Welcome to the Ultralytics xView YOLOv3 repository! Here we provide code to train the powerful YOLOv3 object detection model on the xView dataset for the xView Challenge. This challenge focuses on detecting objects from satellite imagery, advancing the state of the art in computer vision applications for remote sensing.
![]()




To run this project, ensure that you have Python 3.6 or later. You will also need to install several dependencies which can be done easily using pip:
pip3 install -U -r requirements.txtThe following packages should be included:
numpy: For numerical operations.scipy: Useful for scientific and technical computations.torch: The PyTorch machine learning framework.opencv-python: Open Source Computer Vision Library.h5py: For managing and manipulating data in HDF5 format.tqdm: For adding progress bars to loops and command line.
Start by downloading the xView data from the data download page of the xView Challenge.
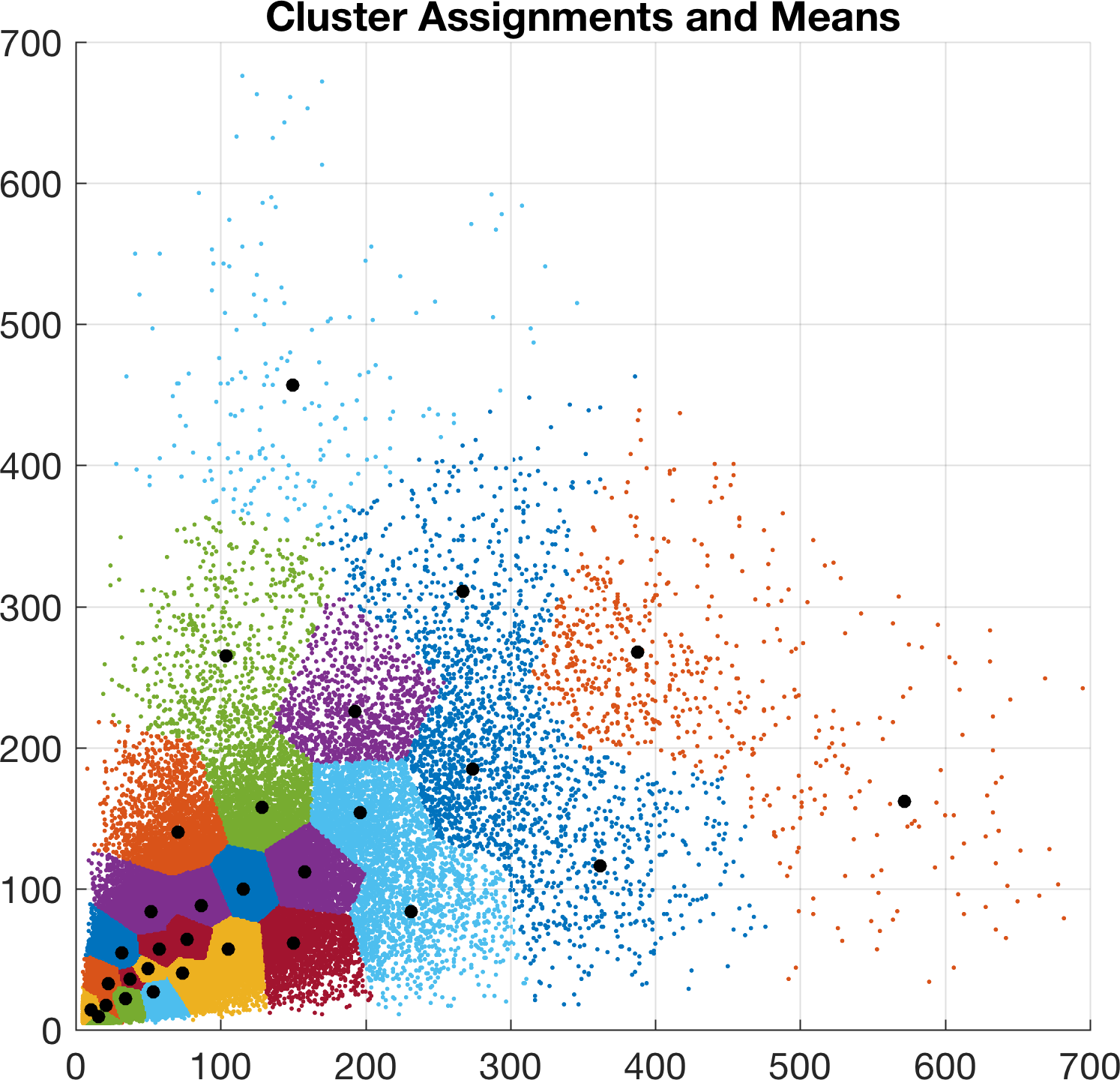
Before we launch into training, we perform preprocessing on the targets to clean them up:
- Outliers are removed using sigma-rejection.
- A new set of 30 k-means anchors are created specifically for
c60_a30symmetric.cfgusing the MATLAB scriptutils/analysis.m:
To start training, execute train.py after you have downloaded the xView data. You'll need to specify the path to your xView data on line 41 (for local execution) or line 43 (if you're working in the cloud).
To resume training, use the following command:
train.py --resume 1Training will continue from the most recent checkpoint found in the latest.pt file.
During training, each epoch will process 8 randomly sampled 608x608 chips from each full-resolution image. If you're using a GPU like the Nvidia GTX 1080 Ti, you can expect to complete around 100 epochs per day.
Watch out for overtraining! It becomes a significant problem after roughly 200 epochs. The best validation mean Average Precision (mAP) observed is 0.16 after 300 epochs, which takes about 3 days, corresponding to a training mAP of 0.30.
You'll see loss plots for bounding boxes, objectness, and class confidence that should resemble the following results:
