We highly recommend you to read BytePS's rationale first before reading this doc.
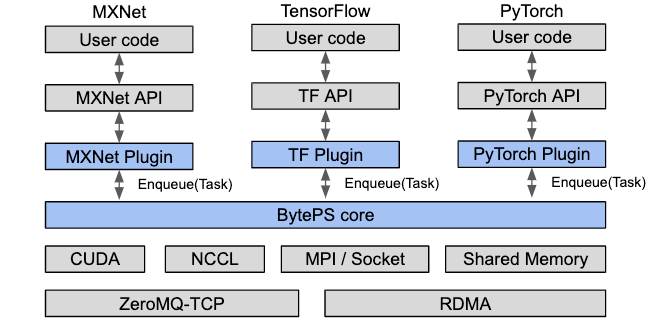
From application views, BytePS is a communication library just like Horovod. The plugins handle framework-specific transformation (e.g., on data structure), and put communication tasks into BytePS priority queues. The BytePS Core then gets the tasks (priority-aware, not FIFO) and handles the actual communication.
To demonstrate the work flow of BytePS, below we use a common data-parallel training scenario as an example. Say we have multiple worker machines (we refer them as "workers"), and each machine (worker) has multiple GPUs. We also have some CPU machines that serve as PS (we refer them as "servers").
In BytePS, a general walk-through of an iteration goes like this (we call each step as a stage):
- Computation: Each GPU performs computation (forward/backward propagation), which is irrelevant to BytePS;
- Local Reduce: Multiple GPUs on the same machine reduces the gradients;
- Push: The workers push the aggregated gradients to the servers;
- Global Reduce: Once the servers receive the gradients from different workers, it aggregates the gradients;
- Pull: The workers pull the aggregated gradients from the servers;
- Local Broadcast: The workers broadcasts the updated gradients to local GPUs;
- Goto next iteration and repeat from 1.
We use NCCL for local communication, including Local Reduce and Local Broadcast.
For Local Reduce stage we use ReduceScatter to evenly distribute the gradients on multiple GPUs.
For Local Broadcast stage we use AllGather to broadcast the gradients back to multiple GPUs.
We use ps-lite for Push and Pull between workers and servers.
For Push stage, the workers send the gradients to servers, as the traditional PS does.
For Pull stage, the workers pull gradients rather than parameters from the servers, which is different from traditional PS. Here is why:
In past, the SGD update is performed on servers, so the workers need to tell the servers what SGD optimizer to use. However, for different frameworks, even the same optimizer algorithm may be implemented in completely different ways, and not to mention there are many user-defined optimizers. So BytePS moves the SGD update from the servers to the workers, leaving the servers only do gradient reduction. We believe this is generic because it applies to all frameworks we know so far.