diff --git a/partial_rollout/README.md b/partial_rollout/README.md
new file mode 100644
index 00000000..b718f539
--- /dev/null
+++ b/partial_rollout/README.md
@@ -0,0 +1,188 @@
+# Recipe: Async Partial Rollout Trainer
+
+**Group:** `Tencent Data & Computation Platform Department`
+
+**Author:** Yue Wang*, Zhipeng Ma*, Yi Yan, Hang Xu, Yang Li, Bo Qian, Peng Chen
+
+Last updated: 01/15/2026.
+
+## 1. Introduction
+
+### 1.1 Background
+
+During synchronous reinforcement learning training in verl, we observe that the training dataset exhibits significant length imbalance, with a small fraction of exceptionally long samples. As illustrated in Figure 1, the maximum response length in the dataset reaches 160k tokens, while approximately 97% of responses are shorter than 80k tokens. Consequently, the minority of long-tail samples (3%) significantly slows down the training of the majority (97%) of the data. Moreover, these long-tail samples often correspond to more challenging cases, which are essential for effectively enhancing the model’s reasoning capabilities. Therefore, they cannot be removed without compromising training effectiveness.
+
+
+
+
+
+### 1.2 Solution
+
+We enhance the partial-rollout mechanism by introducing **sample supplementation** and **interruption techniques**. Since response lengths are unknown at inference time, **inference bubbles** are inevitable. We leverage sample supplementation to effectively utilize this otherwise unavoidable idle GPU time. Specifically, when a GPU worker completes its inference workload earlier than others, we supplement it with additional samples until the total number of samples returned by all GPU workers meets the training requirement. Once this requirement is satisfied, some GPU workers may still be processing ongoing inference tasks. To better utilize these partially processed samples, we **cache unfinished samples** and reuse them in the subsequent inference round.
+
+
+> reference: [APRIL: ACTIVE PARTIAL ROLLOUTS IN REINFORCEMENT LEARNING TO TAME LONG-TAIL GENERATION](
+> https://arxiv.org/pdf/2509.18521)
+
+
+Our core contributions include:
+
+1. **Sample Supplementation and Interruption Mechanisms**:
+ Introducing sample supplementation and interruption mechanisms to enable dynamic sample replenishment and automated scheduling of inference tasks.
+
+2. **Rollout Caching**:
+ Using a prompt manager to resume partial rollouts, managing complete and partial samples in the buffer based on sample staleness.
+
+
+### 1.3 Experimental Results
+
+- **Machine Configuration**: 2 nodes with 8 H20 GPUs
+- **Model**: Qwen3-4B
+- **Rollout Configuration**:
+- **Max Response Length**: 18384 tokens (for DAPO-MATH17k), 1024 tokens (for GSM8K)
+- **Algorithm**: GRPO
+- **Rollout Engine**: vLLM
+
+#### GSM8K
+On the GSM8K dataset, our method achieves comparable convergence and tangible performance gains compared to the baseline. Upon completing the **full dataset** training, it reduces total training time by 11.7% and improves average GPU utilization by 5.93%.
+
+| Training mode | Engine | Step | Total Time |Acc/mean@1 | GPU Avg Utilization |
+|------------------------|---------------|------|------------------|---------------|---------------|
+| GRPO+noPR | VLLM+Megatron | 290 | 4h59m | 94.99 |71.54 |
+| GRPO+PR | VLLM+Megatron | 280 | 4h24m (-35m) | 94.08 |77.47|
+
+
+> source data: https://swanlab.cn/@allenzpma/verl_exp_partial-rollout_gsm8k/runs
+
+#### DAPO-MATH17k
+Furthermore, on the DAPO-math dataset, our approach facilitates **full dataset** training with a 51.1% reduction in end-to-end execution time and an 8.77% boost in GPU utilization. And, our method achieves comparable convergence to the baseline.
+
+| Training Mode | Engine | Step | Total Time |Acc/best@32/mean | Acc/maj@32/mean |GPU Avg Utilization |
+| :--- | :--- | :--- | :--- | :--- | :--- | :--- |
+| GRPO+noPR | VLLM+Megatron | 200 |67h34m | 79.94 | 73.33 |74.64|
+| GRPO+PR | VLLM+Megatron | 110 | 33h02m (-34h32m) | 82.90 | 73.41 |83.41|
+
+
+> source data: https://swanlab.cn/@allenzpma/verl_exp_partial-rollout_dapo-math/runs
+
+
+## 2. Implementation
+
+### 2.1 Sample Supplementation and Interruption Mechanisms (SSIM)
+
+The main components of the SSIM mechanism are as follows:
+
+
+ +
+The event interaction logic of the SSIM mechanism is as follows:
+
+
+
+### 2.2 Rollout Caching
+The rollout caching mechanism is implemented using a prompt manager. The prompt manager uses a queue to control the order of sample resumption, with prompt priority defined by the **get_scheduling_priority** function.
+
+```python
+class PromptsManager:
+ """
+ PromptsManager is used to manage the prompts queue.
+ """
+ def __init__(
+ self,
+ global_config,
+ train_dataloader : StatefulDataLoader,
+ sampling_num : int,
+ rollout_manager_obj,
+ trained_prompts_index: set[int] = set(),
+ ):
+ """
+ Args:
+ global_config: the global config
+ train_dataloader: the train dataloader from `ray_trainer.py`
+ sampling_num: the number of samples to generate for each prompt
+ rollout_manager_obj: the rollout manager object
+ trained_prompts_index: the prompts that have been trained, used to skip the prompts that have been trained
+ """
+ self.global_config = global_config
+ self.sampling_num = sampling_num
+ self.prompt_queue = PromptsQueue()
+ self.trained_prompts_index = trained_prompts_index
+
+ # init dataloader_iter
+ self.dataloader_iter = iter(train_dataloader)
+ self.dataloader_iter_exhausted = False
+ self.filter_cnt = 0
+ self.model_version = 0
+
+
+ # Sort Priority (for each prompt)
+ def get_scheduling_priority(self, ignored_samples: set[Sample] = set()) -> tuple[int, float, int]:
+ """
+ Return a priority key for prompt scheduling.
+
+ The tuple is ordered so that it can be directly used in `sort(key=...)`:
+ (
+ unfinished_samples_num,
+ finished_mean_response_length (1e9 if no finished samples),
+ max_staleness
+ )
+ """
+ unfinished_samples = set(self.get_unfinished_samples()) - set(ignored_samples)
+ finished_samples = self.get_finished_samples()
+
+ # 1. unfinished samples number
+ unfinished_num = len(unfinished_samples)
+ # 2. mean response length of finished samples
+ finished_mean_resp_len = (
+ np.mean([sample.get_responses_length() for sample in finished_samples])
+ if finished_samples
+ else 1e9
+ )
+ # 3. max staleness
+ max_staleness = np.max(
+ [sample.get_staleness(expected_version=self.expected_model_version)
+ for sample in self.samples]
+ )
+
+ return unfinished_num, finished_mean_resp_len, max_staleness
+```
+
+### 2.3 Off-Policy Correctness
+To ensure the correctness of the PPO algorithm, PPO importance sampling is performed using **rollout log probs** with a decoupled trick, which preserves algorithmic correctness under interruptible generation and policy updates.
+
+$$
+J(\theta)=\mathbb{E}_{q \sim \mathcal{D}, a_t \sim \pi_{\text {behav}}^{\text{rollout}}}[\sum_{t=1}^H \min (\frac{\pi_{\theta}^{\text{train}}}{\pi_{\text {behav}}^{\text{rollout}}} \hat{A}_t, \frac{\pi_{\text {prox }}^{\text{rollout}}}{\pi_{\text {behav }}^{\text{rollout}}} \operatorname{clip}\left(\frac{\pi_{\theta}^{\text{train}}}{\pi_{\text {prox }}^{\text{rollout}}}, 1-\epsilon, 1+\epsilon\right) \hat{A}_t)] \\
+$$
+> reference: [AREAL: A Large-Scale Asynchronous Reinforcement Learning System for Language Reasoning](
+> https://arxiv.org/pdf/2505.24298)
+
+### 2.4 AgentLoop
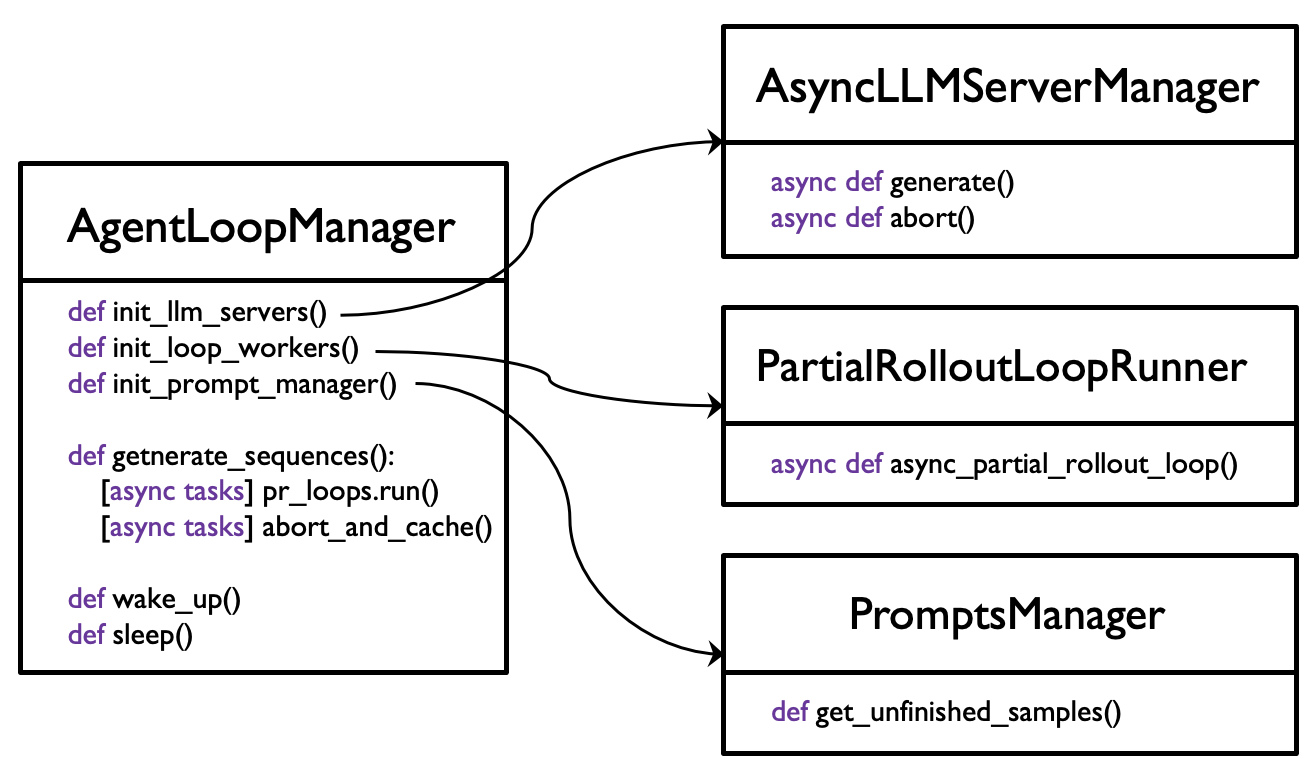
+In the current implementation, we use AgentLoop mode, which also supports multi-turn tool calling.
+
+## 3.Usage
+### GSM8K Configuration Example
+```shell
+bash recipe/partial_rollout/run_gsm8k_nopr_4b_bs128.sh
+bash recipe/partial_rollout/run_gsm8k_pr_4b_bs128.sh
+```
+
+### DAPO_MATH Configuration Example
+```shell
+bash recipe/partial_rollout/run_dapo_math17k_nopr_4b_2node.sh
+bash recipe/partial_rollout/run_dapo_math17k_pr_4b_2node.sh
+```
+
+## 4. Functional Support
+
+Furthermore, **our implementation supports both verl 0.5.0 and 0.6.1.** We recommend freezing the verl version in your environment to ensure long-term stability and prevent potential breaking changes from future upstream PRs.
+
+| Category | Support Situation |
+|--------------------|-----------------------------------------------------------------------------------------------------------------|
+| train engine | FSDP2
+
+The event interaction logic of the SSIM mechanism is as follows:
+
+
+
+### 2.2 Rollout Caching
+The rollout caching mechanism is implemented using a prompt manager. The prompt manager uses a queue to control the order of sample resumption, with prompt priority defined by the **get_scheduling_priority** function.
+
+```python
+class PromptsManager:
+ """
+ PromptsManager is used to manage the prompts queue.
+ """
+ def __init__(
+ self,
+ global_config,
+ train_dataloader : StatefulDataLoader,
+ sampling_num : int,
+ rollout_manager_obj,
+ trained_prompts_index: set[int] = set(),
+ ):
+ """
+ Args:
+ global_config: the global config
+ train_dataloader: the train dataloader from `ray_trainer.py`
+ sampling_num: the number of samples to generate for each prompt
+ rollout_manager_obj: the rollout manager object
+ trained_prompts_index: the prompts that have been trained, used to skip the prompts that have been trained
+ """
+ self.global_config = global_config
+ self.sampling_num = sampling_num
+ self.prompt_queue = PromptsQueue()
+ self.trained_prompts_index = trained_prompts_index
+
+ # init dataloader_iter
+ self.dataloader_iter = iter(train_dataloader)
+ self.dataloader_iter_exhausted = False
+ self.filter_cnt = 0
+ self.model_version = 0
+
+
+ # Sort Priority (for each prompt)
+ def get_scheduling_priority(self, ignored_samples: set[Sample] = set()) -> tuple[int, float, int]:
+ """
+ Return a priority key for prompt scheduling.
+
+ The tuple is ordered so that it can be directly used in `sort(key=...)`:
+ (
+ unfinished_samples_num,
+ finished_mean_response_length (1e9 if no finished samples),
+ max_staleness
+ )
+ """
+ unfinished_samples = set(self.get_unfinished_samples()) - set(ignored_samples)
+ finished_samples = self.get_finished_samples()
+
+ # 1. unfinished samples number
+ unfinished_num = len(unfinished_samples)
+ # 2. mean response length of finished samples
+ finished_mean_resp_len = (
+ np.mean([sample.get_responses_length() for sample in finished_samples])
+ if finished_samples
+ else 1e9
+ )
+ # 3. max staleness
+ max_staleness = np.max(
+ [sample.get_staleness(expected_version=self.expected_model_version)
+ for sample in self.samples]
+ )
+
+ return unfinished_num, finished_mean_resp_len, max_staleness
+```
+
+### 2.3 Off-Policy Correctness
+To ensure the correctness of the PPO algorithm, PPO importance sampling is performed using **rollout log probs** with a decoupled trick, which preserves algorithmic correctness under interruptible generation and policy updates.
+
+$$
+J(\theta)=\mathbb{E}_{q \sim \mathcal{D}, a_t \sim \pi_{\text {behav}}^{\text{rollout}}}[\sum_{t=1}^H \min (\frac{\pi_{\theta}^{\text{train}}}{\pi_{\text {behav}}^{\text{rollout}}} \hat{A}_t, \frac{\pi_{\text {prox }}^{\text{rollout}}}{\pi_{\text {behav }}^{\text{rollout}}} \operatorname{clip}\left(\frac{\pi_{\theta}^{\text{train}}}{\pi_{\text {prox }}^{\text{rollout}}}, 1-\epsilon, 1+\epsilon\right) \hat{A}_t)] \\
+$$
+> reference: [AREAL: A Large-Scale Asynchronous Reinforcement Learning System for Language Reasoning](
+> https://arxiv.org/pdf/2505.24298)
+
+### 2.4 AgentLoop
+In the current implementation, we use AgentLoop mode, which also supports multi-turn tool calling.
+
+## 3.Usage
+### GSM8K Configuration Example
+```shell
+bash recipe/partial_rollout/run_gsm8k_nopr_4b_bs128.sh
+bash recipe/partial_rollout/run_gsm8k_pr_4b_bs128.sh
+```
+
+### DAPO_MATH Configuration Example
+```shell
+bash recipe/partial_rollout/run_dapo_math17k_nopr_4b_2node.sh
+bash recipe/partial_rollout/run_dapo_math17k_pr_4b_2node.sh
+```
+
+## 4. Functional Support
+
+Furthermore, **our implementation supports both verl 0.5.0 and 0.6.1.** We recommend freezing the verl version in your environment to ensure long-term stability and prevent potential breaking changes from future upstream PRs.
+
+| Category | Support Situation |
+|--------------------|-----------------------------------------------------------------------------------------------------------------|
+| train engine | FSDP2
Megatron |
+| rollout engine | vLLM |
+| AdvantageEstimator | GRPO
GSPO
SAPO
GRPO_PASSK
REINFORCE_PLUS_PLUS
RLOO
OPO
REINFORCE_PLUS_PLUS_BASELINE
GPG |
+| Reward | all |
diff --git a/partial_rollout/agent_loop/__init__.py b/partial_rollout/agent_loop/__init__.py
new file mode 100644
index 00000000..d49e02d0
--- /dev/null
+++ b/partial_rollout/agent_loop/__init__.py
@@ -0,0 +1,20 @@
+# Copyright 2025 Meituan Ltd. and/or its affiliates
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+from .agent_loop import PRv3AgentLoopManager
+from .partial_single_turn_agent_loop import PartialSingleTurnAgentLoop
+from .partial_tool_agent_loop import PartialToolAgentLoop
+
+_ = [PartialSingleTurnAgentLoop, PartialToolAgentLoop]
+__all__ = [PRv3AgentLoopManager]
diff --git a/partial_rollout/agent_loop/agent_loop.py b/partial_rollout/agent_loop/agent_loop.py
new file mode 100644
index 00000000..ad8ff43d
--- /dev/null
+++ b/partial_rollout/agent_loop/agent_loop.py
@@ -0,0 +1,373 @@
+# Copyright 2025 Meituan Ltd. and/or its affiliates
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import asyncio
+import logging
+import time
+from typing import Any, Optional, Sequence
+
+import hydra
+import numpy as np
+import ray
+from omegaconf import DictConfig
+from recipe.partial_rollout.prompt_manager import RolloutPrompt
+from recipe.partial_rollout.vllm_rollout.vllm_async_server import PRv3vLLMReplica
+
+from verl.experimental.agent_loop.agent_loop import (
+ AgentLoopManager,
+ AgentLoopOutput,
+ AgentLoopWorkerBase,
+ AsyncLLMServerManager,
+ DictConfigWrap,
+ _agent_loop_registry,
+ get_trajectory_info,
+)
+from verl.protocol import DataProto
+from verl.single_controller.ray.base import RayResourcePool, RayWorkerGroup
+from verl.utils.rollout_trace import (
+ rollout_trace_attr,
+ rollout_trace_op,
+)
+
+logger = logging.getLogger(__file__)
+logger.setLevel("INFO")
+
+
+class PRv3AsyncLLMServerManager(AsyncLLMServerManager):
+ @rollout_trace_op
+ async def generate_for_partial(
+ self,
+ request_id,
+ *,
+ prompt_ids: list[int],
+ sampling_params: dict[str, Any],
+ image_data: Optional[list[Any]] = None,
+ ) -> tuple[list[Any], list[Any], Any] | tuple[Sequence[int], list[float], bool]:
+ """Generate tokens from prompt ids, used for async partial.
+
+ Args:
+ request_id (str): request id for sticky session.
+ prompt_ids (List[int]): List of prompt token ids.
+ sampling_params (Dict[str, Any]): Sampling parameters for the chat completion.
+
+ Returns:
+ output: A tuple representing the generation output.
+ - Element 0 (Sequence[int]): Generated response token IDs.
+ - Element 1 (list[float]): Log probabilities for the response token IDs.
+ - Element 2 (bool): A flag or status indicating cancellation.
+ """
+ server = self._choose_server(request_id)
+ output = await server.generate_for_partial.remote(
+ request_id=request_id,
+ prompt_ids=prompt_ids,
+ sampling_params=sampling_params,
+ image_data=image_data,
+ )
+ return output
+
+
+@ray.remote
+class PRv3AgentLoopWorker(AgentLoopWorkerBase):
+ def __init__(
+ self,
+ config: DictConfig,
+ server_handles: list[ray.actor.ActorHandle],
+ reward_router_address: str = None,
+ prompt_manager_handler: ray.actor.ActorHandle = None,
+ ):
+ self.server_manager = PRv3AsyncLLMServerManager(config, server_handles)
+ super().__init__(config, server_handles, reward_router_address)
+ self.cancellation_event = asyncio.Event()
+ self.prompt_manager_handler = prompt_manager_handler
+
+ async def generate_sequences_async(self, batch: DataProto) -> bool:
+ num_rollout_prompts = batch.batch.size(0) // self.config.actor_rollout_ref.rollout.n
+ num_rollout_prompts = int(num_rollout_prompts * 1)
+ rollout_prompts: list[RolloutPrompt] = ray.get(
+ self.prompt_manager_handler.pull_pending_prompts.remote(num_rollout_prompts)
+ )
+
+ running_set: set[asyncio.Task] = {
+ asyncio.create_task(self._generate_sequences_no_post(rp)) for rp in rollout_prompts
+ }
+
+ while running_set:
+ done, _ = await asyncio.wait(running_set, return_when=asyncio.FIRST_COMPLETED)
+ logger.info(f"[PRv3AgentLoopWorker] done: {len(done)}")
+ for task in done:
+ running_set.remove(task)
+
+ rollout_prompt, is_cancel = task.result()
+ logger.info(f"[PRv3AgentLoopWorker] generate_sequences_async: is_cancel: {is_cancel}")
+ ray.get(self.prompt_manager_handler.push_done_prompt.remote(rollout_prompt, is_cancel))
+ logger.info("[PRv3AgentLoopWorker] push_done_prompt done")
+
+ if self.cancellation_event.is_set():
+ continue
+
+ new_rollout_prompts: list[RolloutPrompt] = ray.get(
+ self.prompt_manager_handler.pull_pending_prompts.remote(1)
+ )
+
+ running_set.update(
+ asyncio.create_task(self._generate_sequences_no_post(new_rp)) for new_rp in new_rollout_prompts
+ )
+ return "DONE"
+
+ async def _generate_sequences_no_post(
+ self,
+ rollout_prompt: RolloutPrompt,
+ ) -> tuple[RolloutPrompt, bool]:
+ """Generate sequences from agent loop. (one rollout prompt with n rollout samples)
+
+ Args:
+ rollout_prompt (RolloutPrompt): Rollout prompt (one prompt with n rollout samples).
