diff --git a/.github/workflows/e2e_transferqueue.yml b/.github/workflows/e2e_transferqueue.yml
new file mode 100644
index 00000000000..da5443f43aa
--- /dev/null
+++ b/.github/workflows/e2e_transferqueue.yml
@@ -0,0 +1,180 @@
+# # Tests layout
+
+# Each folder under tests/ corresponds to a test category for a sub-namespace in verl. For instance:
+# - `tests/trainer` for testing functionality related to `verl/trainer`
+# - `tests/models` for testing functionality related to `verl/models`
+# - ...
+
+# There are a few folders with `special_` prefix, created for special purposes:
+# - `special_distributed`: unit tests that must run with multiple GPUs
+# - `special_e2e`: end-to-end tests with training/generation scripts
+# - `special_npu`: tests for NPUs
+# - `special_sanity`: a suite of quick sanity tests
+# - `special_standalone`: a set of test that are designed to run in dedicated environments
+
+# Accelerators for tests
+# - By default tests are run with GPU available, except for the ones under `special_npu`, and any test script whose name ends with `on_cpu.py`.
+# - For test scripts with `on_cpu.py` name suffix would be tested on CPU resources in linux environment.
+
+# # Workflow layout
+
+# All CI tests are configured by yaml files in `.github/workflows/`. Here's an overview of all test configs:
+# 1. A list of always triggered CPU sanity tests: `check-pr-title.yml`, `secrets_scan.yml`, `check-pr-title,yml`, `pre-commit.yml`, `doc.yml`
+# 2. Some heavy multi-GPU unit tests, such as `model.yml`, `vllm.yml`, `sgl.yml`
+# 3. End-to-end tests: `e2e_*.yml`
+# 4. Unit tests
+# - `cpu_unit_tests.yml`, run pytest on all scripts with file name pattern `tests/**/test_*_on_cpu.py`
+# - `gpu_unit_tests.yml`, run pytest on all scripts with file without the `on_cpu.py` suffix.
+# - Since cpu/gpu unit tests by default runs all tests under `tests`, please make sure tests are manually excluded in them when
+# - new workflow yaml is added to `.github/workflows`
+# - new tests are added to workflow mentioned in 2.
+
+
+name: e2e_transferqueue
+
+on:
+ # Trigger the workflow on push or pull request,
+ # but only for the main branch
+ # For push, for now only anti-patterns are specified so it is more conservative
+ # and achieves higher coverage.
+ push:
+ branches:
+ - main
+ - v0.*
+ paths:
+ - "**/*.py"
+ - "!**/*.md"
+ - "!**/*.sh"
+ # Other entrypoints
+ - "!examples/*trainer*"
+ - "!tests/**"
+ - "!verl/trainer/main_*.py"
+ - "!verl/trainer/fsdp_sft_trainer.py"
+ - "!recipe/**"
+ - "recipe/transfer_queue/**"
+ pull_request:
+ branches:
+ - main
+ - v0.*
+ paths:
+ - "**/*.py"
+ - "!**/*.md"
+ - "!**/*.sh"
+ # Other entrypoints
+ - "!examples/**"
+ - "!tests/**"
+ - "!verl/trainer/main_*.py"
+ - "!verl/trainer/fsdp_sft_trainer.py"
+ # Other recipes
+ - "!recipe/**"
+ # Home
+ - "recipe/transfer_queue"
+ # Entrypoints
+ - ".github/workflows/e2e_transferqueue.yml"
+ - "examples/data_preprocess/gsm8k.py"
+ - "tests/special_e2e/run_transferqueue.sh"
+
+# Cancel jobs on the same ref if a new one is triggered
+concurrency:
+ group: ${{ github.workflow }}-${{ github.ref }}
+ cancel-in-progress: ${{ github.ref != 'refs/heads/main' }}
+
+# Declare permissions just read content.
+permissions:
+ contents: read
+
+env:
+ IMAGE: "verl-ci-cn-beijing.cr.volces.com/verlai/verl:vllm011.dev7"
+ DYNAMIC_RUNNER_ENDPOINT: "https://sd10g3clalm04ug7alq90.apigateway-cn-beijing.volceapi.com/runner"
+ TRANSFORMERS_VERSION: "4.56.2"
+
+jobs:
+ setup:
+ if: github.repository_owner == 'volcengine'
+ runs-on: ubuntu-latest
+ outputs:
+ runner-label: ${{ steps.create-runner.outputs.runner-label }}
+ mlp-task-id: ${{ steps.create-runner.outputs.mlp-task-id }}
+ steps:
+ - uses: actions/checkout@v4
+ - id: create-runner
+ uses: volcengine/vemlp-github-runner@v1
+ with:
+ mode: "create"
+ faas-url: "${{ env.DYNAMIC_RUNNER_ENDPOINT }}"
+ mlp-image: "${{ env.IMAGE }}"
+
+ # Test FSDP strategy
+ e2e_transferqueue_fsdp:
+ needs: setup
+ runs-on: [ "${{ needs.setup.outputs.runner-label || 'L20x8' }}" ]
+ timeout-minutes: 10 # Increase timeout for async training
+ env:
+ HTTP_PROXY: ${{ secrets.PROXY_HTTP }}
+ HTTPS_PROXY: ${{ secrets.PROXY_HTTPS }}
+ NO_PROXY: "localhost,127.0.0.1,hf-mirror.com"
+ HF_ENDPOINT: "https://hf-mirror.com"
+ HF_HUB_ENABLE_HF_TRANSFER: "0" # This is more stable
+ ACTOR_STRATEGY: "fsdp"
+ steps:
+ - uses: actions/checkout@11bd71901bbe5b1630ceea73d27597364c9af683 # v4.2.2
+ with:
+ fetch-depth: 0
+ - name: Install the current repository
+ run: |
+ pip3 install --no-deps -e .[test,gpu]
+ pip3 install transformers==$TRANSFORMERS_VERSION
+ pip3 install -i https://mirrors.tuna.tsinghua.edu.cn/pypi/web/simple TransferQueue==0.1.2.dev0
+ - name: Prepare GSM8K dataset
+ run: |
+ python3 examples/data_preprocess/gsm8k.py --local_dataset_path ${HOME}/models/hf_data/gsm8k
+ - name: Running the E2E test with TransferQueue (FSDP)
+ run: |
+ ray stop --force
+ bash tests/special_e2e/run_transferqueue.sh
+
+ # Test Megatron strategy
+ e2e_transferqueue_megatron:
+ needs: setup
+ runs-on: [ "${{ needs.setup.outputs.runner-label || 'L20x8' }}" ]
+ timeout-minutes: 10 # Increase timeout for async training
+ env:
+ HTTP_PROXY: ${{ secrets.PROXY_HTTP }}
+ HTTPS_PROXY: ${{ secrets.PROXY_HTTPS }}
+ NO_PROXY: "localhost,127.0.0.1,hf-mirror.com"
+ HF_ENDPOINT: "https://hf-mirror.com"
+ HF_HUB_ENABLE_HF_TRANSFER: "0" # This is more stable
+ ACTOR_STRATEGY: "megatron"
+ steps:
+ - uses: actions/checkout@11bd71901bbe5b1630ceea73d27597364c9af683 # v4.2.2
+ with:
+ fetch-depth: 0
+ - name: Install the current repository
+ run: |
+ pip3 install --no-deps -e .[test,gpu]
+ pip3 install transformers==$TRANSFORMERS_VERSION
+ pip3 install -i https://mirrors.tuna.tsinghua.edu.cn/pypi/web/simple TransferQueue==0.1.2.dev0
+ - name: Prepare GSM8K dataset
+ run: |
+ python3 examples/data_preprocess/gsm8k.py --local_dataset_path ${HOME}/models/hf_data/gsm8k
+ - name: Running the E2E test with TransferQueue (Megatron)
+ run: |
+ ray stop --force
+ bash tests/special_e2e/run_transferqueue.sh
+
+ cleanup:
+ runs-on: ubuntu-latest
+ needs:
+ [
+ setup,
+ e2e_transferqueue_fsdp,
+ e2e_transferqueue_megatron
+ ]
+ if: always()
+ steps:
+ - id: destroy-runner
+ uses: volcengine/vemlp-github-runner@v1
+ with:
+ mode: "destroy"
+ faas-url: "${{ env.DYNAMIC_RUNNER_ENDPOINT }}"
+ mlp-task-id: "${{ needs.setup.outputs.mlp-task-id }}"
diff --git a/docs/data/transfer_queue.md b/docs/data/transfer_queue.md
index 4532d42ed56..e30e14cd739 100644
--- a/docs/data/transfer_queue.md
+++ b/docs/data/transfer_queue.md
@@ -1,52 +1,73 @@
# TransferQueue Data System
-Last updated: 09/28/2025.
+Last updated: 11/17/2025.
This doc introduce [TransferQueue](https://github.com/TransferQueue/TransferQueue), an asynchronous streaming data management system for efficient post-training.
Overview
-TransferQueue is a high-performance data storage and transfer system with panoramic data visibility and streaming scheduling capabilities, optimized for efficient dataflow in post-training workflows.
+TransferQueue is a high-performance data storage and transfer module with panoramic data visibility and streaming scheduling capabilities, optimized for efficient dataflow in post-training workflows.
-  +
+ 
-
-TransferQueue offers **fine-grained, sample-level** data management capabilities, serving as a data gateway that decouples explicit data dependencies across computational tasks. This enables a divide-and-conquer approach, significantly simplifying the design of the algorithm controller.
-
+TransferQueue offers **fine-grained, sample-level** data management and **load-balancing** (on the way) capabilities, serving as a data gateway that decouples explicit data dependencies across computational tasks. This enables a divide-and-conquer approach, significantly simplifies the algorithm controller design.
-  +
+ 
+ Updates
-
+ - **Nov 10, 2025**: We disentangle the data retrieval logic from TransferQueueController [PR#101](https://github.com/TransferQueue/TransferQueue/pull/101). Now you can implement your own `Sampler` to control how to consume the data.
+ - **Nov 5, 2025**: We provide a `KVStorageManager` that simplifies the integration with KV-based storage backends [PR#96](https://github.com/TransferQueue/TransferQueue/pull/96). The first available KV-based backend is [Yuanrong](https://gitee.com/openeuler/yuanrong-datasystem).
+ - **Nov 4, 2025**: Data partition capability is available in [PR#98](https://github.com/TransferQueue/TransferQueue/pull/98). Now you can define logical data partitions to manage your train/val/test datasets.
+ - **Oct 25, 2025**: We make storage backends pluggable in [PR#66](https://github.com/TransferQueue/TransferQueue/pull/66). You can try to integrate your own storage backend with TransferQueue now!
+ - **Oct 21, 2025**: Official integration into verl is ready [verl/pulls/3649](https://github.com/volcengine/verl/pull/3649). Following PRs will optimize the single controller architecture by fully decoupling data & control flows.
+ - **July 22, 2025**: We present a series of Chinese blogs on Zhihu 1, 2.
+ - **July 21, 2025**: We started an RFC on verl community [verl/RFC#2662](https://github.com/volcengine/verl/discussions/2662).
+ - **July 2, 2025**: We publish the paper [AsyncFlow](https://arxiv.org/abs/2507.01663).
