diff --git a/.github/workflows/comfyui-publish.yml b/.github/workflows/comfyui-publish.yml
deleted file mode 100644
index c282bcada26..00000000000
--- a/.github/workflows/comfyui-publish.yml
+++ /dev/null
@@ -1,27 +0,0 @@
-name: ComfyUI Integration -- Publish to Comfy registry
-on:
- workflow_dispatch:
- push:
- tags:
- - "*"
- paths:
- - "apps/ComfyUI-vLLM-Omni/**"
-
-permissions:
- issues: write
-
-defaults:
- run:
- working-directory: apps/ComfyUI-vLLM-Omni
-
-jobs:
- publish-node:
- name: Publish Custom Node to registry
- runs-on: ubuntu-latest
- steps:
- - name: ♻️ Check out code
- uses: actions/checkout@v4
- - name: 📦 Publish Custom Node
- uses: Comfy-Org/publish-node-action@main
- with:
- personal_access_token: ${{ secrets.REGISTRY_ACCESS_TOKEN }}
diff --git a/.github/workflows/comfyui-validate.yml b/.github/workflows/comfyui-validate.yml
deleted file mode 100644
index 06b9b1f913e..00000000000
--- a/.github/workflows/comfyui-validate.yml
+++ /dev/null
@@ -1,40 +0,0 @@
-name: ComfyUI Integration -- Validate backwards compatibility
-
-on:
- pull_request:
- branches:
- - master
- - main
- paths:
- - "apps/ComfyUI-vLLM-Omni/**"
-
-defaults:
- run:
- working-directory: apps/ComfyUI-vLLM-Omni
-
-jobs:
- check-base-path:
- runs-on: ubuntu-latest
- outputs:
- exists: ${{ steps.check.outputs.exists }}
- defaults:
- run:
- working-directory: .
- steps:
- - uses: actions/checkout@v4
- with:
- ref: ${{ github.event.pull_request.base.sha }}
- fetch-depth: 1
- - id: check
- run: |
- if [ -d "apps/ComfyUI-vLLM-Omni" ]; then
- echo "exists=true" >> "$GITHUB_OUTPUT"
- else
- echo "exists=false" >> "$GITHUB_OUTPUT"
- fi
- validate:
- needs: check-base-path
- if: needs.check-base-path.outputs.exists == 'true'
- runs-on: ubuntu-latest
- steps:
- - uses: comfy-org/node-diff@main
diff --git a/apps/ComfyUI-vLLM-Omni/README.md b/apps/ComfyUI-vLLM-Omni/README.md
index dd530174f3f..23bbe5b7293 100644
--- a/apps/ComfyUI-vLLM-Omni/README.md
+++ b/apps/ComfyUI-vLLM-Omni/README.md
@@ -47,12 +47,12 @@ If no, check your shell running the ComfyUI process. There may be some error mes
This extension offers the following nodes based on the output modalities (at **ComfyUI sidebar -> Node Library**):
- **Generate Image** for text-to-image and image-to-image tasks
-- **Multimodality Comprehension** for multimodality-to-text and multimodality-to-audio tasks
+- **Multimodality Understanding** for multimodality-to-text and multimodality-to-audio tasks
- **TTS** and **TTS Voice Clone** for TTS tasks
This extension also offers example workflows (at **ComfyUI sidebar -> Templates -> vLLM-Omni**)
-> [!INFO]
+> [!NOTE]
> The node UI and feature designs are intended to match vLLM-Omni online serving interfaces. It cannot offer more than what the interfaces support.
To build a simple workflow yourself,
@@ -65,28 +65,16 @@ To build a simple workflow yourself,
- For some multi-stage models like BAGEL, [only one stage's sampling parameters are exposed and tunable via vLLM-Omni's online serving API](https://docs.vllm.ai/projects/vllm-omni/en/latest/user_guide/examples/online_serving/bagel/). Thus, these models are treated as single-stage ones. Please check the vLLM-Omni documentation on how to correctly set each model's sampling parameters.
- For multi-stage models where all stages are either autoregression or diffusion, you can also connect only a single Sampling Params node, indicating that this set of sampling parameters will be used for all stages.
-**The following features are tested**:
-
-- Single-node workflows for
- - Multimodal Comprehension (e.g., Qwen Omni, BAGEL)
- - Text-to-Image Generation (e.g., Qwen-Image)
- - Image-to-Image Generation (e.g., Qwen-Image-Edit)
- - TTS (e.g., Qwen TTS, including VoiceDesign, VoiceClone, CustomVoice)
-
-**The following features are not currently tested**. They may work or break. You are welcomed to test it out and offer comments.
-
-- Multi-node workflow that connects multiple model services together.
-
## Screenshots and Examples
-### Multimodal comprehension (e.g., Qwen Omni series, BAGEL)
+### Multimodal understanding (e.g., Qwen Omni series, BAGEL)
-(Also available at **ComfyUI sidebar->Template->vLLM-Omni->vLLM-Omni Annotated Example**)
+(Also available at **ComfyUI sidebar->Template->vLLM-Omni->vLLM-Omni Multimodal Understanding**)
-
-
+
+
@@ -98,7 +86,7 @@ You can configure per-stage sampling parameters for multi-stage models.
-
+
@@ -109,7 +97,7 @@ You can configure per-stage sampling parameters for multi-stage models.
-
+
@@ -123,13 +111,24 @@ You can configure per-stage sampling parameters for multi-stage models.
-
+
> [!TIP]
> There is a dedicated node for VoiceClone tasks with reference audio input. Other simple text-to-speech tasks should use the regular TTS node.
+### Chaining multiple model services
+
+(Also available at **ComfyUI sidebar->Template->vLLM-Omni->vLLM-Omni Chaining Services**)
+
+
+
+
+
+
+
+
## Develop
Follow the [development convention and rules of vLLM-Omni](https://docs.vllm.ai/projects/vllm-omni/en/latest/contributing/).
diff --git a/apps/ComfyUI-vLLM-Omni/__init__.py b/apps/ComfyUI-vLLM-Omni/__init__.py
index ffb86ddb3c4..641824add78 100644
--- a/apps/ComfyUI-vLLM-Omni/__init__.py
+++ b/apps/ComfyUI-vLLM-Omni/__init__.py
@@ -6,18 +6,18 @@
"WEB_DIRECTORY",
]
-__author__ = """Zeyu Huang"""
-__email__ = "11222265+fhfuih@users.noreply.github.com"
+__author__ = """vLLM-Omni Team"""
+__email__ = "vllm-omni@vllm.ai"
__version__ = "0.0.1"
from .comfyui_vllm_omni.nodes import (
VLLMOmniARSampling,
- VLLMOmniComprehension,
VLLMOmniDiffusionSampling,
VLLMOmniGenerateImage,
VLLMOmniQwenTTSParams,
VLLMOmniSamplingParamsList,
VLLMOmniTTS,
+ VLLMOmniUnderstanding,
VLLMOmniVoiceClone,
)
@@ -25,7 +25,7 @@
NODE_CLASS_MAPPINGS = {
# === Generation ===
"VLLMOmniGenerateImage": VLLMOmniGenerateImage,
- "VLLMOmniComprehension": VLLMOmniComprehension,
+ "VLLMOmniUnderstanding": VLLMOmniUnderstanding,
"VLLMOmniTTS": VLLMOmniTTS,
"VLLMOmniVoiceClone": VLLMOmniVoiceClone,
# === Params ===
@@ -39,7 +39,7 @@
NODE_DISPLAY_NAME_MAPPINGS = {
# === Generation ===
"VLLMOmniGenerateImage": "Generate Image",
- "VLLMOmniComprehension": "Multimodality Comprehension",
+ "VLLMOmniUnderstanding": "Multimodality Understanding",
"VLLMOmniTTS": "TTS (Text to Speech)",
"VLLMOmniVoiceClone": "TTS Voice Cloning",
# === Params ===
diff --git a/apps/ComfyUI-vLLM-Omni/comfyui_vllm_omni/nodes.py b/apps/ComfyUI-vLLM-Omni/comfyui_vllm_omni/nodes.py
index ebc2822df64..5caa3869ed3 100644
--- a/apps/ComfyUI-vLLM-Omni/comfyui_vllm_omni/nodes.py
+++ b/apps/ComfyUI-vLLM-Omni/comfyui_vllm_omni/nodes.py
@@ -1,4 +1,4 @@
-from typing import Literal, cast
+from typing import Literal
import torch
from comfy_api.input import AudioInput, VideoInput
@@ -6,7 +6,12 @@
from .utils.api_client import VLLMOmniClient
from .utils.logger import get_logger
from .utils.models import lookup_model_spec
-from .utils.types import AudioFormat
+from .utils.types import (
+ AudioFormat,
+ AutoregressionSamplingParams,
+ DiffusionSamplingParams,
+ QwenTTSModelSpecificParams,
+)
from .utils.validators import (
add_sampling_parameters_to_stage,
validate_model_and_sampling_params_types,
@@ -86,7 +91,10 @@ async def generate(
# Prefer DALL-E compatible API for simple (one-stage) diffusion models
if (spec is None or spec["stages"] == ["diffusion"]) and not is_bagel:
- sampling_params = cast(dict | None, sampling_params)
+ # The number of sampling parameter groups should have been validated.
+ # Now, simply convert single-item list to dict.
+ if isinstance(sampling_params, list):
+ sampling_params = sampling_params[0]
if audio is None and image is None and video is None:
# No multimodal input --- use DALL-E image generation
logger.info("Using DALL-E image generation endpoint")
@@ -133,7 +141,7 @@ async def generate(
return (output,)
-class VLLMOmniComprehension(_VLLMOmniGenerateBase):
+class VLLMOmniUnderstanding(_VLLMOmniGenerateBase):
@classmethod
def INPUT_TYPES(cls):
return {
@@ -197,7 +205,7 @@ async def generate(
(
text_response,
_,
- ) = await client.generate_comprehension_chat_completion(
+ ) = await client.generate_understanding_chat_completion(
model=model,
prompt=prompt,
image=image,
@@ -221,7 +229,7 @@ async def generate(
(
text_response,
audio,
- ) = await client.generate_comprehension_chat_completion(
+ ) = await client.generate_understanding_chat_completion(
model=model,
prompt=prompt,
image=image,
@@ -287,15 +295,13 @@ async def generate(
logger.info("Got extra kwargs in TTS: %s", kwargs)
is_qwen_tts = "qwen3-tts" in model.lower()
- extra_params_type = None if model_specific_params is None else model_specific_params["type"]
- if not is_qwen_tts and extra_params_type == "qwen-tts":
+ if not is_qwen_tts and isinstance(model_specific_params, QwenTTSModelSpecificParams):
raise ValueError(
"You have provided Qwen-specific TTS params."
"However, the model appears to not be a Qwen TTS model (no 'Qwen3-TTS' in model name)."
)
combined_params = {**kwargs, **(model_specific_params or {})}
- combined_params.pop("type", None) # Internal fields in model_specific_params
client = VLLMOmniClient(url)
@@ -352,8 +358,7 @@ async def generate(
**kwargs,
):
is_qwen_tts = "qwen3-tts" in model.lower()
- extra_params_type = None if model_specific_params is None else model_specific_params["type"]
- if not is_qwen_tts and extra_params_type == "qwen-tts":
+ if not is_qwen_tts and isinstance(model_specific_params, QwenTTSModelSpecificParams):
raise ValueError(
"You have provided Qwen-specific TTS params."
"However, the model appears to not be a Qwen TTS model (no 'Qwen3-TTS' in model name)."
@@ -366,7 +371,6 @@ async def generate(
**kwargs,
**(model_specific_params or {}),
}
- combined_params.pop("type", None) # Internal fields in model_specific_params
client = VLLMOmniClient(url)
@@ -419,10 +423,7 @@ def INPUT_TYPES(cls):
CATEGORY = "vLLM-Omni/Sampling Params"
def get_params(self, seed, **kwargs):
- params = {
- "type": "autoregression", # for internal use, removed before sending the request
- **kwargs,
- }
+ params = AutoregressionSamplingParams(kwargs)
if seed >= 0:
params["seed"] = seed
return (params,)
@@ -479,6 +480,13 @@ def INPUT_TYPES(cls):
"tooltip": "Enable VAE slicing for reduced memory usage (slight quality trade-off)",
},
),
+ "vae_use_tiling": (
+ "BOOLEAN",
+ {
+ "default": False,
+ "tooltip": "Enable VAE tiling for reduced memory usage (slight quality trade-off)",
+ },
+ ),
# === Put seed at last. ===
# Whenever a field named "seed" is present, ComfyUI adds another field called "control after generate"
"seed": (
@@ -499,10 +507,7 @@ def INPUT_TYPES(cls):
CATEGORY = "vLLM-Omni/Sampling Params"
def get_params(self, seed, **kwargs):
- params = {
- "type": "diffusion", # for internal use, removed before sending the request
- **kwargs,
- }
+ params = DiffusionSamplingParams(kwargs)
if seed >= 0:
params["seed"] = seed
return (params,)
@@ -566,4 +571,4 @@ def INPUT_TYPES(cls):
CATEGORY = "vLLM-Omni/TTS Params"
def get_params(self, **kwargs):
- return ({"type": "qwen-tts", **kwargs},)
+ return (QwenTTSModelSpecificParams(kwargs),)
diff --git a/apps/ComfyUI-vLLM-Omni/comfyui_vllm_omni/utils/api_client.py b/apps/ComfyUI-vLLM-Omni/comfyui_vllm_omni/utils/api_client.py
index c5372641f51..d340073bc24 100644
--- a/apps/ComfyUI-vLLM-Omni/comfyui_vllm_omni/utils/api_client.py
+++ b/apps/ComfyUI-vLLM-Omni/comfyui_vllm_omni/utils/api_client.py
@@ -57,16 +57,7 @@ async def generate_image(
if negative_prompt:
payload["negative_prompt"] = negative_prompt
if sampling_params is not None:
- # Only select specific sampling params
- for k in (
- "n",
- "num_inference_steps",
- "guidance_scale",
- "true_cfg_scale",
- "vae_use_slicing",
- ):
- if k in sampling_params and sampling_params[k] is not None:
- payload[k] = sampling_params[k]
+ payload.update(sampling_params)
logger.debug("img gen payload: %s", payload)
url = self.base_url + "/images/generations"
@@ -138,10 +129,8 @@ async def edit_image(
if negative_prompt:
form.add_field("negative_prompt", negative_prompt)
if sampling_params is not None:
- # Only select specific sampling params
- for k in ("n", "num_inference_steps", "guidance_scale", "true_cfg_scale"):
- if k in sampling_params and sampling_params[k] is not None:
- form.add_field(k, str(sampling_params[k]))
+ for k, v in sampling_params.items():
+ form.add_field(k, str(v))
if mask is not None:
mask_filename = "mask.png"
form.add_field(
@@ -217,7 +206,7 @@ async def generate_image_chat_completion(
return torch.stack(image_tensors, dim=0)
- async def generate_comprehension_chat_completion(
+ async def generate_understanding_chat_completion(
self,
*,
model: str,
@@ -427,30 +416,28 @@ def _prepare_chat_completion_messages(
message_content.append({"type": "video_url", "video_url": {"url": video_to_base64(video)}})
messages = [{"role": "user", "content": message_content}]
+ payload: dict[str, Any] = {"messages": messages, "model": model}
+ if modalities:
+ payload["modalities"] = modalities
+
combined_extra_body: dict[str, Any] = {}
if sampling_params is not None:
spec, _ = lookup_model_spec(model)
is_single_sampling_param = isinstance(sampling_params, dict) or len(sampling_params) == 1
- # Exclude internal key
- if isinstance(sampling_params, dict):
- sampling_params = {k: v for k, v in sampling_params.items() if k != "type"}
- else:
- sampling_params = [{k: v for k, v in sp.items() if k != "type"} for sp in sampling_params]
-
if (spec is None and is_single_sampling_param) or (spec is not None and spec["stages"] == ["diffusion"]):