+
+ Returns:
+ list[AgentLoopOutput]: List of agent loop outputs, one per sample in the batch.
+ """
+ # batch (DataProto): Input batch (one prompt with n rollout samples).
+ # partial_output_list: Optional[List[AgentLoopOutput]]: already rollout result.
+ batch = rollout_prompt.full_batch
+ partial_output_list = rollout_prompt.agent_loop_output_list
+ config = self.config.actor_rollout_ref.rollout
+ sampling_params = dict(
+ temperature=config.temperature,
+ top_p=config.top_p,
+ repetition_penalty=1.0,
+ logprobs=config.calculate_log_probs,
+ )
+
+ # override sampling params for validation
+ if batch.meta_info.get("validate", False):
+ sampling_params["top_p"] = config.val_kwargs.top_p
+ sampling_params["temperature"] = config.val_kwargs.temperature
+
+ if "agent_name" not in batch.non_tensor_batch:
+ batch.non_tensor_batch["agent_name"] = np.array(["single_turn_agent"] * len(batch), dtype=object)
+
+ if "index" in batch.non_tensor_batch:
+ index = batch.non_tensor_batch["index"]
+ else:
+ index = np.arange(len(batch))
+
+ trajectory_info = await get_trajectory_info(
+ batch.meta_info.get("global_steps", -1), index, batch.meta_info.get("validate", False)
+ )
+
+ if not partial_output_list:
+ partial_output_list = [None] * len(batch)
+ try:
+ tasks = []
+ for i in range(len(batch)):
+ kwargs = {k: v[i] for k, v in batch.non_tensor_batch.items()}
+ kwargs["output"] = partial_output_list[i]
+ tasks.append(
+ asyncio.create_task(self._partial_run_agent_loop(sampling_params, trajectory_info[i], **kwargs))
+ )
+ outputs = await asyncio.gather(*tasks)
+ except Exception:
+ logger.exception("_partial_run_agent_loop failed")
+ raise
+
+ is_cancel = any(output.extra_fields.get("is_cancel", False) for output in outputs)
+ if not is_cancel:
+ output = self._postprocess(outputs)
+ output = self._addition_process(output)
+ rollout_prompt.full_batch = output
+ rollout_prompt.agent_loop_output_list = []
+ return rollout_prompt, is_cancel
+ else:
+ rollout_prompt.agent_loop_output_list = outputs
+ return rollout_prompt, is_cancel
+
+ def _addition_process(self, output: DataProto):
+ """collect metirics"""
+ metrics = output.meta_info["metrics"] # List[Dict[str, str]]
+ processing_times_list = [item["generate_sequences"] for item in metrics]
+ tool_calls_times_list = [item["tool_calls"] for item in metrics]
+ output.non_tensor_batch["processing_times"] = processing_times_list
+ output.non_tensor_batch["tool_calls_times"] = tool_calls_times_list
+ return output
+
+ async def _partial_run_agent_loop(
+ self,
+ sampling_params: dict[str, Any],
+ trajectory: dict[str, Any],
+ *,
+ agent_name: str,
+ **kwargs,
+ ) -> AgentLoopOutput:
+ """Run agent loop for partial rollout (one sample within a prompt)"""
+ # Completed, return directly
+ if kwargs["output"] is not None and not kwargs["output"].extra_fields.get("is_cancel", False):
+ logger.info("In _partial_run_agent_loop, already completed, return derictly!")
+ return kwargs["output"]
+ try:
+ with rollout_trace_attr(
+ step=trajectory["step"],
+ sample_index=trajectory["sample_index"],
+ rollout_n=trajectory["rollout_n"],
+ validate=trajectory["validate"],
+ name="agent_loop",
+ ):
+ assert agent_name in _agent_loop_registry, (
+ f"Agent loop {agent_name} not registered, registered agent loops: {_agent_loop_registry.keys()}"
+ )
+
+ agent_loop_config = _agent_loop_registry[agent_name]
+ agent_loop = hydra.utils.instantiate(
+ config=agent_loop_config,
+ trainer_config=DictConfigWrap(config=self.config),
+ server_manager=self.server_manager,
+ tokenizer=self.tokenizer,
+ processor=self.processor,
+ )
+ output: AgentLoopOutput = await agent_loop.run(
+ sampling_params, cancellation_event=self.cancellation_event, **kwargs
+ )
+ if not output.extra_fields.get("is_cancel", False):
+ kwargs.pop("output", None)
+ output = await self._agent_loop_postprocess(output, **kwargs)
+ return output
+ except Exception:
+ logger.exception("Agent_loop run failed")
+ raise
+
+ async def cancel_agent_loops(self):
+ """Set the shared cancellation event to stop all agent loops."""
+ self.cancellation_event.set()
+
+ async def resume_agent_loops(self):
+ """Clear the shared cancellation event."""
+ self.cancellation_event.clear()
+
+
+class PRv3AgentLoopManager(AgentLoopManager):
+ def __init__(
+ self,
+ config: DictConfig,
+ worker_group: RayWorkerGroup = None,
+ rm_resource_pool: RayResourcePool = None,
+ prompt_manager_handler: ray.actor.ActorHandle = None,
+ ):
+ self.config = config
+ self.worker_group = worker_group
+ self.reward_model_manager = None
+ self.reward_router_address = None
+ if self.config.reward_model.enable and self.config.reward_model.enable_resource_pool:
+ from verl.experimental.reward import RewardModelManager
+
+ # TODO (dyy): current rm is colocated with the legacy fsdp/megatron rm
+ # future pr will depericate fsdp/megatron rm and init RewardModelManager in standalone mode
+ self.reward_model_manager = RewardModelManager(config.reward_model, rm_resource_pool)
+ self.reward_router_address = self.reward_model_manager.get_router_address()
+
+ self.rollout_replica_class = PRv3vLLMReplica
+ self.agent_loop_workers_class = PRv3AgentLoopWorker
+ self.prompt_manager_handler = prompt_manager_handler
+
+ self._initialize_llm_servers()
+ self._init_agent_loop_workers()
+
+ # Initially we're in sleep mode.
+ if self.config.actor_rollout_ref.rollout.free_cache_engine:
+ self.sleep()
+
+ def _init_agent_loop_workers(self):
+ self.agent_loop_workers = []
+ num_workers = self.config.actor_rollout_ref.rollout.agent.num_workers
+
+ node_ids = [node["NodeID"] for node in ray.nodes() if node["Alive"] and node["Resources"].get("CPU", 0) > 0]
+ for i in range(num_workers):
+ # Round-robin scheduling over the all nodes
+ node_id = node_ids[i % len(node_ids)]
+ self.agent_loop_workers.append(
+ self.agent_loop_workers_class.options(
+ name=f"agent_loop_worker_{i}",
+ scheduling_strategy=ray.util.scheduling_strategies.NodeAffinitySchedulingStrategy(
+ node_id=node_id, soft=True
+ ),
+ ).remote(self.config, self.server_handles, self.reward_router_address, self.prompt_manager_handler)
+ )
+
+ def generate_sequences(self, prompts: DataProto) -> DataProto:
+ """Split input batch and dispatch to agent loop workers."""
+ self.wake_up()
+ if self.reward_model_manager:
+ self.reward_model_manager.wake_up()
+
+ chunks = prompts.chunk(len(self.agent_loop_workers))
+ if prompts.meta_info.get("validate", False):
+ self.resume()
+ outputs = ray.get(
+ [
+ worker.generate_sequences.remote(chunk)
+ for worker, chunk in zip(self.agent_loop_workers, chunks, strict=True)
+ ]
+ )
+ # In sync rollout mode, no need to call cancel()
+ else:
+ self.resume()
+ # 1. Prepare generation
+ num_rollout_prompts = prompts.batch.size(0) // self.config.actor_rollout_ref.rollout.n
+ ray.get(self.prompt_manager_handler.prepare_generation.remote(prompts.meta_info.get("global_steps", 0)))
+ # 2. Launch all AgentLoopWorker's generate_sequences_async task
+ worker_tasks = [
+ worker.generate_sequences_async.remote(chunk)
+ for worker, chunk in zip(self.agent_loop_workers, chunks, strict=True)
+ ]
+ # 3. Monitor generation (if cache containing `num_rollout_prompts` or dataloader is exhausted, return)
+ while True:
+ done = ray.get(self.prompt_manager_handler.check_generation_once.remote(num_rollout_prompts))
+ if done:
+ logger.info(f"[PRv3AgentLoopManager] check_generation_once done: {done}")
+ break
+ time.sleep(0.01)
+ # 4. Cancel all AgentLoopWorker's generate_sequences_async task
+ self.cancel()
+ # 5. Wait for all AgentLoopWorker's generate_sequences_async task to return "DONE"
+ assert all(result == "DONE" for result in ray.get(worker_tasks)), (
+ "PRv3AgentLoopWorker generate sequences failed"
+ )
+ # 6. Pull valid prompts from prompt manager
+ is_full = ray.get(self.prompt_manager_handler.check_generation_post_state.remote(num_rollout_prompts))
+ outputs = ray.get(self.prompt_manager_handler.pull_done_prompts.remote(num_rollout_prompts))
+ outputs[0].meta_info["is_full"] = is_full
+
+ output = DataProto.concat(outputs)
+
+ # Fix for Issue #4147: Always call sleep() to ensure proper cleanup
+ self.sleep()
+ if self.reward_model_manager:
+ self.reward_model_manager.sleep()
+
+ # calculate performance metrics
+ if output.meta_info.get("is_full", True):
+ metrics = [output.meta_info.pop("metrics") for output in outputs] # List[List[Dict[str, str]]]
+ timing = self._performance_metrics(metrics, output)
+
+ output.meta_info = {"timing": timing, **outputs[0].meta_info}
+ return output
+
+ def cancel(self):
+ worker_cancel_tasks = [worker.cancel_agent_loops.remote() for worker in self.agent_loop_workers]
+ ray.get(worker_cancel_tasks)
+ rollout_cancel_tasks = [replica.cancel() for replica in self.rollout_replicas]
+ self._run_all(rollout_cancel_tasks)
+
+ def resume(self):
+ rollout_resume_tasks = [replica.resume() for replica in self.rollout_replicas]
+ self._run_all(rollout_resume_tasks)
+ worker_resume_tasks = [worker.resume_agent_loops.remote() for worker in self.agent_loop_workers]
+ ray.get(worker_resume_tasks)
diff --git a/partial_rollout/agent_loop/partial_single_turn_agent_loop.py b/partial_rollout/agent_loop/partial_single_turn_agent_loop.py
new file mode 100644
index 00000000..30f3fb92
--- /dev/null
+++ b/partial_rollout/agent_loop/partial_single_turn_agent_loop.py
@@ -0,0 +1,115 @@
+# Copyright 2025 Meituan Ltd. and/or its affiliates
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import logging
+import os
+from typing import Any, Optional
+from uuid import uuid4
+
+from verl.experimental.agent_loop import AgentLoopBase
+from verl.experimental.agent_loop.agent_loop import AgentLoopOutput, register
+from verl.utils.profiler import simple_timer
+
+logger = logging.getLogger(__file__)
+logger.setLevel(os.getenv("VERL_LOGGING_LEVEL", "WARN"))
+
+
+@register("partial_single_turn_agent")
+class PartialSingleTurnAgentLoop(AgentLoopBase):
+ """Naive agent loop that only do single turn chat completion."""
+
+ def __init__(self, *args, **kwargs):
+ super().__init__(*args, **kwargs)
+ self.prompt_length = self.config.actor_rollout_ref.rollout.prompt_length
+ self.response_length = self.config.actor_rollout_ref.rollout.response_length
+ self.apply_chat_template_kwargs = self.config.data.get("apply_chat_template_kwargs", {})
+
+ async def run(self, sampling_params: dict[str, Any], **kwargs) -> AgentLoopOutput:
+ output: Optional[AgentLoopOutput] = kwargs.get("output", None)
+ messages = list(kwargs["raw_prompt"])
+ param_version = kwargs.get("param_version", 0)
+
+ metrics = {}
+ request_id = uuid4().hex
+ image_data = (kwargs.get("multi_modal_data") or {}).get("image", None)
+
+ param_version_start = param_version
+ param_version_end = param_version
+
+ if not output:
+ # TODO(baiyan): it is supposed to use the correct processor,
+ # but I found the async training would hang if use_correct_processor=True.
+ # so we use the tokenizer to tokenize the prompt for now.
+ use_correct_processor = False
+ if self.processor is not None and use_correct_processor:
+
+ def get_prompt_ids():
+ raw_prompt = self.processor.apply_chat_template(
+ messages,
+ add_generation_prompt=True,
+ tokenize=False,
+ **self.apply_chat_template_kwargs,
+ )
+ model_inputs = self.processor(text=[raw_prompt], images=image_data, return_tensors="pt")
+ return model_inputs.pop("input_ids").squeeze(0).tolist()
+
+ prompt_ids = await self.loop.run_in_executor(None, get_prompt_ids)
+ else:
+ prompt_ids = await self.loop.run_in_executor(
+ None,
+ lambda: self.tokenizer.apply_chat_template(
+ messages, add_generation_prompt=True, tokenize=True, **self.apply_chat_template_kwargs
+ ),
+ )
+ else:
+ if output.extra_fields.get("is_cancel", False):
+ # Resume the paused sample,
+ # add the result directly after prompt_ids,
+ # and reset generate_sequences metric
+ prompt_ids = output.prompt_ids + output.response_ids
+ metrics["generate_sequences"] = output.metrics.generate_sequences
+ param_version_start = output.extra_fields.get("param_version_start", param_version)
+ else:
+ # In the same batch of samples,
+ # some are canceled and some are not.
+ # The samples without partial rollout are returned directly.
+ return output
+ with simple_timer("generate_sequences", metrics):
+ response_ids, response_logprobs, is_cancel = await self.server_manager.generate_for_partial(
+ request_id=request_id, prompt_ids=prompt_ids, sampling_params=sampling_params, image_data=image_data
+ )
+ if not output:
+ response_mask = [1] * len(response_ids)
+ else:
+ # Pause the sample to be resumed, add the output result to response_ids, and reset response_mask
+ prompt_ids = output.prompt_ids
+ response_logprobs = output.response_logprobs + response_logprobs
+ response_ids = output.response_ids + response_ids
+ response_mask = [1] * len(response_ids)
+ if len(response_ids) >= self.response_length:
+ is_cancel = False
+
+ return AgentLoopOutput(
+ prompt_ids=prompt_ids,
+ response_ids=response_ids[: self.response_length],
+ response_mask=response_mask[: self.response_length],
+ response_logprobs=response_logprobs[: self.response_length],
+ num_turns=2,
+ metrics=metrics,
+ extra_fields={
+ "is_cancel": is_cancel,
+ "param_version_start": param_version_start,
+ "param_version_end": param_version_end,
+ },
+ # multi_modal_data={"image": image_data} if image_data is not None else {},
+ )
diff --git a/partial_rollout/agent_loop/partial_tool_agent_loop.py b/partial_rollout/agent_loop/partial_tool_agent_loop.py
new file mode 100644
index 00000000..4581add3
--- /dev/null
+++ b/partial_rollout/agent_loop/partial_tool_agent_loop.py
@@ -0,0 +1,279 @@
+# Copyright 2025 Meituan Ltd. and/or its affiliates
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import asyncio
+import copy
+import logging
+import os
+from typing import Any, Optional
+from uuid import uuid4
+
+from verl.experimental.agent_loop.agent_loop import AgentLoopOutput, register
+from verl.experimental.agent_loop.tool_agent_loop import AgentData, AgentState, ToolAgentLoop
+from verl.utils.profiler import simple_timer
+
+logger = logging.getLogger(__file__)
+logger.setLevel(os.getenv("VERL_LOGGING_LEVEL", "WARN"))
+
+
+@register("partial_tool_agent")
+class PartialToolAgentLoop(ToolAgentLoop):
+ """
+ Support for partial rollout with multiple tool invocations in Agent Loop
+
+ """
+
+ def __init__(self, trainer_config, **kwargs):
+ super().__init__(trainer_config, **kwargs)
+ self.enable_partial_rollout = trainer_config.config.async_training.get("partial_rollout", False)
+
+ # async def run(self, sampling_params: dict[str, Any], **kwargs) -> AgentLoopOutput:
+ async def run(
+ self, sampling_params: dict[str, Any], *, cancellation_event: asyncio.Event = None, **kwargs
+ ) -> AgentLoopOutput:
+ """
+ Main entrance, supports interruption/recovery
+
+ Args:
+ sampling_params: Sampling parameters
+ cancellation_event: cancellation sginal
+ **kwargs: Contains output (for recovery), raw_prompt, param_version, etc.
+
+ Returns:
+ AgentLoopOutput: Include the is_cancel flag
+ """
+ param_version = kwargs.get("param_version", 0)
+ agent_data = None
+ state = None
+
+ # 1. check whether is the partial task
+ output: Optional[AgentLoopOutput] = kwargs.get("output", None)
+ if output and output.extra_fields.get("is_cancel", False):
+ agent_data, state = self._restore_from_output(output)
+
+ logger.info(f"[PartialToolAgent] Resuming from {state.value}")
+ else:
+ if output and not output.extra_fields.get("is_cancel", False):
+ # Completed, return directly
+ return output
+
+ agent_data = await self._init_agent_data(kwargs, param_version)
+ state = AgentState.PENDING
+ logger.info("[PartialToolAgent] Start from scratch")
+ # 2. run state machine
+ state = await self._run_state_machine(agent_data, state, sampling_params, cancellation_event)
+
+ # 3. bulid output
+ if state == AgentState.TERMINATED:
+ return self._build_completed_output(agent_data, param_version)
+ else:
+ # build cancelled output
+ return self._build_cancelled_output(agent_data, state)
+
+ async def _init_agent_data(self, kwargs: dict, param_version: int) -> AgentData:
+ messages = list(kwargs["raw_prompt"])
+ image_data = copy.deepcopy(kwargs.get("multi_modal_data", {}).get("image", None))
+ metrics = {}
+ request_id = uuid4().hex
+ tools_kwargs = kwargs.get("tools_kwargs", {})
+
+ # Initialize interaction if needed
+ interaction = None
+ interaction_kwargs = {}
+ if self.interaction_config_file:
+ interaction_kwargs = kwargs["extra_info"]["interaction_kwargs"]
+ if "name" not in interaction_kwargs:
+ raise ValueError("'name' key is required in interaction_kwargs")
+ interaction_name = interaction_kwargs["name"]
+ if interaction_name not in self.interaction_map:
+ raise ValueError(
+ f"Interaction '{interaction_name}' not found in interaction_map. Available interactions: "
+ f"{list(self.interaction_map.keys())}"
+ )
+ interaction = self.interaction_map[interaction_name]
+ await interaction.start_interaction(request_id, **interaction_kwargs)
+ # Create AgentData instance to encapsulate all state
+ agent_data = AgentData(
+ messages=messages,
+ image_data=image_data,
+ metrics=metrics,
+ request_id=request_id,
+ tools_kwargs=tools_kwargs,
+ interaction=interaction,
+ interaction_kwargs=interaction_kwargs,
+ )
+
+ # additional param version record
+ agent_data.extra_fields["param_version_start"] = param_version
+ agent_data.extra_fields["param_version_end"] = param_version
+
+ return agent_data
+
+ def _restore_from_output(self, output: AgentLoopOutput) -> tuple[AgentData, AgentState]:
+ """restore AgentState and AgentData from output"""
+ agent_data = output.extra_fields.get("agent_data", None)
+ agent_state = output.extra_fields.get("agent_state", None)
+ if agent_data is None or agent_state is None:
+ raise ValueError(f"Unexpected situation: agent_data is {agent_data}, agent_state is {agent_state}")
+ return agent_data, agent_state
+
+ async def _run_state_machine(
+ self,
+ agent_data: AgentData,
+ state: AgentState,
+ sampling_params: dict[str, Any],
+ cancellation_event: asyncio.Event = None,
+ ) -> AgentState:
+ """
+ State machine.
+ Currently, interruptions are only supported to occur in the GENERATING state or other states have ended.
+ """
+ # State machine loop
+ while state != AgentState.TERMINATED:
+ if cancellation_event and cancellation_event.is_set():
+ logger.info(f"[PartialToolAgent] Cancellation detected. Interrupted before/at state: {state.value}")
+ return state
+ if state == AgentState.PENDING:
+ state = await self._handle_pending_state(agent_data, sampling_params)
+ elif state == AgentState.GENERATING:
+ state = await self._handle_generating_state_partial(agent_data, sampling_params)
+ elif state == AgentState.PROCESSING_TOOLS:
+ state = await self._handle_processing_tools_state(agent_data)
+ elif state == AgentState.INTERACTING:
+ state = await self._handle_interacting_state(agent_data)
+ else:
+ logger.error(f"[PartialToolAgent] Invalid state: {state}")
+ return AgentState.TERMINATED
+
+ return AgentState.TERMINATED
+
+ async def _handle_generating_state_partial(
+ self, agent_data: AgentData, sampling_params: dict[str, Any], ignore_termination: bool = False
+ ) -> AgentState:
+ """
+ Handle GENERATING state, support partial rollout
+ """
+ add_messages: list[dict[str, Any]] = []
+
+ with simple_timer("generate_sequences", agent_data.metrics):
+ # partial interface
+ if self.enable_partial_rollout:
+ response_ids, log_probs, is_cancel = await self.server_manager.generate_for_partial(
+ request_id=agent_data.request_id,
+ prompt_ids=agent_data.prompt_ids,
+ sampling_params=sampling_params,
+ image_data=agent_data.image_data,
+ )
+
+ if is_cancel:
+ # Save the generated parts
+ agent_data.response_ids = response_ids
+ agent_data.prompt_ids += agent_data.response_ids
+ agent_data.response_mask += [1] * len(response_ids)
+ if log_probs:
+ agent_data.response_logprobs += log_probs
+ if not ignore_termination and len(agent_data.response_mask) >= self.response_length:
+ # If response_length has reached the limit,
+ # it is considered to have ended normally.
