
A Reactive CLI that generates git commit messages with Ollama, ChatGPT, Gemini, Claude, Mistral and other AI


aicommit2 is a reactive CLI tool that automatically generates Git commit messages using various AI models. It supports simultaneous requests to multiple AI providers, allowing users to select the most suitable commit message. The core functionalities and architecture of this project are inspired by AICommits.
- Multi-AI Support: Integrates with OpenAI, Anthropic Claude, Google Gemini, Mistral AI, Cohere, Groq and more.
- Local Model Support: Use local AI models via Ollama.
- Reactive CLI: Enables simultaneous requests to multiple AIs and selection of the best commit message.
- Git Hook Integration: Can be used as a prepare-commit-msg hook.
- Custom Prompt: Supports user-defined system prompt templates.
- OpenAI
- Anthropic Claude
- Gemini
- Mistral AI (including Codestral)
- Cohere
- Groq
- Perplexity
- DeepSeek
- Huggingface (Unofficial)
The minimum supported version of Node.js is the v18. Check your Node.js version with
node --version.
- Install aicommit2:
npm install -g aicommit2- Set up API keys (at least ONE key must be set):
aicommit2 config set OPENAI.key=<your key>
aicommit2 config set ANTHROPIC.key=<your key>
# ... (similar commands for other providers)- Run aicommit2 with your staged files in git repository:
git add <files...>
aicommit2👉 Tip: Use the
aic2alias ifaicommit2is too long for you.
You can also use your model for free with Ollama and it is available to use both Ollama and remote providers simultaneously.
-
Install Ollama from https://ollama.com
-
Start it with your model
ollama run llama3.2 # model you want use. ex) codellama, deepseek-coder- Set the model and host
aicommit2 config set OLLAMA.model=<your model>If you want to use Ollama, you must set OLLAMA.model.
- Run aicommit2 with your staged in git repository
git add <files...>
aicommit2👉 Tip: Ollama can run LLMs in parallel from v0.1.33. Please see this section.
This CLI tool runs git diff to grab all your latest code changes, sends them to configured AI, then returns the AI generated commit message.
If the diff becomes too large, AI will not function properly. If you encounter an error saying the message is too long or it's not a valid commit message, try reducing the commit unit.
You can call aicommit2 directly to generate a commit message for your staged changes:
git add <files...>
aicommit2aicommit2 passes down unknown flags to git commit, so you can pass in commit flags.
For example, you can stage all changes in tracked files with as you commit:
aicommit2 --all # or -a--localeor-l: Locale to use for the generated commit messages (default: en)--allor-a: Automatically stage changes in tracked files for the commit (default: false)--typeor-t: Git commit message format (default: conventional). It supportsconventionalandgitmoji--confirmor-y: Skip confirmation when committing after message generation (default: false)--clipboardor-c: Copy the selected message to the clipboard (default: false).- If you give this option, aicommit2 will not commit.
--generateor-g: Number of messages to generate (default: 1)- Warning: This uses more tokens, meaning it costs more.
--excludeor-x: Files to exclude from AI analysis
Example:
aicommit2 --locale "jp" --all --type "conventional" --generate 3 --clipboard --exclude "*.json" --exclude "*.ts"You can also integrate aicommit2 with Git via the prepare-commit-msg hook. This lets you use Git like you normally would, and edit the commit message before committing.
In the Git repository you want to install the hook in:
aicommit2 hook installIn the Git repository you want to uninstall the hook from:
aicommit2 hook uninstall- READ:
aicommit2 config get <key> - SET:
aicommit2 config set <key>=<value>
Example:
aicommit2 config get OPENAI
aicommit2 config get GEMINI.key
aicommit2 config set OPENAI.generate=3 GEMINI.temperature=0.5- Command-line arguments: use the format
--[Model].[Key]=value
aicommit2 --OPENAI.locale="jp" --GEMINI.temperatue="0.5"- Configuration file: use INI format in the
~/.aicommit2file or usesetcommand. Example~/.aicommit2:
# General Settings
logging=true
generate=2
temperature=1.0
# Model-Specific Settings
[OPENAI]
key="<your-api-key>"
temperature=0.8
generate=1
systemPromptPath="<your-prompt-path>"
[GEMINI]
key="<your-api-key>"
generate=5
includeBody=true
[OLLAMA]
temperature=0.7
model[]=llama3.2
model[]=codestralThe priority of settings is: Command-line Arguments > Model-Specific Settings > General Settings > Default Values.
The following settings can be applied to most models, but support may vary. Please check the documentation for each specific model to confirm which settings are supported.
| Setting | Description | Default |
|---|---|---|
systemPrompt |
System Prompt text | - |
systemPromptPath |
Path to system prompt file | - |
exclude |
Files to exclude from AI analysis | - |
type |
Type of commit message to generate | conventional |
locale |
Locale for the generated commit messages | en |
generate |
Number of commit messages to generate | 1 |
logging |
Enable logging | true |
includeBody |
Whether the commit message includes body | false |
maxLength |
Maximum character length of the Subject of generated commit message | 50 |
timeout |
Request timeout (milliseconds) | 10000 |
temperature |
Model's creativity (0.0 - 2.0) | 0.7 |
maxTokens |
Maximum number of tokens to generate | 1024 |
topP |
Nucleus sampling | 0.9 |
codeReview |
Whether to include an automated code review in the process | false |
codeReviewPromptPath |
Path to code review prompt file | - |
disabled |
Whether a specific model is enabled or disabled | false |
👉 Tip: To set the General Settings for each model, use the following command.
aicommit2 config set OPENAI.locale="jp" aicommit2 config set CODESTRAL.type="gitmoji" aicommit2 config set GEMINI.includeBody=true
- Allow users to specify a custom system prompt
aicommit2 config set systemPrompt="Generate git commit message."
systemPrompttakes precedence oversystemPromptPathand does not apply at the same time.
- Allow users to specify a custom file path for their own system prompt template
- Please see Custom Prompt Template
aicommit2 config set systemPromptPath="/path/to/user/prompt.txt"- Files to exclude from AI analysis
- It is applied with the
--excludeoption of the CLI option. All files excluded through--excludein CLI andexcludegeneral setting.
aicommit2 config set exclude="*.ts"
aicommit2 config set exclude="*.ts,*.json"NOTE:
excludeoption does not support per model. It is only supported by General Settings.
Default: conventional
Supported: conventional, gitmoji
The type of commit message to generate. Set this to "conventional" to generate commit messages that follow the Conventional Commits specification:
aicommit2 config set type="conventional"Default: en
The locale to use for the generated commit messages. Consult the list of codes in: https://wikipedia.org/wiki/List_of_ISO_639_language_codes.
aicommit2 config set locale="jp"Default: 1
The number of commit messages to generate to pick from.
Note, this will use more tokens as it generates more results.
aicommit2 config set generate=2Default: true
Option that allows users to decide whether to generate a log file capturing the responses.
The log files will be stored in the ~/.aicommit2_log directory(user's home).
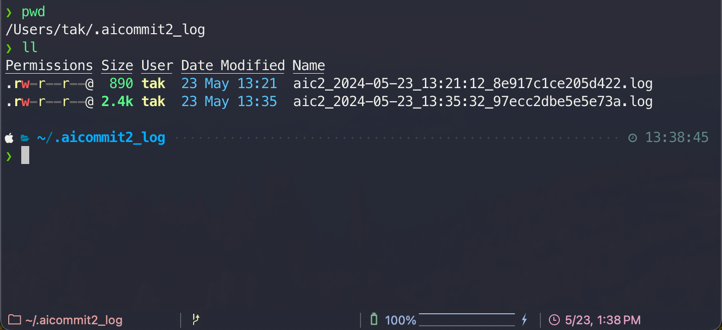
- You can remove all logs below comamnd.
aicommit2 log removeAllDefault: false
This option determines whether the commit message includes body. If you want to include body in message, you can set it to true.