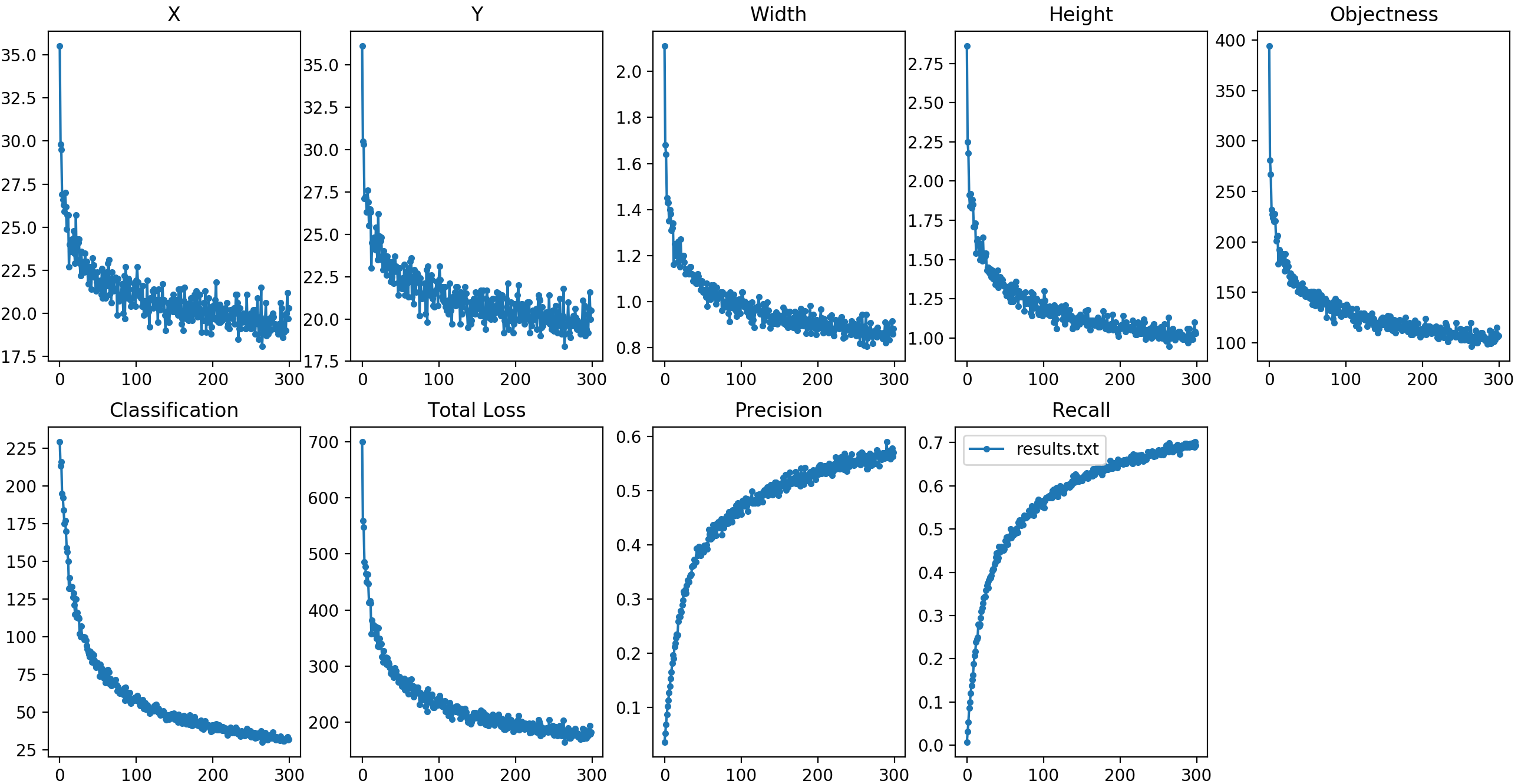
During training, datasets.py will apply various augmentations to the full-resolution input images using OpenCV. Here are the specifications for each augmentation applied:
| Augmentation | Description |
|---|---|
| Translation | +/- 1% (vertical and horizontal) |
| Rotation | +/- 20 degrees |
| Shear | +/- 3 degrees (vertical and horizontal) |
| Scale | +/- 30% |
| Reflection | 50% probability (vertical and horizontal) |
| HSV Saturation | +/- 50% |
| HSV Intensity | +/- 50% |
Please note that augmentation is applied only during training and not during inference. All corresponding bounding boxes are automatically adjusted to match the augmented images.
Once training is done, model checkpoints will be available in the /checkpoints directory. Use detect.py to apply your trained weights to any xView image—for instance, 5.tif from the training set:

If you use this repository or the associated tools and datasets in your research, please cite accordingly:
🤝 We love contributions from the community! Our open-source projects thrive on your help. To start contributing, please check out our Contributing Guide. Additionally, we'd love to hear from you through our Survey. It's a way to impact the future of our projects. A big shoutout and thank you 🙏 to all our contributors!

At Ultralytics, we provide two different licensing options to suit various use cases:
- AGPL-3.0 License: The AGPL-3.0 License is an OSI-approved open-source format that's best suited for students, researchers, and enthusiasts to promote collaboration and knowledge sharing. The full terms can be found in the LICENSE file.
- Enterprise License: If you're looking for a commercial application of our software and models, the Enterprise License enables integration into commercial products while bypassing the open-source stipulations of the AGPL-3.0. For embedding our solutions into your commercial offerings, please contact us through Ultralytics Licensing.
🐞 For reporting bugs or suggesting new features, please open an issue on our GitHub Issues page. And if you have questions or fancy engaging with us, join our vibrant Discord community!