Components
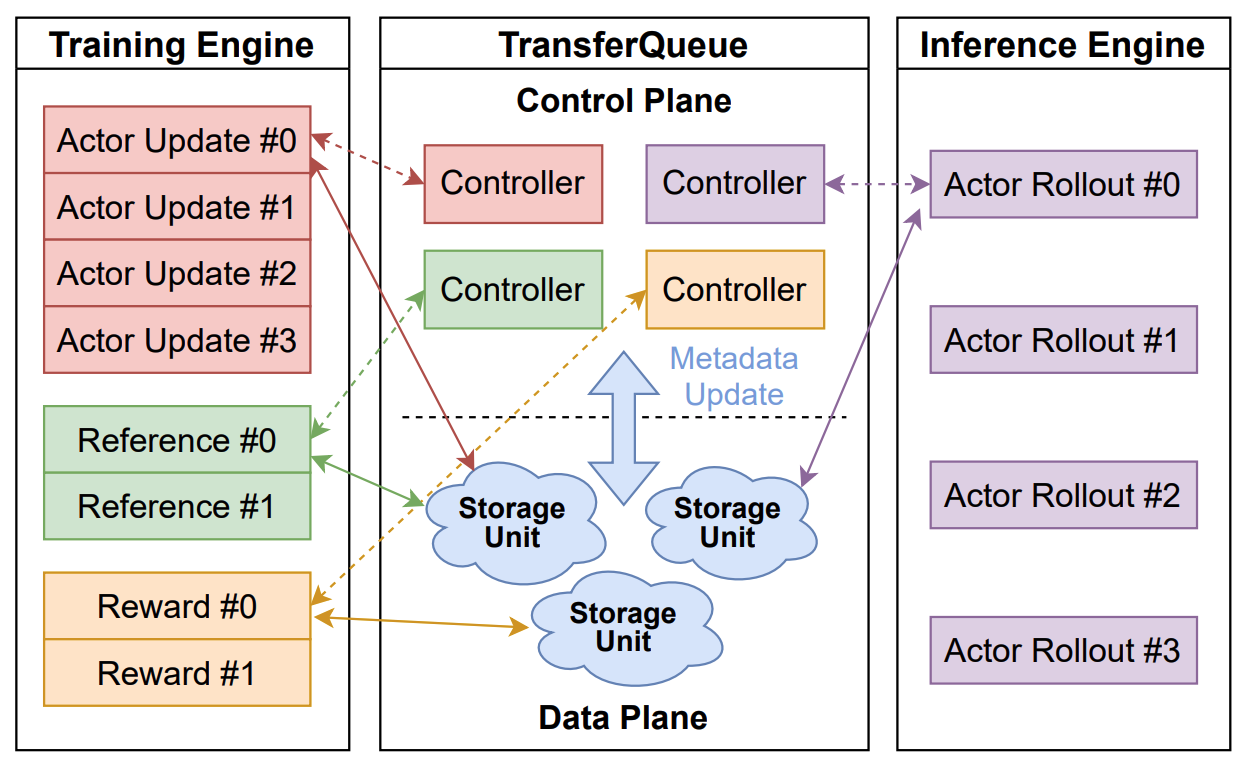
+### Control Plane: Panoramic Data Management
+In the control plane, `TransferQueueController` tracks the **production status** and **consumption status** of each training sample as metadata. When all the required data fields are ready (i.e., written to the `TransferQueueStorageManager`), we know that this data sample can be consumed by downstream tasks.
-### Control Plane: Panoramic Data Management
-
-In the control plane, `TransferQueueController` tracks the **production status** and **consumption status** of each training sample as metadata. When all the required data fields are ready (i.e., written to the `TransferQueueStorage`), we know that this data sample can be consumed by downstream tasks.
-
-For consumption status, we record the consumption records for each computational task (e.g., `generate_sequences`, `compute_log_prob`, etc.). Therefore, even different computation tasks require the same data field, they can consume the data independently without interfering with each other.
-
+For consumption status, we record the consumption records for each computational task (e.g., `generate_sequences`, `compute_log_prob`, etc.). Therefore, even when different computation tasks require the same data field, they can consume the data independently without interfering with each other.
-  +
+ 
+To make the data retrieval process more customizable, we provide a `Sampler` class that allows users to define their own data retrieval and consumption logic. Refer to the [Customize](#customize) section for details.
-> In the future, we plan to support **load-balancing** and **dynamic batching** capabilities in the control plane. Besides, we will support data management for disaggregated frameworks where each rank manages the data retrieval by itself, rather than coordinated by a single controller.
+> In the future, we plan to support **load-balancing** and **dynamic batching** capabilities in the control plane. Additionally, we will support data management for disaggregated frameworks where each rank manages the data retrieval by itself, rather than coordinated by a single controller.
### Data Plane: Distributed Data Storage
-In the data plane, `TransferQueueStorageSimpleUnit` serves as a naive storage unit based on CPU memory, responsible for the actual storage and retrieval of data. Each storage unit can be deployed on a separate node, allowing for distributed data management.
+In the data plane, we provide a pluggable design that enables TransferQueue to integrate with different storage backends according to user requirements.
+
+Specifically, we provide a `TransferQueueStorageManager` abstraction class that defines the core APIs as follows:
-`TransferQueueStorageSimpleUnit` employs a 2D data structure as follows:
+- `async def put_data(self, data: TensorDict, metadata: BatchMeta) -> None`
+- `async def get_data(self, metadata: BatchMeta) -> TensorDict`
+- `async def clear_data(self, metadata: BatchMeta) -> None`
+
+This class encapsulates the core interaction logic within the TransferQueue system. You only need to write a simple subclass to integrate your own storage backend. Refer to the [Customize](#customize) section for details.
+
+Currently, we support the following storage backends:
+
+- SimpleStorageUnit: A basic CPU memory storage with minimal data format constraints and easy usability.
+- [Yuanrong](https://gitee.com/openeuler/yuanrong-datasystem): An Ascend native data system that provides hierarchical storage interfaces including HBM/DRAM/SSD.
+- [MoonCakeStore](https://github.com/kvcache-ai/Mooncake) (WIP): A high-performance, KV-based hierarchical storage that supports RDMA transport between GPU and DRAM.
+- [Ray Direct Transport](https://docs.ray.io/en/master/ray-core/direct-transport.html) ([WIP](https://github.com/TransferQueue/TransferQueue/pull/108)): Ray's new feature that allows Ray to store and pass objects directly between Ray actors.
+
+Among them, `SimpleStorageUnit` serves as our default storage backend, coordinated by the `AsyncSimpleStorageManager` class. Each storage unit can be deployed on a separate node, allowing for distributed data management.
+
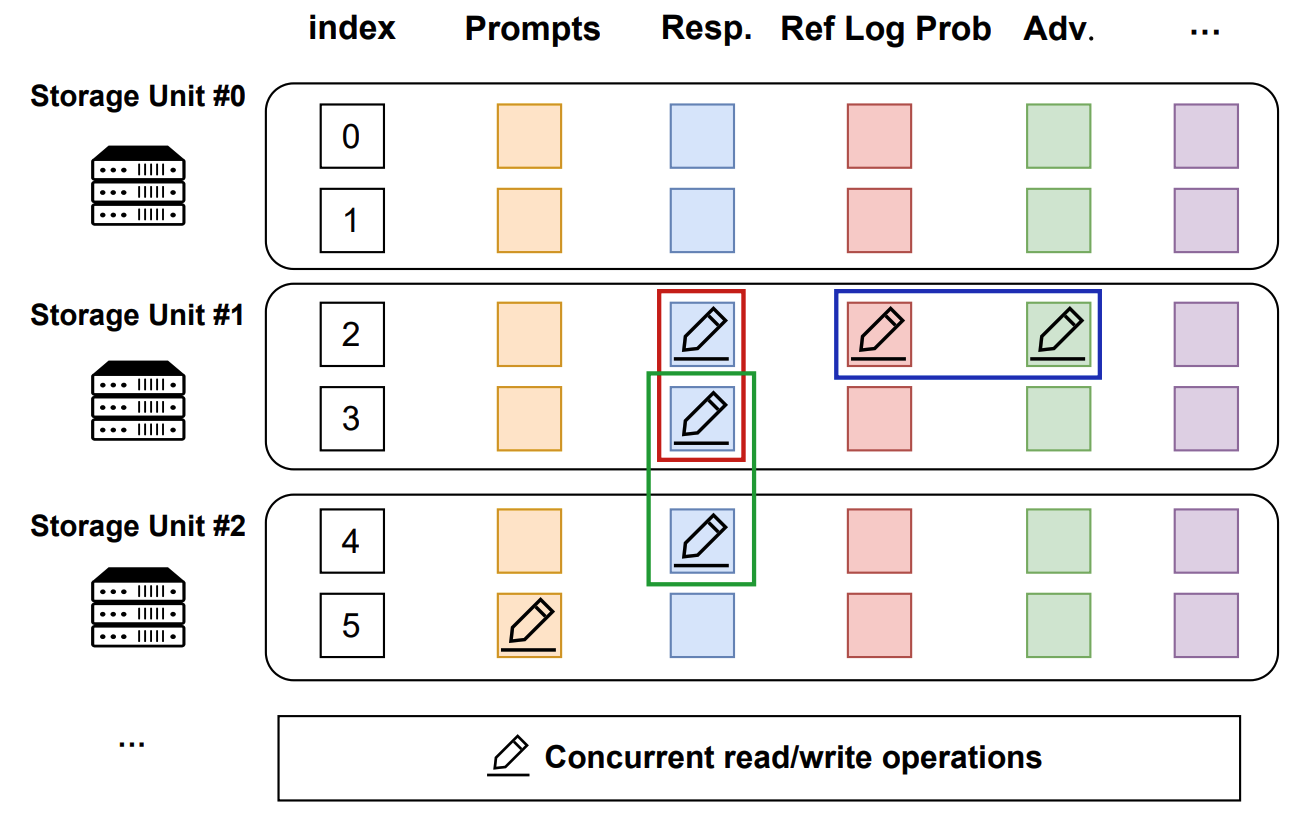
+`SimpleStorageUnit` employs a 2D data structure as follows:
- Each row corresponds to a training sample, assigned a unique index within the corresponding global batch.
- Each column represents the input/output data fields for computational tasks.
@@ -54,29 +75,22 @@ In the data plane, `TransferQueueStorageSimpleUnit` serves as a naive storage un
This data structure design is motivated by the computational characteristics of the post-training process, where each training sample is generated in a relayed manner across task pipelines. It provides an accurate addressing capability, which allows fine-grained, concurrent data read/write operations in a streaming manner.
-  +
+ 
-
-> In the future, we plan to implement a **general storage abstraction layer** to support various storage backends. Through this abstraction, we hope to integrate high-performance storage solutions such as [MoonCakeStore](https://github.com/kvcache-ai/Mooncake) to support device-to-device data transfer through RDMA, further enhancing data transfer efficiency for large-scale data.