aicommit2 config set includeBody="true"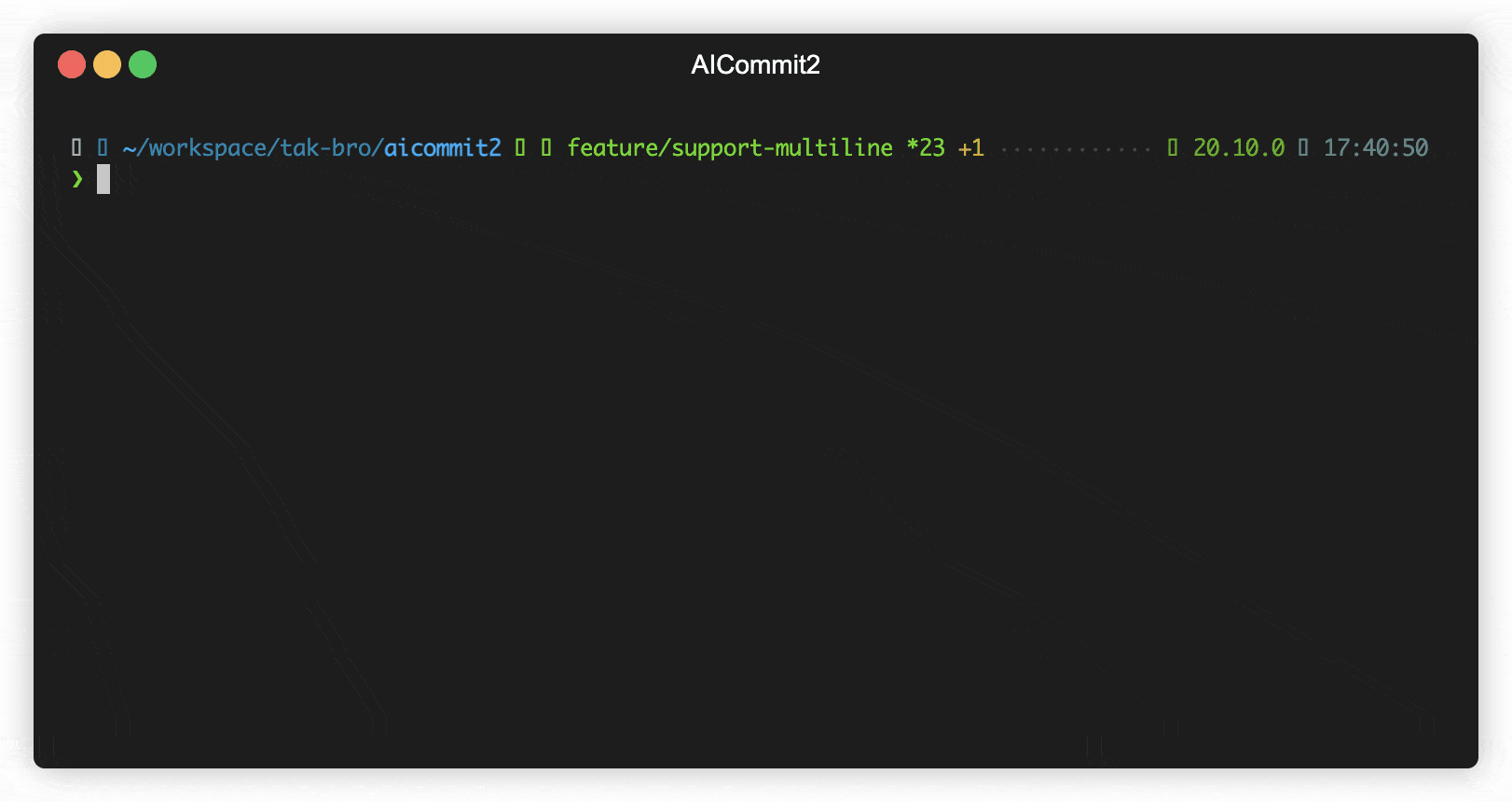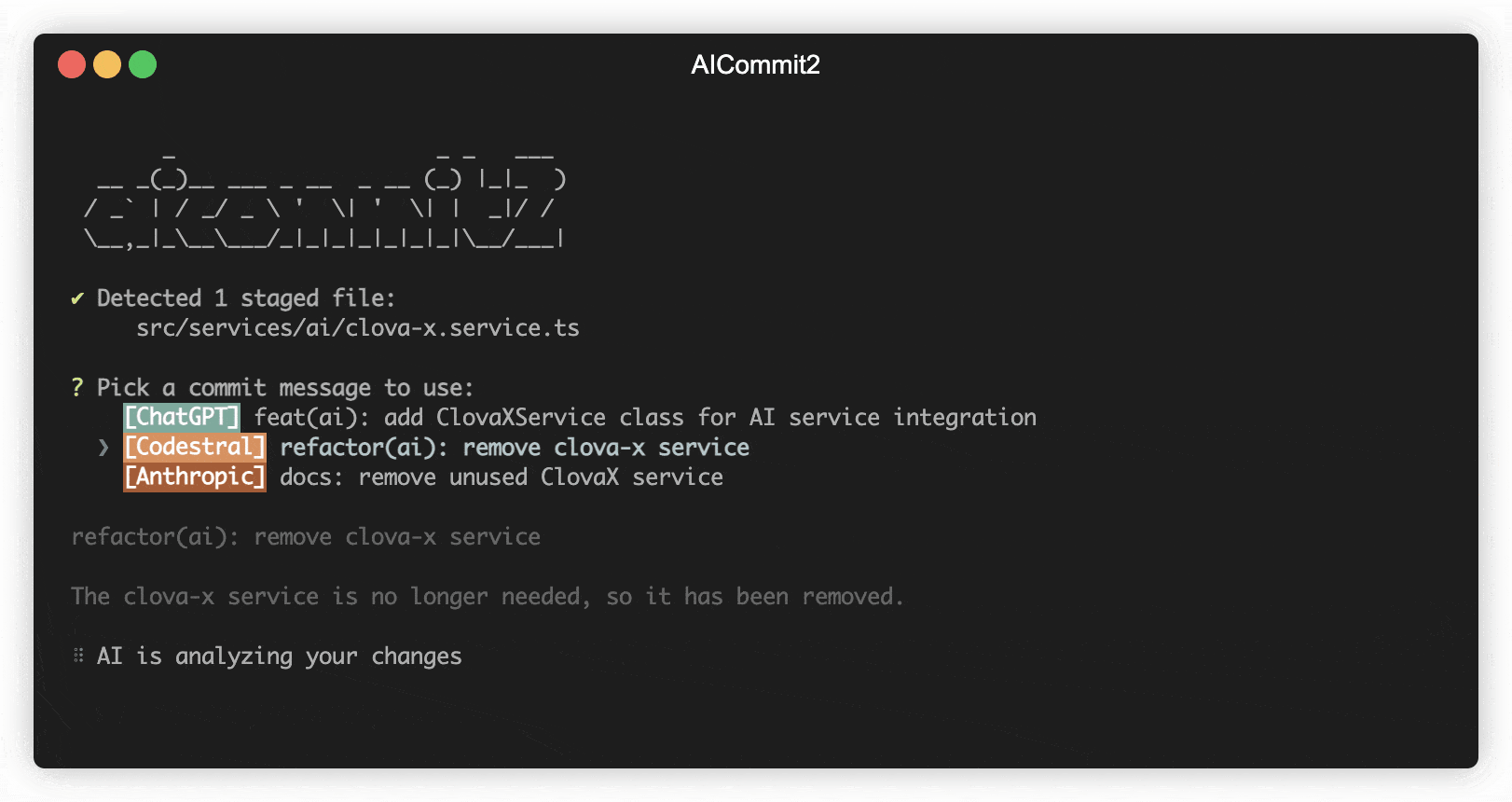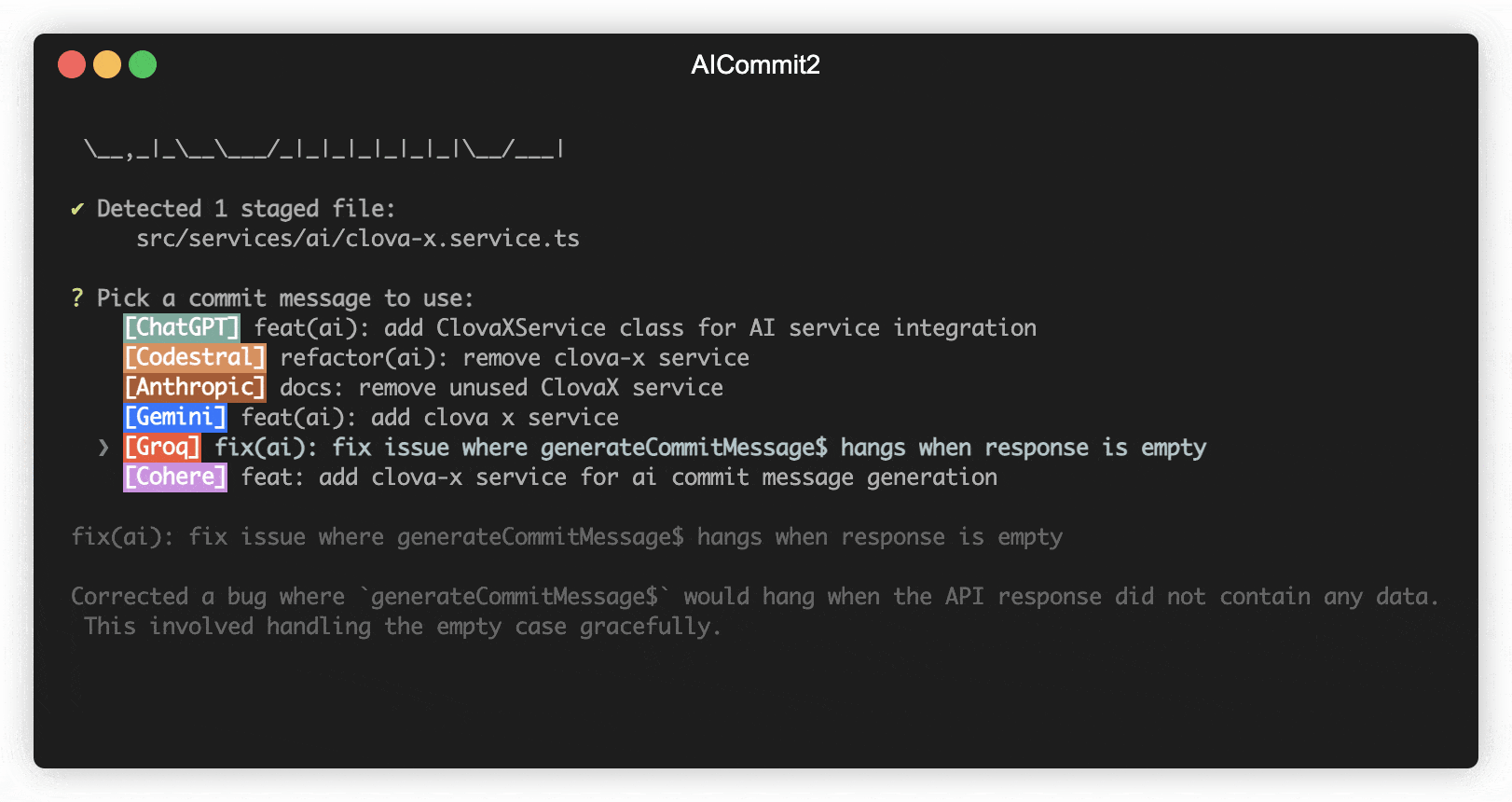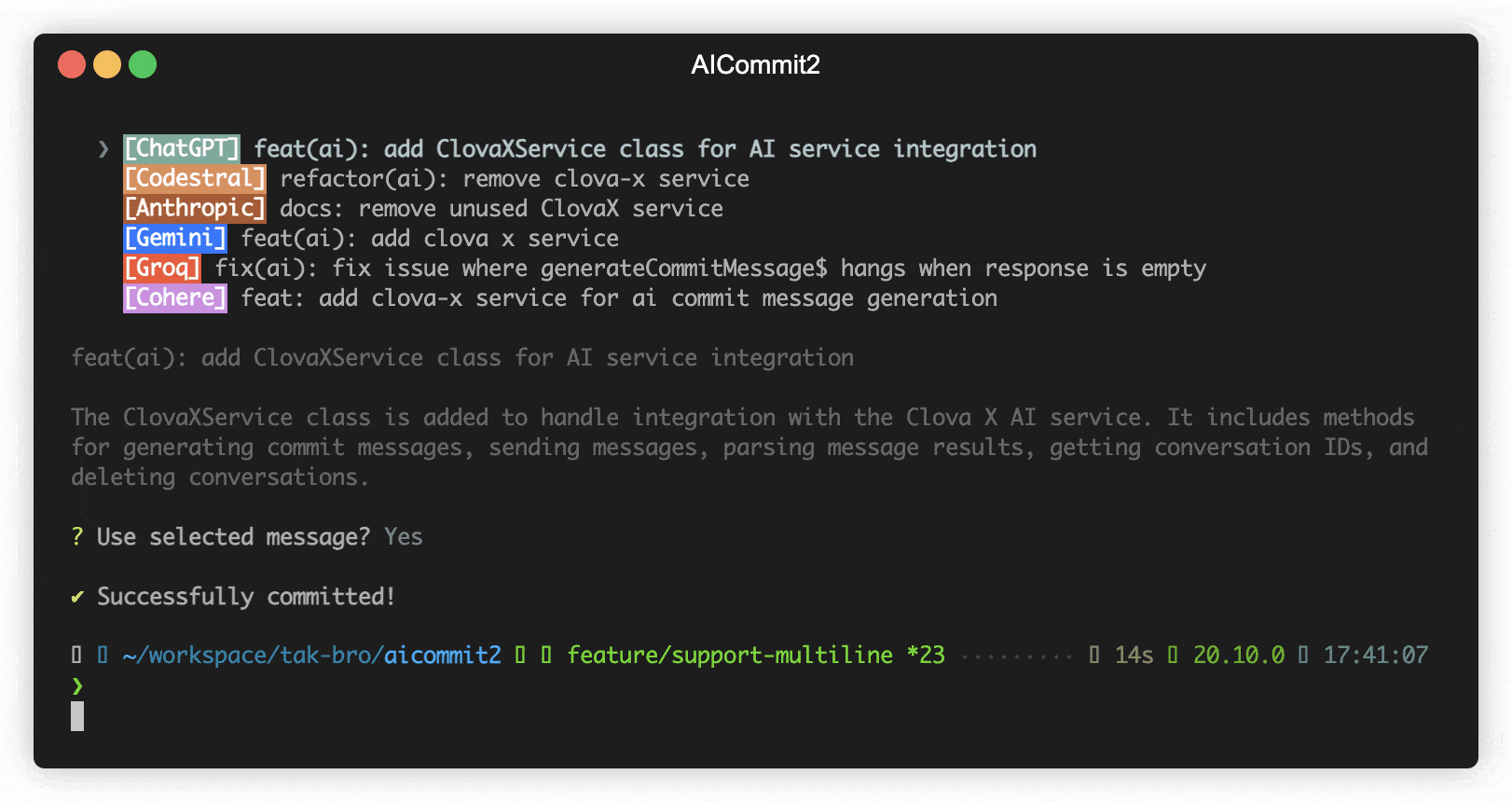
aicommit2 config set includeBody="false"
The maximum character length of the Subject of generated commit message
Default: 50
aicommit2 config set maxLength=100The timeout for network requests in milliseconds.
Default: 10_000 (10 seconds)
aicommit2 config set timeout=20000 # 20sThe temperature (0.0-2.0) is used to control the randomness of the output
Default: 0.7
aicommit2 config set temperature=0.3The maximum number of tokens that the AI models can generate.
Default: 1024
aicommit2 config set maxTokens=3000Default: 0.9
Nucleus sampling, where the model considers the results of the tokens with top_p probability mass.
aicommit2 config set topP=0.2Default: false
This option determines whether a specific model is enabled or disabled. If you want to disable a particular model, you can set this option to true.
To disable a model, use the following commands:
aicommit2 config set GEMINI.disabled="true"
aicommit2 config set GROQ.disabled="true"Default: false
The codeReview parameter determines whether to include an automated code review in the process.
aicommit2 config set codeReview=trueNOTE: When enabled, aicommit2 will perform a code review before generating commit messages.