# Diffusion format: extra_body directly contains sampling params.
- # Validation should have taken care of matching sampling params' types.
+ # Validation has already taken care of matching sampling params' types and length. Safe to take [0].
# * Use this mode if the model is a simple one-stage diffusion model.
# * Fallback to this mode if model is not registered and a single sampling param is provided.
sampling_params = sampling_params if isinstance(sampling_params, dict) else sampling_params[0]
- combined_extra_body: dict[str, Any] = {**sampling_params}
+ combined_extra_body: dict[str, Any] = sampling_params.copy()
if "n" in combined_extra_body:
- combined_extra_body["num_outputs_per_prompt"] = combined_extra_body["n"]
- del combined_extra_body["n"]
+ combined_extra_body["num_outputs_per_prompt"] = combined_extra_body.pop("n")
else:
- # Use AR style payload, extra_body has a sampling_params_list field
- combined_extra_body: dict[str, Any] = {"sampling_params_list": sampling_params}
+ # AR format: the payload has a sampling_params_list field, containing a list.
+ sampling_params_list = sampling_params if isinstance(sampling_params, list) else [sampling_params]
+ payload["sampling_params_list"] = sampling_params_list
if negative_prompt:
combined_extra_body["negative_prompt"] = negative_prompt
@@ -458,12 +445,11 @@ def _prepare_chat_completion_messages(
if extra_body:
combined_extra_body.update(extra_body)
- payload: dict[str, Any] = {"messages": messages, "model": model}
+ # Add extra_body only if it has any content.
if combined_extra_body:
payload["extra_body"] = combined_extra_body
- if modalities:
- payload["modalities"] = modalities
+ # Place to inject any model-specific payload adjustment
spec, _ = lookup_model_spec(model)
if spec:
preprocessor = spec.get("payload_preprocessor", None)
diff --git a/apps/ComfyUI-vLLM-Omni/comfyui_vllm_omni/utils/models.py b/apps/ComfyUI-vLLM-Omni/comfyui_vllm_omni/utils/models.py
index 83bf64fe7d4..bfeddd82b87 100644
--- a/apps/ComfyUI-vLLM-Omni/comfyui_vllm_omni/utils/models.py
+++ b/apps/ComfyUI-vLLM-Omni/comfyui_vllm_omni/utils/models.py
@@ -11,8 +11,7 @@ def _bagel_payload_preprocessor(payload: dict) -> dict:
content["text"] = "<|im_start|>" + content["text"] + "<|im_end|>"
except (KeyError, TypeError):
raise RuntimeError("Internal Error: malformatted BAGEL payload")
- extra_body = payload.pop("extra_body", {})
- return {**payload, **extra_body}
+ return payload
def _qwen25_payload_preprocessor(payload: dict) -> dict:
@@ -37,7 +36,7 @@ def _qwen25_payload_preprocessor(payload: dict) -> dict:
],
"modes": [
{
- "mode": ModelMode.COMPREHENSION,
+ "mode": ModelMode.UNDERSTANDING,
"input_modalities": [Modality.TEXT, Modality.IMAGE],
}
],
@@ -48,7 +47,7 @@ def _qwen25_payload_preprocessor(payload: dict) -> dict:
"payload_preprocessor": _qwen25_payload_preprocessor,
"modes": [
{
- "mode": ModelMode.COMPREHENSION,
+ "mode": ModelMode.UNDERSTANDING,
"input_modalities": [
Modality.TEXT,
Modality.IMAGE,
@@ -62,7 +61,7 @@ def _qwen25_payload_preprocessor(payload: dict) -> dict:
"stages": ["autoregression", "autoregression", "autoregression"],
"modes": [
{
- "mode": ModelMode.COMPREHENSION,
+ "mode": ModelMode.UNDERSTANDING,
"input_modalities": [
Modality.TEXT,
Modality.IMAGE,
diff --git a/apps/ComfyUI-vLLM-Omni/comfyui_vllm_omni/utils/types.py b/apps/ComfyUI-vLLM-Omni/comfyui_vllm_omni/utils/types.py
index 29be9648c9c..6cc79f3ed97 100644
--- a/apps/ComfyUI-vLLM-Omni/comfyui_vllm_omni/utils/types.py
+++ b/apps/ComfyUI-vLLM-Omni/comfyui_vllm_omni/utils/types.py
@@ -11,11 +11,23 @@
AudioFormat: TypeAlias = Literal["mp3", "opus", "aac", "flac", "wav", "pcm"]
+class AutoregressionSamplingParams(dict):
+ pass
+
+
+class DiffusionSamplingParams(dict):
+ pass
+
+
+class QwenTTSModelSpecificParams(dict):
+ pass
+
+
class ModelMode(Enum):
IMAGE_GENERATION = auto()
VIDEO_GENERATION = auto()
AUDIO_GENERATION = auto()
- COMPREHENSION = auto()
+ UNDERSTANDING = auto()
class Modality(Enum):
diff --git a/apps/ComfyUI-vLLM-Omni/comfyui_vllm_omni/utils/validators.py b/apps/ComfyUI-vLLM-Omni/comfyui_vllm_omni/utils/validators.py
index f1af7b2e97d..2abdd21006e 100644
--- a/apps/ComfyUI-vLLM-Omni/comfyui_vllm_omni/utils/validators.py
+++ b/apps/ComfyUI-vLLM-Omni/comfyui_vllm_omni/utils/validators.py
@@ -1,5 +1,6 @@
from .logger import get_logger
from .models import lookup_model_spec
+from .types import AutoregressionSamplingParams, DiffusionSamplingParams
logger = get_logger(__name__)
@@ -31,24 +32,20 @@ def validate_model_and_sampling_params_types(
)
# Check that each stage's type match
for i, sp in enumerate(sampling_param_list):
- if "type" not in sp:
- raise RuntimeError("Internal error: unknown sampling parameter type")
- if sp["type"] != stages[i]:
+ if not _check_sampling_param_matches_stage(sp, stages[i]):
raise ValueError(
- f"Sampling parameter type ({sp['type']}) does not match "
+ f"Sampling parameter type ({sp.__class__.__name__}) does not match "
f"stage type ({stages[i]}) at index {i} for model {model_name}."
)
elif isinstance(sampling_param_list, dict):
- if "type" not in sampling_param_list:
- raise RuntimeError("Internal error: unknown sampling parameter type")
# Check that the provided single sampling param matches all stages
- elif any(stage != sampling_param_list["type"] for stage in stages):
- raise ValueError(
- f"When passing a single sampling parameter node, all stages of the model must match "
- f"the provided sampling parameter's type. "
- f"However, the stages of model {model_name} are: {stages}. "
- f"The provided sampling parameter is {sampling_param_list['type']}"
- )
+ for i, stage in enumerate(stages):
+ if not _check_sampling_param_matches_stage(sampling_param_list, stage):
+ raise ValueError(
+ f"Provided single sampling parameter type ({sampling_param_list.__class__.__name__}) must match "
+ f"the types of all stages of the model. "
+ f"However, stage {i} of model {model_name} is of type {stage}."
+ )
def add_sampling_parameters_to_stage(
@@ -82,3 +79,11 @@ def add_sampling_parameters_to_stage(
sampling_param_list[i].update(params_to_add)
return sampling_param_list
+
+
+def _check_sampling_param_matches_stage(sampling_param: dict, stage_type: str) -> bool:
+ if stage_type == "autoregression":
+ return isinstance(sampling_param, AutoregressionSamplingParams)
+ if stage_type == "diffusion":
+ return isinstance(sampling_param, DiffusionSamplingParams)
+ raise RuntimeError(f"Internal error: unknown stage type {stage_type}.")
diff --git a/apps/ComfyUI-vLLM-Omni/docs/images/comfyui-chaining-services.jpg b/apps/ComfyUI-vLLM-Omni/docs/images/comfyui-chaining-services.jpg
new file mode 100644
index 00000000000..20d9d077938
Binary files /dev/null and b/apps/ComfyUI-vLLM-Omni/docs/images/comfyui-chaining-services.jpg differ
diff --git a/apps/ComfyUI-vLLM-Omni/docs/images/comfyui-comprehension.jpg b/apps/ComfyUI-vLLM-Omni/docs/images/comfyui-understanding.jpg
similarity index 100%
rename from apps/ComfyUI-vLLM-Omni/docs/images/comfyui-comprehension.jpg
rename to apps/ComfyUI-vLLM-Omni/docs/images/comfyui-understanding.jpg
diff --git a/apps/ComfyUI-vLLM-Omni/example_workflows/vLLM-Omni Annotated Example.json b/apps/ComfyUI-vLLM-Omni/example_workflows/vLLM-Omni Annotated Example.json
deleted file mode 100644
index 16657df0efc..00000000000
--- a/apps/ComfyUI-vLLM-Omni/example_workflows/vLLM-Omni Annotated Example.json
+++ /dev/null
@@ -1 +0,0 @@
-{"id":"1c99f525-0a37-45ba-a28a-7df7c3af66b4","revision":0,"last_node_id":12,"last_link_id":14,"nodes":[{"id":1,"type":"VLLMOmniComprehension","pos":[1191.2177053682556,144.66829928181377],"size":[400,268],"flags":{},"order":8,"mode":0,"inputs":[{"localized_name":"image","name":"image","shape":7,"type":"IMAGE","link":1},{"localized_name":"video","name":"video","shape":7,"type":"VIDEO","link":2},{"localized_name":"audio","name":"audio","shape":7,"type":"AUDIO","link":3},{"localized_name":"sampling_params","name":"sampling_params","shape":7,"type":"SAMPLING_PARAMS","link":14},{"localized_name":"url","name":"url","type":"STRING","widget":{"name":"url"},"link":null},{"localized_name":"model","name":"model","type":"STRING","widget":{"name":"model"},"link":null},{"localized_name":"prompt","name":"prompt","type":"STRING","widget":{"name":"prompt"},"link":null},{"localized_name":"output_text","name":"output_text","type":"BOOLEAN","widget":{"name":"output_text"},"link":null},{"localized_name":"output_audio","name":"output_audio","type":"BOOLEAN","widget":{"name":"output_audio"},"link":null},{"localized_name":"use_audio_in_video","name":"use_audio_in_video","type":"BOOLEAN","widget":{"name":"use_audio_in_video"},"link":null}],"outputs":[{"localized_name":"text_response","name":"text_response","type":"STRING","links":[8]},{"localized_name":"audio_response","name":"audio_response","type":"AUDIO","links":[9]}],"properties":{"Node name for S&R":"VLLMOmniComprehension"},"widgets_values":["http://localhost:8000/v1","Qwen/Qwen2.5-Omni-7B","",true,true,true]},{"id":3,"type":"LoadVideo","pos":[729.5984141255855,-198.631920454299],"size":[282.798828125,233.0743408203125],"flags":{},"order":0,"mode":0,"inputs":[{"localized_name":"file","name":"file","type":"COMBO","widget":{"name":"file"},"link":null},{"localized_name":"choose file to upload","name":"upload","type":"IMAGEUPLOAD","widget":{"name":"upload"},"link":null}],"outputs":[{"localized_name":"VIDEO","name":"VIDEO","type":"VIDEO","links":[2]}],"properties":{"Node name for S&R":"LoadVideo"},"widgets_values":["draw.mp4","image"]},{"id":4,"type":"LoadAudio","pos":[729.8037086965753,99.86963519703949],"size":[282.798828125,136],"flags":{},"order":1,"mode":0,"inputs":[{"localized_name":"audio","name":"audio","type":"COMBO","widget":{"name":"audio"},"link":null},{"localized_name":"audioUI","name":"audioUI","type":"AUDIO_UI","widget":{"name":"audioUI"},"link":null},{"localized_name":"choose file to upload","name":"upload","type":"AUDIOUPLOAD","widget":{"name":"upload"},"link":null}],"outputs":[{"localized_name":"AUDIO","name":"AUDIO","type":"AUDIO","links":[3]}],"properties":{"Node name for S&R":"LoadAudio"},"widgets_values":["Megan-Fox.mp3",null,null]},{"id":5,"type":"VLLMOmniARSampling","pos":[510.3517536642828,658.073751009259],"size":[270,178],"flags":{},"order":2,"mode":0,"inputs":[{"localized_name":"max_tokens","name":"max_tokens","type":"INT","widget":{"name":"max_tokens"},"link":null},{"localized_name":"temperature","name":"temperature","type":"FLOAT","widget":{"name":"temperature"},"link":null},{"localized_name":"top_p","name":"top_p","type":"FLOAT","widget":{"name":"top_p"},"link":null},{"localized_name":"repetition_penalty","name":"repetition_penalty","type":"FLOAT","widget":{"name":"repetition_penalty"},"link":null},{"localized_name":"seed","name":"seed","type":"INT","widget":{"name":"seed"},"link":null}],"outputs":[{"localized_name":"AR