


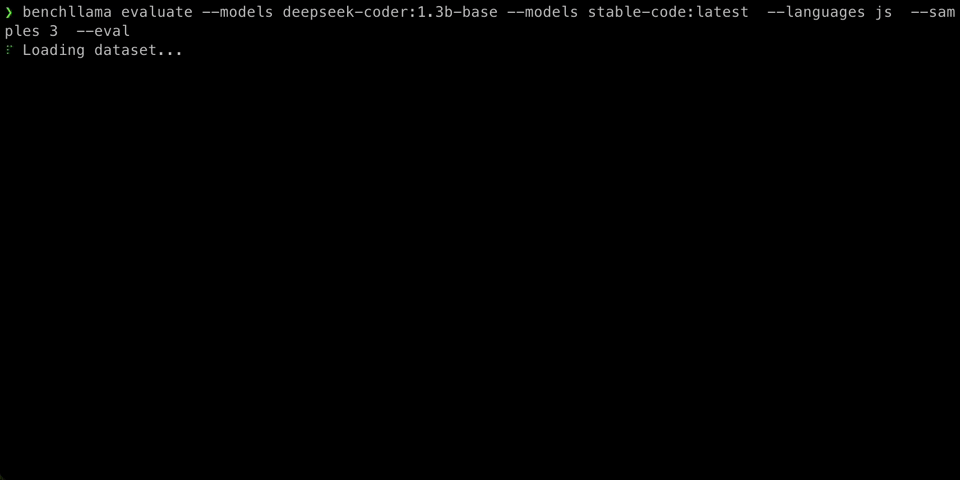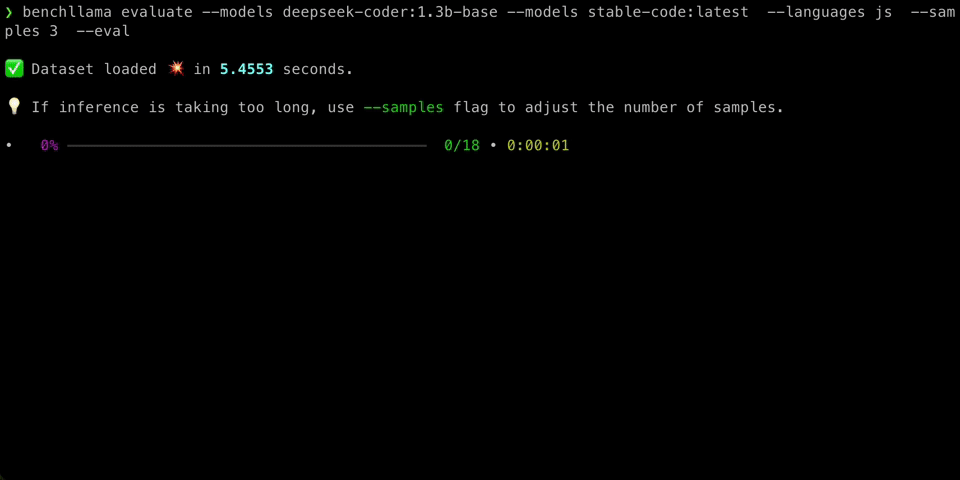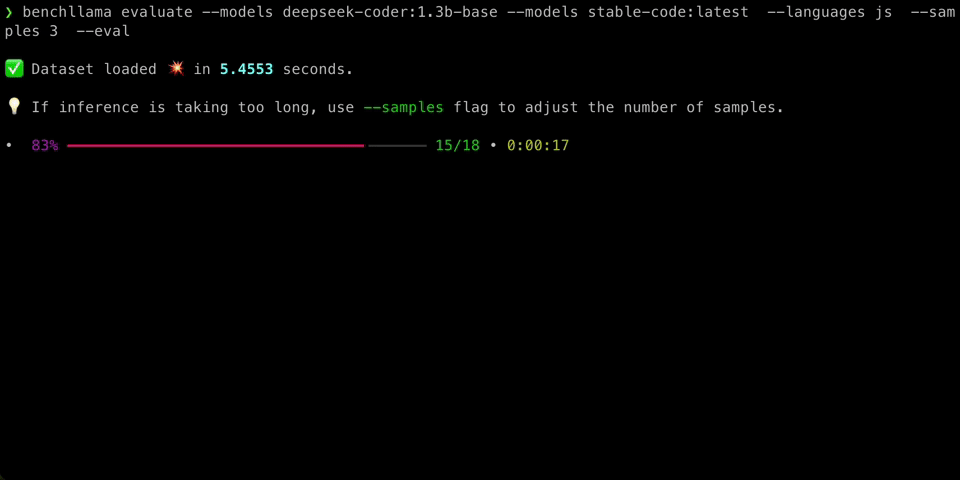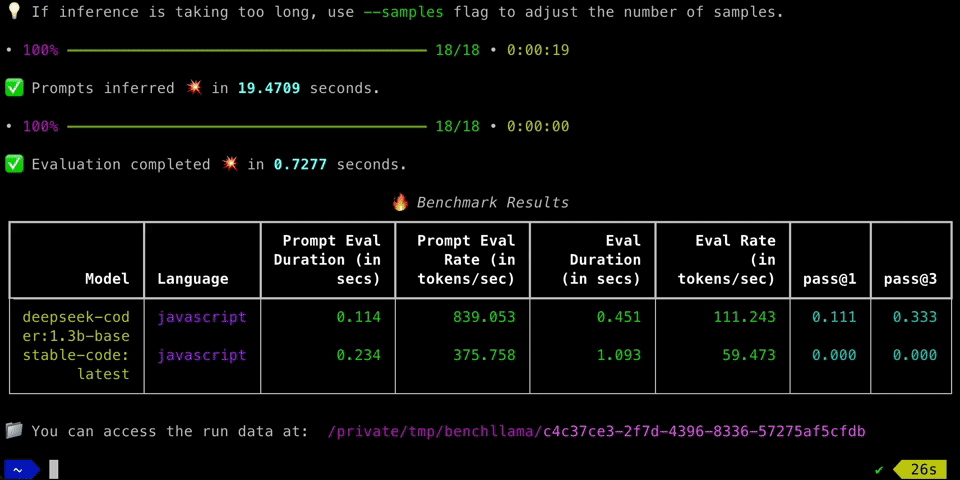
Benchllama helps with benchmarking your local LLMs. Currently, it only supports benchmarking models served via Ollama. By default, it pulls bigcode/humanevalpack from HuggingFace. There is out-of-box support for evaluating code coding models (you need to use --eval flag for triggering this). Currently, it supports the following languages: Python, JavaScript, Java, Go, C++. You can also bring your dataset (see this example to help you with creating one) by specifying the path to it in the --dataset flag.
With the explosion of open source LLMs and toolbox to further customize these models like Modelfiles, Mergekit, LoRA etc, it can be daunting to end users to choose the right LLM. From our experience with running local LLMs, the two key metrics that matter are performance and quality of responses. We created a simple CLI tool that enables the users to pick the right LLM by evaluating them across these two parameters.
Given our experience in coding LLMs, we felt it would be useful to add out-of-box support for calculating pass@k for coding models. In case, if you are into coding LLMs, please checkout our related project i.e Privy (github repo, vscode link, openvsx link).
- Evaluate: Evaluate the performance of your models on various tasks, such as code generation.
