Decoding an image into a set of people detections using an end-to-end network with a LSTM layer
- Multiple detections on the same object can be avoided by remebering the previously generated outputs.
- End-to-end system allows joint training of all components via back propagation.
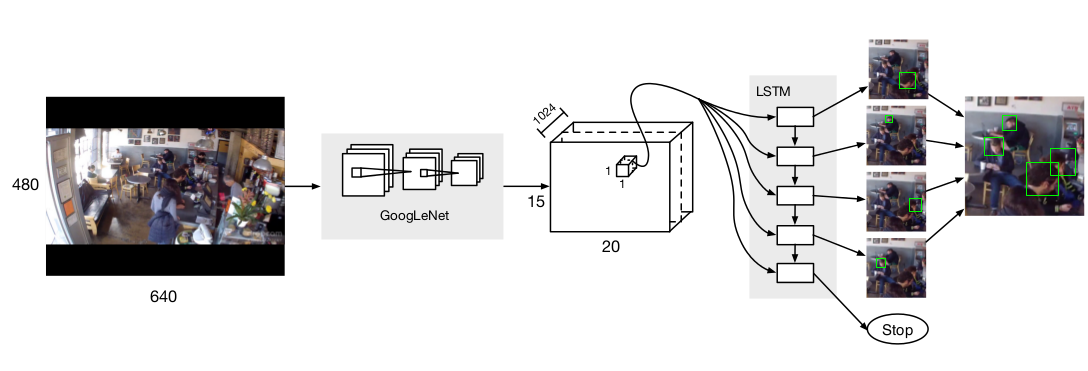
- Using GoogleNet to generate a 15*20*1024 image feature map;
- For each cell in an image feature map, use a LSTM controller to predict a set(at most 5) of bounding boxes;
- Using Hungarian Algorithm to assign an unique candidate bounding box to each ground truth box. Bounding boxes with high overlap with ground truths, lower rank and low distances are matched first.
- Calculate loss function based on the matching result.
- In the test process, the network predicts few bounding boxes for each cell in the image feature map, so a "stiching algorithm" is introduced to merge all boxes from each cell. This stiching algorithm use yet again the Hungarian Algorithm to match new generated boxes from a region in focus to existing bounding boxes, and destroy any bounding box with nonzero overlap with existing bounding boxes, remaining boxes are added to the whole image box set.
-
Hungarian Algorithm can be used to match object detection candidates with ground truth boxes. This paper uses three measurements to make sure that the network can predict bounding boxes with higher confidence, smaller distances(easy boxes) first:
- The paramount measurement is whether a predicted bounding box overlaps sufficiently with a ground truth box
- The second measurement is its rank in the LSTM predictions
- The last measurement is its smallest distance from the ground truth box
-
Using LSTM to do object detection is a cool thing since:
- it "remembers" history predictions so it can avoid multiple predictions on a same object
- it predicts arbitrarily number of objects in an image
Stewart R, Andriluka M. End-to-end people detection in crowded scenes[J]. arXiv preprint arXiv:1506.04878, 2015.