sampling params","name":"AR sampling params","type":"SAMPLING_PARAMS","links":[12]}],"properties":{"Node name for S&R":"VLLMOmniARSampling"},"widgets_values":[100,1,1,1,-1,"randomize"]},{"id":7,"type":"VLLMOmniARSampling","pos":[503.33235181647115,419.34158016181806],"size":[270,178],"flags":{},"order":3,"mode":0,"inputs":[{"localized_name":"max_tokens","name":"max_tokens","type":"INT","widget":{"name":"max_tokens"},"link":null},{"localized_name":"temperature","name":"temperature","type":"FLOAT","widget":{"name":"temperature"},"link":null},{"localized_name":"top_p","name":"top_p","type":"FLOAT","widget":{"name":"top_p"},"link":null},{"localized_name":"repetition_penalty","name":"repetition_penalty","type":"FLOAT","widget":{"name":"repetition_penalty"},"link":null},{"localized_name":"seed","name":"seed","type":"INT","widget":{"name":"seed"},"link":null}],"outputs":[{"localized_name":"AR sampling params","name":"AR sampling params","type":"SAMPLING_PARAMS","links":[5,13]}],"properties":{"Node name for S&R":"VLLMOmniARSampling"},"widgets_values":[100,1,1,1,-1,"randomize"]},{"id":8,"type":"VLLMOmniSamplingParamsList","pos":[820.6056617389042,426.38372037182273],"size":[263.066015625,66],"flags":{},"order":7,"mode":0,"inputs":[{"localized_name":"param1","name":"param1","type":"SAMPLING_PARAMS","link":5},{"localized_name":"param2","name":"param2","shape":7,"type":"SAMPLING_PARAMS","link":12},{"localized_name":"param3","name":"param3","shape":7,"type":"SAMPLING_PARAMS","link":13}],"outputs":[{"localized_name":"param list","name":"param list","type":"SAMPLING_PARAMS","links":[14]}],"properties":{"Node name for S&R":"VLLMOmniSamplingParamsList"},"widgets_values":[]},{"id":11,"type":"MarkdownNote","pos":[826.2328280438272,569.1890318701705],"size":[333.8220435590464,261.63596728060656],"flags":{},"order":4,"mode":0,"inputs":[],"outputs":[],"title":"Note: Sampling Parameters","properties":{},"widgets_values":["## Sampling Parameter Types\n\nThere are two types of sampling parameters: one for autoregression and one for diffusion.\nYou should ensure that you have chosen the correct type of sampling parameters for the model you request.\n\n## Stages & Shorthand\n\nFor multi-stage models such as Qwen Omni, you can either\n- connect one sampling parameter node, which is applied to all stages.\n- connect exactly the same number of sampling parameter nodes to a \"Multi-Stage Sampling Parameter List\" node, then connect this node to the primary request node.\n\nNote that this shorthand is intended to stay consistent with the [online serving API](https://docs.vllm.ai/projects/vllm-omni/en/latest/user_guide/examples/online_serving/qwen2_5_omni/)"],"color":"#432","bgcolor":"#000"},{"id":12,"type":"MarkdownNote","pos":[378.9866207003777,152.59550252215752],"size":[319.7287574247016,107.15904081906785],"flags":{},"order":6,"mode":0,"inputs":[],"outputs":[],"title":"Note: Input","properties":{},"widgets_values":["Note that not all models support every modality as input. For example, `ByteDance-Seed/BAGEL-7B-MoT` in Multimodality Comprehension mode only support text and image input.\n\nYou should ensure that the input are supported by the model. You can check the corresponding [online serving documentation](https://docs.vllm.ai/projects/vllm-omni/en/latest/user_guide/examples/online_serving/bagel/) for confirmation."],"color":"#432","bgcolor":"#000"},{"id":2,"type":"LoadImage","pos":[394.4674804308822,-207.6987397548834],"size":[282.798828125,314],"flags":{},"order":5,"mode":0,"inputs":[{"localized_name":"image","name":"image","type":"COMBO","widget":{"name":"image"},"link":null},{"localized_name":"choose file to upload","name":"upload","type":"IMAGEUPLOAD","widget":{"name":"upload"},"link":null}],"outputs":[{"localized_name":"IMAGE","name":"IMAGE","type":"IMAGE","links":[1]},{"localized_name":"MASK","name":"MASK","type":"MASK","links":null}],"properties":{"Node name for S&R":"LoadImage"},"widgets_values":["example.png","image"]},{"id":10,"type":"PreviewAudio","pos":[1664.548345556043,297.5921292054054],"size":[270,88],"flags":{},"order":10,"mode":0,"inputs":[{"localized_name":"audio","name":"audio","type":"AUDIO","link":9},{"localized_name":"audioUI","name":"audioUI","type":"AUDIO_UI","widget":{"name":"audioUI"},"link":null}],"outputs":[],"properties":{"Node name for S&R":"PreviewAudio"},"widgets_values":[]},{"id":9,"type":"ShowText|pysssss","pos":[1649.2506875091847,66.22823888292349],"size":[318.7188464232943,173.38502269972975],"flags":{},"order":9,"mode":0,"inputs":[{"localized_name":"text","name":"text","type":"STRING","link":8}],"outputs":[{"localized_name":"STRING","name":"STRING","shape":6,"type":"STRING","links":null}],"properties":{"Node name for S&R":"ShowText|pysssss"},"widgets_values":[]}],"links":[[1,2,0,1,0,"IMAGE"],[2,3,0,1,1,"VIDEO"],[3,4,0,1,2,"AUDIO"],[5,7,0,8,0,"SAMPLING_PARAMS"],[8,1,0,9,0,"STRING"],[9,1,1,10,0,"AUDIO"],[12,5,0,8,1,"SAMPLING_PARAMS"],[13,7,0,8,2,"SAMPLING_PARAMS"],[14,8,0,1,3,"SAMPLING_PARAMS"]],"groups":[{"id":1,"title":"Sampling Parameters","bounding":[480.1649301181556,341.08402513937995,692.4113568972277,510.48648853403665],"color":"#3f789e","font_size":24,"flags":{}},{"id":2,"title":"Input","bounding":[344.2364817813528,-287.5850484183313,704.8832238768634,559.5124009832894],"color":"#3f789e","font_size":24,"flags":{}}],"config":{},"extra":{"workflowRendererVersion":"LG","ds":{"scale":0.9478575057427204,"offset":[33.81037136029557,307.1974296197726]}},"version":0.4}
diff --git a/apps/ComfyUI-vLLM-Omni/example_workflows/vLLM-Omni Chaining Services.json b/apps/ComfyUI-vLLM-Omni/example_workflows/vLLM-Omni Chaining Services.json
new file mode 100644
index 00000000000..3031f83444e
--- /dev/null
+++ b/apps/ComfyUI-vLLM-Omni/example_workflows/vLLM-Omni Chaining Services.json
@@ -0,0 +1,552 @@
+{
+ "id": "6643e5fd-fa2a-4f25-935a-483173a8097c",
+ "revision": 0,
+ "last_node_id": 8,
+ "last_link_id": 6,
+ "nodes": [
+ {
+ "id": 1,
+ "type": "PreviewImage",
+ "pos": [
+ 1446.2005205859512,
+ -316.7359686049902
+ ],
+ "size": [
+ 305.6628685610174,
+ 307.0336884172169
+ ],
+ "flags": {},
+ "order": 5,
+ "mode": 0,
+ "inputs": [
+ {
+ "localized_name": "images",
+ "name": "images",
+ "type": "IMAGE",
+ "link": 1
+ }
+ ],
+ "outputs": [],
+ "properties": {
+ "Node name for S&R": "PreviewImage"
+ },
+ "widgets_values": []
+ },
+ {
+ "id": 8,
+ "type": "PreviewImage",
+ "pos": [
+ 1010.1848219273943,
+ -311.54216706114363
+ ],
+ "size": [
+ 305.6628685610174,
+ 307.0336884172169
+ ],
+ "flags": {},
+ "order": 4,
+ "mode": 0,
+ "inputs": [
+ {
+ "localized_name": "images",
+ "name": "images",
+ "type": "IMAGE",
+ "link": 6
+ }
+ ],
+ "outputs": [],
+ "properties": {
+ "Node name for S&R": "PreviewImage"
+ },
+ "widgets_values": []
+ },
+ {
+ "id": 7,
+ "type": "VLLMOmniDiffusionSampling",
+ "pos": [
+ 234.61958293819296,
+ 9.405681270043619
+ ],
+ "size": [
+ 284.205078125,
+ 226
+ ],
+ "flags": {},
+ "order": 0,
+ "mode": 0,
+ "inputs": [
+ {
+ "localized_name": "n",
+ "name": "n",
+ "type": "INT",
+ "widget": {
+ "name": "n"
+ },
+ "link": null
+ },
+ {
+ "localized_name": "num_inference_steps",
+ "name": "num_inference_steps",
+ "type": "INT",
+ "widget": {
+ "name": "num_inference_steps"
+ },
+ "link": null
+ },
+ {
+ "localized_name": "guidance_scale",
+ "name": "guidance_scale",
+ "type": "FLOAT",
+ "widget": {
+ "name": "guidance_scale"
+ },
+ "link": null
+ },
+ {
+ "localized_name": "true_cfg_scale",
+ "name": "true_cfg_scale",
+ "type": "FLOAT",
+ "widget": {
+ "name": "true_cfg_scale"
+ },
+ "link": null
+ },
+ {
+ "localized_name": "vae_use_slicing",
+ "name": "vae_use_slicing",
+ "type": "BOOLEAN",
+ "widget": {
+ "name": "vae_use_slicing"
+ },
+ "link": null
+ },
+ {
+ "localized_name": "vae_use_tiling",
+ "name": "vae_use_tiling",
+ "type": "BOOLEAN",
+ "widget": {
+ "name": "vae_use_tiling"
+ },
+ "link": null
+ },
+ {
+ "localized_name": "seed",
+ "name": "seed",
+ "type": "INT",
+ "widget": {
+ "name": "seed"
+ },
+ "link": null
+ }
+ ],
+ "outputs": [
+ {
+ "localized_name": "diffusion sampling params",
+ "name": "diffusion sampling params",
+ "type": "SAMPLING_PARAMS",
+ "links": [
+ 5
+ ]
+ }
+ ],
+ "properties": {
+ "Node name for S&R": "VLLMOmniDiffusionSampling"
+ },
+ "widgets_values": [
+ 1,
+ 50,
+ 1,
+ 1,
+ false,
+ false,
+ 1525,
+ "randomize"
+ ]
+ },
+ {
+ "id": 4,
+ "type": "VLLMOmniDiffusionSampling",
+ "pos": [
+ 666.8380026154548,
+ 268.86271068330126
+ ],
+ "size": [
+ 284.205078125,
+ 226
+ ],
+ "flags": {},
+ "order": 1,
+ "mode": 0,
+ "inputs": [
+ {
+ "localized_name": "n",
+ "name": "n",
+ "type": "INT",
+ "widget": {
+ "name": "n"
+ },
+ "link": null
+ },
+ {
+ "localized_name": "num_inference_steps",
+ "name": "num_inference_steps",
+ "type": "INT",
+ "widget": {
+ "name": "num_inference_steps"
+ },
+ "link": null
+ },
+ {
+ "localized_name": "guidance_scale",
+ "name": "guidance_scale",
+ "type": "FLOAT",
+ "widget": {
+ "name": "guidance_scale"
+ },
+ "link": null
+ },
+ {
+ "localized_name": "true_cfg_scale",
+ "name": "true_cfg_scale",
+ "type": "FLOAT",
+ "widget": {
+ "name": "true_cfg_scale"
+ },
+ "link": null
+ },
+ {
+ "localized_name": "vae_use_slicing",
+ "name": "vae_use_slicing",
+ "type": "BOOLEAN",
+ "widget": {
+ "name": "vae_use_slicing"
+ },
+ "link": null
+ },
+ {
+ "localized_name": "vae_use_tiling",
+ "name": "vae_use_tiling",
+ "type": "BOOLEAN",
+ "widget": {
+ "name": "vae_use_tiling"
+ },
+ "link": null
+ },
+ {
+ "localized_name": "seed",
+ "name": "seed",
+ "type": "INT",
+ "widget": {
+ "name": "seed"
+ },
+ "link": null
+ }
+ ],
+ "outputs": [
+ {
+ "localized_name": "diffusion sampling params",
+ "name": "diffusion sampling params",
+ "type": "SAMPLING_PARAMS",
+ "links": [
+ 2
+ ]
+ }
+ ],
+ "properties": {
+ "Node name for S&R": "VLLMOmniDiffusionSampling"
+ },
+ "widgets_values": [
+ 4,
+ 50,
+ 7,
+ 1,
+ false,
+ false,
+ 42,
+ "fixed"
+ ]
+ },
+ {
+ "id": 5,
+ "type": "VLLMOmniGenerateImage",
+ "pos": [
+ 984.723613585788,
+ 63.376900027553276
+ ],
+ "size": [
+ 416.56628685610167,
+ 372.1662621294205
+ ],
+ "flags": {},
+ "order": 3,
+ "mode": 0,
+ "inputs": [
+ {
+ "localized_name": "image",
+ "name": "image",
+ "shape": 7,
+ "type": "IMAGE",
+ "link": 4
+ },
+ {
+ "localized_name": "mask",
+ "name": "mask",
+ "shape": 7,
+ "type": "MASK",
+ "link": null
+ },
+ {
+ "localized_name": "sampling_params",
+ "name": "sampling_params",
+ "shape": 7,
+ "type": "SAMPLING_PARAMS",
+ "link": 2
+ },
+ {
+ "localized_name": "url",
+ "name": "url",
+ "type": "STRING",
+ "widget": {
+ "name": "url"
+ },
+ "link": null
+ },
+ {
+ "localized_name": "model",
+ "name": "model",