- Clean: Clean up temporary files generated by Benchllama.
$ pip install benchllama$ benchllama [OPTIONS] COMMAND [ARGS]...Options:
--install-completion: Install completion for the current shell.--show-completion: Show completion for the current shell, to copy it or customize the installation.--help: Show this message and exit.
Commands:
evaluateclean
Usage:
$ benchllama evaluate [OPTIONS]Options:
--models TEXT: Names of models that need to be evaluated. [required]--provider-url TEXT: The endpoint of the model provider. [default: http://localhost:11434]--dataset FILE: By default, bigcode/humanevalpack from Hugging Face will be used. If you want to use your own dataset, specify the path here.--languages [python|js|java|go|cpp]: List of languages to evaluate from bigcode/humanevalpack. Ignore this if you are brining your own data [default: Language.python]--num-completions INTEGER: Number of completions to be generated for each task. [default: 3]--no-eval / --eval: If true, evaluation will be done [default: no-eval]--k INTEGER: The k for calculating pass@k. The values shouldn't exceed num_completions [default: 1, 2]--samples INTEGER: Number of dataset samples to evaluate. By default, all the samples get processed. [default: -1]--output PATH: Output directory [default: /tmp]--help: Show this message and exit.
Usage:
$ benchllama clean [OPTIONS]Options:
--run-id TEXT: Run id--output PATH: Output directory [default: /tmp]--help: Show this message and exit.