-
-
### User Interface: Asynchronous & Synchronous Client
-
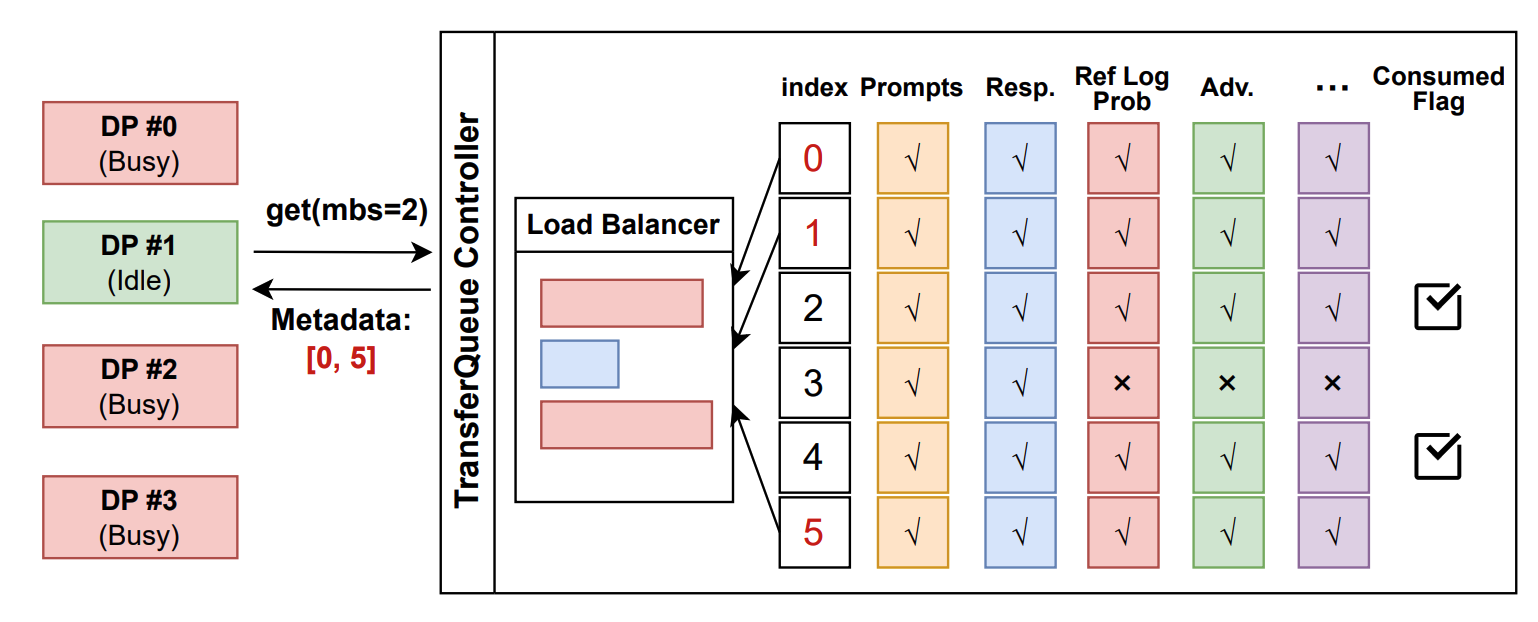
The interaction workflow of TransferQueue system is as follows:
1. A process sends a read request to the `TransferQueueController`.
2. `TransferQueueController` scans the production and consumption metadata for each sample (row), and dynamically assembles a micro-batch metadata according to the load-balancing policy. This mechanism enables sample-level data scheduling.
3. The process retrieves the actual data from distributed storage units using the metadata provided by the controller.
-To simplify the usage of TransferQueue, we have encapsulated this process into `AsyncTransferQueueClient` and `TransferQueueClient`. These clients provide both asynchronous and synchronous interfaces for data transfer, allowing users to easily integrate TransferQueue to their framework.
-
-
-> In the future, we will provide a `StreamingDataLoader` interface for disaggregated frameworks as discussed in [RFC#2662](https://github.com/volcengine/verl/discussions/2662). Leveraging this abstraction, each rank can automatically get its own data like `DataLoader` in PyTorch. The TransferQueue system will handle the underlying data scheduling and transfer logic caused by different parallelism strategies, significantly simplifying the design of disaggregated frameworks.
+To simplify the usage of TransferQueue, we have encapsulated this process into `AsyncTransferQueueClient` and `TransferQueueClient`. These clients provide both asynchronous and synchronous interfaces for data transfer, allowing users to easily integrate TransferQueue into their framework.
+> In the future, we will provide a `StreamingDataLoader` interface for disaggregated frameworks as discussed in [issue#85](https://github.com/TransferQueue/TransferQueue/issues/85) and [verl/RFC#2662](https://github.com/volcengine/verl/discussions/2662). Leveraging this abstraction, each rank can automatically get its own data like `DataLoader` in PyTorch. The TransferQueue system will handle the underlying data scheduling and transfer logic caused by different parallelism strategies, significantly simplifying the design of disaggregated frameworks.
- Show Cases
+🔥 Showcases
### General Usage
@@ -89,16 +103,15 @@ Core interfaces:
- (async_)put(data:TensorDict, metadata:BatchMeta, global_step)
- (async_)clear(global_step: int)
-
We will soon release a detailed tutorial and API documentation.
### verl Example
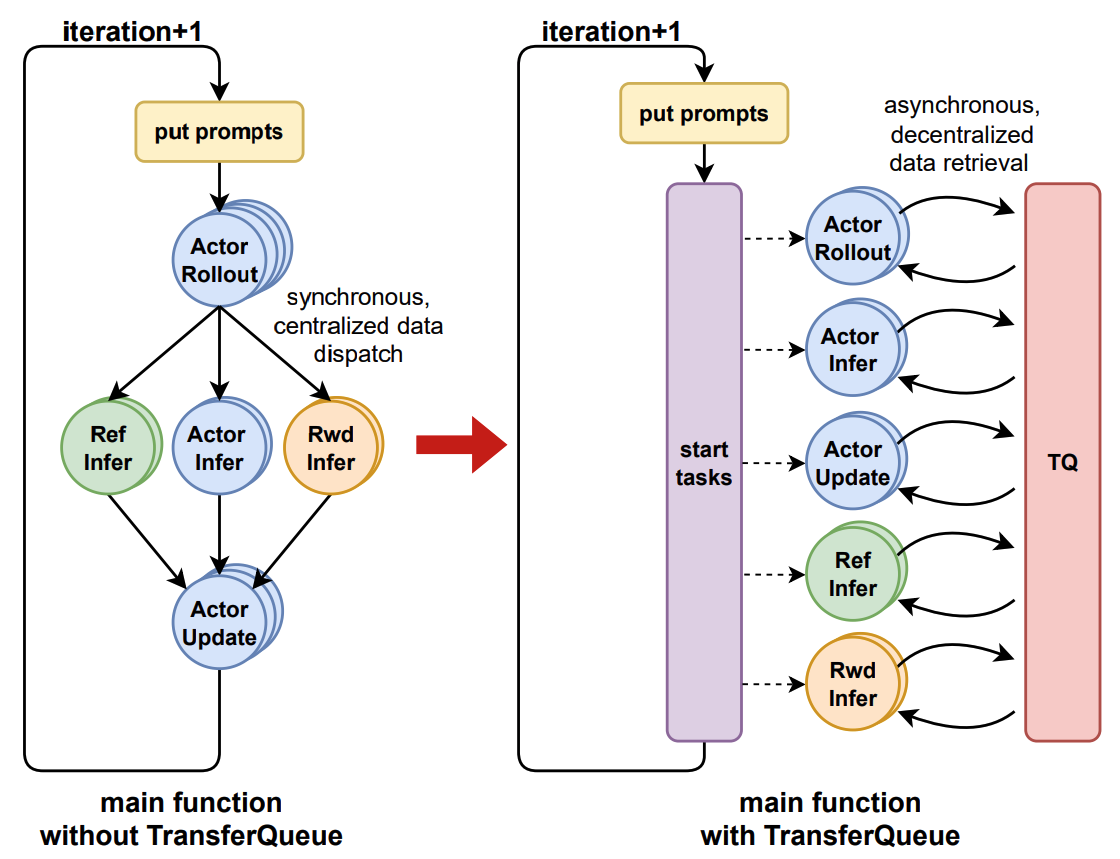
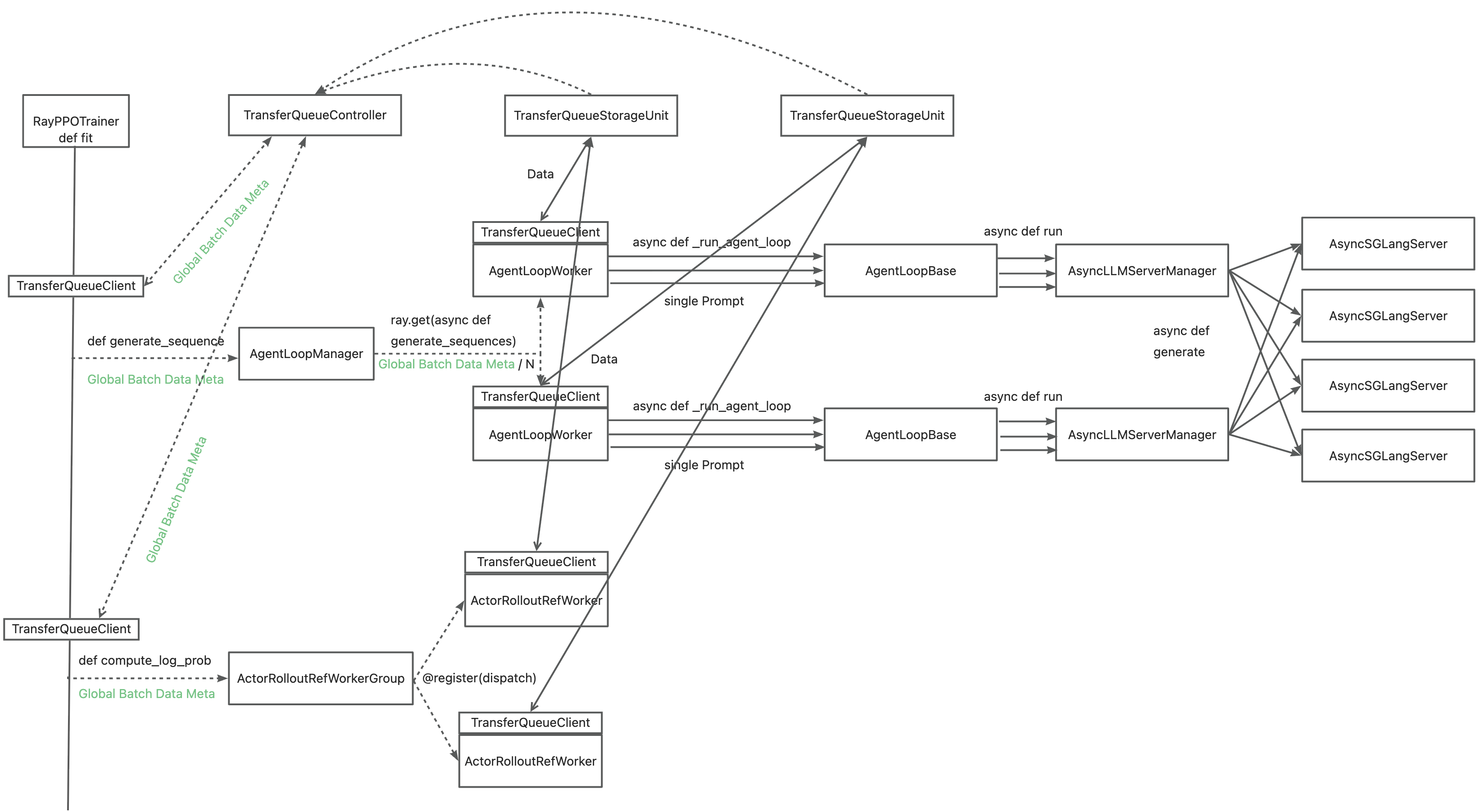
+The primary motivation for integrating TransferQueue to verl now is to **alleviate the data transfer bottleneck of the single controller `RayPPOTrainer`**. Currently, all `DataProto` objects must be routed through `RayPPOTrainer`, resulting in a single point bottleneck of the whole post-training system.
-The primary motivation for integrating TransferQueue to verl now is to **alleviate the data transfer bottleneck of the single controller `RayPPOTrainer`**. Currently, all `DataProto` objects must be routed through `RayPPOTrainer`, resulting in a single point bottleneck of the whole post-training system.