+ "type": "STRING",
+ "widget": {
+ "name": "model"
+ },
+ "link": null
+ },
+ {
+ "localized_name": "prompt",
+ "name": "prompt",
+ "type": "STRING",
+ "widget": {
+ "name": "prompt"
+ },
+ "link": null
+ },
+ {
+ "localized_name": "negative_prompt",
+ "name": "negative_prompt",
+ "type": "STRING",
+ "widget": {
+ "name": "negative_prompt"
+ },
+ "link": null
+ },
+ {
+ "localized_name": "width",
+ "name": "width",
+ "type": "INT",
+ "widget": {
+ "name": "width"
+ },
+ "link": null
+ },
+ {
+ "localized_name": "height",
+ "name": "height",
+ "type": "INT",
+ "widget": {
+ "name": "height"
+ },
+ "link": null
+ }
+ ],
+ "outputs": [
+ {
+ "localized_name": "image",
+ "name": "image",
+ "type": "IMAGE",
+ "links": [
+ 1
+ ]
+ }
+ ],
+ "properties": {
+ "Node name for S&R": "VLLMOmniGenerateImage"
+ },
+ "widgets_values": [
+ "http://localhost:8001/v1",
+ "/home/models/Qwen/Qwen-Image-Edit",
+ "A high-quality, high contrast, stylized portrait of the object in the uploaded reference image. Pop art and doodle style, with abundant scribbling patterns, such as a teal crown, orange lightning bolts, colorful handwritten scripts.",
+ "Realistic",
+ 800,
+ 800
+ ]
+ },
+ {
+ "id": 6,
+ "type": "VLLMOmniGenerateImage",
+ "pos": [
+ 541.2702717429818,
+ -160.70392744708548
+ ],
+ "size": [
+ 416.56628685610167,
+ 372.1662621294205
+ ],
+ "flags": {},
+ "order": 2,
+ "mode": 0,
+ "inputs": [
+ {
+ "localized_name": "image",
+ "name": "image",
+ "shape": 7,
+ "type": "IMAGE",
+ "link": null
+ },
+ {
+ "localized_name": "mask",
+ "name": "mask",
+ "shape": 7,
+ "type": "MASK",
+ "link": null
+ },
+ {
+ "localized_name": "sampling_params",
+ "name": "sampling_params",
+ "shape": 7,
+ "type": "SAMPLING_PARAMS",
+ "link": 5
+ },
+ {
+ "localized_name": "url",
+ "name": "url",
+ "type": "STRING",
+ "widget": {
+ "name": "url"
+ },
+ "link": null
+ },
+ {
+ "localized_name": "model",
+ "name": "model",
+ "type": "STRING",
+ "widget": {
+ "name": "model"
+ },
+ "link": null
+ },
+ {
+ "localized_name": "prompt",
+ "name": "prompt",
+ "type": "STRING",
+ "widget": {
+ "name": "prompt"
+ },
+ "link": null
+ },
+ {
+ "localized_name": "negative_prompt",
+ "name": "negative_prompt",
+ "type": "STRING",
+ "widget": {
+ "name": "negative_prompt"
+ },
+ "link": null
+ },
+ {
+ "localized_name": "width",
+ "name": "width",
+ "type": "INT",
+ "widget": {
+ "name": "width"
+ },
+ "link": null
+ },
+ {
+ "localized_name": "height",
+ "name": "height",
+ "type": "INT",
+ "widget": {
+ "name": "height"
+ },
+ "link": null
+ }
+ ],
+ "outputs": [
+ {
+ "localized_name": "image",
+ "name": "image",
+ "type": "IMAGE",
+ "links": [
+ 4,
+ 6
+ ]
+ }
+ ],
+ "properties": {
+ "Node name for S&R": "VLLMOmniGenerateImage"
+ },
+ "widgets_values": [
+ "http://localhost:8000/v1",
+ "/home/models/Tongyi-MAI/Z-Image-Turbo",
+ "A headshot of a cute Siamese kitty. Blurred background due to wide aperture. Close-up look. Realistic.",
+ "Cartoonish.",
+ 800,
+ 800
+ ]
+ }
+ ],
+ "links": [
+ [
+ 1,
+ 5,
+ 0,
+ 1,
+ 0,
+ "IMAGE"
+ ],
+ [
+ 2,
+ 4,
+ 0,
+ 5,
+ 2,
+ "SAMPLING_PARAMS"
+ ],
+ [
+ 4,
+ 6,
+ 0,
+ 5,
+ 0,
+ "IMAGE"
+ ],
+ [
+ 5,
+ 7,
+ 0,
+ 6,
+ 2,
+ "SAMPLING_PARAMS"
+ ],
+ [
+ 6,
+ 6,
+ 0,
+ 8,
+ 0,
+ "IMAGE"
+ ]
+ ],
+ "groups": [],
+ "config": {},
+ "extra": {
+ "workflowRendererVersion": "LG",
+ "ds": {
+ "scale": 1.0426432563169903,
+ "offset": [
+ -90.4071374799346,
+ 575.2948920069742
+ ]
+ }
+ },
+ "version": 0.4
+}
diff --git a/apps/ComfyUI-vLLM-Omni/example_workflows/vLLM-Omni Image Generation.json b/apps/ComfyUI-vLLM-Omni/example_workflows/vLLM-Omni Image Generation.json
index d1495bc9459..86194ee70d5 100644
--- a/apps/ComfyUI-vLLM-Omni/example_workflows/vLLM-Omni Image Generation.json
+++ b/apps/ComfyUI-vLLM-Omni/example_workflows/vLLM-Omni Image Generation.json
@@ -1 +1 @@
-{"id":"91f75acc-8040-40f6-865a-2e8a7cfd6672","revision":0,"last_node_id":11,"last_link_id":23,"nodes":[{"id":3,"type":"PreviewImage","pos":[1281.8455167767304,-69.02638461454333],"size":[305.6628685610174,307.0336884172169],"flags":{},"order":4,"mode":0,"inputs":[{"localized_name":"images","name":"images","type":"IMAGE","link":22}],"outputs":[],"properties":{"Node name for S&R":"PreviewImage"},"widgets_values":[]},{"id":11,"type":"VLLMOmniGenerateImage","pos":[816.0962515873642,-137.51112584854445],"size":[400,278],"flags":{},"order":3,"mode":0,"inputs":[{"localized_name":"image","name":"image","shape":7,"type":"IMAGE","link":21},{"localized_name":"mask","name":"mask","shape":7,"type":"MASK","link":null},{"localized_name":"sampling_params","name":"sampling_params","shape":7,"type":"SAMPLING_PARAMS","link":23},{"localized_name":"url","name":"url","type":"STRING","widget":{"name":"url"},"link":null},{"localized_name":"model","name":"model","type":"STRING","widget":{"name":"model"},"link":null},{"localized_name":"prompt","name":"prompt","type":"STRING","widget":{"name":"prompt"},"link":null},{"localized_name":"negative_prompt","name":"negative_prompt","type":"STRING","widget":{"name":"negative_prompt"},"link":null},{"localized_name":"width","name":"width","type":"INT","widget":{"name":"width"},"link":null},{"localized_name":"height","name":"height","type":"INT","widget":{"name":"height"},"link":null}],"outputs":[{"localized_name":"image","name":"image","type":"IMAGE","links":[22]}],"properties":{"Node name for S&R":"VLLMOmniGenerateImage"},"widgets_values":["http://localhost:8000/v1","Qwen/Qwen-Image-Edit","Put this figure in a realistic mountain view","",512,512]},{"id":8,"type":"VLLMOmniDiffusionSampling","pos":[478.59266934006774,183.67711984955648],"size":[284.205078125,202],"flags":{},"order":0,"mode":0,"inputs":[{"localized_name":"n","name":"n","type":"INT","widget":{"name":"n"},"link":null},{"localized_name":"num_inference_steps","name":"num_inference_steps","type":"INT","widget":{"name":"num_inference_steps"},"link":null},{"localized_name":"guidance_scale","name":"guidance_scale","type":"FLOAT","widget":{"name":"guidance_scale"},"link":null},{"localized_name":"true_cfg_scale","name":"true_cfg_scale","type":"FLOAT","widget":{"name":"true_cfg_scale"},"link":null},{"localized_name":"vae_use_slicing","name":"vae_use_slicing","type":"BOOLEAN","widget":{"name":"vae_use_slicing"},"link":null},{"localized_name":"seed","name":"seed","type":"INT","widget":{"name":"seed"},"link":null}],"outputs":[{"localized_name":"diffusion sampling params","name":"diffusion sampling params","type":"SAMPLING_PARAMS","links":[23]}],"properties":{"Node name for S&R":"VLLMOmniDiffusionSampling"},"widgets_values":[4,50,1,1,false,42,"fixed"]},{"id":10,"type":"MarkdownNote","pos":[227.99306819575278,-231.24143306069843],"size":[240.3326478922474,136.3505820791881],"flags":{},"order":2,"mode":0,"inputs":[],"outputs":[],"title":"Note: Task and Input","properties":{},"widgets_values":["vLLM-Omni nodes are categorized based on the output modality. The \"Generate Image\" node supports both text-to-image generation or image-to-image generation (a.k.a. image editing). The node will route to the correct endpoint depending on whether an input image is present or not."],"color":"#432","bgcolor":"#000"},{"id":4,"type":"LoadImage","pos":[496.31859627609606,-229.71277089860084],"size":[270,314],"flags":{},"order":1,"mode":0,"inputs":[{"localized_name":"image","name":"image","type":"COMBO","widget":{"name":"image"},"link":null},{"localized_name":"choose file to upload","name":"upload","type":"IMAGEUPLOAD","widget":{"name":"upload"},"link":null}],"outputs":[{"localized_name":"IMAGE","name":"IMAGE","type":"IMAGE","links":[21]},{"localized_name":"MASK","name":"MASK","type":"MASK","links":null}],"properties":{"Node name for S&R":"LoadImage"},"widgets_values":["example.png","image"]}],"links":[[21,4,0,11,0,"IMAGE"],[22,11,0,3,0,"IMAGE"],[23,8,0,11,2,"SAMPLING_PARAMS"]],"groups":[{"id":1,"title":"Input","bounding":[213.1706010087147,-313.20095750667554,560.8246471437027,407.4246532472182],"color":"#3f789e","font_size":24,"flags":{}}],"config":{},"extra":{"workflowRendererVersion":"LG","ds":{"scale":1.1469075819486894,"offset":[276.8427259980847,549.4885226647582]}},"version":0.4}
+{"id":"91f75acc-8040-40f6-865a-2e8a7cfd6672","revision":0,"last_node_id":11,"last_link_id":23,"nodes":[{"id":3,"type":"PreviewImage","pos":[1281.8455167767304,-69.02638461454333],"size":[305.6628685610174,307.0336884172169],"flags":{},"order":4,"mode":0,"inputs":[{"localized_name":"图像","name":"images","type":"IMAGE","link":22}],"outputs":[],"properties":{"Node name for S&R":"PreviewImage"},"widgets_values":[]},{"id":11,"type":"VLLMOmniGenerateImage","pos":[816.0962515873642,-137.51112584854445],"size":[400,278],"flags":{},"order":3,"mode":0,"inputs":[{"localized_name":"image","name":"image","shape":7,"type":"IMAGE","link":21},{"localized_name":"mask","name":"mask","shape":7,"type":"MASK","link":null},{"localized_name":"sampling_params","name":"sampling_params","shape":7,"type":"SAMPLING_PARAMS","link":23},{"localized_name":"url","name":"url","type":"STRING","widget":{"name":"url"},"link":null},{"localized_name":"model","name":"model","type":"STRING","widget":{"name":"model"},"link":null},{"localized_name":"prompt","name":"prompt","type":"STRING","widget":{"name":"prompt"},"link":null},{"localized_name":"negative_prompt","name":"negative_prompt","type":"STRING","widget":{"name":"negative_prompt"},"link":null},{"localized_name":"width","name":"width","type":"INT","widget":{"name":"width"},"link":null},{"localized_name":"height","name":"height","type":"INT","widget":{"name":"height"},"link":null}],"outputs":[{"localized_name":"image","name":"image","type":"IMAGE","links":[22]}],"properties":{"Node name for S&R":"VLLMOmniGenerateImage"},"widgets_values":["http://localhost:8000/v1","Qwen/Qwen-Image-Edit","Put this figure in a realistic mountain view","",512,512]},{"id":10,"type":"MarkdownNote","pos":[227.99306819575278,-231.24143306069843],"size":[240.3326478922474,136.3505820791881],"flags":{},"order":1,"mode":0,"inputs":[],"outputs":[],"title":"Note: Task and Input","properties":{},"widgets_values":["vLLM-Omni nodes are categorized based on the output modality. The \"Generate Image\" node supports both text-to-image generation or image-to-image generation (a.k.a. image editing). The node will route to the correct endpoint depending on whether an input image is present or not."],"color":"#432","bgcolor":"#000"},{"id":4,"type":"LoadImage","pos":[496.31859627609606,-229.71277089860084],"size":[270,314],"flags":{},"order":2,"mode":0,"inputs":[{"localized_name":"图像","name":"image","type":"COMBO","widget":{"name":"image"},"link":null},{"localized_name":"选择文件上传","name":"upload","type":"IMAGEUPLOAD","widget":{"name":"upload"},"link":null}],"outputs":[{"localized_name":"图像","name":"IMAGE","type":"IMAGE","links":[21]},{"localized_name":"遮罩","name":"MASK","type":"MASK","links":null}],"properties":{"Node