diff --git a/docs/design/feature/async_chunk_design.md b/docs/design/feature/async_chunk_design.md
index 202ef0e18e8..45314a0aec6 100644
--- a/docs/design/feature/async_chunk_design.md
+++ b/docs/design/feature/async_chunk_design.md
@@ -19,7 +19,7 @@ The `async_chunk` feature enables asynchronous, chunked processing of data acros
For qwen3-omni:
- **Thinker → Talker**: Per decode step (typically chunk_size=1)
-- **Talker → Code2Wav**: Accumulated to `codec_chunk_frames` (default=25) before sending. During the initial phase, a dynamic initial chunk size (IC) is automatically selected based on server load to reduce TTFA. Use the per-request `initial_codec_chunk_frames` API field to override.
+- **Talker → Code2Wav**: Accumulated to `codec_chunk_frames` (default=25) before sending. During the initial phase, a dynamic initial chunk size (IC) is automatically selected based on server load to reduce TTFP. Use the per-request `initial_codec_chunk_frames` API field to override.
- **Code2Wav**: Streaming decode with code2wav chunk_size
With `async_chunk`:
@@ -75,26 +75,84 @@ Enabling **async_chunk** (False→True) sharply reduces time-to-first-audio (TTF
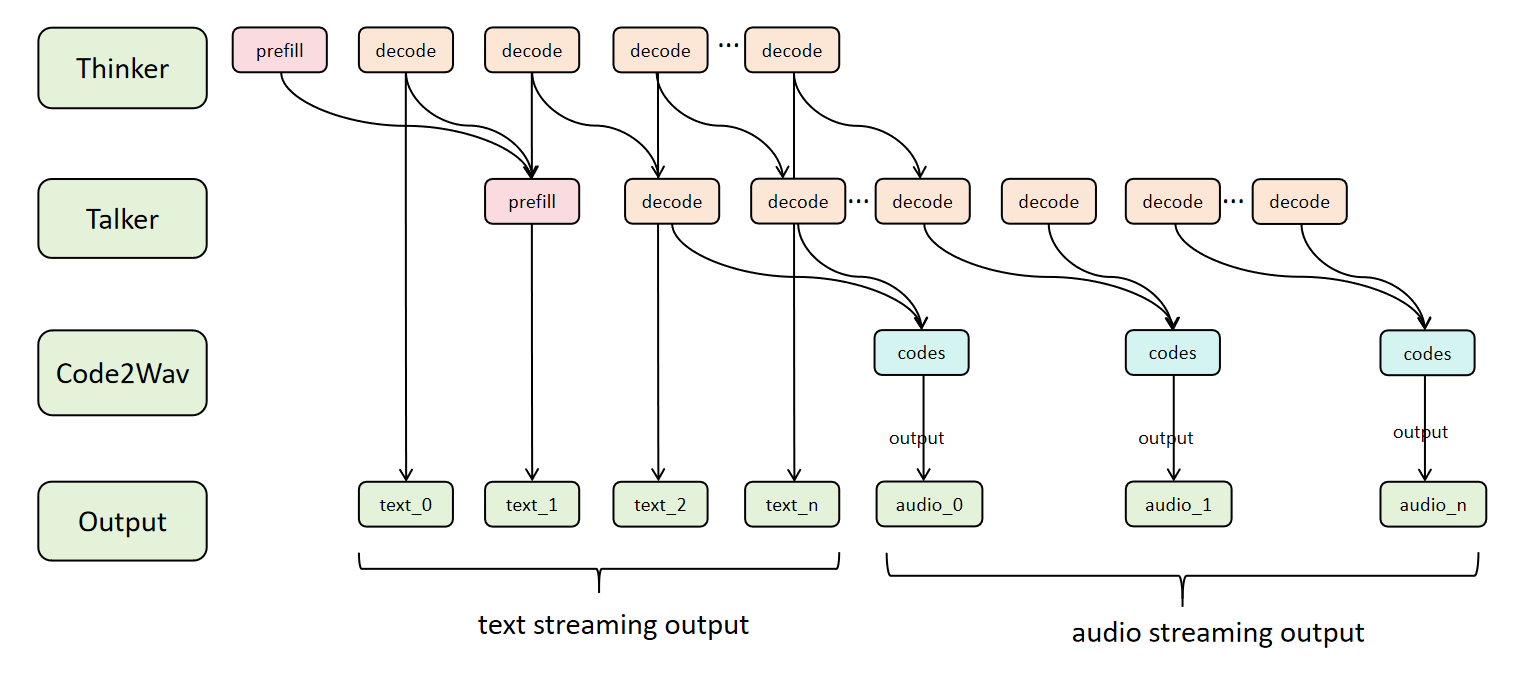
## Architecture
-### Data Flow
-#### Sequential Flow
+### Async Chunk Pipeline Overview
+
+The following diagram illustrates the **Async Chunk Architecture** for multi-stage models (e.g., Qwen3-Omni with Thinker → Talker → Code2Wav), showing how data flows through the 4-stage pipeline with parallel processing and dual-stream output:
+
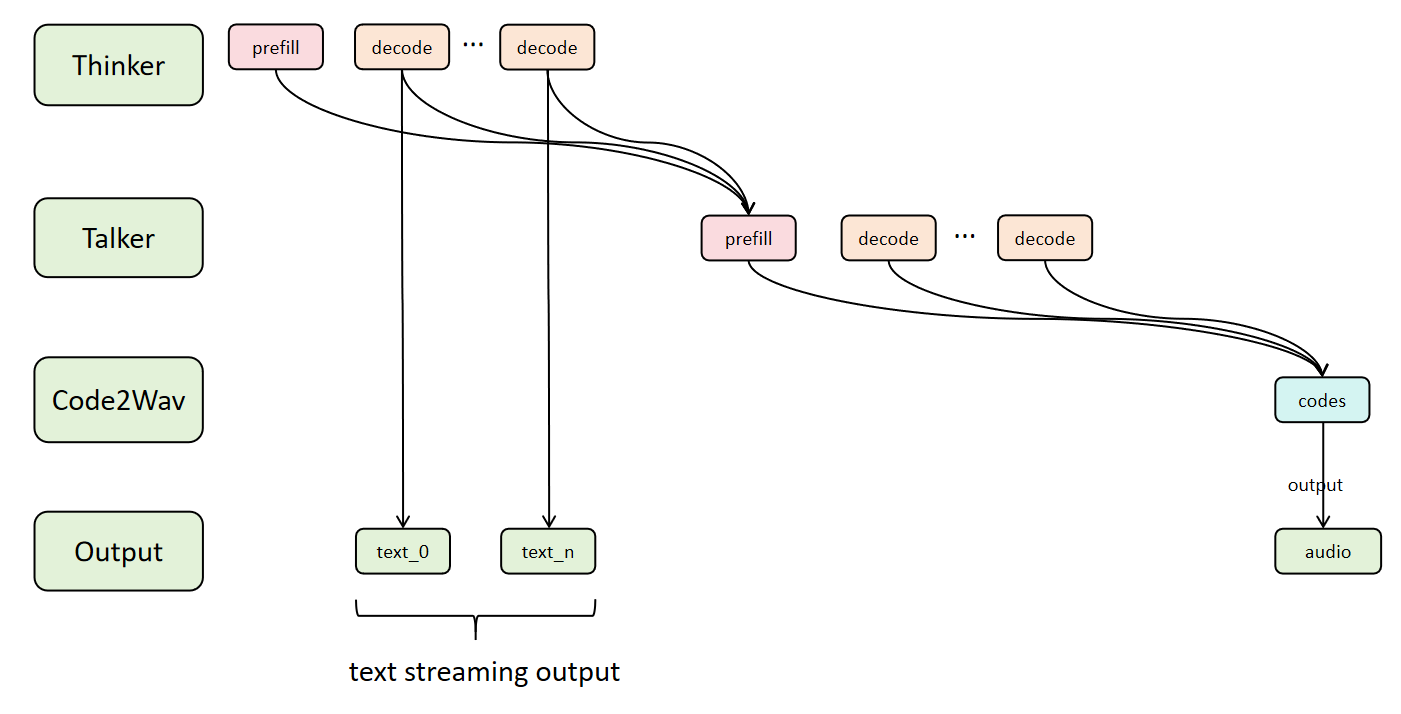
-### Async Chunk architecture
+In sequential mode, each stage must wait for the previous stage to complete entirely before starting.
+
+### Async Chunk System Architecture
diff --git a/docs/source/architecture/qwen3-omni-async-chunk.png b/docs/source/architecture/qwen3-omni-async-chunk.png
index b2d98b80f33..e73ca84b283 100644
Binary files a/docs/source/architecture/qwen3-omni-async-chunk.png and b/docs/source/architecture/qwen3-omni-async-chunk.png differ
diff --git a/docs/source/architecture/qwen3-omni-non-async-chunk.png b/docs/source/architecture/qwen3-omni-non-async-chunk.png
index da5610a11bb..47a9ba66a5e 100644
Binary files a/docs/source/architecture/qwen3-omni-non-async-chunk.png and b/docs/source/architecture/qwen3-omni-non-async-chunk.png differ
 +
+