+
-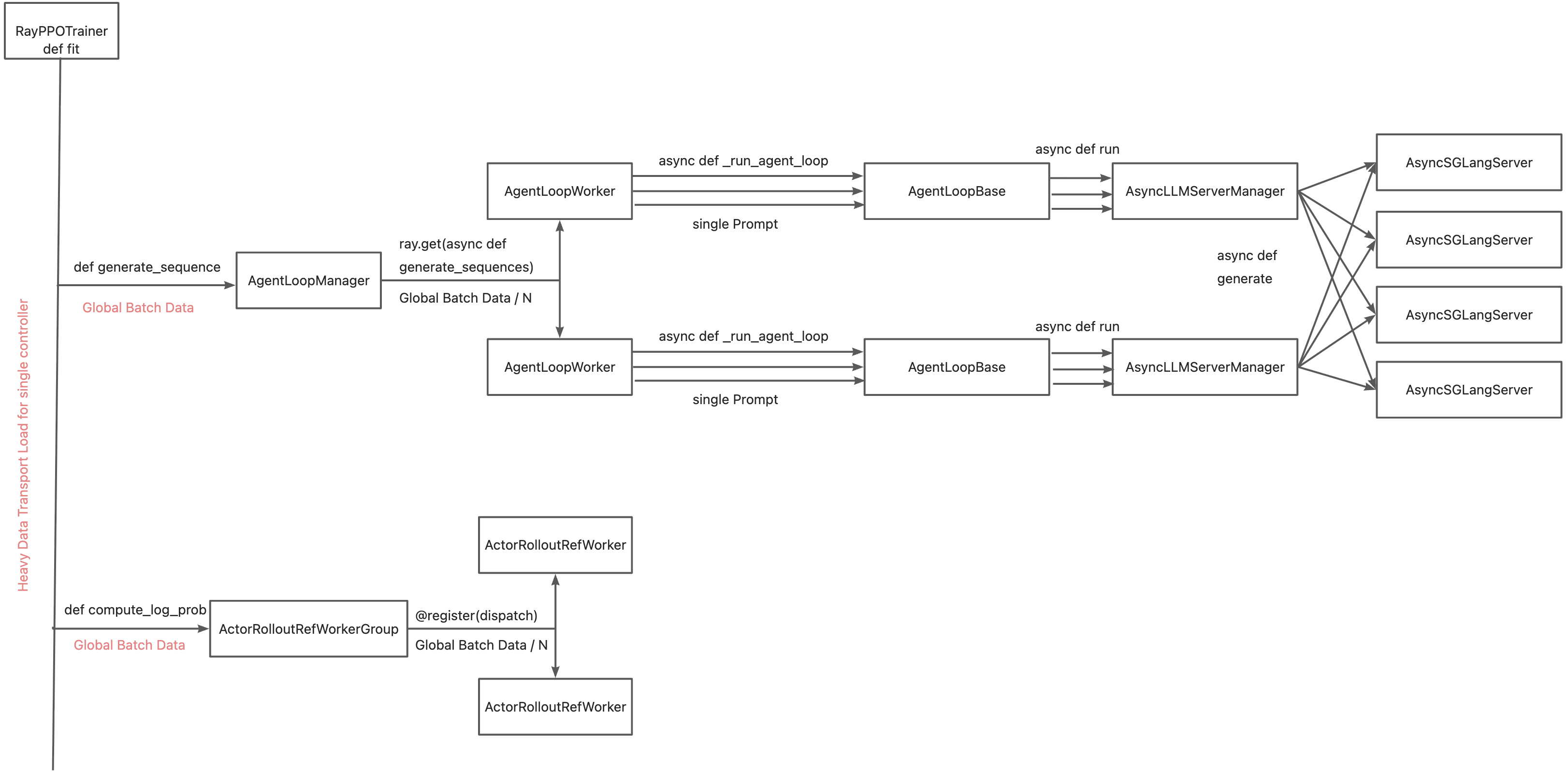
Leveraging TransferQueue, we separate experience data transfer from metadata dispatch by
@@ -106,12 +119,134 @@ Leveraging TransferQueue, we separate experience data transfer from metadata dis
- Preserving verl's original Dispatch/Collect logic via BatchMeta (maintaining single-controller debuggability)
- Accelerating data transfer by TransferQueue's distributed storage units
-
+
+
+
+You may refer to the [recipe](https://github.com/TransferQueue/TransferQueue/tree/dev/recipe/simple_use_case), where we mimic the verl usage in both async & sync scenarios. Official integration to verl is also available now at [verl/pulls/3649](https://github.com/volcengine/verl/pull/3649) (with subsequent PRs to further optimize the integration).
-You may refer to the [recipe](https://github.com/TransferQueue/TransferQueue/tree/dev/recipe/simple_use_case), where we mimic the verl usage in both async & sync scenarios.
+### Use Python package
+```bash
+pip install TransferQueue==0.1.1.dev2
+```
+### Build wheel package from source code
+
+Follow these steps to build and install:
+1. Clone the source code from the GitHub repository
+ ```bash
+ git clone https://github.com/TransferQueue/TransferQueue/
+ cd TransferQueue
+ ```
+
+2. Install dependencies
+ ```bash
+ pip install -r requirements.txt
+ ```
+
+3. Build and install
+ ```bash
+ python -m build --wheel
+ pip install dist/*.whl
+ ```
+
+
+
+
+  +
+
+> Note: The above benchmark for TransferQueue is based on our naive `SimpleStorageUnit` backend. By introducing high-performance storage backends and optimizing serialization/deserialization, we expect to achieve even better performance. Warmly welcome contributions from the community!
+
+For detailed performance benchmarks, please refer to [this blog](https://www.yuque.com/haomingzi-lfse7/hlx5g0/tml8ke0zkgn6roey?singleDoc#).
+
+ 🛠️ Customize TransferQueue
+
+### Define your own data retrieval logic
+We provide a `BaseSampler` abstraction class, which defines the following interface:
+
+```python3
+@abstractmethod
+def sample(
+ self,
+ ready_indexes: list[int],
+ batch_size: int,
+ *args: Any,
+ **kwargs: Any,
+) -> tuple[list[int], list[int]]:
+ """Sample a batch of indices from the ready indices.
+
+ Args:
+ ready_indexes: List of global indices for which all required fields of the
+ corresponding samples have been produced, and the samples are not labeled as
+ consumed in the corresponding task.
+ batch_size: Number of samples to select
+ *args: Additional positional arguments for specific sampler implementations
+ **kwargs: Additional keyword arguments for specific sampler implementations
+
+ Returns:
+ List of sampled global indices of length batch_size
+ List of global indices of length batch_size that should be labeled as consumed
+ (will never be retrieved in the future)
+
+ Raises:
+ ValueError: If batch_size is invalid or ready_indexes is insufficient
+ """
+ raise NotImplementedError("Subclasses must implement sample")
+```
+
+In this design, we separate data retrieval and data consumption through the two return values, which enables us to easily control sample replacement. We have implemented two reference designs: `SequentialSampler` and `GRPOGroupNSampler`.
+
+The `Sampler` class or instance should be passed to the `TransferQueueController` during initialization. During each `get_meta` call, you can provide dynamic sampling parameters to the `Sampler`.
+
+```python3
+from transfer_queue import TransferQueueController, TransferQueueClient, GRPOGroupNSampler, process_zmq_server_info
+
+# Option 1: Pass the sampler class to the TransferQueueController
+controller = TransferQueueController.remote(GRPOGroupNSampler)
+
+# Option 2: Pass the sampler instance to the TransferQueueController (if you need custom configuration)
+your_own_sampler = YourOwnSampler(config)
+controller = TransferQueueController.remote(your_own_sampler)
+
+# Use the sampler
+batch_meta = client.get_meta(
+ data_fields=["input_ids", "attention_mask"],
+ batch_size=8,
+ partition_id="train_0",
+ task_name="generate_sequences",
+ sampling_config={"n_samples_per_prompt": 4} # Put the required sampling parameters here
+)
+```
+
+### How to integrate a new storage backend
+
+The data plane is organized as follows:
+```text
+ transfer_queue/
+ ├── storage/
+ │ ├── __init__.py
+ │ │── simple_backend.py # SimpleStorageUnit、StorageUnitData、StorageMetaGroup
+ │ ├── managers/ # Managers are upper level interfaces that encapsulate the interaction logic with TQ system.
+ │ │ ├── __init__.py
+ │ │ ├──base.py # TransferQueueStorageManager, KVStorageManager
+ │ │ ├──simple_backend_manager.py # AsyncSimpleStorageManager
+ │ │ ├──yuanrong_manager.py # YuanrongStorageManager
+ │ │ ├──mooncake_manager.py # MooncakeStorageManager
+ │ │ └──factory.py # TransferQueueStorageManagerFactory
+ │ └── clients/ # Clients are lower level interfaces that directly manipulate the target storage backend.
+ │ │ ├── __init__.py
+ │ │ ├── base.py # TransferQueueStorageKVClient
+ │ │ ├── yuanrong_client.py # YRStorageClient
+ │ │ ├── mooncake_client.py # MooncakeStoreClient
+ │ │ └── factory.py # TransferQueueStorageClientFactory
+```
+
+To integrate TransferQueue with a custom storage backend, start by implementing a subclass that inherits from `TransferQueueStorageManager`. This subclass acts as an adapter between the TransferQueue system and the target storage backend. For KV-based storage backends, you can simply inherit from `KVStorageManager`, which can serve as the general manager for all KV-based backends.
+
+Distributed storage backends often come with their own native clients serving as the interface of the storage system. In such cases, a low-level adapter for this client can be written, following the examples provided in the `storage/clients` directory.
+
+Factory classes are provided for both `StorageManager` and `StorageClient` to facilitate easy integration. Adding necessary descriptions of required parameters in the factory class helps enhance the overall user experience.
diff --git a/recipe/transfer_queue/agent_loop.py b/recipe/transfer_queue/agent_loop.py
index 871ae8025c0..6e38a954fb7 100644
--- a/recipe/transfer_queue/agent_loop.py
+++ b/recipe/transfer_queue/agent_loop.py
@@ -16,7 +16,6 @@
from transfer_queue import BatchMeta
import verl.experimental.agent_loop.agent_loop as agent_loop
-from verl import DataProto
class AgentLoopManager(agent_loop.AgentLoopManager):
@@ -30,12 +29,11 @@ def generate_sequences(self, prompts: BatchMeta) -> BatchMeta:
BatchMeta: Output batch metadata.