+ agent_data.assistant_turns += 1
+ return AgentState.TERMINATED
+ return AgentState.GENERATING
+ else:
+ # original generate interface
+ output = await self.server_manager.generate(
+ request_id=agent_data.request_id,
+ prompt_ids=agent_data.prompt_ids,
+ sampling_params=sampling_params,
+ image_data=agent_data.image_data,
+ )
+ response_ids = output.token_ids
+ log_probs = output.log_probs
+
+ agent_data.assistant_turns += 1
+ agent_data.response_ids = response_ids
+ agent_data.prompt_ids += agent_data.response_ids
+ agent_data.response_mask += [1] * len(agent_data.response_ids)
+ if log_probs:
+ agent_data.response_logprobs += log_probs
+
+ if not ignore_termination and len(agent_data.response_mask) >= self.response_length:
+ return AgentState.TERMINATED
+ if self.max_assistant_turns and agent_data.assistant_turns >= self.max_assistant_turns:
+ return AgentState.TERMINATED
+ if self.max_user_turns and agent_data.user_turns >= self.max_user_turns:
+ return AgentState.TERMINATED
+
+ # Extract tool calls
+ _, agent_data.tool_calls = await self.tool_parser.extract_tool_calls(agent_data.response_ids)
+
+ # Handle interaction if needed
+ if self.interaction_config_file:
+ assistant_message = await self.loop.run_in_executor(
+ None, lambda: self.tokenizer.decode(agent_data.response_ids, skip_special_tokens=True)
+ )
+ add_messages.append({"role": "assistant", "content": assistant_message})
+ agent_data.messages.extend(add_messages)
+
+ # Determine next state
+ if agent_data.tool_calls:
+ return AgentState.PROCESSING_TOOLS
+ elif self.interaction_config_file:
+ return AgentState.INTERACTING
+ else:
+ return AgentState.TERMINATED
+
+ def _build_completed_output(self, agent_data: AgentData, param_version: int) -> AgentLoopOutput:
+ """build completed output"""
+ response_ids = agent_data.prompt_ids[-len(agent_data.response_mask) :]
+ prompt_ids = agent_data.prompt_ids[: len(agent_data.prompt_ids) - len(agent_data.response_mask)]
+ multi_modal_data = {"image": agent_data.image_data} if agent_data.image_data is not None else {}
+ output = AgentLoopOutput(
+ prompt_ids=prompt_ids,
+ response_ids=response_ids[: self.response_length],
+ response_mask=agent_data.response_mask[: self.response_length],
+ multi_modal_data=multi_modal_data,
+ response_logprobs=agent_data.response_logprobs[: self.response_length]
+ if agent_data.response_logprobs
+ else None,
+ num_turns=agent_data.user_turns + agent_data.assistant_turns + 1,
+ metrics=agent_data.metrics,
+ extra_fields={},
+ )
+ output.extra_fields.update(
+ {
+ "turn_scores": agent_data.turn_scores,
+ "tool_rewards": agent_data.tool_rewards,
+ "is_cancel": False,
+ "param_version_start": agent_data.extra_fields["param_version_start"],
+ "param_version_end": param_version,
+ }
+ )
+ return output
+
+ def _build_cancelled_output(self, agent_data: AgentData, state: AgentState) -> AgentLoopOutput:
+ """build cancelled output"""
+ return AgentLoopOutput(
+ prompt_ids=[],
+ response_ids=[],
+ response_mask=[],
+ multi_modal_data={},
+ response_logprobs=None,
+ num_turns=0,
+ metrics=agent_data.metrics,
+ extra_fields={
+ "is_cancel": True,
+ "agent_data": agent_data,
+ "agent_state": state,
+ },
+ )
diff --git a/partial_rollout/main_ppo.py b/partial_rollout/main_ppo.py
new file mode 100644
index 00000000..61ab0abd
--- /dev/null
+++ b/partial_rollout/main_ppo.py
@@ -0,0 +1,475 @@
+# Copyright 2024 Bytedance Ltd. and/or its affiliates
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""
+Note that we don't combine the main with ray_trainer as ray_trainer is used by other main.
+"""
+
+import os
+import socket
+
+import hydra
+import ray
+from omegaconf import OmegaConf
+from recipe.partial_rollout.ray_trainer import RayPPOTrainer
+
+from verl.experimental.dataset.sampler import AbstractSampler
+from verl.trainer.constants_ppo import get_ppo_ray_runtime_env
+from verl.trainer.ppo.reward import load_reward_manager
+from verl.trainer.ppo.utils import need_critic, need_reference_policy
+from verl.utils.config import validate_config
+from verl.utils.device import auto_set_ascend_device_name, is_cuda_available
+from verl.utils.import_utils import load_extern_object
+
+
+@hydra.main(config_path="config", config_name="ppo_trainer", version_base=None)
+def main(config):
+ """Main entry point for PPO training with Hydra configuration management.
+
+ Args:
+ config_dict: Hydra configuration dictionary containing training parameters.
+ """
+ # Automatically set `config.trainer.device = npu` when running on Ascend NPU.
+ auto_set_ascend_device_name(config)
+
+ run_ppo(config)
+
+
+# Define a function to run the PPO-like training process
+def run_ppo(config, task_runner_class=None) -> None:
+ """Initialize Ray cluster and run distributed PPO training process.
+
+ Args:
+ config: Training configuration object containing all necessary parameters
+ for distributed PPO training including Ray initialization settings,
+ model paths, and training hyperparameters.
+ task_runner_class: For recipe to change TaskRunner.
+ """
+ # Check if Ray is not initialized
+ if not ray.is_initialized():
+ # Initialize Ray with a local cluster configuration
+ # Set environment variables in the runtime environment to control tokenizer parallelism,
+ # NCCL debug level, VLLM logging level, and allow runtime LoRA updating
+ # `num_cpus` specifies the number of CPU cores Ray can use, obtained from the configuration
+ default_runtime_env = get_ppo_ray_runtime_env()
+ ray_init_kwargs = config.ray_kwargs.get("ray_init", {})
+ runtime_env_kwargs = ray_init_kwargs.get("runtime_env", {})
+
+ if config.transfer_queue.enable:
+ # Add runtime environment variables for transfer queue
+ runtime_env_vars = runtime_env_kwargs.get("env_vars", {})
+ runtime_env_vars["TRANSFER_QUEUE_ENABLE"] = "1"
+ runtime_env_kwargs["env_vars"] = runtime_env_vars
+
+ runtime_env = OmegaConf.merge(default_runtime_env, runtime_env_kwargs)
+ ray_init_kwargs = OmegaConf.create({**ray_init_kwargs, "runtime_env": runtime_env})
+ print(f"ray init kwargs: {ray_init_kwargs}")
+ ray.init(**OmegaConf.to_container(ray_init_kwargs))
+
+ if task_runner_class is None:
+ task_runner_class = ray.remote(num_cpus=1)(TaskRunner) # please make sure main_task is not scheduled on head
+
+ # Create a remote instance of the TaskRunner class, and
+ # Execute the `run` method of the TaskRunner instance remotely and wait for it to complete
+ if (
+ is_cuda_available
+ and config.global_profiler.tool == "nsys"
+ and config.global_profiler.get("steps") is not None
+ and len(config.global_profiler.get("steps", [])) > 0
+ ):
+ from verl.utils.import_utils import is_nvtx_available
+
+ assert is_nvtx_available(), "nvtx is not available in CUDA platform. Please 'pip3 install nvtx'"
+ nsight_options = OmegaConf.to_container(
+ config.global_profiler.global_tool_config.nsys.controller_nsight_options
+ )
+ runner = task_runner_class.options(runtime_env={"nsight": nsight_options}).remote()
+ else:
+ runner = task_runner_class.remote()
+ ray.get(runner.run.remote(config))
+
+ # [Optional] get the path of the timeline trace file from the configuration, default to None
+ # This file is used for performance analysis
+ timeline_json_file = config.ray_kwargs.get("timeline_json_file", None)
+ if timeline_json_file:
+ ray.timeline(filename=timeline_json_file)
+
+
+class TaskRunner:
+ """Ray remote class for executing distributed PPO training tasks.
+
+ This class encapsulates the main training logic and runs as a Ray remote actor
+ to enable distributed execution across multiple nodes and GPUs.
+
+ Attributes:
+ role_worker_mapping: Dictionary mapping Role enums to Ray remote worker classes
+ mapping: Dictionary mapping Role enums to resource pool IDs for GPU allocation
+ """
+
+ def __init__(self):
+ self.role_worker_mapping = {}
+ self.mapping = {}
+
+ def add_actor_rollout_worker(self, config):
+ """Add actor rollout worker based on the actor strategy."""
+ from verl.single_controller.ray import RayWorkerGroup
+ from verl.trainer.ppo.ray_trainer import Role
+
+ use_legacy_worker_impl = config.trainer.get("use_legacy_worker_impl", "auto")
+
+ # use new model engine implementation
+ if use_legacy_worker_impl == "disable":
+ from verl.workers.engine_workers import ActorRolloutRefWorker
+
+ actor_rollout_cls = ActorRolloutRefWorker
+ ray_worker_group_cls = RayWorkerGroup
+ # NOTE: In new model engine, ref policy and actor rollout are in same ActorRolloutRefWorker,
+ # while in legacy model engine, ref policy is in a separate ActorRolloutRefWorker.
+ if config.algorithm.use_kl_in_reward or config.actor_rollout_ref.actor.use_kl_loss:
+ role = Role.ActorRolloutRef
+ else:
+ role = Role.ActorRollout
+ self.role_worker_mapping[role] = ray.remote(actor_rollout_cls)
+ self.mapping[role] = "global_pool"
+ return actor_rollout_cls, ray_worker_group_cls
+
+ if config.actor_rollout_ref.rollout.mode == "sync":
+ raise ValueError(
+ "Rollout mode 'sync' has been removed. Please set "
+ "`actor_rollout_ref.rollout.mode=async` to use the native server rollout."
+ )
+
+ if config.actor_rollout_ref.actor.strategy in {"fsdp", "fsdp2"}:
+ from verl.workers.fsdp_workers import ActorRolloutRefWorker, AsyncActorRolloutRefWorker
+
+ actor_rollout_cls = (
+ AsyncActorRolloutRefWorker
+ if config.actor_rollout_ref.rollout.mode == "async"
+ else ActorRolloutRefWorker
+ )
+ ray_worker_group_cls = RayWorkerGroup
+
+ elif config.actor_rollout_ref.actor.strategy == "megatron":
+ from verl.workers.megatron_workers import ActorRolloutRefWorker, AsyncActorRolloutRefWorker
+
+ actor_rollout_cls = (
+ AsyncActorRolloutRefWorker
+ if config.actor_rollout_ref.rollout.mode == "async"
+ else ActorRolloutRefWorker
+ )
+ ray_worker_group_cls = RayWorkerGroup
+
+ else:
+ raise NotImplementedError
+
+ self.role_worker_mapping[Role.ActorRollout] = ray.remote(actor_rollout_cls)
+ self.mapping[Role.ActorRollout] = "global_pool"
+ return actor_rollout_cls, ray_worker_group_cls
+
+ def add_critic_worker(self, config):
+ """Add critic worker to role mapping."""
+ use_legacy_worker_impl = config.trainer.get("use_legacy_worker_impl", "auto")
+ if config.critic.strategy in {"fsdp", "fsdp2"}:
+ if use_legacy_worker_impl in ["auto", "enable"]:
+ from verl.workers.fsdp_workers import CriticWorker
+ elif use_legacy_worker_impl == "disable":
+ # we don't need to specialize critic worker. Just use TrainingWorker
+ from verl.workers.engine_workers import TrainingWorker
+
+ CriticWorker = TrainingWorker
+ print("Using new worker implementation")
+ else:
+ raise ValueError(f"Invalid use_legacy_worker_impl: {use_legacy_worker_impl}")
+
+ elif config.critic.strategy == "megatron":
+ # TODO: switch this to TrainingWorker as well
+ from verl.workers.megatron_workers import CriticWorker
+
+ else:
+ raise NotImplementedError
+
+ from verl.trainer.ppo.ray_trainer import Role
+
+ self.role_worker_mapping[Role.Critic] = ray.remote(CriticWorker)
+ self.mapping[Role.Critic] = "global_pool"
+
+ def init_resource_pool_mgr(self, config):
+ """Initialize resource pool manager."""
+
+ global_pool_id = "global_pool"
+ resource_pool_spec = {
+ global_pool_id: [config.trainer.n_gpus_per_node] * config.trainer.nnodes,
+ }
+ # TODO Here you can use the new registration method to support dynamic registration of roles
+ if config.reward_model.enable_resource_pool:
+ if config.reward_model.n_gpus_per_node <= 0:
+ raise ValueError("config.reward_model.n_gpus_per_node must be greater than 0")
+ if config.reward_model.nnodes <= 0:
+ raise ValueError("config.reward_model.nnodes must be greater than 0")
+
+ reward_pool = [config.reward_model.n_gpus_per_node] * config.reward_model.nnodes
+ resource_pool_spec["reward_pool"] = reward_pool
+
+ from verl.trainer.ppo.ray_trainer import ResourcePoolManager
+
+ resource_pool_manager = ResourcePoolManager(resource_pool_spec=resource_pool_spec, mapping=self.mapping)
+ return resource_pool_manager
+
+ def add_reward_model_worker(self, config):
+ """Add reward model worker if enabled."""
+ from verl.trainer.ppo.ray_trainer import Role
+
+ if config.reward_model.enable:
+ use_legacy_worker_impl = config.trainer.get("use_legacy_worker_impl", "auto")
+ if use_legacy_worker_impl in ["auto", "enable", "disable"]:
+ if config.reward_model.strategy in {"fsdp", "fsdp2"}:
+ from verl.workers.fsdp_workers import RewardModelWorker
+ elif config.reward_model.strategy == "megatron":
+ from verl.workers.megatron_workers import RewardModelWorker
+ else:
+ raise NotImplementedError
+ # elif use_legacy_worker_impl == "disable":
+ # from verl.workers.engine_workers import RewardModelWorker
+ #
+ # print("Using new worker implementation")
+ else:
+ raise ValueError(f"Invalid use_legacy_worker_impl: {use_legacy_worker_impl}")
+
+ self.role_worker_mapping[Role.RewardModel] = ray.remote(RewardModelWorker)
+ if config.reward_model.enable_resource_pool:
+ self.mapping[Role.RewardModel] = "reward_pool"
+ else:
+ self.mapping[Role.RewardModel] = "global_pool"
+
+ def add_ref_policy_worker(self, config, ref_policy_cls):
+ """Add reference policy worker if KL loss or KL reward is used."""
+ from verl.trainer.ppo.ray_trainer import Role
+
+ # Ref policy has been fused into ActorRolloutRefWorker in new model engine,
+ # we don't need to add a separate ref policy worker group.
+ use_legacy_worker_impl = config.trainer.get("use_legacy_worker_impl", "auto")
+ if use_legacy_worker_impl == "disable":
+ return
+
+ if config.algorithm.use_kl_in_reward or config.actor_rollout_ref.actor.use_kl_loss:
+ self.role_worker_mapping[Role.RefPolicy] = ray.remote(ref_policy_cls)
+ self.mapping[Role.RefPolicy] = "global_pool"
+
+ def run(self, config):
+ """Execute the main PPO training workflow.
+
+ This method sets up the distributed training environment, initializes
+ workers, datasets, and reward functions, then starts the training process.
+
+ Args:
+ config: Training configuration object containing all parameters needed
+ for setting up and running the PPO training process.
+ """
+ # Print the initial configuration. `resolve=True` will evaluate symbolic values.
+ from pprint import pprint
+
+ from omegaconf import OmegaConf
+
+ from verl.utils.fs import copy_to_local
+
+ print(f"TaskRunner hostname: {socket.gethostname()}, PID: {os.getpid()}")
+ pprint(OmegaConf.to_container(config, resolve=True))
+ OmegaConf.resolve(config)
+
+ actor_rollout_cls, ray_worker_group_cls = self.add_actor_rollout_worker(config)
+ self.add_critic_worker(config)
+
+ # We should adopt a multi-source reward function here:
+ # - for rule-based rm, we directly call a reward score
+ # - for model-based rm, we call a model
+ # - for code related prompt, we send to a sandbox if there are test cases
+ # finally, we combine all the rewards together
+ # The reward type depends on the tag of the data
+ self.add_reward_model_worker(config)
+
+ # Add a reference policy worker if KL loss or KL reward is used.
+ self.add_ref_policy_worker(config, actor_rollout_cls)
+
+ # validate config
+ validate_config(
+ config=config,
+ use_reference_policy=need_reference_policy(self.role_worker_mapping),
+ use_critic=need_critic(config),
+ )
+
+ # Download the checkpoint from HDFS to the local machine.
+ # `use_shm` determines whether to use shared memory, which could lead to faster model loading if turned on
+ local_path = copy_to_local(
+ config.actor_rollout_ref.model.path, use_shm=config.actor_rollout_ref.model.get("use_shm", False)
+ )
+
+ # Instantiate the tokenizer and processor.
+ from verl.utils import hf_processor, hf_tokenizer
+
+ trust_remote_code = config.data.get("trust_remote_code", False)
+ tokenizer = hf_tokenizer(local_path, trust_remote_code=trust_remote_code)
+ # Used for multimodal LLM, could be None
+ processor = hf_processor(local_path, trust_remote_code=trust_remote_code, use_fast=True)
+
+ # Load the reward manager for training and validation.
+ reward_fn = load_reward_manager(
+ config, tokenizer, num_examine=0, **config.reward_model.get("reward_kwargs", {})
+ )
+ val_reward_fn = load_reward_manager(
+ config, tokenizer, num_examine=1, **config.reward_model.get("reward_kwargs", {})
+ )
+
+ resource_pool_manager = self.init_resource_pool_mgr(config)
+
+ from verl.utils.dataset.rl_dataset import collate_fn
+
+ # Create training and validation datasets.
+ train_dataset = create_rl_dataset(
+ config.data.train_files,
+ config.data,
+ tokenizer,
+ processor,
+ is_train=True,
+ max_samples=config.data.get("train_max_samples", -1),
+ )
+ val_dataset = create_rl_dataset(
+ config.data.val_files,
+ config.data,
+ tokenizer,
+ processor,
+ is_train=False,
+ max_samples=config.data.get("val_max_samples", -1),
+ )
+ train_sampler = create_rl_sampler(config.data, train_dataset)
+
+ # Initialize the PPO trainer.
+ trainer = RayPPOTrainer(
+ config=config,
+ tokenizer=tokenizer,
+ processor=processor,
+ role_worker_mapping=self.role_worker_mapping,
+ resource_pool_manager=resource_pool_manager,
+ ray_worker_group_cls=ray_worker_group_cls,
+ reward_fn=reward_fn,
+ val_reward_fn=val_reward_fn,
+ train_dataset=train_dataset,
+ val_dataset=val_dataset,
+ collate_fn=collate_fn,
+ train_sampler=train_sampler,
+ )
+ # Initialize the workers of the trainer.
+ trainer.init_workers()
+
+ # Start the training process.
+ trainer.fit()
+
+
+def create_rl_dataset(data_paths, data_config, tokenizer, processor, is_train=True, max_samples: int = -1):
+ """Create a dataset.
+
+ Arguments:
+ data_paths: List of paths to data files.
+ data_config: The data config.
+ tokenizer (Tokenizer): The tokenizer.
+ processor (Processor): The processor.
+
+ Returns:
+ dataset (Dataset): The dataset.
+ """
+ from torch.utils.data import Dataset
+
+ from verl.utils.dataset.rl_dataset import RLHFDataset
+
+ # Check if a custom dataset class is specified in the data configuration
+ # and if the path to the custom class is provided
+ if "custom_cls" in data_config and data_config.custom_cls.get("path", None) is not None:
+ # Dynamically load the custom dataset class
+ dataset_cls = load_extern_object(data_config.custom_cls.path, data_config.custom_cls.name)
+ # Verify that the custom dataset class inherits from torch.utils.data.Dataset
+ if not issubclass(dataset_cls, Dataset):
+ raise TypeError(
+ f"The custom dataset class '{data_config.custom_cls.name}' from "
+ f"'{data_config.custom_cls.path}' must inherit from torch.utils.data.Dataset"
+ )
+ elif "datagen" in data_config and data_config.datagen.get("path", None) is not None and is_train:
+ # If a data generation strategy is specified, use the DynamicGenDataset class
+ from verl.utils.dataset.dynamicgen_dataset import DynamicGenDataset
+
+ dataset_cls = DynamicGenDataset
+ print("Using DynamicGenDataset for data generation.")
+ else:
+ # Use the default RLHFDataset class if no custom class is specified
+ dataset_cls = RLHFDataset
+ print(f"Using dataset class: {dataset_cls.__name__}")
+
+ # Instantiate the dataset using the determined dataset class
+ dataset = dataset_cls(
+ data_files=data_paths,
+ tokenizer=tokenizer,
+ processor=processor,
+ config=data_config,
+ max_samples=max_samples,
+ )
+
+ return dataset
+
+
+def create_rl_sampler(data_config, dataset):
+ """Create a sampler for the dataset.
+
+ Arguments:
+ data_config: The data config.
+ dataset (Dataset): The dataset.
+
+ Returns:
+ sampler (Sampler): The sampler.
+ """
+ import torch
+ from torch.utils.data import SequentialSampler
+
+ # torch.utils.data.RandomSampler could not recover properly
+ from torchdata.stateful_dataloader.sampler import RandomSampler
+
+ if data_config.sampler is not None and data_config.sampler.get("class_path", None) is not None:
+ curriculum_class = load_extern_object(
+ data_config.sampler.class_path,
+ data_config.sampler.class_name,
+ )
+ sampler = curriculum_class(
+ data_source=dataset,
+ data_config=data_config,
+ )
+ assert isinstance(sampler, AbstractSampler)
+ assert data_config.get("dataloader_num_workers", 8) == 0, (
+ "If using curriculum, num_workers must be 0 to prevent data caching. "
+ "If the dataloader caches data before the batch is done the "
+ "curriculum sampler won't have the opportunity to reorder it. "
+ )
+
+ # Use a sampler to facilitate checkpoint resumption.
+ # If shuffling is enabled in the data configuration, create a random sampler.
+ elif data_config.shuffle:
+ train_dataloader_generator = torch.Generator()
+ seed = data_config.get("seed")
+ if seed is not None:
+ train_dataloader_generator.manual_seed(seed)
+ sampler = RandomSampler(data_source=dataset, generator=train_dataloader_generator)
+ else:
+ # If shuffling is disabled, use a sequential sampler to iterate through the dataset in order.
