git clone https://github.com/modelscope/swift.git
cd swift
pip install -e '.[llm]'Model link:
- cogvlm2-19b-chat: https://modelscope.cn/models/ZhipuAI/cogvlm2-llama3-chinese-chat-19B/summary
- cogvlm2-en-19b-chat: https://modelscope.cn/models/ZhipuAI/cogvlm2-llama3-chat-19B/summary
Inference cogvlm2-19b-chat:
# Experimental environment: A100
# 43GB GPU memory
CUDA_VISIBLE_DEVICES=0 swift infer --model_type cogvlm2-19b-chatOutput: (supports passing local path or URL)
"""
<<< Describe this image.
Input a media path or URL <<< http://modelscope-open.oss-cn-hangzhou.aliyuncs.com/images/cat.png
This image features a very young, fluffy kitten with a look of innocent curiosity. The kitten's fur is a mix of white, light brown, and dark gray with distinctive dark stripes that give it a tabby appearance. Its large, round eyes are a striking shade of blue with light reflections, which accentuate its youthful and tender expression. The ears are perky and alert, with a light pink hue inside, adding to the kitten's endearing look.
The kitten's fur is thick and appears to be well-groomed, with a soft, plush texture that suggests it is a breed known for its long, luxurious coat, such as a Maine Coon or a Persian. The white fur around its neck and chest stands out, providing a stark contrast to the darker shades on its back and head.
The background is blurred and warm-toned, providing a soft, neutral environment that ensures the kitten is the central focus of the image. The lighting is gentle, highlighting the kitten's features without casting harsh shadows, which further contributes to the image's warm and comforting ambiance.
Overall, the image captures the essence of a kitten's first year of life, characterized by its inquisitive nature, soft fur, and the endearing charm of youth.
--------------------------------------------------
<<< clear
<<< How many sheep are in the picture?
Input a media path or URL <<< http://modelscope-open.oss-cn-hangzhou.aliyuncs.com/images/animal.png
There are four sheep in the picture.
--------------------------------------------------
<<< clear
<<< What is the calculation result?
Input a media path or URL <<< http://modelscope-open.oss-cn-hangzhou.aliyuncs.com/images/math.png
The calculation result is 46556.
--------------------------------------------------
<<< clear
<<< Write a poem based on the content of the picture.
Input a media path or URL <<< http://modelscope-open.oss-cn-hangzhou.aliyuncs.com/images/poem.png
A boat drifts on the calm river,
Surrounded by lush greenery.
The gentle ripples on the water's surface,
Reflect the stars in the sky.
The night is serene and peaceful,
The only sound is the lapping of the waves.
The boat is like a floating island,
Isolated in the vastness of the river.
The stars shine brightly in the sky,
As if watching over the boat.
The lush greenery on the riverbank,
Gives the boat a sense of warmth.
The boat drifts on the river,
Carrying the beauty of nature.
Let us enjoy this moment together,
And feel the tranquility of life.
"""Example images are shown below:
cat:

animal:

math:
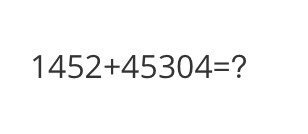
poem:

Single-sample inference
import os
os.environ['CUDA_VISIBLE_DEVICES'] = '0'
from swift.llm import (
get_model_tokenizer, get_template, inference, ModelType,
get_default_template_type, inference_stream
)
from swift.utils import seed_everything
import torch
model_type = ModelType.cogvlm2_19b_chat
template_type = get_default_template_type(model_type)
print(f'template_type: {template_type}')
model, tokenizer = get_model_tokenizer(model_type, torch.float16,
model_kwargs={'device_map': 'auto'})
model.generation_config.max_new_tokens = 256
template = get_template(template_type, tokenizer)
seed_everything(42)
images = ['http://modelscope-open.oss-cn-hangzhou.aliyuncs.com/images/road.png']
query = 'How far is it from each city?'
response, _ = inference(model, template, query, images=images)
print(f'query: {query}')
print(f'response: {response}')
# Streaming
query = 'Which city is the farthest?'
images = images
gen = inference_stream(model, template, query, images=images)
print_idx = 0
print(f'query: {query}\nresponse: ', end='')
for response, _ in gen:
delta = response[print_idx:]
print(delta, end='', flush=True)
print_idx = len(response)
print()
"""
query: How far is it from each city?
response: To determine the distance from each city, we will need to look at the information provided on the road sign:
1. From "Mata" to "Yangjiang," it is 62 kilometers.
2. From "Yangjiang" to "Guangzhou," it is 293 kilometers.
These distances are indicated in kilometers and are shown for the two cities immediately following on the sign.
query: Which city is the farthest?
response: The farthest city on this sign is Guangzhou, which is 293 kilometers away.
"""Example image is shown below:
road:

Fine-tuning multimodal large models usually uses custom datasets. Here is a demo that can be run directly:
# Experimental environment: A100
# 70GB GPU memory
CUDA_VISIBLE_DEVICES=0 swift sft \
--model_type cogvlm2-19b-chat \
--dataset coco-en-2-mini \Custom datasets support json, jsonl formats. Here is an example of a custom dataset:
(Supports multi-turn dialogue, but each conversation can only include one image. Support local file paths or URLs for input)
{"query": "55555", "response": "66666", "images": ["image_path"]}
{"query": "eeeee", "response": "fffff", "history": [], "images": ["image_path"]}
{"query": "EEEEE", "response": "FFFFF", "history": [["query1", "response1"], ["query2", "response2"]], "images": ["image_path"]}Direct inference:
CUDA_VISIBLE_DEVICES=0 swift infer \
--ckpt_dir output/cogvlm2-19b-chat/vx-xxx/checkpoint-xxx \
--load_dataset_config true \merge-lora and inference:
CUDA_VISIBLE_DEVICES=0 swift export \
--ckpt_dir output/cogvlm2-19b-chat/vx-xxx/checkpoint-xxx \
--merge_lora true
CUDA_VISIBLE_DEVICES=0 swift infer \
--ckpt_dir output/cogvlm2-19b-chat/vx-xxx/checkpoint-xxx-merged \
--load_dataset_config true