.to_zarr() or .to_netcdf slow and uses excess memory when datetime64[ns] variable in output; a reproducible example #7028
Labels
Comments
|
The way to test would be: |
|
Ah now I see #7132 . Let's close this since the example there is a lot smaller. |
Closed
4 tasks
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
What happened?
This bug report is a reproducible example with code of an issue that may be in #7018, #2912 and other bug reports reporting slow performance and memory exhaustion when using .to_zarr() or .to_netcdf(). I think this has been hard to track down because it only occurs for large data sets. I have included code that replicates the problem without the need for downloading a large dataset.
The problem is that saving a xarray dataset which includes a variable with type datetime64[ns] is several orders of magnitude slower (!!) and uses a great deal of memory (!!) relative to the same dataset where that variable has another type. The work around is obvious -- turn off time decoding and treat time as a float64. But this is in-elegant, and I think this problem has lead to many un-answered questions on the issues page, such as the one above.
If I save a dataset whose structure (based on my use case, the ocean-parcels Lagrangian particle tracker) is:
I have no problems, even if the data set is much larger than the machine's memory. However, if I change the time variable to have the data type datetime64[ns]
the time it takes to write this dataSet becomes much greater, and increases much more quickly with an increase in the "trajectory" coordinate then the case where time has type "float64." The increase in time is NOT in the writing time, but in the time it takes to compute the dask graph. At the same time the time to compute the graph increases, the memory usage increases, finally leading to memory exhaustion as the data set gets larger. This can be seen in the attached figure, which shows the time to create the graph with
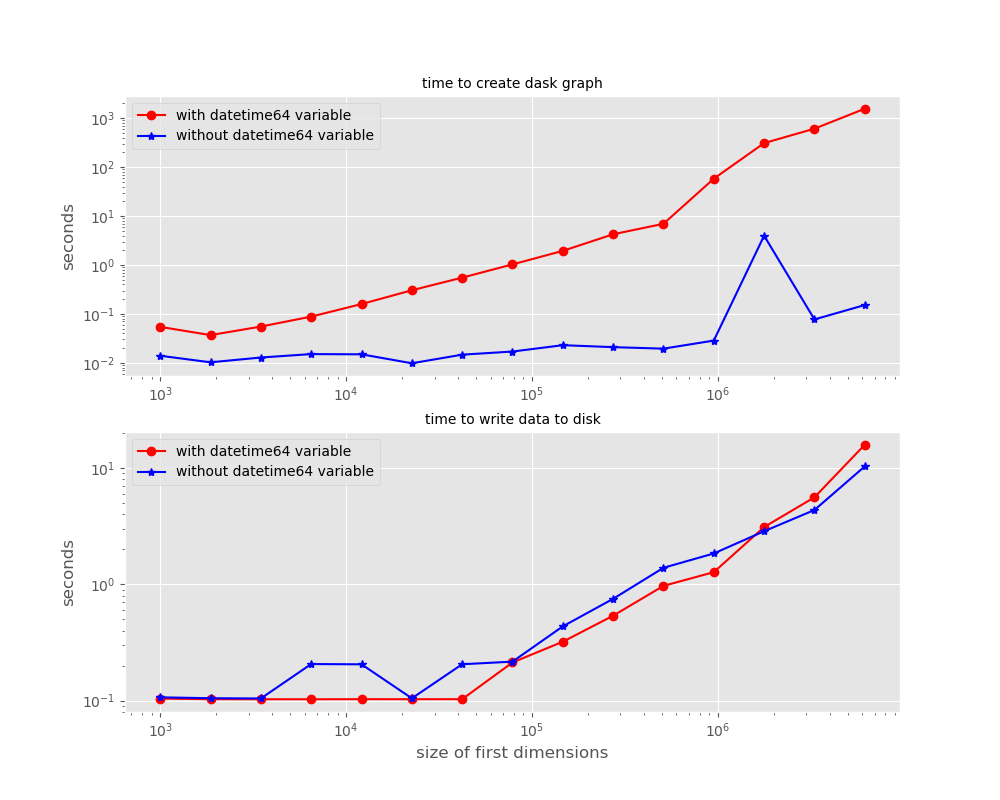
dataOut.to_zarr(outputDir,compute=False)and the time to write the data withdelayedObj.compute(). By the time the data set is 10 million long in the first dimension, the dataset with datetime64[ns] takes 4 orders of magnitude longer (!!!) to compute -- hours instead of seconds!To recreate this graph, and to see a very simple code that replicates this problem, see the attached python code. Note that the directory you run it in should have at least 30Gb free for the data set it writes, and for machines with less than 256Gb of memory, it will crash before completing after exhausting the memory. However, the last figure will be saved in jnk_out.png, and you can always change the largest size it attempts to create.
SmallestExample_zarrOutProblem.zip
What did you expect to happen?
I expect that the time to save a dataset with .to_zarr or .to_netcdf does not change dramatically if one of the variables has a datetime64[ns] type.
Minimal Complete Verifiable Example
MVCE confirmation
Relevant log output
No response
Anything else we need to know?
No response
Environment
Note -- I see the same thing on my linux machine
xarray: 2022.6.0
pandas: 1.4.3
numpy: 1.23.2
scipy: 1.9.0
netCDF4: None
pydap: None
h5netcdf: None
h5py: None
Nio: None
zarr: 2.12.0
cftime: None
nc_time_axis: None
PseudoNetCDF: None
rasterio: None
cfgrib: None
iris: None
bottleneck: None
dask: 2022.8.1
distributed: 2022.8.1
matplotlib: 3.5.3
cartopy: 0.20.3
seaborn: None
numbagg: None
fsspec: 2022.7.1
cupy: None
pint: None
sparse: None
flox: None
numpy_groupies: None
setuptools: 65.3.0
pip: 22.2.2
conda: None
pytest: None
IPython: 8.4.0
sphinx: None
The text was updated successfully, but these errors were encountered: