D80P52AM8APgG2ARgE+AX4B5AKQA3gDvAOYA4ADiAOkA8gEgAUoBXAFCAUABMgEmARwBGAEcAQoA+gDkAOMA2ADHAL8AqgCJgGKAWAA2wCJgEWAdsAsP/e/pj9nPzA+kj5APkA+Qj5CPkY+fD4OPjA9xj4gPiA+MD48Pjg+Jj4UPkQ+pj66Prw+lj7WPsI+5j7KPyc/IT8xPwk/RD9hPyU/MD8+PyA/Ej8fPxk/DD8kPtw+3j7APvY+rj6sPro+XD5OPlA+QD5+Pgw+Sj5uPhQ+Kj4APkw+VD5qPkQ+hj6IPqY+lj78PsY/WL+Cf/u/v7+V//jAOwBHAN4BFAF8AXgBWgGMAdACFAJIApACgAK0AmQCpALIAxgDDAMgAsACuAJQArwCtAKkAowCkAJ4AfYBoAGWAaoBQgFqATsAzADyAKMAvwBqADk/2f//v60/sb+Kf/k/jb+jP1Q/Rj9tPyc/KD8nPxI/Fj8YPxc/AT8wPuw+5j7YPs4+5D74Pvw+8D70PvY+8D7sPug+5D7iPu4+zD8cPx8/CD8EPz4++D78Pss/Ez8bPxQ/GD8fPyQ/HD8RPwQ/PD78Pvw+2T8nPzY/Jz8XPw0/Fj8wPwU/XD9jP3U/cz99P02/n7+2P7g/lf/x/9dALMA3ABgAdYBQAKMAsgCHANoA9wDeATwBEAFsAWwBXgFeAWQBSgGiAbABvgG8AaQBjgGMAY4BugFiAVoBZAFgAU4BfgEwASYBDAE8APAA5wDVAM8AzAD+ALAAnACWAIYAqABQAEYASoBBgG+AHkAhAAyANH/Sf9O/2H/YP9O/xT/6P6u/rz+vP6i/kr+PP4g/mz+KP4w/vz92P2c/Zj9wP2M/UT97PwU/RD9/PzY/MD8gPxI/Bz8+Pvo+5j7uPvY+8D7oPuo+6D7cPtA+3D7uPuY+1D7QPuo+wD88Pvo+wD8LPws/Dz8vPww/VT9eP20/fz9KP4a/p7+Uv/x/8r/kP+z/14AfAEgAigCrAG+ASwCBANsA7AD5AMIBBgEcATIBOgE6AQIBSgFQAUgBWAF+AXwBUgF6AQwBagFiAUoBegEGAUQBcAEoASYBFAE2AN0A6wDxAOsA2QD4AJIAqQBpgG2Ad4BZAHJAJEAmwBzAO//lv9R/3H/Pv/+/rz+pv5a/gD+6P3M/ZT9IP30/Aj9LP3k/Jz8ZPyE/IT8ePw8/Nj76Pvw+yz8IPzw++j7CPwY/BD8DPzA+9j78Ptc/Hz8ZPx4/Jz83PzI/PT8HP2g/Zj9oP3Y/VL+oP6M/rr+/P5c/3H/p//s/1wAVgBtAPcATAF6AVoBeAHQARQCFAJQAngC4AKIAmQCPALEAjgDaANUAzADOANgA6gDqANcAygDFANcA5ADiAM8A9wC/AIQA0ADJAPkApwCeAJ8AowCsAJoAjQCCAIIAtABnAGGAZQBcgEGAbgAgQBwAFkASgAtAPf/rP+H/4z/Xf8W/9r+vP7A/rL+fP4s/vD9xP3U/bT9vP2U/VT9KP0k/VD9XP00/fj85Pz4/Az9PP08/VT9NP00/SD9TP2I/bj95P3M/eT97P0E/vz9ZP6M/rT+YP5g/vb+Wv+N/yf/X/9n/63/Yv/H/+X///8mAEUAjwAcABMAjAASAcgA+v8PAKgAlAG8AXgBAgGWAJAAHAGUAQQCxgFKAbQAvQByASACGAJeAdYA5QAyAbQBFAIIAm4BqgCTACgBrgHIAUoB7gCQAH8AjQDiACgBIgG6AP3/nP+t/1EAvQBmAMD/Nv9N/5n/tP+w/3v/W/8l/+7+tP6i/rr+3P7k/rL+fP44/kr+Rv5+/pD+kP58/kL+Tv5c/sT++P4T/+b+yP7W/tb+If9d/7H/mv96/07/hf++/wcAKwAdAAIABABXAMcA5QCyAG0AQwCBAMQACgEUAeYAtwCaAN8AEgE8AQ4BygDKAOcALgEmARwB+gDuAPEA0QDrANgA9wDFALcAsQDoABQBAgG0AFAAOQBdAN8ACAHGABQAr/+7/2AAtwC+AAcAkP9w/+P/SgAvAOL/XP9J/zr/1/8RAA0AEf/U/hj/u//z/43/nv8d/+D+qv6P/0YA2P8d/6j+Af9Y/77/yf9R/+b+5P6A/6P/ov+u/87/fP+o/lP/ZwDqAMr/Mf9m/00AQgBXAFsApQD4/3v/yv+0ABoBiQAbAAkASwCBANoAQAH5AFEAzv+HAPIARAHeAMYAdgBwAEkAzQD3AOkAmQBgAFwAPwChAMwAvgCBAB0ASwAbAD8AJQBxADEAHgD2/04AKwD4/+7/AgA0AOT/BwD6/xUAyv/C/+r/CQDZ/6X/vf/Y/xwA///a/1X/EP9d//L/VAAtANr/gv9k/zn/df/G/7//rv+L/3z/df9r/4T/nf+N/1n/M/9d/6n/o/+Q/1f/gP95/3j/Pf+B/8n/+P/X/3n/Mf8R/4r/EgBYAAoAf/81/3T/FgClAOQAbADG/3L/5P+xAGgBIAEsAIr/tv/LAC4BVgHSAIEAQgADAHkA3gBQAcAAXQAWAHoApwDRAN4AnwBoAPf/PwCjABgBuwAjAMX/4/+KAKkAngD2/+L/5P93AIsAdQD0/6j/0P9ZAKUAWQD0/7H/9P8PABIAGwA3AB0Avv+m//f/fgBxADAApv+C/6r/OQB1AFAAtP84/33/IwCNAIoA6P8T/8L+b/+WACABiQCw/xr/Rf9z/yIAZQCAAP7/Z/9a/3H/5P/f/2EACQAPAKz/nf/u/yQAfAD+//7/pv8rAA4AAADu/xEANAAHAN//xf8nAEkAMQDp/+3/9f9UAEcALgD0/93/PQDHAJQAlf/u/nb/mwD5ADgAb/+B/9P/5//l/8n/sf+Z/4r/0f/o/8L/V/86/0//lf+5/63/wf+V/3X/NP+L/7n/2f94/0v/aP+e//j/+/82AL//mf9V/7//VQCXAGgAo/+h//L/tgCLAEcAz//8/1UAYQC5ADUADwDk/xcAiwBNAIAASgBmAO7/iv/G/zcATQAiAOf/2v8UAMH/+P8bAPT/Zf8G/6D/PgCdABwAxf9i/0T/dv8BADgAwf+R/6r/FQC4/4P/ov/S/7b/kP/K/zQA+f/G/67/IgBfABwATgDO/+n/iP8SAGgAqwAwALL/uP+a/9r/lf9xAKoAkgAv/4z+bv81AJAAk/+H/7v/7f9+/0//mf8kAPj/Vf8X/xf/rP/u/xoAzv+v/3n/jv8EABgA7v9+/63/EgDdAMQAMgDB/3D/TACmAPkAjQCUAIcA+P/v/2AAbAF0AVMAFQD9/3QASwDYAH4B4gDS/y//SADCAEoBnQBvAI//Tf/v/+IAagHBAIH/uv7Y/o0AbAEuAdr/Tv95/1X/zP9DAE4BEwAD/5b+ff9XAKwA9gA0ANr+xP2O/y4BBAHs/0H/+v/Z/5L/MgC7AJIApv62/qr/RgFWAcz/uv78/Xj/2f/VAEkAJgBR/2z+gP6M/zQBjwDf/5z+wP5V/5//kwBlAFEAjP5+/i7/yABKASIAef8O/5L/Rv+2ACABSAHL/+D+BAB2AN4AmQCkAO7/3f8ZADgB2ACfAJsAcACm//b+SwCGAXIBaQBcADkA7P/e/rP/RAH+APf/8P4OAJ4AmACc/5X/1v8SAGf/aP8wADYBjQAZ/xT+Mv+EAN8AMQDe/3j/DP9p/wwAGAFPAKH/Gv+o/xMA9P88AMgA6gBG/zj+VP4eAfIBTgGo/4j+bv4s/rsALALYAgAAjP24/TP/OgEqAaoBDABI/7L+wP/zAGgA9/8W/wYAnf+RACMAwQCT/5j+FP8AALYAwP+dAPL/2ACo/9D/JwCG/xL/oP+0AXABPAB8/tT+EgB+AAoBSgG4AHf/mv6K/04BAAJiAav/Cf+y/qP/BAGIAagBkv96/yv/qAA4AM//EwDA/8MACQBIAA0A/v4f/7//8gBhALr/R//Y/rj+Kv8oAZoBTACE/oj+qP7Q/wYBCAKeAOD9cP0IAGABsABMADQAtv8o/iL+wgBAAiYB+v7S/v3/1f8MABgA/wAoASH/3v4c/mcADAFoAdP/tv4W/97+N/9V/wgBdAGI/+T+FP7V/zD/BwAYAWQBaf/Q/bD+aADeAL4A0gADAPD+GP6d/+gAwgFuAc4A6f/U/dD+CAGwAtYBrv92ADr/9v/8/6QCiAJsAAH/Mv5OAVEA7gHOAYQBh//W/kgAvACuAQ0A2QD7/68A//9lAFoAhwCFALz/EwCB/48AaQAqAW0Akv+u/nb+fgGrAEIBbP9S/7L/xP7u/+v/uAH8/9b/hP2Q/oP/9AD2AET/Wv8z/8r+/P32//QBxAFu/jT8Ev6qARQC2wDe/7z9OP16/mQCdAIUAbz9cP0p/zf/iACeAXwCjv6c/LT9lAH0A7IBWf98/cT+d/8YAoACoALO/4D+kP4Z/3QCOAPwAlz+xP2Q/0wDfALo/8r/9v7x/4wANANMAoT/oPyM/mIBvAK+AagApP8U/az9e/8oBFwDKgEs/fD7NP40AbwDmgHCAZD9qP1W/j4B3AIwAA7+sP14A2QC4P74+7n/uAFcAcz/Kf8L/y3/j/+KATABVgCj/wz/sP0c/JEAMASIAqr/IP1I/uz9CP7VANgCKgEi/tT8Kv9SACkA5gB6AMX/nPwi/r7/AALmAP7/WP7Q/Gj/BgFMAg7+HP63/9oB3/80/c3/QgByASn/PQDQACgB9/+O/jsAlP/SAa8Asv+A/6MApwD8/54BegH3AMj9kv7c/8ABMgEmAY4Bqv/2/rj8Bv8wAGgCUAO+ATj9TPw/AP4BZAIQ/nP/0QBkADv/MP9sAqwBnv4c/Rj/jAI4AeT/F//W/24Atf9WAOQAhgFt/3D9XP7ZALwD4gHS/xz94P1AAGsASgFGALgAaP5Q/24AqwCy/3P/0P8k/yH/j//2Af4BFv84/QT/ZgA8AEgAQAFG/9D9XP4GAQADTP80/sz+LgFkAFz+sv48ASQCrv+i/pX/QwCK/37/Tv8+AQ8AnQCVAMr/zv6o/eYA+gFUAmf/fP5/AKL+kwCF/0gCGAPx/2r+mPxqAbQCWAK4/xj+cv98APACPgFNAGX/a/9mAMX/u/8DAKUA2gAnAF4BeP8+ANj9BP1EAOoBCAQTACH/sv4XAF7+BP1IAYAD0AKA/TD+rP7cAJX//AByAez9eP20/SAEvAMQ/6z8G/9VAFb+Yv66APAEZAF8/SD7C/8EApoBp/8A/k7+Lv+xACAC4f8c/VD+nP9CAR//MP0/ABYB8wDM/eT9GgDS/pP/QP6iAXX/sgHq/2z+QP38/OABAAPEA4j+ZP46/rL+YgFUAu4BuAHo/+L+IP5h/7wC3AIAAUj+tQBqAQsA0v7TAFQCDAB8/n7/2AGpAO7/LgAQApL/8P0W/o4AcgDb/zAEzAPoAAj6cPpkARAE7APU/fn/SwAq/t7+agEABBgAyPyY+ikA9AJIAvQBp/+g/oT8BP7o/5gBeALZ/xQAzP0w/nQAGAJaAVr/ZP2U/TQA1AKwARz+fv62//QB5/9g/nD9/QCTAG0AYAJ4Ao7+yPr4/aACzAPtADEA9/92/gj73v54BGgE6/8M/WYA0v4m/tD+QANYAyEAYv9U/7r/VP1RANAB3AJN/wUAHAEyAOj9vP7EAZwCugC0/pH/Kv8fAEkAFAOKAVH/4P2k/fj/FQCwArwBQAJA/pD9TP6J/4gBTgAEAZsAOAMhAPD84Ptn/9gEuALo/3D9xgArALz9lf9YAYwDdAAg/Wj+dgBRAC//rgA8AswBDP5Q/A//lAG4/4z/sAJQApj/mPk4/WgB9AIEAdYA9wAo/HT8BP70A+YB9P0g/of/5QDw/kQBqwBsAHz+4P4qAZMACgE6/1cAOwAmAXAAIv+AAWQBXwBU/Iz+CAPoBLABzP2S/pn/0QBf/0wBiAEsAtb/yP+2/17/ZP6v/+gDKAQoAKj6KP21APQC6AHYADYB6P3w/Dr+TAF4AWQC1AKY/1j7APusAdAFpAJk/JD9TP+YAF4AWgFYASz/AP+0/W7//P61/6wAegAlAIv/wgDB/87+zP2A/Ob+8gAgBEwCwACQ+2D8QP4l/ygCHAKiAez9iPzY/IQBlAOp/+r+WP78/QD+lwDEApwBD/9w/ekAYQCA/Uz/zABsAYD/tACGAdb/sPzA/AQCsAJ0AmgBFABg/+T80v4YAfwCDAKkACQByv6u/hL+SAEMAk4BtP4u/ywBuAFs/8z+9/84AWABLQBi/5T/DABb/1gCoANsAob+kPpw/HABMATABOQC6P+o+4D60P0IAxgFwgHuAIf/xP3o+0D93AKcAh4Bbv4KAJEAK/+o/sD+MQDF/yABQAK5AI7/mPs0/xAEUARcAAD8QPvB/7wCZAFIAvgCYwAY/Aj76PySARQDFAICAT0ATv64/QL/e/9Z/9z/AwBWAXgC3P7w/Ej+Pf9yAZoAwv/NAAoA9PwM/fIBMANMAjP/4P3Y/jP/NP5lAMABWAIMA3IAaP4Q+0D+XgAQA+QBSgBmATAAXP6Y/aABZwCSAKcALgFyASD/ef+lAIoBIP1c/6oBcAIzAAz9af+o/zYBYAHWAUIAzPzQ/kj/hP95/5QC7AP0ADj9XP0SATEANP0I/hwDKAQkAp7+VP2k/ej9iv9QAlAD4AJv/0D8WPxQ/lgC6AKMArz+oP18/d7+HgE4ASQCngCh/4D86PvA/g4BUAKvAGYBbgC8/tD7yPtO/rQAOAKgAkQDyP/0/Aj7CP7rANYBTAK9ADwAEP7k/d7/gAFQAvX/B/8A/lr/RABnADACTAIQAlL+Xv6M/V7/4v+hACwDUAMyAez8nv6+/tT/JwAQAyQD5wAy/sz9pgGAAQoBkP8fAPT+DADdAKgBfAI4ASEA6Pz0/Df/aANUA2YB/P9G/jD9BP4AAdgCIAJ6/lj/7v8b/2j+ff/3/5YAvQAcAhcAaP04/KT9kQBGAYQCyAGQ/9j7MP1SAFwBHQBiANQAQ/9W/nD+pAHyAW8AAP/s/iD+rv7m/3wCRgDC/mIASAJiARD9HP2w/IcAygD4A5gE2wCE/YD8AgBl/+L/sABIBFgCSv9c/mz/2QCZADIBEAK6AMD9WP3W/0QC5AO0AhkAxP2E/S7+/QCfAMAByALaAGL/Vv5k/SD+8P9oAtAEigGk/QD8iv6FAEYAlgEkA+wC1P3I/Fj9nACWAQwBfALWAQcAiPwY/7L/fAG2AJYBEgEQ/4r+xf8gAaMA7ABw/wUAoP1C/v3/kgHWAbYB+AC4/dj7NPz1ABQC9gHx//4AAwAq/zL+yv6MAM//kf/s/+wCzwAa/37+/AC8Ac0Akv5M/Vz+4P0kArAC4AMGAUT+MP2w++T9gP/AAmQC0AJKAdT+PP3s/XIANQCA/1D/fwAsAZoAKwDsAHD/Kv82/3X/Ov4g/WYA9APwBaYBbv7M/JD82Pwz/ygDoARsA+L+RP7s/of/D//K/3QAlABsABQCJALw/xX/Jf8OAbz+5v4lAOIBMgEG/+L/lgH2AF7/aP5k/TT9Z//sApQDQAFw/S7+av7c/fD9oQD4A1gCVACY/eT8iP2u/zgDDAKUAFz/nwCj/2T9yP5cAcgCOgDJ/6UA3//k/R7+lAEAAqz/Kv8uAB4BRf9X/7YA6QDt/y//1gCE//D9K/8UA0QD1wBi/qT+4v41/wH/cwCSAQwBTgEnAHD+JP0WAfIB0wC0/QX/FAJCAeT+1v58AoQBEP/I/iYAhABi/yIAqwCZ/6f/8wCoAjMA2P04/wwB4wBf/2IBdgFz/yT9Mv5cAswCaAJUAND+NPzI+xn/oALoA3QCTAEs/yz9oP2W/jQBlAG6Af3/cf+R/wEATgAF/7T+tv/f/9j+bv7i/xwBhgFT/zj+uPwq/ub+LQAUAg4BHgBY/nz+yP1M/pz/SgGMAm8A/v74/jUAc/8G/x0AAAE2AX4ATgH5APP/jP6o/yoBuQCTANMAngFWAB4AcABmAVYAmv6Q/i0ATgHkAUwCXAEaAGT90Py0/V4AKALkAuYBLADi/q7+Hf/e/ib/O/+9ALYB7AI0AQr/Jv6C/ggA/v+cAPEA6gAgAP3/AAFWASYAEP9E/lj+cv6vADwDJAPKAHT9iP22/vn/ugA4ATIBlQDW/1b/5P/m/9UAdgDA/3T/jABKATwAbv8K/3oAPwCA//z+RQC8AKEALwDm/nf/FP8VAB8ACgG/AJgAqP9a/ir/nv9AAWYBngFqAH7+4P22/tIBBAOEAXT/av6w/kf/kAB6AXQC7gE8AEr+9P2i/qL/iwCHAEABLAG6AHX/Mf8A/qz9fP5+AKACpgEDAFj+lP7i/nT/kAA3AMcAYQDj/0b/8v7w/y4BbgE+AAIA/f9k/0z/PQBMASgC8gBx/8D+cP4H/0sAvgG+ARQCGQBm/oj9tP27/8oB9AIYAnIAOP5M/YD9Lf8aAXACIAIoALT/tv4I/uj9Vf/jANwAvf9h/2H/7P4+/xr/5/+1/xn/zv5x//T/IQDhACgBugA1AIr+zP2O/h0AfAEwAnQCdAECAJT9QP3M/kQBGALuAVIBxv/u/i//0//bAAoBgwDe/2j/0/8CAJAACgAfANH/3P9y/2n/sP9k/zYADAAEATIAlv6g/QD+AwAmAdQBwADu/qT9Cv5s/6kABAHNAHYAK/+0/mn/AAGwAW8AJf+2/jf/OwA4AVgBtwD0/3n/XP+R/4//Tv8rABQBVAGkAET/gP66/gT/BgAuAWwBbwCj/xv/lv7Y/cT+YgHYAuwBmv/u/nX/Rv8N/27/nQBmASoBNgHBABEA7P7+/jUAlgFaAfj/W/+R/30ABgHeATgCJgES/9D9iv7x/6QBfAKcAvQBUgD2/ib+uv6k/7wAUgFAAVYB5gABABL/6P6U/0AAigBAAKMAkQChABoAxf8AABsAY/+0/kD/yv92ABYARQCfAIAAVf8C/lj9nP3I/j0ApAGoAbsAKf+k/fT8lP0+/xIAfQCPAMUA+f/E/mL+Gf/N/5D/Mf9g/ywAdwCrAO8A7AAgAPT+VP6S/nX/LwBCAYACZAJKAWz/VP7w/ZD9mv72ADQDfAPeAdr/VP6c/Uz9fP7F/+kAtAHgAVoBDgDQ/qb+Iv+M/8H/6v+cAAgBpAE0AZMAEwDY/5P/2v7o/un/oAEcAigChAGhAID/eP52/vb+XgBMARgC6AE+AT8AKP9a/vj9zP7h/+sAQgEyAbMAaf/O/rL+GP8//0//+v8bAOv/2v9NAE0Azf+8/iD+aP78/gIA6QAmAa0Avv8J/2j+iP4Z/73/BgA/AJYA0gBtAMX/bf9e/7f/1v9RALQA6QCzAFUA7v/u/8b/yv8yALgA5gBcADAAJgDQ/0P/VP9kAAYB+gBkAAcAn/8t/3T/7v+AAKgA3gCjADIA7v/4/xUA4f/k/3MAJgE2AfAApQBiAO7/hf+r/18A5wAEAZYAYQA1AAQA+/+8/xAAQgA5AB4A4P8tAE4AagBZACEAgP9K/5T/DQB9ALEA0wCHALP/tP6m/mT/NwDKAAIBxAD0/2n/Mf+k//n/1P81ACkAYgBTAEIAIQDH/6z/4f/7/7//uv/x/z4AYABpAJAAUwCm/zn/Ff9I/77/nQBYAVgBawBQ/8r+tv5G/6//OwCcAFQADgC1/8D/gP9D/x7/If+y/wEAJwApABUA3v+Z/4D/eP9r/0r/i//h/xgAmAC6AI4A7P8p/7L+xP5Z/ykADAFMAeYAJwCb/2f/Tv+B//j/fQDlAOYAbQASAAUA/f8OACUAQgBUAEoAPAB0AJIApQB0AGkAYAD8/7v/KwC1ACIBBgEmAf8AiAAvACMAoQDdAEABhgG4AbQBqgFQATQB1gDqAGIB1gHWAb4BugFWASwBIAFkAU4B4gCYALAA6ADlAMIApQCRAC0A2v+y/1X//v7e/hv/Zf94/wr/mv7w/Yz9ZP1o/cD9uP1s/Tj9JP3s/KD8iPx4/Cj8JPxM/Kz8GP3M/GT8HPz4+yj8mPwk/UD96Pxw/Dz8aPz0/HT9Cv7w/aj9hP2w/eT9MP5o/sL+XP/R//j/FgDh/6f/EgDgAIABOAKwAgADGAPkAvQCqAOIBPgEYAXoBZAGKAdIB5gHgAc4B5gHMAggCYAJ0AmQCVAJ4AhQCCAIIAgwCCAIEAjIB5AHoAZYBZAEUAQIBHAD+AJ8AtIBtgDP/y//hP5o/YD86PtY+5D6CPq4+Vj52PgY+HD30PYQ9qD1oPXQ9bD1sPVg9XD18PSQ9ED0QPSg9CD1sPXA9QD2sPUQ9iD2IPaQ9gD3sPfw95j4UPnw+UD6QPpg+tj6APuI+/j8Ev5w/3AAEgGkAcABlAHiAcAC2ASQBnAIkAlgCpAKUAowCvAKIAxQDdAOYBAAESAR4BCAEEAQQBCgEOAQgBFAEUAQcA9gDpAN0AzAC8AK0AnACKAHsAawBTAE2AJcAQgAmv5Y/Tz8cPvI+vj5iPmY+JD3oPbQ9RD1kPTA9ED1cPVw9UD1MPXA9LD0wPRw9ZD1APbA9hD3oPeg9+D3wPeg97D3CPig+Cj5uPm4+fD56Pkg+tD50PkY+jD6gPpA+sD68Pr4+pD62PoQ+3D7WPtQ+3j7wPqw+lD66Pow+4D7oPto/Nj8yPwc/ej8XP1U/RD+IgBgAnAECAVABSAEVAOAA2AFMAjgCnANEA7gDEAM0AswDIAMYA3gDmAQgBGAEQARQBDgDWAMcAzgDLANIA7gDdAMsAoQCeAHOAdoBqgFOAVoBGgDkALAAcYAI/+Y/cz8MPxY++D6UPoI+lj5IPnY+Ej4MPeQ9jD2APaA9vD2CPig+GD4MPgI+ND3oPcA+OD46Pn4+oj7RPwM/KD7SPto+7D7sPyU/UL+lv7W/rT+Sv70/dj9xP0E/oz+Dv9l/yb/fP7Q/VT97Pz0/Dj9IP1g/dT8dPwI/MD7kPvY+sD6QPpY+lD68Poo+7D7TPzQ/Ij9cP2k/Zz9KP6M/oL/bAIwBHgFOAUYBcgFYAUIBnAHsAmgCuALoAxADUANwAywDOAMcA2gDZAOAA/wDhAO8AwgDCALIAvwCrAKIAogCTAIUAd4BmgFmAR4A2ACzAEaAYoAd/9O/qj95Pwg/Ij7KPuQ+sj5OPno+HD5ePmg+XD5YPnQ+JD4qPiA+cj5OPqo+kD7KPso+yj7SPvg+8j7bPxM/cD9oP2A/WD9lP10/Xz9IP4k/g7+rP1Y/fj8yPyk/Kz8dPwY/LD7cPso+4j6YPoY+rD5IPnw+Kj4cPgI+ND3sPeQ9/D2kPZg9pD20Pag98j5mPvY/ED84Pu4+5j6MPsA/rIBmAXYBhAHqAbYBRgFyAXoB3AKoAzADkAQIBHgD9AOgA1gDfANMA8gEUASIBKgEDAPgA1ADKALEAvgCoAKMAoQCZAI6AZIBdwDhAKyAasAJADy/sz9JP2M/PD7cPuw+oj5aPgw99D2oPZg98D3aPhY+OD3gPfw9vD2APfQ9wD52PnQ+jD7GPvI+oj6APtw+2j8VP0A/nT+VP5k/oz+qP6k/qD+1P4c/4T/G/8B/9T+nv5E/uj9vP1g/fD8aPxI/Fj88PuA++D6cPrY+Vj5GPnQ+Kj4iPgg+Fj4cPfQ9gD3EPdg+Pj5wPug/Nj8IPwQ+6D68Pt+/kwC+ARIBqgG6AZABiAGkAYwCHAKUAyQDkAQoBFgEHAPYA6wDZAOcA+AESAS4BHgEFAPYA7QDDAMgAvgCgAKgAkwCTAIuAZQBfADdAJeAZ0A6//G/pT9CP14/Bz8kPvY+lj6EPnQ94D3kPcY+Fj42PhI+WD56Pho+AD4QPiw+KD54Prw+4D8QPxI/Pj78PtI/PD8GP5Y/gH/Bf90/y//4v7Q/rz+zP7O/gD/vv7S/kb+Ev7U/VD9/Pxg/PD7iPtg+0D74PqA+iD6ePkw+Xj4EPiw93D3UPdA91D3QPfg9nD2gPYg94j4WPpw/Cz90Pyo+/j6rPzM/YQAlAMABhgHgAdwB2gHQAfwB1AJgAsQDgAQwBHgEaAQMA+gDtAOIA9gEIARwBEgEQAQQA8gDoAMQAtgCuAJYAnQCEAIKAeYBTgExAKmAWkAd/+c/pD9vPwQ/MD7SPtA+mj5qPjQ9xD3sPaw9sD2IPew90j4cPgA+ID3cPeA9wj4EPmA+jj70PvY++j7yPvQ+1D89Pyw/Xb+Av9h/2r/Uv/m/rr+6P72/i3/MP8U/wv/Xv5c/sj91P00/XT8OPyA+3D7yPq4+mj68PlI+bj4cPgA+JD30PaA9lD2YPbA9nD2APbQ9XD2QPdQ+Jj6nPzU/CT8KPso+9j8Pv4uASgEaAaoBvAGiAd4ByAIAAiACcALMA4AEOAQQBFAEBAPYA6ADiAPQBDAEKAQIBBgD2AOAA3QC7AK0AngCJAIIAh4BxgGaARMAyACAAHJ/w3/9P3o/Bj8oPto+9D6CPqI+aD4CPgg91D3YPew9wj4mPgg+TD54PiI+KD40PiQ+Vj6qPuY/Cj9HP30/AT99PzM/dz9G/+v/14AiAATACAAj/9W/xv/Vf+2/+v/cP/s/mj+9P1g/eD8cPx0/Oj7QPuI+iD6CPqI+aD4kPjQ97D30PZw9rD2YPbw9UD14PVw9qD1EPXQ9VD32PgA+zD8FP3U/FD7QPus/DX/DAIgBSgHYAhwCEAIUAiQCEAJYAqwDCAPQBGAEoASQBHQD/AOwA6QD2AQgBGAEcAQ0A9wDgANkAugCqAJEAlACJgHuAZoBTAEFAMwAtwApv+I/lD9NPxw+9D60Pqg+ij6sPnY+Aj4IPfg9tD2EPfg96D4ePmQ+aD5WPkI+bD4OPlg+tD74Pxw/dj96P2w/Yj9tP0g/tD+dP9LAN8AxwBhABwAx/+T/0//iv/M/6L/X//k/nj+2P00/cj8bPwE/KD7cPvg+oj6wPlQ+ej4cPhI+OD3kPeQ9lD28PVQ9nD24PaA9nD1cPTg9CD3cPlI+4z8Gv7g/KD7iPuM/Ob+6QAIBAAH4AhQCRAJ4AhACCAIMAkADLAO4BAAEoASoBGgD4AOYA6QDuAOgA8AENAPAA/ADaAMMAugCYAIyAcAB0AGeAWQBKwDaAKOAZsAr/+Y/kD9LPxI+8j6uPoI+/j6yPpA+nj5kPjg99D3IPjA+GD5SPro+kj7IPvQ+qj6yPo4+0j8aP2G/hf/Df8M/8T+sv6m/vb+kP8bAGYAzwC2AIAA4v98/zD/P/8A/xn/4P6e/uj9WP3U/FD8JPyo+4D7qPog+qj5QPkI+Sj4wPhw+HD3UPcQ95D2UPYA9hD3UPew9gD2wPUQ9gD20PaI+JD6APwY/fD9wP2E/fj8mP1L/9QB+ASQB0AJYAnACOgH0AfACDAKUAzgDfAOwA/AD7APIA9ADpAN8AwADXANsA3ADfAM8AvQCnAJQAgoB0AGQAX4AxgDkAIYAoYBlACQ/3L+MP0s/CD7gPoo+gj6IPow+lD6+Pk4+Xj48PfA9xD4oPiQ+UD6wPrw+vD6CPv4+jj7oPto/Fz9Vv4A/0b/Jv8K/w3/QP+e/ywAtADYAN0A0wCSAEcA5v+z/6j/pv+d/3D/7v48/mT98PyI/Fj8UPwc/Nj7IPt4+hD6qPkg+QD5MPnA+CD4sPew96D3kPeQ94j4iPjg9hD3sPZA91D3QPg4+mz8zP0+/jj/5P7c/Tz99P48AegDOAYQCKAJUAlACCAIoAhQCUAKAAywDeAOMA8AD5AOkA2QDIAMsAzADLAMcAzQCwALEApgCdAIoAdYBigFOAQEA0wCIALEAfYALwCn/wj/xP1Y/Fj72Pp4+pD6SPvo+8D7APtg+tj5oPlw+dj5WPro+nj7OPzc/Cz9HP0A/dD84PxU/VT+gP8SADEAPABEABIA+v8ZAE0AYwBZAHAAsgClAEoA5v+m/2n/JP/4/sr+jv4W/nz9EP0A/dz8oPw4/Mj7cPvw+mj6IPow+gD6wPm4+cD5oPlA+QD5APno+Mj4qPjI+OD46Pj4+Pj4SPlY+XD6QPxc/Vz/5/+0/3b+Vv6x/y4B4AJ4BMAGEAggCNAHAAiQCBAIwAcgCfAKEAyADPAMsAxADOAKgAqACoAKIApACQAJ0AiwCDAIcAcoBiAF+AP8AkwC6AFoAZkA/f/D/6L/Jf8s/pT9uPz4+5D7SPu4+7j7ePuI+8j7APwA/Aj80PuY+4j7+PuI/Dj9yP0y/nb+gP6s/rL+3P7o/iP/o/8mAIQAywDHAIYAGwDg//v/FwBFAEEAFwDI/1r/Qf8U/+L+sv6A/kL+tP0k/aj8TPzg+6j72PsM/Pj7wPtI+6D6CPqY+Yj5oPm4+eD56Pmg+YD5sPmw+aj5WPl4+SD5cPhY+Aj5gPpA+3j8pP2+/kj/ov48/y3/cP8lAOABvAO4BfAGuAcQCKgHsAewB2AIsAiQCZAKUAvQCxAMUAzwCwALcArwCZAJ0AiACEAIIAioBwgHuAbYBaAEKANEAnIB5wCUADgA0/8+/7r+IP50/UT9+Px0/BT8wPvY+6D7cPu4+xj8ePx8/MD8yPxs/ND7mPu4+yD8wPyo/Zj+A/8A/8L+Zv4K/uj9MP6e/gz/e//s/w8A3v+x/5D/UP/m/rb+0P7e/uL+5P7i/tD+kv5+/m7+HP6k/Sj9xPxo/Ej8aPyg/Mj8wPyY/CT8iPv4+rj6ePpY+oD68Ppo+6j7mPt4+wj7ePoY+hD6mPo4+wD8zPxY/cT90P1K/uz+jP+7ANYBYAKsAkADEAQYBagFuAbAB2AIsAjACPAIAAnwCDAJwAlwCtAK0ArQCnAKkAngCIAIQAggCNAHcAfIBgAGKAVYBMQDNAPUAmgC8gFQAcwAGwBv/xT/wv60/nD+Tv4m/gT+rP1s/VT9aP2Q/YT9qP3M/Q7+Tv5e/n7+tP62/pD+hv6+/tb+8v76/kP/jP+w/3T/Pf8r/9T+kv54/pj+yP64/nb+NP74/bz9cP34/AD9PP08/TD99PwM/dT8YPxE/Jj8HP0Q/RT9HP1M/VT9DP1A/Tj9EP3U/Pj8UP2o/bj9FP4U/jj+2P3k/Tj9wPy0/MD8OP2M/Tj+lv6I/uT9oP0K/gT+NP58/vb+TP/B/5wAdAFgAuQCKANcA3ADsAPwA2gEqAQ4BfgF+AaAB9gHMAj4BzgHqAZgBkAGAAa4BeAFKAawBQgFWASwA8gCxgFsAX4BdgHhAHgABgCh/xn/hv5U/kr+KP4E/kb+Yv50/iT+1P0e/q7+9v4i/3r/0//r/9H/7v9hAKwAsQC5AOUADgHHAHYASgA0AOb/if+N/2n/7v48/oz9FP2U/AD8kPtI+/D6ePrg+XD5+PiY+Gj4gPiY+Ij4aPhQ+ED4ePio+Dj54Pl4+ij74PuA/Oz8YP24/W7+Iv8jAAgBvgF0AugCSANsA+ADKASYBPgEWAW4BdAFqAWABbgFoAWABZAFuAXABUAF2ATABHAE9AOIA5gD3ANYAyQDOAMYA+ACcAJcAkgC7gHoATwCeAJYAtAB6AHeAbIBngHIAeQB5AGaAcoBAAK0AXABcgGEAUwBGAEAAeYAcwAYAJn/gP9H/7r+nv4y/oT9DP28/LD8aPzo+8j7mPsw+8D6iPqA+gj6sPnA+dj5yPmI+Yj5qPlo+Uj5kPlI+sD6UPtA/Pz8TP1k/eT9VP6Y/vr+qv+aABgB7gHUApQD8AMoBKgE0ATABLAE8AQoBWgFCAbYBigH0AZIBoAFYAQ8A5wCdALoARABCABy/7r+GP64/Wj9EP04/FD7sPr4+TD5cPgA+Aj4cPiQ+VD6yPrQ+tj6kPpo+tj6gPtw/AD9yP3O/lj/o//2/5EAKAF2AQgCvAIUAwwDAAM8A4wD1AM4BLAEyAR4BBAEzAN8AyQD+AL4AvgC3AKgAjQCwAE4AeMA7wDaAOMA5wDdAJcANAD1//T/BgA5AIgA/QBgAXYBaAFiAVwBdgG+ATQCkALwAiwDWANsA1gDaAOAA5ADiAOEA5ADWAMAA5wCSAIUAsoBlAFcAQYBiQDf/y3/iP4O/rj9hP10/Uz9/PyY/CT8yPuA+3D7ePug+/j7QPyI/Lj81Pwk/ZD9AP6C/in/wP8xAIYA4gBWAdIBNAKYAvwCOAN0A5ADiAOQA6ADuAOcA4gDiAN8A0ADzAKAAngCOALMAZABVAEkAYcABgDa/53/Xv8M/wv/F//c/oj+ev5k/j7+DP4k/jD+PP42/kT+WP5i/mr+iv6q/tL+7v4A/xD/AP8L/yv/Lf8//07/c/+T/57/sv/F/7f/fv9U/0X/Yv8e/yb/N/82/0L/Pf9Q/1X/Kv/4/hr/L/8Y/xL/Iv86/1b/cf+5/9r/9v/R/wUAGQBSALUA4AAOAQgBCAEsAUYBOgFGAUQBQAEwATwBPgEaAfMA5wDcALwAqgDBAM4ApgBZAD0AKwA+ADMAVwBzAGoASABLAGEAUwAlAOb/6//6/wgAFAAgABgACADe/+H/7//m/8H/rf96/1//ZP8r/+7+2P6O/lr+Sv4o/gj+9P3M/Yz9bP1Q/Tj9IP0M/fz82PzE/ND8BP1A/Wz9dP2E/ZT9oP2g/bT9xP3g/RT+TP6S/sj+4v7s/vz+Cv8a/xL/I/9N/1f/a/+C/5j/xf/Z/9H/2f/7/xgAKAArAPf/yP/d/+f/RADRAJQBeALwAjADsAMoBIgE4AS4BYgGsAaIBiAGUAZYBiAGWAYIB9gHuAegB4AHCAcABuAEYAQgBMADMAPMAnQC0gHMAAsAeP8X/6b+Jv7g/Uz96PxU/PD7sPuY+9D78Ps8/ID8tPyU/Gj8aPzE/CD9PP2E/dT9Ev4i/nb+6P5H/23/fP+g/6v/o/98/2T/WP88/xb/If8q/wv/7P7e/rD+fv5w/pb+pP6W/pz+rv64/rr+wv78/jL/Ov9L/6j/+f8ZAF0ArwAKAVIBkgH8AUACgAKEAogCrAKwAsgC5AL0AuwC3ALoAuACwAKgAlQCCALIAYwBRAECAcEAfQBFABAA1/+2/4H/RP/+/rb+tP6a/mz+Uv42/jb+JP4m/jL+Tv5m/lT+aP60/tL+Af/w/vj+/v74/jL/af+7/8f/vP+Y/5r/kv90/2f/Tv8+/x//8P7M/q7+rP6c/n7+iP6Y/pL+gP6g/rj+sP6w/qT+3v4G/zb/WP9p/4z/qf/j/ygATwBoAGQAXQBoAGsAeAB+AHwAkQCiAMsAzgDHAKkAdgBzAFwAagCDAIcAfgBMACUAFwAZABkAGwAQABcAGAAOADEANAAzACsAFwAMAAkA+f/Z/8j/p/+c/17/R/9N/zb/Nv80/y7/Lv9n/2D/Kv8V/w//Dv/U/tD+6v4Q//T+vP7Y/vb+3v7O/vj+NP9w/53/q/+d/4z/gv+j/+L/8/8GAC0AQQAIAPv/EwAWAOj/3//2/xYA9v+D/3//lf91/2P/fv/b/xMA0//h/yYAbQBOAEAAcQDHALcAjgDBADQBhAF8AbYBKAJAAuYB6gHAAuADuAT4BGgFaAVwBJQDSAMcA3gCgAFgAQwB3QBpAHgALwCH/+T+tv6S/uj9WP3c/Ej8oPs4+6j7+Psw/FD87Pwk/Vj9nP0y/sz++P5X/+z/QgBpAEsAqwDWAEIBbAEcAlQCbAIgAugBrAF0ASQBAgHGAGQABwDb/5r/cP9V/5H/xP8JAFgAngCkAHAAKABQAGoAuwAIAaQB+gFgAoAC4AJMA6wD0AMIBGgEwASwBIgEgASQBHgEQAQ4BDgEAARsA/QCpAIgAlwBhgARAHz/tP7g/XD94PxU/Mj7gPuA+zD74PrA+rj6oPpo+lD6IPr4+cj56PlY+rD6CPtY+9D7MPy0/HT9CP5W/nj+rv7c/vD+G/9Z/67/BQBeAMQAHAEoARoBQgGGAcQB6AHoAboBgAEgAaMAPADB/4P/Nv/K/oT+Uv52/p7+vP7O/gr/Iv/i/gb/OP8r//D+xP7y/kn/Wv90/xMAiADLACABtgFkArQC7AJUA9QD7AMwBJAEyAS4BOAE6ATQBMgEsATYBAAFGAVABUAF4ARoBPQDkAMAA5QCbAIIApoBCgGlADkA2P9l/1L/Sv81//L+wv6c/g7+8P3Q/cT98P0Y/hj+KP4O/g7+NP42/l7+vv4F/z//Pf9R/1z/T/9Y/03/pf+E/zf/0P5q/hL+pP10/YD9YP34/JD8LPzQ+0D74Prw+gD7EPso+4j72Pu4+/D7NPys/DT9pP1i/rj+DP9A/4T/1f8gALoAWAHiASQCiALwAvQCJAMwA4QDUAP0AsQCaAIcAn4BNgHwAKEAUgBvAGkAwwAMAcQAzQC+AJABnAIsA2wDRAMIA4ACHAIoAuACnAMQBKgEYAXYBdAFuAWwBbgFmAUoBVgEiANYAgoBtf++/lj+0P10/Sz9RP00/cT8kPyM/KD8fPxw/Ij8iPwY/MD74Ps8/OT8fP0C/pz+IP+Q/wcAdgDBAOEA8QAKAUwBjgGOAWoBcgFwAXIBhgFeAUoB9gCeAEIA8P+8/2f/8P5i/uz9vP18/Uz9VP2k/eD9CP52/iX/b/99/9D/SgC1AOMAPgHgAUQCKAJYAvACWAN4A7ADKASIBEgEEARABCgEoAMQA7ACQAKEAd0AQgCt/8z+KP6Q/RT9tPxs/Dj84PuY+6j74PvA+6j70Psk/Cj8MPys/DT9fP14/cz9KP5i/kr+cv7k/jX/V/+L/wwARQB+ALwANgGEAYwBoAHEAcIBuAGGAXoBTAH9AOMA+gAuAQ4BOAFyAYABWgFGAWwBRgHeAJsAkwCEAAAAoP+r/77/l/9R/5z/3P+q/33/kv+n/0z//v7w/tb+lv5O/lr+Pv4C/uz9Pv5W/iL+8P0u/kL+IP4M/j7+Kv6s/Sz9HP3M/BT8YPv4+vD6oPpw+nj6oPo4+uj5CPqA+uj6CPtQ+7j76PuM/Cj9yP1O/qT+AP+H/xMAgQDyAHgBxgHqAXgCwAKkAnAC2AI0A0wDeAMQBJgEuASIBLgEuARgBOwDqAPEA0QD5ALoAiADOAN8A0gE4AQ4BXAFGAbIBZgFkAXgBrAHWAdwB+AGAAZoBDADTAOAA8QCIAK8AgwDiAIsAmQCxAJ8AgACDAIUAvIAJP9s/vD9KP3k/ET9Ev5k/p7+iv9+ABgBtgFwAgADCAPAAsQClALeATYBGgHnAIkALgAqAAYA4P/P/6H/bf+m/gD+nP0Y/UD8WPv4+mj6+PnI+UD6sPro+gj7mPt0/Lj84PxE/Zj93P2g/Tj9EP2k/BT8wPvw+wD8MPw0/AT8XPys/BT9xPy8/AD9ZP0k/RT9UP1A/QD9nPxE/Rz+VP4o/nz+Ov/C/w0AmgBCAZIBjAEwAUYBQgHzAG0AYABeAIoApADbADoBagHEARwCrAIoA3wDaANEA8gClAI8AvAB6gEAAlACTAIcAnwChALMAswCUAOkA4QDfANQAygDzALIArACuAJoAvoBxgG0AZgBlgHWATwCbAJsAmwCYAKEAjwCFALoAcIBeAEYAfYA8ADaAJgAvQD1ADwBNAEeAfwAcgAIAKf/EP9S/nz9xPzg+yj7uPpY+uD5SPkQ+bj4UPjQ9zD3wPbg9fD0cPQw9NDzcPMw82Dz4POQ9MD1cPdI+Rj74Px8/jQA1AFEA3AEmAVQBgAHUAdIB2AH+AaIBmAFmAQoBNADfANYA6QDrAOYA0QDRAMEAzwCygGyAbIBGgHTAMYAvQDCAOIAegEEAmwCQAMIBOgEmAUoBsAG2AYQB0gHYAf4BjgG2AVYBaAEIATwA/QDpAMIA9QCqAJoAiACBAIYAvQBhAHkAGUA3v9Q/z//TP9P/zj/Vv90/9v/GgC0AFABqAG6AaQBsAGYAUoB/gD7AK8APgC//1j/Gf/4/uL+qv6C/mL+Mv40/tT9eP0g/bD8RPz4+5D7cPvY+kj66PnA+cj5SPnY+KD4IPhw9yD3UPeg97D3kPew90j4qPho+ZD6SPtU/Dj9Xv6r/9wA0AFAAtQCEAN4A5wDiAP4AswC8AK0AtQCNAO4A7gDtAO8A1gDgAM8AwAD5AJQAgQCgAFKASYBSgF0AbQBFAKEAnADIATABIAFOAagBnAGKAbIBYgF+ARIBOADpANIA8wC7AJEAzgDKAOAA4wD1APAA3QDQAOAAtABcgEuARIBpwCSAJQAUwD7/xYAgwBoAHwA7AASAacAagA5ALQAiQCMAGkAjwBHAND/xf+x/3r/6P4V/0L/3v5q/tD93Pzg++D6cPpI+sD5UPko+fj4wPhQ+ED48Pfw9vD1YPWg9KDz0PJQ8mDyoPIQ8/Dz8PTw9SD3EPmg+2z+CAGkA0gF6AUQBjAGUAYgBhgGuAUoBawDYAJEAgwCkgGYARQCAAN4A5gDGASwBCgEpANEAwgD7AHOAMH/R//e/lT+1P7//y4BaAIoBEAG2AfACGAJ4AnQCWAJoAiwB7AGeAUABEgDhALEAZYBsgFkAsACTAOUA4gDYAMYA8wChAKAAuoBNAFQAO3/vP+D/5H/EwC2APAAXAG6ATQCRAIUAmgCyALAAlAC5gFyAaEA+f9A/1b+8P2c/bT9sP04/fD8gPwg/PD7sPsg+9D6uPkA+cj4ePiw9+D2YPbA9RD1IPTA82DzEPOg8gDzIPTA9ID1cPYw+Aj6MPwu/tsAlAJoA4AE6ATABSgGcAZ4BlAGGAaABbAEWASgA4QDBAP0AhwDwAPYA4QDcANQA5QDFAOQAvgBdAG5AMH/yf8pAGcAtgCYAfwC5AN4BDgFSAbABngGcAawBmAG0AVwBYAFcAUoBegE2ATgBKAEcASABFAEEATIA5wDcANIAwgDhAIIAuYByAGoAWoBMAEsAVYBMAE+AQABFgEIAc8ACgHzAPwAlwB8AJcATwDa/1z/L/9w/tD9AP3A/Ez8iPvw+qD6WPqY+TD5sPgg+FD3oPYQ9tD1QPWQ9DD0gPMQ80DyoPHg8IDw4O9A8PDwYPLA9ED3GPp4/GD+AQCCAVwDeAVwB1AIIAioBxAHIAYoBdAEyARIAzAC3AEoAhgCrAH+AcACVANUAzgDXAPgAhAC0gG+ARYBWAAUAGUAXgCtALIB4AL8AwAFgAb4B4AIwAgQCXAJIAkgCJAHGAcoBjgFeARYBLwDMAPgAsQCpAKcAjQDnAOwA1gDQAM0A7ACJAIIAhAC0AF0AVABNgH5AJQA1wAyAWwBwgEsAkwCbAIoAv4BwAGOAUwBrQDb/+b+8P0k/YD86Ptw+wj7mPrY+Uj5uPg4+LD3oPZQ9pD1kPRg83Dy4PGw8ADwYO8g74DugO6A7mDvwPAg83D2kPmI/LT+AgGAAgQDuARABngHAAcQBigGeAXsA8ACvAJ4AjACegGuASACHAIsAiQDeATABOAEqATgBGAEcAPAAgQC0gGSAVIBSAFmAfQBEANYBIgFGAdwCDAJwAlACrAKkAqwCUAJsAjAB3gGaAXgBFgEiAOwAuQCGANIA5QDUAT4BEgFCAVYBSgFuAQIBOQDaAO0AuwBQgE6AbEAUgCLADwBZAGYAfQBdAKcAlwCkAKkAmACgAG7AN3/1v58/XD8iPuo+uj5KPnA+BD4gPcg96D2EPaA9QD1kPSQ87DyoPEQ8cDvoO6g7UDt4Owg7ODsIO+Q8mD1ePh0/PL+MQAQAmAEkAfwCHAIUAhACCgHkAV4BMQDFAMsApQB9AHYAYwBPAH+ASQD3AM4BIgEsARABNgDOAPgArgCUALGAVQBpgGSASgC3ALQA1AF6AYwCPAI8AmgCqAKwAqwCgAKIAkACPgGKAYoBWAEIAOQAhQCVAJkAnQCAANYA7gDyAPgA0gEMAQABPwD4ANoA3QC6gFuAQgBvACCANEA3wDgACoBqgEIAhwCIAIIAjACfAGiAMD/9v7k/Zj8oPuo+sD5qPgA+LD3EPdQ9pD1MPXg9ID08PMQ8xDyQPHg74DvgO5g7QDtIOzg64DsgO5g8cD0EPhQ+4D9m/+uAZgECAcQCBAIoAiQCBAIuAbABVgFYAQ8A4wCAANMArQBngHmAegCBAO4AzgEQAQgBIgDWAMQA7QCPAIQAqYBaAF8AfQBeAJYA+gEYAZQB1AIYAlQCqAK8AowCyALgApwCcAIMAgYB/gF+ASABAgEjAOIA+wDOARwBDgEiASwBNgE2ASwBKAEKAS8AyADbAKcAQgBAgGiAJwAjAD5AE4BjgH0AVQCeAJMAkgCvAE8AToACv/4/bT8iPtY+pD54Pgw+LD3APcw9tD1QPUg9aD00PMQ8yDy0PCA74DuoO2g7IDr4OpA62DsYO7Q8aD14Pgg+wD99QDQAxAGAAiwCTAKwAkACXAIIAeoBYgEsANMAygChgG4AbYBwgEwAngD7AMIBFAEuASIBNQDOAMkA9wCMAK4AX4BmAGKAewB4AIgBIgFqAYACAAJ4AmwCkALgAswC9AKQApQCTAIIAcoBjgFEAQ4A9wCuAKwAgQDgAMABCgEUATQBBgFEAUoBdAEuAQABFQDdALWAWgBDAHlAAQBIAFEAXwBvgHsARACTAIsAtoBRAGQAL7/Zv6I/WD8cPtw+nj5APkQ+GD3cPYw9lD14PRA9LDz0PJQ8aDwoO9A7sDswOvg6yDrAOog6mDs4O+g8mD1gPmk/Jj+JAH0AwgHMAiQCMAIUAkACPAF0AS8A0gDzAECAasAZwBiAHwAXAF8AnwDIATwBBgFIAUIBVAEjAMYA6QC1AHgAHYAnAB7AP0ABALEA1AFQAagBxAJcAoQC5ALEAwADGALkArACcAIIAfgBZgE6AOkAlACcAKkAhADYAMwBOAEYAVgBfgFOAYYBoAFyAQoBCwDGAJgAQwBkACPAEwAwgDoAE4BxgHUAYACWAJkAuYBIAErAFb/QP7k/Ij7iPrA+eD4oPcA9zD2kPWw9AD0APSA80DyUPHA8EDwQO6A7GDswOsg6wDqQOqA7KDvIPKA9TD5iPsQ/sYA+AP4BnAIcAmwCRAKAAmYB1AGeAUoBAgDTAJ4ASgBiwCVANkArAHwApwDWASYBKAEqAT4BGAEOATUAzADeAIQArYBfAEMAowCuAPoBFAGaAcwCKAJcAqQC6ALoAugCyAL8AnQCMgHmAYQBYgDyAJoAgQCngHGAXAC7AI4A6gDsAQgBVAFWAWYBSAFWASYAwwDoAL8AZABPAEQAeAAEgFiAXoBZgF0AZ4BcgHWAD0AsP/8/gb+9PwM/CD7KPpg+bD4wPeA9pD18PRA9EDzkPKg8bDwoO+g7uDtoOxA7IDrYOvA6gDrAO0Q8NDy8PXw+PD7av7pALADkAaACIAIgAngCQAJIAgYB1AG8ATkAyADoALWAQAB6AAoAYgB5AHsAogDnANMA2QD6AO8AywDSAM8A6QC/AHOARQCbALcAswDKAUwBtAGEAggCTAKAAuwC0AMQAygC/AKAAoQCaAHWAYgBQgEOAPEApwCgAKQAgQDtAMYBFgE2AQoBTAF2ATIBKgEyAP8AnACRAKEAR4BHAFgAWYBOAE8AWgBWAEEAf0A4gBGAHv/mv6s/bT8aPuA+uj5MPkA+OD2kPXA9PDzMPNA8iDxIPBA74DuAO0g7EDroOrg6eDowOlg6yDtwO+Q86D2KPlI+1z+7AGoBHgGyAcgCUAJwAhQCOAH4AZABXAEyAPgAtABQgHlAMgAiwA6Af4BZAK4AnwC+AJIAxADCAMcA9gCpAJQAugBugEAAvACYANwBJgFaAaAB3AIoAmACmALwAsQDOALQAtgCgAJYAgIB4AFWASUAygDYAIoAmQCwAI0A0wD+APwBBAFOAVgBXgFUAXQBFAE1ANkA3wCPAIcAgACpgF0AYYBKAHhAOUA8gCVADgA2v9W/6L+kP3Q/DD8UPv4+Uj5WPjg9vD1oPQQ9ADzcPFQ8ADvQO5A7cDsYOuA6sDpQOnA6eDqQO3g78DycPWY+FD7Iv5gALgDQAaIByAIIAiwCLAI2AdABxAGYAXMA9gCiAIIApIBLgHIAcQBsALMAvgCJANwA5ADoAO8A0ADzAKQAiACEAIsAnQCuAJcA1AEMAUwBvAGMAhwCYAKUAvAC0AMYAwADEALIAoQCegHwAaQBZAEEAQABKwDAAQgBEgEwAToBEAF4AUABggGcAVABeAESARkA0gDOAPkAigCFAIwAjwCtgFsAeQBfAEMAcIAPgD1/xT/Kv54/ej8APyQ+gD6KPlY+FD34PUw9TD08PKA8UDw4O+A7iDtoOzA60DqoOhA6IDpgOuA7eDvcPJQ9QD4wPpo/lwBEATgBbAHUAnwCKAIoAiQCDAIOAeQBVgEaANYAgQCsgG8AaoBoAEoAkwC7AIAA4gDAAToA+wDoANsA4gCTALgAUQCbAKAAjADhANoBEAFkAaoB9AIgAlgCvAKsAvgC0ALsArgCQAJqAcwBgAFcASgA6wC7AIgA/QCOAKMAnQD2AMQBOgDiASYBEAEYANgAywD2AKgArACwAL6AUABhAGEASoBwQBHAGEA2P80/6L+Rv4A/jT9OPwU/OD6CPrY+Dj4cPcw9uD0IPTg8jDxwO+A7iDugO1g7ADrgOmg6MDoIOpA7ADuAPCQ88D1mPjA+4j+0gHsA2gGmAdwCNAI4AjwCMAIcAh4B3AG2AQYBBwDjAJgAhgCYAI4ArAB8gEsApgCGAMYA3ADXAMcA7gCNAIoAlwCDAKMAhADhAPcA0AESAXQBuAH4AjACdAKcAvQC1AMAAxAC0AKkAmQCHAHEAZIBfgEkAQYBNQDvAPQA4gDZAP0A0gEKARIBBgEMASYA0wD+AJIA3ADEAOsArwCnAIUAsoBtAG+ATwB+ABWAOP/Mv9q/hr+cP0Q/Qj8YPu4+rD5OPnw99D2oPWg9DDzQPGg74DuAO4A7eDqoOmA6KDnYOhg6uDswO7w8MDzoPbY+dD8xv/QAvgEyAYgCMAIAAnwCGAJUAlwCBAHIAYYBTgEQAMEA7wClAJgAiQCaAIoAmAC4AIgA4QDcANUA1gD9AIwAoACzALsAjADoANABPgEkAVgBtAHsAhgCSAKAAuAC4ALUAtQC+AKwAmQCLAHiAawBeAEqAQgBNwDkANwA4gD/AMIBAgEcARYBGgEiAR4BAgE5AO0A2QDQAP8AswCMAIAAqgBUgEKAaEARwAVACgAW/8h/zj+5P3A/Xz9mPxw+9D6GPo4+dD3wPUA9TDzMPHA74DuoO0g7EDqAOlA6ODmgOdA6cDroO2g7zDyQPVQ+DD7gP4yAXADkAT4BWAHmAeAB3gHqAcIBygGAAVABKwD1AKgAnwCdAJIAjACXAKQAmQCwAJAAzgD+AK4ApACYAI8AhgCFAIgAlgCvAJcA+QD4ARYBfgG6AeQCEAJcAqgChALcAsAC8AKgAlwCLAHMAcwBtAFgAUwBfAEYASgBLAE2AToBCgF2ASgBIAEgARQBEgEGASsA0AD5AKsApwCQALAAYQBNgG8AB0ADwBz/wD/UP4u/sj94Pwo/AD8nPzA+7j6ePkA+dD4QPcA9RD0UPKw8MDvwO5A7QDrwOgA6ODnIOgA6eDqQO2g70DxcPTA9zj7Jv4WAVADQAWQBigHUAjACKAIMAjoBxAH6AUIBdQDsAMoA4ACKAJAAlwCkAKsAvwCKANwA/gD1AO8A1QD2AKYAmwCuAJMAowCmAIoA6wDYASABXgGoAcgCBAJ8AnQCiALUAuACyALgApACVAIUAf4BngG0AUYBUAE7APcAwgECAQYBOgDIATgA/ADCATcA7ADiAOkA1gD5AKYAmQCLAK6ASYBkgAyALT/Bv+y/jz+hP1o/QT9HP2Y/AD8gPto++j6QPpg+QD4APfw9XD0IPIQ8cDvwO6A7eDrAOog6QDoAOig6aDrYO1g7xDygPQg+KD66P1oAYQDKAVwBvgH4AhQCUAJEAnACNgHMAcwBlAF/ANYAxQDBAPgAmgCeAJgAogC8AIYAywDOANoAwgDcAI8AjwCLAJQAjwCtAL8AhwDpAOwBNgFuAZ4B7AIkAlwCuAKcAvgC3AL4AogCsAJAAkwCHAHKAeYBsgFgAXoBIgE9APcA9wDxAN4AzgDpAMgA+QC4AIYAxADMAPsAtwClALcAawBcgHIACQAxv9B//L+0P1A/Qj96Pys/Dj8wPtY+/j6aPqw+aj4kPdg9uD04PIQ8YDvgO5A7SDrwOkA6MDm4Oag6KDqwOyg7iDxQPRw94j6mP3hADAD+ATIBuAH0AjQCDAJUAmQCMAHyAb4BbAEZAMAA6ACWAIUAqwB0gHcAa4B3AFgApwCwALYApgCGALCAfIB0AEgAoQCrAIQA1ADEASoBJgFkAaIB7AIIAnACRAK4ArgCoAKQArwCZAJYAigBzAHgAYoBjAF0ASQBMQDXAM8AyAD7AKQAnwCfAKQAkACJAI0AoACWAJgAmQC9AFeARQB8gBoAAgAk/8T/3z+AP6g/aT9PP2U/Lj8ZPyA+8D6qPlA+Vj4wPZg9VDzkPHA7+DuQO3g6yDqIOhA58DmgOcA6SDrQO0A8KDyYPUg+AD8V//GAZwD8AS4BrAH6AdgCDAIcAhQB6AGGAYQBSAELANcA9ACQAO8AogCoAKoArgC2AJoA2QDOAP4AoACXAL6AfQB7gFEArgC+AJkA5QDiARgBWgGeAdQCHAJMArACgALAAsAC8AKkArwCTAJgAgwCJgHuAcoB7AGYAagBRAFAAXABKgEIAQYBBAE1ANIA1wDZANcAxQDKAMYA/gCTALAAe4BHAGCAAoAm/8m/3j++P1o/VT9xPwU/Az8cPsI+wj6EPlo+AD3gPWw8yDyEPEg70DtIOzg6iDpYOeg5kDnoOiA6qDsAO+Q8RD0IPcA+/j9/wCgAuAE+AZ4BzAIoAgACQAJoAhgB2gGgAWABPgDaANIA4wC6AHYAaABUAIkApAC6AIAA2ADMAMoA4QChAJUAtACDAMwA3QDYAMIBKAEmAU4BgAH6AfwCJAJcArACqAKsAqgCoAKAApgCbAIUAjQB+AG4AaYBtgFuASABJAESAQQBMgD5AOoA1gD1AJAA0wDRANAA1ADXANsAs4BogFOAbQA4v8v/+r+Iv6U/Rz94Pzo/GT8yPsU/Dj76PrY+UD5aPjg9lD1APSQ8sDwIO+A7aDsgOsA6qDooOcA6GDpQOug7YDv4PFg9QD4ePuU/joBvAMoBVAHAAjQCGAJgAmgCQAJUAg4B0gG+ASQBNQDVAPcAhACKALMAaABDAJIArwC1AK0AvwC3ALgAsAC1AIQA2ADFAOcAwgEcATgBFAFMAYQB+AHoAhgCYAKwAoQC4ALQAvAClAKEAqwCRAJUAjwB6gHCAcQBlgF4ASIBOwDiAO0A3ADuAKYApQC/AL4AgADzALoAsgCHAKaAWYB8AASAGn/5v5a/nD91Pwg/BT82PtA+xj7uPqI+uD5gPm4+JD3oPbQ9JDz0PFQ8KDuIO0A7MDqYOkA6ODmwOdg6WDroO0A8LDyMPWY+Aj88P6UAaQDuAUoB/gH0AiQCZAJgAnQCCAIAAe4BZgESAScA7QC6AG4AVwBQAEmAUgB8gHgAVwCwAKkAugCuAIoA0wDNAMsA9gDSASIBNgEWAXgBWgG6AaoB8AIEAlQCeAJUApgChAKoAmACUAJYAgACLgHMAeoBsAFSAWQBCAEyANcAxADAANYAgwCFALCASgCEAL8AZgBYgFQAawAbwAnANr/C/9+/hr+kP0c/UT8EPzY+8j7APsA+8D6UPrQ+fj4EPjQ9rD1UPSw8gDxIO9g7sDsoOtA6sDoYOhA6CDpYOvA7WDv0PFw9KD3kPq4/aAAqAJ4BPAFUAdgCAAJIAlgCWAJcAh4B6AG+AUQBVAE7AMoA6wCHAJAAkwCOAJMAnwC4AL8AsAC/AI0AwwDPANMA7AD7AM4BNAEOAWIBdAFaAboBsgHoAjQCMAJ0AkACnAK0AoACgAKwAlgCUAJgAhACAAImAewBgAGYAXoBHAE8APMAzQDsAKMAlQCSAI0AiwC6gF2AVABGAGwACcA1f+H/wD/Rv7I/Vz91PwU/Ij7kPsA+4j6MPoo+uD5GPkw+HD3cPbg9HDzwPGA8CDvoO1g7GDroOmA6IDoQOlA6+DsIO+w8TDzcPZw+bD8Tf+aATwDoAUIBxAI4AigCdAJsAkwCSAIKAdgBmAFqAT8AwgDhAIQAs4BLALkASACdALUAhQD+AL4AngDuAOwA6QD0AOYBOAE8ARgBYgF0AUgBsAGgAcQCEAIcAhACYAJYAlwCaAJkAnwCMAIkAhQCNgHiAcwB2AGcAUIBbAEmATwA3wDOAO8AnACPAKAAoACTALCAb4BYAHtAG8A7f/I/yT/WP4A/oj9yPxI/AD8oPtA+wD7cPqo+lD6sPlw+XD4oPeA9oD1QPSg8lDx4O/A7mDt4OvA6mDpgOnA6gDswO1A75DxsPPQ9kj5VPwI/zIBIAMABfAGsAfwCHAJEAowChAJgAjYBygH0AWIBCAEOAN8ApIBfgGKAagBqAEMAnQCdAKAAsgCRANQA3gD3AP4A5AECAVwBXgFgAXwBWgGuAYIB4gHQAhgCJAIAAlACWAJMAkgCXAJ4AiwCHAIcAgQCAAHkAbABWgFwAQgBMwDaAOwAhQCUALcAfYBnAGoAWAB1wB4ACsA8f9L/9z+jv4q/rD9BP18/Dz8uPtI+/D6mPog+gj60Pkw+cD40Pcg9wD2sPRw8/DxsPCg72DuQO2g6wDqYOmA6aDqAOzA7YDvsPHg81D24PlI/L7+uQAIA/gEWAawB4AIMAmACZAJMAlgCEgHqAYgBggFGAQIA4wC8gFSAWABmAGuAZ4B6AGIAnQCoALsAnADAAQgBKgEWAW4BRgGOAawBsgG4AZQB8gHEAjoByAIgAjACMAIcAiACIAIEAjoB/AH0AdgB+gGcAb4BXAF2ATQBIgE3AOAA9wCxAJ4AmwCDAK+AZIBGgGqADkAzv8w/wj/pv4a/qD9SP0E/aT8QPwQ/Oj7iPtY+yj7+PqQ+tD5OPlw+JD3APbw9HDzIPLg8KDvYO7A7IDrYOpg6iDrQOxA7kDvMPGA8wD2KPlY+xT+fgBcAvgDIAaAB6AIEAmwCfAJwAkwCVAIuAfgBigGEAV4BIgDlAJwAnQCcAI8AlQCvALUAgADIAOUA9gDMASgBDAF4AUYBlAG2Ab4BggHMAeQB9gHAAhACGAIoAigCMAI4AjQCLAIkAhwCNAIQAggCBAIuAewBqgGIAbYBXgFmARgBNwDUAOYAmQCKAKIAcgATADx/zr/qP46/g7+nP1s/Qz92Pxw/Dz8DPzA+5j7SPsw+/j6sPpg+tD5CPkQ+CD3IPZg9EDz4PHA8MDvQO7g7ODr4OqA6kDrYOwA7oDvwPDw8oD1sPd4+uj8If8aAcAC+ASQBoAHgAjQCHAJcAkQCYAIUAhAB5AG8AUoBSgENAPgAoQCrAJUAhgCLAJMApwC6AIYA1ADCASIBHAF6AVoBqgG4AYYB0gHeAeoB9gHMAiACDAIIAhQCHAIkAhQCCAIEAhQCAAI0AfgB1gH8AaoBlgG6AV4BWAFyARABKgDEAPMAjwCwAFOAY8AEQBY//T+dP7A/WD9CP3Y/Gj8EPyg+7D7WPsg+/j64Pro+lD6KPoI+nj5oPiw9wD3wPWw9GDzEPJA8cDvgO6A7YDsAOzA6+DsIO5A77DwUPJQ9ID2yPg4+zD96v7PAEQCWATIBfgGeAcgCFAI4AjACEAIsAcYB7gG2AVYBTAEzAOAA/QC/AJ0AjAC7AH+AYwCVAKIAsQCkANYBNgEgAUABmAGwAYAB2gHuAfoBzAIgAhgCHAIYAhwCEAIIAggCOAH4AewB8AHsAcwB/AGsAZoBiAGuAVgBTAFcATsA1wDDANkApIBOAE/AKr/vv7w/Zz96PxM/Kj7sPtQ+wD7yPqg+mj6SPpI+lD6UPro+dj5yPlg+dj48Pfw9hD24PTA88DygPEg8ADv4O3g7IDsYOwA7QDuIO9w8PDx0PPg9QD4OPoA/KD9cP8UATADwAQIBgAHmAfgB1AI0AhwCDAIsAdIB7gGAAZIBagEOATMA4QDZAMkA8wCzAIQAxgDRANcA/ADeAQYBQAGcAa4BvgGeAcwCEAIgAiwCOAIIAmwCJAIsAhgCBAIAAjYB7gHgAdYBzAH8AbQBpAGWAY4BuAFwAWIBSAFoAQoBKwDIAOIAsQB+QALAFD/sv7s/Qz9VPzo+4j7SPsA+8j6sPqI+mj6mPqQ+nj6ePpI+lD60PlY+Wj4oPfQ9sD14PTQ84DyIPEg8CDvYO4A7iDuoO6A76DwAPKA80D14PYA+fD6kPw+/vr/vAGkA8gEGAYQB3AHMAhgCLAIgAgwCMAHIAe4BggGqAXYBFgE+APQA4QDYAMcAyQD0AI0A4wDIASwBOgEeAWABugGiAeQB0AIgAiACOAIsAjQCIAIoAggCDAI2AdIBxgH+AbYBmgGWAYYBvgFEAb4BfgF2AWwBZgFWAUoBaAEWASUA/ACMAJiAXUAd/9y/pz90Pzw+xD7iPoQ+vj5uPmY+YD5kPlg+cD50PnA+ej5wPlo+Rj5MPjQ9+D2APYQ9RD0wPJg8TDwYO+g7kDuYO4A76DvUPDA8UDz0PSA9hD4GPoQ/Oj9pP+KASwDUASgBaAGaAcgCGAIkAigCJAIEAg4B+AGUAaoBSAFcARIBOADoANwA1wDZANUA1gDxANwBMgEUAWYBTgGmAYYB+gH+AcACDAIUAigCNAIgAhgCFAI+AcQCLAHaAcgB7gGwAZYBlAG4AXQBQgGqAWYBSAFEAWgBHAE7AOAAwQDPAKyAdEADwAP/1T+hP2w/ND7MPuQ+hD64PmY+Yj5SPlQ+Yj5gPmQ+aj50Plw+dj4gPgo+JD3wPbg9eD0EPSA8oDxoPAA8GDvQO+A7wDwwPCQ8RDzkPTQ9ZD3OPkI+/T8gP45ANoBUANYBGAFiAY4B2gH6AfAB9gHYAfwBlAG0AUoBbgEaAT8A8ADSAMwA0gDTAMwAzwDjAMABIgEQAWwBZAFmAYAB6AHIAj4B3AIQAigCJAIgAhwCDAIEAjYB6AHMAf4BqAGiAYwBuAF2AWYBXgFkAVQBUgF6ASwBJgECAS4AyQDlAL4AQgBLwCk/77+8P34/ET8qPv4+mD6MPrY+bD5aPmQ+Yj5UPmg+Wj5aPko+cj4iPgw+LD38PZQ9mD1YPRg82DywPEQ8aDwgPCw8ODw0PGQ8qDz8PRw9vD3ePlI+9z8Yv7f/3QBwAIYBCAFOAYQB8gH2AcgCBAIoAc4B4gGUAbYBYAFGAV4BEAExAOUA5ADbAOAA6gDGARwBMAEYAWwBSgGwAZgB/AHIAiACOAIIAlgCVAJUAkwCRAJAAmwCHAIEAiYB1gH8AaoBmAGOAboBagFiAVgBTAF2ASoBHAEEASYA/ACSAKcAd8AAwAJ/yb+KP1g/LD78Ppg+rj5UPkg+ej42PjI+PD44PjY+ND42PjQ+KD4ePgw+MD3IPeA9sD14PQg9HDz4PKA8lDyIPJQ8sDyMPPw8+D0IPZw99j4MPqo+xz9Uv4PAGgBzAIQBPAE8AXIBnAHsAeYB0gH6AaABhAGmAUQBYgESASYAzwD2AKUAoACbAKwAqACJAOIAxAEWAQYBYgFKAaABgAHwAfQBzAIcAigCJAIgAhACEAIEAiwB0gHCAegBkAG+AWoBagFaAX4BPgEsAS4BIAEWAQQBLADMAO4AjQCVgGsAMH/+P4a/hT9XPxw+7j6EPpQ+QD5iPgo+AD4IPjw9wD48PcQ+BD4IPgg+PD3sPdQ9/D2gPbQ9UD1sPQg9PDzUPNw80DzMPNw8wD0APWQ9aD2gPf4+CD6QPuU/PT9Pf9XAOgB6AIoBNgEiAVIBpAGgAZwBkgG2AWwBVAF6ASABPwDpANoAxQD2AKgAuACGAMkA4gDAARYBOAEMAXQBXgGCAeQBxAIcAjACPAIIAlACSAJAAnwCNAIoAhQCNgHiAdAB9AGkAY4BtAFiAVIBeAEmARoBOgDmAM8A+QCXALmAUYBdwDP//b+QP6Y/fz8KPyA+wD7WPoA+oD5IPmo+HD4SPgg+Bj4wPfQ96D3gPdQ9wD30PYw9uD1cPUg9aD0UPRg9BD0IPQg9ID0APVQ9UD2APfw9/j42Pkw+2T8nP2U/sr/4QDsAQwD+AOgBDgFkAW4BdAFqAWgBVgFKAXgBHgEWAQABLwDnAOUA6QDlAPMAwAEQASYBAAFQAWoBRAGcAboBmAHsAcACDAIUAhwCHAIUAggCEAI6AfAB2gHGAfIBoAGOAbABYgFGAXgBHAEEATwA3QDTAP0ApwCQALWAUYBxwAxAHD/vP4e/nT9wPwo/Gj72PpI+rD5SPmw+GD4KPjA95D3QPcw9yD34PbQ9oD2QPbg9ZD1cPUg9QD1oPSQ9MD0wPTQ9ED1kPUA9rD2YPcY+Pj4sPm4+pj7uPy8/bT+wP+pAK4BbAIcA8QDOAS4BMAE8AQYBQgFAAXYBOgEgARoBDgEKAQQBBAECAQoBEAEcASoBAAFWAWgBQAGYAboBmAH4AcgCJAIoAjACNAIwAjQCIAIcAhACPgHkAdIB/AGeAYQBqAFUAXwBKAESAQABKgDTAPoArgCaALkAZwBNAG6ACIAgP8T/2j+2P1Q/aT8DPyI+xD7qPoo+qD5UPnw+MD4ePhI+BD4wPeg91D3MPfw9sD2wPaQ9nD2YPZg9kD2cPaA9sD2IPeA9/D3YPgY+cj5kPpA+wT8+Pzs/cL+p/9yAE4B9gGQAjADnAMYBHAEwAT4BPgEAAX4BAgF8ATwBOAE4ATQBMAE8ATgBAAFIAVYBagF4AVABogG4AZIB6AH6AcwCFAIgAigCKAIkAhwCDAIAAioB1gH6AaYBhgGuAVYBQgFmAQQBLgDTAPoAnwCGAKsAUgByQBWAOb/V//W/jr+wP0c/Zz8HPyY+/j6cPrw+XD5CPm4+FD4GPjQ97D3gPdw90D3EPcg9+D20Paw9qD2sPbA9tD2wPbw9hD3gPeQ9/D3UPjI+ED5yPmI+hD70Pt4/Ej9Gv7O/qD/PgD8AJYBHAK0AgADiAO8AxgESASABIgEsASwBMAEwATQBMgEyATYBAgFEAUgBWAFcAWoBdgF+AVQBoAGqAbgBiAHEAcwB0gHQAdABygH6AbQBngGMAbYBZAFMAXQBGAECASkA0gD4AKUAiwCwgFoAQQBmwA4AM//YP/y/nT+6P14/QD9jPwQ/KD7MPu4+lD68PmY+Vj5EPnQ+Kj4gPhI+Cj4APjw98D3oPeA96D3sPeA95D3sPfg9xD4aPio+Pj4WPnA+Vj66Ppw+xj8xPx4/Tb+zv6F/y4AwgBGAdIBRAKwAhgDeAO0A9gDGAQwBGAEcASQBLgEyATgBPAEIAUoBUgFiAXABQAGMAaIBsgGCAdAB3AHsAe4B8AH0AfQB7gHkAdoBzgH8AaYBlgGAAawBTgF+ASYBCgEwANYAxADoAJAAsYBagEKAY4AIgCv/y7/qv4e/qD9IP2Q/BD8kPsI+4j6APqg+TD5wPhw+Cj44Pew92D3MPcA9+D2wPag9pD2kPag9rD24PYQ90D3kPfw92j40PhQ+cD5SPro+mj7CPyU/Bz9tP08/sj+RP+4/zkAoAAGAVgBtAEQAlACsAIEA0QDlAPcAygEcASoBPgEMAVwBbAF6AUwBmgGkAbQBggHMAdQB3AHeAeIB3gHaAdwB0AHMAf4BtgGmAZQBhgGwAWIBSAFyARwBBAEtANYA/ACgAIIApQBHgGtAEcA1/9p/wL/hv4i/qz9RP3Q/Fz8+PuY+zj76PqQ+kj6CPrI+Yj5UPkw+Qj58PjA+ND4uPi4+MD4uPjY+PD4CPk4+XD5mPnA+QD6SPqY+vj6WPu4+yD8iPwE/YT9+P1s/tr+V//L/z0AtAAYAXwB5gFIApgC7AJEA5gD5AMgBFgEkATIBAAFOAVwBaAFwAXoBRAGOAZYBnAGgAaABoAGgAZwBmAGSAYwBggG6AWwBYgFUAUYBdgEkARIBAAErANUAwgDuAJoAhACsgFWAQIBrwBSAPj/nP9A/+j+kP5A/uT9iP08/ej8qPxg/CD84Puo+3D7QPsY+/D64PrI+rj6qPqg+qD6sPrA+tD66PoA+yD7QPtg+5D7sPvY+wj8QPx8/MD8/PxA/Yj90P0W/mT+sP4C/1D/n//v/z8AjwDgADIBdAHAAQQCRAKIAsQCAAMsA1QDdAOUA7QD0APsAwAEIAQwBDgEUARgBGgEcARoBGgEWARIBDAEKAQYBPgD0AOgA3wDTAMcA+ACsAJ4AjwC/gHKAYoBSAEEAcsAlgBIAP//wf+A/0j//P7C/oT+Uv4c/uD9xP2E/VT9JP0I/eD8xPyo/JD8dPxY/Ez8OPws/BD8APzw+/D76Pvo+/j7+PsI/CT8QPxg/IT8tPzk/BD9RP14/bD95P0Q/lD+jP7C/vr+Mf9g/5P/wf/w/ygATQB2AKAA0QD8ACYBVAF4AaYBwgHgAQgCOAJcAnwCmAKoArgCxALUAuAC5ALkAuAC1ALQAsQCsAKYAngCYAJIAjACEAL4AeABwAGgAYIBZAFKASwBDAHwANEArQCRAHkAWgA5ABsAAgDp/8r/p/+F/2z/UP81/xv/Av/u/t7+yv68/q7+nv6S/oz+hP58/nD+av5o/mj+Zv5o/mz+cv54/oT+lv6m/rT+xP7a/vD+Bv8c/zL/RP9W/2j/ff+T/6f/uv/R/+v/AAATACEANgBOAGkAfwCZAK8AwgDWAOUA9gAAAQoBEAEaASIBKgEuASwBKAEkAR4BFgEQAQwBCAECAfgA8wDuAOgA4QDTAMoAvACsAJ0AiAB9AGcAWABGADoALQAfABgAEgAKAAIA9//v/+X/4P/Z/9X/1f/R/8r/wv+//8H/wf++/7r/rf+j/5r/l/+S/4n/gf98/3r/df9y/3H/c/90/3X/ef99/3//iP+U/5//qP+u/7r/w//M/9T/2v/g/+b/7//5//7///8AAAEAAgAEAAcADAAPABAADwAUABYAFwAYABgAGQAaABsAHgAiACYAKgArACoAJQAoACgAJgAgABgAEQAOAAUABQD5//j/8f/0//L/7v/r/+v/6f/U/93/z//Q/8X/u//B/7P/pf+k/6H/kv+B/3//ff9//4D/f/+C/4L/fv+F/5L/oP+j/6j/tP+//8b/zv/T/9n/3//l/+j/6//w//L/9f/3//b/9//6//3///8GAA0ADwATABkAJAAvADYAPQBDAEkATABPAFQAWwBfAGIAZQBnAGoAagBrAGkAZQBgAFwAVQBLAEMAPwA7AC8AIgAWABIAEAAJAP3/9P/r/+H/2v/T/8n/wP+4/7H/rP+k/53/l/+T/4//jP+J/4j/if+I/4f/g/+D/4X/if+M/4//kv+U/5b/lv+Y/5n/mP+X/5j/m/+e/6H/ov+k/6j/rP+u/7H/tP+6/8D/xf/L/9H/2P/e/+f/7f/1//z/AwANABUAHAAgACEAIwAkACcAKgAtADEANgA8AEIASQBPAFYAWwBeAF8AYQBjAGYAawByAHYAdwB3AHwAgwCIAIkAjwCSAJUAkwCVAJUAlACRAI4AjgCIAH4AcgBpAGYAVQBLAEQAQgA3ACoALAAhAB0AEAATAA4ACwAFAAIA/P/3//T/8//v/+f/4P/Y/9j/0f/L/8b/v/++/7z/vv/E/8P/xv/J/8j/zf/O/87/0P/O/9P/1//a/97/3f/b/9//3//i/+b/4v/g/+L/5P/l/+n/6P/m/+r/6f/p//P/+////wgADAANABQAGgAjACwAMwA4AD0AQwBKAFEAVQBYAFkAXABfAGEAYQBgAGAAXQBaAFcAVABTAE8ASgBEAD4AOAA0ADIALgAqACcAJAAjAB8AGwAWABIADgAKAAQA/v/5//P/7f/n/+D/2f/R/8n/wP+4/6//pf+e/5f/kf+M/4j/hf+C/4D/gP+B/4H/gv+D/4X/h/+I/4n/h/+G/4X/h/+J/43/kP+U/5j/nP+f/6P/qP+u/7X/vf/F/8z/0v/X/9z/4f/l/+n/7P/w//T/9//6//z//v///wEAAwAFAAgACgAMAA4AEAAUABcAGgAcAB4AHwAgACEAIgAlACcAKQArAC4AMwA4AD4ARABIAEwATQBPAE4ATQBLAEkARgBCADwAOAA1ADQANAAwACsAJAAfABsAGQAXABMADgALAAsACwAKAAkACAAIAAcABgAFAAMAAwAEAAYABgAGAAYABgAFAAUABQAEAAQABgAJAAsADAAMAA0ADgARABUAGAAbABwAHAAfACEAIwAiACIAIgAjACQAJQAmACcAKgAqACsAKgAuADEAMgAwAC4ALQAtACkAKgAlACUAHwAkACIAHwAaABsAGAAMABEABwAMAAQA//8HAAMA/v8EAAcABgADAAcADQATABcAFQAZABwAGQAYABsAIAAZABIAEQAPAAsABQAAAP3/+//3//T/8v/y//H/8P/x//L/8//2//f/+P/5//v/+//7//z//f///////v/8//v/+f/2//T/9f/0//P/8v/x//H/8v/z//T/8//y//P/8//w/+//8P/z//H/7//u//D/9f/2//X/9f/2//f/+f/7//z//v8AAAMABQAHAAgACgANABAAEQATABQAFgAWABUAEgAQAA8ADwAMAAkABwAEAAAA/f/6//f/8//w/+3/7f/s/+v/6v/p/+j/5//l/+L/3//d/9r/1v/T/8//y//I/8T/wP+9/7r/uP+4/7j/uP+2/7T/s/+0/7X/t/+5/73/wf/G/8z/0v/Y/93/4f/k/+f/6f/s/+//8//3//r//P/+/wEABgAKAA0AEAATABYAFgAYABoAHAAeAB4AIgAjACMAIAAgACYAIgAkACUALAAtACsAMgAxADYAMQA4ADgAOQA4ADgANgA0ADQANAAzADAALgArAC0AKwApACgAJgAmACQAJgAoACUAJAAhABsAGQATAAsABgD+//r/9f/v/+3/5v/g/9//2//a/9r/1P/R/9L/0P/R/9P/0P/P/9D/zv/N/9P/1P/U/9f/1v/V/9f/1//a/9z/3P/c/93/3v/g/+H/4v/i/+P/5P/m/+j/6f/r/+z/7v/w//L/9f/5//z//v8AAAIABAAIAAsADgARABMAFgAZABoAGwAbABsAGwAbABoAGgAaABkAGQAZABkAGgAZABkAGQAZABgAGAAYABgAGQAaABsAHAAdAB0AHQAeAB4AHQAdABwAGwAZABcAFAARAA8ADQAMAAwADAAMAAsACgAJAAgABwAGAAUABAADAAIA///8//j/9f/x/+3/6v/n/+T/4v/g/97/3f/c/9v/3P/c/93/3v/e/9//4P/i/+T/5v/n/+j/6f/q/+v/7f/v//L/9P/3//r//f8BAAUACQALAA0ADQANAAwADAAKAAkACAAGAAQAAwAEAAYACQAKAAoACQAKAAsADgAQABEAEgATABUAFwAZABoAGgAaABoAGgAZABcAFgAWABYAFgAVABQAEwARABAADwANAA0ADAANAA0ADAAKAAcABgAEAAMAAQD///v/+P/1//L/8P/r/+f/5P/h/9//3P/Z/9f/1v/T/9H/zf/M/8v/yf/E/8D/vf+6/7X/tP+u/67/qf+t/6v/q/+o/6v/qv+k/6z/p/+x/63/rv+5/7n/uv/D/8f/yv/L/9L/1//e/+P/4//o/+3/7f/v//T/+//5//n//f8BAAQABgAIAA0AEgAXABsAIAAnACwAMAA2ADwAQQBGAEkATQBPAFIAUwBTAFQAVQBVAFUAVABSAFAATwBNAEoASQBIAEYAQwBAAD4APAA5ADYAMAAsACkAIwAdABcAEwAQAAoABAD+//v/+v/2//H/7f/p/+b/5P/h/9//3P/a/9n/2P/X/9X/0//T/9P/0//S/9L/0v/S/9H/z//P/9D/0f/R/9H/0//U/9X/1//Z/9z/3v/g/+P/5//s//D/9P/4//z/AAADAAYACQAMAA8AEgAUABcAGQAbAB0AHgAgACEAIgAlACgAKgAsAC0ALwAyADUAOAA7AD4AQQBFAEkATABPAFAAUQBQAE8ATQBMAEoASQBIAEYAQwBAAD8APgA9ADsAOQA2ADMALwArACYAIwAfABkAFwATAA4ABgABAAAA9//0//D/8f/s/+b/6f/j/+P/3P/f/9v/2f/V/9L/zv/K/8j/x//E/8L/v/+8/77/vP+8/7v/uv+7/7r/vP/A/7//wf/B/7//wf/A/7//wP++/7//wP+//8L/wv/D/8b/x//L/8//z//R/9b/2f/e/+T/5v/p/+7/8P/0//z///8CAAcACAAKAA0ADwASABUAFgAXABkAGwAdACAAIgAjACUAJwApACsALQAuAC8ALwAwADEAMgAzADQANAAzADIAMgAyADIAMgAxADEAMQAwADAALwAuACwAKgAoACYAIwAgAB0AGQAWABIADwAKAAYAAgD+//r/9//0//L/8P/v/+7/7v/t/+z/6//r/+r/6f/o/+f/5v/l/+P/4f/f/97/3v/e/9//4f/i/+T/5f/n/+n/6//t/+//8f/0//X/9//4//j/+f/5//n/+v/6//v/+//9//7///8BAAMABQAHAAkACgAMAA0ADwAQABIAEwAVABYAFwAXABkAGgAcAB4AHwAgACEAIgAjACUAJQAlACQAIwAhAB8AHQAaABgAFQASAA4ADAAKAAgABwAFAAIA/v/6//j/9v/1//L/7//t/+v/6//q/+r/6P/n/+X/5P/h/9//3P/b/9n/2P/X/9X/0//S/9D/z//P/8//z//Q/9L/0//U/9X/1v/Z/9v/3f/g/+H/4v/k/+f/6v/q/+z/7v/w//L/8//1//b/+f/6//v/+//9/wAAAQABAAEAAwAFAAQABwAGAAgABQALAAsACwAIAAsACgAEAAgAAAAHAAEA//8FAAIA//8EAAQAAwACAAQABgAIAAkABgAHAAkABgAEAAQABgABAP7//P/7//n/9v/z//H/8f/v/+7/7P/t/+z/7P/t/+7/8P/x//H/8v/0//X/9v/2//f/+P/5//r/+v/6//r/+v/6//n/+v/6//r/+v/5//r/+//8//3//f/9/wAAAAAAAAEAAwAGAAcABwAHAAkADQAOAA0ADQANAA4ADwAQABAAEQASABMAFQAWABcAGAAZABsAHQAdAB4AIAAhACAAHwAeAB8AHwAeAB0AHAAcABsAGgAaABkAGAAXABYAFgAWABYAFQAVABQAFAASABEAEAAPAA0ADAAKAAgABwAEAAIA///8//j/9v/0//L/8f/v/+z/6//q/+r/6f/p/+n/6f/q/+v/7f/u/+7/7//v//D/8f/y//T/9v/5//v//f///wIABQAIAAsADAAOABAAEAARABEAEwAVABUAFwAZABsAGgAbACAAHgAhACEAJgAnACUAKgApACwAKAAtACsALAAqACoAKAAnACcAJgAlACUAJAAiACMAIgAhACEAHgAeABsAGwAbABcAFwAUABAADwALAAYABAD///3/+f/1//T/7//r/+r/5f/j/+H/2//Y/9f/0//S/9L/zv/M/8z/yf/H/8n/yP/G/8f/xf/D/8T/w//D/8T/w//D/8T/xP/F/8X/xv/G/8f/yP/J/8r/y//M/83/zv/Q/9L/1P/W/9n/3P/e/+H/4//n/+r/7v/x//T/9//6//7/AQADAAYACAAKAAwADgAQABEAEwAUABYAFwAYABkAGgAbABwAHQAeAB8AIAAiACMAJAAkACUAJQAkACQAIwAjACIAIQAhACAAHgAdABwAHAAbABwAHAAcABwAGwAaABkAGAAXABYAFQAUABMAEQAQAA4ADAAKAAgABgAFAAMAAQAAAP7//f/7//r/+f/3//b/9P/z//H/8P/v/+//7v/u/+7/7v/u/+//8P/x//P/9P/1//b/+P/5//v//P/9//7//v///wAAAQABAAIAAwAEAAUABgAIAAoADAAOAA8ADwAQABIAFAAWABcAFwAYABoAHAAeACAAIQAiACIAIgAiACEAIQAhACEAIgAiACMAIgAiACEAIQAhACEAIQAiACIAIgAhACAAHwAeAB0AHAAbABkAFwAVABQAEwAQAA4ADAAKAAkABgAEAAIAAAD+//v/+P/2//X/8//w/+3/6//q/+b/5f/g/+D/2v/c/9r/2P/U/9X/0//N/9L/y//S/87/zf/U/9P/0v/Y/9n/2v/b/97/4P/j/+b/5P/n/+r/6v/q/+3/8v/x//H/8//2//j/+v/7//7/AQAEAAYACAALAA4ADwATABUAFwAaABsAHAAdAB4AHwAfAB8AHwAgACAAHwAeAB0AHAAbABoAGQAYABcAFQASABEADwAOAAwACQAHAAUAAwD///z/+v/6//f/8//w/+7/7v/s/+n/5f/j/+L/4P/e/93/3P/b/9v/2v/Z/9j/2P/Y/9j/2P/X/9f/1//Y/9f/1v/W/9f/2P/Y/9j/2v/b/9z/3f/f/+H/4v/j/+T/5//p/+v/7P/u//D/8f/z//P/9P/1//b/9//5//r/+//8//3//v/+////AAABAAMABQAGAAcACQAKAAwADgAPABAAEgAUABUAFwAYABkAGQAaABoAGgAbABwAHAAeAB4AHQAdAB0AHgAdAB0AHAAbABoAFwAWABQAFAATABEAEQARABEADgANAA8ACwAMAAoADQAKAAYACQAGAAcAAQAFAAIAAQAAAP///f/8//z//f/8//z//P/7//3//f/9//3/+//8//r/+//8//n/+v/5//f/+P/3//b/9//1//b/9v/2//j/9v/3//n/+P/5//v/+f/5//v/+//8/////v/+/wAAAAAAAAQABAAEAAYABQAFAAYABgAHAAgACAAIAAgACAAJAAkACQAJAAkACQAJAAkACQAIAAgACAAIAAgACAAIAAgACAAHAAcABgAGAAYABQAEAAMAAgAAAP///v/8//v/+f/4//b/9f/z//L/8f/w/+//7v/t/+z/6//q/+n/6f/o/+j/5//n/+f/5//n/+f/5v/m/+X/5f/m/+b/5v/n/+j/6P/p/+r/6//s/+7/8P/y//P/9P/1//b/9//4//n/+v/7//z//f/+/wAAAQACAAMABAAFAAcACAAJAAoADAANAA4ADwAQABEAEgATABQAFQAWABcAGQAaABsAHAAdAB4AHwAgACEAIQAgACAAHwAfAB8AHgAcABsAGQAYABcAFgAVABQAEwARABAADwAOAA4ADgANAAsACQAHAAYABgAFAAMAAgAAAP///////////v/9//z//P/6//n/+f/5//n/+v/6//v/+//7//v//P/8//3//f/+////AAAAAAAAAAABAAEAAgADAAMAAgADAAQABQAFAAUABQAGAAcABwAHAAcACAAIAAgABgAHAAgACAAHAAUABgAGAAQABQADAAQAAAAEAAMAAwAAAAMAAgD+/wMA/f8EAP////8FAAIAAAAEAAMAAQD/////////////+//7//v/+f/4//j/+v/4//f/9//4//j/+P/3//j/+f/5//n/+P/6//n/+f/5//n/+f/6//j/+P/4//j/9//2//b/9v/2//f/9//2//b/9v/2//X/9v/2//b/9v/1//X/9f/2//b/9f/1//X/9f/1//T/9f/3//b/9f/1//b/+P/5//j/9//4//j/+f/5//r/+v/7//z//P/9//z//P/9//3//f/9//3//f/9//3/+//7//v//P/7//v/+//7//v/+//8//z/+//6//n/+f/5//n/+P/4//f/9//2//X/9P/z//P/8//z//P/8//z//P/8//y//L/8v/z//T/9f/1//X/9v/3//j/+P/5//n/+v/7//z//f/9//7//v/+//7//////wAAAQADAAMAAwAEAAQABgAGAAcABwAHAAgABwAIAAgACQAKAAsADAAOAA8ADgAPABIAEAARABAAEwASABAAEwARABMADwASABEAEQARABEAEAAPABAAEAAQABAADwANAA8ADgANAAwACQAJAAYABgAGAAMAAwABAP//AAD+//3//f/7//v/+v/5//r/+P/4//n/9//3//f/9P/0//T/8//0//X/8//z//T/8v/y//X/9P/0//X/8//z//T/9P/0//X/9f/1//b/9v/3//f/+P/4//j/+f/6//v//P/8//3//v///wAAAQACAAMAAwADAAMABAAEAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABQAFAAUABgAGAAUABQAFAAUABAAEAAQABAAEAAQABAADAAMAAgACAAEAAAAAAAAAAAAAAP/////+//7//v/+//7//v/+//3//f/8//v/+//6//r/+v/5//r/+f/6//r/+v/6//r/+//7//v//P/8//3//f/+//7//////wAAAAABAAEAAgACAAMABAAFAAYABgAHAAcACAAJAAkACQAJAAkACQAJAAkACQAIAAgACAAIAAgACAAJAAkACQAKAAkACgAKAAsADAAMAAsACgAKAAoACgAKAAoACQAIAAgACQAJAAkACQAJAAkACQAIAAcABwAHAAcABwAHAAcABwAGAAYABgAFAAQABAAEAAQAAwACAAEAAQAAAAAA//////7//f/9//3//v/8//v/+//7//v/+v/5//n/+f/4//f/9v/2//b/9v/1//T/9P/1//P/9f/z//T/8f/1//T/9f/y//X/9f/y//b/8f/4//T/8//5//b/9f/5//j/9//2//f/9v/4//j/9f/2//j/9//3//j/+//6//n/+v/8//3//f/9//7///8AAAAA//8AAAAAAAAAAAAAAAABAAAAAAAAAAAAAAD///////8AAAAAAAD//////////////////////v/9//3//f/+//7//f/9//3//f/8//z//P/+//7//P/7//z//v/+//3//P/8//z//P/8//v/+//7//v/+//7//r/+v/6//r/+f/5//j/+P/5//j/9//2//f/9//3//b/9v/3//b/9//3//f/9//2//b/9v/2//f/9//3//f/9//3//f/9//3//j/+P/5//n/+v/7//z//P/9//3//v///wAAAQACAAMAAwAEAAUABgAGAAYABwAHAAgACQAJAAoACgAKAAoACgAKAAsADAANAA0ADQANAA0ADgAOAA4ADgAOAA4ADQANAA0ADgAOAA0ADgAPABAADgAOABAADQAOAAwADwANAAoADQAKAAsABwAKAAgABwAGAAYABAADAAMAAwACAAIAAQD//wAA//////7//P/8//r/+v/7//n/+v/5//f/+f/4//f/+P/2//f/9//3//j/9//3//n/+P/5//r/+P/3//n/+P/5//v/+v/5//r/+f/5//z/+//7//3/+//7//z//P/9//7//v/+//////8AAAAAAQABAAEAAgACAAIAAgACAAMAAgADAAMAAwADAAQAAwADAAMAAwADAAMAAgACAAEAAQABAAAAAAD//////v/+//3//f/8//z//P/7//v/+//7//v/+//7//v/+v/6//r/+v/6//r/+v/6//r/+f/5//j/+P/4//j/+P/4//j/+P/4//j/+P/5//n/+v/6//r/+//7//v/+//7//v/+//7//z//P/9//7//v//////AAABAAIAAgADAAQABQAFAAYABwAHAAgACAAIAAgACQAJAAoACgALAAsACwALAAwADAAMAA0ADQANAAwADAAMAAwADAALAAsACgAKAAoACgAKAAoACgAJAAkACQAJAAkACgAKAAkACAAHAAcACAAIAAcABgAFAAUABQAGAAYABQAFAAUABAADAAIAAQABAAAAAAABAAAAAAAAAP////////7//v/+//7//v/+//3//P/8//z//P/8//v/+v/6//r/+v/5//n/+P/5//n/+P/4//j/+f/4//j/9//4//n/+f/5//j/+f/6//n/+v/5//r/9//7//r/+//5//z//P/5//3/+f////v/+/8AAP3//P8AAP/////+/////v8AAAAA/f/+/////v/9//7/AQD///7//v8AAAAAAAD//wAAAQABAAEAAAABAAEAAAABAAEAAQACAAAAAAAAAAAA//////7//v/+//7//v/9//z//P/8//v//P/8//z/+//7//r/+//8//v/+v/6//v/+//6//n/+v/7//v/+f/4//n/+v/7//r/+f/4//j/+P/4//j/+P/4//j/+f/5//j/+P/5//n/+f/4//j/+f/5//n/+P/4//j/+f/5//j/+f/5//n/+f/6//v/+//6//r/+v/7//v//P/8//3//f/9//3//f/+//7//v/+////AAAAAAEAAQACAAIAAgADAAQABQAFAAYABgAHAAgACAAJAAkACQAJAAoACgALAAsACgAKAAoACQAJAAkACQAKAAoACQAJAAkACgAKAAoACQAJAAkACAAHAAYABgAGAAUABgAGAAcABQAEAAcABAAFAAMABgAEAAEABAACAAMA//8DAAEAAQAAAAAA/v/+//7//v/9//3//f/7//3//P/8//z/+//7//r/+v/8//r//P/7//n/+//7//r/+//6//v/+//6//z/+//7//3//P/9//7//f/9//7//f///wAAAAAAAAEA//8AAAIAAQABAAMAAQABAAEAAQABAAIAAQABAAEAAQABAAEAAQABAAEAAQACAAIAAgABAAEAAQABAAEAAQAAAAEAAAAAAAAA//////////////7//v/+//7//f/9//3//P/8//v/+//7//r/+v/5//n/+f/6//n/+f/5//n/+f/5//n/+f/5//r/+v/7//v/+//7//v/+//7//v/+//8//z//P/8//z//P/9//3//v//////AAAAAAAAAAABAAEAAQABAAIAAgACAAIAAwADAAMABAAEAAQABAAEAAUABQAFAAYABgAGAAcABwAHAAcABwAHAAgACAAIAAkACAAIAAgACQAJAAkACQAJAAgACAAIAAgACAAHAAcABgAGAAUABQAFAAUABQAEAAQAAwADAAMABAAEAAMAAwACAAIAAgACAAIAAQAAAAAAAAABAAEAAgACAAIAAgABAAEAAAD////////////////+//7//v/+//7//f/+//7//v/+//7//f/9//7//v/+//7//f/9//3//v/9//z//P/8//z//P/8//z//P/8//z/+//7//z//P/8//v//P/9//z//f/8//3/+v/9//3//v/8//7//v/7////+v8AAPz//P8AAP3//P8AAAAA/////wAA//8BAAEA//8AAAEA///+////AQD///7//v///////v/+//7///////7//v///////v/+///////////////////////+//7//v/+//7//v/+//7//f/9//z//P/9//3//P/7//v/+//8//z/+//7//z//P/7//r/+//8//z/+//6//v//f/9//3//P/8//z/+//7//v/+//7//v/+//7//v/+//7//z//P/7//v//P/8//z/+//7//v//P/7//v/+//7//v/+//7//z//P/7//v/+//7//z//P/8//3//f/+//7//v/+//7//v/+//7//v//////////////////////AAAAAAAAAQABAAIAAgADAAMAAwADAAQABQAGAAYABgAGAAYABgAFAAYABgAGAAYABgAFAAUABgAGAAcABwAHAAcABgAGAAQABQAEAAMABAAEAAUAAwADAAUAAwAEAAIABQAEAAIABQACAAQAAQAEAAIAAwACAAIAAQABAAEAAQABAAEAAAD//wAAAAAAAAAA//8AAP7///8AAP7/AAD///7///////7////+//7//v/9/////f/9/////v///wAA/v/+/////f/+/wAA/////wAA/v/+/wEAAAABAAIAAQABAAEAAQABAAIAAQABAAEAAQABAAEAAQAAAAAAAAAAAAAAAQAAAAAAAAAAAP//AAD//wAAAAD///////////////////7//v/+//7//v/+//7//v/9//3//f/9//z//P/8//v/+//7//v/+//7//r/+v/6//n/+f/5//r/+v/6//v/+//7//v/+//7//v//P/8//z//P/8//z//P/8//z//f/9//7//v/+/////////////////wAAAAAAAAEAAQABAAEAAgACAAIAAgACAAMAAwADAAMABAAEAAQABAAEAAQABAAEAAQABQAFAAUABQAFAAUABgAGAAcABwAHAAcABwAHAAcACAAHAAcABwAHAAYABgAGAAYABgAGAAUABAAEAAQABQAFAAUABAADAAMAAwAEAAMAAgABAAEAAAABAAEAAQACAAIAAwACAAIAAQABAAEAAQACAAIAAQABAAEAAQAAAAAA/////wAAAAAAAP////////////8AAP//////////AAD//////v///////v/+//7//v/+//7//P/8//3//f/9//z//f/9//z//f/8//3/+v/9//3//v/8//7//v/7//7/+f8AAPv/+v/+//v/+v/+//3//f/8//3//f/+/////f/+/////v/9//7/AAD///7//v///////v/9//7//v/+//7//f/+//7//P/9//3//f/+//3//f/9//7//v/9//3//f/9//7//v/+//7//v/+//3//f/+//7//f/8//z//P/9//3/+//8//z//P/7//r/+//8//z/+v/5//r//P/8//z//P/8//z//P/8//v/+//7//v/+//7//v/+//7//z/+//7//v//P/9//z//P/8//z//f/8//z//P/8//z//P/9//3//f/8//z//P/8//z//P/8//3//f/9//3//f/9//3//f/9//7//v///////////////////////////////////wAAAAAAAAAAAAAAAAEAAQACAAMAAwAEAAQABAAEAAQABAAFAAUABQAEAAQABQAFAAYABgAHAAgABwAHAAYABwAGAAUABgAGAAYABQAEAAcABAAFAAQABgAFAAMABgAEAAUAAgAFAAQABAAEAAQABAADAAMAAwADAAMAAgABAAIAAgACAAIAAQACAAAAAAABAP//AQAAAP//AAAAAP//AAD+/////v/9/////f/9/////f/+/////f/9//3//P/8//7//f/8//3/+//7//3//P/8//7//f/9//7//f/+//7//v/+//7//v/+///////+//7///////////////////////7//////////////////////////////////v/+///////////////////////////////+//7///////////////7//v/9//3//P/8//z//P/8//z//P/8//z//P/8//z//f/9//3//f/9//3//f/9//3//f/9//3//v/+//7//v/+//7/////////////////AAAAAAAAAAABAAEAAQABAAEAAQABAAIAAgACAAMAAwADAAMAAwADAAMAAwAEAAQABAADAAMAAwAEAAQABQAFAAQABQAFAAUABgAGAAYABgAGAAYABgAGAAcABwAGAAYABQAFAAUABgAGAAYABgAFAAUABgAGAAYABQAEAAMAAgACAAIAAgACAAIAAwACAAIAAQABAAEAAQABAAEAAQABAAEAAQABAAEAAAAAAAAAAQAAAAAA//////////8AAP///v/+////////////////////////////AAD//////v/+///////+//3//v/+//3//v/9//7/+//+//3//v/8///////8/wAA+/8BAPz//P8AAPz/+//+//3//f/8//z//P/9//7//P/9//7//f/8//7/AAD+//7//v///wAA///+////AAAAAP////8AAAAA/v////////8AAP/////////////+//7//v/+//////////////////7///8AAAAA//////////8AAP///////wAA///+//3//v////7//P/7//z//f/9//3//f/9//3//f/9//3//f/8//3//f/8//z//P/8//z//P/7//v//P/8//z//P/8//z//P/8//z//P/8//z//P/9//7//f/9//3//f/8//z//P/8//z//f/9//3//P/8//z//P/8//z//P/9//3//v/+//3//f/9//7//v/+//7//v/+//7//v/+//3//f/9//3//f/+//7//v////////////////8AAAAAAAD/////AAAAAAEAAQACAAMAAwADAAMABAADAAIAAwAEAAUAAwADAAYAAwAEAAMABQAEAAIABQADAAQAAQAFAAMABAAEAAQABAADAAMAAwADAAMAAwACAAMAAwADAAQAAwADAAIAAgADAAEAAwACAAEAAwACAAEAAgABAAEAAQAAAAEAAAD//wEA//8BAAIAAAAAAAAA/////wEA/////////f/9//7//f/9/////f/9//7//f/9//7//v/+//7//v/+//7//v/+//7//v//////////////////////////////////////////////////////////////////////////////////////////////////////AAAAAAAAAAAAAP///////////v/+//7//v/+//3//f/9//3//f/9//7//v/+//3//f/8//z//P/8//z//f/9//3//f/9//3//f/9//3//f/9//3//f/9//3//v/+//7//v/+//7//v/+//7/////////AAAAAAAAAAAAAAAAAQABAAEAAQABAAEAAQABAAEAAQABAAEAAQABAAIAAgACAAIAAwADAAMAAwAEAAQABQAFAAQABAADAAMABAAFAAUABQAEAAUABgAHAAcABwAGAAUABQAEAAQABAAEAAQABQAEAAQAAwADAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAgACAAIAAQABAAEAAQACAAEAAAAAAAEAAQAAAAAAAAAAAAAA////////AAAAAAAA/////wAAAAAAAP//AAAAAP//AQD//wAA/f////7////9/wAA///9/wEA/P8CAP3//v8BAP3//f8AAP///v/9//7//f/+//7//P/+//7//P/8//3////9//3//f/+//7//f/9//7///////7//////////v//////AAAAAP//AAAAAAAAAAD///////////////////////////7///8AAAAA//////////8AAAAA//8AAAEAAQAAAAAAAQACAAEAAAD+//7////////////////////////////+//7///////7//v/+/////v/9//3//v/+//7//f/9//3//f/9//3//f/8//z//P/9//7//v/+//3//f/9//3//f/9//3//f/9//3//f/9//3//P/8//z//P/8//z//f/9//z//P/8//z//f/9//3//f/9//3//v/9//3//P/8//z//P/8//z//P/8//z//P/8//z//P/9//3//f/8//z//P/7//z//P/9//3//f/+//3//v/+//3//////wAA//8AAAIA//8AAAAAAwABAAAAAwAAAAIA//8DAAEAAgACAAMAAgACAAIAAgADAAMAAgABAAMAAgADAAQAAwAEAAIAAwADAAIABAADAAIABAADAAMABAADAAMAAgACAAMAAQABAAIAAQADAAMAAgACAAIAAQACAAMAAgADAAMAAAABAAIAAAABAAIAAAAAAAAA//8AAAAA//////////////////////7//////////////wAA/////////////////////////////wAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAP////////////////////8AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAP/////////////////////////////+//7//v/+//7//f/9//3//f/9//3//f/9//3//f/9//z//P/8//z//P/8//z//P/8//z//P/8//z//P/8//3//f/9//3//f/9//3//f/+//7//v/+//7//v////////////7//v/+//7//v/+//7//v/+//////8AAAAAAQABAAEAAAAAAAAAAAABAAEAAQABAAEAAgADAAQABAAEAAQABAAEAAQABAAFAAUABQAGAAUABQAFAAQABAAEAAQABAAEAAMABAAEAAQABAADAAQABAAFAAQABAADAAMABAAEAAMAAwADAAMABAADAAMAAgACAAIAAQABAAEAAgACAAEAAAABAAEAAQABAAEAAgACAAIABAACAAMAAAACAAEAAQAAAAIAAQD//wMAAAAEAP//AQAEAP//AQADAAEAAAAAAAEAAAABAAAAAAACAAEA/v/+////AQD//////////////v/+//7//v/+//7///////7//v/+//////////////////////////////////////////////////7////////////+//7//v////7//v//////AAAAAAAAAAABAAEAAAD//wAAAAAAAAEAAQAAAAAAAAAAAAAAAAD//wAAAAAAAAAAAAAAAAAAAAD//wAAAAAAAAAAAAAAAP//AAD////////+//7//v/+//////////7//v/+//7//f/9//3//f/9//7//v/9//3//f/9//3//f/9//3//f/9//z//f/8//3//f/9//3//P/8//3//f/9//3//f/9//3//f/9//3//P/8//3//f/9//z//P/9//3//f/8//3//P/8//z//f8="
- }
- }
- ]
- },
- {
- "role": "user",
- "content": [
- {
- "type": "audio_url",
- "audio_url": {
- "url": "data:audio/wav;base64,UklGRkqYAABXQVZFZm10IBAAAAABAAEAwF0AAIC7AAACABAAZGF0YSaYAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAABAAAAAAAAAAAAAAAAAAAAAAAAAP//AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAEAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAD//wAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAP//AAAAAP//AAAAAAAA///o/9T/xv/G/8b/yP/K/8r/y//M/8z/zf/O/83/zf/P/87/zv/O/87/zv/P/8//z//P/8//z//P/8//z//P/8//z//P/8//0P/Q/8//z//Q/9D/0f/R/9D/0f/R/9H/0f/R/9H/0f/R/9H/0f/S/9L/0v/S/9L/0v/S/9L/0v/T/9P/0//T/9P/0//T/9P/0//T/9P/0//T/9P/0//U/9T/1f/V/9T/1P/U/9X/1P/V/9X/1f/V/9b/1v/W/9b/1v/W/9b/1v/W/9f/1//X/9f/1//X/9f/1//X/9j/2P/Y/9j/2P/Y/9j/2P/Y/9j/2f/Z/9r/2v/a/9r/2v/b/9v/2//b/9v/2//c/9v/3P/c/9z/3P/d/9z/3P/c/93/3f/e/93/3f/e/97/3v/e/97/3//f/+D/4P/g/9//3//g/+D/4P/g/+H/4f/g/+H/4P/h/+H/4f/h/+L/4v/i/+H/4f/i/+L/4v/i/+L/4v/j/+L/4//j/+P/4//j/+P/4//j/+P/5P/k/+T/4//l/+T/5P/k/+T/5P/l/+T/5f/l/+X/5f/m/+X/5v/m/+b/5v/m/+b/5v/m/+b/5v/n/+b/5//n/+b/5v/o/+f/5//n/+j/5//p/+f/5//o/+j/6P/n/+j/6P/p/+n/6f/o/+j/6P/p/+j/6P/o/+n/6P/p/+j/6P/p/+n/6f/q/+n/6v/p/+n/6f/q/+n/6f/p/+n/6f/p/+n/6f/p/+n/6v/p/+n/6f/p/+n/6f/p/+n/6f/r/+r/6v/q/+r/6v/r/+n/6v/p/+r/6v/r/+n/6v/q/+r/6v/q/+r/6v/q/+r/6v/q/+r/6//q/+v/6//r/+r/6//r/+r/6v/q/+r/6v/q/+r/6v/q/+r/6//q/+v/6//s/+r/6//q/+r/6v/s/+n/6v/q/+v/6v/r/+v/6//s/+v/6//s/+v/7P/r/+r/6//s/+z/6//r/+v/7P/r/+z/6//r/+v/6//r/+r/6//r/+v/6//r/+v/6//s/+v/6//r/+z/7P/r/+v/6//s/+v/7P/r/+v/6//r/+v/6//s/+v/6//r/+z/7P/s/+z/7P/r/+z/6//s/+v/6//r/+v/6//s/+v/7P/r/+z/7P/s/+z/6//t/+v/7P/s/+v/7P/r/+z/6//s/+z/7P/r/+z/6//t/+v/7P/s/+v/7P/s/+z/6//s/+z/7P/s/+z/7P/s/+v/6//s/+z/7P/r/+z/7P/r/+z/7P/t/+z/7P/s/+z/7P/s/+z/7P/s/+z/7P/s/+z/7P/s/+z/7P/t/+z/7P/s/+z/7P/s/+z/7P/s/+v/6//s/+z/7P/s/+z/6//r/+z/7P/s/+v/7P/s/+v/7P/s/+v/6//s/+v/7P/s/+z/6//s/+v/7P/q/+v/6//s/+v/6//r/+z/6//r/+z/7P/r/+z/6//s/+z/7P/r/+z/7P/s/+v/6//t/+r/7P/r/+v/6//s/+v/7P/s/+v/7P/r/+z/6//s/+v/6//r/+z/6//r/+v/6//r/+v/6//t/+v/7P/r/+z/6//r/+z/7P/s/+v/6//r/+v/6//s/+v/7P/r/+z/7P/r/+v/6//s/+v/6//r/+z/6//s/+v/6//s/+v/7P/s/+z/7P/r/+v/6//s/+v/7P/r/+z/6//r/+v/6//s/+v/6//r/+z/7P/r/+z/6//s/+v/6//r/+v/6//s/+v/6//s/+r/6//r/+v/6//r/+v/6//r/+v/7P/r/+v/6//s/+v/6//r/+z/6//s/+v/6//q/+v/6//s/+v/6//s/+v/6//s/+v/6//r/+v/6//s/+v/6//r/+z/6//s/+v/6//s/+v/7P/q/+z/6//s/+v/6//s/+v/6//r/+v/6//r/+v/6//r/+v/6//s/+v/6//r/+v/6//s/+v/7P/r/+v/6//r/+v/6//r/+v/6//r/+v/6//s/+v/6//r/+v/6//r/+v/6//s/+r/6//r/+v/6//r/+r/6//r/+v/6//s/+v/6//q/+v/6v/s/+r/6//r/+v/6//r/+v/6//s/+v/6//r/+v/6//r/+v/6//r/+v/6//s/+v/6//r/+r/6//q/+v/6//r/+v/6//r/+v/6//r/+r/6//r/+v/6//r/+v/6//r/+v/6//r/+v/6//r/+v/6//r/+v/6//r/+v/6//r/+v/6//r/+v/6//r/+v/6//r/+v/6//r/+v/6//r/+v/6//r/+v/6//r/+v/6//r/+v/6//r/+v/6//r/+v/6//r/+v/6//r/+v/6//r/+v/6//r/+v/6//r/+v/6//s/+v/6//r/+v/6//r/+v/6//s/+v/6//r/+v/6//r/+v/6//r/+v/6//r/+v/6//r/+v/6//r/+v/6//r/+v/6//r/+v/6//s/+v/6//r/+v/6//r/+v/6//s/+v/6//r/+v/6//s/+v/6//r/+z/6//r/+v/6//r/+v/6//r/+v/6//r/+v/6//s/+v/6//r/+v/6//r/+v/6//r/+v/6//r/+v/6//r/+v/6//r/+v/6//r/+v/6//s/+v/6//r/+v/6//s/+v/6//r/+v/6//r/+v/6//r/+v/6//r/+v/6//r/+v/6//r/+v/6//r/+v/6//s/+v/6//s/+v/6//r/+v/6//s/+v/6//r/+v/6//s/+v/6//s/+v/6//r/+z/6//r/+v/7P/r/+v/6//s/+v/6//q/+v/6//s/+r/6//r/+v/6//s/+v/6//r/+v/6//r/+v/6//r/+v/6//r/+v/6//s/+v/6//r/+v/6//s/+v/6//s/+v/7P/r/+z/6//s/+v/6//r/+v/6//r/+v/6//r/+v/6//s/+v/6//r/+v/6//r/+v/6//r/+v/6//r/+z/6//r/+v/6//s/+v/6//r/+v/6//r/+v/6//s/+v/6//s/+v/7P/r/+v/6//r/+v/6//s/+v/6//r/+v/6//r/+v/6v/s/+v/6//r/+v/6//r/+v/6//s/+v/6//r/+v/6//s/+v/6//s/+z/7P/r/+v/7P/s/+v/6//s/+v/6//r/+v/6//r/+z/7P/s/+v/6//r/+z/6//s/+v/7P/r/+z/6//s/+v/6//s/+v/6//r/+z/6//s/+v/6//s/+v/7P/r/+v/6//s/+v/7P/r/+v/6//s/+v/7P/s/+v/7P/r/+z/7P/r/+z/6//s/+v/6//r/+z/6//s/+z/7P/s/+v/6//r/+v/6//r/+z/6//s/+v/6//r/+v/6//r/+v/6//s/+v/6//r/+v/6//s/+z/6//s/+v/6//s/+v/7P/s/+z/6//s/+v/6//s/+v/7P/s/+z/7P/s/+z/6//r/+v/6//s/+v/7P/s/+z/6//s/+v/6//r/+z/6//s/+v/6//r/+z/6//r/+v/6//s/+v/6//s/+v/6//r/+v/6//s/+v/7P/r/+z/7P/r/+v/7P/s/+z/7P/s/+v/7P/s/+z/6//s/+v/7P/s/+v/7P/s/+z/7P/s/+v/6//r/+v/6//s/+v/7P/r/+z/6//r/+z/6//s/+v/7P/r/+v/7P/r/+z/6//s/+v/6//s/+v/7P/r/+z/6//s/+z/7P/s/+v/7P/r/+z/7P/s/+v/6//r/+z/7P/s/+z/6//s/+v/6//s/+z/7P/s/+z/7P/s/+z/7P/s/+z/7P/s/+z/7P/s/+z/6//t/+v/7P/s/+z/7P/s/+z/7P/s/+z/7P/s/+z/7P/s/+z/7P/s/+z/7P/s/+z/7P/s/+z/7P/s/+z/7P/s/+z/7P/s/+v/7P/r/+z/7P/t/+z/7P/s/+z/6//t/+v/7f/r/+3/6//t/+z/7P/t/+z/7P/s/+z/7P/t/+z/7P/t/+z/7P/s/+z/7P/s/+z/6//u/+z/7f/s/+z/7f/s/+3/7P/t/+z/7P/t/+z/7P/s/+z/7f/s/+z/7P/s/+3/7P/t/+z/7f/s/+z/7P/t/+z/7P/r/+z/7P/t/+z/7P/s/+z/7P/s/+z/7P/t/+z/7P/s/+z/7P/s/+z/7P/t/+v/7f/r/+v/6//s/+z/6//u/+v/7P/q/+z/7P/s/+z/6//s/+v/7P/r/+z/7P/s/+z/7P/t/+v/7P/r/+v/6//r/+z/6//t/+v/7P/r/+z/6//s/+z/7P/s/+z/6//s/+z/7P/s/+v/7P/r/+v/6//t/+v/7P/r/+z/7P/s/+v/7P/s/+z/7P/t/+z/7P/s/+3/6//u/+z/7f/t/+z/7f/s/+3/7P/t/+z/7f/u/+3/7f/t/+3/7f/t/+3/7f/t/+7/7P/u/+z/7f/s/+7/7f/v/+z/7v/t/+7/7f/v/+3/7v/s/+3/7P/t/+7/7P/w/+z/7//s/+7/7f/v/+z/7v/t/+7/7f/u/+3/7f/t/+3/7f/t/+7/7f/t/+3/7f/t/+3/7P/u/+z/7P/t/+z/7f/u/+z/7f/s/+7/7f/s/+z/6//s/+z/7f/s/+//7P/t/+7/7f/w/+3/7f/s/+z/6v/s/+v/7f/s/+v/6v/r/+r/7P/q/+r/6P/q/+r/6P/r/+j/6v/s/+z/6f/u/+r/7P/q/+z/7v/t/+3/6//t/+j/6//n/+z/6//t/+n/7P/q/+7/7f/r/+7/6//w/+3/7f/t/+3/7f/w/+3/7//s/+7/7v/y//L/9f/0//P/8//v//T/9v/0//r/+f/8//n/9//+//n//f/3//n/+f8AAP3/AAD+//7/AAD8////AAAEAP////8FAP//AwD7/wEA+//+//z//P8AAAEABAD+/wEAAgAAAAYA/v8GAAIA//8JAPz/BQD+/wgADAANABEADwAPAA8AAQALABoAOQBcAGAAXABPADgAHwACAPv/+P8BABEANABQAGEAXwDs/7L/dv9Z/yH/5f7j/vr+I/9Z/57/+v9GACgAGADp/6L/cf88/xX/u/57/n/+ev7+/jj/av+B/1n/fv+Y/zUAPwBJAP3/3f+f/yH/eP59/dD8vvz6/OH9K/81ANEA1ACkAEgA6v9x/+/+R/6Z/R/9Hf2Y/eH+BwA6Ae4BlALPArkCbgLpAW8BjwCq/8L+Vv4o/nr+tP4L/5//FAAzAJAANQCm/1b+6/ya+6r6JPpV+ov6Hvt4+4/7C/zO/Mz9j/4B/z7/RP86/1v/Uf+B/wQAsAABARACJANZBAIFMAXzBFYEcwMCA5wCcQI2AtIBZAFjAWEBwQEdArQCDAPaAloCowE9AbgAOwCY/6v/5/+wADEB6AGoAhYDsgKnAlQCIQL/ARoBFgDU/pL9C/0H/VL9bv56/1YAGgFbAZQBfAFOAeAAbgDt/4j/gf/i/1oA4gBiAQECtgKIA/IDVARjBEME1gM2A74CXQJAAkUCdwKGAvcCYAO/AxAEMQQ/BBMEvQOHAxsD2wJjArUBLQG9AKoAygDYAPUAyQCYAFcAHQDU/3z/LP+c/gr+cP0J/eH8wfy4/Mn8mPxq/Ar80/t/+xP7k/rk+UD5z/ic+Cv4GPj29wj4AvhR+If47fhJ+W/5e/mC+Sn5/vje+AH5SPmO+eD5Ffpe+qv6+Pof+y37Vftk+1H7VPtB+yX7A/vc+uX6APtn+6j76/sq/E78T/xs/Fr8hvyf/Mn8RP2Q/TX+7/6k/yAAiAAEAU4B0QFmAgwDlwP6A0YE0wRDBSwGCwfXB88ISwmbCf4JJgqdCvIKOwtyC78LKQy6DG4N6g1fDpoOBA9tD70POxBiEJgQ1xBxEb8RHxJUEu8SkRMdFO8UBRaMFjoXsBegGHgaxRxGH5ghqyO/JTYnHynVKl4s1iskKwcmbx2LEF8CLPj/8WHzO/sLA1EHZAZ5//72fu625sfhMdwP1yTU0tGS0hvWhtlc3aLfwOHz5D7onOrM6tnmJeGE273Zot0u5uzxw/zCBNoIoQkMCJ8F7QKNAO/+Pv4V/3cBWQTrBvIHOghECJYHUwdTBt8DpP9r+fjypO2Q6rnqGu0/8P/yF/Qj85Lw1ewX6Zzl/uI74kbjEuZ66d3slu8O8c/xt/JN9GP2xfjN+rT7ufvZ+5f8of7uAegFsQmLDB4OiA4gDnoMvwpHCQIInQcrCFMJgwrBCr8JLgj2BcYDFAKeAD3/d/1F++n4//bb9dD1cfbk9p33jfcL9471NvQC82jylfJO8yz1J/dy+TX71PwP/iP/NQBWAcECdQN8BPwE+QXgBvYHFwmhCUoJ9gjFCAcIEwahBC4DcgFH/yr9pfsJ+hb4ePYI9S30QPM08qjwtO7n7IvrP+oV6g3q/Onv6fPpVepW6ynsRO0V7pnu1O+M8OTxTfMX9VP2iPcn+Y36V/wE/sH/JAHtAYUCTwM/BHgFPgZxBr0GagaVBh8HUwhaCbgJhAnzCJIIPgiUCL0IhQlNCqAKIwtzCwQM2gyxDe8OZBClEdYSuhNCFOIVZhdtGV4czR5iISYj5yT2JlAoLSpDLCIuljBnMl014TgFPIw/jULORRtJUUyKTQ9KNUROPHUtfBnbBl/5mfOr+CcHdRgdIL0YCwfE77Xaxc1zyqfNnNBr0knSG9MG1LHWi9mp2OvVndNZ01zVZNd72RDa5NgB2+Tize59/M4GfwvDCIYApfla9pT5XgBFCWERahfqGgwb3RiYFB4Oxge/AtkAogFpA5MEhAPP/+36d/ag83HyD/H+7hfqg+QW38Lbu9uI3QrhiuSv5oznquY35eTiHeF14BniFuZW7DDz7vkc/qb/CP9z/bb9rP/FA2EIBAzvDrIQnhGjEgsUSRVzFbUUtRN3Et8QMg9UDdkL6wmTCNQHJAcyBqsDvf+I+mb1tvEA8Hjw2fGl8hzyWPCc7RvrdOn66EXpDeob67bsnu7E8JfyL/Ta9Mz1Gfej+Db7e/16/zwBugLPBFkHSwpVDc8ORw/NDtUNrAwiDDwNLQ5BD2wPvA++D7MNZwsiCPADLP739//yj++J7X3uo+9Q8L3uiewg6VfkGOBK3SncRtyN3WrgcOO05UHnKejh6L/oCul66prsn+4w8HPybPWe9xT6vfws/7QA4gDZADgAAQA+AK4BAgQaBtAHIgliCboIMQeEBbUDuwLRAqUDsAU1BykIQAiXB+8GMAYxBoAGkgYNB1wHUwh/CWMLBg1jDjUPSRBbEWQTlBUmGO0ZRxzMHeAfmyKwJTcqjC4CMtE08jUkNi43sjmtPQ9CmkVnSfNJVEoiSVdIdkVFPiw0dyL6DRn+dPrt/4YPzyG/KvMeKggR7DvXUcnYyPXPT9YT3Gzda94S3dzYitMhzMLESMLcxZbOZtev3Qrfotws2ybfDedK8RT4b/r89gTzmfGl9Bn9vwaDD10VHBdKFpYSCw6PCZwFZwR6BsIL6xCJFI0TkQ6nBin+2vdh9OjzXvQw9Jrz1vGj74/srekS56nka+Jt4RnhduFq4bLhPuJr43blzOgo7CHuUu5V7V7s/OwH8Gj1nPvwAQQGjwiGCWwJnAhTCBIJrwrMDb0RhRXuFy4Y+xaWFM8RpA8rDo8NRw3WDOoL9grbCXUHkgS9AYL+gftM+VP4e/dI9vz0fPNw8tLxRvFP8Ufw5e4r7XDs9OwM7prwO/PW9OP1sfar91T4ZPm7+kL89v1BACwDJwZoCJ4JBgryCTEKMQsPDVUOxw9aEOgPLg+JDuUNWw2+DPMLwwp8CUcIIQcIBS8CKP9V+2L21vIK8Uzw/u8t8OPvce4o7HDoSeWY4sDhzuEC49/k7ub0517oqOiN6L/oeOkQ69Tsku7U8L3yvfSW9mj4wvmO+j37IPyG/aT+fwBwArkD3ATeBNoEZQTHA+YDIATRBLwFBgYyBiMGqQaYBjkGQwZQBSEF0wRgBVQGSQcyCMMI+AhuCcYJbwplC6kMuA1DDpAPmBHmE+MVjxfIGKwZhRoUHOweHiJSJconyin0KoorfC1UL2oyiTUSOPY5LztiPUo+UD88QM0/tkCLP0A/qDpiMAIc+Ab5+qT77wfRHUUsfSmGFfr4Y95qzZTNQdb+4uHo9urs5wzi+9rQ0s7LAcWMwOnDm8zm16ffJeJp3lTXvNOs1YfcauST6sDsNusD6gTtA/Sz/GUDWgdICHkFRAOUAq0DzAULCPMLig+BEuQTshJ0DtQHZgF6/Yr9YABEBH8F3wPb/5v5svQY8ZzvUe7o7AHsHOtI6tjpMunz5/nl9uR95JDl0ubw547oVuig56voSuse75jzBvfO+IX4DvgC+PD5CP3rAMEEtgeoCaUKUQuFCwoMAwxoDIUN+g6bEHwRchGHEOYOKg1SDDMMwws8C8EJTQg8BsoEzgPqAigCEAGW/439Kvsi+cX3tfZG9iD2QfaX9lz2/fVh9UH0NfPH8ufyS/R09hD4tfmK+tn6ffql+jP7Xvy1/VD/3AA9ArkDsgR0BUQGYQbrBlUHjwfzB6gIIAkhCZ8JkwmjCQEJkAjAB/IGfwVqBOkD/QNRBNwErQTjA7YARP0U+mr4IviC+OL4svhX9tvyefCw7yzuh+1v7hDuDu0a7FHsOOvQ6lzr/OtE7CTspOx87Svusu5x71vx6vKI9Ob1iPbk9ar1fPb19xj6NfxE/jX/rP8iANAAewGlAZQCFgPwA/UECAbWB2IIUghyCHMI1wg4CX8KZwsVDDQMLgycDCgNVQ3fDQEOJg4WDm8OKA8WENIQVxEaEowSHxM4FNsUIxWNFe4VuhbzF3wZQBvkHJgdwB08HgIfRx+SIAoiTSPEJF0lqiaiJ1UnASgAKe0qhSs+LFUuoy3CLKcpfiSBGK8LwwT8AXsJkBV5IUAgyBIA/yfsnuC53ebmePGF93T2evDe537f5dgX1vnUkdH90RXW4trb4FrjHeFZ207VYNLM1HLb1uCn5Urnq+dP6e7s9PD38xT1MfRd80fzJ/Z6+2cB8QX5COwI+gesBpMFjwQxBJME6wWqBxUK7AvxC/sIZQVvAef9Zfzi/Jr9A/4c/Vn8c/rY9571D/MB8cfuBO7b7tjv1PDA8DDwf+687L3re+yG7Rbv4vBX8nTzffTw9Qf3P/j7+EH5zfpf/O7+dwHxA+cFegYAB6IHsAjuCcMKmwsVDFcM8gyFDTUOog41DooNfAyPC04Khgn+COYHUwfZBjIGPAXEA7EBBQDV/ZT89/tX/H38H/xX+5j5Ifjf9mH2avYM9xn3rPfE9873MPgy+F/4pfgQ+Xr5NPpO+4L89/0Z/+v/bwCuADEBbgHGAeQC5ANlBC4FygV8BlUHFwi5B8UGxgW+BHwE3wSlBa4FZgWkBCsDWQHQ/7P+fv17/BP8+vr0+e74BPdl9UTzbvBm7xnvSu/J7mjvAu/N7RnsJ+vy6tXq2+vt7PbtXu557jXv9e/C8F7xUvLq8lX0NvZp9474evmT+tz7X/3x/uP/1QDDAS0C4gLiA+8FegdiCJAJ6gkaCucJYArXCqcLgAwxDSgOtQ73DnIPDQ+HDgoOyg2KDtYO2A+eELYQcBCZDxcPyQ68DmkP4g/dEBoSpBKMEpsToRNmE0ETYxOtE7cU7RVsGCAaSxofG2wbXRpDGq8bqhxBHsofLCClIB8hWyF/IVQihyJKIgcgbB85Hm0aGhdSEL0KmQbzBNUI6g3gD8kLnwN/+cjubOmZ6ZrtuvCn85/xf+yD5RLgTdwD20DbCtzM3Xfe9t824Ubgud5n3HvbZNyi3s7gtuOE5U/nO+lB6zHuk/Dy8cTy2vKh84T1mPgN/fwAjAOtBKAE4wN+A7cDmgQxBnoH6giWCpYLgQtLCj8I0QU2BF8DOARtBVwF4wT4AtcA0v4z/U78Ovs5+vH4+/d39xL36/Zp9iz1kvMc8knxFfFD8QDyrPIz88HzFfTI9BL1J/XS9DD13vUt99n4U/tJ/Yn+P/97/8X/TgBpAYcCCQSBBd0G8Qf1CMEJ/AnnCcYJswnxCY0KNAtIC3kLEQtKCl0JbAjPB1sH2QaUBuwFaAWtBIwDnAJ6AUYAFf8v/mX9FP2B/Ev82/s8+8D6Kfqj+Sb5mvhX+CP4NfiT+P74Xvm7+bn5nPlj+U35r/mS+nv7j/yG/Rv+LP4E/tz91v0o/qn+Sv/v/38A6wARAQwBWwB1/wP+ufyi/Nf8oPyp/IX8jfsW+rH5r/hM9/z1xvUS9Rz1bPWp9Xb1ifT78rvxq/CP8Lnx3/Jp82bzyvI88lfy6vJ+8zz0dvS89Bv1QfZZ96/4e/nC+Q36i/pD+8/8Sf5K/34AZAEvAvgCBwTjBFQFygUcBgAHWAi1CXwLdAyyDCMMxwuvC/gLHg07Dv8OSQ+aD+APcA9DDx8P9A4dDzcQzhAoEYQRDxF8ED0Q6Q+FEDgRKxH9EOEQ2xA5EVAS2BPUFJQUkRMBExESthEdErITdBWWFs0XuxiZGKIXpRbjFaoVMhe9GKsaNRz6G0cadRl8GU8aURsCGlITXAubBFQBgAObCjIQHxEmDtQEdPmi8XbujO5+8pj2f/eY9UXxDezx5kbkt+ET4A/gFuKW5NzlRuZK5Anhh99E37ngheKF4yrkMeRz5Wroa+zi7wnx2/B57+zuqu8E8j32Rfr8/N3+i/+S/+7/MQB9ALkAOwFyAs0ESweUCIQIRwcTBcYDCAOJAycEZAQEBHMD8wI1An8BSwDn/iD9FPs3+tP5J/q6+rL6NPrg+Jz3dfaV9az0SfQC9G/0UvW59hn4kvg/+E73hPZN9iD3mfim+kL8dv1s/gX/Y/8rAHcArgApATsCVAPQBFgGQwfxB9YH4gfVByQIcAjoCGMJjAndCcwJlglwCdQIJggmB4sGFQaoBYMFMAXbBB4EBgPyAbMAAAD5/m7+D/7J/cL9Qv2p/ND73vph+rf5bflv+XD5e/nH+RT6Kfol+jj6S/o0+pr6wvoX+7T7VPwa/bb9Ef5W/iT+Hf4m/mb+Ef+B/3H/UP+k/nT9C/x7/BD9JP2t/Un9c/vi+b74iPiN+Ar5Bfl/+JP3Gva39Lb01/QD9fj0TPXk9OXzgvOc86Dz9POD9MT0H/Uk9Zb1t/UY9uX1dPaR93j4fPlJ+hX7mvt++wf82fyK/Yz+m/+tAIgBFgJbAq4C6wJFA/gD6gS3BZUGMAdAB/gG7gYxB6wHbAhACZIJ7QnnCc8J2AniCQ4KeQpKC8EL7gsYDAMMPAwADdkMsA12DvIOKg+0DowOLg4tDgkPdRAsEUgSwBKxESASCRKbEbIR5BHDEvUTeBSeFNQUDxTiE00UdBTIFPUUNxV0FfsVXhXUFTQW/hWhFTQVJBVhFgkW7xbDFggTggwcBmICzQEABu0KpQ4pDUoGr/6c9/LyivLc9L/2RPie93T00PGM7UfqwOjE5/Tm++aB5z/oh+iI54bmguVv5Rbm0Oa15tblneVi5nrpuuxp7zHxIPEu8Bjv8+5x8Efzz/ZG+un7RP2E/Wj9wf2q/ez92f6AAJACjARkBs4GAAa8BG0DRwOAA0kEQQVuBSoFkQTbA/EDWwOCAgwB7f8E/3f+9/7h/tv+Yf5w/X78WvtP+h76Yfnu+NT4J/nV+VD6cPo4+kf5X/jY92b4WfmH+nz7Zfzp/Aj9cv3C/Q3+Nf52/gX/GgAhAVMCPgOpA6cDEgQvBFcEtwQFBVsFowXOBYQG2QbUBp0GJQagBUAFmwR4BGMEiQRLBDsE2gMaA1ICTgF/ALT/nP+E/4H/Vv/8/kr+ov2o/Dj8+vud+277Ivsh+wD7Jvtt+5b7gvtv+876bvpV+uv6c/sg/LP8Bf0G/e/88vxj/S/9qPzO+zb7CvsG+/37yvzY/N/7B/uT+E33xfZK+FP5+vkO+if5hfef9cP0lvT19Hz14PWI9lH2evWU9Hn0MfQf9Nn0MvVh9Vf1rPXu9VP2ofY+9/v3Pvh6+M34ofmT+uL7xvza/YP+k/7c/nX/FgBZAWwCawNLBOQEgQXaBT8GKQZABhwH5wfSCNIJJArrCXcJVAmDCRoK2go0C5ILoQsnC0ELKQtXC2MLPAsnC70LsQsWDJcMuwwvDAUMowsiDJYMxgw5DeMNig2RDR0OIQ+9DuoOWA8DEL0PzA94EH8QTBB7EBcRrBFtEZQRExIrEg4SaRLKElYS9RGREhsTrBJQE7kTgRPCEvkRhhEDEnsSiBGWDwMLgwYbBE4EJAfCCdsKWQlxA/z9DvqA97H3vPlL+x/60vj89Qbz+PAO78Dt6ux07OLs6eyG7Ozr+ult6HHoUegh6d3p1+kk6VHoKuiM6Z/sbe6S7wzv0+0V7Zjtne9G8nb0MfY79wX4c/j++JT51Pl8+n37af18/5UADwE8AYwARwDVAIoCkgNvBCcEYgNEA/YCYwMkBEEEGQRgA4wCTgIkAjcCJwLAAfAAmwArAOb/Yv/T/oP+8/2W/bH9sP11/br8+Pt9+3b7mPse/IX8Vvzx+4D7YPs9+5f7NPxg/Kn8tfwj/T79nv3e/S3+U/45/vX+jP8CAIMAwAAsAXMBhwHVAd0B3wHGAdYBWwLvApUDzgOmAzgDkQLXARQCUALIAgcD9wKlAhoCrwF6ASABUAH9AOsAdwAjAKf/R//w/lv+oP6+/of+5P30/Hv8w/tG+238XP0w/oX8EPsT+Q/5dPoS+zX7AfuR+OP2p/WQ92b4ePkE+sv44PZ69QD1kPRU9d72/fZm9+P2pvWk9SH1SvRP9Fn2Wfd19/T2j/bz9U317/XA9/z4evmp+Z34MfgU+KX5pfoD/L/8PP29/Of8pP2F/vj+vf9XAKQBPwLHAjEDKwONAwoEmwSBBZ8GJQdQBxoHcAc4CKAITQnMCbsJgwn2CQUKaQoMC6sLjQuaCwkLlQvUC28LfQvaC6gLswvgC7MLpAtKC5oL0wv0C5oLaAt6C50L1AtOC84LKwwzDAEMIAyZDDEMoAstDFEMAwwHDD8MlQzuDCsNmA0xDskN1Q3fDZgNZg3TDToOJg+hDvsOBg8nD8EOrw4BD7MPiQ8nDzgOgAsGCToH6QUPBqIH4wjzCagIRgUMAgj/Zvzb+1r8Ef1R/eH8QvvJ+VL3rfRn8+nx0PEV8pPxP/GC8Pjuae4I7rbtz+2j7bTs0etM607r4ey+7eHuxe/w74nvNO9F71Lv4e/j8IvyBPSy9WH2pfaC9oP2pfak9wn5Zfpo+y38hfzJ/NH8xv2G/u3+kf9k/6b/+P9+AAIBkwHiAUICFwI7AgsCsgFxAWYBYgGiAV0CjwJjAuABQgHNAIsAuQDiAAIBBwGkAGkALgDm/7H/iP9B/27/Wv9//0P/TP/5/tL+9/7T/hr/Nv+H///+xf7K/vr+Nf9+/9z/CQC6/+T/uf+//97/5P8+AHsA0QAhAQ4BPgGZAIYAbAC5AM8AAgEYAc0A0wCrAKMAuwDZAL0AxgAzAOX/4/+S/6L/kP8TAHX/wv94/zv/mf5h/sf9pf1k/RX+6f0f/ub9Bv30/EX8Tvz2+zv8Qfw1/Or7y/tr+wb7Rvtd+0/7l/rI+jf6dfkE+lH6Qvqn+jD7v/pb+g365Pno+fP5hfrn+lr7xftV+4H7bftW+9L79Pud/MH8lf26/ZX91/3L/eb9E/4C/47/V/+//+//JAAVABoBAAIJASkBwwInBGQAoAIPA14EBAMuBB4FoQQXBGsFmgTPBDAFrAVTAzMGUgb4Bn8FkAWeBv4FAgarBTsGhgZwB+cFqQZpBz0GwQXvBu0FRwb+BpsGIwalBYoG8QWRBl4FBQY3BmkFDwb3BUsF5QVUBB0FiAW2BMoEVwWeBFMFogT1BMoElwQlBY8EeQTcBLwEqgTLBC8FiwTCBKIEFAUtBdwEbAV8BSYFfgXJBXUFoAU3BWoFcgQOBLwDtAPOAwsEVARlBJwDQQMSAh4ClgE/AWQBvABYAd4AbQABAAv/z/6P/QD+ov3D/f38vPxf/Mv7b/ux+0D7GvvK+on6LPqD+cb5gPmo+Yb5iPnI+YX5efkV+fb4DvnB+Dz5X/lu+cD5T/l/+T/5Qflj+Ur5tvlN+cj5sPnz+R/6Afr/+SL6Avpg+kr6uPqf+sX6QPsV+7v7xfsA/CL8I/yP/K78Kf2Q/Xz97P3y/W7+hP63/uv+Kf8S/6f/mf9hAD8AiAD+ALwACgG0AD8BTgFQAbABwwEPAhQCLQIVAjECAwIkAlMCcQJOApoCYgJ9AncCWgJvAk0CVQIyAlgCJQJaAhYCEwIhArcBHgIaAs8BwQFVAbgBeQF5AXQBQAEvAQYBCAEBAaMAtQCEAGoATgAIAIsAFABWAL//1P+L/7r/s/95/3//nf9+/zv/Pf+g/z3/KP8u/wb/Sf/v/kr/Bf8n/zL/TP8V/+n+8v4C/0r/wP64/hT/vf4w/9n+hv7Y/of+rv64/kz+e/6V/mL+3/1m/hT+Mv4L/s79m/3M/rD9q/2Q/Z79Dv6F/aH9hP2n/bn93f36/K79yP1g/nL95v0I/qD9TP7V/ej91v2//lL+cv4h/rj+aP45/rL+MP+X/pz+6/96/sT+m/81/0v/iv+1/5L/k/9SAPr/6P9hAMf/OwDqABoAbADOAMgAtgC/AJAA7gA6ARgBngDNAT4BeAETAU0BlAE0AbQB7AEvAaQBMAJdAcwBJwG4AhYCbwGgAgEC4QHbAccBRQICAhYCOgILAsEBtQHBAuUBogFfAtgBJwLyAQYC7AHSAeEBgwHEATQC/wHEAe8BygFVATYC2QHHAXABzgE7ApYBxgGYAesBbQG7AegBbAECAg4CtQHnAcMBtQHNAcIBzgH7Ab4BIwKpAbkB6QHDASQCygEzAtgBHwIiAt4BOQJeAj0CEgIXAkMCHwLrAUgCCwI+AscB+QGxAaMBywGvAVIBogFZASYB0wAZAdsAzgB1AKYAUgCxAAIA6f8LAJL/v/8u/5H/Vf/F/mj/Gf+A/nr+p/7+/kP+Pv7H/if+RP5U/vr9BP6Z/WT+rP3C/UX+iP34/Qr+Y/3+/cL91v2O/Ur9/v2E/bD9kv2l/Yj9lP18/ar91/1u/aP9vf2O/Z/9s/2+/ez9xP30/QP+9/09/T7+Jf7l/Rv+y/6C/j/+Z/64/mH+n/6//u3+Wv5i/6n/C/+R/h7/gf87/w//9v9H/wAAaf+J//L/cf9pAAsAnf/Z/2sADQAPAPT/TwAUAC4ALgD3/6gADgAsAC8AHgBfAJgAJAByAP3/ZQC8ANf/CABmACoAHwAMABIASAAXAKz/3/9RALn/GwDE/1X/s/9IAN7/o/+O/1P/k/8X/2L/zP/9/nH/Tf/y/qL/3v6e/1T/+v7K/sD/E/9x/m//A/8p//P+r/42/03/Wf4m/1b/rP6s/kz/+f7S/hX/3v49/+f+Zv5e/x//M/6r/0T/FP+h/tn+D//G/1z+K/9I/6n//P5h/+L+k/83/1b/zP+O/mP/1f+WABn/3v/6/w//EwDE//D/kwBg/z8AXwB2APr/3QCq/yYAfwGmAAYAxQAJAYIAUwDzAF8BVQEcAdgAGgGeAGkBbgClAUMBQgFbAiUBPABbAiICvgBLAe4BhwHvAOwBIAEqAekB8QG5AD0BiQHMAUcBVQHcABkCvwF4AFwBlgFeAeIAJAECAkcBBQGDAaUAOAHbAJMBEwAqAAwCCwGW/2UBngHF/38A7wAFASwALQGLAYsAngCfAbwARAA8/9kBrQDoAGABsAAkAQUAYv/zAYAAn/9dASEBpwAr/98AiQCf/7r/swDfAPP/uADyAHr/pP+HAEUAcwAaAHgA+//c/0kAyQCp/mX/MACYAub+f/+x/9H/Gv9MAOj/dP8tAZP/Sv45AmUAxf5p/osAwf85AIf/9/++/9H/6f55/9T/z/7dADMAjv4sALf/DP5v/6EAVP+T/2f/vP9CAFX/Ov5l/gsBQABK/k/+YAFP/tv/Jv6R/psAj/57//YAb/5U/pUBo//E/kL/yv9NACgAwP+2/nUAkf5V/7ABhP7I/6QAtf4QAUgAGP+jAAEAW/+PACQBXgAt/6sBo//q/G0A+wFF/sv/0QA9/0L/HQD8//D/c/9MAPMAjQC4/Xf/SAO+/pj98f/CAD4BZf/T/qX+7wAuAIn/dP8CAXv/5gAF/zf+g/+lAWz/SQAtADT/HQGw/SL/8gC0/Q//4gAa/UIBUAGn/Vr9EAJn/ln/sf/B/+IARwDK+w0A6QF+/jD+pwCUAGP+Wf8uAWEAPf08AZUBF/07+8YDr/8S/n7+RAGTAWz+Nv7wAXYAXACf/gEAWv8V/QcDSP7Z+9n/WQGwAL/+v//Y/lD+6/+aAbX/sv6G+wUEKwCs+Qb/zwAHAa//3P1bBJsAoP3vAYL/5f6Z/v8B8ADu+qD/hwT6/T792v7hAR//DP76AWEAUf/z/sAA8AGe+wv/GQKH/sf+2AHsBHP7r/9oBU8BVQCX/cf+RQJSAMb/NgGY+8P+sgAMABT+qPuAAaYDSP7u+/QBgADb+pICFAAU+ugCMAMEAPv/ufsxBe4C0Pxt/NoBYAFW/G//twKH/mX8lP8KA1EAyvztAfv/Zf0yAsYAJf4HA/r9xf8PAxv+Lf08Au0A+v5j/MUAOQHtAe0A4v2A+dgB0QX2+/3+zf0YAv4BTwBA/Gv8xgM4AeL94P7bAE4BdP9E/04Ck/8K/jX/vQF6/9P9JQKB/5MB1/+5/MAANwIr/n4BoPyK/wcGmPue/3YFFP7zAZwAyfolB/oEUfzw/MUCbQFn/1oBZv+h/qX/OgNc/S/9w//IAOj/Jv5p/yEFl/7Q+4P++AbK/Wn7nQEuBfr/nP7x+RQFjgSY/Lz+Ev/W/GsGdAFx+BACjQUnAE3//fy+/CUHYv4r+R8EIwgZ+8j/Yv1QBPMB9Pnf/ugICf7Z/UIDRf70/iQDXf/8/DEBUf8MBT0Bv/xEAY3/4ABHBJX+p/1hBecASPvY/I8CTQK4/goAqgQu/iL7FwU1ArH4pP5eCTMBpfyY+rUEcwHu+h7/8wEEANz+GAXsATH+SP2k/pj+6P/mDU8AY/RH+y4EUAh5+hv67ACdA3QAGgUm9Tn7mgdmA238bf1dANkAs/4XAXsAl/kE/KMFIwKUAdX+Jf27/Wj8cAPLAQ78ov/dB0v9D/yIArz9ewHsBKj6k/v2/AYGfASG9+H8dgHaAWkDbv6p9r78vAeeANv5/fxwBh3/af0fBXv/hfqz+2oDSAUkA4L3sv/iBEMEUv7/9Ir8yf1LCtwGVPlq8DwFrAiK/zH3gP6qBeoANv+++wT/1QHQ+2sEKALJ+YsBXgHy/psBBfkr+zsC6wZJDBb5HfnhAWoDXfuK/W4BvP9/Ay8FkvwX/NsCTwDqA1f7ov+zAtb/CgHG/OP+ygCIAJoEo/+a+nwEjP4F/AX5VADvCikKfPsP/dP6dAErBm333fxeAaIHUwJ3/er/SfnT/xsFBv4X/tEAif7eAtoDHAGr/AX6OAfrA8n8VPjaA18C4f5RBfIACPtiA8gHsP+y/H/4yP0DBv4GxACD9y0GtgTD+toAI/46/AQA1wPiAjH+OAJlB1EFZP4G9VL73gAeBfwE2QGn/9gC7ALd/Sr6jv27B60BjQAF/Z0BywZaAoz/N/6DAp7/pfRBCNsH/vyo/cz93/0uChYOg/nu9jr7UwFrA2X/6AGZAJACDgE2A0f8ovzz/6f9CAEFArf9/gTPBYoABQEh9+r9ZwLEBFwAYvWw+0gKVwnu/TL+1f6h/28Akf/O+9/51wAEA5wFCQFQ/1gABwMu/Fn3AAAuBAz+qwM8Bd3/EAGe/l8AAf+h+Ev7vf+yAZICNgfNBY76if+lAN3+Ef5p/7j/Y/xp+fMD4wQdAuUBJgLsAWn69fu1/N/6ngCKBAkCKwSCCAYBNvnu+Xz8Cvh4/g0ABwZSDG8ER/3E+Wn7tvyr/BD8gAKgBqEDBvzp/pcAuQO5AnYAz/vS8pwAHQgk//j57QazCXECdPuK/tr60PeG/VQF+QDA+0gMNwlB/mD32PdY/JcB/gT//o4A8wMdBv7/YwHG/WYAiwLP/q/+uvpi+mACDAfWARUADgFVAMsCM/0p+bX1V/5qBqwHogILAZwDbfyW9ez9Vv6w/dEAuwJjAS4AGQF/AVL+UvfuAJUFdP/OAbEAm/0UAH7+fQADAhUAVQJeAv76LfcGA5QHrv0X/c/9jgJ9BvP/D/xeAGb93Pnc+y4GZAPMAz8DDvso+jz8K/8zANkADAOX/5f9pP0mAT4EnABw/h72LfxwBVEECgVO/gf6jfpsAWsGowDe+Wj6dfns/C0FTAQgA5kDIgC6/GX5H/7SBJL9/P3T/q0C+QHqAN8FfQGs9Sr4WAGYBsL+ZQIPAi7/lf5D/rP8V/6OARoD3f93+xn/mwH9Ar77Iv7f/3wBaQgQ/mH7Tf8q+Tr9HgXoAMz/rAGF/b399QFNAHf8Mfu+BMQE3AMr/k8Ayv+e+oT6fvzOAQ4IEgSjA4EA3/zu+CL6EQBfB/oBcgImBcQCqgAF/1D4i/vhA0gCawShA5f/gwGAArL9VvxM/yIAk//2/5z/LgDfAm7/6P8jAZsAqQDL/Sj+O/0S/vAB5QLMAn4CFPo8+G0CgwEEAUIDggPTARr8b/rJ/Y3+BQPlBYr+Avs2AXkF8f6v+3L8dQBDApIFCgOz/JH9GP0p/OkBTQKsBR4FCAKT/hb66Pj5//UDjgMR/bwC/QPSARAADvw++B/8PQK5BYEF5APj/+39uP7g+8f/KgAx/oYB5QGn/1X/Xf8AA8QAEf3BALcBuQDC/7IABv7S+ncBewVQBE0E/f9i+/v7Pv4NA2L/QAFrA+oDSATvALIAIf5W+8gAegOaAA8CLgPmA6H/0QA5AioElQM0/yT/Yv/X/rUCKwPYA5QBWP2Q/nkE3wTIBI4A0fhl/gUD3QVcBv0BXP/7/nj9FQBbAEYBwv4l/noAQAXtAzgCJQO1AS3+Tfnp+hYC+gFYA3sE2QMYAiYA2/9A/6X+v/5E/mQD3QUZBnwBz/6CAXUBRwHpAv8DBAM//3j/X/5A/Y3+hwWyBg0Cgf4f/Fz6cPsa/5MA0//N/3v/9QHJ/XL3XPdp92v5Qfsu/oX/qP0w/o/5PvTD8zz2I/iX+Wf5b/f182j1H/cI+Pb5SvfM8zTzefTR8m7zhPNX9X76ZfwD/dP4I/TI8a7ytvOX9TH7EP4K/on7B/cj9Hv0l/ZA/OX+o/2h+rH5MPse+dz5QPpe/Zj/RQCsAEP89fjd+Sv98gDXAzMDuwCmA+T//PuB+079lgLjB/EH8wVTAqgBHwPR/8v/TP81BG0JHgztBuwB2QGtAJEAYQQEBjwFwgfbCq4GXgJFA/0DrQT1BSEJyQsyDIYJMgalBAsDaAiDDhEOjA1lDM8IbwaMCEMMZw25DjcODAyVCq4KggkZCjkPyQ+LENQP5g+sDwAOEQqcCxcNmxGiFOYVNRWBEnURARG3EMsS5xg/G/UZkxiZF5IUcBKaFPYPzgvKCwANIRGuFG0Spg6nCq8CTf5fAV4AEgGYAsIADwCD/WP65/cq9N/y8vH+7unuMu91717ukOyd6vjo6ug26ZPoQuii5UPl3+Xb5b7nV+oM7Djr5OmF6Nfnz+np6hvt6e7x79Dy7PR69pv2gfUf9b31bvYW+B37U/4HADAAiAANAL3/fwCMARQDeQKlAkADpAMLBa8FWwUcBfwERARFA2oDbQPnApIDcAPaAvUCjAK5ARwAW/5x/V/9r/0h/uX9hP0r/MH65fgX9yr23PWh9q/2jvZe9YX0o/Ow8lPyUPLd8cDxIfJW8TbxwvA+8YvxvfHc8XjxzvHE8eHxkfE48fHxzvLX80P16vUD9kv1oPSc9Eb19vZp+EL5fPmn+ab5gfkM+pz63vok+9f7gfs5/C39I/7G/dD8d/yh/WMA4ABfANf+Wv0t/RT/0gAcAisD3gKzAssBzwGXAVwCfQU4B5kGOwbtBpII3AhzCbwJUAnGCssMwA0ZDqINsA7lD5sRcBMPFRAVoxXPFRUVfBUoF3Masx0FHwseVB2LHMcduR6rH+0h+iPFJdEm8yfmKGEpNypYK/0tmDB/MlgzkTK5MBEp5iEvHoIchiCCJesoKSoDJN0a+xKgCycIWgfkB+4JOQm5B0sCf/w++APzhe496mnnw+cQ6MzmF+Su4B7dzdnT2ALZP9gq1+DT5NGx0VbSUtXE1yLaR9v52RXZ/td42P/a9dy+4CTkROen6mbsYu3G7YDtY+5e8Bf0J/ho+5n9g/4I/2H/XwAaAmAD/AQvBgIHCQg1COUIRAmoCCcJtAjQCfMJRAmvCEEHOwaQBU4FEwWxBMADlQKqAJj/Bv9O/iz++v1L/XL8NvtM+l75CPlS+N73dvds9xX49feG9xr3j/Yw9r71vvWW9vr2NfdE91H3GPcg90b39/YJ98/2yfZP97D3MfgP+J72f/WB9F/10vU39nv2EPbB9Ivz7fJ88sfyMvOk8hLzKPMF81/yYfGc8NXv+O5Q71DwF/Hh8fPw8++t7nzueO/m8PvxCPNT827zFvMg80j07vRC9YP2Zvf7+Nv5MvuT/D79Df6L/mv/zQAoAmIEGAUTBsUHLgglCUcKzws6DQUOKA8CEPQQUBIWE+kUbBaSF2kYghgUGWUafBqTGyEd7R5QIYghgSKEIuUi4CPDJKQmtCcaKR8qiirdK3kuRjFTMkQ2nTncOwE+wT4uQJ8/qDytO/wyoiiPI2MjfCgJM846QD3rNLQfQRAzBff/MQfjDMMRqRPvDo0El/qz8AXrk+VM4T/i7+QG6JfoXOZx4GrXKc/Nyt3Mns+80VPSWtC+z+TPzdAg0vPTDNRC07rSttJZ1EXYwNtj3wzj7OUW6Evpn+m+6aLpm+qs7B3xPveM++j+0v9M/jX9h/ty+8b9LABjA24F7wbCCOEHVQfSBWgEtAPhAvYC8APOBOAEXgTiAtABLwBP/3/+mP1s/Tn8kfvt+y/8u/xV/aP8t/ug+lH5wvlt+ob7gvzW/FX93Pz9/Kj8HPwU/DT8Xfxf/Xz+dv4v//r+Cv7k/JX8V/yZ/LD89/tt+4f6B/ne+Cr5Tfk++HT2H/QE8rrwxu8M7xzvne4G7mztaOw37NPqTel155Ln0OfQ6JHp8ekP6lTpoeiv52ro++hj6iPsH+3b7Vzur+5q75/wHvE58kPzU/Ra9nP3BfnI+eX6hfy8/dH/pgAWAgsDtAM7BY0GwwisCkQLkgyXDBANcA1wDf4OAhAiEVgSOhPNFAIVDBU0Fc0UbhU8Fp0XaRkDG7McJR6BH8sgoCFCI3AjiySEJn8nJirALMYvtDLaNGY34ji2OyQ+iT8lRcNGIEvpTAxOxEtGQl00xSmlJvMqaTQuRUJIi0AoMQgdgg3JBRUEkwj+Du0R1BFuDvoF1fml7ijjItqa2Q7eW+TK6mDqduQy2XTNtsbgxDvIIM2Zz//RpdLJ0QnSWtDWzsnNjs7a0J/UYNms3Ifex99/3gXhfeNj5Z/o9Onh6rrqEOt37c3wgvQd96j3YPff9Rb10vWI9m74kfnE+nb8OP0X/1H+Xv38+zr6evo9+2P9k/6K/9v+E/18+yz7tvvz/cf+u//P//X+XP9X/wEAZwEqAowDIwRaBasGTgfJB6kHSQeWB08HPwgDCTsJXgmXCAkIOAexBggHzQUsBcUCVwFrAD//x/59/un8ovuz+PT2XvUk80fx7u7z7U7uxu3R7XHsE+oG51fkseJj4objOeQi5cPkdOSK5IPjCONR49HjG+Uu5jHoxOn26kzrDuua6wvsb+3q79jxyvPp9K/1FfZy9jf38/ei+Ev67fo0/Cv+4P70/9AAuQDPAcABSwLUA4YEHAX/BeMGigdECBAJpQmbCngKXwsiDLMMHg4DD9AP4hBEEksTuRTSFTYX4BhXGhscpx4DISQjcyWlJ7Eogyq6KywuXzDhMtY1DDiTO0o/vkGeRL5GJ0koTOJPbVJaVZFR6kHSNrEs7SWvLHY7b0ZbSxpCVy+LHk4PwAQ0BUgFBAo6EJMTxRO6C0sAJu/C3krX/tUp3TropO7m7z7pON+604XMl8n+yHLMldEi1M3XntkK2BzVttB/zaHOi9Lm1iDcFN+33srcaNyd3qffl+Jo5SfnRejK5yLnp+Zc5krnuul/7WvvGfJ7877xNO8y7Pnpq+rA7eXyHPjY+4D8KPuw+Lv11/Px83r1K/nn/fgBKAXcBa8EOAJM/x//4f8iA8UGaAqoDR0Pkg/ZDnkNeAwHDD0NNA5BEMMRQBLBEf4PXA7RDLQLSAunCo8JuweYBiAEoQHW/6D9nfwQ+8P5BvlT9mPzafC+7djrAeu46mzqq+r06YvoLufQ5DvjQuGJ4Gbhh+Ic5Dbl5uTO5DXkG+QG5J/kOuVe5yroDOl76nHr1euo7DDtJO4970HwFvF+8r7yGPPH84H0rPVt90H4bfnl+Sj6n/qb+kb72fvS/Dn+4/9+AUkCFgO/AtkCuwNTBDYGdQcBCc4JrAoMC/gLMA0uDuIP4RFAEw0VHBYlF+UXuRkxG4AchB/jIA0jjCViJk4oKilcKigs/C2+MBAyBjRjNTY35jmlPD4/cEHcQpNFeUdSTIRP0FEdUrZGyDn9LQkl/SQfLpw3oDzXPi8ydyaHGxINZgcBAWX+KQMJCe8NSQ7eCO/6/uxA42Tf9+QA5sroc+m85TPiuNyX2BPVINIg0+XUe9hK2h7ZO9b20IjN88xW0H3W+tob34jfxN182wTZyNfI2NbZ0tw24SjlBujK6ezn1eSs4SnhMuO15vbqtu2w7wDvDu6b7Xfthe4Y8an0ovjW+zf98fyb+0/6ivo3/TUBgwXeCPkKkwtcCj0J0geMB5UIngpcDqIQthInEw8SjhFIEGMQ1xAQEd0RbBETEewPog6oDBcLhArDCa8JuwiXB3cF3wGC/kj7Jvl890j2VfZ99QP19fK+7+XsZeqZ51/mLOYC5mbmROZP5bfkn+Nv4obhauGw4RDje+PC48fj9+Mp5ObjyeQ15grnXOhO6R/qWeoU6k3qxurm69jsce5Z76Hwg/HK8RPyZfIE87zzzPSk9tj2Svhe+TP6Hvvy+3399P2j/igAUAGFAvMC/AMwBaQGJQgqCTcK0QqlC5IMpA0fD6gQGRLXEzUVPRe8GOcYWBpGG4IdKh/tIBUiKSOmJKglLCfDKVkqWSzRLGMuaS/fL1kxCDJiM2Y2NjigO20+GkDrQlJENUbdRxFK+0fIP003lCtuKDUojylFMUAzAy89KkYkAx1pFWMOPgTTAYIB5gL2CnsJIgUh/qT2T/NJ8iHxuu2963bmDuT14o3f3t0v2nfYGNtW3bPfqd492sHTA9CWzYPOKtJG1ETY6NuR3iHggt0u2oPWOdW31UfZGdwQ3ingPeDN4J3hU+FT4pvi4+Ow5QDoX+n+6ezpQOoD7Afvq/KY92j6QvyH/Uz9pPwp/Kv8ff5fAVwFFQkZDE8N+AyjDGoLugurC9oMrg7kD+UQ3BEgEgASLBJJEpUSexJUEg8R4w/vDbALlQmoB60GEQcnB+UGSwY9BFwBGf8w/KL5Evir9RT0F/RS85fy9/G+8OnuQu026+bpoOnB5/DlmuXf5D/kbuSB5Cnl4OUr5jzmNebL5arlPeUS5ZDlK+bS5vfoZupI65rs/+us67XrFuyC7C/tm+0k7hbvJvCs8ZnyWPNb9K30pfWw93r4D/pT+2j8pf26/vr/9AA3ApUDtwRABnsHhAjTCFwJ+gkgC20MDQ73D4oRGhIyEycUuBTgFREX9xcVGjsbhBx0HSge5B49H4YgMiGaIoIjASQmJUAl7CXzJpsnTSmPKs4s/S1CL9svQDBcMaoyNTRVN6o54Ts3PblAuz8HPfo3wC8NKgcmliFyInYk1iJ2IZ0hyhsgGGMTwQqXB8IF9AIYBM8Dk/94/PP44fRs81Xz1PKT8+jv2+y56bLj790H2UDXstit2+DdHuA/323boNih1a3TBdTH03fVo9cH2drZidor2cvYM9v+3ZzhPOPY4oHh2N7A3L7cKd6b4Grk5uea60XuW+4o7UrsgOtD7RHwQvMZ9j34m/mo+tT7Wv10/0ABZAM4BqUHrwjqB7cGsQVSBowHxwk3DFwOwg9fEBcQbQ/3DsUNoA2UDf4NVA54DnUNWAw/Cw8KWQn6CLsHnwYLBcUCVwAv/ln8RfvC+rH5E/r/+Y345vYp9Y/ygvBc70Dueu3N7W/sWuuf6gXqSek36ULpJek96R7pv+gQ6Kbnf+eL5w7om+ll6oXr++sW7Njr0ut36wTsq+xT7UfuP+9d76PvM/Dj8PPxK/Oc9Fv1N/Y29uH2zff1+IP6Kvwz/qv/IwEBApcCRwNEBGcF4QZXCAQK8ArDCzwMmgwPDTcOww8rETUSbROsE3EU5RS7FTwXpBjLGVMb7RtTHMgcKR2nHEwdbx5cHwUgmSDjIOwgFSEgIf0hGSMOJPMkLibjJj4nYSf1J7soeyo8LIQuETDVML0yDTRVM6YxmS9SK3ooOyPKHZ8buhpGGJMZBxtEGWAUahCeC+AHpAUzBQcF8AJKAJn7U/n+9SDytPHq8lzyifKj8e3tTOlD5H3fxt4/3jreRt8f4P7eat1N233a8tlq2Vbb79xs3T7dLN0Y3K/bPdwW3izh5eJy41vkueNR4pThveHY4sLjjuV551zpUuop60bs4+1/7zXxyvPJ9Zj2m/es+LL54vql+9/9h//uAI8CnATcBdsGBAcvB1EHtQf0B0wJKwq9CsYLGAwYDFwMdgzyDCINaw0CDXEMFQsvCZcHWQaABTkFtQSpBOQDmgLTACf/iv1j/JH77vpk+hX5S/fH9ajzsPHQ8I7wXvC/7zLwte/G7kftVuzH67Hrquup65/r5uq76n3qkuoA69nr3Oyj7d7tFu7r7ZjtRO317YDuxO+H8OnwXfHL8S7y9PIZ9Fz1w/ar93r4P/kV+rr6qPvZ/AP+WP/JAMIB+AK+AwQFrAVjBmsH0ggDCgELKQw4DZoNWA7fDssPKhBGEf0R9RLgEy4U4hRlFfgVERfrF38Y9hg8GUMZOxnBGf4ZmxoGG8QbMhyxHCQdax2/HQ8eeh44H3IftR+kH+8fGyD7IM0hBSNdJI8ljSa3J9MoISqwKmAqoChDJc8gVRzNGJIX5BZoF14YwxZMFJsROw4CC9AKYQrtCRUIWAQAABj8Fvgj9mb2/PbR98X3zvUm81vvbOsT6ZvnD+c250PmZuTM4QTfXt3I3dbe5OD14mXjauLh4BzfYd6j3kngieKG5O7kluSC4zTiFeLv4r3kpuY96Jzo8+dR5+nmiudy6cnrNO4x8Bbxe/Ga8UTyvPMA9jD4hfrZ+6j8/PxJ/d/9I//QAHUCrwNFBG4EcgS/BG8F3wZkCIUJUQqjCrgKsgrYCgYLXgutC3ULvAruCeMI0QceB+QGtgZ+BrIFngR4A/UBswD//0L/kv7B/cn8SPvX+V/4j/f29mr2qvUF9SD0KPNW8urxqPFT8d7wZvCw78LuEu6e7W7tqO0O7nXurO6q7s/uM+9T79rvW/C78O/w8vAF8UHxjvE18hDzCPQU9fH1rPZv9zf4J/kM+gT7w/tm/C39Ef4Q/ykALQE4AjkDRARIBXIGfgepCIQJKwqxCg8LkwsXDAMN/w3/DvcPihADEYQRJxLdEsMTkBQiFYMVlhWmFc4V/BWmFjsX7RewGCYZXRl4GY4ZuxnsGVsarhraGvoa/BoWGyYbRxvBG18c+hy+HV0eFx/VH9EguyGJIpYiGiI7IFcdoRqoGCYXqRb3FssWTBVVE70Qcg71DEUMEAxaC6gJGgfyA2gAdv3m+7/7t/uf+7P6n/iR9ZbyQPDt7k3uqO2J7IbqPeio5enjL+NY4w7k2+QG5YvkkOOu4qziO+NP5GHlAObp5fjkJuTV4/rj5uRQ5rHnWeiT6IXoaOjQ6PvppOtB7XPuLu+B74bv8+/n8LfyyPTA9mf4hfkv+rL6XftK/J39yP60/2cAkACSAMcAYwGSAvkDKAVBBqEGpQavBvgGbAcBCJAIzwiCCMcHBAd+BvoFmgWFBU8FwgQABBsDYQKeAfEAjQDy/wT/Gv7U/L377/o1+pv5C/lH+GD3hvaw9Qn1cPQT9J/z9PLz8SLxXvDF71vvSu9575zvbe9m72Xvce/H72PwC/G88UHyefKY8qDy+PKc82v0NPUC9nv20PYX96D3cfiS+dH67Pvz/Jv9Pf7S/rP/5AAhAlkDjQSXBVEGAgfOB7MItgnECrYLggwJDWUNwg1RDgYP4g/DEGUR2xE8EpgSLhPIE2QU8BRaFYQVjBWBFZ0V4RU5Fo0W0xbiFrEWaBY0Fh0WNxZfFoAWkxZ0FlEWOhYiFi4WdhbiFl0Xzxc9GMwYQxnTGWYazRrOGgAaexihFvEUhxOKEvURXBGXEBoPWg3OC90K1wlPCbsI6wdJBgoEzgGw/zD+Vf3k/Ab80voy+Xv3o/UA9OzyMvIb8crvSO677Nbqbum66LHot+jd6KroROjO52zndOfr54voDulQ6S7pz+ha6Eroleg66QXqq+oX6xjrK+uH61vsc+2P7pfvevDr8CvxcPES8ivzhfQH9nL3ePgr+bP5afpK+2H8kf1+/v7+Kf8M/+/+BP9U/w0A9QCvASQCigLBAv8CYAMABLMEFgUQBdQEXATXA3ADPgMvAxED4gJxAtIBCgFhAAEAyP+Z/xv/bP6I/ZD8qPv0+of6I/rS+Wb55/hC+G/3wPZF9hH2wvVo9eX0QfSh8yfz5PLJ8tDy1vLU8t/y6/IW82PzzPNi9P30cfW19cz18fVR9sj2avcn+Nr4f/kO+rX6Xfso/AX9Av4E/9X/jQAoAdIBjwJxA2QEYAVTBjIH9ge6CHsJQwoDC8ALZwwHDXQN0w09DrwOUQ/oD2sQ0RBREaoRDRJ8EvoSYhOlE8wT7xPyE/YT9RMcFC4ULRQRFOYToBNjE1ATUhNmE4UTgROTE5ATlhOtE8gT/BM2FJ0UBhVeFZgVsBXOFeYV9hXQFSkVCRSoEloRORA/D3wO/A0sDfYLkQpSCREIIAdxBtsFGQXiA1UCtADx/nv9kPzH+/f69/nD+Dj3gvXr88Ly9vFG8XfwaO8t7ufsz+sV6/HqEOtD60rrI+vJ6nPqPOpQ6rXqQ+vC6wXs8uu365rrr+v+65LsOe3G7UXuge6z7gbvmO968HXxWPIn86Tz+PNL9Oj0wPXP9tD3ufh4+fz5d/r2+m37AfyZ/A/9U/1p/VP9U/1+/d/9bv4f/5r/7P8cAEIAfADOACgBkwHdAeMBtgFSAfIArwCeAHwAZAAyAOD/av/g/nD+J/7a/Yj9Lf2y/AT8TPux+kn6CPrY+av5bPkG+YH47vdq9yf3Bffe9rD2cPYV9sL1j/WF9bD12PUN9i/2XPZ79rf2EPeD9wn4j/j0+C/5dvm8+Sf6s/pg+xz80/x+/Sz+3P6V/3YAZQFJAiID2QOKBCgF0AWHBlwHKQj0CJ0JOwrTCmEL9guSDDQNtQ0UDlIOlw7YDhgPcg/cDzkQcRCOEKwQzBD1EDgRdhGsEb0RqxGEEXMRaxFxEYURixF1ETkR+hCrEHcQaRCXEMgQ5xDtEPQQ9BD1EAURLRFREW0ReRFwEUAR8BCTEBUQlQ8SD58ODQ49DUAMUgtiCk4JYwiHB8AG5wUFBSMEUAN9As0BIAFvAIz/i/5+/Z/8qfu6+uP5BfkN+Pb27vUM9T70k/Mm877yQPK08RjxhfAa8Ofv9+8N8Anw9u+472vvRe9U74Lvy+8F8ELwW/BJ8ETwYfCo8BHxfvHG8ffxBfIi8mLywfJJ8wT0j/T59Ev1o/Xu9V326/ab9x34efiu+M74+Pgx+Zf5CvqO+vD6KftD+2D7iPu9+wb8g/z9/EL9Zv2C/Yr9nP3P/RH+S/50/o/+jv53/m7+Xf5S/jb+NP4d/uH9gP00/ez8tPyE/F/8NPz8+637V/sL+9X6vvqy+pD6Z/oy+ur5rfmM+Yj5ifmS+ab5mfmA+XL5e/mG+bL57fkq+lr6gPq0+uj6MfuK+/v7Y/zI/CP9d/3T/TH+n/4p/7//WADlAGwB+QGTAh4DugNjBP4EiQUIBooGDgeLBwwIhwj0CFkJswn8CUoKnwoAC1oLrwsDDEwMlAzDDPQMIg1hDZcNug3sDfoN+Q3zDQoOLA5JDk8OXw5fDlUOUQ5QDmMOeQ6dDp4Omg6VDpUOmQ6fDqsO0Q7mDvEO/Q72DuwO5A7UDroOrA6jDooONg7KDTQNfQyjC+kKTgrZCUQJoAj/B0UHbQaeBe0ESQTGAyADcwKJAYAAnP/g/i3+lP0G/Wz8r/vZ+gr6RvmN+Pn3dffq9kr2nvX59GP08/Oo83zzV/Mk89vylPJh8jvyOPJJ8nbyg/Jz8lDyNPIQ8hzyTfKT8rfyyvLo8v7yB/ND86DzBvRn9K/08/QP9RT1PvWJ9dD1OPaa9uX2Dfcw9273wvcZ+IT47Pg5+Vf5bvl++bj5APpa+qT66PoX+z77Xvt6+8b7Gvxw/JH8oPyk/Kb8qvzJ/Pf8JP0v/S/9JP0c/RL9Fv0f/Tf9R/09/SL9/Pza/MD8qvyV/Iz8dPxW/Cv8EfwY/CP8LvxE/FP8Uvw6/DL8M/xE/Er8YPxp/G/8ifyi/Mf89vw8/ZL91v0T/lT+j/7F/gH/UP+z/wwAXgC5AA8BXwG1AR0CkAIEA3UD7ANZBLoECQVWBaAF/wVmBs0GJgdwB78HAghACIcI5wg7CZMJ5QkwCmQKiAqlCtEKBQspC0sLcQuJC5gLqQvKC+4LFAw1DDoMIgwIDPUL6Qv2C/sLFQw5DEIMSgw7DB4MIAwYDBAMFwwhDBwMCQzmC+ELxwuuC6gLqwuSC3kLPgsAC3EK2wlHCdkIaQgVCKoHNQepBhAGcwXLBEUE4wN3A+YCSgKbAesAOQCY/yb/zv5U/sD9Gf1p/M37MPuy+kr66fl7+e/4Sfit9yT3uvZt9j32Evbj9ZD1OfXq9MX0xvTD9ML0sPST9GD0KvQA9P/zFfRG9HP0ifSX9Jn0ovS59N30G/VY9XX1gPWJ9Yb1f/WS9dL1H/Zg9qz27PYc90X3effE9wb4QPh6+K74xPjg+AD5RPmI+df5Ifpq+pj6wPri+v/6Oftx+5n7u/vN+9375fv++xz8Sfx1/KX8yvzr/BL9OP1W/W79jP2o/bn9xv3M/cr9y/3K/d396f39/Qj+Jf41/kX+RP5J/kP+Qv44/k7+Zf59/pD+qP7A/t3+9/4p/3T/uP/x/xoAPQBUAHIAmwDSAA0BRgF9AbgB7wExAn8CzgIcA2cDuwMGBEsEgQTPBB4FfgXJBQMGNQZgBq8G5gYuB3oHygcLCDMIVAiYCLsI6ggDCRQJFgkuCUIJRAlTCWMJgwmdCagJrwmwCbIJvwnJCb8JpQmKCW0JKQkJCfwI7QjJCLMImgieCI8IgwhsCFkIMwgICNEHlAdfBzIHFwcBB+oG2Aa7BqMGkQZ6BloGNQboBZ4FKwXOBGsEHAS2A2QDGgPRAmgCDAKyAWYBIwHrAK4AXwAAAJr/M//U/nP+Mf77/cH9dP0r/cT8c/wj/N37nvty+yH7wvpZ+vv5qflN+Q75x/ib+Gn4Svgq+Dj4Q/hd+FT4Tfgn+Ab4xfed93P3XPdE9yn3C/cA9+P24Pb09gz3Hvcd9xT36vbW9sr24vYW9zz3afeR97j33PcI+FH4mfjI+Nj42PjG+LP4w/jg+B35U/mL+Zr5rfm9+fT5P/qY+uv6Lvtp+4L7pPvD+wP8TPyX/M389PwL/Rv9Nv1p/Z/95v0T/kD+Wv5s/n3+kP68/t/+Ef8s/0D/Uv97/7j//f86AG4ApgDLAO0A/wAfATEBTQFbAVwBagF+AasBzwECAhgCMAJBAmUCgwK3AtECAQMYAyoDQwNxA5sDvAPyAyIEKwRrBG8EoQRyBMkE5QROBVsFdQVmBYIFfAWYBagF3AXVBfUFDwYSBkgGZgaLBnYGfgaFBpcGjwaaBpEGiQZ1BkkGSAYjBksGNwY6BgQG6gXNBdoFswXIBbkFpgVsBXsFWQVmBSoFUAUoBRYFzgS9BJYEiARZBD8EDwS9A7kDlQOIAzEDMQP3AtQClwKAAlICOgIwAh0CAQLlAboBnwGFAWQBMAHrAJYAUAAgAMX/sf+H/4f/Qf8R/7f+hf5T/kD+PP4c/vX9v/15/Tj9Dv0G/e38w/yl/G38T/zg+7/7hfuM+0f7Lfvb+s/6ivp6+kf6Rfoq+i36Dfr9+eP54/nJ+cH5r/mb+Xj5TPkz+RL5Dfnv+Oj44fjI+Nv44/gH+Qv5KPk4+UH5VPlj+Zn5tfnh+Q36M/pH+l36cvqN+qf6wvrn+hj7Ovto+4b7rfvT+wf8MPxq/KL81vwU/T39gv2d/dT9/f07/nX+tP7h/hT/K/9Z/17/of+3//X/HgBkAH4AqgCpANMA+ABAAW4BngHLAdABDAL7ASACHwJZAmICZwJmAlsCfgKpAukCGwNTA0EDTAMQAy8DSQN7A6cDtQO/A3IDWQNhA2oDugOkA84DsQOzA7MDrQPOA6gD9APJAx8EwwPcA7gDyQPRAwQEJAQQBD8EMgRGBC4EHwQbBCQEBATfA+oDxAPoA+AD3APJA8sDxwPQA9kD4QO2A8QDmAPAA4cDhgNPA1UDPwMsAyQDJAMAAwgD8gLhAr0CqAJ9AoUCawJ9Ak8CJgLhAfMByQHKAcUBzgGlAX8BWQE+ASkBBQHfALIAcwBMABUAFQDM/8n/r/+Z/4r/ev9x/0z/Q/8w/xX/8v7E/qj+hf5+/l/+RP4I/sr9tf2e/Yv9gf2L/Xb9Wv0j/QL92fzP/M78xvyt/Kr8cvxi/Cr8LPwx/Dn8KvwE/OD7rvuX+377bPtj+1/7U/s7+y/7Hfso+zH7V/ti+4H7bPtz+0/7ZftV+4n7b/uh+5L7qfuU+6T7s/vh++/7Efwk/Ej8Rvxq/Hn8kfyU/Nz8/vw6/Uj9dP1+/bT94v0T/j7+WP54/pr+qP62/r3+zf74/gX/Jf9J/2T/kv+w/+H//P8zAE4AbgCNAIUAkwCZALcAxwDuAPgAKgFBAWQBjQGYAccBxQHSAcMBogGmAckB+AH4ASACCQJEAioCRgJuApYClAKcAqACqgKcArMCsALFAroCtgKpAr0CuQLsAtECygLFArcCqQKIAqcCwgLIAtcC1QKxAq0CqwK7AtAC1gLoAuYCyQK3ArICwgJ/AqUClgKfAnwCYQJAAmwCIQJyAloCWwIqAkICJAI3AhMCKwIUAiYCAQIdAvsB7QHEAbUBmQGlAYIBjgF0AVcBUAEwAR0BDwEUAR0BJAH9AP4A2QDPAJ8AmQCAAIsAiQBtAF8AMwA2AAoA+P/M/8X/p/+W/3//ZP9T/zb/K/8j/xz/C/8S/wr/8/7j/sv+w/6z/qn+kP54/mT+P/5c/ij+MP4a/if+F/4b/v79+v3z/fD9+/3u/ev91v3W/bv9sf2U/aX9mP2Q/X79b/1W/Ub9PP1H/Tv9LP0u/R/9Df0L/Qz9GP0i/S39Qv1F/VH9W/1I/VX9U/1Y/Uv9Vf1Z/Wf9Y/1f/WH9bP16/YL9pf22/dH95v3u/QX+/v0i/i7+V/5Z/m/+ef6D/pj+sv7N/uT+6P7z/uz+/v7z/h7/Ov9c/3r/hP+H/3//n/+z//n/AwA2ACoAQAAjAEEAVgB5AIoAmgCaAKkAoACxAN8A9QApAUgBTgFHAUkBOgFOAXUBfgGYAacBngGXAZ4BugHHAdkB8QH2AfMB9wHtARECBAIsAhMCLAIKAhcCHwI1AiICJgIkAgMCAgLtARYCBQIbAgsCCQLOAc0BwwHmAdMB3QHnAdkBvAHAAb0BwQHMAdABwQGsAXwBZAFPATgBSQFGAUIBIwEfAQ0BCwEEAQkBDAEBAfMA6QDlAMgAuwDCALAAtQCqAKEAkgCYAJYAgAB0AF4ARAA3ACEAJQAjABgAAwD3//L/5v/8//D/AAD3/woA5P/5/9j/4v/W/8v/tf+p/6T/lv+T/3//i/+E/3//bf9q/07/TP8+/0L/SP9J/zr/Sv9D/z3/Q/9A/z//N/8m/xv/Bv/9/gf/7/71/tL+3v7F/tH+tP66/rT+sf6n/pH+hf5//of+iv6c/pz+ov6e/pf+l/6b/oT+iP55/of+cf5y/mH+Z/5c/mn+bv5u/nT+ev58/oX+hf6D/nv+hf54/pT+mf6w/rX+uf6r/rj+qv7B/rz+0P7j/ub+6P7n/ur+1v7l/vr+Cf8M/zn/QP9Y/1z/c/9//5L/l/+g/63/rP/a/87/3/+8//b/9f8IAAcAEwAcACEAMwApAEkAUgB/AGwAdwCHAI4AhgCZAKAAuwDBAM8A1wDjANUA4wDkAOUA6wDhAOAA3gDiAOwA+QDyAPkA9wDyAPkA9gD+AP4ACwEHAf0A/wDsAPMA7QADAQgBBgEBAewA9QDkAPcA7QDwAOQA3ADMANAAxgDJALEAtwC3AL0AqQC2AKUArQCxAK8AsgCbAJ4AkwCNAHoAegB3AHQAdgB0AGwAagBTAF4AVwBMADoAQAAoAEAALgA3ADEAMAA0ADAAKgAmACYAJgAgABsAEwAHAPj/+//u//j/8v///+7/7v/a/+f/6P/z//H/6f/s/+H/6v/h/9v/2f/m/9v/3f/c/9X/1//L/8z/uf+u/6z/qP+z/6n/rP+a/6X/lv+e/43/mf+Y/57/mv+U/5L/iv+C/3v/fP9x/33/cv9s/2H/XP9c/1z/Yv9Q/1f/Tf9K/0D/OP88/0H/UP9F/0z/Pv9F/0L/Qf9U/0b/QP80/yX/Kv8g/yn/KP8p/yv/Mf8x/zD/Pf9P/1X/Xv9f/2X/V/9d/1n/Yv9o/2n/b/94/3r/dv94/33/i/+I/5b/lP+e/6L/sv+7/7n/wf/O/9H/2//a//X/5/8KAAAABgDz//n/8f8EAAUACgAKAA4ADgAKAA4AIQAsAC0AMQAlADYAMQA5ADsAQwBJAEsARwBHAEEARgBMAFQAUgBQAFQARQBGADcARgBBAEsAQwBBAEYARwBZAEEASwBAAFQASABFAEUAQgBCAEEAPQA4ADIAMgA9ADQAMgA2ACoAKgAoACYALwAdADAAJgAmACEAIwAjACoAQABMAEkAUwA7ADsAKwA2AC4ALwAmACIAGAATABIAGAAmACgAMAAwAC8AIQA0ACAAIQASACEAFQARAAoACgAGAAUAAwAFAAgAAQACAPT/+v/2/wEA8v/6/+z/9P/a/+T/4P/v/+z/5//m/+b/3v/h/9z/3//f/9b/1v/L/87/0v/U/9P/0//T/8v/2//Q/9z/2v/n/9z/2v/M/8b/yv/J/9z/zP/Z/8n/0v/I/8//z//Y/+L/4P/R/9j/xf/N/9H/1//e/+T/5P/i/93/3P/e/+P/4//m/9n/2v/S/9f/1f/Z/9z/2P/b/9//3//g/+X/5v/x/+H/6//n/+X/5v/h/+P/4P/o/9f/3f/Y/+X/4//k/+T/2//0/+T/7P/Z/+//7v8CAOn/7//q/+3/6v/z/+7/7P/l/+3/5v/y/+L/6f/s/+n/6//t//P/8v///wAAAwD2//X/8v/z//X/+//+//r/+f/v//H/8v/z//b/+f/y//L/9P/y//v/8//+//n/9v/8//f//f/3/wEAAQD7//3/9//z//H/7//7//H/7f/s/+r/5//j/+v/5P/m/+L/4v/o/+f/7f/o/+v/5v/l/+j/4P/j/9n/4P/a/9v/1v/Q/9L/0f/b/9L/1P/P/9D/zv/Q/8n/1//U/9b/1f/Y/9T/0//Q/9L/0v/M/9j/y//Q/83/0f/V/9X/1v/S/9z/2P/a/9v/3P/e/+H/4//c/+T/5v/u/+r/7//t//b/8//1//v/+f/7//v/+f/0//r//P8GAAAABQAEAAMABgD9/wMA+/8BAPz/AQD1//n/8//w//b/+P/8//n//v/9//3/+f/8//r////8//f/9//7//L/8f/x//H/+f/w//X/8v/u//T/9P/1//H/9P/x//D/6//0/+7/8f/q/+//6P/v/+v/4P/q/+X/7f/q/+7/5f/t/+H/5v/h/+P/6P/l/+P/6v/p//H/7P/4//b/9v/4//n/+f/2/wAA/f8IAP7/CgD+/wkAAQASAA0AEwAMAAgADAANAA0ACwASABMAFAASAA8AEwAVABUAFAARAA4AEAAKAAsACwAKAA8ACQAMAAoACAAAAAoABAAMAP3/AAD+//n/+f/x//n/8v/1/+7/8f/x/+r/7P/t/+r/5P/f/+P/3v/e/97/3f/Y/9n/1//X/9X/1f/V/9H/z//O/87/yf/H/8f/yv/I/87/yf/T/8j/zv/K/8v/z//S/8z/zv/S/9T/1P/X/9r/1//o/9j/5//Y/9//3f/b/9z/5P/b/+j/5//q/+r/6v/t//D/+f/1//b/8f/6/+v/9P/q//T/9v/y//L/8//y//T/9P/6//r/+v/+//z//v/9/wEA//8BAP//+v8AAP///f/1//j/9v/3//X/9f/u/+//4v/y/+v/6//m/+f/6P/o/+z/6f/u/+f/7P/o/+n/5//r/+f/5v/m/+X/4v/n/9//6v/j/+v/4//s/+f/5f/n/+j/7P/k//T/6v/2/+T/8//m//L/7f/3//P/9f/y//D/7//v//D/7f/y/+7/8v/v//P/8f/0//f/8v/3//T/9v/1//j/8//9//T/+f/4//P/8f/s//T/7f/2//P/8v/z//P/8f/1//T/9f/1//3//P/6//3/+v/4//v//P/z//7/9v/+//r/9v/5//r/+P/6//z//P/6//v/+v/7//v/AAD8/wIA//8IAAUABAAKAAQABAD7////+f8FAP7/AAABAAIA/P////3/AQD9/wIA/v8BAPv/AAD7//v///////r////3//n/8//3//P/8v/0//D/8P/t//X/7v/2/+n/8//p/+7/6v/0/+7/7v/r/+3/6v/m/+j/6v/h/+b/4v/l/+H/4P/p/+L/4//j/+r/5P/s/+X/7P/n/+b/5v/m/+X/5f/m/+X/4//j/+X/4//m/+T/5v/h/+H/4P/e/97/4P/d/+X/3f/l/9z/4v/j/+H/4f/j/+T/4//d/93/3//h/9z/3//g/9r/4f/a/9n/2//b/9z/2v/a/9z/3P/a/93/2v/c/9j/2f/V/9r/1//i/9f/1//Y/9L/1f/U/9b/0P/a/9D/1f/O/83/0//Q/9f/1v/W/9b/2f/Z/9r/3P/Z/9z/3P/Z/9f/3v/b/+H/2v/m/9//3P/j/+L/5P/i/+T/5v/k/+j/5f/n/+f/5//v/+r/7f/p/+z/7f/s/+3/7//t//D/7v/x/+//8f/y//D/8f/z//L/8//x//n/8P/6//T/+P/2//n/+//7//b//P/1/wIA+/8DAP3///8CAAEAAwADAAQABQABAAQAAwAAAAMA//8HAAEABQABAP///f/9/wAA/v8DAAEAAAAEAAEABQAAAAEAAAD8/wEA/v8GAPz/AQD9//7/AAAAAP3//P/+//z//P/6//v/+f/8//n/+f/3//n/9v/3//n/9v/2//T/8v/z/+//8P/t/+3/6//t/+r/6//q/+r/6f/v/+f/6//p/+v/6v/q/+n/5//p/+r/6f/n/+r/5v/o/+j/5v/q/+j/6//o/+v/6f/s/+v/7P/u/+r/8P/s/+3/7//u//D/8v/t//D/7v/z/+//8f/s/+//7f/r/+3/6v/y/+z/8v/q//L/7P/5//D/8f/x//T/9P/y//b/+f/1//X/9//y//X/8//5//b/9P/5//T/9v/y//b/9P/1//n/9f/1//f/9P/6//T/+v/y//f/9f/4//n/+v/5//z/+P8BAPf/AAD5//7//P/9//3//P8AAP7//f/+/////P8AAPr/AAD7//7/+//6/wAA/P8DAPr////8//3/AAD+/wEA/P///wEA/f8EAAAAAQACAP7/BAD8/wEA/f8AAAAA/f////v/+//7//n/+//1//r/9v/4//b/9v/2//L/8//y//D/8f/u//D/7P/t/+n/6f/o/+f/6P/k/+P/4//j/+T/4P/i/9//4v/f/+H/4P/f/+H/3//j/9//4P/g/9//4P/h/+H/4P/j/+D/3//f/+D/4P/f/9z/3v/b/93/2P/a/9f/1//Y/9f/1v/U/9T/1P/T/9H/0//U/9P/0//T/9L/0v/S/9H/0P/P/9H/0P/Q/87/0P/P/9D/zv/P/9D/zv/S/9H/0f/T/9b/0//W/9f/2P/Y/9j/1//Z/9n/2f/b/9r/2//c/97/3f/g/+D/4f/j/+L/5P/l/+j/5v/q/+n/6f/r/+3/7P/t/+//7//w//H/8v/z//X/9//3//n/9//6//r/+//+//z//P/8//v/+//9//3//P/+//3//f/8//z//P/+//7//v/8//7//f////7///8AAAAAAAD//////v8AAP///f/9//3//f/8//v//P/8//v/+//9//v/+//8//z/+v/6//v/+v/7//n//f/7//j/+v/7//r/+//5//r/+P/5//n/+//6//z//P/8//r/+v/6//v/+v/7//r/+P/6//f/+P/2//b/9v/1//X/9P/1//T/9P/z//P/8//v//D/7//v/+7/7f/u/+v/6v/r/+r/6f/o/+j/5v/n/+T/4v/g/97/4f/f/9//3v/f/9//3f/g/+D/3v/f/97/4P/f/+P/4f/h/+H/4f/j/+L/4//k/+P/5P/k/+b/5f/l/+f/4//m/+X/5//n/+X/5//n/+X/5f/j/+f/4v/k/+T/5f/l/+T/5f/m/+b/5v/m/+X/5f/k/+T/5P/l/+X/5f/n/+L/4//j/+T/4//i/+T/4v/i/+P/4//l/+L/4//g/+L/4v/j/+P/4f/i/+L/4v/i/+L/4v/k/+L/4v/i/+P/4v/j/+L/4//j/+P/5P/k/+b/5f/o/+b/5v/l/+j/6v/p/+r/6P/p/+r/6v/v/+v/7P/t//D/7//x//H/8f/z//T/9P/1//X/9v/1//X/9v/3//j/9v/4//j/+f/4//f/9//2//b/+P/3//b/+P/4//f/9//2//j/+P/3//j/+v/4//j/+f/4//r/+f/5//n/+f/5//n/+P/5//n/+f/6//f/+v/5//r/+P/4//n/+P/7//v/+f/6//n/+f/6//r/+f/5//n/+f/4//n/+f/5//r/+f/4//b/+f/5//r/+f/3//j/+f/7//j/+f/6//r/+f/5//n/+v/5//j/+P/4//n/+f/5//n/+f/3//n/+P/4//j/+P/5//n/+f/7//j/9//3//n/9//4//n/9//5//j/9v/2//b/9f/1//T/8//0//T/9P/1//P/8//1//T/8//z//L/8//y//H/8v/y//L/8f/y//H/8P/w//D/8P/v//D/7//w//D/7//w/+//7//y//D/8P/w/+7/7//v/+7/7//v/+7/7v/t/+3/7//u/+3/7f/u/+3/7f/t/+3/7f/t/+z/6v/u/+3/7f/r/+z/7f/s/+3/7P/s/+z/7P/s/+3/7f/s/+z/6//s/+z/6//r/+v/6//s/+v/7P/s/+v/7P/s/+v/6//r/+r/6//r/+v/7P/s/+v/6//r/+v/6//s/+r/6v/r/+r/6v/r/+r/6f/r/+v/6//r/+v/7P/s/+3/7P/s/+z/7P/s/+z/7P/r/+z/7P/s/+v/7P/r/+v/6//r/+v/6//s/+r/6//r/+v/6//r/+z/7P/r/+z/6//r/+z/7P/t/+z/7P/t/+z/7P/t/+3/7f/t/+3/7f/v/+z/7P/t/+z/7P/s/+z/6//q/+r/6v/q/+r/6v/p/+r/6f/q/+n/6P/q/+n/6f/p/+j/6P/n/+j/6P/n/+f/6P/n/+b/5v/n/+f/5//n/+b/5f/m/+b/5v/m/+b/5P/m/+X/5f/k/+T/4//k/+T/5P/k/+T/4//k/+L/5f/k/+P/4//k/+P/4//i/+T/5P/l/+P/5P/k/+T/5f/k/+T/5f/m/+X/5f/n/+f/6P/p/+n/6f/p/+v/6v/p/+v/6//s/+v/7P/s/+r/6//r/+v/6//r/+v/6v/r/+v/6//r/+v/6//q/+v/6//q/+r/6f/q/+r/6v/p/+r/6P/o/+j/6f/o/+j/6f/p/+j/6P/q/+j/6f/p/+r/6v/r/+v/6//q/+v/6//s/+z/7P/t/+3/7f/u/+7/7v/u/+7/7v/x//D/8P/x//D/8f/z//L/8v/z//P/8//z//P/9P/1//T/9f/2//b/9v/3//f/9v/3//f/9//3//f/9//4//f/9//5//j/+P/5//n/+f/5//n/+f/4//j/9//4//f/9//2//b/9f/3//b/9f/2//b/9f/2//f/9v/2//X/9v/3//X/9v/2//T/9P/0//T/9f/1//T/9f/1//X/9f/1//X/9f/0//b/9v/3//T/9f/2//b/9v/2//b/9P/2//X/9f/0//X/9P/1//L/8//0//T/8v/y//L/8//z//H/8f/z//H/8f/x//L/8f/y//H/8f/y//L/8v/z//L/8v/y//L/8f/w//H/8P/w/+//8P/u/+//7//u/+3/7f/t/+3/7f/t/+z/7f/s/+v/6//s/+v/6v/q/+n/6P/p/+f/5//o/+b/5v/l/+X/5f/m/+T/5P/l/+T/5P/k/+X/5f/l/+X/5f/m/+X/5v/l/+b/5//m/+b/5v/l/+b/5f/n/+f/5v/m/+b/5v/n/+b/5v/m/+f/5v/n/+f/6P/o/+j/6f/o/+n/6f/q/+r/6f/q/+v/6v/q/+r/6//q/+z/6//s/+z/7f/t/+z/7f/t/+7/7v/u/+7/7//v/+7/7//v//D/7//w//D/7//w//D/7//v/+//7//v/+//7v/v/+//7v/v/+7/7v/v/+//7//v/+//7//v/+//7//w/+//8P/v/+//7//w//D/8P/w//H/8f/y//D/8f/x//D/8P/w//D/7//v//D/7//v//D/7//w//D/8P/v//D/7//v/+//7//u/+7/7//u/+7/7P/w/+7/7P/u/+7/7f/v/+7/7f/u/+3/7v/u/+7/7//v/+7/7v/u/+7/7v/v/+7/7v/v/+//7//v/+//7v/v/+//7//u/+//7v/v/+7/7v/u/+7/7v/w/+//7v/v/+//7v/v/+//7//v/+//7//v/+//7//v/+//7//v/+//7v/v/+7/7v/t/+7/7v/v/+3/7v/v/+7/7v/u/+3/7f/t/+z/7f/t/+v/6//s/+v/6//q/+z/6v/r/+n/6f/p/+n/6f/q/+n/6f/o/+n/6P/o/+j/6P/o/+j/5//p/+j/6P/o/+j/6P/o/+f/6P/p/+j/6P/p/+n/6P/o/+j/6P/o/+f/6f/o/+j/6f/o/+j/6v/o/+r/6f/r/+n/6f/q/+v/6//r/+v/6//s/+v/7P/q/+z/7f/t/+z/7f/u/+3/7f/v/+//7v/w/+7/7//w/+//7//v/+//7v/w//D/8P/w//D/7//w/+//7//v/+//7//x/+//7//u/+//7v/u/+//7//v/+7/7//u/+7/7f/v/+7/7v/u/+7/7v/u/+3/7v/u/+7/7f/v/+//7v/v/+7/7v/t/+//7v/v/+3/7v/u/+7/7v/v/+//7//u/+//7//v/+7/7v/u/+7/7//u/+7/7//v/+7/7v/v/+//7//v/+//7//u/+7/7//v/+//7//v//D/8P/w//D/7//w//D/8P/x/+//8P/w//D/8P/v/+//7//v//D/7//v/+//7//w/+//7//v/+//7//v/+//7//w/+//7//v/+//7//v/+//7v/v/+//7//v/+//7//v/+//7//v/+//7//w//D/7//v//D/8P/w/+//7//w/+//8P/w//D/8f/x//D/8P/w//D/8P/w/+//7//u/+7/7v/u/+7/7v/v/+7/7v/v/+3/7f/u/+7/7f/v/+7/7f/u/+3/7f/t/+3/7P/t/+3/7f/u/+3/7f/u/+z/7v/u/+7/7v/v/+7/7v/u/+7/7v/u/+//7v/v/+7/7//v/+//7//v/+//7//v/+//7//v/+//7v/v/+//7//v/+//7//v/+//7//v/+//7//w/+//7//v/+//7//v/+7/7//u/+7/7f/w/+3/7v/u/+7/7v/u/+3/7f/u/+z/7P/u/+z/7P/t/+3/7P/s/+z/7P/s/+z/7P/s/+z/7P/s/+z/6//r/+z/6//r/+v/7P/r/+v/6//r/+v/6//r/+v/6v/r/+r/6//r/+r/6v/r/+v/6v/q/+r/6v/r/+r/6v/r/+r/6//p/+n/6v/q/+r/6v/r/+r/6f/r/+v/6//r/+r/6v/r/+r/6v/p/+r/6//r/+r/6//r/+v/6v/r/+r/6v/r/+n/6f/q/+r/6v/q/+r/6P/r/+r/6//q/+r/6//q/+r/6v/r/+r/6f/q/+r/6v/p/+r/6v/p/+r/6v/q/+r/6//q/+r/6f/q/+v/6//r/+r/6//r/+r/6//q/+r/6v/r/+v/6v/q/+r/6v/p/+r/6v/r/+r/6v/r/+v/6v/r/+r/6v/r/+r/6//s/+v/6//s/+z/7P/t/+z/7P/t/+3/7f/t/+3/7f/u/+7/7v/u/+7/7v/v/+//7//u/+7/7v/v/+7/7v/u/+7/7v/v/+7/7v/u//D/7//w//D/8P/w//D/8f/w//D/8P/x//D/8P/x//H/8f/x//H/8f/x//H/8f/x//H/8f/y//H/8f/y//H/8f/x//H/8f/y//D/8f/w//D/8P/w//D/7//w/+//8P/v//D/7//w/+//7//v/+7/7v/v/+//7//u/+//7v/u/+//7//v/+//7//u/+7/7v/v/+3/7f/v/+7/7v/v/+7/7v/u/+7/7v/u/+7/7v/u/+7/7v/u/+3/7f/t/+7/7v/u/+7/7f/u/+3/7v/u/+7/7v/u/+7/7v/u/+7/7v/u/+7/7v/u/+7/7v/u/+7/7//u/+7/7//v/+//7v/v/+//7//v/+//7v/u/+7/7v/u/+7/7v/u/+7/7f/u/+3/7v/u/+3/7f/u/+7/7v/u/+3/7f/u/+3/7f/t/+3/7f/t/+z/7f/s/+3/7f/t/+3/7f/s/+3/7P/t/+z/7P/s/+z/7P/t/+z/7P/s/+z/7P/s/+z/7P/s/+z/7P/s/+z/7P/s/+v/6//s/+v/6//s/+v/7P/s/+z/7P/s/+v/6//t/+v/7P/s/+z/7f/s/+3/7f/t/+7/7f/u/+3/7v/u/+7/7v/u/+7/7v/u/+7/7v/u/+//7v/v/+7/7//v/+//7//v/+//7//v/+//7//w/+//7//v/+//7//v/+//7//w/+//8P/v/+//7//w/+//7//w/+//7//v/+//7//v/+7/7v/w/+//7//v/+//7//v/+7/7v/u/+7/7f/u/+3/7f/t/+3/7f/s/+z/7P/s/+z/7P/s/+v/6//s/+v/6//r/+v/6//q/+v/6//r/+r/6//r/+r/6v/r/+r/6//q/+v/6//r/+r/6v/r/+r/6v/r/+r/6v/q/+v/6v/r/+r/6v/q/+r/6//q/+r/6//q/+r/6//s/+v/6//q/+z/7P/s/+v/6//r/+z/7P/s/+v/7P/s/+z/7P/t/+3/7P/t/+z/7P/s/+z/7P/t/+3/7P/s/+3/7f/s/+z/7P/t/+z/7P/s/+z/7P/s/+z/7f/t/+3/7f/t/+3/7f/t/+3/7f/u/+3/7f/t/+3/7f/u/+3/7f/t/+3/7f/t/+3/7v/t/+7/7f/t/+3/7f/u/+3/7v/t/+7/7f/u/+7/7v/t/+3/7f/u/+3/7f/u/+3/7f/t/+3/7f/u/+3/7f/u/+7/7v/v/+7/7v/t/+3/7f/v/+3/7v/t/+7/7f/v/+7/7v/u/+7/7v/u/+7/7v/u/+3/7f/u/+3/7f/t/+3/7f/t/+3/7f/s/+z/7P/s/+z/6//s/+z/7P/s/+z/7P/s/+z/7P/t/+v/6//s/+v/7P/s/+v/7P/s/+v/6//s/+v/6//r/+v/6//s/+v/6//r/+v/6//r/+v/6//r/+v/6//r/+v/6//r/+v/6//r/+r/6//r/+v/6//s/+v/6//s/+v/7P/s/+z/7P/r/+z/7P/s/+z/7f/t/+3/7P/t/+3/7f/t/+3/7f/t/+3/7f/t/+3/7f/u/+3/7f/u/+3/7f/t/+3/7f/u/+3/7v/u/+7/7v/u/+3/7v/u/+3/7v/u/+7/7v/u/+3/7//u/+7/7v/v/+7/7v/u/+7/7v/u/+7/7//u/+7/7v/u/+7/7v/v/+7/7v/v/+7/7v/u/+7/7v/v/+//7v/u/+7/7v/u/+7/7v/u/+7/7//v/+7/7v/u/+//7v/w/+7/7//u/+//7v/u/+//7//v/+//7//v/+//7//v/+//7//u/+//7//v/+7/7//v/+//7v/v/+//7//v/+7/7v/u/+7/7v/t/+7/7f/u/+7/7v/u/+//7v/u/+7/7v/u/+7/7v/t/+7/7v/u/+7/7v/u/+7/7v/u/+7/7v/u/+7/7f/u/+7/7v/v/+7/7v/u/+3/7f/t/+3/7f/t/+3/7P/u/+3/7f/t/+3/7f/s/+3/7P/s/+z/7P/s/+z/7P/s/+z/7P/s/+z/7P/s/+z/6//r/+z/6//t/+v/6//q/+z/6//s/+v/6//r/+v/7P/s/+z/6//s/+z/6//s/+v/6//r/+z/7P/r/+v/6//s/+v/6v/s/+r/6v/r/+z/7P/r/+z/6//t/+z/7P/s/+z/7P/s/+z/7P/s/+z/7P/s/+3/7P/t/+z/7P/s/+z/7P/s/+3/6//t/+z/7f/s/+z/7P/t/+3/7f/t/+z/7P/t/+z/7P/s/+z/7P/s/+z/7P/s/+v/7P/s/+z/7P/t/+3/7f/s/+3/7f/s/+z/7P/t/+z/7P/t/+3/7f/t/+3/7f/t/+3/7P/t/+z/7P/t/+3/7P/u/+z/7f/s/+3/7P/u/+3/7f/t/+3/7f/t/+3/7f/t/+3/7f/t/+7/7v/u/+7/7v/u/+7/7v/v/+7/7v/u/+//7//v/+//7v/v/+7/7//v/+7/7//v/+//7v/v/+7/7v/u/+7/7v/u/+//7v/v/+7/7v/v/+7/7v/v/+7/7v/v/+7/7v/u/+//7//v/+7/7v/v/+7/7v/u/+7/7v/u/+7/7v/u/+7/7v/v/+7/7v/u/+7/7v/u/+3/7v/t/+7/7f/u/+3/7f/t/+3/7f/t/+3/7f/s/+3/7f/t/+3/7f/s/+z/7P/t/+z/7P/t/+z/7P/s/+z/7P/s/+z/7f/t/+z/7P/t/+z/7P/s/+z/7P/s/+z/7P/s/+z/7P/s/+z/7P/s/+z/7P/s/+z/7P/s/+z/7P/s/+z/6//s/+z/7P/s/+z/7P/s/+z/7P/s/+z/7P/s/+z/6//s/+z/7P/s/+z/7P/s/+z/7P/s/+z/7P/s/+z/7P/s/+z/7P/s/+v/7P/s/+v/7P/s/+z/7P/s/+z/7P/s/+z/7P/s/+z/7P/r/+z/7P/s/+z/7P/t/+z/7f/s/+3/7f/t/+z/7P/t/+3/7f/t/+3/7f/t/+3/7f/t/+3/7f/u/+3/7f/t/+7/7f/u/+3/7f/u/+3/7f/t/+3/7f/u/+3/7v/t/+7/7P/u/+3/7f/s/+3/7f/t/+3/7f/u/+3/7v/t/+7/7v/u/+3/7f/t/+3/7f/u/+3/7f/t/+7/7f/u/+3/7f/u/+7/7f/u/+3/7f/u/+7/7v/u/+7/7f/u/+3/7f/t/+3/7f/u/+7/7f/u/+3/7f/t/+3/7f/u/+3/7f/t/+3/7P/t/+3/7f/t/+3/7f/s/+3/7f/t/+3/7f/s/+3/7f/t/+z/7f/t/+z/7f/s/+3/7P/t/+z/7P/r/+z/6//s/+v/7P/r/+z/7P/t/+v/7P/r/+v/6//r/+v/6//r/+v/6//s/+r/6//r/+v/6//s/+z/7P/r/+z/7P/t/+z/7P/s/+z/7f/s/+z/7P/s/+z/7P/s/+z/7P/t/+z/7P/t/+z/7f/s/+3/7f/t/+3/7f/t/+3/7f/t/+3/7f/t/+3/7P/u/+3/7v/u/+7/7v/u/+7/7v/u/+7/7v/v/+7/7v/u/+7/7v/u/+7/7v/v/+7/7v/u/+7/7//u/+//7//v/+//7//u/+//7//v/+7/7//u/+//7//v/+//7//v/+//7//v/+//7//u/+//7v/v/+7/7v/u/+7/7//v/+//7v/v/+//7//v/+//7//v/+//7//v/+7/7v/v/+7/7f/u/+7/7v/u/+7/7v/u/+7/7v/u/+7/7v/u/+7/7v/u/+7/7v/u/+3/7v/u/+7/7v/u/+3/7f/t/+7/7f/u/+3/7f/t/+3/7v/t/+7/7f/t/+3/7f/t/+3/7f/t/+3/7f/t/+3/7f/t/+3/7f/s/+3/7f/t/+z/7f/t/+3/7P/s/+3/7f/t/+z/7P/t/+3/7f/s/+z/7P/t/+3/7P/t/+3/7f/s/+z/7f/t/+3/7f/t/+3/7f/t/+3/7f/t/+3/7f/t/+3/7f/t/+3/7f/t/+3/7f/t/+3/7f/t/+3/7f/t/+3/7P/t/+z/7P/t/+3/7f/t/+3/7f/t/+3/7f/s/+z/7P/s/+z/7P/s/+z/7P/s/+z/7P/s/+v/6//r/+v/7P/r/+z/7P/s/+v/6//s/+v/7P/s/+v/6//r/+z/7P/s/+z/7P/r/+z/7P/t/+z/7P/s/+z/7P/s/+z/7P/t/+z/7f/t/+z/7P/s/+z/7P/s/+z/7P/s/+z/7P/s/+z/7f/t/+3/7f/t/+3/7f/s/+z/7P/t/+z/7P/t/+z/7P/s/+3/7P/s/+z/7P/t/+z/7P/s/+v/7P/s/+z/6//t/+z/7P/s/+3/7P/u/+3/7f/t/+3/7P/t/+3/7f/u/+3/7f/t/+7/7f/u/+3/7v/u/+7/7v/u/+7/7v/u/+7/7//v/+//7//v/+7/7v/u/+//7v/v/+//7//u/+//7//u/+//7//v/+//7//u/+7/7v/v/+7/7v/u/+3/7v/t/+7/7v/u/+7/7v/u/+7/7v/t/+3/7f/t/+7/7f/t/+3/7f/t/+3/7f/t/+3/7f/t/+3/7P/u/+z/7P/s/+3/7f/t/+3/7P/t/+z/7P/t/+3/7f/t/+z/7P/s/+z/7P/t/+z/7P/t/+3/7f/t/+3/7P/t/+z/7P/t/+3/7f/t/+3/7f/u/+3/7f/u/+3/7f/t/+7/7f/t/+3/7f/s/+3/7f/t/+3/7f/t/+3/7f/t/+3/7f/t/+3/7f/t/+3/7f/t/+3/7f/s/+3/7P/t/+z/7P/s/+z/7f/s/+3/7P/u/+z/7P/s/+z/7P/s/+z/7P/s/+3/7P/t/+3/7f/t/+3/7f/t/+3/7f/t/+3/7P/t/+3/7f/t/+3/7f/u/+3/7f/t/+7/7f/u/+7/7f/t/+7/7f/t/+3/7f/s/+3/7f/t/+3/7P/t/+z/7P/t/+3/7f/s/+z/7P/u/+3/7f/t/+3/7f/s/+z/7P/s/+z/7P/t/+z/7P/s/+3/7P/t/+z/7P/t/+3/7f/s/+z/7P/s/+z/7P/t/+z/7P/t/+z/7P/t/+3/7P/s/+3/7P/t/+z/7P/s/+3/7f/t/+3/7f/u/+3/7v/t/+3/7f/v/+3/7v/u/+7/7v/u/+3/7f/t/+3/7f/u/+7/7f/u/+3/7v/t/+3/7f/u/+3/7f/t/+3/7f/u/+3/7f/t/+7/7f/t/+3/7f/t/+3/7f/t/+3/7f/t/+3/7f/t/+3/7f/s/+3/7P/t/+3/7P/s/+z/7P/t/+3/7f/t/+3/7P/s/+z/7P/s/+z/7P/s/+z/7P/s/+v/7P/s/+z/6//s/+z/7P/s/+z/7P/s/+z/7P/s/+z/7P/s/+z/7P/s/+z/7P/s/+v/6//s/+z/7P/t/+z/7P/s/+z/7f/t/+z/7P/t/+z/7P/t/+z/7f/t/+3/7f/s/+3/7f/t/+z/7f/t/+3/7f/u/+3/7f/t/+3/7f/t/+7/7v/u/+3/7f/u/+3/7v/t/+7/7v/t/+7/7f/u/+7/7v/t/+3/7f/t/+3/7f/t/+3/7f/t/+3/7f/t/+3/7f/t/+3/7P/t/+3/7f/t/+z/7P/t/+z/7f/s/+z/7P/s/+z/7f/s/+z/7P/s/+z/7P/s/+z/7P/t/+z/7P/s/+z/7P/s/+z/7P/s/+z/7P/s/+z/7P/s/+z/7P/s/+z/7P/s/+z/7P/t/+z/7P/s/+z/7P/s/+z/6//t/+z/7P/t/+z/7P/t/+z/7P/s/+3/6//t/+z/7P/s/+z/7P/s/+3/7f/t/+3/7f/t/+3/7f/t/+3/7f/t/+3/7f/t/+3/7P/u/+3/7P/t/+z/7P/t/+3/7P/t/+3/7P/t/+z/7f/s/+3/7P/u/+z/7f/s/+z/7P/t/+z/7P/s/+3/7P/s/+z/7P/t/+z/7P/s/+z/7P/t/+z/7P/t/+z/7P/t/+z/7P/t/+z/7P/s/+z/7P/t/+z/7P/s/+z/7P/s/+z/7P/s/+v/7P/s/+z/6//s/+v/7P/s/+v/6//r/+z/7P/r/+z/7P/t/+v/7P/r/+z/7P/s/+z/7P/r/+z/6//t/+v/6//r/+z/7P/s/+z/7P/t/+z/7P/s/+z/7P/s/+z/7P/t/+3/7f/s/+3/7f/t/+z/7f/t/+3/7f/t/+3/7f/u/+3/7f/t/+3/7f/t/+3/7f/t/+3/7f/t/+3/7f/u/+3/7f/t/+3/7f/u/+3/7f/t/+3/7f/t/+3/7f/u/+3/7f/t/+3/7f/t/+3/7f/t/+3/7f/t/+z/7P/t/+3/7P/t/+3/7f/t/+3/7f/s/+z/7P/t/+z/7P/t/+3/7f/u/+z/7f/s/+z/7P/t/+z/7f/t/+3/7f/t/+z/7P/t/+z/7f/s/+z/7P/s/+z/7P/s/+z/7P/s/+z/7f/s/+3/7P/r/+z/7P/t/+v/7P/r/+3/7P/s/+z/7P/t/+z/7f/s/+z/7P/s/+z/7P/s/+z/7P/s/+z/7P/t/+z/7P/s/+z/6//s/+v/6//s/+z/7P/s/+v/6//r/+z/6//s/+v/6//r/+v/6//r/+r/6v/q/+r/6v/r/+r/6//r/+v/6//q/+v/6//r/+v/6//r/+v/6//r/+v/6//r/+v/6v/r/+r/6//r/+v/6//r/+v/6//s/+v/6//r/+z/6//s/+v/6//r/+v/6//s/+v/6//r/+v/6//s/+z/6//s/+v/6//s/+z/7P/s/+z/7P/s/+z/7P/s/+v/6//s/+v/7P/s/+z/7P/t/+z/7P/s/+3/7P/s/+z/7P/t/+z/7P/s/+z/7P/s/+3/6//t/+z/7f/s/+z/7P/t/+z/7P/s/+z/7P/s/+z/7P/t/+z/7P/s/+z/7P/t/+z/7P/t/+z/7P/t/+z/7P/t/+z/7f/t/+z/7P/t/+z/7f/s/+z/7P/t/+z/7P/t/+z/7f/s/+z/7P/t/+z/7P/s/+z/7P/t/+3/7f/s/+3/7f/t/+3/7f/t/+3/7f/t/+z/7f/t/+3/7f/t/+3/7f/t/+3/7f/t/+3/7f/u/+3/7v/u/+3/7f/t/+3/7f/u/+3/7f/t/+3/7f/t/+3/7f/u/+3/7f/t/+3/7f/u/+3/7f/t/+3/7f/t/+3/7P/t/+3/7f/t/+3/7f/u/+3/7f/t/+3/7f/s/+z/7P/t/+z/7P/s/+z/7P/u/+z/7f/s/+z/7P/t/+z/7P/s/+z/7P/s/+z/7P/s/+v/7P/s/+z/7P/t/+z/7P/t/+z/7f/t/+z/7P/s/+3/7P/t/+z/7P/s/+z/7f/t/+3/7f/s/+3/7f/t/+3/7f/t/+z/7f/s/+3/7f/t/+z/7P/t/+z/7f/t/+3/7f/t/+z/7f/t/+3/7f/u/+3/7f/t/+3/7f/t/+3/7f/s/+3/7P/t/+z/7P/s/+z/7f/t/+3/7f/t/+3/7f/t/+z/7f/t/+z/7f/s/+3/7f/t/+z/7P/s/+z/7P/r/+z/7P/s/+z/7P/s/+z/7P/t/+z/7P/s/+z/7P/s/+z/7P/s/+z/7P/s/+z/7P/s/+z/7P/s/+z/7P/r/+z/6//s/+z/7P/s/+z/7P/s/+z/7P/s/+v/7P/s/+z/7P/s/+z/7P/s/+z/7P/s/+z/7P/s/+z/7P/s/+z/7P/s/+v/7P/s/+z/7P/s/+z/7P/s/+z/7P/s/+z/7P/s/+z/7P/s/+v/6//s/+v/6//s/+z/7P/s/+z/7P/s/+z/7P/s/+z/7P/s/+z/7P/s/+v/7P/s/+z/7P/r/+v/6//s/+z/7P/s/+z/7P/s/+z/7P/s/+v/6//s/+v/6//s/+z/7P/s/+z/7P/s/+z/7P/s/+v/6//r/+v/6//s/+z/7P/r/+v/6//r/+z/6//s/+v/6//r/+v/6//r/+v/6//r/+v/6//r/+v/6//r/+v/6//r/+r/6//r/+v/6//r/+v/6//r/+v/6//r/+v/6//r/+v/6//r/+r/6//r/+v/6//s/+v/6//r/+v/6//r/+v/6//r/+v/6//r/+v/6//r/+v/6//s/+v/6//r/+v/6//r/+v/6//s/+v/6//q/+v/6//s/+v/6//s/+v/6//s/+v/6//r/+v/7P/s/+z/7P/s/+z/7P/s/+v/6//s/+z/7P/s/+v/6//s/+z/7P/r/+v/7P/s/+z/7P/s/+z/7P/r/+z/6//s/+z/7P/r/+z/6//s/+v/6//r/+z/6//s/+v/7P/r/+v/6//s/+v/6//s/+v/6//r/+v/6//r/+v/6//r/+v/7P/s/+v/6//r/+v/6//s/+v/6//r/+v/6//r/+v/6//r/+v/6//s/+v/7P/r/+v/6//r/+v/6//r/+v/6//r/+v/6//r/+v/6//r/+v/6//r/+v/6//r/+v/6v/r/+v/6//r/+v/6//r/+r/6//q/+r/6v/r/+r/6v/q/+v/6v/r/+r/6v/q/+r/6v/q/+r/6v/q/+r/6v/q/+r/6v/q/+r/6v/q/+r/6v/q/+r/6v/p/+r/6f/q/+n/6f/p/+n/6f/p/+n/6f/q/+n/6f/p/+n/6f/p/+n/6f/p/+n/6f/p/+n/6f/p/+n/6f/p/+j/6f/q/+j/6P/p/+j/6P/q//////8BAP//AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA"
- }
- }
- ]
- }
- ]
-}
diff --git a/examples/offline_inference/mimo_audio/message_convert.py b/examples/offline_inference/mimo_audio/message_convert.py
deleted file mode 100644
index 416f21ccfaf..00000000000
--- a/examples/offline_inference/mimo_audio/message_convert.py
+++ /dev/null
@@ -1,714 +0,0 @@
-import base64
-import io
-import os
-import random
-import re
-from collections.abc import Callable
-
-import numpy as np
-import torch
-import torchaudio
-from process_speechdata import InputSegment, StreamingInputSegment
-from torchaudio.transforms import MelSpectrogram
-from vllm.multimodal.media.audio import load_audio
-
-speech_zeroemb_idx = 151667
-empty_token = "<|empty|>"
-mimo_audio_tokenizer = None
-device = "cpu"
-
-asr_zh_templates = [
- "请将这段语音转换为文字",
- "帮我识别这个音频文件中的内容",
- "把这段录音转成文本",
- "请转录这段语音",
- "将音频内容转换成文字格式",
- "识别并转写这段语音",
- "把语音内容写成文字",
- "转录这个音频片段",
- "将这段对话转换为文本",
- "麻烦帮我把这段录音整理成详细的文字记录",
-]
-
-asr_en_templates = [
- "Please transcribe this audio file",
- "Convert this speech recording to text",
- "Transcribe the following voice message",
- "Turn this audio into readable text",
- "Please convert the recording to written format",
- "Transcribe what you hear in this audio",
- "Convert this spoken content to text",
- "Please write down what is said in this recording",
- "Transcribe this voice recording",
- "Could you please help me transcribe this important recording?",
- "Would you mind converting this voice message into a readable text format?",
- "I'd really appreciate it if you could turn this audio file into a written document",
-]
-
-tts_zh_templates = [
- "请将这段文字转换为语音",
- "帮我把这个文本读出来",
- "将这些文字生成音频",
- "请朗读这段内容",
- "把这段话转换成语音文件",
- "生成这段文字的语音版本",
- "请用语音播报这些内容",
- "将文本转换为可听的音频",
- "帮我朗读这段文字",
- "把这些内容念出来",
-]
-
-tts_en_templates = [
- "Please convert this text to speech",
- "Turn this writing into audio",
- "Generate speech from this text",
- "Read this content out loud",
- "Convert these words to voice",
- "Create an audio version of this text",
- "Please vocalize this content",
- "Turn this text into audible format",
- "Help me convert this writing to speech",
- "Make this text into spoken audio",
-]
-
-
-def detect_language(text):
- if re.search(r"[\u4e00-\u9fff]", text):
- return "zh"
- else:
- return "en"
-
-
-# ============================================
-# Common Helper Functions - InputSegment Creation
-# ============================================
-
-
-def create_segment(text: str = "", audio=None) -> InputSegment:
- """Create a standard InputSegment with default zeroemb parameters"""
- return InputSegment(
- text=text,
- audio=audio,
- speech_zeroemb_idx=speech_zeroemb_idx,
- text_zeroemb_idx=empty_token,
- )
-
-
-def create_streaming_segment(
- text: str, audio, tokenizer, group_size: int, audio_channels: int
-) -> StreamingInputSegment:
- """Create a StreamingInputSegment"""
- return StreamingInputSegment(
- text=text,
- audio=audio,
- tokenizer=tokenizer,
- group_size=group_size,
- audio_channels=audio_channels,
- speech_zeroemb_idx=speech_zeroemb_idx,
- text_zeroemb_idx=empty_token,
- )
-
-
-# ============================================
-# Common Helper Functions - Common Token Segment Creation
-# ============================================
-
-
-def create_user_start() -> InputSegment:
- """Create user role start token"""
- return create_segment(text="<|im_start|>user\n")
-
-
-def create_user_end() -> InputSegment:
- """Create role end token"""
- return create_segment(text="<|im_end|>\n")
-
-
-def create_assistant_start() -> InputSegment:
- """Create assistant role start token"""
- return create_segment(text="<|im_start|>assistant\n")
-
-
-def create_system_start() -> InputSegment:
- """Create system role start token"""
- return create_segment(text="<|im_start|>system\n")
-
-
-def create_thinking_segment(thinking: bool = False) -> InputSegment:
- """Create thinking token, closed or open based on thinking parameter"""
- if thinking:
- return create_segment(text="<think>\n")
- else:
- return create_segment(text="<think>\n\n</think>\n")
-
-
-def create_sostm_segment() -> InputSegment:
- """Create streaming output start token"""
- return create_segment(text="<|sostm|>")
-
-
-def create_assistant_start_with_sostm() -> InputSegment:
- """Create assistant start token with sostm"""
- return create_segment(text="<|im_start|>assistant\n<|sostm|>")
-
-
-def create_assistant_start_with_think() -> InputSegment:
- """Create assistant start token with think opening"""
- return create_segment(text="<|im_start|>assistant\n<think>\n")
-
-
-# ============================================
-# Common Helper Functions - Composite Segment Creation
-# ============================================
-
-
-def create_user_turn_with_audio(audio_tokenized, extra_text: str = None) -> list[InputSegment]:
- """Create a user turn containing audio"""
- segments = [
- create_user_start(),
- create_segment(audio=audio_tokenized),
- ]
- if extra_text:
- segments.append(create_segment(text=extra_text))
- segments.append(create_user_end())
- return segments
-
-
-def create_user_turn_with_text(text: str) -> list[InputSegment]:
- """Create a text-only user turn"""
- return [
- create_user_start(),
- create_segment(text=text),
- create_user_end(),
- ]
-
-
-def create_system_turn_with_voice_prompt(prompt_text: str, audio_token) -> list[InputSegment]:
- """Create a system turn with voice prompt"""
- return [
- create_system_start(),
- create_segment(text=prompt_text),
- create_segment(text="", audio=audio_token),
- create_user_end(),
- ]
-
-
-def create_system_turn_text_only(system_text: str) -> list[InputSegment]:
- """Create a text-only system turn"""
- return [
- create_system_start(),
- create_segment(text=system_text),
- create_user_end(),
- ]
-
-
-# ============================================
-# Common Helper Functions - Multi-turn Dialogue Processing
-# ============================================
-
-
-def process_multiturn_messages(
- message_list: list[dict],
- user_processor: Callable[[dict], list[InputSegment]],
- assistant_processor: Callable[[dict], list[InputSegment]],
-) -> list[InputSegment]:
- """
- Generic multi-turn dialogue message processing function
-
- Args:
- message_list: List of messages, each containing 'role' and 'content'
- user_processor: Function to process user messages
- assistant_processor: Function to process assistant messages
-
- Returns:
- Processed list of InputSegments
- """
- lm_prompt = []
- for message in message_list:
- role = message["role"]
- if role == "user":
- lm_prompt.extend(user_processor(message))
- elif role == "assistant":
- lm_prompt.extend(assistant_processor(message))
- else:
- raise ValueError(f"Invalid role: {role}")
- return lm_prompt
-
-
-def create_text_user_message(message: dict) -> list[InputSegment]:
- """Process a text-only user message"""
- return [
- create_user_start(),
- create_segment(text=message["content"]),
- create_user_end(),
- ]
-
-
-def create_text_assistant_message(message: dict) -> list[InputSegment]:
- """Process a text-only assistant message"""
- return [
- create_assistant_start(),
- create_segment(text=message["content"]),
- create_user_end(),
- ]
-
-
-def create_audio_user_message(message: dict) -> list[InputSegment]:
- """Process an audio user message"""
- return [
- create_user_start(),
- create_segment(audio=preprocess_input(message["content"])),
- create_user_end(),
- ]
-
-
-def append_assistant_ending(
- lm_prompt: list[InputSegment], thinking: bool = False, use_sostm: bool = False
-) -> list[InputSegment]:
- """
- Append assistant ending to the prompt
-
- Args:
- lm_prompt: Existing prompt list
- thinking: Whether to use open thinking token
- use_sostm: Whether to use sostm token (for speech output)
- """
- if use_sostm:
- lm_prompt.append(create_assistant_start_with_sostm())
- else:
- lm_prompt.append(create_assistant_start())
- lm_prompt.append(create_thinking_segment(thinking))
- return lm_prompt
-
-
-def get_asr_sft_prompt(
- input: None | str = None,
-):
- """Build prompt for ASR (Automatic Speech Recognition) task"""
- audio_tokenized = preprocess_input(input)
- template = random.choice(asr_zh_templates + asr_en_templates)
-
- lm_prompt = create_user_turn_with_audio(audio_tokenized, extra_text=template)
- lm_prompt = append_assistant_ending(lm_prompt, thinking=False)
- return lm_prompt
-
-
-def resample_audio_if_needed(wav_tensor: torch.Tensor, original_sr: int):
- target_sr = 24000
- if original_sr != target_sr:
- wav_tensor = torchaudio.functional.resample(wav_tensor, original_sr, target_sr)
- return wav_tensor
-
-
-def wav2mel(wav, device="cpu"):
- mel_transform = MelSpectrogram(
- sample_rate=mimo_audio_tokenizer.config.sampling_rate,
- n_fft=mimo_audio_tokenizer.config.nfft,
- hop_length=mimo_audio_tokenizer.config.hop_length,
- win_length=mimo_audio_tokenizer.config.window_size,
- f_min=mimo_audio_tokenizer.config.fmin,
- f_max=mimo_audio_tokenizer.config.fmax,
- n_mels=mimo_audio_tokenizer.config.n_mels,
- power=1.0,
- center=True,
- ).to(device)
- spec = mel_transform(wav[None, :])
- return torch.log(torch.clip(spec, min=1e-7)).squeeze()
-
-
-def group_by_length(features: torch.Tensor, lengths: torch.Tensor, max_length: int):
- if features.size(0) != lengths.sum().item():
- raise ValueError(f"Feature size mismatch: {features.size(0)} vs {lengths.sum().item()}")
-
- split_points = []
- current_sum = 0
-
- for i, seq_len in enumerate(lengths):
- if current_sum + seq_len > max_length and current_sum > 0:
- split_points.append(i)
- current_sum = seq_len.item()
- else:
- current_sum += seq_len.item()
-
- # Convert split points to group sizes
- group_sizes = []
- prev = 0
- for point in split_points:
- group_sizes.append(point - prev)
- prev = point
- if prev < len(lengths):
- group_sizes.append(len(lengths) - prev)
-
- len_groups = torch.split(lengths, group_sizes)
- feature_sizes = [group.sum().item() for group in len_groups]
- feature_groups = torch.split(features, feature_sizes)
-
- return feature_groups, len_groups
-
-
-def encode_batch(input_features: torch.Tensor, input_lens: torch.Tensor, max_length: int = 256000):
- feature_groups, len_groups = group_by_length(input_features, input_lens, max_length)
-
- encoded_parts = []
- for features, lengths in zip(feature_groups, len_groups):
- with torch.no_grad():
- codes, _ = mimo_audio_tokenizer.encoder.encode(
- input_features=features.to(device), input_lens=lengths.to(device), return_codes_only=True
- )
- encoded_parts.append(codes)
-
- return torch.cat(encoded_parts, dim=-1)
-
-
-def preprocess_input(input: None | str | torch.Tensor = None, device="cpu", audio_channels=4, group_size=8):
- if isinstance(input, torch.Tensor) or (isinstance(input, str) and os.path.isfile(input)):
- return "<|sosp|><|empty|><|eosp|>"
-
- else:
- text = input
- if (
- text.isupper() or text.islower()
- ): # If the text only contains upper-case or lower-case letters, capitalize it.
- text = text.capitalize()
- return text
-
-
-def _build_tts_system_prompt(has_voice_prompt: bool, voice_audio_token=None) -> list[InputSegment]:
- """Build system prompt for TTS task"""
- if has_voice_prompt and voice_audio_token is not None:
- return [
- create_system_start(),
- create_segment(
- # text="You need to generate a speech with the same timbre as the speech prompt, based on the specified style instructions and text content. Your timbre should be: "
- text="你需要根据指定的风格指令和文本内容来生成和语音prompt具有相同音色的语音。你的音色应该是:"
- ),
- create_segment(text="", audio=voice_audio_token),
- create_user_end(),
- ]
- else:
- return create_system_turn_text_only("你需要根据指定的风格指令和文本内容来生成语音。")
- # return create_system_turn_text_only(
- # "You need to generate speech based on the specified style instructions and text content."
- # )
-
-
-def _build_tts_system_prompt_no_instruct(has_voice_prompt: bool, voice_audio_token=None) -> list[InputSegment]:
- """Build system prompt for TTS task"""
- if has_voice_prompt and voice_audio_token is not None:
- return [
- create_system_start(),
- create_segment(
- # text="You need to generate a speech with the same timbre as the speech prompt, based on the specified style instructions and text content. Your timbre should be:"
- text="你需要根据指定的风格指令和文本内容来生成和语音prompt具有相同音色的语音。你的音色应该是:"
- ),
- create_segment(text="", audio=voice_audio_token),
- create_user_end(),
- ]
- else:
- return []
-
-
-def get_tts_sft_prompt(
- input: None | str = None,
- instruct=None,
- read_text_only=True,
- prompt_speech=None,
-):
- """
- Build prompt for TTS (Text-to-Speech) task
-
- Args:
- input: Input text
- instruct: Style instruction (e.g., "speak happily in a child's voice")
- read_text_only: Whether to read only plain text (False means text contains template)
- prompt_speech: Reference audio (for voice cloning)
- """
- assistant_prompt_audio_token = preprocess_input(prompt_speech) if prompt_speech is not None else None
-
- if not read_text_only:
- # Not just reading text, text contains template (template:text format)
- text = preprocess_input(input)
- lm_prompt = _build_tts_system_prompt(
- has_voice_prompt=assistant_prompt_audio_token is not None,
- voice_audio_token=assistant_prompt_audio_token,
- )
- lm_prompt.append(create_segment(text=f"<|im_start|>user\n{text}<|im_end|>\n"))
- lm_prompt.append(create_assistant_start_with_think())
- else:
- # Plain text (no instruction inside)
- language = detect_language(input)
- template = random.choice(tts_zh_templates if language == "zh" else tts_en_templates)
- text = preprocess_input(input)
-
- if instruct is None:
- # No instruct instruction
- lm_prompt = _build_tts_system_prompt_no_instruct(
- has_voice_prompt=assistant_prompt_audio_token is not None,
- voice_audio_token=assistant_prompt_audio_token,
- )
- lm_prompt.extend(
- [
- create_segment(text=f"<|im_start|>user\n{template}: {text}<|im_end|>\n"),
- create_assistant_start_with_sostm(),
- ]
- )
- else:
- # Has instruct instruction
- lm_prompt = _build_tts_system_prompt(
- has_voice_prompt=assistant_prompt_audio_token is not None,
- voice_audio_token=assistant_prompt_audio_token,
- )
- lm_prompt.append(create_segment(text=f"<|im_start|>user\n{template}: {text}({instruct})<|im_end|>\n"))
- lm_prompt.append(create_assistant_start_with_think())
-
- return lm_prompt
-
-
-def get_audio_understanding_sft_prompt(
- input_speech,
- input_text,
- thinking=False,
- use_sostm=False,
-):
- """Build prompt for audio understanding task"""
- audio_tokenized = preprocess_input(input_speech)
-
- lm_prompt = create_user_turn_with_audio(audio_tokenized, extra_text=input_text)
- lm_prompt = append_assistant_ending(lm_prompt, thinking=thinking, use_sostm=use_sostm)
- return lm_prompt
-
-
-def _build_voice_prompt_system(prompt_speech) -> list[InputSegment]:
- """Build system prompt with voice prompt"""
- return create_system_turn_with_voice_prompt(
- prompt_text="Your voice should be:", audio_token=preprocess_input(prompt_speech)
- )
-
-
-def get_spoken_dialogue_sft_prompt(
- input_speech,
- system_prompt=None,
- prompt_speech=None,
- add_history=False,
-):
- """
- Build prompt for spoken dialogue task
-
- Args:
- input_speech: Input speech
- system_prompt: System prompt text
- prompt_speech: Reference audio (for voice cloning)
- add_history: Whether to add history (Note: history variable is undefined in original code)
- """
- audio_tokenized = preprocess_input(input_speech)
- lm_prompt = []
-
- # Note: history variable is undefined in original code, this branch may never execute
- # To use history feature, history should be passed as a parameter
- if add_history:
- # Simplified form of adding history
- lm_prompt = create_user_turn_with_audio(audio_tokenized)
- lm_prompt.append(create_assistant_start_with_sostm())
- else:
- # Add voice prompt (if available)
- if prompt_speech:
- lm_prompt.extend(_build_voice_prompt_system(prompt_speech))
-
- # Add user turn
- lm_prompt.append(create_user_start())
- if system_prompt:
- lm_prompt.append(create_segment(text=system_prompt))
- lm_prompt.append(create_segment(audio=audio_tokenized))
- lm_prompt.append(create_user_end())
- lm_prompt.append(create_assistant_start_with_sostm())
-
- return lm_prompt
-
-
-def get_spoken_dialogue_sft_multiturn_prompt(
- message_list,
- system_prompt=None,
- prompt_speech=None,
- tokenizer=None,
- group_size=8,
- audio_channels=4,
-):
- """
- Build prompt for multi-turn spoken dialogue task
-
- Args:
- message_list: List of messages containing role and content
- system_prompt: System prompt text
- prompt_speech: Reference audio (for voice cloning)
- tokenizer: Tokenizer
- group_size: Group size
- audio_channels: Number of audio channels
- """
- lm_prompt = []
-
- # Add voice prompt (if available)
- if prompt_speech:
- lm_prompt.extend(
- create_system_turn_with_voice_prompt(
- prompt_text="Your voice should be:", audio_token=preprocess_input(prompt_speech)
- )
- )
-
- # Define message processors
- def user_processor(msg):
- segments = [create_user_start()]
- if system_prompt:
- segments.append(create_segment(text=system_prompt))
- segments.append(create_segment(audio=preprocess_input(msg["content"])))
- segments.append(create_user_end())
- return segments
-
- def assistant_processor(msg):
- return [
- create_assistant_start(),
- create_streaming_segment(
- text=msg["content"]["text"],
- audio=preprocess_input(msg["content"]["audio"]),
- tokenizer=tokenizer,
- group_size=group_size,
- audio_channels=audio_channels,
- ),
- create_user_end(),
- ]
-
- # Process message list
- lm_prompt.extend(process_multiturn_messages(message_list, user_processor, assistant_processor))
- lm_prompt.append(create_assistant_start_with_sostm())
-
- return lm_prompt
-
-
-def get_s2t_dialogue_sft_prompt(
- input_speech,
- thinking=False,
-):
- """Build prompt for speech-to-text dialogue task"""
- audio_tokenized = preprocess_input(input_speech)
-
- lm_prompt = create_user_turn_with_audio(audio_tokenized)
- lm_prompt = append_assistant_ending(lm_prompt, thinking=thinking)
- return lm_prompt
-
-
-def get_s2t_dialogue_sft_multiturn_prompt(message_list, thinking=False):
- """Build prompt for multi-turn speech-to-text dialogue task"""
- lm_prompt = process_multiturn_messages(
- message_list, user_processor=create_audio_user_message, assistant_processor=create_text_assistant_message
- )
- lm_prompt = append_assistant_ending(lm_prompt, thinking=thinking)
- return lm_prompt
-
-
-def get_text_dialogue_sft_prompt(
- input_text,
- thinking=False,
-):
- """Build prompt for text-only dialogue task"""
- lm_prompt = create_user_turn_with_text(input_text)
- lm_prompt = append_assistant_ending(lm_prompt, thinking=thinking)
- return lm_prompt
-
-
-def get_text_dialogue_sft_multiturn_prompt(
- message_list,
- thinking=False,
-):
- """Build prompt for multi-turn text-only dialogue task"""
- lm_prompt = process_multiturn_messages(
- message_list, user_processor=create_text_user_message, assistant_processor=create_text_assistant_message
- )
- lm_prompt = append_assistant_ending(lm_prompt, thinking=thinking)
- return lm_prompt
-
-
-def get_in_context_learning_s2s_prompt(
- instruction,
- prompt_examples,
- audio,
- tokenizer=None,
- group_size=8,
- audio_channels=4,
-):
- """
- Build prompt for In-Context Learning speech-to-speech task
-
- Args:
- instruction: Instruction text
- prompt_examples: List of examples, each containing input_audio, output_transcription, output_audio
- audio: Input audio to be processed
- tokenizer: Tokenizer
- group_size: Group size
- audio_channels: Number of audio channels
- """
- prompt = [create_segment(text=f"[Int]:{instruction}\n")]
-
- # Add examples
- for example in prompt_examples:
- prompt.extend(
- [
- create_segment(audio=preprocess_input(example["input_audio"])),
- create_segment(text="\n"),
- create_streaming_segment(
- text=example["output_transcription"],
- audio=preprocess_input(example["output_audio"]),
- tokenizer=tokenizer,
- group_size=group_size,
- audio_channels=audio_channels,
- ),
- create_segment(text=" \n\n"),
- ]
- )
-
- # Add input audio to be processed
- prompt.extend(
- [
- create_segment(audio=preprocess_input(audio)),
- create_segment(text="\n"),
- create_sostm_segment(),
- ]
- )
-
- return prompt
-
-
-def get_audio_data(audio_url):
- if audio_url.startswith("data:"):
- header, b64_data = audio_url.split(",", 1)
- audio_bytes = base64.b64decode(b64_data.strip())
- audio_file = io.BytesIO(audio_bytes)
- else:
- # File path
- audio_file = audio_url
-
- audio_signal, sr = load_audio(audio_file, sr=24000)
- audio_data = (audio_signal.astype(np.float32), sr)
- return audio_data
-
-
-def to_prompt(input_segs):
- out_put = []
-
- for input_seg in input_segs:
- if isinstance(input_seg, StreamingInputSegment) and input_seg.text:
- out_put.append("<|sostm|>")
- if input_seg.audio is not None and isinstance(input_seg.audio, str):
- out_put.append(input_seg.text)
- out_put.append("<|eot|>")
- out_put.append("<|empty|>")
- else:
- out_put.append(input_seg.text)
- out_put.append("<|eot|>")
- out_put.append("<|eostm|>")
-
- else:
- out_put.append(input_seg.text)
- if input_seg.audio is not None:
- out_put.append(input_seg.audio)
-
- prompt = "".join(out_put)
- return prompt
diff --git a/examples/offline_inference/mimo_audio/process_speechdata.py b/examples/offline_inference/mimo_audio/process_speechdata.py
deleted file mode 100644
index 22479231444..00000000000
--- a/examples/offline_inference/mimo_audio/process_speechdata.py
+++ /dev/null
@@ -1,261 +0,0 @@
-#!/usr/bin/env python3
-# Copyright 2025 Xiaomi Corporation.
-# Copyright (c) 2023, NVIDIA CORPORATION. All rights reserved.
-
-
-import torch
-
-
-class InputSegment:
- def __init__(
- self,
- text: str = "",
- audio: torch.Tensor = None,
- tokenized_text: torch.Tensor = None,
- speech_zeroemb_idx: int | list[int] = 1024,
- text_zeroemb_idx: int = 152067,
- add_sosp_eosp=True,
- ) -> None:
- has_text = text is not None
- has_tokenized_text = tokenized_text is not None
- assert has_text or has_tokenized_text, "Text or tokenized text must be provided"
-
- self.audio = audio
- self.text = text
- self.tokenized_text = tokenized_text
- self.speech_zeroemb_idx = speech_zeroemb_idx
- self.text_zeroemb_idx = text_zeroemb_idx
- self.add_sosp_eosp = add_sosp_eosp
-
- @staticmethod
- def insert_between(tensor, i, value=-1):
- return torch.scatter(
- torch.full(
- (1, tensor.shape[1] + (tensor.shape[1] - 1) * i + i),
- value,
- dtype=tensor.dtype,
- ),
- 1,
- torch.arange(0, tensor.shape[1], dtype=torch.int64)[None] * (i + 1),
- tensor,
- )
-
- def to_input_id(
- self,
- tokenizer,
- group_size: int,
- audio_channels: int = 8,
- ) -> tuple[torch.Tensor, torch.Tensor]:
- if (
- self.audio is None
- ): ## If no audio is provided, tokenize the text with (group_size-1) tokens inserted between each, fill with -100; and set audio to empty indices
- if self.tokenized_text is None:
- tokenized_text = tokenizer(
- self.text,
- return_tensors="pt",
- truncation=True,
- max_length=999999,
- padding=False,
- add_special_tokens=False,
- )["input_ids"].int()
- else:
- tokenized_text = self.tokenized_text.unsqueeze(0)
-
- if group_size > 1:
- tokenized_text = self.insert_between(tokenized_text, group_size - 1, value=-100)
-
- if isinstance(self.speech_zeroemb_idx, list):
- audio_part_input_id = torch.zeros((audio_channels, tokenized_text.shape[1]), dtype=torch.int)
- for i, idx in enumerate(self.speech_zeroemb_idx):
- audio_part_input_id[i, :] = idx
- else:
- audio_part_input_id = torch.full(
- (audio_channels, tokenized_text.shape[1]), self.speech_zeroemb_idx, dtype=torch.int
- )
-
- else: # If audio is provided, add sosp/eosp markers and convert audio: fill with empty tokens based on audio length
- sosp_token = tokenizer.convert_tokens_to_ids("<|sosp|>") if self.add_sosp_eosp else None
- eosp_token = tokenizer.convert_tokens_to_ids("<|eosp|>") if self.add_sosp_eosp else None
- audio_part = self.audio.reshape(-1, audio_channels).T # [audio_channels, seqlen]
-
- assert audio_part.shape[1] % group_size == 0, (
- f"Audio shape {audio_part.shape} is not divisible by group_size {group_size}"
- )
-
- text_len = audio_part.shape[1] // group_size
- empty_token = self.text_zeroemb_idx
- if empty_token is None:
- empty_token = tokenizer.eod
- tokenized_text = torch.full((1, text_len), empty_token, dtype=torch.int)
-
- tokenized_text = (
- torch.cat(
- [
- torch.tensor([[sosp_token]], dtype=torch.int),
- tokenized_text,
- torch.tensor([[eosp_token]], dtype=torch.int),
- ],
- dim=1,
- )
- if self.add_sosp_eosp
- else tokenized_text
- )
- tokenized_text = self.insert_between(tokenized_text, group_size - 1, value=-100)
-
- if self.add_sosp_eosp:
- if isinstance(self.speech_zeroemb_idx, list):
- sosp_part = torch.zeros((audio_channels, group_size), dtype=torch.int)
- eosp_part = torch.zeros((audio_channels, group_size), dtype=torch.int)
- for i, idx in enumerate(self.speech_zeroemb_idx):
- sosp_part[i, :] = idx
- eosp_part[i, :] = idx
- audio_part_input_id = torch.cat([sosp_part, audio_part, eosp_part], dim=1)
- else:
- audio_part_input_id = torch.cat(
- [
- torch.full((audio_channels, group_size), self.speech_zeroemb_idx, dtype=torch.int),
- audio_part,
- torch.full((audio_channels, group_size), self.speech_zeroemb_idx, dtype=torch.int),
- ],
- dim=1,
- )
- else:
- audio_part_input_id = audio_part
-
- input_ids = torch.cat([tokenized_text, audio_part_input_id], dim=0) # [n_rvq + 1, seqlen]
-
- return input_ids
-
-
-class StreamingInputSegment:
- def __init__(
- self,
- text: str = "",
- audio: torch.Tensor = None,
- tokenized_text: torch.Tensor = None,
- speech_zeroemb_idx: int | list[int] = 1024,
- text_zeroemb_idx: int = 152067,
- text_segment_size: int = 5,
- audio_segment_size: int = 5,
- tokenizer=None,
- group_size=None,
- audio_channels=None,
- ) -> None:
- has_text = text is not None
- has_tokenized_text = tokenized_text is not None
- assert has_text or has_tokenized_text, "Text or tokenized text must be provided"
-
- self.audio = audio
- self.text = text
- self.tokenized_text = tokenized_text
- self.speech_zeroemb_idx = speech_zeroemb_idx
- self.text_zeroemb_idx = text_zeroemb_idx
- self.text_segment_size = text_segment_size
- self.audio_segment_size = audio_segment_size
- self.tokenizer = tokenizer
- self.group_size = group_size
- self.audio_channels = audio_channels
-
- def to_input_id(
- self,
- tokenizer,
- group_size: int,
- audio_channels: int = 8,
- ):
- if self.tokenized_text is None:
- tokenized_text = tokenizer(
- self.text,
- return_tensors="pt",
- truncation=True,
- max_length=999999,
- padding=False,
- add_special_tokens=False,
- )["input_ids"].int() # [1, seqlen]
- else:
- tokenized_text = self.tokenized_text.unsqueeze(0)
-
- tokenized_text = tokenized_text.squeeze(0)
-
- text_segments = tokenized_text.split(self.text_segment_size, dim=0)
- audio_segments = self.audio.split(self.audio_segment_size * group_size * audio_channels, dim=0)
-
- tokenized_segments = []
- tokenized_segments.append(
- InputSegment(
- text="<|sostm|>",
- speech_zeroemb_idx=self.speech_zeroemb_idx,
- text_zeroemb_idx=self.text_zeroemb_idx,
- ),
- )
-
- eot_tokens = tokenizer(
- "<|eot|>",
- return_tensors="pt",
- truncation=True,
- max_length=999999,
- padding=False,
- add_special_tokens=False,
- )["input_ids"][0].to(text_segments[-1])
-
- text_segments = text_segments[:-1] + (torch.cat([text_segments[-1], eot_tokens], dim=0),)
-
- length = min(len(text_segments), len(audio_segments)) # The number of empty tokens here may vary
- for i in range(length):
- text_segment = text_segments[i]
- audio_segment = audio_segments[i]
-
- tokenized_segments.append(
- InputSegment(
- tokenized_text=text_segment,
- speech_zeroemb_idx=self.speech_zeroemb_idx,
- text_zeroemb_idx=self.text_zeroemb_idx,
- ),
- )
- tokenized_segments.append(
- InputSegment(
- audio=audio_segment,
- add_sosp_eosp=False,
- speech_zeroemb_idx=self.speech_zeroemb_idx,
- text_zeroemb_idx=self.text_zeroemb_idx,
- ),
- )
-
- for j in range(length, len(text_segments)):
- tokenized_segments.append(
- InputSegment(
- tokenized_text=text_segments[j],
- speech_zeroemb_idx=self.speech_zeroemb_idx,
- text_zeroemb_idx=self.text_zeroemb_idx,
- ),
- )
-
- for j in range(length, len(audio_segments)):
- tokenized_segments.append(
- InputSegment(
- audio=audio_segments[j],
- add_sosp_eosp=False,
- speech_zeroemb_idx=self.speech_zeroemb_idx,
- text_zeroemb_idx=self.text_zeroemb_idx,
- ),
- )
-
- tokenized_segments.append(
- InputSegment(
- text="<|eostm|>",
- speech_zeroemb_idx=self.speech_zeroemb_idx,
- text_zeroemb_idx=self.text_zeroemb_idx,
- ),
- )
-
- input_ids = [
- seg.to_input_id(
- self.tokenizer,
- self.group_size,
- self.audio_channels,
- )
- for seg in tokenized_segments
- ]
-
- input_ids = torch.cat(input_ids, dim=1).type(torch.int64) # [n_rvq + 1, seqlen]
-
- return input_ids
diff --git a/examples/offline_inference/ming_flash_omni/README.md b/examples/offline_inference/ming_flash_omni/README.md
deleted file mode 100644
index be90b408d14..00000000000
--- a/examples/offline_inference/ming_flash_omni/README.md
+++ /dev/null
@@ -1,92 +0,0 @@
-# Ming-flash-omni 2.0
-
-[Ming-flash-omni-2.0](https://github.com/inclusionAI/Ming) is an omni-modal model supporting text, image, video, and audio understanding, with text and speech outputs.
-
-vLLM-Omni supports two deployment modes:
-
-| Mode | Stage config | Output |
-|------|-------------|--------|
-| Thinker only (multimodal understanding) | `ming_flash_omni_thinker.yaml` (default `--omni`) | Text |
-| Thinker + Talker (omni-speech) | `ming_flash_omni.yaml` | Text + Audio |
-
-For standalone TTS (talker only), see [`examples/offline_inference/ming_flash_omni_tts/`](../ming_flash_omni_tts/).
-
-## Setup
-
-Please refer to the [stage configuration documentation](https://docs.vllm.ai/projects/vllm-omni/en/latest/configuration/stage_configs/) to configure memory allocation appropriately for your hardware setup.
-
-The default `--omni` flag runs thinker only. For omni-speech, pass the two-stage config explicitly:
-
-```bash
---stage-configs-path vllm_omni/model_executor/stage_configs/ming_flash_omni.yaml
-```
-
-## Run examples
-
-The end-to-end script defaults to built-in assets; pass `--image-path`,
-`--audio-path`, or `--video-path` to override.
-
-```bash
-# Text-only
-python examples/offline_inference/ming_flash_omni/end2end.py --query-type text
-
-# Image / audio / video / mixed understanding
-python examples/offline_inference/ming_flash_omni/end2end.py --query-type use_image
-python examples/offline_inference/ming_flash_omni/end2end.py --query-type use_audio
-python examples/offline_inference/ming_flash_omni/end2end.py --query-type use_video --num-frames 16
-python examples/offline_inference/ming_flash_omni/end2end.py --query-type use_mixed_modalities \
- --image-path /path/to/image.jpg --audio-path /path/to/audio.wav
-```
-
-#### Reasoning (Thinking Mode)
-
-Reasoning ("detailed thinking on") is applied by the script when
-`--query-type reasoning` is set. The default prompt matches Ming's cookbook
-and expects the reference figure from the upstream repo — see
-`get_reasoning_query` in `end2end.py`.
-
-```bash
-python examples/offline_inference/ming_flash_omni/end2end.py -q reasoning --image-path ./3_0.png
-```
-
-### Omni-speech (thinker + talker)
-
-To enable spoken output, use the two-stage config and request `audio` (or `text,audio`) modalities.
-The thinker processes your multimodal input, generates text, then the talker synthesises the response as speech.
-
-**Audio-only output** (speech response, no text):
-```bash
-python examples/offline_inference/ming_flash_omni/end2end.py \
- --query-type text \
- --stage-configs-path vllm_omni/model_executor/stage_configs/ming_flash_omni.yaml \
- --modalities audio \
- --output-dir output_ming_omni_speech
-```
-
-**Both text and audio output**:
-```bash
-python examples/offline_inference/ming_flash_omni/end2end.py \
- --query-type use_audio \
- --stage-configs-path vllm_omni/model_executor/stage_configs/ming_flash_omni.yaml \
- --modalities text,audio \
- --output-dir output_ming_omni_speech
-```
-
-Generated `.wav` files are saved to `--output-dir` (default `output_ming`), one per request.
-
-The stage config allocates thinker on GPUs 0–3 and talker on GPU 3 by default. Adjust `devices` in the YAML to match your hardware.
-
-### Modality control
-
-| `--modalities` | Thinker output | Talker | Saved files |
-|---------------|----------------|--------|-------------|
-| `text` (default) | Text | Not run | `<id>.txt` |
-| `audio` | Text (internal) | Runs | `<id>.wav` |
-| `text,audio` | Text | Runs | `<id>.txt` + `<id>.wav` |
-
-Pass `--stage-configs-path /path/to/your_config.yaml` to any of the commands
-above to override the stage config.
-
-## Online serving
-
-For online serving via the OpenAI-compatible API, see [examples/online_serving/ming_flash_omni/README.md](../../online_serving/ming_flash_omni/README.md).
diff --git a/examples/offline_inference/ming_flash_omni/end2end.py b/examples/offline_inference/ming_flash_omni/end2end.py
deleted file mode 100644
index e00dcea7bb3..00000000000
--- a/examples/offline_inference/ming_flash_omni/end2end.py
+++ /dev/null
@@ -1,507 +0,0 @@
-# SPDX-License-Identifier: Apache-2.0
-# SPDX-FileCopyrightText: Copyright contributors to the vLLM project
-# Partial example cases are referred from
-# https://github.com/inclusionAI/Ming/blob/3954fcb880ff5e61ff128bcf7f1ec344d46a6fe3/cookbook.ipynb
-import os
-import time
-from typing import NamedTuple
-
-import numpy as np
-import soundfile as sf
-import vllm
-from PIL import Image
-from transformers import AutoProcessor
-from vllm import SamplingParams
-from vllm.assets.audio import AudioAsset
-from vllm.assets.image import ImageAsset
-from vllm.assets.video import VideoAsset, video_to_ndarrays
-from vllm.multimodal.image import convert_image_mode
-from vllm.multimodal.media.audio import load_audio
-from vllm.utils.argparse_utils import FlexibleArgumentParser
-
-import vllm_omni
-from vllm_omni.entrypoints.omni import Omni
-
-# Imports the processor also registers itself
-from vllm_omni.transformers_utils.processors.ming import MingFlashOmniProcessor # noqa: F401
-
-SEED = 42
-MODEL_NAME = "Jonathan1909/Ming-flash-omni-2.0"
-
-
-class QueryResult(NamedTuple):
- inputs: dict
- limit_mm_per_prompt: dict[str, int]
-
-
-def get_text_query(processor: MingFlashOmniProcessor, question: str | None = None) -> QueryResult:
- if question is None:
- question = "请详细介绍鹦鹉的生活习性。"
- conversation = [{"role": "HUMAN", "content": question}]
- prompt = processor.apply_chat_template(conversation, tokenize=False)
- return QueryResult(
- inputs={"prompt": prompt},
- limit_mm_per_prompt={},
- )
-
-
-def get_image_query(
- processor: MingFlashOmniProcessor,
- question: str | None = None,
- image_path: str | None = None,
-) -> QueryResult:
- if question is None:
- question = "Describe this image in detail."
-
- if image_path:
- if not os.path.exists(image_path):
- raise FileNotFoundError(f"Image file not found: {image_path}")
- image_data = convert_image_mode(Image.open(image_path), "RGB")
- else:
- image_data = convert_image_mode(ImageAsset("cherry_blossom").pil_image, "RGB")
-
- conversation = [
- {
- "role": "HUMAN",
- "content": [
- {"type": "image", "image": image_data},
- {"type": "text", "text": question},
- ],
- }
- ]
- prompt = processor.apply_chat_template(conversation, tokenize=False)
-
- return QueryResult(
- inputs={
- "prompt": prompt,
- "multi_modal_data": {"image": image_data},
- },
- limit_mm_per_prompt={"image": 1},
- )
-
-
-def get_audio_query(
- processor: MingFlashOmniProcessor,
- question: str | None = None,
- audio_path: str | None = None,
- sampling_rate: int = 16000,
-) -> QueryResult:
- if question is None:
- question = "Please recognize the language of this speech and transcribe it. Format: oral."
-
- if audio_path:
- if not os.path.exists(audio_path):
- raise FileNotFoundError(f"Audio file not found: {audio_path}")
- audio_signal, sr = load_audio(audio_path, sr=sampling_rate)
- audio_data = (audio_signal.astype(np.float32), sr)
- else:
- audio_data = AudioAsset("mary_had_lamb").audio_and_sample_rate
-
- # Use a string for "audio" so the processor counts it as 1 audio input
- conversation = [
- {
- "role": "HUMAN",
- "content": [
- {"type": "audio", "audio": "input"},
- {"type": "text", "text": question},
- ],
- }
- ]
- prompt = processor.apply_chat_template(conversation, tokenize=False)
-
- return QueryResult(
- inputs={
- "prompt": prompt,
- "multi_modal_data": {"audio": audio_data},
- },
- limit_mm_per_prompt={"audio": 1},
- )
-
-
-def get_video_query(
- processor: MingFlashOmniProcessor,
- question: str | None = None,
- video_path: str | None = None,
- num_frames: int = 16,
-) -> QueryResult:
- if question is None:
- question = "Describe what is happening in this video."
-
- if video_path:
- if not os.path.exists(video_path):
- raise FileNotFoundError(f"Video file not found: {video_path}")
- video_frames = video_to_ndarrays(video_path, num_frames=num_frames)
- else:
- video_frames = VideoAsset(name="baby_reading", num_frames=num_frames).np_ndarrays
-
- conversation = [
- {
- "role": "HUMAN",
- "content": [
- {"type": "video"},
- {"type": "text", "text": question},
- ],
- }
- ]
- prompt = processor.apply_chat_template(conversation, tokenize=False)
-
- return QueryResult(
- inputs={
- "prompt": prompt,
- "multi_modal_data": {"video": video_frames},
- },
- limit_mm_per_prompt={"video": 1},
- )
-
-
-def get_mixed_modalities_query(
- processor: MingFlashOmniProcessor,
- image_path: str | None = None,
- audio_path: str | None = None,
- sampling_rate: int = 16000,
-) -> QueryResult:
- """Mixed image + audio understanding."""
- question = "Describe the image, and recognize the language of this speech and transcribe it. Format: oral"
-
- if image_path:
- if not os.path.exists(image_path):
- raise FileNotFoundError(f"Image file not found: {image_path}")
- image_data = convert_image_mode(Image.open(image_path), "RGB")
- else:
- image_data = convert_image_mode(ImageAsset("cherry_blossom").pil_image, "RGB")
-
- if audio_path:
- if not os.path.exists(audio_path):
- raise FileNotFoundError(f"Audio file not found: {audio_path}")
- sig, sr = load_audio(audio_path, sr=sampling_rate)
- audio_data = (sig.astype(np.float32), sr)
- else:
- audio_data = AudioAsset("mary_had_lamb").audio_and_sample_rate
-
- conversation = [
- {
- "role": "HUMAN",
- "content": [
- {"type": "image", "image": image_data},
- {"type": "audio", "audio": "input"},
- {"type": "text", "text": question},
- ],
- }
- ]
- prompt = processor.apply_chat_template(conversation, tokenize=False)
-
- return QueryResult(
- inputs={
- "prompt": prompt,
- "multi_modal_data": {"image": image_data, "audio": audio_data},
- },
- limit_mm_per_prompt={"image": 1, "audio": 1},
- )
-
-
-def get_reasoning_query(
- processor: MingFlashOmniProcessor,
- question: str | None = None,
- image_path: str | None = None,
-) -> QueryResult:
- if question is None:
- # NOTE: To use the following default question, input with example figure provided by Ming
- # https://github.com/inclusionAI/Ming/blob/3954fcb880ff5e61ff128bcf7f1ec344d46a6fe3/figures/cases/3_0.png
- # E.g.,
- # python examples/offline_inference/ming_flash_omni/end2end.py -q reasoning --image-path ./3_0.png
- # Otherwise, the problem solving might be false.
- question = (
- "Based on the following rules:\n•\tYou control the smiley face character\n"
- "•\tYou can move up, down, left, and right, and only a single square at a time\n"
- "•\tWalls are dark grey and cannot be moved into\n•\tThe brown square is a box\n•"
- "\tThe box can be pushed by moving into it (i.e., if you are in the square "
- "adjacent to the box to the left, and move onto the square with the box, "
- "the box will move one square to the right).\n"
- "•\tThe box cannot be pushed into walls\n"
- "•\tThe blue door at the bottom is locked and cannot be passed through, "
- "unless the box is placed on the blue square\n"
- "•\tThe square beneath the blue door is the exit\n"
- "•\tMoving from one square to another\n\n"
- "Let's assume a coordinate system where the smiley face is "
- "on the top left at (1,1) and the square below it is (1,2). "
- "The smiley face performs the following moves: {down, right, right, right}, "
- "such that the smiley face is at square (4,2) and the box is in square (5,2). "
- "What are the next sequence of moves that must be done to move the box down to (5,3)? "
- "Give your answer as a comma separated list."
- )
-
- if image_path:
- if not os.path.exists(image_path):
- raise FileNotFoundError(f"Image file not found: {image_path}")
- image_data = convert_image_mode(Image.open(image_path), "RGB")
- conversation = [
- {
- "role": "HUMAN",
- "content": [
- {"type": "image", "image": image_data},
- {"type": "text", "text": question},
- ],
- }
- ]
- prompt = processor.apply_chat_template(conversation, tokenize=False, use_cot_system_prompt=True)
- return QueryResult(
- inputs={
- "prompt": prompt,
- "multi_modal_data": {"image": image_data},
- },
- limit_mm_per_prompt={"image": 1},
- )
-
- conversation = [{"role": "HUMAN", "content": question}]
- prompt = processor.apply_chat_template(conversation, tokenize=False, use_cot_system_prompt=True)
- return QueryResult(
- inputs={"prompt": prompt},
- limit_mm_per_prompt={},
- )
-
-
-query_map = {
- "text": get_text_query,
- "use_audio": get_audio_query,
- "use_image": get_image_query,
- "use_video": get_video_query,
- "use_mixed_modalities": get_mixed_modalities_query,
- "reasoning": get_reasoning_query,
-}
-
-
-def main(args):
- print(
- "=" * 20,
- "\n",
- f"vllm version: {vllm.__version__}\n",
- f"vllm-omni version: {vllm_omni.__version__}\n",
- "=" * 20,
- sep="",
- )
-
- processor = AutoProcessor.from_pretrained(MODEL_NAME, trust_remote_code=True)
- assert isinstance(processor, MingFlashOmniProcessor), f"Wrong processor type being used: {type(processor)}"
-
- query_func = query_map[args.query_type]
- if args.query_type == "use_image":
- query_result = query_func(processor, image_path=args.image_path)
- elif args.query_type == "use_audio":
- query_result = query_func(processor, audio_path=args.audio_path, sampling_rate=args.sampling_rate)
- elif args.query_type == "use_video":
- query_result = query_func(processor, video_path=args.video_path, num_frames=args.num_frames)
- elif args.query_type == "use_mixed_modalities":
- query_result = query_func(
- processor,
- image_path=args.image_path,
- audio_path=args.audio_path,
- sampling_rate=args.sampling_rate,
- )
- elif args.query_type == "reasoning":
- query_result = query_func(processor, image_path=args.image_path)
- else:
- query_result = query_func(processor)
-
- # Initialize Omni (with thinker-only stage config)
- omni = Omni(
- model=MODEL_NAME,
- stage_configs_path=args.stage_configs_path,
- log_stats=args.log_stats,
- init_timeout=args.init_timeout,
- stage_init_timeout=args.stage_init_timeout,
- )
-
- # Thinker sampling params
- thinker_sampling_params = SamplingParams(
- temperature=0.4,
- top_p=0.9,
- max_tokens=args.max_tokens,
- repetition_penalty=1.05,
- seed=SEED,
- detokenize=True,
- )
- # Talker (ming_tts) uses a custom generation loop (CFM + AudioVAE);
- # vLLM sampling is a no-op here — max_tokens=1 just satisfies the scheduler.
- talker_sampling_params = SamplingParams(
- temperature=0.0,
- max_tokens=1,
- )
- all_sampling_params = [thinker_sampling_params, talker_sampling_params]
- # Match sampling params to the number of configured stages
- # (thinker-only yaml → 1, thinker+talker yaml → 2).
- sampling_params_list = all_sampling_params[: omni.num_stages]
-
- prompts = [query_result.inputs for _ in range(args.num_prompts)]
-
- if args.modalities is not None:
- output_modalities = args.modalities.split(",")
- for prompt in prompts:
- prompt["modalities"] = output_modalities
-
- total_requests = len(prompts)
- processed_count = 0
- print(f"Query type: {args.query_type}")
- print(f"Number of prompts: {total_requests}")
-
- output_dir = args.output_dir
- os.makedirs(output_dir, exist_ok=True)
-
- profiler_enabled = args.enable_profiler
- if profiler_enabled:
- omni.start_profile(stages=args.profiler_stages)
-
- for stage_outputs in omni.generate(prompts, sampling_params_list):
- output = stage_outputs.request_output
- if stage_outputs.final_output_type == "text":
- request_id = output.request_id
- text_output = output.outputs[0].text
- lines = []
- lines.append("Prompt:\n")
- lines.append(str(output.prompt) + "\n")
- lines.append("Text Output:\n")
- lines.append(str(text_output).strip() + "\n")
- print(*lines, sep="")
-
- # Save to file
- out_txt = os.path.join(output_dir, f"{request_id}.txt")
- try:
- with open(out_txt, "w", encoding="utf-8") as f:
- f.writelines(lines)
- print(f"Request ID: {request_id}, text saved to {out_txt}")
- except Exception as e:
- print(f"Failed to write output file {out_txt}: {e}")
-
- elif stage_outputs.final_output_type == "audio":
- request_id = output.request_id
- mm = output.outputs[0].multimodal_output
- if mm and "audio" in mm:
- audio = mm["audio"]
- sr_raw = mm.get("sr", 44100)
- sample_rate = int(sr_raw.item() if hasattr(sr_raw, "item") else sr_raw)
- audio_numpy = audio.float().squeeze().cpu().numpy()
- output_wav = os.path.join(output_dir, f"{request_id}.wav")
- sf.write(output_wav, audio_numpy, samplerate=sample_rate, format="WAV")
- print(
- f"Request ID: {request_id}, audio saved to {output_wav} "
- f"({len(audio_numpy) / sample_rate:.2f}s, {sample_rate}Hz)"
- )
-
- processed_count += 1
- if profiler_enabled and processed_count >= total_requests:
- print(f"[Info] Processed {processed_count}/{total_requests}. Stopping profiler inside active loop...")
- # Stop the profiler while workers are still alive
- omni.stop_profile(stages=args.profiler_stages)
-
- print("[Info] Waiting 30s for workers to write trace files to disk...")
- time.sleep(30)
- print("[Info] Trace export wait time finished.")
-
- omni.close()
-
-
-def parse_args():
- parser = FlexibleArgumentParser(description="Ming-flash-omni 2.0 offline inference example")
- parser.add_argument(
- "--query-type",
- "-q",
- type=str,
- default="text",
- choices=query_map.keys(),
- help="Query type.",
- )
- parser.add_argument(
- "--stage-configs-path",
- type=str,
- default=None,
- help="Path to a stage configs YAML file.",
- )
- parser.add_argument(
- "--log-stats",
- action="store_true",
- default=False,
- help="Enable detailed statistics logging.",
- )
- parser.add_argument("--init-timeout", type=int, default=2000, help="Timeout for initializing in seconds.")
- parser.add_argument(
- "--stage-init-timeout",
- type=int,
- default=2000,
- help="Timeout for initializing a single stage in seconds.",
- )
- parser.add_argument(
- "--enable-profiler",
- action="store_true",
- default=False,
- help="Enables profiling when set.",
- )
- parser.add_argument(
- "--profiler-stages",
- type=int,
- nargs="*",
- default=[0],
- help="List of stage IDs to profile. If not set, profiles all stages.",
- )
- parser.add_argument(
- "--image-path",
- "-i",
- type=str,
- default=None,
- help="Path to local image file. Uses default asset if not provided.",
- )
- parser.add_argument(
- "--audio-path",
- "-a",
- type=str,
- default=None,
- help="Path to local audio file. Uses default asset if not provided.",
- )
- parser.add_argument(
- "--video-path",
- "-v",
- type=str,
- default=None,
- help="Path to local video file. Uses default asset if not provided.",
- )
- parser.add_argument(
- "--num-frames",
- type=int,
- default=16,
- help="Number of frames to extract from video.",
- )
- parser.add_argument(
- "--sampling-rate",
- type=int,
- default=16000,
- help="Sampling rate for audio loading.",
- )
- parser.add_argument(
- "--max-tokens",
- type=int,
- default=16384,
- help="Maximum tokens to generate.",
- )
- parser.add_argument(
- "--num-prompts",
- type=int,
- default=1,
- help="Number of prompts to generate.",
- )
- parser.add_argument(
- "--modalities",
- type=str,
- default=None,
- help="Output modalities (comma-separated).",
- )
- parser.add_argument(
- "--output-dir",
- type=str,
- default="output_ming",
- help="Output directory for results.",
- )
-
- return parser.parse_args()
-
-
-if __name__ == "__main__":
- args = parse_args()
- main(args)
diff --git a/examples/offline_inference/ming_flash_omni_tts/README.md b/examples/offline_inference/ming_flash_omni_tts/README.md
deleted file mode 100644
index 15b84041df2..00000000000
--- a/examples/offline_inference/ming_flash_omni_tts/README.md
+++ /dev/null
@@ -1,47 +0,0 @@
-# Ming-flash-omni Standalone TTS (Offline)
-
-This example runs **Ming-flash-omni-2.0 talker-only** offline inference with:
-
-- `model`: `Jonathan1909/Ming-flash-omni-2.0`
-- `stage config`: `vllm_omni/model_executor/stage_configs/ming_flash_omni_tts.yaml`
-
-It follows the Ming cookbook parameter style:
-
-- `prompt`: `"Please generate speech based on the following description.\n"`
-- `max_decode_steps`: `200`
-- `cfg`: `2.0`
-- `sigma`: `0.25`
-- `temperature`: `0.0`
-
-## Quick Start
-
-```bash
-python examples/offline_inference/ming_flash_omni_tts/end2end.py --case style
-```
-
-## Cases
-
-```bash
-# Style
-python examples/offline_inference/ming_flash_omni_tts/end2end.py --case style
-
-# IP
-python examples/offline_inference/ming_flash_omni_tts/end2end.py --case ip
-
-# Basic (speed/pitch/volume control)
-python examples/offline_inference/ming_flash_omni_tts/end2end.py --case basic
-```
-
-## Useful Arguments
-
-- `--text`: override default text in the selected case
-- `--output`: custom output wav path
-- `--model`: local model path or HF repo id
-- `--stage-configs-path`: custom talker stage config path
-- `--log-stats`: enable runtime stats logs
-
-## Notes
-
-- This directory is for **standalone talker deployment (TTS)**.
-- For Ming thinker multimodal understanding examples, see:
- `examples/offline_inference/ming_flash_omni/`.
diff --git a/examples/offline_inference/ming_flash_omni_tts/end2end.py b/examples/offline_inference/ming_flash_omni_tts/end2end.py
deleted file mode 100644
index 928994510a6..00000000000
--- a/examples/offline_inference/ming_flash_omni_tts/end2end.py
+++ /dev/null
@@ -1,128 +0,0 @@
-"""Offline e2e example for Ming-flash-omni-2.0 standalone talker (TTS)."""
-
-import os
-from typing import Any
-
-import soundfile as sf
-import torch
-from vllm.utils.argparse_utils import FlexibleArgumentParser
-
-os.environ["VLLM_WORKER_MULTIPROC_METHOD"] = "spawn"
-
-from vllm_omni.entrypoints.omni import Omni
-from vllm_omni.inputs.data import OmniTokensPrompt
-from vllm_omni.model_executor.models.ming_flash_omni.prompt_utils import (
- DEFAULT_PROMPT,
- create_instruction,
-)
-
-MODEL_NAME = "Jonathan1909/Ming-flash-omni-2.0"
-DEFAULT_STAGE_CONFIG = "vllm_omni/model_executor/stage_configs/ming_flash_omni_tts.yaml"
-
-
-def get_messages(case: str, text_override: str | None) -> dict[str, Any]:
- if case == "style":
- text = text_override or "我会一直在这里陪着你,直到你慢慢、慢慢地沉入那个最温柔的梦里……好吗?"
- instruction = create_instruction(
- {
- "风格": "这是一种ASMR耳语,属于一种旨在引发特殊感官体验的创意风格。这个女性使用轻柔的普通话进行耳语,声音气音成分重。音量极低,紧贴麦克风,语速极慢,旨在制造触发听者颅内快感的声学刺激。",
- }
- )
- return {
- "prompt": DEFAULT_PROMPT,
- "text": text,
- "instruction": instruction,
- "use_zero_spk_emb": True,
- }
- if case == "ip":
- text = text_override or "这款产品的名字,叫变态坑爹牛肉丸。"
- return {
- "prompt": DEFAULT_PROMPT,
- "text": text,
- "instruction": create_instruction({"IP": "灵小甄"}),
- "use_zero_spk_emb": True,
- }
- if case == "basic":
- text = text_override or "我们当迎着阳光辛勤耕作,去摘取,去制作,去品尝,去馈赠。"
- return {
- "prompt": DEFAULT_PROMPT,
- "text": text,
- "instruction": create_instruction({"语速": "快速", "基频": "中", "音量": "中"}),
- "use_zero_spk_emb": True,
- }
- raise ValueError(f"Unknown case: {case}")
-
-
-def save_audio(mm: dict[str, Any], output_path: str) -> None:
- if not mm or "audio" not in mm:
- raise RuntimeError("No audio found in model output")
- audio = mm["audio"]
- sr_raw = mm.get("sr", 44100)
- if isinstance(sr_raw, torch.Tensor):
- sample_rate = int(sr_raw.item())
- else:
- sample_rate = int(sr_raw)
- waveform = audio.squeeze().float().cpu().numpy()
- sf.write(output_path, waveform, sample_rate)
- print(f"Saved {output_path} ({len(waveform) / sample_rate:.2f}s, {sample_rate}Hz)")
-
-
-def parse_args():
- parser = FlexibleArgumentParser(description="Ming-flash-omni standalone talker offline e2e example")
- parser.add_argument("--model", type=str, default=MODEL_NAME, help="Model name or local path.")
- parser.add_argument(
- "--stage-configs-path",
- type=str,
- default=DEFAULT_STAGE_CONFIG,
- help="Path to stage configs yaml for standalone talker deployment.",
- )
- parser.add_argument(
- "--case",
- type=str,
- default="style",
- choices=["style", "ip", "basic"],
- help="Example case.",
- )
- parser.add_argument("--text", type=str, default=None, help="Override default text for the selected case.")
- parser.add_argument("--output", type=str, default=None, help="Output wav path.")
- parser.add_argument("--log-stats", action="store_true", default=False, help="Enable stats logging.")
- parser.add_argument("--init-timeout", type=int, default=600, help="Engine init timeout in seconds.")
- parser.add_argument("--stage-init-timeout", type=int, default=300, help="Single stage init timeout in seconds.")
- return parser.parse_args()
-
-
-def main():
- args = parse_args()
-
- omni = Omni(
- model=args.model,
- stage_configs_path=args.stage_configs_path,
- log_stats=args.log_stats,
- init_timeout=args.init_timeout,
- stage_init_timeout=args.stage_init_timeout,
- )
-
- messages = get_messages(args.case, args.text)
- decode_args = {
- # Standalone TTS deployment
- "ming_task": "instruct",
- "max_decode_steps": 200,
- "cfg": 2.0,
- "sigma": 0.25,
- "temperature": 0.0,
- }
- req = OmniTokensPrompt(
- prompt_token_ids=[0],
- additional_information={**messages, **decode_args},
- )
-
- outputs = omni.generate(req)
- mm = outputs[0].outputs[0].multimodal_output
-
- output_path = args.output or f"output_{args.case}.wav"
- save_audio(mm, output_path)
- omni.close()
-
-
-if __name__ == "__main__":
- main()
diff --git a/examples/offline_inference/moss_tts_nano/README.md b/examples/offline_inference/moss_tts_nano/README.md
deleted file mode 100644
index 8534d0549ca..00000000000
--- a/examples/offline_inference/moss_tts_nano/README.md
+++ /dev/null
@@ -1,101 +0,0 @@
-# MOSS-TTS-Nano Offline Inference
-
-## Overview
-
-Single-stage offline TTS pipeline using the 0.1B MOSS-TTS-Nano AR LM and MOSS-Audio-Tokenizer-Nano codec. Outputs 48 kHz stereo WAV.
-
-## Quick Start
-
-```bash
-python end2end.py --text "Hello, this is MOSS-TTS-Nano."
-```
-
-The first run downloads `OpenMOSS-Team/MOSS-TTS-Nano` and `OpenMOSS-Team/MOSS-Audio-Tokenizer-Nano` from Hugging Face.
-
-## Usage
-
-```
-python end2end.py [OPTIONS]
-
-Options:
- --text TEXT Text to synthesize (default: "Hello, this is MOSS-TTS-Nano speaking.")
- --voice VOICE Built-in voice preset (default: Junhao). See voice table below.
- --mode MODE voice_clone (default) or continuation
- --prompt-audio PATH Reference WAV/MP3 for custom voice cloning
- --prompt-text TEXT Reference transcript (continuation mode)
- --max-new-frames N Max AR frames, default 375 (~14 s audio)
- --seed INT Random seed for reproducibility
- --audio-temperature F Audio sampling temperature (default: 0.8)
- --audio-top-k N Audio top-k sampling (default: 25)
- --audio-top-p F Audio top-p sampling (default: 0.95)
- --text-temperature F Text layer temperature (default: 1.0)
- --batch Run a built-in batch of diverse samples (ZH/EN/FR)
- --output-dir DIR Directory for WAV outputs (default: /tmp/moss_tts_nano_output)
- --deploy-config PATH Override deploy YAML (defaults to vllm_omni/deploy/moss_tts_nano.yaml)
- --stage-init-timeout INT Timeout in seconds for stage init (default: 120)
-```
-
-## Examples
-
-```bash
-# Built-in Chinese voice
-python end2end.py --text "你好,这是MOSS-TTS-Nano的语音合成演示。" --voice Junhao
-
-# Built-in English voice
-python end2end.py --text "Hello from MOSS-TTS-Nano." --voice Ava
-
-# Custom voice clone
-python end2end.py \
- --text "Hello, this is a cloned voice." \
- --prompt-audio /path/to/reference.wav \
- --prompt-text "Exact transcript of the reference audio."
-
-# Batch synthesis (ZH/EN/FR)
-python end2end.py --batch --output-dir /tmp/batch_output
-
-# Reproducible output
-python end2end.py --text "Deterministic test." --seed 42
-```
-
-## Built-in Voice Presets
-
-| Voice | Language |
-|-------|----------|
-| `Junhao` | ZH |
-| `Zhiming` | ZH |
-| `Weiguo` | ZH |
-| `Xiaoyu` | ZH |
-| `Yuewen` | ZH |
-| `Lingyu` | ZH |
-| `Ava` | EN |
-| `Bella` | EN |
-| `Adam` | EN |
-| `Nathan` | EN |
-| `Sakura` | JA |
-| `Yui` | JA |
-| `Aoi` | JA |
-| `Hina` | JA |
-| `Mei` | JA |
-
-## Deploy Config
-
-Runtime knobs live in `vllm_omni/deploy/moss_tts_nano.yaml` (auto-loaded;
-override with `--deploy-config PATH`). Key stage-level settings:
-
-```yaml
-stages:
- - stage_id: 0
- gpu_memory_utilization: 0.3 # ~2 GB VRAM; increase for faster init
- max_num_seqs: 4 # concurrent requests
- max_model_len: 4096
-```
-
-## Output Format
-
-WAV files, 48 kHz, stereo (2-channel). The codec interleaves stereo as `[L, R, L, R, ...]` in the flat tensor returned by the model.
-
-## Troubleshooting
-
-- **`libnvrtc.so.13: cannot open shared object file`**: torchaudio 2.10+ torchcodec backend requires NVRTC. The model patches `torchaudio.load/save` automatically at load time to fall back to soundfile.
-- **`flash_attn not installed`**: The model falls back to `sdpa` attention automatically.
-- **Empty audio**: Check that `--text` is non-empty and the model loaded successfully (look for "MOSS-TTS-Nano LM loaded" in logs).
diff --git a/examples/offline_inference/moss_tts_nano/end2end.py b/examples/offline_inference/moss_tts_nano/end2end.py
deleted file mode 100644
index 177e0379116..00000000000
--- a/examples/offline_inference/moss_tts_nano/end2end.py
+++ /dev/null
@@ -1,180 +0,0 @@
-# SPDX-License-Identifier: Apache-2.0
-# SPDX-FileCopyrightText: Copyright contributors to the vLLM project
-"""Offline inference example for MOSS-TTS-Nano via vLLM-Omni.
-
-Single-stage pipeline: the 0.1B AR LM and MOSS-Audio-Tokenizer-Nano codec
-both run inside one generation stage. Output is 48 kHz stereo WAV.
-
-Supports:
- - Built-in voice presets (--voice)
- - Custom voice cloning via reference audio (--prompt-audio)
- - Batch synthesis of multiple texts
- - Reproducible output via --seed
-
-Usage examples:
- # Built-in voice
- python end2end.py --text "Hello from MOSS-TTS-Nano."
-
- # Voice clone with reference audio
- python end2end.py --text "Hello!" --prompt-audio /path/to/ref.wav
-
- # Batch with different voices
- python end2end.py --batch --output-dir /tmp/moss_output
-"""
-
-from __future__ import annotations
-
-import os
-from pathlib import Path
-
-import soundfile as sf
-import torch
-from vllm import SamplingParams
-from vllm.utils.argparse_utils import FlexibleArgumentParser
-
-# Prevent multiprocessing from re-importing CUDA in the wrong context.
-os.environ.setdefault("VLLM_WORKER_MULTIPROC_METHOD", "spawn")
-
-from vllm_omni import Omni # noqa: E402
-
-MODEL = "OpenMOSS-Team/MOSS-TTS-Nano"
-
-BATCH_SAMPLES = [
- {"text": "Hello, this is a test of MOSS-TTS-Nano.", "voice": "Ava", "label": "en_hello"},
- {"text": "你好,这是 MOSS-TTS-Nano 的语音合成测试。", "voice": "Junhao", "label": "zh_hello"},
- {"text": "Bonjour, ceci est un test de synthèse vocale.", "voice": "Bella", "label": "fr_hello"},
-]
-
-
-def build_request(
- text: str,
- voice: str = "Junhao",
- mode: str = "voice_clone",
- prompt_audio_path: str | None = None,
- prompt_text: str | None = None,
- max_new_frames: int = 375,
- seed: int | None = None,
- audio_temperature: float = 0.8,
- audio_top_k: int = 25,
- audio_top_p: float = 0.95,
- text_temperature: float = 1.0,
-) -> dict:
- """Build an Omni request payload for MOSS-TTS-Nano."""
- additional: dict = {
- "text": [text],
- "voice": [voice],
- "mode": [mode],
- "max_new_frames": [max_new_frames],
- "audio_temperature": [audio_temperature],
- "audio_top_k": [audio_top_k],
- "audio_top_p": [audio_top_p],
- "text_temperature": [text_temperature],
- }
- if prompt_audio_path:
- additional["prompt_audio_path"] = [str(prompt_audio_path)]
- if prompt_text:
- additional["prompt_text"] = [prompt_text]
- if seed is not None:
- additional["seed"] = [seed]
-
- return {
- "prompt": "<|im_start|>assistant\n", # minimal placeholder prompt
- "additional_information": additional,
- }
-
-
-def save_audio(waveform: torch.Tensor, path: str, sample_rate: int = 48000) -> None:
- audio_np = waveform.float().numpy()
- # Reshape stereo: inference_stream yields interleaved [samples*2]; reshape to [samples, 2]
- if audio_np.ndim == 1 and audio_np.shape[0] % 2 == 0:
- audio_np = audio_np.reshape(-1, 2)
- sf.write(path, audio_np, sample_rate)
- print(f" Saved {path} ({audio_np.shape}, {sample_rate} Hz)")
-
-
-def main(args) -> None:
- omni = Omni(
- model=MODEL,
- deploy_config=args.deploy_config,
- stage_init_timeout=args.stage_init_timeout,
- )
-
- sampling_params = SamplingParams(
- temperature=1.0,
- top_p=1.0,
- top_k=50,
- max_tokens=4096,
- seed=args.seed if args.seed is not None else 42,
- detokenize=False,
- )
-
- output_dir = Path(args.output_dir)
- output_dir.mkdir(parents=True, exist_ok=True)
-
- if args.batch:
- print(f"Running batch synthesis ({len(BATCH_SAMPLES)} samples)...")
- inputs = [build_request(s["text"], voice=s["voice"], seed=args.seed) for s in BATCH_SAMPLES]
- params_list = [sampling_params] * len(inputs)
- else:
- print(f"Synthesizing: {args.text!r}")
- inputs = build_request(
- text=args.text,
- voice=args.voice,
- mode=args.mode,
- prompt_audio_path=args.prompt_audio,
- prompt_text=args.prompt_text,
- max_new_frames=args.max_new_frames,
- seed=args.seed,
- audio_temperature=args.audio_temperature,
- audio_top_k=args.audio_top_k,
- audio_top_p=args.audio_top_p,
- text_temperature=args.text_temperature,
- )
- params_list = sampling_params
-
- for stage_outputs in omni.generate(inputs, params_list):
- for i, req_output in enumerate(stage_outputs.request_output):
- for j, out in enumerate(req_output.outputs):
- mm = out.multimodal_output
- if mm is None:
- print(f" [req {i}] No audio output.")
- continue
- audio = mm.get("audio")
- sr_tensor = mm.get("sr")
- if audio is None:
- print(f" [req {i}] No waveform in multimodal_output.")
- continue
- sr = int(sr_tensor.item()) if sr_tensor is not None else 48000
- label = BATCH_SAMPLES[i]["label"] if args.batch else f"output_{i}_{j}"
- out_path = str(output_dir / f"{label}.wav")
- save_audio(audio.cpu(), out_path, sr)
-
- print("Done.")
-
-
-def parse_args():
- parser = FlexibleArgumentParser(description="MOSS-TTS-Nano offline inference")
- parser.add_argument("--text", default="Hello, this is MOSS-TTS-Nano speaking.", help="Text to synthesize.")
- parser.add_argument("--voice", default="Junhao", help="Built-in voice preset name.")
- parser.add_argument("--mode", default="voice_clone", choices=["voice_clone", "continuation"])
- parser.add_argument("--prompt-audio", default=None, help="Path to reference audio for voice cloning.")
- parser.add_argument("--prompt-text", default=None, help="Reference transcript (continuation mode).")
- parser.add_argument("--max-new-frames", type=int, default=375, help="Max AR frames (~14s at default).")
- parser.add_argument("--seed", type=int, default=None, help="Random seed.")
- parser.add_argument("--audio-temperature", type=float, default=0.8)
- parser.add_argument("--audio-top-k", type=int, default=25)
- parser.add_argument("--audio-top-p", type=float, default=0.95)
- parser.add_argument("--text-temperature", type=float, default=1.0)
- parser.add_argument("--batch", action="store_true", help="Run built-in batch of diverse samples.")
- parser.add_argument("--output-dir", default="/tmp/moss_tts_nano_output", help="Directory for WAV outputs.")
- parser.add_argument(
- "--deploy-config",
- default=None,
- help="Path to a deploy YAML; leave unset to auto-load vllm_omni/deploy/moss_tts_nano.yaml.",
- )
- parser.add_argument("--stage-init-timeout", type=int, default=120)
- return parser.parse_args()
-
-
-if __name__ == "__main__":
- main(parse_args())
diff --git a/examples/offline_inference/omnivoice/README.md b/examples/offline_inference/omnivoice/README.md
deleted file mode 100644
index d804b61b570..00000000000
--- a/examples/offline_inference/omnivoice/README.md
+++ /dev/null
@@ -1,73 +0,0 @@
-# OmniVoice
-
-This directory contains an offline demo for running OmniVoice TTS models with vLLM Omni. It generates speech from text and saves WAV files locally.
-
-## Model Overview
-
-[OmniVoice](https://huggingface.co/k2-fsa/OmniVoice) is a zero-shot multilingual TTS model supporting 600+ languages. It uses a diffusion language model (Qwen3-0.6B backbone) with iterative masked unmasking to generate speech.
-
-Three inference modes are supported:
-
-- **Auto Voice**: Generate speech without any reference — the model picks a voice automatically.
-- **Voice Clone**: Clone a voice from a reference audio + transcription.
-- **Voice Design**: Control voice style via natural language instruction (e.g., "female, low pitch, british accent").
-
-## Setup
-
-Ensure the model is downloaded:
-
-```bash
-huggingface-cli download k2-fsa/OmniVoice
-```
-
-> **Note:** Voice cloning requires `transformers>=5.3.0` for `HiggsAudioV2TokenizerModel`. Auto voice and voice design modes work with `transformers>=4.57.0`.
-
-## Quick Start
-
-Auto voice (text only):
-
-```bash
-python end2end.py --model k2-fsa/OmniVoice --text "Hello, this is a test."
-```
-
-Voice design (with style instruction):
-
-```bash
-python end2end.py --model k2-fsa/OmniVoice \
- --text "Hello, this is a test." \
- --instruct "female, low pitch, british accent"
-```
-
-Voice clone (with reference audio):
-
-```bash
-python end2end.py --model k2-fsa/OmniVoice \
- --text "Hello, this is a test." \
- --ref-audio ref.wav \
- --ref-text "This is the reference transcription."
-```
-
-## Language Support
-
-Specify a language for improved quality:
-
-```bash
-python end2end.py --model k2-fsa/OmniVoice \
- --text "你好,这是一个测试。" \
- --lang zh
-```
-
-## Architecture
-
-OmniVoice uses a two-stage pipeline:
-
-- **Stage 0 (Generator)**: Qwen3-0.6B transformer with 32-step iterative unmasking and classifier-free guidance. Generates 8-codebook audio tokens from text.
-- **Stage 1 (Decoder)**: HiggsAudioV2 RVQ quantizer + DAC acoustic decoder. Converts tokens to 24kHz waveform.
-
-Both stages use `GPUGenerationWorker` with `OmniGenerationScheduler`.
-
-## Notes
-
-- Output audio is saved to `output.wav` by default. Use `--output` to change the path.
-- The model estimates duration from text automatically via `RuleDurationEstimator`.
-- Use `--stage-init-timeout` to increase the stage initialization timeout for first-time model downloads.
diff --git a/examples/offline_inference/omnivoice/end2end.py b/examples/offline_inference/omnivoice/end2end.py
deleted file mode 100644
index cc6f585c50e..00000000000
--- a/examples/offline_inference/omnivoice/end2end.py
+++ /dev/null
@@ -1,163 +0,0 @@
-# SPDX-License-Identifier: Apache-2.0
-# SPDX-FileCopyrightText: Copyright contributors to the vLLM project
-"""End-to-end OmniVoice TTS inference via vLLM-Omni.
-
-Supports:
-- Auto voice mode: text only → generated speech
-- Voice cloning mode: text + reference audio → cloned voice speech
-
-Usage:
- # Auto voice
- python end2end.py --model k2-fsa/OmniVoice --text "Hello world"
-
- # Voice cloning
- python end2end.py --model k2-fsa/OmniVoice --text "Hello" \
- --ref-audio ref.wav --ref-text "reference transcription"
-"""
-
-import argparse
-import os
-
-import numpy as np
-import soundfile as sf
-
-from vllm_omni.entrypoints.omni import Omni
-from vllm_omni.inputs.data import OmniDiffusionSamplingParams
-
-
-def run_e2e():
- parser = argparse.ArgumentParser(description="OmniVoice E2E TTS inference")
- parser.add_argument(
- "--model",
- type=str,
- default="k2-fsa/OmniVoice",
- help="Model name or path (HuggingFace or local)",
- )
- parser.add_argument(
- "--stage-config",
- type=str,
- default="vllm_omni/model_executor/stage_configs/omnivoice.yaml",
- )
- parser.add_argument(
- "--text",
- type=str,
- default="Hello, this is a test of the OmniVoice text to speech system.",
- )
- parser.add_argument(
- "--ref-audio",
- type=str,
- default=None,
- help="Reference audio for voice cloning (WAV file)",
- )
- parser.add_argument(
- "--ref-text",
- type=str,
- default=None,
- help="Transcription of reference audio",
- )
- parser.add_argument(
- "--lang",
- type=str,
- default=None,
- help="Language code (e.g., 'en', 'zh')",
- )
- parser.add_argument(
- "--instruct",
- type=str,
- default=None,
- help="Voice design instruction (e.g., 'female, low pitch, british accent')",
- )
- parser.add_argument(
- "--output",
- type=str,
- default="output.wav",
- help="Output audio file path",
- )
- parser.add_argument(
- "--stage-init-timeout",
- type=int,
- default=600,
- help="Stage initialization timeout in seconds",
- )
- args = parser.parse_args()
-
- if not os.path.exists(args.stage_config):
- raise FileNotFoundError(f"Stage config not found: {args.stage_config}")
-
- print(f"Initializing OmniVoice with model={args.model}")
-
- omni = Omni(
- model=args.model,
- stage_configs_path=args.stage_config,
- log_stats=True,
- )
-
- print("Model initialized. Preparing inputs...")
-
- # Build prompt
- mm_processor_kwargs = {}
- multi_modal_data = {}
-
- if args.ref_audio:
- if not os.path.exists(args.ref_audio):
- raise FileNotFoundError(f"Reference audio not found: {args.ref_audio}")
-
- from vllm.multimodal.media.audio import load_audio
-
- audio_signal, sr = load_audio(args.ref_audio, sr=None)
- multi_modal_data["audio"] = (audio_signal.astype(np.float32), sr)
- mm_processor_kwargs["ref_text"] = args.ref_text or ""
- mm_processor_kwargs["sample_rate"] = sr
-
- if args.lang:
- mm_processor_kwargs["lang"] = args.lang
- if args.instruct:
- mm_processor_kwargs["instruct"] = args.instruct
-
- prompts = {"prompt": args.text}
- if multi_modal_data:
- prompts["multi_modal_data"] = multi_modal_data
- if mm_processor_kwargs:
- prompts["mm_processor_kwargs"] = mm_processor_kwargs
-
- sampling_params_list = [OmniDiffusionSamplingParams()]
-
- print(f"Generating speech for: {args.text}")
-
- outputs = list(omni.generate(prompts, sampling_params_list=sampling_params_list))
-
- print(f"Received {len(outputs)} outputs.")
- for i, output in enumerate(outputs):
- try:
- ro = output.request_output
- if ro is None:
- print("No request_output found.")
- continue
-
- mm = getattr(ro, "multimodal_output", None)
- if not mm and ro.outputs:
- mm = getattr(ro.outputs[0], "multimodal_output", None)
-
- if mm:
- print(f"Multimodal output keys: {mm.keys()}")
- if "audio" in mm:
- audio_out = mm["audio"]
- sr = mm.get("sr", 24000)
- if isinstance(audio_out, np.ndarray):
- audio_np = audio_out
- else:
- audio_np = audio_out.cpu().numpy().squeeze()
- out_path = args.output if i == 0 else f"output_{i}.wav"
- sf.write(out_path, audio_np, sr)
- print(f"Saved audio to {out_path} ({sr}Hz, {len(audio_np) / sr:.2f}s)")
- else:
- print("No multimodal output found.")
- except Exception as e:
- print(f"Error inspecting output: {e}")
-
- omni.close()
- print("Done.")
-
-
-if __name__ == "__main__":
- run_e2e()
diff --git a/examples/offline_inference/qwen2_5_omni/README.md b/examples/offline_inference/qwen2_5_omni/README.md
deleted file mode 100644
index e2eae8a96b5..00000000000
--- a/examples/offline_inference/qwen2_5_omni/README.md
+++ /dev/null
@@ -1,62 +0,0 @@
-# Qwen2.5-Omni
-
-## Setup
-Please refer to the [stage configuration documentation](https://docs.vllm.ai/projects/vllm-omni/en/latest/configuration/stage_configs/) to configure memory allocation appropriately for your hardware setup.
-
-## Run examples
-
-### Multiple Prompts
-Get into the example folder
-```bash
-cd examples/offline_inference/qwen2_5_omni
-```
-Then run the command below. Note: for processing large volume data, it uses py_generator mode, which will return a python generator from Omni class.
-```bash
-bash run_multiple_prompts.sh
-```
-
-### Single Prompt
-Get into the example folder
-```bash
-cd examples/offline_inference/qwen2_5_omni
-```
-Then run the command below.
-```bash
-bash run_single_prompt.sh
-```
-
-### Modality control
-If you want to control output modalities, e.g. only output text, you can run the command below:
-```bash
-python end2end.py --output-wav output_audio \
- --query-type mixed_modalities \
- --modalities text
-```
-
-#### Using Local Media Files
-The `end2end.py` script supports local media files (audio, video, image) via CLI arguments:
-
-```bash
-# Use single local media files
-python end2end.py --query-type use_image --image-path /path/to/image.jpg
-python end2end.py --query-type use_video --video-path /path/to/video.mp4
-python end2end.py --query-type use_audio --audio-path /path/to/audio.wav
-
-# Combine multiple local media files
-python end2end.py --query-type mixed_modalities \
- --video-path /path/to/video.mp4 \
- --image-path /path/to/image.jpg \
- --audio-path /path/to/audio.wav
-
-# Use audio from video file
-python end2end.py --query-type use_audio_in_video --video-path /path/to/video.mp4
-
-```
-
-If media file paths are not provided, the script will use default assets. Supported query types:
-- `use_image`: Image input only
-- `use_video`: Video input only
-- `use_audio`: Audio input only
-- `mixed_modalities`: Audio + image + video
-- `use_audio_in_video`: Extract audio from video
-- `text`: Text-only query
diff --git a/examples/offline_inference/qwen2_5_omni/end2end.py b/examples/offline_inference/qwen2_5_omni/end2end.py
deleted file mode 100644
index a65c554a9b0..00000000000
--- a/examples/offline_inference/qwen2_5_omni/end2end.py
+++ /dev/null
@@ -1,558 +0,0 @@
-# SPDX-License-Identifier: Apache-2.0
-# SPDX-FileCopyrightText: Copyright contributors to the vLLM project
-"""
-This example shows how to use vLLM-Omni for running offline inference
-with the correct prompt format on Qwen2.5-Omni
-"""
-
-import json
-import os
-import time
-from typing import NamedTuple
-
-import numpy as np
-import soundfile as sf
-from PIL import Image
-from vllm.assets.audio import AudioAsset
-from vllm.assets.image import ImageAsset
-from vllm.assets.video import VideoAsset, video_to_ndarrays
-from vllm.multimodal.image import convert_image_mode
-from vllm.multimodal.media.audio import load_audio
-from vllm.sampling_params import SamplingParams
-from vllm.utils.argparse_utils import FlexibleArgumentParser
-
-from vllm_omni.entrypoints.omni import Omni
-
-SEED = 42
-
-
-class QueryResult(NamedTuple):
- inputs: dict
- limit_mm_per_prompt: dict[str, int]
-
-
-# NOTE: The default `max_num_seqs` and `max_model_len` may result in OOM on
-# lower-end GPUs.
-# Unless specified, these settings have been tested to work on a single L4.
-
-default_system = (
- "You are Qwen, a virtual human developed by the Qwen Team, Alibaba "
- "Group, capable of perceiving auditory and visual inputs, as well as "
- "generating text and speech."
-)
-
-
-def get_text_query(question: str = None) -> QueryResult:
- if question is None:
- question = "Explain the system architecture for a scalable audio generation pipeline. Answer in 15 words."
- prompt = (
- f"<|im_start|>system\n{default_system}<|im_end|>\n"
- "<|im_start|>user\n"
- f"{question}<|im_end|>\n"
- f"<|im_start|>assistant\n"
- )
- return QueryResult(
- inputs={
- "prompt": prompt,
- },
- limit_mm_per_prompt={},
- )
-
-
-def get_mixed_modalities_query(
- video_path: str | None = None,
- image_path: str | None = None,
- audio_path: str | None = None,
- num_frames: int = 16,
- sampling_rate: int = 16000,
-) -> QueryResult:
- question = "What is recited in the audio? What is the content of this image? Why is this video funny?"
- prompt = (
- f"<|im_start|>system\n{default_system}<|im_end|>\n"
- "<|im_start|>user\n<|audio_bos|><|AUDIO|><|audio_eos|>"
- "<|vision_bos|><|IMAGE|><|vision_eos|>"
- "<|vision_bos|><|VIDEO|><|vision_eos|>"
- f"{question}<|im_end|>\n"
- f"<|im_start|>assistant\n"
- )
-
- # Load video
- if video_path:
- if not os.path.exists(video_path):
- raise FileNotFoundError(f"Video file not found: {video_path}")
- video_frames = video_to_ndarrays(video_path, num_frames=num_frames)
- else:
- video_frames = VideoAsset(name="baby_reading", num_frames=num_frames).np_ndarrays
-
- # Load image
- if image_path:
- if not os.path.exists(image_path):
- raise FileNotFoundError(f"Image file not found: {image_path}")
- pil_image = Image.open(image_path)
- image_data = convert_image_mode(pil_image, "RGB")
- else:
- image_data = convert_image_mode(ImageAsset("cherry_blossom").pil_image, "RGB")
-
- # Load audio
- if audio_path:
- if not os.path.exists(audio_path):
- raise FileNotFoundError(f"Audio file not found: {audio_path}")
- audio_signal, sr = load_audio(audio_path, sr=sampling_rate)
- audio_data = (audio_signal.astype(np.float32), sr)
- else:
- audio_data = AudioAsset("mary_had_lamb").audio_and_sample_rate
-
- return QueryResult(
- inputs={
- "prompt": prompt,
- "multi_modal_data": {
- "audio": audio_data,
- "image": image_data,
- "video": video_frames,
- },
- },
- limit_mm_per_prompt={"audio": 1, "image": 1, "video": 1},
- )
-
-
-def get_use_audio_in_video_query(
- video_path: str | None = None, num_frames: int = 16, sampling_rate: int = 16000
-) -> QueryResult:
- question = "Describe the content of the video, then convert what the baby say into text."
- prompt = (
- f"<|im_start|>system\n{default_system}<|im_end|>\n"
- "<|im_start|>user\n<|vision_bos|><|VIDEO|><|vision_eos|><|audio_bos|><|AUDIO|><|audio_eos|>"
- f"{question}<|im_end|>\n"
- f"<|im_start|>assistant\n"
- )
-
- if video_path:
- if not os.path.exists(video_path):
- raise FileNotFoundError(f"Video file not found: {video_path}")
- video_frames = video_to_ndarrays(video_path, num_frames=num_frames)
- # Extract audio from video file
- audio_signal, sr = load_audio(video_path, sr=sampling_rate)
- audio = (audio_signal.astype(np.float32), sr)
- else:
- asset = VideoAsset(name="baby_reading", num_frames=num_frames)
- video_frames = asset.np_ndarrays
- audio = asset.get_audio(sampling_rate=sampling_rate)
-
- return QueryResult(
- inputs={
- "prompt": prompt,
- "multi_modal_data": {
- "video": video_frames,
- "audio": audio,
- },
- "mm_processor_kwargs": {
- "use_audio_in_video": True,
- },
- },
- limit_mm_per_prompt={"audio": 1, "video": 1},
- )
-
-
-def get_multi_audios_query(audio_path: str | None = None, sampling_rate: int = 16000) -> QueryResult:
- question = "Are these two audio clips the same?"
- prompt = (
- f"<|im_start|>system\n{default_system}<|im_end|>\n"
- "<|im_start|>user\n<|audio_bos|><|AUDIO|><|audio_eos|>"
- "<|audio_bos|><|AUDIO|><|audio_eos|>"
- f"{question}<|im_end|>\n"
- f"<|im_start|>assistant\n"
- )
-
- if audio_path:
- if not os.path.exists(audio_path):
- raise FileNotFoundError(f"Audio file not found: {audio_path}")
- audio_signal, sr = load_audio(audio_path, sr=sampling_rate)
- audio_data = (audio_signal.astype(np.float32), sr)
- # Use the provided audio as the first audio, default as second
- audio_list = [
- audio_data,
- AudioAsset("mary_had_lamb").audio_and_sample_rate,
- ]
- else:
- audio_list = [
- AudioAsset("winning_call").audio_and_sample_rate,
- AudioAsset("mary_had_lamb").audio_and_sample_rate,
- ]
-
- return QueryResult(
- inputs={
- "prompt": prompt,
- "multi_modal_data": {
- "audio": audio_list,
- },
- },
- limit_mm_per_prompt={
- "audio": 2,
- },
- )
-
-
-def get_image_query(question: str = None, image_path: str | None = None) -> QueryResult:
- if question is None:
- question = "What is the content of this image?"
- prompt = (
- f"<|im_start|>system\n{default_system}<|im_end|>\n"
- "<|im_start|>user\n<|vision_bos|><|IMAGE|><|vision_eos|>"
- f"{question}<|im_end|>\n"
- f"<|im_start|>assistant\n"
- )
-
- if image_path:
- if not os.path.exists(image_path):
- raise FileNotFoundError(f"Image file not found: {image_path}")
- pil_image = Image.open(image_path)
- image_data = convert_image_mode(pil_image, "RGB")
- else:
- image_data = convert_image_mode(ImageAsset("cherry_blossom").pil_image, "RGB")
-
- return QueryResult(
- inputs={
- "prompt": prompt,
- "multi_modal_data": {
- "image": image_data,
- },
- },
- limit_mm_per_prompt={"image": 1},
- )
-
-
-def get_video_query(question: str = None, video_path: str | None = None, num_frames: int = 16) -> QueryResult:
- if question is None:
- question = "Why is this video funny?"
- prompt = (
- f"<|im_start|>system\n{default_system}<|im_end|>\n"
- "<|im_start|>user\n<|vision_bos|><|VIDEO|><|vision_eos|>"
- f"{question}<|im_end|>\n"
- f"<|im_start|>assistant\n"
- )
-
- if video_path:
- if not os.path.exists(video_path):
- raise FileNotFoundError(f"Video file not found: {video_path}")
- video_frames = video_to_ndarrays(video_path, num_frames=num_frames)
- else:
- video_frames = VideoAsset(name="baby_reading", num_frames=num_frames).np_ndarrays
-
- return QueryResult(
- inputs={
- "prompt": prompt,
- "multi_modal_data": {
- "video": video_frames,
- },
- },
- limit_mm_per_prompt={"video": 1},
- )
-
-
-def get_audio_query(question: str = None, audio_path: str | None = None, sampling_rate: int = 16000) -> QueryResult:
- if question is None:
- question = "What is the content of this audio?"
- prompt = (
- f"<|im_start|>system\n{default_system}<|im_end|>\n"
- "<|im_start|>user\n<|audio_bos|><|AUDIO|><|audio_eos|>"
- f"{question}<|im_end|>\n"
- f"<|im_start|>assistant\n"
- )
-
- if audio_path:
- if not os.path.exists(audio_path):
- raise FileNotFoundError(f"Audio file not found: {audio_path}")
- audio_signal, sr = load_audio(audio_path, sr=sampling_rate)
- audio_data = (audio_signal.astype(np.float32), sr)
- else:
- audio_data = AudioAsset("mary_had_lamb").audio_and_sample_rate
-
- return QueryResult(
- inputs={
- "prompt": prompt,
- "multi_modal_data": {
- "audio": audio_data,
- },
- },
- limit_mm_per_prompt={"audio": 1},
- )
-
-
-query_map = {
- "use_mixed_modalities": get_mixed_modalities_query,
- "use_audio_in_video": get_use_audio_in_video_query,
- "use_multi_audios": get_multi_audios_query,
- "use_image": get_image_query,
- "use_video": get_video_query,
- "use_audio": get_audio_query,
- "text": get_text_query,
-}
-
-
-def main(args):
- model_name = args.model
- quantization_config = None
- if args.quantization_config is not None:
- quantization_config = json.loads(args.quantization_config)
-
- # Get paths from args
- video_path = getattr(args, "video_path", None)
- image_path = getattr(args, "image_path", None)
- audio_path = getattr(args, "audio_path", None)
- num_frames = getattr(args, "num_frames", 16)
- sampling_rate = getattr(args, "sampling_rate", 16000)
-
- # Get the query function and call it with appropriate parameters
- query_func = query_map[args.query_type]
- if args.query_type == "mixed_modalities":
- query_result = query_func(
- video_path=video_path,
- image_path=image_path,
- audio_path=audio_path,
- num_frames=num_frames,
- sampling_rate=sampling_rate,
- )
- elif args.query_type == "use_audio_in_video":
- query_result = query_func(video_path=video_path, num_frames=num_frames, sampling_rate=sampling_rate)
- elif args.query_type == "multi_audios":
- query_result = query_func(audio_path=audio_path, sampling_rate=sampling_rate)
- elif args.query_type == "use_image":
- query_result = query_func(image_path=image_path)
- elif args.query_type == "use_video":
- query_result = query_func(video_path=video_path, num_frames=num_frames)
- elif args.query_type == "use_audio":
- query_result = query_func(audio_path=audio_path, sampling_rate=sampling_rate)
- else:
- query_result = query_func()
- args.quantization_config = quantization_config
- omni = Omni.from_cli_args(args, model=model_name)
- thinker_sampling_params = SamplingParams(
- temperature=0.0, # Deterministic - no randomness
- top_p=1.0, # Disable nucleus sampling
- top_k=-1, # Disable top-k sampling
- max_tokens=2048,
- seed=SEED, # Fixed seed for sampling
- detokenize=True,
- repetition_penalty=1.1,
- )
- talker_sampling_params = SamplingParams(
- temperature=0.9,
- top_p=0.8,
- top_k=40,
- max_tokens=2048,
- seed=SEED, # Fixed seed for sampling
- detokenize=True,
- repetition_penalty=1.05,
- stop_token_ids=[8294],
- )
- code2wav_sampling_params = SamplingParams(
- temperature=0.0, # Deterministic - no randomness
- top_p=1.0, # Disable nucleus sampling
- top_k=-1, # Disable top-k sampling
- max_tokens=2048,
- seed=SEED, # Fixed seed for sampling
- detokenize=True,
- repetition_penalty=1.1,
- )
-
- sampling_params_list = [
- thinker_sampling_params,
- talker_sampling_params,
- code2wav_sampling_params,
- ]
-
- if args.txt_prompts is None:
- prompts = [query_result.inputs for _ in range(args.num_prompts)]
- else:
- assert args.query_type == "text", "txt-prompts is only supported for text query type"
- with open(args.txt_prompts, encoding="utf-8") as f:
- lines = [ln.strip() for ln in f.readlines()]
- prompts = [get_text_query(ln).inputs for ln in lines if ln != ""]
- print(f"[Info] Loaded {len(prompts)} prompts from {args.txt_prompts}")
-
- if args.modalities is not None:
- output_modalities = args.modalities.split(",")
- for i, prompt in enumerate(prompts):
- prompt["modalities"] = output_modalities
-
- profiler_enabled = bool(os.getenv("VLLM_TORCH_PROFILER_DIR"))
- if profiler_enabled and hasattr(omni, "start_profile"):
- omni.start_profile(stages=[0])
- elif profiler_enabled:
- print("[Warn] VLLM_TORCH_PROFILER_DIR is set, but current engine does not support profiler controls.")
- omni_generator = omni.generate(prompts, sampling_params_list, py_generator=args.py_generator)
-
- # Determine output directory: prefer --output-dir; fallback to --output-wav
- output_dir = args.output_dir if getattr(args, "output_dir", None) else args.output_wav
- os.makedirs(output_dir, exist_ok=True)
-
- total_requests = len(prompts)
- processed_count = 0
- for stage_outputs in omni_generator:
- output = stage_outputs.request_output
- if stage_outputs.final_output_type == "text":
- request_id = output.request_id
- text_output = output.outputs[0].text
- # Save aligned text file per request
- prompt_text = output.prompt
- out_txt = os.path.join(output_dir, f"{request_id}.txt")
- lines = []
- lines.append("Prompt:\n")
- lines.append(str(prompt_text) + "\n")
- lines.append("vllm_text_output:\n")
- lines.append(str(text_output).strip() + "\n")
- try:
- with open(out_txt, "w", encoding="utf-8") as f:
- f.writelines(lines)
- except Exception as e:
- print(f"[Warn] Failed writing text file {out_txt}: {e}")
- print(f"Request ID: {request_id}, Text saved to {out_txt}")
- elif stage_outputs.final_output_type == "audio":
- request_id = output.request_id
- audio_tensor = output.outputs[0].multimodal_output["audio"]
- output_wav = os.path.join(output_dir, f"output_{request_id}.wav")
- sf.write(output_wav, audio_tensor.detach().cpu().numpy(), samplerate=24000)
- print(f"Request ID: {request_id}, Saved audio to {output_wav}")
-
- processed_count += 1
- if profiler_enabled and hasattr(omni, "stop_profile") and processed_count >= total_requests:
- print(f"[Info] Processed {processed_count}/{total_requests}. Stopping profiler inside active loop...")
- # Stop the profiler while workers are still alive
- omni.stop_profile()
-
- print("[Info] Waiting 30s for workers to write massive trace files to disk...")
- time.sleep(30)
- print("[Info] Trace export wait finished.")
-
- omni.close()
-
-
-def parse_args():
- parser = FlexibleArgumentParser(description="Demo on using vLLM for offline inference with audio language models")
- parser.add_argument(
- "--model",
- type=str,
- default="Qwen/Qwen2.5-Omni-7B",
- help="Model name or local path.",
- )
- parser.add_argument(
- "--quantization-config",
- type=str,
- default=None,
- help="Optional JSON string forwarded to Omni(quantization_config=...).",
- )
- parser.add_argument(
- "--query-type",
- "-q",
- type=str,
- default="use_mixed_modalities",
- choices=query_map.keys(),
- help="Query type.",
- )
- parser.add_argument(
- "--log-stats",
- action="store_true",
- default=False,
- help="Enable writing detailed statistics (default: disabled)",
- )
- parser.add_argument(
- "--stage-init-timeout",
- type=int,
- default=300,
- help="Timeout for initializing a single stage in seconds (default: 300)",
- )
- parser.add_argument(
- "--batch-timeout",
- type=int,
- default=5,
- help="Timeout for batching in seconds (default: 5)",
- )
- parser.add_argument(
- "--init-timeout",
- type=int,
- default=300,
- help="Timeout for initializing stages in seconds (default: 300)",
- )
- parser.add_argument(
- "--shm-threshold-bytes",
- type=int,
- default=65536,
- help="Threshold for using shared memory in bytes (default: 65536)",
- )
- parser.add_argument(
- "--output-wav",
- default="output_audio",
- help="[Deprecated] Output wav directory (use --output-dir).",
- )
- parser.add_argument(
- "--num-prompts",
- type=int,
- default=1,
- help="Number of prompts to generate.",
- )
- parser.add_argument(
- "--txt-prompts",
- type=str,
- default=None,
- help="Path to a .txt file with one prompt per line (preferred).",
- )
- parser.add_argument(
- "--video-path",
- "-v",
- type=str,
- default=None,
- help="Path to local video file. If not provided, uses default video asset.",
- )
- parser.add_argument(
- "--image-path",
- "-i",
- type=str,
- default=None,
- help="Path to local image file. If not provided, uses default image asset.",
- )
- parser.add_argument(
- "--audio-path",
- "-a",
- type=str,
- default=None,
- help="Path to local audio file. If not provided, uses default audio asset.",
- )
- parser.add_argument(
- "--num-frames",
- type=int,
- default=16,
- help="Number of frames to extract from video (default: 16).",
- )
- parser.add_argument(
- "--sampling-rate",
- type=int,
- default=16000,
- help="Sampling rate for audio loading (default: 16000).",
- )
- parser.add_argument(
- "--worker-backend", type=str, default="multi_process", choices=["multi_process", "ray"], help="backend"
- )
- parser.add_argument(
- "--ray-address",
- type=str,
- default=None,
- help="Address of the Ray cluster.",
- )
- parser.add_argument(
- "--modalities",
- type=str,
- default=None,
- help="Modalities to use for the prompts.",
- )
- parser.add_argument(
- "--py-generator",
- action="store_true",
- default=False,
- help="Use py_generator mode. The returned type of Omni.generate() is a Python Generator object.",
- )
- return parser.parse_args()
-
-
-if __name__ == "__main__":
- args = parse_args()
- main(args)
diff --git a/examples/offline_inference/qwen2_5_omni/extract_prompts.py b/examples/offline_inference/qwen2_5_omni/extract_prompts.py
deleted file mode 100644
index dce0788dbf4..00000000000
--- a/examples/offline_inference/qwen2_5_omni/extract_prompts.py
+++ /dev/null
@@ -1,44 +0,0 @@
-#!/usr/bin/env python3
-import argparse
-
-
-def extract_prompt(line: str) -> str | None:
- # Extract the content between the first '|' and the second '|'
- i = line.find("|")
- if i == -1:
- return None
- j = line.find("|", i + 1)
- if j == -1:
- return None
- return line[i + 1 : j].strip()
-
-
-def main() -> None:
- parser = argparse.ArgumentParser()
- parser.add_argument("--input", "-i", required=True, help="Input .lst file path")
- parser.add_argument("--output", "-o", required=True, help="Output file path")
- parser.add_argument(
- "--topk",
- "-k",
- type=int,
- default=100,
- help="Extract the top K prompts (default: 100)",
- )
- args = parser.parse_args()
-
- prompts = []
- with open(args.input, encoding="utf-8", errors="ignore") as f:
- for line in f:
- if len(prompts) >= args.topk:
- break
- p = extract_prompt(line.rstrip("\n"))
- if p:
- prompts.append(p)
-
- with open(args.output, "w", encoding="utf-8") as f:
- for p in prompts:
- f.write(p + "\n")
-
-
-if __name__ == "__main__":
- main()
diff --git a/examples/offline_inference/qwen2_5_omni/run_multiple_prompts.sh b/examples/offline_inference/qwen2_5_omni/run_multiple_prompts.sh
deleted file mode 100644
index b7c8edd38b9..00000000000
--- a/examples/offline_inference/qwen2_5_omni/run_multiple_prompts.sh
+++ /dev/null
@@ -1,4 +0,0 @@
-python end2end.py --output-wav output_audio \
- --query-type text \
- --txt-prompts ../qwen3_omni/text_prompts_10.txt \
- --py-generator
diff --git a/examples/offline_inference/qwen2_5_omni/run_single_prompt.sh b/examples/offline_inference/qwen2_5_omni/run_single_prompt.sh
deleted file mode 100644
index c8e4cd2cbf3..00000000000
--- a/examples/offline_inference/qwen2_5_omni/run_single_prompt.sh
+++ /dev/null
@@ -1,2 +0,0 @@
-python end2end.py --output-wav output_audio \
- --query-type use_mixed_modalities
diff --git a/examples/offline_inference/qwen3_omni/README.md b/examples/offline_inference/qwen3_omni/README.md
deleted file mode 100644
index 0710faa133c..00000000000
--- a/examples/offline_inference/qwen3_omni/README.md
+++ /dev/null
@@ -1,110 +0,0 @@
-# Qwen3-Omni
-
-## Setup
-Please refer to the [stage configuration documentation](https://docs.vllm.ai/projects/vllm-omni/en/latest/configuration/stage_configs/) to configure memory allocation appropriately for your hardware setup.
-
-## Run examples
-
-### Multiple Prompts
-Get into the example folder
-```bash
-cd examples/offline_inference/qwen3_omni
-```
-Then run the command below. Note: for processing large volume data, it uses py_generator mode, which will return a python generator from Omni class.
-```bash
-bash run_multiple_prompts.sh
-```
-### Single Prompt
-Get into the example folder
-```bash
-cd examples/offline_inference/qwen3_omni
-```
-Then run the command below.
-```bash
-bash run_single_prompt.sh
-```
-If you have not enough memory, you can set thinker with tensor parallel. Just run the command below.
-```bash
-bash run_single_prompt_tp.sh
-```
-
-### Modality control
-If you want to control output modalities, e.g. only output text, you can run the command below:
-```bash
-python end2end.py --output-wav output_audio \
- --query-type use_audio \
- --modalities text
-```
-
-#### Using Local Media Files
-The `end2end.py` script supports local media files (audio, video, image) via command-line arguments:
-
-```bash
-# Use local video file
-python end2end.py --query-type use_video --video-path /path/to/video.mp4
-
-# Use local image file
-python end2end.py --query-type use_image --image-path /path/to/image.jpg
-
-# Use local audio file
-python end2end.py --query-type use_audio --audio-path /path/to/audio.wav
-
-# Combine multiple local media files
-python end2end.py --query-type mixed_modalities \
- --video-path /path/to/video.mp4 \
- --image-path /path/to/image.jpg \
- --audio-path /path/to/audio.wav
-```
-
-If media file paths are not provided, the script will use default assets. Supported query types:
-- `use_video`: Video input
-- `use_image`: Image input
-- `use_audio`: Audio input
-- `text`: Text-only query
-- `multi_audios`: Multiple audio inputs
-- `mixed_modalities`: Combination of video, image, and audio inputs
-
-### Async-chunk (offline)
-
-For true stage-level concurrency -- where downstream stages (Talker, Code2Wav)
-start **before** the upstream stage (Thinker) finishes -- use the async_chunk
-example. This requires:
-
-1. A deploy config YAML with ``async_chunk: true`` (e.g.
- ``qwen3_omni_moe.yaml``).
-2. Hardware that matches the config (e.g. 2x H100 for the default 3-stage
- config).
-
-The async_chunk example uses ``AsyncOmni`` instead of the synchronous ``Omni``
-class, which enables the async orchestrator to receive stage-0 intermediate
-outputs and trigger downstream stages early. Chunk data flows directly between
-stage workers via the in-worker ``OmniChunkTransferAdapter`` / connector,
-**not** through the orchestrator.
-
-#### Single prompt
-```bash
-cd examples/offline_inference/qwen3_omni
-bash run_single_prompt_async_chunk.sh
-```
-
-#### Multiple prompts with concurrency control
-```bash
-bash run_multiple_prompts_async_chunk.sh --max-in-flight 4
-```
-
-#### Text-only output (skip audio generation)
-```bash
-python end2end_async_chunk.py --query-type text --modalities text
-```
-
-#### Custom stage config
-```bash
-python end2end_async_chunk.py \
- --query-type use_audio \
- --deploy-config /path/to/your_deploy_config.yaml
-```
-
-> **Note**: The synchronous ``end2end.py`` (using ``Omni``) is still the
-> recommended entry point for non-async-chunk workflows. Only use the
-> async_chunk example when you need the stage-level concurrency semantics
-> described in PR #962 / #1151.
diff --git a/examples/offline_inference/qwen3_omni/end2end.py b/examples/offline_inference/qwen3_omni/end2end.py
deleted file mode 100644
index 04aa7914db1..00000000000
--- a/examples/offline_inference/qwen3_omni/end2end.py
+++ /dev/null
@@ -1,560 +0,0 @@
-# SPDX-License-Identifier: Apache-2.0
-# SPDX-FileCopyrightText: Copyright contributors to the vLLM project
-"""
-This example shows how to use vLLM for running offline inference
-with the correct prompt format on Qwen3-Omni (thinker only).
-"""
-
-import os
-import time
-from typing import NamedTuple
-
-import numpy as np
-import soundfile as sf
-import vllm
-from PIL import Image
-from vllm import SamplingParams
-from vllm.assets.audio import AudioAsset
-from vllm.assets.image import ImageAsset
-from vllm.assets.video import VideoAsset, video_to_ndarrays
-from vllm.multimodal.image import convert_image_mode
-from vllm.multimodal.media.audio import load_audio
-from vllm.utils.argparse_utils import FlexibleArgumentParser
-
-from vllm_omni.engine.arg_utils import nullify_stage_engine_defaults
-from vllm_omni.entrypoints.omni import Omni
-
-SEED = 42
-
-
-class QueryResult(NamedTuple):
- inputs: dict
- limit_mm_per_prompt: dict[str, int]
-
-
-# NOTE: The default `max_num_seqs` and `max_model_len` may result in OOM on
-# lower-end GPUs.
-# Unless specified, these settings have been tested to work on a single L4.
-
-default_system = (
- "You are Qwen, a virtual human developed by the Qwen Team, Alibaba "
- "Group, capable of perceiving auditory and visual inputs, as well as "
- "generating text and speech."
-)
-
-
-def get_text_query(question: str = None) -> QueryResult:
- if question is None:
- question = "Explain the system architecture for a scalable audio generation pipeline. Answer in 15 words."
- prompt = (
- f"<|im_start|>system\n{default_system}<|im_end|>\n"
- "<|im_start|>user\n"
- f"{question}<|im_end|>\n"
- f"<|im_start|>assistant\n"
- )
- return QueryResult(
- inputs={
- "prompt": prompt,
- },
- limit_mm_per_prompt={},
- )
-
-
-def get_video_query(question: str = None, video_path: str | None = None, num_frames: int = 16) -> QueryResult:
- if question is None:
- question = "Why is this video funny?"
- prompt = (
- f"<|im_start|>system\n{default_system}<|im_end|>\n"
- "<|im_start|>user\n<|vision_start|><|video_pad|><|vision_end|>"
- f"{question}<|im_end|>\n"
- f"<|im_start|>assistant\n"
- )
-
- if video_path:
- if not os.path.exists(video_path):
- raise FileNotFoundError(f"Video file not found: {video_path}")
- video_frames = video_to_ndarrays(video_path, num_frames=num_frames)
- else:
- video_frames = VideoAsset(name="baby_reading", num_frames=num_frames).np_ndarrays
-
- return QueryResult(
- inputs={
- "prompt": prompt,
- "multi_modal_data": {
- "video": video_frames,
- },
- },
- limit_mm_per_prompt={"video": 1},
- )
-
-
-def get_image_query(question: str = None, image_path: str | None = None) -> QueryResult:
- if question is None:
- question = "What is the content of this image?"
- prompt = (
- f"<|im_start|>system\n{default_system}<|im_end|>\n"
- "<|im_start|>user\n<|vision_start|><|image_pad|><|vision_end|>"
- f"{question}<|im_end|>\n"
- f"<|im_start|>assistant\n"
- )
-
- if image_path:
- if not os.path.exists(image_path):
- raise FileNotFoundError(f"Image file not found: {image_path}")
- pil_image = Image.open(image_path)
- image_data = convert_image_mode(pil_image, "RGB")
- else:
- image_data = convert_image_mode(ImageAsset("cherry_blossom").pil_image, "RGB")
-
- return QueryResult(
- inputs={
- "prompt": prompt,
- "multi_modal_data": {
- "image": image_data,
- },
- },
- limit_mm_per_prompt={"image": 1},
- )
-
-
-def get_audio_query(question: str = None, audio_path: str | None = None, sampling_rate: int = 16000) -> QueryResult:
- if question is None:
- question = "What is the content of this audio?"
- prompt = (
- f"<|im_start|>system\n{default_system}<|im_end|>\n"
- "<|im_start|>user\n<|audio_start|><|audio_pad|><|audio_end|>"
- f"{question}<|im_end|>\n"
- f"<|im_start|>assistant\n"
- )
-
- if audio_path:
- if not os.path.exists(audio_path):
- raise FileNotFoundError(f"Audio file not found: {audio_path}")
- audio_signal, sr = load_audio(audio_path, sr=sampling_rate)
- audio_data = (audio_signal.astype(np.float32), sr)
- else:
- audio_data = AudioAsset("mary_had_lamb").audio_and_sample_rate
-
- return QueryResult(
- inputs={
- "prompt": prompt,
- "multi_modal_data": {
- "audio": audio_data,
- },
- },
- limit_mm_per_prompt={"audio": 1},
- )
-
-
-def get_mixed_modalities_query(
- video_path: str | None = None,
- image_path: str | None = None,
- audio_path: str | None = None,
- num_frames: int = 16,
- sampling_rate: int = 16000,
-) -> QueryResult:
- question = "What is recited in the audio? What is the content of this image? Why is this video funny?"
- prompt = (
- f"<|im_start|>system\n{default_system}<|im_end|>\n"
- "<|im_start|>user\n<|audio_start|><|audio_pad|><|audio_end|>"
- "<|vision_start|><|image_pad|><|vision_end|>"
- "<|vision_start|><|video_pad|><|vision_end|>"
- f"{question}<|im_end|>\n"
- f"<|im_start|>assistant\n"
- )
-
- # Load video
- if video_path:
- if not os.path.exists(video_path):
- raise FileNotFoundError(f"Video file not found: {video_path}")
- video_frames = video_to_ndarrays(video_path, num_frames=num_frames)
- else:
- video_frames = VideoAsset(name="baby_reading", num_frames=num_frames).np_ndarrays
-
- # Load image
- if image_path:
- if not os.path.exists(image_path):
- raise FileNotFoundError(f"Image file not found: {image_path}")
- pil_image = Image.open(image_path)
- image_data = convert_image_mode(pil_image, "RGB")
- else:
- image_data = convert_image_mode(ImageAsset("cherry_blossom").pil_image, "RGB")
-
- # Load audio
- if audio_path:
- if not os.path.exists(audio_path):
- raise FileNotFoundError(f"Audio file not found: {audio_path}")
- audio_signal, sr = load_audio(audio_path, sr=sampling_rate)
- audio_data = (audio_signal.astype(np.float32), sr)
- else:
- audio_data = AudioAsset("mary_had_lamb").audio_and_sample_rate
-
- return QueryResult(
- inputs={
- "prompt": prompt,
- "multi_modal_data": {
- "audio": audio_data,
- "image": image_data,
- "video": video_frames,
- },
- },
- limit_mm_per_prompt={"audio": 1, "image": 1, "video": 1},
- )
-
-
-def get_multi_audios_query() -> QueryResult:
- question = "Are these two audio clips the same?"
- prompt = (
- f"<|im_start|>system\n{default_system}<|im_end|>\n"
- "<|im_start|>user\n<|audio_start|><|audio_pad|><|audio_end|>"
- "<|audio_start|><|audio_pad|><|audio_end|>"
- f"{question}<|im_end|>\n"
- f"<|im_start|>assistant\n"
- )
- return QueryResult(
- inputs={
- "prompt": prompt,
- "multi_modal_data": {
- "audio": [
- AudioAsset("winning_call").audio_and_sample_rate,
- AudioAsset("mary_had_lamb").audio_and_sample_rate,
- ],
- },
- },
- limit_mm_per_prompt={
- "audio": 2,
- },
- )
-
-
-def get_use_audio_in_video_query() -> QueryResult:
- question = "Describe the content of the video in details, then convert what the baby say into text."
- prompt = (
- f"<|im_start|>system\n{default_system}<|im_end|>\n"
- "<|im_start|>user\n<|vision_start|><|video_pad|><|vision_end|>"
- f"{question}<|im_end|>\n"
- f"<|im_start|>assistant\n"
- )
- asset = VideoAsset(name="baby_reading", num_frames=16)
- audio = asset.get_audio(sampling_rate=16000)
- return QueryResult(
- inputs={
- "prompt": prompt,
- "multi_modal_data": {
- "video": asset.np_ndarrays,
- "audio": audio,
- },
- "mm_processor_kwargs": {
- "use_audio_in_video": True,
- },
- },
- limit_mm_per_prompt={"audio": 1, "video": 1},
- )
-
-
-query_map = {
- "text": get_text_query,
- "use_audio": get_audio_query,
- "use_image": get_image_query,
- "use_video": get_video_query,
- "use_multi_audios": get_multi_audios_query,
- "use_mixed_modalities": get_mixed_modalities_query,
- "use_audio_in_video": get_use_audio_in_video_query,
-}
-
-
-def main(args):
- model_name = args.model
- print("=" * 20, "\n", f"vllm version: {vllm.__version__}", "\n", "=" * 20)
-
- # Get paths from args
- video_path = getattr(args, "video_path", None)
- image_path = getattr(args, "image_path", None)
- audio_path = getattr(args, "audio_path", None)
-
- # Get the query function and call it with appropriate parameters
- query_func = query_map[args.query_type]
- if args.query_type == "use_video":
- query_result = query_func(video_path=video_path, num_frames=getattr(args, "num_frames", 16))
- elif args.query_type == "use_image":
- query_result = query_func(image_path=image_path)
- elif args.query_type == "use_audio":
- query_result = query_func(audio_path=audio_path, sampling_rate=getattr(args, "sampling_rate", 16000))
- elif args.query_type == "mixed_modalities":
- query_result = query_func(
- video_path=video_path,
- image_path=image_path,
- audio_path=audio_path,
- num_frames=getattr(args, "num_frames", 16),
- sampling_rate=getattr(args, "sampling_rate", 16000),
- )
- elif args.query_type == "multi_audios":
- query_result = query_func()
- elif args.query_type == "use_audio_in_video":
- query_result = query_func()
- else:
- query_result = query_func()
-
- omni = Omni.from_cli_args(args, model=model_name)
-
- thinker_sampling_params = SamplingParams(
- temperature=0.9,
- top_p=0.9,
- top_k=-1,
- max_tokens=1200,
- repetition_penalty=1.05,
- logit_bias={},
- seed=SEED,
- )
-
- talker_sampling_params = SamplingParams(
- temperature=0.9,
- top_k=50,
- max_tokens=4096,
- seed=SEED,
- detokenize=False,
- repetition_penalty=1.05,
- stop_token_ids=[2150], # TALKER_CODEC_EOS_TOKEN_ID
- )
-
- # Sampling parameters for Code2Wav stage (audio generation)
- code2wav_sampling_params = SamplingParams(
- temperature=0.0,
- top_p=1.0,
- top_k=-1,
- max_tokens=4096 * 16,
- seed=SEED,
- detokenize=True,
- repetition_penalty=1.1,
- )
-
- all_sampling_params = [
- thinker_sampling_params,
- talker_sampling_params, # code predictor is integrated into talker for Qwen3 Omni
- code2wav_sampling_params,
- ]
- # Match sampling params to the number of configured stages
- num_stages = omni.num_stages
- sampling_params_list = all_sampling_params[:num_stages]
-
- if args.txt_prompts is None:
- prompts = [query_result.inputs for _ in range(args.num_prompts)]
- else:
- assert args.query_type == "text", "txt-prompts is only supported for text query type"
- with open(args.txt_prompts, encoding="utf-8") as f:
- lines = [ln.strip() for ln in f.readlines()]
- prompts = [get_text_query(ln).inputs for ln in lines if ln != ""]
- print(f"[Info] Loaded {len(prompts)} prompts from {args.txt_prompts}")
-
- if args.modalities is not None:
- output_modalities = args.modalities.split(",")
- for i, prompt in enumerate(prompts):
- prompt["modalities"] = output_modalities
-
- profiler_enabled = args.enable_profiler
- if profiler_enabled:
- omni.start_profile(stages=args.profiler_stages)
- omni_generator = omni.generate(prompts, sampling_params_list, py_generator=args.py_generator)
- # Determine output directory: prefer --output-dir; fallback to --output-wav
- output_dir = args.output_dir if getattr(args, "output_dir", None) else args.output_wav
- os.makedirs(output_dir, exist_ok=True)
-
- total_requests = len(prompts)
- processed_count = 0
-
- print(f"query type: {args.query_type}")
-
- for stage_outputs in omni_generator:
- output = stage_outputs.request_output
- if stage_outputs.final_output_type == "text":
- request_id = output.request_id
- text_output = output.outputs[0].text
- # Save aligned text file per request
- prompt_text = output.prompt
- out_txt = os.path.join(output_dir, f"{request_id}.txt")
- lines = []
- lines.append("Prompt:\n")
- lines.append(str(prompt_text) + "\n")
- lines.append("vllm_text_output:\n")
- lines.append(str(text_output).strip() + "\n")
- try:
- with open(out_txt, "w", encoding="utf-8") as f:
- f.writelines(lines)
- except Exception as e:
- print(f"[Warn] Failed writing text file {out_txt}: {e}")
- print(f"Request ID: {request_id}, Text saved to {out_txt}")
- elif stage_outputs.final_output_type == "audio":
- request_id = output.request_id
- audio_tensor = output.outputs[0].multimodal_output["audio"]
- output_wav = os.path.join(output_dir, f"output_{request_id}.wav")
-
- # Convert to numpy array and ensure correct format
- audio_numpy = audio_tensor.float().detach().cpu().numpy()
-
- # Ensure audio is 1D (flatten if needed)
- if audio_numpy.ndim > 1:
- audio_numpy = audio_numpy.flatten()
-
- # Save audio file with explicit WAV format
- sf.write(output_wav, audio_numpy, samplerate=24000, format="WAV")
- print(f"Request ID: {request_id}, Saved audio to {output_wav}")
-
- processed_count += 1
- if profiler_enabled and processed_count >= total_requests:
- print(f"[Info] Processed {processed_count}/{total_requests}. Stopping profiler inside active loop...")
- # Stop the profiler while workers are still alive
- omni.stop_profile(stages=args.profiler_stages)
-
- print("[Info] Waiting 30s for workers to write trace files to disk...")
- time.sleep(30)
- print("[Info] Trace export wait time finished.")
- omni.close()
-
-
-def parse_args():
- parser = FlexibleArgumentParser(description="Demo on using vLLM for offline inference with audio language models")
- parser.add_argument(
- "--model",
- type=str,
- default="Qwen/Qwen3-Omni-30B-A3B-Instruct",
- help="Model name or path.",
- )
- parser.add_argument(
- "--query-type",
- "-q",
- type=str,
- default="use_mixed_modalities",
- choices=query_map.keys(),
- help="Query type.",
- )
- parser.add_argument(
- "--log-stats",
- action="store_true",
- default=False,
- help="Enable writing detailed statistics (default: disabled)",
- )
- parser.add_argument(
- "--stage-init-timeout",
- type=int,
- default=300,
- help="Timeout for initializing a single stage in seconds (default: 300)",
- )
- parser.add_argument(
- "--batch-timeout",
- type=int,
- default=5,
- help="Timeout for batching in seconds (default: 5)",
- )
- parser.add_argument(
- "--init-timeout",
- type=int,
- default=300,
- help="Timeout for initializing stages in seconds (default: 300)",
- )
- parser.add_argument(
- "--shm-threshold-bytes",
- type=int,
- default=65536,
- help="Threshold for using shared memory in bytes (default: 65536)",
- )
- parser.add_argument(
- "--output-wav",
- default="output_audio",
- help="[Deprecated] Output wav directory (use --output-dir).",
- )
- parser.add_argument(
- "--num-prompts",
- type=int,
- default=1,
- help="Number of prompts to generate.",
- )
- parser.add_argument(
- "--txt-prompts",
- type=str,
- default=None,
- help="Path to a .txt file with one prompt per line (preferred).",
- )
- parser.add_argument(
- "--stage-configs-path",
- type=str,
- default=None,
- help="Path to a stage configs file.",
- )
- parser.add_argument(
- "--video-path",
- "-v",
- type=str,
- default=None,
- help="Path to local video file. If not provided, uses default video asset.",
- )
- parser.add_argument(
- "--image-path",
- "-i",
- type=str,
- default=None,
- help="Path to local image file. If not provided, uses default image asset.",
- )
- parser.add_argument(
- "--audio-path",
- "-a",
- type=str,
- default=None,
- help="Path to local audio file. If not provided, uses default audio asset.",
- )
- parser.add_argument(
- "--num-frames",
- type=int,
- default=16,
- help="Number of frames to extract from video (default: 16).",
- )
- parser.add_argument(
- "--sampling-rate",
- type=int,
- default=16000,
- help="Sampling rate for audio loading (default: 16000).",
- )
- parser.add_argument(
- "--log-dir",
- type=str,
- default="logs",
- help="Log directory (default: logs).",
- )
- parser.add_argument(
- "--modalities",
- type=str,
- default=None,
- help="Output modalities to use for the prompts.",
- )
- parser.add_argument(
- "--py-generator",
- action="store_true",
- default=False,
- help="Use py_generator mode. The returned type of Omni.generate() is a Python Generator object.",
- )
- parser.add_argument(
- "--enable-profiler",
- action="store_true",
- default=False,
- help="Enables profiling when set.",
- )
- parser.add_argument(
- "--profiler-stages",
- type=int,
- nargs="*",
- default=None,
- help="List of stage IDs to profile. If not set, profiles all stages.",
- )
- parser.add_argument(
- "--dtype",
- type=str,
- default="auto",
- help="Model dtype (auto, half, float16, bfloat16, float, float32).",
- )
-
- nullify_stage_engine_defaults(parser)
- return parser.parse_args()
-
-
-if __name__ == "__main__":
- args = parse_args()
- main(args)
diff --git a/examples/offline_inference/qwen3_omni/end2end_async_chunk.py b/examples/offline_inference/qwen3_omni/end2end_async_chunk.py
deleted file mode 100644
index 85c2da20b04..00000000000
--- a/examples/offline_inference/qwen3_omni/end2end_async_chunk.py
+++ /dev/null
@@ -1,619 +0,0 @@
-# SPDX-License-Identifier: Apache-2.0
-# SPDX-FileCopyrightText: Copyright contributors to the vLLM project
-"""Offline inference with async_chunk enabled via AsyncOmni.
-
-This script uses AsyncOmni (the async orchestrator) to run offline inference
-with async_chunk semantics: downstream stages (Talker, Code2Wav) start
-*before* upstream stages finish, consuming chunks as they arrive via
-the in-worker OmniChunkTransferAdapter / connector.
-
-Compared to the synchronous ``end2end.py`` (which uses ``Omni``), this
-entry point achieves true stage-level concurrency -- stage-1/2 are
-actively processing while stage-0 is still generating.
-
-Usage
------
- python end2end_async_chunk.py --query-type use_audio \
- --deploy-config <path-to-deploy-config-yaml>
-
-See ``--help`` for all options.
-"""
-
-import asyncio
-import logging
-import os
-import time
-import uuid
-from typing import NamedTuple
-
-import numpy as np
-import soundfile as sf
-import torch
-
-os.environ["VLLM_WORKER_MULTIPROC_METHOD"] = "spawn"
-
-from PIL import Image
-from vllm import SamplingParams
-from vllm.assets.audio import AudioAsset
-from vllm.assets.image import ImageAsset
-from vllm.assets.video import VideoAsset, video_to_ndarrays
-from vllm.multimodal.image import convert_image_mode
-from vllm.multimodal.media.audio import load_audio
-from vllm.utils.argparse_utils import FlexibleArgumentParser
-
-from vllm_omni.entrypoints.async_omni import AsyncOmni
-
-logger = logging.getLogger(__name__)
-
-# ---------------------------------------------------------------------------
-# Query builders (reuse the patterns from end2end.py)
-# ---------------------------------------------------------------------------
-
-default_system = (
- "You are Qwen, a virtual human developed by the Qwen Team, Alibaba "
- "Group, capable of perceiving auditory and visual inputs, as well as "
- "generating text and speech."
-)
-
-
-class QueryResult(NamedTuple):
- inputs: dict
- limit_mm_per_prompt: dict[str, int]
-
-
-def get_text_query(question: str = None) -> QueryResult:
- if question is None:
- question = "Explain the system architecture for a scalable audio generation pipeline. Answer in 15 words."
- prompt = (
- f"<|im_start|>system\n{default_system}<|im_end|>\n"
- "<|im_start|>user\n"
- f"{question}<|im_end|>\n"
- "<|im_start|>assistant\n"
- )
- return QueryResult(inputs={"prompt": prompt}, limit_mm_per_prompt={})
-
-
-def get_audio_query(
- question: str = None,
- audio_path: str | None = None,
- sampling_rate: int = 16000,
-) -> QueryResult:
- if question is None:
- question = "What is the content of this audio?"
- prompt = (
- f"<|im_start|>system\n{default_system}<|im_end|>\n"
- "<|im_start|>user\n<|audio_start|><|audio_pad|><|audio_end|>"
- f"{question}<|im_end|>\n"
- "<|im_start|>assistant\n"
- )
- if audio_path:
- if not os.path.exists(audio_path):
- raise FileNotFoundError(f"Audio file not found: {audio_path}")
- audio_signal, sr = load_audio(audio_path, sr=sampling_rate)
- audio_data = (audio_signal.astype(np.float32), sr)
- else:
- audio_data = AudioAsset("mary_had_lamb").audio_and_sample_rate
- return QueryResult(
- inputs={
- "prompt": prompt,
- "multi_modal_data": {"audio": audio_data},
- },
- limit_mm_per_prompt={"audio": 1},
- )
-
-
-def get_image_query(question: str = None, image_path: str | None = None) -> QueryResult:
- if question is None:
- question = "What is the content of this image?"
- prompt = (
- f"<|im_start|>system\n{default_system}<|im_end|>\n"
- "<|im_start|>user\n<|vision_start|><|image_pad|><|vision_end|>"
- f"{question}<|im_end|>\n"
- "<|im_start|>assistant\n"
- )
- if image_path:
- if not os.path.exists(image_path):
- raise FileNotFoundError(f"Image file not found: {image_path}")
- pil_image = Image.open(image_path)
- image_data = convert_image_mode(pil_image, "RGB")
- else:
- image_data = convert_image_mode(ImageAsset("cherry_blossom").pil_image, "RGB")
- return QueryResult(
- inputs={
- "prompt": prompt,
- "multi_modal_data": {"image": image_data},
- },
- limit_mm_per_prompt={"image": 1},
- )
-
-
-def get_video_query(
- question: str = None,
- video_path: str | None = None,
- num_frames: int = 16,
-) -> QueryResult:
- if question is None:
- question = "Why is this video funny?"
- prompt = (
- f"<|im_start|>system\n{default_system}<|im_end|>\n"
- "<|im_start|>user\n<|vision_start|><|video_pad|><|vision_end|>"
- f"{question}<|im_end|>\n"
- "<|im_start|>assistant\n"
- )
- if video_path:
- if not os.path.exists(video_path):
- raise FileNotFoundError(f"Video file not found: {video_path}")
- video_frames = video_to_ndarrays(video_path, num_frames=num_frames)
- else:
- video_frames = VideoAsset(name="baby_reading", num_frames=num_frames).np_ndarrays
- return QueryResult(
- inputs={
- "prompt": prompt,
- "multi_modal_data": {"video": video_frames},
- },
- limit_mm_per_prompt={"video": 1},
- )
-
-
-query_map = {
- "text": get_text_query,
- "use_audio": get_audio_query,
- "use_image": get_image_query,
- "use_video": get_video_query,
-}
-
-# ---------------------------------------------------------------------------
-# Core async routine
-# ---------------------------------------------------------------------------
-
-
-def clone_prompt_for_request(template: dict) -> dict:
- """Shallow-clone prompt dict so concurrent requests own independent containers."""
- cloned = dict(template)
- for key in ("multi_modal_data", "mm_processor_kwargs", "additional_information"):
- value = template.get(key)
- if isinstance(value, dict):
- cloned[key] = dict(value)
- elif isinstance(value, list):
- cloned[key] = list(value)
- return cloned
-
-
-def _default_deploy_config_path() -> str | None:
- """Best-effort default deploy config for running Qwen3-Omni with async_chunk.
-
- The default ``vllm_omni/deploy/qwen3_omni_moe.yaml`` ships with
- ``async_chunk: true`` at the top level, so loading it is enough to
- enable async-chunk semantics. To disable it, copy the YAML and set
- ``async_chunk: false`` (or pass ``--deploy-config`` to a YAML that
- overrides the flag).
-
- When this example is executed from within the repository, we resolve
- the default YAML path relative to this file. When installed elsewhere,
- the file may not exist and callers should pass ``--deploy-config``
- explicitly.
- """
- repo_root = os.path.abspath(os.path.join(os.path.dirname(__file__), "../../.."))
- candidate = os.path.join(
- repo_root,
- "vllm_omni",
- "deploy",
- "qwen3_omni_moe.yaml",
- )
- return candidate if os.path.exists(candidate) else None
-
-
-async def run_single_request(
- async_omni: AsyncOmni,
- prompt: dict,
- request_id: str,
- sampling_params_list: list[SamplingParams] | None,
- output_dir: str,
- output_modalities: list[str] | None = None,
- stream_audio_to_disk: bool = False,
-) -> dict:
- """Run one request through AsyncOmni and collect outputs.
-
- Returns a dict with timing information and saved file paths.
- """
- t_start = time.perf_counter()
- text_parts: list[str] = []
- audio_chunks: list[torch.Tensor] = []
- audio_sr: int | None = None
- first_audio_ts: float | None = None
- audio_list_consumed: int = 0
- audio_last_tensor: torch.Tensor | None = None
- stage_0_first_output_ts: float | None = None
-
- samplerate = 24000
- wav_file = os.path.join(output_dir, f"output_{request_id}.wav")
- sf_writer: sf.SoundFile | None = None
- audio_samples_written: int = 0
-
- try:
- async for omni_output in async_omni.generate(
- prompt=prompt,
- request_id=request_id,
- sampling_params_list=sampling_params_list,
- output_modalities=output_modalities,
- ):
- output = omni_output.request_output
- if omni_output.final_output_type == "text":
- if stage_0_first_output_ts is None:
- stage_0_first_output_ts = time.perf_counter()
- text_output = output.outputs[0].text
- text_parts.append(text_output)
- elif omni_output.final_output_type == "audio":
- mm_out = output.outputs[0].multimodal_output
- if mm_out and "audio" in mm_out:
- if first_audio_ts is None:
- first_audio_ts = time.perf_counter()
- if audio_sr is None and "sr" in mm_out:
- sr_val = mm_out["sr"]
- audio_sr = sr_val.item() if hasattr(sr_val, "item") else int(sr_val)
- samplerate = audio_sr
- audio_data = mm_out["audio"]
- if isinstance(audio_data, list):
- new_chunks = audio_data[audio_list_consumed:]
- audio_list_consumed = len(audio_data)
- elif isinstance(audio_data, torch.Tensor):
- new_chunks = [audio_data]
- audio_last_tensor = audio_data
- else:
- new_chunks = []
-
- if stream_audio_to_disk and new_chunks:
- if sf_writer is None:
- sf_writer = sf.SoundFile(
- wav_file,
- mode="w",
- samplerate=samplerate,
- channels=1,
- subtype="FLOAT",
- )
- for chunk in new_chunks:
- chunk_np = chunk.float().detach().cpu().numpy().flatten()
- sf_writer.write(chunk_np)
- audio_samples_written += len(chunk_np)
- else:
- audio_chunks.extend(new_chunks)
- finally:
- if sf_writer is not None:
- sf_writer.close()
-
- t_end = time.perf_counter()
- result = {
- "request_id": request_id,
- "e2e_latency_s": t_end - t_start,
- "saved_files": [],
- }
-
- # Save text output
- if text_parts:
- text_file = os.path.join(output_dir, f"{request_id}.txt")
- with open(text_file, "w", encoding="utf-8") as f:
- f.write("".join(text_parts))
- result["saved_files"].append(text_file)
- print(
- f"[Request {request_id}] Text saved to {text_file} "
- f"(stage-0 first output at {stage_0_first_output_ts - t_start:.3f}s)"
- )
-
- # Save audio output
- if stream_audio_to_disk and audio_samples_written > 0:
- result["saved_files"].append(wav_file)
- result["audio_duration_s"] = audio_samples_written / samplerate
- result["num_audio_chunks"] = audio_list_consumed
- ttfa = (first_audio_ts - t_start) if first_audio_ts else None
- result["time_to_first_audio_s"] = ttfa
- ttfa_str = f"{ttfa:.3f}s" if ttfa is not None else "N/A"
- print(
- f"[Request {request_id}] Audio streamed to {wav_file} "
- f"(duration={result['audio_duration_s']:.2f}s, "
- f"TTFA={ttfa_str}, "
- f"e2e={result['e2e_latency_s']:.3f}s)"
- )
- elif audio_chunks or audio_last_tensor is not None:
- if audio_chunks:
- if len(audio_chunks) > 1:
- audio_tensor = torch.cat(audio_chunks, dim=-1)
- else:
- audio_tensor = audio_chunks[0]
- else:
- audio_tensor = audio_last_tensor
- audio_numpy = audio_tensor.float().detach().cpu().numpy()
- if audio_numpy.ndim > 1:
- audio_numpy = audio_numpy.flatten()
- sf.write(wav_file, audio_numpy, samplerate=samplerate, format="WAV")
- result["saved_files"].append(wav_file)
- result["audio_duration_s"] = len(audio_numpy) / samplerate
- result["num_audio_chunks"] = len(audio_chunks)
- ttfa = (first_audio_ts - t_start) if first_audio_ts else None
- result["time_to_first_audio_s"] = ttfa
- ttfa_str = f"{ttfa:.3f}s" if ttfa is not None else "N/A"
- print(
- f"[Request {request_id}] Audio saved to {wav_file} "
- f"({len(audio_chunks)} chunks, "
- f"duration={result['audio_duration_s']:.2f}s, "
- f"TTFA={ttfa_str}, "
- f"e2e={result['e2e_latency_s']:.3f}s)"
- )
-
- return result
-
-
-async def run_all(args):
- """Main async entry: build prompts, create AsyncOmni, run requests."""
- # Build query
- query_func = query_map[args.query_type]
- if args.query_type == "use_video":
- query_result = query_func(
- video_path=getattr(args, "video_path", None),
- num_frames=getattr(args, "num_frames", 16),
- )
- elif args.query_type == "use_image":
- query_result = query_func(image_path=getattr(args, "image_path", None))
- elif args.query_type == "use_audio":
- query_result = query_func(
- audio_path=getattr(args, "audio_path", None),
- sampling_rate=getattr(args, "sampling_rate", 16000),
- )
- else:
- query_result = query_func()
-
- # Build prompt list
- if args.txt_prompts is not None:
- assert args.query_type == "text", "txt-prompts is only supported for text query type"
- with open(args.txt_prompts, encoding="utf-8") as f:
- lines = [ln.strip() for ln in f if ln.strip()]
- prompts = [get_text_query(ln).inputs for ln in lines]
- print(f"[Info] Loaded {len(prompts)} prompts from {args.txt_prompts}")
- else:
- prompts = [clone_prompt_for_request(query_result.inputs) for _ in range(args.num_prompts)]
-
- # Inject output modalities if specified
- output_modalities = None
- if args.modalities is not None:
- output_modalities = args.modalities.split(",")
- for prompt in prompts:
- prompt["modalities"] = output_modalities
-
- # Create AsyncOmni
- print(f"[Info] Creating AsyncOmni with deploy_config={args.deploy_config}")
- async_omni = None
- try:
- # ``from_cli_args`` expands vars(args) into kwargs and auto-captures
- # ``_cli_explicit_keys`` from ``sys.argv[1:]`` so argparse defaults
- # do not silently override deploy YAML values. Mirrors the
- # ``EngineArgs.from_cli_args`` pattern used throughout vllm /
- # vllm-omni. ``deploy_config=None`` (the default) falls through to
- # the bundled ``vllm_omni/deploy/qwen3_omni_moe.yaml``.
- async_omni = AsyncOmni.from_cli_args(args)
-
- # Use default sampling params from stage config (they are pre-configured
- # in the YAML for each stage).
- #
- # NOTE: Since we do not set the sampling params directly, .generate in
- # will automatically set the output kind to delta, since this is what
- # makes sense for most multimodal use-cases.
- sampling_params_list = None
-
- output_dir = args.output_dir
- os.makedirs(output_dir, exist_ok=True)
-
- # Run requests with concurrency control
- semaphore = asyncio.Semaphore(args.max_in_flight)
- request_timeout = getattr(args, "request_timeout_s", None)
- stream_audio = getattr(args, "stream_audio_to_disk", False)
-
- async def _run_one(idx: int, prompt: dict):
- async with semaphore:
- request_id = f"req_{idx}_{uuid.uuid4().hex[:8]}"
- coro = run_single_request(
- async_omni=async_omni,
- prompt=prompt,
- request_id=request_id,
- sampling_params_list=sampling_params_list,
- output_dir=output_dir,
- output_modalities=output_modalities,
- stream_audio_to_disk=stream_audio,
- )
- if request_timeout and request_timeout > 0:
- return await asyncio.wait_for(coro, timeout=request_timeout)
- return await coro
-
- wall_start = time.perf_counter()
- tasks = [_run_one(i, p) for i, p in enumerate(prompts)]
- all_results = await asyncio.gather(*tasks, return_exceptions=True)
- wall_end = time.perf_counter()
-
- # Print summary
- print("\n" + "=" * 60)
- print("Summary")
- print("=" * 60)
- success_count = 0
- total_audio_dur = 0.0
- for r in all_results:
- if isinstance(r, Exception):
- print(f" [ERROR] {type(r).__name__}: {r}")
- else:
- success_count += 1
- total_audio_dur += r.get("audio_duration_s", 0.0)
- print(f" [{r['request_id']}] e2e={r['e2e_latency_s']:.3f}s files={r['saved_files']}")
- wall_time = wall_end - wall_start
- print(f"\nTotal: {success_count}/{len(prompts)} succeeded")
- print(f"Wall time: {wall_time:.3f}s")
- if total_audio_dur > 0:
- print(f"Total audio duration: {total_audio_dur:.2f}s")
- print(f"Real-time factor: {total_audio_dur / wall_time:.2f}x")
- print("=" * 60)
- finally:
- if async_omni is not None:
- async_omni.shutdown()
-
-
-# ---------------------------------------------------------------------------
-# CLI
-# ---------------------------------------------------------------------------
-
-
-def parse_args():
- parser = FlexibleArgumentParser(
- description=(
- "Offline inference with async_chunk enabled via AsyncOmni. "
- "Downstream stages start before upstream stages finish, "
- "achieving true stage-level concurrency."
- )
- )
- parser.add_argument(
- "--model",
- type=str,
- default="Qwen/Qwen3-Omni-30B-A3B-Instruct",
- help="Model name or path.",
- )
- parser.add_argument(
- "--query-type",
- "-q",
- type=str,
- default="use_audio",
- choices=query_map.keys(),
- help="Query type.",
- )
- parser.add_argument(
- "--deploy-config",
- type=str,
- default=_default_deploy_config_path(),
- help=(
- "Path to a deploy config YAML. "
- "If not set, uses the model's default config "
- "(make sure it has async_chunk: true)."
- ),
- )
- parser.add_argument(
- "--log-stats",
- action="store_true",
- default=False,
- help="Enable writing detailed statistics.",
- )
- parser.add_argument(
- "--stage-init-timeout",
- type=int,
- default=300,
- help="Timeout for initializing a single stage (seconds).",
- )
- parser.add_argument(
- "--output-dir",
- type=str,
- default="output_audio_async_chunk",
- help="Directory to save output files.",
- )
- parser.add_argument(
- "--num-prompts",
- type=int,
- default=1,
- help="Number of prompts to generate (duplicated from query).",
- )
- parser.add_argument(
- "--txt-prompts",
- type=str,
- default=None,
- help="Path to a .txt file with one prompt per line.",
- )
- parser.add_argument(
- "--max-in-flight",
- type=int,
- default=1,
- help="Maximum concurrent requests (default: 1).",
- )
- parser.add_argument(
- "--request-timeout-s",
- type=float,
- default=None,
- help=(
- "Per-request timeout in seconds. When set, a request that "
- "exceeds this duration is cancelled and reported as an error. "
- "Default: None (no timeout)."
- ),
- )
- parser.add_argument(
- "--batch-timeout-s",
- type=float,
- default=None,
- help=(
- "Global timeout for the entire batch in seconds. When set, "
- "the whole run_all() is cancelled if it exceeds this duration. "
- "Default: None (no global timeout)."
- ),
- )
- parser.add_argument(
- "--stream-audio-to-disk",
- action="store_true",
- default=False,
- help=(
- "Write audio chunks to WAV incrementally instead of "
- "accumulating in memory. Useful for very long audio or "
- "high --max-in-flight to reduce memory footprint."
- ),
- )
- parser.add_argument(
- "--modalities",
- type=str,
- default=None,
- help="Comma-separated output modalities filter (e.g. 'text', 'audio', 'text,audio').",
- )
- parser.add_argument(
- "--audio-path",
- "-a",
- type=str,
- default=None,
- help="Path to local audio file.",
- )
- parser.add_argument(
- "--image-path",
- "-i",
- type=str,
- default=None,
- help="Path to local image file.",
- )
- parser.add_argument(
- "--video-path",
- "-v",
- type=str,
- default=None,
- help="Path to local video file.",
- )
- parser.add_argument(
- "--num-frames",
- type=int,
- default=16,
- help="Number of frames to extract from video.",
- )
- parser.add_argument(
- "--sampling-rate",
- type=int,
- default=16000,
- help="Sampling rate for audio loading.",
- )
- return parser.parse_args()
-
-
-if __name__ == "__main__":
- args = parse_args()
-
- async def _main():
- batch_timeout = getattr(args, "batch_timeout_s", None)
- if batch_timeout and batch_timeout > 0:
- await asyncio.wait_for(run_all(args), timeout=batch_timeout)
- else:
- await run_all(args)
-
- try:
- asyncio.run(_main())
- except asyncio.TimeoutError:
- print(
- f"\n[TIMEOUT] Batch exceeded --batch-timeout-s="
- f"{args.batch_timeout_s}s. AsyncOmni shutdown was handled "
- f"by finally block."
- )
- except KeyboardInterrupt:
- print("\nInterrupted by user. AsyncOmni shutdown was handled by finally block.")
diff --git a/examples/offline_inference/qwen3_omni/run_multiple_prompts.sh b/examples/offline_inference/qwen3_omni/run_multiple_prompts.sh
deleted file mode 100644
index a48068af938..00000000000
--- a/examples/offline_inference/qwen3_omni/run_multiple_prompts.sh
+++ /dev/null
@@ -1,4 +0,0 @@
-python end2end.py --output-wav output_audio \
- --query-type text \
- --txt-prompts text_prompts_10.txt \
- --py-generator
diff --git a/examples/offline_inference/qwen3_omni/run_multiple_prompts_async_chunk.sh b/examples/offline_inference/qwen3_omni/run_multiple_prompts_async_chunk.sh
deleted file mode 100755
index 2f2be20915a..00000000000
--- a/examples/offline_inference/qwen3_omni/run_multiple_prompts_async_chunk.sh
+++ /dev/null
@@ -1,23 +0,0 @@
-#!/bin/bash
-# Run multiple Qwen3-Omni requests with async_chunk enabled.
-#
-# Uses AsyncOmni with --max-in-flight to control request-level
-# concurrency (each request still gets true stage-level concurrency
-# via async_chunk).
-#
-# Usage:
-# bash run_multiple_prompts_async_chunk.sh
-# bash run_multiple_prompts_async_chunk.sh --max-in-flight 4
-
-set -euo pipefail
-
-SCRIPT_DIR="$(cd "$(dirname "${BASH_SOURCE[0]}")" && pwd)"
-REPO_ROOT="$(cd "${SCRIPT_DIR}/../../.." && pwd)"
-
-python "${SCRIPT_DIR}/end2end_async_chunk.py" \
- --query-type text \
- --txt-prompts "${SCRIPT_DIR}/text_prompts_10.txt" \
- --deploy-config "${REPO_ROOT}/vllm_omni/deploy/qwen3_omni_moe.yaml" \
- --output-dir output_audio_async_chunk \
- --max-in-flight 2 \
- "$@"
diff --git a/examples/offline_inference/qwen3_omni/run_single_prompt.sh b/examples/offline_inference/qwen3_omni/run_single_prompt.sh
deleted file mode 100644
index c6ca09da6e2..00000000000
--- a/examples/offline_inference/qwen3_omni/run_single_prompt.sh
+++ /dev/null
@@ -1,2 +0,0 @@
-python end2end.py --output-wav output_audio \
- --query-type use_audio
diff --git a/examples/offline_inference/qwen3_omni/run_single_prompt_async_chunk.sh b/examples/offline_inference/qwen3_omni/run_single_prompt_async_chunk.sh
deleted file mode 100755
index 9ef69293cb5..00000000000
--- a/examples/offline_inference/qwen3_omni/run_single_prompt_async_chunk.sh
+++ /dev/null
@@ -1,26 +0,0 @@
-#!/bin/bash
-# Run a single Qwen3-Omni request with async_chunk enabled.
-#
-# This uses AsyncOmni (async orchestrator) so that downstream stages
-# (Talker, Code2Wav) start *before* stage-0 (Thinker) finishes,
-# achieving true stage-level concurrency via chunk-level streaming.
-#
-# Prerequisites:
-# - A deploy config YAML (e.g. qwen3_omni_moe.yaml)
-# - Hardware matching the config (e.g. 2x H100 for the default 3-stage config)
-#
-# Usage:
-# bash run_single_prompt_async_chunk.sh
-# bash run_single_prompt_async_chunk.sh --query-type text --modalities text
-# bash run_single_prompt_async_chunk.sh --deploy-config /path/to/custom.yaml
-
-set -euo pipefail
-
-SCRIPT_DIR="$(cd "$(dirname "${BASH_SOURCE[0]}")" && pwd)"
-REPO_ROOT="$(cd "${SCRIPT_DIR}/../../.." && pwd)"
-
-python "${SCRIPT_DIR}/end2end_async_chunk.py" \
- --query-type use_audio \
- --deploy-config "${REPO_ROOT}/vllm_omni/deploy/qwen3_omni_moe.yaml" \
- --output-dir output_audio_async_chunk \
- "$@"
diff --git a/examples/offline_inference/qwen3_omni/run_single_prompt_tp.sh b/examples/offline_inference/qwen3_omni/run_single_prompt_tp.sh
deleted file mode 100644
index 0cb459eab77..00000000000
--- a/examples/offline_inference/qwen3_omni/run_single_prompt_tp.sh
+++ /dev/null
@@ -1,5 +0,0 @@
-python end2end.py --output-wav output_audio \
- --query-type use_audio \
- --stage-init-timeout 300
-
-# stage-init-timeout sets the maximum wait to avoid two vLLM stages initializing at the same time on the same card.
diff --git a/examples/offline_inference/qwen3_omni/text_prompts_10.txt b/examples/offline_inference/qwen3_omni/text_prompts_10.txt
deleted file mode 100644
index 6e5fbe0e3db..00000000000
--- a/examples/offline_inference/qwen3_omni/text_prompts_10.txt
+++ /dev/null
@@ -1,10 +0,0 @@
-What is the capital of France?
-How many planets are in our solar system?
-What is the largest ocean on Earth?
-Who wrote the novel "1984"?
-What is the chemical symbol for water?
-What year did World War II end?
-What is the tallest mountain in the world?
-What is the speed of light in vacuum?
-Who painted the Mona Lisa?
-What is the smallest prime number?
diff --git a/examples/offline_inference/qwen3_tts/README.md b/examples/offline_inference/qwen3_tts/README.md
deleted file mode 100644
index 2971ad716a2..00000000000
--- a/examples/offline_inference/qwen3_tts/README.md
+++ /dev/null
@@ -1,121 +0,0 @@
-# Qwen3-TTS
-
-This directory contains an offline demo for running Qwen3 TTS models with vLLM Omni. It builds task-specific inputs and generates WAV files locally.
-
-## Model Overview
-
-Qwen3 TTS provides multiple task variants for speech generation:
-
-- **CustomVoice**: Generate speech with a known speaker identity (speaker ID) and optional instruction.
-- **VoiceDesign**: Generate speech from text plus a descriptive instruction that designs a new voice.
-- **Base**: Voice cloning using a reference audio + reference transcript, with optional mode selection. The `ref_audio` field accepts a local file path, HTTP URL, or base64 data URL.
-
-## Setup
-Please refer to the [stage configuration documentation](https://docs.vllm.ai/projects/vllm-omni/en/latest/configuration/stage_configs/) to configure memory allocation appropriately for your hardware setup.
-
-### ROCm Dependencies
-
-You will need to install the dependency `onnxruntime-rocm`.
-
-```
-pip uninstall onnxruntime # should be removed before we can install onnxruntime-rocm
-pip install onnxruntime-rocm
-```
-
-## Quick Start
-
-Run a single sample for a task:
-
-```
-python end2end.py --query-type CustomVoice
-```
-
-Generated audio files are saved to `output_audio/` by default.
-
-## Task Usage
-
-### CustomVoice
-
-Single sample:
-
-```
-python end2end.py --query-type CustomVoice
-```
-
-Batch sample (multiple prompts in one run):
-
-```
-python end2end.py --query-type CustomVoice --use-batch-sample
-```
-
-### VoiceDesign
-
-Single sample:
-
-```
-python end2end.py --query-type VoiceDesign
-```
-
-Batch sample:
-
-```
-python end2end.py --query-type VoiceDesign --use-batch-sample
-```
-
-### Base (Voice Clone)
-
-Single sample:
-
-```
-python end2end.py --query-type Base
-```
-
-Batch sample:
-
-```
-python end2end.py --query-type Base --use-batch-sample
-```
-
-Mode selection for Base:
-
-- `--mode-tag icl` (default): standard mode
-- `--mode-tag xvec_only`: enable `x_vector_only_mode` in the request
-
-Examples:
-
-```
-python end2end.py --query-type Base --mode-tag icl
-```
-
-## Streaming Mode
-
-Add `--streaming` to stream audio chunks progressively via `AsyncOmni` (requires `async_chunk: true` in the stage config):
-
-```bash
-python end2end.py --query-type CustomVoice --streaming --output-dir /tmp/out_stream
-```
-
-Each Code2Wav chunk is logged as it arrives (default 25 frames; configurable via `codec_chunk_frames`
-in the stage config). The initial chunk size is dynamically selected based on server load for reduced
-TTFA, and can be overridden per-request via the `initial_codec_chunk_frames` API field. The final WAV file is written once generation
-completes. This demonstrates that audio data is available progressively rather than only at the end.
-
-> **Note:** Streaming uses `AsyncOmni` internally. The non-streaming path (`Omni`) is unchanged.
-
-## Batched Decoding
-
-The Code2Wav stage (stage 1) supports batched decoding, where multiple requests are decoded in a single forward pass through the SpeechTokenizer. To use it, set `max_num_seqs > 1` on both stages via `--stage-overrides` and pass multiple prompts via `--txt-prompts` with a matching `--batch-size`.
-
-```
-python end2end.py --query-type CustomVoice \
- --txt-prompts benchmark_prompts.txt \
- --batch-size 4 \
- --stage-overrides '{"0":{"max_num_seqs":4,"gpu_memory_utilization":0.2},"1":{"max_num_seqs":4,"gpu_memory_utilization":0.2}}'
-```
-
-**Important:** `--batch-size` must match a CUDA graph capture size (1, 2, 4, 8, 16...) because the Talker's code predictor KV cache is sized to `max_num_seqs`, and CUDA graphs pad the batch to the next capture size. Both stages need `max_num_seqs >= batch_size` in the stage config for batching to take effect. If only stage 1 has a higher `max_num_seqs`, it won't help — stage 1 can only batch chunks from requests that are in-flight simultaneously, which requires stage 0 to also process multiple requests concurrently.
-
-## Notes
-
-- The script uses the model paths embedded in `end2end.py`. Update them if your local cache path differs.
-- Use `--output-dir` to change the output folder.
diff --git a/examples/offline_inference/qwen3_tts/benchmark_prompts.txt b/examples/offline_inference/qwen3_tts/benchmark_prompts.txt
deleted file mode 100644
index 92577a418cd..00000000000
--- a/examples/offline_inference/qwen3_tts/benchmark_prompts.txt
+++ /dev/null
@@ -1,12 +0,0 @@
-Hello, welcome to the voice synthesis benchmark test.
-She said she would be here by noon, but nobody showed up.
-The quick brown fox jumps over the lazy dog near the riverbank.
-I can't believe how beautiful the sunset looks from up here on the mountain.
-Please remember to bring your identification documents to the appointment tomorrow morning.
-Have you ever wondered what it would be like to travel through time and visit ancient civilizations?
-The restaurant on the corner serves the best pasta I have ever tasted in my entire life.
-After the meeting, we should discuss the quarterly results and plan for the next phase.
-Learning a new language takes patience, practice, and a genuine curiosity about other cultures.
-The train leaves at half past seven, so we need to arrive at the station before then.
-Could you please turn down the music a little bit, I'm trying to concentrate on my work.
-It was a dark and stormy night when the old lighthouse keeper heard a knock at the door.
diff --git a/examples/offline_inference/qwen3_tts/end2end.py b/examples/offline_inference/qwen3_tts/end2end.py
deleted file mode 100644
index a042f7e4658..00000000000
--- a/examples/offline_inference/qwen3_tts/end2end.py
+++ /dev/null
@@ -1,552 +0,0 @@
-"""Offline inference demo for Qwen3 TTS via vLLM Omni.
-
-Provides single and batch sample inputs for CustomVoice, VoiceDesign, and Base
-tasks, then runs Omni generation and saves output wav files.
-"""
-
-import asyncio
-import logging
-import os
-import time
-from typing import Any, NamedTuple
-
-import soundfile as sf
-import torch
-
-os.environ["VLLM_WORKER_MULTIPROC_METHOD"] = "spawn"
-
-from vllm.utils.argparse_utils import FlexibleArgumentParser
-
-from vllm_omni import AsyncOmni, Omni
-
-logger = logging.getLogger(__name__)
-
-
-class QueryResult(NamedTuple):
- """Container for a prepared Omni request."""
-
- inputs: dict
- model_name: str
-
-
-def _estimate_prompt_len(
- additional_information: dict[str, Any],
- model_name: str,
- _cache: dict[str, Any] = {},
-) -> int:
- """Estimate prompt_token_ids placeholder length for the Talker stage.
-
- The AR Talker replaces all input embeddings via ``preprocess``, so the
- placeholder values are irrelevant but the **length** must match the
- embeddings that ``preprocess`` will produce.
- """
- try:
- from vllm_omni.model_executor.models.qwen3_tts.configuration_qwen3_tts import Qwen3TTSConfig
- from vllm_omni.model_executor.models.qwen3_tts.qwen3_tts_talker import (
- Qwen3TTSTalkerForConditionalGeneration,
- )
-
- if model_name not in _cache:
- from transformers import AutoTokenizer
-
- tok = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True, padding_side="left")
- cfg = Qwen3TTSConfig.from_pretrained(model_name, trust_remote_code=True)
-
- # Load speech tokenizer (codec encoder) for exact ref_code_len.
- speech_tok = None
- try:
- import os
-
- from transformers.utils import cached_file
-
- from vllm_omni.model_executor.models.qwen3_tts.qwen3_tts_tokenizer import Qwen3TTSTokenizer
-
- st_cfg_path = cached_file(model_name, "speech_tokenizer/config.json")
- if st_cfg_path:
- speech_tok = Qwen3TTSTokenizer.from_pretrained(
- os.path.dirname(st_cfg_path), torch_dtype=torch.bfloat16
- )
- logger.info("Loaded speech tokenizer for exact ref_code_len estimation")
- except Exception as e:
- logger.debug("Could not load speech tokenizer: %s", e)
-
- _cache[model_name] = (tok, getattr(cfg, "talker_config", None), speech_tok)
-
- tok, tcfg, speech_tok = _cache[model_name]
- task_type = (additional_information.get("task_type") or ["CustomVoice"])[0]
-
- def _estimate_ref_code_len(ref_audio: object) -> int | None:
- """Encode ref_audio with the actual codec to get exact frame count."""
- if not isinstance(ref_audio, (str, list)):
- return None
- audio_path = ref_audio[0] if isinstance(ref_audio, list) else ref_audio
- if not isinstance(audio_path, str) or not audio_path.strip():
- return None
- try:
- from urllib.parse import urlparse
-
- import numpy as np
-
- def _is_url(path: str) -> bool:
- try:
- parsed = urlparse(path)
- if parsed.scheme in ("http", "https"):
- return bool(parsed.netloc)
- return parsed.scheme in ("file", "data")
- except Exception:
- return False
-
- if _is_url(audio_path):
- from vllm.multimodal.media import MediaConnector
-
- connector = MediaConnector(allowed_local_media_path="/")
- audio, sr = connector.fetch_audio(audio_path)
- else:
- from vllm.multimodal.media.audio import load_audio
-
- audio, sr = load_audio(audio_path, sr=None, mono=True)
-
- wav_np = np.asarray(audio, dtype=np.float32)
-
- if speech_tok is not None:
- enc = speech_tok.encode(wav_np, sr=int(sr), return_dict=True)
- ref_code = getattr(enc, "audio_codes", None)
- if isinstance(ref_code, list):
- ref_code = ref_code[0] if ref_code else None
- if ref_code is not None and hasattr(ref_code, "shape"):
- shape = ref_code.shape
- return int(shape[0]) if len(shape) == 2 else int(shape[1]) if len(shape) == 3 else None
-
- # Fallback: estimate from duration
- codec_hz = getattr(tcfg, "codec_frame_rate", None) or 12
- return int(len(audio) / sr * codec_hz)
- except Exception:
- return None
-
- return Qwen3TTSTalkerForConditionalGeneration.estimate_prompt_len_from_additional_information(
- additional_information=additional_information,
- task_type=task_type,
- tokenize_prompt=lambda t: tok(t, padding=False)["input_ids"],
- codec_language_id=getattr(tcfg, "codec_language_id", None),
- spk_is_dialect=getattr(tcfg, "spk_is_dialect", None),
- estimate_ref_code_len=_estimate_ref_code_len,
- )
- except Exception as exc:
- logger.warning("Failed to estimate prompt length, using fallback 2048: %s", exc)
- return 2048
-
-
-def get_custom_voice_query(use_batch_sample: bool = False) -> QueryResult:
- """Build CustomVoice sample inputs.
-
- Args:
- use_batch_sample: When True, return a batch of prompts; otherwise a single prompt.
-
- Returns:
- QueryResult with Omni inputs and the CustomVoice model path.
- """
- task_type = "CustomVoice"
- model_name = "Qwen/Qwen3-TTS-12Hz-1.7B-CustomVoice"
- if use_batch_sample:
- texts = [
- "其实我真的有发现,我是一个特别善于观察别人情绪的人。",
- "She said she would be here by noon.",
- "I like you very much.",
- "Really, you do?",
- "Yes, absolutely.",
- ]
- instructs = ["", "Very happy.", "Very happy.", "Very happy.", "Very happy."]
- languages = ["Chinese", "English", "English", "English", "English"]
- speakers = ["Vivian", "Ryan", "Ryan", "Ryan", "Ryan"]
- inputs = []
- for text, instruct, language, speaker in zip(texts, instructs, languages, speakers):
- additional_information = {
- "task_type": [task_type],
- "text": [text],
- "instruct": [instruct],
- "language": [language],
- "speaker": [speaker],
- "max_new_tokens": [2048],
- }
- inputs.append(
- {
- "prompt_token_ids": [0] * _estimate_prompt_len(additional_information, model_name),
- "additional_information": additional_information,
- }
- )
- else:
- text = "其实我真的有发现,我是一个特别善于观察别人情绪的人。"
- language = "Chinese"
- speaker = "Vivian"
- instruct = "用特别愤怒的语气说"
- additional_information = {
- "task_type": [task_type],
- "text": [text],
- "language": [language],
- "speaker": [speaker],
- "instruct": [instruct],
- "max_new_tokens": [2048],
- }
- inputs = {
- "prompt_token_ids": [0] * _estimate_prompt_len(additional_information, model_name),
- "additional_information": additional_information,
- }
- return QueryResult(
- inputs=inputs,
- model_name=model_name,
- )
-
-
-def get_voice_design_query(use_batch_sample: bool = False) -> QueryResult:
- """Build VoiceDesign sample inputs.
-
- Args:
- use_batch_sample: When True, return a batch of prompts; otherwise a single prompt.
-
- Returns:
- QueryResult with Omni inputs and the VoiceDesign model path.
- """
- task_type = "VoiceDesign"
- model_name = "Qwen/Qwen3-TTS-12Hz-1.7B-VoiceDesign"
- if use_batch_sample:
- texts = [
- "哥哥,你回来啦,人家等了你好久好久了,要抱抱!",
- "It's in the top drawer... wait, it's empty? No way, that's impossible! I'm sure I put it there!",
- ]
- instructs = [
- "体现撒娇稚嫩的萝莉女声,音调偏高且起伏明显,营造出黏人、做作又刻意卖萌的听觉效果。",
- "Speak in an incredulous tone, but with a hint of panic beginning to creep into your voice.",
- ]
- languages = ["Chinese", "English"]
- inputs = []
- for text, instruct, language in zip(texts, instructs, languages):
- additional_information = {
- "task_type": [task_type],
- "text": [text],
- "language": [language],
- "instruct": [instruct],
- "max_new_tokens": [2048],
- "non_streaming_mode": [True],
- }
- inputs.append(
- {
- "prompt_token_ids": [0] * _estimate_prompt_len(additional_information, model_name),
- "additional_information": additional_information,
- }
- )
- else:
- text = "哥哥,你回来啦,人家等了你好久好久了,要抱抱!"
- instruct = "体现撒娇稚嫩的萝莉女声,音调偏高且起伏明显,营造出黏人、做作又刻意卖萌的听觉效果。"
- language = "Chinese"
- additional_information = {
- "task_type": [task_type],
- "text": [text],
- "language": [language],
- "instruct": [instruct],
- "max_new_tokens": [2048],
- "non_streaming_mode": [True],
- }
- inputs = {
- "prompt_token_ids": [0] * _estimate_prompt_len(additional_information, model_name),
- "additional_information": additional_information,
- }
- return QueryResult(
- inputs=inputs,
- model_name=model_name,
- )
-
-
-def get_base_query(use_batch_sample: bool = False, mode_tag: str = "icl") -> QueryResult:
- """Build Base (voice clone) sample inputs.
-
- Args:
- use_batch_sample: When True, return a batch of prompts (Case 2).
- mode_tag: "icl" or "xvec_only" to control x_vector_only_mode behavior.
-
- Returns:
- QueryResult with Omni inputs and the Base model path.
- """
- task_type = "Base"
- model_name = "Qwen/Qwen3-TTS-12Hz-1.7B-Base"
- ref_audio_path_1 = "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen3-TTS-Repo/clone_2.wav"
- ref_audio_single = ref_audio_path_1
- ref_text_single = (
- "Okay. Yeah. I resent you. I love you. I respect you. But you know what? You blew it! And thanks to you."
- )
- syn_text_single = "Good one. Okay, fine, I'm just gonna leave this sock monkey here. Goodbye."
- syn_lang_single = "Auto"
- x_vector_only_mode = mode_tag == "xvec_only"
- if use_batch_sample:
- syn_text_batch = [
- "Good one. Okay, fine, I'm just gonna leave this sock monkey here. Goodbye.",
- "其实我真的有发现,我是一个特别善于观察别人情绪的人。",
- ]
- syn_lang_batch = ["Chinese", "English"]
- inputs = []
- for text, language in zip(syn_text_batch, syn_lang_batch):
- additional_information = {
- "task_type": [task_type],
- "ref_audio": [ref_audio_single],
- "ref_text": [ref_text_single],
- "text": [text],
- "language": [language],
- "x_vector_only_mode": [x_vector_only_mode],
- "max_new_tokens": [2048],
- }
- inputs.append(
- {
- "prompt_token_ids": [0] * _estimate_prompt_len(additional_information, model_name),
- "additional_information": additional_information,
- }
- )
- else:
- additional_information = {
- "task_type": [task_type],
- "ref_audio": [ref_audio_single],
- "ref_text": [ref_text_single],
- "text": [syn_text_single],
- "language": [syn_lang_single],
- "x_vector_only_mode": [x_vector_only_mode],
- "max_new_tokens": [2048],
- }
- inputs = {
- "prompt_token_ids": [0] * _estimate_prompt_len(additional_information, model_name),
- "additional_information": additional_information,
- }
- return QueryResult(
- inputs=inputs,
- model_name=model_name,
- )
-
-
-query_map = {
- "CustomVoice": get_custom_voice_query,
- "VoiceDesign": get_voice_design_query,
- "Base": get_base_query,
-}
-
-
-def _build_inputs(args) -> tuple[str, list]:
- """Resolve model name and inputs list from CLI args."""
- if args.batch_size < 1 or (args.batch_size & (args.batch_size - 1)) != 0:
- raise ValueError(
- f"--batch-size must be a power of two (got {args.batch_size}); "
- "non-power-of-two values do not align with CUDA graph capture sizes "
- "of Code2Wav."
- )
-
- query_func = query_map[args.query_type]
- if args.query_type in {"CustomVoice", "VoiceDesign"}:
- query_result = query_func(use_batch_sample=args.use_batch_sample)
- elif args.query_type == "Base":
- query_result = query_func(use_batch_sample=args.use_batch_sample, mode_tag=args.mode_tag)
- else:
- query_result = query_func()
-
- model_name = query_result.model_name
-
- if args.txt_prompts:
- with open(args.txt_prompts) as f:
- lines = [line.strip() for line in f if line.strip()]
- if not lines:
- raise ValueError(f"No valid prompts found in {args.txt_prompts}")
- template = query_result.inputs if not isinstance(query_result.inputs, list) else query_result.inputs[0]
- template_info = template["additional_information"]
- inputs = [
- {
- "prompt_token_ids": [0] * _estimate_prompt_len({**template_info, "text": [t]}, model_name),
- "additional_information": {**template_info, "text": [t]},
- }
- for t in lines
- ]
- else:
- inputs = query_result.inputs if isinstance(query_result.inputs, list) else [query_result.inputs]
-
- return model_name, inputs
-
-
-def _save_wav(output_dir: str, request_id: str, mm: dict) -> None:
- """Concatenate audio chunks and write to a wav file."""
- audio_data = mm["audio"]
- sr_raw = mm["sr"]
- sr_val = sr_raw[-1] if isinstance(sr_raw, list) and sr_raw else sr_raw
- sr = sr_val.item() if hasattr(sr_val, "item") else int(sr_val)
- audio_tensor = torch.cat(audio_data, dim=-1) if isinstance(audio_data, list) else audio_data
- out_wav = os.path.join(output_dir, f"output_{request_id}.wav")
- sf.write(out_wav, audio_tensor.float().cpu().numpy().flatten(), samplerate=sr, format="WAV")
- logger.info(f"Request ID: {request_id}, Saved audio to {out_wav}")
-
-
-def main(args):
- """Run offline inference with Omni."""
- model_name, inputs = _build_inputs(args)
- output_dir = args.output_dir
- os.makedirs(output_dir, exist_ok=True)
-
- omni = Omni.from_cli_args(args, model=model_name)
-
- batch_size = args.batch_size
- for batch_start in range(0, len(inputs), batch_size):
- batch = inputs[batch_start : batch_start + batch_size]
- for stage_outputs in omni.generate(batch):
- output = stage_outputs.request_output
- _save_wav(output_dir, output.request_id, output.outputs[0].multimodal_output)
-
-
-async def main_streaming(args):
- """Run offline inference with AsyncOmni, logging each audio chunk as it arrives."""
- model_name, inputs = _build_inputs(args)
- output_dir = args.output_dir
- os.makedirs(output_dir, exist_ok=True)
-
- omni = AsyncOmni.from_cli_args(args, model=model_name)
-
- for i, prompt in enumerate(inputs):
- request_id = str(i)
- t_start = time.perf_counter()
- t_prev = t_start
- chunk_idx = 0
- async for stage_output in omni.generate(prompt, request_id=request_id):
- mm = stage_output.request_output.outputs[0].multimodal_output
- if not stage_output.finished:
- t_now = time.perf_counter()
- audio = mm.get("audio")
- n = len(audio) if isinstance(audio, list) else (0 if audio is None else 1)
- dt_ms = (t_now - t_prev) * 1000
- ttfa_ms = (t_now - t_start) * 1000
- if chunk_idx == 0:
- logger.info(f"Request {request_id}: chunk {chunk_idx} samples={n} TTFA={ttfa_ms:.1f}ms")
- else:
- logger.info(f"Request {request_id}: chunk {chunk_idx} samples={n} inter_chunk={dt_ms:.1f}ms")
- t_prev = t_now
- chunk_idx += 1
- else:
- t_end = time.perf_counter()
- total_ms = (t_end - t_start) * 1000
- logger.info(f"Request {request_id}: done total={total_ms:.1f}ms chunks={chunk_idx}")
- _save_wav(output_dir, request_id, mm)
-
-
-def parse_args():
- parser = FlexibleArgumentParser(description="Demo on using vLLM for offline inference with audio language models")
- parser.add_argument(
- "--query-type",
- "-q",
- type=str,
- default="CustomVoice",
- choices=query_map.keys(),
- help="Query type.",
- )
- parser.add_argument(
- "--log-stats",
- action="store_true",
- default=False,
- help="Enable writing detailed statistics (default: disabled)",
- )
- parser.add_argument(
- "--stage-init-timeout",
- type=int,
- default=300,
- help="Timeout for initializing a single stage in seconds (default: 300)",
- )
- parser.add_argument(
- "--batch-timeout",
- type=int,
- default=5,
- help="Timeout for batching in seconds (default: 5)",
- )
- parser.add_argument(
- "--init-timeout",
- type=int,
- default=300,
- help="Timeout for initializing stages in seconds (default: 300)",
- )
- parser.add_argument(
- "--shm-threshold-bytes",
- type=int,
- default=65536,
- help="Threshold for using shared memory in bytes (default: 65536)",
- )
- parser.add_argument(
- "--output-dir",
- default="output_audio",
- help="Output directory for generated wav files (default: output_audio).",
- )
- parser.add_argument(
- "--num-prompts",
- type=int,
- default=1,
- help="Number of prompts to generate.",
- )
- parser.add_argument(
- "--txt-prompts",
- type=str,
- default=None,
- help="Path to a .txt file with one prompt per line (preferred).",
- )
- parser.add_argument(
- "--stage-configs-path",
- type=str,
- default=None,
- help="Path to a stage configs file.",
- )
- parser.add_argument(
- "--audio-path",
- "-a",
- type=str,
- default=None,
- help="Path to local audio file. If not provided, uses default audio asset.",
- )
- parser.add_argument(
- "--sampling-rate",
- type=int,
- default=16000,
- help="Sampling rate for audio loading (default: 16000).",
- )
- parser.add_argument(
- "--log-dir",
- type=str,
- default="logs",
- help="Log directory (default: logs).",
- )
- parser.add_argument(
- "--py-generator",
- action="store_true",
- default=False,
- help="Use py_generator mode. The returned type of Omni.generate() is a Python Generator object.",
- )
- parser.add_argument(
- "--use-batch-sample",
- action="store_true",
- default=False,
- help="Use batch input sample for CustomVoice/VoiceDesign/Base query.",
- )
- parser.add_argument(
- "--mode-tag",
- type=str,
- default="icl",
- choices=["icl", "xvec_only"],
- help="Mode tag for Base query x_vector_only_mode (default: icl).",
- )
- parser.add_argument(
- "--streaming",
- action="store_true",
- default=False,
- help="Stream audio chunks as they arrive via AsyncOmni (async_chunk mode only).",
- )
- parser.add_argument(
- "--batch-size",
- type=int,
- default=1,
- help="Number of prompts per batch (default: 1, sequential).",
- )
-
- return parser.parse_args()
-
-
-if __name__ == "__main__":
- args = parse_args()
- if args.streaming:
- asyncio.run(main_streaming(args))
- else:
- main(args)
diff --git a/examples/offline_inference/text_to_audio/README.md b/examples/offline_inference/text_to_audio/README.md
deleted file mode 100644
index 10a8ae37ed1..00000000000
--- a/examples/offline_inference/text_to_audio/README.md
+++ /dev/null
@@ -1,58 +0,0 @@
-# Text-To-Audio
-
-The `stabilityai/stable-audio-open-1.0` pipeline generates audio from text prompts.
-
-## Prerequisites
-
-If you use a gated model (e.g., `stabilityai/stable-audio-open-1.0`), ensure you have access:
-
-1. **Accept Model License**: Visit the model page on Hugging Face (e.g., [stabilityai/stable-audio-open-1.0]) and accept the user agreement.
-2. **Authenticate**: Log in to Hugging Face locally to access the gated model.
- ```bash
- huggingface-cli login
- ```
-
-## Local CLI Usage
-
-```bash
-python text_to_audio.py \
- --model stabilityai/stable-audio-open-1.0 \
- --prompt "The sound of a hammer hitting a wooden surface" \
- --negative-prompt "Low quality" \
- --seed 42 \
- --guidance-scale 7.0 \
- --audio-length 10.0 \
- --num-inference-steps 100 \
- --cache-backend tea_cache \
- --output stable_audio_output.wav
-```
-
-To reduce per-GPU memory for multi-GPU inference, launch with HSDP:
-
-```bash
-python text_to_audio.py \
- --model stabilityai/stable-audio-open-1.0 \
- --prompt "The sound of a hammer hitting a wooden surface" \
- --negative-prompt "Low quality" \
- --seed 42 \
- --guidance-scale 7.0 \
- --audio-length 10.0 \
- --num-inference-steps 100 \
- --use-hsdp \
- --hsdp-shard-size 2 \
- --output stable_audio_output.wav
-```
-
-Key arguments:
-
-- `--prompt`: text description (string).
-- `--negative-prompt`: negative prompt for classifier-free guidance.
-- `--seed`: integer seed for deterministic generation.
-- `--guidance-scale`: classifier-free guidance scale.
-- `--audio-length`: audio duration in seconds.
-- `--num-inference-steps`: diffusion sampling steps.(more steps = higher quality, slower).
-- `--use-hsdp`: enable HSDP weight sharding for the Stable Audio DiT.
-- `--hsdp-shard-size`: number of GPUs used for HSDP sharding.
-- `--hsdp-replicate-size`: number of HSDP replica groups.
-- `--cache-backend`: cache acceleration backend. Stable Audio currently supports `tea_cache`.
-- `--output`: path to save the generated WAV file.
diff --git a/examples/offline_inference/text_to_audio/text_to_audio.py b/examples/offline_inference/text_to_audio/text_to_audio.py
deleted file mode 100644
index 2a1613e5e91..00000000000
--- a/examples/offline_inference/text_to_audio/text_to_audio.py
+++ /dev/null
@@ -1,320 +0,0 @@
-# SPDX-License-Identifier: Apache-2.0
-# SPDX-FileCopyrightText: Copyright contributors to the vLLM project
-
-"""
-Example script for text-to-audio generation using Stable Audio Open.
-
-This script demonstrates how to generate audio from text prompts using
-the Stable Audio Open model with vLLM-Omni.
-
-Usage:
- python text_to_audio.py --prompt "The sound of a dog barking"
- python text_to_audio.py --prompt "A piano playing a gentle melody" --audio-length 10.0
- python text_to_audio.py --prompt "Thunder and rain sounds" --negative-prompt "Low quality"
- python text_to_audio.py --prompt "A soft synth pad" --cache-backend tea_cache
-"""
-
-import argparse
-import time
-from pathlib import Path
-
-import numpy as np
-import torch
-
-from vllm_omni.diffusion.data import DiffusionParallelConfig
-from vllm_omni.entrypoints.omni import Omni
-from vllm_omni.inputs.data import OmniDiffusionSamplingParams
-from vllm_omni.platforms import current_omni_platform
-
-
-def parse_args() -> argparse.Namespace:
- parser = argparse.ArgumentParser(description="Generate audio with Stable Audio Open.")
- parser.add_argument(
- "--model",
- default="stabilityai/stable-audio-open-1.0",
- help="Stable Audio model name or local path.",
- )
- parser.add_argument(
- "--prompt",
- default="The sound of a hammer hitting a wooden surface.",
- help="Text prompt for audio generation.",
- )
- parser.add_argument(
- "--negative-prompt",
- default="Low quality.",
- help="Negative prompt for classifier-free guidance.",
- )
- parser.add_argument(
- "--seed",
- type=int,
- default=42,
- help="Random seed for deterministic results.",
- )
- parser.add_argument(
- "--guidance-scale",
- type=float,
- default=7.0,
- help="Classifier-free guidance scale.",
- )
- parser.add_argument(
- "--audio-start",
- type=float,
- default=0.0,
- help="Audio start time in seconds.",
- )
- parser.add_argument(
- "--audio-length",
- type=float,
- default=10.0,
- help="Audio length in seconds (max ~47s for stable-audio-open-1.0).",
- )
- parser.add_argument(
- "--num-inference-steps",
- type=int,
- default=100,
- help="Number of denoising steps for the diffusion sampler.",
- )
- parser.add_argument(
- "--num-waveforms",
- type=int,
- default=1,
- help="Number of audio waveforms to generate for the given prompt.",
- )
- parser.add_argument(
- "--output",
- type=str,
- default="stable_audio_output.wav",
- help="Path to save the generated audio (WAV format).",
- )
- parser.add_argument(
- "--sample-rate",
- type=int,
- default=44100,
- help="Sample rate for output audio (Stable Audio uses 44100 Hz).",
- )
- parser.add_argument(
- "--cache-backend",
- type=str,
- default=None,
- choices=["tea_cache"],
- help=(
- "Cache backend to use for acceleration. "
- "Stable Audio currently supports 'tea_cache'. "
- "Default: None (no cache acceleration)."
- ),
- )
- parser.add_argument(
- "--tea-cache-rel-l1-thresh",
- type=float,
- default=0.2,
- help="[tea_cache] Threshold for accumulated relative L1 distance.",
- )
- parser.add_argument(
- "--enable-diffusion-pipeline-profiler",
- action="store_true",
- help="Enable diffusion pipeline profiler to display stage durations.",
- )
- parser.add_argument(
- "--use-hsdp",
- action="store_true",
- help="Enable HSDP for Stable Audio DiT weight sharding.",
- )
- parser.add_argument(
- "--hsdp-shard-size",
- type=int,
- default=1,
- help="Number of GPUs to shard Stable Audio DiT weights across when HSDP is enabled.",
- )
- parser.add_argument(
- "--hsdp-replicate-size",
- type=int,
- default=1,
- help="Number of HSDP replica groups. Default 1 means pure sharding.",
- )
- parser.add_argument(
- "--tensor-parallel-size",
- type=int,
- default=1,
- help="Number of GPUs used for tensor parallelism (TP) inside the DiT.",
- )
- parser.add_argument(
- "--ulysses-degree",
- type=int,
- default=1,
- help="Number of GPUs used for ulysses sequence parallelism.",
- )
- parser.add_argument(
- "--ulysses-mode",
- type=str,
- default="strict",
- choices=["strict", "advanced_uaa"],
- help="Ulysses sequence-parallel mode: 'strict' (divisibility required) or 'advanced_uaa' (UAA).",
- )
- parser.add_argument(
- "--ring-degree",
- type=int,
- default=1,
- help="Number of GPUs used for ring sequence parallelism.",
- )
- parser.add_argument(
- "--cfg-parallel-size",
- type=int,
- default=1,
- choices=[1, 2],
- help="Number of GPUs used for classifier free guidance parallel size.",
- )
- parser.add_argument(
- "--vae-patch-parallel-size",
- type=int,
- default=1,
- help="Number of GPUs used for VAE patch/tile parallelism (decode).",
- )
- return parser.parse_args()
-
-
-def save_audio(audio_data: np.ndarray, output_path: str, sample_rate: int = 44100):
- """Save audio data to a WAV file."""
- try:
- import soundfile as sf
-
- sf.write(output_path, audio_data, sample_rate)
- except ImportError:
- try:
- import scipy.io.wavfile as wav
-
- # Ensure audio is in the correct format for scipy
- if audio_data.dtype == np.float32 or audio_data.dtype == np.float64:
- # Normalize to int16 range
- audio_data = np.clip(audio_data, -1.0, 1.0)
- audio_data = (audio_data * 32767).astype(np.int16)
- wav.write(output_path, sample_rate, audio_data)
- except ImportError:
- raise ImportError(
- "Either 'soundfile' or 'scipy' is required to save audio files. "
- "Install with: pip install soundfile or pip install scipy"
- )
-
-
-def main():
- args = parse_args()
- generator = torch.Generator(device=current_omni_platform.device_type).manual_seed(args.seed)
- cache_config = None
- if args.cache_backend == "tea_cache":
- cache_config = {
- "rel_l1_thresh": args.tea_cache_rel_l1_thresh,
- }
-
- print(f"\n{'=' * 60}")
- print("Stable Audio Open - Text-to-Audio Generation")
- print(f"{'=' * 60}")
- print(f" Model: {args.model}")
- print(f" Prompt: {args.prompt}")
- print(f" Negative prompt: {args.negative_prompt}")
- print(f" Audio length: {args.audio_length}s")
- print(f" Inference steps: {args.num_inference_steps}")
- print(f" Guidance scale: {args.guidance_scale}")
- print(f" Cache backend: {args.cache_backend if args.cache_backend else 'None (no acceleration)'}")
- if args.use_hsdp:
- print(f" HSDP: enabled (shard_size={args.hsdp_shard_size}, replicate_size={args.hsdp_replicate_size})")
- else:
- print(" HSDP: disabled")
- print(f" Seed: {args.seed}")
- print(f"{'=' * 60}\n")
-
- parallel_config = DiffusionParallelConfig(
- use_hsdp=args.use_hsdp,
- hsdp_shard_size=args.hsdp_shard_size,
- hsdp_replicate_size=args.hsdp_replicate_size,
- )
-
- # Initialize Omni with Stable Audio model
- omni = Omni(
- model=args.model,
- parallel_config=parallel_config,
- cache_backend=args.cache_backend,
- cache_config=cache_config,
- enable_diffusion_pipeline_profiler=args.enable_diffusion_pipeline_profiler,
- )
-
- # Calculate audio end time
- audio_end_in_s = args.audio_start + args.audio_length
-
- # Time profiling for generation
- generation_start = time.perf_counter()
-
- # Generate audio
- outputs = omni.generate(
- {
- "prompt": args.prompt,
- "negative_prompt": args.negative_prompt,
- },
- OmniDiffusionSamplingParams(
- generator=generator,
- guidance_scale=args.guidance_scale,
- num_inference_steps=args.num_inference_steps,
- num_outputs_per_prompt=args.num_waveforms,
- extra_args={
- "audio_start_in_s": args.audio_start,
- "audio_end_in_s": audio_end_in_s,
- },
- ),
- )
-
- generation_end = time.perf_counter()
- generation_time = generation_end - generation_start
-
- print(f"Total generation time: {generation_time:.2f} seconds")
-
- # Process and save audio
- output_path = Path(args.output)
- output_path.parent.mkdir(parents=True, exist_ok=True)
- suffix = output_path.suffix or ".wav"
- stem = output_path.stem or "stable_audio_output"
-
- # Extract audio from omni.generate() outputs
- if not outputs:
- raise ValueError("No output generated from omni.generate()")
-
- output = outputs[0]
- if not hasattr(output, "request_output") or not output.request_output:
- raise ValueError("No request_output found in OmniRequestOutput")
- request_output = output.request_output
- if not hasattr(request_output, "multimodal_output"):
- raise ValueError("No multimodal_output found in request_output")
-
- audio = request_output.multimodal_output.get("audio")
- if audio is None:
- raise ValueError("No audio output found in request_output")
-
- # Handle different output formats
- if isinstance(audio, torch.Tensor):
- audio = audio.cpu().float().numpy()
-
- # Audio shape is typically [batch, channels, samples] or [channels, samples]
- if audio.ndim == 3:
- # [batch, channels, samples]
- if args.num_waveforms <= 1:
- audio_data = audio[0].T # [samples, channels]
- save_audio(audio_data, str(output_path), args.sample_rate)
- print(f"Saved generated audio to {output_path}")
- else:
- for idx in range(audio.shape[0]):
- audio_data = audio[idx].T # [samples, channels]
- save_path = output_path.parent / f"{stem}_{idx}{suffix}"
- save_audio(audio_data, str(save_path), args.sample_rate)
- print(f"Saved generated audio to {save_path}")
- elif audio.ndim == 2:
- # [channels, samples]
- audio_data = audio.T # [samples, channels]
- save_audio(audio_data, str(output_path), args.sample_rate)
- print(f"Saved generated audio to {output_path}")
- else:
- # [samples] - mono audio
- save_audio(audio, str(output_path), args.sample_rate)
- print(f"Saved generated audio to {output_path}")
-
- print(f"\nGenerated {args.audio_length}s of audio at {args.sample_rate} Hz")
-
-
-if __name__ == "__main__":
- main()
diff --git a/examples/offline_inference/text_to_image/README.md b/examples/offline_inference/text_to_image/README.md
deleted file mode 100644
index c71773972b3..00000000000
--- a/examples/offline_inference/text_to_image/README.md
+++ /dev/null
@@ -1,282 +0,0 @@
-# Text-To-Image
-
-Generate images from text prompts using vLLM-Omni's diffusion pipeline entrypoints.
-
-- `text_to_image.py`: command-line script for single image generation with advanced options.
-- `gradio_demo.py`: lightweight Gradio UI for interactive prompt/seed/CFG exploration.
-
-## Table of Contents
-
-- [Overview](#overview)
-- [Quick Start](#quick-start)
-- [Key Arguments](#key-arguments)
-- [More CLI Examples](#more-cli-examples)
-- [Web UI Demo](#web-ui-demo)
-
-## Overview
-
-This folder provides several entrypoints for experimenting with text-to-image diffusion models using vLLM-Omni. Note that `NextStep-1.1` has a different architecture, so it is treated differently regarding running arguments and pipeline.
-
-### Supported Models
-
-| Model | Image Shape | Peak VRAM (GiB) * | Model Weights (GiB) |
-| ----- | ----------- | ----------- | ----------------- |
-| `Qwen/Qwen-Image` | 1024 x 1024 | 60.0 | 53.7 |
-| `Qwen/Qwen-Image-2512` |1024 x 1024 | 60.0 | 53.7 |
-| `Tongyi-MAI/Z-Image-Turbo` | 1024 x 1024 | 24.8 | 19.2 |
-| `stepfun-ai/NextStep-1.1` | 512 x 512 | 71.8 | 28.1 |
-| `meituan-longcat/LongCat-Image` | 1024 x 1024 | 71.2 | 27.3 |
-| `AIDC-AI/Ovis-Image-7B` | 1024 x 1024 | 71.8 | 17.1 |
-| `OmniGen2/OmniGen2` | 1024 x 1024 | 20.1 | 14.7 |
-| `stabilityai/stable-diffusion-3.5-medium` | 1024 x 1024 | 20.1 | 15.6 |
-| `black-forest-labs/FLUX.1-dev` | 1024 x 1024 | 33.9 | 31.4 |
-| `black-forest-labs/FLUX.1-schnell` | 1024 x 1024 | 33.9 | 31.4 |
-| `black-forest-labs/FLUX.2-klein-4B` | 1024 x 1024 | 72.7 | 14.9 |
-| `black-forest-labs/FLUX.2-klein-9B` | 1024 x 1024 | 37.1 | 32.3 |
-| `black-forest-labs/FLUX.2-dev` | 1024 x 1024 | 65.7 | >80 (CPU offload required) |
-| `HunyuanImage-3.0` | 1024 x 1024 | 80.0 (TP≥3) | 160 |
-
-!!! info
-*Peak VRAM: based on basic single-card usage, batch size =1, without any acceleration/optimization features. FLUX.2-dev requires `--enable-cpu-offload` on a single 80 GiB GPU.
-
-Default model: `Qwen/Qwen-Image`
-
-## Quick Start
-
-### Python API
-
-Single-prompt generation:
-
-```python
-from vllm_omni.entrypoints.omni import Omni
-
-if __name__ == "__main__":
- omni = Omni(model="Qwen/Qwen-Image")
- prompt = "a cup of coffee on the table"
- outputs = omni.generate(prompt)
- images = outputs[0].request_output.images
- images[0].save("coffee.png")
-```
-
-### Local CLI Usage
-
-```bash
-python text_to_image.py \
- --model Qwen/Qwen-Image \
- --prompt "a cup of coffee on the table" \
- --output coffee.png
-```
-
-## Key Arguments
-
-**Common arguments:**
-
-| Argument | Type | Default | Description |
-| -------- | ---- | ------- | ----------- |
-| `--prompt` | str | `"a cup of coffee on the table"` | Text description for image generation |
-| `--seed` | int | `142` | Integer seed for deterministic sampling |
-| `--negative-prompt` | str | `None` | Negative prompt for classifier-free conditional guidance |
-| `--cfg-scale` | float | `4.0` | True CFG scale (model-specific guidance strength) |
-| `--guidance-scale` | float | `1.0` | Classifier-free guidance scale |
-| `--num-images-per-prompt` | int | `1` | Number of images per prompt (saved as `output`, `output_1`, ...) |
-| `--num-inference-steps` | int | `50` | Diffusion sampling steps (more steps = higher quality, slower) |
-| `--height` | int | `1024` | Output image height in pixels |
-| `--width` | int | `1024` | Output image width in pixels |
-| `--output` | str | `"qwen_image_output.png"` | Path to save the generated image |
-| `--vae-use-slicing` | flag | off | Enable VAE slicing for memory optimization |
-| `--vae-use-tiling` | flag | off | Enable VAE tiling for memory optimization |
-| `--cfg-parallel-size` | int | `1` | Set to `2` to enable CFG Parallel |
-| `--ulysses-degree` | int | `1` | Ulysses sequence parallel degree for multi-GPU inference |
-| `--ring-degree` | int | `1` | Ring sequence parallel degree for hybrid Ulysses + Ring inference |
-| `--ulysses-mode` | str | `"strict"` | Ulysses SP mode: `"strict"` or `"advanced_uaa"` |
-| `--enable-cpu-offload` | flag | off | Enable CPU offloading for diffusion models |
-| `--lora-path` | str | — | Path to PEFT LoRA adapter folder |
-| `--lora-scale` | float | `1.0` | Scale factor for LoRA weights |
-| `--use-system-prompt` | str | `None` | System prompt preset: `en_unified`, `en_vanilla`, `en_recaption`, `en_think_recaption`, `dynamic`, `None`, or custom text. Recommended: `en_unified`. Only for HunyuanImage-3.0.|
-| `--system-prompt` | str | `None` | Custom system prompt text. Only used when `--use-system-prompt` is set to `custom`. Only for HunyuanImage-3.0.|
-
-**NextStep-1.1 specific arguments:**
-
-| Argument | Type | Default | Description |
-| -------- | ---- | ------- | ----------- |
-| `--guidance-scale-2` | float | `1.0` | Secondary guidance scale (e.g. image-level CFG) |
-| `--timesteps-shift` | float | `1.0` | Timesteps shift parameter for sampling |
-| `--cfg-schedule` | str | `"constant"` | CFG schedule type: `"constant"` or `"linear"` |
-| `--use-norm` | flag | off | Apply layer normalization to sampled tokens |
-
-> If you encounter OOM errors, try using `--vae-use-slicing` and `--vae-use-tiling` to reduce memory usage.
-
-> Qwen-Image currently publishes best-effort presets at `1328x1328`, `1664x928`, `928x1664`, `1472x1140`, `1140x1472`, `1584x1056`, and `1056x1584`. Adjust `--height/--width` accordingly for the most reliable outcomes.
-
-## More CLI Examples
-
-### Tongyi Models
-
-```bash
-python text_to_image.py \
- --model Tongyi-MAI/Z-Image-Turbo \
- --prompt "a cup of coffee on the table" \
- --seed 42 \
- --guidance-scale 0.0 \
- --num-images-per-prompt 1 \
- --num-inference-steps 9 \
- --height 1024 \
- --width 1024 \
- --output outputs/coffee.png
-```
-
-`Tongyi-MAI/Z-Image-Turbo` is a distilled version of Z-Image. Distilled diffusion models usually require less number of inference steps (4~9), and Classifier-Free Guidance (CFG) is usually NOT applied. Similar distilled models are `black-forest-labs/FLUX.2-klein-4B` and `black-forest-labs/FLUX.2-klein-9B`.