+ sampler = SequentialSampler(data_source=dataset)
+
+ return sampler
+
+
+if __name__ == "__main__":
+ main()
diff --git a/partial_rollout/prompt_manager.py b/partial_rollout/prompt_manager.py
new file mode 100644
index 00000000..b8a235d9
--- /dev/null
+++ b/partial_rollout/prompt_manager.py
@@ -0,0 +1,390 @@
+# Copyright 2025 Meituan Ltd. and/or its affiliates
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import asyncio
+import logging
+import time
+import uuid
+from collections import deque
+from dataclasses import dataclass
+from typing import Any
+
+import numpy as np
+import ray
+import torch
+from omegaconf import DictConfig
+from tensordict import TensorDict
+from torch.utils.data import DataLoader
+from torchdata.stateful_dataloader import StatefulDataLoader
+
+from verl import DataProto
+from verl.experimental.agent_loop.agent_loop import AgentLoopOutput
+from verl.trainer.ppo.ray_trainer import compute_response_mask
+
+logger = logging.getLogger(__file__)
+logger.setLevel("INFO")
+
+
+@dataclass
+class RolloutPrompt:
+ """Enhanced rollout prompt (with n rollout samples) containing both original batch info and AgentLoopOutput"""
+
+ # Original batch information
+ full_batch: DataProto
+
+ # AgentLoopOutput from generation
+ agent_loop_output_list: list[AgentLoopOutput] # length: n
+
+ # Metadata
+ prompt_id: str
+ epoch: int
+
+ # Processing metadata
+ processing_times: list[float] # length: n
+ tool_calls: list[float] # length: n
+ param_version: int
+ param_version_start: list[int] # length: n
+ param_version_end: list[int] # length: n
+ rollout_status: dict[str, Any]
+ original_batch: DataProto
+
+
+def dict_of_list_to_list_of_dict(metrics: dict) -> list[dict]:
+ """
+ Convert:
+ {k: [v1, v2, ...]}
+ to:
+ [{k: v1}, {k: v2}, ...]
+ """
+ if not metrics:
+ return []
+
+ keys = list(metrics.keys())
+ length = len(next(iter(metrics.values())))
+
+ for k, v in metrics.items():
+ assert len(v) == length, f"Length mismatch for key '{k}'"
+
+ return [{k: metrics[k][i] for k in keys} for i in range(length)]
+
+
+def assemble_batch_from_rollout_prompts(
+ rollout_prompts: list[RolloutPrompt], current_param_version: int = None
+) -> DataProto:
+ """
+ Assemble gen_batch_output from RolloutPrompt objects
+ Assembles batches from RolloutPrompt objects, similar to the _post_generate_batch logic in ray_trainer.
+
+ Args:
+ rollout_prompts: List of RolloutPrompt objects
+ current_param_version: Current parameter version
+ Returns:
+ DataProto: Assembled gen_batch_output
+
+ Raises:
+ ValueError: If rollout_prompts is empty
+ """
+ try:
+ start_time = time.time()
+
+ if not rollout_prompts:
+ print("[Warning!!!] Empty rollout_prompts provided for batch assembly")
+ return DataProto(batch=TensorDict({}, batch_size=(0,)), meta_info={})
+
+ print(f"[BatchUtils] Assembling batch from {len(rollout_prompts)} RolloutPrompt objects")
+
+ rollout_prompts_batch = []
+ processing_times = []
+ tool_calls = []
+ rollout_status = rollout_prompts[0].rollout_status
+ # Add a prefix to all rollout_status keys
+ rollout_status = {f"partial_rollout/{key}": value for key, value in rollout_status.items()}
+
+ for rp in rollout_prompts:
+ rollout_prompts_batch.append(rp.full_batch)
+
+ final_batch = DataProto.concat(rollout_prompts_batch)
+
+ # Calculate response_mask (if not present)
+ if "response_mask" not in final_batch.batch.keys():
+ final_batch.batch["response_mask"] = compute_response_mask(final_batch)
+
+ # Calculate the global valid token number
+ if "attention_mask" in final_batch.batch:
+ final_batch.meta_info["global_token_num"] = torch.sum(final_batch.batch["attention_mask"], dim=-1).tolist()
+
+ processing_times = final_batch.non_tensor_batch["processing_times"]
+ tool_calls = final_batch.non_tensor_batch["tool_calls_times"]
+ # Collect statistics
+
+ processing_time_stats = {
+ "processing_time/avg": np.mean(processing_times),
+ "processing_time/max": np.max(processing_times),
+ "processing_time/min": np.min(processing_times),
+ "processing_time/tp50": np.percentile(processing_times, 50),
+ "processing_time/tp99": np.percentile(processing_times, 99),
+ "processing_time/tp95": np.percentile(processing_times, 95),
+ }
+ tool_calls_stats = {}
+ if len(tool_calls) > 0:
+ tool_calls_stats = {
+ # "timing_s/agent_loop/tool_calls/max": np.max(tool_calls),
+ # "timing_s/agent_loop/tool_calls/min": np.min(tool_calls),
+ # "timing_s/agent_loop/tool_calls/mean": np.mean(tool_calls),
+ }
+ processing_time_stats = {f"partial_rollout/{key}": value for key, value in processing_time_stats.items()}
+
+ param_version_start = final_batch.non_tensor_batch["param_version_start"]
+ param_version_end = final_batch.non_tensor_batch["param_version_end"]
+ param_version_diff = [abs(a - b) for a, b in zip(param_version_end, param_version_start, strict=False)]
+ num_diff0 = param_version_diff.count(0)
+ partial_stats = {
+ "partial_rollout/partial/total_partial_num": len(param_version_diff) - num_diff0,
+ "partial_rollout/partial/partial_ratio": (len(param_version_diff) - num_diff0) / len(param_version_diff),
+ "partial_rollout/partial/max_partial_span": max(param_version_diff),
+ }
+ staleness_stats = {}
+ if current_param_version is not None:
+ staleness = [current_param_version - version_start for version_start in param_version_start]
+ staleness_stats.update(
+ {
+ "partial_rollout/partial/staleness_max": np.max(staleness),
+ "partial_rollout/partial/staleness_min": np.min(staleness),
+ "partial_rollout/partial/staleness_avg": np.mean(staleness),
+ "partial_rollout/partial/staleness_tp50": np.percentile(staleness, 50),
+ "partial_rollout/partial/staleness_tp99": np.percentile(staleness, 99),
+ "partial_rollout/partial/staleness_tp95": np.percentile(staleness, 95),
+ }
+ )
+ # add meta_info
+ param_versions = [rp.param_version for rp in rollout_prompts]
+ trajectorys_param_versions = final_batch.non_tensor_batch["param_version_end"]
+
+ final_batch.meta_info.update(
+ {
+ "rollout_param_versions": param_versions,
+ "param_version_diversity": len(set(param_versions)) if param_versions else 0,
+ "trajectory_param_versions": trajectorys_param_versions,
+ **processing_time_stats,
+ **rollout_status,
+ **partial_stats,
+ **staleness_stats,
+ **tool_calls_stats,
+ }
+ )
+
+ final_batch.meta_info["metrics"] = dict_of_list_to_list_of_dict(final_batch.meta_info["metrics"])
+
+ print(f"[BatchUtils] Batch assembly completed in {time.time() - start_time:.2f}s")
+
+ except Exception as e:
+ logger.error(f"[BatchUtils] Batch assembly failed: {e}")
+ raise e
+
+ return final_batch
+
+
+@ray.remote
+class RolloutPromptManager:
+ """
+ Ray-based asynchronous rollout prompt manager for communication between AgentLoop and Trainer
+ """
+
+ def __init__(self, config: DictConfig, tokenizer, processor, dataloader: DataLoader):
+ self.config = config
+ self.cancellation_event = asyncio.Event()
+ self._lock = asyncio.Lock()
+ self.epoch = 0
+ self.current_param_version = 0
+ self.ongoing_set = set()
+ self.pending_queue = deque()
+ self.done_queue = deque()
+
+ from recipe.partial_rollout.main_ppo import create_rl_dataset, create_rl_sampler
+
+ from verl.utils.dataset.rl_dataset import collate_fn
+
+ self.dataset = create_rl_dataset(
+ config.data.train_files,
+ config.data,
+ tokenizer,
+ processor,
+ max_samples=config.data.get("train_max_samples", -1),
+ )
+ self.sampler = create_rl_sampler(config.data, self.dataset)
+ self.dataloader = StatefulDataLoader(
+ dataset=self.dataset,
+ batch_size=config.data.get("gen_batch_size", config.data.train_batch_size),
+ num_workers=config.data.get("dataloader_num_workers", 8),
+ drop_last=True,
+ collate_fn=collate_fn,
+ sampler=self.sampler,
+ )
+
+ self.dataiter = iter(self.dataloader)
+ self.is_dataiter_exhausted = False
+
+ def on_epoch_start(self, epoch: int):
+ """On epoch start for the rollout prompt manager."""
+ self.epoch = epoch
+ if self.is_dataiter_exhausted:
+ self.dataiter = iter(self.dataloader)
+ self.is_dataiter_exhausted = False
+
+ def prepare_generation(self, param_version: int):
+ """Prepare generation for the rollout prompt manager."""
+ self.cancellation_event.clear()
+ self.ongoing_set.clear()
+ self.current_param_version = param_version
+
+ def check_generation_once(self, num_rollout_prompts: int) -> bool:
+ """Check generation for the rollout prompt manager."""
+ done = len(self.done_queue) >= num_rollout_prompts or (
+ len(self.ongoing_set) == 0 and len(self.pending_queue) == 0 and self.is_dataiter_exhausted
+ )
+
+ if done:
+ logger.info(
+ f"[RolloutPromptManager] check_generation_once:\n"
+ f" - num_rollout_prompts: {num_rollout_prompts}\n"
+ f" - num_done_queue: {len(self.done_queue)}\n"
+ f" - num_pending_queue: {len(self.pending_queue)}\n"
+ f" - num_ongoing_set: {len(self.ongoing_set)}\n"
+ )
+ self.cancellation_event.set()
+ return done
+
+ def check_generation_post_state(self, num_rollout_prompts: int) -> bool:
+ """Check generation post state for the rollout prompt manager."""
+ logger.info(
+ "==========================================================\n"
+ f"[RolloutPromptManager] check_generation_post_state:\n"
+ f" - num_rollout_prompts: {num_rollout_prompts}\n"
+ f" - num_done_queue: {len(self.done_queue)}\n"
+ f" - num_pending_queue: {len(self.pending_queue)}\n"
+ f" - num_ongoing_set: {len(self.ongoing_set)}\n"
+ "==========================================================\n"
+ )
+ return len(self.ongoing_set) == 0 and len(self.done_queue) >= num_rollout_prompts
+
+ def pull_done_prompts(self, num_rollout_prompts: int) -> list[DataProto]:
+ """Pull done prompts from the rollout prompt manager."""
+ n = min(num_rollout_prompts, len(self.done_queue))
+ return [
+ assemble_batch_from_rollout_prompts(
+ [self.done_queue.popleft() for _ in range(n)],
+ self.current_param_version,
+ )
+ ]
+
+ def push_done_prompt(self, rollout_prompt: RolloutPrompt, is_cancel: bool = False):
+ """Push done prompts to the rollout prompt manager."""
+ try:
+ if is_cancel:
+ self.pending_queue.appendleft(rollout_prompt)
+ else:
+ rollout_prompt.full_batch.non_tensor_batch["uid"] = np.array(
+ [f"uid_{rollout_prompt.prompt_id}"] * len(rollout_prompt.full_batch), dtype=object
+ )
+ rollout_prompt.full_batch.union(rollout_prompt.original_batch)
+ rollout_prompt.param_version = self.current_param_version
+ param_version_start = rollout_prompt.full_batch.non_tensor_batch["param_version_start"]
+ param_version_end = rollout_prompt.full_batch.non_tensor_batch["param_version_end"]
+ param_version_diff = [abs(a - b) for a, b in zip(param_version_end, param_version_start, strict=False)]
+ if max(param_version_diff) < 10:
+ self.done_queue.append(rollout_prompt)
+
+ assert rollout_prompt.prompt_id in self.ongoing_set, (
+ f"prompt {rollout_prompt.prompt_id} not in ongoing_set"
+ )
+
+ self.ongoing_set.remove(rollout_prompt.prompt_id)
+ except Exception as e:
+ logger.error(f"[RolloutPromptManager] push_done_prompt: {e}")
+
+ def pull_pending_prompts(self, num_rollout_prompts: int) -> list[RolloutPrompt]:
+ """Pull pending prompts from the rollout prompt manager."""
+ try:
+ pending_prompts = []
+
+ while len(pending_prompts) < num_rollout_prompts:
+ if self.is_dataiter_exhausted or self.cancellation_event.is_set():
+ break
+
+ n = min(num_rollout_prompts - len(pending_prompts), len(self.pending_queue))
+ if len(self.pending_queue) > 0:
+ pending_prompts.extend([self.pending_queue.popleft() for _ in range(n)])
+ else:
+ try:
+ batch_dict = next(self.dataiter)
+ batch = DataProto.from_single_dict(batch_dict)
+ batch: list[DataProto] = batch.chunk(batch.batch.size(0))
+ self.pending_queue.extend(self._prepare_single_rollout_prompt(data) for data in batch)
+ except StopIteration:
+ self.is_dataiter_exhausted = True
+
+ for prompt in pending_prompts:
+ assert prompt.prompt_id not in self.ongoing_set, f"prompt {prompt.prompt_id} already in ongoing_set"
+ self.ongoing_set.add(prompt.prompt_id)
+
+ except Exception as e:
+ logger.error(f"[RolloutPromptManager] pull_pending_prompts: {e}")
+
+ return pending_prompts
+
+ def _prepare_single_rollout_prompt(self, data: DataProto) -> RolloutPrompt:
+ """Prepare a single rollout prompt."""
+ import copy
+
+ config = self.config
+ original_batch = copy.deepcopy(data)
+
+ reward_model_keys = (
+ set({"data_source", "reward_model", "extra_info", "uid"}) & original_batch.non_tensor_batch.keys()
+ )
+
+ batch_keys_to_pop = ["input_ids", "attention_mask", "position_ids"]
+ non_tensor_batch_keys_to_pop = set(original_batch.non_tensor_batch.keys()) - reward_model_keys
+ gen_batch = original_batch.pop(
+ batch_keys=batch_keys_to_pop,
+ non_tensor_batch_keys=list(non_tensor_batch_keys_to_pop),
+ )
+
+ # For agent loop, we need reward model keys to compute score.
+ gen_batch.non_tensor_batch.update(original_batch.non_tensor_batch)
+
+ # Setting selected agent, that supports partial
+ if config.actor_rollout_ref.rollout.multi_turn.enable:
+ gen_batch.non_tensor_batch["agent_name"] = np.array(["partial_tool_agent"] * len(gen_batch), dtype=object)
+ else:
+ gen_batch.non_tensor_batch["agent_name"] = np.array(
+ ["partial_single_turn_agent"] * len(gen_batch), dtype=object
+ )
+
+ original_batch = original_batch.repeat(repeat_times=config.actor_rollout_ref.rollout.n, interleave=True)
+ gen_batch = gen_batch.repeat(repeat_times=config.actor_rollout_ref.rollout.n, interleave=True)
+ gen_batch.non_tensor_batch["param_version"] = [self.current_param_version] * len(gen_batch)
+
+ return RolloutPrompt(
+ full_batch=gen_batch,
+ agent_loop_output_list=[None] * self.config.actor_rollout_ref.rollout.n,
+ prompt_id=f"prompt_{uuid.uuid4()}",
+ epoch=self.epoch,
+ param_version=self.current_param_version, # finish param version
+ param_version_start=[], # len()=n, start param version
+ param_version_end=[], # len()=n, end param version
+ processing_times=[],
+ tool_calls=[],
+ rollout_status={},
+ original_batch=original_batch,
+ )
diff --git a/partial_rollout/ray_trainer.py b/partial_rollout/ray_trainer.py
new file mode 100644
index 00000000..adb87c08
--- /dev/null
+++ b/partial_rollout/ray_trainer.py
@@ -0,0 +1,1545 @@
+# Copyright 2024 Bytedance Ltd. and/or its affiliates
+# Copyright 2023-2024 SGLang Team
+# Copyright 2025 ModelBest Inc. and/or its affiliates
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""
+PPO Trainer with Ray-based single controller.
+This trainer supports model-agonistic model initialization with huggingface
+"""
+
+import json
+import os
+import uuid
+from collections import defaultdict
+from dataclasses import dataclass, field
+from pprint import pprint
+from typing import Optional
+
+import numpy as np
+import ray
+import torch
+from omegaconf import OmegaConf, open_dict
+from torch.utils.data import Dataset, Sampler
+from torchdata.stateful_dataloader import StatefulDataLoader
+from tqdm import tqdm
+
+from verl import DataProto
+from verl.experimental.dataset.sampler import AbstractCurriculumSampler
+from verl.protocol import pad_dataproto_to_divisor, unpad_dataproto
+from verl.single_controller.ray import RayClassWithInitArgs, RayResourcePool, RayWorkerGroup
+from verl.single_controller.ray.base import create_colocated_worker_cls
+from verl.trainer.config import AlgoConfig
+from verl.trainer.ppo import core_algos
+from verl.trainer.ppo.core_algos import AdvantageEstimator, agg_loss
+from verl.trainer.ppo.metric_utils import (
+ compute_data_metrics,
+ compute_throughout_metrics,
+ compute_timing_metrics,
+ process_validation_metrics,
+)
+from verl.trainer.ppo.reward import compute_reward, compute_reward_async
+from verl.trainer.ppo.utils import Role, WorkerType, need_critic, need_reference_policy, need_reward_model
+from verl.utils import tensordict_utils as tu
+from verl.utils.checkpoint.checkpoint_manager import find_latest_ckpt_path, should_save_ckpt_esi
+from verl.utils.config import omega_conf_to_dataclass
+from verl.utils.debug import marked_timer
+from verl.utils.metric import reduce_metrics
+from verl.utils.py_functional import rename_dict
+from verl.utils.rollout_skip import RolloutSkip
+from verl.utils.seqlen_balancing import calculate_workload, get_seqlen_balanced_partitions, log_seqlen_unbalance
+from verl.utils.torch_functional import masked_mean
+from verl.utils.tracking import ValidationGenerationsLogger
+from verl.workers.config import FSDPEngineConfig
+from verl.workers.utils.padding import left_right_2_no_padding, no_padding_2_padding
+
+
+@dataclass
+class ResourcePoolManager:
+ """
+ Define a resource pool specification. Resource pool will be initialized first.
+ """
+
+ resource_pool_spec: dict[str, list[int]]
+ mapping: dict[Role, str]
+ resource_pool_dict: dict[str, RayResourcePool] = field(default_factory=dict)
+
+ def create_resource_pool(self):
+ """Create Ray resource pools for distributed training.
+
+ Initializes resource pools based on the resource pool specification,
+ with each pool managing GPU resources across multiple nodes.
+ For FSDP backend, uses max_colocate_count=1 to merge WorkerGroups.
+ For Megatron backend, uses max_colocate_count>1 for different models.
+ """
+ for resource_pool_name, process_on_nodes in self.resource_pool_spec.items():
+ # max_colocate_count means the number of WorkerGroups (i.e. processes) in each RayResourcePool
+ # For FSDP backend, using max_colocate_count=3: actor_critic_ref, rollout, reward model (optional)
+ # For Megatron backend, we recommend using max_colocate_count>1
+ # that can utilize different WorkerGroup for differnt models
+ resource_pool = RayResourcePool(
+ process_on_nodes=process_on_nodes, use_gpu=True, max_colocate_count=3, name_prefix=resource_pool_name
+ )
+ self.resource_pool_dict[resource_pool_name] = resource_pool
+
+ self._check_resource_available()
+
+ def get_resource_pool(self, role: Role) -> RayResourcePool:
+ """Get the resource pool of the worker_cls"""
+ return self.resource_pool_dict[self.mapping[role]]
+
+ def get_n_gpus(self) -> int:
+ """Get the number of gpus in this cluster."""
+ return sum([n_gpus for process_on_nodes in self.resource_pool_spec.values() for n_gpus in process_on_nodes])
+
+ def _check_resource_available(self):
+ """Check if the resource pool can be satisfied in this ray cluster."""
+ node_available_resources = ray._private.state.available_resources_per_node()
+ node_available_gpus = {
+ node: node_info.get("GPU", 0) if "GPU" in node_info else node_info.get("NPU", 0)
+ for node, node_info in node_available_resources.items()
+ }
+
+ # check total required gpus can be satisfied
+ total_available_gpus = sum(node_available_gpus.values())
+ total_required_gpus = sum(
+ [n_gpus for process_on_nodes in self.resource_pool_spec.values() for n_gpus in process_on_nodes]
+ )
+ if total_available_gpus < total_required_gpus:
+ raise ValueError(
+ f"Total available GPUs {total_available_gpus} is less than total desired GPUs {total_required_gpus}"
+ )
+
+
+def apply_kl_penalty(data: DataProto, kl_ctrl: core_algos.AdaptiveKLController, kl_penalty="kl"):
+ """Apply KL penalty to the token-level rewards.
+
+ This function computes the KL divergence between the reference policy and current policy,
+ then applies a penalty to the token-level rewards based on this divergence.
+
+ Args:
+ data (DataProto): The data containing batched model outputs and inputs.
+ kl_ctrl (core_algos.AdaptiveKLController): Controller for adaptive KL penalty.
+ kl_penalty (str, optional): Type of KL penalty to apply. Defaults to "kl".
+
+ Returns:
+ tuple: A tuple containing:
+ - The updated data with token-level rewards adjusted by KL penalty
+ - A dictionary of metrics related to the KL penalty
+ """
+ response_mask = data.batch["response_mask"]
+ token_level_scores = data.batch["token_level_scores"]
+ batch_size = data.batch.batch_size[0]
+
+ # compute kl between ref_policy and current policy
+ # When apply_kl_penalty, algorithm.use_kl_in_reward=True, so the reference model has been enabled.
+ kld = core_algos.kl_penalty(
+ data.batch["old_log_probs"], data.batch["ref_log_prob"], kl_penalty=kl_penalty
+ ) # (batch_size, response_length)
+ kld = kld * response_mask
+ beta = kl_ctrl.value
+
+ token_level_rewards = token_level_scores - beta * kld
+
+ current_kl = masked_mean(kld, mask=response_mask, axis=-1) # average over sequence
+ current_kl = torch.mean(current_kl, dim=0).item()
+
+ # according to https://github.com/huggingface/trl/blob/951ca1841f29114b969b57b26c7d3e80a39f75a0/trl/trainer/ppo_trainer.py#L837
+ kl_ctrl.update(current_kl=current_kl, n_steps=batch_size)
+ data.batch["token_level_rewards"] = token_level_rewards
+
+ metrics = {"actor/reward_kl_penalty": current_kl, "actor/reward_kl_penalty_coeff": beta}
+
+ return data, metrics
+
+
+def compute_response_mask(data: DataProto):
+ """Compute the attention mask for the response part of the sequence.