"""
- if self.rm_micro_batch_size and len(prompts) % self.rm_micro_batch_size != 0:
- raise ValueError(
- f"The length of prompts {len(prompts)} cannot divide the world size of rm_wg {self.rm_micro_batch_size}"
- )
if self.config.actor_rollout_ref.rollout.free_cache_engine:
self.wake_up()
+ if self.reward_model_manager and self.config.reward_model.rollout.free_cache_engine:
+ self.reward_model_manager.wake_up()
+
chunkes = prompts.chunk(len(self.agent_loop_workers))
outputs = ray.get(
[
@@ -46,6 +44,8 @@ def generate_sequences(self, prompts: BatchMeta) -> BatchMeta:
output = BatchMeta.concat(outputs)
if self.config.actor_rollout_ref.rollout.free_cache_engine:
self.sleep()
+ if self.reward_model_manager and self.config.reward_model.rollout.free_cache_engine:
+ self.reward_model_manager.sleep()
# calculate performance metrics
metrics = [output.extra_info.pop("metrics") for output in outputs] # List[List[Dict[str, str]]]
@@ -54,7 +54,7 @@ def generate_sequences(self, prompts: BatchMeta) -> BatchMeta:
output.set_extra_info("timing", timing)
return output
- def _performance_metrics(self, metrics: list[list[dict[str, str]]], output: DataProto) -> dict[str, float]:
+ def _performance_metrics(self, metrics: list[list[dict[str, str]]], output: BatchMeta) -> dict[str, float]:
timing = {}
t_generate_sequences = np.array([metric["generate_sequences"] for chunk in metrics for metric in chunk])
t_tool_calls = np.array([metric["tool_calls"] for chunk in metrics for metric in chunk])
@@ -65,12 +65,19 @@ def _performance_metrics(self, metrics: list[list[dict[str, str]]], output: Data
timing["agent_loop/tool_calls/max"] = t_tool_calls.max()
timing["agent_loop/tool_calls/mean"] = t_tool_calls.mean()
+ # TODO (TQ): pass tq info throughout AgentLoop so we can retrieve tensor for these metrics
+ # batch sequence generation is bounded by the slowest sample
+ # slowest = np.argmax(t_generate_sequences + t_tool_calls)
+ # attention_mask = output.extra_info.pop("attention_mask_perf")[slowest]
+ # prompt_length = output.extra_info.pop("prompts_perf").shape[1]
+ # timing["agent_loop/slowest/generate_sequences"] = t_generate_sequences[slowest]
+ # timing["agent_loop/slowest/tool_calls"] = t_tool_calls[slowest]
+ # timing["agent_loop/slowest/prompt_length"] = attention_mask[:prompt_length].sum().item()
+ # timing["agent_loop/slowest/response_length"] = attention_mask[prompt_length:].sum().item()
+
return timing
- def create_transferqueue_client(self, controller_infos, storage_infos, role):
+ def create_transferqueue_client(self, controller_info, config):
ray.get(
- [
- worker.create_transferqueue_client.remote(controller_infos, storage_infos, role)
- for worker in self.agent_loop_workers
- ]
+ [worker.create_transferqueue_client.remote(controller_info, config) for worker in self.agent_loop_workers]
)
diff --git a/recipe/transfer_queue/config/transfer_queue_ppo_megatron_trainer.yaml b/recipe/transfer_queue/config/transfer_queue_ppo_megatron_trainer.yaml
new file mode 100644
index 00000000000..61dffe6595a
--- /dev/null
+++ b/recipe/transfer_queue/config/transfer_queue_ppo_megatron_trainer.yaml
@@ -0,0 +1,11 @@
+hydra:
+ searchpath:
+ - file://verl/trainer/config
+
+defaults:
+ - ppo_megatron_trainer
+ - _self_
+
+# config for TransferQueue
+transfer_queue:
+ enable: True
diff --git a/recipe/transfer_queue/ray_trainer.py b/recipe/transfer_queue/ray_trainer.py
index d6adbddb676..86d6b9ed5e3 100644
--- a/recipe/transfer_queue/ray_trainer.py
+++ b/recipe/transfer_queue/ray_trainer.py
@@ -41,8 +41,8 @@
from tqdm import tqdm
from transfer_queue import (
BatchMeta,
+ SimpleStorageUnit,
TransferQueueController,
- TransferQueueStorageSimpleUnit,
get_placement_group,
process_zmq_server_info,
)
@@ -81,6 +81,7 @@
from verl.utils.metric import reduce_metrics
from verl.utils.rollout_skip import RolloutSkip
from verl.utils.seqlen_balancing import (
+ calculate_workload,
get_seqlen_balanced_partitions,
log_seqlen_unbalance,
)
@@ -89,7 +90,6 @@
from verl.utils.transferqueue_utils import (
create_transferqueue_client,
get_transferqueue_client,
- get_val_transferqueue_client,
tqbridge,
)
@@ -412,109 +412,62 @@ def __init__(
self._create_dataloader(train_dataset, val_dataset, collate_fn, train_sampler)
- self.data_system_client = self._initialize_train_data_system(
- self.config.data.train_batch_size, self.config.actor_rollout_ref.rollout.n
- )
- self.val_data_system_client = self._initialize_val_data_system(
- self.val_batch_size, self.config.actor_rollout_ref.rollout.val_kwargs.n
- )
+ self.data_system_client = self._initialize_data_system()
- def _initialize_train_data_system(self, global_batch_size, num_n_samples, role="train"):
+ def _initialize_data_system(self):
# 1. initialize TransferQueueStorage
- total_storage_size = global_batch_size * self.config.trainer.num_global_batch * num_n_samples
+ train_data_size = (
+ self.config.data.train_batch_size
+ * self.config.trainer.num_global_batch
+ * self.config.actor_rollout_ref.rollout.n
+ )
+ val_data_size = self.val_dataset_size * self.config.actor_rollout_ref.rollout.val_kwargs.n
+
+ total_storage_size = train_data_size + val_data_size
self.data_system_storage_units = {}
storage_placement_group = get_placement_group(self.config.trainer.num_data_storage_units, num_cpus_per_actor=1)
for storage_unit_rank in range(self.config.trainer.num_data_storage_units):
- storage_node = TransferQueueStorageSimpleUnit.options(
+ storage_node = SimpleStorageUnit.options(
placement_group=storage_placement_group, placement_group_bundle_index=storage_unit_rank
- ).remote(storage_size=math.ceil(total_storage_size / self.config.trainer.num_data_storage_units))
+ ).remote(storage_unit_size=math.ceil(total_storage_size / self.config.trainer.num_data_storage_units))
self.data_system_storage_units[storage_unit_rank] = storage_node
- logging.info(f"TransferQueueStorageSimpleUnit #{storage_unit_rank} has been created.")
-
- # 2. initialize TransferQueueController
- # we support inilialize multiple controller instances for large-scale scenario. Please allocate exactly
- # one controller for a single WorkerGroup.
- self.data_system_controllers = {}
- controller_placement_group = get_placement_group(self.config.trainer.num_data_controllers, num_cpus_per_actor=1)
- for controller_rank in range(self.config.trainer.num_data_controllers):
- self.data_system_controllers[controller_rank] = TransferQueueController.options(
- placement_group=controller_placement_group, placement_group_bundle_index=controller_rank
- ).remote(
- num_storage_units=self.config.trainer.num_data_storage_units,
- global_batch_size=global_batch_size,
- num_global_batch=self.config.trainer.num_global_batch,
- num_n_samples=num_n_samples,
- )
- logging.info(f"TransferQueueController #{controller_rank} has been created.")
+ logging.info(f"SimpleStorageUnit #{storage_unit_rank} has been created.")
- # 3. register controller & storage
- self.data_system_controller_infos = process_zmq_server_info(self.data_system_controllers)
- self.data_system_storage_unit_infos = process_zmq_server_info(self.data_system_storage_units)
+ # 2. Initialize TransferQueueController (single controller only)
- ray.get(
- [
- storage_unit.register_controller_info.remote(self.data_system_controller_infos)
- for storage_unit in self.data_system_storage_units.values()
- ]
- )
+ # Sampler usage instructions:
+ # For GRPO grouped sampling, you can initialize the controller with GRPOGroupNSampler:
+ # Option 1: Pass sampler class (will be instantiated automatically)
+ # self.data_system_controller = TransferQueueController.remote(sampler=GRPOGroupNSampler)
- # 4. create client
- # each client should be allocated to exactly one controller
- create_transferqueue_client(
- client_id="Trainer-" + role,
- controller_infos=self.data_system_controller_infos,
- storage_infos=self.data_system_storage_unit_infos,
- )
- data_system_client = get_transferqueue_client()
- return data_system_client
+ # Option 2: Pass sampler instance (if you need custom configuration)
+ # grpo_sampler = GRPOGroupNSampler()
+ # self.data_system_controller = TransferQueueController.remote(sampler=grpo_sampler)
- def _initialize_val_data_system(self, global_batch_size, num_n_samples, role="val"):
- # 1. initialize TransferQueueStorage
- total_storage_size = global_batch_size * self.config.trainer.num_global_batch * num_n_samples
- self.val_data_system_storage_units = {}
- storage_placement_group = get_placement_group(self.config.trainer.num_data_storage_units, num_cpus_per_actor=1)
- for storage_unit_rank in range(self.config.trainer.num_data_storage_units):
- storage_node = TransferQueueStorageSimpleUnit.options(
- placement_group=storage_placement_group, placement_group_bundle_index=storage_unit_rank
- ).remote(storage_size=math.ceil(total_storage_size / self.config.trainer.num_data_storage_units))
- self.val_data_system_storage_units[storage_unit_rank] = storage_node
- logging.info(f"TransferQueueStorageSimpleUnit #{storage_unit_rank} has been created.")
-
- # 2. initialize TransferQueueController
- # we support inilialize multiple controller instances for large-scale scenario. Please allocate exactly
- # one controller for a single WorkerGroup.
- self.val_data_system_controllers = {}
- controller_placement_group = get_placement_group(self.config.trainer.num_data_controllers, num_cpus_per_actor=1)
- for controller_rank in range(self.config.trainer.num_data_controllers):
- self.val_data_system_controllers[controller_rank] = TransferQueueController.options(
- placement_group=controller_placement_group, placement_group_bundle_index=controller_rank
- ).remote(
- num_storage_units=self.config.trainer.num_data_storage_units,
- global_batch_size=global_batch_size,
- num_global_batch=self.config.trainer.num_global_batch,
- num_n_samples=num_n_samples,
- )
- logging.info(f"TransferQueueController #{controller_rank} has been created.")
+ # Then use sampling_config in get_meta calls:
+ # sampling_config={"n_samples_per_prompt": 4}
+ self.data_system_controller = TransferQueueController.remote()
+ logging.info("TransferQueueController has been created.")
- # 3. register controller & storage
- self.val_data_system_controller_infos = process_zmq_server_info(self.val_data_system_controllers)
- self.val_data_system_storage_unit_infos = process_zmq_server_info(self.val_data_system_storage_units)
+ # 3. register controller & storage and prepare necessary information
+ self.data_system_controller_info = process_zmq_server_info(self.data_system_controller)
+ self.data_system_storage_unit_infos = process_zmq_server_info(self.data_system_storage_units)
- ray.get(
- [
- storage_unit.register_controller_info.remote(self.val_data_system_controller_infos)
- for storage_unit in self.val_data_system_storage_units.values()
- ]
- )
+ # Note: Need to generate a new DictConfig with allow_objects=True to preserve ZMQServerInfo instances
+ # (which contain socket connection details). Without this flag, OmegaConf would flatten these objects to dicts,
+ # breaking the transfer queue client initialization.
+ tq_config = OmegaConf.create({}, flags={"allow_objects": True})
+ tq_config.controller_info = self.data_system_controller_info
+ tq_config.storage_unit_infos = self.data_system_storage_unit_infos
+ self.config = OmegaConf.merge(tq_config, self.config)
# 4. create client
- # each client should be allocated to exactly one controller
create_transferqueue_client(
- client_id="Trainer-" + role,
- controller_infos=self.val_data_system_controller_infos,
- storage_infos=self.val_data_system_storage_unit_infos,
+ client_id="Trainer",
+ controller_info=self.data_system_controller_info,
+ config=self.config,
)
- data_system_client = get_val_transferqueue_client()
+ data_system_client = get_transferqueue_client()
return data_system_client
def _create_dataloader(self, train_dataset, val_dataset, collate_fn, train_sampler: Optional[Sampler]):
@@ -534,6 +487,8 @@ def _create_dataloader(self, train_dataset, val_dataset, collate_fn, train_sampl
)
self.train_dataset, self.val_dataset = train_dataset, val_dataset
+ self.val_dataset_size = len(val_dataset)
+
if train_sampler is None:
train_sampler = create_rl_sampler(self.config.data, self.train_dataset)
if collate_fn is None:
@@ -726,19 +681,18 @@ def _validate(self):
if self.config.reward_model.enable and test_batch[0]["reward_model"]["style"] == "model":
return {}
- asyncio.run(self.val_data_system_client.async_put(data=test_batch, global_step=self.global_steps - 1))
+ asyncio.run(self.data_system_client.async_put(data=test_batch, partition_id=f"val_{self.global_steps - 1}"))
# Store original inputs
batch_meta = asyncio.run(
- self.val_data_system_client.async_get_meta(
+ self.data_system_client.async_get_meta(
data_fields=["input_ids", "uid", "reward_model"],
- batch_size=self.val_batch_size * self.config.actor_rollout_ref.rollout.val_kwargs.n,
- global_step=self.global_steps - 1,
- get_n_samples=False,
+ batch_size=test_batch.batch_size[0],
+ partition_id=f"val_{self.global_steps - 1}",
task_name="get_data",
)
)
- data = asyncio.run(self.val_data_system_client.async_get_data(batch_meta))
+ data = asyncio.run(self.data_system_client.async_get_data(batch_meta))
input_ids = data["input_ids"]