-
-Advanced UAA example (requires 2 GPUs):
-
-```bash
-python text_to_image.py \
- --model Tongyi-MAI/Z-Image-Turbo \
- --prompt "a cup of coffee on the table" \
- --ulysses-degree 2 \
- --ulysses-mode advanced_uaa \
- --height 1024 \
- --width 1024 \
- --output outputs/coffee_hybrid.png
-```
-
-### NextStep Models
-
-NextStep-1.1 supports extra arguments for dual-level CFG control:
-
-```bash
-python text_to_image.py \
- --model stepfun-ai/NextStep-1.1 \
- --prompt "A baby panda wearing an Iron Man mask, holding a board with 'NextStep-1' written on it" \
- --height 512 \
- --width 512 \
- --num-inference-steps 28 \
- --guidance-scale 7.5 \
- --guidance-scale-2 1.0 \
- --cfg-schedule constant \
- --output nextstep_output.png \
- --seed 42
-```
-
-### FLUX.2-dev Models
-
-To run FLUX.2-dev on a single GPU, `--enable-cpu-offload` is required because the model weights exceed 80 GiB:
-
-```bash
-python examples/offline_inference/text_to_image/text_to_image.py \
- --model black-forest-labs/FLUX.2-dev \
- --prompt "a lovely bunny holding a sign that says 'vllm-omni'" \
- --seed 42 \
- --tensor-parallel-size 1 \
- --num-images-per-prompt 1 \
- --num-inference-steps 50 \
- --guidance-scale 4.0 \
- --height 1024 \
- --width 1024 \
- --enable-cpu-offload \
- --output flux2-dev.png
-```
-
-### Batch Requests (Multiple Prompts)
-
-You can pass multiple prompts in a single `generate` call.
-
-```python
-from vllm_omni.entrypoints.omni import Omni
-
-if __name__ == "__main__":
- omni = Omni(model="Qwen/Qwen-Image")
- prompts = [
- "a cup of coffee on a table",
- "a toy dinosaur on a sandy beach",
- "a fox waking up in bed and yawning",
- ]
- outputs = omni.generate(prompts)
- for i, output in enumerate(outputs):
- output.request_output.images[0].save(f"{i}.jpg")
-```
-
-!!! info
-
- Not all models support batch inference, and batch requesting mostly does not provide significant
- performance improvement. This feature is primarily for interface compatibility with vLLM and to
- allow for future improvements.
-
-!!! info
-
- For diffusion pipelines, the stage config field `stage_args.[].runtime.max_batch_size` is 1 by
- default, and the input list is sliced into single-item requests before feeding into the diffusion
- pipeline. For models that do internally support batched inputs, you can
- [modify this configuration](../../../configuration/stage_configs.md) to let the model accept a
- longer batch of prompts.
-
-### Negative Prompts
-
-vLLM-Omni supports dictionary prompts for models that accept negative prompts:
-
-```python
-from vllm_omni.entrypoints.omni import Omni
-
-if __name__ == "__main__":
- omni = Omni(model="Qwen/Qwen-Image")
- outputs = omni.generate([
- {
- "prompt": "a cup of coffee on a table",
- "negative_prompt": "low resolution"
- },
- {
- "prompt": "a toy dinosaur on a sandy beach",
- "negative_prompt": "cinematic, realistic"
- }
- ])
- for i, output in enumerate(outputs):
- output.request_output.images[0].save(f"{i}.jpg")
-```
-
-You can also pass a negative prompt via the CLI argument `--negative-prompt`:
-
-```bash
-python examples/offline_inference/text_to_image/text_to_image.py \
- --model Qwen/Qwen-Image \
- --prompt "a cup of coffee on a table" \
- --negative-prompt "low resolution, blurry" \
- --output coffee.png
-```
-
-### Advanced Features
-
-#### CFG Parallel
-
-Set `--cfg-parallel-size 2` to enable CFG Parallel for faster inference on multi-GPU setups.
-See more examples in the [cfg_parallel user guide](../../../docs/user_guide/parallelism/cfg_parallel.md#using-cfg-parallel).
-
-#### LoRA
-
-This example supports PEFT-compatible LoRA (Low-Rank Adaptation) adapters for diffusion models. Pass `--lora-path` to use a LoRA adapter and optionally `--lora-scale` (default `1.0`); omit it to use the base model only.
-
-```bash
-python text_to_image.py \
- --model Tongyi-MAI/Z-Image-Turbo \
- --prompt "A piece of cheesecake" \
- --lora-path /path/to/lora/ \
- --lora-scale 1.0 \
- --output output.png
-```
-
-LoRA adapters must be in PEFT format. A typical adapter directory structure:
-
-```
-lora_adapter/
-├── adapter_config.json
-└── adapter_model.safetensors
-```
-
-## Web UI Demo
-
-Launch the Gradio demo:
-
-```bash
-python gradio_demo.py --port 7862
-```
-
-Then open `http://localhost:7862/` in your local browser to interact with the web UI.
diff --git a/examples/offline_inference/text_to_image/gradio_demo.py b/examples/offline_inference/text_to_image/gradio_demo.py
deleted file mode 100644
index 09e0112409a..00000000000
--- a/examples/offline_inference/text_to_image/gradio_demo.py
+++ /dev/null
@@ -1,240 +0,0 @@
-import argparse
-from functools import lru_cache
-
-try:
- import gradio as gr
-except ImportError:
- raise ImportError("gradio is required to run this demo. Install it with: pip install 'vllm-omni[demo]'") from None
-import torch
-
-from vllm_omni.entrypoints.omni import Omni
-from vllm_omni.inputs.data import OmniDiffusionSamplingParams
-from vllm_omni.outputs import OmniRequestOutput
-from vllm_omni.platforms import current_omni_platform
-
-ASPECT_RATIOS: dict[str, tuple[int, int]] = {
- "1:1": (1328, 1328),
- "16:9": (1664, 928),
- "9:16": (928, 1664),
- "4:3": (1472, 1140),
- "3:4": (1140, 1472),
- "3:2": (1584, 1056),
- "2:3": (1056, 1584),
-}
-ASPECT_RATIO_CHOICES = [f"{ratio} ({w}x{h})" for ratio, (w, h) in ASPECT_RATIOS.items()]
-
-
-def parse_args() -> argparse.Namespace:
- parser = argparse.ArgumentParser(description="Gradio demo for Qwen-Image offline inference.")
- parser.add_argument("--model", default="Qwen/Qwen-Image", help="Diffusion model name or local path.")
- parser.add_argument(
- "--height",
- type=int,
- default=1328,
- help="Default image height (must match one of the supported presets).",
- )
- parser.add_argument(
- "--width",
- type=int,
- default=1328,
- help="Default image width (must match one of the supported presets).",
- )
- parser.add_argument("--default-prompt", default="a cup of coffee on the table", help="Initial prompt shown in UI.")
- parser.add_argument("--default-seed", type=int, default=42, help="Initial seed shown in UI.")
- parser.add_argument("--default-cfg-scale", type=float, default=4.0, help="Initial CFG scale shown in UI.")
- parser.add_argument(
- "--num-inference-steps",
- type=int,
- default=50,
- help="Default number of denoising steps shown in the UI.",
- )
- parser.add_argument("--ip", default="127.0.0.1", help="Host/IP for Gradio `launch`.")
- parser.add_argument("--port", type=int, default=7862, help="Port for Gradio `launch`.")
- parser.add_argument("--share", action="store_true", help="Share the Gradio demo publicly.")
- args = parser.parse_args()
- args.aspect_ratio_label = next(
- (ratio for ratio, dims in ASPECT_RATIOS.items() if dims == (args.width, args.height)),
- None,
- )
- if args.aspect_ratio_label is None:
- supported = ", ".join(f"{ratio} ({w}x{h})" for ratio, (w, h) in ASPECT_RATIOS.items())
- parser.error(f"Unsupported resolution {args.width}x{args.height}. Please pick one of: {supported}.")
- return args
-
-
-@lru_cache(maxsize=1)
-def get_omni(model_name: str) -> Omni:
- # Enable VAE memory optimizations on NPU
- vae_use_slicing = current_omni_platform.is_npu()
- vae_use_tiling = current_omni_platform.is_npu()
- return Omni(
- model=model_name,
- vae_use_slicing=vae_use_slicing,
- vae_use_tiling=vae_use_tiling,
- )
-
-
-def build_demo(args: argparse.Namespace) -> gr.Blocks:
- omni = get_omni(args.model)
-
- def run_inference(
- prompt: str,
- seed_value: float,
- cfg_scale_value: float,
- resolution_choice: str,
- num_steps_value: float,
- num_images_choice: float,
- ):
- if not prompt or not prompt.strip():
- raise gr.Error("Please enter a non-empty prompt.")
- ratio_label = resolution_choice.split(" ", 1)[0]
- if ratio_label not in ASPECT_RATIOS:
- raise gr.Error(f"Unsupported aspect ratio: {ratio_label}")
- width, height = ASPECT_RATIOS[ratio_label]
- try:
- seed = int(seed_value)
- num_steps = int(num_steps_value)
- num_images = int(num_images_choice)
- except (TypeError, ValueError) as exc:
- raise gr.Error("Seed, inference steps, and number of images must be valid integers.") from exc
- if num_steps <= 0:
- raise gr.Error("Inference steps must be a positive integer.")
- if num_images not in {1, 2, 3, 4}:
- raise gr.Error("Number of images must be 1, 2, 3, or 4.")
- generator = torch.Generator(device=current_omni_platform.device_type).manual_seed(seed)
- outputs = omni.generate(
- prompt.strip(),
- OmniDiffusionSamplingParams(
- height=height,
- width=width,
- generator=generator,
- true_cfg_scale=float(cfg_scale_value),
- num_inference_steps=num_steps,
- num_outputs_per_prompt=num_images,
- ),
- )
- images_outputs = []
- for output in outputs:
- req_out = output.request_output
- if not isinstance(req_out, OmniRequestOutput) or not hasattr(req_out, "images"):
- raise ValueError("Invalid request_output structure or missing 'images' key")
- images = req_out.images
- if not images:
- raise ValueError("No images found in request_output")
- # Extend the list with individual images (not append the entire list)
- images_outputs.extend(images)
- if len(images_outputs) >= num_images:
- break
- # Return only the requested number of images
- return images_outputs[:num_images]
-
- with gr.Blocks(
- title="vLLM-Omni Web Serving Demo",
- css="""
- /* Left column button width */
- .left-column button {
- width: 100%;
- }
- /* Right preview area: fixed height, hide unnecessary buttons */
- .fixed-image {
- height: 660px;
- display: flex;
- flex-direction: column;
- justify-content: center;
- align-items: center;
- }
- .fixed-image .duplicate-button,
- .fixed-image .svelte-drgfj2 {
- display: none !important;
- }
- /* Gallery container: fill available space and center content */
- #image-gallery {
- width: 100%;
- height: 100%;
- display: flex;
- align-items: center;
- justify-content: center;
- }
- /* Gallery grid: center horizontally and vertically, set gap */
- #image-gallery .grid {
- display: flex;
- flex-wrap: wrap;
- justify-content: center;
- align-items: center;
- align-content: center;
- gap: 16px;
- width: 100%;
- height: 100%;
- }
- /* Gallery grid items: center content */
- #image-gallery .grid > div {
- display: flex;
- align-items: center;
- justify-content: center;
- }
- /* Gallery images: limit max height, maintain aspect ratio */
- .fixed-image img {
- max-height: 660px !important;
- width: auto !important;
- object-fit: contain;
- }
- """,
- ) as demo:
- gr.Markdown("# vLLM-Omni Web Serving Demo")
- gr.Markdown(f"**Model:** {args.model}")
-
- with gr.Row():
- with gr.Column(scale=1, elem_classes="left-column"):
- prompt_input = gr.Textbox(
- label="Prompt",
- value=args.default_prompt,
- placeholder="Describe the image you want to generate...",
- lines=5,
- )
- seed_input = gr.Number(label="Seed", value=args.default_seed, precision=0)
- cfg_input = gr.Number(label="CFG Scale", value=args.default_cfg_scale)
- steps_input = gr.Number(
- label="Inference Steps",
- value=args.num_inference_steps,
- precision=0,
- minimum=1,
- )
- aspect_dropdown = gr.Dropdown(
- label="Aspect Ratio (W:H)",
- choices=ASPECT_RATIO_CHOICES,
- value=f"{args.aspect_ratio_label} ({ASPECT_RATIOS[args.aspect_ratio_label][0]}x{ASPECT_RATIOS[args.aspect_ratio_label][1]})",
- )
- num_images = gr.Dropdown(
- label="Number of images",
- choices=["1", "2", "3", "4"],
- value="1",
- )
- generate_btn = gr.Button("Generate", variant="primary")
- with gr.Column(scale=2, elem_classes="fixed-image"):
- gallery = gr.Gallery(
- label="Preview",
- columns=2,
- rows=2,
- height=660,
- allow_preview=True,
- show_label=True,
- elem_id="image-gallery",
- )
-
- generate_btn.click(
- fn=run_inference,
- inputs=[prompt_input, seed_input, cfg_input, aspect_dropdown, steps_input, num_images],
- outputs=gallery,
- )
-
- return demo
-
-
-def main():
- args = parse_args()
- demo = build_demo(args)
- demo.launch(server_name=args.ip, server_port=args.port, share=args.share)
-
-
-if __name__ == "__main__":
- main()
diff --git a/examples/offline_inference/text_to_image/text_to_image.py b/examples/offline_inference/text_to_image/text_to_image.py
deleted file mode 100644
index c0fd337bd93..00000000000
--- a/examples/offline_inference/text_to_image/text_to_image.py
+++ /dev/null
@@ -1,528 +0,0 @@
-# SPDX-License-Identifier: Apache-2.0
-# SPDX-FileCopyrightText: Copyright contributors to the vLLM project
-
-import argparse
-import json
-import time
-from pathlib import Path
-from typing import Any
-
-import torch
-
-from vllm_omni.diffusion.data import logger
-from vllm_omni.entrypoints.omni import Omni
-from vllm_omni.inputs.data import OmniDiffusionSamplingParams
-from vllm_omni.lora.request import LoRARequest
-from vllm_omni.lora.utils import stable_lora_int_id
-from vllm_omni.platforms import current_omni_platform
-
-
-def is_nextstep_model(model_name: str) -> bool:
- """Check if the model is a NextStep model by reading its config."""
- from vllm.transformers_utils.config import get_hf_file_to_dict
-
- try:
- cfg = get_hf_file_to_dict("config.json", model_name)
- if cfg and cfg.get("model_type") == "nextstep":
- return True
- except Exception:
- pass
- return False
-
-
-def parse_profiler_config(value: str) -> dict[str, Any]:
- try:
- config = json.loads(value)
- except json.JSONDecodeError as e:
- raise argparse.ArgumentTypeError(f"--profiler-config must be valid JSON: {e}") from e
- if not isinstance(config, dict):
- raise argparse.ArgumentTypeError("--profiler-config must be a JSON object")
- return config
-
-
-def parse_args() -> argparse.Namespace:
- parser = argparse.ArgumentParser(description="Generate an image with supported diffusion models.")
- parser.add_argument(
- "--model",
- default="Qwen/Qwen-Image",
- help="Diffusion model name or local path. Supported models: "
- "Qwen/Qwen-Image, Tongyi-MAI/Z-Image-Turbo, Qwen/Qwen-Image-2512, stepfun-ai/NextStep-1.1, "
- "black-forest-labs/FLUX.1-dev, black-forest-labs/FLUX.2-klein-9B, "
- "black-forest-labs/FLUX.2-dev, tencent/HunyuanImage-3.0-Instruct, "
- "meituan-longcat/LongCat-Image, OvisAI/Ovis-Image, "
- "stabilityai/stable-diffusion-3.5-medium, Tongyi-MAI/Z-Image-Turbo and etc.",
- )
- parser.add_argument(
- "--stage-configs-path",
- type=str,
- default=None,
- help="Path to a YAML file containing stage configurations for Omni.",
- )
- parser.add_argument("--prompt", default="a cup of coffee on the table", help="Text prompt for image generation.")
- parser.add_argument(
- "--negative-prompt",
- default=None,
- help="negative prompt for classifier-free conditional guidance.",
- )
- parser.add_argument("--seed", type=int, default=142, help="Random seed for deterministic results.")
- parser.add_argument(
- "--cfg-scale",
- type=float,
- default=4.0,
- help="True classifier-free guidance scale specific to Qwen-Image.",
- )
- parser.add_argument(
- "--guidance-scale",
- type=float,
- default=4.0,
- help="Classifier-free guidance scale. HunyuanImage3 recommends 4.0-5.0.",
- )
- parser.add_argument("--height", type=int, default=1024, help="Height of generated image.")
- parser.add_argument("--width", type=int, default=1024, help="Width of generated image.")
- parser.add_argument(
- "--output",
- type=str,
- default="qwen_image_output.png",
- help="Path to save the generated image (PNG).",
- )
- parser.add_argument(
- "--num-images-per-prompt",
- type=int,
- default=1,
- help="Number of images to generate for the given prompt.",
- )
- parser.add_argument(
- "--num-inference-steps",
- type=int,
- default=50,
- help="Number of denoising steps for the diffusion sampler.",
- )
- parser.add_argument(
- "--cache-backend",
- type=str,
- default=None,
- choices=["cache_dit", "tea_cache"],
- help=(
- "Cache backend to use for acceleration. "
- "Options: 'cache_dit' (DBCache + SCM + TaylorSeer), 'tea_cache' (Timestep Embedding Aware Cache). "
- "Default: None (no cache acceleration)."
- ),
- )
- parser.add_argument(
- "--enable-cache-dit-summary",
- action="store_true",
- help="Enable cache-dit summary logging after diffusion forward passes.",
- )
- parser.add_argument(
- "--ulysses-degree",
- type=int,
- default=1,
- help="Number of GPUs used for ulysses sequence parallelism.",
- )
- parser.add_argument(
- "--ulysses-mode",
- type=str,
- default="strict",
- choices=["strict", "advanced_uaa"],
- help="Ulysses sequence-parallel mode: 'strict' (divisibility required) or 'advanced_uaa' (UAA).",
- )
- parser.add_argument(
- "--ring-degree",
- type=int,
- default=1,
- help="Number of GPUs used for ring sequence parallelism.",
- )
- parser.add_argument(
- "--cfg-parallel-size",
- type=int,
- default=1,
- choices=[1, 2],
- help="Number of GPUs used for classifier free guidance parallel size.",
- )
- parser.add_argument(
- "--enforce-eager",
- action="store_true",
- help="Disable torch.compile and force eager execution.",
- )
- parser.add_argument(
- "--enable-cpu-offload",
- action="store_true",
- help="Enable CPU offloading for diffusion models.",
- )
- parser.add_argument(
- "--enable-layerwise-offload",
- action="store_true",
- help="Enable layerwise (blockwise) offloading on DiT modules.",
- )
- parser.add_argument(
- "--use-hsdp",
- action="store_true",
- help="Enable HSDP (Hybrid Sharded Data Parallel) for diffusion models.",
- )
- parser.add_argument(
- "--hsdp-shard-size",
- type=int,
- default=1,
- help="Number of GPUs to shard weights across for HSDP.",
- )
- parser.add_argument(
- "--hsdp-replicate-size",
- type=int,
- default=1,
- help="Number of HSDP replica groups.",
- )
- parser.add_argument(
- "--quantization",
- type=str,
- default=None,
- choices=["fp8", "int8", "gguf"],
- help="Quantization method for the transformer. "
- "Options: 'fp8' (FP8 W8A8 on Ada/Hopper, weight-only on older GPUs), 'int8' (Int8 W8A8), 'gguf' (GGUF quantized weights). "
- "Default: None (no quantization, uses BF16).",
- )
- parser.add_argument(
- "--gguf-model",
- type=str,
- default=None,
- help=("GGUF file path or HF reference for transformer weights. Required when --quantization gguf is set."),
- )
- parser.add_argument(
- "--ignored-layers",
- type=str,
- default=None,
- help="Comma-separated list of layer name patterns to skip quantization. "
- "Only used when --quantization is set. "
- "Available layers: to_qkv, to_out, add_kv_proj, to_add_out, img_mlp, txt_mlp, proj_out. "
- "Example: --ignored-layers 'add_kv_proj,to_add_out'",
- )
- parser.add_argument(
- "--vae-use-slicing",
- action="store_true",
- help="Enable VAE slicing for memory optimization.",
- )
- parser.add_argument(
- "--vae-use-tiling",
- action="store_true",
- help="Enable VAE tiling for memory optimization.",
- )
- parser.add_argument(
- "--tensor-parallel-size",
- type=int,
- default=1,
- help="Number of GPUs used for tensor parallelism (TP) inside the DiT.",
- )
- parser.add_argument(
- "--enable-expert-parallel",
- action="store_true",
- help="Enable expert parallelism for MoE layers.",
- )
- parser.add_argument(
- "--lora-path",
- type=str,
- default=None,
- help="Path to LoRA adapter folder (PEFT format). Loaded at initialization and used for generation.",
- )
- parser.add_argument(
- "--lora-scale",
- type=float,
- default=1.0,
- help="Scale factor for LoRA weights (default: 1.0).",
- )
- parser.add_argument(
- "--vae-patch-parallel-size",
- type=int,
- default=1,
- help="Number of ranks used for VAE patch/tile parallelism (decode/encode).",
- )
- # NextStep-1.1 specific arguments
- parser.add_argument(
- "--guidance-scale-2",
- type=float,
- default=1.0,
- help="Secondary guidance scale (e.g. image-level CFG for NextStep-1.1).",
- )
- parser.add_argument(
- "--timesteps-shift",
- type=float,
- default=1.0,
- help="[NextStep-1.1 only] Timesteps shift parameter for sampling.",
- )
- parser.add_argument(
- "--cfg-schedule",
- type=str,
- default="constant",
- choices=["constant", "linear"],
- help="[NextStep-1.1 only] CFG schedule type.",
- )
- parser.add_argument(
- "--use-norm",
- action="store_true",
- help="[NextStep-1.1 only] Apply layer normalization to sampled tokens.",
- )
- parser.add_argument(
- "--enable-diffusion-pipeline-profiler",
- action="store_true",
- help="Enable diffusion pipeline profiler to display stage durations.",
- )
- parser.add_argument(
- "--profiler-config",
- type=parse_profiler_config,
- default=None,
- help='JSON profiler config for torch/cuda profiling, e.g. \'{"profiler":"torch","torch_profiler_dir":"./perf"}\'.',
- )
- parser.add_argument(
- "--log-stats",
- action="store_true",
- help="Enable logging of diffusion pipeline stats.",
- )
- parser.add_argument(
- "--init-timeout",
- type=int,
- default=600,
- help="Timeout for initializing a single stage in seconds (default: 600s)",
- )
- parser.add_argument(
- "--stage-init-timeout",
- type=int,
- default=600,
- help="Timeout for initializing a single stage in seconds (default: 600s)",
- )
- parser.add_argument(
- "--use-system-prompt",
- type=str,
- default=None,
- choices=["None", "dynamic", "en_vanilla", "en_recaption", "en_think_recaption", "en_unified", "custom"],
- help="System prompt preset for generation. Recommended: en_unified.",
- )
- parser.add_argument(
- "--system-prompt",
- type=str,
- default=None,
- help=("Custom system prompt. Used when --use-system-prompt is custom. "),
- )
- current_omni_platform.pre_register_and_update(parser)
- from vllm_omni.engine.arg_utils import nullify_stage_engine_defaults
-
- nullify_stage_engine_defaults(parser)
- return parser.parse_args()
-
-
-def main():
- args = parse_args()
- generator = torch.Generator(device=current_omni_platform.device_type).manual_seed(args.seed)
- use_nextstep = is_nextstep_model(args.model)
-
- cache_config = None
- cache_backend = args.cache_backend
-
- if cache_backend == "cache_dit":
- # cache-dit configuration: Hybrid DBCache + SCM + TaylorSeer
- # All parameters marked with [cache-dit only] in DiffusionCacheConfig
- cache_config = {
- # DBCache parameters [cache-dit only]
- "Fn_compute_blocks": 1, # Optimized for single-transformer models
- "Bn_compute_blocks": 0, # Number of backward compute blocks
- "max_warmup_steps": 4, # Maximum warmup steps (works for few-step models)
- "residual_diff_threshold": 0.24, # Higher threshold for more aggressive caching
- "max_continuous_cached_steps": 3, # Limit to prevent precision degradation
- # TaylorSeer parameters [cache-dit only]
- "enable_taylorseer": False, # Disabled by default (not suitable for few-step models)
- "taylorseer_order": 1, # TaylorSeer polynomial order
- # SCM (Step Computation Masking) parameters [cache-dit only]
- "scm_steps_mask_policy": None, # SCM mask policy: None (disabled), "slow", "medium", "fast", "ultra"
- "scm_steps_policy": "dynamic", # SCM steps policy: "dynamic" or "static"
- }
- elif cache_backend == "tea_cache":
- # TeaCache configuration
- # All parameters marked with [tea_cache only] in DiffusionCacheConfig
- cache_config = {
- # TeaCache parameters [tea_cache only]
- "rel_l1_thresh": 0.2, # Threshold for accumulated relative L1 distance
- # Note: coefficients will use model-specific defaults based on model_type
- # (e.g., QwenImagePipeline or FluxPipeline)
- }
-
- profiler_enabled = args.profiler_config is not None
-
- # Prepare LoRA kwargs for Omni initialization
- lora_args: dict[str, Any] = {}
- if args.lora_path:
- lora_args["lora_path"] = args.lora_path
- print(f"Using LoRA from: {args.lora_path}")
-
- # Build quantization kwargs: use quantization_config dict when
- # ignored_layers is specified so the list flows through OmniDiffusionConfig
- quant_kwargs: dict[str, Any] = {}
- ignored_layers = [s.strip() for s in args.ignored_layers.split(",") if s.strip()] if args.ignored_layers else None
- if args.quantization == "gguf":
- if not args.gguf_model:
- raise ValueError("--gguf-model is required when --quantization gguf is set.")
- quant_kwargs["quantization_config"] = {
- "method": "gguf",
- "gguf_model": args.gguf_model,
- }
- elif args.quantization and ignored_layers:
- quant_kwargs["quantization_config"] = {
- "method": args.quantization,
- "ignored_layers": ignored_layers,
- }
- elif args.quantization:
- quant_kwargs["quantization"] = args.quantization
-
- omni_kwargs = {
- "model": args.model,
- "enable_layerwise_offload": args.enable_layerwise_offload,
- "vae_use_slicing": args.vae_use_slicing,
- "vae_use_tiling": args.vae_use_tiling,
- "cache_backend": args.cache_backend,
- "cache_config": cache_config,
- "enable_cache_dit_summary": args.enable_cache_dit_summary,
- "ulysses_degree": args.ulysses_degree,
- "ring_degree": args.ring_degree,
- "ulysses_mode": args.ulysses_mode,
- "cfg_parallel_size": args.cfg_parallel_size,
- "tensor_parallel_size": args.tensor_parallel_size,
- "vae_patch_parallel_size": args.vae_patch_parallel_size,
- "enable_expert_parallel": args.enable_expert_parallel,
- "enforce_eager": args.enforce_eager,
- "enable_cpu_offload": args.enable_cpu_offload,
- "mode": "text-to-image",
- "log_stats": args.log_stats,
- "enable_diffusion_pipeline_profiler": args.enable_diffusion_pipeline_profiler,
- "profiler_config": args.profiler_config,
- "init_timeout": args.init_timeout,
- "stage_init_timeout": args.stage_init_timeout,
- **lora_args,
- **quant_kwargs,
- }
- if args.stage_configs_path:
- omni_kwargs["stage_configs_path"] = args.stage_configs_path
- if use_nextstep:
- # NextStep-1.1 requires explicit pipeline class
- omni_kwargs["model_class_name"] = "NextStep11Pipeline"
- omni = Omni(**omni_kwargs)
-
- if profiler_enabled:
- print("[Profiler] Starting profiling...")
- omni.start_profile()
-
- # Time profiling for generation
- print(f"\n{'=' * 60}")
- print("Generation Configuration:")
- print(f" Model: {args.model}")
- print(f" Inference steps: {args.num_inference_steps}")
- print(f" Cache backend: {cache_backend if cache_backend else 'None (no acceleration)'}")
- print(f" Quantization: {args.quantization if args.quantization else 'None (BF16)'}")
- if ignored_layers:
- print(f" Ignored layers: {ignored_layers}")
- print(
- f" Parallel configuration: tensor_parallel_size={args.tensor_parallel_size}, "
- f"ulysses_degree={args.ulysses_degree}, ulysses_mode={args.ulysses_mode}, "
- f"ring_degree={args.ring_degree}, cfg_parallel_size={args.cfg_parallel_size}, "
- f"vae_patch_parallel_size={args.vae_patch_parallel_size}, "
- f"enable_expert_parallel={args.enable_expert_parallel}."
- )
- print(f" CPU offload: {args.enable_cpu_offload}; CPU Layerwise Offload: {args.enable_layerwise_offload}")
- print(f" Image size: {args.width}x{args.height}")
- if args.lora_path:
- print(f" LoRA: scale={args.lora_scale}")
- if args.stage_configs_path:
- print(f" stage-configs-path: {args.stage_configs_path}")
- print(f"{'=' * 60}\n")
-
- # Build LoRA request when --lora-path is set
- lora_request = None
- if args.lora_path:
- lora_request_id = stable_lora_int_id(args.lora_path)
- lora_request = LoRARequest(
- lora_name=Path(args.lora_path).stem,
- lora_int_id=lora_request_id,
- lora_path=args.lora_path,
- )
-
- generation_start = time.perf_counter()
- extra_args = {
- "timesteps_shift": args.timesteps_shift,
- "cfg_schedule": args.cfg_schedule,
- "use_norm": args.use_norm,
- "use_system_prompt": args.use_system_prompt,
- "system_prompt": args.system_prompt,
- }
- if lora_request:
- extra_args["lora_request"] = lora_request
- extra_args["lora_scale"] = args.lora_scale
-
- outputs = omni.generate(
- {
- "prompt": args.prompt,
- "negative_prompt": args.negative_prompt,
- },
- OmniDiffusionSamplingParams(
- height=args.height,
- width=args.width,
- generator=generator,
- true_cfg_scale=args.cfg_scale,
- guidance_scale=args.guidance_scale,
- guidance_scale_2=args.guidance_scale_2,
- num_inference_steps=args.num_inference_steps,
- num_outputs_per_prompt=args.num_images_per_prompt,
- extra_args=extra_args,
- ),
- )
-
- generation_end = time.perf_counter()
- generation_time = generation_end - generation_start
-
- # Print profiling results
- print(f"Total generation time: {generation_time:.4f} seconds ({generation_time * 1000:.2f} ms)")
-
- if profiler_enabled:
- print("\n[Profiler] Stopping profiler and collecting results...")
- profile_results = omni.stop_profile()
- if profile_results and isinstance(profile_results, dict):
- traces = profile_results.get("traces", [])
- print("\n" + "=" * 60)
- print("PROFILING RESULTS:")
- for rank, trace in enumerate(traces):
- print(f"\nRank {rank}:")
- if trace:
- print(f" • Trace: {trace}")
- if not traces:
- print(" No traces collected.")
- print("=" * 60)
- else:
- print("[Profiler] No valid profiling data returned.")
-
- # omni.generate() returns list[OmniRequestOutput]
- if not outputs or len(outputs) == 0:
- raise ValueError("No output generated from omni.generate()")
- logger.info(f"Outputs: {outputs}")
-
- first_output = outputs[0]
- if not hasattr(first_output, "request_output") or not first_output.request_output:
- raise ValueError("No request_output found in OmniRequestOutput")
-
- req_out = first_output.request_output
- if not hasattr(req_out, "images"):
- raise ValueError("Invalid request_output structure or missing 'images'.")
-
- images = req_out.images
- if not images:
- raise ValueError("No images found in request_output")
-
- output_path = Path(args.output)
- output_path.parent.mkdir(parents=True, exist_ok=True)
- suffix = output_path.suffix or ".png"
- stem = output_path.stem or "qwen_image_output"
- if len(images) <= 1:
- images[0].save(output_path)
- print(f"Saved generated image to {output_path}")
- else:
- for idx, img in enumerate(images):
- save_path = output_path.parent / f"{stem}_{idx}{suffix}"
- img.save(save_path)
- print(f"Saved generated image to {save_path}")
-
-
-if __name__ == "__main__":
- main()
diff --git a/examples/offline_inference/text_to_video/text_to_video.md b/examples/offline_inference/text_to_video/text_to_video.md
deleted file mode 100644
index f852e980a78..00000000000
--- a/examples/offline_inference/text_to_video/text_to_video.md
+++ /dev/null
@@ -1,144 +0,0 @@
-# Text-To-Video
-
-A unified script for text-to-video generation. Supports multiple models with model-aware defaults.
-
-## Supported Models
-
-| Model | Default Resolution | Default Frames | Default Steps | Guidance | VRAM (BF16) |
-|---|---|---|---|---|---|
-| `Wan-AI/Wan2.2-T2V-A14B-Diffusers` | 720x1280 | 81 | 40 | 4.0 | ~60 GiB |
-| `hunyuanvideo-community/HunyuanVideo-1.5-Diffusers-480p_t2v` | 480x832 | 121 | 50 | 6.0 | 1×A100 80GB |
-| `hunyuanvideo-community/HunyuanVideo-1.5-Diffusers-720p_t2v` | 720x1280 | 121 | 50 | 6.0 | FP8 + VAE tiling required |
-
-## Local CLI Usage
-
-### Wan2.2 (default)
-
-```bash
-python text_to_video.py \
- --prompt "Two anthropomorphic cats in comfy boxing gear and bright gloves fight intensely on a spotlighted stage." \
- --negative-prompt "<optional quality filter>" \
- --height 480 \
- --width 832 \
- --num-frames 33 \
- --guidance-scale 4.0 \
- --guidance-scale-high 3.0 \
- --flow-shift 12.0 \
- --num-inference-steps 40 \
- --fps 16 \
- --output t2v_out.mp4
-```
-
-LTX2 example:
-
-```bash
-python text_to_video.py \
- --model "Lightricks/LTX-2" \
- --prompt "A cinematic close-up of ocean waves at golden hour." \
- --negative-prompt "worst quality, inconsistent motion, blurry, jittery, distorted" \
- --height 512 \
- --width 768 \
- --num-frames 121 \
- --num-inference-steps 40 \
- --guidance-scale 4.0 \
- --frame-rate 24 \
- --output ltx2_out.mp4
-```
-
-### HunyuanVideo-1.5 (480p)
-
-```bash
-python text_to_video.py \
- --model hunyuanvideo-community/HunyuanVideo-1.5-Diffusers-480p_t2v \
- --prompt "A cat walks through a sunlit garden, flowers swaying gently in the breeze." \
- --height 480 \
- --width 832 \
- --num-frames 121 \
- --guidance-scale 6.0 \
- --flow-shift 5.0 \
- --num-inference-steps 50 \
- --fps 24 \
- --output hunyuan_video_15_output.mp4
-```
-
-### HunyuanVideo-1.5 (720p)
-
-```bash
-python text_to_video.py \
- --model hunyuanvideo-community/HunyuanVideo-1.5-Diffusers-720p_t2v \
- --prompt "A serene lakeside sunrise with mist over the water." \
- --height 720 \
- --width 1280 \
- --num-frames 121 \
- --guidance-scale 6.0 \
- --flow-shift 9.0 \
- --num-inference-steps 50 \
- --fps 24 \
- --output hunyuan_720p.mp4
-```
-
-### HunyuanVideo-1.5 with FP8 Quantization
-
-```bash
-python text_to_video.py \
- --model hunyuanvideo-community/HunyuanVideo-1.5-Diffusers-480p_t2v \
- --prompt "A dog running across a field of golden wheat." \
- --quantization fp8 \
- --height 480 --width 832 --num-frames 121 \
- --guidance-scale 6.0 --flow-shift 5.0 \
- --output hunyuan_fp8.mp4
-```
-
-Quick test (smaller resolution, fewer frames):
-
-```bash
-python text_to_video.py \
- --model hunyuanvideo-community/HunyuanVideo-1.5-Diffusers-480p_t2v \
- --prompt "A serene lakeside sunrise with mist over the water." \
- --height 320 --width 576 --num-frames 17 --num-inference-steps 30 \
- --flow-shift 5.0 \
- --output quick_test.mp4
-```
-
-## Key Arguments
-
-### Common
-
-- `--model`: Diffusers model ID or local path.
-- `--prompt`: text description (string).
-- `--height/--width`: output resolution. Default depends on model.
-- `--num-frames`: number of frames. Default depends on model.
-- `--guidance-scale`: CFG scale. Default depends on model.
-- `--num-inference-steps`: sampling steps. Default depends on model.
-- `--fps`: frames per second for the saved MP4.
-- `--output`: path to save the generated video.
-- `--vae-use-slicing`: enable VAE slicing for memory optimization.
-- `--vae-use-tiling`: enable VAE tiling for memory optimization.
-- `--cfg-parallel-size`: set it to 2 to enable CFG Parallel. See more examples in [`user_guide`](../../../docs/user_guide/diffusion/parallelism_acceleration.md#cfg-parallel).
-- `--tensor-parallel-size`: tensor parallel size (effective for models that support TP, e.g. LTX2).
-- `--enable-cpu-offload`: enable CPU offloading for diffusion models.
-- `--enable-layerwise-offload`: enable layerwise offloading on DiT modules.
-- `--frame-rate`: generation FPS for pipelines that require it (e.g., LTX2).
-- `--audio-sample-rate`: audio sample rate for embedded audio (when the pipeline returns audio).
-- `--quantization`: quantization method (`fp8` for FP8, `gguf` for GGUF).
-- `--flow-shift`: scheduler flow_shift parameter.
-
-### Wan2.2-specific
-
-- `--negative-prompt`: artifacts to suppress.
-- `--guidance-scale-high`: separate CFG scale for high-noise stage.
-- `--boundary-ratio`: boundary split for low/high DiT (default 0.875).
-- `--flow-shift`: scheduler flow_shift (5.0 for 720p, 12.0 for 480p).
-- `--cache-backend`: `cache_dit` for acceleration.
-
-### HunyuanVideo-1.5 Optimal Configs
-
-| Variant | flow_shift | guidance_scale | steps |
-|---------|-----------|----------------|-------|
-| 480p T2V | 5.0 | 6.0 | 50 |
-| 720p T2V | 9.0 | 6.0 | 50 |
-| 480p I2V | 5.0 | 6.0 | 50 |
-| 720p I2V | 7.0 | 6.0 | 50 |
-| CFG-distilled | (same) | 1.0 | 50 |
-
-> If you encounter OOM errors, try `--vae-use-slicing`, `--vae-use-tiling`, `--enable-cpu-offload`, or `--quantization fp8`.
diff --git a/examples/offline_inference/text_to_video/text_to_video.py b/examples/offline_inference/text_to_video/text_to_video.py
deleted file mode 100644
index 1dba97c2095..00000000000
--- a/examples/offline_inference/text_to_video/text_to_video.py
+++ /dev/null
@@ -1,525 +0,0 @@
-# SPDX-License-Identifier: Apache-2.0
-# SPDX-FileCopyrightText: Copyright contributors to the vLLM project
-
-import argparse
-import json
-import time
-from pathlib import Path
-from typing import Any
-
-import numpy as np
-import torch
-
-from vllm_omni.diffusion.data import DiffusionParallelConfig
-from vllm_omni.entrypoints.omni import Omni
-from vllm_omni.inputs.data import OmniDiffusionSamplingParams
-from vllm_omni.outputs import OmniRequestOutput
-from vllm_omni.platforms import current_omni_platform
-
-_MODEL_PRESETS = {
- "wan": {
- "height": 720,
- "width": 1280,
- "num_frames": 81,
- "num_inference_steps": 40,
- "guidance_scale": 4.0,
- "fps": 24,
- "output": "wan22_output.mp4",
- },
- "hunyuan": {
- "height": 480,
- "width": 832,
- "num_frames": 121,
- "num_inference_steps": 50,
- "guidance_scale": 6.0,
- "fps": 24,
- "output": "hunyuan_video_15_output.mp4",
- },
-}
-
-
-def _detect_preset(model: str) -> dict:
- model_lower = model.lower()
- if "hunyuan" in model_lower:
- return _MODEL_PRESETS["hunyuan"]
- return _MODEL_PRESETS["wan"]
-
-
-def parse_profiler_config(value: str) -> dict[str, Any]:
- try:
- config = json.loads(value)
- except json.JSONDecodeError as e:
- raise argparse.ArgumentTypeError(f"--profiler-config must be valid JSON: {e}") from e
- if not isinstance(config, dict):
- raise argparse.ArgumentTypeError("--profiler-config must be a JSON object")
- return config
-
-
-def parse_args() -> argparse.Namespace:
- parser = argparse.ArgumentParser(
- description="Generate a video from a text prompt. "
- "Supports Wan2.2, HunyuanVideo-1.5, and other text-to-video models."
- )
- parser.add_argument(
- "--model",
- default="Wan-AI/Wan2.2-T2V-A14B-Diffusers",
- help="Diffusers model ID or local path. "
- "Examples: Wan-AI/Wan2.2-T2V-A14B-Diffusers, "
- "hunyuanvideo-community/HunyuanVideo-1.5-480p_t2v",
- )
- parser.add_argument(
- "--model-class-name",
- default=None,
- help="Override model class name (e.g., LTX2TwoStagesVideoPipeline).",
- )
- parser.add_argument("--prompt", default="A serene lakeside sunrise with mist over the water.", help="Text prompt.")
- parser.add_argument("--negative-prompt", default="", help="Negative prompt.")
- parser.add_argument("--seed", type=int, default=42, help="Random seed.")
- parser.add_argument("--guidance-scale", type=float, default=None, help="CFG scale. Default: model-specific.")
- parser.add_argument(
- "--guidance-scale-high", type=float, default=None, help="Separate CFG for high-noise stage (Wan2.2 only)."
- )
- parser.add_argument("--height", type=int, default=None, help="Video height. Default: model-specific.")
- parser.add_argument("--width", type=int, default=None, help="Video width. Default: model-specific.")
- parser.add_argument("--num-frames", type=int, default=None, help="Number of frames. Default: model-specific.")
- parser.add_argument(
- "--frame-rate",
- type=float,
- default=None,
- help="Optional generation frame rate (used by models like LTX2). Defaults to --fps.",
- )
- parser.add_argument(
- "--num-inference-steps", type=int, default=None, help="Sampling steps. Default: model-specific."
- )
- parser.add_argument(
- "--boundary-ratio",
- type=float,
- default=None,
- help="(Wan2.2) Boundary split ratio for low/high DiT. Default 0.875.",
- )
- parser.add_argument(
- "--flow-shift",
- type=float,
- default=None,
- help="Scheduler flow_shift. Wan2.2: 5.0(720p)/12.0(480p). HunyuanVideo-1.5: 5.0(480p)/9.0(720p).",
- )
- parser.add_argument(
- "--cache-backend",
- type=str,
- default=None,
- choices=["cache_dit"],
- help="Cache backend for acceleration (Wan2.2). Default: None.",
- )
- parser.add_argument(
- "--enable-cache-dit-summary",
- action="store_true",
- help="Enable cache-dit summary logging after diffusion forward passes.",
- )
- parser.add_argument("--output", type=str, default=None, help="Output path (mp4). Default: model-specific.")
- parser.add_argument("--fps", type=int, default=None, help="Frames per second for the output video.")
- parser.add_argument(
- "--vae-use-slicing",
- action="store_true",
- help="Enable VAE slicing for memory optimization.",
- )
- parser.add_argument(
- "--vae-use-tiling",
- action="store_true",
- help="Enable VAE tiling for memory optimization.",
- )
- parser.add_argument(
- "--enforce-eager",
- action="store_true",
- help="Disable torch.compile and force eager execution.",
- )
- parser.add_argument(
- "--enable-cpu-offload",
- action="store_true",
- help="Enable CPU offloading for diffusion models.",
- )
- parser.add_argument(
- "--enable-layerwise-offload",
- action="store_true",
- help="Enable layerwise (blockwise) offloading on DiT modules.",
- )
- parser.add_argument(
- "--ulysses-mode",
- type=str,
- default="strict",
- choices=["strict", "advanced_uaa"],
- help="Ulysses sequence-parallel mode: 'strict' (divisibility required) or 'advanced_uaa' (UAA).",
- )
- parser.add_argument(
- "--ulysses-degree",
- type=int,
- default=1,
- help="Number of GPUs used for ulysses sequence parallelism.",
- )
- parser.add_argument(
- "--ring-degree",
- type=int,
- default=1,
- help="Number of GPUs used for ring sequence parallelism.",
- )
- parser.add_argument(
- "--cfg-parallel-size",
- type=int,
- default=1,
- choices=[1, 2],
- help="Number of GPUs used for classifier free guidance parallel size.",
- )
- parser.add_argument(
- "--tensor-parallel-size",
- type=int,
- default=1,
- help="Number of GPUs used for tensor parallelism (TP) inside the DiT.",
- )
- parser.add_argument(
- "--audio-sample-rate",
- type=int,
- default=24000,
- help="Sample rate for audio output when saved (default: 24000).",
- )
- parser.add_argument(
- "--vae-patch-parallel-size",
- type=int,
- default=1,
- help="Number of GPUs used for VAE patch/tile parallelism (decode).",
- )
- parser.add_argument(
- "--enable-expert-parallel",
- action="store_true",
- help="Enable expert parallelism for MoE layers.",
- )
- parser.add_argument(
- "--enable-diffusion-pipeline-profiler",
- action="store_true",
- help="Enable diffusion pipeline profiler to display stage durations.",
- )
- parser.add_argument(
- "--profiler-config",
- type=parse_profiler_config,
- default=None,
- help='JSON profiler config for torch/cuda profiling, e.g. \'{"profiler":"torch","torch_profiler_dir":"./perf"}\'.',
- )
- parser.add_argument(
- "--quantization",
- type=str,
- default=None,
- choices=["fp8", "gguf"],
- help="Quantization method for the transformer (fp8 for online FP8 quantization).",
- )
- parser.add_argument(
- "--use-hsdp",
- action="store_true",
- help="Enable HSDP (Hybrid Sharded Data Parallel) for diffusion models.",
- )
- parser.add_argument(
- "--hsdp-shard-size",
- type=int,
- default=1,
- help="Number of GPUs to shard weights across for HSDP.",
- )
- parser.add_argument(
- "--hsdp-replicate-size",
- type=int,
- default=1,
- help="Number of HSDP replica groups.",
- )
- return parser.parse_args()
-
-
-def main():
- args = parse_args()
- model_class_name = args.model_class_name
-
- preset = _detect_preset(args.model)
- for key, default_val in preset.items():
- if getattr(args, key.replace("-", "_"), None) is None:
- setattr(args, key.replace("-", "_"), default_val)
-
- generator = torch.Generator(device=current_omni_platform.device_type).manual_seed(args.seed)
- # Cache-dit config (Wan2.2 only)
- cache_config = None
- if args.cache_backend == "cache_dit":
- cache_config = {
- "Fn_compute_blocks": 1,
- "Bn_compute_blocks": 0,
- "max_warmup_steps": 4,
- "max_cached_steps": 20,
- "residual_diff_threshold": 0.24,
- "max_continuous_cached_steps": 3,
- "enable_taylorseer": False,
- "taylorseer_order": 1,
- "scm_steps_mask_policy": None,
- "scm_steps_policy": "dynamic",
- }
-
- # Configure parallel settings
- parallel_config = DiffusionParallelConfig(
- ulysses_degree=args.ulysses_degree,
- ring_degree=args.ring_degree,
- cfg_parallel_size=args.cfg_parallel_size,
- tensor_parallel_size=args.tensor_parallel_size,
- vae_patch_parallel_size=args.vae_patch_parallel_size,
- enable_expert_parallel=args.enable_expert_parallel,
- )
-
- profiler_enabled = args.profiler_config is not None
-
- omni_kwargs = dict(
- model=args.model,
- enable_layerwise_offload=args.enable_layerwise_offload,
- vae_use_slicing=args.vae_use_slicing,
- vae_use_tiling=args.vae_use_tiling,
- enable_cpu_offload=args.enable_cpu_offload,
- parallel_config=parallel_config,
- enforce_eager=args.enforce_eager,
- model_class_name=model_class_name,
- cache_backend=args.cache_backend,
- cache_config=cache_config,
- enable_diffusion_pipeline_profiler=args.enable_diffusion_pipeline_profiler,
- profiler_config=args.profiler_config,
- )
- if args.boundary_ratio is not None:
- omni_kwargs["boundary_ratio"] = args.boundary_ratio
- if args.flow_shift is not None:
- omni_kwargs["flow_shift"] = args.flow_shift
- if args.quantization is not None:
- omni_kwargs["quantization"] = args.quantization
- if args.cache_backend is not None:
- omni_kwargs["cache_backend"] = args.cache_backend
- omni_kwargs["cache_config"] = cache_config
- omni_kwargs["enable_cache_dit_summary"] = args.enable_cache_dit_summary
-
- omni = Omni(**omni_kwargs)
-
- if profiler_enabled:
- print("[Profiler] Starting profiling...")
- omni.start_profile()
-
- # Print generation configuration
- print(f"\n{'=' * 60}")
- print("Generation Configuration:")
- print(f" Model: {args.model}")
- print(f" Inference steps: {args.num_inference_steps}")
- print(f" Frames: {args.num_frames}")
- print(
- f" Parallel configuration: ulysses_degree={args.ulysses_degree}, ring_degree={args.ring_degree},"
- f" cfg_parallel_size={args.cfg_parallel_size}, tensor_parallel_size={args.tensor_parallel_size},"
- f" vae_patch_parallel_size={args.vae_patch_parallel_size}, enable_expert_parallel={args.enable_expert_parallel}"
- )
- print(f" Video size: {args.width}x{args.height}")
- print(f"{'=' * 60}\n")
-
- prompt_dict = {"prompt": args.prompt}
- if args.negative_prompt:
- prompt_dict["negative_prompt"] = args.negative_prompt
-
- sampling_kwargs = dict(
- height=args.height,
- width=args.width,
- generator=generator,
- guidance_scale=args.guidance_scale,
- num_inference_steps=args.num_inference_steps,
- num_frames=args.num_frames,
- )
- if args.guidance_scale_high is not None:
- sampling_kwargs["guidance_scale_2"] = args.guidance_scale_high
-
- generation_start = time.perf_counter()
- frames = omni.generate(
- prompt_dict,
- OmniDiffusionSamplingParams(**sampling_kwargs),
- )
- generation_end = time.perf_counter()
- generation_time = generation_end - generation_start
-
- # Print profiling results
- print(f"Total generation time: {generation_time:.4f} seconds ({generation_time * 1000:.2f} ms)")
-
- audio = None
- if isinstance(frames, list):
- frames = frames[0] if frames else None
-
- if isinstance(frames, OmniRequestOutput):
- if frames.final_output_type != "image":
- raise ValueError(
- f"Unexpected output type '{frames.final_output_type}', expected 'image' for video generation."
- )
- if frames.multimodal_output and "audio" in frames.multimodal_output:
- audio = frames.multimodal_output["audio"]
- if frames.is_pipeline_output and frames.request_output is not None:
- inner_output = frames.request_output
- if isinstance(inner_output, OmniRequestOutput):
- if inner_output.multimodal_output and "audio" in inner_output.multimodal_output:
- audio = inner_output.multimodal_output["audio"]
- frames = inner_output
- if isinstance(frames, OmniRequestOutput):
- if frames.images:
- if len(frames.images) == 1 and isinstance(frames.images[0], tuple) and len(frames.images[0]) == 2:
- frames, audio = frames.images[0]
- elif len(frames.images) == 1 and isinstance(frames.images[0], dict):
- audio = frames.images[0].get("audio")
- frames = frames.images[0].get("frames") or frames.images[0].get("video")
- else:
- frames = frames.images
- else:
- raise ValueError("No video frames found in OmniRequestOutput.")
-
- if isinstance(frames, list) and frames:
- first_item = frames[0]
- if isinstance(first_item, tuple) and len(first_item) == 2:
- frames, audio = first_item
- elif isinstance(first_item, dict):
- audio = first_item.get("audio")
- frames = first_item.get("frames") or first_item.get("video")
- elif isinstance(first_item, list):
- frames = first_item
-
- if isinstance(frames, tuple) and len(frames) == 2:
- frames, audio = frames
- elif isinstance(frames, dict):
- audio = frames.get("audio")
- frames = frames.get("frames") or frames.get("video")
-
- if frames is None:
- raise ValueError("No video frames found in output.")
-
- output_path = Path(args.output)
- output_path.parent.mkdir(parents=True, exist_ok=True)
- try:
- from diffusers.utils import export_to_video
- except ImportError:
- raise ImportError("diffusers is required for export_to_video.")
-
- def _normalize_frame(frame):
- if isinstance(frame, torch.Tensor):
- frame_tensor = frame.detach().cpu()
- if frame_tensor.dim() == 4 and frame_tensor.shape[0] == 1:
- frame_tensor = frame_tensor[0]
- if frame_tensor.dim() == 3 and frame_tensor.shape[0] in (3, 4):
- frame_tensor = frame_tensor.permute(1, 2, 0)
- if frame_tensor.is_floating_point():
- frame_tensor = frame_tensor.clamp(-1, 1) * 0.5 + 0.5
- return frame_tensor.float().numpy()
- if isinstance(frame, np.ndarray):
- frame_array = frame
- if frame_array.ndim == 4 and frame_array.shape[0] == 1:
- frame_array = frame_array[0]
- if np.issubdtype(frame_array.dtype, np.integer):
- frame_array = frame_array.astype(np.float32) / 255.0
- return frame_array
- try:
- from PIL import Image
- except ImportError:
- Image = None
- if Image is not None and isinstance(frame, Image.Image):
- return np.asarray(frame).astype(np.float32) / 255.0
- return frame
-
- def _ensure_frame_list(video_array):
- if isinstance(video_array, list):
- if len(video_array) == 0:
- return video_array
- first_item = video_array[0]
- if isinstance(first_item, np.ndarray):
- if first_item.ndim == 5:
- return list(first_item[0])
- if first_item.ndim == 4:
- if len(video_array) == 1:
- return list(first_item)
- return list(first_item)
- if first_item.ndim == 3:
- return video_array
- return video_array
- if isinstance(video_array, np.ndarray):
- if video_array.ndim == 5:
- return list(video_array[0])
- if video_array.ndim == 4:
- return list(video_array)
- if video_array.ndim == 3:
- return [video_array]
- return video_array
-
- # frames may be np.ndarray, torch.Tensor, or list of tensors/arrays/images
- # export_to_video expects a list of frames with values in [0, 1]
- if isinstance(frames, torch.Tensor):
- video_tensor = frames.detach().cpu()
- if video_tensor.dim() == 5:
- if video_tensor.shape[1] in (3, 4):
- video_tensor = video_tensor[0].permute(1, 2, 3, 0)
- else:
- video_tensor = video_tensor[0]
- elif video_tensor.dim() == 4 and video_tensor.shape[0] in (3, 4):
- video_tensor = video_tensor.permute(1, 2, 3, 0)
- if video_tensor.is_floating_point():
- video_tensor = video_tensor.clamp(-1, 1) * 0.5 + 0.5
- video_array = video_tensor.float().numpy()
- elif isinstance(frames, np.ndarray):
- video_array = frames
- if video_array.ndim == 5:
- video_array = video_array[0]
- if np.issubdtype(video_array.dtype, np.integer):
- video_array = video_array.astype(np.float32) / 255.0
- elif isinstance(frames, list):
- if len(frames) == 0:
- raise ValueError("No video frames found in output.")
- video_array = [_normalize_frame(frame) for frame in frames]
- else:
- video_array = frames
-
- video_array = _ensure_frame_list(video_array)
-
- if audio is not None:
- from vllm_omni.diffusion.utils.media_utils import mux_video_audio_bytes
-
- if isinstance(video_array, list):
- frames_np = np.stack(video_array, axis=0)
- elif isinstance(video_array, np.ndarray):
- frames_np = video_array
- else:
- frames_np = np.asarray(video_array)
-
- frames_u8 = (np.clip(frames_np, 0.0, 1.0) * 255).round().clip(0, 255).astype("uint8")
-
- audio_np = audio
- if isinstance(audio_np, list):
- audio_np = audio_np[0] if audio_np else None
- if isinstance(audio_np, torch.Tensor):
- audio_np = audio_np.detach().cpu().float().numpy()
- if isinstance(audio_np, np.ndarray):
- audio_np = np.squeeze(audio_np).astype(np.float32)
-
- video_bytes = mux_video_audio_bytes(
- frames_u8,
- audio_np,
- fps=float(args.fps),
- audio_sample_rate=args.audio_sample_rate,
- )
- with open(str(output_path), "wb") as f:
- f.write(video_bytes)
- else:
- export_to_video(video_array, str(output_path), fps=args.fps)
- print(f"Saved generated video to {output_path}")
-
- if profiler_enabled:
- print("\n[Profiler] Stopping profiler and collecting results...")
- profile_results = omni.stop_profile()
- if profile_results and isinstance(profile_results, dict):
- traces = profile_results.get("traces", [])
- print("\n" + "=" * 60)
- print("PROFILING RESULTS:")
- for rank, trace in enumerate(traces):
- print(f"\nRank {rank}:")
- if trace:
- print(f" • Trace: {trace}")
- if not traces:
- print(" No traces collected.")
- print("=" * 60)
- else:
- print("[Profiler] No valid profiling data returned.")
-
-
-if __name__ == "__main__":
- main()
diff --git a/examples/offline_inference/vace/vace_video_generation.md b/examples/offline_inference/vace/vace_video_generation.md
deleted file mode 100644
index bbaf9945283..00000000000
--- a/examples/offline_inference/vace/vace_video_generation.md
+++ /dev/null
@@ -1,88 +0,0 @@
-# VACE Video Generation
-
-[VACE](https://github.com/ali-vilab/VACE) (Video All-in-one Creation Engine) supports multiple video tasks through a single model.
-
-| Model | Architecture | Model Weights (bf16) | HuggingFace |
-|-------|-------------|----------------------|-------------|
-| Wan2.1-VACE (1.3B) | Wan2.1 | ~10 GB | [Wan-AI/Wan2.1-VACE-1.3B-diffusers](https://huggingface.co/Wan-AI/Wan2.1-VACE-1.3B-diffusers) |
-| Wan2.1-VACE (14B) | Wan2.1 | ~38 GB | [Wan-AI/Wan2.1-VACE-14B-diffusers](https://huggingface.co/Wan-AI/Wan2.1-VACE-14B-diffusers) |
-
-## Text-to-Video (T2V)
-
-```bash
-python vace_video_generation.py \
- --mode t2v \
- --prompt "A sleek robot stands in a vast warehouse filled with boxes" \
- --height 480 --width 832 --num-frames 81 \
- --num-inference-steps 30 --guidance-scale 5.0 --flow-shift 5.0 \
- --output t2v_output.mp4
-```
-
-## Image-to-Video (I2V)
-
-First frame is kept, remaining frames are generated:
-
-```bash
-python vace_video_generation.py \
- --mode i2v \
- --image astronaut.jpg \
- --prompt "An astronaut emerging from a cracked egg on the moon" \
- --height 480 --width 832 --num-frames 81 \
- --output i2v_output.mp4
-```
-
-## First-Last-Frame Interpolation (FLF2V)
-
-```bash
-python vace_video_generation.py \
- --mode flf2v \
- --image first_frame.jpg --last-image last_frame.jpg \
- --prompt "A bird takes off from a branch and lands on another" \
- --height 512 --width 512 --num-frames 81 \
- --output flf2v_output.mp4
-```
-
-## Inpainting
-
-Center vertical stripe is masked and regenerated:
-
-```bash
-python vace_video_generation.py \
- --mode inpaint \
- --image scene.jpg \
- --prompt "Shrek walks out of a building" \
- --height 480 --width 832 --num-frames 81 \
- --output inpaint_output.mp4
-```
-
-## Reference Image-guided (R2V)
-
-```bash
-python vace_video_generation.py \
- --mode r2v \
- --image reference.jpg \
- --prompt "Camera slowly zooms out from the character" \
- --height 480 --width 832 --num-frames 81 \
- --output r2v_output.mp4
-```
-
-## Key Arguments
-
-- `--mode`: VACE task mode (`t2v`, `i2v`, `flf2v`, `inpaint`, `r2v`).
-- `--model`: Model ID (default: `Wan-AI/Wan2.1-VACE-1.3B-diffusers`).
-- `--image`: Input image for I2V, inpainting, and R2V modes.
-- `--last-image`: Last frame image for FLF2V mode.
-- `--prompt`: Text description of desired video.
-- `--height/--width`: Output resolution (default 480x832). Dimensions should be multiples of 16.
-- `--num-frames`: Number of frames (default 81).
-- `--guidance-scale`: CFG scale (default 5.0).
-- `--flow-shift`: Scheduler flow shift (default 5.0).
-- `--num-inference-steps`: Number of denoising steps (default 30).
-- `--fps`: Frames per second for the saved MP4 (default 16).
-- `--output`: Path to save the generated video.
-- `--vae-use-tiling`: Enable VAE tiling for memory optimization.
-- `--ulysses-degree`: Ulysses sequence parallelism degree for multi-GPU.
-- `--cfg-parallel-size`: CFG parallel size for multi-GPU.
-- `--tensor-parallel-size`: Tensor parallel size.
-
-> If you encounter OOM errors, try `--vae-use-tiling` or multi-GPU parallelism options.
diff --git a/examples/offline_inference/vace/vace_video_generation.py b/examples/offline_inference/vace/vace_video_generation.py
deleted file mode 100644
index 6ca0d74c52e..00000000000
--- a/examples/offline_inference/vace/vace_video_generation.py
+++ /dev/null
@@ -1,209 +0,0 @@
-# SPDX-License-Identifier: Apache-2.0
-# SPDX-FileCopyrightText: Copyright contributors to the vLLM project
-
-"""VACE video generation example.
-
-VACE (Video All-in-one Creation Engine) supports multiple video tasks:
- - T2V: Text-to-Video
- - I2V: Image-to-Video (first frame conditioning)
- - V2LF: Video-to-Last-Frame
- - FLF2V: First-Last-Frame interpolation
- - Inpainting: Masked region generation
- - R2V: Reference image-guided generation
-
-Usage examples:
- # T2V (text-to-video)
- python vace_video_generation.py --mode t2v --prompt "A robot in a warehouse"
-
- # I2V (image-to-video, first frame kept)
- python vace_video_generation.py --mode i2v --image input.jpg --prompt "..."
-
- # FLF2V (first-last frame interpolation)
- python vace_video_generation.py --mode flf2v --image first.jpg --last-image last.jpg
-
- # R2V (reference image guided)
- python vace_video_generation.py --mode r2v --image ref.jpg --prompt "..."
-"""
-
-import argparse
-import time
-from pathlib import Path
-
-import numpy as np
-import PIL.Image
-import torch
-
-from vllm_omni.diffusion.data import DiffusionParallelConfig
-from vllm_omni.entrypoints.omni import Omni
-from vllm_omni.inputs.data import OmniDiffusionSamplingParams
-from vllm_omni.platforms import current_omni_platform
-
-
-def parse_args() -> argparse.Namespace:
- parser = argparse.ArgumentParser(description="VACE video generation.")
- parser.add_argument(
- "--model",
- default="Wan-AI/Wan2.1-VACE-14B-diffusers",
- help="VACE model ID or local path.",
- )
- parser.add_argument(
- "--mode",
- default="t2v",
- choices=["t2v", "i2v", "v2lf", "flf2v", "inpaint", "r2v"],
- help="Generation mode.",
- )
- parser.add_argument("--prompt", default="A cat walking in a garden", help="Text prompt.")
- parser.add_argument("--negative-prompt", default="", help="Negative prompt.")
- parser.add_argument("--image", type=str, default=None, help="Input image path (for I2V, R2V, FLF2V, inpaint).")
- parser.add_argument("--last-image", type=str, default=None, help="Last frame image path (for FLF2V).")
- parser.add_argument("--video-dir", type=str, default=None, help="Directory of video frames (for inpaint).")
- parser.add_argument("--seed", type=int, default=42, help="Random seed.")
- parser.add_argument("--guidance-scale", type=float, default=5.0, help="CFG guidance scale.")
- parser.add_argument("--height", type=int, default=480, help="Video height.")
- parser.add_argument("--width", type=int, default=832, help="Video width.")
- parser.add_argument("--num-frames", type=int, default=81, help="Number of frames.")
- parser.add_argument("--num-inference-steps", type=int, default=30, help="Sampling steps.")
- parser.add_argument("--flow-shift", type=float, default=5.0, help="Scheduler flow_shift.")
- parser.add_argument("--output", type=str, default="vace_output.mp4", help="Output video path.")
- parser.add_argument("--fps", type=int, default=16, help="Output video FPS.")
- parser.add_argument("--vae-use-tiling", action="store_true", default=True, help="Enable VAE tiling.")
- parser.add_argument("--enforce-eager", action="store_true", help="Disable torch.compile.")
- parser.add_argument("--ulysses-degree", type=int, default=1, help="Ulysses SP degree.")
- parser.add_argument("--ring-degree", type=int, default=1, help="Ring attention degree.")
- parser.add_argument("--cfg-parallel-size", type=int, default=1, choices=[1, 2], help="CFG parallel size.")
- return parser.parse_args()
-
-
-def build_prompts(args):
- """Build prompt dict with multi_modal_data based on mode."""
- h, w, nf = args.height, args.width, args.num_frames
-
- gray = PIL.Image.new("RGB", (w, h), (128, 128, 128))
- mask_black = PIL.Image.new("L", (w, h), 0)
- mask_white = PIL.Image.new("L", (w, h), 255)
-
- prompt_data = {
- "prompt": args.prompt,
- "negative_prompt": args.negative_prompt,
- }
-
- if args.mode == "t2v":
- return prompt_data
-
- if args.mode == "r2v":
- assert args.image, "--image required for R2V mode"
- ref_img = PIL.Image.open(args.image).convert("RGB").resize((w, h))
- prompt_data["multi_modal_data"] = {"reference_images": [ref_img]}
- return prompt_data
-
- if args.mode == "i2v":
- assert args.image, "--image required for I2V mode"
- img = PIL.Image.open(args.image).convert("RGB").resize((w, h))
- prompt_data["multi_modal_data"] = {
- "video": [img] + [gray] * (nf - 1),
- "mask": [mask_black] + [mask_white] * (nf - 1),
- }
- return prompt_data
-
- if args.mode == "v2lf":
- assert args.image, "--image required for V2LF mode"
- img = PIL.Image.open(args.image).convert("RGB").resize((w, h))
- prompt_data["multi_modal_data"] = {
- "video": [gray] * (nf - 1) + [img],
- "mask": [mask_white] * (nf - 1) + [mask_black],
- }
- return prompt_data
-
- if args.mode == "flf2v":
- assert args.image and args.last_image, "--image and --last-image required for FLF2V"
- first = PIL.Image.open(args.image).convert("RGB").resize((w, h))
- last = PIL.Image.open(args.last_image).convert("RGB").resize((w, h))
- prompt_data["multi_modal_data"] = {
- "video": [first] + [gray] * (nf - 2) + [last],
- "mask": [mask_black] + [mask_white] * (nf - 2) + [mask_black],
- }
- return prompt_data
-
- if args.mode == "inpaint":
- assert args.image, "--image required for inpaint mode"
- img = PIL.Image.open(args.image).convert("RGB").resize((w, h))
- d = 80
- frames, masks = [], []
- for _ in range(nf):
- base = np.array(img).copy()
- mask = PIL.Image.new("L", (w, h), 0)
- stripe = PIL.Image.new("L", (2 * d, h), 255)
- mask.paste(stripe, (w // 2 - d, 0))
- base[np.array(mask) > 128] = 128
- frames.append(PIL.Image.fromarray(base))
- masks.append(mask)
- prompt_data["multi_modal_data"] = {"video": frames, "mask": masks}
- return prompt_data
-
- raise ValueError(f"Unknown mode: {args.mode}")
-
-
-def main():
- args = parse_args()
- generator = torch.Generator(device=current_omni_platform.device_type).manual_seed(args.seed)
-
- parallel_config = DiffusionParallelConfig(
- ulysses_degree=args.ulysses_degree,
- ring_degree=args.ring_degree,
- cfg_parallel_size=args.cfg_parallel_size,
- )
-
- omni = Omni(
- model=args.model,
- vae_use_tiling=args.vae_use_tiling,
- flow_shift=args.flow_shift,
- enforce_eager=args.enforce_eager,
- parallel_config=parallel_config,
- )
-
- prompt_data = build_prompts(args)
-
- print(f"\n{'=' * 60}")
- print(f"VACE {args.mode.upper()} Generation")
- print(f" Model: {args.model}")
- print(f" Size: {args.width}x{args.height}, {args.num_frames} frames, {args.num_inference_steps} steps")
- print(f"{'=' * 60}\n")
-
- start = time.perf_counter()
- outputs = omni.generate(
- prompt_data,
- OmniDiffusionSamplingParams(
- height=args.height,
- width=args.width,
- num_frames=args.num_frames,
- num_inference_steps=args.num_inference_steps,
- guidance_scale=args.guidance_scale,
- generator=generator,
- ),
- )
- elapsed = time.perf_counter() - start
-
- video = outputs[0].images
- if isinstance(video, list):
- video = video[0]
- if isinstance(video, torch.Tensor):
- video = video.cpu().numpy()
- if video.ndim == 5:
- video = video[0]
- print(f"Output shape: {video.shape}, Time: {elapsed:.1f}s")
-
- output_path = Path(args.output)
- output_path.parent.mkdir(parents=True, exist_ok=True)
-
- from diffusers.utils import export_to_video
-
- if np.issubdtype(video.dtype, np.integer):
- video = video.astype(np.float32) / 255.0
- export_to_video(list(video), str(output_path), fps=args.fps)
- print(f"Saved to {output_path}")
-
- omni.close()
-
-
-if __name__ == "__main__":
- main()
diff --git a/examples/offline_inference/voxcpm/README.md b/examples/offline_inference/voxcpm/README.md
deleted file mode 100644
index 1eaea9b0dba..00000000000
--- a/examples/offline_inference/voxcpm/README.md
+++ /dev/null
@@ -1,123 +0,0 @@
-# VoxCPM Offline Example
-
-This directory contains the minimal offline VoxCPM example for vLLM Omni.
-
-`end2end.py` is intentionally small and only covers:
-
-- single text-to-speech
-- single voice cloning with `ref_audio` + `ref_text`
-- non-streaming with `vllm_omni/model_executor/stage_configs/voxcpm.yaml`
-- streaming with `vllm_omni/model_executor/stage_configs/voxcpm_async_chunk.yaml`
-
-Advanced workflows were moved out of the getting-started example:
-
-- `benchmarks/voxcpm/vllm_omni/bench_tts_offline.py`: warmup, batch prompts, profiler, offline TTFP / RTF
-- `benchmarks/voxcpm/vllm_omni/run_offline_matrix.py`: fixed offline smoke matrix
-- `benchmarks/voxcpm/`: benchmark scripts and benchmark docs
-
-## Prerequisites
-
-Install VoxCPM in one of these ways:
-
-```bash
-pip install voxcpm
-```
-
-or point vLLM Omni to the local VoxCPM source tree:
-
-```bash
-export VLLM_OMNI_VOXCPM_CODE_PATH=/path/to/VoxCPM/src
-```
-
-The example writes WAV files with `soundfile`:
-
-```bash
-pip install soundfile
-```
-
-## Model Path
-
-Pass the native VoxCPM model directory directly:
-
-```bash
-export VOXCPM_MODEL=/path/to/voxcpm-model
-```
-
-If the native VoxCPM `config.json` does not contain HuggingFace metadata such as
-`model_type`, prepare a persistent HF-compatible config directory and point the
-stage configs to it with `VLLM_OMNI_VOXCPM_HF_CONFIG_PATH`:
-
-```bash
-export VLLM_OMNI_VOXCPM_HF_CONFIG_PATH=/tmp/voxcpm_hf_config
-mkdir -p "$VLLM_OMNI_VOXCPM_HF_CONFIG_PATH"
-cp "$VOXCPM_MODEL/config.json" "$VLLM_OMNI_VOXCPM_HF_CONFIG_PATH/config.json"
-cp "$VOXCPM_MODEL/generation_config.json" "$VLLM_OMNI_VOXCPM_HF_CONFIG_PATH/generation_config.json" 2>/dev/null || true
-python3 -c 'import json, os; p=os.path.join(os.environ["VLLM_OMNI_VOXCPM_HF_CONFIG_PATH"], "config.json"); cfg=json.load(open(p, "r", encoding="utf-8")); cfg["model_type"]="voxcpm"; cfg.setdefault("architectures", ["VoxCPMForConditionalGeneration"]); json.dump(cfg, open(p, "w", encoding="utf-8"), indent=2, ensure_ascii=False)'
-```
-
-If the model directory itself already has `model_type`, this extra directory is
-not required.
-
-## Quick Start
-
-Single text-to-speech, non-streaming:
-
-```bash
-python examples/offline_inference/voxcpm/end2end.py \
- --model "$VOXCPM_MODEL" \
- --text "This is a split-stage VoxCPM synthesis example running on vLLM Omni."
-```
-
-Single voice cloning, non-streaming:
-
-```bash
-python examples/offline_inference/voxcpm/end2end.py \
- --model "$VOXCPM_MODEL" \
- --text "This sentence is synthesized with a cloned voice." \
- --ref-audio /path/to/reference.wav \
- --ref-text "The exact transcript spoken in reference.wav."
-```
-
-Streaming:
-
-```bash
-python examples/offline_inference/voxcpm/end2end.py \
- --model "$VOXCPM_MODEL" \
- --stage-configs-path vllm_omni/model_executor/stage_configs/voxcpm_async_chunk.yaml \
- --text "This is a split-stage VoxCPM streaming example running on vLLM Omni."
-```
-
-By default, `end2end.py` writes to `output_audio/` for non-streaming and
-`output_audio_streaming/` for streaming.
-
-## Advanced Workflows
-
-Use `benchmarks/voxcpm/vllm_omni/bench_tts_offline.py` when you need:
-
-- warmup runs
-- prompt files
-- batch JSONL inputs
-- profiler injection
-- offline TTFP / RTF emission
-
-Use `benchmarks/voxcpm/vllm_omni/run_offline_matrix.py` when you need the fixed offline smoke matrix that previously lived in `test.py`.
-
-Full matrix benchmark example:
-
-```bash
-python benchmarks/voxcpm/vllm_omni/run_offline_matrix.py \
- --model "$VOXCPM_MODEL" \
- --ref-audio /path/to/reference.wav \
- --ref-text "The exact transcript spoken in reference.wav."
-```
-
-For online serving examples, see [examples/online_serving/voxcpm](../../online_serving/voxcpm/README.md).
-
-For benchmark reporting, see [benchmarks/voxcpm](../../../benchmarks/voxcpm/README.md).
-
-## Notes
-
-- `voxcpm.yaml` is the default non-streaming stage config.
-- `voxcpm_async_chunk.yaml` is the streaming stage config.
-- Streaming is currently single-request oriented; the fixed smoke matrix now lives in `benchmarks/voxcpm/vllm_omni/run_offline_matrix.py`.
-- `ref_text` must be the real transcript of the reference audio. Mismatched text usually causes obvious quality degradation.
diff --git a/examples/offline_inference/voxcpm/end2end.py b/examples/offline_inference/voxcpm/end2end.py
deleted file mode 100644
index 980410feaeb..00000000000
--- a/examples/offline_inference/voxcpm/end2end.py
+++ /dev/null
@@ -1,206 +0,0 @@
-"""Minimal offline VoxCPM example for vLLM Omni."""
-
-from __future__ import annotations
-
-import asyncio
-import time
-from pathlib import Path
-from typing import Any
-
-import soundfile as sf
-import torch
-from vllm.utils.argparse_utils import FlexibleArgumentParser
-
-from vllm_omni import AsyncOmni, Omni
-
-REPO_ROOT = Path(__file__).resolve().parents[3]
-DEFAULT_SYNC_STAGE_CONFIG = REPO_ROOT / "vllm_omni" / "model_executor" / "stage_configs" / "voxcpm.yaml"
-
-
-def _build_prompt(args) -> dict[str, Any]:
- additional_information: dict[str, list[Any]] = {
- "text": [args.text],
- "cfg_value": [args.cfg_value],
- "inference_timesteps": [args.inference_timesteps],
- "min_len": [args.min_len],
- "max_new_tokens": [args.max_new_tokens],
- }
- if args.streaming_prefix_len is not None:
- additional_information["streaming_prefix_len"] = [args.streaming_prefix_len]
- if args.ref_audio is not None:
- additional_information["ref_audio"] = [args.ref_audio]
- if args.ref_text is not None:
- additional_information["ref_text"] = [args.ref_text]
- return {
- "prompt_token_ids": [1],
- "additional_information": additional_information,
- }
-
-
-def _extract_audio_tensor(mm: dict[str, Any]) -> torch.Tensor:
- audio = mm.get("audio", mm.get("model_outputs"))
- if audio is None:
- raise ValueError("No audio output found in multimodal output.")
- if isinstance(audio, list):
- parts = [torch.as_tensor(item).float().cpu().reshape(-1) for item in audio]
- audio = torch.cat(parts, dim=-1) if parts else torch.zeros(0)
- if not isinstance(audio, torch.Tensor):
- audio = torch.as_tensor(audio)
- return audio.float().cpu().reshape(-1)
-
-
-def _extract_sample_rate(mm: dict[str, Any]) -> int:
- sr_raw = mm.get("sr", 24000)
- if isinstance(sr_raw, list) and sr_raw:
- sr_raw = sr_raw[-1]
- if hasattr(sr_raw, "item"):
- return int(sr_raw.item())
- return int(sr_raw)
-
-
-def _is_streaming_stage_config(stage_config_path: str) -> bool:
- return "async_chunk" in Path(stage_config_path).stem
-
-
-def _save_audio(audio: torch.Tensor, sample_rate: int, output_dir: Path, request_id: str) -> Path:
- output_dir.mkdir(parents=True, exist_ok=True)
- output_path = output_dir / f"output_{request_id}.wav"
- sf.write(
- output_path,
- audio.float().cpu().clamp(-1.0, 1.0).numpy(),
- sample_rate,
- format="WAV",
- subtype="PCM_16",
- )
- return output_path
-
-
-async def _run_streaming(args) -> Path:
- prompt = _build_prompt(args)
- output_dir = Path(args.output_dir) if args.output_dir is not None else Path("output_audio_streaming")
- request_id = "streaming_example"
- sample_rate = 24000
- buffered_samples = 0
- chunks: list[torch.Tensor] = []
- started = time.perf_counter()
- omni = AsyncOmni(
- model=args.model,
- stage_configs_path=args.stage_configs_path,
- log_stats=args.log_stats,
- stage_init_timeout=args.stage_init_timeout,
- )
- try:
- async for stage_output in omni.generate(prompt, request_id=request_id):
- mm = getattr(stage_output, "multimodal_output", None)
- if not isinstance(mm, dict):
- request_output = getattr(stage_output, "request_output", None)
- if request_output is None:
- continue
- mm = getattr(request_output, "multimodal_output", None)
- if not isinstance(mm, dict) and getattr(request_output, "outputs", None):
- mm = getattr(request_output.outputs[0], "multimodal_output", None)
- if not isinstance(mm, dict):
- continue
- audio = _extract_audio_tensor(mm)
- if audio.numel() == 0:
- continue
- sample_rate = _extract_sample_rate(mm)
- if audio.numel() > buffered_samples:
- delta = audio[buffered_samples:]
- buffered_samples = int(audio.numel())
- else:
- delta = audio
- buffered_samples += int(delta.numel())
- if delta.numel() > 0:
- chunks.append(delta)
- if not chunks:
- raise RuntimeError("No streaming audio chunks received from VoxCPM.")
- output_audio = torch.cat(chunks, dim=0)
- output_path = _save_audio(output_audio, sample_rate, output_dir, request_id)
- print(f"Saved streaming audio to: {output_path} ({time.perf_counter() - started:.2f}s)")
- return output_path
- finally:
- omni.shutdown()
-
-
-def _run_sync(args) -> Path:
- prompt = _build_prompt(args)
- output_dir = Path(args.output_dir) if args.output_dir is not None else Path("output_audio")
- request_id = "sync_example"
- started = time.perf_counter()
- last_mm: dict[str, Any] | None = None
- omni = Omni(
- model=args.model,
- stage_configs_path=args.stage_configs_path,
- log_stats=args.log_stats,
- stage_init_timeout=args.stage_init_timeout,
- )
- for stage_outputs in omni.generate(prompt):
- request_output = getattr(stage_outputs, "request_output", None)
- if request_output is None:
- continue
- outputs = getattr(request_output, "outputs", None)
- if outputs:
- for output in outputs:
- mm = getattr(output, "multimodal_output", None)
- if isinstance(mm, dict):
- last_mm = mm
- mm = getattr(request_output, "multimodal_output", None)
- if isinstance(mm, dict):
- last_mm = mm
- if last_mm is None:
- raise RuntimeError("No audio output received from VoxCPM.")
- output_path = _save_audio(
- _extract_audio_tensor(last_mm),
- _extract_sample_rate(last_mm),
- output_dir,
- request_id,
- )
- print(f"Saved audio to: {output_path} ({time.perf_counter() - started:.2f}s)")
- return output_path
-
-
-def parse_args():
- parser = FlexibleArgumentParser(description="Minimal offline VoxCPM example for vLLM Omni.")
- parser.add_argument("--model", type=str, required=True, help="Local VoxCPM model directory.")
- parser.add_argument(
- "--stage-configs-path",
- type=str,
- default=str(DEFAULT_SYNC_STAGE_CONFIG),
- help=("Stage config path. Use voxcpm.yaml for non-streaming or voxcpm_async_chunk.yaml for streaming."),
- )
- parser.add_argument("--text", type=str, required=True, help="Input text for synthesis.")
- parser.add_argument("--ref-audio", type=str, default=None, help="Reference audio path for voice cloning.")
- parser.add_argument("--ref-text", type=str, default=None, help="Transcript of the reference audio.")
- parser.add_argument("--output-dir", type=str, default=None, help="Output directory for generated wav files.")
- parser.add_argument("--cfg-value", type=float, default=2.0, help="Guidance value passed to VoxCPM.")
- parser.add_argument("--inference-timesteps", type=int, default=10, help="Number of diffusion timesteps.")
- parser.add_argument("--min-len", type=int, default=2, help="Minimum latent length.")
- parser.add_argument("--max-new-tokens", type=int, default=4096, help="Maximum latent length.")
- parser.add_argument(
- "--streaming-prefix-len",
- type=int,
- default=3,
- help="Streaming prefix length used by voxcpm_async_chunk.yaml.",
- )
- parser.add_argument("--stage-init-timeout", type=int, default=600, help="Stage initialization timeout in seconds.")
- parser.add_argument("--log-stats", action="store_true", help="Enable vLLM Omni stats logging.")
- args = parser.parse_args()
- if (args.ref_audio is None) != (args.ref_text is None):
- raise ValueError("Voice cloning requires --ref-audio and --ref-text together.")
- return args
-
-
-def main(args) -> None:
- route = "streaming" if _is_streaming_stage_config(args.stage_configs_path) else "sync"
- print(f"Model: {args.model}")
- print(f"Stage config: {args.stage_configs_path}")
- print(f"Route: {route}")
- if route == "streaming":
- asyncio.run(_run_streaming(args))
- else:
- _run_sync(args)
-
-
-if __name__ == "__main__":
- main(parse_args())
diff --git a/examples/offline_inference/voxcpm2/README.md b/examples/offline_inference/voxcpm2/README.md
deleted file mode 100644
index e9827307997..00000000000
--- a/examples/offline_inference/voxcpm2/README.md
+++ /dev/null
@@ -1,83 +0,0 @@
-# VoxCPM2 Offline Inference (Native AR)
-
-VoxCPM2 is a 2B-parameter tokenizer-free diffusion AR TTS model. It produces 48kHz audio and supports 30+ languages with a single-stage native AR pipeline backed by MiniCPM4.
-
-## Prerequisites
-
-Install the `voxcpm` package, or set the environment variable pointing to the source tree:
-
-```bash
-# Option A: install package
-pip install voxcpm
-
-# Option B: use source checkout
-export VLLM_OMNI_VOXCPM_CODE_PATH=/path/to/voxcpm
-```
-
-## Quick Start
-
-Zero-shot synthesis:
-
-```bash
-python examples/offline_inference/voxcpm2/end2end.py \
- --model openbmb/VoxCPM2 \
- --text "Hello, this is a VoxCPM2 demo." \
- --output-dir output_audio
-```
-
-Voice cloning with a reference audio:
-
-```bash
-python examples/offline_inference/voxcpm2/end2end.py \
- --text "Hello, this is a voice clone demo." \
- --reference-audio /path/to/reference.wav \
- --output-dir output_clone
-```
-
-Prompt continuation (matched audio + text prefix):
-
-```bash
-python examples/offline_inference/voxcpm2/end2end.py \
- --text "Continuation target sentence." \
- --prompt-audio /path/to/prompt.wav \
- --prompt-text "Transcript of the prompt audio." \
- --output-dir output_cont
-```
-
-The script accepts the following arguments:
-
-| Argument | Default | Description |
-|---|---|---|
-| `--model` | `openbmb/VoxCPM2` | HuggingFace repo ID or local path |
-| `--text` | (example sentence) | Text to synthesize |
-| `--output-dir` | `output_audio` | Directory for output WAV files |
-| `--stage-configs-path` | `voxcpm2.yaml` | Stage config YAML path |
-| `--reference-audio` | `None` | Reference audio for voice cloning (isolated) |
-| `--prompt-audio` | `None` | Prompt audio for continuation mode |
-| `--prompt-text` | `None` | Transcript matching `--prompt-audio` |
-
-## Performance
-
-Measured on a single H20 GPU (80 GB):
-
-| Input length | RTF | Sample rate |
-|---|---|---|
-| Short (~10 tokens) | ~0.28 | 48 kHz |
-| Long (~100 tokens) | ~0.34 | 48 kHz |
-
-RTF < 1.0 means faster than real time.
-
-## Architecture
-
-VoxCPM2 uses a single-stage native AR pipeline:
-
-```
-feat_encoder
-└─► MiniCPM4 (base LM)
- └─► FSQ (finite scalar quantization)
- └─► residual_lm (residual AR)
- └─► LocDiT (local diffusion transformer)
- └─► AudioVAE → 48 kHz waveform
-```
-
-All stages are fused into one vllm-native execution graph via `voxcpm2.yaml`, eliminating inter-stage coordination overhead and enabling true end-to-end batching.
diff --git a/examples/offline_inference/voxcpm2/end2end.py b/examples/offline_inference/voxcpm2/end2end.py
deleted file mode 100644
index 6b6bf78ddf1..00000000000
--- a/examples/offline_inference/voxcpm2/end2end.py
+++ /dev/null
@@ -1,171 +0,0 @@
-"""Offline VoxCPM2 inference example (native AR pipeline).
-
-Uses the single-stage native AR config (voxcpm2.yaml).
-Requires the `voxcpm` package or VLLM_OMNI_VOXCPM_CODE_PATH env var.
-"""
-
-from __future__ import annotations
-
-import os
-import time
-from pathlib import Path
-
-import soundfile as sf
-import torch
-from vllm.utils.argparse_utils import FlexibleArgumentParser
-
-from vllm_omni import Omni
-
-REPO_ROOT = Path(__file__).resolve().parents[3]
-DEFAULT_STAGE_CONFIGS_PATH = str(REPO_ROOT / "vllm_omni" / "model_executor" / "stage_configs" / "voxcpm2.yaml")
-SAMPLE_RATE = 48_000
-
-
-def parse_args():
- parser = FlexibleArgumentParser(description="Offline VoxCPM2 native AR inference")
- parser.add_argument(
- "--model",
- type=str,
- default="openbmb/VoxCPM2",
- help="VoxCPM2 model path or HuggingFace repo ID.",
- )
- parser.add_argument(
- "--text",
- type=str,
- default="This is a VoxCPM2 native AR synthesis example running on vLLM Omni.",
- help="Text to synthesize.",
- )
- parser.add_argument(
- "--output-dir",
- type=str,
- default="output_audio",
- help="Directory for output WAV files.",
- )
- parser.add_argument(
- "--stage-configs-path",
- type=str,
- default=DEFAULT_STAGE_CONFIGS_PATH,
- help="Path to the stage config YAML file.",
- )
- parser.add_argument(
- "--reference-audio",
- type=str,
- default=None,
- help="Path to reference audio for voice cloning (isolated ref mode).",
- )
- parser.add_argument(
- "--prompt-audio",
- type=str,
- default=None,
- help="Path to prompt audio for continuation mode (requires --prompt-text).",
- )
- parser.add_argument(
- "--prompt-text",
- type=str,
- default=None,
- help="Text matching --prompt-audio for continuation mode.",
- )
- parser.add_argument(
- "--ref-text",
- type=str,
- default=None,
- help="Optional transcript of --reference-audio (enables ref_continuation mode).",
- )
- return parser.parse_args()
-
-
-def extract_audio(multimodal_output: dict) -> torch.Tensor:
- """Extract the final complete audio tensor from multimodal output.
-
- The output processor concatenates per-step delta tensors under
- ``model_outputs``. Falls back to ``audio`` for backwards compat.
- """
- audio = multimodal_output.get("model_outputs")
- if audio is None:
- audio = multimodal_output.get("audio")
- if audio is None:
- raise ValueError(f"No audio key in multimodal_output: {list(multimodal_output.keys())}")
-
- if isinstance(audio, list):
- # Defensive: usually the output processor consolidates into a single
- # tensor at request completion, but concatenate here too in case the
- # caller consumes intermediate (pre-consolidation) outputs.
- valid = [torch.as_tensor(a).float().cpu().reshape(-1) for a in audio if a is not None]
- if not valid:
- raise ValueError("Audio list is empty or all elements are None.")
- return torch.cat(valid, dim=0) if len(valid) > 1 else valid[0]
-
- return torch.as_tensor(audio).float().cpu().reshape(-1)
-
-
-def main():
- args = parse_args()
-
- output_dir = Path(args.output_dir)
- output_dir.mkdir(parents=True, exist_ok=True)
-
- engine = Omni(
- model=args.model,
- stage_configs_path=args.stage_configs_path,
- )
-
- from transformers import AutoTokenizer
-
- from vllm_omni.model_executor.models.voxcpm2.voxcpm2_talker import (
- build_cjk_split_map,
- build_voxcpm2_prompt,
- )
-
- tokenizer = AutoTokenizer.from_pretrained(args.model, trust_remote_code=True)
- split_map = build_cjk_split_map(tokenizer)
- hf_config = engine.engine.stage_vllm_configs[0].model_config.hf_config
-
- ref_audio_arg = args.reference_audio or args.prompt_audio
- ref_text_arg = args.ref_text or args.prompt_text
- ref_wav, ref_sr = (None, None)
- if ref_audio_arg:
- ref_wav_arr, ref_sr = sf.read(ref_audio_arg)
- ref_wav = ref_wav_arr.mean(axis=-1).tolist() if ref_wav_arr.ndim > 1 else ref_wav_arr.tolist()
-
- prompt = build_voxcpm2_prompt(
- hf_config=hf_config,
- tokenizer=tokenizer,
- split_map=split_map,
- text=args.text,
- ref_audio=ref_wav,
- ref_sr=ref_sr,
- ref_text=ref_text_arg,
- )
-
- print(f"Model : {args.model}")
- print(f"Text : {args.text}")
- if ref_audio_arg:
- print(f"Ref audio : {ref_audio_arg}")
- if ref_text_arg:
- print(f"Ref text : {ref_text_arg}")
- print(f"Output dir : {output_dir}")
-
- t_start = time.perf_counter()
- outputs = engine.generate([prompt])
- elapsed = time.perf_counter() - t_start
-
- # outputs[0].outputs[0].multimodal_output["audio"] is a list of tensors
- request_output = outputs[0]
- mm = request_output.outputs[0].multimodal_output
- audio = extract_audio(mm)
-
- duration = audio.numel() / SAMPLE_RATE
- rtf = elapsed / duration if duration > 0 else float("inf")
-
- output_path = output_dir / "output.wav"
- sf.write(str(output_path), audio.numpy(), SAMPLE_RATE, format="WAV")
-
- print(f"Saved : {output_path}")
- print(f"Duration : {duration:.2f}s")
- print(f"Inference : {elapsed:.2f}s")
- print(f"RTF : {rtf:.3f}")
-
-
-if __name__ == "__main__":
- os.environ["VLLM_WORKER_MULTIPROC_METHOD"] = "spawn"
- main()
diff --git a/examples/offline_inference/voxtral_tts/README.md b/examples/offline_inference/voxtral_tts/README.md
deleted file mode 100644
index a55ce8830ee..00000000000
--- a/examples/offline_inference/voxtral_tts/README.md
+++ /dev/null
@@ -1,59 +0,0 @@
-# Voxtral TTS Offline Inference
-
-`end2end.py` runs Voxtral TTS end-to-end offline inference using vLLM. It supports both blocking (`Omni`) and streaming (`AsyncOmni`) generation, batched prompts with configurable concurrency, and voice selection via preset name or reference audio file.
-
-When `mistral_common` has `SpeechRequest` support, prompt token IDs are built via `encode_speech_request`. Otherwise, the script falls back to manual token construction.
-
-## Usage Examples
-
-
-```bash
-# Basic single-prompt with cheerful_female voice preset
-python3 examples/offline_inference/voxtral_tts/end2end.py \
- --write-audio --voice cheerful_female \
- --model mistralai/Voxtral-4B-TTS-2603 \
- --text "That eerie silence after the first storm was just the calm before another round of chaos, wasn't it?"
-
-# 32 replicate prompts with cheerful_female voice preset
-python3 examples/offline_inference/voxtral_tts/end2end.py \
- --num-prompts 32 --write-audio --voice cheerful_female \
- --model mistralai/Voxtral-4B-TTS-2603 \
- --text "That eerie silence after the first storm was just the calm before another round of chaos, wasn't it?"
-
-# Streaming with neutral_female voice preset
-python3 examples/offline_inference/voxtral_tts/end2end.py \
- --streaming --write-audio --voice neutral_female \
- --model mistralai/Voxtral-4B-TTS-2603 \
- --text "That eerie silence after the first storm was just the calm before another round of chaos, wasn't it?"
-
-# 32 prompts, 8 concurrent requests per wave, streaming with neutral_female voice
-python3 examples/offline_inference/voxtral_tts/end2end.py \
- --num-prompts 32 --concurrency 8 --streaming --write-audio --voice neutral_female \
- --model mistralai/Voxtral-4B-TTS-2603 \
- --text "That eerie silence after the first storm was just the calm before another round of chaos, wasn't it?"
-
-# Short debug prompt with reference audio
-# Note: Reference audio capability is not yet released.
-python3 examples/offline_inference/voxtral_tts/end2end.py \
- --write-audio \
- --model mistralai/Voxtral-4B-TTS-2603 \
- --text "This is a test message." \
- --audio-path path/to/reference_audio.wav
-```
-
-## Arguments
-
-| Argument | Description |
-|---|---|
-| `--model PATH` | HuggingFace repo ID or local directory path (default: `mistralai/Voxtral-4B-TTS-2603`) |
-| `--text TEXT` | Text to synthesize (default: `"This is a test message."`) |
-| `--audio-path PATH` | Path to reference audio file for voice cloning |
-| `--output-dir DIR` | Directory to write output WAV files (default: `output_audio`) |
-| `--deploy-config PATH` | Override the deploy config path. If unset, auto-loads `vllm_omni/deploy/voxtral_tts.yaml` from the HF `model_type`. |
-| `--num-prompts N` | Number of replicate prompts to run for measuring performance (default: 1) |
-| `--streaming` | Use streaming generation via `AsyncOmni` (default: blocking `Omni`) |
-| `--concurrency N` | Max concurrent requests per wave (must be used with `--streaming`, must evenly divide `--num-prompts`) |
-| `--voice NAME` | Voice preset to use instead of reference audio file. Check Huggingface `mistralai/Voxtral-4B-TTS-2603` to get the list of available voices |
-| `--write-audio` | Write generated audio to WAV files |
-| `--profiling-mode` | Enable profiling mode (reduces max tokens to 50) |
-| `--log-stats` | Enable detailed statistics logging |
diff --git a/examples/offline_inference/voxtral_tts/end2end.py b/examples/offline_inference/voxtral_tts/end2end.py
deleted file mode 100644
index 0a6f88715a9..00000000000
--- a/examples/offline_inference/voxtral_tts/end2end.py
+++ /dev/null
@@ -1,391 +0,0 @@
-"""
-This example shows how to use vLLM for running Voxtral TTS
-"""
-
-import asyncio
-import gc
-import logging
-import os
-import time
-import uuid
-from argparse import Namespace
-from pathlib import Path
-from typing import Any
-
-import numpy as np
-import soundfile as sf
-import torch
-from mistral_common.protocol.instruct.chunk import TextChunk
-
-try:
- from mistral_common.protocol.speech.request import SpeechRequest
- from mistral_common.tokens.tokenizers.mistral import MistralTokenizer
-except ImportError:
- raise ImportError(
- "Could not import SpeechRequest or MistralTokenizer from mistral_common. "
- "Please pull the latest mistral-common code and install it with: "
- "pip install -e ."
- )
-from vllm import SamplingParams
-from vllm.utils.argparse_utils import FlexibleArgumentParser
-
-from vllm_omni import AsyncOmni
-from vllm_omni.entrypoints.omni import Omni
-
-logger = logging.getLogger(__name__)
-
-
-# ---- Streaming version ----
-async def run_streaming(inputs, sampling_params_list, model_name, args, output_dir):
- async_omni = AsyncOmni(
- model=model_name,
- deploy_config=args.deploy_config,
- log_stats=args.log_stats,
- )
-
- # Normalize to a list so batch and single-input share the same code path
- if isinstance(inputs, list):
- inputs_list = inputs
- else:
- inputs_list = [inputs]
-
- total_audio_dur = 0.0
- total_gen_time = 0.0
- total_ttfa = 0.0
- ttfa_count = 0
- total_waits = 0
- total_chunks = 0
- results_lock = asyncio.Lock()
-
- async def _generate_one(batch_idx, single_input):
- nonlocal total_audio_dur, total_gen_time, total_ttfa, ttfa_count
- nonlocal total_waits, total_chunks
- request_id = str(uuid.uuid4())
- all_audio_chunks = []
- chunk_arrival_times = []
- chunk_durations = []
- chunk_idx = 0
- gen_start = time.time()
- ttfa = None
- accumulated_sample = 0
-
- async for stage_output in async_omni.generate(
- single_input, request_id=request_id, sampling_params_list=sampling_params_list
- ):
- mm_output = stage_output.multimodal_output
- finished = stage_output.finished
- if not mm_output or "audio" not in mm_output:
- continue
-
- now = time.time()
- if ttfa is None:
- ttfa = now - gen_start
-
- audio_chunk = mm_output["audio"]
- # audio_chunk is a 1-D tensor from decode_helper_async
- if isinstance(audio_chunk, torch.Tensor):
- if finished:
- # Last chunk may return whole audio instead of chunk delta.
- # Cut accumulated samples from previous chunks.
- audio_numpy = audio_chunk[accumulated_sample:].float().detach().cpu().numpy()
- else:
- audio_numpy = audio_chunk.float().detach().cpu().numpy()
- elif isinstance(audio_chunk, list):
- # Audio_chunk list contain all previous chunks. Use chunk_idx to index
- audio_numpy = audio_chunk[chunk_idx].float().detach().cpu().numpy()
- else:
- audio_numpy = audio_chunk
-
- accumulated_sample += len(audio_numpy)
- all_audio_chunks.append(audio_numpy)
- chunk_arrival_times.append(now)
- chunk_durations.append(len(audio_numpy) / 24000)
- chunk_idx += 1
-
- gen_elapsed = time.time() - gen_start
-
- # Analyze wait/no-wait per chunk:
- # A "wait" means the client has finished playing all previous audio
- # before this chunk arrived, so there is a playback gap.
- # buffer_time > 0: client still has audio to play (no wait)
- # buffer_time <= 0: client ran out of audio and had to wait
- chunk_labels = []
- accumulated_audio_dur = 0.0
- if chunk_arrival_times:
- first_arrival = chunk_arrival_times[0]
- for i in range(len(chunk_arrival_times)):
- if i == 0:
- chunk_labels.append("no_wait")
- else:
- playback_elapsed = chunk_arrival_times[i] - first_arrival
- buffer_time = accumulated_audio_dur - playback_elapsed
- if buffer_time <= 0:
- chunk_labels.append("wait")
- else:
- chunk_labels.append("no_wait")
- accumulated_audio_dur += chunk_durations[i]
-
- req_wait_count = sum(1 for chunk_label in chunk_labels if chunk_label == "wait")
- req_wait_rate = req_wait_count / len(chunk_labels) if chunk_labels else 0.0
-
- # Concatenate all chunks for this request's audio
- if all_audio_chunks:
- full_audio = np.concatenate(all_audio_chunks)
- output_audio_dur = len(full_audio) / 24000
- output_path = os.path.join(output_dir, f"tts_output_{batch_idx}.wav")
- if args.write_audio:
- sf.write(output_path, full_audio, 24000)
- print(
- f"Request {batch_idx}: saved {len(full_audio)} samples ({output_audio_dur:.2f}s) to {output_path}"
- )
- # Per-chunk wait details
- for i, label in enumerate(chunk_labels):
- dur_ms = chunk_durations[i] * 1000
- arrival_ms = (chunk_arrival_times[i] - first_arrival) * 1000 if i > 0 else 0.0
- print(
- f" Request {batch_idx} chunk {i}: {label} | arrived={arrival_ms:.1f}ms | chunk_dur={dur_ms:.1f}ms"
- )
- print(
- f"Request {batch_idx}: TTFA={ttfa:.4f}s | "
- f"Generation={gen_elapsed:.4f}s | "
- f"Audio={output_audio_dur:.2f}s | "
- f"RTF={output_audio_dur / gen_elapsed:.4f} | "
- f"WaitRate={req_wait_rate:.2%} ({req_wait_count}/{len(chunk_labels)})"
- )
- async with results_lock:
- total_audio_dur += output_audio_dur
- total_gen_time += gen_elapsed
- total_waits += req_wait_count
- total_chunks += len(chunk_labels)
- if ttfa is not None:
- total_ttfa += ttfa
- ttfa_count += 1
-
- # Launch requests in waves of `concurrency` size
- concurrency = args.concurrency or len(inputs_list)
- gen_start_all = time.time()
- for wave_start in range(0, len(inputs_list), concurrency):
- wave = inputs_list[wave_start : wave_start + concurrency]
- wave_idx_offset = wave_start
- print(f"\n--- Wave {wave_start // concurrency + 1} (requests {wave_start}-{wave_start + len(wave) - 1}) ---")
- await asyncio.gather(*[_generate_one(wave_idx_offset + i, inp) for i, inp in enumerate(wave)])
- generation_time = time.time() - gen_start_all
- avg_ttfa = total_ttfa / ttfa_count if ttfa_count else float("nan")
- overall_wait_rate = total_waits / total_chunks if total_chunks else float("nan")
- print(
- f"\nAll requests: Generation={generation_time:.4f}s | "
- f"TotalAudio={total_audio_dur:.2f}s | "
- f"Concurrency={concurrency} | "
- f"AvgTTFA={avg_ttfa:.4f}s | "
- f"RTF(total)={total_audio_dur / generation_time:.4f} | "
- f"RTF(per-request)={total_audio_dur / total_gen_time:.4f} | "
- f"WaitRate={overall_wait_rate:.2%} ({total_waits}/{total_chunks})"
- )
-
- async_omni.shutdown()
- torch.cuda.empty_cache()
- gc.collect()
-
-
-# ---- Non-streaming version ----
-def run_non_streaming(inputs, sampling_params_list, model_name, args, output_dir):
- llm = Omni(
- model=model_name,
- log_stats=args.log_stats,
- deploy_config=args.deploy_config,
- )
-
- if args.profiling_mode:
- llm.start_profile()
-
- vllm_start = time.time()
- outputs = llm.generate(inputs, sampling_params_list)
- vllm_elapsed = time.time() - vllm_start
-
- if args.profiling_mode:
- llm.stop_profile()
- time.sleep(10)
-
- print(f"vLLM run time: {vllm_elapsed:.4f}s")
- output_audio_dur = 0.0
-
- for batch_idx, o in enumerate(outputs):
- audio_tensor = torch.cat(o.multimodal_output["audio"])
- audio_array = audio_tensor.tolist()
- output_audio_dur += float(len(audio_array)) / 24000
- if args.write_audio:
- output_path = os.path.join(output_dir, f"tts_output_{batch_idx}.wav")
- sf.write(output_path, audio_array, 24000)
- print(f"Audio saved to {output_path}")
-
- print(f"Total audio duration: {output_audio_dur:.2f}s")
- print(f"RTF: {output_audio_dur / vllm_elapsed:.4f}")
-
- del llm
- torch.cuda.empty_cache()
- gc.collect()
-
-
-def parse_args() -> Namespace:
- parser = FlexibleArgumentParser(description="Demo on using vLLM for offline inference with Voxtral TTS")
- parser.add_argument(
- "--model",
- type=str,
- default="mistralai/Voxtral-4B-TTS-2603",
- help="Model name or path.",
- )
- parser.add_argument(
- "--text",
- type=str,
- default="This is a test message.",
- help="Text to synthesize.",
- )
- parser.add_argument(
- "--audio-path",
- type=str,
- default=None,
- help="Path to reference audio file for voice cloning.",
- )
- parser.add_argument(
- "--output-dir",
- type=str,
- default="output_audio",
- help="Directory to write output wav files.",
- )
- parser.add_argument(
- "--deploy-config",
- type=str,
- default=None,
- help="Override the deploy config path. If unset, auto-loads "
- "vllm_omni/deploy/voxtral_tts.yaml based on the HF model_type.",
- )
- parser.add_argument(
- "--num-prompts", type=int, default=1, help="Number of replicate prompts to run for measuring performance"
- )
- parser.add_argument(
- "--profiling-mode",
- default=False,
- action="store_true",
- help="Set max_num_tokens=2 to reduce profiling time",
- )
- parser.add_argument(
- "--log-stats",
- action="store_true",
- default=False,
- help="Enable writing detailed statistics (default: disabled)",
- )
- parser.add_argument(
- "--write-audio",
- action="store_true",
- default=False,
- help="Write audio output to files.",
- )
- parser.add_argument(
- "--streaming",
- action="store_true",
- default=False,
- help="Use streaming generation via AsyncOmni instead of blocking Omni.",
- )
- parser.add_argument(
- "--concurrency",
- type=int,
- default=None,
- help="Max concurrent requests per wave (default: all at once). Must evenly divide --num-prompts.",
- )
- parser.add_argument(
- "--voice",
- type=str,
- default=None,
- help="Voice to use instead of audio file.",
- )
- parser.add_argument(
- "--cfg-alpha",
- type=float,
- default=None,
- help="CFG alpha for flow-matching guidance (default: use value from stage config, typically 1.2).",
- )
- return parser.parse_args()
-
-
-def compose_request(
- model_name: str,
- text_chunk: TextChunk,
- audio_prompt_file: str,
- args: Any,
-) -> dict:
- """Build the full TTS input dict (prompt_token_ids, multi_modal_data or additional_information)."""
- inputs: dict[str, Any] = {}
- if Path(model_name).is_dir():
- mistral_tokenizer = MistralTokenizer.from_file(str(Path(model_name) / "tekken.json"))
- else:
- mistral_tokenizer = MistralTokenizer.from_hf_hub(model_name)
- instruct_tokenizer = mistral_tokenizer.instruct_tokenizer
-
- if args.voice is not None:
- tokenized = instruct_tokenizer.encode_speech_request(SpeechRequest(input=text_chunk.text, voice=args.voice))
- inputs["additional_information"] = {"voice": [args.voice]}
- inputs["prompt_token_ids"] = tokenized.tokens
- else:
- with open(audio_prompt_file, "rb") as f:
- ref_audio_bytes = f.read()
- tokenized = instruct_tokenizer.encode_speech_request(
- SpeechRequest(input=text_chunk.text, ref_audio=ref_audio_bytes)
- )
- audio = tokenized.audios[0]
- inputs["multi_modal_data"] = {"audio": [(audio.audio_array, audio.sampling_rate)]}
- inputs["prompt_token_ids"] = tokenized.tokens
-
- return inputs
-
-
-def main(args: Any) -> None:
- max_num_tokens = 50 if args.profiling_mode else 2500
-
- model_name = args.model
- output_dir = args.output_dir
-
- if args.voice is None and args.audio_path is None:
- raise ValueError("Either --voice or --audio-path must be provided.")
-
- audio_prompt_file = args.audio_path
- text_chunk = TextChunk(text=args.text)
-
- if args.write_audio:
- os.makedirs(output_dir, exist_ok=True)
-
- inputs = compose_request(model_name, text_chunk, audio_prompt_file, args)
-
- extra_args = {}
- if args.cfg_alpha is not None:
- extra_args["cfg_alpha"] = args.cfg_alpha
-
- sampling_params = SamplingParams(
- max_tokens=max_num_tokens,
- extra_args=extra_args if extra_args else None,
- )
- sampling_params_list = [
- sampling_params,
- sampling_params,
- ]
-
- if args.num_prompts > 1:
- inputs = [inputs] * args.num_prompts
-
- if args.concurrency is not None:
- assert args.streaming, "--concurrency must be used with --streaming on AsyncOmni"
- assert args.num_prompts % args.concurrency == 0, (
- f"--num-prompts ({args.num_prompts}) must be divisible by --concurrency ({args.concurrency})"
- )
-
- torch.cuda.empty_cache()
- gc.collect()
-
- if args.streaming:
- asyncio.run(run_streaming(inputs, sampling_params_list, model_name, args, output_dir))
- else:
- run_non_streaming(inputs, sampling_params_list, model_name, args, output_dir)
-
-
-if __name__ == "__main__":
- args = parse_args()
- main(args)
diff --git a/examples/offline_inference/x_to_video_audio/download_dreamid_omni.py b/examples/offline_inference/x_to_video_audio/download_dreamid_omni.py
deleted file mode 100644
index 2f66d5f7789..00000000000
--- a/examples/offline_inference/x_to_video_audio/download_dreamid_omni.py
+++ /dev/null
@@ -1,108 +0,0 @@
-import argparse
-import fcntl
-import os
-import site
-import subprocess
-import tempfile
-import time
-from pathlib import Path
-
-from huggingface_hub import snapshot_download
-
-DEPENDENCY_REPO = "https://github.com/bytedance/DreamID-V.git"
-DEPENDENCY_BRANCH = "omni"
-CACHE_DIR = Path(tempfile.gettempdir()) / "vllm-omni-dependency"
-LOCK_FILE = CACHE_DIR / ".install.lock"
-DEPENDENCY_DIR = CACHE_DIR / "DreamID-Omni"
-
-
-def download_dependency():
- CACHE_DIR.mkdir(parents=True, exist_ok=True)
-
- with open(LOCK_FILE, "w") as f:
- fcntl.flock(f, fcntl.LOCK_EX)
- if not DEPENDENCY_DIR.exists():
- print(f"Downloading DreamID-Omni to {DEPENDENCY_DIR} ...")
- subprocess.run(
- ["git", "clone", "--depth", "1", DEPENDENCY_REPO, "--branch", DEPENDENCY_BRANCH, str(DEPENDENCY_DIR)],
- check=True,
- )
- print("Download finished.")
- fcntl.flock(f, fcntl.LOCK_UN)
-
- # write .pth to site-packages
- site_packages = Path(site.getsitepackages()[0])
- pth_file = site_packages / "vllm_omni_dependency.pth"
- pth_file.write_text(str(DEPENDENCY_DIR))
- print(f"Added {DEPENDENCY_DIR} to site-packages via {pth_file}")
-
-
-def timed_download(repo_id: str, local_dir: str, allow_patterns: list | None = None):
- """Download files from HF repo and log time + destination."""
- if os.path.exists(local_dir):
- print(f"Directory {local_dir} already exists. Skipping download.")
- return
- print(f"Starting download from {repo_id} into {local_dir}")
- start_time = time.time()
-
- snapshot_download(
- repo_id=repo_id,
- local_dir=local_dir,
- local_dir_use_symlinks=False,
- allow_patterns=allow_patterns,
- )
-
- elapsed = time.time() - start_time
- print(f"✅ Finished downloading {repo_id} in {elapsed:.2f} seconds. Files saved at: {local_dir}")
-
-
-def main(output_dir: str):
- # Wan2.2
- wan_dir = os.path.join(output_dir, "Wan2.2-TI2V-5B")
- timed_download(
- repo_id="Wan-AI/Wan2.2-TI2V-5B",
- local_dir=wan_dir,
- allow_patterns=["google/*", "models_t5_umt5-xxl-enc-bf16.pth", "Wan2.2_VAE.pth"],
- )
-
- # MMAudio
- mm_audio_dir = os.path.join(output_dir, "MMAudio")
- timed_download(
- repo_id="hkchengrex/MMAudio",
- local_dir=mm_audio_dir,
- allow_patterns=["ext_weights/best_netG.pt", "ext_weights/v1-16.pth"],
- )
-
- dreamid_dir = os.path.join(output_dir, "DreamID-Omni")
-
- timed_download(repo_id="XuGuo699/DreamID-Omni", local_dir=dreamid_dir)
-
- # Now we construct the config file
- import json
-
- data = {
- "_class_name": "DreamIDOmniPipeline",
- }
-
- with open(os.path.join(output_dir, "model_index.json"), "w", encoding="utf-8") as f:
- json.dump(data, f, indent=2)
-
- print(f"model_index.json created at {os.path.join(output_dir, 'model_index.json')}")
-
- transformer_dir = os.path.join(output_dir, "transformer")
- os.makedirs(transformer_dir, exist_ok=True)
- with open(os.path.join(transformer_dir, "config.json"), "w", encoding="utf-8") as f:
- json.dump({"fusion": "DreamID-Omni/dreamid_omni.safetensors"}, f)
- print(f"transformer/config.json created at {os.path.join(transformer_dir, 'config.json')}")
-
- # now we download the dependency code
- download_dependency()
-
-
-if __name__ == "__main__":
- parser = argparse.ArgumentParser(description="Download models from Hugging Face")
- parser.add_argument(
- "--output-dir", type=str, default="./dreamid_omni", help="Base directory to save downloaded models"
- )
- args = parser.parse_args()
- main(args.output_dir)
diff --git a/examples/offline_inference/x_to_video_audio/x_to_video_audio.md b/examples/offline_inference/x_to_video_audio/x_to_video_audio.md
deleted file mode 100644
index 13f2cfe7c0a..00000000000
--- a/examples/offline_inference/x_to_video_audio/x_to_video_audio.md
+++ /dev/null
@@ -1,82 +0,0 @@
-# X-To-Video-Audio
-
-The `DreamID-Omni` pipeline generates short videos from text, image and video.
-
-## Local CLI Usage
-### Download the Model locally
-Since DreamID-Omni combine multiple models, and without any config, so we need to download them locally.
-
-```bash
-python download_dreamid_omni.py --output-dir ./dreamid_omni
-```
-After download, the model directory will look like this:
-
-```
-dreamid_omni/
-├── DreamID-Omni/
-│ ├── dreamid_omni.safetensors
-├── MMAudio/
-│ ├── ext_weights/
-│ │ ├── best_netG.pt
-│ │ ├── v1-16.pth
-├── Wan2.2-TI2V-5B/
-│ ├── google/*
-│ ├── models_t5_umt5-xxl-enc-bf16.pth
-│ ├── Wan2.2_VAE.pth
-│
-├── model_index.json
-└── transformer/
- └── config.json # create by download_dreamid_omni.py
-```
-
-### Run the Inference
-```python
-python x_to_video_audio.py \
- --model /path/to/dreamid_omni \
- --prompt "Two people walking together and singing happily" \
- --image-path ./example0.png ./example1.png \
- --audio-path ./example0.wav ./example1.wav \
- --video-negative-prompt "jitter, bad hands, blur, distortion" \
- --audio-negative-prompt "robotic, muffled, echo, distorted" \
- --cfg-parallel-size 2 \
- --num-inference-steps 45 \
- --height 704 \
- --width 1280 \
- --output out_dreamid_omni_twoip.mp4
-```
-In the current test scenario (2 images + 2 audio inputs), the VRAM requirement is 72GB, regardless of whether cfg-parallel is enabled or disabled.
-The VRAM usage can be reduced by enabling CPU offload via --enable-cpu-offload.
-
-
-You could take reference images/audios from the test cases in the official repo: https://github.com/Guoxu1233/DreamID-Omni
-
-For example, single IP ref resources can be found under https://github.com/Guoxu1233/DreamID-Omni/tree/main/test_case/oneip, you could download them correspondingly to your local and use them for testing.
-
-```python
-# Example usage for oneip, ref media from the official repo DreamID-Omni
-python x_to_video_audio.py \
- --model /path/to/dreamid_omni \
- --prompt "<img1>: In the frame, a woman with black long hair is identified as <sub1>.\n**Overall Environment/Scene**: A lively open-kitchen café at night; stove flames flare, steam rises, and warm pendant lights swing slightly as staff move behind her. The shot is an upper-body close-up.\n**Main Characters/Subjects Appearance**: <sub1> is a young woman with thick dark wavy hair and a side part. She wears a fitted black top under a light apron, a thin gold chain necklace, and small stud earrings.\n**Main Characters/Subjects Actions**: <sub1> tastes the sauce with a spoon, then turns her face toward the camera while still holding the spoon, her expression shifting from focused to conflicted.\n<sub1> maintains eye contact, swallows as if choosing her words, and says, <S>I keep telling myself I’m fine,but some nights it feels like I’m just performing calm.<E>" \
- --image-path 9.png \
- --audio-path 9.wav \
- --video-negative-prompt "jitter, bad hands, blur, distortion" \
- --audio-negative-prompt "robotic, muffled, echo, distorted" \
- --cfg-parallel-size 2 \
- --num-inference-steps 45 \
- --height 704 \
- --width 1280 \
- --output out_dreamid_omni_oneip.mp4
-```
-
-
-Key arguments:
-- `--prompt`: text description (string).
-- `--model`: path to the model local directory.
-- `--height/--width`: output resolution (defaults 704 * 1024).
-- `--image-path`: path to the input image list.
-- `--audio-path`: path to the input audio list, indicate the timbre of the output video.
-- `--cfg-parallel-size`: number of parallel cfg parallel (defaults 1).
-- `--num-inference-steps`: number of denoising steps (defaults 45).
-- `--video-negative-prompt`: negative prompt for video generation.
-- `--audio-negative-prompt`: negative prompt for audio generation.
-- `--enable-cpu-offload`: enable CPU offload (defaults False).
diff --git a/examples/offline_inference/x_to_video_audio/x_to_video_audio.py b/examples/offline_inference/x_to_video_audio/x_to_video_audio.py
deleted file mode 100644
index 497284ceb96..00000000000
--- a/examples/offline_inference/x_to_video_audio/x_to_video_audio.py
+++ /dev/null
@@ -1,176 +0,0 @@
-# SPDX-License-Identifier: Apache-2.0
-# SPDX-FileCopyrightText: Copyright contributors to the vLLM project
-
-import argparse
-import re
-import time
-
-import numpy as np
-from PIL import Image
-from vllm.multimodal.media.audio import load_audio
-
-from vllm_omni.diffusion.data import DiffusionParallelConfig
-from vllm_omni.diffusion.utils.media_utils import mux_video_audio_bytes
-from vllm_omni.entrypoints.omni import Omni
-from vllm_omni.inputs.data import OmniDiffusionSamplingParams
-
-IMAGE_EXTENSIONS = {".jpg", ".jpeg", ".png", ".bmp", ".webp", ".gif"}
-AUDIO_EXTENSIONS = {".wav", ".mp3", ".flac", ".m4a", ".aac", ".ogg"}
-
-
-def parse_args() -> argparse.Namespace:
- parser = argparse.ArgumentParser(description="Offline inference for DreamID-Omni (video + audio).")
- parser.add_argument("--model", required=True, help="DreamID ckpt root directory.")
- parser.add_argument("--model-type", default="dreamid-omni", help="Model type.")
- parser.add_argument("--prompt", default=None, help="Text prompt.")
-
- parser.add_argument("--image-path", type=str, nargs="+", help="list of image-path")
- parser.add_argument("--audio-path", type=str, nargs="+", help="list of audio-path")
- parser.add_argument("--prompt-file", type=str, default=None, help="Text prompt in json format.")
-
- parser.add_argument("--height", type=int, default=704, help="Video height.")
- parser.add_argument("--width", type=int, default=1280, help="Video width.")
- parser.add_argument("--num-inference-steps", type=int, default=45, help="Sampling steps.")
- parser.add_argument("--solver-name", default="unipc", help="Solver name: unipc|dpm++|euler.")
- parser.add_argument("--shift", type=float, default=5.0, help="Scheduler shift.")
- parser.add_argument("--seed", type=int, default=103, help="Random seed for reproducible generation.")
- parser.add_argument(
- "--cfg-parallel-size",
- type=int,
- default=1,
- choices=[1, 2, 3, 4],
- help="Number of GPUs used for classifier free guidance parallel size (max 4 branches).",
- )
- parser.add_argument(
- "--video-negative-prompt",
- default="jitter, bad hands, blur, distortion",
- help="Negative prompt for video.",
- )
- parser.add_argument(
- "--audio-negative-prompt",
- default="robotic, muffled, echo, distorted",
- help="Negative prompt for audio.",
- )
- parser.add_argument("--output", default="dreamid_output.mp4", help="Output video path.")
- parser.add_argument(
- "--enable-cpu-offload",
- action="store_true",
- default=False,
- help="Enable CPU offloading for diffusion models.",
- )
- parser.add_argument(
- "--enable-layerwise-offload",
- action="store_true",
- help="Enable layerwise (blockwise) offloading on DiT modules.",
- )
- return parser.parse_args()
-
-
-def load_image_and_audio(image_paths, audio_paths):
- image = []
- audio = []
-
- for path in image_paths:
- with Image.open(path) as img:
- img = img.convert("RGB")
- image.append(img)
-
- for path in audio_paths:
- audio_array, sr = load_audio(path, sr=16000)
- audio_array = audio_array[int(sr * 1) : int(sr * 3)]
- audio.append(audio_array)
- return image, audio
-
-
-def main() -> None:
- args = parse_args()
- if args.prompt is None and args.prompt_file is None:
- raise ValueError("Either --prompt or --prompt-file must be provided.")
-
- text_prompt = args.prompt
- if args.prompt_file:
- import json
-
- with open(args.prompt_file) as f:
- text_prompt = json.load(f)
- text_prompt = re.sub(
- r"\[SPEAKER_TIMESTAMPS_START\].*?\[SPEAKER_TIMESTAMPS_END\]", "", text_prompt, flags=re.DOTALL
- ).strip()
- text_prompt = re.sub(
- r"\[AUDIO_DESCRIPTION_START].*?\[AUDIO_DESCRIPTION_END]", "", text_prompt, flags=re.DOTALL
- ).strip()
- text_prompt = re.sub(r"\[[A-Z_]+\]", "", text_prompt)
- text_prompt = re.sub(r"\n\s*\n", "\n", text_prompt).strip()
-
- image, audio = load_image_and_audio(args.image_path, args.audio_path)
-
- prompt = {
- "prompt": text_prompt,
- "video_negative_prompt": args.video_negative_prompt,
- "audio_negative_prompt": args.audio_negative_prompt,
- "multi_modal_data": {"image": image, "audio": audio},
- }
-
- sampling_params = OmniDiffusionSamplingParams(
- height=args.height,
- width=args.width,
- num_inference_steps=args.num_inference_steps,
- seed=args.seed,
- extra_args={
- "solver_name": args.solver_name,
- "shift": args.shift,
- },
- )
-
- parallel_config = DiffusionParallelConfig(
- cfg_parallel_size=args.cfg_parallel_size,
- )
-
- omni = Omni(
- model=args.model,
- parallel_config=parallel_config,
- model_type=args.model_type,
- enable_cpu_offload=args.enable_cpu_offload,
- enable_layerwise_offload=args.enable_layerwise_offload,
- )
- start = time.perf_counter()
- outputs = omni.generate(prompt, sampling_params)
- elapsed = time.perf_counter() - start
-
- if not outputs:
- raise RuntimeError("No output returned from DreamID-Omni.")
- result = outputs[0]
- if not result.images:
- raise RuntimeError("No video frames found in DreamID-Omni output.")
- generated_video = result.images[0]
- mm = result.multimodal_output or {}
- generated_audio = mm.get("audio")
- fps = int(mm.get("fps", 24))
- sample_rate = int(mm.get("audio_sample_rate", 16000))
-
- # DreamID-Omni returns video as (C, F, H, W) float32 in [-1, 1].
- # mux_video_audio_bytes expects (F, H, W, C) uint8.
- if not isinstance(generated_video, np.ndarray) or generated_video.ndim != 4:
- raise RuntimeError(f"Unexpected video shape: {getattr(generated_video, 'shape', None)}")
- frames = generated_video.transpose(1, 2, 3, 0)
- frames = (np.clip((frames + 1.0) / 2.0, 0.0, 1.0) * 255.0).round().astype(np.uint8)
-
- audio_np = None
- if generated_audio is not None:
- audio_np = np.squeeze(np.asarray(generated_audio)).astype(np.float32)
-
- output_path = args.output
- video_bytes = mux_video_audio_bytes(
- frames,
- audio_np,
- fps=float(fps),
- audio_sample_rate=sample_rate,
- )
- with open(output_path, "wb") as f:
- f.write(video_bytes)
- print(f"Saved generated video to {output_path}")
- print(f"Total time: {elapsed:.2f}s")
-
-
-if __name__ == "__main__":
- main()
diff --git a/examples/online_serving/bagel/README.md b/examples/online_serving/bagel/README.md
deleted file mode 100644
index 763927222cf..00000000000
--- a/examples/online_serving/bagel/README.md
+++ /dev/null
@@ -1,322 +0,0 @@
-# BAGEL-7B-MoT
-
-## Installation
-
-Please refer to [README.md](../../../README.md)
-
-## Architecture
-
-BAGEL-7B-MoT is a Mixture-of-Transformers (MoT) model supporting both image generation and understanding. It offers two deployment topologies:
-
-| Topology | Stages | Description |
-| :------- | :----- | :---------- |
-| **Two-stage** (default) | Stage 0 (Thinker, AR) + Stage 1 (DiT, Diffusion) | Thinker handles text/understanding via vLLM AR engine; DiT handles image generation. KV cache is transferred between stages. |
-| **Single-stage** | Stage 0 (DiT, Diffusion) only | The DiT stage contains a full LLM, ViT, VAE, and tokenizer internally. All modalities are handled within a single diffusion process. |
-
-Both topologies support all four modalities: `text2img`, `img2img`, `img2text`, `text2text`.
-
-> **Note**: These examples work with the default configuration on an **NVIDIA A100 (80GB)**. We also tested on dual **NVIDIA RTX 5000 Ada (32GB each)**. For dual-GPU setups, modify the deploy YAML to distribute stages across devices.
-
-## Launch the Server
-
-### Two-Stage (Default)
-
-The default pipeline is auto-detected from the model. No extra flags needed:
-
-```bash
-vllm serve ByteDance-Seed/BAGEL-7B-MoT --omni --port 8091
-```
-
-Or use the convenience script:
-
-```bash
-cd examples/online_serving/bagel
-bash run_server.sh
-
-# Initialize each stage in a discrete isolated process terminal
-bash run_server_stage_cli.sh --stage 0
-bash run_server_stage_cli.sh --stage 1
-```
-
-To use a custom deploy YAML, pass it via `--deploy-config`:
-
-```bash
-vllm serve ByteDance-Seed/BAGEL-7B-MoT --omni --port 8091 \
- --deploy-config /path/to/deploy_config.yaml
-```
-
-See [`bagel.yaml`](../../../vllm_omni/deploy/bagel.yaml) for the default two-stage deploy configuration.
-
-### Single-Stage
-
-The DiT stage contains a full LLM, ViT, VAE, and tokenizer, so it can handle all modalities (text2img, img2img, img2text, text2text, think) without a separate Thinker stage:
-
-```bash
-vllm serve ByteDance-Seed/BAGEL-7B-MoT --omni --port 8091 \
- --deploy-config vllm_omni/deploy/bagel_single_stage.yaml
-```
-
-See [`bagel_single_stage.yaml`](../../../vllm_omni/deploy/bagel_single_stage.yaml) for configuration. The `pipeline: bagel_single_stage` field selects the single-stage topology from the pipeline registry.
-
-### Tensor Parallelism (TP)
-
-For larger models or multi-GPU environments, enable TP via CLI:
-
-```bash
-vllm serve ByteDance-Seed/BAGEL-7B-MoT --omni --port 8091 --tensor-parallel-size 2
-```
-
-Or set `tensor_parallel_size` per stage in a custom deploy YAML.
-
-### Multi-Node Deployment
-
-Deploy each stage on a **separate node** for better resource utilization. Replace `<ORCHESTRATOR_IP>` with the actual IP address of your orchestrator node.
-
-**1. Launch Stage 0 (Thinker / Orchestrator)** on the orchestrator node:
-
-```bash
-# API server port for client requests: 8000
-vllm serve ByteDance-Seed/BAGEL-7B-MoT --omni \
- --port 8000 \
- --stage-id 0 \
- --omni-master-address <ORCHESTRATOR_IP> \
- --omni-master-port 8091
-```
-
-**2. Launch Stage 1 (DiT)** on the remote node in headless mode:
-
-```bash
-vllm serve ByteDance-Seed/BAGEL-7B-MoT --omni \
- --stage-id 1 \
- --headless \
- --omni-master-address <ORCHESTRATOR_IP> \
- --omni-master-port 8091
-```
-
-Or use the convenience script:
-
-```bash
-# Terminal 1: Stage 0
-bash run_server_stage_cli.sh --stage 0
-
-# Terminal 2: Stage 1
-bash run_server_stage_cli.sh --stage 1
-
-# With extra args
-bash run_server_stage_cli.sh --stage 0 -- --tensor-parallel-size 2
-bash run_server_stage_cli.sh --stage 1 -- --gpu-memory-utilization 0.9
-```
-
-**vllm serve arguments:**
-
-| Argument | Description |
-| :------- | :---------- |
-| `--stage-id` | Which stage this process runs (0 = Thinker, 1 = DiT) |
-| `--headless` | Run without the API server (worker-only mode) |
-| `-oma` / `--omni-master-address` | Orchestrator master address |
-| `-omp` / `--omni-master-port` | Orchestrator master port |
-
-> [!IMPORTANT]
-> **Startup Order**: Stage 0 (orchestrator) must be launched **before** Stage 1 (headless).
-> Stage 0 will appear to hang on startup until Stage 1 (worker) connects — this is expected behavior.
-
-### Inter-Stage Connectors
-
-When deploying stages across nodes, configure the connector type in the deploy YAML:
-
-- **SharedMemoryConnector** (default): Used for single-node deployments. No explicit configuration needed.
-- **MooncakeTransferEngineConnector**: For multi-node setups with RDMA hardware. Defined in [`bagel.yaml`](../../../vllm_omni/deploy/bagel.yaml) under `connectors.rdma_connector`.
-
-To use Mooncake, create a custom deploy YAML that binds `output_connectors` / `input_connectors` on each stage to the `rdma_connector` defined in the `connectors` section.
-
-## Send Requests
-
-```bash
-cd examples/online_serving/bagel
-```
-
-### Text to Image (text2img)
-
-**Python client:**
-
-```bash
-python openai_chat_client.py \
- --prompt "A beautiful sunset over mountains" \
- --modality text2img \
- --output sunset.png \
- --steps 50
-```
-
-**curl:**
-
-```bash
-curl http://localhost:8091/v1/chat/completions \
- -H "Content-Type: application/json" \
- -d '{
- "messages": [{"role": "user", "content": [{"type": "text", "text": "<|im_start|>A beautiful sunset over mountains<|im_end|>"}]}],
- "modalities": ["image"],
- "height": 512,
- "width": 512,
- "num_inference_steps": 50,
- "seed": 42
- }'
-```
-
-### Image to Image (img2img)
-
-**Python client:**
-
-```bash
-python openai_chat_client.py \
- --prompt "Make the cat stand up" \
- --modality img2img \
- --image-url /path/to/input.jpg \
- --output transformed.png
-```
-
-**curl:**
-
-```bash
-IMAGE_BASE64=$(base64 -w 0 cat.jpg)
-
-cat <<EOF > payload.json
-{
- "messages": [{
- "role": "user",
- "content": [
- {"type": "text", "text": "<|im_start|>Make the cat stand up<|im_end|>"},
- {"type": "image_url", "image_url": {"url": "data:image/jpeg;base64,${IMAGE_BASE64}"}}
- ]
- }],
- "modalities": ["image"],
- "height": 512,
- "width": 512,
- "num_inference_steps": 50,
- "seed": 42
-}
-EOF
-
-curl http://localhost:8091/v1/chat/completions \
- -H "Content-Type: application/json" \
- -d @payload.json
-```
-
-### Image to Text (img2text)
-
-**Python client:**
-
-```bash
-python openai_chat_client.py \
- --prompt "Describe this image in detail" \
- --modality img2text \
- --image-url /path/to/image.jpg
-```
-
-**curl:**
-
-```bash
-IMAGE_BASE64=$(base64 -w 0 cat.jpg)
-
-cat <<EOF > payload.json
-{
- "messages": [{
- "role": "user",
- "content": [
- {"type": "text", "text": "<|im_start|>user\n<|image_pad|>\nDescribe this image in detail<|im_end|>\n<|im_start|>assistant\n"},
- {"type": "image_url", "image_url": {"url": "data:image/jpeg;base64,${IMAGE_BASE64}"}}
- ]
- }],
- "modalities": ["text"]
-}
-EOF
-
-curl http://localhost:8091/v1/chat/completions \
- -H "Content-Type: application/json" \
- -d @payload.json
-```
-
-### Text to Text (text2text)
-
-**Python client:**
-
-```bash
-python openai_chat_client.py \
- --prompt "What is the capital of France?" \
- --modality text2text
-```
-
-**curl:**
-
-```bash
-curl http://localhost:8091/v1/chat/completions \
- -H "Content-Type: application/json" \
- -d '{
- "messages": [{"role": "user", "content": [{"type": "text", "text": "<|im_start|>user\nWhat is the capital of France?<|im_end|>\n<|im_start|>assistant\n"}]}],
- "modalities": ["text"]
- }'
-```
-
-### Python Client Arguments
-
-| Argument | Default | Description |
-| :------- | :------ | :---------- |
-| `--prompt` / `-p` | `A cute cat` | Text prompt |
-| `--output` / `-o` | `bagel_output.png` | Output file path |
-| `--server` / `-s` | `http://localhost:8091` | Server URL |
-| `--image-url` / `-i` | `None` | Input image URL or local path (img2img/img2text) |
-| `--modality` / `-m` | `text2img` | `text2img`, `img2img`, `img2text`, `text2text` |
-| `--height` | `512` | Image height in pixels |
-| `--width` | `512` | Image width in pixels |
-| `--steps` | `25` | Number of inference steps |
-| `--seed` | `42` | Random seed |
-| `--negative` | `None` | Negative prompt for CFG |
-
-Example with custom parameters:
-
-```bash
-python openai_chat_client.py \
- --prompt "A futuristic city" \
- --modality text2img \
- --height 768 \
- --width 768 \
- --steps 50 \
- --seed 42 \
- --negative "blurry, low quality"
-```
-
-## Configuration Reference
-
-### Deploy YAML Files
-
-| File | Description |
-| :--- | :---------- |
-| [`bagel.yaml`](../../../vllm_omni/deploy/bagel.yaml) | Two-stage default (Thinker + DiT on GPU 0) |
-| [`bagel_single_stage.yaml`](../../../vllm_omni/deploy/bagel_single_stage.yaml) | Single-stage (DiT only) |
-
-### Key Deploy YAML Fields
-
-| Field | Scope | Description |
-| :---- | :---- | :---------- |
-| `pipeline` | top-level | Override auto-detected pipeline (e.g. `bagel_single_stage`) |
-| `stages[].stage_id` | per-stage | Stage identifier (0, 1, ...) |
-| `stages[].devices` | per-stage | GPU device IDs (e.g. `"0"`, `"0,1"`) |
-| `stages[].max_num_seqs` | per-stage | Maximum concurrent sequences |
-| `stages[].gpu_memory_utilization` | per-stage | Fraction of GPU memory to use |
-| `stages[].enforce_eager` | per-stage | Disable CUDA graphs |
-| `stages[].tensor_parallel_size` | per-stage | TP degree for this stage |
-| `connectors` | top-level | Define available connector instances (SHM, Mooncake) |
-| `platforms` | top-level | Platform-specific overrides (e.g. `xpu`) |
-
-## FAQ
-
-- If you encounter OOM errors, try decreasing `max_model_len` or `gpu_memory_utilization` in the deploy YAML.
-
-**Two-stage VRAM usage:**
-
-| Stage | VRAM |
-| :---- | :--- |
-| Stage 0 (Thinker) | **15.04 GiB + KV Cache** |
-| Stage 1 (DiT) | **26.50 GiB** |
-| Total | **~42 GiB + KV Cache** |
-
-**Single-stage VRAM usage:** The DiT loads the full model (~42 GiB) in one process.
diff --git a/examples/online_serving/bagel/openai_chat_client.py b/examples/online_serving/bagel/openai_chat_client.py
deleted file mode 100755
index cc9ec32db91..00000000000
--- a/examples/online_serving/bagel/openai_chat_client.py
+++ /dev/null
@@ -1,184 +0,0 @@
-#!/usr/bin/env python3
-"""
-Bagel OpenAI-compatible chat client for image generation and multimodal tasks.
-
-Usage:
- python openai_chat_client.py --prompt "A cute cat" --output output.png
- python openai_chat_client.py --prompt "Describe this image" --image-url https://example.com/image.png
-"""
-
-import argparse
-import base64
-from pathlib import Path
-
-import requests
-
-
-def generate_image(
- prompt: str,
- server_url: str = "http://localhost:8091",
- image_url: str | None = None,
- height: int | None = None,
- width: int | None = None,
- steps: int | None = None,
- seed: int | None = None,
- negative_prompt: str | None = None,
- modality: str = "text2img", # "text2img" (default), "img2img", "img2text", "text2text"
-) -> bytes | str | None:
- """Generate an image or text using the chat completions API.
-
- Args:
- prompt: Text description or prompt
- server_url: Server URL
- image_url: URL or path to input image (for img2img/img2text)
- height: Image height in pixels
- width: Image width in pixels
- steps: Number of inference steps
- seed: Random seed
- negative_prompt: Negative prompt
- modality: Task modality hint
-
- Returns:
- Image bytes (for image outputs) or Text string (for text outputs) or None if failed
- """
-
- # Construct Message Content
- content = [{"type": "text", "text": f"<|im_start|>{prompt}<|im_end|>"}]
-
- if image_url:
- # Check if local file
- if Path(image_url).exists():
- with open(image_url, "rb") as f:
- b64_data = base64.b64encode(f.read()).decode("utf-8")
- final_image_url = f"data:image/jpeg;base64,{b64_data}"
- else:
- final_image_url = image_url
-
- content.append({"type": "image_url", "image_url": {"url": final_image_url}})
-
- messages = [{"role": "user", "content": content}]
-
- # Build request payload with all parameters at top level
- # Note: vLLM ignores "extra_body", so we put parameters directly in the payload
- payload = {"messages": messages}
-
- # Set output modalities at top level
- if modality == "text2img" or modality == "img2img":
- payload["modalities"] = ["image"]
- elif modality == "img2text" or modality == "text2text":
- payload["modalities"] = ["text"]
-
- # Add generation parameters directly to payload
- if height is not None:
- payload["height"] = height
- if width is not None:
- payload["width"] = width
- if steps is not None:
- payload["num_inference_steps"] = steps
- if seed is not None:
- payload["seed"] = seed
- if negative_prompt:
- payload["negative_prompt"] = negative_prompt
-
- # Send request
- try:
- print(f"Sending request to {server_url} with modality {modality}...")
- response = requests.post(
- f"{server_url}/v1/chat/completions",
- headers={"Content-Type": "application/json"},
- json=payload,
- timeout=300,
- )
- response.raise_for_status()
- data = response.json()
-
- # Extract content - check ALL choices since server may return multiple
- # (e.g., text in choices[0], image in choices[1])
- choices = data.get("choices", [])
-
- # First pass: look for image output in any choice
- for choice in choices:
- choice_content = choice.get("message", {}).get("content")
-
- # Handle Image Output
- if isinstance(choice_content, list) and len(choice_content) > 0:
- first_item = choice_content[0]
- if isinstance(first_item, dict) and "image_url" in first_item:
- img_url_str = first_item["image_url"].get("url", "")
- if img_url_str.startswith("data:image"):
- _, b64_data = img_url_str.split(",", 1)
- return base64.b64decode(b64_data)
-
- # Second pass: look for text output if no image found
- for choice in choices:
- choice_content = choice.get("message", {}).get("content")
- if isinstance(choice_content, str) and choice_content:
- return choice_content
-
- print(f"Unexpected response format: {choices}")
- return None
-
- except Exception as e:
- print(f"Error: {e}")
- return None
-
-
-def main():
- parser = argparse.ArgumentParser(description="Bagel multimodal chat client")
- parser.add_argument("--prompt", "-p", default="A cute cat", help="Text prompt")
- parser.add_argument("--output", "-o", default="bagel_output.png", help="Output file (for image results)")
- parser.add_argument("--server", "-s", default="http://localhost:8091", help="Server URL")
-
- # Modality Control
- parser.add_argument("--image-url", "-i", type=str, help="Input image URL or local path")
- parser.add_argument(
- "--modality",
- "-m",
- default="text2img",
- choices=["text2img", "img2img", "img2text", "text2text"],
- help="Task modality",
- )
-
- # Generation Params
- parser.add_argument("--height", type=int, default=512, help="Image height")
- parser.add_argument("--width", type=int, default=512, help="Image width")
- parser.add_argument("--steps", type=int, default=25, help="Inference steps")
- parser.add_argument("--seed", type=int, default=42, help="Random seed")
- parser.add_argument("--negative", help="Negative prompt")
-
- args = parser.parse_args()
-
- print(f"Mode: {args.modality}")
- if args.image_url:
- print(f"Input Image: {args.image_url}")
-
- result = generate_image(
- prompt=args.prompt,
- server_url=args.server,
- image_url=args.image_url,
- height=args.height,
- width=args.width,
- steps=args.steps,
- seed=args.seed,
- negative_prompt=args.negative,
- modality=args.modality,
- )
-
- if result:
- if isinstance(result, bytes):
- # It's an image
- output_path = Path(args.output)
- output_path.write_bytes(result)
- print(f"Image saved to: {output_path}")
- print(f"Size: {len(result) / 1024:.1f} KB")
- elif isinstance(result, str):
- # It's text
- print("Response:")
- print(result)
- else:
- print("Failed to generate response")
- exit(1)
-
-
-if __name__ == "__main__":
- main()
diff --git a/examples/online_serving/bagel/run_server.sh b/examples/online_serving/bagel/run_server.sh
deleted file mode 100755
index a64057ef033..00000000000
--- a/examples/online_serving/bagel/run_server.sh
+++ /dev/null
@@ -1,12 +0,0 @@
-#!/bin/bash
-# Bagel online serving startup script
-
-MODEL="${MODEL:-ByteDance-Seed/BAGEL-7B-MoT}"
-PORT="${PORT:-8091}"
-
-echo "Starting Bagel server..."
-echo "Model: $MODEL"
-echo "Port: $PORT"
-
-vllm serve "$MODEL" --omni \
- --port "$PORT"
diff --git a/examples/online_serving/bagel/run_server_stage_cli.sh b/examples/online_serving/bagel/run_server_stage_cli.sh
deleted file mode 100644
index 912e212f97e..00000000000
--- a/examples/online_serving/bagel/run_server_stage_cli.sh
+++ /dev/null
@@ -1,164 +0,0 @@
-#!/bin/bash
-# Bagel multi-stage online serving startup script.
-#
-# Usage:
-# ./run_server_stage_cli.sh --stage 0
-# ./run_server_stage_cli.sh --stage 1
-# ./run_server_stage_cli.sh --stage 0 -- --tensor-parallel-size 2
-# ./run_server_stage_cli.sh --stage 1 -- --gpu-memory-utilization 0.9
-#
-# By default, `--stage all` keeps the old behavior and launches both stages in
-# one session. Use `--stage 0` / `--stage 1` to launch each stage separately in
-# different terminal sessions, with stage-specific extra CLI arguments passed
-# after `--`.
-
-set -euo pipefail
-
-MODEL="${MODEL:-ByteDance-Seed/BAGEL-7B-MoT}"
-PORT="${PORT:-8091}"
-MASTER_ADDRESS="${MASTER_ADDRESS:-127.0.0.1}"
-MASTER_PORT="${MASTER_PORT:-8092}"
-STAGE="all"
-SCRIPT_DIR="$(cd "$(dirname "${BASH_SOURCE[0]}")" && pwd)"
-DEPLOY_CONFIG="${DEPLOY_CONFIG:-$SCRIPT_DIR/../../../vllm_omni/deploy/bagel.yaml}"
-EXTRA_ARGS=()
-
-usage() {
- cat <<EOF
-Usage: $0 [OPTIONS] [-- EXTRA_VLLM_ARGS...]
-
-Options:
- --stage {0|1|all} Stage to launch (default: all)
- --model MODEL Model name/path (default: $MODEL)
- --port PORT API port for stage 0 (default: $PORT)
- --master-address ADDRESS Master/orchestrator address (default: $MASTER_ADDRESS)
- --master-port PORT Master/orchestrator port (default: $MASTER_PORT)
- --deploy-config PATH Deploy config YAML path (default: $DEPLOY_CONFIG)
- --help Show this help message
-
-Examples:
- $0 --stage 0
- $0 --stage 1
- $0 --stage 0 -- --tensor-parallel-size 2
- $0 --stage 1 -- --gpu-memory-utilization 0.9
-
-Notes:
- - Use different terminal sessions to launch stage 0 and stage 1 separately.
- - Extra args after '--' are forwarded only to the selected stage.
- - When using '--stage all', the extra args are forwarded to both stages.
-EOF
-}
-
-while [[ $# -gt 0 ]]; do
- case "$1" in
- --stage)
- STAGE="$2"
- shift 2
- ;;
- --model)
- MODEL="$2"
- shift 2
- ;;
- --port)
- PORT="$2"
- shift 2
- ;;
- --master-address)
- MASTER_ADDRESS="$2"
- shift 2
- ;;
- --master-port)
- MASTER_PORT="$2"
- shift 2
- ;;
- --deploy-config)
- DEPLOY_CONFIG="$2"
- shift 2
- ;;
- --help|-h)
- usage
- exit 0
- ;;
- --)
- shift
- EXTRA_ARGS=("$@")
- break
- ;;
- *)
- echo "Unknown option: $1" >&2
- usage
- exit 1
- ;;
- esac
-done
-
-if [[ "$STAGE" != "0" && "$STAGE" != "1" && "$STAGE" != "all" ]]; then
- echo "Invalid --stage value: $STAGE" >&2
- usage
- exit 1
-fi
-
-print_config() {
- echo "Model: $MODEL"
- echo "API Port: $PORT"
- echo "Master Address: $MASTER_ADDRESS"
- echo "Master Port: $MASTER_PORT"
- echo "Deploy Config: $DEPLOY_CONFIG"
- echo "Selected Stage: $STAGE"
- if [[ ${#EXTRA_ARGS[@]} -gt 0 ]]; then
- echo "Extra Args: ${EXTRA_ARGS[*]}"
- fi
-}
-
-run_stage_0() {
- echo "Starting Stage 0 (Thinker) as master..."
- vllm serve "$MODEL" --omni \
- --port "$PORT" \
- --deploy-config "$DEPLOY_CONFIG" \
- --stage-id 0 \
- --omni-master-address "$MASTER_ADDRESS" \
- --omni-master-port "$MASTER_PORT" \
- "${EXTRA_ARGS[@]}"
-}
-
-run_stage_1() {
- echo "Starting Stage 1 (DiT) in headless mode..."
- vllm serve "$MODEL" --omni \
- --deploy-config "$DEPLOY_CONFIG" \
- --stage-id 1 \
- --headless \
- --omni-master-address "$MASTER_ADDRESS" \
- --omni-master-port "$MASTER_PORT" \
- "${EXTRA_ARGS[@]}"
-}
-
-echo "Starting Bagel multi-stage server..."
-print_config
-
-case "$STAGE" in
- 0)
- run_stage_0
- ;;
- 1)
- run_stage_1
- ;;
- all)
- echo "Launching both stages in one session (legacy mode)..."
- echo "Starting Stage 0 (Thinker) in background first..."
- run_stage_0 &
- STAGE_0_PID=$!
-
- cleanup() {
- if [[ -n "${STAGE_0_PID:-}" ]]; then
- kill "$STAGE_0_PID" 2>/dev/null || true
- wait "$STAGE_0_PID" 2>/dev/null || true
- fi
- }
-
- trap cleanup EXIT INT TERM
-
- echo "Waiting briefly for Stage 0 to initialize..."
- sleep 2
- run_stage_1
- ;;
-esac
diff --git a/examples/online_serving/chart-helm/.helmignore b/examples/online_serving/chart-helm/.helmignore
deleted file mode 100644
index 6ad16c56872..00000000000
--- a/examples/online_serving/chart-helm/.helmignore
+++ /dev/null
@@ -1,6 +0,0 @@
-*.png
-.git/
-ct.yaml
-lintconf.yaml
-values.schema.json
-/workflows
diff --git a/examples/online_serving/chart-helm/Chart.yaml b/examples/online_serving/chart-helm/Chart.yaml
deleted file mode 100644
index 974eee93cc3..00000000000
--- a/examples/online_serving/chart-helm/Chart.yaml
+++ /dev/null
@@ -1,15 +0,0 @@
-apiVersion: v2
-name: chart-vllm-omni
-description: A Helm chart for deploying vLLM-Omni on Kubernetes for omni-modality model serving
-
-# Application chart that can be packaged and deployed
-type: application
-
-# Chart version - increment on each change to the chart
-version: 0.1.0
-
-# vllm-omni application version — keep in sync with image.tag in values.yaml
-appVersion: "0.16.0"
-
-maintainers:
- - name: vllm-omni-team
diff --git a/examples/online_serving/chart-helm/README.md b/examples/online_serving/chart-helm/README.md
deleted file mode 100644
index a3b413a35c8..00000000000
--- a/examples/online_serving/chart-helm/README.md
+++ /dev/null
@@ -1,144 +0,0 @@
-# vLLM-Omni Helm Chart
-
-Helm chart for deploying [vLLM-Omni](https://github.com/vllm-project/vllm-omni) on Kubernetes. vLLM-Omni extends vLLM with omni-modality model serving, supporting text-to-image, multimodal chat, text-to-speech, and more.
-
-## Prerequisites
-
-- Kubernetes 1.24+
-- Helm 3.x
-- NVIDIA GPU nodes with [NVIDIA Device Plugin](https://github.com/NVIDIA/k8s-device-plugin)
-
-## Quick Start
-
-```bash
-helm install my-release ./chart-helm \
- --set model=Tongyi-MAI/Z-Image-Turbo
-```
-
-## Configuration
-
-### Model Selection
-
-Set the `model` value to any supported HuggingFace model ID:
-
-| Model | Type | GPUs | Notes |
-|-------|------|------|-------|
-| `Tongyi-MAI/Z-Image-Turbo` | text-to-image | 1 | Small, fast (default) |
-| `stabilityai/stable-diffusion-3.5-medium` | text-to-image | 1 | ~6GB VRAM |
-| `Qwen/Qwen-Image` | text-to-image | 1 | Large, ~40GB+ VRAM |
-| `Qwen/Qwen2.5-Omni-7B` | multimodal | 2 | Text + audio + image + video |
-| `Qwen/Qwen3-Omni-7B-Chat` | multimodal | 2 | Latest omni model |
-| `Qwen/Qwen3-TTS` | text-to-speech | 1 | TTS |
-
-### HuggingFace Token
-
-For gated models that require authentication:
-
-```bash
-helm install my-release ./chart-helm \
- --set model=Qwen/Qwen2.5-Omni-7B \
- --set hfToken=hf_xxxxx \
- --set resources.requests."nvidia\.com/gpu"=2 \
- --set resources.limits."nvidia\.com/gpu"=2
-```
-
-### Omni-Specific Flags
-
-Enable VAE memory optimizations for diffusion models:
-
-```bash
-helm install my-release ./chart-helm \
- --set model=Qwen/Qwen-Image \
- --set omniArgs.vaeUseSlicing=true \
- --set omniArgs.vaeUseTiling=true
-```
-
-Enable CPU offloading:
-
-```bash
-helm install my-release ./chart-helm \
- --set model=Qwen/Qwen-Image \
- --set omniArgs.enableCpuOffload=true
-```
-
-Pass additional raw CLI flags:
-
-```bash
-helm install my-release ./chart-helm \
- --set model=Qwen/Qwen-Image \
- --set omniArgs.extraArgs[0]="--enable-layerwise-offload"
-```
-
-### Model Cache
-
-By default, a PersistentVolumeClaim is created for the HuggingFace model cache to avoid re-downloading models on pod restarts:
-
-```yaml
-modelCache:
- enabled: true
- storageSize: "50Gi"
- storageClassName: ""
-```
-
-To use an ephemeral volume instead:
-
-```bash
-helm install my-release ./chart-helm \
- --set modelCache.enabled=false
-```
-
-### Custom Command Override
-
-To fully override the container command:
-
-```bash
-helm install my-release ./chart-helm \
- --set image.command[0]=vllm \
- --set image.command[1]=serve \
- --set image.command[2]=my-model \
- --set image.command[3]=--omni \
- --set image.command[4]=--host \
- --set image.command[5]=0.0.0.0
-```
-
-## API Endpoints
-
-Once deployed, vLLM-Omni exposes the following OpenAI-compatible endpoints:
-
-| Endpoint | Method | Description |
-|----------|--------|-------------|
-| `/health` | GET | Health check |
-| `/v1/models` | GET | List available models |
-| `/v1/chat/completions` | POST | Chat completions (text/multimodal) |
-| `/v1/images/generations` | POST | Image generation |
-| `/v1/images/edits` | POST | Image editing |
-| `/v1/audio/speech` | POST | Text-to-speech |
-
-## Files
-
-| File | Description |
-|------|-------------|
-| `Chart.yaml` | Chart metadata (name, version, maintainers) |
-| `values.yaml` | Default configuration values |
-| `values.schema.json` | JSON schema for validating values |
-| `templates/_helpers.tpl` | Helper templates for common configurations |
-| `templates/deployment.yaml` | Kubernetes Deployment |
-| `templates/service.yaml` | Kubernetes Service (ClusterIP) |
-| `templates/secrets.yaml` | Secrets (generic + HuggingFace token) |
-| `templates/pvc.yaml` | PersistentVolumeClaim for model cache |
-| `templates/configmap.yaml` | Optional ConfigMap |
-| `templates/hpa.yaml` | HorizontalPodAutoscaler |
-| `templates/poddisruptionbudget.yaml` | PodDisruptionBudget |
-| `templates/custom-objects.yaml` | Custom Kubernetes objects |
-
-## Running Tests
-
-This chart includes unit tests using [helm-unittest](https://github.com/helm-unittest/helm-unittest). Install the plugin and run tests:
-
-```bash
-# Install plugin
-helm plugin install https://github.com/helm-unittest/helm-unittest
-
-# Run tests
-helm unittest .
-```
diff --git a/examples/online_serving/chart-helm/ct.yaml b/examples/online_serving/chart-helm/ct.yaml
deleted file mode 100644
index 157243f9e8b..00000000000
--- a/examples/online_serving/chart-helm/ct.yaml
+++ /dev/null
@@ -1,3 +0,0 @@
-chart-dirs:
- - charts
-validate-maintainers: false
diff --git a/examples/online_serving/chart-helm/lintconf.yaml b/examples/online_serving/chart-helm/lintconf.yaml
deleted file mode 100644
index a63c814d450..00000000000
--- a/examples/online_serving/chart-helm/lintconf.yaml
+++ /dev/null
@@ -1,42 +0,0 @@
----
-rules:
- braces:
- min-spaces-inside: 0
- max-spaces-inside: 0
- min-spaces-inside-empty: -1
- max-spaces-inside-empty: -1
- brackets:
- min-spaces-inside: 0
- max-spaces-inside: 0
- min-spaces-inside-empty: -1
- max-spaces-inside-empty: -1
- colons:
- max-spaces-before: 0
- max-spaces-after: 1
- commas:
- max-spaces-before: 0
- min-spaces-after: 1
- max-spaces-after: 1
- comments:
- require-starting-space: true
- min-spaces-from-content: 2
- document-end: disable
- document-start: disable
- empty-lines:
- max: 2
- max-start: 0
- max-end: 0
- hyphens:
- max-spaces-after: 1
- indentation:
- spaces: consistent
- indent-sequences: whatever
- check-multi-line-strings: false
- key-duplicates: enable
- line-length: disable
- new-line-at-end-of-file: disable
- new-lines:
- type: unix
- trailing-spaces: enable
- truthy:
- level: warning
diff --git a/examples/online_serving/chart-helm/templates/_helpers.tpl b/examples/online_serving/chart-helm/templates/_helpers.tpl
deleted file mode 100644
index 00f407baba0..00000000000
--- a/examples/online_serving/chart-helm/templates/_helpers.tpl
+++ /dev/null
@@ -1,203 +0,0 @@
-{{/*
-Define the vllm-omni serve command from model + omniArgs.
-If image.command is set, uses that as a full override.
-*/}}
-{{- define "chart.omni-command" -}}
-{{- if .Values.image.command }}
-{{- toYaml .Values.image.command }}
-{{- else }}
-- "vllm"
-- "serve"
-- {{ .Values.model | quote }}
-- "--omni"
-- "--host"
-- "0.0.0.0"
-- "--port"
-- {{ include "chart.container-port" . | quote }}
-{{- if .Values.omniArgs.vaeUseSlicing }}
-- "--vae-use-slicing"
-{{- end }}
-{{- if .Values.omniArgs.vaeUseTiling }}
-- "--vae-use-tiling"
-{{- end }}
-{{- if .Values.omniArgs.enableCpuOffload }}
-- "--enable-cpu-offload"
-{{- end }}
-{{- if .Values.omniArgs.numGpus }}
-- "--num-gpus"
-- {{ .Values.omniArgs.numGpus | quote }}
-{{- end }}
-{{- if .Values.omniArgs.stageConfigsPath }}
-- "--stage-configs-path"
-- {{ .Values.omniArgs.stageConfigsPath | quote }}
-{{- end }}
-{{- if and .Values.omniArgs.cacheBackend (ne .Values.omniArgs.cacheBackend "none") }}
-- "--cache-backend"
-- {{ .Values.omniArgs.cacheBackend | quote }}
-{{- end }}
-{{- if .Values.omniArgs.defaultSamplingParams }}
-- "--default-sampling-params"
-- {{ .Values.omniArgs.defaultSamplingParams | quote }}
-{{- end }}
-{{- if and .Values.omniArgs.workerBackend (ne .Values.omniArgs.workerBackend "multi_process") }}
-- "--worker-backend"
-- {{ .Values.omniArgs.workerBackend | quote }}
-{{- end }}
-{{- range .Values.omniArgs.extraArgs }}
-- {{ . | quote }}
-{{- end }}
-{{- end }}
-{{- end }}
-
-{{/*
-Define HuggingFace environment variables
-*/}}
-{{- define "chart.hf-env" -}}
-- name: HF_HOME
- value: "/cache/huggingface"
-- name: HOME
- value: "/cache"
-{{- if .Values.hfToken }}
-- name: HF_TOKEN
- valueFrom:
- secretKeyRef:
- name: {{ .Release.Name }}-hf-token
- key: token
-{{- end }}
-{{- end }}
-
-{{/*
-Define ports for the pods
-*/}}
-{{- define "chart.container-port" -}}
-{{- default "8000" .Values.containerPort }}
-{{- end }}
-
-{{/*
-Define service name
-*/}}
-{{- define "chart.service-name" -}}
-{{- if .Values.serviceName -}}
-{{ .Values.serviceName | lower | trim }}
-{{- else -}}
-{{ printf "%s-service" .Release.Name }}
-{{- end -}}
-{{- end }}
-
-{{/*
-Define service port
-*/}}
-{{- define "chart.service-port" -}}
-{{- if .Values.servicePort }}
-{{- .Values.servicePort }}
-{{- else }}
-{{- include "chart.container-port" . }}
-{{- end }}
-{{- end }}
-
-{{/*
-Define service port name
-*/}}
-{{- define "chart.service-port-name" -}}
-"service-port"
-{{- end }}
-
-{{/*
-Define container port name
-*/}}
-{{- define "chart.container-port-name" -}}
-"container-port"
-{{- end }}
-
-{{/*
-Define deployment strategy
-*/}}
-{{- define "chart.strategy" -}}
-strategy:
-{{- if not .Values.deploymentStrategy }}
- type: Recreate
-{{- else }}
-{{ toYaml .Values.deploymentStrategy | indent 2 }}
-{{- end }}
-{{- end }}
-
-{{/*
-Define additional ports
-*/}}
-{{- define "chart.extraPorts" }}
-{{- with .Values.extraPorts }}
-{{ toYaml . }}
-{{- end }}
-{{- end }}
-
-{{/*
-Define chart external ConfigMaps and Secrets
-*/}}
-{{- define "chart.externalConfigs" -}}
-{{- with .Values.externalConfigs -}}
-{{ toYaml . }}
-{{- end }}
-{{- end }}
-
-{{/*
-Define startup, liveness and readiness probes
-*/}}
-{{- define "chart.probes" -}}
-{{- if .Values.startupProbe }}
-startupProbe:
-{{- with .Values.startupProbe }}
-{{- toYaml . | nindent 2 }}
-{{- end }}
-{{- end }}
-{{- if .Values.readinessProbe }}
-readinessProbe:
-{{- with .Values.readinessProbe }}
-{{- toYaml . | nindent 2 }}
-{{- end }}
-{{- end }}
-{{- if .Values.livenessProbe }}
-livenessProbe:
-{{- with .Values.livenessProbe }}
-{{- toYaml . | nindent 2 }}
-{{- end }}
-{{- end }}
-{{- end }}
-
-{{/*
-Define resources
-*/}}
-{{- define "chart.resources" -}}
-requests:
- memory: {{ required "Value 'resources.requests.memory' must be defined !" .Values.resources.requests.memory | quote }}
- cpu: {{ required "Value 'resources.requests.cpu' must be defined !" .Values.resources.requests.cpu | quote }}
- {{- if and (gt (int (index .Values.resources.requests "nvidia.com/gpu")) 0) (gt (int (index .Values.resources.limits "nvidia.com/gpu")) 0) }}
- nvidia.com/gpu: {{ required "Value 'resources.requests.nvidia.com/gpu' must be defined !" (index .Values.resources.requests "nvidia.com/gpu") }}
- {{- end }}
-limits:
- memory: {{ required "Value 'resources.limits.memory' must be defined !" .Values.resources.limits.memory | quote }}
- cpu: {{ required "Value 'resources.limits.cpu' must be defined !" .Values.resources.limits.cpu | quote }}
- {{- if and (gt (int (index .Values.resources.requests "nvidia.com/gpu")) 0) (gt (int (index .Values.resources.limits "nvidia.com/gpu")) 0) }}
- nvidia.com/gpu: {{ required "Value 'resources.limits.nvidia.com/gpu' must be defined !" (index .Values.resources.limits "nvidia.com/gpu") }}
- {{- end }}
-{{- end }}
-
-{{/*
-Define user for the main container
-*/}}
-{{- define "chart.user" }}
-{{- if .Values.image.runAsUser }}
-runAsUser:
-{{- with .Values.image.runAsUser }}
-{{- toYaml . | nindent 2 }}
-{{- end }}
-{{- end }}
-{{- end }}
-
-{{/*
-Define chart labels
-*/}}
-{{- define "chart.labels" -}}
-{{- with .Values.labels -}}
-{{ toYaml . }}
-{{- end }}
-{{- end }}
diff --git a/examples/online_serving/chart-helm/templates/configmap.yaml b/examples/online_serving/chart-helm/templates/configmap.yaml
deleted file mode 100644
index e185c7e0adb..00000000000
--- a/examples/online_serving/chart-helm/templates/configmap.yaml
+++ /dev/null
@@ -1,11 +0,0 @@
-{{- if .Values.configs -}}
-apiVersion: v1
-kind: ConfigMap
-metadata:
- name: "{{ .Release.Name }}-configs"
- namespace: {{ .Release.Namespace }}
-data:
- {{- with .Values.configs }}
- {{- toYaml . | nindent 2 }}
- {{- end }}
-{{- end -}}
diff --git a/examples/online_serving/chart-helm/templates/custom-objects.yaml b/examples/online_serving/chart-helm/templates/custom-objects.yaml
deleted file mode 100644
index f3b4781c813..00000000000
--- a/examples/online_serving/chart-helm/templates/custom-objects.yaml
+++ /dev/null
@@ -1,6 +0,0 @@
-{{- if .Values.customObjects }}
-{{- range .Values.customObjects }}
-{{- tpl (. | toYaml) $ }}
----
-{{- end }}
-{{- end }}
diff --git a/examples/online_serving/chart-helm/templates/deployment.yaml b/examples/online_serving/chart-helm/templates/deployment.yaml
deleted file mode 100644
index c36f8df0067..00000000000
--- a/examples/online_serving/chart-helm/templates/deployment.yaml
+++ /dev/null
@@ -1,106 +0,0 @@
-apiVersion: apps/v1
-kind: Deployment
-metadata:
- name: "{{ .Release.Name }}-deployment-vllm-omni"
- namespace: {{ .Release.Namespace }}
- labels:
- {{- include "chart.labels" . | nindent 4 }}
-spec:
- {{- if not .Values.autoscaling.enabled }}
- replicas: {{ .Values.replicaCount }}
- {{- end }}
- {{- include "chart.strategy" . | nindent 2 }}
- selector:
- matchLabels:
- {{- include "chart.labels" . | nindent 6 }}
- progressDeadlineSeconds: 1800
- template:
- metadata:
- labels:
- {{- include "chart.labels" . | nindent 8 }}
- spec:
- containers:
- - name: "vllm-omni"
- image: "{{ required "Required value 'image.repository' must be defined !" .Values.image.repository }}:{{ required "Required value 'image.tag' must be defined !" .Values.image.tag }}"
- command:
- {{- include "chart.omni-command" . | nindent 12 }}
- securityContext:
- {{- if .Values.image.securityContext }}
- {{- with .Values.image.securityContext }}
- {{- toYaml . | nindent 12 }}
- {{- end }}
- {{- else }}
- runAsNonRoot: false
- {{- include "chart.user" . | indent 12 }}
- {{- end }}
- imagePullPolicy: IfNotPresent
- env:
- {{- include "chart.hf-env" . | nindent 12 }}
- {{- if .Values.image.env }}
- {{- toYaml .Values.image.env | nindent 12 }}
- {{- end }}
- {{- if or .Values.externalConfigs .Values.configs .Values.secrets }}
- envFrom:
- {{- if .Values.configs }}
- - configMapRef:
- name: "{{ .Release.Name }}-configs"
- {{- end }}
- {{- if .Values.secrets }}
- - secretRef:
- name: "{{ .Release.Name }}-secrets"
- {{- end }}
- {{- include "chart.externalConfigs" . | nindent 12 }}
- {{- end }}
- ports:
- - name: {{ include "chart.container-port-name" . }}
- containerPort: {{ include "chart.container-port" . }}
- {{- include "chart.extraPorts" . | nindent 12 }}
- {{- include "chart.probes" . | indent 10 }}
- resources: {{- include "chart.resources" . | nindent 12 }}
- volumeMounts:
- - name: shm
- mountPath: /dev/shm
- - name: model-cache
- mountPath: /cache
-
- {{- with .Values.extraContainers }}
- {{ toYaml . | nindent 8 }}
- {{- end }}
-
- {{- if .Values.extraInit.initContainers }}
- initContainers:
- {{- toYaml .Values.extraInit.initContainers | nindent 8 }}
- {{- end }}
-
- volumes:
- - name: shm
- emptyDir:
- medium: Memory
- sizeLimit: {{ .Values.shmSize }}
- - name: model-cache
- {{- if .Values.modelCache.enabled }}
- persistentVolumeClaim:
- claimName: {{ .Release.Name }}-model-cache
- {{- else }}
- emptyDir: {}
- {{- end }}
-
- {{- with .Values.nodeSelector }}
- nodeSelector:
- {{- toYaml . | nindent 8 }}
- {{- end }}
- {{- with .Values.tolerations }}
- tolerations:
- {{- toYaml . | nindent 8 }}
- {{- end }}
- {{- if .Values.gpuModels }}
- affinity:
- nodeAffinity:
- requiredDuringSchedulingIgnoredDuringExecution:
- nodeSelectorTerms:
- - matchExpressions:
- - key: nvidia.com/gpu.product
- operator: In
- values:
- {{- toYaml .Values.gpuModels | nindent 20 }}
- {{- end }}
diff --git a/examples/online_serving/chart-helm/templates/hpa.yaml b/examples/online_serving/chart-helm/templates/hpa.yaml
deleted file mode 100644
index cadc92ed5a1..00000000000
--- a/examples/online_serving/chart-helm/templates/hpa.yaml
+++ /dev/null
@@ -1,31 +0,0 @@
-{{- if .Values.autoscaling.enabled }}
-apiVersion: autoscaling/v2
-kind: HorizontalPodAutoscaler
-metadata:
- name: "{{ .Release.Name }}-hpa"
- namespace: {{ .Release.Namespace }}
-spec:
- scaleTargetRef:
- apiVersion: apps/v1
- kind: Deployment
- name: "{{ .Release.Name }}-deployment-vllm-omni"
- minReplicas: {{ .Values.autoscaling.minReplicas }}
- maxReplicas: {{ .Values.autoscaling.maxReplicas }}
- metrics:
- {{- if .Values.autoscaling.targetCPUUtilizationPercentage }}
- - type: Resource
- resource:
- name: cpu
- target:
- type: Utilization
- averageUtilization: {{ .Values.autoscaling.targetCPUUtilizationPercentage }}
- {{- end }}
- {{- if .Values.autoscaling.targetMemoryUtilizationPercentage }}
- - type: Resource
- resource:
- name: memory
- target:
- type: Utilization
- averageUtilization: {{ .Values.autoscaling.targetMemoryUtilizationPercentage }}
- {{- end }}
-{{- end }}
diff --git a/examples/online_serving/chart-helm/templates/ingress.yaml b/examples/online_serving/chart-helm/templates/ingress.yaml
deleted file mode 100644
index 1749ec24211..00000000000
--- a/examples/online_serving/chart-helm/templates/ingress.yaml
+++ /dev/null
@@ -1,32 +0,0 @@
-{{- if .Values.ingress.enabled }}
-apiVersion: networking.k8s.io/v1
-kind: Ingress
-metadata:
- name: "{{ .Release.Name }}-ingress"
- namespace: {{ .Release.Namespace }}
- labels:
- {{- include "chart.labels" . | nindent 4 }}
- {{- with .Values.ingress.annotations }}
- annotations:
- {{- toYaml . | nindent 4 }}
- {{- end }}
-spec:
- {{- if .Values.ingress.ingressClassName }}
- ingressClassName: {{ .Values.ingress.ingressClassName }}
- {{- end }}
- {{- if .Values.ingress.tls }}
- tls:
- {{- toYaml .Values.ingress.tls | nindent 4 }}
- {{- end }}
- rules:
- - host: {{ .Values.ingress.host }}
- http:
- paths:
- - path: /
- pathType: Prefix
- backend:
- service:
- name: "{{ include "chart.service-name" . }}"
- port:
- number: {{ include "chart.service-port" . }}
-{{- end }}
diff --git a/examples/online_serving/chart-helm/templates/poddisruptionbudget.yaml b/examples/online_serving/chart-helm/templates/poddisruptionbudget.yaml
deleted file mode 100644
index b5d12502bea..00000000000
--- a/examples/online_serving/chart-helm/templates/poddisruptionbudget.yaml
+++ /dev/null
@@ -1,12 +0,0 @@
-{{- if gt (int .Values.replicaCount) 1 }}
-apiVersion: policy/v1
-kind: PodDisruptionBudget
-metadata:
- name: "{{ .Release.Name }}-pdb"
- namespace: {{ .Release.Namespace }}
-spec:
- maxUnavailable: {{ default 1 .Values.maxUnavailablePodDisruptionBudget }}
- selector:
- matchLabels:
- {{- include "chart.labels" . | nindent 6 }}
-{{- end }}
diff --git a/examples/online_serving/chart-helm/templates/pvc.yaml b/examples/online_serving/chart-helm/templates/pvc.yaml
deleted file mode 100644
index a433c10dac1..00000000000
--- a/examples/online_serving/chart-helm/templates/pvc.yaml
+++ /dev/null
@@ -1,16 +0,0 @@
-{{- if .Values.modelCache.enabled }}
-apiVersion: v1
-kind: PersistentVolumeClaim
-metadata:
- name: "{{ .Release.Name }}-model-cache"
- namespace: {{ .Release.Namespace }}
-spec:
- accessModes:
- {{- toYaml .Values.modelCache.accessModes | nindent 4 }}
- {{- if .Values.modelCache.storageClassName }}
- storageClassName: {{ .Values.modelCache.storageClassName }}
- {{- end }}
- resources:
- requests:
- storage: {{ .Values.modelCache.storageSize }}
-{{- end }}
diff --git a/examples/online_serving/chart-helm/templates/secrets.yaml b/examples/online_serving/chart-helm/templates/secrets.yaml
deleted file mode 100644
index 4d94409f0c5..00000000000
--- a/examples/online_serving/chart-helm/templates/secrets.yaml
+++ /dev/null
@@ -1,23 +0,0 @@
-{{- if .Values.secrets }}
-apiVersion: v1
-kind: Secret
-metadata:
- name: "{{ .Release.Name }}-secrets"
- namespace: {{ .Release.Namespace }}
-type: Opaque
-data:
- {{- range $key, $val := .Values.secrets }}
- {{ $key }}: {{ $val | b64enc | quote }}
- {{- end }}
----
-{{- end }}
-{{- if .Values.hfToken }}
-apiVersion: v1
-kind: Secret
-metadata:
- name: "{{ .Release.Name }}-hf-token"
- namespace: {{ .Release.Namespace }}
-type: Opaque
-data:
- token: {{ .Values.hfToken | b64enc | quote }}
-{{- end }}
diff --git a/examples/online_serving/chart-helm/templates/service.yaml b/examples/online_serving/chart-helm/templates/service.yaml
deleted file mode 100644
index ad243a3aafd..00000000000
--- a/examples/online_serving/chart-helm/templates/service.yaml
+++ /dev/null
@@ -1,14 +0,0 @@
-apiVersion: v1
-kind: Service
-metadata:
- name: "{{ include "chart.service-name" . }}"
- namespace: {{ .Release.Namespace }}
-spec:
- type: ClusterIP
- ports:
- - name: {{ include "chart.service-port-name" . }}
- port: {{ include "chart.service-port" . }}
- targetPort: {{ include "chart.container-port-name" . }}
- protocol: TCP
- selector:
- {{- include "chart.labels" . | nindent 4 }}
diff --git a/examples/online_serving/chart-helm/tests/deployment_test.yaml b/examples/online_serving/chart-helm/tests/deployment_test.yaml
deleted file mode 100644
index e2c7b32c4b4..00000000000
--- a/examples/online_serving/chart-helm/tests/deployment_test.yaml
+++ /dev/null
@@ -1,181 +0,0 @@
-suite: test deployment
-templates:
- - deployment.yaml
-tests:
- - it: should create deployment with default omni command
- asserts:
- - hasDocuments:
- count: 1
- - isKind:
- of: Deployment
- - equal:
- path: spec.template.spec.containers[0].name
- value: vllm-omni
- - equal:
- path: spec.template.spec.containers[0].command[0]
- value: vllm
- - equal:
- path: spec.template.spec.containers[0].command[1]
- value: serve
- - equal:
- path: spec.template.spec.containers[0].command[2]
- value: Tongyi-MAI/Z-Image-Turbo
- - equal:
- path: spec.template.spec.containers[0].command[3]
- value: "--omni"
- - equal:
- path: spec.template.spec.containers[0].command[4]
- value: "--host"
- - equal:
- path: spec.template.spec.containers[0].command[5]
- value: "0.0.0.0"
- - equal:
- path: spec.template.spec.containers[0].command[6]
- value: "--port"
- - equal:
- path: spec.template.spec.containers[0].command[7]
- value: "8000"
-
- - it: should use custom model when set
- set:
- model: "Qwen/Qwen2.5-Omni-7B"
- asserts:
- - equal:
- path: spec.template.spec.containers[0].command[2]
- value: Qwen/Qwen2.5-Omni-7B
-
- - it: should include omniArgs flags in command
- set:
- omniArgs:
- vaeUseSlicing: true
- vaeUseTiling: true
- enableCpuOffload: true
- numGpus: 2
- cacheBackend: "tea_cache"
- workerBackend: "ray"
- extraArgs:
- - "--enable-layerwise-offload"
- asserts:
- - contains:
- path: spec.template.spec.containers[0].command
- content: "--vae-use-slicing"
- - contains:
- path: spec.template.spec.containers[0].command
- content: "--vae-use-tiling"
- - contains:
- path: spec.template.spec.containers[0].command
- content: "--enable-cpu-offload"
- - contains:
- path: spec.template.spec.containers[0].command
- content: "--num-gpus"
- - contains:
- path: spec.template.spec.containers[0].command
- content: "--cache-backend"
- - contains:
- path: spec.template.spec.containers[0].command
- content: "--worker-backend"
- - contains:
- path: spec.template.spec.containers[0].command
- content: "--enable-layerwise-offload"
-
- - it: should use full command override when image.command is set
- set:
- image:
- command:
- - "custom-binary"
- - "--flag"
- asserts:
- - equal:
- path: spec.template.spec.containers[0].command[0]
- value: custom-binary
- - equal:
- path: spec.template.spec.containers[0].command[1]
- value: "--flag"
-
- - it: should mount shm and model-cache volumes
- asserts:
- - contains:
- path: spec.template.spec.containers[0].volumeMounts
- content:
- name: shm
- mountPath: /dev/shm
- - contains:
- path: spec.template.spec.containers[0].volumeMounts
- content:
- name: model-cache
- mountPath: /cache
- - contains:
- path: spec.template.spec.volumes
- content:
- name: shm
- emptyDir:
- medium: Memory
- sizeLimit: 8Gi
-
- - it: should use PVC for model-cache when modelCache is enabled
- set:
- modelCache:
- enabled: true
- storageSize: "50Gi"
- accessModes:
- - ReadWriteOnce
- asserts:
- - contains:
- path: spec.template.spec.volumes
- content:
- name: model-cache
- persistentVolumeClaim:
- claimName: RELEASE-NAME-model-cache
-
- - it: should use emptyDir for model-cache when modelCache is disabled
- set:
- modelCache:
- enabled: false
- storageSize: "50Gi"
- accessModes:
- - ReadWriteOnce
- asserts:
- - contains:
- path: spec.template.spec.volumes
- content:
- name: model-cache
- emptyDir: {}
-
- - it: should set HF_HOME environment variable
- asserts:
- - contains:
- path: spec.template.spec.containers[0].env
- content:
- name: HF_HOME
- value: /cache/huggingface
-
- - it: should set HF_TOKEN env when hfToken is provided
- set:
- hfToken: "hf_test_token_123"
- asserts:
- - contains:
- path: spec.template.spec.containers[0].env
- content:
- name: HF_TOKEN
- valueFrom:
- secretKeyRef:
- name: RELEASE-NAME-hf-token
- key: token
-
- - it: should create custom init containers when specified
- set:
- extraInit:
- initContainers:
- - name: my-init
- image: busybox:latest
- command: ["echo", "init"]
- asserts:
- - lengthEqual:
- path: spec.template.spec.initContainers
- count: 1
- - equal:
- path: spec.template.spec.initContainers[0].name
- value: my-init
- - equal:
- path: spec.template.spec.initContainers[0].image
- value: busybox:latest
diff --git a/examples/online_serving/chart-helm/tests/ingress_test.yaml b/examples/online_serving/chart-helm/tests/ingress_test.yaml
deleted file mode 100644
index 938cab824c8..00000000000
--- a/examples/online_serving/chart-helm/tests/ingress_test.yaml
+++ /dev/null
@@ -1,86 +0,0 @@
-suite: test ingress
-templates:
- - ingress.yaml
-tests:
- - it: should not create Ingress when disabled
- set:
- ingress:
- enabled: false
- asserts:
- - hasDocuments:
- count: 0
-
- - it: should create Ingress when enabled
- set:
- ingress:
- enabled: true
- host: "vllm-omni.example.com"
- asserts:
- - hasDocuments:
- count: 1
- - isKind:
- of: Ingress
- - equal:
- path: spec.rules[0].host
- value: vllm-omni.example.com
- - equal:
- path: spec.rules[0].http.paths[0].path
- value: /
- - equal:
- path: spec.rules[0].http.paths[0].pathType
- value: Prefix
- - equal:
- path: spec.rules[0].http.paths[0].backend.service.name
- value: RELEASE-NAME-service
- - equal:
- path: spec.rules[0].http.paths[0].backend.service.port.number
- value: 80
-
- - it: should set ingressClassName when specified
- set:
- ingress:
- enabled: true
- host: "vllm-omni.example.com"
- ingressClassName: "nginx"
- asserts:
- - equal:
- path: spec.ingressClassName
- value: nginx
-
- - it: should not set ingressClassName when empty
- set:
- ingress:
- enabled: true
- host: "vllm-omni.example.com"
- ingressClassName: ""
- asserts:
- - notExists:
- path: spec.ingressClassName
-
- - it: should include annotations when specified
- set:
- ingress:
- enabled: true
- host: "vllm-omni.example.com"
- annotations:
- nginx.ingress.kubernetes.io/proxy-body-size: "100m"
- asserts:
- - isNotEmpty:
- path: metadata.annotations
-
- - it: should include TLS configuration when specified
- set:
- ingress:
- enabled: true
- host: "vllm-omni.example.com"
- tls:
- - secretName: vllm-omni-tls
- hosts:
- - vllm-omni.example.com
- asserts:
- - equal:
- path: spec.tls[0].secretName
- value: vllm-omni-tls
- - equal:
- path: spec.tls[0].hosts[0]
- value: vllm-omni.example.com
diff --git a/examples/online_serving/chart-helm/tests/pvc_test.yaml b/examples/online_serving/chart-helm/tests/pvc_test.yaml
deleted file mode 100644
index f27bed618f8..00000000000
--- a/examples/online_serving/chart-helm/tests/pvc_test.yaml
+++ /dev/null
@@ -1,73 +0,0 @@
-suite: test pvc
-templates:
- - pvc.yaml
-tests:
- - it: should create PVC when modelCache is enabled
- set:
- modelCache:
- enabled: true
- storageSize: "50Gi"
- storageClassName: ""
- accessModes:
- - ReadWriteOnce
- asserts:
- - hasDocuments:
- count: 1
- - isKind:
- of: PersistentVolumeClaim
- - equal:
- path: spec.accessModes[0]
- value: ReadWriteOnce
- - equal:
- path: spec.resources.requests.storage
- value: 50Gi
-
- - it: should not create PVC when modelCache is disabled
- set:
- modelCache:
- enabled: false
- storageSize: "50Gi"
- accessModes:
- - ReadWriteOnce
- asserts:
- - hasDocuments:
- count: 0
-
- - it: should use custom storage size
- set:
- modelCache:
- enabled: true
- storageSize: "100Gi"
- storageClassName: ""
- accessModes:
- - ReadWriteOnce
- asserts:
- - equal:
- path: spec.resources.requests.storage
- value: 100Gi
-
- - it: should set storageClassName when specified
- set:
- modelCache:
- enabled: true
- storageSize: "50Gi"
- storageClassName: "fast-ssd"
- accessModes:
- - ReadWriteOnce
- asserts:
- - equal:
- path: spec.storageClassName
- value: fast-ssd
-
- - it: should support ReadWriteMany access mode
- set:
- modelCache:
- enabled: true
- storageSize: "50Gi"
- storageClassName: ""
- accessModes:
- - ReadWriteMany
- asserts:
- - equal:
- path: spec.accessModes[0]
- value: ReadWriteMany
diff --git a/examples/online_serving/chart-helm/tests/secrets_test.yaml b/examples/online_serving/chart-helm/tests/secrets_test.yaml
deleted file mode 100644
index 9de12603934..00000000000
--- a/examples/online_serving/chart-helm/tests/secrets_test.yaml
+++ /dev/null
@@ -1,48 +0,0 @@
-suite: test secrets
-templates:
- - secrets.yaml
-tests:
- - it: should create HF token secret when hfToken is provided
- set:
- hfToken: "hf_test_token_123"
- asserts:
- - hasDocuments:
- count: 1
- - isKind:
- of: Secret
- - equal:
- path: metadata.name
- value: RELEASE-NAME-hf-token
- - exists:
- path: data.token
-
- - it: should not create any secrets when hfToken is empty and no secrets defined
- set:
- hfToken: ""
- secrets: {}
- asserts:
- - hasDocuments:
- count: 0
-
- - it: should create both generic and HF token secrets
- set:
- hfToken: "hf_test_token_123"
- secrets:
- mykey: myvalue
- asserts:
- - hasDocuments:
- count: 2
-
- - it: should create only generic secrets when no hfToken
- set:
- hfToken: ""
- secrets:
- mykey: myvalue
- asserts:
- - hasDocuments:
- count: 1
- - isKind:
- of: Secret
- - equal:
- path: metadata.name
- value: RELEASE-NAME-secrets
diff --git a/examples/online_serving/chart-helm/values.yaml b/examples/online_serving/chart-helm/values.yaml
deleted file mode 100644
index 52c5bacbdb1..00000000000
--- a/examples/online_serving/chart-helm/values.yaml
+++ /dev/null
@@ -1,197 +0,0 @@
-# -- Default values for chart vllm-omni
-# -- Declare variables to be passed into your templates.
-
-# -- HuggingFace model ID to serve
-model: "Tongyi-MAI/Z-Image-Turbo"
-
-# -- Image configuration
-image:
- # -- Image repository
- repository: "vllm/vllm-omni"
- # -- Image tag
- tag: "v0.16.0"
- # -- Override the container command entirely. If empty, the chart constructs
- # -- it automatically from model + omniArgs.
- command: []
- # -- Optional environment variables for the container
- env: []
- # -- Security context override
- securityContext: {}
-
-# -- Container port
-containerPort: 8000
-# -- Service name (auto-generated from release name if empty)
-serviceName:
-# -- Service port
-servicePort: 80
-# -- Additional ports configuration
-extraPorts: []
-
-# -- Number of replicas
-replicaCount: 1
-
-# -- Deployment strategy configuration
-deploymentStrategy: {}
-
-# -- Resource configuration
-resources:
- requests:
- # -- Number of CPUs
- cpu: 4
- # -- CPU memory
- memory: 24Gi
- # -- Number of GPUs
- nvidia.com/gpu: 1
- limits:
- # -- Number of CPUs
- cpu: 4
- # -- CPU memory
- memory: 24Gi
- # -- Number of GPUs
- nvidia.com/gpu: 1
-
-# -- GPU model types for node affinity scheduling (optional)
-# -- Leave empty to schedule on any GPU node. Set to restrict to specific GPU types.
-# -- Example: ["NVIDIA-A100-SXM4-40GB"]
-gpuModels: []
-
-# -- vllm-omni specific CLI arguments
-omniArgs:
- # -- Additional raw CLI flags appended to the serve command (list of strings)
- extraArgs: []
- # -- Enable VAE slicing for memory optimization
- vaeUseSlicing: false
- # -- Enable VAE tiling for memory optimization
- vaeUseTiling: false
- # -- Enable CPU offloading for diffusion models
- enableCpuOffload: false
- # -- Number of GPUs for diffusion inference (empty = auto)
- numGpus:
- # -- Path to stage configs file (empty = auto-detected from model)
- stageConfigsPath:
- # -- Cache backend: none, tea_cache, or cache_dit
- cacheBackend: "none"
- # -- Default sampling params as a JSON string
- defaultSamplingParams:
- # -- Worker backend: multi_process or ray
- workerBackend: "multi_process"
-
-# -- HuggingFace token for gated models (optional)
-hfToken: ""
-
-# -- Shared memory size for PyTorch multiprocessing
-shmSize: "8Gi"
-
-# -- Model cache configuration (HuggingFace downloads)
-modelCache:
- # -- Use a PersistentVolumeClaim for model cache (recommended for production)
- enabled: true
- # -- Storage size for the PVC
- storageSize: "50Gi"
- # -- Storage class name (empty = cluster default)
- storageClassName: ""
- # -- Access modes
- accessModes:
- - ReadWriteOnce
-
-# -- Autoscaling configuration
-autoscaling:
- # -- Enable autoscaling
- enabled: false
- # -- Minimum replicas
- minReplicas: 1
- # -- Maximum replicas
- maxReplicas: 10
- # -- Target CPU utilization for autoscaling
- targetCPUUtilizationPercentage: 80
- # targetMemoryUtilizationPercentage: 80
-
-# -- ConfigMap data (key-value pairs injected as environment variables)
-configs: {}
-
-# -- Secrets data (key-value pairs, base64-encoded automatically)
-secrets: {}
-
-# -- External ConfigMaps/Secrets references
-externalConfigs: []
-
-# -- Custom Kubernetes objects
-customObjects: []
-
-# -- PodDisruptionBudget max unavailable
-maxUnavailablePodDisruptionBudget: ""
-
-# -- Additional init containers
-extraInit:
- initContainers: []
-
-# -- Additional sidecar containers
-extraContainers: []
-
-# -- Startup probe configuration
-# -- Protects slow-starting containers. Liveness and readiness probes
-# -- do not start until the startup probe succeeds.
-# -- failureThreshold * periodSeconds = max startup time (40 * 30 = 1200s = 20 min)
-startupProbe:
- # -- HTTP check configuration
- httpGet:
- # -- Path to check
- path: /health
- # -- Port to check (uses named port to stay in sync with containerPort)
- port: "container-port"
- # -- Failures before killing the container
- failureThreshold: 40
- # -- How often to perform the probe
- periodSeconds: 30
-
-# -- Readiness probe configuration
-readinessProbe:
- # -- How often to perform the probe
- periodSeconds: 10
- # -- Failures before marking unready
- failureThreshold: 3
- # -- HTTP check configuration
- httpGet:
- # -- Path to check
- path: /health
- # -- Port to check (uses named port to stay in sync with containerPort)
- port: "container-port"
-
-# -- Liveness probe configuration
-livenessProbe:
- # -- Failures before restarting
- failureThreshold: 3
- # -- How often to perform the probe
- periodSeconds: 15
- # -- HTTP check configuration
- httpGet:
- # -- Path to check
- path: /health
- # -- Port to check (uses named port to stay in sync with containerPort)
- port: "container-port"
-
-# -- Ingress configuration
-ingress:
- # -- Enable Ingress
- enabled: false
- # -- Ingress class name (e.g., nginx, traefik)
- ingressClassName: ""
- # -- Hostname for the Ingress rule
- host: "vllm-omni.example.com"
- # -- Additional annotations
- annotations: {}
- # -- TLS configuration
- tls: []
- # - secretName: vllm-omni-tls
- # hosts:
- # - vllm-omni.example.com
-
-# -- Node selector for pod scheduling
-nodeSelector: {}
-
-# -- Tolerations for pod scheduling
-tolerations: []
-
-# -- Labels applied to all resources
-labels:
- app: "vllm-omni"
diff --git a/examples/online_serving/diffusers_pipeline_adapter/README.md b/examples/online_serving/diffusers_pipeline_adapter/README.md
deleted file mode 100644
index 8dbf9369ae8..00000000000
--- a/examples/online_serving/diffusers_pipeline_adapter/README.md
+++ /dev/null
@@ -1,83 +0,0 @@
-# Diffusers Backend Adapter Example
-
-This example demonstrates how to serve any 🤗 Diffusers pipeline through vLLM-Omni
-using the `diffusers` load format.
-
-## Supported Models
-
-Any model loadable via `DiffusionPipeline.from_pretrained()` should be supported, including text-to-image, image-to-image, text-to-video, image-to-video, and text-to-audio.
-
-## Limitations
-
-The diffusers backend is a black-box adapter. The following features are NOT yet supported.
-It is not guaranteed whether they will be supported in the future.
-
-- CFG parallel execution
-- Sequence parallel execution
-- TeaCache / Cache-DiT acceleration
-- Step-wise execution (continuous batching)
-
-For these features, it is recommended to use natively supported pipelines instead.
-
-## Usage
-
-### Option 1: CLI arguments
-
-```bash
-vllm serve "stable-diffusion-v1-5/stable-diffusion-v1-5" \
- --omni \
- --diffusion-load-format diffusers \
- --diffusers-load-kwargs '{"use_safetensors": true}' \
- --diffusers-call-kwargs '{"num_inference_steps": 30, "guidance_scale": 7.5}'
-```
-
-`--diffusers-load-kwargs` and `--diffusers-call-kwargs` are only valid together with `--diffusion-load-format diffusers`.
-
-### Option 2: Stage config YAML
-
-```bash
-vllm serve stable-diffusion-v1-5/stable-diffusion-v1-5 --stage-configs-path examples/online_serving/diffusers_pipeline_adapter/stage_config.yaml --omni
-```
-
-The particular fields of interest are `model`, `diffusion_load_format`, `diffusers_load_kwargs`, and `diffusers_call_kwargs` under `engine_args`. They are the same as the CLI arguments.
-
-## Send a Request
-
-```bash
-curl http://localhost:8000/v1/images/generations \
- -H "Content-Type: application/json" \
- -d '{
- "model": "stable-diffusion-v1-5/stable-diffusion-v1-5",
- "prompt": "a photo of an astronaut riding a horse on mars",
- "n": 1,
- "size": "512x512"
- }'
-```
-
-Or refer to other documentation pages on how to request a particular input/output modality, such as `examples/online_serving/text_to_image/openai_chat_client.py`.
-
-## Configuration Reference
-
-For the diffusers adapter, set options under **`engine_args`**:
-
-### `diffusion_load_format: "diffusers"`
-
-This field selects the Hugging Face diffusers adapter path (see `DiffusersPipelineLoader`).
-
-### `diffusers_load_kwargs`
-
-Passed to `DiffusionPipeline.from_pretrained()`.
-
-This is suitable for model-specific configurations not available through the vLLM-Omni interface (such as `Omni.__init__()`, `vllm serve` CLI arguments, and stage config YAML fields outside `diffusers_load_kwargs`).
-
-When a parameter is available in the vLLM-Omni interface, it will be adapted here.
-But if that parameter is simultaneously set in both the vLLM-Omni interface and `diffusers_load_kwargs`, the **latter** will take precedence.
-
-### `diffusers_call_kwargs`
-
-Passed to `pipeline.__call__()`.
-
-This is suitable for sampling parameters not available through the vLLM-Omni interface (such as `Omni.generate()` and online serving payloads).
-
-When a parameter is available in the vLLM-Omni interface, it will be adapted here.
-But if that parameter is simultaneously set in both the vLLM-Omni interface and `diffusers_call_kwargs`, the **former** will take precedence (because it is set at request time).
diff --git a/examples/online_serving/diffusers_pipeline_adapter/stage_config.yaml b/examples/online_serving/diffusers_pipeline_adapter/stage_config.yaml
deleted file mode 100644
index 7c96eb6c167..00000000000
--- a/examples/online_serving/diffusers_pipeline_adapter/stage_config.yaml
+++ /dev/null
@@ -1,31 +0,0 @@
-# Example stage config for diffusers backend
-# This config demonstrates serving Stable Diffusion 1.5 via the diffusers adapter.
-# Users should copy and modify this for their own models.
-
-model_type: diffusion
-
-stage_args:
- - stage_id: 0
- stage_type: diffusion
- engine_args:
- model_stage: diffusion
- model: "stable-diffusion-v1-5/stable-diffusion-v1-5"
- distributed_executor_backend: "mp"
- # gpu_memory_utilization: 0.9
- engine_output_type: image
- # Select the HF diffusers adapter
- diffusion_load_format: "diffusers"
- # model_class_name: "DiffusersAdapterPipeline" # default when diffusion_load_format is diffusers
- diffusers_load_kwargs:
- # Passed to DiffusionPipeline.from_pretrained().
- # Good for model-specific loading parameters not covered by OmniDiffusionConfig.
- # During model load time, parameters here override their counterparts in the vLLM-Omni interface.
- use_safetensors: true
- diffusers_call_kwargs:
- # Passed to pipeline.__call__().
- # Good for model-specific sampling parameters not covered by OmniDiffusionSamplingParams.
- # During request time, parameters here are overridden by the counterparts in OmniDiffusionSamplingParams.
- num_inference_steps: 30
- guidance_scale: 7.5
- final_output: true
- final_output_type: image
diff --git a/examples/online_serving/dynin_omni/README.md b/examples/online_serving/dynin_omni/README.md
deleted file mode 100644
index d8526d42373..00000000000
--- a/examples/online_serving/dynin_omni/README.md
+++ /dev/null
@@ -1,97 +0,0 @@
-# Dynin-Omni Online Serving Example
-
-## Installation
-
-Please refer to [README.md](../../../README.md).
-
-## Launch the Server
-
-First, find the `transformers_modules` path:
-
-```bash
-python - <<'PY'
-from transformers.utils.hub import HF_MODULES_CACHE
-print(HF_MODULES_CACHE)
-PY
-```
-
-Then export it for both `PYTHONPATH` and `HF_MODULES_CACHE`:
-
-```bash
-export PYTHONPATH=<transformers_modules_path>:$PYTHONPATH
-export HF_MODULES_CACHE=<transformers_modules_path>
-```
-
-Run from repository root:
-
-```bash
-vllm-omni serve snu-aidas/Dynin-Omni \
- --omni \
- --port 8091 \
- --stage-configs-path "$(pwd)/vllm_omni/model_executor/stage_configs/dynin_omni.yaml"
-```
-
-If `vllm-omni` is not in PATH, run:
-
-```bash
-PYTHONPATH="$(pwd)" python -m vllm_omni.entrypoints.cli.main serve snu-aidas/Dynin-Omni \
- --omni \
- --port 8091 \
- --stage-configs-path "$(pwd)/vllm_omni/model_executor/stage_configs/dynin_omni.yaml"
-```
-
-Wait until the server logs show both `All stages initialized successfully` and
-`Application startup complete.` before sending requests.
-
-## Send Requests via Python Client
-
-Move to the example directory:
-
-```bash
-cd examples/online_serving/dynin_omni
-```
-
-### Text -> Image
-
-```bash
-python openai_chat_completion_client_for_multimodal_generation.py \
- --query-type t2i \
- --prompt "A realistic indoor living room with natural daylight."
-```
-
-### Image -> Image
-
-```bash
-python openai_chat_completion_client_for_multimodal_generation.py \
- --query-type i2i \
- --image-path ../../offline_inference/dynin_omni/data/image/sofa_under_water.jpg \
- --prompt "Transform this surreal underwater setting into a realistic indoor living room while preserving the sofa layout."
-```
-
-### Text -> Speech
-
-```bash
-python openai_chat_completion_client_for_multimodal_generation.py \
- --query-type t2s \
- --prompt "Hello. This is Dynin-omni."
-```
-
-## CLI Arguments
-
-- `--query-type` (`t2i|t2s|i2i`)
-- `--model` (default: `snu-aidas/Dynin-Omni`)
-- `--host` / `--port` (OpenAI-compatible vLLM endpoint)
-- `--prompt` (custom text)
-- `--image-path` (required for `i2i`)
-- `--modalities` (optional output modalities override)
-- `--output-dir` (default: `/tmp/dynin_online_outputs`)
-
-## Notes
-
-- This client currently supports only `t2i`, `t2s`, and `i2i`.
-- `t2t` is intentionally not exposed in this online example.
-- This example intentionally uses the OpenAI-compatible chat completion endpoint.
-- Task routing for non-text outputs relies on Dynin task trigger tokens (`<|t2i|>`, `<|i2i|>`, `<|t2s|>`) injected by the client.
-- Outputs are saved under `/tmp/dynin_online_outputs` by default.
-- Dynin stage-0 warmup can take a while on first startup; do not send requests before startup completes.
-- Dynin itself can execute text-returning tasks such as `t2t`, `s2t`, `i2t`, and `v2t`, but this online serving example currently runs stage-0 in `generation` mode. In that path, the generation worker does not surface the final text as `output.text`, so OpenAI chat responses for those text-output tasks may complete internally but still return empty text.
diff --git a/examples/online_serving/dynin_omni/openai_chat_completion_client_for_multimodal_generation.py b/examples/online_serving/dynin_omni/openai_chat_completion_client_for_multimodal_generation.py
deleted file mode 100644
index 9728555431f..00000000000
--- a/examples/online_serving/dynin_omni/openai_chat_completion_client_for_multimodal_generation.py
+++ /dev/null
@@ -1,342 +0,0 @@
-#!/usr/bin/env python3
-# SPDX-License-Identifier: Apache-2.0
-
-from __future__ import annotations
-
-import argparse
-import base64
-import json
-import mimetypes
-import os
-import time
-from pathlib import Path
-from typing import Any
-
-DEFAULT_MODEL = "snu-aidas/Dynin-Omni"
-DEFAULT_OUTPUT_DIR = "/tmp/dynin_online_outputs"
-
-QUERY_CHOICES = ("t2i", "t2s", "i2i")
-DEFAULT_PROMPT_BY_QUERY = {
- "t2i": "A high quality detailed living room interior photo.",
- "t2s": "Please read this sentence naturally: Hello from Dynin-Omni online serving.",
- "i2i": "Transform this image into a realistic indoor living room while preserving layout.",
-}
-DEFAULT_MODALITIES_BY_QUERY = {
- "t2i": ["image"],
- "t2s": ["audio"],
- "i2i": ["image"],
-}
-OFFLINE_PARITY_STAGE_COUNT = 3
-OFFLINE_PARITY_STAGE_SAMPLING = {
- "max_tokens": 1,
- "temperature": 0.0,
- "top_p": 1.0,
- "detokenize": False,
-}
-
-
-def _infer_mime_type(path: Path) -> str:
- mime_type, _ = mimetypes.guess_type(str(path))
- return mime_type or "application/octet-stream"
-
-
-def _encode_file_as_data_url(path: Path) -> str:
- mime_type = _infer_mime_type(path)
- raw = path.read_bytes()
- encoded = base64.b64encode(raw).decode("utf-8")
- return f"data:{mime_type};base64,{encoded}"
-
-
-def _to_image_url(path_or_url: str) -> str:
- value = str(path_or_url)
- if value.startswith(("http://", "https://", "data:image/")):
- return value
- path = Path(value).expanduser().resolve()
- if not path.exists():
- raise FileNotFoundError(f"Image file not found: {path}")
- return _encode_file_as_data_url(path)
-
-
-def _build_user_content(query_type: str, prompt: str, image_path: str | None) -> list[dict[str, Any]]:
- if query_type == "t2i":
- return [{"type": "text", "text": f"<|t2i|> {prompt}"}]
-
- if query_type == "t2s":
- return [{"type": "text", "text": f"<|t2s|> {prompt}"}]
-
- if query_type == "i2i":
- if not image_path:
- raise ValueError("--image-path is required for query type i2i")
- return [
- {"type": "text", "text": f"<|i2i|> {prompt}"},
- {"type": "image_url", "image_url": {"url": _to_image_url(image_path)}},
- ]
-
- raise ValueError(f"Unsupported query_type: {query_type}")
-
-
-def _collect_text_from_content(content: Any) -> list[str]:
- texts: list[str] = []
- if isinstance(content, str):
- stripped = content.strip()
- if stripped:
- texts.append(stripped)
- return texts
-
- if isinstance(content, dict):
- for key in ("text", "content", "value", "output_text"):
- text_value = content.get(key)
- if isinstance(text_value, str) and text_value.strip():
- texts.append(text_value.strip())
- return texts
-
- if isinstance(content, list):
- for item in content:
- texts.extend(_collect_text_from_content(item))
- return texts
-
- content_text = getattr(content, "text", None)
- if isinstance(content_text, str) and content_text.strip():
- texts.append(content_text.strip())
- content_value = getattr(content, "content", None)
- if isinstance(content_value, str) and content_value.strip():
- texts.append(content_value.strip())
- output_text = getattr(content, "output_text", None)
- if isinstance(output_text, str) and output_text.strip():
- texts.append(output_text.strip())
- return texts
-
-
-def _extract_text_outputs(chat_completion: Any) -> list[str]:
- texts: list[str] = []
- for choice in getattr(chat_completion, "choices", []) or []:
- message = getattr(choice, "message", None)
- if message is None:
- continue
- content = getattr(message, "content", None)
- texts.extend(_collect_text_from_content(content))
- reasoning_content = getattr(message, "reasoning_content", None)
- if isinstance(reasoning_content, str) and reasoning_content.strip():
- texts.append(reasoning_content.strip())
- choice_text = getattr(choice, "text", None)
- if isinstance(choice_text, str) and choice_text.strip():
- texts.append(choice_text.strip())
- top_level_output_text = getattr(chat_completion, "output_text", None)
- if isinstance(top_level_output_text, str) and top_level_output_text.strip():
- texts.append(top_level_output_text.strip())
- return texts
-
-
-def _extract_image_data_urls(chat_completion: Any) -> list[str]:
- urls: list[str] = []
- for choice in getattr(chat_completion, "choices", []) or []:
- message = getattr(choice, "message", None)
- if message is None:
- continue
- content = getattr(message, "content", None)
- if not isinstance(content, list):
- continue
- for item in content:
- if not isinstance(item, dict):
- continue
- if item.get("type") != "image_url":
- continue
- image_url = (item.get("image_url") or {}).get("url")
- if isinstance(image_url, str) and image_url.startswith("data:image"):
- urls.append(image_url)
- return urls
-
-
-def _extract_audio_payloads(chat_completion: Any) -> list[bytes]:
- payloads: list[bytes] = []
- for choice in getattr(chat_completion, "choices", []) or []:
- message = getattr(choice, "message", None)
- if message is None:
- continue
- message_audio = getattr(message, "audio", None)
- if message_audio is None:
- continue
- data_b64 = getattr(message_audio, "data", None)
- if isinstance(data_b64, str) and data_b64:
- try:
- payloads.append(base64.b64decode(data_b64))
- except Exception:
- continue
- return payloads
-
-
-def _decode_data_url(data_url: str) -> tuple[bytes, str]:
- header, data = data_url.split(",", 1)
- mime_type = "image/png"
- if ";" in header and ":" in header:
- mime_type = header.split(":", 1)[1].split(";", 1)[0]
- return base64.b64decode(data), mime_type
-
-
-def _image_extension_from_mime(mime_type: str) -> str:
- if mime_type == "image/jpeg":
- return ".jpg"
- if mime_type == "image/webp":
- return ".webp"
- if mime_type == "image/gif":
- return ".gif"
- return ".png"
-
-
-def _save_outputs(
- *,
- query_type: str,
- chat_completion: Any,
- output_dir: Path,
-) -> None:
- output_dir.mkdir(parents=True, exist_ok=True)
- stamp = time.strftime("%Y%m%d_%H%M%S")
-
- text_outputs = _extract_text_outputs(chat_completion)
- image_data_urls = _extract_image_data_urls(chat_completion)
- audio_payloads = _extract_audio_payloads(chat_completion)
-
- if text_outputs:
- text_path = output_dir / f"{query_type}_{stamp}.txt"
- text_path.write_text("\n\n".join(text_outputs) + "\n", encoding="utf-8")
- print(f"[dynin-online] text saved: {text_path}")
- print(text_outputs[0])
-
- for idx, image_url in enumerate(image_data_urls):
- image_bytes, mime_type = _decode_data_url(image_url)
- ext = _image_extension_from_mime(mime_type)
- image_path = output_dir / f"{query_type}_{stamp}_{idx}{ext}"
- image_path.write_bytes(image_bytes)
- print(f"[dynin-online] image saved: {image_path}")
-
- for idx, audio_bytes in enumerate(audio_payloads):
- audio_path = output_dir / f"{query_type}_{stamp}_{idx}.wav"
- audio_path.write_bytes(audio_bytes)
- print(f"[dynin-online] audio saved: {audio_path}")
-
- if not text_outputs and not image_data_urls and not audio_payloads:
- print("[dynin-online] no output extracted from response")
- raw_path = output_dir / f"{query_type}_{stamp}_raw_response.json"
- try:
- if hasattr(chat_completion, "model_dump_json"):
- serialized = chat_completion.model_dump_json(indent=2)
- else:
- if hasattr(chat_completion, "model_dump"):
- raw_payload: Any = chat_completion.model_dump(mode="json")
- else:
- raw_payload = chat_completion
- try:
- serialized = json.dumps(raw_payload, ensure_ascii=False, indent=2)
- except Exception:
- serialized = json.dumps({"repr": repr(raw_payload)}, ensure_ascii=False, indent=2)
- raw_path.write_text(serialized + "\n", encoding="utf-8")
- print(f"[dynin-online] raw response saved: {raw_path}")
- except Exception:
- pass
-
-
-def _build_offline_parity_sampling_params_list() -> list[dict[str, Any]]:
- return [dict(OFFLINE_PARITY_STAGE_SAMPLING) for _ in range(OFFLINE_PARITY_STAGE_COUNT)]
-
-
-def run_request(args: argparse.Namespace) -> None:
- from openai import OpenAI
-
- client = OpenAI(
- api_key="EMPTY",
- base_url=f"http://{args.host}:{args.port}/v1",
- )
- prompt = args.prompt.strip() if args.prompt else DEFAULT_PROMPT_BY_QUERY[args.query_type]
- user_content = _build_user_content(
- query_type=args.query_type,
- prompt=prompt,
- image_path=args.image_path,
- )
- if args.modalities:
- modalities = [item.strip() for item in args.modalities.split(",") if item.strip()]
- else:
- modalities = DEFAULT_MODALITIES_BY_QUERY[args.query_type]
-
- extra_body = {
- "sampling_params_list": _build_offline_parity_sampling_params_list(),
- }
- chat_completion = client.chat.completions.create(
- model=args.model,
- messages=[{"role": "user", "content": user_content}],
- modalities=modalities,
- extra_body=extra_body,
- )
- _save_outputs(
- query_type=args.query_type,
- chat_completion=chat_completion,
- output_dir=Path(args.output_dir).expanduser(),
- )
-
-
-def parse_args() -> argparse.Namespace:
- parser = argparse.ArgumentParser(description="Dynin-Omni online chat completion client")
- parser.add_argument(
- "--query-type",
- "-q",
- type=str,
- default="t2i",
- choices=QUERY_CHOICES,
- help="Dynin query type",
- )
- parser.add_argument(
- "--model",
- "-m",
- type=str,
- default=DEFAULT_MODEL,
- help="Model name/path",
- )
- parser.add_argument(
- "--host",
- type=str,
- default="localhost",
- help="Host/IP of the vLLM Omni API server",
- )
- parser.add_argument(
- "--port",
- type=int,
- default=8091,
- help="Port of the vLLM Omni API server",
- )
- parser.add_argument(
- "--prompt",
- "-p",
- type=str,
- default="",
- help="Custom prompt text",
- )
- parser.add_argument(
- "--image-path",
- "-i",
- type=str,
- default=None,
- help="Image path/URL for i2i",
- )
- parser.add_argument(
- "--modalities",
- type=str,
- default="",
- help="Comma-separated output modalities override (e.g., text,image,audio)",
- )
- parser.add_argument(
- "--output-dir",
- "-o",
- type=str,
- default=DEFAULT_OUTPUT_DIR,
- help="Directory to save outputs",
- )
- return parser.parse_args()
-
-
-def main() -> None:
- args = parse_args()
- os.environ.setdefault("HF_HUB_DISABLE_XET", "1")
- run_request(args)
-
-
-if __name__ == "__main__":
- main()
diff --git a/examples/online_serving/fish_speech/README.md b/examples/online_serving/fish_speech/README.md
deleted file mode 100644
index 9b4e3cc403d..00000000000
--- a/examples/online_serving/fish_speech/README.md
+++ /dev/null
@@ -1,169 +0,0 @@
-# Fish Speech S2 Pro
-
-## Model
-
-| Model | Description |
-|-------|-------------|
-| `fishaudio/s2-pro` | Fish Speech S2 Pro -- 4B dual-AR TTS model with DAC codec (44.1 kHz) |
-
-## Gradio Demo
-
-An interactive Gradio demo is available with text-to-speech synthesis, voice cloning, and streaming support.