+
+ This function extracts the portion of the attention mask that corresponds to the model's response,
+ which is used for masking computations that should only apply to response tokens.
+
+ Args:
+ data (DataProto): The data containing batched model outputs and inputs.
+
+ Returns:
+ torch.Tensor: The attention mask for the response tokens.
+ """
+ responses = data.batch["responses"]
+ response_length = responses.size(1)
+ attention_mask = data.batch["attention_mask"]
+ return attention_mask[:, -response_length:]
+
+
+def compute_advantage(
+ data: DataProto,
+ adv_estimator: AdvantageEstimator,
+ gamma: float = 1.0,
+ lam: float = 1.0,
+ num_repeat: int = 1,
+ norm_adv_by_std_in_grpo: bool = True,
+ config: Optional[AlgoConfig] = None,
+) -> DataProto:
+ """Compute advantage estimates for policy optimization.
+
+ This function computes advantage estimates using various estimators like GAE, GRPO, REINFORCE++, etc.
+ The advantage estimates are used to guide policy optimization in RL algorithms.
+
+ Args:
+ data (DataProto): The data containing batched model outputs and inputs.
+ adv_estimator (AdvantageEstimator): The advantage estimator to use (e.g., GAE, GRPO, REINFORCE++).
+ gamma (float, optional): Discount factor for future rewards. Defaults to 1.0.
+ lam (float, optional): Lambda parameter for GAE. Defaults to 1.0.
+ num_repeat (int, optional): Number of times to repeat the computation. Defaults to 1.
+ norm_adv_by_std_in_grpo (bool, optional): Whether to normalize advantages by standard deviation in
+ GRPO. Defaults to True.
+ config (dict, optional): Configuration dictionary for algorithm settings. Defaults to None.
+
+ Returns:
+ DataProto: The updated data with computed advantages and returns.
+ """
+ # Back-compatible with trainers that do not compute response mask in fit
+ if "response_mask" not in data.batch.keys():
+ data.batch["response_mask"] = compute_response_mask(data)
+ # prepare response group
+ if adv_estimator == AdvantageEstimator.GAE:
+ # Compute advantages and returns using Generalized Advantage Estimation (GAE)
+ advantages, returns = core_algos.compute_gae_advantage_return(
+ token_level_rewards=data.batch["token_level_rewards"],
+ values=data.batch["values"],
+ response_mask=data.batch["response_mask"],
+ gamma=gamma,
+ lam=lam,
+ )
+ data.batch["advantages"] = advantages
+ data.batch["returns"] = returns
+ if config.get("use_pf_ppo", False):
+ data = core_algos.compute_pf_ppo_reweight_data(
+ data,
+ config.pf_ppo.get("reweight_method"),
+ config.pf_ppo.get("weight_pow"),
+ )
+ elif adv_estimator == AdvantageEstimator.GRPO:
+ # Initialize the mask for GRPO calculation
+ grpo_calculation_mask = data.batch["response_mask"]
+
+ # Call compute_grpo_outcome_advantage with parameters matching its definition
+ advantages, returns = core_algos.compute_grpo_outcome_advantage(
+ token_level_rewards=data.batch["token_level_rewards"],
+ response_mask=grpo_calculation_mask,
+ index=data.non_tensor_batch["uid"],
+ norm_adv_by_std_in_grpo=norm_adv_by_std_in_grpo,
+ )
+ data.batch["advantages"] = advantages
+ data.batch["returns"] = returns
+ else:
+ # handle all other adv estimator type other than GAE and GRPO
+ adv_estimator_fn = core_algos.get_adv_estimator_fn(adv_estimator)
+ adv_kwargs = {
+ "token_level_rewards": data.batch["token_level_rewards"],
+ "response_mask": data.batch["response_mask"],
+ "config": config,
+ }
+ if "uid" in data.non_tensor_batch: # optional
+ adv_kwargs["index"] = data.non_tensor_batch["uid"]
+ if "reward_baselines" in data.batch: # optional
+ adv_kwargs["reward_baselines"] = data.batch["reward_baselines"]
+
+ # calculate advantage estimator
+ advantages, returns = adv_estimator_fn(**adv_kwargs)
+ data.batch["advantages"] = advantages
+ data.batch["returns"] = returns
+ return data
+
+
+class RayPPOTrainer:
+ """Distributed PPO trainer using Ray for scalable reinforcement learning.
+
+ This trainer orchestrates distributed PPO training across multiple nodes and GPUs,
+ managing actor rollouts, critic training, and reward computation with Ray backend.
+ Supports various model architectures including FSDP, Megatron, vLLM, and SGLang integration.
+ """
+
+ # TODO: support each role have individual ray_worker_group_cls,
+ # i.e., support different backend of different role
+ def __init__(
+ self,
+ config,
+ tokenizer,
+ role_worker_mapping: dict[Role, WorkerType],
+ resource_pool_manager: ResourcePoolManager,
+ ray_worker_group_cls: type[RayWorkerGroup] = RayWorkerGroup,
+ processor=None,
+ reward_fn=None,
+ val_reward_fn=None,
+ train_dataset: Optional[Dataset] = None,
+ val_dataset: Optional[Dataset] = None,
+ collate_fn=None,
+ train_sampler: Optional[Sampler] = None,
+ device_name=None,
+ ):
+ """
+ Initialize distributed PPO trainer with Ray backend.
+ Note that this trainer runs on the driver process on a single CPU/GPU node.
+
+ Args:
+ config: Configuration object containing training parameters.
+ tokenizer: Tokenizer used for encoding and decoding text.
+ role_worker_mapping (dict[Role, WorkerType]): Mapping from roles to worker classes.
+ resource_pool_manager (ResourcePoolManager): Manager for Ray resource pools.
+ ray_worker_group_cls (RayWorkerGroup, optional): Class for Ray worker groups. Defaults to RayWorkerGroup.
+ processor: Optional data processor, used for multimodal data
+ reward_fn: Function for computing rewards during training.
+ val_reward_fn: Function for computing rewards during validation.
+ train_dataset (Optional[Dataset], optional): Training dataset. Defaults to None.
+ val_dataset (Optional[Dataset], optional): Validation dataset. Defaults to None.
+ collate_fn: Function to collate data samples into batches.
+ train_sampler (Optional[Sampler], optional): Sampler for the training dataset. Defaults to None.
+ device_name (str, optional): Device name for training (e.g., "cuda", "cpu"). Defaults to None.
+ """
+
+ # Store the tokenizer for text processing
+ self.tokenizer = tokenizer
+ self.processor = processor
+ self.config = config
+ self.reward_fn = reward_fn
+ self.val_reward_fn = val_reward_fn
+
+ self.hybrid_engine = config.actor_rollout_ref.hybrid_engine
+ assert self.hybrid_engine, "Currently, only support hybrid engine"
+
+ if self.hybrid_engine:
+ assert Role.ActorRollout in role_worker_mapping or Role.ActorRolloutRef in role_worker_mapping, (
+ f"{role_worker_mapping.keys()=}"
+ )
+
+ self.role_worker_mapping = role_worker_mapping
+ self.resource_pool_manager = resource_pool_manager
+ self.use_reference_policy = need_reference_policy(self.role_worker_mapping)
+ # legacy reward model implementation
+ self.use_rm = need_reward_model(self.role_worker_mapping)
+ self.use_reward_loop = self.config.reward_model.use_reward_loop
+
+ self.use_critic = need_critic(self.config)
+ self.ray_worker_group_cls = ray_worker_group_cls
+ self.device_name = device_name if device_name else self.config.trainer.device
+ self.validation_generations_logger = ValidationGenerationsLogger(
+ project_name=self.config.trainer.project_name,
+ experiment_name=self.config.trainer.experiment_name,
+ )
+
+ # if ref_in_actor is True, the reference policy will be actor without lora applied
+ self.ref_in_actor = (
+ config.actor_rollout_ref.model.get("lora_rank", 0) > 0
+ or config.actor_rollout_ref.model.get("lora_adapter_path") is not None
+ )
+
+ # define in-reward KL control
+ # kl loss control currently not supported
+ if self.config.algorithm.use_kl_in_reward:
+ self.kl_ctrl_in_reward = core_algos.get_kl_controller(self.config.algorithm.kl_ctrl)
+
+ self.use_legacy_worker_impl = config.trainer.get("use_legacy_worker_impl", "auto")
+
+ self._create_dataloader(train_dataset, val_dataset, collate_fn, train_sampler)
+
+ def _create_dataloader(self, train_dataset, val_dataset, collate_fn, train_sampler: Optional[Sampler]):
+ """
+ Creates the train and validation dataloaders.
+ """
+ # TODO: we have to make sure the batch size is divisible by the dp size
+ from verl.trainer.main_ppo import create_rl_dataset, create_rl_sampler
+
+ if train_dataset is None:
+ train_dataset = create_rl_dataset(
+ self.config.data.train_files,
+ self.config.data,
+ self.tokenizer,
+ self.processor,
+ max_samples=self.config.data.get("train_max_samples", -1),
+ )
+ if val_dataset is None:
+ val_dataset = create_rl_dataset(
+ self.config.data.val_files,
+ self.config.data,
+ self.tokenizer,
+ self.processor,
+ max_samples=self.config.data.get("val_max_samples", -1),
+ )
+ self.train_dataset, self.val_dataset = train_dataset, val_dataset
+
+ if train_sampler is None:
+ train_sampler = create_rl_sampler(self.config.data, self.train_dataset)
+ if collate_fn is None:
+ from verl.utils.dataset.rl_dataset import collate_fn as default_collate_fn
+
+ collate_fn = default_collate_fn
+
+ num_workers = self.config.data["dataloader_num_workers"]
+
+ self.train_dataloader = StatefulDataLoader(
+ dataset=self.train_dataset,
+ batch_size=self.config.data.get("gen_batch_size", self.config.data.train_batch_size),
+ num_workers=num_workers,
+ drop_last=True,
+ collate_fn=collate_fn,
+ sampler=train_sampler,
+ )
+
+ val_batch_size = self.config.data.val_batch_size # Prefer config value if set
+ if val_batch_size is None:
+ val_batch_size = len(self.val_dataset)
+
+ self.val_dataloader = StatefulDataLoader(
+ dataset=self.val_dataset,
+ batch_size=val_batch_size,
+ num_workers=num_workers,
+ shuffle=self.config.data.get("validation_shuffle", True),
+ drop_last=False,
+ collate_fn=collate_fn,
+ )
+
+ assert len(self.train_dataloader) >= 1, "Train dataloader is empty!"
+ assert len(self.val_dataloader) >= 1, "Validation dataloader is empty!"
+
+ print(
+ f"Size of train dataloader: {len(self.train_dataloader)}, Size of val dataloader: "
+ f"{len(self.val_dataloader)}"
+ )
+
+ total_training_steps = len(self.train_dataloader) * self.config.trainer.total_epochs
+
+ if self.config.trainer.total_training_steps is not None:
+ total_training_steps = self.config.trainer.total_training_steps
+
+ self.total_training_steps = total_training_steps
+ print(f"Total training steps: {self.total_training_steps}")
+
+ try:
+ OmegaConf.set_struct(self.config, True)
+ with open_dict(self.config):
+ if OmegaConf.select(self.config, "actor_rollout_ref.actor.optim"):
+ self.config.actor_rollout_ref.actor.optim.total_training_steps = total_training_steps
+ if OmegaConf.select(self.config, "critic.optim"):
+ self.config.critic.optim.total_training_steps = total_training_steps
+ except Exception as e:
+ print(f"Warning: Could not set total_training_steps in config. Structure missing? Error: {e}")
+
+ def _dump_generations(self, inputs, outputs, gts, scores, reward_extra_infos_dict, dump_path):
+ """Dump rollout/validation samples as JSONL."""
+ os.makedirs(dump_path, exist_ok=True)
+ filename = os.path.join(dump_path, f"{self.global_steps}.jsonl")
+
+ n = len(inputs)
+ base_data = {
+ "input": inputs,
+ "output": outputs,
+ "gts": gts,
+ "score": scores,
+ "step": [self.global_steps] * n,
+ }
+
+ for k, v in reward_extra_infos_dict.items():
+ if len(v) == n:
+ base_data[k] = v
+
+ lines = []
+ for i in range(n):
+ entry = {k: v[i] for k, v in base_data.items()}
+ lines.append(json.dumps(entry, ensure_ascii=False))
+
+ with open(filename, "w") as f:
+ f.write("\n".join(lines) + "\n")
+
+ print(f"Dumped generations to {filename}")
+
+ def _log_rollout_data(
+ self, batch: DataProto, reward_extra_infos_dict: dict, timing_raw: dict, rollout_data_dir: str
+ ):
+ """Log rollout data to disk.
+ Args:
+ batch (DataProto): The batch containing rollout data
+ reward_extra_infos_dict (dict): Additional reward information to log
+ timing_raw (dict): Timing information for profiling
+ rollout_data_dir (str): Directory path to save the rollout data
+ """
+ with marked_timer("dump_rollout_generations", timing_raw, color="green"):
+ inputs = self.tokenizer.batch_decode(batch.batch["prompts"], skip_special_tokens=True)
+ outputs = self.tokenizer.batch_decode(batch.batch["responses"], skip_special_tokens=True)
+ scores = batch.batch["token_level_scores"].sum(-1).cpu().tolist()
+ sample_gts = [item.non_tensor_batch.get("reward_model", {}).get("ground_truth", None) for item in batch]
+
+ reward_extra_infos_to_dump = reward_extra_infos_dict.copy()
+ if "request_id" in batch.non_tensor_batch:
+ reward_extra_infos_dict.setdefault(
+ "request_id",
+ batch.non_tensor_batch["request_id"].tolist(),
+ )
+
+ self._dump_generations(
+ inputs=inputs,
+ outputs=outputs,
+ gts=sample_gts,
+ scores=scores,
+ reward_extra_infos_dict=reward_extra_infos_to_dump,
+ dump_path=rollout_data_dir,
+ )
+
+ def _maybe_log_val_generations(self, inputs, outputs, scores):
+ """Log a table of validation samples to the configured logger (wandb or swanlab)"""
+
+ generations_to_log = self.config.trainer.log_val_generations
+
+ if generations_to_log == 0:
+ return
+
+ import numpy as np
+
+ # Create tuples of (input, output, score) and sort by input text
+ samples = list(zip(inputs, outputs, scores, strict=True))
+ samples.sort(key=lambda x: x[0]) # Sort by input text
+
+ # Use fixed random seed for deterministic shuffling
+ rng = np.random.RandomState(42)
+ rng.shuffle(samples)
+
+ # Take first N samples after shuffling
+ samples = samples[:generations_to_log]
+
+ # Log to each configured logger
+ self.validation_generations_logger.log(self.config.trainer.logger, samples, self.global_steps)
+
+ def _get_gen_batch(self, batch: DataProto) -> DataProto:
+ reward_model_keys = set({"data_source", "reward_model", "extra_info", "uid"}) & batch.non_tensor_batch.keys()
+
+ # pop those keys for generation
+ batch_keys_to_pop = ["input_ids", "attention_mask", "position_ids"]
+ non_tensor_batch_keys_to_pop = set(batch.non_tensor_batch.keys()) - reward_model_keys
+ gen_batch = batch.pop(
+ batch_keys=batch_keys_to_pop,
+ non_tensor_batch_keys=list(non_tensor_batch_keys_to_pop),
+ )
+
+ # For agent loop, we need reward model keys to compute score.
+ if self.async_rollout_mode:
+ gen_batch.non_tensor_batch.update(batch.non_tensor_batch)
+
+ return gen_batch
+
+ def _validate(self):
+ data_source_lst = []
+ reward_extra_infos_dict: dict[str, list] = defaultdict(list)
+
+ # Lists to collect samples for the table
+ sample_inputs = []
+ sample_outputs = []
+ sample_gts = []
+ sample_scores = []
+ sample_turns = []
+ sample_uids = []
+
+ for test_data in self.val_dataloader:
+ test_batch = DataProto.from_single_dict(test_data)
+
+ if "uid" not in test_batch.non_tensor_batch:
+ test_batch.non_tensor_batch["uid"] = np.array(
+ [str(uuid.uuid4()) for _ in range(len(test_batch.batch))], dtype=object
+ )
+
+ # repeat test batch
+ test_batch = test_batch.repeat(
+ repeat_times=self.config.actor_rollout_ref.rollout.val_kwargs.n, interleave=True
+ )
+
+ # we only do validation on rule-based rm
+ if self.config.reward_model.enable and test_batch[0].non_tensor_batch["reward_model"]["style"] == "model":
+ return {}
+
+ # Store original inputs
+ input_ids = test_batch.batch["input_ids"]
+ # TODO: Can we keep special tokens except for padding tokens?
+ input_texts = [self.tokenizer.decode(ids, skip_special_tokens=True) for ids in input_ids]
+ sample_inputs.extend(input_texts)
+ sample_uids.extend(test_batch.non_tensor_batch["uid"])
+
+ ground_truths = [
+ item.non_tensor_batch.get("reward_model", {}).get("ground_truth", None) for item in test_batch
+ ]
+ sample_gts.extend(ground_truths)
+
+ test_gen_batch = self._get_gen_batch(test_batch)
+ test_gen_batch.meta_info = {
+ "eos_token_id": self.tokenizer.eos_token_id,
+ "pad_token_id": self.tokenizer.pad_token_id,
+ "recompute_log_prob": False,
+ "do_sample": self.config.actor_rollout_ref.rollout.val_kwargs.do_sample,
+ "validate": True,
+ "global_steps": self.global_steps,
+ }
+ print(f"test_gen_batch meta info: {test_gen_batch.meta_info}")
+
+ # pad to be divisible by dp_size
+ size_divisor = (
+ self.actor_rollout_wg.world_size
+ if not self.async_rollout_mode
+ else self.config.actor_rollout_ref.rollout.agent.num_workers
+ )
+ test_gen_batch_padded, pad_size = pad_dataproto_to_divisor(test_gen_batch, size_divisor)
+ if not self.async_rollout_mode:
+ test_output_gen_batch_padded = self.actor_rollout_wg.generate_sequences(test_gen_batch_padded)
+ else:
+ test_output_gen_batch_padded = self.async_rollout_manager.generate_sequences(test_gen_batch_padded)
+
+ # unpad
+ test_output_gen_batch = unpad_dataproto(test_output_gen_batch_padded, pad_size=pad_size)
+
+ print("validation generation end")
+
+ # Store generated outputs
+ output_ids = test_output_gen_batch.batch["responses"]
+ output_texts = [self.tokenizer.decode(ids, skip_special_tokens=True) for ids in output_ids]
+ sample_outputs.extend(output_texts)
+
+ test_batch = test_batch.union(test_output_gen_batch)
+ test_batch.meta_info["validate"] = True
+
+ # evaluate using reward_function
+ if self.val_reward_fn is None:
+ raise ValueError("val_reward_fn must be provided for validation.")
+ result = self.val_reward_fn(test_batch, return_dict=True)
+ reward_tensor = result["reward_tensor"]
+ scores = reward_tensor.sum(-1).cpu().tolist()
+ sample_scores.extend(scores)
+
+ reward_extra_infos_dict["reward"].extend(scores)
+ if "reward_extra_info" in result:
+ for key, lst in result["reward_extra_info"].items():
+ reward_extra_infos_dict[key].extend(lst)
+
+ # collect num_turns of each prompt
+ if "__num_turns__" in test_batch.non_tensor_batch:
+ sample_turns.append(test_batch.non_tensor_batch["__num_turns__"])
+
+ data_source_lst.append(test_batch.non_tensor_batch.get("data_source", ["unknown"] * reward_tensor.shape[0]))
+
+ self._maybe_log_val_generations(inputs=sample_inputs, outputs=sample_outputs, scores=sample_scores)
+
+ # dump generations
+ val_data_dir = self.config.trainer.get("validation_data_dir", None)
+ if val_data_dir:
+ self._dump_generations(
+ inputs=sample_inputs,
+ outputs=sample_outputs,
+ gts=sample_gts,
+ scores=sample_scores,
+ reward_extra_infos_dict=reward_extra_infos_dict,
+ dump_path=val_data_dir,
+ )
+
+ for key_info, lst in reward_extra_infos_dict.items():
+ assert len(lst) == 0 or len(lst) == len(sample_scores), f"{key_info}: {len(lst)=}, {len(sample_scores)=}"
+
+ data_sources = np.concatenate(data_source_lst, axis=0)
+
+ data_src2var2metric2val = process_validation_metrics(data_sources, sample_uids, reward_extra_infos_dict)
+ metric_dict = {}
+ for data_source, var2metric2val in data_src2var2metric2val.items():
+ core_var = "acc" if "acc" in var2metric2val else "reward"
+ for var_name, metric2val in var2metric2val.items():
+ n_max = max([int(name.split("@")[-1].split("/")[0]) for name in metric2val.keys()])
+ for metric_name, metric_val in metric2val.items():
+ if (
+ (var_name == core_var)
+ and any(metric_name.startswith(pfx) for pfx in ["mean", "maj", "best"])
+ and (f"@{n_max}" in metric_name)
+ ):
+ metric_sec = "val-core"
+ else:
+ metric_sec = "val-aux"
+ pfx = f"{metric_sec}/{data_source}/{var_name}/{metric_name}"
+ metric_dict[pfx] = metric_val
+
+ if len(sample_turns) > 0:
+ sample_turns = np.concatenate(sample_turns)
+ metric_dict["val-aux/num_turns/min"] = sample_turns.min()
+ metric_dict["val-aux/num_turns/max"] = sample_turns.max()
+ metric_dict["val-aux/num_turns/mean"] = sample_turns.mean()
+
+ return metric_dict
+
+ def init_workers(self):
+ """Initialize distributed training workers using Ray backend.
+
+ Creates:
+ 1. Ray resource pools from configuration
+ 2. Worker groups for each role (actor, critic, etc.)
+ """
+ self.resource_pool_manager.create_resource_pool()
+
+ self.resource_pool_to_cls = {pool: {} for pool in self.resource_pool_manager.resource_pool_dict.values()}
+
+ # create actor and rollout
+ actor_role = Role.ActorRolloutRef if Role.ActorRolloutRef in self.role_worker_mapping else Role.ActorRollout
+ if self.hybrid_engine:
+ resource_pool = self.resource_pool_manager.get_resource_pool(actor_role)
+ actor_rollout_cls = RayClassWithInitArgs(
+ cls=self.role_worker_mapping[actor_role],
+ config=self.config.actor_rollout_ref,
+ role=str(actor_role),
+ )
+ self.resource_pool_to_cls[resource_pool][str(actor_role)] = actor_rollout_cls
+ else:
+ raise NotImplementedError
+
+ # create critic
+ if self.use_critic:
+ resource_pool = self.resource_pool_manager.get_resource_pool(Role.Critic)
+
+ from verl.workers.config import CriticConfig
+
+ critic_cfg: CriticConfig = omega_conf_to_dataclass(self.config.critic)
+
+ if self.use_legacy_worker_impl == "disable":
+ # convert critic_cfg into TrainingWorkerConfig
+ from verl.workers.engine_workers import TrainingWorkerConfig
+
+ orig_critic_cfg = critic_cfg
+ if orig_critic_cfg.strategy == "fsdp":
+ engine_config: FSDPEngineConfig = orig_critic_cfg.model.fsdp_config
+ engine_config.infer_max_token_len_per_gpu = critic_cfg.ppo_infer_max_token_len_per_gpu
+ engine_config.max_token_len_per_gpu = critic_cfg.ppo_max_token_len_per_gpu
+ else:
+ raise NotImplementedError(f"Unknown strategy {orig_critic_cfg.strategy=}")
+
+ critic_cfg = TrainingWorkerConfig(
+ model_type="value_model",
+ model_config=orig_critic_cfg.model_config,
+ engine_config=engine_config,
+ optimizer_config=orig_critic_cfg.optim,
+ checkpoint_config=orig_critic_cfg.checkpoint,
+ )
+
+ critic_cls = RayClassWithInitArgs(cls=self.role_worker_mapping[Role.Critic], config=critic_cfg)
+ self.resource_pool_to_cls[resource_pool][str(Role.Critic)] = critic_cls
+
+ # create reference policy if needed
+ if self.use_reference_policy and Role.RefPolicy in self.role_worker_mapping:
+ resource_pool = self.resource_pool_manager.get_resource_pool(Role.RefPolicy)
+ ref_policy_cls = RayClassWithInitArgs(
+ self.role_worker_mapping[Role.RefPolicy],
+ config=self.config.actor_rollout_ref,
+ role=str(Role.RefPolicy),
+ )
+ self.resource_pool_to_cls[resource_pool][str(Role.RefPolicy)] = ref_policy_cls
+
+ # create a reward model if reward_fn is None
+ # for legacy discriminative reward model, we create a reward model worker here
+ # for reward loop discriminative reward model, we create a reward loop manager here
+ if not self.use_reward_loop:
+ # legacy reward model only handle reward-model based scenario
+ if self.use_rm:
+ # we create a RM here
+ resource_pool = self.resource_pool_manager.get_resource_pool(Role.RewardModel)
+ rm_cls = RayClassWithInitArgs(
+ self.role_worker_mapping[Role.RewardModel], config=self.config.reward_model
+ )
+ self.resource_pool_to_cls[resource_pool][str(Role.RewardModel)] = rm_cls
+ else:
+ # reward loop handle hybrid reward scenario (rule, disrm, genrm, ...)
+ can_reward_loop_parallelize = self.config.actor_rollout_ref.rollout.mode == "async" and (
+ not self.use_rm or self.config.reward_model.enable_resource_pool
+ )
+ # judge if we can asynchronously parallelize reward model with actor rollout
+ # two condition that we can parallelize reward model with actor rollout:
+ # 1. reward model is not enabled (rule-based reward can parallelize)
+ # 2. reward model is enabled but extra resource pool is enabled
+ # If we cannot parallelize, we should enable synchronous mode here, and launch a reward loop manager here
+ # else for parallelize mode, we launch a reward worker for each rollout worker (in agent loop, not here)
+ if not can_reward_loop_parallelize:
+ from verl.experimental.reward import RewardLoopManager
+
+ self.config.reward_model.n_gpus_per_node = self.config.trainer.n_gpus_per_node
+ resource_pool = self.resource_pool_manager.get_resource_pool(Role.RewardModel)
+ self.reward_loop_manager = RewardLoopManager(
+ config=self.config,
+ rm_resource_pool=resource_pool,
+ )
+
+ # initialize WorkerGroup
+ # NOTE: if you want to use a different resource pool for each role, which can support different parallel size,
+ # you should not use `create_colocated_worker_cls`.
+ # Instead, directly pass different resource pool to different worker groups.
+ # See https://github.com/volcengine/verl/blob/master/examples/ray/tutorial.ipynb for more information.
+ all_wg = {}
+ wg_kwargs = {} # Setting up kwargs for RayWorkerGroup
+ if OmegaConf.select(self.config.trainer, "ray_wait_register_center_timeout") is not None:
+ wg_kwargs["ray_wait_register_center_timeout"] = self.config.trainer.ray_wait_register_center_timeout
+ if OmegaConf.select(self.config.global_profiler, "steps") is not None:
+ wg_kwargs["profile_steps"] = OmegaConf.select(self.config.global_profiler, "steps")
+ # Only require nsight worker options when tool is nsys
+ if OmegaConf.select(self.config.global_profiler, "tool") == "nsys":
+ assert (
+ OmegaConf.select(self.config.global_profiler.global_tool_config.nsys, "worker_nsight_options")
+ is not None
+ ), "worker_nsight_options must be set when using nsys with profile_steps"
+ wg_kwargs["worker_nsight_options"] = OmegaConf.to_container(
+ OmegaConf.select(self.config.global_profiler.global_tool_config.nsys, "worker_nsight_options")
+ )
+ wg_kwargs["device_name"] = self.device_name
+
+ for resource_pool, class_dict in self.resource_pool_to_cls.items():
+ worker_dict_cls = create_colocated_worker_cls(class_dict=class_dict)
+ wg_dict = self.ray_worker_group_cls(
+ resource_pool=resource_pool,
+ ray_cls_with_init=worker_dict_cls,
+ **wg_kwargs,
+ )
+ spawn_wg = wg_dict.spawn(prefix_set=class_dict.keys())
+ all_wg.update(spawn_wg)
+
+ if self.use_critic:
+ self.critic_wg = all_wg[str(Role.Critic)]
+ if self.use_legacy_worker_impl == "disable":
+ self.critic_wg.reset()
+ # assign critic loss
+ from functools import partial
+
+ from verl.workers.utils.losses import value_loss
+
+ value_loss_ = partial(value_loss, config=orig_critic_cfg)
+ self.critic_wg.set_loss_fn(value_loss_)
+ else:
+ self.critic_wg.init_model()
+
+ if self.use_reference_policy and not self.ref_in_actor:
+ if str(Role.RefPolicy) in all_wg:
+ self.ref_policy_wg = all_wg[str(Role.RefPolicy)]
+ self.ref_policy_wg.init_model()
+ else:
+ # Model engine: ActorRolloutRefWorker
+ assert str(Role.ActorRolloutRef) in all_wg, f"{all_wg.keys()=}"
+ self.ref_policy_wg = all_wg[str(Role.ActorRolloutRef)]
+
+ self.rm_wg = None
+ # initalization of rm_wg will be deprecated in the future
+ if self.use_rm and not self.use_reward_loop:
+ self.rm_wg = all_wg[str(Role.RewardModel)]
+ self.rm_wg.init_model()
+
+ # we should create rollout at the end so that vllm can have a better estimation of kv cache memory
+ self.actor_rollout_wg = all_wg[str(actor_role)]
+ self.actor_rollout_wg.init_model()
+
+ if self.ref_in_actor:
+ self.ref_policy_wg = self.actor_rollout_wg
+
+ # create async rollout manager and request scheduler
+ self.async_rollout_mode = False
+ if self.config.actor_rollout_ref.rollout.mode == "async":
+ # Support custom AgentLoopManager via config
+ # manager_class_fqn = self.config.actor_rollout_ref.rollout.get("agent", {}).get("agent_loop_manager_class")
+ # if manager_class_fqn:
+ # AgentLoopManager = load_class_from_fqn(manager_class_fqn, "AgentLoopManager")
+ # else:
+ # from verl.experimental.agent_loop import AgentLoopManager
+ from recipe.partial_rollout.agent_loop import PRv3AgentLoopManager
+ from recipe.partial_rollout.prompt_manager import RolloutPromptManager
+
+ AgentLoopManager = PRv3AgentLoopManager
+
+ self.async_rollout_mode = True
+ if self.config.reward_model.enable and self.config.reward_model.enable_resource_pool:
+ rm_resource_pool = self.resource_pool_manager.get_resource_pool(Role.RewardModel)
+ else:
+ rm_resource_pool = None
+
+ self.rollout_prompt_manager = RolloutPromptManager.remote(
+ config=self.config,
+ tokenizer=self.tokenizer,
+ processor=self.processor,
+ dataloader=self.train_dataloader,
+ )
+ self.async_rollout_manager = AgentLoopManager(
+ config=self.config,
+ worker_group=self.actor_rollout_wg,
+ rm_resource_pool=rm_resource_pool,
+ prompt_manager_handler=self.rollout_prompt_manager,
+ )
+
+ def _save_checkpoint(self):
+ from verl.utils.fs import local_mkdir_safe
+
+ # path: given_path + `/global_step_{global_steps}` + `/actor`
+ local_global_step_folder = os.path.join(
+ self.config.trainer.default_local_dir, f"global_step_{self.global_steps}"
+ )
+
+ print(f"local_global_step_folder: {local_global_step_folder}")
+ actor_local_path = os.path.join(local_global_step_folder, "actor")
+
+ actor_remote_path = (
+ None
+ if self.config.trainer.default_hdfs_dir is None
+ else os.path.join(self.config.trainer.default_hdfs_dir, f"global_step_{self.global_steps}", "actor")
+ )
+
+ remove_previous_ckpt_in_save = self.config.trainer.get("remove_previous_ckpt_in_save", False)
+ if remove_previous_ckpt_in_save:
+ print(
+ "Warning: remove_previous_ckpt_in_save is deprecated,"
+ + " set max_actor_ckpt_to_keep=1 and max_critic_ckpt_to_keep=1 instead"
+ )
+ max_actor_ckpt_to_keep = (
+ self.config.trainer.get("max_actor_ckpt_to_keep", None) if not remove_previous_ckpt_in_save else 1
+ )
+ max_critic_ckpt_to_keep = (
+ self.config.trainer.get("max_critic_ckpt_to_keep", None) if not remove_previous_ckpt_in_save else 1
+ )
+
+ self.actor_rollout_wg.save_checkpoint(
+ actor_local_path, actor_remote_path, self.global_steps, max_ckpt_to_keep=max_actor_ckpt_to_keep
+ )
+
+ if self.use_critic:
+ critic_local_path = os.path.join(local_global_step_folder, str(Role.Critic))
+ critic_remote_path = (
+ None
+ if self.config.trainer.default_hdfs_dir is None
+ else os.path.join(
+ self.config.trainer.default_hdfs_dir, f"global_step_{self.global_steps}", str(Role.Critic)
+ )
+ )
+ self.critic_wg.save_checkpoint(
+ critic_local_path, critic_remote_path, self.global_steps, max_ckpt_to_keep=max_critic_ckpt_to_keep
+ )
+
+ # save dataloader
+ local_mkdir_safe(local_global_step_folder)
+ dataloader_local_path = os.path.join(local_global_step_folder, "data.pt")
+ dataloader_state_dict = self.train_dataloader.state_dict()
+ torch.save(dataloader_state_dict, dataloader_local_path)
+
+ # latest checkpointed iteration tracker (for atomic usage)
+ if (
+ hasattr(self.config.actor_rollout_ref.actor.checkpoint, "async_save")
+ and self.config.actor_rollout_ref.actor.checkpoint.async_save
+ ) or (
+ "async_save" in self.config.actor_rollout_ref.actor.checkpoint
+ and self.config.actor_rollout_ref.actor.checkpoint["async_save"]
+ ):
+ print("skip write latest_checkpointed_iteration.txt when async_save is True")
+ return
+ local_latest_checkpointed_iteration = os.path.join(
+ self.config.trainer.default_local_dir, "latest_checkpointed_iteration.txt"
+ )
+ with open(local_latest_checkpointed_iteration, "w") as f:
+ f.write(str(self.global_steps))
+
+ def _load_checkpoint(self):
+ if self.config.trainer.resume_mode == "disable":
+ return 0
+
+ # load from hdfs
+ if self.config.trainer.default_hdfs_dir is not None:
+ raise NotImplementedError("load from hdfs is not implemented yet")
+ else:
+ checkpoint_folder = self.config.trainer.default_local_dir # TODO: check path
+ if not os.path.isabs(checkpoint_folder):
+ working_dir = os.getcwd()
+ checkpoint_folder = os.path.join(working_dir, checkpoint_folder)
+ global_step_folder = find_latest_ckpt_path(checkpoint_folder) # None if no latest
+
+ # find global_step_folder
+ if self.config.trainer.resume_mode == "auto":
+ if global_step_folder is None:
+ print("Training from scratch")
+ return 0
+ else:
+ if self.config.trainer.resume_mode == "resume_path":
+ assert isinstance(self.config.trainer.resume_from_path, str), "resume ckpt must be str type"
+ assert "global_step_" in self.config.trainer.resume_from_path, (
+ "resume ckpt must specify the global_steps"
+ )
+ global_step_folder = self.config.trainer.resume_from_path
+ if not os.path.isabs(global_step_folder):
+ working_dir = os.getcwd()
+ global_step_folder = os.path.join(working_dir, global_step_folder)
+ print(f"Load from checkpoint folder: {global_step_folder}")
+ # set global step
+ self.global_steps = int(global_step_folder.split("global_step_")[-1])
+
+ print(f"Setting global step to {self.global_steps}")
+ print(f"Resuming from {global_step_folder}")
+
+ actor_path = os.path.join(global_step_folder, "actor")
+ critic_path = os.path.join(global_step_folder, str(Role.Critic))
+ # load actor
+ self.actor_rollout_wg.load_checkpoint(
+ actor_path, del_local_after_load=self.config.trainer.del_local_ckpt_after_load
+ )
+ # load critic
+ if self.use_critic:
+ self.critic_wg.load_checkpoint(
+ critic_path, del_local_after_load=self.config.trainer.del_local_ckpt_after_load
+ )
+
+ # load dataloader,
+ # TODO: from remote not implemented yet
+ dataloader_local_path = os.path.join(global_step_folder, "data.pt")
+ if os.path.exists(dataloader_local_path):
+ dataloader_state_dict = torch.load(dataloader_local_path, weights_only=False)
+ self.train_dataloader.load_state_dict(dataloader_state_dict)
+ else:
+ print(f"Warning: No dataloader state found at {dataloader_local_path}, will start from scratch")
+
+ def _start_profiling(self, do_profile: bool) -> None:
+ """Start profiling for all worker groups if profiling is enabled."""
+ if do_profile:
+ self.actor_rollout_wg.start_profile(role="e2e", profile_step=self.global_steps)
+ if self.use_reference_policy:
+ self.ref_policy_wg.start_profile(profile_step=self.global_steps)
+ if self.use_critic:
+ self.critic_wg.start_profile(profile_step=self.global_steps)
+ if self.use_rm and not self.use_reward_loop:
+ self.rm_wg.start_profile(profile_step=self.global_steps)
+
+ def _stop_profiling(self, do_profile: bool) -> None:
+ """Stop profiling for all worker groups if profiling is enabled."""
+ if do_profile:
+ self.actor_rollout_wg.stop_profile()
+ if self.use_reference_policy:
+ self.ref_policy_wg.stop_profile()
+ if self.use_critic:
+ self.critic_wg.stop_profile()
+ if self.use_rm and not self.use_reward_loop:
+ self.rm_wg.stop_profile()
+
+ def _balance_batch(self, batch: DataProto, metrics, logging_prefix="global_seqlen", keep_minibatch=False):
+ """Reorder the data on single controller such that each dp rank gets similar total tokens"""
+ attention_mask = batch.batch["attention_mask"]
+ batch_size = attention_mask.shape[0]
+ global_seqlen_lst = batch.batch["attention_mask"].view(batch_size, -1).sum(-1) # (train_batch_size,)
+ workload_lst = calculate_workload(global_seqlen_lst)
+ world_size = self.actor_rollout_wg.world_size
+ if keep_minibatch:
+ # Decouple the DP balancing and mini-batching.
+ minibatch_size = self.config.actor_rollout_ref.actor.get("ppo_mini_batch_size")
+ minibatch_num = len(workload_lst) // minibatch_size
+ global_partition_lst = [[] for _ in range(world_size)]
+ for i in range(minibatch_num):
+ rearrange_minibatch_lst = get_seqlen_balanced_partitions(
+ workload_lst[i * minibatch_size : (i + 1) * minibatch_size],
+ k_partitions=world_size,
+ equal_size=True,
+ )
+ for j, part in enumerate(rearrange_minibatch_lst):
+ global_partition_lst[j].extend([x + minibatch_size * i for x in part])
+ else:
+ global_partition_lst = get_seqlen_balanced_partitions(
+ workload_lst, k_partitions=world_size, equal_size=True
+ )
+ # Place smaller micro-batches at both ends to reduce the bubbles in pipeline parallel.
+ for idx, partition in enumerate(global_partition_lst):
+ partition.sort(key=lambda x: (workload_lst[x], x))
+ ordered_partition = partition[::2] + partition[1::2][::-1]
+ global_partition_lst[idx] = ordered_partition
+ # reorder based on index. The data will be automatically equally partitioned by dispatch function
+ global_idx = torch.tensor([j for partition in global_partition_lst for j in partition])
+ batch.reorder(global_idx)
+ global_balance_stats = log_seqlen_unbalance(
+ seqlen_list=global_seqlen_lst, partitions=global_partition_lst, prefix=logging_prefix
+ )
+ metrics.update(global_balance_stats)
+
+ def _compute_values(self, batch: DataProto) -> DataProto:
+ if self.use_legacy_worker_impl == "disable":
+ batch_td = batch.to_tensordict()
+ # step 2: convert from padding to nopadding
+ batch_td = left_right_2_no_padding(batch_td)
+ # step 3: add meta info
+ tu.assign_non_tensor(batch_td, compute_loss=False)
+ output = self.critic_wg.infer_batch(batch_td)
+ output = output.get()
+ values = tu.get(output, "values")
+ values = no_padding_2_padding(values, batch_td)
+ values = tu.get_tensordict({"values": values.float()})
+ values = DataProto.from_tensordict(values)
+ else:
+ values = self.critic_wg.compute_values(batch)
+ return values
+
+ def _compute_ref_log_prob(self, batch: DataProto) -> DataProto:
+ if self.use_legacy_worker_impl == "disable":
+ # step 1: convert dataproto to tensordict.
+ batch_td = batch.to_tensordict()
+ # step 2: convert from padding to nopadding
+ batch_td = left_right_2_no_padding(batch_td)
+ # step 3: add meta info
+ tu.assign_non_tensor(batch_td, calculate_entropy=False, compute_loss=False)
+ output = self.ref_policy_wg.compute_ref_log_prob(batch_td)
+ # gather output
+ log_probs = tu.get(output, "log_probs")
+ # step 4. No padding to padding
+ log_probs = no_padding_2_padding(log_probs, batch_td)
+ # step 5: rebuild a tensordict and convert to dataproto
+ ref_log_prob = tu.get_tensordict({"ref_log_prob": log_probs.float()})
+ ref_log_prob = DataProto.from_tensordict(ref_log_prob)
+ else:
+ ref_log_prob = self.ref_policy_wg.compute_ref_log_prob(batch)
+
+ return ref_log_prob
+
+ def _compute_old_log_prob(self, batch: DataProto):
+ if self.use_legacy_worker_impl == "disable":
+ # TODO: remove step 1, 2, 4 after we make the whole training tensordict and padding free
+ # step 1: convert dataproto to tensordict.
+ batch_td = batch.to_tensordict()
+ # step 2: convert from padding to nopadding
+ batch_td = left_right_2_no_padding(batch_td)
+ # step 3: add meta info
+ tu.assign_non_tensor(batch_td, calculate_entropy=True, compute_loss=False)
+ output = self.actor_rollout_wg.compute_log_prob(batch_td)
+ # gather output
+ entropy = tu.get(output, "entropy")
+ log_probs = tu.get(output, "log_probs")
+ old_log_prob_mfu = tu.get(output, "metrics")["mfu"]
+ # step 4. No padding to padding
+ entropy = no_padding_2_padding(entropy, batch_td)
+ log_probs = no_padding_2_padding(log_probs, batch_td)
+ # step 5: rebuild a tensordict and convert to dataproto
+ old_log_prob = tu.get_tensordict({"old_log_probs": log_probs.float(), "entropys": entropy.float()})
+ old_log_prob = DataProto.from_tensordict(old_log_prob)
+ else:
+ old_log_prob = self.actor_rollout_wg.compute_log_prob(batch)
+ old_log_prob_mfu = 0
+ return old_log_prob, old_log_prob_mfu
+
+ def _update_actor(self, batch: DataProto) -> DataProto:
+ rollout_config = self.config.actor_rollout_ref.rollout
+ batch.meta_info["multi_turn"] = rollout_config.multi_turn.enable
+ # TODO: Make "temperature" single source of truth from generation.