name for S&R":"LoadImage"},"widgets_values":["example.png","image"]},{"id":8,"type":"VLLMOmniDiffusionSampling","pos":[478.59266934006774,183.67711984955648],"size":[284.205078125,226],"flags":{},"order":0,"mode":0,"inputs":[{"localized_name":"n","name":"n","type":"INT","widget":{"name":"n"},"link":null},{"localized_name":"num_inference_steps","name":"num_inference_steps","type":"INT","widget":{"name":"num_inference_steps"},"link":null},{"localized_name":"guidance_scale","name":"guidance_scale","type":"FLOAT","widget":{"name":"guidance_scale"},"link":null},{"localized_name":"true_cfg_scale","name":"true_cfg_scale","type":"FLOAT","widget":{"name":"true_cfg_scale"},"link":null},{"localized_name":"vae_use_slicing","name":"vae_use_slicing","type":"BOOLEAN","widget":{"name":"vae_use_slicing"},"link":null},{"localized_name":"vae_use_tiling","name":"vae_use_tiling","type":"BOOLEAN","widget":{"name":"vae_use_tiling"},"link":null},{"localized_name":"seed","name":"seed","type":"INT","widget":{"name":"seed"},"link":null}],"outputs":[{"localized_name":"diffusion sampling params","name":"diffusion sampling params","type":"SAMPLING_PARAMS","links":[23]}],"properties":{"Node name for S&R":"VLLMOmniDiffusionSampling"},"widgets_values":[4,50,1,1,false,false,42,"randomize"]}],"links":[[21,4,0,11,0,"IMAGE"],[22,11,0,3,0,"IMAGE"],[23,8,0,11,2,"SAMPLING_PARAMS"]],"groups":[{"id":1,"title":"Input","bounding":[213.1706010087147,-313.20095750667554,560.8246471437027,407.4246532472182],"color":"#3f789e","font_size":24,"flags":{}}],"config":{},"extra":{"workflowRendererVersion":"LG","ds":{"scale":1.1469075819486894,"offset":[-55.18047513099182,220.2553505195962]}},"version":0.4}
diff --git a/apps/ComfyUI-vLLM-Omni/example_workflows/vLLM-Omni Multimodal Understanding.json b/apps/ComfyUI-vLLM-Omni/example_workflows/vLLM-Omni Multimodal Understanding.json
new file mode 100644
index 00000000000..4d32d5368c2
--- /dev/null
+++ b/apps/ComfyUI-vLLM-Omni/example_workflows/vLLM-Omni Multimodal Understanding.json
@@ -0,0 +1,761 @@
+{
+ "id": "1c99f525-0a37-45ba-a28a-7df7c3af66b4",
+ "revision": 0,
+ "last_node_id": 12,
+ "last_link_id": 14,
+ "nodes": [
+ {
+ "id": 1,
+ "type": "VLLMOmniUnderstanding",
+ "pos": [
+ 1191.2177053682556,
+ 144.66829928181377
+ ],
+ "size": [
+ 400,
+ 268
+ ],
+ "flags": {},
+ "order": 8,
+ "mode": 0,
+ "inputs": [
+ {
+ "localized_name": "image",
+ "name": "image",
+ "shape": 7,
+ "type": "IMAGE",
+ "link": 1
+ },
+ {
+ "localized_name": "video",
+ "name": "video",
+ "shape": 7,
+ "type": "VIDEO",
+ "link": 2
+ },
+ {
+ "localized_name": "audio",
+ "name": "audio",
+ "shape": 7,
+ "type": "AUDIO",
+ "link": 3
+ },
+ {
+ "localized_name": "sampling_params",
+ "name": "sampling_params",
+ "shape": 7,
+ "type": "SAMPLING_PARAMS",
+ "link": 14
+ },
+ {
+ "localized_name": "url",
+ "name": "url",
+ "type": "STRING",
+ "widget": {
+ "name": "url"
+ },
+ "link": null
+ },
+ {
+ "localized_name": "model",
+ "name": "model",
+ "type": "STRING",
+ "widget": {
+ "name": "model"
+ },
+ "link": null
+ },
+ {
+ "localized_name": "prompt",
+ "name": "prompt",
+ "type": "STRING",
+ "widget": {
+ "name": "prompt"
+ },
+ "link": null
+ },
+ {
+ "localized_name": "output_text",
+ "name": "output_text",
+ "type": "BOOLEAN",
+ "widget": {
+ "name": "output_text"
+ },
+ "link": null
+ },
+ {
+ "localized_name": "output_audio",
+ "name": "output_audio",
+ "type": "BOOLEAN",
+ "widget": {
+ "name": "output_audio"
+ },
+ "link": null
+ },
+ {
+ "localized_name": "use_audio_in_video",
+ "name": "use_audio_in_video",
+ "type": "BOOLEAN",
+ "widget": {
+ "name": "use_audio_in_video"
+ },
+ "link": null
+ }
+ ],
+ "outputs": [
+ {
+ "localized_name": "text_response",
+ "name": "text_response",
+ "type": "STRING",
+ "links": [
+ 8
+ ]
+ },
+ {
+ "localized_name": "audio_response",
+ "name": "audio_response",
+ "type": "AUDIO",
+ "links": [
+ 9
+ ]
+ }
+ ],
+ "properties": {
+ "Node name for S&R": "VLLMOmniUnderstanding"
+ },
+ "widgets_values": [
+ "http://localhost:8000/v1",
+ "Qwen/Qwen2.5-Omni-7B",
+ "",
+ true,
+ true,
+ true
+ ]
+ },
+ {
+ "id": 3,
+ "type": "LoadVideo",
+ "pos": [
+ 729.5984141255855,
+ -198.631920454299
+ ],
+ "size": [
+ 282.798828125,
+ 233.0743408203125
+ ],
+ "flags": {},
+ "order": 0,
+ "mode": 0,
+ "inputs": [
+ {
+ "localized_name": "file",
+ "name": "file",
+ "type": "COMBO",
+ "widget": {
+ "name": "file"
+ },
+ "link": null
+ },
+ {
+ "localized_name": "choose file to upload",
+ "name": "upload",
+ "type": "IMAGEUPLOAD",
+ "widget": {
+ "name": "upload"
+ },
+ "link": null
+ }
+ ],
+ "outputs": [
+ {
+ "localized_name": "VIDEO",
+ "name": "VIDEO",
+ "type": "VIDEO",
+ "links": [
+ 2
+ ]
+ }
+ ],
+ "properties": {
+ "Node name for S&R": "LoadVideo"
+ },
+ "widgets_values": [
+ "draw.mp4",
+ "image"
+ ]
+ },
+ {
+ "id": 4,
+ "type": "LoadAudio",
+ "pos": [
+ 729.8037086965753,
+ 99.86963519703949
+ ],
+ "size": [
+ 282.798828125,
+ 136
+ ],
+ "flags": {},
+ "order": 1,
+ "mode": 0,
+ "inputs": [
+ {
+ "localized_name": "audio",
+ "name": "audio",
+ "type": "COMBO",
+ "widget": {
+ "name": "audio"
+ },
+ "link": null
+ },
+ {
+ "localized_name": "audioUI",
+ "name": "audioUI",
+ "type": "AUDIO_UI",
+ "widget": {
+ "name": "audioUI"
+ },
+ "link": null
+ },
+ {
+ "localized_name": "choose file to upload",
+ "name": "upload",
+ "type": "AUDIOUPLOAD",
+ "widget": {
+ "name": "upload"
+ },
+ "link": null
+ }
+ ],
+ "outputs": [
+ {
+ "localized_name": "AUDIO",
+ "name": "AUDIO",
+ "type": "AUDIO",
+ "links": [
+ 3
+ ]
+ }
+ ],
+ "properties": {
+ "Node name for S&R": "LoadAudio"
+ },
+ "widgets_values": [
+ "Megan-Fox.mp3",
+ null,
+ null
+ ]
+ },
+ {
+ "id": 5,
+ "type": "VLLMOmniARSampling",
+ "pos": [
+ 510.3517536642828,
+ 658.073751009259
+ ],
+ "size": [
+ 270,
+ 178
+ ],
+ "flags": {},
+ "order": 2,
+ "mode": 0,
+ "inputs": [
+ {
+ "localized_name": "max_tokens",
+ "name": "max_tokens",
+ "type": "INT",
+ "widget": {
+ "name": "max_tokens"
+ },
+ "link": null
+ },
+ {
+ "localized_name": "temperature",
+ "name": "temperature",
+ "type": "FLOAT",
+ "widget": {
+ "name": "temperature"
+ },
+ "link": null
+ },
+ {
+ "localized_name": "top_p",
+ "name": "top_p",
+ "type": "FLOAT",
+ "widget": {
+ "name": "top_p"
+ },
+ "link": null
+ },
+ {
+ "localized_name": "repetition_penalty",
+ "name": "repetition_penalty",
+ "type": "FLOAT",
+ "widget": {
+ "name": "repetition_penalty"
+ },
+ "link": null
+ },
+ {
+ "localized_name": "seed",
+ "name": "seed",
+ "type": "INT",
+ "widget": {
+ "name": "seed"
+ },
+ "link": null
+ }
+ ],
+ "outputs": [
+ {
+ "localized_name": "AR sampling params",
+ "name": "AR sampling params",
+ "type": "SAMPLING_PARAMS",
+ "links": [
+ 12
+ ]
+ }
+ ],
+ "properties": {
+ "Node name for S&R": "VLLMOmniARSampling"
+ },
+ "widgets_values": [
+ 100,
+ 1,
+ 1,
+ 1,
+ -1,
+ "randomize"
+ ]
+ },
+ {
+ "id": 7,
+ "type": "VLLMOmniARSampling",
+ "pos": [
+ 503.33235181647115,
+ 419.34158016181806
+ ],
+ "size": [
+ 270,
+ 178
+ ],
+ "flags": {},
+ "order": 3,
+ "mode": 0,
+ "inputs": [
+ {
+ "localized_name": "max_tokens",
+ "name": "max_tokens",
+ "type": "INT",
+ "widget": {
+ "name": "max_tokens"
+ },
+ "link": null
+ },
+ {
+ "localized_name": "temperature",
+ "name": "temperature",
+ "type": "FLOAT",
+ "widget": {
+ "name": "temperature"
+ },
+ "link": null
+ },
+ {
+ "localized_name": "top_p",
+ "name": "top_p",
+ "type": "FLOAT",
+ "widget": {
+ "name": "top_p"
+ },
+ "link": null
+ },
+ {
+ "localized_name": "repetition_penalty",
+ "name": "repetition_penalty",
+ "type": "FLOAT",
+ "widget": {
+ "name": "repetition_penalty"
+ },
+ "link": null
+ },
+ {
+ "localized_name": "seed",
+ "name": "seed",
+ "type": "INT",
+ "widget": {
+ "name": "seed"
+ },
+ "link": null
+ }
+ ],
+ "outputs": [
+ {
+ "localized_name": "AR sampling params",
+ "name": "AR sampling params",
+ "type": "SAMPLING_PARAMS",
+ "links": [
+ 5,
+ 13
+ ]
+ }
+ ],
+ "properties": {
+ "Node name for S&R": "VLLMOmniARSampling"
+ },
+ "widgets_values": [
+ 100,
+ 1,
+ 1,
+ 1,
+ -1,
+ "randomize"
+ ]
+ },
+ {
+ "id": 8,
+ "type": "VLLMOmniSamplingParamsList",
+ "pos": [
+ 820.6056617389042,
+ 426.38372037182273
+ ],
+ "size": [
+ 263.066015625,
+ 66
+ ],
+ "flags": {},
+ "order": 7,
+ "mode": 0,
+ "inputs": [
+ {
+ "localized_name": "param1",
+ "name": "param1",
+ "type": "SAMPLING_PARAMS",
+ "link": 5
+ },
+ {
+ "localized_name": "param2",
+ "name": "param2",
+ "shape": 7,
+ "type": "SAMPLING_PARAMS",
+ "link": 12
+ },
+ {
+ "localized_name": "param3",
+ "name": "param3",
+ "shape": 7,
+ "type": "SAMPLING_PARAMS",
+ "link": 13
+ }
+ ],
+ "outputs": [
+ {
+ "localized_name": "param list",
+ "name": "param list",
+ "type": "SAMPLING_PARAMS",
+ "links": [
+ 14
+ ]
+ }
+ ],
+ "properties": {
+ "Node name for S&R": "VLLMOmniSamplingParamsList"
+ },
+ "widgets_values": []
+ },
+ {
+ "id": 11,
+ "type": "MarkdownNote",
+ "pos": [
+ 826.2328280438272,
+ 569.1890318701705
+ ],
+ "size": [
+ 333.8220435590464,
+ 261.63596728060656
+ ],
+ "flags": {},
+ "order": 4,
+ "mode": 0,
+ "inputs": [],
+ "outputs": [],
+ "title": "Note: Sampling Parameters",
+ "properties": {},
+ "widgets_values": [
+ "## Sampling Parameter Types\n\nThere are two types of sampling parameters: one for autoregression and one for diffusion.\nYou should ensure that you have chosen the correct type of sampling parameters for the model you request.\n\n## Stages & Shorthand\n\nFor multi-stage models such as Qwen Omni, you can either\n- connect one sampling parameter node, which is applied to all stages.\n- connect exactly the same number of sampling parameter nodes to a \"Multi-Stage Sampling Parameter List\" node, then connect this node to the primary request node.\n\nNote that this shorthand is intended to stay consistent with the [online serving API](https://docs.vllm.ai/projects/vllm-omni/en/latest/user_guide/examples/online_serving/qwen2_5_omni/)"
+ ],
+ "color": "#432",
+ "bgcolor": "#000"
+ },
+ {
+ "id": 12,
+ "type": "MarkdownNote",
+ "pos": [
+ 378.9866207003777,
+ 152.59550252215752
+ ],
+ "size": [
+ 319.7287574247016,
+ 107.15904081906785
+ ],
+ "flags": {},
+ "order": 6,
+ "mode": 0,
+ "inputs": [],
+ "outputs": [],
+ "title": "Note: Input",
+ "properties": {},
+ "widgets_values": [
+ "Note that not all models support every modality as input. For example, `ByteDance-Seed/BAGEL-7B-MoT` in Multimodality Understanding mode only support text and image input.\n\nYou should ensure that the input are supported by the model. You can check the corresponding [online serving documentation](https://docs.vllm.ai/projects/vllm-omni/en/latest/user_guide/examples/online_serving/bagel/) for confirmation."
+ ],
+ "color": "#432",
+ "bgcolor": "#000"
+ },
+ {
+ "id": 2,
+ "type": "LoadImage",
+ "pos": [
+ 394.4674804308822,
+ -207.6987397548834
+ ],
+ "size": [
+ 282.798828125,
+ 314
+ ],
+ "flags": {},
+ "order": 5,
+ "mode": 0,
+ "inputs": [
+ {
+ "localized_name": "image",
+ "name": "image",
+ "type": "COMBO",
+ "widget": {
+ "name": "image"
+ },
+ "link": null
+ },
+ {
+ "localized_name": "choose file to upload",
+ "name": "upload",
+ "type": "IMAGEUPLOAD",
+ "widget": {
+ "name": "upload"
+ },
+ "link": null
+ }
+ ],
+ "outputs": [
+ {
+ "localized_name": "IMAGE",
+ "name": "IMAGE",
+ "type": "IMAGE",
+ "links": [
+ 1
+ ]
+ },
+ {
+ "localized_name": "MASK",
+ "name": "MASK",
+ "type": "MASK",
+ "links": null
+ }
+ ],
+ "properties": {
+ "Node name for S&R": "LoadImage"
+ },
+ "widgets_values": [
+ "example.png",
+ "image"
+ ]
+ },
+ {
+ "id": 10,
+ "type": "PreviewAudio",
+ "pos": [
+ 1664.548345556043,
+ 297.5921292054054
+ ],
+ "size": [
+ 270,
+ 88
+ ],
+ "flags": {},
+ "order": 10,
+ "mode": 0,
+ "inputs": [
+ {
+ "localized_name": "audio",
+ "name": "audio",
+ "type": "AUDIO",
+ "link": 9
+ },
+ {
+ "localized_name": "audioUI",
+ "name": "audioUI",
+ "type": "AUDIO_UI",
+ "widget": {
+ "name": "audioUI"
+ },
+ "link": null
+ }
+ ],
+ "outputs": [],
+ "properties": {
+ "Node name for S&R": "PreviewAudio"
+ },
+ "widgets_values": []
+ },
+ {
+ "id": 9,
+ "type": "ShowText|pysssss",
+ "pos": [
+ 1649.2506875091847,
+ 66.22823888292349
+ ],
+ "size": [
+ 318.7188464232943,
+ 173.38502269972975
+ ],
+ "flags": {},
+ "order": 9,
+ "mode": 0,
+ "inputs": [
+ {
+ "localized_name": "text",
+ "name": "text",
+ "type": "STRING",
+ "link": 8
+ }
+ ],
+ "outputs": [
+ {
+ "localized_name": "STRING",
+ "name": "STRING",
+ "shape": 6,
+ "type": "STRING",
+ "links": null
+ }
+ ],
+ "properties": {
+ "Node name for S&R": "ShowText|pysssss"
+ },
+ "widgets_values": []
+ }
+ ],
+ "links": [
+ [
+ 1,
+ 2,
+ 0,
+ 1,
+ 0,
+ "IMAGE"
+ ],
+ [
+ 2,
+ 3,
+ 0,
+ 1,
+ 1,
+ "VIDEO"
+ ],
+ [
+ 3,
+ 4,
+ 0,
+ 1,
+ 2,
+ "AUDIO"
+ ],
+ [
+ 5,
+ 7,
+ 0,
+ 8,
+ 0,
+ "SAMPLING_PARAMS"
+ ],
+ [
+ 8,
+ 1,
+ 0,
+ 9,
+ 0,
+ "STRING"
+ ],
+ [
+ 9,
+ 1,
+ 1,
+ 10,
+ 0,
+ "AUDIO"
+ ],
+ [
+ 12,
+ 5,
+ 0,
+ 8,
+ 1,
+ "SAMPLING_PARAMS"
+ ],
+ [
+ 13,
+ 7,
+ 0,
+ 8,
+ 2,
+ "SAMPLING_PARAMS"
+ ],
+ [
+ 14,
+ 8,
+ 0,
+ 1,
+ 3,
+ "SAMPLING_PARAMS"
+ ]
+ ],
+ "groups": [
+ {
+ "id": 1,
+ "title": "Sampling Parameters",
+ "bounding": [
+ 480.1649301181556,
+ 341.08402513937995,
+ 692.4113568972277,
+ 510.48648853403665
+ ],
+ "color": "#3f789e",
+ "font_size": 24,
+ "flags": {}
+ },
+ {
+ "id": 2,
+ "title": "Input",
+ "bounding": [
+ 344.2364817813528,
+ -287.5850484183313,
+ 704.8832238768634,
+ 559.5124009832894
+ ],
+ "color": "#3f789e",
+ "font_size": 24,
+ "flags": {}
+ }
+ ],
+ "config": {},
+ "extra": {
+ "workflowRendererVersion": "LG",
+ "ds": {
+ "scale": 0.9478575057427204,
+ "offset": [
+ 33.81037136029557,
+ 307.1974296197726
+ ]
+ }
+ },
+ "version": 0.4
+}
diff --git a/pyproject.toml b/pyproject.toml
index 965a3e4b20c..4d6bc033317 100644
--- a/pyproject.toml
+++ b/pyproject.toml
@@ -48,7 +48,8 @@ dev = [
"soundfile>=0.13.1",
"imageio[ffmpeg]>=0.6.0",
"opencv-python>=4.12.0.88",
- "mooncake-transfer-engine==0.3.8.post1"
+ "mooncake-transfer-engine==0.3.8.post1",
+ "av" # for ComfyUI tests
]
docs = [
diff --git a/tests/comfyui/conftest.py b/tests/comfyui/conftest.py
new file mode 100644
index 00000000000..7c9770b8e98
--- /dev/null
+++ b/tests/comfyui/conftest.py
@@ -0,0 +1,82 @@
+"""
+Conftest for ComfyUI-vLLM-Omni tests.
+
+This module sets up the test environment by:
+1. Adding the ComfyUI plugin to Python path
+2. Mocking comfy_api.input module (AudioInput, VideoInput) since comfyui is not installed
+3. Mocking comfy_extras.nodes_audio module
+"""
+
+import os
+import sys
+from typing import BinaryIO, TypedDict
+from unittest.mock import MagicMock
+
+
+def pytest_configure(config):
+ """
+ Called after command line options have been parsed and before test collection.
+ This is the right place to set up sys.path and mock modules.
+ """
+ _setup_comfyui_test_environment()
+
+
+def _setup_comfyui_test_environment():
+ """Set up the test environment for ComfyUI plugin testing."""
+ # === Add ComfyUI plugin path to allow importing comfyui_vllm_omni ===
+ _COMFYUI_PLUGIN_PATH = os.path.abspath(
+ os.path.join(os.path.dirname(__file__), "..", "..", "apps", "ComfyUI-vLLM-Omni")
+ )
+ if not os.path.isdir(_COMFYUI_PLUGIN_PATH):
+ raise FileNotFoundError(
+ f"ComfyUI plugin not found at {_COMFYUI_PLUGIN_PATH}. "
+ "If it is moved elsewhere, please update the path in this conftest.py."
+ )
+ if _COMFYUI_PLUGIN_PATH not in sys.path:
+ sys.path.insert(0, _COMFYUI_PLUGIN_PATH)
+
+ # Import torch after changing import paths. (To be used later)
+ import torch
+
+ # === Mock ComfyUI internal modules (comfy_api & comfy_extras) and "import" them to sys.module ===
+ class AudioInput(TypedDict):
+ """Mock AudioInput TypedDict from comfy_api.input"""
+
+ waveform: torch.Tensor # Shape: (B, C, T)
+ sample_rate: int
+
+ class VideoInput:
+ """Mock VideoInput class from comfy_api.input"""
+
+ def __init__(self, data: bytes = b"mock_video_data"):
+ self._data = data
+
+ def save_to(self, file: str | BinaryIO):
+ """Save video data to file or file-like object."""
+ if isinstance(file, str):
+ print("Called VideoInput.save_to with file path. Saving to a path is no-op in tests.")
+ else:
+ file.write(self._data)
+
+ mock_comfy_api = MagicMock()
+ mock_comfy_api_input = MagicMock()
+ mock_comfy_api_input.AudioInput = AudioInput
+ mock_comfy_api_input.VideoInput = VideoInput
+ mock_comfy_api.input = mock_comfy_api_input
+
+ def mock_load(_: str | BinaryIO):
+ """Mock nodes_audio.load that returns a waveform tensor (channels, samples) and sample rate."""
+ waveform = torch.zeros((1, 24000), dtype=torch.float32)
+ sample_rate = 24000
+ return waveform, sample_rate
+
+ mock_comfy_extras = MagicMock()
+ mock_nodes_audio = MagicMock()
+ mock_nodes_audio.load = mock_load
+ mock_comfy_extras.nodes_audio = mock_nodes_audio
+
+ # Install mock modules BEFORE importing any comfyui_vllm_omni code
+ sys.modules["comfy_api"] = mock_comfy_api
+ sys.modules["comfy_api.input"] = mock_comfy_api_input
+ sys.modules["comfy_extras"] = mock_comfy_extras
+ sys.modules["comfy_extras.nodes_audio"] = mock_nodes_audio
diff --git a/tests/comfyui/test_comfyui_integration.py b/tests/comfyui/test_comfyui_integration.py
new file mode 100644
index 00000000000..46359632609
--- /dev/null
+++ b/tests/comfyui/test_comfyui_integration.py
@@ -0,0 +1,567 @@
+"""
+Integration tests for ComfyUI nodes that use the Omni API client, with a mocked AsyncOmni and a real API server running in a background process.
+These tests cover the integration between ComfyUI node and the API server, without actual model inference logic.
+It ensures that
+1. Changes made to the API (e.g., request and response formats) do not break the ComfyUI frontend that use it.
+2. The sampling parameters are correctly passed from the node to AsyncOmni through the API layer.
+"""
+
+import multiprocessing
+import time
+import traceback
+from collections.abc import Iterable, Sequence
+from enum import StrEnum, auto
+from typing import Any, NamedTuple
+from unittest.mock import AsyncMock, MagicMock, patch
+
+import pytest
+import requests
+import torch
+from comfy_api.input import AudioInput, VideoInput
+from comfyui_vllm_omni.nodes import (
+ VLLMOmniGenerateImage,
+ VLLMOmniTTS,
+ VLLMOmniUnderstanding,
+ VLLMOmniVoiceClone,
+)
+from comfyui_vllm_omni.utils.types import AutoregressionSamplingParams, DiffusionSamplingParams
+from PIL import Image
+from vllm import SamplingParams
+from vllm.outputs import CompletionOutput, RequestOutput
+from vllm.utils.argparse_utils import FlexibleArgumentParser
+
+from vllm_omni.entrypoints.cli.serve import OmniServeCommand
+from vllm_omni.inputs.data import OmniSamplingParams
+from vllm_omni.outputs import OmniRequestOutput
+
+
+class ServerCase(NamedTuple):
+ """Parametrizing the model to serve."""
+
+ served_model: str
+ stage_list: list
+ stage_configs: list[dict]
+ outputs: list[OmniRequestOutput]
+
+
+class SamplingCase(NamedTuple):
+ """Parametrizing the input sampling parameters."""