-
-```bash
-# Option 1: Launch server + Gradio together
-./run_gradio_demo.sh
-
-# Option 2: If server is already running
-python gradio_demo.py --api-base http://localhost:8091
-```
-
-Then open http://localhost:7860 in your browser.
-
-Features:
-
-- Text-to-speech synthesis
-- Voice cloning from uploaded audio or URL
-- Streaming mode (progressive PCM playback)
-
-## Launch the Server
-
-```bash
-vllm serve fishaudio/s2-pro --omni --port 8091
-```
-
-The deploy config is auto-loaded from `vllm_omni/deploy/fish_qwen3_omni.yaml`
-(the HF `model_type` on the fishaudio checkpoints is `fish_qwen3_omni`).
-
-Or use the convenience script:
-
-```bash
-./run_server.sh
-```
-
-## Send TTS Request
-
-### Using curl
-
-```bash
-# Basic TTS
-curl -X POST http://localhost:8091/v1/audio/speech \
- -H "Content-Type: application/json" \
- -d '{
- "input": "Hello, how are you?",
- "voice": "default",
- "response_format": "wav"
- }' --output output.wav
-```
-
-### Voice Cloning
-
-Provide a reference audio (URL or base64 data URL) and its transcript:
-
-```bash
-curl -X POST http://localhost:8091/v1/audio/speech \
- -H "Content-Type: application/json" \
- -d '{
- "input": "Hello, this is a cloned voice.",
- "voice": "default",
- "ref_audio": "https://example.com/reference.wav",
- "ref_text": "Transcript of the reference audio."
- }' --output cloned.wav
-```
-
-### Using Python
-
-```python
-import httpx
-
-# Basic TTS
-response = httpx.post(
- "http://localhost:8091/v1/audio/speech",
- json={
- "input": "Hello, how are you?",
- "voice": "default",
- "response_format": "wav",
- },
- timeout=300.0,
-)
-
-with open("output.wav", "wb") as f:
- f.write(response.content)
-```
-
-### Using the CLI Client
-
-```bash
-cd examples/online_serving/fish_speech
-
-# Basic TTS
-python speech_client.py --text "Hello, how are you?"
-
-# Voice cloning
-python speech_client.py \
- --text "Hello, this is a cloned voice." \
- --ref-audio /path/to/reference.wav \
- --ref-text "Transcript of the reference audio."
-
-# Streaming PCM output
-python speech_client.py --text "Hello world" --stream --output output.pcm
-```
-
-The CLI client supports:
-
-- `--api-base`: API base URL (default: `http://localhost:8091`)
-- `--model` (or `-m`): Model name (default: `fishaudio/s2-pro`)
-- `--text`: Text to synthesize (required)
-- `--ref-audio`: Reference audio for voice cloning (local path or URL)
-- `--ref-text`: Transcript of the reference audio
-- `--stream`: Enable streaming (PCM output)
-- `--response-format`: Audio format: wav, mp3, flac, pcm, aac, opus (default: wav)
-- `--output` (or `-o`): Output file path
-
-## Streaming
-
-Set `stream=true` with `response_format="pcm"` to receive raw PCM audio chunks as they are decoded:
-
-```bash
-curl -X POST http://localhost:8091/v1/audio/speech \
- -H "Content-Type: application/json" \
- -d '{
- "input": "Hello, how are you?",
- "voice": "default",
- "stream": true,
- "response_format": "pcm"
- }' --no-buffer | play -t raw -r 44100 -e signed -b 16 -c 1 -
-```
-
-**Note:** Fish Speech outputs at 44.1 kHz (unlike Qwen3-TTS which outputs at 24 kHz).
-
-## API Parameters
-
-Fish Speech uses the same `/v1/audio/speech` endpoint as Qwen3-TTS. See the [Speech API reference](https://docs.vllm.ai/projects/vllm-omni/en/latest/serving/speech_api/) for full parameter documentation.
-
-Key parameters for Fish Speech:
-
-| Parameter | Type | Default | Description |
-|-----------|------|---------|-------------|
-| `input` | string | **required** | Text to synthesize |
-| `voice` | string | "default" | Voice name (use "default" for Fish Speech) |
-| `response_format` | string | "wav" | Audio format: wav, mp3, flac, pcm, aac, opus |
-| `ref_audio` | string | null | Reference audio URL or base64 data URL for voice cloning |
-| `ref_text` | string | null | Transcript of reference audio (required for voice cloning) |
-| `max_new_tokens` | int | 4096 | Maximum tokens to generate |
-| `stream` | bool | false | Stream raw PCM chunks |
-
-## Prerequisites
-
-Install the `fish-speech` package for the DAC codec:
-
-```bash
-pip install fish-speech
-```
-
-## Troubleshooting
-
-1. **No audio output**: Make sure the `fish-speech` package is installed for the DAC decoder
-2. **Connection refused**: Ensure the server is running on the correct port
-3. **Flashinfer version mismatch**: Set `FLASHINFER_DISABLE_VERSION_CHECK=1` if you see version warnings
-4. **Out of memory**: Reduce `--gpu-memory-utilization` or use a GPU with more VRAM
diff --git a/examples/online_serving/fish_speech/gradio_demo.py b/examples/online_serving/fish_speech/gradio_demo.py
deleted file mode 100644
index 7db4e04411f..00000000000
--- a/examples/online_serving/fish_speech/gradio_demo.py
+++ /dev/null
@@ -1,275 +0,0 @@
-"""Gradio demo for Fish Speech S2 Pro online serving via /v1/audio/speech API.
-
-Supports:
- - Text-to-speech synthesis
- - Voice cloning from reference audio (upload or URL)
- - Streaming (progressive PCM chunks) and non-streaming modes
-
-Usage:
- # Start the server first (see run_server.sh), then:
- python gradio_demo.py --api-base http://localhost:8091
-
- # Or use run_gradio_demo.sh to start both server and demo together.
-"""
-
-import argparse
-import base64
-import io
-
-try:
- import gradio as gr
-except ImportError:
- raise ImportError("gradio is required to run this demo. Install it with: pip install 'vllm-omni[demo]'") from None
-import httpx
-import numpy as np
-import soundfile as sf
-
-PCM_SAMPLE_RATE = 44100
-DEFAULT_API_BASE = "http://localhost:8091"
-
-
-def encode_audio_to_base64(audio_data: tuple) -> str:
- """Encode Gradio audio input (sample_rate, numpy_array) to base64 data URL."""
- sample_rate, audio_np = audio_data
- if audio_np.dtype != np.int16:
- if audio_np.dtype in (np.float32, np.float64):
- audio_np = np.clip(audio_np, -1.0, 1.0)
- audio_np = (audio_np * 32767).astype(np.int16)
- else:
- audio_np = audio_np.astype(np.int16)
- buf = io.BytesIO()
- sf.write(buf, audio_np, sample_rate, format="WAV")
- wav_b64 = base64.b64encode(buf.getvalue()).decode("utf-8")
- return f"data:audio/wav;base64,{wav_b64}"
-
-
-def build_payload(
- text: str,
- ref_audio: tuple | None,
- ref_audio_url: str,
- ref_text: str,
- response_format: str = "wav",
- stream: bool = False,
-) -> dict:
- """Build the /v1/audio/speech request payload."""
- if not text or not text.strip():
- raise gr.Error("Please enter text to synthesize.")
-
- payload: dict = {
- "input": text.strip(),
- "voice": "default",
- "response_format": "pcm" if stream else response_format,
- "stream": stream,
- }
-
- # Voice cloning: ref_audio takes priority over URL.
- ref_url_stripped = ref_audio_url.strip() if ref_audio_url else ""
- if ref_audio is not None:
- payload["ref_audio"] = encode_audio_to_base64(ref_audio)
- elif ref_url_stripped:
- payload["ref_audio"] = ref_url_stripped
-
- if "ref_audio" in payload:
- if not ref_text or not ref_text.strip():
- raise gr.Error("Voice cloning requires a transcript of the reference audio.")
- payload["ref_text"] = ref_text.strip()
-
- return payload
-
-
-def generate_speech(api_base: str, text: str, ref_audio, ref_audio_url, ref_text, response_format):
- """Non-streaming: call /v1/audio/speech and return full audio."""
- payload = build_payload(text, ref_audio, ref_audio_url, ref_text, response_format, stream=False)
-
- try:
- with httpx.Client(timeout=300.0) as client:
- resp = client.post(
- f"{api_base}/v1/audio/speech",
- json=payload,
- headers={"Content-Type": "application/json", "Authorization": "Bearer EMPTY"},
- )
- except httpx.TimeoutException:
- raise gr.Error("Request timed out. The server may be busy.")
- except httpx.ConnectError:
- raise gr.Error(f"Cannot connect to server at {api_base}. Is the server running?")
-
- if resp.status_code != 200:
- raise gr.Error(f"Server error ({resp.status_code}): {resp.text}")
-
- content_type = resp.headers.get("content-type", "")
- if "application/json" in content_type:
- try:
- raise gr.Error(f"Server error: {resp.json()}")
- except ValueError:
- pass
-
- try:
- if response_format == "pcm":
- audio_np = np.frombuffer(resp.content, dtype=np.int16).astype(np.float32) / 32767.0
- return (PCM_SAMPLE_RATE, audio_np)
- audio_np, sample_rate = sf.read(io.BytesIO(resp.content))
- if audio_np.ndim > 1:
- audio_np = audio_np[:, 0]
- return (sample_rate, audio_np.astype(np.float32))
- except Exception as e:
- raise gr.Error(f"Failed to decode audio: {e}")
-
-
-def generate_speech_stream(api_base, text, ref_audio, ref_audio_url, ref_text, response_format, chunk_seconds=0.5):
- """Streaming: yield PCM chunks for progressive playback."""
- payload = build_payload(text, ref_audio, ref_audio_url, ref_text, response_format, stream=True)
-
- min_chunk_samples = int(PCM_SAMPLE_RATE * chunk_seconds)
- prebuffer_chunks = 2
- pending: list[np.ndarray] = []
- pending_len = 0
- chunks_yielded = 0
- prebuffer: list[np.ndarray] = []
-
- try:
- leftover = b""
- with httpx.Client(timeout=300.0) as client:
- with client.stream(
- "POST",
- f"{api_base}/v1/audio/speech",
- json=payload,
- headers={"Content-Type": "application/json", "Authorization": "Bearer EMPTY"},
- ) as resp:
- if resp.status_code != 200:
- resp.read()
- raise gr.Error(f"Server error ({resp.status_code}): {resp.text}")
- for chunk in resp.iter_bytes():
- if not chunk:
- continue
- raw = leftover + chunk
- usable = len(raw) - (len(raw) % 2)
- leftover = raw[usable:]
- if usable == 0:
- continue
- float_samples = np.frombuffer(raw[:usable], dtype=np.int16).copy().astype(np.float32) / 32767.0
- pending.append(float_samples)
- pending_len += len(float_samples)
- if pending_len >= min_chunk_samples:
- audio_chunk = np.concatenate(pending)
- pending.clear()
- pending_len = 0
- if chunks_yielded < prebuffer_chunks:
- prebuffer.append(audio_chunk)
- chunks_yielded += 1
- if chunks_yielded == prebuffer_chunks:
- yield (PCM_SAMPLE_RATE, np.concatenate(prebuffer))
- prebuffer.clear()
- else:
- yield (PCM_SAMPLE_RATE, audio_chunk)
- remaining = prebuffer + pending
- if remaining:
- yield (PCM_SAMPLE_RATE, np.concatenate(remaining))
- except httpx.TimeoutException:
- raise gr.Error("Request timed out. The server may be busy.")
- except httpx.ConnectError:
- raise gr.Error(f"Cannot connect to server at {api_base}. Is the server running?")
-
-
-def on_stream_change(stream: bool):
- """Lock format to PCM when streaming."""
- if stream:
- return gr.update(value="pcm", interactive=False)
- return gr.update(value="wav", interactive=True)
-
-
-def build_interface(api_base: str, stream_chunk_seconds: float = 0.5):
- """Build the Gradio interface."""
- with gr.Blocks(title="Fish Speech S2 Pro Demo") as demo:
- gr.Markdown("# Fish Speech S2 Pro - Text to Speech")
- gr.Markdown(f"**Server:** `{api_base}` | **Model:** fishaudio/s2-pro | **Output:** 44.1kHz")
-
- with gr.Row():
- with gr.Column(scale=3):
- text_input = gr.Textbox(
- label="Text to Synthesize",
- placeholder="Enter text here...",
- lines=4,
- )
-
- with gr.Accordion("Voice Cloning (optional)", open=False):
- gr.Markdown(
- "Upload or link a short reference audio (10-30s) and provide its transcript to clone the voice."
- )
- ref_audio = gr.Audio(
- label="Reference Audio",
- type="numpy",
- sources=["upload", "microphone"],
- )
- ref_audio_url = gr.Textbox(
- label="Reference Audio URL (alternative to upload)",
- placeholder="https://example.com/reference.wav",
- lines=1,
- )
- ref_text = gr.Textbox(
- label="Reference Audio Transcript (required for cloning)",
- placeholder="Exact transcript of the reference audio...",
- lines=2,
- )
-
- with gr.Row():
- response_format = gr.Dropdown(
- choices=["wav", "mp3", "flac", "pcm"],
- value="wav",
- label="Audio Format",
- scale=1,
- )
- stream_checkbox = gr.Checkbox(
- label="Stream output",
- value=False,
- info="Progressive PCM streaming",
- scale=1,
- )
-
- generate_btn = gr.Button("Generate Speech", variant="primary", size="lg")
-
- with gr.Column(scale=2):
- audio_output = gr.Audio(
- label="Generated Audio",
- interactive=False,
- streaming=True,
- autoplay=True,
- )
- gr.Markdown(
- "### About\n"
- "- **Fish Speech S2 Pro** by FishAudio: 4B dual-AR model\n"
- "- **Voice cloning**: upload 10-30s reference + transcript\n"
- "- **Streaming**: real-time PCM output\n"
- "- **44.1kHz** output via DAC codec"
- )
-
- stream_checkbox.change(fn=on_stream_change, inputs=[stream_checkbox], outputs=[response_format])
-
- all_inputs = [text_input, ref_audio, ref_audio_url, ref_text, response_format]
-
- def dispatch(stream_enabled, *args):
- if stream_enabled:
- yield from generate_speech_stream(api_base, *args, chunk_seconds=stream_chunk_seconds)
- else:
- yield generate_speech(api_base, *args)
-
- generate_btn.click(fn=dispatch, inputs=[stream_checkbox] + all_inputs, outputs=[audio_output])
- demo.queue()
- return demo
-
-
-def main():
- parser = argparse.ArgumentParser(description="Gradio demo for Fish Speech S2 Pro")
- parser.add_argument("--api-base", default=DEFAULT_API_BASE, help=f"API base URL (default: {DEFAULT_API_BASE})")
- parser.add_argument("--host", default="0.0.0.0", help="Gradio host (default: 0.0.0.0)")
- parser.add_argument("--port", type=int, default=7860, help="Gradio port (default: 7860)")
- parser.add_argument("--share", action="store_true", help="Share publicly")
- parser.add_argument("--stream-chunk-seconds", type=float, default=0.5, help="Seconds per streaming chunk")
- args = parser.parse_args()
-
- print(f"Connecting to vLLM server at: {args.api_base}")
- demo = build_interface(args.api_base, stream_chunk_seconds=args.stream_chunk_seconds)
- demo.launch(server_name=args.host, server_port=args.port, share=args.share)
-
-
-if __name__ == "__main__":
- main()
diff --git a/examples/online_serving/fish_speech/run_gradio_demo.sh b/examples/online_serving/fish_speech/run_gradio_demo.sh
deleted file mode 100755
index a0370b9cc88..00000000000
--- a/examples/online_serving/fish_speech/run_gradio_demo.sh
+++ /dev/null
@@ -1,43 +0,0 @@
-#!/bin/bash
-# Launch Fish Speech S2 Pro server + Gradio demo together.
-#
-# Usage:
-# ./run_gradio_demo.sh
-# CUDA_VISIBLE_DEVICES=0 PORT=8091 GRADIO_PORT=7860 ./run_gradio_demo.sh
-
-set -e
-
-MODEL="${MODEL:-fishaudio/s2-pro}"
-PORT="${PORT:-8091}"
-GRADIO_PORT="${GRADIO_PORT:-7860}"
-SCRIPT_DIR="$(cd "$(dirname "$0")" && pwd)"
-
-echo "Starting Fish Speech S2 Pro server (port $PORT)..."
-FLASHINFER_DISABLE_VERSION_CHECK=1 \
-vllm serve "$MODEL" \
- --omni \
- --host 0.0.0.0 \
- --port "$PORT" &
-SERVER_PID=$!
-
-cleanup() {
- echo "Stopping server (PID $SERVER_PID)..."
- kill $SERVER_PID 2>/dev/null
- wait $SERVER_PID 2>/dev/null
-}
-trap cleanup EXIT
-
-# Wait for server to be ready.
-echo "Waiting for server to start..."
-for i in $(seq 1 120); do
- if curl -s "http://localhost:$PORT/health" > /dev/null 2>&1; then
- echo "Server ready."
- break
- fi
- sleep 2
-done
-
-echo "Starting Gradio demo (port $GRADIO_PORT)..."
-python "$SCRIPT_DIR/gradio_demo.py" \
- --api-base "http://localhost:$PORT" \
- --port "$GRADIO_PORT"
diff --git a/examples/online_serving/fish_speech/run_server.sh b/examples/online_serving/fish_speech/run_server.sh
deleted file mode 100755
index a865daf9378..00000000000
--- a/examples/online_serving/fish_speech/run_server.sh
+++ /dev/null
@@ -1,19 +0,0 @@
-#!/bin/bash
-# Launch vLLM-Omni server for Fish Speech S2 Pro
-#
-# Usage:
-# ./run_server.sh
-# CUDA_VISIBLE_DEVICES=0 ./run_server.sh
-
-set -e
-
-MODEL="${MODEL:-fishaudio/s2-pro}"
-PORT="${PORT:-8091}"
-
-echo "Starting Fish Speech S2 Pro server with model: $MODEL"
-
-FLASHINFER_DISABLE_VERSION_CHECK=1 \
-vllm serve "$MODEL" \
- --omni \
- --host 0.0.0.0 \
- --port "$PORT"
diff --git a/examples/online_serving/fish_speech/speech_client.py b/examples/online_serving/fish_speech/speech_client.py
deleted file mode 100644
index e3ace37e599..00000000000
--- a/examples/online_serving/fish_speech/speech_client.py
+++ /dev/null
@@ -1,129 +0,0 @@
-"""Client for Fish Speech S2 Pro via /v1/audio/speech endpoint.
-
-Examples:
- # Basic TTS
- python speech_client.py --text "Hello, how are you?"
-
- # Voice cloning
- python speech_client.py --text "Hello, how are you?" \
- --ref-audio ref.wav --ref-text "This is the reference transcript."
-
- # Streaming PCM output
- python speech_client.py --text "Hello world" --stream --output output.pcm
-"""
-
-import argparse
-import base64
-import os
-
-import httpx
-
-DEFAULT_API_BASE = "http://localhost:8091"
-DEFAULT_API_KEY = "EMPTY"
-
-
-def encode_audio_to_base64(audio_path: str) -> str:
- """Encode a local audio file to base64 data URL."""
- if not os.path.exists(audio_path):
- raise FileNotFoundError(f"Audio file not found: {audio_path}")
- ext = audio_path.lower().rsplit(".", 1)[-1]
- mime_map = {"wav": "audio/wav", "mp3": "audio/mpeg", "flac": "audio/flac", "ogg": "audio/ogg"}
- mime_type = mime_map.get(ext, "audio/wav")
- with open(audio_path, "rb") as f:
- audio_b64 = base64.b64encode(f.read()).decode("utf-8")
- return f"data:{mime_type};base64,{audio_b64}"
-
-
-def run_tts(args) -> None:
- """Generate speech via /v1/audio/speech API."""
- payload = {
- "model": args.model,
- "input": args.text,
- "voice": "default",
- "response_format": args.response_format,
- }
-
- # Voice cloning parameters.
- if args.ref_audio:
- if args.ref_audio.startswith(("http://", "https://")):
- payload["ref_audio"] = args.ref_audio
- else:
- payload["ref_audio"] = encode_audio_to_base64(args.ref_audio)
- if args.ref_text:
- payload["ref_text"] = args.ref_text
-
- if args.stream:
- payload["stream"] = True
- payload["response_format"] = "pcm"
-
- print(f"Model: {args.model}")
- print(f"Text: {args.text}")
- if args.ref_audio:
- print(f"Voice cloning: ref_audio={args.ref_audio}, ref_text={args.ref_text}")
- print("Generating audio...")
-
- api_url = f"{args.api_base}/v1/audio/speech"
- headers = {
- "Content-Type": "application/json",
- "Authorization": f"Bearer {args.api_key}",
- }
-
- if args.stream:
- output_path = args.output or "output.pcm"
- with httpx.Client(timeout=300.0) as client:
- with client.stream("POST", api_url, json=payload, headers=headers) as resp:
- if resp.status_code != 200:
- print(f"Error: {resp.status_code}")
- print(resp.read().decode())
- return
- total_bytes = 0
- with open(output_path, "wb") as f:
- for chunk in resp.iter_bytes():
- f.write(chunk)
- total_bytes += len(chunk)
- print(f"Streamed {total_bytes} bytes to: {output_path}")
- else:
- with httpx.Client(timeout=300.0) as client:
- response = client.post(api_url, json=payload, headers=headers)
-
- if response.status_code != 200:
- print(f"Error: {response.status_code}")
- print(response.text)
- return
-
- try:
- text = response.content.decode("utf-8")
- if text.startswith('{"error"'):
- print(f"Error: {text}")
- return
- except UnicodeDecodeError:
- pass
-
- output_path = args.output or "output.wav"
- with open(output_path, "wb") as f:
- f.write(response.content)
- print(f"Audio saved to: {output_path}")
-
-
-def main():
- parser = argparse.ArgumentParser(description="Fish Speech S2 Pro TTS client")
- parser.add_argument("--api-base", default=DEFAULT_API_BASE, help="API base URL")
- parser.add_argument("--api-key", default=DEFAULT_API_KEY, help="API key")
- parser.add_argument("--model", "-m", default="fishaudio/s2-pro", help="Model name")
- parser.add_argument("--text", required=True, help="Text to synthesize")
- parser.add_argument("--ref-audio", default=None, help="Reference audio for voice cloning (path or URL)")
- parser.add_argument("--ref-text", default=None, help="Transcript of reference audio")
- parser.add_argument("--stream", action="store_true", help="Enable streaming (PCM output)")
- parser.add_argument(
- "--response-format",
- default="wav",
- choices=["wav", "mp3", "flac", "pcm", "aac", "opus"],
- help="Audio format (default: wav)",
- )
- parser.add_argument("--output", "-o", default=None, help="Output file path")
- args = parser.parse_args()
- run_tts(args)
-
-
-if __name__ == "__main__":
- main()
diff --git a/examples/online_serving/helios/README.md b/examples/online_serving/helios/README.md
deleted file mode 100644
index 5e13df19d63..00000000000
--- a/examples/online_serving/helios/README.md
+++ /dev/null
@@ -1,175 +0,0 @@
-# Helios Video Generation via Online API
-
-This example demonstrates how to use the `/v1/videos` API with Helios models using the generic `extra_params` field.
-
-## Overview
-
-The `/v1/videos` API now supports model-specific parameters through the `extra_params` field, which accepts a JSON object containing any model-specific configuration. This allows supporting new models like Helios without modifying the API.
-
-## Helios Model Variants
-
-- **Helios-Base**: Basic T2V/I2V/V2V generation (Stage 1 only)
-- **Helios-Mid**: Advanced generation with CFG-Zero* (Stage 2)
-- **Helios-Distilled**: Fast generation with DMD (Stage 2)
-
-## API Usage Examples
-
-### 1. T2V (Text-to-Video) - Helios-Base
-
-Basic text-to-video generation:
-
-```bash
-curl -X POST http://localhost:8000/v1/videos \
- -F "prompt=A serene lakeside sunrise with mist over the water." \
- -F "model=BestWishYsh/Helios-Base" \
- -F "width=640" \
- -F "height=384" \
- -F "num_frames=99" \
- -F "num_inference_steps=50" \
- -F "guidance_scale=5.0" \
- -F "seed=42"
-```
-
-### 2. I2V (Image-to-Video) - Helios-Base
-
-Generate video from an input image:
-
-```bash
-curl -X POST http://localhost:8000/v1/videos \
- -F "prompt=The lake water gently ripples as morning mist rises." \
- -F "model=BestWishYsh/Helios-Base" \
- -F "input_reference=@/path/to/image.jpg" \
- -F "width=640" \
- -F "height=384" \
- -F "num_frames=99" \
- -F "guidance_scale=5.0"
-```
-
-### 3. Helios-Mid with Stage 2 + CFG-Zero*
-
-Advanced generation with pyramid multi-stage denoising:
-
-```bash
-curl -X POST http://localhost:8000/v1/videos \
- -F "prompt=A serene lakeside sunrise with mist over the water." \
- -F "model=BestWishYsh/Helios-Mid" \
- -F "width=640" \
- -F "height=384" \
- -F "guidance_scale=5.0" \
- -F 'extra_params={
- "is_enable_stage2": true,
- "pyramid_num_stages": 3,
- "pyramid_num_inference_steps_list": [20, 20, 20],
- "use_cfg_zero_star": true,
- "use_zero_init": true,
- "zero_steps": 1
- }'
-```
-
-### 4. Helios-Distilled with DMD
-
-Fast generation with Distribution Matching Distillation:
-
-```bash
-curl -X POST http://localhost:8000/v1/videos \
- -F "prompt=A serene lakeside sunrise with mist over the water." \
- -F "model=BestWishYsh/Helios-Distilled" \
- -F "width=640" \
- -F "height=384" \
- -F "guidance_scale=1.0" \
- -F 'extra_params={
- "is_enable_stage2": true,
- "pyramid_num_stages": 3,
- "pyramid_num_inference_steps_list": [2, 2, 2],
- "is_amplify_first_chunk": true
- }'
-```
-
-## Model-Specific Parameters
-
-The `extra_params` field accepts a JSON object with model-specific parameters. For Helios models, supported parameters include:
-
-### Stage 2 Parameters
-- `is_enable_stage2` (bool): Enable pyramid multi-stage denoising
-- `pyramid_num_stages` (int): Number of pyramid stages (default: 3)
-- `pyramid_num_inference_steps_list` (array): Steps per stage, e.g., `[20, 20, 20]`
-
-### CFG Zero Star Parameters (Helios-Mid)
-- `use_cfg_zero_star` (bool): Enable CFG Zero Star guidance
-- `use_zero_init` (bool): Use zero initialization for first steps
-- `zero_steps` (int): Number of initial zero prediction steps (default: 1)
-
-### DMD Parameters (Helios-Distilled)
-- `is_amplify_first_chunk` (bool): Enable DMD amplification for first chunk
-
-### Video Input (V2V mode)
-For video-to-video generation, upload a video file via `input_reference`:
-
-```bash
-curl -X POST http://localhost:8000/v1/videos \
- -F "prompt=Transform the video into a watercolor painting style." \
- -F "model=BestWishYsh/Helios-Base" \
- -F "input_reference=@/path/to/video.mp4" \
- -F "guidance_scale=5.0"
-```
-
-## Python Example
-
-```python
-import requests
-import json
-
-url = "http://localhost:8000/v1/videos"
-
-# Helios-Mid with Stage 2
-data = {
- "prompt": "A serene lakeside sunrise with mist over the water.",
- "model": "BestWishYsh/Helios-Mid",
- "width": 640,
- "height": 384,
- "guidance_scale": 5.0,
- "extra_params": json.dumps({
- "is_enable_stage2": True,
- "pyramid_num_stages": 3,
- "pyramid_num_inference_steps_list": [20, 20, 20],
- "use_cfg_zero_star": True,
- "use_zero_init": True,
- "zero_steps": 1
- })
-}
-
-response = requests.post(url, data=data)
-video_job = response.json()
-print(f"Video job created: {video_job['id']}")
-
-# Poll for completion
-import time
-while True:
- status_response = requests.get(f"{url}/{video_job['id']}")
- status = status_response.json()
-
- if status['status'] == 'completed':
- print(f"Video generated: {status['file_name']}")
- break
- elif status['status'] == 'failed':
- print(f"Generation failed: {status.get('error')}")
- break
-
- print(f"Progress: {status['progress']}%")
- time.sleep(2)
-```
-
-## Benefits of This Approach
-
-1. **No API Changes**: New models can be supported without modifying the API
-2. **Backward Compatible**: Existing clients continue to work
-3. **Flexible**: Any model-specific parameter can be passed
-4. **Type-Safe**: Parameters are validated at the model level
-5. **Future-Proof**: Supports models that don't exist yet
-
-## Notes
-
-- The `extra_params` field must be a valid JSON object
-- Parameters are passed directly to the model's `extra_args`
-- Invalid parameters will be caught by the model implementation
-- Tensor inputs (images/videos) should use `input_reference`, not `extra_params`
diff --git a/examples/online_serving/helios/helios_client.py b/examples/online_serving/helios/helios_client.py
deleted file mode 100644
index d5024996620..00000000000
--- a/examples/online_serving/helios/helios_client.py
+++ /dev/null
@@ -1,212 +0,0 @@
-#!/usr/bin/env python3
-# SPDX-License-Identifier: Apache-2.0
-# SPDX-FileCopyrightText: Copyright contributors to the vLLM project
-
-"""
-Helios video generation client example using the /v1/videos API.
-
-This example demonstrates how to use the generic extra_params field
-to pass Helios-specific parameters without modifying the API.
-"""
-
-import argparse
-import json
-import time
-from pathlib import Path
-
-import requests
-
-
-def create_video_job(
- api_url: str,
- prompt: str,
- model: str,
- width: int = 640,
- height: int = 384,
- num_frames: int = 99,
- guidance_scale: float = 5.0,
- seed: int = 42,
- extra_params: dict | None = None,
- input_image: Path | None = None,
-) -> dict:
- """Create a video generation job."""
- data = {
- "prompt": prompt,
- "model": model,
- "width": width,
- "height": height,
- "num_frames": num_frames,
- "guidance_scale": guidance_scale,
- "seed": seed,
- }
-
- files = {}
- if input_image:
- files["input_reference"] = open(input_image, "rb")
-
- if extra_params:
- data["extra_params"] = json.dumps(extra_params)
-
- response = requests.post(f"{api_url}/v1/videos", data=data, files=files)
- response.raise_for_status()
-
- if files:
- files["input_reference"].close()
-
- return response.json()
-
-
-def poll_video_status(api_url: str, video_id: str, poll_interval: int = 2) -> dict:
- """Poll video generation status until completion."""
- print(f"Polling video job: {video_id}")
-
- while True:
- response = requests.get(f"{api_url}/v1/videos/{video_id}")
- response.raise_for_status()
- status_data = response.json()
-
- status = status_data["status"]
- progress = status_data.get("progress", 0)
-
- print(f"Status: {status}, Progress: {progress}%")
-
- if status == "completed":
- print("Video generation completed!")
- return status_data
- elif status == "failed":
- error = status_data.get("error", {})
- raise RuntimeError(f"Video generation failed: {error}")
-
- time.sleep(poll_interval)
-
-
-def main():
- parser = argparse.ArgumentParser(description="Helios video generation client")
- parser.add_argument(
- "--api-url",
- default="http://localhost:8000",
- help="API server URL",
- )
- parser.add_argument(
- "--model",
- default="BestWishYsh/Helios-Base",
- help="Model name (Helios-Base, Helios-Mid, Helios-Distilled)",
- )
- parser.add_argument(
- "--prompt",
- default="A serene lakeside sunrise with mist over the water.",
- help="Text prompt",
- )
- parser.add_argument(
- "--width",
- type=int,
- default=640,
- help="Video width",
- )
- parser.add_argument(
- "--height",
- type=int,
- default=384,
- help="Video height",
- )
- parser.add_argument(
- "--num-frames",
- type=int,
- default=99,
- help="Number of frames",
- )
- parser.add_argument(
- "--guidance-scale",
- type=float,
- default=5.0,
- help="Guidance scale",
- )
- parser.add_argument(
- "--seed",
- type=int,
- default=42,
- help="Random seed",
- )
- parser.add_argument(
- "--input-image",
- type=Path,
- help="Input image for I2V mode",
- )
- parser.add_argument(
- "--preset",
- choices=["base", "mid-stage2", "distilled"],
- default="base",
- help="Helios preset configuration",
- )
-
- args = parser.parse_args()
-
- # Define preset configurations
- presets = {
- "base": None, # No extra params for base model
- "mid-stage2": {
- "is_enable_stage2": True,
- "pyramid_num_stages": 3,
- "pyramid_num_inference_steps_list": [20, 20, 20],
- "use_cfg_zero_star": True,
- "use_zero_init": True,
- "zero_steps": 1,
- },
- "distilled": {
- "is_enable_stage2": True,
- "pyramid_num_stages": 3,
- "pyramid_num_inference_steps_list": [2, 2, 2],
- "is_amplify_first_chunk": True,
- },
- }
-
- extra_params = presets[args.preset]
-
- print("=" * 50)
- print("Helios Video Generation")
- print("=" * 50)
- print(f"API URL: {args.api_url}")
- print(f"Model: {args.model}")
- print(f"Preset: {args.preset}")
- print(f"Prompt: {args.prompt}")
- print(f"Size: {args.width}x{args.height}")
- print(f"Frames: {args.num_frames}")
- print(f"Guidance Scale: {args.guidance_scale}")
- if extra_params:
- print(f"Extra Params: {json.dumps(extra_params, indent=2)}")
- print()
-
- # Create video job
- print("Creating video generation job...")
- job = create_video_job(
- api_url=args.api_url,
- prompt=args.prompt,
- model=args.model,
- width=args.width,
- height=args.height,
- num_frames=args.num_frames,
- guidance_scale=args.guidance_scale,
- seed=args.seed,
- extra_params=extra_params,
- input_image=args.input_image,
- )
-
- video_id = job["id"]
- print(f"Video job created: {video_id}")
- print()
-
- # Poll for completion
- result = poll_video_status(args.api_url, video_id)
-
- print()
- print("=" * 50)
- print("Generation Complete")
- print("=" * 50)
- print(f"Video ID: {result['id']}")
- print(f"File: {result.get('file_name', 'N/A')}")
- print(f"Inference Time: {result.get('inference_time_s', 'N/A')}s")
- print()
-
-
-if __name__ == "__main__":
- main()
diff --git a/examples/online_serving/helios/run_helios_distilled.sh b/examples/online_serving/helios/run_helios_distilled.sh
deleted file mode 100644
index 15b6d8c3032..00000000000
--- a/examples/online_serving/helios/run_helios_distilled.sh
+++ /dev/null
@@ -1,79 +0,0 @@
-#!/bin/bash
-# SPDX-License-Identifier: Apache-2.0
-# SPDX-FileCopyrightText: Copyright contributors to the vLLM project
-
-# Helios-Distilled with DMD Example
-# Fast generation with Distribution Matching Distillation
-
-API_URL="${API_URL:-http://localhost:8000}"
-MODEL="${MODEL:-BestWishYsh/Helios-Distilled}"
-PROMPT="${PROMPT:-A serene lakeside sunrise with mist over the water.}"
-
-echo "==================================="
-echo "Helios-Distilled with DMD"
-echo "==================================="
-echo "API URL: $API_URL"
-echo "Model: $MODEL"
-echo "Prompt: $PROMPT"
-echo ""
-
-# Model-specific parameters for Helios-Distilled
-extra_params='{
- "is_enable_stage2": true,
- "pyramid_num_stages": 3,
- "pyramid_num_inference_steps_list": [2, 2, 2],
- "is_amplify_first_chunk": true
-}'
-
-echo "Model extra params: $extra_params"
-echo ""
-
-# Create video generation job
-echo "Creating video generation job..."
-RESPONSE=$(curl -s -X POST "$API_URL/v1/videos" \
- -F "prompt=$PROMPT" \
- -F "model=$MODEL" \
- -F "width=640" \
- -F "height=384" \
- -F "guidance_scale=1.0" \
- -F "seed=42" \
- -F "extra_params=$extra_params")
-
-echo "Response: $RESPONSE"
-echo ""
-
-# Extract video ID
-VIDEO_ID=$(echo "$RESPONSE" | grep -o '"id":"[^"]*"' | cut -d'"' -f4)
-
-if [ -z "$VIDEO_ID" ]; then
- echo "Error: Failed to create video job"
- exit 1
-fi
-
-echo "Video job created: $VIDEO_ID"
-echo ""
-
-# Poll for completion
-echo "Polling for completion..."
-while true; do
- STATUS_RESPONSE=$(curl -s "$API_URL/v1/videos/$VIDEO_ID")
- STATUS=$(echo "$STATUS_RESPONSE" | grep -o '"status":"[^"]*"' | cut -d'"' -f4)
- PROGRESS=$(echo "$STATUS_RESPONSE" | grep -o '"progress":[0-9]*' | cut -d':' -f2)
-
- echo "Status: $STATUS, Progress: $PROGRESS%"
-
- if [ "$STATUS" = "completed" ]; then
- echo ""
- echo "Video generation completed!"
- echo "Full response:"
- echo "$STATUS_RESPONSE" | jq '.'
- break
- elif [ "$STATUS" = "failed" ]; then
- echo ""
- echo "Video generation failed!"
- echo "$STATUS_RESPONSE" | jq '.'
- exit 1
- fi
-
- sleep 2
-done
diff --git a/examples/online_serving/helios/run_helios_mid_stage2.sh b/examples/online_serving/helios/run_helios_mid_stage2.sh
deleted file mode 100644
index d5da9b22c0b..00000000000
--- a/examples/online_serving/helios/run_helios_mid_stage2.sh
+++ /dev/null
@@ -1,81 +0,0 @@
-#!/bin/bash
-# SPDX-License-Identifier: Apache-2.0
-# SPDX-FileCopyrightText: Copyright contributors to the vLLM project
-
-# Helios-Mid with Stage 2 + CFG-Zero* Example
-# This demonstrates advanced generation with pyramid multi-stage denoising
-
-API_URL="${API_URL:-http://localhost:8000}"
-MODEL="${MODEL:-BestWishYsh/Helios-Mid}"
-PROMPT="${PROMPT:-A serene lakeside sunrise with mist over the water.}"
-
-echo "==================================="
-echo "Helios-Mid Stage 2 + CFG-Zero*"
-echo "==================================="
-echo "API URL: $API_URL"
-echo "Model: $MODEL"
-echo "Prompt: $PROMPT"
-echo ""
-
-# Model-specific parameters for Helios-Mid
-extra_params='{
- "is_enable_stage2": true,
- "pyramid_num_stages": 3,
- "pyramid_num_inference_steps_list": [20, 20, 20],
- "use_cfg_zero_star": true,
- "use_zero_init": true,
- "zero_steps": 1
-}'
-
-echo "Model extra params: $extra_params"
-echo ""
-
-# Create video generation job
-echo "Creating video generation job..."
-RESPONSE=$(curl -s -X POST "$API_URL/v1/videos" \
- -F "prompt=$PROMPT" \
- -F "model=$MODEL" \
- -F "width=640" \
- -F "height=384" \
- -F "guidance_scale=5.0" \
- -F "seed=42" \
- -F "extra_params=$extra_params")
-
-echo "Response: $RESPONSE"
-echo ""
-
-# Extract video ID
-VIDEO_ID=$(echo "$RESPONSE" | grep -o '"id":"[^"]*"' | cut -d'"' -f4)
-
-if [ -z "$VIDEO_ID" ]; then
- echo "Error: Failed to create video job"
- exit 1
-fi
-
-echo "Video job created: $VIDEO_ID"
-echo ""
-
-# Poll for completion
-echo "Polling for completion..."
-while true; do
- STATUS_RESPONSE=$(curl -s "$API_URL/v1/videos/$VIDEO_ID")
- STATUS=$(echo "$STATUS_RESPONSE" | grep -o '"status":"[^"]*"' | cut -d'"' -f4)
- PROGRESS=$(echo "$STATUS_RESPONSE" | grep -o '"progress":[0-9]*' | cut -d':' -f2)
-
- echo "Status: $STATUS, Progress: $PROGRESS%"
-
- if [ "$STATUS" = "completed" ]; then
- echo ""
- echo "Video generation completed!"
- echo "Full response:"
- echo "$STATUS_RESPONSE" | jq '.'
- break
- elif [ "$STATUS" = "failed" ]; then
- echo ""
- echo "Video generation failed!"
- echo "$STATUS_RESPONSE" | jq '.'
- exit 1
- fi
-
- sleep 2
-done
diff --git a/examples/online_serving/helios/run_helios_t2v.sh b/examples/online_serving/helios/run_helios_t2v.sh
deleted file mode 100644
index e920fc872b6..00000000000
--- a/examples/online_serving/helios/run_helios_t2v.sh
+++ /dev/null
@@ -1,69 +0,0 @@
-#!/bin/bash
-# SPDX-License-Identifier: Apache-2.0
-# SPDX-FileCopyrightText: Copyright contributors to the vLLM project
-
-# Helios Text-to-Video Generation Example
-# This script demonstrates how to use the /v1/videos API with Helios models
-
-API_URL="${API_URL:-http://localhost:8000}"
-MODEL="${MODEL:-BestWishYsh/Helios-Base}"
-PROMPT="${PROMPT:-A serene lakeside sunrise with mist over the water.}"
-
-echo "==================================="
-echo "Helios T2V Generation"
-echo "==================================="
-echo "API URL: $API_URL"
-echo "Model: $MODEL"
-echo "Prompt: $PROMPT"
-echo ""
-
-# Create video generation job
-echo "Creating video generation job..."
-RESPONSE=$(curl -s -X POST "$API_URL/v1/videos" \
- -F "prompt=$PROMPT" \
- -F "model=$MODEL" \
- -F "width=640" \
- -F "height=384" \
- -F "num_frames=99" \
- -F "num_inference_steps=50" \
- -F "guidance_scale=5.0" \
- -F "seed=42")
-
-echo "Response: $RESPONSE"
-echo ""
-
-# Extract video ID
-VIDEO_ID=$(echo "$RESPONSE" | grep -o '"id":"[^"]*"' | cut -d'"' -f4)
-
-if [ -z "$VIDEO_ID" ]; then
- echo "Error: Failed to create video job"
- exit 1
-fi
-
-echo "Video job created: $VIDEO_ID"
-echo ""
-
-# Poll for completion
-echo "Polling for completion..."
-while true; do
- STATUS_RESPONSE=$(curl -s "$API_URL/v1/videos/$VIDEO_ID")
- STATUS=$(echo "$STATUS_RESPONSE" | grep -o '"status":"[^"]*"' | cut -d'"' -f4)
- PROGRESS=$(echo "$STATUS_RESPONSE" | grep -o '"progress":[0-9]*' | cut -d':' -f2)
-
- echo "Status: $STATUS, Progress: $PROGRESS%"
-
- if [ "$STATUS" = "completed" ]; then
- echo ""
- echo "Video generation completed!"
- echo "Full response:"
- echo "$STATUS_RESPONSE" | jq '.'
- break
- elif [ "$STATUS" = "failed" ]; then
- echo ""
- echo "Video generation failed!"
- echo "$STATUS_RESPONSE" | jq '.'
- exit 1
- fi
-
- sleep 2
-done
diff --git a/examples/online_serving/image_to_image/README.md b/examples/online_serving/image_to_image/README.md
deleted file mode 100644
index 59b1f0e2c15..00000000000
--- a/examples/online_serving/image_to_image/README.md
+++ /dev/null
@@ -1,363 +0,0 @@
-# Image-To-Image
-
-This example demonstrates how to deploy Qwen-Image-Edit model for online image editing service using vLLM-Omni.
-
-For **multi-image** input editing, use **Qwen-Image-Edit-2509** (QwenImageEditPlusPipeline) and send multiple images in the user message content.
-
-## Start Server
-
-### Basic Start
-
-```bash
-vllm serve Qwen/Qwen-Image-Edit --omni --port 8092
-```
-
-!!! note
- If you encounter Out-of-Memory (OOM) issues or have limited GPU memory, you can enable VAE slicing and tiling to reduce memory usage, --vae-use-slicing --vae-use-tiling
-
-### Multi-Image Edit (Qwen-Image-Edit-2509)
-
-```bash
-vllm serve Qwen/Qwen-Image-Edit-2509 --omni --port 8092
-```
-
-### Start with Parameters
-
-
-Or use the startup script:
-
-```bash
-bash run_server.sh
-```
-
-To serve Qwen-Image-Edit-2509 with the script:
-
-```bash
-MODEL=Qwen/Qwen-Image-Edit-2509 bash run_server.sh
-```
-
-## API Calls
-
-### Method 1: Using curl (Image Editing)
-
-```bash
-# Image editing
-bash run_curl_image_edit.sh input.png "Convert this image to watercolor style"
-
-# Or execute directly
-IMG_B64=$(base64 -w0 input.png)
-
-cat <<EOF > request.json
-{
- "messages": [{
- "role": "user",
- "content": [
- {"type": "text", "text": "Convert this image to watercolor style"},
- {"type": "image_url", "image_url": {"url": "data:image/png;base64,$IMG_B64"}}
- ]
- }],
- "extra_body": {
- "height": 1024,
- "width": 1024,
- "num_inference_steps": 50,
- "guidance_scale": 1,
- "seed": 42
- }
-}
-EOF
-
-curl -s http://localhost:8092/v1/chat/completions -H "Content-Type: application/json" -d @request.json | jq -r '.choices[0].message.content[0].image_url.url' | cut -d',' -f2 | base64 -d > output.png
-```
-
-### Method 2: Using OpenAI Python SDK
-
-```python
-import base64
-from openai import OpenAI
-
-client = OpenAI(base_url="http://localhost:8092/v1", api_key="none")
-
-with open("input.png", "rb") as f:
- img_b64 = base64.b64encode(f.read()).decode()
-
-response = client.chat.completions.create(
- model="Qwen/Qwen-Image-Edit",
- messages=[{
- "role": "user",
- "content": [
- {"type": "text", "text": "Convert to watercolor style"},
- {"type": "image_url", "image_url": {
- "url": f"data:image/png;base64,{img_b64}"
- }},
- ],
- }],
- extra_body={
- "num_inference_steps": 50,
- "guidance_scale": 1,
- "seed": 42,
- },
-)
-
-img_url = response.choices[0].message.content[0].image_url.url
-_, b64_data = img_url.split(",", 1)
-with open("output.png", "wb") as f:
- f.write(base64.b64decode(b64_data))
-```
-
-!!! note
- The OpenAI SDK's `extra_body` keyword argument merges parameters into the
- top-level request body automatically. When using curl or Python `requests`,
- wrap generation parameters inside a literal `"extra_body"` key in the JSON
- instead (as shown in the curl example above).
-
-### Method 3: Using Python Client Script
-
-```bash
-python openai_chat_client.py --input input.png --prompt "Convert to oil painting style" --output output.png
-
-# Multi-image editing (Qwen-Image-Edit-2509 server required)
-python openai_chat_client.py --input input1.png input2.png --prompt "Combine these images into a single scene" --output output.png
-```
-
-### Method 4: Using Gradio Demo
-
-```bash
-python gradio_demo.py
-# Visit http://localhost:7861
-```
-
-## Request Format
-
-### Image Editing (Using image_url Format)
-
-```json
-{
- "messages": [
- {
- "role": "user",
- "content": [
- {"type": "text", "text": "Convert this image to watercolor style"},
- {"type": "image_url", "image_url": {"url": "data:image/png;base64,..."}}
- ]
- }
- ]
-}
-```
-
-### Image Editing (Using Simplified image Format)
-
-```json
-{
- "messages": [
- {
- "role": "user",
- "content": [
- {"text": "Convert this image to watercolor style"},
- {"image": "BASE64_IMAGE_DATA"}
- ]
- }
- ]
-}
-```
-
-### Image Editing with Parameters
-
-Use `extra_body` to pass generation parameters:
-
-```json
-{
- "messages": [
- {
- "role": "user",
- "content": [
- {"type": "text", "text": "Convert to ink wash painting style"},
- {"type": "image_url", "image_url": {"url": "data:image/png;base64,..."}}
- ]
- }
- ],
- "extra_body": {
- "height": 1024,
- "width": 1024,
- "num_inference_steps": 50,
- "guidance_scale": 7.5,
- "seed": 42
- }
-}
-```
-
-### Layered Image Generation (Qwen-Image-Layered)
-
-Qwen-Image-Layered generates multiple decomposed layers from a reference image and a text prompt.
-Start the server with:
-
-```bash
-vllm serve Qwen/Qwen-Image-Layered --omni --port 8093
-```
-
-**Using curl**
-
-```bash
-IMG_B64=$(base64 -w0 input.png)
-
-curl -sS http://localhost:8093/v1/chat/completions \
- -H "Content-Type: application/json" \
- -d "$(jq -n --arg img "$IMG_B64" '{
- messages: [{
- role: "user",
- content: [
- {type: "image_url", image_url: {url: ("data:image/png;base64," + $img)}},
- {type: "text", text: "a rabbit"}
- ]
- }],
- extra_body: {
- num_inference_steps: 50,
- cfg_scale: 4.0,
- seed: 0,
- layers: 4,
- resolution: 640
- }
- }')" \
- | jq -r '.choices[0].message.content[] | .image_url.url | split(",")[1]' \
- | while IFS= read -r b64; do
- ((i++)); echo "$b64" | base64 -d > "layer_${i}.png"
- done
-```
-
-**Using Python**
-
-```python
-import base64
-import requests
-
-with open("input.png", "rb") as f:
- img_b64 = base64.b64encode(f.read()).decode()
-
-payload = {
- "messages": [{
- "role": "user",
- "content": [
- {"type": "image_url", "image_url": {
- "url": f"data:image/png;base64,{img_b64}"
- }},
- {"type": "text", "text": "a rabbit"},
- ],
- }],
- "extra_body": {
- "num_inference_steps": 50,
- "cfg_scale": 4.0,
- "seed": 0,
- "layers": 4,
- "resolution": 640,
- },
-}
-
-resp = requests.post(
- "http://localhost:8093/v1/chat/completions",
- json=payload,
- timeout=600,
-)
-data = resp.json()
-
-for i, item in enumerate(data["choices"][0]["message"]["content"]):
- _, b64_data = item["image_url"]["url"].split(",", 1)
- with open(f"layer_{i}.png", "wb") as f:
- f.write(base64.b64decode(b64_data))
-```
-
-The response contains multiple images in `choices[0].message.content` — one per generated layer.
-
-#### Qwen-Image-Layered Parameters
-
-| Parameter | Type | Default | Description |
-|-----------|------|---------|-------------|
-| `layers` | int | 4 | Number of layers to decompose |
-| `resolution` | int | 640 | Resolution for dimension calculation (640 or 1024) |
-| `cfg_scale` | float | 4.0 | Classifier-free guidance scale (alias for `true_cfg_scale`) |
-| `num_inference_steps` | int | 50 | Number of denoising steps |
-| `seed` | int | None | Random seed for reproducibility |
-
-### Multi-Image Editing (Qwen-Image-Edit-2509)
-
-Provide multiple images in `content` (order matters):
-
-```json
-{
- "messages": [
- {
- "role": "user",
- "content": [
- {"type": "text", "text": "Combine these images into a single scene"},
- {"type": "image_url", "image_url": {"url": "data:image/png;base64,..."} },
- {"type": "image_url", "image_url": {"url": "data:image/png;base64,..."} }
- ]
- }
- ]
-}
-```
-
-## Generation Parameters
-
-When using `/v1/chat/completions`, pass these inside `extra_body` in the curl
-JSON, or via the `extra_body` keyword argument in the OpenAI Python SDK.
-When using the dedicated `/v1/images/edits` endpoint, pass the supported
-generation controls as top-level form fields directly. For image dimensions and
-count, use `size` and `n` rather than `height`, `width`, or
-`num_outputs_per_prompt`.
-
-| Parameter | Type | Default | Description |
-| ------------------------ | ----- | ------- | ------------------------------------- |
-| `height` | int | None | Output image height in pixels |
-| `width` | int | None | Output image width in pixels |
-| `size` | str | None | Output image size (e.g., "1024x1024") |
-| `num_inference_steps` | int | 50 | Number of denoising steps |
-| `guidance_scale` | float | 1.0 | CFG guidance scale |
-| `seed` | int | None | Random seed (reproducible) |
-| `negative_prompt` | str | None | Negative prompt |
-| `num_outputs_per_prompt` | int | 1 | Number of images to generate |
-| `strength` | float | 0.6 | **Z-Image only** - Denoising start timestep for I2I. Range: [0.0, 1.0]. Lower preserves more of original image. |
-| `layers` | int | 4 | Number of layers (Qwen-Image-Layered) |
-| `resolution` | int | 640 | Resolution, 640 or 1024 (Qwen-Image-Layered) |
-
-## Response Format
-
-```json
-{
- "id": "chatcmpl-xxx",
- "created": 1234567890,
- "model": "Qwen/Qwen-Image-Edit",
- "choices": [{
- "index": 0,
- "message": {
- "role": "assistant",
- "content": [{
- "type": "image_url",
- "image_url": {
- "url": "data:image/png;base64,..."
- }
- }]
- },
- "finish_reason": "stop"
- }],
- "usage": {...}
-}
-```
-
-## Common Editing Instructions Examples
-
-| Instruction | Description |
-| ---------------------------------------- | ---------------- |
-| `Convert this image to watercolor style` | Style transfer |
-| `Convert the image to black and white` | Desaturation |
-| `Enhance the color saturation` | Color adjustment |
-| `Convert to cartoon style` | Cartoonization |
-| `Add vintage filter effect` | Filter effect |
-| `Convert daytime scene to nighttime` | Scene conversion |
-
-## File Description
-
-| File | Description |
-| ------------------------ | ---------------------------- |
-| `run_server.sh` | Server startup script |
-| `run_curl_image_edit.sh` | curl image editing example |
-| `openai_chat_client.py` | Python client |
-| `gradio_demo.py` | Gradio interactive interface |
diff --git a/examples/online_serving/image_to_image/gradio_demo.py b/examples/online_serving/image_to_image/gradio_demo.py
deleted file mode 100644
index 7cf062ca8f9..00000000000
--- a/examples/online_serving/image_to_image/gradio_demo.py
+++ /dev/null
@@ -1,204 +0,0 @@
-#!/usr/bin/env python3
-"""
-Qwen-Image-Edit Gradio Demo for online serving.
-
-Usage:
- python gradio_demo.py [--server http://localhost:8092] [--port 7861]
-"""
-
-import argparse
-import base64
-from io import BytesIO
-
-try:
- import gradio as gr
-except ImportError:
- raise ImportError("gradio is required to run this demo. Install it with: pip install 'vllm-omni[demo]'") from None
-import requests
-from PIL import Image
-
-
-def _pil_to_b64_png(img: Image.Image) -> str:
- buffer = BytesIO()
- img.save(buffer, format="PNG")
- return base64.b64encode(buffer.getvalue()).decode("utf-8")
-
-
-def edit_image(
- input_image: Image.Image,
- extra_images: list[str] | None,
- prompt: str,
- steps: int,
- guidance_scale: float,
- seed: int | None,
- negative_prompt: str,
- server_url: str,
-) -> Image.Image | None:
- """Edit an image using the chat completions API."""
- if input_image is None:
- raise gr.Error("Please upload an image first")
-
- images: list[Image.Image] = [input_image]
- if extra_images:
- for p in extra_images:
- try:
- images.append(Image.open(p).convert("RGB"))
- except Exception as e:
- raise gr.Error(f"Failed to open image: {p}. Error: {e}") from e
-
- # Build user message with text and image
- content: list[dict[str, object]] = [{"type": "text", "text": prompt}]
- for img in images:
- content.append({"type": "image_url", "image_url": {"url": f"data:image/png;base64,{_pil_to_b64_png(img)}"}})
-
- messages = [
- {
- "role": "user",
- "content": content,
- }
- ]
-
- # Build extra_body with generation parameters
- extra_body = {
- "num_inference_steps": steps,
- "guidance_scale": guidance_scale,
- }
- if seed is not None and seed >= 0:
- extra_body["seed"] = seed
- if negative_prompt:
- extra_body["negative_prompt"] = negative_prompt
-
- # Build request payload
- payload = {"messages": messages, "extra_body": extra_body}
-
- try:
- response = requests.post(
- f"{server_url}/v1/chat/completions",
- headers={"Content-Type": "application/json"},
- json=payload,
- timeout=300,
- )
- response.raise_for_status()
- data = response.json()
-
- content = data["choices"][0]["message"]["content"]
- if isinstance(content, list) and len(content) > 0:
- image_url = content[0].get("image_url", {}).get("url", "")
- if image_url.startswith("data:image"):
- _, b64_data = image_url.split(",", 1)
- image_bytes = base64.b64decode(b64_data)
- return Image.open(BytesIO(image_bytes))
-
- return None
-
- except Exception as e:
- print(f"Error: {e}")
- raise gr.Error(f"Edit failed: {e}")
-
-
-def create_demo(server_url: str):
- """Create Gradio demo interface."""
-
- with gr.Blocks(title="Qwen-Image-Edit Demo") as demo:
- gr.Markdown("# Qwen-Image-Edit Online Editing")
- gr.Markdown(
- "Upload an image and describe the editing effect you want. "
- "For multi-image editing, upload extra images (requires Qwen-Image-Edit-2509 server)."
- )
-
- with gr.Row():
- with gr.Column(scale=1):
- input_image = gr.Image(
- label="Input Image",
- type="pil",
- )
- extra_images = gr.File(
- label="Additional Images (Optional)",
- file_count="multiple",
- type="filepath",
- )
- prompt = gr.Textbox(
- label="Edit Instruction",
- placeholder="Describe the editing effect you want...",
- lines=2,
- )
- negative_prompt = gr.Textbox(
- label="Negative Prompt",
- placeholder="Describe what you don't want...",
- lines=2,
- )
-
- with gr.Row():
- steps = gr.Slider(
- label="Inference Steps",
- minimum=10,
- maximum=100,
- value=50,
- step=5,
- )
- guidance_scale = gr.Slider(
- label="Guidance Scale (CFG)",
- minimum=1.0,
- maximum=20.0,
- value=7.5,
- step=0.5,
- )
-
- with gr.Row():
- seed = gr.Number(
- label="Random Seed (-1 for random)",
- value=-1,
- precision=0,
- )
-
- edit_btn = gr.Button("Edit Image", variant="primary")
-
- with gr.Column(scale=1):
- output_image = gr.Image(
- label="Edited Image",
- type="pil",
- )
-
- # Examples
- gr.Examples(
- examples=[
- ["Convert this image to watercolor style"],
- ["Convert the image to black and white"],
- ["Enhance the color saturation"],
- ["Convert to cartoon style"],
- ["Add vintage filter effect"],
- ["Convert daytime to nighttime"],
- ["Convert to oil painting style"],
- ["Add dreamy blur effect"],
- ],
- inputs=[prompt],
- )
-
- def process_edit(img, imgs, p, st, g, se, n):
- actual_seed = se if se >= 0 else None
- return edit_image(img, imgs, p, st, g, actual_seed, n, server_url)
-
- edit_btn.click(
- fn=process_edit,
- inputs=[input_image, extra_images, prompt, steps, guidance_scale, seed, negative_prompt],
- outputs=[output_image],
- )
-
- return demo
-
-
-def main():
- parser = argparse.ArgumentParser(description="Qwen-Image-Edit Gradio Demo")
- parser.add_argument("--server", default="http://localhost:8092", help="Server URL")
- parser.add_argument("--port", type=int, default=7861, help="Gradio port")
- parser.add_argument("--share", action="store_true", help="Create public link")
-
- args = parser.parse_args()
-
- print(f"Connecting to server: {args.server}")
- demo = create_demo(args.server)
- demo.launch(server_port=args.port, share=args.share)
-
-
-if __name__ == "__main__":
- main()
diff --git a/examples/online_serving/image_to_image/openai_chat_client.py b/examples/online_serving/image_to_image/openai_chat_client.py
deleted file mode 100644
index 7aac2b214e2..00000000000
--- a/examples/online_serving/image_to_image/openai_chat_client.py
+++ /dev/null
@@ -1,168 +0,0 @@
-#!/usr/bin/env python3
-"""
-Qwen-Image-Edit OpenAI-compatible chat client for image editing.
-
-Usage:
- python openai_chat_client.py --input qwen_image_output.png --prompt "Convert to watercolor style" --output output.png
- python openai_chat_client.py --input input.png --prompt "Convert to oil painting" --seed 42
- python openai_chat_client.py --input input1.png input2.png --prompt "Combine these images into a single scene"
-"""
-
-import argparse
-import base64
-from io import BytesIO
-from pathlib import Path
-
-import requests
-from PIL import Image
-
-
-def _encode_image_as_data_url(input_path: Path) -> str:
- image_bytes = input_path.read_bytes()
- try:
- img = Image.open(BytesIO(image_bytes))
- mime_type = f"image/{img.format.lower()}" if img.format else "image/png"
- except Exception:
- mime_type = "image/png"
- image_b64 = base64.b64encode(image_bytes).decode("utf-8")
- return f"data:{mime_type};base64,{image_b64}"
-
-
-def edit_image(
- input_image: str | Path | list[str | Path],
- prompt: str,
- server_url: str = "http://localhost:8092",
- height: int | None = None,
- width: int | None = None,
- steps: int | None = None,
- guidance_scale: float | None = None,
- seed: int | None = None,
- negative_prompt: str | None = None,
-) -> bytes | None:
- """Edit an image using the chat completions API.
-
- Args:
- input_image: Path(s) to input image(s). For multi-image editing, pass multiple paths.
- prompt: Text description of the edit
- server_url: Server URL
- height: Output image height in pixels
- width: Output image width in pixels
- steps: Number of inference steps
- guidance_scale: CFG guidance scale
- seed: Random seed
- negative_prompt: Negative prompt
-
- Returns:
- Edited image bytes or None if failed
- """
- input_images = input_image if isinstance(input_image, list) else [input_image]
- input_paths = [Path(p) for p in input_images]
- for p in input_paths:
- if not p.exists():
- print(f"Error: Input image not found: {p}")
- return None
-
- # Build user message with text and image
- content: list[dict[str, object]] = [{"type": "text", "text": prompt}]
- for p in input_paths:
- content.append({"type": "image_url", "image_url": {"url": _encode_image_as_data_url(p)}})
-
- messages = [
- {
- "role": "user",
- "content": content,
- }
- ]
-
- # Build extra_body with generation parameters
- extra_body = {}
- if height is not None:
- extra_body["height"] = height
- if width is not None:
- extra_body["width"] = width
- if steps is not None:
- extra_body["num_inference_steps"] = steps
- if guidance_scale is not None:
- extra_body["guidance_scale"] = guidance_scale
- if seed is not None:
- extra_body["seed"] = seed
- if negative_prompt:
- extra_body["negative_prompt"] = negative_prompt
-
- # Build request payload
- payload = {"messages": messages}
- if extra_body:
- payload["extra_body"] = extra_body
-
- # Send request
- try:
- response = requests.post(
- f"{server_url}/v1/chat/completions",
- headers={"Content-Type": "application/json"},
- json=payload,
- timeout=300,
- )
- response.raise_for_status()
- data = response.json()
-
- # Extract image from response
- content = data["choices"][0]["message"]["content"]
- if isinstance(content, list) and len(content) > 0:
- image_url = content[0].get("image_url", {}).get("url", "")
- if image_url.startswith("data:image"):
- _, b64_data = image_url.split(",", 1)
- return base64.b64decode(b64_data)
-
- print(f"Unexpected response format: {content}")
- return None
-
- except Exception as e:
- print(f"Error: {e}")
- return None
-
-
-def main():
- parser = argparse.ArgumentParser(description="Qwen-Image-Edit chat client")
- parser.add_argument("--input", "-i", required=True, nargs="+", help="Input image path(s)")
- parser.add_argument("--prompt", "-p", required=True, help="Edit prompt")
- parser.add_argument("--output", "-o", default="output.png", help="Output file")
- parser.add_argument("--server", "-s", default="http://localhost:8092", help="Server URL")
- parser.add_argument("--height", type=int, default=1024, help="Output image height")
- parser.add_argument("--width", type=int, default=1024, help="Output image width")
- parser.add_argument("--steps", type=int, default=50, help="Inference steps")
- parser.add_argument("--guidance", type=float, default=7.5, help="Guidance scale")
- parser.add_argument("--seed", type=int, default=0, help="Random seed")
- parser.add_argument("--negative", help="Negative prompt")
-
- args = parser.parse_args()
-
- if len(args.input) == 1:
- print(f"Input: {args.input[0]}")
- else:
- print(f"Inputs ({len(args.input)}): {', '.join(args.input)}")
- print(f"Prompt: {args.prompt}")
-
- image_bytes = edit_image(
- input_image=args.input,
- prompt=args.prompt,
- server_url=args.server,
- height=args.height,
- width=args.width,
- steps=args.steps,
- guidance_scale=args.guidance,
- seed=args.seed,
- negative_prompt=args.negative,
- )
-
- if image_bytes:
- output_path = Path(args.output)
- output_path.write_bytes(image_bytes)
- print(f"Image saved to: {output_path}")
- print(f"Size: {len(image_bytes) / 1024:.1f} KB")
- else:
- print("Failed to edit image")
- exit(1)
-
-
-if __name__ == "__main__":
- main()
diff --git a/examples/online_serving/image_to_image/run_curl_image_edit.sh b/examples/online_serving/image_to_image/run_curl_image_edit.sh
deleted file mode 100644
index 1a532868597..00000000000
--- a/examples/online_serving/image_to_image/run_curl_image_edit.sh
+++ /dev/null
@@ -1,61 +0,0 @@
-#!/bin/bash
-# Qwen-Image image-edit (image-to-image) curl example
-
-set -euo pipefail
-
-if [[ $# -lt 2 ]]; then
- echo "Usage: $0 <input_image> \"<edit_prompt>\" [output_file]" >&2
- exit 1
-fi
-
-INPUT_IMG=$1
-PROMPT=$2
-SERVER="${SERVER:-http://localhost:8092}"
-CURRENT_TIME=$(date +%Y%m%d%H%M%S)
-OUTPUT="${3:-image_edit_${CURRENT_TIME}.png}"
-
-if [[ ! -f "$INPUT_IMG" ]]; then
- echo "Input image not found: $INPUT_IMG" >&2
- exit 1
-fi
-
-REQUEST_JSON_FILE=$(mktemp)
-trap 'rm -f "$REQUEST_JSON_FILE"' EXIT
-
-# Pipe base64 into jq via stdin to avoid ARG_MAX limit on large images
-base64 -w0 "$INPUT_IMG" \
- | jq -Rs --arg prompt "$PROMPT" '{
- messages: [{
- role: "user",
- content: [
- {"type": "text", "text": $prompt},
- {"type": "image_url", "image_url": {"url": ("data:image/png;base64," + .)}}
- ]
- }],
- extra_body: {
- num_inference_steps: 50,
- guidance_scale: 1,
- seed: 42
- }
- }' > "$REQUEST_JSON_FILE"
-
-echo "Generating edited image..."
-echo "Server: $SERVER"
-echo "Prompt: $PROMPT"
-echo "Input : $INPUT_IMG"
-echo "Output: $OUTPUT"
-
-curl -s "$SERVER/v1/chat/completions" \
- -H "Content-Type: application/json" \
- -d @"$REQUEST_JSON_FILE" \
- | jq -r '.choices[0].message.content[0].image_url.url' \
- | cut -d',' -f2 \
- | base64 -d > "$OUTPUT"
-
-if [[ -f "$OUTPUT" ]]; then
- echo "Image saved to: $OUTPUT"
- echo "Size: $(du -h "$OUTPUT" | cut -f1)"
-else
- echo "Failed to generate image"
- exit 1
-fi
diff --git a/examples/online_serving/image_to_image/run_server.sh b/examples/online_serving/image_to_image/run_server.sh
deleted file mode 100755
index 6b8e081d91f..00000000000
--- a/examples/online_serving/image_to_image/run_server.sh
+++ /dev/null
@@ -1,12 +0,0 @@
-#!/bin/bash
-# Qwen-Image-Edit online serving startup script
-
-MODEL="${MODEL:-Qwen/Qwen-Image-Edit}"
-PORT="${PORT:-8092}"
-
-echo "Starting Qwen-Image-Edit server..."
-echo "Model: $MODEL"
-echo "Port: $PORT"
-
-vllm serve "$MODEL" --omni \
- --port "$PORT"
diff --git a/examples/online_serving/image_to_video/README.md b/examples/online_serving/image_to_video/README.md
deleted file mode 100644
index 285eeb27983..00000000000
--- a/examples/online_serving/image_to_video/README.md
+++ /dev/null
@@ -1,279 +0,0 @@
-# Image-To-Video
-
-This example demonstrates how to deploy the Wan2.2 image-to-video model for online video generation using vLLM-Omni.
-
-## Start Server
-
-### Basic Start
-
-```bash
-vllm serve Wan-AI/Wan2.2-I2V-A14B-Diffusers --omni --port 8091
-```
-
-### Start with Parameters
-
-Or use the startup script:
-
-```bash
-bash run_server.sh
-```
-
-The script allows overriding:
-- `MODEL` (default: `Wan-AI/Wan2.2-I2V-A14B-Diffusers`)
-- `PORT` (default: `8091`)
-- `BOUNDARY_RATIO` (default: `0.875`)
-- `FLOW_SHIFT` (default: `12.0`)
-- `CACHE_BACKEND` (default: `none`)
-- `ENABLE_CACHE_DIT_SUMMARY` (default: `0`)
-
-### Ascend / Local LightX2V Example
-
-For a local Wan2.2-LightX2V Diffusers directory on Ascend/NPU, you can start the server like this:
-
-```bash
-vllm serve /path/to/Wan2.2-I2V-A14B-LightX2V-Diffusers-Lightning \
- --omni \
- --port 8091 \
- --flow-shift 12 \
- --cfg-parallel-size 1 \
- --ulysses-degree 4 \
- --use-hsdp \
- --trust-remote-code \
- --allowed-local-media-path / \
- --seed 42
-```
-
-## Async Job Behavior
-
-`POST /v1/videos` is asynchronous. It creates a video job and immediately
-returns metadata like the job ID and initial `queued` status. To get the final
-artifact, poll the job status and then download the completed file from the
-content endpoint.
-
-The main endpoints are:
-- `POST /v1/videos`: create a video generation job (async)
-- `POST /v1/videos/sync`: generate a video and return raw bytes (sync, for benchmarks)
-- `GET /v1/videos/{video_id}`: retrieve the current job status and metadata
-- `GET /v1/videos`: list stored video jobs
-- `GET /v1/videos/{video_id}/content`: download the generated video file
-- `DELETE /v1/videos/{video_id}`: delete the job and any stored output
-
-## Sync API (Benchmark / Testing)
-
-`POST /v1/videos/sync` is a synchronous alternative that blocks until generation
-completes and returns the raw video bytes (`video/mp4`) directly in the response
-body. It is designed for benchmark and testing scenarios where one-shot
-request/response latency measurement is needed.
-
-The sync endpoint accepts the same form parameters as `POST /v1/videos`. It does
-not create any stored job record — the response is purely the generated video
-file. Metadata is returned via response headers:
-
-- `X-Request-Id`: unique identifier for this generation request
-- `X-Model`: model name used for generation
-- `X-Inference-Time-S`: wall-clock inference time in seconds
-
-```bash
-curl -X POST http://localhost:8091/v1/videos/sync \
- -F "prompt=A bear playing with yarn, smooth motion" \
- -F "input_reference=@/path/to/input.png" \
- -F "size=832x480" \
- -F "num_frames=33" \
- -F "fps=16" \
- -F "negative_prompt=low quality, blurry, static" \
- -F "num_inference_steps=40" \
- -F "guidance_scale=1.0" \
- -F "guidance_scale_2=1.0" \
- -F "boundary_ratio=0.875" \
- -F "flow_shift=12.0" \
- -F 'extra_params={"sample_solver":"euler"}' \
- -F "seed=42" \
- -o sync_i2v_output.mp4
-```
-
-For Wan Lightning/Distill checkpoints, pass `{"sample_solver":"euler"}` via `extra_params`. The default solver is `unipc`.
-
-Example matching the local LightX2V deployment above:
-
-```bash
-curl -sS -X POST http://localhost:8091/v1/videos/sync \
- -H "Accept: video/mp4" \
- -F "prompt=A cat playing with yarn" \
- -F "input_reference=@/path/to/input.jpg" \
- -F "width=832" \
- -F "height=480" \
- -F "num_frames=81" \
- -F "fps=16" \
- -F "num_inference_steps=4" \
- -F "guidance_scale=1.0" \
- -F "guidance_scale_2=1.0" \
- -F "boundary_ratio=0.875" \
- -F "seed=42" \
- -F 'extra_params={"sample_solver":"euler"}' \
- -o ./output.mp4
-```
-
-Use `/v1/videos/sync` if you want to write the MP4 directly to a file. `POST /v1/videos` is async and returns job metadata, not inline `b64_json`.
-
-## Storage
-
-Generated video files are stored on local disk by the async video API.
-Local file storage behavior can be controlled via the following environment variables:
-
-- `VLLM_OMNI_STORAGE_PATH`: directory used for generated files (default: `/tmp/storage`)
-- `VLLM_OMNI_STORAGE_MAX_CONCURRENCY`: max concurrent save/delete operations (default: `4`)
-
-Example:
-
-```bash
-export VLLM_OMNI_STORAGE_PATH=/var/tmp/vllm-omni-videos
-export VLLM_OMNI_STORAGE_MAX_CONCURRENCY=8
-```
-
-## API Calls
-
-### Method 1: Using curl
-
-```bash
-# Basic image-to-video generation
-bash run_curl_image_to_video.sh
-
-# Wan Lightning/Distill checkpoints
-SAMPLE_SOLVER=euler bash run_curl_image_to_video.sh
-
-# Or execute directly (OpenAI-style multipart)
-create_response=$(curl -s http://localhost:8091/v1/videos \
- -H "Accept: application/json" \
- -F "prompt=A bear playing with yarn, smooth motion" \
- -F "negative_prompt=low quality, blurry, static" \
- -F "input_reference=@/path/to/qwen-bear.png" \
- -F "width=832" \
- -F "height=480" \
- -F "num_frames=33" \
- -F "fps=16" \
- -F "num_inference_steps=40" \
- -F "guidance_scale=1.0" \
- -F "guidance_scale_2=1.0" \
- -F "boundary_ratio=0.875" \
- -F "flow_shift=12.0" \
- -F 'extra_params={"sample_solver":"euler"}' \
- -F "seed=42")
-
-video_id=$(echo "$create_response" | jq -r '.id')
-while true; do
- status=$(curl -s "http://localhost:8091/v1/videos/${video_id}" | jq -r '.status')
- if [ "$status" = "completed" ]; then
- break
- fi
- if [ "$status" = "failed" ]; then
- echo "Video generation failed"
- exit 1
- fi
- sleep 2
-done
-
-curl -s "http://localhost:8091/v1/videos/${video_id}" | jq .
-curl -L "http://localhost:8091/v1/videos/${video_id}/content" -o wan22_i2v_output.mp4
-```
-
-## Request Format
-
-### Required Fields
-
-```bash
-curl -X POST http://localhost:8091/v1/videos \
- -F "prompt=A bear playing with yarn, smooth motion" \
- -F "negative_prompt=low quality, blurry, static" \
- -F "input_reference=@/path/to/qwen-bear.png"
-```
-
-### Alternative JSON-Safe Reference Input
-
-Use `image_reference` when you want to pass a URL or JSON-safe image reference
-instead of uploading a file. Do not send `input_reference` and
-`image_reference` together.
-
-```bash
-curl -X POST http://localhost:8091/v1/videos \
- -F "prompt=A bear playing with yarn, smooth motion" \
- -F 'image_reference={"image_url":"https://example.com/qwen-bear.png"}'
-```
-
-### Generation with Parameters
-
-```bash
-curl -X POST http://localhost:8091/v1/videos \
- -F "prompt=A bear playing with yarn, smooth motion" \
- -F "negative_prompt=low quality, blurry, static" \
- -F "input_reference=@/path/to/qwen-bear.png" \
- -F "width=832" \
- -F "height=480" \
- -F "num_frames=33" \
- -F "fps=16" \
- -F "num_inference_steps=40" \
- -F "guidance_scale=1.0" \
- -F "guidance_scale_2=1.0" \
- -F "boundary_ratio=0.875" \
- -F "flow_shift=12.0" \
- -F 'extra_params={"sample_solver":"euler"}' \
- -F "seed=42"
-```
-
-`sample_solver` is supported by Wan2.2 online serving through the existing `extra_params` field, which is merged into the pipeline `extra_args`. Use `unipc` for the default multistep solver, or `euler` for Lightning/Distill checkpoints.
-
-## Create Response Format
-
-`POST /v1/videos` returns a job record, not inline base64 video data.
-
-```json
-{
- "id": "video_gen_123",
- "object": "video",
- "status": "queued",
- "model": "Wan-AI/Wan2.2-I2V-A14B-Diffusers",
- "prompt": "A bear playing with yarn, smooth motion",
- "created_at": 1234567890
-}
-```
-
-## Retrieve, List, Download, and Delete
-
-### Retrieve a job
-
-```bash
-curl -s http://localhost:8091/v1/videos/${video_id} | jq .
-```
-
-### List jobs
-
-```bash
-curl -s http://localhost:8091/v1/videos | jq .
-```
-
-### Download the completed video
-
-```bash
-curl -L http://localhost:8091/v1/videos/${video_id}/content -o wan22_i2v_output.mp4
-```
-
-### Delete a job and its stored file
-
-```bash
-curl -X DELETE http://localhost:8091/v1/videos/${video_id} | jq .
-```
-
-## Poll Until Complete
-
-```bash
-while true; do
- status=$(curl -s http://localhost:8091/v1/videos/${video_id} | jq -r '.status')
- if [ "$status" = "completed" ]; then
- break
- fi
- if [ "$status" = "failed" ]; then
- echo "Video generation failed"
- exit 1
- fi
- sleep 2
-done
-```
diff --git a/examples/online_serving/image_to_video/run_curl_hunyuan_video_15.sh b/examples/online_serving/image_to_video/run_curl_hunyuan_video_15.sh
deleted file mode 100644
index 23a5fcf0734..00000000000
--- a/examples/online_serving/image_to_video/run_curl_hunyuan_video_15.sh
+++ /dev/null
@@ -1,68 +0,0 @@
-#!/bin/bash
-# HunyuanVideo-1.5 image-to-video curl example using the async video job API.
-
-set -euo pipefail
-
-INPUT_IMAGE="${INPUT_IMAGE:-test_input.jpg}"
-BASE_URL="${BASE_URL:-http://localhost:8099}"
-OUTPUT_PATH="${OUTPUT_PATH:-hunyuan_video_15_i2v.mp4}"
-POLL_INTERVAL="${POLL_INTERVAL:-2}"
-
-if [ ! -f "$INPUT_IMAGE" ]; then
- echo "Input image not found: $INPUT_IMAGE"
- echo "Provide an image via INPUT_IMAGE env var."
- exit 1
-fi
-
-create_response=$(
- curl -sS -X POST "${BASE_URL}/v1/videos" \
- -H "Accept: application/json" \
- -F "prompt=The camera follows the puppy as it runs forward on the grass, its four legs alternating steps, its tail held high and wagging side to side." \
- -F "input_reference=@${INPUT_IMAGE}" \
- -F "size=832x480" \
- -F "num_frames=33" \
- -F "fps=24" \
- -F "num_inference_steps=30" \
- -F "guidance_scale=6.0" \
- -F "flow_shift=5.0" \
- -F "seed=42"
-)
-
-video_id="$(echo "${create_response}" | jq -r '.id')"
-if [ -z "${video_id}" ] || [ "${video_id}" = "null" ]; then
- echo "Failed to create video job:"
- echo "${create_response}" | jq .
- exit 1
-fi
-
-echo "Created video job ${video_id}"
-echo "${create_response}" | jq .
-
-while true; do
- status_response="$(curl -sS "${BASE_URL}/v1/videos/${video_id}")"
- status="$(echo "${status_response}" | jq -r '.status')"
-
- case "${status}" in
- queued|in_progress)
- echo "Video job ${video_id} status: ${status}"
- sleep "${POLL_INTERVAL}"
- ;;
- completed)
- echo "${status_response}" | jq .
- break
- ;;
- failed)
- echo "Video generation failed:"
- echo "${status_response}" | jq .
- exit 1
- ;;
- *)
- echo "Unexpected status response:"
- echo "${status_response}" | jq .
- exit 1
- ;;
- esac
-done
-
-curl -sS -L "${BASE_URL}/v1/videos/${video_id}/content" -o "${OUTPUT_PATH}"
-echo "Saved video to ${OUTPUT_PATH}"
diff --git a/examples/online_serving/image_to_video/run_curl_image_to_video.sh b/examples/online_serving/image_to_video/run_curl_image_to_video.sh
deleted file mode 100644
index 6f6a6f96d59..00000000000
--- a/examples/online_serving/image_to_video/run_curl_image_to_video.sh
+++ /dev/null
@@ -1,80 +0,0 @@
-#!/bin/bash
-# Wan2.2 image-to-video curl example using the async video job API.
-
-set -euo pipefail
-
-INPUT_IMAGE="${INPUT_IMAGE:-../../offline_inference/image_to_video/qwen-bear.png}"
-BASE_URL="${BASE_URL:-http://localhost:8099}"
-OUTPUT_PATH="${OUTPUT_PATH:-wan22_i2v_output.mp4}"
-NEGATIVE_PROMPT="${NEGATIVE_PROMPT:-}"
-SAMPLE_SOLVER="${SAMPLE_SOLVER:-}"
-POLL_INTERVAL="${POLL_INTERVAL:-2}"
-
-if [ ! -f "$INPUT_IMAGE" ]; then
- echo "Input image not found: $INPUT_IMAGE"
- exit 1
-fi
-
-create_cmd=(
- curl -sS -X POST "${BASE_URL}/v1/videos"
- -H "Accept: application/json"
- -F "prompt=A bear playing with yarn, smooth motion"
- -F "input_reference=@${INPUT_IMAGE}"
- -F "seconds=2"
- -F "size=832x480"
- -F "fps=16"
- -F "num_inference_steps=40"
- -F "guidance_scale=1.0"
- -F "guidance_scale_2=1.0"
- -F "boundary_ratio=0.875"
- -F "flow_shift=12.0"
- -F "seed=42"
-)
-
-if [ -n "${NEGATIVE_PROMPT}" ]; then
- create_cmd+=(-F "negative_prompt=${NEGATIVE_PROMPT}")
-fi
-
-if [ -n "${SAMPLE_SOLVER}" ]; then
- create_cmd+=(-F "extra_params={\"sample_solver\":\"${SAMPLE_SOLVER}\"}")
-fi
-
-create_response="$("${create_cmd[@]}")"
-video_id="$(echo "${create_response}" | jq -r '.id')"
-if [ -z "${video_id}" ] || [ "${video_id}" = "null" ]; then
- echo "Failed to create video job:"
- echo "${create_response}" | jq .
- exit 1
-fi
-
-echo "Created video job ${video_id}"
-echo "${create_response}" | jq .
-
-while true; do
- status_response="$(curl -sS "${BASE_URL}/v1/videos/${video_id}")"
- status="$(echo "${status_response}" | jq -r '.status')"
-
- case "${status}" in
- queued|in_progress)
- echo "Video job ${video_id} status: ${status}"
- sleep "${POLL_INTERVAL}"
- ;;
- completed)
- echo "${status_response}" | jq .
- break
- ;;
- failed)
- echo "Video generation failed:"
- echo "${status_response}" | jq .
- exit 1
- ;;
- *)
- echo "Unexpected status response:"
- echo "${status_response}" | jq .
- exit 1
- ;;
- esac
-done
-
-curl -sS -L "${BASE_URL}/v1/videos/${video_id}/content" -o "${OUTPUT_PATH}"
-echo "Saved video to ${OUTPUT_PATH}"
diff --git a/examples/online_serving/image_to_video/run_server.sh b/examples/online_serving/image_to_video/run_server.sh
deleted file mode 100644
index a488f5340ee..00000000000
--- a/examples/online_serving/image_to_video/run_server.sh
+++ /dev/null
@@ -1,25 +0,0 @@
-#!/bin/bash
-# Wan2.2 image-to-video server start script
-
-MODEL="${MODEL:-Wan-AI/Wan2.2-I2V-A14B-Diffusers}"
-PORT="${PORT:-8099}"
-CACHE_BACKEND="${CACHE_BACKEND:-none}"
-ENABLE_CACHE_DIT_SUMMARY="${ENABLE_CACHE_DIT_SUMMARY:-0}"
-
-echo "Starting Wan2.2 I2V server..."
-echo "Model: $MODEL"
-echo "Port: $PORT"
-echo "Cache backend: $CACHE_BACKEND"
-if [ "$ENABLE_CACHE_DIT_SUMMARY" != "0" ]; then
- echo "Cache-DiT summary: enabled"
-fi
-
-CACHE_BACKEND_FLAG=""
-if [ "$CACHE_BACKEND" != "none" ]; then
- CACHE_BACKEND_FLAG="--cache-backend $CACHE_BACKEND"
-fi
-
-vllm serve "$MODEL" --omni \
- --port "$PORT" \
- $CACHE_BACKEND_FLAG \
- $(if [ "$ENABLE_CACHE_DIT_SUMMARY" != "0" ]; then echo "--enable-cache-dit-summary"; fi)
diff --git a/examples/online_serving/image_to_video/run_server_hunyuan_video_15.sh b/examples/online_serving/image_to_video/run_server_hunyuan_video_15.sh
deleted file mode 100644
index 50a78372fc6..00000000000
--- a/examples/online_serving/image_to_video/run_server_hunyuan_video_15.sh
+++ /dev/null
@@ -1,31 +0,0 @@
-#!/bin/bash
-# HunyuanVideo-1.5 image-to-video online serving startup script
-#
-# 480p: ~35 GB VRAM (BF16), fits 1x A100 80GB
-# 720p: needs FP8 + VAE tiling, ~35 GB VRAM
-
-MODEL="${MODEL:-hunyuanvideo-community/HunyuanVideo-1.5-Diffusers-480p_i2v}"
-PORT="${PORT:-8099}"
-FLOW_SHIFT="${FLOW_SHIFT:-5.0}"
-QUANTIZATION="${QUANTIZATION:-}"
-CACHE_BACKEND="${CACHE_BACKEND:-none}"
-
-echo "Starting HunyuanVideo-1.5 I2V server..."
-echo "Model: $MODEL"
-echo "Port: $PORT"
-echo "Flow shift: $FLOW_SHIFT"
-echo "Quantization: ${QUANTIZATION:-none}"
-echo "Cache backend: $CACHE_BACKEND"
-
-EXTRA_FLAGS=""
-if [ -n "$QUANTIZATION" ]; then
- EXTRA_FLAGS="$EXTRA_FLAGS --quantization $QUANTIZATION"
-fi
-if [ "$CACHE_BACKEND" != "none" ]; then
- EXTRA_FLAGS="$EXTRA_FLAGS --cache-backend $CACHE_BACKEND"
-fi
-
-vllm serve "$MODEL" --omni \
- --port "$PORT" \
- --flow-shift "$FLOW_SHIFT" \
- $EXTRA_FLAGS
diff --git a/examples/online_serving/mimo_audio/README.md b/examples/online_serving/mimo_audio/README.md
deleted file mode 100644
index 9c1be7f21c8..00000000000
--- a/examples/online_serving/mimo_audio/README.md
+++ /dev/null
@@ -1,61 +0,0 @@
-# Online serving Example of vLLM-Omni for MiMo-Audio
-
-## 🛠️ Installation
-
-Please refer to [README.md](../../../README.md)
-
-> ⚠️ **Important (audio generation)**
-> For **audio generation** (TTS, responses that include synthesized audio, etc.), install **`flash-attn`** for your **CUDA** and **PyTorch** stack. Without it on GPU, **output audio may be noise-only or unusable**. See the [FlashAttention](https://github.com/Dao-AILab/flash-attention) repository for compatible builds.
-
-## Run examples (MiMo-Audio)
-
-### Launch the Server
-```bash
-export MIMO_AUDIO_TOKENIZER_PATH="XiaomiMiMo/MiMo-Audio-Tokenizer"
-
-vllm serve XiaomiMiMo/MiMo-Audio-7B-Instruct --omni \
- --served-model-name "MiMo-Audio-7B-Instruct" \
- --port 18091 \
- --chat-template ./examples/online_serving/mimo_audio/chat_template.jinja
-```
-> ⚠️ **Important**
-> **MiMo-Audio is not compatible with the default chat template.**
-> The provided `chat_template.jinja` implements MiMo-specific role, audio token, and instruction formatting and **must be used for all inference**.
-
-
-### Send Multi-modal Request
-
-Get into the example folder
-```bash
-cd examples/online_serving/mimo_audio
-```
-
-#### Send request via python
-
-```bash
-# Audio dialogue task
-python openai_chat_completion_client_for_multimodal_generation.py \
---query-type multi_audios \
---message-json ../../offline_inference/mimo_audio/message_base64_wav.json
-```
-
-The Python client supports the following command-line arguments:
-
-- `--query-type` (or `-q`): Query type (default: `multi_audios`)
- - Options: `multi_audios`, `text`
-- `--message-json` (or `-m`): Path to `base64` multi rounds audio messages json file
- - Do not pass any value for "text" query type
- - Supports local file paths (automatically encoded to base64) or HTTP/HTTPS URLs, only for "Are these two audio clips the same?" task
- - Example: `---message-json ./examples/offline_inference/mimo_audio/message_base64_wav.json`
-- `--prompt` (or `-p`): Custom text prompt/question, only for query type is "text"(TTS task)
- - Attention! Do not pass any value for "multi_audios" query type
- - Example: `--prompt "What are the main activities shown in this video?"`
-
-
-For example, to use multi rounds audios with local files:
-
-```bash
-python openai_chat_completion_client_for_multimodal_generation.py \
---query-type multi_audios \
---message-json ../../offline_inference/mimo_audio/message_base64_wav.json
-```
diff --git a/examples/online_serving/mimo_audio/chat_template.jinja b/examples/online_serving/mimo_audio/chat_template.jinja
deleted file mode 100644
index dc93c4487fa..00000000000
--- a/examples/online_serving/mimo_audio/chat_template.jinja
+++ /dev/null
@@ -1,86 +0,0 @@
-{%- if tools %}
- {{- '<|im_start|>system\n' }}
- {%- if messages[0]['role'] == 'system' %}
- {{- messages[0]['content'] }}
- {%- else %}
- {{- 'You are a helpful assistant.' }}
- {%- endif %}
- {{- "\n\n# Tools\n\nYou may call one or more functions to assist with the user query.\n\nYou are provided with function signatures within <tools></tools> XML tags:\n<tools>" }}
- {%- for tool in tools %}
- {{- "\n" }}
- {{- tool | tojson }}
- {%- endfor %}
- {{- "\n</tools>\n\nFor each function call, return a json object with function name and arguments within <tool_call></tool_call> XML tags:\n<tool_call>\n{\"name\": <function-name>, \"arguments\": <args-json-object>}\n</tool_call><|im_end|>\n" }}
-{%- else %}
- {%- if messages[0]['role'] == 'system' %}
- {%- set _m = '<|sosp|><|empty|><|eosp|>' -%}
- {%- set _raw0 = messages[0]['content'] if messages[0]['content'] is string else '' -%}
- {%- if _m in _raw0 %}
- {%- set _t0 = (_raw0 | replace(_m ~ '\n', '') | replace(_m, '') | trim) -%}
- {{- '<|im_start|>system\n' + (_t0 ~ _m if _t0 else _m) + '<|im_end|>\n' }}
- {%- else %}
- {{- '<|im_start|>system\n' + _raw0 + '<|im_end|>\n' }}
- {%- endif %}
- {%- else %}
- {{- '<|im_start|>system\nYou are a helpful assistant.<|im_end|>\n' }}
- {%- endif %}
-{%- endif %}
-
-{%- for message in messages %}
- {%- if message['role'] == 'assistant' %}
- {{- '<|im_start|>assistant' }}
- {%- set _sosp = '<|sosp|><|empty|><|eosp|>' -%}
- {%- set _text = message['content'] if message['content'] is string else '' -%}
- {%- if _sosp in _text %}
- {%- set _clean = _text | replace(_sosp, '') -%}
- {%- set _body = _clean[1:] if (_clean and _clean[0] == '\n') else _clean -%}
- {{- '\n<|sostm|>' + _body + '<|eot|><|empty|><|eostm|>' }}
- {%- else %}
- {%- set _body = _text[1:] if (_text and _text[0] == '\n') else _text -%}
- {{- '\n<|sostm|>' + _body + '<|eot|><|eostm|>' }}
- {%- endif %}
- {{- '<|im_end|>\n' }}
-
- {%- elif message['role'] == 'user' %}
- {%- set _m = '<|sosp|><|empty|><|eosp|>' -%}
- {%- set _raw = message['content'] if message['content'] is string else '' -%}
- {%- if _m in _raw %}
- {%- set _t = (_raw | replace(_m ~ '\n', '') | replace(_m, '') | trim) -%}
- {{- '<|im_start|>user\n' + (_t ~ _m if _t else _m) + '<|im_end|>\n' }}
- {%- else %}
- {{- '<|im_start|>user\n' + _raw + '<|im_end|>\n' }}
- {%- endif %}
-
- {%- elif message['role'] == 'system' %}
- {%- if not loop.first %}
- {%- set _m = '<|sosp|><|empty|><|eosp|>' -%}
- {%- set _raw = message['content'] if message['content'] is string else '' -%}
- {%- if _m in _raw %}
- {%- set _t = (_raw | replace(_m ~ '\n', '') | replace(_m, '') | trim) -%}
- {{- '<|im_start|>system\n' + (_t ~ _m if _t else _m) + '<|im_end|>\n' }}
- {%- else %}
- {{- '<|im_start|>system\n' + _raw + '<|im_end|>\n' }}
- {%- endif %}
- {%- endif %}
-
- {%- elif message['role'] == 'tool' %}
- {%- if (loop.index0 == 0) or (messages[loop.index0 - 1]['role'] != 'tool') %}
- {{- '<|im_start|>user' }}
- {%- endif %}
- {%- set _m = '<|sosp|><|empty|><|eosp|>' -%}
- {%- set _raw = message['content'] if message['content'] is string else '' -%}
- {%- if _m in _raw %}
- {%- set _t = (_raw | replace(_m ~ '\n', '') | replace(_m, '') | trim) -%}
- {{- '\n<tool_response>\n' + (_t ~ _m if _t else _m) + '\n</tool_response>' }}
- {%- else %}
- {{- '\n<tool_response>\n' + _raw + '\n</tool_response>' }}
- {%- endif %}
- {%- if loop.last or (messages[loop.index0 + 1]['role'] != 'tool') %}
- {{- '<|im_end|>\n' }}
- {%- endif %}
- {%- endif %}
-{%- endfor %}
-
-{%- if add_generation_prompt %}
- {{- '<|im_start|>assistant\n<|sostm|>' }}
-{%- endif %}
diff --git a/examples/online_serving/mimo_audio/openai_chat_completion_client_for_multimodal_generation.py b/examples/online_serving/mimo_audio/openai_chat_completion_client_for_multimodal_generation.py
deleted file mode 100644
index 4053f810da0..00000000000
--- a/examples/online_serving/mimo_audio/openai_chat_completion_client_for_multimodal_generation.py
+++ /dev/null
@@ -1,545 +0,0 @@
-import base64
-import concurrent.futures
-import datetime
-import json
-import os
-import queue
-import sys
-import threading
-import time
-from typing import Any
-
-import requests
-from openai import OpenAI
-from vllm.assets.audio import AudioAsset
-from vllm.utils.argparse_utils import FlexibleArgumentParser
-
-# Modify OpenAI's API key and API base to use vLLM's API server.
-openai_api_key = "EMPTY"
-openai_api_base = "http://localhost:18091/v1"
-
-
-# Modify OpenAI's API key and API base to use vLLM's API server.
-
-
-client = OpenAI(
- # defaults to os.environ.get("OPENAI_API_KEY")
- api_key=openai_api_key,
- base_url=openai_api_base,
-)
-
-SEED = 42
-
-
-def encode_base64_content_from_url(content_url: str) -> str:
- """Encode a content retrieved from a remote url to base64 format."""
-
- with requests.get(content_url) as response:
- response.raise_for_status()
- result = base64.b64encode(response.content).decode("utf-8")
-
- return result
-
-
-def encode_base64_content_from_file(file_path: str) -> str:
- """Encode a local file to base64 format."""
- with open(file_path, "rb") as f:
- content = f.read()
- result = base64.b64encode(content).decode("utf-8")
- return result
-
-
-def get_video_url_from_path(video_path: str | None) -> str:
- """Convert a video path (local file or URL) to a video URL format for the API.
-
- If video_path is None or empty, returns the default URL.
- If video_path is a local file path, encodes it to base64 data URL.
- If video_path is a URL, returns it as-is.
- """
- if not video_path:
- # Default video URL
- return "https://huggingface.co/datasets/raushan-testing-hf/videos-test/resolve/main/sample_demo_1.mp4"
-
- # Check if it's a URL (starts with http:// or https://)
- if video_path.startswith(("http://", "https://")):
- return video_path
-
- # Otherwise, treat it as a local file path
- if not os.path.exists(video_path):
- raise FileNotFoundError(f"Video file not found: {video_path}")
-
- # Detect video MIME type from file extension
- video_path_lower = video_path.lower()
- if video_path_lower.endswith(".mp4"):
- mime_type = "video/mp4"
- elif video_path_lower.endswith(".webm"):
- mime_type = "video/webm"
- elif video_path_lower.endswith(".mov"):
- mime_type = "video/quicktime"
- elif video_path_lower.endswith(".avi"):
- mime_type = "video/x-msvideo"
- elif video_path_lower.endswith(".mkv"):
- mime_type = "video/x-matroska"
- else:
- # Default to mp4 if extension is unknown
- mime_type = "video/mp4"
-
- video_base64 = encode_base64_content_from_file(video_path)
- return f"data:{mime_type};base64,{video_base64}"
-
-
-def get_image_url_from_path(image_path: str | None) -> str:
- """Convert an image path (local file or URL) to an image URL format for the API.
-
- If image_path is None or empty, returns the default URL.
- If image_path is a local file path, encodes it to base64 data URL.
- If image_path is a URL, returns it as-is.
- """
- if not image_path:
- # Default image URL
- return "https://vllm-public-assets.s3.us-west-2.amazonaws.com/vision_model_images/cherry_blossom.jpg"
-
- # Check if it's a URL (starts with http:// or https://)
- if image_path.startswith(("http://", "https://")):
- return image_path
-
- # Otherwise, treat it as a local file path
- if not os.path.exists(image_path):
- raise FileNotFoundError(f"Image file not found: {image_path}")
-
- # Detect image MIME type from file extension
- image_path_lower = image_path.lower()
- if image_path_lower.endswith((".jpg", ".jpeg")):
- mime_type = "image/jpeg"
- elif image_path_lower.endswith(".png"):
- mime_type = "image/png"
- elif image_path_lower.endswith(".gif"):
- mime_type = "image/gif"
- elif image_path_lower.endswith(".webp"):
- mime_type = "image/webp"
- else:
- # Default to jpeg if extension is unknown
- mime_type = "image/jpeg"
-
- image_base64 = encode_base64_content_from_file(image_path)
- return f"data:{mime_type};base64,{image_base64}"
-
-
-def get_audio_url_from_path(audio_path: str | None) -> str:
- """Convert an audio path (local file or URL) to an audio URL format for the API.
-
- If audio_path is None or empty, returns the default URL.
- If audio_path is already a base64 data URL (starts with "data:"), returns it as-is.
- If audio_path is a URL (starts with http:// or https://), returns it as-is.
- If audio_path is a local file path, encodes it to base64 data URL.
- """
- if not audio_path:
- # Default audio URL
- return AudioAsset("mary_had_lamb").url
-
- # Check if it's already a base64 data URL
- if audio_path.startswith("data:"):
- return audio_path
-
- # Check if it's a URL (starts with http:// or https://)
- if audio_path.startswith(("http://", "https://")):
- return audio_path
-
- # Otherwise, treat it as a local file path
- if not os.path.exists(audio_path):
- raise FileNotFoundError(f"Audio file not found: {audio_path}")
-
- # Detect audio MIME type from file extension
- audio_path_lower = audio_path.lower()
- if audio_path_lower.endswith((".mp3", ".mpeg")):
- mime_type = "audio/mpeg"
- elif audio_path_lower.endswith(".wav"):
- mime_type = "audio/wav"
- elif audio_path_lower.endswith(".ogg"):
- mime_type = "audio/ogg"
- elif audio_path_lower.endswith(".flac"):
- mime_type = "audio/flac"
- elif audio_path_lower.endswith(".m4a"):
- mime_type = "audio/mp4"
- else:
- # Default to wav if extension is unknown
- mime_type = "audio/wav"
-
- audio_base64 = encode_base64_content_from_file(audio_path)
- return f"data:{mime_type};base64,{audio_base64}"
-
-
-def load_messages_from_json(message_json_path: str) -> dict[str, Any]:
- """Load messages from a JSON file."""
- with open(message_json_path, encoding="utf-8") as f:
- data = json.load(f)
- return data
-
-
-def process_audio_url_in_content(content: dict[str, Any]) -> dict[str, Any]:
- """Process audio_url in content, handling both file paths and base64 URLs."""
- if content.get("type") == "audio_url":
- audio_url = content.get("audio_url", {}).get("url")
- if audio_url:
- # Process the audio URL (handles base64, file paths, and URLs)
- processed_url = get_audio_url_from_path(audio_url)
- content = content.copy()
- content["audio_url"] = {"url": processed_url}
- return content
-
-
-def get_system_prompt(message_json_path: str | None = None):
- """Get system prompt, optionally from message.json file."""
- if message_json_path and os.path.exists(message_json_path):
- data = load_messages_from_json(message_json_path)
- messages = data.get("messages", [])
- # Find the first system message
- for msg in messages:
- if msg.get("role") == "system":
- # Process audio URLs in the content
- processed_content = []
- for content_item in msg.get("content", []):
- processed_item = process_audio_url_in_content(content_item)
- processed_content.append(processed_item)
- return {
- "role": "system",
- "content": processed_content,
- }
-
-
-def get_text_query(custom_prompt: str | None = None):
- question = f"Please convert this text to speech: {custom_prompt}"
- prompt = {
- "role": "user",
- "content": [
- {
- "type": "text",
- "text": f"{question}",
- }
- ],
- }
- return prompt
-
-
-def get_multi_audios_query(
- audio_path: str | None = None,
- custom_prompt: str | None = None,
- message_json_path: str | None = None,
-) -> list[dict[str, Any]] | dict[str, Any]:
- """Get multi-audios query, optionally from message.json file."""
- if message_json_path and os.path.exists(message_json_path):
- data = load_messages_from_json(message_json_path)
- messages = data.get("messages", [])
-
- # Skip the first system role and return all other messages
- rebuild_prompt_messages = []
- skipped_first_system = False
-
- for msg in messages:
- if msg.get("role") == "system" and not skipped_first_system:
- skipped_first_system = True
- continue
-
- # Process all content items in the message
- processed_content = []
- for content_item in msg.get("content", []):
- processed_item = process_audio_url_in_content(content_item)
- processed_content.append(processed_item)
-
- rebuild_prompt_messages.append(
- {
- "role": msg.get("role"),
- "content": processed_content,
- }
- )
-
- return rebuild_prompt_messages
-
- # Original behavior when message_json_path is not provided
- question = custom_prompt or "Are these two audio clips the same?"
- audio_url = get_audio_url_from_path(audio_path)
- prompt = {
- "role": "user",
- "content": [
- {
- "type": "audio_url",
- "audio_url": {"url": audio_url},
- },
- {
- "type": "audio_url",
- "audio_url": {"url": AudioAsset("winning_call").url},
- },
- {
- "type": "text",
- "text": f"{question}",
- },
- ],
- }
- return prompt
-
-
-query_map = {
- "multi_audios": get_multi_audios_query,
- "text": get_text_query,
-}
-
-
-def run_multimodal_generation(args) -> None:
- model_name = "MiMo-Audio-7B-Instruct"
- thinker_sampling_params = {
- "temperature": 0.0, # Deterministic - no randomness
- "top_p": 1.0, # Disable nucleus sampling
- "top_k": -1, # Disable top-k sampling
- "max_tokens": 3200,
- "seed": SEED, # Fixed seed for sampling
- "detokenize": True,
- "repetition_penalty": 1.1,
- }
- code2wav_sampling_params = {
- "temperature": 0.0, # Deterministic - no randomness
- "top_p": 1.0, # Disable nucleus sampling
- "top_k": -1, # Disable top-k sampling
- "max_tokens": 4096 * 16,
- "seed": SEED, # Fixed seed for sampling
- "detokenize": True,
- "repetition_penalty": 1.1,
- }
-
- sampling_params_list = [
- thinker_sampling_params,
- code2wav_sampling_params,
- ]
-
- # Get paths and custom prompt from args
- audio_path = getattr(args, "audio_path", None)
- custom_prompt = getattr(args, "prompt", None)
- message_json_path = getattr(args, "message_json", None)
- output_audio_path = getattr(args, "output_audio_path", None)
-
- # Get the query function and call it with appropriate parameters
- query_func = query_map[args.query_type]
- if args.query_type == "multi_audios":
- prompt = query_func(audio_path=audio_path, custom_prompt=custom_prompt, message_json_path=message_json_path)
- elif args.query_type == "text":
- prompt = query_func(custom_prompt=custom_prompt)
- else:
- prompt = query_func()
-
- extra_body = {
- "sampling_params_list": sampling_params_list
- # Optional, it has a default setting in stage_configs of the corresponding model.
- }
-
- # Build messages list (filter None so concurrent tasks get valid structure)
- system = get_system_prompt(message_json_path=message_json_path)
- if args.query_type == "multi_audios" and isinstance(prompt, list):
- messages = ([system] if system else []) + prompt
- elif args.query_type == "text":
- messages = [prompt]
-
- num_concurrent_requests = args.num_concurrent_requests
- start_time = time.perf_counter()
-
- def run_one_request(req_id: int):
- """Submit one request and return (req_id, response) to preserve request order."""
- return req_id, client.chat.completions.create(
- messages=messages,
- model=model_name,
- extra_body=extra_body,
- stream=args.stream,
- )
-
- with concurrent.futures.ThreadPoolExecutor(max_workers=num_concurrent_requests) as executor:
- futures = [executor.submit(run_one_request, req_id) for req_id in range(num_concurrent_requests)]
-
- if not args.stream:
- # Collect by req_id so chat_completions[i] = response for request i
- results_by_req = [None] * num_concurrent_requests
- for future in concurrent.futures.as_completed(futures):
- req_id, completion = future.result()
- results_by_req[req_id] = completion
- chat_completions = results_by_req
-
- assert len(chat_completions) == num_concurrent_requests
- count = 0
- for req_id, chat_completion in enumerate(chat_completions):
- chat_completion_id = getattr(chat_completion, "id", "")
- for choice in chat_completion.choices:
- if choice.message.audio:
- audio_data = base64.b64decode(choice.message.audio.data)
- audio_file_path = f"{output_audio_path}/{args.query_type}/audio_{count}.wav"
- os.makedirs(os.path.dirname(audio_file_path), exist_ok=True)
- with open(audio_file_path, "wb") as f:
- f.write(audio_data)
- print(f"[req {req_id}_{chat_completion_id}] Audio saved to {audio_file_path}")
- count += 1
- elif choice.message.content:
- print(
- f"[req {req_id}_{chat_completion_id}] Chat completion output from text:",
- choice.message.content,
- )
- else:
- # Stream mode: process chunks from all requests in real-time,
- # displaying them in the order they arrive.
- chunk_queue = queue.Queue()
- audio_counters = {}
- chat_completion_id_by_req = {}
- chat_completion_id_lock = threading.Lock()
- last_text_req_id = None
-
- def _stream_reader(req_id: int, stream):
- """Read one stream and relay every chunk to the shared queue."""
- try:
- for chunk in stream:
- chunk_queue.put((req_id, time.perf_counter(), chunk))
- chunk_queue.put((req_id, time.perf_counter(), None))
- except Exception as e:
- print(f"\n[Request {req_id}] stream error: {e}", file=sys.stderr, flush=True)
- chunk_queue.put((req_id, time.time(), None))
-
- # Kick off a reader thread per request
- reader_threads = []
- for req_id, future in enumerate(futures):
- req_id_from_future, stream = future.result()
- assert req_id == req_id_from_future, f"Request ID mismatch: {req_id} != {req_id_from_future}"
- audio_counters[req_id] = 0
- t = threading.Thread(target=_stream_reader, args=(req_id, stream), daemon=True)
- t.start()
- reader_threads.append(t)
-
- # Main loop – consume chunks in arrival order
- active_streams = set(range(num_concurrent_requests))
- while active_streams:
- try:
- request_id, ts, chunk = chunk_queue.get(timeout=2.0)
- except queue.Empty:
- if all(not t.is_alive() for t in reader_threads):
- break
- continue
-
- if chunk is None:
- elapsed = ts - start_time
- print(f" ({elapsed:.2f}s)", flush=True)
- with chat_completion_id_lock:
- chat_completion_id = chat_completion_id_by_req.get(request_id, "")
- print(
- f" [req {request_id}_{chat_completion_id}] Time finished for streaming: ",
- datetime.datetime.now(),
- file=sys.stderr,
- flush=True,
- )
- active_streams.discard(request_id)
- continue
-
- with chat_completion_id_lock:
- if request_id not in chat_completion_id_by_req:
- chat_completion_id_by_req[request_id] = getattr(chunk, "id", "")
- chat_completion_id = chat_completion_id_by_req[request_id]
-
- modality = getattr(chunk, "modality", None)
- elapsed = ts - start_time
- for choice in chunk.choices:
- content = getattr(choice.delta, "content", None) if hasattr(choice, "delta") else None
-
- if modality == "audio" and content:
- audio_data = base64.b64decode(content)
- audio_dir = (
- f"{output_audio_path}/{args.query_type}/{num_concurrent_requests}/{chat_completion_id}"
- )
- os.makedirs(audio_dir, exist_ok=True)
- audio_file_path = f"{audio_dir}/audio_{audio_counters[request_id]}.wav"
- with open(audio_file_path, "wb") as f:
- f.write(audio_data)
- print(
- f"\n[{elapsed:7.2f}s][req {request_id}_{chat_completion_id}] Audio saved to {audio_file_path}",
- file=sys.stderr,
- flush=True,
- )
- audio_counters[request_id] += 1
-
- elif modality == "text" and content:
- if last_text_req_id != request_id:
- if last_text_req_id is not None:
- print(flush=True)
- print(
- f"\n[{elapsed:7.2f}s][req {request_id}_{chat_completion_id}] content:",
- end="",
- flush=True,
- )
- last_text_req_id = request_id
- print(
- f"\n[{elapsed:7.2f}s][req {request_id}_{chat_completion_id}] {content}", end="", flush=True
- )
-
- # Final newline if the last output was streaming text
- if last_text_req_id is not None:
- print(flush=True)
-
- for t in reader_threads:
- t.join(timeout=1.0)
-
- elapsed = time.perf_counter() - start_time
- print(
- f"num_concurrent_requests_{num_concurrent_requests}>>>>>>>>>Time finished for streaming<<<<<<<<: ",
- elapsed,
- file=sys.stderr,
- flush=True,
- )
- timing_audio_folder = f"{output_audio_path}/{args.query_type}/{num_concurrent_requests}"
- os.makedirs(timing_audio_folder, exist_ok=True)
- timing_file = os.path.join(timing_audio_folder, "streaming_finish_time.txt")
- with open(timing_file, "w") as f:
- f.write(f"num_concurrent_requests_{num_concurrent_requests} elapsed_seconds: {elapsed}\n")
-
-
-def parse_args():
- parser = FlexibleArgumentParser(description="Demo on using vLLM for offline inference with audio language models")
- parser.add_argument(
- "--query-type",
- "-q",
- type=str,
- default="multi_audios",
- choices=query_map.keys(),
- help="Query type.",
- )
- parser.add_argument(
- "--prompt",
- "-p",
- type=str,
- default="Who are you?",
- help="Custom text prompt/question to use instead of the default prompt for the selected query type.",
- )
- parser.add_argument(
- "--message-json",
- "-m",
- type=str,
- # default="../../offline_inference/mimo_audio/message_base64_wav.json",
- default="../../offline_inference/mimo_audio/message_base64_wav_tts.json",
- help="Path to message.json file containing conversation history. When provided, "
- "system prompt and multi_audios query will be loaded from this file.",
- )
- parser.add_argument(
- "--output-audio-path",
- "-o",
- type=str,
- default="./",
- help="Path to save the generated audio files.",
- )
- parser.add_argument(
- "--stream",
- action="store_true",
- help="Stream the response.",
- )
- parser.add_argument(
- "--num-concurrent-requests",
- type=int,
- default=1,
- help="Number of concurrent requests to send. Default is 1.",
- )
-
- return parser.parse_args()
-
-
-if __name__ == "__main__":
- args = parse_args()
- run_multimodal_generation(args)
diff --git a/examples/online_serving/ming_flash_omni/README.md b/examples/online_serving/ming_flash_omni/README.md
deleted file mode 100644
index 8b7d03e211a..00000000000
--- a/examples/online_serving/ming_flash_omni/README.md
+++ /dev/null
@@ -1,95 +0,0 @@
-# Ming-flash-omni 2.0
-
-## Installation
-
-Please refer to [README.md](../../../README.md)
-
-## Deployment modes
-
-| Mode | Launch command | Output |
-|------|---------------|--------|
-| Thinker only (multimodal understanding) | `vllm serve ... --omni` | Text |
-| Thinker + Talker (omni-speech) | `vllm serve ... --omni --stage-configs-path ming_flash_omni.yaml` | Text + Audio |
-
-For standalone TTS (talker only), see [`examples/online_serving/ming_flash_omni_tts/`](../ming_flash_omni_tts/).
-
-## Run examples (Ming-flash-omni 2.0)
-
-### Launch the Server
-
-**Thinker only (text output):**
-```bash
-vllm serve Jonathan1909/Ming-flash-omni-2.0 --omni --port 8091
-```
-
-**Thinker + Talker (omni-speech, text + audio output):**
-```bash
-vllm serve Jonathan1909/Ming-flash-omni-2.0 --omni --port 8091 \
- --stage-configs-path vllm_omni/model_executor/stage_configs/ming_flash_omni.yaml
-```
-
-Pass `--stage-configs-path /path/to/your_config.yaml` to use a custom stage
-config.
-
-### Send Multi-modal Request
-
-Shared Python client (supports `text | use_image | use_audio | use_video |
-use_mixed_modalities`; pass `--image-path` / `--audio-path` / `--video-path`
-for local files or URLs, `--modalities text` for output, `--help` for the
-full flag list):
-
-```bash
-python examples/online_serving/openai_chat_completion_client_for_multimodal_generation.py \
- --model Jonathan1909/Ming-flash-omni-2.0 \
- --query-type use_mixed_modalities \
- --port 8091 --host localhost \
- --modalities text
-```
-
-Parameterized curl wrapper in this directory:
-
-```bash
-bash run_curl_multimodal_generation.sh text
-bash run_curl_multimodal_generation.sh use_image
-bash run_curl_multimodal_generation.sh use_audio
-bash run_curl_multimodal_generation.sh use_video
-bash run_curl_multimodal_generation.sh use_mixed_modalities
-```
-
-## Modality control
-
-| `modalities` | Server config | Output |
-|-------------|--------------|--------|
-| `["text"]` or omitted | Thinker only | Text |
-| `["audio"]` | Thinker + Talker | Audio (speech) |
-| `["text", "audio"]` | Thinker + Talker | Text + Audio |
-
-For ready-to-copy curl examples (text / audio / multimodal input, SSE
-streaming, reasoning mode), see the recipe at
-[`recipes/inclusionAI/Ming-flash-omni-2.0.md`](../../../recipes/inclusionAI/Ming-flash-omni-2.0.md).
-
-## OpenAI Python SDK — streaming
-
-```python
-from openai import OpenAI
-
-client = OpenAI(base_url="http://localhost:8091/v1", api_key="EMPTY")
-
-response = client.chat.completions.create(
- model="Jonathan1909/Ming-flash-omni-2.0",
- messages=[
- {"role": "system", "content": [{"type": "text", "text": "你是一个友好的AI助手。\n\ndetailed thinking off"}]},
- {"role": "user", "content": "请详细介绍鹦鹉的生活习性。"},
- ],
- modalities=["text"],
- stream=True,
-)
-for chunk in response:
- for choice in chunk.choices:
- if hasattr(choice, "delta") and choice.delta.content:
- print(choice.delta.content, end="", flush=True)
-print()
-```
-
-The `--stream` flag on the Python client script above shows the same pattern
-driven by the shared multimodal client.
diff --git a/examples/online_serving/ming_flash_omni/run_curl_multimodal_generation.sh b/examples/online_serving/ming_flash_omni/run_curl_multimodal_generation.sh
deleted file mode 100755
index 768a424e451..00000000000
--- a/examples/online_serving/ming_flash_omni/run_curl_multimodal_generation.sh
+++ /dev/null
@@ -1,145 +0,0 @@
-#!/usr/bin/env bash
-set -euo pipefail
-
-# Server port
-PORT="${PORT:-8091}"
-# Default query type
-QUERY_TYPE="${1:-text}"
-
-# Validate query type
-if [[ ! "$QUERY_TYPE" =~ ^(text|use_audio|use_image|use_video|use_mixed_modalities)$ ]]; then
- echo "Error: Invalid query type '$QUERY_TYPE'"
- echo "Usage: $0 [text|use_audio|use_image|use_video|use_mixed_modalities]"
- echo " text: Text-only query"
- echo " use_audio: Audio + Text query"
- echo " use_image: Image + Text query"
- echo " use_video: Video + Text query"
- echo " use_mixed_modalities: Audio + Image + Video + Text query"
- exit 1
-fi
-
-thinker_sampling_params='{
- "temperature": 0.4,
- "top_p": 0.9,
- "top_k": -1,
- "max_tokens": 16384,
- "seed": 42,
- "detokenize": true,
- "repetition_penalty": 1.05
-}'
-# Above is optional, it has a default setting in stage_configs of the corresponding model.
-
-# Define URLs for assets
-MARY_HAD_LAMB_AUDIO_URL="https://vllm-public-assets.s3.us-west-2.amazonaws.com/multimodal_asset/mary_had_lamb.ogg"
-CHERRY_BLOSSOM_IMAGE_URL="https://vllm-public-assets.s3.us-west-2.amazonaws.com/vision_model_images/cherry_blossom.jpg"
-SAMPLE_VIDEO_URL="https://huggingface.co/datasets/raushan-testing-hf/videos-test/resolve/main/sample_demo_1.mp4"
-
-# Build user content based on query type
-case "$QUERY_TYPE" in
- text)
- user_content='[
- {
- "type": "text",
- "text": "请详细介绍鹦鹉的生活习性。"
- }
- ]'
- ;;
- use_image)
- user_content='[
- {
- "type": "image_url",
- "image_url": {
- "url": "'"$CHERRY_BLOSSOM_IMAGE_URL"'"
- }
- },
- {
- "type": "text",
- "text": "Describe this image in detail."
- }
- ]'
- ;;
- use_audio)
- user_content='[
- {
- "type": "audio_url",
- "audio_url": {
- "url": "'"$MARY_HAD_LAMB_AUDIO_URL"'"
- }
- },
- {
- "type": "text",
- "text": "Please recognize the language of this speech and transcribe it. Format: oral."
- }
- ]'
- ;;
- use_video)
- user_content='[
- {
- "type": "video_url",
- "video_url": {
- "url": "'"$SAMPLE_VIDEO_URL"'"
- }
- },
- {
- "type": "text",
- "text": "Describe what is happening in this video."
- }
- ]'
- ;;
- use_mixed_modalities)
- user_content='[
- {
- "type": "image_url",
- "image_url": {
- "url": "'"$CHERRY_BLOSSOM_IMAGE_URL"'"
- }
- },
- {
- "type": "audio_url",
- "audio_url": {
- "url": "'"$MARY_HAD_LAMB_AUDIO_URL"'"
- }
- },
- {
- "type": "text",
- "text": "Describe the image, and recognize the language of this speech and transcribe it. Format: oral"
- }
- ]'
- ;;
-esac
-
-echo "Running query type: $QUERY_TYPE"
-echo ""
-
-request_body=$(cat <<EOF
-{
- "model": "Jonathan1909/Ming-flash-omni-2.0",
- "sampling_params_list": [
- $thinker_sampling_params
- ],
- "modalities": ["text"],
- "messages": [
- {
- "role": "system",
- "content": [
- {
- "type": "text",
- "text": "你是一个友好的AI助手。\n\ndetailed thinking off"
- }
- ]
- },
- {
- "role": "user",
- "content": $user_content
- }
- ]
-}
-EOF
-)
-
-output=$(curl -sS --retry 3 --retry-delay 3 --retry-connrefused \
- -X POST http://localhost:${PORT}/v1/chat/completions \
- -H "Content-Type: application/json" \
- -d "$request_body")
-
-echo "Output of request: $(echo "$output" | jq '.choices[0].message.content')"
diff --git a/examples/online_serving/ming_flash_omni_tts/README.md b/examples/online_serving/ming_flash_omni_tts/README.md
deleted file mode 100644
index e56d9ea12ae..00000000000
--- a/examples/online_serving/ming_flash_omni_tts/README.md
+++ /dev/null
@@ -1,54 +0,0 @@
-# Ming-flash-omni Standalone TTS (Online Serving)
-
-This directory contains online e2e examples for **Ming-flash-omni-2.0 standalone talker deployment**.
-
-Server uses:
-
-- `model`: `Jonathan1909/Ming-flash-omni-2.0`
-- `stage config`: `vllm_omni/model_executor/stage_configs/ming_flash_omni_tts.yaml`
-
-## Launch the Server
-
-```bash
-# from repo root
-bash examples/online_serving/ming_flash_omni_tts/run_server.sh
-```
-
-Equivalent manual command:
-
-```bash
-vllm serve Jonathan1909/Ming-flash-omni-2.0 \
- --stage-configs-path vllm_omni/model_executor/stage_configs/ming_flash_omni_tts.yaml \
- --host 0.0.0.0 \
- --port 8091 \
- --trust-remote-code \
- --omni
-```
-
-## Send TTS Request
-
-Python client:
-
-```bash
-python examples/online_serving/ming_flash_omni_tts/speech_client.py \
- --text "我们当迎着阳光辛勤耕作,去摘取,去制作,去品尝,去馈赠。" \
- --output ming_online.wav
-```
-
-Long-form `instructions` (e.g. ASMR whisper style) via the client:
-
-```bash
-python examples/online_serving/ming_flash_omni_tts/speech_client.py \
- --text "我会一直在这里陪着你,直到你慢慢、慢慢地沉入那个最温柔的梦里……好吗?" \
- --instructions "这是一种ASMR耳语,属于一种旨在引发特殊感官体验的创意风格。这个女性使用轻柔的普通话进行耳语,声音气音成分重。音量极低,紧贴麦克风,语速极慢,旨在制造触发听者颅内快感的声学刺激。" \
- --output ming_online_asmr.wav
-```
-
-## Notes
-
-- This is the **online serving** counterpart of `examples/offline_inference/ming_flash_omni_tts/`.
-- The server uses `use_zero_spk_emb=True` and the default decode args
- (`max_decode_steps=200`, `cfg=2.0`, `sigma=0.25`, `temperature=0.0`).
- For other caption fields (`语速`, `基频`, `IP`, BGM, etc.) or overriding
- decode args, use the offline e2e example where `additional_information`
- is set explicitly.
diff --git a/examples/online_serving/ming_flash_omni_tts/run_server.sh b/examples/online_serving/ming_flash_omni_tts/run_server.sh
deleted file mode 100755
index 91be35c6c58..00000000000
--- a/examples/online_serving/ming_flash_omni_tts/run_server.sh
+++ /dev/null
@@ -1,25 +0,0 @@
-#!/bin/bash
-# Launch vLLM-Omni server for Ming-flash-omni-2.0 standalone talker (TTS).
-#
-# Usage:
-# ./run_server.sh
-# MODEL=/path/to/local/model ./run_server.sh
-# PORT=8091 ./run_server.sh
-# HOST=127.0.0.1 ./run_server.sh # bind only to loopback
-
-set -e
-
-MODEL="${MODEL:-Jonathan1909/Ming-flash-omni-2.0}"
-HOST="${HOST:-0.0.0.0}"
-PORT="${PORT:-8091}"
-STAGE_CONFIG="${STAGE_CONFIG:-vllm_omni/model_executor/stage_configs/ming_flash_omni_tts.yaml}"
-
-echo "Starting Ming standalone TTS server with model: $MODEL"
-echo "Stage config: $STAGE_CONFIG"
-
-vllm serve "$MODEL" \
- --stage-configs-path "$STAGE_CONFIG" \
- --host "$HOST" \
- --port "$PORT" \
- --trust-remote-code \
- --omni
diff --git a/examples/online_serving/ming_flash_omni_tts/speech_client.py b/examples/online_serving/ming_flash_omni_tts/speech_client.py
deleted file mode 100644
index b3fceba25ee..00000000000
--- a/examples/online_serving/ming_flash_omni_tts/speech_client.py
+++ /dev/null
@@ -1,93 +0,0 @@
-"""Client for Ming standalone TTS via /v1/audio/speech endpoint."""
-
-import argparse
-import json
-import sys
-
-import httpx
-
-DEFAULT_API_BASE = "http://localhost:8091"
-DEFAULT_API_KEY = "EMPTY"
-DEFAULT_MODEL = "Jonathan1909/Ming-flash-omni-2.0"
-
-
-def run_tts(args) -> None:
- payload = {
- "model": args.model,
- "input": args.text,
- "response_format": args.response_format,
- }
-
- instructions = args.instructions
- if args.instruction_json:
- if instructions:
- sys.exit("--instructions and --instruction-json are mutually exclusive")
-
- try:
- parsed = json.loads(args.instruction_json)
- except json.JSONDecodeError as exc:
- sys.exit(f"--instruction-json must be valid JSON: {exc}")
- if not isinstance(parsed, dict):
- sys.exit("--instruction-json must decode to a JSON object")
- # Re-encode with ensure_ascii=False so UTF-8 Chinese keys/values
- # arrive at the server intact rather than as \\uXXXX escapes.
- instructions = json.dumps(parsed, ensure_ascii=False)
- if instructions:
- payload["instructions"] = instructions
-
- print(f"Model: {args.model}")
- print(f"Text: {args.text}")
- print("Generating audio...")
-
- api_url = f"{args.api_base}/v1/audio/speech"
- headers = {
- "Content-Type": "application/json",
- "Authorization": f"Bearer {args.api_key}",
- }
-
- with httpx.Client(timeout=300.0) as client:
- response = client.post(api_url, json=payload, headers=headers)
-
- if response.status_code != 200:
- print(f"Error: {response.status_code}")
- print(response.text)
- return
-
- output_path = args.output or "ming_tts_output.wav"
- with open(output_path, "wb") as f:
- f.write(response.content)
- print(f"Audio saved to: {output_path}")
-
-
-def main():
- parser = argparse.ArgumentParser(description="Ming standalone TTS speech client")
- parser.add_argument("--api-base", default=DEFAULT_API_BASE, help="API base URL")
- parser.add_argument("--api-key", default=DEFAULT_API_KEY, help="API key")
- parser.add_argument("--model", "-m", default=DEFAULT_MODEL, help="Model name or local path")
- parser.add_argument("--text", required=True, help="Text to synthesize")
- parser.add_argument(
- "--response-format",
- default="wav",
- choices=["wav", "mp3", "flac", "pcm", "aac", "opus"],
- help="Audio format (default: wav)",
- )
- parser.add_argument("--output", "-o", default=None, help="Output file path")
- parser.add_argument(
- "--instructions",
- default=None,
- help="Free-form style description (mapped to caption 风格 on the server).",
- )
- parser.add_argument(
- "--instruction-json",
- default=None,
- help=(
- "Structured caption JSON forwarded as `instructions`. Accepts Ming "
- "caption keys: 方言, 风格, 语速, 基频, 音量, 情感, IP, 说话人, BGM. "
- ),
- )
- args = parser.parse_args()
- run_tts(args)
-
-
-if __name__ == "__main__":
- main()
diff --git a/examples/online_serving/moss_tts_nano/README.md b/examples/online_serving/moss_tts_nano/README.md
deleted file mode 100644
index c366ce02e11..00000000000
--- a/examples/online_serving/moss_tts_nano/README.md
+++ /dev/null
@@ -1,158 +0,0 @@
-# MOSS-TTS-Nano
-
-## Model checkpoint
-
-| Model | Description |
-|-------|-------------|
-| `OpenMOSS-Team/MOSS-TTS-Nano` | 0.1B AR LM + MOSS-Audio-Tokenizer-Nano codec, 48 kHz stereo, ZH/EN/JA |
-
-## Gradio Demo
-
-An interactive Gradio demo is available with multilingual voice presets, custom voice cloning, and streaming support.
-
-```bash
-# Option 1: Launch server + Gradio together
-./run_gradio_demo.sh
-
-# Option 2: If server is already running
-python gradio_demo.py --api-base http://localhost:8091
-```
-
-Then open http://localhost:7860 in your browser.
-
-Features:
-
-- 15 built-in voice presets (6 ZH · 4 EN · 5 JA)
-- Custom voice cloning from uploaded reference audio
-- Streaming mode (progressive PCM playback)
-
-## Launch the Server
-
-```bash
-vllm serve OpenMOSS-Team/MOSS-TTS-Nano --omni --port 8091
-```
-
-The deploy config at `vllm_omni/deploy/moss_tts_nano.yaml` auto-loads; no
-`--stage-configs-path`, `--trust-remote-code`, or `--enforce-eager` flags
-are needed.
-
-Or use the convenience script:
-
-```bash
-./run_server.sh
-```
-
-## Send TTS Request
-
-### Using curl
-
-```bash
-# Built-in voice preset
-curl -X POST http://localhost:8091/v1/audio/speech \
- -H "Content-Type: application/json" \
- -d '{
- "input": "你好,这是语音合成测试。",
- "voice": "Junhao",
- "response_format": "wav"
- }' --output output.wav
-
-# English preset
-curl -X POST http://localhost:8091/v1/audio/speech \
- -H "Content-Type: application/json" \
- -d '{
- "input": "Hello, this is MOSS-TTS-Nano.",
- "voice": "Ava",
- "response_format": "wav"
- }' --output output_en.wav
-```
-
-### Custom Voice Cloning
-
-Provide a reference audio (base64 data URL) and its transcript:
-
-```bash
-REF_AUDIO=$(base64 -w 0 /path/to/reference.wav)
-curl -X POST http://localhost:8091/v1/audio/speech \
- -H "Content-Type: application/json" \
- -d "{
- \"input\": \"Hello, this is a cloned voice.\",
- \"voice\": \"Junhao\",
- \"ref_audio\": \"data:audio/wav;base64,${REF_AUDIO}\",
- \"ref_text\": \"Exact transcript of the reference audio.\"
- }" --output cloned.wav
-```
-
-### Using Python
-
-```python
-import httpx
-
-response = httpx.post(
- "http://localhost:8091/v1/audio/speech",
- json={
- "input": "你好,这是语音合成测试。",
- "voice": "Junhao",
- "response_format": "wav",
- },
- timeout=300.0,
-)
-
-with open("output.wav", "wb") as f:
- f.write(response.content)
-```
-
-### Streaming
-
-```bash
-curl -X POST http://localhost:8091/v1/audio/speech \
- -H "Content-Type: application/json" \
- -d '{
- "input": "Hello, streaming output from MOSS-TTS-Nano.",
- "voice": "Ava",
- "stream": true,
- "response_format": "pcm"
- }' --no-buffer | play -t raw -r 48000 -e signed -b 16 -c 2 -
-```
-
-**Note:** MOSS-TTS-Nano outputs at 48 kHz stereo (2-channel).
-
-## API Parameters
-
-MOSS-TTS-Nano uses the standard `/v1/audio/speech` endpoint.
-
-| Parameter | Type | Default | Description |
-|-----------|------|---------|-------------|
-| `input` | string | **required** | Text to synthesize (ZH / EN / JA) |
-| `voice` | string | `"Junhao"` | Built-in voice name (see table below) |
-| `response_format` | string | `"wav"` | Audio format: wav, mp3, flac, pcm |
-| `ref_audio` | string | null | Base64 data URL for custom voice cloning |
-| `ref_text` | string | null | Transcript of reference audio (required when `ref_audio` is set) |
-| `stream` | bool | false | Stream raw PCM chunks |
-| `max_new_tokens` | int | 4096 | Maximum tokens to generate |
-
-## Built-in Voice Presets
-
-| Voice | Language | Description |
-|-------|----------|-------------|
-| `Junhao` | ZH | Male, standard Mandarin |
-| `Zhiming` | ZH | Male |
-| `Weiguo` | ZH | Male |
-| `Xiaoyu` | ZH | Female |
-| `Yuewen` | ZH | Female |
-| `Lingyu` | ZH | Female |
-| `Ava` | EN | Female, American English |
-| `Bella` | EN | Female |
-| `Adam` | EN | Male |
-| `Nathan` | EN | Male |
-| `Sakura` | JA | Female |
-| `Yui` | JA | Female |
-| `Aoi` | JA | Female |
-| `Hina` | JA | Female |
-| `Mei` | JA | Female |
-
-## Troubleshooting
-
-1. **`libnvrtc.so.13: cannot open shared object file`**: torchaudio 2.10+ defaults to torchcodec which requires NVRTC. vLLM-Omni patches this automatically at model load time to use soundfile instead.
-2. **Connection refused**: Ensure the server is running on the correct port.
-3. **Flashinfer version mismatch**: Set `FLASHINFER_DISABLE_VERSION_CHECK=1` if you see version warnings.
-4. **Out of memory**: The default `gpu_memory_utilization=0.3` is conservative. Increase it in the stage config if you have more VRAM available.
diff --git a/examples/online_serving/moss_tts_nano/gradio_demo.py b/examples/online_serving/moss_tts_nano/gradio_demo.py
deleted file mode 100644
index f120f838c72..00000000000
--- a/examples/online_serving/moss_tts_nano/gradio_demo.py
+++ /dev/null
@@ -1,690 +0,0 @@
-"""Gradio demo for MOSS-TTS-Nano with gapless streaming audio playback.
-
-Uses a custom AudioWorklet-based player (adapted from the Qwen3-TTS demo)
-for gap-free streaming. Audio is streamed from the vLLM-Omni server
-through a same-origin proxy and played via the Web Audio API's AudioWorklet.
-
-MOSS-TTS-Nano outputs 48 kHz stereo (2-channel interleaved L,R,L,R,...).
-The AudioWorklet downmixes stereo to mono during playback.
-
-Also supports non-streaming mode (full audio download) via gr.Audio.
-
-Usage:
- # Start the server first (see run_server.sh), then:
- python gradio_demo.py --api-base http://localhost:8091
-
- # Or use run_gradio_demo.sh to start both server and demo together.
-"""
-
-from __future__ import annotations
-
-import argparse
-import base64
-import io
-import json
-import logging
-
-try:
- import gradio as gr
-except ImportError:
- raise ImportError("gradio is required to run this demo. Install it with: pip install 'vllm-omni[demo]'") from None
-
-import httpx
-import numpy as np
-import soundfile as sf
-from fastapi import FastAPI, Request
-from fastapi.responses import Response, StreamingResponse
-
-logger = logging.getLogger(__name__)
-
-# MOSS-TTS-Nano outputs 48 kHz stereo (2-channel interleaved).
-PCM_SAMPLE_RATE = 48000
-PCM_CHANNELS = 2
-DEFAULT_API_BASE = "http://localhost:8091"
-
-# Built-in voice presets (matches the MOSS-TTS-Nano GitHub repo assets/)
-VOICE_PRESETS = {
- # Chinese
- "Junhao (ZH)": "Junhao",
- "Zhiming (ZH)": "Zhiming",
- "Weiguo (ZH)": "Weiguo",
- "Xiaoyu (ZH)": "Xiaoyu",
- "Yuewen (ZH)": "Yuewen",
- "Lingyu (ZH)": "Lingyu",
- # English
- "Ava (EN)": "Ava",
- "Bella (EN)": "Bella",
- "Adam (EN)": "Adam",
- "Nathan (EN)": "Nathan",
- # Japanese
- "Sakura (JA)": "Sakura",
- "Yui (JA)": "Yui",
- "Aoi (JA)": "Aoi",
- "Hina (JA)": "Hina",
- "Mei (JA)": "Mei",
-}
-PRESET_LABELS = list(VOICE_PRESETS.keys())
-DEFAULT_PRESET = "Junhao (ZH)"
-
-# ── AudioWorklet processor (loaded in browser via Blob URL) ──────────
-# Downmixes stereo-interleaved int16 PCM to mono float32 for playback.
-WORKLET_JS = r"""
-class TTSPlaybackProcessor extends AudioWorkletProcessor {
- constructor() {
- super();
- this.queue = [];
- this.buf = null;
- this.pos = 0;
- this.playing = false;
- this.played = 0;
- this.port.onmessage = (e) => {
- if (e.data && e.data.type === 'clear') {
- this.queue = []; this.buf = null; this.pos = 0; this.played = 0;
- if (this.playing) { this.playing = false; this.port.postMessage({type:'stopped'}); }
- return;
- }
- // Input: Int16Array of stereo-interleaved samples [L0,R0,L1,R1,...]
- // Convert to mono float32 by averaging L+R channels.
- const pcm = e.data;
- const monoLen = Math.floor(pcm.length / 2);
- const mono = new Float32Array(monoLen);
- for (let i = 0; i < monoLen; i++) {
- mono[i] = (pcm[i * 2] + pcm[i * 2 + 1]) / 65536.0;
- }
- this.queue.push(mono);
- };
- }
- process(inputs, outputs) {
- const out = outputs[0][0];
- for (let i = 0; i < out.length; i++) {
- if (!this.buf || this.pos >= this.buf.length) {
- if (this.queue.length > 0) {
- this.buf = this.queue.shift(); this.pos = 0;
- } else {
- for (let j = i; j < out.length; j++) out[j] = 0;
- if (this.playing) { this.playing = false; this.port.postMessage({type:'stopped', played:this.played}); }
- return true;
- }
- }
- out[i] = this.buf[this.pos++];
- this.played++;
- }
- if (!this.playing) { this.playing = true; this.port.postMessage({type:'started'}); }
- return true;
- }
-}
-registerProcessor('tts-playback-processor', TTSPlaybackProcessor);
-"""
-
-# ── Player HTML (container with metric cards) ────────────────────────
-PLAYER_HTML = """
-<div id="tts-player">
- <div style="display:flex; align-items:center; gap:10px;">
- <div id="tts-status-dot" style="width:10px;height:10px;border-radius:50%;background:#ccc;flex-shrink:0;"></div>
- <span id="tts-status" style="font-weight:600;font-size:1.05em;">Ready</span>
- <button id="tts-stop-btn" onclick="window.ttsStop()"
- style="display:none; margin-left:auto; padding:5px 16px; border-radius:6px; border:1px solid #EF5552;
- background:#fff; color:#EF5552; cursor:pointer; font-size:0.85em; transition:all 0.15s;">Stop</button>
- </div>
- <div id="tts-metrics" style="display:none; grid-template-columns:repeat(4,1fr); gap:10px; margin-top:12px;">
- <div style="background:#f8f9fa;border-radius:6px;padding:8px 10px;text-align:center;">
- <div style="font-size:0.7em;text-transform:uppercase;color:#888;letter-spacing:0.5px;margin-bottom:2px;">TTFP</div>
- <div id="tts-m-ttfp" style="font-size:1.2em;font-weight:700;color:#333;">—</div>
- </div>
- <div style="background:#f8f9fa;border-radius:6px;padding:8px 10px;text-align:center;">
- <div style="font-size:0.7em;text-transform:uppercase;color:#888;letter-spacing:0.5px;margin-bottom:2px;">RTF</div>
- <div id="tts-m-rtf" style="font-size:1.2em;font-weight:700;color:#333;">—</div>
- </div>
- <div style="background:#f8f9fa;border-radius:6px;padding:8px 10px;text-align:center;">
- <div style="font-size:0.7em;text-transform:uppercase;color:#888;letter-spacing:0.5px;margin-bottom:2px;">Audio</div>
- <div id="tts-m-dur" style="font-size:1.2em;font-weight:700;color:#333;">—</div>
- </div>
- <div style="background:#f8f9fa;border-radius:6px;padding:8px 10px;text-align:center;">
- <div style="font-size:0.7em;text-transform:uppercase;color:#888;letter-spacing:0.5px;margin-bottom:2px;">Speed</div>
- <div id="tts-m-speed" style="font-size:1.2em;font-weight:700;color:#333;">—</div>
- </div>
- </div>
- <div id="tts-rtf-bar-wrap" style="display:none; background:#e8ecf1; border-radius:4px; height:20px; overflow:hidden; position:relative; margin-top:10px;">
- <div id="tts-rtf-bar" style="height:100%; border-radius:4px; transition:width 0.3s ease, background 0.3s ease; width:0%;"></div>
- <span id="tts-rtf-label" style="position:absolute;top:50%;left:50%;transform:translate(-50%,-50%);font-size:0.75em;font-weight:600;color:#444;"></span>
- </div>
- <div id="tts-elapsed" style="display:none; margin-top:6px; font-size:0.8em; color:#999; text-align:right;"></div>
-</div>
-"""
-
-
-def _build_player_js(sample_rate: int) -> str:
- """Build the JavaScript that powers the AudioWorklet player."""
- return f"""
- <script>
- const SR = {sample_rate};
- const WC = {json.dumps(WORKLET_JS)};
- let ctx = null, node = null, abort = null, gen = false, st = {{}};
-
- async function init() {{
- if (ctx) return;
- ctx = new AudioContext({{ sampleRate: SR }});
- const b = new Blob([WC], {{ type: 'application/javascript' }});
- const u = URL.createObjectURL(b);
- await ctx.audioWorklet.addModule(u);
- URL.revokeObjectURL(u);
- node = new AudioWorkletNode(ctx, 'tts-playback-processor');
- node.connect(ctx.destination);
- node.port.onmessage = (e) => {{
- if (e.data.type === 'started') setStatus('Playing...', '#2E7D32');
- else if (e.data.type === 'stopped' && !gen) {{
- setStatus('Done', '#2E7D32'); showStats(true);
- const btn = document.getElementById('tts-stop-btn');
- if (btn) btn.style.display = 'none';
- }}
- }};
- }}
-
- function setStatus(text, color) {{
- const s = document.getElementById('tts-status');
- const d = document.getElementById('tts-status-dot');
- if (s) s.textContent = text;
- if (d) d.style.background = color || '#ccc';
- }}
-
- function showStats(fin) {{
- if (!st.t0) return;
- const elapsed = (fin && st.streamEnd ? (st.streamEnd - st.t0) : (performance.now() - st.t0)) / 1000;
- // st.samples counts stereo int16 samples; mono frames = samples / 2
- const dur = (st.samples / 2) / SR;
- const mTtfp = document.getElementById('tts-m-ttfp');
- const mRtf = document.getElementById('tts-m-rtf');
- const mDur = document.getElementById('tts-m-dur');
- const mSpeed = document.getElementById('tts-m-speed');
- const bar = document.getElementById('tts-rtf-bar');
- const barLabel = document.getElementById('tts-rtf-label');
- const elapsedEl = document.getElementById('tts-elapsed');
-
- if (mTtfp && st.ttfp != null) mTtfp.textContent = st.ttfp.toFixed(0) + 'ms';
- if (mDur) mDur.textContent = dur.toFixed(1) + 's';
-
- if (dur > 0 && elapsed > 0) {{
- const rtf = elapsed / dur;
- const speed = 1 / rtf;
- if (mRtf) {{
- mRtf.textContent = rtf.toFixed(2) + 'x';
- mRtf.style.color = rtf < 1 ? '#2E7D32' : rtf < 1.5 ? '#e8a317' : '#EF5552';
- }}
- if (mSpeed) {{
- mSpeed.textContent = speed.toFixed(1) + 'x';
- mSpeed.style.color = speed > 1 ? '#2E7D32' : speed > 0.7 ? '#e8a317' : '#EF5552';
- }}
- if (bar) {{
- const pct = Math.min(speed / 3 * 100, 100);
- bar.style.width = pct + '%';
- bar.style.background = speed > 1 ? 'linear-gradient(90deg,#66BB6A,#2E7D32)' : speed > 0.7 ? 'linear-gradient(90deg,#e8a317,#f0b866)' : 'linear-gradient(90deg,#EF5552,#f87171)';
- }}
- if (barLabel) barLabel.textContent = speed.toFixed(1) + 'x realtime';
- }}
- if (elapsedEl) {{
- elapsedEl.style.display = 'block';
- elapsedEl.textContent = fin ? 'Completed in ' + elapsed.toFixed(1) + 's (' + st.chunks + ' chunks)' : elapsed.toFixed(1) + 's elapsed (' + st.chunks + ' chunks)';
- }}
- }}
-
- window.ttsStop = function() {{
- if (abort) abort.abort();
- if (node) node.port.postMessage({{ type: 'clear' }});
- gen = false;
- setStatus('Stopped', '#999');
- const btn = document.getElementById('tts-stop-btn');
- if (btn) btn.style.display = 'none';
- }};
-
- window.ttsGenerate = async function(payload) {{
- try {{ await init(); if (ctx.state === 'suspended') await ctx.resume(); }}
- catch (e) {{ const s = document.getElementById('tts-status'); if (s) s.textContent = 'Audio init error: ' + e.message; return; }}
-
- if (abort) abort.abort();
- node.port.postMessage({{ type: 'clear' }});
- await new Promise(r => setTimeout(r, 50));
- node.port.postMessage({{ type: 'clear' }});
-
- gen = true;
- st = {{ t0: null, chunks: 0, samples: 0, ttfp: null }};
- setStatus('Connecting...', '#2E7D32');
- const bEl = document.getElementById('tts-stop-btn');
- if (bEl) bEl.style.display = 'inline-block';
- const mp = document.getElementById('tts-metrics');
- if (mp) {{ mp.style.display = 'grid'; ['tts-m-ttfp','tts-m-rtf','tts-m-dur','tts-m-speed'].forEach(id => {{ const e = document.getElementById(id); if(e) {{ e.textContent = '\\u2014'; e.style.color = '#333'; }} }}); }}
- const bw = document.getElementById('tts-rtf-bar-wrap');
- if (bw) bw.style.display = 'block';
- const bar = document.getElementById('tts-rtf-bar');
- if (bar) bar.style.width = '0%';
- const bl = document.getElementById('tts-rtf-label');
- if (bl) bl.textContent = '';
- const ee = document.getElementById('tts-elapsed');
- if (ee) {{ ee.style.display = 'none'; ee.textContent = ''; }}
- abort = new AbortController();
-
- try {{
- st.t0 = performance.now();
- const r = await fetch('/proxy/v1/audio/speech', {{
- method: 'POST',
- headers: {{ 'Content-Type': 'application/json' }},
- body: JSON.stringify(payload),
- signal: abort.signal,
- }});
- if (!r.ok) {{ const t = await r.text(); throw new Error('Server ' + r.status + ': ' + t.slice(0, 200)); }}
- setStatus('Streaming...', '#43A047');
-
- const reader = r.body.getReader();
- let left = new Uint8Array(0);
- while (true) {{
- const {{ done, value }} = await reader.read();
- if (done) break;
- let raw;
- if (left.length > 0) {{
- raw = new Uint8Array(left.length + value.length);
- raw.set(left); raw.set(value, left.length);
- }} else {{ raw = value; }}
- const usable = raw.length - (raw.length % 2);
- left = usable < raw.length ? raw.slice(usable) : new Uint8Array(0);
- if (usable > 0) {{
- const ab = new ArrayBuffer(usable);
- new Uint8Array(ab).set(raw.subarray(0, usable));
- const pcm = new Int16Array(ab);
- node.port.postMessage(pcm);
- st.chunks++;
- st.samples += pcm.length;
- if (st.ttfp == null) st.ttfp = performance.now() - st.t0;
- showStats(false);
- }}
- }}
- }} catch (e) {{
- if (e.name !== 'AbortError') {{
- setStatus('Error: ' + e.message, '#EF5552');
- console.error('TTS error:', e);
- }}
- }} finally {{
- st.streamEnd = performance.now();
- showStats(true);
- gen = false;
- if (st.samples > 0) setStatus('Finishing playback...', '#2E7D32');
- else {{
- setStatus('No audio received', '#999');
- if (bEl) bEl.style.display = 'none';
- }}
- }}
- }};
- </script>
-"""
-
-
-def encode_audio_to_base64(audio_data: tuple) -> str:
- """Encode Gradio audio input (sample_rate, numpy_array) to base64 data URL."""
- sample_rate, audio_np = audio_data
- if audio_np.dtype != np.int16:
- if audio_np.dtype in (np.float32, np.float64):
- audio_np = np.clip(audio_np, -1.0, 1.0)
- audio_np = (audio_np * 32767).astype(np.int16)
- else:
- audio_np = audio_np.astype(np.int16)
- buf = io.BytesIO()
- sf.write(buf, audio_np, sample_rate, format="WAV")
- wav_b64 = base64.b64encode(buf.getvalue()).decode("utf-8")
- return f"data:audio/wav;base64,{wav_b64}"
-
-
-def build_payload(
- text: str,
- voice_preset: str,
- ref_audio: tuple | None,
- ref_text: str,
- response_format: str = "pcm",
- stream: bool = True,
-) -> dict:
- """Build the /v1/audio/speech request payload."""
- if not text or not text.strip():
- raise gr.Error("Please enter text to synthesize.")
-
- voice_name = VOICE_PRESETS.get(voice_preset, "Junhao")
-
- payload: dict = {
- "input": text.strip(),
- "voice": voice_name,
- "response_format": "pcm" if stream else response_format,
- "stream": stream,
- }
-
- has_ref = ref_audio is not None
- if has_ref:
- payload["ref_audio"] = encode_audio_to_base64(ref_audio)
- ref_text_stripped = ref_text.strip() if ref_text else ""
- if ref_text_stripped:
- payload["ref_text"] = ref_text_stripped
- else:
- raise gr.Error("Voice cloning requires a transcript of the reference audio.")
-
- return payload
-
-
-def generate_speech(
- api_base: str,
- text: str,
- voice_preset: str,
- ref_audio: tuple | None,
- ref_text: str,
- response_format: str,
-) -> tuple:
- """Non-streaming: call /v1/audio/speech and return full audio as (sr, np_array)."""
- payload = build_payload(text, voice_preset, ref_audio, ref_text, response_format, stream=False)
-
- try:
- with httpx.Client(timeout=300.0) as client:
- resp = client.post(
- f"{api_base}/v1/audio/speech",
- json=payload,
- headers={"Content-Type": "application/json", "Authorization": "Bearer EMPTY"},
- )
- except httpx.TimeoutException:
- raise gr.Error("Request timed out. The server may be busy.")
- except httpx.ConnectError:
- raise gr.Error(f"Cannot connect to server at {api_base}. Is the server running?")
-
- if resp.status_code != 200:
- raise gr.Error(f"Server error ({resp.status_code}): {resp.text}")
-
- try:
- if response_format == "pcm":
- # PCM is stereo interleaved; downmix to mono for Gradio.
- samples = np.frombuffer(resp.content, dtype=np.int16)
- n = len(samples) - (len(samples) % 2)
- left = samples[:n:2].astype(np.float32)
- right = samples[1:n:2].astype(np.float32)
- mono = (left + right) / 65536.0
- return (PCM_SAMPLE_RATE, mono)
- # WAV/MP3/FLAC: soundfile handles header parsing.
- audio_np, sample_rate = sf.read(io.BytesIO(resp.content))
- if audio_np.ndim > 1:
- audio_np = audio_np.mean(axis=1)
- return (int(sample_rate), audio_np.astype(np.float32))
- except Exception as e:
- raise gr.Error(f"Failed to decode audio: {e}")
-
-
-def create_app(api_base: str):
- """Create the FastAPI app with streaming proxy + Gradio UI."""
- fastapi_app = FastAPI()
-
- # ── Streaming proxy (same-origin, no CORS issues) ────────────
- @fastapi_app.post("/proxy/v1/audio/speech")
- async def proxy_speech(request: Request):
- body = await request.json()
- logger.info(
- "Proxy request: input=%r voice=%s stream=%s",
- body.get("input", "")[:50],
- body.get("voice"),
- body.get("stream"),
- )
- try:
- client = httpx.AsyncClient(timeout=300)
- resp = await client.send(
- client.build_request(
- "POST",
- f"{api_base}/v1/audio/speech",
- json=body,
- headers={"Authorization": "Bearer EMPTY", "Content-Type": "application/json"},
- ),
- stream=True,
- )
- except Exception as exc:
- logger.exception("Proxy connection error")
- await client.aclose()
- return Response(content=str(exc), status_code=502)
-
- if resp.status_code != 200:
- content = await resp.aread()
- logger.error("Proxy upstream error %d: %s", resp.status_code, content[:200])
- await resp.aclose()
- await client.aclose()
- return Response(content=content, status_code=resp.status_code)
-
- async def relay():
- total = 0
- try:
- async for chunk in resp.aiter_bytes():
- total += len(chunk)
- yield chunk
- except Exception:
- logger.exception("Proxy relay error after %d bytes", total)
- finally:
- logger.info("Proxy relay done: %d bytes", total)
- await resp.aclose()
- await client.aclose()
-
- return StreamingResponse(relay(), media_type="application/octet-stream")
-
- # ── Gradio UI ────────────────────────────────────────────────
- css = """
- #generate-btn button { width: 100%; }
- #streaming-player { border: 1px solid var(--border-color-primary) !important; border-radius: var(--block-radius) !important; padding: var(--block-padding) !important; }
- """
-
- theme = gr.themes.Default(
- primary_hue=gr.themes.Color(
- c50="#E8F5E9",
- c100="#C8E6C9",
- c200="#A5D6A7",
- c300="#81C784",
- c400="#66BB6A",
- c500="#4CAF50",
- c600="#43A047",
- c700="#388E3C",
- c800="#2E7D32",
- c900="#1B5E20",
- c950="#0D3B10",
- ),
- )
-
- with gr.Blocks(title="MOSS-TTS-Nano Demo") as demo:
- gr.HTML(f"""
- <div style="display:flex; align-items:center; gap:16px; margin-bottom:8px;">
- <img src="https://raw.githubusercontent.com/vllm-project/vllm-omni/main/docs/source/logos/vllm-omni-logo.png"
- alt="vLLM-Omni" style="height:42px;">
- <div>
- <h1 style="margin:0; font-size:1.5em;">MOSS-TTS-Nano Streaming Demo</h1>
- <span style="font-size:0.85em; color:#666;">
- 0.1B AR LM + MOSS-Audio-Tokenizer-Nano · 48 kHz · ZH / EN / JA
- · Served by
- <a href="https://github.com/vllm-project/vllm-omni" target="_blank"
- style="color:#43A047; text-decoration:none; font-weight:600;">vLLM-Omni</a>
- · <code style="background:#eef2f7; padding:2px 6px; border-radius:4px; font-size:0.9em;">{api_base}</code>
- </span>
- </div>
- </div>
- """)
-
- with gr.Row():
- with gr.Column(scale=3):
- text_input = gr.Textbox(
- label="Text to Synthesize",
- placeholder="Enter text in Chinese, English, or Japanese...",
- lines=4,
- )
-
- voice_preset = gr.Dropdown(
- choices=PRESET_LABELS,
- value=DEFAULT_PRESET,
- label="Voice Preset",
- info="Built-in multilingual voices. ZH = Chinese, EN = English, JA = Japanese.",
- )
-
- with gr.Accordion("Custom Voice Clone (optional)", open=False):
- gr.Markdown(
- "Upload a reference audio clip (10-30 s) and provide its transcript "
- "to clone that voice instead of using the built-in preset."
- )
- ref_audio = gr.Audio(
- label="Reference Audio",
- type="numpy",
- sources=["upload", "microphone"],
- )
- ref_text = gr.Textbox(
- label="Reference Audio Transcript (required for cloning)",
- placeholder="Exact transcript of the reference audio...",
- lines=2,
- )
-
- with gr.Row():
- response_format = gr.Dropdown(
- choices=["wav", "mp3", "flac", "pcm"],
- value="pcm",
- label="Audio Format",
- interactive=False,
- scale=1,
- )
- stream_checkbox = gr.Checkbox(
- label="Stream (gapless)",
- value=True,
- info="AudioWorklet streaming (recommended)",
- scale=1,
- )
-
- with gr.Row():
- generate_btn = gr.Button(
- "Generate Speech",
- variant="primary",
- size="lg",
- elem_id="generate-btn",
- scale=3,
- )
- reset_btn = gr.Button(
- "Reset",
- variant="secondary",
- size="lg",
- scale=1,
- )
-
- with gr.Column(scale=2):
- player_html = gr.HTML(
- value=PLAYER_HTML,
- visible=True,
- label="streaming player",
- elem_id="streaming-player",
- )
- audio_output = gr.Audio(
- label="Generated Audio",
- interactive=False,
- autoplay=True,
- visible=False,
- )
- gr.Examples(
- examples=[
- ["Hello, this is MOSS-TTS-Nano speaking.", "Ava (EN)"],
- ["The quick brown fox jumps over the lazy dog.", "Adam (EN)"],
- ["MOSS-TTS-Nanoは、軽量なテキスト読み上げモデルです。", "Sakura (JA)"],
- ],
- inputs=[text_input, voice_preset],
- label="Examples",
- )
- gr.HTML("""
- <div style="text-align:center; padding:8px 0; margin-top:4px;">
- <a href="https://github.com/vllm-project/vllm-omni" target="_blank">
- <img src="https://raw.githubusercontent.com/vllm-project/vllm-omni/main/docs/source/logos/vllm-omni-logo.png"
- alt="vLLM-Omni" style="height:28px; opacity:0.7;">
- </a>
- </div>
- """)
-
- # Hidden textbox to pass payload from Python -> JavaScript
- hidden_payload = gr.Textbox(visible=False, elem_id="tts-payload")
-
- # ── Event wiring ─────────────────────────────────────────
- def on_stream_change(stream: bool):
- if stream:
- return (
- gr.update(value="pcm", interactive=False),
- gr.update(visible=True), # player
- gr.update(visible=False), # audio
- )
- return (
- gr.update(value="wav", interactive=True),
- gr.update(visible=False),
- gr.update(visible=True),
- )
-
- stream_checkbox.change(
- fn=on_stream_change,
- inputs=[stream_checkbox],
- outputs=[response_format, player_html, audio_output],
- )
-
- def on_reset():
- return (
- "", # text
- None, # audio_output
- "", # hidden_payload
- PLAYER_HTML, # reset player
- )
-
- reset_btn.click(
- fn=on_reset,
- outputs=[text_input, audio_output, hidden_payload, player_html],
- js="() => { if (window.ttsStop) window.ttsStop(); }",
- )
-
- all_inputs = [text_input, voice_preset, ref_audio, ref_text, response_format]
-
- def on_generate(stream_enabled, *args):
- import time as _time
-
- text, voice, ref_a, ref_t, _fmt = args
- if stream_enabled:
- payload = build_payload(text, voice, ref_a, ref_t, stream=True)
- payload["_nonce"] = int(_time.time() * 1000)
- return json.dumps(payload), gr.update()
- else:
- audio = generate_speech(api_base, text, voice, ref_a, ref_t, _fmt)
- return "", audio
-
- generate_btn.click(
- fn=on_generate,
- inputs=[stream_checkbox] + all_inputs,
- outputs=[hidden_payload, audio_output],
- ).then(
- fn=lambda p: p,
- inputs=[hidden_payload],
- outputs=[hidden_payload],
- js="(p) => { if (p && p.trim()) { const d = JSON.parse(p); delete d._nonce; window.ttsGenerate(d); } return p; }",
- )
-
- demo.queue()
-
- return gr.mount_gradio_app(
- fastapi_app,
- demo,
- path="/",
- css=css,
- theme=theme,
- head=_build_player_js(PCM_SAMPLE_RATE),
- )
-
-
-def main():
- parser = argparse.ArgumentParser(
- description="Gradio demo for MOSS-TTS-Nano with gapless AudioWorklet streaming.",
- )
- parser.add_argument("--api-base", default=DEFAULT_API_BASE, help=f"API base URL (default: {DEFAULT_API_BASE})")
- parser.add_argument("--host", default="0.0.0.0", help="Gradio host (default: 0.0.0.0)")
- parser.add_argument("--port", type=int, default=7860, help="Gradio port (default: 7860)")
- parser.add_argument("--share", action="store_true", help="Share publicly via Gradio tunnel")
- args = parser.parse_args()
-
- logging.basicConfig(level=logging.INFO)
- print(f"Connecting to vLLM-Omni server at: {args.api_base}")
-
- app = create_app(args.api_base)
-
- import uvicorn
-
- uvicorn.run(app, host=args.host, port=args.port)
-
-
-if __name__ == "__main__":
- main()
diff --git a/examples/online_serving/moss_tts_nano/run_gradio_demo.sh b/examples/online_serving/moss_tts_nano/run_gradio_demo.sh
deleted file mode 100755
index cd96c6b4f43..00000000000
--- a/examples/online_serving/moss_tts_nano/run_gradio_demo.sh
+++ /dev/null
@@ -1,43 +0,0 @@
-#!/bin/bash
-# Launch MOSS-TTS-Nano server + Gradio demo together.
-#
-# Usage:
-# ./run_gradio_demo.sh
-# CUDA_VISIBLE_DEVICES=0 PORT=8091 GRADIO_PORT=7860 ./run_gradio_demo.sh
-
-set -e
-
-MODEL="${MODEL:-OpenMOSS-Team/MOSS-TTS-Nano}"
-PORT="${PORT:-8091}"
-GRADIO_PORT="${GRADIO_PORT:-7860}"
-SCRIPT_DIR="$(cd "$(dirname "$0")" && pwd)"
-
-echo "Starting MOSS-TTS-Nano server (port $PORT)..."
-FLASHINFER_DISABLE_VERSION_CHECK=1 \
-vllm serve "$MODEL" \
- --host 0.0.0.0 \
- --port "$PORT" \
- --omni &
-SERVER_PID=$!
-
-cleanup() {
- echo "Stopping server (PID $SERVER_PID)..."
- kill $SERVER_PID 2>/dev/null
- wait $SERVER_PID 2>/dev/null
-}
-trap cleanup EXIT
-
-# Wait for server to be ready.
-echo "Waiting for server to start..."
-for i in $(seq 1 120); do
- if curl -s "http://localhost:$PORT/health" > /dev/null 2>&1; then
- echo "Server ready."
- break
- fi
- sleep 2
-done
-
-echo "Starting Gradio demo (port $GRADIO_PORT)..."
-python "$SCRIPT_DIR/gradio_demo.py" \
- --api-base "http://localhost:$PORT" \
- --port "$GRADIO_PORT"
diff --git a/examples/online_serving/moss_tts_nano/run_server.sh b/examples/online_serving/moss_tts_nano/run_server.sh
deleted file mode 100755
index 5ddbac09c17..00000000000
--- a/examples/online_serving/moss_tts_nano/run_server.sh
+++ /dev/null
@@ -1,19 +0,0 @@
-#!/bin/bash
-# Launch vLLM-Omni server for MOSS-TTS-Nano
-#
-# Usage:
-# ./run_server.sh
-# CUDA_VISIBLE_DEVICES=0 PORT=8091 ./run_server.sh
-
-set -e
-
-MODEL="${MODEL:-OpenMOSS-Team/MOSS-TTS-Nano}"
-PORT="${PORT:-8091}"
-
-echo "Starting MOSS-TTS-Nano server with model: $MODEL"
-
-FLASHINFER_DISABLE_VERSION_CHECK=1 \
-vllm serve "$MODEL" \
- --host 0.0.0.0 \
- --port "$PORT" \
- --omni
diff --git a/examples/online_serving/omnivoice/README.md b/examples/online_serving/omnivoice/README.md
deleted file mode 100644
index 1d8f00421b9..00000000000
--- a/examples/online_serving/omnivoice/README.md
+++ /dev/null
@@ -1,131 +0,0 @@
-# OmniVoice
-
-## Model Overview
-
-| Model | Description |
-|-------|-------------|
-| `k2-fsa/OmniVoice` | Zero-shot multilingual TTS (600+ languages) with diffusion language model (Qwen3-0.6B backbone) |
-
-> **Note:** Requires `transformers>=5.3.0` for voice cloning (HiggsAudioV2 tokenizer). Auto voice and voice design work with `transformers>=4.57.0`.
-
-## Launch the Server
-
-```bash
-vllm serve k2-fsa/OmniVoice \
- --omni \
- --port 8091 \
- --trust-remote-code
-```
-
-Or use the convenience script:
-
-```bash
-./run_server.sh
-```
-
-## Send TTS Request
-
-### Using curl
-
-```bash
-# Basic TTS (auto voice)
-curl -X POST http://localhost:8091/v1/audio/speech \
- -H "Content-Type: application/json" \
- -d '{
- "input": "Hello, how are you?",
- "voice": "default",
- "response_format": "wav"
- }' --output output.wav
-```
-
-### Using Python
-
-```python
-import httpx
-
-response = httpx.post(
- "http://localhost:8091/v1/audio/speech",
- json={
- "input": "Hello, how are you?",
- "voice": "default",
- "response_format": "wav",
- },
- timeout=300.0,
-)
-
-with open("output.wav", "wb") as f:
- f.write(response.content)
-```
-
-### Using OpenAI SDK
-
-```python
-from openai import OpenAI
-
-client = OpenAI(base_url="http://localhost:8091/v1", api_key="none")
-
-response = client.audio.speech.create(
- model="k2-fsa/OmniVoice",
- voice="default",
- input="Hello, how are you?",
-)
-
-response.stream_to_file("output.wav")
-```
-
-### Using the CLI Client
-
-```bash
-cd examples/online_serving/omnivoice
-
-# Basic TTS
-python speech_client.py --text "Hello, how are you?"
-
-# Specify language for improved quality
-python speech_client.py --text "Bonjour, comment allez-vous?" --language French
-```
-
-The CLI client supports:
-
-- `--api-base`: API base URL (default: `http://localhost:8091`)
-- `--model` (or `-m`): Model name (default: `k2-fsa/OmniVoice`)
-- `--text`: Text to synthesize (required)
-- `--response-format`: Audio format: wav, mp3, flac, pcm, aac, opus (default: wav)
-- `--language`: Language hint (default: Auto)
-- `--output` (or `-o`): Output file path (default: `omnivoice_output.wav`)
-
-## Inference Modes
-
-OmniVoice supports three inference modes. Currently, **auto voice** is supported through the online Speech API. Voice cloning and voice design are available via offline inference (see `examples/offline_inference/omnivoice/`).
-
-| Mode | Description | Online API | Offline |
-|------|-------------|:----------:|:-------:|
-| Auto Voice | Generate speech without reference | Yes | Yes |
-| Voice Clone | Clone from reference audio + transcript | - | Yes |
-| Voice Design | Control style via natural language instruction | - | Yes |
-
-## Architecture
-
-OmniVoice uses a single-stage diffusion pipeline:
-
-- **Stage 0 (Generator)**: Qwen3-0.6B transformer with 32-step iterative masked unmasking and classifier-free guidance. Generates 8-codebook audio tokens from text, then decodes to 24kHz waveform via HiggsAudioV2 RVQ quantizer + DAC acoustic decoder.
-
-## API Parameters
-
-OmniVoice uses the standard `/v1/audio/speech` endpoint. See the [Speech API reference](https://docs.vllm.ai/projects/vllm-omni/en/latest/serving/speech_api/) for full documentation.
-
-Key parameters:
-
-| Parameter | Type | Default | Description |
-|-----------|------|---------|-------------|
-| `input` | string | **required** | Text to synthesize |
-| `voice` | string | "default" | Voice name |
-| `response_format` | string | "wav" | Audio format: wav, mp3, flac, pcm, aac, opus |
-| `speed` | float | 1.0 | Playback speed (0.25-4.0) |
-
-## Troubleshooting
-
-1. **TTS model did not produce audio output**: Ensure the model is fully downloaded (`huggingface-cli download k2-fsa/OmniVoice`)
-2. **Connection refused**: Make sure the server is running on the correct port
-3. **Out of memory**: Reduce `--gpu-memory-utilization` (default stage config uses 0.5)
-4. **Slow first request**: The model performs warmup on first inference; subsequent requests are faster
diff --git a/examples/online_serving/omnivoice/run_server.sh b/examples/online_serving/omnivoice/run_server.sh
deleted file mode 100755
index abe9bb79897..00000000000
--- a/examples/online_serving/omnivoice/run_server.sh
+++ /dev/null
@@ -1,19 +0,0 @@
-#!/bin/bash
-# Launch vLLM-Omni server for OmniVoice TTS
-#
-# Usage:
-# ./run_server.sh
-# CUDA_VISIBLE_DEVICES=0 ./run_server.sh
-
-set -e
-
-MODEL="${MODEL:-k2-fsa/OmniVoice}"
-PORT="${PORT:-8091}"
-
-echo "Starting OmniVoice server with model: $MODEL"
-
-vllm serve "$MODEL" \
- --host 0.0.0.0 \
- --port "$PORT" \
- --trust-remote-code \
- --omni
diff --git a/examples/online_serving/omnivoice/speech_client.py b/examples/online_serving/omnivoice/speech_client.py
deleted file mode 100644
index b8e6f38890e..00000000000
--- a/examples/online_serving/omnivoice/speech_client.py
+++ /dev/null
@@ -1,84 +0,0 @@
-"""Client for OmniVoice TTS via /v1/audio/speech endpoint.
-
-Examples:
- # Basic TTS (auto voice)
- python speech_client.py --text "Hello, how are you?"
-
- # Specify language
- python speech_client.py --text "Bonjour, comment allez-vous?" --language French
-"""
-
-import argparse
-
-import httpx
-
-DEFAULT_API_BASE = "http://localhost:8091"
-DEFAULT_API_KEY = "EMPTY"
-
-
-def run_tts(args) -> None:
- """Generate speech via /v1/audio/speech API."""
- payload = {
- "model": args.model,
- "input": args.text,
- "voice": "default",
- "response_format": args.response_format,
- }
-
- if args.language:
- payload["language"] = args.language
-
- print(f"Model: {args.model}")
- print(f"Text: {args.text}")
- if args.language:
- print(f"Language: {args.language}")
- print("Generating audio...")
-
- api_url = f"{args.api_base}/v1/audio/speech"
- headers = {
- "Content-Type": "application/json",
- "Authorization": f"Bearer {args.api_key}",
- }
-
- with httpx.Client(timeout=300.0) as client:
- response = client.post(api_url, json=payload, headers=headers)
-
- if response.status_code != 200:
- print(f"Error: {response.status_code}")
- print(response.text)
- return
-
- try:
- text = response.content.decode("utf-8")
- if text.startswith('{"error"'):
- print(f"Error: {text}")
- return
- except UnicodeDecodeError:
- pass
-
- output_path = args.output or "omnivoice_output.wav"
- with open(output_path, "wb") as f:
- f.write(response.content)
- print(f"Audio saved to: {output_path}")
-
-
-def main():
- parser = argparse.ArgumentParser(description="OmniVoice TTS client")
- parser.add_argument("--api-base", default=DEFAULT_API_BASE, help="API base URL")
- parser.add_argument("--api-key", default=DEFAULT_API_KEY, help="API key")
- parser.add_argument("--model", "-m", default="k2-fsa/OmniVoice", help="Model name")
- parser.add_argument("--text", required=True, help="Text to synthesize")
- parser.add_argument("--language", default=None, help="Language hint (e.g., English, Chinese, French)")
- parser.add_argument(
- "--response-format",
- default="wav",
- choices=["wav", "mp3", "flac", "pcm", "aac", "opus"],
- help="Audio format (default: wav)",
- )
- parser.add_argument("--output", "-o", default=None, help="Output file path")
- args = parser.parse_args()
- run_tts(args)
-
-
-if __name__ == "__main__":
- main()
diff --git a/examples/online_serving/openai_chat_completion_client_for_multimodal_generation.py b/examples/online_serving/openai_chat_completion_client_for_multimodal_generation.py
deleted file mode 100644
index 2609945c334..00000000000
--- a/examples/online_serving/openai_chat_completion_client_for_multimodal_generation.py
+++ /dev/null
@@ -1,590 +0,0 @@
-import base64
-import concurrent.futures
-import os
-from typing import NamedTuple
-
-import requests
-from openai import OpenAI
-from vllm.assets.audio import AudioAsset
-from vllm.utils.argparse_utils import FlexibleArgumentParser
-
-SEED = 42
-
-
-class QueryResult(NamedTuple):
- inputs: dict
- limit_mm_per_prompt: dict[str, int]
-
-
-def make_audio_output_filename(request_id: str | None, index: int) -> str:
- """Build a stable output filename using request ID when available."""
- if not request_id:
- request_id = f"unknown_{index}"
- safe_request_id = "".join(ch if (ch.isalnum() or ch in ("-", "_")) else "_" for ch in request_id)
- return f"audio_{safe_request_id}_{index}.wav"
-
-
-def encode_base64_content_from_url(content_url: str) -> str:
- """Encode a content retrieved from a remote url to base64 format."""
-
- with requests.get(content_url) as response:
- response.raise_for_status()
- result = base64.b64encode(response.content).decode("utf-8")
-
- return result
-
-
-def encode_base64_content_from_file(file_path: str) -> str:
- """Encode a local file to base64 format."""
- with open(file_path, "rb") as f:
- content = f.read()
- result = base64.b64encode(content).decode("utf-8")
- return result
-
-
-def get_video_url_from_path(video_path: str | None) -> str:
- """Convert a video path (local file or URL) to a video URL format for the API.
-
- If video_path is None or empty, returns the default URL.
- If video_path is a local file path, encodes it to base64 data URL.
- If video_path is a URL, returns it as-is.
- """
- if not video_path:
- # Default video URL
- return "https://huggingface.co/datasets/raushan-testing-hf/videos-test/resolve/main/sample_demo_1.mp4"
-
- # Check if it's a URL (starts with http:// or https://)
- if video_path.startswith(("http://", "https://")):
- return video_path
-
- # Otherwise, treat it as a local file path
- if not os.path.exists(video_path):
- raise FileNotFoundError(f"Video file not found: {video_path}")
-
- # Detect video MIME type from file extension
- video_path_lower = video_path.lower()
- if video_path_lower.endswith(".mp4"):
- mime_type = "video/mp4"
- elif video_path_lower.endswith(".webm"):
- mime_type = "video/webm"
- elif video_path_lower.endswith(".mov"):
- mime_type = "video/quicktime"
- elif video_path_lower.endswith(".avi"):
- mime_type = "video/x-msvideo"
- elif video_path_lower.endswith(".mkv"):
- mime_type = "video/x-matroska"
- else:
- # Default to mp4 if extension is unknown
- mime_type = "video/mp4"
-
- video_base64 = encode_base64_content_from_file(video_path)
- return f"data:{mime_type};base64,{video_base64}"
-
-
-def get_image_url_from_path(image_path: str | None) -> str:
- """Convert an image path (local file or URL) to an image URL format for the API.
-
- If image_path is None or empty, returns the default URL.
- If image_path is a local file path, encodes it to base64 data URL.
- If image_path is a URL, returns it as-is.
- """
- if not image_path:
- # Default image URL
- return "https://vllm-public-assets.s3.us-west-2.amazonaws.com/vision_model_images/cherry_blossom.jpg"
-
- # Check if it's a URL (starts with http:// or https://)
- if image_path.startswith(("http://", "https://")):
- return image_path
-
- # Otherwise, treat it as a local file path
- if not os.path.exists(image_path):
- raise FileNotFoundError(f"Image file not found: {image_path}")
-
- # Detect image MIME type from file extension
- image_path_lower = image_path.lower()
- if image_path_lower.endswith((".jpg", ".jpeg")):
- mime_type = "image/jpeg"
- elif image_path_lower.endswith(".png"):
- mime_type = "image/png"
- elif image_path_lower.endswith(".gif"):
- mime_type = "image/gif"
- elif image_path_lower.endswith(".webp"):
- mime_type = "image/webp"
- else:
- # Default to jpeg if extension is unknown
- mime_type = "image/jpeg"
-
- image_base64 = encode_base64_content_from_file(image_path)
- return f"data:{mime_type};base64,{image_base64}"
-
-
-def get_audio_url_from_path(audio_path: str | None) -> str:
- """Convert an audio path (local file or URL) to an audio URL format for the API.
-
- If audio_path is None or empty, returns the default URL.
- If audio_path is a local file path, encodes it to base64 data URL.
- If audio_path is a URL, returns it as-is.
- """
- if not audio_path:
- # Default audio URL
- return AudioAsset("mary_had_lamb").url
-
- # Check if it's a URL (starts with http:// or https://)
- if audio_path.startswith(("http://", "https://")):
- return audio_path
-
- # Otherwise, treat it as a local file path
- if not os.path.exists(audio_path):
- raise FileNotFoundError(f"Audio file not found: {audio_path}")
-
- # Detect audio MIME type from file extension
- audio_path_lower = audio_path.lower()
- if audio_path_lower.endswith((".mp3", ".mpeg")):
- mime_type = "audio/mpeg"
- elif audio_path_lower.endswith(".wav"):
- mime_type = "audio/wav"
- elif audio_path_lower.endswith(".ogg"):
- mime_type = "audio/ogg"
- elif audio_path_lower.endswith(".flac"):
- mime_type = "audio/flac"
- elif audio_path_lower.endswith(".m4a"):
- mime_type = "audio/mp4"
- else:
- # Default to wav if extension is unknown
- mime_type = "audio/wav"
-
- audio_base64 = encode_base64_content_from_file(audio_path)
- return f"data:{mime_type};base64,{audio_base64}"
-
-
-def get_system_prompt():
- return {
- "role": "system",
- "content": [
- {
- "type": "text",
- "text": (
- "You are Qwen, a virtual human developed by the Qwen Team, "
- "Alibaba Group, capable of perceiving auditory and visual inputs, "
- "as well as generating text and speech."
- ),
- }
- ],
- }
-
-
-def _parse_csv_arg(value: str | None) -> list[str]:
- if not value:
- return []
- return [item.strip() for item in value.split(",") if item.strip()]
-
-
-def _build_prompt_for_query_type(
- query_type: str,
- custom_prompt: str | None,
- video_path: str | None,
- image_path: str | None,
- audio_path: str | None,
-):
- query_func = query_map[query_type]
- if query_type == "use_video":
- return query_func(video_path=video_path, custom_prompt=custom_prompt)
- if query_type == "use_image":
- return query_func(image_path=image_path, custom_prompt=custom_prompt)
- if query_type == "use_audio":
- return query_func(audio_path=audio_path, custom_prompt=custom_prompt)
- if query_type == "text":
- return query_func(custom_prompt=custom_prompt)
- if query_type == "use_audio_in_video":
- return query_func(video_path=video_path, custom_prompt=custom_prompt)
- # use_mixed_modalities / use_multi_audios
- return query_func(custom_prompt=custom_prompt)
-
-
-def get_text_query(custom_prompt: str | None = None):
- question = (
- custom_prompt or "Explain the system architecture for a scalable audio generation pipeline. Answer in 15 words."
- )
- prompt = {
- "role": "user",
- "content": [
- {
- "type": "text",
- "text": f"{question}",
- }
- ],
- }
- return prompt
-
-
-default_system = (
- "You are Qwen, a virtual human developed by the Qwen Team, Alibaba "
- "Group, capable of perceiving auditory and visual inputs, as well as "
- "generating text and speech."
-)
-
-
-def get_video_query(video_path: str | None = None, custom_prompt: str | None = None):
- question = custom_prompt or "Why is this video funny?"
- video_url = get_video_url_from_path(video_path)
- prompt = {
- "role": "user",
- "content": [
- {
- "type": "video_url",
- "video_url": {"url": video_url},
- },
- {
- "type": "text",
- "text": f"{question}",
- },
- ],
- }
- return prompt
-
-
-def get_image_query(image_path: str | None = None, custom_prompt: str | None = None):
- question = custom_prompt or "What is the content of this image?"
- image_url = get_image_url_from_path(image_path)
- prompt = {
- "role": "user",
- "content": [
- {
- "type": "image_url",
- "image_url": {"url": image_url},
- },
- {
- "type": "text",
- "text": f"{question}",
- },
- ],
- }
- return prompt
-
-
-def get_audio_query(audio_path: str | None = None, custom_prompt: str | None = None):
- question = custom_prompt or "What is the content of this audio?"
- audio_url = get_audio_url_from_path(audio_path)
- prompt = {
- "role": "user",
- "content": [
- {
- "type": "audio_url",
- "audio_url": {"url": audio_url},
- },
- {
- "type": "text",
- "text": f"{question}",
- },
- ],
- }
- return prompt
-
-
-def get_mixed_modalities_query(
- video_path: str | None = None,
- image_path: str | None = None,
- audio_path: str | None = None,
- custom_prompt: str | None = None,
-):
- """
- Online-friendly multimodal user message:
- - Uses URLs (or base64 data URLs) for audio / image / video.
- - Returns the OpenAI-style message dict directly (not the offline QueryResult).
- """
- question = (
- custom_prompt or "What is recited in the audio? What is the content of this image? Why is this video funny?"
- )
-
- audio_url = get_audio_url_from_path(audio_path)
- image_url = get_image_url_from_path(image_path)
- video_url = get_video_url_from_path(video_path)
-
- return {
- "role": "user",
- "content": [
- {"type": "audio_url", "audio_url": {"url": audio_url}},
- {"type": "image_url", "image_url": {"url": image_url}},
- {"type": "video_url", "video_url": {"url": video_url}},
- {"type": "text", "text": question},
- ],
- }
-
-
-def get_multi_audios_query(custom_prompt: str | None = None):
- """
- Online-friendly two-audio comparison request.
- - Encodes both audio clips as URLs (or data URLs).
- - Returns the OpenAI-style message dict.
- """
- question = custom_prompt or "Are these two audio clips the same?"
- # Use default demo clips; you can point to your own via --audio-path if needed.
- audio_url_1 = get_audio_url_from_path(AudioAsset("winning_call").url)
- audio_url_2 = get_audio_url_from_path(AudioAsset("mary_had_lamb").url)
-
- return {
- "role": "user",
- "content": [
- {"type": "audio_url", "audio_url": {"url": audio_url_1}},
- {"type": "audio_url", "audio_url": {"url": audio_url_2}},
- {"type": "text", "text": question},
- ],
- }
-
-
-def get_use_audio_in_video_query(
- video_path: str | None = None,
- custom_prompt: str | None = None,
-):
- """Query for use_audio_in_video mode.
-
- When use_audio_in_video=True, audio is automatically extracted from the video
- by the server. Do NOT send a separate audio_url - this would cause a mismatch
- between the number of audio and video items.
- """
- question = custom_prompt or (
- "Describe the content of the video in details, then convert what the baby say into text."
- )
- video_url = get_video_url_from_path(video_path)
- # Note: audio is extracted from video automatically when use_audio_in_video=True
- # Do not include a separate audio_url here
- return {
- "role": "user",
- "content": [
- {"type": "video_url", "video_url": {"url": video_url}},
- {"type": "text", "text": question},
- ],
- }
-
-
-query_map = {
- "text": get_text_query,
- "use_audio": get_audio_query,
- "use_image": get_image_query,
- "use_video": get_video_query,
- "use_mixed_modalities": get_mixed_modalities_query,
- "use_multi_audios": get_multi_audios_query,
- "use_audio_in_video": get_use_audio_in_video_query,
-}
-
-
-def run_multimodal_generation(args, client: OpenAI) -> None:
- model_name = args.model
-
- # Get paths and custom prompt from args
- video_path = getattr(args, "video_path", None)
- image_path = getattr(args, "image_path", None)
- audio_path = getattr(args, "audio_path", None)
- custom_prompt = getattr(args, "prompt", None)
-
- if args.modalities is not None:
- output_modalities = args.modalities.split(",")
- else:
- output_modalities = None
-
- # Test multiple concurrent completions
- num_concurrent_requests = args.num_concurrent_requests
- prompt_list = _parse_csv_arg(getattr(args, "prompts", None))
- speaker_list = _parse_csv_arg(getattr(args, "speakers", None))
-
- request_payloads = []
- for idx in range(num_concurrent_requests):
- per_req_prompt = (
- prompt_list[idx]
- if idx < len(prompt_list)
- else (custom_prompt if idx == 0 or not prompt_list else prompt_list[-1])
- )
- per_req_speaker = (
- speaker_list[idx]
- if idx < len(speaker_list)
- else (args.speaker if idx == 0 or not speaker_list else speaker_list[-1])
- )
- prompt = _build_prompt_for_query_type(
- query_type=args.query_type,
- custom_prompt=per_req_prompt,
- video_path=video_path,
- image_path=image_path,
- audio_path=audio_path,
- )
- extra_body = {
- # Optional, it has default settings in stage configs. you can override them here.
- }
- if args.query_type == "use_audio_in_video":
- extra_body["mm_processor_kwargs"] = {"use_audio_in_video": True}
- if per_req_speaker and per_req_speaker.strip():
- extra_body["speaker"] = per_req_speaker.strip()
- request_payloads.append({"prompt": prompt, "extra_body": extra_body})
-
- with concurrent.futures.ThreadPoolExecutor(max_workers=num_concurrent_requests) as executor:
- # Submit multiple completion requests concurrently
- futures = [
- executor.submit(
- client.chat.completions.create,
- messages=[
- get_system_prompt(),
- payload["prompt"],
- ],
- model=model_name,
- modalities=output_modalities,
- extra_body=payload["extra_body"],
- stream=args.stream,
- )
- for payload in request_payloads
- ]
-
- # Wait for all requests to complete and collect results
- chat_completions = [future.result() for future in concurrent.futures.as_completed(futures)]
-
- assert len(chat_completions) == num_concurrent_requests
- count = 0
- if not args.stream:
- # Verify all completions succeeded
- for chat_completion in chat_completions:
- request_id = getattr(chat_completion, "id", None)
- for choice in chat_completion.choices:
- if choice.message.audio:
- audio_data = base64.b64decode(choice.message.audio.data)
- audio_file_path = make_audio_output_filename(request_id=request_id, index=count)
- with open(audio_file_path, "wb") as f:
- f.write(audio_data)
- print(f"Audio saved to {audio_file_path}")
- count += 1
- elif choice.message.content:
- print("Chat completion output from text:", choice.message.content)
- else:
- printed_content = False
- for chat_completion in chat_completions:
- for chunk in chat_completion:
- for choice in chunk.choices:
- if hasattr(choice, "delta"):
- content = getattr(choice.delta, "content", None)
- else:
- content = None
-
- if getattr(chunk, "modality", None) == "audio" and content:
- audio_data = base64.b64decode(content)
- request_id = getattr(chunk, "id", None)
- audio_file_path = make_audio_output_filename(request_id=request_id, index=count)
- with open(audio_file_path, "wb") as f:
- f.write(audio_data)
- print(f"\nAudio saved to {audio_file_path}")
- count += 1
-
- elif getattr(chunk, "modality", None) == "text":
- if not printed_content:
- printed_content = True
- print("\ncontent:", end="", flush=True)
- print(content, end="", flush=True)
-
-
-def parse_args():
- parser = FlexibleArgumentParser(description="Demo on using vLLM for offline inference with audio language models")
- parser.add_argument(
- "--query-type",
- "-q",
- type=str,
- default="use_audio_in_video",
- choices=query_map.keys(),
- help="Query type.",
- )
- parser.add_argument(
- "--model",
- "-m",
- type=str,
- default="Qwen/Qwen3-Omni-30B-A3B-Instruct",
- help="Model Name / Path",
- )
- parser.add_argument(
- "--video-path",
- "-v",
- type=str,
- default=None,
- help="Path to local video file or URL. If not provided and query-type is 'use_video', uses default video URL.",
- )
- parser.add_argument(
- "--image-path",
- "-i",
- type=str,
- default=None,
- help="Path to local image file or URL. If not provided and query-type is 'use_image', uses default image URL.",
- )
- parser.add_argument(
- "--audio-path",
- "-a",
- type=str,
- default=None,
- help="Path to local audio file or URL. If not provided and query-type is 'use_audio', uses default audio URL.",
- )
- parser.add_argument(
- "--prompt",
- "-p",
- type=str,
- default=None,
- help="Custom text prompt/question to use instead of the default prompt for the selected query type.",
- )
- parser.add_argument(
- "--modalities",
- type=str,
- default=None,
- help="Output modalities to use for the prompts.",
- )
- parser.add_argument(
- "--stream",
- action="store_true",
- help="Stream the response.",
- )
- parser.add_argument(
- "--num-concurrent-requests",
- type=int,
- default=1,
- help="Number of concurrent requests to send. Default is 1.",
- )
- parser.add_argument(
- "--port",
- type=int,
- default=8091,
- help="Port of the vLLM Omni API server.",
- )
- parser.add_argument(
- "--host",
- type=str,
- default="localhost",
- help="Host/IP of the vLLM Omni API server.",
- )
- parser.add_argument(
- "--speaker",
- type=str,
- default=None,
- help="TTS speaker/voice for audio output (e.g. Ethan, Vivian). Passed via extra_body to the talker stage.",
- )
- parser.add_argument(
- "--speakers",
- type=str,
- default=None,
- help=(
- "Comma-separated speakers for concurrent requests, e.g. "
- "'Ethan,Vivian,Ryan'. Overrides --speaker per request."
- ),
- )
- parser.add_argument(
- "--prompts",
- type=str,
- default=None,
- help=(
- "Comma-separated prompts for concurrent requests. "
- "If fewer than --num-concurrent-requests, the last prompt is reused."
- ),
- )
- return parser.parse_args()
-
-
-if __name__ == "__main__":
- args = parse_args()
- host = args.host
- port = args.port
- openai_api_base = f"http://{host}:{port}/v1"
- client = OpenAI(
- api_key="EMPTY",
- base_url=openai_api_base,
- )
- run_multimodal_generation(args, client)
diff --git a/examples/online_serving/qwen2_5_omni/README.md b/examples/online_serving/qwen2_5_omni/README.md
deleted file mode 100644
index c528732064a..00000000000
--- a/examples/online_serving/qwen2_5_omni/README.md
+++ /dev/null
@@ -1,210 +0,0 @@
-# Qwen2.5-Omni
-
-## 🛠️ Installation
-
-Please refer to [README.md](../../../README.md)
-
-## Run examples (Qwen2.5-Omni)
-
-### Launch the Server
-
-```bash
-vllm serve Qwen/Qwen2.5-Omni-7B --omni --port 8091
-```
-
-If you have custom stage configs file, launch the server with command below
-```bash
-vllm serve Qwen/Qwen2.5-Omni-7B --omni --port 8091 --stage-configs-path /path/to/stage_configs_file
-```
-
-### Send Multi-modal Request
-
-Get into the example folder
-```bash
-cd examples/online_serving/qwen2_5_omni
-```
-
-#### Send request via python
-
-```bash
-python examples/online_serving/openai_chat_completion_client_for_multimodal_generation.py --model Qwen/Qwen2.5-Omni-7B --query-type use_mixed_modalities --port 8091 --host "localhost"
-```
-
-The Python client supports the following command-line arguments:
-
-- `--query-type` (or `-q`): Query type (default: `mixed_modalities`). Options: `mixed_modalities`, `use_audio_in_video`, `multi_audios`, `text`
-- `--video-path` (or `-v`): Path to local video file or URL. If not provided and query-type uses video, uses default video URL. Supports local file paths (automatically encoded to base64) or HTTP/HTTPS URLs. Example: `--video-path /path/to/video.mp4` or `--video-path https://example.com/video.mp4`
-- `--image-path` (or `-i`): Path to local image file or URL. If not provided and query-type uses image, uses default image URL. Supports local file paths (automatically encoded to base64) or HTTP/HTTPS URLs and common image formats: JPEG, PNG, GIF, WebP. Example: `--image-path /path/to/image.jpg` or `--image-path https://example.com/image.png`
-- `--audio-path` (or `-a`): Path to local audio file or URL. If not provided and query-type uses audio, uses default audio URL. Supports local file paths (automatically encoded to base64) or HTTP/HTTPS URLs and common audio formats: MP3, WAV, OGG, FLAC, M4A. Example: `--audio-path /path/to/audio.wav` or `--audio-path https://example.com/audio.mp3`
-- `--prompt` (or `-p`): Custom text prompt/question. If not provided, uses default prompt for the selected query type. Example: `--prompt "What are the main activities shown in this video?"`
-
-
-For example, to use mixed modalities with all local files:
-
-```bash
-python examples/online_serving/openai_chat_completion_client_for_multimodal_generation.py \
- --query-type use_mixed_modalities \
- --video-path /path/to/your/video.mp4 \
- --image-path /path/to/your/image.jpg \
- --audio-path /path/to/your/audio.wav \
- --model Qwen/Qwen2.5-Omni-7B \
- --prompt "Analyze all the media content and provide a comprehensive summary."
-```
-
-#### Send request via curl
-
-```bash
-bash run_curl_multimodal_generation.sh mixed_modalities
-```
-
-## Modality control
-You can control output modalities to specify which types of output the model should generate. This is useful when you only need text output and want to skip audio generation stages for better performance.
-
-### Supported modalities
-
-| Modalities | Output |
-|------------|--------|
-| `["text"]` | Text only |
-| `["audio"]` | Text + Audio |
-| `["text", "audio"]` | Text + Audio |
-| Not specified | Text + Audio (default) |
-
-### Using curl
-
-#### Text only
-
-```bash
-curl http://localhost:8091/v1/chat/completions \
- -H "Content-Type: application/json" \
- -d '{
- "model": "Qwen/Qwen2.5-Omni-7B",
- "messages": [{"role": "user", "content": "Describe vLLM in brief."}],
- "modalities": ["text"]
- }'
-```
-
-#### Text + Audio
-
-```bash
-curl http://localhost:8091/v1/chat/completions \
- -H "Content-Type: application/json" \
- -d '{
- "model": "Qwen/Qwen2.5-Omni-7B",
- "messages": [{"role": "user", "content": "Describe vLLM in brief."}],
- "modalities": ["audio"]
- }'
-```
-
-### Using Python client
-
-```bash
-python examples/online_serving/openai_chat_completion_client_for_multimodal_generation.py \
- --query-type use_mixed_modalities \
- --model Qwen/Qwen2.5-Omni-7B \
- --modalities text
-```
-
-### Using OpenAI Python SDK
-
-#### Text only
-
-```python
-from openai import OpenAI
-
-client = OpenAI(base_url="http://localhost:8091/v1", api_key="EMPTY")
-
-response = client.chat.completions.create(
- model="Qwen/Qwen2.5-Omni-7B",
- messages=[{"role": "user", "content": "Describe vLLM in brief."}],
- modalities=["text"]
-)
-print(response.choices[0].message.content)
-```
-
-#### Text + Audio
-
-```python
-from openai import OpenAI
-
-client = OpenAI(base_url="http://localhost:8091/v1", api_key="EMPTY")
-
-response = client.chat.completions.create(
- model="Qwen/Qwen2.5-Omni-7B",
- messages=[{"role": "user", "content": "Describe vLLM in brief."}],
- modalities=["audio"]
-)
-# Response contains two choices: one with text, one with audio
-print(response.choices[0].message.content) # Text response
-print(response.choices[1].message.audio) # Audio response
-```
-
-## Streaming Output
-If you want to enable streaming output, please set the argument as below. The final output will be obtained just after generated by corresponding stage. Now we only support text streaming output. Other modalities can output normally.
-```bash
-python examples/online_serving/openai_chat_completion_client_for_multimodal_generation.py \
- --query-type use_mixed_modalities \
- --model Qwen/Qwen2.5-Omni-7B \
- --stream
-```
-
-## Run Local Web UI Demo
-
-This Web UI demo allows users to interact with the model through a web browser.
-
-### Running Gradio Demo
-
-The Gradio demo connects to a vLLM API server. You have two options:
-
-#### Option 1: One-step Launch Script (Recommended)
-
-The convenience script launches both the vLLM server and Gradio demo together:
-
-```bash
-./run_gradio_demo.sh --model Qwen/Qwen2.5-Omni-7B --server-port 8091 --gradio-port 7861
-```
-
-This script will:
-1. Start the vLLM server in the background
-2. Wait for the server to be ready
-3. Launch the Gradio demo
-4. Handle cleanup when you press Ctrl+C
-
-The script supports the following arguments:
-- `--model`: Model name/path (default: Qwen/Qwen2.5-Omni-7B)
-- `--server-port`: Port for vLLM server (default: 8091)
-- `--gradio-port`: Port for Gradio demo (default: 7861)
-- `--stage-configs-path`: Path to custom stage configs YAML file (optional)
-- `--server-host`: Host for vLLM server (default: 0.0.0.0)
-- `--gradio-ip`: IP for Gradio demo (default: 127.0.0.1)
-- `--share`: Share Gradio demo publicly (creates a public link)
-
-#### Option 2: Manual Launch (Two-Step Process)
-
-**Step 1: Launch the vLLM API server**
-
-```bash
-vllm serve Qwen/Qwen2.5-Omni-7B --omni --port 8091
-```
-
-If you have custom stage configs file:
-```bash
-vllm serve Qwen/Qwen2.5-Omni-7B --omni --port 8091 --stage-configs-path /path/to/stage_configs_file
-```
-
-**Step 2: Run the Gradio demo**
-
-In a separate terminal:
-
-```bash
-python gradio_demo.py --model Qwen/Qwen2.5-Omni-7B --api-base http://localhost:8091/v1 --port 7861
-```
-
-Then open `http://localhost:7861/` on your local browser to interact with the web UI.
-
-The gradio script supports the following arguments:
-
-- `--model`: Model name/path (should match the server model)
-- `--api-base`: Base URL for the vLLM API server (default: http://localhost:8091/v1)
-- `--ip`: Host/IP for Gradio server (default: 127.0.0.1)
-- `--port`: Port for Gradio server (default: 7861)
-- `--share`: Share the Gradio demo publicly (creates a public link)
diff --git a/examples/online_serving/qwen2_5_omni/gradio_demo.py b/examples/online_serving/qwen2_5_omni/gradio_demo.py
deleted file mode 100644
index 11dd76088a5..00000000000
--- a/examples/online_serving/qwen2_5_omni/gradio_demo.py
+++ /dev/null
@@ -1,592 +0,0 @@
-import argparse
-import base64
-import io
-import os
-import random
-from pathlib import Path
-from typing import Any
-
-try:
- import gradio as gr
-except ImportError:
- raise ImportError("gradio is required to run this demo. Install it with: pip install 'vllm-omni[demo]'") from None
-import numpy as np
-import soundfile as sf
-import torch
-from openai import OpenAI
-from PIL import Image
-
-SEED = 42
-
-DEFAULT_SAMPLING_PARAMS = {
- "thinker": {
- "temperature": 0.0,
- "top_p": 1.0,
- "top_k": -1,
- "max_tokens": 2048,
- "seed": SEED,
- "detokenize": True,
- "repetition_penalty": 1.1,
- },
- "talker": {
- "temperature": 0.9,
- "top_p": 0.8,
- "top_k": 40,
- "max_tokens": 2048,
- "seed": SEED,
- "detokenize": True,
- "repetition_penalty": 1.05,
- "stop_token_ids": [8294],
- },
- "code2wav": {
- "temperature": 0.0,
- "top_p": 1.0,
- "top_k": -1,
- "max_tokens": 2048,
- "seed": SEED,
- "detokenize": True,
- "repetition_penalty": 1.1,
- },
-}
-
-SUPPORTED_MODELS: dict[str, dict[str, Any]] = {
- "Qwen/Qwen2.5-Omni-3B": {
- "sampling_params": DEFAULT_SAMPLING_PARAMS,
- },
- "Qwen/Qwen2.5-Omni-7B": {
- "sampling_params": DEFAULT_SAMPLING_PARAMS,
- },
-}
-# Ensure deterministic behavior across runs.
-random.seed(SEED)
-np.random.seed(SEED)
-torch.manual_seed(SEED)
-torch.cuda.manual_seed(SEED)
-torch.cuda.manual_seed_all(SEED)
-torch.backends.cudnn.deterministic = True
-torch.backends.cudnn.benchmark = False
-os.environ["PYTHONHASHSEED"] = str(SEED)
-os.environ["CUBLAS_WORKSPACE_CONFIG"] = ":4096:8"
-
-
-def parse_args():
- parser = argparse.ArgumentParser(description="Gradio demo for Qwen2.5-Omni online inference.")
- parser.add_argument(
- "--model",
- default="Qwen/Qwen2.5-Omni-7B",
- help="Model name/path (should match the server model).",
- )
- parser.add_argument(
- "--api-base",
- default="http://localhost:8091/v1",
- help="Base URL for the vLLM API server.",
- )
- parser.add_argument(
- "--ip",
- default="127.0.0.1",
- help="Host/IP for gradio `launch`.",
- )
- parser.add_argument("--port", type=int, default=7861, help="Port for gradio `launch`.")
- parser.add_argument("--share", action="store_true", help="Share the Gradio demo publicly.")
- return parser.parse_args()
-
-
-def build_sampling_params_dict(seed: int, model_key: str) -> list[dict]:
- """Build sampling params as dict for HTTP API mode."""
- model_conf = SUPPORTED_MODELS.get(model_key)
- if model_conf is None:
- raise ValueError(f"Unsupported model '{model_key}'")
-
- sampling_templates: dict[str, dict[str, Any]] = model_conf["sampling_params"]
- sampling_params: list[dict] = []
- for stage_name, template in sampling_templates.items():
- params = dict(template)
- params["seed"] = seed
- sampling_params.append(params)
- return sampling_params
-
-
-def image_to_base64_data_url(image: Image.Image) -> str:
- """Convert PIL Image to base64 data URL."""
- buffered = io.BytesIO()
- # Convert to RGB if needed
- if image.mode != "RGB":
- image = image.convert("RGB")
- image.save(buffered, format="JPEG")
- img_bytes = buffered.getvalue()
- img_b64 = base64.b64encode(img_bytes).decode("utf-8")
- return f"data:image/jpeg;base64,{img_b64}"
-
-
-def audio_to_base64_data_url(audio_data: tuple[np.ndarray, int]) -> str:
- """Convert audio (numpy array, sample_rate) to base64 data URL."""
- audio_np, sample_rate = audio_data
- # Convert to int16 format for WAV
- if audio_np.dtype != np.int16:
- # Normalize to [-1, 1] range if needed
- if audio_np.dtype == np.float32 or audio_np.dtype == np.float64:
- audio_np = np.clip(audio_np, -1.0, 1.0)
- audio_np = (audio_np * 32767).astype(np.int16)
- else:
- audio_np = audio_np.astype(np.int16)
-
- # Write to WAV bytes
- buffered = io.BytesIO()
- sf.write(buffered, audio_np, sample_rate, format="WAV")
- wav_bytes = buffered.getvalue()
- wav_b64 = base64.b64encode(wav_bytes).decode("utf-8")
- return f"data:audio/wav;base64,{wav_b64}"
-
-
-def video_to_base64_data_url(video_file: str) -> str:
- """Convert video file to base64 data URL."""
- video_path = Path(video_file)
- if not video_path.exists():
- raise FileNotFoundError(f"Video file not found: {video_file}")
-
- # Detect MIME type from extension
- video_path_lower = str(video_path).lower()
- if video_path_lower.endswith(".mp4"):
- mime_type = "video/mp4"
- elif video_path_lower.endswith(".webm"):
- mime_type = "video/webm"
- elif video_path_lower.endswith(".mov"):
- mime_type = "video/quicktime"
- elif video_path_lower.endswith(".avi"):
- mime_type = "video/x-msvideo"
- elif video_path_lower.endswith(".mkv"):
- mime_type = "video/x-matroska"
- else:
- mime_type = "video/mp4"
-
- with open(video_path, "rb") as f:
- video_bytes = f.read()
- video_b64 = base64.b64encode(video_bytes).decode("utf-8")
- return f"data:{mime_type};base64,{video_b64}"
-
-
-def process_audio_file(
- audio_file: Any | None,
-) -> tuple[np.ndarray, int] | None:
- """Normalize Gradio audio input to (np.ndarray, sample_rate)."""
- if audio_file is None:
- return None
-
- sample_rate: int | None = None
- audio_np: np.ndarray | None = None
-
- def _load_from_path(path_str: str) -> tuple[np.ndarray, int] | None:
- if not path_str:
- return None
- path = Path(path_str)
- if not path.exists():
- return None
- data, sr = sf.read(path)
- if data.ndim > 1:
- data = data[:, 0]
- return data.astype(np.float32), int(sr)
-
- if isinstance(audio_file, tuple):
- if len(audio_file) == 2:
- first, second = audio_file
- # Case 1: (sample_rate, np.ndarray)
- if isinstance(first, (int, float)) and isinstance(second, np.ndarray):
- sample_rate = int(first)
- audio_np = second
- # Case 2: (filepath, (sample_rate, np.ndarray or list))
- elif isinstance(first, str):
- if isinstance(second, tuple) and len(second) == 2:
- sr_candidate, data_candidate = second
- if isinstance(sr_candidate, (int, float)) and isinstance(data_candidate, np.ndarray):
- sample_rate = int(sr_candidate)
- audio_np = data_candidate
- if audio_np is None:
- loaded = _load_from_path(first)
- if loaded is not None:
- audio_np, sample_rate = loaded
- # Case 3: (None, (sample_rate, np.ndarray))
- elif first is None and isinstance(second, tuple) and len(second) == 2:
- sr_candidate, data_candidate = second
- if isinstance(sr_candidate, (int, float)) and isinstance(data_candidate, np.ndarray):
- sample_rate = int(sr_candidate)
- audio_np = data_candidate
- elif len(audio_file) == 1 and isinstance(audio_file[0], str):
- loaded = _load_from_path(audio_file[0])
- if loaded is not None:
- audio_np, sample_rate = loaded
- elif isinstance(audio_file, str):
- loaded = _load_from_path(audio_file)
- if loaded is not None:
- audio_np, sample_rate = loaded
-
- if audio_np is None or sample_rate is None:
- return None
-
- if audio_np.ndim > 1:
- audio_np = audio_np[:, 0]
-
- return audio_np.astype(np.float32), sample_rate
-
-
-def process_image_file(image_file: Image.Image | None) -> Image.Image | None:
- """Process image file from Gradio input.
-
- Returns:
- PIL Image in RGB mode or None if no image provided.
- """
- if image_file is None:
- return None
- # Convert to RGB if needed
- if image_file.mode != "RGB":
- image_file = image_file.convert("RGB")
- return image_file
-
-
-def run_inference_api(
- client: OpenAI,
- model: str,
- sampling_params_dict: list[dict],
- user_prompt: str,
- audio_file: tuple[str, tuple[int, np.ndarray]] | None = None,
- image_file: Image.Image | None = None,
- video_file: str | None = None,
- use_audio_in_video: bool = False,
- output_modalities: str | None = None,
- stream: bool = False,
-):
- """Run inference using OpenAI API client with multimodal support."""
- if not user_prompt.strip() and not audio_file and not image_file and not video_file:
- yield "Please provide at least a text prompt or multimodal input.", None
- return
-
- try:
- # Build message content list
- content_list = []
-
- # Process audio
- audio_data = process_audio_file(audio_file)
- if audio_data is not None:
- audio_url = audio_to_base64_data_url(audio_data)
- content_list.append(
- {
- "type": "audio_url",
- "audio_url": {"url": audio_url},
- }
- )
-
- # Process image
- if image_file is not None:
- image_data = process_image_file(image_file)
- if image_data is not None:
- image_url = image_to_base64_data_url(image_data)
- content_list.append(
- {
- "type": "image_url",
- "image_url": {"url": image_url},
- }
- )
-
- # Process video
- mm_processor_kwargs = {}
- if video_file is not None:
- video_url = video_to_base64_data_url(video_file)
- video_content = {
- "type": "video_url",
- "video_url": {"url": video_url},
- }
- if use_audio_in_video:
- video_content["video_url"]["num_frames"] = 32 # Default max frames
- mm_processor_kwargs["use_audio_in_video"] = True
- content_list.append(video_content)
-
- # Add text prompt
- if user_prompt.strip():
- content_list.append(
- {
- "type": "text",
- "text": user_prompt,
- }
- )
-
- # Build messages
- messages = [
- {
- "role": "system",
- "content": [
- {
- "type": "text",
- "text": (
- "You are Qwen, a virtual human developed by the Qwen Team, "
- "Alibaba Group, capable of perceiving auditory and visual inputs, "
- "as well as generating text and speech."
- ),
- }
- ],
- },
- {
- "role": "user",
- "content": content_list,
- },
- ]
-
- # Build extra_body
- extra_body = {
- "sampling_params_list": sampling_params_dict,
- }
- if mm_processor_kwargs:
- extra_body["mm_processor_kwargs"] = mm_processor_kwargs
-
- # Parse output modalities
- if output_modalities and output_modalities.strip():
- output_modalities_list = [m.strip() for m in output_modalities.split(",")]
- else:
- output_modalities_list = None
-
- # Call API
- chat_completion = client.chat.completions.create(
- messages=messages,
- model=model,
- modalities=output_modalities_list,
- extra_body=extra_body,
- stream=stream,
- )
-
- if not stream:
- # Non-streaming mode: extract outputs and yield once
- text_outputs: list[str] = []
- audio_output = None
-
- for choice in chat_completion.choices:
- if choice.message.content:
- text_outputs.append(choice.message.content)
- if choice.message.audio:
- # Decode base64 audio
- audio_data = base64.b64decode(choice.message.audio.data)
- # Load audio from bytes
- audio_np, sample_rate = sf.read(io.BytesIO(audio_data))
- # Convert to mono if needed
- if audio_np.ndim > 1:
- audio_np = audio_np[:, 0]
- audio_output = (int(sample_rate), audio_np.astype(np.float32))
-
- text_response = "\n\n".join(text_outputs) if text_outputs else "No text output."
- yield text_response, audio_output
- else:
- # Streaming mode: yield incremental updates
- text_content = ""
- audio_output = None
-
- for chunk in chat_completion:
- for choice in chunk.choices:
- if hasattr(choice, "delta"):
- content = getattr(choice.delta, "content", None)
- else:
- content = None
-
- # Handle audio modality
- if getattr(chunk, "modality", None) == "audio" and content:
- try:
- # Decode base64 audio
- audio_data = base64.b64decode(content)
- # Load audio from bytes
- audio_np, sample_rate = sf.read(io.BytesIO(audio_data))
- # Convert to mono if needed
- if audio_np.ndim > 1:
- audio_np = audio_np[:, 0]
- audio_output = (int(sample_rate), audio_np.astype(np.float32))
- # Yield current text and audio
- yield text_content if text_content else "", audio_output
- except Exception: # pylint: disable=broad-except
- # If audio processing fails, just yield text
- yield text_content if text_content else "", None
-
- # Handle text modality
- elif getattr(chunk, "modality", None) == "text":
- if content:
- text_content += content
- # Yield updated text content (keep existing audio if any)
- yield text_content, audio_output
-
- # Final yield with accumulated text and last audio (if any)
- yield text_content if text_content else "No text output.", audio_output
-
- except Exception as exc: # pylint: disable=broad-except
- error_msg = f"Inference failed: {exc}"
- yield error_msg, None
-
-
-def build_interface(
- client: OpenAI,
- model: str,
- sampling_params_dict: list[dict],
-):
- """Build Gradio interface for API server mode."""
-
- def run_inference(
- user_prompt: str,
- audio_file: tuple[str, tuple[int, np.ndarray]] | None,
- image_file: Image.Image | None,
- video_file: str | None,
- use_audio_in_video: bool,
- output_modalities: str | None = None,
- stream: bool = False,
- ):
- # Always yield from the API function to maintain consistent generator behavior
- yield from run_inference_api(
- client,
- model,
- sampling_params_dict,
- user_prompt,
- audio_file,
- image_file,
- video_file,
- use_audio_in_video,
- output_modalities,
- stream,
- )
-
- css = """
- .media-input-container {
- display: flex;
- gap: 10px;
- }
- .media-input-container > div {
- flex: 1;
- }
- .media-input-container .image-input,
- .media-input-container .audio-input {
- height: 300px;
- }
- .media-input-container .video-column {
- height: 300px;
- display: flex;
- flex-direction: column;
- }
- .media-input-container .video-input {
- flex: 1;
- min-height: 0;
- }
- #generate-btn button {
- width: 100%;
- }
- """
-
- with gr.Blocks(css=css) as demo:
- gr.Markdown("# vLLM-Omni Online Serving Demo")
- gr.Markdown(f"**Model:** {model} \n\n")
-
- with gr.Column():
- with gr.Row():
- input_box = gr.Textbox(
- label="Text Prompt",
- placeholder="For example: Describe what happens in the media inputs.",
- lines=4,
- scale=1,
- )
- with gr.Row(elem_classes="media-input-container"):
- image_input = gr.Image(
- label="Image Input (optional)",
- type="pil",
- sources=["upload"],
- scale=1,
- elem_classes="image-input",
- )
- with gr.Column(scale=1, elem_classes="video-column"):
- video_input = gr.Video(
- label="Video Input (optional)",
- sources=["upload"],
- elem_classes="video-input",
- )
- use_audio_in_video_checkbox = gr.Checkbox(
- label="Use audio from video",
- value=False,
- info="Extract the video's audio track when provided.",
- )
- audio_input = gr.Audio(
- label="Audio Input (optional)",
- type="numpy",
- sources=["upload", "microphone"],
- scale=1,
- elem_classes="audio-input",
- )
-
- with gr.Row():
- output_modalities = gr.Textbox(
- label="Output Modalities",
- value=None,
- placeholder="For example: text, image, video. Use comma to separate multiple modalities.",
- lines=1,
- scale=2,
- )
- stream_checkbox = gr.Checkbox(
- label="Stream output",
- value=False,
- info="Enable streaming to see output as it's generated.",
- scale=1,
- )
-
- with gr.Row():
- generate_btn = gr.Button(
- "Generate",
- variant="primary",
- size="lg",
- elem_id="generate-btn",
- )
-
- with gr.Row():
- text_output = gr.Textbox(label="Text Output", lines=10, scale=2)
- audio_output = gr.Audio(label="Audio Output", interactive=False, scale=1)
-
- generate_btn.click(
- fn=run_inference,
- inputs=[
- input_box,
- audio_input,
- image_input,
- video_input,
- use_audio_in_video_checkbox,
- output_modalities,
- stream_checkbox,
- ],
- outputs=[text_output, audio_output],
- )
- demo.queue()
- return demo
-
-
-def main():
- args = parse_args()
-
- model_name = "/".join(args.model.split("/")[-2:])
- assert model_name in SUPPORTED_MODELS, (
- f"Unsupported model '{model_name}'. Supported models: {SUPPORTED_MODELS.keys()}"
- )
-
- # Initialize OpenAI client
- print(f"Connecting to API server at: {args.api_base}")
- client = OpenAI(
- api_key="EMPTY",
- base_url=args.api_base,
- )
- print("✓ Connected to API server")
-
- # Build sampling params
- sampling_params_dict = build_sampling_params_dict(SEED, model_name)
-
- demo = build_interface(
- client,
- args.model,
- sampling_params_dict,
- )
- try:
- demo.launch(
- server_name=args.ip,
- server_port=args.port,
- share=args.share,
- )
- except KeyboardInterrupt:
- print("\nShutting down...")
-
-
-if __name__ == "__main__":
- main()
diff --git a/examples/online_serving/qwen2_5_omni/run_curl_multimodal_generation.sh b/examples/online_serving/qwen2_5_omni/run_curl_multimodal_generation.sh
deleted file mode 100644
index ed09bac140b..00000000000
--- a/examples/online_serving/qwen2_5_omni/run_curl_multimodal_generation.sh
+++ /dev/null
@@ -1,194 +0,0 @@
-#!/usr/bin/env bash
-set -euo pipefail
-
-# Default query type
-QUERY_TYPE="${1:-mixed_modalities}"
-
-# Default modalities argument
-MODALITIES="${2:-null}"
-
-# Validate query type
-if [[ ! "$QUERY_TYPE" =~ ^(mixed_modalities|use_audio_in_video|multi_audios|text)$ ]]; then
- echo "Error: Invalid query type '$QUERY_TYPE'"
- echo "Usage: $0 [mixed_modalities|use_audio_in_video|multi_audios|text] [modalities]"
- echo " mixed_modalities: Audio + Image + Video + Text query"
- echo " use_audio_in_video: Video + Text query (with audio extraction from video)"
- echo " multi_audios: Two audio clips + Text query"
- echo " text: Text query"
- echo " modalities: Modalities parameter (default: null)"
- exit 1
-fi
-
-SEED=42
-
-thinker_sampling_params='{
- "temperature": 0.0,
- "top_p": 1.0,
- "top_k": -1,
- "max_tokens": 2048,
- "seed": 42,
- "detokenize": true,
- "repetition_penalty": 1.1
-}'
-
-talker_sampling_params='{
- "temperature": 0.9,
- "top_p": 0.8,
- "top_k": 40,
- "max_tokens": 2048,
- "seed": 42,
- "detokenize": true,
- "repetition_penalty": 1.05,
- "stop_token_ids": [8294]
-}'
-
-code2wav_sampling_params='{
- "temperature": 0.0,
- "top_p": 1.0,
- "top_k": -1,
- "max_tokens": 2048,
- "seed": 42,
- "detokenize": true,
- "repetition_penalty": 1.1
-}'
-# Above is optional, it has a default setting in stage_configs of the corresponding model.
-
-# Define URLs for assets
-MARY_HAD_LAMB_AUDIO_URL="https://vllm-public-assets.s3.us-west-2.amazonaws.com/multimodal_asset/mary_had_lamb.ogg"
-WINNING_CALL_AUDIO_URL="https://vllm-public-assets.s3.us-west-2.amazonaws.com/multimodal_asset/winning_call.ogg"
-CHERRY_BLOSSOM_IMAGE_URL="https://vllm-public-assets.s3.us-west-2.amazonaws.com/vision_model_images/cherry_blossom.jpg"
-SAMPLE_VIDEO_URL="https://huggingface.co/datasets/raushan-testing-hf/videos-test/resolve/main/sample_demo_1.mp4"
-
-# Build user content and extra fields based on query type
-case "$QUERY_TYPE" in
- text)
- user_content='[
- {
- "type": "text",
- "text": "Explain the system architecture for a scalable audio generation pipeline. Answer in 15 words."
- }
- ]'
- sampling_params_list='[
- '"$thinker_sampling_params"',
- '"$talker_sampling_params"',
- '"$code2wav_sampling_params"'
- ]'
- mm_processor_kwargs="{}"
- ;;
- mixed_modalities)
- user_content='[
- {
- "type": "audio_url",
- "audio_url": {
- "url": "'"$MARY_HAD_LAMB_AUDIO_URL"'"
- }
- },
- {
- "type": "image_url",
- "image_url": {
- "url": "'"$CHERRY_BLOSSOM_IMAGE_URL"'"
- }
- },
- {
- "type": "video_url",
- "video_url": {
- "url": "'"$SAMPLE_VIDEO_URL"'"
- }
- },
- {
- "type": "text",
- "text": "What is recited in the audio? What is the content of this image? Why is this video funny?"
- }
- ]'
- sampling_params_list='[
- '"$thinker_sampling_params"',
- '"$talker_sampling_params"',
- '"$code2wav_sampling_params"'
- ]'
- mm_processor_kwargs="{}"
- ;;
- use_audio_in_video)
- user_content='[
- {
- "type": "video_url",
- "video_url": {
- "url": "'"$SAMPLE_VIDEO_URL"'"
- }
- },
- {
- "type": "text",
- "text": "Describe the content of the video, then convert what the baby say into text."
- }
- ]'
- sampling_params_list='[
- '"$thinker_sampling_params"',
- '"$talker_sampling_params"',
- '"$code2wav_sampling_params"'
- ]'
- mm_processor_kwargs='{
- "use_audio_in_video": true
- }'
- ;;
- multi_audios)
- user_content='[
- {
- "type": "audio_url",
- "audio_url": {
- "url": "'"$MARY_HAD_LAMB_AUDIO_URL"'"
- }
- },
- {
- "type": "audio_url",
- "audio_url": {
- "url": "'"$WINNING_CALL_AUDIO_URL"'"
- }
- },
- {
- "type": "text",
- "text": "Are these two audio clips the same?"
- }
- ]'
- sampling_params_list='[
- '"$thinker_sampling_params"',
- '"$talker_sampling_params"',
- '"$code2wav_sampling_params"'
- ]'
- mm_processor_kwargs="{}"
- ;;
-esac
-
-echo "Running query type: $QUERY_TYPE"
-echo ""
-
-request_body=$(cat <<EOF
-{
- "model": "Qwen/Qwen2.5-Omni-7B",
- "sampling_params_list": $sampling_params_list,
- "mm_processor_kwargs": $mm_processor_kwargs,
- "modalities": $MODALITIES,
- "messages": [
- {
- "role": "system",
- "content": [
- {
- "type": "text",
- "text": "You are Qwen, a virtual human developed by the Qwen Team, Alibaba Group, capable of perceiving auditory and visual inputs, as well as generating text and speech."
- }
- ]
- },
- {
- "role": "user",
- "content": $user_content
- }
- ]
-}
-EOF
-)
-
-output=$(curl -sS --retry 3 --retry-delay 3 --retry-connrefused \
- -X POST http://localhost:8091/v1/chat/completions \
- -H "Content-Type: application/json" \
- -d "$request_body")
-
-# Here it only shows the text content of the first choice. Audio content has many binaries, so it's not displayed here.
-echo "Output of request: $(echo "$output" | jq '.choices[0].message.content')"
diff --git a/examples/online_serving/qwen2_5_omni/run_gradio_demo.sh b/examples/online_serving/qwen2_5_omni/run_gradio_demo.sh
deleted file mode 100755
index 296cc7fa523..00000000000
--- a/examples/online_serving/qwen2_5_omni/run_gradio_demo.sh
+++ /dev/null
@@ -1,212 +0,0 @@
-#!/bin/bash
-# Convenience script to launch both vLLM server and Gradio demo for Qwen2.5-Omni
-#
-# Usage:
-# ./run_gradio_demo.sh [OPTIONS]
-#
-# Example:
-# ./run_gradio_demo.sh --model Qwen/Qwen2.5-Omni-7B --server-port 8091 --gradio-port 7861
-
-set -e
-
-# Default values
-MODEL="Qwen/Qwen2.5-Omni-7B"
-SERVER_PORT=8091
-GRADIO_PORT=7861
-STAGE_CONFIGS_PATH=""
-SERVER_HOST="0.0.0.0"
-GRADIO_IP="127.0.0.1"
-GRADIO_SHARE=false
-
-# Parse command line arguments
-while [[ $# -gt 0 ]]; do
- case $1 in
- --model)
- MODEL="$2"
- shift 2
- ;;
- --server-port)
- SERVER_PORT="$2"
- shift 2
- ;;
- --gradio-port)
- GRADIO_PORT="$2"
- shift 2
- ;;
- --stage-configs-path)
- STAGE_CONFIGS_PATH="$2"
- shift 2
- ;;
- --server-host)
- SERVER_HOST="$2"
- shift 2
- ;;
- --gradio-ip)
- GRADIO_IP="$2"
- shift 2
- ;;
- --share)
- GRADIO_SHARE=true
- shift
- ;;
- --help)
- echo "Usage: $0 [OPTIONS]"
- echo ""
- echo "Options:"
- echo " --model MODEL Model name/path (default: Qwen/Qwen2.5-Omni-7B)"
- echo " --server-port PORT Port for vLLM server (default: 8091)"
- echo " --gradio-port PORT Port for Gradio demo (default: 7861)"
- echo " --stage-configs-path PATH Path to custom stage configs YAML file (optional)"
- echo " --server-host HOST Host for vLLM server (default: 0.0.0.0)"
- echo " --gradio-ip IP IP for Gradio demo (default: 127.0.0.1)"
- echo " --share Share Gradio demo publicly"
- echo " --help Show this help message"
- echo ""
- exit 0
- ;;
- *)
- echo "Unknown option: $1"
- echo "Use --help for usage information"
- exit 1
- ;;
- esac
-done
-
-# Get the directory where this script is located
-SCRIPT_DIR="$(cd "$(dirname "${BASH_SOURCE[0]}")" && pwd)"
-API_BASE="http://localhost:${SERVER_PORT}/v1"
-HEALTH_URL="http://localhost:${SERVER_PORT}/health"
-
-echo "=========================================="
-echo "Starting vLLM-Omni Gradio Demo"
-echo "=========================================="
-echo "Model: $MODEL"
-echo "Server: http://${SERVER_HOST}:${SERVER_PORT}"
-echo "Gradio: http://${GRADIO_IP}:${GRADIO_PORT}"
-echo "=========================================="
-
-# Build vLLM server command
-SERVER_CMD=("vllm" "serve" "$MODEL" "--omni" "--port" "$SERVER_PORT" "--host" "$SERVER_HOST")
-if [ -n "$STAGE_CONFIGS_PATH" ]; then
- SERVER_CMD+=("--stage-configs-path" "$STAGE_CONFIGS_PATH")
-fi
-
-# Function to cleanup on exit
-cleanup() {
- echo ""
- echo "Shutting down..."
- if [ -n "$SERVER_PID" ]; then
- echo "Stopping vLLM server (PID: $SERVER_PID)..."
- kill "$SERVER_PID" 2>/dev/null || true
- wait "$SERVER_PID" 2>/dev/null || true
- fi
- if [ -n "$GRADIO_PID" ]; then
- echo "Stopping Gradio demo (PID: $GRADIO_PID)..."
- kill "$GRADIO_PID" 2>/dev/null || true
- wait "$GRADIO_PID" 2>/dev/null || true
- fi
- echo "Cleanup complete"
- exit 0
-}
-
-# Set up signal handlers
-trap cleanup SIGINT SIGTERM
-
-# Start vLLM server with output shown in real-time and saved to log
-echo ""
-echo "Starting vLLM server..."
-LOG_FILE="/tmp/vllm_server_${SERVER_PORT}.log"
-"${SERVER_CMD[@]}" 2>&1 | tee "$LOG_FILE" &
-SERVER_PID=$!
-
-# Start a background process to monitor the log for startup completion
-STARTUP_COMPLETE=false
-TAIL_PID=""
-
-# Function to cleanup tail process
-cleanup_tail() {
- if [ -n "$TAIL_PID" ]; then
- kill "$TAIL_PID" 2>/dev/null || true
- wait "$TAIL_PID" 2>/dev/null || true
- fi
-}
-
-# Wait for server to be ready by checking log output
-echo ""
-echo "Waiting for vLLM server to be ready (checking for 'Application startup complete' message)..."
-echo ""
-
-# Monitor log file for startup completion message
-MAX_WAIT=300 # 5 minutes timeout as fallback
-ELAPSED=0
-
-# Use a temporary file to track startup completion
-STARTUP_FLAG="/tmp/vllm_startup_flag_${SERVER_PORT}.tmp"
-rm -f "$STARTUP_FLAG"
-
-# Start monitoring in background
-(
- tail -f "$LOG_FILE" 2>/dev/null | grep -m 1 "Application startup complete" > /dev/null && touch "$STARTUP_FLAG"
-) &
-TAIL_PID=$!
-
-while [ $ELAPSED -lt $MAX_WAIT ]; do
- # Check if startup flag file exists (startup complete)
- if [ -f "$STARTUP_FLAG" ]; then
- cleanup_tail
- echo ""
- echo "✓ vLLM server is ready!"
- STARTUP_COMPLETE=true
- break
- fi
-
- # Check if server process is still running
- if ! kill -0 "$SERVER_PID" 2>/dev/null; then
- cleanup_tail
- echo ""
- echo "Error: vLLM server failed to start (process terminated)"
- wait "$SERVER_PID" 2>/dev/null || true
- exit 1
- fi
-
- sleep 1
- ELAPSED=$((ELAPSED + 1))
-done
-
-cleanup_tail
-rm -f "$STARTUP_FLAG"
-
-if [ "$STARTUP_COMPLETE" != "true" ]; then
- echo ""
- echo "Error: vLLM server did not complete startup within ${MAX_WAIT} seconds"
- kill "$SERVER_PID" 2>/dev/null || true
- exit 1
-fi
-
-# Start Gradio demo
-echo ""
-echo "Starting Gradio demo..."
-cd "$SCRIPT_DIR"
-GRADIO_CMD=("python" "gradio_demo.py" "--model" "$MODEL" "--api-base" "$API_BASE" "--ip" "$GRADIO_IP" "--port" "$GRADIO_PORT")
-if [ "$GRADIO_SHARE" = true ]; then
- GRADIO_CMD+=("--share")
-fi
-
-"${GRADIO_CMD[@]}" > /tmp/gradio_demo.log 2>&1 &
-GRADIO_PID=$!
-
-echo ""
-echo "=========================================="
-echo "Both services are running!"
-echo "=========================================="
-echo "vLLM Server: http://${SERVER_HOST}:${SERVER_PORT}"
-echo "Gradio Demo: http://${GRADIO_IP}:${GRADIO_PORT}"
-echo ""
-echo "Press Ctrl+C to stop both services"
-echo "=========================================="
-echo ""
-
-# Wait for either process to exit
-wait $SERVER_PID $GRADIO_PID || true
-
-cleanup
diff --git a/examples/online_serving/qwen3_omni/README.md b/examples/online_serving/qwen3_omni/README.md
deleted file mode 100644
index 2f40b83474d..00000000000
--- a/examples/online_serving/qwen3_omni/README.md
+++ /dev/null
@@ -1,526 +0,0 @@
-# Qwen3-Omni
-
-## 🛠️ Installation
-
-Please refer to [README.md](../../../README.md)
-
-## Run examples (Qwen3-Omni)
-
-### Launch the Server
-
-```bash
-vllm serve Qwen/Qwen3-Omni-30B-A3B-Instruct --omni --port 8091
-```
-
-The default deployment configuration, situated at `vllm_omni/deploy/qwen3_omni_moe.yaml`, is resolved and loaded
-automatically via the model registry, obviating the `--deploy-config` flag in standard deployment topologies.
-Asynchronous chunk streaming operates as **enabled by default** within this bundled configuration.
-Additionally, NPU, ROCm, and XPU per-platform configuration deltas are deterministically merged from the
-`platforms`: section of the corresponding YAML.
-
-**Note:** The OpenAI-style **`/v1/realtime`** WebSocket interface (facilitating streaming PCM audio input alongside audio and transcription output)
-is currently **unsupported** while the `async_chunk` configuration attribute is enabled.
-It is requisite to instantiate the default omni architecture or utilize a deployment configuration specifying `async_chunk: false` to facilitate real-time streaming sessions.
-
-To explicitly utilize a custom deployment YAML, mandate the configuration path accordingly:
-```bash
-vllm serve Qwen/Qwen3-Omni-30B-A3B-Instruct --omni --port 8091 \
- --deploy-config /path/to/your_deploy_config.yaml
-```
-
-### Launch individual stages (stage-based CLI)
-
-Use the stage-based CLI when you want to run one stage per process.
-The example below pins Stage 0 to GPU 0 and Stage 1/2 to GPU 1 via
-`CUDA_VISIBLE_DEVICES`.
-
-**1. Stage 0 (Thinker + API server)**
-
-```bash
-CUDA_VISIBLE_DEVICES=0 vllm serve Qwen/Qwen3-Omni-30B-A3B-Instruct --omni \
- --port 8091 \
- --stage-id 0 \
- --omni-master-address 127.0.0.1 \
- --omni-master-port 26000
-```
-
-**2. Stage 1 (Talker)**
-
-```bash
-CUDA_VISIBLE_DEVICES=1 vllm serve Qwen/Qwen3-Omni-30B-A3B-Instruct --omni \
- --stage-id 1 \
- --headless \
- --omni-master-address 127.0.0.1 \
- --omni-master-port 26000
-```
-
-**3. Stage 2 (Code2Wav)**
-
-```bash
-CUDA_VISIBLE_DEVICES=1 vllm serve Qwen/Qwen3-Omni-30B-A3B-Instruct --omni \
- --stage-id 2 \
- --headless \
- --omni-master-address 127.0.0.1 \
- --omni-master-port 26000
-```
-
-Append `--deploy-config /path/to/your_deploy_config.yaml` to each node invocation if it is necessary
-to explicitly override the bundled deployment YAML schema.
-
-For standard **unified-process** launcher, stage-specific CLI configuration tuning is conventionally implemented
-via the `--stage-overrides` directive, as demonstrated below:
-
-```bash
-vllm serve Qwen/Qwen3-Omni-30B-A3B-Instruct --omni --port 8091 \
- --stage-overrides '{"1": {"gpu_memory_utilization": 0.5}}'
-```
-
-Conversely, within the stage-based CLI paradigm, `--stage-overrides` modifiers are typically **unnecessary**
-for this category of optimization. Given that each instantiation strictly initiates a single functional stage,
-parameter flags can be systematically assigned directly onto that specific stage's command sequence:
-
-```bash
-CUDA_VISIBLE_DEVICES=1 vllm serve Qwen/Qwen3-Omni-30B-A3B-Instruct --omni \
- --stage-id 1 \
- --headless \
- --gpu-memory-utilization 0.5 \
- --omni-master-address 127.0.0.1 \
- --omni-master-port 26000
-```
-
-### Tuning deployment parameters
-
-Most engine knobs (`max_num_batched_tokens`, `max_model_len`, `enforce_eager`,
-`gpu_memory_utilization`, `tensor_parallel_size`, …) can be tuned without
-editing the YAML. There are three layers, in increasing specificity:
-
-#### 1. Global CLI flags (apply to every stage)
-
-```bash
-# Tighter memory budget on a smaller GPU
-vllm serve Qwen/Qwen3-Omni-30B-A3B-Instruct --omni --port 8091 \
- --gpu-memory-utilization 0.85
-
-# Disable cudagraphs (e.g. for debugging)
-vllm serve Qwen/Qwen3-Omni-30B-A3B-Instruct --omni --port 8091 \
- --enforce-eager
-
-# Reduce context length
-vllm serve Qwen/Qwen3-Omni-30B-A3B-Instruct --omni --port 8091 \
- --max-model-len 32768
-
-# Toggle prefix caching on every stage (yaml default: off)
-vllm serve Qwen/Qwen3-Omni-30B-A3B-Instruct --omni --port 8091 \
- --enable-prefix-caching
-# ...or force it off if the yaml turned it on
-vllm serve Qwen/Qwen3-Omni-30B-A3B-Instruct --omni --port 8091 \
- --no-enable-prefix-caching
-
-# Toggle pipeline-wide async chunked streaming between stages
-# (yaml default for qwen3_omni_moe: on)
-vllm serve Qwen/Qwen3-Omni-30B-A3B-Instruct --omni --port 8091 \
- --no-async-chunk
-```
-
-For the TTS counterpart (synchronous codec variant), see
-[qwen3_tts README](../qwen3_tts/README.md#sync-vs-async-chunk-mode).
-
-Explicit CLI flags **override** the deploy YAML (which itself overrides the
-parser defaults). If you don't pass a flag, the YAML value wins.
-
-> **Note on `--no-async-chunk`**: Flips the deploy yaml's `async_chunk:`
-> bool. Pipelines that implement alternate processor functions for
-> chunked vs end-to-end modes (e.g. qwen3_tts code2wav) dispatch
-> automatically based on that bool — no extra flag or variant yaml is
-> needed.
-
-> ⚠️ **For multi-stage models that share GPUs (qwen3_omni_moe by default
-> shares cuda:1 between stages 1 and 2), avoid using global memory flags.**
-> A global `--gpu-memory-utilization 0.85` would apply to every stage and
-> oversubscribe the shared device. Use per-stage overrides instead — see
-> below.
-
-#### 2. Per-stage overrides via `--stage-overrides` (recommended for memory)
-
-```bash
-# Lower stage 1's memory budget; leave others at the YAML default
-vllm serve Qwen/Qwen3-Omni-30B-A3B-Instruct --omni --port 8091 \
- --stage-overrides '{
- "1": {"gpu_memory_utilization": 0.5},
- "2": {"max_num_batched_tokens": 65536}
- }'
-```
-
-Per-stage values are always treated as explicit and beat YAML defaults for
-the named stage. Other stages keep their YAML values.
-
-If you switch to the stage-based CLI, the same per-stage tuning can usually be
-passed directly on that stage's command instead of using `--stage-overrides`.
-
-#### 3. Custom deploy YAML
-
-When per-stage overrides get long, write a small overlay YAML that inherits
-from the bundled default:
-
-```yaml
-# my_qwen3_omni_overrides.yaml
-base_config: /path/to/vllm_omni/deploy/qwen3_omni_moe.yaml
-
-stages:
- - stage_id: 0
- max_num_batched_tokens: 65536
- enforce_eager: true
- - stage_id: 1
- gpu_memory_utilization: 0.5
- - stage_id: 2
- max_model_len: 8192
-```
-
-Then start the server with `--deploy-config my_qwen3_omni_overrides.yaml`.
-The `base_config:` line tells the loader to inherit everything else (stages,
-connectors, edges, platforms section) from the bundled production YAML, so
-you only need to spell out the deltas.
-
-#### 4. Multi-node deployment (cross-host transfer connector)
-
-The bundled `qwen3_omni_moe.yaml` uses `SharedMemoryConnector` between stages,
-which only works when all stages run on the same physical host. For
-**cross-node** deployments, write a small overlay YAML that swaps in a
-network-capable connector (e.g. `MooncakeStoreConnector`) and re-points each
-stage's connector wiring at it. The connector spec carries your own server
-addresses — there is no checked-in default because every cluster is
-different.
-
-```yaml
-# my_qwen3_omni_multinode.yaml
-base_config: /path/to/vllm_omni/deploy/qwen3_omni_moe.yaml
-
-connectors:
- mooncake_connector:
- name: MooncakeStoreConnector
- extra:
- host: "127.0.0.1"
- metadata_server: "http://YOUR_METADATA_HOST:8080/metadata"
- master: "YOUR_MASTER_HOST:50051"
- segment: 512000000 # 512 MB transfer segment
- localbuf: 64000000 # 64 MB local buffer
- proto: "tcp"
-
-stages:
- - stage_id: 0
- output_connectors:
- to_stage_1: mooncake_connector
- - stage_id: 1
- input_connectors:
- from_stage_0: mooncake_connector
- output_connectors:
- to_stage_2: mooncake_connector
- - stage_id: 2
- input_connectors:
- from_stage_1: mooncake_connector
-```
-
-Then launch with `--deploy-config my_qwen3_omni_multinode.yaml`. Same
-pattern works for Qwen2.5-Omni — replace `base_config:` with the path to
-`vllm_omni/deploy/qwen2_5_omni.yaml`.
-
-> ⚠️ Replace `YOUR_METADATA_HOST` / `YOUR_MASTER_HOST` with the actual
-> mooncake server addresses for your cluster. The `base_config:` overlay
-> inherits all stage budgets, devices, and edges from the bundled prod
-> YAML — you only need to spell out the connector swap.
-
-### Send Multi-modal Request
-
-Get into the example folder
-```bash
-cd examples/online_serving/qwen3_omni
-```
-
-#### Send request via python
-
-```bash
-python examples/online_serving/openai_chat_completion_client_for_multimodal_generation.py --model Qwen/Qwen3-Omni-30B-A3B-Instruct --query-type use_image --port 8091 --host "localhost"
-```
-
-#### Realtime WebSocket client (`openai_realtime_client.py`)
-
-[`openai_realtime_client.py`](./openai_realtime_client.py) connects to **`ws://<host>:<port>/v1/realtime`**, streams a local WAV as **PCM16 mono @ 16 kHz** in fixed-size chunks (OpenAI-style `input_audio_buffer.append` / `commit`), and receives **`response.audio.delta`** (incremental PCM for the reply) plus **`transcription.*`** events. By default it concatenates audio deltas and writes **`--output-wav`** (model output is typically **24 kHz**). Optional **`--delta-dump-dir`** saves each delta as `delta_000001.wav`, … for debugging.
-
-Streaming input works well for translation-style use cases; if the Thinker runs while input is still incomplete, consider limiting **`max_tokens`** in your session / server defaults to avoid over-generation.
-
-**Dependencies:**
-
-```bash
-pip install websockets
-```
-
-**From this directory** (`examples/online_serving/qwen3_omni`):
-
-```bash
-python openai_realtime_client.py \
- --url ws://localhost:8091/v1/realtime \
- --model Qwen/Qwen3-Omni-30B-A3B-Instruct \
- --input-wav /path/to/input_16k_mono.wav \
- --output-wav realtime_output.wav \
- --delta-dump-dir ./rt_delta_wavs
-```
-
-**Arguments:**
-
-| Flag | Default | Description |
-|------|---------|-------------|
-| `--url` | `ws://localhost:8091/v1/realtime` | Full WebSocket URL including path |
-| `--model` | `Qwen/Qwen3-Omni-30B-A3B-Instruct` | Must match the served model (sent in `session.update`) |
-| `--input-wav` | *(required)* | Input WAV: mono, 16-bit PCM, **16 kHz** |
-| `--output-wav` | `realtime_output.wav` | Output path for concatenated reply audio |
-| `--output-text` | *(optional)* | If set, write final transcription text to this path |
-| `--chunk-ms` | `200` | Size of each uploaded audio chunk (milliseconds of audio) |
-| `--send-delay-ms` | `0` | Delay between chunk sends (simulate realtime upload) |
-| `--delta-dump-dir` | *(optional)* | Directory to write per-`response.audio.delta` WAV files |
-| `--num-requests` | `1` | Number of sequential sessions (see `--concurrency`) |
-| `--concurrency` | `1` | Max concurrent WebSocket sessions when `--num-requests` > 1 |
-
-Ensure the server is running **without** `async_chunk` if you use `/v1/realtime`, for example:
-
-```bash
-vllm serve Qwen/Qwen3-Omni-30B-A3B-Instruct --omni --port 8091
-```
-
-The Python client supports the following command-line arguments:
-
-- `--query-type` (or `-q`): Query type (default: `use_video`). Options: `text`, `use_audio`, `use_image`, `use_video`
-- `--model` (or `-m`): Model name/path (default: `Qwen/Qwen3-Omni-30B-A3B-Instruct`)
-- `--video-path` (or `-v`): Path to local video file or URL. If not provided and query-type is `use_video`, uses default video URL. Supports local file paths (automatically encoded to base64) or HTTP/HTTPS URLs. Example: `--video-path /path/to/video.mp4` or `--video-path https://example.com/video.mp4`
-- `--image-path` (or `-i`): Path to local image file or URL. If not provided and query-type is `use_image`, uses default image URL. Supports local file paths (automatically encoded to base64) or HTTP/HTTPS URLs and common image formats: JPEG, PNG, GIF, WebP. Example: `--image-path /path/to/image.jpg` or `--image-path https://example.com/image.png`
-- `--audio-path` (or `-a`): Path to local audio file or URL. If not provided and query-type is `use_audio`, uses default audio URL. Supports local file paths (automatically encoded to base64) or HTTP/HTTPS URLs and common audio formats: MP3, WAV, OGG, FLAC, M4A. Example: `--audio-path /path/to/audio.wav` or `--audio-path https://example.com/audio.mp3`
-- `--prompt` (or `-p`): Custom text prompt/question. If not provided, uses default prompt for the selected query type. Example: `--prompt "What are the main activities shown in this video?"`
-- `--speaker`: TTS speaker/voice for audio output when requesting audio (e.g. `ethan`, `chelsie`, `aiden`). Omit to use the model default. Example: `--speaker "chelsie"`
-
-
-For example, to use a local video file with custom prompt:
-
-```bash
-python examples/online_serving/openai_chat_completion_client_for_multimodal_generation.py \
- --query-type use_video \
- --video-path /path/to/your/video.mp4 \
- --model Qwen/Qwen3-Omni-30B-A3B-Instruct \
- --prompt "What are the main activities shown in this video?"
-```
-
-#### Send request via curl
-
-```bash
-bash run_curl_multimodal_generation.sh use_image
-```
-
-
-### FAQ
-
-## Modality control
-You can control output modalities to specify which types of output the model should generate. This is useful when you only need text output and want to skip audio generation stages for better performance.
-
-### Supported modalities
-
-| Modalities | Output |
-|------------|--------|
-| `["text"]` | Text only |
-| `["audio"]` | Audio only |
-| `["text", "audio"]` | Text + Audio |
-| Not specified | Text + Audio (default) |
-
-### Using curl
-
-#### Text only
-
-```bash
-curl http://localhost:8091/v1/chat/completions \
- -H "Content-Type: application/json" \
- -d '{
- "model": "Qwen/Qwen3-Omni-30B-A3B-Instruct",
- "messages": [{"role": "user", "content": "Describe vLLM in brief."}],
- "modalities": ["text"]
- }'
-```
-
-#### Text + Audio
-
-```bash
-curl -s http://localhost:8091/v1/chat/completions \
- -H "Content-Type: application/json" \
- -d '{
- "model": "Qwen/Qwen3-Omni-30B-A3B-Instruct",
- "messages": [{"role": "user", "content": "Describe vLLM in brief."}],
- "modalities": ["audio"]
- }' | jq -r '.choices[0].message.audio.data' | base64 -d > output.wav
-```
-
-### Using Python client
-
-```bash
-python examples/online_serving/openai_chat_completion_client_for_multimodal_generation.py \
- --query-type use_image \
- --model Qwen/Qwen3-Omni-30B-A3B-Instruct \
- --modalities text
-```
-
-### Using OpenAI Python SDK
-
-#### Text only
-
-```python
-from openai import OpenAI
-
-client = OpenAI(base_url="http://localhost:8091/v1", api_key="EMPTY")
-
-response = client.chat.completions.create(
- model="Qwen/Qwen3-Omni-30B-A3B-Instruct",
- messages=[{"role": "user", "content": "Describe vLLM in brief."}],
- modalities=["text"]
-)
-print(response.choices[0].message.content)
-```
-
-#### Text + Audio
-
-```python
-import base64
-from openai import OpenAI
-
-client = OpenAI(base_url="http://localhost:8091/v1", api_key="EMPTY")
-
-response = client.chat.completions.create(
- model="Qwen/Qwen3-Omni-30B-A3B-Instruct",
- messages=[{"role": "user", "content": "Describe vLLM in brief."}],
- modalities=["text", "audio"]
-)
-# Response contains two choices: one with text, one with audio
-print(response.choices[0].message.content) # Text response
-
-# Save audio to file
-audio_data = base64.b64decode(response.choices[1].message.audio.data)
-with open("output.wav", "wb") as f:
- f.write(audio_data)
-```
-
-## Speaker selection
-
-When requesting audio output, you can choose the TTS speaker (voice) used for synthesis. If not specified, the model uses its default speaker.
-
-### Using curl
-
-Pass a `speaker` field in the request body:
-
-```bash
-curl http://localhost:8091/v1/chat/completions \
- -H "Content-Type: application/json" \
- -d '{
- "model": "Qwen/Qwen3-Omni-30B-A3B-Instruct",
- "messages": [{"role": "user", "content": "Say hello in one sentence."}],
- "modalities": ["audio"],
- "speaker": "chelsie"
- }'
-```
-
-### Using Python client
-
-Use the `--speaker` argument when generating audio:
-
-```bash
-python examples/online_serving/openai_chat_completion_client_for_multimodal_generation.py \
- --query-type use_image \
- --modalities audio \
- --model Qwen/Qwen3-Omni-30B-A3B-Instruct \
- --speaker "chelsie"
-```
-
-### Using OpenAI Python SDK
-
-Pass `speaker` in `extra_body`:
-
-```python
-from openai import OpenAI
-
-client = OpenAI(base_url="http://localhost:8091/v1", api_key="EMPTY")
-
-response = client.chat.completions.create(
- model="Qwen/Qwen3-Omni-30B-A3B-Instruct",
- messages=[{"role": "user", "content": "Say hello in one sentence."}],
- modalities=["audio"],
- extra_body={"speaker": "chelsie"}
-)
-# Audio uses the specified speaker
-print(response.choices[1].message.audio)
-```
-
-Supported speaker names depend on the model (e.g. `Ethan`, `Chelsie`, `Aiden`). Omit `speaker` to use the default.
-
-## Streaming Output
-If you want to enable streaming output, please set the argument as below. The final output will be obtained just after generated by corresponding stage. We support both text streaming output and audio streaming output. Other modalities can output normally.
-```bash
-python examples/online_serving/openai_chat_completion_client_for_multimodal_generation.py \
- --query-type use_image \
- --model Qwen/Qwen3-Omni-30B-A3B-Instruct \
- --stream
-```
-
-## Run Local Web UI Demo
-
-This Web UI demo allows users to interact with the model through a web browser.
-
-### Running Gradio Demo
-
-The Gradio demo connects to a vLLM API server. You have two options:
-
-#### Option 1: One-step Launch Script (Recommended)
-
-The convenience script launches both the vLLM server and Gradio demo together:
-
-```bash
-./run_gradio_demo.sh --model Qwen/Qwen3-Omni-30B-A3B-Instruct --server-port 8091 --gradio-port 7861
-```
-
-This script will:
-1. Start the vLLM server in the background
-2. Wait for the server to be ready
-3. Launch the Gradio demo
-4. Handle cleanup when you press Ctrl+C
-
-The script supports the following arguments:
-- `--model`: Model name/path (default: Qwen/Qwen3-Omni-30B-A3B-Instruct)
-- `--server-port`: Port for vLLM server (default: 8091)
-- `--gradio-port`: Port for Gradio demo (default: 7861)
-- `--deploy-config`: Path to custom deploy config YAML file (optional)
-- `--server-host`: Host for vLLM server (default: 0.0.0.0)
-- `--gradio-ip`: IP for Gradio demo (default: 127.0.0.1)
-- `--share`: Share Gradio demo publicly (creates a public link)
-
-#### Option 2: Manual Launch (Two-Step Process)
-
-**Step 1: Launch the vLLM API server**
-
-```bash
-vllm serve Qwen/Qwen3-Omni-30B-A3B-Instruct --omni --port 8091
-```
-
-If you have custom stage configs file:
-```bash
-vllm serve Qwen/Qwen3-Omni-30B-A3B-Instruct --omni --port 8091 --deploy-config /path/to/deploy_config_file
-```
-
-**Step 2: Run the Gradio demo**
-
-In a separate terminal:
-
-```bash
-python gradio_demo.py --model Qwen/Qwen3-Omni-30B-A3B-Instruct --api-base http://localhost:8091/v1 --port 7861
-```
-
-Then open `http://localhost:7861/` on your local browser to interact with the web UI.
-
-The gradio script supports the following arguments:
-
-- `--model`: Model name/path (should match the server model)
-- `--api-base`: Base URL for the vLLM API server (default: http://localhost:8091/v1)
-- `--ip`: Host/IP for Gradio server (default: 127.0.0.1)
-- `--port`: Port for Gradio server (default: 7861)
-- `--share`: Share the Gradio demo publicly (creates a public link)
diff --git a/examples/online_serving/qwen3_omni/gradio_demo.py b/examples/online_serving/qwen3_omni/gradio_demo.py
deleted file mode 100644
index e0516dc4a16..00000000000
--- a/examples/online_serving/qwen3_omni/gradio_demo.py
+++ /dev/null
@@ -1,586 +0,0 @@
-import argparse
-import base64
-import io
-import os
-import random
-from pathlib import Path
-from typing import Any
-
-try:
- import gradio as gr
-except ImportError:
- raise ImportError("gradio is required to run this demo. Install it with: pip install 'vllm-omni[demo]'") from None
-import numpy as np
-import soundfile as sf
-import torch
-from openai import OpenAI
-from PIL import Image
-
-SEED = 42
-
-SUPPORTED_MODELS: dict[str, dict[str, Any]] = {
- "Qwen/Qwen3-Omni-30B-A3B-Instruct": {
- "sampling_params": {
- "thinker": {
- "temperature": 0.4,
- "top_p": 0.9,
- "top_k": 1,
- "max_tokens": 16384,
- "detokenize": True,
- "repetition_penalty": 1.05,
- "stop_token_ids": [151645],
- "seed": SEED,
- },
- "talker": {
- "temperature": 0.9,
- "top_k": 50,
- "max_tokens": 4096,
- "seed": SEED,
- "detokenize": False,
- "repetition_penalty": 1.05,
- "stop_token_ids": [2150],
- },
- "code2wav": {
- "temperature": 0.0,
- "top_p": 1.0,
- "top_k": -1,
- "max_tokens": 4096 * 16,
- "seed": SEED,
- "detokenize": True,
- "repetition_penalty": 1.1,
- },
- },
- },
-}
-# Ensure deterministic behavior across runs.
-random.seed(SEED)
-np.random.seed(SEED)
-torch.manual_seed(SEED)
-torch.cuda.manual_seed(SEED)
-torch.cuda.manual_seed_all(SEED)
-torch.backends.cudnn.deterministic = True
-torch.backends.cudnn.benchmark = False
-os.environ["PYTHONHASHSEED"] = str(SEED)
-os.environ["CUBLAS_WORKSPACE_CONFIG"] = ":4096:8"
-
-
-def parse_args():
- parser = argparse.ArgumentParser(description="Gradio demo for Qwen3-Omni online inference.")
- parser.add_argument(
- "--model",
- default="Qwen/Qwen3-Omni-30B-A3B-Instruct",
- help="Model name/path (should match the server model).",
- )
- parser.add_argument(
- "--api-base",
- default="http://localhost:8091/v1",
- help="Base URL for the vLLM API server.",
- )
- parser.add_argument(
- "--ip",
- default="127.0.0.1",
- help="Host/IP for gradio `launch`.",
- )
- parser.add_argument("--port", type=int, default=7861, help="Port for gradio `launch`.")
- parser.add_argument("--share", action="store_true", help="Share the Gradio demo publicly.")
- return parser.parse_args()
-
-
-def build_sampling_params_dict(seed: int, model_key: str) -> list[dict]:
- """Build sampling params as dict for HTTP API mode."""
- model_conf = SUPPORTED_MODELS.get(model_key)
- if model_conf is None:
- raise ValueError(f"Unsupported model '{model_key}'")
-
- sampling_templates: dict[str, dict[str, Any]] = model_conf["sampling_params"]
- sampling_params: list[dict] = []
- for stage_name, template in sampling_templates.items():
- params = dict(template)
- params["seed"] = seed
- sampling_params.append(params)
- return sampling_params
-
-
-def image_to_base64_data_url(image: Image.Image) -> str:
- """Convert PIL Image to base64 data URL."""
- buffered = io.BytesIO()
- # Convert to RGB if needed
- if image.mode != "RGB":
- image = image.convert("RGB")
- image.save(buffered, format="JPEG")
- img_bytes = buffered.getvalue()
- img_b64 = base64.b64encode(img_bytes).decode("utf-8")
- return f"data:image/jpeg;base64,{img_b64}"
-
-
-def audio_to_base64_data_url(audio_data: tuple[np.ndarray, int]) -> str:
- """Convert audio (numpy array, sample_rate) to base64 data URL."""
- audio_np, sample_rate = audio_data
- # Convert to int16 format for WAV
- if audio_np.dtype != np.int16:
- # Normalize to [-1, 1] range if needed
- if audio_np.dtype == np.float32 or audio_np.dtype == np.float64:
- audio_np = np.clip(audio_np, -1.0, 1.0)
- audio_np = (audio_np * 32767).astype(np.int16)
- else:
- audio_np = audio_np.astype(np.int16)
-
- # Write to WAV bytes
- buffered = io.BytesIO()
- sf.write(buffered, audio_np, sample_rate, format="WAV")
- wav_bytes = buffered.getvalue()
- wav_b64 = base64.b64encode(wav_bytes).decode("utf-8")
- return f"data:audio/wav;base64,{wav_b64}"
-
-
-def video_to_base64_data_url(video_file: str) -> str:
- """Convert video file to base64 data URL."""
- video_path = Path(video_file)
- if not video_path.exists():
- raise FileNotFoundError(f"Video file not found: {video_file}")
-
- # Detect MIME type from extension
- video_path_lower = str(video_path).lower()
- if video_path_lower.endswith(".mp4"):
- mime_type = "video/mp4"
- elif video_path_lower.endswith(".webm"):
- mime_type = "video/webm"
- elif video_path_lower.endswith(".mov"):
- mime_type = "video/quicktime"
- elif video_path_lower.endswith(".avi"):
- mime_type = "video/x-msvideo"
- elif video_path_lower.endswith(".mkv"):
- mime_type = "video/x-matroska"
- else:
- mime_type = "video/mp4"
-
- with open(video_path, "rb") as f:
- video_bytes = f.read()
- video_b64 = base64.b64encode(video_bytes).decode("utf-8")
- return f"data:{mime_type};base64,{video_b64}"
-
-
-def process_audio_file(
- audio_file: Any | None,
-) -> tuple[np.ndarray, int] | None:
- """Normalize Gradio audio input to (np.ndarray, sample_rate)."""
- if audio_file is None:
- return None
-
- sample_rate: int | None = None
- audio_np: np.ndarray | None = None
-
- def _load_from_path(path_str: str) -> tuple[np.ndarray, int] | None:
- if not path_str:
- return None
- path = Path(path_str)
- if not path.exists():
- return None
- data, sr = sf.read(path)
- if data.ndim > 1:
- data = data[:, 0]
- return data.astype(np.float32), int(sr)
-
- if isinstance(audio_file, tuple):
- if len(audio_file) == 2:
- first, second = audio_file
- # Case 1: (sample_rate, np.ndarray)
- if isinstance(first, (int, float)) and isinstance(second, np.ndarray):
- sample_rate = int(first)
- audio_np = second
- # Case 2: (filepath, (sample_rate, np.ndarray or list))
- elif isinstance(first, str):
- if isinstance(second, tuple) and len(second) == 2:
- sr_candidate, data_candidate = second
- if isinstance(sr_candidate, (int, float)) and isinstance(data_candidate, np.ndarray):
- sample_rate = int(sr_candidate)
- audio_np = data_candidate
- if audio_np is None:
- loaded = _load_from_path(first)
- if loaded is not None:
- audio_np, sample_rate = loaded
- # Case 3: (None, (sample_rate, np.ndarray))
- elif first is None and isinstance(second, tuple) and len(second) == 2:
- sr_candidate, data_candidate = second
- if isinstance(sr_candidate, (int, float)) and isinstance(data_candidate, np.ndarray):
- sample_rate = int(sr_candidate)
- audio_np = data_candidate
- elif len(audio_file) == 1 and isinstance(audio_file[0], str):
- loaded = _load_from_path(audio_file[0])
- if loaded is not None:
- audio_np, sample_rate = loaded
- elif isinstance(audio_file, str):
- loaded = _load_from_path(audio_file)
- if loaded is not None:
- audio_np, sample_rate = loaded
-
- if audio_np is None or sample_rate is None:
- return None
-
- if audio_np.ndim > 1:
- audio_np = audio_np[:, 0]
-
- return audio_np.astype(np.float32), sample_rate
-
-
-def process_image_file(image_file: Image.Image | None) -> Image.Image | None:
- """Process image file from Gradio input.
-
- Returns:
- PIL Image in RGB mode or None if no image provided.
- """
- if image_file is None:
- return None
- # Convert to RGB if needed
- if image_file.mode != "RGB":
- image_file = image_file.convert("RGB")
- return image_file
-
-
-def run_inference_api(
- client: OpenAI,
- model: str,
- sampling_params_dict: list[dict],
- user_prompt: str,
- audio_file: tuple[str, tuple[int, np.ndarray]] | None = None,
- image_file: Image.Image | None = None,
- video_file: str | None = None,
- use_audio_in_video: bool = False,
- output_modalities: str | None = None,
- stream: bool = False,
-):
- """Run inference using OpenAI API client with multimodal support."""
- if not user_prompt.strip() and not audio_file and not image_file and not video_file:
- yield "Please provide at least a text prompt or multimodal input.", None
-
- try:
- # Build message content list
- content_list = []
-
- # Process audio
- audio_data = process_audio_file(audio_file)
- if audio_data is not None:
- audio_url = audio_to_base64_data_url(audio_data)
- content_list.append(
- {
- "type": "audio_url",
- "audio_url": {"url": audio_url},
- }
- )
-
- # Process image
- if image_file is not None:
- image_data = process_image_file(image_file)
- if image_data is not None:
- image_url = image_to_base64_data_url(image_data)
- content_list.append(
- {
- "type": "image_url",
- "image_url": {"url": image_url},
- }
- )
-
- # Process video
- mm_processor_kwargs = {}
- if video_file is not None:
- video_url = video_to_base64_data_url(video_file)
- video_content = {
- "type": "video_url",
- "video_url": {"url": video_url},
- }
- if use_audio_in_video:
- video_content["video_url"]["num_frames"] = 32 # Default max frames
- mm_processor_kwargs["use_audio_in_video"] = True
- content_list.append(video_content)
-
- # Add text prompt
- if user_prompt.strip():
- content_list.append(
- {
- "type": "text",
- "text": user_prompt,
- }
- )
-
- # Build messages
- messages = [
- {
- "role": "system",
- "content": [
- {
- "type": "text",
- "text": (
- "You are Qwen, a virtual human developed by the Qwen Team, "
- "Alibaba Group, capable of perceiving auditory and visual inputs, "
- "as well as generating text and speech."
- ),
- }
- ],
- },
- {
- "role": "user",
- "content": content_list,
- },
- ]
-
- # Build extra_body
- extra_body = {
- "sampling_params_list": sampling_params_dict,
- }
- if mm_processor_kwargs:
- extra_body["mm_processor_kwargs"] = mm_processor_kwargs
-
- # Parse output modalities
- if output_modalities and output_modalities.strip():
- output_modalities_list = [m.strip() for m in output_modalities.split(",")]
- else:
- output_modalities_list = None
-
- # Call API
- chat_completion = client.chat.completions.create(
- messages=messages,
- model=model,
- modalities=output_modalities_list,
- extra_body=extra_body,
- stream=stream,
- )
-
- if not stream:
- # Non-streaming mode: extract outputs and yield once
- text_outputs: list[str] = []
- audio_output = None
-
- for choice in chat_completion.choices:
- if choice.message.content:
- text_outputs.append(choice.message.content)
- if choice.message.audio:
- # Decode base64 audio
- audio_data = base64.b64decode(choice.message.audio.data)
- # Load audio from bytes
- audio_np, sample_rate = sf.read(io.BytesIO(audio_data))
- # Convert to mono if needed
- if audio_np.ndim > 1:
- audio_np = audio_np[:, 0]
- audio_output = (int(sample_rate), audio_np.astype(np.float32))
-
- text_response = "\n\n".join(text_outputs) if text_outputs else "No text output."
- yield text_response, audio_output
- else:
- # Streaming mode: yield incremental updates
- text_content = ""
- audio_output = None
-
- for chunk in chat_completion:
- for choice in chunk.choices:
- if hasattr(choice, "delta"):
- content = getattr(choice.delta, "content", None)
- else:
- content = None
-
- # Handle audio modality
- if getattr(chunk, "modality", None) == "audio" and content:
- try:
- # Decode base64 audio
- audio_data = base64.b64decode(content)
- # Load audio from bytes
- audio_np, sample_rate = sf.read(io.BytesIO(audio_data))
- # Convert to mono if needed
- if audio_np.ndim > 1:
- audio_np = audio_np[:, 0]
- audio_output = (int(sample_rate), audio_np.astype(np.float32))
- # Yield current text and audio
- yield text_content if text_content else "", audio_output
- except Exception: # pylint: disable=broad-except
- # If audio processing fails, just yield text
- yield text_content if text_content else "", None
-
- # Handle text modality
- elif getattr(chunk, "modality", None) == "text":
- if content:
- text_content += content
- # Yield updated text content (keep existing audio if any)
- yield text_content, audio_output
-
- # Final yield with accumulated text and last audio (if any)
- yield text_content if text_content else "No text output.", audio_output
-
- except Exception as exc: # pylint: disable=broad-except
- error_msg = f"Inference failed: {exc}"
- yield error_msg, None
-
-
-def build_interface(
- client: OpenAI,
- model: str,
- sampling_params_dict: list[dict],
-):
- """Build Gradio interface for API server mode."""
-
- def run_inference(
- user_prompt: str,
- audio_file: tuple[str, tuple[int, np.ndarray]] | None,
- image_file: Image.Image | None,
- video_file: str | None,
- use_audio_in_video: bool,
- output_modalities: str | None = None,
- stream: bool = False,
- ):
- # Always yield from the API function to maintain consistent generator behavior
- yield from run_inference_api(
- client,
- model,
- sampling_params_dict,
- user_prompt,
- audio_file,
- image_file,
- video_file,
- use_audio_in_video,
- output_modalities,
- stream,
- )
-
- css = """
- .media-input-container {
- display: flex;
- gap: 10px;
- }
- .media-input-container > div {
- flex: 1;
- }
- .media-input-container .image-input,
- .media-input-container .audio-input {
- height: 300px;
- }
- .media-input-container .video-column {
- height: 300px;
- display: flex;
- flex-direction: column;
- }
- .media-input-container .video-input {
- flex: 1;
- min-height: 0;
- }
- #generate-btn button {
- width: 100%;
- }
- """
-
- with gr.Blocks(css=css) as demo:
- gr.Markdown("# vLLM-Omni Online Serving Demo")
- gr.Markdown(f"**Model:** {model} \n\n")
-
- with gr.Column():
- with gr.Row():
- input_box = gr.Textbox(
- label="Text Prompt",
- placeholder="For example: Describe what happens in the media inputs.",
- lines=4,
- scale=1,
- )
- with gr.Row(elem_classes="media-input-container"):
- image_input = gr.Image(
- label="Image Input (optional)",
- type="pil",
- sources=["upload"],
- scale=1,
- elem_classes="image-input",
- )
- with gr.Column(scale=1, elem_classes="video-column"):
- video_input = gr.Video(
- label="Video Input (optional)",
- sources=["upload"],
- elem_classes="video-input",
- )
- use_audio_in_video_checkbox = gr.Checkbox(
- label="Use audio from video",
- value=False,
- info="Extract the video's audio track when provided.",
- )
- audio_input = gr.Audio(
- label="Audio Input (optional)",
- type="numpy",
- sources=["upload", "microphone"],
- scale=1,
- elem_classes="audio-input",
- )
-
- with gr.Row():
- output_modalities = gr.Textbox(
- label="Output Modalities",
- value=None,
- placeholder="For example: text, image, video. Use comma to separate multiple modalities.",
- lines=1,
- scale=2,
- )
- stream_checkbox = gr.Checkbox(
- label="Stream output",
- value=False,
- info="Enable streaming to see output as it's generated.",
- scale=1,
- )
-
- with gr.Row():
- generate_btn = gr.Button(
- "Generate",
- variant="primary",
- size="lg",
- elem_id="generate-btn",
- )
-
- with gr.Row():
- text_output = gr.Textbox(label="Text Output", lines=10, scale=2)
- audio_output = gr.Audio(label="Audio Output", interactive=False, scale=1)
-
- generate_btn.click(
- fn=run_inference,
- inputs=[
- input_box,
- audio_input,
- image_input,
- video_input,
- use_audio_in_video_checkbox,
- output_modalities,
- stream_checkbox,
- ],
- outputs=[text_output, audio_output],
- )
- demo.queue()
- return demo
-
-
-def main():
- args = parse_args()
-
- model_name = "/".join(args.model.split("/")[-2:])
- assert model_name in SUPPORTED_MODELS, (
- f"Unsupported model '{model_name}'. Supported models: {SUPPORTED_MODELS.keys()}"
- )
-
- # Initialize OpenAI client
- print(f"Connecting to API server at: {args.api_base}")
- client = OpenAI(
- api_key="EMPTY",
- base_url=args.api_base,
- )
- print("✓ Connected to API server")
-
- # Build sampling params
- sampling_params_dict = build_sampling_params_dict(SEED, model_name)
-
- demo = build_interface(
- client,
- args.model,
- sampling_params_dict,
- )
- try:
- demo.launch(
- server_name=args.ip,
- server_port=args.port,
- share=args.share,
- )
- except KeyboardInterrupt:
- print("\nShutting down...")
-
-
-if __name__ == "__main__":
- main()
diff --git a/examples/online_serving/qwen3_omni/openai_realtime_client.py b/examples/online_serving/qwen3_omni/openai_realtime_client.py
deleted file mode 100644
index 79e30a3f50b..00000000000
--- a/examples/online_serving/qwen3_omni/openai_realtime_client.py
+++ /dev/null
@@ -1,332 +0,0 @@
-"""Realtime client for vLLM-Omni /v1/realtime (audio + text events).
-
-This client:
-1) Reads a local WAV file (must be mono, 16-bit PCM, 16kHz),
-2) Streams PCM16 chunks to /v1/realtime with OpenAI-style events,
-3) Receives response.audio.* and transcription.* events,
-4) Saves synthesized audio to an output WAV file and optional text file.
-
-By default each ``response.audio.delta`` is treated as an **incremental PCM**
-chunk and all chunks are concatenated into the final ``--output-wav``.
-
-Optional debugging: pass ``--delta-dump-dir DIR`` to write every
-``response.audio.delta`` payload as ``delta_000001.wav``, ``delta_000002.wav``, …
-
-Usage:
- python openai_realtime_client.py \
- --url ws://localhost:8091/v1/realtime \
- --model Qwen/Qwen3-Omni-30B-A3B-Instruct \
- --input-wav input_16k_mono.wav \
- --output-wav realtime_output.wav \
- --delta-dump-dir ./rt_delta_wavs
-
-Dependencies:
- pip install websockets
-"""
-
-from __future__ import annotations
-
-import argparse
-import asyncio
-import base64
-import json
-import wave
-from pathlib import Path
-
-try:
- import websockets
-except ImportError:
- print("Please install websockets: pip install websockets")
- raise SystemExit(1)
-
-
-def _read_wav_pcm16(path: Path) -> bytes:
- with wave.open(str(path), "rb") as wf:
- nchannels = wf.getnchannels()
- sampwidth = wf.getsampwidth()
- framerate = wf.getframerate()
- comptype = wf.getcomptype()
- nframes = wf.getnframes()
-
- if nchannels != 1:
- raise ValueError(f"Input WAV must be mono (got {nchannels} channels).")
- if sampwidth != 2:
- raise ValueError(f"Input WAV must be 16-bit PCM (got sample width={sampwidth}).")
- if framerate != 16000:
- raise ValueError(f"Input WAV must be 16kHz (got {framerate} Hz).")
- if comptype != "NONE":
- raise ValueError(f"Input WAV must be uncompressed PCM (got comptype={comptype}).")
- if nframes <= 0:
- raise ValueError("Input WAV has no audio frames.")
-
- return wf.readframes(nframes)
-
-
-def _write_wav_pcm16(path: Path, pcm16_bytes: bytes, sample_rate_hz: int) -> None:
- with wave.open(str(path), "wb") as wf:
- wf.setnchannels(1)
- wf.setsampwidth(2)
- wf.setframerate(sample_rate_hz)
- wf.writeframes(pcm16_bytes)
-
-
-async def run_client(
- url: str,
- model: str,
- input_wav: Path,
- output_wav: Path,
- output_text: Path | None,
- chunk_ms: int,
- send_delay_ms: int,
- delta_dump_dir: Path | None,
- request_idx: int = 1,
- total_requests: int = 1,
-) -> None:
- log_prefix = f"[req {request_idx:02d}/{total_requests:02d}] " if total_requests > 1 else ""
- pcm16 = _read_wav_pcm16(input_wav)
- bytes_per_ms = 16000 * 2 // 1000 # mono PCM16 at 16kHz
- chunk_bytes = max(bytes_per_ms * chunk_ms, 2)
-
- incremental_pcm_parts: list[bytes] = []
- output_sample_rate = 24000
- delta_index = 0
- text_chunks: list[str] = []
- final_text: str = ""
-
- if delta_dump_dir is not None:
- delta_dump_dir.mkdir(parents=True, exist_ok=True)
-
- async with websockets.connect(url, max_size=64 * 1024 * 1024) as ws:
- # 1) Validate model.
- await ws.send(
- json.dumps(
- {
- "type": "session.update",
- "model": model,
- }
- )
- )
-
- # 2) Start generation once (non-final commit).
- await ws.send(json.dumps({"type": "input_audio_buffer.commit", "final": False}))
-
- # 3) Stream audio chunks.
- for i in range(0, len(pcm16), chunk_bytes):
- chunk = pcm16[i : i + chunk_bytes]
- await ws.send(
- json.dumps(
- {
- "type": "input_audio_buffer.append",
- "audio": base64.b64encode(chunk).decode("utf-8"),
- }
- )
- )
- if send_delay_ms > 0:
- await asyncio.sleep(send_delay_ms / 1000.0)
-
- # 4) Final commit closes input stream.
- await ws.send(json.dumps({"type": "input_audio_buffer.commit", "final": True}))
-
- # 5) Receive server events until audio done.
- while True:
- message = await ws.recv()
- if isinstance(message, bytes):
- # We only expect JSON text frames.
- continue
-
- event = json.loads(message)
- event_type = event.get("type")
-
- if event_type == "session.created":
- continue
-
- if event_type == "response.audio.delta":
- sr = event.get("sample_rate_hz")
- if isinstance(sr, int) and sr > 0:
- output_sample_rate = sr
- audio_b64 = event.get("audio", "")
- if audio_b64:
- pcm_delta = base64.b64decode(audio_b64)
- incremental_pcm_parts.append(pcm_delta)
- if delta_dump_dir is not None and pcm_delta:
- delta_index += 1
- dump_path = delta_dump_dir / f"delta_{delta_index:06d}.wav"
- _write_wav_pcm16(dump_path, pcm_delta, output_sample_rate)
- print(
- f"{log_prefix}delta dump #{delta_index}: {dump_path} "
- f"(pcm bytes={len(pcm_delta)}, sr={output_sample_rate})"
- )
- continue
-
- if event_type == "transcription.delta":
- delta = event.get("delta", "")
- if delta:
- text_chunks.append(delta)
- print(delta, end="", flush=True)
- continue
-
- if event_type == "transcription.done":
- final_text = event.get("text", "") or "".join(text_chunks)
- usage = event.get("usage")
- final_text_with_tag = f"Final transcription: {final_text}"
- if text_chunks:
- print()
- print(f"{log_prefix}{final_text_with_tag}")
- if usage:
- print(f"{log_prefix}text usage: {usage}")
- continue
-
- if event_type == "response.audio.done":
- break
-
- if event_type == "error":
- raise RuntimeError(f"Server error: {event}")
-
- all_pcm16 = b"".join(incremental_pcm_parts)
- if not all_pcm16:
- raise RuntimeError("No audio received from server.")
-
- output_wav.parent.mkdir(parents=True, exist_ok=True)
- _write_wav_pcm16(output_wav, all_pcm16, output_sample_rate)
- print(f"{log_prefix}Saved realtime audio to: {output_wav} (incremental chunks joined)")
-
- if output_text is not None:
- text_to_save = final_text if final_text else "".join(text_chunks)
- output_text.parent.mkdir(parents=True, exist_ok=True)
- output_text.write_text(text_to_save, encoding="utf-8")
- print(f"{log_prefix}Saved realtime text to: {output_text}")
-
-
-def _indexed_output_path(path: Path | None, index: int, total: int) -> Path | None:
- if path is None or total <= 1:
- return path
- return path.with_name(f"{path.stem}_{index:02d}{path.suffix}")
-
-
-async def run_clients_concurrent(
- *,
- url: str,
- model: str,
- input_wav: Path,
- output_wav: Path,
- output_text: Path | None,
- chunk_ms: int,
- send_delay_ms: int,
- delta_dump_dir: Path | None,
- num_requests: int,
- concurrency: int,
-) -> None:
- sem = asyncio.Semaphore(concurrency)
-
- async def _run_one(index: int) -> tuple[int, bool, str | None]:
- per_output_wav = _indexed_output_path(output_wav, index, num_requests)
- per_output_text = _indexed_output_path(output_text, index, num_requests)
- per_delta_dir = None
- if delta_dump_dir is not None:
- per_delta_dir = delta_dump_dir / f"req_{index:02d}"
- async with sem:
- try:
- await run_client(
- url=url,
- model=model,
- input_wav=input_wav,
- output_wav=per_output_wav,
- output_text=per_output_text,
- chunk_ms=chunk_ms,
- send_delay_ms=send_delay_ms,
- delta_dump_dir=per_delta_dir,
- request_idx=index,
- total_requests=num_requests,
- )
- return index, True, None
- except Exception as exc:
- return index, False, str(exc)
-
- tasks = [asyncio.create_task(_run_one(i), name=f"rt-client-{i}") for i in range(1, num_requests + 1)]
- results = await asyncio.gather(*tasks)
-
- failed = [(idx, err) for idx, ok, err in results if not ok]
- succeeded = num_requests - len(failed)
- print(f"[summary] succeeded={succeeded}, failed={len(failed)}, total={num_requests}")
- if failed:
- for idx, err in failed:
- print(f"[summary] req {idx:02d} failed: {err}")
- raise RuntimeError(f"{len(failed)} concurrent request(s) failed")
-
-
-def main() -> None:
- parser = argparse.ArgumentParser(description="Realtime audio/text client for vLLM-Omni")
- parser.add_argument("--url", default="ws://localhost:8091/v1/realtime", help="WebSocket URL")
- parser.add_argument(
- "--model",
- default="Qwen/Qwen3-Omni-30B-A3B-Instruct",
- help="Model name for session.update",
- )
- parser.add_argument("--input-wav", required=True, type=Path, help="Input WAV (mono, PCM16, 16kHz)")
- parser.add_argument("--output-wav", default=Path("realtime_output.wav"), type=Path, help="Output WAV path")
- parser.add_argument(
- "--output-text",
- default=None,
- type=Path,
- help="Optional output text path for final transcription",
- )
- parser.add_argument("--chunk-ms", type=int, default=200, help="Input chunk size in milliseconds")
- parser.add_argument(
- "--send-delay-ms",
- type=int,
- default=0,
- help="Delay between chunk sends; set >0 to simulate realtime upload",
- )
- parser.add_argument(
- "--delta-dump-dir",
- type=Path,
- default=None,
- help="If set, each response.audio.delta is saved as delta_NNNNNN.wav under this directory",
- )
- parser.add_argument("--num-requests", type=int, default=1, help="Total number of requests to send")
- parser.add_argument(
- "--concurrency",
- type=int,
- default=1,
- help="Maximum number of concurrent websocket requests",
- )
- args = parser.parse_args()
-
- if args.num_requests <= 0:
- raise ValueError("--num-requests must be >= 1")
- if args.concurrency <= 0:
- raise ValueError("--concurrency must be >= 1")
- concurrency = min(args.concurrency, args.num_requests)
-
- if args.num_requests == 1:
- asyncio.run(
- run_client(
- url=args.url,
- model=args.model,
- input_wav=args.input_wav,
- output_wav=args.output_wav,
- output_text=args.output_text,
- chunk_ms=args.chunk_ms,
- send_delay_ms=args.send_delay_ms,
- delta_dump_dir=args.delta_dump_dir,
- )
- )
- else:
- asyncio.run(
- run_clients_concurrent(
- url=args.url,
- model=args.model,
- input_wav=args.input_wav,
- output_wav=args.output_wav,
- output_text=args.output_text,
- chunk_ms=args.chunk_ms,
- send_delay_ms=args.send_delay_ms,
- delta_dump_dir=args.delta_dump_dir,
- num_requests=args.num_requests,
- concurrency=concurrency,
- )
- )
-
-
-if __name__ == "__main__":
- main()
diff --git a/examples/online_serving/qwen3_omni/qwen3_omni_moe_thinking.yaml b/examples/online_serving/qwen3_omni/qwen3_omni_moe_thinking.yaml
deleted file mode 100644
index a32ca7d2dec..00000000000
--- a/examples/online_serving/qwen3_omni/qwen3_omni_moe_thinking.yaml
+++ /dev/null
@@ -1,36 +0,0 @@
-# Stage config for running Qwen3-Omni-MoE-Thinking (text-only output)
-# This config is for models like Qwen3-Omni-30B-A3B-Thinking that only have the
-# thinker component and do not support audio output.
-#
-# Single stage: Thinker (multimodal understanding + text generation)
-
-# The following config has been verified on 2x H100-80G GPUs.
-stage_args:
- - stage_id: 0
- runtime:
- devices: "0,1"
- engine_args:
- model_stage: thinker
- max_num_seqs: 1
- model_arch: Qwen3OmniMoeForConditionalGeneration
- worker_type: ar
- scheduler_cls: vllm_omni.core.sched.omni_ar_scheduler.OmniARScheduler
- gpu_memory_utilization: 0.9
- enforce_eager: true
- trust_remote_code: true
- engine_output_type: text
- distributed_executor_backend: "mp"
- enable_prefix_caching: false
- hf_config_name: thinker_config
- tensor_parallel_size: 2
- final_output: true
- final_output_type: text
- is_comprehension: true
- default_sampling_params:
- temperature: 0.4
- top_p: 0.9
- top_k: 1
- max_tokens: 2048
- seed: 42
- detokenize: True
- repetition_penalty: 1.05
diff --git a/examples/online_serving/qwen3_omni/run_curl_multimodal_generation.sh b/examples/online_serving/qwen3_omni/run_curl_multimodal_generation.sh
deleted file mode 100644
index 399c654819d..00000000000
--- a/examples/online_serving/qwen3_omni/run_curl_multimodal_generation.sh
+++ /dev/null
@@ -1,172 +0,0 @@
-#!/usr/bin/env bash
-set -euo pipefail
-
-# Default query type
-QUERY_TYPE="${1:-use_video}"
-
-# Default modalities argument
-MODALITIES="${2:-null}"
-
-# Validate query type
-if [[ ! "$QUERY_TYPE" =~ ^(text|use_audio|use_image|use_video)$ ]]; then
- echo "Error: Invalid query type '$QUERY_TYPE'"
- echo "Usage: $0 [text|use_audio|use_image|use_video] [modalities]"
- echo " text: Text query"
- echo " use_audio: Audio + Text query"
- echo " use_image: Image + Text query"
- echo " use_video: Video + Text query"
- echo " modalities: Modalities parameter (default: null)"
- exit 1
-fi
-
-SEED=42
-
-thinker_sampling_params='{
- "temperature": 0.4,
- "top_p": 0.9,
- "top_k": 1,
- "max_tokens": 16384,
- "seed": 42,
- "repetition_penalty": 1.05,
- "stop_token_ids": [151645]
-}'
-
-talker_sampling_params='{
- "temperature": 0.9,
- "top_k": 50,
- "max_tokens": 4096,
- "seed": 42,
- "detokenize": false,
- "repetition_penalty": 1.05,
- "stop_token_ids": [2150]
-}'
-
-code2wav_sampling_params='{
- "temperature": 0.0,
- "top_p": 1.0,
- "top_k": -1,
- "max_tokens": 65536,
- "seed": 42,
- "detokenize": true,
- "repetition_penalty": 1.1
-}'
-# Above is optional, it has a default setting in stage_configs of the corresponding model.
-
-# Define URLs for assets
-MARY_HAD_LAMB_AUDIO_URL="https://vllm-public-assets.s3.us-west-2.amazonaws.com/multimodal_asset/mary_had_lamb.ogg"
-CHERRY_BLOSSOM_IMAGE_URL="https://vllm-public-assets.s3.us-west-2.amazonaws.com/vision_model_images/cherry_blossom.jpg"
-SAMPLE_VIDEO_URL="https://huggingface.co/datasets/raushan-testing-hf/videos-test/resolve/main/sample_demo_1.mp4"
-
-# Build user content and extra fields based on query type
-case "$QUERY_TYPE" in
- text)
- user_content='[
- {
- "type": "text",
- "text": "Explain the system architecture for a scalable audio generation pipeline. Answer in 15 words."
- }
- ]'
- sampling_params_list='[
- '"$thinker_sampling_params"',
- '"$talker_sampling_params"',
- '"$code2wav_sampling_params"'
- ]'
- mm_processor_kwargs="{}"
- ;;
- use_audio)
- user_content='[
- {
- "type": "audio_url",
- "audio_url": {
- "url": "'"$MARY_HAD_LAMB_AUDIO_URL"'"
- }
- },
- {
- "type": "text",
- "text": "What is the content of this audio?"
- }
- ]'
- sampling_params_list='[
- '"$thinker_sampling_params"',
- '"$talker_sampling_params"',
- '"$code2wav_sampling_params"'
- ]'
- mm_processor_kwargs="{}"
- ;;
- use_image)
- user_content='[
- {
- "type": "image_url",
- "image_url": {
- "url": "'"$CHERRY_BLOSSOM_IMAGE_URL"'"
- }
- },
- {
- "type": "text",
- "text": "What is the content of this image?"
- }
- ]'
- sampling_params_list='[
- '"$thinker_sampling_params"',
- '"$talker_sampling_params"',
- '"$code2wav_sampling_params"'
- ]'
- mm_processor_kwargs="{}"
- ;;
- use_video)
- user_content='[
- {
- "type": "video_url",
- "video_url": {
- "url": "'"$SAMPLE_VIDEO_URL"'"
- }
- },
- {
- "type": "text",
- "text": "Why is this video funny?"
- }
- ]'
- sampling_params_list='[
- '"$thinker_sampling_params"',
- '"$talker_sampling_params"',
- '"$code2wav_sampling_params"'
- ]'
- mm_processor_kwargs="{}"
- ;;
-esac
-
-echo "Running query type: $QUERY_TYPE"
-echo ""
-
-request_body=$(cat <<EOF
-{
- "model": "Qwen/Qwen3-Omni-30B-A3B-Instruct",
- "sampling_params_list": $sampling_params_list,
- "mm_processor_kwargs": $mm_processor_kwargs,
- "modalities": $MODALITIES,
- "messages": [
- {
- "role": "system",
- "content": [
- {
- "type": "text",
- "text": "You are Qwen, a virtual human developed by the Qwen Team, Alibaba Group, capable of perceiving auditory and visual inputs, as well as generating text and speech."
- }
- ]
- },
- {
- "role": "user",
- "content": $user_content
- }
- ]
-}
-EOF
-)
-
-output=$(curl -sS --retry 3 --retry-delay 3 --retry-connrefused \
- -X POST http://localhost:8091/v1/chat/completions \
- -H "Content-Type: application/json" \
- -d "$request_body")
-
-# Here it only shows the text content of the first choice. Audio content has many binaries, so it's not displayed here.
-echo "Output of request: $(echo "$output" | jq '.choices[0].message.content')"
diff --git a/examples/online_serving/qwen3_omni/run_gradio_demo.sh b/examples/online_serving/qwen3_omni/run_gradio_demo.sh
deleted file mode 100755
index 73ce273d9a9..00000000000
--- a/examples/online_serving/qwen3_omni/run_gradio_demo.sh
+++ /dev/null
@@ -1,212 +0,0 @@
-#!/bin/bash
-# Convenience script to launch both vLLM server and Gradio demo for Qwen3-Omni
-#
-# Usage:
-# ./run_gradio_demo.sh [OPTIONS]
-#
-# Example:
-# ./run_gradio_demo.sh --model Qwen/Qwen3-Omni-30B-A3B-Instruct --server-port 8091 --gradio-port 7861
-
-set -e
-
-# Default values
-MODEL="Qwen/Qwen3-Omni-30B-A3B-Instruct"
-SERVER_PORT=8091
-GRADIO_PORT=7861
-STAGE_CONFIGS_PATH=""
-SERVER_HOST="0.0.0.0"
-GRADIO_IP="127.0.0.1"
-GRADIO_SHARE=false
-
-# Parse command line arguments
-while [[ $# -gt 0 ]]; do
- case $1 in
- --model)
- MODEL="$2"
- shift 2
- ;;
- --server-port)
- SERVER_PORT="$2"
- shift 2
- ;;
- --gradio-port)
- GRADIO_PORT="$2"
- shift 2
- ;;
- --stage-configs-path)
- STAGE_CONFIGS_PATH="$2"
- shift 2
- ;;
- --server-host)
- SERVER_HOST="$2"
- shift 2
- ;;
- --gradio-ip)
- GRADIO_IP="$2"
- shift 2
- ;;
- --share)
- GRADIO_SHARE=true
- shift
- ;;
- --help)
- echo "Usage: $0 [OPTIONS]"
- echo ""
- echo "Options:"
- echo " --model MODEL Model name/path (default: Qwen/Qwen3-Omni-30B-A3B-Instruct)"
- echo " --server-port PORT Port for vLLM server (default: 8091)"
- echo " --gradio-port PORT Port for Gradio demo (default: 7861)"
- echo " --stage-configs-path PATH Path to custom stage configs YAML file (optional)"
- echo " --server-host HOST Host for vLLM server (default: 0.0.0.0)"
- echo " --gradio-ip IP IP for Gradio demo (default: 127.0.0.1)"
- echo " --share Share Gradio demo publicly"
- echo " --help Show this help message"
- echo ""
- exit 0
- ;;
- *)
- echo "Unknown option: $1"
- echo "Use --help for usage information"
- exit 1
- ;;
- esac
-done
-
-# Get the directory where this script is located
-SCRIPT_DIR="$(cd "$(dirname "${BASH_SOURCE[0]}")" && pwd)"
-API_BASE="http://localhost:${SERVER_PORT}/v1"
-HEALTH_URL="http://localhost:${SERVER_PORT}/health"
-
-echo "=========================================="
-echo "Starting vLLM-Omni Gradio Demo"
-echo "=========================================="
-echo "Model: $MODEL"
-echo "Server: http://${SERVER_HOST}:${SERVER_PORT}"
-echo "Gradio: http://${GRADIO_IP}:${GRADIO_PORT}"
-echo "=========================================="
-
-# Build vLLM server command
-SERVER_CMD=("vllm" "serve" "$MODEL" "--omni" "--port" "$SERVER_PORT" "--host" "$SERVER_HOST")
-if [ -n "$STAGE_CONFIGS_PATH" ]; then
- SERVER_CMD+=("--stage-configs-path" "$STAGE_CONFIGS_PATH")
-fi
-
-# Function to cleanup on exit
-cleanup() {
- echo ""
- echo "Shutting down..."
- if [ -n "$SERVER_PID" ]; then
- echo "Stopping vLLM server (PID: $SERVER_PID)..."
- kill "$SERVER_PID" 2>/dev/null || true
- wait "$SERVER_PID" 2>/dev/null || true
- fi
- if [ -n "$GRADIO_PID" ]; then
- echo "Stopping Gradio demo (PID: $GRADIO_PID)..."
- kill "$GRADIO_PID" 2>/dev/null || true
- wait "$GRADIO_PID" 2>/dev/null || true
- fi
- echo "Cleanup complete"
- exit 0
-}
-
-# Set up signal handlers
-trap cleanup SIGINT SIGTERM
-
-# Start vLLM server with output shown in real-time and saved to log
-echo ""
-echo "Starting vLLM server..."
-LOG_FILE="/tmp/vllm_server_${SERVER_PORT}.log"
-"${SERVER_CMD[@]}" 2>&1 | tee "$LOG_FILE" &
-SERVER_PID=$!
-
-# Start a background process to monitor the log for startup completion
-STARTUP_COMPLETE=false
-TAIL_PID=""
-
-# Function to cleanup tail process
-cleanup_tail() {
- if [ -n "$TAIL_PID" ]; then
- kill "$TAIL_PID" 2>/dev/null || true
- wait "$TAIL_PID" 2>/dev/null || true
- fi
-}
-
-# Wait for server to be ready by checking log output
-echo ""
-echo "Waiting for vLLM server to be ready (checking for 'Application startup complete' message)..."
-echo ""
-
-# Monitor log file for startup completion message
-MAX_WAIT=300 # 5 minutes timeout as fallback
-ELAPSED=0
-
-# Use a temporary file to track startup completion
-STARTUP_FLAG="/tmp/vllm_startup_flag_${SERVER_PORT}.tmp"
-rm -f "$STARTUP_FLAG"
-
-# Start monitoring in background
-(
- tail -f "$LOG_FILE" 2>/dev/null | grep -m 1 "Application startup complete" > /dev/null && touch "$STARTUP_FLAG"
-) &
-TAIL_PID=$!
-
-while [ $ELAPSED -lt $MAX_WAIT ]; do
- # Check if startup flag file exists (startup complete)
- if [ -f "$STARTUP_FLAG" ]; then
- cleanup_tail
- echo ""
- echo "✓ vLLM server is ready!"
- STARTUP_COMPLETE=true
- break
- fi
-
- # Check if server process is still running
- if ! kill -0 "$SERVER_PID" 2>/dev/null; then
- cleanup_tail
- echo ""
- echo "Error: vLLM server failed to start (process terminated)"
- wait "$SERVER_PID" 2>/dev/null || true
- exit 1
- fi
-
- sleep 1
- ELAPSED=$((ELAPSED + 1))
-done
-
-cleanup_tail
-rm -f "$STARTUP_FLAG"
-
-if [ "$STARTUP_COMPLETE" != "true" ]; then
- echo ""
- echo "Error: vLLM server did not complete startup within ${MAX_WAIT} seconds"
- kill "$SERVER_PID" 2>/dev/null || true
- exit 1
-fi
-
-# Start Gradio demo
-echo ""
-echo "Starting Gradio demo..."
-cd "$SCRIPT_DIR"
-GRADIO_CMD=("python" "gradio_demo.py" "--model" "$MODEL" "--api-base" "$API_BASE" "--ip" "$GRADIO_IP" "--port" "$GRADIO_PORT")
-if [ "$GRADIO_SHARE" = true ]; then
- GRADIO_CMD+=("--share")
-fi
-
-"${GRADIO_CMD[@]}" > /tmp/gradio_demo.log 2>&1 &
-GRADIO_PID=$!
-
-echo ""
-echo "=========================================="
-echo "Both services are running!"
-echo "=========================================="
-echo "vLLM Server: http://${SERVER_HOST}:${SERVER_PORT}"
-echo "Gradio Demo: http://${GRADIO_IP}:${GRADIO_PORT}"
-echo ""
-echo "Press Ctrl+C to stop both services"
-echo "=========================================="
-echo ""
-
-# Wait for either process to exit
-wait $SERVER_PID $GRADIO_PID || true
-
-cleanup
diff --git a/examples/online_serving/qwen3_omni/streaming_video_client.py b/examples/online_serving/qwen3_omni/streaming_video_client.py
deleted file mode 100644
index 58f26d24557..00000000000
--- a/examples/online_serving/qwen3_omni/streaming_video_client.py
+++ /dev/null
@@ -1,208 +0,0 @@
-#!/usr/bin/env python3
-# SPDX-License-Identifier: Apache-2.0
-# SPDX-FileCopyrightText: Copyright contributors to the vLLM project
-"""Example WebSocket client for the /v1/video/chat/stream endpoint.
-
-Sends video frames from a local file (or generates synthetic ones), submits a
-query, and prints the streamed text response.
-
-Requirements:
- pip install websockets pillow
-
-Usage:
- # With a video file (requires opencv-python):
- python streaming_video_client.py --video my_clip.mp4 \\
- --query "What is happening in this video?"
-
- # Synthetic frames (no extra deps):
- python streaming_video_client.py \\
- --query "Describe what you see." \\
- --synthetic-frames 10
-
- # With audio (Phase 3):
- python streaming_video_client.py --video my_clip.mp4 \\
- --audio my_audio.pcm \\
- --query "What is the person saying and doing?"
-"""
-
-from __future__ import annotations
-
-import argparse
-import asyncio
-import base64
-import io
-import json
-import sys
-
-try:
- import websockets
-except ImportError:
- print("Please install websockets: pip install websockets")
- sys.exit(1)
-
-from PIL import Image
-
-
-def _generate_synthetic_frame(index: int, width: int = 320, height: int = 240) -> bytes:
- """Generate a simple synthetic JPEG frame with a colour gradient."""
- r = (index * 37) % 256
- g = (index * 73) % 256
- b = (index * 113) % 256
- img = Image.new("RGB", (width, height), (r, g, b))
- buf = io.BytesIO()
- img.save(buf, format="JPEG", quality=80)
- return buf.getvalue()
-
-
-def _load_video_frames(path: str, max_frames: int = 64, fps: int = 2) -> list[bytes]:
- """Extract frames from a video file using OpenCV."""
- try:
- import cv2
- except ImportError:
- print("opencv-python is required to read video files: pip install opencv-python")
- sys.exit(1)
-
- cap = cv2.VideoCapture(path)
- if not cap.isOpened():
- print(f"Cannot open video: {path}")
- sys.exit(1)
-
- video_fps = cap.get(cv2.CAP_PROP_FPS) or 30.0
- frame_interval = max(1, int(video_fps / fps))
-
- frames: list[bytes] = []
- idx = 0
- while len(frames) < max_frames:
- ret, frame = cap.read()
- if not ret:
- break
- if idx % frame_interval == 0:
- _, buf = cv2.imencode(".jpg", frame, [cv2.IMWRITE_JPEG_QUALITY, 80])
- frames.append(buf.tobytes())
- idx += 1
-
- cap.release()
- print(f"Loaded {len(frames)} frames from {path} (interval={frame_interval})")
- return frames
-
-
-async def run(args: argparse.Namespace) -> None:
- uri = f"ws://{args.host}:{args.port}/v1/video/chat/stream"
-
- # Prepare frames
- if args.video:
- frames = _load_video_frames(args.video, max_frames=args.max_frames, fps=args.fps)
- else:
- frames = [_generate_synthetic_frame(i) for i in range(args.synthetic_frames)]
- print(f"Generated {len(frames)} synthetic frames")
-
- # Prepare audio (optional, Phase 3)
- audio_data: bytes | None = None
- if args.audio:
- with open(args.audio, "rb") as f:
- audio_data = f.read()
- print(f"Loaded audio: {len(audio_data)} bytes")
-
- async with websockets.connect(uri, max_size=16 * 1024 * 1024) as ws:
- # 1. Send session.config
- config = {
- "type": "session.config",
- "model": args.model,
- "modalities": ["text", "audio"] if audio_data else ["text"],
- "max_frames": args.max_frames,
- "num_frames": args.num_sample_frames,
- "enable_frame_filter": args.evs,
- "frame_filter_threshold": args.evs_threshold,
- "use_audio_in_video": bool(audio_data),
- }
- await ws.send(json.dumps(config))
- print(f"Sent session.config: model={args.model} evs={args.evs}")
-
- # 2. Send frames
- for i, frame in enumerate(frames):
- msg = {
- "type": "video.frame",
- "data": base64.b64encode(frame).decode(),
- }
- await ws.send(json.dumps(msg))
- if (i + 1) % 10 == 0:
- print(f" Sent {i + 1}/{len(frames)} frames")
- print(f"Sent all {len(frames)} frames")
-
- # 3. Send audio chunks (Phase 3)
- if audio_data:
- chunk_size = 16000 * 2 # 1 second of 16 kHz 16-bit PCM
- for offset in range(0, len(audio_data), chunk_size):
- chunk = audio_data[offset : offset + chunk_size]
- msg = {
- "type": "audio.chunk",
- "data": base64.b64encode(chunk).decode(),
- }
- await ws.send(json.dumps(msg))
- print(f"Sent audio in {(len(audio_data) + chunk_size - 1) // chunk_size} chunks")
-
- # 4. Send query, then immediately send video.done so the server
- # knows the session is complete (avoids deadlock where client
- # waits for session.done while server waits for video.done).
- await ws.send(json.dumps({"type": "video.query", "text": args.query}))
- print(f"\nQuery: {args.query}")
- print("Response: ", end="", flush=True)
-
- # Signal end of session right after the query. The server will
- # process the query first (it's already queued), then handle
- # video.done and reply with session.done.
- await ws.send(json.dumps({"type": "video.done"}))
-
- # 5. Receive response until session.done
- recv_timeout = 120 # seconds — avoid infinite hang if server stalls
- while True:
- raw = await asyncio.wait_for(ws.recv(), timeout=recv_timeout)
- data = json.loads(raw)
- msg_type = data.get("type")
-
- if msg_type == "response.text.delta":
- print(data.get("delta", ""), end="", flush=True)
- elif msg_type == "response.text.done":
- print() # newline
- elif msg_type == "response.evs_stats":
- retained = data.get("retained_count", 0)
- dropped = data.get("dropped_count", 0)
- rate = data.get("drop_rate", 0)
- print(f"\nEVS stats: retained={retained} dropped={dropped} drop_rate={rate:.1%}")
- elif msg_type == "session.done":
- print("Session complete.")
- break
- elif msg_type == "error":
- print(f"\nError: {data.get('message')}")
- break
- elif msg_type == "response.start":
- pass # expected
- else:
- print(f"\n[unknown message] {data}")
-
-
-def main() -> None:
- parser = argparse.ArgumentParser(description="Streaming video chat client")
- parser.add_argument("--host", default="localhost")
- parser.add_argument("--port", type=int, default=8000)
- parser.add_argument("--model", default="Qwen/Qwen3-Omni-MoE")
- parser.add_argument("--video", help="Path to video file (requires opencv-python)")
- parser.add_argument("--audio", help="Path to raw PCM 16kHz audio file (Phase 3)")
- parser.add_argument("--query", default="What do you see in this video?")
- parser.add_argument(
- "--synthetic-frames", type=int, default=10, help="Number of synthetic frames if --video is not set"
- )
- parser.add_argument("--max-frames", type=int, default=64)
- parser.add_argument("--num-sample-frames", type=int, default=16)
- parser.add_argument("--fps", type=int, default=2, help="Frame extraction rate from video")
- parser.add_argument(
- "--no-evs", dest="evs", action="store_false", help="Disable EVS frame filtering (enabled by default)"
- )
- parser.set_defaults(evs=True)
- parser.add_argument("--evs-threshold", type=float, default=0.95)
- args = parser.parse_args()
- asyncio.run(run(args))
-
-
-if __name__ == "__main__":
- main()
diff --git a/examples/online_serving/qwen3_tts/README.md b/examples/online_serving/qwen3_tts/README.md
deleted file mode 100644
index 350fcb71cac..00000000000
--- a/examples/online_serving/qwen3_tts/README.md
+++ /dev/null
@@ -1,455 +0,0 @@
-# Qwen3-TTS
-
-## 🛠️ Installation
-
-Please refer to [README.md](https://github.com/vllm-project/vllm-omni/tree/main/README.md)
-
-## Supported Models
-
-| Model | Task Type | Description |
-| -------------------------------------- | ----------- | ----------------------------------------------------- |
-| `Qwen/Qwen3-TTS-12Hz-1.7B-CustomVoice` | CustomVoice | Predefined speaker voices with optional style control |
-| `Qwen/Qwen3-TTS-12Hz-1.7B-VoiceDesign` | VoiceDesign | Natural language voice style description |
-| `Qwen/Qwen3-TTS-12Hz-1.7B-Base` | Base | Voice cloning from reference audio |
-| `Qwen/Qwen3-TTS-12Hz-0.6B-CustomVoice` | CustomVoice | Smaller/faster variant |
-| `Qwen/Qwen3-TTS-12Hz-0.6B-Base` | Base | Smaller/faster variant for voice cloning |
-
-## Gradio Demo
-
-Two interactive Gradio demos are available, both supporting all 3 task types:
-
-| Demo | File | Transport | Streaming Quality |
-| -------- | ------------------------ | ------------ | -------------------------------------------------- |
-| Standard | `gradio_demo.py` | HTTP chunked | May have small gaps between chunks |
-| FastRTC | `gradio_fastrtc_demo.py` | WebRTC | Gapless streaming (requires `pip install fastrtc`) |
-
-```bash
-# Option 1: Launch server + Standard Gradio together
-./run_gradio_demo.sh # CustomVoice (default)
-./run_gradio_demo.sh --task-type VoiceDesign # VoiceDesign
-./run_gradio_demo.sh --task-type Base # Voice cloning
-
-# Option 2: If server is already running
-python gradio_demo.py --api-base http://localhost:8000
-
-# Option 3: FastRTC demo (gapless streaming)
-pip install fastrtc
-python gradio_fastrtc_demo.py --api-base http://localhost:8000
-```
-
-Then open http://localhost:7860 in your browser.
-
-## Run examples (Qwen3-TTS)
-
-### Launch the Server
-
-The default deploy config is located at `vllm_omni/deploy/qwen3_tts.yaml` and is loaded automatically by the model registry — no `--deploy-config` flag needed for default use. Platform-specific deltas (NPU, ROCm, XPU) are merged in automatically from the `platforms:` block of the same YAML based on the detected runtime.
-
-```bash
-# CustomVoice model (predefined speakers)
-vllm serve Qwen/Qwen3-TTS-12Hz-1.7B-CustomVoice \
- --omni \
- --port 8091
-
-# VoiceDesign model
-vllm serve Qwen/Qwen3-TTS-12Hz-1.7B-VoiceDesign \
- --omni \
- --port 8091
-
-# Base model (voice cloning)
-vllm serve Qwen/Qwen3-TTS-12Hz-1.7B-Base \
- --omni \
- --port 8091
-```
-
-If you have custom stage configs file, launch the server with command below
-```bash
-vllm serve Qwen/Qwen3-TTS-12Hz-1.7B-CustomVoice \
- --stage-configs-path /path/to/stage_configs_file \
- --omni \
- --port 8091
-```
-
-#### Sync vs async-chunk mode
-
-Qwen3-TTS supports both **chunked streaming** (default, lower latency) and
-**synchronous end-to-end** modes from the same deploy YAML. The bundled
-`qwen3_tts.yaml` ships with `async_chunk: true`; flip with `--no-async-chunk`
-and the pipeline automatically dispatches to the end-to-end codec processor:
-
-```bash
-vllm serve Qwen/Qwen3-TTS-12Hz-1.7B-CustomVoice --omni --port 8091 \
- --no-async-chunk
-```
-
-No variant YAML or extra flag is needed — the `StagePipelineConfig` on each
-stage declares both processor functions and the runtime picks based on the
-`async_chunk:` bool.
-
-Alternatively, use the convenience script:
-```bash
-./run_server.sh # Default: CustomVoice model
-./run_server.sh CustomVoice # CustomVoice model
-./run_server.sh VoiceDesign # VoiceDesign model
-./run_server.sh Base # Base (voice clone) model
-```
-
-### Send TTS Request
-
-Get into the example folder
-```bash
-cd examples/online_serving/qwen3_tts
-```
-
-#### Send request via python
-
-```bash
-# CustomVoice: Use predefined speaker
-python openai_speech_client.py \
- --model Qwen/Qwen3-TTS-12Hz-1.7B-CustomVoice \
- --text "你好,我是通义千问" \
- --voice vivian \
- --language Chinese
-
-# CustomVoice with style instruction
-python openai_speech_client.py \
- --model Qwen/Qwen3-TTS-12Hz-1.7B-CustomVoice \
- --text "今天天气真好" \
- --voice ryan \
- --instructions "用开心的语气说"
-
-# VoiceDesign: Describe the voice style
-python openai_speech_client.py \
- --model Qwen/Qwen3-TTS-12Hz-1.7B-VoiceDesign \
- --task-type VoiceDesign \
- --text "哥哥,你回来啦" \
- --instructions "体现撒娇稚嫩的萝莉女声,音调偏高"
-
-# Base: Voice cloning
-python openai_speech_client.py \
- --model Qwen/Qwen3-TTS-12Hz-1.7B-Base \
- --task-type Base \
- --text "Hello, this is a cloned voice" \
- --ref-audio /path/to/reference.wav \
- --ref-text "Original transcript of the reference audio"
-```
-
-The Python client supports the following command-line arguments:
-
-- `--api-base`: API base URL (default: `http://localhost:8091`)
-- `--model` (or `-m`): Model name/path (default: `Qwen/Qwen3-TTS-12Hz-1.7B-CustomVoice`)
-- `--task-type` (or `-t`): TTS task type. Options: `CustomVoice`, `VoiceDesign`, `Base`
-- `--text`: Text to synthesize (required)
-- `--voice`: Speaker/voice name (default: `vivian`). Options: `vivian`, `ryan`, `aiden`, etc.
-- `--language`: Language. Options: `Auto`, `Chinese`, `English`, `Japanese`, `Korean`, `German`, `French`, `Russian`, `Portuguese`, `Spanish`, `Italian`
-- `--instructions`: Voice style/emotion instructions
-- `--ref-audio`: Reference audio file path or URL for voice cloning (Base task). Local paths are automatically base64-encoded by the client before sending to the server.
-- `--ref-text`: Reference audio transcript for voice cloning (Base task).
-- `--response-format`: Audio output format (default: `wav`). Options: `wav`, `mp3`, `flac`, `pcm`, `aac`, `opus`
-- `--output` (or `-o`): Output audio file path (default: `tts_output.wav`)
-
-#### Send request via curl
-
-```bash
-# Simple TTS request
-curl -X POST http://localhost:8091/v1/audio/speech \
- -H "Content-Type: application/json" \
- -d '{
- "input": "Hello, how are you?",
- "voice": "vivian",
- "language": "English"
- }' --output output.wav
-
-# With style instruction
-curl -X POST http://localhost:8091/v1/audio/speech \
- -H "Content-Type: application/json" \
- -d '{
- "input": "I am so excited!",
- "voice": "vivian",
- "instructions": "Speak with great enthusiasm"
- }' --output excited.wav
-
-# List available voices in CustomVoice models
-curl http://localhost:8091/v1/audio/voices
-```
-
-### Using OpenAI SDK
-
-```python
-from openai import OpenAI
-
-client = OpenAI(base_url="http://localhost:8091/v1", api_key="none")
-
-response = client.audio.speech.create(
- model="Qwen/Qwen3-TTS-12Hz-1.7B-CustomVoice",
- voice="vivian",
- input="Hello, how are you?",
-)
-
-response.stream_to_file("output.wav")
-```
-
-### Using Python httpx
-
-```python
-import httpx
-
-response = httpx.post(
- "http://localhost:8091/v1/audio/speech",
- json={
- "input": "Hello, how are you?",
- "voice": "vivian",
- "language": "English",
- },
- timeout=300.0,
-)
-
-with open("output.wav", "wb") as f:
- f.write(response.content)
-```
-
-## API Reference
-
-### Voices Endpoint
-
-#### GET /v1/audio/voices
-
-List all available voices/speakers from the loaded model, including both built-in model voices and uploaded custom voices.
-
-**Response Example:**
-```json
-{
- "voices": ["vivian", "ryan", "custom_voice_1"],
- "uploaded_voices": [
- {
- "name": "custom_voice_1",
- "consent": "user_consent_id",
- "created_at": 1738660000,
- "file_size": 1024000,
- "mime_type": "audio/wav"
- }
- ]
-}
-```
-
-#### POST /v1/audio/voices
-
-Upload a new voice sample for voice cloning in Base task TTS requests.
-
-**Form Parameters:**
-- `audio_sample` (required): Audio file (max 10MB, supported formats: wav, mp3, flac, ogg, aac, webm, mp4)
-- `consent` (required): Consent recording ID
-- `name` (required): Name for the new voice
-- `ref_text` (optional): Transcript of the audio. Enables in-context voice cloning (higher quality).
-- `speaker_description` (optional): Free-form description of the voice (e.g. "warm narrator", "energetic presenter").
-
-**Response Example:**
-```json
-{
- "success": true,
- "voice": {
- "name": "custom_voice_1",
- "consent": "user_consent_id",
- "created_at": 1738660000,
- "mime_type": "audio/wav",
- "file_size": 1024000,
- "ref_text": "The exact transcript of the audio sample.",
- "speaker_description": "warm narrator"
- }
-}
-```
-
-Fields `ref_text` and `speaker_description` are omitted when not provided at upload time.
-
-**Usage Example:**
-```bash
-curl -X POST http://localhost:8000/v1/audio/voices \
- -F "audio_sample=@/path/to/voice_sample.wav" \
- -F "consent=user_consent_id" \
- -F "name=custom_voice_1" \
- -F "ref_text=The exact transcript of the audio sample." \
- -F "speaker_description=warm narrator"
-```
-
-### Endpoint
-
-```
-POST /v1/audio/speech
-Content-Type: application/json
-```
-
-This endpoint follows the [OpenAI Audio Speech API](https://platform.openai.com/docs/api-reference/audio/createSpeech) format with additional Qwen3-TTS parameters.
-
-### Request Body
-
-```json
-{
- "input": "Text to synthesize",
- "voice": "vivian",
- "response_format": "wav",
- "task_type": "CustomVoice",
- "language": "Auto",
- "instructions": "Optional style instructions",
- "ref_audio": "HTTP URL, base64 data URL, or file:// URI for voice cloning",
- "ref_text": "Reference audio transcript",
- "x_vector_only_mode": false,
- "max_new_tokens": 2048
-}
-```
-
-> **Note:** The `model` field is optional when serving a single model, as the server already knows which model is loaded.
-
-### Response
-
-Returns binary audio data with appropriate `Content-Type` header (e.g., `audio/wav`).
-
-## Parameters
-
-### OpenAI Standard Parameters
-
-| Parameter | Type | Default | Description |
-| ----------------- | ------ | -------------- | ----------------------------------------------------------- |
-| `input` | string | **required** | Text to synthesize |
-| `model` | string | server's model | Model to use (optional, should match server if specified) |
-| `voice` | string | "vivian" | Speaker name (e.g., vivian, ryan, aiden) |
-| `response_format` | string | "wav" | Audio format: wav, mp3, flac, pcm, aac, opus |
-| `speed` | float | 1.0 | Playback speed (0.25-4.0, not supported with `stream=true`) |
-
-### vLLM-Omni Extension Parameters
-
-| Parameter | Type | Default | Description |
-| ---------------------------- | ------ | ------------- | -------------------------------------------------------------------------------------------------------------------- |
-| `task_type` | string | "CustomVoice" | Task: CustomVoice, VoiceDesign, or Base |
-| `language` | string | "Auto" | Language (see supported languages below) |
-| `instructions` | string | "" | Voice style/emotion instructions |
-| `max_new_tokens` | int | 2048 | Maximum tokens to generate |
-| `initial_codec_chunk_frames` | int | null | Per-request initial chunk size override for TTFA tuning. When null, IC is computed dynamically based on server load. |
-| `stream` | bool | false | Stream raw PCM chunks as they are decoded (requires `response_format="pcm"`) |
-
-**Supported languages:** Auto, Chinese, English, Japanese, Korean, German, French, Russian, Portuguese, Spanish, Italian
-
-### Voice Clone Parameters (Base task)
-
-| Parameter | Type | Required | Description |
-| -------------------- | ------ | -------- | ----------------------------------------------------------------------------------------------- |
-| `ref_audio` | string | **Yes** | Reference audio (HTTP URL, base64 data URL, or `file://` URI with `--allowed-local-media-path`) |
-| `ref_text` | string | No | Transcript of reference audio (for ICL mode) |
-| `x_vector_only_mode` | bool | No | Use speaker embedding only (no ICL) |
-
-## Streaming
-
-Set `stream=true` with `response_format="pcm"` to receive raw PCM audio chunks as they are decoded
-(one chunk per Code2Wav window, default 25 frames; configurable in the stage config):
-
-```bash
-curl -X POST http://localhost:8091/v1/audio/speech \
- -H "Content-Type: application/json" \
- -d '{
- "input": "Hello, how are you?",
- "voice": "vivian",
- "language": "English",
- "stream": true,
- "response_format": "pcm"
- }' --no-buffer | play -t raw -r 24000 -e signed -b 16 -c 1 -
-```
-
-**Constraints:**
-- `stream=true` requires `response_format="pcm"` (raw 16-bit signed PCM, 24 kHz mono).
-- `speed` adjustment is not supported when streaming.
-- Requires the server stage config to have `async_chunk: true` (default in `qwen3_tts.yaml`).
-
-## Streaming Text Input (WebSocket)
-
-The `/v1/audio/speech/stream` WebSocket endpoint accepts text incrementally, buffers and splits it at sentence boundaries, and generates audio per sentence.
-
-When `stream_audio=true`, each sentence is emitted as `audio.start`, one or more binary PCM frames, and `audio.done`.
-
-### Quick Start
-
-```bash
-python streaming_speech_client.py \
- --text "Hello world. How are you? I am fine."
-
-python streaming_speech_client.py \
- --text "Hello world. How are you? I am fine." \
- --simulate-stt --stt-delay 0.1
-```
-
-### WebSocket Protocol
-
-Client -> Server:
-
-```jsonc
-{"type": "session.config", "voice": "Vivian", "task_type": "CustomVoice", "language": "Auto", "split_granularity": "sentence", "stream_audio": true, "response_format": "pcm"}
-{"type": "input.text", "text": "Hello, how are you? "}
-{"type": "input.done"}
-```
-
-Server -> Client:
-
-```jsonc
-{"type": "audio.start", "sentence_index": 0, "sentence_text": "Hello, how are you?", "format": "pcm", "sample_rate": 24000}
-// binary PCM frame(s)
-{"type": "audio.done", "sentence_index": 0, "total_bytes": 96000, "error": false}
-{"type": "session.done", "total_sentences": 1}
-```
-
-## Choosing an Execution Backend: Uniproc vs Multiprocessing
-
-Qwen3-TTS stage configs support two execution backends controlled by the
-`distributed_executor_backend` engine arg. The performance tradeoff between
-them is **both hardware- and task-dependent**, so there is no single best
-default (see [#2603](https://github.com/vllm-project/vllm-omni/issues/2603),
-[#2604](https://github.com/vllm-project/vllm-omni/pull/2604) for the full
-investigation).
-
-| Backend | Stage config setting | Behaviour |
-| ------- | -------------------- | --------- |
-| **Uniproc** (default, world_size=1) | `distributed_executor_backend` omitted | Both stages run inside the orchestrator process. Avoids IPC serialisation, D2H copies, and msgpack overhead between stages. |
-| **Multiprocessing** | `distributed_executor_backend: "mp"` | Each stage runs in its own subprocess. The Talker can continue decoding while Code2Wav runs the vocoder in parallel, improving pipeline utilisation under concurrency. |
-
-> **Note:** When `distributed_executor_backend` is omitted and `world_size=1`,
-> vLLM [automatically uses the uniproc executor](https://github.com/vllm-project/vllm/blob/main/vllm/config/parallel.py#L825).
-> When `world_size > 1`, it defaults to `mp`.
-
-### When uniproc wins
-
-The uniproc path eliminates inter-process data transfer (D2H copies,
-msgpack serialisation/deserialisation, tensor detaching). This matters most
-when per-request processing is heavy relative to autoregressive decode.
-
-The Base cloning task involves reference-audio encoding on every request, making IPC
-overhead a larger fraction of total cost. Qwen3-Omni shows a similar pattern.
-
-### When multiprocessing (`mp`) wins
-
-For lighter per-request workloads, process-level parallelism between the
-Talker and Code2Wav stages dominates.
-
-CustomVoice is lighter per-request (no reference audio encoding), so the
-process-level parallelism of `mp` outweighs its serialisation cost at
-concurrency ≥ 4.
-
-### How to switch
-
-To use the uniproc executor on a single-GPU setup, pass the
-`qwen3_tts_uniproc.yaml` stage config:
-
-```bash
-vllm serve Qwen/Qwen3-TTS-12Hz-1.7B-Base \
- --omni \
- --stage-configs-path vllm_omni/model_executor/stage_configs/qwen3_tts_uniproc.yaml \
- --port 8091
-```
-
-## Limitations
-
-- **Single request**: Batch processing is not yet optimized for online serving.
-
-## Troubleshooting
-
-1. **TTS model did not produce audio output**: Ensure you're using the correct model variant for your task type (CustomVoice task → CustomVoice model, etc.)
-2. **Connection refused**: Make sure the server is running on the correct port
-3. **Out of memory**: Use smaller model variant (`Qwen/Qwen3-TTS-12Hz-0.6B-CustomVoice`) or reduce `--gpu-memory-utilization`
-4. **Unsupported speaker**: Use `/v1/audio/voices` to list available voices for the loaded model
-5. **Voice clone fails**: Ensure you're using the Base model variant for voice cloning
diff --git a/examples/online_serving/qwen3_tts/batch_speech_client.py b/examples/online_serving/qwen3_tts/batch_speech_client.py
deleted file mode 100644
index 47fdc3691c7..00000000000
--- a/examples/online_serving/qwen3_tts/batch_speech_client.py
+++ /dev/null
@@ -1,163 +0,0 @@
-"""Batch speech client for Qwen3-TTS via /v1/audio/speech/batch endpoint.
-
-This script demonstrates how to synthesize multiple texts in a single request.
-A particularly useful scenario is voice cloning: set ref_audio once at the
-batch level and generate many utterances in the cloned voice without repeating
-the reference for each item.
-
-Start the server (with batch-optimized stage settings for best throughput):
-
- vllm serve Qwen/Qwen3-TTS-12Hz-1.7B-CustomVoice \
- --omni \
- --trust-remote-code \
- --stage-overrides '{"0":{"max_num_seqs":4,"gpu_memory_utilization":0.2},
- "1":{"max_num_seqs":4,"gpu_memory_utilization":0.2}}'
-
-Examples:
- # Batch with a predefined voice
- python batch_speech_client.py \
- --texts "Hello, how are you?" "Goodbye, see you later!"
-
- # Voice cloning: one ref_audio, many outputs
- python batch_speech_client.py \
- --task-type Base \
- --ref-audio /path/to/reference.wav \
- --ref-text "Transcript of the reference audio" \
- --texts "First cloned sentence." "Second cloned sentence." \
- "Third cloned sentence."
-"""
-
-import argparse
-import base64
-import os
-
-import httpx
-
-DEFAULT_API_BASE = "http://localhost:8091"
-DEFAULT_API_KEY = "EMPTY"
-
-
-def encode_audio_to_base64(audio_path: str) -> str:
- """Encode a local audio file to a base64 data URL."""
- if not os.path.exists(audio_path):
- raise FileNotFoundError(f"Audio file not found: {audio_path}")
-
- ext = os.path.splitext(audio_path)[1].lower()
- mime_map = {".wav": "audio/wav", ".mp3": "audio/mpeg", ".flac": "audio/flac", ".ogg": "audio/ogg"}
- mime_type = mime_map.get(ext, "audio/wav")
-
- with open(audio_path, "rb") as f:
- audio_b64 = base64.b64encode(f.read()).decode("utf-8")
- return f"data:{mime_type};base64,{audio_b64}"
-
-
-def run_batch(args) -> None:
- """Send a batch TTS request and save each result to a file."""
- items = [{"input": text} for text in args.texts]
-
- payload: dict = {
- "items": items,
- "response_format": args.response_format,
- }
- if args.voice:
- payload["voice"] = args.voice
- if args.language:
- payload["language"] = args.language
- if args.task_type:
- payload["task_type"] = args.task_type
- if args.instructions:
- payload["instructions"] = args.instructions
- if args.max_new_tokens:
- payload["max_new_tokens"] = args.max_new_tokens
-
- # Voice cloning parameters (shared across all items)
- if args.ref_audio:
- if args.ref_audio.startswith(("http://", "https://")):
- payload["ref_audio"] = args.ref_audio
- else:
- payload["ref_audio"] = encode_audio_to_base64(args.ref_audio)
- if args.ref_text:
- payload["ref_text"] = args.ref_text
-
- print(f"Sending batch of {len(items)} item(s) to {args.api_base}")
- if args.ref_audio:
- print("Voice cloning mode — ref_audio applied to all items")
-
- url = f"{args.api_base}/v1/audio/speech/batch"
- headers = {
- "Content-Type": "application/json",
- "Authorization": f"Bearer {args.api_key}",
- }
-
- with httpx.Client(timeout=300.0) as client:
- response = client.post(url, json=payload, headers=headers)
-
- if response.status_code != 200:
- print(f"Error {response.status_code}: {response.text}")
- return
-
- data = response.json()
- print(f"Total: {data['total']} Succeeded: {data['succeeded']} Failed: {data['failed']}")
-
- os.makedirs(args.output_dir, exist_ok=True)
- for result in data["results"]:
- idx = result["index"]
- if result["status"] == "success":
- audio_bytes = base64.b64decode(result["audio_data"])
- out_path = os.path.join(args.output_dir, f"batch_{idx}.{args.response_format}")
- with open(out_path, "wb") as f:
- f.write(audio_bytes)
- print(f" [{idx}] saved {len(audio_bytes)} bytes -> {out_path}")
- else:
- print(f" [{idx}] FAILED: {result['error']}")
-
-
-def parse_args():
- parser = argparse.ArgumentParser(
- description="Batch speech client for /v1/audio/speech/batch",
- formatter_class=argparse.RawDescriptionHelpFormatter,
- epilog=__doc__,
- )
-
- parser.add_argument("--api-base", default=DEFAULT_API_BASE, help="API base URL")
- parser.add_argument("--api-key", default=DEFAULT_API_KEY, help="API key")
-
- # Texts to synthesize
- parser.add_argument(
- "--texts",
- nargs="+",
- required=True,
- help="One or more texts to synthesize",
- )
-
- # Shared voice settings
- parser.add_argument("--voice", default="vivian", help="Speaker name (default: vivian)")
- parser.add_argument("--language", default=None, help="Language: Auto, Chinese, English, etc.")
- parser.add_argument("--instructions", default=None, help="Voice style/emotion instructions")
- parser.add_argument(
- "--task-type",
- default=None,
- choices=["CustomVoice", "VoiceDesign", "Base"],
- help="TTS task type (default: CustomVoice)",
- )
-
- # Voice cloning (Base task)
- parser.add_argument("--ref-audio", default=None, help="Reference audio path or URL for voice cloning")
- parser.add_argument("--ref-text", default=None, help="Reference audio transcript for voice cloning")
-
- # Generation
- parser.add_argument("--max-new-tokens", type=int, default=None, help="Max new tokens per item")
- parser.add_argument(
- "--response-format",
- default="wav",
- choices=["wav", "mp3", "flac", "pcm", "aac", "opus"],
- help="Audio format (default: wav)",
- )
- parser.add_argument("--output-dir", "-o", default="batch_output", help="Output directory (default: batch_output)")
-
- return parser.parse_args()
-
-
-if __name__ == "__main__":
- args = parse_args()
- run_batch(args)
diff --git a/examples/online_serving/qwen3_tts/gradio_demo.py b/examples/online_serving/qwen3_tts/gradio_demo.py
deleted file mode 100644
index 8b39b9eab1b..00000000000
--- a/examples/online_serving/qwen3_tts/gradio_demo.py
+++ /dev/null
@@ -1,804 +0,0 @@
-"""Gradio demo for Qwen3-TTS with gapless streaming audio playback.
-
-Uses a custom AudioWorklet-based player for gap-free streaming,
-inspired by github.com/KoljaB/RealtimeVoiceChat. Audio is streamed
-from the vLLM server through a same-origin proxy and played via the
-Web Audio API's AudioWorklet, which maintains a FIFO buffer queue
-and plays samples at the audio clock rate — eliminating inter-chunk
-gaps inherent in Gradio's built-in streaming audio component.
-
-Also supports non-streaming mode (full audio download) via gr.Audio.
-
-Supports all 3 task types:
- - CustomVoice: Predefined speaker with optional style instructions
- - VoiceDesign: Natural language voice description
- - Base: Voice cloning from reference audio (upload or URL)
-
-Usage:
- # Start the vLLM server first (see run_server.sh), then:
- python gradio_demo.py --api-base http://localhost:8000
-"""
-
-import argparse
-import io
-import json
-import logging
-
-try:
- import gradio as gr
-except ImportError:
- raise ImportError("gradio is required to run this demo. Install it with: pip install 'vllm-omni[demo]'") from None
-import httpx
-import numpy as np
-import soundfile as sf
-from fastapi import FastAPI, Request
-from fastapi.responses import Response, StreamingResponse
-from tts_common import (
- PCM_SAMPLE_RATE,
- SUPPORTED_LANGUAGES,
- TASK_TYPES,
- add_common_args,
- build_payload,
- fetch_voices,
-)
-
-logger = logging.getLogger(__name__)
-
-# ── AudioWorklet processor (loaded in browser via Blob URL) ──────────
-WORKLET_JS = r"""
-class TTSPlaybackProcessor extends AudioWorkletProcessor {
- constructor() {
- super();
- this.queue = [];
- this.buf = null;
- this.pos = 0;
- this.playing = false;
- this.played = 0;
- this.port.onmessage = (e) => {
- if (e.data && e.data.type === 'clear') {
- this.queue = []; this.buf = null; this.pos = 0; this.played = 0;
- if (this.playing) { this.playing = false; this.port.postMessage({type:'stopped'}); }
- return;
- }
- this.queue.push(e.data);
- };
- }
- process(inputs, outputs) {
- const out = outputs[0][0];
- for (let i = 0; i < out.length; i++) {
- if (!this.buf || this.pos >= this.buf.length) {
- if (this.queue.length > 0) {
- this.buf = this.queue.shift(); this.pos = 0;
- } else {
- for (let j = i; j < out.length; j++) out[j] = 0;
- if (this.playing) { this.playing = false; this.port.postMessage({type:'stopped', played:this.played}); }
- return true;
- }
- }
- out[i] = this.buf[this.pos++] / 32768;
- this.played++;
- }
- if (!this.playing) { this.playing = true; this.port.postMessage({type:'started'}); }
- return true;
- }
-}
-registerProcessor('tts-playback-processor', TTSPlaybackProcessor);
-"""
-
-# ── Player HTML (container with metric cards) ────────────────────────
-PLAYER_HTML = """
-<div id="tts-player">
- <div style="display:flex; align-items:center; gap:10px;">
- <div id="tts-status-dot" style="width:10px;height:10px;border-radius:50%;background:#ccc;flex-shrink:0;"></div>
- <span id="tts-status" style="font-weight:600;font-size:1.05em;">Ready</span>
- <button id="tts-stop-btn" onclick="window.ttsStop()"
- style="display:none; margin-left:auto; padding:5px 16px; border-radius:6px; border:1px solid #EF5552;
- background:#fff; color:#EF5552; cursor:pointer; font-size:0.85em; transition:all 0.15s;">Stop</button>
- </div>
- <div id="tts-metrics" style="display:none; grid-template-columns:repeat(4,1fr); gap:10px; margin-top:12px;">
- <div style="background:#f8f9fa;border-radius:6px;padding:8px 10px;text-align:center;">
- <div style="font-size:0.7em;text-transform:uppercase;color:#888;letter-spacing:0.5px;margin-bottom:2px;">TTFP</div>
- <div id="tts-m-ttfp" style="font-size:1.2em;font-weight:700;color:#333;">—</div>
- </div>
- <div style="background:#f8f9fa;border-radius:6px;padding:8px 10px;text-align:center;">
- <div style="font-size:0.7em;text-transform:uppercase;color:#888;letter-spacing:0.5px;margin-bottom:2px;">RTF</div>
- <div id="tts-m-rtf" style="font-size:1.2em;font-weight:700;color:#333;">—</div>
- </div>
- <div style="background:#f8f9fa;border-radius:6px;padding:8px 10px;text-align:center;">
- <div style="font-size:0.7em;text-transform:uppercase;color:#888;letter-spacing:0.5px;margin-bottom:2px;">Audio</div>
- <div id="tts-m-dur" style="font-size:1.2em;font-weight:700;color:#333;">—</div>
- </div>
- <div style="background:#f8f9fa;border-radius:6px;padding:8px 10px;text-align:center;">
- <div style="font-size:0.7em;text-transform:uppercase;color:#888;letter-spacing:0.5px;margin-bottom:2px;">Speed</div>
- <div id="tts-m-speed" style="font-size:1.2em;font-weight:700;color:#333;">—</div>
- </div>
- </div>
- <div id="tts-rtf-bar-wrap" style="display:none; background:#e8ecf1; border-radius:4px; height:20px; overflow:hidden; position:relative; margin-top:10px;">
- <div id="tts-rtf-bar" style="height:100%; border-radius:4px; transition:width 0.3s ease, background 0.3s ease; width:0%;"></div>
- <span id="tts-rtf-label" style="position:absolute;top:50%;left:50%;transform:translate(-50%,-50%);font-size:0.75em;font-weight:600;color:#444;"></span>
- </div>
- <div id="tts-elapsed" style="display:none; margin-top:6px; font-size:0.8em; color:#999; text-align:right;"></div>
-</div>
-"""
-
-
-def _build_player_js(sample_rate: int) -> str:
- """Build the JavaScript that powers the AudioWorklet player."""
- return f"""
- <script>
- const SR = {sample_rate};
- const WC = {json.dumps(WORKLET_JS)};
- let ctx = null, node = null, abort = null, gen = false, st = {{}};
-
- async function init() {{
- if (ctx) return;
- ctx = new AudioContext({{ sampleRate: SR }});
- const b = new Blob([WC], {{ type: 'application/javascript' }});
- const u = URL.createObjectURL(b);
- await ctx.audioWorklet.addModule(u);
- URL.revokeObjectURL(u);
- node = new AudioWorkletNode(ctx, 'tts-playback-processor');
- node.connect(ctx.destination);
- node.port.onmessage = (e) => {{
- if (e.data.type === 'started') setStatus('Playing...', '#64dd17');
- else if (e.data.type === 'stopped' && !gen) {{
- setStatus('Done', '#64dd17'); showStats(true);
- const btn = document.getElementById('tts-stop-btn');
- if (btn) btn.style.display = 'none';
- }}
- }};
- }}
-
- function setStatus(text, color) {{
- const s = document.getElementById('tts-status');
- const d = document.getElementById('tts-status-dot');
- if (s) s.textContent = text;
- if (d) d.style.background = color || '#ccc';
- }}
-
- function showStats(fin) {{
- if (!st.t0) return;
- const elapsed = (fin && st.streamEnd ? (st.streamEnd - st.t0) : (performance.now() - st.t0)) / 1000;
- const dur = st.samples / SR;
- const mTtfp = document.getElementById('tts-m-ttfp');
- const mRtf = document.getElementById('tts-m-rtf');
- const mDur = document.getElementById('tts-m-dur');
- const mSpeed = document.getElementById('tts-m-speed');
- const bar = document.getElementById('tts-rtf-bar');
- const barLabel = document.getElementById('tts-rtf-label');
- const elapsedEl = document.getElementById('tts-elapsed');
-
- if (mTtfp && st.ttfp != null) mTtfp.textContent = st.ttfp.toFixed(0) + 'ms';
- if (mDur) mDur.textContent = dur.toFixed(1) + 's';
-
- if (dur > 0 && elapsed > 0) {{
- const rtf = elapsed / dur;
- const speed = 1 / rtf;
- if (mRtf) {{
- mRtf.textContent = rtf.toFixed(2) + 'x';
- mRtf.style.color = rtf < 1 ? '#64dd17' : rtf < 1.5 ? '#e8a317' : '#EF5552';
- }}
- if (mSpeed) {{
- mSpeed.textContent = speed.toFixed(1) + 'x';
- mSpeed.style.color = speed > 1 ? '#64dd17' : speed > 0.7 ? '#e8a317' : '#EF5552';
- }}
- if (bar) {{
- const pct = Math.min(speed / 3 * 100, 100);
- bar.style.width = pct + '%';
- bar.style.background = speed > 1 ? 'linear-gradient(90deg,#4A90D9,#64dd17)' : speed > 0.7 ? 'linear-gradient(90deg,#e8a317,#f0b866)' : 'linear-gradient(90deg,#EF5552,#f87171)';
- }}
- if (barLabel) barLabel.textContent = speed.toFixed(1) + 'x realtime';
- }}
- if (elapsedEl) {{
- elapsedEl.style.display = 'block';
- elapsedEl.textContent = fin ? 'Completed in ' + elapsed.toFixed(1) + 's (' + st.chunks + ' chunks)' : elapsed.toFixed(1) + 's elapsed (' + st.chunks + ' chunks)';
- }}
- }}
-
- window.ttsStop = function() {{
- if (abort) abort.abort();
- if (node) node.port.postMessage({{ type: 'clear' }});
- gen = false;
- setStatus('Stopped', '#999');
- const btn = document.getElementById('tts-stop-btn');
- if (btn) btn.style.display = 'none';
- }};
-
- window.ttsGenerate = async function(payload) {{
- try {{ await init(); if (ctx.state === 'suspended') await ctx.resume(); }}
- catch (e) {{ const s = document.getElementById('tts-status'); if (s) s.textContent = 'Audio init error: ' + e.message; return; }}
-
- // Abort previous request and clear worklet buffer
- if (abort) abort.abort();
- node.port.postMessage({{ type: 'clear' }});
- // Wait for worklet to process clear before sending new data
- await new Promise(r => setTimeout(r, 50));
- node.port.postMessage({{ type: 'clear' }});
-
- gen = true;
- st = {{ t0: null, chunks: 0, samples: 0, ttfp: null }};
- setStatus('Connecting...', '#4A90D9');
- const bEl = document.getElementById('tts-stop-btn');
- if (bEl) bEl.style.display = 'inline-block';
- const mp = document.getElementById('tts-metrics');
- if (mp) {{ mp.style.display = 'grid'; ['tts-m-ttfp','tts-m-rtf','tts-m-dur','tts-m-speed'].forEach(id => {{ const e = document.getElementById(id); if(e) {{ e.textContent = '—'; e.style.color = '#333'; }} }}); }}
- const bw = document.getElementById('tts-rtf-bar-wrap');
- if (bw) bw.style.display = 'block';
- const bar = document.getElementById('tts-rtf-bar');
- if (bar) bar.style.width = '0%';
- const bl = document.getElementById('tts-rtf-label');
- if (bl) bl.textContent = '';
- const ee = document.getElementById('tts-elapsed');
- if (ee) {{ ee.style.display = 'none'; ee.textContent = ''; }}
- abort = new AbortController();
-
- try {{
- console.log('fetch payload:', JSON.stringify({{input: payload.input?.slice(0,30), task: payload.task_type, has_ref: !!payload.ref_audio, stream: payload.stream}}));
- st.t0 = performance.now();
- const r = await fetch('/proxy/v1/audio/speech', {{
- method: 'POST',
- headers: {{ 'Content-Type': 'application/json' }},
- body: JSON.stringify(payload),
- signal: abort.signal,
- }});
- if (!r.ok) {{ const t = await r.text(); throw new Error('Server ' + r.status + ': ' + t.slice(0, 200)); }}
- setStatus('Streaming...', '#4A90D9');
-
- const reader = r.body.getReader();
- let left = new Uint8Array(0);
- while (true) {{
- const {{ done, value }} = await reader.read();
- if (done) break;
- let raw;
- if (left.length > 0) {{
- raw = new Uint8Array(left.length + value.length);
- raw.set(left); raw.set(value, left.length);
- }} else {{ raw = value; }}
- const usable = raw.length - (raw.length % 2);
- left = usable < raw.length ? raw.slice(usable) : new Uint8Array(0);
- if (usable > 0) {{
- const ab = new ArrayBuffer(usable);
- new Uint8Array(ab).set(raw.subarray(0, usable));
- const pcm = new Int16Array(ab);
- node.port.postMessage(pcm);
- st.chunks++;
- st.samples += pcm.length;
- if (st.ttfp == null) st.ttfp = performance.now() - st.t0;
- showStats(false);
- }}
- }}
- }} catch (e) {{
- if (e.name !== 'AbortError') {{
- setStatus('Error: ' + e.message, '#EF5552');
- console.error('TTS error:', e);
- }}
- }} finally {{
- // Freeze RTF at stream-end time (before playback finishes)
- st.streamEnd = performance.now();
- showStats(true);
- gen = false;
- if (st.samples > 0) setStatus('Finishing playback...', '#64dd17');
- else {{
- setStatus('No audio received', '#999');
- if (bEl) bEl.style.display = 'none';
- }}
- }}
- }};
- </script>
-"""
-
-
-def generate_speech(
- api_base: str,
- text: str,
- task_type: str,
- voice: str,
- language: str,
- instructions: str,
- ref_audio: tuple | None,
- ref_audio_url: str,
- ref_text: str,
- x_vector_only: bool,
- response_format: str,
- speed: float,
-):
- """Non-streaming: call /v1/audio/speech and return complete audio."""
- payload = build_payload(
- text,
- task_type,
- voice,
- language,
- instructions,
- ref_audio,
- ref_audio_url,
- ref_text,
- x_vector_only,
- response_format,
- speed,
- stream=False,
- )
- try:
- with httpx.Client(timeout=300.0) as client:
- resp = client.post(
- f"{api_base}/v1/audio/speech",
- json=payload,
- headers={"Content-Type": "application/json", "Authorization": "Bearer EMPTY"},
- )
- except httpx.TimeoutException:
- raise gr.Error("Request timed out. The server may be busy.")
- except httpx.ConnectError:
- raise gr.Error(f"Cannot connect to server at {api_base}.")
-
- if resp.status_code != 200:
- raise gr.Error(f"Server error ({resp.status_code}): {resp.text}")
-
- content_type = resp.headers.get("content-type", "")
- if "application/json" in content_type:
- try:
- raise gr.Error(f"Server error: {resp.json()}")
- except ValueError:
- pass
-
- try:
- if response_format == "pcm":
- audio_np = np.frombuffer(resp.content, dtype=np.int16).astype(np.float32) / 32767.0
- return (PCM_SAMPLE_RATE, audio_np)
- audio_np, sample_rate = sf.read(io.BytesIO(resp.content))
- if audio_np.ndim > 1:
- audio_np = audio_np[:, 0]
- return (sample_rate, audio_np.astype(np.float32))
- except Exception as e:
- raise gr.Error(f"Failed to decode audio: {e}")
-
-
-def create_app(api_base: str):
- """Create the FastAPI app with streaming proxy + Gradio UI."""
- fastapi_app = FastAPI()
-
- # Server-side payload store (avoids sending large base64 through Gradio textbox)
- _pending_payloads: dict[str, dict] = {}
-
- # ── Streaming proxy (same-origin, no CORS issues) ────────────
- @fastapi_app.post("/proxy/v1/audio/speech")
- async def proxy_speech(request: Request):
- body = await request.json()
- # Check if this is a request ID referencing a stored payload
- req_id = body.get("_req_id")
- if req_id and req_id in _pending_payloads:
- body = _pending_payloads.pop(req_id)
- # Pass ref_audio URL directly to vLLM server (it handles URL resolution).
- # Pre-downloading and re-encoding adds ~2-3s to TTFP for large files.
- logger.info(
- "Proxy request: %s",
- {k: (f"<{len(str(v))} chars>" if k == "ref_audio" else v) for k, v in body.items()},
- )
- try:
- client = httpx.AsyncClient(timeout=300)
- resp = await client.send(
- client.build_request(
- "POST",
- f"{api_base}/v1/audio/speech",
- json=body,
- headers={"Authorization": "Bearer EMPTY", "Content-Type": "application/json"},
- ),
- stream=True,
- )
- except Exception as exc:
- logger.exception("Proxy connection error")
- await client.aclose()
- return Response(content=str(exc), status_code=502)
-
- if resp.status_code != 200:
- content = await resp.aread()
- logger.error("Proxy upstream error %d: %s", resp.status_code, content[:200])
- await resp.aclose()
- await client.aclose()
- return Response(content=content, status_code=resp.status_code)
-
- async def relay():
- total = 0
- try:
- async for chunk in resp.aiter_bytes():
- total += len(chunk)
- yield chunk
- except Exception:
- logger.exception("Proxy relay error after %d bytes", total)
- finally:
- logger.info("Proxy relay done: %d bytes", total)
- await resp.aclose()
- await client.aclose()
-
- return StreamingResponse(relay(), media_type="application/octet-stream")
-
- # ── Gradio UI ────────────────────────────────────────────────
- voices = fetch_voices(api_base)
-
- css = """
- #generate-btn button { width: 100%; }
- #streaming-player { border: 1px solid var(--border-color-primary) !important; border-radius: var(--block-radius) !important; padding: var(--block-padding) !important; }
- """
-
- theme = gr.themes.Default(
- primary_hue=gr.themes.Color(
- c50="#f0f5ff",
- c100="#dce6f9",
- c200="#b8cef3",
- c300="#8eb2eb",
- c400="#6496e0",
- c500="#4A90D9",
- c600="#3a7bc8",
- c700="#2d66b0",
- c800="#1f4f8f",
- c900="#163a6e",
- c950="#0e2650",
- ),
- )
-
- with gr.Blocks(
- title="Qwen3-TTS Demo",
- ) as demo:
- gr.HTML(f"""
- <div style="display:flex; align-items:center; gap:16px; margin-bottom:8px;">
- <img src="https://raw.githubusercontent.com/vllm-project/vllm-omni/main/docs/source/logos/vllm-omni-logo.png"
- alt="vLLM-Omni" style="height:42px;">
- <div>
- <h1 style="margin:0; font-size:1.5em;">Qwen3-TTS Streaming Demo</h1>
- <span style="font-size:0.85em; color:#666;">
- Served by <a href="https://github.com/vllm-project/vllm-omni" target="_blank"
- style="color:#4A90D9; text-decoration:none; font-weight:600;">vLLM-Omni</a>
- · <code style="background:#eef2f7; padding:2px 6px; border-radius:4px; font-size:0.9em;">{api_base}</code>
- </span>
- </div>
- </div>
- """)
-
- with gr.Row():
- with gr.Column(scale=3):
- text_input = gr.Textbox(
- label="Text to Synthesize",
- placeholder="Enter text here, e.g., Hello, how are you?",
- lines=4,
- )
- with gr.Row():
- task_type = gr.Radio(
- choices=TASK_TYPES,
- value="CustomVoice",
- label="Task Type",
- scale=2,
- )
- language = gr.Dropdown(
- choices=SUPPORTED_LANGUAGES,
- value="Auto",
- label="Language",
- scale=1,
- )
- voice = gr.Dropdown(
- choices=voices,
- value=voices[0] if voices else None,
- label="speaker",
- visible=True,
- allow_custom_value=True,
- )
- instructions = gr.Textbox(
- label="Instructions",
- placeholder="e.g., Speak with excitement / A warm, friendly female voice",
- lines=2,
- visible=True,
- info="Optional style/emotion instructions",
- )
- with gr.Column(visible=False) as ref_group:
- ref_audio = gr.Audio(
- label="Reference Audio (upload for voice cloning)",
- type="numpy",
- sources=["upload", "microphone"],
- )
- ref_audio_url = gr.Textbox(
- label="Reference Audio URL",
- placeholder="https://example.com/reference.wav",
- lines=1,
- )
- ref_text = gr.Textbox(
- label="Reference Audio Transcript",
- placeholder="Transcript of reference audio (optional, improves quality)",
- lines=2,
- )
- x_vector_only = gr.Checkbox(
- label="Use x-vector only",
- value=False,
- info="Skip reference transcript, use speaker embedding only",
- )
-
- with gr.Row():
- response_format = gr.Dropdown(
- choices=["wav", "mp3", "flac", "pcm", "aac", "opus"],
- value="pcm",
- label="Audio Format",
- scale=1,
- interactive=False,
- )
- speed = gr.Slider(
- minimum=0.25,
- maximum=4.0,
- value=1.0,
- step=0.05,
- label="Speed",
- scale=1,
- interactive=False,
- )
- stream_checkbox = gr.Checkbox(
- label="Stream (gapless)",
- value=True,
- info="AudioWorklet streaming (recommended)",
- scale=1,
- )
-
- with gr.Row():
- generate_btn = gr.Button(
- "Generate Speech",
- variant="primary",
- size="lg",
- elem_id="generate-btn",
- scale=3,
- )
- reset_btn = gr.Button(
- "Reset",
- variant="secondary",
- size="lg",
- scale=1,
- )
-
- with gr.Column(scale=2):
- player_html = gr.HTML(
- value=PLAYER_HTML,
- visible=True,
- label="streaming player",
- elem_id="streaming-player",
- )
- audio_output = gr.Audio(
- label="generated audio",
- interactive=False,
- autoplay=True,
- visible=False,
- )
- with gr.Column(visible=True) as examples_cv:
- gr.Examples(
- examples=[
- [
- "Have you ever wondered what it would be like to travel through time and visit ancient civilizations? The possibilities are endless, from witnessing the construction of the pyramids to experiencing the Renaissance firsthand.",
- "ryan",
- "English",
- "",
- ],
- [
- "其实我真的有发现,我是一个特别善于观察别人情绪的人。比如说在一个聚会上,我总能第一时间察觉到谁不太开心,然后想办法让大家都能融入到欢乐的氛围中来。",
- "vivian",
- "Chinese",
- "用特别愤怒的语气说",
- ],
- [
- "It was a dark and stormy night when the old lighthouse keeper heard a knock at the door. He set down his cup of tea, adjusted his glasses, and walked slowly toward the entrance.",
- "aiden",
- "English",
- "Speak in a mysterious, suspenseful tone",
- ],
- ],
- inputs=[text_input, voice, language, instructions],
- label="examples",
- )
- with gr.Column(visible=False) as examples_vd:
- gr.Examples(
- examples=[
- [
- "It's in the top drawer... wait, it's empty? No way, that's impossible! I'm sure I put it there! Someone must have moved it while I was gone.",
- "English",
- "Speak in an incredulous tone, but with a hint of panic beginning to creep into your voice.",
- ],
- [
- "哥哥,你回来啦,人家等了你好久好久了,要抱抱!你去哪里了呀,都不跟人家说一声,人家好担心你哦。",
- "Chinese",
- "体现撒娇稚嫩的萝莉女声,音调偏高且起伏明显,营造出黏人、做作又刻意卖萌的听觉效果。",
- ],
- ],
- inputs=[text_input, language, instructions],
- label="examples",
- )
- with gr.Column(visible=False) as examples_base:
- gr.Examples(
- examples=[
- [
- "Good one. Okay, fine, I'm just gonna leave this sock monkey here. Goodbye. I hope you enjoy the rest of your evening and have a wonderful time.",
- "English",
- "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen3-TTS-Repo/clone_2.wav",
- "Okay. Yeah. I resent you. I love you. I respect you. But you know what? You blew it! And thanks to you.",
- ],
- [
- "其实我真的有发现,我是一个特别善于观察别人情绪的人。比如说在一个聚会上,我总能第一时间察觉到谁不太开心。",
- "Chinese",
- "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen3-TTS-Repo/clone_2.wav",
- "Okay. Yeah. I resent you. I love you. I respect you. But you know what? You blew it! And thanks to you.",
- ],
- ],
- inputs=[text_input, language, ref_audio_url, ref_text],
- label="examples",
- )
- gr.HTML("""
- <div style="text-align:center; padding:8px 0; margin-top:4px;">
- <a href="https://github.com/vllm-project/vllm-omni" target="_blank">
- <img src="https://raw.githubusercontent.com/vllm-project/vllm-omni/main/docs/source/logos/vllm-omni-logo.png"
- alt="vLLM-Omni" style="height:28px; opacity:0.7;">
- </a>
- </div>
- """)
-
- # Hidden textbox to pass payload from Python → JavaScript
- hidden_payload = gr.Textbox(visible=False, elem_id="tts-payload")
-
- # ── Event wiring ─────────────────────────────────────────
- def on_task_change(tt):
- is_cv = tt == "CustomVoice"
- is_vd = tt == "VoiceDesign"
- is_base = tt == "Base"
- return (
- gr.update(visible=is_cv), # voice
- gr.update(
- visible=(is_cv or is_vd),
- info="Required: describe the voice style" if is_vd else "Optional style/emotion instructions",
- ), # instructions
- gr.update(visible=is_base), # ref_group
- gr.update(visible=is_cv), # examples_cv
- gr.update(visible=is_vd), # examples_vd
- gr.update(visible=is_base), # examples_base
- )
-
- task_type.change(
- fn=on_task_change,
- inputs=[task_type],
- outputs=[
- voice,
- instructions,
- ref_group,
- examples_cv,
- examples_vd,
- examples_base,
- ],
- )
-
- def on_stream_change(stream: bool):
- if stream:
- return (
- gr.update(value="pcm", interactive=False),
- gr.update(interactive=False),
- gr.update(visible=True), # player
- gr.update(visible=False), # audio
- )
- return (
- gr.update(value="wav", interactive=True),
- gr.update(interactive=True),
- gr.update(visible=False),
- gr.update(visible=True),
- )
-
- stream_checkbox.change(
- fn=on_stream_change,
- inputs=[stream_checkbox],
- outputs=[response_format, speed, player_html, audio_output],
- )
-
- def on_reset():
- return (
- "", # text
- None, # audio_output
- "", # hidden_payload
- PLAYER_HTML, # reset player
- )
-
- reset_btn.click(
- fn=on_reset,
- outputs=[text_input, audio_output, hidden_payload, player_html],
- js="() => { if (window.ttsStop) window.ttsStop(); }",
- )
-
- all_inputs = [
- text_input,
- task_type,
- voice,
- language,
- instructions,
- ref_audio,
- ref_audio_url,
- ref_text,
- x_vector_only,
- response_format,
- speed,
- ]
-
- def on_generate(stream_enabled, *args):
- if stream_enabled:
- import time as _time
-
- text, task_type_v, voice_v, lang_v, instr_v, ref_a, ref_url, ref_t, xvec, _fmt, _spd = args
- # For streaming, use URL for ref_audio (base64 is too large
- # for the Gradio textbox → JS → fetch pipeline).
- # If user uploaded audio but no URL, encode and store server-side.
- if ref_a is not None and not (ref_url and ref_url.strip()):
- req_id = f"req-{int(_time.time() * 1000)}"
- full_payload = build_payload(
- text,
- task_type_v,
- voice_v,
- lang_v,
- instr_v,
- ref_a,
- ref_url,
- ref_t,
- xvec,
- stream=True,
- )
- _pending_payloads[req_id] = full_payload
- browser_payload = {"_req_id": req_id, "_nonce": int(_time.time() * 1000)}
- return json.dumps(browser_payload), gr.update()
-
- # URL-only path: payload is small, pass directly to browser
- payload = build_payload(
- text,
- task_type_v,
- voice_v,
- lang_v,
- instr_v,
- None,
- ref_url,
- ref_t,
- xvec,
- stream=True,
- )
- payload["_nonce"] = int(_time.time() * 1000)
- return json.dumps(payload), gr.update()
- else:
- audio = generate_speech(api_base, *args)
- return "", audio
-
- generate_btn.click(
- fn=on_generate,
- inputs=[stream_checkbox] + all_inputs,
- outputs=[hidden_payload, audio_output],
- ).then(
- fn=lambda p: p,
- inputs=[hidden_payload],
- outputs=[hidden_payload],
- js="(p) => { if (p && p.trim()) { const d = JSON.parse(p); delete d._nonce; window.ttsGenerate(d); } return p; }",
- )
-
- demo.queue()
-
- return gr.mount_gradio_app(
- fastapi_app,
- demo,
- path="/",
- css=css,
- theme=theme,
- head=_build_player_js(PCM_SAMPLE_RATE),
- )
-
-
-def parse_args():
- parser = argparse.ArgumentParser(
- description="Gradio demo for Qwen3-TTS with gapless AudioWorklet streaming.",
- )
- add_common_args(parser)
- return parser.parse_args()
-
-
-def main():
- args = parse_args()
- logging.basicConfig(level=logging.INFO)
- print(f"Connecting to vLLM server at: {args.api_base}")
-
- app = create_app(args.api_base)
-
- import uvicorn
-
- uvicorn.run(app, host=args.host, port=args.port)
-
-
-if __name__ == "__main__":
- main()
diff --git a/examples/online_serving/qwen3_tts/openai_speech_client.py b/examples/online_serving/qwen3_tts/openai_speech_client.py
deleted file mode 100644
index 77e13b08ed2..00000000000
--- a/examples/online_serving/qwen3_tts/openai_speech_client.py
+++ /dev/null
@@ -1,262 +0,0 @@
-"""OpenAI-compatible client for Qwen3-TTS via /v1/audio/speech endpoint.
-
-This script demonstrates how to use the OpenAI-compatible speech API
-to generate audio from text using Qwen3-TTS models.
-
-Examples:
- # CustomVoice task (predefined speaker)
- python openai_speech_client.py --text "Hello, how are you?" --voice vivian
-
- # CustomVoice with emotion instruction
- python openai_speech_client.py --text "I'm so happy!" --voice vivian \
- --instructions "Speak with excitement"
-
- # VoiceDesign task (voice from description)
- python openai_speech_client.py --text "Hello world" \
- --task-type VoiceDesign \
- --instructions "A warm, friendly female voice"
-
- # Base task (voice cloning)
- python openai_speech_client.py --text "Hello world" \
- --task-type Base \
- --ref-audio "https://example.com/reference.wav" \
- --ref-text "This is the reference transcript"
-
- # Base task with pre-computed speaker embedding
- python openai_speech_client.py --text "Hello world" \
- --task-type Base \
- --speaker-embedding embedding.json
-"""
-
-import argparse
-import base64
-import json
-import os
-
-import httpx
-
-# Default server configuration
-DEFAULT_API_BASE = "http://localhost:8091"
-DEFAULT_API_KEY = "EMPTY"
-
-
-def encode_audio_to_base64(audio_path: str) -> str:
- """Encode a local audio file to base64 data URL."""
- if not os.path.exists(audio_path):
- raise FileNotFoundError(f"Audio file not found: {audio_path}")
-
- # Detect MIME type from extension
- audio_path_lower = audio_path.lower()
- if audio_path_lower.endswith(".wav"):
- mime_type = "audio/wav"
- elif audio_path_lower.endswith((".mp3", ".mpeg")):
- mime_type = "audio/mpeg"
- elif audio_path_lower.endswith(".flac"):
- mime_type = "audio/flac"
- elif audio_path_lower.endswith(".ogg"):
- mime_type = "audio/ogg"
- else:
- mime_type = "audio/wav" # Default
-
- with open(audio_path, "rb") as f:
- audio_bytes = f.read()
- audio_b64 = base64.b64encode(audio_bytes).decode("utf-8")
- return f"data:{mime_type};base64,{audio_b64}"
-
-
-def run_tts_generation(args) -> None:
- """Run TTS generation via OpenAI-compatible /v1/audio/speech API."""
-
- # Build request payload
- payload = {
- "model": args.model,
- "input": args.text,
- "voice": args.speaker,
- "response_format": args.response_format,
- }
-
- # Add optional parameters
- if args.instructions:
- payload["instructions"] = args.instructions
- if args.task_type:
- payload["task_type"] = args.task_type
- if args.language:
- payload["language"] = args.language
- if args.max_new_tokens:
- payload["max_new_tokens"] = args.max_new_tokens
-
- # Voice clone parameters (Base task)
- if args.ref_audio:
- if args.ref_audio.startswith(("http://", "https://")):
- payload["ref_audio"] = args.ref_audio
- elif args.ref_audio.startswith("data:"):
- payload["ref_audio"] = args.ref_audio
- else:
- payload["ref_audio"] = encode_audio_to_base64(args.ref_audio)
- if args.ref_text:
- payload["ref_text"] = args.ref_text
- if args.x_vector_only:
- payload["x_vector_only_mode"] = True
- if args.speaker_embedding:
- with open(args.speaker_embedding) as f:
- payload["speaker_embedding"] = json.load(f)
-
- print(f"Model: {args.model}")
- print(f"Task type: {args.task_type or 'CustomVoice'}")
- print(f"Text: {args.text}")
- print(f"Speaker: {args.speaker}")
- print("Generating audio...")
-
- # Make the API call
- api_url = f"{args.api_base}/v1/audio/speech"
- headers = {
- "Content-Type": "application/json",
- "Authorization": f"Bearer {args.api_key}",
- }
-
- with httpx.Client(timeout=300.0) as client:
- response = client.post(api_url, json=payload, headers=headers)
-
- if response.status_code != 200:
- print(f"Error: {response.status_code}")
- print(response.text)
- return
-
- # Check for JSON error response (only if content is valid UTF-8 text)
- try:
- text = response.content.decode("utf-8")
- if text.startswith('{"error"'):
- print(f"Error: {text}")
- return
- except UnicodeDecodeError:
- pass # Binary audio data, not an error
-
- # Save audio response
- output_path = args.output or "tts_output.wav"
- with open(output_path, "wb") as f:
- f.write(response.content)
- print(f"Audio saved to: {output_path}")
-
-
-def parse_args():
- """Parse command line arguments."""
- parser = argparse.ArgumentParser(
- description="OpenAI-compatible client for Qwen3-TTS via /v1/audio/speech",
- formatter_class=argparse.RawDescriptionHelpFormatter,
- epilog=__doc__,
- )
-
- # Server configuration
- parser.add_argument(
- "--api-base",
- type=str,
- default=DEFAULT_API_BASE,
- help=f"API base URL (default: {DEFAULT_API_BASE})",
- )
- parser.add_argument(
- "--api-key",
- type=str,
- default=DEFAULT_API_KEY,
- help="API key (default: EMPTY)",
- )
- parser.add_argument(
- "--model",
- "-m",
- type=str,
- default="Qwen/Qwen3-TTS-12Hz-1.7B-CustomVoice",
- help="Model name/path",
- )
-
- # Task configuration
- parser.add_argument(
- "--task-type",
- "-t",
- type=str,
- default=None,
- choices=["CustomVoice", "VoiceDesign", "Base"],
- help="TTS task type (default: CustomVoice)",
- )
-
- # Input text
- parser.add_argument(
- "--text",
- type=str,
- required=True,
- help="Text to synthesize",
- )
-
- # Voice/speaker
- parser.add_argument(
- "--speaker",
- type=str,
- default="vivian",
- help="Speaker name (default: vivian). Options: vivian, ryan, aiden, etc.",
- )
- parser.add_argument(
- "--language",
- type=str,
- default=None,
- help="Language: Auto, Chinese, English, etc.",
- )
- parser.add_argument(
- "--instructions",
- type=str,
- default=None,
- help="Voice style/emotion instructions",
- )
-
- # Base (voice clone) parameters
- parser.add_argument(
- "--ref-audio",
- type=str,
- default=None,
- help="Reference audio file path, URL, or base64 for voice cloning (Base task)",
- )
- parser.add_argument(
- "--ref-text",
- type=str,
- default=None,
- help="Reference audio transcript for voice cloning (Base task)",
- )
- parser.add_argument(
- "--x-vector-only",
- action="store_true",
- help="Use x-vector only mode for voice cloning (no ICL)",
- )
- parser.add_argument(
- "--speaker-embedding",
- type=str,
- default=None,
- help="Path to JSON file containing a pre-computed speaker embedding vector (1024-dim for 0.6B, 2048-dim for 1.7B)",
- )
-
- # Generation parameters
- parser.add_argument(
- "--max-new-tokens",
- type=int,
- default=None,
- help="Maximum new tokens to generate",
- )
-
- # Output
- parser.add_argument(
- "--response-format",
- type=str,
- default="wav",
- choices=["wav", "mp3", "flac", "pcm", "aac", "opus"],
- help="Audio output format (default: wav)",
- )
- parser.add_argument(
- "--output",
- "-o",
- type=str,
- default=None,
- help="Output audio file path (default: tts_output.wav)",
- )
-
- return parser.parse_args()
-
-
-if __name__ == "__main__":
- args = parse_args()
- run_tts_generation(args)
diff --git a/examples/online_serving/qwen3_tts/run_gradio_demo.sh b/examples/online_serving/qwen3_tts/run_gradio_demo.sh
deleted file mode 100644
index d79be3c2abd..00000000000
--- a/examples/online_serving/qwen3_tts/run_gradio_demo.sh
+++ /dev/null
@@ -1,202 +0,0 @@
-#!/bin/bash
-# Launch both vLLM server and Gradio demo for Qwen3-TTS
-#
-# Usage:
-# ./run_gradio_demo.sh # Default: CustomVoice
-# ./run_gradio_demo.sh --task-type VoiceDesign # VoiceDesign model
-# ./run_gradio_demo.sh --task-type Base --gradio-port 7861
-#
-# Options:
-# --task-type TYPE Task type: CustomVoice, VoiceDesign, Base (default: CustomVoice)
-# --server-port PORT Port for vLLM server (default: 8000)
-# --gradio-port PORT Port for Gradio demo (default: 7860)
-# --server-host HOST Host for vLLM server (default: 0.0.0.0)
-# --gradio-ip IP IP for Gradio demo (default: 127.0.0.1)
-# --share Share Gradio demo publicly
-
-set -e
-
-# Default values
-TASK_TYPE="CustomVoice"
-SERVER_PORT=8000
-GRADIO_PORT=7860
-SERVER_HOST="0.0.0.0"
-GRADIO_IP="127.0.0.1"
-GRADIO_SHARE=false
-
-# Parse command line arguments
-while [[ $# -gt 0 ]]; do
- case $1 in
- --task-type)
- TASK_TYPE="$2"
- shift 2
- ;;
- --server-port)
- SERVER_PORT="$2"
- shift 2
- ;;
- --gradio-port)
- GRADIO_PORT="$2"
- shift 2
- ;;
- --server-host)
- SERVER_HOST="$2"
- shift 2
- ;;
- --gradio-ip)
- GRADIO_IP="$2"
- shift 2
- ;;
- --share)
- GRADIO_SHARE=true
- shift
- ;;
- --help)
- echo "Usage: $0 [OPTIONS]"
- echo ""
- echo "Options:"
- echo " --task-type TYPE Task type: CustomVoice, VoiceDesign, Base (default: CustomVoice)"
- echo " --server-port PORT Port for vLLM server (default: 8000)"
- echo " --gradio-port PORT Port for Gradio demo (default: 7860)"
- echo " --server-host HOST Host for vLLM server (default: 0.0.0.0)"
- echo " --gradio-ip IP IP for Gradio demo (default: 127.0.0.1)"
- echo " --share Share Gradio demo publicly"
- echo ""
- exit 0
- ;;
- *)
- echo "Unknown option: $1"
- echo "Use --help for usage information"
- exit 1
- ;;
- esac
-done
-
-# Map task type to model
-case "$TASK_TYPE" in
- CustomVoice)
- MODEL="Qwen/Qwen3-TTS-12Hz-1.7B-CustomVoice"
- ;;
- VoiceDesign)
- MODEL="Qwen/Qwen3-TTS-12Hz-1.7B-VoiceDesign"
- ;;
- Base)
- MODEL="Qwen/Qwen3-TTS-12Hz-1.7B-Base"
- ;;
- *)
- echo "Unknown task type: $TASK_TYPE"
- echo "Supported: CustomVoice, VoiceDesign, Base"
- exit 1
- ;;
-esac
-
-SCRIPT_DIR="$(cd "$(dirname "${BASH_SOURCE[0]}")" && pwd)"
-API_BASE="http://localhost:${SERVER_PORT}"
-
-echo "=========================================="
-echo "Qwen3-TTS Gradio Demo"
-echo "=========================================="
-echo "Task Type : $TASK_TYPE"
-echo "Model : $MODEL"
-echo "Server : http://${SERVER_HOST}:${SERVER_PORT}"
-echo "Gradio : http://${GRADIO_IP}:${GRADIO_PORT}"
-echo "=========================================="
-
-# Cleanup on exit
-cleanup() {
- echo ""
- echo "Shutting down..."
- if [ -n "$SERVER_PID" ]; then
- echo "Stopping vLLM server (PID: $SERVER_PID)..."
- kill "$SERVER_PID" 2>/dev/null || true
- wait "$SERVER_PID" 2>/dev/null || true
- fi
- if [ -n "$GRADIO_PID" ]; then
- echo "Stopping Gradio demo (PID: $GRADIO_PID)..."
- kill "$GRADIO_PID" 2>/dev/null || true
- wait "$GRADIO_PID" 2>/dev/null || true
- fi
- echo "Cleanup complete"
- exit 0
-}
-trap cleanup SIGINT SIGTERM
-
-# Start vLLM server
-echo ""
-echo "Starting vLLM server..."
-LOG_FILE="/tmp/vllm_tts_server_${SERVER_PORT}.log"
-
-vllm-omni serve "$MODEL" \
- --deploy-config vllm_omni/deploy/qwen3_tts.yaml \
- --host "$SERVER_HOST" \
- --port "$SERVER_PORT" \
- --gpu-memory-utilization 0.9 \
- --trust-remote-code \
- --omni 2>&1 | tee "$LOG_FILE" &
-SERVER_PID=$!
-
-# Wait for server startup
-echo ""
-echo "Waiting for vLLM server to be ready..."
-STARTUP_FLAG="/tmp/vllm_tts_startup_flag_${SERVER_PORT}.tmp"
-rm -f "$STARTUP_FLAG"
-
-(
- tail -f "$LOG_FILE" 2>/dev/null | grep -m 1 "Application startup complete" > /dev/null && touch "$STARTUP_FLAG"
-) &
-TAIL_PID=$!
-
-MAX_WAIT=300
-ELAPSED=0
-while [ $ELAPSED -lt $MAX_WAIT ]; do
- if [ -f "$STARTUP_FLAG" ]; then
- kill "$TAIL_PID" 2>/dev/null || true
- wait "$TAIL_PID" 2>/dev/null || true
- echo ""
- echo "vLLM server is ready!"
- break
- fi
- if ! kill -0 "$SERVER_PID" 2>/dev/null; then
- kill "$TAIL_PID" 2>/dev/null || true
- echo ""
- echo "Error: vLLM server failed to start"
- exit 1
- fi
- sleep 1
- ELAPSED=$((ELAPSED + 1))
-done
-
-rm -f "$STARTUP_FLAG"
-
-if [ $ELAPSED -ge $MAX_WAIT ]; then
- kill "$TAIL_PID" 2>/dev/null || true
- echo "Error: Server startup timed out after ${MAX_WAIT}s"
- kill "$SERVER_PID" 2>/dev/null || true
- exit 1
-fi
-
-# Start Gradio demo
-echo ""
-echo "Starting Gradio demo..."
-cd "$SCRIPT_DIR"
-GRADIO_CMD=("python" "gradio_demo.py" "--api-base" "$API_BASE" "--host" "$GRADIO_IP" "--port" "$GRADIO_PORT")
-if [ "$GRADIO_SHARE" = true ]; then
- GRADIO_CMD+=("--share")
-fi
-
-"${GRADIO_CMD[@]}" &
-GRADIO_PID=$!
-
-echo ""
-echo "=========================================="
-echo "Both services are running!"
-echo "=========================================="
-echo "vLLM Server : http://${SERVER_HOST}:${SERVER_PORT}"
-echo "Gradio Demo : http://${GRADIO_IP}:${GRADIO_PORT}"
-echo ""
-echo "Press Ctrl+C to stop both services"
-echo "=========================================="
-echo ""
-
-wait $SERVER_PID $GRADIO_PID || true
-cleanup
diff --git a/examples/online_serving/qwen3_tts/run_server.sh b/examples/online_serving/qwen3_tts/run_server.sh
deleted file mode 100755
index 78dd2c305d3..00000000000
--- a/examples/online_serving/qwen3_tts/run_server.sh
+++ /dev/null
@@ -1,39 +0,0 @@
-#!/bin/bash
-# Launch vLLM-Omni server for Qwen3-TTS models
-#
-# Usage:
-# ./run_server.sh # Default: CustomVoice model
-# ./run_server.sh CustomVoice # CustomVoice model
-# ./run_server.sh VoiceDesign # VoiceDesign model
-# ./run_server.sh Base # Base (voice clone) model
-
-set -e
-
-TASK_TYPE="${1:-CustomVoice}"
-
-case "$TASK_TYPE" in
- CustomVoice)
- MODEL="Qwen/Qwen3-TTS-12Hz-1.7B-CustomVoice"
- ;;
- VoiceDesign)
- MODEL="Qwen/Qwen3-TTS-12Hz-1.7B-VoiceDesign"
- ;;
- Base)
- MODEL="Qwen/Qwen3-TTS-12Hz-1.7B-Base"
- ;;
- *)
- echo "Unknown task type: $TASK_TYPE"
- echo "Supported: CustomVoice, VoiceDesign, Base"
- exit 1
- ;;
-esac
-
-echo "Starting Qwen3-TTS server with model: $MODEL"
-
-vllm-omni serve "$MODEL" \
- --deploy-config vllm_omni/deploy/qwen3_tts.yaml \
- --host 0.0.0.0 \
- --port 8091 \
- --gpu-memory-utilization 0.9 \
- --trust-remote-code \
- --omni
diff --git a/examples/online_serving/qwen3_tts/speaker_embedding_interpolation.py b/examples/online_serving/qwen3_tts/speaker_embedding_interpolation.py
deleted file mode 100644
index 7790fa51276..00000000000
--- a/examples/online_serving/qwen3_tts/speaker_embedding_interpolation.py
+++ /dev/null
@@ -1,379 +0,0 @@
-"""Speaker embedding extraction and interpolation for Qwen3-TTS.
-
-Extracts speaker embeddings from reference audio files using the ECAPA-TDNN
-speaker encoder from a Qwen3-TTS checkpoint, then interpolates between them
-using SLERP and sends the result to the /v1/audio/speech API.
-
-Requirements:
- pip install torch soundfile numpy httpx
-
-Examples:
- # Extract and save an embedding
- python speaker_embedding_interpolation.py extract \
- --model Qwen/Qwen3-TTS-12Hz-1.7B-Base \
- --audio voice_a.wav \
- --output voice_a_embedding.json
-
- # Interpolate between two embeddings and generate speech
- python speaker_embedding_interpolation.py interpolate \
- --embedding-a voice_a_embedding.json \
- --embedding-b voice_b_embedding.json \
- --ratio 0.5 \
- --text "Hello, this is a blended voice." \
- --output blended.wav
-
- # Full pipeline: extract from two audio files + interpolate + generate
- python speaker_embedding_interpolation.py pipeline \
- --model Qwen/Qwen3-TTS-12Hz-1.7B-Base \
- --audio-a voice_a.wav \
- --audio-b voice_b.wav \
- --ratios 0.0 0.25 0.5 0.75 1.0 \
- --text "Hello, this is a blended voice." \
- --output-dir ./interpolated/
-"""
-
-import argparse
-import json
-import os
-import sys
-
-import httpx
-import numpy as np
-import torch
-
-DEFAULT_API_BASE = "http://localhost:8000"
-DEFAULT_API_KEY = "EMPTY"
-
-# ──────────────────────────────────────────────
-# Speaker embedding extraction (offline)
-# ──────────────────────────────────────────────
-
-
-def load_speaker_encoder(model_path: str, device: str = "cpu") -> torch.nn.Module:
- """Load just the ECAPA-TDNN speaker encoder from a Qwen3-TTS checkpoint.
-
- This avoids loading the full TTS model by only instantiating the speaker
- encoder sub-module from the checkpoint weights.
- """
- from transformers import AutoConfig
-
- # Register the config class so AutoConfig can resolve it
- sys.path.insert(0, os.path.dirname(__file__))
- try:
- from vllm_omni.model_executor.models.qwen3_tts.configuration_qwen3_tts import (
- Qwen3TTSConfig,
- )
- from vllm_omni.model_executor.models.qwen3_tts.qwen3_tts_talker import (
- Qwen3TTSSpeakerEncoder,
- )
-
- AutoConfig.register("qwen3_tts", Qwen3TTSConfig)
- except ImportError:
- # If running outside the vllm-omni tree, try importing from the HF hub
- config = AutoConfig.from_pretrained(model_path, trust_remote_code=True)
- # Dynamically import from the downloaded model files
- import importlib
-
- from huggingface_hub import snapshot_download
-
- model_dir = snapshot_download(model_path)
- spec = importlib.util.spec_from_file_location(
- "modeling_qwen3_tts",
- os.path.join(model_dir, "modeling_qwen3_tts.py"),
- )
- mod = importlib.util.module_from_spec(spec)
- spec.loader.exec_module(mod)
- Qwen3TTSSpeakerEncoder = mod.Qwen3TTSSpeakerEncoder
-
- spec2 = importlib.util.spec_from_file_location(
- "configuration_qwen3_tts",
- os.path.join(model_dir, "configuration_qwen3_tts.py"),
- )
- mod2 = importlib.util.module_from_spec(spec2)
- spec2.loader.exec_module(mod2)
- Qwen3TTSConfig = mod2.Qwen3TTSConfig
- config_obj = Qwen3TTSConfig.from_pretrained(model_path)
- encoder = Qwen3TTSSpeakerEncoder(config_obj.speaker_encoder_config)
- # Load weights
- _load_speaker_encoder_weights(encoder, model_path)
- encoder = encoder.to(device).eval()
- return encoder
-
- config = AutoConfig.from_pretrained(model_path, trust_remote_code=True)
- encoder = Qwen3TTSSpeakerEncoder(config.speaker_encoder_config)
-
- _load_speaker_encoder_weights(encoder, model_path)
- encoder = encoder.to(device).eval()
- return encoder
-
-
-def _load_speaker_encoder_weights(encoder: torch.nn.Module, model_path: str) -> None:
- """Load only the speaker_encoder.* weights from the checkpoint."""
- from huggingface_hub import snapshot_download
- from safetensors.torch import load_file
-
- model_dir = snapshot_download(model_path)
-
- prefix = "speaker_encoder."
- state_dict = {}
-
- # Try safetensors first, then pytorch bin
- safetensor_files = sorted(f for f in os.listdir(model_dir) if f.endswith(".safetensors"))
- if safetensor_files:
- for fname in safetensor_files:
- shard = load_file(os.path.join(model_dir, fname))
- for k, v in shard.items():
- if k.startswith(prefix):
- state_dict[k[len(prefix) :]] = v
- else:
- bin_files = sorted(f for f in os.listdir(model_dir) if f.endswith(".bin"))
- for fname in bin_files:
- shard = torch.load(os.path.join(model_dir, fname), map_location="cpu", weights_only=True)
- for k, v in shard.items():
- if k.startswith(prefix):
- state_dict[k[len(prefix) :]] = v
-
- if not state_dict:
- raise RuntimeError(
- f"No speaker_encoder weights found in {model_path}. Make sure this is a Qwen3-TTS-*-Base checkpoint."
- )
-
- encoder.load_state_dict(state_dict)
-
-
-def compute_mel_spectrogram(audio: np.ndarray, sr: int = 24000) -> torch.Tensor:
- """Compute 128-bin mel spectrogram matching Qwen3-TTS's extraction pipeline."""
- from vllm.multimodal.audio import AudioResampler
-
- # Resample to 24kHz if needed
- if sr != 24000:
- resampler = AudioResampler(target_sr=24000)
- audio = resampler.resample(audio.astype(np.float32), orig_sr=sr)
-
- y = torch.from_numpy(audio).unsqueeze(0).float()
-
- from vllm_omni.utils.audio import mel_filter_bank
-
- mel_basis = mel_filter_bank(sr=24000, n_fft=1024, n_mels=128, fmin=0, fmax=12000)
-
- n_fft = 1024
- hop_size = 256
- win_size = 1024
- padding = (n_fft - hop_size) // 2
- y = torch.nn.functional.pad(y.unsqueeze(1), (padding, padding), mode="reflect").squeeze(1)
-
- hann_window = torch.hann_window(win_size)
- spec = torch.stft(
- y,
- n_fft,
- hop_length=hop_size,
- win_length=win_size,
- window=hann_window,
- center=False,
- return_complex=True,
- )
- spec = torch.abs(spec)
- mel = torch.matmul(mel_basis, spec)
- mel = torch.log(torch.clamp(mel, min=1e-5))
- return mel.transpose(1, 2) # (1, T, 128)
-
-
-@torch.inference_mode()
-def extract_embedding(encoder: torch.nn.Module, audio_path: str, device: str = "cpu") -> np.ndarray:
- """Extract a 1024-dim speaker embedding from an audio file."""
- from vllm.multimodal.media.audio import load_audio
-
- audio, sr = load_audio(audio_path, sr=None, mono=True)
- mel = compute_mel_spectrogram(audio, sr).to(device)
- embedding = encoder(mel.to(next(encoder.parameters()).dtype))[0]
- return embedding.float().cpu().numpy()
-
-
-# ──────────────────────────────────────────────
-# Interpolation
-# ──────────────────────────────────────────────
-
-
-def slerp(v0: np.ndarray, v1: np.ndarray, t: float) -> np.ndarray:
- """Spherical linear interpolation between two vectors."""
- v0_norm = v0 / (np.linalg.norm(v0) + 1e-8)
- v1_norm = v1 / (np.linalg.norm(v1) + 1e-8)
-
- dot = np.clip(np.dot(v0_norm, v1_norm), -1.0, 1.0)
- omega = np.arccos(dot)
-
- if np.abs(omega) < 1e-6:
- # Vectors are nearly parallel, fall back to lerp
- return (1.0 - t) * v0 + t * v1
-
- sin_omega = np.sin(omega)
- return (np.sin((1.0 - t) * omega) / sin_omega) * v0 + (np.sin(t * omega) / sin_omega) * v1
-
-
-# ──────────────────────────────────────────────
-# API client
-# ──────────────────────────────────────────────
-
-
-def generate_speech(
- text: str,
- speaker_embedding: list[float],
- output_path: str,
- api_base: str = DEFAULT_API_BASE,
- api_key: str = DEFAULT_API_KEY,
- model: str = "Qwen/Qwen3-TTS-12Hz-1.7B-Base",
-) -> None:
- """Send a speaker_embedding to the TTS API and save the output."""
- payload = {
- "model": model,
- "input": text,
- "task_type": "Base",
- "speaker_embedding": speaker_embedding,
- "response_format": "wav",
- }
- headers = {
- "Content-Type": "application/json",
- "Authorization": f"Bearer {api_key}",
- }
- with httpx.Client(timeout=300.0) as client:
- resp = client.post(f"{api_base}/v1/audio/speech", json=payload, headers=headers)
-
- if resp.status_code != 200:
- print(f"Error {resp.status_code}: {resp.text}")
- sys.exit(1)
-
- with open(output_path, "wb") as f:
- f.write(resp.content)
- print(f"Saved: {output_path}")
-
-
-# ──────────────────────────────────────────────
-# CLI commands
-# ──────────────────────────────────────────────
-
-
-def cmd_extract(args):
- """Extract a speaker embedding from audio and save as JSON."""
- print(f"Loading speaker encoder from {args.model}...")
- encoder = load_speaker_encoder(args.model, device=args.device)
-
- print(f"Extracting embedding from {args.audio}...")
- emb = extract_embedding(encoder, args.audio, device=args.device)
- print(f"Embedding shape: {emb.shape}")
-
- output_path = args.output or os.path.splitext(args.audio)[0] + "_embedding.json"
- with open(output_path, "w") as f:
- json.dump(emb.tolist(), f)
- print(f"Saved embedding to {output_path}")
-
-
-def cmd_interpolate(args):
- """Interpolate between two embeddings and generate speech."""
- with open(args.embedding_a) as f:
- emb_a = np.array(json.load(f), dtype=np.float32)
- with open(args.embedding_b) as f:
- emb_b = np.array(json.load(f), dtype=np.float32)
-
- print(f"Embedding A: {args.embedding_a} (dim={emb_a.shape[0]})")
- print(f"Embedding B: {args.embedding_b} (dim={emb_b.shape[0]})")
- print(f"SLERP ratio: {args.ratio}")
-
- blended = slerp(emb_a, emb_b, args.ratio)
- output_path = args.output or f"interpolated_t{args.ratio:.2f}.wav"
-
- print(f"Generating speech: {args.text!r}")
- generate_speech(
- text=args.text,
- speaker_embedding=blended.tolist(),
- output_path=output_path,
- api_base=args.api_base,
- api_key=args.api_key,
- model=args.model,
- )
-
-
-def cmd_pipeline(args):
- """Full pipeline: extract two embeddings, SLERP at multiple ratios, generate."""
- print(f"Loading speaker encoder from {args.model}...")
- encoder = load_speaker_encoder(args.model, device=args.device)
-
- print(f"Extracting embedding A from {args.audio_a}...")
- emb_a = extract_embedding(encoder, args.audio_a, device=args.device)
- print(f"Extracting embedding B from {args.audio_b}...")
- emb_b = extract_embedding(encoder, args.audio_b, device=args.device)
-
- # Save extracted embeddings
- os.makedirs(args.output_dir, exist_ok=True)
- for label, emb, audio_path in [("a", emb_a, args.audio_a), ("b", emb_b, args.audio_b)]:
- emb_path = os.path.join(args.output_dir, f"embedding_{label}.json")
- with open(emb_path, "w") as f:
- json.dump(emb.tolist(), f)
- print(f"Saved embedding {label} to {emb_path}")
-
- # Generate at each ratio
- for t in args.ratios:
- blended = slerp(emb_a, emb_b, t)
- out_path = os.path.join(args.output_dir, f"t{t:.2f}.wav")
- print(f"\n--- SLERP t={t:.2f} ---")
- print(f"Generating: {args.text!r}")
- generate_speech(
- text=args.text,
- speaker_embedding=blended.tolist(),
- output_path=out_path,
- api_base=args.api_base,
- api_key=args.api_key,
- model=args.model,
- )
-
- print(f"\nAll outputs saved to {args.output_dir}/")
-
-
-def main():
- parser = argparse.ArgumentParser(
- description="Speaker embedding extraction and interpolation for Qwen3-TTS",
- formatter_class=argparse.RawDescriptionHelpFormatter,
- )
- parser.add_argument("--api-base", default=DEFAULT_API_BASE, help="TTS API base URL")
- parser.add_argument("--api-key", default=DEFAULT_API_KEY, help="API key")
- parser.add_argument(
- "--model",
- default="Qwen/Qwen3-TTS-12Hz-1.7B-Base",
- help="Model name (used for both weight loading and API requests)",
- )
- parser.add_argument("--device", default="cpu", help="Device for embedding extraction (cpu/cuda)")
-
- sub = parser.add_subparsers(dest="command", required=True)
-
- # extract
- p_ext = sub.add_parser("extract", help="Extract speaker embedding from audio")
- p_ext.add_argument("--audio", required=True, help="Input audio file")
- p_ext.add_argument("--output", "-o", help="Output JSON path (default: <audio>_embedding.json)")
-
- # interpolate
- p_interp = sub.add_parser("interpolate", help="Interpolate between two embeddings and generate speech")
- p_interp.add_argument("--embedding-a", required=True, help="JSON file with embedding A")
- p_interp.add_argument("--embedding-b", required=True, help="JSON file with embedding B")
- p_interp.add_argument("--ratio", "-r", type=float, default=0.5, help="SLERP ratio (0=A, 1=B)")
- p_interp.add_argument("--text", required=True, help="Text to synthesize")
- p_interp.add_argument("--output", "-o", help="Output wav path")
-
- # pipeline
- p_pipe = sub.add_parser("pipeline", help="Full pipeline: extract + interpolate + generate")
- p_pipe.add_argument("--audio-a", required=True, help="Audio file for voice A")
- p_pipe.add_argument("--audio-b", required=True, help="Audio file for voice B")
- p_pipe.add_argument(
- "--ratios",
- nargs="+",
- type=float,
- default=[0.0, 0.25, 0.5, 0.75, 1.0],
- help="SLERP ratios to generate (default: 0.0 0.25 0.5 0.75 1.0)",
- )
- p_pipe.add_argument("--text", required=True, help="Text to synthesize")
- p_pipe.add_argument("--output-dir", default="./interpolated", help="Output directory")
-
- args = parser.parse_args()
- {"extract": cmd_extract, "interpolate": cmd_interpolate, "pipeline": cmd_pipeline}[args.command](args)
-
-
-if __name__ == "__main__":
- main()
diff --git a/examples/online_serving/qwen3_tts/streaming_speech_client.py b/examples/online_serving/qwen3_tts/streaming_speech_client.py
deleted file mode 100644
index 8f09409ceac..00000000000
--- a/examples/online_serving/qwen3_tts/streaming_speech_client.py
+++ /dev/null
@@ -1,249 +0,0 @@
-"""WebSocket client for streaming text-input TTS.
-
-Connects to the /v1/audio/speech/stream endpoint, sends text incrementally
-(simulating real-time STT output), and saves per-sentence audio files.
-
-Usage:
- # Send full text at once
- python streaming_speech_client.py --text "Hello world. How are you? I am fine."
-
- # Simulate STT: send text word-by-word with delay
- python streaming_speech_client.py \
- --text "Hello world. How are you? I am fine." \
- --simulate-stt --stt-delay 0.1
-
- # VoiceDesign task
- python streaming_speech_client.py \
- --text "Today is a great day. The weather is nice." \
- --task-type VoiceDesign \
- --instructions "A cheerful young female voice"
-
- # Base task (voice cloning)
- python streaming_speech_client.py \
- --text "Hello world. How are you?" \
- --task-type Base \
- --ref-audio /path/to/reference.wav \
- --ref-text "Transcript of reference audio"
-
-Requirements:
- pip install websockets
-"""
-
-import argparse
-import asyncio
-import json
-import os
-
-try:
- import websockets
-except ImportError:
- print("Please install websockets: pip install websockets")
- raise SystemExit(1)
-
-
-async def stream_tts(
- url: str,
- text: str,
- config: dict,
- output_dir: str,
- simulate_stt: bool = False,
- stt_delay: float = 0.1,
-) -> None:
- """Connect to the streaming TTS endpoint and process audio responses."""
- os.makedirs(output_dir, exist_ok=True)
-
- async with websockets.connect(url) as ws:
- # 1. Send session config
- config_msg = {"type": "session.config", **config}
- await ws.send(json.dumps(config_msg))
- print(f"Sent session config: {config}")
-
- # 2. Send text (either all at once or word-by-word)
- async def send_text():
- if simulate_stt:
- words = text.split(" ")
- for i, word in enumerate(words):
- chunk = word + (" " if i < len(words) - 1 else "")
- await ws.send(
- json.dumps(
- {
- "type": "input.text",
- "text": chunk,
- }
- )
- )
- print(f" Sent: {chunk!r}")
- await asyncio.sleep(stt_delay)
- else:
- await ws.send(
- json.dumps(
- {
- "type": "input.text",
- "text": text,
- }
- )
- )
- print(f"Sent full text: {text!r}")
-
- # 3. Signal end of input
- await ws.send(json.dumps({"type": "input.done"}))
- print("Sent input.done")
-
- # Run sender and receiver concurrently
- sender_task = asyncio.create_task(send_text())
-
- response_format = config.get("response_format", "wav")
- current_sentence_index = 0
- current_chunks: list[bytes] = []
-
- try:
- while True:
- message = await ws.recv()
-
- if isinstance(message, bytes):
- current_chunks.append(message)
- print(f" Received audio chunk for sentence {current_sentence_index}: {len(message)} bytes")
- else:
- # JSON frame
- msg = json.loads(message)
- msg_type = msg.get("type")
-
- if msg_type == "audio.start":
- current_sentence_index = msg["sentence_index"]
- current_chunks = []
- print(f" [sentence {msg['sentence_index']}] Generating: {msg['sentence_text']!r}")
- elif msg_type == "audio.done":
- filename = os.path.join(
- output_dir,
- f"sentence_{msg['sentence_index']:03d}.{response_format}",
- )
- with open(filename, "wb") as f:
- f.write(b"".join(current_chunks))
- print(
- f" [sentence {msg['sentence_index']}] Done"
- f" bytes={msg.get('total_bytes', len(b''.join(current_chunks)))}"
- f" error={msg.get('error', False)}"
- f" -> {filename}"
- )
- current_chunks = []
- elif msg_type == "session.done":
- print(f"\nSession complete: {msg['total_sentences']} sentence(s) generated")
- break
- elif msg_type == "error":
- print(f" ERROR: {msg['message']}")
- else:
- print(f" Unknown message: {msg}")
- finally:
- sender_task.cancel()
- try:
- await sender_task
- except asyncio.CancelledError:
- pass # Task cancellation is expected during shutdown
-
- print(f"\nAudio files saved to: {output_dir}/")
-
-
-def main():
- parser = argparse.ArgumentParser(description="Streaming text-input TTS client")
- parser.add_argument(
- "--url",
- default="ws://localhost:8000/v1/audio/speech/stream",
- help="WebSocket endpoint URL",
- )
- parser.add_argument(
- "--text",
- required=True,
- help="Text to synthesize",
- )
- parser.add_argument(
- "--output-dir",
- default="streaming_tts_output",
- help="Directory to save audio files (default: streaming_tts_output)",
- )
-
- # Session config options
- parser.add_argument("--model", default=None, help="Model name")
- parser.add_argument("--speaker", default="Vivian", help="Speaker name")
- parser.add_argument(
- "--task-type",
- default="CustomVoice",
- choices=["CustomVoice", "VoiceDesign", "Base"],
- help="TTS task type",
- )
- parser.add_argument("--language", default="Auto", help="Language")
- parser.add_argument("--instructions", default=None, help="Voice style instructions")
- parser.add_argument(
- "--response-format",
- default="wav",
- choices=["wav", "pcm", "flac", "mp3", "aac", "opus"],
- help="Audio format",
- )
- parser.add_argument(
- "--stream-audio",
- action="store_true",
- help="Receive one or more PCM chunks per sentence (requires --response-format pcm)",
- )
- parser.add_argument("--speed", type=float, default=1.0, help="Playback speed (0.25-4.0)")
- parser.add_argument("--max-new-tokens", type=int, default=None, help="Max tokens")
-
- # Base task options
- parser.add_argument("--ref-audio", default=None, help="Reference audio")
- parser.add_argument("--ref-text", default=None, help="Reference text")
- parser.add_argument(
- "--x-vector-only-mode",
- action="store_true",
- default=False,
- help="Speaker embedding only mode",
- )
-
- # STT simulation
- parser.add_argument(
- "--simulate-stt",
- action="store_true",
- help="Simulate STT by sending text word-by-word",
- )
- parser.add_argument(
- "--stt-delay",
- type=float,
- default=0.1,
- help="Delay between words in STT simulation (seconds)",
- )
-
- args = parser.parse_args()
-
- # Build session config (only include non-None values)
- config = {}
- for key in [
- "model",
- "speaker",
- "task_type",
- "language",
- "instructions",
- "response_format",
- "speed",
- "max_new_tokens",
- "ref_audio",
- "ref_text",
- ]:
- val = getattr(args, key.replace("-", "_"), None)
- if val is not None:
- config[key] = val
- if args.stream_audio:
- config["stream_audio"] = True
- if args.x_vector_only_mode:
- config["x_vector_only_mode"] = True
-
- asyncio.run(
- stream_tts(
- url=args.url,
- text=args.text,
- config=config,
- output_dir=args.output_dir,
- simulate_stt=args.simulate_stt,
- stt_delay=args.stt_delay,
- )
- )
-
-
-if __name__ == "__main__":
- main()
diff --git a/examples/online_serving/qwen3_tts/tts_common.py b/examples/online_serving/qwen3_tts/tts_common.py
deleted file mode 100644
index 44ba7c3ab7b..00000000000
--- a/examples/online_serving/qwen3_tts/tts_common.py
+++ /dev/null
@@ -1,223 +0,0 @@
-"""Shared constants, helpers, and payload building for Qwen3-TTS Gradio demos."""
-
-import base64
-import io
-
-try:
- import gradio as gr
-except ImportError:
- raise ImportError("gradio is required to run this demo. Install it with: pip install 'vllm-omni[demo]'") from None
-import httpx
-import numpy as np
-import soundfile as sf
-
-SUPPORTED_LANGUAGES = [
- "Auto",
- "Chinese",
- "English",
- "Japanese",
- "Korean",
- "German",
- "French",
- "Russian",
- "Portuguese",
- "Spanish",
- "Italian",
-]
-
-TASK_TYPES = ["CustomVoice", "VoiceDesign", "Base"]
-
-PCM_SAMPLE_RATE = 24000
-
-DEFAULT_API_BASE = "http://localhost:8000"
-
-
-def fetch_voices(api_base: str) -> list[str]:
- """Fetch available voices from the server."""
- try:
- with httpx.Client(timeout=10.0) as client:
- resp = client.get(
- f"{api_base}/v1/audio/voices",
- headers={"Authorization": "Bearer EMPTY"},
- )
- if resp.status_code == 200:
- data = resp.json()
- voices = data.get("voices") or []
- if voices:
- return voices
- except Exception:
- pass
- return ["Vivian", "Ryan"]
-
-
-def encode_audio_to_base64(audio_data: tuple) -> str:
- """Encode Gradio audio input (sample_rate, numpy_array) to base64 data URL."""
- sample_rate, audio_np = audio_data
-
- if audio_np.dtype != np.int16:
- if audio_np.dtype in (np.float32, np.float64):
- audio_np = np.clip(audio_np, -1.0, 1.0)
- audio_np = (audio_np * 32767).astype(np.int16)
- else:
- audio_np = audio_np.astype(np.int16)
-
- buf = io.BytesIO()
- sf.write(buf, audio_np, sample_rate, format="WAV")
- wav_b64 = base64.b64encode(buf.getvalue()).decode("utf-8")
- return f"data:audio/wav;base64,{wav_b64}"
-
-
-def build_payload(
- text: str,
- task_type: str,
- voice: str,
- language: str,
- instructions: str,
- ref_audio: tuple | None,
- ref_audio_url: str,
- ref_text: str,
- x_vector_only: bool,
- response_format: str = "pcm",
- speed: float = 1.0,
- stream: bool = True,
-) -> dict:
- """Build the /v1/audio/speech request payload.
-
- Raises gr.Error for invalid input so callers don't need to validate.
- """
- if not text or not text.strip():
- raise gr.Error("Please enter text to synthesize.")
-
- payload: dict = {
- "input": text.strip(),
- "response_format": "pcm" if stream else response_format,
- "stream": stream,
- }
- if not stream:
- payload["speed"] = speed
-
- if task_type:
- payload["task_type"] = task_type
- if language:
- payload["language"] = language
-
- if task_type == "CustomVoice":
- if voice:
- payload["voice"] = voice
- if instructions and instructions.strip():
- payload["instructions"] = instructions.strip()
-
- elif task_type == "VoiceDesign":
- if not instructions or not instructions.strip():
- raise gr.Error("VoiceDesign task requires voice style instructions.")
- payload["instructions"] = instructions.strip()
-
- elif task_type == "Base":
- ref_audio_url_stripped = ref_audio_url.strip() if ref_audio_url else ""
- if ref_audio_url_stripped:
- payload["ref_audio"] = ref_audio_url_stripped
- elif ref_audio is not None:
- payload["ref_audio"] = encode_audio_to_base64(ref_audio)
- else:
- raise gr.Error("Base (voice clone) task requires reference audio. Upload a file or provide a URL.")
- if ref_text and ref_text.strip():
- payload["ref_text"] = ref_text.strip()
- if x_vector_only:
- payload["x_vector_only_mode"] = True
-
- return payload
-
-
-def on_task_type_change(task_type: str):
- """Update UI visibility based on selected task type."""
- if task_type == "CustomVoice":
- return (
- gr.update(visible=True), # voice dropdown
- gr.update(visible=True, info="Optional style/emotion instructions"),
- gr.update(visible=False), # ref_audio
- gr.update(visible=False), # ref_audio_url
- gr.update(visible=False), # ref_text
- gr.update(visible=False), # x_vector_only
- )
- elif task_type == "VoiceDesign":
- return (
- gr.update(visible=False),
- gr.update(visible=True, info="Required: describe the voice style"),
- gr.update(visible=False),
- gr.update(visible=False),
- gr.update(visible=False),
- gr.update(visible=False),
- )
- elif task_type == "Base":
- return (
- gr.update(visible=False),
- gr.update(visible=False),
- gr.update(visible=True),
- gr.update(visible=True),
- gr.update(visible=True),
- gr.update(visible=True),
- )
- return (
- gr.update(visible=True),
- gr.update(visible=True),
- gr.update(visible=False),
- gr.update(visible=False),
- gr.update(visible=False),
- gr.update(visible=False),
- )
-
-
-def stream_pcm_chunks(api_base: str, payload: dict):
- """Stream raw PCM bytes from the server, yielding int16 numpy arrays.
-
- Handles odd-byte boundaries between network chunks.
- """
- leftover = b""
- with httpx.Client(timeout=300.0) as client:
- with client.stream(
- "POST",
- f"{api_base}/v1/audio/speech",
- json=payload,
- headers={
- "Content-Type": "application/json",
- "Authorization": "Bearer EMPTY",
- },
- ) as resp:
- if resp.status_code != 200:
- resp.read()
- raise gr.Error(f"Server error ({resp.status_code}): {resp.text}")
- for chunk in resp.iter_bytes():
- if not chunk:
- continue
- raw = leftover + chunk
- usable = len(raw) - (len(raw) % 2)
- leftover = raw[usable:]
- if usable == 0:
- continue
- yield np.frombuffer(raw[:usable], dtype=np.int16).copy()
-
-
-def add_common_args(parser):
- """Add CLI arguments shared by both demos."""
- parser.add_argument(
- "--api-base",
- default=DEFAULT_API_BASE,
- help=f"Base URL for the vLLM API server (default: {DEFAULT_API_BASE}).",
- )
- parser.add_argument(
- "--host",
- default="0.0.0.0",
- help="Host/IP for Gradio server (default: 0.0.0.0).",
- )
- parser.add_argument(
- "--port",
- type=int,
- default=7860,
- help="Port for Gradio server (default: 7860).",
- )
- parser.add_argument(
- "--share",
- action="store_true",
- help="Share the Gradio demo publicly.",
- )
- return parser
diff --git a/examples/online_serving/stable_audio/README.md b/examples/online_serving/stable_audio/README.md
deleted file mode 100644
index 3aaf34e5673..00000000000
--- a/examples/online_serving/stable_audio/README.md
+++ /dev/null
@@ -1,234 +0,0 @@
-# Stable Audio Online Serving
-
-Generate audio from text prompts using Stable Audio models via an OpenAI-compatible API endpoint.
-
-## Features
-
-- **OpenAI-compatible API**: Use `/v1/audio/generate` endpoint
-- **Flexible control**: Adjust audio length, guidance scale, inference steps
-- **Quality control**: Use negative prompts to avoid unwanted characteristics
-- **Reproducible**: Set random seed for deterministic generation
-
-## Quick Start
-
-### 1. Start the Server
-
-```bash
-vllm-omni serve stabilityai/stable-audio-open-1.0 \
- --host 0.0.0.0 \
- --port 8091 \
- --gpu-memory-utilization 0.9 \
- --trust-remote-code \
- --enforce-eager \
- --omni
-```
-
-### 2. Generate Audio
-
-#### Using curl
-
-```bash
-curl -X POST http://localhost:8091/v1/audio/generate \
- -H "Content-Type: application/json" \
- -d '{
- "input": "The sound of a cat purring",
- "audio_length": 10.0
- }' --output cat.wav
-```
-
-#### Using Python Client
-
-```bash
-python stable_audio_client.py \
- --text "The sound of a cat purring" \
- --audio_length 10.0 \
- --output cat.wav
-```
-
-#### Using Bash Script
-
-```bash
-bash curl_examples.sh
-```
-
-## API Reference
-
-### Endpoint
-
-```
-POST /v1/audio/generate
-```
-
-### Request Body
-
-```json
-{
- "input": "Text description of the audio",
- "audio_length": 10.0,
- "audio_start": 0.0,
- "negative_prompt": "Low quality",
- "guidance_scale": 7.0,
- "num_inference_steps": 100,
- "seed": 42,
- "response_format": "wav"
-}
-```
-
-### Parameters
-
-| Parameter | Type | Default | Description |
-|-----------|------|---------|-------------|
-| `input` | string | **required** | Text prompt describing the audio to generate |
-| `audio_length` | float | ~47s | Audio duration in seconds (max ~47s for stable-audio-open-1.0) |
-| `audio_start` | float | 0.0 | Audio start time in seconds |
-| `negative_prompt` | string | null | Text describing what to avoid in generation |
-| `guidance_scale` | float | 7.0 | Classifier-free guidance scale (higher = more adherence to prompt) |
-| `num_inference_steps` | int | 50 | Number of denoising steps (higher = better quality, slower) |
-| `seed` | int | null | Random seed for reproducibility |
-| `response_format` | string | "wav" | Output format: wav, mp3, flac, pcm |
-
-### Response
-
-Returns audio data in the requested format (default: WAV).
-
-## Usage Examples
-
-### Basic Generation
-
-```bash
-curl -X POST http://localhost:8091/v1/audio/generate \
- -H "Content-Type: application/json" \
- -d '{
- "input": "The sound of ocean waves"
- }' --output ocean.wav
-```
-
-### Custom Duration
-
-```bash
-curl -X POST http://localhost:8091/v1/audio/generate \
- -H "Content-Type: application/json" \
- -d '{
- "input": "A dog barking",
- "audio_length": 5.0
- }' --output dog_5s.wav
-```
-
-### High Quality with Negative Prompt
-
-```bash
-curl -X POST http://localhost:8091/v1/audio/generate \
- -H "Content-Type: application/json" \
- -d '{
- "input": "A piano playing a gentle melody",
- "audio_length": 10.0,
- "negative_prompt": "Low quality, distorted, noisy",
- "guidance_scale": 8.0,
- "num_inference_steps": 150
- }' --output piano_hq.wav
-```
-
-### Reproducible Generation
-
-```bash
-curl -X POST http://localhost:8091/v1/audio/generate \
- -H "Content-Type: application/json" \
- -d '{
- "input": "Thunder and rain sounds",
- "audio_length": 15.0,
- "seed": 42
- }' --output thunder.wav
-```
-
-### Quick Generation (Fewer Steps)
-
-For faster generation with slightly lower quality:
-
-```bash
-curl -X POST http://localhost:8091/v1/audio/generate \
- -H "Content-Type: application/json" \
- -d '{
- "input": "Birds chirping in a forest",
- "audio_length": 8.0,
- "num_inference_steps": 50
- }' --output birds_quick.wav
-```
-
-## Python Client Examples
-
-### Simple Generation
-
-```bash
-python stable_audio_client.py \
- --text "The sound of a cat purring"
-```
-
-### Custom Parameters
-
-```bash
-python stable_audio_client.py \
- --text "Thunder and rain" \
- --audio_length 15.0 \
- --negative_prompt "Low quality" \
- --guidance_scale 7.0 \
- --num_inference_steps 100 \
- --seed 42 \
- --output thunder.wav
-```
-
-### Different Output Format
-
-```bash
-python stable_audio_client.py \
- --text "Guitar playing" \
- --response_format mp3 \
- --output guitar.mp3
-```
-
-## Tips
-
-1. **Audio Length**: Keep under 47 seconds for `stable-audio-open-1.0`
-2. **Quality vs Speed**:
- - 50 steps: Fast, decent quality
- - 100 steps: Good balance (default)
- - 150+ steps: High quality, slower
-3. **Guidance Scale**:
- - Lower (3-5): More creative/varied
- - Default (7): Good balance
- - Higher (10+): More literal to prompt
-4. **Negative Prompts**: Use to avoid "Low quality", "distorted", "noisy", etc.
-5. **Seeds**: Use same seed for reproducible results
-
-## Performance
-
-| Inference Steps | Quality | Speed | Use Case |
-|----------------|---------|-------|----------|
-| 50 | Good | Fast | Quick previews |
-| 100 (default) | Very Good | Medium | Production |
-| 150+ | Excellent | Slow | Final/critical audio |
-
-## Troubleshooting
-
-### Server not responding
-- Check if server is running: `curl http://localhost:8091/health`
-- Check server logs for errors
-
-### Audio quality issues
-- Increase `num_inference_steps` (e.g., 150)
-- Add negative prompts: `"Low quality, distorted, noisy"`
-- Increase `guidance_scale` for more prompt adherence
-
-### Generation timeout
-- Reduce `num_inference_steps`
-- Reduce `audio_length`
-- Check GPU memory with `nvidia-smi`
-
-### Wrong audio length
-- Ensure `audio_length` is within model limits (~47s max)
-- Adjust `audio_start` if trimming is needed
-
-## See Also
-
-- [Offline Inference Example](../../offline_inference/text_to_audio/README.md)
-- [Stable Audio Model Card](https://huggingface.co/stabilityai/stable-audio-open-1.0)
-- [vLLM-Omni Documentation](https://github.com/vllm-project/vllm-omni)
diff --git a/examples/online_serving/stable_audio/curl_examples.sh b/examples/online_serving/stable_audio/curl_examples.sh
deleted file mode 100755
index 16a12ef1c16..00000000000
--- a/examples/online_serving/stable_audio/curl_examples.sh
+++ /dev/null
@@ -1,54 +0,0 @@
-#!/bin/bash
-# Examples for using Stable Audio with curl via /v1/audio/generate endpoint
-
-# Example 1: Simple request with default parameters
-echo "Example 1: Simple request with default parameters"
-curl -X POST http://localhost:8091/v1/audio/generate \
- -H "Content-Type: application/json" \
- -d '{
- "input": "The sound audience clapping and cheering in a stadium"
- }' --output stadium.wav
-
-# Example 2: Request with custom audio_length
-echo "Example 2: Custom audio length (5 seconds)"
-curl -X POST http://localhost:8091/v1/audio/generate \
- -H "Content-Type: application/json" \
- -d '{
- "input": "The sound of a dog barking",
- "audio_length": 5.0
- }' --output dog_5s.wav
-
-# Example 3: Request with negative prompt for quality control
-echo "Example 3: With negative prompt"
-curl -X POST http://localhost:8091/v1/audio/generate \
- -H "Content-Type: application/json" \
- -d '{
- "input": "A piano playing a gentle melody",
- "audio_length": 10.0,
- "negative_prompt": "Low quality, distorted, noisy"
- }' --output piano.wav
-
-# Example 4: Full control with all parameters
-echo "Example 4: Full control (custom length, guidance, steps, seed)"
-curl -X POST http://localhost:8091/v1/audio/generate \
- -H "Content-Type: application/json" \
- -d '{
- "input": "Thunder and rain sounds",
- "audio_length": 15.0,
- "negative_prompt": "Low quality",
- "guidance_scale": 7.0,
- "num_inference_steps": 100,
- "seed": 42
- }' --output thunder_rain.wav
-
-# Example 5: Quick generation with fewer steps (faster but lower quality)
-echo "Example 5: Quick generation (fewer steps)"
-curl -X POST http://localhost:8091/v1/audio/generate \
- -H "Content-Type: application/json" \
- -d '{
- "input": "Ocean waves crashing on a beach",
- "audio_length": 8.0,
- "num_inference_steps": 50
- }' --output ocean.wav
-
-echo "All examples completed!"
diff --git a/examples/online_serving/stable_audio/stable_audio_client.py b/examples/online_serving/stable_audio/stable_audio_client.py
deleted file mode 100755
index 7f28a5245ec..00000000000
--- a/examples/online_serving/stable_audio/stable_audio_client.py
+++ /dev/null
@@ -1,170 +0,0 @@
-#!/usr/bin/env python3
-"""
-OpenAI-compatible client for Stable Audio via /v1/audio/generate endpoint.
-
-This script demonstrates how to use the OpenAI-compatible speech API
-to generate audio from text using Stable Audio models.
-
-Examples:
- # Simple generation
- python stable_audio_client.py --text "The sound of a cat purring"
-
- # With custom duration
- python stable_audio_client.py --text "A dog barking" --audio_length 5.0
-
- # With all parameters
- python stable_audio_client.py --text "Thunder and rain" \
- --audio_length 15.0 \
- --negative_prompt "Low quality" \
- --guidance_scale 7.0 \
- --num_inference_steps 100 \
- --seed 42 \
- --output thunder.wav
-"""
-
-import argparse
-import sys
-
-import requests
-
-
-def parse_args():
- parser = argparse.ArgumentParser(description="Generate audio with Stable Audio via OpenAI-compatible API")
- parser.add_argument(
- "--api_url",
- default="http://localhost:8091/v1/audio/generate",
- help="API endpoint URL",
- )
- parser.add_argument(
- "--text",
- default="The sound of a cat purring",
- help="Text prompt for audio generation",
- )
- parser.add_argument(
- "--audio_length",
- type=float,
- default=10.0,
- help="Audio length in seconds (max ~47s for stable-audio-open-1.0)",
- )
- parser.add_argument(
- "--audio_start",
- type=float,
- default=0.0,
- help="Audio start time in seconds",
- )
- parser.add_argument(
- "--negative_prompt",
- default="Low quality",
- help="Negative prompt for classifier-free guidance",
- )
- parser.add_argument(
- "--guidance_scale",
- type=float,
- default=7.0,
- help="Guidance scale for diffusion (higher = more adherence to prompt)",
- )
- parser.add_argument(
- "--num_inference_steps",
- type=int,
- default=100,
- help="Number of inference steps (higher = better quality, slower)",
- )
- parser.add_argument(
- "--seed",
- type=int,
- default=None,
- help="Random seed for reproducibility",
- )
- parser.add_argument(
- "--output",
- default="stable_audio_output.wav",
- help="Output file path",
- )
- parser.add_argument(
- "--response_format",
- default="wav",
- choices=["wav", "mp3", "flac", "pcm"],
- help="Audio output format",
- )
- return parser.parse_args()
-
-
-def generate_audio(args):
- """Generate audio using the API."""
-
- # Build request payload
- payload = {
- "input": args.text,
- "audio_length": args.audio_length,
- "audio_start": args.audio_start,
- "response_format": args.response_format,
- }
-
- # Add optional parameters
- if args.negative_prompt:
- payload["negative_prompt"] = args.negative_prompt
- if args.guidance_scale:
- payload["guidance_scale"] = args.guidance_scale
- if args.num_inference_steps:
- payload["num_inference_steps"] = args.num_inference_steps
- if args.seed is not None:
- payload["seed"] = args.seed
-
- print(f"\n{'=' * 60}")
- print("Stable Audio - Text-to-Audio Generation")
- print(f"{'=' * 60}")
- print(f"API URL: {args.api_url}")
- print(f"Prompt: {args.text}")
- print(f"Audio length: {args.audio_length}s")
- print(f"Negative prompt: {args.negative_prompt}")
- print(f"Guidance scale: {args.guidance_scale}")
- print(f"Inference steps: {args.num_inference_steps}")
- if args.seed is not None:
- print(f"Seed: {args.seed}")
- print(f"Output: {args.output}")
- print(f"{'=' * 60}\n")
-
- try:
- # Make the API request
- print("Generating audio...")
- response = requests.post(
- args.api_url,
- json=payload,
- headers={"Content-Type": "application/json"},
- timeout=300, # 5 minute timeout for long generations
- )
-
- # Check for errors
- if response.status_code != 200:
- print(f"Error: API returned status code {response.status_code}")
- print(f"Response: {response.text}")
- return False
-
- # Save the audio
- with open(args.output, "wb") as f:
- f.write(response.content)
-
- print(f"✓ Audio saved to {args.output}")
- print(f" File size: {len(response.content) / 1024:.1f} KB")
- return True
-
- except requests.exceptions.Timeout:
- print("Error: Request timed out. Try reducing inference steps or audio length.")
- return False
- except requests.exceptions.ConnectionError:
- print(f"Error: Could not connect to {args.api_url}")
- print("Make sure the server is running.")
- return False
- except Exception as e:
- print(f"Error: {e}")
- return False
-
-
-def main():
- args = parse_args()
- success = generate_audio(args)
- sys.exit(0 if success else 1)
-
-
-if __name__ == "__main__":
- main()
diff --git a/examples/online_serving/text_to_image/README.md b/examples/online_serving/text_to_image/README.md
deleted file mode 100644
index 17d377ea3e2..00000000000
--- a/examples/online_serving/text_to_image/README.md
+++ /dev/null
@@ -1,275 +0,0 @@
-# Text-To-Image
-
-This example demonstrates how to deploy Qwen-Image model for online image generation service using vLLM-Omni.
-
-## Start Server
-
-### Basic Start
-
-```bash
-vllm serve Qwen/Qwen-Image --omni --port 8091
-```
-!!! note
- If you encounter Out-of-Memory (OOM) issues or have limited GPU memory, you can enable VAE slicing and tiling to reduce memory usage, --vae-use-slicing --vae-use-tiling
-
-### Start with Parameters
-
-Or use the startup script:
-
-```bash
-bash run_server.sh
-```
-
-### Start with Parallelism Acceleration
-
-Enable Tensor Parallelism and VAE Patch Parallelism for faster inference:
-
-```bash
-# With Tensor Parallelism (requires >= 2 GPUs)
-vllm serve Qwen/Qwen-Image --omni --port 8091 --tensor-parallel-size 2
-
-# With Tensor Parallelism and VAE Patch Parallelism (requires >= 2 GPUs)
-vllm serve Qwen/Qwen-Image --omni --port 8091 --tensor-parallel-size 2 --vae-patch-parallel-size 2 --vae-use-tiling
-
-# With Sequence Parallelism (Ulysses-SP, requires >= 2 GPUs)
-vllm serve Qwen/Qwen-Image --omni --port 8091 --usp 2
-
-# With Ring-Attention (requires >= 2 GPUs)
-vllm serve Qwen/Qwen-Image --omni --port 8091 --ring 2
-
-# Combined: Ulysses + Ring (requires >= 4 GPUs)
-vllm serve Qwen/Qwen-Image --omni --port 8091 --usp 2 --ring 2
-```
-
-For more details on parallelism acceleration, see the [Parallelism Acceleration Guide](../../diffusion/parallelism_acceleration.md).
-
-## API Calls
-
-### Method 1: Using curl
-
-```bash
-# Basic text-to-image generation
-bash run_curl_text_to_image.sh
-
-# Or execute directly
-curl -s http://localhost:8091/v1/chat/completions \
- -H "Content-Type: application/json" \
- -d '{
- "messages": [
- {"role": "user", "content": "A beautiful landscape painting"}
- ],
- "extra_body": {
- "height": 1024,
- "width": 1024,
- "num_inference_steps": 50,
- "true_cfg_scale": 4.0,
- "seed": 42
- }
- }' | jq -r '.choices[0].message.content[0].image_url.url' | cut -d',' -f2- | base64 -d > output.png
-```
-
-### Method 2: Using OpenAI Python SDK
-
-```python
-from openai import OpenAI
-import base64
-
-client = OpenAI(base_url="http://localhost:8091/v1", api_key="none")
-
-response = client.chat.completions.create(
- model="Qwen/Qwen-Image",
- messages=[{"role": "user", "content": "A beautiful landscape painting"}],
- extra_body={
- "height": 1024,
- "width": 1024,
- "num_inference_steps": 50,
- "true_cfg_scale": 4.0,
- "seed": 42,
- },
-)
-
-img_url = response.choices[0].message.content[0].image_url.url
-_, b64_data = img_url.split(",", 1)
-with open("output.png", "wb") as f:
- f.write(base64.b64decode(b64_data))
-```
-
-!!! note
- The OpenAI SDK's `extra_body` keyword argument merges parameters into the
- top-level request body automatically. When using curl or Python `requests`,
- wrap generation parameters inside a literal `"extra_body"` key in the JSON
- instead (as shown in the curl example above).
-
-### Method 3: Using Python Client Script
-
-```bash
-python openai_chat_client.py --prompt "A beautiful landscape painting" --output output.png
-```
-
-### Method 4: Using Gradio Demo
-
-```bash
-python gradio_demo.py
-# Visit http://localhost:7860
-```
-
-## LoRA
-
-This example supports Peft-compatible LoRA (Low-Rank Adaptation) adapters for diffusion models. The LoRA adapter path must be readable on the **server** machine (usually a local path or a mounted directory).
-
-### Using Python Client with LoRA
-
-```bash
-python openai_chat_client.py \
- --prompt "A piece of cheesecake" \
- --lora-path /path/to/lora_adapter \
- --lora-name my_lora \
- --lora-scale 1.0 \
- --output output.png
-```
-
-### Using curl with LoRA (Images API)
-
-The `/v1/images/generations` endpoint supports a `lora` field in the request body:
-
-```bash
-curl -X POST http://localhost:8091/v1/images/generations \
- -H "Content-Type: application/json" \
- -d '{
- "prompt": "A piece of cheesecake",
- "size": "1024x1024",
- "seed": 42,
- "lora": {
- "name": "my_lora",
- "local_path": "/path/to/lora_adapter",
- "scale": 1.0
- }
- }' | jq -r '.data[0].b64_json' | base64 -d > output.png
-```
-
-### LoRA Parameters
-
-| Parameter | Type | Description |
-| ------------ | ----- | ------------------------------------------------------------------------- |
-| `name` | str | LoRA adapter name (optional, defaults to path stem) |
-| `local_path` | str | Server-local path to LoRA adapter folder (PEFT format, required) |
-| `scale` | float | LoRA scale factor (default: 1.0) |
-| `int_id` | int | LoRA integer ID for caching (optional, derived from path if not provided) |
-
-### LoRA Adapter Format
-
-LoRA adapters must be in PEFT (Parameter-Efficient Fine-Tuning) format. A typical LoRA adapter directory structure:
-
-```
-lora_adapter/
-├── adapter_config.json
-└── adapter_model.safetensors
-```
-
-## Request Format
-
-### Simple Text Generation
-
-```json
-{
- "messages": [
- {"role": "user", "content": "A beautiful landscape painting"}
- ]
-}
-```
-
-### Generation with Parameters
-
-Use `extra_body` to pass generation parameters:
-
-```json
-{
- "messages": [
- {"role": "user", "content": "A beautiful landscape painting"}
- ],
- "extra_body": {
- "height": 1024,
- "width": 1024,
- "num_inference_steps": 50,
- "true_cfg_scale": 4.0,
- "seed": 42
- }
-}
-```
-
-### Multimodal Input (Text + Structured Content)
-
-```json
-{
- "messages": [
- {
- "role": "user",
- "content": [
- {"type": "text", "text": "A beautiful landscape painting"}
- ]
- }
- ]
-}
-```
-
-## Generation Parameters
-
-When using `/v1/chat/completions`, pass these inside `extra_body` in the curl
-JSON, or via the `extra_body` keyword argument in the OpenAI Python SDK.
-When using the dedicated `/v1/images/generations` endpoint, pass the supported
-generation controls as top-level JSON fields directly. For image dimensions and
-count, use `size` and `n` rather than `height`, `width`, or
-`num_outputs_per_prompt`.
-
-| Parameter | Type | Default | Description |
-| ------------------------ | ----- | ------- | ------------------------------ |
-| `height` | int | None | Image height in pixels |
-| `width` | int | None | Image width in pixels |
-| `size` | str | None | Image size (e.g., "1024x1024") |
-| `num_inference_steps` | int | 50 | Number of denoising steps |
-| `true_cfg_scale` | float | 4.0 | Qwen-Image CFG scale |
-| `seed` | int | None | Random seed (reproducible) |
-| `negative_prompt` | str | None | Negative prompt |
-| `num_outputs_per_prompt` | int | 1 | Number of images to generate |
-| `use_system_prompt` | str | None | System prompt preset: `en_unified`, `en_vanilla`, `en_recaption`, `en_think_recaption`, `dynamic`, `None`, or custom text string. Only for HunyuanImage-3.0. |
-| `system_prompt` | str | None | Custom system prompt text. Only used when `use_system_prompt` is set to `custom`. Only for HunyuanImage-3.0. |
-
-## Response Format
-
-```json
-{
- "id": "chatcmpl-xxx",
- "created": 1234567890,
- "model": "Qwen/Qwen-Image",
- "choices": [{
- "index": 0,
- "message": {
- "role": "assistant",
- "content": [{
- "type": "image_url",
- "image_url": {
- "url": "data:image/png;base64,..."
- }
- }]
- },
- "finish_reason": "stop"
- }],
- "usage": {...}
-}
-```
-
-## Extract Image
-
-```bash
-# Extract base64 from response and decode to image
-cat response.json | jq -r '.choices[0].message.content[0].image_url.url' | cut -d',' -f2- | base64 -d > output.png
-```
-
-## File Description
-
-| File | Description |
-| --------------------------- | ---------------------------- |
-| `run_server.sh` | Server startup script |
-| `run_curl_text_to_image.sh` | curl example |
-| `openai_chat_client.py` | Python client |
-| `gradio_demo.py` | Gradio interactive interface |
diff --git a/examples/online_serving/text_to_image/gradio_demo.py b/examples/online_serving/text_to_image/gradio_demo.py
deleted file mode 100644
index c8329c02ac1..00000000000
--- a/examples/online_serving/text_to_image/gradio_demo.py
+++ /dev/null
@@ -1,189 +0,0 @@
-#!/usr/bin/env python3
-"""
-Qwen-Image Gradio Demo for online serving.
-
-Usage:
- python gradio_demo.py [--server http://localhost:8091] [--port 7860]
-"""
-
-import argparse
-import base64
-from io import BytesIO
-
-try:
- import gradio as gr
-except ImportError:
- raise ImportError("gradio is required to run this demo. Install it with: pip install 'vllm-omni[demo]'") from None
-import requests
-from PIL import Image
-
-
-def generate_image(
- prompt: str,
- height: int,
- width: int,
- steps: int,
- cfg_scale: float,
- seed: int | None,
- negative_prompt: str,
- server_url: str,
- num_outputs_per_prompt: int = 1,
-) -> Image.Image | None:
- """Generate an image using the chat completions API."""
- messages = [{"role": "user", "content": prompt}]
-
- # Build extra_body with generation parameters
- extra_body = {
- "height": height,
- "width": width,
- "num_inference_steps": steps,
- "true_cfg_scale": cfg_scale,
- }
- if seed is not None and seed >= 0:
- extra_body["seed"] = seed
- if negative_prompt:
- extra_body["negative_prompt"] = negative_prompt
- # Keep consistent with run_curl_text_to_image.sh, always send num_outputs_per_prompt
- extra_body["num_outputs_per_prompt"] = num_outputs_per_prompt
-
- # Build request payload
- payload = {"messages": messages, "extra_body": extra_body}
-
- try:
- response = requests.post(
- f"{server_url}/v1/chat/completions",
- headers={"Content-Type": "application/json"},
- json=payload,
- timeout=300,
- )
- response.raise_for_status()
- data = response.json()
-
- content = data["choices"][0]["message"]["content"]
- if isinstance(content, list) and len(content) > 0:
- image_url = content[0].get("image_url", {}).get("url", "")
- if image_url.startswith("data:image"):
- _, b64_data = image_url.split(",", 1)
- image_bytes = base64.b64decode(b64_data)
- return Image.open(BytesIO(image_bytes))
-
- return None
-
- except Exception as e:
- print(f"Error: {e}")
- raise gr.Error(f"Generation failed: {e}")
-
-
-def create_demo(server_url: str):
- """Create Gradio demo interface."""
-
- with gr.Blocks(title="Qwen-Image Demo") as demo:
- gr.Markdown("# Qwen-Image Online Generation")
- gr.Markdown("Generate images using Qwen-Image model")
-
- with gr.Row():
- with gr.Column(scale=1):
- prompt = gr.Textbox(
- label="Prompt",
- placeholder="Describe the image you want to generate...",
- lines=3,
- )
- negative_prompt = gr.Textbox(
- label="Negative Prompt",
- placeholder="Describe what you don't want...",
- lines=2,
- )
-
- with gr.Row():
- height = gr.Slider(
- label="Height",
- minimum=256,
- maximum=2048,
- value=1024,
- step=64,
- )
- width = gr.Slider(
- label="Width",
- minimum=256,
- maximum=2048,
- value=1024,
- step=64,
- )
-
- with gr.Row():
- steps = gr.Slider(
- label="Inference Steps",
- minimum=10,
- maximum=100,
- # Default steps aligned with run_curl_text_to_image.sh to 100
- value=100,
- step=5,
- )
- cfg_scale = gr.Slider(
- label="True CFG Scale",
- minimum=1.0,
- maximum=20.0,
- value=4.0,
- step=0.5,
- )
-
- with gr.Row():
- seed = gr.Number(
- label="Random Seed (-1 for random)",
- value=-1,
- precision=0,
- )
-
- generate_btn = gr.Button("Generate Image", variant="primary")
-
- with gr.Column(scale=1):
- output_image = gr.Image(
- label="Generated Image",
- type="pil",
- )
-
- # Examples
- gr.Examples(
- examples=[
- ["A beautiful landscape painting with misty mountains", "", 1024, 1024, 100, 4.0, 42],
- ["A cute cat sitting on a windowsill with sunlight", "", 1024, 1024, 100, 4.0, 123],
- ["Cyberpunk style futuristic city with neon lights", "blurry, low quality", 1024, 768, 100, 4.0, 456],
- ["Chinese ink painting of bamboo forest with a house", "", 768, 1024, 100, 4.0, 789],
- ],
- inputs=[prompt, negative_prompt, height, width, steps, cfg_scale, seed],
- )
-
- generate_btn.click(
- fn=lambda p, h, w, st, c, se, n: generate_image(
- p,
- h,
- w,
- st,
- c,
- se if se >= 0 else None,
- n,
- server_url,
- 1,
- ),
- inputs=[prompt, height, width, steps, cfg_scale, seed, negative_prompt],
- outputs=[output_image],
- )
-
- return demo
-
-
-def main():
- parser = argparse.ArgumentParser(description="Qwen-Image Gradio Demo")
- parser.add_argument("--server", default="http://localhost:8091", help="Server URL")
- parser.add_argument("--port", type=int, default=7860, help="Gradio port")
- parser.add_argument("--share", action="store_true", help="Create public link")
-
- args = parser.parse_args()
-
- print(f"Connecting to server: {args.server}")
- demo = create_demo(args.server)
- demo.launch(server_port=args.port, share=args.share)
-
-
-if __name__ == "__main__":
- main()
diff --git a/examples/online_serving/text_to_image/openai_chat_client.py b/examples/online_serving/text_to_image/openai_chat_client.py
deleted file mode 100644
index f3c43086a14..00000000000
--- a/examples/online_serving/text_to_image/openai_chat_client.py
+++ /dev/null
@@ -1,183 +0,0 @@
-#!/usr/bin/env python3
-"""
-Qwen-Image OpenAI-compatible image generation client.
-
-Usage:
- python openai_chat_client.py --prompt "A beautiful landscape" --output output.png
- python openai_chat_client.py --prompt "A sunset" --height 1024 --width 1024 --steps 50 --seed 42
-"""
-
-import argparse
-import base64
-from pathlib import Path
-
-import requests
-
-
-def generate_image(
- prompt: str,
- server_url: str = "http://localhost:8091",
- height: int | None = None,
- width: int | None = None,
- steps: int | None = None,
- true_cfg_scale: float | None = None,
- seed: int | None = None,
- negative_prompt: str | None = None,
- num_outputs_per_prompt: int = 1,
- lora_path: str | None = None,
- lora_name: str | None = None,
- lora_scale: float | None = None,
- lora_int_id: int | None = None,
- use_system_prompt: str | None = None,
- system_prompt: str | None = None,
-) -> bytes | None:
- """Generate an image using the images generation API.
-
- Args:
- prompt: Text description of the image
- server_url: Server URL
- height: Image height in pixels
- width: Image width in pixels
- steps: Number of diffusion steps
- true_cfg_scale: Qwen-Image CFG scale
- seed: Random seed
- negative_prompt: Negative prompt
- num_outputs_per_prompt: Number of images to generate
- lora_path: Server-local LoRA adapter folder path (PEFT format)
- lora_name: LoRA name (optional, defaults to path stem)
- lora_scale: LoRA scale factor (default: 1.0)
- lora_int_id: LoRA integer ID (optional, derived from path if not provided)
- use_system_prompt: System prompt for generation.
- system_prompt: Custom system prompt.
-
- Returns:
- Image bytes or None if failed
- """
- payload: dict[str, object] = {
- "prompt": prompt,
- "response_format": "b64_json",
- "n": num_outputs_per_prompt,
- }
-
- if width is not None and height is not None:
- payload["size"] = f"{width}x{height}"
- elif width is not None:
- payload["size"] = f"{width}x{width}"
- elif height is not None:
- payload["size"] = f"{height}x{height}"
-
- if steps is not None:
- payload["num_inference_steps"] = steps
- if true_cfg_scale is not None:
- payload["true_cfg_scale"] = true_cfg_scale
- if negative_prompt:
- payload["negative_prompt"] = negative_prompt
- if seed is not None:
- payload["seed"] = seed
- if use_system_prompt is not None:
- payload["use_system_prompt"] = use_system_prompt
- if system_prompt is not None:
- payload["system_prompt"] = system_prompt
- # Add LoRA if provided
- if lora_path:
- lora_body: dict = {
- "local_path": lora_path,
- "name": lora_name or Path(lora_path).stem,
- }
- if lora_scale is not None:
- lora_body["scale"] = float(lora_scale)
- if lora_int_id is not None:
- lora_body["int_id"] = int(lora_int_id)
- payload["lora"] = lora_body
-
- try:
- response = requests.post(
- f"{server_url}/v1/images/generations",
- headers={"Content-Type": "application/json"},
- json=payload,
- timeout=300,
- )
- response.raise_for_status()
- data = response.json()
-
- items = data.get("data")
- if isinstance(items, list) and items:
- first = items[0].get("b64_json") if isinstance(items[0], dict) else None
- if isinstance(first, str):
- return base64.b64decode(first)
-
- print(f"Unexpected response format: {data}")
- return None
-
- except Exception as e:
- print(f"Error: {e}")
- return None
-
-
-def main():
- parser = argparse.ArgumentParser(description="Qwen-Image chat client")
- parser.add_argument("--prompt", "-p", default="a cup of coffee on the table", help="Text prompt")
- parser.add_argument("--output", "-o", default="qwen_image_output.png", help="Output file")
- parser.add_argument("--server", "-s", default="http://localhost:8091", help="Server URL")
- parser.add_argument("--height", type=int, default=1024, help="Image height")
- parser.add_argument("--width", type=int, default=1024, help="Image width")
- parser.add_argument("--steps", type=int, default=50, help="Inference steps")
- parser.add_argument("--cfg-scale", type=float, default=4.0, help="True CFG scale")
- parser.add_argument("--seed", type=int, default=0, help="Random seed")
- parser.add_argument("--negative", help="Negative prompt")
-
- parser.add_argument("--lora-path", default=None, help="Server-local LoRA adapter folder (PEFT format)")
- parser.add_argument("--lora-name", default=None, help="LoRA name (optional)")
- parser.add_argument("--lora-scale", type=float, default=1.0, help="LoRA scale")
- parser.add_argument(
- "--lora-int-id",
- type=int,
- default=None,
- help="LoRA integer id (cache key). If omitted, the server derives a stable id from lora_path.",
- )
- parser.add_argument(
- "--use-system-prompt",
- type=str,
- default=None,
- help=(
- "System prompt for generation. Use predefined types: 'en_unified', 'en_vanilla', 'en_recaption', 'en_think_recaption', 'dynamic', or 'None'; Or provide custom text string directly. Recommended en_unified. "
- ),
- )
- parser.add_argument(
- "--system-prompt",
- type=str,
- default=None,
- help=("Custom system prompt. Used when --use-system-prompt is custom. "),
- )
- args = parser.parse_args()
- print(f"Generating image for: {args.prompt}")
-
- image_bytes = generate_image(
- prompt=args.prompt,
- server_url=args.server,
- height=args.height,
- width=args.width,
- steps=args.steps,
- true_cfg_scale=args.cfg_scale,
- seed=args.seed,
- negative_prompt=args.negative,
- lora_path=args.lora_path,
- lora_name=args.lora_name,
- lora_scale=args.lora_scale if args.lora_path else None,
- lora_int_id=args.lora_int_id if args.lora_path else None,
- use_system_prompt=args.use_system_prompt,
- system_prompt=args.system_prompt,
- )
-
- if image_bytes:
- output_path = Path(args.output)
- output_path.write_bytes(image_bytes)
- print(f"Image saved to: {output_path}")
- print(f"Size: {len(image_bytes) / 1024:.1f} KB")
- else:
- print("Failed to generate image")
- exit(1)
-
-
-if __name__ == "__main__":
- main()
diff --git a/examples/online_serving/text_to_image/run_curl_text_to_image.sh b/examples/online_serving/text_to_image/run_curl_text_to_image.sh
deleted file mode 100755
index 151df89485c..00000000000
--- a/examples/online_serving/text_to_image/run_curl_text_to_image.sh
+++ /dev/null
@@ -1,10 +0,0 @@
-#!/bin/bash
-# Qwen-Image text-to-image curl example
-
-curl -X POST http://localhost:8091/v1/images/generations \
- -H "Content-Type: application/json" \
- -d '{
- "prompt": "a dragon laying over the spine of the Green Mountains of Vermont",
- "size": "1024x1024",
- "seed": 42
- }' | jq -r '.data[0].b64_json' | base64 -d > dragon.png
diff --git a/examples/online_serving/text_to_image/run_server.sh b/examples/online_serving/text_to_image/run_server.sh
deleted file mode 100755
index b25337a0e93..00000000000
--- a/examples/online_serving/text_to_image/run_server.sh
+++ /dev/null
@@ -1,12 +0,0 @@
-#!/bin/bash
-# Qwen-Image online serving startup script
-
-MODEL="${MODEL:-Qwen/Qwen-Image}"
-PORT="${PORT:-8091}"
-
-echo "Starting Qwen-Image server..."
-echo "Model: $MODEL"
-echo "Port: $PORT"
-
-vllm serve "$MODEL" --omni \
- --port "$PORT"
diff --git a/examples/online_serving/text_to_video/README.md b/examples/online_serving/text_to_video/README.md
deleted file mode 100644
index c01e0602ff9..00000000000
--- a/examples/online_serving/text_to_video/README.md
+++ /dev/null
@@ -1,322 +0,0 @@
-# Text-To-Video
-
-This example demonstrates how to deploy text-to-video models for online video generation using vLLM-Omni.
-
-## Supported Models
-
-| Model | Model ID |
-|-------|----------|
-| Wan2.1 T2V (1.3B) | `Wan-AI/Wan2.1-T2V-1.3B-Diffusers` |
-| Wan2.1 T2V (14B) | `Wan-AI/Wan2.1-T2V-14B-Diffusers` |
-| Wan2.2 T2V | `Wan-AI/Wan2.2-T2V-A14B-Diffusers` |
-| LTX-2 | `Lightricks/LTX-2` |
-
-## Wan2.2 T2V
-
-### Start Server
-
-#### Basic Start
-
-```bash
-vllm serve Wan-AI/Wan2.2-T2V-A14B-Diffusers --omni --port 8091
-```
-
-#### Start with Parameters
-
-Or use the startup script:
-
-```bash
-bash run_server.sh
-```
-
-The script allows overriding:
-- `MODEL` (default: `Wan-AI/Wan2.2-T2V-A14B-Diffusers`)
-- `PORT` (default: `8091`)
-- `BOUNDARY_RATIO` (default: `0.875`)
-- `FLOW_SHIFT` (default: `5.0`)
-- `CACHE_BACKEND` (default: `none`)
-- `ENABLE_CACHE_DIT_SUMMARY` (default: `0`)
-
-## Async Job Behavior
-
-`POST /v1/videos` is asynchronous. It creates a video job and immediately
-returns metadata like the job ID and initial `queued` status. To get the final
-artifact, poll the job status and then download the completed file from the
-content endpoint.
-
-The main endpoints are:
-- `POST /v1/videos`: create a video generation job (async)
-- `POST /v1/videos/sync`: generate a video and return raw bytes (sync, for benchmarks)
-- `GET /v1/videos/{video_id}`: retrieve the current job status and metadata
-- `GET /v1/videos`: list stored video jobs
-- `GET /v1/videos/{video_id}/content`: download the generated video file
-- `DELETE /v1/videos/{video_id}`: delete the job and any stored output
-
-## Sync API (Benchmark / Testing)
-
-`POST /v1/videos/sync` is a synchronous alternative that blocks until generation
-completes and returns the raw video bytes (`video/mp4`) directly in the response
-body. It is designed for benchmark and testing scenarios where one-shot
-request/response latency measurement is needed.
-
-The sync endpoint accepts the same form parameters as `POST /v1/videos`. It does
-not create any stored job record — the response is purely the generated video
-file. Metadata is returned via response headers:
-
-- `X-Request-Id`: unique identifier for this generation request
-- `X-Model`: model name used for generation
-- `X-Inference-Time-S`: wall-clock inference time in seconds
-
-```bash
-curl -X POST http://localhost:8091/v1/videos/sync \
- -F "prompt=Two anthropomorphic cats in comfy boxing gear and bright gloves fight intensely on a spotlighted stage." \
- -F "size=832x480" \
- -F "num_frames=33" \
- -F "fps=16" \
- -F "num_inference_steps=40" \
- -F "guidance_scale=4.0" \
- -F "guidance_scale_2=4.0" \
- -F "boundary_ratio=0.875" \
- -F "flow_shift=5.0" \
- -F "seed=42" \
- -o sync_t2v_output.mp4
-```
-
-## Storage
-
-Generated video files are stored on local disk by the async video API.
-Local file storage behavior can be controlled via the following environment variables:
-
-- `VLLM_OMNI_STORAGE_PATH`: directory used for generated files (default: `/tmp/storage`)
-- `VLLM_OMNI_STORAGE_MAX_CONCURRENCY`: max concurrent save/delete operations (default: `4`)
-
-Example:
-
-```bash
-export VLLM_OMNI_STORAGE_PATH=/var/tmp/vllm-omni-videos
-export VLLM_OMNI_STORAGE_MAX_CONCURRENCY=8
-```
-
-## API Calls
-
-### Method 1: Using curl
-
-```bash
-# Basic text-to-video generation
-bash run_curl_text_to_video.sh
-
-# Or execute directly (OpenAI-style multipart)
-create_response=$(curl -s http://localhost:8091/v1/videos \
- -H "Accept: application/json" \
- -F "prompt=Two anthropomorphic cats in comfy boxing gear and bright gloves fight intensely on a spotlighted stage." \
- -F "width=832" \
- -F "height=480" \
- -F "num_frames=33" \
- -F "negative_prompt=色调艳丽 ,过曝,静态,细节模糊不清,字幕,风格,作品,画作,画面,静止,整体发灰,最差质量,低质量,JPEG压缩残留,丑陋的,残缺的,多余的手指,画得不好的手部,画得不好的脸部,畸形的,毁容的,形态畸形的肢体,手指融合,静止不动的画面,杂乱的背景,三条腿,背景人很多,倒着走" \
- -F "fps=16" \
- -F "num_inference_steps=40" \
- -F "guidance_scale=4.0" \
- -F "guidance_scale_2=4.0" \
- -F "boundary_ratio=0.875" \
- -F "flow_shift=5.0" \
- -F "seed=42")
-
-video_id=$(echo "$create_response" | jq -r '.id')
-while true; do
- status=$(curl -s "http://localhost:8091/v1/videos/${video_id}" | jq -r '.status')
- if [ "$status" = "completed" ]; then
- break
- fi
- if [ "$status" = "failed" ]; then
- echo "Video generation failed"
- exit 1
- fi
- sleep 2
-done
-
-curl -s "http://localhost:8091/v1/videos/${video_id}" | jq .
-curl -L "http://localhost:8091/v1/videos/${video_id}/content" -o wan22_output.mp4
-```
-
-## Request Format
-
-### Simple Text-to-Video Generation
-
-```bash
-curl -X POST http://localhost:8091/v1/videos \
- -F "prompt=A cinematic view of a futuristic city at sunset"
-```
-
-### Generation with Parameters
-
-```bash
-curl -X POST http://localhost:8091/v1/videos \
- -F "prompt=A cinematic view of a futuristic city at sunset" \
- -F "width=832" \
- -F "height=480" \
- -F "num_frames=33" \
- -F "negative_prompt=low quality, blurry, static" \
- -F "fps=16" \
- -F "num_inference_steps=40" \
- -F "guidance_scale=4.0" \
- -F "guidance_scale_2=4.0" \
- -F "boundary_ratio=0.875" \
- -F "flow_shift=5.0" \
- -F "seed=42"
-```
-
-## Generation Parameters
-
-| Parameter | Type | Default | Description |
-| --------------------- | ------ | ------- | ------------------------------------------------ |
-| `prompt` | str | - | Text description of the desired video |
-| `seconds` | str | None | Clip duration in seconds |
-| `size` | str | None | Output size in `WIDTHxHEIGHT` format |
-| `negative_prompt` | str | None | Negative prompt |
-| `width` | int | None | Video width in pixels |
-| `height` | int | None | Video height in pixels |
-| `num_frames` | int | None | Number of frames to generate |
-| `fps` | int | None | Frames per second for output video |
-| `num_inference_steps` | int | None | Number of denoising steps |
-| `guidance_scale` | float | None | CFG guidance scale (low-noise stage) |
-| `guidance_scale_2` | float | None | CFG guidance scale (high-noise stage, Wan2.2) |
-| `boundary_ratio` | float | None | Boundary split ratio for low/high DiT (Wan2.2) |
-| `flow_shift` | float | None | Scheduler flow shift (Wan2.2) |
-| `seed` | int | None | Random seed (reproducible) |
-| `lora` | object | None | LoRA configuration |
-
-## Create Response Format
-
-`POST /v1/videos` returns a job record, not inline base64 video data.
-
-```json
-{
- "id": "video_gen_123",
- "object": "video",
- "status": "queued",
- "model": "Wan-AI/Wan2.2-T2V-A14B-Diffusers",
- "prompt": "A cinematic view of a futuristic city at sunset",
- "created_at": 1234567890
-}
-```
-
-## Retrieve, List, Download, and Delete
-
-### Retrieve a job
-
-```bash
-curl -s http://localhost:8091/v1/videos/${video_id} | jq .
-```
-
-### List jobs
-
-```bash
-curl -s http://localhost:8091/v1/videos | jq .
-```
-
-### Download the completed video
-
-```bash
-curl -L http://localhost:8091/v1/videos/${video_id}/content -o wan22_output.mp4
-```
-
-### Delete a job and its stored file
-
-```bash
-curl -X DELETE http://localhost:8091/v1/videos/${video_id} | jq .
-```
-
-## Poll Until Complete
-
-```bash
-while true; do
- status=$(curl -s http://localhost:8091/v1/videos/${video_id} | jq -r '.status')
- if [ "$status" = "completed" ]; then
- break
- fi
- if [ "$status" = "failed" ]; then
- echo "Video generation failed"
- exit 1
- fi
- sleep 2
-done
-```
-
-## LTX-2
-
-### Start Server
-
-#### Basic Start
-
-```bash
-vllm serve Lightricks/LTX-2 --omni --port 8098 \
- --enforce-eager --flow-shift 1.0 --boundary-ratio 1.0
-```
-
-#### Start with Optimization Presets
-
-Use the LTX-2 startup script with built-in optimization presets:
-
-```bash
-# Baseline (1 GPU, eager)
-bash run_server_ltx2.sh baseline
-
-# 4-GPU Ulysses sequence parallelism (lossless)
-bash run_server_ltx2.sh ulysses4
-
-# Cache-DiT lossy acceleration (1 GPU, ~1.4× speedup)
-bash run_server_ltx2.sh cache-dit
-
-# Best combo: 4-GPU Ulysses SP + Cache-DiT (~2.2× speedup)
-bash run_server_ltx2.sh best-combo
-```
-
-#### Optimization Benchmarks
-
-Benchmarked on H800, online serving (480×768, 41 frames, 20 steps, `seed=42`).
-"Inference" is the server-reported inference time; excludes HTTP/poll overhead.
-
-| Preset | Server Command | Inference (s) | Speedup | Type |
-|--------|---------------|---------------|---------|------|
-| `baseline` | `--enforce-eager` | 10.3 | 1.00× | — |
-| `compile` | *(default, no --enforce-eager)* | ~10.3 (warm) | ~1.00× | Lossless |
-| `ulysses4` | `--enforce-eager --usp 4` | ~10.3 | ~1.00× | Lossless |
-| `cache-dit` | `--enforce-eager --cache-backend cache_dit` | 7.4 avg | ~1.4× | Lossy |
-| `best-combo` | `--enforce-eager --usp 4 --cache-backend cache_dit` | 4.7 avg | **~2.2×** | Lossless + Lossy |
-
-**Observations**:
-- **torch.compile**: On H800, warm-request inference time matches the eager baseline (~10.3s).
- The first request pays ~6s compilation overhead. Benefit depends on model architecture and GPU.
-- **Ulysses SP (4 GPU)**: No measurable speedup alone for 41-frame generation at this resolution.
- Communication overhead outweighs gains at this sequence length.
-- **Cache-DiT**: Inference varies per request (6–10s) due to dynamic caching decisions.
- Average is ~7.4s (~1.4× speedup) with slight quality tradeoff.
-- **Best combo**: 4-GPU Ulysses SP + Cache-DiT synergize well — Cache-DiT reduces per-step
- computation, making the communication overhead of Ulysses SP worthwhile. Average ~4.7s
- (~2.2× speedup).
-- **FP8 quantization**: Reduces VRAM but does not speed up LTX-2 on H800 (compute-bound).
-
-**Deployment Recommendations**:
-- For **production with quality priority**: use `baseline` with `--enforce-eager`
-- For **maximum throughput** (4 GPUs, quality tradeoff): use `best-combo` (~2.2× speedup)
-- For **single-GPU throughput**: use `cache-dit` (~1.4× speedup)
-- `--enforce-eager` is recommended to avoid torch.compile warmup latency on first request
-
-### Send Requests (curl)
-
-```bash
-# Using the provided script
-bash run_curl_ltx2.sh
-
-# Or directly
-curl -sS -X POST http://localhost:8098/v1/videos \
- -H "Accept: application/json" \
- -F "prompt=A serene lakeside sunrise with mist over the water." \
- -F "width=768" \
- -F "height=480" \
- -F "num_frames=41" \
- -F "fps=24" \
- -F "num_inference_steps=20" \
- -F "guidance_scale=3.0" \
- -F "seed=42"
-```
diff --git a/examples/online_serving/text_to_video/run_curl_hunyuan_video_15.sh b/examples/online_serving/text_to_video/run_curl_hunyuan_video_15.sh
deleted file mode 100644
index e6a655704e9..00000000000
--- a/examples/online_serving/text_to_video/run_curl_hunyuan_video_15.sh
+++ /dev/null
@@ -1,60 +0,0 @@
-#!/bin/bash
-# HunyuanVideo-1.5 text-to-video curl example using the async video job API.
-
-set -euo pipefail
-
-BASE_URL="${BASE_URL:-http://localhost:8098}"
-OUTPUT_PATH="${OUTPUT_PATH:-hunyuan_video_15_t2v.mp4}"
-POLL_INTERVAL="${POLL_INTERVAL:-2}"
-
-create_response=$(
- curl -sS -X POST "${BASE_URL}/v1/videos" \
- -H "Accept: application/json" \
- -F "prompt=A little girl wearing a straw hat runs through a summer meadow full of wildflowers. A wide shot is used, with the camera panning right to follow her." \
- -F "size=832x480" \
- -F "num_frames=33" \
- -F "fps=24" \
- -F "num_inference_steps=30" \
- -F "guidance_scale=6.0" \
- -F "flow_shift=5.0" \
- -F "seed=42"
-)
-
-video_id="$(echo "${create_response}" | jq -r '.id')"
-if [ -z "${video_id}" ] || [ "${video_id}" = "null" ]; then
- echo "Failed to create video job:"
- echo "${create_response}" | jq .
- exit 1
-fi
-
-echo "Created video job ${video_id}"
-echo "${create_response}" | jq .
-
-while true; do
- status_response="$(curl -sS "${BASE_URL}/v1/videos/${video_id}")"
- status="$(echo "${status_response}" | jq -r '.status')"
-
- case "${status}" in
- queued|in_progress)
- echo "Video job ${video_id} status: ${status}"
- sleep "${POLL_INTERVAL}"
- ;;
- completed)
- echo "${status_response}" | jq .
- break
- ;;
- failed)
- echo "Video generation failed:"
- echo "${status_response}" | jq .
- exit 1
- ;;
- *)
- echo "Unexpected status response:"
- echo "${status_response}" | jq .
- exit 1
- ;;
- esac
-done
-
-curl -sS -L "${BASE_URL}/v1/videos/${video_id}/content" -o "${OUTPUT_PATH}"
-echo "Saved video to ${OUTPUT_PATH}"
diff --git a/examples/online_serving/text_to_video/run_curl_ltx2.sh b/examples/online_serving/text_to_video/run_curl_ltx2.sh
deleted file mode 100644
index b82f672eaab..00000000000
--- a/examples/online_serving/text_to_video/run_curl_ltx2.sh
+++ /dev/null
@@ -1,66 +0,0 @@
-#!/bin/bash
-# SPDX-License-Identifier: Apache-2.0
-# SPDX-FileCopyrightText: Copyright contributors to the vLLM project
-#
-# LTX-2 text-to-video curl example using the async video job API.
-# Start the server first: bash run_server_ltx2.sh best-combo
-
-set -euo pipefail
-
-BASE_URL="${BASE_URL:-http://localhost:8098}"
-OUTPUT_PATH="${OUTPUT_PATH:-ltx2_output.mp4}"
-POLL_INTERVAL="${POLL_INTERVAL:-2}"
-
-PROMPT="${PROMPT:-A serene lakeside sunrise with mist over the water.}"
-
-create_response=$(
- curl -sS -X POST "${BASE_URL}/v1/videos" \
- -H "Accept: application/json" \
- -F "prompt=${PROMPT}" \
- -F "width=768" \
- -F "height=480" \
- -F "num_frames=41" \
- -F "fps=24" \
- -F "num_inference_steps=20" \
- -F "guidance_scale=3.0" \
- -F "seed=42"
-)
-
-video_id="$(echo "${create_response}" | jq -r '.id')"
-if [ -z "${video_id}" ] || [ "${video_id}" = "null" ]; then
- echo "Failed to create video job:"
- echo "${create_response}" | jq .
- exit 1
-fi
-
-echo "Created video job ${video_id}"
-echo "${create_response}" | jq .
-
-while true; do
- status_response="$(curl -sS "${BASE_URL}/v1/videos/${video_id}")"
- status="$(echo "${status_response}" | jq -r '.status')"
-
- case "${status}" in
- queued|in_progress)
- echo "Video job ${video_id} status: ${status}"
- sleep "${POLL_INTERVAL}"
- ;;
- completed)
- echo "${status_response}" | jq .
- break
- ;;
- failed)
- echo "Video generation failed:"
- echo "${status_response}" | jq .
- exit 1
- ;;
- *)
- echo "Unexpected status response:"
- echo "${status_response}" | jq .
- exit 1
- ;;
- esac
-done
-
-curl -sS -L "${BASE_URL}/v1/videos/${video_id}/content" -o "${OUTPUT_PATH}"
-echo "Saved video to ${OUTPUT_PATH}"
diff --git a/examples/online_serving/text_to_video/run_curl_text_to_video.sh b/examples/online_serving/text_to_video/run_curl_text_to_video.sh
deleted file mode 100644
index a95fa53f8a9..00000000000
--- a/examples/online_serving/text_to_video/run_curl_text_to_video.sh
+++ /dev/null
@@ -1,63 +0,0 @@
-#!/bin/bash
-# Wan2.2 text-to-video curl example using the async video job API.
-
-set -euo pipefail
-
-BASE_URL="${BASE_URL:-http://localhost:8098}"
-OUTPUT_PATH="${OUTPUT_PATH:-wan22_output.mp4}"
-POLL_INTERVAL="${POLL_INTERVAL:-2}"
-
-create_response=$(
- curl -sS -X POST "${BASE_URL}/v1/videos" \
- -H "Accept: application/json" \
- -F "prompt=Two anthropomorphic cats in comfy boxing gear and bright gloves fight intensely on a spotlighted stage." \
- -F "seconds=2" \
- -F "size=832x480" \
- -F "negative_prompt=色调艳丽,过曝,静态,细节模糊不清,字幕,风格,作品,画作,画面,静止,整体发灰,最差质量,低质量,JPEG压缩残留,丑陋的,残缺的,多余的手指,画得不好的手部,画得不好的脸部,畸形的,毁容的,形态畸形的肢体,手指融合,静止不动的画面,杂乱的背景,三条腿,背景人很多,倒着走" \
- -F "fps=16" \
- -F "num_inference_steps=40" \
- -F "guidance_scale=4.0" \
- -F "guidance_scale_2=4.0" \
- -F "boundary_ratio=0.875" \
- -F "flow_shift=5.0" \
- -F "seed=42"
-)
-
-video_id="$(echo "${create_response}" | jq -r '.id')"
-if [ -z "${video_id}" ] || [ "${video_id}" = "null" ]; then
- echo "Failed to create video job:"
- echo "${create_response}" | jq .
- exit 1
-fi
-
-echo "Created video job ${video_id}"
-echo "${create_response}" | jq .
-
-while true; do
- status_response="$(curl -sS "${BASE_URL}/v1/videos/${video_id}")"
- status="$(echo "${status_response}" | jq -r '.status')"
-
- case "${status}" in
- queued|in_progress)
- echo "Video job ${video_id} status: ${status}"
- sleep "${POLL_INTERVAL}"
- ;;
- completed)
- echo "${status_response}" | jq .
- break
- ;;
- failed)
- echo "Video generation failed:"
- echo "${status_response}" | jq .
- exit 1
- ;;
- *)
- echo "Unexpected status response:"
- echo "${status_response}" | jq .
- exit 1
- ;;
- esac
-done
-
-curl -sS -L "${BASE_URL}/v1/videos/${video_id}/content" -o "${OUTPUT_PATH}"
-echo "Saved video to ${OUTPUT_PATH}"
diff --git a/examples/online_serving/text_to_video/run_server.sh b/examples/online_serving/text_to_video/run_server.sh
deleted file mode 100644
index 2d7ce1d7a36..00000000000
--- a/examples/online_serving/text_to_video/run_server.sh
+++ /dev/null
@@ -1,31 +0,0 @@
-#!/bin/bash
-# Wan2.2 online serving startup script
-
-MODEL="${MODEL:-Wan-AI/Wan2.2-T2V-A14B-Diffusers}"
-PORT="${PORT:-8098}"
-BOUNDARY_RATIO="${BOUNDARY_RATIO:-0.875}"
-FLOW_SHIFT="${FLOW_SHIFT:-5.0}"
-CACHE_BACKEND="${CACHE_BACKEND:-none}"
-ENABLE_CACHE_DIT_SUMMARY="${ENABLE_CACHE_DIT_SUMMARY:-0}"
-
-echo "Starting Wan2.2 server..."
-echo "Model: $MODEL"
-echo "Port: $PORT"
-echo "Boundary ratio: $BOUNDARY_RATIO"
-echo "Flow shift: $FLOW_SHIFT"
-echo "Cache backend: $CACHE_BACKEND"
-if [ "$ENABLE_CACHE_DIT_SUMMARY" != "0" ]; then
- echo "Cache-DiT summary: enabled"
-fi
-
-CACHE_BACKEND_FLAG=""
-if [ "$CACHE_BACKEND" != "none" ]; then
- CACHE_BACKEND_FLAG="--cache-backend $CACHE_BACKEND"
-fi
-
-vllm serve "$MODEL" --omni \
- --port "$PORT" \
- --boundary-ratio "$BOUNDARY_RATIO" \
- --flow-shift "$FLOW_SHIFT" \
- $CACHE_BACKEND_FLAG \
- $(if [ "$ENABLE_CACHE_DIT_SUMMARY" != "0" ]; then echo "--enable-cache-dit-summary"; fi)
diff --git a/examples/online_serving/text_to_video/run_server_hunyuan_video_15.sh b/examples/online_serving/text_to_video/run_server_hunyuan_video_15.sh
deleted file mode 100644
index 5f6af72d78e..00000000000
--- a/examples/online_serving/text_to_video/run_server_hunyuan_video_15.sh
+++ /dev/null
@@ -1,31 +0,0 @@
-#!/bin/bash
-# HunyuanVideo-1.5 text-to-video online serving startup script
-#
-# 480p: ~35 GB VRAM (BF16), fits 1x A100 80GB
-# 720p: needs FP8 + VAE tiling, ~35 GB VRAM
-
-MODEL="${MODEL:-hunyuanvideo-community/HunyuanVideo-1.5-Diffusers-480p_t2v}"
-PORT="${PORT:-8098}"
-FLOW_SHIFT="${FLOW_SHIFT:-5.0}"
-QUANTIZATION="${QUANTIZATION:-}"
-CACHE_BACKEND="${CACHE_BACKEND:-none}"
-
-echo "Starting HunyuanVideo-1.5 T2V server..."
-echo "Model: $MODEL"
-echo "Port: $PORT"
-echo "Flow shift: $FLOW_SHIFT"
-echo "Quantization: ${QUANTIZATION:-none}"
-echo "Cache backend: $CACHE_BACKEND"
-
-EXTRA_FLAGS=""
-if [ -n "$QUANTIZATION" ]; then
- EXTRA_FLAGS="$EXTRA_FLAGS --quantization $QUANTIZATION"
-fi
-if [ "$CACHE_BACKEND" != "none" ]; then
- EXTRA_FLAGS="$EXTRA_FLAGS --cache-backend $CACHE_BACKEND"
-fi
-
-vllm serve "$MODEL" --omni \
- --port "$PORT" \
- --flow-shift "$FLOW_SHIFT" \
- $EXTRA_FLAGS
diff --git a/examples/online_serving/text_to_video/run_server_ltx2.sh b/examples/online_serving/text_to_video/run_server_ltx2.sh
deleted file mode 100644
index f4597d3cd28..00000000000
--- a/examples/online_serving/text_to_video/run_server_ltx2.sh
+++ /dev/null
@@ -1,84 +0,0 @@
-#!/bin/bash
-# SPDX-License-Identifier: Apache-2.0
-# SPDX-FileCopyrightText: Copyright contributors to the vLLM project
-#
-# LTX-2 online serving startup script with optimization presets.
-#
-# Usage:
-# bash run_server_ltx2.sh # baseline (1 GPU, eager)
-# bash run_server_ltx2.sh ulysses4 # 4-GPU Ulysses SP
-# bash run_server_ltx2.sh cache-dit # 1 GPU + Cache-DiT
-# bash run_server_ltx2.sh best-combo # 4-GPU Ulysses SP + Cache-DiT
-#
-# Online serving benchmarks on H800 (480×768, 41 frames, 20 steps):
-# baseline : 10.3s inference (1.00×)
-# compile : ~10.3s warm (~1.00×) first request +6s warmup
-# ulysses4 : ~10.3s (~1.00×) no gain at 41 frames
-# cache-dit : 7.4s avg (~1.4×) lossy, variable per request
-# best-combo : 4.7s avg (~2.2×) 4-GPU ulysses + cache-dit
-
-set -euo pipefail
-
-MODEL="${MODEL:-Lightricks/LTX-2}"
-PORT="${PORT:-8098}"
-FLOW_SHIFT="${FLOW_SHIFT:-1.0}"
-BOUNDARY_RATIO="${BOUNDARY_RATIO:-1.0}"
-
-PRESET="${1:-baseline}"
-
-EXTRA_ARGS=()
-case "$PRESET" in
- baseline)
- echo "=== LTX-2 Preset: baseline (1 GPU, enforce-eager) ==="
- EXTRA_ARGS+=(--enforce-eager)
- ;;
- ulysses2)
- echo "=== LTX-2 Preset: 2-GPU Ulysses SP (lossless) ==="
- EXTRA_ARGS+=(--enforce-eager --usp 2)
- ;;
- ulysses4)
- echo "=== LTX-2 Preset: 4-GPU Ulysses SP (lossless) ==="
- EXTRA_ARGS+=(--enforce-eager --usp 4)
- ;;
- cache-dit)
- echo "=== LTX-2 Preset: Cache-DiT (1 GPU, lossy) ==="
- EXTRA_ARGS+=(--enforce-eager --cache-backend cache_dit)
- ;;
- best-combo)
- echo "=== LTX-2 Preset: 4-GPU Ulysses SP + Cache-DiT (best combo) ==="
- EXTRA_ARGS+=(--enforce-eager --usp 4 --cache-backend cache_dit)
- ;;
- compile)
- echo "=== LTX-2 Preset: torch.compile (1 GPU, lossless) ==="
- # torch.compile is the default (no --enforce-eager)
- ;;
- *)
- echo "Usage: $0 {baseline|ulysses2|ulysses4|cache-dit|best-combo|compile}"
- echo ""
- echo "Presets:"
- echo " baseline - 1 GPU, eager execution (reference)"
- echo " ulysses2 - 2-GPU Ulysses SP (lossless)"
- echo " ulysses4 - 4-GPU Ulysses SP (lossless)"
- echo " cache-dit - 1 GPU + Cache-DiT (lossy, ~1.4× speedup)"
- echo " best-combo - 4-GPU Ulysses SP + Cache-DiT (~2.2× speedup)"
- echo " compile - 1 GPU + torch.compile (slower first request)"
- echo ""
- echo "Environment variables:"
- echo " MODEL - Model path (default: Lightricks/LTX-2)"
- echo " PORT - Server port (default: 8098)"
- echo " FLOW_SHIFT - Scheduler flow shift (default: 1.0)"
- echo " BOUNDARY_RATIO - Boundary ratio (default: 1.0)"
- exit 1
- ;;
-esac
-
-echo "Model: $MODEL"
-echo "Port: $PORT"
-echo "Flow shift: $FLOW_SHIFT"
-echo "Boundary ratio: $BOUNDARY_RATIO"
-
-vllm serve "$MODEL" --omni \
- --port "$PORT" \
- --flow-shift "$FLOW_SHIFT" \
- --boundary-ratio "$BOUNDARY_RATIO" \
- "${EXTRA_ARGS[@]}"
diff --git a/examples/online_serving/voxcpm/README.md b/examples/online_serving/voxcpm/README.md
deleted file mode 100644
index 78e1bf4aaa3..00000000000
--- a/examples/online_serving/voxcpm/README.md
+++ /dev/null
@@ -1,166 +0,0 @@
-# VoxCPM
-
-## Prerequisites
-
-Install VoxCPM in one of these ways:
-
-```bash
-pip install voxcpm
-```
-
-or point vLLM-Omni to a local VoxCPM source tree:
-
-```bash
-export VLLM_OMNI_VOXCPM_CODE_PATH=/path/to/VoxCPM/src
-```
-
-If the native VoxCPM `config.json` lacks HF metadata such as `model_type`,
-prepare a persistent HF-compatible config directory and export:
-
-```bash
-export VLLM_OMNI_VOXCPM_HF_CONFIG_PATH=/tmp/voxcpm_hf_config
-mkdir -p "$VLLM_OMNI_VOXCPM_HF_CONFIG_PATH"
-cp "$VOXCPM_MODEL/config.json" "$VLLM_OMNI_VOXCPM_HF_CONFIG_PATH/config.json"
-cp "$VOXCPM_MODEL/generation_config.json" "$VLLM_OMNI_VOXCPM_HF_CONFIG_PATH/generation_config.json" 2>/dev/null || true
-python3 -c 'import json, os; p=os.path.join(os.environ["VLLM_OMNI_VOXCPM_HF_CONFIG_PATH"], "config.json"); cfg=json.load(open(p, "r", encoding="utf-8")); cfg["model_type"]="voxcpm"; cfg.setdefault("architectures", ["VoxCPMForConditionalGeneration"]); json.dump(cfg, open(p, "w", encoding="utf-8"), indent=2, ensure_ascii=False)'
-```
-
-The VoxCPM stage configs read `VLLM_OMNI_VOXCPM_HF_CONFIG_PATH` directly. The `python3 -c` form above avoids heredoc/indentation issues in interactive shells.
-
-## Launch the Server
-
-Use the async-chunk stage config by default:
-
-```bash
-export VOXCPM_MODEL=/path/to/voxcpm-model
-cd examples/online_serving/voxcpm
-./run_server.sh
-```
-
-Use the non-streaming stage config:
-
-```bash
-./run_server.sh sync
-```
-
-You can also launch the server directly:
-
-```bash
-vllm serve "$VOXCPM_MODEL" \
- --stage-configs-path vllm_omni/model_executor/stage_configs/voxcpm_async_chunk.yaml \
- --trust-remote-code \
- --enforce-eager \
- --omni \
- --port 8091
-```
-
-## Send Requests
-
-### Basic text-to-speech
-
-```bash
-python openai_speech_client.py \
- --model "$VOXCPM_MODEL" \
- --text "This is a VoxCPM online text-to-speech example."
-```
-
-### Voice cloning
-
-```bash
-python openai_speech_client.py \
- --model "$VOXCPM_MODEL" \
- --text "This sentence is synthesized with a cloned voice." \
- --ref-audio /path/to/reference.wav \
- --ref-text "The exact transcript spoken in reference.wav."
-```
-
-`ref_text` must be the real transcript of the reference audio. Placeholder text or mismatched text will usually degrade quality badly.
-
-### Streaming PCM output
-
-```bash
-python openai_speech_client.py \
- --model "$VOXCPM_MODEL" \
- --text "This is a streaming VoxCPM request." \
- --stream \
- --output voxcpm_stream.pcm
-```
-
-### Using curl
-
-```bash
-curl -X POST http://localhost:8091/v1/audio/speech \
- -H "Content-Type: application/json" \
- -d '{
- "model": "OpenBMB/VoxCPM1.5",
- "input": "Hello from VoxCPM online serving.",
- "response_format": "wav"
- }' --output output.wav
-```
-
-Voice cloning:
-
-```bash
-curl -X POST http://localhost:8091/v1/audio/speech \
- -H "Content-Type: application/json" \
- -d '{
- "model": "OpenBMB/VoxCPM1.5",
- "input": "This sentence uses a cloned voice.",
- "ref_audio": "https://example.com/reference.wav",
- "ref_text": "The exact transcript spoken in the reference audio.",
- "response_format": "wav"
- }' --output cloned.wav
-```
-
-Streaming PCM:
-
-```bash
-curl -X POST http://localhost:8091/v1/audio/speech \
- -H "Content-Type: application/json" \
- -d '{
- "model": "OpenBMB/VoxCPM1.5",
- "input": "This is a streaming VoxCPM request.",
- "stream": true,
- "response_format": "pcm"
- }' --output output.pcm
-```
-
-## Supported Request Shape
-
-VoxCPM online serving currently supports:
-
-- plain text-to-speech
-- voice cloning with `ref_audio` + `ref_text`
-- `stream=true` with `response_format=pcm` or `wav`
-
-VoxCPM online serving does not use these generic TTS fields:
-
-- `voice`
-- `instructions`
-- `language`
-- `speaker_embedding`
-- `x_vector_only_mode`
-
-## Streaming vs Non-Streaming
-
-- `voxcpm_async_chunk.yaml` enables async-chunk streaming and is best for single-request streaming latency.
-- `voxcpm.yaml` performs one-shot latent generation then VAE decode.
-
-Like native VoxCPM, the async streaming path should be treated as single-request. If you need stable throughput benchmarking, prefer `voxcpm.yaml`.
-
-Do not use `voxcpm_async_chunk.yaml` for concurrent online streaming or `/v1/audio/speech/batch`. For multiple requests, prefer `voxcpm.yaml`.
-
-## Benchmark
-
-The serving benchmark reports TTFP and RTF:
-
-```bash
-python benchmarks/voxcpm/vllm_omni/bench_tts_serve.py \
- --host 127.0.0.1 \
- --port 8091 \
- --num-prompts 10 \
- --max-concurrency 1 \
- --result-dir /tmp/voxcpm_bench
-```
-
-For the async-chunk server, keep `--max-concurrency 1`.
diff --git a/examples/online_serving/voxcpm/openai_speech_client.py b/examples/online_serving/voxcpm/openai_speech_client.py
deleted file mode 100644
index c400114e8be..00000000000
--- a/examples/online_serving/voxcpm/openai_speech_client.py
+++ /dev/null
@@ -1,155 +0,0 @@
-"""OpenAI-compatible client for VoxCPM via /v1/audio/speech.
-
-Examples:
- # Basic text-to-speech
- python openai_speech_client.py --text "Hello from VoxCPM"
-
- # Voice cloning
- python openai_speech_client.py \
- --text "This sentence uses the cloned voice." \
- --ref-audio /path/to/reference.wav \
- --ref-text "The exact transcript spoken in the reference audio."
-
- # Streaming PCM output
- python openai_speech_client.py \
- --text "This is a streaming VoxCPM request." \
- --stream \
- --output output.pcm
-"""
-
-import argparse
-import base64
-import os
-
-import httpx
-
-DEFAULT_API_BASE = "http://localhost:8091"
-DEFAULT_API_KEY = "EMPTY"
-DEFAULT_MODEL = "OpenBMB/VoxCPM1.5"
-
-
-def encode_audio_to_base64(audio_path: str) -> str:
- """Encode a local audio file to base64 data URL."""
- if not os.path.exists(audio_path):
- raise FileNotFoundError(f"Audio file not found: {audio_path}")
-
- ext = audio_path.lower().rsplit(".", 1)[-1]
- mime_map = {
- "wav": "audio/wav",
- "mp3": "audio/mpeg",
- "flac": "audio/flac",
- "ogg": "audio/ogg",
- }
- mime_type = mime_map.get(ext, "audio/wav")
-
- with open(audio_path, "rb") as f:
- audio_b64 = base64.b64encode(f.read()).decode("utf-8")
- return f"data:{mime_type};base64,{audio_b64}"
-
-
-def build_payload(args) -> dict[str, object]:
- payload: dict[str, object] = {
- "model": args.model,
- "input": args.text,
- "response_format": "pcm" if args.stream else args.response_format,
- }
-
- if args.ref_audio:
- if args.ref_audio.startswith(("http://", "https://", "data:")):
- payload["ref_audio"] = args.ref_audio
- else:
- payload["ref_audio"] = encode_audio_to_base64(args.ref_audio)
- if args.ref_text:
- payload["ref_text"] = args.ref_text
- if args.max_new_tokens is not None:
- payload["max_new_tokens"] = args.max_new_tokens
- if args.stream:
- payload["stream"] = True
-
- return payload
-
-
-def run_tts(args) -> None:
- payload = build_payload(args)
- api_url = f"{args.api_base}/v1/audio/speech"
- headers = {
- "Content-Type": "application/json",
- "Authorization": f"Bearer {args.api_key}",
- }
-
- print(f"Model: {args.model}")
- print(f"Text: {args.text}")
- if args.ref_audio:
- print("Mode: voice cloning")
- print(f"Reference audio: {args.ref_audio}")
- else:
- print("Mode: text-to-speech")
-
- if args.stream:
- output_path = args.output or "voxcpm_output.pcm"
- with httpx.Client(timeout=300.0) as client:
- with client.stream("POST", api_url, json=payload, headers=headers) as response:
- if response.status_code != 200:
- print(f"Error: {response.status_code}")
- print(response.read().decode("utf-8", errors="ignore"))
- return
-
- total_bytes = 0
- with open(output_path, "wb") as f:
- for chunk in response.iter_bytes():
- if not chunk:
- continue
- f.write(chunk)
- total_bytes += len(chunk)
- print(f"Streamed {total_bytes} bytes to: {output_path}")
- return
-
- with httpx.Client(timeout=300.0) as client:
- response = client.post(api_url, json=payload, headers=headers)
-
- if response.status_code != 200:
- print(f"Error: {response.status_code}")
- print(response.text)
- return
-
- try:
- text = response.content.decode("utf-8")
- if text.startswith('{"error"'):
- print(f"Error: {text}")
- return
- except UnicodeDecodeError:
- pass
-
- output_path = args.output or "voxcpm_output.wav"
- with open(output_path, "wb") as f:
- f.write(response.content)
- print(f"Audio saved to: {output_path}")
-
-
-def main():
- parser = argparse.ArgumentParser(description="VoxCPM OpenAI-compatible speech client")
- parser.add_argument("--api-base", default=DEFAULT_API_BASE, help="API base URL")
- parser.add_argument("--api-key", default=DEFAULT_API_KEY, help="API key")
- parser.add_argument("--model", "-m", default=DEFAULT_MODEL, help="Model name or path")
- parser.add_argument("--text", required=True, help="Text to synthesize")
- parser.add_argument("--ref-audio", default=None, help="Reference audio path, URL, or data URL")
- parser.add_argument(
- "--ref-text",
- default=None,
- help="The exact transcript spoken in the reference audio",
- )
- parser.add_argument("--stream", action="store_true", help="Enable streaming PCM output")
- parser.add_argument(
- "--response-format",
- default="wav",
- choices=["wav", "pcm", "flac", "mp3", "aac", "opus"],
- help="Audio format for non-streaming mode (default: wav)",
- )
- parser.add_argument("--max-new-tokens", type=int, default=None, help="Maximum tokens to generate")
- parser.add_argument("--output", "-o", default=None, help="Output file path")
- args = parser.parse_args()
- run_tts(args)
-
-
-if __name__ == "__main__":
- main()
diff --git a/examples/online_serving/voxcpm/run_server.sh b/examples/online_serving/voxcpm/run_server.sh
deleted file mode 100755
index ab4b6fe854e..00000000000
--- a/examples/online_serving/voxcpm/run_server.sh
+++ /dev/null
@@ -1,38 +0,0 @@
-#!/bin/bash
-# Launch vLLM-Omni server for VoxCPM online speech serving.
-#
-# Usage:
-# ./run_server.sh # default: async_chunk stage config
-# ./run_server.sh async # async_chunk stage config
-# ./run_server.sh sync # no-async-chunk stage config
-# VOXCPM_MODEL=/path/to/model ./run_server.sh
-
-set -e
-
-MODE="${1:-async}"
-MODEL="${VOXCPM_MODEL:-OpenBMB/VoxCPM1.5}"
-
-case "$MODE" in
- async)
- STAGE_CONFIG="vllm_omni/model_executor/stage_configs/voxcpm_async_chunk.yaml"
- ;;
- sync)
- STAGE_CONFIG="vllm_omni/model_executor/stage_configs/voxcpm.yaml"
- ;;
- *)
- echo "Unknown mode: $MODE"
- echo "Supported: async, sync"
- exit 1
- ;;
-esac
-
-echo "Starting VoxCPM server with model: $MODEL"
-echo "Stage config: $STAGE_CONFIG"
-
-vllm serve "$MODEL" \
- --stage-configs-path "$STAGE_CONFIG" \
- --host 0.0.0.0 \
- --port 8091 \
- --trust-remote-code \
- --enforce-eager \
- --omni
diff --git a/examples/online_serving/voxcpm2/README.md b/examples/online_serving/voxcpm2/README.md
deleted file mode 100644
index 9ca2ae708a3..00000000000
--- a/examples/online_serving/voxcpm2/README.md
+++ /dev/null
@@ -1,43 +0,0 @@
-# VoxCPM2 Online Serving
-
-Serve VoxCPM2 TTS via the OpenAI-compatible `/v1/audio/speech` endpoint.
-
-## Start the Server
-
-```bash
-vllm serve openbmb/VoxCPM2 --omni --host 0.0.0.0 --port 8000
-```
-
-The deploy config is auto-loaded from `vllm_omni/deploy/voxcpm2.yaml`. Pass
-`--deploy-config <path>` to override, or `--stage-N-<field> <value>` (e.g.
-`--stage-0-max-num-seqs 8`) for per-stage runtime overrides.
-
-## Zero-shot Synthesis
-
-```bash
-python openai_speech_client.py --text "Hello, this is VoxCPM2."
-```
-
-Or with curl:
-
-```bash
-curl -X POST http://localhost:8000/v1/audio/speech \
- -H "Content-Type: application/json" \
- -d '{"model": "voxcpm2", "input": "Hello, this is VoxCPM2.", "voice": "default"}' \
- --output output.wav
-```
-
-## Voice Cloning
-
-Clone a speaker's voice using a reference audio file:
-
-```bash
-python openai_speech_client.py \
- --text "This should sound like the reference speaker." \
- --ref-audio /path/to/reference.wav
-```
-
-The `--ref-audio` parameter accepts:
-- Local file path (auto-encoded to base64)
-- URL (`https://...`)
-- Base64 data URI (`data:audio/wav;base64,...`)
diff --git a/examples/online_serving/voxcpm2/gradio_demo.py b/examples/online_serving/voxcpm2/gradio_demo.py
deleted file mode 100644
index c6706198ae4..00000000000
--- a/examples/online_serving/voxcpm2/gradio_demo.py
+++ /dev/null
@@ -1,599 +0,0 @@
-"""Gradio demo for VoxCPM2 TTS with gapless streaming audio playback.
-
-Uses a custom AudioWorklet-based player for gap-free streaming
-(adapted from the Qwen3-TTS demo). Audio is streamed from the vLLM
-server through a same-origin proxy and played via the Web Audio API's
-AudioWorklet, which maintains a FIFO buffer queue and plays samples at
-the audio clock rate.
-
-Usage:
- # Start the vLLM server first:
- vllm serve openbmb/VoxCPM2 --omni --host 0.0.0.0 --port 8000
-
- # Then launch the demo:
- python gradio_demo.py --api-base http://localhost:8000
-"""
-
-from __future__ import annotations
-
-import argparse
-import base64
-import io
-import json
-import logging
-
-import gradio as gr
-import httpx
-import numpy as np
-import soundfile as sf
-from fastapi import FastAPI, Request
-from fastapi.responses import Response, StreamingResponse
-
-logger = logging.getLogger(__name__)
-
-SAMPLE_RATE = 48000
-
-# ── AudioWorklet processor (loaded in browser via Blob URL) ──────────
-WORKLET_JS = r"""
-class TTSPlaybackProcessor extends AudioWorkletProcessor {
- constructor() {
- super();
- this.queue = [];
- this.buf = null;
- this.pos = 0;
- this.playing = false;
- this.played = 0;
- this.port.onmessage = (e) => {
- if (e.data && e.data.type === 'clear') {
- this.queue = []; this.buf = null; this.pos = 0; this.played = 0;
- if (this.playing) { this.playing = false; this.port.postMessage({type:'stopped'}); }
- return;
- }
- this.queue.push(e.data);
- };
- }
- process(inputs, outputs) {
- const out = outputs[0][0];
- for (let i = 0; i < out.length; i++) {
- if (!this.buf || this.pos >= this.buf.length) {
- if (this.queue.length > 0) {
- this.buf = this.queue.shift(); this.pos = 0;
- } else {
- for (let j = i; j < out.length; j++) out[j] = 0;
- if (this.playing) { this.playing = false; this.port.postMessage({type:'stopped', played:this.played}); }
- return true;
- }
- }
- out[i] = this.buf[this.pos++] / 32768;
- this.played++;
- }
- if (!this.playing) { this.playing = true; this.port.postMessage({type:'started'}); }
- return true;
- }
-}
-registerProcessor('tts-playback-processor', TTSPlaybackProcessor);
-"""
-
-PLAYER_HTML = """
-<div id="tts-player">
- <div style="display:flex; align-items:center; gap:10px;">
- <div id="tts-status-dot" style="width:10px;height:10px;border-radius:50%;background:#ccc;flex-shrink:0;"></div>
- <span id="tts-status" style="font-weight:600;font-size:1.05em;">Ready</span>
- <button id="tts-stop-btn" onclick="window.ttsStop()"
- style="display:none; margin-left:auto; padding:5px 16px; border-radius:6px; border:1px solid #EF5552;
- background:#fff; color:#EF5552; cursor:pointer; font-size:0.85em;">Stop</button>
- </div>
- <div id="tts-metrics" style="display:none; grid-template-columns:repeat(4,1fr); gap:10px; margin-top:12px;">
- <div style="background:#f8f9fa;border-radius:6px;padding:8px 10px;text-align:center;">
- <div style="font-size:0.7em;text-transform:uppercase;color:#888;letter-spacing:0.5px;margin-bottom:2px;">TTFP</div>
- <div id="tts-m-ttfp" style="font-size:1.2em;font-weight:700;color:#333;">—</div>
- </div>
- <div style="background:#f8f9fa;border-radius:6px;padding:8px 10px;text-align:center;">
- <div style="font-size:0.7em;text-transform:uppercase;color:#888;letter-spacing:0.5px;margin-bottom:2px;">RTF</div>
- <div id="tts-m-rtf" style="font-size:1.2em;font-weight:700;color:#333;">—</div>
- </div>
- <div style="background:#f8f9fa;border-radius:6px;padding:8px 10px;text-align:center;">
- <div style="font-size:0.7em;text-transform:uppercase;color:#888;letter-spacing:0.5px;margin-bottom:2px;">Audio</div>
- <div id="tts-m-dur" style="font-size:1.2em;font-weight:700;color:#333;">—</div>
- </div>
- <div style="background:#f8f9fa;border-radius:6px;padding:8px 10px;text-align:center;">
- <div style="font-size:0.7em;text-transform:uppercase;color:#888;letter-spacing:0.5px;margin-bottom:2px;">Speed</div>
- <div id="tts-m-speed" style="font-size:1.2em;font-weight:700;color:#333;">—</div>
- </div>
- </div>
- <div id="tts-rtf-bar-wrap" style="display:none; background:#e8ecf1; border-radius:4px; height:20px; overflow:hidden; position:relative; margin-top:10px;">
- <div id="tts-rtf-bar" style="height:100%; border-radius:4px; transition:width 0.3s ease, background 0.3s ease; width:0%;"></div>
- <span id="tts-rtf-label" style="position:absolute;top:50%;left:50%;transform:translate(-50%,-50%);font-size:0.75em;font-weight:600;color:#444;"></span>
- </div>
- <div id="tts-elapsed" style="display:none; margin-top:6px; font-size:0.8em; color:#999; text-align:right;"></div>
-</div>
-"""
-
-
-def _build_player_js() -> str:
- return f"""
- <script>
- const SR = {SAMPLE_RATE};
- const WC = {json.dumps(WORKLET_JS)};
- let ctx = null, node = null, abort = null, gen = false, st = {{}};
-
- async function init() {{
- if (ctx) return;
- ctx = new AudioContext({{ sampleRate: SR }});
- const b = new Blob([WC], {{ type: 'application/javascript' }});
- const u = URL.createObjectURL(b);
- await ctx.audioWorklet.addModule(u);
- URL.revokeObjectURL(u);
- node = new AudioWorkletNode(ctx, 'tts-playback-processor');
- node.connect(ctx.destination);
- node.port.onmessage = (e) => {{
- if (e.data.type === 'started') setStatus('Playing...', '#64dd17');
- else if (e.data.type === 'stopped' && !gen) {{
- setStatus('Done', '#64dd17'); showStats(true);
- const btn = document.getElementById('tts-stop-btn');
- if (btn) btn.style.display = 'none';
- }}
- }};
- }}
-
- function setStatus(text, color) {{
- const s = document.getElementById('tts-status');
- const d = document.getElementById('tts-status-dot');
- if (s) s.textContent = text;
- if (d) d.style.background = color || '#ccc';
- }}
-
- function showStats(fin) {{
- if (!st.t0) return;
- const elapsed = (fin && st.streamEnd ? (st.streamEnd - st.t0) : (performance.now() - st.t0)) / 1000;
- const dur = st.samples / SR;
- const mTtfp = document.getElementById('tts-m-ttfp');
- const mRtf = document.getElementById('tts-m-rtf');
- const mDur = document.getElementById('tts-m-dur');
- const mSpeed = document.getElementById('tts-m-speed');
- const bar = document.getElementById('tts-rtf-bar');
- const barLabel = document.getElementById('tts-rtf-label');
- const elapsedEl = document.getElementById('tts-elapsed');
- if (mTtfp && st.ttfp != null) mTtfp.textContent = st.ttfp.toFixed(0) + 'ms';
- if (mDur) mDur.textContent = dur.toFixed(1) + 's';
- if (dur > 0 && elapsed > 0) {{
- const rtf = elapsed / dur;
- const speed = 1 / rtf;
- if (mRtf) {{
- mRtf.textContent = rtf.toFixed(2) + 'x';
- mRtf.style.color = rtf < 1 ? '#64dd17' : rtf < 1.5 ? '#e8a317' : '#EF5552';
- }}
- if (mSpeed) {{
- mSpeed.textContent = speed.toFixed(1) + 'x';
- mSpeed.style.color = speed > 1 ? '#64dd17' : speed > 0.7 ? '#e8a317' : '#EF5552';
- }}
- if (bar) {{
- const pct = Math.min(speed / 10 * 100, 100);
- bar.style.width = pct + '%';
- bar.style.background = speed > 1 ? 'linear-gradient(90deg,#4A90D9,#64dd17)' : 'linear-gradient(90deg,#EF5552,#f87171)';
- }}
- if (barLabel) barLabel.textContent = speed.toFixed(1) + 'x realtime';
- }}
- if (elapsedEl) {{
- elapsedEl.style.display = 'block';
- elapsedEl.textContent = fin ? 'Completed in ' + elapsed.toFixed(1) + 's (' + st.chunks + ' chunks)' : elapsed.toFixed(1) + 's elapsed (' + st.chunks + ' chunks)';
- }}
- }}
-
- window.ttsStop = function() {{
- if (abort) abort.abort();
- if (node) node.port.postMessage({{ type: 'clear' }});
- gen = false;
- setStatus('Stopped', '#999');
- const btn = document.getElementById('tts-stop-btn');
- if (btn) btn.style.display = 'none';
- }};
-
- window.ttsGenerate = async function(payload) {{
- try {{ await init(); if (ctx.state === 'suspended') await ctx.resume(); }}
- catch (e) {{ setStatus('Audio init error: ' + e.message, '#EF5552'); return; }}
- if (abort) abort.abort();
- node.port.postMessage({{ type: 'clear' }});
- await new Promise(r => setTimeout(r, 50));
- node.port.postMessage({{ type: 'clear' }});
-
- gen = true;
- st = {{ t0: null, chunks: 0, samples: 0, ttfp: null }};
- setStatus('Connecting...', '#4A90D9');
- const bEl = document.getElementById('tts-stop-btn');
- if (bEl) bEl.style.display = 'inline-block';
- const mp = document.getElementById('tts-metrics');
- if (mp) {{ mp.style.display = 'grid'; ['tts-m-ttfp','tts-m-rtf','tts-m-dur','tts-m-speed'].forEach(id => {{ const e = document.getElementById(id); if(e) {{ e.textContent = '\\u2014'; e.style.color = '#333'; }} }}); }}
- const bw = document.getElementById('tts-rtf-bar-wrap');
- if (bw) bw.style.display = 'block';
- const bar = document.getElementById('tts-rtf-bar');
- if (bar) bar.style.width = '0%';
- const bl = document.getElementById('tts-rtf-label');
- if (bl) bl.textContent = '';
- const ee = document.getElementById('tts-elapsed');
- if (ee) {{ ee.style.display = 'none'; ee.textContent = ''; }}
- abort = new AbortController();
-
- try {{
- st.t0 = performance.now();
- const r = await fetch('/proxy/v1/audio/speech', {{
- method: 'POST',
- headers: {{ 'Content-Type': 'application/json' }},
- body: JSON.stringify(payload),
- signal: abort.signal,
- }});
- if (!r.ok) {{ const t = await r.text(); throw new Error('Server ' + r.status + ': ' + t.slice(0, 200)); }}
- setStatus('Streaming...', '#4A90D9');
- const reader = r.body.getReader();
- let left = new Uint8Array(0);
- while (true) {{
- const {{ done, value }} = await reader.read();
- if (done) break;
- let raw;
- if (left.length > 0) {{
- raw = new Uint8Array(left.length + value.length);
- raw.set(left); raw.set(value, left.length);
- }} else {{ raw = value; }}
- const usable = raw.length - (raw.length % 2);
- left = usable < raw.length ? raw.slice(usable) : new Uint8Array(0);
- if (usable > 0) {{
- const ab = new ArrayBuffer(usable);
- new Uint8Array(ab).set(raw.subarray(0, usable));
- const pcm = new Int16Array(ab);
- node.port.postMessage(pcm);
- st.chunks++;
- st.samples += pcm.length;
- if (st.ttfp == null) st.ttfp = performance.now() - st.t0;
- showStats(false);
- }}
- }}
- }} catch (e) {{
- if (e.name !== 'AbortError') {{
- setStatus('Error: ' + e.message, '#EF5552');
- console.error('TTS error:', e);
- }}
- }} finally {{
- st.streamEnd = performance.now();
- showStats(true);
- gen = false;
- if (st.samples > 0) setStatus('Finishing playback...', '#64dd17');
- else {{
- setStatus('No audio received', '#999');
- if (bEl) bEl.style.display = 'none';
- }}
- }}
- }};
- </script>
-"""
-
-
-def _encode_audio(audio_data: tuple) -> str:
- sr, audio_np = audio_data
- if audio_np.dtype in (np.float32, np.float64):
- audio_np = np.clip(audio_np, -1.0, 1.0)
- audio_np = (audio_np * 32767).astype(np.int16)
- elif audio_np.dtype != np.int16:
- audio_np = audio_np.astype(np.int16)
- buf = io.BytesIO()
- sf.write(buf, audio_np, sr, format="WAV")
- return f"data:audio/wav;base64,{base64.b64encode(buf.getvalue()).decode()}"
-
-
-def create_app(api_base: str):
- app = FastAPI()
- _pending: dict[str, dict] = {}
-
- @app.post("/proxy/v1/audio/speech")
- async def proxy_speech(request: Request):
- body = await request.json()
- req_id = body.get("_req_id")
- if req_id and req_id in _pending:
- body = _pending.pop(req_id)
- logger.info("Proxy: %s", {k: (f"<{len(str(v))} chars>" if k == "ref_audio" else v) for k, v in body.items()})
- try:
- client = httpx.AsyncClient(timeout=300)
- resp = await client.send(
- client.build_request(
- "POST",
- f"{api_base}/v1/audio/speech",
- json=body,
- headers={"Authorization": "Bearer EMPTY", "Content-Type": "application/json"},
- ),
- stream=True,
- )
- except Exception as exc:
- logger.exception("Proxy connection error")
- await client.aclose()
- return Response(content=str(exc), status_code=502)
- if resp.status_code != 200:
- content = await resp.aread()
- await resp.aclose()
- await client.aclose()
- return Response(content=content, status_code=resp.status_code)
-
- async def relay():
- try:
- async for chunk in resp.aiter_bytes():
- yield chunk
- finally:
- await resp.aclose()
- await client.aclose()
-
- return StreamingResponse(relay(), media_type="application/octet-stream")
-
- css = """
- #generate-btn button { width: 100%; }
- #streaming-player { border: 1px solid var(--border-color-primary) !important; border-radius: var(--block-radius) !important; padding: var(--block-padding) !important; }
- """
- theme = gr.themes.Default(
- primary_hue=gr.themes.Color(
- c50="#f0f5ff",
- c100="#dce6f9",
- c200="#b8cef3",
- c300="#8eb2eb",
- c400="#6496e0",
- c500="#4A90D9",
- c600="#3a7bc8",
- c700="#2d66b0",
- c800="#1f4f8f",
- c900="#163a6e",
- c950="#0e2650",
- ),
- )
-
- with gr.Blocks(title="VoxCPM2 TTS Demo") as demo:
- gr.HTML(f"""
- <div style="display:flex; align-items:center; gap:16px; margin-bottom:8px;">
- <img src="https://raw.githubusercontent.com/vllm-project/vllm-omni/main/docs/source/logos/vllm-omni-logo.png"
- alt="vLLM-Omni" style="height:42px;">
- <div>
- <h1 style="margin:0; font-size:1.5em;">VoxCPM2 Streaming Demo</h1>
- <span style="font-size:0.85em; color:#666;">
- Served by <a href="https://github.com/vllm-project/vllm-omni" target="_blank"
- style="color:#4A90D9; text-decoration:none; font-weight:600;">vLLM-Omni</a>
- · <code style="background:#eef2f7; padding:2px 6px; border-radius:4px; font-size:0.9em;">{api_base}</code>
- · 48 kHz
- </span>
- </div>
- </div>
- """)
-
- gr.Markdown(
- "**Three modes:** "
- "**Voice Design** (control instruction only) · "
- "**Controllable Cloning** (ref audio + optional style control) · "
- "**Ultimate Cloning** (ref audio + transcript for audio continuation)"
- )
-
- with gr.Row():
- with gr.Column(scale=3):
- text_input = gr.Textbox(
- label="Target Text",
- placeholder="Enter text to synthesize...",
- lines=4,
- )
- control_instruction = gr.Textbox(
- label="Control Instruction (optional)",
- placeholder="e.g. A warm young woman / Excited and fast-paced",
- lines=2,
- info="Describe voice style, emotion, pace. Works for both Voice Design and Controllable Cloning.",
- )
-
- with gr.Accordion("Voice Cloning", open=False):
- ref_audio = gr.Audio(
- label="Reference Audio (upload for cloning)",
- type="numpy",
- sources=["upload", "microphone"],
- )
- ref_audio_url = gr.Textbox(
- label="or Reference Audio URL",
- placeholder="https://example.com/reference.wav",
- )
- ultimate_clone = gr.Checkbox(
- label="Ultimate Cloning Mode",
- value=False,
- info="Provide transcript of ref audio for audio continuation (disables control instruction)",
- )
- prompt_text = gr.Textbox(
- label="Reference Audio Transcript",
- placeholder="Transcript of your reference audio (for ultimate cloning)",
- lines=2,
- visible=False,
- )
-
- with gr.Row():
- stream_checkbox = gr.Checkbox(
- label="Stream (gapless)",
- value=True,
- info="AudioWorklet streaming",
- )
- with gr.Row():
- generate_btn = gr.Button(
- "Generate Speech",
- variant="primary",
- size="lg",
- elem_id="generate-btn",
- scale=3,
- )
- reset_btn = gr.Button("Reset", variant="secondary", size="lg", scale=1)
-
- with gr.Column(scale=2):
- player_html = gr.HTML(
- value=PLAYER_HTML,
- visible=True,
- label="streaming player",
- elem_id="streaming-player",
- )
- audio_output = gr.Audio(
- label="generated audio",
- interactive=False,
- autoplay=True,
- visible=False,
- )
- gr.Examples(
- examples=[
- ["Hello, this is a VoxCPM2 demo running on vLLM-Omni.", ""],
- [
- "I have a dream that my four little children will one day live in a nation "
- "where they will not be judged by the color of their skin but by the content "
- "of their character.",
- "",
- ],
- [
- "I never asked you to stay. It's not like I care or anything. "
- "But why does it still hurt so much now that you're gone?",
- "A young girl with a soft, sweet voice. Speaks slowly with a melancholic tone.",
- ],
- ],
- inputs=[text_input, control_instruction],
- label="examples",
- )
- gr.HTML("""
- <div style="text-align:center; padding:8px 0; margin-top:4px;">
- <a href="https://github.com/vllm-project/vllm-omni" target="_blank">
- <img src="https://raw.githubusercontent.com/vllm-project/vllm-omni/main/docs/source/logos/vllm-omni-logo.png"
- alt="vLLM-Omni" style="height:28px; opacity:0.7;">
- </a>
- </div>
- """)
-
- hidden_payload = gr.Textbox(visible=False, elem_id="tts-payload")
-
- def on_ultimate_toggle(checked):
- return (
- gr.update(visible=checked), # prompt_text
- gr.update(interactive=not checked), # control_instruction
- )
-
- ultimate_clone.change(
- fn=on_ultimate_toggle,
- inputs=[ultimate_clone],
- outputs=[prompt_text, control_instruction],
- )
-
- def on_stream_change(stream: bool):
- if stream:
- return gr.update(visible=True), gr.update(visible=False)
- return gr.update(visible=False), gr.update(visible=True)
-
- stream_checkbox.change(
- fn=on_stream_change,
- inputs=[stream_checkbox],
- outputs=[player_html, audio_output],
- )
-
- def on_reset():
- return "", "", None, "", False, "", PLAYER_HTML
-
- reset_btn.click(
- fn=on_reset,
- outputs=[
- text_input,
- control_instruction,
- audio_output,
- hidden_payload,
- ultimate_clone,
- prompt_text,
- player_html,
- ],
- js="() => { if (window.ttsStop) window.ttsStop(); }",
- )
-
- def on_generate(stream_enabled, text, ctrl_instr, ref_a, ref_url, ult_clone, p_text):
- import time as _time
-
- if not text or not text.strip():
- raise gr.Error("Please enter text to synthesize.")
-
- # VoxCPM2 uses "(instruction)text" format for control
- ctrl = ctrl_instr.strip() if ctrl_instr and not ult_clone else ""
- final_text = f"({ctrl}){text.strip()}" if ctrl else text.strip()
-
- payload: dict = {
- "input": final_text,
- "voice": "default",
- "response_format": "pcm" if stream_enabled else "wav",
- "stream": stream_enabled,
- }
-
- # Reference audio for cloning
- ref_url_s = ref_url.strip() if ref_url else ""
- if ref_url_s:
- payload["ref_audio"] = ref_url_s
- elif ref_a is not None:
- payload["ref_audio"] = _encode_audio(ref_a)
-
- # Ultimate cloning: prompt_audio + prompt_text for continuation
- if ult_clone and p_text and p_text.strip():
- if ref_url_s:
- payload["prompt_audio"] = ref_url_s
- elif ref_a is not None:
- payload["prompt_audio"] = payload.get("ref_audio", "")
- payload["prompt_text"] = p_text.strip()
-
- if stream_enabled:
- if ref_a is not None and not ref_url_s:
- req_id = f"req-{int(_time.time() * 1000)}"
- _pending[req_id] = payload
- browser_payload = {"_req_id": req_id, "_nonce": int(_time.time() * 1000)}
- return json.dumps(browser_payload), gr.update()
- payload["_nonce"] = int(_time.time() * 1000)
- return json.dumps(payload), gr.update()
- else:
- try:
- with httpx.Client(timeout=300.0) as client:
- resp = client.post(
- f"{api_base}/v1/audio/speech",
- json=payload,
- headers={"Content-Type": "application/json", "Authorization": "Bearer EMPTY"},
- )
- except httpx.ConnectError:
- raise gr.Error(f"Cannot connect to server at {api_base}.")
- if resp.status_code != 200:
- raise gr.Error(f"Server error ({resp.status_code}): {resp.text[:200]}")
- audio_np, sr = sf.read(io.BytesIO(resp.content))
- if audio_np.ndim > 1:
- audio_np = audio_np[:, 0]
- return "", (sr, audio_np.astype(np.float32))
-
- generate_btn.click(
- fn=on_generate,
- inputs=[
- stream_checkbox,
- text_input,
- control_instruction,
- ref_audio,
- ref_audio_url,
- ultimate_clone,
- prompt_text,
- ],
- outputs=[hidden_payload, audio_output],
- ).then(
- fn=lambda p: p,
- inputs=[hidden_payload],
- outputs=[hidden_payload],
- js="(p) => { if (p && p.trim()) { const d = JSON.parse(p); delete d._nonce; window.ttsGenerate(d); } return p; }",
- )
-
- demo.queue()
-
- return gr.mount_gradio_app(app, demo, path="/", css=css, theme=theme, head=_build_player_js())
-
-
-def main():
- parser = argparse.ArgumentParser(description="VoxCPM2 streaming Gradio demo")
- parser.add_argument("--api-base", default="http://localhost:8000", help="vLLM API server URL")
- parser.add_argument("--host", default="0.0.0.0", help="Gradio server host")
- parser.add_argument("--port", type=int, default=7860, help="Gradio server port")
- args = parser.parse_args()
-
- logging.basicConfig(level=logging.INFO)
- print(f"Connecting to vLLM server at: {args.api_base}")
-
- import uvicorn
-
- uvicorn.run(create_app(args.api_base), host=args.host, port=args.port)
-
-
-if __name__ == "__main__":
- main()
diff --git a/examples/online_serving/voxcpm2/openai_speech_client.py b/examples/online_serving/voxcpm2/openai_speech_client.py
deleted file mode 100644
index 127b8cebb09..00000000000
--- a/examples/online_serving/voxcpm2/openai_speech_client.py
+++ /dev/null
@@ -1,105 +0,0 @@
-"""OpenAI-compatible client for VoxCPM2 TTS via /v1/audio/speech endpoint.
-
-Examples:
- # Zero-shot synthesis
- python openai_speech_client.py --text "Hello, this is VoxCPM2."
-
- # Voice cloning with a local reference audio file
- python openai_speech_client.py --text "Hello world" \
- --ref-audio /path/to/reference.wav
-
- # Voice cloning with a URL
- python openai_speech_client.py --text "Hello world" \
- --ref-audio "https://example.com/reference.wav"
-
-Server setup:
- vllm serve openbmb/VoxCPM2 --omni --host 0.0.0.0 --port 8000
-"""
-
-from __future__ import annotations
-
-import argparse
-import base64
-import os
-
-import httpx
-
-DEFAULT_API_BASE = "http://localhost:8000"
-DEFAULT_API_KEY = "sk-empty"
-
-
-def encode_audio_to_base64(audio_path: str) -> str:
- """Encode a local audio file to a base64 data URL."""
- if not os.path.exists(audio_path):
- raise FileNotFoundError(f"Audio file not found: {audio_path}")
-
- ext = audio_path.lower().rsplit(".", 1)[-1]
- mime = {
- "wav": "audio/wav",
- "mp3": "audio/mpeg",
- "flac": "audio/flac",
- "ogg": "audio/ogg",
- }.get(ext, "audio/wav")
-
- with open(audio_path, "rb") as f:
- b64 = base64.b64encode(f.read()).decode("utf-8")
- return f"data:{mime};base64,{b64}"
-
-
-def main() -> None:
- parser = argparse.ArgumentParser(description="VoxCPM2 OpenAI speech client")
- parser.add_argument("--text", type=str, required=True, help="Text to synthesize")
- parser.add_argument(
- "--ref-audio",
- type=str,
- default=None,
- help="Reference audio for voice cloning (local path, URL, or data: URI)",
- )
- parser.add_argument("--model", type=str, default="voxcpm2")
- parser.add_argument("--output", type=str, default="output.wav")
- parser.add_argument("--api-base", type=str, default=DEFAULT_API_BASE)
- parser.add_argument("--api-key", type=str, default=DEFAULT_API_KEY)
- parser.add_argument("--response-format", type=str, default="wav")
- args = parser.parse_args()
-
- # VoxCPM2 has no predefined voices. The "voice" field is required by
- # the OpenAI API schema but ignored by VoxCPM2 — use any placeholder.
- # For voice cloning, pass --ref-audio instead.
- payload: dict = {
- "model": args.model,
- "input": args.text,
- "voice": "default",
- "response_format": args.response_format,
- }
-
- if args.ref_audio:
- ref = args.ref_audio
- if ref.startswith(("http://", "https://", "data:")):
- payload["ref_audio"] = ref
- else:
- payload["ref_audio"] = encode_audio_to_base64(ref)
-
- url = f"{args.api_base}/v1/audio/speech"
- print(f"POST {url}")
- print(f" text: {args.text}")
- if args.ref_audio:
- print(f" ref_audio: {args.ref_audio[:80]}...")
-
- with httpx.Client(timeout=300) as client:
- resp = client.post(
- url,
- json=payload,
- headers={"Authorization": f"Bearer {args.api_key}"},
- )
-
- if resp.status_code != 200:
- print(f"Error {resp.status_code}: {resp.text[:500]}")
- return
-
- with open(args.output, "wb") as f:
- f.write(resp.content)
- print(f"Saved: {args.output} ({len(resp.content):,} bytes)")
-
-
-if __name__ == "__main__":
- main()
diff --git a/examples/online_serving/voxtral_tts/gradio_demo.py b/examples/online_serving/voxtral_tts/gradio_demo.py
deleted file mode 100644
index 7905c62618c..00000000000
--- a/examples/online_serving/voxtral_tts/gradio_demo.py
+++ /dev/null
@@ -1,522 +0,0 @@
-"""
-- Make sure to install the following for this example to function correctly:
-- `pip install -e .`
-- `pip install gradio==5.50 mistral_common=1.10.0`
-
-Example use case:
-
-python examples/online_serving/voxtral_tts/gradio_demo.py --host slurm-199-077 --port 8000
-
-"""
-
-import argparse
-import io
-import json
-import logging
-import socket
-import time
-import uuid
-from datetime import datetime
-from pathlib import Path
-from typing import Any
-
-try:
- import gradio as gr
-except ImportError:
- raise ImportError("gradio is required to run this demo. Install it with: pip install 'vllm-omni[demo]'") from None
-import httpx
-import numpy as np
-import soundfile as sf
-from text_preprocess import sanitize_tts_input_text_for_demo
-
-logger = logging.getLogger()
-
-LOGFORMAT = "%(asctime)s - %(levelname)s - %(message)s"
-TIMEFORMAT = "%Y-%m-%d %H:%M:%S"
-
-logging.basicConfig(level=logging.INFO, force=True, format=LOGFORMAT, datefmt=TIMEFORMAT)
-logger.setLevel(logging.INFO)
-
-
-_BASE_URL = f"{socket.gethostname()}:7860"
-
-# Default fallback voices - comprehensive list
-_DEFAULT_VOICES = [
- "casual_female",
- "casual_male",
- "cheerful_female",
- "neutral_female",
- "neutral_male",
- "ar_male",
- "de_female",
- "de_male",
- "es_female",
- "es_male",
- "fr_female",
- "fr_male",
- "hi_female",
- "hi_male",
- "it_female",
- "it_male",
- "nl_female",
- "nl_male",
- "pt_female",
- "pt_male",
-]
-
-
-def organize_voices_by_language(voices: list[str]) -> tuple[list[str], dict[str, list[str]]]:
- """Organize voices into language categories.
-
- Args:
- voices: List of voice names (e.g., ["neutral_male", "es_female", "fr_male"])
-
- Returns:
- Tuple of (sorted list of language categories, dictionary mapping language to voices)
- """
- # Define language prefixes and their display names
- LANGUAGE_PREFIXES = {
- "ar": "Arabic",
- "de": "German",
- "es": "Spanish",
- "fr": "French",
- "it": "Italian",
- "nl": "Dutch",
- "pt": "Portuguese",
- "hi": "Hindi",
- }
-
- # Initialize language to voices mapping
- language_voices: dict[str, list[str]] = {}
-
- for voice in voices:
- # Check for language prefix
- found_language = None
- for prefix, lang_name in LANGUAGE_PREFIXES.items():
- if voice.lower().startswith(f"{prefix}_"):
- found_language = lang_name
- break
-
- if found_language:
- # Add voice to its language category
- if found_language not in language_voices:
- language_voices[found_language] = []
- language_voices[found_language].append(voice)
- else:
- # Add to English (voices without language prefix)
- if "English" not in language_voices:
- language_voices["English"] = []
- language_voices["English"].append(voice)
-
- # Sort voices within each language category, with neutral_male first for English
- for lang in language_voices:
- if lang == "English":
- language_voices[lang].sort(key=lambda v: (0 if v == "neutral_male" else 1, v))
- else:
- language_voices[lang].sort()
-
- # Sort language categories (English first, then alphabetically)
- sorted_languages = sorted(language_voices.keys(), key=lambda x: (0 if x == "English" else 1, x.lower()))
-
- return sorted_languages, language_voices
-
-
-# Configuration for server health check
-_SERVER_CHECK_TIMEOUT = 300.0 # 5 minutes max wait
-_SERVER_CHECK_INTERVAL = 5.0 # 5 seconds between retries
-
-
-def wait_for_server(base_url: str, timeout: float = _SERVER_CHECK_TIMEOUT) -> bool:
- """Block until the server is available or timeout is reached.
-
- Args:
- base_url: Base URL of the server (e.g., "http://localhost:8091/v1")
- timeout: Maximum time to wait in seconds
-
- Returns:
- True if server became available, False if timeout reached
- """
- start_time = time.time()
- # Health endpoint is at /health (not /v1/health)
- health_url = base_url.replace("/v1", "") + "/health"
-
- logger.info(f"Waiting for server at {base_url} to become available...")
-
- with httpx.Client(timeout=5.0) as client:
- while time.time() - start_time < timeout:
- try:
- resp = client.get(health_url)
- if resp.status_code == 200:
- logger.info("Server is now available!")
- return True
- except Exception:
- pass
- elapsed = time.time() - start_time
- logger.info(f"Server not yet available ({elapsed:.1f}s elapsed), retrying in {_SERVER_CHECK_INTERVAL}s...")
- time.sleep(_SERVER_CHECK_INTERVAL)
-
- logger.warning(f"Server did not become available within {timeout}s timeout")
- return False
-
-
-def fetch_voices_and_languages(base_url: str, model: str) -> tuple[list[str], dict[str, list[str]]]:
- """Fetch available voices from the server API and organize by language.
-
- This function blocks until the server is available, then fetches the list
- of available voices from the /v1/audio/voices endpoint and organizes them.
-
- Args:
- base_url: Base URL of the server API (e.g., "http://localhost:8091/v1")
- model: Model name (used for logging)
-
- Returns:
- Tuple of (sorted language list, dictionary mapping language to voices)
- """
- # Always wait for server - if server is not up, demo cannot do anything
- if not wait_for_server(base_url):
- logger.warning("Server unavailable, using fallback voices")
- languages, language_voices = organize_voices_by_language(_DEFAULT_VOICES)
- return languages, language_voices
-
- try:
- with httpx.Client(timeout=10.0) as client:
- # The audio/voices endpoint is directly under /v1, not nested
- resp = client.get(
- f"{base_url}/audio/voices",
- headers={"Authorization": "Bearer EMPTY"},
- )
- if resp.status_code == 200:
- data = resp.json()
- voices = data.get("voices", [])
- if voices:
- logger.info(f"Fetched {len(voices)} voices from server: {voices}")
- languages, language_voices = organize_voices_by_language(sorted(voices))
- return languages, language_voices
- logger.warning("Server returned empty voices list")
- except Exception as e:
- logger.warning(f"Failed to fetch voices from server: {e}")
-
- # Fallback to default voices
- logger.info(f"Using fallback voices: {_DEFAULT_VOICES}")
- languages, language_voices = organize_voices_by_language(_DEFAULT_VOICES)
- return languages, language_voices
-
-
-def make_update_voice_dropdown(language_voices: dict[str, list[str]]):
- """Return a callback that updates the voice dropdown when the user
- selects a different language."""
-
- def update_voice_dropdown(language: str) -> gr.Dropdown:
- voices = language_voices.get(language, [])
- return gr.Dropdown(choices=voices, value=voices[0] if voices else None, interactive=True)
-
- return update_voice_dropdown
-
-
-def run_inference(
- voice_name: str,
- text_prompt: str,
- cfg_alpha: float,
- base_url: str,
- model: str,
-) -> tuple[int, np.ndarray]:
- """Call /v1/audio/speech and return (sample_rate, audio_array)."""
- user_text_prompt = text_prompt.strip()
- if not user_text_prompt:
- raise gr.Error("Please enter a text prompt.")
- try:
- text_prompt = sanitize_tts_input_text_for_demo(user_text_prompt)
- except Exception as exc:
- raise gr.Error(f"Text preprocessing failed: {exc}") from exc
-
- payload: dict[str, Any] = {
- "input": text_prompt,
- "model": model,
- "response_format": "wav",
- "voice": voice_name,
- "extra_params": {"cfg_alpha": cfg_alpha},
- }
-
- response = httpx.post(
- f"{base_url}/audio/speech",
- json=payload,
- timeout=120.0,
- )
- response.raise_for_status()
-
- audio_array, sr = sf.read(io.BytesIO(response.content), dtype="float32")
- return sr, audio_array
-
-
-def _save_example(
- outputs_dir: Path,
- voice_name: str,
- text_prompt: str,
- sr: int,
- audio_array: np.ndarray,
-) -> tuple[str, str]:
- """
- Save inputs/outputs for sharing.
- Returns (share_id, saved_audio_path)
- """
- share_id = uuid.uuid4().hex
-
- # Save generated audio
- saved_audio_path = outputs_dir / f"{share_id}_gen.wav"
- sf.write(str(saved_audio_path), audio_array, sr)
-
- meta = {
- "id": share_id,
- "created_at": datetime.utcnow().isoformat(),
- "voice_name": voice_name,
- "text_prompt": text_prompt,
- "generated_audio_path": str(saved_audio_path),
- }
-
- with open(outputs_dir / f"{share_id}.json", "w") as f:
- json.dump(meta, f, ensure_ascii=False)
-
- return share_id, str(saved_audio_path)
-
-
-def _load_from_share(
- outputs_dir: Path | None,
- request: gr.Request,
- languages: list[str] | None = None,
- language_voices: dict[str, list[str]] | None = None,
-) -> tuple[str, str, str | None, str | None, dict[str, Any], str]:
- """
- Called on page load. If ?share_id=... is present, load stored example.
- Returns: (language, voice_name, text_prompt, output_audio, submit_btn_update, share_link_text)
- """
- fallback_language = (
- "English" if languages and "English" in languages else (languages[0] if languages else "English")
- )
- if language_voices:
- voices_list = language_voices.get(fallback_language, [])
- fallback_voice = voices_list[0] if voices_list else None
- else:
- fallback_voice = None
-
- if outputs_dir is None:
- return fallback_language, fallback_voice, "", None, gr.update(interactive=False), ""
-
- share_id = None
- if request and request.query_params:
- share_id = request.query_params.get("share_id")
-
- if not share_id:
- return fallback_language, fallback_voice, "", None, gr.update(interactive=False), ""
-
- meta_path = outputs_dir / f"{share_id}.json"
- if not meta_path.exists():
- logger.warning("No stored example for share_id=%s", share_id)
- return fallback_language, fallback_voice, "", None, gr.update(interactive=False), ""
-
- with open(meta_path) as f:
- meta = json.load(f)
-
- # Determine language and voice from the stored voice name
- voice = meta.get("voice_name", fallback_voice)
- text_prompt = meta.get("text_prompt", "")
- gen_path = meta.get("generated_audio_path")
-
- # Find which language this voice belongs to
- language = fallback_language
- if language_voices:
- for lang, voices in language_voices.items():
- if voice in voices:
- language = lang
- break
-
- if _BASE_URL:
- share_link = f"http://{_BASE_URL}?share_id={share_id}"
- else:
- share_link = f"Use this query on your current URL: ?share_id={share_id}"
-
- return language, voice, text_prompt, gen_path, gr.update(interactive=True), share_link
-
-
-def main(
- model: str,
- host: str,
- port: str,
- output_dir: str | None = None,
-) -> None:
- base_url = f"http://{host}:{port}/v1"
- logger.info(f"Using speech API at: {base_url}/audio/speech")
-
- outputs_dir: Path | None = None
- if output_dir is not None:
- outputs_dir = Path(output_dir)
- outputs_dir.mkdir(parents=True, exist_ok=True)
-
- # Load available voices and organize by language
- # This will block until the server is available
- languages, language_voices = fetch_voices_and_languages(base_url, model)
-
- with gr.Blocks(title="Voxtral TTS", fill_height=True) as demo:
- gr.Markdown("## Voxtral TTS")
-
- with gr.Row():
- with gr.Column():
- # Language dropdown (first level)
- default_language = "English" if "English" in languages else languages[0]
- language_dropdown = gr.Dropdown(
- choices=languages,
- label="Language",
- value=default_language,
- )
- # Voice dropdown (second level, updates based on language)
- voices_for_default_lang = language_voices.get(default_language, [])
- voice_name = gr.Dropdown(
- choices=voices_for_default_lang,
- label="Voice",
- value=voices_for_default_lang[0] if voices_for_default_lang else None,
- )
- text_prompt = gr.Textbox(
- label="Text prompt",
- placeholder="Enter the text you want to synthesize...",
- lines=4,
- )
- cfg_alpha_slider = gr.Slider(
- minimum=1.0,
- maximum=2.0,
- step=0.1,
- value=1.2,
- label="CFG Alpha",
- info="Flow-matching guidance strength (default: 1.2)",
- )
- with gr.Row():
- reset_btn = gr.Button("Clear")
- submit_btn = gr.Button("Generate audio", interactive=False)
-
- with gr.Column():
- output_audio = gr.Audio(
- label="Generated audio",
- show_download_button=True,
- interactive=False,
- autoplay=True,
- type="filepath",
- )
- share_link_box = gr.Textbox(
- label="Shareable link",
- interactive=False,
- show_copy_button=True,
- visible=outputs_dir is not None,
- )
-
- # --- Cascading dropdown: update voice list when language changes ---
- language_dropdown.change(
- fn=make_update_voice_dropdown(language_voices),
- inputs=[language_dropdown],
- outputs=voice_name,
- )
-
- # --- UI logic: disable submit until text is non-empty ---
- def _toggle_submit(text: str):
- enabled = bool(text.strip())
- return gr.update(interactive=enabled)
-
- text_prompt.change(
- fn=_toggle_submit,
- inputs=[text_prompt],
- outputs=submit_btn,
- )
-
- # --- Wiring inference + persistence to the button ---
- def _on_submit(voice: str, text: str, cfg_alpha: float):
- assert text.strip() != ""
- sr, audio_array = run_inference(voice, text, cfg_alpha, base_url, model)
- if outputs_dir is not None:
- share_id, saved_audio_path = _save_example(
- outputs_dir,
- voice_name=voice,
- text_prompt=text,
- sr=sr,
- audio_array=audio_array,
- )
- share_link = f"{_BASE_URL}?share_id={share_id}"
- return saved_audio_path, share_link
- return (sr, audio_array), ""
-
- submit_btn.click(
- fn=_on_submit,
- inputs=[voice_name, text_prompt, cfg_alpha_slider],
- outputs=[output_audio, share_link_box],
- )
-
- # --- Clear everything and disable submit again ---
- def make_on_reset(languages: list[str], language_voices: dict[str, list[str]]):
- def _on_reset():
- language = "English" if "English" in languages else languages[0]
- voices_list = language_voices.get(language, [])
- voice = voices_list[0] if voices_list else None
- return (
- language, # language_dropdown
- voice, # voice_name
- "", # text_prompt
- 1.2, # cfg_alpha_slider
- None, # output_audio
- gr.update(interactive=False), # submit_btn
- "", # share_link_box
- )
-
- return _on_reset
-
- reset_btn.click(
- fn=make_on_reset(languages, language_voices),
- inputs=[],
- outputs=[
- language_dropdown,
- voice_name,
- text_prompt,
- cfg_alpha_slider,
- output_audio,
- submit_btn,
- share_link_box,
- ],
- )
-
- def make_load_from_share(outputs_dir: Path | None, languages: list[str], language_voices: dict[str, list[str]]):
- def _load(request: gr.Request):
- return _load_from_share(outputs_dir, request, languages, language_voices)
-
- return _load
-
- demo.load(
- fn=make_load_from_share(outputs_dir, languages, language_voices),
- inputs=[],
- outputs=[language_dropdown, voice_name, text_prompt, output_audio, submit_btn, share_link_box],
- )
-
- launch_kwargs: dict[str, Any] = {
- "server_name": "0.0.0.0",
- "share": True,
- }
- if outputs_dir is not None:
- launch_kwargs["allowed_paths"] = [str(outputs_dir)]
- demo.launch(**launch_kwargs)
-
-
-if __name__ == "__main__":
- parser = argparse.ArgumentParser(description="Voxtral TTS Gradio Demo")
- parser.add_argument("--model", type=str, default="mistralai/Voxtral-4B-TTS-2603", help="Name of model repo on HF")
- parser.add_argument("--host", type=str, default="localhost", help="Name of host")
- parser.add_argument("--port", type=str, default="8091", help="port number")
- parser.add_argument(
- "--output-dir",
- type=str,
- default=None,
- help="Directory to save generated audio and share links. "
- "If not provided, save/share functionality is disabled.",
- )
-
- args = parser.parse_args()
-
- main(
- model=args.model,
- host=args.host,
- port=args.port,
- output_dir=args.output_dir,
- )
diff --git a/examples/online_serving/voxtral_tts/text_preprocess.py b/examples/online_serving/voxtral_tts/text_preprocess.py
deleted file mode 100644
index 5fd3152c372..00000000000
--- a/examples/online_serving/voxtral_tts/text_preprocess.py
+++ /dev/null
@@ -1,404 +0,0 @@
-"""Text preprocessing utilities for the Voxtral TTS demo.
-
-Provides text normalization and cleanup before sending input to the TTS model,
-including:
-
-- Removal of invisible Unicode characters (zero-width spaces, bidi marks, etc.)
-- Flattening of Markdown and HTML formatting
-- Verbalization of numbers and currency ($1.50 -> "one dollar and fifty cents")
-- Normalization of punctuation and dashes
-- Insertion of terminal punctuation when missing
-
-"""
-
-import re
-from html import unescape
-
-# Invisible Unicode chars often introduced by copy/paste.
-_INVISIBLE_UNICODE_RE = re.compile(
- "["
- "\u200b" # zero-width space
- "\u200e-\u200f" # bidi marks
- "\u2028-\u2029" # line/paragraph separators
- "\u2060-\u2064" # word joiner, invisible math operators
- "\u00ad" # soft hyphen
- "\u180e" # mongolian vowel separator
- "\ufeff" # BOM / zero-width no-break space
- "\ufff9-\ufffb" # interlinear annotations
- "]"
-)
-# Keeps U+200C (ZWNJ) and U+200D (ZWJ).
-
-_LINE_BREAK_RE = re.compile(r"(?:\r\n|\r|\n)+")
-_REPEATED_PUNCT_RE = re.compile(r"([!?])\1+")
-_ASCII_ELLIPSIS_RUN_RE = re.compile(r"\.{3,}")
-_UNICODE_HYPHEN_TO_ASCII_RE = re.compile("[\u2010\u2011]")
-
-_DASH_LIKE_CHARS = "\u002d\u2013\u2212"
-_DASH_LIKE_CLASS = re.escape(_DASH_LIKE_CHARS)
-_CURRENCY_CHARS = "$€£¥₹¢"
-_MULTI_HYPHEN_RE = re.compile(rf"[{_DASH_LIKE_CLASS}]{{2,}}")
-_STANDALONE_HYPHEN_RE = re.compile(rf"(?<=\s)[{_DASH_LIKE_CLASS}](?=\s)")
-_TERMINAL_PUNCT = ".!?\u2026\u061f\u3002\uff01\uff1f"
-
-_PARENTHETICAL_RE = re.compile(r"\s*\(([^()]+)\)\s*")
-_SIMPLE_NUMERIC_PAREN_CONTENT_RE = re.compile(r"^\s*[$€£¥₹¢]?\s*[+\-−–]?\d+(?:[.,]\d+)?\s*%?\s*$")
-
-_MD_FENCE_RE = re.compile(r"```[\s\S]*?```|~~~[\s\S]*?~~~")
-_MD_IMAGE_LINK_RE = re.compile(r"!\[([^\]]*)\]\(([^)]*)\)")
-_MD_LINK_RE = re.compile(r"\[([^\]]+)\]\(([^)]*)\)")
-_MD_INLINE_CODE_RE = re.compile(r"`([^`]+)`")
-_MD_HEADING_RE = re.compile(r"^\s{0,3}#{1,6}\s*", re.MULTILINE)
-_MD_UNORDERED_RE = re.compile(r"^\s*[-*+]\s+", re.MULTILINE)
-_MD_ORDERED_RE = re.compile(r"^\s*\d{1,4}[.)]\s+", re.MULTILINE)
-_MD_BLOCKQUOTE_RE = re.compile(r"^\s{0,3}>\s?", re.MULTILINE)
-_MD_BR_TAG_RE = re.compile(r"(?i)<br\s*/?>")
-_MD_HTML_TAG_RE = re.compile(r"</?[a-zA-Z][^>]*>")
-_MD_AUTOLINK_RE = re.compile(r"<https?://[^>]+>")
-_MD_URL_RE = re.compile(r"https?://\S+")
-
-_ONES = {
- 0: "zero",
- 1: "one",
- 2: "two",
- 3: "three",
- 4: "four",
- 5: "five",
- 6: "six",
- 7: "seven",
- 8: "eight",
- 9: "nine",
-}
-_TEENS = {
- 10: "ten",
- 11: "eleven",
- 12: "twelve",
- 13: "thirteen",
- 14: "fourteen",
- 15: "fifteen",
- 16: "sixteen",
- 17: "seventeen",
- 18: "eighteen",
- 19: "nineteen",
-}
-_TENS = {
- 20: "twenty",
- 30: "thirty",
- 40: "forty",
- 50: "fifty",
- 60: "sixty",
- 70: "seventy",
- 80: "eighty",
- 90: "ninety",
-}
-_SCALES = ["", "thousand", "million", "billion", "trillion", "quadrillion"]
-
-_TOKEN_RE = re.compile(
- r"""
- (?P<currency>
- (?P<symbol>[$£€¥₹¢])
- (?P<amount>\d[\d,]*(?:\.\d+)?)
- )
- |
- (?P<number>
- (?<!\w)-?\d[\d,]*(?:\.\d+)?\b
- )
- """,
- re.VERBOSE,
-)
-
-_CURRENCY_INFO = {
- "$": ("dollar", "dollars", "cent", "cents"),
- "£": ("pound", "pounds", "penny", "pence"),
- "€": ("euro", "euros", "cent", "cents"),
- "¥": ("yen", "yen", None, None),
- "₹": ("rupee", "rupees", "paise", "paise"),
- "¢": ("cent", "cents", None, None),
-}
-
-
-def _flatten_markdown_for_tts(text: str) -> str:
- text = _MD_FENCE_RE.sub(" Code example omitted. ", text)
- text = unescape(text)
- text = _MD_BR_TAG_RE.sub(" ", text)
- text = _MD_IMAGE_LINK_RE.sub(lambda match: match.group(1).strip() or "image", text)
- text = _MD_LINK_RE.sub(lambda match: match.group(1), text)
- text = _MD_AUTOLINK_RE.sub("link", text)
- text = _MD_URL_RE.sub("link", text)
- text = _MD_INLINE_CODE_RE.sub(lambda match: match.group(1), text)
- text = _MD_HEADING_RE.sub("", text)
- text = _MD_UNORDERED_RE.sub("", text)
- text = _MD_ORDERED_RE.sub("", text)
- text = _MD_BLOCKQUOTE_RE.sub("", text)
- text = _MD_HTML_TAG_RE.sub(" ", text)
- return text
-
-
-def _next_non_space_char(text: str, start_index: int) -> str | None:
- index = start_index
- while index < len(text) and text[index].isspace():
- index += 1
- if index >= len(text):
- return None
- return text[index]
-
-
-def _replace_standalone_hyphens(text: str) -> str:
- def replace(match: re.Match[str]) -> str:
- next_char = _next_non_space_char(text, match.end())
- if next_char is None:
- return match.group(0)
- if next_char.isdigit() or next_char in _CURRENCY_CHARS:
- return match.group(0)
- return "\u2014"
-
- return _STANDALONE_HYPHEN_RE.sub(replace, text)
-
-
-def _replace_textual_parentheticals(text: str) -> str:
- def normalize_parenthetical(inner: str) -> str:
- normalized = inner
- normalized = re.sub(r"(?i)\bN\s*/\s*A\b", "not available", normalized)
- normalized = re.sub(r"\s*(?:\+/-|±)\s*", " plus or minus ", normalized)
- normalized = re.sub(r"\s*>=\s*", " greater than or equal to ", normalized)
- normalized = re.sub(r"\s*<=\s*", " less than or equal to ", normalized)
- normalized = re.sub(r"\s*>\s*", " greater than ", normalized)
- normalized = re.sub(r"\s*<\s*", " less than ", normalized)
- normalized = re.sub(r"\s*~\s*", " about ", normalized)
- normalized = re.sub(r"#\s*(\d+)\b", r"number \1", normalized)
- normalized = re.sub(r"(\d+(?:\.\d+)?)\s*ms\b", r"\1 milliseconds", normalized, flags=re.IGNORECASE)
- normalized = re.sub(r"(\d+(?:\.\d+)?)\s*h\b", r"\1 hours", normalized, flags=re.IGNORECASE)
- normalized = re.sub(r"(\d+(?:\.\d+)?)\s*%", r"\1 percent", normalized)
- normalized = re.sub(r"\s*\+\s*", " plus ", normalized)
- normalized = re.sub(r"\s*=\s*", " equals ", normalized)
- normalized = re.sub(r"\s+", " ", normalized).strip()
- return normalized
-
- def replace(match: re.Match[str]) -> str:
- inner = match.group(1).strip()
- if not inner:
- return match.group(0)
- if _SIMPLE_NUMERIC_PAREN_CONTENT_RE.fullmatch(inner):
- return match.group(0)
- normalized = normalize_parenthetical(inner)
- return f"\u2014{normalized}\u2014"
-
- return _PARENTHETICAL_RE.sub(replace, text)
-
-
-def _verbalize_sub_thousand(n: int, *, use_and: bool = False) -> str:
- if not 0 <= n <= 999:
- raise ValueError(f"Expected sub-thousand integer in [0, 999], got {n=}")
- parts: list[str] = []
- hundreds = n // 100
- rem = n % 100
- if hundreds:
- parts.append(f"{_ONES[hundreds]} hundred")
- if rem and use_and:
- parts.append("and")
- if rem:
- if rem < 10:
- parts.append(_ONES[rem])
- elif rem < 20:
- parts.append(_TEENS[rem])
- else:
- tens = (rem // 10) * 10
- ones = rem % 10
- if ones:
- parts.append(f"{_TENS[tens]}-{_ONES[ones]}")
- else:
- parts.append(_TENS[tens])
- return " ".join(parts) if parts else "zero"
-
-
-def _verbalize_integer_en(num_str: str, *, use_and: bool = False) -> str:
- s = num_str.replace(",", "").strip()
- if not re.fullmatch(r"\d+", s):
- raise ValueError(f"Not a plain integer: {num_str}")
- n = int(s)
- if n == 0:
- return "zero"
- groups: list[int] = []
- while n > 0:
- groups.append(n % 1000)
- n //= 1000
- if len(groups) > len(_SCALES):
- raise ValueError(f"Integer magnitude too large to verbalize safely: {num_str}")
- parts: list[str] = []
- for scale_idx in range(len(groups) - 1, -1, -1):
- group_val = groups[scale_idx]
- if group_val == 0:
- continue
- group_words = _verbalize_sub_thousand(
- group_val,
- use_and=use_and and scale_idx == 0 and len(groups) > 1,
- )
- scale_word = _SCALES[scale_idx]
- parts.append(f"{group_words} {scale_word}".strip())
- return " ".join(parts)
-
-
-def _verbalize_decimal_en(num_str: str, *, use_and: bool = False) -> str:
- s = num_str.replace(",", "").strip()
- match = re.fullmatch(r"(\d+)\.(\d+)", s)
- if not match:
- raise ValueError(f"Not a plain decimal: {num_str}")
- int_part, frac_part = match.groups()
- int_words = _verbalize_integer_en(int_part, use_and=use_and)
- frac_words = "-".join(_ONES[int(ch)] for ch in frac_part)
- return f"{int_words} point {frac_words}"
-
-
-def _verbalize_number_en(num_str: str, *, use_and: bool = False) -> str:
- s = num_str.strip()
- if s.startswith("-"):
- inner = s[1:]
- if not inner:
- raise ValueError(f"Unsupported numeric format: {num_str}")
- return f"negative {_verbalize_number_en(inner, use_and=use_and)}"
- if re.fullmatch(r"\d{4}", s):
- year = int(s)
- if 1400 <= year < 2100:
- if year == 2000:
- return "two thousand"
- first_two = year // 100
- last_two = year % 100
- if 1400 <= year <= 1999:
- if last_two == 0:
- return f"{_verbalize_integer_en(str(first_two), use_and=use_and)} hundred"
- return f"{_verbalize_integer_en(str(first_two), use_and=use_and)} {_verbalize_sub_thousand(last_two)}"
- if 2001 <= year <= 2009:
- return f"two thousand {_ONES[last_two]}"
- if 2010 <= year <= 2099:
- return f"twenty {_verbalize_sub_thousand(last_two)}"
- if re.fullmatch(r"\d[\d,]*", s):
- return _verbalize_integer_en(s, use_and=use_and)
- if re.fullmatch(r"\d[\d,]*\.\d+", s):
- return _verbalize_decimal_en(s, use_and=use_and)
- raise ValueError(f"Unsupported numeric format: {num_str}")
-
-
-def _parse_currency_token(token: str) -> tuple[str, int, str | None]:
- match = re.fullmatch(r"([$£€¥₹¢])(\d[\d,]*)(?:\.(\d+))?", token.strip())
- if not match:
- raise ValueError(f"Not a supported currency amount: {token}")
- symbol, whole_part, frac_part = match.groups()
- whole = int(whole_part.replace(",", ""))
- return symbol, whole, frac_part
-
-
-def _verbalize_currency_decimal_en(symbol: str, whole: int, frac_part: str) -> str:
- singular_major, plural_major, _, _ = _CURRENCY_INFO[symbol]
- major_unit = singular_major if whole == 1 else plural_major
- whole_words = _verbalize_integer_en(str(whole), use_and=False)
- frac_words = "-".join(_ONES[int(ch)] for ch in frac_part)
- return f"{whole_words} point {frac_words} {major_unit}"
-
-
-def _verbalize_currency_en(token: str, *, use_and: bool = True, short: bool = False) -> str:
- symbol, whole, frac_part = _parse_currency_token(token)
- singular_major, plural_major, singular_minor, plural_minor = _CURRENCY_INFO[symbol]
- if short and symbol != "$":
- short = False
- if frac_part is not None and len(frac_part) > 2:
- return _verbalize_currency_decimal_en(symbol, whole, frac_part)
-
- minor = None
- if frac_part is not None:
- frac_2 = (frac_part + "00")[:2]
- minor = int(frac_2)
-
- if not short:
- whole_words = _verbalize_integer_en(str(whole), use_and=use_and)
- major_unit = singular_major if whole == 1 else plural_major
- if symbol in {"¥", "¢"}:
- if frac_part is None or set(frac_part) == {"0"}:
- return f"{whole_words} {major_unit}"
- return _verbalize_currency_decimal_en(symbol, whole, frac_part)
- if minor is None or minor == 0:
- return f"{whole_words} {major_unit}"
- if whole == 0:
- minor_words = _verbalize_integer_en(str(minor), use_and=False)
- minor_unit = singular_minor if minor == 1 else plural_minor
- return f"{minor_words} {minor_unit}"
- minor_words = _verbalize_integer_en(str(minor), use_and=False)
- minor_unit = singular_minor if minor == 1 else plural_minor
- return f"{whole_words} {major_unit} and {minor_words} {minor_unit}"
-
- if minor is None or minor == 0:
- whole_words = _verbalize_integer_en(str(whole), use_and=False)
- major_unit = singular_major if whole == 1 else plural_major
- return f"{whole_words} {major_unit}"
- if whole == 0:
- minor_words = _verbalize_integer_en(str(minor), use_and=False)
- minor_unit = singular_minor if minor == 1 else plural_minor
- return f"{minor_words} {minor_unit}"
- if 0 <= minor <= 9:
- return f"{_verbalize_integer_en(str(whole), use_and=False)} oh {_ONES[minor]}"
- return f"{_verbalize_integer_en(str(whole), use_and=False)} {_verbalize_integer_en(str(minor), use_and=False)}"
-
-
-def _should_verbalize_plain_number(token: str) -> bool:
- s = token.strip()
- if s.startswith("-"):
- s = s[1:]
- raw_int_part = s.split(".", 1)[0]
- int_no_commas = raw_int_part.replace(",", "")
- if not re.fullmatch(r"\d+", int_no_commas):
- return False
- value = int(int_no_commas)
- # Only rewrite large comma-separated values (e.g. 1,234,567).
- return 1_000_000 <= value < 1e18 and "," in raw_int_part
-
-
-def _auto_verbalize_safe_numbers_in_text(text: str) -> str:
- matches = list(_TOKEN_RE.finditer(text))
- currency_symbols = [m.group("symbol") for m in matches if m.group("currency") is not None]
- only_dollar_repetitions = currency_symbols and set(currency_symbols) == {"$"} and len(currency_symbols) > 1
- first_dollar_done = False
-
- def repl(match: re.Match[str]) -> str:
- nonlocal first_dollar_done
- if match.group("currency") is not None:
- token = match.group("currency")
- symbol = match.group("symbol")
- try:
- short = False
- if only_dollar_repetitions and symbol == "$":
- if first_dollar_done:
- short = True
- else:
- first_dollar_done = True
- return _verbalize_currency_en(token, use_and=True, short=short)
- except (ValueError, IndexError):
- return token
- token = match.group("number")
- try:
- if not _should_verbalize_plain_number(token):
- return token
- return _verbalize_number_en(token, use_and=True)
- except (ValueError, IndexError):
- return token
-
- return _TOKEN_RE.sub(repl, text)
-
-
-def sanitize_tts_input_text_for_demo(text: str) -> str:
- """Normalize text before sending it to TTS."""
- raw_text = text
- text = _flatten_markdown_for_tts(text)
- text = _INVISIBLE_UNICODE_RE.sub("", text)
- text = _LINE_BREAK_RE.sub(" ", text)
- text = _auto_verbalize_safe_numbers_in_text(text)
- text = _replace_textual_parentheticals(text)
- text = _UNICODE_HYPHEN_TO_ASCII_RE.sub("-", text)
- text = _ASCII_ELLIPSIS_RUN_RE.sub("...", text)
- text = _REPEATED_PUNCT_RE.sub(r"\1", text)
- text = _MULTI_HYPHEN_RE.sub("\u2014", text)
- text = _replace_standalone_hyphens(text)
- text = re.sub(r"\s+", " ", text).strip()
- if text and text[-1] not in _TERMINAL_PUNCT:
- text += "."
- if not text:
- raise ValueError(f"Speech input is empty after sanitization, got {raw_text=}")
- return text
diff --git a/mkdocs.yml b/mkdocs.yml
deleted file mode 100644
index 6461c65f220..00000000000
--- a/mkdocs.yml
+++ /dev/null
@@ -1,173 +0,0 @@
-site_name: vLLM-Omni
-site_description: Efficient omni-modality model serving for everyone
-site_author: vLLM-Omni Team
-site_url: https://vllm-project.github.io/vllm-omni/
-
-repo_name: vllm-project/vllm-omni
-repo_url: https://github.com/vllm-project/vllm-omni
-edit_uri: edit/main/docs/
-
-# Copyright
-copyright: Copyright © 2026 vLLM-Omni Team
-
-# Theme
-theme:
- name: material
- logo: source/logos/vllm-logo-only-light.ico
- favicon: source/logos/vllm-logo-only-light.ico
- palette:
- # Palette toggle for automatic mode
- - media: "(prefers-color-scheme)"
- toggle:
- icon: material/brightness-auto
- name: Switch to light mode
- # Palette toggle for light mode
- - media: "(prefers-color-scheme: light)"
- scheme: default
- primary: white
- toggle:
- icon: material/brightness-7
- name: Switch to dark mode
- # Palette toggle for dark mode
- - media: "(prefers-color-scheme: dark)"
- scheme: slate
- primary: black
- toggle:
- icon: material/brightness-2
- name: Switch to system preference
- features:
- - content.action.edit
- - content.code.copy
- - navigation.instant
- - navigation.instant.progress
- - navigation.tracking
- - navigation.tabs
- - navigation.tabs.sticky
- - navigation.sections
- - navigation.indexes
- - navigation.top
- - search.suggest
- - search.highlight
- - search.share
- - content.code.annotate
- - content.tabs
- - content.tooltips
- - toc.follow
- custom_dir: docs/mkdocs/overrides
-
-hooks:
- - docs/mkdocs/hooks/generate_api_readme.py
- - docs/mkdocs/hooks/url_schemes.py
- - docs/mkdocs/hooks/generate_examples.py
- - docs/mkdocs/hooks/generate_argparse.py
-
-# Exclude include files from navigation warnings
-exclude_docs: |
- **/*.inc.md
-
-# Plugins
-plugins:
- - meta
- - search
- - autorefs
- - awesome-nav
- - glightbox
- - git-revision-date-localized:
- # exclude files
- exclude:
- - api/*
- # Hook-generated content under docs/generated/ is gitignored; no git history for per-file dates.
- - generated/**
- - user_guide/examples/**
- - contributing/design_documents/api_design_template.md
- - DOCS_GUIDE.md
- - minify:
- minify_html: true
- minify_js: true
- minify_css: true
- cache_safe: true
- js_files: [docs/mkdocs/javascript/*.js]
- css_files: [docs/mkdocs/stylesheets/*.css]
- - api-autonav:
- modules: ["vllm_omni"]
- api_root_uri: "api"
- nav_item_prefix: "" # No prefix in navigation tree (clean names)
- show_full_namespace: false # Show only module name, not full path
- on_implicit_namespace_package: skip # Skip directories without __init__.py (e.g., assets)
- exclude:
- - "re:vllm_omni\\._.*" # Internal modules
- - "vllm_omni.diffusion.models.qwen_image" # avoid importing vllm in mkdocs building
- - "vllm_omni.diffusion.quantization" # avoid importing vllm in mkdocs building
- - "vllm_omni.quantization" # avoid importing vllm in mkdocs building
- - "vllm_omni.entrypoints.async_diffusion" # avoid importing vllm in mkdocs building
- - "vllm_omni.entrypoints.openai" # avoid importing vllm in mkdocs building
- - "vllm_omni.entrypoints.openai.protocol" # avoid importing vllm in mkdocs building
- - mkdocstrings:
- handlers:
- python:
- options:
- show_symbol_type_heading: true
- show_symbol_type_toc: true
- filters:
- - "!^_" # Exclude private members (methods/classes starting with underscore)
- summary:
- modules: true
- show_if_no_docstring: true
- show_signature_annotations: true
- separate_signature: true
- show_overloads: true
- signature_crossrefs: true
- inventories:
- - https://docs.python.org/3/objects.inv
- - https://typing-extensions.readthedocs.io/en/latest/objects.inv
- - https://docs.aiohttp.org/en/stable/objects.inv
- - https://pillow.readthedocs.io/en/stable/objects.inv
- - https://numpy.org/doc/stable/objects.inv
- # Temporarily disabled due to decompression errors
- # - https://pytorch.org/docs/stable/objects.inv
- - https://psutil.readthedocs.io/stable/objects.inv
-
-markdown_extensions:
- - attr_list
- - md_in_html
- - admonition
- - pymdownx.details
- # For content tabs
- - pymdownx.superfences:
- custom_fences:
- - name: mermaid
- class: mermaid
- format: !!python/name:pymdownx.superfences.fence_code_format
- - pymdownx.tabbed:
- slugify: !!python/object/apply:pymdownx.slugs.slugify
- kwds:
- case: lower
- alternate_style: true
- # For code highlighting
- - pymdownx.highlight:
- anchor_linenums: true
- line_spans: __span
- pygments_lang_class: true
- - pymdownx.inlinehilite
- - pymdownx.snippets
- # For emoji and icons
- - pymdownx.emoji:
- emoji_index: !!python/name:material.extensions.emoji.twemoji
- emoji_generator: !!python/name:material.extensions.emoji.to_svg
- # For in page [TOC] (not sidebar)
- - toc:
- permalink: true
- # For math rendering
- - pymdownx.arithmatex:
- generic: true
-
-extra_css:
- - mkdocs/stylesheets/extra.css
-
-extra_javascript:
- - mkdocs/javascript/mathjax.js
- - https://unpkg.com/mathjax@3.2.2/es5/tex-mml-chtml.js
- - https://unpkg.com/mermaid@10/dist/mermaid.min.js
- - mkdocs/javascript/mermaid.js
- - mkdocs/javascript/edit_and_feedback.js
- - mkdocs/javascript/slack_and_forum.js
diff --git a/pyproject.toml b/pyproject.toml
deleted file mode 100644
index d21f3c4758a..00000000000
--- a/pyproject.toml
+++ /dev/null
@@ -1,238 +0,0 @@
-[build-system]
-requires = [
- "setuptools>=77.0.3,<81.0.0",
- "wheel",
- "setuptools-scm>=8.0",
-]
-build-backend = "setuptools.build_meta"
-
-[project]
-name = "vllm-omni"
-dynamic = ["version", "dependencies"]
-description = "A framework for efficient model inference with omni-modality models"
-readme = "README.md"
-requires-python = ">=3.10,<3.14"
-license = "Apache-2.0"
-authors = [
- {name = "vLLM-Omni Team"}
-]
-keywords = ["vllm", "multimodal", "diffusion", "transformer", "inference", "serving"]
-classifiers = [
- "Development Status :: 3 - Alpha",
- "Intended Audience :: Developers",
- "Intended Audience :: Science/Research",
- "Programming Language :: Python :: 3.10",
- "Programming Language :: Python :: 3.11",
- "Programming Language :: Python :: 3.12",
- "Programming Language :: Python :: 3.13",
- "Topic :: Scientific/Engineering :: Artificial Intelligence",
- "Topic :: Software Development :: Libraries :: Python Modules",
-]
-
-# Dependencies are now managed dynamically via setup.py based on detected hardware platform.
-# This allows automatic installation of the correct platform-specific dependencies (CUDA/ROCm/CPU/XPU/NPU)
-# without requiring extras like [cuda]. See requirements/ directory for platform-specific dependencies.
-
-[project.optional-dependencies]
-
-dev = [
- "pytest>=7.0.0",
- "pytest-asyncio>=0.21.0",
- "pytest-cov>=4.0.0",
- "pytest-mock>=3.10.0",
- "datasets>=2.14.0",
- "mypy==1.11.1",
- "pre-commit==4.0.1",
- "openai-whisper>=20250625",
- "psutil>=7.2.0",
- "soundfile>=0.13.1",
- "imageio[ffmpeg]>=0.6.0",
- "opencv-python>=4.12.0.88",
- "mooncake-transfer-engine-cuda13>=0.3.9",
- "av", # for ComfyUI tests
- "openpyxl>=3.0.0", # for nightly CI
- "pyttsx3>=2.99",
- "opencc>=1.2.0",
- "mistune>=3.2.0", # for example tests
- "torchmetrics>=1.4.0", # for accuracy similarity metrics
- "jiwer>=3.0.0",
- "zhon>=2.0.0",
- "zhconv>=1.4.2",
- "scipy>=1.10.0",
- "funasr>=1.0.0",
-]
-
-demo = [
- "gradio>=6.7.0",
-]
-
-docs = [
- "mkdocs>=1.5.0",
- "mkdocs-api-autonav",
- "mkdocs-material",
- "mkdocstrings-python",
- "mkdocs-gen-files",
- "mkdocs-awesome-nav",
- "mkdocs-glightbox",
- "mkdocs-git-revision-date-localized-plugin",
- "mkdocs-minify-plugin",
- "regex",
- "ruff",
- "pydantic",
-]
-
-
-[project.urls]
-Homepage = "https://github.com/vllm-project/vllm-omni"
-Repository = "https://github.com/vllm-project/vllm-omni"
-Documentation = "https://vllm-omni.readthedocs.io"
-"Bug Tracker" = "https://github.com/vllm-project/vllm-omni/issues"
-
-[project.scripts]
-vllm-omni = "vllm_omni.entrypoints.cli.main:main"
-
-
-[tool.setuptools.packages.find]
-where = ["."]
-include = ["vllm_omni*"]
-
-[tool.setuptools.package-data]
-"vllm_omni" = ["_version.py", "py.typed"]
-"vllm_omni.model_executor.stage_configs" = ["*.yaml"]
-
-[tool.setuptools_scm]
-# no extra settings needed, presence enables setuptools-scm
-
-[tool.ruff]
-line-length = 120
-exclude = [
- ".eggs",
- ".git",
- ".hg",
- ".mypy_cache",
- ".tox",
- ".venv",
- "build",
- "dist",
- "vllm_omni.egg-info",
-]
-
-[tool.ruff.lint]
-select = [
- "E", # pycodestyle errors
- "W", # pycodestyle warnings
- "F", # pyflakes
- "I", # isort (handled separately, but included for compatibility)
- "N", # pep8-naming
- "UP", # pyupgrade
- "TID251", # flake8-tidy-imports.banned-api
-]
-ignore = [
- "E203", # whitespace before ':' (conflicts with black)
- # W503 is not needed in ruff as it's compatible with black by default
- "N801", # class names should use CapWords convention
- "N802", # function name should follow snake_case
- "N806", # variable in function should follow snake_case
- "N812", # lowercase imported as non-lowercase: functional as F
-]
-
-[tool.ruff.lint.per-file-ignores]
-"examples/**" = ["E501"] # Allow long lines in examples
-"tests/**" = ["E501"] # Allow long lines in tests
-
-[tool.ruff.lint.flake8-tidy-imports.banned-api]
-"librosa".msg = "The librosa module is banned, use vllm.multimodal helpers instead"
-
-[tool.mypy]
-python_version = "3.12, 3.13"
-warn_return_any = true
-warn_unused_configs = true
-disallow_untyped_defs = true
-disallow_incomplete_defs = true
-check_untyped_defs = true
-disallow_untyped_decorators = true
-no_implicit_optional = true
-warn_redundant_casts = true
-warn_unused_ignores = true
-warn_no_return = true
-warn_unreachable = true
-strict_equality = true
-
-[tool.pytest.ini_options]
-asyncio_mode = "auto"
-testpaths = ["tests"]
-python_files = ["test_*.py", "*_test.py"]
-python_classes = ["Test*"]
-python_functions = ["test_*"]
-addopts = [
- "--strict-markers",
- "--strict-config"
-]
-markers = [
- # ci/cd required
- "core_model: L1&L2 tests (run in each PR)",
- "advanced_model: L3 level tests (run on each merge)",
- "full_model: L4 level tests (run nightly)",
- # function module markers
- "diffusion: Diffusion model tests",
- "omni: Omni model tests",
- "cache: Cache backend tests",
- "parallel: Parallelism/distributed tests",
- "example: Doc example code tests",
- # platform markers
- "cpu: Tests that run on CPU",
- "gpu: Tests that run on GPU (auto-added)",
- "cuda: Tests that run on CUDA (auto-added)",
- "rocm: Tests that run on AMD/ROCm (auto-added)",
- "xpu: Tests that run on XPU (auto-added)",
- "npu: Tests that run on NPU/Ascend (auto-added)",
- "musa: Tests that run on MUSA/Moore Threads (auto-added)",
- # specified computation resources marks (auto-added)
- "H100: Tests that require H100 GPU",
- "L4: Tests that require L4 GPU",
- "MI325: Tests that require MI325 GPU (AMD/ROCm)",
- "B60: Tests that require Intel Arc Pro B60 XPU",
- "S5000: Tests that require S5000 GPU (Moore Threads/MUSA)",
- "A2: Tests that require A2 NPU",
- "A3: Tests that require A3 NPU",
- "distributed_cuda: Tests that require multi cards on CUDA platform",
- "distributed_rocm: Tests that require multi cards on ROCm platform",
- "distributed_xpu: Tests that require multi cards on XPU platform",
- "distributed_npu: Tests that require multi cards on NPU platform",
- "distributed_musa: Tests that require multi cards on MUSA platform",
- "skipif_cuda: Skip if the num of CUDA cards is less than the required",
- "skipif_rocm: Skip if the num of ROCm cards is less than the required",
- "skipif_xpu: Skip if the num of XPU cards is less than the required",
- "skipif_npu: Skip if the num of NPU cards is less than the required",
- "skipif_musa: Skip if the num of MUSA cards is less than the required",
- # more detailed markers
- "slow: Slow tests (may skip in quick CI)",
- "benchmark: Benchmark tests",
-]
-filterwarnings = [
- "ignore:.*does not have '__test__' attribute.*:UserWarning",
- "ignore:.*does not have '__bases__' attribute.*:UserWarning",
-]
-
-[tool.typos.default]
-extend-ignore-identifiers-re = [
- ".*_thw",
- ".*thw",
- "ein",
- ".*arange",
- ".*MoBA",
- ".*temperal_downsample",
- ".*_nd",
- ".*nothink.*",
- ".*NOTHINK.*",
- ".*nin.*",
- ".*[Oo]no_[Aa]nna.*",
- ".*cann.*",
-]
-[tool.typos.default.extend-words]
-ue = "ue"
-semantics = "semantics"
-fullset = "fullset"
-Vai = "Vai"
-tockens = "tockens"
-CANN = "CANN"
diff --git a/recipes/LTX/LTX-2.3.md b/recipes/LTX/LTX-2.3.md
deleted file mode 100644
index 8d92562fb04..00000000000
--- a/recipes/LTX/LTX-2.3.md
+++ /dev/null
@@ -1,112 +0,0 @@
-# LTX-2.3 Text-to-Video with Audio on 1x GPU (96GB VRAM)
-
-> 22B parameter text-to-video + audio generation model served via vLLM-Omni
-
-## Summary
-
-- Vendor: Lightricks
-- Model: `dg845/LTX-2.3-Diffusers`
-- Task: Text-to-video with synchronized audio generation
-- Mode: Online serving (pure diffusion)
-- Maintainer: @oglok
-
-## When to use this recipe
-
-Use this recipe when you want to serve LTX-2.3 for text-to-video generation
-with audio. The model generates videos up to 20+ seconds at 768x512 resolution
-with 48kHz audio, all from a single text prompt. Requires a GPU with at least
-96GB VRAM due to the 22B parameter transformer (~44GB weights) plus text
-encoder, VAE, and vocoder components.
-
-## References
-
-- Model: <https://huggingface.co/dg845/LTX-2.3-Diffusers>
-- Requires `diffusers >= 0.38.0` (install from git: `pip install git+https://github.com/huggingface/diffusers.git`)
-
-## Serving
-
-### Command
-
-```bash
-vllm serve dg845/LTX-2.3-Diffusers \
- --omni \
- --model-class-name LTX23Pipeline \
- --stage-init-timeout 600
-```
-
-### Verification
-
-```bash
-# Health check
-curl http://localhost:8000/health
-
-# Generate a 3-second video (81 frames at 24fps)
-curl -X POST http://localhost:8000/v1/videos \
- -F "prompt=A majestic bald eagle soaring over a misty mountain valley at dawn, golden sunlight breaking through clouds" \
- -F "negative_prompt=blurry, low quality, distorted, watermark" \
- -F "model=dg845/LTX-2.3-Diffusers" \
- -F "num_frames=81" \
- -F "fps=24" \
- -F "size=768x512" \
- -F "num_inference_steps=30" \
- -F "guidance_scale=4.0" \
- -F "seed=42"
-
-# Generate a 10-second video (241 frames)
-curl -X POST http://localhost:8000/v1/videos \
- -F "prompt=A cozy Japanese ramen shop at night in the rain, steam rising from bowls, neon signs reflecting on wet cobblestone streets" \
- -F "model=dg845/LTX-2.3-Diffusers" \
- -F "num_frames=241" \
- -F "fps=24" \
- -F "size=768x512" \
- -F "num_inference_steps=30" \
- -F "guidance_scale=4.0"
-
-# Generate a 20-second video (481 frames)
-curl -X POST http://localhost:8000/v1/videos \
- -F "prompt=An underwater coral reef teeming with tropical fish, sea turtles gliding gracefully, National Geographic documentary style" \
- -F "model=dg845/LTX-2.3-Diffusers" \
- -F "num_frames=481" \
- -F "fps=24" \
- -F "size=768x512" \
- -F "num_inference_steps=30" \
- -F "guidance_scale=4.0"
-```
-
-### Notes
-
-- Memory usage: Model loads at ~36 GiB, peaks at ~62 GiB during inference
-- Key flags:
- - `--stage-init-timeout 600`: Required for the initial `torch.compile` warmup (~90-140 seconds on first request)
- - `--model-class-name LTX23Pipeline`: Selects the LTX-2.3 pipeline (not LTX-2)
-- Audio: 48kHz AAC via BWE vocoder, automatically synced with video
-- CPU offloading: Text encoder (Gemma-3-12B), connectors, VAE, audio VAE, and vocoder stay on CPU and are moved to GPU only when needed
-- Supported resolutions: 768x512, 512x384 (must be divisible by 32)
-- Frame rate: 24 fps
-- Duration: Controlled by `num_frames` (frames = duration_seconds * 24 + 1)
-- Known limitations:
- - No image-to-video support yet (LTX23ImageToVideoPipeline is a placeholder)
- - No CFG-parallel support (single-GPU only)
- - Requires `diffusers >= 0.38.0` (not yet on PyPI, install from git)
-
-## Hardware Support
-
-## GPU
-
-### 1x NVIDIA RTX PRO 6000 Blackwell (96GB)
-
-#### Environment
-
-- OS: Ubuntu 22.04
-- Python: 3.10+
-- Driver / runtime: CUDA 13.0, Driver 580.126.09
-- vLLM version: 0.19.x
-- vLLM-Omni version: 0.19.x
-
-### Validated configurations
-
-| Duration | Frames | Resolution | Steps | Guidance | Inference Time | Peak VRAM |
-|----------|--------|------------|-------|----------|----------------|-----------|
-| 3s | 81 | 768x512 | 30 | 4.0 | ~110s | ~62 GB |
-| 10s | 241 | 768x512 | 30 | 4.0 | ~130s | ~62 GB |
-| 20s | 481 | 768x512 | 30 | 4.0 | ~420s | ~62 GB |
diff --git a/recipes/Qwen/Qwen3-Omni.md b/recipes/Qwen/Qwen3-Omni.md
deleted file mode 100644
index 49552d8712a..00000000000
--- a/recipes/Qwen/Qwen3-Omni.md
+++ /dev/null
@@ -1,245 +0,0 @@
-# Qwen3-Omni
-
-## Summary
-
-- Vendor: Qwen
-- Model: `Qwen/Qwen3-Omni-30B-A3B-Instruct`
-- Task: Multimodal chat with text/image/audio/video input
-- Mode: Online serving with the OpenAI-compatible API
-- Maintainer: Community
-
-## When to use this recipe
-
-Use this recipe as a practical baseline for running
-`Qwen/Qwen3-Omni-30B-A3B-Instruct` with the same serving paths already
-exercised by repository examples and tests.
-
-## References
-
-- User guide:
- [`docs/user_guide/examples/online_serving/qwen3_omni.md`](../../docs/user_guide/examples/online_serving/qwen3_omni.md)
-- Example guide:
- [`examples/online_serving/qwen3_omni/README.md`](../../examples/online_serving/qwen3_omni/README.md)
-
-## Environment
-
-- OS: Linux
-- Python: 3.10+
-- vLLM / vLLM-Omni: use versions from your current checkout, >=0.18.0
-
-## Start server (single command)
-
-From repository root:
-
-```bash
-vllm serve Qwen/Qwen3-Omni-30B-A3B-Instruct --omni --port 8091
-```
-
-Notes:
-
-- `--omni` is required.
-- The default deploy config `vllm_omni/deploy/qwen3_omni_moe.yaml` is loaded
- automatically by model registry.
-- `async_chunk` is enabled by default in this deploy config.
-- Platform deltas under `platforms:` (NPU/ROCm/XPU) are merged automatically on
- matching runtimes.
-
-For advanced customization, pass an overlay YAML:
-
-```bash
-vllm serve Qwen/Qwen3-Omni-30B-A3B-Instruct --omni --port 8091 \
- --deploy-config /path/to/your_qwen3_omni_overrides.yaml
-```
-
-#### Runtime tuning
-
-Prefer CLI overrides for day-to-day tuning:
-
-```bash
-# Disable async chunking when using /v1/realtime
-vllm serve Qwen/Qwen3-Omni-30B-A3B-Instruct --omni --port 8091 \
- --no-async-chunk
-
-# Example per-stage tuning in unified launch
-vllm serve Qwen/Qwen3-Omni-30B-A3B-Instruct --omni --port 8091 \
- --stage-overrides '{"1": {"gpu_memory_utilization": 0.5}}'
-
-# Tune max_num_seqs per stage (single process launch)
-vllm serve Qwen/Qwen3-Omni-30B-A3B-Instruct --omni --port 8091 \
- --stage-overrides '{
- "0": {"max_num_seqs": 8},
- "1": {"max_num_seqs": 4},
- "2": {"max_num_seqs": 4}
- }'
-```
-
-#### Stage-based launch (one stage per process)
-
-Use three terminals (one per stage). Start with the default commands below, then
-add `--max-num-seqs` only if you need explicit per-stage concurrency control.
-
-Default stage-based commands:
-
-```bash
-# Stage 0: Thinker + API server
-CUDA_VISIBLE_DEVICES=0 vllm serve Qwen/Qwen3-Omni-30B-A3B-Instruct --omni \
- --port 8091 \
- --stage-id 0 \
- --omni-master-address 127.0.0.1 \
- --omni-master-port 26000 &
-
-# Stage 1: Talker
-CUDA_VISIBLE_DEVICES=1 vllm serve Qwen/Qwen3-Omni-30B-A3B-Instruct --omni \
- --stage-id 1 \
- --headless \
- --omni-master-address 127.0.0.1 \
- --omni-master-port 26000 &
-
-# Stage 2: Code2Wav
-CUDA_VISIBLE_DEVICES=1 vllm serve Qwen/Qwen3-Omni-30B-A3B-Instruct --omni \
- --stage-id 2 \
- --headless \
- --omni-master-address 127.0.0.1 \
- --omni-master-port 26000 &
-```
-
-Optional: explicit per-stage `max_num_seqs` tuning:
-
-```bash
-# Stage 0
-CUDA_VISIBLE_DEVICES=0 vllm serve Qwen/Qwen3-Omni-30B-A3B-Instruct --omni \
- --port 8091 \
- --stage-id 0 \
- --max-num-seqs 8 \
- --omni-master-address 127.0.0.1 \
- --omni-master-port 26000 &
-
-# Stage 1
-CUDA_VISIBLE_DEVICES=1 vllm serve Qwen/Qwen3-Omni-30B-A3B-Instruct --omni \
- --stage-id 1 \
- --headless \
- --max-num-seqs 4 \
- --omni-master-address 127.0.0.1 \
- --omni-master-port 26000 &
-
-# Stage 2
-CUDA_VISIBLE_DEVICES=1 vllm serve Qwen/Qwen3-Omni-30B-A3B-Instruct --omni \
- --stage-id 2 \
- --headless \
- --max-num-seqs 4 \
- --omni-master-address 127.0.0.1 \
- --omni-master-port 26000 &
-```
-
-If you use custom deploy YAML, add `--deploy-config` to each stage command.
-
-#### Verification
-
-After server startup, run a multimodal example client:
-
-```bash
-python examples/online_serving/openai_chat_completion_client_for_multimodal_generation.py \
- --model Qwen/Qwen3-Omni-30B-A3B-Instruct \
- --query-type use_image \
- --port 8091 \
- --host localhost
-```
-
-Quick API smoke test (text-only output):
-
-```bash
-curl http://localhost:8091/v1/chat/completions \
- -H "Content-Type: application/json" \
- -d '{
- "model": "Qwen/Qwen3-Omni-30B-A3B-Instruct",
- "messages": [{"role": "user", "content": "Describe vLLM in brief."}],
- "modalities": ["text"]
- }'
-```
-
-`{"modalities":["text","audio"]}` means the model returns both text and audio in
-the same response. Use it when you want transcription/content text and TTS audio
-together.
-
-Quick API smoke test (text + audio output):
-
-```bash
-curl http://localhost:8091/v1/chat/completions \
- -H "Content-Type: application/json" \
- -d '{
- "model": "Qwen/Qwen3-Omni-30B-A3B-Instruct",
- "messages": [{"role": "user", "content": "Describe vLLM in brief."}],
- "modalities": ["text", "audio"]
- }'
-```
-
-Realtime WebSocket check (`/v1/realtime`) requires async chunk disabled:
-
-```bash
-python examples/online_serving/qwen3_omni/openai_realtime_client.py \
- --url ws://localhost:8091/v1/realtime \
- --model Qwen/Qwen3-Omni-30B-A3B-Instruct \
- --input-wav /path/to/input_16k_mono.wav \
- --output-wav realtime_output.wav
-```
-
-#### Benchmark with `vllm bench`
-
-After the server is up, you can run online serving benchmarks with
-`vllm bench serve --omni`.
-
-Text-focused random workload:
-
-```bash
-vllm bench serve \
- --omni \
- --host localhost \
- --port 8091 \
- --model Qwen/Qwen3-Omni-30B-A3B-Instruct \
- --endpoint /v1/chat/completions \
- --backend openai-chat-omni \
- --dataset-name random \
- --num-prompts 40 \
- --max-concurrency 4 \
- --random-input-len 2500 \
- --random-output-len 900 \
- --ignore-eos \
- --extra-body '{"modalities":["text"]}' \
- --percentile-metrics ttft,tpot,itl,e2el
-```
-
-If you want benchmark requests to return both text and audio, switch
-`--extra-body` to:
-
-```bash
---extra-body '{"modalities":["text","audio"]}'
-```
-
-Synthetic multimodal workload (`random-mm`):
-
-```bash
-vllm bench serve \
- --omni \
- --host localhost \
- --port 8091 \
- --model Qwen/Qwen3-Omni-30B-A3B-Instruct \
- --endpoint /v1/chat/completions \
- --backend openai-chat-omni \
- --dataset-name random-mm \
- --num-prompts 40 \
- --max-concurrency 4 \
- --random-input-len 2500 \
- --random-output-len 900 \
- --random-mm-base-items-per-request 2 \
- --random-mm-limit-mm-per-prompt '{"image":1,"video":1,"audio":1}' \
- --random-mm-bucket-config '{"(32, 32, 1)": 0.5, "(0, 1, 1)": 0.5}' \
- --ignore-eos \
- --extra-body '{"modalities":["text"]}' \
- --percentile-metrics ttft,tpot,itl,e2el
-```
-
-#### Notes
-
-- `/v1/realtime` is unsupported while `async_chunk` is enabled.
-- The default deploy uses `SharedMemoryConnector`; this is for single-host
- stage wiring.
diff --git a/recipes/README.md b/recipes/README.md
deleted file mode 100644
index 69ce4d7504d..00000000000
--- a/recipes/README.md
+++ /dev/null
@@ -1,39 +0,0 @@
-# Community Recipes
-
-This directory contains community-maintained recipes for answering a
-practical user question:
-
-> How do I run model X on hardware Y for task Z?
-
-Add recipes for this repository under this in-repo `recipes/` directory. To
-keep naming and layout consistent, organize recipes by model vendor in a way
-that is aligned with
-[`vllm-project/recipes`](https://github.com/vllm-project/recipes), but treat
-that external repository as a reference for structure rather than the place to
-add files for this repo. Use one Markdown file per model family by default.
-
-Example layout:
-
-```text
-recipes/
- Qwen/
- Qwen3-Omni.md
- Qwen3-TTS.md
- Tencent-Hunyuan/
- HunyuanVideo.md
-```
-
-## Available Recipes
-
-- [`Qwen/Qwen3-Omni.md`](./Qwen/Qwen3-Omni.md): online serving recipe for
- multimodal chat on `1x A100 80GB`
-- [`Wan-AI/Wan2.2-I2V.md`](./Wan-AI/Wan2.2-I2V.md): image-to-video serving
- recipe for Wan2.2 14B on `8x Ascend NPU (A2/A3)`
-- [`inclusionAI/Ming-flash-omni-2.0.md`](./inclusionAI/Ming-flash-omni-2.0.md):
- online serving recipe for multimodal chat (`4x H100 80GB`) and standalone TTS (`1x H100 80GB`)
-
-Within a single recipe file, include different hardware support sections such
-as `GPU`, `ROCm`, and `NPU`, and add concrete tested configurations like
-`1x A100 80GB` or `2x L40S` inside those sections when applicable.
-
-See [TEMPLATE.md](./TEMPLATE.md) for the recommended format.
diff --git a/recipes/TEMPLATE.md b/recipes/TEMPLATE.md
deleted file mode 100644
index 9bf8cb9c759..00000000000
--- a/recipes/TEMPLATE.md
+++ /dev/null
@@ -1,82 +0,0 @@
-# Recipe Title
-
-> Example: Qwen3-Omni for speech chat on 1x A100 80GB
-
-## Summary
-
-- Vendor:
-- Model:
-- Task:
-- Mode:
-- Maintainer:
-
-## When to use this recipe
-
-Briefly describe the concrete scenario this recipe covers.
-
-## References
-
-- Upstream or canonical docs:
-- Related example under `examples/`:
-- Related issue or discussion:
-
-## Hardware Support
-
-Add one section per platform, such as `GPU`, `ROCm`, or `NPU`. Under each
-platform section, document one or more tested hardware configurations.
-
-## GPU
-
-### 1x A100 80GB
-
-#### Environment
-
-- OS:
-- Python:
-- Driver / runtime:
-- vLLM version:
-- vLLM-Omni version or commit:
-
-#### Command
-
-```bash
-# Add the exact command(s) here
-```
-
-#### Verification
-
-```bash
-# Add a quick validation command or expected output here
-```
-
-#### Notes
-
-- Memory usage:
-- Key flags:
-- Known limitations:
-
-### 2x L40S
-
-Repeat the same structure for other hardware setups as needed.
-
-## ROCm
-
-### Example hardware configuration
-
-Repeat the same nested structure for ROCm setups as needed:
-
-- `#### Environment`
-- `#### Command`
-- `#### Verification`
-- `#### Notes`
-
-## NPU
-
-### Example hardware configuration
-
-Repeat the same nested structure for NPU setups as needed:
-
-- `#### Environment`
-- `#### Command`
-- `#### Verification`
-- `#### Notes`
diff --git a/recipes/Wan-AI/Wan2.2-I2V.md b/recipes/Wan-AI/Wan2.2-I2V.md
deleted file mode 100644
index 99ceac3cebe..00000000000
--- a/recipes/Wan-AI/Wan2.2-I2V.md
+++ /dev/null
@@ -1,136 +0,0 @@
-# Wan2.2 Image To Video
-
-## Summary
-
-- Vendor: Wan-AI
-- Model: `Wan-AI/Wan2.2-I2V-A14B-Diffusers`
-- Task: Image-to-video generation
-- Mode: Online serving with the OpenAI-compatible API
-- Maintainer: Community
-
-## When to use this recipe
-
-Use this recipe when you want to deploy the Wan2.2 14B image-to-video model
-with vLLM-Omni using multi-card parallelism. Two configurations are provided:
-
-1. **Distilled model (no negative-prompt / CFG computation)** — higher
- throughput, recommended when using a distilled checkpoint that does not
- require classifier-free guidance.
-2. **Official open-source model (with CFG)** — uses `--cfg 2` to run negative
- and positive samples in parallel for the original released weights.
-
-## References
-
-- Upstream model card: <https://huggingface.co/Wan-AI/Wan2.2-I2V-A14B-Diffusers>
-
-## Hardware Support
-
-## NPU
-
-### 8x Ascend A2 / A3
-
-#### Environment
-
-- OS: Linux
-- Python: 3.10+
-- Driver / runtime: Ascend NPU driver with CANN toolkit
-- Recommended operator library: **mindie-sd** (Ascend high-performance fused
- operators — enables `adalayernorm` and other fused kernels automatically upon
- installation)
-- vLLM version: Match the repository requirements for your checkout
-- vLLM-Omni version or commit: Use the commit you are deploying from
-
-#### Prerequisites
-
-Install the **mindie-sd** operator library to enable Ascend-optimized fused
-operators (`adalayernorm`, etc.):
-
-```bash
-git clone https://gitcode.com/Ascend/MindIE-SD.git && cd MindIE-SD
-
-# Comment out the tik_ops build step (not needed for this use case)
-sed -i 's|^\(\s*\)source ${current_script_dir}/build_tik_ops.sh|\1# source ${current_script_dir}/build_tik_ops.sh|' build/build_ops.sh
-
-python setup.py bdist_wheel
-cd dist
-pip install mindiesd-*.whl
-```
-
-After installation, enable the Laser Attention kernel for significant
-long-sequence speedups (up to ~40% at 720p in tested workloads):
-
-```bash
-export MINDIE_SD_FA_TYPE=ascend_laser_attention
-```
-
-When using HSDP with FSDP2, set the following environment variable to work
-around a PyTorch NPU multi-stream memory reuse issue
-([pytorch/pytorch#147168](https://github.com/pytorch/pytorch/issues/147168)).
-This issue has been fixed on CUDA but still applies to NPU:
-
-```bash
-export MULTI_STREAM_MEMORY_REUSE=2
-```
-
-#### Command
-
-**Distilled model (no CFG, recommended for distilled checkpoints):**
-
-```bash
-export MINDIE_SD_FA_TYPE=ascend_laser_attention
-export MULTI_STREAM_MEMORY_REUSE=2
-
-vllm serve \
- --omni Wan-AI/Wan2.2-I2V-A14B-Diffusers \
- --use-hsdp \
- --usp 8 \
- --vae-patch-parallel-size 8 \
- --vae-use-tiling
-```
-
-**Official open-source model (with CFG):**
-
-```bash
-export MINDIE_SD_FA_TYPE=ascend_laser_attention
-export MULTI_STREAM_MEMORY_REUSE=2
-
-vllm serve \
- --omni Wan-AI/Wan2.2-I2V-A14B-Diffusers \
- --use-hsdp \
- --usp 4 \
- --cfg 2 \
- --vae-patch-parallel-size 8 \
- --vae-use-tiling
-```
-
-> **Why the difference?** With `--cfg 2`, two copies of the input (positive and
-> negative prompts) are processed in parallel, effectively doubling the compute
-> for the DiT backbone. USP is therefore halved from 8 to 4 so that the total
-> parallelism across the 8 cards remains balanced (`usp * cfg = 8`).
-
-#### Verification
-
-After the server is ready, see
-[`examples/online_serving/image_to_video/README.md`](../../examples/online_serving/image_to_video/README.md)
-for complete client examples and request formats.
-
-#### Notes
-
-- **Key flags:**
- - `--omni` — enables vLLM-Omni diffusion serving.
- - `--use-hsdp` — enables Hybrid Sharded Data Parallelism for the DiT model
- weights.
- - `--usp <N>` — Unified Sequence Parallelism degree.
- - `--cfg <N>` — Classifier-Free Guidance parallelism; set to 2 for models
- that require negative-prompt computation, omit for distilled models.
- - `--vae-patch-parallel-size 8` — parallelizes VAE decoding across all 8
- cards.
- - `--vae-use-tiling` — enables tiled VAE decoding to reduce peak memory.
-- **Performance tips:**
- - Installing mindie-sd and enabling Laser Attention
- (`MINDIE_SD_FA_TYPE=ascend_laser_attention`) provides up to ~40%
- performance improvement at 720p resolution due to long-sequence attention
- optimization.
-- **Known limitations:**
- - `MULTI_STREAM_MEMORY_REUSE=2` is required on NPU when using HSDP/FSDP2
- due to a multi-stream memory reuse bug. This is not needed on CUDA.
diff --git a/recipes/inclusionAI/Ming-flash-omni-2.0.md b/recipes/inclusionAI/Ming-flash-omni-2.0.md
deleted file mode 100644
index 873158c8adc..00000000000
--- a/recipes/inclusionAI/Ming-flash-omni-2.0.md
+++ /dev/null
@@ -1,210 +0,0 @@
-# Ming-flash-omni 2.0 for omni-speech chat and standalone TTS
-
-## Summary
-
-- Vendor: inclusionAI
-- Model: `Jonathan1909/Ming-flash-omni-2.0`
-- Task: Multimodal chat with text, image, audio, or video input; standalone text-to-speech (TTS);
-and image generation
-- Mode: Online serving with the OpenAI-compatible API
-- Maintainer: Community
-
-## When to use this recipe
-
-Use this recipe when you want a known-good starting point for serving
-`Jonathan1909/Ming-flash-omni-2.0` with vLLM-Omni in one of three modes:
-
-- **Thinker only** — multimodal understanding with text output.
-- **Thinker + Talker (omni-speech)** — multimodal understanding with text and spoken output.
-- **Talker only (TTS)** — standalone text-to-speech via the OpenAI `/v1/audio/speech` endpoint.
-
-## References
-
-- Upstream model:
- [`inclusionAI/Ming`](https://github.com/inclusionAI/Ming)
-- For offline inference and additional client variants, see
- `examples/offline_inference/ming_flash_omni{,_tts}/` and
- `examples/online_serving/ming_flash_omni{,_tts}/`.
-
-
-## Hardware Support
-
-This recipe documents reference GPU configurations for the two-stage
-omni-speech deployment and the standalone TTS deployment.
-Other hardware and configurations are welcome as community validation lands.
-
-## GPU
-
-### 4x H100 80GB — omni-speech/chat (thinker + talker)
-
-The bundled `ming_flash_omni.yaml` runs the thinker with tensor parallel size
-4 on GPUs 0–3 and the talker on GPU 3.
-Adjust `devices` in the YAML to match your hardware.
-
-#### Environment
-
-- OS: Linux
-- Python: 3.10+
-- CUDA Driver Version: 590.48.01
-- CUDA 12.5
-- vLLM version: 0.19.0
-- vLLM-Omni version or commit: 0.19.0rc1
-
-#### Command
-
-Thinker only (text output):
-
-```bash
-vllm serve Jonathan1909/Ming-flash-omni-2.0 --omni --port 8091
-```
-
-Thinker + talker (text and/or audio output):
-
-```bash
-vllm serve Jonathan1909/Ming-flash-omni-2.0 \
- --omni \
- --port 8091 \
- --stage-configs-path vllm_omni/model_executor/stage_configs/ming_flash_omni.yaml \
- --log-stats
-```
-
-`--log-stats` is optional but recommended while validating the deployment.
-
-#### Verification
-
-Text output from a multimodal (image) input:
-
-```bash
-curl http://localhost:8091/v1/chat/completions \
- -H "Content-Type: application/json" \
- -d '{
- "model": "Jonathan1909/Ming-flash-omni-2.0",
- "messages": [
- {"role": "system", "content": [{"type": "text", "text": "你是一个友好的AI助手。\n\ndetailed thinking off"}]},
- {"role": "user", "content": [
- {"type": "image_url", "image_url": {"url": "https://vllm-public-assets.s3.us-west-2.amazonaws.com/vision_model_images/cherry_blossom.jpg"}},
- {"type": "text", "text": "Describe this image in detail."}
- ]}
- ],
- "modalities": ["text"]
- }'
-```
-
-Spoken response from a text query (save the WAV bytes):
-
-```bash
-curl http://localhost:8091/v1/chat/completions \
- -H "Content-Type: application/json" \
- -d '{
- "model": "Jonathan1909/Ming-flash-omni-2.0",
- "messages": [
- {"role": "system", "content": [{"type": "text", "text": "你是一个友好的AI助手。\n\ndetailed thinking off"}]},
- {"role": "user", "content": "请详细介绍鹦鹉的生活习性。"}
- ],
- "modalities": ["audio"]
- }' | jq -r '.choices[0].message.audio.data' | base64 -d > ming_omni_parrot.wav
-```
-
-Text + audio output from an audio input (swap `audio_url` for `video_url`
-or `image_url` to exercise the other multimodal input paths):
-
-```bash
-curl http://localhost:8091/v1/chat/completions \
- -H "Content-Type: application/json" \
- -d '{
- "model": "Jonathan1909/Ming-flash-omni-2.0",
- "messages": [
- {"role": "system", "content": [{"type": "text", "text": "你是一个友好的AI助手。\n\ndetailed thinking off"}]},
- {"role": "user", "content": [
- {"type": "audio_url", "audio_url": {"url": "https://vllm-public-assets.s3.us-west-2.amazonaws.com/multimodal_asset/mary_had_lamb.ogg"}},
- {"type": "text", "text": "Please recognize the language of this speech and transcribe it. Format: oral."}
- ]}
- ],
- "modalities": ["text", "audio"]
- }' | jq -r '.choices[0].message.content'
-```
-
-Streaming text output via SSE (set `"stream": true`):
-
-```bash
-curl -N http://localhost:8091/v1/chat/completions \
- -H "Content-Type: application/json" \
- -d '{
- "model": "Jonathan1909/Ming-flash-omni-2.0",
- "messages": [
- {"role": "system", "content": [{"type": "text", "text": "你是一个友好的AI助手。\n\ndetailed thinking off"}]},
- {"role": "user", "content": "请详细介绍鹦鹉的生活习性。"}
- ],
- "modalities": ["text"],
- "stream": true
- }'
-```
-
-Each SSE event carries a `data:` line with a chat-completion chunk; text
-deltas appear at `choices[0].delta.content`.
-
-#### Notes
-
-- Output modality is selected by the request body: `"modalities": ["text"]`,
- `["audio"]`, or `["text", "audio"]`. The two-stage omni-speech server must be launched
- for any request containing `audio`.
-- Reasoning mode: flip the system prompt suffix from `detailed thinking off`
- to `detailed thinking on` in any request above.
-- Memory usage: size depends on output modalities and multimodal input; leave
- headroom for video frames and audio caches.
-
-### 1x H100 80GB — standalone TTS (talker only)
-
-The bundled `ming_flash_omni_tts.yaml` runs the talker on a single GPU and exposes the OpenAI `/v1/audio/speech` endpoint.
-
-#### Environment
-
-- OS: Linux
-- Python: 3.10+
-- CUDA Driver Version: 590.48.01
-- CUDA 12.5
-- vLLM version: 0.19.0
-- vLLM-Omni version or commit: 0.19.0rc1
-
-#### Command
-
-```bash
-vllm serve Jonathan1909/Ming-flash-omni-2.0 \
- --omni \
- --stage-configs-path vllm_omni/model_executor/stage_configs/ming_flash_omni_tts.yaml \
- --port 8091 \
- --log-stats
-```
-
-`--log-stats` is optional but recommended while validating the deployment.
-
-#### Verification
-
-Basic curl:
-
-```bash
-curl -X POST http://localhost:8091/v1/audio/speech \
- -H "Content-Type: application/json" \
- -d '{
- "model": "Jonathan1909/Ming-flash-omni-2.0",
- "input": "我会一直在这里陪着你。",
- "response_format": "wav"
- }' --output ming_online.wav
-```
-
-Speaker selection (e.g. `lingguang`):
-
-```bash
-curl -X POST http://localhost:8091/v1/audio/speech \
- -H "Content-Type: application/json" \
- -d '{
- "model": "Jonathan1909/Ming-flash-omni-2.0",
- "input": "春天来了,万物复苏,大地一片生机盎然。田野里的油菜花开得金灿灿的,蜜蜂在花丛中忙碌地采蜜。远处的山坡上,桃花和杏花竞相绽放,粉的白的交织在一起,美不胜收。清晨的微风带着泥土的芬芳,轻轻拂过脸颊,让人感到无比惬意。孩子们在田间小路上追逐嬉戏,老人们坐在门前晒太阳,享受着这份宁静与美好。",
- "speaker": "lingguang",
- "response_format": "wav"
- }' --output ming_online_lingguang.wav
-```
-
-#### Notes
-
-- The OpenAI `instructions` field is forwarded to the talker as the caption JSON — pass a raw string for `风格` (style) only, or a JSON-encoded object for multiple entries such as `方言` (dialect) and `情感` (emotion).
diff --git a/requirements/common.txt b/requirements/common.txt
deleted file mode 100644
index 63e16d580ff..00000000000
--- a/requirements/common.txt
+++ /dev/null
@@ -1,18 +0,0 @@
-# Common dependencies for all platforms
-av>=14.0.0
-omegaconf>=2.3.0
-diffusers>=0.36.0
-accelerate==1.12.0
-soundfile>=0.13.1
-cache-dit==1.3.0
-tqdm>=4.66.0
-torchsde>=0.2.6
-openai-whisper>=20250625
-imageio[ffmpeg]>=2.37.2
-x-transformers>=2.12.2
-einops>=0.8.1
-prettytable>=3.8.0
-aenum==3.1.16
-pyzmq>=25.0.0
-janus>=1.0.0
-pydub
diff --git a/requirements/cpu.txt b/requirements/cpu.txt
deleted file mode 100644
index c7732b1e13f..00000000000
--- a/requirements/cpu.txt
+++ /dev/null
@@ -1,2 +0,0 @@
--r common.txt
-onnxruntime>=1.23.2
diff --git a/requirements/cuda.txt b/requirements/cuda.txt
deleted file mode 100644
index a290be9c25c..00000000000
--- a/requirements/cuda.txt
+++ /dev/null
@@ -1,5 +0,0 @@
--r common.txt
-onnxruntime>=1.23.2
-fa3-fwd==0.0.3
-# nvidia-cublas-cu12 is pinned to 12.9.1.4 via force-reinstall in Dockerfile.ci
-# because torch pins its own cublas version, making it unsatisfiable at resolve time.
diff --git a/requirements/musa.txt b/requirements/musa.txt
deleted file mode 100644
index 66bd542ccae..00000000000
--- a/requirements/musa.txt
+++ /dev/null
@@ -1,6 +0,0 @@
--r common.txt
-# MUSA platform dependencies
-torchada>=0.1.52
-onnxruntime>=1.23.2
-mate>=0.2.0
-flash_attn_3>=0.1.4
diff --git a/requirements/npu.txt b/requirements/npu.txt
deleted file mode 100644
index 9557427573c..00000000000
--- a/requirements/npu.txt
+++ /dev/null
@@ -1,3 +0,0 @@
--r common.txt
-onnxruntime-cann>=1.23.2
-torchaudio==2.9.0
diff --git a/requirements/rocm.txt b/requirements/rocm.txt
deleted file mode 100644
index 849610eec82..00000000000
--- a/requirements/rocm.txt
+++ /dev/null
@@ -1,2 +0,0 @@
--r common.txt
-onnxruntime-rocm>=1.22.2
diff --git a/requirements/xpu.txt b/requirements/xpu.txt
deleted file mode 100644
index c7732b1e13f..00000000000
--- a/requirements/xpu.txt
+++ /dev/null
@@ -1,2 +0,0 @@
--r common.txt
-onnxruntime>=1.23.2
diff --git a/scripts/build_wheel.sh b/scripts/build_wheel.sh
deleted file mode 100755
index 54769a3079b..00000000000
--- a/scripts/build_wheel.sh
+++ /dev/null
@@ -1,139 +0,0 @@
-#!/usr/bin/env bash
-
-set -euo pipefail
-
-SCRIPT_DIR="$(cd -- "$(dirname -- "${BASH_SOURCE[0]}")" && pwd)"
-REPO_ROOT="$(cd -- "${SCRIPT_DIR}/.." && pwd)"
-PROJECT_NAME="vllm-omni"
-RUN_QUALITY=false
-SKIP_CLEAN=false
-CREATE_VENV=false
-VENV_DIR=".venv-build"
-PYTHON_BIN="python"
-UV_BIN="uv"
-
-log() {
- local level="$1"
- shift
- printf '[%s] %s\n' "${level}" "$*"
-}
-
-abort() {
- log "ERROR" "$*"
- exit 1
-}
-
-usage() {
- cat <<EOF
-Usage: $(basename "$0") [options]
-
-Options:
- --run-quality Run pre-commit, install dev deps, and pytest before building
- --skip-clean Skip removing previous build artifacts
- --create-venv Build inside a fresh virtual environment (default path: .venv-build)
- --venv-dir PATH Custom directory for the virtual environment (implies --create-venv)
- --python PATH Python executable to use (default: python)
- -h, --help Show this help message
-EOF
-}
-
-while [[ $# -gt 0 ]]; do
- case "$1" in
- --run-quality)
- RUN_QUALITY=true
- ;;
- --skip-clean)
- SKIP_CLEAN=true
- ;;
- --create-venv)
- CREATE_VENV=true
- ;;
- --venv-dir)
- CREATE_VENV=true
- shift
- [[ $# -gt 0 ]] || abort "--venv-dir requires a path"
- VENV_DIR="$1"
- ;;
- --python)
- shift
- [[ $# -gt 0 ]] || abort "--python requires a path"
- PYTHON_BIN="$1"
- ;;
- -h|--help)
- usage
- exit 0
- ;;
- *)
- usage
- abort "Unknown option: $1"
- ;;
- esac
- shift
-done
-
-HOST_PYTHON="${PYTHON_BIN}"
-
-log "INFO" "Switching to repository root: ${REPO_ROOT}"
-cd "${REPO_ROOT}" || abort "Cannot enter repository root"
-
-[[ -f pyproject.toml ]] || abort "pyproject.toml not found, please ensure correct script location"
-
-ensure_uv() {
- if ! command -v "${UV_BIN}" >/dev/null 2>&1; then
- log "INFO" "uv not found, installing via ${HOST_PYTHON}"
- "${HOST_PYTHON}" -m pip install --upgrade pip
- "${HOST_PYTHON}" -m pip install uv
- fi
-}
-
-ensure_uv
-
-if [[ "${CREATE_VENV}" == "true" ]]; then
- log "INFO" "Creating fresh virtual environment at ${VENV_DIR} via uv"
- "${UV_BIN}" venv --python "${HOST_PYTHON}" --seed "${VENV_DIR}"
- PYTHON_BIN="${VENV_DIR}/bin/python"
- [[ -x "${PYTHON_BIN}" ]] || abort "Failed to locate python inside ${VENV_DIR}"
- log "INFO" "Installing build module inside virtual environment"
- "${UV_BIN}" pip install --python "${PYTHON_BIN}" build
-else
- log "INFO" "Ensuring build module is available via uv pip"
- "${UV_BIN}" pip install --python "${PYTHON_BIN}" build
-fi
-
-log "INFO" "Checking build module"
-if ! "${PYTHON_BIN}" -m build --version >/dev/null 2>&1; then
- abort "${PYTHON_BIN} -m build is not available, install build first"
-fi
-
-run_quality_steps() {
- log "INFO" "Running quality checks"
- "${UV_BIN}" pip install --python "${PYTHON_BIN}" -e ".[dev]"
- "${PYTHON_BIN}" -m pre_commit run --all-files
- "${PYTHON_BIN}" -m pytest tests/ -v -m "not slow"
-}
-
-if [[ "${RUN_QUALITY}" == "true" ]]; then
- run_quality_steps
-else
- log "INFO" "Quality steps available via --run-quality"
- log "INFO" " - pre-commit run --all-files"
- log "INFO" " - pip install -e '.[dev]'"
- log "INFO" " - pytest tests/ -v -m \"not slow\""
-fi
-
-cleanup_artifacts() {
- log "INFO" "Cleaning previous build artifacts"
- rm -rf build dist "${PROJECT_NAME}.egg-info" "${PROJECT_NAME//-/_}.egg-info"
-}
-
-if [[ "${SKIP_CLEAN}" == "true" ]]; then
- log "INFO" "Skipping cleanup as requested"
-else
- cleanup_artifacts
-fi
-
-log "INFO" "Building source and wheel distributions"
-"${PYTHON_BIN}" -m build
-
-log "INFO" "Build finished, artifacts:"
-ls -lh dist
diff --git a/setup.py b/setup.py
deleted file mode 100644
index 057212d67fe..00000000000
--- a/setup.py
+++ /dev/null
@@ -1,244 +0,0 @@
-"""
-Setup script for vLLM-Omni with hardware-dependent installation.
-
-This setup.py implements platform-aware dependency routing so users can run
-`pip install vllm-omni` and automatically receive the correct platform-specific
-dependencies (CUDA/ROCm/CPU/XPU/NPU/MUSA) without requiring extras like `[cuda]`.
-"""
-
-import os
-import subprocess
-import sys
-from pathlib import Path
-
-from setuptools import setup
-from setuptools_scm import get_version
-
-
-def uninstall_onnxruntime() -> None:
- """
- Uninstall onnxruntime package if it exists.
-
- This is necessary for ROCm environments where onnxruntime may conflict
- with ROCm-specific dependencies.
- """
- try:
- import pkg_resources
-
- try:
- pkg_resources.get_distribution("onnxruntime")
- print("Found onnxruntime installed, uninstalling for ROCm compatibility...")
- subprocess.check_call(
- [sys.executable, "-m", "pip", "uninstall", "-y", "onnxruntime"],
- stdout=subprocess.DEVNULL,
- stderr=subprocess.DEVNULL,
- )
- print("Successfully uninstalled onnxruntime")
- except pkg_resources.DistributionNotFound:
- print("onnxruntime not installed, skipping uninstall")
- except Exception as e:
- print(f"Warning: Failed to uninstall onnxruntime: {e}")
-
-
-def detect_target_device() -> str:
- """
- Detect the target device for installation following RFC priority rules.
-
- Priority order:
- 1. VLLM_OMNI_TARGET_DEVICE environment variable (highest priority)
- 2. Torch backend detection (cuda, rocm, npu, xpu, musa)
- 3. CPU fallback (default)
-
- Returns:
- str: Device name ('cuda', 'rocm', 'npu', 'xpu', 'musa', or 'cpu')
- """
- # Priority 1: Explicit override via environment variable
- target_device = os.environ.get("VLLM_OMNI_TARGET_DEVICE")
- if target_device:
- valid_devices = ["cuda", "rocm", "npu", "xpu", "musa", "cpu"]
- if target_device.lower() in valid_devices:
- print(f"Using target device from VLLM_OMNI_TARGET_DEVICE: {target_device.lower()}")
- return target_device.lower()
- else:
- print(f"Warning: Invalid VLLM_OMNI_TARGET_DEVICE '{target_device}', falling back to auto-detection")
-
- # Priority 2: Torch backend detection
- # This is a code path for when user is using
- # --no-build-isolation flag
- try:
- import torch
-
- # Check for CUDA
- if torch.version.cuda is not None:
- print("Detected CUDA backend from torch")
- return "cuda"
-
- # Check for ROCm (AMD)
- if torch.version.hip is not None:
- print("Detected ROCm backend from torch")
- uninstall_onnxruntime()
- return "rocm"
-
- # Check for NPU (Ascend)
- if hasattr(torch, "npu"):
- try:
- if torch.npu.is_available():
- print("Detected NPU backend from torch")
- return "npu"
- except Exception:
- pass
-
- # Check for XPU (Intel)
- if hasattr(torch, "xpu"):
- try:
- if torch.xpu.is_available():
- print("Detected XPU backend from torch")
- return "xpu"
- except Exception:
- pass
-
- # Check for MUSA (Moore Threads)
- if hasattr(torch, "musa"):
- try:
- if torch.musa.is_available():
- print("Detected MUSA backend from torch")
- return "musa"
- except Exception:
- pass
-
- print("No GPU backend detected in torch, defaulting to CPU")
- return "cpu"
-
- except ImportError:
- print("PyTorch not found, defaulting to CUDA installation")
- return "cuda"
-
-
-def get_vllm_omni_version() -> str:
- """
- Get the vLLM-Omni version with device-specific suffix.
-
- Version format: {base_version}+{device}
- Examples:
- - 0.14.0+cuda (release version with CUDA)
- - 0.14.1.dev23+g1a2b3c4.rocm (dev version with ROCm)
- - 0.15.0+npu (release version with NPU)
-
- Environment variables:
- VLLM_OMNI_VERSION_OVERRIDE: Override version completely
- VLLM_OMNI_TARGET_DEVICE: Override device detection
-
- Returns:
- Version string with device suffix
- """
- # Allow complete version override via environment variable
- if env_version := os.getenv("VLLM_OMNI_VERSION_OVERRIDE"):
- print(f"Overriding vLLM-Omni version with {env_version} from VLLM_OMNI_VERSION_OVERRIDE")
- os.environ["SETUPTOOLS_SCM_PRETEND_VERSION"] = env_version
- # Get version without device suffix for override case
- version = get_version(write_to="vllm_omni/_version.py")
- else:
- # Generate version from git tags via setuptools_scm (without writing yet)
- try:
- version = get_version()
- except Exception as e:
- print(f"Warning: Failed to get version from git, using fallback: {e}")
- version = "dev"
-
- # Determine separator: '+' for normal versions, '.' for dev versions with '+'
- sep = "+" if "+" not in version else "."
-
- # Append device-specific suffix
- device = detect_target_device()
-
- if device == "cuda":
- # if it is cuda, following vLLM
- # we don't need to add any suffix
- pass
- elif device == "rocm":
- version += f"{sep}rocm"
- elif device == "npu":
- version += f"{sep}npu"
- elif device == "xpu":
- version += f"{sep}xpu"
- elif device == "musa":
- version += f"{sep}musa"
- elif device == "cpu":
- version += f"{sep}cpu"
- else:
- raise RuntimeError(f"Unknown target device: {device}")
-
- # Tell setuptools_scm to use this version
- # This will be picked up by write_to and written to _version.py
- os.environ["SETUPTOOLS_SCM_PRETEND_VERSION"] = version
- get_version(write_to="vllm_omni/_version.py") # Write the correct version
- print(f"Generated version: {version}")
- return version
-
-
-def load_requirements(file_path: Path) -> list[str]:
- """
- Load requirements from a file, supporting -r directive for recursive loading.
-
- Args:
- file_path: Path to the requirements file
-
- Returns:
- List of requirement strings
- """
- requirements = []
-
- if not file_path.exists():
- print(f"Warning: Requirements file not found: {file_path}")
- return requirements
-
- with open(file_path) as f:
- for line in f:
- line = line.strip()
-
- # Skip empty lines and comments
- if not line or line.startswith("#"):
- continue
-
- # Handle -r directive for recursive loading
- if line.startswith("-r "):
- nested_file = line[3:].strip()
- nested_path = file_path.parent / nested_file
- requirements.extend(load_requirements(nested_path))
- else:
- requirements.append(line)
-
- return requirements
-
-
-def get_install_requires() -> list[str]:
- """
- Get the list of dependencies based on detected platform.
-
- Returns:
- List of requirement strings for the detected platform
- """
- device = detect_target_device()
- requirements_dir = Path(__file__).parent / "requirements"
- requirements_file = requirements_dir / f"{device}.txt"
-
- print(f"Loading requirements from: {requirements_file}")
- requirements = load_requirements(requirements_file)
-
- if not requirements:
- print(f"Warning: No requirements loaded for device '{device}'")
- else:
- print(f"Loaded {len(requirements)} requirements for {device}")
-
- return requirements
-
-
-if __name__ == "__main__":
- # Get platform-specific dependencies
- install_requires = get_install_requires()
-
- # Setup configuration
- setup(
- version=get_vllm_omni_version(),
- install_requires=install_requires,
- )
diff --git a/tests/__init__.py b/tests/__init__.py
deleted file mode 100644
index bacd68e5d22..00000000000
--- a/tests/__init__.py
+++ /dev/null
@@ -1,6 +0,0 @@
-"""
-Test suite for vLLM-Omni.
-
-This package contains unit tests, integration tests, and benchmarks
-for vLLM-Omni.
-"""
diff --git a/tests/assets/cosyvoice3/zero_shot_prompt.wav b/tests/assets/cosyvoice3/zero_shot_prompt.wav
deleted file mode 100644
index a7b9d954289..00000000000
Binary files a/tests/assets/cosyvoice3/zero_shot_prompt.wav and /dev/null differ
diff --git a/tests/assets/qwen3_tts/clone_2.wav b/tests/assets/qwen3_tts/clone_2.wav
deleted file mode 100644
index 9b6eab23097..00000000000
Binary files a/tests/assets/qwen3_tts/clone_2.wav and /dev/null differ
diff --git a/tests/benchmarks/conftest.py b/tests/benchmarks/conftest.py
deleted file mode 100644
index 7af6c3f8cb8..00000000000
--- a/tests/benchmarks/conftest.py
+++ /dev/null
@@ -1,103 +0,0 @@
-# SPDX-License-Identifier: Apache-2.0
-# SPDX-FileCopyrightText: Copyright contributors to the vLLM project
-
-"""conftest.py for benchmarks unit tests.
-
-Installs lightweight mock stubs for ``vllm`` (and sub-packages) so the
-data-module unit tests can run without a full vLLM installation. Only the
-symbols actually imported by
-``vllm_omni.benchmarks.data_modules.seed_tts_dataset`` are emulated.
-"""
-
-from __future__ import annotations
-
-import sys
-import types
-from dataclasses import dataclass
-from typing import Any
-
-
-def _install_vllm_stubs() -> None:
- """Register minimal vllm stubs in sys.modules.
-
- Only installs when real vllm is unavailable. We actively probe the
- import because an empty or partial vllm may not yet have imported
- the submodules we rely on, and unconditionally registering stubs
- would shadow the real package for sibling tests (e.g.
- ``tests/benchmarks/metrics/test_metrics.py`` needs the real
- ``vllm.benchmarks.serve``).
- """
- try:
- import vllm.benchmarks.datasets # noqa: F401
- import vllm.tokenizers # noqa: F401
- except ImportError:
- pass
- else:
- return # real vllm available — do not shadow it
- if "vllm.benchmarks.datasets" in sys.modules:
- return
-
- # ------------------------------------------------------------------ #
- # vllm.benchmarks.datasets #
- # ------------------------------------------------------------------ #
- @dataclass
- class SampleRequest:
- prompt: str = ""
- prompt_len: int = 0
- expected_output_len: int = 0
- multi_modal_data: Any = None
- request_id: str = ""
-
- class BenchmarkDataset:
- def __init__(
- self,
- dataset_path: str = "",
- random_seed: int = 0,
- disable_shuffle: bool = False,
- **kwargs: Any,
- ) -> None:
- self.dataset_path = dataset_path
- self.random_seed = random_seed
- self.disable_shuffle = disable_shuffle
-
- def maybe_oversample_requests(
- self,
- out: list,
- num_requests: int,
- request_id_prefix: str,
- no_oversample: bool,
- ) -> None:
- pass
-
- # ------------------------------------------------------------------ #
- # vllm.tokenizers / vllm.tokenizers.hf #
- # ------------------------------------------------------------------ #
- class TokenizerLike:
- pass
-
- def get_cached_tokenizer(t: Any) -> Any:
- return t
-
- # ------------------------------------------------------------------ #
- # Wire up sys.modules #
- # ------------------------------------------------------------------ #
- vllm_mod = types.ModuleType("vllm")
- vllm_benchmarks = types.ModuleType("vllm.benchmarks")
- vllm_benchmarks_datasets = types.ModuleType("vllm.benchmarks.datasets")
- vllm_tokenizers = types.ModuleType("vllm.tokenizers")
- vllm_tokenizers_hf = types.ModuleType("vllm.tokenizers.hf")
-
- vllm_benchmarks_datasets.BenchmarkDataset = BenchmarkDataset # type: ignore[attr-defined]
- vllm_benchmarks_datasets.SampleRequest = SampleRequest # type: ignore[attr-defined]
- vllm_tokenizers.TokenizerLike = TokenizerLike # type: ignore[attr-defined]
- vllm_tokenizers_hf.get_cached_tokenizer = get_cached_tokenizer # type: ignore[attr-defined]
-
- sys.modules["vllm"] = vllm_mod
- sys.modules["vllm.benchmarks"] = vllm_benchmarks
- sys.modules["vllm.benchmarks.datasets"] = vllm_benchmarks_datasets
- sys.modules["vllm.tokenizers"] = vllm_tokenizers
- sys.modules["vllm.tokenizers.hf"] = vllm_tokenizers_hf
-
-
-# Install stubs immediately at collection time (before any test import).
-_install_vllm_stubs()
diff --git a/tests/benchmarks/metrics/test_metrics.py b/tests/benchmarks/metrics/test_metrics.py
deleted file mode 100644
index f531a5026a3..00000000000
--- a/tests/benchmarks/metrics/test_metrics.py
+++ /dev/null
@@ -1,67 +0,0 @@
-# SPDX-License-Identifier: Apache-2.0
-# SPDX-FileCopyrightText: Copyright contributors to the vLLM project
-
-"""
-Unit tests for metrics.py
-"""
-
-import pytest
-from vllm.benchmarks.serve import TaskType
-
-from vllm_omni.benchmarks.metrics.metrics import calculate_metrics
-from vllm_omni.benchmarks.patch.patch import MixRequestFuncOutput
-
-pytestmark = [pytest.mark.core_model, pytest.mark.benchmark, pytest.mark.cpu]
-
-
-def _make_output(prompt_len: int, output_tokens: int = 10) -> MixRequestFuncOutput:
- """Build a minimal successful MixRequestFuncOutput for metrics aggregation."""
- output = MixRequestFuncOutput()
- output.success = True
- output.prompt_len = prompt_len
- output.output_tokens = output_tokens
- output.generated_text = "x" * output_tokens
- output.ttft = 0.1
- output.text_latency = 1.0
- output.latency = 1.0
- output.start_time = 0.0
- output.itl = [0.1] * max(output_tokens - 1, 0)
- output.audio_ttfp = 0.0
- output.audio_rtf = 0.0
- output.audio_duration = 0.0
- output.audio_frames = 0
- output.input_audio_duration = 0.0
- output.error = ""
- return output
-
-
-# ============================================================================
-# total_input Tests
-# ============================================================================
-
-
-def test_total_input_aggregated_from_output_prompt_len():
- """Test that total_input sums outputs[i].prompt_len, not input_requests[i].prompt_len."""
- outputs = [_make_output(4992), _make_output(3000)]
-
- metrics, _ = calculate_metrics(
- input_requests=[],
- outputs=outputs,
- dur_s=10.0,
- tokenizer=None,
- selected_percentiles=[99.0],
- goodput_config_dict={},
- task_type=TaskType.GENERATION,
- selected_percentile_metrics=[],
- max_concurrency=None,
- request_rate=float("inf"),
- benchmark_duration=10.0,
- )
-
- assert metrics.total_input == 7992, (
- "total_input should aggregate from outputs[i].prompt_len to reflect the true multimodal input token count"
- )
-
-
-if __name__ == "__main__":
- pytest.main([__file__, "-v", "-s"])
diff --git a/tests/benchmarks/patch/test_patch.py b/tests/benchmarks/patch/test_patch.py
deleted file mode 100644
index 35a18aea33c..00000000000
--- a/tests/benchmarks/patch/test_patch.py
+++ /dev/null
@@ -1,632 +0,0 @@
-# SPDX-License-Identifier: Apache-2.0
-# SPDX-FileCopyrightText: Copyright contributors to the vLLM project
-
-"""
-Unit tests for patch.py
-"""
-
-import asyncio
-import json
-
-import pytest
-from pytest_mock import MockerFixture
-from vllm.benchmarks.lib.endpoint_request_func import RequestFuncInput
-
-from vllm_omni.benchmarks.patch.patch import MixRequestFuncOutput, async_request_openai_chat_omni_completions
-
-pytestmark = [pytest.mark.core_model, pytest.mark.benchmark, pytest.mark.cpu]
-
-
-class MockResponse:
- """Mock aiohttp response for testing"""
-
- def __init__(self, status, chunks, delay_between_chunks=0):
- self.status = status
- self.reason = "OK" if status == 200 else "Error"
- self._chunks = chunks
- self._delay = delay_between_chunks
- self.content = self
-
- async def iter_any(self):
- for chunk in self._chunks:
- if self._delay > 0:
- await asyncio.sleep(self._delay)
- yield chunk
-
- async def __aenter__(self):
- return self
-
- async def __aexit__(self, exc_type, exc_val, exc_tb):
- pass
-
-
-def create_sse_chunk(data_dict):
- """Helper to create SSE formatted chunk"""
- return f"data: {json.dumps(data_dict)}\n\n".encode()
-
-
-# ============================================================================
-# output_tokens Tests
-# ============================================================================
-
-
-@pytest.mark.asyncio
-async def test_output_tokens_assigned_with_metrics(mocker: MockerFixture):
- """Test that output.output_tokens is assigned when metrics are present"""
- # Arrange
- request_input = RequestFuncInput(
- model="test-model",
- model_name="test-model",
- prompt="test prompt",
- api_url="http://test.com/v1/chat/completions",
- prompt_len=10,
- output_len=20,
- )
-
- # Create response chunks with metrics
- chunks = [
- create_sse_chunk(
- {
- "choices": [{"delta": {"content": "Hello"}}],
- "modality": "text",
- }
- ),
- create_sse_chunk(
- {
- "choices": [{"delta": {"content": " world"}}],
- "modality": "text",
- "metrics": {"num_tokens_out": 42, "num_tokens_in": 10},
- }
- ),
- b"data: [DONE]\n\n",
- ]
-
- mock_response = MockResponse(200, chunks)
- mock_session = mocker.AsyncMock()
- mock_session.post = mocker.MagicMock(return_value=mock_response)
-
- # Act
- output = await async_request_openai_chat_omni_completions(request_input, mock_session)
-
- # Assert
- assert output.success is True
- assert output.output_tokens == 42, "output_tokens should be assigned from metrics"
- assert output.generated_text == "Hello world"
-
-
-@pytest.mark.asyncio
-async def test_output_tokens_not_assigned_without_metrics(mocker: MockerFixture):
- """Test that output.output_tokens defaults to 0 when no metrics present"""
- # Arrange
- request_input = RequestFuncInput(
- model="test-model",
- model_name="test-model",
- prompt="test prompt",
- api_url="http://test.com/v1/chat/completions",
- prompt_len=10,
- output_len=20,
- )
-
- # Create response chunks without metrics
- chunks = [
- create_sse_chunk(
- {
- "choices": [{"delta": {"content": "Hello"}}],
- "modality": "text",
- }
- ),
- create_sse_chunk(
- {
- "choices": [{"delta": {"content": " world"}}],
- "modality": "text",
- }
- ),
- b"data: [DONE]\n\n",
- ]
-
- mock_response = MockResponse(200, chunks)
- mock_session = mocker.AsyncMock()
- mock_session.post = mocker.MagicMock(return_value=mock_response)
-
- # Act
- output = await async_request_openai_chat_omni_completions(request_input, mock_session)
-
- # Assert
- assert output.success is True
- assert output.output_tokens == 0, "output_tokens should default to 0 when no metrics"
- assert output.generated_text == "Hello world"
-
-
-@pytest.mark.asyncio
-async def test_output_tokens_assigned_multiple_metrics(mocker: MockerFixture):
- """Test that output.output_tokens is updated with the latest metrics value"""
- # Arrange
- request_input = RequestFuncInput(
- model="test-model",
- model_name="test-model",
- prompt="test prompt",
- api_url="http://test.com/v1/chat/completions",
- prompt_len=10,
- output_len=20,
- )
-
- # Create response chunks with multiple metrics updates
- chunks = [
- create_sse_chunk(
- {
- "choices": [{"delta": {"content": "Hello"}}],
- "modality": "text",
- "metrics": {"num_tokens_out": 5},
- }
- ),
- create_sse_chunk(
- {
- "choices": [{"delta": {"content": " world"}}],
- "modality": "text",
- "metrics": {"num_tokens_out": 10},
- }
- ),
- create_sse_chunk(
- {
- "choices": [{"delta": {"content": "!"}}],
- "modality": "text",
- "metrics": {"num_tokens_out": 15},
- }
- ),
- b"data: [DONE]\n\n",
- ]
-
- mock_response = MockResponse(200, chunks)
- mock_session = mocker.AsyncMock()
- mock_session.post = mocker.MagicMock(return_value=mock_response)
-
- # Act
- output = await async_request_openai_chat_omni_completions(request_input, mock_session)
-
- # Assert
- assert output.success is True
- assert output.output_tokens == 15, "output_tokens should be updated to the latest value"
- assert output.generated_text == "Hello world!"
-
-
-@pytest.mark.asyncio
-async def test_output_tokens_with_audio_and_text(mocker: MockerFixture):
- """Test output_tokens assignment in mixed audio and text response"""
- # Arrange
- request_input = RequestFuncInput(
- model="test-model",
- model_name="test-model",
- prompt="test prompt",
- api_url="http://test.com/v1/chat/completions",
- prompt_len=10,
- output_len=20,
- )
-
- # Create response chunks with both audio and text, with metrics
- chunks = [
- create_sse_chunk(
- {
- "choices": [{"delta": {"content": "Text response"}}],
- "modality": "text",
- }
- ),
- create_sse_chunk(
- {
- "choices": [{"delta": {"content": ""}}],
- "modality": "audio",
- }
- ),
- create_sse_chunk(
- {
- "modality": "text",
- "metrics": {"num_tokens_out": 25, "num_tokens_in": 10},
- }
- ),
- b"data: [DONE]\n\n",
- ]
-
- mock_response = MockResponse(200, chunks)
- mock_session = mocker.AsyncMock()
- mock_session.post = mocker.MagicMock(return_value=mock_response)
-
- # Act
- output = await async_request_openai_chat_omni_completions(request_input, mock_session)
-
- # Assert
- assert output.success is True
- assert output.output_tokens == 25, "output_tokens should be assigned even with audio modality"
-
-
-@pytest.mark.asyncio
-async def test_output_tokens_with_missing_num_tokens_out(mocker: MockerFixture):
- """Test that output_tokens defaults to 0 when num_tokens_out is missing in metrics"""
- # Arrange
- request_input = RequestFuncInput(
- model="test-model",
- model_name="test-model",
- prompt="test prompt",
- api_url="http://test.com/v1/chat/completions",
- prompt_len=10,
- output_len=20,
- )
-
- # Create response chunks with metrics but without num_tokens_out
- chunks = [
- create_sse_chunk(
- {
- "choices": [{"delta": {"content": "Hello"}}],
- "modality": "text",
- }
- ),
- create_sse_chunk(
- {
- "choices": [{"delta": {"content": " world"}}],
- "modality": "text",
- "metrics": {"num_tokens_in": 10}, # Missing num_tokens_out
- }
- ),
- b"data: [DONE]\n\n",
- ]
-
- mock_response = MockResponse(200, chunks)
- mock_session = mocker.AsyncMock()
- mock_session.post = mocker.MagicMock(return_value=mock_response)
-
- # Act
- output = await async_request_openai_chat_omni_completions(request_input, mock_session)
-
- # Assert
- assert output.success is True
- assert output.output_tokens == 0, "output_tokens should default to 0 when num_tokens_out is missing"
-
-
-@pytest.mark.asyncio
-async def test_output_tokens_initialization():
- """Test that MixRequestFuncOutput initializes output_tokens correctly"""
- # Arrange & Act
- output = MixRequestFuncOutput()
-
- # Assert
- assert hasattr(output, "output_tokens"), "MixRequestFuncOutput should have output_tokens attribute"
- assert output.output_tokens == 0, "output_tokens should be initialized to 0"
-
-
-# ============================================================================
-# text_latency Tests
-# ============================================================================
-
-
-class TestTextLatencyAttribute:
- """Tests for text_latency attribute existence and assignment"""
-
- def test_mix_request_func_output_has_text_latency(self):
- """Test that MixRequestFuncOutput has text_latency attribute"""
- output = MixRequestFuncOutput()
- assert hasattr(output, "text_latency"), "MixRequestFuncOutput should have text_latency attribute"
-
- def test_text_latency_initial_value(self):
- """Test that text_latency initializes to a default value"""
- output = MixRequestFuncOutput()
- # Check if attribute exists and has a value (should be 0.0 or similar default)
- text_latency = getattr(output, "text_latency", None)
- assert text_latency is not None or hasattr(output, "text_latency"), "text_latency attribute should exist"
-
- @pytest.mark.asyncio
- async def test_text_latency_assigned_with_text_response(self, mocker: MockerFixture):
- """Test that text_latency is assigned when text response is received"""
- request_input = RequestFuncInput(
- model="test-model",
- model_name="test-model",
- prompt="test prompt",
- api_url="http://test.com/v1/chat/completions",
- prompt_len=10,
- output_len=20,
- )
-
- # Create response chunks with text modality
- chunks = [
- create_sse_chunk(
- {
- "choices": [{"delta": {"content": "Hello"}}],
- "modality": "text",
- }
- ),
- create_sse_chunk(
- {
- "choices": [{"delta": {"content": " world"}}],
- "modality": "text",
- }
- ),
- b"data: [DONE]\n\n",
- ]
-
- mock_response = MockResponse(200, chunks)
- mock_session = mocker.AsyncMock()
- mock_session.post = mocker.MagicMock(return_value=mock_response)
-
- # Act
- output = await async_request_openai_chat_omni_completions(request_input, mock_session)
-
- # Assert
- assert output.success is True
- assert hasattr(output, "text_latency"), "Output should have text_latency attribute"
- assert output.text_latency > 0, "text_latency should be greater than 0 for text response"
-
- @pytest.mark.asyncio
- async def test_text_latency_updated_with_multiple_text_chunks(self, mocker: MockerFixture):
- """Test that text_latency is updated as more text chunks arrive"""
- request_input = RequestFuncInput(
- model="test-model",
- model_name="test-model",
- prompt="test prompt",
- api_url="http://test.com/v1/chat/completions",
- prompt_len=10,
- output_len=20,
- )
-
- # Create response chunks with small delays to simulate streaming
- chunks = [
- create_sse_chunk(
- {
- "choices": [{"delta": {"content": "First"}}],
- "modality": "text",
- }
- ),
- create_sse_chunk(
- {
- "choices": [{"delta": {"content": " second"}}],
- "modality": "text",
- }
- ),
- create_sse_chunk(
- {
- "choices": [{"delta": {"content": " third"}}],
- "modality": "text",
- }
- ),
- b"data: [DONE]\n\n",
- ]
-
- mock_response = MockResponse(200, chunks)
- mock_session = mocker.AsyncMock()
- mock_session.post = mocker.MagicMock(return_value=mock_response)
-
- # Act
- output = await async_request_openai_chat_omni_completions(request_input, mock_session)
-
- # Assert
- assert output.success is True
- assert hasattr(output, "text_latency"), "Output should have text_latency attribute"
- assert output.text_latency > 0, "text_latency should accumulate"
- assert output.generated_text == "First second third"
-
- @pytest.mark.asyncio
- async def test_text_latency_with_only_audio_response(self, mocker: MockerFixture):
- """Test text_latency behavior when only audio is received"""
- request_input = RequestFuncInput(
- model="test-model",
- model_name="test-model",
- prompt="test prompt",
- api_url="http://test.com/v1/chat/completions",
- prompt_len=10,
- output_len=20,
- )
-
- # Create response chunks with only audio modality (no text)
- chunks = [
- create_sse_chunk(
- {
- "choices": [{"delta": {"content": ""}}],
- "modality": "audio",
- }
- ),
- b"data: [DONE]\n\n",
- ]
-
- mock_response = MockResponse(200, chunks)
- mock_session = mocker.AsyncMock()
- mock_session.post = mocker.MagicMock(return_value=mock_response)
-
- # Act
- output = await async_request_openai_chat_omni_completions(request_input, mock_session)
-
- # Assert
- assert output.success is True
- assert hasattr(output, "text_latency"), "Output should have text_latency attribute even with audio-only"
- # text_latency should either be 0 or the initial value since no text was processed
- assert output.text_latency >= 0, "text_latency should be non-negative"
-
- @pytest.mark.asyncio
- async def test_text_latency_not_affected_by_metrics(self, mocker: MockerFixture):
- """Test that text_latency is independent of metrics data"""
- request_input = RequestFuncInput(
- model="test-model",
- model_name="test-model",
- prompt="test prompt",
- api_url="http://test.com/v1/chat/completions",
- prompt_len=10,
- output_len=20,
- )
-
- # Create response with text and metrics
- chunks = [
- create_sse_chunk(
- {
- "choices": [{"delta": {"content": "Response text"}}],
- "modality": "text",
- }
- ),
- create_sse_chunk(
- {
- "choices": [{"delta": {"content": ""}}],
- "modality": "text",
- "metrics": {"num_tokens_out": 100, "num_tokens_in": 20},
- }
- ),
- b"data: [DONE]\n\n",
- ]
-
- mock_response = MockResponse(200, chunks)
- mock_session = mocker.AsyncMock()
- mock_session.post = mocker.MagicMock(return_value=mock_response)
-
- # Act
- output = await async_request_openai_chat_omni_completions(request_input, mock_session)
-
- # Assert
- assert output.success is True
- assert hasattr(output, "text_latency"), "text_latency should exist"
- assert output.text_latency > 0, "text_latency should be set for text response"
- # Verify metrics are also present
- assert output.output_tokens == 100, "metrics should not affect text_latency"
-
- @pytest.mark.asyncio
- async def test_text_latency_mixed_modalities(self, mocker: MockerFixture):
- """Test text_latency with mixed text and audio modalities"""
- request_input = RequestFuncInput(
- model="test-model",
- model_name="test-model",
- prompt="test prompt",
- api_url="http://test.com/v1/chat/completions",
- prompt_len=10,
- output_len=20,
- )
-
- # Create response with both text and audio
- chunks = [
- create_sse_chunk(
- {
- "choices": [{"delta": {"content": "Text"}}],
- "modality": "text",
- }
- ),
- create_sse_chunk(
- {
- "choices": [{"delta": {"content": ""}}],
- "modality": "audio",
- }
- ),
- create_sse_chunk(
- {
- "choices": [{"delta": {"content": " more text"}}],
- "modality": "text",
- }
- ),
- b"data: [DONE]\n\n",
- ]
-
- mock_response = MockResponse(200, chunks)
- mock_session = mocker.AsyncMock()
- mock_session.post = mocker.MagicMock(return_value=mock_response)
-
- # Act
- output = await async_request_openai_chat_omni_completions(request_input, mock_session)
-
- # Assert
- assert output.success is True
- assert hasattr(output, "text_latency"), "text_latency should exist with mixed modalities"
- assert output.text_latency > 0, "text_latency should be set when text is present"
- assert output.generated_text == "Text more text"
-
- @pytest.mark.asyncio
- async def test_text_latency_value_consistency(self, mocker: MockerFixture):
- """Test that text_latency matches latency minus ttft relationship"""
- request_input = RequestFuncInput(
- model="test-model",
- model_name="test-model",
- prompt="test prompt",
- api_url="http://test.com/v1/chat/completions",
- prompt_len=10,
- output_len=20,
- )
-
- chunks = [
- create_sse_chunk(
- {
- "choices": [{"delta": {"content": "Hello"}}],
- "modality": "text",
- }
- ),
- create_sse_chunk(
- {
- "choices": [{"delta": {"content": " world"}}],
- "modality": "text",
- }
- ),
- b"data: [DONE]\n\n",
- ]
-
- mock_response = MockResponse(200, chunks)
- mock_session = mocker.AsyncMock()
- mock_session.post = mocker.MagicMock(return_value=mock_response)
-
- # Act
- output = await async_request_openai_chat_omni_completions(request_input, mock_session)
-
- # Assert
- assert output.success is True
- assert hasattr(output, "text_latency"), "text_latency should exist"
- assert hasattr(output, "ttft"), "ttft should exist"
- assert hasattr(output, "latency"), "latency should exist"
- # text_latency should be between ttft and total latency
- assert output.ttft <= output.text_latency <= output.latency, (
- "text_latency should be between ttft and total latency"
- )
-
-
-# ============================================================================
-# prompt_len Tests
-# ============================================================================
-
-
-@pytest.mark.asyncio
-async def test_prompt_len_assigned_from_usage(mocker: MockerFixture):
- # Arrange: request claims prompt_len=100, but server reports 4992 (multimodal).