+ batch.meta_info["temperature"] = rollout_config.temperature
+ # update actor
+ if self.use_legacy_worker_impl == "disable":
+ batch_td = batch.to_tensordict()
+ # step 2: convert from padding to no-padding
+ batch_td = left_right_2_no_padding(batch_td)
+ calculate_entropy = self.config.actor_rollout_ref.actor.entropy_coeff != 0.0
+ ppo_mini_batch_size = self.config.actor_rollout_ref.actor.ppo_mini_batch_size
+ ppo_mini_batch_size = ppo_mini_batch_size * self.config.actor_rollout_ref.rollout.n
+ ppo_epochs = self.config.actor_rollout_ref.actor.ppo_epochs
+ seed = self.config.actor_rollout_ref.actor.data_loader_seed
+ shuffle = self.config.actor_rollout_ref.actor.shuffle
+ tu.assign_non_tensor(
+ batch_td,
+ calculate_entropy=calculate_entropy,
+ global_batch_size=ppo_mini_batch_size,
+ mini_batch_size=ppo_mini_batch_size,
+ epochs=ppo_epochs,
+ seed=seed,
+ dataloader_kwargs={"shuffle": shuffle},
+ )
+
+ actor_output = self.actor_rollout_wg.update_actor(batch_td)
+ actor_output = tu.get(actor_output, "metrics")
+ actor_output = rename_dict(actor_output, "actor/")
+ # modify key name
+ actor_output["perf/mfu/actor"] = actor_output.pop("actor/mfu")
+ actor_output = DataProto.from_single_dict(data={}, meta_info={"metrics": actor_output})
+ else:
+ actor_output = self.actor_rollout_wg.update_actor(batch)
+ return actor_output
+
+ def _update_critic(self, batch: DataProto) -> DataProto:
+ if self.use_legacy_worker_impl == "disable":
+ batch_td = batch.to_tensordict()
+ # step 2: convert from padding to no-padding
+ batch_td = left_right_2_no_padding(batch_td)
+ ppo_mini_batch_size = self.config.critic.ppo_mini_batch_size
+ ppo_mini_batch_size = ppo_mini_batch_size * self.config.actor_rollout_ref.rollout.n
+ ppo_epochs = self.config.critic.ppo_epochs
+ seed = self.config.critic.data_loader_seed
+ shuffle = self.config.critic.shuffle
+ tu.assign_non_tensor(
+ batch_td,
+ global_batch_size=ppo_mini_batch_size,
+ mini_batch_size=ppo_mini_batch_size,
+ epochs=ppo_epochs,
+ seed=seed,
+ dataloader_kwargs={"shuffle": shuffle},
+ )
+
+ output = self.critic_wg.train_mini_batch(batch_td)
+ output = output.get()
+ output = tu.get(output, "metrics")
+ output = rename_dict(output, "critic/")
+ # modify key name
+ output["perf/mfu/critic"] = output.pop("critic/mfu")
+ critic_output = DataProto.from_single_dict(data={}, meta_info={"metrics": output})
+ else:
+ critic_output = self.critic_wg.update_critic(batch)
+ return critic_output
+
+ def fit(self):
+ """
+ The training loop of PPO.
+ The driver process only need to call the compute functions of the worker group through RPC
+ to construct the PPO dataflow.
+ The light-weight advantage computation is done on the driver process.
+ """
+ from omegaconf import OmegaConf
+
+ from verl.utils.tracking import Tracking
+
+ logger = Tracking(
+ project_name=self.config.trainer.project_name,
+ experiment_name=self.config.trainer.experiment_name,
+ default_backend=self.config.trainer.logger,
+ config=OmegaConf.to_container(self.config, resolve=True),
+ )
+
+ self.global_steps = 0
+
+ # load checkpoint before doing anything
+ self._load_checkpoint()
+
+ current_epoch = self.global_steps // len(self.train_dataloader)
+
+ # perform validation before training
+ # currently, we only support validation using the reward_function.
+ if self.val_reward_fn is not None and self.config.trainer.get("val_before_train", True):
+ val_metrics = self._validate()
+ assert val_metrics, f"{val_metrics=}"
+ pprint(f"Initial validation metrics: {val_metrics}")
+ logger.log(data=val_metrics, step=self.global_steps)
+ if self.config.trainer.get("val_only", False):
+ return
+
+ if self.config.actor_rollout_ref.rollout.get("skip_rollout", False):
+ rollout_skip = RolloutSkip(self.config, self.actor_rollout_wg)
+ rollout_skip.wrap_generate_sequences()
+
+ # add tqdm
+ progress_bar = tqdm(total=self.total_training_steps, initial=self.global_steps, desc="Training Progress")
+
+ # we start from step 1
+ self.global_steps += 1
+ last_val_metrics = None
+ self.max_steps_duration = 0
+
+ prev_step_profile = False
+ curr_step_profile = (
+ self.global_steps in self.config.global_profiler.steps
+ if self.config.global_profiler.steps is not None
+ else False
+ )
+ next_step_profile = False
+
+ for epoch in range(current_epoch, self.config.trainer.total_epochs):
+ # 这里on-epoch-start,需要有判断当dataloader-exhausted=True,则重置dataloader,否则跳过,进行下一步
+ ray.get(self.rollout_prompt_manager.on_epoch_start.remote(current_epoch))
+ for batch_dict in self.train_dataloader:
+ if hasattr(self.actor_rollout_wg, "async_calls_finalize_fn_exec"):
+ self.actor_rollout_wg.async_calls_finalize_fn_exec(blocking=False)
+ metrics = {}
+ timing_raw = {}
+
+ with marked_timer("start_profile", timing_raw):
+ self._start_profiling(
+ not prev_step_profile and curr_step_profile
+ if self.config.global_profiler.profile_continuous_steps
+ else curr_step_profile
+ )
+ batch: DataProto = DataProto.from_single_dict(batch_dict)
+ batch.meta_info["temperature"] = self.config.actor_rollout_ref.rollout.temperature
+
+ # add uid to batch
+ batch.non_tensor_batch["uid"] = np.array(
+ [str(uuid.uuid4()) for _ in range(len(batch.batch))], dtype=object
+ )
+
+ gen_batch = self._get_gen_batch(batch)
+
+ # pass global_steps to trace
+ gen_batch.meta_info["global_steps"] = self.global_steps
+ gen_batch_output = gen_batch.repeat(
+ repeat_times=self.config.actor_rollout_ref.rollout.n, interleave=True
+ )
+
+ is_last_step = self.global_steps >= self.total_training_steps
+ with marked_timer("step", timing_raw):
+ # generate a batch
+ with marked_timer("gen", timing_raw, color="red"):
+ if not self.async_rollout_mode:
+ gen_batch_output = self.actor_rollout_wg.generate_sequences(gen_batch_output)
+ else:
+ gen_batch_output = self.async_rollout_manager.generate_sequences(gen_batch_output)
+ gen_batch_output.meta_info.update(batch.meta_info)
+ if not gen_batch_output.meta_info.get("is_full", True):
+ print("[RayTrainer] generate_sequences: batch is not full, break")
+ break
+ batch = gen_batch_output
+
+ timing_raw.update(gen_batch_output.meta_info["timing"])
+ gen_batch_output.meta_info.pop("timing", None)
+
+ # repeat to align with repeated responses in rollout
+ # batch = batch.repeat(repeat_times=self.config.actor_rollout_ref.rollout.n, interleave=True)
+ # batch = batch.union(gen_batch_output)
+
+ if "response_mask" not in batch.batch.keys():
+ batch.batch["response_mask"] = compute_response_mask(batch)
+ # Balance the number of valid tokens across DP ranks.
+ # NOTE: This usually changes the order of data in the `batch`,
+ # which won't affect the advantage calculation (since it's based on uid),
+ # but might affect the loss calculation (due to the change of mini-batching).
+ if self.config.trainer.balance_batch:
+ self._balance_batch(batch, metrics=metrics)
+
+ # compute global_valid tokens
+ batch.meta_info["global_token_num"] = torch.sum(batch.batch["attention_mask"], dim=-1).tolist()
+
+ with marked_timer("reward", timing_raw, color="yellow"):
+ # compute reward model score
+ if self.use_rm and "rm_scores" not in batch.batch.keys():
+ if not self.use_reward_loop:
+ reward_tensor = self.rm_wg.compute_rm_score(batch)
+ else:
+ assert self.reward_loop_manager is not None, "RewardLoopManager is None"
+ reward_tensor = self.reward_loop_manager.compute_rm_score(batch)
+ batch = batch.union(reward_tensor)
+
+ if self.config.reward_model.launch_reward_fn_async:
+ future_reward = compute_reward_async.remote(
+ data=batch, config=self.config, tokenizer=self.tokenizer
+ )
+ else:
+ reward_tensor, reward_extra_infos_dict = compute_reward(batch, self.reward_fn)
+
+ # Operating Mode Selection:
+ # - Bypass mode: Sets old_log_probs = rollout_log_probs (2 policies: π_rollout, π_θ)
+ # - Decoupled mode: Recomputes old_log_probs as proximal anchor (3 policies: π_rollout, π_old, π_θ)
+ # Note: π_old computed once per data batch, serves as stable reference during mini-batch updates
+ rollout_corr_config = self.config.algorithm.get("rollout_correction", None)
+ bypass_recomputing_logprobs = rollout_corr_config and rollout_corr_config.get("bypass_mode", False)
+ if bypass_recomputing_logprobs: # Use `rollout_log_probs`
+ from verl.trainer.ppo.rollout_corr_helper import apply_bypass_mode
+
+ apply_bypass_mode(
+ batch=batch,
+ rollout_corr_config=rollout_corr_config,
+ policy_loss_config=self.config.actor_rollout_ref.actor.policy_loss,
+ )
+ else: # Recompute old_log_probs
+ with marked_timer("old_log_prob", timing_raw, color="blue"):
+ old_log_prob, old_log_prob_mfu = self._compute_old_log_prob(batch)
+ entropys = old_log_prob.batch["entropys"]
+ response_masks = batch.batch["response_mask"]
+ actor_config = self.config.actor_rollout_ref.actor
+ entropy_agg = agg_loss(
+ loss_mat=entropys,
+ loss_mask=response_masks,
+ loss_agg_mode=actor_config.loss_agg_mode,
+ loss_scale_factor=actor_config.loss_scale_factor,
+ )
+ old_log_prob_metrics = {
+ "actor/entropy": entropy_agg.detach().item(),
+ "perf/mfu/actor_infer": old_log_prob_mfu,
+ }
+ metrics.update(old_log_prob_metrics)
+ old_log_prob.batch.pop("entropys")
+ batch = batch.union(old_log_prob)
+ if "rollout_log_probs" in batch.batch.keys():
+ # TODO: we may want to add diff of probs too.
+ from verl.utils.debug.metrics import calculate_debug_metrics
+
+ metrics.update(calculate_debug_metrics(batch))
+
+ assert "old_log_probs" in batch.batch, f'"old_log_prob" not in {batch.batch.keys()=}'
+
+ if self.use_reference_policy:
+ # compute reference log_prob
+ with marked_timer(str(Role.RefPolicy), timing_raw, color="olive"):
+ ref_log_prob = self._compute_ref_log_prob(batch)
+ batch = batch.union(ref_log_prob)
+
+ # compute values
+ if self.use_critic:
+ with marked_timer("values", timing_raw, color="cyan"):
+ values = self._compute_values(batch)
+ batch = batch.union(values)
+
+ with marked_timer("adv", timing_raw, color="brown"):
+ # we combine with rule-based rm
+ reward_extra_infos_dict: dict[str, list]
+ if self.config.reward_model.launch_reward_fn_async:
+ reward_tensor, reward_extra_infos_dict = ray.get(future_reward)
+ batch.batch["token_level_scores"] = reward_tensor
+
+ if reward_extra_infos_dict:
+ batch.non_tensor_batch.update({k: np.array(v) for k, v in reward_extra_infos_dict.items()})
+
+ # compute rewards. apply_kl_penalty if available
+ if self.config.algorithm.use_kl_in_reward:
+ batch, kl_metrics = apply_kl_penalty(
+ batch, kl_ctrl=self.kl_ctrl_in_reward, kl_penalty=self.config.algorithm.kl_penalty
+ )
+ metrics.update(kl_metrics)
+ else:
+ batch.batch["token_level_rewards"] = batch.batch["token_level_scores"]
+
+ # Compute rollout correction: IS weights, rejection sampling, and metrics
+ # Only runs in decoupled mode (computes once per batch using stable π_old)
+ # In bypass mode, this is skipped - actor computes metrics from evolving π_θ vs π_rollout
+ if (
+ rollout_corr_config is not None
+ and "rollout_log_probs" in batch.batch
+ and not bypass_recomputing_logprobs # Only in decoupled mode
+ ):
+ from verl.trainer.ppo.rollout_corr_helper import compute_rollout_correction_and_add_to_batch
+
+ # Compute IS weights, apply rejection sampling, compute metrics
+ batch, is_metrics = compute_rollout_correction_and_add_to_batch(batch, rollout_corr_config)
+ # IS and off-policy metrics already have rollout_corr/ prefix
+ metrics.update(is_metrics)
+
+ # compute advantages, executed on the driver process
+ norm_adv_by_std_in_grpo = self.config.algorithm.get(
+ "norm_adv_by_std_in_grpo", True
+ ) # GRPO adv normalization factor
+
+ batch = compute_advantage(
+ batch,
+ adv_estimator=self.config.algorithm.adv_estimator,
+ gamma=self.config.algorithm.gamma,
+ lam=self.config.algorithm.lam,
+ num_repeat=self.config.actor_rollout_ref.rollout.n,
+ norm_adv_by_std_in_grpo=norm_adv_by_std_in_grpo,
+ config=self.config.algorithm,
+ )
+
+ # update critic
+ if self.use_critic:
+ with marked_timer("update_critic", timing_raw, color="pink"):
+ critic_output = self._update_critic(batch)
+ critic_output_metrics = reduce_metrics(critic_output.meta_info["metrics"])
+ metrics.update(critic_output_metrics)
+
+ # implement critic warmup
+ if self.config.trainer.critic_warmup <= self.global_steps:
+ # update actor
+ with marked_timer("update_actor", timing_raw, color="red"):
+ actor_output = self._update_actor(batch)
+ actor_output_metrics = reduce_metrics(actor_output.meta_info["metrics"])
+ metrics.update(actor_output_metrics)
+
+ # Log rollout generations if enabled
+ rollout_data_dir = self.config.trainer.get("rollout_data_dir", None)
+ if rollout_data_dir:
+ self._log_rollout_data(batch, reward_extra_infos_dict, timing_raw, rollout_data_dir)
+
+ # validate
+ if (
+ self.val_reward_fn is not None
+ and self.config.trainer.test_freq > 0
+ and (is_last_step or self.global_steps % self.config.trainer.test_freq == 0)
+ ):
+ with marked_timer("testing", timing_raw, color="green"):
+ val_metrics: dict = self._validate()
+ if is_last_step:
+ last_val_metrics = val_metrics
+ metrics.update(val_metrics)
+
+ # Check if the ESI (Elastic Server Instance)/training plan is close to expiration.
+ esi_close_to_expiration = should_save_ckpt_esi(
+ max_steps_duration=self.max_steps_duration,
+ redundant_time=self.config.trainer.esi_redundant_time,
+ )
+ # Check if the conditions for saving a checkpoint are met.
+ # The conditions include a mandatory condition (1) and
+ # one of the following optional conditions (2/3/4):
+ # 1. The save frequency is set to a positive value.
+ # 2. It's the last training step.
+ # 3. The current step number is a multiple of the save frequency.
+ # 4. The ESI(Elastic Server Instance)/training plan is close to expiration.
+ if self.config.trainer.save_freq > 0 and (
+ is_last_step or self.global_steps % self.config.trainer.save_freq == 0 or esi_close_to_expiration
+ ):
+ if esi_close_to_expiration:
+ print("Force saving checkpoint: ESI instance expiration approaching.")
+ with marked_timer("save_checkpoint", timing_raw, color="green"):
+ self._save_checkpoint()
+
+ with marked_timer("stop_profile", timing_raw):
+ next_step_profile = (
+ self.global_steps + 1 in self.config.global_profiler.steps
+ if self.config.global_profiler.steps is not None
+ else False
+ )
+ self._stop_profiling(
+ curr_step_profile and not next_step_profile
+ if self.config.global_profiler.profile_continuous_steps
+ else curr_step_profile
+ )
+ prev_step_profile = curr_step_profile
+ curr_step_profile = next_step_profile
+
+ steps_duration = timing_raw["step"]
+ self.max_steps_duration = max(self.max_steps_duration, steps_duration)
+
+ # training metrics
+ metrics.update(
+ {
+ "training/global_step": self.global_steps,
+ "training/epoch": epoch,
+ }
+ )
+ # collect metrics
+ metrics.update({k: v for k, v in batch.meta_info.items() if k.startswith("partial_rollout/")})
+ metrics.update(compute_data_metrics(batch=batch, use_critic=self.use_critic))
+ metrics.update(compute_timing_metrics(batch=batch, timing_raw=timing_raw))
+ # TODO: implement actual tflpo and theoretical tflpo
+ n_gpus = self.resource_pool_manager.get_n_gpus()
+ metrics.update(compute_throughout_metrics(batch=batch, timing_raw=timing_raw, n_gpus=n_gpus))
+ # Note: mismatch metrics (KL, PPL, etc.) are collected at line 1179 after advantage computation
+
+ # this is experimental and may be changed/removed in the future in favor of a general-purpose one
+ if isinstance(self.train_dataloader.sampler, AbstractCurriculumSampler):
+ self.train_dataloader.sampler.update(batch=batch)
+
+ # TODO: make a canonical logger that supports various backend
+ logger.log(data=metrics, step=self.global_steps)
+
+ progress_bar.update(1)
+ self.global_steps += 1
+
+ if (
+ hasattr(self.config.actor_rollout_ref.actor, "profiler")
+ and self.config.actor_rollout_ref.actor.profiler.tool == "torch_memory"
+ ):
+ self.actor_rollout_wg.dump_memory_snapshot(
+ tag=f"post_update_step{self.global_steps}", sub_dir=f"step{self.global_steps}"
+ )
+
+ if is_last_step:
+ if hasattr(self.actor_rollout_wg, "async_calls_finalize_fn_exec"):
+ self.actor_rollout_wg.async_calls_finalize_fn_exec(blocking=True)
+ pprint(f"Final validation metrics: {last_val_metrics}")
+ progress_bar.close()
+ return
+
+ # this is experimental and may be changed/removed in the future
+ # in favor of a general-purpose data buffer pool
+ if hasattr(self.train_dataset, "on_batch_end"):
+ # The dataset may be changed after each training batch
+ self.train_dataset.on_batch_end(batch=batch)
diff --git a/partial_rollout/run_dapomath_nopr_grpo_4b_bs64.sh b/partial_rollout/run_dapomath_nopr_grpo_4b_bs64.sh
new file mode 100644
index 00000000..aff9a627
--- /dev/null
+++ b/partial_rollout/run_dapomath_nopr_grpo_4b_bs64.sh
@@ -0,0 +1,129 @@
+set -x
+
+DATE_TIME=$(date +%Y%m%d_%H%M%S)
+
+project_name='verl_exp_partial_rollout_dapo_math'
+exp_name="v070-qwen3-4b-sample10k-nopr-grpo-bs64-${DATE_TIME}"
+
+# Paths
+RAY_DATA_HOME=/apdcephfs_gy2/share_303055091/allenzpma_tmp
+MODEL_PATH="/apdcephfs_gy2/share_303055091/Qwen3-4B"
+CKPTS_DIR="${RAY_DATA_HOME}/checkpoint/${project_name}/${exp_name}"
+TRAIN_FILE="${RAY_DATA_HOME}/data/dapo-math17k/DAPO-Math-17k_25k.parquet"
+TEST_FILE="${RAY_DATA_HOME}/data/aime/DAPO-Math-AIME-2024.parquet"
+LOG_PATH="${RAY_DATA_HOME}/partial_rollout/output/logs"
+
+NNODES=1
+NGPUS_PER_NODE=8
+
+export RAY_DEBUG=1
+export HYDRA_FULL_ERROR=1
+export VERL_LOGGING_LEVEL=INFO
+
+# For async rollout mode, dataset should return raw chat.