# TODO: Can we keep special tokens except for padding tokens?
input_texts = [self.tokenizer.decode(ids, skip_special_tokens=True) for ids in input_ids]
@@ -749,11 +703,10 @@ def _validate(self):
sample_gts.extend(ground_truths)
test_gen_meta = asyncio.run(
- self.val_data_system_client.async_get_meta(
+ self.data_system_client.async_get_meta(
data_fields=list(test_batch.keys()), # TODO: (TQ) Get metadata by specified fields
- batch_size=self.val_batch_size * self.config.actor_rollout_ref.rollout.val_kwargs.n,
- global_step=self.global_steps - 1, # self.global_steps start from 1
- get_n_samples=False,
+ batch_size=test_batch.batch_size[0],
+ partition_id=f"val_{self.global_steps - 1}", # self.global_steps start from 1
task_name="generate_sequences",
)
)
@@ -779,15 +732,14 @@ def _validate(self):
# Store generated outputs
test_response_meta = asyncio.run(
- self.val_data_system_client.async_get_meta(
+ self.data_system_client.async_get_meta(
data_fields=["responses"],
- batch_size=self.val_batch_size * self.config.actor_rollout_ref.rollout.val_kwargs.n,
- global_step=self.global_steps - 1, # self.global_steps start from 1
- get_n_samples=False,
+ batch_size=test_batch.batch_size[0],
+ partition_id=f"val_{self.global_steps - 1}", # self.global_steps start from 1
task_name="get_response",
)
)
- data = asyncio.run(self.val_data_system_client.async_get_data(test_response_meta))
+ data = asyncio.run(self.data_system_client.async_get_data(test_response_meta))
output_ids = data["responses"]
output_texts = [self.tokenizer.decode(ids, skip_special_tokens=True) for ids in output_ids]
sample_outputs.extend(output_texts)
@@ -808,11 +760,10 @@ def _validate(self):
if "rm_scores" in batch_meta.field_names:
compute_reward_fields = ["rm_scores"]
val_reward_meta = asyncio.run(
- self.val_data_system_client.async_get_meta(
+ self.data_system_client.async_get_meta(
data_fields=compute_reward_fields,
- batch_size=self.val_batch_size * self.config.actor_rollout_ref.rollout.val_kwargs.n,
- global_step=self.global_steps - 1,
- get_n_samples=False,
+ batch_size=test_batch.batch_size[0],
+ partition_id=f"val_{self.global_steps - 1}",
task_name="compute_reward",
)
)
@@ -832,33 +783,33 @@ def _validate(self):
# collect num_turns of each prompt
if "__num_turns__" in test_batch_meta.field_names:
num_turns_meta = asyncio.run(
- self.val_data_system_client.async_get_meta(
+ self.data_system_client.async_get_meta(
data_fields=["__num_turns__"],
- batch_size=self.val_batch_size * self.config.actor_rollout_ref.rollout.val_kwargs.n,
- global_step=self.global_steps - 1, # self.global_steps start from 1
- get_n_samples=False,
+ batch_size=test_batch.batch_size[0],
+ partition_id=f"val_{self.global_steps - 1}", # self.global_steps start from 1
task_name="get_num_turns",
)
)
- data = asyncio.run(self.val_data_system_client.async_get_data(num_turns_meta))
+ data = asyncio.run(self.data_system_client.async_get_data(num_turns_meta))
sample_turns.append(data["__num_turns__"])
data_source = ["unknown"] * reward_tensor.shape[0]
if "data_source" in test_batch_meta.field_names:
data_source_meta = asyncio.run(
- self.val_data_system_client.async_get_meta(
+ self.data_system_client.async_get_meta(
data_fields=["data_source"],
- batch_size=self.val_batch_size * self.config.actor_rollout_ref.rollout.val_kwargs.n,
- global_step=self.global_steps - 1, # self.global_steps start from 1
- get_n_samples=False,
+ batch_size=test_batch.batch_size[0],
+ partition_id=f"val_{self.global_steps - 1}", # self.global_steps start from 1
task_name="get_data_source",
)
)
- data = asyncio.run(self.val_data_system_client.async_get_data(data_source_meta))
+ data = asyncio.run(self.data_system_client.async_get_data(data_source_meta))
data_source = data["data_source"]
data_source_lst.append(data_source)
+ asyncio.run(self.data_system_client.async_clear(partition_id=f"val_{self.global_steps - 1}"))
+
self._maybe_log_val_generations(inputs=sample_inputs, outputs=sample_outputs, scores=sample_scores)
# dump generations
@@ -902,7 +853,7 @@ def _validate(self):
metric_dict["val-aux/num_turns/max"] = sample_turns.max()
metric_dict["val-aux/num_turns/mean"] = sample_turns.mean()
- asyncio.run(self.val_data_system_client.async_clear(self.global_steps - 1))
+ asyncio.run(self.data_system_client.async_clear(partition_id=f"val_{self.global_steps - 1}"))
return metric_dict
def init_workers(self):
@@ -1003,12 +954,7 @@ def init_workers(self):
# set transferqueue server info for each worker
for _, wg in all_wg.items():
- wg.create_transferqueue_client(
- self.data_system_controller_infos, self.data_system_storage_unit_infos, role="train"
- )
- wg.create_transferqueue_client(
- self.val_data_system_controller_infos, self.val_data_system_storage_unit_infos, role="val"
- )
+ wg.create_transferqueue_client(self.data_system_controller_info, self.config)
# create async rollout manager and request scheduler
self.async_rollout_mode = False
@@ -1020,12 +966,7 @@ def init_workers(self):
config=self.config, worker_group=self.actor_rollout_wg, rm_wg=self.rm_wg
)
- self.async_rollout_manager.create_transferqueue_client(
- self.data_system_controller_infos, self.data_system_storage_unit_infos, role="train"
- )
- self.async_rollout_manager.create_transferqueue_client(
- self.val_data_system_controller_infos, self.val_data_system_storage_unit_infos, role="val"
- )
+ self.async_rollout_manager.create_transferqueue_client(self.data_system_controller_info, self.config)
def _save_checkpoint(self):
from verl.utils.fs import local_mkdir_safe
@@ -1164,17 +1105,41 @@ def _stop_profiling(self, do_profile: bool) -> None:
if self.use_rm:
self.rm_wg.stop_profile()
- def _balance_batch(self, batch: BatchMeta, data_system_client, metrics, logging_prefix="global_seqlen"):
+ def _balance_batch(
+ self, batch: BatchMeta, data_system_client, metrics, logging_prefix="global_seqlen", keep_minibatch=False
+ ):
"""Reorder the batchmeta on single controller such that each dp rank gets similar total tokens"""
data = asyncio.run(data_system_client.async_get_data(batch))
attention_mask = data["attention_mask"]
batch_size = attention_mask.shape[0]
- global_seqlen_lst = data["attention_mask"].view(batch_size, -1).sum(-1).tolist() # (train_batch_size,)
+ global_seqlen_lst = data["attention_mask"].view(batch_size, -1).sum(-1) # (train_batch_size,)
+ global_seqlen_lst = calculate_workload(global_seqlen_lst)
world_size = self.actor_rollout_wg.world_size
- global_partition_lst = get_seqlen_balanced_partitions(
- global_seqlen_lst, k_partitions=world_size, equal_size=True
- )
+ if keep_minibatch:
+ # Decouple the DP balancing and mini-batching.
+ minibatch_size = self.config.actor_rollout_ref.actor.get("ppo_mini_batch_size", None)
+ if minibatch_size is None:
+ raise ValueError("'ppo_mini_batch_size' must be set in actor config when 'keep_minibatch' is True.")
+ minibatch_num = len(global_seqlen_lst) // minibatch_size
+ global_partition_lst = [[] for _ in range(world_size)]
+ for i in range(minibatch_num):
+ rearrange_minibatch_lst = get_seqlen_balanced_partitions(
+ global_seqlen_lst[i * minibatch_size : (i + 1) * minibatch_size],
+ k_partitions=world_size,
+ equal_size=True,
+ )
+ for j, part in enumerate(rearrange_minibatch_lst):
+ global_partition_lst[j].extend([x + minibatch_size * i for x in part])
+ else:
+ global_partition_lst = get_seqlen_balanced_partitions(
+ global_seqlen_lst, k_partitions=world_size, equal_size=True
+ )
+ # Place smaller micro-batches at both ends to reduce the bubbles in pipeline parallel.
+ for idx, partition in enumerate(global_partition_lst):
+ partition.sort(key=lambda x: (global_seqlen_lst[x], x))
+ ordered_partition = partition[::2] + partition[1::2][::-1]
+ global_partition_lst[idx] = ordered_partition
# reorder based on index. The data will be automatically equally partitioned by dispatch function
global_idx = [j for partition in global_partition_lst for j in partition]
global_balance_stats = log_seqlen_unbalance(
@@ -1313,8 +1278,7 @@ def fit(self):
timing_raw = {}
base_get_meta_kwargs = dict(
batch_size=self.config.data.train_batch_size * self.config.actor_rollout_ref.rollout.n,
- global_step=self.global_steps - 1, # self.global_steps starts from 1
- get_n_samples=False,
+ partition_id=f"train_{self.global_steps - 1}", # self.global_steps starts from 1
)
with marked_timer("start_profile", timing_raw):
@@ -1333,7 +1297,9 @@ def fit(self):
batch_dict, repeat_times=self.config.actor_rollout_ref.rollout.n, interleave=True
)
batch: TensorDict = self.dict_to_tensordict(repeated_batch_dict)
- asyncio.run(self.data_system_client.async_put(data=batch, global_step=self.global_steps - 1))
+ asyncio.run(
+ self.data_system_client.async_put(data=batch, partition_id=f"train_{self.global_steps - 1}")
+ )
gen_meta = asyncio.run(
self.data_system_client.async_get_meta(
@@ -1709,8 +1675,7 @@ def fit(self):
],
batch_size=self.config.data.train_batch_size
* self.config.actor_rollout_ref.rollout.n,
- global_step=self.global_steps - 1,
- get_n_samples=False,
+ partition_id=f"train_{self.global_steps - 1}",
task_name="update_actor",
)
)
@@ -1735,8 +1700,7 @@ def fit(self):
self.data_system_client.async_get_meta(
data_fields=data_fields,
batch_size=self.config.data.train_batch_size * self.config.actor_rollout_ref.rollout.n,
- global_step=self.global_steps - 1,
- get_n_samples=False,
+ partition_id=f"train_{self.global_steps - 1}",
task_name="log_rollout",
)
)
@@ -1857,7 +1821,7 @@ def fit(self):
# TODO: (TQ) support transfer queue
self.train_dataloader.sampler.update(batch=batch)
- asyncio.run(self.data_system_client.async_clear(self.global_steps - 1))
+ asyncio.run(self.data_system_client.async_clear(partition_id=f"train_{self.global_steps - 1}"))
# TODO: make a canonical logger that supports various backend
logger.log(data=metrics, step=self.global_steps)
diff --git a/recipe/transfer_queue/run_qwen3-8b_transferqueue.sh b/recipe/transfer_queue/run_qwen3-8b_transferqueue.sh
new file mode 100644
index 00000000000..26edb250029
--- /dev/null
+++ b/recipe/transfer_queue/run_qwen3-8b_transferqueue.sh
@@ -0,0 +1,69 @@
+set -x
+
+MODEL_PATH="/workspace/models/Qwen3-8B"
+TRAIN_FILE="/workspace/datasets/preprocessed/gsm8k/train.parquet"
+TEST_FILE="/workspace/datasets/preprocessed/gsm8k/test.parquet"
+
+log_dir="./logs"
+mkdir -p ${log_dir}
+timestamp=$(date +"%Y%m%d%H%M%S")
+log_file="${log_dir}/qwen3-8b_tq_${timestamp}.log"
+
+rollout_mode="async"
+rollout_name="vllm" # sglang or vllm
+if [ "$rollout_mode" = "async" ]; then