- request_input = RequestFuncInput(
- model="test-model",
- model_name="test-model",
- prompt="test prompt",
- api_url="http://test.com/v1/chat/completions",
- prompt_len=100,
- output_len=20,
- )
-
- chunks = [
- create_sse_chunk(
- {
- "choices": [{"delta": {"content": "Hello"}}],
- "modality": "text",
- }
- ),
- create_sse_chunk(
- {
- "choices": [{"delta": {"content": " world"}}],
- "modality": "text",
- }
- ),
- # Final usage chunk emitted because stream_options.include_usage=True.
- create_sse_chunk(
- {
- "choices": [],
- "usage": {"prompt_tokens": 4992, "completion_tokens": 2, "total_tokens": 4994},
- }
- ),
- b"data: [DONE]\n\n",
- ]
-
- mock_response = MockResponse(200, chunks)
- mock_session = mocker.AsyncMock()
- mock_session.post = mocker.MagicMock(return_value=mock_response)
-
- # Act
- output = await async_request_openai_chat_omni_completions(request_input, mock_session)
-
- # Assert
- assert output.success is True
- assert output.prompt_len == 4992, (
- "prompt_len should be overridden by usage.prompt_tokens to reflect the true multimodal input token count"
- )
-
-
-if __name__ == "__main__":
- pytest.main([__file__, "-v", "-s"])
diff --git a/tests/benchmarks/test_accuracy_bench_utils.py b/tests/benchmarks/test_accuracy_bench_utils.py
deleted file mode 100644
index 6ceebb11b79..00000000000
--- a/tests/benchmarks/test_accuracy_bench_utils.py
+++ /dev/null
@@ -1,747 +0,0 @@
-# ruff: noqa: E402, I001
-import argparse
-import math
-import os
-import sys
-import types
-from pathlib import Path
-
-import pytest
-from PIL import Image
-
-pytestmark = [pytest.mark.core_model, pytest.mark.diffusion, pytest.mark.cpu]
-
-
-REPO_ROOT = Path(__file__).resolve().parents[2]
-if str(REPO_ROOT) not in sys.path:
- sys.path.insert(0, str(REPO_ROOT))
-
-from benchmarks.accuracy.common import VllmOmniImageClient
-from benchmarks.accuracy.image_to_image.gedit_bench import (
- GROUPS as GEDIT_GROUPS,
- GEditBenchEvaluator,
- GEditBenchRunner,
- _load_gedit_dataset,
- _resolve_gedit_split,
- infer_model_name,
- resolve_model_name,
- select_balanced_gedit_rows,
- parse_score_payload,
- summarize_generated_records as summarize_gedit_generated_records,
- summarize_gedit_rows,
- summarize_gedit_rows_with_backbone,
-)
-from benchmarks.accuracy.text_to_image.gbench import (
- _expand_sample_path,
- _trajectory_judge_payload,
- _write_json_with_timestamp,
- LocalJudgeClient,
- GEBenchEvaluator,
- TYPE_TO_FOLDER,
- select_balanced_gebench_samples,
- summarize_generated_records as summarize_gebench_generated_records,
- summarize_gebench_results,
-)
-from tests.e2e.accuracy.qwen3_omni.qwen3_omni_acc_bench_core import seed_tts_bench_argv
-from tests.e2e.accuracy.qwen3_omni.run_qwen_omni_acc_benchmark import sync_dataset_env_from_ns
-from vllm_omni.benchmarks.data_modules.seed_tts_dataset import resolve_seed_tts_root
-
-
-def test_seed_tts_bench_argv_preserves_hf_repo_id_from_env(monkeypatch):
- monkeypatch.setenv("VLLM_SEED_TTS_DATASET_PATH", "zhaochenyang20/seed-tts-eval")
- monkeypatch.delenv("VLLM_SEED_TTS_REPO", raising=False)
-
- argv = seed_tts_bench_argv(locale="en")
-
- dataset_idx = argv.index("--dataset-path")
- assert argv[dataset_idx + 1] == "zhaochenyang20/seed-tts-eval"
-
-
-def test_sync_dataset_env_preserves_seed_tts_hf_repo_id(monkeypatch):
- ns = argparse.Namespace(
- daily_omni_repo=None,
- daily_omni_qa_json=None,
- daily_omni_video_dir=None,
- seed_tts_dataset_path="zhaochenyang20/seed-tts-eval",
- seed_tts_root=None,
- )
-
- monkeypatch.delenv("VLLM_SEED_TTS_DATASET_PATH", raising=False)
- sync_dataset_env_from_ns(ns)
-
- assert os.environ["VLLM_SEED_TTS_DATASET_PATH"] == "zhaochenyang20/seed-tts-eval"
-
-
-def test_resolve_seed_tts_root_downloads_only_requested_locale(monkeypatch, tmp_path: Path):
- downloaded_root = tmp_path / "seed_tts_cache"
- (downloaded_root / "zh" / "prompt-wavs").mkdir(parents=True)
- (downloaded_root / "zh" / "meta.lst").write_text("", encoding="utf-8")
- captured: dict[str, object] = {}
-
- def fake_snapshot_download(*, repo_id, repo_type, allow_patterns):
- captured["repo_id"] = repo_id
- captured["repo_type"] = repo_type
- captured["allow_patterns"] = allow_patterns
- return str(downloaded_root)
-
- monkeypatch.setitem(
- sys.modules,
- "huggingface_hub",
- types.SimpleNamespace(snapshot_download=fake_snapshot_download),
- )
-
- resolved = resolve_seed_tts_root(
- "zhaochenyang20/seed-tts-eval",
- explicit_root=None,
- locale="zh",
- )
-
- assert resolved == downloaded_root.resolve()
- assert captured["repo_id"] == "zhaochenyang20/seed-tts-eval"
- assert captured["repo_type"] == "dataset"
- assert captured["allow_patterns"] == ["zh/**"]
-
-
-def test_summarize_gebench_generated_records_groups_by_type():
- records = [
- {"data_type": "type1", "sample_name": "english_phone/folder_1", "output_path": "a.png"},
- {"data_type": "type1", "sample_name": "english_phone/folder_2", "output_path": "b.png"},
- {"data_type": "type2", "sample_name": "english_phone/folder_3", "output_path": "c.png"},
- ]
-
- summary = summarize_gebench_generated_records(records)
-
- assert summary["count"] == 3
- assert summary["by_type"]["type1"]["count"] == 2
- assert summary["by_type"]["type2"]["count"] == 1
- assert "samples" not in summary["by_type"]["type1"]
-
-
-def test_summarize_gebench_results_computes_type_and_global_means():
- results = [
- {"data_type": "type1", "overall": 0.8, "scores": {"goal": 5, "logic": 4}},
- {"data_type": "type1", "overall": 0.6, "scores": {"goal": 3, "logic": 4}},
- {"data_type": "type2", "overall": 0.5, "scores": {"goal": 2, "logic": 3}},
- ]
-
- summary = summarize_gebench_results(results)
-
- assert math.isclose(summary["overall_mean"], (0.8 + 0.6 + 0.5) / 3)
- assert math.isclose(summary["by_type"]["type1"]["overall_mean"], 0.7)
- assert math.isclose(summary["by_type"]["type2"]["overall_mean"], 0.5)
- assert math.isclose(summary["by_type"]["type1"]["score_means"]["goal"], 4.0)
-
-
-def test_write_json_with_timestamp_writes_stable_and_timestamped_files(monkeypatch, tmp_path: Path):
- monkeypatch.setattr(
- "benchmarks.accuracy.text_to_image.gbench._utc_timestamp",
- lambda: "20260325T130000Z",
- )
-
- timestamped_path = _write_json_with_timestamp(tmp_path / "summary.json", {"ok": True})
-
- assert (tmp_path / "summary.json").exists()
- assert timestamped_path == tmp_path / "summary_20260325T130000Z.json"
- assert timestamped_path.exists()
-
-
-def test_select_balanced_gebench_samples_limits_each_type_independently():
- sample_paths_by_type = {
- "type1": [Path(f"/tmp/type1_{idx}") for idx in range(12)],
- "type2": [Path(f"/tmp/type2_{idx}") for idx in range(8)],
- "type3": [Path(f"/tmp/type3_{idx}") for idx in range(15)],
- }
-
- selected = select_balanced_gebench_samples(sample_paths_by_type, samples_per_type=10)
-
- assert len(selected["type1"]) == 10
- assert len(selected["type2"]) == 8
- assert len(selected["type3"]) == 10
- assert selected["type1"][0].name == "type1_0"
- assert selected["type3"][-1].name == "type3_9"
-
-
-def test_expand_sample_path_flattens_json_list_samples(tmp_path: Path):
- sample_path = tmp_path / "trajectories.json"
- sample_path.write_text(
- """
-[
- {"id": "sample_a", "lang_device": "english_phone", "instruction": "do a"},
- {"id": "sample_b", "lang_device": "english_phone", "instruction": "do b"}
-]
-""".strip(),
- encoding="utf-8",
- )
-
- specs = _expand_sample_path(sample_path)
-
- assert len(specs) == 2
- assert specs[0].sample_name == "sample_a"
- assert specs[1].sample_name == "sample_b"
- assert specs[0].lang_device == "english_phone"
-
-
-def test_gebench_evaluate_skips_missing_output_folder(tmp_path: Path):
- dataset_type_root = tmp_path / TYPE_TO_FOLDER["type3"] / "english_phone"
- sample_dir = dataset_type_root / "sample_a"
- sample_dir.mkdir(parents=True)
- (sample_dir / "meta_data.json").write_text("{}", encoding="utf-8")
-
- judge = LocalJudgeClient(base_url="http://127.0.0.1:8094", api_key="EMPTY", model="judge")
- evaluator = GEBenchEvaluator(dataset_root=tmp_path, output_root=tmp_path / "outputs", judge=judge)
-
- payload = evaluator.evaluate(data_type="type3")
-
- assert payload["results"] == []
- assert payload["summary"]["count"] == 0
-
-
-def test_local_judge_client_retries_when_first_response_is_not_json(monkeypatch):
- responses = iter(
- [
- "The image looks like a GUI screenshot with several controls.",
- '{"goal": 4, "logic": 4, "cons": 5, "ui": 4, "qual": 4, "reasoning": "mostly correct"}',
- ]
- )
-
- def fake_request_text(self, prompt, images):
- return next(responses)
-
- monkeypatch.setattr(LocalJudgeClient, "_request_text", fake_request_text)
-
- judge = LocalJudgeClient(base_url="http://127.0.0.1:8094", api_key="EMPTY", model="judge")
- result = judge.evaluate(prompt="Evaluate this GUI trajectory.", images=[Image.new("RGB", (2, 2), color="white")])
-
- assert result["goal"] == 4
- assert result["cons"] == 5
-
-
-def test_local_judge_client_returns_zero_scores_when_retry_is_still_invalid(monkeypatch):
- responses = iter(
- [
- "not json",
- "still not json",
- ]
- )
-
- def fake_request_text(self, prompt, images):
- return next(responses)
-
- monkeypatch.setattr(LocalJudgeClient, "_request_text", fake_request_text)
-
- judge = LocalJudgeClient(base_url="http://127.0.0.1:8094", api_key="EMPTY", model="judge")
- result = judge.evaluate(prompt="Evaluate this GUI trajectory.", images=[Image.new("RGB", (2, 2), color="white")])
-
- assert result["goal"] == 0
- assert result["logic"] == 0
- assert result["cons"] == 0
- assert result["ui"] == 0
- assert result["qual"] == 0
- assert result["reasoning"] == "still not json"
-
-
-def test_trajectory_judge_payload_collapses_six_frames_into_single_storyboard():
- frames = [Image.new("RGB", (8, 6), color=(idx * 10, idx * 10, idx * 10)) for idx in range(6)]
-
- prompt_suffix, judge_images = _trajectory_judge_payload(frames)
-
- assert "frame0" in prompt_suffix
- assert len(judge_images) == 1
- assert judge_images[0].size == (24, 12)
-
-
-def test_image_edit_client_uses_openai_image_edit_endpoint(monkeypatch):
- captured = {}
-
- class FakeResponse:
- status_code = 200
-
- def raise_for_status(self):
- return None
-
- def json(self):
- return {
- "data": [
- {
- "b64_json": "iVBORw0KGgoAAAANSUhEUgAAAAEAAAABCAQAAAC1HAwCAAAAC0lEQVR42mP8/x8AAwMCAO+aY0cAAAAASUVORK5CYII="
- }
- ]
- }
-
- def fake_post(url, data=None, files=None, headers=None, timeout=None, **kwargs):
- captured["url"] = url
- captured["data"] = data
- captured["files"] = files
- captured["headers"] = headers
- captured["timeout"] = timeout
- return FakeResponse()
-
- monkeypatch.setattr("benchmarks.accuracy.common.requests.post", fake_post)
-
- client = VllmOmniImageClient(base_url="http://127.0.0.1:8093", api_key="EMPTY")
- image = Image.new("RGB", (2, 2), color="white")
- output = client.generate_image_edit(
- model="Qwen/Qwen-Image-Edit",
- prompt="edit this image",
- images=image,
- width=512,
- height=512,
- )
-
- assert output.size == (1, 1)
- assert captured["url"] == "http://127.0.0.1:8093/v1/images/edits"
- assert captured["data"]["prompt"] == "edit this image"
- assert captured["data"]["size"] == "512x512"
- assert captured["files"][0][0] == "image"
-
-
-def test_text_to_image_client_forwards_output_compression(monkeypatch):
- captured = {}
-
- class FakeResponse:
- status_code = 200
-
- def raise_for_status(self):
- return None
-
- def json(self):
- return {
- "data": [
- {
- "b64_json": "iVBORw0KGgoAAAANSUhEUgAAAAEAAAABCAQAAAC1HAwCAAAAC0lEQVR42mP8/x8AAwMCAO+aY0cAAAAASUVORK5CYII="
- }
- ]
- }
-
- def fake_post(url, json=None, headers=None, timeout=None, **kwargs):
- captured["url"] = url
- captured["json"] = json
- return FakeResponse()
-
- monkeypatch.setattr("benchmarks.accuracy.common.requests.post", fake_post)
-
- client = VllmOmniImageClient(base_url="http://127.0.0.1:8093", api_key="EMPTY")
- output = client.generate_text_to_image(
- model="Qwen/Qwen-Image",
- prompt="generate a gui",
- width=768,
- height=576,
- num_inference_steps=8,
- output_compression=98,
- )
-
- assert output.size == (1, 1)
- assert captured["url"] == "http://127.0.0.1:8093/v1/images/generations"
- assert captured["json"]["size"] == "768x576"
- assert captured["json"]["num_inference_steps"] == 8
- assert captured["json"]["output_compression"] == 98
-
-
-def test_parse_score_payload_handles_raw_json_and_delimited_json():
- raw = '{"score": [7, 8], "reasoning": "ok"}'
- wrapped = 'prefix ||V^=^V|| {"score": [6], "reasoning": "fine"} ||V^=^V|| suffix'
-
- assert parse_score_payload(raw)["score"] == [7, 8]
- assert parse_score_payload(wrapped)["score"] == [6]
-
-
-def test_summarize_gedit_generated_records_groups_by_task_and_language():
- records = []
- for group in GEDIT_GROUPS[:2]:
- records.append(
- {
- "task_type": group,
- "instruction_language": "en",
- "key": f"{group}_en",
- "output_path": f"{group}_en.png",
- }
- )
- records.append(
- {
- "task_type": group,
- "instruction_language": "cn",
- "key": f"{group}_cn",
- "output_path": f"{group}_cn.png",
- }
- )
-
- summary = summarize_gedit_generated_records(records)
-
- assert summary["count"] == 4
- assert summary["by_task"][GEDIT_GROUPS[0]]["count"] == 2
- assert summary["by_language"]["en"]["count"] == 2
- assert summary["by_language"]["cn"]["samples"] == [
- f"{GEDIT_GROUPS[0]}_cn",
- f"{GEDIT_GROUPS[1]}_cn",
- ]
-
-
-def test_select_balanced_gedit_rows_limits_each_group_independently():
- rows = []
- for idx in range(12):
- rows.append(
- {
- "task_type": "background_change",
- "instruction_language": "en",
- "key": f"background_change_{idx}",
- }
- )
- for idx in range(7):
- rows.append(
- {
- "task_type": "color_alter",
- "instruction_language": "en",
- "key": f"color_alter_{idx}",
- }
- )
-
- selected = select_balanced_gedit_rows(
- rows,
- task_type="all",
- instruction_language="en",
- samples_per_group=10,
- )
-
- selected_background = [row for row in selected if row["task_type"] == "background_change"]
- selected_color = [row for row in selected if row["task_type"] == "color_alter"]
-
- assert len(selected_background) == 10
- assert len(selected_color) == 7
- assert selected_background[0]["key"] == "background_change_0"
- assert selected_background[-1]["key"] == "background_change_9"
-
-
-def test_select_balanced_gedit_rows_balances_languages_when_all_requested():
- rows = []
- for idx in range(10):
- rows.append(
- {
- "task_type": "background_change",
- "instruction_language": "cn",
- "key": f"background_change_cn_{idx}",
- }
- )
- for idx in range(10):
- rows.append(
- {
- "task_type": "background_change",
- "instruction_language": "en",
- "key": f"background_change_en_{idx}",
- }
- )
-
- selected = select_balanced_gedit_rows(
- rows,
- task_type="all",
- instruction_language="all",
- samples_per_group=10,
- )
-
- selected_background = [row for row in selected if row["task_type"] == "background_change"]
-
- assert len(selected_background) == 10
- assert sum(1 for row in selected_background if row["instruction_language"] == "en") == 5
- assert sum(1 for row in selected_background if row["instruction_language"] == "cn") == 5
-
-
-def test_infer_model_name_uses_last_path_segment():
- assert infer_model_name("/workspace/models/Qwen/Qwen-Image-Edit") == "Qwen-Image-Edit"
-
-
-def test_resolve_model_name_prefers_explicit_value_then_model_then_output_root(tmp_path: Path):
- assert (
- resolve_model_name(
- model_name="explicit_name",
- model="/workspace/models/Qwen/Qwen-Image-Edit",
- )
- == "explicit_name"
- )
- assert (
- resolve_model_name(
- model_name=None,
- model="/workspace/models/Qwen/Qwen-Image-Edit",
- )
- == "Qwen-Image-Edit"
- )
-
- output_root = tmp_path / "results"
- (output_root / "qwen_image_edit").mkdir(parents=True)
- assert resolve_model_name(model_name=None, output_root=output_root) == "qwen_image_edit"
-
-
-def test_resolve_gedit_split_accepts_dataset_dict_like_input():
- train_rows = [{"key": "a"}]
- dataset = {"train": train_rows}
-
- assert _resolve_gedit_split(dataset) == train_rows
-
-
-def test_resolve_gedit_split_accepts_dataset_like_input():
- rows = [{"key": "a"}]
-
- assert _resolve_gedit_split(rows) == rows
-
-
-def test_load_gedit_dataset_uses_load_from_disk_for_saved_dataset(monkeypatch, tmp_path: Path):
- (tmp_path / "state.json").write_text("{}", encoding="utf-8")
- (tmp_path / "dataset_info.json").write_text("{}", encoding="utf-8")
- captured = {}
-
- def fake_load_dataset(path):
- captured["load_dataset"] = path
- return "load_dataset"
-
- def fake_load_from_disk(path):
- captured["load_from_disk"] = path
- return "load_from_disk"
-
- monkeypatch.setattr(
- "benchmarks.accuracy.image_to_image.gedit_bench._require_datasets",
- lambda: (fake_load_dataset, fake_load_from_disk),
- )
-
- result = _load_gedit_dataset(str(tmp_path))
-
- assert result == "load_from_disk"
- assert captured["load_from_disk"] == str(tmp_path)
- assert "load_dataset" not in captured
-
-
-def test_load_gedit_dataset_uses_load_dataset_for_local_snapshot_path(monkeypatch, tmp_path: Path):
- (tmp_path / "README.md").write_text("dataset repo snapshot", encoding="utf-8")
- captured = {}
-
- def fake_load_dataset(path):
- captured["load_dataset"] = path
- return "load_dataset"
-
- def fake_load_from_disk(path):
- captured["load_from_disk"] = path
- return "load_from_disk"
-
- monkeypatch.setattr(
- "benchmarks.accuracy.image_to_image.gedit_bench._require_datasets",
- lambda: (fake_load_dataset, fake_load_from_disk),
- )
-
- result = _load_gedit_dataset(str(tmp_path))
-
- assert result == "load_dataset"
- assert captured["load_dataset"] == str(tmp_path)
- assert "load_from_disk" not in captured
-
-
-def test_gedit_runner_generate_skips_failed_samples(monkeypatch, tmp_path: Path):
- rows = [
- {"key": "ok", "task_type": "background_change", "instruction_language": "en"},
- {"key": "bad", "task_type": "background_change", "instruction_language": "en"},
- ]
-
- monkeypatch.setattr("benchmarks.accuracy.image_to_image.gedit_bench._load_gedit_dataset", lambda ref: rows)
- runner = GEditBenchRunner(
- dataset_ref="dataset",
- output_root=tmp_path,
- base_url="http://127.0.0.1:8093",
- model="model",
- )
-
- def fake_generate_one(self, model_name, item):
- if item["key"] == "bad":
- raise RuntimeError("boom")
- return {
- "key": item["key"],
- "task_type": item["task_type"],
- "instruction_language": item["instruction_language"],
- }
-
- monkeypatch.setattr(GEditBenchRunner, "_generate_one", fake_generate_one)
-
- outputs = runner.generate(model_name="demo", workers=1)
-
- assert outputs == [{"key": "ok", "task_type": "background_change", "instruction_language": "en"}]
-
-
-def test_gedit_runner_uses_tqdm_progress(monkeypatch, tmp_path: Path):
- rows = [
- {"key": "one", "task_type": "background_change", "instruction_language": "en"},
- {"key": "two", "task_type": "background_change", "instruction_language": "en"},
- ]
- updates = []
-
- monkeypatch.setattr("benchmarks.accuracy.image_to_image.gedit_bench._load_gedit_dataset", lambda ref: rows)
- runner = GEditBenchRunner(
- dataset_ref="dataset",
- output_root=tmp_path,
- base_url="http://127.0.0.1:8093",
- model="model",
- )
-
- def fake_generate_one(self, model_name, item):
- return {
- "key": item["key"],
- "task_type": item["task_type"],
- "instruction_language": item["instruction_language"],
- }
-
- monkeypatch.setattr(GEditBenchRunner, "_generate_one", fake_generate_one)
-
- class FakeTqdm:
- def __init__(self, total, desc, unit):
- self.total = total
- self.desc = desc
- self.unit = unit
-
- def __enter__(self):
- return self
-
- def __exit__(self, exc_type, exc, tb):
- return False
-
- def update(self, value):
- updates.append(value)
-
- monkeypatch.setattr("benchmarks.accuracy.image_to_image.gedit_bench.tqdm", FakeTqdm)
-
- runner.generate(model_name="demo", workers=1)
-
- assert updates == [1, 1]
-
-
-def test_gedit_evaluator_skips_failed_samples(monkeypatch, tmp_path: Path):
- rows = [
- {"key": "ok", "task_type": "background_change", "instruction_language": "en"},
- {"key": "bad", "task_type": "background_change", "instruction_language": "en"},
- ]
-
- monkeypatch.setattr("benchmarks.accuracy.image_to_image.gedit_bench._load_gedit_dataset", lambda ref: rows)
- evaluator = GEditBenchEvaluator(dataset_ref="dataset", output_root=tmp_path / "results", scorer=object())
-
- def fake_evaluate_one(self, model_name, item):
- if item["key"] == "bad":
- raise RuntimeError("boom")
- return {
- "key": item["key"],
- "task_type": item["task_type"],
- "edited_image": "ok.png",
- "instruction": "edit",
- "semantics_score": 8.0,
- "quality_score": 7.0,
- "overall_score": math.sqrt(56.0),
- "intersection_exist": True,
- "instruction_language": item["instruction_language"],
- }
-
- monkeypatch.setattr(GEditBenchEvaluator, "_evaluate_one", fake_evaluate_one)
- monkeypatch.setattr(
- "benchmarks.accuracy.image_to_image.gedit_bench._utc_timestamp",
- lambda: "20260325T120000Z",
- )
-
- payload = evaluator.evaluate(
- model_name="demo",
- save_dir=tmp_path / "scores",
- instruction_language="en",
- workers=1,
- )
-
- assert len(payload["results"]) == 1
- assert payload["results"][0]["key"] == "ok"
- assert payload["summary"]["overall"]["count"] == 1
- assert Path(payload["csv_path"]).name == "demo_all_en_vie_score.csv"
- assert Path(payload["summary_path"]).name == "demo_all_en_summary.json"
- assert Path(payload["timestamped_csv_path"]).name == "demo_all_en_vie_score_20260325T120000Z.csv"
- assert Path(payload["timestamped_summary_path"]).name == "demo_all_en_summary_20260325T120000Z.json"
- assert Path(payload["timestamped_csv_path"]).exists()
- assert Path(payload["timestamped_summary_path"]).exists()
-
-
-def test_summarize_gedit_rows_computes_group_and_intersection_means():
- rows = []
- for group in GEDIT_GROUPS:
- rows.append(
- {
- "task_type": group,
- "instruction_language": "en",
- "semantics_score": 8.0,
- "quality_score": 9.0,
- "intersection_exist": True,
- }
- )
- rows.append(
- {
- "task_type": group,
- "instruction_language": "en",
- "semantics_score": 6.0,
- "quality_score": 4.0,
- "intersection_exist": False,
- }
- )
-
- summary = summarize_gedit_rows(rows, language="en")
-
- expected_overall = (math.sqrt(8.0 * 9.0) + math.sqrt(6.0 * 4.0)) / 2
- assert math.isclose(summary["overall"]["Q_SC"], 7.0)
- assert math.isclose(summary["overall"]["Q_PQ"], 6.5)
- assert math.isclose(summary["overall"]["Q_O"], expected_overall)
- assert math.isclose(summary["intersection"]["Q_SC"], 8.0)
-
-
-def test_summarize_gedit_rows_uses_macro_average_across_groups():
- rows = []
- for idx in range(10):
- rows.append(
- {
- "task_type": "background_change",
- "instruction_language": "en",
- "semantics_score": 10.0,
- "quality_score": 10.0,
- "intersection_exist": True,
- }
- )
- for group in GEDIT_GROUPS[1:]:
- rows.append(
- {
- "task_type": group,
- "instruction_language": "en",
- "semantics_score": 1.0,
- "quality_score": 1.0,
- "intersection_exist": True,
- }
- )
-
- summary = summarize_gedit_rows_with_backbone(rows, language="en")
-
- expected_macro = (10.0 + 10.0 * 1.0) / 11
- assert math.isclose(summary["overall"]["Q_SC"], expected_macro)
- assert math.isclose(summary["overall"]["Q_O"], expected_macro)
- assert math.isclose(summary["by_group"]["background_change"]["Q_SC"], 10.0)
-
-
-def test_summarize_gedit_rows_with_all_language_splits_en_and_cn():
- rows = []
- for group in GEDIT_GROUPS:
- rows.append(
- {
- "task_type": group,
- "instruction_language": "en",
- "semantics_score": 8.0,
- "quality_score": 6.0,
- "intersection_exist": True,
- }
- )
- rows.append(
- {
- "task_type": group,
- "instruction_language": "cn",
- "semantics_score": 4.0,
- "quality_score": 2.0,
- "intersection_exist": True,
- }
- )
-
- summary = summarize_gedit_rows_with_backbone(rows, language="all")
-
- assert set(summary["languages"]) == {"en", "cn"}
- assert math.isclose(summary["languages"]["en"]["overall"]["Q_SC"], 8.0)
- assert math.isclose(summary["languages"]["en"]["overall"]["Q_PQ"], 6.0)
- assert math.isclose(summary["languages"]["cn"]["overall"]["Q_O"], math.sqrt(8.0))
diff --git a/tests/benchmarks/test_bench_tts_cli.py b/tests/benchmarks/test_bench_tts_cli.py
deleted file mode 100644
index b8a487f80c6..00000000000
--- a/tests/benchmarks/test_bench_tts_cli.py
+++ /dev/null
@@ -1,139 +0,0 @@
-"""Tests for the universal benchmarks/tts/bench_tts.py CLI."""
-
-from __future__ import annotations
-
-import json
-import sys
-from pathlib import Path
-
-import pytest
-import yaml
-
-# Add benchmarks/tts to path for import
-sys.path.insert(0, str(Path(__file__).parent.parent.parent / "benchmarks" / "tts"))
-import bench_tts
-
-pytestmark = [pytest.mark.core_model, pytest.mark.cpu]
-
-
-@pytest.fixture()
-def model_configs_path(tmp_path: Path) -> Path:
- cfg = {
- "models": {
- "test/ModelA": {
- "stage_config": "model_a.yaml",
- "supported_tasks": ["voice_clone", "default_voice"],
- "backend": "openai-audio-speech",
- "endpoint": "/v1/audio/speech",
- "task_extra_body": {
- "voice_clone": {"task_type": "Base"},
- "default_voice": {"voice": "Vivian", "task_type": "CustomVoice"},
- },
- },
- "test/ModelB": {
- "stage_config": "model_b.yaml",
- "supported_tasks": ["voice_clone"],
- "backend": "openai-audio-speech",
- "endpoint": "/v1/audio/speech",
- "task_extra_body": {"voice_clone": {}},
- },
- }
- }
- p = tmp_path / "model_configs.yaml"
- p.write_text(yaml.dump(cfg), encoding="utf-8")
- return p
-
-
-def test_load_model_configs(model_configs_path: Path) -> None:
- configs = bench_tts.load_model_configs(model_configs_path)
- assert "test/ModelA" in configs
- assert "test/ModelB" in configs
- assert configs["test/ModelA"]["supported_tasks"] == ["voice_clone", "default_voice"]
-
-
-def test_build_bench_args_voice_clone(model_configs_path: Path) -> None:
- configs = bench_tts.load_model_configs(model_configs_path)
- cmd = bench_tts.build_bench_args(
- host="localhost",
- port=8000,
- model="test/ModelA",
- task="voice_clone",
- model_cfg=configs["test/ModelA"],
- locale="en",
- num_prompts=10,
- concurrency=1,
- dataset_path="/data/seed-tts",
- wer_eval=False,
- output_dir=None,
- result_filename=None,
- extra_cli_args=[],
- )
- assert "--dataset-name" in cmd
- idx = cmd.index("--dataset-name")
- assert cmd[idx + 1] == "seed-tts"
- assert "--max-concurrency" in cmd
- assert "--extra-body" in cmd
- extra_body = json.loads(cmd[cmd.index("--extra-body") + 1])
- assert extra_body.get("task_type") == "Base"
-
-
-def test_build_bench_args_default_voice_has_voice_param(model_configs_path: Path) -> None:
- configs = bench_tts.load_model_configs(model_configs_path)
- cmd = bench_tts.build_bench_args(
- host="localhost",
- port=8000,
- model="test/ModelA",
- task="default_voice",
- model_cfg=configs["test/ModelA"],
- locale="en",
- num_prompts=10,
- concurrency=1,
- dataset_path="/data/seed-tts",
- wer_eval=False,
- output_dir=None,
- result_filename=None,
- extra_cli_args=[],
- )
- idx = cmd.index("--dataset-name")
- assert cmd[idx + 1] == "seed-tts-text"
- extra_body = json.loads(cmd[cmd.index("--extra-body") + 1])
- assert extra_body.get("voice") == "Vivian"
-
-
-def test_build_bench_args_wer_eval_adds_flag(model_configs_path: Path) -> None:
- configs = bench_tts.load_model_configs(model_configs_path)
- cmd = bench_tts.build_bench_args(
- host="localhost",
- port=8000,
- model="test/ModelA",
- task="voice_clone",
- model_cfg=configs["test/ModelA"],
- locale="en",
- num_prompts=10,
- concurrency=1,
- dataset_path="/data/seed-tts",
- wer_eval=True,
- output_dir=None,
- result_filename=None,
- extra_cli_args=[],
- )
- assert "--seed-tts-wer-eval" in cmd
-
-
-def test_unsupported_task_exits(model_configs_path: Path, capsys: pytest.CaptureFixture, mocker) -> None:
- # ModelB does not support voice_design
- mocker.patch.object(
- sys,
- "argv",
- [
- "bench_tts.py",
- "--model",
- "test/ModelB",
- "--task",
- "voice_design",
- "--model-configs",
- str(model_configs_path),
- ],
- )
- with pytest.raises(SystemExit):
- bench_tts.main()
diff --git a/tests/benchmarks/test_diffusion_backends_metrics.py b/tests/benchmarks/test_diffusion_backends_metrics.py
deleted file mode 100644
index 2d51d0f1d38..00000000000
--- a/tests/benchmarks/test_diffusion_backends_metrics.py
+++ /dev/null
@@ -1,107 +0,0 @@
-import pytest
-
-from benchmarks.diffusion.backends import RequestFuncInput, async_request_chat_completions
-
-
-class _MockResponse:
- def __init__(self, payload: dict, status: int = 200):
- self._payload = payload
- self.status = status
-
- async def __aenter__(self):
- return self
-
- async def __aexit__(self, exc_type, exc, tb):
- return False
-
- async def json(self):
- return self._payload
-
- async def text(self):
- return str(self._payload)
-
-
-class _MockSession:
- def __init__(self, payload: dict):
- self._payload = payload
-
- def post(self, *args, **kwargs):
- return _MockResponse(self._payload)
-
-
-@pytest.mark.core_model
-@pytest.mark.benchmark
-@pytest.mark.cpu
-@pytest.mark.asyncio
-async def test_chat_completions_metrics_fallback_to_top_level():
- payload = {
- "choices": [
- {
- "message": {
- "content": [
- {
- "type": "image_url",
- "image_url": {"url": "data:image/png;base64,abc"},
- }
- ]
- }
- }
- ],
- "metrics": {
- "stage_durations": {"diffusion": 1.25},
- "peak_memory_mb": 4096.0,
- },
- }
-
- output = await async_request_chat_completions(
- RequestFuncInput(
- prompt="draw a cat",
- api_url="http://test.local/v1/chat/completions",
- model="ByteDance-Seed/BAGEL-7B-MoT",
- ),
- session=_MockSession(payload),
- )
-
- assert output.success is True
- assert output.stage_durations == {"diffusion": 1.25}
- assert output.peak_memory_mb == 4096.0
-
-
-@pytest.mark.core_model
-@pytest.mark.benchmark
-@pytest.mark.cpu
-@pytest.mark.asyncio
-async def test_chat_completions_metrics_message_level_takes_precedence():
- payload = {
- "choices": [
- {
- "message": {
- "content": [
- {
- "type": "image_url",
- "image_url": {"url": "data:image/png;base64,abc"},
- "stage_durations": {"message_stage": 0.7},
- "peak_memory_mb": 1234.0,
- }
- ]
- }
- }
- ],
- "metrics": {
- "stage_durations": {"top_level_stage": 9.9},
- "peak_memory_mb": 9999.0,
- },
- }
-
- output = await async_request_chat_completions(
- RequestFuncInput(
- prompt="draw a dog",
- api_url="http://test.local/v1/chat/completions",
- model="ByteDance-Seed/BAGEL-7B-MoT",
- ),
- session=_MockSession(payload),
- )
-
- assert output.success is True
- assert output.stage_durations == {"message_stage": 0.7}
- assert output.peak_memory_mb == 1234.0
diff --git a/tests/benchmarks/test_seed_tts_dataset_variants.py b/tests/benchmarks/test_seed_tts_dataset_variants.py
deleted file mode 100644
index d27fca8d6dd..00000000000
--- a/tests/benchmarks/test_seed_tts_dataset_variants.py
+++ /dev/null
@@ -1,226 +0,0 @@
-"""Tests for SeedTTSTextDataset, SeedTTSTextSampleRequest, SeedTTSDesignDataset,
-and SeedTTSDesignSampleRequest.
-
-vllm stubs are installed by tests/benchmarks/conftest.py before collection.
-"""
-
-from __future__ import annotations
-
-import importlib.util
-import sys
-import types
-from pathlib import Path
-
-import numpy as np
-import pytest
-
-pytestmark = [pytest.mark.core_model, pytest.mark.cpu]
-
-# Load the data module directly (bypasses vllm_omni.__init__ heavy imports).
-_REPO_ROOT = Path(__file__).resolve().parents[2]
-_MODULE_PATH = _REPO_ROOT / "vllm_omni" / "benchmarks" / "data_modules" / "seed_tts_dataset.py"
-_MODULE_NAME = "vllm_omni.benchmarks.data_modules.seed_tts_dataset"
-
-if _MODULE_NAME not in sys.modules:
- _spec = importlib.util.spec_from_file_location(_MODULE_NAME, _MODULE_PATH)
- _mod = importlib.util.module_from_spec(_spec)
- sys.modules[_MODULE_NAME] = _mod
- _spec.loader.exec_module(_mod)
-
-from vllm_omni.benchmarks.data_modules.seed_tts_dataset import ( # noqa: E402
- SeedTTSDesignDataset,
- SeedTTSDesignSampleRequest,
- SeedTTSTextDataset,
- SeedTTSTextSampleRequest,
-)
-
-# ---------------------------------------------------------------------------
-# Fixtures
-# ---------------------------------------------------------------------------
-
-
-@pytest.fixture()
-def seed_tts_root(tmp_path: Path) -> Path:
- """Minimal seed-tts-style directory with 5 entries."""
- locale_dir = tmp_path / "en"
- locale_dir.mkdir()
- wav_dir = locale_dir / "prompt-wavs"
- wav_dir.mkdir()
- for i in range(5):
- (wav_dir / f"utt{i:03d}.wav").write_bytes(b"RIFF\x00\x00\x00\x00WAVE")
- meta = "\n".join(f"utt{i:03d}|ref text {i}|prompt-wavs/utt{i:03d}.wav|target text {i}" for i in range(5))
- (locale_dir / "meta.lst").write_text(meta, encoding="utf-8")
- return tmp_path
-
-
-@pytest.fixture()
-def mock_tokenizer(mocker):
- tokenizer = mocker.MagicMock()
- tokenizer.encode = lambda text, **kw: [0] * len(text.split())
- tokenizer.get_vocab.return_value = {"<pad>": 0}
- tokenizer.all_special_ids = []
- tokenizer.all_special_tokens = []
- tokenizer.vocab_size = 1
- tokenizer.__len__.return_value = 1
- return tokenizer
-
-
-# ---------------------------------------------------------------------------
-# Tests
-# ---------------------------------------------------------------------------
-
-
-def test_seed_tts_text_dataset_omits_ref_audio(seed_tts_root, mock_tokenizer):
- ds = SeedTTSTextDataset(
- dataset_path=str(seed_tts_root),
- random_seed=0,
- locale="en",
- disable_shuffle=True,
- )
- requests = ds.sample(mock_tokenizer, num_requests=3)
- assert len(requests) == 3
- for req in requests:
- assert isinstance(req, SeedTTSTextSampleRequest)
- assert req.seed_tts_speech_extra is None or "ref_audio" not in (req.seed_tts_speech_extra or {})
- assert req.seed_tts_ref_wav_path == ""
- assert "target text" in req.prompt
-
-
-# ---------------------------------------------------------------------------
-# SeedTTSDesignDataset tests
-# ---------------------------------------------------------------------------
-
-
-@pytest.fixture()
-def seed_tts_design_root(tmp_path: Path) -> Path:
- """seed-tts-design directory with 5-field meta.lst entries."""
- locale_dir = tmp_path / "en"
- locale_dir.mkdir()
- meta = "\n".join(
- f"des{i:03d}|||target text {i}|A warm {['female', 'male'][i % 2]} voice with neutral accent." for i in range(5)
- )
- (locale_dir / "meta.lst").write_text(meta, encoding="utf-8")
- return tmp_path
-
-
-def test_seed_tts_design_dataset_has_instructions(seed_tts_design_root, mock_tokenizer):
- ds = SeedTTSDesignDataset(
- dataset_path=str(seed_tts_design_root),
- random_seed=0,
- locale="en",
- disable_shuffle=True,
- )
- requests = ds.sample(mock_tokenizer, num_requests=3)
- assert len(requests) == 3
- for req in requests:
- assert isinstance(req, SeedTTSDesignSampleRequest)
- extra = req.seed_tts_speech_extra or {}
- assert "instructions" in extra
- assert extra["instructions"], "instructions must be non-empty"
- assert extra.get("task_type") == "VoiceDesign"
- assert "ref_audio" not in extra
- assert req.seed_tts_ref_wav_path == ""
-
-
-def test_seed_tts_design_dataset_rejects_missing_description(seed_tts_design_root, mock_tokenizer):
- """Lines without a voice_description should be skipped."""
- locale_dir = seed_tts_design_root / "en"
- # The bad line has 4 fields, not 5, so will be filtered
- meta = "bad|||target text without description\n" + "\n".join(
- f"ok|||target text {i}|A clear female voice." for i in range(9)
- )
- (locale_dir / "meta.lst").write_text(meta, encoding="utf-8")
- ds = SeedTTSDesignDataset(
- dataset_path=str(seed_tts_design_root),
- random_seed=0,
- locale="en",
- disable_shuffle=True,
- )
- requests = ds.sample(mock_tokenizer, num_requests=10, no_oversample=True)
- assert len(requests) == 9 # since we filter the bad row out and don't oversample
- for req in requests:
- assert isinstance(req, SeedTTSDesignSampleRequest)
- assert req.seed_tts_utterance_id == "ok"
-
-
-def test_attach_sets_seed_tts_row_even_without_extra_body():
- """seed_tts_row=True must be set for SeedTTSTextSampleRequest (no extra body)."""
- from vllm_omni.benchmarks.data_modules.seed_tts_dataset import SeedTTSTextSampleRequest
-
- req = SeedTTSTextSampleRequest(
- prompt="hello world",
- prompt_len=2,
- expected_output_len=100,
- multi_modal_data=None,
- request_id="test-0",
- seed_tts_speech_extra=None,
- seed_tts_ref_wav_path="",
- )
- assert req.seed_tts_speech_extra is None
- assert req.seed_tts_ref_wav_path == ""
- # The fix ensures that even with speech_extra=None, the function
- # sets seed_tts_row=True. We verify the source code has the fix.
- import inspect
-
- import vllm_omni.benchmarks.patch.patch as patch_mod
-
- src = inspect.getsource(patch_mod._attach_seed_tts_to_request_func_input)
- # seed_tts_row must be set BEFORE the 'if not ex: return' check
- row_pos = src.index("seed_tts_row")
- not_ex_pos = src.index("if not ex:")
- assert row_pos < not_ex_pos, "seed_tts_row must be set before 'if not ex: return'"
-
-
-def test_seed_tts_whisper_transcribe_passes_attention_mask(monkeypatch):
- from vllm_omni.benchmarks.data_modules import seed_tts_eval
-
- calls = {}
-
- class FakeTensor:
- def __init__(self, name: str):
- self.name = name
- self.device = None
-
- def to(self, device):
- self.device = device
- return self
-
- class FakeProcessor:
- def __call__(self, wav, *, sampling_rate, return_tensors, return_attention_mask=False):
- calls["return_attention_mask"] = return_attention_mask
- assert sampling_rate == 16000
- assert return_tensors == "pt"
- assert len(wav) > 0
- return types.SimpleNamespace(
- input_features=FakeTensor("features"),
- attention_mask=FakeTensor("mask") if return_attention_mask else None,
- )
-
- def get_decoder_prompt_ids(self, *, language, task):
- assert language == "english"
- assert task == "transcribe"
- return [(1, 2)]
-
- def batch_decode(self, predicted_ids, *, skip_special_tokens):
- assert skip_special_tokens
- assert predicted_ids == [[42]]
- return ["hello"]
-
- class FakeModel:
- def generate(self, input_features, **kwargs):
- calls["input_features"] = input_features
- calls["generate_kwargs"] = kwargs
- return [[42]]
-
- monkeypatch.setattr(seed_tts_eval, "_ensure_en_asr", lambda: None)
- monkeypatch.setattr(seed_tts_eval, "_en_processor", FakeProcessor())
- monkeypatch.setattr(seed_tts_eval, "_en_model", FakeModel())
- monkeypatch.setattr(seed_tts_eval, "_device", "cuda:1")
-
- text = seed_tts_eval._transcribe_en_f32_16k(np.ones(1600, dtype=np.float32))
-
- assert text == "hello"
- assert calls["return_attention_mask"] is True
- assert calls["input_features"].device == "cuda:1"
- assert calls["generate_kwargs"]["attention_mask"].device == "cuda:1"
- assert calls["generate_kwargs"]["forced_decoder_ids"] == [(1, 2)]
diff --git a/tests/benchmarks/test_serve_cli.py b/tests/benchmarks/test_serve_cli.py
deleted file mode 100644
index ab7b09f7b8c..00000000000
--- a/tests/benchmarks/test_serve_cli.py
+++ /dev/null
@@ -1,143 +0,0 @@
-import json
-import os
-import subprocess
-import textwrap
-from pathlib import Path
-
-import pytest
-
-
-@pytest.mark.core_model
-@pytest.mark.benchmark
-@pytest.mark.cpu
-def test_bench_serve_cli_mocks_http_request(tmp_path: Path):
- num_prompts = 5
- port = 18000
- result_filename = "bench-result.json"
- calls_filename = "http-post-calls.json"
- result_path = tmp_path / result_filename
- calls_path = tmp_path / calls_filename
-
- sitecustomize_path = tmp_path / "sitecustomize.py"
- sitecustomize_path.write_text(
- textwrap.dedent(
- """
- import atexit
- import json
- import os
-
- POST_CALLS = []
- SSE_CHUNKS = [
- b'data: {"choices":[{"delta":{"content":"hi"}}],"modality":"text"}\\n\\n',
- b'data: {"choices":[{"delta":{"content":" there"}}],"modality":"text","metrics":{"num_tokens_out":4,"num_tokens_in":5}}\\n\\n',
- b"data: [DONE]\\n\\n",
- ]
-
- class _Content:
- def __init__(self, chunks):
- self._chunks = chunks
-
- async def iter_any(self):
- for chunk in self._chunks:
- yield chunk
-
- class MockResponse:
- def __init__(self):
- self.status = 200
- self.reason = "OK"
- self.content = _Content(SSE_CHUNKS)
-
- async def __aenter__(self):
- return self
-
- async def __aexit__(self, exc_type, exc, tb):
- return False
-
- class MockClientSession:
- def __init__(self, *args, **kwargs):
- pass
-
- def post(self, url=None, *args, **kwargs):
- if url is not None:
- POST_CALLS.append(url)
- return MockResponse()
-
- async def close(self):
- return None
-
- import vllm_omni.benchmarks.patch.patch as patch_mod
-
- patch_mod.aiohttp.ClientSession = MockClientSession
- patch_mod.aiohttp.TCPConnector = lambda *args, **kwargs: object()
-
- calls_file = os.environ.get("VLLM_OMNI_TEST_POST_CALLS_FILE")
-
- if calls_file:
- def _write_calls():
- with open(calls_file, "w", encoding="utf-8") as f:
- json.dump({"requested_urls": POST_CALLS}, f)
-
- atexit.register(_write_calls)
- """
- ),
- encoding="utf-8",
- )
-
- env = os.environ.copy()
- env["PYTHONPATH"] = str(tmp_path) + os.pathsep + env.get("PYTHONPATH", "")
- env["VLLM_OMNI_TEST_POST_CALLS_FILE"] = str(calls_path)
-
- cmd = [
- "vllm",
- "bench",
- "serve",
- "--omni",
- "--model",
- "Qwen/Qwen2.5-Omni-7B",
- "--port",
- str(port),
- "--dataset-name",
- "random",
- "--random-input-len",
- "32",
- "--random-output-len",
- "4",
- "--num-prompts",
- str(num_prompts),
- "--endpoint",
- "/v1/chat/completions",
- "--backend",
- "openai-chat-omni",
- "--disable-tqdm",
- "--num-warmups",
- "0",
- "--ready-check-timeout-sec",
- "0",
- "--save-result",
- "--result-dir",
- str(tmp_path),
- "--result-filename",
- result_filename,
- ]
- proc = subprocess.run(
- cmd,
- cwd=str(Path(__file__).resolve().parents[2]),
- env=env,
- capture_output=True,
- text=True,
- )
-
- assert proc.returncode == 0, f"CLI failed: stdout={proc.stdout}\nstderr={proc.stderr}"
- print(f"CLI output: {proc.stdout}")
- assert result_path.exists()
- result = json.loads(result_path.read_text(encoding="utf-8"))
- assert calls_path.exists()
- calls = json.loads(calls_path.read_text(encoding="utf-8"))
-
- expected_url = f"http://127.0.0.1:{port}/v1/chat/completions"
- requested_urls = calls["requested_urls"]
- sent_requests = len(requested_urls)
-
- assert result["completed"] == sent_requests == num_prompts
- assert requested_urls
- assert all(url == expected_url for url in requested_urls), f"Unexpected target URLs: {requested_urls}"
diff --git a/tests/comfyui/conftest.py b/tests/comfyui/conftest.py
deleted file mode 100644
index 4280d3506ff..00000000000
--- a/tests/comfyui/conftest.py
+++ /dev/null
@@ -1,89 +0,0 @@
-"""
-Conftest for ComfyUI-vLLM-Omni tests.
-
-This module sets up the test environment by:
-1. Adding the ComfyUI plugin to Python path
-2. Mocking comfy_api.input module (AudioInput, VideoInput) since comfyui is not installed
-3. Mocking comfy_extras.nodes_audio module
-"""
-
-import os
-import sys
-from types import ModuleType, SimpleNamespace
-from typing import BinaryIO, TypedDict
-
-
-def pytest_configure(config):
- """
- Called after command line options have been parsed and before test collection.
- This is the right place to set up sys.path and mock modules.
- """
- _setup_comfyui_test_environment()
-
-
-def _setup_comfyui_test_environment():
- """Set up the test environment for ComfyUI plugin testing."""
- # === Add ComfyUI plugin path to allow importing comfyui_vllm_omni ===
- _COMFYUI_PLUGIN_PATH = os.path.abspath(
- os.path.join(os.path.dirname(__file__), "..", "..", "apps", "ComfyUI-vLLM-Omni")
- )
- if not os.path.isdir(_COMFYUI_PLUGIN_PATH):
- raise FileNotFoundError(
- f"ComfyUI plugin not found at {_COMFYUI_PLUGIN_PATH}. "
- "If it is moved elsewhere, please update the path in this conftest.py."
- )
- if _COMFYUI_PLUGIN_PATH not in sys.path:
- sys.path.insert(0, _COMFYUI_PLUGIN_PATH)
-
- # Import torch after changing import paths. (To be used later)
- import torch
-
- # === Mock ComfyUI internal modules (comfy_api & comfy_extras) and "import" them to sys.module ===
- class AudioInput(TypedDict):
- """Mock AudioInput TypedDict from comfy_api.input"""
-
- waveform: torch.Tensor # Shape: (B, C, T)
- sample_rate: int
-
- class VideoInput:
- """Mock VideoInput class from comfy_api.input"""
-
- def __init__(self, data: bytes = b"mock_video_data"):
- self._data = data
-
- def save_to(self, file: str | BinaryIO):
- """Save video data to file or file-like object."""
- if isinstance(file, str):
- print("Called VideoInput.save_to with file path. Saving to a path is no-op in tests.")
- else:
- file.write(self._data)
-
- mock_comfy_api = ModuleType("comfy_api")
- mock_comfy_api_input = ModuleType("comfy_api.input")
- mock_comfy_api_input.AudioInput = AudioInput
- mock_comfy_api_input.VideoInput = VideoInput
- mock_comfy_api.input = mock_comfy_api_input
- mock_comfy_api_latest = ModuleType("comfy_api.latest")
- mock_comfy_api_latest.Types = SimpleNamespace(VideoComponents=lambda **kwargs: kwargs)
- mock_comfy_api_latest.InputImpl = SimpleNamespace(
- VideoFromComponents=lambda _: VideoInput(b"mock_video_from_components")
- )
- mock_comfy_api.latest = mock_comfy_api_latest
-
- def mock_load(_: str | BinaryIO):
- """Mock nodes_audio.load that returns a waveform tensor (channels, samples) and sample rate."""
- waveform = torch.zeros((1, 24000), dtype=torch.float32)
- sample_rate = 24000
- return waveform, sample_rate
-
- mock_comfy_extras = ModuleType("comfy_extras")
- mock_nodes_audio = ModuleType("comfy_extras.nodes_audio")
- mock_nodes_audio.load = mock_load
- mock_comfy_extras.nodes_audio = mock_nodes_audio
-
- # Install mock modules BEFORE importing any comfyui_vllm_omni code
- sys.modules["comfy_api"] = mock_comfy_api
- sys.modules["comfy_api.input"] = mock_comfy_api_input
- sys.modules["comfy_api.latest"] = mock_comfy_api_latest
- sys.modules["comfy_extras"] = mock_comfy_extras
- sys.modules["comfy_extras.nodes_audio"] = mock_nodes_audio
diff --git a/tests/comfyui/test_comfyui_integration.py b/tests/comfyui/test_comfyui_integration.py
deleted file mode 100644
index 80e86d82412..00000000000
--- a/tests/comfyui/test_comfyui_integration.py
+++ /dev/null
@@ -1,786 +0,0 @@
-"""
-Integration tests for ComfyUI nodes that use the Omni API client, with a mocked AsyncOmni and a real API server running in a background process.
-These tests cover the integration between ComfyUI node and the API server, without actual model inference logic.
-It ensures that
-1. Changes made to the API (e.g., request and response formats) do not break the ComfyUI frontend that use it.
-2. The sampling parameters are correctly passed from the node to AsyncOmni through the API layer.
-"""
-
-import multiprocessing
-import time
-import traceback
-from collections.abc import Iterable, Sequence
-from enum import StrEnum, auto
-from types import SimpleNamespace
-from typing import Any, NamedTuple
-
-import pytest
-import requests
-import torch
-from comfy_api.input import AudioInput, VideoInput
-from comfyui_vllm_omni.nodes import (
- VLLMOmniGenerateImage,
- VLLMOmniGenerateVideo,
- VLLMOmniTTS,
- VLLMOmniUnderstanding,
- VLLMOmniVoiceClone,
-)
-from comfyui_vllm_omni.utils.types import AutoregressionSamplingParams, DiffusionSamplingParams, WanModelSpecificParams
-from PIL import Image
-from pytest_mock import MockerFixture
-from vllm import SamplingParams
-from vllm.outputs import CompletionOutput, RequestOutput
-from vllm.utils.argparse_utils import FlexibleArgumentParser
-
-from vllm_omni.entrypoints.async_omni import AsyncOmni as RealAsyncOmni
-from vllm_omni.entrypoints.cli.serve import OmniServeCommand
-from vllm_omni.inputs.data import OmniSamplingParams
-from vllm_omni.outputs import OmniRequestOutput
-
-pytestmark = [pytest.mark.core_model, pytest.mark.cpu]
-
-
-class ServerCase(NamedTuple):
- """Parametrizing the model to serve."""
-
- served_model: str
- stage_list: list
- stage_configs: list[Any]
- outputs: list[OmniRequestOutput]
-
-
-class SamplingCase(NamedTuple):
- """Parametrizing the input sampling parameters."""
-
- kind: "SamplingKind"
- sampling_params: dict | list[dict] | None
- lora: dict | None = None
-
-
-class SamplingKind(StrEnum):
- IMAGE_NONE = auto()
- IMAGE_DIFFUSION_SINGLE = auto()
- UNDERSTANDING_NONE = auto()
- UNDERSTANDING_AR_LIST = auto()
- TTS_NONE = auto()
- TTS_DIFFUSION_SINGLE = auto()
- VIDEO_NONE = auto()
- VIDEO_DIFFUSION_SINGLE = auto()
-
-
-# Pre-defined arguments to be used in function calls during the tests
-IMAGE_WIDTH = 64
-IMAGE_HEIGHT = 64
-VIDEO_WIDTH = 32
-VIDEO_HEIGHT = 32
-VIDEO_FPS = 8
-VIDEO_NUM_FRAMES = 5
-DIFFUSION_SINGLE_SAMPLING_PARAMS = DiffusionSamplingParams(
- {
- "n": 2,
- "num_inference_steps": 30,
- "guidance_scale": 6.0,
- "true_cfg_scale": 1.5,
- }
-)
-
-DIFFUSION_VIDEO_SINGLE_SAMPLING_PARAMS = DiffusionSamplingParams(
- {
- "num_inference_steps": 30,
- "guidance_scale": 6.0,
- "true_cfg_scale": 1.5,
- }
-)
-
-
-AR_LIST_SAMPLING_PARAMS = [
- AutoregressionSamplingParams(
- {
- "max_tokens": 64,
- "temperature": 0.6,
- "top_p": 0.9,
- "repetition_penalty": 1.0,
- "seed": 21,
- }
- ),
- AutoregressionSamplingParams(
- {
- "max_tokens": 96,
- "temperature": 0.75,
- "top_p": 0.85,
- "repetition_penalty": 1.05,
- "seed": 22,
- }
- ),
- AutoregressionSamplingParams(
- {
- "max_tokens": 128,
- "temperature": 0.8,
- "top_p": 0.8,
- "repetition_penalty": 1.1,
- "seed": 23,
- }
- ),
-]
-
-VIDEO_MODEL_PARAMS = WanModelSpecificParams({"guidance_scale_2": 5.0, "boundary_ratio": 0.98, "flow_shift": 12.0})
-
-LORA_PARAMS = {"local_path": "test_lora_path", "name": "test_name", "scale": 0.7, "int_id": 10}
-
-
-def _build_image_output(size: tuple[int, int] = (IMAGE_WIDTH, IMAGE_HEIGHT), color: str = "red") -> Image.Image:
- return Image.new("RGB", size, color=color)
-
-
-def _build_text_output(text: str = "This is a test response.") -> OmniRequestOutput:
- completion_output = CompletionOutput(
- index=0,
- text=text,
- token_ids=[1, 2, 3],
- cumulative_logprob=0.0,
- logprobs=None,
- finish_reason="stop",
- stop_reason=None,
- )
- request_output = RequestOutput(
- request_id="test_req_text",
- prompt="test prompt",
- prompt_token_ids=[1, 2, 3],
- prompt_logprobs=None,
- outputs=[completion_output],
- finished=True,
- metrics=None,
- lora_request=None,
- )
- return OmniRequestOutput(
- request_id="test_req_text",
- finished=True,
- final_output_type="text",
- request_output=request_output,
- )
-
-
-def _build_audio_chat_output(num_samples: int = 24000) -> OmniRequestOutput:
- completion_output = CompletionOutput(
- index=0,
- text="",
- token_ids=[],
- cumulative_logprob=0.0,
- logprobs=None,
- finish_reason="stop",
- stop_reason=None,
- )
- completion_output.multimodal_output = {"audio": [torch.zeros(1, num_samples)]}
- request_output = RequestOutput(
- request_id="test_req_audio_chat",
- prompt="test prompt",
- prompt_token_ids=[1, 2, 3],
- prompt_logprobs=None,
- outputs=[completion_output],
- finished=True,
- metrics=None,
- lora_request=None,
- )
- return OmniRequestOutput(
- request_id="test_req_audio_chat",
- finished=True,
- final_output_type="audio",
- request_output=request_output,
- )
-
-
-def _build_audio_speech_output(num_samples: int = 24000) -> OmniRequestOutput:
- return OmniRequestOutput.from_diffusion(
- request_id="test_req_audio_speech",
- images=[],
- multimodal_output={"audio": torch.zeros(num_samples), "sr": 24000},
- final_output_type="audio",
- )
-
-
-def _build_diffusion_image_output_for_images_endpoint() -> OmniRequestOutput:
- return OmniRequestOutput.from_diffusion(
- request_id="test_req_img_dalle",
- images=[_build_image_output()],
- final_output_type="image",
- )
-
-
-def _build_diffusion_video_output() -> OmniRequestOutput:
- # Small video: VIDEO_NUM_FRAMES frames of (VIDEO_HEIGHT x VIDEO_WIDTH) RGB, shape (F, H, W, C)
- video_frames = torch.zeros((VIDEO_NUM_FRAMES, VIDEO_HEIGHT, VIDEO_WIDTH, 3), dtype=torch.float32)
- return OmniRequestOutput.from_diffusion(
- request_id="test_req_video",
- images=[video_frames],
- final_output_type="video",
- )
-
-
-def _build_diffusion_image_output_for_chat_endpoint() -> OmniRequestOutput:
- request_output = SimpleNamespace(
- images=[_build_image_output(color="blue")],
- finished=True,
- )
- return OmniRequestOutput(
- request_id="test_req_img_chat",
- finished=True,
- final_output_type="image",
- request_output=request_output,
- )
-
-
-def _assert_sampling_param_values(
- received: OmniSamplingParams, expected: dict[str, Any], expected_lora: dict | None = None
-):
- for key, expected_value in expected.items():
- actual_value = getattr(received, key)
- assert actual_value == expected_value, (
- f"Expected sampling param '{key}'={expected_value}, got {actual_value}. The received sampling params: {received}"
- )
- if expected_lora:
- assert received.lora_request.lora_name == expected_lora["name"], (
- f"Expected lora name={(expected_lora['name'])}, got {received.lora_request.lora_name}. The received sampling params: {received}"
- )
- assert received.lora_request.lora_int_id == expected_lora["int_id"], (
- f"Expected lora int_id={expected_lora['int_id']}, got {received.lora_request.lora_int_id}. The received sampling params: {received}"
- )
- assert received.lora_request.lora_path == expected_lora["local_path"], (
- f"Expected lora path={expected_lora['local_path']}, got {received.lora_request.lora_path}. The received sampling params: {received}"
- )
- assert received.lora_scale == expected_lora["scale"], (
- f"Expected lora scale={expected_lora['scale']}, got {received.lora_scale}. The received sampling params: {received}"
- )
-
-
-def _assert_model_param_values(received: OmniSamplingParams, expected: dict):
- for key, expected_value in expected.items():
- try:
- actual_value = getattr(received, key)
- expected_param_name = key
- except AttributeError:
- actual_value = received.extra_args.get(key, None)
- expected_param_name = f'extra_args["{key}"]'
- assert actual_value == expected_value, (
- f"Expected model param '{expected_param_name}'={expected_value}, got {actual_value}. The received sampling params: {received}"
- )
-
-
-def _make_stage_config(
- stage_type: str,
- *,
- is_comprehension: bool = False,
- model_stage: str | None = None,
-):
- engine_args = SimpleNamespace()
- if model_stage is not None:
- engine_args.model_stage = model_stage
- return SimpleNamespace(
- stage_type=stage_type,
- is_comprehension=is_comprehension,
- engine_args=engine_args,
- )
-
-
-def _stage_type(stage: Any) -> str | None:
- return getattr(stage, "stage_type", None)
-
-
-def _build_output_modalities(stage_configs: list[Any]) -> list[str]:
- modalities: list[str] = []
- for stage in stage_configs:
- final_output = getattr(stage, "final_output", False)
- final_output_type = getattr(stage, "final_output_type", None)
- if final_output and isinstance(final_output_type, str):
- modalities.append(final_output_type)
- if modalities:
- return modalities
- if any(_stage_type(stage) == "diffusion" for stage in stage_configs):
- return ["image"]
- return ["text", "audio"]
-
-
-def _build_mock_outputs(outputs: Iterable[OmniRequestOutput], sampling_case: SamplingCase, server_case: ServerCase):
- async def _mock_generate(*args, **kwargs):
- received_sampling_params_list: Sequence[OmniSamplingParams] | None = (
- args[2] if len(args) > 2 else kwargs.get("sampling_params_list")
- )
-
- assert received_sampling_params_list is not None, (
- "In the current codebase, the API layer always provides not-None sampling parameter list when calling `AsyncOmni.generate`"
- "This test also uses this assumption for now."
- "If this assertion fails, it means the API layer has changed and this test needs to be updated accordingly."
- "It does not necessarily mean there is a bug, because `AsyncOmni.generate` does allow sampling_params_list to be None."
- )
- assert isinstance(received_sampling_params_list, Sequence), "sampling_params_list should be a Sequence"
-
- if sampling_case.kind is SamplingKind.IMAGE_NONE:
- assert len(received_sampling_params_list) == 1
- _assert_sampling_param_values(
- received_sampling_params_list[0],
- {
- "width": IMAGE_WIDTH,
- "height": IMAGE_HEIGHT,
- },
- )
- elif sampling_case.kind is SamplingKind.IMAGE_DIFFUSION_SINGLE:
- assert len(received_sampling_params_list) == 1
- expected = DIFFUSION_SINGLE_SAMPLING_PARAMS.copy()
- expected["num_outputs_per_prompt"] = expected.pop("n") # convert from n to num_outputs_per_prompt
- _assert_sampling_param_values(
- received_sampling_params_list[0],
- {
- "width": IMAGE_WIDTH,
- "height": IMAGE_HEIGHT,
- **expected,
- },
- LORA_PARAMS,
- )
- elif sampling_case.kind is SamplingKind.UNDERSTANDING_NONE:
- assert len(received_sampling_params_list) == 3
- elif sampling_case.kind is SamplingKind.UNDERSTANDING_AR_LIST:
- assert len(received_sampling_params_list) == 3
- for i, expected in enumerate(AR_LIST_SAMPLING_PARAMS):
- _assert_sampling_param_values(received_sampling_params_list[i], expected)
- elif sampling_case.kind in {SamplingKind.TTS_NONE, SamplingKind.TTS_DIFFUSION_SINGLE}:
- assert len(received_sampling_params_list) == 1
- elif sampling_case.kind is SamplingKind.VIDEO_NONE:
- assert len(received_sampling_params_list) == 1
- _assert_sampling_param_values(
- received_sampling_params_list[0],
- {
- "width": VIDEO_WIDTH,
- "height": VIDEO_HEIGHT,
- "num_frames": VIDEO_NUM_FRAMES,
- "fps": VIDEO_FPS,
- },
- )
- elif sampling_case.kind is SamplingKind.VIDEO_DIFFUSION_SINGLE:
- assert len(received_sampling_params_list) == 1
- expected = DIFFUSION_VIDEO_SINGLE_SAMPLING_PARAMS.copy()
- # expected["num_outputs_per_prompt"] = expected.pop("n") # convert from n to num_outputs_per_prompt
- _assert_sampling_param_values(
- received_sampling_params_list[0],
- {
- "width": VIDEO_WIDTH,
- "height": VIDEO_HEIGHT,
- "num_frames": VIDEO_NUM_FRAMES,
- "fps": VIDEO_FPS,
- **expected,
- },
- LORA_PARAMS,
- )
- _assert_model_param_values(received_sampling_params_list[0], VIDEO_MODEL_PARAMS)
- else:
- raise AssertionError(f"Unknown sampling case: {sampling_case.kind}")
-
- for output in outputs:
- yield output
-
- return _mock_generate
-
-
-@pytest.fixture
-def server_case(request) -> ServerCase:
- return request.param
-
-
-@pytest.fixture
-def sampling_case(request) -> SamplingCase:
- return request.param
-
-
-@pytest.fixture
-def mock_async_omni(
- server_case: ServerCase,
- sampling_case: SamplingCase,
- monkeypatch: pytest.MonkeyPatch,
- mocker: MockerFixture,
-):
- async def _mock_preprocess_chat(self, *args, **kwargs):
- return ([{"role": "user", "content": "test"}], [{"prompt": "test prompt"}])
-
- # Need to mock AsyncOmni itself (not only its generate method) because
- # 1. The API layer uses its stage_list and stage_configs attributes
- # 2. Its __init__ method has slow side effects (model & config loading).
- mock_async_omni_cls = mocker.patch("vllm_omni.entrypoints.openai.api_server.AsyncOmni")
- monkeypatch.setattr(
- "vllm_omni.entrypoints.openai.serving_chat.OmniOpenAIServingChat._preprocess_chat",
- _mock_preprocess_chat,
- )
-
- mock_instance = mocker.AsyncMock(spec=RealAsyncOmni)
- mock_instance.generate = _build_mock_outputs(server_case.outputs, sampling_case, server_case)
-
- mock_instance.stage_list = server_case.stage_list
- mock_instance.stage_configs = server_case.stage_configs
- mock_instance.output_modalities = _build_output_modalities(server_case.stage_configs)
- mock_instance.default_sampling_params_list = [
- SamplingParams() if _stage_type(stage) != "diffusion" else mocker.MagicMock()
- for stage in server_case.stage_configs
- ]
- mock_instance.errored = False
- mock_instance.dead_error = RuntimeError("Mock engine error")
- mock_instance.model_config = mocker.MagicMock(
- max_model_len=4096,
- io_processor_plugin=None,
- allowed_local_media_path=None,
- allowed_media_domains=None,
- )
- # Mimic Qwen3-TTS talker speaker config so CustomVoice validation passes.
- mock_instance.model_config.hf_config = mocker.MagicMock()
- mock_instance.model_config.hf_config.talker_config = mocker.MagicMock()
- mock_instance.model_config.hf_config.talker_config.speaker_id = {"Vivian": 0}
- mock_instance.io_processor = mocker.MagicMock()
- mock_instance.input_processor = mocker.MagicMock()
- mock_instance.shutdown = mocker.MagicMock()
- mock_instance.get_vllm_config = mocker.AsyncMock(return_value=None)
- mock_instance.get_supported_tasks = mocker.AsyncMock(return_value=["generate"])
- mock_instance.get_tokenizer = mocker.AsyncMock(return_value=None)
-
- mock_async_omni_cls.return_value = mock_instance
- yield mock_async_omni_cls
-
-
-@pytest.fixture
-def api_server(unused_tcp_port_factory, server_case: ServerCase, mock_async_omni):
- """Set up a API server in background process from command line with parametrized model name and mocked AsyncOmni."""
- parser = FlexibleArgumentParser()
- subparsers = parser.add_subparsers(dest="command")
- cmd = OmniServeCommand()
- cmd.subparser_init(subparsers)
-
- port = unused_tcp_port_factory()
- args = parser.parse_args(["serve", server_case.served_model, "--omni", "--port", str(port)])
-
- def run_server():
- try:
- cmd.cmd(args)
- except Exception:
- traceback.print_exc()
-
- server_process = multiprocessing.Process(target=run_server)
- server_process.start()
-
- # Wait for the server to be ready by polling the health endpoint.
- wait_time = 30
- wait_poll_interval = 1
- for _ in range(wait_time // wait_poll_interval):
- try:
- response = requests.get(f"http://127.0.0.1:{port}/health")
- if response.status_code == 200:
- break
- except requests.ConnectionError:
- time.sleep(wait_poll_interval)
- else:
- if server_process.is_alive():
- server_process.terminate()
- server_process.join(timeout=5)
- if server_process.is_alive():
- server_process.kill()
- server_process.join(timeout=5)
- pytest.fail(f"API server failed to start within {wait_time} seconds")
-
- yield f"http://127.0.0.1:{port}/v1"
-
- if server_process.is_alive():
- server_process.terminate()
- server_process.join(timeout=10)
-
-
-@pytest.mark.asyncio
-@pytest.mark.parametrize(
- "server_case,model,image_input",
- [
- pytest.param(
- ServerCase(
- served_model="Tongyi-MAI/Z-Image-Turbo",
- stage_list=["diffusion"],
- stage_configs=[_make_stage_config("diffusion")],
- outputs=[_build_diffusion_image_output_for_images_endpoint()],
- ),
- "Tongyi-MAI/Z-Image-Turbo",
- False,
- id="text-to-image-dalle-endpoint",
- ),
- pytest.param(
- ServerCase(
- served_model="ByteDance-Seed/BAGEL-7B-MoT",
- stage_list=["diffusion"],
- stage_configs=[_make_stage_config("diffusion")],
- outputs=[_build_diffusion_image_output_for_chat_endpoint()],
- ),
- "ByteDance-Seed/BAGEL-7B-MoT",
- False,
- id="text-to-image-bagel-chat-endpoint",
- ),
- pytest.param(
- ServerCase(
- served_model="Qwen/Qwen-Image-Edit",
- stage_list=["diffusion"],
- stage_configs=[_make_stage_config("diffusion")],
- outputs=[_build_diffusion_image_output_for_images_endpoint()],
- ),
- "Qwen/Qwen-Image-Edit",
- True,
- id="image-to-image-dalle-endpoint",
- ),
- pytest.param(
- ServerCase(
- served_model="ByteDance-Seed/BAGEL-7B-MoT",
- stage_list=["diffusion"],
- stage_configs=[_make_stage_config("diffusion")],
- outputs=[_build_diffusion_image_output_for_chat_endpoint()],
- ),
- "ByteDance-Seed/BAGEL-7B-MoT",
- True,
- id="image-to-image-bagel-chat-endpoint",
- ),
- ],
- indirect=["server_case"],
-)
-@pytest.mark.parametrize(
- "sampling_case",
- [
- pytest.param(
- SamplingCase(kind=SamplingKind.IMAGE_NONE, sampling_params=None, lora=None), id="no-sampling-params"
- ),
- pytest.param(
- SamplingCase(
- kind=SamplingKind.IMAGE_DIFFUSION_SINGLE,
- sampling_params=DIFFUSION_SINGLE_SAMPLING_PARAMS,
- lora=LORA_PARAMS,
- ),
- id="single-diffusion-sampling-params",
- ),
- ],
- indirect=["sampling_case"],
-)
-async def test_image_generation_node(api_server: str, model: str, image_input: bool, sampling_case: SamplingCase):
- node = VLLMOmniGenerateImage()
-
- kwargs = {
- "url": api_server,
- "model": model,
- "prompt": "A beautiful sunset",
- "width": IMAGE_WIDTH,
- "height": IMAGE_HEIGHT,
- }
- if image_input:
- kwargs["image"] = torch.zeros((1, IMAGE_WIDTH, IMAGE_HEIGHT, 3), dtype=torch.float32)
- if sampling_case.sampling_params is not None:
- kwargs["sampling_params"] = sampling_case.sampling_params
- if sampling_case.lora:
- kwargs["lora"] = sampling_case.lora
-
- result = await node.generate(**kwargs)
-
- assert isinstance(result, tuple)
- assert len(result) == 1
- assert isinstance(result[0], torch.Tensor)
- assert result[0].shape == (1, IMAGE_WIDTH, IMAGE_HEIGHT, 3)
-
-
-@pytest.mark.asyncio
-@pytest.mark.parametrize(
- "server_case",
- [
- pytest.param(
- ServerCase(
- served_model="Qwen/Qwen2.5-Omni-7B",
- stage_list=[
- SimpleNamespace(is_comprehension=True, model_stage="llm"),
- SimpleNamespace(is_comprehension=False, model_stage="llm"),
- SimpleNamespace(is_comprehension=False, model_stage="llm"),
- ],
- stage_configs=[
- _make_stage_config("llm", is_comprehension=True, model_stage="thinker"),
- _make_stage_config("llm", is_comprehension=False, model_stage="talker"),
- _make_stage_config("llm", is_comprehension=False, model_stage="code2wav"),
- ],
- outputs=[_build_audio_chat_output(), _build_text_output("Understanding response")],
- ),
- id="multimodal-understanding",
- )
- ],
- indirect=["server_case"],
-)
-@pytest.mark.parametrize(
- "sampling_case",
- [
- pytest.param(SamplingCase(kind=SamplingKind.UNDERSTANDING_NONE, sampling_params=None), id="no-sampling-params"),
- pytest.param(
- SamplingCase(kind=SamplingKind.UNDERSTANDING_AR_LIST, sampling_params=AR_LIST_SAMPLING_PARAMS),
- id="ar-sampling-params-list",
- ),
- ],
- indirect=["sampling_case"],
-)
-async def test_understanding_node(api_server: str, sampling_case: SamplingCase):
- node = VLLMOmniUnderstanding()
-
- image = torch.zeros((1, IMAGE_WIDTH, IMAGE_HEIGHT, 3), dtype=torch.float32)
- video = VideoInput(b"mock_video_for_test") # type: ignore[reportAbstractUsage]
- audio: AudioInput = {"waveform": torch.zeros((1, 1, 24000), dtype=torch.float32), "sample_rate": 24000}
-
- text_response, audio_response = await node.generate(
- url=api_server,
- model="Qwen/Qwen2.5-Omni-7B",
- prompt="Describe all modalities.",
- image=image,
- audio=audio,
- video=video,
- sampling_params=sampling_case.sampling_params,
- output_text=True,
- output_audio=True,
- use_audio_in_video=True,
- )
-
- assert text_response == "Understanding response"
- assert isinstance(audio_response, dict)
- assert audio_response["sample_rate"] == 24000
- assert isinstance(audio_response["waveform"], torch.Tensor)
- assert audio_response["waveform"].shape == (1, 1, 24000)
-
-
-@pytest.mark.asyncio
-@pytest.mark.parametrize(
- "server_case,node_cls,call_kwargs",
- [
- pytest.param(
- ServerCase(
- served_model="Qwen/Qwen3-TTS-12Hz-1.7B-CustomVoice",
- stage_list=["llm"],
- stage_configs=[_make_stage_config("llm", model_stage="qwen3_tts")],
- outputs=[_build_audio_speech_output()],
- ),
- VLLMOmniTTS,
- {
- "model": "Qwen/Qwen3-TTS-12Hz-1.7B-CustomVoice",
- "input": "Hello from TTS test",
- "voice": "Vivian",
- "response_format": "wav",
- "speed": 1.0,
- "model_specific_params": None,
- },
- id="tts",
- ),
- pytest.param(
- ServerCase(
- served_model="Qwen/Qwen3-TTS-12Hz-1.7B-Base",
- stage_list=["llm"],
- stage_configs=[_make_stage_config("llm", model_stage="qwen3_tts")],
- outputs=[_build_audio_speech_output()],
- ),
- VLLMOmniVoiceClone,
- {
- "model": "Qwen/Qwen3-TTS-12Hz-1.7B-Base",
- "input": "Hello from voice clone test",
- "voice": "Vivian",
- "response_format": "wav",
- "speed": 1.0,
- "ref_audio": {"waveform": torch.zeros((1, 1, 24000), dtype=torch.float32), "sample_rate": 24000},
- "ref_text": "Reference transcript",
- "x_vector_only_mode": False,
- "model_specific_params": None,
- },
- id="tts-voice-clone",
- ),
- ],
- indirect=["server_case"],
-)
-@pytest.mark.parametrize(
- "sampling_case",
- [
- pytest.param(SamplingCase(kind=SamplingKind.TTS_NONE, sampling_params=None), id="no-sampling-params"),
- pytest.param(
- SamplingCase(kind=SamplingKind.TTS_DIFFUSION_SINGLE, sampling_params=DIFFUSION_SINGLE_SAMPLING_PARAMS),
- id="single-diffusion-sampling-params",
- ),
- ],
- indirect=["sampling_case"],
-)
-async def test_tts_nodes(api_server: str, node_cls, call_kwargs: dict, sampling_case: SamplingCase):
- node = node_cls()
- actual_kwargs = dict(call_kwargs)
- if sampling_case.sampling_params is not None:
- actual_kwargs["model_specific_params"] = sampling_case.sampling_params
- result = await node.generate(url=api_server, **actual_kwargs)
-
- assert isinstance(result, tuple)
- assert len(result) == 1
- assert isinstance(result[0], dict)
- assert result[0]["sample_rate"] == 24000
- assert isinstance(result[0]["waveform"], torch.Tensor)
- assert result[0]["waveform"].shape == (1, 1, 24000)
-
-
-@pytest.mark.asyncio
-@pytest.mark.parametrize(
- "server_case,model,image_input",
- [
- pytest.param(
- ServerCase(
- served_model="Wan-AI/Wan2.2-T2V-A14B-Diffusers",
- stage_list=["diffusion"],
- stage_configs=[{"stage_type": "diffusion"}],
- outputs=[_build_diffusion_video_output()],
- ),
- "Wan-AI/Wan2.2-T2V-A14B-Diffusers",
- False,
- id="text-to-video",
- ),
- pytest.param(
- ServerCase(
- served_model="Wan-AI/Wan2.2-I2V-A14B-Diffusers",
- stage_list=["diffusion"],
- stage_configs=[{"stage_type": "diffusion"}],
- outputs=[_build_diffusion_video_output()],
- ),
- "Wan-AI/Wan2.2-I2V-A14B-Diffusers",
- True,
- id="image-to-video",
- ),
- ],
- indirect=["server_case"],
-)
-@pytest.mark.parametrize(
- "sampling_case",
- [
- pytest.param(SamplingCase(kind=SamplingKind.VIDEO_NONE, sampling_params=None), id="no-sampling-params"),
- pytest.param(
- SamplingCase(
- kind=SamplingKind.VIDEO_DIFFUSION_SINGLE,
- sampling_params=DIFFUSION_VIDEO_SINGLE_SAMPLING_PARAMS,
- lora=LORA_PARAMS,
- ),
- id="single-diffusion-sampling-params",
- ),
- ],
- indirect=["sampling_case"],
-)
-async def test_video_generation_node(api_server: str, model: str, image_input: bool, sampling_case: SamplingCase):
- node = VLLMOmniGenerateVideo()
-
- kwargs = {
- "url": api_server,
- "model": model,
- "prompt": "A beautiful sunset timelapse",
- "negative_prompt": "",
- "width": VIDEO_WIDTH,
- "height": VIDEO_HEIGHT,
- "fps": VIDEO_FPS,
- "num_frames": VIDEO_NUM_FRAMES,
- "model_params": VIDEO_MODEL_PARAMS,
- }
- if image_input:
- kwargs["image"] = torch.zeros((1, VIDEO_HEIGHT, VIDEO_WIDTH, 3), dtype=torch.float32)
- if sampling_case.sampling_params is not None:
- kwargs["sampling_params"] = sampling_case.sampling_params
- if sampling_case.lora:
- kwargs["lora"] = sampling_case.lora
-
- result = await node.generate(**kwargs)
-
- assert isinstance(result, tuple)
- assert len(result) == 1
- assert isinstance(result[0], VideoInput)
diff --git a/tests/config/__init__.py b/tests/config/__init__.py
deleted file mode 100644
index e69de29bb2d..00000000000
diff --git a/tests/config/test_pipeline_registry.py b/tests/config/test_pipeline_registry.py
deleted file mode 100644
index 6cc7c9258ed..00000000000
--- a/tests/config/test_pipeline_registry.py
+++ /dev/null
@@ -1,99 +0,0 @@
-# SPDX-License-Identifier: Apache-2.0
-# SPDX-FileCopyrightText: Copyright contributors to the vLLM project
-"""Tests for the central pipeline registry (2.5/N)."""
-
-from __future__ import annotations
-
-import pytest
-
-from vllm_omni.config.pipeline_registry import _OMNI_PIPELINES
-from vllm_omni.config.stage_config import (
- _PIPELINE_REGISTRY,
- PipelineConfig,
- StageExecutionType,
- StagePipelineConfig,
- register_pipeline,
-)
-
-
-class TestCentralRegistryDeclarations:
- """Every in-tree pipeline must be declared exactly once in the central registry."""
-
- def test_omni_entries_visible_in_registry(self):
- for key in _OMNI_PIPELINES:
- assert key in _PIPELINE_REGISTRY
-
- def test_expected_omni_pipelines_present(self):
- # Guard against accidental removal during future refactors.
- assert "qwen2_5_omni" in _OMNI_PIPELINES
- assert "qwen2_5_omni_thinker_only" in _OMNI_PIPELINES
- assert "qwen3_omni_moe" in _OMNI_PIPELINES
- assert "qwen3_tts" in _OMNI_PIPELINES
-
-
-class TestLazyLoading:
- """Pipelines are imported only on first access."""
-
- def test_contains_without_import(self):
- # ``in`` hits the lazy map, not the loaded cache.
- assert "qwen3_omni_moe" in _PIPELINE_REGISTRY
-
- def test_getitem_loads_correct_pipeline(self):
- pipeline = _PIPELINE_REGISTRY["qwen3_omni_moe"]
- assert pipeline.model_type == "qwen3_omni_moe"
- assert pipeline.model_arch == "Qwen3OmniMoeForConditionalGeneration"
-
- def test_unknown_model_type_returns_none_via_get(self):
- assert _PIPELINE_REGISTRY.get("not_a_real_pipeline") is None
-
- def test_unknown_model_type_raises_keyerror_via_getitem(self):
- with pytest.raises(KeyError):
- _PIPELINE_REGISTRY["not_a_real_pipeline"]
-
- def test_iteration_yields_registered_pipelines(self):
- keys = set(_PIPELINE_REGISTRY)
- assert "qwen2_5_omni" in keys
- assert "qwen3_omni_moe" in keys
-
-
-class TestDynamicRegistration:
- """``register_pipeline()`` still works for plugins and tests."""
-
- def test_register_adds_to_registry(self):
- custom = PipelineConfig(
- model_type="_test_dynamic_registration",
- model_arch="DynamicTestModel",
- stages=(
- StagePipelineConfig(
- stage_id=0,
- model_stage="test",
- execution_type=StageExecutionType.LLM_AR,
- input_sources=(),
- final_output=True,
- ),
- ),
- )
- register_pipeline(custom)
- try:
- assert "_test_dynamic_registration" in _PIPELINE_REGISTRY
- assert _PIPELINE_REGISTRY["_test_dynamic_registration"] is custom
- finally:
- # Don't leak the test registration into other tests.
- if "_test_dynamic_registration" in _PIPELINE_REGISTRY:
- del _PIPELINE_REGISTRY["_test_dynamic_registration"]
-
- def test_dynamic_registration_overrides_lazy_entry(self):
- # Build a substitute for qwen3_omni_moe that we can distinguish.
- original = _PIPELINE_REGISTRY["qwen3_omni_moe"]
- override = PipelineConfig(
- model_type="qwen3_omni_moe",
- model_arch="OverriddenArch",
- stages=original.stages,
- )
- register_pipeline(override)
- try:
- assert _PIPELINE_REGISTRY["qwen3_omni_moe"].model_arch == "OverriddenArch"
- finally:
- # Remove the dynamic override so later tests see the original.
- if "qwen3_omni_moe" in _PIPELINE_REGISTRY._loaded:
- del _PIPELINE_REGISTRY["qwen3_omni_moe"]
diff --git a/tests/conftest.py b/tests/conftest.py
deleted file mode 100644
index 77075f9525a..00000000000
--- a/tests/conftest.py
+++ /dev/null
@@ -1,62 +0,0 @@
-"""
-Root pytest entrypoint for the vLLM-Omni test suite.
-
-- `tests/conftest.py` stays thin: plugin registration + compatibility re-exports.
-- Importable utilities live under `tests/helpers/`.
-- Fixtures live under `tests/helpers/fixtures/` and are loaded via `pytest_plugins`.
-"""
-
-from __future__ import annotations
-
-pytest_plugins = (
- "tests.helpers.fixtures.env",
- "tests.helpers.fixtures.log",
- "tests.helpers.fixtures.run_args",
- "tests.helpers.fixtures.runtime",
-)
-
-
-def pytest_terminal_summary(terminalreporter, exitstatus, config):
- # Marker for Buildkite log folding before pytest summary lines.
- terminalreporter.write_line("--- Running Summary")
-
-
-# Backward-compatible lazy re-exports.
-# (Many tests still import from `tests.conftest`; migrate these imports to `tests.helpers.*` over time.)
-# Keep these lazy so conftest import does not trigger heavy helper dependencies.
-_ASSERTION_EXPORT_NAMES = (
- "assert_audio_speech_response",
- "assert_diffusion_response",
- "assert_image_diffusion_response",
- "assert_image_valid",
- "assert_omni_response",
- "assert_video_diffusion_response",
- "assert_video_valid",
-)
-_MEDIA_EXPORT_NAMES = (
- "convert_audio_bytes_to_text",
- "convert_audio_file_to_text",
- "cosine_similarity_text",
- "decode_b64_image",
- "generate_synthetic_audio",
- "generate_synthetic_image",
- "generate_synthetic_video",
-)
-_STAGE_CONFIG_EXPORT_NAMES = ("modify_stage_config",)
-_RUNTIME_EXPORT_NAMES = (
- "DiffusionResponse",
- "OmniResponse",
- "OmniRunner",
- "OmniRunnerHandler",
- "OmniServer",
- "OmniServerParams",
- "OmniServerStageCli",
- "OpenAIClientHandler",
- "dummy_messages_from_mix_data",
-)
-_LAZY_EXPORT_MODULES = {
- **{name: "tests.helpers.assertions" for name in _ASSERTION_EXPORT_NAMES},
- **{name: "tests.helpers.media" for name in _MEDIA_EXPORT_NAMES},
- **{name: "tests.helpers.stage_config" for name in _STAGE_CONFIG_EXPORT_NAMES},
- **{name: "tests.helpers.runtime" for name in _RUNTIME_EXPORT_NAMES},
-}
diff --git a/tests/core/sched/test_chunk_scheduling_coordinator.py b/tests/core/sched/test_chunk_scheduling_coordinator.py
deleted file mode 100644
index 5e19465e224..00000000000
--- a/tests/core/sched/test_chunk_scheduling_coordinator.py
+++ /dev/null
@@ -1,690 +0,0 @@
-# SPDX-License-Identifier: Apache-2.0
-# SPDX-FileCopyrightText: Copyright contributors to the vLLM project
-"""Unit tests for OmniSchedulingCoordinator (formerly ChunkSchedulingCoordinator).
-
-These tests use mock request objects and mock queues. They do not require
-GPU, vLLM runtime, or any connector.
-"""
-
-from __future__ import annotations
-
-import unittest
-from types import SimpleNamespace
-
-import vllm_omni.core.sched.omni_scheduling_coordinator as coord_mod
-from vllm_omni.core.sched.omni_scheduling_coordinator import (
- ChunkSchedulingCoordinator,
- OmniSchedulingCoordinator,
-)
-
-# ------------------------------------------------------------------ #
-# Mock helpers
-# ------------------------------------------------------------------ #
-
-
-class _RequestStatus:
- WAITING = "waiting"
- RUNNING = "running"
- WAITING_FOR_CHUNK = "waiting_for_chunk"
- WAITING_FOR_INPUT = "waiting_for_input"
- FINISHED_STOPPED = "finished_stopped"
-
-
-# Patch RequestStatus for tests that don't import vllm
-try:
- from vllm.v1.request import RequestStatus
-except ImportError:
- RequestStatus = _RequestStatus # type: ignore[misc,assignment]
-
-if not hasattr(RequestStatus, "WAITING_FOR_INPUT"):
- coord_mod.RequestStatus = _RequestStatus # type: ignore[assignment]
- RequestStatus = _RequestStatus # type: ignore[misc,assignment]
-
-
-def _make_request(req_id: str, status: str = "waiting") -> SimpleNamespace:
- return SimpleNamespace(
- request_id=req_id,
- external_req_id=req_id,
- status=status,
- additional_information=None,
- prompt_token_ids=[],
- num_prompt_tokens=0,
- num_computed_tokens=0,
- _all_token_ids=[],
- _output_token_ids=[],
- )
-
-
-class MockQueue:
- """Simplified queue that mimics the Scheduler waiting queue interface."""
-
- def __init__(self, items: list | None = None):
- self._items: list = list(items or [])
-
- def __iter__(self):
- return iter(self._items)
-
- def __len__(self):
- return len(self._items)
-
- def __contains__(self, item):
- return item in self._items
-
- def add_request(self, request):
- self._items.append(request)
-
- def prepend_requests(self, requests):
- self._items = list(requests) + self._items
-
- def remove(self, request):
- self._items.remove(request)
-
- def remove_requests(self, requests):
- remove_set = set(id(r) for r in requests)
- self._items = [r for r in self._items if id(r) not in remove_set]
-
-
-# ------------------------------------------------------------------ #
-# Tests
-# ------------------------------------------------------------------ #
-
-
-class TestChunkCoordinatorStateTransition(unittest.TestCase):
- """Test 5: process_pending_chunks transitions WAITING_FOR_CHUNK → target."""
-
- def test_ready_request_transitions_to_waiting(self):
- coord = ChunkSchedulingCoordinator(scheduler_max_num_seqs=10, stage_id=1, async_chunk=True)
-
- req = _make_request("r1", status=RequestStatus.WAITING_FOR_CHUNK)
- waiting = MockQueue([req])
- running: list = []
-
- coord.process_pending_chunks(
- waiting,
- running,
- chunk_ready_req_ids={"r1"},
- chunk_finished_req_ids=set(),
- )
-
- self.assertEqual(req.status, RequestStatus.WAITING)
- self.assertIn("r1", coord.requests_with_ready_chunks)
-
- def test_non_ready_stays_waiting_for_chunk(self):
- coord = ChunkSchedulingCoordinator(scheduler_max_num_seqs=10, stage_id=1, async_chunk=True)
-
- req = _make_request("r1", status=RequestStatus.WAITING_FOR_CHUNK)
- waiting = MockQueue([req])
- running: list = []
-
- coord.process_pending_chunks(
- waiting,
- running,
- chunk_ready_req_ids=set(),
- chunk_finished_req_ids=set(),
- )
-
- self.assertEqual(req.status, RequestStatus.WAITING_FOR_CHUNK)
-
- def test_stage_0_is_noop(self):
- coord = ChunkSchedulingCoordinator(scheduler_max_num_seqs=10, stage_id=0)
- req = _make_request("r1")
- waiting = MockQueue([req])
- running: list = []
-
- coord.process_pending_chunks(
- waiting,
- running,
- chunk_ready_req_ids={"r1"},
- chunk_finished_req_ids=set(),
- )
- self.assertNotEqual(req.status, RequestStatus.WAITING_FOR_CHUNK)
-
-
-class TestChunkCoordinatorRestoreQueues(unittest.TestCase):
- """Test 6: restore_queues returns waiting-for-chunk requests."""
-
- def test_restore(self):
- coord = ChunkSchedulingCoordinator(scheduler_max_num_seqs=10, stage_id=1)
-
- r1 = _make_request("r1")
- r2 = _make_request("r2")
- coord._waiting_for_chunk_waiting.append(r1)
- coord._waiting_for_chunk_running.append(r2)
-
- waiting = MockQueue()
- running: list = []
-
- coord.restore_queues(waiting, running)
-
- self.assertIn(r1, waiting)
- self.assertIn(r2, running)
- self.assertEqual(len(coord._waiting_for_chunk_waiting), 0)
- self.assertEqual(len(coord._waiting_for_chunk_running), 0)
-
-
-class TestChunkCoordinatorFinishedSignal(unittest.TestCase):
- """Test 8: chunk_finished_req_ids → finished_requests."""
-
- def test_finished_signal(self):
- coord = ChunkSchedulingCoordinator(scheduler_max_num_seqs=10, stage_id=1, async_chunk=True)
-
- req = _make_request("r1", status=RequestStatus.WAITING_FOR_CHUNK)
- waiting = MockQueue([req])
- running: list = []
-
- coord.process_pending_chunks(
- waiting,
- running,
- chunk_ready_req_ids={"r1"},
- chunk_finished_req_ids={"r1"},
- )
-
- self.assertIn("r1", coord.finished_requests)
-
-
-class TestChunkCoordinatorUpdateRequestMetadata(unittest.TestCase):
- """Test update_request_metadata applies scheduling metadata to requests."""
-
- def test_ar_mode_no_longer_sets_additional_information(self):
- """AR mode only processes scheduling metadata, not full payloads."""
- coord = ChunkSchedulingCoordinator(scheduler_max_num_seqs=10, stage_id=1)
-
- req = _make_request("r1")
- requests = {"r1": req}
-
- # Only scheduling metadata is passed now (full payload stays in model runner)
- request_metadata = {"r1": {"next_stage_prompt_len": 50}}
-
- coord.update_request_metadata(requests, request_metadata, model_mode="ar")
-
- # next_stage_prompt_len should update prompt_token_ids
- self.assertEqual(len(req.prompt_token_ids), 50)
- self.assertEqual(req.num_prompt_tokens, 50)
- # additional_information should NOT be set
- self.assertIsNone(getattr(req, "additional_information", None))
-
- def test_generation_mode(self):
- coord = ChunkSchedulingCoordinator(scheduler_max_num_seqs=10, stage_id=1)
-
- req = _make_request("r1")
- req.prompt_token_ids = [0, 0, 0]
- requests = {"r1": req}
-
- request_metadata = {
- "r1": {
- "code_predictor_codes": [10, 20, 30],
- "left_context_size": 25,
- }
- }
-
- coord.update_request_metadata(requests, request_metadata, model_mode="generation")
-
- self.assertEqual(req.prompt_token_ids, [10, 20, 30])
- self.assertEqual(req.num_computed_tokens, 0)
- self.assertIsNone(req.additional_information)
- self.assertEqual(req._omni_initial_model_buffer, {"left_context_size": 25})
-
-
-class TestChunkCoordinatorPostprocess(unittest.TestCase):
- """Test postprocess_scheduler_output clears ready chunks."""
-
- def test_clear_ready(self):
- coord = ChunkSchedulingCoordinator(scheduler_max_num_seqs=10, stage_id=1)
- coord.requests_with_ready_chunks = {"r1", "r2"}
-
- new_req = SimpleNamespace(req_id="r1")
- cached_reqs = SimpleNamespace(req_ids=["r2"])
- scheduler_output = SimpleNamespace(
- scheduled_new_reqs=[new_req],
- scheduled_cached_reqs=cached_reqs,
- )
-
- coord.postprocess_scheduler_output(scheduler_output)
-
- self.assertEqual(coord.requests_with_ready_chunks, set())
-
-
-class TestWaitingForInputTransition(unittest.TestCase):
- """Test B8: process_pending_full_payload_inputs transitions WAITING_FOR_INPUT."""
-
- def test_transition_on_recv(self):
- coord = OmniSchedulingCoordinator(scheduler_max_num_seqs=10, stage_id=1)
-
- req = _make_request("r1", status=RequestStatus.WAITING_FOR_INPUT)
- waiting = MockQueue([req])
- running: list = []
-
- coord.process_pending_full_payload_inputs(
- waiting,
- running,
- stage_recv_req_ids={"r1"},
- )
-
- self.assertEqual(req.status, RequestStatus.WAITING)
-
- def test_stays_waiting_for_input_if_not_received(self):
- coord = OmniSchedulingCoordinator(scheduler_max_num_seqs=10, stage_id=1)
-
- req = _make_request("r1", status=RequestStatus.WAITING_FOR_INPUT)
- waiting = MockQueue([req])
- running: list = []
-
- coord.process_pending_full_payload_inputs(
- waiting,
- running,
- stage_recv_req_ids=set(),
- )
-
- self.assertEqual(req.status, RequestStatus.WAITING_FOR_INPUT)
- self.assertEqual(len(coord._waiting_for_input), 1)
-
- def test_stage_0_is_noop(self):
- coord = OmniSchedulingCoordinator(scheduler_max_num_seqs=10, stage_id=0)
-
- req = _make_request("r1", status=RequestStatus.WAITING_FOR_INPUT)
- waiting = MockQueue([req])
- running: list = []
-
- coord.process_pending_full_payload_inputs(
- waiting,
- running,
- stage_recv_req_ids={"r1"},
- )
- self.assertEqual(req.status, RequestStatus.WAITING_FOR_INPUT)
-
- def test_restore_queues_includes_waiting_for_input(self):
- coord = OmniSchedulingCoordinator(scheduler_max_num_seqs=10, stage_id=1)
-
- r1 = _make_request("r1")
- coord._waiting_for_input.append(r1)
-
- waiting = MockQueue()
- running: list = []
-
- coord.restore_queues(waiting, running)
-
- self.assertIn(r1, waiting)
- self.assertEqual(len(coord._waiting_for_input), 0)
-
- def test_full_payload_mode_auto_transitions_waiting_to_waiting_for_input(self):
- """In full_payload_mode (async_chunk=False), fresh WAITING requests on
- non-Stage-0 should be transitioned to WAITING_FOR_INPUT."""
- coord = OmniSchedulingCoordinator(
- scheduler_max_num_seqs=10,
- stage_id=1,
- async_chunk=False,
- )
-
- req = _make_request("r1", status=RequestStatus.WAITING)
- waiting = MockQueue([req])
- running: list = []
-
- coord.process_pending_full_payload_inputs(
- waiting,
- running,
- stage_recv_req_ids=set(),
- )
-
- self.assertEqual(req.status, RequestStatus.WAITING_FOR_INPUT)
- self.assertEqual(len(coord._waiting_for_input), 1)
- self.assertEqual(len(coord.pending_input_registrations), 1)
-
- def test_async_chunk_mode_does_not_auto_transition(self):
- """In async_chunk mode, fresh WAITING requests should NOT be
- transitioned to WAITING_FOR_INPUT."""
- coord = OmniSchedulingCoordinator(
- scheduler_max_num_seqs=10,
- stage_id=1,
- async_chunk=True,
- )
-
- req = _make_request("r1", status=RequestStatus.WAITING)
- waiting = MockQueue([req])
- running: list = []
-
- coord.process_pending_full_payload_inputs(
- waiting,
- running,
- stage_recv_req_ids=set(),
- )
-
- self.assertEqual(req.status, RequestStatus.WAITING)
-
- def test_pending_input_registrations(self):
- coord = OmniSchedulingCoordinator(scheduler_max_num_seqs=10, stage_id=1)
-
- req = _make_request("r1", status=RequestStatus.WAITING_FOR_INPUT)
- waiting = MockQueue([req])
- running: list = []
-
- coord.process_pending_full_payload_inputs(
- waiting,
- running,
- stage_recv_req_ids=set(),
- )
-
- self.assertEqual(len(coord.pending_input_registrations), 1)
- self.assertEqual(coord.pending_input_registrations[0].request_id, "r1")
-
-
-class TestTimeoutDetection(unittest.TestCase):
- """Regression tests for orphaned pending-recv timeout detection.
-
- Covers the full lifecycle:
- 1. Request enters WAITING_FOR_CHUNK from either waiting or running queue
- 2. restore_queues() moves it back to the scheduler queue
- 3. Timeout fires via collect_timed_out_request_ids()
- 4. Scheduler removes from both queues and calls _free_request()
- """
-
- def test_waiting_since_recorded_on_chunk_wait(self):
- """_waiting_since is set when a request enters WAITING_FOR_CHUNK."""
- coord = OmniSchedulingCoordinator(
- scheduler_max_num_seqs=10,
- stage_id=1,
- async_chunk=True,
- )
- req = _make_request("r1", status=RequestStatus.WAITING)
- waiting = MockQueue([req])
-
- coord.process_pending_chunks(
- waiting,
- [],
- chunk_ready_req_ids=set(),
- chunk_finished_req_ids=set(),
- )
-
- self.assertIn("r1", coord._waiting_since)
- self.assertEqual(req.status, RequestStatus.WAITING_FOR_CHUNK)
-
- def test_waiting_since_cleared_on_chunk_arrival(self):
- """_waiting_since is cleared when a chunk arrives."""
- coord = OmniSchedulingCoordinator(
- scheduler_max_num_seqs=10,
- stage_id=1,
- async_chunk=True,
- )
- req = _make_request("r1", status=RequestStatus.WAITING_FOR_CHUNK)
- waiting = MockQueue([req])
-
- coord.process_pending_chunks(
- waiting,
- [],
- chunk_ready_req_ids={"r1"},
- chunk_finished_req_ids=set(),
- )
-
- self.assertNotIn("r1", coord._waiting_since)
-
- def test_waiting_since_recorded_on_input_wait(self):
- """_waiting_since is set when a request enters WAITING_FOR_INPUT."""
- coord = OmniSchedulingCoordinator(
- scheduler_max_num_seqs=10,
- stage_id=1,
- async_chunk=False,
- )
- req = _make_request("r1", status=RequestStatus.WAITING)
- waiting = MockQueue([req])
-
- coord.process_pending_full_payload_inputs(
- waiting,
- [],
- stage_recv_req_ids=set(),
- )
-
- self.assertIn("r1", coord._waiting_since)
-
- def test_waiting_since_cleared_on_input_arrival(self):
- """_waiting_since is cleared when input data arrives."""
- coord = OmniSchedulingCoordinator(
- scheduler_max_num_seqs=10,
- stage_id=1,
- async_chunk=False,
- )
- req = _make_request("r1", status=RequestStatus.WAITING_FOR_INPUT)
- coord._waiting_for_input.append(req)
- coord._waiting_since["r1"] = 0.0
-
- waiting = MockQueue()
- coord.process_pending_full_payload_inputs(
- waiting,
- [],
- stage_recv_req_ids={"r1"},
- )
-
- self.assertNotIn("r1", coord._waiting_since)
- self.assertEqual(req.status, RequestStatus.WAITING)
-
- def test_collect_timed_out_request_ids_no_timeout(self):
- """No IDs returned when nothing has timed out."""
- coord = OmniSchedulingCoordinator(
- scheduler_max_num_seqs=10,
- stage_id=1,
- )
- import time
-
- coord._waiting_since["r1"] = time.monotonic()
-
- result = coord.collect_timed_out_request_ids(timeout_s=300.0)
- self.assertEqual(result, set())
-
- def test_collect_timed_out_request_ids_expired(self):
- """Timed-out IDs are returned and _waiting_since is cleared."""
- coord = OmniSchedulingCoordinator(
- scheduler_max_num_seqs=10,
- stage_id=1,
- )
- coord._waiting_since["r1"] = 0.0 # epoch → definitely expired
- coord._waiting_since["r2"] = 0.0
-
- import time
-
- coord._waiting_since["r3"] = time.monotonic() + 9999 # far future
-
- result = coord.collect_timed_out_request_ids(timeout_s=1.0)
-
- self.assertEqual(result, {"r1", "r2"})
- self.assertNotIn("r1", coord._waiting_since)
- self.assertNotIn("r2", coord._waiting_since)
- self.assertIn("r3", coord._waiting_since)
-
- def test_collect_removes_from_coordinator_queues(self):
- """Timed-out requests are defensively removed from internal queues."""
- coord = OmniSchedulingCoordinator(
- scheduler_max_num_seqs=10,
- stage_id=1,
- )
- r1 = _make_request("r1")
- r2 = _make_request("r2")
- coord._waiting_for_chunk_waiting.append(r1)
- coord._waiting_for_input.append(r2)
- coord._waiting_since["r1"] = 0.0
- coord._waiting_since["r2"] = 0.0
-
- result = coord.collect_timed_out_request_ids(timeout_s=1.0)
-
- self.assertEqual(result, {"r1", "r2"})
- self.assertEqual(len(coord._waiting_for_chunk_waiting), 0)
- self.assertEqual(len(coord._waiting_for_input), 0)
-
- def test_free_finished_request_clears_waiting_since(self):
- """free_finished_request clears _waiting_since."""
- coord = OmniSchedulingCoordinator(
- scheduler_max_num_seqs=10,
- stage_id=1,
- )
- coord._waiting_since["r1"] = 0.0
- coord.free_finished_request("r1")
- self.assertNotIn("r1", coord._waiting_since)
-
- def test_timeout_from_running_queue_full_lifecycle(self):
- """End-to-end: request from running → WAITING_FOR_CHUNK → restore →
- timeout → removed from running list.
-
- This is the critical regression case: WAITING_FOR_CHUNK requests
- that originated from self.running are placed back into self.running
- by restore_queues(), but their status remains WAITING_FOR_CHUNK.
- The scheduler must remove from BOTH queues unconditionally.
- """
- coord = OmniSchedulingCoordinator(
- scheduler_max_num_seqs=10,
- stage_id=1,
- async_chunk=True,
- )
-
- # 1) Request starts in running queue with WAITING status
- req = _make_request("r1", status=RequestStatus.WAITING)
- running = [req]
- waiting = MockQueue()
-
- # 2) process_pending_chunks: moves to WAITING_FOR_CHUNK
- coord.process_pending_chunks(
- waiting,
- running,
- chunk_ready_req_ids=set(),
- chunk_finished_req_ids=set(),
- )
- self.assertEqual(req.status, RequestStatus.WAITING_FOR_CHUNK)
- self.assertIn("r1", coord._waiting_since)
- self.assertEqual(len(coord._waiting_for_chunk_running), 1)
-
- # 3) restore_queues: back to running (status stays WAITING_FOR_CHUNK)
- coord.restore_queues(waiting, running)
- self.assertIn(req, running)
- self.assertEqual(len(coord._waiting_for_chunk_running), 0)
- self.assertEqual(req.status, RequestStatus.WAITING_FOR_CHUNK)
-
- # 4) Force timeout by setting _waiting_since to epoch
- coord._waiting_since["r1"] = 0.0
-
- timed_out_ids = coord.collect_timed_out_request_ids(timeout_s=1.0)
- self.assertEqual(timed_out_ids, {"r1"})
-
- # 5) Scheduler removes from both queues (simulating the scheduler path)
- timed_out_id_set = {id(req)}
- running = [r for r in running if id(r) not in timed_out_id_set]
- waiting.remove_requests([req])
-
- self.assertNotIn(req, running)
- self.assertEqual(len(waiting), 0)
-
- def test_timeout_from_waiting_queue_full_lifecycle(self):
- """End-to-end: request from waiting → WAITING_FOR_CHUNK → restore →
- timeout → removed from waiting queue."""
- coord = OmniSchedulingCoordinator(
- scheduler_max_num_seqs=10,
- stage_id=1,
- async_chunk=True,
- )
-
- req = _make_request("r1", status=RequestStatus.WAITING)
- waiting = MockQueue([req])
- running: list = []
-
- coord.process_pending_chunks(
- waiting,
- running,
- chunk_ready_req_ids=set(),
- chunk_finished_req_ids=set(),
- )
- self.assertEqual(len(coord._waiting_for_chunk_waiting), 1)
-
- coord.restore_queues(waiting, running)
- self.assertIn(req, waiting)
-
- coord._waiting_since["r1"] = 0.0
- timed_out_ids = coord.collect_timed_out_request_ids(timeout_s=1.0)
- self.assertEqual(timed_out_ids, {"r1"})
-
- waiting.remove_requests([req])
- self.assertEqual(len(waiting), 0)
-
-
-class TestOverflowPreemption(unittest.TestCase):
- """Tests for P1-1: overflow requests must get WAITING status.
-
- Overflow happens when multiple WAITING_FOR_CHUNK requests in
- ``_waiting_for_chunk_running`` receive their chunk in the same cycle.
- ``_process_chunk_queue`` restores them to RUNNING (``continue``
- path) while RUNNING requests without chunks are moved out. If the
- net result exceeds ``scheduler_max_num_seqs``, the tail is pushed
- to ``waiting_queue`` and must have status == WAITING.
- """
-
- def test_overflow_sets_waiting_status(self):
- coord = OmniSchedulingCoordinator(
- scheduler_max_num_seqs=1,
- stage_id=1,
- async_chunk=True,
- )
-
- # r1 is currently RUNNING in the queue.
- # r2, r3 were previously moved to _waiting_for_chunk_running.
- r1 = _make_request("r1", status=RequestStatus.RUNNING)
- r2 = _make_request("r2", status=RequestStatus.WAITING_FOR_CHUNK)
- r3 = _make_request("r3", status=RequestStatus.WAITING_FOR_CHUNK)
-
- running = [r1]
- waiting = MockQueue([])
- coord._waiting_for_chunk_running.extend([r2, r3])
-
- # restore_queues puts r2, r3 back into running
- coord.restore_queues(waiting, running)
- self.assertEqual(len(running), 3)
-
- # Now process_pending_chunks with r2, r3 chunks ready:
- # _process_chunk_queue will:
- # r1 (RUNNING) → no chunk → move to _waiting_for_chunk_running
- # r2 (WAITING_FOR_CHUNK, chunk ready) → set RUNNING, stay in running
- # r3 (WAITING_FOR_CHUNK, chunk ready) → set RUNNING, stay in running
- # running = [r2, r3], len=2 > max=1 → overflow
- coord.process_pending_chunks(
- waiting,
- running,
- chunk_ready_req_ids={"r2", "r3"},
- chunk_finished_req_ids=set(),
- )
-
- self.assertEqual(len(running), 1)
- self.assertEqual(len(waiting), 1)
- overflow_req = list(waiting)[0]
- self.assertEqual(
- overflow_req.status,
- RequestStatus.WAITING,
- f"Overflowed request should have WAITING status, got {overflow_req.status}",
- )
-
- def test_overflow_does_not_strand_request(self):
- """Without the fix, the overflowed request would keep its
- RUNNING status in the waiting queue and never be re-scheduled."""
- coord = OmniSchedulingCoordinator(
- scheduler_max_num_seqs=1,
- stage_id=1,
- async_chunk=True,
- )
-
- r1 = _make_request("r1", status=RequestStatus.WAITING_FOR_CHUNK)
- r2 = _make_request("r2", status=RequestStatus.WAITING_FOR_CHUNK)
- coord._waiting_for_chunk_running.extend([r1, r2])
-
- running: list = []
- waiting = MockQueue([])
-
- coord.restore_queues(waiting, running)
- self.assertEqual(len(running), 2)
-
- coord.process_pending_chunks(
- waiting,
- running,
- chunk_ready_req_ids={"r1", "r2"},
- chunk_finished_req_ids=set(),
- )
-
- self.assertEqual(len(running), 1)
- self.assertEqual(len(waiting), 1)
- for req in waiting:
- self.assertNotEqual(req.status, RequestStatus.RUNNING, "Overflowed request must not keep RUNNING status")
-
-
-if __name__ == "__main__":
- unittest.main()
diff --git a/tests/core/sched/test_generation_scheduler_restore.py b/tests/core/sched/test_generation_scheduler_restore.py
deleted file mode 100644
index 5cc1cab7025..00000000000
--- a/tests/core/sched/test_generation_scheduler_restore.py
+++ /dev/null
@@ -1,105 +0,0 @@
-"""Test that OmniGenerationScheduler restores chunk-waiting requests
-even when the OmniNewRequestData rewrapping fails.
-
-Regression test: if process_pending_chunks() moves requests into
-internal deques but restore_queues() is not called due to an exception,
-those requests are permanently orphaned.
-"""
-
-from collections import deque
-
-import pytest
-
-pytestmark = [pytest.mark.core_model, pytest.mark.cpu]
-
-
-class FakeAdapter:
- """Minimal mock of OmniChunkTransferAdapter tracking restore calls."""
-
- def __init__(self):
- self.waiting_for_chunk_waiting_requests = deque()
- self.waiting_for_chunk_running_requests = deque()
- self.restore_called = False
-
- def process_pending_chunks(self, waiting, running):
- """Simulate moving requests out of the scheduler queues."""
- # Move one request from running into internal deque
- if running:
- req = running.pop()
- self.waiting_for_chunk_running_requests.append(req)
-
- def restore_queues(self, waiting, running):
- """Put requests back."""
- self.restore_called = True
- running.extend(self.waiting_for_chunk_running_requests)
- self.waiting_for_chunk_running_requests = deque()
-
- def postprocess_scheduler_output(self, output):
- pass
-
-
-class TestRestoreQueuesOnError:
- """Verify that restore_queues is called even when rewrapping raises."""
-
- def test_requests_not_lost_on_exception(self):
- """Simulate the error path: process_pending_chunks moves a request
- out, then an exception occurs during rewrapping.
- The finally block must restore the request to the queue."""
-
- adapter = FakeAdapter()
- running = ["req-A", "req-B"]
-
- # Step 1: process_pending_chunks moves req-B out
- adapter.process_pending_chunks(waiting=[], running=running)
- assert running == ["req-A"]
- assert len(adapter.waiting_for_chunk_running_requests) == 1
-
- # Step 2: simulate the try/except/finally pattern
- try:
- raise RuntimeError("OmniNewRequestData construction failed")
- except Exception:
- pass # Log error, leave output unchanged
- finally:
- # This is what guarantees restore always runs
- adapter.restore_queues(waiting=[], running=running)
-
- # Step 3: verify request is restored
- assert adapter.restore_called is True
- assert "req-B" in running
- assert len(adapter.waiting_for_chunk_running_requests) == 0
-
- def test_requests_lost_without_fix(self):
- """Demonstrate the bug: without restore in except, request is lost."""
-
- adapter = FakeAdapter()
- running = ["req-A", "req-B"]
-
- adapter.process_pending_chunks(waiting=[], running=running)
- assert running == ["req-A"]
-
- # Simulate the BUGGY code: except without restore
- try:
- raise RuntimeError("OmniNewRequestData construction failed")
- except Exception:
- pass # Bug: no restore_queues call
-
- # Request is lost!
- assert "req-B" not in running
- assert len(adapter.waiting_for_chunk_running_requests) == 1
-
- def test_happy_path_restores_via_finally(self):
- """When no exception, restore_queues is still called via finally."""
-
- adapter = FakeAdapter()
- running = ["req-A", "req-B"]
-
- adapter.process_pending_chunks(waiting=[], running=running)
-
- # Happy path: no exception, finally still runs
- try:
- pass # Rewrapping succeeds
- finally:
- adapter.restore_queues(waiting=[], running=running)
-
- assert adapter.restore_called is True
- assert "req-B" in running
diff --git a/tests/core/sched/test_omni_scheduler_mixin.py b/tests/core/sched/test_omni_scheduler_mixin.py
deleted file mode 100644
index e04a9c39fbc..00000000000
--- a/tests/core/sched/test_omni_scheduler_mixin.py
+++ /dev/null
@@ -1,129 +0,0 @@
-"""Unit tests for OmniSchedulerMixin streaming session replacement.
-
-These tests pin the behavior of `_replace_session_with_streaming_update` against
-current vLLM `Request` / `StreamingUpdate` (and Omni patches). When upgrading
-vLLM, failures here should highlight incompatible changes to request state or
-update payloads early.
-"""
-
-from __future__ import annotations
-
-from dataclasses import replace
-
-import pytest
-
-# Imports must run in this order: vllm_omni applies patches to vllm.v1.request before
-# Request / StreamingUpdate are bound in this module. Ruff isort would reorder them.
-# isort: off
-import vllm_omni # noqa: F401 - import for side effects (patch vLLM)
-from vllm.sampling_params import SamplingParams
-from vllm.v1.engine import EngineCoreEventType
-from vllm.v1.request import Request, RequestStatus, StreamingUpdate
-from vllm_omni.core.sched.omni_scheduler_mixin import OmniSchedulerMixin
-
-# isort: on
-
-pytestmark = [pytest.mark.core_model, pytest.mark.cpu]
-
-
-class _SchedulerStub(OmniSchedulerMixin):
- """Minimal scheduler surface required by OmniSchedulerMixin."""
-
- def __init__(self, *, log_stats: bool = False) -> None:
- self.num_waiting_for_streaming_input = 0
- self.log_stats = log_stats
-
-
-def _make_request(**kwargs) -> Request:
- sp = SamplingParams(max_tokens=8)
- defaults = dict(
- request_id="req-mixin-test",
- prompt_token_ids=[1, 2, 3],
- sampling_params=sp,
- pooling_params=None,
- arrival_time=100.0,
- block_hasher=None,
- )
- defaults.update(kwargs)
- return Request(**defaults)
-
-
-def _make_update(**kwargs) -> StreamingUpdate:
- sp_new = SamplingParams(max_tokens=16)
- defaults = dict(
- mm_features=None,
- prompt_token_ids=[10, 20],
- max_tokens=32,
- arrival_time=200.0,
- sampling_params=sp_new,
- )
- defaults.update(kwargs)
- return StreamingUpdate(**defaults)
-
-
-class TestReplaceSessionWithStreamingUpdate:
- def test_resets_tokens_and_prompt_from_update(self) -> None:
- sched = _SchedulerStub()
- session = _make_request()
- session.append_output_token_ids([7, 8])
- session.num_computed_tokens = 99
- session.status = RequestStatus.WAITING_FOR_STREAMING_REQ
-
- update = _make_update(prompt_token_ids=[40, 41, 42])
- sched.num_waiting_for_streaming_input = 3
- sched._replace_session_with_streaming_update(session, update)
-
- assert session._output_token_ids == []
- assert list(session._all_token_ids) == [40, 41, 42]
- assert session.prompt_token_ids == [40, 41, 42]
- assert session.num_computed_tokens == 0
- assert session.num_prompt_tokens == 3
- assert session.arrival_time == 200.0
- assert session.sampling_params is update.sampling_params
- assert session.status == RequestStatus.WAITING
- assert sched.num_waiting_for_streaming_input == 2
-
- def test_none_prompt_token_ids_becomes_empty(self) -> None:
- sched = _SchedulerStub()
- session = _make_request()
- session.status = RequestStatus.RUNNING
- update = _make_update(prompt_token_ids=None)
- sched._replace_session_with_streaming_update(session, update)
-
- assert session.prompt_token_ids == ()
- assert list(session._all_token_ids) == []
- assert session.num_prompt_tokens == 0
- assert sched.num_waiting_for_streaming_input == 0
-
- def test_additional_information_cleared_when_update_omits_it(self) -> None:
- sched = _SchedulerStub()
- session = _make_request()
- if not hasattr(session, "additional_information"):
- pytest.skip("Request has no additional_information (Omni patch inactive?)")
- session.additional_information = {"keep": True}
- session.status = RequestStatus.RUNNING
-
- base = _make_update()
- if not hasattr(base, "additional_information"):
- pytest.skip("StreamingUpdate has no additional_information (Omni patch inactive?)")
- update = replace(base, additional_information=None)
-
- sched._replace_session_with_streaming_update(session, update)
- assert session.additional_information is None
-
- def test_does_not_decrement_waiting_when_not_streaming_status(self) -> None:
- sched = _SchedulerStub()
- session = _make_request()
- session.status = RequestStatus.RUNNING
- sched.num_waiting_for_streaming_input = 5
- sched._replace_session_with_streaming_update(session, _make_update())
- assert sched.num_waiting_for_streaming_input == 5
-
- def test_records_queued_event_when_log_stats_enabled(self) -> None:
- sched = _SchedulerStub(log_stats=True)
- session = _make_request()
- session.status = RequestStatus.WAITING_FOR_STREAMING_REQ
- sched._replace_session_with_streaming_update(session, _make_update())
-
- assert session.events
- assert session.events[-1].type == EngineCoreEventType.QUEUED
diff --git a/tests/core/test_prefix_cache.py b/tests/core/test_prefix_cache.py
deleted file mode 100644
index b5d0e96d305..00000000000
--- a/tests/core/test_prefix_cache.py
+++ /dev/null
@@ -1,349 +0,0 @@
-import pytest
-import torch
-
-from vllm_omni.core.prefix_cache import OmniTensorPrefixCache
-
-DEFAULT_SEQ_LEN = 15
-NUM_BLOCKS = 10
-BLOCK_SIZE = 4
-HIDDEN_SIZE = 2
-DTYPE = torch.float32
-OTHER_DTYPE = torch.float16
-DEFAULT_SHAPE = torch.Size([NUM_BLOCKS, BLOCK_SIZE, HIDDEN_SIZE])
-
-
-class MockInputBatch:
- def __init__(self, num_computed_tokens_cpu):
- self.req_ids = ["req1", "req2"]
- self.req_id_to_index = {req_id: i for i, req_id in enumerate(self.req_ids)}
- self.num_computed_tokens_cpu = num_computed_tokens_cpu
-
- # Block table is only mocked for validation of length;
- # we don't actually need to add valid values here since
- # we patch the table when testing.
- class _DummyBlockTable:
- pass
-
- self.block_table = _DummyBlockTable()
- self.block_table.block_tables = [None]
-
-
-def get_omni_pcache_with_mm_tensors(feat_dims, seq_len) -> OmniTensorPrefixCache:
- """Build an OmniTensorPrefixCache and init mm tensors."""
- cache = get_omni_pcache()
- mm_outputs = get_multimodal_outputs(feat_dims, seq_len)
- cache.maybe_init_missing_mm_cache_keys(mm_outputs, seq_len)
- return cache
-
-
-def get_omni_pcache() -> OmniTensorPrefixCache:
- """Build an OmniTensorPrefixCache, but don't init mm tensors."""
- cache = OmniTensorPrefixCache(
- num_blocks=NUM_BLOCKS,
- block_size=BLOCK_SIZE,
- hidden_size=HIDDEN_SIZE,
- hs_dtype=DTYPE,
- )
- return cache
-
-
-def get_multimodal_outputs(feat_dims: dict[str, int], seq_len: int) -> dict[str, torch.Tensor]:
- fake_mm_inputs = {}
- for mm_key, feat_dim in feat_dims.items():
- fake_mm_inputs[mm_key] = torch.rand((seq_len, feat_dim), dtype=DTYPE)
- return fake_mm_inputs
-
-
-### Tests for initialization
-def test_initialization_simple():
- """Check default initialization only creates the hidden states."""
- cache = get_omni_pcache()
- assert isinstance(cache.hidden_states_cache, torch.Tensor)
- assert cache.hidden_states_cache.shape == DEFAULT_SHAPE
- assert len(cache.mm_outputs_cache) == 0
- assert len(cache.mm_cache_keys) == 0
-
-
-def test_initialization_with_multimodal():
- """Check initialization + registration of multimodal outputs."""
- cache = get_omni_pcache()
- feat_dims = {"foo": 100, "bar": 50, "baz": 10}
- mm_outputs = get_multimodal_outputs(
- feat_dims,
- seq_len=DEFAULT_SEQ_LEN,
- )
- # Cast one of the keys to a different dtype; the dtype of the tensor
- # that is used to initialize the cache dictates the cache dtype.
- mm_outputs["foo"] = mm_outputs["foo"].to(OTHER_DTYPE)
-
- cache.maybe_init_missing_mm_cache_keys(mm_outputs, DEFAULT_SEQ_LEN)
- assert len(cache.mm_cache_keys) == 3
- assert set(cache.mm_cache_keys) == set(feat_dims.keys())
- for mm_key in cache.mm_cache_keys:
- cache_tensor = cache.mm_outputs_cache[mm_key]
- assert isinstance(cache_tensor, torch.Tensor)
- assert cache_tensor.shape[-1] == feat_dims[mm_key]
- assert mm_outputs[mm_key].dtype == cache_tensor.dtype
-
-
-def test_init_missing_mm_cache_keys_is_idempotent():
- """Ensure that the cache doesn't reinitialize old keys."""
- cache = get_omni_pcache()
- mm_key = "foo"
- feat_dims = {mm_key: 100}
- mm_outputs = get_multimodal_outputs(
- feat_dims,
- seq_len=DEFAULT_SEQ_LEN,
- )
- cache.maybe_init_missing_mm_cache_keys(mm_outputs, DEFAULT_SEQ_LEN)
- assert len(cache.mm_cache_keys) == 1
- assert mm_key in cache.mm_cache_keys
-
- # Cache is initialized to 0 - fill it with 1s
- cache.mm_outputs_cache[mm_key].fill_(1)
-
- # Ensure that running another initialization
- # doesn't zero out our cache values
- cache.maybe_init_missing_mm_cache_keys(mm_outputs, DEFAULT_SEQ_LEN)
- assert len(cache.mm_cache_keys) == 1
- assert mm_key in cache.mm_cache_keys
- assert torch.all(cache.mm_outputs_cache[mm_key] == 1)
-
-
-### Tests for Update
-def test_update_no_multimodal():
- """Test that slot mappings act as row indices hidden states."""
- cache = get_omni_pcache()
-
- num_tokens_unpadded = 8
- slot_offset = 8
- slot_mapping = torch.arange(slot_offset, slot_offset + num_tokens_unpadded)
- new_hidden_states = torch.rand((num_tokens_unpadded, HIDDEN_SIZE), dtype=DTYPE)
-
- cache.update_omni_tensor_prefix_cache(
- hidden_states=new_hidden_states,
- multimodal_outputs=None,
- num_tokens_unpadded=num_tokens_unpadded,
- slot_mapping=slot_mapping,
- )
-
- # Ensure that if we reshape our 3D cache back to 2D, we can use the
- # indices in our slot mappings to access the hidden states as expected
- hs_rows = cache.hidden_states_cache.view(NUM_BLOCKS * BLOCK_SIZE, HIDDEN_SIZE)
- for slot_idx, new_states in zip(slot_mapping, new_hidden_states):
- slot_states = hs_rows[slot_idx]
- assert torch.all(slot_states == new_states)
-
-
-@pytest.mark.parametrize(
- "feat_dims",
- [
- {"foo": 100, "bar": 100},
- {"foo": 100, "bar": 50, "baz": 10},
- ],
-)
-def test_update_with_multimodal_outputs(feat_dims):
- """Test that slot mappings are correct for multimodal tensors."""
- cache = get_omni_pcache_with_mm_tensors(feat_dims, seq_len=DEFAULT_SEQ_LEN)
-
- num_tokens_unpadded = 8
- slot_offset = 8
- slot_mapping = torch.arange(slot_offset, slot_offset + num_tokens_unpadded)
- feature_dims = {key: val.shape[-1] for key, val in cache.mm_outputs_cache.items()}
- mm_outputs = {key: torch.rand((num_tokens_unpadded, feature_dims[key]), dtype=DTYPE) for key in cache.mm_cache_keys}
- cache.update_omni_tensor_prefix_cache(
- hidden_states=None,
- multimodal_outputs=mm_outputs,
- num_tokens_unpadded=num_tokens_unpadded,
- slot_mapping=slot_mapping,
- )
-
- for mm_key in feat_dims.keys():
- assert mm_key in cache.mm_outputs_cache
- key_feat_dim = feature_dims[mm_key]
- mm_state_rows = cache.mm_outputs_cache[mm_key].view(NUM_BLOCKS * BLOCK_SIZE, key_feat_dim)
-
- # Similar to hidden states, but for each key in the dict;
- # Different tensors may have different feature dims
- new_mm_outputs = mm_outputs[mm_key]
- for slot_idx, new_output in zip(slot_mapping, new_mm_outputs):
- slot_states = mm_state_rows[slot_idx]
- assert torch.all(slot_states == new_output)
-
-
-### Tests for Merging
-def fake_get_cached_block_ids(self, req_idx, *args, **kwargs):
- """Fake block table lookup.
-
- Assumption:
- req_idx 0 is a cache hit with slots 8, 9, ..., 15
- req_idx 1 is a cache miss
- """
- assert req_idx < 2
- if req_idx == 0:
- # With the slot offset we provided (8), the corresponding
- # blocks IDs are 2 & 3 because the block size is 4.
- return torch.tensor([2, 3], dtype=torch.long)
- return torch.tensor([], dtype=torch.long)
-
-
-@pytest.mark.parametrize("num_tokens_padded", [None, 16])
-def test_get_merged_hidden_states(num_tokens_padded, mocker):
- """Ensure that hidden states are merged correctly."""
- cache = get_omni_pcache()
-
- orig_num_tokens_unpadded = 8
- slot_offset = 8 # We'll put our states in slots 8, 9, 10, ..., 15
- orig_slot_mapping = torch.arange(slot_offset, slot_offset + orig_num_tokens_unpadded)
- orig_hidden_states = torch.rand((orig_num_tokens_unpadded, HIDDEN_SIZE), dtype=DTYPE)
-
- cache.update_omni_tensor_prefix_cache(
- hidden_states=orig_hidden_states,
- multimodal_outputs=None,
- num_tokens_unpadded=orig_num_tokens_unpadded,
- slot_mapping=orig_slot_mapping,
- num_tokens_padded=num_tokens_padded,
- )
-
- # Say that we have two requests, but only one of them is a cache hit
- num_new_toks_req1 = 3
- num_new_toks_req2 = 2
- cache.add_prefix_cached_new_req_id("req1")
-
- num_scheduled_tokens = {
- "req1": num_new_toks_req1,
- "req2": num_new_toks_req2,
- }
- new_hidden_states = torch.rand(
- (num_new_toks_req1 + num_new_toks_req2, HIDDEN_SIZE),
- dtype=DTYPE,
- )
- req1_new_states = new_hidden_states[:num_new_toks_req1]
- req2_new_states = new_hidden_states[-num_new_toks_req2:]
-
- input_batch = MockInputBatch(num_computed_tokens_cpu=torch.Tensor([orig_num_tokens_unpadded, 0]))
-
- mocker.patch(
- "vllm_omni.core.prefix_cache.OmniTensorPrefixCache._get_cached_block_ids",
- new=fake_get_cached_block_ids,
- )
- merged_states = cache.get_merged_hidden_states(
- query_start_loc=[0, num_new_toks_req1],
- input_batch=input_batch,
- hidden_states=new_hidden_states,
- num_scheduled_tokens=num_scheduled_tokens,
- )
-
- assert "req1" in merged_states and "req2" in merged_states
- req1_merged_states = merged_states["req1"]
- req2_merged_states = merged_states["req2"]
-
- # First, check the cache hit case
- assert req1_merged_states.shape == torch.Size([orig_num_tokens_unpadded + num_new_toks_req1, HIDDEN_SIZE])
- # Ensure that the req1 merged states are the cached states + the new req1 states
- assert torch.all(req1_merged_states[:orig_num_tokens_unpadded] == orig_hidden_states)
- assert torch.all(req1_merged_states[-num_new_toks_req1:] == req1_new_states)
-
- # Next, ensure that the cache miss case only has the new states
- assert req2_merged_states.shape == torch.Size([num_new_toks_req2, HIDDEN_SIZE])
- assert torch.all(req2_merged_states == req2_new_states)
-
-
-@pytest.mark.parametrize("num_tokens_padded", [None, 16])
-@pytest.mark.parametrize(
- "feat_dims",
- [
- {"foo": 100, "bar": 100},
- {"foo": 100, "bar": 50, "baz": 10},
- ],
-)
-def test_get_merged_multimodal_outputs(feat_dims, num_tokens_padded, mocker):
- cache = get_omni_pcache_with_mm_tensors(feat_dims, seq_len=DEFAULT_SEQ_LEN)
-
- orig_num_tokens_unpadded = 8
- slot_offset = 8 # We'll put our states in slots 8, 9, 10, ..., 15
- orig_slot_mapping = torch.arange(slot_offset, slot_offset + orig_num_tokens_unpadded)
- feature_dims = {key: val.shape[-1] for key, val in cache.mm_outputs_cache.items()}
- orig_mm_outputs = {
- key: torch.rand((orig_num_tokens_unpadded, feature_dims[key]), dtype=DTYPE) for key in cache.mm_cache_keys
- }
-
- cache.update_omni_tensor_prefix_cache(
- hidden_states=None,
- multimodal_outputs=orig_mm_outputs,
- num_tokens_unpadded=orig_num_tokens_unpadded,
- slot_mapping=orig_slot_mapping,
- num_tokens_padded=num_tokens_padded,
- )
-
- # Similar to hs test- say that we have two requests, but only one of them is a cache hit
- num_new_toks_req1 = 3
- num_new_toks_req2 = 2
- cache.add_prefix_cached_new_req_id("req1")
-
- num_scheduled_tokens = {
- "req1": num_new_toks_req1,
- "req2": num_new_toks_req2,
- }
-
- new_mm_outputs = {}
- for mm_key in cache.mm_cache_keys:
- new_mm_outputs[mm_key] = torch.rand(
- (num_new_toks_req1 + num_new_toks_req2, feature_dims[mm_key]),
- dtype=DTYPE,
- )
- # We also want to make sure passthrough data (outside of our keys) isn't dropped
- new_mm_outputs["passthrough_data"] = "Something else"
- # Lists are a special case because we can't split them yet if we want to match
- # the nonprefix cache behavior, because this runs before post process.
- new_mm_outputs["passthrough_list"] = ["should", "not", "split"]
-
- input_batch = MockInputBatch(num_computed_tokens_cpu=torch.Tensor([orig_num_tokens_unpadded, 0]))
-
- mocker.patch(
- "vllm_omni.core.prefix_cache.OmniTensorPrefixCache._get_cached_block_ids",
- new=fake_get_cached_block_ids,
- )
- merged_mm_outputs = cache.get_merged_multimodal_states(
- query_start_loc=[0, num_new_toks_req1],
- input_batch=input_batch,
- multimodal_outputs=new_mm_outputs,
- num_scheduled_tokens=num_scheduled_tokens,
- )
-
- # Ensure the passthrough data wasn't dropped
- assert "passthrough_data" in merged_mm_outputs
- assert "passthrough_list" in merged_mm_outputs
-
- for mm_key, mm_output in merged_mm_outputs.items():
- # Ensure passthrough data is just forwarded normally and not duplicated
- assert isinstance(mm_output, dict)
- assert "req1" in mm_output and "req2" in mm_output
- if mm_key == "passthrough_data":
- assert mm_key not in cache.mm_cache_keys
- assert new_mm_outputs[mm_key] == mm_output["req1"]
- assert new_mm_outputs[mm_key] == mm_output["req2"]
- elif mm_key == "passthrough_list":
- assert mm_key not in cache.mm_cache_keys
- assert new_mm_outputs[mm_key] == mm_output["req1"]
- assert new_mm_outputs[mm_key] == mm_output["req2"]
- else:
- assert mm_key in cache.mm_cache_keys
- curr_feat_dim = feature_dims[mm_key]
- # Ensure that req1 (cache hit) merged the mm data
- req1_merged_mm_outputs = mm_output["req1"]
- req1_new_mm_outputs = new_mm_outputs[mm_key][:num_new_toks_req1]
-
- assert req1_merged_mm_outputs.shape == torch.Size(
- [orig_num_tokens_unpadded + num_new_toks_req1, curr_feat_dim]
- )
- # Ensure that the req1 merged mm data are the cached data + the new data
- assert torch.all(req1_merged_mm_outputs[:orig_num_tokens_unpadded] == orig_mm_outputs[mm_key])
- assert torch.all(req1_merged_mm_outputs[-num_new_toks_req1:] == req1_new_mm_outputs)
-
- # Ensure that req2 (cache miss) only has the new mm data
- req2_merged_mm_outputs = mm_output["req2"]
- req2_new_mm_outputs = new_mm_outputs[mm_key][-num_new_toks_req2:]
-
- assert req2_merged_mm_outputs.shape == torch.Size([num_new_toks_req2, curr_feat_dim])
- assert torch.all(req2_merged_mm_outputs == req2_new_mm_outputs)
diff --git a/tests/dfx/conftest.py b/tests/dfx/conftest.py
deleted file mode 100644
index 29bb33302a7..00000000000
--- a/tests/dfx/conftest.py
+++ /dev/null
@@ -1,412 +0,0 @@
-import json
-import os
-import re
-import subprocess
-import time
-from datetime import datetime
-from pathlib import Path
-from typing import Any
-
-import pytest
-
-from tests.dfx.reliability.helpers import list_remote_process_pids_by_pattern, post_chat_completions_raw
-from tests.helpers.runtime import OmniServerParams
-from tests.helpers.stage_config import modify_stage_config
-from vllm_omni.platforms import current_omni_platform
-
-
-def load_configs(config_path: str) -> list[dict[str, Any]]:
- try:
- abs_path = Path(config_path).resolve()
- with open(abs_path, encoding="utf-8") as f:
- configs = json.load(f)
-
- return configs
-
- except json.JSONDecodeError as e:
- raise ValueError(f"JSON parsing error: {str(e)}")
- except FileNotFoundError:
- raise ValueError(f"Configuration file not found: {config_path}")
- except Exception as e:
- raise RuntimeError(f"Failed to load configuration file: {str(e)}")
-
-
-def modify_stage(default_path: str, updates: dict[str, Any] | None, deletes: dict[str, Any] | None) -> str:
- kwargs: dict[str, Any] = {}
- if updates is not None:
- kwargs["updates"] = updates
- if deletes is not None:
- kwargs["deletes"] = deletes
- if kwargs:
- return modify_stage_config(default_path, **kwargs)
- return default_path
-
-
-def _build_serve_args(serve_args: Any) -> list[str]:
- """Convert server_params.serve_args to a flat CLI args list."""
- if serve_args is None:
- return []
- if isinstance(serve_args, list):
- return [str(item) for item in serve_args]
- if not isinstance(serve_args, dict):
- raise TypeError(f"serve_args must be dict/list/None, got {type(serve_args).__name__}")
-
- args: list[str] = []
- for key, value in serve_args.items():
- flag = f"--{str(key).replace('_', '-')}"
- if isinstance(value, bool):
- if value:
- args.append(flag)
- continue
- if value is None:
- continue
- if isinstance(value, (dict, list)):
- args.extend([flag, json.dumps(value, ensure_ascii=False, separators=(",", ":"))])
- continue
- args.extend([flag, str(value)])
- return args
-
-
-def create_unique_server_params(
- configs: list[dict[str, Any]],
- stage_configs_dir: Path,
-) -> list[tuple[str, str, str | None, str | None, tuple[str, ...]]]:
- """Return one row per unique server configuration (same 5-tuple shape as upstream).
-
- ``(test_name, model, deploy_yaml_path, stage_overrides_json, extra_cli_args)``.
-
- JSON ``server_params.serve_args`` (dict/list) is expanded via ``_build_serve_args``
- and **prepended** to ``extra_cli_args`` so perf / stability ``omni_server`` fixtures
- stay identical to main while still honoring ``serve_args`` in benchmark JSON.
- """
- unique_params: list[tuple[str, str, str | None, str | None, tuple[str, ...]]] = []
- seen: set[tuple[str, str, str | None, str | None, tuple[str, ...]]] = set()
- for config in configs:
- test_name = config["test_name"]
- server_params = config["server_params"]
- model = server_params["model"]
- stage_config_name = server_params.get("stage_config_name")
- if stage_config_name:
- stage_config_path = str(stage_configs_dir / stage_config_name)
- delete = server_params.get("delete", None)
- update = server_params.get("update", None)
- stage_config_path = modify_stage(stage_config_path, update, delete)
- else:
- stage_config_path = None
-
- stage_overrides = server_params.get("stage_overrides")
- stage_overrides_json = json.dumps(stage_overrides) if stage_overrides else None
-
- # ``extra_cli_args`` passes raw CLI flags straight through to
- # ``vllm_omni.entrypoints.cli.main serve`` — used for flags that
- # don't map to stage-level overrides, e.g. ``--async-chunk`` /
- # ``--no-async-chunk`` toggling the deploy-level async_chunk bool.
- serve_flat = _build_serve_args(server_params.get("serve_args"))
- raw_extra = tuple(server_params.get("extra_cli_args") or ())
- extra_cli_args = tuple(serve_flat) + raw_extra
-
- server_param = (test_name, model, stage_config_path, stage_overrides_json, extra_cli_args)
- if server_param not in seen:
- seen.add(server_param)
- unique_params.append(server_param)
-
- return unique_params
-
-
-def configs_with_platform_stage_configs(configs: list[dict[str, Any]]) -> list[dict[str, Any]]:
- """Resolve stage config for XPU vs CUDA/ROCm."""
- out: list[dict[str, Any]] = []
- for config in configs:
- config_copy = json.loads(json.dumps(config))
- if current_omni_platform.is_xpu():
- config_copy["server_params"]["stage_config_name"] = "xpu/qwen3_omni_ci.yaml"
- out.append(config_copy)
- return out
-
-
-def extract_server_args_by_test_name(configs: list[dict[str, Any]]) -> dict[str, list[str] | None]:
- mapping: dict[str, list[str] | None] = {}
- for cfg in configs:
- test_name = str(cfg.get("test_name"))
- server_params = cfg.get("server_params") or {}
- raw_args = server_params.get("server_args")
- mapping[test_name] = [str(item) for item in raw_args] if isinstance(raw_args, list) else None
- return mapping
-
-
-def create_reliability_omni_server_params(
- configs: list[dict[str, Any]], stage_configs_dir: Path
-) -> list[OmniServerParams]:
- adjusted_configs = configs_with_platform_stage_configs(configs)
- unique_params = create_unique_server_params(adjusted_configs, stage_configs_dir)
- server_args_by_name = extract_server_args_by_test_name(adjusted_configs)
- return [
- OmniServerParams(
- model=model,
- stage_config_path=stage_config_path,
- server_args=server_args_by_name.get(test_name),
- )
- for test_name, model, stage_config_path, _stage_overrides_json, _extra_cli_args in unique_params
- ]
-
-
-def supports_video_generation(model_name: str) -> bool:
- lower = model_name.lower()
- return any(key in lower for key in ("wan", "video", "i2v", "t2v"))
-
-
-def supports_chat_generation(model_name: str) -> bool:
- return not supports_video_generation(model_name)
-
-
-def parse_stage_devices(stage_config_path: str) -> str:
- text = Path(stage_config_path).read_text(encoding="utf-8")
- raw_devices: list[str] = re.findall(r"^\s*devices:\s*\"?([0-9,\s]+)\"?\s*$", text, flags=re.MULTILINE)
- devices: set[int] = set()
- for item in raw_devices:
- for token in item.split(","):
- token = token.strip()
- if token:
- devices.add(int(token))
- if not devices:
- raise ValueError(f"No runtime.devices found in stage config: {stage_config_path}")
- return ",".join(str(x) for x in sorted(devices))
-
-
-def resolve_oom_device_spec(config: dict[str, Any], stage_config_path: str | None) -> str:
- explicit = config.get("device")
- if explicit is not None:
- return str(explicit)
- if not stage_config_path:
- return "0"
- return parse_stage_devices(stage_config_path)
-
-
-def assert_fault_exception(exc: Exception, error_keywords: tuple[str, ...]) -> None:
- text = str(exc).lower()
- assert any(key in text for key in error_keywords), f"unexpected error under fault injection: {exc}"
-
-
-def wait_chat_request_ready(host: str, port: int, model: str, timeout_sec: int = 180) -> None:
- """Poll a minimal chat request until success."""
- deadline = time.time() + timeout_sec
- payload = json.dumps(
- {
- "model": model,
- "messages": [{"role": "user", "content": "Say hello in one short sentence."}],
- "stream": False,
- "modalities": ["text"],
- }
- )
- last_error: str | None = None
- while time.time() < deadline:
- try:
- status, body = post_chat_completions_raw(host, port, payload)
- if status == 200:
- return
- last_error = f"http={status} body={body[:200]!r}"
- except Exception as exc: # noqa: BLE001
- last_error = str(exc)
- time.sleep(2)
- raise TimeoutError(f"runtime-teardown warmup request did not succeed within {timeout_sec}s: {last_error}")
-
-
-def assert_no_extra_worker_processes(
- baseline_pids: set[int],
- worker_pattern: str,
- timeout_sec: int = 60,
-) -> None:
- """Ensure no extra worker PIDs remain after teardown."""
- deadline = time.time() + timeout_sec
- while time.time() < deadline:
- current = set(list_remote_process_pids_by_pattern(worker_pattern))
- extra = current - baseline_pids
- if not extra:
- return
- time.sleep(2)
- current = set(list_remote_process_pids_by_pattern(worker_pattern))
- extra = sorted(current - baseline_pids)
- assert not extra, f"orphan worker processes remain after container teardown: {extra}"
-
-
-def create_test_parameter_mapping(configs: list[dict[str, Any]]) -> dict[str, dict]:
- mapping = {}
- for config in configs:
- test_name = config["test_name"]
- if test_name not in mapping:
- mapping[test_name] = {
- "test_name": test_name,
- "benchmark_params": [],
- }
- for entry in config["benchmark_params"]:
- # Skip disabled entries
- if not entry.get("enabled", True):
- continue
- mapping[test_name]["benchmark_params"].append(entry)
- return mapping
-
-
-def get_benchmark_params_for_server(test_name: str, server_to_benchmark_mapping: dict[str, dict]) -> list:
- if test_name not in server_to_benchmark_mapping:
- return []
- return server_to_benchmark_mapping[test_name]["benchmark_params"]
-
-
-def create_benchmark_indices(
- benchmark_configs: list[dict[str, Any]],
- server_to_benchmark_mapping: dict[str, dict],
-) -> list[tuple[str, int]]:
- indices = []
- seen = set()
- for config in benchmark_configs:
- test_name = config["test_name"]
- if test_name not in seen:
- seen.add(test_name)
- params_list = get_benchmark_params_for_server(test_name, server_to_benchmark_mapping)
- for idx in range(len(params_list)):
- indices.append((test_name, idx))
-
- return indices
-
-
-def _safe_filename_token(value: Any | None, *, default: str = "na") -> str:
- """Make a single path segment safe for result filenames on common filesystems."""
- if value is None:
- return default
- s = str(value).strip()
- for bad in ("/", "\\", ":", "*", "?", '"', "<", ">", "|"):
- s = s.replace(bad, "_")
- return s if s else default
-
-
-def _resolve_baseline_value(
- baseline_raw: Any,
- *,
- sweep_index: int | None,
- max_concurrency: Any = None,
- request_rate: Any = None,
-) -> Any:
- """Pick the baseline threshold for this sweep step."""
- if baseline_raw is None:
- return 100000
- if isinstance(baseline_raw, dict):
- if max_concurrency is not None:
- for key in (max_concurrency, str(max_concurrency)):
- if key in baseline_raw:
- return baseline_raw[key]
- if request_rate is not None:
- for key in (request_rate, str(request_rate)):
- if key in baseline_raw:
- return baseline_raw[key]
- raise KeyError(
- f"baseline dict has no key for max_concurrency={max_concurrency!r} "
- f"or request_rate={request_rate!r}; keys={list(baseline_raw.keys())!r}"
- )
- if isinstance(baseline_raw, (list, tuple)):
- if sweep_index is None:
- raise ValueError("list baseline requires sweep_index")
- if not (0 <= sweep_index < len(baseline_raw)):
- raise IndexError(f"baseline list len={len(baseline_raw)} has no index {sweep_index}")
- return baseline_raw[sweep_index]
- return baseline_raw
-
-
-def _baseline_thresholds_for_step(
- baseline_data: dict[str, Any],
- *,
- sweep_index: int | None = None,
- max_concurrency: Any = None,
- request_rate: Any = None,
-) -> dict[str, Any]:
- """Resolve baseline config to one threshold per metric for this iteration."""
- return {
- metric_name: _resolve_baseline_value(
- baseline_raw,
- sweep_index=sweep_index,
- max_concurrency=max_concurrency,
- request_rate=request_rate,
- )
- for metric_name, baseline_raw in baseline_data.items()
- }
-
-
-def run_benchmark(
- args: list[str],
- test_name: str,
- flow: Any,
- dataset_name: str,
- num_prompt: int,
- *,
- baseline_config: dict[str, Any] | None = None,
- sweep_index: int | None = None,
- request_rate: Any | None = None,
- max_concurrency: Any | None = None,
- random_input_len: Any | None = None,
- random_output_len: Any | None = None,
-) -> dict[str, Any]:
- """Run one ``vllm bench serve --omni`` iteration and return parsed metrics."""
- current_dt = datetime.now().strftime("%Y%m%d-%H%M%S")
- ri = _safe_filename_token(random_input_len)
- ro = _safe_filename_token(random_output_len)
- result_filename = f"result_{test_name}_{dataset_name}_{flow}_{num_prompt}_in{ri}_out{ro}_{current_dt}.json"
- if "--result-filename" in args:
- print(f"The result file will be overwritten by {result_filename}")
- command = (
- ["vllm", "bench", "serve", "--omni"]
- + args
- + [
- "--num-warmups",
- "2",
- "--save-result",
- "--result-dir",
- os.environ.get("BENCHMARK_DIR", "tests"),
- "--result-filename",
- result_filename,
- ]
- )
- process = subprocess.Popen(
- command, stdout=subprocess.PIPE, stderr=subprocess.PIPE, text=True, bufsize=1, universal_newlines=True
- )
-
- for line in iter(process.stdout.readline, ""):
- print(line, end=" ")
-
- for line in iter(process.stderr.readline, ""):
- print(line, end=" ")
-
- if "--result-dir" in command:
- index = command.index("--result-dir")
- result_dir = command[index + 1]
- else:
- result_dir = "./"
-
- result_path = os.path.join(result_dir, result_filename)
- with open(result_path, encoding="utf-8") as f:
- result = json.load(f)
-
- if baseline_config:
- result["baseline"] = _baseline_thresholds_for_step(
- baseline_config,
- sweep_index=sweep_index,
- request_rate=request_rate,
- max_concurrency=max_concurrency,
- )
- else:
- result["baseline"] = {}
- if random_input_len is not None:
- result["random_input_len"] = random_input_len
- if random_output_len is not None:
- result["random_output_len"] = random_output_len
- with open(result_path, "w", encoding="utf-8") as f:
- json.dump(result, f, ensure_ascii=False, indent=2)
- return result
-
-
-def pytest_addoption(parser: pytest.Parser) -> None:
- """Register shared CLI options for DFX benchmark suites."""
- parser.addoption(
- "--test-config-file",
- action="store",
- default=None,
- help=("Path to benchmark config JSON. Example: --test-config-file tests/dfx/perf/tests/test_tts.json"),
- )
diff --git a/tests/dfx/perf/scripts/diffusion_result_template.json b/tests/dfx/perf/scripts/diffusion_result_template.json
deleted file mode 100644
index 86bdf1bc7aa..00000000000
--- a/tests/dfx/perf/scripts/diffusion_result_template.json
+++ /dev/null
@@ -1,86 +0,0 @@
-[
- {
- "test_name": null,
- "backend": null,
- "timestamp": null,
- "server_params": {
- "model": null,
- "serve_args": {
- "enable-diffusion-pipeline-profiler": false
- }
- },
- "benchmark_params": {
- "name": null,
- "dataset": null,
- "task": null,
- "width": 0,
- "height": 0,
- "num-inference-steps": 0,
- "num-prompts": 0,
- "max-concurrency": 0,
- "num-input-images": 0,
- "enable-negative-prompt": false,
- "baseline": {
- "throughput_qps": 0,
- "latency_mean": 0,
- "peak_memory_mb_max": 0,
- "peak_memory_mb_mean": 0
- }
- },
- "result": {
- "duration": 0,
- "completed_requests": 0,
- "failed_requests": 0,
- "throughput_qps": 0,
- "latency_mean": 0,
- "latency_median": 0,
- "latency_p99": 0,
- "latency_p95": 0,
- "latency_p50": 0,
- "peak_memory_mb_max": 0,
- "peak_memory_mb_mean": 0,
- "peak_memory_mb_median": 0,
- "stage_durations_mean": {},
- "stage_durations_p50": {},
- "stage_durations_p99": {},
- "backend": null,
- "model": null,
- "dataset": null,
- "task": null
- },
- "log_file": null,
- "Model": null,
- "Framework": null,
- "Hardware": null,
- "Deployment": null,
- "Task": null,
- "Dataset": null,
- "resolution": null,
- "Parallelism": null,
- "max_concurrency": 0,
- "Cache": null,
- "Quantization": null,
- "offload": null,
- "compile": null,
- "Attn_backend": null,
- "num_inference_steps": 0,
- "completed": 0,
- "failed": 0,
- "throughput_qps": 0,
- "latency_mean": 0,
- "latency_median": 0,
- "latency_p99": 0,
- "latency_p95": 0,
- "latency_p50": 0,
- "peak_memory_mb_max": 0,
- "peak_memory_mb_mean": 0,
- "peak_memory_mb_median": 0,
- "stage_durations_mean": {},
- "stage_durations_p50": {},
- "stage_durations_p99": {},
- "commit_sha": null,
- "build_id": null,
- "build_url": null,
- "source_file": null
- }
-]
diff --git a/tests/dfx/perf/scripts/result_omni_template.json b/tests/dfx/perf/scripts/result_omni_template.json
deleted file mode 100644
index 1d61321407e..00000000000
--- a/tests/dfx/perf/scripts/result_omni_template.json
+++ /dev/null
@@ -1,55 +0,0 @@
-{
- "date": null,
- "endpoint_type": null,
- "backend": null,
- "label": null,
- "model_id": null,
- "tokenizer_id": null,
- "num_prompts": 0,
- "request_rate": null,
- "burstiness": 0,
- "max_concurrency": 0,
- "duration": 0,
- "completed": 0,
- "failed": 0,
- "total_input_tokens": 0,
- "total_output_tokens": 0,
- "request_throughput": 0,
- "request_goodput": null,
- "output_throughput": 0,
- "total_token_throughput": 0,
- "total_audio_duration_s": 0,
- "total_audio_frames": 0,
- "audio_throughput": 0,
- "max_output_tokens_per_s": 0,
- "max_concurrent_requests": 0,
- "rtfx": 0,
- "mean_ttft_ms": 0,
- "median_ttft_ms": 0,
- "p99_ttft_ms": 0,
- "mean_tpot_ms": 0,
- "median_tpot_ms": 0,
- "p99_tpot_ms": 0,
- "mean_itl_ms": 0,
- "median_itl_ms": 0,
- "p99_itl_ms": 0,
- "mean_e2el_ms": 0,
- "median_e2el_ms": 0,
- "p99_e2el_ms": 0,
- "mean_audio_rtf": 0,
- "median_audio_rtf": 0,
- "p99_audio_rtf": 0,
- "mean_audio_ttfp_ms": 0,
- "median_audio_ttfp_ms": 0,
- "p99_audio_ttfp_ms": 0,
- "mean_audio_duration_s": 0,
- "median_audio_duration_s": 0,
- "p99_audio_duration_s": 0,
- "baseline": {
- "mean_ttft_ms": 0,
- "mean_audio_ttfp_ms": 0,
- "mean_audio_rtf": 0
- },
- "random_input_len": 0,
- "random_output_len": 0
-}
diff --git a/tests/dfx/perf/scripts/run_benchmark.py b/tests/dfx/perf/scripts/run_benchmark.py
deleted file mode 100644
index 9036508cb1c..00000000000
--- a/tests/dfx/perf/scripts/run_benchmark.py
+++ /dev/null
@@ -1,398 +0,0 @@
-import json
-import os
-import subprocess
-import threading
-from datetime import datetime
-from pathlib import Path
-from typing import Any
-
-import pytest
-
-from tests.dfx.conftest import (
- create_benchmark_indices,
- create_test_parameter_mapping,
- create_unique_server_params,
- get_benchmark_params_for_server,
- load_configs,
-)
-from tests.helpers.runtime import OmniServer
-
-pytestmark = [pytest.mark.full_model, pytest.mark.omni]
-
-
-os.environ["VLLM_WORKER_MULTIPROC_METHOD"] = "spawn"
-os.environ["VLLM_TEST_CLEAN_GPU_MEMORY"] = "0"
-
-
-def _get_config_file_from_argv() -> str | None:
- """Read ``--test-config-file`` from ``sys.argv`` at import time so parametrization can use it."""
- import sys
-
- for i, arg in enumerate(sys.argv):
- if arg == "--test-config-file" and i + 1 < len(sys.argv):
- return sys.argv[i + 1]
- if arg.startswith("--test-config-file="):
- return arg.split("=", 1)[1]
- return None
-
-
-_PERF_TESTS_DIR = Path(__file__).resolve().parent.parent / "tests"
-_DEFAULT_CONFIG_FILE = str(_PERF_TESTS_DIR / "test_qwen_omni.json")
-
-CONFIG_FILE_PATH = _get_config_file_from_argv()
-if CONFIG_FILE_PATH is None:
- print(
- "No --test-config-file in argv, using default: tests/dfx/perf/tests/test_qwen_omni.json "
- "(override with e.g. --test-config-file tests/dfx/perf/tests/test_tts.json)"
- )
- CONFIG_FILE_PATH = _DEFAULT_CONFIG_FILE
-
-BENCHMARK_CONFIGS = load_configs(CONFIG_FILE_PATH)
-OMNI_RESULT_TEMPLATE_PATH = Path(__file__).parent / "result_omni_template.json"
-
-
-DEPLOY_CONFIGS_DIR = Path(__file__).parent.parent / "deploy"
-test_params = create_unique_server_params(BENCHMARK_CONFIGS, DEPLOY_CONFIGS_DIR)
-server_to_benchmark_mapping = create_test_parameter_mapping(BENCHMARK_CONFIGS)
-
-_omni_server_lock = threading.Lock()
-
-
-@pytest.fixture(scope="module")
-def omni_server(request):
- """Start vLLM-Omni server as a subprocess with actual model weights.
- Uses session scope so the server starts only once for the entire test session.
- Multi-stage initialization can take 10-20+ minutes.
- """
- with _omni_server_lock:
- test_name, model, stage_config_path, stage_overrides, extra_cli_args = request.param
-
- print(f"Starting OmniServer with test: {test_name}, model: {model}")
-
- server_args = ["--stage-init-timeout", "600", "--init-timeout", "900"]
- # --deploy-config and --stage-overrides compose at the CLI (see vllm_omni/entrypoints/utils.py):
- # deploy-config sets the base; stage-overrides are applied on top. Both can be set.
- if stage_config_path:
- server_args = ["--deploy-config", stage_config_path] + server_args
- if stage_overrides:
- server_args = ["--stage-overrides", stage_overrides] + server_args
- if extra_cli_args:
- server_args = list(extra_cli_args) + server_args
- with OmniServer(model, server_args) as server:
- server.test_name = test_name
- print("OmniServer started successfully")
- yield server
- print("OmniServer stopping...")
-
- print("OmniServer stopped")
-
-
-def _safe_filename_token(value: Any | None, *, default: str = "na") -> str:
- """Make a single path segment safe for result filenames on common filesystems."""
- if value is None:
- return default
- s = str(value).strip()
- for bad in ("/", "\\", ":", "*", "?", '"', "<", ">", "|"):
- s = s.replace(bad, "_")
- return s if s else default
-
-
-def run_benchmark(
- args: list,
- test_name: str,
- flow,
- dataset_name: str,
- num_prompt,
- *,
- baseline_config: dict[str, Any] | None = None,
- sweep_index: int | None = None,
- request_rate: Any | None = None,
- max_concurrency: Any | None = None,
- random_input_len: Any | None = None,
- random_output_len: Any | None = None,
-) -> Any:
- """Run a single benchmark iteration and return the parsed result JSON.
-
- After ``vllm bench`` writes the JSON, ``result["baseline"]`` holds the same
- per-metric resolved thresholds as ``assert_result`` (via ``_baseline_thresholds_for_step``).
- When ``random_input_len`` / ``random_output_len`` are set, they are also written into the result JSON;
- omitted keys when not configured.
- """
- current_dt = datetime.now().strftime("%Y%m%d-%H%M%S")
- ri = _safe_filename_token(random_input_len)
- ro = _safe_filename_token(random_output_len)
- result_filename = f"result_{test_name}_{dataset_name}_{flow}_{num_prompt}_in{ri}_out{ro}_{current_dt}.json"
- if "--result-filename" in args:
- print(f"The result file will be overwritten by {result_filename}")
- command = (
- ["vllm", "bench", "serve", "--omni"]
- + args
- + [
- "--save-result",
- "--result-dir",
- os.environ.get("BENCHMARK_DIR", "tests"),
- "--result-filename",
- result_filename,
- ]
- )
- process = subprocess.Popen(
- command, stdout=subprocess.PIPE, stderr=subprocess.PIPE, text=True, bufsize=1, universal_newlines=True
- )
-
- for line in iter(process.stdout.readline, ""):
- print(line, end=" ")
-
- for line in iter(process.stderr.readline, ""):
- print(line, end=" ")
-
- if "--result-dir" in command:
- index = command.index("--result-dir")
- result_dir = command[index + 1]
- else:
- result_dir = "./"
-
- result_path = os.path.join(result_dir, result_filename)
- if not os.path.exists(result_path):
- with open(OMNI_RESULT_TEMPLATE_PATH, encoding="utf-8") as f:
- template_result: dict[str, Any] = json.load(f)
- Path(result_path).parent.mkdir(parents=True, exist_ok=True)
- with open(result_path, "w", encoding="utf-8") as f:
- json.dump(template_result, f, ensure_ascii=False, indent=2)
- print(f"Benchmark result file not generated, fallback to template: {result_path}")
- result = template_result
- else:
- with open(result_path, encoding="utf-8") as f:
- result = json.load(f)
-
- if baseline_config:
- result["baseline"] = _baseline_thresholds_for_step(
- baseline_config,
- sweep_index=sweep_index,
- request_rate=request_rate,
- max_concurrency=max_concurrency,
- )
- else:
- result["baseline"] = {}
- if random_input_len is not None:
- result["random_input_len"] = random_input_len
- if random_output_len is not None:
- result["random_output_len"] = random_output_len
- with open(result_path, "w", encoding="utf-8") as f:
- json.dump(result, f, ensure_ascii=False, indent=2)
- return result
-
-
-benchmark_indices = create_benchmark_indices(BENCHMARK_CONFIGS, server_to_benchmark_mapping)
-
-
-@pytest.fixture(params=benchmark_indices)
-def benchmark_params(request, omni_server):
- """Benchmark parameters fixture with proper parametrization"""
- test_name, param_index = request.param
-
- if test_name != omni_server.test_name:
- pytest.skip(f"Skipping parameter for {test_name} - current server is {omni_server.test_name}")
-
- all_params = get_benchmark_params_for_server(test_name, server_to_benchmark_mapping)
-
- if not all_params:
- raise ValueError(f"No benchmark parameters found for test: {test_name}")
-
- if param_index >= len(all_params):
- raise ValueError(f"No benchmark parameters found for index {param_index} in test: {test_name}")
-
- current = param_index + 1
- total = len(all_params)
- print(f"\n Running benchmark {current}/{total} for {test_name}")
-
- return {
- "test_name": test_name,
- "params": all_params[param_index],
- }
-
-
-def _resolve_baseline_value(
- baseline_raw: Any,
- *,
- sweep_index: int | None,
- max_concurrency: Any = None,
- request_rate: Any = None,
-) -> Any:
- """Pick the baseline threshold for this sweep step.
-
- Supported shapes per metric:
- - **Scalar** — same threshold for every concurrency / QPS.
- - **List** — aligned with ``max_concurrency`` / ``request_rate`` sweep order; use ``sweep_index``.
- - **Dict** — keyed by concurrency or rate, e.g. ``{"1": 500, "4": 800}`` (keys are strings in JSON).
-
- For dict lookup, ``max_concurrency`` is preferred when both are set (concurrency sweep).
- """
- if baseline_raw is None:
- # If no baseline is set, the maximum value will be used.
- return 100000
- if isinstance(baseline_raw, dict):
- if max_concurrency is not None:
- for key in (max_concurrency, str(max_concurrency)):
- if key in baseline_raw:
- return baseline_raw[key]
- if request_rate is not None:
- for key in (request_rate, str(request_rate)):
- if key in baseline_raw:
- return baseline_raw[key]
- raise KeyError(
- f"baseline dict has no key for max_concurrency={max_concurrency!r} "
- f"or request_rate={request_rate!r}; keys={list(baseline_raw.keys())!r}"
- )
- if isinstance(baseline_raw, (list, tuple)):
- return baseline_raw[sweep_index]
- return baseline_raw
-
-
-def _baseline_thresholds_for_step(
- baseline_data: dict[str, Any],
- *,
- sweep_index: int | None = None,
- max_concurrency: Any = None,
- request_rate: Any = None,
-) -> dict[str, Any]:
- """Resolve ``test.json`` ``baseline`` block to one threshold per metric (same as ``assert_result``)."""
- return {
- metric_name: _resolve_baseline_value(
- baseline_raw,
- sweep_index=sweep_index,
- max_concurrency=max_concurrency,
- request_rate=request_rate,
- )
- for metric_name, baseline_raw in baseline_data.items()
- }
-
-
-def assert_result(
- result,
- params,
- num_prompt,
- *,
- sweep_index: int | None = None,
- max_concurrency: Any = None,
- request_rate: Any = None,
-) -> None:
- assert result["completed"] == num_prompt, "Request failures exist"
- baseline_data = params.get("baseline", {})
- for metric_name, baseline_raw in baseline_data.items():
- current_value = result[metric_name]
- baseline_value = _resolve_baseline_value(
- baseline_raw,
- sweep_index=sweep_index,
- max_concurrency=max_concurrency,
- request_rate=request_rate,
- )
- if "throughput" in metric_name:
- if current_value <= baseline_value:
- print(
- f"ERROR: Throughput test results were below baseline: {metric_name}: {current_value} > {baseline_value}"
- )
- else:
- if current_value >= baseline_value:
- print(f"ERROR: Test results exceeded baseline: {metric_name}: {current_value} < {baseline_value}")
-
-
-@pytest.mark.benchmark
-@pytest.mark.parametrize("omni_server", test_params, indirect=True)
-@pytest.mark.parametrize("benchmark_params", benchmark_indices, indirect=True)
-def test_performance_benchmark(omni_server, benchmark_params):
- test_name = benchmark_params["test_name"]
- params = benchmark_params["params"]
- dataset_name = params.get("dataset_name", "")
-
- host = omni_server.host
- port = omni_server.port
- model = omni_server.model
-
- print(f"Running benchmark for model: {model}")
- print(f"Benchmark parameters: {benchmark_params}")
-
- def to_list(value, default=None):
- if value is None:
- return [] if default is None else [default]
- return [value] if not isinstance(value, (list, tuple)) else list(value)
-
- qps_list = to_list(params.get("request_rate"))
- num_prompt_list = to_list(params.get("num_prompts"))
- max_concurrency_list = to_list(params.get("max_concurrency"))
-
- max_len = max(len(qps_list), len(max_concurrency_list))
- if len(num_prompt_list) == 1 and max_len > 1:
- num_prompt_list = num_prompt_list * max_len
- elif max_len == 1 and len(num_prompt_list) > 1:
- if len(qps_list) == 1:
- qps_list = qps_list * len(num_prompt_list)
- if len(max_concurrency_list) == 1:
- max_concurrency_list = max_concurrency_list * len(num_prompt_list)
- max_len = max(len(qps_list), len(max_concurrency_list))
- elif len(num_prompt_list) != max_len and max_len > 0:
- raise ValueError("The number of prompts does not match the QPS or max_concurrency")
-
- args = ["--host", host, "--port", str(port)]
- exclude_keys = {"request_rate", "baseline", "num_prompts", "max_concurrency", "task", "enabled", "eval_phase"}
-
- for key, value in params.items():
- if key in exclude_keys or value is None:
- continue
-
- arg_name = f"--{key.replace('_', '-')}"
-
- if isinstance(value, bool) and value:
- args.append(arg_name)
- elif isinstance(value, dict):
- json_str = json.dumps(value, ensure_ascii=False, separators=(",", ":"))
- args.extend([arg_name, json_str])
- elif not isinstance(value, bool):
- args.extend([arg_name, str(value)])
-
- # QPS test (sweep_index aligns with qps_list / num_prompt_list for this loop)
- for i, (qps, num_prompt) in enumerate(zip(qps_list, num_prompt_list)):
- args = args + ["--request-rate", str(qps), "--num-prompts", str(num_prompt)]
- result = run_benchmark(
- args=args,
- test_name=test_name,
- flow=qps,
- dataset_name=dataset_name,
- num_prompt=num_prompt,
- baseline_config=params.get("baseline"),
- sweep_index=i,
- request_rate=qps,
- max_concurrency=None,
- random_input_len=params.get("random_input_len"),
- random_output_len=params.get("random_output_len"),
- )
- assert_result(
- result,
- params,
- num_prompt=num_prompt,
- sweep_index=i,
- request_rate=qps,
- )
-
- # concurrency test (sweep_index aligns with max_concurrency_list for separate thresholds per concurrency)
- for i, (concurrency, num_prompt) in enumerate(zip(max_concurrency_list, num_prompt_list)):
- args = args + ["--max-concurrency", str(concurrency), "--num-prompts", str(num_prompt), "--request-rate", "inf"]
- result = run_benchmark(
- args=args,
- test_name=test_name,
- flow=concurrency,
- dataset_name=dataset_name,
- num_prompt=num_prompt,
- baseline_config=params.get("baseline"),
- sweep_index=i,
- request_rate=None,
- max_concurrency=concurrency,
- random_input_len=params.get("random_input_len"),
- random_output_len=params.get("random_output_len"),
- )
- assert_result(
- result,
- params,
- num_prompt=num_prompt,
- sweep_index=i,
- max_concurrency=concurrency,
- )
diff --git a/tests/dfx/perf/scripts/run_diffusion_benchmark.py b/tests/dfx/perf/scripts/run_diffusion_benchmark.py
deleted file mode 100644
index 7513c2d3f98..00000000000
--- a/tests/dfx/perf/scripts/run_diffusion_benchmark.py
+++ /dev/null
@@ -1,742 +0,0 @@
-"""
-Performance benchmark CI runner for diffusion models.
-
-This runner separates two concepts:
-
-1. ``server_type``: how the serving process is started.
- Currently only ``vllm-omni`` is supported here.
-2. ``benchmark_backend``: which serving API the benchmark client calls.
- Examples: ``vllm-omni`` for ``/v1/chat/completions`` and ``v1/videos``
- for async video jobs.
-
-A config JSON file is REQUIRED via --test-config-file:
- pytest run_diffusion_benchmark.py --test-config-file tests/dfx/perf/tests/test_qwen_image_vllm_omni.json
-
-All benchmark results for a session are consolidated into a single JSON file under
-BENCHMARK_RESULT_DIR (override via the DIFFUSION_BENCHMARK_DIR environment variable).
-Each entry in the file contains the test metadata (test_name, backend, benchmark_params,
-timestamp) together with the raw metrics returned by the benchmark script.
-"""
-
-import json
-import os
-import socket
-import subprocess
-import sys
-import tempfile
-import threading
-import time
-from datetime import datetime
-from pathlib import Path
-from typing import Any, cast
-
-import psutil
-import pytest
-
-pytestmark = [pytest.mark.diffusion, pytest.mark.full_model]
-
-os.environ["VLLM_WORKER_MULTIPROC_METHOD"] = "spawn"
-os.environ["VLLM_TEST_CLEAN_GPU_MEMORY"] = "0"
-os.environ.setdefault("DIFFUSION_ATTENTION_BACKEND", "FLASH_ATTN")
-
-# ---------------------------------------------------------------------------
-# Paths
-# ---------------------------------------------------------------------------
-
-_DEFAULT_RESULT_DIR = Path(__file__).parent.parent / "results"
-BENCHMARK_RESULT_DIR = Path(os.environ.get("DIFFUSION_BENCHMARK_DIR", str(_DEFAULT_RESULT_DIR)))
-
-BENCHMARK_SCRIPT = str(
- Path(__file__).parent.parent.parent.parent.parent / "benchmarks" / "diffusion" / "diffusion_benchmark_serving.py"
-)
-
-# Single aggregated result file for the entire benchmark session.
-# Populated lazily after CONFIG_FILE_PATH is resolved.
-_SESSION_TIMESTAMP = datetime.now().strftime("%Y%m%d-%H%M%S")
-_RESULT_LOCK = threading.Lock()
-_BRANCHPOINT_COMMIT_SHA: str | None = None
-DIFFUSION_RESULT_TEMPLATE_PATH = Path(__file__).parent / "diffusion_result_template.json"
-
-
-def _get_config_file_from_argv() -> str | None:
- """Read --test-config-file from sys.argv at import time so pytest parametrize can use it.
-
- pytest_addoption (below) registers the same flag so pytest does not reject it.
- Supports both ``--test-config-file path`` and ``--test-config-file=path`` forms.
- Returns None if the flag is not present; callers must handle the missing case.
- """
- for i, arg in enumerate(sys.argv):
- if arg == "--test-config-file" and i + 1 < len(sys.argv):
- return sys.argv[i + 1]
- if arg.startswith("--test-config-file="):
- return arg.split("=", 1)[1]
- return None
-
-
-CONFIG_FILE_PATH = _get_config_file_from_argv()
-if CONFIG_FILE_PATH is None:
- print("No config file provided, using default config file: tests/dfx/perf/tests/test_qwen_image_vllm_omni.json")
- CONFIG_FILE_PATH = "tests/dfx/perf/tests/test_qwen_image_vllm_omni.json"
-
-# ---------------------------------------------------------------------------
-# Config loading
-# ---------------------------------------------------------------------------
-
-
-def _resolve_refs(configs: list[dict[str, Any]], config_dir: Path) -> list[dict[str, Any]]:
- """Resolve {"$ref": "filename.json"} in benchmark_params fields."""
- for cfg in configs:
- bp = cfg.get("benchmark_params")
- if isinstance(bp, dict) and "$ref" in bp:
- ref_path = config_dir / bp["$ref"]
- try:
- with open(ref_path, encoding="utf-8") as f:
- cfg["benchmark_params"] = json.load(f)
- except FileNotFoundError:
- raise ValueError(f"benchmark_params $ref not found: {ref_path}")
- except json.JSONDecodeError as e:
- raise ValueError(f"JSON parsing error in {ref_path}: {e}")
- return configs
-
-
-def load_configs(config_path: str) -> list[dict[str, Any]]:
- try:
- abs_path = Path(config_path).resolve()
- with open(abs_path, encoding="utf-8") as f:
- configs = json.load(f)
- return _resolve_refs(configs, abs_path.parent)
- except json.JSONDecodeError as e:
- raise ValueError(f"JSON parsing error: {str(e)}")
- except FileNotFoundError:
- raise ValueError(f"Configuration file not found: {config_path}")
- except Exception as e:
- raise RuntimeError(f"Failed to load configuration file: {str(e)}")
-
-
-BENCHMARK_CONFIGS = load_configs(CONFIG_FILE_PATH)
-
-_config_stem = Path(CONFIG_FILE_PATH).stem # e.g. "test_qwen_image_vllm_omni"
-AGGREGATED_RESULT_FILE = BENCHMARK_RESULT_DIR / f"diffusion_result_{_config_stem}_{_SESSION_TIMESTAMP}.json"
-
-
-def _append_to_aggregated_file(record: dict[str, Any]) -> None:
- """Thread-safe append of *record* to the session-level aggregated JSON file.
-
- The file contains a JSON array; each call loads the existing array (or
- starts a new one), appends the record, and writes the file back atomically.
- """
- with _RESULT_LOCK:
- BENCHMARK_RESULT_DIR.mkdir(parents=True, exist_ok=True)
- if AGGREGATED_RESULT_FILE.exists():
- with open(AGGREGATED_RESULT_FILE, encoding="utf-8") as f:
- records: list[dict] = json.load(f)
- else:
- records = []
- records.append(record)
- with open(AGGREGATED_RESULT_FILE, "w", encoding="utf-8") as f:
- json.dump(records, f, indent=2, ensure_ascii=False)
-
-
-_server_lock = threading.Lock()
-
-# ---------------------------------------------------------------------------
-# Shared helpers
-# ---------------------------------------------------------------------------
-
-
-def _get_open_port() -> int:
- """Return an available TCP port on localhost."""
- with socket.socket(socket.AF_INET, socket.SOCK_STREAM) as s:
- s.bind(("", 0))
- s.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
- return s.getsockname()[1]
-
-
-def _wait_for_port(host: str, port: int, timeout: int = 1200) -> None:
- """Block until the given host:port accepts connections or timeout expires."""
- start = time.time()
- while time.time() - start < timeout:
- try:
- with socket.socket(socket.AF_INET, socket.SOCK_STREAM) as s:
- s.settimeout(1)
- if s.connect_ex((host, port)) == 0:
- return
- except Exception:
- pass
- time.sleep(2)
- raise RuntimeError(f"Server did not start on {host}:{port} within {timeout}s")
-
-
-def _kill_process_tree(pid: int) -> None:
- try:
- parent = psutil.Process(pid)
- children = parent.children(recursive=True)
- all_pids = [pid] + [c.pid for c in children]
-
- for child in children:
- try:
- child.terminate()
- except psutil.NoSuchProcess:
- pass
-
- gone, alive = psutil.wait_procs(children, timeout=10)
- for child in alive:
- try:
- child.kill()
- except psutil.NoSuchProcess:
- pass
-
- try:
- parent.terminate()
- parent.wait(timeout=10)
- except (psutil.NoSuchProcess, psutil.TimeoutExpired):
- try:
- parent.kill()
- except psutil.NoSuchProcess:
- pass
-
- time.sleep(1)
- still_alive = [p for p in all_pids if psutil.pid_exists(p)]
- if still_alive:
- print(f"Warning: processes still alive after shutdown: {still_alive}")
- for p in still_alive:
- try:
- subprocess.run(["kill", "-9", str(p)], timeout=2)
- except Exception:
- pass
- except psutil.NoSuchProcess:
- pass
-
-
-# ---------------------------------------------------------------------------
-# Server classes
-# ---------------------------------------------------------------------------
-
-
-class DiffusionServer:
- """Start a vLLM-Omni diffusion model server as a subprocess.
-
- Launched via vllm_omni.entrypoints.cli.main with the diffusion-specific
- parallelism flags (--usp, --ring, --cfg-parallel-size, etc.) passed directly
- on the CLI. Minimum hardware: 4× NVIDIA H100 80 GB.
- """
-
- server_type = "vllm-omni"
-
- def __init__(
- self,
- server_cfg: dict[str, Any],
- *,
- port: int | None = None,
- ) -> None:
- self.server_cfg: dict[str, Any] = server_cfg
- self.model = server_cfg["model"]
- self.serve_args = server_cfg["serve_args"]
- self.host = "127.0.0.1"
- self.port = port if port is not None else _get_open_port()
- self.proc: subprocess.Popen | None = None
- self.test_name: str = ""
-
- def _start_server(self) -> None:
- env = os.environ.copy()
- env["VLLM_WORKER_MULTIPROC_METHOD"] = "spawn"
-
- cmd = [
- sys.executable,
- "-m",
- "vllm_omni.entrypoints.cli.main",
- "serve",
- self.model,
- "--omni",
- "--host",
- self.host,
- "--port",
- str(self.port),
- ] + self.serve_args
-
- print(f"Launching DiffusionServer: {' '.join(cmd)}")
- self.proc = subprocess.Popen(
- cmd,
- env=env,
- cwd=str(Path(__file__).parent.parent.parent.parent),
- )
- _wait_for_port(self.host, self.port)
- print(f"DiffusionServer ready on {self.host}:{self.port}")
-
- def __enter__(self):
- self._start_server()
- return self
-
- def __exit__(self, *_):
- if self.proc:
- _kill_process_tree(self.proc.pid)
-
-
-# ---------------------------------------------------------------------------
-# Config helpers
-# ---------------------------------------------------------------------------
-
-
-def _build_serve_args(serve_args_dict: dict[str, Any]) -> list[str]:
- """Convert a serve_args dict from test.json into a flat CLI argument list."""
- args: list[str] = []
- for key, value in serve_args_dict.items():
- flag = f"--{key}"
- if isinstance(value, bool):
- if value:
- args.append(flag)
- elif isinstance(value, dict):
- args.extend([flag, json.dumps(value, separators=(",", ":"))])
- else:
- args.extend([flag, str(value)])
- return args
-
-
-def _get_branchpoint_commit_sha() -> str:
- """Return the branch-point commit SHA against main.
-
- Uses git command: ``git merge-base HEAD origin/main``.
- """
- global _BRANCHPOINT_COMMIT_SHA
- if _BRANCHPOINT_COMMIT_SHA is not None:
- return _BRANCHPOINT_COMMIT_SHA
-
- repo_root = Path(__file__).parent.parent.parent.parent
- try:
- sha = (
- subprocess.check_output(
- ["git", "merge-base", "HEAD", "origin/main"],
- cwd=str(repo_root),
- stderr=subprocess.STDOUT,
- text=True,
- )
- .strip()
- .splitlines()[0]
- )
- _BRANCHPOINT_COMMIT_SHA = sha
- except Exception as e:
- print(f"Warning: failed to get branch-point commit SHA: {e}")
- _BRANCHPOINT_COMMIT_SHA = ""
- return _BRANCHPOINT_COMMIT_SHA
-
-
-def _to_resolution_string(params: dict[str, Any]) -> str:
- width = params.get("width", "unknown width")
- height = params.get("height", "unknown height")
- return f"{width}x{height}"
-
-
-def _to_parallelism_string(framework: str, serve_args_dict: dict[str, Any]) -> str:
- parts: list[str] = []
- if framework == "vllm-omni":
- keys = [
- "num-gpus",
- "usp",
- "ulysses-degree",
- "ring",
- "ring-degree",
- "cfg-parallel-size",
- "vae-patch-parallel-size",
- "vae-use-tiling",
- "tensor-parallel-size",
- ]
- for key in keys:
- if key in serve_args_dict:
- parts.append(f"{key}={serve_args_dict[key]}")
- return ",".join(parts) if parts else "none"
-
-
-def _to_cache_string(framework: str, serve_args_dict: dict[str, Any]) -> str:
- if framework == "vllm-omni":
- if "cache-backend" in serve_args_dict:
- return str(serve_args_dict["cache-backend"])
- return "disabled"
-
-
-def _to_offload_string(framework: str, serve_args_dict: dict[str, Any]) -> str:
- selected: list[str] = []
- if framework == "vllm-omni":
- offload_keys = [
- "enable-cpu-offload",
- "enable-layerwise-offload",
- ]
- for key in offload_keys:
- if key in serve_args_dict:
- selected.append(key)
- return f"enabled({';'.join(selected)})" if selected else "disabled"
-
-
-def _to_compile_value(framework: str, serve_args_dict: dict[str, Any]) -> str:
- if framework == "vllm-omni":
- if "enforce-eager" in serve_args_dict:
- return "disabled"
- return "enabled"
- return "disabled"
-
-
-def _to_quantization_value(framework: str, serve_args_dict: dict[str, Any]) -> str:
- if framework == "vllm-omni":
- quant = serve_args_dict.get("quantization")
- return str(quant) if quant else "disabled"
- return "disabled"
-
-
-def _unique_server_params(configs: list[dict[str, Any]]) -> list[dict[str, Any]]:
- """Return one server-config dict per unique test_name."""
- seen: set[str] = set()
- result: list[dict[str, Any]] = []
- for cfg in configs:
- test_name = cfg["test_name"]
- if test_name in seen:
- continue
- seen.add(test_name)
- server_type = cfg.get("server_type", "vllm-omni")
- if server_type != "vllm-omni":
- raise ValueError(f"Unsupported server_type in config: {server_type}")
- serve_args_dict = cfg["server_params"].get("serve_args", {})
- result.append(
- {
- "test_name": test_name,
- "server_type": server_type,
- "model": cfg["server_params"]["model"],
- "serve_args_dict": serve_args_dict,
- "serve_args": _build_serve_args(serve_args_dict),
- "benchmark_backend": cfg.get("benchmark_backend"),
- "server_params": cfg["server_params"],
- }
- )
- return result
-
-
-def _test_param_mapping(configs: list[dict[str, Any]]) -> dict[str, list[dict]]:
- mapping: dict[str, list[dict]] = {}
- for cfg in configs:
- name = cfg["test_name"]
- mapping.setdefault(name, [])
- mapping[name].extend(cfg["benchmark_params"])
- return mapping
-
-
-def _make_server(server_cfg: dict[str, Any]) -> DiffusionServer:
- """Factory: return a vLLM-Omni diffusion server instance for the config."""
- return DiffusionServer(server_cfg=server_cfg)
-
-
-# ---------------------------------------------------------------------------
-# Parametrize data
-# ---------------------------------------------------------------------------
-
-server_params = _unique_server_params(BENCHMARK_CONFIGS)
-test_param_map = _test_param_mapping(BENCHMARK_CONFIGS)
-
-benchmark_indices: list[int] = list(range(max(len(v) for v in test_param_map.values())))
-
-# ---------------------------------------------------------------------------
-# Pytest fixtures
-# ---------------------------------------------------------------------------
-
-
-@pytest.fixture(scope="module")
-def diffusion_server(request):
- """Start one vLLM-Omni server per unique test configuration."""
- with _server_lock:
- server_cfg: dict[str, Any] = request.param
- test_name = server_cfg["test_name"]
- server_type = server_cfg["server_type"]
-
- print(f"\nStarting {server_type} server for test: {test_name}")
- with _make_server(server_cfg) as server:
- server.test_name = test_name
- print(f"{server_type} server started successfully")
- yield server
- print(f"{server_type} server stopping…")
-
- print(f"{server_type} server stopped")
-
-
-@pytest.fixture
-def benchmark_params(request, diffusion_server):
- """Yield the benchmark params dict for the current (server, index) pair."""
- param_index: int = request.param
- test_name = diffusion_server.test_name
-
- params_list = test_param_map.get(test_name, [])
- if not params_list:
- raise ValueError(f"No benchmark params for test: {test_name}")
- if param_index >= len(params_list):
- pytest.skip(f"Param index {param_index} out of range for {test_name} (has {len(params_list)} params)")
-
- current = param_index + 1
- total = len(params_list)
- print(f"\n Running benchmark {current}/{total} for {test_name}")
- return {"test_name": test_name, "params": params_list[param_index]}
-
-
-# ---------------------------------------------------------------------------
-# Benchmark runner
-# ---------------------------------------------------------------------------
-
-
-def run_benchmark(
- host: str,
- port: int,
- model: str,
- params: dict[str, Any],
- test_name: str,
- backend: str = "vllm-omni",
- server_cfg: dict[str, Any] | None = None,
- source_file: str = "",
-) -> dict[str, Any]:
- """Run diffusion_benchmark_serving.py as a subprocess and return parsed metrics.
-
- The raw metrics are written to a temporary file by the subprocess. After
- the run completes the metrics are merged with full metadata (test_name,
- backend, benchmark_params, timestamp, flat reporting fields) and appended
- to the session-wide aggregated JSON file (AGGREGATED_RESULT_FILE). The
- temporary file is removed afterwards. Subprocess stdout/stderr are tee'd
- to a .log file under BENCHMARK_RESULT_DIR/logs/; its path is stored in
- the record.
- """
- timestamp = datetime.now().strftime("%Y%m%d-%H%M%S")
-
- log_dir = BENCHMARK_RESULT_DIR / "logs"
- log_dir.mkdir(parents=True, exist_ok=True)
- backend_label = backend.replace("/", "_")
- log_file = log_dir / f"{test_name}_{backend_label}_{timestamp}.log"
-
- with tempfile.NamedTemporaryFile(mode="w", suffix=".json", prefix="diffusion_bench_tmp_", delete=False) as tmp:
- tmp_result_file = Path(tmp.name)
-
- exclude_keys = {"baseline", "dataset", "task", "name"}
-
- cmd = [
- sys.executable,
- BENCHMARK_SCRIPT,
- "--host",
- host,
- "--port",
- str(port),
- "--model",
- model,
- "--backend",
- backend,
- "--dataset",
- params.get("dataset", "random"),
- "--task",
- params.get("task", "t2i"),
- "--output-file",
- str(tmp_result_file),
- ]
-
- for key, value in params.items():
- if key in exclude_keys or value is None:
- continue
- flag = f"--{key}"
- if isinstance(value, bool):
- if value:
- cmd.append(flag)
- elif isinstance(value, (dict, list)):
- cmd.extend([flag, json.dumps(value, separators=(",", ":"))])
- else:
- cmd.extend([flag, str(value)])
-
- # Insert -u so the subprocess runs with unbuffered stdout/stderr, ensuring
- # all print() output is flushed to the pipe immediately instead of being
- # held in Python's internal block-buffer until process exit (which can
- # cause truncated or out-of-order log output when stdout is piped).
- cmd = [cmd[0], "-u"] + cmd[1:]
-
- print(f"\nRunning benchmark (backend={backend}): {' '.join(cmd)}")
- print(f" Log file: {log_file}")
-
- # Redirect stdout + stderr directly to the log file at the OS level
- # (equivalent to `cmd > log 2>&1`), so no output is ever lost regardless
- # of how the subprocess exits. The log is echoed to the terminal afterwards.
- with open(log_file, "w", encoding="utf-8") as log_fh:
- log_fh.write(f"cmd: {' '.join(cmd)}\n\n")
- log_fh.flush()
-
- process = subprocess.Popen(
- cmd,
- stdout=log_fh,
- stderr=log_fh,
- cwd=str(Path(__file__).parent.parent.parent.parent),
- )
- process.wait()
-
- with open(log_file, encoding="utf-8") as log_fh:
- print(log_fh.read(), end="")
-
- if process.returncode != 0:
- tmp_result_file.unlink(missing_ok=True)
- print(f"ERROR:Benchmark script exited with code {process.returncode}")
-
- if not tmp_result_file.exists():
- with open(DIFFUSION_RESULT_TEMPLATE_PATH, encoding="utf-8") as f:
- template_payload = json.load(f)
- # Template schema is fixed and owned by this repo:
- # ``diffusion_result_template.json`` is a one-item list and metrics live at [0]["result"].
- template_metrics: dict[str, Any] = template_payload[0]["result"]
- with open(tmp_result_file, "w", encoding="utf-8") as f:
- json.dump(template_metrics, f, ensure_ascii=False, indent=2)
- print(f"Benchmark result file not generated, fallback to template: {tmp_result_file}")
-
- try:
- with open(tmp_result_file, encoding="utf-8") as f:
- metrics: dict[str, Any] = json.load(f)
- finally:
- tmp_result_file.unlink(missing_ok=True)
-
- server_cfg = server_cfg or {}
- server_type = cast(str, server_cfg.get("server_type", "vllm-omni"))
- serve_args_dict = server_cfg.get("serve_args_dict", {})
- if not isinstance(serve_args_dict, dict):
- serve_args_dict = {}
-
- completed = metrics.get("completed_requests", metrics.get("completed", 0))
- failed = metrics.get("failed_requests", metrics.get("failed", 0))
-
- record: dict[str, Any] = {
- "test_name": test_name,
- "backend": backend,
- "timestamp": timestamp,
- "server_params": server_cfg.get("server_params"),
- "benchmark_params": params,
- "result": metrics,
- "log_file": str(log_file),
- "Model": model,
- "Framework": server_type,
- "API Backend": backend,
- "Hardware": "",
- "Deployment": "",
- "Task": params.get("task", "t2i"),
- "Dataset": params.get("dataset", "random"),
- "resolution": _to_resolution_string(params),
- "Parallelism": _to_parallelism_string(server_type, serve_args_dict),
- "max_concurrency": params.get("max-concurrency", ""),
- "Cache": _to_cache_string(server_type, serve_args_dict),
- "Quantization": _to_quantization_value(server_type, serve_args_dict),
- "offload": _to_offload_string(server_type, serve_args_dict),
- "compile": _to_compile_value(server_type, serve_args_dict),
- "Attn_backend": os.environ.get("DIFFUSION_ATTENTION_BACKEND", ""),
- "num_inference_steps": params.get("num-inference-steps", ""),
- "completed": completed,
- "failed": failed,
- "throughput_qps": metrics.get("throughput_qps"),
- "latency_mean": metrics.get("latency_mean"),
- "latency_median": metrics.get("latency_median"),
- "latency_p99": metrics.get("latency_p99"),
- "latency_p95": metrics.get("latency_p95"),
- "latency_p50": metrics.get("latency_p50"),
- "peak_memory_mb_max": metrics.get("peak_memory_mb_max"),
- "peak_memory_mb_mean": metrics.get("peak_memory_mb_mean"),
- "peak_memory_mb_median": metrics.get("peak_memory_mb_median"),
- "stage_durations_mean": metrics.get("stage_durations_mean"),
- "stage_durations_p50": metrics.get("stage_durations_p50"),
- "stage_durations_p99": metrics.get("stage_durations_p99"),
- "commit_sha": _get_branchpoint_commit_sha(),
- "build_id": os.environ.get("BUILDKITE_BUILD_ID", ""),
- "build_url": os.environ.get("BUILDKITE_BUILD_URL", ""),
- "source_file": source_file,
- }
- _append_to_aggregated_file(record)
- print(f"\n Result appended to: {AGGREGATED_RESULT_FILE}")
- print(f" Log saved to: {log_file}")
-
- return metrics
-
-
-# ---------------------------------------------------------------------------
-# Assertions
-# ---------------------------------------------------------------------------
-
-
-def assert_result(result: dict[str, Any], params: dict[str, Any]) -> None:
- """Assert that benchmark metrics satisfy the configured baselines."""
- num_prompts = params.get("num-prompts", 10)
- completed = result.get("completed_requests", result.get("completed", 0))
- assert completed == num_prompts, f"Expected {num_prompts} completed requests, got {completed}"
-
- for metric, threshold in params.get("baseline", {}).items():
- current = result.get(metric)
- assert current is not None, f"Metric '{metric}' not found in result: {list(result.keys())}"
- if "throughput" in metric:
- assert current >= threshold, f"{metric}: {current:.4f} < baseline {threshold}"
- else:
- assert current <= threshold, f"{metric}: {current:.4f} > baseline {threshold}"
-
-
-def _default_benchmark_backend_for_task(task: str) -> str:
- """Return the default client-side benchmark backend for a diffusion task."""
- if task in {"t2v", "i2v", "ti2v"}:
- return "v1/videos"
- if task in {"t2i", "i2i", "ti2i"}:
- return "vllm-omni"
- raise ValueError(f"Unsupported task for benchmark backend resolution: {task}")
-
-
-def _resolve_benchmark_backend(server_cfg: dict[str, Any], params: dict[str, Any]) -> str:
- """Resolve which serving API the benchmark client should call."""
- configured = server_cfg.get("benchmark_backend")
- if configured:
- return cast(str, configured)
- return _default_benchmark_backend_for_task(cast(str, params.get("task", "t2i")))
-
-
-# ---------------------------------------------------------------------------
-# Test entry point
-# ---------------------------------------------------------------------------
-@pytest.mark.benchmark
-@pytest.mark.parametrize(
- "diffusion_server",
- server_params,
- ids=[p["test_name"] for p in server_params],
- indirect=True,
-)
-@pytest.mark.parametrize("benchmark_params", benchmark_indices, indirect=True)
-def test_diffusion_performance_benchmark(diffusion_server, benchmark_params):
- """Run the diffusion performance benchmark and assert against baselines.
-
- One server is started per unique parallel configuration (module scope).
- For each server, all benchmark parameter sets defined in the config JSON
- are executed sequentially; results are asserted against the baselines.