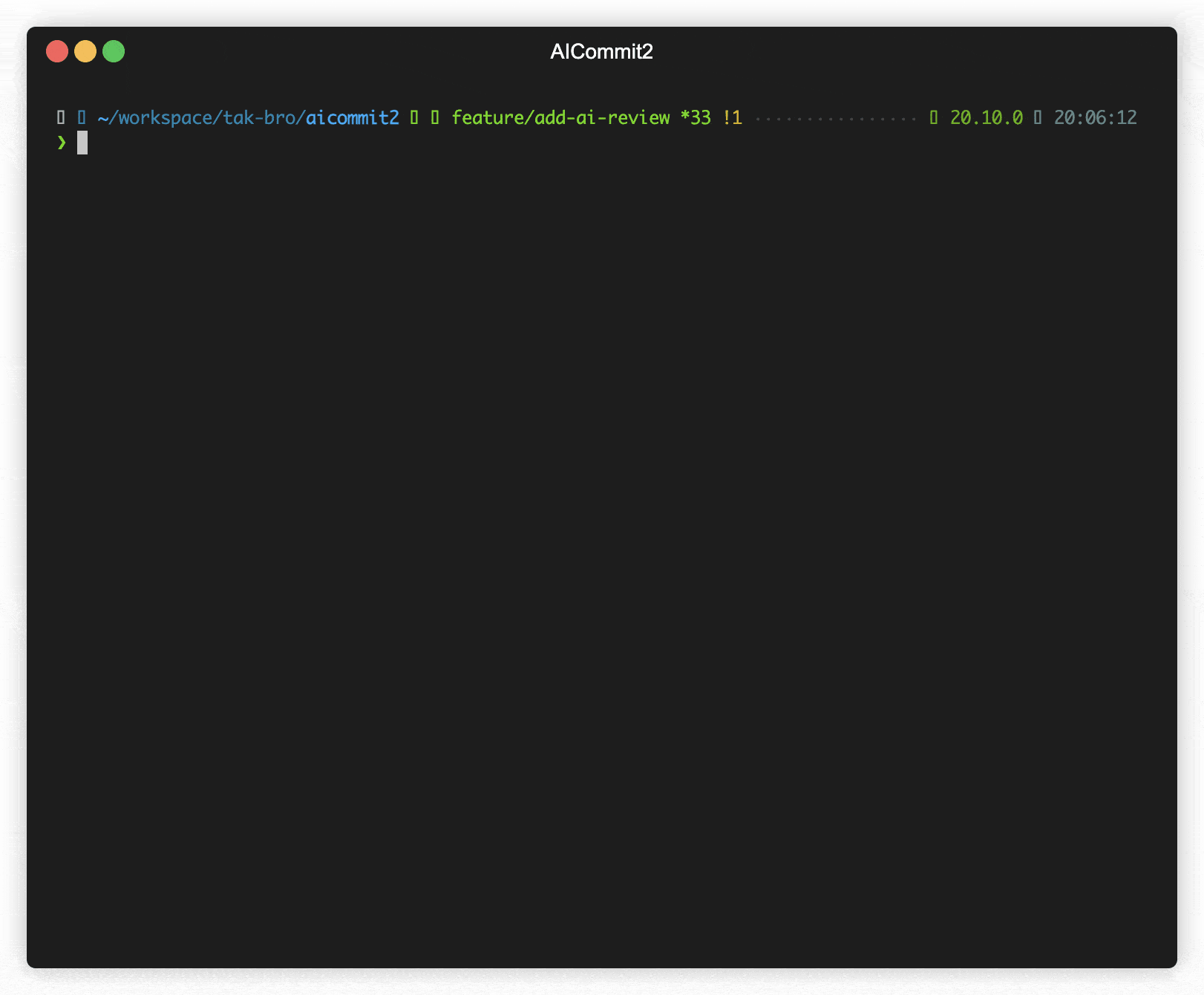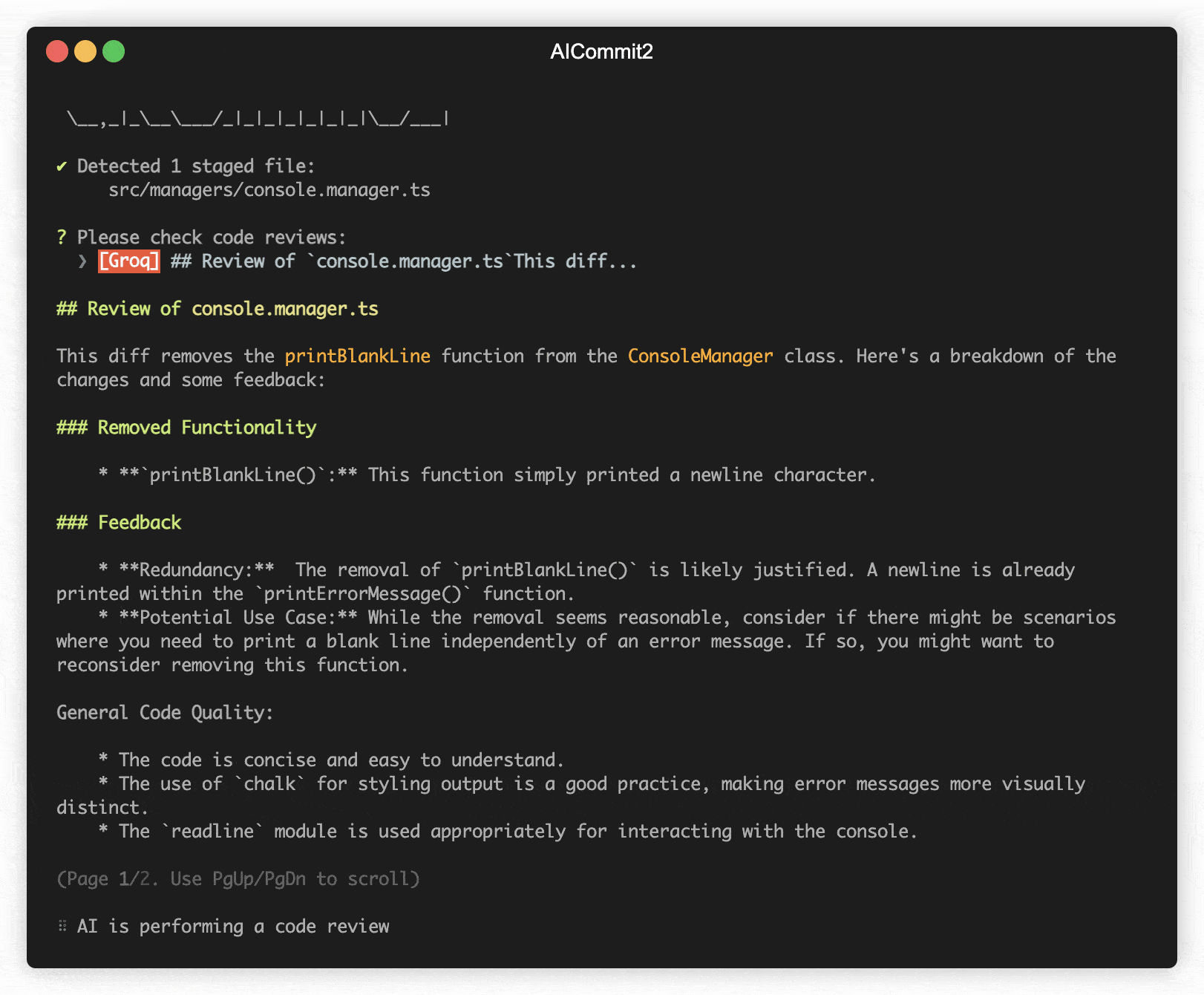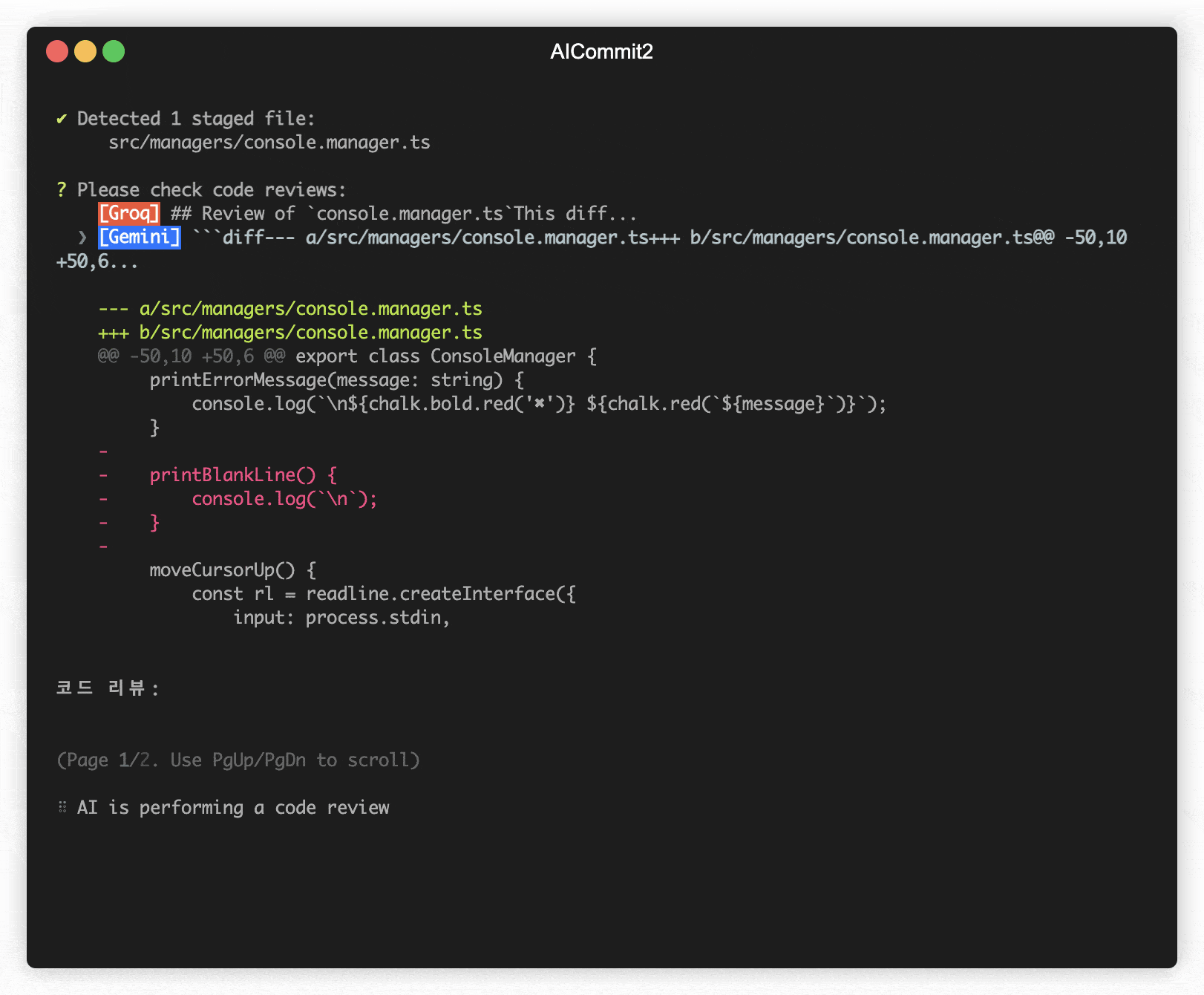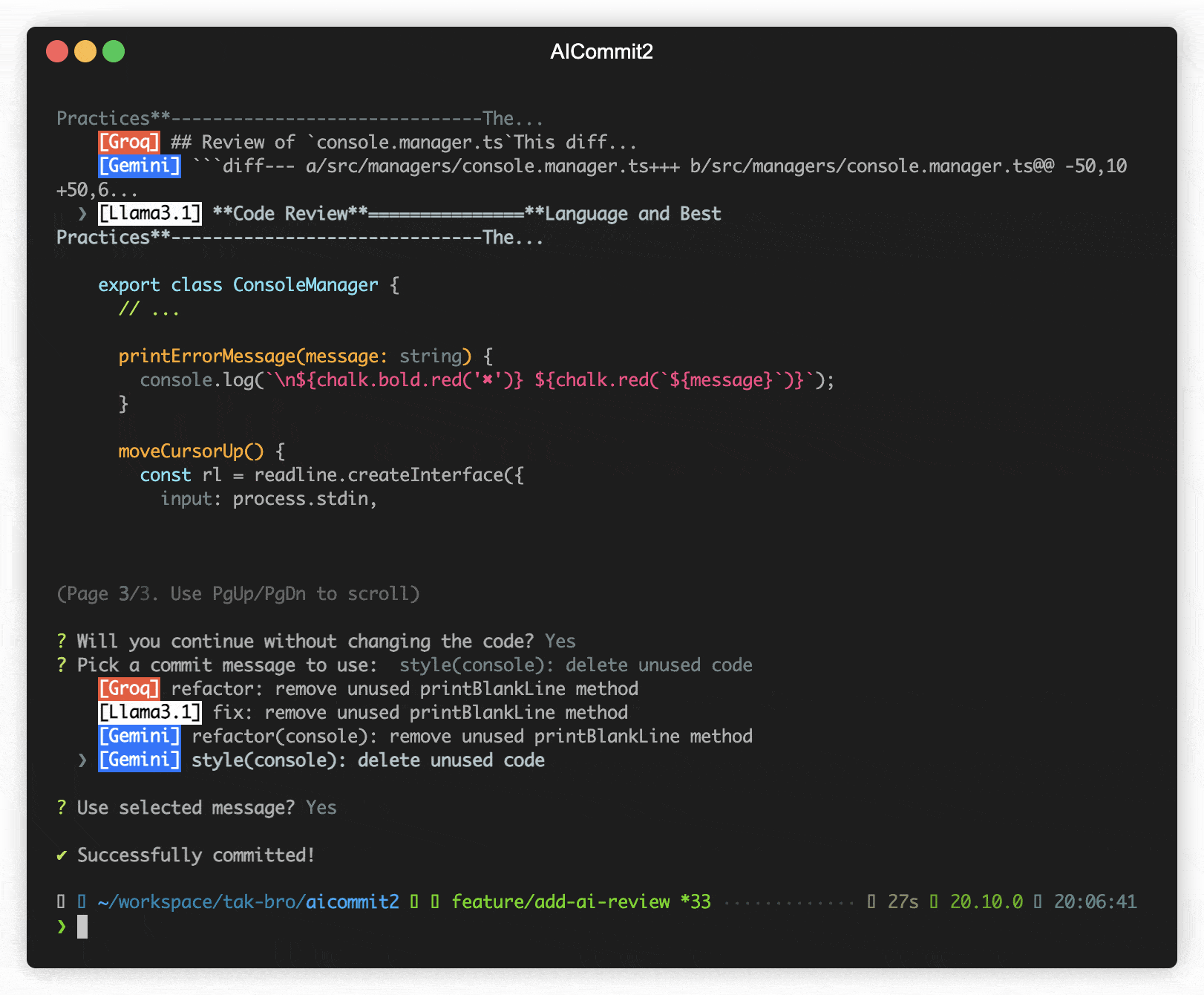
- The
codeReviewfeature is currently experimental. - This feature performs a code review before generating commit messages.
- Using this feature will significantly increase the overall processing time.
- It may significantly impact performance and cost.
- The code review process consumes a large number of tokens.
- Allow users to specify a custom file path for code review
aicommit2 config set codeReviewPromptPath="/path/to/user/prompt.txt"| timeout | temperature | maxTokens | topP | |
|---|---|---|---|---|
| OpenAI | ✓ | ✓ | ✓ | ✓ |
| Anthropic Claude | ✓ | ✓ | ✓ | |
| Gemini | ✓ | ✓ | ✓ | |
| Mistral AI | ✓ | ✓ | ✓ | ✓ |
| Codestral | ✓ | ✓ | ✓ | ✓ |
| Cohere | ✓ | ✓ | ✓ | |
| Groq | ✓ | ✓ | ✓ | ✓ |
| Perplexity | ✓ | ✓ | ✓ | ✓ |
| DeepSeek | ✓ | ✓ | ✓ | ✓ |
| Huggingface | ||||
| Ollama | ✓ | ✓ | ✓ |
All AI support the following options in General Settings.
- systemPrompt, systemPromptPath, codeReview, codeReviewPromptPath, exclude, type, locale, generate, logging, includeBody, maxLength
Some models mentioned below are subject to change.
| Setting | Description | Default |
|---|---|---|
key |
API key | - |
model |
Model to use | gpt-4o-mini |
url |
API endpoint URL | https://api.openai.com |