+ export VLLM_USE_V1=1
+ return_raw_chat="True"
+fi
+
+# You may also refer to tests/special_e2e/run_transferqueue.sh for more demo scripts
+
+python3 -m recipe.transfer_queue.main_ppo \
+ --config-name='transfer_queue_ppo_trainer' \
+ algorithm.adv_estimator=grpo \
+ data.train_files=${TRAIN_FILE} \
+ data.val_files=${TEST_FILE} \
+ data.return_raw_chat=$return_raw_chat \
+ data.train_batch_size=128 \
+ data.max_prompt_length=2048 \
+ data.max_response_length=8192 \
+ data.filter_overlong_prompts_workers=128 \
+ data.filter_overlong_prompts=True \
+ data.truncation='error' \
+ actor_rollout_ref.model.path=${MODEL_PATH} \
+ actor_rollout_ref.actor.optim.lr=1e-6 \
+ actor_rollout_ref.model.use_remove_padding=True \
+ actor_rollout_ref.actor.ppo_mini_batch_size=32 \
+ actor_rollout_ref.actor.ppo_micro_batch_size_per_gpu=4 \
+ actor_rollout_ref.actor.use_kl_loss=True \
+ actor_rollout_ref.actor.kl_loss_coef=0.001 \
+ actor_rollout_ref.actor.kl_loss_type=low_var_kl \
+ actor_rollout_ref.actor.entropy_coeff=0 \
+ actor_rollout_ref.model.enable_gradient_checkpointing=True \
+ actor_rollout_ref.actor.fsdp_config.param_offload=True \
+ actor_rollout_ref.actor.fsdp_config.optimizer_offload=True \
+ actor_rollout_ref.rollout.log_prob_micro_batch_size_per_gpu=4 \
+ actor_rollout_ref.rollout.tensor_model_parallel_size=4 \
+ actor_rollout_ref.rollout.max_num_batched_tokens=10240 \
+ actor_rollout_ref.rollout.name=$rollout_name \
+ actor_rollout_ref.rollout.mode=$rollout_mode \
+ actor_rollout_ref.rollout.gpu_memory_utilization=0.8 \
+ actor_rollout_ref.rollout.n=5 \
+ actor_rollout_ref.ref.log_prob_micro_batch_size_per_gpu=8 \
+ actor_rollout_ref.ref.fsdp_config.param_offload=True \
+ algorithm.use_kl_in_reward=False \
+ trainer.critic_warmup=0 \
+ trainer.logger=console \
+ trainer.project_name='verl_grpo_example_gsm8k' \
+ trainer.experiment_name='qwen3_8b_function_rm' \
+ trainer.n_gpus_per_node=8 \
+ trainer.nnodes=1 \
+ trainer.save_freq=-1 \
+ trainer.test_freq=1000 \
+ trainer.total_epochs=15 \
+ trainer.total_training_steps=2 \
+ trainer.val_before_train=False \
+ +trainer.num_global_batch=1 \
+ +trainer.num_data_storage_units=8 \
+ 2>&1 | tee "$log_file"
+echo "Finished, log is saved in: $log_file"
\ No newline at end of file
diff --git a/recipe/transfer_queue/run_qwen3-8b_transferqueue_npu.sh b/recipe/transfer_queue/run_qwen3-8b_transferqueue_npu.sh
deleted file mode 100644
index 70b7e23976d..00000000000
--- a/recipe/transfer_queue/run_qwen3-8b_transferqueue_npu.sh
+++ /dev/null
@@ -1,63 +0,0 @@
-set -x
-
-project_name='GRPO-Qwen3'
-exp_name='GRPO-Qwen3-8B-npu'
-gen_tp=2
-RAY_DATA_HOME=${RAY_DATA_HOME:-"${HOME}/verl"}
-MODEL_PATH=${MODEL_PATH:-"${RAY_DATA_HOME}/models/Qwen3-8B"}
-CKPTS_DIR=${CKPTS_DIR:-"${RAY_DATA_HOME}/ckpts/${project_name}/${exp_name}"}
-TRAIN_FILE=${TRAIN_FILE:-"${RAY_DATA_HOME}/data/dapo-math-17k.parquet"}
-TEST_FILE=${TEST_FILE:-"${RAY_DATA_HOME}/data/aime-2024.parquet"}
-
-python3 -m recipe.transfer_queue.main_ppo \
- --config-name='transfer_queue_ppo_trainer' \
- algorithm.adv_estimator=grpo \
- data.train_files="${TRAIN_FILE}" \
- data.val_files="${TEST_FILE}" \
- data.train_batch_size=256 \
- data.max_prompt_length=512 \
- data.max_response_length=1024 \
- data.filter_overlong_prompts=True \
- data.truncation='error' \
- actor_rollout_ref.model.path=${MODEL_PATH} \
- actor_rollout_ref.actor.optim.lr=1e-6 \
- actor_rollout_ref.model.use_remove_padding=True \
- actor_rollout_ref.actor.ppo_mini_batch_size=64 \
- actor_rollout_ref.actor.ppo_micro_batch_size_per_gpu=10 \
- actor_rollout_ref.actor.use_kl_loss=True \
- actor_rollout_ref.actor.kl_loss_coef=0.001 \
- actor_rollout_ref.actor.kl_loss_type=low_var_kl \
- actor_rollout_ref.actor.entropy_coeff=0 \
- actor_rollout_ref.actor.use_torch_compile=False \
- actor_rollout_ref.ref.use_torch_compile=False \
- actor_rollout_ref.model.enable_gradient_checkpointing=True \
- actor_rollout_ref.actor.fsdp_config.param_offload=False \
- actor_rollout_ref.actor.fsdp_config.optimizer_offload=False \
- actor_rollout_ref.rollout.log_prob_micro_batch_size_per_gpu=32 \
- actor_rollout_ref.rollout.tensor_model_parallel_size=${gen_tp} \
- actor_rollout_ref.rollout.name=vllm \
- actor_rollout_ref.rollout.gpu_memory_utilization=0.6 \
- actor_rollout_ref.rollout.n=5 \
- actor_rollout_ref.ref.log_prob_micro_batch_size_per_gpu=32 \
- actor_rollout_ref.ref.fsdp_config.param_offload=True \
- algorithm.use_kl_in_reward=False \
- trainer.critic_warmup=0 \
- trainer.logger='["console","wandb"]' \
- trainer.project_name="${project_name}" \
- trainer.experiment_name="${exp_name}" \
- trainer.n_gpus_per_node=8 \
- trainer.nnodes=1 \
- trainer.default_local_dir=${CKPTS_DIR} \
- trainer.device=npu \
- trainer.resume_mode=auto \
- actor_rollout_ref.actor.fsdp_config.forward_prefetch=True \
- actor_rollout_ref.ref.fsdp_config.forward_prefetch=True \
- ++actor_rollout_ref.actor.entropy_from_logits_with_chunking=True \
- ++actor_rollout_ref.ref.entropy_from_logits_with_chunking=True \
- trainer.val_before_train=False \
- trainer.save_freq=5 \
- trainer.test_freq=5 \
- trainer.total_epochs=15 \
- +trainer.num_global_batch=1 \
- +trainer.num_data_storage_units=2 \
- +trainer.num_data_controllers=1
\ No newline at end of file
diff --git a/requirements_transferqueue.txt b/requirements_transferqueue.txt
index 8479d27bb21..b4a1034f42d 100644
--- a/requirements_transferqueue.txt
+++ b/requirements_transferqueue.txt
@@ -1,2 +1,2 @@
# requirements.txt records the full set of dependencies for development
-git+https://github.com/TransferQueue/TransferQueue.git@68c04e7
+TransferQueue==0.1.2.dev0
diff --git a/setup.py b/setup.py
index c799661eb67..e16c737e848 100644
--- a/setup.py
+++ b/setup.py
@@ -57,7 +57,7 @@
]
TRL_REQUIRES = ["trl<=0.9.6"]
MCORE_REQUIRES = ["mbridge"]
-TRANSFERQUEUE_REQUIRES = ["TransferQueue @ git+https://github.com/TransferQueue/TransferQueue.git@68c04e7"]
+TRANSFERQUEUE_REQUIRES = ["TransferQueue==0.1.2.dev0"]
extras_require = {
"test": TEST_REQUIRES,
diff --git a/tests/special_e2e/run_transferqueue.sh b/tests/special_e2e/run_transferqueue.sh
new file mode 100644
index 00000000000..1534ba23e42
--- /dev/null
+++ b/tests/special_e2e/run_transferqueue.sh
@@ -0,0 +1,193 @@
+#!/usr/bin/env bash
+set -xeuo pipefail
+
+
+NUM_GPUS=${NUM_GPUS:-8}
+ACTOR_STRATEGY=${ACTOR_STRATEGY:-"fsdp"} # fsdp or megatron
+
+# Download model if not exists
+MODEL_ID=${MODEL_ID:-Qwen/Qwen2.5-0.5B-Instruct}
+MODEL_PATH=${MODEL_PATH:-${HOME}/models/${MODEL_ID}}
+huggingface-cli download "${MODEL_ID}" --local-dir "${MODEL_PATH}"
+
+
+rollout_mode="async"
+rollout_name="vllm" # sglang or vllm
+if [ "$rollout_mode" = "async" ]; then
+ export VLLM_USE_V1=1
+ return_raw_chat="True"
+fi
+
+# Algorithm parameters
+adv_estimator=grpo
+
+use_kl_in_reward=False
+kl_coef=0.0
+use_kl_loss=False
+kl_loss_coef=0.0
+
+clip_ratio_low=0.2
+clip_ratio_high=0.28
+
+# Response length parameters
+max_prompt_length=512
+max_response_length=1024
+enable_overlong_buffer=True
+overlong_buffer_len=128
+overlong_penalty_factor=1.0
+
+# Training parameters
+loss_agg_mode="token-mean"
+
+# Temperature parameters
+temperature=1.0
+top_p=1.0
+top_k=-1
+val_top_p=0.7
+
+n_gpus_training=8
+train_prompt_bsz=128
+val_prompt_bsz=128
+n_resp_per_prompt=5
+train_prompt_mini_bsz=32
+test_freq=-1
+
+log_dir="./logs"
+mkdir -p $log_dir
+timestamp=$(date +"%Y%m%d%H%M%S")
+log_file="${log_dir}/qwen2_5-0_5b_transferqueue_${timestamp}.log"
+
+exp_name="$(basename "${MODEL_ID,}")-transferqueue-${ACTOR_STRATEGY}-minimal"
+
+echo "Running transferqueue with ${ACTOR_STRATEGY} strategy"
+echo "Total GPUs: ${NUM_GPUS}"
+
+# Common parameters for both FSDP and Megatron
+# For Ascend NPU, please add
+# trainer.device=npu
+common_params=(
+ data.train_files="${HOME}/data/gsm8k/train.parquet"
+ data.val_files="${HOME}/data/gsm8k/test.parquet"
+ data.prompt_key=prompt
+ data.truncation='error'
+ data.max_prompt_length=${max_prompt_length}
+ data.max_response_length=${max_response_length}
+ data.filter_overlong_prompts_workers=128
+ data.filter_overlong_prompts=True
+ data.train_batch_size=${train_prompt_bsz}
+ data.val_batch_size=${val_prompt_bsz}
+ data.return_raw_chat=${return_raw_chat}
+ actor_rollout_ref.rollout.n=${n_resp_per_prompt}
+ algorithm.adv_estimator=${adv_estimator}
+ algorithm.use_kl_in_reward=${use_kl_in_reward}
+ algorithm.kl_ctrl.kl_coef=${kl_coef}
+ actor_rollout_ref.actor.use_kl_loss=${use_kl_loss}
+ actor_rollout_ref.actor.kl_loss_coef=${kl_loss_coef}
+ actor_rollout_ref.actor.clip_ratio_low=${clip_ratio_low}
+ actor_rollout_ref.actor.clip_ratio_high=${clip_ratio_high}
+ actor_rollout_ref.actor.clip_ratio_c=10.0
+ actor_rollout_ref.actor.use_kl_loss=True
+ actor_rollout_ref.model.path="${MODEL_PATH}"
+ actor_rollout_ref.actor.optim.lr=1e-6
+ actor_rollout_ref.actor.optim.lr_warmup_steps=-1
+ actor_rollout_ref.actor.optim.weight_decay=0.1
+ actor_rollout_ref.actor.ppo_mini_batch_size=${train_prompt_mini_bsz}
+ actor_rollout_ref.actor.ppo_micro_batch_size_per_gpu=4
+ actor_rollout_ref.actor.entropy_coeff=0
+ actor_rollout_ref.actor.loss_agg_mode=${loss_agg_mode}
+ actor_rollout_ref.rollout.log_prob_micro_batch_size_per_gpu=4
+ actor_rollout_ref.ref.log_prob_micro_batch_size_per_gpu=8
+ actor_rollout_ref.rollout.gpu_memory_utilization=0.80
+ actor_rollout_ref.rollout.temperature=${temperature}
+ actor_rollout_ref.rollout.top_p=${top_p}
+ actor_rollout_ref.rollout.top_k=${top_k}
+ actor_rollout_ref.rollout.max_num_batched_tokens=10240
+ actor_rollout_ref.rollout.val_kwargs.temperature=${temperature}
+ actor_rollout_ref.rollout.val_kwargs.top_p=${val_top_p}
+ actor_rollout_ref.rollout.val_kwargs.top_k=${top_k}
+ actor_rollout_ref.rollout.val_kwargs.do_sample=True
+ actor_rollout_ref.rollout.val_kwargs.n=1
+ actor_rollout_ref.rollout.enable_chunked_prefill=True
+ actor_rollout_ref.rollout.name=${rollout_name}
+ actor_rollout_ref.rollout.mode=${rollout_mode}
+ actor_rollout_ref.rollout.disable_log_stats=True
+ trainer.logger=console
+ trainer.project_name='verl-test-transferqueue'
+ trainer.experiment_name="${exp_name}"
+ trainer.test_freq="${test_freq}"
+ trainer.save_freq=-1
+ trainer.resume_mode=disable
+ trainer.nnodes=1
+ trainer.n_gpus_per_node=${n_gpus_training}
+ trainer.total_training_steps=2
+ trainer.total_epochs=15
+ trainer.val_before_train=True
+ +trainer.num_global_batch=1
+ +trainer.num_data_storage_units=8
+)
+
+if [ "${ACTOR_STRATEGY}" == "fsdp" ]; then
+ echo "Running TransferQueue training with FSDP strategy..."