-
- Tracked metrics:
- - throughput_qps (higher is better)
- - latency_p50, latency_p99 (lower is better)
- """
- test_name = benchmark_params["test_name"]
- params = benchmark_params["params"]
- server_cfg = getattr(diffusion_server, "server_cfg", {})
- backend = _resolve_benchmark_backend(server_cfg, params)
-
- result = run_benchmark(
- host=diffusion_server.host,
- port=diffusion_server.port,
- model=diffusion_server.model,
- params=params,
- test_name=test_name,
- backend=backend,
- server_cfg=server_cfg,
- source_file=cast(str, CONFIG_FILE_PATH),
- )
-
- print(f"\n{'=' * 60}")
- print(f"Results for {test_name} (server={diffusion_server.server_type}, backend={backend}):")
- for key in (
- "throughput_qps",
- "latency_mean",
- "latency_median",
- "latency_p50",
- "latency_p99",
- "peak_memory_mb_max",
- "peak_memory_mb_mean",
- "peak_memory_mb_median",
- ):
- if key in result:
- print(f" {key}: {result[key]:.4f}")
-
- print(f"\n Aggregated results: {AGGREGATED_RESULT_FILE}")
- print("=" * 60)
-
- assert_result(result, params)
diff --git a/tests/dfx/perf/tests/test_ltx2_vllm_omni.json b/tests/dfx/perf/tests/test_ltx2_vllm_omni.json
deleted file mode 100644
index 4a6f9e3501f..00000000000
--- a/tests/dfx/perf/tests/test_ltx2_vllm_omni.json
+++ /dev/null
@@ -1,217 +0,0 @@
-[
- {
- "test_name": "test_ltx2_baseline_eager",
- "description": "Single-device baseline with enforce-eager (no torch.compile)",
- "server_type": "vllm-omni",
- "server_params": {
- "model": "Lightricks/LTX-2",
- "serve_args": {
- "enforce-eager": true,
- "enable-diffusion-pipeline-profiler": true
- }
- },
- "benchmark_params": [
- {
- "name": "256x256_145f_steps6",
- "dataset": "random",
- "task": "t2v",
- "backend": "v1/videos",
- "width": 256,
- "height": 256,
- "num-frames": 145,
- "fps": 24,
- "num-inference-steps": 6,
- "num-prompts": 3,
- "max-concurrency": 1,
- "enable-negative-prompt": true
- },
- {
- "name": "480x768_41f_steps20",
- "dataset": "random",
- "task": "t2v",
- "backend": "v1/videos",
- "width": 768,
- "height": 480,
- "num-frames": 41,
- "fps": 24,
- "num-inference-steps": 20,
- "num-prompts": 3,
- "max-concurrency": 1,
- "enable-negative-prompt": true
- }
- ]
- },
-
- {
- "test_name": "test_ltx2_torch_compile",
- "description": "Single-device with torch.compile (default, no enforce-eager)",
- "server_type": "vllm-omni",
- "server_params": {
- "model": "Lightricks/LTX-2",
- "serve_args": {
- "enable-diffusion-pipeline-profiler": true
- }
- },
- "benchmark_params": [
- {
- "name": "256x256_145f_steps6",
- "dataset": "random",
- "task": "t2v",
- "backend": "v1/videos",
- "width": 256,
- "height": 256,
- "num-frames": 145,
- "fps": 24,
- "num-inference-steps": 6,
- "num-prompts": 3,
- "max-concurrency": 1,
- "enable-negative-prompt": true
- },
- {
- "name": "480x768_41f_steps20",
- "dataset": "random",
- "task": "t2v",
- "backend": "v1/videos",
- "width": 768,
- "height": 480,
- "num-frames": 41,
- "fps": 24,
- "num-inference-steps": 20,
- "num-prompts": 3,
- "max-concurrency": 1,
- "enable-negative-prompt": true
- }
- ]
- },
-
- {
- "test_name": "test_ltx2_cfg2_eager",
- "description": "CFG-parallel=2 with enforce-eager",
- "server_type": "vllm-omni",
- "server_params": {
- "model": "Lightricks/LTX-2",
- "serve_args": {
- "cfg-parallel-size": 2,
- "enforce-eager": true,
- "enable-diffusion-pipeline-profiler": true
- }
- },
- "benchmark_params": [
- {
- "name": "256x256_145f_steps6",
- "dataset": "random",
- "task": "t2v",
- "backend": "v1/videos",
- "width": 256,
- "height": 256,
- "num-frames": 145,
- "fps": 24,
- "num-inference-steps": 6,
- "num-prompts": 3,
- "max-concurrency": 1,
- "enable-negative-prompt": true
- },
- {
- "name": "480x768_41f_steps20",
- "dataset": "random",
- "task": "t2v",
- "backend": "v1/videos",
- "width": 768,
- "height": 480,
- "num-frames": 41,
- "fps": 24,
- "num-inference-steps": 20,
- "num-prompts": 3,
- "max-concurrency": 1,
- "enable-negative-prompt": true
- }
- ]
- },
-
- {
- "test_name": "test_ltx2_cfg2_compile",
- "description": "CFG-parallel=2 with torch.compile",
- "server_type": "vllm-omni",
- "server_params": {
- "model": "Lightricks/LTX-2",
- "serve_args": {
- "cfg-parallel-size": 2,
- "enable-diffusion-pipeline-profiler": true
- }
- },
- "benchmark_params": [
- {
- "name": "256x256_145f_steps6",
- "dataset": "random",
- "task": "t2v",
- "backend": "v1/videos",
- "width": 256,
- "height": 256,
- "num-frames": 145,
- "fps": 24,
- "num-inference-steps": 6,
- "num-prompts": 3,
- "max-concurrency": 1,
- "enable-negative-prompt": true
- },
- {
- "name": "480x768_41f_steps20",
- "dataset": "random",
- "task": "t2v",
- "backend": "v1/videos",
- "width": 768,
- "height": 480,
- "num-frames": 41,
- "fps": 24,
- "num-inference-steps": 20,
- "num-prompts": 3,
- "max-concurrency": 1,
- "enable-negative-prompt": true
- }
- ]
- },
-
- {
- "test_name": "test_ltx2_cache_dit_eager",
- "description": "CacheDiT with enforce-eager",
- "server_type": "vllm-omni",
- "server_params": {
- "model": "Lightricks/LTX-2",
- "serve_args": {
- "cache-backend": "cache_dit",
- "enforce-eager": true,
- "enable-diffusion-pipeline-profiler": true
- }
- },
- "benchmark_params": [
- {
- "name": "256x256_145f_steps6",
- "dataset": "random",
- "task": "t2v",
- "backend": "v1/videos",
- "width": 256,
- "height": 256,
- "num-frames": 145,
- "fps": 24,
- "num-inference-steps": 6,
- "num-prompts": 3,
- "max-concurrency": 1,
- "enable-negative-prompt": true
- },
- {
- "name": "480x768_41f_steps20",
- "dataset": "random",
- "task": "t2v",
- "backend": "v1/videos",
- "width": 768,
- "height": 480,
- "num-frames": 41,
- "fps": 24,
- "num-inference-steps": 20,
- "num-prompts": 3,
- "max-concurrency": 1,
- "enable-negative-prompt": true
- }
- ]
- }
-]
diff --git a/tests/dfx/perf/tests/test_qwen_image_edit_2509_vllm_omni.json b/tests/dfx/perf/tests/test_qwen_image_edit_2509_vllm_omni.json
deleted file mode 100644
index 7d1fbbfa704..00000000000
--- a/tests/dfx/perf/tests/test_qwen_image_edit_2509_vllm_omni.json
+++ /dev/null
@@ -1,167 +0,0 @@
-[
- {
- "test_name": "test_qwen_image_edit_2509_single_device",
- "description": "Single-device baseline (two input images)",
- "server_type": "vllm-omni",
- "server_params": {
- "model": "Qwen/Qwen-Image-Edit-2509",
- "serve_args": {
- "enable-diffusion-pipeline-profiler": true
- }
- },
- "benchmark_params": [
- {
- "name": "512x512_steps20_i2i_2img",
- "dataset": "random",
- "task": "i2i",
- "width": 512,
- "height": 512,
- "num-inference-steps": 20,
- "num-prompts": 10,
- "max-concurrency": 1,
- "num-input-images": 2,
- "enable-negative-prompt": true,
- "baseline": {
- "throughput_qps": 0.05,
- "latency_mean": 18,
- "peak_memory_mb_max": 78500,
- "peak_memory_mb_mean": 78500
- }
- },
- {
- "name": "1536x1536_steps35_i2i_2img",
- "dataset": "random",
- "task": "i2i",
- "width": 1536,
- "height": 1536,
- "num-inference-steps": 35,
- "num-prompts": 10,
- "max-concurrency": 1,
- "num-input-images": 2,
- "enable-negative-prompt": true,
- "baseline": {
- "throughput_qps": 0.01,
- "latency_mean": 70,
- "peak_memory_mb_max": 81000,
- "peak_memory_mb_mean": 81000
- }
- }
- ]
- },
- {
- "test_name": "test_qwen_image_edit_2509_ulysses2_cfg2_vae_patch4",
- "description": "Ulysses SP=2 + CFG=2 + VAE patch parallel=4",
- "server_type": "vllm-omni",
- "server_params": {
- "model": "Qwen/Qwen-Image-Edit-2509",
- "serve_args": {
- "ulysses-degree": 2,
- "cfg-parallel-size": 2,
- "vae-patch-parallel-size": 4,
- "vae-use-tiling": true,
- "enable-diffusion-pipeline-profiler": true
- }
- },
- "benchmark_params": [
- {
- "name": "512x512_steps20_i2i_2img",
- "dataset": "random",
- "task": "i2i",
- "width": 512,
- "height": 512,
- "num-inference-steps": 20,
- "num-prompts": 10,
- "max-concurrency": 1,
- "num-input-images": 2,
- "enable-negative-prompt": true,
- "baseline": {
- "throughput_qps": 0.1,
- "latency_mean": 12,
- "peak_memory_mb_max": 69000,
- "peak_memory_mb_mean": 69000
- }
- },
- {
- "name": "1536x1536_steps35_i2i_2img",
- "dataset": "random",
- "task": "i2i",
- "width": 1536,
- "height": 1536,
- "num-inference-steps": 35,
- "num-prompts": 10,
- "max-concurrency": 1,
- "num-input-images": 2,
- "enable-negative-prompt": true,
- "baseline": {
- "throughput_qps": 0.03,
- "latency_mean": 28,
- "peak_memory_mb_max": 69000,
- "peak_memory_mb_mean": 69000
- }
- }
- ]
- },
- {
- "test_name": "test_qwen_image_edit_2509_ulysses2_cfg2_cache_dit",
- "description": "Ulysses SP=2 + CFG=2 + CacheDiT",
- "server_type": "vllm-omni",
- "server_params": {
- "model": "Qwen/Qwen-Image-Edit-2509",
- "serve_args": {
- "ulysses-degree": 2,
- "cfg-parallel-size": 2,
- "cache-backend": "cache_dit",
- "cache-config": {
- "Fn_compute_blocks": 1,
- "Bn_compute_blocks": 0,
- "max_warmup_steps": 4,
- "residual_diff_threshold": 0.24,
- "max_continuous_cached_steps": 3,
- "enable_taylorseer": false,
- "taylorseer_order": 1,
- "scm_steps_mask_policy": null,
- "scm_steps_policy": "dynamic"
- },
- "enable-diffusion-pipeline-profiler": true
- }
- },
- "benchmark_params": [
- {
- "name": "512x512_steps20_i2i_2img",
- "dataset": "random",
- "task": "i2i",
- "width": 512,
- "height": 512,
- "num-inference-steps": 20,
- "num-prompts": 10,
- "max-concurrency": 1,
- "num-input-images": 2,
- "enable-negative-prompt": true,
- "baseline": {
- "throughput_qps": 0.10,
- "latency_mean": 12,
- "peak_memory_mb_max": 73000,
- "peak_memory_mb_mean": 73000
- }
- },
- {
- "name": "1536x1536_steps35_i2i_2img",
- "dataset": "random",
- "task": "i2i",
- "width": 1536,
- "height": 1536,
- "num-inference-steps": 35,
- "num-prompts": 10,
- "max-concurrency": 1,
- "num-input-images": 2,
- "enable-negative-prompt": true,
- "baseline": {
- "throughput_qps": 0.05,
- "latency_mean": 20,
- "peak_memory_mb_max": 81000,
- "peak_memory_mb_mean": 81000
- }
- }
- ]
- }
-]
diff --git a/tests/dfx/perf/tests/test_qwen_image_edit_vllm_omni.json b/tests/dfx/perf/tests/test_qwen_image_edit_vllm_omni.json
deleted file mode 100644
index f68201db5f5..00000000000
--- a/tests/dfx/perf/tests/test_qwen_image_edit_vllm_omni.json
+++ /dev/null
@@ -1,161 +0,0 @@
-[
- {
- "test_name": "test_qwen_image_edit_single_device",
- "description": "Single-device baseline",
- "server_type": "vllm-omni",
- "server_params": {
- "model": "Qwen/Qwen-Image-Edit",
- "serve_args": {
- "enable-diffusion-pipeline-profiler": true
- }
- },
- "benchmark_params": [
- {
- "name": "512x512_steps20_i2i",
- "dataset": "random",
- "task": "i2i",
- "width": 512,
- "height": 512,
- "num-inference-steps": 20,
- "num-prompts": 10,
- "max-concurrency": 1,
- "enable-negative-prompt": true,
- "baseline": {
- "throughput_qps": 0.05,
- "latency_mean": 15.0,
- "peak_memory_mb_max": 72500,
- "peak_memory_mb_mean": 72500
- }
- },
- {
- "name": "1536x1536_steps35_i2i",
- "dataset": "random",
- "task": "i2i",
- "width": 1536,
- "height": 1536,
- "num-inference-steps": 35,
- "num-prompts": 10,
- "max-concurrency": 1,
- "enable-negative-prompt": true,
- "baseline": {
- "throughput_qps": 0.01,
- "latency_mean": 65.6,
- "peak_memory_mb_max": 80777,
- "peak_memory_mb_mean": 80777
- }
- }
- ]
- },
- {
- "test_name": "test_qwen_image_edit_ulysses2_cfg2_vae_patch4",
- "description": "Ulysses SP=2 + CFG=2 + VAE patch parallel=4",
- "server_type": "vllm-omni",
- "server_params": {
- "model": "Qwen/Qwen-Image-Edit",
- "serve_args": {
- "ulysses-degree": 2,
- "cfg-parallel-size": 2,
- "vae-patch-parallel-size": 4,
- "vae-use-tiling": true,
- "enable-diffusion-pipeline-profiler": true
- }
- },
- "benchmark_params": [
- {
- "name": "512x512_steps20_i2i",
- "dataset": "random",
- "task": "i2i",
- "width": 512,
- "height": 512,
- "num-inference-steps": 20,
- "num-prompts": 10,
- "max-concurrency": 1,
- "enable-negative-prompt": true,
- "baseline": {
- "throughput_qps": 0.10,
- "latency_mean": 7.2,
- "peak_memory_mb_max": 68100,
- "peak_memory_mb_mean": 68100
- }
- },
- {
- "name": "1536x1536_steps35_i2i",
- "dataset": "random",
- "task": "i2i",
- "width": 1536,
- "height": 1536,
- "num-inference-steps": 35,
- "num-prompts": 10,
- "max-concurrency": 1,
- "enable-negative-prompt": true,
- "baseline": {
- "throughput_qps": 0.03,
- "latency_mean": 24.0,
- "peak_memory_mb_max": 68100,
- "peak_memory_mb_mean": 68100
- }
- }
- ]
- },
- {
- "test_name": "test_qwen_image_edit_ulysses2_cfg2_cache_dit",
- "description": "Ulysses SP=2 + CFG=2 + CacheDiT",
- "server_type": "vllm-omni",
- "server_params": {
- "model": "Qwen/Qwen-Image-Edit",
- "serve_args": {
- "ulysses-degree": 2,
- "cfg-parallel-size": 2,
- "cache-backend": "cache_dit",
- "cache-config": {
- "Fn_compute_blocks": 1,
- "Bn_compute_blocks": 0,
- "max_warmup_steps": 4,
- "residual_diff_threshold": 0.24,
- "max_continuous_cached_steps": 3,
- "enable_taylorseer": false,
- "taylorseer_order": 1,
- "scm_steps_mask_policy": null,
- "scm_steps_policy": "dynamic"
- },
- "enable-diffusion-pipeline-profiler": true
- }
- },
- "benchmark_params": [
- {
- "name": "512x512_steps20_i2i",
- "dataset": "random",
- "task": "i2i",
- "width": 512,
- "height": 512,
- "num-inference-steps": 20,
- "num-prompts": 10,
- "max-concurrency": 1,
- "enable-negative-prompt": true,
- "baseline": {
- "throughput_qps": 0.1,
- "latency_mean": 6.5,
- "peak_memory_mb_max": 72600,
- "peak_memory_mb_mean": 72600
- }
- },
- {
- "name": "1536x1536_steps35_i2i",
- "dataset": "random",
- "task": "i2i",
- "width": 1536,
- "height": 1536,
- "num-inference-steps": 35,
- "num-prompts": 10,
- "max-concurrency": 1,
- "enable-negative-prompt": true,
- "baseline": {
- "throughput_qps": 0.05,
- "latency_mean": 16.0,
- "peak_memory_mb_max": 81000,
- "peak_memory_mb_mean": 81000
- }
- }
- ]
- }
-]
diff --git a/tests/dfx/perf/tests/test_qwen_image_layered_vllm_omni.json b/tests/dfx/perf/tests/test_qwen_image_layered_vllm_omni.json
deleted file mode 100644
index 3cf13509c8d..00000000000
--- a/tests/dfx/perf/tests/test_qwen_image_layered_vllm_omni.json
+++ /dev/null
@@ -1,49 +0,0 @@
-[
- {
- "test_name": "test_qwen_image_layered_single_device",
- "description": "Single-device baseline",
- "server_type": "vllm-omni",
- "server_params": {
- "model": "Qwen/Qwen-Image-Layered",
- "serve_args": {
- "enable-diffusion-pipeline-profiler": true
- }
- },
- "benchmark_params": [
- {
- "name": "640x640_steps20_i2i",
- "dataset": "random",
- "task": "i2i",
- "width": 640,
- "height": 640,
- "num-inference-steps": 20,
- "num-prompts": 10,
- "max-concurrency": 1,
- "enable-negative-prompt": true,
- "baseline": {
- "throughput_qps": 0.02,
- "latency_mean": 40.0,
- "peak_memory_mb_max": 70000,
- "peak_memory_mb_mean": 70000
- }
- },
- {
- "name": "1024x1024_steps35_i2i",
- "dataset": "random",
- "task": "i2i",
- "width": 1024,
- "height": 1024,
- "num-inference-steps": 35,
- "num-prompts": 10,
- "max-concurrency": 1,
- "enable-negative-prompt": true,
- "baseline": {
- "throughput_qps": 0.005,
- "latency_mean": 80.0,
- "peak_memory_mb_max": 70000,
- "peak_memory_mb_mean": 70000
- }
- }
- ]
- }
-]
diff --git a/tests/dfx/perf/tests/test_qwen_image_vllm_omni.json b/tests/dfx/perf/tests/test_qwen_image_vllm_omni.json
deleted file mode 100644
index cdd0cac2c03..00000000000
--- a/tests/dfx/perf/tests/test_qwen_image_vllm_omni.json
+++ /dev/null
@@ -1,185 +0,0 @@
-[
- {
- "test_name": "test_qwen_image_single_device",
- "description": "Single-device baseline (no parallelism)",
- "server_type": "vllm-omni",
- "server_params": {
- "model": "Qwen/Qwen-Image",
- "serve_args": {
- "enable-diffusion-pipeline-profiler": true
- }
- },
- "benchmark_params": [
- {
- "name": "512x512_steps20",
- "dataset": "random",
- "task": "t2i",
- "width": 512,
- "height": 512,
- "num-inference-steps": 20,
- "num-prompts": 10,
- "max-concurrency": 1,
- "enable-negative-prompt": true,
- "baseline": {
- "throughput_qps": 0.30,
- "latency_mean": 3.50,
- "peak_memory_mb_mean": 67000
- }
- },
- {
- "name": "1536x1536_steps35",
- "dataset": "random",
- "task": "t2i",
- "width": 1536,
- "height": 1536,
- "num-inference-steps": 35,
- "num-prompts": 10,
- "max-concurrency": 1,
- "enable-negative-prompt": true,
- "baseline": {
- "throughput_qps": 0.037,
- "latency_mean": 27.0,
- "peak_memory_mb_mean": 74000
- }
- }
- ]
- },
- {
- "test_name": "test_qwen_image_single_device_step_execution",
- "description": "Single-device baseline (no parallelism) with step execution",
- "server_type": "vllm-omni",
- "server_params": {
- "model": "Qwen/Qwen-Image",
- "serve_args": {
- "enable-diffusion-pipeline-profiler": true,
- "step-execution": true
- }
- },
- "benchmark_params": [
- {
- "name": "512x512_steps20",
- "dataset": "random",
- "task": "t2i",
- "width": 512,
- "height": 512,
- "num-inference-steps": 20,
- "num-prompts": 10,
- "max-concurrency": 1,
- "enable-negative-prompt": true,
- "baseline": {
- "throughput_qps": 0.30,
- "latency_mean": 3.50,
- "peak_memory_mb_mean": 67000
- }
- },
- {
- "name": "1536x1536_steps35",
- "dataset": "random",
- "task": "t2i",
- "width": 1536,
- "height": 1536,
- "num-inference-steps": 35,
- "num-prompts": 10,
- "max-concurrency": 1,
- "enable-negative-prompt": true,
- "baseline": {
- "throughput_qps": 0.037,
- "latency_mean": 27.0,
- "peak_memory_mb_mean": 74000
- }
- }
- ]
- },
- {
- "test_name": "test_qwen_image_ulysses2_cfg2_vae_patch4",
- "description": "Ulysses SP=2 + CFG-parallel=2 + VAE Patch Parallel=4",
- "server_type": "vllm-omni",
- "server_params": {
- "model": "Qwen/Qwen-Image",
- "serve_args": {
- "ulysses-degree": 2,
- "cfg-parallel-size": 2,
- "vae-patch-parallel-size": 4,
- "vae-use-tiling": true,
- "enable-diffusion-pipeline-profiler": true
- }
- },
- "benchmark_params": [
- {
- "name": "1536x1536_steps35",
- "dataset": "random",
- "task": "t2i",
- "width": 1536,
- "height": 1536,
- "num-inference-steps": 35,
- "num-prompts": 10,
- "max-concurrency": 1,
- "enable-negative-prompt": true,
- "baseline": {
- "throughput_qps": 0.1,
- "latency_mean": 9.1,
- "peak_memory_mb_mean": 61000
- }
- }
- ]
- },
- {
- "test_name": "test_qwen_image_ulysses2_cfg2_cache_dit",
- "description": "Ulysses SP=2 + CFG-parallel=2 + CacheDiT acceleration",
- "server_type": "vllm-omni",
- "server_params": {
- "model": "Qwen/Qwen-Image",
- "serve_args": {
- "ulysses-degree": 2,
- "cfg-parallel-size": 2,
- "cache-backend": "cache_dit",
- "cache-config": {
- "Fn_compute_blocks": 1,
- "Bn_compute_blocks": 0,
- "max_warmup_steps": 4,
- "residual_diff_threshold": 0.24,
- "max_continuous_cached_steps": 3,
- "enable_taylorseer": false,
- "taylorseer_order": 1,
- "scm_steps_mask_policy": null,
- "scm_steps_policy": "dynamic"
- },
- "enable-diffusion-pipeline-profiler": true
- }
- },
- "benchmark_params": [
- {
- "name": "512x512_steps20",
- "dataset": "random",
- "task": "t2i",
- "width": 512,
- "height": 512,
- "num-inference-steps": 20,
- "num-prompts": 10,
- "max-concurrency": 1,
- "enable-negative-prompt": true,
- "baseline": {
- "throughput_qps": 0.1,
- "latency_mean": 3.50,
- "peak_memory_mb_mean": 67000
- }
- },
- {
- "name": "1536x1536_steps35",
- "dataset": "random",
- "task": "t2i",
- "width": 1536,
- "height": 1536,
- "num-inference-steps": 35,
- "num-prompts": 10,
- "max-concurrency": 1,
- "enable-negative-prompt": true,
- "baseline": {
- "throughput_qps": 0.1,
- "latency_mean": 6.15,
- "peak_memory_mb_mean": 74000
- }
- }
- ]
- }
-]
diff --git a/tests/dfx/perf/tests/test_qwen_omni.json b/tests/dfx/perf/tests/test_qwen_omni.json
deleted file mode 100644
index eda9720c417..00000000000
--- a/tests/dfx/perf/tests/test_qwen_omni.json
+++ /dev/null
@@ -1,315 +0,0 @@
-[
- {
- "test_name": "test_qwen3_omni",
- "server_params": {
- "model": "Qwen/Qwen3-Omni-30B-A3B-Instruct",
- "extra_cli_args": ["--no-async-chunk"]
- },
- "benchmark_params": [
- {
- "dataset_name": "random",
- "backend": "openai-chat-omni",
- "endpoint": "/v1/chat/completions",
- "num_prompts": [4, 16, 32, 64, 128],
- "max_concurrency": [1, 4, 8, 16, 32],
- "random_input_len": 2500,
- "random_output_len": 900,
- "ignore_eos": true,
- "percentile-metrics": "ttft,tpot,itl,e2el,audio_rtf,audio_ttfp,audio_duration",
- "baseline": {
- "mean_ttft_ms": [1000, 3000, 5000, 7000, 9000],
- "mean_audio_ttfp_ms": [30000, 60000, 90000, 120000, 150000],
- "mean_audio_rtf": [0.35, 0.45, 0.55, 0.65, 0.75]
- }
- },
- {
- "dataset_name": "random-mm",
- "backend": "openai-chat-omni",
- "endpoint": "/v1/chat/completions",
- "num_prompts": [10],
- "request_rate": [0.1],
- "random_input_len": 100,
- "random_output_len": 100,
- "random_range_ratio": 0.0,
- "ignore_eos": true,
- "random_mm_base_items_per_request": 1,
- "random_mm_num_mm_items_range_ratio": 0.5,
- "random_mm_limit_mm_per_prompt": {
- "audio": 1
- },
- "random_mm_bucket_config": {
- "(0, 60, 3)": 1.0
- },
- "percentile-metrics": "ttft,tpot,itl,e2el,audio_rtf,audio_ttfp,audio_duration",
- "baseline": {
- "mean_ttft_ms": [2000],
- "mean_audio_ttfp_ms": [10000],
- "mean_audio_rtf": [0.25]
- }
- },
- {
- "dataset_name": "random-mm",
- "backend": "openai-chat-omni",
- "endpoint": "/v1/chat/completions",
- "num_prompts": [40],
- "request_rate": [0.5],
- "random_input_len": 100,
- "random_output_len": 100,
- "random_range_ratio": 0.0,
- "ignore_eos": true,
- "random_mm_base_items_per_request": 2,
- "random_mm_num_mm_items_range_ratio": 0.5,
- "random_mm_limit_mm_per_prompt": {
- "image": 1,
- "video": 1
- },
- "random_mm_bucket_config": {
- "(256, 256, 1)": 0.5,
- "(720, 1280, 2)": 0.5
- },
- "percentile-metrics": "ttft,tpot,itl,e2el,audio_rtf,audio_ttfp,audio_duration",
- "baseline": {
- "mean_ttft_ms": [6000],
- "mean_audio_ttfp_ms": [15000],
- "mean_audio_rtf": [0.45]
- }
- },
- {
- "dataset_name": "random-mm",
- "backend": "openai-chat-omni",
- "endpoint": "/v1/chat/completions",
- "num_prompts": [100],
- "request_rate": [1.0],
- "random_input_len": 100,
- "random_output_len": 100,
- "random_range_ratio": 0.0,
- "ignore_eos": true,
- "random_mm_base_items_per_request": 3,
- "random_mm_num_mm_items_range_ratio": 0.5,
- "random_mm_limit_mm_per_prompt": {
- "image": 1,
- "video": 1,
- "audio": 1
- },
- "random_mm_bucket_config": {
- "(256, 256, 1)": 0.34,
- "(720, 1280, 2)": 0.33,
- "(0, 60, 3)": 0.33
- },
- "percentile-metrics": "ttft,tpot,itl,e2el,audio_rtf,audio_ttfp,audio_duration",
- "baseline": {
- "mean_ttft_ms": [12000],
- "mean_audio_ttfp_ms": [18000],
- "mean_audio_rtf": [0.9]
- }
- }
- ]
- },
- {
- "test_name": "test_qwen3_omni_chunk",
- "server_params": {
- "model": "Qwen/Qwen3-Omni-30B-A3B-Instruct",
- "extra_cli_args": ["--async-chunk"]
- },
- "benchmark_params": [
- {
- "dataset_name": "random",
- "backend": "openai-chat-omni",
- "endpoint": "/v1/chat/completions",
- "num_prompts": [4, 16, 32, 64],
- "max_concurrency": [1, 4, 8, 16],
- "random_input_len": 2500,
- "random_output_len": 900,
- "ignore_eos": true,
- "percentile-metrics": "ttft,tpot,itl,e2el,audio_rtf,audio_ttfp,audio_duration",
- "baseline": {
- "mean_ttft_ms": [1000, 3000, 5000, 7000],
- "mean_audio_ttfp_ms": [1000, 3000, 5000, 7000],
- "mean_audio_rtf": [0.2, 0.35, 0.6, 0.85]
- }
- },
- {
- "dataset_name": "random-mm",
- "backend": "openai-chat-omni",
- "endpoint": "/v1/chat/completions",
- "num_prompts": [10],
- "request_rate": [0.1],
- "random_input_len": 100,
- "random_output_len": 100,
- "random_range_ratio": 0.0,
- "ignore_eos": true,
- "random_mm_base_items_per_request": 1,
- "random_mm_num_mm_items_range_ratio": 0.5,
- "random_mm_limit_mm_per_prompt": {
- "audio": 1
- },
- "random_mm_bucket_config": {
- "(0, 60, 3)": 1.0
- },
- "percentile-metrics": "ttft,tpot,itl,e2el,audio_rtf,audio_ttfp,audio_duration",
- "baseline": {
- "mean_ttft_ms": [2000],
- "mean_audio_ttfp_ms": [2000],
- "mean_audio_rtf": [0.25]
- }
- },
- {
- "dataset_name": "random-mm",
- "backend": "openai-chat-omni",
- "endpoint": "/v1/chat/completions",
- "num_prompts": [40],
- "request_rate": [0.5],
- "random_input_len": 100,
- "random_output_len": 100,
- "random_range_ratio": 0.0,
- "ignore_eos": true,
- "random_mm_base_items_per_request": 2,
- "random_mm_num_mm_items_range_ratio": 0.5,
- "random_mm_limit_mm_per_prompt": {
- "image": 1,
- "video": 1
- },
- "random_mm_bucket_config": {
- "(256, 256, 1)": 0.5,
- "(720, 1280, 2)": 0.5
- },
- "percentile-metrics": "ttft,tpot,itl,e2el,audio_rtf,audio_ttfp,audio_duration",
- "baseline": {
- "mean_ttft_ms": [6000],
- "mean_audio_ttfp_ms": [6000],
- "mean_audio_rtf": [0.7]
- }
- },
- {
- "dataset_name": "random-mm",
- "backend": "openai-chat-omni",
- "endpoint": "/v1/chat/completions",
- "num_prompts": [100],
- "request_rate": [1.0],
- "random_input_len": 100,
- "random_output_len": 100,
- "random_range_ratio": 0.0,
- "ignore_eos": true,
- "random_mm_base_items_per_request": 3,
- "random_mm_num_mm_items_range_ratio": 0.5,
- "random_mm_limit_mm_per_prompt": {
- "image": 1,
- "video": 1,
- "audio": 1
- },
- "random_mm_bucket_config": {
- "(256, 256, 1)": 0.34,
- "(720, 1280, 2)": 0.33,
- "(0, 60, 3)": 0.33
- },
- "percentile-metrics": "ttft,tpot,itl,e2el,audio_rtf,audio_ttfp,audio_duration",
- "baseline": {
- "mean_ttft_ms": [12000],
- "mean_audio_ttfp_ms": [12000],
- "mean_audio_rtf": [1.0]
- }
- },
- {
- "dataset_name": "random",
- "backend": "openai-chat-omni",
- "endpoint": "/v1/chat/completions",
- "num_prompts": [4, 16, 32, 64, 128],
- "max_concurrency": [1, 4, 8, 16, 32],
- "random_input_len": 2500,
- "random_output_len": 900,
- "ignore_eos": true,
- "extra_body": {
- "modalities": ["text"]
- },
- "percentile-metrics": "ttft,tpot,itl,e2el",
- "baseline": {
- "mean_ttft_ms": [1000, 3000, 5000, 7000, 9000]
- }
- },
- {
- "dataset_name": "random-mm",
- "backend": "openai-chat-omni",
- "endpoint": "/v1/chat/completions",
- "num_prompts": [10],
- "request_rate": [0.1],
- "random_input_len": 100,
- "random_output_len": 100,
- "random_range_ratio": 0.0,
- "ignore_eos": true,
- "extra_body": {
- "modalities": ["text"]
- },
- "random_mm_base_items_per_request": 1,
- "random_mm_num_mm_items_range_ratio": 0.5,
- "random_mm_limit_mm_per_prompt": {
- "audio": 1
- },
- "random_mm_bucket_config": {
- "(0, 60, 3)": 1.0
- },
- "percentile-metrics": "ttft,tpot,itl,e2el",
- "baseline": {
- "mean_ttft_ms": [2000]
- }
- },
- {
- "dataset_name": "random-mm",
- "backend": "openai-chat-omni",
- "endpoint": "/v1/chat/completions",
- "num_prompts": [40],
- "request_rate": [0.5],
- "random_input_len": 100,
- "random_output_len": 100,
- "random_range_ratio": 0.0,
- "ignore_eos": true,
- "extra_body": {
- "modalities": ["text"]
- },
- "random_mm_base_items_per_request": 2,
- "random_mm_num_mm_items_range_ratio": 0.5,
- "random_mm_limit_mm_per_prompt": {
- "image": 1,
- "video": 1
- },
- "random_mm_bucket_config": {
- "(256, 256, 1)": 0.5,
- "(720, 1280, 2)": 0.5
- },
- "percentile-metrics": "ttft,tpot,itl,e2el",
- "baseline": {
- "mean_ttft_ms": [6000]
- }
- },
- {
- "dataset_name": "random-mm",
- "backend": "openai-chat-omni",
- "endpoint": "/v1/chat/completions",
- "num_prompts": [100],
- "request_rate": [1.0],
- "random_input_len": 100,
- "random_output_len": 100,
- "random_range_ratio": 0.0,
- "ignore_eos": true,
- "extra_body": {
- "modalities": ["text"]
- },
- "random_mm_base_items_per_request": 3,
- "random_mm_num_mm_items_range_ratio": 0.5,
- "random_mm_limit_mm_per_prompt": {
- "image": 1,
- "video": 1,
- "audio": 1
- },
- "random_mm_bucket_config": {
- "(256, 256, 1)": 0.34,
- "(720, 1280, 2)": 0.33,
- "(0, 60, 3)": 0.33
- },
- "percentile-metrics": "ttft,tpot,itl,e2el",
- "baseline": {
- "mean_ttft_ms": [6000]
- }
- }
- ]
- }
-]
diff --git a/tests/dfx/perf/tests/test_runner_metadata.py b/tests/dfx/perf/tests/test_runner_metadata.py
deleted file mode 100644
index 1276a847069..00000000000
--- a/tests/dfx/perf/tests/test_runner_metadata.py
+++ /dev/null
@@ -1,79 +0,0 @@
-"""Tests for DFX runner metadata field exclusion."""
-
-import json
-
-import pytest
-
-pytestmark = [pytest.mark.core_model, pytest.mark.cpu]
-
-
-def test_task_excluded_from_cli_args():
- """'task' field must not become --task CLI arg."""
- params = {
- "task": "voice_clone",
- "dataset_name": "seed-tts",
- "backend": "openai-audio-speech",
- "endpoint": "/v1/audio/speech",
- "percentile-metrics": "audio_rtf,audio_ttfp",
- "baseline": {"mean_audio_rtf": [0.5]},
- }
- exclude_keys = {"request_rate", "baseline", "num_prompts", "max_concurrency", "task", "enabled", "eval_phase"}
- args = []
- for key, value in params.items():
- if key in exclude_keys or value is None:
- continue
- arg_name = f"--{key.replace('_', '-')}"
- if isinstance(value, bool) and value:
- args.append(arg_name)
- elif isinstance(value, dict):
- args.extend([arg_name, json.dumps(value)])
- elif not isinstance(value, bool):
- args.extend([arg_name, str(value)])
- assert "--task" not in args
- assert "--enabled" not in args
- assert "--dataset-name" in args
-
-
-def test_enabled_false_entry_is_skipped():
- """benchmark_params entry with enabled=false should be skipped."""
- import sys
- from pathlib import Path
-
- sys.path.insert(0, str(Path(__file__).parent.parent.parent.parent))
- from tests.dfx.conftest import create_test_parameter_mapping
-
- configs = [
- {
- "test_name": "test_model",
- "server_params": {"model": "some/model"},
- "benchmark_params": [
- {
- "task": "voice_clone",
- "enabled": True,
- "dataset_name": "seed-tts",
- "backend": "openai-audio-speech",
- "endpoint": "/v1/audio/speech",
- "num_prompts": [10],
- "max_concurrency": [1],
- "percentile-metrics": "audio_rtf",
- "baseline": {},
- },
- {
- "task": "voice_design",
- "enabled": False,
- "dataset_name": "seed-tts-design",
- "backend": "openai-audio-speech",
- "endpoint": "/v1/audio/speech",
- "num_prompts": [5],
- "max_concurrency": [1],
- "percentile-metrics": "audio_rtf",
- "baseline": {},
- },
- ],
- }
- ]
- mapping = create_test_parameter_mapping(configs)
- params = mapping["test_model"]["benchmark_params"]
- # Only the enabled=True entry should appear
- assert len(params) == 1
- assert params[0].get("task") == "voice_clone"
diff --git a/tests/dfx/perf/tests/test_tts.json b/tests/dfx/perf/tests/test_tts.json
deleted file mode 100644
index 06c9c4d2384..00000000000
--- a/tests/dfx/perf/tests/test_tts.json
+++ /dev/null
@@ -1,155 +0,0 @@
-[
- {
- "test_name": "test_qwen3_tts_base",
- "server_params": {
- "model": "Qwen/Qwen3-TTS-12Hz-1.7B-Base"
- },
- "benchmark_params": [
- {
- "task": "voice_clone",
- "eval_phase": "latency",
- "enabled": false,
- "dataset_name": "seed-tts",
- "backend": "openai-audio-speech",
- "endpoint": "/v1/audio/speech",
- "num_prompts": [20],
- "max_concurrency": [1],
- "seed_tts_locale": "en",
- "percentile-metrics": "ttft,e2el,audio_rtf,audio_ttfp,audio_duration",
- "baseline": {
- "median_audio_ttfp_ms": [350],
- "median_audio_rtf": [0.25]
- }
- },
- {
- "task": "voice_clone",
- "eval_phase": "throughput",
- "enabled": false,
- "dataset_name": "seed-tts",
- "backend": "openai-audio-speech",
- "endpoint": "/v1/audio/speech",
- "num_prompts": [80],
- "max_concurrency": [8],
- "seed_tts_locale": "en",
- "percentile-metrics": "ttft,e2el,audio_rtf,audio_ttfp,audio_duration",
- "baseline": {
- "median_audio_ttfp_ms": [3500],
- "median_audio_rtf": [0.75],
- "audio_throughput": [10.0]
- }
- },
- {
- "task": "voice_clone",
- "eval_phase": "quality",
- "enabled": false,
- "dataset_name": "seed-tts",
- "backend": "openai-audio-speech",
- "endpoint": "/v1/audio/speech",
- "num_prompts": [200],
- "max_concurrency": [4],
- "seed_tts_locale": "en",
- "seed_tts_wer_eval": true,
- "percentile-metrics": "ttft,e2el,audio_rtf,audio_ttfp,audio_duration",
- "baseline": {
- "mean_audio_rtf": [0.45]
- }
- }
- ]
- },
- {
- "test_name": "test_qwen3_tts_customvoice",
- "server_params": {
- "model": "Qwen/Qwen3-TTS-12Hz-1.7B-CustomVoice"
- },
- "benchmark_params": [
- {
- "task": "default_voice",
- "eval_phase": "latency",
- "dataset_name": "seed-tts-text",
- "backend": "openai-audio-speech",
- "endpoint": "/v1/audio/speech",
- "dataset_path": "benchmarks/build_dataset/seed_tts_smoke",
- "num_prompts": [20],
- "max_concurrency": [1],
- "seed_tts_locale": "en",
- "extra_body": {"voice": "Vivian", "language": "English", "task_type": "CustomVoice"},
- "percentile-metrics": "ttft,e2el,audio_rtf,audio_ttfp,audio_duration",
- "baseline": {
- "median_audio_ttfp_ms": [150],
- "median_audio_rtf": [0.15]
- }
- },
- {
- "task": "default_voice",
- "eval_phase": "throughput",
- "dataset_name": "seed-tts-text",
- "backend": "openai-audio-speech",
- "endpoint": "/v1/audio/speech",
- "dataset_path": "benchmarks/build_dataset/seed_tts_smoke",
- "num_prompts": [80],
- "max_concurrency": [8],
- "seed_tts_locale": "en",
- "extra_body": {"voice": "Vivian", "language": "English", "task_type": "CustomVoice"},
- "percentile-metrics": "ttft,e2el,audio_rtf,audio_ttfp,audio_duration",
- "baseline": {
- "median_audio_ttfp_ms": [1500],
- "median_audio_rtf": [0.30],
- "audio_throughput": [30.0]
- }
- },
- {
- "task": "default_voice",
- "eval_phase": "quality",
- "enabled": false,
- "dataset_name": "seed-tts-text",
- "backend": "openai-audio-speech",
- "endpoint": "/v1/audio/speech",
- "dataset_path": "benchmarks/build_dataset/seed_tts_smoke",
- "num_prompts": [200],
- "max_concurrency": [4],
- "seed_tts_locale": "en",
- "extra_body": {"voice": "Vivian", "language": "English", "task_type": "CustomVoice"},
- "seed_tts_wer_eval": true,
- "percentile-metrics": "ttft,e2el,audio_rtf,audio_ttfp,audio_duration",
- "baseline": {
- "mean_audio_rtf": [0.35]
- }
- },
- {
- "task": "voice_design",
- "eval_phase": "latency",
- "dataset_name": "seed-tts-design",
- "backend": "openai-audio-speech",
- "endpoint": "/v1/audio/speech",
- "dataset_path": "benchmarks/build_dataset/seed_tts_design",
- "num_prompts": [20],
- "max_concurrency": [1],
- "seed_tts_locale": "en",
- "extra_body": {"task_type": "VoiceDesign", "language": "English"},
- "percentile-metrics": "ttft,e2el,audio_rtf,audio_ttfp,audio_duration",
- "baseline": {
- "median_audio_ttfp_ms": [150],
- "median_audio_rtf": [0.15]
- }
- },
- {
- "task": "voice_design",
- "eval_phase": "throughput",
- "dataset_name": "seed-tts-design",
- "backend": "openai-audio-speech",
- "endpoint": "/v1/audio/speech",
- "dataset_path": "benchmarks/build_dataset/seed_tts_design",
- "num_prompts": [80],
- "max_concurrency": [8],
- "seed_tts_locale": "en",
- "extra_body": {"task_type": "VoiceDesign", "language": "English"},
- "percentile-metrics": "ttft,e2el,audio_rtf,audio_ttfp,audio_duration",
- "baseline": {
- "median_audio_ttfp_ms": [1500],
- "median_audio_rtf": [0.35],
- "audio_throughput": [25.0]
- }
- }
- ]
- }
-]
diff --git a/tests/dfx/perf/tests/test_wan22_i2v_vllm_omni.json b/tests/dfx/perf/tests/test_wan22_i2v_vllm_omni.json
deleted file mode 100644
index 58a17c980bd..00000000000
--- a/tests/dfx/perf/tests/test_wan22_i2v_vllm_omni.json
+++ /dev/null
@@ -1,107 +0,0 @@
-[
- {
- "test_name": "test_wan22_i2v_single_device",
- "description": "Single-device baseline",
- "server_type": "vllm-omni",
- "server_params": {
- "model": "Wan-AI/Wan2.2-I2V-A14B-Diffusers",
- "serve_args": {
- "enable-diffusion-pipeline-profiler": true
- }
- },
- "benchmark_params": [
- {
- "name": "832x480_frames81_steps4",
- "dataset": "random",
- "task": "i2v",
- "num-prompts": 10,
- "max-concurrency": 1,
- "num-input-images": 1,
- "seed": 42,
- "enable-negative-prompt": true,
- "random-request-config": [
- {
- "width": 832,
- "height": 480,
- "num_inference_steps": 4,
- "num_frames": 81,
- "fps": 16,
- "weight": 1
- }
- ],
- "baseline": {
- "throughput_qps": 0.034,
- "latency_mean": 26.0,
- "peak_memory_mb_mean": 80000
- }
- }
- ]
- },
- {
- "test_name": "test_wan22_i2v_usp2_vae_patch2_hsdp_slicing",
- "description": "USP=2 + VAE patch parallel=2 + HSDP + VAE slicing",
- "server_type": "vllm-omni",
- "server_params": {
- "model": "Wan-AI/Wan2.2-I2V-A14B-Diffusers",
- "serve_args": {
- "usp": 2,
- "vae-patch-parallel-size": 2,
- "use-hsdp": true,
- "vae-use-slicing": true,
- "enable-diffusion-pipeline-profiler": true
- }
- },
- "benchmark_params": [
- {
- "name": "832x480_frames81_steps4",
- "dataset": "random",
- "task": "i2v",
- "num-prompts": 10,
- "max-concurrency": 1,
- "num-input-images": 1,
- "seed": 42,
- "enable-negative-prompt": true,
- "random-request-config": [
- {
- "width": 832,
- "height": 480,
- "num_inference_steps": 4,
- "num_frames": 81,
- "fps": 16,
- "weight": 1
- }
- ],
- "baseline": {
- "throughput_qps": 0.042,
- "latency_mean": 21.6,
- "peak_memory_mb_mean": 55300
- }
- },
- {
- "name": "1280x720_frames121_steps4",
- "dataset": "random",
- "task": "i2v",
- "num-prompts": 10,
- "max-concurrency": 1,
- "num-input-images": 1,
- "seed": 42,
- "enable-negative-prompt": true,
- "random-request-config": [
- {
- "width": 1280,
- "height": 720,
- "num_inference_steps": 4,
- "num_frames": 121,
- "fps": 16,
- "weight": 1
- }
- ],
- "baseline": {
- "throughput_qps": 0.0085,
- "latency_mean": 101.6,
- "peak_memory_mb_mean": 65200
- }
- }
- ]
- }
-]
diff --git a/tests/dfx/reliability/README.md b/tests/dfx/reliability/README.md
deleted file mode 100644
index 7196101bcdd..00000000000
--- a/tests/dfx/reliability/README.md
+++ /dev/null
@@ -1,14 +0,0 @@
-# L5(b) Reliability (`tests/dfx/reliability`)
-
-This directory contains reliability fault-injection tests for key models.
-The detailed RFC document is maintained outside this repository (local/internal only).
-
-- Fault helpers: `conftest.py`, `helpers.py`
-- Qwen3 tests: `test_reliability_qwen3_omni.py`
-- Wan2.2 tests: `test_reliability_wan22.py`
-
-```bash
-pytest --collect-only tests/dfx/reliability
-pytest -s -v tests/dfx/reliability/test_reliability_qwen3_omni.py -m slow
-pytest -s -v tests/dfx/reliability/test_reliability_wan22.py -m slow
-```
diff --git a/tests/dfx/reliability/conftest.py b/tests/dfx/reliability/conftest.py
deleted file mode 100644
index 7cf79847f47..00000000000
--- a/tests/dfx/reliability/conftest.py
+++ /dev/null
@@ -1,29 +0,0 @@
-"""Pytest fixtures for reliability tests."""
-
-from __future__ import annotations
-
-from typing import Any
-
-import pytest
-
-from tests.dfx.reliability.helpers import FaultInjector
-
-
-@pytest.fixture
-def fault_injector(request: pytest.FixtureRequest) -> FaultInjector:
- """Indirect only: ``request.param`` must be a ``FaultInjector`` callable."""
- return request.param
-
-
-@pytest.fixture
-def omni_server_after_fault(omni_server: Any, fault_injector: FaultInjector):
- """After ``omni_server`` is up, run ``fault_injector(omni_server)``, then yield the server."""
- fault_injector(omni_server)
- yield omni_server
-
-
-@pytest.fixture
-def omni_server_after_fault_function(omni_server_function: Any, fault_injector: FaultInjector):
- """Inject fault after function-scoped server startup, then yield server."""
- fault_injector(omni_server_function)
- yield omni_server_function
diff --git a/tests/dfx/reliability/helpers.py b/tests/dfx/reliability/helpers.py
deleted file mode 100644
index 9ebd0ce97a6..00000000000
--- a/tests/dfx/reliability/helpers.py
+++ /dev/null
@@ -1,567 +0,0 @@
-"""Shared reliability fault-injection helpers.
-
-This module keeps fault injection callable from tests directly:
-- GPU OOM (CUDA sidecar memory hog)
-- process kill by pattern and signal
-- post-ready hooks via ``fault_injector`` / ``omni_server_after_fault`` fixtures
-"""
-
-from __future__ import annotations
-
-import http.client
-import json
-import logging
-import os
-import select
-import shlex
-import signal
-import subprocess
-import sys
-import time
-from collections.abc import Callable, Sequence
-from dataclasses import dataclass
-from typing import Any
-
-import psutil
-import pytest
-
-logger = logging.getLogger(__name__)
-
-
-@dataclass
-class OomHandle:
- """Handle for a started CUDA memory hog subprocess."""
-
- proc: subprocess.Popen | None
- device: int
- target_mem_ratio: float
- start_ts: float
-
-
-def post_chat_completions_raw(
- host: str,
- port: int,
- body: bytes | str,
- *,
- content_type: str = "application/json",
- timeout_sec: int = 120,
-) -> tuple[int, bytes]:
- """POST /v1/chat/completions with raw bytes; returns (status, response_body)."""
- conn = http.client.HTTPConnection(host, port, timeout=timeout_sec)
- try:
- headers = {"Content-Type": content_type}
- payload = body.encode("utf-8") if isinstance(body, str) else body
- conn.request("POST", "/v1/chat/completions", body=payload, headers=headers)
- resp = conn.getresponse()
- data = resp.read()
- return resp.status, data
- finally:
- conn.close()
-
-
-def get_health_raw(host: str, port: int, *, timeout_sec: int = 20) -> tuple[int, bytes]:
- """GET /health with stdlib HTTP client; returns (status, body)."""
- conn = http.client.HTTPConnection(host, port, timeout=timeout_sec)
- try:
- conn.request("GET", "/health")
- resp = conn.getresponse()
- return resp.status, resp.read()
- finally:
- conn.close()
-
-
-def post_json_raw_http_client(
- host: str,
- port: int,
- path: str,
- payload: dict[str, Any],
- *,
- timeout_sec: int = 30,
-) -> tuple[int, bytes]:
- """POST JSON to one endpoint with stdlib HTTP client; returns (status, body)."""
- conn = http.client.HTTPConnection(host, port, timeout=timeout_sec)
- try:
- body = json.dumps(payload).encode("utf-8")
- conn.request("POST", path, body=body, headers={"Content-Type": "application/json"})
- resp = conn.getresponse()
- return resp.status, resp.read()
- finally:
- conn.close()
-
-
-def post_json_raw(
- host: str,
- port: int,
- path: str,
- payload: dict[str, Any],
- *,
- timeout_sec: int = 30,
-) -> tuple[int, bytes]:
- """POST JSON to one endpoint; returns (status, body)."""
- return (
- post_chat_completions_raw(
- host,
- port,
- json.dumps(payload),
- content_type="application/json",
- timeout_sec=timeout_sec,
- )
- if path == "/v1/chat/completions"
- else post_json_raw_http_client(
- host,
- port,
- path,
- payload,
- timeout_sec=timeout_sec,
- )
- )
-
-
-def extract_openai_error_contract_from_bytes(response_body: bytes) -> dict[str, Any] | None:
- """Best-effort parse OpenAI-style error object from raw response bytes."""
- try:
- payload = json.loads(response_body.decode("utf-8", errors="replace"))
- except Exception: # noqa: BLE001
- return None
- return extract_openai_error_contract_from_payload(payload)
-
-
-def extract_openai_error_contract_from_payload(payload: Any) -> dict[str, Any] | None:
- """Best-effort parse OpenAI-style error object from decoded JSON payload."""
- if not isinstance(payload, dict):
- return None
- error_obj = payload.get("error")
- if not isinstance(error_obj, dict):
- return None
- if not isinstance(error_obj.get("message"), str):
- return None
- return error_obj
-
-
-def _build_sidecar_cmd(device: int, target_mem_ratio: float, hold_seconds: int, strict: bool) -> list[str]:
- sidecar = r"""
-import sys
-import time
-import torch
-
-device = int(sys.argv[1])
-target_ratio = float(sys.argv[2])
-hold_seconds = int(sys.argv[3])
-strict = sys.argv[4] == "1"
-
-torch.cuda.init()
-torch.cuda.set_device(device)
-props = torch.cuda.get_device_properties(device)
-free_before, total_bytes = torch.cuda.mem_get_info(device)
-target_bytes = int(free_before * target_ratio)
-chunk_bytes = 256 * 1024 * 1024
-chunks = []
-allocated = 0
-
-while allocated < target_bytes:
- req_bytes = min(chunk_bytes, target_bytes - allocated)
- req_elems = max(1, req_bytes // 2) # float16 -> 2 bytes
- try:
- chunk = torch.empty((req_elems,), dtype=torch.float16, device=f"cuda:{device}")
- chunks.append(chunk)
- allocated += chunk.numel() * 2
- except RuntimeError:
- break
-
-# In strict mode, keep filling with smaller chunks until allocator rejects.
-# This minimizes residual free memory and makes fault-path assertions steadier.
-if strict:
- tail_chunk_bytes = [64 * 1024 * 1024, 16 * 1024 * 1024, 4 * 1024 * 1024, 1 * 1024 * 1024]
- for tail_bytes in tail_chunk_bytes:
- while True:
- req_elems = max(1, tail_bytes // 2)
- try:
- chunk = torch.empty((req_elems,), dtype=torch.float16, device=f"cuda:{device}")
- chunks.append(chunk)
- allocated += chunk.numel() * 2
- except RuntimeError:
- break
-
-achieved_ratio = allocated / max(1, props.total_memory)
-achieved_free_ratio = allocated / max(1, int(free_before))
-free_after, _ = torch.cuda.mem_get_info(device)
-if strict and allocated < target_bytes:
- print(
- "ERROR:"
- f"achieved_free_ratio={achieved_free_ratio:.4f};"
- f"achieved_total_ratio={achieved_ratio:.4f};"
- f"free_before={int(free_before)};"
- f"free_after={int(free_after)};"
- f"target_bytes={target_bytes};"
- f"allocated={allocated}",
- flush=True,
- )
- sys.exit(2)
-
-print(
- "READY:"
- f"achieved_free_ratio={achieved_free_ratio:.4f};"
- f"achieved_total_ratio={achieved_ratio:.4f};"
- f"free_before={int(free_before)};"
- f"free_after={int(free_after)};"
- f"target_bytes={target_bytes};"
- f"allocated={allocated}",
- flush=True,
-)
-if hold_seconds <= 0:
- while True:
- time.sleep(3600)
-time.sleep(hold_seconds)
-print("DONE", flush=True)
-"""
- return [
- sys.executable,
- "-u",
- "-c",
- sidecar,
- str(device),
- str(target_mem_ratio),
- str(hold_seconds),
- "1" if strict else "0",
- ]
-
-
-def start_gpu_oom_hog(
- *,
- device: int = 0,
- target_mem_ratio: float = 0.95,
- hold_seconds: int = 60,
- startup_timeout_sec: int = 20,
- strict: bool = True,
- poll_interval_sec: float = 0.2,
-) -> OomHandle:
- """Start a CUDA sidecar process that occupies GPU memory to trigger OOM.
-
- Note:
- ``target_mem_ratio`` is evaluated against free memory at injection start
- (not total GPU memory), i.e. success gate is ``allocated / free_before``.
- ``hold_seconds <= 0`` means keeping OOM pressure until the sidecar is
- explicitly stopped via ``stop_gpu_oom_hog(s)``.
- """
- if os.name == "nt":
- raise RuntimeError("CUDA OOM sidecar is intended for Linux CI/runtime.")
- if not (0.0 <= target_mem_ratio < 1.0):
- raise ValueError("target_mem_ratio should be in [0.0, 1.0).")
-
- # Explicit opt-out for debugging: keep API shape stable while disabling injection.
- if target_mem_ratio == 0.0:
- print(f"[oom-sidecar][gpu={device}] DISABLED: target_mem_ratio=0.0 (no OOM injection)", flush=True)
- return OomHandle(
- proc=None,
- device=device,
- target_mem_ratio=target_mem_ratio,
- start_ts=time.time(),
- )
-
- cmd = _build_sidecar_cmd(device, target_mem_ratio, hold_seconds, strict)
- proc = subprocess.Popen(
- cmd,
- stdout=subprocess.PIPE,
- stderr=subprocess.STDOUT,
- text=True,
- bufsize=1,
- )
- assert proc.stdout is not None
-
- deadline = time.time() + startup_timeout_sec
- logs: list[str] = []
- while time.time() < deadline:
- ready, _, _ = select.select([proc.stdout], [], [], poll_interval_sec)
- if ready:
- line = proc.stdout.readline().strip()
- if line:
- logs.append(line)
- print(f"[oom-sidecar][gpu={device}] {line}", flush=True)
- if line.startswith("READY:"):
- return OomHandle(
- proc=proc,
- device=device,
- target_mem_ratio=target_mem_ratio,
- start_ts=time.time(),
- )
- if line.startswith("ERROR:"):
- proc.terminate()
- raise RuntimeError(f"OOM sidecar failed to reach target: {line}")
- if proc.poll() is not None:
- break
-
- proc.terminate()
- if logs:
- print(f"[oom-sidecar][gpu={device}] startup logs: {' | '.join(logs)}", flush=True)
- raise TimeoutError(f"OOM sidecar startup timeout. logs={logs}")
-
-
-def stop_gpu_oom_hog(handle: OomHandle, *, timeout_sec: int = 5) -> None:
- """Stop and cleanup CUDA OOM sidecar."""
- proc = handle.proc
- if proc is None:
- return
- if proc.poll() is not None:
- return
- proc.terminate()
- try:
- proc.wait(timeout=timeout_sec)
- except subprocess.TimeoutExpired:
- proc.kill()
- proc.wait(timeout=timeout_sec)
-
-
-def inject_gpu_oom(
- *,
- device: int | str | list[int] = 0,
- target_mem_ratio: float = 0.95,
- hold_seconds: int = 60,
- startup_timeout_sec: int = 20,
- strict: bool = True,
-) -> OomHandle | list[OomHandle]:
- """Convenience wrapper to start CUDA OOM sidecar(s).
-
- Args:
- device: One device id (``0``), comma-separated string (``"0,1,2"``),
- or a list of device ids (``[0, 1, 2]``).
- hold_seconds: OOM hold time in seconds; ``<=0`` keeps pressure until
- ``stop_gpu_oom_hogs`` is called.
- """
- if isinstance(device, int):
- devices = [device]
- elif isinstance(device, str):
- devices = [int(x.strip()) for x in device.split(",") if x.strip()]
- else:
- devices = [int(x) for x in device]
- if not devices:
- raise ValueError("device must not be empty.")
-
- handles = [
- start_gpu_oom_hog(
- device=dev,
- target_mem_ratio=target_mem_ratio,
- hold_seconds=hold_seconds,
- startup_timeout_sec=startup_timeout_sec,
- strict=strict,
- )
- for dev in devices
- ]
- if len(handles) == 1:
- return handles[0]
- return handles
-
-
-def stop_gpu_oom_hogs(handles: OomHandle | list[OomHandle], *, timeout_sec: int = 5) -> None:
- """Stop one or multiple OOM sidecars."""
- if isinstance(handles, OomHandle):
- stop_gpu_oom_hog(handles, timeout_sec=timeout_sec)
- return
- for handle in handles:
- stop_gpu_oom_hog(handle, timeout_sec=timeout_sec)
-
-
-def _runtime_teardown_ssh_target() -> str:
- target = os.getenv("RUNTIME_TEARDOWN_SSH_TARGET", "").strip()
- # Default to root@127.0.0.1 for same-host SSH control path.
- return target or "root@127.0.0.1"
-
-
-def _runtime_teardown_ssh_cmd(remote_cmd: str, *, step: str | None = None) -> subprocess.CompletedProcess[str]:
- ssh_target = _runtime_teardown_ssh_target()
- default_reuse_opts = "-o ControlMaster=auto -o ControlPersist=10m -o ControlPath=/tmp/vllm-rt-ssh-%r@%h:%p"
- raw_opts = os.getenv("RUNTIME_TEARDOWN_SSH_OPTS", "").strip()
- ssh_opts = shlex.split(raw_opts or default_reuse_opts)
- timeout_sec = int(os.getenv("RUNTIME_TEARDOWN_SSH_TIMEOUT_SEC", "600"))
- step_prefix = f"[runtime-teardown][ssh]{f'[{step}]' if step else ''}"
- print(f"{step_prefix} target={ssh_target} running remote command...", flush=True)
- # IMPORTANT: SSH joins remote argv into one shell command string. If we pass
- # ["bash", "-c", remote_cmd] as separate argv items, remote shell parsing can
- # make `-c` consume only the first word (e.g. "docker"), causing docker help.
- # Wrap the whole command as one quoted string for remote bash -c.
- remote_invocation = f"bash --noprofile --norc -c {shlex.quote(remote_cmd)}"
- try:
- out = subprocess.run(
- ["ssh", *ssh_opts, ssh_target, remote_invocation],
- check=False,
- capture_output=True,
- text=True,
- timeout=timeout_sec,
- )
- except subprocess.TimeoutExpired as exc:
- raise RuntimeError(
- f"{step_prefix} timed out after {timeout_sec}s. Increase RUNTIME_TEARDOWN_SSH_TIMEOUT_SEC if needed."
- ) from exc
- print(f"{step_prefix} exit_code={out.returncode}", flush=True)
- return out
-
-
-def list_remote_process_pids_by_pattern(pattern: str) -> list[int]:
- """Return matched PIDs from remote host ``pgrep -f <pattern>`` via SSH."""
- cmd = f"pgrep -f {shlex.quote(pattern)} || true"
- out = _runtime_teardown_ssh_cmd(cmd, step="pgrep")
- if out.returncode not in (0, 1):
- raise RuntimeError(f"remote pgrep failed for pattern={pattern!r}: {out.stderr.strip()}")
- return [int(item) for item in out.stdout.split() if item.strip().isdigit()]
-
-
-def inject_process_kill(
- *,
- grep_pattern: str,
- signal_name: str = "SIGTERM",
- limit: int | None = None,
- allow_zero_match: bool = False,
- execute_kill: bool = True,
-) -> list[int]:
- """Kill processes matching pattern with selected signal."""
- if os.name == "nt":
- raise RuntimeError("process-kill helper currently supports POSIX platforms only.")
- if not grep_pattern.strip():
- raise ValueError("grep_pattern must not be empty.")
-
- sig = getattr(signal, signal_name, None)
- if sig is None:
- raise ValueError(f"Unsupported signal_name: {signal_name}")
-
- out = subprocess.run(
- ["pgrep", "-f", grep_pattern],
- check=False,
- capture_output=True,
- text=True,
- )
- pids = [int(item) for item in out.stdout.split() if item.strip().isdigit()]
- if limit is not None:
- pids = pids[:limit]
-
- if not pids and not allow_zero_match:
- raise RuntimeError(f"No process matched pattern: {grep_pattern}")
-
- if execute_kill:
- for pid in pids:
- os.kill(pid, sig)
- return pids
-
-
-def _safe_proc_info(pid: int) -> tuple[str, str]:
- """Best-effort process name/cmdline lookup for debug logging."""
- try:
- proc = psutil.Process(pid)
- name = proc.name()
- cmdline = " ".join(proc.cmdline()) or "<empty-cmdline>"
- return name, cmdline
- except Exception: # noqa: BLE001
- return "<unknown>", "<unavailable>"
-
-
-def _list_server_process_tree(server: Any) -> list[int]:
- """Return [root, descendants...] PIDs for the current test server instance."""
- root_proc = getattr(server, "proc", None)
- if root_proc is None or getattr(root_proc, "pid", None) is None:
- return []
-
- root_pid = int(root_proc.pid)
- try:
- root = psutil.Process(root_pid)
- except Exception: # noqa: BLE001
- return [root_pid]
-
- descendants = [child.pid for child in root.children(recursive=True)]
- return [root_pid, *descendants]
-
-
-def _log_server_process_tree(server: Any) -> None:
- """Print server process tree for debugging fault injection targets."""
- pids = _list_server_process_tree(server)
- if not pids:
- logger.warning("[reliability][process-kill] current server has no visible process tree")
- return
- for pid in pids:
- name, cmdline = _safe_proc_info(pid)
- print(
- f"[reliability][process-kill] current_server_proc pid={pid} name={name} cmdline={cmdline}",
- flush=True,
- )
-
-
-FaultInjector = Callable[[Any], None]
-"""Callable invoked with the live ``OmniServer`` after it is ready (see ``omni_server_after_fault``)."""
-
-
-def make_process_kill_fault_injector(
- *,
- grep_patterns: str | Sequence[str],
- signal_name: str = "SIGKILL",
- limit: int = 1,
- post_kill_wait_seconds: float = 0.0,
-) -> FaultInjector:
- """Build a post-ready injector that kills processes matched by ``pgrep -f``.
-
- Tries each pattern in order until at least one PID is killed. If none match,
- the returned callable issues ``pytest.skip`` (same behavior as the previous
- inline reliability test).
-
- Args:
- grep_patterns: One pattern or an ordered list of patterns.
- signal_name: Passed to :func:`inject_process_kill` (e.g. ``SIGKILL``).
- limit: Maximum PIDs to kill per pattern (default ``1``).
- post_kill_wait_seconds: Optional wait time after kill before test request starts.
- """
- patterns: tuple[str, ...] = (grep_patterns,) if isinstance(grep_patterns, str) else tuple(grep_patterns)
-
- def _inject(server: Any) -> None:
- _log_server_process_tree(server)
- server_tree = set(_list_server_process_tree(server))
- if not server_tree:
- logger.warning(
- "[reliability][process-kill] no server process tree found; fallback to global pgrep matching"
- )
- for pattern in patterns:
- print(
- f"[reliability][process-kill] trying pattern={pattern} signal={signal_name} limit={limit}",
- flush=True,
- )
- pids = inject_process_kill(
- grep_pattern=pattern,
- signal_name=signal_name,
- limit=limit,
- allow_zero_match=True,
- execute_kill=False,
- )
- filtered = [pid for pid in pids if not server_tree or pid in server_tree]
- if pids and not filtered:
- logger.warning(
- "[reliability][process-kill] pattern=%s matched non-server pids=%s, skip them",
- pattern,
- pids,
- )
- continue
- if filtered:
- sig = getattr(signal, signal_name, None)
- if sig is None:
- raise ValueError(f"Unsupported signal_name: {signal_name}")
- for pid in filtered:
- name, cmdline = _safe_proc_info(pid)
- print(
- f"[reliability][process-kill] killing pid={pid} name={name} signal={signal_name} cmdline={cmdline}",
- flush=True,
- )
- os.kill(pid, sig)
- print(
- f"[reliability][process-kill] matched pattern={pattern} killed_pids={filtered} killed_count={len(filtered)}",
- flush=True,
- )
- if post_kill_wait_seconds > 0:
- print(
- f"[reliability][process-kill] waiting {post_kill_wait_seconds:.2f}s after kill",
- flush=True,
- )
- time.sleep(post_kill_wait_seconds)
- return
- logger.warning(
- "[reliability][process-kill] no process matched patterns=%s signal=%s limit=%s",
- patterns,
- signal_name,
- limit,
- )
- pytest.skip("no matching runtime process found for kill injection")
-
- return _inject
diff --git a/tests/dfx/reliability/test_reliability_qwen3_omni.py b/tests/dfx/reliability/test_reliability_qwen3_omni.py
deleted file mode 100644
index 18251946d25..00000000000
--- a/tests/dfx/reliability/test_reliability_qwen3_omni.py
+++ /dev/null
@@ -1,682 +0,0 @@
-"""
-Qwen3-Omni reliability integration tests.
-"""
-
-from __future__ import annotations
-
-import concurrent.futures
-import errno
-import json
-import os
-import time
-from pathlib import Path
-from typing import Any, Protocol
-
-import pytest
-import torch
-
-from tests.dfx.conftest import (
- assert_fault_exception,
- create_reliability_omni_server_params,
- resolve_oom_device_spec,
-)
-from tests.dfx.reliability.helpers import (
- extract_openai_error_contract_from_bytes,
- get_health_raw,
- inject_gpu_oom,
- make_process_kill_fault_injector,
- post_chat_completions_raw,
- post_json_raw,
- stop_gpu_oom_hogs,
-)
-from tests.helpers.mark import hardware_test
-from tests.helpers.media import generate_synthetic_audio, generate_synthetic_image, generate_synthetic_video
-from tests.helpers.runtime import dummy_messages_from_mix_data
-
-RELIABILITY_SCENARIOS: list[dict[str, Any]] = [
- {
- "test_name": "qwen3_omni_reliability_async_chunk",
- "server_params": {
- "model": "Qwen/Qwen3-Omni-30B-A3B-Instruct",
- "stage_config_name": "qwen3_omni_moe.yaml",
- "server_args": ["--async-chunk"],
- },
- },
- {
- "test_name": "qwen3_omni_reliability_default",
- "server_params": {
- "model": "Qwen/Qwen3-Omni-30B-A3B-Instruct",
- "stage_config_name": "qwen3_omni_moe.yaml",
- "server_args": ["--no-async-chunk"],
- },
- },
-]
-
-DEPLOY_CONFIGS_DIR = Path(__file__).resolve().parent.parent.parent.parent / "vllm_omni" / "deploy"
-
-
-def _default_oom_device_spec() -> str:
- """Use currently visible CUDA ordinals to avoid invalid device index in sidecar."""
- count = torch.cuda.device_count()
- if count <= 0:
- return "0"
- return ",".join(str(i) for i in range(count))
-
-
-OOM_INJECTION_CONFIG = {
- "device": _default_oom_device_spec(),
- "target_mem_ratio": 0.92,
- "hold_seconds": 0,
- "startup_timeout_sec": 20,
- "strict": False,
-}
-# Post-fault recovery probe: keep the API process alive on the same GPU.
-# ``strict=True`` sidecars keep allocating until CUDA refuses, which often
-# evicts/kills the server; here we only take a fraction of *initial* free
-# memory and stop, then rely on a heavy multimodal forward to hit OOM.
-OOM_RECOVER_INJECTION_CONFIG = {
- "device": _default_oom_device_spec(),
- # ``strict=False`` stops at this fraction of *initial* free memory per GPU (see helpers sidecar).
- # On multi-GPU hosts a mild ratio plus a small e2e-style mix can still leave several GB free
- # on a data-parallel device and the request succeeds; 0.92+ pairs better with the heavy
- # probe payload below. Raise toward 0.94 only if fault phase still never fails; avoid strict=True
- # here so the API process is not squeezed to zero slack.
- "target_mem_ratio": 0.8,
- "hold_seconds": 0,
- "startup_timeout_sec": 20,
- "strict": False,
-}
-FAULT_ERROR_KEYWORDS = (
- "the request failed",
- "oom",
- "out of memory",
- "cuda",
- "orchestrator",
- "timeout",
- "connection",
- "500",
- "503",
-)
-RUNTIME_WORKER_PATTERN = "VLLM::Worker"
-
-
-class _HasServeArgs(Protocol):
- model: str
- serve_args: list[str]
-
-
-def _get_system_prompt() -> dict:
- return {
- "role": "system",
- "content": [
- {
- "type": "text",
- "text": (
- "You are Qwen, a virtual human developed by the Qwen Team, Alibaba Group, "
- "capable of perceiving auditory and visual inputs, as well as generating text and speech."
- ),
- }
- ],
- }
-
-
-def _get_mix_prompt() -> str:
- return "What is recited in the audio? What is in this image? Describe the video briefly."
-
-
-def _mix_chat_completions_probe_payload(omni_server: _HasServeArgs) -> dict[str, Any]:
- """Heavy multimodal ``/v1/chat/completions`` body for OOM recover tests.
-
- Uses the same synthetic sizes as ``test_reliability_fault_gpu_oom_chat_large_payload_failure``
- (large vision tensors + long text), not the light expansion mix (224² / 5s audio): under
- ``strict=False`` sidecars, a small mix often still completes on a GPU that retains multi-GB
- free after the hog stops at ``target_mem_ratio``.
- """
- video_data_url = f"data:video/mp4;base64,{generate_synthetic_video(1280, 720, 161)['base64']}"
- image_data_url = f"data:image/jpeg;base64,{generate_synthetic_image(1280, 720)['base64']}"
- audio_data_url = f"data:audio/wav;base64,{generate_synthetic_audio(20, 1)['base64']}"
- messages = dummy_messages_from_mix_data(
- system_prompt=_get_system_prompt(),
- video_data_url=video_data_url,
- image_data_url=image_data_url,
- audio_data_url=audio_data_url,
- content_text="What is recited in the audio? What is in this image? What is in this video? " * 200,
- )
- return {
- "model": omni_server.model,
- "messages": messages,
- "stream": True,
- "modalities": ["text", "audio"],
- }
-
-
-def _fault_keywords_match_response(*, status: int, body: bytes) -> bool:
- """True when HTTP status or body text looks like an expected fault / OOM class outcome."""
- if status >= 400:
- return True
- text = body.decode("utf-8", errors="replace").lower()
- # Avoid matching bare ``"500"`` / ``"503"`` in successful streamed bodies (base64/SSE noise).
- body_fault_hints = (
- "the request failed",
- "oom",
- "out of memory",
- "cuda",
- "orchestrator",
- "timeout",
- "connection refused",
- "connection reset",
- )
- return any(key in text for key in body_fault_hints)
-
-
-def _stage_config_path_from_omni_server(omni_server: _HasServeArgs) -> str | None:
- args: list[str] = omni_server.serve_args
- for i, arg in enumerate(args):
- if arg == "--stage-configs-path" and i + 1 < len(args):
- return args[i + 1]
- if arg.startswith("--stage-configs-path="):
- return arg.split("=", 1)[1]
- return None
-
-
-def _looks_like_server_unreachable(exc: BaseException) -> bool:
- """True when /health cannot be reached because nothing is listening (process exited)."""
- if isinstance(exc, (ConnectionRefusedError, BrokenPipeError, ConnectionResetError)):
- return True
- errno_val = getattr(exc, "errno", None)
- if isinstance(exc, OSError) and errno_val is not None:
- return errno_val in (
- errno.ECONNREFUSED,
- errno.ECONNRESET,
- errno.EPIPE,
- )
- msg = str(exc).lower()
- return "connection refused" in msg or "actively refused" in msg
-
-
-QWEN_PARAMS = create_reliability_omni_server_params(RELIABILITY_SCENARIOS, DEPLOY_CONFIGS_DIR)
-
-
-@pytest.mark.slow
-@hardware_test(res={"cuda": "H100"}, num_cards=2)
-@pytest.mark.parametrize("omni_server_function", QWEN_PARAMS, indirect=True)
-def test_reliability_fault_gpu_oom_error_contract_consistent_chat_speech(
- omni_server_function,
-) -> None:
- """Black-box: text chat vs omni audio output should expose a consistent error contract under OOM.
-
- Speech-style output is requested via ``/v1/chat/completions`` with ``modalities`` that include ``audio``.
- """
- device_spec = resolve_oom_device_spec(
- OOM_INJECTION_CONFIG,
- _stage_config_path_from_omni_server(omni_server_function),
- )
- handle = inject_gpu_oom(
- device=device_spec,
- target_mem_ratio=OOM_INJECTION_CONFIG["target_mem_ratio"],
- hold_seconds=OOM_INJECTION_CONFIG["hold_seconds"],
- startup_timeout_sec=OOM_INJECTION_CONFIG["startup_timeout_sec"],
- strict=OOM_INJECTION_CONFIG["strict"],
- )
- host = omni_server_function.host
- port = omni_server_function.port
- mix_base = _mix_chat_completions_probe_payload(omni_server_function)
- oom_contract_timeout_sec = 120
- try:
- chat_status, chat_body = post_json_raw(
- host,
- port,
- "/v1/chat/completions",
- {
- "model": mix_base["model"],
- "messages": mix_base["messages"],
- "stream": False,
- "modalities": ["text"],
- },
- timeout_sec=oom_contract_timeout_sec,
- )
- speech_status, speech_body = post_json_raw(
- host,
- port,
- "/v1/chat/completions",
- {
- "model": mix_base["model"],
- "messages": mix_base["messages"],
- "stream": False,
- "modalities": ["text", "audio"],
- },
- timeout_sec=oom_contract_timeout_sec,
- )
- finally:
- stop_gpu_oom_hogs(handle)
-
- # Under OOM pressure both chat and speech should surface runtime-class (5xx)
- # failures instead of request-validation-class (4xx) errors.
- chat_error = extract_openai_error_contract_from_bytes(chat_body)
- speech_error = extract_openai_error_contract_from_bytes(speech_body)
- print(chat_status, chat_error, speech_status, speech_error)
-
- assert chat_status >= 500, f"expected chat error under OOM, got status={chat_status}"
- assert speech_status >= 500, f"expected speech runtime error under OOM, got status={speech_status}"
-
- assert chat_error is not None, f"chat error payload not OpenAI-compatible: {chat_body[:300]!r}"
- assert speech_error is not None, f"speech error payload not OpenAI-compatible: {speech_body[:300]!r}"
- assert "code" in chat_error, f"chat error lacks code field: {chat_error!r}"
- assert "code" in speech_error, f"speech error lacks code field: {speech_error!r}"
-
-
-@pytest.mark.slow
-@hardware_test(res={"cuda": "H100"}, num_cards=2)
-@pytest.mark.parametrize("omni_server_function", QWEN_PARAMS, indirect=True)
-def test_reliability_fault_gpu_oom_chat_large_payload_failure(omni_server_function, openai_client_function) -> None:
- device_spec = resolve_oom_device_spec(
- OOM_INJECTION_CONFIG,
- _stage_config_path_from_omni_server(omni_server_function),
- )
- handle = inject_gpu_oom(
- device=device_spec,
- target_mem_ratio=OOM_INJECTION_CONFIG["target_mem_ratio"],
- hold_seconds=OOM_INJECTION_CONFIG["hold_seconds"],
- startup_timeout_sec=OOM_INJECTION_CONFIG["startup_timeout_sec"],
- strict=OOM_INJECTION_CONFIG["strict"],
- )
- try:
- video_data_url = f"data:video/mp4;base64,{generate_synthetic_video(1280, 720, 161)['base64']}"
- image_data_url = f"data:image/jpeg;base64,{generate_synthetic_image(1280, 720)['base64']}"
- audio_data_url = f"data:audio/wav;base64,{generate_synthetic_audio(20, 1)['base64']}"
- messages = dummy_messages_from_mix_data(
- system_prompt=_get_system_prompt(),
- video_data_url=video_data_url,
- image_data_url=image_data_url,
- audio_data_url=audio_data_url,
- content_text=f"{_get_mix_prompt()} " * 200,
- )
- request_config = {
- "model": omni_server_function.model,
- "messages": messages,
- "stream": True,
- "key_words": {"audio": ["test"]},
- }
- try:
- openai_client_function.send_omni_request(request_config, request_num=1)
- except Exception as exc:
- assert_fault_exception(exc, FAULT_ERROR_KEYWORDS)
- else:
- pytest.fail("expected large chat payload request failure during GPU OOM injection")
- finally:
- stop_gpu_oom_hogs(handle)
-
-
-@pytest.mark.slow
-@hardware_test(res={"cuda": "H100"}, num_cards=2)
-@pytest.mark.parametrize("omni_server_function", QWEN_PARAMS, indirect=True)
-def test_reliability_fault_gpu_oom_concurrent_pressure_failure(omni_server_function, openai_client_function) -> None:
- device_spec = resolve_oom_device_spec(
- OOM_INJECTION_CONFIG,
- _stage_config_path_from_omni_server(omni_server_function),
- )
- handle = inject_gpu_oom(
- device=device_spec,
- target_mem_ratio=OOM_INJECTION_CONFIG["target_mem_ratio"],
- hold_seconds=OOM_INJECTION_CONFIG["hold_seconds"],
- startup_timeout_sec=OOM_INJECTION_CONFIG["startup_timeout_sec"],
- strict=OOM_INJECTION_CONFIG["strict"],
- )
- try:
- video_data_url = f"data:video/mp4;base64,{generate_synthetic_video(1280, 720, 161)['base64']}"
- image_data_url = f"data:image/jpeg;base64,{generate_synthetic_image(1280, 720)['base64']}"
- audio_data_url = f"data:audio/wav;base64,{generate_synthetic_audio(20, 1)['base64']}"
- messages = dummy_messages_from_mix_data(
- system_prompt=_get_system_prompt(),
- video_data_url=video_data_url,
- image_data_url=image_data_url,
- audio_data_url=audio_data_url,
- content_text=f"{_get_mix_prompt()} " * 200,
- )
- request_config = {
- "model": omni_server_function.model,
- "messages": messages,
- "stream": True,
- "modalities": ["text", "audio"],
- "key_words": {"audio": ["test"]},
- }
- try:
- openai_client_function.send_omni_request(request_config, request_num=4)
- except Exception as exc:
- assert_fault_exception(exc, FAULT_ERROR_KEYWORDS)
- else:
- pytest.fail("expected concurrent request failure under OOM injection")
- finally:
- stop_gpu_oom_hogs(handle)
-
-
-@pytest.mark.slow
-@pytest.mark.skipif(os.name == "nt", reason="process-kill injection helper is POSIX-only")
-@pytest.mark.parametrize(
- "fault_injector",
- [
- pytest.param(
- make_process_kill_fault_injector(
- grep_patterns="VLLM::Worker",
- signal_name="SIGKILL",
- limit=1,
- post_kill_wait_seconds=2.0,
- ),
- id="runtime_process_chain",
- ),
- ],
- indirect=True,
-)
-@pytest.mark.parametrize("omni_server_function", QWEN_PARAMS, indirect=True)
-def test_reliability_fault_process_kill_request_failure(
- omni_server_after_fault_function, openai_client_function
-) -> None:
- messages = dummy_messages_from_mix_data(
- system_prompt=_get_system_prompt(),
- content_text="What is the capital of China? Answer in 20 words.",
- )
- request_config = {
- "model": omni_server_after_fault_function.model,
- "messages": messages,
- "stream": False,
- "modalities": ["text"],
- "key_words": {"text": ["beijing"]},
- }
- try:
- openai_client_function.send_omni_request(request_config, request_num=1)
- except Exception as exc:
- assert_fault_exception(exc, FAULT_ERROR_KEYWORDS)
- else:
- pytest.fail("expected request failure after process-kill injection")
-
-
-@pytest.mark.slow
-@pytest.mark.skipif(os.name == "nt", reason="process-kill injection helper is POSIX-only")
-@pytest.mark.parametrize(
- "fault_injector",
- [
- pytest.param(
- make_process_kill_fault_injector(
- grep_patterns="VLLM::Worker",
- signal_name="SIGKILL",
- limit=1,
- post_kill_wait_seconds=2.0,
- ),
- id="runtime_process_chain",
- ),
- ],
- indirect=True,
-)
-@pytest.mark.parametrize("omni_server_function", QWEN_PARAMS, indirect=True)
-def test_reliability_fault_process_kill_health_fast_fail_and_concurrent(
- omni_server_after_fault_function,
-) -> None:
- """Black-box: after worker SIGKILL, /health→503, chat fails fast, concurrent chat does not hang."""
- host = omni_server_after_fault_function.host
- port = omni_server_after_fault_function.port
- model = omni_server_after_fault_function.model
-
- deadline = time.monotonic() + 20.0
- last_observation = ""
- saw_503 = False
- health_final_status: int | None = None
- health_final_body = b""
- while time.monotonic() < deadline:
- try:
- status, body = get_health_raw(host, port, timeout_sec=5)
- last_observation = f"http={status}, body={body[:200]!r}"
- health_final_status, health_final_body = status, body
- if status == 503:
- saw_503 = True
- break
- except Exception as exc: # noqa: BLE001
- last_observation = f"exception={exc!r}"
- time.sleep(0.5)
- assert saw_503, (
- f"[process_kill health] expected /health to become 503 after fault injection, got {last_observation}"
- )
-
- payload = {
- "model": model,
- "messages": [{"role": "user", "content": "Say hello in one short sentence."}],
- "stream": False,
- "modalities": ["text"],
- }
- ff_status: int | None = None
- ff_body = b""
- ff_exc: BaseException | None = None
- start = time.monotonic()
- try:
- ff_status, ff_body = post_json_raw(host, port, "/v1/chat/completions", payload, timeout_sec=20)
- elapsed = time.monotonic() - start
- assert elapsed < 15, f"[process_kill fast_fail] request did not fail fast after fault: {elapsed:.2f}s"
- assert ff_status >= 500, (
- f"[process_kill fast_fail] expected server-side failure after fault, "
- f"got status={ff_status}, body={ff_body[:200]!r}"
- )
- except Exception as exc:
- ff_exc = exc
- elapsed = time.monotonic() - start
- assert elapsed < 15, f"[process_kill fast_fail] request exception was too slow after fault: {elapsed:.2f}s"
-
- payload_json = json.dumps(
- {
- "model": model,
- "messages": [{"role": "user", "content": "What is the capital of China? Answer in one word."}],
- "stream": False,
- "modalities": ["text"],
- }
- )
- start = time.monotonic()
- with concurrent.futures.ThreadPoolExecutor(max_workers=4) as executor:
- futures = [
- executor.submit(
- post_chat_completions_raw,
- host,
- port,
- payload_json,
- timeout_sec=20,
- )
- for _ in range(4)
- ]
- done, pending = concurrent.futures.wait(
- futures,
- timeout=30,
- return_when=concurrent.futures.ALL_COMPLETED,
- )
-
- elapsed = time.monotonic() - start
- assert not pending, f"[process_kill concurrent] some fault-time requests hung: pending={len(pending)}"
- assert elapsed < 30, f"[process_kill concurrent] fault-time request convergence is too slow: {elapsed:.2f}s"
-
- fault_observed = False
- conc_debug: list[Any] = []
- for future in done:
- try:
- status, body = future.result()
- conc_debug.append((status, body[:200]))
- if status >= 500:
- fault_observed = True
- except Exception as exc:
- conc_debug.append(repr(exc))
- fault_observed = True
- # DEBUG: remove before merge
- print(
- health_final_status,
- health_final_body[:200],
- ff_status,
- ff_body[:200],
- ff_exc,
- conc_debug,
- )
- assert fault_observed, (
- "[process_kill concurrent] expected at least one request to fail after process-kill fault injection"
- )
-
-
-@pytest.mark.slow
-@pytest.mark.skip(reason="issue#2327")
-@hardware_test(res={"cuda": "H100"}, num_cards=2)
-@pytest.mark.parametrize("omni_server_function", QWEN_PARAMS, indirect=True)
-def test_reliability_fault_gpu_oom_state_converges_after_fault_removed(
- omni_server_function,
-) -> None:
- """Black-box: under bounded GPU pressure, a heavy mix chat fails; after hog stops, the same request succeeds.
-
- Uses a milder sidecar than ``OOM_INJECTION_CONFIG`` (``strict=False`` and a capped
- ``target_mem_ratio``) so the serving process stays alive: pressure should starve
- the multimodal forward pass, not exhaust the whole device allocator.
-
- Fault and recovery phases use raw ``/v1/chat/completions`` HTTP so tests can assert
- on status codes and JSON error payloads (or fault keywords in streamed bodies).
- """
- device_spec = resolve_oom_device_spec(
- OOM_RECOVER_INJECTION_CONFIG,
- _stage_config_path_from_omni_server(omni_server_function),
- )
- handle = inject_gpu_oom(
- device=device_spec,
- target_mem_ratio=OOM_RECOVER_INJECTION_CONFIG["target_mem_ratio"],
- hold_seconds=OOM_RECOVER_INJECTION_CONFIG["hold_seconds"],
- startup_timeout_sec=OOM_RECOVER_INJECTION_CONFIG["startup_timeout_sec"],
- strict=OOM_RECOVER_INJECTION_CONFIG["strict"],
- )
- host = omni_server_function.host
- port = omni_server_function.port
- mix_payload = _mix_chat_completions_probe_payload(omni_server_function)
- mix_chat_timeout_sec = 180
- print(
- "[oom-recover] injection ready "
- f"device={device_spec} target_mem_ratio={OOM_RECOVER_INJECTION_CONFIG['target_mem_ratio']} "
- f"strict={OOM_RECOVER_INJECTION_CONFIG['strict']} hold_seconds={OOM_RECOVER_INJECTION_CONFIG['hold_seconds']}"
- )
- print(f"[oom-recover] target endpoint http://{host}:{port}/v1/chat/completions")
-
- failure_observed = False
- fault_status: int | None = None
- fault_body = b""
- try:
- try:
- print(f"[oom-recover] fault-phase request start timeout={mix_chat_timeout_sec}s")
- fault_status, fault_body = post_json_raw(
- host,
- port,
- "/v1/chat/completions",
- mix_payload,
- timeout_sec=mix_chat_timeout_sec,
- )
- print(f"[oom-recover] fault-phase request done status={fault_status} body_prefix={fault_body[:200]!r}")
- except Exception as exc:
- failure_observed = True
- print(f"[oom-recover] fault-phase request raised {type(exc).__name__}: {exc!r}")
- assert_fault_exception(exc, FAULT_ERROR_KEYWORDS)
- else:
- assert fault_status is not None
- failure_observed = fault_status != 200 or _fault_keywords_match_response(
- status=fault_status,
- body=fault_body,
- )
- assert failure_observed, (
- "expected mix multimodal request failure while OOM pressure is active; "
- f"status={fault_status}, body_prefix={fault_body[:500]!r}"
- )
- if fault_status >= 400:
- err = extract_openai_error_contract_from_bytes(fault_body)
- if err is None:
- assert _fault_keywords_match_response(status=fault_status, body=fault_body), (
- "non-2xx without OpenAI-style error object should still mention fault hints in body; "
- f"status={fault_status}, body_prefix={fault_body[:500]!r}"
- )
- else:
- assert isinstance(err.get("message"), str) and err["message"].strip(), (
- f"structured error should carry a non-empty message: {err!r}"
- )
- else:
- assert _fault_keywords_match_response(status=fault_status, body=fault_body), (
- "HTTP 200 under pressure should still surface fault hints in the response body; "
- f"body_prefix={fault_body[:500]!r}"
- )
- finally:
- print("[oom-recover] stopping OOM sidecar(s)")
- stop_gpu_oom_hogs(handle)
- print("[oom-recover] OOM sidecar(s) stopped")
-
- recovery_deadline = time.monotonic() + 90.0
- terminal_health: int | None = None
- unreachable_streak = 0
- last_health_exc: BaseException | None = None
- while time.monotonic() < recovery_deadline:
- try:
- status, _ = get_health_raw(host, port, timeout_sec=5)
- unreachable_streak = 0
- if status in (200, 503):
- terminal_health = status
- print(f"[oom-recover] terminal health reached status={terminal_health}")
- break
- except Exception as exc:
- last_health_exc = exc
- if _looks_like_server_unreachable(exc):
- unreachable_streak += 1
- if unreachable_streak >= 5:
- pytest.fail(
- "after OOM sidecar stopped, /health is unreachable (connection refused / reset). "
- "The APIServer process likely exited (e.g. orchestrator thread crash under OOM); "
- "this test expects the server to stay up for post-fault health polling. "
- f"last_exc={last_health_exc!r}"
- )
- else:
- unreachable_streak = 0
- time.sleep(1.0)
- else:
- pytest.fail(
- "server did not converge to a terminal health state after OOM pressure was removed; "
- f"last_health_exc={last_health_exc!r}"
- )
-
- probe_payload = {
- "model": omni_server_function.model,
- "messages": [{"role": "user", "content": "What is the capital of China? Answer in one word."}],
- "stream": False,
- "modalities": ["text"],
- }
- start = time.monotonic()
- post_mix_status: int | None = None
- post_mix_body = b""
- request_status: int | None = None
- try:
- assert terminal_health is not None
- if terminal_health == 200:
- print(f"[oom-recover] recovery-phase mix request start timeout={mix_chat_timeout_sec}s")
- post_mix_status, post_mix_body = post_json_raw(
- host,
- port,
- "/v1/chat/completions",
- mix_payload,
- timeout_sec=mix_chat_timeout_sec,
- )
- print(
- "[oom-recover] recovery-phase mix request done "
- f"status={post_mix_status} body_prefix={post_mix_body[:200]!r}"
- )
- else:
- print("[oom-recover] terminal health=503, send lightweight probe request")
- request_status, _ = post_json_raw(host, port, "/v1/chat/completions", probe_payload, timeout_sec=20)
- print(f"[oom-recover] lightweight probe done status={request_status}")
- except Exception:
- post_mix_status = None
- request_status = None
- elapsed = time.monotonic() - start
- assert elapsed < 200, f"post-fault request should not hang after OOM removal: {elapsed:.2f}s"
-
- if terminal_health == 200:
- assert post_mix_status == 200, (
- "health recovered but repeated mix multimodal request did not return HTTP 200; "
- f"status={post_mix_status}, body_prefix={post_mix_body[:600]!r}"
- )
- recover_err = extract_openai_error_contract_from_bytes(post_mix_body)
- assert recover_err is None, f"unexpected error object after recovery: {recover_err!r}"
- else:
- assert request_status is None or request_status >= 500, (
- "unhealthy terminal state should fail fast on requests, "
- f"got health={terminal_health}, request_status={request_status}"
- )
diff --git a/tests/dfx/reliability/test_reliability_wan22.py b/tests/dfx/reliability/test_reliability_wan22.py
deleted file mode 100644
index e27db616f0e..00000000000
--- a/tests/dfx/reliability/test_reliability_wan22.py
+++ /dev/null
@@ -1,411 +0,0 @@
-"""
-Wan2.2 reliability integration tests.
-"""
-
-from __future__ import annotations
-
-import concurrent.futures
-import os
-import time
-from pathlib import Path
-from typing import Any
-
-import pytest
-import requests
-
-from tests.dfx.conftest import (
- assert_fault_exception,
- create_reliability_omni_server_params,
- resolve_oom_device_spec,
- supports_video_generation,
-)
-from tests.dfx.reliability.helpers import (
- get_health_raw,
- inject_gpu_oom,
- make_process_kill_fault_injector,
- stop_gpu_oom_hogs,
-)
-from tests.helpers.mark import hardware_test
-from tests.helpers.media import generate_synthetic_image
-
-RELIABILITY_SCENARIOS: list[dict[str, Any]] = [
- {
- "test_name": "wan22_t2v_reliability_default",
- "server_params": {
- "model": "Wan-AI/Wan2.2-T2V-A14B-Diffusers",
- "server_args": [
- "--num-gpus",
- "1",
- "--boundary-ratio",
- "0.875",
- "--flow-shift",
- "5.0",
- "--disable-log-stats",
- ],
- },
- }
-]
-
-E2E_STAGE_CONFIGS_DIR = Path(__file__).resolve().parent.parent / "e2e" / "stage_configs"
-OOM_INJECTION_CONFIG = {
- "target_mem_ratio": 0.95,
- "hold_seconds": 0,
- "startup_timeout_sec": 20,
- "strict": True,
-}
-FAULT_ERROR_KEYWORDS = (
- "oom",
- "out of memory",
- "cuda",
- "job failed",
- "unknown error",
- "internal server error",
- "500 server error",
-)
-PROCESS_KILL_ERROR_KEYWORDS = (
- "timeout",
- "did not complete within",
- "connection",
- "engine",
- "orchestrator",
- "dead",
- "internal",
- "500",
- "503",
-)
-
-WAN_PARAMS = create_reliability_omni_server_params(RELIABILITY_SCENARIOS, E2E_STAGE_CONFIGS_DIR)
-DIFFUSION_VIDEO_PARAMS = [param for param in WAN_PARAMS if supports_video_generation(param.model)]
-
-
-@pytest.mark.slow
-@hardware_test(res={"cuda": "H100"}, num_cards=1)
-@pytest.mark.parametrize("omni_server_function", DIFFUSION_VIDEO_PARAMS, indirect=True)
-def test_reliability_fault_gpu_oom_video_large_request_failure(omni_server_function, openai_client_function) -> None:
- stage_config_path = getattr(omni_server_function, "stage_config_path", None)
- device_spec = resolve_oom_device_spec(OOM_INJECTION_CONFIG, stage_config_path)
- handle = inject_gpu_oom(
- device=device_spec,
- target_mem_ratio=OOM_INJECTION_CONFIG["target_mem_ratio"],
- hold_seconds=OOM_INJECTION_CONFIG["hold_seconds"],
- startup_timeout_sec=OOM_INJECTION_CONFIG["startup_timeout_sec"],
- strict=OOM_INJECTION_CONFIG["strict"],
- )
- try:
- image_data_url = f"data:image/jpeg;base64,{generate_synthetic_image(1280, 720)['base64']}"
- request_config = {
- "form_data": {
- "prompt": "Generate a realistic road-driving video with camera motion.",
- "width": 512,
- "height": 512,
- "fps": 8,
- "num_frames": 8,
- "guidance_scale": 1.0,
- "flow_shift": 5.0,
- "num_inference_steps": 4,
- "seed": 42,
- },
- "image_reference": image_data_url,
- "stream": False,
- }
- try:
- openai_client_function.send_video_diffusion_request(request_config, request_num=1)
- except Exception as exc:
- assert_fault_exception(exc, FAULT_ERROR_KEYWORDS)
- else:
- pytest.fail("expected large /v1/videos request failure during GPU OOM injection")
- finally:
- stop_gpu_oom_hogs(handle)
-
-
-@pytest.mark.slow
-@pytest.mark.skipif(os.name == "nt", reason="process-kill injection helper is POSIX-only")
-@pytest.mark.parametrize(
- "fault_injector",
- [
- pytest.param(
- make_process_kill_fault_injector(
- grep_patterns="multiprocessing.spawn",
- signal_name="SIGKILL",
- limit=1,
- post_kill_wait_seconds=2.0,
- ),
- id="runtime_process_chain",
- ),
- ],
- indirect=True,
-)
-@pytest.mark.parametrize("omni_server_function", DIFFUSION_VIDEO_PARAMS, indirect=True)
-def test_reliability_fault_process_kill_video_request_failure(
- omni_server_after_fault_function,
- openai_client_function,
-) -> None:
- image_data_url = f"data:image/jpeg;base64,{generate_synthetic_image(1280, 720)['base64']}"
- request_config = {
- "form_data": {
- "prompt": "Generate a realistic road-driving video with camera motion.",
- "width": 512,
- "height": 512,
- "fps": 8,
- "num_frames": 8,
- "guidance_scale": 1.0,
- "flow_shift": 5.0,
- "num_inference_steps": 4,
- "seed": 42,
- },
- "image_reference": image_data_url,
- "stream": False,
- }
- try:
- openai_client_function.send_video_diffusion_request(request_config, request_num=1)
- except Exception as exc:
- assert_fault_exception(exc, PROCESS_KILL_ERROR_KEYWORDS)
- else:
- pytest.fail("expected /v1/videos request failure after process-kill injection")
-
-
-@pytest.mark.slow
-@pytest.mark.skipif(os.name == "nt", reason="process-kill injection helper is POSIX-only")
-@pytest.mark.parametrize(
- "fault_injector",
- [
- pytest.param(
- make_process_kill_fault_injector(
- grep_patterns="multiprocessing.spawn",
- signal_name="SIGKILL",
- limit=1,
- post_kill_wait_seconds=2.0,
- ),
- id="runtime_process_chain",
- ),
- ],
- indirect=True,
-)
-@pytest.mark.parametrize("omni_server_function", DIFFUSION_VIDEO_PARAMS, indirect=True)
-def test_reliability_fault_process_kill_video_health_fast_fail_and_concurrent(
- omni_server_after_fault_function,
- openai_client_function,
-) -> None:
- """Black-box: after process kill, /v1/videos fails fast and concurrent calls don't hang.
-
- /health→503 is checked last: optional ``pytest.skip`` then ``assert`` (drop the ``if`` to harden).
- """
- host = omni_server_after_fault_function.host
- port = omni_server_after_fault_function.port
- url = f"http://{host}:{port}/v1/videos"
- image_data_url = f"data:image/jpeg;base64,{generate_synthetic_image(1280, 720)['base64']}"
- request_config = {
- "form_data": {
- "prompt": "Generate a realistic road-driving video with camera motion.",
- "width": 512,
- "height": 512,
- "fps": 8,
- "num_frames": 8,
- "guidance_scale": 1.0,
- "flow_shift": 5.0,
- "num_inference_steps": 4,
- "seed": 42,
- },
- "image_reference": image_data_url,
- "stream": False,
- }
-
- # Phase-1: one new /v1/videos request should fail fast.
- payload = {
- "prompt": "fast-fail check",
- "width": "512",
- "height": "512",
- "fps": "8",
- "num_frames": "8",
- "num_inference_steps": "4",
- }
- start = time.monotonic()
- try:
- response = requests.post(
- url,
- data=payload,
- headers={"Accept": "application/json"},
- timeout=20,
- )
- elapsed = time.monotonic() - start
- assert elapsed < 15, f"[process_kill fast_fail] /v1/videos did not fail fast after fault: {elapsed:.2f}s"
- assert response.status_code >= 500, (
- "[process_kill fast_fail] expected server-side error after fatal fault, "
- f"got status={response.status_code}, body={response.text[:200]!r}"
- )
- except Exception:
- elapsed = time.monotonic() - start
- assert elapsed < 15, f"[process_kill fast_fail] /v1/videos exception was too slow after fault: {elapsed:.2f}s"
-
- # Phase-2: concurrent requests should converge and at least one should fail.
- start = time.monotonic()
- with concurrent.futures.ThreadPoolExecutor(max_workers=3) as executor:
- futures = [
- executor.submit(openai_client_function.send_video_diffusion_request, request_config, 1) for _ in range(3)
- ]
- done, pending = concurrent.futures.wait(
- futures,
- timeout=40,
- return_when=concurrent.futures.ALL_COMPLETED,
- )
-
- elapsed = time.monotonic() - start
- assert not pending, f"[process_kill concurrent] some fault-time video requests hung: pending={len(pending)}"
- assert elapsed < 40, f"[process_kill concurrent] fault-time video request convergence is too slow: {elapsed:.2f}s"
-
- fault_observed = False
- conc_debug: list[Any] = []
- for future in done:
- try:
- future.result()
- conc_debug.append("ok")
- except Exception as exc:
- fault_observed = True
- conc_debug.append(repr(exc))
- assert_fault_exception(exc, PROCESS_KILL_ERROR_KEYWORDS)
- assert fault_observed, (
- "[process_kill concurrent] expected at least one /v1/videos request to fail after fault; "
- f"conc_debug={conc_debug}"
- )
-
- # Phase-3: /health→503 after fault. Optional skip today; remove the ``if`` later to harden.
- deadline = time.monotonic() + 20.0
- last_observation = ""
- final_health_status: int | None = None
- while time.monotonic() < deadline:
- try:
- status, body = get_health_raw(host, port, timeout_sec=5)
- last_observation = f"http={status}, body={body[:200]!r}"
- final_health_status = status
- if status == 503:
- break
- except Exception as exc: # noqa: BLE001
- last_observation = f"exception={exc!r}"
- time.sleep(0.5)
- if final_health_status != 503:
- pytest.skip("issue#3050")
- assert final_health_status == 503, (
- "[process_kill health] expected /health 503 after fatal fault, "
- f"got status={final_health_status}, last_observation={last_observation}"
- )
-
-
-@pytest.mark.slow
-@hardware_test(res={"cuda": "H100"}, num_cards=1)
-@pytest.mark.skip(reason="issue#2327")
-@pytest.mark.parametrize("omni_server_function", DIFFUSION_VIDEO_PARAMS, indirect=True)
-def test_reliability_video_oom_recovers_after_fault_removed(
- omni_server_function,
-) -> None:
- """Black-box: after removing OOM pressure, service converges to a terminal state and requests do not hang."""
- stage_config_path = getattr(omni_server_function, "stage_config_path", None)
- device_spec = resolve_oom_device_spec(OOM_INJECTION_CONFIG, stage_config_path)
- handle = inject_gpu_oom(
- device=device_spec,
- target_mem_ratio=OOM_INJECTION_CONFIG["target_mem_ratio"],
- hold_seconds=OOM_INJECTION_CONFIG["hold_seconds"],
- startup_timeout_sec=OOM_INJECTION_CONFIG["startup_timeout_sec"],
- strict=OOM_INJECTION_CONFIG["strict"],
- )
- host = omni_server_function.host
- port = omni_server_function.port
- create_url = f"http://{host}:{port}/v1/videos"
-
- failure_observed = False
- try:
- for _ in range(3):
- try:
- response = requests.post(
- create_url,
- data={
- "prompt": "oom recover probe",
- "width": "512",
- "height": "512",
- "fps": "8",
- "num_frames": "8",
- "num_inference_steps": "4",
- },
- headers={"Accept": "application/json"},
- timeout=25,
- )
- if response.status_code >= 500:
- failure_observed = True
- break
- except Exception:
- failure_observed = True
- break
- time.sleep(1.0)
- finally:
- stop_gpu_oom_hogs(handle)
-
- assert failure_observed, "expected at least one video request failure while OOM pressure is active"
-
- recovery_deadline = time.monotonic() + 90.0
- terminal_health: int | None = None
- unreachable_streak = 0
- last_health_exc: BaseException | None = None
- while time.monotonic() < recovery_deadline:
- try:
- status, _ = get_health_raw(host, port, timeout_sec=5)
- unreachable_streak = 0
- if status in (200, 503):
- terminal_health = status
- break
- except Exception as exc: # noqa: BLE001
- last_health_exc = exc
- msg = str(exc).lower()
- if "connection refused" in msg or "actively refused" in msg:
- unreachable_streak += 1
- if unreachable_streak >= 5:
- pytest.fail(
- "after OOM sidecar stopped, /health is unreachable repeatedly; "
- "the APIServer process likely exited unexpectedly "
- f"(last_exc={last_health_exc!r})"
- )
- else:
- unreachable_streak = 0
- time.sleep(1.0)
- else:
- pytest.fail(
- "wan22 server did not converge to terminal health (200/503) after OOM pressure was removed; "
- f"last_health_exc={last_health_exc!r}"
- )
-
- assert terminal_health is not None
- start = time.monotonic()
- recovery_resp: requests.Response | None = None
- try:
- recovery_resp = requests.post(
- create_url,
- data={
- "prompt": "post-recovery admission check",
- "width": "512",
- "height": "512",
- "fps": "8",
- "num_frames": "8",
- "num_inference_steps": "4",
- },
- headers={"Accept": "application/json"},
- timeout=30,
- )
- recovery_status = recovery_resp.status_code
- recovery_text_prefix = recovery_resp.text[:300]
- except Exception as exc: # noqa: BLE001
- recovery_status = None
- recovery_text_prefix = repr(exc)
- elapsed = time.monotonic() - start
- assert elapsed < 30, f"post-fault /v1/videos should not hang after OOM removal: {elapsed:.2f}s"
-
- if terminal_health == 200:
- assert recovery_status == 200, (
- "health recovered but /v1/videos admission did not succeed; "
- f"status={recovery_status}, body={recovery_text_prefix!r}"
- )
- assert recovery_resp is not None
- recovery_payload = recovery_resp.json()
- assert "id" in recovery_payload, f"post-recovery create payload missing id: {recovery_payload!r}"
- else:
- assert recovery_status is None or recovery_status >= 500, (
- "unhealthy terminal state should fail fast on /v1/videos, "
- f"got health={terminal_health}, request_status={recovery_status}, body={recovery_text_prefix!r}"
- )
diff --git a/tests/dfx/stability/README.md b/tests/dfx/stability/README.md
deleted file mode 100644
index 121bb610df9..00000000000
--- a/tests/dfx/stability/README.md
+++ /dev/null
@@ -1,90 +0,0 @@
-# Resource Monitor Script Guide (GPU / Reserved CPU·NPU)
-
-The **`scripts/resource_monitor.sh`** script in this directory is the unified entry point for resource monitoring: it collects GPU memory and related metrics while running any command (such as long-running stability tests or unit tests), then bundles the results and generates a single-file HTML report when the command finishes. The script generates **`report.html` and CSV** files; open `report.html` in the output directory after the run completes.
-
-Currently only the **GPU** backend is implemented. The backend is selected with the subcommand option `--backend gpu|cpu|npu` (`gpu` by default), with CPU/NPU reserved for future extension.
-
----
-
-## Subcommands
-
-All functionality is provided by a single script and should be run from the repository root:
-
-| Subcommand | Description |
-|--------|------|
-| `scripts/resource_monitor.sh start [--backend gpu\|cpu\|npu] [gpu_ids] [interval]` | Collect data in the background (currently only `gpu`: `nvidia-smi` writes CSV) |
-| `scripts/resource_monitor.sh finalize [--backend gpu\|cpu\|npu] [run_id]` | Bundle the current run, generate `report.html`, and print `GPU_MONITOR_BUNDLE_DIR=` / `RESOURCE_MONITOR_BUNDLE_DIR=` |
-| `scripts/resource_monitor.sh run [--backend gpu\|cpu\|npu] -- <command>` | Complete everything in one step: `start` -> run your command -> `finalize` |
-
-`--backend` is optional. If omitted, the **gpu** backend is used by default.
-
----
-
-## Environment Variables (monitoring script only)
-
-| Environment Variable | Description | Default |
-|----------|------|--------|
-| `RESOURCE_MONITOR_DATA_ROOT` | Root directory for monitoring data | `tests/dfx/stability/gpu_monitor_data` |
-| `RESOURCE_MONITOR_INTERVAL` | Sampling interval (seconds) | 5 |
-| `RESOURCE_MONITOR_LOG_INTERVAL` | Log print interval (seconds) | 15 |
-| `GPU_MONITOR_DEVICES` | [GPU backend] GPU device IDs to monitor, such as `0,1` or `all` | all |
-
----
-
-## Recommended Usage: one-step `run`
-
-Run this in **finally** or **after script** blocks so cleanup still happens even if the tested command fails:
-
-```bash
-# Monitor + run any command, then automatically bundle results and generate report.html
-# If --backend is omitted, gpu is used by default; use --backend cpu or --backend npu for other backends
-bash tests/dfx/stability/scripts/resource_monitor.sh run [--backend gpu|cpu|npu] -- <your-command>
-```
-
-Examples (from the repository root):
-
-```bash
-# Example: run a pytest case (gpu backend by default, so --backend can be omitted)
-bash tests/dfx/stability/scripts/resource_monitor.sh run -- pytest -s -v tests/e2e/online_serving/test_foo.py -k test_xxx
-
-# Explicitly select the gpu backend, customize the sampling interval and GPUs 0,1, and print one log line every 30s
-export RESOURCE_MONITOR_INTERVAL=10
-export GPU_MONITOR_DEVICES=0,1
-export RESOURCE_MONITOR_LOG_INTERVAL=30
-bash tests/dfx/stability/scripts/resource_monitor.sh run --backend gpu -- pytest -s -v tests/e2e/online_serving/test_foo.py
-```
-
-During execution, the log will show `[GPU] ...` every few seconds. When the run ends, the log prints the bundle path, for example: `Line chart: open in browser: .../report.html`.
-
----
-
-## Step-by-step Usage: `start` -> your command -> `finalize`
-
-If you need to start monitoring first and then manually run a long task, you can call the steps separately:
-
-```bash
-# 1. Start monitoring (run from the `scripts` directory or set `DATA_ROOT`; gpu is the default if `--backend` is omitted)
-cd tests/dfx/stability/scripts
-./resource_monitor.sh start [--backend gpu] all 5 &
-MONITOR_PID=$!
-
-# 2. Run your long-running/stability test command (any command)
-# ...
-
-# 3. Finalize (must run before environment cleanup; putting it in `finally` / `after script` is recommended; the backend must match `start`)
-BUNDLE_LINE=$(./resource_monitor.sh finalize [--backend gpu] 2>/dev/null | grep '^GPU_MONITOR_BUNDLE_DIR=')
-eval "$BUNDLE_LINE"
-echo "Report directory: $GPU_MONITOR_BUNDLE_DIR"
-```
-
----
-
-## Directories and Outputs (monitoring only)
-
-- **Scripts**: `tests/dfx/stability/scripts/resource_monitor.sh` (entry point) and `scripts/generate_report.py` (called by `finalize` to generate HTML).
-- **Data directory**: `tests/dfx/stability/gpu_monitor_data/` by default (can be overridden with `RESOURCE_MONITOR_DATA_ROOT`).
- - Each run generates `run_<run_id>/gpu_metrics.csv`.
- - After `finalize`, you get `gpu_monitor_bundle_<run_id>/` containing `gpu_metrics.csv`, `report.html`, and `README.txt`.
-- **View the report**: open `report.html` in the bundle directory with a browser to inspect memory usage curves and statistics.
-
-The script only generates `report.html` and CSV files. If you need to keep the report, archive or download it from the working directory yourself.
diff --git a/tests/dfx/stability/conftest.py b/tests/dfx/stability/conftest.py
deleted file mode 100644
index 30718d4bf5a..00000000000
--- a/tests/dfx/stability/conftest.py
+++ /dev/null
@@ -1,125 +0,0 @@
-"""
-Stability-specific conftest: when pytest is executed under this directory,
-resource monitoring is started before each test and finalized after each test,
-so each stability test case gets its own HTML report (one report per case).
-No need to wrap pytest with `bash resource_monitor.sh run -- pytest ...`.
-
-Duration-based benchmark helper functions are hosted in ``helpers.py``,
-while this file focuses on pytest fixtures and setup/teardown.
-"""
-
-from __future__ import annotations
-
-import subprocess
-import sys
-import threading
-
-import pytest
-
-from tests.dfx.conftest import get_benchmark_params_for_server
-from tests.dfx.stability.helpers import (
- finalize_resource_monitor,
- report_latest_gpu_samples,
- start_resource_monitor,
- wait_for_run_dir,
-)
-from tests.helpers.runtime import OmniServer
-
-DEFAULT_STABILITY_SERVER_TIMEOUT_ARGS = ["--stage-init-timeout", "600", "--init-timeout", "900"]
-
-_omni_server_lock = threading.Lock()
-
-
-@pytest.fixture(scope="module")
-def omni_server(request: pytest.FixtureRequest):
- """Start OmniServer for stability tests, with per-module timeout override."""
- timeout_args = getattr(request.module, "STABILITY_SERVER_TIMEOUT_ARGS", DEFAULT_STABILITY_SERVER_TIMEOUT_ARGS)
- with _omni_server_lock:
- # Same 5-tuple and CLI composition as ``tests/dfx/perf/scripts/run_benchmark.py`` on main;
- # ``serve_args`` from JSON are folded into ``extra_cli_args`` inside
- # ``create_unique_server_params``.
- test_name, model, deploy_path, stage_overrides, extra_cli_args = request.param
-
- print(f"Starting OmniServer with test: {test_name}, model: {model}")
- server_args = list(timeout_args)
- if deploy_path:
- server_args = ["--deploy-config", deploy_path] + server_args
- if stage_overrides:
- server_args = ["--stage-overrides", stage_overrides] + server_args
- if extra_cli_args:
- server_args = list(extra_cli_args) + server_args
- with OmniServer(model, server_args) as server:
- server.test_name = test_name
- print("OmniServer started successfully")
- yield server
- print("OmniServer stopping...")
- print("OmniServer stopped")
-
-
-@pytest.fixture
-def stability_benchmark_params(request: pytest.FixtureRequest, omni_server):
- test_name, param_index = request.param
- if test_name != omni_server.test_name:
- pytest.skip(f"Skipping parameter for {test_name} - current server is {omni_server.test_name}")
-
- server_to_benchmark_mapping = getattr(request.module, "server_to_benchmark_mapping", None)
- if server_to_benchmark_mapping is None:
- raise ValueError("server_to_benchmark_mapping must be defined in the test module")
-
- all_params = get_benchmark_params_for_server(test_name, server_to_benchmark_mapping)
- if not all_params:
- raise ValueError(f"No benchmark parameters found for test: {test_name}")
- if param_index >= len(all_params):
- raise ValueError(f"No benchmark parameters found for index {param_index} in test: {test_name}")
-
- current = param_index + 1
- total = len(all_params)
- print(f"\n Running benchmark {current}/{total} for {test_name}")
- return {"test_name": test_name, "params": all_params[param_index]}
-
-
-@pytest.fixture(autouse=True)
-def stability_resource_monitor_per_test(request: pytest.FixtureRequest):
- """
- For each test under this directory: start GPU monitor before the test,
- then finalize after the test so this case gets its own report.html.
- """
- proc = start_resource_monitor()
- stop_event = threading.Event()
- reporter: threading.Thread | None = None
-
- if proc is not None:
- reporter = threading.Thread(
- target=report_latest_gpu_samples,
- args=(stop_event,),
- name="stability-resource-monitor-reporter",
- daemon=True,
- )
- reporter.start()
- run_dir = wait_for_run_dir(timeout_sec=5)
- node_name = request.node.name
- if run_dir is not None:
- sys.stderr.write(f"[Stability] Resource monitor started for test: {node_name} | run dir: {run_dir}\n")
- else:
- sys.stderr.write(f"[Stability] Resource monitor started for test: {node_name} (run dir not ready yet)\n")
-
- yield
-
- # Teardown: stop reporter, stop monitor, finalize → one HTML per test
- if proc is not None:
- stop_event.set()
- if reporter is not None and reporter.is_alive():
- reporter.join(timeout=2)
- if proc.poll() is None:
- proc.terminate()
- try:
- proc.wait(timeout=10)
- except subprocess.TimeoutExpired:
- proc.kill()
- proc.wait()
- bundle_dir = finalize_resource_monitor()
- node_name = request.node.name
- if bundle_dir:
- sys.stderr.write(f"[Stability] Report for test «{node_name}»: {bundle_dir}/report.html\n")
- else:
- sys.stderr.write(f"[Stability] Finalize skipped or failed for test «{node_name}»\n")
diff --git a/tests/dfx/stability/helpers.py b/tests/dfx/stability/helpers.py
deleted file mode 100644
index 3a873f69ca4..00000000000
--- a/tests/dfx/stability/helpers.py
+++ /dev/null
@@ -1,504 +0,0 @@
-"""Stability helpers for resource monitoring and benchmark execution."""
-
-from __future__ import annotations
-
-import json
-import os
-import random
-import re
-import shlex
-import subprocess
-import sys
-import tempfile
-import threading
-import time
-from collections.abc import Callable
-from pathlib import Path
-from typing import Any
-
-from tests.dfx.conftest import run_benchmark
-
-STABILITY_DIR = Path(__file__).resolve().parent
-RESOURCE_MONITOR_SCRIPT = STABILITY_DIR / "scripts" / "resource_monitor.sh"
-REPO_ROOT = STABILITY_DIR.parent.parent.parent
-_BUCKET_KEY_PATTERN = re.compile(r"^\(\s*([^,]+)\s*,\s*([^,]+)\s*,\s*([^,]+)\s*\)$")
-
-RunOneBatchFn = Callable[
- [str, int, str, dict[str, Any], int, float | None, int | None, str, int],
- dict[str, Any],
-]
-
-
-def start_resource_monitor():
- """Start `resource_monitor.sh start` in the background and return `Popen` or `None`."""
- if not RESOURCE_MONITOR_SCRIPT.is_file():
- return None
- try:
- proc = subprocess.Popen(
- ["bash", str(RESOURCE_MONITOR_SCRIPT), "start", "--backend", "gpu"],
- cwd=str(REPO_ROOT),
- stdout=subprocess.DEVNULL,
- stderr=subprocess.PIPE,
- start_new_session=True,
- )
- try:
- proc.wait(timeout=2)
- if proc.returncode != 0:
- stderr = proc.stderr.read().decode("utf-8", errors="ignore") if proc.stderr else ""
- if stderr.strip():
- sys.stderr.write(f"[Stability] Resource monitor failed to start: {stderr.strip()}\n")
- return None
- except subprocess.TimeoutExpired:
- pass
- return proc
- except (FileNotFoundError, OSError):
- return None
-
-
-def get_monitor_data_root() -> Path:
- data_root = os.environ.get("RESOURCE_MONITOR_DATA_ROOT") or os.environ.get("GPU_MONITOR_DATA_ROOT")
- if data_root:
- return Path(data_root)
- return STABILITY_DIR / "gpu_monitor_data"
-
-
-def wait_for_run_dir(timeout_sec: int = 10) -> Path | None:
- data_root = get_monitor_data_root()
- run_id_file = data_root / "current_run_id"
- deadline = time.time() + timeout_sec
- while time.time() < deadline:
- if run_id_file.is_file():
- run_id = run_id_file.read_text(encoding="utf-8").strip()
- if run_id:
- run_dir = data_root / run_id
- if run_dir.is_dir():
- return run_dir
- time.sleep(0.5)
- return None
-
-
-def report_latest_gpu_samples(stop_event: threading.Event) -> None:
- """Periodically print the latest sampled GPU line."""
- log_interval = int(
- os.environ.get("RESOURCE_MONITOR_LOG_INTERVAL") or os.environ.get("GPU_MONITOR_LOG_INTERVAL") or "15"
- )
- log_interval = max(log_interval, 1)
- last_line = ""
-
- time.sleep(min(log_interval, 5))
- while not stop_event.wait(log_interval):
- run_dir = wait_for_run_dir(timeout_sec=1)
- if run_dir is None:
- continue
- csv_file = run_dir / "gpu_metrics.csv"
- if not csv_file.is_file():
- continue
- try:
- lines = csv_file.read_text(encoding="utf-8").splitlines()
- except OSError:
- continue
- if len(lines) <= 1:
- continue
- latest = lines[-1].strip()
- if latest and latest != last_line:
- last_line = latest
- sys.stderr.write(f"[GPU] {latest}\n")
-
-
-def finalize_resource_monitor() -> str | None:
- """
- Run `resource_monitor.sh finalize` for the current run and generate the report.
- Returns the bundle dir path (for this test case's report) if successful, else None.
- """
- if not RESOURCE_MONITOR_SCRIPT.is_file():
- return None
- try:
- result = subprocess.run(
- ["bash", str(RESOURCE_MONITOR_SCRIPT), "finalize", "--backend", "gpu"],
- cwd=str(REPO_ROOT),
- capture_output=True,
- text=True,
- timeout=60,
- check=False,
- )
- if result.returncode != 0:
- return None
- for line in (result.stdout or "").splitlines():
- if line.startswith("GPU_MONITOR_BUNDLE_DIR=") or line.startswith("RESOURCE_MONITOR_BUNDLE_DIR="):
- _, _, value = line.partition("=")
- return value.strip() if value else None
- return None
- except (FileNotFoundError, OSError, subprocess.TimeoutExpired):
- return None
-
-
-def _normalize_bench_metrics(raw: dict[str, Any]) -> dict[str, Any]:
- completed = int(raw.get("completed", raw.get("completed_requests", 0) or 0))
- failed = int(raw.get("failed", raw.get("failed_requests", 0) or 0))
- duration = float(raw.get("duration", 0.0) or 0.0)
- errors = list(raw.get("errors") or [])
- if failed and not errors:
- errors = [f"{failed} benchmark request(s) failed"]
- return {"completed": completed, "failed": failed, "duration": duration, "errors": errors}
-
-
-def _build_base_args(params: dict[str, Any], host: str, port: int) -> list[str]:
- exclude = {
- "request_rate",
- "max_concurrency",
- "num_prompts",
- "baseline",
- "duration_sec",
- "num_prompts_per_batch",
- }
- args = ["--host", host, "--port", str(port)]
- for key, value in params.items():
- if key in exclude or value is None:
- continue
- arg_name = f"--{key.replace('_', '-')}"
- if isinstance(value, bool) and value:
- args.append(arg_name)
- elif isinstance(value, dict):
- args.extend([arg_name, json.dumps(value, ensure_ascii=False, separators=(",", ":"))])
- elif not isinstance(value, bool):
- args.extend([arg_name, str(value)])
- return args
-
-
-def _build_diffusion_cmd(
- host: str,
- port: int,
- model: str,
- params: dict[str, Any],
- num_prompts: int,
- request_rate: float | None,
- max_concurrency: int | None,
- output_path: Path,
- diffusion_benchmark_script: Path,
-) -> list[str]:
- skip_keys = {
- "request_rate",
- "max_concurrency",
- "num_prompts",
- "baseline",
- "duration_sec",
- "num_prompts_per_batch",
- }
- cmd: list[str] = [
- sys.executable,
- "-u",
- str(diffusion_benchmark_script),
- "--host",
- host,
- "--port",
- str(port),
- "--model",
- model,
- "--output-file",
- str(output_path),
- ]
- for key, value in params.items():
- if key in skip_keys or value is None:
- continue
- flag = f"--{str(key).replace('_', '-')}"
- if isinstance(value, bool) and value:
- cmd.append(flag)
- elif isinstance(value, bool):
- continue
- elif isinstance(value, (dict, list)):
- cmd.extend([flag, json.dumps(value, ensure_ascii=False, separators=(",", ":"))])
- else:
- cmd.extend([flag, str(value)])
-
- cmd.extend(["--num-prompts", str(num_prompts)])
- if request_rate is not None:
- cmd.extend(["--request-rate", str(request_rate)])
- else:
- cmd.extend(["--max-concurrency", str(max_concurrency), "--request-rate", "inf"])
- return cmd
-
-
-def _sample_int_from_range_spec(value: Any, rng: random.Random) -> Any:
- """Resolve one value that may be scalar or range spec into an int."""
- if isinstance(value, int):
- return value
-
- if isinstance(value, (list, tuple)) and len(value) == 2 and all(isinstance(v, int) for v in value):
- low, high = int(value[0]), int(value[1])
- if low > high:
- low, high = high, low
- return rng.randint(low, high)
-
- if isinstance(value, dict) and {"min", "max"} <= set(value):
- low, high = int(value["min"]), int(value["max"])
- if low > high:
- low, high = high, low
- return rng.randint(low, high)
-
- if isinstance(value, str):
- raw = value.strip()
- if raw.isdigit():
- return int(raw)
- if "-" in raw:
- parts = [p.strip() for p in raw.split("-", 1)]
- if len(parts) == 2 and parts[0].isdigit() and parts[1].isdigit():
- low, high = int(parts[0]), int(parts[1])
- if low > high:
- low, high = high, low
- return rng.randint(low, high)
-
- return value
-
-
-def _sample_bucket_key(raw_key: str, rng: random.Random) -> str:
- """Sample bucket tuple keys that use range syntax, e.g. ``(128-512, 128-512, 1)``."""
- match = _BUCKET_KEY_PATTERN.match(raw_key.strip())
- if not match:
- return raw_key
-
- sampled_parts: list[int] = []
- for token in match.groups():
- sampled = _sample_int_from_range_spec(token.strip(), rng)
- if not isinstance(sampled, int):
- return raw_key
- sampled_parts.append(sampled)
-
- # For video buckets (height>0 and num_frames>1), enforce even H/W to avoid
- # ffmpeg yuv420p encoding/decoding failures ("Could not open video stream").
- if sampled_parts[0] > 0 and sampled_parts[2] > 1:
- sampled_parts[0] = max(2, sampled_parts[0] - (sampled_parts[0] % 2))
- sampled_parts[1] = max(2, sampled_parts[1] - (sampled_parts[1] % 2))
-
- return f"({sampled_parts[0]}, {sampled_parts[1]}, {sampled_parts[2]})"
-
-
-def _sample_stability_batch_params(params: dict[str, Any], batch_index: int) -> dict[str, Any]:
- """Materialize per-batch random values for configured range fields."""
- sampled = dict(params)
- rng = random.Random(time.time_ns() + batch_index)
-
- for field_name in (
- "random_input_len",
- "random_output_len",
- "random_mm_base_items_per_request",
- "width",
- "height",
- ):
- if field_name in sampled:
- sampled[field_name] = _sample_int_from_range_spec(sampled[field_name], rng)
-
- bucket_config = sampled.get("random_mm_bucket_config")
- if isinstance(bucket_config, dict):
- sampled_bucket_config: dict[str, float] = {}
- for raw_key, probability in bucket_config.items():
- sampled_key = _sample_bucket_key(str(raw_key), rng)
- sampled_bucket_config[sampled_key] = sampled_bucket_config.get(sampled_key, 0.0) + float(probability)
- sampled["random_mm_bucket_config"] = sampled_bucket_config
-
- return sampled
-
-
-def _run_one_vllm_bench_batch(
- host: str,
- port: int,
- _model: str,
- params: dict[str, Any],
- num_prompts: int,
- request_rate: float | None,
- max_concurrency: int | None,
- result_dir: str,
- batch_index: int,
-) -> dict[str, Any]:
- base = _build_base_args(params, host, port)
- if request_rate is not None:
- args = base + ["--request-rate", str(request_rate), "--num-prompts", str(num_prompts)]
- flow = request_rate
- else:
- args = base + [
- "--max-concurrency",
- str(max_concurrency),
- "--num-prompts",
- str(num_prompts),
- "--request-rate",
- "inf",
- ]
- flow = max_concurrency
-
- # Print the exact per-batch benchmark CLI (randomized params are already materialized).
- preview_cmd = ["vllm", "bench", "serve", "--omni", *args]
- print(f"\n[Stability][Batch {batch_index}] Benchmark command:")
- print(shlex.join(preview_cmd))
-
- dataset_name = params.get("dataset_name", "random")
- old_benchmark_dir = os.environ.get("BENCHMARK_DIR")
- try:
- os.environ["BENCHMARK_DIR"] = result_dir
- result = run_benchmark(
- args=args,
- test_name="stability",
- flow=flow,
- dataset_name=dataset_name,
- num_prompt=num_prompts,
- random_input_len=params.get("random_input_len"),
- random_output_len=params.get("random_output_len"),
- )
- return _normalize_bench_metrics(result)
- except (FileNotFoundError, OSError) as exc:
- return {
- "completed": 0,
- "failed": 1,
- "duration": 0.0,
- "errors": [f"Benchmark batch failed: {type(exc).__name__}: {exc}"],
- }
- finally:
- if old_benchmark_dir is not None:
- os.environ["BENCHMARK_DIR"] = old_benchmark_dir
- elif "BENCHMARK_DIR" in os.environ:
- os.environ.pop("BENCHMARK_DIR")
-
-
-def _run_one_diffusion_batch(
- host: str,
- port: int,
- model: str,
- params: dict[str, Any],
- num_prompts: int,
- request_rate: float | None,
- max_concurrency: int | None,
- _result_dir: str,
- _batch_index: int,
-) -> dict[str, Any]:
- diffusion_benchmark_script = Path(REPO_ROOT / "benchmarks" / "diffusion" / "diffusion_benchmark_serving.py")
- with tempfile.NamedTemporaryFile(mode="w", suffix=".json", prefix="stability_diffusion_", delete=False) as tmp:
- out_path = Path(tmp.name)
- try:
- cmd = _build_diffusion_cmd(
- host,
- port,
- model,
- params,
- num_prompts,
- request_rate,
- max_concurrency,
- out_path,
- diffusion_benchmark_script,
- )
- proc = subprocess.run(
- cmd,
- cwd=str(REPO_ROOT),
- capture_output=True,
- text=True,
- )
- if proc.stdout:
- print(proc.stdout, end="" if proc.stdout.endswith("\n") else "\n")
- if proc.stderr:
- print(proc.stderr, end="" if proc.stderr.endswith("\n") else "\n")
- if proc.returncode != 0:
- return {
- "completed": 0,
- "failed": 1,
- "duration": 0.0,
- "errors": [f"diffusion_benchmark_serving.py exited {proc.returncode}"],
- }
- if not out_path.is_file():
- return {
- "completed": 0,
- "failed": 1,
- "duration": 0.0,
- "errors": [f"Missing benchmark output: {out_path}"],
- }
- with open(out_path, encoding="utf-8") as file:
- metrics = json.load(file)
- return _normalize_bench_metrics(metrics)
- except (FileNotFoundError, OSError, json.JSONDecodeError) as exc:
- return {
- "completed": 0,
- "failed": 1,
- "duration": 0.0,
- "errors": [f"Diffusion batch failed: {type(exc).__name__}: {exc}"],
- }
- finally:
- out_path.unlink(missing_ok=True)
-
-
-def merge_batch_results(batch_results: list[dict[str, Any]], total_duration_sec: float) -> dict[str, Any]:
- if not batch_results:
- return {"completed": 0, "failed": 0, "duration": total_duration_sec, "errors": []}
-
- completed = sum(result.get("completed", 0) for result in batch_results)
- failed = sum(result.get("failed", 0) for result in batch_results)
- merged: dict[str, Any] = {
- "completed": completed,
- "failed": failed,
- "duration": total_duration_sec,
- "errors": [],
- }
- for result in batch_results:
- merged["errors"].extend(result.get("errors") or [])
- return merged
-
-
-def print_merged_report(result: dict[str, Any]) -> None:
- fmt = "{:<40} {:<10}"
- fmt_float = "{:<40} {:<10.2f}"
- completed = result.get("completed", 0)
- failed = result.get("failed", 0)
- duration = float(result.get("duration", 0.0) or 0.0)
- print("\n============ Stability Benchmark Summary ============")
- print(fmt.format("Successful requests:", completed))
- print(fmt.format("Failed requests:", failed))
- print(fmt_float.format("Total duration (s):", duration))
- print("==================================================\n")
-
-
-def run_stability_benchmark_loop(
- host: str,
- port: int,
- model: str,
- duration_sec: int | float,
- params: dict[str, Any],
- *,
- request_rate: float | None,
- max_concurrency: int | None,
- result_dir: str,
- num_prompts_per_batch: int,
- run_one_batch: RunOneBatchFn,
- result_filename: str | None = None,
-) -> dict[str, Any]:
- if (request_rate is None) == (max_concurrency is None):
- raise ValueError("Exactly one of request_rate or max_concurrency must be specified")
-
- start_time = time.perf_counter()
- batch_results: list[dict[str, Any]] = []
- batch_index = 0
-
- while True:
- if (time.perf_counter() - start_time) >= duration_sec:
- break
- sampled_params = _sample_stability_batch_params(params, batch_index)
- result = run_one_batch(
- host,
- port,
- model,
- sampled_params,
- num_prompts_per_batch,
- request_rate,
- max_concurrency,
- result_dir,
- batch_index,
- )
- batch_results.append(result)
- batch_index += 1
- if (time.perf_counter() - start_time) >= duration_sec:
- break
-
- total_duration = time.perf_counter() - start_time
- merged = merge_batch_results(batch_results, total_duration)
- print_merged_report(merged)
-
- if result_filename and result_dir:
- result_path = Path(result_dir) / result_filename
- with open(result_path, "w", encoding="utf-8") as file:
- json.dump(merged, file, indent=2, ensure_ascii=False)
-
- return merged
diff --git a/tests/dfx/stability/scripts/__init__.py b/tests/dfx/stability/scripts/__init__.py
deleted file mode 100644
index 6d73ea952aa..00000000000
--- a/tests/dfx/stability/scripts/__init__.py
+++ /dev/null
@@ -1 +0,0 @@
-# scripts package for stability benchmark
diff --git a/tests/dfx/stability/scripts/generate_report.py b/tests/dfx/stability/scripts/generate_report.py
deleted file mode 100644
index 986a8083105..00000000000
--- a/tests/dfx/stability/scripts/generate_report.py
+++ /dev/null
@@ -1,364 +0,0 @@
-#!/usr/bin/env python3
-"""
-Generate a GPU memory monitoring report (HTML with charts and simple anomaly markers)
-from the CSV produced by `resource_monitor.sh`.
-
-This is used to generate an archivable report in CI after a long-running stability
-test so that the report remains available even after environment cleanup.
-"""
-
-from __future__ import annotations
-
-import csv
-import os
-import sys
-from collections import defaultdict
-from datetime import datetime
-from pathlib import Path
-
-from vllm.logger import init_logger
-
-logger = init_logger(__name__)
-
-
-def load_csv(csv_path: str) -> list[dict]:
- """Load and parse rows from a GPU monitoring CSV file.
-
- Args:
- csv_path: Path to the CSV file.
-
- Returns:
- A list of parsed row dicts. Each row contains keys such as
- `timestamp_epoch`, `gpu_index`, and `memory_*`.
- Invalid rows are skipped and logged.
- """
- rows = []
- with open(csv_path, newline="", encoding="utf-8") as f:
- for r in csv.DictReader(f):
- try:
- r["timestamp_epoch"] = int(float(r["timestamp_epoch"]))
- r["gpu_index"] = int(r["gpu_index"])
- r["memory_used_mb"] = int(r["memory_used_mb"])
- r["memory_total_mb"] = int(r["memory_total_mb"])
- r["memory_util_pct"] = int(r["memory_util_pct"])
- rows.append(r)
- except (KeyError, ValueError) as e:
- logger.debug("Skip invalid CSV row: %s", e)
- continue
- return rows
-
-
-def compute_stats(rows: list[dict]) -> dict:
- """Compute per-GPU min/max/avg/P50/P95 memory utilization and sample counts.
-
- Args:
- rows: Rows returned by `load_csv`.
-
- Returns:
- A stats dict keyed by `gpu_index`, with values containing
- `min`/`max`/`avg`/`p50`/`p95`/`samples`.
- """
- by_gpu = defaultdict(list)
- for r in rows:
- by_gpu[r["gpu_index"]].append(r["memory_util_pct"])
- stats = {}
- for gpu, pcts in by_gpu.items():
- if not pcts:
- continue
- pcts_sorted = sorted(pcts)
- n = len(pcts_sorted)
- stats[gpu] = {
- "min": min(pcts),
- "max": max(pcts),
- "avg": round(sum(pcts) / n, 1),
- "p50": pcts_sorted[n // 2] if n else 0,
- "p95": pcts_sorted[int(n * 0.95)] if n > 1 else pcts_sorted[0],
- "samples": n,
- }
- return stats
-
-
-def find_anomalies(rows: list[dict], high_pct: int = 95, low_pct: int = 5) -> list[dict]:
- """Find simple anomalies where memory utilization exceeds `high_pct` or drops below `low_pct`."""
- anomalies = []
- for r in rows:
- pct = r["memory_util_pct"]
- ts_iso = r.get("timestamp_iso") or datetime.fromtimestamp(r["timestamp_epoch"]).strftime("%Y-%m-%d %H:%M:%S")
- extra = {"timestamp_iso": ts_iso}
- if pct >= high_pct:
- anomalies.append({**r, **extra, "type": "high", "threshold": high_pct})
- elif pct <= low_pct:
- anomalies.append({**r, **extra, "type": "low", "threshold": low_pct})
- return anomalies
-
-
-def _anomaly_sort_key(a: dict) -> tuple[int, str, int]:
- return (a["gpu_index"], a["type"], a["timestamp_epoch"])
-
-
-def merge_anomalies_into_periods(anomalies: list[dict], max_gap_seconds: int = 120) -> list[dict]:
- """Merge consecutive anomalies (same GPU, same type) into time periods for display.
-
- This avoids truncation: instead of showing only the first N raw points, we show
- each continuous period once, so all below-threshold (or above-threshold) periods
- are visible in the report.
- """
- if not anomalies:
- return []
- # Sort by GPU, type, then time so we can merge consecutive same-GPU same-type.
- sorted_anomalies = sorted(anomalies, key=_anomaly_sort_key)
- periods = []
- for a in sorted_anomalies:
- ts = a["timestamp_epoch"]
- ts_iso = a.get("timestamp_iso") or datetime.fromtimestamp(ts).strftime("%Y-%m-%d %H:%M:%S")
- if not periods:
- periods.append(
- {
- "gpu_index": a["gpu_index"],
- "type": a["type"],
- "threshold": a["threshold"],
- "start_epoch": ts,
- "end_epoch": ts,
- "start_iso": ts_iso,
- "end_iso": ts_iso,
- "min_pct": a["memory_util_pct"],
- "max_pct": a["memory_util_pct"],
- "samples": 1,
- }
- )
- continue
- last = periods[-1]
- if (
- last["gpu_index"] == a["gpu_index"]
- and last["type"] == a["type"]
- and (ts - last["end_epoch"]) <= max_gap_seconds
- ):
- last["end_epoch"] = ts
- last["end_iso"] = ts_iso
- last["min_pct"] = min(last["min_pct"], a["memory_util_pct"])
- last["max_pct"] = max(last["max_pct"], a["memory_util_pct"])
- last["samples"] += 1
- else:
- periods.append(
- {
- "gpu_index": a["gpu_index"],
- "type": a["type"],
- "threshold": a["threshold"],
- "start_epoch": ts,
- "end_epoch": ts,
- "start_iso": ts_iso,
- "end_iso": ts_iso,
- "min_pct": a["memory_util_pct"],
- "max_pct": a["memory_util_pct"],
- "samples": 1,
- }
- )
- return periods
-
-
-def build_series_by_gpu(rows: list[dict]) -> tuple[list[float], dict[int, list[float]]]:
- """Deduplicate timestamps in time order and build a memory usage series (GB) for each GPU."""
- times = []
- by_ts_gpu = defaultdict(dict)
- for r in rows:
- t = r["timestamp_epoch"]
- g = r["gpu_index"]
- # Convert MB to GB for chart display.
- by_ts_gpu[t][g] = r["memory_used_mb"] / 1024.0
- for t in sorted(by_ts_gpu.keys()):
- times.append(t)
- gpu_series = defaultdict(list)
- for t in times:
- gpus = by_ts_gpu[t]
- for g in sorted(gpus.keys()):
- gpu_series[g].append(gpus[g])
- return times, dict(gpu_series)
-
-
-def render_html(
- run_id: str,
- csv_path: str,
- rows: list[dict],
- stats: dict,
- anomalies: list[dict],
- out_path: str,
-) -> None:
- """Generate a single-file HTML report and write it to `out_path`.
-
- Args:
- run_id: Run identifier used in the title.
- csv_path: Source CSV path, used only for displaying the file name.
- rows: Raw data rows.
- stats: Statistics returned by `compute_stats`.
- anomalies: Anomaly list returned by `find_anomalies`.
- out_path: Output HTML path; parent directories are created if needed.
- """
- times, gpu_series = build_series_by_gpu(rows)
- # X-axis time, e.g. 02-27 11:38:07 (local timezone), which is easier to read for long stability runs.
- labels_js = [f'"{datetime.fromtimestamp(t).strftime("%m-%d %H:%M:%S")}"' for t in times]
- datasets_js = []
- colors = ["#e94560", "#0f3460", "#533483", "#16c79a"]
- for i, (gpu, series) in enumerate(sorted(gpu_series.items())):
- color = colors[i % len(colors)]
- data_str = ",".join(str(v) for v in series)
- datasets_js.append(
- f'{{ label: "GPU {gpu}", data: [{data_str}], borderColor: "{color}", '
- f'backgroundColor: "{color}20", fill: true, tension: 0.2 }}'
- )
-
- stats_rows = []
- for gpu in sorted(stats.keys()):
- s = stats[gpu]
- stats_rows.append(
- f"<tr><td>GPU {gpu}</td><td>{s['min']}%</td><td>{s['max']}%</td>"
- f"<td>{s['avg']}%</td><td>{s['p50']}</td><td>{s['p95']}</td><td>{s['samples']}</td></tr>"
- )
- stats_table = "\n".join(stats_rows)
-
- # Use merged periods so every below/above-threshold time period is shown (no truncation).
- periods = merge_anomalies_into_periods(anomalies)
- anomaly_cells = []
- for p in periods:
- time_range = f"{p['start_iso']} — {p['end_iso']}" if p["start_iso"] != p["end_iso"] else p["start_iso"]
- pct_str = f"{p['min_pct']}–{p['max_pct']}%" if p["min_pct"] != p["max_pct"] else f"{p['min_pct']}%"
- anomaly_cells.append(
- f"<tr><td>{time_range}</td><td>GPU {p['gpu_index']}</td>"
- f"<td>{pct_str}</td><td>{p['type']} (threshold {p['threshold']}%)</td><td>{p['samples']}</td></tr>"
- )
- anomaly_table = "\n".join(anomaly_cells) if anomaly_cells else "<tr><td colspan='5'>None</td></tr>"
-
- html = f"""<!DOCTYPE html>
-<html lang="en">
-<head>
- <meta charset="UTF-8">
- <title>GPU memory monitor report - {run_id}
-
-
-
-
-
-
-
-
-
-
-
-
-
-Test Examples
- -When you want to add L5-level stability test cases, add or extend the appropriate JSON file under `tests/dfx/stability/tests/` (for example `test_qwen3_omni.json` for Omni bench traffic, or `test_wan22.json` for diffusion `/v1/videos` workloads). The following illustrates the Qwen3-Omni shape: - -```json -{ - "test_name": "test_qwen3_omni_stability", - "server_params": { - "model": "Qwen/Qwen3-Omni-30B-A3B-Instruct", - "stage_config_name": "qwen3_omni.yaml" - }, - "benchmark_params": [ - { - "dataset_name": "random", - "backend": "openai-chat-omni", - "endpoint": "/v1/chat/completions", - "duration_sec": 43200, - "request_rate": 0.5, - "num_prompts_per_batch": 20, - "random_input_len": 2500, - "random_output_len": 900, - "ignore_eos": true, - "percentile-metrics": "ttft,tpot,itl,e2el,audio_rtf,audio_ttfp,audio_duration" - } - ] -} -``` - -#### Parameter Explanation - -***Overview*** - -| Field | Required | Description | -| ---------------- | -------- | --------------------------------------------------------------------------- | -| test_name | Yes | Unique identifier for the stability test case | -| server_params | Yes | Server-side configuration parameters (model, stage configuration, etc.) | -| benchmark_params | Yes | Stability benchmark running parameters (supports multiple configurations) | - -#### server_params Configuration - -##### Basic Parameters - -| Parameter | Required | Example | Description | -| ----------------- | -------- | ---------------------------------- | ----------------------------------- | -| model | Yes | "Qwen/Qwen3-Omni-30B-A3B-Instruct" | Model name or path | -| stage_config_name | Yes | "qwen3_omni.yaml" | Stage configuration file name | - -##### Dynamic Configuration (update/delete) - -Supports incremental modifications based on the basic configuration: - -| Operation | Description | -| --------- | ------------------------------------ | -| update | Update or add configuration items | -| delete | Delete specified configuration items | - -***Example***: -You can refer to Test Examples in Chapter 3.4 - -#### benchmark_params Configuration - -For stability testing, the key parameters are: - -- **duration_sec**: Total duration (in seconds) during which benchmark traffic is sent. The stability benchmark will keep sending batches until this duration is reached. -- **request_rate** / **max_concurrency**: Exactly one of them must be specified. They control how the traffic is generated for each batch: - - `request_rate`: Number of requests per second. The benchmark will send `num_prompts_per_batch` requests at the given rate. - - `max_concurrency`: Maximum number of concurrent requests. When this is used, `request_rate` is set to `inf` internally. -- **num_prompts_per_batch**: Number of prompts sent in each batch. Multiple batches will be executed sequentially within `duration_sec`. - -All other optional parameters follow the same rules as the in Chapter 3.4. - -
- Reliability test suite (
-
-#### Purpose and relationship to stability
-
-Reliability tests are **short fault-injection** integration runs (L5 **(b)** in `tests/dfx/reliability/README.md`). They complement **stability** JSON-driven long runs: instead of hours of steady traffic, they **perturb** the server (GPU OOM sidecar, fatal signals on selected processes) and check **failure mode** and **latency bounds** (e.g. chat or `/v1/videos` must not hang under concurrent fault-time load).
-
-#### Directory layout
-
-| Path | Responsibility |
-| ---- | -------------- |
-| `helpers.py` | Shared helpers used by current reliability suites: raw `POST`/`GET` probes (`/v1/chat/completions`, `/health`), OpenAI error parsing (`extract_openai_error_contract_from_bytes`), GPU OOM sidecar lifecycle (`inject_gpu_oom`, `stop_gpu_oom_hogs`), and process-kill injector builder (`make_process_kill_fault_injector`). |
-| `conftest.py` | Pytest fixtures: indirect `fault_injector`, `omni_server_after_fault` / `omni_server_after_fault_function` (run injector after server is ready, then yield server). |
-| `test_reliability_qwen3_omni.py` | Qwen3-Omni: OOM vs **text vs text+audio** error contract, large multimodal chat under OOM, concurrent pressure, **SIGKILL** on `VLLM::Worker`, `/health` → 503 + fast-fail + concurrent chat; optional OOM recovery scenario (may be skipped while tracked in issues). |
-| `test_reliability_wan22.py` | Wan2.2 T2V: large `/v1/videos` under OOM, **SIGKILL** on `multiprocessing.spawn` chain, health / fast-fail / concurrent video requests; optional recovery test (may be skipped). |
-| `README.md` | Minimal run / collect examples. |
-
-#### Parametrization and markers
-
-- Each test module defines a **`RELIABILITY_SCENARIOS`** list (`test_name`, `server_params`: model, `stage_config_name` or diffusion `server_args`, etc.). **`create_reliability_omni_server_params()`** in `tests/dfx/conftest.py` resolves stage paths (including XPU substitutions where applicable) and builds **`OmniServerParams`** lists consumed by **`@pytest.mark.parametrize(..., indirect=True)`** on `omni_server` or `omni_server_function`.
-- Cases are tagged **`@pytest.mark.slow`** for weekly / selective CI. GPU-heavy suites use **`@hardware_test(res={"cuda": "H100"}, num_cards=...)`** (Qwen3-Omni paths often require **2** cards; Wan2.2 video paths **1** card).
-- **Process-kill** tests use **`@pytest.mark.skipif(os.name == "nt", ...)`** because injection uses POSIX **`pgrep` / `kill`**.
-
-#### CI trigger
-
-Weekly Buildkite (`.buildkite/test-weekly.yml`) runs, for example:
-
-```bash
-pytest -s -v tests/dfx/reliability/test_reliability_qwen3_omni.py -m "slow"
-pytest -s -v tests/dfx/reliability/test_reliability_wan22.py -m "slow"
-```
-
-#### Local commands
-
-```bash
-pytest --collect-only tests/dfx/reliability
-pytest -s -v tests/dfx/reliability/test_reliability_qwen3_omni.py -m slow
-pytest -s -v tests/dfx/reliability/test_reliability_wan22.py -m slow
-```
-
-#### Adding a new model suite
-
-1. Add `test_reliability_.py` under `tests/dfx/reliability/`.
-2. Define **`RELIABILITY_SCENARIOS`** and pass them through **`create_reliability_omni_server_params()`** with the correct deploy or e2e stage-config directory (same pattern as existing files).
-3. Reuse **`helpers`** for OOM / kill / raw HTTP; prefer **`assert_fault_exception()`** and **`resolve_oom_device_spec()`** from `tests/dfx/conftest.py` for consistent device selection vs stage YAML.
-4. Register **`slow`** (and **`hardware_test`** if needed); extend **`.buildkite/test-weekly.yml`** when the suite should run in weekly L5.
-
-
-
-- - ***Stability***: `pytest -s -v tests/dfx/stability/scripts/test_stability_qwen3_omni.py` or `pytest -s -v tests/dfx/stability/scripts/test_stability_wan22.py` (or add `test_stability_ Reliability test suite (tests/dfx/reliability)
-
-#### Purpose and relationship to stability
-
-Reliability tests are **short fault-injection** integration runs (L5 **(b)** in `tests/dfx/reliability/README.md`). They complement **stability** JSON-driven long runs: instead of hours of steady traffic, they **perturb** the server (GPU OOM sidecar, fatal signals on selected processes) and check **failure mode** and **latency bounds** (e.g. chat or `/v1/videos` must not hang under concurrent fault-time load).
-
-#### Directory layout
-
-| Path | Responsibility |
-| ---- | -------------- |
-| `helpers.py` | Shared helpers used by current reliability suites: raw `POST`/`GET` probes (`/v1/chat/completions`, `/health`), OpenAI error parsing (`extract_openai_error_contract_from_bytes`), GPU OOM sidecar lifecycle (`inject_gpu_oom`, `stop_gpu_oom_hogs`), and process-kill injector builder (`make_process_kill_fault_injector`). |
-| `conftest.py` | Pytest fixtures: indirect `fault_injector`, `omni_server_after_fault` / `omni_server_after_fault_function` (run injector after server is ready, then yield server). |
-| `test_reliability_qwen3_omni.py` | Qwen3-Omni: OOM vs **text vs text+audio** error contract, large multimodal chat under OOM, concurrent pressure, **SIGKILL** on `VLLM::Worker`, `/health` → 503 + fast-fail + concurrent chat; optional OOM recovery scenario (may be skipped while tracked in issues). |
-| `test_reliability_wan22.py` | Wan2.2 T2V: large `/v1/videos` under OOM, **SIGKILL** on `multiprocessing.spawn` chain, health / fast-fail / concurrent video requests; optional recovery test (may be skipped). |
-| `README.md` | Minimal run / collect examples. |
-
-#### Parametrization and markers
-
-- Each test module defines a **`RELIABILITY_SCENARIOS`** list (`test_name`, `server_params`: model, `stage_config_name` or diffusion `server_args`, etc.). **`create_reliability_omni_server_params()`** in `tests/dfx/conftest.py` resolves stage paths (including XPU substitutions where applicable) and builds **`OmniServerParams`** lists consumed by **`@pytest.mark.parametrize(..., indirect=True)`** on `omni_server` or `omni_server_function`.
-- Cases are tagged **`@pytest.mark.slow`** for weekly / selective CI. GPU-heavy suites use **`@hardware_test(res={"cuda": "H100"}, num_cards=...)`** (Qwen3-Omni paths often require **2** cards; Wan2.2 video paths **1** card).
-- **Process-kill** tests use **`@pytest.mark.skipif(os.name == "nt", ...)`** because injection uses POSIX **`pgrep` / `kill`**.
-
-#### CI trigger
-
-Weekly Buildkite (`.buildkite/test-weekly.yml`) runs, for example:
-
-```bash
-pytest -s -v tests/dfx/reliability/test_reliability_qwen3_omni.py -m "slow"
-pytest -s -v tests/dfx/reliability/test_reliability_wan22.py -m "slow"
-```
-
-#### Local commands
-
-```bash
-pytest --collect-only tests/dfx/reliability
-pytest -s -v tests/dfx/reliability/test_reliability_qwen3_omni.py -m slow
-pytest -s -v tests/dfx/reliability/test_reliability_wan22.py -m slow
-```
-
-#### Adding a new model suite
-
-1. Add `test_reliability_
- 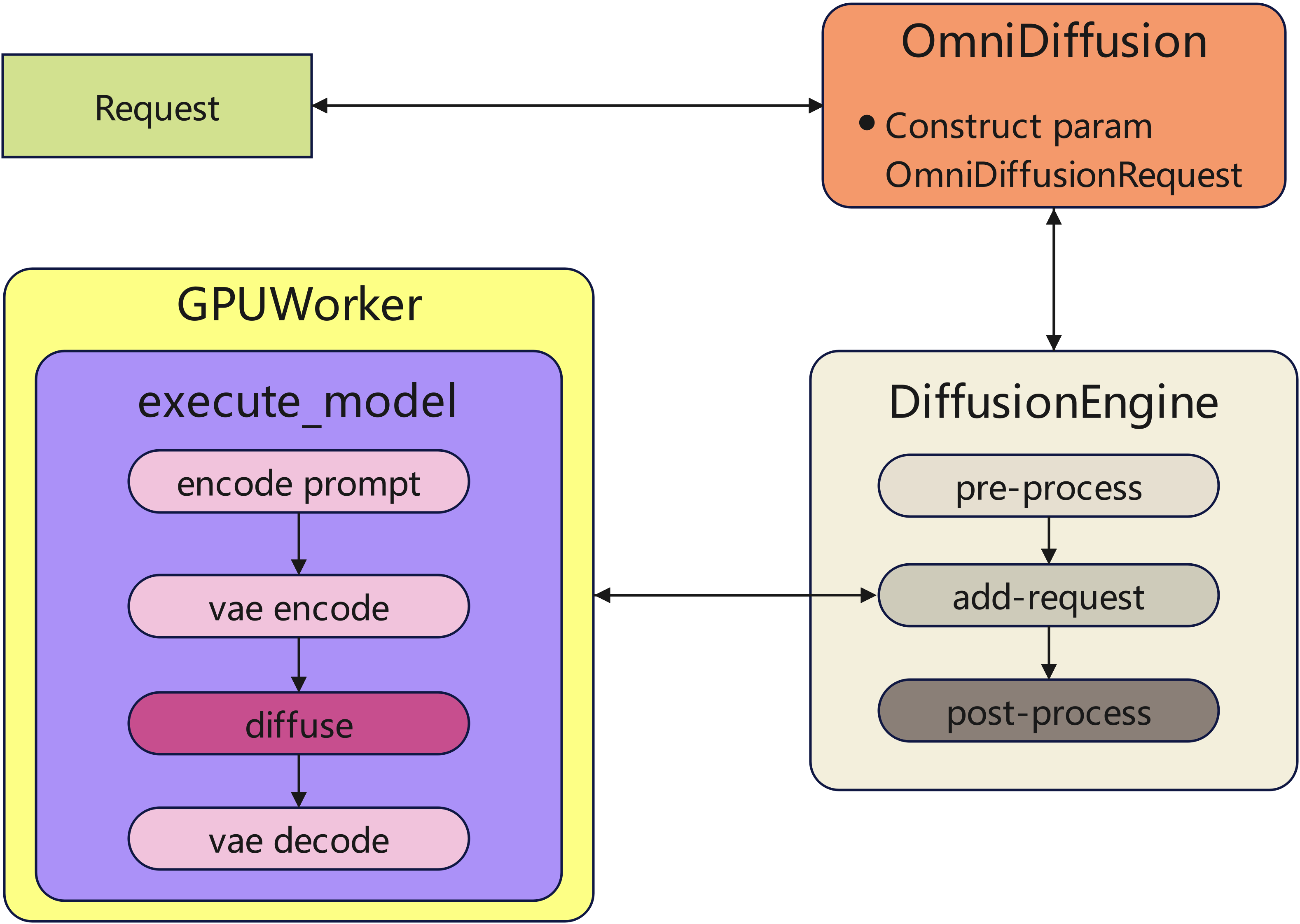 -
-
- 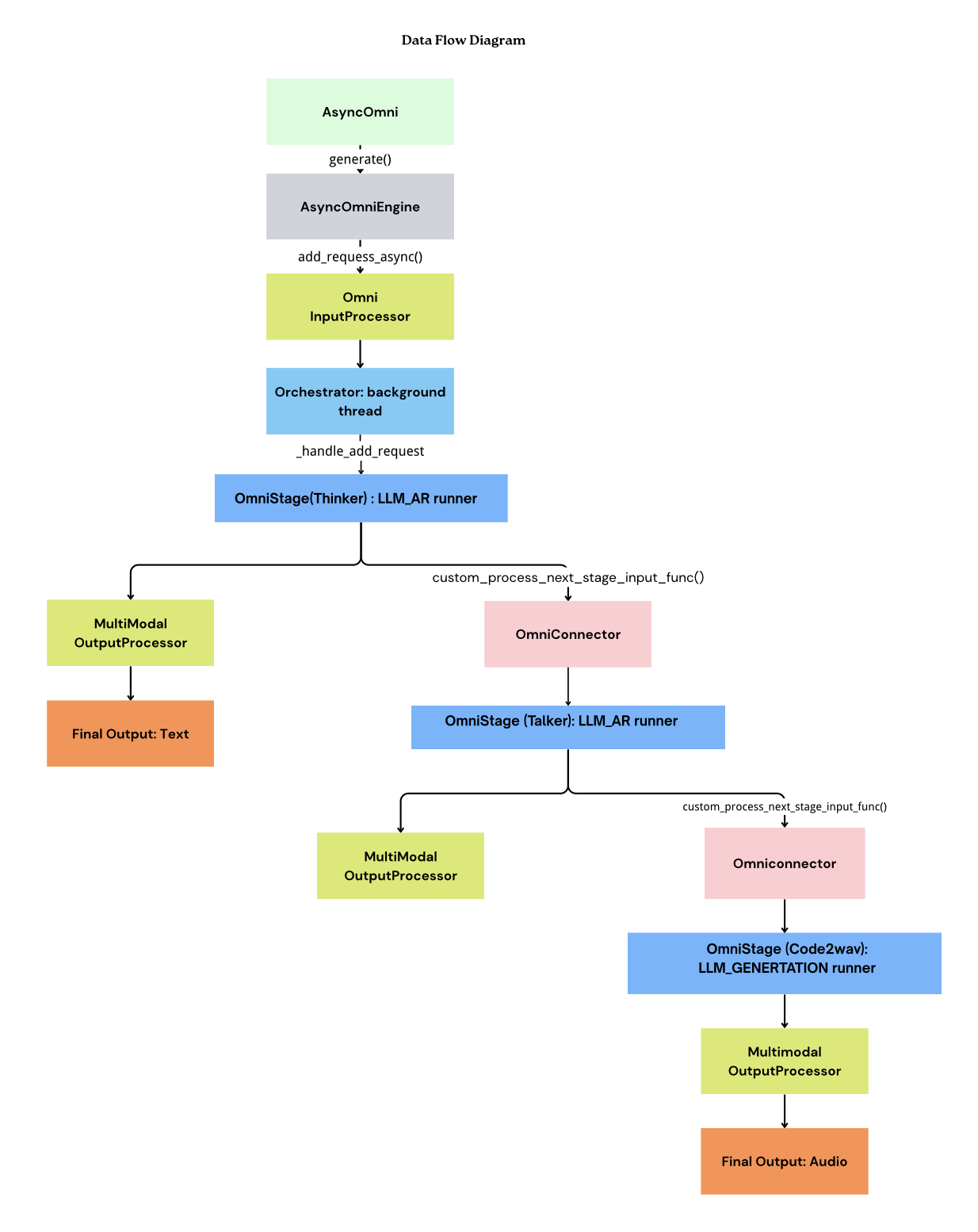 -
-
-
-
- 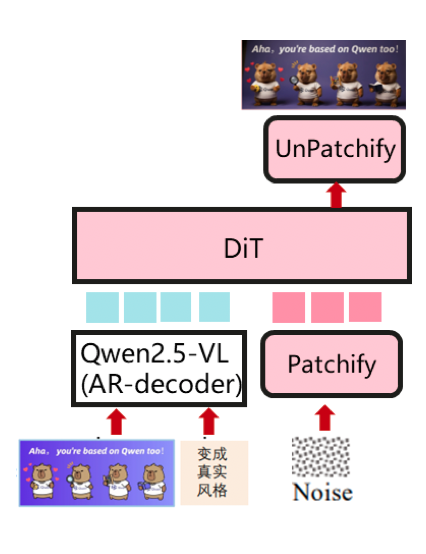 -
-
- 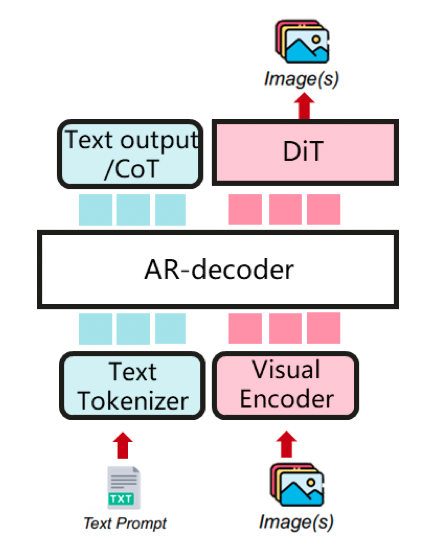 -
-
- 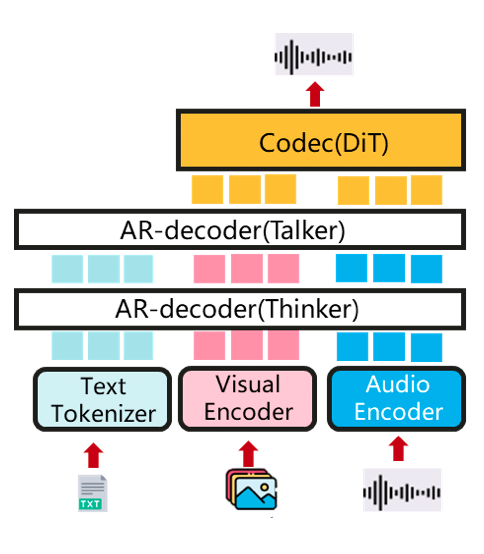 -
-
- 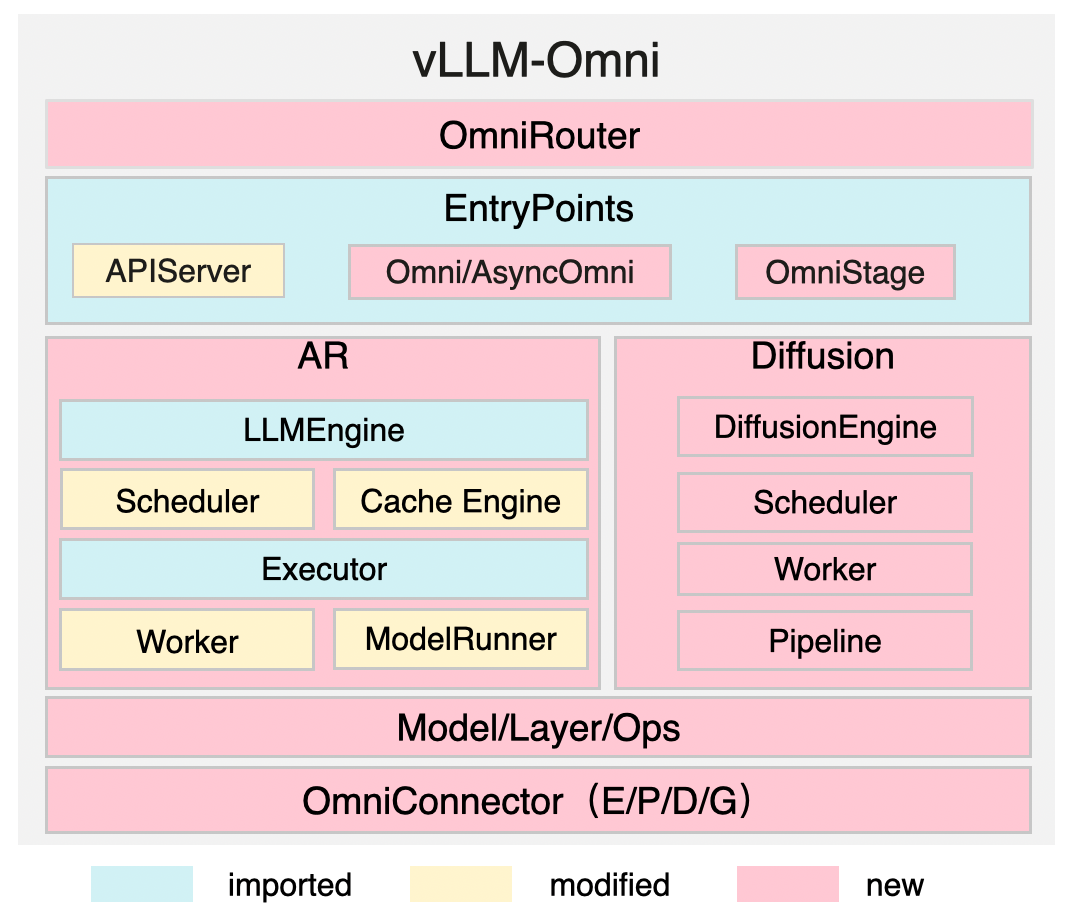 -
-
- 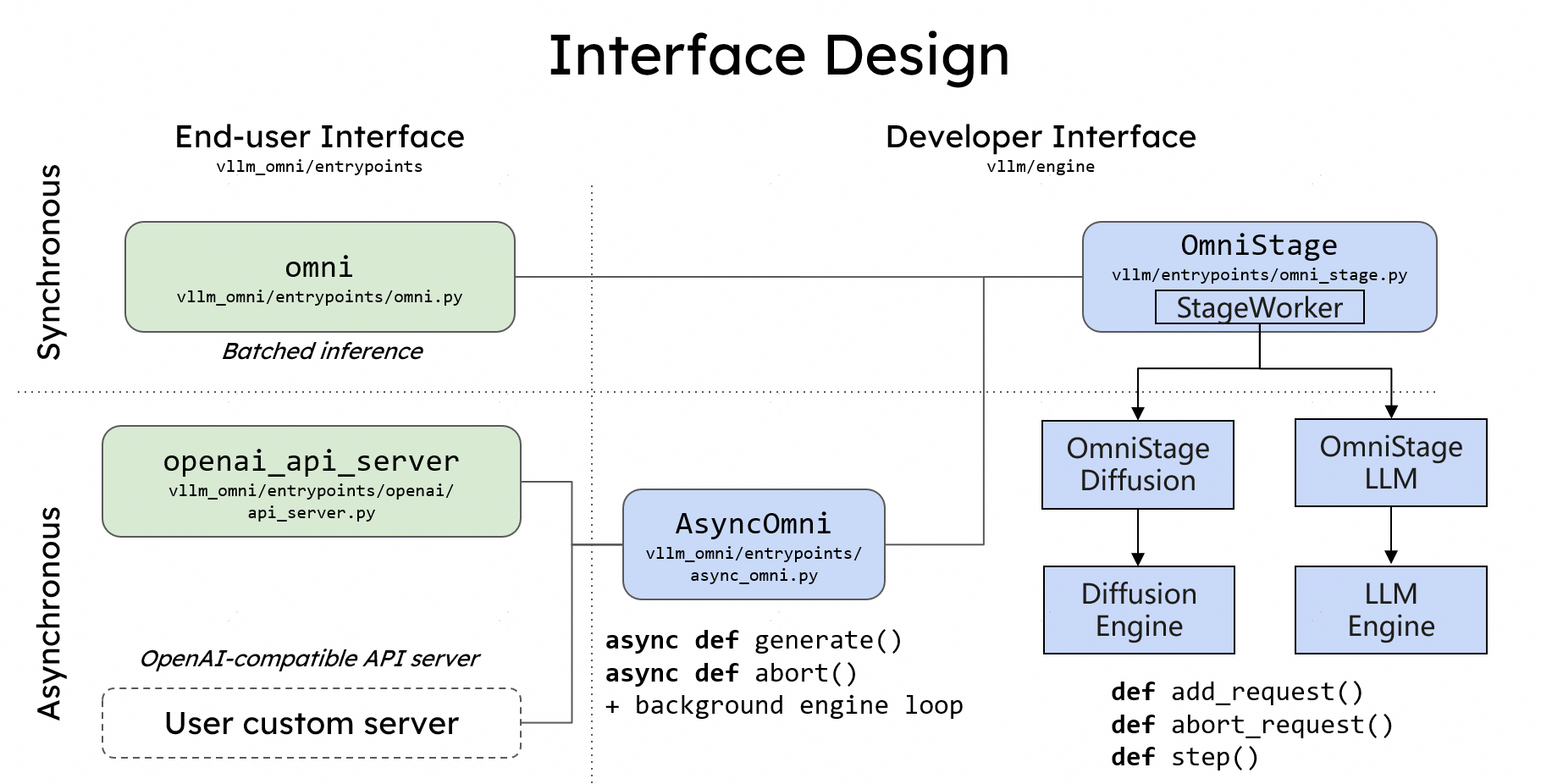 -
-
-
- 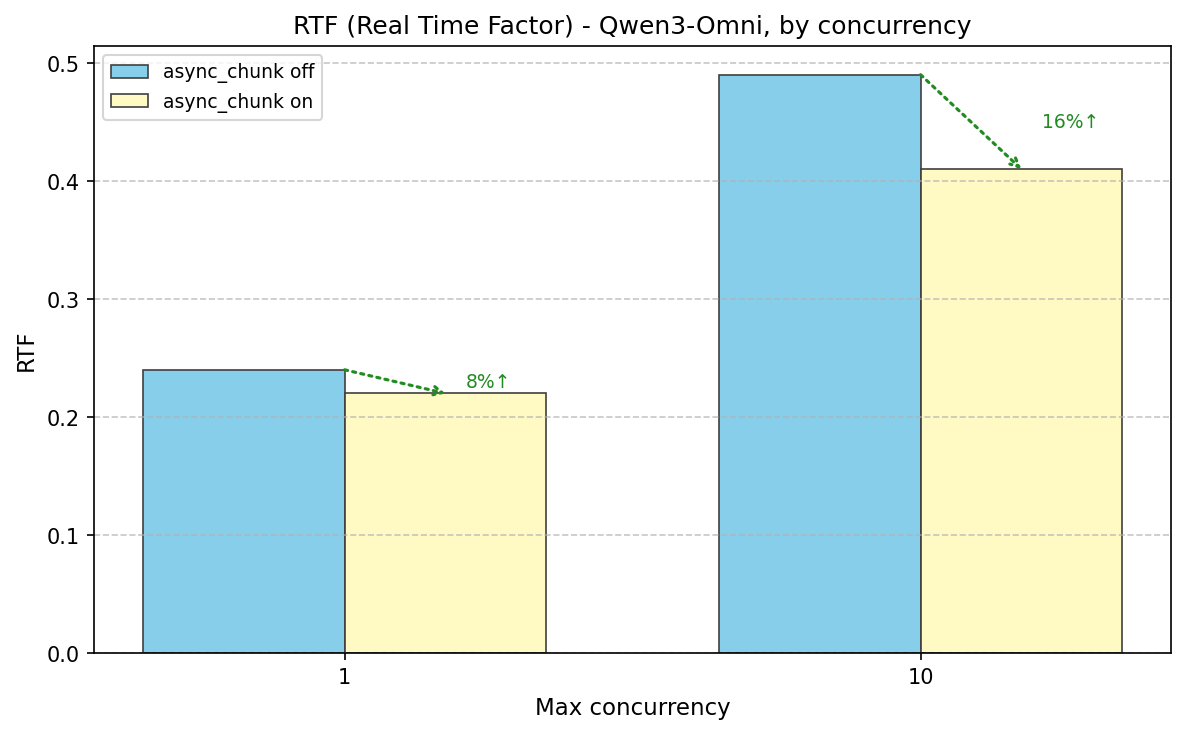 -
-
- 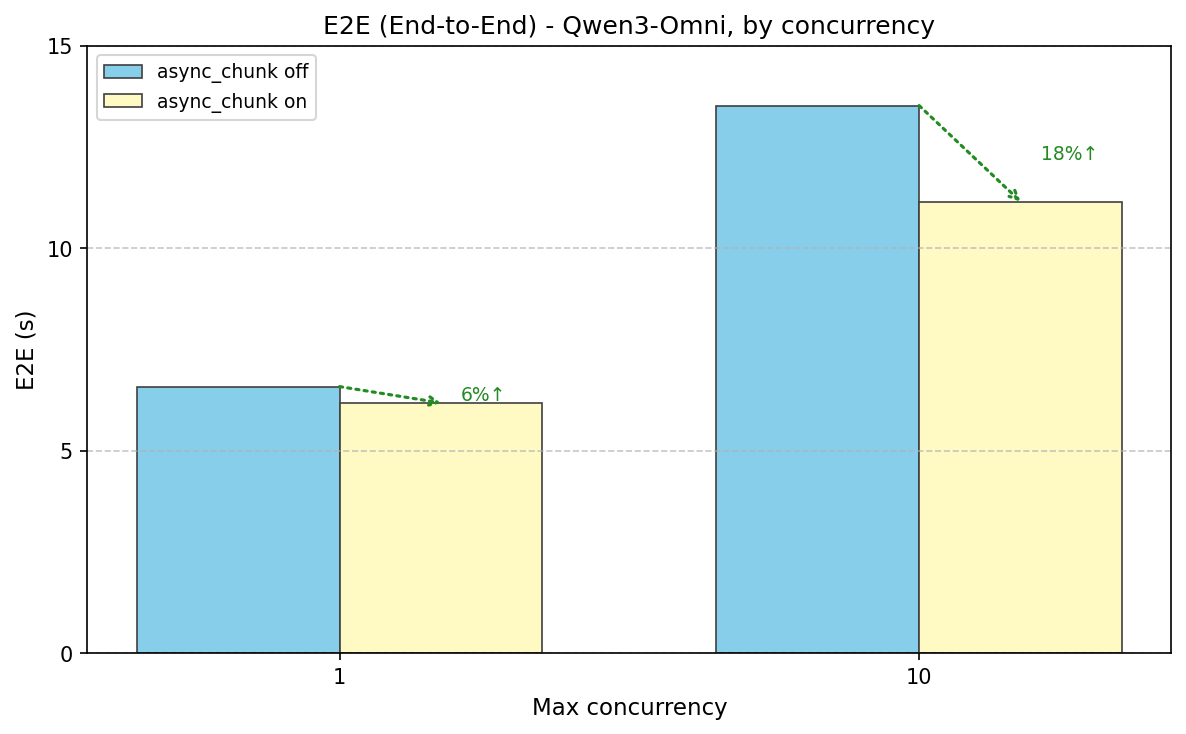 -
-
- 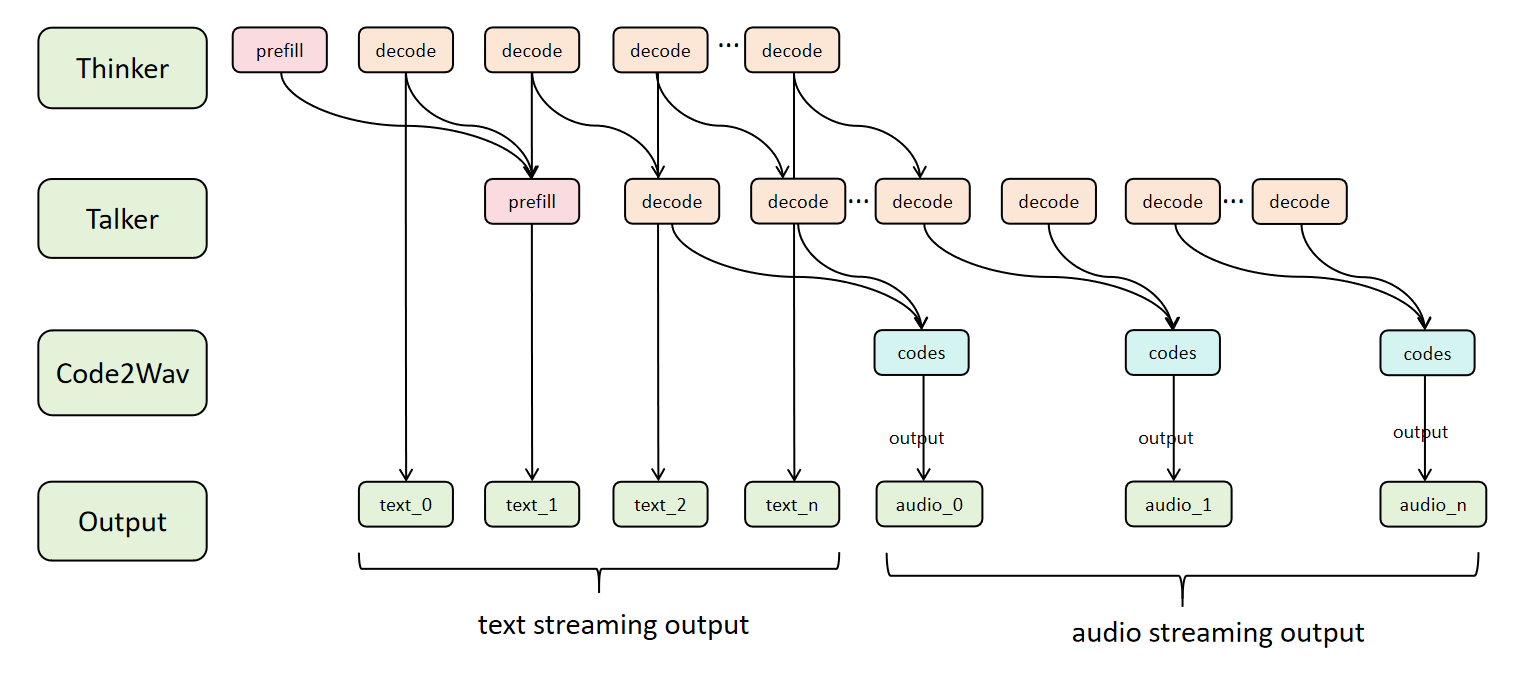 -
-
- 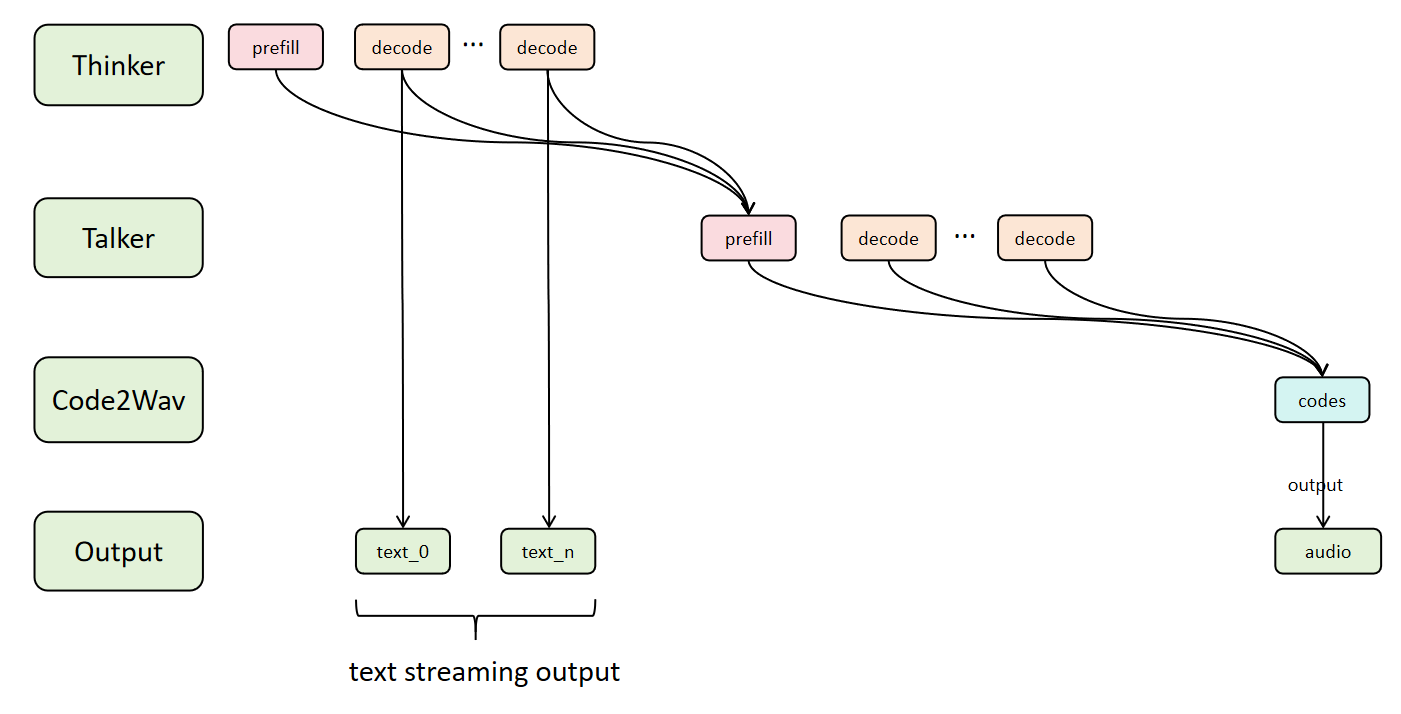 -
-
- 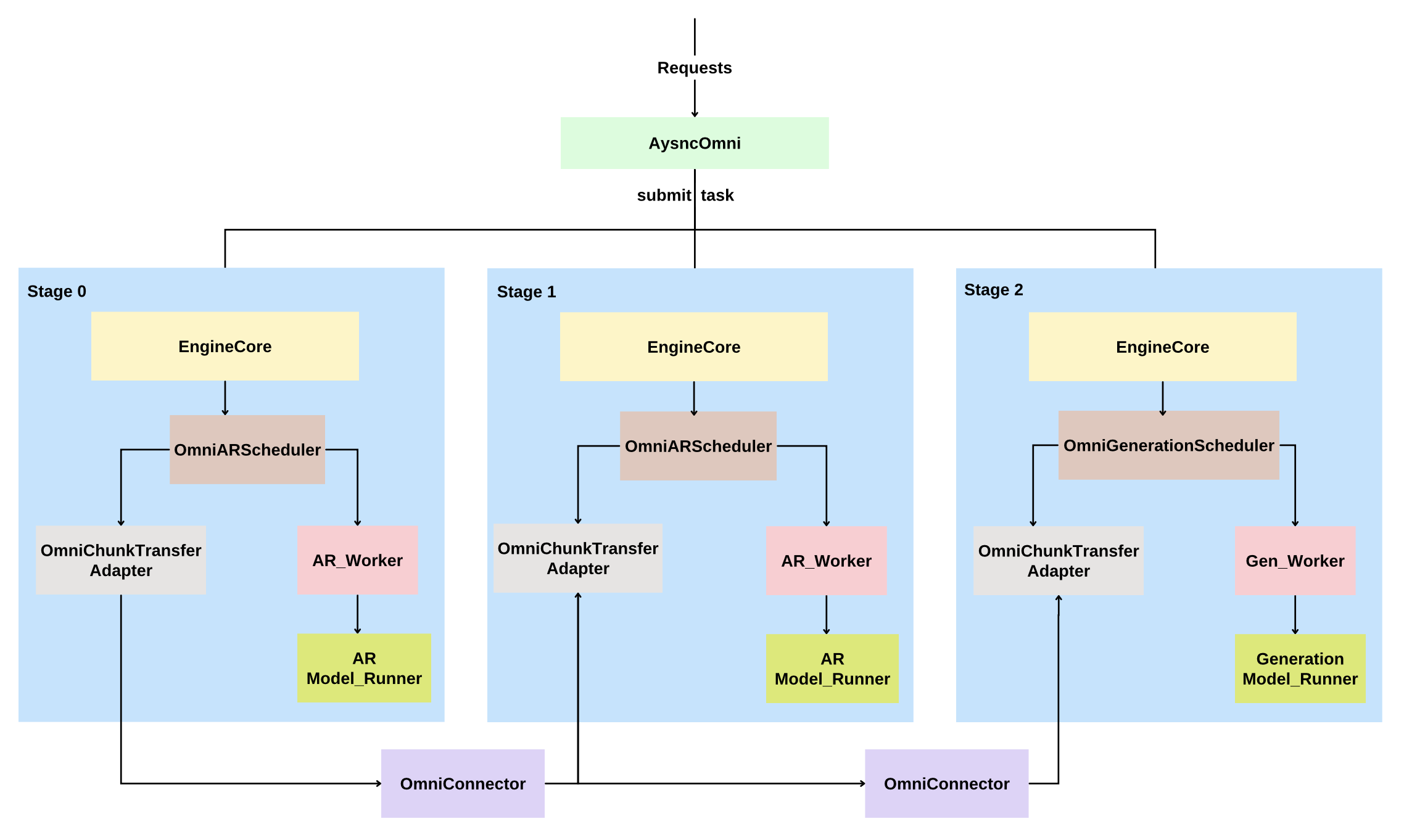 -
-
-
-
- Main Components of the Diffusion Module -
- - -**Table of Content:** - -- [Architecture Overview](#architecture-overview) -- [Diffusion Engine](#1-diffusion-engine) -- [Scheduler](#2-scheduler) -- [Worker](#3-worker) -- [Diffusion Pipeline](#4-diffusion-pipeline) -- [Acceleration Components](#5-acceleration-components) - - [Attention Backends](#51-attention-backends) - - [Parallel Attention](#52-parallel-attention) - - [Cache Backends](#53-cache-backends) - - [Parallel Strategies](#54-parallel-strategies) -- [Data Flow](#6-data-flow) - ---- - -## Architecture Overview - -The diffusion module follows a **multi-process, distributed architecture** with clear separation of concerns: - -
-
-
- Diffusion Architecture Overview -
- - ---- - -## 1. Diffusion Engine - -**Location**: `vllm_omni/diffusion/diffusion_engine.py` - -### Responsibilities - -The `DiffusionEngine` is the **orchestrator** of the diffusion inference system. It manages the lifecycle of worker processes and coordinates the execution flow. - -### Key Components - -#### 1.1 Initialization - -```python -class DiffusionEngine: - def __init__(self, od_config: OmniDiffusionConfig): - self.od_config = od_config - self.post_process_func = get_diffusion_post_process_func(od_config) - self.pre_process_func = get_diffusion_pre_process_func(od_config) - self._processes: list[mp.Process] = [] - self._make_client() -``` - -**Key Features**: - -- **Pre/Post Processing**: Registers model-specific pre-processing and post-processing functions via registry pattern - -- **Worker Management**: Launches and manages multiple worker processes (one per GPU) - -- **Process Isolation**: Uses multiprocessing for true parallelism - -#### 1.2 Worker Launch Process - -The engine launches workers using a **spawn** method: - -```python -def _launch_workers(self, broadcast_handle): - # Creates one process per GPU - for i in range(num_gpus): - process = mp.Process( - target=worker_proc.worker_main, - args=(i, od_config, writer, broadcast_handle), - name=f"DiffusionWorker-{i}", - ) - process.start() -``` - -**Design Decisions**: - -- **Spawn Method**: Ensures clean state for each worker (no shared memory issues) - -- **Pipe Communication**: Uses `mp.Pipe` for initialization handshake - -- **Device Selection**: Each worker is assigned a specific GPU (`cuda:{rank}`) - -#### 1.3 Request Processing Flow - -```python -def step(self, requests: list[OmniDiffusionRequest]): - # 1. Pre-process requests - requests = self.pre_process_func(requests) - - # 2. Send to scheduler and wait for response - output = self.add_req_and_wait_for_response(requests) - - # 3. Post-process results - result = self.post_process_func(output.output) - return result -``` - -**Flow**: - -1. **Pre-processing**: Applies model-specific transformations - -2. **Scheduling**: Delegates to scheduler for distribution - -3. **Post-processing**: Converts raw outputs to final format (e.g., PIL images) - ---- - -## 2. Scheduler - -**Location**: `vllm_omni/diffusion/sched/` - -### Architecture - -The scheduler is a **request-state scheduler**. It owns request lifecycle management and scheduling decisions, while execution stays in `DiffusionEngine` and the executor. - -### Key Components - -#### 2.1 Scheduler Interface - -```python -class SchedulerInterface(ABC): - def add_request(self, request: OmniDiffusionRequest) -> str: ... - def schedule(self) -> DiffusionSchedulerOutput: ... - def update_from_output( - self, - sched_output: DiffusionSchedulerOutput, - output: DiffusionOutput, - ) -> set[str]: ... -``` - -**Responsibilities**: - -- **Lifecycle contract**: Defines how the engine adds requests, triggers one scheduling cycle, and feeds executor results back. - -- **Stable boundary**: `DiffusionSchedulerOutput` is the only scheduling result consumed by `DiffusionEngine`. - -- **Pluggability**: Different scheduler policies can reuse the same engine integration path. - -#### 2.2 Request State Model - -```python -class DiffusionRequestStatus(enum.IntEnum): - WAITING = ... - RUNNING = ... - PREEMPTED = ... - FINISHED_COMPLETED = ... - FINISHED_ABORTED = ... - FINISHED_ERROR = ... - -@dataclass -class DiffusionRequestState: - sched_req_id: str - req: OmniDiffusionRequest - status: DiffusionRequestStatus = DiffusionRequestStatus.WAITING -``` - -**Design Features**: - -- **Scheduler-owned ID**: Each `OmniDiffusionRequest` is tracked by an internal `sched_req_id`, separated from public `request_id` values. - -- **Explicit lifecycle**: Requests move through waiting, running, optional preemption, and terminal states. - -- **Centralized error handling**: Completion, abort, and error states are all normalized in the scheduler layer. - -#### 2.3 Shared Bookkeeping in `_BaseScheduler` - -```python -class _BaseScheduler(SchedulerInterface): - def __init__(self) -> None: - self._request_states = {} - self._request_id_to_sched_req_id = {} - self._waiting = deque() - self._running = [] - self._finished_req_ids = set() - self.max_num_running_reqs = 1 -``` - -**Design Features**: - -- **Common state storage**: Shared request maps and waiting/running sets live in the base class. - -- **Shared cleanup logic**: Request-id registration, finish handling, and state removal are centralized instead of duplicated in each policy. - -- **Current constraint**: `max_num_running_reqs` remains `1` because the current engine path is still synchronous request-mode execution. - -#### 2.4 Current `RequestScheduler` Policy - -```python -class RequestScheduler(_BaseScheduler): - def schedule(self) -> DiffusionSchedulerOutput: - # 1. keep existing RUNNING requests in the scheduling result - # 2. pull WAITING requests while capacity remains - # 3. move newly admitted requests into RUNNING -``` - -**Behavior**: - -- **FIFO request scheduling**: Waiting requests are promoted in queue order. - -- **Single-request admission**: The current policy only admits one active request at a time. - -- **Executor result feedback**: `update_from_output()` converts executor output into `FINISHED_COMPLETED` or `FINISHED_ERROR` and returns finished scheduler ids. - -#### 2.5 Engine-Driven Execution Loop - -```python -sched_req_id = scheduler.add_request(request) -while True: - sched_output = scheduler.schedule() - output = executor.add_req(req) - finished_req_ids = scheduler.update_from_output(sched_output, output) -``` - -**Design Decisions**: - -- **Separation of concerns**: Scheduler manages state and policy; executor handles runtime execution. - -- **No scheduler-owned IPC**: Scheduler no longer talks to workers directly. - -- **Conservative concurrency**: The current request-mode implementation still allows only one active request at a time. - ---- - -## 3. Worker - -**Location**: `vllm_omni/diffusion/worker/gpu_worker.py` - -### Architecture - -Workers are **independent processes** that execute the actual model inference. Each worker runs on a dedicated GPU and participates in distributed inference. - -### Key Components - -#### 3.1 Worker Process Structure - -```python -class WorkerProc: - def __init__(self, od_config, gpu_id, broadcast_handle): - # Initialize ZMQ context for IPC - self.context = zmq.Context(io_threads=2) - - # Connect to broadcast queue (receive requests) - self.mq = MessageQueue.create_from_handle(broadcast_handle, gpu_id) - - # Create result queue (only rank 0) - if gpu_id == 0: - self.result_mq = MessageQueue(n_reader=1, ...) - - # Initialize GPU worker - self.worker = GPUWorker(local_rank=gpu_id, rank=gpu_id, od_config=od_config) -``` - -**Initialization Steps**: - -1. **IPC Setup**: Creates ZMQ context and message queues - -2. **Distributed Environment Setup**: Initializes PyTorch distributed communication - - - For CUDA GPUs: Uses NCCL (fast GPU communication) - - - For NPU: Uses HCCL (Huawei Collective Communications Library) - - - For other devices: Uses appropriate backend (GLOO, MCCL, etc.) - -3. **Model Loading**: Loads diffusion pipeline on assigned GPU - -4. **Cache Setup**: Enables cache backend if configured. - -#### 3.2 GPU Worker - -```python -class GPUWorker: - def init_device_and_model(self): - # Set distributed environment variables - os.environ["RANK"] = str(rank) - os.environ["WORLD_SIZE"] = str(world_size) - - # Initialize PyTorch distributed - init_distributed_environment(world_size, rank) - parallel_config = self.od_config.parallel_config - initialize_model_parallel( - data_parallel_size=parallel_config.data_parallel_size, - cfg_parallel_size=parallel_config.cfg_parallel_size, - sequence_parallel_size=parallel_config.sequence_parallel_size, - tensor_parallel_size=parallel_config.tensor_parallel_size, - pipeline_parallel_size=parallel_config.pipeline_parallel_size, - ) - - # Load model - model_loader = DiffusersPipelineLoader(load_config) - self.pipeline = model_loader.load_model(od_config, load_device=f"cuda:{rank}") - - # Setup cache backend - from vllm_omni.diffusion.cache.selector import get_cache_backend - self.cache_backend = get_cache_backend(od_config.cache_backend, od_config.cache_config) - - if self.cache_backend is not None: - self.cache_backend.enable(self.pipeline) -``` - -**Key Features**: - -- **Tensor Parallelism**: Supports multi-GPU tensor parallelism via PyTorch distributed - -- **Model Loading**: Uses `DiffusersPipelineLoader` for efficient weight loading - -- **Cache Integration**: Enables cache backends (TeaCache, cache-dit, etc.) transparently - -#### 3.3 Worker Busy Loop - -```python -def worker_busy_loop(self): - while self._running: - # 1. Receive unified message (generation request, RPC request, or shutdown) - msg = self.recv_message() - - # 2. Route message based on type - if isinstance(msg, dict) and msg.get("type") == "rpc": - # Handle RPC request - result, should_reply = self.execute_rpc(msg) - if should_reply: - self.return_result(result) - - elif isinstance(msg, dict) and msg.get("type") == "shutdown": - # Handle shutdown message - self._running = False - - else: - # Handle generation request (OmniDiffusionRequest list) - output = self.worker.execute_model(msg, self.od_config) - self.return_result(output) -``` - -**Execution Flow**: - -1. **Receive**: Dequeues unified messages from shared memory queue - -2. **Route**: Handles different message types (generation, RPC, shutdown) - -3. **Execute**: Runs forward pass through pipeline for generation requests - -4. **Respond**: Sends results back (rank 0 for generation, specified rank for RPC) - -#### 3.4 Model Execution - -```python -@torch.inference_mode() -def execute_model(self, reqs: list[OmniDiffusionRequest], od_config): - req = reqs[0] # TODO: support batching - - # Refresh cache backend if enabled - if self.cache_backend is not None and self.cache_backend.is_enabled(): - self.cache_backend.refresh(self.pipeline, req.num_inference_steps) - - # Set forward context for parallelism - with set_forward_context( - vllm_config=self.vllm_config, - omni_diffusion_config=self.od_config - ): - output = self.pipeline.forward(req) - return output -``` - -The model execution leverages multiple parallelism strategies that are transparently applied during the forward pass. The `set_forward_context()` context manager makes parallel group information available throughout the forward pass: - -```python -# Inside transformer layers, parallel groups are accessed via: -from vllm_omni.diffusion.distributed.parallel_state import ( - get_sp_group, get_dp_group, get_cfg_group, get_pp_group -) -``` - -**Optimizations**: - -- **Cache Refresh**: Clears cache state before each generation for clean state - -- **Context Management**: Forward context ensures parallel groups are available during execution - -- **Single Request**: Currently processes one request at a time (batching TODO) - ---- - -## 4. Diffusion Pipeline - -**Location**: `vllm_omni/diffusion/models/*/pipeline_*.py` - -The pipeline is the **model-specific implementation** that orchestrates the diffusion process. Different models (QwenImage, Wan2.2, Z-Image) have their own pipeline implementations. - -Most pipeline implementation are referred from `diffusers`. The multi-step diffusion loop is usually the most time-consuming part during the overall inference process, which is defined by the `diffuse` function in the pipeline class. An example is as follows: - -```python -def diffuse(self, ...): - for i, t in enumerate(timesteps): - # Forward pass for positive prompt - transformer_kwargs = { - "hidden_states": latents, - "timestep": timestep / 1000, - "encoder_hidden_states": prompt_embeds, - } - noise_pred = self.transformer(**transformer_kwargs)[0] - - # Forward pass for negative prompt (CFG) - if do_true_cfg: - neg_transformer_kwargs = {...} - neg_transformer_kwargs["cache_branch"] = "negative" - neg_noise_pred = self.transformer(**neg_transformer_kwargs)[0] - - # Combine predictions - comb_pred = neg_noise_pred + true_cfg_scale * (noise_pred - neg_noise_pred) - noise_pred = comb_pred * (cond_norm / noise_norm) - - # Scheduler step - latents = self.scheduler.step(noise_pred, t, latents)[0] - - return latents -``` - -**Key Features**: - -- **CFG Support**: Handles classifier-free guidance with separate forward passes - -- **Cache Branching**: Uses `cache_branch` parameter for cache-aware execution - -- **True CFG**: Implements advanced CFG with norm preservation - -To learn more about the diffusion pipeline and how to add a new diffusion pipeline, please view [Adding Diffusion Model](https://docs.vllm.ai/projects/vllm-omni/en/latest/contributing/model/adding_diffusion_model) - ---- - -## 5. Acceleration Components - -### 5.1 Attention Backends - -**Location**: `vllm_omni/diffusion/attention/` - -#### Architecture - -The attention system uses a **backend selector pattern** that automatically chooses the optimal attention implementation based on hardware and model configuration. - -#### Backend Selection - -**Location**: `vllm_omni/diffusion/attention/selector.py` - -```python -class Attention(nn.Module): - def __init__(self, num_heads, head_size, causal, softmax_scale, ...): - # Auto-select backend - self.attn_backend = get_attn_backend(-1) - self.attn_impl_cls = self.attn_backend.get_impl_cls() - self.attention = self.attn_impl_cls(...) -``` - -**Available Backends**: - -- **FlashAttention**: Optimized CUDA kernel (FA2/FA3) - memory efficient via tiling - -- **SDPA**: PyTorch's scaled dot-product attention - default, cross-platform - -- **SageAttention**: Sparse attention implementation from SageAttention library - -- **AscendAttention**: NPU-optimized attention for Ascend hardware - -These backends provide the **kernel implementations** for attention computation. For attention-level sequence parallelism strategies (Ring Attention, Ulysses), see [Parallel Attention](#52-parallel-attention). - -#### Backend Selection Mechanism - -```python -def get_attn_backend(head_size: int) -> type[AttentionBackend]: - # Check environment variable - backend_name = os.environ.get("DIFFUSION_ATTENTION_BACKEND") - - if backend_name: - return load_backend(backend_name.upper()) - - # Default to SDPA - return SDPABackend -``` - -**Selection Priority**: - -1. **Environment Variable**: `DIFFUSION_ATTENTION_BACKEND` for manual override - - - Valid values: `FLASH_ATTN`, `TORCH_SDPA`, `SAGE_ATTN`, `ASCEND` - - - Example: `export DIFFUSION_ATTENTION_BACKEND=SAGE_ATTN` - -2. **Automatic Fallback**: Falls back to SDPA if selected backend unavailable - -3. **Hardware Detection**: Can select based on device type (NPU, CUDA, etc.) - -**Backend Availability**: - -- **SDPA**: Always available (PyTorch built-in) - -- **FlashAttention**: Requires `flash-attn` package installed - -- **SageAttention**: Requires `sage-attention` package (from THU-ML GitHub) - -- **AscendAttention**: Only available on Ascend NPU hardware - -#### Attention Backend Registry - -**Location**: `vllm_omni/diffusion/attention/selector.py` - -The attention system uses a **registry pattern** to manage and dynamically load attention backends. This allows for easy extension and runtime selection of backends. - - -**Registry Structure**: - -```python -# Registry mapping backend names to their module paths and class names -_BACKEND_CONFIG = { - "FLASH_ATTN": { - "module": "vllm_omni.diffusion.attention.backends.flash_attn", - "class": "FlashAttentionBackend", - }, - "TORCH_SDPA": { - "module": "vllm_omni.diffusion.attention.backends.sdpa", - "class": "SDPABackend", - }, - "SAGE_ATTN": { - "module": "vllm_omni.diffusion.attention.backends.sage_attn", - "class": "SageAttentionBackend", - }, - "ASCEND": { - "module": "vllm_omni.diffusion.attention.backends.ascend_attn", - "class": "AscendAttentionBackend", - }, -} -``` - -#### Attention Backend Integration - -The `Attention` layer integrates backends through a unified interface. Here's how **FlashAttentionBackend** is integrated as an example: - -```python -# attention/backends/flash_attn.py - -class FlashAttentionBackend(AttentionBackend): - @staticmethod - def get_name() -> str: - return "FLASH_ATTN" - - @staticmethod - def get_impl_cls() -> type["FlashAttentionImpl"]: - return FlashAttentionImpl - - @staticmethod - def get_supported_head_sizes() -> list[int]: - return [64, 96, 128, 192, 256] # FlashAttention supports these head sizes - - -class FlashAttentionImpl(AttentionImpl): - def __init__(self, num_heads, head_size, softmax_scale, causal, ...): - self.num_heads = num_heads - self.causal = causal - self.softmax_scale = softmax_scale - - def forward(self, query, key, value, attn_metadata=None): - # Call FlashAttention kernel - out = flash_attn_func( - query, key, value, - causal=self.causal, - softmax_scale=self.softmax_scale, - ) - return out -``` - ---- - -### 5.2 Parallel Attention - -**Location**: `vllm_omni/diffusion/attention/parallel/` - -#### Architecture - -Parallel attention strategies implement **Sequence Parallelism (SP) at the attention layer level**. These strategies distribute attention computation across multiple GPUs by splitting the sequence dimension, using different communication patterns. They work **on top of** AttentionBackend implementations (FlashAttention, SDPA, etc.), handling the parallelization/communication while the backends handle the actual attention computation. - -**Key Distinction**: Unlike AttentionBackend (which provides kernel implementations), ParallelAttentionStrategy provides communication patterns for multi-GPU attention parallelism. These strategies implement the `ParallelAttentionStrategy` interface and use AttentionBackend implementations internally. - -Both Ring Attention and Ulysses are forms of Sequence Parallelism (SP) that: - -- Split the sequence dimension across GPUs - -- Contribute to `sequence_parallel_size` (via `ring_degree` and `ulysses_degree`) - -- Work at the attention layer level (not model/pipeline level) - -#### Ulysses Sequence Parallelism (USP) - -**Location**: `vllm_omni/diffusion/attention/parallel/ulysses.py` - -USP is a sequence-parallel attention strategy that splits attention computation across multiple GPUs by distributing both the sequence dimension and attention heads. It uses **all-to-all communication** to efficiently parallelize attention for very long sequences. Specifically, it uses **all-to-all** collective operations to redistribute Q/K/V tensors before attention computation and gather results afterward. - -Ulysses splits attention computation in two dimensions: - -1. **Sequence Dimension**: Splits the sequence length across GPUs - -2. **Head Dimension**: Splits attention heads across GPUs - -**Configuration**: `ulysses_degree` contributes to `sequence_parallel_size` - -#### Ring Sequence Parallelism - -**Location**: `vllm_omni/diffusion/attention/parallel/ring.py` - -Ring Attention is a **parallel attention strategy** that implements sequence parallelism using ring-based point-to-point (P2P) communication. Unlike attention backends that provide the attention kernel implementation, Ring Attention is a **communication pattern** that works on top of attention backends (FlashAttention or SDPA). - -Ring Attention splits sequence dimension across GPUs in a ring topology, implemented via the `ParallelAttentionStrategy` interface, instead of `AttentionBackend`. P2P ring communication is applied to circulate Key/Value blocks across GPUs. Internally, `ring_flash_attn_func` or `ring_pytorch_attn_func` is used depending on available backends. - -**Architecture**: -```python -class RingParallelAttention: - """Ring sequence-parallel strategy.""" - - def run_attention(self, query, key, value, attn_metadata, ...): - # Selects underlying attention kernel (FlashAttention or SDPA) - if backend_pref == "sdpa": - return ring_pytorch_attn_func(...) # Uses SDPA kernel - else: - return ring_flash_attn_func(...) # Uses FlashAttention kernel -``` - -**Integration**: - -- Ring Attention is activated when `ring_degree > 1` in parallel config - -- It's selected by `build_parallel_attention_strategy()` in the attention layer - -- The `Attention` layer routes to `_run_ring_attention()` when Ring is enabled - -- Works alongside attention backends: Ring handles communication, backends handle computation - -**Configuration**: `ring_degree` contributes to `sequence_parallel_size` - -#### Relationship with AttentionBackend - -Parallel attention strategies (Ring, Ulysses) work **on top of** AttentionBackend implementations: - -- They use AttentionBackend for the actual attention computation (FlashAttention, SDPA, etc.) - -- They handle the multi-GPU communication/parallelization layer - -- They implement `ParallelAttentionStrategy` interface (not `AttentionBackend`) - -For general parallelism strategies (Data Parallelism, Tensor Parallelism, Pipeline Parallelism), see [Parallel Strategies](#54-parallel-strategies). - ---- - -### 5.3 Cache Backends - -**Location**: `vllm_omni/diffusion/cache/` - -#### Architecture - -Cache backends provide a **unified interface** for applying different caching strategies to accelerate diffusion inference. The system supports multiple backends (TeaCache, cache-dit) with a consistent API for enabling and refreshing cache state. - -#### Cache Backend Interface - -```python -class CacheBackend(ABC): - def __init__(self, config: DiffusionCacheConfig): - self.config = config - self.enabled = False - - @abstractmethod - def enable(self, pipeline: Any) -> None: - """Enable cache on the pipeline.""" - raise NotImplementedError - - @abstractmethod - def refresh(self, pipeline: Any, num_inference_steps: int, verbose: bool = True) -> None: - """Refresh cache state for new generation.""" - raise NotImplementedError - - def is_enabled(self) -> bool: - """Check if cache is enabled.""" - return self.enabled -``` - -**Design Pattern**: - -- **Abstract Base Class**: Defines contract for all cache backends - -- **Pipeline-based**: Works with pipeline instances (not just transformers) - -- **State Management**: Provides refresh mechanism for clean state between generations - -#### Available Backends - -**1. TeaCache Backend** - -**Location**: `vllm_omni/diffusion/cache/teacache/backend.py` - -```python -class TeaCacheBackend(CacheBackend): - def enable(self, pipeline: Any): - # Extract transformer from pipeline - transformer = pipeline.transformer - transformer_type = transformer.__class__.__name__ - - # Create TeaCacheConfig from DiffusionCacheConfig - teacache_config = TeaCacheConfig( - transformer_type=transformer_type, - rel_l1_thresh=self.config.rel_l1_thresh, - coefficients=self.config.coefficients, - ) - - # Apply hooks to transformer - apply_teacache_hook(transformer, teacache_config) - self.enabled = True - - def refresh(self, pipeline: Any, num_inference_steps: int, verbose: bool = True): - transformer = pipeline.transformer - if hasattr(transformer, "_hook_registry"): - transformer._hook_registry.reset_hook(TeaCacheHook._HOOK_NAME) -``` - -**TeaCache Features**: - -- **Timestep-aware**: Caches based on timestep embedding similarity - -- **Adaptive**: Dynamically decides when to reuse cached computations - -- **CFG-aware**: Handles positive/negative branches separately - -- **Custom Hook System**: Uses a custom forward interception mechanism (via `HookRegistry`) that wraps the module's `forward` method, allowing transparent integration without modifying model code - -**2. Cache-DiT Backend** - -**Location**: `vllm_omni/diffusion/cache/cache_dit_backend.py` - -```python -class CacheDiTBackend(CacheBackend): - def enable(self, pipeline: Any): - # Uses cache-dit library for acceleration - # Supports DBCache, SCM (Step Computation Masking), TaylorSeer - # Works with single and dual-transformer architectures - ... - self.enabled = True - - def refresh(self, pipeline: Any, num_inference_steps: int, verbose: bool = True): - # Updates cache context with new num_inference_steps - ... -``` - -**Cache-DiT Features**: - -- **DBCache**: Dynamic block caching with configurable compute blocks - -- **SCM**: Step Computation Masking for additional speedup - -- **TaylorSeer**: Advanced calibration for cache accuracy - -- **Dual-transformer Support**: Handles models like Wan2.2 with two transformers - -#### Cache Backend Selector - -**Location**: `vllm_omni/diffusion/cache/selector.py` - -```python -def get_cache_backend( - cache_backend: str | None, - cache_config: dict | DiffusionCacheConfig -) -> CacheBackend | None: - """Get cache backend instance based on cache_backend string. - - Args: - cache_backend: Cache backend name ("cache_dit", "tea_cache", or None) - cache_config: Cache configuration (dict or DiffusionCacheConfig) - - Returns: - Cache backend instance or None if cache_backend is "none" - """ - if cache_backend is None or cache_backend == "none": - return None - - if isinstance(cache_config, dict): - cache_config = DiffusionCacheConfig.from_dict(cache_config) - - if cache_backend == "cache_dit": - return CacheDiTBackend(cache_config) - elif cache_backend == "tea_cache": - return TeaCacheBackend(cache_config) - else: - raise ValueError(f"Unsupported cache backend: {cache_backend}") -``` - -**Usage Flow**: - -1. **Selection**: `get_cache_backend()` returns appropriate backend instance - -2. **Enable**: `backend.enable(pipeline)` called during worker initialization - -3. **Refresh**: `backend.refresh(pipeline, num_inference_steps)` called before each generation - -4. **Check**: `backend.is_enabled()` verifies cache is active - -### 5.4 Parallel Strategies - -**Location**: `vllm_omni/diffusion/distributed/parallel_state.py` - -#### Parallelism Types - -The system supports multiple orthogonal parallelism strategies: - -**Sequence Parallelism (SP)** - -- **Purpose**: Split sequence dimension across GPUs - -- **Attention-level SP**: Ring Attention and Ulysses (USP) implement SP at the attention layer level - - - See [Parallel Attention](#52-parallel-attention) for details - - - Configuration: `ulysses_degree` × `ring_degree` = `sequence_parallel_size` - -- **Use Case**: Very long sequences (e.g., high-resolution images) - -**Data Parallelism (DP)** - -- **Purpose**: Replicate model across GPUs, split batch - -- **Use Case**: Batch processing, throughput optimization - -**Tensor Parallelism (TP)** (Experimental) - -- **Purpose**: Split model weights across GPUs - -- **Implementation**: Uses vLLM's tensor parallel groups - -- **Use Case**: Large models that don't fit on single GPU - -**CFG Parallelism** (under development) - -- **Purpose**: Parallelize Classifier-Free Guidance (positive/negative prompts) - -- **Infrastructure**: CFG parallel groups are initialized and available via `get_cfg_group()` - -#### Parallel Group Management - -```python -def initialize_model_parallel( - data_parallel_size: int = 1, - cfg_parallel_size: int = 1, - sequence_parallel_size: int | None = None, - ulysses_degree: int = 1, - ring_degree: int = 1, - tensor_parallel_size: int = 1, - pipeline_parallel_size: int = 1, - vae_parallel_size: int = 0, -): - # Generate orthogonal parallel groups - rank_generator = RankGenerator( - tensor_parallel_size, - sequence_parallel_size, - pipeline_parallel_size, - cfg_parallel_size, - data_parallel_size, - "tp-sp-pp-cfg-dp", - ) - - # Initialize each parallel group - _DP = init_model_parallel_group(rank_generator.get_ranks("dp"), ...) - _CFG = init_model_parallel_group(rank_generator.get_ranks("cfg"), ...) - _SP = init_model_parallel_group(rank_generator.get_ranks("sp"), ...) - _PP = init_model_parallel_group(rank_generator.get_ranks("pp"), ...) - _TP = init_model_parallel_group(rank_generator.get_ranks("tp"), ...) -``` - -**Rank Order**: `tp-sp-pp-cfg-dp` (tensor → sequence → pipeline → cfg → data) - -**Note**: For attention-level Sequence Parallelism implementations (Ring Attention and Ulysses), see [Parallel Attention](#52-parallel-attention). This section covers higher-level parallelism strategies. - - ---- - -## 6. Data Flow - -### Complete Request Flow - -
-
-
- End-to-end Data Flow in the vLLM-Omni Diffusion Module -
- - -``` -1. User Request - └─> OmniDiffusion.generate(prompt) - └─> Prepare OmniDiffusionRequest - └─> DiffusionEngine.step(requests) - -2. Pre-processing - └─> pre_process_func(requests) - └─> Model-specific transformations - -3. Scheduling - └─> scheduler.add_request(request) - └─> scheduler.schedule() - └─> DiffusionEngine submits scheduled request to executor.add_req(req) - -4. Worker Execution - └─> WorkerProc.worker_busy_loop() - └─> GPUWorker.execute_model(reqs) - └─> Pipeline.forward(req) - ├─> encode_prompt() - ├─> prepare_latents() - ├─> diffuse() [loop] - │ ├─> transformer.forward() [with cache backend hooks] - │ └─> scheduler.step() - └─> vae.decode() - -5. Result Collection - └─> Executor returns DiffusionOutput - └─> scheduler.update_from_output(...) - └─> DiffusionEngine pops finished request state - -6. Post-processing - └─> post_process_func(output) - └─> Convert to PIL images / final format -``` - ---- diff --git a/docs/design/module/entrypoint_module.md b/docs/design/module/entrypoint_module.md deleted file mode 100644 index 7a26fbb7f05..00000000000 --- a/docs/design/module/entrypoint_module.md +++ /dev/null @@ -1 +0,0 @@ -Architecture design of the entrypoint (update soon) diff --git a/docs/design/qwen3_omni_tts_performance_optimization.md b/docs/design/qwen3_omni_tts_performance_optimization.md deleted file mode 100644 index 2f18a1b1bc0..00000000000 --- a/docs/design/qwen3_omni_tts_performance_optimization.md +++ /dev/null @@ -1,539 +0,0 @@ -# Speech Generation on vLLM-Omni: Performance Optimizations for Qwen3-Omni and Qwen3-TTS - -## Summary - -vLLM-Omni supports end-to-end serving for speech-generating models, including both **Qwen3-Omni** (multimodal understanding + speech) and **Qwen3-TTS** (text-to-speech). Despite their different architectures, both models share the same multi-stage pipeline design and benefit from the same set of stacked optimizations: - -1. **Batching** improves GPU utilization stage by stage and increases overall throughput. -2. **CUDA Graph** reduces CPU launch overhead and decode-time jitter on stable shapes. -3. **Async Chunk and Streaming Output** overlap compute and communication across stages and emit audio incrementally, improving both TTFP and E2E. - -### Model architectures - -**Qwen3-Omni** is a native multimodal model that understands text, audio, image, and video inputs, and generates both text and speech outputs. Its pipeline has three stages: - -- **Thinker**: multimodal understanding and text generation -- **Talker (+ Talker-MTP / code predictor path)**: converts semantic/text representations into codec tokens -- **Code2Wav**: decodes codec tokens into waveform audio - -**Qwen3-TTS** is a lightweight, high-quality text-to-speech model. Its pipeline has two stages: - -- **Talker (AR decoder)**: auto-regressively generates codec tokens from text input -- **Code2Wav (vocoder)**: decodes codec tokens into waveform audio - -The optimizations described in this post apply to both models. We present results for each side by side. - -### vLLM-Omni vs HF Transformers - -Compared with **HF Transformers** (offline, single request), vLLM-Omni with the full optimization stack delivers dramatically lower latency and higher efficiency for both models. - -**Qwen3-Omni** (A100): - - |
- |
- |
-
_vllm_omni_vs_transformers.png) |
-_vllm_omni_vs_transformers.png) |
- |
-
 |
- |
- |
-
 |
- |
- |
-
 |
- |
- |
-
 |
- |
- |
-
 |
- |
- |
-
 |
- |
- |
-
 |
- |
- |
-
 |
- |
- |
-
(Optional) Installation of vLLM from source
-If you want to check, modify or debug with source code of vLLM, install the library from source with the following instructions: - -```bash -git clone https://github.com/vllm-project/vllm.git -cd vllm -git checkout v0.20.0 -``` -Set up environment variables to get pre-built wheels. If there are internet problems, just download the whl file manually. And set `VLLM_PRECOMPILED_WHEEL_LOCATION` as your local absolute path of whl file. -```bash -#For CUDA 13.0 (the default for v0.20.0; the wheel filename has no `+cu130` suffix) -export VLLM_PRECOMPILED_WHEEL_LOCATION=https://github.com/vllm-project/vllm/releases/download/v0.20.0/vllm-0.20.0-cp38-abi3-manylinux_2_35_x86_64.whl -``` -Install vllm with command below (If you have no existing PyTorch). -```bash -uv pip install --editable . -``` -Install vllm with command below (If you already have PyTorch). -```bash -python use_existing_torch.py -uv pip install -r requirements/build/cuda.txt -uv pip install --no-build-isolation --editable . -``` -(Optional) Installation of vLLM from source
-If you want to check, modify or debug with source code of vLLM, install the library from source with the following instructions: - -```bash -git clone https://github.com/vllm-project/vllm.git -cd vllm -git checkout v0.20.0 -python3 -m pip install -r requirements/rocm.txt -python3 setup.py develop -``` - -# --8<-- [end:build-wheel-from-source] - -# --8<-- [start:build-docker] - -#### Build docker image - -```bash -DOCKER_BUILDKIT=1 docker build -f docker/Dockerfile.rocm -t vllm-omni-rocm . -``` - -#### Launch the docker image - -##### Launch with OpenAI API Server - -``` -docker run --rm \ ---group-add=video \ ---ipc=host \ ---cap-add=SYS_PTRACE \ ---security-opt seccomp=unconfined \ ---device /dev/kfd \ ---device /dev/dri \ --v ~/.cache/huggingface:/root/.cache/huggingface \ ---env "HF_TOKEN=$HF_TOKEN" \ --p 8091:8091 \ ---ipc=host \ -vllm-omni-rocm \ ---model Qwen/Qwen3-Omni-30B-A3B-Instruct --port 8091 -``` - -##### Launch with interactive session for development - -``` -docker run --rm -it \ ---network=host \ ---group-add=video \ ---ipc=host \ ---cap-add=SYS_PTRACE \ ---security-opt seccomp=unconfined \ ---device /dev/kfd \ ---device /dev/dri \ --vStability GPU memory monitor report
- -Statistics
-| GPU | Min % | Max % | Avg % | P50 | P95 | Samples |
|---|
Memory utilization over time
- -
-
-
- Anomalies (high/low threshold)
- -| Period | GPU | Util % | Type | Samples |
|---|