path |
API path | /v1/chat/completions |
proxy |
Proxy settings | - |
The OpenAI API key. You can retrieve it from OpenAI API Keys page.
aicommit2 config set OPENAI.key="your api key"Default: gpt-4o-mini
The Chat Completions (/v1/chat/completions) model to use. Consult the list of models available in the OpenAI Documentation.
aicommit2 config set OPENAI.model=gpt-4oDefault: https://api.openai.com
The OpenAI URL. Both https and http protocols supported. It allows to run local OpenAI-compatible server.
aicommit2 config set OPENAI.url="<your-host>"Default: /v1/chat/completions
The OpenAI Path.
Default: 0.9
The top_p parameter selects tokens whose combined probability meets a threshold. Please see detail.
aicommit2 config set OPENAI.topP=0.2NOTE: If
topPis less than 0, it does not deliver thetop_pparameter to the request.
| Setting | Description | Default |
|---|---|---|
key |
API key | - |
model |
Model to use | claude-3-haiku-20240307 |
The Anthropic API key. To get started with Anthropic Claude, request access to their API at anthropic.com/earlyaccess.
Default: claude-3-haiku-20240307
Supported:
claude-3-haiku-20240307claude-3-sonnet-20240229claude-3-opus-20240229claude-3-5-sonnet-20240620claude-3-5-sonnet-20241022
aicommit2 config set ANTHROPIC.model="claude-3-5-sonnet-20240620"Anthropic does not support the following options in General Settings.
- timeout
| Setting | Description | Default |
|---|---|---|
key |
API key | - |
model |
Model to use | gemini-1.5-pro |
The Gemini API key. If you don't have one, create a key in Google AI Studio.
aicommit2 config set GEMINI.key="your api key"Default: gemini-1.5-pro
Supported:
gemini-1.5-progemini-1.5-flashgemini-1.5-pro-exp-0801
aicommit2 config set GEMINI.model="gemini-1.5-pro-exp-0801"Gemini does not support the following options in General Settings.
- timeout
| Setting | Description | Default |
|---|---|---|
key |
API key | - |
model |
Model to use | mistral-tiny |
The Mistral API key. If you don't have one, please sign up and subscribe in Mistral Console.
Default: mistral-tiny
Supported:
open-mistral-7bmistral-tiny-2312mistral-tinyopen-mixtral-8x7bmistral-small-2312mistral-smallmistral-small-2402mistral-small-latestmistral-medium-latestmistral-medium-2312mistral-mediummistral-large-latestmistral-large-2402mistral-embed
| Setting | Description | Default |
|---|---|---|
key |
API key | - |
model |
Model to use | codestral-latest |
The Codestral API key. If you don't have one, please sign up and subscribe in Mistral Console.
Default: codestral-latest
Supported:
codestral-latestcodestral-2405
aicommit2 config set CODESTRAL.model="codestral-2405"| Setting | Description | Default |
|---|---|---|
key |
API key | - |
model |
Model to use | command |
The Cohere API key. If you don't have one, please sign up and get the API key in Cohere Dashboard.
Default: command
Supported models:
commandcommand-nightlycommand-lightcommand-light-nightly
aicommit2 config set COHERE.model="command-nightly"Cohere does not support the following options in General Settings.
- timeout
| Setting | Description | Default |
|---|---|---|
key |
API key | - |
model |
Model to use | gemma2-9b-it |
The Groq API key. If you don't have one, please sign up and get the API key in Groq Console.
Default: gemma2-9b-it
Supported:
llama3-groq-70b-8192-tool-use-previewdistil-whisper-large-v3-enllama3-70b-8192llama-3.2-11b-vision-previewwhisper-large-v3-turbogemma-7b-itllama3-groq-8b-8192-tool-use-previewllama-3.2-1b-previewllama-3.1-8b-instantmixtral-8x7b-32768llama-3.2-90b-text-previewllama3-8b-8192llama-guard-3-8bllama-3.2-90b-vision-previewllama-3.2-11b-text-previewllama-3.2-3b-previewllava-v1.5-7b-4096-previewwhisper-large-v3llama-3.1-70b-versatilegemma2-9b-it
aicommit2 config set GROQ.model="llama3-8b-8192"| Setting | Description | Default |
|---|---|---|
key |
API key | - |
model |
Model to use | llama-3.1-sonar-small-128k-chat |
The Perplexity API key. If you don't have one, please sign up and get the API key in Perplexity
Default: llama-3.1-sonar-small-128k-chat
Supported:
llama-3.1-sonar-small-128k-chatllama-3.1-sonar-large-128k-chatllama-3.1-sonar-large-128k-onlinellama-3.1-sonar-small-128k-onlinellama-3.1-8b-instructllama-3.1-70b-instructllama-3.1-8bllama-3.1-70b
The models mentioned above are subject to change.
aicommit2 config set PERPLEXITY.model="llama-3.1-70b"| Setting | Description | Default |
|---|---|---|
key |
API key | - |
model |
Model to use | deepseek-coder |
The DeepSeek API key. If you don't have one, please sign up and subscribe in DeepSeek Platform.
Default: deepseek-coder
Supported:
deepseek-coderdeepseek-chat
aicommit2 config set DEEPSEEK.model="deepseek-chat"| Setting | Description | Default |
|---|---|---|
cookie |
Authentication cookie | - |
model |
Model to use | CohereForAI/c4ai-command-r-plus |
The Huggingface Chat Cookie. Please check how to get cookie
# Please be cautious of Escape characters(\", \') in browser cookie string
aicommit2 config set HUGGINGFACE.cookie="your-cooke"Default: CohereForAI/c4ai-command-r-plus
Supported:
CohereForAI/c4ai-command-r-plusmeta-llama/Meta-Llama-3-70B-InstructHuggingFaceH4/zephyr-orpo-141b-A35b-v0.1mistralai/Mixtral-8x7B-Instruct-v0.1NousResearch/Nous-Hermes-2-Mixtral-8x7B-DPO01-ai/Yi-1.5-34B-Chatmistralai/Mistral-7B-Instruct-v0.2microsoft/Phi-3-mini-4k-instruct
aicommit2 config set HUGGINGFACE.model="mistralai/Mistral-7B-Instruct-v0.2"Huggingface does not support the following options in General Settings.
- maxTokens
- timeout
- temperature
- topP
| Setting | Description | Default |
|---|---|---|
model |
Model(s) to use (comma-separated list) | - |
host |
Ollama host URL | http://localhost:11434 |
auth |
Authentication type | Bearer |
key |
Authentication key | - |
timeout |
Request timeout (milliseconds) | 100_000 (100sec) |
The Ollama Model. Please see a list of models available
aicommit2 config set OLLAMA.model="llama3.1"
aicommit2 config set OLLAMA.model="llama3,codellama" # for multiple models
aicommit2 config add OLLAMA.model="gemma2" # Only Ollama.model can be added.OLLAMA.model is string array type to support multiple Ollama. Please see this section.
Default: http://localhost:11434
The Ollama host
aicommit2 config set OLLAMA.host=<host>Not required. Use when your Ollama server requires authentication. Please see this issue.
aicommit2 config set OLLAMA.auth=<auth>Not required. Use when your Ollama server requires authentication. Please see this issue.
aicommit2 config set OLLAMA.key=<key>Few examples of authentication methods:
| Authentication Method | OLLAMA.auth | OLLAMA.key |
|---|---|---|
| Bearer | Bearer |
<API key> |
| Basic | Basic |
<Base64 Encoded username:password> |
| JWT | Bearer |
<JWT Token> |
| OAuth 2.0 | Bearer |
<Access Token> |
| HMAC-SHA256 | HMAC |
<Base64 Encoded clientId:signature> |
Default: 100_000 (100 seconds)
Request timeout for the Ollama.
aicommit2 config set OLLAMA.timeout=<timeout>Ollama does not support the following options in General Settings.
- maxTokens
Check the installed version with:
aicommit2 --version
If it's not the latest version, run:
npm update -g aicommit2aicommit2 supports custom prompt templates through the systemPromptPath option. This feature allows you to define your own prompt structure, giving you more control over the commit message generation process.
To use a custom prompt template, specify the path to your template file when running the tool:
aicommit2 config set systemPromptPath="/path/to/user/prompt.txt"
aicommit2 config set OPENAI.systemPromptPath="/path/to/another-prompt.txt"
For the above command, OpenAI uses the prompt in the another-prompt.txt file, and the rest of the model uses prompt.txt.
NOTE: For the
systemPromptPathoption, set the template path, not the template content
Your custom template can include placeholders for various commit options.
Use curly braces {} to denote these placeholders for options. The following placeholders are supported:
- {locale}: The language for the commit message (string)
- {maxLength}: The maximum length for the commit message (number)
- {type}: The type of the commit message (conventional or gitmoji)
- {generate}: The number of commit messages to generate (number)
Here's an example of how your custom template might look:
Generate a {type} commit message in {locale}.
The message should not exceed {maxLength} characters.
Please provide {generate} messages.
Remember to follow these guidelines:
1. Use the imperative mood
2. Be concise and clear
3. Explain the 'why' behind the change
Please note that the following text will ALWAYS be appended to the end of your custom prompt:
Lastly, Provide your response as a JSON array containing exactly {generate} object, each with the following keys:
- "subject": The main commit message using the {type} style. It should be a concise summary of the changes.
- "body": An optional detailed explanation of the changes. If not needed, use an empty string.
- "footer": An optional footer for metadata like BREAKING CHANGES. If not needed, use an empty string.
The array must always contain {generate} element, no more and no less.
Example response format:
[
{
"subject": "fix: fix bug in user authentication process",
"body": "- Update login function to handle edge cases\n- Add additional error logging for debugging",
"footer": ""
}
]
Ensure you generate exactly {generate} commit message, even if it requires creating slightly varied versions for similar changes.
The response should be valid JSON that can be parsed without errors.
This ensures that the output is consistently formatted as a JSON array, regardless of the custom template used.