+
+ kind: "SamplingKind"
+ sampling_params: dict | list[dict] | None
+
+
+class SamplingKind(StrEnum):
+ IMAGE_NONE = auto()
+ IMAGE_DIFFUSION_SINGLE = auto()
+ UNDERSTANDING_NONE = auto()
+ UNDERSTANDING_AR_LIST = auto()
+ TTS_NONE = auto()
+ TTS_DIFFUSION_SINGLE = auto()
+
+
+# Pre-defined arguments to be used in function calls during the tests
+IMAGE_WIDTH = 64
+IMAGE_HEIGHT = 64
+DIFFUSION_SINGLE_SAMPLING_PARAMS = DiffusionSamplingParams(
+ {
+ "n": 2,
+ "num_inference_steps": 30,
+ "guidance_scale": 6.0,
+ "true_cfg_scale": 1.5,
+ }
+)
+
+AR_LIST_SAMPLING_PARAMS = [
+ AutoregressionSamplingParams(
+ {
+ "max_tokens": 64,
+ "temperature": 0.6,
+ "top_p": 0.9,
+ "repetition_penalty": 1.0,
+ "seed": 21,
+ }
+ ),
+ AutoregressionSamplingParams(
+ {
+ "max_tokens": 96,
+ "temperature": 0.75,
+ "top_p": 0.85,
+ "repetition_penalty": 1.05,
+ "seed": 22,
+ }
+ ),
+ AutoregressionSamplingParams(
+ {
+ "max_tokens": 128,
+ "temperature": 0.8,
+ "top_p": 0.8,
+ "repetition_penalty": 1.1,
+ "seed": 23,
+ }
+ ),
+]
+
+
+def _build_image_output(size: tuple[int, int] = (IMAGE_WIDTH, IMAGE_HEIGHT), color: str = "red") -> Image.Image:
+ return Image.new("RGB", size, color=color)
+
+
+def _build_text_output(text: str = "This is a test response.") -> OmniRequestOutput:
+ completion_output = CompletionOutput(
+ index=0,
+ text=text,
+ token_ids=[1, 2, 3],
+ cumulative_logprob=0.0,
+ logprobs=None,
+ finish_reason="stop",
+ stop_reason=None,
+ )
+ request_output = RequestOutput(
+ request_id="test_req_text",
+ prompt="test prompt",
+ prompt_token_ids=[1, 2, 3],
+ prompt_logprobs=None,
+ outputs=[completion_output],
+ finished=True,
+ metrics=None,
+ lora_request=None,
+ )
+ return OmniRequestOutput(
+ request_id="test_req_text",
+ finished=True,
+ final_output_type="text",
+ request_output=request_output,
+ )
+
+
+def _build_audio_chat_output(num_samples: int = 24000) -> OmniRequestOutput:
+ completion_output = CompletionOutput(
+ index=0,
+ text="",
+ token_ids=[],
+ cumulative_logprob=0.0,
+ logprobs=None,
+ finish_reason="stop",
+ stop_reason=None,
+ )
+ completion_output.multimodal_output = {"audio": [torch.zeros(1, num_samples)]}
+ request_output = RequestOutput(
+ request_id="test_req_audio_chat",
+ prompt="test prompt",
+ prompt_token_ids=[1, 2, 3],
+ prompt_logprobs=None,
+ outputs=[completion_output],
+ finished=True,
+ metrics=None,
+ lora_request=None,
+ )
+ return OmniRequestOutput(
+ request_id="test_req_audio_chat",
+ finished=True,
+ final_output_type="audio",
+ request_output=request_output,
+ )
+
+
+def _build_audio_speech_output(num_samples: int = 24000) -> OmniRequestOutput:
+ return OmniRequestOutput.from_diffusion(
+ request_id="test_req_audio_speech",
+ images=[],
+ multimodal_output={"audio": torch.zeros(num_samples), "sr": 24000},
+ final_output_type="audio",
+ )
+
+
+def _build_diffusion_image_output_for_images_endpoint() -> OmniRequestOutput:
+ return OmniRequestOutput.from_diffusion(
+ request_id="test_req_img_dalle",
+ images=[_build_image_output()],
+ final_output_type="image",
+ )
+
+
+def _build_diffusion_image_output_for_chat_endpoint() -> OmniRequestOutput:
+ request_output = MagicMock()
+ request_output.images = [_build_image_output(color="blue")]
+ request_output.finished = True
+ return OmniRequestOutput(
+ request_id="test_req_img_chat",
+ finished=True,
+ final_output_type="image",
+ request_output=request_output,
+ )
+
+
+def _assert_sampling_param_values(received: OmniSamplingParams, expected: dict[str, Any]):
+ for key, expected_value in expected.items():
+ actual_value = getattr(received, key, None)
+ assert actual_value == expected_value, (
+ f"Expected sampling param '{key}'={expected_value}, got {actual_value}. The received sampling params: {received}"
+ )
+
+
+def _build_mock_outputs(outputs: Iterable[OmniRequestOutput], sampling_case: SamplingCase, server_case: ServerCase):
+ async def _mock_generate(*args, **kwargs):
+ received_sampling_params_list: Sequence[OmniSamplingParams] | None = (
+ args[2] if len(args) > 2 else kwargs.get("sampling_params_list")
+ )
+
+ assert received_sampling_params_list is not None, (
+ "In the current codebase, the API layer always provides not-None sampling parameter list when calling `AsyncOmni.generate`"
+ "This test also uses this assumption for now."
+ "If this assertion fails, it means the API layer has changed and this test needs to be updated accordingly."
+ "It does not necessarily mean there is a bug, because `AsyncOmni.generate` does allow sampling_params_list to be None."
+ )
+ assert isinstance(received_sampling_params_list, Sequence), "sampling_params_list should be a Sequence"
+
+ if sampling_case.kind is SamplingKind.IMAGE_NONE:
+ assert len(received_sampling_params_list) == 1
+ _assert_sampling_param_values(
+ received_sampling_params_list[0],
+ {
+ "width": IMAGE_WIDTH,
+ "height": IMAGE_HEIGHT,
+ },
+ )
+ elif sampling_case.kind is SamplingKind.IMAGE_DIFFUSION_SINGLE:
+ assert len(received_sampling_params_list) == 1
+ expected = DIFFUSION_SINGLE_SAMPLING_PARAMS.copy()
+ expected["num_outputs_per_prompt"] = expected.pop("n") # convert from n to num_outputs_per_prompt
+ _assert_sampling_param_values(
+ received_sampling_params_list[0],
+ {
+ "width": IMAGE_WIDTH,
+ "height": IMAGE_HEIGHT,
+ **expected,
+ },
+ )
+ elif sampling_case.kind is SamplingKind.UNDERSTANDING_NONE:
+ assert len(received_sampling_params_list) == 3
+ elif sampling_case.kind is SamplingKind.UNDERSTANDING_AR_LIST:
+ assert len(received_sampling_params_list) == 3
+ for i, expected in enumerate(AR_LIST_SAMPLING_PARAMS):
+ _assert_sampling_param_values(received_sampling_params_list[i], expected)
+ elif sampling_case.kind in {SamplingKind.TTS_NONE, SamplingKind.TTS_DIFFUSION_SINGLE}:
+ assert len(received_sampling_params_list) == 1
+ else:
+ raise AssertionError(f"Unknown sampling case: {sampling_case.kind}")
+
+ for output in outputs:
+ yield output
+
+ return _mock_generate
+
+
+@pytest.fixture
+def server_case(request) -> ServerCase:
+ return request.param
+
+
+@pytest.fixture
+def sampling_case(request) -> SamplingCase:
+ return request.param
+
+
+@pytest.fixture
+def mock_async_omni(server_case: ServerCase, sampling_case: SamplingCase):
+ async def _mock_preprocess_chat(self, *args, **kwargs):
+ return ([{"role": "user", "content": "test"}], [{"prompt": "test prompt"}])
+
+ # Need to mock AsyncOmni itself (not only its generate method) because
+ # 1. The API layer uses its stage_list and stage_configs attributes
+ # 2. Its __init__ method has slow side effects (model & config loading).
+ with (
+ patch("vllm_omni.entrypoints.openai.api_server.AsyncOmni") as MockAsyncOmni,
+ patch(
+ "vllm_omni.entrypoints.openai.serving_chat.OmniOpenAIServingChat._preprocess_chat",
+ new=_mock_preprocess_chat,
+ ),
+ ):
+ mock_instance = AsyncMock()
+ mock_instance.generate = _build_mock_outputs(server_case.outputs, sampling_case, server_case)
+
+ mock_instance.stage_list = server_case.stage_list
+ mock_instance.stage_configs = server_case.stage_configs
+ mock_instance.default_sampling_params_list = [
+ SamplingParams() if stage.get("stage_type") != "diffusion" else MagicMock()
+ for stage in server_case.stage_configs
+ ]
+ mock_instance.errored = False
+ mock_instance.dead_error = RuntimeError("Mock engine error")
+ mock_instance.model_config = MagicMock(max_model_len=4096, io_processor_plugin=None)
+ mock_instance.io_processor = MagicMock()
+ mock_instance.input_processor = MagicMock()
+ mock_instance.shutdown = MagicMock()
+ mock_instance.get_vllm_config = AsyncMock(return_value=None)
+ mock_instance.get_supported_tasks = AsyncMock(return_value=["generate"])
+ mock_instance.get_tokenizer = AsyncMock(return_value=None)
+
+ MockAsyncOmni.return_value = mock_instance
+ yield MockAsyncOmni
+
+
+@pytest.fixture
+def api_server(unused_tcp_port_factory, server_case: ServerCase, mock_async_omni):
+ """Set up a API server in background process from command line with parametrized model name and mocked AsyncOmni."""