+rollout_mode="async" # sync or async,async会单独判断
+rollout_name="vllm" # sglang or vllm
+
+if [ "$rollout_mode" = "async" ]; then
+ export VLLM_USE_V1=1
+ return_raw_chat="True"
+fi
+
+clip_ratio_low=0.2
+clip_ratio_high=0.28
+
+max_prompt_length=2048
+max_response_length=8192
+
+train_prompt_bsz=128
+train_prompt_mini_bsz=64
+
+# Algorithm
+temperature=1.0
+top_p=1.0
+top_k=-1 # 0 for HF rollout, -1 for vLLM rollout
+val_top_p=0.7
+
+# Performance Related Parameter
+use_dynamic_bsz=True
+actor_ppo_max_token_len=$((max_prompt_length + max_response_length))
+infer_ppo_max_token_len=$((max_prompt_length + max_response_length))
+offload=True
+gen_tp=2
+sp_size=2
+fsdp_size=4
+
+
+python3 -m verl.trainer.main_ppo \
+ --config-path=config \
+ algorithm.adv_estimator=grpo \
+ algorithm.use_kl_in_reward=False \
+ algorithm.kl_ctrl.kl_coef=0.0 \
+ data.train_files="${TRAIN_FILE}" \
+ data.val_files="${TEST_FILE}" \
+ data.train_batch_size=${train_prompt_bsz} \
+ data.max_prompt_length=${max_prompt_length} \
+ data.max_response_length=${max_response_length} \
+ data.filter_overlong_prompts=True \
+ data.truncation='error' \
+ data.return_raw_chat="${return_raw_chat}" \
+ rollout.partial_rollout.enable=False \
+ rollout.partial_rollout.max_chunk_response_length=${max_response_length} \
+ rollout.partial_rollout.clip_tis_c=null \
+ actor_rollout_ref.actor.strategy=fsdp2 \
+ critic.strategy=fsdp2 \
+ actor_rollout_ref.actor.use_kl_loss=False \
+ actor_rollout_ref.actor.kl_loss_coef=0.0 \
+ actor_rollout_ref.actor.clip_ratio_low=${clip_ratio_low} \
+ actor_rollout_ref.actor.clip_ratio_high=${clip_ratio_high} \
+ actor_rollout_ref.actor.clip_ratio_c=10.0 \
+ actor_rollout_ref.model.use_remove_padding=True \
+ +actor_rollout_ref.model.override_config.max_position_embeddings=32768 \
+ actor_rollout_ref.actor.use_dynamic_bsz=${use_dynamic_bsz} \
+ actor_rollout_ref.ref.log_prob_use_dynamic_bsz=${use_dynamic_bsz} \
+ actor_rollout_ref.rollout.log_prob_use_dynamic_bsz=${use_dynamic_bsz} \
+ actor_rollout_ref.actor.ppo_max_token_len_per_gpu=${actor_ppo_max_token_len} \
+ actor_rollout_ref.ref.log_prob_max_token_len_per_gpu=${infer_ppo_max_token_len} \
+ actor_rollout_ref.rollout.log_prob_max_token_len_per_gpu=${infer_ppo_max_token_len} \
+ actor_rollout_ref.model.path="${MODEL_PATH}" \
+ actor_rollout_ref.model.enable_gradient_checkpointing=True \
+ actor_rollout_ref.hybrid_engine=True \
+ actor_rollout_ref.actor.optim.lr=1e-6 \
+ actor_rollout_ref.actor.optim.lr_warmup_steps=10 \
+ actor_rollout_ref.actor.optim.weight_decay=0.1 \
+ actor_rollout_ref.actor.ppo_mini_batch_size=${train_prompt_mini_bsz} \
+ actor_rollout_ref.actor.fsdp_config.param_offload=${offload} \
+ actor_rollout_ref.actor.fsdp_config.optimizer_offload=${offload} \
+ actor_rollout_ref.actor.entropy_coeff=0 \
+ actor_rollout_ref.actor.grad_clip=1.0 \
+ actor_rollout_ref.actor.loss_agg_mode="token-mean" \
+ actor_rollout_ref.actor.ulysses_sequence_parallel_size=${sp_size} \
+ actor_rollout_ref.rollout.gpu_memory_utilization=0.80 \
+ actor_rollout_ref.rollout.n=8 \
+ actor_rollout_ref.rollout.tensor_model_parallel_size=${gen_tp} \
+ actor_rollout_ref.rollout.enable_chunked_prefill=True \
+ actor_rollout_ref.rollout.max_num_batched_tokens=$((max_prompt_length + max_response_length)) \
+ actor_rollout_ref.rollout.temperature=${temperature} \
+ actor_rollout_ref.rollout.top_p=${top_p} \
+ actor_rollout_ref.rollout.top_k=${top_k} \
+ actor_rollout_ref.rollout.name="${rollout_name}" \
+ actor_rollout_ref.rollout.mode="${rollout_mode}" \
+ actor_rollout_ref.rollout.val_kwargs.temperature=${temperature} \
+ actor_rollout_ref.rollout.val_kwargs.top_p=${val_top_p} \
+ actor_rollout_ref.rollout.val_kwargs.top_k=${top_k} \
+ actor_rollout_ref.rollout.val_kwargs.do_sample=True \
+ actor_rollout_ref.rollout.val_kwargs.n=32 \
+ actor_rollout_ref.ref.fsdp_config.param_offload=${offload} \
+ actor_rollout_ref.ref.ulysses_sequence_parallel_size=${sp_size} \
+ actor_rollout_ref.actor.fsdp_config.fsdp_size=${fsdp_size} \
+ trainer.val_before_train=True \
+ trainer.n_gpus_per_node="${NGPUS_PER_NODE}" \
+ trainer.nnodes="${NNODES}" \
+ trainer.logger=['console','swanlab'] \
+ trainer.project_name="${project_name}" \
+ trainer.experiment_name="${exp_name}" \
+ trainer.save_freq=40 \
+ trainer.test_freq=10 \
+ trainer.default_local_dir="${CKPTS_DIR}" \
+ trainer.rollout_data_dir="${CKPTS_DIR}" \
+ trainer.total_epochs=1 $@ 2>&1 | tee -a ${LOG_PATH}/log_${DATE_TIME}.txt
\ No newline at end of file
diff --git a/partial_rollout/run_dapomath_pr_grpo_4b_bs64.sh b/partial_rollout/run_dapomath_pr_grpo_4b_bs64.sh
new file mode 100644
index 00000000..940df373
--- /dev/null
+++ b/partial_rollout/run_dapomath_pr_grpo_4b_bs64.sh
@@ -0,0 +1,75 @@
+set -x
+
+DATE_TIME=$(date +%Y%m%d_%H%M%S)
+
+project_name='verl_exp_partial_rollout_gsm8k'
+exp_name="v070-qwen3-4b-gsm8k-nopr-grpo-bs128-${DATE_TIME}"
+
+# Paths
+RAY_DATA_HOME=/apdcephfs_gy2/share_303055091/allenzpma_tmp
+MODEL_PATH="/apdcephfs_gy2/share_303055091/Qwen3-4B"
+CKPTS_DIR="${RAY_DATA_HOME}/checkpoint/${project_name}/${exp_name}"
+TRAIN_FILE="${RAY_DATA_HOME}/data/gsm8k/train.parquet"
+TEST_FILE="${RAY_DATA_HOME}/data/gsm8k/test.parquet"
+LOG_PATH="${RAY_DATA_HOME}/partial_rollout/output/logs"
+
+NNODES=1
+NGPUS_PER_NODE=8
+
+export RAY_DEBUG=1
+export HYDRA_FULL_ERROR=1
+export VERL_LOGGING_LEVEL=INFO
+
+# For async rollout mode, dataset should return raw chat.
+rollout_mode="async" # sync or async,async会单独判断
+rollout_name="vllm" # sglang or vllm
+
+if [ "$rollout_mode" = "async" ]; then
+ export VLLM_USE_V1=1
+ return_raw_chat="True"
+fi
+
+python3 -m verl.trainer.main_ppo \
+ --config-path=config \
+ algorithm.adv_estimator=grpo \
+ data.train_files="${TRAIN_FILE}" \
+ data.val_files="${TEST_FILE}" \
+ data.train_batch_size=128 \
+ data.max_prompt_length=512 \
+ data.max_response_length=1024 \
+ data.filter_overlong_prompts=True \
+ data.truncation='error' \
+ actor_rollout_ref.model.path="${MODEL_PATH}" \
+ actor_rollout_ref.actor.optim.lr=1e-6 \
+ actor_rollout_ref.hybrid_engine=True \
+ actor_rollout_ref.model.use_remove_padding=True \
+ actor_rollout_ref.actor.ppo_mini_batch_size=128 \
+ actor_rollout_ref.actor.ppo_micro_batch_size_per_gpu=32 \
+ actor_rollout_ref.actor.use_kl_loss=True \
+ actor_rollout_ref.actor.kl_loss_coef=0.001 \
+ actor_rollout_ref.actor.kl_loss_type=low_var_kl \
+ actor_rollout_ref.actor.entropy_coeff=0 \
+ actor_rollout_ref.model.enable_gradient_checkpointing=True \
+ actor_rollout_ref.actor.fsdp_config.param_offload=False \
+ actor_rollout_ref.actor.fsdp_config.optimizer_offload=False \
+ actor_rollout_ref.rollout.log_prob_micro_batch_size_per_gpu=32 \
+ actor_rollout_ref.rollout.tensor_model_parallel_size=1 \
+ actor_rollout_ref.rollout.name="${rollout_name}" \
+ actor_rollout_ref.rollout.mode="${rollout_mode}" \
+ actor_rollout_ref.rollout.gpu_memory_utilization=0.7 \
+ actor_rollout_ref.rollout.n=8 \
+ actor_rollout_ref.ref.log_prob_micro_batch_size_per_gpu=32 \
+ actor_rollout_ref.ref.fsdp_config.param_offload=True \
+ algorithm.use_kl_in_reward=False \
+ trainer.critic_warmup=0 \
+ trainer.val_before_train=True \
+ trainer.logger=['console','swanlab'] \
+ trainer.project_name="${project_name}" \
+ trainer.experiment_name="${exp_name}" \
+ trainer.n_gpus_per_node=${NGPUS_PER_NODE} \
+ trainer.nnodes=${NNODES} \
+ trainer.save_freq=25 \
+ trainer.test_freq=5 \
+ trainer.default_local_dir="${CKPTS_DIR}" \
+ trainer.rollout_data_dir="${CKPTS_DIR}" \
+ trainer.total_epochs=5 $@ 2>&1 | tee -a ${LOG_PATH}/log_${DATE_TIME}.txt
\ No newline at end of file
diff --git a/partial_rollout/run_gsm8k_nopr_grpo_4b_bs128.sh b/partial_rollout/run_gsm8k_nopr_grpo_4b_bs128.sh
new file mode 100644
index 00000000..940df373
--- /dev/null
+++ b/partial_rollout/run_gsm8k_nopr_grpo_4b_bs128.sh
@@ -0,0 +1,75 @@
+set -x
+
+DATE_TIME=$(date +%Y%m%d_%H%M%S)
+
+project_name='verl_exp_partial_rollout_gsm8k'
+exp_name="v070-qwen3-4b-gsm8k-nopr-grpo-bs128-${DATE_TIME}"
+
+# Paths
+RAY_DATA_HOME=/apdcephfs_gy2/share_303055091/allenzpma_tmp
+MODEL_PATH="/apdcephfs_gy2/share_303055091/Qwen3-4B"
+CKPTS_DIR="${RAY_DATA_HOME}/checkpoint/${project_name}/${exp_name}"
+TRAIN_FILE="${RAY_DATA_HOME}/data/gsm8k/train.parquet"
+TEST_FILE="${RAY_DATA_HOME}/data/gsm8k/test.parquet"
+LOG_PATH="${RAY_DATA_HOME}/partial_rollout/output/logs"
+
+NNODES=1
+NGPUS_PER_NODE=8
+
+export RAY_DEBUG=1
+export HYDRA_FULL_ERROR=1
+export VERL_LOGGING_LEVEL=INFO
+
+# For async rollout mode, dataset should return raw chat.
+rollout_mode="async" # sync or async,async会单独判断
+rollout_name="vllm" # sglang or vllm
+
+if [ "$rollout_mode" = "async" ]; then
+ export VLLM_USE_V1=1
+ return_raw_chat="True"
+fi
+
+python3 -m verl.trainer.main_ppo \
+ --config-path=config \
+ algorithm.adv_estimator=grpo \
+ data.train_files="${TRAIN_FILE}" \
+ data.val_files="${TEST_FILE}" \
+ data.train_batch_size=128 \
+ data.max_prompt_length=512 \
+ data.max_response_length=1024 \
+ data.filter_overlong_prompts=True \
+ data.truncation='error' \
+ actor_rollout_ref.model.path="${MODEL_PATH}" \
+ actor_rollout_ref.actor.optim.lr=1e-6 \
+ actor_rollout_ref.hybrid_engine=True \
+ actor_rollout_ref.model.use_remove_padding=True \
+ actor_rollout_ref.actor.ppo_mini_batch_size=128 \
+ actor_rollout_ref.actor.ppo_micro_batch_size_per_gpu=32 \
+ actor_rollout_ref.actor.use_kl_loss=True \
+ actor_rollout_ref.actor.kl_loss_coef=0.001 \
+ actor_rollout_ref.actor.kl_loss_type=low_var_kl \
+ actor_rollout_ref.actor.entropy_coeff=0 \
+ actor_rollout_ref.model.enable_gradient_checkpointing=True \
+ actor_rollout_ref.actor.fsdp_config.param_offload=False \
+ actor_rollout_ref.actor.fsdp_config.optimizer_offload=False \
+ actor_rollout_ref.rollout.log_prob_micro_batch_size_per_gpu=32 \
+ actor_rollout_ref.rollout.tensor_model_parallel_size=1 \
+ actor_rollout_ref.rollout.name="${rollout_name}" \
+ actor_rollout_ref.rollout.mode="${rollout_mode}" \
+ actor_rollout_ref.rollout.gpu_memory_utilization=0.7 \
+ actor_rollout_ref.rollout.n=8 \
+ actor_rollout_ref.ref.log_prob_micro_batch_size_per_gpu=32 \
+ actor_rollout_ref.ref.fsdp_config.param_offload=True \
+ algorithm.use_kl_in_reward=False \
+ trainer.critic_warmup=0 \
+ trainer.val_before_train=True \
+ trainer.logger=['console','swanlab'] \
+ trainer.project_name="${project_name}" \
+ trainer.experiment_name="${exp_name}" \
+ trainer.n_gpus_per_node=${NGPUS_PER_NODE} \
+ trainer.nnodes=${NNODES} \
+ trainer.save_freq=25 \
+ trainer.test_freq=5 \
+ trainer.default_local_dir="${CKPTS_DIR}" \
+ trainer.rollout_data_dir="${CKPTS_DIR}" \
+ trainer.total_epochs=5 $@ 2>&1 | tee -a ${LOG_PATH}/log_${DATE_TIME}.txt
\ No newline at end of file
diff --git a/partial_rollout/run_gsm8k_pr_grpo_4b_bs128.sh b/partial_rollout/run_gsm8k_pr_grpo_4b_bs128.sh
new file mode 100644
index 00000000..f250a420
--- /dev/null
+++ b/partial_rollout/run_gsm8k_pr_grpo_4b_bs128.sh
@@ -0,0 +1,76 @@
+set -x
+
+DATE_TIME=$(date +%Y%m%d_%H%M%S)
+
+project_name='verl_exp_partial_rollout_gsm8k'
+exp_name="v070-qwen3-4b-gsm8k-pr-grpo-bs128-${DATE_TIME}"
+
+# Paths
+RAY_DATA_HOME=/apdcephfs_gy2/share_303055091/allenzpma_tmp
+MODEL_PATH="/apdcephfs_gy2/share_303055091/Qwen3-4B"
+CKPTS_DIR="${RAY_DATA_HOME}/checkpoint/${project_name}/${exp_name}"
+TRAIN_FILE="${RAY_DATA_HOME}/data/gsm8k/train.parquet"
+TEST_FILE="${RAY_DATA_HOME}/data/gsm8k/test.parquet"
+LOG_PATH="${RAY_DATA_HOME}/partial_rollout/output/logs"
+
+NNODES=1
+NGPUS_PER_NODE=8
+MICRO_BATCH_SIZE_PER_GPU=8
+
+export RAY_DEBUG=1
+export HYDRA_FULL_ERROR=1
+export VERL_LOGGING_LEVEL=INFO
+
+# For async rollout mode, dataset should return raw chat.
+rollout_mode="async" # sync or async,async会单独判断
+rollout_name="vllm" # sglang or vllm
+
+if [ "$rollout_mode" = "async" ]; then
+ export VLLM_USE_V1=1
+ return_raw_chat="True"
+fi
+
+python3 -m recipe.partial_rollout.main_ppo \
+ --config-path=../../verl/trainer/config \
+ algorithm.adv_estimator=grpo \
+ data.train_files="${TRAIN_FILE}" \
+ data.val_files="${TEST_FILE}" \
+ data.train_batch_size=128 \
+ data.max_prompt_length=512 \
+ data.max_response_length=1024 \
+ data.filter_overlong_prompts=True \
+ data.truncation='error' \
+ actor_rollout_ref.model.path="${MODEL_PATH}" \
+ actor_rollout_ref.actor.optim.lr=1e-6 \
+ actor_rollout_ref.hybrid_engine=True \
+ actor_rollout_ref.model.use_remove_padding=True \
+ actor_rollout_ref.actor.ppo_mini_batch_size=128 \
+ actor_rollout_ref.actor.ppo_micro_batch_size_per_gpu=32 \
+ actor_rollout_ref.actor.use_kl_loss=True \
+ actor_rollout_ref.actor.kl_loss_coef=0.001 \
+ actor_rollout_ref.actor.kl_loss_type=low_var_kl \
+ actor_rollout_ref.actor.entropy_coeff=0 \
+ actor_rollout_ref.model.enable_gradient_checkpointing=True \
+ actor_rollout_ref.actor.fsdp_config.param_offload=False \
+ actor_rollout_ref.actor.fsdp_config.optimizer_offload=False \
+ actor_rollout_ref.rollout.log_prob_micro_batch_size_per_gpu=32 \
+ actor_rollout_ref.rollout.tensor_model_parallel_size=1 \
+ actor_rollout_ref.rollout.name="${rollout_name}" \
+ actor_rollout_ref.rollout.mode="${rollout_mode}" \
+ actor_rollout_ref.rollout.gpu_memory_utilization=0.7 \
+ actor_rollout_ref.rollout.n=8 \
+ actor_rollout_ref.ref.log_prob_micro_batch_size_per_gpu=32 \
+ actor_rollout_ref.ref.fsdp_config.param_offload=True \
+ algorithm.use_kl_in_reward=False \
+ trainer.critic_warmup=0 \
+ trainer.val_before_train=True \
+ trainer.logger=['console','swanlab'] \
+ trainer.project_name="${project_name}" \
+ trainer.experiment_name="${exp_name}" \
+ trainer.n_gpus_per_node=${NGPUS_PER_NODE} \
+ trainer.nnodes=${NNODES} \
+ trainer.save_freq=25 \
+ trainer.test_freq=5 \
+ trainer.default_local_dir="${CKPTS_DIR}" \
+ trainer.rollout_data_dir="${CKPTS_DIR}" \
+ trainer.total_epochs=5 $@ 2>&1 | tee -a ${LOG_PATH}/log_${DATE_TIME}.txt
\ No newline at end of file
diff --git a/partial_rollout/vllm_rollout/__init__.py b/partial_rollout/vllm_rollout/__init__.py
new file mode 100644
index 00000000..9cd3ed5b
--- /dev/null
+++ b/partial_rollout/vllm_rollout/__init__.py
@@ -0,0 +1,13 @@
+# Copyright 2025 Meituan Ltd. and/or its affiliates
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
diff --git a/partial_rollout/vllm_rollout/vllm_async_server.py b/partial_rollout/vllm_rollout/vllm_async_server.py
new file mode 100644
index 00000000..1d0cb42e
--- /dev/null
+++ b/partial_rollout/vllm_rollout/vllm_async_server.py
@@ -0,0 +1,150 @@
+# Copyright 2025 Meituan Ltd. and/or its affiliates
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import asyncio
+import logging
+from typing import Any, Optional, Sequence
+
+import ray
+from ray.actor import ActorHandle
+from vllm import SamplingParams
+from vllm.inputs import TokensPrompt
+from vllm.outputs import RequestOutput
+
+from verl.workers.config import HFModelConfig, RolloutConfig
+from verl.workers.rollout.replica import RolloutMode
+from verl.workers.rollout.vllm_rollout.vllm_async_server import (
+ _qwen2_5_vl_dedup_image_tokens,
+ vLLMHttpServerBase,
+ vLLMReplica,
+)
+
+logger = logging.getLogger(__file__)
+logger.setLevel(logging.INFO)
+
+
+@ray.remote(num_cpus=1)
+class vLLMHttpServerForPartial(vLLMHttpServerBase):
+ def __init__(
+ self,
+ config: RolloutConfig,
+ model_config: HFModelConfig,
+ rollout_mode: RolloutMode,
+ workers: list[ActorHandle],
+ replica_rank: int,
+ node_rank: int,
+ gpus_per_node: int,
+ nnodes: int,
+ ):
+ super().__init__(config, model_config, rollout_mode, workers, replica_rank, node_rank, gpus_per_node, nnodes)
+
+ # for cancel LLMServer
+ self.paused = False
+ self.lock = asyncio.Lock()
+ self.cancel_event: dict[str, asyncio.Event] = {}
+ self.req_output: dict[str, Optional[RequestOutput]] = {}
+
+ async def _generate_step(
+ self,
+ prompt_ids: list[int],
+ sampling_params: dict[str, Any],
+ request_id: str,
+ image_data: Optional[list[Any]] = None,
+ ):
+ max_tokens = self.config.max_model_len - len(prompt_ids)
+ sampling_params["logprobs"] = 1
+ sampling_params.setdefault("repetition_penalty", self.config.get("repetition_penalty", 1.0))
+ sampling_params = SamplingParams(max_tokens=max_tokens, **sampling_params)
+ prompt_ids = _qwen2_5_vl_dedup_image_tokens(prompt_ids, self.model_config.processor)
+ prompt = TokensPrompt(
+ prompt_token_ids=prompt_ids, multi_modal_data={"image": image_data} if image_data else None
+ )
+ generator = self.engine.generate(prompt=prompt, sampling_params=sampling_params, request_id=request_id)
+
+ # Get final response
+ async for output in generator:
+ self.req_output[request_id] = output
+ assert self.req_output[request_id] is not None
+
+ async def generate_for_partial(
+ self,
+ prompt_ids: list[int],
+ sampling_params: dict[str, Any],
+ request_id: str,
+ image_data: Optional[list[Any]] = None,
+ ) -> tuple[list[Any], list[Any], bool] | tuple[Sequence[int], list[float], Any]:
+ async with self.lock:
+ if self.paused:
+ # After cancel, all tasks will return directly and wait for the next submission
+ return [], [], True
+ self.req_output[request_id]: Optional[RequestOutput] = None
+ self.cancel_event[request_id] = asyncio.Event()
+ cancel_handle = asyncio.create_task(self.cancel_event[request_id].wait())
+ generation_handle = asyncio.create_task(
+ self._generate_step(prompt_ids, sampling_params, request_id, image_data)
+ )
+
+ done, pend = await asyncio.wait([generation_handle, cancel_handle], return_when=asyncio.FIRST_COMPLETED)
+
+ for task in done:
+ await task
+
+ for task in pend:
+ task.cancel()
+
+ async with self.lock:
+ if self.req_output[request_id] is None:
+ return [], [], True
+ token_ids = self.req_output[request_id].outputs[0].token_ids
+ log_probs: list[float] = []
+ for i, x in enumerate(self.req_output[request_id].outputs[0].logprobs):
+ # In sampling_params, logprobs is set to 1, which should return 1,
+ # but in practice there are multiple. Take the log_prob corresponding to token_id
+ token_id = self.req_output[request_id].outputs[0].token_ids[i]
+ log_probs.append(x[token_id].logprob)
+ is_cancel = generation_handle not in done
+ self.cancel_event.pop(request_id, None)
+ self.req_output.pop(request_id, None)
+ await self.engine.abort(request_id)
+ return token_ids, log_probs, is_cancel
+
+ async def cancel(self):
+ async with self.lock:
+ self.paused = True
+ for request_id in self.cancel_event:
+ self.cancel_event[request_id].set()
+
+ async def resume(self):
+ async with self.lock:
+ self.paused = False
+
+
+class PRv3vLLMReplica(vLLMReplica):
+ def __init__(
+ self,
+ replica_rank: int,
+ config: RolloutConfig,
+ model_config: HFModelConfig,
+ gpus_per_node: int = 8,
+ is_reward_model: bool = False,
+ ):
+ super().__init__(replica_rank, config, model_config, gpus_per_node, is_reward_model)
+ self.server_class = vLLMHttpServerForPartial
+
+ async def cancel(self):
+ """Cancel each rollout server."""
+ await asyncio.gather(*[server.cancel.remote() for server in self.servers])
+
+ async def resume(self):
+ """Resume each rollout server."""
+ await asyncio.gather(*[server.resume.remote() for server in self.servers])