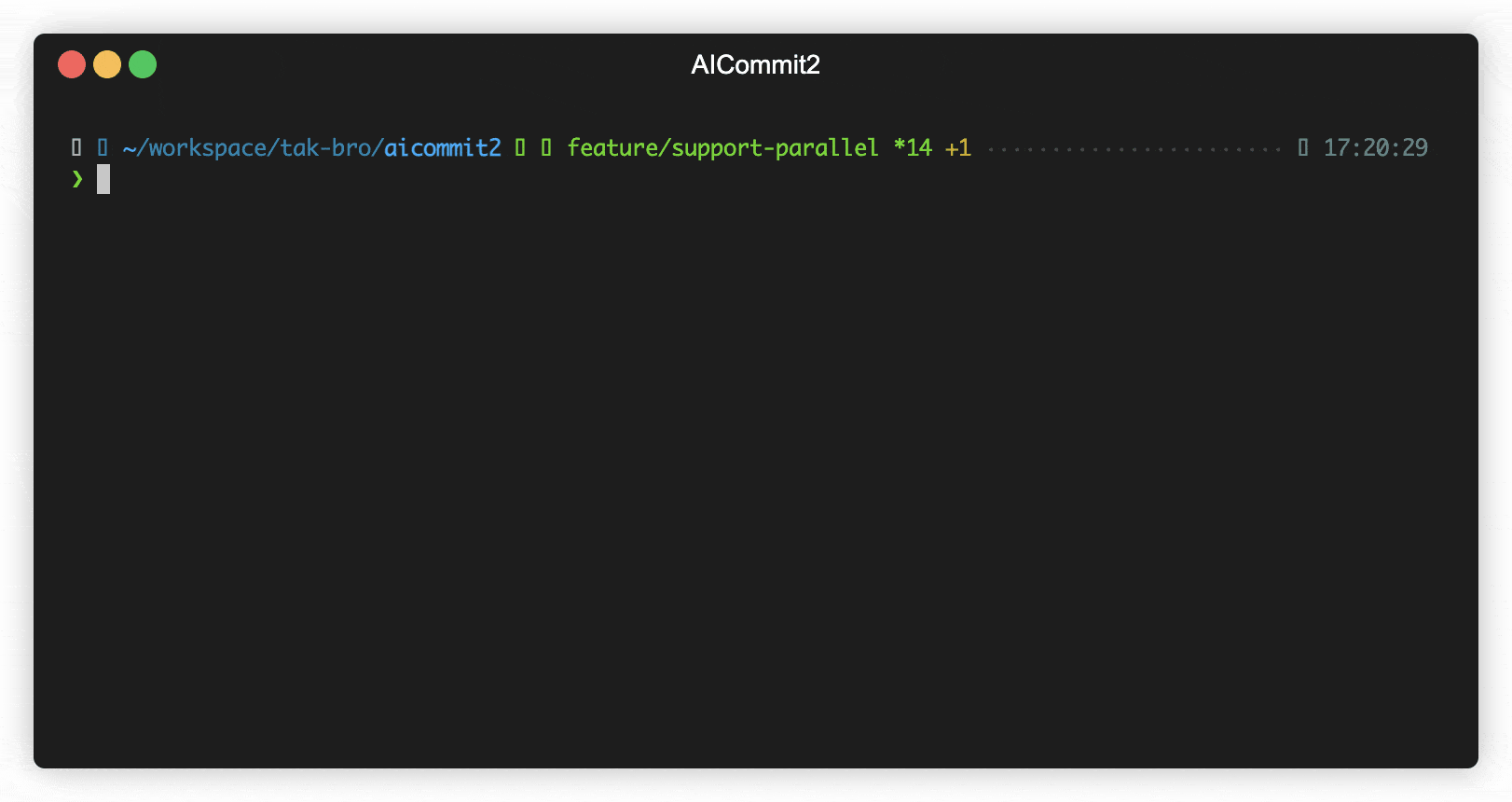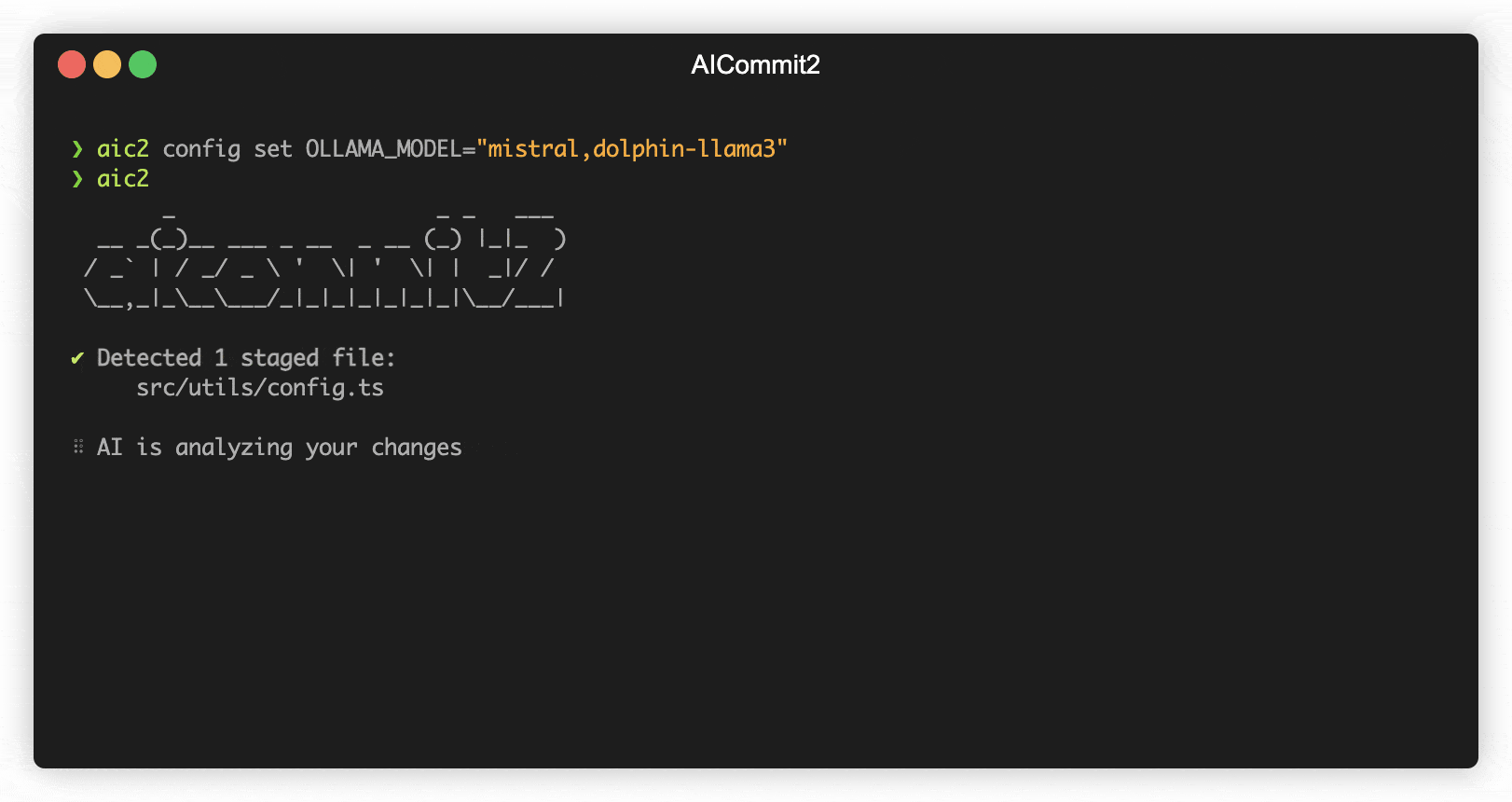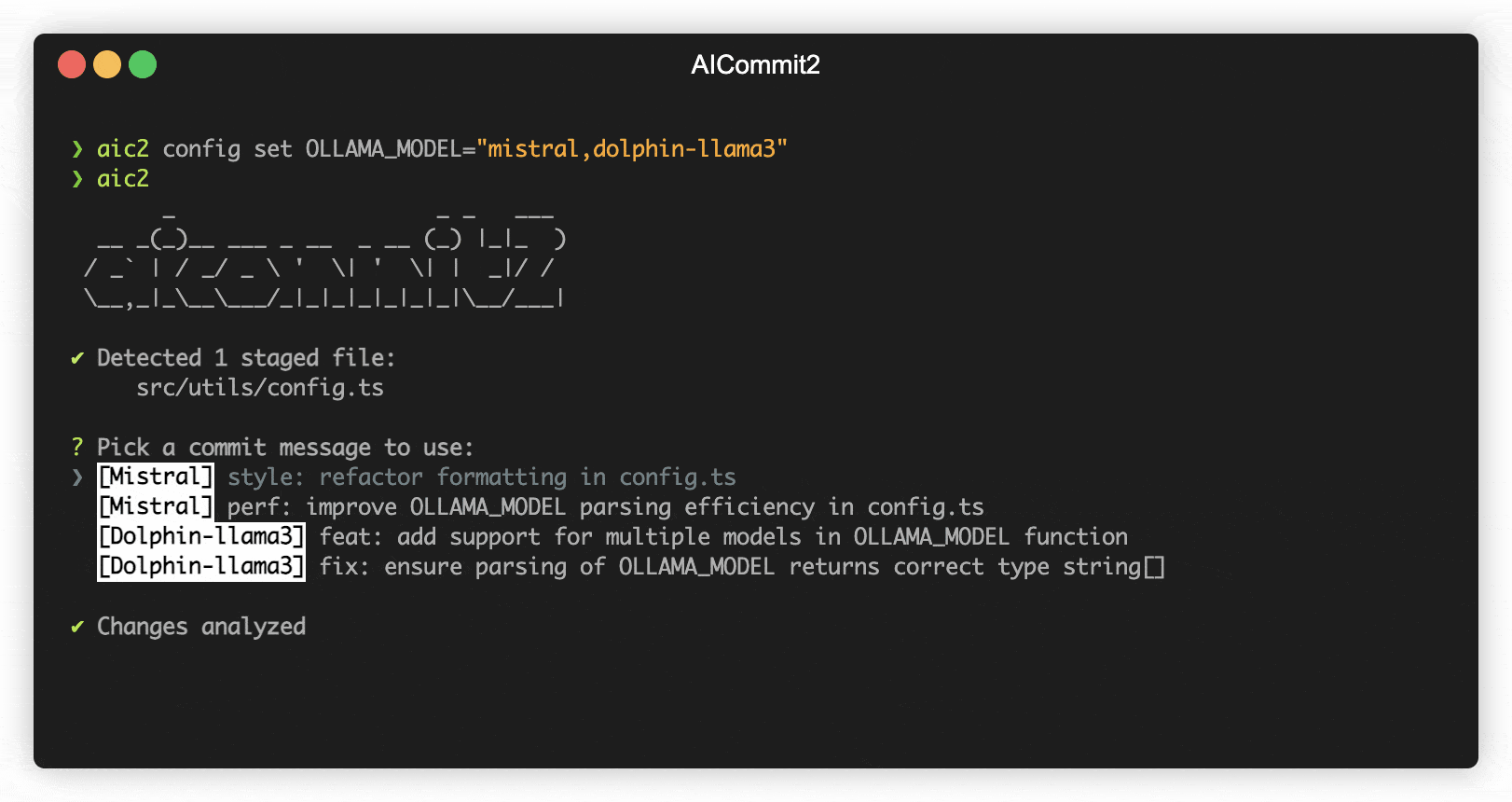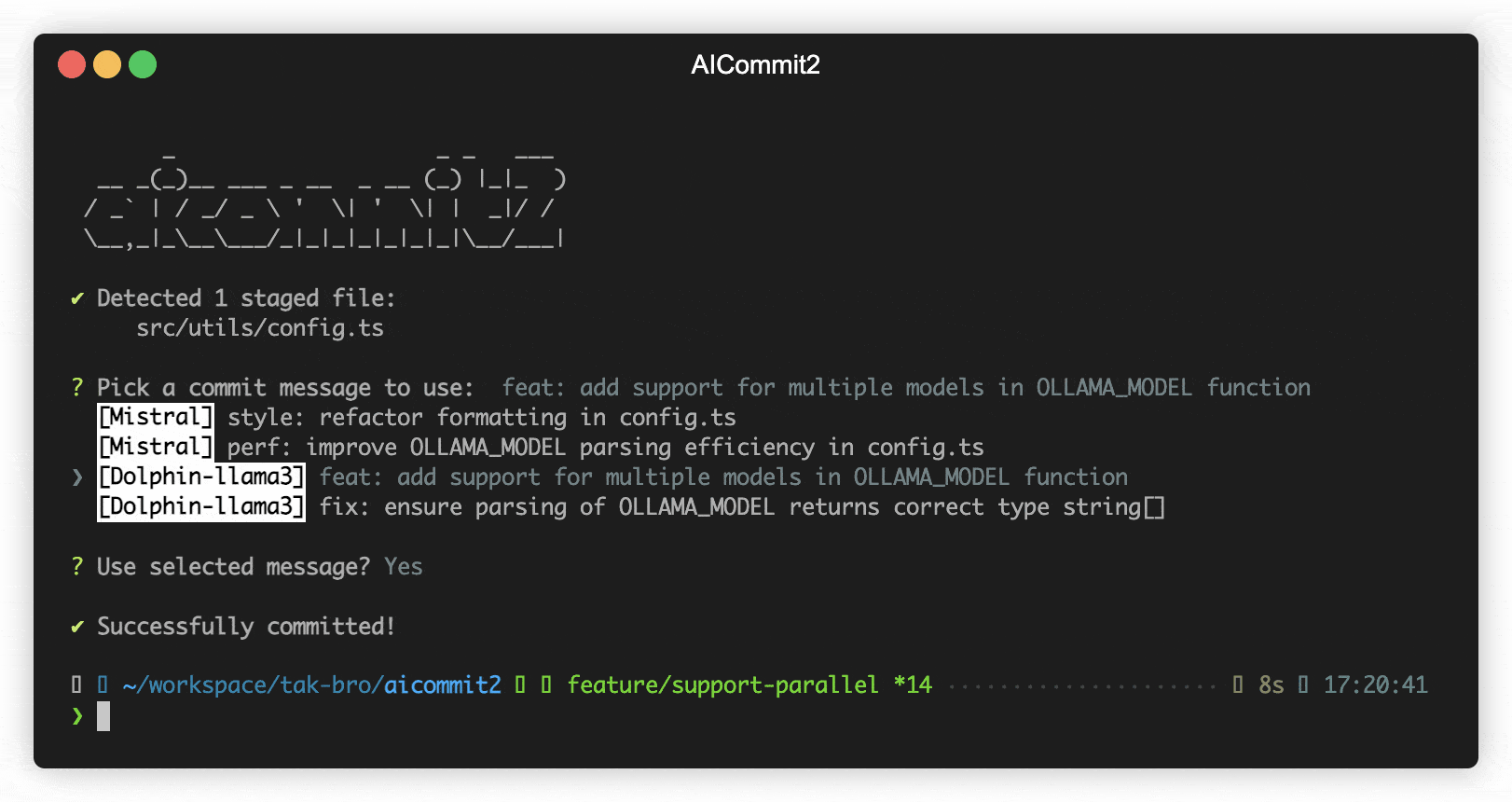
You can load and make simultaneous requests to multiple models using Ollama's experimental feature, the OLLAMA_MAX_LOADED_MODELS option.
OLLAMA_MAX_LOADED_MODELS: Load multiple models simultaneously
Follow these steps to set up and utilize multiple models simultaneously:
First, launch the Ollama server with the OLLAMA_MAX_LOADED_MODELS environment variable set. This variable specifies the maximum number of models to be loaded simultaneously.
For example, to load up to 3 models, use the following command:
OLLAMA_MAX_LOADED_MODELS=3 ollama serveRefer to configuration for detailed instructions.
Next, set up aicommit2 to specify multiple models. You can assign a list of models, separated by commas(,), to the OLLAMA.model environment variable. Here's how you do it:
aicommit2 config set OLLAMA.model="mistral,dolphin-llama3"With this command, aicommit2 is instructed to utilize both the "mistral" and "dolphin-llama3" models when making requests to the Ollama server.
aicommit2Note that this feature is available starting from Ollama version 0.1.33 and aicommit2 version 1.9.5.
- Login to the site you want
- You can get cookie from the browser's developer tools network tab
- See for any requests check out the Cookie, Copy whole value
- Check below image for the format of cookie
When setting cookies with long string values, ensure to escape characters like ", ', and others properly.
- For double quotes ("), use \"
- For single quotes ('), use \'

This project uses functionalities from external APIs but is not officially affiliated with or endorsed by their providers. Users are responsible for complying with API terms, rate limits, and policies.
For bug fixes or feature implementations, please check the Contribution Guide.
Thanks goes to these wonderful people (emoji key):
 @eltociear 📖 |
 @ubranch 💻 |
 @bhodrolok 💻 |
 @ryicoh 💻 |
 @noamsto 💻 |
If this project has been helpful, please consider giving it a Star ⭐️!
Maintainer: @tak-bro