+ parser = FlexibleArgumentParser()
+ subparsers = parser.add_subparsers(dest="command")
+ cmd = OmniServeCommand()
+ cmd.subparser_init(subparsers)
+
+ port = unused_tcp_port_factory()
+ args = parser.parse_args(["serve", server_case.served_model, "--omni", "--port", str(port)])
+
+ def run_server():
+ try:
+ cmd.cmd(args)
+ except Exception:
+ traceback.print_exc()
+
+ server_process = multiprocessing.Process(target=run_server)
+ server_process.start()
+
+ # Wait for the server to be ready by polling the health endpoint.
+ wait_time = 30
+ wait_poll_interval = 1
+ for _ in range(wait_time // wait_poll_interval):
+ try:
+ response = requests.get(f"http://127.0.0.1:{port}/health")
+ if response.status_code == 200:
+ break
+ except requests.ConnectionError:
+ time.sleep(wait_poll_interval)
+ else:
+ if server_process.is_alive():
+ server_process.terminate()
+ server_process.join(timeout=5)
+ if server_process.is_alive():
+ server_process.kill()
+ server_process.join(timeout=5)
+ pytest.fail(f"API server failed to start within {wait_time} seconds")
+
+ yield f"http://127.0.0.1:{port}/v1"
+
+ if server_process.is_alive():
+ server_process.terminate()
+ server_process.join(timeout=10)
+
+
+@pytest.mark.asyncio
+@pytest.mark.parametrize(
+ "server_case,model,image_input",
+ [
+ pytest.param(
+ ServerCase(
+ served_model="Tongyi-MAI/Z-Image-Turbo",
+ stage_list=["diffusion"],
+ stage_configs=[{"stage_type": "diffusion"}],
+ outputs=[_build_diffusion_image_output_for_images_endpoint()],
+ ),
+ "Tongyi-MAI/Z-Image-Turbo",
+ False,
+ id="text-to-image-dalle-endpoint",
+ ),
+ pytest.param(
+ ServerCase(
+ served_model="ByteDance-Seed/BAGEL-7B-MoT",
+ stage_list=["diffusion"],
+ stage_configs=[{"stage_type": "diffusion"}],
+ outputs=[_build_diffusion_image_output_for_chat_endpoint()],
+ ),
+ "ByteDance-Seed/BAGEL-7B-MoT",
+ False,
+ id="text-to-image-bagel-chat-endpoint",
+ ),
+ pytest.param(
+ ServerCase(
+ served_model="Qwen/Qwen-Image-Edit",
+ stage_list=["diffusion"],
+ stage_configs=[{"stage_type": "diffusion"}],
+ outputs=[_build_diffusion_image_output_for_images_endpoint()],
+ ),
+ "Qwen/Qwen-Image-Edit",
+ True,
+ id="image-to-image-dalle-endpoint",
+ ),
+ pytest.param(
+ ServerCase(
+ served_model="ByteDance-Seed/BAGEL-7B-MoT",
+ stage_list=["diffusion"],
+ stage_configs=[{"stage_type": "diffusion"}],
+ outputs=[_build_diffusion_image_output_for_chat_endpoint()],
+ ),
+ "ByteDance-Seed/BAGEL-7B-MoT",
+ True,
+ id="image-to-image-bagel-chat-endpoint",
+ ),
+ ],
+ indirect=["server_case"],
+)
+@pytest.mark.parametrize(
+ "sampling_case",
+ [
+ pytest.param(SamplingCase(kind=SamplingKind.IMAGE_NONE, sampling_params=None), id="no-sampling-params"),
+ pytest.param(
+ SamplingCase(kind=SamplingKind.IMAGE_DIFFUSION_SINGLE, sampling_params=DIFFUSION_SINGLE_SAMPLING_PARAMS),
+ id="single-diffusion-sampling-params",
+ ),
+ ],
+ indirect=["sampling_case"],
+)
+async def test_image_generation_node(api_server: str, model: str, image_input: bool, sampling_case: SamplingCase):
+ node = VLLMOmniGenerateImage()
+
+ kwargs = {
+ "url": api_server,
+ "model": model,
+ "prompt": "A beautiful sunset",
+ "width": IMAGE_WIDTH,
+ "height": IMAGE_HEIGHT,
+ }
+ if image_input:
+ kwargs["image"] = torch.zeros((1, IMAGE_WIDTH, IMAGE_HEIGHT, 3), dtype=torch.float32)
+ if sampling_case.sampling_params is not None:
+ kwargs["sampling_params"] = sampling_case.sampling_params
+ print(f"!!!!!! Calling {model} node.generate with kwargs: {sampling_case.sampling_params}")
+
+ result = await node.generate(**kwargs)
+
+ assert isinstance(result, tuple)
+ assert len(result) == 1
+ assert isinstance(result[0], torch.Tensor)
+ assert result[0].shape == (1, IMAGE_WIDTH, IMAGE_HEIGHT, 3)
+
+
+@pytest.mark.asyncio
+@pytest.mark.parametrize(
+ "server_case",
+ [
+ pytest.param(
+ ServerCase(
+ served_model="Qwen/Qwen2.5-Omni-7B",
+ stage_list=[
+ MagicMock(is_comprehension=True, model_stage="llm"),
+ MagicMock(is_comprehension=False, model_stage="llm"),
+ MagicMock(is_comprehension=False, model_stage="llm"),
+ ],
+ stage_configs=[
+ {"stage_type": "llm"},
+ {"stage_type": "llm"},
+ {"stage_type": "llm"},
+ ],
+ outputs=[_build_audio_chat_output(), _build_text_output("Understanding response")],
+ ),
+ id="multimodal-understanding",
+ )
+ ],
+ indirect=["server_case"],
+)
+@pytest.mark.parametrize(
+ "sampling_case",
+ [
+ pytest.param(SamplingCase(kind=SamplingKind.UNDERSTANDING_NONE, sampling_params=None), id="no-sampling-params"),
+ pytest.param(
+ SamplingCase(kind=SamplingKind.UNDERSTANDING_AR_LIST, sampling_params=AR_LIST_SAMPLING_PARAMS),
+ id="ar-sampling-params-list",
+ ),
+ ],
+ indirect=["sampling_case"],
+)
+async def test_understanding_node(api_server: str, sampling_case: SamplingCase):
+ node = VLLMOmniUnderstanding()
+
+ image = torch.zeros((1, IMAGE_WIDTH, IMAGE_HEIGHT, 3), dtype=torch.float32)
+ video = VideoInput(b"mock_video_for_test") # type: ignore[reportAbstractUsage]
+ audio: AudioInput = {"waveform": torch.zeros((1, 1, 24000), dtype=torch.float32), "sample_rate": 24000}
+
+ text_response, audio_response = await node.generate(
+ url=api_server,
+ model="Qwen/Qwen2.5-Omni-7B",
+ prompt="Describe all modalities.",
+ image=image,
+ audio=audio,
+ video=video,
+ sampling_params=sampling_case.sampling_params,
+ output_text=True,
+ output_audio=True,
+ use_audio_in_video=True,
+ )
+
+ assert text_response == "Understanding response"
+ assert isinstance(audio_response, dict)
+ assert audio_response["sample_rate"] == 24000
+ assert isinstance(audio_response["waveform"], torch.Tensor)
+ assert audio_response["waveform"].shape == (1, 1, 24000)
+
+
+@pytest.mark.asyncio
+@pytest.mark.parametrize(
+ "server_case,node_cls,call_kwargs",
+ [
+ pytest.param(
+ ServerCase(
+ served_model="Qwen/Qwen3-TTS-12Hz-1.7B-CustomVoice",
+ stage_list=["llm"],
+ stage_configs=[{"stage_type": "llm"}],
+ outputs=[_build_audio_speech_output()],
+ ),
+ VLLMOmniTTS,
+ {
+ "model": "Qwen/Qwen3-TTS-12Hz-1.7B-CustomVoice",
+ "input": "Hello from TTS test",
+ "voice": "Vivian",
+ "response_format": "wav",
+ "speed": 1.0,
+ "model_specific_params": None,
+ },
+ id="tts",
+ ),
+ pytest.param(
+ ServerCase(
+ served_model="Qwen/Qwen3-TTS-12Hz-1.7B-Base",
+ stage_list=["llm"],
+ stage_configs=[{"stage_type": "llm"}],
+ outputs=[_build_audio_speech_output()],
+ ),
+ VLLMOmniVoiceClone,
+ {
+ "model": "Qwen/Qwen3-TTS-12Hz-1.7B-Base",
+ "input": "Hello from voice clone test",
+ "voice": "Vivian",
+ "response_format": "wav",
+ "speed": 1.0,
+ "ref_audio": {"waveform": torch.zeros((1, 1, 24000), dtype=torch.float32), "sample_rate": 24000},
+ "ref_text": "Reference transcript",
+ "x_vector_only_mode": False,
+ "model_specific_params": None,
+ },
+ id="tts-voice-clone",
+ ),
+ ],
+ indirect=["server_case"],
+)
+@pytest.mark.parametrize(
+ "sampling_case",
+ [
+ pytest.param(SamplingCase(kind=SamplingKind.TTS_NONE, sampling_params=None), id="no-sampling-params"),
+ pytest.param(
+ SamplingCase(kind=SamplingKind.TTS_DIFFUSION_SINGLE, sampling_params=DIFFUSION_SINGLE_SAMPLING_PARAMS),
+ id="single-diffusion-sampling-params",
+ ),
+ ],
+ indirect=["sampling_case"],
+)
+async def test_tts_nodes(api_server: str, node_cls, call_kwargs: dict, sampling_case: SamplingCase):
+ node = node_cls()
+ actual_kwargs = dict(call_kwargs)
+ if sampling_case.sampling_params is not None:
+ actual_kwargs["model_specific_params"] = sampling_case.sampling_params
+ result = await node.generate(url=api_server, **actual_kwargs)
+
+ assert isinstance(result, tuple)
+ assert len(result) == 1
+ assert isinstance(result[0], dict)
+ assert result[0]["sample_rate"] == 24000
+ assert isinstance(result[0]["waveform"], torch.Tensor)
+ assert result[0]["waveform"].shape == (1, 1, 24000)
 +
+ 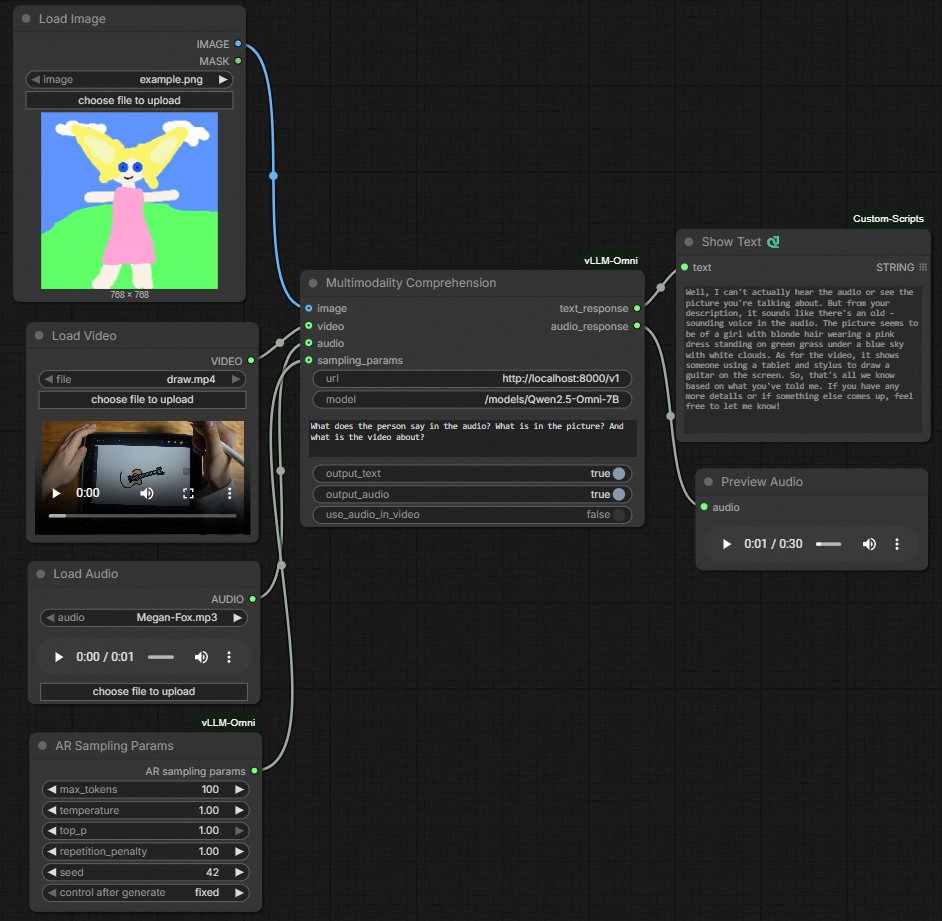
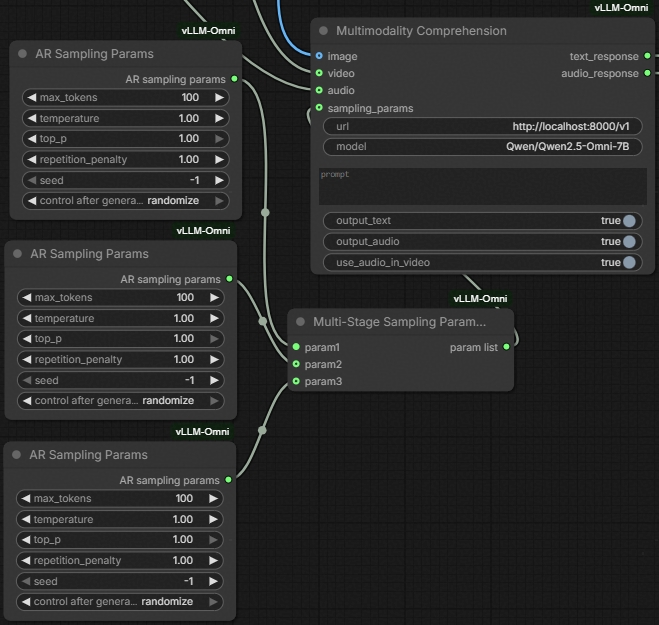 +
+ 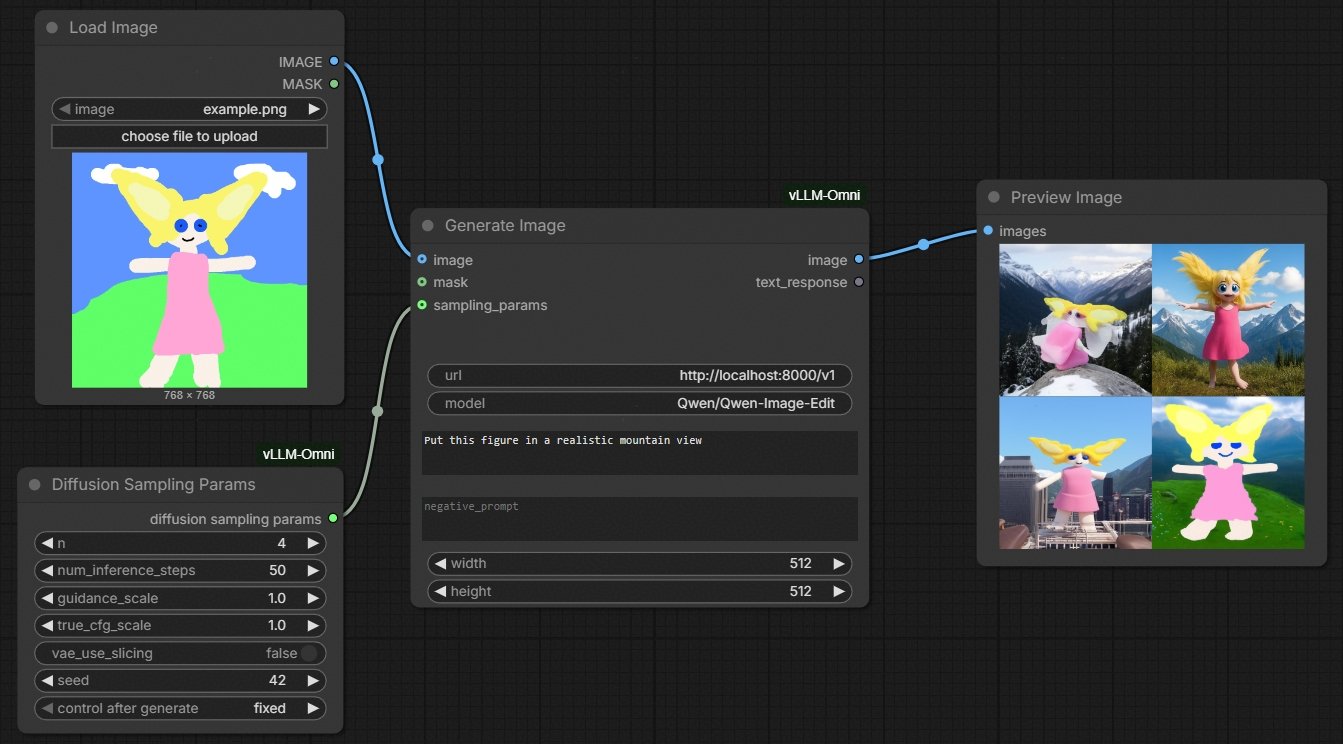 +
+ 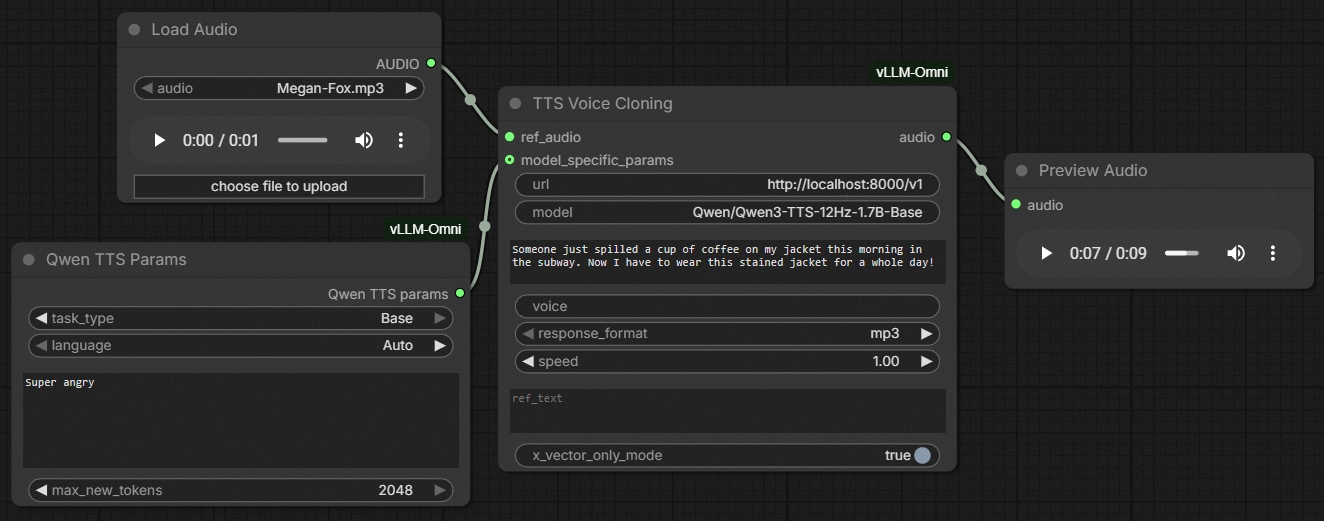 +
+  +
+