+ # FSDP specific parameters; fsdp_size need to be -1
+ gen_tp=1
+ sp_size=1
+ fsdp_size=-1
+ ref_offload=True
+ actor_offload=False
+
+ python3 -m recipe.transfer_queue.main_ppo \
+ --config-path=config \
+ --config-name='transfer_queue_ppo_trainer' \
+ "${common_params[@]}" \
+ actor_rollout_ref.model.enable_gradient_checkpointing=True \
+ actor_rollout_ref.actor.strategy=fsdp \
+ critic.strategy=fsdp \
+ actor_rollout_ref.actor.grad_clip=1.0 \
+ actor_rollout_ref.model.use_remove_padding=True \
+ actor_rollout_ref.actor.use_dynamic_bsz=True \
+ actor_rollout_ref.ref.log_prob_use_dynamic_bsz=True \
+ actor_rollout_ref.rollout.log_prob_use_dynamic_bsz=True \
+ actor_rollout_ref.actor.fsdp_config.param_offload=${actor_offload} \
+ actor_rollout_ref.actor.fsdp_config.optimizer_offload=${actor_offload} \
+ actor_rollout_ref.actor.ulysses_sequence_parallel_size=${sp_size} \
+ actor_rollout_ref.rollout.tensor_model_parallel_size=${gen_tp} \
+ actor_rollout_ref.ref.fsdp_config.param_offload=${ref_offload} \
+ actor_rollout_ref.ref.ulysses_sequence_parallel_size=${sp_size} \
+ actor_rollout_ref.actor.fsdp_config.fsdp_size=${fsdp_size} \
+ 2>&1 | tee "$log_file" $@
+
+elif [ "${ACTOR_STRATEGY}" == "megatron" ]; then
+ echo "Running TransferQueue training with Megatron strategy..."
+ # Megatron specific parameters
+ gen_tp=2
+ train_tp=1
+ train_pp=2
+ ref_offload=True
+ actor_offload=False
+
+ # For Ascend NPU, please add:
+ #++actor_rollout_ref.actor.megatron.override_transformer_config.use_flash_attn=True \
+ #++actor_rollout_ref.ref.megatron.override_transformer_config.use_flash_attn=True \
+ python3 -m recipe.transfer_queue.main_ppo \
+ --config-path=config \
+ --config-name='transfer_queue_ppo_megatron_trainer' \
+ "${common_params[@]}" \
+ actor_rollout_ref.actor.strategy=megatron \
+ critic.strategy=megatron \
+ actor_rollout_ref.actor.optim.lr_decay_steps=10000000 \
+ actor_rollout_ref.actor.megatron.param_offload=${actor_offload} \
+ actor_rollout_ref.actor.megatron.optimizer_offload=${actor_offload} \
+ actor_rollout_ref.actor.megatron.grad_offload=${actor_offload} \
+ actor_rollout_ref.actor.megatron.pipeline_model_parallel_size=${train_pp} \
+ actor_rollout_ref.actor.megatron.tensor_model_parallel_size=${train_tp} \
+ actor_rollout_ref.rollout.tensor_model_parallel_size=${gen_tp} \
+ actor_rollout_ref.ref.megatron.pipeline_model_parallel_size=${train_pp} \
+ actor_rollout_ref.ref.megatron.tensor_model_parallel_size=${train_tp} \
+ actor_rollout_ref.ref.megatron.param_offload=${ref_offload} \
+ 2>&1 | tee "$log_file" $@
+else
+ echo "Error: Unknown strategy ${ACTOR_STRATEGY}. Please use 'fsdp' or 'megatron'"
+ exit 1
+fi
+
+echo "TransferQueue test completed successfully with ${ACTOR_STRATEGY} strategy"
\ No newline at end of file
diff --git a/verl/experimental/agent_loop/agent_loop.py b/verl/experimental/agent_loop/agent_loop.py
index d6c1319ea75..3190ffd8885 100644
--- a/verl/experimental/agent_loop/agent_loop.py
+++ b/verl/experimental/agent_loop/agent_loop.py
@@ -178,7 +178,7 @@ def __init__(self, config: DictConfig) -> None:
class AgentLoopBase(ABC):
- """An agent loop takes a input message, chat with OpenAI compatible LLM server and interact with various
+ """An agent loop takes an input message, chat with OpenAI compatible LLM server and interact with various
environments."""
_class_initialized = False
@@ -364,6 +364,7 @@ async def generate_sequences(self, batch: DataProto) -> DataProto:
outputs = await asyncio.gather(*tasks)
output = self._postprocess(outputs)
+
return output
async def _run_agent_loop(
@@ -608,7 +609,7 @@ def _postprocess(self, inputs: list[_InternalAgentLoopOutput]) -> DataProto:
meta_info={"metrics": metrics, "reward_extra_keys": reward_extra_keys},
)
- def create_transferqueue_client(self, controller_infos, storage_infos, role):
+ def create_transferqueue_client(self, controller_info, role):
"""Create a client for data system(transfer queue)."""
from verl.single_controller.ray.base import get_random_string
from verl.utils.transferqueue_utils import create_transferqueue_client
@@ -616,8 +617,8 @@ def create_transferqueue_client(self, controller_infos, storage_infos, role):
client_name = get_random_string(length=6)
create_transferqueue_client(
client_id=f"{role}_worker_{client_name}",
- controller_infos=controller_infos,
- storage_infos=storage_infos,
+ controller_info=controller_info,
+ config=self.config,
)
diff --git a/verl/single_controller/base/worker.py b/verl/single_controller/base/worker.py
index 2513c57f99c..399ac75a063 100644
--- a/verl/single_controller/base/worker.py
+++ b/verl/single_controller/base/worker.py
@@ -131,13 +131,13 @@ def _query_collect_info(self, mesh_name: str):
return self.__collect_dp_rank[mesh_name]
@register(dispatch_mode=Dispatch.ONE_TO_ALL, blocking=True)
- def create_transferqueue_client(self, controller_infos, storage_infos, role="train"):
+ def create_transferqueue_client(self, controller_info, config):
from verl.utils.transferqueue_utils import create_transferqueue_client
create_transferqueue_client(
- client_id=f"{role}_worker_{self.rank}",
- controller_infos=controller_infos,
- storage_infos=storage_infos,
+ client_id=f"worker_{self.rank}",
+ controller_info=controller_info,
+ config=config,
)
@classmethod
diff --git a/verl/utils/transferqueue_utils.py b/verl/utils/transferqueue_utils.py
index 27160571ef3..5002539e675 100644
--- a/verl/utils/transferqueue_utils.py
+++ b/verl/utils/transferqueue_utils.py
@@ -38,32 +38,24 @@ class BatchMeta:
from verl.protocol import DataProto
_TRANSFER_QUEUE_CLIENT = None
-_VAL_TRANSFER_QUEUE_CLIENT = None
is_transferqueue_enabled = os.environ.get("TRANSFER_QUEUE_ENABLE", False)
def create_transferqueue_client(
client_id: str,
- controller_infos: dict[Any, "ZMQServerInfo"],
- storage_infos: dict[Any, "ZMQServerInfo"],
+ controller_info: "ZMQServerInfo",
+ config,
) -> None:
global _TRANSFER_QUEUE_CLIENT
- global _VAL_TRANSFER_QUEUE_CLIENT
- if "val" in client_id:
- _VAL_TRANSFER_QUEUE_CLIENT = AsyncTransferQueueClient(client_id, controller_infos, storage_infos)
- else:
- _TRANSFER_QUEUE_CLIENT = AsyncTransferQueueClient(client_id, controller_infos, storage_infos)
+ _TRANSFER_QUEUE_CLIENT = AsyncTransferQueueClient(client_id, controller_info)
+ _TRANSFER_QUEUE_CLIENT.initialize_storage_manager(manager_type="AsyncSimpleStorageManager", config=config)
def get_transferqueue_client() -> "AsyncTransferQueueClient":
return _TRANSFER_QUEUE_CLIENT
-def get_val_transferqueue_client() -> "AsyncTransferQueueClient":
- return _VAL_TRANSFER_QUEUE_CLIENT
-
-
def _run_async_in_temp_loop(async_func: Callable[..., Any], *args, **kwargs) -> Any:
# Use a temporary event loop in a new thread because event
# loop may already exist in server mode
@@ -109,10 +101,7 @@ async def _async_batchmeta_to_dataproto(batchmeta: "BatchMeta") -> DataProto:
meta_info=batchmeta.extra_info.copy(),
)
- if batchmeta.extra_info.get("validate", False):
- tensordict = await _VAL_TRANSFER_QUEUE_CLIENT.async_get_data(batchmeta)
- else:
- tensordict = await _TRANSFER_QUEUE_CLIENT.async_get_data(batchmeta)
+ tensordict = await _TRANSFER_QUEUE_CLIENT.async_get_data(batchmeta)
return DataProto.from_tensordict(tensordict, meta_info=batchmeta.extra_info.copy())
@@ -130,10 +119,7 @@ async def _async_update_batchmeta_with_output(output: DataProto, batchmeta: "Bat
for key in output.meta_info.keys():
tensordict.pop(key)
batchmeta.add_fields(tensordict)
- if batchmeta.extra_info.get("validate", False):
- await _VAL_TRANSFER_QUEUE_CLIENT.async_put(data=tensordict, metadata=batchmeta)
- else:
- await _TRANSFER_QUEUE_CLIENT.async_put(data=tensordict, metadata=batchmeta)
+ await _TRANSFER_QUEUE_CLIENT.async_put(data=tensordict, metadata=batchmeta)
def _update_batchmeta_with_output(output: DataProto, batchmeta: "BatchMeta") -> None: